RU2500023C2 - Синхронизация документа по протоколу, не использующему информацию о состоянии - Google Patents
Синхронизация документа по протоколу, не использующему информацию о состоянии Download PDFInfo
- Publication number
- RU2500023C2 RU2500023C2 RU2010144794/08A RU2010144794A RU2500023C2 RU 2500023 C2 RU2500023 C2 RU 2500023C2 RU 2010144794/08 A RU2010144794/08 A RU 2010144794/08A RU 2010144794 A RU2010144794 A RU 2010144794A RU 2500023 C2 RU2500023 C2 RU 2500023C2
- Authority
- RU
- Russia
- Prior art keywords
- cell
- version
- identifier
- document
- manifest
- Prior art date
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/27—Replication, distribution or synchronisation of data between databases or within a distributed database system; Distributed database system architectures therefor
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/17—Details of further file system functions
- G06F16/178—Techniques for file synchronisation in file systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/166—Editing, e.g. inserting or deleting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/194—Calculation of difference between files
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/197—Version control
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Computing Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Information Transfer Between Computers (AREA)
Abstract
Изобретение относится к средствам синхронизации документов. Технический результат заключается в уменьшении объема изменяемой информации. Принимают первую версию и, по меньшей мере, одну ячейку, ассоциированную с документом, причем, по меньшей мере, одна ячейка содержит идентификатор ячейки, а идентификатор ячейки ассоциирован с первой версией, содержащей, по меньшей мере, один идентификатор первой версии, причем каждый из, по меньшей мере, одного идентификатора первой версии представляет состояние ячеек в момент времени, а область действия задает совокупность ячеек и версий, причем область действий включает в себя, по меньшей мере, один корневой объект. Принимают обновления для первого вычислительного устройства, причем обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом. Сохраняют первую версию каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки. Генерируют новую версию каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии идентификатора новой версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки. Стирают любую ячейку, на которую не было ссылки в корневых объектах, и синхронизируют документ путем замены ячеек на новую версию каждой ячейки. 3 н. и 9 з.п. ф-лы, 6 ил.
Description
УРОВЕНЬ ТЕХНИКИ
В типичных документальных информационных системах к документам есть доступ на всем уровне документа, вследствие чего весь документ поступает на клиентский компьютер с сервера для редактирования. Это требует наличия низкоуровневых данных, ассоциированных с базовым форматом документа, передаваемым с сервера на клиентский компьютер. Кроме того, инкрементные форматы документа приходится подвергать операции очистки памяти и дефрагментации через сетевое соединение. Более того, блокировками необходимо управлять через сеть. Управление блокировками может представлять собой сложную и недолговечную задачу, которая требует значительного объема изменяемого информационного наполнения. Передача низкоуровневых данных, включая информацию по очистке памяти и дефрагментации, а также по механизму блокировки, чрезмерно привязывает приложение к его низкоуровневому формату файла и может быть негибкой и приводить к неэффективности.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Примерные системы и способы, описанные в настоящем документе, относятся к синхронизации файла (например, документа) и/или загрузке по протоколу, не использующему информацию о состоянии.
Согласно одному аспекту, структура данных для хранения документа в первом вычислительном устройстве не зависит от формата документа, причем структура данных включает в себя: множество ячеек и множество объектов данных, задающих содержание документа. Каждая из ячеек имеет идентификатор ячейки, который однозначно идентифицирует конкретную ячейку в рамках документа и ассоциирован, по меньшей мере, с одной версией. Каждый объект данных ассоциирован с одной из ячеек и имеет один идентификатор объекта, который однозначно идентифицирует объект данных в рамках соответствующей ячейки, и сконфигурирован для обеспечения связи с другими ячейками и с объектами в пределах соответствующей ячейки. В дополнение, каждая из ячеек задана таким образом, чтобы каждая другая ячейка оставалась незатронутой изменениями, относящимися к объектам данных этой ячейки.
Согласно другой особенности, манифест версии хранится на машиночитаемом носителе первого вычислительного устройства. Манифест версии задает версию, представляющую состояние ячейки в момент времени. Манифест версии включает в себя: множество объектных групп, где каждая объектная группа содержит, по меньшей мере, один объект данных; и блок совместимых данных, содержащий, по меньшей мере, один объект данных, где каждый блок совместимых данных задан так, чтобы редактирование одного из блоков совместимых данных не оказывало воздействия ни на один другой блок совместимых данных.
Согласно еще одному аспекту, способу синхронизации документа на первом вычислительном устройстве, документ разбивается на ячейки, каждая ячейка задается, по меньшей мере, одним манифестом версии, причем способ включает в себя: получение первой версии и, по меньшей мере, одной ячейки, ассоциированной с документом; получение обновления первым вычислительным устройством, где обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом; сохранение первой версии каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки; генерирование новой версии каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии нового идентификатора версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки; стирание любой ячейки, на которую не ссылаются корневые объекты; и синхронизацию документа путем замены ячеек на новую версию каждой ячейки. Идентификатор ячейки включает в себя пару глобально уникального идентификатора (globally unique identifier, GUID) и целого числа (integer, INT), причем GUID представляет собой глобально уникальную область действия, определяющую совокупность ячеек и версий, включает в себя корневые объекты, причем к ячейкам в пределах области имеется доступ через корневые объекты. Идентификатор ячейки ассоциирован с первой версией, обладающей, по меньшей мере, с одним идентификатором первой версии. Каждый, по меньшей мере, из одного идентификатора версии представляет состояние ячеек в каждый момент времени. Ячейка включает в себя область действия, определяющая совокупность ячеек и версий, и область действия включает в себя, по меньшей мере, один корневой объект. Ячейки в пределах области определения доступны через корневой объект.
Данное описание сущности изобретения обеспечено для предложения выбора в упрощенной форме концепций, которые дополнительно описаны ниже в Подробном описании. Данное описание сущности изобретения не следует рассматривать как идентифицирующее ключевые признаки или основные признаки заявленного объекта изобретения. Также данное описание сущности изобретения не должно использоваться для ограничения заявленного объема объекта изобретения.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Не ограничивающие и не исчерпывающие варианты воплощения описаны со ссылкой на следующие фигуры, на которых одинаковые номера ссылок относятся к одинаковым деталям на всех различных изображениях, если не указано иное.
Фиг.1 представляет собой схематическую блок-схему, иллюстрирующую примерную авторскую систему.
Фиг.2 представляет собой блок-схему, иллюстрирующую авторскую систему согласно фиг.1, в которой документ, хранящийся в первом вычислительном устройстве, может включать в себя блоки согласованного информационного наполнения.
Фиг.3 представляет собой схематическую блок-схему блока совместимых данных.
Фиг. 4 представляет собой схематическую блок-схему области определения.
Фиг.5 представляет собой схематическую блок-схему примерной клиентской вычислительной системы, сконфигурированной для внедрения среды авторских разработок; и
фиг.6 представляет собой блок-схему, иллюстрирующую примерную технологию синхронизации, осуществляемую авторским приложением.
ПОДРОБНОЕ ОПИСАНИЕ
В следующем подробном описании приведены ссылки на прилагаемые чертежи, которые составляют его часть и на которых в виде иллюстрации показаны конкретные варианты воплощения или примеры. Тогда как раскрытие будет описано в общем контексте программных модулей, которые функционируют совместно с прикладной программой, работающей на операционной системе, установленной на системе ЭВМ, специалистам в данной области техники должно быть понятно, что раскрытие также может быть внедрено в сочетании с другими программными модулями. Варианты воплощения, описанные в настоящем документе, могут сочетаться между собой, а другие варианты воплощения могут быть использованы без отступлений от сущности или объема настоящего раскрытия. Поэтому следующее подробное описание не должно рассматриваться в ограничительном смысле, а объем раскрытия задан прилагаемыми пунктами формулы изобретения и их эквивалентами.
Варианты воплощения настоящего раскрытия обеспечивают среду, в которой одиночный клиент может создавать документ, или несколько клиентов могут совместно создавать документ при потреблении минимальных серверных и обменных ресурсов. В примерных вариантах воплощения, когда возможное совместное использование приложения состоит в редактировании документа, приложение воздействует только на определенные элементы документа. Прежде чем клиент получил доступ к элементам документа, модель данных приложения была разбита на заданные блоки совместимых данных.
В примерных вариантах воплощения, описанных в настоящем раскрытии, документ разбивают на последовательность частей, называемых блоками совместимых данных. По умолчанию, документ можно преобразовать в один-единственный блок совместимых данных, который охватывает весь документ. Когда конкретные сведения о структуре документа известны, документ можно разбивать на более чем один блок совместимых данных. Например, презентационную программу, например, программу, созданную с использованием презентационной графической программы POWERPOINT®, состоящей более чем из одного слайда, можно разделить на несколько блоков совместимых данных, где каждый блок совместимых данных включает в себя один слайд. Например, презентацию, состоящую из десяти слайдов, можно разбивать на десять блоков совместимых данных.
В примере, описанном выше, возможны больше или меньше чем десять блоков совместимых данных. Например, каждый слайд может включать себя нижний колонтитул, а каждый нижний колонтитул может представлять собой блок совместимых данных. Поэтому презентация, состоящая из десяти слайдов, может иметь 20 блоков совместимых данных. Также, по умолчанию, весь документ может представлять собой один блок совместимых данных.
Существуют два основных подхода к внедрению допустимых ошибок. Первый состоит в том, что допустимые ошибки могут быть точно вычислены с помощью алгоритма «diff». Например, используемый алгоритм может представлять собой библиотеку «Удаленная дифференциальная компрессия» (Remote Differential Compression, RDC), библиотека обнаружена в платформе WINDOWS. Алгоритмический подход обладает преимуществом, состоящим в том, что данные можно считать неявными, и тогда никакой структуры или структурных сведений может не потребоваться. Это является идеальным для сценариев, когда формат документа фиксирован, неизвестен или не может быть изменен. Не ограничивающие примеры форматов файла, которые является фиксированными, неизвестными или которые нельзя изменить, включают в себя текстовые форматы, растровые изображения и аудиофайлы.
Однако ценой за эту приспособляемость является высокая себестоимость вычислений и неэффективность передачи данных, вызванной изменениями, которые невозможно хорошо отследить с помощью алгоритма. Это может произойти, если не была разработана эффективная синхронизация данных. То есть данные не обладают «явно заданными» допустимыми ошибками или хорошей локальностью изменений.
Второй подход состоит в том, что допустимые ошибки можно подразделить на меньшие блоки изменений, называемые «гранулами», которые можно относительно близко выровнять с ожидаемыми изменениями. Относительная ошибка в таком случае представляет собой набор гранул, которые могут различаться по двум состояниям. Эта схема является менее дорогостоящей для вычислений и потенциально более эффективна, когда данные можно удачно разделить на небольшие блоки изменений, которые близко выровнены с ожидаемыми корректировками.
Два подхода можно использовать независимо или в сочетании друг с другом. Например, при использовании двух подходов в сочетании друг с другом модель доступа к документу может обеспечить произвольный уровень крупности разбиения на модули в блоках совместимых данных. Через схему явно заданной допустимой ошибки механизмы синхронизации могут повысить произвольный уровень крупности разбиения, что приводит к повышению эффективности.
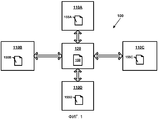
Обратимся теперь к фигурам: фиг.1 иллюстрирует примерную авторскую систему 100, обладающую признаками, которые иллюстрируют примерные особенности раскрытия. Авторская система 100 включает в себя устройство хранения данных 120, на котором хранится главная копия документа 150. В одном варианте воплощения устройство хранения 120 может включать в себя (но не ограничено) сервер, клиентский компьютер или другое вычислительное устройство. В другом варианте воплощения устройство хранения 120 может включать в себя одно или несколько устройств хранения (например, сеть вычислительных устройств).
Авторская система 100 также включает в себя одно или несколько клиентских вычислительных устройств 110A, 110B, 110C, 110D, связанные с возможностью обмена данными с устройством хранения данных 120. Каждое из клиентских вычислительных устройств может редактировать документ 150 путем получения обновления на один или несколько блоков совместимых данных 155 и редактирования объектов данных в блоке совместимых данных 155. Блоки совместимых данных 155 синхронизируют, когда клиентские вычислительные устройства периодически посылают на устройство хранения данных 120 обновления, которые оно разделяет с другими клиентскими вычислительными устройствами.
Как вытекает из термина, используемого в настоящем документе, клиентское вычислительное устройство включает в себя любое вычислительное устройство, которое достигает блока совместимых данных, создаваемого из главной копии документа. Клиентское вычислительное устройство может быть отличным от устройства хранения данных 120 или может включать в себя другую клиентскую учетную запись, реализуемую на устройстве хранения данных 120. В одном варианте воплощения вычислительное устройство, которое действует как устройство хранения данных 120 для одного документа, может действовать как клиентское вычислительное устройство для другого документа и наоборот.
В показанном примере четыре клиентских вычислительных устройства 110A, 110B, 110C и 110D соединены, с возможностью обмена данными, с устройством хранения данных 120. Однако в других вариантах воплощения с устройством хранения данных 120 может быть соединено любое количество вычислительных устройств. В показанном примере каждое клиентское вычислительное устройство 110A, 110B, 110C, 110D может посылать на устройство хранения данных 120 обновления, созданные клиентом клиентского вычислительного устройства, и может запрашивать с устройства хранения данных 120 другие блоки совместимых данных для редактирования/авторинга. В одном варианте воплощения устройство хранения данных 120 может представлять собой серверное вычислительное устройство, а клиентские вычислительные устройства могут представлять собой клиентские вычислительные устройства 110A, 110B, 110C, 110D. Возможны и другие конфигурации системы. Например, в альтернативном варианте воплощения можно использовать несколько серверных вычислительных устройств.
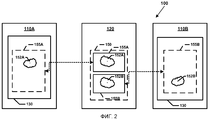
Как показано на фиг.2, документ 150, хранимый на устройстве хранения данных 120, может включать в себя контент 152A и 152B, разбитый на блоки совместимых данных 155A, 155B. Авторские приложения 130 на клиентских вычислительных устройствах 110 обрабатывают и управляют контентом блоков совместимых данных 155A, 155B документа 150. Вообще говоря, клиентское вычислительное устройство 11 OA может синхронизировать обновления для контента 152A отдельно от обновлений, обеспечиваемых клиентским вычислительным устройством 110B. Поскольку обновления делаются для различных блоков совместимых данных, между блоками совместимых данных конфликт слияния не возникнет.
Обратимся к фиг.3. Показан блок совместимых данных 155A (то есть структура данных), включающий в себя множество версий программы для блока совместимых данных 155A 305, 310 и 315. Ячейки представляют собой группы объектов данных со сходными свойствами. Например, ячейка может содержать группу текстов, группу рисунков и т.д. Каждая из ячеек 305, 310 и 315 включает в себя идентификатор ячейки 320 (показанный лишь для ячейки 305), который однозначно идентифицирует конкретную ячейку в документе 150. Каждая из ячеек 305, 310 и 315 может сообщаться, по меньшей мере, с одной другой ячейкой внутри документа 150, с использованием идентификаторов ячеек. Также каждая из ячеек 305, 310 и 315 ассоциирована, по меньшей мере, с одной версией программы 325 (показанной лишь для ячейки 305). Следует отметить, что состояние ячейки описывается версией, которая содержит состояние группы объектов данных.
Каждая ячейка может включать в себя идентификатор ячейки, включающий в себя пару глобально уникального идентификатора (globally unique identifier, GUID) и целого числа (integer, INT). Каждая ячейка также может быть включена в файл, задающий совокупность ячеек и версий. Область действия также может включать в себя, по меньшей мере, один корневой объект. Ячейки в области определения могут быть доступны через корневые объекты. Идентификатор ячейки может быть ассоциирован с первой версией, включающей в себя, по меньшей мере, один первый идентификатор версии. Каждый, по меньшей мере, из одного идентификатора версии может представлять состояние ячеек в момент времени. Под термином «файл» понимается не то, что он используется для представления поименованного сохраняемого «логического объекта», и он не должен представлять собой физический файл, такой как текстовой файл или изображение jpeg.
Блок совместимых данных 155A включает в себя множество объектов данных 330, 335, 340 и 345, задающих содержание документа 150. Как правило, объекты данных могут представлять собой произвольные двоичные данные. Неисключительные примеры объектов данных включают в себя текст, рисунок, таблицу, гиперссылку, файл кинофрагмента, аудиофайл и т.д. Каждый объект данных 330, 335, 340 и 345 ассоциирован с одной из ячеек 305, 310 и 315 и имеет идентификатор объекта, который однозначно идентифицирует объект данных в ассоциированной ячейке. Например, идентификатор объекта 350 однозначно идентифицирует объект данных 330 в ячейке 305. Идентификаторы ячеек, идентификаторы объектов и идентификаторы версий могут включать в себя пару GUID и INT. Кроме того, GUID может быть глобально уникальной внутри ячейки.
Каждый объект данных 330, 335, 340 и 345 сконфигурирован таким образом, чтобы он сообщался с другими ячейками и с объектами внутри ассоциированной ячейки. Например, объект данных 330 может сообщаться с опорными ячейками 310 и 315, причем в опорных ячейках 310 и 315 не содержатся объекты. Это помогает обеспечивать согласованность, даже если одна ячейка изменяется независимо от другой. Обычно объект может адресоваться к любому другому объекту в пределах той же ячейки и к другим ячейкам, но не к объектам в других ячейках. В дополнение, каждая из ячеек 305, 310 и 315 задана таким образом, чтобы каждая другая ячейка оставалась неподверженной изменениям объектов данных ячейки. Также, каждая ячейка 305, 310 и 315 может быть способна адресоваться, по меньшей мере, к одной ячейке в пределах области действия. Область действия может задавать совокупность ячеек и версий. См. фиг.4, где схематически изображена область действия.
В ходе разбиения каждый из объектов данных 330, 335, 340 и 345 можно сгруппировать, по меньшей мере, в одну группу объектов. Использование групп объектов минимизирует служебные сигналы сопровождаемых объектов каждого по отдельности. В сценарии, когда все объекты относительно крупные, наличие групп объектов может быть необязательным, поскольку служебные сигналы малы. Однако в сценарии, когда объекты могут быть произвольно малы, группы объектов используют для контроля служебных сигналов. Группы объектов также учитывают отбор объектов (то есть блоков изменений) и их группирование в более крупные блоки. В ходе разделения на части возникает необходимость в тестировании и поддержании характеристик «блока изменений» как раз созданных групп.
Устройство хранения данных 120 может сортировать объекты данных 330, 335, 340 и 345 по группам объектов, исходя из различных факторов, таких как вероятность (то есть эвристика, основанная на применении), с которой каждый объект данных будет обновлен клиентским компьютером 110. Например, объекты могут быть сгруппированы по нескольким категориям. Не ограничивающие примеры этих категорий включают в себя: 1) типы объектов, про которые известно, что они часто изменяются (например, свойства метаданных документа, такие как подсчет слов и последний момент изменений); ii) типы объектов, про которые известно, что они изменяются очень часто (например, рисунки); iii) объекты, частота изменений который неизвестна; и iv) объекты, которые часто изменялись (например, списковая структура для списка, который пользователь непрерывно изменял).
В дополнение, устройство хранения данных 120 может сортировать объекты данных 330, 335, 340 и 345 по группам объектов, исходя из размера каждого объекта данных. Например, в алгоритм сортировки можно вводить размер. Если объект считается крупным, то служебный сигнал отслеживания объекта как одиночный объект становится незначительным. Это особенно верно, когда выгода просчитывалась (то есть это способствует предотвращению выборки или синхронизации объекта, которая не обязательна). Если объект очень мал по отношению к служебному сигналу группы объектов, то объект может быть включен в группу независимо от того, как часто объект изменяется.
Как указывалось выше, каждая ячейка 305, 310 и 315 может быть пригодной для адресации, по меньшей мере, к одной ячейке в области действия, и область действия может определять совокупность ячеек и версий. Фиг.4 показывает схематическую блок-схему области действия 400. Область действия 400 включает в себя корневую ячейку 405, ячейку 410 и ячейку «мусорных» данных 415. Например, корневая ячейка 405 включает в себя версии 420, 425 и 430. Пример версии может включать в себя последний автосохраненный экземпляр блока сохраненных данных 155A, то есть состояние файла перед последним изменением. Например, версия может включать в себя состояние текстового поля перед тем, как текст был добавлен (версия один). Если текст добавляют к текстовому полю, может быть создана новая версия (версия два). Поэтому, операция «отмена выполненного действия» может приводить к возвращению от версии два к версии один. Также, каждая ячейка может включать в себя различное количество версий. Например, ячейка 405 включает в себя две версии (версии 435 и 440), а ячейка ненужной информации включает в себя одну версию (версию 445).
Версии ячеек достигаются за счет разбиения документа на блоки совместимых данных, которые позволяют блоку репликации (или обновления) быть значительно меньше, чем весь документ. Использование версий ячеек позволяет повысить быстродействие изменений. В случае частичной синхронизации (то есть наличия синхронизирующих блоков совместимых данных в противовес синхронизации всего документа) разбиение позволяет замечать обновления, которые в противном случае не были бы заметны. Эффективное разбиение позволяет также осуществлять слияние приложений, чтобы запускать меньшее их количество. Например, конфликты, по определению, могут возникать, только когда возникают изменения в самом блоке совместимых данных, а любые другие изменения в других блоках совместимых данных не могут породить конфликты, и синхронизационное приложение можно запускать без обязательного слияния. В дополнение, блоки совместимых данных могут образовывать эффективный базис для операций пошаговой загрузки/сохранения. Сценарии загрузки и синхронизации, когда они полностью интегрированы с приложением, являются более быстродействующими, и, таким образом, могут быть получены новые свойства раздельного/совместного использования данных.
Для поддержания совместимости в пределах блока совместимых данных необходимо гарантировать, чтобы все обновления были совместимыми. Это влечет за собой то, что потенциально несовместимые обновления должны быть укомплектованы друг с другом, с образованием совместимого обновления и транзакции. Прикладной программный интерфейс (access application programming interface, API) субфайла может производить обновления через транзакции, без неконтролируемого уровня диапазона побайтового доступа.
Для контроля эффективной синхронизации и репликации может быть использован субфайл репликации, который может быть создан на уровне блока совместимых данных (то есть разбиение на разделы). В такой простейшей форме это может вызвать не что иное, как назначение GUID каждому разделу, который изменяется всякий раз, когда создается обновление для этого раздела.
Обновления могут быть сделаны на уровне блока совместимых данных за счет новых версий в форме переходов. Синхронизации могут повлечь за собой пересылку новой версии (то есть состояний) между клиентом и сервером. Однако обновления обычно бывают небольшими и основываются на некотором предыдущем состоянии, которое может быть в наличии как у клиента, так и у сервера. Это может быть выгодно использовано при передаче приращений или дельт, что делает синхронизацию более эффективной.
Каждая версия может включать в себя любое количество объектов данных. Например, версия 425 имеет три объекта данных (объекты данных 450, 455 и 460). Для каждой версии ячейки можно создать манифест версии 470. Манифест версии 470 может указывать на корневую совокупность объектов, содержащихся в версии, любую зависимость/ссылки для манифестов других версий и группы объектов (то есть каким образом объекты расположены в группе объектов). Каждый манифест версии 470 может указывать на другие группы объектов, заданные в манифесте предыдущей версии.
Манифест версии 470 может задавать версию, представляющую состояние документа 150 в момент времени. Манифест версии 470 включает в себя, по меньшей мере, одну группу объектов, а каждая группа объектов включает в себя, по меньшей мере, один объект данных. Манифест версии 470 также описывает одиночную версию, которую, по определению, можно использовать лишь для описания состояния объектов в одиночной ячейке (которая представляет собой блок совместимых данных).
Второе вычислительное устройство (например, устройство хранения данных 120) может частично или полностью определять, какие объекты данных в какую группу объектов помещены. Второе вычислительное устройство также может задавать каждую группу объектов, исходя из того, как часто каждый объект обновляется. В дополнение, второе вычислительное устройство может задавать каждую группу объектов, исходя из размера объекта. Также, первое вычислительное устройство (например, клиентский компьютер 110) может влиять на то, какие объекты данных в какие группы объектов помещены.
Обратимся теперь к фиг.5, где клиентское устройство 110A показано более подробно. Клиентское устройство 110A может представлять собой персональный компьютер, серверный компьютер, компьютер-ноутбук, персональный цифровой секретарь, смартфон или любое другое подобное вычислительное устройство.
На фиг.5 примерное клиентское вычислительное устройство 11 OA обычно включает в себя, по меньшей мере, один блок обработки данных 515 для исполнения программных приложений и программ, хранящихся в системной памяти 520. В зависимости от конкретной конфигурации и типа вычислительного устройства 110A системная память 520 может включать в себя (но не ограничена) RAM (random access memory, оперативное запоминающее устройство, ОЗУ), ROM (read-only memory, постоянное запоминающее устройство, ПЗУ), EEPROM (Electrically Erasable Programmable Read-Only Memory, электрически стираемое программируемое постоянное запоминающее устройство, ЭСППЗУ), флэш-память, CD-ROM, digital versatile disks (цифровой универсальный диск, DVD) или другие оптические устройства хранения данных, магнитные кассеты, магнитные ленты, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, или другие запоминающие технологии.
В памяти системы 520 обычно хранится операционная система 522, такая как операционная система WINDOWS® от Корпорации Майкрософт, Редмонд, Вашингтон, пригодная для регулирования работы вычислительного устройства 110A. Память системы 520 также может включать в себя кэш документа 526, в котором может храниться блок совместимых данных 527 документа. В кэше клиента 526 также могут храниться метаданные 529 документа.
В памяти системы 520 также может храниться одно или несколько прикладных программ, таких как приложения для создания авторских разработок 130, которые используют для создания и редактирования документов. Один не ограничивающий пример авторских приложений 130, пригодных для создания документов в соответствии с принципами настоящего раскрытия, - это программное средство обработки текстов WORD® от корпорации Майкрософт. Другие неограничивающие примеры приложений для создания авторских разработок включают в себя презентационное программное обеспечение POWERPOINT®, программное обеспечение VISIO® для черчения и составления графиков и Интернет-браузер INTERNET EXPLORER®, - все от корпорации Майкрософт. Также можно использовать и другие прикладные программы.
Вычислительное устройство 110A также может иметь устройство (устройства) ввода 530, такие как клавиатура, мышь, «перо», устройство для речевого ввода, сенсорное устройство ввода и т.д., для ввода и управления данными. Также может быть включено устройство (устройства) вывода 535, такое как экран дисплея, динамик ПК, принтер и т.д. Эти устройства вывода 535 хорошо известны в данной области техники и не нуждаются здесь в подробном обсуждении.
Вычислительное устройство 110A также может содержать средства связи 540, которые позволяют устройству 110A иметь связь с другими вычислительными устройствами, например, устройством хранения 120 из фиг.1, по сети в распределенной вычислительной среде (например, интрасеть или Интернет). В качестве примера и без ограничений, среда устройств связи 540 включает в себя проводную среду, такую как проводная сеть или однопроводное соединение, и беспроводную среду, такую как акустическая, радиочастотная, инфракрасная и другие беспроводные среды.
Фиг.6 представляет собой блок-схему, излагающую основные стадии, включенные в способ 600, соответствующий варианту воплощения раскрытия для синхронизации документа после изменений, сделанных для создания блока совместимых данных. Способ 600 может быть внедрен с использованием вычислительного устройства 110A, как было описано выше применительно к фиг.5. Пути внедрения стадий способа 600 будут подробнее описаны ниже.
Способ 600 начинается с запуска блока 605 и перехода к стадии 610, где вычислительное устройство 110A может принимать версию и любые ячейки, к которым эта версия приложена. Например, совокупность версий может быть получена вместе с соответствующими командами относительно того, какие ячейки должны обладать состоянием, настроенным на определенную версию. Иными словами, при синхронизации происходит прием следующего: i) {версии} - совокупности версий; ii) {(ячейки, версии)} - совокупности идентификаторов ячеек, кортежи идентификаторов версии, которые описывают ячейки, которые «модифицируются», и каково их новое состояние с точки зрения полученных версий. Термин «модифицируется» означает, что некоторая часть информации в версии изменяется. Например, клиент, используя вычислительное устройство 110A (например, клиентский компьютер) может принимать слайд из презентации или информацию из заголовка/сноски документа обработки текста. Как только изменения были применены, средство хранения документов может обходиться без каких-либо ячеек и/или версий, которые не могут быть «раскрыты» путем запуска в корневых ячейках и прослеживания ссылок на объект/ячейку. Термин «раскрытие» относится к оптимизации, которую средства хранения могут осуществлять, чтобы избавиться от посторонней информации, которая больше не используется клиентами, поскольку у клиентов нет никакой возможности получить доступ к этим данным. Например, как только изменения были применены, средство хранения данных может освободиться от любых ячеек и/или версий, к которым они больше не адресуются прямо или косвенно в корневых ячейках.
После стадии 610, где вычислительное устройство 110A принимает версию и соответствующие ячейки, к которым эти версии прилагаются, способ 600 может перейти к стадии 620, на которой вычислительное устройство 110A может принимать обновления к блоку совместимых данных 527. Обновления могут указывать на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с блоком совместимых данных 527 или документом 150. Например, на вычислительном устройстве 110A можно запускать презентационную графическую программу POWERPOINT®, а блок совместимых данных 527 может представлять собой слайд. Обновления к слайду могут быть получены, когда пользователь редактирует слайд.
Как только вычислительное устройство 11 OA принимает обновления на блок совместимости 527 на стадии 620, способ 600 может перейти к стадии 680, где вычислительное устройство 110A определяет, надо ли сохранять первую версию, или следует генерировать новую версию. Когда вычислительное устройство 110A определяет, что первую версию следует сохранить, способ 600 переходит к стадии 630, где вычислительное устройство 110A может сохранять первую версию. Первую версию можно сохранять, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки. Пример, когда идентификатор первой версии может соответствовать идентификатору обновленной версии, - это когда версия создается, а затем версия отменяется. Например, пользователь может печатать слово на слайде, а затем стирать вновь напечатанное слово. Поскольку слайд не изменялся, нет необходимости в генерировании новой версии.
Когда вычислительное устройство 110A определяет, что новая версия создана, способ 600 переходит от стадии 680 к стадии 640, где вычислительное устройство 110A генерирует новую версию. Генерирование новой версии может включать в себя назначение новой версии нового идентификатора версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки. Генерирование новой версии также может включать в себя определение для каждой ячейки, соответствует ли идентификатор каждого объекта в ячейке идентификатору обновленной версии. Идентификатор обновленного объекта может определять манифест версии. Манифест версии может определять версию блока совместимых данных 527 или документа и может включать в себя, по меньшей мере, первую группу объектов, которая содержит, по меньшей мере, первый объект данных. Манифест версии также может указывать на манифест предыдущей версии. Например, в ходе редактирования пользователем приложение отслеживает совокупность объектов, которые модифицируются в виде части пользовательской редакторской правки. Затем создают идентификатор новой версии с использованием стандартного алгоритма генерирования GUID. Совокупность объектов затем упаковывают в группы объектов (как обсуждалось выше), а затем группы объектов и манифест предыдущей версии извлекают из манифеста новой версии, который представляет новую версию.
Сразу после генерирования новой версии на стадии 640 вычислительным устройством 110A способ 600 может переходить к стадии 650, где вычислительное устройство 110A может очищать память любой ячейки, на которую не ссылаются корневые объекты. Очистка памяти включает в себя определение объектов, которые невозможно «раскрыть» путем отслеживания ссылок на объект/ячейку, возникающих в корневых ячейках. Поскольку ячейки с очищенной памятью не могут быть доступны, в них никогда не возникнет необходимость, и дисковое пространство/ресурс можно очищать, стирая их.
Как только вычислительное устройство 110A стирает любую ячейку, на которую корневые объекты не ссылаются на стадии 650, способ 600 может переходить к стадии 660, где вычислительное устройство 110A может синхронизировать документ 150 или блок совместимых данных 527. Например, вычислительное устройство 110A может синхронизировать документ путем замены существующих ячеек на новую версию каждой ячейки. Как только вычислительное устройство 110A синхронизировало документ 150 или блок совместимых данных 527 на стадии 660, способ 600 может затем завершиться на стадии 670.
На всем протяжении данного описания могли упоминаться выражения «один вариант воплощения», «вариант воплощения», «варианты воплощения», «особенность» или «особенности», означающие, что конкретный описанный признак, структура или характеристика может быть включена, по меньшей мере, в один вариант воплощения настоящего раскрытия. Таким образом, использование таких фраз может относиться более чем только к одному варианту воплощения или особенности. В дополнение, описанные признаки, структуры или характеристики могут сочетаться между собой любым подходящим образом в одном или более вариантах воплощения или особенностях. Кроме того, ссылка на одиночный предмет может означать одиночный предмет или множество предметов, точно так же как ссылка на множество предметов может означать одиночный предмет. Более того, использование термина «и», встроенного в перечень, должно подразумевать, что были рассмотрены все элементы перечня, одиночный пункт перечня или любое сочетание пунктов в перечне.
Варианты воплощения раскрытия могут быть внедрены в виде компьютерного процесса (способа), вычислительной системы или в виде готового изделия, такого как компьютерный программный продукт или машиночитаемый носитель. Процессы (программы) можно внедрять любым числом способов, включая структуры, описанные в данном документе. Один такой способ состоит в машинных операциях, и устройства этого типа описаны в данном документе. Другой способ (не обязательный) предназначен для одной или нескольких отдельных операций согласно способам, выполняемым на вычислительном устройстве совместно с одним или несколькими операторами-людьми, выполняющими некоторые из этих операций. Эти люди-операторы не нуждаются в том, чтобы находиться рядом друг с другом, и каждый из них может находиться лишь рядом с машиной, которая выполняет свою часть программы.
Компьютерный программный продукт может представлять собой среду для хранения информации компьютера, считываемую компьютерной системой и кодирующую компьютерную программу в виде команд для исполнения компьютерного процесса. Компьютерный программный продукт также может представлять собой сигнал, распространяющийся на носителе, считываемом вычислительной системой, и кодирующий компьютерную программу в виде команд для исполнения компьютерного процесса. Термин «среда для хранения информации компьютера», используемый в настоящем документе, включает в себя как среду хранения данных, так и среду передачи данных.
Специалистам в данной области техники должно быть понятно, что раскрытие можно применять с использованием компьютеров с другими конфигурациями системы, включая портативные устройства, многопроцессорные системы, электронику на основе микропроцессоров или программируемую бытовую электронику, миникомпьютеры, мэйнфреймы и т.п. Раскрытие также можно применять в распределенной вычислительной среде, где задачи выполняются с использованием устройств дистанционной обработки, связанных через сети передачи данных. В распределенной вычислительной среде программные модули могут быть расположены как в локальных, так и в удаленных устройствах памяти. Обычно программные модули включают в себя подпрограммы, программы, компоненты, структуры данных и другие типы структур, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных.
Claims (12)
1. Способ синхронизации документа на первом вычислительном устройстве, причем документ разбивают на ячейки, а каждая ячейка задается, по меньшей мере, одним манифестом версии, причем способ включает в себя:
прием первой версии и, по меньшей мере, одной ячейки, ассоциированной с документом, причем, по меньшей мере, одна ячейка содержит идентификатор ячейки, содержащий пару глобально уникального идентификатора и целого числа, причем глобально уникальный идентификатор является глобально уникальным, а идентификатор ячейки ассоциирован с первой версией, содержащей, по меньшей мере, один идентификатор первой версии, причем каждый из, по меньшей мере, одного идентификатора первой версии представляет состояние ячеек в момент времени, а область действия задает совокупность ячеек и версий, и причем область действий включает в себя, по меньшей мере, один корневой объект, причем ячейки в пределах области действия доступны, по меньшей мере, через один корневой объект;
прием обновления для первого вычислительного устройства, причем обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом;
сохранение первой версии каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки;
генерирование новой версии каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии идентификатора новой версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки;
стирание любой ячейки, на которую не было ссылки в корневых объектах;
и
синхронизацию документа путем замены ячеек на новую версию каждой ячейки.
прием первой версии и, по меньшей мере, одной ячейки, ассоциированной с документом, причем, по меньшей мере, одна ячейка содержит идентификатор ячейки, содержащий пару глобально уникального идентификатора и целого числа, причем глобально уникальный идентификатор является глобально уникальным, а идентификатор ячейки ассоциирован с первой версией, содержащей, по меньшей мере, один идентификатор первой версии, причем каждый из, по меньшей мере, одного идентификатора первой версии представляет состояние ячеек в момент времени, а область действия задает совокупность ячеек и версий, и причем область действий включает в себя, по меньшей мере, один корневой объект, причем ячейки в пределах области действия доступны, по меньшей мере, через один корневой объект;
прием обновления для первого вычислительного устройства, причем обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом;
сохранение первой версии каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки;
генерирование новой версии каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии идентификатора новой версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки;
стирание любой ячейки, на которую не было ссылки в корневых объектах;
и
синхронизацию документа путем замены ячеек на новую версию каждой ячейки.
2. Способ по п.1, в котором генерирование новой версии включает в себя определение для каждой ячейки, соответствует ли идентификатор объекта каждого объекта в ячейке идентификатору обновленного объекта.
3. Способ по п.2, в котором идентификатор обновленного объекта задает манифест версии, задающий версию документа и включающий в себя, по меньшей мере, первую группу объектов, которая содержит, по меньшей мере, первый объект данных.
4. Способ по п.3, в котором манифест версии указывает на группу объектов, заданную в предыдущем манифесте версии.
5. Машиночитаемый запоминающий носитель, содержащий сохраненные на нем машиноисполняемые команды, которые при исполнении выполняют способ синхронизации документа на первом вычислительном устройстве, причем документ разбивается на ячейки, а каждая ячейка задается, по меньшей мере, одним манифестом версии, причем способ включает в себя:
прием первой версии и, по меньшей мере, одной ячейки, ассоциированной с документом, причем, по меньшей мере, одна ячейка содержит идентификатор ячейки, содержащий пару глобально уникального идентификатора и целого числа, причем глобально уникальный идентификатор является глобально уникальным, а идентификатор ячейки ассоциирован с первой версией, содержащей, по меньшей мере, один идентификатор первой версии, причем каждый из, по меньшей мере, одного идентификатора первой версии представляет состояние ячеек в момент времени, а область действия задает совокупность ячеек и версий, и причем область действий включает в себя, по меньшей мере, один корневой объект, причем ячейки в пределах области действия доступны, по меньшей мере, через один корневой объект;
прием обновления для первого вычислительного устройства, причем обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом;
сохранение первой версии каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки;
генерирование новой версии каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии идентификатора новой версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки;
стирание любой ячейки, на которую не было ссылки в корневых объектах; и
синхронизацию документа путем замены ячеек на новую версию каждой ячейки.
прием первой версии и, по меньшей мере, одной ячейки, ассоциированной с документом, причем, по меньшей мере, одна ячейка содержит идентификатор ячейки, содержащий пару глобально уникального идентификатора и целого числа, причем глобально уникальный идентификатор является глобально уникальным, а идентификатор ячейки ассоциирован с первой версией, содержащей, по меньшей мере, один идентификатор первой версии, причем каждый из, по меньшей мере, одного идентификатора первой версии представляет состояние ячеек в момент времени, а область действия задает совокупность ячеек и версий, и причем область действий включает в себя, по меньшей мере, один корневой объект, причем ячейки в пределах области действия доступны, по меньшей мере, через один корневой объект;
прием обновления для первого вычислительного устройства, причем обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом;
сохранение первой версии каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки;
генерирование новой версии каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии идентификатора новой версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки;
стирание любой ячейки, на которую не было ссылки в корневых объектах; и
синхронизацию документа путем замены ячеек на новую версию каждой ячейки.
6. Машиночитаемый запоминающий носитель по п.5, в котором генерирование новой версии включает в себя определение для каждой ячейки, соответствует ли идентификатор объекта каждого объекта в ячейке идентификатору обновленного объекта.
7. Машиночитаемый запоминающий носитель по п.5, в котором идентификатор обновленного объекта задает манифест версии, задающий версию документа и включающий в себя, по меньшей мере, первую группу объектов, которая содержит, по меньшей мере, первый объект данных.
8. Машиночитаемый запоминающий носитель по п.5, в котором манифест версии указывает на группу объектов, заданную в предыдущем манифесте версии.
9. Компьютерная система для обновления множества имеющихся публикаций с использованием одного запроса на комплектование публикации, причем компьютерная система содержит:
по меньшей мере, один процессор; и
по меньшей мере, одно запоминающее устройство, соединенное с возможностью связи с, по меньшей мере, одним процессором и содержащее машиночитаемые команды, которые, при исполнении по меньшей мере одним процессором, выполняют способ синхронизации документа на первом вычислительном устройстве, причем документ разбивается на ячейки, а каждая ячейка задается, по меньшей мере, одним манифестом версии, причем способ включает в себя:
прием первой версии и, по меньшей мере, одной ячейки, ассоциированной с документом, причем, по меньшей мере, одна ячейка содержит идентификатор ячейки, содержащий пару глобально уникального идентификатора и целого числа, причем глобально уникальный идентификатор является глобально уникальным, а идентификатор ячейки ассоциирован с первой версией, содержащей, по меньшей мере, один идентификатор первой версии, причем каждый из, по меньшей мере, одного идентификатора первой версии
представляет состояние ячеек в момент времени, а область действия задает совокупность ячеек и версий, и причем область действий включает в себя, по меньшей мере, один корневой объект, причем ячейки в пределах области действия доступны, по меньшей мере, через один корневой объект;
прием обновления для первого вычислительного устройства, причем обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом;
сохранение первой версии каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки;
генерирование новой версии каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии идентификатора новой версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки;
стирание любой ячейки, на которую не было ссылки в корневых объектах; и
синхронизацию документа путем замены ячеек на новую версию каждой ячейки.
по меньшей мере, один процессор; и
по меньшей мере, одно запоминающее устройство, соединенное с возможностью связи с, по меньшей мере, одним процессором и содержащее машиночитаемые команды, которые, при исполнении по меньшей мере одним процессором, выполняют способ синхронизации документа на первом вычислительном устройстве, причем документ разбивается на ячейки, а каждая ячейка задается, по меньшей мере, одним манифестом версии, причем способ включает в себя:
прием первой версии и, по меньшей мере, одной ячейки, ассоциированной с документом, причем, по меньшей мере, одна ячейка содержит идентификатор ячейки, содержащий пару глобально уникального идентификатора и целого числа, причем глобально уникальный идентификатор является глобально уникальным, а идентификатор ячейки ассоциирован с первой версией, содержащей, по меньшей мере, один идентификатор первой версии, причем каждый из, по меньшей мере, одного идентификатора первой версии
представляет состояние ячеек в момент времени, а область действия задает совокупность ячеек и версий, и причем область действий включает в себя, по меньшей мере, один корневой объект, причем ячейки в пределах области действия доступны, по меньшей мере, через один корневой объект;
прием обновления для первого вычислительного устройства, причем обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом;
сохранение первой версии каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки;
генерирование новой версии каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии идентификатора новой версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки;
стирание любой ячейки, на которую не было ссылки в корневых объектах; и
синхронизацию документа путем замены ячеек на новую версию каждой ячейки.
10. Компьютерная система по п.9, в которой генерирование новой версии включает в себя определение для каждой ячейки, соответствует ли идентификатор объекта каждого объекта в ячейке идентификатору обновленного объекта.
11. Компьютерная система по п.9, в которой идентификатор обновленного объекта задает манифест версии, задающий версию документа и включающий в себя, по меньшей мере, первую группу объектов, которая содержит, по меньшей мере, первый объект данных.
12. Компьютерная система по п.9, в которой манифест версии указывает на группу объектов, заданную в предыдущем манифесте версии.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US12/113,975 | 2008-05-02 | ||
| US12/113,975 US8078957B2 (en) | 2008-05-02 | 2008-05-02 | Document synchronization over stateless protocols |
| PCT/US2009/039796 WO2009134596A2 (en) | 2008-05-02 | 2009-04-07 | Document synchronization over stateless protocols |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| RU2010144794A RU2010144794A (ru) | 2012-05-10 |
| RU2500023C2 true RU2500023C2 (ru) | 2013-11-27 |
Family
ID=41255667
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| RU2010144794/08A RU2500023C2 (ru) | 2008-05-02 | 2009-04-07 | Синхронизация документа по протоколу, не использующему информацию о состоянии |
Country Status (12)
| Country | Link |
|---|---|
| US (2) | US8078957B2 (ru) |
| EP (1) | EP2283439B1 (ru) |
| JP (2) | JP4977801B2 (ru) |
| KR (1) | KR20110010598A (ru) |
| CN (1) | CN102016835B (ru) |
| AU (1) | AU2009241494B2 (ru) |
| BR (1) | BRPI0910917A2 (ru) |
| CA (1) | CA2720235C (ru) |
| HK (1) | HK1154670A1 (ru) |
| MX (1) | MX2010011958A (ru) |
| RU (1) | RU2500023C2 (ru) |
| WO (1) | WO2009134596A2 (ru) |
Families Citing this family (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8078957B2 (en) | 2008-05-02 | 2011-12-13 | Microsoft Corporation | Document synchronization over stateless protocols |
| US9396279B1 (en) | 2009-02-17 | 2016-07-19 | Jpmorgan Chase Bank, Na | Collaborative virtual markup |
| US20100268784A1 (en) * | 2009-04-17 | 2010-10-21 | Marc Henness | Data synchronization system and method |
| US8219526B2 (en) | 2009-06-05 | 2012-07-10 | Microsoft Corporation | Synchronizing file partitions utilizing a server storage model |
| US10140588B2 (en) * | 2009-12-28 | 2018-11-27 | International Business Machines Corporation | Bill of material synchronization |
| US8224874B2 (en) * | 2010-01-05 | 2012-07-17 | Symantec Corporation | Systems and methods for removing unreferenced data segments from deduplicated data systems |
| US11611595B2 (en) | 2011-05-06 | 2023-03-21 | David H. Sitrick | Systems and methodologies providing collaboration among a plurality of computing appliances, utilizing a plurality of areas of memory to store user input as associated with an associated computing appliance providing the input |
| US10402485B2 (en) | 2011-05-06 | 2019-09-03 | David H. Sitrick | Systems and methodologies providing controlled collaboration among a plurality of users |
| US10733151B2 (en) | 2011-10-27 | 2020-08-04 | Microsoft Technology Licensing, Llc | Techniques to share media files |
| US9053079B2 (en) * | 2011-12-12 | 2015-06-09 | Microsoft Technology Licensing, Llc | Techniques to manage collaborative documents |
| US8744999B2 (en) | 2012-01-30 | 2014-06-03 | Microsoft Corporation | Identifier compression for file synchronization via soap over HTTP |
| US20140082473A1 (en) * | 2012-09-14 | 2014-03-20 | David H. Sitrick | Systems And Methodologies Of Event Content Based Document Editing, Generating Of Respective Events Comprising Event Content, Then Defining A Selected Set Of Events, And Generating Of A Display Presentation Responsive To Processing Said Selected Set Of Events, For One To Multiple Users |
| US20140082472A1 (en) * | 2012-09-14 | 2014-03-20 | David H. Sitrick | Systems And Methodologies For Event Processing Of Events For Edits Made Relative To A Presentation, Selecting A Selected Set Of Events; And Generating A Modified Presentation Of The Events In The Selected Set |
| US9372833B2 (en) | 2012-09-14 | 2016-06-21 | David H. Sitrick | Systems and methodologies for document processing and interacting with a user, providing storing of events representative of document edits relative to a document; selection of a selected set of document edits; generating presentation data responsive to said selected set of documents edits and the stored events; and providing a display presentation responsive to the presentation data |
| US9336226B2 (en) | 2013-01-11 | 2016-05-10 | Commvault Systems, Inc. | Criteria-based data synchronization management |
| US10025464B1 (en) | 2013-10-07 | 2018-07-17 | Google Llc | System and method for highlighting dependent slides while editing master slides of a presentation |
| US10423713B1 (en) | 2013-10-15 | 2019-09-24 | Google Llc | System and method for updating a master slide of a presentation |
| US9336228B2 (en) * | 2013-12-18 | 2016-05-10 | Verizon Patent And Licensing Inc. | Synchronization of program code between revision management applications utilizing different version-control architectures |
| US10169121B2 (en) | 2014-02-27 | 2019-01-01 | Commvault Systems, Inc. | Work flow management for an information management system |
| US9785637B2 (en) * | 2014-03-18 | 2017-10-10 | Google Inc. | System and method for computing, applying, and displaying document deltas |
| US9898520B2 (en) | 2014-03-25 | 2018-02-20 | Open Text Sa Ulc | Systems and methods for seamless access to remotely managed documents using synchronization of locally stored documents |
| US9645891B2 (en) | 2014-12-04 | 2017-05-09 | Commvault Systems, Inc. | Opportunistic execution of secondary copy operations |
| US9753816B2 (en) | 2014-12-05 | 2017-09-05 | Commvault Systems, Inc. | Synchronization based on filtered browsing |
| US9588849B2 (en) | 2015-01-20 | 2017-03-07 | Commvault Systems, Inc. | Synchronizing selected portions of data in a storage management system |
| US9952934B2 (en) * | 2015-01-20 | 2018-04-24 | Commvault Systems, Inc. | Synchronizing selected portions of data in a storage management system |
| US20160321226A1 (en) * | 2015-05-01 | 2016-11-03 | Microsoft Technology Licensing, Llc | Insertion of unsaved content via content channel |
| US11003632B2 (en) | 2016-11-28 | 2021-05-11 | Open Text Sa Ulc | System and method for content synchronization |
| US11301431B2 (en) | 2017-06-02 | 2022-04-12 | Open Text Sa Ulc | System and method for selective synchronization |
| US20200327116A1 (en) * | 2017-10-03 | 2020-10-15 | Lyconos, Inc. | Systems and methods for document automation |
| US11570099B2 (en) | 2020-02-04 | 2023-01-31 | Bank Of America Corporation | System and method for autopartitioning and processing electronic resources |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5774868A (en) * | 1994-12-23 | 1998-06-30 | International Business And Machines Corporation | Automatic sales promotion selection system and method |
| RU2314547C2 (ru) * | 2002-02-19 | 2008-01-10 | Квэлкомм Инкорпорейтед | Способ и устройство, предназначенные для двухэтапного фиксирования изменений при распределении данных в web-ферме |
| US7322012B2 (en) * | 2001-05-29 | 2008-01-22 | Fujitsu Limited | Display program, display method and display device |
| US7325202B2 (en) * | 2003-03-31 | 2008-01-29 | Sun Microsystems, Inc. | Method and system for selectively retrieving updated information from one or more websites |
Family Cites Families (63)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5867399A (en) * | 1990-04-06 | 1999-02-02 | Lsi Logic Corporation | System and method for creating and validating structural description of electronic system from higher-level and behavior-oriented description |
| US6182121B1 (en) * | 1995-02-03 | 2001-01-30 | Enfish, Inc. | Method and apparatus for a physical storage architecture having an improved information storage and retrieval system for a shared file environment |
| US5924092A (en) * | 1997-02-07 | 1999-07-13 | International Business Machines Corporation | Computer system and method which sort array elements to optimize array modifications |
| JPH10301828A (ja) | 1997-04-23 | 1998-11-13 | Fujitsu Ltd | データベース管理方法 |
| JPH11232159A (ja) | 1998-02-13 | 1999-08-27 | The Japan Reserch Institute Ltd | ファイル管理方法およびファイル管理のためのプログラムを記憶した媒体 |
| US6801938B1 (en) | 1999-06-18 | 2004-10-05 | Torrent Systems, Inc. | Segmentation and processing of continuous data streams using transactional semantics |
| US6671757B1 (en) | 2000-01-26 | 2003-12-30 | Fusionone, Inc. | Data transfer and synchronization system |
| US6694336B1 (en) * | 2000-01-25 | 2004-02-17 | Fusionone, Inc. | Data transfer and synchronization system |
| EP2487607A3 (en) * | 2000-08-29 | 2013-03-27 | Open Text S.A. | Tool for collaborative edit/search of dynamic objects |
| EP1532543A4 (en) | 2000-09-11 | 2008-04-16 | Agami Systems Inc | STORAGE SYSTEM COMPRISING PARTITIONED METADATA THAT MIGRATE LIKELY |
| JP2002251350A (ja) * | 2001-02-22 | 2002-09-06 | Sony Corp | 送信装置、受信装置、送受信装置、送信方法および受信方法 |
| US7389201B2 (en) * | 2001-05-30 | 2008-06-17 | Microsoft Corporation | System and process for automatically providing fast recommendations using local probability distributions |
| US7702563B2 (en) * | 2001-06-11 | 2010-04-20 | Otc Online Partners | Integrated electronic exchange of structured contracts with dynamic risk-based transaction permissioning |
| US6928458B2 (en) * | 2001-06-27 | 2005-08-09 | Microsoft Corporation | System and method for translating synchronization information between two networks based on different synchronization protocols |
| TW579463B (en) | 2001-06-30 | 2004-03-11 | Ibm | System and method for a caching mechanism for a central synchronization server |
| KR20040053142A (ko) | 2001-09-26 | 2004-06-23 | 이엠씨 코포레이션 | 대형 파일들의 효율적 관리 |
| US20030117398A1 (en) * | 2001-12-21 | 2003-06-26 | Hubrecht Alain Yves Nestor | Systems and methods for rendering frames of complex virtual environments |
| US7200668B2 (en) * | 2002-03-05 | 2007-04-03 | Sun Microsystems, Inc. | Document conversion with merging |
| US7058664B1 (en) | 2002-04-29 | 2006-06-06 | Sprint Communications Company L.P. | Method and system for data recovery |
| US6925467B2 (en) | 2002-05-13 | 2005-08-02 | Innopath Software, Inc. | Byte-level file differencing and updating algorithms |
| US7096311B2 (en) | 2002-09-30 | 2006-08-22 | Innopath Software, Inc. | Updating electronic files using byte-level file differencing and updating algorithms |
| US7138998B2 (en) | 2002-11-14 | 2006-11-21 | Intel Corporation | Multi-resolution spatial partitioning |
| US7750908B2 (en) * | 2003-04-04 | 2010-07-06 | Agilent Technologies, Inc. | Focus plus context viewing and manipulation of large collections of graphs |
| US7299404B2 (en) | 2003-05-06 | 2007-11-20 | International Business Machines Corporation | Dynamic maintenance of web indices using landmarks |
| US7406499B2 (en) | 2003-05-09 | 2008-07-29 | Microsoft Corporation | Architecture for partition computation and propagation of changes in data replication |
| US20040230903A1 (en) | 2003-05-16 | 2004-11-18 | Dethe Elza | Method and system for enabling collaborative authoring of hierarchical documents with associated business logic |
| US20050010576A1 (en) | 2003-07-09 | 2005-01-13 | Liwei Ren | File differencing and updating engines |
| US20050033811A1 (en) | 2003-08-07 | 2005-02-10 | International Business Machines Corporation | Collaborative email |
| US7401104B2 (en) | 2003-08-21 | 2008-07-15 | Microsoft Corporation | Systems and methods for synchronizing computer systems through an intermediary file system share or device |
| JP2005092583A (ja) | 2003-09-18 | 2005-04-07 | Nippon Telegr & Teleph Corp <Ntt> | メタデータ保存方法及び装置並びにプログラム、メタデータ保存プログラムを記録した記録媒体 |
| US20050289152A1 (en) | 2004-06-10 | 2005-12-29 | Earl William J | Method and apparatus for implementing a file system |
| US7313575B2 (en) * | 2004-06-14 | 2007-12-25 | Hewlett-Packard Development Company, L.P. | Data services handler |
| US7873669B2 (en) | 2004-07-09 | 2011-01-18 | Microsoft Corporation | Direct write back systems and methodologies |
| US7853615B2 (en) * | 2004-09-03 | 2010-12-14 | International Business Machines Corporation | Hierarchical space partitioning for scalable data dissemination in large-scale distributed interactive applications |
| US7613787B2 (en) * | 2004-09-24 | 2009-11-03 | Microsoft Corporation | Efficient algorithm for finding candidate objects for remote differential compression |
| US7401192B2 (en) | 2004-10-04 | 2008-07-15 | International Business Machines Corporation | Method of replicating a file using a base, delta, and reference file |
| US7933868B2 (en) | 2004-11-04 | 2011-04-26 | Microsoft Corporation | Method and system for partition level cleanup of replication conflict metadata |
| WO2006052904A2 (en) | 2004-11-08 | 2006-05-18 | Innopath Software, Inc. | Updating compressed read-only memory file system (cramfs) images |
| US7480654B2 (en) | 2004-12-20 | 2009-01-20 | International Business Machines Corporation | Achieving cache consistency while allowing concurrent changes to metadata |
| US7519579B2 (en) | 2004-12-20 | 2009-04-14 | Microsoft Corporation | Method and system for updating a summary page of a document |
| US7953794B2 (en) | 2005-01-14 | 2011-05-31 | Microsoft Corporation | Method and system for transitioning between synchronous and asynchronous communication modes |
| US7720890B2 (en) | 2005-02-22 | 2010-05-18 | Microsoft Corporation | Ghosted synchronization |
| US7680835B2 (en) | 2005-02-28 | 2010-03-16 | Microsoft Corporation | Online storage with metadata-based retrieval |
| WO2006113597A2 (en) * | 2005-04-14 | 2006-10-26 | The Regents Of The University Of California | Method for information retrieval |
| KR100733054B1 (ko) * | 2005-07-27 | 2007-06-27 | 주식회사 유텍 | 구조화 문서의 동기화를 이용한 문서변환 시스템 및문서변환 방법 |
| US7606812B2 (en) * | 2005-11-04 | 2009-10-20 | Sun Microsystems, Inc. | Dynamic intent log |
| US7660807B2 (en) * | 2005-11-28 | 2010-02-09 | Commvault Systems, Inc. | Systems and methods for cataloging metadata for a metabase |
| CN101005428A (zh) | 2006-01-19 | 2007-07-25 | 华为技术有限公司 | 一种检测与解决数据同步冲突的实现方法 |
| US20070198659A1 (en) | 2006-01-25 | 2007-08-23 | Lam Wai T | Method and system for storing data |
| US8307119B2 (en) | 2006-03-31 | 2012-11-06 | Google Inc. | Collaborative online spreadsheet application |
| AU2007243966B2 (en) * | 2006-05-03 | 2011-05-12 | Telefonaktiebolaget Lm Ericsson (Publ) | Method and apparatus for re-constructing media from a media representation |
| US20080059539A1 (en) * | 2006-08-08 | 2008-03-06 | Richard Chin | Document Collaboration System and Method |
| JP2008077485A (ja) | 2006-09-22 | 2008-04-03 | Sharp Corp | 通信端末装置および制御プログラム |
| JP2008165299A (ja) | 2006-12-27 | 2008-07-17 | Update It Inc | ドキュメント作成システム |
| US20080163056A1 (en) * | 2006-12-28 | 2008-07-03 | Thibaut Lamadon | Method and apparatus for providing a graphical representation of content |
| US7933952B2 (en) | 2007-06-29 | 2011-04-26 | Microsoft Corporation | Collaborative document authoring |
| CN100501744C (zh) * | 2007-09-29 | 2009-06-17 | 腾讯科技(深圳)有限公司 | 一种文档同步方法及系统 |
| US20090144654A1 (en) * | 2007-10-03 | 2009-06-04 | Robert Brouwer | Methods and apparatus for facilitating content consumption |
| US7941399B2 (en) | 2007-11-09 | 2011-05-10 | Microsoft Corporation | Collaborative authoring |
| US9436927B2 (en) * | 2008-03-14 | 2016-09-06 | Microsoft Technology Licensing, Llc | Web-based multiuser collaboration |
| US9262764B2 (en) * | 2008-04-30 | 2016-02-16 | Yahoo! Inc. | Modification of content representation by a brand engine in a social network |
| US8078957B2 (en) | 2008-05-02 | 2011-12-13 | Microsoft Corporation | Document synchronization over stateless protocols |
| US8219526B2 (en) | 2009-06-05 | 2012-07-10 | Microsoft Corporation | Synchronizing file partitions utilizing a server storage model |
-
2008
- 2008-05-02 US US12/113,975 patent/US8078957B2/en active Active
-
2009
- 2009-04-07 EP EP09739398.7A patent/EP2283439B1/en active Active
- 2009-04-07 JP JP2011507525A patent/JP4977801B2/ja active Active
- 2009-04-07 AU AU2009241494A patent/AU2009241494B2/en active Active
- 2009-04-07 CA CA2720235A patent/CA2720235C/en active Active
- 2009-04-07 RU RU2010144794/08A patent/RU2500023C2/ru active
- 2009-04-07 WO PCT/US2009/039796 patent/WO2009134596A2/en active Application Filing
- 2009-04-07 MX MX2010011958A patent/MX2010011958A/es active IP Right Grant
- 2009-04-07 CN CN2009801159031A patent/CN102016835B/zh active Active
- 2009-04-07 BR BRPI0910917A patent/BRPI0910917A2/pt not_active IP Right Cessation
- 2009-04-07 KR KR1020107024015A patent/KR20110010598A/ko active IP Right Grant
-
2011
- 2011-08-16 HK HK11108654.7A patent/HK1154670A1/xx unknown
- 2011-12-08 US US13/315,064 patent/US8984392B2/en active Active
-
2012
- 2012-04-16 JP JP2012093148A patent/JP5376696B2/ja active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5774868A (en) * | 1994-12-23 | 1998-06-30 | International Business And Machines Corporation | Automatic sales promotion selection system and method |
| US7322012B2 (en) * | 2001-05-29 | 2008-01-22 | Fujitsu Limited | Display program, display method and display device |
| RU2314547C2 (ru) * | 2002-02-19 | 2008-01-10 | Квэлкомм Инкорпорейтед | Способ и устройство, предназначенные для двухэтапного фиксирования изменений при распределении данных в web-ферме |
| US7325202B2 (en) * | 2003-03-31 | 2008-01-29 | Sun Microsystems, Inc. | Method and system for selectively retrieving updated information from one or more websites |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2009241494A1 (en) | 2009-11-05 |
| JP5376696B2 (ja) | 2013-12-25 |
| CA2720235A1 (en) | 2009-11-05 |
| AU2009241494B2 (en) | 2014-06-26 |
| EP2283439B1 (en) | 2017-02-15 |
| EP2283439A2 (en) | 2011-02-16 |
| MX2010011958A (es) | 2010-11-30 |
| KR20110010598A (ko) | 2011-02-01 |
| US20120204090A1 (en) | 2012-08-09 |
| RU2010144794A (ru) | 2012-05-10 |
| JP4977801B2 (ja) | 2012-07-18 |
| WO2009134596A2 (en) | 2009-11-05 |
| CN102016835B (zh) | 2013-04-03 |
| US20090276698A1 (en) | 2009-11-05 |
| CA2720235C (en) | 2017-03-21 |
| HK1154670A1 (en) | 2012-04-27 |
| WO2009134596A3 (en) | 2010-01-21 |
| US8984392B2 (en) | 2015-03-17 |
| US8078957B2 (en) | 2011-12-13 |
| CN102016835A (zh) | 2011-04-13 |
| EP2283439A4 (en) | 2013-05-29 |
| JP2011520189A (ja) | 2011-07-14 |
| BRPI0910917A2 (pt) | 2015-09-29 |
| JP2012168968A (ja) | 2012-09-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| RU2500023C2 (ru) | Синхронизация документа по протоколу, не использующему информацию о состоянии | |
| KR102240557B1 (ko) | 데이터 저장 방법, 장치 및 시스템 | |
| JP7158482B2 (ja) | クライアント同期における違反の解決のための方法、コンピュータ可読媒体、及びシステム | |
| US10740087B2 (en) | Providing access to a hybrid application offline | |
| CN102880663B (zh) | 部分去重复的文件的优化 | |
| AU2013210018B2 (en) | Location independent files | |
| KR20160003682A (ko) | 플레이스홀더에 의한 하이드레이션 및 디하이드레이션 기법 | |
| US10909086B2 (en) | File lookup in a distributed file system | |
| WO2010064116A1 (en) | Method, apparatus and computer program product for sub-file level synchronization | |
| CN113282540A (zh) | 一种云对象存储同步方法、装置、计算机设备及存储介质 | |
| CN109614383A (zh) | 数据复制方法、装置、电子设备及存储介质 | |
| EP2336911A1 (en) | Efficient change tracking of transcoded copies | |
| CN113760860B (zh) | 一种数据读取方法和装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PC41 | Official registration of the transfer of exclusive right |
Effective date: 20150306 |