KR20230162800A - 항-sema3a 항체 및 그의 용도 - Google Patents
항-sema3a 항체 및 그의 용도 Download PDFInfo
- Publication number
- KR20230162800A KR20230162800A KR1020237036770A KR20237036770A KR20230162800A KR 20230162800 A KR20230162800 A KR 20230162800A KR 1020237036770 A KR1020237036770 A KR 1020237036770A KR 20237036770 A KR20237036770 A KR 20237036770A KR 20230162800 A KR20230162800 A KR 20230162800A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- antigen
- heavy chain
- light chain
- cdr3
- Prior art date
Links
- 230000027455 binding Effects 0.000 claims abstract description 604
- 239000000427 antigen Substances 0.000 claims abstract description 523
- 108091007433 antigens Proteins 0.000 claims abstract description 523
- 102000036639 antigens Human genes 0.000 claims abstract description 523
- 239000012634 fragment Substances 0.000 claims abstract description 300
- 108010090319 Semaphorin-3A Proteins 0.000 claims abstract description 261
- 241000282414 Homo sapiens Species 0.000 claims abstract description 168
- 210000004027 cell Anatomy 0.000 claims abstract description 112
- 230000000694 effects Effects 0.000 claims abstract description 56
- 238000003556 assay Methods 0.000 claims abstract description 49
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 claims abstract description 37
- 102000013008 Semaphorin-3A Human genes 0.000 claims abstract description 27
- 238000000338 in vitro Methods 0.000 claims abstract description 26
- 210000000020 growth cone Anatomy 0.000 claims abstract description 16
- 241000282465 Canis Species 0.000 claims abstract description 15
- 238000010494 dissociation reaction Methods 0.000 claims abstract description 12
- 230000005593 dissociations Effects 0.000 claims abstract description 12
- 230000012292 cell migration Effects 0.000 claims abstract description 11
- 238000010232 migration assay Methods 0.000 claims abstract description 9
- 238000000034 method Methods 0.000 claims description 70
- 150000007523 nucleic acids Chemical group 0.000 claims description 38
- 238000011282 treatment Methods 0.000 claims description 34
- 239000008194 pharmaceutical composition Substances 0.000 claims description 31
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 29
- 239000003814 drug Substances 0.000 claims description 28
- 239000013598 vector Substances 0.000 claims description 23
- 102000039446 nucleic acids Human genes 0.000 claims description 20
- 108020004707 nucleic acids Proteins 0.000 claims description 20
- 150000001875 compounds Chemical class 0.000 claims description 18
- 125000000539 amino acid group Chemical group 0.000 claims description 17
- 239000000562 conjugate Substances 0.000 claims description 15
- 201000010099 disease Diseases 0.000 claims description 15
- 208000017169 kidney disease Diseases 0.000 claims description 15
- 208000035475 disorder Diseases 0.000 claims description 14
- 206010001580 Albuminuria Diseases 0.000 claims description 13
- 208000009304 Acute Kidney Injury Diseases 0.000 claims description 12
- 208000033626 Renal failure acute Diseases 0.000 claims description 12
- 201000011040 acute kidney failure Diseases 0.000 claims description 12
- 208000020832 chronic kidney disease Diseases 0.000 claims description 12
- 229910052698 phosphorus Inorganic materials 0.000 claims description 12
- 229910052720 vanadium Inorganic materials 0.000 claims description 12
- 229940127121 immunoconjugate Drugs 0.000 claims description 11
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 10
- 208000024985 Alport syndrome Diseases 0.000 claims description 9
- 208000001344 Macular Edema Diseases 0.000 claims description 9
- 206010025415 Macular oedema Diseases 0.000 claims description 9
- 206010028980 Neoplasm Diseases 0.000 claims description 9
- 208000003215 hereditary nephritis Diseases 0.000 claims description 9
- 201000010230 macular retinal edema Diseases 0.000 claims description 9
- 230000001154 acute effect Effects 0.000 claims description 8
- 201000011510 cancer Diseases 0.000 claims description 8
- 230000002265 prevention Effects 0.000 claims description 8
- 201000001474 proteinuria Diseases 0.000 claims description 7
- 206010053198 Inappropriate antidiuretic hormone secretion Diseases 0.000 claims description 6
- 201000008284 inappropriate ADH syndrome Diseases 0.000 claims description 6
- 230000002401 inhibitory effect Effects 0.000 claims description 6
- 208000030761 polycystic kidney disease Diseases 0.000 claims description 6
- 230000002062 proliferating effect Effects 0.000 claims description 6
- 208000011580 syndromic disease Diseases 0.000 claims description 6
- 230000002792 vascular Effects 0.000 claims description 6
- 206010016654 Fibrosis Diseases 0.000 claims description 5
- 230000004761 fibrosis Effects 0.000 claims description 5
- 208000024827 Alzheimer disease Diseases 0.000 claims description 4
- 208000007502 anemia Diseases 0.000 claims description 4
- 229910052739 hydrogen Inorganic materials 0.000 claims description 4
- 230000004770 neurodegeneration Effects 0.000 claims description 4
- 208000037157 Azotemia Diseases 0.000 claims description 3
- 208000003174 Brain Neoplasms Diseases 0.000 claims description 3
- 206010048962 Brain oedema Diseases 0.000 claims description 3
- 206010006187 Breast cancer Diseases 0.000 claims description 3
- 208000026310 Breast neoplasm Diseases 0.000 claims description 3
- 206010008025 Cerebellar ataxia Diseases 0.000 claims description 3
- 206010008027 Cerebellar atrophy Diseases 0.000 claims description 3
- 206010008342 Cervix carcinoma Diseases 0.000 claims description 3
- 208000006332 Choriocarcinoma Diseases 0.000 claims description 3
- 206010009944 Colon cancer Diseases 0.000 claims description 3
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims description 3
- 208000007342 Diabetic Nephropathies Diseases 0.000 claims description 3
- 206010012688 Diabetic retinal oedema Diseases 0.000 claims description 3
- 206010012689 Diabetic retinopathy Diseases 0.000 claims description 3
- 206010014733 Endometrial cancer Diseases 0.000 claims description 3
- 206010014759 Endometrial neoplasm Diseases 0.000 claims description 3
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 3
- 206010019280 Heart failures Diseases 0.000 claims description 3
- 208000023105 Huntington disease Diseases 0.000 claims description 3
- 208000002682 Hyperkalemia Diseases 0.000 claims description 3
- 206010021036 Hyponatraemia Diseases 0.000 claims description 3
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 3
- 206010025323 Lymphomas Diseases 0.000 claims description 3
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 3
- 206010033128 Ovarian cancer Diseases 0.000 claims description 3
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 3
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 3
- 208000018737 Parkinson disease Diseases 0.000 claims description 3
- 208000009565 Pharyngeal Neoplasms Diseases 0.000 claims description 3
- 206010060862 Prostate cancer Diseases 0.000 claims description 3
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 3
- 206010037423 Pulmonary oedema Diseases 0.000 claims description 3
- 208000006265 Renal cell carcinoma Diseases 0.000 claims description 3
- 208000000453 Skin Neoplasms Diseases 0.000 claims description 3
- 208000010112 Spinocerebellar Degenerations Diseases 0.000 claims description 3
- 208000000102 Squamous Cell Carcinoma of Head and Neck Diseases 0.000 claims description 3
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 3
- 206010042971 T-cell lymphoma Diseases 0.000 claims description 3
- 208000027585 T-cell non-Hodgkin lymphoma Diseases 0.000 claims description 3
- 208000030886 Traumatic Brain injury Diseases 0.000 claims description 3
- 208000006593 Urologic Neoplasms Diseases 0.000 claims description 3
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 claims description 3
- 206010002026 amyotrophic lateral sclerosis Diseases 0.000 claims description 3
- 210000004155 blood-retinal barrier Anatomy 0.000 claims description 3
- 230000004378 blood-retinal barrier Effects 0.000 claims description 3
- 210000000988 bone and bone Anatomy 0.000 claims description 3
- 230000004097 bone metabolism Effects 0.000 claims description 3
- 208000006752 brain edema Diseases 0.000 claims description 3
- 230000023852 carbohydrate metabolic process Effects 0.000 claims description 3
- 235000021256 carbohydrate metabolism Nutrition 0.000 claims description 3
- 210000003169 central nervous system Anatomy 0.000 claims description 3
- 201000010881 cervical cancer Diseases 0.000 claims description 3
- 238000012258 culturing Methods 0.000 claims description 3
- 230000007850 degeneration Effects 0.000 claims description 3
- 230000006866 deterioration Effects 0.000 claims description 3
- 208000033679 diabetic kidney disease Diseases 0.000 claims description 3
- 201000011190 diabetic macular edema Diseases 0.000 claims description 3
- 239000000032 diagnostic agent Substances 0.000 claims description 3
- 229940039227 diagnostic agent Drugs 0.000 claims description 3
- 239000003792 electrolyte Substances 0.000 claims description 3
- 201000004101 esophageal cancer Diseases 0.000 claims description 3
- 206010017758 gastric cancer Diseases 0.000 claims description 3
- 201000000459 head and neck squamous cell carcinoma Diseases 0.000 claims description 3
- 201000002313 intestinal cancer Diseases 0.000 claims description 3
- 206010023841 laryngeal neoplasm Diseases 0.000 claims description 3
- 208000032839 leukemia Diseases 0.000 claims description 3
- 201000007270 liver cancer Diseases 0.000 claims description 3
- 208000014018 liver neoplasm Diseases 0.000 claims description 3
- 201000005202 lung cancer Diseases 0.000 claims description 3
- 208000020816 lung neoplasm Diseases 0.000 claims description 3
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 3
- 201000001441 melanoma Diseases 0.000 claims description 3
- 201000006417 multiple sclerosis Diseases 0.000 claims description 3
- 208000004296 neuralgia Diseases 0.000 claims description 3
- 208000015122 neurodegenerative disease Diseases 0.000 claims description 3
- 208000021722 neuropathic pain Diseases 0.000 claims description 3
- 201000002528 pancreatic cancer Diseases 0.000 claims description 3
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 3
- 210000001428 peripheral nervous system Anatomy 0.000 claims description 3
- 201000002212 progressive supranuclear palsy Diseases 0.000 claims description 3
- 210000001236 prokaryotic cell Anatomy 0.000 claims description 3
- 208000005333 pulmonary edema Diseases 0.000 claims description 3
- 230000008085 renal dysfunction Effects 0.000 claims description 3
- 201000000849 skin cancer Diseases 0.000 claims description 3
- 208000020431 spinal cord injury Diseases 0.000 claims description 3
- 201000011549 stomach cancer Diseases 0.000 claims description 3
- 210000003523 substantia nigra Anatomy 0.000 claims description 3
- 230000009529 traumatic brain injury Effects 0.000 claims description 3
- 208000009852 uremia Diseases 0.000 claims description 3
- 208000030090 Acute Disease Diseases 0.000 claims description 2
- 201000003741 Gastrointestinal carcinoma Diseases 0.000 claims description 2
- 206010023825 Laryngeal cancer Diseases 0.000 claims description 2
- 240000007817 Olea europaea Species 0.000 claims description 2
- 208000012998 acute renal failure Diseases 0.000 claims description 2
- 208000022831 chronic renal failure syndrome Diseases 0.000 claims description 2
- 210000003527 eukaryotic cell Anatomy 0.000 claims description 2
- 201000008006 pharynx cancer Diseases 0.000 claims description 2
- 208000015347 renal cell adenocarcinoma Diseases 0.000 claims description 2
- 229910052721 tungsten Inorganic materials 0.000 claims description 2
- 102100027974 Semaphorin-3A Human genes 0.000 description 240
- 108090000623 proteins and genes Proteins 0.000 description 62
- DDRJAANPRJIHGJ-UHFFFAOYSA-N creatinine Chemical compound CN1CC(=O)NC1=N DDRJAANPRJIHGJ-UHFFFAOYSA-N 0.000 description 56
- 102000004169 proteins and genes Human genes 0.000 description 49
- 235000018102 proteins Nutrition 0.000 description 46
- 235000001014 amino acid Nutrition 0.000 description 38
- 108020004414 DNA Proteins 0.000 description 37
- 230000014509 gene expression Effects 0.000 description 36
- 241000699670 Mus sp. Species 0.000 description 34
- 229940024606 amino acid Drugs 0.000 description 34
- 150000001413 amino acids Chemical class 0.000 description 32
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 31
- 241000699666 Mus <mouse, genus> Species 0.000 description 28
- 229940109239 creatinine Drugs 0.000 description 28
- 239000003112 inhibitor Substances 0.000 description 28
- 108090000765 processed proteins & peptides Proteins 0.000 description 28
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 26
- 239000002953 phosphate buffered saline Substances 0.000 description 26
- 241001465754 Metazoa Species 0.000 description 25
- 108010088751 Albumins Proteins 0.000 description 23
- 102000009027 Albumins Human genes 0.000 description 23
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 20
- 210000002966 serum Anatomy 0.000 description 20
- 230000001976 improved effect Effects 0.000 description 19
- 230000005764 inhibitory process Effects 0.000 description 19
- 230000035772 mutation Effects 0.000 description 19
- 238000005516 engineering process Methods 0.000 description 18
- 238000002347 injection Methods 0.000 description 18
- 239000007924 injection Substances 0.000 description 18
- 102000004196 processed proteins & peptides Human genes 0.000 description 18
- 230000002829 reductive effect Effects 0.000 description 18
- 230000001225 therapeutic effect Effects 0.000 description 18
- 238000002474 experimental method Methods 0.000 description 17
- 230000006870 function Effects 0.000 description 17
- -1 i.e. Proteins 0.000 description 17
- 229920001184 polypeptide Polymers 0.000 description 17
- 238000002965 ELISA Methods 0.000 description 16
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 16
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 16
- 239000003795 chemical substances by application Substances 0.000 description 16
- 230000029142 excretion Effects 0.000 description 16
- 230000036515 potency Effects 0.000 description 16
- 210000002700 urine Anatomy 0.000 description 16
- 108060003951 Immunoglobulin Proteins 0.000 description 15
- 241000700159 Rattus Species 0.000 description 15
- 125000003275 alpha amino acid group Chemical group 0.000 description 15
- 102000018358 immunoglobulin Human genes 0.000 description 15
- 239000000203 mixture Substances 0.000 description 15
- 239000000243 solution Substances 0.000 description 15
- 230000002485 urinary effect Effects 0.000 description 15
- 229940079593 drug Drugs 0.000 description 14
- 239000013604 expression vector Substances 0.000 description 14
- 210000004962 mammalian cell Anatomy 0.000 description 14
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 13
- 239000005557 antagonist Substances 0.000 description 13
- 238000002823 phage display Methods 0.000 description 13
- 239000000047 product Substances 0.000 description 13
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 12
- 239000000872 buffer Substances 0.000 description 12
- 210000003734 kidney Anatomy 0.000 description 12
- 230000004048 modification Effects 0.000 description 12
- 238000012986 modification Methods 0.000 description 12
- 238000006467 substitution reaction Methods 0.000 description 12
- 238000001890 transfection Methods 0.000 description 12
- 238000004113 cell culture Methods 0.000 description 11
- 239000012636 effector Substances 0.000 description 11
- 238000004519 manufacturing process Methods 0.000 description 11
- 238000012216 screening Methods 0.000 description 11
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 10
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 10
- 239000004202 carbamide Substances 0.000 description 10
- 230000000875 corresponding effect Effects 0.000 description 10
- 238000009396 hybridization Methods 0.000 description 10
- 238000002360 preparation method Methods 0.000 description 10
- 235000002639 sodium chloride Nutrition 0.000 description 10
- 229940124597 therapeutic agent Drugs 0.000 description 10
- 108700012359 toxins Proteins 0.000 description 10
- 208000027418 Wounds and injury Diseases 0.000 description 9
- 150000001412 amines Chemical class 0.000 description 9
- 238000001727 in vivo Methods 0.000 description 9
- 229940049595 antibody-drug conjugate Drugs 0.000 description 8
- 230000001580 bacterial effect Effects 0.000 description 8
- 201000005206 focal segmental glomerulosclerosis Diseases 0.000 description 8
- 231100000854 focal segmental glomerulosclerosis Toxicity 0.000 description 8
- 210000004602 germ cell Anatomy 0.000 description 8
- 238000011534 incubation Methods 0.000 description 8
- 208000028867 ischemia Diseases 0.000 description 8
- 238000010149 post-hoc-test Methods 0.000 description 8
- 230000008569 process Effects 0.000 description 8
- 238000000159 protein binding assay Methods 0.000 description 8
- 241000894007 species Species 0.000 description 8
- 239000006228 supernatant Substances 0.000 description 8
- 238000012360 testing method Methods 0.000 description 8
- 239000003053 toxin Substances 0.000 description 8
- 231100000765 toxin Toxicity 0.000 description 8
- 241000588724 Escherichia coli Species 0.000 description 7
- 101000632261 Homo sapiens Semaphorin-3A Proteins 0.000 description 7
- 241001529936 Murinae Species 0.000 description 7
- 238000004458 analytical method Methods 0.000 description 7
- 210000004369 blood Anatomy 0.000 description 7
- 239000008280 blood Substances 0.000 description 7
- 230000006378 damage Effects 0.000 description 7
- 230000013595 glycosylation Effects 0.000 description 7
- 238000006206 glycosylation reaction Methods 0.000 description 7
- 230000003993 interaction Effects 0.000 description 7
- 239000003446 ligand Substances 0.000 description 7
- 239000011780 sodium chloride Substances 0.000 description 7
- 239000000126 substance Substances 0.000 description 7
- 238000002560 therapeutic procedure Methods 0.000 description 7
- HSINOMROUCMIEA-FGVHQWLLSA-N (2s,4r)-4-[(3r,5s,6r,7r,8s,9s,10s,13r,14s,17r)-6-ethyl-3,7-dihydroxy-10,13-dimethyl-2,3,4,5,6,7,8,9,11,12,14,15,16,17-tetradecahydro-1h-cyclopenta[a]phenanthren-17-yl]-2-methylpentanoic acid Chemical compound C([C@@]12C)C[C@@H](O)C[C@H]1[C@@H](CC)[C@@H](O)[C@@H]1[C@@H]2CC[C@]2(C)[C@@H]([C@H](C)C[C@H](C)C(O)=O)CC[C@H]21 HSINOMROUCMIEA-FGVHQWLLSA-N 0.000 description 6
- LMDZBCPBFSXMTL-UHFFFAOYSA-N 1-Ethyl-3-(3-dimethylaminopropyl)carbodiimide Substances CCN=C=NCCCN(C)C LMDZBCPBFSXMTL-UHFFFAOYSA-N 0.000 description 6
- FPQQSJJWHUJYPU-UHFFFAOYSA-N 3-(dimethylamino)propyliminomethylidene-ethylazanium;chloride Chemical compound Cl.CCN=C=NCCCN(C)C FPQQSJJWHUJYPU-UHFFFAOYSA-N 0.000 description 6
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 6
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 6
- 241000196324 Embryophyta Species 0.000 description 6
- 239000004471 Glycine Substances 0.000 description 6
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 6
- 108091034117 Oligonucleotide Proteins 0.000 description 6
- 206010063837 Reperfusion injury Diseases 0.000 description 6
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 6
- 239000003613 bile acid Substances 0.000 description 6
- 230000004071 biological effect Effects 0.000 description 6
- 230000008878 coupling Effects 0.000 description 6
- 238000010168 coupling process Methods 0.000 description 6
- 238000005859 coupling reaction Methods 0.000 description 6
- 229940127089 cytotoxic agent Drugs 0.000 description 6
- 239000002254 cytotoxic agent Substances 0.000 description 6
- 238000009472 formulation Methods 0.000 description 6
- 208000014674 injury Diseases 0.000 description 6
- 239000007788 liquid Substances 0.000 description 6
- 230000009467 reduction Effects 0.000 description 6
- 230000004044 response Effects 0.000 description 6
- 239000000725 suspension Substances 0.000 description 6
- 238000003786 synthesis reaction Methods 0.000 description 6
- 239000005541 ACE inhibitor Substances 0.000 description 5
- 241000282472 Canis lupus familiaris Species 0.000 description 5
- 102000008186 Collagen Human genes 0.000 description 5
- 108010035532 Collagen Proteins 0.000 description 5
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 5
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 5
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 5
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 5
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 5
- 108020004511 Recombinant DNA Proteins 0.000 description 5
- 206010063897 Renal ischaemia Diseases 0.000 description 5
- 241000282887 Suidae Species 0.000 description 5
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 5
- 238000007792 addition Methods 0.000 description 5
- 229940044094 angiotensin-converting-enzyme inhibitor Drugs 0.000 description 5
- 239000003472 antidiabetic agent Substances 0.000 description 5
- 230000009286 beneficial effect Effects 0.000 description 5
- 210000004899 c-terminal region Anatomy 0.000 description 5
- 238000004587 chromatography analysis Methods 0.000 description 5
- 229920001436 collagen Polymers 0.000 description 5
- 230000002860 competitive effect Effects 0.000 description 5
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 5
- 238000013461 design Methods 0.000 description 5
- 239000002934 diuretic Substances 0.000 description 5
- 238000005259 measurement Methods 0.000 description 5
- 239000002609 medium Substances 0.000 description 5
- 102000040430 polynucleotide Human genes 0.000 description 5
- 108091033319 polynucleotide Proteins 0.000 description 5
- 239000002157 polynucleotide Substances 0.000 description 5
- 229920000136 polysorbate Polymers 0.000 description 5
- 239000012460 protein solution Substances 0.000 description 5
- 238000000746 purification Methods 0.000 description 5
- 230000002285 radioactive effect Effects 0.000 description 5
- 230000001105 regulatory effect Effects 0.000 description 5
- 239000000523 sample Substances 0.000 description 5
- 238000001542 size-exclusion chromatography Methods 0.000 description 5
- 238000001356 surgical procedure Methods 0.000 description 5
- 108010064733 Angiotensins Proteins 0.000 description 4
- 102000015427 Angiotensins Human genes 0.000 description 4
- KNMRXHIAVXHCLW-ZLUOBGJFSA-N Asp-Asn-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)C(=O)O KNMRXHIAVXHCLW-ZLUOBGJFSA-N 0.000 description 4
- 241000701022 Cytomegalovirus Species 0.000 description 4
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 4
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 4
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 4
- 241000880493 Leptailurus serval Species 0.000 description 4
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 4
- 102100022691 NACHT, LRR and PYD domains-containing protein 3 Human genes 0.000 description 4
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 4
- 241000283973 Oryctolagus cuniculus Species 0.000 description 4
- 206010048988 Renal artery occlusion Diseases 0.000 description 4
- 102000014105 Semaphorin Human genes 0.000 description 4
- 108050003978 Semaphorin Proteins 0.000 description 4
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 4
- 102000007637 Soluble Guanylyl Cyclase Human genes 0.000 description 4
- 108010007205 Soluble Guanylyl Cyclase Proteins 0.000 description 4
- 239000012190 activator Substances 0.000 description 4
- 229940083712 aldosterone antagonist Drugs 0.000 description 4
- 238000010171 animal model Methods 0.000 description 4
- 230000004888 barrier function Effects 0.000 description 4
- 239000002876 beta blocker Substances 0.000 description 4
- 239000011230 binding agent Substances 0.000 description 4
- 230000000903 blocking effect Effects 0.000 description 4
- 238000001818 capillary gel electrophoresis Methods 0.000 description 4
- 239000002775 capsule Substances 0.000 description 4
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 4
- 238000000576 coating method Methods 0.000 description 4
- 238000012937 correction Methods 0.000 description 4
- 231100000599 cytotoxic agent Toxicity 0.000 description 4
- 238000001514 detection method Methods 0.000 description 4
- 229940030606 diuretics Drugs 0.000 description 4
- 231100000673 dose–response relationship Toxicity 0.000 description 4
- 239000008298 dragée Substances 0.000 description 4
- 239000003937 drug carrier Substances 0.000 description 4
- 125000003147 glycosyl group Chemical group 0.000 description 4
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 4
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 4
- 230000001900 immune effect Effects 0.000 description 4
- 238000005462 in vivo assay Methods 0.000 description 4
- 230000003907 kidney function Effects 0.000 description 4
- 230000004060 metabolic process Effects 0.000 description 4
- 229960000485 methotrexate Drugs 0.000 description 4
- 239000002394 mineralocorticoid antagonist Substances 0.000 description 4
- 239000000178 monomer Substances 0.000 description 4
- 229920001542 oligosaccharide Polymers 0.000 description 4
- 150000002482 oligosaccharides Chemical class 0.000 description 4
- 238000001543 one-way ANOVA Methods 0.000 description 4
- 238000005457 optimization Methods 0.000 description 4
- 239000000825 pharmaceutical preparation Substances 0.000 description 4
- 239000013612 plasmid Substances 0.000 description 4
- 229920000642 polymer Polymers 0.000 description 4
- 230000003389 potentiating effect Effects 0.000 description 4
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 4
- 238000003259 recombinant expression Methods 0.000 description 4
- 238000011084 recovery Methods 0.000 description 4
- 210000003594 spinal ganglia Anatomy 0.000 description 4
- 238000010186 staining Methods 0.000 description 4
- 235000000346 sugar Nutrition 0.000 description 4
- 210000001519 tissue Anatomy 0.000 description 4
- 230000001988 toxicity Effects 0.000 description 4
- 231100000419 toxicity Toxicity 0.000 description 4
- 230000009261 transgenic effect Effects 0.000 description 4
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 4
- PMUNIMVZCACZBB-UHFFFAOYSA-N 2-hydroxyethylazanium;chloride Chemical compound Cl.NCCO PMUNIMVZCACZBB-UHFFFAOYSA-N 0.000 description 3
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 3
- 102000007469 Actins Human genes 0.000 description 3
- 108010085238 Actins Proteins 0.000 description 3
- HJCMDXDYPOUFDY-WHFBIAKZSA-N Ala-Gln Chemical compound C[C@H](N)C(=O)N[C@H](C(O)=O)CCC(N)=O HJCMDXDYPOUFDY-WHFBIAKZSA-N 0.000 description 3
- 206010002091 Anaesthesia Diseases 0.000 description 3
- 102100040214 Apolipoprotein(a) Human genes 0.000 description 3
- XTMZYFMTYJNABC-ZLUOBGJFSA-N Asn-Ser-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N XTMZYFMTYJNABC-ZLUOBGJFSA-N 0.000 description 3
- BSYNRYMUTXBXSQ-UHFFFAOYSA-N Aspirin Chemical compound CC(=O)OC1=CC=CC=C1C(O)=O BSYNRYMUTXBXSQ-UHFFFAOYSA-N 0.000 description 3
- 244000063299 Bacillus subtilis Species 0.000 description 3
- 235000014469 Bacillus subtilis Nutrition 0.000 description 3
- 229940127291 Calcium channel antagonist Drugs 0.000 description 3
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 3
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 3
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 3
- 102000053602 DNA Human genes 0.000 description 3
- 229920002307 Dextran Polymers 0.000 description 3
- 238000012286 ELISA Assay Methods 0.000 description 3
- 102000002045 Endothelin Human genes 0.000 description 3
- 108050009340 Endothelin Proteins 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 3
- 108010010803 Gelatin Proteins 0.000 description 3
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 3
- VNNRLUNBJSWZPF-ZKWXMUAHSA-N Gly-Ser-Ile Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNNRLUNBJSWZPF-ZKWXMUAHSA-N 0.000 description 3
- 241000238631 Hexapoda Species 0.000 description 3
- MDOBWSFNSNPENN-PMVVWTBXSA-N His-Thr-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O MDOBWSFNSNPENN-PMVVWTBXSA-N 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 3
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 description 3
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 3
- NZOCIWKZUVUNDW-ZKWXMUAHSA-N Ile-Gly-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O NZOCIWKZUVUNDW-ZKWXMUAHSA-N 0.000 description 3
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 3
- 206010061218 Inflammation Diseases 0.000 description 3
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 3
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 3
- 108010033266 Lipoprotein(a) Proteins 0.000 description 3
- 239000004472 Lysine Substances 0.000 description 3
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 3
- 229930195725 Mannitol Natural products 0.000 description 3
- NQTADLQHYWFPDB-UHFFFAOYSA-N N-Hydroxysuccinimide Chemical compound ON1C(=O)CCC1=O NQTADLQHYWFPDB-UHFFFAOYSA-N 0.000 description 3
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 3
- 108010016731 PPAR gamma Proteins 0.000 description 3
- 102100038824 Peroxisome proliferator-activated receptor delta Human genes 0.000 description 3
- 102100038825 Peroxisome proliferator-activated receptor gamma Human genes 0.000 description 3
- 229920002873 Polyethylenimine Polymers 0.000 description 3
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 3
- 241000589516 Pseudomonas Species 0.000 description 3
- 208000001647 Renal Insufficiency Diseases 0.000 description 3
- 241000293869 Salmonella enterica subsp. enterica serovar Typhimurium Species 0.000 description 3
- 241000191940 Staphylococcus Species 0.000 description 3
- 241000187747 Streptomyces Species 0.000 description 3
- 239000012505 Superdex™ Substances 0.000 description 3
- 108010022394 Threonine synthase Proteins 0.000 description 3
- QYSXJUFSXHHAJI-XFEUOLMDSA-N Vitamin D3 Natural products C1(/[C@@H]2CC[C@@H]([C@]2(CCC1)C)[C@H](C)CCCC(C)C)=C/C=C1\C[C@@H](O)CCC1=C QYSXJUFSXHHAJI-XFEUOLMDSA-N 0.000 description 3
- 206010052428 Wound Diseases 0.000 description 3
- 108010084455 Zeocin Proteins 0.000 description 3
- 229960001138 acetylsalicylic acid Drugs 0.000 description 3
- 239000002253 acid Substances 0.000 description 3
- 239000004480 active ingredient Substances 0.000 description 3
- 239000003463 adsorbent Substances 0.000 description 3
- 239000000556 agonist Substances 0.000 description 3
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 3
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 3
- 230000037005 anaesthesia Effects 0.000 description 3
- 229940125708 antidiabetic agent Drugs 0.000 description 3
- 108010047857 aspartylglycine Proteins 0.000 description 3
- 239000012131 assay buffer Substances 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 150000001720 carbohydrates Chemical class 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 230000000295 complement effect Effects 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- ZOOGRGPOEVQQDX-KHLHZJAASA-N cyclic guanosine monophosphate Chemical compound C([C@H]1O2)O[P@](O)(=O)O[C@@H]1[C@H](O)[C@H]2N1C(N=C(NC2=O)N)=C2N=C1 ZOOGRGPOEVQQDX-KHLHZJAASA-N 0.000 description 3
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 3
- 230000003436 cytoskeletal effect Effects 0.000 description 3
- 230000002950 deficient Effects 0.000 description 3
- 230000022811 deglycosylation Effects 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 238000003745 diagnosis Methods 0.000 description 3
- 102000004419 dihydrofolate reductase Human genes 0.000 description 3
- 239000000539 dimer Substances 0.000 description 3
- 238000010828 elution Methods 0.000 description 3
- ZUBDGKVDJUIMQQ-UBFCDGJISA-N endothelin-1 Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)NC(=O)[C@H]1NC(=O)[C@H](CC=2C=CC=CC=2)NC(=O)[C@@H](CC=2C=CC(O)=CC=2)NC(=O)[C@H](C(C)C)NC(=O)[C@H]2CSSC[C@@H](C(N[C@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N2)=O)NC(=O)[C@@H](CO)NC(=O)[C@H](N)CSSC1)C1=CNC=N1 ZUBDGKVDJUIMQQ-UBFCDGJISA-N 0.000 description 3
- 239000003623 enhancer Substances 0.000 description 3
- 229940088598 enzyme Drugs 0.000 description 3
- 230000033581 fucosylation Effects 0.000 description 3
- 239000008273 gelatin Substances 0.000 description 3
- 229920000159 gelatin Polymers 0.000 description 3
- 235000019322 gelatine Nutrition 0.000 description 3
- 235000011852 gelatine desserts Nutrition 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 230000024924 glomerular filtration Effects 0.000 description 3
- 239000001963 growth medium Substances 0.000 description 3
- 230000036541 health Effects 0.000 description 3
- 230000008642 heat stress Effects 0.000 description 3
- 238000004128 high performance liquid chromatography Methods 0.000 description 3
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 3
- 210000004408 hybridoma Anatomy 0.000 description 3
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 3
- 230000003053 immunization Effects 0.000 description 3
- 238000002649 immunization Methods 0.000 description 3
- 238000010820 immunofluorescence microscopy Methods 0.000 description 3
- 238000010832 independent-sample T-test Methods 0.000 description 3
- 230000004054 inflammatory process Effects 0.000 description 3
- 238000010253 intravenous injection Methods 0.000 description 3
- 208000012947 ischemia reperfusion injury Diseases 0.000 description 3
- 201000006370 kidney failure Diseases 0.000 description 3
- 239000000594 mannitol Substances 0.000 description 3
- 235000010355 mannitol Nutrition 0.000 description 3
- 229960001855 mannitol Drugs 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 230000035800 maturation Effects 0.000 description 3
- 230000002503 metabolic effect Effects 0.000 description 3
- 235000013336 milk Nutrition 0.000 description 3
- 239000008267 milk Substances 0.000 description 3
- 210000004080 milk Anatomy 0.000 description 3
- 230000003278 mimic effect Effects 0.000 description 3
- 238000010172 mouse model Methods 0.000 description 3
- 210000003205 muscle Anatomy 0.000 description 3
- AZNHWXAFPBYFGH-UHFFFAOYSA-N n-[4-(4-fluorophenyl)-2,2-dimethyl-3-oxo-1,4-benzoxazin-7-yl]methanesulfonamide Chemical compound O=C1C(C)(C)OC2=CC(NS(C)(=O)=O)=CC=C2N1C1=CC=C(F)C=C1 AZNHWXAFPBYFGH-UHFFFAOYSA-N 0.000 description 3
- 229910052757 nitrogen Inorganic materials 0.000 description 3
- 238000003199 nucleic acid amplification method Methods 0.000 description 3
- 229940082615 organic nitrates used in cardiac disease Drugs 0.000 description 3
- 108091008765 peroxisome proliferator-activated receptors β/δ Proteins 0.000 description 3
- 239000000546 pharmaceutical excipient Substances 0.000 description 3
- CWCMIVBLVUHDHK-ZSNHEYEWSA-N phleomycin D1 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC[C@@H](N=1)C=1SC=C(N=1)C(=O)NCCCCNC(N)=N)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C CWCMIVBLVUHDHK-ZSNHEYEWSA-N 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 235000013930 proline Nutrition 0.000 description 3
- 239000000018 receptor agonist Substances 0.000 description 3
- 229940044601 receptor agonist Drugs 0.000 description 3
- 210000002254 renal artery Anatomy 0.000 description 3
- 239000002461 renin inhibitor Substances 0.000 description 3
- 229940086526 renin-inhibitors Drugs 0.000 description 3
- 230000010410 reperfusion Effects 0.000 description 3
- 230000010076 replication Effects 0.000 description 3
- 239000012146 running buffer Substances 0.000 description 3
- 150000003839 salts Chemical class 0.000 description 3
- 239000002904 solvent Substances 0.000 description 3
- 239000000600 sorbitol Substances 0.000 description 3
- 239000003381 stabilizer Substances 0.000 description 3
- 238000010561 standard procedure Methods 0.000 description 3
- 230000035882 stress Effects 0.000 description 3
- 208000024891 symptom Diseases 0.000 description 3
- 230000008646 thermal stress Effects 0.000 description 3
- AYEKOFBPNLCAJY-UHFFFAOYSA-O thiamine pyrophosphate Chemical compound CC1=C(CCOP(O)(=O)OP(O)(O)=O)SC=[N+]1CC1=CN=C(C)N=C1N AYEKOFBPNLCAJY-UHFFFAOYSA-O 0.000 description 3
- 102000004217 thyroid hormone receptors Human genes 0.000 description 3
- 108090000721 thyroid hormone receptors Proteins 0.000 description 3
- 238000003146 transient transfection Methods 0.000 description 3
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 3
- 235000002374 tyrosine Nutrition 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- 230000003442 weekly effect Effects 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- JWDFQMWEFLOOED-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(pyridin-2-yldisulfanyl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCSSC1=CC=CC=N1 JWDFQMWEFLOOED-UHFFFAOYSA-N 0.000 description 2
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 2
- YYGNTYWPHWGJRM-UHFFFAOYSA-N (6E,10E,14E,18E)-2,6,10,15,19,23-hexamethyltetracosa-2,6,10,14,18,22-hexaene Chemical compound CC(C)=CCCC(C)=CCCC(C)=CCCC=C(C)CCC=C(C)CCC=C(C)C YYGNTYWPHWGJRM-UHFFFAOYSA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 2
- VPFUWHKTPYPNGT-UHFFFAOYSA-N 3-(3,4-dihydroxyphenyl)-1-(5-hydroxy-2,2-dimethylchromen-6-yl)propan-1-one Chemical compound OC1=C2C=CC(C)(C)OC2=CC=C1C(=O)CCC1=CC=C(O)C(O)=C1 VPFUWHKTPYPNGT-UHFFFAOYSA-N 0.000 description 2
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 2
- LMFXXZPPZDCPTA-ZKWXMUAHSA-N Ala-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N LMFXXZPPZDCPTA-ZKWXMUAHSA-N 0.000 description 2
- LFFOJBOTZUWINF-ZANVPECISA-N Ala-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O)=CNC2=C1 LFFOJBOTZUWINF-ZANVPECISA-N 0.000 description 2
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 2
- OTOXOKCIIQLMFH-KZVJFYERSA-N Arg-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N OTOXOKCIIQLMFH-KZVJFYERSA-N 0.000 description 2
- UVTGNSWSRSCPLP-UHFFFAOYSA-N Arg-Tyr Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O UVTGNSWSRSCPLP-UHFFFAOYSA-N 0.000 description 2
- VPSHHQXIWLGVDD-ZLUOBGJFSA-N Asp-Asp-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O VPSHHQXIWLGVDD-ZLUOBGJFSA-N 0.000 description 2
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 2
- MJJIHRWNWSQTOI-VEVYYDQMSA-N Asp-Thr-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O MJJIHRWNWSQTOI-VEVYYDQMSA-N 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- JZUFKLXOESDKRF-UHFFFAOYSA-N Chlorothiazide Chemical compound C1=C(Cl)C(S(=O)(=O)N)=CC2=C1NCNS2(=O)=O JZUFKLXOESDKRF-UHFFFAOYSA-N 0.000 description 2
- 229940127328 Cholesterol Synthesis Inhibitors Drugs 0.000 description 2
- DCJNIJAWIRPPBB-CIUDSAMLSA-N Cys-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CS)N DCJNIJAWIRPPBB-CIUDSAMLSA-N 0.000 description 2
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 2
- 102000016607 Diphtheria Toxin Human genes 0.000 description 2
- 108010053187 Diphtheria Toxin Proteins 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- 241001131785 Escherichia coli HB101 Species 0.000 description 2
- 108010087819 Fc receptors Proteins 0.000 description 2
- 102000009109 Fc receptors Human genes 0.000 description 2
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 2
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 2
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 2
- 208000022461 Glomerular disease Diseases 0.000 description 2
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 2
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 2
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 2
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 2
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 2
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 2
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 2
- FKYQEVBRZSFAMJ-QWRGUYRKSA-N Gly-Ser-Tyr Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FKYQEVBRZSFAMJ-QWRGUYRKSA-N 0.000 description 2
- 108010078321 Guanylate Cyclase Proteins 0.000 description 2
- 102000014469 Guanylate cyclase Human genes 0.000 description 2
- 208000032759 Hemolytic-Uremic Syndrome Diseases 0.000 description 2
- 102000004286 Hydroxymethylglutaryl CoA Reductases Human genes 0.000 description 2
- 108090000895 Hydroxymethylglutaryl CoA Reductases Proteins 0.000 description 2
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 2
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 2
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 2
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 2
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 2
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 2
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- UIARLYUEJFELEN-LROUJFHJSA-N LSM-1231 Chemical compound C12=C3N4C5=CC=CC=C5C3=C3C(=O)NCC3=C2C2=CC=CC=C2N1[C@]1(C)[C@](CO)(O)C[C@H]4O1 UIARLYUEJFELEN-LROUJFHJSA-N 0.000 description 2
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 2
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 2
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 2
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 2
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 229940127470 Lipase Inhibitors Drugs 0.000 description 2
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 2
- 108010052285 Membrane Proteins Proteins 0.000 description 2
- CAODKDAPYGUMLK-FXQIFTODSA-N Met-Asn-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CAODKDAPYGUMLK-FXQIFTODSA-N 0.000 description 2
- 244000302512 Momordica charantia Species 0.000 description 2
- 235000009811 Momordica charantia Nutrition 0.000 description 2
- 238000005481 NMR spectroscopy Methods 0.000 description 2
- 102100028762 Neuropilin-1 Human genes 0.000 description 2
- 108090000772 Neuropilin-1 Proteins 0.000 description 2
- PVNIIMVLHYAWGP-UHFFFAOYSA-N Niacin Chemical compound OC(=O)C1=CC=CN=C1 PVNIIMVLHYAWGP-UHFFFAOYSA-N 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- 102100038831 Peroxisome proliferator-activated receptor alpha Human genes 0.000 description 2
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 2
- 102000004861 Phosphoric Diester Hydrolases Human genes 0.000 description 2
- 108090001050 Phosphoric Diester Hydrolases Proteins 0.000 description 2
- 241000276498 Pollachius virens Species 0.000 description 2
- 239000002202 Polyethylene glycol Substances 0.000 description 2
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 2
- WIPAMEKBSHNFQE-IUCAKERBSA-N Pro-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@@H]1CCCN1 WIPAMEKBSHNFQE-IUCAKERBSA-N 0.000 description 2
- 108010029485 Protein Isoforms Proteins 0.000 description 2
- 102000001708 Protein Isoforms Human genes 0.000 description 2
- 108010039491 Ricin Proteins 0.000 description 2
- 239000008156 Ringer's lactate solution Substances 0.000 description 2
- YASAKCUCGLMORW-UHFFFAOYSA-N Rosiglitazone Chemical compound C=1C=CC=NC=1N(C)CCOC(C=C1)=CC=C1CC1SC(=O)NC1=O YASAKCUCGLMORW-UHFFFAOYSA-N 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 2
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 2
- 108020004682 Single-Stranded DNA Proteins 0.000 description 2
- UIIMBOGNXHQVGW-UHFFFAOYSA-M Sodium bicarbonate Chemical compound [Na+].OC([O-])=O UIIMBOGNXHQVGW-UHFFFAOYSA-M 0.000 description 2
- 229920002472 Starch Polymers 0.000 description 2
- 229930006000 Sucrose Natural products 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- 241000282898 Sus scrofa Species 0.000 description 2
- BHEOSNUKNHRBNM-UHFFFAOYSA-N Tetramethylsqualene Natural products CC(=C)C(C)CCC(=C)C(C)CCC(C)=CCCC=C(C)CCC(C)C(=C)CCC(C)C(C)=C BHEOSNUKNHRBNM-UHFFFAOYSA-N 0.000 description 2
- DJDSEDOKJTZBAR-ZDLURKLDSA-N Thr-Gly-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O DJDSEDOKJTZBAR-ZDLURKLDSA-N 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- GWEVSGVZZGPLCZ-UHFFFAOYSA-N Titan oxide Chemical compound O=[Ti]=O GWEVSGVZZGPLCZ-UHFFFAOYSA-N 0.000 description 2
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 2
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 2
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- OOEUVMFKKZYSRX-LEWSCRJBSA-N Tyr-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OOEUVMFKKZYSRX-LEWSCRJBSA-N 0.000 description 2
- NKUGCYDFQKFVOJ-JYJNAYRXSA-N Tyr-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NKUGCYDFQKFVOJ-JYJNAYRXSA-N 0.000 description 2
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 2
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 2
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 2
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 229930003316 Vitamin D Natural products 0.000 description 2
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical compound [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- 229960002964 adalimumab Drugs 0.000 description 2
- 230000002411 adverse Effects 0.000 description 2
- 238000001042 affinity chromatography Methods 0.000 description 2
- 230000009824 affinity maturation Effects 0.000 description 2
- 235000004279 alanine Nutrition 0.000 description 2
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 2
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 2
- 239000002160 alpha blocker Substances 0.000 description 2
- 229940124308 alpha-adrenoreceptor antagonist Drugs 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 239000012491 analyte Substances 0.000 description 2
- 230000003042 antagnostic effect Effects 0.000 description 2
- 239000000611 antibody drug conjugate Substances 0.000 description 2
- 229940124691 antibody therapeutics Drugs 0.000 description 2
- 239000003146 anticoagulant agent Substances 0.000 description 2
- 230000000890 antigenic effect Effects 0.000 description 2
- 229940030600 antihypertensive agent Drugs 0.000 description 2
- 239000002220 antihypertensive agent Substances 0.000 description 2
- 239000002246 antineoplastic agent Substances 0.000 description 2
- 229940127218 antiplatelet drug Drugs 0.000 description 2
- 230000006907 apoptotic process Effects 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 108010008355 arginyl-glutamine Proteins 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 235000003704 aspartic acid Nutrition 0.000 description 2
- 210000003719 b-lymphocyte Anatomy 0.000 description 2
- 229940097320 beta blocking agent Drugs 0.000 description 2
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 2
- 230000001588 bifunctional effect Effects 0.000 description 2
- 238000013357 binding ELISA Methods 0.000 description 2
- 230000017531 blood circulation Effects 0.000 description 2
- 230000036772 blood pressure Effects 0.000 description 2
- 230000037396 body weight Effects 0.000 description 2
- 238000009395 breeding Methods 0.000 description 2
- 230000001488 breeding effect Effects 0.000 description 2
- 239000007975 buffered saline Substances 0.000 description 2
- RMRJXGBAOAMLHD-IHFGGWKQSA-N buprenorphine Chemical compound C([C@]12[C@H]3OC=4C(O)=CC=C(C2=4)C[C@@H]2[C@]11CC[C@]3([C@H](C1)[C@](C)(O)C(C)(C)C)OC)CN2CC1CC1 RMRJXGBAOAMLHD-IHFGGWKQSA-N 0.000 description 2
- 239000001506 calcium phosphate Substances 0.000 description 2
- 229910000389 calcium phosphate Inorganic materials 0.000 description 2
- 235000011010 calcium phosphates Nutrition 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 239000001768 carboxy methyl cellulose Substances 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 230000001906 cholesterol absorption Effects 0.000 description 2
- 239000003354 cholesterol ester transfer protein inhibitor Substances 0.000 description 2
- 230000002759 chromosomal effect Effects 0.000 description 2
- 238000003776 cleavage reaction Methods 0.000 description 2
- 239000002872 contrast media Substances 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- ZYGHJZDHTFUPRJ-UHFFFAOYSA-N coumarin Chemical compound C1=CC=C2OC(=O)C=CC2=C1 ZYGHJZDHTFUPRJ-UHFFFAOYSA-N 0.000 description 2
- CVSVTCORWBXHQV-UHFFFAOYSA-N creatine Chemical compound NC(=[NH2+])N(C)CC([O-])=O CVSVTCORWBXHQV-UHFFFAOYSA-N 0.000 description 2
- 230000009260 cross reactivity Effects 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- 108010060199 cysteinylproline Proteins 0.000 description 2
- 239000000824 cytostatic agent Substances 0.000 description 2
- 231100000433 cytotoxic Toxicity 0.000 description 2
- 230000001472 cytotoxic effect Effects 0.000 description 2
- 238000007405 data analysis Methods 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 230000008021 deposition Effects 0.000 description 2
- 230000001627 detrimental effect Effects 0.000 description 2
- NIJJYAXOARWZEE-UHFFFAOYSA-N di-n-propyl-acetic acid Natural products CCCC(C(O)=O)CCC NIJJYAXOARWZEE-UHFFFAOYSA-N 0.000 description 2
- 239000010432 diamond Substances 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- PRAKJMSDJKAYCZ-UHFFFAOYSA-N dodecahydrosqualene Natural products CC(C)CCCC(C)CCCC(C)CCCCC(C)CCCC(C)CCCC(C)C PRAKJMSDJKAYCZ-UHFFFAOYSA-N 0.000 description 2
- 239000002552 dosage form Substances 0.000 description 2
- 238000004520 electroporation Methods 0.000 description 2
- 210000002889 endothelial cell Anatomy 0.000 description 2
- HQPMKSGTIOYHJT-UHFFFAOYSA-N ethane-1,2-diol;propane-1,2-diol Chemical compound OCCO.CC(O)CO HQPMKSGTIOYHJT-UHFFFAOYSA-N 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 239000010685 fatty oil Substances 0.000 description 2
- 239000000945 filler Substances 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 125000002485 formyl group Chemical group [H]C(*)=O 0.000 description 2
- 238000002825 functional assay Methods 0.000 description 2
- 230000002538 fungal effect Effects 0.000 description 2
- 108020001507 fusion proteins Proteins 0.000 description 2
- 102000037865 fusion proteins Human genes 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- BRZYSWJRSDMWLG-CAXSIQPQSA-N geneticin Natural products O1C[C@@](O)(C)[C@H](NC)[C@@H](O)[C@H]1O[C@@H]1[C@@H](O)[C@H](O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](C(C)O)O2)N)[C@@H](N)C[C@H]1N BRZYSWJRSDMWLG-CAXSIQPQSA-N 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- 235000004554 glutamine Nutrition 0.000 description 2
- 102000005396 glutamine synthetase Human genes 0.000 description 2
- 108020002326 glutamine synthetase Proteins 0.000 description 2
- 235000011187 glycerol Nutrition 0.000 description 2
- 229960005150 glycerol Drugs 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 239000003966 growth inhibitor Substances 0.000 description 2
- 150000003278 haem Chemical class 0.000 description 2
- 229960002897 heparin Drugs 0.000 description 2
- 229920000669 heparin Polymers 0.000 description 2
- 229940088597 hormone Drugs 0.000 description 2
- 239000005556 hormone Substances 0.000 description 2
- 102000057183 human SEMA3A Human genes 0.000 description 2
- 239000001257 hydrogen Substances 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 230000002163 immunogen Effects 0.000 description 2
- 230000016784 immunoglobulin production Effects 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 229960003444 immunosuppressant agent Drugs 0.000 description 2
- 239000003018 immunosuppressive agent Substances 0.000 description 2
- 239000002596 immunotoxin Substances 0.000 description 2
- 238000000126 in silico method Methods 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 238000001802 infusion Methods 0.000 description 2
- 239000004041 inotropic agent Substances 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 229910052742 iron Inorganic materials 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical compound CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 2
- 239000008101 lactose Substances 0.000 description 2
- 229950001845 lestaurtinib Drugs 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 210000004379 membrane Anatomy 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 229930182817 methionine Natural products 0.000 description 2
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 2
- 244000309715 mini pig Species 0.000 description 2
- 239000003607 modifier Substances 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 210000000651 myofibroblast Anatomy 0.000 description 2
- 201000008383 nephritis Diseases 0.000 description 2
- 230000001607 nephroprotective effect Effects 0.000 description 2
- 201000009925 nephrosclerosis Diseases 0.000 description 2
- 210000002569 neuron Anatomy 0.000 description 2
- 229940021182 non-steroidal anti-inflammatory drug Drugs 0.000 description 2
- 239000002773 nucleotide Substances 0.000 description 2
- 125000003729 nucleotide group Chemical group 0.000 description 2
- GVEAYVLWDAFXET-XGHATYIMSA-N pancuronium Chemical compound C[N+]1([C@@H]2[C@@H](OC(C)=O)C[C@@H]3CC[C@H]4[C@@H]5C[C@@H]([C@@H]([C@]5(CC[C@@H]4[C@@]3(C)C2)C)OC(=O)C)[N+]2(C)CCCCC2)CCCCC1 GVEAYVLWDAFXET-XGHATYIMSA-N 0.000 description 2
- 229960005457 pancuronium Drugs 0.000 description 2
- 238000004091 panning Methods 0.000 description 2
- 238000007911 parenteral administration Methods 0.000 description 2
- 108091008725 peroxisome proliferator-activated receptors alpha Proteins 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 2
- 239000010452 phosphate Substances 0.000 description 2
- HYAFETHFCAUJAY-UHFFFAOYSA-N pioglitazone Chemical compound N1=CC(CC)=CC=C1CCOC(C=C1)=CC=C1CC1C(=O)NC(=O)S1 HYAFETHFCAUJAY-UHFFFAOYSA-N 0.000 description 2
- 239000000106 platelet aggregation inhibitor Substances 0.000 description 2
- 210000000557 podocyte Anatomy 0.000 description 2
- 229920001993 poloxamer 188 Polymers 0.000 description 2
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 2
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 2
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 2
- 239000011591 potassium Substances 0.000 description 2
- 229910052700 potassium Inorganic materials 0.000 description 2
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 2
- 230000000069 prophylactic effect Effects 0.000 description 2
- 238000011321 prophylaxis Methods 0.000 description 2
- 230000001681 protective effect Effects 0.000 description 2
- 231100000654 protein toxin Toxicity 0.000 description 2
- 230000005180 public health Effects 0.000 description 2
- 239000012264 purified product Substances 0.000 description 2
- 229950010131 puromycin Drugs 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 230000006798 recombination Effects 0.000 description 2
- 238000005215 recombination Methods 0.000 description 2
- 230000008929 regeneration Effects 0.000 description 2
- 238000011069 regeneration method Methods 0.000 description 2
- 201000002793 renal fibrosis Diseases 0.000 description 2
- 210000005084 renal tissue Anatomy 0.000 description 2
- 230000008439 repair process Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000002207 retinal effect Effects 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 230000007017 scission Effects 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 238000012163 sequencing technique Methods 0.000 description 2
- 235000004400 serine Nutrition 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- BNRNXUUZRGQAQC-UHFFFAOYSA-N sildenafil Chemical compound CCCC1=NN(C)C(C(N2)=O)=C1N=C2C(C(=CC=1)OCC)=CC=1S(=O)(=O)N1CCN(C)CC1 BNRNXUUZRGQAQC-UHFFFAOYSA-N 0.000 description 2
- 238000002741 site-directed mutagenesis Methods 0.000 description 2
- 150000003384 small molecules Chemical class 0.000 description 2
- 235000019812 sodium carboxymethyl cellulose Nutrition 0.000 description 2
- 229920001027 sodium carboxymethylcellulose Polymers 0.000 description 2
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 2
- 229940031439 squalene Drugs 0.000 description 2
- TUHBEKDERLKLEC-UHFFFAOYSA-N squalene Natural products CC(=CCCC(=CCCC(=CCCC=C(/C)CCC=C(/C)CC=C(C)C)C)C)C TUHBEKDERLKLEC-UHFFFAOYSA-N 0.000 description 2
- 239000008107 starch Substances 0.000 description 2
- 235000019698 starch Nutrition 0.000 description 2
- 210000000130 stem cell Anatomy 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- 239000005720 sucrose Substances 0.000 description 2
- 239000013589 supplement Substances 0.000 description 2
- 230000002194 synthesizing effect Effects 0.000 description 2
- 239000000454 talc Substances 0.000 description 2
- 229910052623 talc Inorganic materials 0.000 description 2
- 235000012222 talc Nutrition 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- RMMXLENWKUUMAY-UHFFFAOYSA-N telmisartan Chemical compound CCCC1=NC2=C(C)C=C(C=3N(C4=CC=CC=C4N=3)C)C=C2N1CC(C=C1)=CC=C1C1=CC=CC=C1C(O)=O RMMXLENWKUUMAY-UHFFFAOYSA-N 0.000 description 2
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 2
- 231100001274 therapeutic index Toxicity 0.000 description 2
- 235000008521 threonine Nutrition 0.000 description 2
- 231100000331 toxic Toxicity 0.000 description 2
- 230000002588 toxic effect Effects 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 2
- LZAJKCZTKKKZNT-PMNGPLLRSA-N trichothecene Chemical compound C12([C@@]3(CC[C@H]2OC2C=C(CCC23C)C)C)CO1 LZAJKCZTKKKZNT-PMNGPLLRSA-N 0.000 description 2
- 229930013292 trichothecene Natural products 0.000 description 2
- 238000002604 ultrasonography Methods 0.000 description 2
- 210000003606 umbilical vein Anatomy 0.000 description 2
- 241000701161 unidentified adenovirus Species 0.000 description 2
- 241001515965 unidentified phage Species 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- MSRILKIQRXUYCT-UHFFFAOYSA-M valproate semisodium Chemical compound [Na+].CCCC(C(O)=O)CCC.CCCC(C([O-])=O)CCC MSRILKIQRXUYCT-UHFFFAOYSA-M 0.000 description 2
- 229960000604 valproic acid Drugs 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- 235000019166 vitamin D Nutrition 0.000 description 2
- 239000011710 vitamin D Substances 0.000 description 2
- 150000003710 vitamin D derivatives Chemical class 0.000 description 2
- 229940046008 vitamin d Drugs 0.000 description 2
- OZFAFGSSMRRTDW-UHFFFAOYSA-N (2,4-dichlorophenyl) benzenesulfonate Chemical compound ClC1=CC(Cl)=CC=C1OS(=O)(=O)C1=CC=CC=C1 OZFAFGSSMRRTDW-UHFFFAOYSA-N 0.000 description 1
- JKHVDAUOODACDU-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(2,5-dioxopyrrol-1-yl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCN1C(=O)C=CC1=O JKHVDAUOODACDU-UHFFFAOYSA-N 0.000 description 1
- PVGATNRYUYNBHO-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-(2,5-dioxopyrrol-1-yl)butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCN1C(=O)C=CC1=O PVGATNRYUYNBHO-UHFFFAOYSA-N 0.000 description 1
- BQWBEDSJTMWJAE-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[(2-iodoacetyl)amino]benzoate Chemical compound C1=CC(NC(=O)CI)=CC=C1C(=O)ON1C(=O)CCC1=O BQWBEDSJTMWJAE-UHFFFAOYSA-N 0.000 description 1
- PMJWDPGOWBRILU-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[4-(2,5-dioxopyrrol-1-yl)phenyl]butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCC(C=C1)=CC=C1N1C(=O)C=CC1=O PMJWDPGOWBRILU-UHFFFAOYSA-N 0.000 description 1
- VLARLSIGSPVYHX-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 6-(2,5-dioxopyrrol-1-yl)hexanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCN1C(=O)C=CC1=O VLARLSIGSPVYHX-UHFFFAOYSA-N 0.000 description 1
- WCMOHMXWOOBVMZ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 6-[3-(2,5-dioxopyrrol-1-yl)propanoylamino]hexanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCNC(=O)CCN1C(=O)C=CC1=O WCMOHMXWOOBVMZ-UHFFFAOYSA-N 0.000 description 1
- IHVODYOQUSEYJJ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 6-[[4-[(2,5-dioxopyrrol-1-yl)methyl]cyclohexanecarbonyl]amino]hexanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCNC(=O)C(CC1)CCC1CN1C(=O)C=CC1=O IHVODYOQUSEYJJ-UHFFFAOYSA-N 0.000 description 1
- WCWUXEGQKLTGDX-LLVKDONJSA-N (2R)-1-[[4-[(4-fluoro-2-methyl-1H-indol-5-yl)oxy]-5-methyl-6-pyrrolo[2,1-f][1,2,4]triazinyl]oxy]-2-propanol Chemical compound C1=C2NC(C)=CC2=C(F)C(OC2=NC=NN3C=C(C(=C32)C)OC[C@H](O)C)=C1 WCWUXEGQKLTGDX-LLVKDONJSA-N 0.000 description 1
- XUFXOAAUWZOOIT-SXARVLRPSA-N (2R,3R,4R,5S,6R)-5-[[(2R,3R,4R,5S,6R)-5-[[(2R,3R,4S,5S,6R)-3,4-dihydroxy-6-methyl-5-[[(1S,4R,5S,6S)-4,5,6-trihydroxy-3-(hydroxymethyl)-1-cyclohex-2-enyl]amino]-2-oxanyl]oxy]-3,4-dihydroxy-6-(hydroxymethyl)-2-oxanyl]oxy]-6-(hydroxymethyl)oxane-2,3,4-triol Chemical compound O([C@H]1O[C@H](CO)[C@H]([C@@H]([C@H]1O)O)O[C@H]1O[C@@H]([C@H]([C@H](O)[C@H]1O)N[C@@H]1[C@@H]([C@@H](O)[C@H](O)C(CO)=C1)O)C)[C@@H]1[C@@H](CO)O[C@@H](O)[C@H](O)[C@H]1O XUFXOAAUWZOOIT-SXARVLRPSA-N 0.000 description 1
- LNAZSHAWQACDHT-XIYTZBAFSA-N (2r,3r,4s,5r,6s)-4,5-dimethoxy-2-(methoxymethyl)-3-[(2s,3r,4s,5r,6r)-3,4,5-trimethoxy-6-(methoxymethyl)oxan-2-yl]oxy-6-[(2r,3r,4s,5r,6r)-4,5,6-trimethoxy-2-(methoxymethyl)oxan-3-yl]oxyoxane Chemical compound CO[C@@H]1[C@@H](OC)[C@H](OC)[C@@H](COC)O[C@H]1O[C@H]1[C@H](OC)[C@@H](OC)[C@H](O[C@H]2[C@@H]([C@@H](OC)[C@H](OC)O[C@@H]2COC)OC)O[C@@H]1COC LNAZSHAWQACDHT-XIYTZBAFSA-N 0.000 description 1
- MFRNYXJJRJQHNW-DEMKXPNLSA-N (2s)-2-[[(2r,3r)-3-methoxy-3-[(2s)-1-[(3r,4s,5s)-3-methoxy-5-methyl-4-[methyl-[(2s)-3-methyl-2-[[(2s)-3-methyl-2-(methylamino)butanoyl]amino]butanoyl]amino]heptanoyl]pyrrolidin-2-yl]-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CN[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFRNYXJJRJQHNW-DEMKXPNLSA-N 0.000 description 1
- BIDNLKIUORFRQP-XYGFDPSESA-N (2s,4s)-4-cyclohexyl-1-[2-[[(1s)-2-methyl-1-propanoyloxypropoxy]-(4-phenylbutyl)phosphoryl]acetyl]pyrrolidine-2-carboxylic acid Chemical compound C([P@@](=O)(O[C@H](OC(=O)CC)C(C)C)CC(=O)N1[C@@H](C[C@H](C1)C1CCCCC1)C(O)=O)CCCC1=CC=CC=C1 BIDNLKIUORFRQP-XYGFDPSESA-N 0.000 description 1
- ZGGHKIMDNBDHJB-NRFPMOEYSA-M (3R,5S)-fluvastatin sodium Chemical compound [Na+].C12=CC=CC=C2N(C(C)C)C(\C=C\[C@@H](O)C[C@@H](O)CC([O-])=O)=C1C1=CC=C(F)C=C1 ZGGHKIMDNBDHJB-NRFPMOEYSA-M 0.000 description 1
- CABVTRNMFUVUDM-VRHQGPGLSA-N (3S)-3-hydroxy-3-methylglutaryl-CoA Chemical compound O[C@@H]1[C@H](OP(O)(O)=O)[C@@H](COP(O)(=O)OP(O)(=O)OCC(C)(C)[C@@H](O)C(=O)NCCC(=O)NCCSC(=O)C[C@@](O)(CC(O)=O)C)O[C@H]1N1C2=NC=NC(N)=C2N=C1 CABVTRNMFUVUDM-VRHQGPGLSA-N 0.000 description 1
- BTBHLEZXCOBLCY-QGZVFWFLSA-N (4s)-4-(4-cyano-2-methoxyphenyl)-5-ethoxy-2,8-dimethyl-1,4-dihydro-1,6-naphthyridine-3-carboxamide Chemical compound C1([C@@H]2C(=C(C)NC=3C(C)=CN=C(C2=3)OCC)C(N)=O)=CC=C(C#N)C=C1OC BTBHLEZXCOBLCY-QGZVFWFLSA-N 0.000 description 1
- IEUUDEWWMRQUDS-UHFFFAOYSA-N (6-azaniumylidene-1,6-dimethoxyhexylidene)azanium;dichloride Chemical compound Cl.Cl.COC(=N)CCCCC(=N)OC IEUUDEWWMRQUDS-UHFFFAOYSA-N 0.000 description 1
- BJEPYKJPYRNKOW-REOHCLBHSA-N (S)-malic acid Chemical compound OC(=O)[C@@H](O)CC(O)=O BJEPYKJPYRNKOW-REOHCLBHSA-N 0.000 description 1
- VYEWZWBILJHHCU-OMQUDAQFSA-N (e)-n-[(2s,3r,4r,5r,6r)-2-[(2r,3r,4s,5s,6s)-3-acetamido-5-amino-4-hydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-6-[2-[(2r,3s,4r,5r)-5-(2,4-dioxopyrimidin-1-yl)-3,4-dihydroxyoxolan-2-yl]-2-hydroxyethyl]-4,5-dihydroxyoxan-3-yl]-5-methylhex-2-enamide Chemical compound N1([C@@H]2O[C@@H]([C@H]([C@H]2O)O)C(O)C[C@@H]2[C@H](O)[C@H](O)[C@H]([C@@H](O2)O[C@@H]2[C@@H]([C@@H](O)[C@H](N)[C@@H](CO)O2)NC(C)=O)NC(=O)/C=C/CC(C)C)C=CC(=O)NC1=O VYEWZWBILJHHCU-OMQUDAQFSA-N 0.000 description 1
- XYGVIBXOJOOCFR-BTJKTKAUSA-N (z)-but-2-enedioic acid;8-chloro-6-(2-fluorophenyl)-1-methyl-4h-imidazo[1,5-a][1,4]benzodiazepine Chemical compound OC(=O)\C=C/C(O)=O.C12=CC(Cl)=CC=C2N2C(C)=NC=C2CN=C1C1=CC=CC=C1F XYGVIBXOJOOCFR-BTJKTKAUSA-N 0.000 description 1
- ZOBPZXTWZATXDG-UHFFFAOYSA-N 1,3-thiazolidine-2,4-dione Chemical compound O=C1CSC(=O)N1 ZOBPZXTWZATXDG-UHFFFAOYSA-N 0.000 description 1
- VILFTWLXLYIEMV-UHFFFAOYSA-N 1,5-difluoro-2,4-dinitrobenzene Chemical compound [O-][N+](=O)C1=CC([N+]([O-])=O)=C(F)C=C1F VILFTWLXLYIEMV-UHFFFAOYSA-N 0.000 description 1
- ZUHZNKJIJDAJFD-UHFFFAOYSA-N 1-(2-ethoxyethyl)-5-[ethyl(methyl)amino]-7-[(4-methylpyridin-2-yl)amino]-n-methylsulfonylpyrazolo[4,3-d]pyrimidine-3-carboxamide Chemical compound C=12N(CCOCC)N=C(C(=O)NS(C)(=O)=O)C2=NC(N(C)CC)=NC=1NC1=CC(C)=CC=N1 ZUHZNKJIJDAJFD-UHFFFAOYSA-N 0.000 description 1
- NOSNHVJANRODGR-UHFFFAOYSA-N 1-(2-hydroxyethyl)-4-methyl-n-(4-methylsulfonylphenyl)-5-[2-(trifluoromethyl)phenyl]pyrrole-3-carboxamide Chemical compound CC=1C(C(=O)NC=2C=CC(=CC=2)S(C)(=O)=O)=CN(CCO)C=1C1=CC=CC=C1C(F)(F)F NOSNHVJANRODGR-UHFFFAOYSA-N 0.000 description 1
- PKYCWFICOKSIHZ-UHFFFAOYSA-N 1-(3,7-dihydroxyphenoxazin-10-yl)ethanone Chemical compound OC1=CC=C2N(C(=O)C)C3=CC=C(O)C=C3OC2=C1 PKYCWFICOKSIHZ-UHFFFAOYSA-N 0.000 description 1
- DIYPCWKHSODVAP-UHFFFAOYSA-N 1-[3-(2,5-dioxopyrrol-1-yl)benzoyl]oxy-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)C1=CC=CC(N2C(C=CC2=O)=O)=C1 DIYPCWKHSODVAP-UHFFFAOYSA-N 0.000 description 1
- CULQNACJHGHAER-UHFFFAOYSA-N 1-[4-[(2-iodoacetyl)amino]benzoyl]oxy-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)C1=CC=C(NC(=O)CI)C=C1 CULQNACJHGHAER-UHFFFAOYSA-N 0.000 description 1
- IXPNQXFRVYWDDI-UHFFFAOYSA-N 1-methyl-2,4-dioxo-1,3-diazinane-5-carboximidamide Chemical compound CN1CC(C(N)=N)C(=O)NC1=O IXPNQXFRVYWDDI-UHFFFAOYSA-N 0.000 description 1
- PNDPGZBMCMUPRI-HVTJNCQCSA-N 10043-66-0 Chemical compound [131I][131I] PNDPGZBMCMUPRI-HVTJNCQCSA-N 0.000 description 1
- GUSVHVVOABZHAH-OPZWKQDFSA-N 1aw8p77hkj Chemical compound O([C@@H]1[C@@H](CO)O[C@H]([C@@H]([C@H]1O)O)O[C@@H]1C[C@@H]2CC[C@H]3[C@@H]4C[C@H]5[C@@H]([C@]4(CC[C@@H]3[C@@]2(C)CC1)C)[C@@H]([C@]1(OC[C@H](C)CC1)O5)C)[C@@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@H]1O GUSVHVVOABZHAH-OPZWKQDFSA-N 0.000 description 1
- YBBNVCVOACOHIG-UHFFFAOYSA-N 2,2-diamino-1,4-bis(4-azidophenyl)-3-butylbutane-1,4-dione Chemical compound C=1C=C(N=[N+]=[N-])C=CC=1C(=O)C(N)(N)C(CCCC)C(=O)C1=CC=C(N=[N+]=[N-])C=C1 YBBNVCVOACOHIG-UHFFFAOYSA-N 0.000 description 1
- SGTNSNPWRIOYBX-UHFFFAOYSA-N 2-(3,4-dimethoxyphenyl)-5-{[2-(3,4-dimethoxyphenyl)ethyl](methyl)amino}-2-(propan-2-yl)pentanenitrile Chemical compound C1=C(OC)C(OC)=CC=C1CCN(C)CCCC(C#N)(C(C)C)C1=CC=C(OC)C(OC)=C1 SGTNSNPWRIOYBX-UHFFFAOYSA-N 0.000 description 1
- OFJRNBWSFXEHSA-UHFFFAOYSA-N 2-(3-amino-1,2-benzoxazol-5-yl)-n-[4-[2-[(dimethylamino)methyl]imidazol-1-yl]-2-fluorophenyl]-5-(trifluoromethyl)pyrazole-3-carboxamide Chemical compound CN(C)CC1=NC=CN1C(C=C1F)=CC=C1NC(=O)C1=CC(C(F)(F)F)=NN1C1=CC=C(ON=C2N)C2=C1 OFJRNBWSFXEHSA-UHFFFAOYSA-N 0.000 description 1
- IJMBOKOTALXLKS-UHFFFAOYSA-N 2-(6-morpholin-4-ylpyrimidin-4-yl)-4-(triazol-1-yl)-1h-pyrazol-3-one Chemical compound O=C1C(N2N=NC=C2)=CNN1C(N=CN=1)=CC=1N1CCOCC1 IJMBOKOTALXLKS-UHFFFAOYSA-N 0.000 description 1
- UOJMJBUYXYEPFX-UHFFFAOYSA-N 2-[4-(4-hydroxy-3-propan-2-ylphenoxy)-3,5-dimethylanilino]-2-oxoacetic acid Chemical compound C1=C(O)C(C(C)C)=CC(OC=2C(=CC(NC(=O)C(O)=O)=CC=2C)C)=C1 UOJMJBUYXYEPFX-UHFFFAOYSA-N 0.000 description 1
- ZYPDJSJJXZWZJJ-UHFFFAOYSA-N 2-[4-[2-(2,3-dihydro-1H-inden-2-ylamino)pyrimidin-5-yl]-3-piperidin-4-yloxypyrazol-1-yl]-1-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)ethanone Chemical compound C1C(CC2=CC=CC=C12)NC1=NC=C(C=N1)C=1C(=NN(C=1)CC(=O)N1CC2=C(CC1)NN=N2)OC1CCNCC1 ZYPDJSJJXZWZJJ-UHFFFAOYSA-N 0.000 description 1
- QHVBWSIFLCIXBD-UHFFFAOYSA-N 2-[[2-[3-(diaminomethylidene)-6-oxocyclohexa-1,4-dien-1-yl]oxy-3,5-difluoro-6-[3-(1-methyl-4,5-dihydroimidazol-2-yl)phenoxy]pyridin-4-yl]-methylamino]acetic acid Chemical compound N=1C(OC=2C=C(C=CC=2)C=2N(CCN=2)C)=C(F)C(N(CC(O)=O)C)=C(F)C=1OC1=CC(=C(N)N)C=CC1=O QHVBWSIFLCIXBD-UHFFFAOYSA-N 0.000 description 1
- FBUTXZSKZCQABC-UHFFFAOYSA-N 2-amino-1-methyl-7h-purine-6-thione Chemical compound S=C1N(C)C(N)=NC2=C1NC=N2 FBUTXZSKZCQABC-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- BFSVOASYOCHEOV-UHFFFAOYSA-N 2-diethylaminoethanol Chemical compound CCN(CC)CCO BFSVOASYOCHEOV-UHFFFAOYSA-N 0.000 description 1
- AUYYCJSJGJYCDS-UHFFFAOYSA-N 2/3/6893 Natural products IC1=CC(CC(N)C(O)=O)=CC(I)=C1OC1=CC=C(O)C(I)=C1 AUYYCJSJGJYCDS-UHFFFAOYSA-N 0.000 description 1
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 description 1
- NSMXQKNUPPXBRG-WHPHVCHMSA-N 3,7-dimethyl-1-[(5s)-4,4,6,6,6-pentadeuterio-5-hydroxyhexyl]purine-2,6-dione Chemical compound O=C1N(CCCC([2H])([2H])[C@@H](O)C([2H])([2H])[2H])C(=O)N(C)C2=C1N(C)C=N2 NSMXQKNUPPXBRG-WHPHVCHMSA-N 0.000 description 1
- NCGICGYLBXGBGN-UHFFFAOYSA-N 3-morpholin-4-yl-1-oxa-3-azonia-2-azanidacyclopent-3-en-5-imine;hydrochloride Chemical compound Cl.[N-]1OC(=N)C=[N+]1N1CCOCC1 NCGICGYLBXGBGN-UHFFFAOYSA-N 0.000 description 1
- QFVHZQCOUORWEI-UHFFFAOYSA-N 4-[(4-anilino-5-sulfonaphthalen-1-yl)diazenyl]-5-hydroxynaphthalene-2,7-disulfonic acid Chemical compound C=12C(O)=CC(S(O)(=O)=O)=CC2=CC(S(O)(=O)=O)=CC=1N=NC(C1=CC=CC(=C11)S(O)(=O)=O)=CC=C1NC1=CC=CC=C1 QFVHZQCOUORWEI-UHFFFAOYSA-N 0.000 description 1
- XXJWYDDUDKYVKI-UHFFFAOYSA-N 4-[(4-fluoro-2-methyl-1H-indol-5-yl)oxy]-6-methoxy-7-[3-(1-pyrrolidinyl)propoxy]quinazoline Chemical compound COC1=CC2=C(OC=3C(=C4C=C(C)NC4=CC=3)F)N=CN=C2C=C1OCCCN1CCCC1 XXJWYDDUDKYVKI-UHFFFAOYSA-N 0.000 description 1
- ZMRMMAOBSFSXLN-UHFFFAOYSA-N 4-[4-(2,5-dioxopyrrol-1-yl)phenyl]butanehydrazide Chemical compound C1=CC(CCCC(=O)NN)=CC=C1N1C(=O)C=CC1=O ZMRMMAOBSFSXLN-UHFFFAOYSA-N 0.000 description 1
- YRNWIFYIFSBPAU-UHFFFAOYSA-N 4-[4-(dimethylamino)phenyl]-n,n-dimethylaniline Chemical compound C1=CC(N(C)C)=CC=C1C1=CC=C(N(C)C)C=C1 YRNWIFYIFSBPAU-UHFFFAOYSA-N 0.000 description 1
- QFCXANHHBCGMAS-UHFFFAOYSA-N 4-[[4-(4-chloroanilino)furo[2,3-d]pyridazin-7-yl]oxymethyl]-n-methylpyridine-2-carboxamide Chemical compound C1=NC(C(=O)NC)=CC(COC=2C=3OC=CC=3C(NC=3C=CC(Cl)=CC=3)=NN=2)=C1 QFCXANHHBCGMAS-UHFFFAOYSA-N 0.000 description 1
- LUUMLYXKTPBTQR-UHFFFAOYSA-N 4-chloro-n-[5-methyl-2-(7h-pyrrolo[2,3-d]pyrimidine-4-carbonyl)pyridin-3-yl]-3-(trifluoromethyl)benzenesulfonamide Chemical compound C=1C(C)=CN=C(C(=O)C=2C=3C=CNC=3N=CN=2)C=1NS(=O)(=O)C1=CC=C(Cl)C(C(F)(F)F)=C1 LUUMLYXKTPBTQR-UHFFFAOYSA-N 0.000 description 1
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 1
- RCJYGWGQCPDYSL-HZPDHXFCSA-N 7-[(3-bromo-4-methoxyphenyl)methyl]-1-ethyl-8-[[(1r,2r)-2-hydroxycyclopentyl]amino]-3-(2-hydroxyethyl)purine-2,6-dione Chemical compound C=1C=C(OC)C(Br)=CC=1CN1C=2C(=O)N(CC)C(=O)N(CCO)C=2N=C1N[C@@H]1CCC[C@H]1O RCJYGWGQCPDYSL-HZPDHXFCSA-N 0.000 description 1
- 108010066676 Abrin Proteins 0.000 description 1
- 244000215068 Acacia senegal Species 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 1
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 1
- IPZQNYYAYVRKKK-FXQIFTODSA-N Ala-Pro-Ala Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IPZQNYYAYVRKKK-FXQIFTODSA-N 0.000 description 1
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 1
- UXOWGYHJODZGMF-QORCZRPOSA-N Aliskiren Chemical compound COCCCOC1=CC(C[C@@H](C[C@H](N)[C@@H](O)C[C@@H](C(C)C)C(=O)NCC(C)(C)C(N)=O)C(C)C)=CC=C1OC UXOWGYHJODZGMF-QORCZRPOSA-N 0.000 description 1
- 102100021266 Alpha-(1,6)-fucosyltransferase Human genes 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- QGZKDVFQNNGYKY-OUBTZVSYSA-N Ammonia-15N Chemical compound [15NH3] QGZKDVFQNNGYKY-OUBTZVSYSA-N 0.000 description 1
- 206010002329 Aneurysm Diseases 0.000 description 1
- 229940123413 Angiotensin II antagonist Drugs 0.000 description 1
- QNZCBYKSOIHPEH-UHFFFAOYSA-N Apixaban Chemical compound C1=CC(OC)=CC=C1N1C(C(=O)N(CC2)C=3C=CC(=CC=3)N3C(CCCC3)=O)=C2C(C(N)=O)=N1 QNZCBYKSOIHPEH-UHFFFAOYSA-N 0.000 description 1
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 208000002109 Argyria Diseases 0.000 description 1
- APHUDFFMXFYRKP-CIUDSAMLSA-N Asn-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N APHUDFFMXFYRKP-CIUDSAMLSA-N 0.000 description 1
- PUUPMDXIHCOPJU-HJGDQZAQSA-N Asn-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O PUUPMDXIHCOPJU-HJGDQZAQSA-N 0.000 description 1
- NECWUSYTYSIFNC-DLOVCJGASA-N Asp-Ala-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 NECWUSYTYSIFNC-DLOVCJGASA-N 0.000 description 1
- FANQWNCPNFEPGZ-WHFBIAKZSA-N Asp-Asp-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O FANQWNCPNFEPGZ-WHFBIAKZSA-N 0.000 description 1
- SPKCGKRUYKMDHP-GUDRVLHUSA-N Asp-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N SPKCGKRUYKMDHP-GUDRVLHUSA-N 0.000 description 1
- DONWIPDSZZJHHK-HJGDQZAQSA-N Asp-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)O DONWIPDSZZJHHK-HJGDQZAQSA-N 0.000 description 1
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 1
- 241001465318 Aspergillus terreus Species 0.000 description 1
- 241000416162 Astragalus gummifer Species 0.000 description 1
- XUKUURHRXDUEBC-KAYWLYCHSA-N Atorvastatin Chemical compound C=1C=CC=CC=1C1=C(C=2C=CC(F)=CC=2)N(CC[C@@H](O)C[C@@H](O)CC(O)=O)C(C(C)C)=C1C(=O)NC1=CC=CC=C1 XUKUURHRXDUEBC-KAYWLYCHSA-N 0.000 description 1
- XUKUURHRXDUEBC-UHFFFAOYSA-N Atorvastatin Natural products C=1C=CC=CC=1C1=C(C=2C=CC(F)=CC=2)N(CCC(O)CC(O)CC(O)=O)C(C(C)C)=C1C(=O)NC1=CC=CC=C1 XUKUURHRXDUEBC-UHFFFAOYSA-N 0.000 description 1
- 239000005485 Azilsartan Substances 0.000 description 1
- 239000005552 B01AC04 - Clopidogrel Substances 0.000 description 1
- 239000005528 B01AC05 - Ticlopidine Substances 0.000 description 1
- 229940125524 BAY 1101042 Drugs 0.000 description 1
- MLDQJTXFUGDVEO-UHFFFAOYSA-N BAY-43-9006 Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=CC(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 MLDQJTXFUGDVEO-UHFFFAOYSA-N 0.000 description 1
- 231100000699 Bacterial toxin Toxicity 0.000 description 1
- WPTTVJLTNAWYAO-KPOXMGGZSA-N Bardoxolone methyl Chemical group C([C@@]12C)=C(C#N)C(=O)C(C)(C)[C@@H]1CC[C@]1(C)C2=CC(=O)[C@@H]2[C@@H]3CC(C)(C)CC[C@]3(C(=O)OC)CC[C@]21C WPTTVJLTNAWYAO-KPOXMGGZSA-N 0.000 description 1
- SPFYMRJSYKOXGV-UHFFFAOYSA-N Baytril Chemical compound C1CN(CC)CCN1C(C(=C1)F)=CC2=C1C(=O)C(C(O)=O)=CN2C1CC1 SPFYMRJSYKOXGV-UHFFFAOYSA-N 0.000 description 1
- KUVIULQEHSCUHY-XYWKZLDCSA-N Beclometasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(Cl)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)COC(=O)CC)(OC(=O)CC)[C@@]1(C)C[C@@H]2O KUVIULQEHSCUHY-XYWKZLDCSA-N 0.000 description 1
- XPCFTKFZXHTYIP-PMACEKPBSA-N Benazepril Chemical compound C([C@@H](C(=O)OCC)N[C@@H]1C(N(CC(O)=O)C2=CC=CC=C2CC1)=O)CC1=CC=CC=C1 XPCFTKFZXHTYIP-PMACEKPBSA-N 0.000 description 1
- 102100023995 Beta-nerve growth factor Human genes 0.000 description 1
- 229940123208 Biguanide Drugs 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 244000293889 Bombax malabaricum Species 0.000 description 1
- 235000004480 Bombax malabaricum Nutrition 0.000 description 1
- VOVIALXJUBGFJZ-KWVAZRHASA-N Budesonide Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@@H]2[C@@H]1[C@@H]1C[C@H]3OC(CCC)O[C@@]3(C(=O)CO)[C@@]1(C)C[C@@H]2O VOVIALXJUBGFJZ-KWVAZRHASA-N 0.000 description 1
- 102100031172 C-C chemokine receptor type 1 Human genes 0.000 description 1
- 101710149814 C-C chemokine receptor type 1 Proteins 0.000 description 1
- 239000002083 C09CA01 - Losartan Substances 0.000 description 1
- 239000002080 C09CA02 - Eprosartan Substances 0.000 description 1
- 239000004072 C09CA03 - Valsartan Substances 0.000 description 1
- 239000002947 C09CA04 - Irbesartan Substances 0.000 description 1
- 239000002053 C09CA06 - Candesartan Substances 0.000 description 1
- 239000005537 C09CA07 - Telmisartan Substances 0.000 description 1
- 238000011746 C57BL/6J (JAX™ mouse strain) Methods 0.000 description 1
- 102100031168 CCN family member 2 Human genes 0.000 description 1
- 101000810443 Caenorhabditis elegans Hypoxia-inducible factor prolyl hydroxylase Proteins 0.000 description 1
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 229940122434 Calcium sensitizer Drugs 0.000 description 1
- 239000005461 Canertinib Substances 0.000 description 1
- 101710158575 Cap-specific mRNA (nucleoside-2'-O-)-methyltransferase Proteins 0.000 description 1
- OKTJSMMVPCPJKN-OUBTZVSYSA-N Carbon-13 Chemical compound [13C] OKTJSMMVPCPJKN-OUBTZVSYSA-N 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-L Carbonate Chemical compound [O-]C([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-L 0.000 description 1
- 102100025064 Cellular tumor antigen p53 Human genes 0.000 description 1
- 102220583904 Cellular tumor antigen p53_S96P_mutation Human genes 0.000 description 1
- 229940122444 Chemokine receptor antagonist Drugs 0.000 description 1
- 229940122502 Cholesterol absorption inhibitor Drugs 0.000 description 1
- 229920001268 Cholestyramine Polymers 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 229920002905 Colesevelam Polymers 0.000 description 1
- 229920002911 Colestipol Polymers 0.000 description 1
- 206010010356 Congenital anomaly Diseases 0.000 description 1
- 241000557626 Corvus corax Species 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- 108700032819 Croton tiglium crotin II Proteins 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 1
- 108010036949 Cyclosporine Proteins 0.000 description 1
- OHLLDUNVMPPUMD-DCAQKATOSA-N Cys-Leu-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N OHLLDUNVMPPUMD-DCAQKATOSA-N 0.000 description 1
- 208000026292 Cystic Kidney disease Diseases 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical group OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- XUIIKFGFIJCVMT-GFCCVEGCSA-N D-thyroxine Chemical compound IC1=CC(C[C@@H](N)C(O)=O)=CC(I)=C1OC1=CC(I)=C(O)C(I)=C1 XUIIKFGFIJCVMT-GFCCVEGCSA-N 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 230000004568 DNA-binding Effects 0.000 description 1
- ZBNZXTGUTAYRHI-UHFFFAOYSA-N Dasatinib Chemical compound C=1C(N2CCN(CCO)CC2)=NC(C)=NC=1NC(S1)=NC=C1C(=O)NC1=C(C)C=CC=C1Cl ZBNZXTGUTAYRHI-UHFFFAOYSA-N 0.000 description 1
- WEAHRLBPCANXCN-UHFFFAOYSA-N Daunomycin Natural products CCC1(O)CC(OC2CC(N)C(O)C(C)O2)c3cc4C(=O)c5c(OC)cccc5C(=O)c4c(O)c3C1 WEAHRLBPCANXCN-UHFFFAOYSA-N 0.000 description 1
- 101000783577 Dendroaspis angusticeps Thrombostatin Proteins 0.000 description 1
- 101000783578 Dendroaspis jamesoni kaimosae Dendroaspin Proteins 0.000 description 1
- 208000036828 Device occlusion Diseases 0.000 description 1
- FEWJPZIEWOKRBE-JCYAYHJZSA-N Dextrotartaric acid Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O FEWJPZIEWOKRBE-JCYAYHJZSA-N 0.000 description 1
- 239000012591 Dulbecco’s Phosphate Buffered Saline Substances 0.000 description 1
- 102220473545 ELAV-like protein 1_A90R_mutation Human genes 0.000 description 1
- HGVDHZBSSITLCT-JLJPHGGASA-N Edoxaban Chemical compound N([C@H]1CC[C@@H](C[C@H]1NC(=O)C=1SC=2CN(C)CCC=2N=1)C(=O)N(C)C)C(=O)C(=O)NC1=CC=C(Cl)C=N1 HGVDHZBSSITLCT-JLJPHGGASA-N 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- 102220498105 Electron transfer flavoprotein subunit beta_N53A_mutation Human genes 0.000 description 1
- 108010061435 Enalapril Proteins 0.000 description 1
- 102220590441 Epoxide hydrolase 3_S30D_mutation Human genes 0.000 description 1
- 102000003951 Erythropoietin Human genes 0.000 description 1
- 108090000394 Erythropoietin Proteins 0.000 description 1
- HKVAMNSJSFKALM-GKUWKFKPSA-N Everolimus Chemical compound C1C[C@@H](OCCO)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 HKVAMNSJSFKALM-GKUWKFKPSA-N 0.000 description 1
- 101710082714 Exotoxin A Proteins 0.000 description 1
- RZSYLLSAWYUBPE-UHFFFAOYSA-L Fast green FCF Chemical compound [Na+].[Na+].C=1C=C(C(=C2C=CC(C=C2)=[N+](CC)CC=2C=C(C=CC=2)S([O-])(=O)=O)C=2C(=CC(O)=CC=2)S([O-])(=O)=O)C=CC=1N(CC)CC1=CC=CC(S([O-])(=O)=O)=C1 RZSYLLSAWYUBPE-UHFFFAOYSA-L 0.000 description 1
- 241000724791 Filamentous phage Species 0.000 description 1
- PXGOKWXKJXAPGV-UHFFFAOYSA-N Fluorine Chemical compound FF PXGOKWXKJXAPGV-UHFFFAOYSA-N 0.000 description 1
- 102000004961 Furin Human genes 0.000 description 1
- 108090001126 Furin Proteins 0.000 description 1
- 229910052688 Gadolinium Inorganic materials 0.000 description 1
- 229940126043 Galectin-3 inhibitor Drugs 0.000 description 1
- 101100042266 Gallus gallus SEMA3A gene Proteins 0.000 description 1
- JRZJKWGQFNTSRN-UHFFFAOYSA-N Geldanamycin Natural products C1C(C)CC(OC)C(O)C(C)C=C(C)C(OC(N)=O)C(OC)CCC=C(C)C(=O)NC2=CC(=O)C(OC)=C1C2=O JRZJKWGQFNTSRN-UHFFFAOYSA-N 0.000 description 1
- 108700004714 Gelonium multiflorum GEL Proteins 0.000 description 1
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 1
- 206010018366 Glomerulonephritis acute Diseases 0.000 description 1
- 206010018374 Glomerulonephritis minimal lesion Diseases 0.000 description 1
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 1
- LTUVYLVIZHJCOQ-KKUMJFAQSA-N Glu-Arg-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LTUVYLVIZHJCOQ-KKUMJFAQSA-N 0.000 description 1
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 1
- HUFCEIHAFNVSNR-IHRRRGAJSA-N Glu-Gln-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUFCEIHAFNVSNR-IHRRRGAJSA-N 0.000 description 1
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 1
- DTHNMHAUYICORS-KTKZVXAJSA-N Glucagon-like peptide 1 Chemical class C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 DTHNMHAUYICORS-KTKZVXAJSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- KQDMENMTYNBWMR-WHFBIAKZSA-N Gly-Asp-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KQDMENMTYNBWMR-WHFBIAKZSA-N 0.000 description 1
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 1
- UTYGDAHJBBDPBA-BYULHYEWSA-N Gly-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)CN UTYGDAHJBBDPBA-BYULHYEWSA-N 0.000 description 1
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 1
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 1
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 1
- FULZDMOZUZKGQU-ONGXEEELSA-N Gly-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN FULZDMOZUZKGQU-ONGXEEELSA-N 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 229940121672 Glycosylation inhibitor Drugs 0.000 description 1
- 208000024869 Goodpasture syndrome Diseases 0.000 description 1
- 206010072579 Granulomatosis with polyangiitis Diseases 0.000 description 1
- 229920000084 Gum arabic Polymers 0.000 description 1
- 229940121710 HMGCoA reductase inhibitor Drugs 0.000 description 1
- 239000012981 Hank's balanced salt solution Substances 0.000 description 1
- 102000003745 Hepatocyte Growth Factor Human genes 0.000 description 1
- 108090000100 Hepatocyte Growth Factor Proteins 0.000 description 1
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 1
- HZWWOGWOBQBETJ-CUJWVEQBSA-N His-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O HZWWOGWOBQBETJ-CUJWVEQBSA-N 0.000 description 1
- 101000690301 Homo sapiens Aldo-keto reductase family 1 member C4 Proteins 0.000 description 1
- 101000819490 Homo sapiens Alpha-(1,6)-fucosyltransferase Proteins 0.000 description 1
- 101000777550 Homo sapiens CCN family member 2 Proteins 0.000 description 1
- 101000878605 Homo sapiens Low affinity immunoglobulin epsilon Fc receptor Proteins 0.000 description 1
- 101001116548 Homo sapiens Protein CBFA2T1 Proteins 0.000 description 1
- 101000739767 Homo sapiens Semaphorin-7A Proteins 0.000 description 1
- 101001059454 Homo sapiens Serine/threonine-protein kinase MARK2 Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 201000002980 Hyperparathyroidism Diseases 0.000 description 1
- 206010020772 Hypertension Diseases 0.000 description 1
- 201000001431 Hyperuricemia Diseases 0.000 description 1
- 208000001953 Hypotension Diseases 0.000 description 1
- 206010021118 Hypotonia Diseases 0.000 description 1
- HEFNNWSXXWATRW-UHFFFAOYSA-N Ibuprofen Chemical compound CC(C)CC1=CC=C(C(C)C(O)=O)C=C1 HEFNNWSXXWATRW-UHFFFAOYSA-N 0.000 description 1
- 208000010159 IgA glomerulonephritis Diseases 0.000 description 1
- 206010021263 IgA nephropathy Diseases 0.000 description 1
- RKQAYOWLSFLJEE-SVSWQMSJSA-N Ile-Thr-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N RKQAYOWLSFLJEE-SVSWQMSJSA-N 0.000 description 1
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 1
- 102100021711 Ileal sodium/bile acid cotransporter Human genes 0.000 description 1
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 1
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 1
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 1
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102100023915 Insulin Human genes 0.000 description 1
- 102100025306 Integrin alpha-IIb Human genes 0.000 description 1
- 101710149643 Integrin alpha-IIb Proteins 0.000 description 1
- 102000015696 Interleukins Human genes 0.000 description 1
- 108010063738 Interleukins Proteins 0.000 description 1
- 208000005016 Intestinal Neoplasms Diseases 0.000 description 1
- ZCYVEMRRCGMTRW-AHCXROLUSA-N Iodine-123 Chemical compound [123I] ZCYVEMRRCGMTRW-AHCXROLUSA-N 0.000 description 1
- 206010022971 Iron Deficiencies Diseases 0.000 description 1
- PIWKPBJCKXDKJR-UHFFFAOYSA-N Isoflurane Chemical compound FC(F)OC(Cl)C(F)(F)F PIWKPBJCKXDKJR-UHFFFAOYSA-N 0.000 description 1
- KLDXJTOLSGUMSJ-JGWLITMVSA-N Isosorbide Chemical compound O[C@@H]1CO[C@@H]2[C@@H](O)CO[C@@H]21 KLDXJTOLSGUMSJ-JGWLITMVSA-N 0.000 description 1
- 229940122245 Janus kinase inhibitor Drugs 0.000 description 1
- 206010023439 Kidney transplant rejection Diseases 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 1
- 239000005517 L01XE01 - Imatinib Substances 0.000 description 1
- 239000005411 L01XE02 - Gefitinib Substances 0.000 description 1
- 239000005551 L01XE03 - Erlotinib Substances 0.000 description 1
- 239000002147 L01XE04 - Sunitinib Substances 0.000 description 1
- 239000005511 L01XE05 - Sorafenib Substances 0.000 description 1
- 239000002067 L01XE06 - Dasatinib Substances 0.000 description 1
- 239000002136 L01XE07 - Lapatinib Substances 0.000 description 1
- 239000005536 L01XE08 - Nilotinib Substances 0.000 description 1
- 239000003798 L01XE11 - Pazopanib Substances 0.000 description 1
- 239000002145 L01XE14 - Bosutinib Substances 0.000 description 1
- 239000002144 L01XE18 - Ruxolitinib Substances 0.000 description 1
- 239000002138 L01XE21 - Regorafenib Substances 0.000 description 1
- 229910017569 La2(CO3)3 Inorganic materials 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 1
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 1
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 1
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 1
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 1
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 1
- VUBIPAHVHMZHCM-KKUMJFAQSA-N Leu-Tyr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 VUBIPAHVHMZHCM-KKUMJFAQSA-N 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 229940086609 Lipase inhibitor Drugs 0.000 description 1
- 208000004883 Lipoid Nephrosis Diseases 0.000 description 1
- 108010007859 Lisinopril Proteins 0.000 description 1
- 102100038007 Low affinity immunoglobulin epsilon Fc receptor Human genes 0.000 description 1
- FUKDBQGFSJUXGX-RWMBFGLXSA-N Lys-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N)C(=O)O FUKDBQGFSJUXGX-RWMBFGLXSA-N 0.000 description 1
- NTBFKPBULZGXQL-KKUMJFAQSA-N Lys-Asp-Tyr Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTBFKPBULZGXQL-KKUMJFAQSA-N 0.000 description 1
- HGNRJCINZYHNOU-LURJTMIESA-N Lys-Gly Chemical compound NCCCC[C@H](N)C(=O)NCC(O)=O HGNRJCINZYHNOU-LURJTMIESA-N 0.000 description 1
- LUTDBHBIHHREDC-IHRRRGAJSA-N Lys-Pro-Lys Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O LUTDBHBIHHREDC-IHRRRGAJSA-N 0.000 description 1
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 1
- CTJUSALVKAWFFU-CIUDSAMLSA-N Lys-Ser-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N CTJUSALVKAWFFU-CIUDSAMLSA-N 0.000 description 1
- YKBSXQFZWFXFIB-VOAKCMCISA-N Lys-Thr-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O YKBSXQFZWFXFIB-VOAKCMCISA-N 0.000 description 1
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 1
- 102220471249 M-phase inducer phosphatase 1_S82A_mutation Human genes 0.000 description 1
- 241000282567 Macaca fascicularis Species 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- LRUUNMYPIBZBQH-UHFFFAOYSA-N Methazole Chemical compound O=C1N(C)C(=O)ON1C1=CC=C(Cl)C(Cl)=C1 LRUUNMYPIBZBQH-UHFFFAOYSA-N 0.000 description 1
- CESYKOGBSMNBPD-UHFFFAOYSA-N Methyclothiazide Chemical compound ClC1=C(S(N)(=O)=O)C=C2S(=O)(=O)N(C)C(CCl)NC2=C1 CESYKOGBSMNBPD-UHFFFAOYSA-N 0.000 description 1
- FQISKWAFAHGMGT-SGJOWKDISA-M Methylprednisolone sodium succinate Chemical compound [Na+].C([C@@]12C)=CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2[C@@H](O)C[C@]2(C)[C@@](O)(C(=O)COC(=O)CCC([O-])=O)CC[C@H]21 FQISKWAFAHGMGT-SGJOWKDISA-M 0.000 description 1
- 206010027525 Microalbuminuria Diseases 0.000 description 1
- PCZOHLXUXFIOCF-UHFFFAOYSA-N Monacolin X Natural products C12C(OC(=O)C(C)CC)CC(C)C=C2C=CC(C)C1CCC1CC(O)CC(=O)O1 PCZOHLXUXFIOCF-UHFFFAOYSA-N 0.000 description 1
- 208000004221 Multiple Trauma Diseases 0.000 description 1
- 208000023637 Multiple injury Diseases 0.000 description 1
- 241000699660 Mus musculus Species 0.000 description 1
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 1
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 1
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 description 1
- OVRNDRQMDRJTHS-RTRLPJTCSA-N N-acetyl-D-glucosamine Chemical compound CC(=O)N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-RTRLPJTCSA-N 0.000 description 1
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- JOOXLOJCABQBSG-UHFFFAOYSA-N N-tert-butyl-3-[[5-methyl-2-[4-[2-(1-pyrrolidinyl)ethoxy]anilino]-4-pyrimidinyl]amino]benzenesulfonamide Chemical compound N1=C(NC=2C=C(C=CC=2)S(=O)(=O)NC(C)(C)C)C(C)=CN=C1NC(C=C1)=CC=C1OCCN1CCCC1 JOOXLOJCABQBSG-UHFFFAOYSA-N 0.000 description 1
- 102000004019 NADPH Oxidase 1 Human genes 0.000 description 1
- 108090000424 NADPH Oxidase 1 Proteins 0.000 description 1
- CMWTZPSULFXXJA-UHFFFAOYSA-N Naproxen Natural products C1=C(C(C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-UHFFFAOYSA-N 0.000 description 1
- 241001045988 Neogene Species 0.000 description 1
- 206010029164 Nephrotic syndrome Diseases 0.000 description 1
- SNIOPGDIGTZGOP-UHFFFAOYSA-N Nitroglycerin Chemical compound [O-][N+](=O)OCC(O[N+]([O-])=O)CO[N+]([O-])=O SNIOPGDIGTZGOP-UHFFFAOYSA-N 0.000 description 1
- 239000000006 Nitroglycerin Substances 0.000 description 1
- 208000036576 Obstructive uropathy Diseases 0.000 description 1
- 239000005480 Olmesartan Substances 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 208000002193 Pain Diseases 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 108090000284 Pepsin A Proteins 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 108010067902 Peptide Library Proteins 0.000 description 1
- JOXIIFVCSATTDH-IHPCNDPISA-N Phe-Asn-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N JOXIIFVCSATTDH-IHPCNDPISA-N 0.000 description 1
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 1
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 1
- ZJPGOXWRFNKIQL-JYJNAYRXSA-N Phe-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 ZJPGOXWRFNKIQL-JYJNAYRXSA-N 0.000 description 1
- 229940123333 Phosphodiesterase 5 inhibitor Drugs 0.000 description 1
- UJEWTUDSLQGTOA-UHFFFAOYSA-N Piretanide Chemical compound C=1C=CC=CC=1OC=1C(S(=O)(=O)N)=CC(C(O)=O)=CC=1N1CCCC1 UJEWTUDSLQGTOA-UHFFFAOYSA-N 0.000 description 1
- 231100000742 Plant toxin Toxicity 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- CYLWJCABXYDINA-UHFFFAOYSA-N Polythiazide Polymers ClC1=C(S(N)(=O)=O)C=C2S(=O)(=O)N(C)C(CSCC(F)(F)F)NC2=C1 CYLWJCABXYDINA-UHFFFAOYSA-N 0.000 description 1
- TUZYXOIXSAXUGO-UHFFFAOYSA-N Pravastatin Natural products C1=CC(C)C(CCC(O)CC(O)CC(O)=O)C2C(OC(=O)C(C)CC)CC(O)C=C21 TUZYXOIXSAXUGO-UHFFFAOYSA-N 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 1
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 1
- HWLKHNDRXWTFTN-GUBZILKMSA-N Pro-Pro-Cys Chemical compound C1C[C@H](NC1)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CS)C(=O)O HWLKHNDRXWTFTN-GUBZILKMSA-N 0.000 description 1
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 1
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 1
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 1
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 1
- 241000589517 Pseudomonas aeruginosa Species 0.000 description 1
- 206010037549 Purpura Diseases 0.000 description 1
- 241001672981 Purpura Species 0.000 description 1
- 206010037596 Pyelonephritis Diseases 0.000 description 1
- 241000700157 Rattus norvegicus Species 0.000 description 1
- 229940123934 Reductase inhibitor Drugs 0.000 description 1
- 206010038423 Renal cyst Diseases 0.000 description 1
- 206010061481 Renal injury Diseases 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- RYMZZMVNJRMUDD-UHFFFAOYSA-N SJ000286063 Natural products C12C(OC(=O)C(C)(C)CC)CC(C)C=C2C=CC(C)C1CCC1CC(O)CC(=O)O1 RYMZZMVNJRMUDD-UHFFFAOYSA-N 0.000 description 1
- 108091006614 SLC10A2 Proteins 0.000 description 1
- 108091006649 SLC9A3 Proteins 0.000 description 1
- 108091058545 Secretory proteins Proteins 0.000 description 1
- 102000040739 Secretory proteins Human genes 0.000 description 1
- 102000009203 Sema domains Human genes 0.000 description 1
- 108050000099 Sema domains Proteins 0.000 description 1
- 101150079815 Sema3a gene Proteins 0.000 description 1
- 102100037545 Semaphorin-7A Human genes 0.000 description 1
- 206010040047 Sepsis Diseases 0.000 description 1
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 1
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 1
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 1
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 1
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 1
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 1
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 1
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 1
- ZKOKTQPHFMRSJP-YJRXYDGGSA-N Ser-Thr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKOKTQPHFMRSJP-YJRXYDGGSA-N 0.000 description 1
- AXKJPUBALUNJEO-UBHSHLNASA-N Ser-Trp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O AXKJPUBALUNJEO-UBHSHLNASA-N 0.000 description 1
- QYBRQMLZDDJBSW-AVGNSLFASA-N Ser-Tyr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O QYBRQMLZDDJBSW-AVGNSLFASA-N 0.000 description 1
- KIEIJCFVGZCUAS-MELADBBJSA-N Ser-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CO)N)C(=O)O KIEIJCFVGZCUAS-MELADBBJSA-N 0.000 description 1
- 102100028904 Serine/threonine-protein kinase MARK2 Human genes 0.000 description 1
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 1
- 102100030375 Sodium/hydrogen exchanger 3 Human genes 0.000 description 1
- 229920002125 Sokalan® Polymers 0.000 description 1
- 244000061456 Solanum tuberosum Species 0.000 description 1
- 235000002595 Solanum tuberosum Nutrition 0.000 description 1
- 238000000692 Student's t-test Methods 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-N Succinic acid Natural products OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 1
- 229940100389 Sulfonylurea Drugs 0.000 description 1
- 108091008874 T cell receptors Proteins 0.000 description 1
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 1
- 239000005463 Tandutinib Substances 0.000 description 1
- FEWJPZIEWOKRBE-UHFFFAOYSA-N Tartaric acid Natural products [H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-N 0.000 description 1
- 229940123237 Taxane Drugs 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- 101000712605 Theromyzon tessulatum Theromin Proteins 0.000 description 1
- 229940123464 Thiazolidinedione Drugs 0.000 description 1
- MQCPGOZXFSYJPS-KZVJFYERSA-N Thr-Ala-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MQCPGOZXFSYJPS-KZVJFYERSA-N 0.000 description 1
- UNURFMVMXLENAZ-KJEVXHAQSA-N Thr-Arg-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UNURFMVMXLENAZ-KJEVXHAQSA-N 0.000 description 1
- PQLXHSACXPGWPD-GSSVUCPTSA-N Thr-Asn-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PQLXHSACXPGWPD-GSSVUCPTSA-N 0.000 description 1
- KGKWKSSSQGGYAU-SUSMZKCASA-N Thr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KGKWKSSSQGGYAU-SUSMZKCASA-N 0.000 description 1
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 1
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 1
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 1
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 1
- 229940122388 Thrombin inhibitor Drugs 0.000 description 1
- AUYYCJSJGJYCDS-LBPRGKRZSA-N Thyrolar Chemical compound IC1=CC(C[C@H](N)C(O)=O)=CC(I)=C1OC1=CC=C(O)C(I)=C1 AUYYCJSJGJYCDS-LBPRGKRZSA-N 0.000 description 1
- 239000004012 Tofacitinib Substances 0.000 description 1
- 101710183280 Topoisomerase Proteins 0.000 description 1
- NGBFQHCMQULJNZ-UHFFFAOYSA-N Torsemide Chemical compound CC(C)NC(=O)NS(=O)(=O)C1=CN=CC=C1NC1=CC=CC(C)=C1 NGBFQHCMQULJNZ-UHFFFAOYSA-N 0.000 description 1
- 231100000777 Toxicophore Toxicity 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- 229920001615 Tragacanth Polymers 0.000 description 1
- VXFJYXUZANRPDJ-WTNASJBWSA-N Trandopril Chemical compound C([C@@H](C(=O)OCC)N[C@@H](C)C(=O)N1[C@@H](C[C@H]2CCCC[C@@H]21)C(O)=O)CC1=CC=CC=C1 VXFJYXUZANRPDJ-WTNASJBWSA-N 0.000 description 1
- 102000004338 Transferrin Human genes 0.000 description 1
- 108090000901 Transferrin Proteins 0.000 description 1
- FNYLWPVRPXGIIP-UHFFFAOYSA-N Triamterene Chemical compound NC1=NC2=NC(N)=NC(N)=C2N=C1C1=CC=CC=C1 FNYLWPVRPXGIIP-UHFFFAOYSA-N 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- 235000021307 Triticum Nutrition 0.000 description 1
- 244000098338 Triticum aestivum Species 0.000 description 1
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 1
- 102000004243 Tubulin Human genes 0.000 description 1
- 108090000704 Tubulin Proteins 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 1
- 206010054094 Tumour necrosis Diseases 0.000 description 1
- YJQCOFNZVFGCAF-UHFFFAOYSA-N Tunicamycin II Natural products O1C(CC(O)C2C(C(O)C(O2)N2C(NC(=O)C=C2)=O)O)C(O)C(O)C(NC(=O)C=CCCCCCCCCC(C)C)C1OC1OC(CO)C(O)C(O)C1NC(C)=O YJQCOFNZVFGCAF-UHFFFAOYSA-N 0.000 description 1
- PZXUIGWOEWWFQM-SRVKXCTJSA-N Tyr-Asn-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O PZXUIGWOEWWFQM-SRVKXCTJSA-N 0.000 description 1
- JJNXZIPLIXIGBX-HJPIBITLSA-N Tyr-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JJNXZIPLIXIGBX-HJPIBITLSA-N 0.000 description 1
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 1
- WYOBRXPIZVKNMF-IRXDYDNUSA-N Tyr-Tyr-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)NCC(O)=O)C1=CC=C(O)C=C1 WYOBRXPIZVKNMF-IRXDYDNUSA-N 0.000 description 1
- RMRFSFXLFWWAJZ-HJOGWXRNSA-N Tyr-Tyr-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 RMRFSFXLFWWAJZ-HJOGWXRNSA-N 0.000 description 1
- SQUMHUZLJDUROQ-YDHLFZDLSA-N Tyr-Val-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O SQUMHUZLJDUROQ-YDHLFZDLSA-N 0.000 description 1
- GNWUWQAVVJQREM-NHCYSSNCSA-N Val-Asn-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N GNWUWQAVVJQREM-NHCYSSNCSA-N 0.000 description 1
- BMGOFDMKDVVGJG-NHCYSSNCSA-N Val-Asp-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BMGOFDMKDVVGJG-NHCYSSNCSA-N 0.000 description 1
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 1
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 1
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 1
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 1
- KRAHMIJVUPUOTQ-DCAQKATOSA-N Val-Ser-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KRAHMIJVUPUOTQ-DCAQKATOSA-N 0.000 description 1
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 1
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 1
- BZDGLJPROOOUOZ-XGEHTFHBSA-N Val-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N)O BZDGLJPROOOUOZ-XGEHTFHBSA-N 0.000 description 1
- 240000001866 Vernicia fordii Species 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- 238000012452 Xenomouse strains Methods 0.000 description 1
- 240000008042 Zea mays Species 0.000 description 1
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 description 1
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 1
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 1
- 229960003697 abatacept Drugs 0.000 description 1
- 229960000446 abciximab Drugs 0.000 description 1
- 210000001015 abdomen Anatomy 0.000 description 1
- 230000003187 abdominal effect Effects 0.000 description 1
- 210000003815 abdominal wall Anatomy 0.000 description 1
- 230000005856 abnormality Effects 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 235000010489 acacia gum Nutrition 0.000 description 1
- 239000000205 acacia gum Substances 0.000 description 1
- 229960002632 acarbose Drugs 0.000 description 1
- XUFXOAAUWZOOIT-UHFFFAOYSA-N acarviostatin I01 Natural products OC1C(O)C(NC2C(C(O)C(O)C(CO)=C2)O)C(C)OC1OC(C(C1O)O)C(CO)OC1OC1C(CO)OC(O)C(O)C1O XUFXOAAUWZOOIT-UHFFFAOYSA-N 0.000 description 1
- 229960000571 acetazolamide Drugs 0.000 description 1
- BZKPWHYZMXOIDC-UHFFFAOYSA-N acetazolamide Chemical compound CC(=O)NC1=NN=C(S(N)(=O)=O)S1 BZKPWHYZMXOIDC-UHFFFAOYSA-N 0.000 description 1
- 235000011054 acetic acid Nutrition 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 239000008186 active pharmaceutical agent Substances 0.000 description 1
- 231100000851 acute glomerulonephritis Toxicity 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 229960002833 aflibercept Drugs 0.000 description 1
- 108010081667 aflibercept Proteins 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 235000010419 agar Nutrition 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 108010087924 alanylproline Proteins 0.000 description 1
- 150000001299 aldehydes Chemical class 0.000 description 1
- 235000010443 alginic acid Nutrition 0.000 description 1
- 239000000783 alginic acid Substances 0.000 description 1
- 229920000615 alginic acid Polymers 0.000 description 1
- 229960001126 alginic acid Drugs 0.000 description 1
- 150000004781 alginic acids Chemical class 0.000 description 1
- 229960004601 aliskiren Drugs 0.000 description 1
- 229960003459 allopurinol Drugs 0.000 description 1
- OFCNXPDARWKPPY-UHFFFAOYSA-N allopurinol Chemical compound OC1=NC=NC2=C1C=NN2 OFCNXPDARWKPPY-UHFFFAOYSA-N 0.000 description 1
- BJEPYKJPYRNKOW-UHFFFAOYSA-N alpha-hydroxysuccinic acid Natural products OC(=O)C(O)CC(O)=O BJEPYKJPYRNKOW-UHFFFAOYSA-N 0.000 description 1
- 108010001818 alpha-sarcin Proteins 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 229960002414 ambrisentan Drugs 0.000 description 1
- OUJTZYPIHDYQMC-LJQANCHMSA-N ambrisentan Chemical compound O([C@@H](C(OC)(C=1C=CC=CC=1)C=1C=CC=CC=1)C(O)=O)C1=NC(C)=CC(C)=N1 OUJTZYPIHDYQMC-LJQANCHMSA-N 0.000 description 1
- XSDQTOBWRPYKKA-UHFFFAOYSA-N amiloride Chemical compound NC(=N)NC(=O)C1=NC(Cl)=C(N)N=C1N XSDQTOBWRPYKKA-UHFFFAOYSA-N 0.000 description 1
- 229960002576 amiloride Drugs 0.000 description 1
- HTIQEAQVCYTUBX-UHFFFAOYSA-N amlodipine Chemical compound CCOC(=O)C1=C(COCCN)NC(C)=C(C(=O)OC)C1C1=CC=CC=C1Cl HTIQEAQVCYTUBX-UHFFFAOYSA-N 0.000 description 1
- 229960000528 amlodipine Drugs 0.000 description 1
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 1
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 1
- 238000012870 ammonium sulfate precipitation Methods 0.000 description 1
- 235000011130 ammonium sulphate Nutrition 0.000 description 1
- 206010002022 amyloidosis Diseases 0.000 description 1
- 230000000202 analgesic effect Effects 0.000 description 1
- 238000012436 analytical size exclusion chromatography Methods 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 239000002333 angiotensin II receptor antagonist Substances 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 150000001450 anions Chemical class 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000003510 anti-fibrotic effect Effects 0.000 description 1
- 229940121363 anti-inflammatory agent Drugs 0.000 description 1
- 239000002260 anti-inflammatory agent Substances 0.000 description 1
- 229940124599 anti-inflammatory drug Drugs 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 229940127219 anticoagulant drug Drugs 0.000 description 1
- 229960004676 antithrombotic agent Drugs 0.000 description 1
- 239000003698 antivitamin K Substances 0.000 description 1
- 210000000702 aorta abdominal Anatomy 0.000 description 1
- 229950009097 apararenone Drugs 0.000 description 1
- 229960003886 apixaban Drugs 0.000 description 1
- 230000001640 apoptogenic effect Effects 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 1
- 210000002565 arteriole Anatomy 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 1
- 108010068265 aspartyltyrosine Proteins 0.000 description 1
- 229960005370 atorvastatin Drugs 0.000 description 1
- 229950010993 atrasentan Drugs 0.000 description 1
- MOTJMGVDPWRKOC-QPVYNBJUSA-N atrasentan Chemical compound C1([C@H]2[C@@H]([C@H](CN2CC(=O)N(CCCC)CCCC)C=2C=C3OCOC3=CC=2)C(O)=O)=CC=C(OC)C=C1 MOTJMGVDPWRKOC-QPVYNBJUSA-N 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 229960000307 avanafil Drugs 0.000 description 1
- WEAJZXNPAWBCOA-INIZCTEOSA-N avanafil Chemical compound C1=C(Cl)C(OC)=CC=C1CNC1=NC(N2[C@@H](CCC2)CO)=NC=C1C(=O)NCC1=NC=CC=N1 WEAJZXNPAWBCOA-INIZCTEOSA-N 0.000 description 1
- 229950011524 avosentan Drugs 0.000 description 1
- 229960003005 axitinib Drugs 0.000 description 1
- RITAVMQDGBJQJZ-FMIVXFBMSA-N axitinib Chemical compound CNC(=O)C1=CC=CC=C1SC1=CC=C(C(\C=C\C=2N=CC=CC=2)=NN2)C2=C1 RITAVMQDGBJQJZ-FMIVXFBMSA-N 0.000 description 1
- 210000003050 axon Anatomy 0.000 description 1
- KGSXMPPBFPAXLY-UHFFFAOYSA-N azilsartan Chemical compound CCOC1=NC2=CC=CC(C(O)=O)=C2N1CC(C=C1)=CC=C1C1=CC=CC=C1C1=NOC(=O)N1 KGSXMPPBFPAXLY-UHFFFAOYSA-N 0.000 description 1
- 229960002731 azilsartan Drugs 0.000 description 1
- 239000000688 bacterial toxin Substances 0.000 description 1
- 229950000971 baricitinib Drugs 0.000 description 1
- XUZMWHLSFXCVMG-UHFFFAOYSA-N baricitinib Chemical compound C1N(S(=O)(=O)CC)CC1(CC#N)N1N=CC(C=2C=3C=CNC=3N=CN=2)=C1 XUZMWHLSFXCVMG-UHFFFAOYSA-N 0.000 description 1
- 229960004495 beclometasone Drugs 0.000 description 1
- 229960003270 belimumab Drugs 0.000 description 1
- 229960004530 benazepril Drugs 0.000 description 1
- 229960003515 bendroflumethiazide Drugs 0.000 description 1
- HDWIHXWEUNVBIY-UHFFFAOYSA-N bendroflumethiazidum Chemical compound C1=C(C(F)(F)F)C(S(=O)(=O)N)=CC(S(N2)(=O)=O)=C1NC2CC1=CC=CC=C1 HDWIHXWEUNVBIY-UHFFFAOYSA-N 0.000 description 1
- WPYMKLBDIGXBTP-UHFFFAOYSA-N benzoic acid Chemical compound OC(=O)C1=CC=CC=C1 WPYMKLBDIGXBTP-UHFFFAOYSA-N 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 229960002537 betamethasone Drugs 0.000 description 1
- UREBDLICKHMUKA-DVTGEIKXSA-N betamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-DVTGEIKXSA-N 0.000 description 1
- 229960000397 bevacizumab Drugs 0.000 description 1
- 150000004283 biguanides Chemical class 0.000 description 1
- 230000008033 biological extinction Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 238000007413 biotinylation Methods 0.000 description 1
- 230000006287 biotinylation Effects 0.000 description 1
- 108010055460 bivalirudin Proteins 0.000 description 1
- 229960001500 bivalirudin Drugs 0.000 description 1
- OIRCOABEOLEUMC-GEJPAHFPSA-N bivalirudin Chemical compound C([C@@H](C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)CNC(=O)CNC(=O)CNC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 OIRCOABEOLEUMC-GEJPAHFPSA-N 0.000 description 1
- 229930189065 blasticidin Natural products 0.000 description 1
- 101150038738 ble gene Proteins 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 230000036760 body temperature Effects 0.000 description 1
- 229960003065 bosentan Drugs 0.000 description 1
- GJPICJJJRGTNOD-UHFFFAOYSA-N bosentan Chemical compound COC1=CC=CC=C1OC(C(=NC(=N1)C=2N=CC=CN=2)OCCO)=C1NS(=O)(=O)C1=CC=C(C(C)(C)C)C=C1 GJPICJJJRGTNOD-UHFFFAOYSA-N 0.000 description 1
- 229960003736 bosutinib Drugs 0.000 description 1
- UBPYILGKFZZVDX-UHFFFAOYSA-N bosutinib Chemical compound C1=C(Cl)C(OC)=CC(NC=2C3=CC(OC)=C(OCCCN4CCN(C)CC4)C=C3N=CC=2C#N)=C1Cl UBPYILGKFZZVDX-UHFFFAOYSA-N 0.000 description 1
- 101150046240 bsd gene Proteins 0.000 description 1
- 229960004436 budesonide Drugs 0.000 description 1
- MAEIEVLCKWDQJH-UHFFFAOYSA-N bumetanide Chemical compound CCCCNC1=CC(C(O)=O)=CC(S(N)(=O)=O)=C1OC1=CC=CC=C1 MAEIEVLCKWDQJH-UHFFFAOYSA-N 0.000 description 1
- 229960004064 bumetanide Drugs 0.000 description 1
- 229960001736 buprenorphine Drugs 0.000 description 1
- KDYFGRWQOYBRFD-NUQCWPJISA-N butanedioic acid Chemical compound O[14C](=O)CC[14C](O)=O KDYFGRWQOYBRFD-NUQCWPJISA-N 0.000 description 1
- 230000002092 calcimimetic effect Effects 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 239000000480 calcium channel blocker Substances 0.000 description 1
- ZJKZKKPIKDNHDM-UHFFFAOYSA-L calcium;6-(5-carboxylato-5-methylhexoxy)-2,2-dimethylhexanoate Chemical compound [Ca+2].[O-]C(=O)C(C)(C)CCCCOCCCCC(C)(C)C([O-])=O ZJKZKKPIKDNHDM-UHFFFAOYSA-L 0.000 description 1
- ZEWYCNBZMPELPF-UHFFFAOYSA-J calcium;potassium;sodium;2-hydroxypropanoic acid;sodium;tetrachloride Chemical compound [Na].[Na+].[Cl-].[Cl-].[Cl-].[Cl-].[K+].[Ca+2].CC(O)C(O)=O ZEWYCNBZMPELPF-UHFFFAOYSA-J 0.000 description 1
- 238000011088 calibration curve Methods 0.000 description 1
- 229930195731 calicheamicin Natural products 0.000 description 1
- HXCHCVDVKSCDHU-LULTVBGHSA-N calicheamicin Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-LULTVBGHSA-N 0.000 description 1
- 229960000932 candesartan Drugs 0.000 description 1
- SGZAIDDFHDDFJU-UHFFFAOYSA-N candesartan Chemical compound CCOC1=NC2=CC=CC(C(O)=O)=C2N1CC(C=C1)=CC=C1C1=CC=CC=C1C1=NN=N[N]1 SGZAIDDFHDDFJU-UHFFFAOYSA-N 0.000 description 1
- 229950002826 canertinib Drugs 0.000 description 1
- OMZCMEYTWSXEPZ-UHFFFAOYSA-N canertinib Chemical compound C1=C(Cl)C(F)=CC=C1NC1=NC=NC2=CC(OCCCN3CCOCC3)=C(NC(=O)C=C)C=C12 OMZCMEYTWSXEPZ-UHFFFAOYSA-N 0.000 description 1
- 229960005057 canrenone Drugs 0.000 description 1
- UJVLDDZCTMKXJK-WNHSNXHDSA-N canrenone Chemical compound C([C@H]1[C@H]2[C@@H]([C@]3(CCC(=O)C=C3C=C2)C)CC[C@@]11C)C[C@@]11CCC(=O)O1 UJVLDDZCTMKXJK-WNHSNXHDSA-N 0.000 description 1
- 210000000692 cap cell Anatomy 0.000 description 1
- 229960000830 captopril Drugs 0.000 description 1
- FAKRSMQSSFJEIM-RQJHMYQMSA-N captopril Chemical compound SC[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O FAKRSMQSSFJEIM-RQJHMYQMSA-N 0.000 description 1
- 229910002091 carbon monoxide Inorganic materials 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 208000025188 carcinoma of pharynx Diseases 0.000 description 1
- 238000007675 cardiac surgery Methods 0.000 description 1
- 230000002612 cardiopulmonary effect Effects 0.000 description 1
- 238000013130 cardiovascular surgery Methods 0.000 description 1
- 210000001715 carotid artery Anatomy 0.000 description 1
- 238000005277 cation exchange chromatography Methods 0.000 description 1
- 229960002412 cediranib Drugs 0.000 description 1
- 230000003833 cell viability Effects 0.000 description 1
- 230000010094 cellular senescence Effects 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 208000015114 central nervous system disease Diseases 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000002604 chemokine receptor CCR2 antagonist Substances 0.000 description 1
- 239000002559 chemokine receptor antagonist Substances 0.000 description 1
- 229940044683 chemotherapy drug Drugs 0.000 description 1
- 229960002155 chlorothiazide Drugs 0.000 description 1
- JIVPVXMEBJLZRO-UHFFFAOYSA-N chlorthalidone Chemical compound C1=C(Cl)C(S(=O)(=O)N)=CC(C2(O)C3=CC=CC=C3C(=O)N2)=C1 JIVPVXMEBJLZRO-UHFFFAOYSA-N 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 229960001265 ciclosporin Drugs 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 238000012411 cloning technique Methods 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- GKTWGGQPFAXNFI-HNNXBMFYSA-N clopidogrel Chemical compound C1([C@H](N2CC=3C=CSC=3CC2)C(=O)OC)=CC=CC=C1Cl GKTWGGQPFAXNFI-HNNXBMFYSA-N 0.000 description 1
- 229960003009 clopidogrel Drugs 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- GMRWGQCZJGVHKL-UHFFFAOYSA-N colestipol Chemical compound ClCC1CO1.NCCNCCNCCNCCN GMRWGQCZJGVHKL-UHFFFAOYSA-N 0.000 description 1
- 229960002604 colestipol Drugs 0.000 description 1
- 238000002648 combination therapy Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 235000005822 corn Nutrition 0.000 description 1
- 210000004351 coronary vessel Anatomy 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 229960000956 coumarin Drugs 0.000 description 1
- 235000001671 coumarin Nutrition 0.000 description 1
- 239000007822 coupling agent Substances 0.000 description 1
- 229960003624 creatine Drugs 0.000 description 1
- 239000006046 creatine Substances 0.000 description 1
- 239000003431 cross linking reagent Substances 0.000 description 1
- 238000009295 crossflow filtration Methods 0.000 description 1
- 239000000287 crude extract Substances 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- NZNMSOFKMUBTKW-UHFFFAOYSA-N cyclohexanecarboxylic acid Chemical compound OC(=O)C1CCCCC1 NZNMSOFKMUBTKW-UHFFFAOYSA-N 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 229930182912 cyclosporin Natural products 0.000 description 1
- 108010016616 cysteinylglycine Proteins 0.000 description 1
- 238000002784 cytotoxicity assay Methods 0.000 description 1
- 231100000263 cytotoxicity test Toxicity 0.000 description 1
- 229960003850 dabigatran Drugs 0.000 description 1
- YBSJFWOBGCMAKL-UHFFFAOYSA-N dabigatran Chemical compound N=1C2=CC(C(=O)N(CCC(O)=O)C=3N=CC=CC=3)=CC=C2N(C)C=1CNC1=CC=C(C(N)=N)C=C1 YBSJFWOBGCMAKL-UHFFFAOYSA-N 0.000 description 1
- 229950008833 darusentan Drugs 0.000 description 1
- FEJVSJIALLTFRP-LJQANCHMSA-N darusentan Chemical compound COC1=CC(OC)=NC(O[C@H](C(O)=O)C(OC)(C=2C=CC=CC=2)C=2C=CC=CC=2)=N1 FEJVSJIALLTFRP-LJQANCHMSA-N 0.000 description 1
- 229950003418 dasantafil Drugs 0.000 description 1
- 229960002448 dasatinib Drugs 0.000 description 1
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- WOUOLAUOZXOLJQ-MBSDFSHPSA-N delapril Chemical compound C([C@@H](C(=O)OCC)N[C@@H](C)C(=O)N(CC(O)=O)C1CC2=CC=CC=C2C1)CC1=CC=CC=C1 WOUOLAUOZXOLJQ-MBSDFSHPSA-N 0.000 description 1
- 229960005227 delapril Drugs 0.000 description 1
- 238000002716 delivery method Methods 0.000 description 1
- 238000011033 desalting Methods 0.000 description 1
- 229960003957 dexamethasone Drugs 0.000 description 1
- UREBDLICKHMUKA-CXSFZGCWSA-N dexamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-CXSFZGCWSA-N 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 229960001767 dextrothyroxine Drugs 0.000 description 1
- 206010012601 diabetes mellitus Diseases 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- 229930191339 dianthin Natural products 0.000 description 1
- 229960005081 diclofenamide Drugs 0.000 description 1
- GJQPMPFPNINLKP-UHFFFAOYSA-N diclofenamide Chemical compound NS(=O)(=O)C1=CC(Cl)=C(Cl)C(S(N)(=O)=O)=C1 GJQPMPFPNINLKP-UHFFFAOYSA-N 0.000 description 1
- 235000005911 diet Nutrition 0.000 description 1
- 230000037213 diet Effects 0.000 description 1
- 235000014113 dietary fatty acids Nutrition 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 238000011496 digital image analysis Methods 0.000 description 1
- 125000005442 diisocyanate group Chemical group 0.000 description 1
- 229960004166 diltiazem Drugs 0.000 description 1
- HSUGRBWQSSZJOP-RTWAWAEBSA-N diltiazem Chemical compound C1=CC(OC)=CC=C1[C@H]1[C@@H](OC(C)=O)C(=O)N(CCN(C)C)C2=CC=CC=C2S1 HSUGRBWQSSZJOP-RTWAWAEBSA-N 0.000 description 1
- 229940090124 dipeptidyl peptidase 4 (dpp-4) inhibitors for blood glucose lowering Drugs 0.000 description 1
- 206010013023 diphtheria Diseases 0.000 description 1
- IZEKFCXSFNUWAM-UHFFFAOYSA-N dipyridamole Chemical compound C=12N=C(N(CCO)CCO)N=C(N3CCCCC3)C2=NC(N(CCO)CCO)=NC=1N1CCCCC1 IZEKFCXSFNUWAM-UHFFFAOYSA-N 0.000 description 1
- 229960002768 dipyridamole Drugs 0.000 description 1
- 239000007884 disintegrant Substances 0.000 description 1
- XEYBHCRIKKKOSS-UHFFFAOYSA-N disodium;azanylidyneoxidanium;iron(2+);pentacyanide Chemical compound [Na+].[Na+].[Fe+2].N#[C-].N#[C-].N#[C-].N#[C-].N#[C-].[O+]#N XEYBHCRIKKKOSS-UHFFFAOYSA-N 0.000 description 1
- ZWIBGKZDAWNIFC-UHFFFAOYSA-N disuccinimidyl suberate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCCC(=O)ON1C(=O)CCC1=O ZWIBGKZDAWNIFC-UHFFFAOYSA-N 0.000 description 1
- 230000001882 diuretic effect Effects 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- AMRJKAQTDDKMCE-UHFFFAOYSA-N dolastatin Chemical compound CC(C)C(N(C)C)C(=O)NC(C(C)C)C(=O)N(C)C(C(C)C)C(OC)CC(=O)N1CCCC1C(OC)C(C)C(=O)NC(C=1SC=CN=1)CC1=CC=CC=C1 AMRJKAQTDDKMCE-UHFFFAOYSA-N 0.000 description 1
- 229930188854 dolastatin Natural products 0.000 description 1
- 238000011162 downstream development Methods 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 235000020188 drinking water Nutrition 0.000 description 1
- 239000003651 drinking water Substances 0.000 description 1
- 238000001647 drug administration Methods 0.000 description 1
- 239000000890 drug combination Substances 0.000 description 1
- 229960002224 eculizumab Drugs 0.000 description 1
- 229960000622 edoxaban Drugs 0.000 description 1
- XFLQIRAKKLNXRQ-UUWRZZSWSA-N elobixibat Chemical compound C12=CC(SC)=C(OCC(=O)N[C@@H](C(=O)NCC(O)=O)C=3C=CC=CC=3)C=C2S(=O)(=O)CC(CCCC)(CCCC)CN1C1=CC=CC=C1 XFLQIRAKKLNXRQ-UUWRZZSWSA-N 0.000 description 1
- 210000002257 embryonic structure Anatomy 0.000 description 1
- 230000001804 emulsifying effect Effects 0.000 description 1
- GBXSMTUPTTWBMN-XIRDDKMYSA-N enalapril Chemical compound C([C@@H](C(=O)OCC)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(O)=O)CC1=CC=CC=C1 GBXSMTUPTTWBMN-XIRDDKMYSA-N 0.000 description 1
- 229960000873 enalapril Drugs 0.000 description 1
- 238000013171 endarterectomy Methods 0.000 description 1
- 210000003038 endothelium Anatomy 0.000 description 1
- 108010028531 enomycin Proteins 0.000 description 1
- 229960000610 enoxaparin Drugs 0.000 description 1
- 229960000740 enrofloxacin Drugs 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 229960001208 eplerenone Drugs 0.000 description 1
- JUKPWJGBANNWMW-VWBFHTRKSA-N eplerenone Chemical compound C([C@@H]1[C@]2(C)C[C@H]3O[C@]33[C@@]4(C)CCC(=O)C=C4C[C@H]([C@@H]13)C(=O)OC)C[C@@]21CCC(=O)O1 JUKPWJGBANNWMW-VWBFHTRKSA-N 0.000 description 1
- 229960004563 eprosartan Drugs 0.000 description 1
- OROAFUQRIXKEMV-LDADJPATSA-N eprosartan Chemical compound C=1C=C(C(O)=O)C=CC=1CN1C(CCCC)=NC=C1\C=C(C(O)=O)/CC1=CC=CS1 OROAFUQRIXKEMV-LDADJPATSA-N 0.000 description 1
- 229960001433 erlotinib Drugs 0.000 description 1
- AAKJLRGGTJKAMG-UHFFFAOYSA-N erlotinib Chemical compound C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 AAKJLRGGTJKAMG-UHFFFAOYSA-N 0.000 description 1
- 229940105423 erythropoietin Drugs 0.000 description 1
- 229950006558 esaxerenone Drugs 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 238000012869 ethanol precipitation Methods 0.000 description 1
- FUBBWDWIGBTUPQ-UHFFFAOYSA-N ethyl 2-[4-[3-[(4-fluorophenyl)-hydroxymethyl]-4-hydroxyphenoxy]-3,5-dimethylanilino]-2-oxoacetate Chemical compound CC1=CC(NC(=O)C(=O)OCC)=CC(C)=C1OC1=CC=C(O)C(C(O)C=2C=CC(F)=CC=2)=C1 FUBBWDWIGBTUPQ-UHFFFAOYSA-N 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- 229960005167 everolimus Drugs 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 229960000815 ezetimibe Drugs 0.000 description 1
- OLNTVTPDXPETLC-XPWALMASSA-N ezetimibe Chemical compound N1([C@@H]([C@H](C1=O)CC[C@H](O)C=1C=CC(F)=CC=1)C=1C=CC(O)=CC=1)C1=CC=C(F)C=C1 OLNTVTPDXPETLC-XPWALMASSA-N 0.000 description 1
- 229930195729 fatty acid Natural products 0.000 description 1
- 239000000194 fatty acid Substances 0.000 description 1
- 210000001105 femoral artery Anatomy 0.000 description 1
- PJMPHNIQZUBGLI-UHFFFAOYSA-N fentanyl Chemical compound C=1C=CC=CC=1N(C(=O)CC)C(CC1)CCN1CCC1=CC=CC=C1 PJMPHNIQZUBGLI-UHFFFAOYSA-N 0.000 description 1
- 229960002428 fentanyl Drugs 0.000 description 1
- 210000003754 fetus Anatomy 0.000 description 1
- 229950010034 fidexaban Drugs 0.000 description 1
- 229950004408 finerenone Drugs 0.000 description 1
- 239000000834 fixative Substances 0.000 description 1
- 229960000676 flunisolide Drugs 0.000 description 1
- 238000002073 fluorescence micrograph Methods 0.000 description 1
- 150000002222 fluorine compounds Chemical class 0.000 description 1
- 229960002714 fluticasone Drugs 0.000 description 1
- MGNNYOODZCAHBA-GQKYHHCASA-N fluticasone Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@@H](C)[C@@](C(=O)SCF)(O)[C@@]2(C)C[C@@H]1O MGNNYOODZCAHBA-GQKYHHCASA-N 0.000 description 1
- 229960003765 fluvastatin Drugs 0.000 description 1
- 229960001318 fondaparinux Drugs 0.000 description 1
- KANJSNBRCNMZMV-ABRZTLGGSA-N fondaparinux Chemical compound O[C@@H]1[C@@H](NS(O)(=O)=O)[C@@H](OC)O[C@H](COS(O)(=O)=O)[C@H]1O[C@H]1[C@H](OS(O)(=O)=O)[C@@H](O)[C@H](O[C@@H]2[C@@H]([C@@H](OS(O)(=O)=O)[C@H](O[C@H]3[C@@H]([C@@H](O)[C@H](O[C@@H]4[C@@H]([C@@H](O)[C@H](O)[C@@H](COS(O)(=O)=O)O4)NS(O)(=O)=O)[C@H](O3)C(O)=O)O)[C@@H](COS(O)(=O)=O)O2)NS(O)(=O)=O)[C@H](C(O)=O)O1 KANJSNBRCNMZMV-ABRZTLGGSA-N 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- 230000037406 food intake Effects 0.000 description 1
- 210000003194 forelimb Anatomy 0.000 description 1
- 229960002490 fosinopril Drugs 0.000 description 1
- 239000012458 free base Substances 0.000 description 1
- 229950004003 fresolimumab Drugs 0.000 description 1
- 230000005714 functional activity Effects 0.000 description 1
- 229960003883 furosemide Drugs 0.000 description 1
- ZZUFCTLCJUWOSV-UHFFFAOYSA-N furosemide Chemical compound C1=C(Cl)C(S(=O)(=O)N)=CC(C(O)=O)=C1NCC1=CC=CO1 ZZUFCTLCJUWOSV-UHFFFAOYSA-N 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- UIWYJDYFSGRHKR-UHFFFAOYSA-N gadolinium atom Chemical compound [Gd] UIWYJDYFSGRHKR-UHFFFAOYSA-N 0.000 description 1
- 230000005021 gait Effects 0.000 description 1
- 229960002584 gefitinib Drugs 0.000 description 1
- XGALLCVXEZPNRQ-UHFFFAOYSA-N gefitinib Chemical compound C=12C=C(OCCCN3CCOCC3)C(OC)=CC2=NC=NC=1NC1=CC=C(F)C(Cl)=C1 XGALLCVXEZPNRQ-UHFFFAOYSA-N 0.000 description 1
- QTQAWLPCGQOSGP-GBTDJJJQSA-N geldanamycin Chemical compound N1C(=O)\C(C)=C/C=C\[C@@H](OC)[C@H](OC(N)=O)\C(C)=C/[C@@H](C)[C@@H](O)[C@H](OC)C[C@@H](C)CC2=C(OC)C(=O)C=C1C2=O QTQAWLPCGQOSGP-GBTDJJJQSA-N 0.000 description 1
- 210000000585 glomerular basement membrane Anatomy 0.000 description 1
- 206010061989 glomerulosclerosis Diseases 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- 125000000291 glutamic acid group Chemical group N[C@@H](CCC(O)=O)C(=O)* 0.000 description 1
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 1
- 229960003711 glyceryl trinitrate Drugs 0.000 description 1
- 150000002337 glycosamines Chemical group 0.000 description 1
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 1
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 1
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 1
- 108010089804 glycyl-threonine Proteins 0.000 description 1
- 108010010147 glycylglutamine Proteins 0.000 description 1
- 108010084389 glycyltryptophan Proteins 0.000 description 1
- 239000008187 granular material Substances 0.000 description 1
- 238000000227 grinding Methods 0.000 description 1
- 210000003709 heart valve Anatomy 0.000 description 1
- 239000002628 heparin derivative Substances 0.000 description 1
- 102000054751 human RUNX1T1 Human genes 0.000 description 1
- 229940048921 humira Drugs 0.000 description 1
- 229960002003 hydrochlorothiazide Drugs 0.000 description 1
- 229960003313 hydroflumethiazide Drugs 0.000 description 1
- DMDGGSIALPNSEE-UHFFFAOYSA-N hydroflumethiazide Chemical compound C1=C(C(F)(F)F)C(S(=O)(=O)N)=CC2=C1NCNS2(=O)=O DMDGGSIALPNSEE-UHFFFAOYSA-N 0.000 description 1
- 238000012872 hydroxylapatite chromatography Methods 0.000 description 1
- 239000002471 hydroxymethylglutaryl coenzyme A reductase inhibitor Substances 0.000 description 1
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 1
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 1
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 1
- UFVKGYZPFZQRLF-UHFFFAOYSA-N hydroxypropyl methyl cellulose Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(OC3C(C(O)C(O)C(CO)O3)O)C(CO)O2)O)C(CO)O1 UFVKGYZPFZQRLF-UHFFFAOYSA-N 0.000 description 1
- 201000005991 hyperphosphatemia Diseases 0.000 description 1
- 230000001631 hypertensive effect Effects 0.000 description 1
- 229940126904 hypoglycaemic agent Drugs 0.000 description 1
- 230000036543 hypotension Effects 0.000 description 1
- 229960001680 ibuprofen Drugs 0.000 description 1
- 238000010191 image analysis Methods 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 229960002411 imatinib Drugs 0.000 description 1
- KTUFNOKKBVMGRW-UHFFFAOYSA-N imatinib Chemical compound C1CN(C)CCN1CC1=CC=C(C(=O)NC=2C=C(NC=3N=C(C=CN=3)C=3C=NC=CC=3)C(C)=CC=2)C=C1 KTUFNOKKBVMGRW-UHFFFAOYSA-N 0.000 description 1
- 150000002463 imidates Chemical class 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 230000001861 immunosuppressant effect Effects 0.000 description 1
- 238000009169 immunotherapy Methods 0.000 description 1
- 229940051026 immunotoxin Drugs 0.000 description 1
- 230000002637 immunotoxin Effects 0.000 description 1
- 231100000608 immunotoxin Toxicity 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 229960004569 indapamide Drugs 0.000 description 1
- NDDAHWYSQHTHNT-UHFFFAOYSA-N indapamide Chemical compound CC1CC2=CC=CC=C2N1NC(=O)C1=CC=C(Cl)C(S(N)(=O)=O)=C1 NDDAHWYSQHTHNT-UHFFFAOYSA-N 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- APFVFJFRJDLVQX-UHFFFAOYSA-N indium atom Chemical compound [In] APFVFJFRJDLVQX-UHFFFAOYSA-N 0.000 description 1
- 239000000411 inducer Substances 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 230000017730 intein-mediated protein splicing Effects 0.000 description 1
- 229940047122 interleukins Drugs 0.000 description 1
- 230000009878 intermolecular interaction Effects 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 230000007154 intracellular accumulation Effects 0.000 description 1
- 238000000185 intracerebroventricular administration Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 229960002198 irbesartan Drugs 0.000 description 1
- YCPOHTHPUREGFM-UHFFFAOYSA-N irbesartan Chemical compound O=C1N(CC=2C=CC(=CC=2)C=2C(=CC=CC=2)C=2[N]N=NN=2)C(CCCC)=NC21CCCC2 YCPOHTHPUREGFM-UHFFFAOYSA-N 0.000 description 1
- 229960002725 isoflurane Drugs 0.000 description 1
- FZWBNHMXJMCXLU-BLAUPYHCSA-N isomaltotriose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)[C@@H](OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C=O)O1 FZWBNHMXJMCXLU-BLAUPYHCSA-N 0.000 description 1
- 229960002479 isosorbide Drugs 0.000 description 1
- MOYKHGMNXAOIAT-JGWLITMVSA-N isosorbide dinitrate Chemical compound [O-][N+](=O)O[C@H]1CO[C@@H]2[C@H](O[N+](=O)[O-])CO[C@@H]21 MOYKHGMNXAOIAT-JGWLITMVSA-N 0.000 description 1
- 229960000201 isosorbide dinitrate Drugs 0.000 description 1
- YWXYYJSYQOXTPL-SLPGGIOYSA-N isosorbide mononitrate Chemical compound [O-][N+](=O)O[C@@H]1CO[C@@H]2[C@@H](O)CO[C@@H]21 YWXYYJSYQOXTPL-SLPGGIOYSA-N 0.000 description 1
- 229960003827 isosorbide mononitrate Drugs 0.000 description 1
- 210000004731 jugular vein Anatomy 0.000 description 1
- 229940043355 kinase inhibitor Drugs 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 239000004922 lacquer Substances 0.000 description 1
- 239000004310 lactic acid Substances 0.000 description 1
- 235000014655 lactic acid Nutrition 0.000 description 1
- NZPIUJUFIFZSPW-UHFFFAOYSA-H lanthanum carbonate Chemical compound [La+3].[La+3].[O-]C([O-])=O.[O-]C([O-])=O.[O-]C([O-])=O NZPIUJUFIFZSPW-UHFFFAOYSA-H 0.000 description 1
- 229960001633 lanthanum carbonate Drugs 0.000 description 1
- 229960004891 lapatinib Drugs 0.000 description 1
- BCFGMOOMADDAQU-UHFFFAOYSA-N lapatinib Chemical compound O1C(CNCCS(=O)(=O)C)=CC=C1C1=CC=C(N=CN=C2NC=3C=C(Cl)C(OCC=4C=C(F)C=CC=4)=CC=3)C2=C1 BCFGMOOMADDAQU-UHFFFAOYSA-N 0.000 description 1
- 229950005692 larotaxel Drugs 0.000 description 1
- SEFGUGYLLVNFIJ-QDRLFVHASA-N larotaxel dihydrate Chemical compound O.O.O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@@]23[C@H]1[C@@]1(CO[C@@H]1C[C@@H]2C3)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 SEFGUGYLLVNFIJ-QDRLFVHASA-N 0.000 description 1
- 210000000867 larynx Anatomy 0.000 description 1
- 239000010410 layer Substances 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 231100000636 lethal dose Toxicity 0.000 description 1
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 1
- 239000003199 leukotriene receptor blocking agent Substances 0.000 description 1
- WHXMKTBCFHIYNQ-SECBINFHSA-N levosimendan Chemical compound C[C@@H]1CC(=O)NN=C1C1=CC=C(NN=C(C#N)C#N)C=C1 WHXMKTBCFHIYNQ-SECBINFHSA-N 0.000 description 1
- 229960000692 levosimendan Drugs 0.000 description 1
- 238000012417 linear regression Methods 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 229940057995 liquid paraffin Drugs 0.000 description 1
- 229960002394 lisinopril Drugs 0.000 description 1
- RLAWWYSOJDYHDC-BZSNNMDCSA-N lisinopril Chemical compound C([C@H](N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(O)=O)C(O)=O)CC1=CC=CC=C1 RLAWWYSOJDYHDC-BZSNNMDCSA-N 0.000 description 1
- MVYUCRDXZXLFSB-UHFFFAOYSA-N lodenafil Chemical compound CCCC1=NN(C)C(C(N=2)=O)=C1NC=2C(C(=CC=1)OCC)=CC=1S(=O)(=O)N(CC1)CCN1CCOC(=O)OCCN(CC1)CCN1S(=O)(=O)C(C=1)=CC=C(OCC)C=1C(N1)=NC(=O)C2=C1C(CCC)=NN2C MVYUCRDXZXLFSB-UHFFFAOYSA-N 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 229960004773 losartan Drugs 0.000 description 1
- KJJZZJSZUJXYEA-UHFFFAOYSA-N losartan Chemical compound CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C=2[N]N=NN=2)C=C1 KJJZZJSZUJXYEA-UHFFFAOYSA-N 0.000 description 1
- 229960004844 lovastatin Drugs 0.000 description 1
- PCZOHLXUXFIOCF-BXMDZJJMSA-N lovastatin Chemical compound C([C@H]1[C@@H](C)C=CC2=C[C@H](C)C[C@@H]([C@H]12)OC(=O)[C@@H](C)CC)C[C@@H]1C[C@@H](O)CC(=O)O1 PCZOHLXUXFIOCF-BXMDZJJMSA-N 0.000 description 1
- QLJODMDSTUBWDW-UHFFFAOYSA-N lovastatin hydroxy acid Natural products C1=CC(C)C(CCC(O)CC(O)CC(O)=O)C2C(OC(=O)C(C)CC)CC(C)C=C21 QLJODMDSTUBWDW-UHFFFAOYSA-N 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- 239000008176 lyophilized powder Substances 0.000 description 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 108010003700 lysyl aspartic acid Proteins 0.000 description 1
- 108010064235 lysylglycine Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 229940124302 mTOR inhibitor Drugs 0.000 description 1
- 229960001039 macitentan Drugs 0.000 description 1
- JGCMEBMXRHSZKX-UHFFFAOYSA-N macitentan Chemical compound C=1C=C(Br)C=CC=1C=1C(NS(=O)(=O)NCCC)=NC=NC=1OCCOC1=NC=C(Br)C=N1 JGCMEBMXRHSZKX-UHFFFAOYSA-N 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 238000013227 male C57BL/6J mice Methods 0.000 description 1
- 239000001630 malic acid Substances 0.000 description 1
- 235000011090 malic acid Nutrition 0.000 description 1
- 239000003628 mammalian target of rapamycin inhibitor Substances 0.000 description 1
- WPBNNNQJVZRUHP-UHFFFAOYSA-L manganese(2+);methyl n-[[2-(methoxycarbonylcarbamothioylamino)phenyl]carbamothioyl]carbamate;n-[2-(sulfidocarbothioylamino)ethyl]carbamodithioate Chemical compound [Mn+2].[S-]C(=S)NCCNC([S-])=S.COC(=O)NC(=S)NC1=CC=CC=C1NC(=S)NC(=O)OC WPBNNNQJVZRUHP-UHFFFAOYSA-L 0.000 description 1
- 230000008774 maternal effect Effects 0.000 description 1
- 238000001840 matrix-assisted laser desorption--ionisation time-of-flight mass spectrometry Methods 0.000 description 1
- 235000019988 mead Nutrition 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- DKWNMCUOEDMMIN-PKOBYXMFSA-N melagatran Chemical compound C1=CC(C(=N)N)=CC=C1CNC(=O)[C@H]1N(C(=O)[C@H](NCC(O)=O)C2CCCCC2)CC1 DKWNMCUOEDMMIN-PKOBYXMFSA-N 0.000 description 1
- 229960002137 melagatran Drugs 0.000 description 1
- 201000008350 membranous glomerulonephritis Diseases 0.000 description 1
- KBOPZPXVLCULAV-UHFFFAOYSA-N mesalamine Chemical class NC1=CC=C(O)C(C(O)=O)=C1 KBOPZPXVLCULAV-UHFFFAOYSA-N 0.000 description 1
- 108010005942 methionylglycine Proteins 0.000 description 1
- 229960003739 methyclothiazide Drugs 0.000 description 1
- 229920000609 methyl cellulose Polymers 0.000 description 1
- 239000001923 methylcellulose Substances 0.000 description 1
- 235000010981 methylcellulose Nutrition 0.000 description 1
- 229960002900 methylcellulose Drugs 0.000 description 1
- 229960004584 methylprednisolone Drugs 0.000 description 1
- 229960002817 metolazone Drugs 0.000 description 1
- AQCHWTWZEMGIFD-UHFFFAOYSA-N metolazone Chemical compound CC1NC2=CC(Cl)=C(S(N)(=O)=O)C=C2C(=O)N1C1=CC=CC=C1C AQCHWTWZEMGIFD-UHFFFAOYSA-N 0.000 description 1
- 238000002493 microarray Methods 0.000 description 1
- MIJFNYMSCFYZNY-UHFFFAOYSA-N mirodenafil Chemical compound C1=C(C=2NC=3C(CCC)=CN(CC)C=3C(=O)N=2)C(OCCC)=CC=C1S(=O)(=O)N1CCN(CCO)CC1 MIJFNYMSCFYZNY-UHFFFAOYSA-N 0.000 description 1
- 229950002245 mirodenafil Drugs 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 229950001364 molidustat Drugs 0.000 description 1
- 229950008814 momelotinib Drugs 0.000 description 1
- ZVHNDZWQTBEVRY-UHFFFAOYSA-N momelotinib Chemical compound C1=CC(C(NCC#N)=O)=CC=C1C1=CC=NC(NC=2C=CC(=CC=2)N2CCOCC2)=N1 ZVHNDZWQTBEVRY-UHFFFAOYSA-N 0.000 description 1
- 230000036640 muscle relaxation Effects 0.000 description 1
- 201000000050 myeloid neoplasm Diseases 0.000 description 1
- MPYACSQFXVMWNO-UHFFFAOYSA-N n-[5-[4-(3,3-dimethylazetidine-1-carbonyl)phenyl]-[1,2,4]triazolo[1,5-a]pyridin-2-yl]cyclopropanecarboxamide Chemical compound C1C(C)(C)CN1C(=O)C1=CC=C(C=2N3N=C(NC(=O)C4CC4)N=C3C=CC=2)C=C1 MPYACSQFXVMWNO-UHFFFAOYSA-N 0.000 description 1
- TUYWTLTWNJOZNY-UHFFFAOYSA-N n-[6-(2-hydroxyethoxy)-5-(2-methoxyphenoxy)-2-[2-(2h-tetrazol-5-yl)pyridin-4-yl]pyrimidin-4-yl]-5-propan-2-ylpyridine-2-sulfonamide Chemical compound COC1=CC=CC=C1OC(C(=NC(=N1)C=2C=C(N=CC=2)C2=NNN=N2)OCCO)=C1NS(=O)(=O)C1=CC=C(C(C)C)C=N1 TUYWTLTWNJOZNY-UHFFFAOYSA-N 0.000 description 1
- YBWLTKFZAOSWSM-UHFFFAOYSA-N n-[6-methoxy-5-(2-methoxyphenoxy)-2-pyridin-4-ylpyrimidin-4-yl]-5-methylpyridine-2-sulfonamide Chemical compound COC1=CC=CC=C1OC(C(=NC(=N1)C=2C=CN=CC=2)OC)=C1NS(=O)(=O)C1=CC=C(C)C=N1 YBWLTKFZAOSWSM-UHFFFAOYSA-N 0.000 description 1
- 229960002009 naproxen Drugs 0.000 description 1
- CMWTZPSULFXXJA-VIFPVBQESA-N naproxen Chemical compound C1=C([C@H](C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-VIFPVBQESA-N 0.000 description 1
- 230000017128 negative regulation of NF-kappaB transcription factor activity Effects 0.000 description 1
- 101150091879 neo gene Proteins 0.000 description 1
- 108010068617 neonatal Fc receptor Proteins 0.000 description 1
- 238000013059 nephrectomy Methods 0.000 description 1
- 230000002580 nephropathic effect Effects 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 229960003512 nicotinic acid Drugs 0.000 description 1
- 235000001968 nicotinic acid Nutrition 0.000 description 1
- 239000011664 nicotinic acid Substances 0.000 description 1
- 229960001597 nifedipine Drugs 0.000 description 1
- HYIMSNHJOBLJNT-UHFFFAOYSA-N nifedipine Chemical compound COC(=O)C1=C(C)NC(C)=C(C(=O)OC)C1C1=CC=CC=C1[N+]([O-])=O HYIMSNHJOBLJNT-UHFFFAOYSA-N 0.000 description 1
- 229960001346 nilotinib Drugs 0.000 description 1
- HHZIURLSWUIHRB-UHFFFAOYSA-N nilotinib Chemical compound C1=NC(C)=CN1C1=CC(NC(=O)C=2C=C(NC=3N=C(C=CN=3)C=3C=NC=CC=3)C(C)=CC=2)=CC(C(F)(F)F)=C1 HHZIURLSWUIHRB-UHFFFAOYSA-N 0.000 description 1
- 229960004378 nintedanib Drugs 0.000 description 1
- XZXHXSATPCNXJR-ZIADKAODSA-N nintedanib Chemical compound O=C1NC2=CC(C(=O)OC)=CC=C2\C1=C(C=1C=CC=CC=1)\NC(C=C1)=CC=C1N(C)C(=O)CN1CCN(C)CC1 XZXHXSATPCNXJR-ZIADKAODSA-N 0.000 description 1
- MVPQUSQUURLQKF-MCPDASDXSA-E nonasodium;(2s,3s,4s,5r,6r)-6-[(2r,3r,4s,5r,6r)-6-[(2r,3s,4s,5r,6r)-2-carboxylato-4,5-dimethoxy-6-[(2r,3r,4s,5r,6s)-6-methoxy-4,5-disulfonatooxy-2-(sulfonatooxymethyl)oxan-3-yl]oxyoxan-3-yl]oxy-4,5-disulfonatooxy-2-(sulfonatooxymethyl)oxan-3-yl]oxy-4,5-di Chemical compound [Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[O-]S(=O)(=O)O[C@@H]1[C@@H](OS([O-])(=O)=O)[C@@H](OC)O[C@H](COS([O-])(=O)=O)[C@H]1O[C@H]1[C@H](OC)[C@@H](OC)[C@H](O[C@@H]2[C@@H]([C@@H](OS([O-])(=O)=O)[C@H](O[C@H]3[C@@H]([C@@H](OC)[C@H](O[C@@H]4[C@@H]([C@@H](OC)[C@H](OC)[C@@H](COS([O-])(=O)=O)O4)OC)[C@H](O3)C([O-])=O)OC)[C@@H](COS([O-])(=O)=O)O2)OS([O-])(=O)=O)[C@H](C([O-])=O)O1 MVPQUSQUURLQKF-MCPDASDXSA-E 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 231100000956 nontoxicity Toxicity 0.000 description 1
- 238000010899 nucleation Methods 0.000 description 1
- 238000007899 nucleic acid hybridization Methods 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 229960005117 olmesartan Drugs 0.000 description 1
- VTRAEEWXHOVJFV-UHFFFAOYSA-N olmesartan Chemical compound CCCC1=NC(C(C)(C)O)=C(C(O)=O)N1CC1=CC=C(C=2C(=CC=CC=2)C=2NN=NN=2)C=C1 VTRAEEWXHOVJFV-UHFFFAOYSA-N 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 239000003960 organic solvent Substances 0.000 description 1
- AHLBNYSZXLDEJQ-FWEHEUNISA-N orlistat Chemical compound CCCCCCCCCCC[C@H](OC(=O)[C@H](CC(C)C)NC=O)C[C@@H]1OC(=O)[C@H]1CCCCCC AHLBNYSZXLDEJQ-FWEHEUNISA-N 0.000 description 1
- 229960001243 orlistat Drugs 0.000 description 1
- BWKDAMBGCPRVPI-ZQRPHVBESA-N ortataxel Chemical compound O([C@@H]1[C@]23OC(=O)O[C@H]2[C@@H](C(=C([C@@H](OC(C)=O)C(=O)[C@]2(C)[C@@H](O)C[C@H]4OC[C@]4([C@H]21)OC(C)=O)C3(C)C)C)OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)CC(C)C)C(=O)C1=CC=CC=C1 BWKDAMBGCPRVPI-ZQRPHVBESA-N 0.000 description 1
- 229950001094 ortataxel Drugs 0.000 description 1
- 230000000399 orthopedic effect Effects 0.000 description 1
- 229950009478 otamixaban Drugs 0.000 description 1
- PFGVNLZDWRZPJW-OPAMFIHVSA-N otamixaban Chemical compound C([C@@H](C(=O)OC)[C@@H](C)NC(=O)C=1C=CC(=CC=1)C=1C=C[N+]([O-])=CC=1)C1=CC=CC(C(N)=N)=C1 PFGVNLZDWRZPJW-OPAMFIHVSA-N 0.000 description 1
- 229940043515 other immunoglobulins in atc Drugs 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- HWXVIOGONBBTBY-ONEGZZNKSA-N pacritinib Chemical compound C=1C=C(C=2)NC(N=3)=NC=CC=3C(C=3)=CC=CC=3COC\C=C\COCC=2C=1OCCN1CCCC1 HWXVIOGONBBTBY-ONEGZZNKSA-N 0.000 description 1
- 230000036407 pain Effects 0.000 description 1
- VWMZIGBYZQUQOA-QEEMJVPDSA-N pamaqueside Chemical compound O([C@@H]1[C@@H](CO)O[C@H]([C@@H]([C@H]1O)O)O[C@@H]1C[C@@H]2CC[C@H]3[C@@H]4C[C@H]5[C@@H]([C@]4(CC(=O)[C@@H]3[C@@]2(C)CC1)C)[C@@H]([C@]1(OC[C@H](C)CC1)O5)C)[C@@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@H]1O VWMZIGBYZQUQOA-QEEMJVPDSA-N 0.000 description 1
- 229950005482 pamaqueside Drugs 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 229960000639 pazopanib Drugs 0.000 description 1
- CUIHSIWYWATEQL-UHFFFAOYSA-N pazopanib Chemical compound C1=CC2=C(C)N(C)N=C2C=C1N(C)C(N=1)=CC=NC=1NC1=CC=C(C)C(S(N)(=O)=O)=C1 CUIHSIWYWATEQL-UHFFFAOYSA-N 0.000 description 1
- 230000000149 penetrating effect Effects 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 229960002582 perindopril Drugs 0.000 description 1
- IPVQLZZIHOAWMC-QXKUPLGCSA-N perindopril Chemical compound C1CCC[C@H]2C[C@@H](C(O)=O)N(C(=O)[C@H](C)N[C@@H](CCC)C(=O)OCC)[C@H]21 IPVQLZZIHOAWMC-QXKUPLGCSA-N 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 239000008177 pharmaceutical agent Substances 0.000 description 1
- 230000009038 pharmacological inhibition Effects 0.000 description 1
- 108010076042 phenomycin Proteins 0.000 description 1
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 1
- 108010051242 phenylalanylserine Proteins 0.000 description 1
- 239000002694 phosphate binding agent Substances 0.000 description 1
- 229940080469 phosphocellulose Drugs 0.000 description 1
- 239000002590 phosphodiesterase V inhibitor Substances 0.000 description 1
- 239000003757 phosphotransferase inhibitor Substances 0.000 description 1
- 230000000704 physical effect Effects 0.000 description 1
- 239000000049 pigment Substances 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 229960005095 pioglitazone Drugs 0.000 description 1
- 229960001085 piretanide Drugs 0.000 description 1
- 229960003073 pirfenidone Drugs 0.000 description 1
- ISWRGOKTTBVCFA-UHFFFAOYSA-N pirfenidone Chemical compound C1=C(C)C=CC(=O)N1C1=CC=CC=C1 ISWRGOKTTBVCFA-UHFFFAOYSA-N 0.000 description 1
- 229960002797 pitavastatin Drugs 0.000 description 1
- VGYFMXBACGZSIL-MCBHFWOFSA-N pitavastatin Chemical compound OC(=O)C[C@H](O)C[C@H](O)\C=C\C1=C(C2CC2)N=C2C=CC=CC2=C1C1=CC=C(F)C=C1 VGYFMXBACGZSIL-MCBHFWOFSA-N 0.000 description 1
- 239000003123 plant toxin Substances 0.000 description 1
- 230000036470 plasma concentration Effects 0.000 description 1
- 229940012957 plasmin Drugs 0.000 description 1
- 231100000614 poison Toxicity 0.000 description 1
- 229920000729 poly(L-lysine) polymer Polymers 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229950008882 polysorbate Drugs 0.000 description 1
- 229960005483 polythiazide Drugs 0.000 description 1
- 229920000046 polythiazide Polymers 0.000 description 1
- 229960003975 potassium Drugs 0.000 description 1
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 description 1
- 235000012015 potatoes Nutrition 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 229960002965 pravastatin Drugs 0.000 description 1
- TUZYXOIXSAXUGO-PZAWKZKUSA-N pravastatin Chemical compound C1=C[C@H](C)[C@H](CC[C@@H](O)C[C@@H](O)CC(O)=O)[C@H]2[C@@H](OC(=O)[C@@H](C)CC)C[C@H](O)C=C21 TUZYXOIXSAXUGO-PZAWKZKUSA-N 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 229960005205 prednisolone Drugs 0.000 description 1
- OIGNJSKKLXVSLS-VWUMJDOOSA-N prednisolone Chemical compound O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 OIGNJSKKLXVSLS-VWUMJDOOSA-N 0.000 description 1
- 229960004618 prednisone Drugs 0.000 description 1
- XOFYZVNMUHMLCC-ZPOLXVRWSA-N prednisone Chemical compound O=C1C=C[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 XOFYZVNMUHMLCC-ZPOLXVRWSA-N 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
- 230000000019 pro-fibrinolytic effect Effects 0.000 description 1
- 230000002206 pro-fibrotic effect Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 108010070643 prolylglutamic acid Proteins 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000001902 propagating effect Effects 0.000 description 1
- OLBCVFGFOZPWHH-UHFFFAOYSA-N propofol Chemical compound CC(C)C1=CC=CC(C(C)C)=C1O OLBCVFGFOZPWHH-UHFFFAOYSA-N 0.000 description 1
- 229960004134 propofol Drugs 0.000 description 1
- 150000003815 prostacyclins Chemical class 0.000 description 1
- 235000019833 protease Nutrition 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 239000003586 protic polar solvent Substances 0.000 description 1
- 108010045647 puromycin N-acetyltransferase Proteins 0.000 description 1
- MIXMJCQRHVAJIO-TZHJZOAOSA-N qk4dys664x Chemical compound O.C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2C[C@H]3OC(C)(C)O[C@@]3(C(=O)CO)[C@@]2(C)C[C@@H]1O.C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2C[C@H]3OC(C)(C)O[C@@]3(C(=O)CO)[C@@]2(C)C[C@@H]1O MIXMJCQRHVAJIO-TZHJZOAOSA-N 0.000 description 1
- HDACQVRGBOVJII-JBDAPHQKSA-N ramipril Chemical compound C([C@@H](C(=O)OCC)N[C@@H](C)C(=O)N1[C@@H](C[C@@H]2CCC[C@@H]21)C(O)=O)CC1=CC=CC=C1 HDACQVRGBOVJII-JBDAPHQKSA-N 0.000 description 1
- 229960003401 ramipril Drugs 0.000 description 1
- 229960003876 ranibizumab Drugs 0.000 description 1
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 1
- 229960000424 rasburicase Drugs 0.000 description 1
- 108010084837 rasburicase Proteins 0.000 description 1
- 229950010535 razaxaban Drugs 0.000 description 1
- 238000003753 real-time PCR Methods 0.000 description 1
- 229940044551 receptor antagonist Drugs 0.000 description 1
- 239000002464 receptor antagonist Substances 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 229960004836 regorafenib Drugs 0.000 description 1
- FNHKPVJBJVTLMP-UHFFFAOYSA-N regorafenib Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=C(F)C(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 FNHKPVJBJVTLMP-UHFFFAOYSA-N 0.000 description 1
- 230000001084 renoprotective effect Effects 0.000 description 1
- 230000029058 respiratory gaseous exchange Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 210000001116 retinal neuron Anatomy 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 229960000529 riociguat Drugs 0.000 description 1
- WXXSNCNJFUAIDG-UHFFFAOYSA-N riociguat Chemical compound N1=C(N)C(N(C)C(=O)OC)=C(N)N=C1C(C1=CC=CN=C11)=NN1CC1=CC=CC=C1F WXXSNCNJFUAIDG-UHFFFAOYSA-N 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 229960001148 rivaroxaban Drugs 0.000 description 1
- KGFYHTZWPPHNLQ-AWEZNQCLSA-N rivaroxaban Chemical compound S1C(Cl)=CC=C1C(=O)NC[C@@H]1OC(=O)N(C=2C=CC(=CC=2)N2C(COCC2)=O)C1 KGFYHTZWPPHNLQ-AWEZNQCLSA-N 0.000 description 1
- 238000011808 rodent model Methods 0.000 description 1
- 229960004586 rosiglitazone Drugs 0.000 description 1
- 229960000672 rosuvastatin Drugs 0.000 description 1
- BPRHUIZQVSMCRT-VEUZHWNKSA-N rosuvastatin Chemical compound CC(C)C1=NC(N(C)S(C)(=O)=O)=NC(C=2C=CC(F)=CC=2)=C1\C=C\[C@@H](O)C[C@@H](O)CC(O)=O BPRHUIZQVSMCRT-VEUZHWNKSA-N 0.000 description 1
- YOZBGTLTNGAVFU-UHFFFAOYSA-N roxadustat Chemical compound C1=C2C(C)=NC(C(=O)NCC(O)=O)=C(O)C2=CC=C1OC1=CC=CC=C1 YOZBGTLTNGAVFU-UHFFFAOYSA-N 0.000 description 1
- 229950008113 roxadustat Drugs 0.000 description 1
- 102200110650 rs11466111 Human genes 0.000 description 1
- 102200099928 rs137853185 Human genes 0.000 description 1
- 102220040167 rs141982003 Human genes 0.000 description 1
- 102220267892 rs1555193020 Human genes 0.000 description 1
- 102220289729 rs1555407418 Human genes 0.000 description 1
- 102200068694 rs281865207 Human genes 0.000 description 1
- 102220128896 rs376207606 Human genes 0.000 description 1
- 102220272824 rs563079629 Human genes 0.000 description 1
- 102220297864 rs761846391 Human genes 0.000 description 1
- 102220085078 rs863225382 Human genes 0.000 description 1
- 102220202090 rs864622596 Human genes 0.000 description 1
- 102220177883 rs886056557 Human genes 0.000 description 1
- 229960000215 ruxolitinib Drugs 0.000 description 1
- HFNKQEVNSGCOJV-OAHLLOKOSA-N ruxolitinib Chemical compound C1([C@@H](CC#N)N2N=CC(=C2)C=2C=3C=CNC=3N=CN=2)CCCC1 HFNKQEVNSGCOJV-OAHLLOKOSA-N 0.000 description 1
- FNKQXYHWGSIFBK-RPDRRWSUSA-N sapropterin Chemical compound N1=C(N)NC(=O)C2=C1NC[C@H]([C@@H](O)[C@@H](O)C)N2 FNKQXYHWGSIFBK-RPDRRWSUSA-N 0.000 description 1
- 229960004617 sapropterin Drugs 0.000 description 1
- 229950003647 semaxanib Drugs 0.000 description 1
- WUWDLXZGHZSWQZ-WQLSENKSSA-N semaxanib Chemical compound N1C(C)=CC(C)=C1\C=C/1C2=CC=CC=C2NC\1=O WUWDLXZGHZSWQZ-WQLSENKSSA-N 0.000 description 1
- 239000004017 serum-free culture medium Substances 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- RGYQPQARIQKJKH-UHFFFAOYSA-N setanaxib Chemical compound CN(C)C1=CC=CC(C2=C3C(=O)N(C=4C(=CC=CC=4)Cl)NC3=CC(=O)N2C)=C1 RGYQPQARIQKJKH-UHFFFAOYSA-N 0.000 description 1
- ZNSIZMQNQCNRBW-UHFFFAOYSA-N sevelamer Chemical compound NCC=C.ClCC1CO1 ZNSIZMQNQCNRBW-UHFFFAOYSA-N 0.000 description 1
- 229960005441 sevelamer carbonate Drugs 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 229960003310 sildenafil Drugs 0.000 description 1
- 229960002855 simvastatin Drugs 0.000 description 1
- RYMZZMVNJRMUDD-HGQWONQESA-N simvastatin Chemical compound C([C@H]1[C@@H](C)C=CC2=C[C@H](C)C[C@@H]([C@H]12)OC(=O)C(C)(C)CC)C[C@@H]1C[C@@H](O)CC(=O)O1 RYMZZMVNJRMUDD-HGQWONQESA-N 0.000 description 1
- 239000002356 single layer Substances 0.000 description 1
- 229960002930 sirolimus Drugs 0.000 description 1
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 1
- 229960002578 sitaxentan Drugs 0.000 description 1
- PHWXUGHIIBDVKD-UHFFFAOYSA-N sitaxentan Chemical compound CC1=NOC(NS(=O)(=O)C2=C(SC=C2)C(=O)CC=2C(=CC=3OCOC=3C=2)C)=C1Cl PHWXUGHIIBDVKD-UHFFFAOYSA-N 0.000 description 1
- 239000002002 slurry Substances 0.000 description 1
- 235000010413 sodium alginate Nutrition 0.000 description 1
- 239000000661 sodium alginate Substances 0.000 description 1
- 229940005550 sodium alginate Drugs 0.000 description 1
- 235000017557 sodium bicarbonate Nutrition 0.000 description 1
- 229910000030 sodium bicarbonate Inorganic materials 0.000 description 1
- 229940083618 sodium nitroprusside Drugs 0.000 description 1
- 239000001488 sodium phosphate Substances 0.000 description 1
- 229910000162 sodium phosphate Inorganic materials 0.000 description 1
- 229940121377 sodium-glucose co-transporter inhibitor Drugs 0.000 description 1
- MKNJJMHQBYVHRS-UHFFFAOYSA-M sodium;1-[11-(2,5-dioxopyrrol-1-yl)undecanoyloxy]-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].O=C1C(S(=O)(=O)[O-])CC(=O)N1OC(=O)CCCCCCCCCCN1C(=O)C=CC1=O MKNJJMHQBYVHRS-UHFFFAOYSA-M 0.000 description 1
- ULARYIUTHAWJMU-UHFFFAOYSA-M sodium;1-[4-(2,5-dioxopyrrol-1-yl)butanoyloxy]-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].O=C1C(S(=O)(=O)[O-])CC(=O)N1OC(=O)CCCN1C(=O)C=CC1=O ULARYIUTHAWJMU-UHFFFAOYSA-M 0.000 description 1
- VUFNRPJNRFOTGK-UHFFFAOYSA-M sodium;1-[4-[(2,5-dioxopyrrol-1-yl)methyl]cyclohexanecarbonyl]oxy-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].O=C1C(S(=O)(=O)[O-])CC(=O)N1OC(=O)C1CCC(CN2C(C=CC2=O)=O)CC1 VUFNRPJNRFOTGK-UHFFFAOYSA-M 0.000 description 1
- MIDXXTLMKGZDPV-UHFFFAOYSA-M sodium;1-[6-(2,5-dioxopyrrol-1-yl)hexanoyloxy]-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].O=C1C(S(=O)(=O)[O-])CC(=O)N1OC(=O)CCCCCN1C(=O)C=CC1=O MIDXXTLMKGZDPV-UHFFFAOYSA-M 0.000 description 1
- 239000007901 soft capsule Substances 0.000 description 1
- 239000012439 solid excipient Substances 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 229960003787 sorafenib Drugs 0.000 description 1
- 229960002256 spironolactone Drugs 0.000 description 1
- LXMSZDCAJNLERA-ZHYRCANASA-N spironolactone Chemical compound C([C@@H]1[C@]2(C)CC[C@@H]3[C@@]4(C)CCC(=O)C=C4C[C@H]([C@@H]13)SC(=O)C)C[C@@]21CCC(=O)O1 LXMSZDCAJNLERA-ZHYRCANASA-N 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 238000012409 standard PCR amplification Methods 0.000 description 1
- 239000007858 starting material Substances 0.000 description 1
- 238000011146 sterile filtration Methods 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 229960001796 sunitinib Drugs 0.000 description 1
- WINHZLLDWRZWRT-ATVHPVEESA-N sunitinib Chemical compound CCN(CC)CCNC(=O)C1=C(C)NC(\C=C/2C3=CC(F)=CC=C3NC\2=O)=C1C WINHZLLDWRZWRT-ATVHPVEESA-N 0.000 description 1
- 238000011477 surgical intervention Methods 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 229940037128 systemic glucocorticoids Drugs 0.000 description 1
- 238000012353 t test Methods 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- 229960000835 tadalafil Drugs 0.000 description 1
- IEHKWSGCTWLXFU-IIBYNOLFSA-N tadalafil Chemical compound C1=C2OCOC2=CC([C@@H]2C3=C([C]4C=CC=CC4=N3)C[C@H]3N2C(=O)CN(C3=O)C)=C1 IEHKWSGCTWLXFU-IIBYNOLFSA-N 0.000 description 1
- 229950009893 tandutinib Drugs 0.000 description 1
- UXXQOJXBIDBUAC-UHFFFAOYSA-N tandutinib Chemical compound COC1=CC2=C(N3CCN(CC3)C(=O)NC=3C=CC(OC(C)C)=CC=3)N=CN=C2C=C1OCCCN1CCCCC1 UXXQOJXBIDBUAC-UHFFFAOYSA-N 0.000 description 1
- 239000011975 tartaric acid Substances 0.000 description 1
- 235000002906 tartaric acid Nutrition 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- 229950004186 telatinib Drugs 0.000 description 1
- 229960005187 telmisartan Drugs 0.000 description 1
- DNHPDWGIXIMXSA-CXNSMIOJSA-N tenapanor Chemical compound C12=CC(Cl)=CC(Cl)=C2CN(C)C[C@H]1C1=CC=CC(S(=O)(=O)NCCOCCOCCNC(=O)NCCCCNC(=O)NCCOCCOCCNS(=O)(=O)C=2C=C(C=CC=2)[C@H]2C3=CC(Cl)=CC(Cl)=C3CN(C)C2)=C1 DNHPDWGIXIMXSA-CXNSMIOJSA-N 0.000 description 1
- MODVSQKJJIBWPZ-VLLPJHQWSA-N tesetaxel Chemical compound O([C@H]1[C@@H]2[C@]3(OC(C)=O)CO[C@@H]3CC[C@@]2(C)[C@H]2[C@@H](C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C(=CC=CN=4)F)C[C@]1(O)C3(C)C)O[C@H](O2)CN(C)C)C(=O)C1=CC=CC=C1 MODVSQKJJIBWPZ-VLLPJHQWSA-N 0.000 description 1
- 229950009016 tesetaxel Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 229950000584 tezosentan Drugs 0.000 description 1
- 230000008719 thickening Effects 0.000 description 1
- 125000003396 thiol group Chemical group [H]S* 0.000 description 1
- CNHYKKNIIGEXAY-UHFFFAOYSA-N thiolan-2-imine Chemical compound N=C1CCCS1 CNHYKKNIIGEXAY-UHFFFAOYSA-N 0.000 description 1
- 210000000115 thoracic cavity Anatomy 0.000 description 1
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 1
- 238000013151 thrombectomy Methods 0.000 description 1
- 239000003868 thrombin inhibitor Substances 0.000 description 1
- 238000007395 thrombosis prophylaxis Methods 0.000 description 1
- PHWBOXQYWZNQIN-UHFFFAOYSA-N ticlopidine Chemical compound ClC1=CC=CC=C1CN1CC(C=CS2)=C2CC1 PHWBOXQYWZNQIN-UHFFFAOYSA-N 0.000 description 1
- 229960005001 ticlopidine Drugs 0.000 description 1
- 229950004437 tiqueside Drugs 0.000 description 1
- 229960003425 tirofiban Drugs 0.000 description 1
- COKMIXFXJJXBQG-NRFANRHFSA-N tirofiban Chemical compound C1=CC(C[C@H](NS(=O)(=O)CCCC)C(O)=O)=CC=C1OCCCCC1CCNCC1 COKMIXFXJJXBQG-NRFANRHFSA-N 0.000 description 1
- 239000004408 titanium dioxide Substances 0.000 description 1
- 229960001350 tofacitinib Drugs 0.000 description 1
- UJLAWZDWDVHWOW-YPMHNXCESA-N tofacitinib Chemical compound C[C@@H]1CCN(C(=O)CC#N)C[C@@H]1N(C)C1=NC=NC2=C1C=CN2 UJLAWZDWDVHWOW-YPMHNXCESA-N 0.000 description 1
- RUELTTOHQODFPA-UHFFFAOYSA-N toluene 2,6-diisocyanate Chemical compound CC1=C(N=C=O)C=CC=C1N=C=O RUELTTOHQODFPA-UHFFFAOYSA-N 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 229960005461 torasemide Drugs 0.000 description 1
- 238000002179 total cell area Methods 0.000 description 1
- 239000003440 toxic substance Substances 0.000 description 1
- 235000010487 tragacanth Nutrition 0.000 description 1
- 239000000196 tragacanth Substances 0.000 description 1
- 229940116362 tragacanth Drugs 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 239000012581 transferrin Substances 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 230000014616 translation Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 230000000472 traumatic effect Effects 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- 150000003626 triacylglycerols Chemical class 0.000 description 1
- 229960005294 triamcinolone Drugs 0.000 description 1
- GFNANZIMVAIWHM-OBYCQNJPSA-N triamcinolone Chemical compound O=C1C=C[C@]2(C)[C@@]3(F)[C@@H](O)C[C@](C)([C@@]([C@H](O)C4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 GFNANZIMVAIWHM-OBYCQNJPSA-N 0.000 description 1
- 229960001288 triamterene Drugs 0.000 description 1
- 229960004813 trichlormethiazide Drugs 0.000 description 1
- LMJSLTNSBFUCMU-UHFFFAOYSA-N trichlormethiazide Chemical compound C1=C(Cl)C(S(=O)(=O)N)=CC2=C1NC(C(Cl)Cl)NS2(=O)=O LMJSLTNSBFUCMU-UHFFFAOYSA-N 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 1
- 108010044292 tryptophyltyrosine Proteins 0.000 description 1
- 210000004926 tubular epithelial cell Anatomy 0.000 description 1
- 229940046728 tumor necrosis factor alpha inhibitor Drugs 0.000 description 1
- 239000002452 tumor necrosis factor alpha inhibitor Substances 0.000 description 1
- MEYZYGMYMLNUHJ-UHFFFAOYSA-N tunicamycin Natural products CC(C)CCCCCCCCCC=CC(=O)NC1C(O)C(O)C(CC(O)C2OC(C(O)C2O)N3C=CC(=O)NC3=O)OC1OC4OC(CO)C(O)C(O)C4NC(=O)C MEYZYGMYMLNUHJ-UHFFFAOYSA-N 0.000 description 1
- 229960000438 udenafil Drugs 0.000 description 1
- IYFNEFQTYQPVOC-UHFFFAOYSA-N udenafil Chemical compound C1=C(C=2NC=3C(CCC)=NN(C)C=3C(=O)N=2)C(OCCC)=CC=C1S(=O)(=O)NCCC1CCCN1C IYFNEFQTYQPVOC-UHFFFAOYSA-N 0.000 description 1
- 238000000870 ultraviolet spectroscopy Methods 0.000 description 1
- 210000000626 ureter Anatomy 0.000 description 1
- 238000002562 urinalysis Methods 0.000 description 1
- 201000002327 urinary tract obstruction Diseases 0.000 description 1
- 229960004699 valsartan Drugs 0.000 description 1
- SJSNUMAYCRRIOM-QFIPXVFZSA-N valsartan Chemical compound C1=CC(CN(C(=O)CCCC)[C@@H](C(C)C)C(O)=O)=CC=C1C1=CC=CC=C1C1=NN=N[N]1 SJSNUMAYCRRIOM-QFIPXVFZSA-N 0.000 description 1
- 108010073969 valyllysine Proteins 0.000 description 1
- 230000008728 vascular permeability Effects 0.000 description 1
- 229950000578 vatalanib Drugs 0.000 description 1
- YCOYDOIWSSHVCK-UHFFFAOYSA-N vatalanib Chemical compound C1=CC(Cl)=CC=C1NC(C1=CC=CC=C11)=NN=C1CC1=CC=NC=C1 YCOYDOIWSSHVCK-UHFFFAOYSA-N 0.000 description 1
- 229960001722 verapamil Drugs 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 description 1
- 229960004355 vindesine Drugs 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 235000005282 vitamin D3 Nutrition 0.000 description 1
- 239000011647 vitamin D3 Substances 0.000 description 1
- QYSXJUFSXHHAJI-YRZJJWOYSA-N vitamin D3 Chemical compound C1(/[C@@H]2CC[C@@H]([C@]2(CCC1)C)[C@H](C)CCCC(C)C)=C\C=C1\C[C@@H](O)CCC1=C QYSXJUFSXHHAJI-YRZJJWOYSA-N 0.000 description 1
- 229940021056 vitamin d3 Drugs 0.000 description 1
- 229940019333 vitamin k antagonists Drugs 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
- XLYOFNOQVPJJNP-OUBTZVSYSA-N water-17o Chemical compound [17OH2] XLYOFNOQVPJJNP-OUBTZVSYSA-N 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- 229960000537 xipamide Drugs 0.000 description 1
- MTZBBNMLMNBNJL-UHFFFAOYSA-N xipamide Chemical compound CC1=CC=CC(C)=C1NC(=O)C1=CC(S(N)(=O)=O)=C(Cl)C=C1O MTZBBNMLMNBNJL-UHFFFAOYSA-N 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images








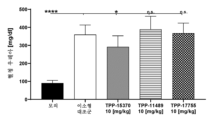


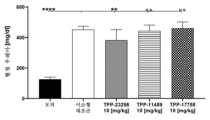







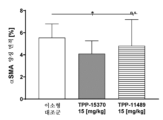








Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/3955—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against proteinaceous materials, e.g. enzymes, hormones, lymphokines
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/10—Drugs for disorders of the cardiovascular system for treating ischaemic or atherosclerotic diseases, e.g. antianginal drugs, coronary vasodilators, drugs for myocardial infarction, retinopathy, cerebrovascula insufficiency, renal arteriosclerosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Abstract
본 개시내용은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이다. 본 개시내용에 따른 단리된 항체 또는 항원-결합 단편은 i) 서열식별번호: 600의 서열의 인간 Sema3A에 ≤ 50 nM, ≤ 20 nM, <10 nM, <1 nM, 또는 ≤ 0.1 nM의 해리 상수 (KD)로 결합하고/거나; ii) 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A와 교차-반응하고, 특히 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A에 ≤ 50 nM, ≤ 20 nM, <10 nM, <1 nM, 또는 ≤ 0.1 nM의 해리 상수 (KD)로 결합하고/거나; iii) 표면 플라즈몬 공명 (SPR)에 의해 측정된 바와 같이 서열식별번호: 600의 서열의 인간 Sema3A에 ≥ 60%, ≥ 70%, ≥ 80%, 또는 ≥ 90%의 결합 활성으로 결합하고/거나; iv) 시험관내 혈관간 세포 이동 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 10 nM, ≤ 5 nM, ≤ 2.5 nM, 또는 ≤ 1 nM의 EC50으로 억제하고/거나; v) 시험관내 성장 원추 붕괴 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 < 50 nM, ≤ 25 nM, ≤ 10 nM, 또는 ≤ 5 nM의 EC50으로 억제하고/거나; vi) 시험관내 HUVEC 반발 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 1 nM, 또는 ≤ 0.3 nM, ≤ 0.1 nM, ≤ 0.07 nM, ≤ 0.06nM의 EC50으로 억제하고/거나, vii) 서열식별번호: 600의 서열의 세포 Sema3A 유도된 HUVEC 반발에 대해 증가된 효력을 나타낸다.
Description
본 발명은 인간 세마포린 3A (Sema3A)에 결합하는 단리된 항체 또는 그의 항원-결합 단편을 제공한다. 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 i) 서열식별번호(SEQ ID NO): 600의 서열의 인간 Sema3A에 ≤ 50 nM, ≤ 20 nM, ≤10 nM, ≤1 nM, 또는 ≤ 0.1 nM의 해리 상수 (KD)로 결합하고/거나; ii) 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A와 교차-반응하고, 특히 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A에 ≤ 50 nM, ≤ 20 nM, ≤10 nM, ≤1 nM, 또는 ≤ 0.1 nM의 해리 상수 (KD)로 결합하고/거나; iii) 표면 플라즈몬 공명 (SPR)에 의해 측정된 바와 같이 서열식별번호: 600의 서열의 인간 Sema3A에 ≥ 60%, ≥ 70%, ≥ 80%, 또는 ≥ 90%의 결합 활성으로 결합하고/거나; iv) 시험관내 혈관간 세포 이동 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 10 nM, ≤ 5 nM, ≤ 2.5 nM, 또는 ≤ 1 nM의 EC50으로 억제하고/거나; v) 시험관내 성장 원추 붕괴 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 50 nM, ≤ 25 nM, ≤ 10 nM, 또는 ≤ 5 nM의 EC50으로 억제하고/거나; vi) 시험관내 HUVEC 반발 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 1 nM, 또는 ≤ 0.3 nM, ≤ 0.1 nM, ≤ 0.07 nM, ≤ 0.06 nM의 EC50으로 억제하고/거나, vii) 서열식별번호: 600의 서열의 세포 Sema3A 유도된 HUVEC 반발에 대해 증가된 효력을 나타낸다. 본 발명은 상기 항체 또는 그의 항원-결합 단편을 코딩하는 단리된 핵산 서열 및 그를 포함하는 벡터, 상기 항체 또는 그의 항원-결합 단편을 발현하는 단리된 세포, 상기 항체 또는 그의 항원-결합 단편을 생산하는 방법, 및 상기 항체 또는 그의 항원-결합 단편을 포함하는 제약 조성물 및 키트를 추가로 제공한다.
본 발명에 따른 항체는 증가된 Sema3A 수준 또는 활성과 연관된 질환, 예컨대 알포트 증후군, 급성 신장 손상 (AKI) 원발성 초점성 분절성 사구체 경화증 (FSGS) 또는 만성 신장 질환 (CKD)의 치료에 사용될 수 있다.
세마포린 3A (Sema3A)는 유도 단백질로서 작용하는 분비된 이량체 단백질이다. 이는 뉴로필린-1 및 상이한 플렉신과 3원 복합체를 형성하고, 이는 상이한 신호전달 경로의 활성화로 이어진다. 이는 세포 이동, 부착, 세포골격 안정화 및 아폽토시스의 주요 조절제이다. Sema3A는 성체 신장 내 족세포에서 발현되며, 손상 후에 유도된다.
과량의 Sema3A는 사구체 여과 장벽을 방해하여 여과 장벽의 초미세구조 변화를 유도하며, 이는 족세포 족 돌기 소실 및 알부민뇨를 초래한다. Sema3A는 또한 AKI 후에 고도로 유도되고, 세관 염증, 세관 상피 세포 아폽토시스 및 여과 장벽의 초미세구조 이상을 촉진함으로써 손상을 악화시킨다. 설치류에서 Sema3A의 유전적 결핍 또는 약리학적 억제는 신장 질환의 상이한 동물 모델에서 감소된 신장 손상을 발생시킨다.
또한, Sema3A는 망막 뉴런 및 내피에서 발현된다. 이는 설치류 모델에서 혈관 투과성을 증가시키고, 망막 염증 및 세포 노쇠를 촉진하고, 망막 혈관 재생을 억제하는 것으로 제시되었다. Sema3A는 또한 CNS 장애에서 소정의 역할을 한다. Sema3A 억제는 손상된 축삭의 증진된 재생 및/또는 보존, 아폽토시스 세포 수의 감소 및 혈관신생의 증진을 발생시켜, 상당히 더 우수한 기능적 회복을 발생시킨다.
WO 20141/23186은 조류-마우스 키메라 항체 (클론 번호 4-2 균주-유래) 및 그의 2종의 인간화 IgG1 변이체를 개시하고, 알츠하이머병의 치료에서의 그의 적합성을 시사한다.
WO 2017/074013은 항-Sema3A IgG 항체 A08, C10 및 F11을 개시하고, 암의 치료에서의 그의 적합성을 시사한다.
현재, 예를 들어 알포트 증후군과 같은 단백뇨 신장 질환을 갖는 환자를 치료하기 위해 Sema3A의 그의 수용체와의 상호작용을 억제하는 치료 옵션은 이용가능하지 않고, 모노클로날 치료 Sema3A 항체가 이에 최적으로 적합할 수 있을 것으로 추정된다. 따라서, 지금까지 충족되지 않은, 상승된 Sema3A 수준 또는 활성과 연관된 질환, 예컨대 알포트 증후군, 급성 신장 손상 (AKI) 원발성 초점성 분절성 사구체 경화증 (FSGS) 또는 만성 신장 질환 (CKD)의 치료에 유용한 신규 치료 Sema3A 항체에 대한 강한 필요가 존재한다.
본 발명의 목적
선행 기술에 비추어, 본 발명의 목적은 선행 기술의 Sema3A 항체의 단점을 극복한 신규 치료 Sema3A 항체를 제공하는 것이다. 특히, 본 발명의 목적은 Sema3A 활성을 효율적으로 차단하는 인간 Sema3A의 고친화도 결합제인 신규 Sema3A 항체를 제공하는 것이다. 바람직한 Sema3A 항체는 전임상 실험을 가능하게 하기 위해 다중 종의 Sema3A에 대해 교차-반응성이다. 이는 인간 요법에서 비-면역원성이며, 즉 이는 인간 또는 인간화 항체이다. 바람직한 Sema3A 항체는 Sema3A에 대해 선택적이며; 이는 오프-타겟에 결합하지 않고, 특히 다른 세마포린 단백질 패밀리 구성원과 교차-반응하지 않는다.
이러한 신규 Sema3A 항체는 상승된 Sema3A 수준 또는 활성과 연관된 질환, 예컨대 알포트 증후군, 급성 신장 손상 (AKI) 원발성 초점성 분절성 사구체 경화증 (FSGS) 또는 만성 신장 질환 (CKD)의 치료에서 주요 진전을 제공할 것이다.
발명의 개요
상기 언급된 목적 및 다른 목적은 본 발명의 교시에 의해 달성된다. 본 발명은 Sema3A에 대해 특이적 친화도를 갖고 대상체에게 치료 이익을 전달할 수 있는 신규 항체의 발견에 기초한다.
따라서, 제1 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 i) 서열식별번호: 600의 서열의 인간 Sema3A에 ≤ 50 nM, ≤ 20 nM, ≤10 nM, ≤1 nM, 또는 ≤ 0.1 nM의 해리 상수 (KD)로 결합하고/거나; ii) 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A와 교차-반응하고, 특히 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A에 ≤ 50 nM, ≤ 20 nM, ≤10 nM, ≤1 nM, 또는 ≤ 0.1 nM의 해리 상수 (KD)로 결합하고/거나; iii) 표면 플라즈몬 공명 (SPR)에 의해 측정된 바와 같이 서열식별번호: 600의 서열의 인간 Sema3A에 ≥ 60%, ≥ 70%, ≥ 80%, 또는 ≥ 90%의 결합 활성으로 결합하고/거나; iv) 시험관내 혈관간 세포 이동 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 10 nM, ≤ 5 nM, ≤ 2.5 nM, 또는 ≤ 1 nM의 EC50으로 억제하고/거나; v) 시험관내 성장 원추 붕괴 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 50 nM, ≤ 25 nM, ≤ 10 nM, 또는 ≤ 5 nM의 EC50으로 억제하고/거나; vi) 시험관내 HUVEC 반발 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 1 nM, 또는 ≤ 0.3 nM, ≤ 0.1 nM, ≤ 0.07 nM, ≤ 0.06nM의 EC50으로 억제하고/거나, vii) 서열식별번호: 600의 서열의 세포 Sema3A 유도된 HUVEC 반발에 대해 증가된 효력을 나타낸다.
본 발명에 따른 단리된 항체 또는 항원-결합 단편은 인간 Sema3A에 높은 친화도로 결합하고, 그의 기능을 억제한다. 따라서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 증가된 Sema3A 수준 또는 활성과 연관된 질환, 예컨대 i) 신질환, 특히 급성 및 만성 신장 질환, 당뇨병성 신장 질환, 알포트 증후군, 급성 및 만성 신부전, 다낭성 신장 질환 (PCKD) 및 부적절한 ADH 분비 증후군 (SIADH); ii) 신기능부전 후유증, 특히 폐 부종, 심부전, 요독증, 빈혈, 전해질 장애 예컨대 고칼륨혈증 및 저나트륨혈증 및 골 및 탄수화물 대사 장애; iii) 혈관 과투과성, 당뇨병성 망막병증, 혈액 망막 장벽 악화, 황반 부종, 특히 연령 관련 황반 부종, 비-증식성 연령-관련 황반 부종 및 비-증식성 당뇨병성 황반 부종; iv) 중추 또는 말초 신경계 질환 특히 신경병증성 통증, 척수 손상, 다발성 경화증, 외상성 뇌 손상, 뇌 부종 및 신경변성 질환, 특히 알츠하이머병, 파킨슨병, 헌팅톤병, 근위축성 측삭 경화증, 진행성 핵상 마비, 흑색질 변성, 샤이-드래거 증후군, 올리브교뇌소뇌 위축 및 척수소뇌 변성; 또는 v) 암, 특히 장암, 결장직장암, 폐암, 유방암, 뇌암, 흑색종, 신세포암, 백혈병, 림프종, T-세포 림프종, 위암, 췌장암, 자궁경부암, 자궁내막암, 난소암, 식도암, 간암, 두경부의 편평 세포 암종, 피부암, 요로암, 전립선암, 융모막암종, 인두암 및 후두암의 치료에 사용될 수 있다.
본 발명에 따른 단리된 항체 또는 항원-결합 단편은 추가로 Sema3A-관련 장애의 진단에 사용될 수 있다.
추가 측면에서, 본 발명은 본 발명에 따른 항체 또는 항원-결합 단편을 코딩하는 단리된 핵산 서열에 관한 것이다.
추가 측면에서, 본 발명은 본 발명에 따른 핵산 서열을 포함하는 벡터에 관한 것이다.
추가 측면에서, 본 발명은 본 발명에 따른 항체 또는 항원-결합 단편을 발현하고/거나 본 발명에 따른 핵산 또는 본 발명에 따른 벡터를 포함하는 단리된 세포에 관한 것이다.
추가 측면에서, 본 발명은 본 발명에 따른 세포를 배양하고, 임의로 항체 또는 그의 항원-결합 단편을 정제하는 것을 포함하는, 본 발명에 따른 단리된 항체 또는 항원-결합 단편을 생산하는 방법에 관한 것이다.
추가 측면에서, 본 발명은 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 본 발명에 따른 항체 접합체를 포함하는 제약 조성물에 관한 것이다.
추가 측면에서, 본 발명은 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 본 발명에 따른 접합체 및 사용에 대한 지침서를 포함하는 키트에 관한 것이다.
발명의 상세한 설명
본 발명은 본 발명의 하기 상세한 설명 및 그에 포함된 예를 참조하여 보다 용이하게 이해될 수 있다.
정의
달리 정의되지 않는 한, 본원에 사용된 모든 기술 과학 용어는 본 발명이 속하는 관련 기술분야의 통상의 기술자에 의해 통상적으로 이해되는 의미를 갖는다. 그러나, 하기 참고문헌은 본 발명이 속하는 관련 기술분야의 통상의 기술자에게 본 발명에 사용된 많은 용어의 일반적 정의를 제공할 수 있고, 이러한 정의가 관련 기술분야에서 통상적으로 이해되는 의미와 일치하는 한 참조되고 사용될 수 있다. 이러한 참고문헌은 문헌 [Singleton et al., Dictionary of Microbiology and Molecular Biology (2nd ed. 1994); The Cambridge Dictionary of Science and Technology (Walker ed., 1988); Hale & Marham, The Harper Collins Dictionary of Biology (1991); Lackie et al., The Dictionary of Cell & Molecular Biology (3d ed. 1999); 및 Cellular and Molecular Immunology, Eds. Abbas, Lichtman and Pober, 2nd Edition, W.B. Saunders Company]을 포함하나, 이에 제한되지는 않는다. 관련 기술분야에서 통상적으로 이해되는 의미를 갖는 본원에 사용된 용어의 정의를 제공하는, 관련 기술분야의 통상의 기술자가 입수가능한 임의의 추가의 기술적 자원을 참고할 수 있다. 본 발명의 목적을 위해, 하기 용어가 추가로 정의된다. 추가의 용어는 상세한 설명의 다른 곳에서 정의된다. 본원 및 첨부된 청구범위에 사용된 단수 형태는 문맥이 달리 명백하게 지시하지 않는 한 복수 지시대상을 포함한다. 따라서, 예를 들어, "유전자"에 대한 언급은 1개 이상의 유전자에 대한 언급이고, 관련 기술분야의 통상의 기술자에게 공지된 그의 등가물 등을 포함한다.
본 발명의 문맥에서, 용어 "포함하다" 또는 "포함하는"은 "포함하나 이에 제한되지는 않는"을 의미한다. 용어는 임의의 언급된 특색, 요소, 정수, 단계 또는 성분의 존재를 명시하기 위해 개방형인 것으로 의도되지만, 하나 이상의 다른 특색, 요소, 정수, 단계, 성분 또는 그의 군의 존재 또는 부가를 배제하지는 않는 것으로 의도된다. 따라서, 용어 "포함하는"은 보다 제한적인 용어 "이루어진" 및 "본질적으로 이루어진"을 포함한다. 한 실시양태에서, 본 출원 전반에 걸쳐, 특히 청구범위 내에서 사용된 용어 "포함하는"은 용어 "이루어진"으로 대체될 수 있다.
이와 관련하여, 용어 "약" 또는 "대략"은 주어진 값 또는 범위의 80% 내지 120% 이내, 대안적으로 90% 내지 110% 이내, 예컨대 95% 내지 105% 이내를 의미한다.
용어 "폴리펩티드" 및 "단백질"은 아미노산 잔기의 중합체를 지칭하는 것으로 본원에서 상호교환가능하게 사용된다. 상기 용어는 적어도 1개의 아미노산 잔기가 상응하는 자연 발생 아미노산의 인공 화학적 모방체인 아미노산 중합체, 뿐만 아니라 자연 발생 아미노산 중합체 및 비-자연 발생 아미노산 중합체에 적용된다. 달리 나타내지 않는 한, 특정한 폴리펩티드 서열은 또한 그의 보존적으로 변형된 변이체를 함축적으로 포괄한다.
본원에 사용된 "Sema3A"는, 또한 "HH16", "SemD", "COLL1", "SEMA1", "SEMAD", "SEMAL", "coll-1", "Hsema-I", "SEMAIII", "Hsema-III", "콜랩신 1", "세마포린 D", "세마포린 III" 및 "세마포린 L"로도 공지되어 있는, "세마포린 3A"를 나타낸다.
용어 "항-Sema3A 항체" 및 "Sema3A에 결합하는 항체"는 항체가 Sema3A를 표적화하는 데 있어서 진단제 및/또는 치료제로서 유용하도록 충분한 친화도로 Sema3A에 결합할 수 있는 항체를 지칭한다. 한 실시양태에서, 비관련, 비-Sema3A 단백질에 대한 항-Sema3A 항체의 결합의 정도는, 예를 들어 표준 ELISA 절차에 의해 측정된 바와 같이, Sema3A에 대한 항체의 결합의 약 10% 미만, 약 5% 미만 또는 약 2% 미만이다. 특정 실시양태에서, Sema3A에 결합하는 항체는 ≤ 1μM, ≤ 100 nM, ≤ 10 nM, ≤ 1 nM, ≤ 0.1 nM, ≤ 0.01 nM, 또는 ≤ 0.001 nM (예를 들어 10-8 M 이하, 예를 들어 10-8 M 내지 10-13 M, 예를 들어 10-9M 내지 10-13 M)의 결합 활성 (EC50)을 갖는다. 특정 실시양태에서, 항-Sema3A 항체는 상이한 종으로부터의 Sema3A 사이에 보존된 Sema3A의 에피토프에 결합한다.
본원에 사용된 용어 "항체"는 이뮤노글로불린 분자를 지칭하는 것으로 의도된다. 항체는 전형적으로 디술피드 결합에 의해 상호-연결된 4개의 폴리펩티드 쇄, 2개의 중쇄 (H) (약 50-70 kDa) 및 2개의 경쇄 (L) (약 25 kDa)를 포함할 수 있다. 특정한 실시양태에서, 항체는 폴리펩티드 쇄의 2개의 동일한 쌍으로 구성된다. 각각의 쇄의 아미노-말단 부분은 주로 항원 인식을 담당하는 약 100 내지 110개 또는 그 초과의 아미노산의 "가변" 영역을 포함한다. 중쇄 가변 영역은 본원에서 VH로 약칭되고, 경쇄 가변 영역은 본원에서 VL로 약칭된다. 각각의 쇄의 카르복실-말단 부분은 주로 이펙터 기능을 담당하는 불변 영역을 규정한다. 중쇄 불변 영역은 예를 들어 3개의 도메인 CH1, CH2 및 CH3을 포함할 수 있다. 경쇄 불변 영역은 1개의 도메인 (CL)으로 구성된다. VH 및 VL 영역은 프레임워크 영역 (FR)으로 불리는 보다 보존된 영역이 사이에 배치되어 있는, 상보성 결정 영역 (CDR)으로 불리는 초가변 영역으로 추가로 세분될 수 있다. 각각의 VH 및 VL은 전형적으로 아미노-말단에서 카르복시-말단으로, 예를 들어 하기 순서: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4로 배열된 3개의 CDR 및 최대 4개의 FR로 구성된다.
본원에 사용된 용어 "상보성 결정 영역" (CDR; 예를 들어, CDR1, CDR2, 및 CDR3)은 그의 존재가 항원 결합에 필요한 항체 가변 도메인의 아미노산 잔기를 지칭한다. 각각의 가변 도메인은 전형적으로 CDR1, CDR2 및 CDR3으로 확인되는 3개의 CDR 영역을 갖는다. 각각의 상보성 결정 영역은 카바트(Kabat)에 의해 정의된 바와 같은 "상보성 결정 영역"으로부터의 아미노산 잔기 (Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD. (1991)) 및/또는 "초가변 루프"로부터의 그러한 잔기 (Chothia and Lesk; J Mol Biol 196: 901-917 (1987))를 포함할 수 있다. 일부 경우에, 상보성 결정 영역은 카바트에 따라 정의된 CDR 영역 및 초가변 루프 둘 다로부터의 아미노산을 포함할 수 있다.
"프레임워크" 또는 FR 잔기는 초가변 영역 잔기 이외의 가변 도메인 잔기이다.
어구 "불변 영역"은 이펙터 기능을 부여하는 항체 분자의 부분을 지칭한다.
본원에서 용어 "Fc 영역"은 불변 영역의 적어도 한 부분을 함유하는 이뮤노글로불린 중쇄의 C-말단 영역을 정의하는 데 사용된다. 상기 용어는 천연 서열 Fc 영역 및 변이체 Fc 영역을 포함한다. 한 실시양태에서, 인간 IgG 중쇄 Fc 영역은 Cys226 또는 Pro230으로부터 중쇄의 카르복실-말단으로 연장된다. 그러나, Fc 영역의 C-말단 리신 (Lys447)은 존재할 수 있거나 또는 존재하지 않을 수 있다. 본원에서 달리 명시되지 않는 한, Fc 영역 또는 불변 영역 내의 아미노산 잔기의 넘버링은 문헌 [Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD, 1991]에 기재된 바와 같은, EU 인덱스로도 불리는 EU 넘버링 시스템에 따른다.
이뮤노글로불린은 그의 중쇄의 불변 도메인의 아미노산 서열에 따라 상이한 부류로 할당될 수 있다. 중쇄는 뮤 (μ), 델타 (Δ), 감마 (γ), 알파 (α), 및 엡실론 (ε)으로 분류되고, 항체의 이소형을 각각 IgM, IgD, IgG, IgA 및 IgE로 규정한다. 특정한 실시양태에서, 본 발명에 따른 항체는 IgG 항체이다. 이들 중 몇몇은 하위부류 또는 이소형, 예를 들어 IgG1, IgG2, IgG3, IgG4, IgA1 및 IgA2로 추가로 나뉠 수 있다. 특정한 실시양태에서, 본 발명에 따른 항체는 IgG1, IgG2, IgG3 또는 IgG4 항체, 보다 특히 IgG1 또는 IgG4 항체이다. 상이한 이소형은 상이한 이펙터 기능을 가질 수 있다. 인간 경쇄는 카파 (K) 및 람다 (λ) 경쇄로 분류된다. 경쇄 및 중쇄 내에서, 가변 및 불변 영역은 약 12개 이상의 아미노산의 "J" 영역에 의해 연결되고, 중쇄는 또한 약 10개 이상의 아미노산의 "D" 영역을 포함한다. 일반적으로, 문헌 [Fundamental Immunology, Ch. 7 (Paul, W., ed., 2nd ed. Raven Press, N.Y. (1989))]을 참조한다.
본원에서 항체/이뮤노글로불린의 "기능적 단편" 또는 "항원-결합 항체 단편"은 항원-결합 영역을 보유하는 항체/이뮤노글로불린의 단편 (예를 들어, IgG의 가변 영역)으로서 정의된다. 항체의 "항원-결합 영역"은 전형적으로 항체의 1개 이상의 초가변 영역(들), 예를 들어 CDR1, -2, 및/또는 -3 영역에서 발견되지만; 가변 "프레임워크" 영역은 또한 예컨대 CDR에 대한 스캐폴드를 제공함으로써 항원 결합에서 중요한 역할을 할 수 있다. 바람직하게는, "항원-결합 영역"은 적어도 가변 경쇄 (VL)의 아미노산 잔기 4 내지 103 및 가변 중쇄 (VH)의 5 내지 109, 보다 바람직하게는 VL의 아미노산 잔기 3 내지 107 및 VH의 4 내지 111을 포함하고, 완전한 VL 및 VH 쇄 (VL의 아미노산 위치 1 내지 109 및 VH의 1 내지 113; WO 97/08320에 따른 넘버링)가 특히 바람직하다.
"기능적 단편" 또는 "항원-결합 항체 단편"의 비제한적 예는 Fab, Fab', F(ab')2, Fv 단편, 도메인 항체 (dAb), 상보성 결정 영역 (CDR) 단편, 단일-쇄 항체 (scFv), 단일 쇄 항체 단편, 디아바디, 트리아바디, 테트라바디, 미니바디, 선형 항체 (Zapata et al., Protein Eng.,8 (10): 1057-1062 (1995)); 킬레이팅 재조합 항체, 트리바디 또는 비바디, 인트라바디, 나노바디, 소형 모듈 면역제약 (SMIP), 항원-결합-도메인 이뮤노글로불린 융합 단백질, 낙타화 항체, VHH 함유 항체, 또는 뮤테인 또는 그의 유도체, 및 항체가 목적하는 생물학적 활성을 보유하는 한, 폴리펩티드에 특이적 항원 결합을 부여하기에 충분한 이뮤노글로불린의 적어도 한 부분, 예컨대 CDR 서열을 함유하는 폴리펩티드; 및 다중특이적 항체, 예컨대 항체 단편으로부터 형성된 이중- 및 삼중특이적 항체 (C. A. K Borrebaeck, editor (1995) Antibody Engineering (Breakthroughs in Molecular Biology), Oxford University Press; R. Kontermann & S. Duebel, editors (2001) Antibody Engineering (Springer Laboratory Manual), Springer Verlag)를 포함한다. "이중특이적" 또는 "이중기능적" 항체 이외의 항체는 각각의 그의 결합 부위가 동일한 것으로 이해된다. F(ab')2 또는 Fab는 CH1 및 CL 도메인 사이에 발생하는 분자간 디술피드 상호작용을 최소화하거나 완전히 제거하도록 조작될 수 있다. 항체의 파파인 소화는 각각 단일 항원-결합 부위를 갖는 "Fab" 단편으로 불리는 2개의 동일한 항원-결합 단편, 및 그의 명칭이 용이하게 결정화되는 그의 능력을 반영하는 것인 나머지 "Fc" 단편을 생산한다. 펩신 처리는 2개의 "Fv" 단편을 갖는 F(ab')2 단편을 생성한다. "Fv" 단편은 완전한 항원 인식 및 결합 부위를 함유하는 최소 항체 단편이다. 이 영역은 단단하게 비-공유 회합된 1개의 중쇄 및 1개의 경쇄 가변 도메인의 이량체로 이루어진다. 각각의 가변 도메인의 3개의 CDR이 상호작용하여 VH-VL 이량체의 표면 상에 항원 결합 부위를 규정하는 것은 이러한 구성이다. 집합적으로, 6개의 CDR은 항체에 항원-결합 특이성을 부여한다. 그러나, 심지어 단일 가변 도메인 (또는 항원에 특이적인 3개의 CDR만을 포함하는 Fv의 절반)도 항원을 인식하고 결합하는 능력을 갖는다.
"단일-쇄 Fv" 또는 "sFv" 또는 "scFv" 항체 단편은 항체의 VH 및 VL 도메인을 포함하며, 여기서 이들 도메인은 단일 폴리펩티드 쇄로 존재한다.
바람직하게는, Fv 폴리펩티드는 Fv가 항원 결합을 위한 목적하는 구조를 형성할 수 있게 하는, VH 및 VL 도메인 사이의 폴리펩티드 링커를 추가로 포함한다. Fv의 검토를 위해, 문헌 [Pluckthun in The Pharmacology of Monoclonal Antibodies, vol. 113, Rosenburg and Moore eds., Springer-Verlag, New York, pp. 269-315 (1994)]을 참조한다.
Fab 단편은 또한 경쇄의 불변 도메인 및 중쇄의 제1 불변 도메인 (CH1)을 함유한다. Fab 단편은 항체 힌지 영역으로부터 1개 이상의 시스테인 잔기를 포함하는 중쇄 CH1 도메인의 카르복실 말단에서 수개의 잔기가 부가된다는 점에서 Fab' 단편과 상이하다. Fab'-SH는 불변 도메인의 시스테인 잔기(들)가 유리 티올 기를 보유하는 Fab'에 대한 본원의 명칭이다. F(ab')2 항체 단편은 원래, 힌지 시스테인 잔기가 사이에 있는 Fab' 단편의 쌍으로서 생산되었다.
용어 "뮤테인" 또는 "변이체"는 상호교환가능하게 사용될 수 있고, 뮤테인 또는 변이체가 목적하는 결합 친화도 또는 생물학적 활성을 보유하는 한, 가변 영역 또는 가변 영역과 등가인 부분에 적어도 1개의 아미노산 치환, 결실, 또는 삽입을 함유하는 항체 또는 항원-결합 단편을 지칭한다. 본 발명에서 고려되는 항체 또는 항원-결합 항체 단편의 변이체는 항체 또는 항원-결합 항체 단편의 결합 활성이 유지되는 분자이다.
"키메라 항체" 또는 그의 항원-결합 단편은 가변 도메인이 비-인간 기원으로부터 유래되고 일부 또는 모든 불변 도메인이 인간 기원으로부터 유래된 것으로 본원에 정의된다.
"인간화 항체"는 예를 들어 임의의 필요한 프레임워크 복귀-돌연변이와 함께 인간 서열-유래 V 영역 내로 생착된 비-인간 종, 예컨대 마우스로부터 유래된 CDR 영역을 함유한다. 따라서, 대부분의 경우에, 인간화 항체는 수용자의 초가변 영역으로부터의 잔기가 목적하는 특이성, 친화도, 및 능력을 갖는 비-인간 종 (공여자 항체), 예컨대 마우스, 래트, 토끼 또는 비-인간 영장류의 초가변 영역으로부터의 잔기로 대체된 인간 이뮤노글로불린 (수용자 항체)이다. 예를 들어, 각각 본원에 참조로 포함되는 미국 특허 번호 5,225,539; 5,585,089; 5,693,761; 5,693,762; 5,859,205를 참조한다. 일부 경우에, 인간 이뮤노글로불린의 프레임워크 잔기는 상응하는 비-인간 잔기에 의해 대체된다 (예를 들어, 각각 본원에 참조로 포함되는 미국 특허 번호 5,585,089; 5,693,761; 5,693,762 참조). 또한, 인간화 항체는 수용자 항체 또는 공여자 항체에서는 발견되지 않는 잔기를 포함할 수 있다. 이들 변형은 항체 성능을 추가로 정밀화하기 위해 (예를 들어, 목적하는 친화도를 수득하기 위해) 이루어진다. 일반적으로, 인간화 항체는 적어도 1개, 전형적으로 2개의 가변 도메인을 실질적으로 모두 포함할 것이며, 여기서 모든 또는 실질적으로 모든 초가변 영역은 비-인간 이뮤노글로불린의 것에 상응하고, 모든 또는 실질적으로 모든 프레임워크 영역은 인간 이뮤노글로불린 서열의 것이다. 인간화 항체는 또한 임의로 이뮤노글로불린 불변 영역 (Fc)의 적어도 한 부분, 전형적으로 인간 이뮤노글로불린의 것을 포함할 것이다. 추가의 세부사항에 대해서는, 각각 본원에 참조로 포함되는 문헌 [Jones et al., Nature 331:522-25 (1986); Riechmann et al., Nature 332:323-27 (1988); 및 Presta, Curr. Opin. Struct. Biol. 2:593-96 (1992)]을 참조한다.
"인간 항체" 또는 "완전 인간 항체"는 인간 유래 CDR, 즉 인간 기원의 CDR을 포함한다. 완전 인간 항체는 IMGT 데이터베이스 (http://www.imgt.org)에 기초하여 결정된 가장 가까운 인간 배선 참조와 비교하여 적은 수의 배선 편차를 포함할 수 있다. 예를 들어, 본 발명에 따른 완전 인간 항체는 가장 가까운 인간 배선 참조와 비교하여 CDR에서 최대 1, 2, 3, 4, 5, 6, 7, 8, 9 또는 10개의 배선 편차를 포함할 수 있다. 완전 인간 항체는 세포 풍부화 또는 불멸화 단계와 조합된 클로닝 기술에 의해 인간 유래 B 세포로부터 발생될 수 있다. 그러나, 대다수의 완전 인간 항체는 인간 IgG 유전자좌에 대해 트랜스제닉인 면역화된 마우스로부터 또는 파지 디스플레이에 의해 정교화된 조합 라이브러리로부터 단리된다 (Brueggemann M., Osborn M.J., Ma B., Hayre J., Avis S., Lundstrom B. and Buelow R., Human Antibody Production in Transgenic Animals, Arch Immunol Ther Exp (Warsz.) 63 (2015), 101-108; Carter P.J., Potent antibody therapeutics by design, Nat Rev Immunol 6 (2006), 343-357; Frenzel A., Schirrmann T. and Hust M., Phage display-derived human antibodies in clinical development and therapy, MAbs 8 (2016), 1177-1194; Nelson A.L., Dhimolea E. and Reichert J.M., Development trends for human monoclonal antibody therapeutics, Nat Rev Drug Discov 9 (2010), 767-774.)).
완전 인간 항체를 생성하기 위해 여러 기술이 이용가능하다 (WO2008/112640 A3 참조). 캠브리지 안티바디 테크놀로지스(Cambridge Antibody Technologies) (CAT) 및 다이액스(Dyax)는 면역화된 인간으로부터 단리된 말초 B 세포로부터 항체 cDNA 서열을 수득하고, 특정한 특이성의 인간 가변 영역 서열의 확인을 위한 파지 디스플레이 라이브러리를 고안하였다. 간략하게, 항체 가변 영역 서열은 M13 박테리오파지의 유전자 III 또는 유전자 VIII 구조와 융합된다. 이들 항체 가변 영역 서열은 각각의 서열을 보유하는 파지의 팁에서 Fab 또는 단일 쇄 Fv (scFv) 구조로서 발현된다. 상이한 수준의 항원 결합 조건 (엄격도)을 사용하는 패닝 과정의 라운드를 통해, 관심 항원에 특이적인 Fab 또는 scFv 구조를 발현하는 파지를 선택하고 단리할 수 있다. 이어서, 선택된 파지의 항체 가변 영역 cDNA 서열을 표준 서열분석 절차를 사용하여 규명할 수 있다. 이어서, 이들 서열은 확립된 항체 조작 기술을 사용하여 목적하는 이소형을 갖는 전체 항체의 재구축을 위해 사용될 수 있다. 이러한 방법에 따라 구축된 항체는 완전 인간 항체 (CDR 포함)로 간주된다. 선택된 항체의 면역반응성 (항원 결합 친화도 및 특이성)을 개선시키기 위해, 상이한 중쇄 및 경쇄의 조합 회합, 중쇄 및 경쇄의 CDR3에서의 결실/부가/돌연변이 (V-J, 및 V-D-J 재조합을 모방하기 위함), 및 무작위 돌연변이 (체세포 과다돌연변이를 모방하기 위함)를 포함한 시험관내 성숙 과정이 도입될 수 있다. 이러한 방법에 의해 생성된 "완전 인간" 항체의 예는 항종양 괴사 인자 α 항체, 휴미라 (아달리무맙)이다.
"휴먼 엔지니어드(Human Engineered)™" 항체는 미국 특허 번호 5,766,886 (Studnicka et al.)에 제시된 방법에 따라 모 서열을 변경시키는 것에 의해 생성되었다.
본 발명의 항체는 재조합 항체 유전자 라이브러리로부터 유래될 수 있다. 재조합 인간 항체 유전자의 레퍼토리의 제조 기술, 및 사상 박테리오파지의 표면 상의 코딩된 항체 단편의 디스플레이 기술의 개발은 인간 항체를 직접 제조하고 선택하기 위한 재조합 수단을 제공하였고, 이는 또한 인간화, 키메라, 뮤린 또는 뮤테인 항체에 적용될 수 있다. 파지 기술에 의해 생산된 항체는 박테리아에서 항원 결합 단편 - 통상적으로 Fv 또는 Fab 단편 - 으로서 생산되고, 따라서 이펙터 기능이 결여되어 있다. 이펙터 기능은 2가지 전략 중 1가지에 의해 도입될 수 있으며: 단편은 포유동물 세포에서의 발현을 위한 완전 항체로, 또는 이펙터 기능을 촉발할 수 있는 제2 결합 부위를 갖는 이중특이적 항체 단편으로 조작될 수 있다. 전형적으로, 항체의 중쇄 VH-CH1 및 경쇄 VL-CL은 PCR에 의해 개별적으로 클로닝되고, 조합 파지 디스플레이 라이브러리에서 무작위로 재조합되며, 이는 이어서 특정한 항원에 대한 결합에 대해 선택될 수 있다. Fab 단편은 파지 표면 상에서 발현되며, 즉 이를 코딩하는 유전자에 물리적으로 연결된다. 따라서, 항원 결합에 의한 Fab의 선택은 Fab 코딩 서열을 동시에 선택하고, 이 서열은 후속적으로 증폭될 수 있다. 패닝으로 불리는 절차인 여러 라운드의 항원 결합 및 재-증폭에 의해, 항원에 특이적인 Fab가 풍부화되고, 최종적으로 단리된다.
파지-디스플레이 라이브러리로부터 유래된 인간 항체에 대한 다양한 절차가 기재되어 있다. 이러한 라이브러리는 단일 마스터 프레임워크 상에 구축될 수 있으며, 그 내에서 다양한 생체내-형성된 (즉, 인간-유래된) CDR이 문헌 [Carlsson and Soederlind Exp. Rev. Mol. Diagn. 1 (1), 102-108 (2001), Soederlin et al., Nat. Biotech. 18, 852-856 (2000)] 및 미국 특허 번호 6,989,250에 기재된 바와 같이 재조합되는 것이 가능하다. 대안적으로, 이러한 항체 라이브러리는 인 실리코 설계되고 합성에 의해 생성된 핵산에 의해 코딩된 아미노산 서열에 기초할 수 있다. 항체 서열의 인 실리코 설계는, 예를 들어 인간 서열의 데이터베이스를 분석하고 그로부터 수득된 데이터를 이용하여 폴리펩티드 서열을 고안함으로써 달성된다. 인 실리코-생성된 서열을 설계하고 수득하는 방법은, 예를 들어 문헌 [Knappik et al., J. Mol. Biol. (2000) 296:57; Krebs et al., J. Immunol. Methods. (2001) 254:67]; 및 미국 특허 번호 6,300,064에 기재되어 있다. 파지 디스플레이 스크리닝의 검토를 위해 (예를 들어, 문헌 [Hoet RM et al., Nat Biotechnol 2005;23(3):344-8] 참조), 널리 확립된 하이브리도마 기술 (예를 들어, 문헌 [Koehler and Milstein Nature. 1975 Aug 7;256(5517):495-7] 참조) 또는 마우스의 면역화, 특히 hMAb 마우스의 면역화 (예를 들어, 벨로크이뮨 마우스(VelocImmune mouse)®).
본원에 사용된 용어 "모노클로날 항체"는 실질적으로 동종인 항체 집단으로부터 수득된 항체를 지칭하며, 즉 집단을 구성하는 개별 항체는 미량으로 존재할 수 있는 가능한 돌연변이, 예를 들어 자연 발생 돌연변이를 제외하고는 동일하다. 따라서, 용어 "모노클로날"은 별개의 항체의 혼합물이 아닌 것으로서 항체의 특징을 나타낸다. 전형적으로 상이한 결정기 (에피토프)에 대해 지시된 상이한 항체를 포함하는 폴리클로날 항체 제제와는 대조적으로, 모노클로날 항체 제제의 각각의 모노클로날 항체는 항원 상의 단일 결정기에 대해 지시된다. 그의 특이성에 더하여, 모노클로날 항체 제제는 전형적으로 다른 이뮤노글로불린에 의해 오염되지 않는다는 점에서 유리하다. 용어 "모노클로날"은 임의의 특정한 방법에 의한 항체의 생산을 필요로 하는 것으로 해석되어서는 안된다. 예를 들어, 사용되는 모노클로날 항체는 문헌 [Kohler et al., Nature, 256: 495 [1975]]에 최초로 기재된 하이브리도마 방법에 의해 제조될 수 있거나, 또는 재조합 DNA 방법 (예를 들어, 미국 특허 번호 4,816,567 참조)에 의해 제조될 수 있다. "모노클로날 항체"는 또한 예를 들어 재조합, 키메라, 인간화, 인간, 휴먼 엔지니어드™, 또는 항체 단편일 수 있다.
"단리된" 항체는 이를 발현하는 세포의 성분으로부터 확인 및 분리된 것이다. 세포의 오염 성분은 항체의 진단 또는 치료 용도를 방해할 물질이고, 효소, 호르몬, 및 다른 단백질성 또는 비-단백질성 용질을 포함할 수 있다.
"단리된" 핵산은 그의 자연 환경의 성분으로부터 확인 및 분리된 것이다. 단리된 핵산은 핵산 분자를 통상적으로 함유하는 세포에 함유된 핵산 분자를 포함하지만, 핵산 분자는 염색체외에 또는 그의 천연 염색체 위치와 상이한 염색체 위치에 존재한다.
본원에 사용된 바와 같이, 관심 항원, 예를 들어 Sema3A에 "특이적으로 결합하거나", "그에 대해 특이적이거나", 또는 "특이적으로 인식하는" 항체는, 항체가 항원을 발현하는 세포 또는 조직을 표적화하는 데 있어서 치료제로서 유용하도록 충분한 친화도로 항원에 결합하는 것이다. 본원에 사용된 용어 특정한 폴리펩티드 또는 특정한 폴리펩티드 표적 상의 에피토프를 "특이적으로 인식한다" 또는 "그에 특이적으로 결합한다" 또는 "그에 대해 특이적이다"는 예를 들어 항원에 대해 약 10-4 M 미만, 대안적으로 약 10-5 M 미만, 대안적으로 약 10-6 M 미만, 대안적으로 약 10-7 M 미만, 대안적으로 약 10-8 M 미만, 대안적으로 약 10-9 M 미만, 대안적으로 약 10-10 M 미만, 대안적으로 약 10-11 M 미만, 대안적으로 약 10-12 M 미만, 또는 그 미만의 1가 KD를 갖는 항체 또는 그의 항원-결합 단편에 의해 나타내어질 수 있다.
항체가 항원과 1개 이상의 참조 항원(들)을 구별할 수 있는 경우에, 이러한 항체는 이러한 항원에 "선택적으로 결합하거나", "그에 대해 선택적이거나" 또는 "선택적으로 인식한다". 특히, 항원에 "선택적으로 결합하는" 항체는 상기 언급된 항원 표적의 오르토로그 및 변이체 (예를 들어 돌연변이체 형태, 스플라이스 변이체 또는 단백질분해적으로 말단절단된 형태) 이외의 단백질과 유의하게 교차-반응하지 않는다. 그의 가장 일반적인 형태에서, "선택적 결합", "그에 선택적으로 결합한다", "그에 대해 선택적이다" 또는 "선택적으로 인식한다"는, 예를 들어 하기 방법 중 하나에 따라 결정된 바와 같은, 관심 항원과 비관련 항원을 구별하는 항체의 능력을 지칭한다. 이러한 방법은 표면 플라즈몬 공명 (SPR), 웨스턴 블롯, ELISA-, RIA-, ECL-, IRMA-시험 및 펩티드 스캔을 포함하나, 이에 제한되지는 않는다. 예를 들어, 표준 ELISA 검정을 수행할 수 있다. 표준 색 발현에 의해 점수화가 수행될 수 있다 (예를 들어, 2차 항체와 양고추냉이 퍼옥시다제 및 테트라메틸 벤지딘과 과산화수소). 특정 웰에서의 반응은, 예를 들어 450 nm에서의 광학 밀도에 의해 점수화된다. 전형적인 배경 (=음성 반응)은 0.1 OD일 수 있고; 전형적인 양성 반응은 1 OD일 수 있다. 이는 양성/음성 차이가 5-배, 10-배, 50-배 초과, 바람직하게는 100-배 초과임을 의미한다. 전형적으로, 결합 선택성의 결정은 단일 참조 항원이 아니라, 약 3 내지 5가지의 비관련 항원, 예컨대 분유, BSA, 트랜스페린 등의 세트를 사용함으로써 수행된다.
"결합 친화도" 또는 "친화도"는 분자의 단일 결합 부위와 그의 결합 파트너 사이의 비-공유 상호작용의 강도의 총 합계를 지칭한다. 달리 나타내지 않는 한, 본원에 사용된 "결합 친화도"는 결합 쌍의 구성원 (예를 들어, 항체 및 항원) 사이의 1:1 상호작용을 반영하는 고유 결합 친화도를 지칭한다. 해리 상수 "KD"는 통상적으로 분자 (예컨대 항체)와 그의 결합 파트너 (예컨대 항원) 사이의 친화도, 즉 리간드가 특정한 단백질에 얼마나 단단하게 결합하는지를 기재하는 데 사용된다. 리간드-단백질 친화도는 2개의 분자 사이의 비-공유 분자간 상호작용에 의해 영향을 받는다. 친화도는 본원에 기재된 방법을 포함한, 관련 기술분야에 공지된 통상의 방법에 의해 측정될 수 있다. 한 실시양태에서, 본 발명에 따른 "KD" 또는 "KD 값"은 비아코어(Biacore) T200 기기 (지이 헬스케어 비아코어, 인크.(GE Healthcare Biacore, Inc.))를 사용하여 표면 플라즈몬 공명 검정을 사용하는 것에 의해 측정된다. 다른 적합한 장치는 비아코어 T100, 비아코어(R)-2000, 비아코어 4000, 비아코어 (R)-3000 (비아코어, 인크., 뉴저지주 피스카타웨이), 또는 프로테온(ProteOn) XPR36 기기 (바이오-라드 래보러토리즈, 인크.(Bio-Rad Laboratories, Inc.))이다.
본원에 사용된 용어 "에피토프"는 이뮤노글로불린 또는 T-세포 수용체에 특이적으로 결합할 수 있는 임의의 단백질 결정기를 포함한다. 에피토프 결정기는 통상적으로 분자의 화학적으로 활성인 표면 기, 예컨대 아미노산 또는 당 측쇄, 또는 그의 조합으로 이루어지고, 통상적으로 특이적 3차원 구조적 특징, 뿐만 아니라 특이적 전하 특징을 갖는다.
참조 항체와 "동일한 에피토프에 결합하는 항체" 또는 참조 항체와 "결합에 대해 경쟁하는 항체"는 경쟁 검정에서 참조 항체의 그의 항원에 대한 결합을 10%, 20%, 30%, 40%, 50% 또는 그 초과로 차단하는 항체를 지칭하고, 반대로 참조 항체는 경쟁 검정에서 항체의 그의 항원에 대한 결합을 10%, 20%, 30%, 40%, 50% 또는 그 초과로 차단한다.
용어 "성숙 항체" 또는 "성숙 항원-결합 단편", 예컨대 성숙 Fab 변이체 또는 "최적화된" 변이체는 주어진 항원, 예컨대 표적 단백질의 세포외 도메인에 대해 보다 강한 결합 - 즉 증가된 친화도에 의한 결합 - 을 나타내는 항체 또는 항체 단편의 유도체를 포함한다. 성숙은 항체 또는 항체 단편의 6개의 CDR 내의 소수의 돌연변이를 확인하여 이러한 친화도 증가를 유발하는 과정이다. 성숙 과정은 항체 내로의 돌연변이의 도입을 위한 분자 생물학 방법 및 개선된 결합제를 확인하기 위한 스크리닝의 조합이다.
참조 폴리뉴클레오티드 또는 폴리펩티드 서열 각각에 대한 "퍼센트 (%) 서열 동일성"은 서열을 정렬하고 필요한 경우에 갭을 도입하여 최대 퍼센트 서열 동일성을 달성한 후에 참조 폴리뉴클레오티드 또는 폴리펩티드 서열 각각 내의 핵산 또는 아미노산 잔기 각각과 동일한 후보 서열 내의 핵산 또는 아미노산 잔기 각각의 백분율로서 정의된다. 보존적 치환은 서열 동일성의 일부로서 간주되지 않는다. 갭이 없는 정렬이 바람직하다. 퍼센트 아미노산 서열 동일성을 결정하기 위한 목적의 정렬은 관련 기술분야의 기술 내에 있는 다양한 방식으로, 예를 들어 공중 이용가능한 컴퓨터 소프트웨어, 예컨대 BLAST, BLAST-2, ALIGN 또는 메갈라인(Megalign) (DNASTAR) 소프트웨어를 사용하여 달성될 수 있다. 관련 기술분야의 통상의 기술자는 비교되는 서열의 전장에 걸쳐 최대 정렬을 달성하는 데 필요한 임의의 알고리즘을 포함한, 서열을 정렬하기 위한 적절한 파라미터를 결정할 수 있다.
"서열 상동성"은 동일하거나 또는 보존적 아미노산 치환을 나타내는 아미노산의 백분율을 나타낸다.
"길항작용" 항체 또는 "차단" 항체는 그것이 결합하는 항원의 생물학적 활성을 유의하게 (부분적으로 또는 완전히) 억제하는 것이다. 특정한 실시양태에서, 본 발명에 따른 항체 또는 항원-결합 단편은 Sema3A 차단 항체 또는 그의 항원-결합 단편이다.
용어 "항체 접합체"는 약물 - 이 경우에 항체 접합체는 "항체-약물 접합체" ("ADC")로 지칭됨 - 및 고분자량 분자, 예컨대 펩티드 또는 단백질을 포함한 1종 이상의 분자에 접합된 항체를 지칭한다.
용어 "항체-약물 접합체" 또는 "ADC"는 1종 이상의 세포독성제 또는 세포증식억제제, 예컨대 화학요법제, 약물, 성장 억제제, 독소 (예를 들어, 단백질 독소, 박테리아, 진균, 식물 또는 동물 기원의 효소적 활성 독소, 또는 그의 단편), 또는 방사성 동위원소 (즉, 방사성접합체)에 접합된 항체를 지칭한다. 면역접합체는 암의 치료에서 세포독성제, 즉 세포를 사멸시키거나 세포의 성장 또는 증식을 억제하는 약물의 국부 전달에 사용되어 왔다 (예를 들어, 문헌 [Liu et al., Proc Natl. Acad. Sci. (1996), 93, 8618-8623]). 면역접합체는 종양으로의 약물 모이어티의 표적화된 전달, 및 그 안의 세포내 축적을 가능하게 하며, 여기서 비접합된 약물의 전신 투여는 정상 세포 및/또는 조직에 허용되지 않는 수준의 독성을 유발할 수 있다. 항체-독소 접합체에 사용되는 독소는 박테리아 독소, 예컨대 디프테리아 독소, 식물 독소, 예컨대 리신, 소분자 독소, 예컨대 겔다나마이신을 포함한다. 독소는 튜불린 결합, DNA 결합 또는 토포이소머라제 억제를 비롯한 메카니즘에 의해 그의 세포독성 효과를 발휘할 수 있다.
아미노산은 본원에서 그의 통상적으로 공지된 3문자 기호에 의해 또는 IUPAC-IUB 생화학적 명명 위원회에 의해 권장되는 1-문자 기호에 의해 지칭될 수 있다. 마찬가지로, 뉴클레오티드도 그의 통상적으로 허용되는 단일-문자 코드에 의해 지칭될 수 있다.
본원에 사용된 용어 "벡터"는 그에 연결된 또 다른 핵산을 증식시킬 수 있는 핵산 분자를 지칭한다. 상기 용어는 자기-복제 핵산 구조로서의 벡터 뿐만 아니라 그것이 도입된 숙주 세포의 게놈 내로 혼입된 벡터를 포함한다. 특정 벡터는 그것이 작동가능하게 연결된 핵산의 발현을 지시할 수 있다. 이러한 벡터는 본원에서 "발현 벡터"로 지칭된다.
용어 "숙주 세포", "숙주 세포주" 및 "숙주 세포 배양물"은 상호교환가능하게 사용되고, 적어도 1개의 외인성 핵산이 도입된 세포를, 이러한 세포의 자손을 포함하여 지칭한다. 숙주 세포는 "형질전환체" 및 "형질전환된 세포", "형질감염체" 및 "형질감염된 세포" 및 "형질도입된 세포"를 포함하며, 이는 1차 형질전환된/형질감염된/형질도입된 세포 및 계대 횟수와 관계 없이 그로부터 유래된 자손을 포함한다. 자손은 모 세포와 핵산 함량이 완전히 동일하지 않을 수 있지만, 돌연변이를 함유할 수 있다. 원래의 형질전환된 세포에 대해 스크리닝 또는 선택된 것과 동일한 기능 또는 생물학적 활성을 갖는 돌연변이체 자손이 본원에 포함된다.
본원에 사용된 어구 "치료 유효량"은 목적하는 치료 요법에 따라 투여되는 경우에, 질환의 이러한 증상의 일부 또는 전부를 완화시키거나 또는 질환에 대한 소인을 감소시키는 것을 포함하여, 목적하는 치료 또는 예방 효과 또는 반응을 도출하는 데 적절할 치료 또는 예방 항체의 양을 지칭하는 것으로 의도된다.
용어 "제약 제제" / "제약 조성물"은 그 안에 함유된 활성 성분의 생물학적 활성이 효과적이도록 하는 형태로 존재하고, 제제가 투여될 대상체에게 허용되지 않는 독성인 추가의 성분은 함유하지 않는 제제를 지칭한다.
본 발명에 따른 항체
한 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 서열식별번호: 600의 서열의 인간 Sema3A에 ≤ 50 nM, ≤ 20 nM, ≤10 nM, ≤1 nM 또는 ≤ 0.1 nM의 해리 상수 (KD)로 결합한다. 특정한 실시양태에서, 단리된 항체 또는 그의 항원-결합 단편은 서열식별번호: 582의 His-태그부착된 인간 Sema3A 도메인에 ≤ 50 nM, ≤ 20 nM, ≤10 nM, ≤1 nM 또는 ≤ 0.1 nM의 해리 상수 (KD)로 결합한다.
또 다른 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A와 교차-반응하고, 특히 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A에 ≤ 50 nM, ≤ 20 nM, ≤10 nM, ≤1 nM 또는 ≤ 0.1 nM의 해리 상수 (KD)로 결합한다.
특정한 이러한 실시양태에서, 상기 친화도는 서열식별번호: 601의 마우스 Sema3A, 서열식별번호: 602의 시노몰구스 Sema3A, 서열식별번호: 603의 래트 Sema3A, 서열식별번호: 604의 돼지 Sema3A 및 서열식별번호: 605의 개 Sema3A에 대한 것이다. 특정한 실시양태에서, 상기 친화도는 서열식별번호: 583의 His-태그부착된 마우스 Sema3A 도메인, 서열식별번호: 586의 His-태그부착된 시노몰구스 Sema3A 도메인, 서열식별번호: 584의 His-태그부착된 래트 Sema3A 도메인, 서열식별번호: 587의 His-태그부착된 돼지 Sema3A 도메인 및 서열식별번호: 585의 His-태그부착된 개 Sema3A 도메인에 대한 것이다.
또 다른 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 표면 플라즈몬 공명 (SPR)에 의해 측정된 바와 같이 인간 Sema3A에 ≥ 60%, ≥ 70%, ≥ 80%, 또는 ≥ 90%의 결합 활성으로 결합한다. 특정한 실시양태에서, 단리된 항체 또는 그의 항원-결합 단편은 표면 플라스민 공명 (SPR)에 의해 측정된 바와 같이 서열식별번호: 600의 서열의 인간 Sema3A에 ≥ 60%, ≥ 70%, ≥ 80%, 또는 ≥ 90%의 결합 활성으로 결합한다. 특정한 실시양태에서, 단리된 항체 또는 그의 항원-결합 단편은 표면 플라스민 공명 (SPR)에 의해 측정된 바와 같이 서열식별번호: 582의 서열의 His-태그부착된 인간 Sema3A 도메인에 ≥ 60%, ≥ 70%, ≥ 80%, 또는 ≥ 90%의 결합 활성으로 결합한다.
또 다른 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 시험관내 혈관간 세포 이동 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 10 nM, ≤ 5 nM, ≤ 2.5 nM 또는 ≤ 1 nM의 EC50으로 억제한다.
특히, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 인간 1차 혈관간 세포를 사용한, 실시예 9에서 보다 상세하게 기재된 시험관내 스크래치 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 억제한다.
또 다른 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 시험관내 성장 원추 붕괴 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 50 nM, ≤ 25 nM, ≤ 10 nM 또는 ≤ 5 nM의 EC50으로 억제한다.
특히, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 실시예 10에서 보다 상세하게 기재된 바와 같이 마우스 후근 신경절 (DRG) 뉴런을 사용한 시험관내 성장 원추 붕괴 검정에서 Sema3A-유도된 세포골격 붕괴를 억제한다. 실시예 10에 기재된 시험관내 성장 원추 검정은 문헌 [Mikule et al., (PMID: 12077190)]에 기재된 성장 원추 검정의 변형된 버전이다.
또 다른 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 시험관내 HUVEC 반발 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 1 nM, 또는 ≤ 0.3 nM, ≤ 0.1 nM, ≤ 0.07 nM, ≤ 0.06nM의 EC50으로 억제한다.
특히, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 실시예 11에 기재된 바와 같이 인간 제대 정맥 내피 세포 (HUVEC)의 전면생장 단층 상에 시딩된 서열식별번호: 600의 서열의 Sema3A 발현 HEK293 세포를 사용한 시험관내 반발 검정에서 Sema3A 유도된 세포 반발을 억제한다.
추가 측면에서, 본 발명은 서열식별번호: 600의 서열의 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 HUVEC 반발 검정에서 개선된 효력을 나타내고; i) 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 HUVEC 반발 검정에서 서열식별번호: 81, 85, 97, 98을 갖는 TPP-17755 또는 서열식별번호: 1, 5, 17, 18을 갖는 TPP-11489 또는 서열식별번호: 800, 804, 810, 811을 갖는 TPP-30788 또는 서열식별번호: 814, 818, 824, 825를 갖는 TPP-30789 또는 서열식별번호: 828, 832, 838, 839를 갖는 TPP-30790 또는 서열식별번호: 842, 846, 852, 853을 갖는 TPP-30791과 비교하여 개선된 효력을 나타내고; ii) 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 세포 Sema3A 유도된 HUVEC 반발에 대해, EC-50 값에 기초하여 서열식별번호: 81, 85, 97, 98을 갖는 TPP-17755 또는 서열식별번호: 1, 5, 17, 18을 갖는 TPP-11489 또는 서열식별번호: 800, 804, 810, 811을 갖는 TPP-30788 또는 서열식별번호: 814, 818, 824, 825를 갖는 TPP-30789 또는 서열식별번호: 828, 832, 838, 839를 갖는 TPP-30790 또는 서열식별번호: 842, 846, 852, 853을 갖는 TPP-30791과 비교하여 바람직하게는 >400-배, 바람직하게는 >50-배, 바람직하게는 >5-배, 바람직하게는 >2-배 증가된 효력을 나타내고; iii) 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 상기 언급된 서열을 갖는 TPP-17755, TPP-11489, TPP-30788, TPP-30789, TPP-30790 또는 TPP-30791과 비교하여 Sema3A의 적어도 30% 증가된 퍼센트 억제, 바람직하게는 적어도 50% 증가된 퍼센트 억제를 나타내고; iv) 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 시험관내 HUVEC 반발 검정에서 인간 Sema3A에 대해 2-자릿수 피코몰 활성을 갖는 반면, 상기 언급된 서열을 갖는 TPP-17755, TPP-11489, TPP-30788, TPP-30789, TPP-30790 또는 TPP-30791의 선행 기술 항체 효력은 3-자릿수 피코몰 또는 심지어 나노몰 범위이고; v) 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 실시예 11에 기재된 바와 같이, 시험관내 HUVEC 반발 검정에서 인간 Sema3A의 활성을 ≤ 1 nM 또는 ≤ 0.3 nM, ≤ 0.1 nM, ≤0.07 nM, ≤0.06 nM의 EC50으로 억제한다.
본 발명의 단리된 항체 또는 항원-결합 단편은 TPP-30788-TPP-30791 (BI 클론 I 내지 IV)과 비교하여 HUVEC 반발 검정에서 개선된 효력을 나타내며, 이는 인간 Sema3A의 상이한 에피토프에 대한 결합으로 인한 것일 수 있다.
또 다른 측면에서, 본 발명은 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 본 발명에 따른 항체가 Sema3A-유도된 뇨 알부민 배설을 감소시키기 때문에 생체내에서 Sema3A의 활성을 억제한다. 따라서, 추가 측면에서, 본 발명은 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 생체내에서 Sema3A의 개선된 억제 활성을 나타내고, i) 여기서 상기 항체는 TPP-30788 (BI 클론 I)과 비교하여 Sema3A-유도된 뇨 알부민 배설의 증가된 감소를 나타내고; ii) 여기서 상기 항체는 TPP-17755 (삼성)와 비교하여 Sema3A-유도된 뇨 알부민 배설의 증가된 감소를 나타내고; iii) 여기서 상기 항체는 실시예 12에 기재된 바와 같이 TPP-11489 (키오메)와 비교하여 Sema3A-유도된 뇨 알부민 배설의 증가된 감소를 나타낸다.
본 발명의 단리된 항체 또는 항원-결합 단편은 TPP-30788-TPP-30791 (BI 클론 I 내지 IV)과 비교하여 유도된 뇨 알부민 배설에 대한 생체내 모델에서 개선된 효능을 나타내며, 이는 인간 Sema3A의 상이한 에피토프에 대한 결합으로 인한 것일 수 있다.
따라서, 추가 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 i) TPP-30788 (BI 클론 I)과 비교하여 증가된 안정성 (예를 들어, PBS 중에서 25 mg/ml로 희석되고 700 rpm 및 40℃에서 2주 동안 인큐베이션된 경우에 증가된 스트레스-안정성)을 나타내고; ii) 여기서 증가된 안정성은 SEC에 의해 측정된 TPP-30788 (BI 클론 I)과 비교하여 단량체 항-Sema3A 항체의 증가된 양을 나타내고; iii) 여기서 증가된 안정성은 cGE에 의해 측정된 TPP-30788 (BI 클론 I)과 비교하여 잔류 LC 및 HC의 존재에 의해 측정되는 감소된 분해 속도를 입증하는 항-Sema3A 항체의 LC 및 HC의 감소된 백분율을 나타내고, iv) 여기서 증가된 안정성은 단량체 항-Sema3A 항체의 양이, 예를 들어 40℃, 700 rpm에서 2주 동안 인큐베이션한 후에 Δ % 단량체 = 1로 유지됨을 나타내고; v) 여기서 증가된 안정성은 항-Sema3A 항체의 LC 및 HC의 양이, 예를 들어 40℃, 700 rpm에서 2주 동안 인큐베이션한 후에 Δ % LC+HC <1로 유지됨을 나타낸다.
따라서, 추가 측면에서, 본 발명은 인간 Sema3A에 결합하는 TPP-23298에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 i) TPP-30788 (BI 클론 I)과 비교하여 증가된 안정성 (예를 들어, PBS 중에서 25 mg/ml로 희석되고 700 rpm 및 40℃에서 2주 동안 인큐베이션된 경우에 증가된 스트레스-안정성)을 나타내고; ii) 여기서 증가된 안정성은 SEC에 의해 측정된 TPP-30788 (BI 클론 I)과 비교하여 단량체 항-Sema3A 항체의 증가된 양을 나타내고; iii) 여기서 증가된 안정성은 cGE에 의해 측정된 TPP-30788 (BI 클론 I)과 비교하여 잔류 LC 및 HC의 존재에 의해 측정되는 감소된 분해 속도를 입증하는 항-Sema3A 항체의 LC 및 HC의 감소된 백분율을 나타내고, iv) 여기서 증가된 안정성은 단량체 항-Sema3A 항체의 양이, 예를 들어 40℃, 700 rpm에서 2주 동안 인큐베이션한 후에 Δ % 단량체 = 1로 유지됨을 나타내고; v) 여기서 증가된 안정성은 항-Sema3A 항체의 LC 및 HC의 양이, 예를 들어 40℃, 700 rpm에서 2주 동안 인큐베이션한 후에 Δ % LC+HC <1로 유지됨을 나타낸다.
따라서, 추가 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 i) 증가된 용해도를 나타내고; ii) 여기서 증가된 용해도는 90% 회수에서 농축 후 mg/ml 단위로 측정되고; iii) 여기서 용해도는 TPP-30788 (BI 클론 I)과 비교하여 증가되고; iv) 여기서 용해도는 TPP-30788 (BI 클론 I)과 비교하여 ≤ 1배, ≤ 1.5배, ≤ 2배 증가되고; v) 여기서 증가된 용해도는 단량체 항-Sema3A 항체의 백분율이 농축 후에 증가되지 않음을, 예를 들어 SEC에 의해 측정된 Δ % 단량체 <1을 나타낸다.
따라서, 추가 측면에서, 본 발명은 인간 Sema3A에 결합하는 TPP-23298에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 i) 증가된 용해도를 나타내고; ii) 여기서 증가된 용해도는 90% 회수에서 농축 후 mg/ml 단위로 측정되고; iii) 여기서 용해도는 TPP-30788 (BI 클론 I)과 비교하여 증가되고; iv) 여기서 용해도는 TPP-30788 (BI 클론 I)과 비교하여 ≤ 1배, ≤ 1.5배, ≤ 2배 증가되고; v) 여기서 증가된 용해도는 단량체 항-Sema3A 항체의 백분율이 농축 후에 증가되지 않음을, 예를 들어 SEC에 의해 측정된 Δ % 단량체 <1을 나타낸다.
따라서, 추가 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 i) 물 또는 PBS와 비교하여 증가된 점도를 나타내고; ii) TPP-30788 (BI 클론 I)과 비교하여 PBS 중에서 감소된 점도를 나타내고; iii) 여기서 점도는 비스코사이저(Viscosizer)에 의해 측정되고, 5.1 (150 mg/ml)의 cP 값을 나타낸다.
따라서, 추가 측면에서, 본 발명은 인간 Sema3A에 결합하는 TPP-23298에 관한 것이며, 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 i) 물 또는 PBS와 비교하여 증가된 점도를 나타내고; ii) TPP-30788 (BI 클론 I)과 비교하여 PBS 중에서 감소된 점도를 나타내고; iii) 여기서 점도는 비스코사이저(Viscosizer)에 의해 측정되고, 5.1 (150 mg/ml)의 cP 값을 나타낸다.
특히 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 실시예 17에 기재된 바와 같이 TPP-30788보다 훨씬 더 높은 용해도 및 안정성을 나타내고, 열 스트레스에 대해 더 저항성이고, PBS 완충제 중에서 덜 점성이다.
특히 TPP-23298은 실시예 17에 기재된 바와 같이 TPP-30788보다 훨씬 더 높은 용해도 및 안정성을 나타내고, 열 스트레스에 대해 더 저항성이고, PBS 완충제 중에서 덜 점성이다.
또 다른 측면에서, 본 발명은 포유동물 세포에서 높은 역가로 생산될 수 있는, 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며; i) 여기서 높은 역가는 실시예 16에 기재된 바와 같이 ≤ 200 mg/L이다.
또 다른 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 항체는 절단된 Sema3A TPP-19068에 비해 활성 Sema3A (TPP-13211)에 대해 더 높은 결합 선택성을 나타내고; i) 여기서 항체는 실시예 8에 기재된 바와 같이 활성 Sema3A에 대한 TPP-30788 - TPP-30791의 결합 선택성과 비교하여 활성 Sema3A (TPP-13211)에 대한 더 높은 결합 선택성을 나타낸다.
또 다른 측면에서, 본 발명은 인간 Sema3A에 결합하는 TPP-23298에 관한 것이며, 여기서 항체는 절단된 Sema3A TPP-19068에 비해 활성 Sema3A (TPP-13211)에 대해 더 높은 결합 선택성을 나타내고; i) 여기서 항체는 실시예 8에 기재된 바와 같이 활성 Sema3A에 대한 TPP-30788 - TPP-30791의 결합 선택성과 비교하여 활성 Sema3A (TPP-13211)에 대한 더 높은 결합 선택성을 나타낸다.
또 다른 측면에서, 본 발명은 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 항체는 TPP-30788과 비교하여 Sema3A 상의 상이한 에피토프에 결합하고; i) 여기서 에피토프 결합은 실시예 5a에 기재된 바와 같이 SPR 검정에서 측정된다. 동일한 에피토프에 결합하고 본 발명에 따른 단리된 항체 또는 항원-결합 단편의 결합과 경쟁하는 모든 항체는 본 발명에 포함된다.
또 다른 측면에서, 본 발명은 인간 Sema3A에 결합하는 TPP-23298에 관한 것이며, 여기서 항체는 TPP-30788과 비교하여 Sema3A 상의 상이한 에피토프에 결합하고; i) 여기서 에피토프 결합은 실시예 5a에 기재된 바와 같이 SPR 검정에서 측정된다. 동일한 에피토프에 결합하고 본 발명에 따른 단리된 항체 또는 항원-결합 단편의 결합과 경쟁하는 모든 항체는 본 발명에 포함된다.
또 다른 측면에서 본 발명은 Sema3A에 대한 결합에 대해 청구항 중 어느 한 항에 따른 단리된 항체 또는 항원-결합 단편과 경쟁하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이며, 여기서 단리된 항체 또는 항원-결합 단편은 서열식별번호: 800, 서열식별번호: 804, 서열식별번호: 810 또는 서열식별번호: 811을 갖는 항체의 Sema3A에 대한 결합과는 경쟁하지 않는다.
본 발명에 따른 단리된 항체 또는 항원-결합 단편은 상기 기재된 특징의 임의의 조합을 나타낼 수 있다.
본 발명에 따른 단리된 항체 또는 항원-결합 단편은 Sema3A 차단 항체 또는 그의 항원-결합 단편이다. 특정한 실시양태에서, 항체는 세마포린3A의 Sema3A 도메인에 특이적으로, 보다 특히 선택적으로 결합하고, 그의 수용체 뉴로필린-1의 상호작용을 방해한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 그의 항원-결합 단편은 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A와 교차-반응하며, 특히 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A에 대한 친화도가 인간 Sema3A에 대한 친화도보다 100-배 미만, 특히 50-배 미만, 보다 특히 25-배 미만, 보다 더 특히 10-배 미만, 가장 특히 5-배 미만으로 상이하다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 그의 항원-결합 단편은 인간 Sema3B, Sema3C, Sema3D, Sema3E, Sema3F 및/또는 Sema3G와 유의하게 교차-반응하지 않는다. 특히, 단리된 항체 또는 그의 항원-결합 단편은 인간 Sema3G와 유의하게 교차-반응하지 않는다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 그의 항원-결합 단편은 Sema3A-유도된 알부민뇨 및/또는 단백뇨를 억제한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 그의 항원-결합 단편은 Sema3A-유도된 섬유증을 억제한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열식별번호: 141과 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100% 동일한 중쇄 가변 도메인 및 서열식별번호: 145와 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100% 동일한 경쇄 가변 도메인을 포함한다.
특정한 다른 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열식별번호: 61과 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100% 동일한 중쇄 가변 도메인 및 서열식별번호: 65와 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100% 동일한 경쇄 가변 도메인을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 RDDYTSRDAFDX (서열식별번호: 594)를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역을 포함하며, 여기서 X는 Y 및 V로 이루어진 군으로부터 선택된다. 특히, X는 Y이다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 X1AWDDSLNX2X3X4V (서열식별번호: 598)를 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역을 포함하며, 여기서 X1은 A 및 H로 이루어진 군으로부터 선택되고, X2는 V, D, 및 G로 이루어진 군으로부터 선택되고, 특히 여기서 X2는 V 및 D로 이루어진 군으로부터 선택되고, 여기서 X3은 I 및 Y로 이루어진 군으로부터 선택되고, 여기서 X4는 P 및 V로 이루어진 군으로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 상기 정의된 바와 같은 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 상기 정의된 바와 같은 L-CDR3을 포함하는 경쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 SGYSSSWFDPDFDY (서열식별번호: 64)를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 X1SYX2GX3NPYVV (서열식별번호: 599)를 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역을 포함하며, 여기서 X1은 S 및 Q로 이루어진 군으로부터 선택되고; 여기서 X2는 E 및 A로 이루어진 군으로부터 선택되고; 여기서 X3은 P, I, 및 S로 이루어진 군으로부터 선택된다. 특히, X3은 P 및 I로 이루어진 군으로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 상기 정의된 바와 같은 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 상기 정의된 바와 같은 L-CDR3을 포함하는 경쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 SYX1MX2 (서열식별번호: 588)를 포함하는 H-CDR1을 포함하는 중쇄 항원-결합 영역을 포함하며, 여기서 X1은 G 및 A로부터 선택되고, 여기서 X2는 H, S 및 L로부터 선택된다. 특히, 중쇄 항원-결합 영역은 서열 SYAMX (서열식별번호: 589)를 포함하는 H-CDR1을 포함하며, 여기서 X는 S 및 L로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 AIGX1GGDTYYADSVX2G (서열식별번호: 590)를 포함하는 H-CDR2를 포함하는 중쇄 항원-결합 영역을 포함하며, 여기서 X1은 T 및 Y로부터 선택되고, 여기서 X2는 K 및 M으로부터 선택된다. 특히, 중쇄 항원-결합 영역은 서열 AIGXGGDTYYADSVKG (서열식별번호: 591)를 포함하는 H-CDR2를 포함하며, 여기서 X는 T 및 Y로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 RDDYTSRDAFDX (서열식별번호: 594)를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역을 포함하며, 여기서 X는 Y 및 V로 이루어진 군으로부터 선택된다. 특히, X는 Y이다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 상기 정의된 바와 같은 H-CDR1, H-CDR2 및 H-CDR3을 포함하는 중쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 SGSSSNIGSNTVN (서열식별번호: 46)을 포함하는 L-CDR1을 포함하는 경쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 YDDLXPS (서열식별번호: 596)를 포함하는 L-CDR2를 포함하는 경쇄 항원-결합 영역을 포함하며, 여기서 X는 L 및 R로부터 선택된다. 특히, 경쇄 항원-결합 영역은 서열 YDDLRPS (서열식별번호: 127)를 포함하는 L-CDR2를 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 X1AWDDSLNX2X3X4V (서열식별번호: 598)를 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역을 포함하며, 여기서 X1은 A 및 H로 이루어진 군으로부터 선택되고, X2는 V, D, 및 G로 이루어진 군으로부터 선택되고, 특히 여기서 X2는 V 및 D로 이루어진 군으로부터 선택되고, 여기서 X3은 I 및 Y로 이루어진 군으로부터 선택되고, 여기서 X4는 P 및 V로 이루어진 군으로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 상기 정의된 바와 같은 L-CDR1, 및 L-CDR2 및 L-CDR3을 포함하는 경쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 상기 정의된 바와 같은 H-CDR1, H-CDR2 및 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 상기 정의된 바와 같은 L-CDR1, 및 L-CDR2 및 L-CDR3을 포함하는 경쇄 항원-결합 영역을 포함한다.
특정한 이러한 실시양태에서, H-CDR1의 5' 단부에 바로 인접한 아미노산 잔기 (서열식별번호: 121의 참조 VH 도메인의 잔기 30에 상응함)는 S 또는 Y이다.
특정한 다른 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 SYEMN (서열식별번호: 62)을 포함하는 H-CDR1을 포함하는 중쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 GISWNSGX1IX2YADSVKG (서열식별번호: 592)를 포함하는 H-CDR2를 포함하는 중쇄 항원-결합 영역을 포함하며, 여기서 X1은 W 및 S로부터 선택되고, X2는 G 및 D로부터 선택된다. 특히, 중쇄 항원-결합 영역은 서열 GISWNSGWIXYADSVKG (서열식별번호: 593)를 포함하는 H-CDR2를 포함하며, 여기서 X는 G 및 D로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 SGYSSSWFDPDFDY (서열식별번호: 64)를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 상기 정의된 바와 같은 H-CDR1, H-CDR2 및 H-CDR3을 포함하는 중쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 TGSSSXIGAGYDVH (서열식별번호: 595)를 포함하는 L-CDR1을 포함하는 경쇄 항원-결합 영역을 포함하며, 여기서 X는 N 및 D로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 GXSNRPS (서열식별번호: 597)를 포함하는 L-CDR2를 포함하는 경쇄 항원-결합 영역을 포함하며, 여기서 X는 N 및 A로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열 X1SYX2GX3NPYVV (서열식별번호: 599)를 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역을 포함하며, 여기서 X1은 S 및 Q로 이루어진 군으로부터 선택되고, 여기서 X2는 E 및 A로 이루어진 군으로부터 선택되고, 여기서 X3은 P, I, 및 S로 이루어진 군으로부터 선택된다. 특히, X3은 P 및 I로 이루어진 군으로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 상기 정의된 바와 같은 L-CDR1, 및 L-CDR2 및 L-CDR3을 포함하는 경쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 상기 정의된 바와 같은 H-CDR1, H-CDR2 및 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 상기 정의된 바와 같은 L-CDR1, 및 L-CDR2 및 L-CDR3을 포함하는 경쇄 항원-결합 영역을 포함한다.
특정한 이러한 실시양태에서, H-CDR1의 5' 단부에 바로 인접한 3개의 아미노산 잔기 (서열식별번호: 101의 참조 VH 도메인의 잔기 28 내지 30에 상응함)는 X1FX2이고, 여기서 X1은 T 및 D로부터 선택되고, X2는 S 및 D로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 하기를 포함한다:
i) 서열식별번호: 44를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 48을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
ii) 서열식별번호: 64를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 68을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
iii) 서열식별번호: 104를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 108을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
iv) 서열식별번호: 124를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 128을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
v) 서열식별번호: 144를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 148을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
vi) 서열식별번호: 164를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 168을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
vii) 서열식별번호: 184를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 188을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
viii) 서열식별번호: 204를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 208을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
ix) 서열식별번호: 224를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 228을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
x) 서열식별번호: 244를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 248을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xi) 서열식별번호: 264를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 268을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xii) 서열식별번호: 284를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 288을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xiii) 서열식별번호: 304를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 308을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xiv) 서열식별번호: 324를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 328을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xv) 서열식별번호: 344를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 348을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xvi) 서열식별번호: 364를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 368을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xvii) 서열식별번호: 384를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 388을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xviii) 서열식별번호: 404를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 408을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xix) 서열식별번호: 424를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 428을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xx) 서열식별번호: 444를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 448을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxi) 서열식별번호: 464를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 468을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxii) 서열식별번호: 484를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 488을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxiii) 서열식별번호: 504를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 508을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxiv) 서열식별번호: 524를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 528을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxv) 서열식별번호: 544를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 548을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxvi) 서열식별번호: 564를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역 및 서열식별번호: 568을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열식별번호: 42, 62, 102, 122, 142, 162, 182, 202, 222, 242, 262, 282, 302, 322, 342, 362, 382, 402, 422, 442, 462, 482, 502, 522, 542, 및 562 중 어느 하나를 포함하는 H-CDR1을 포함하는 중쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열식별번호: 43, 63, 103, 123, 143, 163, 183, 203, 223, 243, 263, 283, 303, 323, 343, 363, 383, 403, 423, 443, 463, 483, 503, 523, 543, 및 563 중 어느 하나를 포함하는 H-CDR2를 포함하는 중쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열식별번호: 46, 66, 106, 126, 146, 166, 186, 206, 226, 246, 266, 286, 306, 326, 346, 366, 386, 406, 426, 446, 466, 486, 506, 526, 546, 및 566 중 어느 하나를 포함하는 L-CDR1을 포함하는 경쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 서열식별번호: 47, 67, 107, 127, 147, 167, 187, 207, 227, 247, 267, 287, 307, 327, 347, 367, 387, 407, 427, 447, 467, 487, 507, 527, 547, 및 567 중 어느 하나를 포함하는 L-CDR2를 포함하는 경쇄 항원-결합 영역을 포함한다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 하기를 포함한다:
i) 서열식별번호: 42를 포함하는 H-CDR1, 서열식별번호: 43을 포함하는 H-CDR2, 및 서열식별번호: 44를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 46을 포함하는 L-CDR1, 서열식별번호: 47을 포함하는 L-CDR2, 및 서열식별번호: 48을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
ii) 서열식별번호: 62를 포함하는 H-CDR1, 서열식별번호: 63을 포함하는 H-CDR2, 및 서열식별번호: 64를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 66을 포함하는 L-CDR1, 서열식별번호: 67을 포함하는 L-CDR2, 및 서열식별번호: 68을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
iii) 서열식별번호: 102를 포함하는 H-CDR1, 서열식별번호: 103을 포함하는 H-CDR2, 및 서열식별번호: 104를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 106을 포함하는 L-CDR1, 서열식별번호: 107을 포함하는 L-CDR2, 및 서열식별번호: 108을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
iv) 서열식별번호: 122를 포함하는 H-CDR1, 서열식별번호: 123을 포함하는 H-CDR2, 및 서열식별번호: 124를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 126을 포함하는 L-CDR1, 서열식별번호: 127을 포함하는 L-CDR2, 및 서열식별번호: 128을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
v) 서열식별번호: 142를 포함하는 H-CDR1, 서열식별번호: 143을 포함하는 H-CDR2, 및 서열식별번호: 144를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 146을 포함하는 L-CDR1, 서열식별번호: 147을 포함하는 L-CDR2, 및 서열식별번호: 148을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
vi) 서열식별번호: 162를 포함하는 H-CDR1, 서열식별번호: 163을 포함하는 H-CDR2, 및 서열식별번호: 164를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 166을 포함하는 L-CDR1, 서열식별번호: 167을 포함하는 L-CDR2, 및 서열식별번호: 168을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
vii) 서열식별번호: 182를 포함하는 H-CDR1, 서열식별번호: 183을 포함하는 H-CDR2, 및 서열식별번호: 184를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 186을 포함하는 L-CDR1, 서열식별번호: 187을 포함하는 L-CDR2, 및 서열식별번호: 188을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
viii) 서열식별번호: 202를 포함하는 H-CDR1, 서열식별번호: 203을 포함하는 H-CDR2, 및 서열식별번호: 204를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 206을 포함하는 L-CDR1, 서열식별번호: 207을 포함하는 L-CDR2, 및 서열식별번호: 208을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
ix) 서열식별번호: 222를 포함하는 H-CDR1, 서열식별번호: 223을 포함하는 H-CDR2, 및 서열식별번호: 224를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 226을 포함하는 L-CDR1, 서열식별번호: 227을 포함하는 L-CDR2, 및 서열식별번호: 228을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
x) 서열식별번호: 242를 포함하는 H-CDR1, 서열식별번호: 243을 포함하는 H-CDR2, 및 서열식별번호: 244를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 246을 포함하는 L-CDR1, 서열식별번호: 247을 포함하는 L-CDR2, 및 서열식별번호: 248을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xi) 서열식별번호: 262를 포함하는 H-CDR1, 서열식별번호: 263을 포함하는 H-CDR2, 및 서열식별번호: 264를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 266을 포함하는 L-CDR1, 서열식별번호: 267을 포함하는 L-CDR2, 및 서열식별번호: 268을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xii) 서열식별번호: 282를 포함하는 H-CDR1, 서열식별번호: 283을 포함하는 H-CDR2, 및 서열식별번호: 284를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 286을 포함하는 L-CDR1, 서열식별번호: 287을 포함하는 L-CDR2, 및 서열식별번호: 288을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xiii) 서열식별번호: 302를 포함하는 H-CDR1, 서열식별번호: 303을 포함하는 H-CDR2, 및 서열식별번호: 304를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 306을 포함하는 L-CDR1, 서열식별번호: 307을 포함하는 L-CDR2, 및 서열식별번호: 308을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xiv) 서열식별번호: 322를 포함하는 H-CDR1, 서열식별번호: 323을 포함하는 H-CDR2, 및 서열식별번호: 324를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 326을 포함하는 L-CDR1, 서열식별번호: 327을 포함하는 L-CDR2, 및 서열식별번호: 328을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xv) 서열식별번호: 342를 포함하는 H-CDR1, 서열식별번호: 343을 포함하는 H-CDR2, 및 서열식별번호: 344를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 346을 포함하는 L-CDR1, 서열식별번호: 347을 포함하는 L-CDR2, 및 서열식별번호: 348을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xvi) 서열식별번호: 362를 포함하는 H-CDR1, 서열식별번호: 363을 포함하는 H-CDR2, 및 서열식별번호: 364를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 366을 포함하는 L-CDR1, 서열식별번호: 367을 포함하는 L-CDR2, 및 서열식별번호: 368을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xvii) 서열식별번호: 382를 포함하는 H-CDR1, 서열식별번호: 383을 포함하는 H-CDR2, 및 서열식별번호: 384를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 386을 포함하는 L-CDR1, 서열식별번호: 387을 포함하는 L-CDR2, 및 서열식별번호: 388을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xviii) 서열식별번호: 402를 포함하는 H-CDR1, 서열식별번호: 403을 포함하는 H-CDR2, 및 서열식별번호: 404를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 406을 포함하는 L-CDR1, 서열식별번호: 407을 포함하는 L-CDR2, 및 서열식별번호: 408을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xix) 서열식별번호: 422를 포함하는 H-CDR1, 서열식별번호: 423을 포함하는 H-CDR2, 및 서열식별번호: 424를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 426을 포함하는 L-CDR1, 서열식별번호: 427을 포함하는 L-CDR2, 및 서열식별번호: 428을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xx) 서열식별번호: 442를 포함하는 H-CDR1, 서열식별번호: 443을 포함하는 H-CDR2, 및 서열식별번호: 444를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 446을 포함하는 L-CDR1, 서열식별번호: 447을 포함하는 L-CDR2, 및 서열식별번호: 448을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxi) 서열식별번호: 462를 포함하는 H-CDR1, 서열식별번호: 463을 포함하는 H-CDR2, 및 서열식별번호: 464를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 466을 포함하는 L-CDR1, 서열식별번호: 467을 포함하는 L-CDR2, 및 서열식별번호: 468을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxii) 서열식별번호: 482를 포함하는 H-CDR1, 서열식별번호: 483을 포함하는 H-CDR2, 및 서열식별번호: 484를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 486을 포함하는 L-CDR1, 서열식별번호: 487을 포함하는 L-CDR2, 및 서열식별번호: 488을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxiii) 서열식별번호: 502를 포함하는 H-CDR1, 서열식별번호: 503을 포함하는 H-CDR2, 및 서열식별번호: 504를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 506을 포함하는 L-CDR1, 서열식별번호: 507을 포함하는 L-CDR2, 및 서열식별번호: 508을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxiv) 서열식별번호: 522를 포함하는 H-CDR1, 서열식별번호: 523을 포함하는 H-CDR2, 및 서열식별번호: 524를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 526을 포함하는 L-CDR1, 서열식별번호: 527을 포함하는 L-CDR2, 및 서열식별번호: 528을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxv) 서열식별번호: 542를 포함하는 H-CDR1, 서열식별번호: 543을 포함하는 H-CDR2, 및 서열식별번호: 544를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 546을 포함하는 L-CDR1, 서열식별번호: 547을 포함하는 L-CDR2, 및 서열식별번호: 548을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxvi) 서열식별번호: 562를 포함하는 H-CDR1, 서열식별번호: 563을 포함하는 H-CDR2, 및 서열식별번호: 564를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 566을 포함하는 L-CDR1, 서열식별번호: 567을 포함하는 L-CDR2, 및 서열식별번호: 568을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 하기를 포함한다:
i) 서열식별번호: 41을 포함하는 가변 중쇄 도메인 및 서열식별번호: 45를 포함하는 가변 경쇄 도메인; 또는
ii) 서열식별번호: 61을 포함하는 가변 중쇄 도메인 및 서열식별번호: 65를 포함하는 가변 경쇄 도메인; 또는
iii) 서열식별번호: 101을 포함하는 가변 중쇄 도메인 및 서열식별번호: 105를 포함하는 가변 경쇄 도메인; 또는
iv) 서열식별번호: 121을 포함하는 가변 중쇄 도메인 및 서열식별번호: 125를 포함하는 가변 경쇄 도메인; 또는
v) 서열식별번호: 141을 포함하는 가변 중쇄 도메인 및 서열식별번호: 145를 포함하는 가변 경쇄 도메인; 또는
vi) 서열식별번호: 161을 포함하는 가변 중쇄 도메인 및 서열식별번호: 165를 포함하는 가변 경쇄 도메인; 또는
vii) 서열식별번호: 181을 포함하는 가변 중쇄 도메인 및 서열식별번호: 185를 포함하는 가변 경쇄 도메인; 또는
viii) 서열식별번호: 201을 포함하는 가변 중쇄 도메인 및 서열식별번호: 205를 포함하는 가변 경쇄 도메인; 또는
ix) 서열식별번호: 221을 포함하는 가변 중쇄 도메인 및 서열식별번호: 225를 포함하는 가변 경쇄 도메인; 또는
x) 서열식별번호: 241을 포함하는 가변 중쇄 도메인 및 서열식별번호: 245를 포함하는 가변 경쇄 도메인; 또는
xi) 서열식별번호: 261을 포함하는 가변 중쇄 도메인 및 서열식별번호: 265를 포함하는 가변 경쇄 도메인; 또는
xii) 서열식별번호: 281을 포함하는 가변 중쇄 도메인 및 서열식별번호: 285를 포함하는 가변 경쇄 도메인; 또는
xiii) 서열식별번호: 301을 포함하는 가변 중쇄 도메인 및 서열식별번호: 305를 포함하는 가변 경쇄 도메인; 또는
xiv) 서열식별번호: 321을 포함하는 가변 중쇄 도메인 및 서열식별번호: 325를 포함하는 가변 경쇄 도메인; 또는
xv) 서열식별번호: 341을 포함하는 가변 중쇄 도메인 및 서열식별번호: 345를 포함하는 가변 경쇄 도메인; 또는
xvi) 서열식별번호: 361을 포함하는 가변 중쇄 도메인 및 서열식별번호: 365를 포함하는 가변 경쇄 도메인; 또는
xvii) 서열식별번호: 381을 포함하는 가변 중쇄 도메인 및 서열식별번호: 385를 포함하는 가변 경쇄 도메인; 또는
xviii) 서열식별번호: 401을 포함하는 가변 중쇄 도메인 및 서열식별번호: 405를 포함하는 가변 경쇄 도메인; 또는
xix) 서열식별번호: 421을 포함하는 가변 중쇄 도메인 및 서열식별번호: 425를 포함하는 가변 경쇄 도메인; 또는
xx) 서열식별번호: 441을 포함하는 가변 중쇄 도메인 및 서열식별번호: 445를 포함하는 가변 경쇄 도메인; 또는
xxi) 서열식별번호: 461을 포함하는 가변 중쇄 도메인 및 서열식별번호: 465를 포함하는 가변 경쇄 도메인; 또는
xxii) 서열식별번호: 481을 포함하는 가변 중쇄 도메인 및 서열식별번호: 485를 포함하는 가변 경쇄 도메인; 또는
xxiii) 서열식별번호: 501을 포함하는 가변 중쇄 도메인 및 서열식별번호: 505를 포함하는 가변 경쇄 도메인; 또는
xxiv) 서열식별번호: 521을 포함하는 가변 중쇄 도메인 및 서열식별번호: 525를 포함하는 가변 경쇄 도메인; 또는
xxv) 서열식별번호: 541을 포함하는 가변 중쇄 도메인 및 서열식별번호: 545를 포함하는 가변 경쇄 도메인; 또는
xxvi) 서열식별번호: 561을 포함하는 가변 중쇄 도메인 및 서열식별번호: 565를 포함하는 가변 경쇄 도메인.
특정한 실시양태에서, 본 발명에 따른 단리된 항체는 IgG 항체이다. 특정한 이러한 실시양태에서, 본 발명에 따른 단리된 항체는 IgG1, IgG2, IgG3 또는 IgG4 항체이다. 가장 특히, 본 발명에 따른 단리된 항체는 IgG1 또는 IgG4 항체이다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체는 하기를 포함한다:
i) 서열식별번호: 57을 포함하는 중쇄 및 서열식별번호: 58을 포함하는 경쇄; 또는
ii) 서열식별번호: 77을 포함하는 중쇄 및 서열식별번호: 78을 포함하는 경쇄; 또는
iii) 서열식별번호: 117을 포함하는 중쇄 및 서열식별번호: 118을 포함하는 경쇄; 또는
iv) 서열식별번호: 137을 포함하는 중쇄 및 서열식별번호: 138을 포함하는 경쇄; 또는
v) 서열식별번호: 157을 포함하는 중쇄 및 서열식별번호: 158을 포함하는 경쇄; 또는
vi) 서열식별번호: 177을 포함하는 중쇄 및 서열식별번호: 178을 포함하는 경쇄; 또는
vii) 서열식별번호: 197을 포함하는 중쇄 및 서열식별번호: 198을 포함하는 경쇄; 또는
viii) 서열식별번호: 217을 포함하는 중쇄 및 서열식별번호: 218을 포함하는 경쇄; 또는
ix) 서열식별번호: 237을 포함하는 중쇄 및 서열식별번호: 238을 포함하는 경쇄; 또는
x) 서열식별번호: 257을 포함하는 중쇄 및 서열식별번호: 258을 포함하는 경쇄; 또는
xi) 서열식별번호: 277을 포함하는 중쇄 및 서열식별번호: 278을 포함하는 경쇄; 또는
xii) 서열식별번호: 297을 포함하는 중쇄 및 서열식별번호: 298을 포함하는 경쇄; 또는
xiii) 서열식별번호: 317을 포함하는 중쇄 및 서열식별번호: 318을 포함하는 경쇄; 또는
xiv) 서열식별번호: 337을 포함하는 중쇄 및 서열식별번호: 338을 포함하는 경쇄; 또는
xv) 서열식별번호: 357을 포함하는 중쇄 및 서열식별번호: 358을 포함하는 경쇄; 또는
xvi) 서열식별번호: 377을 포함하는 중쇄 및 서열식별번호: 378을 포함하는 경쇄; 또는
xvii) 서열식별번호: 397을 포함하는 중쇄 및 서열식별번호: 398을 포함하는 경쇄; 또는
xviii) 서열식별번호: 417을 포함하는 중쇄 및 서열식별번호: 418을 포함하는 경쇄; 또는
xix) 서열식별번호: 437을 포함하는 중쇄 및 서열식별번호: 438을 포함하는 경쇄; 또는
xx) 서열식별번호: 457을 포함하는 중쇄 및 서열식별번호: 458을 포함하는 경쇄; 또는
xxi) 서열식별번호: 477을 포함하는 중쇄 및 서열식별번호: 478을 포함하는 경쇄; 또는
xxii) 서열식별번호: 497을 포함하는 중쇄 및 서열식별번호: 498을 포함하는 경쇄; 또는
xxiii) 서열식별번호: 517을 포함하는 중쇄 및 서열식별번호: 518을 포함하는 경쇄; 또는
xxiv) 서열식별번호: 537을 포함하는 중쇄 및 서열식별번호: 538을 포함하는 경쇄; 또는
xxv) 서열식별번호: 557을 포함하는 중쇄 및 서열식별번호: 558을 포함하는 경쇄; 또는
xxvi) 서열식별번호: 577을 포함하는 중쇄 및 서열식별번호: 578을 포함하는 경쇄.
특정한 실시양태에서, 본 발명에 따른 항원-결합 단편은 scFv, Fab, Fab' 단편 또는 F(ab')2 단편이다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 모노클로날 항체 또는 그의 항원-결합 단편이다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 인간, 인간화 또는 키메라 항체 또는 그의 항원-결합 단편, 보다 특히 완전 인간 항체 또는 그의 항원-결합 단편이다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 단일특이적 항체이다. 특정한 다른 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 Sema3A 및 적어도 1종의 추가의 항원에 결합하는 다중특이적 항체, 예컨대 이중특이적, 삼중특이적 또는 사중특이적 항체이다.
또 다른 측면에서, 본 발명은 인간 Sema3A에 대한 결합에 대해 본 발명에 따른 단리된 항체 또는 항원-결합 단편과 경쟁하는 단리된 항체 또는 그의 항원-결합 단편에 관한 것이다.
추가 측면에서, 본 발명은 본 발명에 따른 단리된 항체 또는 항원 결합 단편을 포함하는 항체 접합체에 관한 것이다. 예를 들어, 항체는 세포독성제, 면역독소, 독성단 또는 방사성동위원소에 접합될 수 있다. 또한, 검출가능한 마커에 접합된 항-Sema3A 항체가 제공된다. 바람직한 마커는 방사성표지, 효소, 발색단 또는 형광단이다. 항체는 또한 고분자량 분자, 예컨대 펩티드 또는 단백질, 예컨대 인터류킨에 접합될 수 있다.
본 발명에 따른 ADC는 1종 이상의 세포독성제, 예컨대 화학요법제 또는 약물, 성장 억제제, 독소 (예를 들어, 단백질 독소, 박테리아, 진균, 식물, 인간 또는 동물 기원의 효소적 활성 독소 또는 그의 단편) 또는 방사성 동위원소에 접합된 항-Sema3A 항체를 포함한다.
한 실시양태에서, 본 발명에 따른 ADC는 메이탄시노이드 (미국 특허 번호 5,208,020, 5,416,064 및 유럽 특허 EP0425235 참조); 아우리스타틴, 예컨대 모노메틸아우리스타틴 약물 모이어티 DE 및 DF (MMAE 및 MMAF) (미국 특허 번호 5,635,483 및 5,780,588, 및 7,498,298 참조); 돌라스타틴; 칼리케아미신 또는 그의 유도체; 안트라시클린, 예컨대 다우노마이신 또는 독소루비신; 메토트렉세이트; 빈데신; 탁산, 예컨대 도세탁셀, 파클리탁셀, 라로탁셀, 테세탁셀 및 오르타탁셀; 트리코테센; 및 CC1065를 포함하나 이에 제한되지는 않는 1종 이상의 약물에 접합된 본원에 기재된 바와 같은 항-Sema3A 항체를 포함한다.
또 다른 실시양태에서, 본 발명에 따른 ADC는 디프테리아 A 쇄, 디프테리아 독소의 비결합 활성 단편, 외독소 A 쇄 (슈도모나스 아에루기노사(Pseudomonas aeruginosa)로부터의 것), 리신 A 쇄, 아브린 A 쇄, 모데신 A 쇄, 알파사르신, 알레우리테스 포르디이(Aleurites fordii) 단백질, 디안틴 단백질, 피토라카 아메리카나(Phytolaca americana) 단백질 (P API, P APII 및 PAP-S), 모모르디카 카란티아(momordica charantia) 억제제, 쿠르신, 크로틴, 사파오나리아 오피시날리스(sapaonaria officinalis) 억제제, 겔로닌, 미토겔린, 레스트릭토신, 페노마이신, 에노마이신 및 트리코테센을 포함하나 이에 제한되지는 않는 효소적 활성 독소 또는 그의 단편에 접합된 본원에 기재된 바와 같은 항-Sema3A 항체를 포함한다.
또 다른 실시양태에서, 본 발명에 따른 ACD는 방사성접합체를 형성하기 위해 방사성 원자에 접합된 본원에 기재된 바와 같은 항-Sema3A 항체를 포함한다. 다양한 방사성 동위원소가 방사성접합체의 제조에 이용가능하다. 예는 227Th, 225Ac, 211At, 131I, 125I, 90Y, 186Re, 188Re, 153Sm, 212Bi, 32P, 212Pb 및 Lu의 방사성 동위원소를 포함한다. 방사성접합체가 검출에 사용되는 경우에, 이는 신티그래피 연구를 위한 방사성 원자, 예를 들어 Tc99m, 또는 핵 자기 공명 (NMR) 영상화를 위한 스핀 표지, 예컨대 다시 아이오딘-123, 아이오딘-131, 인듐-111, 플루오린-19, 탄소-13, 질소-15, 산소-17, 가돌리늄, 망가니즈 또는 철을 포함할 수 있다.
항체 및 세포독성제의 접합체는 다양한 이관능성 단백질 커플링제, 예컨대 N-숙신이미딜-3-(2-피리딜디티오) 프로피오네이트 (SPDP), 숙신이미딜-4-(N-말레이미도메틸) 시클로헥산-1-카르복실레이트 (SMCC), 이미노티올란 (IT), 이미도에스테르의 이관능성 유도체 (예컨대 디메틸 아디프이미데이트 HCl), 활성 에스테르 (예컨대 디숙신이미딜 수베레이트), 알데히드 (예컨대 글루타르알데히드), 비스-아지도 화합물 (예컨대 비스 (p-아지도벤조일) 헥산디아민), 비스-디아조늄 유도체 (예컨대 비스-(p-디아조늄벤조일)-에틸렌디아민), 디이소시아네이트 (예컨대 톨루엔 2,6-디이소시아네이트), 및 비스-활성 플루오린 화합물 (예컨대 1,5-디플루오로-2,4-디니트로벤젠)을 사용하여 제조될 수 있다.
링커는 세포에서 세포독성 약물의 방출을 용이하게 하는 "절단가능한 링커"일 수 있다. 예를 들어, 산-불안정성 링커, 펩티다제-감수성 링커, 광불안정성 링커, 디메틸 링커 또는 디술피드-함유 링커 (Chari et al., Cancer Res. 52: 12 7-131 (1992).
본 발명에 따른 ACD는 (예를 들어, 피어스 바이오테크놀로지, 인크.(Pierce Biotechnology, Inc.), 미국 일리노이주 록포드로부터) 상업적으로 입수가능한 BMPS, EMCS, GMBS, HBVS, LC-SMCC, MBS, MPBH, SBAP, SIA, SIAB, SMCC, SMPB, SMPH, 술포-EMCS, 술포-GMBS, 술포-KMUS, 술포-MBS, 술포-SIAB, 술포-SMCC, 및 술포-SMPB, 및 SVSB (숙신이미딜-(4-비닐술폰)벤조에이트)를 포함하나 이에 제한되지는 않는 가교제 시약에 의해 제조된 ADC를 포함한다.
본 발명에 따른 바람직한 항체 및 3종의 선행 기술 항체의 아미노산 및 핵산 서열을 표 1 및 표 1A에 열거한다.
펩티드 변이체
본 발명의 항체 또는 항원-결합 단편은 본원에 제공된 특정 펩티드 서열로 제한되지 않는다. 오히려, 본 발명은 또한 이들 폴리펩티드의 변이체를 구현한다. 본 개시내용 및 통상적으로 이용가능한 기술 및 참고문헌을 참조하여, 숙련된 작업자는 본원에 개시된 항체의 기능적 변이체를 제조, 시험 및 이용할 수 있을 것이며, Sema3A에 결합하는 능력을 갖는 이들 변이체는 본 발명의 범주 내에 속한다는 것을 인지할 것이다.
변이체는, 예를 들어 본원에 개시된 펩티드 서열과 비교하여 적어도 1개의 변경된 상보성 결정 영역 (CDR) (초가변) 및/또는 프레임워크 (FR) (가변) 도메인/위치를 갖는 항체를 포함할 수 있다.
CDR 또는 FR 영역 내의 1개 이상의 아미노산 잔기를 변경시킴으로써, 숙련된 작업자는 상용적으로 항원에 대해, 예를 들어 새로운 또는 개선된 특성에 대해 스크리닝될 수 있는 돌연변이되거나 다양화된 항체 서열을 생성할 수 있다.
본 발명의 추가의 바람직한 실시양태는 VH 및 VL 서열이 표 1 및 표 1A에 제시된 바와 같이 선택된 항체 또는 그의 항원-결합 단편이다. 관련 기술분야의 통상의 기술자는 표 1 및 표 1A의 데이터를 사용하여 본 발명의 범주 내에 있는 펩티드 변이체를 설계할 수 있다. 변이체는 1개 이상의 CDR 영역 내의 아미노산을 변화시키는 것에 의해 구축되는 것이 바람직하고; 변이체는 또한 1개 이상의 변경된 프레임워크 영역을 가질 수 있다. 예를 들어, 펩티드 FR 도메인은 배선 서열과 비교하여 잔기에서 편차가 존재하도록 변경될 수 있다.
대안적으로, 숙련된 작업자는 예를 들어 문헌 [Knappik A., et al., JMB 2000, 296:57-86]에 기재된 절차를 사용하여 본원에 개시된 아미노산 서열을 이러한 항체의 동일한 부류의 공지된 서열과 비교함으로써 동일한 분석을 할 수 있다.
또한, 변이체는 추가의 최적화를 위한 출발점으로서 1개의 항체를 사용하여, 항체 내의 1개 이상의 아미노산 잔기, 바람직하게는 1개 이상의 CDR 내의 아미노산 잔기를 다양화하고, 생성된 항체 변이체 집합을 개선된 특성을 갖는 변이체에 대해 스크리닝함으로써 수득될 수 있다. VL 및/또는 VH의 CDR3 내의 1개 이상의 아미노산 잔기의 다양화가 특히 바람직하다. 다양화는 예를 들어 트리뉴클레오티드 돌연변이유발 (TRIM) 기술을 사용하여 DNA 분자의 집합을 합성함으로써 수행될 수 있다 (Virnekaes B. et al., Nucl. Acids Res. 1994, 22: 5600.). 항체 또는 그의 항원-결합 단편은 예를 들어 변경된 반감기 (예를 들어 Fc 부분의 변형 또는 추가의 분자, 예컨대 PEG의 부착), 변경된 결합 친화도 또는 변경된 ADCC 또는 CDC 활성을 생성하는 변형을 포함하나 이에 제한되지는 않는 변형/변이를 갖는 분자를 포함한다.
보존적 아미노산 변이체
본원에 기재된 항체 펩티드 서열의 전체 분자 구조가 보존된 폴리펩티드 변이체가 제조될 수 있다. 개별 아미노산의 특성을 고려하여, 숙련된 작업자는 일부 합리적인 치환을 인식할 것이다. 아미노산 치환, 즉, "보존적 치환"은, 예를 들어, 수반되는 잔기의 극성, 전하, 용해도, 소수성, 친수성, 및/또는 양친매성 성질에서의 유사성에 기초하여 이루어질 수 있다.
예를 들어, (a) 비극성 (소수성) 아미노산은 알라닌, 류신, 이소류신, 발린, 프롤린, 페닐알라닌, 트립토판 및 메티오닌을 포함하고; (b) 극성 중성 아미노산은 글리신, 세린, 트레오닌, 시스테인, 티로신, 아스파라긴 및 글루타민을 포함하고; (c) 양으로 하전된 (염기성) 아미노산은 아르기닌, 리신 및 히스티딘을 포함하고; (d) 음으로 하전된 (산성) 아미노산은 아스파르트산 및 글루탐산을 포함한다. 치환은 전형적으로 군 (a)-(d) 내에서 이루어질 수 있다. 또한, 글리신 및 프롤린은 α-나선을 파괴하는 그의 능력에 기초하여 서로 치환될 수 있다. 유사하게, 특정 아미노산, 예컨대 알라닌, 시스테인, 류신, 메티오닌, 글루탐산, 글루타민, 히스티딘 및 리신은 α-나선에서 보다 통상적으로 발견되는 반면, 발린, 이소류신, 페닐알라닌, 티로신, 트립토판 및 트레오닌은 β-병풍 시트에서 보다 통상적으로 발견된다. 글리신, 세린, 아스파르트산, 아스파라긴 및 프롤린은 통상적으로 턴에서 발견된다. 일부 바람직한 치환은 하기 군 사이에서 이루어질 수 있다: (i) S 및 T; (ii) P 및 G; 및 (iii) A, V, L 및 I. 공지된 유전자 코드, 및 재조합 및 합성 DNA 기술을 고려하여, 숙련된 과학자는 보존적 아미노산 변이체를 코딩하는 DNA를 용이하게 구축할 수 있다.
글리코실화 변이체
항체가 Fc 영역을 포함하는 경우, 그에 부착된 탄수화물은 변경될 수 있다. 포유동물 세포에 의해 생산된 천연 항체는 전형적으로 Fc 영역의 CH2 도메인의 카바트 EU 넘버링을 사용하여 Asn297에 N-연결에 의해 일반적으로 부착된 분지형, 이중안테나 올리고사카라이드를 포함하며; 예를 들어, 문헌 [Wright et al., Trends Biotechnol. 15: 26-32 (1997)]을 참조한다.
특정 실시양태에서, 본원에 제공된 항체는 항체가 글리코실화되는 정도를 증가 또는 감소시키도록 변경된다. 항체에 대한 글리코실화 부위의 부가 또는 결실은 1개 이상의 글리코실화 부위가 생성되거나 제거되도록 발현 시스템 (예를 들어 숙주 세포)을 변경시키고/거나 아미노산 서열을 변경시킴으로써 편리하게 달성될 수 있다.
본 발명의 한 실시양태에서, 감소된 이펙터 기능을 갖는 비-글리코실 항체 또는 항체 유도체는 원핵 숙주에서의 발현에 의해 제조된다. 적합한 원핵 숙주는 이. 콜라이(E. coli), 바실루스 서브틸리스(Bacillus subtilis), 살모넬라 티피무리움(Salmonella typhimurium) 및 슈도모나스(Pseudomonas), 스트렙토미세스(Streptomyces), 및 스타필로코쿠스(Staphylococcus) 속 내의 다양한 종을 포함하나, 이에 제한되지는 않는다.
한 실시양태에서, 상기 항체의 Fc 부분의 CH2 도메인 내의 보존된 N-연결 부위에서의 변형을 특징으로 하는, 감소된 이펙터 기능을 갖는 항체 변이체가 제공된다. 본 발명의 한 실시양태에서, 변형은 중쇄 글리코실화 부위에서의 글리코실화를 방지하기 위한 상기 부위에서의 돌연변이를 포함한다. 따라서, 본 발명의 하나의 바람직한 실시양태에서, 비-글리코실 항체 또는 항체 유도체는 중쇄 글리코실화 부위의 돌연변이, - 즉 카바트 EU 넘버링을 사용한 N297의 돌연변이에 의해 제조되고, 적절한 숙주 세포에서 발현된다.
본 발명의 또 다른 실시양태에서, 비-글리코실 항체 또는 항체 유도체는 감소된 이펙터 기능을 가지며, 여기서 상기 항체 또는 항체 유도체의 Fc 부분의 CH2 도메인 내의 보존된 N-연결 부위에서의 변형은 CH2 도메인 글리칸의 제거, - 즉 탈글리코실화를 포함한다. 이들 비-글리코실 항체는 통상적인 방법에 의해 생성된 다음, 효소적으로 탈글리코실화될 수 있다. 항체의 효소적 탈글리코실화 방법은 관련 기술분야에 널리 공지되어 있다 (예를 들어, 문헌 [Winkelhake & Nicolson (1976), J Biol Chem. 251(4):1074-80] 참조).
본 발명의 또 다른 실시양태에서, 탈글리코실화는 글리코실화 억제제 튜니카마이신을 사용하여 달성될 수 있다 (Nose & Wigzell (1983), Proc Natl Acad Sci USA, 80(21):6632-6). 즉, 변형은 상기 항체의 Fc 부분의 CH2 도메인 내의 보존된 N-연결 부위에서의 글리코실화의 방지이다.
한 실시양태에서, Fc 영역에 (직접적으로 또는 간접적으로) 부착된 푸코스가 결여된 탄수화물 구조를 갖는 항체 변이체가 제공된다. 예를 들어, 이러한 항체에서 푸코스의 양은 1% 내지 80%, 1% 내지 65%, 5% 내지 65% 또는 20% 내지 40%일 수 있다. 푸코스의 양은, 예를 들어 WO 2008/077546에 기재된 바와 같은 MALDI-TOF 질량 분광측정법에 의해 측정된 바와 같이, Asn 297에 부착된 모든 당구조물 (예를 들어, 복합체, 하이브리드 및 높은 만노스 구조물)의 합계 대비 Asn297에서의 당 쇄 내의 푸코스의 평균 양을 계산하는 것에 의해 결정된다. Asn297은 Fc 영역 내의 약 위치 297 (Fc 영역 잔기의 Eu 넘버링)에 위치한 아스파라긴 잔기를 지칭하지만; Asn297은 또한 항체에서의 부차적 서열 변이로 인해 위치 297의 약 ± 3개 아미노산 상류 또는 하류, 즉 위치 294와 300 사이에 위치할 수 있다. 이러한 푸코실화 변이체는 개선된 ADCC 기능을 가질 수 있다.
"탈푸코실화" 또는 "푸코스-결핍" 항체 변이체와 관련된 간행물의 예는 문헌 [Okazaki et al., J Mol. Biol. 336: 1239-1249 (2004); Yamane-Ohnuki et al., Biotech. Bioeng. 87: 614 (2004)]을 포함한다.
탈푸코실화 항체를 생산할 수 있는 세포주의 예는 단백질 푸코실화가 결핍된 Lec13 CHO 세포 (Ripka et al., Arch. Biochem. Biophys. 249:533-545 (1986); 및 WO 2004/056312), 및 녹아웃 세포주, 예컨대 알파-1,6-푸코실트랜스퍼라제 유전자, FUT8, 녹아웃 CHO 세포 (예를 들어, 문헌 [Yamane-Ohnuki et al., Biotech. Bioeng. 87: 614 (2004); Kanda, Y. et al., Biotechnol. Bioeng., 94(4):680-688 (2006)] 참조)를 포함한다.
이등분된 올리고사카라이드를 갖는 항체 변이체가 추가로 제공되며, 예를 들어 여기서 항체의 Fc 영역에 부착된 이중안테나 올리고사카라이드는 GlcNAc에 의해 이등분된다. 이러한 항체 변이체는 감소된 푸코실화 및/또는 개선된 ADCC 기능을 가질 수 있다. 이러한 항체 변이체의 예는, 예를 들어 WO 2003/011878; 미국 특허 번호 6,602,684; 및 US 2005/0123546에 기재되어 있다.
Fc 영역에 부착된 올리고사카라이드 내에 적어도 1개의 갈락토스 잔기를 갖는 항체 변이체가 또한 제공된다. 이러한 항체 변이체는 개선된 CDC 기능을 가질 수 있다. 이러한 항체 변이체는, 예를 들어 WO1997/30087; WO1998/58964; 및 WO1999/22764에 기재되어 있다.
Fc 영역 변이체
특정 실시양태에서, 1개 이상의 아미노산 변형 (예를 들어 치환)이 본원에 제공된 항체의 Fc 영역 (예를 들어, 인간 IgG1, IgG2, IgG3 또는 IgG4 Fc 영역) 내로 도입될 수 있고, 그에 의해 Fc 영역 변이체가 생성될 수 있다.
특정 실시양태에서, 본 발명은 모든 이펙터 기능은 아니지만 일부 이펙터 기능을 보유하는 항체 변이체를 고려하며, 이는 생체내 항체의 반감기가 중요하지만 특정 이펙터 기능 (예컨대 보체 및 ADCC)은 불필요하거나 해로운 적용에 대해 바람직한 후보가 되게 한다. 시험관내 및/또는 생체내 세포독성 검정을 수행하여 CDC 및/또는 ADCC 활성의 감소/고갈을 확인할 수 있다. 예를 들어, Fc 수용체 (FcR) 결합 검정을 수행하여, 항체가 FcγR 결합은 결여되어 있지만 (따라서 ADCC 활성이 결여될 가능성이 있음) FcRn 결합 능력은 보유한다는 것을 확실하게 할 수 있다. 일부 실시양태에서, 변경된 (즉, 개선된 또는 감소된) C1q 결합 및/또는 보체 의존성 세포독성 (CDC)을 발생시키는 변경이 Fc 영역에서 이루어진다.
특정 실시양태에서, 본 발명은 증가된 또는 감소된 반감기를 보유하는 항체 변이체를 고려한다. 증가된 반감기 및 모체 IgG의 태아로의 전달을 담당하는 신생아 Fc 수용체 (FcRn)에 대한 개선된 결합을 갖는 항체 (Guyer et al., J Immunol. 117:587 (1976) 및 Kim et al., J Immunol. 24:249 (1994))가 US2005/0014934 (Hinton et al.)에 기재되어 있다. 이들 항체는 FcRn에 대한 Fc 영역의 결합을 개선시키는 1개 이상의 치환을 갖는 Fc 영역을 포함한다.
항체 생성
본 발명의 항체는 다수의 건강한 지원자의 항체로부터 단리된 아미노산 서열에 기초한 재조합 항체 라이브러리로부터, 예를 들어 완전 인간 CDR을 신규한 항체 분자 내로 재조합시키는 n-CoDeR® 기술을 사용하여 유래될 수 있다 (Carlson & Soederlind, Expert Rev Mol Diagn. 2001 May;1(1):102-8). 또는 대안적으로, 예를 들어 문헌 [Hoet RM et al., Nat Biotechnol 2005;23(3):344-8)]에 기재된 완전 인간 항체 파지 디스플레이 라이브러리로서의 항체 라이브러리를 사용하여 Sema3A-특이적 항체를 단리할 수 있다. 인간 항체 라이브러리로부터 단리된 항체 또는 항체 단편은 본원에서 인간 항체 또는 인간 항체 단편으로 간주된다.
인간 항체는 추가로, 항원 챌린지에 반응하여 무손상 인간 항체 또는 인간 가변 영역을 갖는 무손상 항체를 생산하도록 변형된 트랜스제닉 동물에게 면역원을 투여하는 것에 의해 제조될 수 있다. 이러한 동물은 전형적으로 내인성 이뮤노글로불린 유전자좌를 대체하거나 또는 염색체외에 존재하거나 동물의 염색체 내로 무작위로 통합된 인간 이뮤노글로불린 유전자좌의 전부 또는 일부를 함유한다. 예를 들어, 유전자 조작된 마우스의 면역화, 특히 hMAb 마우스 (예를 들어, 벨로크이뮨 마우스® 또는 제노마우스(XENOMOUSE)®)의 면역화가 수행될 수 있다.
추가의 항체는 하이브리도마 기술 (예를 들어, 문헌 [Koehler and Milstein Nature. 1975 Aug 7;256(5517):495-7] 참조)을 사용하여 생성될 수 있고, 이는 예를 들어 키메라 또는 인간화 항체로 전환될 수 있는 뮤린, 래트, 또는 토끼 항체를 발생시킬 수 있다. 인간화 항체 및 그의 제조 방법은 예를 들어 문헌 [Almagro and Fransson, Front. Biosci. 13:1619-1633 (2008)]에서 검토되고, 추가로 예를 들어 문헌 [Riechmann et al., Nature 332:323-329 (1988); Queen et al., Proc. Natl Acad. Sci. USA 86:10029-10033 (1989); 미국 특허 번호 5,821,337, 7,527,791, 6,982,321, 및 7,087,409; Kashmiri et al., Methods 36:25-34 (2005) (특이성 결정 영역 (SDR) 그라프팅을 기재함); Padlan, Mol. Immunol. 28:489-498 (1991) ("재표면화"를 기재함); Dall' Acqua et al., Methods 36:43-60 (2005) ("FR 셔플링"을 기재함); 및 Osboum et al., Methods 36:61-68 (2005) 및 Klimka et al., Br. J. Cancer, 83:252-260 (2000) (FR 셔플링에 대한 "가이드 선택" 접근법을 기재함)]에 기재되어 있다.
재조합 항체 라이브러리를 사용한 항체의 생성에 대한 예가 제공된다.
본 발명에 따른 DNA 분자
본 발명은 또한 본 발명에 따른 항체 또는 항원-결합 단편을 코딩하는 단리된 핵산 서열에 관한 것이다. 본 발명에 따른 항체 또는 항원-결합 단편을 코딩하는 단리된 핵산 서열은 예를 들어 문헌 [Sambrook et al., 1989, 및 Ausubel et al., 1989]에 기재된 기술에 의해, 또는 대안적으로 화학적 합성에 의해 생산될 수 있다. (예를 들어, 문헌 [Oligonucleotide Synthesis (1984, Gait, ed., IRL Press, Oxford)]에 기재된 기술). 발현된 항체에 대해 사용된 DNA 서열 및 각각의 서열식별번호는 표 1 및 1A에 제공된다. 이들 서열은 특정 경우에 포유동물 발현을 위해 최적화된다. 본 발명의 DNA 분자는 본원에 개시된 서열에 제한되지 않고, 또한 그의 변이체를 포함한다. 본 발명 내의 DNA 변이체는 혼성화에서의 그의 물리적 특성을 참조하여 기재될 수 있다. 숙련된 작업자는 핵산 혼성화 기술을 사용하여 DNA가 그의 상보체를 확인하는 데 사용될 수 있고, DNA가 이중 가닥이기 때문에 그의 등가물 또는 상동체를 확인하는 데 사용될 수 있다는 것을 인식할 것이다. 또한, 혼성화는 100% 미만의 상보성으로 발생할 수 있다는 것이 인식될 것이다. 그러나, 조건을 적절하게 선택하면, 혼성화 기술을 사용하여 DNA 서열을 특정한 프로브에 대한 그의 구조적 관련성에 기초하여 구별할 수 있다. 이러한 조건에 관한 지침에 대해, 문헌 [Sambrook et al., 1989 상기 문헌 및 Ausubel et al., 1995 (Ausubel, F. M., Brent, R., Kingston, R. E., Moore, D. D., Sedman, J. G., Smith, J. A., & Struhl, K. eds. (1995). Current Protocols in Molecular Biology. New York: John Wiley and Sons)]을 참조한다.
2개의 폴리뉴클레오티드 서열 사이의 구조적 유사성은 2개의 서열이 서로 혼성화할 조건의 "엄격도"의 함수로서 표현될 수 있다. 본원에 사용된 용어 "엄격도"는 조건이 혼성화에 불리한 정도를 지칭한다. 엄격한 조건은 혼성화에 강하게 불리하고, 가장 구조적으로 관련된 분자만이 이러한 조건 하에 서로 혼성화할 것이다. 반대로, 비-엄격한 조건은 보다 낮은 정도의 구조적 관련성을 나타내는 분자의 혼성화에 유리하다. 따라서, 혼성화 엄격도는 2개의 핵산 서열의 구조적 관계와 직접적으로 상관된다.
혼성화 엄격도는 전체 DNA 농도, 이온 강도, 온도, 프로브 크기 및 수소 결합을 파괴하는 작용제의 존재를 비롯한 많은 인자의 함수이다. 혼성화를 촉진하는 인자는 높은 DNA 농도, 높은 이온 강도, 낮은 온도, 보다 긴 프로브 크기 및 수소 결합을 파괴하는 작용제의 부재를 포함한다. 혼성화는 전형적으로 2개의 단계: "결합" 단계 및 "세척" 단계로 수행된다.
기능적으로 등가인 DNA 변이체
본 발명의 범주 내의 또 다른 부류의 DNA 변이체가 이들이 코딩하는 생성물과 관련하여 기재될 수 있다. 이들 기능적으로 등가인 폴리뉴클레오티드는 이들이 유전자 코드의 축중성으로 인해 동일한 펩티드 서열을 코딩한다는 사실을 특징으로 한다.
본원에 제공된 DNA 분자의 변이체는 여러 상이한 방식으로 구축될 수 있는 것으로 인식된다. 예를 들어, 이는 완전 합성 DNA로서 구축될 수 있다. 올리고뉴클레오티드를 효율적으로 합성하는 방법이 널리 이용가능하다. 문헌 [Ausubel et al., section 2.11, Supplement 21 (1993)]을 참조한다. 중첩 올리고뉴클레오티드는 문헌 [Khorana et al., J. Mol. Biol. 72:209-217 (1971)]에 최초로 보고된 방식으로 합성 및 어셈블리될 수 있고; 또한 문헌 [Ausubel et al., 상기 문헌, Section 8.2]을 참조한다. 합성 DNA는 바람직하게는 적절한 벡터 내로의 클로닝을 용이하게 하기 위해 유전자의 5' 및 3' 단부에서 조작된 편리한 제한 부위를 갖도록 설계된다.
나타낸 바와 같이, 변이체를 생성하는 방법은 본원에 개시된 DNA 중 하나로 출발한 다음, 부위-지정 돌연변이유발을 수행하는 것이다. 문헌 [Ausubel et al., 상기 문헌, chapter 8, Supplement 37 (1997)]을 참조한다. 전형적인 방법에서, 표적 DNA는 단일-가닥 DNA 박테리오파지 비히클 내로 클로닝된다. 단일-가닥 DNA가 단리되고, 목적하는 뉴클레오티드 변경(들)을 함유하는 올리고뉴클레오티드와 혼성화된다. 상보적 가닥이 합성되고, 이중 가닥 파지가 숙주 내로 도입된다. 생성된 자손 중 일부는 목적하는 돌연변이체를 함유할 것이며, 이는 DNA 서열분석을 사용하여 확인될 수 있다. 또한, 자손 파지가 목적하는 돌연변이체일 확률을 증가시키는 다양한 방법이 이용가능하다. 이들 방법은 관련 기술분야의 통상의 기술자에게 널리 공지되어 있고, 이러한 돌연변이체를 생성하기 위한 키트가 상업적으로 입수가능하다.
재조합 DNA 구축물 및 발현
본 발명은 본 발명에 따른 뉴클레오티드 서열 중 1개 이상을 포함하는 재조합 DNA 구축물을 추가로 제공한다. 본 발명의 재조합 구축물은 본 발명의 항체 또는 그의 항원-결합 단편 또는 그의 변이체를 코딩하는 DNA 분자가 삽입된 벡터, 예컨대 플라스미드, 파지미드, 파지 또는 바이러스 벡터와 관련하여 사용될 수 있다.
따라서, 한 측면에서, 본 발명은 본 발명에 따른 핵산 서열을 포함하는 벡터에 관한 것이다.
본원에 제공된 항체, 그의 항원 결합 부분, 또는 변이체는 숙주 세포에서 경쇄 및 중쇄 또는 그의 부분을 코딩하는 핵산 서열의 재조합 발현에 의해 제조될 수 있다. 항체, 그의 항원 결합 부분, 또는 변이체를 재조합적으로 발현시키기 위해, 경쇄 및 중쇄가 숙주 세포에서 발현되도록 경쇄 및/또는 중쇄 또는 그의 부분을 코딩하는 DNA 단편을 보유하는 1개 이상의 재조합 발현 벡터로 숙주 세포를 형질감염시킬 수 있다. 문헌 [Sambrook, Fritsch and Maniatis (eds.), Molecular Cloning; A Laboratory Manual, Second Edition, Cold Spring Harbor, N.Y., (1989), Ausubel, F. M. et al., (eds.) Current Protocols in Molecular Biology, Greene Publishing Associates, (1989)] 및 미국 특허 번호 4,816,397 (Boss et al.)에 기재된 바와 같이, 표준 재조합 DNA 방법론을 사용하여 중쇄 및 경쇄를 코딩하는 핵산을 제조 및/또는 수득하고, 이들 핵산을 재조합 발현 벡터 내로 혼입시키고, 벡터를 숙주 세포 내로 도입한다.
또한, 중쇄 및/또는 경쇄의 가변 영역을 코딩하는 핵산 서열은, 예를 들어 전장 항체 쇄, Fab 단편을 코딩하는 핵산 서열, 또는 scFv로 전환될 수 있다. VL- 또는 VH-코딩 DNA 단편은 예를 들어 항체 불변 영역 또는 가요성 링커를 코딩하는 또 다른 DNA 단편에 (2개의 DNA 단편에 의해 코딩된 아미노산 서열이 인-프레임이도록) 작동가능하게 연결될 수 있다. 인간 중쇄 및 경쇄 불변 영역의 서열은 관련 기술분야에 공지되어 있고 (예를 들어, 문헌 [Kabat, E. A., et al., (1991) Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242] 참조), 이들 영역을 포괄하는 DNA 단편은 표준 PCR 증폭에 의해 수득될 수 있다.
scFv를 코딩하는 폴리뉴클레오티드 서열을 생성하기 위해, VH- 및 VL-코딩 핵산은 가요성 링커를 코딩하는 또 다른 단편에 작동가능하게 연결될 수 있고, 이에 VL 및 VH 영역이 가요성 링커에 의해 연결된, VH 및 VL 서열이 인접한 단일-쇄 단백질로서 발현될 수 있다 (예를 들어, 문헌 [Bird et al., (1988) Science 242:423-426; Huston et al., (1988) Proc. Natl. Acad. Sci. USA 85:5879-5883; McCafferty et al., Nature (1990) 348:552-554] 참조).
항체, 그의 항원 결합 단편 또는 그의 변이체를 발현시키기 위해, 표준 재조합 DNA 발현 방법이 사용될 수 있다 (예를 들어, 문헌 [Goeddel; Gene Expression Technology. Methods in Enzymology 185, Academic Press, San Diego, Calif. (1990)] 참조). 예를 들어, 목적하는 폴리펩티드를 코딩하는 DNA는 발현 벡터 내로 삽입될 수 있고, 이어서 이는 적합한 숙주 세포 내로 형질감염된다. 적합한 숙주 세포는 원핵 및 진핵 세포이다. 원핵 숙주 세포의 예는 예를 들어 박테리아이고, 진핵 숙주 세포의 예는 효모, 곤충 및 곤충 세포, 식물 및 식물 세포, 트랜스제닉 동물, 또는 포유동물 세포이다. 재조합 구축물의 숙주 세포 내로의 도입은 표준 기술, 예컨대 인산칼슘 형질감염, DEAE 덱스트란 매개 형질감염, 전기천공, 형질도입 또는 파지 감염을 사용하여 수행될 수 있다.
일부 실시양태에서, 중쇄 및 경쇄를 코딩하는 DNA는 별개의 벡터 내로 삽입된다. 다른 실시양태에서, 중쇄 및 경쇄를 코딩하는 DNA는 동일한 벡터 내로 삽입된다. 조절 서열의 선택을 비롯한 발현 벡터의 설계는 숙주 세포의 선택, 목적하는 단백질의 발현 수준 및 발현이 구성적인지 또는 유도성인지와 같은 인자에 의해 영향을 받는 것으로 이해된다.
따라서, 추가 측면에서, 본 발명은 본 발명에 따른 항체 또는 항원-결합 단편을 발현하고/거나 본 발명에 따른 핵산 또는 본 발명에 따른 벡터를 포함하는 단리된 세포에 관한 것이다.
단리된 세포는 실질적으로 발현 벡터가 이용가능한 임의의 세포일 수 있다. 단리된 세포는 예를 들어 고등 진핵 숙주 세포, 예컨대 포유동물 세포, 하등 진핵 숙주 세포, 예컨대 효모 세포일 수 있고, 원핵 세포, 예컨대 박테리아 세포일 수 있다.
추가 측면에서, 본 발명은 본 발명에 따른 세포를 배양하는 것을 포함하는, 본 발명에 따른 단리된 항체 또는 항원-결합 단편을 생산하는 방법에 관한 것이다. 특정한 실시양태에서, 본 발명에 따른 세포는 항체 발현에 적합한 조건 하에 배양되고, 항체 또는 그의 항원-결합 단편은 회수된다. 특정한 실시양태에서, 항체 또는 그의 항원-결합 단편은 특히 적어도 95 중량% 균질성으로 정제된다.
박테리아 발현
박테리아 사용에 유용한 발현 벡터는 기능적 프로모터와 작동가능한 판독 상으로 적합한 번역 개시 및 종결 신호와 함께 목적하는 단백질을 코딩하는 DNA 서열을 삽입하는 것에 의해 구축된다. 벡터는 벡터의 유지를 보장하고, 바람직한 경우에 숙주 내에서 증폭을 제공하기 위해 1종 이상의 표현형 선택 마커 및 복제 기점을 포함할 것이다. 형질전환에 적합한 원핵 숙주는 이. 콜라이, 바실루스 서브틸리스, 살모넬라 티피무리움 및 슈도모나스, 스트렙토미세스, 및 스타필로코쿠스 속 내의 다양한 종을 포함하나, 이에 제한되지는 않는다.
박테리아 벡터는 예를 들어 박테리오파지-, 플라스미드- 또는 파지미드-기반일 수 있다. 이들 벡터는 널리 공지된 클로닝 벡터 pBR322 (ATCC 37017)의 요소를 전형적으로 함유하는 상업적으로 입수가능한 플라스미드로부터 유래된 선택 마커 및 박테리아 복제 기점을 함유할 수 있다. 적합한 숙주 균주의 형질전환 및 숙주 균주의 적절한 세포 밀도로의 성장 후에, 선택된 프로모터는 적절한 수단 (예를 들어, 온도 이동 또는 화학적 유도)에 의해 탈억제/유도되고, 세포는 추가의 기간 동안 배양된다. 세포는 전형적으로 원심분리에 의해 수거되고, 물리적 또는 화학적 수단에 의해 파괴되고, 생성된 조 추출물은 추가의 정제를 위해 유지된다.
박테리아 시스템에서, 발현되는 단백질에 대해 의도되는 용도에 따라 다수의 발현 벡터가 유리하게 선택될 수 있다. 예를 들어, 항체의 생성을 위해 또는 펩티드 라이브러리를 스크리닝하기 위해 다량의 이러한 단백질이 생산되어야 하는 경우에, 예를 들어 용이하게 정제되는 융합 단백질 생성물의 높은 수준의 발현을 지시하는 벡터가 바람직할 수 있다.
따라서, 본 발명의 실시양태는 본 발명의 신규 항체를 코딩하는 핵산 서열을 포함하는 발현 벡터이다.
본 발명의 항체 또는 그의 항원-결합 단편 또는 그의 변이체는 자연적으로 정제된 생성물, 화학적 합성 절차의 생성물, 및 예를 들어 이. 콜라이, 바실루스 서브틸리스, 살모넬라 티피무리움 및 슈도모나스, 스트렙토미세스 및 스타필로코쿠스 속 내의 다양한 종을 포함한 원핵 숙주, 바람직하게는 이. 콜라이 세포로부터 재조합 기술에 의해 생산된 생성물을 포함한다.
포유동물 발현
포유동물 숙주 세포 발현을 위한 바람직한 조절 서열은 포유동물 세포에서 높은 수준의 단백질 발현을 지시하는 바이러스 요소, 예컨대 시토메갈로바이러스 (CMV) (예컨대 CMV 프로모터/인핸서), 원숭이 바이러스 40 (SV40) (예컨대 SV40 프로모터/인핸서), 아데노바이러스 (예를 들어, 아데노바이러스 주요 후기 프로모터 (AdMLP)) 및 폴리오마로부터 유래된 프로모터 및/또는 인핸서를 포함한다. 항체의 발현은 구성적일 수 있거나 또는 조절될 수 있다 (예를 들어 Tet 시스템과 함께 소분자 유도제, 예컨대 테트라시클린의 첨가 또는 제거에 의해 유도가능함). 바이러스 조절 요소 및 그의 서열의 추가의 설명에 대해서는, 예를 들어 미국 5,168,062 (Stinski), 미국 4,510,245 (Bell et al.) 및 미국 4,968,615 (Schaffner et al.)를 참조한다. 재조합 발현 벡터는 또한 복제 기점 및 선택 마커를 포함할 수 있다 (예를 들어, 미국 4,399,216, 4,634,665 및 미국 5,179,017 참조). 적합한 선택 마커는 벡터가 도입된 숙주 세포에 대해 약물, 예컨대 G418, 퓨로마이신, 히그로마이신, 블라스티시딘, 제오신/블레오마이신 또는 메토트렉세이트에 대한 저항성을 부여하는 유전자 또는 영양요구성을 이용하는 선택 마커, 예컨대 글루타민 신테타제를 포함한다 (Bebbington et al., Biotechnology (N Y). 1992 Feb;10(2):169-75). 예를 들어, 디히드로폴레이트 리덕타제 (DHFR) 유전자는 메토트렉세이트에 대한 저항성을 부여하고, neo 유전자는 G418에 대한 저항성을 부여하고, 아스페르길루스 테레우스(Aspergillus terreus)로부터의 bsd 유전자는 블라스티시딘에 대한 저항성을 부여하고, 퓨로마이신 N-아세틸-트랜스퍼라제는 퓨로마이신에 대한 저항성을 부여하고, Sh ble 유전자 생성물은 제오신에 대한 저항성을 부여하고, 히그로마이신에 대한 저항성은 이. 콜라이 히그로마이신 저항성 유전자 (hyg 또는 hph)에 의해 부여된다. DHFR 또는 글루타민 신테타제와 같은 선택 마커는 또한 MTX 및 MSX와 함께 증폭 기술에 유용하다.
발현 벡터의 숙주 세포 내로의 형질감염은 표준 기술, 예컨대 전기천공, 뉴클레오펙션, 인산칼슘 침전, 리포펙션, 다가양이온-기반 형질감염, 예컨대 폴리에틸렌이민 (PEI)-기반 형질감염 및 DEAE-덱스트란 형질감염을 사용하여 수행될 수 있다.
본원에 제공된 항체, 그의 항원 결합 단편 또는 그의 변이체를 발현시키는 데 적합한 포유동물 숙주 세포는 차이니즈 햄스터 난소 (CHO 세포) 예컨대 CHO-K1, CHO-S, CHO-K1SV [예를 들어, 문헌 [R. J. Kaufman and P. A. Sharp (1982) Mol. Biol. 159:601-621]에 기재된 바와 같이 DHFR 선택 마커와 함께 사용되는 문헌 [Urlaub and Chasin, (1980) Proc. Natl. Acad. Sci. USA 77:4216-4220 및 Urlaub et al., Cell. 1983 Jun;33(2):405-12]에 기재된 dhfr- CHO 세포; 및 문헌 [Fan et al., Biotechnol Bioeng. 2012 Apr;109(4):1007-15]에 예시된 다른 녹아웃 세포 포함], NS0 골수종 세포, COS 세포, HEK293 세포, HKB11 세포, BHK21 세포, CAP 세포, EB66 세포, 및 SP2 세포를 포함한다.
발현은 또한 발현 시스템, 예컨대 HEK293, HEK293T, HEK293-EBNA, HEK293E, HEK293-6E, HEK293-프리스타일, HKB11, Expi293F, 293EBNALT75, CHO 프리스타일, CHO-S, CHO-K1, CHO-K1SV, CHOEBNALT85, CHOS-XE, CHO-3E7 또는 CAP-T 세포에서 일시적이거나 절반-안정할 수 있다 (예를 들어, 문헌 [Durocher et al., Nucleic Acids Res. 2002 Jan 15;30(2):E9]).
일부 실시양태에서, 발현 벡터는 발현된 단백질이 숙주 세포가 성장하는 배양 배지 내로 분비되도록 설계된다. 항체, 그의 항원 결합 단편 또는 그의 변이체는 표준 단백질 정제 방법을 사용하여 배양 배지로부터 회수될 수 있다.
정제
본 발명의 항체 또는 그의 항원-결합 단편 또는 그의 변이체는 황산암모늄 또는 에탄올 침전, 산 추출, 단백질 A 크로마토그래피, 단백질 G 크로마토그래피, 음이온 또는 양이온 교환 크로마토그래피, 포스포-셀룰로스 크로마토그래피, 소수성 상호작용 크로마토그래피, 친화성 크로마토그래피, 히드록실아파타이트 크로마토그래피 및 렉틴 크로마토그래피를 포함하나 이에 제한되지는 않는 널리 공지된 방법에 의해 재조합 세포 배양물로부터 회수 및 정제될 수 있다. 고성능 액체 크로마토그래피 ("HPLC")가 또한 정제에 사용될 수 있다. 예를 들어, 문헌 [Colligan, Current Protocols in Immunology, or Current Protocols in Protein Science, John Wiley & Sons, NY, N.Y., (1997-2001), e.g., Chapters 1, 4, 6, 8, 9, 10]을 참조하고, 각각은 전체적으로 본원에 참조로 포함된다.
본 발명의 항체 또는 그의 항원-결합 단편 또는 그의 변이체는 자연적으로 정제된 생성물, 화학적 합성 절차의 생성물, 및 예를 들어 효모, 고등 식물, 곤충 및 포유동물 세포를 포함한 진핵 숙주로부터 재조합 기술에 의해 생산된 생성물을 포함한다. 재조합 생산 절차에 사용되는 숙주에 따라, 본 발명의 항체는 글리코실화될 수 있거나 또는 비-글리코실화될 수 있다. 이러한 방법은 많은 표준 실험실 매뉴얼, 예컨대 문헌 [Sambrook, 상기 문헌, Sections 17.37-17.42; Ausubel, 상기 문헌, Chapters 10, 12, 13, 16, 18 and 20]에 기재되어 있다.
바람직한 실시양태에서, 항체는 (1) 예를 들어 로우리(Lowry) 방법, UV-Vis 분광분석법 또는 SDS-모세관 겔 전기영동 (예를 들어 캘리퍼 랩칩 GXII, GX 90 또는 바이오라드 바이오애널라이저 장치 상에서)에 의해 결정된 바와 같이 95 중량% 초과의 항체로, 추가의 바람직한 실시양태에서 99 중량% 초과로, (2) N-말단 또는 내부 아미노산 서열의 적어도 15개의 잔기를 수득하기에 충분한 정도로, 또는 (3) 쿠마시 블루 또는 바람직하게는 은 염색을 사용하는 환원 또는 비-환원 조건 하에서의 SDS-PAGE에 의해 균질한 것으로 정제된다. 단리된 자연 발생 항체는 재조합 세포 내의 계내 항체를 포함하며, 이는 항체의 자연 환경의 적어도 1종의 성분이 존재하지 않을 것이기 때문이다. 그러나, 통상적으로, 단리된 항체는 적어도 1개의 정제 단계에 의해 제조될 것이다.
치료 방법
치료 방법은 치료를 필요로 하는 대상체에게 치료 유효량의 본 발명에 의해 고려되는 항체 또는 그의 항원-결합 단편 또는 그의 변이체를 투여하는 것을 수반한다. 본원에서 "치료 유효"량은 단독으로 또는 다른 작용제와 조합되어 단일 용량으로서 또는 다중 용량 요법에 따라 대상체에서 Sema3A 활성을 감소시키기에 충분한 양으로, 이는 유해 상태의 완화를 유도하지만, 그러한 양은 독성학적으로 허용되는 것인 항체 또는 그의 항원-결합 단편의 양으로서 정의된다. 대상체는 인간 또는 비-인간 동물 (예를 들어, 토끼, 래트, 마우스, 개, 원숭이 또는 다른 하등 영장류)일 수 있다.
따라서, 한 측면에서, 본 발명은 의약으로서 사용하기 위한, 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 본 발명에 따른 단리된 항체 또는 항원-결합 단편을 포함하는 접합체 또는 본 발명에 따른 단리된 항체 또는 항원-결합 단편을 포함하는 제약 조성물에 관한 것이다.
본 발명에 따른 단리된 항체 또는 항원-결합 단편은 다양한 Sema3A-연관 장애에서 치료 또는 진단 도구로서 사용될 수 있다.
따라서, 추가 측면에서, 본 발명은 신질환, 특히 급성 및 만성 신장 질환, 당뇨병성 신장 질환, 알포트 증후군 및 급성 및 만성 신부전의 치료 및/또는 예방에 사용하기 위한, 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 본 발명에 따른 단리된 항체 또는 항원-결합 단편을 포함하는 접합체 또는 본 발명에 따른 단리된 항체 또는 항원-결합 단편을 포함하는 제약 조성물에 관한 것이다. 일반적 용어 '신질환' 또는 '신장 질환'은 신장이 혈액으로부터 폐기물을 여과 및 제거하는 데 실패한 상태의 부류를 기재한다. 신장 질환의 2가지 주요 형태: 급성 신장 질환 (급성 신장 손상, AKI) 및 만성 신장 질환 (CKD)이 존재한다. 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 그를 포함하는 접합체 또는 제약 조성물은 추가로 다발성 손상, 예컨대 허혈-재관류 손상, 방사선조영제 투여, 심폐 우회로 수술, 쇼크 및 패혈증으로부터 발생하는 급성 신장 손상의 후유증의 치료 및/또는 예방에 사용될 수 있다. 본 발명의 문맥에서, 용어 신부전 및 신기능부전은 신기능부전의 급성 및 만성 징후 둘 다, 뿐만 아니라 기저 또는 관련 신장 질환, 예컨대 신저관류, 투석중 저혈압, 폐쇄성 요로병증, 사구체병증, IgA 신병증, 사구체신염, 급성 사구체신염, 사구체경화증, 세관간질성 질환, 신병증성 질환 예컨대 원발성 및 선천성 신장 질환, 신염, 알포트 증후군, 신장 염증, 면역학적 신장 질환 예컨대 신장 이식 거부, 면역 복합체-유발 신장 질환, 독성 물질에 의해 유발된 신병증, 조영제-유발 신병증; 미세 변화 사구체신염 (지질성); 막성 사구체신염; 초점성 분절성 사구체경화증 (FSGS); 용혈성 요독성 증후군 (HUS), 아밀로이드증, 굿패스쳐 증후군, 베게너 육아종증, 자반증 쇤라인-헤노흐, 당뇨병성 및 비-당뇨병성 신병증, 신우신염, 신낭, 신경화증, 고혈압성 신경화증 및 신증후군을 포함하며, 이는 진단상, 예를 들어 비정상적으로 감소된 크레아티닌 및/또는 수분 배설, 비정상적으로 증가된 우레아, 질소, 칼륨 및/또는 크레아티닌의 혈액 농도, 신장 효소, 예컨대 예를 들어 글루타밀 신테타제의 변경된 활성, 변경된 소변 오스몰농도 또는 소변 부피, 증가된 미세알부민뇨, 거대알부민뇨, 사구체 및 세동맥의 병변, 세관 확장, 고인산혈증 및/또는 투석에 대한 필요를 특징으로 할 수 있다. 본 발명은 또한 신기능부전 후유증, 예를 들어 폐 부종, 심부전, 요독증, 빈혈, 전해질 장애 (예를 들어 고칼륨혈증, 저나트륨혈증) 및 골 및 탄수화물 대사 장애의 치료 및/또는 예방에 사용하기 위한 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 그를 포함하는 접합체 또는 제약 조성물에 관한 것이다. 본 발명에 따른 화합물은 또한 다낭성 신장 질환 (PCKD) 및 부적절한 ADH 분비 증후군 (SIADH)의 치료 및/또는 예방에 적합하다.
추가적으로, 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 그를 포함하는 접합체 또는 제약 조성물은 혈관 과투과성, 당뇨병성 망막병증, 혈액 망막 장벽 악화 및 그에 따른 황반 부종, 바람직하게는, 연령 관련 황반 부종, 비-증식성 연령-관련 황반 부종 및 비-증식성 당뇨병성 황반 부종의 치료 및/또는 예방에 사용될 수 있다.
추가로, 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 그를 포함하는 접합체 또는 제약 조성물은 중추 또는 말초 신경계 질환 예컨대 신경병증성 통증, 척수 손상, 다발성 경화증, 외상성 뇌 손상, 뇌 부종 또는 신경변성 질환의 예방 또는 치료에 적합하며, 여기서 신경변성 질환은 알츠하이머병, 파킨슨병, 헌팅톤병, 근위축성 측삭 경화증, 진행성 핵상 마비, 흑색질 변성, 샤이-드래거 증후군, 올리브교뇌소뇌 위축 또는 척수소뇌 변성이다.
또한, 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 그를 포함하는 접합체 또는 제약 조성물은 암의 치료 및/또는 예방에 유용할 수 있으며, 여기서 암은 장암, 결장직장암, 폐암, 유방암, 뇌암, 흑색종, 신세포암, 백혈병, 림프종, T-세포 림프종, 위암, 췌장암, 자궁경부암, 자궁내막암, 난소암, 식도암, 간암, 두경부의 편평 세포 암종, 피부암, 요로암, 전립선암, 융모막암종, 인두암 또는 후두암이다.
상기 언급된 장애는 인간에서 잘 특징화되어 있지만, 또한 포유동물을 비롯한 다른 동물에서도 유사한 병인으로 존재하며, 본 발명에 따른 제약 조성물을 투여하는 것에 의해 치료될 수 있다.
본 발명에 따른 항체 또는 항원-결합 단편 또는 그의 변이체는 공지된 의약과 공-투여될 수 있고, 일부 경우에 항체 또는 그의 항원-결합 단편은 그 자체가 변형될 수 있다. 예를 들어, 항체 또는 그의 항원-결합 단편 또는 그의 변이체는 잠재적으로 효능을 추가로 증가시키기 위해 약물 또는 또 다른 펩티드 또는 단백질에 접합될 수 있다.
본 발명의 항체 또는 그의 항원-결합 단편 또는 그의 변이체는 단독 제약 작용제로서, 또는 조합이 허용되지 않는 유해 효과를 유발하지 않는 경우에 1종 이상의 추가의 치료제와 조합되어 투여될 수 있다.
따라서, 추가 측면에서, 본 발명은 1종 이상의 추가의 치료 활성 화합물과 동시, 개별, 또는 순차적 조합으로 사용하기 위한 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 본 발명에 따른 접합체 또는 본 발명에 따른 제약 조성물에 관한 것이다.
본 발명에 따른 항체 또는 항원-결합 단편과 조합되어 사용될 치료 활성 화합물의 비제한적 예는 하기와 같다:
- 혈압 저하제, 예를 들어 및 바람직하게는 칼슘 길항제, 안지오텐신 II 길항제, ACE 억제제, NEP 억제제, 바소펩티다제 억제제, 엔도텔린 길항제, 레닌 억제제, 알파-차단제, 베타-차단제, 미네랄로코르티코이드 수용체 길항제 및 이뇨제의 군으로부터의 것;
- 항당뇨병제 (혈당강하제 또는 항고혈당제), 예컨대 예를 들어 및 바람직하게는 인슐린 및 유도체, 술포닐우레아, 비구아니드, 티아졸리딘디온, 아카르보스, DPP4 억제제, GLP-1 유사체, 또는 SGLT 억제제 (글리플로진);
- 신호 전달 캐스케이드를 억제하는 화합물, 특히 티로신 및/또는 세린/트레오닌 키나제 억제제, 예컨대 예를 들어 닌테다닙, 다사티닙, 닐로티닙, 보수티닙, 레고라페닙, 소라페닙, 수니티닙, 세디라닙, 악시티닙, 텔라티닙, 이마티닙, 브리바닙, 파조파닙, 바탈라닙, 게피티닙, 에를로티닙, 라파티닙, 카네르티닙, 레스타우르티닙, 펠리티닙, 세막사닙 또는 탄두티닙;
- 항염증 약물 예컨대 비-스테로이드성 항염증 약물 (NSAID), 예컨대 아세틸살리실산 (아스피린), 이부프로펜 및 나프록센, 글루코코르티코이드 예컨대 예를 들어 및 바람직하게는 프레드니손, 프레드니솔론, 메틸프레드니솔론, 트리암시놀론, 덱사메타손, 베클로메타손, 베타메타손, 플루니솔리드, 부데소니드 또는 플루티카손, 또는 5-아미노살리실산 유도체, 류코트리엔 길항제, TNF-알파 억제제 및 케모카인 수용체 길항제 예컨대 CCR1, 2 및/또는 5 억제제, NF-κB 억제제 및 Nerf2 활성화제;
- 항섬유화 약물, 예컨대 TGF베타 길항제, 또는 마이크로RNA-21 억제제;
- 유기 니트레이트 및 NO-공여자, 예를 들어 소듐 니트로프루시드, 니트로글리세린, 이소소르비드 모노니트레이트, 이소소르비드 디니트레이트, 몰시도민 또는 SIN-1, 및 흡입 NO;
- 시클릭 구아노신 모노포스페이트 (cGMP)의 분해를 억제하는 화합물, 예를 들어 포스포디에스테라제 (PDE) 1, 2, 5 및/또는 9의 억제제, 특히 PDE-5 억제제, 예컨대 실데나필, 바르데나필, 타달라필, 우데나필, 다산타필, 아바나필, 미로데나필, 로데나필, CTP-499 또는 PF-00489791;
- 칼슘 감작제, 예컨대 예를 들어 및 바람직하게는 레보시멘단;
- 특히 혈소판 응집 억제제, 항응고제 및 전섬유소용해 물질로 이루어진 군으로부터 선택된 항혈전제;
- NO- 및 헴-의존성뿐만 아니라 NO- 및 헴-비의존성 cGMP 합성을 자극하는 작용제, 예를 들어 바람직하게는 가용성 구아닐레이트 시클라제 (sGC) 조정제, 예를 들어 및 바람직하게는 리오시구아트, 시나시구아트, 베리시구아트 또는 BAY 1101042;
- 지방 대사 변경제, 예를 들어 및 바람직하게는 갑상선 수용체 효능제, 콜레스테롤 합성 억제제, 예컨대 예를 들어 및 바람직하게는 HMG-CoA-리덕타제 또는 스쿠알렌 합성 억제제, ACAT 억제제, CETP 억제제, MTP 억제제, PPAR-알파, PPAR-감마 및/또는 PPAR-델타 효능제, 콜레스테롤 흡수 억제제, 리파제 억제제, 중합체 담즙산 흡착제, 담즙산 재흡수 억제제 및 지단백질(a) 길항제의 군으로부터의 것.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 혈소판 응집 억제제, 특히 아스피린, 클로피도그렐, 티클로피딘 또는 디피리다몰과 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 트롬빈 억제제, 특히 크시멜라가트란, 다비가트란, 멜라가트란, 비발리루딘 또는 에녹사파린과 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 GPIIb/IIIa 길항제, 특히 티로피반 또는 압식시맙과 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 리바록사반, 아픽사반, 오타믹사반, 피덱사반, 라작사반, 폰다파리눅스, 이드라파리눅스, DU-176b, PMD-3112, YM-150, KFA-1982, EMD-503982, MCM-17, MLN-1021, DX 9065a, DPC 906, JTV 803, SSR-126512 및 SSR-128428로부터 선택된 인자 Xa 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 헤파린 또는 저분자량 (LMW) 헤파린 유도체와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 쿠마린으로부터 선택된 비타민 K 길항제와 조합되어 투여된다.
혈압 저하제는 특히 칼슘 길항제, 안지오텐신 AII 길항제, ACE 억제제, NEP 억제제, 바소펩티다제 억제제, 엔도텔린 길항제, 레닌 억제제, 알파-차단제, 베타-차단제, 미네랄로코르티코이드 수용체 길항제 및 이뇨제로 이루어진 군으로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 니페디핀, 암로디핀, 베라파밀 및 딜티아젬으로부터 선택된 칼슘 길항제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 로사르탄, 칸데사르탄, 발사르탄, 텔미사르탄, 이르베사르탄, 올메사르탄, 에프로사르탄, 엠부르사르탄 및 아질사르탄으로 이루어진 군으로부터 선택된 안지오텐신 AII 수용체 길항제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 에날라프릴, 캅토프릴, 리시노프릴, 라미프릴, 델라프릴, 포시노프릴, 퀴노프릴, 페린도프릴, 베나제프릴 및 트란도프릴로 이루어진 군으로부터 선택된 ACE 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 보센탄, 다루센탄, 암브리센탄, 테조센탄, 시탁센탄, 아보센탄, 마시텐탄 및 아트라센탄으로 이루어진 군으로부터 선택된 엔도텔린 길항제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 알리스키렌, SPP-600 및 SPP-800으로 이루어진 군으로부터 선택된 레닌 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 피네레논, 스피로노락톤, 칸레논, 포타슘 칸레노에이트, 에플레레논, 에삭세레논 (CS-3150), 또는 아파라레논 (MT-3995), CS-3150, 및 MT-3995로 이루어진 군으로부터 선택된 미네랄로코르티코이드 수용체 길항제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 푸로세미드, 부메타니드, 피레타니드, 토르세미드, 벤드로플루메티아지드, 클로로티아지드, 히드로클로로티아지드, 크시파미드, 인다파미드, 히드로플루메티아지드, 메티클로티아지드, 폴리티아지드, 트리클로로메티아지드, 클로로탈리돈, 메톨라존, 퀴네타존, 아세타졸아미드, 디클로로페나미드, 메타졸아미드, 글리세린, 이소소르비드, 만니톨, 아밀로리드 및 트리암테렌으로 이루어진 군으로부터 선택된 이뇨제와 조합되어 투여된다.
지방 대사 변경제는 특히 CETP 억제제, 갑상선 수용체 효능제, 콜레스테롤 합성 억제제, 예컨대 HMG-CoA-리덕타제 또는 스쿠알렌 합성 억제제, ACAT 억제제, MTP 억제제, PPAR-알파, PPAR-감마 및/또는 PPAR-델타 효능제, 콜레스테롤 흡수 억제제, 중합체 담즙산 흡착제, 담즙산 재흡수 억제제, 리파제 억제제 및 지단백질(a) 길항제로 이루어진 군으로부터 선택된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 바르독솔론 메틸로부터 선택된 Nerf2 활성화제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 D-티록신, 3,5,3'-트리아이오도티로닌 (T3), CGS 23425 및 악시티롬 (CGS 26214)으로 이루어진 군으로부터 선택된 갑상선 수용체 효능제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 로바스타틴, 심바스타틴, 프라바스타틴, 플루바스타틴, 아토르바스타틴, 로수바스타틴 및 피타바스타틴으로 이루어진 군으로부터 선택된 스타틴 부류로부터의 HMG-CoA-리덕타제 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 피오글리타존 및 로시글리타존으로부터 선택된 PPAR-감마 조정제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 ASP1128, GW 501516 및 BAY 68-5042로 이루어진 군으로부터 선택된 PPAR-델타 조정제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 에제티미브, 티퀘시드 및 파마퀘시드로 이루어진 군으로부터 선택된 콜레스테롤 흡수 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 오를리스타트로부터 선택된 리파제 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 콜레스티라민, 콜레스티폴, 콜레솔밤, 콜레스타겔 및 콜레스티미드로 이루어진 군으로부터 선택된 중합체 담즙산 흡착제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 ASBT (IBAT) 억제제, 예컨대 AZD-7806, S-8921, AK-105, BARI-1741, SC-435 및 SC-635로 이루어진 군으로부터 선택된 담즙산 재흡수 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 겜카벤 칼슘 (CI-1027) 및 니코틴산으로 이루어진 군으로부터 선택된 지단백질(a) 길항제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 피르페니돈 및 프레솔리무맙으로부터 선택된 TGF베타 길항제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 라데미르센으로부터 선택된 항-마이크로RNA-21 올리고뉴클레오티드와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 몰리두스타트 및 록사두스타트로부터 선택된 HIF-PH 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 CCX-140으로부터 선택된 CCR2 길항제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은, 특히 아달리무맙으로부터 선택된 TNF알파 길항제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 GCS-100으로부터 선택된 갈렉틴-3 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 레파날린으로부터 선택된 간세포 성장 인자 모방체와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 QPI-1002로부터 선택된 p53 조정제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 GKT-137831로부터 선택된 NOX1/4 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 콜레칼시페롤 및 파라칼시톨로부터 선택된, 비타민 D 대사에 영향을 미치는 의약과 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 시클로포스파미드로부터 선택된 세포증식억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 라니비주맙, 베바시주맙 및 아플리베르셉트로 이루어진 군으로부터 선택된 항-VEGF 요법과 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 시클로스포린으로부터 선택된 면역억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 세벨라머 및 탄산란타넘으로부터 선택된 포스페이트 결합제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 부갑상선기능항진증 요법을 위한 칼슘모방체와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 철 제품으로부터 선택된 철 결핍 요법을 위한 작용제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 알로퓨리놀 및 라스부리카제로부터 선택된 고요산혈증 요법을 위한 작용제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 에리트로포이에틴으로부터 선택된 빈혈 요법을 위한 당단백질 호르몬과 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 아바타셉트, 리툭시맙, 에쿨리주맙 및 벨리무맙으로 이루어진 군으로부터 선택된 면역 요법을 위한 생물제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 룩솔리티닙, 토파시티닙, 바리시티닙, CYT387, GSK2586184, 레스타우르티닙, 파크리티닙 (SB1518) 및 TG101348로 이루어진 군으로부터 선택된 Jak 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 미세혈전 요법을 위한 프로스타시클린 유사체와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 중탄산나트륨으로부터 선택된 알칼리 요법과 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 에베롤리무스 및 라파마이신으로부터 선택된 mTOR 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 AZD1722로부터 선택된 NHE3 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 사프로프테린으로부터 선택된 eNOS 조정제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 특히 FG-3019로부터 선택된 CTGF 억제제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 이뇨제, 안지오텐신 AII 길항제, ACE 억제제, 베타-수용체 차단제, 미네랄로코르티코이드 수용체 길항제, 항당뇨병제, 유기 니트레이트 및 NO 공여자, 가용성 구아닐레이트 시클라제 (sGC)의 활성화제 및 자극제, 및 양성-수축촉진제로 이루어진 군으로부터 선택된 1종 이상의 추가의 치료제와 조합되어 투여된다.
특정한 실시양태에서, 본 발명에 따른 단리된 항체 또는 항원-결합 단편은 이뇨제, 안지오텐신 AII 길항제, ACE 억제제, 베타-수용체 차단제, 미네랄로코르티코이드 수용체 길항제, 항당뇨병제, 유기 니트레이트 및 NO 공여자, 가용성 구아닐레이트 시클라제 (sGC)의 활성화제 및 자극제, 양성-수축촉진제, 항염증제, 면역억제제, 포스페이트 결합제, 및 비타민 D 대사를 조정하는 항체로 이루어진 군으로부터 선택된 1종 이상의 추가의 치료제와 조합되어 투여된다.
조합 요법은 본 발명에 따른 항체 또는 항원-결합 단편 또는 그의 변이체 및 1종 이상의 추가의 치료제를 포함하는 단일 제약 투여 제제의 투여, 뿐만 아니라 본 발명에 따른 항체 또는 항원-결합 단편 및 각각의 추가의 치료제의 그 자체의 개별 제약 투여 제제로의 투여를 포함한다. 예를 들어, 본 발명의 항체 또는 그의 항원-결합 단편 또는 그의 변이체 및 치료제는 환자에게 단일 액체 조성물로 함께 투여될 수 있거나, 또는 각각의 작용제는 개별 투여 제제로 투여될 수 있다.
개별 투여 제제가 사용되는 경우에, 본 발명에 따른 항체 또는 항원-결합 단편 또는 그의 변이체 및 1종 이상의 추가의 치료제는 본질적으로 동시에 (예를 들어, 공동으로) 또는 개별적으로 시차를 둔 시간에 (예를 들어, 순차적으로) 투여될 수 있다.
본 발명에 따른 항체 또는 항원-결합 단편 또는 그의 변이체는 하기를 포함하나 이에 제한되지는 않는 외과적 개입과 조합되어 사용될 수 있다:
- 주요 심혈관 수술, 예를 들어 관상 동맥 우회로 이식 (CABG), 심장 판막 복구 또는 대체, 박동조율기 또는 이식형 심장율동전환기 제세동기 (ICD)의 삽입, 미로 수술, 동맥류 복구, 경동맥 수술/동맥내막절제술 및 혈전절제술;
- 주요 비-심장 수술, 예를 들어 흉부, 정형외과 비뇨기과 수술.
진단 방법
또한, 본 발명에 따른 항체 또는 항원-결합 단편은 그 자체로 또는 조성물로, 연구 및 진단에서, 또는 분석 참조 표준물 등으로서 이용될 수 있다.
항-Sema3A 항체 또는 그의 항원-결합 단편은 Sema3A의 존재를 검출하는 데 사용될 수 있다. 따라서, 추가 측면에서, 본 발명은 진단제로서 사용하기 위한 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 본 발명에 따른 항체 접합체에 관한 것이다.
제약 조성물 및 투여
추가 측면에서, 본 발명은 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 본 발명에 따른 항체 접합체를 포함하는 제약 조성물에 관한 것이다. 상기 장애 중 임의의 것을 치료하기 위해, 본 발명에 따라 사용하기 위한 제약 조성물은 1종 이상의 생리학상 허용되는 담체, 부형제 또는 보조제를 사용하여 임의의 통상적인 방식으로 제제화될 수 있다. 제제화 및 투여 기술에 대한 추가의 세부사항은 문헌 [Remington's Pharmaceutical Sciences (Ed. Maack Publishing Co, Easton, Pa.)]의 최신판에서 찾아볼 수 있다.
본 발명에 따른 항체 또는 항원-결합 단편은 임의의 적합한 수단에 의해 투여될 수 있으며, 이는 치료될 장애의 유형에 따라 달라질 수 있다. 가능한 투여 경로는 경구, 비경구 및 국소 투여를 포함한다. 비경구 전달 방법은 동맥내, 근육내, 피하, 수질내, 척수강내, 뇌실내, 정맥내, 복강내 또는 비강내 투여를 포함한다. 또한, 본 발명에 따른 항체 또는 항원-결합 단편은 펄스 주입에 의해, 예를 들어 항체의 감소하는 용량으로 투여될 수 있다. 바람직하게는, 투여는 주사, 가장 바람직하게는 부분적으로 투여가 단기적인지 또는 장기적인지에 따라 정맥내 또는 피하 주사에 의한다. 투여되는 양은 다양한 인자, 예컨대 임상 증상, 개체의 체중, 다른 약물이 투여되는지 여부 등에 좌우될 것이다. 통상의 기술자는 투여 경로가 치료될 장애 또는 상태에 따라 달라질 것임을 인식할 것이다.
본 발명에 따른 제약 조성물은 본 발명에 따른 항체 또는 항원-결합 단편을 단독으로 또는 적어도 1종의 다른 작용제, 예컨대 안정화 화합물과 조합하여 포함한다. 본 발명에 따른 항체 또는 항원-결합 단편은 염수, 완충 염수, 덱스트로스, 및 물을 포함하나 이에 제한되지는 않는 임의의 멸균, 생체적합성 제약 담체 중에서 투여될 수 있다. 특정한 실시양태에서, 본 발명에 따른 제약 조성물은 1종 이상의 추가의 제약 활성 화합물, 특히 Sema3A 연관 장애를 치료하는 데 적합한 1종 이상의 추가의 제약 활성 화합물을 포함할 수 있다. 이들 작용제 중 임의의 것은 부형제(들) 또는 제약상 허용되는 담체와 혼합된 제약 조성물로 환자에게 단독으로, 또는 다른 작용제 또는 약물과 조합되어 투여될 수 있다. 특정한 실시양태에서, 제약상 허용되는 담체는 제약상 불활성이다.
경구 투여를 위한 제약 조성물은 경구 투여에 적합한 투여량으로 관련 기술분야에 널리 공지된 제약상 허용되는 담체를 사용하여 제제화될 수 있다. 이러한 담체는 제약 조성물이 환자에 의한 섭취를 위해 정제, 환제, 당의정, 캡슐, 액체, 겔, 시럽, 슬러리, 현탁액 등으로서 제제화될 수 있게 한다.
경구 사용을 위한 제약 제제는 활성 화합물을 고체 부형제와 조합하고, 임의로 생성된 혼합물을 분쇄하고, 원하는 경우에 적합한 보조제를 첨가한 후 과립의 혼합물을 가공하여 정제 또는 당의정 코어를 수득하는 것을 통해 수득될 수 있다. 적합한 부형제는 탄수화물 또는 단백질 충전제, 예컨대 락토스, 수크로스, 만니톨 또는 소르비톨을 포함한 당; 옥수수, 밀, 벼, 감자 또는 다른 식물로부터의 전분; 셀룰로스, 예컨대 메틸-셀룰로스, 히드록시프로필메틸셀룰로스 또는 소듐 카르복시메틸 셀룰로스; 및 아라비아 및 트라가칸트를 포함한 검; 및 단백질, 예컨대 젤라틴 및 콜라겐이다. 원하는 경우에, 붕해제 또는 가용화제, 예컨대 가교된 폴리비닐 피롤리돈, 한천, 알긴산 또는 그의 염, 예컨대 알긴산나트륨이 첨가될 수 있다.
당의정 코어에는 적합한 코팅, 예컨대 농축 당 용액이 제공될 수 있으며, 이는 또한 아라비아 검, 활석, 폴리비닐 피롤리돈, 카르보폴 겔, 폴리에틸렌 글리콜 및/또는 이산화티타늄, 래커 용액, 및 적합한 유기 용매 또는 용매 혼합물을 함유할 수 있다. 염료 또는 안료는 제품 식별을 위해 또는 활성 화합물의 양, 즉 투여량을 특징화하기 위해 정제 또는 당의정 코팅에 첨가될 수 있다.
경구로 사용될 수 있는 제약 제제는 젤라틴으로 제조된 푸시-피트 캡슐, 뿐만 아니라 젤라틴 및 코팅, 예컨대 글리세롤 또는 소르비톨로 제조된 연질 밀봉 캡슐을 포함한다. 푸시-피트 캡슐은 충전제 또는 결합제, 예컨대 락토스 또는 전분, 윤활제, 예컨대 활석 또는 스테아르산마그네슘, 및 임의로 안정화제와 혼합된 활성 성분을 함유할 수 있다. 연질 캡슐에서, 활성 화합물은 안정화제의 존재 또는 부재 하에 적합한 액체, 예컨대 지방 오일, 액체 파라핀, 또는 액체 폴리에틸렌 글리콜 중에 용해 또는 현탁될 수 있다.
비경구 투여를 위한 제약 제제는 활성 화합물의 수용액을 포함한다. 주사를 위해, 본 발명의 제약 조성물은 수용액 중에, 바람직하게는 생리학상 상용성인 완충제, 예컨대 행크 용액, 링거액 또는 생리학상 완충 염수 중에 제제화될 수 있다. 수성 주사 현탁액은 현탁액의 점도를 증가시키는 물질, 예컨대 소듐 카르복시메틸 셀룰로스, 소르비톨 또는 덱스트란을 함유할 수 있다. 추가적으로, 활성 화합물의 현탁액은 적절한 유성 주사 현탁액으로서 제조될 수 있다. 적합한 친지성 용매 또는 비히클은 지방 오일, 예컨대 참깨 오일, 또는 합성 지방산 에스테르, 예컨대 에틸 올레에이트 또는 트리글리세리드, 또는 리포솜을 포함한다. 임의로, 현탁액은 또한 화합물의 용해도를 증가시켜 고도로 농축된 용액의 제조를 가능하게 하는 적합한 안정화제 또는 작용제를 함유할 수 있다.
국소 또는 비강 투여를 위해, 침투될 특정한 장벽에 적절한 침투제가 제제에 사용된다. 이러한 침투제는 일반적으로 관련 기술분야에 공지되어 있다.
본 발명의 제약 조성물은 관련 기술분야에 공지된 방식으로, 예를 들어 통상적인 혼합, 용해, 과립화, 당의정-제조, 연화, 유화, 캡슐화, 포획 또는 동결건조 공정에 의해 제조될 수 있다.
제약 조성물은 염으로서 제공될 수 있고, 염산, 황산, 아세트산, 락트산, 타르타르산, 말산, 숙신산 등을 포함하나 이에 제한되지는 않는 산으로 형성될 수 있다. 염은 상응하는 유리 염기 형태인 수성 또는 다른 양성자성 용매에 보다 가용성인 경향이 있다. 다른 경우에, 바람직한 제제는 사용 전 완충제와 조합된 폴리소르베이트와 같은 추가의 물질을 임의로 포함하는, pH 범위 4.5 내지 7.5의 1 mM - 50 mM 히스티딘 또는 포스페이트 또는 트리스, 0.1%-2% 수크로스 및/또는 2%-7% 만니톨 중의 동결건조된 분말일 수 있다.
허용되는 담체 중에 제제화된 본 발명의 화합물을 포함하는 제약 조성물을 제조한 후, 이를 적절한 용기에 넣고, 표시된 상태의 치료에 대해 라벨링할 수 있다. 항-Sema3A 항체 또는 그의 항원-결합 단편의 투여를 위해, 이러한 라벨링은 투여의 양, 빈도 및 방법을 포함할 것이다.
치료 유효 용량
본 발명에 따라 사용하기에 적합한 제약 조성물은 활성 성분이 의도된 목적, 예를 들어 상승된 Sema3A 수준 또는 활성을 특징으로 하는 특정한 질환 상태의 치료를 달성하기 위한 유효량으로 함유된 조성물을 포함한다.
유효 용량의 결정은 충분히 관련 기술분야의 통상의 기술자의 능력 내에 있다. 본 발명의 신규 항체 또는 그의 항원-결합 단편 또는 그의 변이체의 치료 유효량을 결정하는 것은 주로 특정한 환자 특징, 투여 경로, 및 치료될 장애의 성질에 좌우될 것이다. 일반적 지침은, 예를 들어 국제 조화 회의 및 문헌 [REMINGTON'S PHARMACEUTICAL SCIENCES, chapters 27 and 28, pp. 484-528 (18th ed., Alfonso R. Gennaro, Ed., Easton, Pa.: Mack Pub. Co., 1990)]의 간행물에서 찾아볼 수 있다. 보다 구체적으로, 치료 유효량을 결정하는 것은 의약의 독성 및 효능과 같은 인자에 좌우될 것이다. 독성은 관련 기술분야에 널리 공지되고 상기 참고문헌에서 확인되는 방법을 사용하여 결정될 수 있다. 효능은 하기 실시예에 기재된 방법과 함께 동일한 지침을 이용하여 결정될 수 있다.
임의의 화합물에 대해, 치료 유효 용량은 초기에 세포 배양 검정에서 또는 동물 모델, 통상적으로 마우스, 토끼, 개, 돼지 또는 원숭이에서 추정될 수 있다. 동물 모델은 또한 바람직한 농도 범위 및 투여 경로를 달성하기 위해 사용된다. 이어서, 이러한 정보는 인간에서 유용한 용량 및 투여 경로를 결정하는 데 사용될 수 있다.
치료 유효 용량은 증상 또는 상태를 호전시키는 항체 또는 그의 항원-결합 단편의 양을 지칭한다. 이러한 화합물의 치료 효능 및 독성은 세포 배양물 또는 실험 동물에서 표준 제약 절차에 의해, 예를 들어 ED50 (집단의 50%에서 치료상 유효한 용량) 및 LD50 (집단의 50%에 치명적인 용량)으로 결정될 수 있다. 치료 효과와 독성 효과 사이의 용량 비는 치료 지수이고, 이는 ED50/LD50의 비로 표현될 수 있다. 큰 치료 지수를 나타내는 제약 조성물이 바람직하다. 세포 배양 검정 및 동물 연구로부터 수득된 데이터는 인간 사용을 위한 투여량 범위를 공식화하는 데 사용된다. 이러한 화합물의 투여량은 바람직하게는 독성이 거의 또는 전혀 없이 ED50을 포함하는 순환 농도의 범위 내에 있다. 투여량은 사용되는 투여 형태, 환자의 감수성, 및 투여 경로에 따라 이러한 범위 내에서 달라진다.
정확한 투여량은 치료될 환자를 고려하여 개별 의사에 의해 선택된다. 투여량 및 투여는 충분한 수준의 활성 모이어티를 제공하거나 또는 목적하는 효과를 유지하도록 조정된다. 고려될 수 있는 추가의 인자는 환자의 질환 상태의 중증도, 연령, 체중 및 성별; 식이, 투여 시간 및 빈도, 약물 조합(들), 반응 감수성, 및 요법에 대한 내성/반응을 포함한다. 장기 작용 제약 조성물은 특정한 제제의 반감기 및 클리어런스율에 따라, 예를 들어 3 내지 4일마다, 매주, 2주마다 1회, 또는 3주마다 1회 투여될 수 있다.
통상의 투여량은 투여 경로에 따라 0.1 내지 100,000 마이크로그램에서 약 10 g의 총 용량까지 달라질 수 있다. 특정한 투여량 및 전달 방법에 관한 지침은 문헌에 제공된다. 미국 특허 번호 4,657,760; 5,206,344; 또는 5,225,212를 참조한다.
키트
추가 측면에서, 본 발명은 본 발명에 따른 단리된 항체 또는 항원-결합 단편 또는 본 발명에 따른 접합체 및 사용에 대한 지침서를 포함하는 키트에 관한 것이다. 특정한 실시양태에서, 키트는 본 발명의 상기 언급된 조성물의 성분 중 1종 이상이 충전된 1개 이상의 용기를 포함한다. 인간 투여를 위한 제품의 제조, 사용 또는 판매에 대한 정부 기관의 승인을 반영하는, 제약 또는 생물학적 제품의 제조, 사용 또는 판매를 규제하는 정부 기관에 의해 규정된 형태의 통지서가 이러한 용기(들)에 회합될 수 있다.
도 1a: 마우스에서의 Sema3A-유도된 알부민 배설에 대한 TPP-15370 (회색 막대), TPP-11489 (줄무늬 막대) 및 TPP-17755 (사각형 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=10)가 제시된다. ***, ****: p < 0.001 p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 1b: 마우스에서의 Sema3A-유도된 알부민 배설에 대한 TPP-23298 (회색 막대), TPP-11489 (점선 막대) 및 TPP-17755 (줄무늬 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=10)가 제시된다. ***, ****: p < 0.001 p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 2a: TPP-11489 (흑색 삼각형)와 비교하여 TPP-15370 (백색 원형) 및 TPP-23298 (흑색 원형)에 의한 처리 후 마우스에서의 Sema3A 유도된 알부민뇨. 비교는 2개의 개별 실험에서 수행하였다. 평균 값이 제시된다. (n=10). n.s. = 통계적으로 유의하지 않음 vs. TPP-15370; * = p < 0.05 vs. TPP-23298. 독립표본 T-검정.
도 2b: TPP-17755 (흑색 사각형)와 비교하여 TPP-15370 (백색 원형) 및 TPP-23298 (흑색 원형)에 의한 처리 후 마우스에서의 Sema3A 유도된 알부민뇨. 비교는 2개의 개별 실험에서 수행하였다. 평균 값이 제시된다. (n=10). n.s. = 통계적으로 유의하지 않음 vs. TPP-15370; * = p < 0.05 vs. TPP-23298. 독립표본 T-검정.
도 2c: TPP-30788 (흑색 마름모꼴)과 비교하여 TPP-15370 (백색 원형) 및 TPP-23298 (흑색 원형)에 의한 처리 후 마우스에서의 Sema3A 유도된 알부민뇨. 비교는 2개의 개별 실험에서 수행하였다. 평균 값이 제시된다. (n=10). n.s. = 통계적으로 유의하지 않음 vs. TPP-15370; * = p < 0.05 vs. TPP-23298. 독립표본 T-검정.
도 3: 마우스에서의 I/R 손상 후 a: 혈청 크레아티닌 수준, b: 혈청 우레아 수준 및 c: 뇨 알부민 배설에 대한 TPP-23374 (점선 막대) TPP-23298 (회색 막대) 및 TPP-15370 (줄무늬 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=8-10)가 제시된다. *, **, ****: p < 0.05, p < 0.01, p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 4: 마우스에서의 I/R 손상 후 a: 혈청 크레아티닌 수준, b: 혈청 우레아 수준 및 c: 뇨 알부민 배설에 대한 TPP-15370 (회색 막대), TPP-11489 (줄무늬 막대) 및 TPP-17755 (사각형 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=8-10)가 제시된다. *, **, ****: p < 0.05, p < 0.01, p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 5: 마우스에서의 I/R 손상 후 a: 혈청 크레아티닌 수준, b: 혈청 우레아 수준 및 c: 뇨 알부민 배설에 대한 TPP-23298 (회색 막대), TPP-11489 (줄무늬 막대) 및 TPP-17755 (사각형 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=10-12)가 제시된다. *, **, ****: p < 0.05, p < 0.01, p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 6: 마우스에서의 I/R 손상 후 a: 혈청 크레아티닌 수준, b: 혈청 우레아 수준 및 c: 뇨 알부민 배설에 대한 TPP-15374 (회색 막대), TPP-11489 (줄무늬 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=10-12)가 제시된다. *, **, ***, ****: p < 0.05, p < 0.01, p < 0.001 p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 7: 알포트 마우스에서의 단백뇨에 대한 TPP-15370 (회색 막대), TPP-11489 (줄무늬 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=8-10)가 제시된다. ****: p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 8: 알포트 마우스에서의 a: 혈청 크레아티닌 수준, b: 혈청 우레아 수준 및 섬유증, c: 근섬유모세포 및 d: 콜라겐 침착에 대한 TPP-15370 (회색 막대), TPP-11489 (줄무늬 막대))에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=8-10)가 제시된다. *, ***, ****: p < 0.05, p < 0.001, p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 9: 돼지에서의 105분 허혈의 일측성 신장 IRI 모델에서, 단일 용량 예방 세팅에서의 TPP-23298에 의한 Sema3A 억제의 효과. TPP-23298 (a; 흑색 점) 또는 대조군 IgG (백색 원형) (10 mg/kg)를 좌측 신동맥에서 풍선을 팽창시키기 30분 전에 제공하였다. 모의 동물로부터의 값은 다이아몬드형으로 표시된다. 개별 동물의 혈장 크레아티닌 농도의 시간 경과 (a), 및 실험 시작 시 (0시간) 기준선 값 대비 크레아티닌 혈장 농도의 평균 변화의 시간 경과 (b). 24-27시간 간격 동안의 크레아티닌 클리어런스의 평균 값. 크레아티닌 클리어런스 측면을 좌측 (손상됨) 및 우측 (비-손상됨) 신장 및 모의 동물로부터의 신장에 대해 분리하였다 (c). 전반적 크레아티닌 클리어런스 (d); t-검정으로부터의 (b)에서의 평균 ± SEM, p-값, (c) 및 (d)에서의 */***: p<0.05/0.001, 상응하는 대조군 대비 일원 ANOVA에 이어서 던넷 다중 비교.
도 10: SPR을 사용한 샌드위치-기반 에피토프 비닝 실험의 개략적 표현 (또한 실시예 5A 참조).
도 11: HRA 영상 분석 단계: 11a) DAPI/CM 세포의 형광 현미경검사 영상; 11b) 선택된 구역에서의 세포의 확인; 11c) 무세포 영역 크기 (회색 구역)의 계산.
도 12: HUVEC 반발 검정에서 80 pM의 항체 농도에서의 Sema3A의 퍼센트 억제가 제시된다 (실시예 11 참조). 각각의 칼럼은 좌측에서 우측 순서로 하기 1종의 항체를 나타낸다: TPP-23298 (흑색 칼럼), TPP-30788, TPP- TPP-30789, TPP-30790, 및 TPP-30791.
도 1b: 마우스에서의 Sema3A-유도된 알부민 배설에 대한 TPP-23298 (회색 막대), TPP-11489 (점선 막대) 및 TPP-17755 (줄무늬 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=10)가 제시된다. ***, ****: p < 0.001 p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 2a: TPP-11489 (흑색 삼각형)와 비교하여 TPP-15370 (백색 원형) 및 TPP-23298 (흑색 원형)에 의한 처리 후 마우스에서의 Sema3A 유도된 알부민뇨. 비교는 2개의 개별 실험에서 수행하였다. 평균 값이 제시된다. (n=10). n.s. = 통계적으로 유의하지 않음 vs. TPP-15370; * = p < 0.05 vs. TPP-23298. 독립표본 T-검정.
도 2b: TPP-17755 (흑색 사각형)와 비교하여 TPP-15370 (백색 원형) 및 TPP-23298 (흑색 원형)에 의한 처리 후 마우스에서의 Sema3A 유도된 알부민뇨. 비교는 2개의 개별 실험에서 수행하였다. 평균 값이 제시된다. (n=10). n.s. = 통계적으로 유의하지 않음 vs. TPP-15370; * = p < 0.05 vs. TPP-23298. 독립표본 T-검정.
도 2c: TPP-30788 (흑색 마름모꼴)과 비교하여 TPP-15370 (백색 원형) 및 TPP-23298 (흑색 원형)에 의한 처리 후 마우스에서의 Sema3A 유도된 알부민뇨. 비교는 2개의 개별 실험에서 수행하였다. 평균 값이 제시된다. (n=10). n.s. = 통계적으로 유의하지 않음 vs. TPP-15370; * = p < 0.05 vs. TPP-23298. 독립표본 T-검정.
도 3: 마우스에서의 I/R 손상 후 a: 혈청 크레아티닌 수준, b: 혈청 우레아 수준 및 c: 뇨 알부민 배설에 대한 TPP-23374 (점선 막대) TPP-23298 (회색 막대) 및 TPP-15370 (줄무늬 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=8-10)가 제시된다. *, **, ****: p < 0.05, p < 0.01, p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 4: 마우스에서의 I/R 손상 후 a: 혈청 크레아티닌 수준, b: 혈청 우레아 수준 및 c: 뇨 알부민 배설에 대한 TPP-15370 (회색 막대), TPP-11489 (줄무늬 막대) 및 TPP-17755 (사각형 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=8-10)가 제시된다. *, **, ****: p < 0.05, p < 0.01, p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 5: 마우스에서의 I/R 손상 후 a: 혈청 크레아티닌 수준, b: 혈청 우레아 수준 및 c: 뇨 알부민 배설에 대한 TPP-23298 (회색 막대), TPP-11489 (줄무늬 막대) 및 TPP-17755 (사각형 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=10-12)가 제시된다. *, **, ****: p < 0.05, p < 0.01, p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 6: 마우스에서의 I/R 손상 후 a: 혈청 크레아티닌 수준, b: 혈청 우레아 수준 및 c: 뇨 알부민 배설에 대한 TPP-15374 (회색 막대), TPP-11489 (줄무늬 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=10-12)가 제시된다. *, **, ***, ****: p < 0.05, p < 0.01, p < 0.001 p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 7: 알포트 마우스에서의 단백뇨에 대한 TPP-15370 (회색 막대), TPP-11489 (줄무늬 막대)에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=8-10)가 제시된다. ****: p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 8: 알포트 마우스에서의 a: 혈청 크레아티닌 수준, b: 혈청 우레아 수준 및 섬유증, c: 근섬유모세포 및 d: 콜라겐 침착에 대한 TPP-15370 (회색 막대), TPP-11489 (줄무늬 막대))에 의한 Sema3A 억제의 효과. 평균 ± S.D. (n=8-10)가 제시된다. *, ***, ****: p < 0.05, p < 0.001, p < 0.0001 vs. 이소형 대조군. 던넷 사후 검정.
도 9: 돼지에서의 105분 허혈의 일측성 신장 IRI 모델에서, 단일 용량 예방 세팅에서의 TPP-23298에 의한 Sema3A 억제의 효과. TPP-23298 (a; 흑색 점) 또는 대조군 IgG (백색 원형) (10 mg/kg)를 좌측 신동맥에서 풍선을 팽창시키기 30분 전에 제공하였다. 모의 동물로부터의 값은 다이아몬드형으로 표시된다. 개별 동물의 혈장 크레아티닌 농도의 시간 경과 (a), 및 실험 시작 시 (0시간) 기준선 값 대비 크레아티닌 혈장 농도의 평균 변화의 시간 경과 (b). 24-27시간 간격 동안의 크레아티닌 클리어런스의 평균 값. 크레아티닌 클리어런스 측면을 좌측 (손상됨) 및 우측 (비-손상됨) 신장 및 모의 동물로부터의 신장에 대해 분리하였다 (c). 전반적 크레아티닌 클리어런스 (d); t-검정으로부터의 (b)에서의 평균 ± SEM, p-값, (c) 및 (d)에서의 */***: p<0.05/0.001, 상응하는 대조군 대비 일원 ANOVA에 이어서 던넷 다중 비교.
도 10: SPR을 사용한 샌드위치-기반 에피토프 비닝 실험의 개략적 표현 (또한 실시예 5A 참조).
도 11: HRA 영상 분석 단계: 11a) DAPI/CM 세포의 형광 현미경검사 영상; 11b) 선택된 구역에서의 세포의 확인; 11c) 무세포 영역 크기 (회색 구역)의 계산.
도 12: HUVEC 반발 검정에서 80 pM의 항체 농도에서의 Sema3A의 퍼센트 억제가 제시된다 (실시예 11 참조). 각각의 칼럼은 좌측에서 우측 순서로 하기 1종의 항체를 나타낸다: TPP-23298 (흑색 칼럼), TPP-30788, TPP- TPP-30789, TPP-30790, 및 TPP-30791.
실시예
실시예 1: Sema3A 서열 및 도구 생성
표 2: 본 발명에 사용된 도구

일시적으로 형질감염된 HEK293-6E 세포 (캐나다 국립 연구 협의회)를 사용하여 포유동물 세포 배양에 의해 Sema3A 도메인을 생산하였다. 모든 구축물은 CMV 프로모터의 제어 하에 있었고, 서열은 C-말단 FXa 절단 부위에 이어서 6x his-태그를 함유한다. 세포 배양을 0.1% 플루로닉 F68 (라이프 테크놀로지스(Life Technologies)) 및 4 mM 글루타맥스 (라이프 테크놀로지스)가 보충된 F17 배지 (라이프 테크놀로지스)를 사용하여 수행하였다. 형질감염 24시간 후에, 1% FCS 초저 IgG (라이프 테크놀로지스) 및 0.5 mM 발프로산 (시그마 알드리치(Sigma Aldrich))을 첨가하였다. 세포 상청액을 멸균 여과하고, 후속적으로 정제하거나 또는 정제 전에 교차흐름 여과를 통해 농축시켰다.
Sema3A 도메인을 친화도 및 크기 배제 크로마토그래피로 이루어진 2-단계 정제를 사용하여 정제하였다. 간략하게, 세포 배양 상청액을 악타 아반트(Aekta Avant) 시스템 (지이 헬스케어)에 연결된 Ni2+-NTA 칼럼 (지이 헬스케어) 상에 로딩하였다. 칼럼을 4 CV의 50 mM NaH2PO4, 300 mM NaCl, pH 8로 평형화시키고, 그 후 기준선에 도달할 때까지 10 CV의 구동 완충제로 세척하였다. 250 mM 이미다졸, pH 8.0을 함유하는 6 CV의 구동 완충제를 사용하여 용리를 수행하였다. 용리 피크의 분획을 통합하고, 비바플로우 200 히드로사르트(Vivaflow 200 Hydrosart) 막 (컷-오프 10 kDa, 사르토리우스(Sartorius))을 사용하여 농축시키고, 악타 퓨어 25 시스템에 연결된 슈퍼덱스(Superdex) 200 칼럼 (지이 헬스케어)을 사용하여 크기 배제 크로마토그래피에 적용하였다. 칼럼을 평형화시키고, DPBS, pH 7.4에서 구동시켰다. 도메인 용리 피크의 분획을 통합하고, 비바플로우 200 히드로사르트 막 (컷-오프 10 kDa, 사르토리우스)을 사용하여 농축시켰다. 최종 단백질 품질을 순도 및 단분산도에 대해 분석용 크기 배제 크로마토그래피 (슈퍼덱스 200)뿐만 아니라 SDS-PAGE 상에서 평가하였다. 세마 도메인을 분취하고, 액체 질소에서 순간 동결시키고, 추가 사용 시까지 -80℃에서 저장하였다.
실시예 2: 바이오인벤트(BioInvent) 항체 라이브러리로부터의 항체 생성
완전 인간 항체 파지 디스플레이 라이브러리 (바이오인벤트 n-CoDeR Fab 람다 라이브러리)를 사용하여, 하기 프로토콜을 사용하여 재조합 인간 Sema3A (TPP-13211, 알앤디 시스템즈(R&D Systems))에 대한 선택에 의해 본 발명의 인간 모노클로날 항체를 단리하였다. 간략하게, 이뮤노튜브 (눈크(Nunc))를 실온 (RT)에서 1시간 동안 1 ml PBS (포스페이트 완충 염수) 중 100 μg의 표적 분자 (huSema3A) 또는 비관련 Fc-함유 오프-타겟으로 엔드-오버-엔드 회전에 의해 코팅하였다. 표적 및 고갈 항원-코팅된 이뮤노튜브뿐만 아니라 빈 이뮤노튜브를 PBS + 0.05% 트윈20 (PBST)으로 4회 세척하고, 후속적으로 PBST 용액 중 3% 분유 3 ml를 사용하여 실온에서 1시간 동안 엔드-오버-엔드 회전에 의해 차단하였다. 파지 라이브러리의 분취물을 해동시키고, PBST 중 3% 분유의 용액 중에서 실온에서 1시간 동안 엔드-오버-엔드 회전에 의해 차단되도록 하였다. 비-코팅된 고갈 이뮤노튜브를 4 ml PBS 중에서 3회 세척한 후, 차단된 파지 라이브러리를 첨가하고, 엔드-오버-엔드 회전에 의해 실온에서 30분 동안 인큐베이션하였다. 이 단계를 비-표적 항원-코팅된 고갈 이뮤노튜브에 대해 반복하였다. huSema3A-코팅된 이뮤노튜브를 4 ml PBS 중에서 3회 세척한 후, 고갈된 라이브러리를 첨가하고, 엔드-오버-엔드 회전에 의해 실온에서 90분 동안 인큐베이션하였다. 엄격한 세척 (4 ml PBST로 4 x 및 4 ml PBS로 1 x) 후에, 코팅된 표적에 특이적으로 결합하는 Fab-발현 파지를 500 μl 100 nM TEA를 사용하여 용리시키고, 실온에서 10분 인큐베이션한 후, 500 μl 트리스-HCl pH 7.5의 첨가에 의해 중화시켰다. 500 μl의 용리된 파지를 사용하여 에스케리키아 콜라이(Escherichia coli) 균주 HB101을 감염시켰다. 후속적으로, 파지를 M13KO7 헬퍼 파지 (인비트로젠(Invitrogen)™)를 사용하여 에스케리키아 콜라이 균주 HB101에서 증폭시켰다. 2회의 후속 선택 라운드에서, 표적 농도가 25 μg/ml로 감소되었다. 제1 정성적 평가를 위해, 각각의 선택 라운드로부터의 88개의 무작위로 골라낸 Fab-발현 파지 클론을 단일 웰에서 발현시키고, 비관련 오프-타겟과 비교하여 huSema3A에 대한 결합에 대해 시험하였다. 본 실시예에서 라운드 3으로부터의 클론 풀이 60% 양성 히트율을 함유하는 것으로 발견되었고, 추가의 스크리닝을 위해 선택하였다.
다음 단계에서, 이러한 풀에서 유전자 III 융합체의 벌크 제거에 의해 가용성 Fab의 발현을 가능하게 하고, 에스케리키아 콜라이 균주에서의 최고10 발현 및 huSema3A 결합 ELISA에서의 Fab-함유 상청액의 평가를 위해 2208개의 단일 클론을 골라내었다. 모든 2208개의 클론에 대한 VH 및 VL 서열을 또한 NGS 방법을 사용하여 결정하였다. huSema3A에 대한 결합에 대해 양성인 154개의 별개의 클론을 확인하였다. 이들 양성 결합 Fab 단편을 확증적 결합 ELISA에서 시험하고, 또한 마우스 Sema3A-Fc (TPP-13357, 알앤디 시스템즈)에 대한 결합뿐만 아니라 추가의 오프 타겟 분자, 뮤린 Sema3F (알앤디 시스템즈)를 사용한 특이성 시험에 대해 평가하였다. 이러한 분석에 기초하여, 48개의 인간/마우스 교차-반응성 Sema3A 결합 Fab를 우선순위화하였다. 이들 Fab 단편을 후속적으로 포획 선택 CH1 매트릭스 (라이프테크놀로지스)를 사용하여 25 ml 발현 배양물로부터 정제하고, 12.5 mM 시트르산, pH 2.5를 사용하여 용리시키고, 최종적으로 제바(Zeba)™ 스핀 탈염 플레이트 (써모피셔(ThermoFisher))를 사용하여 PBS로 완충제 교환하였다. 표면 플라즈몬 공명 (SPR)에 의해 모든 48개의 정제된 Fab 단편에 대해 동역학적 순위결정을 수행하고, 인간 및 마우스 Sema3A 둘 다에 대한 결합을 검사하고, 전장 인간 IgG1로 재포맷하고, 다시 SPR에서 결합에 대해 시험하였다 (실시예 4 참조).
실시예 3: 리드 항체 TPP-15370 및 TPP-15374의 서열 최적화, 배선화 & 친화도 성숙
IgG1 항체 TPP-15370 및 TPP-15374를 (i) 그의 친화도를 최적화하고, (ii) 기능적 효율을 증가시키고, (iii) 서열-기반 면역원성의 위험을 감소시키고, (iv) 하류 개발 공정과의 상용성을 개선시키는 것을 목표로, 리드 최적화 절차에 적용하였다.
친화도 성숙은 제1 단일 돌연변이 수집 라운드에 이어서, 배선화되고 서열 최적화된 항체 백본에서의 가장 친화도- 및 효력-증가 아미노산 교환의 재조합에 의해 수행하였다.
돌연변이 수집을 위해, 하기 개별 아미노산 위치에서의 NNK (N = A 또는 G 또는 C 또는 T, K = G 또는 T) 무작위화를 코돈-다양화를 위한 NNK를 포함하는 합성 올리고뉴클레오티드를 사용하여 부위 지정 돌연변이유발에 의해 생성하였다. TPP-15370에 대해, 하기 영역을 친화도에 대한 그의 효과에 대해 분석하였다: GFTFSSYGMH (VH 서열식별번호: 41의 잔기 26 내지 35), WVSAIGTGGDTYYADSVMG (VH 서열식별번호: 41의 잔기 47 내지 65), ARRDDYTSRDAFDV (VH 서열식별번호: 41의 잔기 96 내지 109), SGSSSNIGSNTVNWY (VL 서열식별번호: 45의 잔기 23 내지 37), LLIYYDDLLPS (VL 서열식별번호: 45의 잔기 47 내지 57), 및 AAWDDSLNGYVV (VL 서열식별번호: 45의 잔기 90 내지 101).
TPP-15374에 대해, 하기 영역을 친화도에 대한 그의 효과에 대해 분석하였다: GFTFSSYEMN (VH 서열식별번호: 61의 잔기 26 내지 35), WVSGISWNSGSIGYADSVKG (VH 서열식별번호: 61의 잔기 47 내지 66), ARSGYSSSWFDPDFDY (VH 서열식별번호: 61의 잔기 97 내지 112), TGSSSNIGAGYDVHWY (VL 서열식별번호: 65의 잔기 23 내지 38), LLIYGNSNRPS (VL 서열식별번호: 65의 잔기 48 내지 58), 및 SSYAGSNPYV (VL 서열식별번호: 65의 잔기 91 내지 101).
생성된 단일 NNK 라이브러리를 서열분석하고, 각각 TPP15370 및 TPP-15374의 약 1000개의 단일 아미노산 교환 변이체를 확인하였다. 이들을 포유동물 세포의 일시적 형질감염에 의해 발현시키고, 생성된 발현 상청액을 표면 플라즈몬 공명 및 경쟁 ELISA에서 스크리닝될 항체 농도의 관점에서 정규화하였다.
TPP-15370 및 TPP-15374의 배선화 및 서열 최적화 공정을 위해, 경쇄 및 중쇄에 대해 가장 가까운 배선 패밀리를 선택하고, 잠재적 CMC 관련 잔기에 대해 면밀히 조사하였다. CDR 영역 및 FW 영역 내의 가장 가까운 인간 배선 및 CDR 영역 내의 잠재적 CMC 관련 잔기로부터의 편차를 부위 지정 돌연변이유발에 의해 조정하고, 기능적 및 생물물리학적 검정에서 시험하였다 (비특이적 결합, DSC에서의 온도 안정성). 생성된 단일 복귀 및 하기 조합 IgG 변이체를 포유동물 세포의 일시적 형질감염에 의해 발현시키고, 생성된 발현 상청액을 결합 검정 (SPR, 경쟁 ELISA) 및 기능적 검정에서 스크리닝될 항체 농도의 관점에서 정규화하였다. 이로서 TPP-15370의 경우 TPP-21565 및 TPP-15374의 경우 TPP-18533의 배선화되고 서열 최적화된 분자로 이어졌다. TPP-21565는 TPP-15370과 비교하여 경쇄에 L55R 및 R80Q 및 중쇄에 G33A, H35S, M64K 및 V109Y 복귀를 보유한다. TPP-18533은 TPP-15374와 비교하여 경쇄에 A10V, T13A, S78T, R81Q, S82A 복귀를 보유한다.
TPP-21565의 최종 재조합 라이브러리에 대해, NNK 라이브러리 스크리닝 단계에서 개선된 친화도 및 기능적 효율을 나타내는 것으로 제시된 8가지의 단일 치환 변이체를 선택하였다. 경쇄 돌연변이 A90H, G98D, G98V, Y99I 및 V100P 및 중쇄 돌연변이 S30Y, S35L 및 T53Y를 하나의 재조합 라이브러리에서 재조합하였다 (연속 아미노산 명명, 서열식별번호: 121 - VH 및 125 - VL에 의해 정의된 바와 같은 TPP-21565 참조).
TPP-18533의 최종 재조합 라이브러리에 대해, NNK 라이브러리 스크리닝 단계에서 개선된 친화도 및 기능적 효율을 나타내는 것으로 제시된 11가지의 단일 치환 변이체를 선택하였다. 경쇄 돌연변이 N28D, N53A, S91K, S91Q, A94E, S96I 및 S96P 및 중쇄 돌연변이 T28D, S30D, S57W 및 G59Y를 하나의 재조합 라이브러리에서 재조합하였다 (연속 아미노산 명명, 서열식별번호: 101 - VH 및 105 - VL에 의해 정의된 바와 같은 TPP-18533 참조).
TPP-18533에 대해, 각각의 선택된 위치에 선택된 돌연변이 또는 상응하는 야생형 아미노산을 도입하기 위해 올리고뉴클레오티드를 생성하였다. 라이브러리 구축은 순차적 라운드의 중첩 연장 PCR을 사용하여 수행하였다. 최종 PCR 생성물을 포유동물 IgG4 (S228P) 발현 벡터에 라이게이션하고, 변이체를 대규모-병렬 서열분석 기술을 사용하여 서열분석하였다. TPP-21565의 경우, 재조합 변이체를 별개의 클론으로서 설계하고, IgG4 (S228P) 함유 발현 플라스미드 내로 클로닝하였다.
TPP-18533의 1000개 초과의 고유한 조합 아미노산 교환 변이체 및 TPP-21565의 100개 초과의 고유한 조합 변이체를 그러한 방식으로 생성하였고, 포유동물 세포의 일시적 형질감염에 의해 발현시키고, 생성된 발현 상청액을 SPR, 경쟁 ELISA 및 기능적 검정에서 다양한 횟수로 스크리닝될 항체 농도의 관점에서 정규화하였다. 이들 검정에서 결과에 기초하여, 돌연변이체를 '개선된 것' 또는 '비-개선된 것'으로 카테고리화하였다.
표 1 및 1A는 특히 조합 라이브러리 스크리닝 단계에서 Sema3A에 대한 결합의 관점 및 Sema3A-의존성 생물학적 활성을 길항하는 관점에서 가장 강력한 것으로 선택된 본 발명에 따른 바람직한 항체 후보뿐만 아니라 본 발명에 따른 항체의 각각의 아미노산 및 핵산 서열을 열거한다.
실시예 4: 표면 플라즈몬 공명을 사용한 친화도 및 종 교차-반응성의 결정
항-Sema3A 항체의 결합 동역학 및 친화도뿐만 아니라 그의 종 교차-반응성 프로파일을 평가하기 위해, 표면 플라즈몬 공명 (SPR)을 사용하여 결합 검정을 수행하였다. 결합 검정은 비아코어 T200 기기 상에서 또는 비아코어 8K+ 기기 (시티바(Cytiva)) 상에서 25℃에서 검정 완충제 HBS P+, 300 mM NaCl, 0.75 mM CaCl2, 2.5 mM MgCl2, 1 mg/ml BSA, 0.05% NaN3을 사용하여 수행하였다. 항체를 시리즈 S CM5 센서 칩 (시티바)에 공유 아민 커플링된 항-인간 Fc IgG ("인간 항체 포획 키트", 주문 번호 BR100839, 시티바)를 통해, 또는 Fc-태그부착된 분석물의 경우에는 항-인간 Fab IgG ("인간 Fab 포획 키트", 주문 번호 28958325, 시티바)에 의해 포획하였다. 아민 커플링을 제조업체의 지침에 따라 1-에틸-3-(3-디메틸아미노프로필) 카르보디이미드 히드로클로라이드 (EDC), N-히드록시숙신이미드 (NHS) 및 에탄올아민 HCl, pH 8.5를 사용하여 수행하였다 ("아민 커플링 키트" BR-1000-50, 시티바). 파지 디스플레이를 위해, Fc-태그부착된 인간 및 마우스 Sema3A를 분석물로서 1.56 - 200 nM의 농도 범위로 사용하였다. 인간, 마우스, 시노몰구스, 래트, 개 및 돼지 1가 Sema3A 도메인을 분석물로서 다중 사이클 동역학 모드에서는 0.024 - 3.125 nM의 농도 시리즈로, 또는 오직 결합 분석을 위해서는 100 nM로 사용하였다. 센서 표면을 각각의 항원 주입 후에 글리신 pH 2.0으로 재생시켰다. 수득된 센서그램을 이중 참조하고 (참조 유동 세포 신호 및 완충제 주입의 차감), 1:1 랭뮤어 결합 모델에 피팅하여 비아코어 T200 평가 소프트웨어를 사용하여 동역학적 데이터를 유도하였다. 결과를 표 3, 4 및 4a에 제시한다.
표 3: TPP-13211 및 TPP-13357을 사용하여 SPR에 의해 결정된 파지 디스플레이 히트로부터 유래된 항-Sema3A IgG1 항체의 친화도. n.b. = 결합 없음, n.d. = 결정가능하지 않음


대부분의 파지 디스플레이 히트는 보다 낮은 나노몰 범위에서 인간 및 마우스 이량체 Sema3A에 결합한다.
표 4: 분석물로서 TPP-19068, TPP-19069, TPP-19122, TPP-19120, TPP-19121, TPP-20176뿐만 아니라 선행 기술 항체 (TPP-30972는 HEK 세포 발현으로부터 정제됨)를 사용하여 SPR에 의해 결정된, TPP-15370 및 TPP-15374로부터 유래된 항-Sema3A 항체의 친화도.


TPP-15370 및 TPP-15374의 모든 유래 항체는 그의 모 항체뿐만 아니라 대부분의 선행 기술 항체와 비교하여 Sema3A 도메인에 대해 보다 낮은 피코몰 범위의 유의하게 증가된 친화도를 갖는다.
표 4a: 결합 실험에서 100 nM TPP-19068 (인간)을 사용하여 SPR에 의해 결정된 항-Sema3A IgG1 항체의 친화도. n.d. = 다상 거동으로 인해 결정가능하지 않음

SPR에서 Sema3A 분자에 대해 결합을 나타내지 않은 전장 3H4 IgG1 (TPP-30792)과 대조적으로, TPP-30792의 Fab 변이체인 TPP-31357은 인간 Sema3A에 대해 결합을 나타내지만, TPP-23298보다 친화도가 더 낮다.
실시예 5: 표면 플라즈몬 공명을 사용한 결합 활성의 결정
항-Sema3A 항체의 결합 활성을 평가하기 위해, 표면 플라즈몬 공명 (SPR)을 사용하여 결합 검정을 수행하였다. 결합 검정은 비아코어 T200 기기 (시티바) 상에서 25℃에서 검정 완충제 HBS P+, 300 mM NaCl, 0.75 mM CaCl2, 2.5 mM MgCl2, 1 mg/ml BSA, 0.05% NaN3을 사용하여 수행하였다. 항체를 시리즈 S CM5 센서 칩 (시티바)에 공유 아민 커플링된 항-인간 Fc IgG ("인간 항체 포획 키트", 주문 번호 BR100839, 시티바)를 통해 포획하였다. 아민 커플링을 제조업체의 지침에 따라 1-에틸-3-(3-디메틸아미노프로필) 카르보디이미드 히드로클로라이드 (EDC), N-히드록시숙신이미드 (NHS) 및 에탄올아민 HCl, pH 8.5를 사용하여 수행하였다 ("아민 커플링 키트" BR-1000-50, 시티바). 인간, 마우스, 시노몰구스, 래트, 개 및 돼지 1가 Sema3A 도메인을 분석물로서 다중 사이클 동역학 모드에서 0.024 - 3.125 nM의 농도 시리즈로 사용하였다. 센서 표면을 각각의 항원 주입 후에 글리신 pH 2.0으로 재생시켰다. 수득된 센서그램을 이중 참조하고 (참조 유동 세포 신호 및 완충제 주입의 차감), 1:1 랭뮤어 결합 모델에 피팅하여 비아코어 T200 평가 소프트웨어를 사용하여 실험 피팅된 RMax 값을 수득하였다. 결합 활성을 계산하기 위해, 먼저 이론치 RMax가 식 1에 따라 계산될 필요가 있다:
식 1: RMax의 이론치 계산. R리간드 = 리간드 수준, RU, Mr = 분자량, 원자가리간드 = 항체 분자당 결합 부위의 수, 여기서는 2
결정된 실험치 RMax를 식 2에 따라 계산된 이론치 RMax로 나눔으로써 결합 활성을 결정하였다:
식 2: 결합 활성의 계산, %
표 5: 포획 후 리간드 수준, 실험치, 이론치 및 시험된 항체의 결합 활성의 요약



SPR 실험에서 계산된 결합 활성은 표면-부착된 리간드의 활성의 척도이다. 표 5로부터 알 수 있는 바와 같이, TPP-15370, TPP-15374, TPP-23298 및 TPP 30788-30791은 모든 시험된 Sema3A 도메인에 약 100% 활성으로 결합할 수 있으며, 이는 모든 결합 영역이 완전히 결합할 수 있음을 의미한다. 선행 기술 항체 TPP-17755는 종에 따라 단지 50 - 60%의 활성 수준에 도달한다. 선행 기술 항체 TPP-11489는, 보다 높은 마우스 및 돼지를 제외하고는, 50% 미만의 훨씬 더 감소된 수준을 나타낸다. 놀랍게도, 이러한 활성 수준에 도달하기 위해, TPP-11489의 리간드 수준은 다른 항체와 비교하여 10-배 초과로 더 높을 필요가 있으며, 이는 일반적으로 TPP-15370, TPP-15374 및 TPP-23298과 비교하여 훨씬 더 낮은 결합 활성을 가리킨다.
실시예 6: 경쟁 ELISA
경쟁 ELISA 설정에서의 스크리닝을 위해, 인간 Sema3a (TPP-13211)를 384-웰 플레이트 (그라이너 바이오-원(Greiner bio-one), 781077) 상에 코팅 완충제 (카르보네이트-계 pH 9.6, 칸도르(Candor) 121125) 중 0.5 μg/ml의 농도로 10℃에서 밤새 코팅하였다. 플레이트를 50 μl PBS 0.05% 트윈으로 3회 세척한 후, 플레이트를 50 μl 스마트 블록(Smart Block)® (칸도르 113500)으로 20℃에서 1시간 동안 차단하고, 기재된 바와 같이 다시 3회 세척하였다.
후속적으로, 20 μl의 사전-혼합된 항체 용액을 플레이트에 첨가하고, 18시간 동안 10℃에서 인큐베이션하였다. 사전-혼합된 항체 용액에 대해, 각각의 웰에 대해, TPP-15370 또는 TPP-15374인 1종의 비오티닐화된, 모 항체를 그의 CDR 영역 내에 1개 이상의 아미노산 변이를 함유하고 (재조합 변이체) 어떠한 비오틴 태그도 함유하지 않는 항체와 함께 1:1, 1:5 또는 5:1의 비로 혼합하였다. 추가의 대조군으로서, 인간 Sema3A에 대해 어떠한 결합도 입증하지 않은 이소형 대조군 항체를 또한 경쟁 항체로서 사용하였다. 첨가된 항체 용액의 총 농도는 0.25 μg/ml였다. 인큐베이션 시간 동안 항체는 이들이 인간 Sema3A 단백질 상의 동일한 에피토프에 대해 경쟁함에 따라 경쟁적 방식으로 플레이트에 결합하였다.
50 μl PBS 0.05% 트윈으로 3회 후속 세척한 후, 20 μl의 스트렙타비딘-HRP 용액 (알앤디 시스템즈, DY998, PBS 0.05% 트윈 10% 스마트 블록 중 1:200)을 첨가하고, 1시간 동안 20℃에서 인큐베이션하고, 이어서 50 μl PBS 0.05% 트윈으로 3회 후속 세척하고, 20 μl 암플렉스 레드 용액 (인비트로젠 A12222, 1:10000의 30% H2O2를 함유하는 NaP-완충제 50 mM pH7.6 중 1:1000)을 첨가하였다. 20℃에서 20분 동안 최종 인큐베이션 후, 595 nm의 방출 파장 및 530 nm의 여기를 사용하여 신호를 결정하였다. 모 항체 TPP-15370 및 TPP-15374의 비오티닐화로 인해, 오직 이들 변이체의 결합만이 검출될 수 있다. 따라서, 우수한 결합을 입증한 항체 변이체와의 경쟁은, 예를 들어 모 항체와 그 자체의 비-비오닐화된 버전의 경쟁과 비교하여 보다 낮은 결합 신호를 나타낸다.
TPP-15370의 총 103개의 재조합 변이체 및 TPP-15374에 대한 1136개의 재조합 변이체가 측정되었다. 분석을 위해, 그리고 플레이트-대-플레이트 변동의 보정을 가능하게 하기 위해, ELISA 원시 값을 이소형 대조군 항체 TPP-9809와의 경쟁 값에 대해 정규화하였다.
표 6은 TPP-15370 및 TPP-15374의 선택된 재조합 변이체에 대한 경쟁 ELISA에 대한 값을 열거한다. 각각 1 대 5 또는 1 대 1 비로의 측정에서의 이소형 대조군 항체 TPP-9809에 대한 비가 도시된다.
표 6: TPP-15374 및 TPP-15370의 재조합 변이체에 대한 경쟁 ELISA에 대한 값. 각각 1 대 5 또는 1 대 1 비로의 측정에서 이소형 대조군 항체 TPP-9809에 대해 정규화한 경우에, 선택된 재조합 변이체에 대한 이소형 대조군 항체 각각에 대한 비가 도시된다.

실시예 5a: 표면 플라즈몬 공명 (SPR)을 사용한 에피토프 비닝
SPR을 사용하여 전형적 샌드위치 접근법을 이용함으로써 항-Sema3A 항체의 에피토프 빈을 결정하기 위해 에피토프 비닝 실험을 수행하였다. 이 실험에서, 1종의 항체를 SPR 칩에 고정시키고, Sema3A를 주입하고, 결합을 모니터링한다 (도 10a). 제1 항체에 대한 Sema3A의 성공적인 결합 후에, Sema3A에 결합된 고정된 mAb의 복합체 상에 제2 항체를 주입하고, 추가의 결합을 모니터링한다 (도 10b 및 도 10c). 제2 항체가 Sema3A에 대한 결합에 대해 제1 항체와 경쟁하는 경우에, 제2 항체의 주입 후에 추가의 결합 신호가 검출되지 않으며, 이는 2종의 항체가 동일하거나 매우 인접한 Sema3A 에피토프에 결합한다는 것을 보여준다 (도 10c). 제2 항체가 Sema3A에 대한 결합에 대해 제1 항체와 경쟁하지 않는 경우에, 제2 항체의 주입 후에 추가의 결합 신호가 검출되며, 이는 2종의 항체가 상이한 Sema3A 에피토프에 결합한다는 것을 보여준다 (도 10b).
실험은 비아코어 T200 기기 (시티바) 상에서 25℃에서 검정 완충제 HBS P+, 300 mM NaCl, 0.75 mM CaCl2, 2.5 mM MgCl2, 1 mg/ml BSA, 0.05% NaN3을 사용하여 수행하였다. 항체를 시리즈 S CM5 센서 칩 (시티바)에 공유 아민 커플링시켰다. 아민 커플링을 제조업체의 지침에 따라 1-에틸-3-(3-디메틸아미노프로필) 카르보디이미드 히드로클로라이드 (EDC), N-히드록시숙신이미드 (NHS) 및 에탄올아민 HCl, pH 8.5를 사용하여 수행하였다 ("아민 커플링 키트" BR-1000-50, 시티바). 인간, 1가 Sema3A 도메인을 제1 분석물로서 200 nM의 농도로 사용하고, 이어서 경쟁자 항체를 제2 주입하였다. 이러한 설정은 모든 가능한 조합으로 수행하였다. 센서 표면을 각각의 항원 주입 후에 글리신 pH 2.0으로 재생시켰다. 표 6a는 비닝 결과를 보여준다.
표 6a: 에피토프 비닝 결과의 행렬도 (+=추가의 결합, - = 추가의 결합 없음)

"+"는 제2 항체의 주입이 추가의 결합 신호를 발생시켰다는 것을 의미하며, 이는 2종의 시험된 항체가 2종의 상이한 Sema3A 에피토프에 결합한다는 것을 보여준다.
"-"는 제2 항체의 주입이 추가의 결합 신호를 발생시키지 않았음을 의미하며, 이는 2종의 시험된 항체가 중첩되거나 인접한 에피토프 Sema3A 에피토프에 대한 결합에 대해 경쟁한다는 것을 보여준다.
비닝 실험은 TPP-30788 (BI 클론 I)과 비교하여 TPP-23298에 대한 또 다른 에피토프를 강하게 가리키며, 이는 둘 다의 항체가 Sema3A 상의 독립적인/상이한 에피토프를 표적화하는 반면, TPP-23298은 TPP-17755 (삼성)와 중첩되거나 인접한 에피토프를 가질 수 있다는 것을 의미한다.
실시예 7: 오프-타겟에 대한 결합의 평가
항-Sema3A mAb (TPP-15370, 모 mAb)의 특이성을 평가하기 위해, 레트로게닉스(Retrogenix) 기술을 사용하는 오프-타겟 스크린을 수행하였다. 1차 스크리닝을 위해, ZsGreen1 및 전장 인간 형질 막 단백질 또는 세포-표면 테더링된 인간 분비 단백질 둘 다를 코딩하는 5484개의 발현 벡터를 16개의 마이크로어레이 슬라이드에 걸쳐 이중으로 배치하였다. 인간 HEK293 세포를 역 형질감염/발현에 사용하였다.
세포 고정 후에 시험 항체를 각각의 슬라이드에 첨가하여 20 μg/ml의 최종 농도를 제공하였다. 결합의 검출은 사전-스크린에 사용된 것과 동일한 AF647 항-hIgG Fc 검출 항체를 사용하여 수행하였다. 16개의 슬라이드-세트 각각에 대해 2개의 중복 슬라이드를 스크리닝하였다. 히트를 이중 스팟의 강도에 따라 '강함, 중간, 약함 또는 매우 약함'으로 분류하였다.
5484개의 인간 형질 막 단백질 및 인간 분비 단백질을 발현하는 고정된 HEK293 세포에 대한 결합에 대해 스크리닝한 후, 레트로게닉스 기술은 시험 항체 TPP-15370에 대해 어떠한 특이적 오프-타겟 상호작용도 확인하지 못했다. Sema3A - 그의 1차 표적 - 에 대한 결합이 관찰되었다. 이들 데이터는 TPP-15370의 그의 1차 표적에 대한 높은 특이성을 나타낸다.
실시예 8: 항-Sema3A mAb의 선택성
세마포린 단백질은 척추동물에서 발생하는 5개의 부류 (부류 3-7)로 세분될 수 있다. 세마포린 3 부류 (Sema3A - G)에서 모 항-Sema3A mAb TPP-15370 및 TPP-15374의 선택성 프로파일을 평가하기 위해, 알앤디 시스템즈로부터의 Sema3A, Sema3B, Sema3C, Sema3D, Sema3E 및 Sema3F 분자를 사용하여 ELISA 검정을 수행하였다. 둘 다의 항체는 Sema3B, Sema3C, Sema3D, Sema3E 및 Sema3F에 대해 결합을 나타내지 않았다.
Sema3G는 최근에 신장 보호제로서 확인되었기 때문에 (PMID: 27180624), 항체가 Sema3G에 결합하지 않는지 시험하는 것은 중요하였다. Sema3A 대 Sema3G에 대한 결합 선택성의 평가를 위해, 1 nM 재조합 인간 Sema3A-Fc 키메라 (알앤디 시스템즈) 또는 재조합 인간 GST - Sema3G (압노바(Abnova))를 맥시소르브 플레이트 상에 코팅하고, 항체와 함께 0.00015 - 10 μg/ml의 용량-반응 곡선으로 인큐베이션하고, HRP 커플링된 항-인간 항혈청 및 화학발광 기질을 사용하여 항체의 결합을 정량화하였다.
표 7: 오프-타겟으로서 Sema3G의 시험에 대한 오프-타겟 ELISA 값

본 발명의 모든 시험된 항체뿐만 아니라 선행 기술 항체는 표 7에 제시된 바와 같이 신장 보호 Sema3G에 결합하지 않는다.
Sema3A는 2개의 푸린 절단 부위를 함유하는 분비된 단백질이고, 활성 및 불활성 절단된 형태로 존재한다. 생체내 상황에서, Sema3A는 둘 다의 형태로 공존한다. 항-Sema3A 항체가 불활성 형태와 활성 형태 사이를 구별할 수 있는지 시험하고, 항체가 활성 Sema3A (Sema3A 도메인만을 함유하기 때문에 불활성 버전인 것 (절단된 Sema3A TPP-19068과 유사함)과 대조적으로, 전장 Sema3A (TPP-13211)와 유사함)에 결합하는 데 있어서 수행하는 방식을 시험하기 위해, ELISA 검정을 수행하였다. 판독치로서 활성 Sema3A에 대한 시험된 항체의 ELISA 신호를 불활성 Sema3A에 대한 시험된 항체의 ELISA 신호로 나누었다.
표 7a: ELISA에 의해 결정된 바와 같은 활성 대 불활성 Sema3A에 대한 항-Sema3A 항체의 결합의 비

* 1 미만의 ELISA 결합 TPP-13211 / TPP-19068 비는 활성 Sema3A에 대한 보다 높은 결합 활성을 나타낸다.
1 초과의 ELISA 결합 TPP-13211 / TPP-19068 비는 불활성 Sema3A에 대한 보다 높은 결합 활성을 나타낸다.
표 7a에 제시된 바와 같은 결합 분석은 본 발명의 항체 (TPP-23298)가 TPP-30788 - TPP-30791 (BI 클론)보다 활성 Sema3A에 대해 증가된 결합을 제시한다는 것을 명백하게 제시하였으며, 이는 아마도 이들이 활성 Sema3A에 대해 보다 높은 선택성을 나타내는 상이한 에피토프를 표적화하기 때문일 것이다.
실시예 9: 혈관간 세포 이동 검정에서의 시험관내 효능
혈청-함유 배양 배지 내의 세포를 이미지 록 플레이트 내로 24시간 동안 시딩함으로써 인간 1차 혈관간 세포의 전면생장 단층을 생성하였다. 혈청-무함유 배양 배지로 전환한 후, 운드메이커(WoundMaker) 도구를 사용하여 스크래치 상처를 생성하고, 그 후 세포를 억제 항체의 부재 또는 존재 하에 1 nM 재조합 인간 Sema3A-Fc 키메라 (알앤디 시스템즈)로 처리하였다. 세포를 인큐사이트에서 영상화하고, 24시간 후에 인큐사이트 통합 세포 이동 분석 소프트웨어 모듈을 사용하여 상처 봉합의 정도를 평가하였다.
표 8: MCM 검정에서 파지 디스플레이 히트 및 재조합 변이체에 대한 EC50 값


표 8에 제시된 바와 같이 본 발명자들은 인간 혈관간 세포 이동 검정에서 3-자릿수 피코몰 범위의 효력을 갖는 항체를 확인하였고, 이는 선행 기술 항체보다 상당히 더 강력하다.
실시예 10: 성장 원추 붕괴 검정에서의 시험관내 효능
Sema3A 유도된 세포골격 붕괴에 대한 항체의 효력을 결정하는 방향으로, 성장 원추 붕괴 검정을 기재된 바와 유사하게 (PMID: 12077190) 약간의 변형과 함께 사용하였다. 간략하게, 마우스 후근 신경절 (DRG) 뉴런을 E13 C57Bl/6J 마우스 배아로부터 단리하고, 폴리-L-리신 및 라미닌-코팅된 96-웰 상에서 뉴로베이슬 배지 + 100 ng/mL NGF + B-27 + 10% FCS를 사용하여 배양하였다. 20시간 후, 세포를 억제 항체의 부재 또는 존재 하에 10 nM 재조합 인간 Sema3A-Fc 키메라 (알앤디 시스템즈)로 1시간 동안 처리하고, 이어서 PFA 고정시키고, 알렉사488-팔로이딘으로 염색하였다. 웰당 100개 초과의 성장 원추에 대해 액틴 성장 원추 면적/형상/텍스쳐를 통해 면역형광 현미경검사를 사용하여 성장 원추 붕괴의 정도를 평가하였다.
표 9: GCC 검정에서 파지 디스플레이 히트 및 재조합 변이체에 대한 EC50 값


확인된 항체는 또한 표 9에 제시된 바와 같이 뮤린 성장 원추 붕괴 검정에서 한 자릿수 나노몰 범위의 효력을 제시하며, 이는 다시 시험된 선행 기술 항체 (2- 내지 3-자릿수 나노몰 효력)보다 상당히 더 강력한 효력을 제시한다.
실시예 11: HUVEC 반발 검정에서의 시험관내 효능
재조합 인간 Sema3A-Fc 키메라 (알앤디 시스템즈)는 그의 카르복시-말단에 여러 돌연변이된 아미노산 및 여분의 단백질 단편을 함유하기 때문에 인간 생체유체 내의 Sema3A와 동일하지 않다. 또한, 상기 기재된 검정 (인간 혈관간 세포 이동 검정 및 뮤린 성장 원추 붕괴 검정)은, 조직에서의 Sema3A에 대해 기재되어 있는 구배 분포와 대조적으로, Sema3A를 균질한 분포로 사용한다. 본 발명자들은 이들 차이가 재조합 대 내인성 단백질에 대한 항체의 상이한 효력을 유발할 수 있다고 가설화하였다. 따라서, 본 발명자들은 효능제로서 인간 야생형 Sema3A의 구배를 사용하는 검정을 적합화하였다 (PMID: 17569671). 간략하게, 이러한 HUVEC 반발 검정에서, 서열식별번호: 600의 서열의 인간 Sema3A를 발현하는 인간 배아 신장 293 세포 (HEK293 세포)를 억제 항체의 부재 또는 존재 하에 EGM-2 배지 내의 인간 제대 정맥 내피 세포 (HUVEC)의 전면생장 단층 상에 시딩하고, 72시간 동안 배양하고, 고정시키고, DAPI로 염색하고, 세포 반발의 정도를 면역형광 현미경검사에 의해 평가하였다 (무세포 면적의 측정). 결과적으로, 기질 인간 Sema3A는 과량으로 존재한다.
DAPI/CM 염색된 세포의 면역형광 현미경검사 영상 (CM = HCS 셀마스크(CellMask)™ 염색, 총 세포 면적을 규정하기 위해 전체 세포를 염색함)에 기초하여 데이터 분석을 하기와 같이 수행한다: 세포를 DAPI/CM 신호에 기초하여 확인한다 (도 11b). 분석을 위한 세포 면적을 규정하고 선택한다. 이러한 영역에서, 무세포 영역을 계산한다 (도 11c). 퍼센트 억제는 항체-처리된 웰에서 Sema3A에 의해 유도된 "무세포-영역"에 기초하여 이소형-처리된 웰과 비교하여 계산한다. 퍼센트 억제를 항체 농도에 대해 플롯팅하고, 각각의 항체의 EC-50 값을 계산한다.
상세하게, 데이터 분석을 위해 하기 단계를 수행한다:
1. 웰 면적의 80%에 상응하는 웰당 4개의 필드를 영상화한다. 함께 스티칭된 이들 필드 모두는 DAPI/CM 형광을 통한 세포의 검출에 사용된다.
2. DAPI/CM 면적에 기초하여 "세포 면적"을 계산한다.
3. "무세포 영역"은 "총 면적"에서 "세포 면적"을 차감한 것에 기초하여 계산한다.
4. 퍼센트 억제는 항체-처리된 웰에서 Sema3A에 의해 유도된 "무세포-영역"에 기초하여 이소형-처리된 웰에 대비하여 계산한다.
5. 소프트웨어 그래프패드 프리즘을 사용하여 비선형 회귀 (가변 기울기 모델 = 4-파라미터 용량-반응 곡선)를 사용하여 EC50 값을 결정한다.
표 10: 반발 검정, 제1 실험에서 선택된 항체에 대한 EC50 값

표 10a): 선행 기술 항체와 비교하기 위한 제2 실험에서 반발 검정에서의 TPP-23298에 대한 EC50 값

상기 인간 혈관간 세포 이동 검정 및 뮤린 성장 원추 붕괴 검정에서 선행 기술 항체에 대한 효력 구별은 표 10 및 10a에 제시된 바와 같이 천연 wt Sema3A (프로세싱된 불활성 및 비소화된 활성 Sema3A의 혼합물)의 구배를 사용한 이러한 HUVEC 반발 검정에서 훨씬 더 현저하다. TPP-17755, TPP-11489, TPP-30788, TPP-30789, TPP-30790, 또는 TPP-30791과 비교하여 HUVEC 반발 검정에서의 개선된 효력을 정량화하여 상응하는 EC-50 값에 의해 제시되는 바와 같은 피코몰 활성을 측정한다. TPP-23298은 2-자릿수 피코몰 활성을 나타내지만, TPP-17755, TPP-11489, TPP-30788, TPP-30789, TPP-30790, 또는 TPP-30791의 선행 기술 항체 효력은 3-자릿수 피코몰 또는 심지어 나노몰 범위이다.
결과의 대안적 예시로서, HUVEC 반발 검정에서의 개선된 효력은 각각의 항체의 80 pM의 명시된 농도에서 무세포 영역을 측정하는 것에 의해 정량화된다. TPP-23298은 TPP-30788, TPP-30789, TPP-30790, 또는 TPP-30791보다 Sema3A의 더 높은 퍼센트 억제를 나타낸다 (도 12).
표 10 및 10a에 나타내어진 둘 다의 검정으로부터의 데이터를 분석하면 TPP-23298이 세포 Sema3A 유도된 HUVEC 반발에 대해 가장 높은 효력을 나타낸다. BI 항체 TPP-30788, TPP-30798, TPP-30790 및 TPP-30791은 약간 더 높은 EC50 값 (2-5-배)을 나타내었다. 삼성 항체 TPP-17755는 TPP-23298보다 유의하게 더 낮은 효력을 갖는다 (50-배). 키오메 항체 TPP-11489는 최고 시험 농도에서만 억제 활성을 나타내었고, 그 결과 예측된 EC50 값은 본 발명에 따른 항체보다 >400-배 더 높았다. 이는 어떠한 스파이킹된 외인성 재조합 세마포린3A가 없는 천연 환경과 유사한 조건 하에서, 본 발명에 따른 항체가 표 10 및 10a에 제시된 바와 같이 가장 강한 활성으로 Sema3A-유도된 세포 반발을 억제한다는 것을 보여준다.
실시예 12: 신장 보호 효과를 검출하기 위한 생체내 검정: 마우스에서의 Sema3A-유도된 알부민뇨의 억제
Sema3A 억제제는 재조합 Sema3A의 전신 주사를 통해 유도된 뇨 알부민 배설을 감소시킨다. 알부민뇨 감소에 대한 화합물의 유익한 효과를 하기와 같이 Sema3A-유도된 알부민뇨 모델에서 조사하였다:
타코닉(Taconic)으로부터 구입한 수컷 C57Bl/6 마우스 (8- 내지 10-주령)에게 항-Sema3A 항체를 정맥내로 주사하였다. 항체 적용 30분 후에 인간 재조합 Sema3A (1.0 mg/kg, 알앤디 시스템즈)의 정맥내 주사에 의해 알부민뇨를 유도하였다. 동물을 대사 케이지에 넣고, 소변을 4시간 동안 수집하였다. 뇨 크레아티닌을 임상 생화학 분석기 (펜트라400(Pentra400))를 통해 측정하였다. 뇨 알부민의 평가를 위해, 마우스 특이적 알부민 ELISA (압캠(Abcam))를 제조업체의 프로토콜에 따라 사용하였다. 뇨 크레아티닌 및 알부민 둘 다를 사용하여 뇨 알부민 대 크레아틴 비 (ACR)를 계산하였다. 군 사이의 차이를 일원 ANOVA 및 던넷 다중 비교 보정에 의해 분석하였다. 통계적 유의성은 p < 0.05로 규정된다. 모든 통계적 분석은 그래프패드 프리즘 8을 사용하여 수행하였다.
표 11-15a는 마우스의 Sema3A-유도된 알부민뇨 모델에서 TPP-15370, TPP-15374, TPP-11489, TPP-17755, TPP-30788 및 TPP-23298을 사용한 용량-반응 실험을 보여준다. TPP-11489 및/또는 TPP-17755 및/또는 TPP-30788과 비교하여 TPP-15370, TPP-23298에 의한 알부민뇨 감소에 대한 효과가 도 1-2에 제시된다.
본 발명에 따른 항체는 Sema3A-유도된 뇨 알부민 배설을 감소시킨다.






실시예 13: 신장 보호 효과를 검출하기 위한 생체내 검정: 마우스에서의 급성 허혈/재관류 손상 (I/RI) 모델
일측성 신절제된 마우스는 허혈 재관류 손상 후에 Sema3A 억제제를 사용한 처리로부터 이익을 얻을 수 있다. 신장 기능에 대한 Sema3A 항체의 유익한 효과를 하기와 같이 마우스의 신장 허혈-재관류 손상 모델에서 조사하였다:
6-8주령의 실험실 사육된 수컷 C57Bl/6J 마우스를 찰스 리버(Charles River)로부터 입수하였다. 마우스를 표준 실험실 조건, 12-시간 명-암 주기 하에, 정상 사료 및 음용수에 자유롭게 접근하도록 유지시켰다. 허혈 재관류 손상 모델을 위해, 각각의 대조군 및 실험군에서 총 8-10마리를 사용하였다.
동물을 연속 흡입 이소플루란으로 마취시켰다. 반대측 신장에서의 허혈 절차 7일 전에 우측 측복부 절개를 통해 우측 신절제술을 수행하였다. 신장 허혈의 개시 1-시간 전에 항체 및 적절한 이소형 대조군을 마우스에게 i.v. 주사를 통해 투여하였다. 마우스를 마취시키고, 좌측 옆구리를 절개하였다. 신장 혈관을 좌측 신혈관경의 절개에 의해 노출시켰다. 비-외상성 혈관 클램프를 사용하여 허혈 25분 (마우스) 동안 혈류 (동맥 및 정맥)를 정지시켰다. 클램프를 제거하여 재관류를 확립하였다. 복벽 (근육층 및 피부)을 5.0 폴리프로필렌 봉합사로 봉합하였다. 템게식(Temgesic)® (부프레노르핀, 0.025 mg/kg s.c.)을 진통제로서 적용하였다.
각각의 동물의 소변을 대사 케이지에서 밤새 수집한 후, 허혈 후 24시간째에 희생시켰다. 뇨 크레아티닌을 임상 생화학 분석기 (펜트라400)에 의해 측정하였다. 뇨 알부민의 평가를 위해, 마우스 특이적 알부민 키트 (히타치(Hitachi))를 펜트라 분석기 내에서 사용하였다. 뇨 크레아티닌 및 알부민 둘 다를 사용하여 알부민뇨 (알부민/크레아티닌 비)를 결정하였다. 희생 시, 혈액 샘플을 말단 마취 하에 수득하였다. 혈액 샘플을 원심분리한 후, 혈청을 단리하였다. 혈청 크레아티닌 및 혈청 우레아 둘 다를 임상 생화학 분석기 (펜트라 400)를 통해 측정하였다. 군 사이의 차이를 일원 ANOVA 및 던넷 다중 비교 보정에 의해 분석하였다. 통계적 유의성은 p < 0.05로 규정된다. 모든 통계적 분석은 그래프패드 프리즘 8을 사용하여 수행하였다.
표 16-20은 마우스의 급성 신허혈/재관류 손상 모델에서 TPP-15370, TPP-15374, TPP-11489, TPP-17755 및 TPP-23298을 사용한 용량-반응 실험을 제시한다. 도 3은 I/RI 모델에서 15 mg/kg으로의 처리 후의 TPP-23374, TPP-23298 및 TPP-15370의 효능을 보여준다. TPP-11489 및/또는 TPP-17755와 비교하여 TPP-15370, TPP-23298 및 TPP-15374에 의한 처리 효과가 도 4-6에 제시된다.
항체는 혈청 크레아티닌 및 혈청 우레아 (사구체 여과율에 대한 대용물) 및 뇨 알부민의 배설을 감소시킴으로써 허혈/재관류 유도된 신장 손상을 약화시켰다.





실시예 14: 신장 보호 효과를 검출하기 위한 생체내 검정: 알포트 증후군 모델 (Col4α3 결핍 마우스)
알포트 마우스의 표현형은 알포트 환자의 표현형과 유사하며, 이는 사구체 기저막의 특징적인 비후 및 분할뿐만 아니라 강한 단백뇨를 포함한다. 알포트 마우스는 그러한 마우스의 신장에서의 증가된 Sema3A 발현으로 인해 Sema3A 억제제를 사용한 처리로부터 이익을 얻을 수 있다. 신장 기능에 대한 Sema3A 차단 항체의 유익한 효과를 하기와 같이 알포트 마우스 모델에서 조사하였다: 독일 부퍼탈 소재의 바이엘 아게(Bayer AG)의 사육 시설 내에서 이형접합 동물을 교배시킴으로써 녹아웃 Col4α3 (129-Col4a3<tm1Dec>/J) 마우스 (잭슨 래보러토리(Jackson Laboratory), 미국)의 콜로니를 확립하였다. 4 - 5주령의 수컷 및 암컷 동형접합 및 야생형 Col4α3 마우스를 바이엘 아게의 동물 사육 시설로부터 입수하여, 본 연구에 사용하였다.
동형접합 마우스 (HOM)를 그의 연령 및 성별에 따라 군 (각 군당 n = 10)으로 무작위화하였다. 마우스에게 이소형 대조군 및 TPP-15370 및 TPP-23298을 매주 1회 투여하였다. TPP-11489를 격주로 투여하였다. 각각의 동물의 소변을 처리 개시 전에 시작하여 매주 1회 대사 케이지에서 수집하였다. 뇨 크레아티닌뿐만 아니라 총 단백질을 임상 생화학 분석기 (펜트라400)에 의해 측정하였다. 뇨 크레아티닌 및 알부민 둘 다를 사용하여 단백뇨 (단백질/크레아티닌 비)를 결정하였다. 처리 시작 후 제21일 또는 제28일째의 희생 시, 혈액 샘플을 말단 마취 하에 수득하였다. 혈액 샘플을 원심분리한 후, 혈청을 단리하였다. 혈청 크레아티닌 및 혈청 우레아 둘 다를 임상 생화학 분석기 (펜트라 400)를 통해 측정하였다.
신장을 수집하고, 2개의 부분으로 나누었다. 한 부분은 mRNA 분석을 위해 액체 질소에서 순간-동결시켰다. 다른 부분은 조직학적 절편의 제조를 위해 데이비슨 고정제에서 저장하였다. 수거한 신장의 일부로부터 총 RNA를 단리하였다. 신장 조직을 균질화하고, RNA를 수득하고, cDNA로 전사시켰다. 택맨 실시간 PCR을 사용하여, 신장 조직에서 섬유화유발 마커의 신장 mRNA 발현을 분석하였다. 단백질 수준에 대한 섬유증의 평가를 위해, 파라핀 조직 절편을 표준 절차를 사용하여 알파-평활근 액틴 (αSMA) 및 시리우스 레드/패스트 그린 콜라겐 염색에 의해 염색하였다.
신장 내의 알파-평활근 액틴 (αSMA)-양성뿐만 아니라 시리우스 레드 (콜라겐) 양성 면적의 정량적 측정치를 악시오 스캔 Z1 (자이스(Zeiss)) 현미경 및 젠 소프트웨어를 사용하여 컴퓨터 영상 분석에 의해 수득하였다.
모든 데이터를 평균 ± S.D.로 표현한다. 군 사이의 차이를 일원 ANOVA 및 던넷 다중 비교 보정에 의해 분석하였다. 통계적 유의성은 p<0.05로 규정되었다. 모든 통계적 분석은 그래프패드 프리즘 8을 사용하여 수행하였다.
표 21A-21C 및 22A-22C는 알포트 모델에서 TPP-15370 및 TPP-23298로의 처리 후에 수득된 단백뇨, 신장 기능 및 신장 섬유증에 대한 효과를 보여준다. 단백뇨, 신장 기능 및 신장 섬유증에 대한 TPP-15370에 의한 처리 후의 효과를 TPP-11489와 비교하여 도 7 및 8에 제시한다.
본 발명에 따른 항체는 알포트 증후군의 마우스 모델에서 신장 질환의 진행을 정지시켰다. 본 발명에 따른 항체는 뇨 단백질의 배설을 감소시켰고, 크레아티닌 및 혈청 우레아 (사구체 여과율에 대한 대용물), 뿐만 아니라 근섬유모세포 염색 및 콜라겐 침착을 통해 정량화된 바와 같이 섬유증을 감소시켰다.






실시예 15: 신장 보호 효과를 검출하기 위한 생체내 검정: 돼지에서의 일측성 신장 IRI 모델
TPP-23298을 성체 미니피그에서의 최소 침습성 일측성 신장 동맥 풍선-카테터 폐쇄 모델에서 약 24시간의 재관류-후 추적 하에 시험하였다. 체중 범위 14 내지 17 kg의 암컷 괴팅겐 미니 피그 (덴마크 엘레가르트)를 실험에 사용하였다. 동물을 실험군에 무작위로 배정하였다.
TPP-23298을 맹검, 대조 연구에서 6마리의 매칭되는 IgG-처리 대조군과 비교하여 6마리의 동물에게 투여하였다. 신장 동맥 폐쇄 없이 모든 처리 절차에 적용되었고 포스페이트 완충 염수 비히클만을 제공받은 동물은 모의 처리된 참조군으로서 제공되었다.
TPP-23298을 신장 동맥 폐쇄의 시작 전에 느린 정맥내 주사에 의해 볼루스로서 1 ml/kg 포스페이트 완충 염수의 최종 부피로 중량 조정된 용량으로 투여하였다 (예방 세팅).
실험 제1일의 개입을 위해, 돼지를 프로포폴 및 펜타닐 조합물에 의해 마취시키고, 판쿠로늄에 의한 근육 이완 하에 경구기관내 튜브를 통해 인공 환기시켰다. 링거 락테이트 용액의 연속 주입에 의해 부피를 연속적으로 대체하였다. 수술을 시작하기 전에, 각각 엔로플록사신의 i.m. 투여 및 헤파린의 i.v. 투여에 의해 항생제 및 혈전증 예방제를 제공하였다. 앞다리 커프가 장착된 비-침습성 수의학적 장치를 사용하여 혈압 및 심박수를 모니터링하였다.
모든 하기 개입은 엄격한 무균 조건 하에 수행하였다. 약물 투여를 위해 카테터를 배측 목 피부를 통해 경정맥으로 피하로 터널링하였다. 덮개를 - 바람직하게는 좌측 - 대퇴 동맥에 위치시키고, 고정시키고, 이를 통해 내부에 풍선 카테터를 갖는 하키-스틱 카테터를 복부 대동맥 내로 상류로 전진시키고, 그의 팁을 사용하여 좌측 또는 우측 신장 동맥의 오리피스 내로 삽입하였다. 이어서, 풍선 카테터를 돌출시키고, 풍선을 팽창시켜 신장으로의 혈류를 중단시켰다. 풍선의 정확한 위치설정은 상업용 초음파 진단 장치를 사용하여 도플러 초음파에 의해 제어하였다. 혈장 샘플을 기준선 및 허혈 시작 2시간 후에 수집하였다.
풍선을 수축시키고 카테터 및 덮개를 회수하는 것에 의해 폐쇄의 시작 후 미리-규정된 시점 (90 내지 120분 범위)에 정확하게 신장 허혈을 완화시켰다. 혈관 봉합 및 상처 밀폐 후, 동물을 마취로부터 재-각성시키고, 자발 호흡이 개시된 후 발관하였다.
신장 동맥 폐쇄의 약 22 내지 23시간 후에, 동물을 케타세트/도르미쿰 및 판쿠로늄 조합물에 의해 재-마취시키고, 기재된 바와 같이 인공 환기시켰다. 혈압 및 심박수를 경동맥 카테터를 통해 침습적으로 모니터링하였다. 부피 대체는 정맥내로의 10 ml/kg/h 유량의 링거 락테이트로 제공하였다. 하복부의 작은 절개를 통해 둘 다의 요관을 방광 벽에서 절단하고, 카테터를 삽입하여 부피 결정 및 요분석을 위해 개별적으로 소변 측면을 수집하였다. 모든 파라미터가 안정할 때 기록 및 샘플 수집을 시작하였고, 이는 전형적으로 폐쇄 24시간 후의 경우였다. 혈액 샘플을 기준선에서 수집하고, 매시간 3시간 동안 수집하였다 (24 - 27시간 간격). 이와 병행하여 소변을 3회 1시간 간격으로 수집하였다.
소변 부피 유량 (VU) 및 뇨 크레아티닌 농도 ([Crea]U)를 결정한 후, 크레아티닌 클리어런스 (CLCrea)를 표준 식 CLCrea= VU * [Crea]U / [Crea]Pl에 따라 개별적으로 계산하였고, 여기서 [Crea]Pl는 혈장 크레아티닌 농도를 나타낸다. 전반적 CLCrea는 각각의 동물의 좌측 및 우측 신장의 CLCrea를 더하여 계산하였다.
결과를 도 9에 도시한다. TPP-23298은 폐쇄 30분 전에 예방적 방식으로 투여한 경우에 105분의 일측성 신장 동맥 폐쇄 후에 이러한 실험 세팅에서 허혈/재관류-유도된 크레아티닌 클리어런스의 악화를 유의하게 예방하였다.
실시예 16: 포유동물 세포 배양물에서의 항-Sema3A 항체의 발현 역가
HEK293-6E 세포를 항-Sema3A 항체의 중쇄 및 경쇄를 코딩하는 pTT5 플라스미드로 또는 TPP-30792의 Fab 단편 (TPP-31357)으로 형질감염시켰다. 형질감염 2일 전에, HEK293-6E 세포를 진탕 플라스크에서 0.1% 플루로닉(Pluronic) F68 (깁코(Gibco), 24040032) 및 4 mM 글루타맥스(GlutaMax) (깁코, 35050061)를 함유하는 프리스타일(FreeStyle)™ F17 발현 배지 (깁코, A1383501) 중 5x10^5개 세포/mL의 밀도로 분할하였고, 이는 목적하는 발현 부피의 90%를 구성하였다. HEK293-6E 세포를 75 rpm에서 진탕하면서 37℃, 5% CO2에서 배양하였다.
형질감염을 위해, DNA 및 폴리에틸렌이민 (폴리사이언시스(Polysciences), 29366)을 4 mM 글루타맥스 (깁코, 35050061)를 함유하는 프리스타일™ F17 발현 배지 (깁코, A1383501) 중에서 혼합하며, 이는 최종 발현 부피의 10%를 구성한다. 용액을 10분 동안 인큐베이션하고, 진탕 플라스크에 첨가한다.
형질감염 24시간 후, 1% (v/v) 초저 IgG FBS (깁코, 16250078) 및 0.05% (v/v) 1N 발프로산 (시그마, P4543)을 진탕 플라스크에 첨가한다.
세포 생존율 및 밀도를 형질감염 4일 후에 시작하여 매일 모니터링하고, 생존율이 70%인 것으로 결정될 때 상청액을 원심분리 및 멸균 여과에 의해 수거한다. 생산 역가를 결정하기 위해, 수거한 상청액 100 μL를 구동 완충제로서 50 mM 인산나트륨 (시그마, S0751, S9763), 150 mM NaCl (시그마, S6546), 5% 2-프로판올 (시그마, 34863), pH 7.2를 사용하여 HPLC-시스템 (애질런트(Agilent), 1100 HPLC 시스템)을 통해 0.1 mL 포로스 A 친화도 칼럼 (써모 사이언티픽, 2100100)에 로딩한다. 후속적으로, 12 mM HCl (시그마, H9892), 150 mM NaCl, 5% 2-프로판올 pH 2를 사용하여 단백질을 용리시킨다. 공지된 크기의 단백질을 사용하여 5 μg/mL에서 150 μg/mL까지의 보정 곡선을 설정하고, 이를 또한 HPLC-시스템을 통한 포로스 A 칼럼에 적용한다. 상청액 중 단백질의 크기 및 흡광 계수를 고려하여, 표준 곡선을 사용하여 정확한 역가를 계산할 수 있다. CHO에서의 발현은, 플라스미드 pTT22AKT를 TPP-30792에 사용한 경우를 제외하고, HEK 세포와 유사하다.
표 23: 포유동물 세포에서의 항-Sema3A 항체의 발현 역가 (mg/L)

본 발명의 항체뿐만 아니라 TPP-30792를 제외한 모든 선행 기술 항체는 표 23에 제시된 바와 같이 포유동물 세포에서 높은 역가로 생산될 수 있다. TPP-30792는 HEK 또는 CHO 세포에서 유의한 양으로 발현될 수 없었다. 총 125 μg의 TPP-30792를 4.5 리터의 HEK293 세포 배양물로부터 정제할 수 있었다. 유사하게, TPP30792의 Fab 단편 (TPP-31357)은 5 리터의 HEK293 세포 배양물 중 오직 200 μg의 정제된 Fab만을 산출하였다.
실시예 17: 항-Sema3A 항체의 CMC 파라미터 안정성 및 용해도의 분석
50 mg/ml 초과의 고농축 단백질 용액은 통상적으로 또한 저농축 단백질 용액과 비교하여 더 높은 점도를 나타낸다는 것이 공지되어 있다. 증가된 점도는 특히 낮은 적용 부피에서 단백질 용액의 전달성에 부정적인 영향을 미치고, 주사 시간 및 주사 부위에서의 통증을 증가시킬 수 있다. 이에 더하여, 높은 점도는 산업에서 대규모 단백질 생산에 영향을 미친다. 따라서, 긴 보관 수명 동안 안정성을 유지하면서 고농축 단백질 용액의 점도를 감소시키는 것은 특히 생체내 치료 세팅을 위해 중요하다.
고농축 용액 중의 단백질은 종종 희석된 용액 중의 단백질보다 덜 안정한데, 이는 단백질이 응집하는 경향이 있고 보다 높은 농도에서 가역적으로 자기-회합할 수 있기 때문이다. 응집은 구조적 완전성에 부정적인 영향을 미칠 수 있고, 따라서 또한 생체내 치료 세팅에서 기능적, 생체이용가능한 단백질의 양에 부정적인 영향을 미칠 수 있다. 이는 추가로 주사에 의한 전달을 복잡하게 한다.
단백질의 용해도는 또 다른 중요한 품질 기준이다. 단리된 단백질의 증가된 용해도는 생체내 치료 세팅에 필요한 고도로 농축된 용액의 제조를 가능하게 한다.
따라서, 감소된 점도 및 증가된 안정성 및 용해도를 갖는 고농축 단백질 용액을 제공하는 것은 치료 분자의 치료 적용성에 유익하다.
잠재적 치료 용도를 위한 항-Sema3A 항체의 CMC (화학, 제조, 제어) 파라미터 안정성, 용해도 및 점도를 평가하기 위해, 항체 TPP-23289 및 TPP-30788 (BI 클론 I)을 PBS 중에 25 mg/ml로 희석하고, 700 rpm 및 40℃에서 2주 동안 인큐베이션하였다. 항체는 통상적으로 단기간 동안 4℃-10℃에서 저장되거나 또는 장기간 동안 ≤-18℃ 또는 ≥-81℃에서 동결되며, ≥40℃ 초과의 온도 (포유동물 평균 체온은 36℃ - 39℃임)에 대한 포유동물 항체의 노출은 열적 스트레스 조건과 유사하다. 이러한 열적 스트레스 조건에서 가속화된 단백질 안정성 / 스트레스 안정성이 시험된다. PBS 완충제 중에서 악타 시스템 (시티바)에 커플링된 슈퍼덱스 200 칼럼 (시티바)을 사용하는 크기-배제 크로마토그래피뿐만 아니라 캘리퍼 시스템 (퍼킨 엘머)을 사용하는 모세관 겔 전기영동에 의해 안정성의 분석을 평가하였다. 프로파일의 변화를 비-스트레스 출발 물질에 대한 백분율로서 계산하였다. 용해도는 PBS 완충제 중에서 30 kDa의 컷-오프를 갖는 아미콘 스핀 필터 (밀리포어(Millipore))를 사용하여 항-Sema3A 항체를 농축시킴으로써 결정하였다. 용해도를 농축기로부터 90% 회수에서 결정하고, UV280nm에서의 흡수를 사용하여 단백질 농도를 측정하였다.
표 24: TPP-23298 및 TPP-30788에 대한 CMC 파라미터의 개관; SEC=크기-배제 크로마토그래피, cGE= 모세관 겔 전기영동

* SEC = 크기 배제 크로마토그래피; ** cGE = 모세관 겔 전기영동
안정성, 용해도 및 점도는 상기 기재된 바와 같은 치료 분자에 대한 중요한 CMC 파라미터이다. 40℃에의 노출과 같은 열적 스트레스 조건 또는 농축 단계 후의 구조적 완전성을 SEC 및/또는 cGE를 통해 분석하여 구조적 완전성에 대한 적용된 스트레스의 효과를 관찰한다. 출발점과 비교하여 적용된 스트레스 후 1% 미만의 변화는 안정한 분자를 가리키는 반면, >1%의 편차는 분자에서의 불안정성을 가리킨다. TPP-23289는 TPP-30788과 비교하여 PBS 중에서 >2배의 훨씬 더 높은 용해도를 나타내며, 이는 예를 들어 적은 적용 부피를 가능하게 하는 데 매우 유익하다. 또한, TPP-23298은 TPP-30788보다 열 스트레스에 대해 더 안정하고 더 저항성이며, PBS 완충제 중에서 덜 점성이다.
서열
표 1: 본 발명에 따른 바람직한 항체 및 3종의 선행 기술 항체의 아미노산 서열 및 핵산 서열. TPP-11489는 클론 번호 4-2 균주로부터 유래된 키오메 항체 인간화-2에 상응하고 (WO 2014/123186); TPP-15051은 그의 뮤린 IgG1 변이체를 나타낸다. TPP-30788 - TPP-30791은 베링거 잉겔하임 항체 (BI) 클론 I-IV (WO 2020/225400)에 상응한다. TPP-30792는 라모트 대학교 항체 클론 I (WO 2020/261281)에 상응한다.















표 1A: 각각의 서열식별번호 하에 표 1에 언급된 본 발명에 따른 항체의 상응하는 아미노산 서열 및 핵산 서열. 서열식별번호: 581 내지 587은 호모 사피엔스(Homo sapiens) (서열식별번호: 581, 582), 무스 무스쿨루스(Mus Musculus) (서열식별번호: 583), 라투스 노르베기쿠스(Rattus norvegicus) (서열식별번호: 584), 카니스 루푸스 파밀리아리스(Canis lupus familiaris) (서열식별번호: 585), 마카카 파시쿨라리스(Macaca fascicularis) (서열식별번호: 586), 수스 수크로파(Sus scrofa) (서열식별번호: 587)로부터의 상응하는 Sema3A 단백질 서열이다.

































































SEQUENCE LISTING
<110> Bayer AG
<120> NOVEL ANTI-SEMA3A ANTIBODIES AND USES THEREOF
<130> BHC201071
<160> 691
<170> PatentIn version 3.5
<210> 1
<211> 124
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 1
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Pro Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Gly Ile Asp Asp Asp Gly Asp Ser Asp Thr Arg Tyr Ala Pro Ala
50 55 60
Val Lys Gly Arg Ala Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Lys His Thr Gly Ile Gly Ala Asn Ser Ala Gly Ser Ile Asp
100 105 110
Ala Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 2
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 2
Ser Tyr Pro Met Gly
1 5
<210> 3
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 3
Gly Ile Asp Asp Asp Gly Asp Ser Asp Thr Arg Tyr Ala Pro Ala Val
1 5 10 15
Lys Gly
<210> 4
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 4
His Thr Gly Ile Gly Ala Asn Ser Ala Gly Ser Ile Asp Ala
1 5 10
<210> 5
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 5
Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Ser Val Ser Pro Gly Gln
1 5 10 15
Thr Ala Arg Ile Thr Cys Ser Gly Gly Gly Ser Tyr Thr Gly Ser Tyr
20 25 30
Tyr Tyr Gly Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Thr Val
35 40 45
Ile Tyr Tyr Asn Asn Lys Arg Pro Ser Asp Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Leu Ser Gly Thr Thr Asn Thr Leu Thr Ile Ser Gly Val Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ser Ala Asp Asn Ser Gly
85 90 95
Asp Ala Phe Gly Thr Gly Thr Lys Val Thr Val Leu
100 105
<210> 6
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 6
Ser Gly Gly Gly Ser Tyr Thr Gly Ser Tyr Tyr Tyr Gly
1 5 10
<210> 7
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 7
Tyr Asn Asn Lys Arg Pro Ser
1 5
<210> 8
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 8
Gly Ser Ala Asp Asn Ser Gly Asp Ala
1 5
<210> 9
<211> 372
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 9
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctatccta tgggctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtggccggc atcgacgacg atggcgatag cgatacaaga 180
tacgcccctg ccgtgaaggg cagagccacc atctccagag acaacagcaa gaacaccgtg 240
tacctgcaga tgaacagcct gagagccgag gacaccgccg tgtactattg tgccaagcac 300
acaggcatcg gcgccaattc tgccggctct attgatgcct ggggccaggg aacactggtc 360
acagtttctt ca 372
<210> 10
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 10
agctatccta tgggc 15
<210> 11
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 11
ggcatcgacg acgatggcga tagcgataca agatacgccc ctgccgtgaa gggc 54
<210> 12
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 12
cacacaggca tcggcgccaa ttctgccggc tctattgatg cc 42
<210> 13
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 13
agctatgagc tgacacagcc tccaagcgtg tccgtgtctc ctggacagac cgccagaatc 60
acatgtagcg gcggaggcag ctacaccggc agctactact atggctggta tcagcagaag 120
cccggacagg cccctgtgac cgtgatctac tacaacaaca agcggcccag cgacatcccc 180
gagagatttt ctggctctct gagcggcacc accaacacac tgacaatctc tggcgtgcag 240
gccgaggacg aggccgatta ctattgtggc agcgccgata atagcggcga cgcctttggc 300
accggcacca aagttacagt gcta 324
<210> 14
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 14
agcggcggag gcagctacac cggcagctac tactatggc 39
<210> 15
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 15
tacaacaaca agcggcccag c 21
<210> 16
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 16
ggcagcgccg ataatagcgg cgacgcc 27
<210> 17
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 17
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Pro Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Gly Ile Asp Asp Asp Gly Asp Ser Asp Thr Arg Tyr Ala Pro Ala
50 55 60
Val Lys Gly Arg Ala Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Lys His Thr Gly Ile Gly Ala Asn Ser Ala Gly Ser Ile Asp
100 105 110
Ala Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
355 360 365
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly
450
<210> 18
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 18
Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Ser Val Ser Pro Gly Gln
1 5 10 15
Thr Ala Arg Ile Thr Cys Ser Gly Gly Gly Ser Tyr Thr Gly Ser Tyr
20 25 30
Tyr Tyr Gly Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Thr Val
35 40 45
Ile Tyr Tyr Asn Asn Lys Arg Pro Ser Asp Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Leu Ser Gly Thr Thr Asn Thr Leu Thr Ile Ser Gly Val Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ser Ala Asp Asn Ser Gly
85 90 95
Asp Ala Phe Gly Thr Gly Thr Lys Val Thr Val Leu Gly Gln Pro Lys
100 105 110
Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu Leu Gln
115 120 125
Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr Pro Gly
130 135 140
Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys Ala Gly
145 150 155 160
Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr Ala Ala
165 170 175
Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His Arg Ser
180 185 190
Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys Thr Val
195 200 205
Ala Pro Thr Glu Cys Ser
210
<210> 19
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 19
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctatccta tgggctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtggccggc atcgacgacg atggcgatag cgatacaaga 180
tacgcccctg ccgtgaaggg cagagccacc atctccagag acaacagcaa gaacaccgtg 240
tacctgcaga tgaacagcct gagagccgag gacaccgccg tgtactattg tgccaagcac 300
acaggcatcg gcgccaattc tgccggctct attgatgcct ggggccaggg aacactggtc 360
acagtttctt cagccagcac caagggcccc agcgtgttcc ctctggcccc tagcagcaag 420
agcacatctg gcggaacagc cgccctgggc tgcctcgtga aggactactt tcccgagccc 480
gtgaccgtgt cctggaactc tggcgctctg acaagcggcg tgcacacctt tccagccgtg 540
ctgcagagca gcggcctgta ctctctgagc agcgtcgtga cagtgcccag cagctctctg 600
ggcacccaga cctacatctg caacgtgaac cacaagccca gcaacaccaa ggtggacaag 660
aaggtggaac ccaagagctg cgacaagacc cacacctgtc ccccttgtcc tgcccccgaa 720
ctgctgggag gcccttccgt gttcctgttc cccccaaagc ccaaggacac cctgatgatc 780
agccggaccc ccgaagtgac ctgcgtggtg gtggatgtgt cccacgagga ccctgaagtg 840
aagttcaatt ggtacgtgga cggcgtggaa gtgcacaacg ccaagaccaa gcctagagag 900
gaacagtaca acagcaccta ccgggtggtg tccgtgctga cagtgctgca ccaggactgg 960
ctgaacggca aagagtacaa gtgcaaggtg tccaacaagg ccctgcctgc ccccatcgag 1020
aaaaccatca gcaaggccaa gggccagccc cgcgaacccc aggtgtacac actgccccca 1080
agcagggacg agctgaccaa gaaccaggtg tccctgacct gtctcgtgaa aggcttctac 1140
ccctccgata tcgccgtgga atgggagagc aacggccagc ccgagaacaa ctacaagacc 1200
accccccctg tgctggacag cgacggctca ttcttcctgt acagcaagct gaccgtggac 1260
aagtcccggt ggcagcaggg caacgtgttc agctgcagcg tgatgcacga ggccctgcac 1320
aaccactaca cccagaagtc cctgagcctg agccctggc 1359
<210> 20
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 20
agctatgagc tgacacagcc tccaagcgtg tccgtgtctc ctggacagac cgccagaatc 60
acatgtagcg gcggaggcag ctacaccggc agctactact atggctggta tcagcagaag 120
cccggacagg cccctgtgac cgtgatctac tacaacaaca agcggcccag cgacatcccc 180
gagagatttt ctggctctct gagcggcacc accaacacac tgacaatctc tggcgtgcag 240
gccgaggacg aggccgatta ctattgtggc agcgccgata atagcggcga cgcctttggc 300
accggcacca aagttacagt gctaggccag cctaaagccg cccctagcgt gaccctgttc 360
cctccaagca gcgaggaact gcaggccaac aaggccaccc tcgtgtgcct gatcagcgac 420
ttctatcctg gcgccgtgac cgtggcctgg aaggccgata gctctcctgt gaaggccggc 480
gtggaaacca ccacccctag caagcagagc aacaacaaat acgccgccag cagctacctg 540
agcctgaccc ccgagcagtg gaagtcccac agatcctaca gctgccaagt gacccacgag 600
ggcagcaccg tggaaaagac agtggcccct accgagtgca gc 642
<210> 21
<211> 124
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 21
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Pro Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Gly Ile Asp Asp Asp Gly Asp Ser Asp Thr Arg Tyr Ala Pro Ala
50 55 60
Val Lys Gly Arg Ala Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Lys His Thr Gly Ile Gly Ala Asn Ser Ala Gly Ser Ile Asp
100 105 110
Ala Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 22
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 22
Ser Tyr Pro Met Gly
1 5
<210> 23
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 23
Gly Ile Asp Asp Asp Gly Asp Ser Asp Thr Arg Tyr Ala Pro Ala Val
1 5 10 15
Lys Gly
<210> 24
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 24
His Thr Gly Ile Gly Ala Asn Ser Ala Gly Ser Ile Asp Ala
1 5 10
<210> 25
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 25
Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Ser Val Ser Pro Gly Gln
1 5 10 15
Thr Ala Arg Ile Thr Cys Ser Gly Gly Gly Ser Tyr Thr Gly Ser Tyr
20 25 30
Tyr Tyr Gly Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Thr Val
35 40 45
Ile Tyr Tyr Asn Asn Lys Arg Pro Ser Asp Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Leu Ser Gly Thr Thr Asn Thr Leu Thr Ile Ser Gly Val Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ser Ala Asp Asn Ser Gly
85 90 95
Asp Ala Phe Gly Thr Gly Thr Lys Val Thr Val Leu
100 105
<210> 26
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 26
Ser Gly Gly Gly Ser Tyr Thr Gly Ser Tyr Tyr Tyr Gly
1 5 10
<210> 27
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 27
Tyr Asn Asn Lys Arg Pro Ser
1 5
<210> 28
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 28
Gly Ser Ala Asp Asn Ser Gly Asp Ala
1 5
<210> 29
<211> 372
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 29
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctatccta tgggctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtggccggc atcgacgacg atggcgatag cgatacaaga 180
tacgcccctg ccgtgaaggg cagagccacc atctccagag acaacagcaa gaacaccgtg 240
tacctgcaga tgaacagcct gagagccgag gacaccgccg tgtactattg tgccaagcac 300
acaggcatcg gcgccaattc tgccggctct attgatgcct ggggccaggg aacactggtc 360
acagtttctt ca 372
<210> 30
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 30
agctatccta tgggc 15
<210> 31
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 31
ggcatcgacg acgatggcga tagcgataca agatacgccc ctgccgtgaa gggc 54
<210> 32
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 32
cacacaggca tcggcgccaa ttctgccggc tctattgatg cc 42
<210> 33
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 33
agctatgagc tgacacagcc tccaagcgtg tccgtgtctc ctggacagac cgccagaatc 60
acatgtagcg gcggaggcag ctacaccggc agctactact atggctggta tcagcagaag 120
cccggacagg cccctgtgac cgtgatctac tacaacaaca agcggcccag cgacatcccc 180
gagagatttt ctggctctct gagcggcacc accaacacac tgacaatctc tggcgtgcag 240
gccgaggacg aggccgatta ctattgtggc agcgccgata atagcggcga cgcctttggc 300
accggcacca aagttacagt gcta 324
<210> 34
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 34
agcggcggag gcagctacac cggcagctac tactatggc 39
<210> 35
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 35
tacaacaaca agcggcccag c 21
<210> 36
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 36
ggcagcgccg ataatagcgg cgacgcc 27
<210> 37
<211> 448
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 37
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Pro Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Gly Ile Asp Asp Asp Gly Asp Ser Asp Thr Arg Tyr Ala Pro Ala
50 55 60
Val Lys Gly Arg Ala Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Lys His Thr Gly Ile Gly Ala Asn Ser Ala Gly Ser Ile Asp
100 105 110
Ala Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Lys Thr Thr
115 120 125
Pro Pro Ser Val Tyr Pro Leu Ala Pro Gly Ser Ala Ala Gln Thr Asn
130 135 140
Ser Met Val Thr Leu Gly Cys Leu Val Lys Gly Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Thr Trp Asn Ser Gly Ser Leu Ser Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Asp Leu Tyr Thr Leu Ser Ser Ser Val
180 185 190
Thr Val Pro Ser Ser Thr Trp Pro Ser Glu Thr Val Thr Cys Asn Val
195 200 205
Ala His Pro Ala Ser Ser Thr Lys Val Asp Lys Lys Ile Val Pro Arg
210 215 220
Asp Cys Gly Cys Lys Pro Cys Ile Cys Thr Val Pro Glu Val Ser Ser
225 230 235 240
Val Phe Ile Phe Pro Pro Lys Pro Lys Asp Val Leu Thr Ile Thr Leu
245 250 255
Thr Pro Lys Val Thr Cys Val Val Val Asp Ile Ser Lys Asp Asp Pro
260 265 270
Glu Val Gln Phe Ser Trp Phe Val Asp Asp Val Glu Val His Thr Ala
275 280 285
Gln Thr Gln Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Ser Val
290 295 300
Ser Glu Leu Pro Ile Met His Gln Asp Trp Leu Asn Gly Lys Glu Phe
305 310 315 320
Lys Cys Arg Val Asn Ser Ala Ala Phe Pro Ala Pro Ile Glu Lys Thr
325 330 335
Ile Ser Lys Thr Lys Gly Arg Pro Lys Ala Pro Gln Val Tyr Thr Ile
340 345 350
Pro Pro Pro Lys Glu Gln Met Ala Lys Asp Lys Val Ser Leu Thr Cys
355 360 365
Met Ile Thr Asp Phe Phe Pro Glu Asp Ile Thr Val Glu Trp Gln Trp
370 375 380
Asn Gly Gln Pro Ala Glu Asn Tyr Lys Asn Thr Gln Pro Ile Met Asp
385 390 395 400
Thr Asp Gly Ser Tyr Phe Val Tyr Ser Lys Leu Asn Val Gln Lys Ser
405 410 415
Asn Trp Glu Ala Gly Asn Thr Phe Thr Cys Ser Val Leu His Glu Gly
420 425 430
Leu His Asn His His Thr Glu Lys Ser Leu Ser His Ser Pro Gly Lys
435 440 445
<210> 38
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 38
Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Ser Val Ser Pro Gly Gln
1 5 10 15
Thr Ala Arg Ile Thr Cys Ser Gly Gly Gly Ser Tyr Thr Gly Ser Tyr
20 25 30
Tyr Tyr Gly Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Thr Val
35 40 45
Ile Tyr Tyr Asn Asn Lys Arg Pro Ser Asp Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Leu Ser Gly Thr Thr Asn Thr Leu Thr Ile Ser Gly Val Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ser Ala Asp Asn Ser Gly
85 90 95
Asp Ala Phe Gly Thr Gly Thr Lys Val Thr Val Leu Gly Gln Pro Lys
100 105 110
Ser Ser Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu Leu Glu
115 120 125
Thr Asn Lys Ala Thr Leu Val Cys Thr Ile Thr Asp Phe Tyr Pro Gly
130 135 140
Val Val Thr Val Asp Trp Lys Val Asp Gly Thr Pro Val Thr Gln Gly
145 150 155 160
Met Glu Thr Thr Gln Pro Ser Lys Gln Ser Asn Asn Lys Tyr Met Ala
165 170 175
Ser Ser Tyr Leu Thr Leu Thr Ala Arg Ala Trp Glu Arg His Ser Ser
180 185 190
Tyr Ser Cys Gln Val Thr His Glu Gly His Thr Val Glu Lys Ser Leu
195 200 205
Ser Arg Ala Asp Cys Ser
210
<210> 39
<211> 1344
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 39
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctatccta tgggctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtggccggc atcgacgacg atggcgatag cgatacaaga 180
tacgcccctg ccgtgaaggg cagagccacc atctccagag acaacagcaa gaacaccgtg 240
tacctgcaga tgaacagcct gagagccgag gacaccgccg tgtactattg tgccaagcac 300
acaggcatcg gcgccaattc tgccggctct attgatgcct ggggccaggg aacactggtc 360
acagtttctt cagccaagac cacccccccc agcgtgtacc ctctggctcc tggatctgcc 420
gcccagacca acagcatggt caccctgggc tgcctcgtga agggctactt ccctgagcct 480
gtgaccgtga cctggaacag cggctctctg tctagcggcg tgcacacctt tccagccgtg 540
ctgcagagcg acctgtacac cctgagcagc agcgtgaccg tgcctagcag cacctggcct 600
agcgagacag tgacctgcaa cgtggcccac cctgccagca gcacaaaggt ggacaagaaa 660
atcgtgcccc gggactgcgg ctgcaagccc tgtatctgta ccgtgcccga ggtgtccagc 720
gtgttcatct tcccacccaa gcccaaggac gtgctgacca tcaccctgac ccccaaagtg 780
acctgtgtgg tggtggacat cagcaaggac gaccccgagg tgcagttcag ttggttcgtg 840
gacgacgtgg aagtgcacac agcccagacc cagcccagag aggaacagtt caacagcacc 900
ttcagaagcg tgtccgagct gcccatcatg caccaggact ggctgaacgg caaagagttc 960
aagtgcagag tgaacagcgc cgccttccct gcccccatcg agaaaaccat ctccaagacc 1020
aagggcagac ccaaggcccc tcaggtgtac acaatccccc cacccaaaga acagatggcc 1080
aaggacaagg tgtccctgac ctgcatgatc accgatttct tcccagagga catcaccgtg 1140
gaatggcagt ggaacggcca gcccgccgag aactacaaga acacccagcc tatcatggac 1200
accgacggca gctacttcgt gtacagcaag ctgaacgtgc agaagtccaa ctgggaggcc 1260
ggcaacacct tcacctgtag cgtgctgcac gagggcctgc acaatcacca caccgagaag 1320
tccctgtccc acagccctgg caag 1344
<210> 40
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 40
agctatgagc tgacacagcc tccaagcgtg tccgtgtctc ctggacagac cgccagaatc 60
acatgtagcg gcggaggcag ctacaccggc agctactact atggctggta tcagcagaag 120
cccggacagg cccctgtgac cgtgatctac tacaacaaca agcggcccag cgacatcccc 180
gagagatttt ctggctctct gagcggcacc accaacacac tgacaatctc tggcgtgcag 240
gccgaggacg aggccgatta ctattgtggc agcgccgata atagcggcga cgcctttggc 300
accggcacca aagttacagt gctaggccag cccaagagca gccctagcgt gaccctgttc 360
cctccaagca gcgaggaact ggaaacaaac aaggccaccc tcgtgtgcac catcaccgac 420
ttctaccccg gcgtcgtgac cgtggactgg aaggtggacg gcaccccagt gacccagggc 480
atggaaacca cccagcccag caagcagagc aacaacaagt acatggccag cagctacctg 540
accctgaccg ccagagcctg ggagagacac agctcctaca gctgccaagt gacccacgag 600
ggccacaccg tggaaaagag cctgagcaga gccgactgca gc 642
<210> 41
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 41
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Met
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 42
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 42
Ser Tyr Gly Met His
1 5
<210> 43
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 43
Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Met Gly
1 5 10 15
<210> 44
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 44
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Val
1 5 10
<210> 45
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 45
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Leu Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Gly Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 46
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 46
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 47
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 47
Tyr Asp Asp Leu Leu Pro Ser
1 5
<210> 48
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 48
Ala Ala Trp Asp Asp Ser Leu Asn Gly Tyr Val Val
1 5 10
<210> 49
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 49
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctatggca tgcactgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtgtccgcc atcggcacag gcggcgatac ctactatgcc 180
gatagcgtga tgggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggatgcctt cgatgtgtgg ggccagggaa cactggttac cgtttcttca 360
<210> 50
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 50
agctatggca tgcac 15
<210> 51
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 51
gccatcggca caggcggcga tacctactat gccgatagcg tgatgggc 48
<210> 52
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 52
agggacgact acaccagcag ggatgccttc gatgtg 36
<210> 53
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 53
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgctgcctag cggcgtgccc 180
gatagatttt ctggcagcaa gagcggcaca agcgccagcc tggctatctc tggactgaga 240
tctgaggacg aggccgacta ctattgcgcc gcctgggacg atagcctgaa cggctatgtg 300
gttttcggcg gaggcaccaa gctgaccgtg cta 333
<210> 54
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 54
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 55
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 55
tacgacgacc tgctgcctag c 21
<210> 56
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 56
gccgcctggg acgatagcct gaacggctat gtggtt 36
<210> 57
<211> 449
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 57
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Met
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly
<210> 58
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 58
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Leu Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Gly Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 59
<211> 1347
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 59
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctatggca tgcactgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtgtccgcc atcggcacag gcggcgatac ctactatgcc 180
gatagcgtga tgggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggatgcctt cgatgtgtgg ggccagggaa cactggttac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggccccta gcagcaagag cacatctggc 420
ggaacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gctctctggg cacccagacc 600
tacatctgca acgtgaacca caagcccagc aacaccaagg tggacaagaa ggtggaaccc 660
aagagctgcg acaagaccca cacctgtccc ccttgtcctg cccccgaact gctgggaggc 720
ccttccgtgt tcctgttccc cccaaagccc aaggacaccc tgatgatcag ccggaccccc 780
gaagtgacct gcgtggtggt ggatgtgtcc cacgaggacc ctgaagtgaa gttcaattgg 840
tacgtggacg gcgtggaagt gcacaacgcc aagaccaagc ctagagagga acagtacaac 900
agcacctacc gggtggtgtc cgtgctgaca gtgctgcacc aggactggct gaacggcaaa 960
gagtacaagt gcaaggtgtc caacaaggcc ctgcctgccc ccatcgagaa aaccatcagc 1020
aaggccaagg gccagccccg cgaaccccag gtgtacacac tgcccccaag cagggacgag 1080
ctgaccaaga accaggtgtc cctgacctgt ctcgtgaaag gcttctaccc ctccgatatc 1140
gccgtggaat gggagagcaa cggccagccc gagaacaact acaagaccac cccccctgtg 1200
ctggacagcg acggctcatt cttcctgtac agcaagctga ccgtggacaa gtcccggtgg 1260
cagcagggca acgtgttcag ctgcagcgtg atgcacgagg ccctgcacaa ccactacacc 1320
cagaagtccc tgagcctgag ccctggc 1347
<210> 60
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 60
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgctgcctag cggcgtgccc 180
gatagatttt ctggcagcaa gagcggcaca agcgccagcc tggctatctc tggactgaga 240
tctgaggacg aggccgacta ctattgcgcc gcctgggacg atagcctgaa cggctatgtg 300
gttttcggcg gaggcaccaa gctgaccgtg ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 61
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 61
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Ser Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 62
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 62
Ser Tyr Glu Met Asn
1 5
<210> 63
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 63
Gly Ile Ser Trp Asn Ser Gly Ser Ile Gly Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 64
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 64
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 65
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 65
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu
65 70 75 80
Arg Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Ala Gly Ser
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 66
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 66
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 67
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 67
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 68
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 68
Ser Ser Tyr Ala Gly Ser Asn Pro Tyr Val Val
1 5 10
<210> 69
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 69
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctc tatcggctac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 70
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 70
agctacgaga tgaac 15
<210> 71
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 71
ggcatcagct ggaatagcgg ctctatcggc tacgccgaca gcgtgaaggg c 51
<210> 72
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 72
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 73
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 73
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtaccg gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat ctctggactg 240
agatctgagg acgaggccga ctactactgc agcagctatg ccggcagcaa cccctacgtt 300
gtgtttggcg gaggcaccaa gctgaccgtt cta 333
<210> 74
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 74
accggcagca gctccaatat cggagccggc tatgacgtgc ac 42
<210> 75
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 75
ggcaacagca acagacccag c 21
<210> 76
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 76
agcagctatg ccggcagcaa cccctacgtt gtg 33
<210> 77
<211> 452
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 77
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Ser Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly
450
<210> 78
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 78
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu
65 70 75 80
Arg Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Ala Gly Ser
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 79
<211> 1356
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 79
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctc tatcggctac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggc 1356
<210> 80
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 80
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtaccg gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat ctctggactg 240
agatctgagg acgaggccga ctactactgc agcagctatg ccggcagcaa cccctacgtt 300
gtgtttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 81
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 81
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Thr Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Trp Ile Tyr Tyr Asp Ser Gly Ser Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Leu Asn Gly Asp Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 82
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 82
Asp Tyr Ala Met Ser
1 5
<210> 83
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 83
Trp Ile Tyr Tyr Asp Ser Gly Ser Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 84
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 84
Leu Asn Gly Asp Phe Asp Tyr
1 5
<210> 85
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 85
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn
20 25 30
Asp Val Ser Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Ala Asp Ser His Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Trp Asp Ser Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 86
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 86
Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn Asp Val Ser
1 5 10
<210> 87
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 87
Ala Asp Ser His Arg Pro Ser
1 5
<210> 88
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 88
Gly Ala Trp Asp Ser Ser Leu Ser Gly Tyr Val
1 5 10
<210> 89
<211> 348
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 89
gaagttcagc tgctggaatc tggcggcgga ctggttcaaa caggcggctc tctgagactg 60
agctgtgccg cctctggctt caccttcagc gattacgcca tgagctgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtcctgg atctactacg acagcggcag caagtactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actattgcgc caagctgaac 300
ggcgacttcg actattgggg ccagggcaca ctggtcacag tctcttca 348
<210> 90
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 90
gattacgcca tgagc 15
<210> 91
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 91
tggatctact acgacagcgg cagcaagtac tacgccgaca gcgtgaaggg c 51
<210> 92
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 92
ctgaacggcg acttcgacta t 21
<210> 93
<211> 330
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 93
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc aacaacgacg tgtcctggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac gccgacagcc acagacctag cggcgtgcca 180
gatagattca gcggctctaa gagcggcaca tctgccagcc tggccatctc tggactgaga 240
tctgaggacg aggccgacta ctattgcggc gcctgggatt ctagcctgag cggctatgtt 300
tttggcggag gcaccaagct gaccgtgcta 330
<210> 94
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 94
agcggcagca gctccaacat cggcaacaac gacgtgtcc 39
<210> 95
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 95
gccgacagcc acagacctag c 21
<210> 96
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 96
ggcgcctggg attctagcct gagcggctat gtt 33
<210> 97
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 97
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Thr Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Trp Ile Tyr Tyr Asp Ser Gly Ser Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Leu Asn Gly Asp Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 98
<211> 216
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 98
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn
20 25 30
Asp Val Ser Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Ala Asp Ser His Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Trp Asp Ser Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 99
<211> 1335
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 99
gaagttcagc tgctggaatc tggcggcgga ctggttcaaa caggcggctc tctgagactg 60
agctgtgccg cctctggctt caccttcagc gattacgcca tgagctgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtcctgg atctactacg acagcggcag caagtactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actattgcgc caagctgaac 300
ggcgacttcg actattgggg ccagggcaca ctggtcacag tctcttcagc cagcaccaag 360
ggccccagcg tgttccctct ggcccctagc agcaagagca catctggcgg aacagccgcc 420
ctgggctgcc tcgtgaagga ctactttccc gagcccgtga ccgtgtcctg gaactctggc 480
gctctgacaa gcggcgtgca cacctttcca gccgtgctgc agagcagcgg cctgtactct 540
ctgagcagcg tcgtgacagt gcccagcagc tctctgggca cccagaccta catctgcaac 600
gtgaaccaca agcccagcaa caccaaggtg gacaagaagg tggaacccaa gagctgcgac 660
aagacccaca cctgtccccc ttgtcctgcc cccgaactgc tgggaggccc ttccgtgttc 720
ctgttccccc caaagcccaa ggacaccctg atgatcagcc ggacccccga agtgacctgc 780
gtggtggtgg atgtgtccca cgaggaccct gaagtgaagt tcaattggta cgtggacggc 840
gtggaagtgc acaacgccaa gaccaagcct agagaggaac agtacaacag cacctaccgg 900
gtggtgtccg tgctgacagt gctgcaccag gactggctga acggcaaaga gtacaagtgc 960
aaggtgtcca acaaggccct gcctgccccc atcgagaaaa ccatcagcaa ggccaagggc 1020
cagccccgcg aaccccaggt gtacacactg cccccaagca gggacgagct gaccaagaac 1080
caggtgtccc tgacctgtct cgtgaaaggc ttctacccct ccgatatcgc cgtggaatgg 1140
gagagcaacg gccagcccga gaacaactac aagaccaccc cccctgtgct ggacagcgac 1200
ggctcattct tcctgtacag caagctgacc gtggacaagt cccggtggca gcagggcaac 1260
gtgttcagct gcagcgtgat gcacgaggcc ctgcacaacc actacaccca gaagtccctg 1320
agcctgagcc ctggc 1335
<210> 100
<211> 648
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 100
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc aacaacgacg tgtcctggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac gccgacagcc acagacctag cggcgtgcca 180
gatagattca gcggctctaa gagcggcaca tctgccagcc tggccatctc tggactgaga 240
tctgaggacg aggccgacta ctattgcggc gcctgggatt ctagcctgag cggctatgtt 300
tttggcggag gcaccaagct gaccgtgcta ggccagccta aagccgcccc tagcgtgacc 360
ctgttccctc caagcagcga ggaactgcag gccaacaagg ccaccctcgt gtgcctgatc 420
agcgacttct atcctggcgc cgtgaccgtg gcctggaagg ccgatagctc tcctgtgaag 480
gccggcgtgg aaaccaccac ccctagcaag cagagcaaca acaaatacgc cgccagcagc 540
tacctgagcc tgacccccga gcagtggaag tcccacagat cctacagctg ccaagtgacc 600
cacgagggca gcaccgtgga aaagacagtg gcccctaccg agtgcagc 648
<210> 101
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 101
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Ser Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 102
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 102
Ser Tyr Glu Met Asn
1 5
<210> 103
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 103
Gly Ile Ser Trp Asn Ser Gly Ser Ile Gly Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 104
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 104
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 105
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 105
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Ala Gly Ser
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 106
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 106
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 107
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 107
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 108
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 108
Ser Ser Tyr Ala Gly Ser Asn Pro Tyr Val Val
1 5 10
<210> 109
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 109
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctc tatcggctac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 110
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 110
agctacgaga tgaac 15
<210> 111
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 111
ggcatcagct ggaatagcgg ctctatcggc tacgccgaca gcgtgaaggg c 51
<210> 112
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 112
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 113
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 113
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt tctagctacg ccggcagcaa cccctacgtg 300
gtgtttggcg gaggcaccaa gctgacagtt cta 333
<210> 114
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 114
acaggcagca gctccaatat cggagccggc tatgacgtgc ac 42
<210> 115
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 115
ggcaacagca acagacccag c 21
<210> 116
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 116
tctagctacg ccggcagcaa cccctacgtg gtg 33
<210> 117
<211> 452
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 117
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Ser Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly
450
<210> 118
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 118
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Ala Gly Ser
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 119
<211> 1356
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 119
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctc tatcggctac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggc 1356
<210> 120
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 120
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt tctagctacg ccggcagcaa cccctacgtg 300
gtgtttggcg gaggcaccaa gctgacagtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 121
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 121
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 122
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 122
Ser Tyr Ala Met Ser
1 5
<210> 123
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 123
Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 124
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 124
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 125
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 125
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Gly Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 126
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 126
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 127
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 127
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 128
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 128
Ala Ala Trp Asp Asp Ser Leu Asn Gly Tyr Val Val
1 5 10
<210> 129
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 129
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc attggcacag gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 130
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 130
agctacgcca tgagc 15
<210> 131
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 131
gccattggca caggcggcga tacctactac gccgactctg tgaagggc 48
<210> 132
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 132
agggacgact acaccagcag ggacgccttc gattat 36
<210> 133
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 133
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cggctatgtt 300
gttttcggcg gaggcaccaa gctgaccgtt cta 333
<210> 134
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 134
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 135
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 135
tacgacgacc tgcggcctag c 21
<210> 136
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 136
gccgcctggg acgacagcct gaacggctat gttgtt 36
<210> 137
<211> 449
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 137
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly
<210> 138
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 138
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Gly Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 139
<211> 1347
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 139
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc attggcacag gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggccccta gcagcaagag cacatctggc 420
ggaacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gctctctggg cacccagacc 600
tacatctgca acgtgaacca caagcccagc aacaccaagg tggacaagaa ggtggaaccc 660
aagagctgcg acaagaccca cacctgtccc ccttgtcctg cccccgaact gctgggaggc 720
ccttccgtgt tcctgttccc cccaaagccc aaggacaccc tgatgatcag ccggaccccc 780
gaagtgacct gcgtggtggt ggatgtgtcc cacgaggacc ctgaagtgaa gttcaattgg 840
tacgtggacg gcgtggaagt gcacaacgcc aagaccaagc ctagagagga acagtacaac 900
agcacctacc gggtggtgtc cgtgctgaca gtgctgcacc aggactggct gaacggcaaa 960
gagtacaagt gcaaggtgtc caacaaggcc ctgcctgccc ccatcgagaa aaccatcagc 1020
aaggccaagg gccagccccg cgaaccccag gtgtacacac tgcccccaag cagggacgag 1080
ctgaccaaga accaggtgtc cctgacctgt ctcgtgaaag gcttctaccc ctccgatatc 1140
gccgtggaat gggagagcaa cggccagccc gagaacaact acaagaccac cccccctgtg 1200
ctggacagcg acggctcatt cttcctgtac agcaagctga ccgtggacaa gtcccggtgg 1260
cagcagggca acgtgttcag ctgcagcgtg atgcacgagg ccctgcacaa ccactacacc 1320
cagaagtccc tgagcctgag ccctggc 1347
<210> 140
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 140
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cggctatgtt 300
gttttcggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 141
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 141
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 142
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 142
Ser Tyr Ala Met Ser
1 5
<210> 143
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 143
Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 144
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 144
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 145
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 145
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 146
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 146
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 147
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 147
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 148
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 148
Ala Ala Trp Asp Asp Ser Leu Asn Asp Tyr Val Val
1 5 10
<210> 149
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 149
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgagctgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggcacag gcggcgatac ctactatgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 150
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 150
agctacgcca tgagc 15
<210> 151
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 151
gccatcggca caggcggcga tacctactat gccgactctg tgaagggc 48
<210> 152
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 152
agggacgact acaccagcag ggacgccttc gattat 36
<210> 153
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 153
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgactacgtt 300
gtgtttggcg gaggcaccaa gctgaccgtt cta 333
<210> 154
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 154
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 155
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 155
tacgacgacc tgcggcctag c 21
<210> 156
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 156
gccgcctggg acgacagcct gaacgactac gttgtg 36
<210> 157
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 157
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 158
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 158
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 159
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 159
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgagctgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggcacag gcggcgatac ctactatgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 160
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 160
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgactacgtt 300
gtgtttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 161
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 161
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 162
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 162
Ser Tyr Ala Met Ser
1 5
<210> 163
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 163
Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 164
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 164
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 165
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 165
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Ile Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 166
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 166
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 167
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 167
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 168
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 168
Ala Ala Trp Asp Asp Ser Leu Asn Asp Ile Val Val
1 5 10
<210> 169
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 169
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 170
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 170
agctacgcca tgagc 15
<210> 171
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 171
gccatcggct atggcggcga tacctactac gccgactctg tgaagggc 48
<210> 172
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 172
agggacgact acaccagcag ggacgccttc gattat 36
<210> 173
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 173
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgacatcgtt 300
gttttcggcg gaggcaccaa gctgaccgtt cta 333
<210> 174
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 174
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 175
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 175
tacgacgacc tgcggcctag c 21
<210> 176
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 176
gccgcctggg acgacagcct gaacgacatc gttgtt 36
<210> 177
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 177
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 178
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 178
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Ile Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 179
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 179
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 180
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 180
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgacatcgtt 300
gttttcggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 181
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 181
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 182
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 182
Ser Tyr Ala Met Ser
1 5
<210> 183
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 183
Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 184
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 184
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 185
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 185
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Tyr Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 186
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 186
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 187
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 187
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 188
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 188
Ala Ala Trp Asp Asp Ser Leu Asn Val Tyr Pro Val
1 5 10
<210> 189
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 189
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 190
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 190
agctacgcca tgagc 15
<210> 191
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 191
gccatcggct atggcggcga tacctactac gccgactctg tgaagggc 48
<210> 192
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 192
agggacgact acaccagcag ggacgccttc gattat 36
<210> 193
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 193
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgtgtaccct 300
gtttttggcg gaggcaccaa gctgaccgtt cta 333
<210> 194
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 194
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 195
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 195
tacgacgacc tgcggcctag c 21
<210> 196
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 196
gccgcctggg acgacagcct gaacgtgtac cctgtt 36
<210> 197
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 197
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 198
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 198
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Tyr Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 199
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 199
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 200
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 200
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgtgtaccct 300
gtttttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 201
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 201
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 202
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 202
Ser Tyr Ala Met Ser
1 5
<210> 203
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 203
Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 204
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 204
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 205
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 205
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys His Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Ile Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 206
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 206
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 207
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 207
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 208
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 208
His Ala Trp Asp Asp Ser Leu Asn Asp Ile Val Val
1 5 10
<210> 209
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 209
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 210
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 210
agctacgcca tgagc 15
<210> 211
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 211
gccatcggct atggcggcga tacctactac gccgactctg tgaagggc 48
<210> 212
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 212
agggacgact acaccagcag ggacgccttc gattat 36
<210> 213
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 213
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ctattgtcac gcctgggacg acagcctgaa cgacatcgtg 300
gtttttggcg gaggcaccaa gctgaccgtt cta 333
<210> 214
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 214
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 215
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 215
tacgacgacc tgcggcctag c 21
<210> 216
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 216
cacgcctggg acgacagcct gaacgacatc gtggtt 36
<210> 217
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 217
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 218
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 218
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys His Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Ile Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 219
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 219
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 220
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 220
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ctattgtcac gcctgggacg acagcctgaa cgacatcgtg 300
gtttttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 221
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 221
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 222
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 222
Ser Tyr Ala Met Ser
1 5
<210> 223
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 223
Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 224
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 224
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 225
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 225
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys His Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Tyr Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 226
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 226
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 227
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 227
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 228
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 228
His Ala Trp Asp Asp Ser Leu Asn Asp Tyr Pro Val
1 5 10
<210> 229
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 229
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 230
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 230
agctacgcca tgagc 15
<210> 231
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 231
gccatcggct atggcggcga tacctactac gccgactctg tgaagggc 48
<210> 232
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 232
agggacgact acaccagcag ggacgccttc gattat 36
<210> 233
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 233
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ctattgtcac gcctgggacg acagcctgaa cgactaccct 300
gtttttggcg gaggcaccaa gctgaccgtt cta 333
<210> 234
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 234
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 235
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 235
tacgacgacc tgcggcctag c 21
<210> 236
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 236
cacgcctggg acgacagcct gaacgactac cctgtt 36
<210> 237
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 237
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 238
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 238
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys His Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Tyr Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 239
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 239
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 240
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 240
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ctattgtcac gcctgggacg acagcctgaa cgactaccct 300
gtttttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 241
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 241
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 242
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 242
Ser Tyr Ala Met Ser
1 5
<210> 243
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 243
Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 244
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 244
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 245
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 245
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys His Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Tyr Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 246
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 246
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 247
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 247
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 248
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 248
His Ala Trp Asp Asp Ser Leu Asn Val Tyr Pro Val
1 5 10
<210> 249
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 249
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 250
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 250
agctacgcca tgagc 15
<210> 251
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 251
gccatcggct atggcggcga tacctactac gccgactctg tgaagggc 48
<210> 252
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 252
agggacgact acaccagcag ggacgccttc gattat 36
<210> 253
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 253
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ctattgtcac gcctgggacg acagcctgaa cgtgtaccct 300
gtttttggcg gaggcaccaa gctgaccgtt cta 333
<210> 254
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 254
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 255
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 255
tacgacgacc tgcggcctag c 21
<210> 256
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 256
cacgcctggg acgacagcct gaacgtgtac cctgtt 36
<210> 257
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 257
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 258
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 258
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys His Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Tyr Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 259
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 259
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 260
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 260
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ctattgtcac gcctgggacg acagcctgaa cgtgtaccct 300
gtttttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 261
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 261
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 262
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 262
Ser Tyr Ala Met Ser
1 5
<210> 263
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 263
Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 264
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 264
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 265
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 265
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys His Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Ile Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 266
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 266
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 267
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 267
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 268
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 268
His Ala Trp Asp Asp Ser Leu Asn Val Ile Pro Val
1 5 10
<210> 269
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 269
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 270
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 270
agctacgcca tgagc 15
<210> 271
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 271
gccatcggct atggcggcga tacctactac gccgactctg tgaagggc 48
<210> 272
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 272
agggacgact acaccagcag ggacgccttc gattat 36
<210> 273
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 273
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ctattgtcac gcctgggacg acagcctgaa cgtgatccct 300
gtttttggcg gaggcaccaa gctgaccgtt cta 333
<210> 274
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 274
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 275
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 275
tacgacgacc tgcggcctag c 21
<210> 276
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 276
cacgcctggg acgacagcct gaacgtgatc cctgtt 36
<210> 277
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 277
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 278
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 278
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys His Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Ile Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 279
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 279
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttagc agctacgcca tgagctgggt ccgacaggct 120
cctggcaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 280
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 280
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ctattgtcac gcctgggacg acagcctgaa cgtgatccct 300
gtttttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 281
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 281
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Leu Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 282
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 282
Ser Tyr Ala Met Leu
1 5
<210> 283
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 283
Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 284
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 284
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 285
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 285
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 286
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 286
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 287
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 287
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 288
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 288
Ala Ala Trp Asp Asp Ser Leu Asn Asp Tyr Val Val
1 5 10
<210> 289
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 289
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgctgtgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggcacag gcggcgatac ctactatgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 290
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 290
agctacgcca tgctg 15
<210> 291
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 291
gccatcggca caggcggcga tacctactat gccgactctg tgaagggc 48
<210> 292
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 292
agggacgact acaccagcag ggacgccttc gattat 36
<210> 293
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 293
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgactacgtt 300
gtgtttggcg gaggcaccaa gctgaccgtt cta 333
<210> 294
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 294
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 295
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 295
tacgacgacc tgcggcctag c 21
<210> 296
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 296
gccgcctggg acgacagcct gaacgactac gttgtg 36
<210> 297
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 297
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Leu Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 298
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 298
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 299
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 299
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgctgtgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggcacag gcggcgatac ctactatgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 300
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 300
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgactacgtt 300
gtgtttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 301
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 301
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Leu Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 302
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 302
Ser Tyr Ala Met Leu
1 5
<210> 303
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 303
Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 304
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 304
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 305
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 305
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 306
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 306
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 307
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 307
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 308
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 308
Ala Ala Trp Asp Asp Ser Leu Asn Val Tyr Val Val
1 5 10
<210> 309
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 309
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgctgtgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggcacag gcggcgatac ctactatgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 310
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 310
agctacgcca tgctg 15
<210> 311
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 311
gccatcggca caggcggcga tacctactat gccgactctg tgaagggc 48
<210> 312
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 312
agggacgact acaccagcag ggacgccttc gattat 36
<210> 313
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 313
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgtgtacgtt 300
gtgtttggcg gaggcaccaa gctgaccgtt cta 333
<210> 314
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 314
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 315
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 315
tacgacgacc tgcggcctag c 21
<210> 316
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 316
gccgcctggg acgacagcct gaacgtgtac gttgtg 36
<210> 317
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 317
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Leu Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 318
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 318
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 319
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 319
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgctgtgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggcacag gcggcgatac ctactatgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 320
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 320
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgtgtacgtt 300
gtgtttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 321
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 321
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 322
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 322
Ser Tyr Ala Met Ser
1 5
<210> 323
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 323
Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 324
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 324
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 325
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 325
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys His Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Tyr Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 326
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 326
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 327
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 327
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 328
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 328
His Ala Trp Asp Asp Ser Leu Asn Val Tyr Pro Val
1 5 10
<210> 329
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 329
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgagctgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 330
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 330
agctacgcca tgagc 15
<210> 331
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 331
gccatcggct atggcggcga tacctactac gccgactctg tgaagggc 48
<210> 332
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 332
agggacgact acaccagcag ggacgccttc gattat 36
<210> 333
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 333
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ctattgtcac gcctgggacg acagcctgaa cgtgtaccct 300
gtttttggcg gaggcaccaa gctgaccgtt cta 333
<210> 334
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 334
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 335
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 335
tacgacgacc tgcggcctag c 21
<210> 336
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 336
cacgcctggg acgacagcct gaacgtgtac cctgtt 36
<210> 337
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 337
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 338
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 338
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys His Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Tyr Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 339
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 339
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgagctgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 340
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 340
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ctattgtcac gcctgggacg acagcctgaa cgtgtaccct 300
gtttttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 341
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 341
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 342
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 342
Ser Tyr Ala Met Ser
1 5
<210> 343
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 343
Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 344
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 344
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 345
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 345
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Ile Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 346
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 346
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 347
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 347
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 348
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 348
Ala Ala Trp Asp Asp Ser Leu Asn Asp Ile Pro Val
1 5 10
<210> 349
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 349
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgagctgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 350
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 350
agctacgcca tgagc 15
<210> 351
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 351
gccatcggct atggcggcga tacctactac gccgactctg tgaagggc 48
<210> 352
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 352
agggacgact acaccagcag ggacgccttc gattat 36
<210> 353
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 353
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgacatccct 300
gtttttggcg gaggcaccaa gctgaccgtt cta 333
<210> 354
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 354
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 355
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 355
tacgacgacc tgcggcctag c 21
<210> 356
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 356
gccgcctggg acgacagcct gaacgacatc cctgtt 36
<210> 357
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 357
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 358
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 358
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Asp Ile Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 359
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 359
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgagctgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 360
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 360
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgacatccct 300
gtttttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 361
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 361
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 362
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 362
Ser Tyr Ala Met Ser
1 5
<210> 363
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 363
Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 364
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 364
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr
1 5 10
<210> 365
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 365
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Ile Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 366
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 366
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Asn
1 5 10
<210> 367
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 367
Tyr Asp Asp Leu Arg Pro Ser
1 5
<210> 368
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 368
Ala Ala Trp Asp Asp Ser Leu Asn Val Ile Pro Val
1 5 10
<210> 369
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 369
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgagctgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
<210> 370
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 370
agctacgcca tgagc 15
<210> 371
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 371
gccatcggct atggcggcga tacctactac gccgactctg tgaagggc 48
<210> 372
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 372
agggacgact acaccagcag ggacgccttc gattat 36
<210> 373
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 373
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgtgatccct 300
gtttttggcg gaggcaccaa gctgaccgtt cta 333
<210> 374
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 374
agcggcagca gctccaacat cggcagcaac accgtgaac 39
<210> 375
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 375
tacgacgacc tgcggcctag c 21
<210> 376
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 376
gccgcctggg acgacagcct gaacgtgatc cctgtt 36
<210> 377
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 377
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Tyr Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Tyr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 378
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 378
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asp Leu Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Val Ile Pro Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 379
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 379
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttttac agctacgcca tgagctgggt ccgacaggcc 120
cctggaaaag gccttgaatg ggtgtccgcc atcggctatg gcggcgatac ctactacgcc 180
gactctgtga agggcagatt caccatcagc cgggacaaca gcaagaacac cctgtacctg 240
cagatgaaca gcctgagagc cgaggacacc gccgtgtact attgcgccag aagggacgac 300
tacaccagca gggacgcctt cgattattgg ggccagggca cactggtcac cgtttcttca 360
gccagcacca agggccccag cgtgttccct ctggcccctt gtagcagaag caccagcgag 420
tctacagccg ccctgggctg cctcgtgaag gactactttc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgctctgac aagcggcgtg cacacctttc cagccgtgct gcagagcagc 540
ggcctgtact ctctgagcag cgtcgtgaca gtgcccagca gcagcctggg caccaagacc 600
tacacctgta acgtggacca caagcccagc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc tccttgccca gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccaggaagat cccgaggtgc agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgcccagc tccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcagactg accgtggaca agagccggtg gcaggaaggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtctctga gcctgggcaa g 1341
<210> 380
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 380
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caacatcggc agcaacaccg tgaactggta tcagcagctg 120
cctggcacag cccctaaact gctgatctac tacgacgacc tgcggcctag cggcgtgcca 180
gatagatttt ctggcagcaa gagcggcacc tctgccagcc tggctatttc tggactgcag 240
agcgaggacg aggccgacta ttattgtgcc gcctgggacg acagcctgaa cgtgatccct 300
gtttttggcg gaggcaccaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 381
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 381
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 382
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 382
Ser Tyr Glu Met Asn
1 5
<210> 383
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 383
Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 384
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 384
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 385
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 385
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asp Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 386
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 386
Thr Gly Ser Ser Ser Asp Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 387
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 387
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 388
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 388
Ser Ser Tyr Ala Gly Pro Asn Pro Tyr Val Val
1 5 10
<210> 389
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 389
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 390
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 390
agctacgaga tgaac 15
<210> 391
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 391
ggcatcagct ggaatagcgg ctggatcgac tacgccgaca gcgtgaaggg c 51
<210> 392
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 392
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 393
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 393
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc cgatattggc gccggatacg acgtgcactg gtatcagcaa 120
ctgcctggca cagcccctaa gctgctgatc tacggcaaca gcaacagacc tagcggcgtg 180
cccgatagat tcagcggctc taagtctggc acaagcgcca gcctggccat tactggactg 240
caggccgaag atgaggccga ctactactgc agcagctacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt cta 333
<210> 394
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 394
acaggcagca gctccgatat tggcgccgga tacgacgtgc ac 42
<210> 395
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 395
ggcaacagca acagacctag c 21
<210> 396
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 396
agcagctacg ctggccccaa tccttacgtg gtg 33
<210> 397
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 397
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 398
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 398
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asp Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 399
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 399
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggcaag 1359
<210> 400
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 400
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc cgatattggc gccggatacg acgtgcactg gtatcagcaa 120
ctgcctggca cagcccctaa gctgctgatc tacggcaaca gcaacagacc tagcggcgtg 180
cccgatagat tcagcggctc taagtctggc acaagcgcca gcctggccat tactggactg 240
caggccgaag atgaggccga ctactactgc agcagctacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 401
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 401
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 402
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 402
Ser Tyr Glu Met Asn
1 5
<210> 403
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 403
Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 404
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 404
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 405
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 405
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Ile
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 406
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 406
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 407
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 407
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 408
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 408
Gln Ser Tyr Ala Gly Ile Asn Pro Tyr Val Val
1 5 10
<210> 409
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 409
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 410
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 410
agctacgaga tgaac 15
<210> 411
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 411
ggcatcagct ggaatagcgg ctggatcgac tacgccgaca gcgtgaaggg c 51
<210> 412
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 412
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 413
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 413
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt cagagctacg ccggcatcaa cccctacgtg 300
gtgtttggcg gaggcaccaa gctgacagtt cta 333
<210> 414
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 414
acaggcagca gctccaatat cggagccggc tatgacgtgc ac 42
<210> 415
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 415
ggcaacagca acagacccag c 21
<210> 416
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 416
cagagctacg ccggcatcaa cccctacgtg gtg 33
<210> 417
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 417
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 418
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 418
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Ile
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 419
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 419
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggcaag 1359
<210> 420
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 420
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt cagagctacg ccggcatcaa cccctacgtg 300
gtgtttggcg gaggcaccaa gctgacagtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 421
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 421
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp Phe Ser Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 422
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 422
Ser Tyr Glu Met Asn
1 5
<210> 423
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 423
Gly Ile Ser Trp Asn Ser Gly Trp Ile Gly Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 424
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 424
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 425
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 425
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 426
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 426
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 427
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 427
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 428
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 428
Gln Ser Tyr Ala Gly Pro Asn Pro Tyr Val Val
1 5 10
<210> 429
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 429
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cgatttcagc agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcggctac 180
gccgatagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 430
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 430
agctacgaga tgaac 15
<210> 431
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 431
ggcatcagct ggaatagcgg ctggatcggc tacgccgata gcgtgaaggg c 51
<210> 432
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 432
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 433
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 433
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt cagtcttacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt cta 333
<210> 434
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 434
acaggcagca gctccaatat cggagccggc tatgacgtgc ac 42
<210> 435
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 435
ggcaacagca acagacccag c 21
<210> 436
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 436
cagtcttacg ctggccccaa tccttacgtg gtg 33
<210> 437
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 437
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp Phe Ser Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 438
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 438
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 439
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 439
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cgatttcagc agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcggctac 180
gccgatagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggcaag 1359
<210> 440
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 440
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt cagtcttacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 441
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 441
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp Phe Ser Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 442
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 442
Ser Tyr Glu Met Asn
1 5
<210> 443
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 443
Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 444
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 444
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 445
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 445
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 446
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 446
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 447
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 447
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 448
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 448
Gln Ser Tyr Ala Gly Pro Asn Pro Tyr Val Val
1 5 10
<210> 449
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 449
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cgatttcagc agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 450
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 450
agctacgaga tgaac 15
<210> 451
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 451
ggcatcagct ggaatagcgg ctggatcgac tacgccgaca gcgtgaaggg c 51
<210> 452
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 452
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 453
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 453
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt cagtcttacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt cta 333
<210> 454
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 454
acaggcagca gctccaatat cggagccggc tatgacgtgc ac 42
<210> 455
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 455
ggcaacagca acagacccag c 21
<210> 456
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 456
cagtcttacg ctggccccaa tccttacgtg gtg 33
<210> 457
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 457
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp Phe Ser Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 458
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 458
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 459
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 459
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cgatttcagc agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggcaag 1359
<210> 460
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 460
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt cagtcttacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 461
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 461
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 462
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 462
Ser Tyr Glu Met Asn
1 5
<210> 463
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 463
Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 464
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 464
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 465
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 465
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 466
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 466
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 467
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 467
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 468
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 468
Gln Ser Tyr Ala Gly Pro Asn Pro Tyr Val Val
1 5 10
<210> 469
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 469
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 470
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 470
agctacgaga tgaac 15
<210> 471
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 471
ggcatcagct ggaatagcgg ctggatcgac tacgccgaca gcgtgaaggg c 51
<210> 472
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 472
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 473
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 473
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt cagtcttacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt cta 333
<210> 474
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 474
acaggcagca gctccaatat cggagccggc tatgacgtgc ac 42
<210> 475
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 475
ggcaacagca acagacccag c 21
<210> 476
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 476
cagtcttacg ctggccccaa tccttacgtg gtg 33
<210> 477
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 477
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 478
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 478
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 479
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 479
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggcaag 1359
<210> 480
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 480
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt cagtcttacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 481
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 481
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 482
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 482
Ser Tyr Glu Met Asn
1 5
<210> 483
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 483
Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 484
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 484
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 485
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 485
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 486
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 486
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 487
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 487
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 488
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 488
Gln Ser Tyr Ala Gly Pro Asn Pro Tyr Val Val
1 5 10
<210> 489
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 489
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cgacttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 490
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 490
agctacgaga tgaac 15
<210> 491
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 491
ggcatcagct ggaatagcgg ctggatcgac tacgccgaca gcgtgaaggg c 51
<210> 492
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 492
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 493
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 493
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt cagtcttacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt cta 333
<210> 494
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 494
acaggcagca gctccaatat cggagccggc tatgacgtgc ac 42
<210> 495
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 495
ggcaacagca acagacccag c 21
<210> 496
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 496
cagtcttacg ctggccccaa tccttacgtg gtg 33
<210> 497
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 497
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 498
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 498
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 499
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 499
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cgacttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggcaag 1359
<210> 500
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 500
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt cagtcttacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 501
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 501
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 502
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 502
Ser Tyr Glu Met Asn
1 5
<210> 503
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 503
Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 504
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 504
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 505
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 505
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asp Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Ile
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 506
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 506
Thr Gly Ser Ser Ser Asp Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 507
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 507
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 508
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 508
Gln Ser Tyr Ala Gly Ile Asn Pro Tyr Val Val
1 5 10
<210> 509
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 509
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 510
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 510
agctacgaga tgaac 15
<210> 511
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 511
ggcatcagct ggaatagcgg ctggatcgac tacgccgaca gcgtgaaggg c 51
<210> 512
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 512
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 513
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 513
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc cgatattggc gccggatacg acgtgcactg gtatcagcaa 120
ctgcctggca cagcccctaa gctgctgatc tacggcaaca gcaacagacc tagcggcgtg 180
cccgatagat tcagcggctc taagtctggc acaagcgcca gcctggccat tactggactg 240
caggccgaag atgaggccga ctactactgt cagagctacg ccggcatcaa cccctacgtg 300
gtgtttggcg gaggcaccaa gctgacagtt cta 333
<210> 514
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 514
acaggcagca gctccgatat tggcgccgga tacgacgtgc ac 42
<210> 515
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 515
ggcaacagca acagacctag c 21
<210> 516
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 516
cagagctacg ccggcatcaa cccctacgtg gtg 33
<210> 517
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 517
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 518
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 518
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asp Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ala Gly Ile
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 519
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 519
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggcaag 1359
<210> 520
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 520
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc cgatattggc gccggatacg acgtgcactg gtatcagcaa 120
ctgcctggca cagcccctaa gctgctgatc tacggcaaca gcaacagacc tagcggcgtg 180
cccgatagat tcagcggctc taagtctggc acaagcgcca gcctggccat tactggactg 240
caggccgaag atgaggccga ctactactgt cagagctacg ccggcatcaa cccctacgtg 300
gtgtttggcg gaggcaccaa gctgacagtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 521
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 521
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 522
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 522
Ser Tyr Glu Met Asn
1 5
<210> 523
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 523
Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 524
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 524
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 525
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 525
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asp Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Glu Gly Ile
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 526
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 526
Thr Gly Ser Ser Ser Asp Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 527
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 527
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 528
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 528
Ser Ser Tyr Glu Gly Ile Asn Pro Tyr Val Val
1 5 10
<210> 529
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 529
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cgacttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 530
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 530
agctacgaga tgaac 15
<210> 531
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 531
ggcatcagct ggaatagcgg ctggatcgac tacgccgaca gcgtgaaggg c 51
<210> 532
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 532
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 533
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 533
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc cgatattggc gccggatacg acgtgcactg gtatcagcaa 120
ctgcctggca cagcccctaa gctgctgatc tacggcaaca gcaacagacc tagcggcgtg 180
cccgatagat tcagcggctc taagtctggc acaagcgcca gcctggccat tactggactg 240
caggccgaag atgaggccga ctactactgc agcagctacg agggcatcaa cccctacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt cta 333
<210> 534
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 534
acaggcagca gctccgatat tggcgccgga tacgacgtgc ac 42
<210> 535
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 535
ggcaacagca acagacctag c 21
<210> 536
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 536
agcagctacg agggcatcaa cccctacgtg gtg 33
<210> 537
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 537
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 538
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 538
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asp Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Glu Gly Ile
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 539
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 539
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cgacttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggcaag 1359
<210> 540
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 540
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc cgatattggc gccggatacg acgtgcactg gtatcagcaa 120
ctgcctggca cagcccctaa gctgctgatc tacggcaaca gcaacagacc tagcggcgtg 180
cccgatagat tcagcggctc taagtctggc acaagcgcca gcctggccat tactggactg 240
caggccgaag atgaggccga ctactactgc agcagctacg agggcatcaa cccctacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 541
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 541
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp Phe Ser Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 542
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 542
Ser Tyr Glu Met Asn
1 5
<210> 543
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 543
Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 544
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 544
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 545
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 545
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Ala Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Glu Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 546
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 546
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 547
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 547
Gly Ala Ser Asn Arg Pro Ser
1 5
<210> 548
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 548
Ser Ser Tyr Glu Gly Pro Asn Pro Tyr Val Val
1 5 10
<210> 549
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 549
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cgatttcagc agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 550
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 550
agctacgaga tgaac 15
<210> 551
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 551
ggcatcagct ggaatagcgg ctggatcgac tacgccgaca gcgtgaaggg c 51
<210> 552
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 552
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 553
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 553
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcgcca gcaatagacc tagcggcgtg 180
cccgatagat tcagcggctc taagtctggc acaagcgcca gcctggccat tactggactg 240
caggccgaag atgaggccga ctactactgc agcagctacg agggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt cta 333
<210> 554
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 554
acaggcagca gctccaatat cggagccggc tatgacgtgc ac 42
<210> 555
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 555
ggcgccagca atagacctag c 21
<210> 556
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 556
agcagctacg agggccccaa tccttacgtg gtg 33
<210> 557
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 557
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp Phe Ser Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 558
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 558
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Ala Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Glu Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 559
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 559
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cgatttcagc agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggcaag 1359
<210> 560
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 560
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcgcca gcaatagacc tagcggcgtg 180
cccgatagat tcagcggctc taagtctggc acaagcgcca gcctggccat tactggactg 240
caggccgaag atgaggccga ctactactgc agcagctacg agggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 561
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 561
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 562
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 562
Ser Tyr Glu Met Asn
1 5
<210> 563
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 563
Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 564
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 564
Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
1 5 10
<210> 565
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 565
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 566
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 566
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 567
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 567
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 568
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 568
Ser Ser Tyr Ala Gly Pro Asn Pro Tyr Val Val
1 5 10
<210> 569
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 569
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttca 369
<210> 570
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 570
agctacgaga tgaac 15
<210> 571
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 571
ggcatcagct ggaatagcgg ctggatcgac tacgccgaca gcgtgaaggg c 51
<210> 572
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 572
agcggctaca gcagctcttg gtttgacccc gacttcgact at 42
<210> 573
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 573
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt agctcttacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt cta 333
<210> 574
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 574
acaggcagca gctccaatat cggagccggc tatgacgtgc ac 42
<210> 575
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 575
ggcaacagca acagacccag c 21
<210> 576
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 576
agctcttacg ctggccccaa tccttacgtg gtg 33
<210> 577
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 577
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Ser Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Trp Ile Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Ser Ser Ser Trp Phe Asp Pro Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 578
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 578
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Ala Gly Pro
85 90 95
Asn Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 579
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 579
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt caccttcgat agctacgaga tgaactgggt ccgacaggcc 120
cctggcaaag gccttgaatg ggtgtccggc atcagctgga atagcggctg gatcgactac 180
gccgacagcg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaagcggc 300
tacagcagct cttggtttga ccccgacttc gactattggg gccagggcac actggtcaca 360
gtctcttcag ccagcaccaa gggccccagc gtgttccctc tggcccctag cagcaagagc 420
acatctggcg gaacagccgc cctgggctgc ctcgtgaagg actactttcc cgagcccgtg 480
accgtgtcct ggaactctgg cgctctgaca agcggcgtgc acacctttcc agccgtgctg 540
cagagcagcg gcctgtactc tctgagcagc gtcgtgacag tgcccagcag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagcccagca acaccaaggt ggacaagaag 660
gtggaaccca agagctgcga caagacccac acctgtcccc cttgtcctgc ccccgaactg 720
ctgggaggcc cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatcagc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaaca gcacctaccg ggtggtgtcc gtgctgacag tgctgcacca ggactggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgagaaa 1020
accatcagca aggccaaggg ccagccccgc gaaccccagg tgtacacact gcccccaagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagagcaac ggccagcccg agaacaacta caagaccacc 1200
ccccctgtgc tggacagcga cggctcattc ttcctgtaca gcaagctgac cgtggacaag 1260
tcccggtggc agcagggcaa cgtgttcagc tgcagcgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gagcctgagc cctggcaag 1359
<210> 580
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 580
cagtctgttc tgacacagcc tccatctgtg tctggcgccc ctggacagag agtgaccatc 60
agctgtacag gcagcagctc caatatcgga gccggctatg acgtgcactg gtatcagcag 120
ctgcctggca cagcccctaa actgctgatc tacggcaaca gcaacagacc cagcggcgtg 180
cccgatagat tttccggctc taagagcggc acaagcgcca gcctggctat tactggactg 240
caggccgagg acgaggccga ctactactgt agctcttacg ctggccccaa tccttacgtg 300
gtgtttggcg gcggaacaaa gctgaccgtt ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 581
<211> 990
<212> PRT
<213> Homo sapiens
<400> 581
His His His His His His Lys Asn Asn Val Pro Arg Leu Lys Leu Ser
1 5 10 15
Tyr Lys Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe Asn Gly Leu
20 25 30
Ala Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu Glu Arg Ser
35 40 45
Arg Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe Asp Leu Val
50 55 60
Asn Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser Tyr Thr Arg
65 70 75 80
Arg Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Lys Glu Cys Ala
85 90 95
Asn Phe Ile Lys Val Leu Lys Ala Tyr Asn Gln Thr His Leu Tyr Ala
100 105 110
Cys Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile Glu Ile Gly
115 120 125
His His Pro Glu Asp Asn Ile Phe Lys Leu Glu Asn Ser His Phe Glu
130 135 140
Asn Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu Thr Ala Ser
145 150 155 160
Leu Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala Asp Phe Met
165 170 175
Gly Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His His Pro Ile
180 185 190
Arg Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro Lys Phe Ile
195 200 205
Ser Ala His Leu Ile Ser Glu Ser Asp Asn Pro Glu Asp Asp Lys Val
210 215 220
Tyr Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His Ser Gly Lys
225 230 235 240
Ala Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp Phe Gly Gly
245 250 255
His Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys Ala Arg Leu
260 265 270
Ile Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His Phe Asp Glu
275 280 285
Leu Gln Asp Val Phe Leu Met Asn Phe Lys Asp Pro Lys Asn Pro Val
290 295 300
Val Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys Gly Ser Ala
305 310 315 320
Val Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe Leu Gly Pro
325 330 335
Tyr Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro Tyr Gln Gly
340 345 350
Arg Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys Thr Phe Gly
355 360 365
Gly Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile Thr Phe Ala
370 375 380
Arg Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Met Asn Asn Arg
385 390 395 400
Pro Ile Val Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr Gln Ile Val
405 410 415
Val Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val Met Phe Ile
420 425 430
Gly Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Ile Pro Lys Glu
435 440 445
Thr Trp Tyr Asp Leu Glu Glu Val Leu Leu Glu Glu Met Thr Val Phe
450 455 460
Arg Glu Pro Thr Ala Ile Ser Ala Met Glu Leu Ser Thr Lys Gln Gln
465 470 475 480
Gln Leu Tyr Ile Gly Ser Thr Ala Gly Val Ala Gln Leu Pro Leu His
485 490 495
Arg Cys Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys Leu Ala Arg
500 505 510
Asp Pro Tyr Cys Ala Trp Asp Gly Ser Ala Cys Ser Arg Tyr Phe Pro
515 520 525
Thr Ala Lys Arg Ala Thr Arg Ala Gln Asp Ile Arg Asn Gly Asp Pro
530 535 540
Leu Thr His Cys Ser Asp Leu His His Asp Asn His His Gly His Ser
545 550 555 560
Pro Glu Glu Arg Ile Ile Tyr Gly Val Glu Asn Ser Ser Thr Phe Leu
565 570 575
Glu Cys Ser Pro Lys Ser Gln Arg Ala Leu Val Tyr Trp Gln Phe Gln
580 585 590
Arg Arg Asn Glu Glu Arg Lys Glu Glu Ile Arg Val Asp Asp His Ile
595 600 605
Ile Arg Thr Asp Gln Gly Leu Leu Leu Arg Ser Leu Gln Gln Lys Asp
610 615 620
Ser Gly Asn Tyr Leu Cys His Ala Val Glu His Gly Phe Ile Gln Thr
625 630 635 640
Leu Leu Lys Val Thr Leu Glu Val Ile Asp Thr Glu His Leu Glu Glu
645 650 655
Leu Leu His Lys Asp Asp Asp Gly Asp Gly Ser Lys Thr Lys Glu Met
660 665 670
Ser Asn Ser Met Thr Pro Ser Gln Lys Val Trp Tyr Arg Asp Phe Met
675 680 685
Gln Leu Ile Asn His Pro Asn Leu Asn Thr Met Asp Glu Phe Cys Glu
690 695 700
Gln Val Trp Lys Arg Asp Arg Lys Gln Arg Arg Gln Arg Pro Gly His
705 710 715 720
Thr Pro Gly Asn Ser Asn Lys Trp Lys His Leu Gln Glu Asn Lys Lys
725 730 735
Gly Arg Asn Arg Arg Thr His Glu Phe Glu Arg Ala Pro Arg Ser Val
740 745 750
Asp Ile Glu Gly Arg Met Asp Pro Lys Ser Cys Asp Lys Thr His Thr
755 760 765
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
770 775 780
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
785 790 795 800
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
805 810 815
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
820 825 830
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
835 840 845
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
850 855 860
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
865 870 875 880
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
885 890 895
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
900 905 910
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
915 920 925
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
930 935 940
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
945 950 955 960
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
965 970 975
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
980 985 990
<210> 582
<211> 563
<212> PRT
<213> Homo sapiens
<400> 582
Asn Tyr Gln Asn Gly Lys Asn Asn Val Pro Arg Leu Lys Leu Ser Tyr
1 5 10 15
Lys Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe Asn Gly Leu Ala
20 25 30
Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu Glu Arg Ser Arg
35 40 45
Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe Asp Leu Val Asn
50 55 60
Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser Tyr Thr Arg Arg
65 70 75 80
Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Lys Glu Cys Ala Asn
85 90 95
Phe Ile Lys Val Leu Lys Ala Tyr Asn Gln Thr His Leu Tyr Ala Cys
100 105 110
Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile Glu Ile Gly His
115 120 125
His Pro Glu Asp Asn Ile Phe Lys Leu Glu Asn Ser His Phe Glu Asn
130 135 140
Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu Thr Ala Ser Leu
145 150 155 160
Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala Asp Phe Met Gly
165 170 175
Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His His Pro Ile Arg
180 185 190
Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro Lys Phe Ile Ser
195 200 205
Ala His Leu Ile Ser Glu Ser Asp Asn Pro Glu Asp Asp Lys Val Tyr
210 215 220
Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His Ser Gly Lys Ala
225 230 235 240
Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp Phe Gly Gly His
245 250 255
Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys Ala Arg Leu Ile
260 265 270
Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His Phe Asp Glu Leu
275 280 285
Gln Asp Val Phe Leu Met Asn Phe Lys Asp Pro Lys Asn Pro Val Val
290 295 300
Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys Gly Ser Ala Val
305 310 315 320
Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe Leu Gly Pro Tyr
325 330 335
Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro Tyr Gln Gly Arg
340 345 350
Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys Thr Phe Gly Gly
355 360 365
Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile Thr Phe Ala Arg
370 375 380
Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Met Asn Asn Arg Pro
385 390 395 400
Ile Val Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr Gln Ile Val Val
405 410 415
Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val Met Phe Ile Gly
420 425 430
Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Ile Pro Lys Glu Thr
435 440 445
Trp Tyr Asp Leu Glu Glu Val Leu Leu Glu Glu Met Thr Val Phe Arg
450 455 460
Glu Pro Thr Ala Ile Ser Ala Met Glu Leu Ser Thr Lys Gln Gln Gln
465 470 475 480
Leu Tyr Ile Gly Ser Thr Ala Gly Val Ala Gln Leu Pro Leu His Arg
485 490 495
Cys Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys Leu Ala Arg Asp
500 505 510
Pro Tyr Cys Ala Trp Asp Gly Ser Ala Cys Ser Arg Tyr Phe Pro Thr
515 520 525
Ala Lys Ala Arg Thr Arg Ala Gln Asp Ile Arg Asn Gly Asp Pro Leu
530 535 540
Thr His Cys Ser Asp Gly Gly Ile Glu Gly Arg Met Asp His His His
545 550 555 560
His His His
<210> 583
<211> 563
<212> PRT
<213> Mus musculus (Mouse)
<400> 583
Asn Tyr Ala Asn Gly Lys Asn Asn Val Pro Arg Leu Lys Leu Ser Tyr
1 5 10 15
Lys Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe Asn Gly Leu Ala
20 25 30
Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu Glu Arg Ser Arg
35 40 45
Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe Asn Leu Val Asn
50 55 60
Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser Tyr Thr Arg Arg
65 70 75 80
Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Lys Glu Cys Ala Asn
85 90 95
Phe Ile Lys Val Leu Glu Ala Tyr Asn Gln Thr His Leu Tyr Ala Cys
100 105 110
Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile Glu Val Gly His
115 120 125
His Pro Glu Asp Asn Ile Phe Lys Leu Gln Asp Ser His Phe Glu Asn
130 135 140
Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu Thr Ala Ser Leu
145 150 155 160
Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala Asp Phe Met Gly
165 170 175
Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His His Pro Ile Arg
180 185 190
Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro Arg Phe Ile Ser
195 200 205
Ala His Leu Ile Pro Glu Ser Asp Asn Pro Glu Asp Asp Lys Val Tyr
210 215 220
Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His Ser Gly Lys Ala
225 230 235 240
Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp Phe Gly Gly His
245 250 255
Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys Ala Arg Leu Ile
260 265 270
Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His Phe Asp Glu Leu
275 280 285
Gln Asp Val Phe Leu Met Asn Ser Lys Asp Pro Lys Asn Pro Ile Val
290 295 300
Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys Gly Ser Ala Val
305 310 315 320
Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe Leu Gly Pro Tyr
325 330 335
Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro Tyr Gln Gly Arg
340 345 350
Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys Thr Phe Gly Gly
355 360 365
Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile Thr Phe Ala Arg
370 375 380
Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Ile Asn Asn Arg Pro
385 390 395 400
Ile Met Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr Gln Ile Val Val
405 410 415
Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val Met Phe Ile Gly
420 425 430
Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Val Pro Lys Glu Thr
435 440 445
Trp His Asp Leu Glu Glu Ile Leu Leu Glu Glu Met Thr Val Phe Arg
450 455 460
Glu Pro Thr Thr Ile Ser Ala Met Glu Leu Ser Thr Lys Gln Gln Gln
465 470 475 480
Leu Tyr Ile Gly Ser Thr Ala Gly Val Ala Gln Leu Pro Leu His Arg
485 490 495
Cys Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys Leu Ala Arg Asp
500 505 510
Pro Tyr Cys Ala Trp Asp Gly Ser Ser Cys Ser Arg Tyr Phe Pro Thr
515 520 525
Ala Lys Ala Arg Thr Arg Ala Gln Asp Ile Arg Asn Gly Asp Pro Leu
530 535 540
Thr His Cys Ser Asp Gly Gly Ile Glu Gly Arg Met Asp His His His
545 550 555 560
His His His
<210> 584
<211> 563
<212> PRT
<213> Rattus norvegicus (Rat)
<400> 584
Asn Tyr Ala Asn Gly Lys Asn Asn Val Pro Arg Leu Lys Leu Ser Tyr
1 5 10 15
Lys Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe Asn Gly Leu Ala
20 25 30
Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu Glu Arg Ser Arg
35 40 45
Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe Asn Leu Val Asn
50 55 60
Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser Tyr Thr Arg Arg
65 70 75 80
Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Lys Glu Cys Ala Asn
85 90 95
Phe Ile Lys Val Leu Lys Ala Tyr Asn Gln Thr His Leu Tyr Ala Cys
100 105 110
Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile Glu Val Gly His
115 120 125
His Pro Glu Asp Asn Ile Phe Lys Leu Gln Asp Ser His Phe Glu Asn
130 135 140
Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu Thr Ala Ser Leu
145 150 155 160
Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala Asp Phe Met Gly
165 170 175
Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His His Pro Ile Arg
180 185 190
Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro Arg Phe Ile Ser
195 200 205
Ala His Leu Ile Pro Glu Ser Asp Asn Pro Glu Asp Asp Lys Val Tyr
210 215 220
Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His Ser Gly Lys Ala
225 230 235 240
Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp Phe Gly Gly His
245 250 255
Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys Ala Arg Leu Ile
260 265 270
Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His Phe Asp Glu Leu
275 280 285
Gln Asp Val Phe Leu Met Asn Ser Lys Asp Pro Lys Asn Pro Ile Val
290 295 300
Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys Gly Ser Ala Val
305 310 315 320
Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe Leu Gly Pro Tyr
325 330 335
Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro Tyr Gln Gly Arg
340 345 350
Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys Thr Phe Gly Gly
355 360 365
Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile Thr Phe Ala Arg
370 375 380
Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Ile Asn Asn Arg Pro
385 390 395 400
Ile Met Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr Gln Ile Val Val
405 410 415
Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val Met Phe Ile Gly
420 425 430
Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Val Pro Lys Glu Thr
435 440 445
Trp His Asp Leu Glu Glu Val Leu Leu Glu Glu Met Thr Val Phe Arg
450 455 460
Glu Pro Thr Thr Ile Ser Ala Met Glu Leu Ser Thr Lys Gln Gln Gln
465 470 475 480
Leu Tyr Ile Gly Ser Thr Ala Gly Val Ala Gln Leu Pro Leu His Arg
485 490 495
Cys Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys Leu Ala Arg Asp
500 505 510
Pro Tyr Cys Ala Trp Asp Gly Ser Ser Cys Ser Arg Tyr Phe Pro Thr
515 520 525
Ala Lys Ala Arg Thr Arg Ala Gln Asp Ile Arg Asn Gly Asp Pro Leu
530 535 540
Thr His Cys Ser Asp Gly Gly Ile Glu Gly Arg Met Asp His His His
545 550 555 560
His His His
<210> 585
<211> 563
<212> PRT
<213> Canis lupus familiaris (dog)
<400> 585
Asn Tyr Gln Asn Gly Lys Asn Asn Val Pro Arg Leu Lys Leu Ser Tyr
1 5 10 15
Lys Glu Met Leu Glu Ser Asn Ser Val Ile Thr Phe Asn Gly Leu Ala
20 25 30
Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu Glu Arg Ser Arg
35 40 45
Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe Asn Leu Val Asn
50 55 60
Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser Tyr Thr Arg Arg
65 70 75 80
Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Gln Lys Glu Cys Ala Asn
85 90 95
Phe Ile Lys Val Leu Lys Ala Tyr Asn Gln Thr His Leu Tyr Ala Cys
100 105 110
Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile Glu Ile Gly His
115 120 125
His Pro Glu Asp Asn Ile Phe Lys Leu Glu Asp Ser His Phe Glu Asn
130 135 140
Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu Thr Ala Ser Leu
145 150 155 160
Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala Asp Phe Met Gly
165 170 175
Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His His Pro Ile Arg
180 185 190
Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro Arg Phe Ile Ser
195 200 205
Ala His Leu Ile Pro Glu Ser Asp Asn Pro Glu Asp Asp Lys Val Tyr
210 215 220
Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His Thr Gly Lys Ala
225 230 235 240
Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp Phe Gly Gly His
245 250 255
Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys Ala Arg Leu Ile
260 265 270
Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His Phe Asp Glu Leu
275 280 285
Gln Asp Val Phe Leu Met Asn Ser Lys Asp Pro Lys Asn Pro Ile Val
290 295 300
Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys Gly Ser Ala Val
305 310 315 320
Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe Leu Gly Pro Tyr
325 330 335
Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro Tyr Gln Gly Arg
340 345 350
Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys Thr Phe Gly Gly
355 360 365
Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile Thr Phe Ala Arg
370 375 380
Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Ile Asn Asn Arg Pro
385 390 395 400
Ile Met Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr Gln Ile Val Val
405 410 415
Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val Met Phe Ile Gly
420 425 430
Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Ile Pro Lys Glu Thr
435 440 445
Trp His Asp Leu Glu Glu Val Leu Leu Glu Glu Met Thr Val Phe Arg
450 455 460
Glu Pro Thr Pro Ile Ser Ala Met Glu Leu Ser Thr Lys Gln His Gln
465 470 475 480
Leu Tyr Ala Gly Ser Pro Ala Gly Leu Ala Gln Leu Pro Leu Gln Arg
485 490 495
Cys Ala Ala Tyr Gly Arg Ala Cys Ala Glu Cys Cys Leu Ala Arg Asp
500 505 510
Pro Tyr Cys Ala Trp Asp Gly Ala Ala Cys Ser Arg Tyr Phe Pro Ala
515 520 525
Ala Lys Ala Arg Thr Arg Ala Gln Asp Ile Arg Asn Gly Asp Pro Leu
530 535 540
Thr His Cys Ser Asp Gly Gly Ile Glu Gly Arg Met Asp His His His
545 550 555 560
His His His
<210> 586
<211> 563
<212> PRT
<213> Macaca fascicularis (Cynomolgus monkey)
<400> 586
Asn Tyr Gln Asn Gly Lys Asn Asn Val Pro Arg Leu Lys Leu Ser Tyr
1 5 10 15
Lys Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe Asn Gly Leu Ala
20 25 30
Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu Glu Arg Ser Arg
35 40 45
Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe Asn Leu Val Asn
50 55 60
Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser Tyr Thr Arg Arg
65 70 75 80
Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Lys Glu Cys Ala Asn
85 90 95
Phe Ile Lys Val Leu Lys Ala Tyr Asn Gln Thr His Leu Tyr Ala Cys
100 105 110
Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile Glu Ile Gly His
115 120 125
His Pro Glu Asp Asn Ile Phe Lys Leu Glu Asn Ser His Phe Glu Asn
130 135 140
Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu Thr Ala Ser Leu
145 150 155 160
Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala Asp Phe Met Gly
165 170 175
Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His His Pro Ile Arg
180 185 190
Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro Arg Phe Ile Ser
195 200 205
Ala His Leu Ile Pro Glu Ser Asp Asn Pro Glu Asp Asp Lys Val Tyr
210 215 220
Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His Ser Gly Lys Ala
225 230 235 240
Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp Phe Gly Gly His
245 250 255
Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys Ala Arg Leu Ile
260 265 270
Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His Phe Asp Glu Leu
275 280 285
Gln Asp Val Phe Leu Met Asn Phe Lys Asp Pro Lys Asn Pro Ile Val
290 295 300
Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys Gly Ser Ala Val
305 310 315 320
Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe Leu Gly Pro Tyr
325 330 335
Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro Tyr Gln Gly Arg
340 345 350
Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys Thr Phe Gly Gly
355 360 365
Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile Thr Phe Ala Arg
370 375 380
Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Ile Asn Asn Arg Pro
385 390 395 400
Ile Met Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr Gln Ile Val Val
405 410 415
Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val Met Phe Ile Gly
420 425 430
Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Ile Pro Lys Glu Thr
435 440 445
Trp His Asp Leu Glu Glu Val Leu Leu Glu Glu Met Thr Val Phe Arg
450 455 460
Glu Pro Thr Thr Ile Ser Ala Met Glu Leu Ser Thr Lys Gln Gln Gln
465 470 475 480
Leu Tyr Ile Gly Ser Thr Ala Gly Ile Ala Gln Leu Pro Leu His Arg
485 490 495
Cys Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys Leu Ala Arg Asp
500 505 510
Pro Tyr Cys Ala Trp Asp Gly Ser Ser Cys Ser Arg Tyr Phe Pro Thr
515 520 525
Ala Lys Ala Arg Thr Arg Ala Gln Asp Ile Arg Asn Gly Asp Pro Leu
530 535 540
Thr His Cys Ser Asp Gly Gly Ile Glu Gly Arg Met Asp His His His
545 550 555 560
His His His
<210> 587
<211> 563
<212> PRT
<213> Sus scrofa (Pig)
<400> 587
Asn Tyr Gln Asn Gly Lys Asn Asn Val Pro Arg Leu Lys Leu Ser Tyr
1 5 10 15
Lys Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe Asn Gly Leu Ala
20 25 30
Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu Glu Arg Ser Arg
35 40 45
Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe Asn Leu Val Asn
50 55 60
Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser Tyr Thr Arg Arg
65 70 75 80
Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Lys Glu Cys Ala Asn
85 90 95
Phe Ile Lys Val Leu Lys Ala Tyr Asn Gln Thr His Leu Tyr Ala Cys
100 105 110
Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile Glu Ile Gly His
115 120 125
His Pro Glu Asp Asn Ile Phe Lys Leu Glu Asp Ser His Phe Glu Asn
130 135 140
Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu Thr Ala Ser Leu
145 150 155 160
Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala Asp Phe Met Gly
165 170 175
Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His His Pro Ile Arg
180 185 190
Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro Arg Phe Ile Ser
195 200 205
Ala His Leu Ile Pro Glu Ser Asp Asn Pro Glu Asp Asp Lys Val Tyr
210 215 220
Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His Thr Gly Lys Ala
225 230 235 240
Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp Phe Gly Gly His
245 250 255
Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys Ala Arg Leu Ile
260 265 270
Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His Phe Asp Glu Leu
275 280 285
Gln Asp Val Phe Leu Met Asn Ser Lys Asp Pro Lys Asn Pro Val Val
290 295 300
Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys Gly Ser Ala Val
305 310 315 320
Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe Leu Gly Pro Tyr
325 330 335
Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro Tyr Gln Gly Arg
340 345 350
Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys Thr Phe Gly Gly
355 360 365
Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile Thr Phe Ala Arg
370 375 380
Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Ile Asn Asn Arg Pro
385 390 395 400
Ile Met Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr Gln Ile Val Val
405 410 415
Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val Met Phe Ile Gly
420 425 430
Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Ile Pro Lys Glu Thr
435 440 445
Trp His Asp Leu Glu Glu Val Leu Leu Glu Glu Met Thr Val Phe Arg
450 455 460
Glu Pro Thr Thr Ile Ser Ala Met Glu Leu Ser Thr Lys Gln Gln Gln
465 470 475 480
Leu Tyr Val Gly Ser Ala Ala Gly Val Ala Gln Leu Pro Leu His Arg
485 490 495
Cys Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys Leu Ala Arg Asp
500 505 510
Pro Tyr Cys Ala Trp Asp Gly Ser Ser Cys Ser Arg Tyr Phe Pro Thr
515 520 525
Ala Lys Ala Arg Thr Arg Ala Gln Asp Ile Arg Asn Gly Asp Pro Leu
530 535 540
Thr His Cys Ser Asp Gly Gly Ile Glu Gly Arg Met Asp His His His
545 550 555 560
His His His
<210> 588
<211> 5
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<400> 588
Ser Tyr Xaa Met Xaa
1 5
<210> 589
<211> 5
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<400> 589
Ser Tyr Ala Met Xaa
1 5
<210> 590
<211> 16
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (15)..(15)
<223> Xaa can be any naturally occurring amino acid
<400> 590
Ala Ile Gly Xaa Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Xaa Gly
1 5 10 15
<210> 591
<211> 16
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 591
Ala Ile Gly Xaa Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 592
<211> 17
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (8)..(8)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (10)..(10)
<223> Xaa can be any naturally occurring amino acid
<400> 592
Gly Ile Ser Trp Asn Ser Gly Xaa Ile Xaa Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 593
<211> 17
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (10)..(10)
<223> Xaa can be any naturally occurring amino acid
<400> 593
Gly Ile Ser Trp Asn Ser Gly Trp Ile Xaa Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 594
<211> 12
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (12)..(12)
<223> Xaa can be any naturally occurring amino acid
<400> 594
Arg Asp Asp Tyr Thr Ser Arg Asp Ala Phe Asp Xaa
1 5 10
<210> 595
<211> 14
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (6)..(6)
<223> Xaa can be any naturally occurring amino acid
<400> 595
Thr Gly Ser Ser Ser Xaa Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 596
<211> 7
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<400> 596
Tyr Asp Asp Leu Xaa Pro Ser
1 5
<210> 597
<211> 7
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<400> 597
Gly Xaa Ser Asn Arg Pro Ser
1 5
<210> 598
<211> 12
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (9)..(11)
<223> Xaa can be any naturally occurring amino acid
<400> 598
Xaa Ala Trp Asp Asp Ser Leu Asn Xaa Xaa Xaa Val
1 5 10
<210> 599
<211> 11
<212> PRT
<213> artificial
<220>
<223> antibody sequence
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (6)..(6)
<223> Xaa can be any naturally occurring amino acid
<400> 599
Xaa Ser Tyr Xaa Gly Xaa Asn Pro Tyr Val Val
1 5 10
<210> 600
<211> 750
<212> PRT
<213> Homo sapiens
<400> 600
Tyr Gln Asn Gly Lys Asn Asn Val Pro Arg Leu Lys Leu Ser Tyr Lys
1 5 10 15
Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe Asn Gly Leu Ala Asn
20 25 30
Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu Glu Arg Ser Arg Leu
35 40 45
Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe Asp Leu Val Asn Ile
50 55 60
Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser Tyr Thr Arg Arg Asp
65 70 75 80
Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Lys Glu Cys Ala Asn Phe
85 90 95
Ile Lys Val Leu Lys Ala Tyr Asn Gln Thr His Leu Tyr Ala Cys Gly
100 105 110
Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile Glu Ile Gly His His
115 120 125
Pro Glu Asp Asn Ile Phe Lys Leu Glu Asn Ser His Phe Glu Asn Gly
130 135 140
Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu Thr Ala Ser Leu Leu
145 150 155 160
Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala Asp Phe Met Gly Arg
165 170 175
Asp Phe Ala Ile Phe Arg Thr Leu Gly His His His Pro Ile Arg Thr
180 185 190
Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro Lys Phe Ile Ser Ala
195 200 205
His Leu Ile Ser Glu Ser Asp Asn Pro Glu Asp Asp Lys Val Tyr Phe
210 215 220
Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His Ser Gly Lys Ala Thr
225 230 235 240
His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp Phe Gly Gly His Arg
245 250 255
Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys Ala Arg Leu Ile Cys
260 265 270
Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His Phe Asp Glu Leu Gln
275 280 285
Asp Val Phe Leu Met Asn Phe Lys Asp Pro Lys Asn Pro Val Val Tyr
290 295 300
Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys Gly Ser Ala Val Cys
305 310 315 320
Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe Leu Gly Pro Tyr Ala
325 330 335
His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro Tyr Gln Gly Arg Val
340 345 350
Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys Thr Phe Gly Gly Phe
355 360 365
Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile Thr Phe Ala Arg Ser
370 375 380
His Pro Ala Met Tyr Asn Pro Val Phe Pro Met Asn Asn Arg Pro Ile
385 390 395 400
Val Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr Gln Ile Val Val Asp
405 410 415
Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val Met Phe Ile Gly Thr
420 425 430
Asp Val Gly Thr Val Leu Lys Val Val Ser Ile Pro Lys Glu Thr Trp
435 440 445
Tyr Asp Leu Glu Glu Val Leu Leu Glu Glu Met Thr Val Phe Arg Glu
450 455 460
Pro Thr Ala Ile Ser Ala Met Glu Leu Ser Thr Lys Gln Gln Gln Leu
465 470 475 480
Tyr Ile Gly Ser Thr Ala Gly Val Ala Gln Leu Pro Leu His Arg Cys
485 490 495
Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys Leu Ala Arg Asp Pro
500 505 510
Tyr Cys Ala Trp Asp Gly Ser Ala Cys Ser Arg Tyr Phe Pro Thr Ala
515 520 525
Lys Arg Arg Thr Arg Arg Gln Asp Ile Arg Asn Gly Asp Pro Leu Thr
530 535 540
His Cys Ser Asp Leu His His Asp Asn His His Gly His Ser Pro Glu
545 550 555 560
Glu Arg Ile Ile Tyr Gly Val Glu Asn Ser Ser Thr Phe Leu Glu Cys
565 570 575
Ser Pro Lys Ser Gln Arg Ala Leu Val Tyr Trp Gln Phe Gln Arg Arg
580 585 590
Asn Glu Glu Arg Lys Glu Glu Ile Arg Val Asp Asp His Ile Ile Arg
595 600 605
Thr Asp Gln Gly Leu Leu Leu Arg Ser Leu Gln Gln Lys Asp Ser Gly
610 615 620
Asn Tyr Leu Cys His Ala Val Glu His Gly Phe Ile Gln Thr Leu Leu
625 630 635 640
Lys Val Thr Leu Glu Val Ile Asp Thr Glu His Leu Glu Glu Leu Leu
645 650 655
His Lys Asp Asp Asp Gly Asp Gly Ser Lys Thr Lys Glu Met Ser Asn
660 665 670
Ser Met Thr Pro Ser Gln Lys Val Trp Tyr Arg Asp Phe Met Gln Leu
675 680 685
Ile Asn His Pro Asn Leu Asn Thr Met Asp Glu Phe Cys Glu Gln Val
690 695 700
Trp Lys Arg Asp Arg Lys Gln Arg Arg Gln Arg Pro Gly His Thr Pro
705 710 715 720
Gly Asn Ser Asn Lys Trp Lys His Leu Gln Glu Asn Lys Lys Gly Arg
725 730 735
Asn Arg Arg Thr His Glu Phe Glu Arg Ala Pro Arg Ser Val
740 745 750
<210> 601
<211> 752
<212> PRT
<213> Mus musculus
<400> 601
Asn Tyr Ala Asn Gly Lys Asn Asn Val Pro Arg Leu Lys Leu Ser Tyr
1 5 10 15
Lys Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe Asn Gly Leu Ala
20 25 30
Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu Glu Arg Ser Arg
35 40 45
Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe Asn Leu Val Asn
50 55 60
Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser Tyr Thr Arg Arg
65 70 75 80
Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Lys Glu Cys Ala Asn
85 90 95
Phe Ile Lys Val Leu Glu Ala Tyr Asn Gln Thr His Leu Tyr Ala Cys
100 105 110
Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile Glu Val Gly His
115 120 125
His Pro Glu Asp Asn Ile Phe Lys Leu Gln Asp Ser His Phe Glu Asn
130 135 140
Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu Thr Ala Ser Leu
145 150 155 160
Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala Asp Phe Met Gly
165 170 175
Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His His Pro Ile Arg
180 185 190
Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro Arg Phe Ile Ser
195 200 205
Ala His Leu Ile Pro Glu Ser Asp Asn Pro Glu Asp Asp Lys Val Tyr
210 215 220
Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His Ser Gly Lys Ala
225 230 235 240
Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp Phe Gly Gly His
245 250 255
Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys Ala Arg Leu Ile
260 265 270
Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His Phe Asp Glu Leu
275 280 285
Gln Asp Val Phe Leu Met Asn Ser Lys Asp Pro Lys Asn Pro Ile Val
290 295 300
Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys Gly Ser Ala Val
305 310 315 320
Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe Leu Gly Pro Tyr
325 330 335
Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro Tyr Gln Gly Arg
340 345 350
Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys Thr Phe Gly Gly
355 360 365
Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile Thr Phe Ala Arg
370 375 380
Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Ile Asn Asn Arg Pro
385 390 395 400
Ile Met Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr Gln Ile Val Val
405 410 415
Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val Met Phe Ile Gly
420 425 430
Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Val Pro Lys Glu Thr
435 440 445
Trp His Asp Leu Glu Glu Val Leu Leu Glu Glu Met Thr Val Phe Arg
450 455 460
Glu Pro Thr Thr Ile Ser Ala Met Glu Leu Ser Thr Lys Gln Gln Gln
465 470 475 480
Leu Tyr Ile Gly Ser Thr Ala Gly Val Ala Gln Leu Pro Leu His Arg
485 490 495
Cys Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys Leu Ala Arg Asp
500 505 510
Pro Tyr Cys Ala Trp Asp Gly Ser Ser Cys Ser Arg Tyr Phe Pro Thr
515 520 525
Ala Lys Arg Arg Thr Arg Arg Gln Asp Ile Arg Asn Gly Asp Pro Leu
530 535 540
Thr His Cys Ser Asp Leu Gln His His Asp Asn His His Gly Pro Ser
545 550 555 560
Leu Glu Glu Arg Ile Ile Tyr Gly Val Glu Asn Ser Ser Thr Phe Leu
565 570 575
Glu Cys Ser Pro Lys Ser Gln Arg Ala Leu Val Tyr Trp Gln Phe Gln
580 585 590
Arg Arg Asn Glu Asp Arg Lys Glu Glu Ile Arg Met Gly Asp His Ile
595 600 605
Ile Arg Thr Glu Gln Gly Leu Leu Leu Arg Ser Leu Gln Lys Lys Asp
610 615 620
Ser Gly Asn Tyr Leu Cys His Ala Val Glu His Gly Phe Met Gln Thr
625 630 635 640
Leu Leu Lys Val Thr Leu Glu Val Ile Asp Thr Glu His Leu Glu Glu
645 650 655
Leu Leu His Lys Asp Asp Asp Gly Asp Gly Ser Lys Ile Lys Glu Met
660 665 670
Ser Ser Ser Met Thr Pro Ser Gln Lys Val Trp Tyr Arg Asp Phe Met
675 680 685
Gln Leu Ile Asn His Pro Asn Leu Asn Thr Met Asp Glu Phe Cys Glu
690 695 700
Gln Val Trp Lys Arg Asp Arg Lys Gln Arg Arg Gln Arg Pro Gly His
705 710 715 720
Ser Gln Gly Ser Ser Asn Lys Trp Lys His Met Gln Glu Ser Lys Lys
725 730 735
Gly Arg Asn Arg Arg Thr His Glu Phe Glu Arg Ala Pro Arg Ser Val
740 745 750
<210> 602
<211> 772
<212> PRT
<213> Macaca fascicularis
<400> 602
Met Gly Trp Leu Thr Arg Ile Val Cys Leu Phe Trp Gly Val Leu Leu
1 5 10 15
Thr Ala Arg Ala Asn Tyr Gln Asn Gly Lys Asn Asn Val Pro Arg Leu
20 25 30
Lys Leu Ser Tyr Lys Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe
35 40 45
Asn Gly Leu Ala Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu
50 55 60
Glu Arg Ser Arg Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe
65 70 75 80
Asn Leu Val Asn Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser
85 90 95
Tyr Thr Arg Arg Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Lys
100 105 110
Glu Cys Ala Asn Phe Ile Lys Val Leu Lys Ala Tyr Asn Gln Thr His
115 120 125
Leu Tyr Ala Cys Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile
130 135 140
Glu Ile Gly His His Pro Glu Asp Asn Ile Phe Lys Leu Glu Asn Ser
145 150 155 160
His Phe Glu Asn Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu
165 170 175
Thr Ala Ser Leu Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala
180 185 190
Asp Phe Met Gly Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His
195 200 205
His Pro Ile Arg Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro
210 215 220
Arg Phe Ile Ser Ala His Leu Ile Pro Glu Ser Asp Asn Pro Glu Asp
225 230 235 240
Asp Lys Val Tyr Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His
245 250 255
Ser Gly Lys Ala Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp
260 265 270
Phe Gly Gly His Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys
275 280 285
Ala Arg Leu Ile Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His
290 295 300
Phe Asp Glu Leu Gln Asp Val Phe Leu Met Asn Phe Lys Asp Pro Lys
305 310 315 320
Asn Pro Ile Val Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys
325 330 335
Gly Ser Ala Val Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe
340 345 350
Leu Gly Pro Tyr Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro
355 360 365
Tyr Gln Gly Arg Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys
370 375 380
Thr Phe Gly Gly Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile
385 390 395 400
Thr Phe Ala Arg Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Ile
405 410 415
Asn Asn Arg Pro Ile Met Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr
420 425 430
Gln Ile Val Val Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val
435 440 445
Met Phe Ile Gly Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Ile
450 455 460
Pro Lys Glu Thr Trp His Asp Leu Glu Glu Val Leu Leu Glu Glu Met
465 470 475 480
Thr Val Phe Arg Glu Pro Thr Thr Ile Ser Ala Met Glu Leu Ser Thr
485 490 495
Lys Gln Gln Gln Leu Tyr Ile Gly Ser Thr Ala Gly Ile Ala Gln Leu
500 505 510
Pro Leu His Arg Cys Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys
515 520 525
Leu Ala Arg Asp Pro Tyr Cys Ala Trp Asp Gly Ser Ser Cys Ser Arg
530 535 540
Tyr Phe Pro Thr Ala Lys Arg Arg Thr Arg Arg Gln Asp Ile Arg Asn
545 550 555 560
Gly Asp Pro Leu Thr His Cys Ser Asp Leu Gln His His Asp Asn His
565 570 575
His Gly His Ser Pro Glu Glu Arg Ile Ile Tyr Gly Val Glu Asn Ser
580 585 590
Ser Thr Phe Leu Glu Cys Ser Pro Lys Ser Gln Arg Ala Leu Val Tyr
595 600 605
Trp Gln Phe Gln Arg Arg Asn Glu Glu Arg Lys Glu Glu Ile Arg Val
610 615 620
Asp Asp His Ile Ile Arg Thr Asp Gln Gly Leu Leu Leu Arg Ser Leu
625 630 635 640
Gln Arg Lys Asp Ser Gly Ser Tyr Leu Cys His Ala Val Glu His Gly
645 650 655
Phe Ile Gln Thr Leu Leu Lys Val Thr Leu Glu Val Ile Asp Thr Glu
660 665 670
His Leu Glu Glu Leu Leu His Lys Asp Asp Asp Gly Asp Gly Ser Lys
675 680 685
Thr Lys Glu Met Ser Asn Ser Met Thr Pro Ser Gln Lys Val Trp Tyr
690 695 700
Arg Asp Phe Met Gln Leu Ile Asn His Pro Asn Leu Asn Thr Met Asp
705 710 715 720
Glu Phe Cys Glu Gln Val Trp Lys Arg Asp Arg Lys Gln Arg Arg Gln
725 730 735
Arg Pro Gly His Thr Gln Gly Asn Ser Asn Lys Trp Lys His Leu Gln
740 745 750
Glu Asn Lys Lys Gly Arg Asn Arg Arg Thr His Glu Phe Glu Arg Ala
755 760 765
Pro Arg Ser Val
770
<210> 603
<211> 752
<212> PRT
<213> Rattus norvegicus
<400> 603
Asn Tyr Ala Asn Gly Lys Asn Asn Val Pro Arg Leu Lys Leu Ser Tyr
1 5 10 15
Lys Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe Asn Gly Leu Ala
20 25 30
Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu Glu Arg Ser Arg
35 40 45
Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe Asn Leu Val Asn
50 55 60
Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser Tyr Thr Arg Arg
65 70 75 80
Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Lys Glu Cys Ala Asn
85 90 95
Phe Ile Lys Val Leu Lys Ala Tyr Asn Gln Thr His Leu Tyr Ala Cys
100 105 110
Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile Glu Val Gly His
115 120 125
His Pro Glu Asp Asn Ile Phe Lys Leu Gln Asp Ser His Phe Glu Asn
130 135 140
Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu Thr Ala Ser Leu
145 150 155 160
Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala Asp Phe Met Gly
165 170 175
Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His His Pro Ile Arg
180 185 190
Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro Arg Phe Ile Ser
195 200 205
Ala His Leu Ile Pro Glu Ser Asp Asn Pro Glu Asp Asp Lys Val Tyr
210 215 220
Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His Ser Gly Lys Ala
225 230 235 240
Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp Phe Gly Gly His
245 250 255
Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys Ala Arg Leu Ile
260 265 270
Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His Phe Asp Glu Leu
275 280 285
Gln Asp Val Phe Leu Met Asn Ser Lys Asp Pro Lys Asn Pro Ile Val
290 295 300
Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys Gly Ser Ala Val
305 310 315 320
Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe Leu Gly Pro Tyr
325 330 335
Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro Tyr Gln Gly Arg
340 345 350
Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys Thr Phe Gly Gly
355 360 365
Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile Thr Phe Ala Arg
370 375 380
Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Ile Asn Asn Arg Pro
385 390 395 400
Ile Met Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr Gln Ile Val Val
405 410 415
Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val Met Phe Ile Gly
420 425 430
Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Val Pro Lys Glu Thr
435 440 445
Trp His Asp Leu Glu Glu Val Leu Leu Glu Glu Met Thr Val Phe Arg
450 455 460
Glu Pro Thr Thr Ile Ser Ala Met Glu Leu Ser Thr Lys Gln Gln Gln
465 470 475 480
Leu Tyr Ile Gly Ser Thr Ala Gly Val Ala Gln Leu Pro Leu His Arg
485 490 495
Cys Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys Leu Ala Arg Asp
500 505 510
Pro Tyr Cys Ala Trp Asp Gly Ser Ser Cys Ser Arg Tyr Phe Pro Thr
515 520 525
Ala Lys Arg Arg Thr Arg Arg Gln Asp Ile Arg Asn Gly Asp Pro Leu
530 535 540
Thr His Cys Ser Asp Leu Gln His His Asp Asn His His Gly His Ser
545 550 555 560
Leu Glu Glu Arg Ile Ile Tyr Gly Val Glu Asn Ser Ser Thr Phe Leu
565 570 575
Glu Cys Ser Pro Lys Ser Gln Arg Ala Leu Val Tyr Trp Gln Phe Gln
580 585 590
Arg Arg Asn Glu Asp Arg Lys Glu Glu Ile Arg Val Gly Asp His Ile
595 600 605
Ile Arg Thr Glu Gln Gly Leu Leu Leu Arg Ser Leu Gln Lys Lys Asp
610 615 620
Ser Gly Asn Tyr Leu Cys His Ala Val Glu His Gly Phe Met Gln Thr
625 630 635 640
Leu Leu Lys Val Thr Leu Glu Val Ile Asp Thr Glu His Leu Glu Glu
645 650 655
Leu Leu His Lys Asp Asp Asp Gly Asp Gly Ser Lys Thr Lys Glu Met
660 665 670
Ser Ser Ser Met Thr Pro Ser Gln Lys Val Trp Tyr Arg Asp Phe Met
675 680 685
Gln Leu Ile Asn His Pro Asn Leu Asn Thr Met Asp Glu Phe Cys Glu
690 695 700
Gln Val Trp Lys Arg Asp Arg Lys Gln Arg Arg Gln Arg Pro Gly His
705 710 715 720
Ser Gln Gly Ser Ser Asn Lys Trp Lys His Met Gln Glu Ser Lys Lys
725 730 735
Gly Arg Asn Arg Arg Thr His Glu Phe Glu Arg Ala Pro Arg Ser Val
740 745 750
<210> 604
<211> 772
<212> PRT
<213> Sus scrofa
<400> 604
Met Gly Trp Phe Ser Arg Ile Val Cys Leu Phe Trp Gly Val Leu Leu
1 5 10 15
Thr Ala Arg Ala Asn Tyr Gln Asn Gly Lys Asn Asn Val Pro Arg Leu
20 25 30
Lys Leu Ser Tyr Lys Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe
35 40 45
Asn Gly Leu Ala Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu
50 55 60
Glu Arg Ser Arg Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe
65 70 75 80
Asn Leu Val Asn Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser
85 90 95
Tyr Thr Arg Arg Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Lys
100 105 110
Glu Cys Ala Asn Phe Ile Lys Val Leu Lys Ala Tyr Asn Gln Thr His
115 120 125
Leu Tyr Ala Cys Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile
130 135 140
Glu Ile Gly His His Pro Glu Asp Asn Ile Phe Lys Leu Glu Asp Ser
145 150 155 160
His Phe Glu Asn Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu
165 170 175
Thr Ala Ser Leu Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala
180 185 190
Asp Phe Met Gly Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His
195 200 205
His Pro Ile Arg Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro
210 215 220
Arg Phe Ile Ser Ala His Leu Ile Pro Glu Ser Asp Asn Pro Glu Asp
225 230 235 240
Asp Lys Val Tyr Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His
245 250 255
Thr Gly Lys Ala Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp
260 265 270
Phe Gly Gly His Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys
275 280 285
Ala Arg Leu Ile Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His
290 295 300
Phe Asp Glu Leu Gln Asp Val Phe Leu Met Asn Ser Lys Asp Pro Lys
305 310 315 320
Asn Pro Val Val Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys
325 330 335
Gly Ser Ala Val Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe
340 345 350
Leu Gly Pro Tyr Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro
355 360 365
Tyr Gln Gly Arg Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys
370 375 380
Thr Phe Gly Gly Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile
385 390 395 400
Thr Phe Ala Arg Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Ile
405 410 415
Asn Asn Arg Pro Ile Met Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr
420 425 430
Gln Ile Val Val Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val
435 440 445
Met Phe Ile Gly Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Ile
450 455 460
Pro Lys Glu Thr Trp His Asp Leu Glu Glu Val Leu Leu Glu Glu Met
465 470 475 480
Thr Val Phe Arg Glu Pro Thr Thr Ile Ser Ala Met Glu Leu Ser Thr
485 490 495
Lys Gln Gln Gln Leu Tyr Val Gly Ser Ala Ala Gly Val Ala Gln Leu
500 505 510
Pro Leu His Arg Cys Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys
515 520 525
Leu Ala Arg Asp Pro Tyr Cys Ala Trp Asp Gly Ser Ser Cys Ser Arg
530 535 540
Tyr Phe Pro Thr Ala Lys Arg Arg Thr Arg Arg Gln Asp Ile Arg Asn
545 550 555 560
Gly Asp Pro Leu Thr His Cys Ser Asp Leu Gln His His Asp Asn His
565 570 575
Arg Gly His Asn Phe Glu Glu Arg Ile Ile Tyr Gly Val Glu Asn Ser
580 585 590
Ser Thr Phe Leu Glu Cys Ser Pro Lys Ser Gln Arg Ala Leu Val Tyr
595 600 605
Trp Gln Phe Gln Arg Arg Asn Glu Glu Arg Lys Glu Glu Ile Arg Val
610 615 620
Asp Asp His Ile Ile Arg Thr Glu Gln Gly Leu Leu Leu Arg Ser Leu
625 630 635 640
Gln Arg Lys Asp Ser Gly Ser Tyr Leu Cys His Ala Val Glu His Gly
645 650 655
Phe Met Gln Thr Leu Leu Lys Val Thr Leu Glu Val Ile Asp Thr Glu
660 665 670
His Leu Glu Glu Leu Leu His Lys Asp Asp Asp Gly Asp Ser Ser Lys
675 680 685
Thr Lys Glu Met Ser Asn Ser Met Thr Pro Ser Gln Lys Ile Trp Tyr
690 695 700
Arg Asp Phe Met Gln Leu Ile Asn His Pro Asn Leu Asn Thr Met Asp
705 710 715 720
Glu Phe Cys Glu Gln Val Trp Lys Arg Asp Arg Lys Gln Arg Arg Gln
725 730 735
Arg Pro Gly His Thr Gln Gly Asn Ser Asn Lys Trp Lys His Leu Gln
740 745 750
Glu Asn Lys Lys Cys Arg Asn Arg Arg Thr His Glu Phe Glu Arg Ala
755 760 765
Pro Arg Ser Val
770
<210> 605
<211> 772
<212> PRT
<213> Canis lupus familiaris
<400> 605
Met Gly Trp Leu Ala Arg Ile Ala Cys Leu Phe Trp Gly Val Leu Leu
1 5 10 15
Thr Ala Thr Ala Asn Tyr Gln Asn Gly Lys Asn Asn Val Pro Arg Leu
20 25 30
Lys Leu Ser Tyr Lys Glu Met Leu Glu Ser Asn Ser Val Ile Thr Phe
35 40 45
Asn Gly Leu Ala Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu
50 55 60
Glu Arg Ser Arg Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe
65 70 75 80
Asn Leu Val Asn Ile Lys Asp Phe Gln Lys Ile Val Trp Pro Val Ser
85 90 95
Tyr Thr Arg Arg Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Gln Lys
100 105 110
Glu Cys Ala Asn Phe Ile Lys Val Leu Lys Ala Tyr Asn Gln Thr His
115 120 125
Leu Tyr Ala Cys Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Ile
130 135 140
Glu Ile Gly His His Pro Glu Asp Asn Ile Phe Lys Leu Glu Asp Ser
145 150 155 160
His Phe Glu Asn Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu
165 170 175
Thr Ala Ser Leu Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala
180 185 190
Asp Phe Met Gly Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly His His
195 200 205
His Pro Ile Arg Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro
210 215 220
Arg Phe Ile Ser Ala His Leu Ile Pro Glu Ser Asp Asn Pro Glu Asp
225 230 235 240
Asp Lys Val Tyr Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His
245 250 255
Thr Gly Lys Ala Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp
260 265 270
Phe Gly Gly His Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys
275 280 285
Ala Arg Leu Ile Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His
290 295 300
Phe Asp Glu Leu Gln Asp Val Phe Leu Met Asn Ser Lys Asp Pro Lys
305 310 315 320
Asn Pro Ile Val Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Lys
325 330 335
Gly Ser Ala Val Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe
340 345 350
Leu Gly Pro Tyr Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro
355 360 365
Tyr Gln Gly Arg Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys
370 375 380
Thr Phe Gly Gly Phe Asp Ser Thr Lys Asp Leu Pro Asp Asp Val Ile
385 390 395 400
Thr Phe Ala Arg Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Ile
405 410 415
Asn Asn Arg Pro Ile Met Ile Lys Thr Asp Val Asn Tyr Gln Phe Thr
420 425 430
Gln Ile Val Val Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val
435 440 445
Met Phe Ile Gly Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Ile
450 455 460
Pro Lys Glu Thr Trp His Asp Leu Glu Glu Val Leu Leu Glu Glu Met
465 470 475 480
Thr Val Phe Arg Glu Pro Thr Pro Ile Ser Ala Met Glu Leu Ser Thr
485 490 495
Lys Gln His Gln Leu Tyr Ala Gly Ser Pro Ala Gly Leu Ala Gln Leu
500 505 510
Pro Leu Gln Arg Cys Ala Ala Tyr Gly Arg Ala Cys Ala Glu Cys Cys
515 520 525
Leu Ala Arg Asp Pro Tyr Cys Ala Trp Asp Gly Ala Ala Cys Ser Arg
530 535 540
Tyr Phe Pro Ala Ala Lys Arg Arg Thr Arg Arg Gln Asp Ile Arg Asn
545 550 555 560
Gly Asp Pro Leu Thr His Cys Ser Asp Leu Gln His His Asp Asn His
565 570 575
His Ser His Ser Leu Glu Glu Arg Ile Ile Tyr Gly Val Glu Asn Ser
580 585 590
Ser Thr Phe Leu Glu Cys Ser Pro Lys Ser Gln Arg Ala Leu Val Tyr
595 600 605
Trp Gln Phe Gln Arg Arg Asn Glu Glu Arg Lys Glu Glu Ile Arg Val
610 615 620
Asp Asp His Ile Ile Arg Thr Glu Gln Gly Leu Leu Leu Arg Ser Leu
625 630 635 640
Gln Arg Lys Asp Ser Gly Asn Tyr Leu Cys His Ala Val Glu His Gly
645 650 655
Phe Met Gln Thr Leu Leu Lys Val Thr Leu Glu Val Ile Asp Thr Glu
660 665 670
His Leu Glu Glu Leu Leu His Lys Asp Asp Asp Gly Asp Gly Ser Lys
675 680 685
Thr Lys Glu Ile Ser Asn Ser Met Thr Pro Ser Gln Lys Val Trp Tyr
690 695 700
Arg Asp Phe Met Gln Leu Ile Asn His Pro Asn Leu Asn Thr Met Asp
705 710 715 720
Glu Phe Cys Glu Gln Val Trp Lys Arg Asp Arg Lys Gln Arg Arg Gln
725 730 735
Arg Pro Gly His Thr Gln Gly Asn Ser Asn Lys Trp Lys His Leu Gln
740 745 750
Glu Asn Lys Lys Gly Arg Asn Arg Arg Thr His Glu Phe Glu Arg Ala
755 760 765
Pro Arg Ser Val
770
<210> 800
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 800
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Arg Gly Gly Gln Gly Ala Met Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 801
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 801
Ser Tyr Tyr Met Ser
1 5
<210> 802
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 802
Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val Lys
1 5 10 15
Asp
<210> 803
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 803
Gly Gly Gln Gly Ala Met Asp Tyr
1 5
<210> 804
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 804
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Asp Tyr
20 25 30
Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Thr Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Tyr Ser Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 805
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 805
Arg Ala Ser Gln Ser Ile Gly Asp Tyr Leu His
1 5 10
<210> 806
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 806
Tyr Ala Ser Gln Ser Ile Ser
1 5
<210> 807
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 807
Gln Gln Gly Tyr Ser Phe Pro Tyr Thr
1 5
<210> 808
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 808
gaagtgcagc tggtggaatc tggcggagga ctggttcaac ctggcggctc tctgagactg 60
tcttgtgccg ccagcggctt caccttcagc agctactaca tgagctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtgtccacc atcatcaaga gcggcggcta cgcctactat 180
cccgacagcg tgaaggaccg gttcaccatc tccagagaca acagcaagaa caccctgtac 240
ctgcagatga gcagcctgag agccgaggat accgccgtgt actactgtgt tagaggcgga 300
cagggcgcca tggattattg gggccaggga accacagtga ccgtgtcatc a 351
<210> 809
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 809
gagattgtgc tgacacagtc tcccgccaca ctgtctctta gccctggcga aagagccaca 60
ctgagctgta gagccagcca gagcatcggc gattacctgc actggtatca gcagaagcct 120
ggacaggccc ctcggctgct gattaagtac gccagccagt ccatcagcgg catccctgcc 180
agattttctg gcagcggctc tggcaccgat ttcaccctga ccatcaccag cctggaacct 240
gaggacttcg ccgtgtacta ctgccagcag ggctacagct tcccctacac atttggcgga 300
ggcaccaagc tggaaatcaa a 321
<210> 810
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 810
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Arg Gly Gly Gln Gly Ala Met Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 811
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 811
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Asp Tyr
20 25 30
Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Thr Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Tyr Ser Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 812
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 812
gaagtgcagc tggtggaatc tggcggagga ctggttcaac ctggcggctc tctgagactg 60
tcttgtgccg ccagcggctt caccttcagc agctactaca tgagctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtgtccacc atcatcaaga gcggcggcta cgcctactat 180
cccgacagcg tgaaggaccg gttcaccatc tccagagaca acagcaagaa caccctgtac 240
ctgcagatga gcagcctgag agccgaggat accgccgtgt actactgtgt tagaggcgga 300
cagggcgcca tggattattg gggccaggga accacagtga ccgtgtcatc agccagcacc 360
aagggcccca gcgtgttccc tctggcccct agcagcaaga gcacatctgg cggaacagcc 420
gccctgggct gcctcgtgaa ggactacttt cccgagcccg tgaccgtgtc ctggaactct 480
ggcgctctga caagcggcgt gcacaccttt ccagccgtgc tgcagagcag cggcctgtac 540
tctctgagca gcgtcgtgac agtgcccagc agctctctgg gcacccagac ctacatctgc 600
aacgtgaacc acaagcccag caacaccaag gtggacaaga aggtggaacc caagagctgc 660
gacaagaccc acacctgtcc cccttgtcct gcccccgaac tgctgggagg cccttccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccacgaggac cctgaagtga agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cctagagagg aacagtacaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggc cctgcctgcc cccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcccccaa gcagggacga gctgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcaagctg accgtggaca agtcccggtg gcagcagggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgagcctga gccctggcaa g 1341
<210> 813
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 813
gagattgtgc tgacacagtc tcccgccaca ctgtctctta gccctggcga aagagccaca 60
ctgagctgta gagccagcca gagcatcggc gattacctgc actggtatca gcagaagcct 120
ggacaggccc ctcggctgct gattaagtac gccagccagt ccatcagcgg catccctgcc 180
agattttctg gcagcggctc tggcaccgat ttcaccctga ccatcaccag cctggaacct 240
gaggacttcg ccgtgtacta ctgccagcag ggctacagct tcccctacac atttggcgga 300
ggcaccaagc tggaaatcaa acgaaccgtg gccgctccca gcgtgttcat cttcccacct 360
agcgacgagc agctgaagtc cggcacagcc tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaatgccc tgcagagcgg caacagccag 480
gaaagcgtga ccgagcagga cagcaaggac tccacctaca gcctgagcag caccctgacc 540
ctgagcaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gagcttcaac cggggcgagt gt 642
<210> 814
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 814
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Arg Gly Gly Gln Gly Ala Met Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 815
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 815
Ser Tyr Tyr Met Ser
1 5
<210> 816
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 816
Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val Lys
1 5 10 15
Asp
<210> 817
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 817
Gly Gly Gln Gly Ala Met Asp Tyr
1 5
<210> 818
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 818
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Asp Tyr
20 25 30
Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Thr Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Tyr Ser Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 819
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 819
Arg Ala Ser Gln Ser Ile Gly Asp Tyr Leu His
1 5 10
<210> 820
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 820
Tyr Ala Ser Gln Ser Ile Ser
1 5
<210> 821
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 821
Gln Gln Gly Tyr Ser Phe Pro Tyr Thr
1 5
<210> 822
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 822
gaagtgcagc tggtggaatc tggcggagga ctggttcaac ctggcggctc tctgagactg 60
tcttgtgccg cctctggctt cccattcagc agctactaca tgagctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtgtccacc atcatcaaga gcggcggcta cgcctactat 180
cccgacagcg tgaaggaccg gttcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga gcagcctgag agccgaggat accgccgtgt actactgtgt tagaggcgga 300
cagggcgcca tggattattg gggccaggga accacagtga ccgtgtcatc a 351
<210> 823
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 823
gagattgtgc tgacacagtc tcccgccaca ctgtctctta gccctggcga aagagccaca 60
ctgagctgta gagccagcca gagcatcggc gattacctgc actggtatca gcagaagcct 120
ggacaggccc ctcggctgct gattaagtac gccagccagt ccatcagcgg catccctgcc 180
agattttctg gcagcggctc tggcaccgat ttcaccctga ccatcaccag cctggaacct 240
gaggacttcg ccgtgtacta ctgccagcag ggctacagct tcccctacac atttggcgga 300
ggcaccaagc tggaaatcaa a 321
<210> 824
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 824
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Arg Gly Gly Gln Gly Ala Met Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 825
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 825
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Asp Tyr
20 25 30
Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Thr Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Tyr Ser Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 826
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 826
gaagtgcagc tggtggaatc tggcggagga ctggttcaac ctggcggctc tctgagactg 60
tcttgtgccg cctctggctt cccattcagc agctactaca tgagctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtgtccacc atcatcaaga gcggcggcta cgcctactat 180
cccgacagcg tgaaggaccg gttcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga gcagcctgag agccgaggat accgccgtgt actactgtgt tagaggcgga 300
cagggcgcca tggattattg gggccaggga accacagtga ccgtgtcatc agccagcacc 360
aagggcccca gcgtgttccc tctggcccct agcagcaaga gcacatctgg cggaacagcc 420
gccctgggct gcctcgtgaa ggactacttt cccgagcccg tgaccgtgtc ctggaactct 480
ggcgctctga caagcggcgt gcacaccttt ccagccgtgc tgcagagcag cggcctgtac 540
tctctgagca gcgtcgtgac agtgcccagc agctctctgg gcacccagac ctacatctgc 600
aacgtgaacc acaagcccag caacaccaag gtggacaaga aggtggaacc caagagctgc 660
gacaagaccc acacctgtcc cccttgtcct gcccccgaac tgctgggagg cccttccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccacgaggac cctgaagtga agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cctagagagg aacagtacaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggc cctgcctgcc cccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcccccaa gcagggacga gctgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcaagctg accgtggaca agtcccggtg gcagcagggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgagcctga gccctggcaa g 1341
<210> 827
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 827
gagattgtgc tgacacagtc tcccgccaca ctgtctctta gccctggcga aagagccaca 60
ctgagctgta gagccagcca gagcatcggc gattacctgc actggtatca gcagaagcct 120
ggacaggccc ctcggctgct gattaagtac gccagccagt ccatcagcgg catccctgcc 180
agattttctg gcagcggctc tggcaccgat ttcaccctga ccatcaccag cctggaacct 240
gaggacttcg ccgtgtacta ctgccagcag ggctacagct tcccctacac atttggcgga 300
ggcaccaagc tggaaatcaa acgaaccgtg gccgctccca gcgtgttcat cttcccacct 360
agcgacgagc agctgaagtc cggcacagcc tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaatgccc tgcagagcgg caacagccag 480
gaaagcgtga ccgagcagga cagcaaggac tccacctaca gcctgagcag caccctgacc 540
ctgagcaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gagcttcaac cggggcgagt gt 642
<210> 828
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 828
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Leu Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Lys Gly Gly Gln Gly Ala Met Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 829
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 829
Ser Tyr Tyr Met Ser
1 5
<210> 830
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 830
Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val Lys
1 5 10 15
Asp
<210> 831
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 831
Gly Gly Gln Gly Ala Met Asp Tyr
1 5
<210> 832
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 832
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Asp Tyr
20 25 30
Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Tyr Ser Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 833
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 833
Arg Ala Ser Gln Ser Ile Gly Asp Tyr Leu His
1 5 10
<210> 834
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 834
Tyr Ala Ser Gln Ser Ile Ser
1 5
<210> 835
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 835
Gln Gln Gly Tyr Ser Phe Pro Tyr Thr
1 5
<210> 836
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 836
gaagtgcagc tggtggaatc tggcggagga ctggttcagc tcggcggatc tctgagactg 60
tcttgtgccg ccagcggctt caccttcagc agctactaca tgagctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtgtccacc atcatcaaga gcggcggcta cgcctactat 180
cccgacagcg tgaaggaccg gttcaccatc tccagagaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgt gaaaggtgga 300
cagggcgcca tggactattg gggccaggga acaacagtga ccgtgtcctc a 351
<210> 837
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 837
gagattgtgc tgacacagtc tcccgccaca ctgtctctta gccctggcga aagagccaca 60
ctgagctgta gagccagcca gagcatcggc gattacctgc actggtatca gcagaagcct 120
ggacaggccc ctcggctgct gatctactat gccagccagt ccatcagcgg catccccgcc 180
agattttctg gcagcggctc tggcaccgat ttcaccctga ccataagcag cctggaacct 240
gaggacttcg ccgtgtacta ctgccagcag ggctacagct tcccctacac atttggcgga 300
ggcaccaagc tggaaatcaa a 321
<210> 838
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 838
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Leu Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Lys Gly Gly Gln Gly Ala Met Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 839
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 839
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Asp Tyr
20 25 30
Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Tyr Ser Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 840
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 840
gaagtgcagc tggtggaatc tggcggagga ctggttcagc tcggcggatc tctgagactg 60
tcttgtgccg ccagcggctt caccttcagc agctactaca tgagctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtgtccacc atcatcaaga gcggcggcta cgcctactat 180
cccgacagcg tgaaggaccg gttcaccatc tccagagaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgt gaaaggtgga 300
cagggcgcca tggactattg gggccaggga acaacagtga ccgtgtcctc agccagcacc 360
aagggcccca gcgtgttccc tctggcccct agcagcaaga gcacatctgg cggaacagcc 420
gccctgggct gcctcgtgaa ggactacttt cccgagcccg tgaccgtgtc ctggaactct 480
ggcgctctga caagcggcgt gcacaccttt ccagccgtgc tgcagagcag cggcctgtac 540
tctctgagca gcgtcgtgac agtgcccagc agctctctgg gcacccagac ctacatctgc 600
aacgtgaacc acaagcccag caacaccaag gtggacaaga aggtggaacc caagagctgc 660
gacaagaccc acacctgtcc cccttgtcct gcccccgaac tgctgggagg cccttccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccacgaggac cctgaagtga agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cctagagagg aacagtacaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggc cctgcctgcc cccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcccccaa gcagggacga gctgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcaagctg accgtggaca agtcccggtg gcagcagggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgagcctga gccctggcaa g 1341
<210> 841
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 841
gagattgtgc tgacacagtc tcccgccaca ctgtctctta gccctggcga aagagccaca 60
ctgagctgta gagccagcca gagcatcggc gattacctgc actggtatca gcagaagcct 120
ggacaggccc ctcggctgct gatctactat gccagccagt ccatcagcgg catccccgcc 180
agattttctg gcagcggctc tggcaccgat ttcaccctga ccataagcag cctggaacct 240
gaggacttcg ccgtgtacta ctgccagcag ggctacagct tcccctacac atttggcgga 300
ggcaccaagc tggaaatcaa acgaaccgtg gccgctccca gcgtgttcat cttcccacct 360
agcgacgagc agctgaagtc cggcacagcc tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaatgccc tgcagagcgg caacagccag 480
gaaagcgtga ccgagcagga cagcaaggac tccacctaca gcctgagcag caccctgacc 540
ctgagcaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gagcttcaac cggggcgagt gt 642
<210> 842
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 842
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Leu Gln Leu Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Asn
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Lys Gly Gly Gln Gly Ala Met Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 843
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 843
Ser Tyr Tyr Met Ser
1 5
<210> 844
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 844
Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val Lys
1 5 10 15
Asp
<210> 845
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 845
Gly Gly Gln Gly Ala Met Asp Tyr
1 5
<210> 846
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 846
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Asp Tyr
20 25 30
Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Tyr Ser Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 847
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 847
Arg Ala Ser Gln Ser Ile Gly Asp Tyr Leu His
1 5 10
<210> 848
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 848
Tyr Ala Ser Gln Ser Ile Ser
1 5
<210> 849
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 849
Gln Gln Gly Tyr Ser Phe Pro Tyr Thr
1 5
<210> 850
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 850
gaagtgcagc tggtggaatc tggcggagga ctgctgcagc ttggcggatc tctgagactg 60
tcttgtgccg ccagcggctt caccttcagc agctactaca tgagctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtgtccacc atcatcaaga gcggcggcta cgcctactat 180
cccgacagcg tgaaggaccg gttcaccatc tccagagaca acagcaagaa caccctgaac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgt gaaaggtgga 300
cagggcgcca tggactattg gggccaggga acaacagtga ccgtgtcctc a 351
<210> 851
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 851
gagattgtgc tgacacagtc tcccgccaca ctgtctctta gccctggcga aagagccaca 60
ctgagctgta gagccagcca gagcatcggc gattacctgc actggtatca gcagaagcct 120
ggacaggccc ctcggctgct gattaagtac gccagccagt ccatcagcgg catccctgcc 180
agattttctg gcagcggctc tggcaccgat ttcaccctga ccataagcag cctggaacct 240
gaggacttcg ccgtgtacta ctgccagcag ggctacagct tcccctacac atttggcgga 300
ggcaccaagc tggaaatcaa a 321
<210> 852
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 852
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Leu Gln Leu Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Ile Lys Ser Gly Gly Tyr Ala Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Asn
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Lys Gly Gly Gln Gly Ala Met Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 853
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 853
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Asp Tyr
20 25 30
Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Tyr Ser Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 854
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 854
gaagtgcagc tggtggaatc tggcggagga ctgctgcagc ttggcggatc tctgagactg 60
tcttgtgccg ccagcggctt caccttcagc agctactaca tgagctgggt ccgacaggcc 120
cctggcaaag gacttgaatg ggtgtccacc atcatcaaga gcggcggcta cgcctactat 180
cccgacagcg tgaaggaccg gttcaccatc tccagagaca acagcaagaa caccctgaac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgt gaaaggtgga 300
cagggcgcca tggactattg gggccaggga acaacagtga ccgtgtcctc agccagcacc 360
aagggcccca gcgtgttccc tctggcccct agcagcaaga gcacatctgg cggaacagcc 420
gccctgggct gcctcgtgaa ggactacttt cccgagcccg tgaccgtgtc ctggaactct 480
ggcgctctga caagcggcgt gcacaccttt ccagccgtgc tgcagagcag cggcctgtac 540
tctctgagca gcgtcgtgac agtgcccagc agctctctgg gcacccagac ctacatctgc 600
aacgtgaacc acaagcccag caacaccaag gtggacaaga aggtggaacc caagagctgc 660
gacaagaccc acacctgtcc cccttgtcct gcccccgaac tgctgggagg cccttccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatca gccggacccc cgaagtgacc 780
tgcgtggtgg tggatgtgtc ccacgaggac cctgaagtga agttcaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cctagagagg aacagtacaa cagcacctac 900
cgggtggtgt ccgtgctgac agtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggc cctgcctgcc cccatcgaga aaaccatcag caaggccaag 1020
ggccagcccc gcgaacccca ggtgtacaca ctgcccccaa gcagggacga gctgaccaag 1080
aaccaggtgt ccctgacctg tctcgtgaaa ggcttctacc cctccgatat cgccgtggaa 1140
tgggagagca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggacagc 1200
gacggctcat tcttcctgta cagcaagctg accgtggaca agtcccggtg gcagcagggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgagcctga gccctggcaa g 1341
<210> 855
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 855
gagattgtgc tgacacagtc tcccgccaca ctgtctctta gccctggcga aagagccaca 60
ctgagctgta gagccagcca gagcatcggc gattacctgc actggtatca gcagaagcct 120
ggacaggccc ctcggctgct gattaagtac gccagccagt ccatcagcgg catccctgcc 180
agattttctg gcagcggctc tggcaccgat ttcaccctga ccataagcag cctggaacct 240
gaggacttcg ccgtgtacta ctgccagcag ggctacagct tcccctacac atttggcgga 300
ggcaccaagc tggaaatcaa acgaaccgtg gccgctccca gcgtgttcat cttcccacct 360
agcgacgagc agctgaagtc cggcacagcc tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaatgccc tgcagagcgg caacagccag 480
gaaagcgtga ccgagcagga cagcaaggac tccacctaca gcctgagcag caccctgacc 540
ctgagcaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gagcttcaac cggggcgagt gt 642
<210> 856
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 856
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Tyr
20 25 30
Ala Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Thr Glu Gly Ser Gly Val Gly Thr Ser Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Met Leu Gly Gly Gly Asn Pro Leu Asp Tyr Leu Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 857
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 857
Ser Tyr Ala Val His
1 5
<210> 858
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 858
Ser Thr Glu Gly Ser Gly Val Gly Thr Ser Tyr Thr Asp Ser Val Lys
1 5 10 15
Gly
<210> 859
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 859
Met Leu Gly Gly Gly Asn Pro Leu Asp Tyr Leu Asp Tyr
1 5 10
<210> 860
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 860
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Leu Gly Glu Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Tyr Ser Asp Phe Arg Pro Ser Gly Val Ser Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu
65 70 75 80
Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser
85 90 95
Leu Ser Ser Gln Val Phe Gly Gly Gly Thr Gln Val Thr Val Leu
100 105 110
<210> 861
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 861
Ser Gly Ser Ser Ser Asn Leu Gly Glu Gly Tyr Asp Val His
1 5 10
<210> 862
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 862
Tyr Ser Asp Phe Arg Pro Ser
1 5
<210> 863
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 863
Ala Ala Trp Asp Asp Ser Leu Ser Ser Gln Val
1 5 10
<210> 864
<211> 366
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 864
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttaga agctatgccg tgcactgggt ccgacaggcc 120
cctggaaaag gactggaatg ggtgtccagc accgaaggct ctggcgtggg cacaagctac 180
accgattctg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaatgctc 300
ggcggaggca accctctgga ctacctggat tattggggcc agggcaccct ggtcacagtc 360
tcttca 366
<210> 865
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 865
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caatctcggc gagggctatg acgtgcactg gtatcagcag 120
ctgcctggca aggcccctaa actgctgatc tactacagcg acttcagacc cagcggcgtg 180
tccgatagat tcagcggctc taagagcggc acatctgcca gcctggccat ctctggactg 240
cagagcgaag atgaggccga ctactattgc gccgcctggg atgatagcct gagcagccaa 300
gtttttggcg gcggaaccca agtgaccgtg cta 333
<210> 866
<211> 452
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 866
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Tyr
20 25 30
Ala Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Thr Glu Gly Ser Gly Val Gly Thr Ser Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Met Leu Gly Gly Gly Asn Pro Leu Asp Tyr Leu Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
225 230 235 240
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
245 250 255
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
260 265 270
His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
275 280 285
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
290 295 300
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
305 310 315 320
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro
325 330 335
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
340 345 350
Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val
355 360 365
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
370 375 380
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
385 390 395 400
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
405 410 415
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
420 425 430
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
435 440 445
Ser Pro Gly Lys
450
<210> 867
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 867
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Leu Gly Glu Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Tyr Ser Asp Phe Arg Pro Ser Gly Val Ser Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu
65 70 75 80
Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser
85 90 95
Leu Ser Ser Gln Val Phe Gly Gly Gly Thr Gln Val Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 868
<211> 1356
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 868
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttaga agctatgccg tgcactgggt ccgacaggcc 120
cctggaaaag gactggaatg ggtgtccagc accgaaggct ctggcgtggg cacaagctac 180
accgattctg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaatgctc 300
ggcggaggca accctctgga ctacctggat tattggggcc agggcaccct ggtcacagtc 360
tcttcagcca gcaccaaggg ccccagcgtg ttccctctgg cccctagcag caagagcaca 420
tctggcggaa cagccgccct gggctgcctc gtgaaggact actttcccga gcccgtgacc 480
gtgtcctgga actctggcgc tctgacaagc ggcgtgcaca cctttccagc cgtgctgcag 540
agcagcggcc tgtactctct gagcagcgtc gtgacagtgc ccagcagctc tctgggcacc 600
cagacctaca tctgcaacgt gaaccacaag cccagcaaca ccaaggtgga caagaaggtg 660
gaacccaaga gctgcgacaa gacccacacc tgtccccctt gtcctgcccc cgaactgctg 720
ggaggccctt ccgtgttcct gttcccccca aagcccaagg acaccctgat gatcagccgg 780
acccccgaag tgacctgcgt ggtggtggat gtgtcccacg aggaccctga agtgaagttc 840
aattggtacg tggacggcgt ggaagtgcac aacgccaaga ccaagcctag agaggaacag 900
tacaacagca cctaccgggt ggtgtccgtg ctgacagtgc tgcaccagga ctggctgaac 960
ggcaaagagt acaagtgcaa ggtgtccaac aaggccctgc ctgcccccat cgagaaaacc 1020
atcagcaagg ccaagggcca gccccgcgaa ccccaggtgt acacactgcc cccaagcagg 1080
gacgagctga ccaagaacca ggtgtccctg acctgtctcg tgaaaggctt ctacccctcc 1140
gatatcgccg tggaatggga gagcaacggc cagcccgaga acaactacaa gaccaccccc 1200
cctgtgctgg acagcgacgg ctcattcttc ctgtacagca agctgaccgt ggacaagtcc 1260
cggtggcagc agggcaacgt gttcagctgc agcgtgatgc acgaggccct gcacaaccac 1320
tacacccaga agtccctgag cctgagccct ggcaag 1356
<210> 869
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 869
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caatctcggc gagggctatg acgtgcactg gtatcagcag 120
ctgcctggca aggcccctaa actgctgatc tactacagcg acttcagacc cagcggcgtg 180
tccgatagat tcagcggctc taagagcggc acatctgcca gcctggccat ctctggactg 240
cagagcgaag atgaggccga ctactattgc gccgcctggg atgatagcct gagcagccaa 300
gtttttggcg gcggaaccca agtgaccgtg ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 870
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 870
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Tyr
20 25 30
Ala Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Thr Glu Gly Ser Gly Val Gly Thr Ser Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Met Leu Gly Gly Gly Asn Pro Leu Asp Tyr Leu Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 871
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 871
Ser Tyr Ala Val His
1 5
<210> 872
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 872
Ser Thr Glu Gly Ser Gly Val Gly Thr Ser Tyr Thr Asp Ser Val Lys
1 5 10 15
Gly
<210> 873
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 873
Met Leu Gly Gly Gly Asn Pro Leu Asp Tyr Leu Asp Tyr
1 5 10
<210> 874
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 874
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Leu Gly Glu Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Tyr Ser Asp Phe Arg Pro Ser Gly Val Ser Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu
65 70 75 80
Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser
85 90 95
Leu Ser Ser Gln Val Phe Gly Gly Gly Thr Gln Val Thr Val Leu
100 105 110
<210> 875
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 875
Ser Gly Ser Ser Ser Asn Leu Gly Glu Gly Tyr Asp Val His
1 5 10
<210> 876
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 876
Tyr Ser Asp Phe Arg Pro Ser
1 5
<210> 877
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 877
Ala Ala Trp Asp Asp Ser Leu Ser Ser Gln Val
1 5 10
<210> 878
<211> 366
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 878
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttaga agctatgccg tgcactgggt ccgacaggcc 120
cctggaaaag gactggaatg ggtgtccagc accgaaggct ctggcgtggg cacaagctac 180
accgattctg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaatgctc 300
ggcggaggca accctctgga ctacctggat tattggggcc agggcaccct ggtcacagtc 360
tcttca 366
<210> 879
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 879
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caatctcggc gagggctatg acgtgcactg gtatcagcag 120
ctgcctggca aggcccctaa actgctgatc tactacagcg acttcagacc cagcggcgtg 180
tccgatagat tcagcggctc taagagcggc acatctgcca gcctggccat ctctggactg 240
cagagcgaag atgaggccga ctactattgc gccgcctggg atgatagcct gagcagccaa 300
gtttttggcg gcggaaccca agtgaccgtg cta 333
<210> 880
<211> 251
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 880
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Tyr
20 25 30
Ala Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Thr Glu Gly Ser Gly Val Gly Thr Ser Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Met Leu Gly Gly Gly Asn Pro Leu Asp Tyr Leu Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys Ala Ala Gly Ser Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu Ser
225 230 235 240
Gly Ser Ala Ala Ala His His His His His His
245 250
<210> 881
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 881
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Leu Gly Glu Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Tyr Ser Asp Phe Arg Pro Ser Gly Val Ser Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu
65 70 75 80
Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser
85 90 95
Leu Ser Ser Gln Val Phe Gly Gly Gly Thr Gln Val Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 882
<211> 753
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 882
gaagttcagc tgctggaatc tggcggcgga ctggttcaac ctggcggatc tctgagactg 60
agctgtgccg ccagcggctt cacctttaga agctatgccg tgcactgggt ccgacaggcc 120
cctggaaaag gactggaatg ggtgtccagc accgaaggct ctggcgtggg cacaagctac 180
accgattctg tgaagggcag attcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag agccgaggac accgccgtgt actactgtgc cagaatgctc 300
ggcggaggca accctctgga ctacctggat tattggggcc agggcaccct ggtcacagtc 360
tcttcagcct ccaccaaggg cccatcggtg ttccccctgg caccctcctc caagagcacc 420
tctgggggca cagcggccct gggctgcctg gtcaaggact acttccccga accggtgacg 480
gtgtcgtgga actcaggcgc cctgaccagc ggcgtgcaca ccttcccggc tgtcctacag 540
tcctcaggac tctactccct cagcagcgtg gtgaccgtgc cctccagcag cttgggcacc 600
cagacctaca tctgcaacgt gaatcacaag cccagcaaca ccaaggtgga caagaaagtt 660
gagcccaaat cttgtgcagc gggttctgaa caaaaactca tctcagaaga ggatctgtct 720
ggatcagcgg ccgcccatca tcatcatcat cat 753
<210> 883
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> antibody sequence
<400> 883
cagtctgttc tgacacagcc tcctagcgcc tctggcacac ctggacagag agtgaccatc 60
agctgtagcg gcagcagctc caatctcggc gagggctatg acgtgcactg gtatcagcag 120
ctgcctggca aggcccctaa actgctgatc tactacagcg acttcagacc cagcggcgtg 180
tccgatagat tcagcggctc taagagcggc acatctgcca gcctggccat ctctggactg 240
cagagcgaag atgaggccga ctactattgc gccgcctggg atgatagcct gagcagccaa 300
gtttttggcg gcggaaccca agtgaccgtg ctaggccagc ctaaagccgc ccctagcgtg 360
accctgttcc ctccaagcag cgaggaactg caggccaaca aggccaccct cgtgtgcctg 420
atcagcgact tctatcctgg cgccgtgacc gtggcctgga aggccgatag ctctcctgtg 480
aaggccggcg tggaaaccac cacccctagc aagcagagca acaacaaata cgccgccagc 540
agctacctga gcctgacccc cgagcagtgg aagtcccaca gatcctacag ctgccaagtg 600
acccacgagg gcagcaccgt ggaaaagaca gtggccccta ccgagtgcag c 651
<210> 884
<211> 563
<212> PRT
<213> Oryctolagus cuniculus (Rabbit)
<400> 884
Asn Tyr Gln Asn Gly Lys Asn Asn Val Pro Arg Leu Lys Leu Ser Tyr
1 5 10 15
Lys Glu Met Leu Glu Ser Asn Asn Val Ile Thr Phe Asn Gly Leu Ala
20 25 30
Asn Ser Ser Ser Tyr His Thr Phe Leu Leu Asp Glu Glu Arg Ser Arg
35 40 45
Leu Tyr Val Gly Ala Lys Asp His Ile Phe Ser Phe Asn Leu Val Asn
50 55 60
Ile Lys Asp Phe Gln Lys Ile Ala Trp Pro Val Ser Tyr Thr Arg Arg
65 70 75 80
Asp Glu Cys Lys Trp Ala Gly Lys Asp Ile Leu Arg Glu Cys Ala Asn
85 90 95
Phe Ile Lys Val Leu Lys Val Tyr Asn Gln Thr His Leu Tyr Ala Cys
100 105 110
Gly Thr Gly Ala Phe His Pro Ile Cys Thr Tyr Val Gly Ile Gly His
115 120 125
His Pro Glu Asp Asn Ile Phe Lys Leu Glu Asp Ser His Phe Glu Asn
130 135 140
Gly Arg Gly Lys Ser Pro Tyr Asp Pro Lys Leu Leu Thr Ala Ser Leu
145 150 155 160
Leu Ile Asp Gly Glu Leu Tyr Ser Gly Thr Ala Ala Asp Phe Met Gly
165 170 175
Arg Asp Phe Ala Ile Phe Arg Thr Leu Gly Gln His His Pro Ile Arg
180 185 190
Thr Glu Gln His Asp Ser Arg Trp Leu Asn Asp Pro Arg Phe Ile Ser
195 200 205
Ala His Leu Ile Pro Glu Ser Asp Asn Pro Glu Asp Asp Lys Val Tyr
210 215 220
Phe Phe Phe Arg Glu Asn Ala Ile Asp Gly Glu His Ser Gly Lys Ala
225 230 235 240
Thr His Ala Arg Ile Gly Gln Ile Cys Lys Asn Asp Phe Gly Gly His
245 250 255
Arg Ser Leu Val Asn Lys Trp Thr Thr Phe Leu Lys Ala Arg Leu Ile
260 265 270
Cys Ser Val Pro Gly Pro Asn Gly Ile Asp Thr His Phe Asp Glu Leu
275 280 285
Gln Asp Val Phe Leu Met Asn Ser Lys Asp Pro Lys Asn Pro Ile Val
290 295 300
Tyr Gly Val Phe Thr Thr Ser Ser Asn Ile Phe Arg Gly Ser Ala Val
305 310 315 320
Cys Met Tyr Ser Met Ser Asp Val Arg Arg Val Phe Leu Gly Pro Tyr
325 330 335
Ala His Arg Asp Gly Pro Asn Tyr Gln Trp Val Pro Phe Gln Gly Arg
340 345 350
Val Pro Tyr Pro Arg Pro Gly Thr Cys Pro Ser Lys Thr Phe Gly Gly
355 360 365
Phe Glu Ser Thr Lys Asp Leu Pro Asp Asp Val Ile Thr Phe Ala Arg
370 375 380
Ser His Pro Ala Met Tyr Asn Pro Val Phe Pro Ile Asn Asn Arg Pro
385 390 395 400
Ile Met Val Lys Thr Asp Val Asn Tyr Gln Phe Thr Gln Ile Val Val
405 410 415
Asp Arg Val Asp Ala Glu Asp Gly Gln Tyr Asp Val Met Phe Ile Gly
420 425 430
Thr Asp Val Gly Thr Val Leu Lys Val Val Ser Ile Pro Lys Glu Thr
435 440 445
Trp His Asp Leu Glu Glu Val Leu Leu Glu Glu Met Thr Val Phe Arg
450 455 460
Glu Pro Thr Thr Ile Ser Ala Met Glu Leu Ser Thr Lys Gln Gln Gln
465 470 475 480
Leu Tyr Val Gly Ser Ala Ala Gly Val Ala Gln Leu Pro Leu His Arg
485 490 495
Cys Asp Ile Tyr Gly Lys Ala Cys Ala Glu Cys Cys Leu Ala Arg Asp
500 505 510
Pro Tyr Cys Ala Trp Asp Gly Ser Ser Cys Ser Arg Tyr Phe Pro Thr
515 520 525
Ala Lys Arg Arg Thr Arg Arg Gln Asp Ile Arg Asn Gly Asp Pro Leu
530 535 540
Thr His Cys Ser Asp Gly Gly Ile Glu Gly Arg Met Asp His His His
545 550 555 560
His His His
<210> 885
<211> 1689
<212> DNA
<213> Oryctolagus cuniculus (Rabbit)
<400> 885
aactatcaga acggcaagaa caacgtgccc cggctgaagc tgagctacaa agagatgctg 60
gaaagcaaca acgtgatcac cttcaacggc ctggccaaca gcagcagcta ccacaccttt 120
ctgctggacg aggaacggtc cagactgtac gtgggagcca aggaccacat cttcagcttc 180
aacctggtca acatcaagga cttccagaaa atcgcctggc ctgtgtccta caccagacgg 240
gatgagtgta aatgggccgg caaggacatc ctgagagagt gcgccaactt catcaaggtg 300
ctgaaggtgt acaatcagac ccacctgtac gcctgtggca ccggcgcttt tcaccctatc 360
tgtacctatg tcggcatcgg ccaccatcct gaggacaata tcttcaagct cgaggacagc 420
cacttcgaga acggcagagg caagagcccc tacgatccca aactgctgac agcctctctg 480
ctgatcgacg gcgagctgta ttctggcaca gccgccgatt tcatgggcag agacttcgcc 540
atcttcagaa ccctgggcca gcatcacccc atcagaaccg agcagcacga cagcagatgg 600
ctgaacgacc ccagattcat cagcgcccat ctgatccccg agagcgacaa ccccgaggac 660
gacaaggtgt acttcttctt ccgggaaaac gccatcgacg gggagcactc tggaaaagcc 720
acacacgcca gaatcggcca gatctgcaag aacgacttcg gcggccacag atccctcgtg 780
aacaagtgga ccaccttcct gaaggcccgg ctgatctgtt ctgtgcccgg acctaatggc 840
atcgataccc acttcgacga gctgcaggac gtgttcctga tgaacagcaa ggaccccaag 900
aatcccatcg tgtacggcgt gttcaccacc agcagcaaca tctttagagg cagcgccgtg 960
tgcatgtaca gcatgtccga tgtgcggaga gtgtttctgg gcccctacgc tcacagagat 1020
ggccccaatt atcagtgggt gccattccag ggcagagtgc cctatcctag acctggcacc 1080
tgtcctagca agacctttgg cggcttcgag agcaccaagg acctgcctga cgatgtgatt 1140
accttcgcca gatctcaccc cgccatgtac aaccctgtgt tccccatcaa caacaggccc 1200
atcatggtca agaccgacgt gaactaccag ttcacccaga tcgtggtgga cagagtggat 1260
gccgaggacg gccagtacga cgtgatgttc atcggcaccg atgtgggcac cgtgctgaaa 1320
gtggtgtcta tccccaaaga gacatggcac gacctggaag aggtgctgct ggaagagatg 1380
accgtgttca gagagcccac caccatctcc gccatggaac tgagcacaaa acagcaacag 1440
ctgtatgtgg gctccgccgc tggtgttgct caactgcctc tgcacagatg cgacatctac 1500
ggcaaagcct gcgccgagtg ttgcctggcc agagatcctt actgtgcctg ggatggcagc 1560
agctgcagca gatactttcc caccgccaag cggagaacca gacggcagga tatcagaaac 1620
ggcgaccctc tgacacactg cagcgacggt ggcatcgagg gccgcatgga tcatcatcat 1680
caccatcat 1689
Claims (30)
- 인간 Sema3A에 결합하는 단리된 항체 또는 그의 항원-결합 단편으로서,
i) 서열식별번호: 600의 서열의 인간 Sema3A에 ≤ 50 nM, ≤ 20 nM, ≤10 nM, ≤1 nM 또는 ≤ 0.1 nM의 해리 상수 (KD)로 결합하고/거나;
ii) 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A와 교차-반응하고, 특히 여기서 상기 단리된 항체 또는 그의 항원-결합 단편은 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A에 ≤ 50 nM, ≤ 20 nM, ≤10 nM, ≤1 nM, 또는 ≤ 0.1 nM의 해리 상수 (KD)로 결합하고/거나;
iii) 표면 플라즈몬 공명 (SPR)에 의해 측정된 바와 같이 서열식별번호: 600의 서열의 인간 Sema3A에 ≥ 60%, ≥ 70%, ≥ 80%, 또는 ≥ 90%의 결합 활성으로 결합하고/거나;
iv) 시험관내 혈관간 세포 이동 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 10 nM, ≤ 5 nM, ≤ 2.5 nM 또는 ≤ 1 nM의 EC50으로 억제하고/거나;
v) 시험관내 성장 원추 붕괴 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 50 nM, ≤ 25 nM, ≤ 10 nM 또는 ≤ 5 nM의 EC50으로 억제하고/거나;
vi) 시험관내 HUVEC 반발 검정에서 서열식별번호: 600의 서열의 인간 Sema3A의 활성을 ≤ 1 nM, 또는 ≤ 0.3 nM, ≤ 0.1 nM, ≤ 0.07 nM, ≤ 0.06nM의 EC50으로 억제하는
단리된 항체 또는 그의 항원-결합 단편. - 제1항에 있어서, 상기 단리된 항체 또는 그의 항원-결합 단편이 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A와 교차-반응하며, 특히 마우스, 시노몰구스, 래트, 돼지 및/또는 개 Sema3A에 대한 친화도가 인간 Sema3A에 대한 친화도보다 100-배 미만, 특히 50-배 미만, 보다 특히 25-배 미만, 보다 더 특히 10-배 미만, 가장 특히 5-배 미만으로 상이한 것인 단리된 항체 또는 항원-결합 단편.
- 제1항 또는 제2항에 있어서, 인간 Sema3B, Sema3C, Sema3D, Sema3E, Sema3F 및/또는 Sema3G와 유의하게 교차-반응하지 않고, 특히 인간 Sema3G와 유의하게 교차-반응하지 않는 단리된 항체 또는 항원-결합 단편.
- 제1항 내지 제3항 중 어느 한 항에 있어서, Sema3A 유도된 알부민뇨 및/또는 단백뇨를 억제하는 단리된 항체 또는 항원-결합 단편.
- 제1항 내지 제4항 중 어느 한 항에 있어서, Sema3A 유도된 섬유증을 억제하는 단리된 항체 또는 항원-결합 단편.
- Sema3A에 대한 결합에 대해 제1항 내지 제5항 중 어느 한 항에 따른 단리된 항체 또는 항원-결합 단편과 경쟁하며, 여기서 i) 서열식별번호: 800 및 서열식별번호: 804 또는 ii) 서열식별번호: 810 및 서열식별번호: 811을 포함하는 항체의 Sema3A에 대한 결합과는 경쟁하지 않는 단리된 항체 또는 그의 항원-결합 단편.
- 제1항 또는 제2항에 있어서, 하기를 포함하는 단리된 항체 또는 항원-결합 단편:
i) 서열식별번호: 141과 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100% 동일한 중쇄 가변 도메인 및 서열식별번호: 145와 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100% 동일한 경쇄 가변 도메인; 또는
ii) 서열식별번호: 61과 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100% 동일한 중쇄 가변 도메인 및 서열식별번호: 65와 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100% 동일한 경쇄 가변 도메인. - 제1항 내지 제7항 중 어느 한 항에 있어서, 하기를 포함하는 단리된 항체 또는 항원-결합 단편:
i) a) 서열 RDDYTSRDAFDX (서열식별번호: 594)를 포함하며, 여기서 X는 Y 및 V로 이루어진 군으로부터 선택되고, 특히 X는 Y인 H-CDR3을 포함하는 중쇄 항원-결합 영역; 및 b) 서열 X1AWDDSLNX2X3X4V (서열식별번호: 598)를 포함하며, 여기서 X1은 A 및 H로 이루어진 군으로부터 선택되고; 여기서 X2는 V, D, 및 G로 이루어진 군으로부터 선택되고, 특히 여기서 X2는 V 및 D로 이루어진 군으로부터 선택되고; 여기서 X3은 I 및 Y로 이루어진 군으로부터 선택되고; 여기서 X4는 P 및 V로 이루어진 군으로부터 선택된 것인 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
ii) a) 서열 SGYSSSWFDPDFDY (서열식별번호: 64)를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역; 및 b) 서열 X1SYX2GX3NPYVV (서열식별번호: 599)를 포함하며, 여기서 X1은 S 및 Q로 이루어진 군으로부터 선택되고; 여기서 X2는 E 및 A로 이루어진 군으로부터 선택되고; 여기서 X3은 P, I, 및 S로 이루어진 군으로부터 선택되고, 특히 여기서 X3은 P 및 I로 이루어진 군으로부터 선택된 것인 L-CDR3을 포함하는 경쇄 항원-결합 영역. - 제1항 내지 제8항 중 어느 한 항에 있어서, 하기를 포함하는 단리된 항체 또는 항원-결합 단편:
i) a) 서열 SYX1MX2 (서열식별번호: 588)를 포함하며, 여기서 X1은 G 및 A로부터 선택되고, 여기서 X2는 H, S 및 L로부터 선택된 것인 H-CDR1; 특히 서열 SYAMX (서열식별번호: 589)를 포함하며, 여기서 X는 S 및 L로부터 선택된 것인 H-CDR1; 서열 AIGX1GGDTYYADSVX2G (서열식별번호: 590)를 포함하며, 여기서 X1은 T 및 Y로부터 선택되고, 여기서 X2는 K 및 M으로부터 선택된 것인 H-CDR2; 특히 서열 AIGXGGDTYYADSVKG (서열식별번호: 591)를 포함하며, 여기서 X는 T 및 Y로부터 선택된 것인 H-CDR2; 및 서열 RDDYTSRDAFDX (서열식별번호: 594)를 포함하며, 여기서 X는 Y 및 V로 이루어진 군으로부터 선택되고, 특히 여기서 X는 Y인 H-CDR3을 포함하는 중쇄 항원-결합 영역; 및 b) 서열 SGSSSNIGSNTVN (서열식별번호: 46)을 포함하는 L-CDR1; 서열 YDDLXPS (서열식별번호: 596)를 포함하며, 여기서 X는 L 및 R로부터 선택된 것인 L-CDR2; 특히 서열 YDDLRPS (서열식별번호: 127)를 포함하는 L-CDR2; 및 서열 X1AWDDSLNX2X3X4V (서열식별번호: 598)를 포함하며, 여기서 X1은 A 및 H로 이루어진 군으로부터 선택되고; 여기서 X2는 V, D 및 G로 이루어진 군으로부터 선택되고, 특히 여기서 X2는 V 및 D로 이루어진 군으로부터 선택되고; 여기서 X3은 I 및 Y로 이루어진 군으로부터 선택되고; 여기서 X4는 P 및 V로 이루어진 군으로부터 선택된 것인 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
ii) a) 서열 SYEMN (서열식별번호: 62)을 포함하는 H-CDR1; 서열 GISWNSGX1IX2YADSVKG (서열식별번호: 592)를 포함하며, 여기서 X1은 W 및 S로부터 선택되고, X2는 G 및 D로부터 선택된 것인 H-CDR2; 특히 서열 GISWNSGWIXYADSVKG (서열식별번호: 593)를 포함하며, 여기서 X는 G 및 D로부터 선택된 것인 H-CDR2; 및 서열 SGYSSSWFDPDFDY (서열식별번호: 64)를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역; 및 b) 서열 TGSSSXIGAGYDVH (서열식별번호: 595)를 포함하며, 여기서 X는 N 및 D로부터 선택된 것인 L-CDR1; 서열 GXSNRPS (서열식별번호: 597)를 포함하며, 여기서 X는 N 및 A로부터 선택된 것인 L-CDR2; 및 서열 X1SYX2GX3NPYVV (서열식별번호: 599)를 포함하며, 여기서 X1은 S 및 Q로 이루어진 군으로부터 선택되고; 여기서 X2는 E 및 A로 이루어진 군으로부터 선택되고; 여기서 X3은 P, I, 및 S로 이루어진 군으로부터 선택되고, 특히 여기서 X3은 P 및 I로 이루어진 군으로부터 선택된 것인 L-CDR3을 포함하는 경쇄 항원-결합 영역. - 제8항에 있어서, 제8항의 옵션 i)에 따른 단리된 항체 또는 항원-결합 단편에서 H-CDR1의 5' 단부에 바로 인접한 아미노산 잔기가 S 또는 Y이거나; 또는 제8항의 옵션 ii)에 따른 단리된 항체 또는 항원-결합 단편에서 H-CDR1의 5' 단부에 바로 인접한 3개의 아미노산 잔기가 X1FX2이고, 여기서 X1은 T 및 D로부터 선택되고, X2는 S 및 D로부터 선택된 것인 단리된 항체 또는 항원-결합 단편.
- 제1항 내지 제10항 중 어느 한 항에 있어서, 하기를 포함하는 단리된 항체 또는 항원-결합 단편:
i) 서열식별번호: 42를 포함하는 H-CDR1, 서열식별번호: 43을 포함하는 H-CDR2, 및 서열식별번호: 44를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 46을 포함하는 L-CDR1, 서열식별번호: 47을 포함하는 L-CDR2, 및 서열식별번호: 48을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
ii) 서열식별번호: 62를 포함하는 H-CDR1, 서열식별번호: 63을 포함하는 H-CDR2, 및 서열식별번호: 64를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 66을 포함하는 L-CDR1, 서열식별번호: 67을 포함하는 L-CDR2, 및 서열식별번호: 68을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
iii) 서열식별번호: 102를 포함하는 H-CDR1, 서열식별번호: 103을 포함하는 H-CDR2, 및 서열식별번호: 104를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 106을 포함하는 L-CDR1, 서열식별번호: 107을 포함하는 L-CDR2, 및 서열식별번호: 108을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
iv) 서열식별번호: 122를 포함하는 H-CDR1, 서열식별번호: 123을 포함하는 H-CDR2, 및 서열식별번호: 124를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 126을 포함하는 L-CDR1, 서열식별번호: 127을 포함하는 L-CDR2, 및 서열식별번호: 128을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
v) 서열식별번호: 142를 포함하는 H-CDR1, 서열식별번호: 143을 포함하는 H-CDR2, 및 서열식별번호: 144를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 146을 포함하는 L-CDR1, 서열식별번호: 147을 포함하는 L-CDR2, 및 서열식별번호: 148을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
vi) 서열식별번호: 162를 포함하는 H-CDR1, 서열식별번호: 163을 포함하는 H-CDR2, 및 서열식별번호: 164를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 166을 포함하는 L-CDR1, 서열식별번호: 167을 포함하는 L-CDR2, 및 서열식별번호: 168을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
vii) 서열식별번호: 182를 포함하는 H-CDR1, 서열식별번호: 183을 포함하는 H-CDR2, 및 서열식별번호: 184를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 186을 포함하는 L-CDR1, 서열식별번호: 187을 포함하는 L-CDR2, 및 서열식별번호: 188을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
viii) 서열식별번호: 202를 포함하는 H-CDR1, 서열식별번호: 203을 포함하는 H-CDR2, 및 서열식별번호: 204를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 206을 포함하는 L-CDR1, 서열식별번호: 207을 포함하는 L-CDR2, 및 서열식별번호: 208을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
ix) 서열식별번호: 222를 포함하는 H-CDR1, 서열식별번호: 223을 포함하는 H-CDR2, 및 서열식별번호: 224를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 226을 포함하는 L-CDR1, 서열식별번호: 227을 포함하는 L-CDR2, 및 서열식별번호: 228을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
x) 서열식별번호: 242를 포함하는 H-CDR1, 서열식별번호: 243을 포함하는 H-CDR2, 및 서열식별번호: 244를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 246을 포함하는 L-CDR1, 서열식별번호: 247을 포함하는 L-CDR2, 및 서열식별번호: 248을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xi) 서열식별번호: 262를 포함하는 H-CDR1, 서열식별번호: 263을 포함하는 H-CDR2, 및 서열식별번호: 264를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 266을 포함하는 L-CDR1, 서열식별번호: 267을 포함하는 L-CDR2, 및 서열식별번호: 268을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xii) 서열식별번호: 282를 포함하는 H-CDR1, 서열식별번호: 283을 포함하는 H-CDR2, 및 서열식별번호: 284를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 286을 포함하는 L-CDR1, 서열식별번호: 287을 포함하는 L-CDR2, 및 서열식별번호: 288을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xiii) 서열식별번호: 302를 포함하는 H-CDR1, 서열식별번호: 303을 포함하는 H-CDR2, 및 서열식별번호: 304를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 306을 포함하는 L-CDR1, 서열식별번호: 307을 포함하는 L-CDR2, 및 서열식별번호: 308을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xiv) 서열식별번호: 322를 포함하는 H-CDR1, 서열식별번호: 323을 포함하는 H-CDR2, 및 서열식별번호: 324를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 326을 포함하는 L-CDR1, 서열식별번호: 327을 포함하는 L-CDR2, 및 서열식별번호: 328을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xv) 서열식별번호: 342를 포함하는 H-CDR1, 서열식별번호: 343을 포함하는 H-CDR2, 및 서열식별번호: 344를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 346을 포함하는 L-CDR1, 서열식별번호: 347을 포함하는 L-CDR2, 및 서열식별번호: 348을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xvi) 서열식별번호: 362를 포함하는 H-CDR1, 서열식별번호: 363을 포함하는 H-CDR2, 및 서열식별번호: 364를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 366을 포함하는 L-CDR1, 서열식별번호: 367을 포함하는 L-CDR2, 및 서열식별번호: 368을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xvii) 서열식별번호: 382를 포함하는 H-CDR1, 서열식별번호: 383을 포함하는 H-CDR2, 및 서열식별번호: 384를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 386을 포함하는 L-CDR1, 서열식별번호: 387을 포함하는 L-CDR2, 및 서열식별번호: 388을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xviii) 서열식별번호: 402를 포함하는 H-CDR1, 서열식별번호: 403을 포함하는 H-CDR2, 및 서열식별번호: 404를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 406을 포함하는 L-CDR1, 서열식별번호: 407을 포함하는 L-CDR2, 및 서열식별번호: 408을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xix) 서열식별번호: 422를 포함하는 H-CDR1, 서열식별번호: 423을 포함하는 H-CDR2, 및 서열식별번호: 424를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 426을 포함하는 L-CDR1, 서열식별번호: 427을 포함하는 L-CDR2, 및 서열식별번호: 428을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xx) 서열식별번호: 442를 포함하는 H-CDR1, 서열식별번호: 443을 포함하는 H-CDR2, 및 서열식별번호: 444를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 446을 포함하는 L-CDR1, 서열식별번호: 447을 포함하는 L-CDR2, 및 서열식별번호: 448을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxi) 서열식별번호: 462를 포함하는 H-CDR1, 서열식별번호: 463을 포함하는 H-CDR2, 및 서열식별번호: 464를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 466을 포함하는 L-CDR1, 서열식별번호: 467을 포함하는 L-CDR2, 및 서열식별번호: 468을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxii) 서열식별번호: 482를 포함하는 H-CDR1, 서열식별번호: 483을 포함하는 H-CDR2, 및 서열식별번호: 484를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 486을 포함하는 L-CDR1, 서열식별번호: 487을 포함하는 L-CDR2, 및 서열식별번호: 488을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxiii) 서열식별번호: 502를 포함하는 H-CDR1, 서열식별번호: 503을 포함하는 H-CDR2, 및 서열식별번호: 504를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 506을 포함하는 L-CDR1, 서열식별번호: 507을 포함하는 L-CDR2, 및 서열식별번호: 508을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxiv) 서열식별번호: 522를 포함하는 H-CDR1, 서열식별번호: 523을 포함하는 H-CDR2, 및 서열식별번호: 524를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 526을 포함하는 L-CDR1, 서열식별번호: 527을 포함하는 L-CDR2, 및 서열식별번호: 528을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxv) 서열식별번호: 542를 포함하는 H-CDR1, 서열식별번호: 543을 포함하는 H-CDR2, 및 서열식별번호: 544를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 546을 포함하는 L-CDR1, 서열식별번호: 547을 포함하는 L-CDR2, 및 서열식별번호: 548을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역; 또는
xxvi) 서열식별번호: 562를 포함하는 H-CDR1, 서열식별번호: 563을 포함하는 H-CDR2, 및 서열식별번호: 564를 포함하는 H-CDR3을 포함하는 중쇄 항원-결합 영역, 및 서열식별번호: 566을 포함하는 L-CDR1, 서열식별번호: 567을 포함하는 L-CDR2, 및 서열식별번호: 568을 포함하는 L-CDR3을 포함하는 경쇄 항원-결합 영역. - 제1항 내지 제11항 중 어느 한 항에 있어서, 하기를 포함하는 단리된 항체 또는 항원-결합 단편:
i) 서열식별번호: 41을 포함하는 가변 중쇄 도메인 및 서열식별번호: 45를 포함하는 가변 경쇄 도메인; 또는
ii) 서열식별번호: 61을 포함하는 가변 중쇄 도메인 및 서열식별번호: 65를 포함하는 가변 경쇄 도메인; 또는
iii) 서열식별번호: 101을 포함하는 가변 중쇄 도메인 및 서열식별번호: 105를 포함하는 가변 경쇄 도메인; 또는
iv) 서열식별번호: 121을 포함하는 가변 중쇄 도메인 및 서열식별번호: 125를 포함하는 가변 경쇄 도메인; 또는
v) 서열식별번호: 141을 포함하는 가변 중쇄 도메인 및 서열식별번호: 145를 포함하는 가변 경쇄 도메인; 또는
vi) 서열식별번호: 161을 포함하는 가변 중쇄 도메인 및 서열식별번호: 165를 포함하는 가변 경쇄 도메인; 또는
vii) 서열식별번호: 181을 포함하는 가변 중쇄 도메인 및 서열식별번호: 185를 포함하는 가변 경쇄 도메인; 또는
viii) 서열식별번호: 201을 포함하는 가변 중쇄 도메인 및 서열식별번호: 205를 포함하는 가변 경쇄 도메인; 또는
ix) 서열식별번호: 221을 포함하는 가변 중쇄 도메인 및 서열식별번호: 225를 포함하는 가변 경쇄 도메인; 또는
x) 서열식별번호: 241을 포함하는 가변 중쇄 도메인 및 서열식별번호: 245를 포함하는 가변 경쇄 도메인; 또는
xi) 서열식별번호: 261을 포함하는 가변 중쇄 도메인 및 서열식별번호: 265를 포함하는 가변 경쇄 도메인; 또는
xii) 서열식별번호: 281을 포함하는 가변 중쇄 도메인 및 서열식별번호: 285를 포함하는 가변 경쇄 도메인; 또는
xiii) 서열식별번호: 301을 포함하는 가변 중쇄 도메인 및 서열식별번호: 305를 포함하는 가변 경쇄 도메인; 또는
xiv) 서열식별번호: 321을 포함하는 가변 중쇄 도메인 및 서열식별번호: 325를 포함하는 가변 경쇄 도메인; 또는
xv) 서열식별번호: 341을 포함하는 가변 중쇄 도메인 및 서열식별번호: 345를 포함하는 가변 경쇄 도메인; 또는
xvi) 서열식별번호: 361을 포함하는 가변 중쇄 도메인 및 서열식별번호: 365를 포함하는 가변 경쇄 도메인; 또는
xvii) 서열식별번호: 381을 포함하는 가변 중쇄 도메인 및 서열식별번호: 385를 포함하는 가변 경쇄 도메인; 또는
xviii) 서열식별번호: 401을 포함하는 가변 중쇄 도메인 및 서열식별번호: 405를 포함하는 가변 경쇄 도메인; 또는
xix) 서열식별번호: 421을 포함하는 가변 중쇄 도메인 및 서열식별번호: 425를 포함하는 가변 경쇄 도메인; 또는
xx) 서열식별번호: 441을 포함하는 가변 중쇄 도메인 및 서열식별번호: 445를 포함하는 가변 경쇄 도메인; 또는
xxi) 서열식별번호: 461을 포함하는 가변 중쇄 도메인 및 서열식별번호: 465를 포함하는 가변 경쇄 도메인; 또는
xxii) 서열식별번호: 481을 포함하는 가변 중쇄 도메인 및 서열식별번호: 485를 포함하는 가변 경쇄 도메인; 또는
xxiii) 서열식별번호: 501을 포함하는 가변 중쇄 도메인 및 서열식별번호: 505를 포함하는 가변 경쇄 도메인; 또는
xxiv) 서열식별번호: 521을 포함하는 가변 중쇄 도메인 및 서열식별번호: 525를 포함하는 가변 경쇄 도메인; 또는
xxv) 서열식별번호: 541을 포함하는 가변 중쇄 도메인 및 서열식별번호: 545를 포함하는 가변 경쇄 도메인; 또는
xxvi) 서열식별번호: 561을 포함하는 가변 중쇄 도메인 및 서열식별번호: 565를 포함하는 가변 경쇄 도메인. - 제1항 내지 제12항 중 어느 한 항에 있어서, IgG 항체, 특히 IgG1 또는 IgG4 항체인 단리된 항체.
- 제1항 내지 제13항 중 어느 한 항에 있어서, 하기를 포함하는 단리된 항체:
i) 서열식별번호: 57을 포함하는 중쇄 및 서열식별번호: 58을 포함하는 경쇄; 또는
ii) 서열식별번호: 77을 포함하는 중쇄 및 서열식별번호: 78을 포함하는 경쇄; 또는
iii) 서열식별번호: 117을 포함하는 중쇄 및 서열식별번호: 118을 포함하는 경쇄; 또는
iv) 서열식별번호: 137을 포함하는 중쇄 및 서열식별번호: 138을 포함하는 경쇄; 또는
v) 서열식별번호: 157을 포함하는 중쇄 및 서열식별번호: 158을 포함하는 경쇄; 또는
vi) 서열식별번호: 177을 포함하는 중쇄 및 서열식별번호: 178을 포함하는 경쇄; 또는
vii) 서열식별번호: 197을 포함하는 중쇄 및 서열식별번호: 198을 포함하는 경쇄; 또는
viii) 서열식별번호: 217을 포함하는 중쇄 및 서열식별번호: 218을 포함하는 경쇄; 또는
ix) 서열식별번호: 237을 포함하는 중쇄 및 서열식별번호: 238을 포함하는 경쇄; 또는
x) 서열식별번호: 257을 포함하는 중쇄 및 서열식별번호: 258을 포함하는 경쇄; 또는
xi) 서열식별번호: 277을 포함하는 중쇄 및 서열식별번호: 278을 포함하는 경쇄; 또는
xii) 서열식별번호: 297을 포함하는 중쇄 및 서열식별번호: 298을 포함하는 경쇄; 또는
xiii) 서열식별번호: 317을 포함하는 중쇄 및 서열식별번호: 318을 포함하는 경쇄; 또는
xiv) 서열식별번호: 337을 포함하는 중쇄 및 서열식별번호: 338을 포함하는 경쇄; 또는
xv) 서열식별번호: 357을 포함하는 중쇄 및 서열식별번호: 358을 포함하는 경쇄; 또는
xvi) 서열식별번호: 377을 포함하는 중쇄 및 서열식별번호: 378을 포함하는 경쇄; 또는
xvii) 서열식별번호: 397을 포함하는 중쇄 및 서열식별번호: 398을 포함하는 경쇄; 또는
xviii) 서열식별번호: 417을 포함하는 중쇄 및 서열식별번호: 418을 포함하는 경쇄; 또는
xix) 서열식별번호: 437을 포함하는 중쇄 및 서열식별번호: 438을 포함하는 경쇄; 또는
xx) 서열식별번호: 457을 포함하는 중쇄 및 서열식별번호: 458을 포함하는 경쇄; 또는
xxi) 서열식별번호: 477을 포함하는 중쇄 및 서열식별번호: 478을 포함하는 경쇄; 또는
xxii) 서열식별번호: 497을 포함하는 중쇄 및 서열식별번호: 498을 포함하는 경쇄; 또는
xxiii) 서열식별번호: 517을 포함하는 중쇄 및 서열식별번호: 518을 포함하는 경쇄; 또는
xxiv) 서열식별번호: 537을 포함하는 중쇄 및 서열식별번호: 538을 포함하는 경쇄; 또는
xxv) 서열식별번호: 557을 포함하는 중쇄 및 서열식별번호: 558을 포함하는 경쇄; 또는
xxvi) 서열식별번호: 577을 포함하는 중쇄 및 서열식별번호: 578을 포함하는 경쇄. - 제1항 내지 제14항 중 어느 한 항에 있어서, scFv, Fab, Fab' 단편 또는 F(ab')2 단편인 항원-결합 단편.
- 제1항 내지 제15항 중 어느 한 항에 있어서, 모노클로날 항체 또는 그의 항원-결합 단편인 단리된 항체 또는 항원-결합 단편.
- 제1항 내지 제16항 중 어느 한 항에 있어서, 인간, 인간화 또는 키메라 항체 또는 그의 항원-결합 단편인 단리된 항체 또는 항원-결합 단편.
- 인간 Sema3A에 대한 결합에 대해 제1항 내지 제17항 중 어느 한 항에 따른 단리된 항체 또는 항원-결합 단편과 경쟁하는 단리된 항체 또는 그의 항원-결합 단편.
- 제1항 내지 제18항 중 어느 한 항에 따른 단리된 항체 또는 항원 결합 단편을 포함하는 항체 접합체.
- 제1항 내지 제17항 중 어느 한 항에 따른 항체 또는 항원-결합 단편을 코딩하는 단리된 핵산 서열.
- 제19항에 따른 핵산 서열을 포함하는 벡터.
- 제1항 내지 제17항 중 어느 한 항에 따른 항체 또는 항원-결합 단편을 발현하고/거나 제19항에 따른 핵산 또는 제20항에 따른 벡터를 포함하는 단리된 세포.
- 제21항에 있어서, 원핵 또는 진핵 세포인 단리된 세포.
- 제21항 또는 제22항에 따른 세포를 배양하고, 임의로 항체 또는 그의 항원-결합 단편을 정제하는 것을 포함하는, 제1항 내지 제17항 중 어느 한 항에 따른 단리된 항체 또는 항원-결합 단편을 생산하는 방법.
- 제1항 내지 제17항 중 어느 한 항에 따른 단리된 항체 또는 항원-결합 단편 또는 제18항에 따른 항체 접합체를 포함하는 제약 조성물.
- 제1항 내지 제18항 및 제24항 중 어느 한 항에 있어서, 의약으로서 사용하기 위한 단리된 항체 또는 항원-결합 단편 또는 접합체 또는 제약 조성물.
- 제1항 내지 제18항 중 어느 한 항에 있어서, 진단제로서 사용하기 위한 단리된 항체 또는 항원-결합 단편 또는 항체 접합체.
- 제1항 내지 제18항 및 제24항 중 어느 한 항에 있어서, i) 신질환, 특히 급성 및 만성 신장 질환, 당뇨병성 신장 질환, 알포트 증후군, 급성 및 만성 신부전, 다낭성 신장 질환 (PCKD) 및 부적절한 ADH 분비 증후군 (SIADH); ii) 신기능부전 후유증, 특히 폐 부종, 심부전, 요독증, 빈혈, 전해질 장애 예컨대 고칼륨혈증 및 저나트륨혈증 및 골 및 탄수화물 대사 장애; iii) 혈관 과투과성, 당뇨병성 망막병증, 혈액 망막 장벽 악화, 황반 부종, 특히 연령 관련 황반 부종, 비-증식성 연령-관련 황반 부종 및 비-증식성 당뇨병성 황반 부종; iv) 중추 또는 말초 신경계 질환 특히 신경병증성 통증, 척수 손상, 다발성 경화증, 외상성 뇌 손상, 뇌 부종 및 신경변성 질환, 특히 알츠하이머병, 파킨슨병, 헌팅톤병, 근위축성 측삭 경화증, 진행성 핵상 마비, 흑색질 변성, 샤이-드래거 증후군, 올리브교뇌소뇌 위축 및 척수소뇌 변성; 또는 v) 암, 특히 장암, 결장직장암, 폐암, 유방암, 뇌암, 흑색종, 신세포암, 백혈병, 림프종, T-세포 림프종, 위암, 췌장암, 자궁경부암, 자궁내막암, 난소암, 식도암, 간암, 두경부의 편평 세포 암종, 피부암, 요로암, 전립선암, 융모막암종, 인두암 및 후두암의 치료 및/또는 예방에 사용하기 위한 단리된 항체 또는 항원-결합 단편 또는 접합체 또는 제약 조성물.
- 제1항 내지 제18항 및 제24항 중 어느 한 항에 있어서, 1종 이상의 추가의 치료 활성 화합물과 동시, 개별 또는 순차적 조합으로 사용하기 위한 단리된 항체 또는 항원-결합 단편 또는 접합체 또는 제약 조성물.
- 제1항 내지 제17항 중 어느 한 항에 따른 단리된 항체 또는 항원-결합 단편 또는 제18항에 따른 접합체 및 사용에 대한 지침서를 포함하는 키트.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP21165960.2 | 2021-03-30 | ||
| EP21165960 | 2021-03-30 | ||
| PCT/EP2022/058123 WO2022207554A1 (en) | 2021-03-30 | 2022-03-28 | Anti-sema3a antibodies and uses thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230162800A true KR20230162800A (ko) | 2023-11-28 |
Family
ID=75302351
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237036770A KR20230162800A (ko) | 2021-03-30 | 2022-03-28 | 항-sema3a 항체 및 그의 용도 |
Country Status (12)
| Country | Link |
|---|---|
| US (1) | US20220389096A1 (ko) |
| EP (1) | EP4314047A1 (ko) |
| JP (1) | JP2024512633A (ko) |
| KR (1) | KR20230162800A (ko) |
| CN (1) | CN117396504A (ko) |
| AR (1) | AR125240A1 (ko) |
| AU (1) | AU2022251786A1 (ko) |
| BR (1) | BR112023018061A2 (ko) |
| CA (1) | CA3215274A1 (ko) |
| IL (1) | IL307233A (ko) |
| TW (1) | TW202304975A (ko) |
| WO (1) | WO2022207554A1 (ko) |
Family Cites Families (40)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4657760A (en) | 1979-03-20 | 1987-04-14 | Ortho Pharmaceutical Corporation | Methods and compositions using monoclonal antibody to human T cells |
| US5179017A (en) | 1980-02-25 | 1993-01-12 | The Trustees Of Columbia University In The City Of New York | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| US4399216A (en) | 1980-02-25 | 1983-08-16 | The Trustees Of Columbia University | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| US4634665A (en) | 1980-02-25 | 1987-01-06 | The Trustees Of Columbia University In The City Of New York | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| US4510245A (en) | 1982-11-18 | 1985-04-09 | Chiron Corporation | Adenovirus promoter system |
| GB8308235D0 (en) | 1983-03-25 | 1983-05-05 | Celltech Ltd | Polypeptides |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US5168062A (en) | 1985-01-30 | 1992-12-01 | University Of Iowa Research Foundation | Transfer vectors and microorganisms containing human cytomegalovirus immediate-early promoter-regulatory DNA sequence |
| US5206344A (en) | 1985-06-26 | 1993-04-27 | Cetus Oncology Corporation | Interleukin-2 muteins and polymer conjugation thereof |
| US4968615A (en) | 1985-12-18 | 1990-11-06 | Ciba-Geigy Corporation | Deoxyribonucleic acid segment from a virus |
| US6548640B1 (en) | 1986-03-27 | 2003-04-15 | Btg International Limited | Altered antibodies |
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US5225212A (en) | 1989-10-20 | 1993-07-06 | Liposome Technology, Inc. | Microreservoir liposome composition and method |
| US5208020A (en) | 1989-10-25 | 1993-05-04 | Immunogen Inc. | Cytotoxic agents comprising maytansinoids and their therapeutic use |
| CA2026147C (en) | 1989-10-25 | 2006-02-07 | Ravi J. Chari | Cytotoxic agents comprising maytansinoids and their therapeutic use |
| US5859205A (en) | 1989-12-21 | 1999-01-12 | Celltech Limited | Humanised antibodies |
| DK0590058T3 (da) | 1991-06-14 | 2004-03-29 | Genentech Inc | Humaniseret heregulin-antistof |
| CA2507749C (en) | 1991-12-13 | 2010-08-24 | Xoma Corporation | Methods and materials for preparation of modified antibody variable domains and therapeutic uses thereof |
| US5635483A (en) | 1992-12-03 | 1997-06-03 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Tumor inhibiting tetrapeptide bearing modified phenethyl amides |
| US5780588A (en) | 1993-01-26 | 1998-07-14 | Arizona Board Of Regents | Elucidation and synthesis of selected pentapeptides |
| DK0859841T3 (da) | 1995-08-18 | 2002-09-09 | Morphosys Ag | Protein/(poly)peptidbiblioteker |
| GB9603256D0 (en) | 1996-02-16 | 1996-04-17 | Wellcome Found | Antibodies |
| GB9701425D0 (en) | 1997-01-24 | 1997-03-12 | Bioinvent Int Ab | A method for in vitro molecular evolution of protein function |
| WO1998058964A1 (en) | 1997-06-24 | 1998-12-30 | Genentech, Inc. | Methods and compositions for galactosylated glycoproteins |
| WO1999022764A1 (en) | 1997-10-31 | 1999-05-14 | Genentech, Inc. | Methods and compositions comprising glycoprotein glycoforms |
| ES2375931T3 (es) | 1997-12-05 | 2012-03-07 | The Scripps Research Institute | Humanización de anticuerpo murino. |
| EP2261229A3 (en) | 1998-04-20 | 2011-03-23 | GlycArt Biotechnology AG | Glycosylation engineering of antibodies for improving antibody-dependent cellular cytotoxicity |
| EP1423510A4 (en) | 2001-08-03 | 2005-06-01 | Glycart Biotechnology Ag | ANTIBODY GLYCOSYLATION VARIANTS WITH INCREASED CELL CYTOTOXICITY DEPENDENT OF ANTIBODIES |
| US7361740B2 (en) | 2002-10-15 | 2008-04-22 | Pdl Biopharma, Inc. | Alteration of FcRn binding affinities or serum half-lives of antibodies by mutagenesis |
| PL212899B1 (pl) | 2002-12-16 | 2012-12-31 | Genentech Inc | Humanizowane przeciwcialo, kompozycja zawierajaca to przeciwcialo, wyrób fabryczny, przeciwcialo lub jego fragment do zastosowania w sposobie indukowania apoptozy, izolowany kwas nukleinowy, wektor ekspresji, komórka gospodarza, sposób wytwarzania przeciwciala lub jego fragmentu, plynny preparat i zastosowanie przeciwciala do wytwarzania leku |
| HUE031632T2 (en) | 2003-11-05 | 2017-07-28 | Roche Glycart Ag | Antigen binding molecules with enhanced Fc receptor binding affinity and effector function |
| BR122018071808B8 (pt) | 2003-11-06 | 2020-06-30 | Seattle Genetics Inc | conjugado |
| JP5128935B2 (ja) | 2004-03-31 | 2013-01-23 | ジェネンテック, インコーポレイテッド | ヒト化抗TGF−β抗体 |
| US20080226635A1 (en) | 2006-12-22 | 2008-09-18 | Hans Koll | Antibodies against insulin-like growth factor I receptor and uses thereof |
| CN101720368A (zh) | 2007-03-09 | 2010-06-02 | 中国抗体制药有限公司 | 储备多样性最大化的功能性人化抗体文库之构建及应用 |
| ES2728854T3 (es) | 2013-02-06 | 2019-10-29 | Univ Yokohama City | Anticuerpo anti-semaforina 3A y tratamiento de enfermedad de Alzheimer y enfermedades inmunitarias inflamatorias usando el mismo |
| WO2017074013A1 (ko) | 2015-10-27 | 2017-05-04 | 사회복지법인 삼성생명공익재단 | 인간 및 마우스 sema3a에 교차결합하는 항체 및 그의 용도 |
| MA55872A (fr) * | 2019-05-09 | 2022-03-16 | Boehringer Ingelheim Int | Anticorps anti-sema3a et leurs utilisations pour le traitement de maladies oculaires |
| EP3990488A4 (en) * | 2019-06-27 | 2023-09-13 | Ramot at Tel-Aviv University Ltd. | SEMAPHORIN 3A ANTIBODIES AND THEIR USES |
-
2022
- 2022-03-28 BR BR112023018061A patent/BR112023018061A2/pt unknown
- 2022-03-28 EP EP22713427.7A patent/EP4314047A1/en active Pending
- 2022-03-28 KR KR1020237036770A patent/KR20230162800A/ko unknown
- 2022-03-28 IL IL307233A patent/IL307233A/en unknown
- 2022-03-28 JP JP2023560024A patent/JP2024512633A/ja active Pending
- 2022-03-28 CN CN202280038261.5A patent/CN117396504A/zh active Pending
- 2022-03-28 US US17/706,543 patent/US20220389096A1/en active Pending
- 2022-03-28 CA CA3215274A patent/CA3215274A1/en active Pending
- 2022-03-28 AU AU2022251786A patent/AU2022251786A1/en active Pending
- 2022-03-28 WO PCT/EP2022/058123 patent/WO2022207554A1/en active Application Filing
- 2022-03-29 AR ARP220100753A patent/AR125240A1/es unknown
- 2022-03-30 TW TW111112217A patent/TW202304975A/zh unknown
Also Published As
| Publication number | Publication date |
|---|---|
| AR125240A1 (es) | 2023-06-28 |
| CA3215274A1 (en) | 2022-10-06 |
| AU2022251786A1 (en) | 2023-10-05 |
| EP4314047A1 (en) | 2024-02-07 |
| CN117396504A (zh) | 2024-01-12 |
| TW202304975A (zh) | 2023-02-01 |
| US20220389096A1 (en) | 2022-12-08 |
| IL307233A (en) | 2023-11-01 |
| WO2022207554A1 (en) | 2022-10-06 |
| BR112023018061A2 (pt) | 2023-10-03 |
| JP2024512633A (ja) | 2024-03-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7019198B2 (ja) | 補体関連疾患の予防及び治療のためのc5抗体及び方法 | |
| CN109608544B (zh) | Pd-l1抗体、其抗原结合片段及其医药用途 | |
| KR101836501B1 (ko) | 근육 성장을 증가시키기 위한 조성물 및 방법 | |
| AU2019201141B2 (en) | Novel antibody binding to TFPI and composition comprising the same | |
| TW201605901A (zh) | Pd-1抗體、其抗原結合片段及其醫藥用途 | |
| KR20170099918A (ko) | 항-axl 길항성 항체 | |
| CN113248618B (zh) | 抗pd-l1/抗lag3双特异性抗体及其用途 | |
| TW201018485A (en) | Bispecific anti-VEGF/anti-ANG-2 antibodies | |
| TW201132353A (en) | WISE binding agents and epitopes | |
| CN110678484B (zh) | 抗pd-l1/抗lag3双特异性抗体及其用途 | |
| KR101817265B1 (ko) | 혈청 아밀로이드 p 성분에 특이적인 항원 결합 단백질 | |
| JP2022536358A (ja) | ナトリウム利尿ペプチド受容体1抗体及び使用方法 | |
| US20220389096A1 (en) | Novel anti-sema3a antibodies and uses thereof | |
| AU2013202069B2 (en) | PRLR-specific antibody and uses thereof | |
| US20240034810A1 (en) | Anti-a2ap antibodies and uses thereof | |
| KR20170036505A (ko) | 신규 항-tfpi 항체 및 이를 포함하는 조성물 | |
| KR20230087552A (ko) | Cd45를 다량체화하는 결합 분자 | |
| CA3180665A1 (en) | Binding molecules for the treatment of cancer | |
| KR20230170721A (ko) | Bcma를 표적으로 하는 다중 특이성 항체 |