KR20230096959A - Il-10을 포함하는 이중 시토카인 융합 단백질 - Google Patents
Il-10을 포함하는 이중 시토카인 융합 단백질 Download PDFInfo
- Publication number
- KR20230096959A KR20230096959A KR1020237005848A KR20237005848A KR20230096959A KR 20230096959 A KR20230096959 A KR 20230096959A KR 1020237005848 A KR1020237005848 A KR 1020237005848A KR 20237005848 A KR20237005848 A KR 20237005848A KR 20230096959 A KR20230096959 A KR 20230096959A
- Authority
- KR
- South Korea
- Prior art keywords
- leu
- ser
- gly
- glu
- lys
- Prior art date
Links
- 102000003814 Interleukin-10 Human genes 0.000 title claims abstract description 328
- 108090000174 Interleukin-10 Proteins 0.000 title claims abstract description 328
- 102000004127 Cytokines Human genes 0.000 title claims abstract description 214
- 108090000695 Cytokines Proteins 0.000 title claims abstract description 214
- 102000037865 fusion proteins Human genes 0.000 title claims abstract description 192
- 108020001507 fusion proteins Proteins 0.000 title claims abstract description 192
- 230000009977 dual effect Effects 0.000 title claims abstract description 117
- 238000000034 method Methods 0.000 claims abstract description 68
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 50
- 208000027866 inflammatory disease Diseases 0.000 claims abstract description 19
- 201000011510 cancer Diseases 0.000 claims abstract description 18
- 239000012634 fragment Substances 0.000 claims abstract description 13
- 108010002350 Interleukin-2 Proteins 0.000 claims description 71
- 102000000588 Interleukin-2 Human genes 0.000 claims description 71
- 239000000178 monomer Substances 0.000 claims description 49
- 201000011001 Ebola Hemorrhagic Fever Diseases 0.000 claims description 42
- 239000000427 antigen Substances 0.000 claims description 40
- 102000036639 antigens Human genes 0.000 claims description 40
- 108091007433 antigens Proteins 0.000 claims description 40
- 108060006698 EGF receptor Proteins 0.000 claims description 32
- 108060008682 Tumor Necrosis Factor Proteins 0.000 claims description 30
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 claims description 30
- 108090000623 proteins and genes Proteins 0.000 claims description 30
- -1 IL- 21 Proteins 0.000 claims description 28
- 102000004169 proteins and genes Human genes 0.000 claims description 27
- 238000011282 treatment Methods 0.000 claims description 20
- 102000001301 EGF receptor Human genes 0.000 claims description 16
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 claims description 12
- 102000004388 Interleukin-4 Human genes 0.000 claims description 12
- 108090000978 Interleukin-4 Proteins 0.000 claims description 12
- 101000851007 Homo sapiens Vascular endothelial growth factor receptor 2 Proteins 0.000 claims description 11
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 claims description 11
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 claims description 11
- 102000004887 Transforming Growth Factor beta Human genes 0.000 claims description 10
- 108090001012 Transforming Growth Factor beta Proteins 0.000 claims description 10
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 claims description 9
- 206010040047 Sepsis Diseases 0.000 claims description 9
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 claims description 9
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 claims description 8
- 208000024891 symptom Diseases 0.000 claims description 8
- 101000692455 Homo sapiens Platelet-derived growth factor receptor beta Proteins 0.000 claims description 7
- 101000851018 Homo sapiens Vascular endothelial growth factor receptor 1 Proteins 0.000 claims description 7
- 102100026547 Platelet-derived growth factor receptor beta Human genes 0.000 claims description 7
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 claims description 7
- 230000036436 anti-hiv Effects 0.000 claims description 7
- 101150014060 Ager gene Proteins 0.000 claims description 6
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 claims description 6
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 claims description 6
- 102000008096 B7-H1 Antigen Human genes 0.000 claims description 6
- 108010074708 B7-H1 Antigen Proteins 0.000 claims description 6
- 102100024217 CAMPATH-1 antigen Human genes 0.000 claims description 6
- 108010065524 CD52 Antigen Proteins 0.000 claims description 6
- 101100165942 Caenorhabditis elegans clp-1 gene Proteins 0.000 claims description 6
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 claims description 6
- 102000018651 Epithelial Cell Adhesion Molecule Human genes 0.000 claims description 6
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 claims description 6
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 claims description 6
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 claims description 6
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 claims description 6
- 101100273739 Homo sapiens CD68 gene Proteins 0.000 claims description 6
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 claims description 6
- 101001068133 Homo sapiens Hepatitis A virus cellular receptor 2 Proteins 0.000 claims description 6
- 101000868279 Homo sapiens Leukocyte surface antigen CD47 Proteins 0.000 claims description 6
- 101001137987 Homo sapiens Lymphocyte activation gene 3 protein Proteins 0.000 claims description 6
- 101001018258 Homo sapiens Macrophage receptor MARCO Proteins 0.000 claims description 6
- 101000651021 Homo sapiens Splicing factor, arginine/serine-rich 19 Proteins 0.000 claims description 6
- 102000037982 Immune checkpoint proteins Human genes 0.000 claims description 6
- 108091008036 Immune checkpoint proteins Proteins 0.000 claims description 6
- 108010041012 Integrin alpha4 Proteins 0.000 claims description 6
- 108010064593 Intercellular Adhesion Molecule-1 Proteins 0.000 claims description 6
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 claims description 6
- 108090000172 Interleukin-15 Proteins 0.000 claims description 6
- 102000017578 LAG3 Human genes 0.000 claims description 6
- 102100032913 Leukocyte surface antigen CD47 Human genes 0.000 claims description 6
- 102100033272 Macrophage receptor MARCO Human genes 0.000 claims description 6
- 101100382100 Mus musculus Cd163 gene Proteins 0.000 claims description 6
- 101100256256 Mus musculus Scara3 gene Proteins 0.000 claims description 6
- 101100150295 Mus musculus Scarf1 gene Proteins 0.000 claims description 6
- 101100150293 Mus musculus Scarf2 gene Proteins 0.000 claims description 6
- 101100534470 Mus musculus Stab1 gene Proteins 0.000 claims description 6
- 101150086211 OLR1 gene Proteins 0.000 claims description 6
- 102100040678 Programmed cell death protein 1 Human genes 0.000 claims description 6
- 101710089372 Programmed cell death protein 1 Proteins 0.000 claims description 6
- 102100023832 Prolyl endopeptidase FAP Human genes 0.000 claims description 6
- 206010040070 Septic Shock Diseases 0.000 claims description 6
- 102100027779 Splicing factor, arginine/serine-rich 19 Human genes 0.000 claims description 6
- 108091005425 Sr-CI Proteins 0.000 claims description 6
- 101150086528 Stab2 gene Proteins 0.000 claims description 6
- 108010072257 fibroblast activation protein alpha Proteins 0.000 claims description 6
- 108010021315 integrin beta7 Proteins 0.000 claims description 6
- 108010044426 integrins Proteins 0.000 claims description 6
- 102000006495 integrins Human genes 0.000 claims description 6
- 230000036303 septic shock Effects 0.000 claims description 6
- 208000011231 Crohn disease Diseases 0.000 claims description 5
- 102000000589 Interleukin-1 Human genes 0.000 claims description 5
- 108010002352 Interleukin-1 Proteins 0.000 claims description 5
- 108090001005 Interleukin-6 Proteins 0.000 claims description 5
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 claims description 4
- 102100039619 Granulocyte colony-stimulating factor Human genes 0.000 claims description 4
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 claims description 4
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 claims description 4
- 101001002470 Homo sapiens Interferon lambda-1 Proteins 0.000 claims description 4
- 102100020990 Interferon lambda-1 Human genes 0.000 claims description 4
- 102000006992 Interferon-alpha Human genes 0.000 claims description 4
- 108010047761 Interferon-alpha Proteins 0.000 claims description 4
- 108090000177 Interleukin-11 Proteins 0.000 claims description 4
- 108090000176 Interleukin-13 Proteins 0.000 claims description 4
- 108010066979 Interleukin-27 Proteins 0.000 claims description 4
- 108010002386 Interleukin-3 Proteins 0.000 claims description 4
- 108010002616 Interleukin-5 Proteins 0.000 claims description 4
- 108010002586 Interleukin-7 Proteins 0.000 claims description 4
- 108090001007 Interleukin-8 Proteins 0.000 claims description 4
- 108010002335 Interleukin-9 Proteins 0.000 claims description 4
- 201000004681 Psoriasis Diseases 0.000 claims description 4
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 claims description 4
- 101000853000 Homo sapiens Interleukin-26 Proteins 0.000 claims description 3
- 208000022559 Inflammatory bowel disease Diseases 0.000 claims description 3
- 102100030703 Interleukin-22 Human genes 0.000 claims description 3
- 206010039073 rheumatoid arthritis Diseases 0.000 claims description 3
- 108010074108 interleukin-21 Proteins 0.000 claims description 2
- 102000009024 Epidermal Growth Factor Human genes 0.000 claims 2
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 abstract description 12
- 201000010099 disease Diseases 0.000 abstract description 11
- 239000000203 mixture Substances 0.000 abstract description 9
- 230000001404 mediated effect Effects 0.000 abstract description 7
- 239000008194 pharmaceutical composition Substances 0.000 abstract description 6
- 238000009472 formulation Methods 0.000 abstract description 3
- 208000035475 disorder Diseases 0.000 abstract 1
- HKZAAJSTFUZYTO-LURJTMIESA-N (2s)-2-[[2-[[2-[[2-[(2-aminoacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]-3-hydroxypropanoic acid Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O HKZAAJSTFUZYTO-LURJTMIESA-N 0.000 description 75
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 62
- 150000001413 amino acids Chemical group 0.000 description 57
- 210000001616 monocyte Anatomy 0.000 description 54
- REPPKAMYTOJTFC-DCAQKATOSA-N Leu-Arg-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O REPPKAMYTOJTFC-DCAQKATOSA-N 0.000 description 50
- 210000001744 T-lymphocyte Anatomy 0.000 description 48
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 46
- 230000000694 effects Effects 0.000 description 40
- 108010003700 lysyl aspartic acid Proteins 0.000 description 40
- 230000028327 secretion Effects 0.000 description 38
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 36
- 239000002158 endotoxin Substances 0.000 description 36
- 229920006008 lipopolysaccharide Polymers 0.000 description 36
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 35
- 241000282414 Homo sapiens Species 0.000 description 35
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 35
- YCRAFFCYWOUEOF-DLOVCJGASA-N Ala-Phe-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 YCRAFFCYWOUEOF-DLOVCJGASA-N 0.000 description 34
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 34
- WOZDCBHUGJVJPL-AVGNSLFASA-N Arg-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N WOZDCBHUGJVJPL-AVGNSLFASA-N 0.000 description 33
- VEIKMWOMUYMMMK-FCLVOEFKSA-N Thr-Phe-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 VEIKMWOMUYMMMK-FCLVOEFKSA-N 0.000 description 33
- GLWFAWNYGWBMOC-SRVKXCTJSA-N Asn-Leu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GLWFAWNYGWBMOC-SRVKXCTJSA-N 0.000 description 32
- ZTLGVASZOIKNIX-DCAQKATOSA-N Leu-Gln-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZTLGVASZOIKNIX-DCAQKATOSA-N 0.000 description 32
- 229940024606 amino acid Drugs 0.000 description 32
- 108010034529 leucyl-lysine Proteins 0.000 description 32
- 210000002540 macrophage Anatomy 0.000 description 32
- HVHRPWQEQHIQJF-AVGNSLFASA-N Leu-Lys-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HVHRPWQEQHIQJF-AVGNSLFASA-N 0.000 description 31
- RPWTZTBIFGENIA-VOAKCMCISA-N Lys-Thr-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RPWTZTBIFGENIA-VOAKCMCISA-N 0.000 description 31
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 31
- KJGNDQCYBNBXDA-GUBZILKMSA-N Arg-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N KJGNDQCYBNBXDA-GUBZILKMSA-N 0.000 description 30
- PYXXJFRXIYAESU-PCBIJLKTSA-N Asp-Ile-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PYXXJFRXIYAESU-PCBIJLKTSA-N 0.000 description 30
- ZVQZXPADLZIQFF-FHWLQOOXSA-N Gln-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@H](CCC(N)=O)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 ZVQZXPADLZIQFF-FHWLQOOXSA-N 0.000 description 30
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 30
- JFSNBQJNDMXMQF-XHNCKOQMSA-N Gln-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O JFSNBQJNDMXMQF-XHNCKOQMSA-N 0.000 description 29
- OUBUHIODTNUUTC-WDCWCFNPSA-N Gln-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O OUBUHIODTNUUTC-WDCWCFNPSA-N 0.000 description 29
- LKOAAMXDJGEYMS-ZPFDUUQYSA-N Glu-Met-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LKOAAMXDJGEYMS-ZPFDUUQYSA-N 0.000 description 29
- CJGDTAHEMXLRMB-ULQDDVLXSA-N His-Arg-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O CJGDTAHEMXLRMB-ULQDDVLXSA-N 0.000 description 29
- LEDRIAHEWDJRMF-CFMVVWHZSA-N Ile-Asn-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LEDRIAHEWDJRMF-CFMVVWHZSA-N 0.000 description 29
- RJONUNZIMUXUOI-GUBZILKMSA-N Glu-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N RJONUNZIMUXUOI-GUBZILKMSA-N 0.000 description 28
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 28
- MQVNVZUEPUIAFA-WDSKDSINSA-N Gly-Cys-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)CN MQVNVZUEPUIAFA-WDSKDSINSA-N 0.000 description 28
- 241000880493 Leptailurus serval Species 0.000 description 28
- HGUUMQWGYCVPKG-DCAQKATOSA-N Leu-Pro-Cys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)O)N HGUUMQWGYCVPKG-DCAQKATOSA-N 0.000 description 28
- RVOMPSJXSRPFJT-DCAQKATOSA-N Lys-Ala-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVOMPSJXSRPFJT-DCAQKATOSA-N 0.000 description 28
- DGAAQRAUOFHBFJ-CIUDSAMLSA-N Lys-Asn-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O DGAAQRAUOFHBFJ-CIUDSAMLSA-N 0.000 description 28
- QEDGNYFHLXXIDC-DCAQKATOSA-N Met-Pro-Gln Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O QEDGNYFHLXXIDC-DCAQKATOSA-N 0.000 description 28
- DSGYZICNAMEJOC-AVGNSLFASA-N Ser-Glu-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O DSGYZICNAMEJOC-AVGNSLFASA-N 0.000 description 28
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 28
- 150000007523 nucleic acids Chemical class 0.000 description 28
- NJPMYXWVWQWCSR-ACZMJKKPSA-N Ala-Glu-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NJPMYXWVWQWCSR-ACZMJKKPSA-N 0.000 description 27
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 27
- ZOXBSICWUDAOHX-GUBZILKMSA-N Glu-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O ZOXBSICWUDAOHX-GUBZILKMSA-N 0.000 description 27
- WZDCVAWMBUNDDY-KBIXCLLPSA-N Ile-Glu-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](C)C(=O)O)N WZDCVAWMBUNDDY-KBIXCLLPSA-N 0.000 description 27
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 27
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 27
- DTUZCYRNEJDKSR-NHCYSSNCSA-N Lys-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN DTUZCYRNEJDKSR-NHCYSSNCSA-N 0.000 description 27
- KAHUBGWSIQNZQQ-KKUMJFAQSA-N Phe-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 KAHUBGWSIQNZQQ-KKUMJFAQSA-N 0.000 description 27
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 27
- YRBGRUOSJROZEI-NHCYSSNCSA-N Asp-His-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O YRBGRUOSJROZEI-NHCYSSNCSA-N 0.000 description 26
- NNKLKUUGESXCBS-KBPBESRZSA-N Lys-Gly-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NNKLKUUGESXCBS-KBPBESRZSA-N 0.000 description 26
- JAGGEZACYAAMIL-CQDKDKBSSA-N Tyr-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JAGGEZACYAAMIL-CQDKDKBSSA-N 0.000 description 26
- AVFGBGGRZOKSFS-KJEVXHAQSA-N Tyr-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O AVFGBGGRZOKSFS-KJEVXHAQSA-N 0.000 description 26
- 238000006467 substitution reaction Methods 0.000 description 26
- 230000008685 targeting Effects 0.000 description 26
- VLDMQVZZWDOKQF-AUTRQRHGSA-N Val-Glu-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N VLDMQVZZWDOKQF-AUTRQRHGSA-N 0.000 description 25
- 108010038745 tryptophylglycine Proteins 0.000 description 25
- UWXFFVQPAMBETM-ZLUOBGJFSA-N Cys-Asp-Asn Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O UWXFFVQPAMBETM-ZLUOBGJFSA-N 0.000 description 24
- CZQZSMJXFGGBHM-KKUMJFAQSA-N Phe-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O CZQZSMJXFGGBHM-KKUMJFAQSA-N 0.000 description 24
- DCCGCVLVVSAJFK-NUMRIWBASA-N Thr-Asp-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O DCCGCVLVVSAJFK-NUMRIWBASA-N 0.000 description 24
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 23
- 210000004027 cell Anatomy 0.000 description 23
- PJBVXVBTTFZPHJ-GUBZILKMSA-N Glu-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N PJBVXVBTTFZPHJ-GUBZILKMSA-N 0.000 description 22
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 22
- 108010064235 lysylglycine Proteins 0.000 description 22
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 description 21
- 108091028043 Nucleic acid sequence Proteins 0.000 description 20
- 108010089256 lysyl-aspartyl-glutamyl-leucine Proteins 0.000 description 20
- 102100021277 Beta-secretase 2 Human genes 0.000 description 19
- 101710150190 Beta-secretase 2 Proteins 0.000 description 19
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 18
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 18
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 17
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 17
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 17
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 17
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 17
- 241000699670 Mus sp. Species 0.000 description 16
- GZBKRJVCRMZAST-XKBZYTNZSA-N Ser-Glu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZBKRJVCRMZAST-XKBZYTNZSA-N 0.000 description 16
- 238000003556 assay Methods 0.000 description 16
- 108020004414 DNA Proteins 0.000 description 15
- CSMYMGFCEJWALV-WDSKDSINSA-N Gly-Ser-Gln Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O CSMYMGFCEJWALV-WDSKDSINSA-N 0.000 description 15
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 15
- VFOHXOLPLACADK-GVXVVHGQSA-N Val-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N VFOHXOLPLACADK-GVXVVHGQSA-N 0.000 description 15
- CEKSLIVSNNGOKH-KZVJFYERSA-N Val-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](C(C)C)N)O CEKSLIVSNNGOKH-KZVJFYERSA-N 0.000 description 15
- 230000006870 function Effects 0.000 description 15
- 108010050848 glycylleucine Proteins 0.000 description 15
- 238000004448 titration Methods 0.000 description 15
- QFJPFPCSXOXMKI-BPUTZDHNSA-N Gln-Gln-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N QFJPFPCSXOXMKI-BPUTZDHNSA-N 0.000 description 14
- UGVQELHRNUDMAA-BYPYZUCNSA-N Gly-Ala-Gly Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)NCC([O-])=O UGVQELHRNUDMAA-BYPYZUCNSA-N 0.000 description 14
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 14
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 14
- 108010037850 glycylvaline Proteins 0.000 description 14
- 230000004048 modification Effects 0.000 description 14
- 238000012986 modification Methods 0.000 description 14
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 13
- QQACQIHVWCVBBR-GVARAGBVSA-N Ala-Ile-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QQACQIHVWCVBBR-GVARAGBVSA-N 0.000 description 13
- UGZUVYDKAYNCII-ULQDDVLXSA-N Arg-Phe-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O UGZUVYDKAYNCII-ULQDDVLXSA-N 0.000 description 13
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 13
- LEIKGVHQTKHOLM-IUCAKERBSA-N Pro-Pro-Gly Chemical compound OC(=O)CNC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 LEIKGVHQTKHOLM-IUCAKERBSA-N 0.000 description 13
- 108010081404 acein-2 Proteins 0.000 description 13
- 108010089804 glycyl-threonine Proteins 0.000 description 13
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 12
- ASCFJMSGKUIRDU-ZPFDUUQYSA-N Ile-Arg-Gln Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O ASCFJMSGKUIRDU-ZPFDUUQYSA-N 0.000 description 12
- 108010065920 Insulin Lispro Proteins 0.000 description 12
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 12
- 108010081551 glycylphenylalanine Proteins 0.000 description 12
- 230000002401 inhibitory effect Effects 0.000 description 12
- 108010051242 phenylalanylserine Proteins 0.000 description 12
- 238000012360 testing method Methods 0.000 description 12
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 12
- 239000013598 vector Substances 0.000 description 12
- COWITDLVHMZSIW-CIUDSAMLSA-N Asn-Lys-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O COWITDLVHMZSIW-CIUDSAMLSA-N 0.000 description 11
- HOQGTAIGQSDCHR-SRVKXCTJSA-N Asp-Asn-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HOQGTAIGQSDCHR-SRVKXCTJSA-N 0.000 description 11
- SMZCLQGDQMGESY-ACZMJKKPSA-N Asp-Gln-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)O)N SMZCLQGDQMGESY-ACZMJKKPSA-N 0.000 description 11
- KBKGRMNVKPSQIF-XDTLVQLUSA-N Glu-Ala-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KBKGRMNVKPSQIF-XDTLVQLUSA-N 0.000 description 11
- XVYKMNXXJXQKME-XEGUGMAKSA-N Gly-Ile-Tyr Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 XVYKMNXXJXQKME-XEGUGMAKSA-N 0.000 description 11
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 11
- RMNMUUCYTMLWNA-ZPFDUUQYSA-N Ile-Lys-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N RMNMUUCYTMLWNA-ZPFDUUQYSA-N 0.000 description 11
- 102000004551 Interleukin-10 Receptors Human genes 0.000 description 11
- 108010017550 Interleukin-10 Receptors Proteins 0.000 description 11
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 11
- CANPXOLVTMKURR-WEDXCCLWSA-N Lys-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN CANPXOLVTMKURR-WEDXCCLWSA-N 0.000 description 11
- ZYNBEWGJFXTBDU-ACRUOGEOSA-N Phe-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CC=CC=C2)N ZYNBEWGJFXTBDU-ACRUOGEOSA-N 0.000 description 11
- LCWXSALTPTZKNM-CIUDSAMLSA-N Pro-Cys-Glu Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)O)C(=O)O LCWXSALTPTZKNM-CIUDSAMLSA-N 0.000 description 11
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 11
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 11
- HDBOEVPDIDDEPC-CIUDSAMLSA-N Ser-Lys-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O HDBOEVPDIDDEPC-CIUDSAMLSA-N 0.000 description 11
- QWMPARMKIDVBLV-VZFHVOOUSA-N Thr-Cys-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O QWMPARMKIDVBLV-VZFHVOOUSA-N 0.000 description 11
- 108010010147 glycylglutamine Proteins 0.000 description 11
- 230000006698 induction Effects 0.000 description 11
- 230000000770 proinflammatory effect Effects 0.000 description 11
- YYAVDNKUWLAFCV-ACZMJKKPSA-N Ala-Ser-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O YYAVDNKUWLAFCV-ACZMJKKPSA-N 0.000 description 10
- OANWAFQRNQEDSY-DCAQKATOSA-N Arg-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCN=C(N)N)N OANWAFQRNQEDSY-DCAQKATOSA-N 0.000 description 10
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 10
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 10
- OVZLLFONXILPDZ-VOAKCMCISA-N Leu-Lys-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OVZLLFONXILPDZ-VOAKCMCISA-N 0.000 description 10
- DRIJZWBRGMJCDD-DCAQKATOSA-N Pro-Gln-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O DRIJZWBRGMJCDD-DCAQKATOSA-N 0.000 description 10
- ZSPQUTWLWGWTPS-HJGDQZAQSA-N Thr-Lys-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZSPQUTWLWGWTPS-HJGDQZAQSA-N 0.000 description 10
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 10
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 10
- 230000005764 inhibitory process Effects 0.000 description 10
- 108010057821 leucylproline Proteins 0.000 description 10
- 102000039446 nucleic acids Human genes 0.000 description 10
- 108020004707 nucleic acids Proteins 0.000 description 10
- OTOXOKCIIQLMFH-KZVJFYERSA-N Arg-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N OTOXOKCIIQLMFH-KZVJFYERSA-N 0.000 description 9
- WTXCNOPZMQRTNN-BWBBJGPYSA-N Cys-Thr-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N)O WTXCNOPZMQRTNN-BWBBJGPYSA-N 0.000 description 9
- RZSLYUUFFVHFRQ-FXQIFTODSA-N Gln-Ala-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O RZSLYUUFFVHFRQ-FXQIFTODSA-N 0.000 description 9
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 9
- UMIRPYLZFKOEOH-YVNDNENWSA-N Glu-Gln-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UMIRPYLZFKOEOH-YVNDNENWSA-N 0.000 description 9
- IDEODOAVGCMUQV-GUBZILKMSA-N Glu-Ser-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IDEODOAVGCMUQV-GUBZILKMSA-N 0.000 description 9
- FGPLUIQCSKGLTI-WDSKDSINSA-N Gly-Ser-Glu Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O FGPLUIQCSKGLTI-WDSKDSINSA-N 0.000 description 9
- 241000699666 Mus <mouse, genus> Species 0.000 description 9
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 9
- IUVYJBMTHARMIP-PCBIJLKTSA-N Phe-Asp-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O IUVYJBMTHARMIP-PCBIJLKTSA-N 0.000 description 9
- VYWNORHENYEQDW-YUMQZZPRSA-N Pro-Gly-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 VYWNORHENYEQDW-YUMQZZPRSA-N 0.000 description 9
- KRPKYGOFYUNIGM-XVSYOHENSA-N Thr-Asp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O KRPKYGOFYUNIGM-XVSYOHENSA-N 0.000 description 9
- KIMOCKLJBXHFIN-YLVFBTJISA-N Trp-Ile-Gly Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O)=CNC2=C1 KIMOCKLJBXHFIN-YLVFBTJISA-N 0.000 description 9
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 9
- GUIYPEKUEMQBIK-JSGCOSHPSA-N Val-Tyr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)NCC(O)=O GUIYPEKUEMQBIK-JSGCOSHPSA-N 0.000 description 9
- 239000003112 inhibitor Substances 0.000 description 9
- 108010024607 phenylalanylalanine Proteins 0.000 description 9
- 230000004044 response Effects 0.000 description 9
- 108010026333 seryl-proline Proteins 0.000 description 9
- 230000001225 therapeutic effect Effects 0.000 description 9
- 108010017949 tyrosyl-glycyl-glycine Proteins 0.000 description 9
- 108010003137 tyrosyltyrosine Proteins 0.000 description 9
- CJQAEJMHBAOQHA-DLOVCJGASA-N Ala-Phe-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CJQAEJMHBAOQHA-DLOVCJGASA-N 0.000 description 8
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 8
- YDJVIBMKAMQPPP-LAEOZQHASA-N Asp-Glu-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O YDJVIBMKAMQPPP-LAEOZQHASA-N 0.000 description 8
- QJCKNLPMTPXXEM-AUTRQRHGSA-N Glu-Glu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O QJCKNLPMTPXXEM-AUTRQRHGSA-N 0.000 description 8
- NTNUEBVGKMVANB-NHCYSSNCSA-N Glu-Val-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O NTNUEBVGKMVANB-NHCYSSNCSA-N 0.000 description 8
- HDNXXTBKOJKWNN-WDSKDSINSA-N Gly-Glu-Asn Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O HDNXXTBKOJKWNN-WDSKDSINSA-N 0.000 description 8
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 8
- RIYIFUFFFBIOEU-KBPBESRZSA-N Gly-Tyr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 RIYIFUFFFBIOEU-KBPBESRZSA-N 0.000 description 8
- GYXDQXPCPASCNR-NHCYSSNCSA-N His-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N GYXDQXPCPASCNR-NHCYSSNCSA-N 0.000 description 8
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 8
- WQWZXKWOEVSGQM-DCAQKATOSA-N Lys-Ala-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN WQWZXKWOEVSGQM-DCAQKATOSA-N 0.000 description 8
- ISHNZELVUVPCHY-ZETCQYMHSA-N Lys-Gly-Gly Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O ISHNZELVUVPCHY-ZETCQYMHSA-N 0.000 description 8
- WXJLBSXNUHIGSS-OSUNSFLBSA-N Met-Thr-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WXJLBSXNUHIGSS-OSUNSFLBSA-N 0.000 description 8
- YYKZDTVQHTUKDW-RYUDHWBXSA-N Phe-Gly-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N YYKZDTVQHTUKDW-RYUDHWBXSA-N 0.000 description 8
- AUJWXNGCAQWLEI-KBPBESRZSA-N Phe-Lys-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O AUJWXNGCAQWLEI-KBPBESRZSA-N 0.000 description 8
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 8
- DWAMXBFJNZIHMC-KBPBESRZSA-N Tyr-Leu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O DWAMXBFJNZIHMC-KBPBESRZSA-N 0.000 description 8
- 239000005557 antagonist Substances 0.000 description 8
- 230000003110 anti-inflammatory effect Effects 0.000 description 8
- 239000003814 drug Substances 0.000 description 8
- 208000026278 immune system disease Diseases 0.000 description 8
- 238000000338 in vitro Methods 0.000 description 8
- 230000028709 inflammatory response Effects 0.000 description 8
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 8
- AWNAEZICPNGAJK-FXQIFTODSA-N Ala-Met-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O AWNAEZICPNGAJK-FXQIFTODSA-N 0.000 description 7
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 7
- RWCLSUOSKWTXLA-FXQIFTODSA-N Arg-Asp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RWCLSUOSKWTXLA-FXQIFTODSA-N 0.000 description 7
- HPASIOLTWSNMFB-OLHMAJIHSA-N Asn-Thr-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O HPASIOLTWSNMFB-OLHMAJIHSA-N 0.000 description 7
- YSYTWUMRHSFODC-QWRGUYRKSA-N Asn-Tyr-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O YSYTWUMRHSFODC-QWRGUYRKSA-N 0.000 description 7
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 7
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 7
- ZSESFIFAYQEKRD-CYDGBPFRSA-N Ile-Val-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(=O)O)N ZSESFIFAYQEKRD-CYDGBPFRSA-N 0.000 description 7
- QJUWBDPGGYVRHY-YUMQZZPRSA-N Leu-Gly-Cys Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N QJUWBDPGGYVRHY-YUMQZZPRSA-N 0.000 description 7
- LVTJJOJKDCVZGP-QWRGUYRKSA-N Leu-Lys-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LVTJJOJKDCVZGP-QWRGUYRKSA-N 0.000 description 7
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 7
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 7
- ONPDTSFZAIWMDI-AVGNSLFASA-N Lys-Leu-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ONPDTSFZAIWMDI-AVGNSLFASA-N 0.000 description 7
- GHQFLTYXGUETFD-UFYCRDLUSA-N Met-Tyr-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N GHQFLTYXGUETFD-UFYCRDLUSA-N 0.000 description 7
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 7
- WKTSCAXSYITIJJ-PCBIJLKTSA-N Phe-Ile-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O WKTSCAXSYITIJJ-PCBIJLKTSA-N 0.000 description 7
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 7
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 7
- GRSLLFZTTLBOQX-CIUDSAMLSA-N Ser-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N GRSLLFZTTLBOQX-CIUDSAMLSA-N 0.000 description 7
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 7
- JLFKWDAZBRYCGX-ZKWXMUAHSA-N Val-Asn-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N JLFKWDAZBRYCGX-ZKWXMUAHSA-N 0.000 description 7
- MYLNLEIZWHVENT-VKOGCVSHSA-N Val-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](C(C)C)N MYLNLEIZWHVENT-VKOGCVSHSA-N 0.000 description 7
- 238000007792 addition Methods 0.000 description 7
- 108010068265 aspartyltyrosine Proteins 0.000 description 7
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 7
- 238000001727 in vivo Methods 0.000 description 7
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 6
- DEAGTWNKODHUIY-MRFFXTKBSA-N Ala-Tyr-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DEAGTWNKODHUIY-MRFFXTKBSA-N 0.000 description 6
- HJRBIWRXULGMOA-ACZMJKKPSA-N Asn-Gln-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJRBIWRXULGMOA-ACZMJKKPSA-N 0.000 description 6
- YVXRYLVELQYAEQ-SRVKXCTJSA-N Asn-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N YVXRYLVELQYAEQ-SRVKXCTJSA-N 0.000 description 6
- ORJQQZIXTOYGGH-SRVKXCTJSA-N Asn-Lys-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ORJQQZIXTOYGGH-SRVKXCTJSA-N 0.000 description 6
- BEHQTVDBCLSCBY-CFMVVWHZSA-N Asn-Tyr-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BEHQTVDBCLSCBY-CFMVVWHZSA-N 0.000 description 6
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 6
- JUWISGAGWSDGDH-KKUMJFAQSA-N Asp-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=CC=C1 JUWISGAGWSDGDH-KKUMJFAQSA-N 0.000 description 6
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 6
- AMRLSQGGERHDHJ-FXQIFTODSA-N Cys-Ala-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMRLSQGGERHDHJ-FXQIFTODSA-N 0.000 description 6
- MAGNEQBFSBREJL-DCAQKATOSA-N Gln-Glu-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N MAGNEQBFSBREJL-DCAQKATOSA-N 0.000 description 6
- MTCXQQINVAFZKW-MNXVOIDGSA-N Gln-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MTCXQQINVAFZKW-MNXVOIDGSA-N 0.000 description 6
- BYKZWDGMJLNFJY-XKBZYTNZSA-N Gln-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)O BYKZWDGMJLNFJY-XKBZYTNZSA-N 0.000 description 6
- MLCPTRRNICEKIS-FXQIFTODSA-N Glu-Asn-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLCPTRRNICEKIS-FXQIFTODSA-N 0.000 description 6
- DXVOKNVIKORTHQ-GUBZILKMSA-N Glu-Pro-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O DXVOKNVIKORTHQ-GUBZILKMSA-N 0.000 description 6
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 6
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 6
- IEGFSKKANYKBDU-QWHCGFSZSA-N Gly-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)CN)C(=O)O IEGFSKKANYKBDU-QWHCGFSZSA-N 0.000 description 6
- UIEZQYNXCYHMQS-BJDJZHNGSA-N Ile-Lys-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)O)N UIEZQYNXCYHMQS-BJDJZHNGSA-N 0.000 description 6
- OVDKXUDMKXAZIV-ZPFDUUQYSA-N Ile-Lys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OVDKXUDMKXAZIV-ZPFDUUQYSA-N 0.000 description 6
- WYUHAXJAMDTOAU-IAVJCBSLSA-N Ile-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N WYUHAXJAMDTOAU-IAVJCBSLSA-N 0.000 description 6
- PZWBBXHHUSIGKH-OSUNSFLBSA-N Ile-Thr-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PZWBBXHHUSIGKH-OSUNSFLBSA-N 0.000 description 6
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 6
- QUAAUWNLWMLERT-IHRRRGAJSA-N Leu-Arg-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O QUAAUWNLWMLERT-IHRRRGAJSA-N 0.000 description 6
- ZURHXHNAEJJRNU-CIUDSAMLSA-N Leu-Asp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZURHXHNAEJJRNU-CIUDSAMLSA-N 0.000 description 6
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 6
- OGUUKPXUTHOIAV-SDDRHHMPSA-N Leu-Glu-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N OGUUKPXUTHOIAV-SDDRHHMPSA-N 0.000 description 6
- FAELBUXXFQLUAX-AJNGGQMLSA-N Leu-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C FAELBUXXFQLUAX-AJNGGQMLSA-N 0.000 description 6
- JIHDFWWRYHSAQB-GUBZILKMSA-N Leu-Ser-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JIHDFWWRYHSAQB-GUBZILKMSA-N 0.000 description 6
- RVYDCISQIGHAFC-ZPFDUUQYSA-N Met-Ile-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O RVYDCISQIGHAFC-ZPFDUUQYSA-N 0.000 description 6
- RMLLCGYYVZKKRT-CIUDSAMLSA-N Met-Ser-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O RMLLCGYYVZKKRT-CIUDSAMLSA-N 0.000 description 6
- WYBVBIHNJWOLCJ-UHFFFAOYSA-N N-L-arginyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCCN=C(N)N WYBVBIHNJWOLCJ-UHFFFAOYSA-N 0.000 description 6
- ROOQMPCUFLDOSB-FHWLQOOXSA-N Phe-Phe-Gln Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCC(N)=O)C(O)=O)C1=CC=CC=C1 ROOQMPCUFLDOSB-FHWLQOOXSA-N 0.000 description 6
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 6
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 6
- GNRMAQSIROFNMI-IXOXFDKPSA-N Phe-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GNRMAQSIROFNMI-IXOXFDKPSA-N 0.000 description 6
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 6
- VFEHSAJCWWHDBH-RHYQMDGZSA-N Thr-Arg-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VFEHSAJCWWHDBH-RHYQMDGZSA-N 0.000 description 6
- AHOLTQCAVBSUDP-PPCPHDFISA-N Thr-Ile-Lys Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)[C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O AHOLTQCAVBSUDP-PPCPHDFISA-N 0.000 description 6
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 6
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 6
- ZNFPUOSTMUMUDR-JRQIVUDYSA-N Tyr-Asn-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZNFPUOSTMUMUDR-JRQIVUDYSA-N 0.000 description 6
- HDSKHCBAVVWPCQ-FHWLQOOXSA-N Tyr-Glu-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HDSKHCBAVVWPCQ-FHWLQOOXSA-N 0.000 description 6
- OJCISMMNNUNNJA-BZSNNMDCSA-N Tyr-Tyr-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 OJCISMMNNUNNJA-BZSNNMDCSA-N 0.000 description 6
- MJXNDRCLGDSBBE-FHWLQOOXSA-N Val-His-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N MJXNDRCLGDSBBE-FHWLQOOXSA-N 0.000 description 6
- XPKCFQZDQGVJCX-RHYQMDGZSA-N Val-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N)O XPKCFQZDQGVJCX-RHYQMDGZSA-N 0.000 description 6
- WSUWDIVCPOJFCX-TUAOUCFPSA-N Val-Met-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N WSUWDIVCPOJFCX-TUAOUCFPSA-N 0.000 description 6
- 108010047495 alanylglycine Proteins 0.000 description 6
- 108010087924 alanylproline Proteins 0.000 description 6
- 108010093581 aspartyl-proline Proteins 0.000 description 6
- 230000003915 cell function Effects 0.000 description 6
- 230000004927 fusion Effects 0.000 description 6
- 108010049041 glutamylalanine Proteins 0.000 description 6
- 108010079547 glutamylmethionine Proteins 0.000 description 6
- 230000035772 mutation Effects 0.000 description 6
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 6
- 102000004196 processed proteins & peptides Human genes 0.000 description 6
- 108090000765 processed proteins & peptides Proteins 0.000 description 6
- 108010070643 prolylglutamic acid Proteins 0.000 description 6
- 230000009467 reduction Effects 0.000 description 6
- 108010048818 seryl-histidine Proteins 0.000 description 6
- 230000004936 stimulating effect Effects 0.000 description 6
- 230000004083 survival effect Effects 0.000 description 6
- 229940124597 therapeutic agent Drugs 0.000 description 6
- FVNAUOZKIPAYNA-BPNCWPANSA-N Ala-Met-Tyr Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FVNAUOZKIPAYNA-BPNCWPANSA-N 0.000 description 5
- OTZMRMHZCMZOJZ-SRVKXCTJSA-N Arg-Leu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTZMRMHZCMZOJZ-SRVKXCTJSA-N 0.000 description 5
- JEXPNDORFYHJTM-IHRRRGAJSA-N Arg-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCN=C(N)N JEXPNDORFYHJTM-IHRRRGAJSA-N 0.000 description 5
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 5
- QLSRIZIDQXDQHK-RCWTZXSCSA-N Arg-Val-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QLSRIZIDQXDQHK-RCWTZXSCSA-N 0.000 description 5
- QQEWINYJRFBLNN-DLOVCJGASA-N Asn-Ala-Phe Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QQEWINYJRFBLNN-DLOVCJGASA-N 0.000 description 5
- ZJIFRAPZHAGLGR-MELADBBJSA-N Asn-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)N)N)C(=O)O ZJIFRAPZHAGLGR-MELADBBJSA-N 0.000 description 5
- SPWXXPFDTMYTRI-IUKAMOBKSA-N Asp-Ile-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SPWXXPFDTMYTRI-IUKAMOBKSA-N 0.000 description 5
- BVFQOPGFOQVZTE-ACZMJKKPSA-N Cys-Gln-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O BVFQOPGFOQVZTE-ACZMJKKPSA-N 0.000 description 5
- FJAYYNIXQNERSO-ACZMJKKPSA-N Gln-Cys-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N FJAYYNIXQNERSO-ACZMJKKPSA-N 0.000 description 5
- CITDWMLWXNUQKD-FXQIFTODSA-N Gln-Gln-Asn Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CITDWMLWXNUQKD-FXQIFTODSA-N 0.000 description 5
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 5
- JJKKWYQVHRUSDG-GUBZILKMSA-N Glu-Ala-Lys Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O JJKKWYQVHRUSDG-GUBZILKMSA-N 0.000 description 5
- LHIPZASLKPYDPI-AVGNSLFASA-N Glu-Phe-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O LHIPZASLKPYDPI-AVGNSLFASA-N 0.000 description 5
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 5
- LYDKQVYYCMYNMC-SRVKXCTJSA-N His-Lys-Cys Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CS)C(O)=O)NC(=O)[C@@H](N)CC1=CN=CN1 LYDKQVYYCMYNMC-SRVKXCTJSA-N 0.000 description 5
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 5
- 206010061218 Inflammation Diseases 0.000 description 5
- 108010065805 Interleukin-12 Proteins 0.000 description 5
- 108010065637 Interleukin-23 Proteins 0.000 description 5
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 5
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 5
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 5
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 5
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 5
- WEDZFLRYSIDIRX-IHRRRGAJSA-N Phe-Ser-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 WEDZFLRYSIDIRX-IHRRRGAJSA-N 0.000 description 5
- JFNPBBOGGNMSRX-CIUDSAMLSA-N Pro-Gln-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O JFNPBBOGGNMSRX-CIUDSAMLSA-N 0.000 description 5
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 5
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 5
- YTYHAYZPOARHAP-HOCLYGCPSA-N Trp-Lys-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)O)N YTYHAYZPOARHAP-HOCLYGCPSA-N 0.000 description 5
- 102100040247 Tumor necrosis factor Human genes 0.000 description 5
- LGEYOIQBBIPHQN-UWJYBYFXSA-N Tyr-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 LGEYOIQBBIPHQN-UWJYBYFXSA-N 0.000 description 5
- VTFWAGGJDRSQFG-MELADBBJSA-N Tyr-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O VTFWAGGJDRSQFG-MELADBBJSA-N 0.000 description 5
- 239000002253 acid Substances 0.000 description 5
- 108010005233 alanylglutamic acid Proteins 0.000 description 5
- 108010044940 alanylglutamine Proteins 0.000 description 5
- 230000000259 anti-tumor effect Effects 0.000 description 5
- 108010008355 arginyl-glutamine Proteins 0.000 description 5
- 239000011324 bead Substances 0.000 description 5
- 238000010586 diagram Methods 0.000 description 5
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 5
- 230000002757 inflammatory effect Effects 0.000 description 5
- 230000004054 inflammatory process Effects 0.000 description 5
- 238000002347 injection Methods 0.000 description 5
- 239000007924 injection Substances 0.000 description 5
- 229940076144 interleukin-10 Drugs 0.000 description 5
- 229960000485 methotrexate Drugs 0.000 description 5
- 208000008338 non-alcoholic fatty liver disease Diseases 0.000 description 5
- 239000002773 nucleotide Substances 0.000 description 5
- 239000000546 pharmaceutical excipient Substances 0.000 description 5
- 229920001184 polypeptide Polymers 0.000 description 5
- 230000002829 reductive effect Effects 0.000 description 5
- 125000006850 spacer group Chemical group 0.000 description 5
- 230000000638 stimulation Effects 0.000 description 5
- 231100000419 toxicity Toxicity 0.000 description 5
- 230000001988 toxicity Effects 0.000 description 5
- 210000004881 tumor cell Anatomy 0.000 description 5
- QMOQBVOBWVNSNO-UHFFFAOYSA-N 2-[[2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]acetyl]amino]acetate Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(O)=O QMOQBVOBWVNSNO-UHFFFAOYSA-N 0.000 description 4
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 4
- XKXAZPSREVUCRT-BPNCWPANSA-N Ala-Tyr-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=C(O)C=C1 XKXAZPSREVUCRT-BPNCWPANSA-N 0.000 description 4
- QRIYOHQJRDHFKF-UWJYBYFXSA-N Ala-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 QRIYOHQJRDHFKF-UWJYBYFXSA-N 0.000 description 4
- NVUIWHJLPSZZQC-CYDGBPFRSA-N Arg-Ile-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NVUIWHJLPSZZQC-CYDGBPFRSA-N 0.000 description 4
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 4
- SWLOHUMCUDRTCL-ZLUOBGJFSA-N Asn-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N SWLOHUMCUDRTCL-ZLUOBGJFSA-N 0.000 description 4
- JRVABKHPWDRUJF-UBHSHLNASA-N Asn-Asn-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N JRVABKHPWDRUJF-UBHSHLNASA-N 0.000 description 4
- QPTAGIPWARILES-AVGNSLFASA-N Asn-Gln-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QPTAGIPWARILES-AVGNSLFASA-N 0.000 description 4
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 4
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 4
- RRIJEABIXPKSGP-FXQIFTODSA-N Cys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CS RRIJEABIXPKSGP-FXQIFTODSA-N 0.000 description 4
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 4
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 4
- SYAYROHMAIHWFB-KBIXCLLPSA-N Glu-Ser-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SYAYROHMAIHWFB-KBIXCLLPSA-N 0.000 description 4
- UZWUBBRJWFTHTD-LAEOZQHASA-N Glu-Val-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O UZWUBBRJWFTHTD-LAEOZQHASA-N 0.000 description 4
- YPHPEHMXOYTEQG-LAEOZQHASA-N Glu-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O YPHPEHMXOYTEQG-LAEOZQHASA-N 0.000 description 4
- 101100372760 Homo sapiens FLT1 gene Proteins 0.000 description 4
- 101001033233 Homo sapiens Interleukin-10 Proteins 0.000 description 4
- 101001002709 Homo sapiens Interleukin-4 Proteins 0.000 description 4
- BALLIXFZYSECCF-QEWYBTABSA-N Ile-Gln-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N BALLIXFZYSECCF-QEWYBTABSA-N 0.000 description 4
- HXIDVIFHRYRXLZ-NAKRPEOUSA-N Ile-Ser-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)O)N HXIDVIFHRYRXLZ-NAKRPEOUSA-N 0.000 description 4
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 4
- YVKSMSDXKMSIRX-GUBZILKMSA-N Leu-Glu-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O YVKSMSDXKMSIRX-GUBZILKMSA-N 0.000 description 4
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 4
- OXRLYTYUXAQTHP-YUMQZZPRSA-N Leu-Gly-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(O)=O OXRLYTYUXAQTHP-YUMQZZPRSA-N 0.000 description 4
- HNDWYLYAYNBWMP-AJNGGQMLSA-N Leu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N HNDWYLYAYNBWMP-AJNGGQMLSA-N 0.000 description 4
- LFSQWRSVPNKJGP-WDCWCFNPSA-N Leu-Thr-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(O)=O LFSQWRSVPNKJGP-WDCWCFNPSA-N 0.000 description 4
- KPJJOZUXFOLGMQ-CIUDSAMLSA-N Lys-Asp-Asn Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N KPJJOZUXFOLGMQ-CIUDSAMLSA-N 0.000 description 4
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- 241001529936 Murinae Species 0.000 description 4
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 4
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 4
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 4
- 108010079364 N-glycylalanine Proteins 0.000 description 4
- JNRFYJZCMHHGMH-UBHSHLNASA-N Phe-Ala-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 JNRFYJZCMHHGMH-UBHSHLNASA-N 0.000 description 4
- SWCOXQLDICUYOL-ULQDDVLXSA-N Phe-His-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SWCOXQLDICUYOL-ULQDDVLXSA-N 0.000 description 4
- AAERWTUHZKLDLC-IHRRRGAJSA-N Phe-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O AAERWTUHZKLDLC-IHRRRGAJSA-N 0.000 description 4
- VCYJKOLZYPYGJV-AVGNSLFASA-N Pro-Arg-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VCYJKOLZYPYGJV-AVGNSLFASA-N 0.000 description 4
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 4
- GZNYIXWOIUFLGO-ZJDVBMNYSA-N Pro-Thr-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZNYIXWOIUFLGO-ZJDVBMNYSA-N 0.000 description 4
- BLPYXIXXCFVIIF-FXQIFTODSA-N Ser-Cys-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N)CN=C(N)N BLPYXIXXCFVIIF-FXQIFTODSA-N 0.000 description 4
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 4
- UGHCUDLCCVVIJR-VGDYDELISA-N Ser-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CO)N UGHCUDLCCVVIJR-VGDYDELISA-N 0.000 description 4
- IFPBAGJBHSNYPR-ZKWXMUAHSA-N Ser-Ile-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O IFPBAGJBHSNYPR-ZKWXMUAHSA-N 0.000 description 4
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 4
- FBLNYDYPCLFTSP-IXOXFDKPSA-N Ser-Phe-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FBLNYDYPCLFTSP-IXOXFDKPSA-N 0.000 description 4
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 4
- CTONFVDJYCAMQM-IUKAMOBKSA-N Thr-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H]([C@@H](C)O)N CTONFVDJYCAMQM-IUKAMOBKSA-N 0.000 description 4
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 4
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 4
- GRIUMVXCJDKVPI-IZPVPAKOSA-N Thr-Thr-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GRIUMVXCJDKVPI-IZPVPAKOSA-N 0.000 description 4
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 4
- HYLNRGXEQACDKG-NYVOZVTQSA-N Trp-Asn-Trp Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HYLNRGXEQACDKG-NYVOZVTQSA-N 0.000 description 4
- WLBZWXXGSOLJBA-HOCLYGCPSA-N Trp-Gly-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 WLBZWXXGSOLJBA-HOCLYGCPSA-N 0.000 description 4
- GQHAIUPYZPTADF-FDARSICLSA-N Trp-Ile-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 GQHAIUPYZPTADF-FDARSICLSA-N 0.000 description 4
- HIINQLBHPIQYHN-JTQLQIEISA-N Tyr-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HIINQLBHPIQYHN-JTQLQIEISA-N 0.000 description 4
- ZPFLBLFITJCBTP-QWRGUYRKSA-N Tyr-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O ZPFLBLFITJCBTP-QWRGUYRKSA-N 0.000 description 4
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 4
- QHSSPPHOHJSTML-HOCLYGCPSA-N Val-Trp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)NCC(=O)O)N QHSSPPHOHJSTML-HOCLYGCPSA-N 0.000 description 4
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 4
- 108010013835 arginine glutamate Proteins 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 4
- 210000004899 c-terminal region Anatomy 0.000 description 4
- 239000000969 carrier Substances 0.000 description 4
- 108010016616 cysteinylglycine Proteins 0.000 description 4
- 238000012217 deletion Methods 0.000 description 4
- 230000037430 deletion Effects 0.000 description 4
- 239000003937 drug carrier Substances 0.000 description 4
- 238000011156 evaluation Methods 0.000 description 4
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 4
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 4
- 108010015792 glycyllysine Proteins 0.000 description 4
- 108010092114 histidylphenylalanine Proteins 0.000 description 4
- 102000052620 human IL10 Human genes 0.000 description 4
- 102000055229 human IL4 Human genes 0.000 description 4
- 210000001865 kupffer cell Anatomy 0.000 description 4
- 238000004519 manufacturing process Methods 0.000 description 4
- 230000003278 mimic effect Effects 0.000 description 4
- 238000010172 mouse model Methods 0.000 description 4
- 229940021182 non-steroidal anti-inflammatory drug Drugs 0.000 description 4
- 125000003729 nucleotide group Chemical group 0.000 description 4
- 210000005259 peripheral blood Anatomy 0.000 description 4
- 239000011886 peripheral blood Substances 0.000 description 4
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 4
- 108010004914 prolylarginine Proteins 0.000 description 4
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 4
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 4
- 102000005962 receptors Human genes 0.000 description 4
- 108020003175 receptors Proteins 0.000 description 4
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 4
- 229960002930 sirolimus Drugs 0.000 description 4
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 4
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 4
- 108010084932 tryptophyl-proline Proteins 0.000 description 4
- 239000013603 viral vector Substances 0.000 description 4
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 3
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 3
- WRDANSJTFOHBPI-FXQIFTODSA-N Ala-Arg-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N WRDANSJTFOHBPI-FXQIFTODSA-N 0.000 description 3
- BLGHHPHXVJWCNK-GUBZILKMSA-N Ala-Gln-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BLGHHPHXVJWCNK-GUBZILKMSA-N 0.000 description 3
- QHASENCZLDHBGX-ONGXEEELSA-N Ala-Gly-Phe Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QHASENCZLDHBGX-ONGXEEELSA-N 0.000 description 3
- OEVCHROQUIVQFZ-YTLHQDLWSA-N Ala-Thr-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O OEVCHROQUIVQFZ-YTLHQDLWSA-N 0.000 description 3
- IETUUAHKCHOQHP-KZVJFYERSA-N Ala-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)[C@@H](C)O)C(O)=O IETUUAHKCHOQHP-KZVJFYERSA-N 0.000 description 3
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 3
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 3
- OTUQSEPIIVBYEM-IHRRRGAJSA-N Arg-Asn-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OTUQSEPIIVBYEM-IHRRRGAJSA-N 0.000 description 3
- OGUPCHKBOKJFMA-SRVKXCTJSA-N Arg-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N OGUPCHKBOKJFMA-SRVKXCTJSA-N 0.000 description 3
- SUMJNGAMIQSNGX-TUAOUCFPSA-N Arg-Val-Pro Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N1CCC[C@@H]1C(O)=O SUMJNGAMIQSNGX-TUAOUCFPSA-N 0.000 description 3
- NUCUBYIUPVYGPP-XIRDDKMYSA-N Asn-Leu-Trp Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CC(N)=O)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O NUCUBYIUPVYGPP-XIRDDKMYSA-N 0.000 description 3
- KYQJHBWHRASMKG-ZLUOBGJFSA-N Asn-Ser-Cys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(O)=O KYQJHBWHRASMKG-ZLUOBGJFSA-N 0.000 description 3
- QHAJMRDEWNAIBQ-FXQIFTODSA-N Asp-Arg-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O QHAJMRDEWNAIBQ-FXQIFTODSA-N 0.000 description 3
- UGKZHCBLMLSANF-CIUDSAMLSA-N Asp-Asn-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O UGKZHCBLMLSANF-CIUDSAMLSA-N 0.000 description 3
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 3
- RWGDABDXVXRLLH-ACZMJKKPSA-N Cys-Glu-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CS)N RWGDABDXVXRLLH-ACZMJKKPSA-N 0.000 description 3
- VTJLJQGUMBWHBP-GUBZILKMSA-N Cys-His-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N VTJLJQGUMBWHBP-GUBZILKMSA-N 0.000 description 3
- IZUNQDRIAOLWCN-YUMQZZPRSA-N Cys-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N IZUNQDRIAOLWCN-YUMQZZPRSA-N 0.000 description 3
- YNJBLTDKTMKEET-ZLUOBGJFSA-N Cys-Ser-Ser Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O YNJBLTDKTMKEET-ZLUOBGJFSA-N 0.000 description 3
- 238000002965 ELISA Methods 0.000 description 3
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 3
- LVNILKSSFHCSJZ-IHRRRGAJSA-N Gln-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N LVNILKSSFHCSJZ-IHRRRGAJSA-N 0.000 description 3
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 3
- CELXWPDNIGWCJN-WDCWCFNPSA-N Gln-Lys-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CELXWPDNIGWCJN-WDCWCFNPSA-N 0.000 description 3
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 3
- SZXSSXUNOALWCH-ACZMJKKPSA-N Glu-Ala-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O SZXSSXUNOALWCH-ACZMJKKPSA-N 0.000 description 3
- NJCALAAIGREHDR-WDCWCFNPSA-N Glu-Leu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NJCALAAIGREHDR-WDCWCFNPSA-N 0.000 description 3
- CUPSDFQZTVVTSK-GUBZILKMSA-N Glu-Lys-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O CUPSDFQZTVVTSK-GUBZILKMSA-N 0.000 description 3
- BCYGDJXHAGZNPQ-DCAQKATOSA-N Glu-Lys-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O BCYGDJXHAGZNPQ-DCAQKATOSA-N 0.000 description 3
- OCJRHJZKGGSPRW-IUCAKERBSA-N Glu-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O OCJRHJZKGGSPRW-IUCAKERBSA-N 0.000 description 3
- AQNYKMCFCCZEEL-JYJNAYRXSA-N Glu-Lys-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AQNYKMCFCCZEEL-JYJNAYRXSA-N 0.000 description 3
- QGZSAHIZRQHCEQ-QWRGUYRKSA-N Gly-Asp-Tyr Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QGZSAHIZRQHCEQ-QWRGUYRKSA-N 0.000 description 3
- PAWIVEIWWYGBAM-YUMQZZPRSA-N Gly-Leu-Ala Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O PAWIVEIWWYGBAM-YUMQZZPRSA-N 0.000 description 3
- IUZGUFAJDBHQQV-YUMQZZPRSA-N Gly-Leu-Asn Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IUZGUFAJDBHQQV-YUMQZZPRSA-N 0.000 description 3
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 3
- IDNNYVGVSZMQTK-IHRRRGAJSA-N His-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N IDNNYVGVSZMQTK-IHRRRGAJSA-N 0.000 description 3
- CTGZVVQVIBSOBB-AVGNSLFASA-N His-His-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O CTGZVVQVIBSOBB-AVGNSLFASA-N 0.000 description 3
- GUXQAPACZVVOKX-AVGNSLFASA-N His-Lys-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N GUXQAPACZVVOKX-AVGNSLFASA-N 0.000 description 3
- 101000851181 Homo sapiens Epidermal growth factor receptor Proteins 0.000 description 3
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 3
- RWYCOSAAAJBJQL-KCTSRDHCSA-N Ile-Gly-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N RWYCOSAAAJBJQL-KCTSRDHCSA-N 0.000 description 3
- GTSAALPQZASLPW-KJYZGMDISA-N Ile-His-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N GTSAALPQZASLPW-KJYZGMDISA-N 0.000 description 3
- CSQNHSGHAPRGPQ-YTFOTSKYSA-N Ile-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(=O)O)N CSQNHSGHAPRGPQ-YTFOTSKYSA-N 0.000 description 3
- UFRXVQGGPNSJRY-CYDGBPFRSA-N Ile-Met-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N UFRXVQGGPNSJRY-CYDGBPFRSA-N 0.000 description 3
- ZUWSVOYKBCHLRR-MGHWNKPDSA-N Ile-Tyr-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZUWSVOYKBCHLRR-MGHWNKPDSA-N 0.000 description 3
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 3
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 3
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 3
- GRZSCTXVCDUIPO-SRVKXCTJSA-N Leu-Arg-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRZSCTXVCDUIPO-SRVKXCTJSA-N 0.000 description 3
- KSZCCRIGNVSHFH-UWVGGRQHSA-N Leu-Arg-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O KSZCCRIGNVSHFH-UWVGGRQHSA-N 0.000 description 3
- YKNBJXOJTURHCU-DCAQKATOSA-N Leu-Asp-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YKNBJXOJTURHCU-DCAQKATOSA-N 0.000 description 3
- FOEHRHOBWFQSNW-KATARQTJSA-N Leu-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(C)C)N)O FOEHRHOBWFQSNW-KATARQTJSA-N 0.000 description 3
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 3
- RVVBWTWPNFDYBE-SRVKXCTJSA-N Leu-Glu-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVVBWTWPNFDYBE-SRVKXCTJSA-N 0.000 description 3
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 3
- AVEGDIAXTDVBJS-XUXIUFHCSA-N Leu-Ile-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AVEGDIAXTDVBJS-XUXIUFHCSA-N 0.000 description 3
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 3
- FOBUGKUBUJOWAD-IHPCNDPISA-N Leu-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FOBUGKUBUJOWAD-IHPCNDPISA-N 0.000 description 3
- RTIRBWJPYJYTLO-MELADBBJSA-N Leu-Lys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N RTIRBWJPYJYTLO-MELADBBJSA-N 0.000 description 3
- UCXQIIIFOOGYEM-ULQDDVLXSA-N Leu-Pro-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCXQIIIFOOGYEM-ULQDDVLXSA-N 0.000 description 3
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 3
- HOMFINRJHIIZNJ-HOCLYGCPSA-N Leu-Trp-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O HOMFINRJHIIZNJ-HOCLYGCPSA-N 0.000 description 3
- KNKHAVVBVXKOGX-JXUBOQSCSA-N Lys-Ala-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KNKHAVVBVXKOGX-JXUBOQSCSA-N 0.000 description 3
- YNNPKXBBRZVIRX-IHRRRGAJSA-N Lys-Arg-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O YNNPKXBBRZVIRX-IHRRRGAJSA-N 0.000 description 3
- YKIRNDPUWONXQN-GUBZILKMSA-N Lys-Asn-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YKIRNDPUWONXQN-GUBZILKMSA-N 0.000 description 3
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 3
- RZHLIPMZXOEJTL-AVGNSLFASA-N Lys-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N RZHLIPMZXOEJTL-AVGNSLFASA-N 0.000 description 3
- WGLAORUKDGRINI-WDCWCFNPSA-N Lys-Glu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGLAORUKDGRINI-WDCWCFNPSA-N 0.000 description 3
- ZUGVARDEGWMMLK-SRVKXCTJSA-N Lys-Ser-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN ZUGVARDEGWMMLK-SRVKXCTJSA-N 0.000 description 3
- YCJCEMKOZOYBEF-OEAJRASXSA-N Lys-Thr-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O YCJCEMKOZOYBEF-OEAJRASXSA-N 0.000 description 3
- FBQMBZLJHOQAIH-GUBZILKMSA-N Met-Asp-Met Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O FBQMBZLJHOQAIH-GUBZILKMSA-N 0.000 description 3
- 101001033265 Mus musculus Interleukin-10 Proteins 0.000 description 3
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 3
- 108091005804 Peptidases Proteins 0.000 description 3
- BJEYSVHMGIJORT-NHCYSSNCSA-N Phe-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 BJEYSVHMGIJORT-NHCYSSNCSA-N 0.000 description 3
- PDUVELWDJZOUEI-IHRRRGAJSA-N Phe-Cys-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PDUVELWDJZOUEI-IHRRRGAJSA-N 0.000 description 3
- IILUKIJNFMUBNF-IHRRRGAJSA-N Phe-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O IILUKIJNFMUBNF-IHRRRGAJSA-N 0.000 description 3
- LRBSWBVUCLLRLU-BZSNNMDCSA-N Phe-Leu-Lys Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)Cc1ccccc1)C(=O)N[C@@H](CCCCN)C(O)=O LRBSWBVUCLLRLU-BZSNNMDCSA-N 0.000 description 3
- OSBADCBXAMSPQD-YESZJQIVSA-N Phe-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N OSBADCBXAMSPQD-YESZJQIVSA-N 0.000 description 3
- APMXLWHMIVWLLR-BZSNNMDCSA-N Phe-Tyr-Ser Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(O)=O)C1=CC=CC=C1 APMXLWHMIVWLLR-BZSNNMDCSA-N 0.000 description 3
- WVOXLKUUVCCCSU-ZPFDUUQYSA-N Pro-Glu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WVOXLKUUVCCCSU-ZPFDUUQYSA-N 0.000 description 3
- IIRBTQHFVNGPMQ-AVGNSLFASA-N Pro-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 IIRBTQHFVNGPMQ-AVGNSLFASA-N 0.000 description 3
- 239000004365 Protease Substances 0.000 description 3
- 102100036352 Protein disulfide-isomerase Human genes 0.000 description 3
- 239000006146 Roswell Park Memorial Institute medium Substances 0.000 description 3
- GXXTUIUYTWGPMV-FXQIFTODSA-N Ser-Arg-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O GXXTUIUYTWGPMV-FXQIFTODSA-N 0.000 description 3
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 3
- RFBKULCUBJAQFT-BIIVOSGPSA-N Ser-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CO)N)C(=O)O RFBKULCUBJAQFT-BIIVOSGPSA-N 0.000 description 3
- IOVBCLGAJJXOHK-SRVKXCTJSA-N Ser-His-His Chemical compound C([C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 IOVBCLGAJJXOHK-SRVKXCTJSA-N 0.000 description 3
- JLPMFVAIQHCBDC-CIUDSAMLSA-N Ser-Lys-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N JLPMFVAIQHCBDC-CIUDSAMLSA-N 0.000 description 3
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 3
- ANOQEBQWIAYIMV-AEJSXWLSSA-N Ser-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N ANOQEBQWIAYIMV-AEJSXWLSSA-N 0.000 description 3
- 108091008874 T cell receptors Proteins 0.000 description 3
- 230000005867 T cell response Effects 0.000 description 3
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 3
- 101150006914 TRP1 gene Proteins 0.000 description 3
- JMQUAZXYFAEOIH-XGEHTFHBSA-N Thr-Arg-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N)O JMQUAZXYFAEOIH-XGEHTFHBSA-N 0.000 description 3
- LHEZGZQRLDBSRR-WDCWCFNPSA-N Thr-Glu-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LHEZGZQRLDBSRR-WDCWCFNPSA-N 0.000 description 3
- UGFSAPWZBROURT-IXOXFDKPSA-N Thr-Phe-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)O)N)O UGFSAPWZBROURT-IXOXFDKPSA-N 0.000 description 3
- VBMOVTMNHWPZJR-SUSMZKCASA-N Thr-Thr-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VBMOVTMNHWPZJR-SUSMZKCASA-N 0.000 description 3
- FEZASNVQLJQBHW-CABZTGNLSA-N Trp-Gly-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O)=CNC2=C1 FEZASNVQLJQBHW-CABZTGNLSA-N 0.000 description 3
- UJRIVCPPPMYCNA-HOCLYGCPSA-N Trp-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N UJRIVCPPPMYCNA-HOCLYGCPSA-N 0.000 description 3
- ZHDQRPWESGUDST-JBACZVJFSA-N Trp-Phe-Gln Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O)C1=CC=CC=C1 ZHDQRPWESGUDST-JBACZVJFSA-N 0.000 description 3
- BARBHMSSVWPKPZ-IHRRRGAJSA-N Tyr-Asp-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O BARBHMSSVWPKPZ-IHRRRGAJSA-N 0.000 description 3
- CNLKDWSAORJEMW-KWQFWETISA-N Tyr-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O CNLKDWSAORJEMW-KWQFWETISA-N 0.000 description 3
- ILTXFANLDMJWPR-SIUGBPQLSA-N Tyr-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N ILTXFANLDMJWPR-SIUGBPQLSA-N 0.000 description 3
- KSCVLGXNQXKUAR-JYJNAYRXSA-N Tyr-Leu-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KSCVLGXNQXKUAR-JYJNAYRXSA-N 0.000 description 3
- NHOVZGFNTGMYMI-KKUMJFAQSA-N Tyr-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NHOVZGFNTGMYMI-KKUMJFAQSA-N 0.000 description 3
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 3
- OTJMMKPMLUNTQT-AVGNSLFASA-N Val-Leu-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N OTJMMKPMLUNTQT-AVGNSLFASA-N 0.000 description 3
- DLRZGNXCXUGIDG-KKHAAJSZSA-N Val-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O DLRZGNXCXUGIDG-KKHAAJSZSA-N 0.000 description 3
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 3
- 239000000654 additive Substances 0.000 description 3
- 230000002411 adverse Effects 0.000 description 3
- 230000006023 anti-tumor response Effects 0.000 description 3
- 230000030741 antigen processing and presentation Effects 0.000 description 3
- 239000002246 antineoplastic agent Substances 0.000 description 3
- 230000004071 biological effect Effects 0.000 description 3
- 230000037396 body weight Effects 0.000 description 3
- 230000002301 combined effect Effects 0.000 description 3
- 230000008878 coupling Effects 0.000 description 3
- 238000010168 coupling process Methods 0.000 description 3
- 238000005859 coupling reaction Methods 0.000 description 3
- 108010060199 cysteinylproline Proteins 0.000 description 3
- 229940127089 cytotoxic agent Drugs 0.000 description 3
- 230000002708 enhancing effect Effects 0.000 description 3
- 239000013604 expression vector Substances 0.000 description 3
- 229960002949 fluorouracil Drugs 0.000 description 3
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 3
- 238000001415 gene therapy Methods 0.000 description 3
- 108010084389 glycyltryptophan Proteins 0.000 description 3
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 3
- 102000045108 human EGFR Human genes 0.000 description 3
- 238000002513 implantation Methods 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- 238000002955 isolation Methods 0.000 description 3
- 108010078274 isoleucylvaline Proteins 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 3
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 3
- 210000000822 natural killer cell Anatomy 0.000 description 3
- 206010053219 non-alcoholic steatohepatitis Diseases 0.000 description 3
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 3
- 230000004983 pleiotropic effect Effects 0.000 description 3
- 230000002265 prevention Effects 0.000 description 3
- 108020003519 protein disulfide isomerase Proteins 0.000 description 3
- 102220059797 rs786203763 Human genes 0.000 description 3
- 230000002195 synergetic effect Effects 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 108010073969 valyllysine Proteins 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- 230000003612 virological effect Effects 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 2
- FFZJHQODAYHGPO-KZVJFYERSA-N Ala-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N FFZJHQODAYHGPO-KZVJFYERSA-N 0.000 description 2
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 2
- OTCJMMRQBVDQRK-DCAQKATOSA-N Arg-Asp-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OTCJMMRQBVDQRK-DCAQKATOSA-N 0.000 description 2
- UHFUZWSZQKMDSX-DCAQKATOSA-N Arg-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UHFUZWSZQKMDSX-DCAQKATOSA-N 0.000 description 2
- ACRYGQFHAQHDSF-ZLUOBGJFSA-N Asn-Asn-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ACRYGQFHAQHDSF-ZLUOBGJFSA-N 0.000 description 2
- KUYKVGODHGHFDI-ACZMJKKPSA-N Asn-Gln-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O KUYKVGODHGHFDI-ACZMJKKPSA-N 0.000 description 2
- HZZIFFOVHLWGCS-KKUMJFAQSA-N Asn-Phe-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O HZZIFFOVHLWGCS-KKUMJFAQSA-N 0.000 description 2
- GMUOCGCDOYYWPD-FXQIFTODSA-N Asn-Pro-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O GMUOCGCDOYYWPD-FXQIFTODSA-N 0.000 description 2
- ANRZCQXIXGDXLR-CWRNSKLLSA-N Asn-Trp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CC(=O)N)N)C(=O)O ANRZCQXIXGDXLR-CWRNSKLLSA-N 0.000 description 2
- HTSSXFASOUSJQG-IHPCNDPISA-N Asp-Tyr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HTSSXFASOUSJQG-IHPCNDPISA-N 0.000 description 2
- 241001598984 Bromius obscurus Species 0.000 description 2
- 108010029697 CD40 Ligand Proteins 0.000 description 2
- 102100032937 CD40 ligand Human genes 0.000 description 2
- 101100069857 Caenorhabditis elegans hil-4 gene Proteins 0.000 description 2
- 101100314454 Caenorhabditis elegans tra-1 gene Proteins 0.000 description 2
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 description 2
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 description 2
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 2
- 108010092160 Dactinomycin Proteins 0.000 description 2
- 102100031111 Disintegrin and metalloproteinase domain-containing protein 17 Human genes 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- 108010041356 Estrogen Receptor beta Proteins 0.000 description 2
- 102100029951 Estrogen receptor beta Human genes 0.000 description 2
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 2
- FALJZCPMTGJOHX-SRVKXCTJSA-N Gln-Met-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O FALJZCPMTGJOHX-SRVKXCTJSA-N 0.000 description 2
- SXFPZRRVWSUYII-KBIXCLLPSA-N Gln-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N SXFPZRRVWSUYII-KBIXCLLPSA-N 0.000 description 2
- MKRDNSWGJWTBKZ-GVXVVHGQSA-N Gln-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MKRDNSWGJWTBKZ-GVXVVHGQSA-N 0.000 description 2
- KKCUFHUTMKQQCF-SRVKXCTJSA-N Glu-Arg-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O KKCUFHUTMKQQCF-SRVKXCTJSA-N 0.000 description 2
- ZCOJVESMNGBGLF-GRLWGSQLSA-N Glu-Ile-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZCOJVESMNGBGLF-GRLWGSQLSA-N 0.000 description 2
- IVGJYOOGJLFKQE-AVGNSLFASA-N Glu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N IVGJYOOGJLFKQE-AVGNSLFASA-N 0.000 description 2
- PMSMKNYRZCKVMC-DRZSPHRISA-N Glu-Phe-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CCC(=O)O)N PMSMKNYRZCKVMC-DRZSPHRISA-N 0.000 description 2
- FMNHBTKMRFVGRO-FOHZUACHSA-N Gly-Asn-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CN FMNHBTKMRFVGRO-FOHZUACHSA-N 0.000 description 2
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 2
- DHDOADIPGZTAHT-YUMQZZPRSA-N Gly-Glu-Arg Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DHDOADIPGZTAHT-YUMQZZPRSA-N 0.000 description 2
- FXGRXIATVXUAHO-WEDXCCLWSA-N Gly-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN FXGRXIATVXUAHO-WEDXCCLWSA-N 0.000 description 2
- FKESCSGWBPUTPN-FOHZUACHSA-N Gly-Thr-Asn Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O FKESCSGWBPUTPN-FOHZUACHSA-N 0.000 description 2
- 229940121710 HMGCoA reductase inhibitor Drugs 0.000 description 2
- 108010093488 His-His-His-His-His-His Proteins 0.000 description 2
- ULRFSEJGSHYLQI-YESZJQIVSA-N His-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CN=CN3)N)C(=O)O ULRFSEJGSHYLQI-YESZJQIVSA-N 0.000 description 2
- CWSZWFILCNSNEX-CIUDSAMLSA-N His-Ser-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CWSZWFILCNSNEX-CIUDSAMLSA-N 0.000 description 2
- FOCSWPCHUDVNLP-PMVMPFDFSA-N His-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC4=CN=CN4)N FOCSWPCHUDVNLP-PMVMPFDFSA-N 0.000 description 2
- 101001002657 Homo sapiens Interleukin-2 Proteins 0.000 description 2
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 2
- 241000701024 Human betaherpesvirus 5 Species 0.000 description 2
- DFFTXLCCDFYRKD-MBLNEYKQSA-N Ile-Gly-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N DFFTXLCCDFYRKD-MBLNEYKQSA-N 0.000 description 2
- PARSHQDZROHERM-NHCYSSNCSA-N Ile-Lys-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)O)N PARSHQDZROHERM-NHCYSSNCSA-N 0.000 description 2
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 2
- HQLSBZFLOUHQJK-STECZYCISA-N Ile-Tyr-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HQLSBZFLOUHQJK-STECZYCISA-N 0.000 description 2
- UYODHPPSCXBNCS-XUXIUFHCSA-N Ile-Val-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C UYODHPPSCXBNCS-XUXIUFHCSA-N 0.000 description 2
- 102000003996 Interferon-beta Human genes 0.000 description 2
- 108090000467 Interferon-beta Proteins 0.000 description 2
- 102100026018 Interleukin-1 receptor antagonist protein Human genes 0.000 description 2
- 101710144554 Interleukin-1 receptor antagonist protein Proteins 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 2
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 2
- NTRAGDHVSGKUSF-AVGNSLFASA-N Leu-Arg-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NTRAGDHVSGKUSF-AVGNSLFASA-N 0.000 description 2
- UCOCBWDBHCUPQP-DCAQKATOSA-N Leu-Arg-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O UCOCBWDBHCUPQP-DCAQKATOSA-N 0.000 description 2
- GZAUZBUKDXYPEH-CIUDSAMLSA-N Leu-Cys-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)O)N GZAUZBUKDXYPEH-CIUDSAMLSA-N 0.000 description 2
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 2
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 2
- PDQDCFBVYXEFSD-SRVKXCTJSA-N Leu-Leu-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PDQDCFBVYXEFSD-SRVKXCTJSA-N 0.000 description 2
- UBZGNBKMIJHOHL-BZSNNMDCSA-N Leu-Leu-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 UBZGNBKMIJHOHL-BZSNNMDCSA-N 0.000 description 2
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 2
- HGLKOTPFWOMPOB-MEYUZBJRSA-N Leu-Thr-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HGLKOTPFWOMPOB-MEYUZBJRSA-N 0.000 description 2
- HIIZIQUUHIXUJY-GUBZILKMSA-N Lys-Asp-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HIIZIQUUHIXUJY-GUBZILKMSA-N 0.000 description 2
- IWWMPCPLFXFBAF-SRVKXCTJSA-N Lys-Asp-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O IWWMPCPLFXFBAF-SRVKXCTJSA-N 0.000 description 2
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- QWTGQXGNNMIUCW-BPUTZDHNSA-N Met-Asn-Trp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O QWTGQXGNNMIUCW-BPUTZDHNSA-N 0.000 description 2
- MHQXIBRPDKXDGZ-ZFWWWQNUSA-N Met-Gly-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)CNC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 MHQXIBRPDKXDGZ-ZFWWWQNUSA-N 0.000 description 2
- PZUUMQPMHBJJKE-AVGNSLFASA-N Met-Leu-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCNC(N)=N PZUUMQPMHBJJKE-AVGNSLFASA-N 0.000 description 2
- 102100031545 Microsomal triglyceride transfer protein large subunit Human genes 0.000 description 2
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 2
- 108010066427 N-valyltryptophan Proteins 0.000 description 2
- 108091034117 Oligonucleotide Proteins 0.000 description 2
- 108010035766 P-Selectin Proteins 0.000 description 2
- 102100023472 P-selectin Human genes 0.000 description 2
- NKLDZIPTGKBDBB-HTUGSXCWSA-N Phe-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N)O NKLDZIPTGKBDBB-HTUGSXCWSA-N 0.000 description 2
- 102100033237 Pro-epidermal growth factor Human genes 0.000 description 2
- 108010076504 Protein Sorting Signals Proteins 0.000 description 2
- 101000864964 Rattus norvegicus Septin-9 Proteins 0.000 description 2
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 description 2
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 2
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 2
- OBXVZEAMXFSGPU-FXQIFTODSA-N Ser-Asn-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)CN=C(N)N OBXVZEAMXFSGPU-FXQIFTODSA-N 0.000 description 2
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 2
- BRGQQXQKPUCUJQ-KBIXCLLPSA-N Ser-Glu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRGQQXQKPUCUJQ-KBIXCLLPSA-N 0.000 description 2
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 2
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 2
- HEUVHBXOVZONPU-BJDJZHNGSA-N Ser-Leu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HEUVHBXOVZONPU-BJDJZHNGSA-N 0.000 description 2
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 2
- IXZHZUGGKLRHJD-DCAQKATOSA-N Ser-Leu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IXZHZUGGKLRHJD-DCAQKATOSA-N 0.000 description 2
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 2
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 2
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 2
- CBPNZQVSJQDFBE-FUXHJELOSA-N Temsirolimus Chemical compound C1C[C@@H](OC(=O)C(C)(CO)CO)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 CBPNZQVSJQDFBE-FUXHJELOSA-N 0.000 description 2
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 description 2
- DDPVJPIGACCMEH-XQXXSGGOSA-N Thr-Ala-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DDPVJPIGACCMEH-XQXXSGGOSA-N 0.000 description 2
- GKWNLDNXMMLRMC-GLLZPBPUSA-N Thr-Glu-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O GKWNLDNXMMLRMC-GLLZPBPUSA-N 0.000 description 2
- IMDMLDSVUSMAEJ-HJGDQZAQSA-N Thr-Leu-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IMDMLDSVUSMAEJ-HJGDQZAQSA-N 0.000 description 2
- HOVLHEKTGVIKAP-WDCWCFNPSA-N Thr-Leu-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HOVLHEKTGVIKAP-WDCWCFNPSA-N 0.000 description 2
- VTVVYQOXJCZVEB-WDCWCFNPSA-N Thr-Leu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O VTVVYQOXJCZVEB-WDCWCFNPSA-N 0.000 description 2
- QJIODPFLAASXJC-JHYOHUSXSA-N Thr-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O QJIODPFLAASXJC-JHYOHUSXSA-N 0.000 description 2
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 2
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 2
- IMMPMHKLUUZKAZ-WMZOPIPTSA-N Trp-Phe Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=CC=C1 IMMPMHKLUUZKAZ-WMZOPIPTSA-N 0.000 description 2
- IKUMWSDCGQVGHC-UMPQAUOISA-N Trp-Pro-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC2=CNC3=CC=CC=C32)N)O IKUMWSDCGQVGHC-UMPQAUOISA-N 0.000 description 2
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 2
- XMNDQSYABVWZRK-BZSNNMDCSA-N Tyr-Asn-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XMNDQSYABVWZRK-BZSNNMDCSA-N 0.000 description 2
- TZXFLDNBYYGLKA-BZSNNMDCSA-N Tyr-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 TZXFLDNBYYGLKA-BZSNNMDCSA-N 0.000 description 2
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 2
- QOIKZODVIPOPDD-AVGNSLFASA-N Tyr-Cys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOIKZODVIPOPDD-AVGNSLFASA-N 0.000 description 2
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 2
- LDKDSFQSEUOCOO-RPTUDFQQSA-N Tyr-Thr-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LDKDSFQSEUOCOO-RPTUDFQQSA-N 0.000 description 2
- NWEGIYMHTZXVBP-JSGCOSHPSA-N Tyr-Val-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O NWEGIYMHTZXVBP-JSGCOSHPSA-N 0.000 description 2
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 2
- JIODCDXKCJRMEH-NHCYSSNCSA-N Val-Arg-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N JIODCDXKCJRMEH-NHCYSSNCSA-N 0.000 description 2
- HQYVQDRYODWONX-DCAQKATOSA-N Val-His-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CO)C(=O)O)N HQYVQDRYODWONX-DCAQKATOSA-N 0.000 description 2
- IJGPOONOTBNTFS-GVXVVHGQSA-N Val-Lys-Glu Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O IJGPOONOTBNTFS-GVXVVHGQSA-N 0.000 description 2
- QPPZEDOTPZOSEC-RCWTZXSCSA-N Val-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N)O QPPZEDOTPZOSEC-RCWTZXSCSA-N 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 230000000996 additive effect Effects 0.000 description 2
- 229940121363 anti-inflammatory agent Drugs 0.000 description 2
- 239000002260 anti-inflammatory agent Substances 0.000 description 2
- 230000005975 antitumor immune response Effects 0.000 description 2
- 108010072041 arginyl-glycyl-aspartic acid Proteins 0.000 description 2
- 230000001042 autoregulative effect Effects 0.000 description 2
- 210000003719 b-lymphocyte Anatomy 0.000 description 2
- 229920000080 bile acid sequestrant Polymers 0.000 description 2
- 230000008827 biological function Effects 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 229960000590 celecoxib Drugs 0.000 description 2
- RZEKVGVHFLEQIL-UHFFFAOYSA-N celecoxib Chemical compound C1=CC(C)=CC=C1C1=CC(C(F)(F)F)=NN1C1=CC=C(S(N)(=O)=O)C=C1 RZEKVGVHFLEQIL-UHFFFAOYSA-N 0.000 description 2
- 239000006143 cell culture medium Substances 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 230000036755 cellular response Effects 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- 238000011284 combination treatment Methods 0.000 description 2
- 150000001875 compounds Chemical class 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 239000003246 corticosteroid Substances 0.000 description 2
- 229960001334 corticosteroids Drugs 0.000 description 2
- 239000003255 cyclooxygenase 2 inhibitor Substances 0.000 description 2
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- 235000019152 folic acid Nutrition 0.000 description 2
- 239000011724 folic acid Substances 0.000 description 2
- CHPZKNULDCNCBW-UHFFFAOYSA-N gallium nitrate Chemical compound [Ga+3].[O-][N+]([O-])=O.[O-][N+]([O-])=O.[O-][N+]([O-])=O CHPZKNULDCNCBW-UHFFFAOYSA-N 0.000 description 2
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 2
- 210000001035 gastrointestinal tract Anatomy 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 239000003102 growth factor Substances 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 210000003630 histaminocyte Anatomy 0.000 description 2
- 108010025306 histidylleucine Proteins 0.000 description 2
- 239000000710 homodimer Substances 0.000 description 2
- 229960001101 ifosfamide Drugs 0.000 description 2
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- 230000001976 improved effect Effects 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 229910052738 indium Inorganic materials 0.000 description 2
- CGIGDMFJXJATDK-UHFFFAOYSA-N indomethacin Chemical compound CC1=C(CC(O)=O)C2=CC(OC)=CC=C2N1C(=O)C1=CC=C(Cl)C=C1 CGIGDMFJXJATDK-UHFFFAOYSA-N 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 229960001388 interferon-beta Drugs 0.000 description 2
- 229940028885 interleukin-4 Drugs 0.000 description 2
- 238000011813 knockout mouse model Methods 0.000 description 2
- 229960000681 leflunomide Drugs 0.000 description 2
- VHOGYURTWQBHIL-UHFFFAOYSA-N leflunomide Chemical compound O1N=CC(C(=O)NC=2C=CC(=CC=2)C(F)(F)F)=C1C VHOGYURTWQBHIL-UHFFFAOYSA-N 0.000 description 2
- 239000002502 liposome Substances 0.000 description 2
- 230000003211 malignant effect Effects 0.000 description 2
- 108010082117 matrigel Proteins 0.000 description 2
- 229960001428 mercaptopurine Drugs 0.000 description 2
- 229960004857 mitomycin Drugs 0.000 description 2
- 229960001156 mitoxantrone Drugs 0.000 description 2
- 230000031990 negative regulation of inflammatory response Effects 0.000 description 2
- 239000013612 plasmid Substances 0.000 description 2
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 2
- 108091033319 polynucleotide Proteins 0.000 description 2
- 102000040430 polynucleotide Human genes 0.000 description 2
- 239000002157 polynucleotide Substances 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 239000003755 preservative agent Substances 0.000 description 2
- 230000037452 priming Effects 0.000 description 2
- 230000035755 proliferation Effects 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 229950010131 puromycin Drugs 0.000 description 2
- 229960004622 raloxifene Drugs 0.000 description 2
- GZUITABIAKMVPG-UHFFFAOYSA-N raloxifene Chemical compound C1=CC(O)=CC=C1C1=C(C(=O)C=2C=CC(OCCN3CCCCC3)=CC=2)C2=CC=C(O)C=C2S1 GZUITABIAKMVPG-UHFFFAOYSA-N 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 150000003839 salts Chemical class 0.000 description 2
- 230000002000 scavenging effect Effects 0.000 description 2
- 238000012216 screening Methods 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 150000003384 small molecules Chemical class 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 239000003381 stabilizer Substances 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 230000001629 suppression Effects 0.000 description 2
- 230000001839 systemic circulation Effects 0.000 description 2
- 229960000235 temsirolimus Drugs 0.000 description 2
- 229960001196 thiotepa Drugs 0.000 description 2
- 108010061238 threonyl-glycine Proteins 0.000 description 2
- 229960003087 tioguanine Drugs 0.000 description 2
- 108010044292 tryptophyltyrosine Proteins 0.000 description 2
- 229940046728 tumor necrosis factor alpha inhibitor Drugs 0.000 description 2
- 239000002451 tumor necrosis factor inhibitor Substances 0.000 description 2
- 102000003298 tumor necrosis factor receptor Human genes 0.000 description 2
- JBFQOLHAGBKPTP-NZATWWQASA-N (2s)-2-[[(2s)-4-carboxy-2-[[3-carboxy-2-[[(2s)-2,6-diaminohexanoyl]amino]propanoyl]amino]butanoyl]amino]-4-methylpentanoic acid Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)C(CC(O)=O)NC(=O)[C@@H](N)CCCCN JBFQOLHAGBKPTP-NZATWWQASA-N 0.000 description 1
- FLWWDYNPWOSLEO-HQVZTVAUSA-N (2s)-2-[[4-[1-(2-amino-4-oxo-1h-pteridin-6-yl)ethyl-methylamino]benzoyl]amino]pentanedioic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1C(C)N(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FLWWDYNPWOSLEO-HQVZTVAUSA-N 0.000 description 1
- WZUMSFQGYWBRNX-AVGNSLFASA-N (2s)-6-amino-2-[[(2s)-2-[[(2s)-2-[(2-aminoacetyl)amino]-3-hydroxypropanoyl]amino]-3-(1h-imidazol-5-yl)propanoyl]amino]hexanoic acid Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)CN)CC1=CN=CN1 WZUMSFQGYWBRNX-AVGNSLFASA-N 0.000 description 1
- CGMTUJFWROPELF-YPAAEMCBSA-N (3E,5S)-5-[(2S)-butan-2-yl]-3-(1-hydroxyethylidene)pyrrolidine-2,4-dione Chemical compound CC[C@H](C)[C@@H]1NC(=O)\C(=C(/C)O)C1=O CGMTUJFWROPELF-YPAAEMCBSA-N 0.000 description 1
- ZGGHKIMDNBDHJB-NRFPMOEYSA-M (3R,5S)-fluvastatin sodium Chemical compound [Na+].C12=CC=CC=C2N(C(C)C)C(\C=C\[C@@H](O)C[C@@H](O)CC([O-])=O)=C1C1=CC=C(F)C=C1 ZGGHKIMDNBDHJB-NRFPMOEYSA-M 0.000 description 1
- AESVUZLWRXEGEX-DKCAWCKPSA-N (7S,9R)-7-[(2S,4R,5R,6R)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7H-tetracene-5,12-dione iron(3+) Chemical compound [Fe+3].COc1cccc2C(=O)c3c(O)c4C[C@@](O)(C[C@H](O[C@@H]5C[C@@H](N)[C@@H](O)[C@@H](C)O5)c4c(O)c3C(=O)c12)C(=O)CO AESVUZLWRXEGEX-DKCAWCKPSA-N 0.000 description 1
- JXVAMODRWBNUSF-KZQKBALLSA-N (7s,9r,10r)-7-[(2r,4s,5s,6s)-5-[[(2s,4as,5as,7s,9s,9ar,10ar)-2,9-dimethyl-3-oxo-4,4a,5a,6,7,9,9a,10a-octahydrodipyrano[4,2-a:4',3'-e][1,4]dioxin-7-yl]oxy]-4-(dimethylamino)-6-methyloxan-2-yl]oxy-10-[(2s,4s,5s,6s)-4-(dimethylamino)-5-hydroxy-6-methyloxan-2 Chemical compound O([C@@H]1C2=C(O)C=3C(=O)C4=CC=CC(O)=C4C(=O)C=3C(O)=C2[C@@H](O[C@@H]2O[C@@H](C)[C@@H](O[C@@H]3O[C@@H](C)[C@H]4O[C@@H]5O[C@@H](C)C(=O)C[C@@H]5O[C@H]4C3)[C@H](C2)N(C)C)C[C@]1(O)CC)[C@H]1C[C@H](N(C)C)[C@H](O)[C@H](C)O1 JXVAMODRWBNUSF-KZQKBALLSA-N 0.000 description 1
- FPVKHBSQESCIEP-UHFFFAOYSA-N (8S)-3-(2-deoxy-beta-D-erythro-pentofuranosyl)-3,6,7,8-tetrahydroimidazo[4,5-d][1,3]diazepin-8-ol Natural products C1C(O)C(CO)OC1N1C(NC=NCC2O)=C2N=C1 FPVKHBSQESCIEP-UHFFFAOYSA-N 0.000 description 1
- IEXUMDBQLIVNHZ-YOUGDJEHSA-N (8s,11r,13r,14s,17s)-11-[4-(dimethylamino)phenyl]-17-hydroxy-17-(3-hydroxypropyl)-13-methyl-1,2,6,7,8,11,12,14,15,16-decahydrocyclopenta[a]phenanthren-3-one Chemical compound C1=CC(N(C)C)=CC=C1[C@@H]1C2=C3CCC(=O)C=C3CC[C@H]2[C@H](CC[C@]2(O)CCCO)[C@@]2(C)C1 IEXUMDBQLIVNHZ-YOUGDJEHSA-N 0.000 description 1
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 1
- AGNGYMCLFWQVGX-AGFFZDDWSA-N (e)-1-[(2s)-2-amino-2-carboxyethoxy]-2-diazonioethenolate Chemical compound OC(=O)[C@@H](N)CO\C([O-])=C\[N+]#N AGNGYMCLFWQVGX-AGFFZDDWSA-N 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- BTOTXLJHDSNXMW-POYBYMJQSA-N 2,3-dideoxyuridine Chemical compound O1[C@H](CO)CC[C@@H]1N1C(=O)NC(=O)C=C1 BTOTXLJHDSNXMW-POYBYMJQSA-N 0.000 description 1
- KISWVXRQTGLFGD-UHFFFAOYSA-N 2-[[2-[[6-amino-2-[[2-[[2-[[5-amino-2-[[2-[[1-[2-[[6-amino-2-[(2,5-diamino-5-oxopentanoyl)amino]hexanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]pyrrolidine-2-carbonyl]amino]-3-hydroxypropanoyl]amino]-5-oxopentanoyl]amino]-5-(diaminomethylideneamino)p Chemical compound C1CCN(C(=O)C(CCCN=C(N)N)NC(=O)C(CCCCN)NC(=O)C(N)CCC(N)=O)C1C(=O)NC(CO)C(=O)NC(CCC(N)=O)C(=O)NC(CCCN=C(N)N)C(=O)NC(CO)C(=O)NC(CCCCN)C(=O)NC(C(=O)NC(CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 KISWVXRQTGLFGD-UHFFFAOYSA-N 0.000 description 1
- QCXJFISCRQIYID-IAEPZHFASA-N 2-amino-1-n-[(3s,6s,7r,10s,16s)-3-[(2s)-butan-2-yl]-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-10-propan-2-yl-8-oxa-1,4,11,14-tetrazabicyclo[14.3.0]nonadecan-6-yl]-4,6-dimethyl-3-oxo-9-n-[(3s,6s,7r,10s,16s)-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-3,10-di(propa Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N=C2C(C(=O)N[C@@H]3C(=O)N[C@H](C(N4CCC[C@H]4C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]3C)=O)[C@@H](C)CC)=C(N)C(=O)C(C)=C2O2)C2=C(C)C=C1 QCXJFISCRQIYID-IAEPZHFASA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 description 1
- PWMYMKOUNYTVQN-UHFFFAOYSA-N 3-(8,8-diethyl-2-aza-8-germaspiro[4.5]decan-2-yl)-n,n-dimethylpropan-1-amine Chemical compound C1C[Ge](CC)(CC)CCC11CN(CCCN(C)C)CC1 PWMYMKOUNYTVQN-UHFFFAOYSA-N 0.000 description 1
- 108010091324 3C proteases Proteins 0.000 description 1
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 1
- DODQJNMQWMSYGS-QPLCGJKRSA-N 4-[(z)-1-[4-[2-(dimethylamino)ethoxy]phenyl]-1-phenylbut-1-en-2-yl]phenol Chemical compound C=1C=C(O)C=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 DODQJNMQWMSYGS-QPLCGJKRSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- TVZGACDUOSZQKY-LBPRGKRZSA-N 4-aminofolic acid Chemical compound C1=NC2=NC(N)=NC(N)=C2N=C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 TVZGACDUOSZQKY-LBPRGKRZSA-N 0.000 description 1
- IDPUKCWIGUEADI-UHFFFAOYSA-N 5-[bis(2-chloroethyl)amino]uracil Chemical compound ClCCN(CCCl)C1=CNC(=O)NC1=O IDPUKCWIGUEADI-UHFFFAOYSA-N 0.000 description 1
- NMUSYJAQQFHJEW-KVTDHHQDSA-N 5-azacytidine Chemical compound O=C1N=C(N)N=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 NMUSYJAQQFHJEW-KVTDHHQDSA-N 0.000 description 1
- WYXSYVWAUAUWLD-SHUUEZRQSA-N 6-azauridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=N1 WYXSYVWAUAUWLD-SHUUEZRQSA-N 0.000 description 1
- 229960005538 6-diazo-5-oxo-L-norleucine Drugs 0.000 description 1
- YCWQAMGASJSUIP-YFKPBYRVSA-N 6-diazo-5-oxo-L-norleucine Chemical compound OC(=O)[C@@H](N)CCC(=O)C=[N+]=[N-] YCWQAMGASJSUIP-YFKPBYRVSA-N 0.000 description 1
- ZGXJTSGNIOSYLO-UHFFFAOYSA-N 88755TAZ87 Chemical compound NCC(=O)CCC(O)=O ZGXJTSGNIOSYLO-UHFFFAOYSA-N 0.000 description 1
- HDZZVAMISRMYHH-UHFFFAOYSA-N 9beta-Ribofuranosyl-7-deazaadenin Natural products C1=CC=2C(N)=NC=NC=2N1C1OC(CO)C(O)C1O HDZZVAMISRMYHH-UHFFFAOYSA-N 0.000 description 1
- 108091007505 ADAM17 Proteins 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- WDIYWDJLXOCGRW-ACZMJKKPSA-N Ala-Asp-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WDIYWDJLXOCGRW-ACZMJKKPSA-N 0.000 description 1
- RXTBLQVXNIECFP-FXQIFTODSA-N Ala-Gln-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RXTBLQVXNIECFP-FXQIFTODSA-N 0.000 description 1
- MVBWLRJESQOQTM-ACZMJKKPSA-N Ala-Gln-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O MVBWLRJESQOQTM-ACZMJKKPSA-N 0.000 description 1
- MPLOSMWGDNJSEV-WHFBIAKZSA-N Ala-Gly-Asp Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MPLOSMWGDNJSEV-WHFBIAKZSA-N 0.000 description 1
- CHFFHQUVXHEGBY-GARJFASQSA-N Ala-Lys-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N CHFFHQUVXHEGBY-GARJFASQSA-N 0.000 description 1
- RAAWHFXHAACDFT-FXQIFTODSA-N Ala-Met-Asn Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CC(N)=O)C(O)=O RAAWHFXHAACDFT-FXQIFTODSA-N 0.000 description 1
- VJVQKGYHIZPSNS-FXQIFTODSA-N Ala-Ser-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N VJVQKGYHIZPSNS-FXQIFTODSA-N 0.000 description 1
- MSWSRLGNLKHDEI-ACZMJKKPSA-N Ala-Ser-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O MSWSRLGNLKHDEI-ACZMJKKPSA-N 0.000 description 1
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 1
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 1
- LSMDIAAALJJLRO-XQXXSGGOSA-N Ala-Thr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LSMDIAAALJJLRO-XQXXSGGOSA-N 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- CEIZFXOZIQNICU-UHFFFAOYSA-N Alternaria alternata Crofton-weed toxin Natural products CCC(C)C1NC(=O)C(C(C)=O)=C1O CEIZFXOZIQNICU-UHFFFAOYSA-N 0.000 description 1
- 108091023037 Aptamer Proteins 0.000 description 1
- JSLGXODUIAFWCF-WDSKDSINSA-N Arg-Asn Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(O)=O JSLGXODUIAFWCF-WDSKDSINSA-N 0.000 description 1
- PBSOQGZLPFVXPU-YUMQZZPRSA-N Arg-Glu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PBSOQGZLPFVXPU-YUMQZZPRSA-N 0.000 description 1
- YNSGXDWWPCGGQS-YUMQZZPRSA-N Arg-Gly-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O YNSGXDWWPCGGQS-YUMQZZPRSA-N 0.000 description 1
- GXXWTNKNFFKTJB-NAKRPEOUSA-N Arg-Ile-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O GXXWTNKNFFKTJB-NAKRPEOUSA-N 0.000 description 1
- UZGFHWIJWPUPOH-IHRRRGAJSA-N Arg-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UZGFHWIJWPUPOH-IHRRRGAJSA-N 0.000 description 1
- NMRHDSAOIURTNT-RWMBFGLXSA-N Arg-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N NMRHDSAOIURTNT-RWMBFGLXSA-N 0.000 description 1
- OMKZPCPZEFMBIT-SRVKXCTJSA-N Arg-Met-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OMKZPCPZEFMBIT-SRVKXCTJSA-N 0.000 description 1
- WKPXXXUSUHAXDE-SRVKXCTJSA-N Arg-Pro-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O WKPXXXUSUHAXDE-SRVKXCTJSA-N 0.000 description 1
- DNLQVHBBMPZUGJ-BQBZGAKWSA-N Arg-Ser-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O DNLQVHBBMPZUGJ-BQBZGAKWSA-N 0.000 description 1
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 1
- ASQKVGRCKOFKIU-KZVJFYERSA-N Arg-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ASQKVGRCKOFKIU-KZVJFYERSA-N 0.000 description 1
- MOGMYRUNTKYZFB-UNQGMJICSA-N Arg-Thr-Phe Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MOGMYRUNTKYZFB-UNQGMJICSA-N 0.000 description 1
- UVTGNSWSRSCPLP-UHFFFAOYSA-N Arg-Tyr Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O UVTGNSWSRSCPLP-UHFFFAOYSA-N 0.000 description 1
- 229940122815 Aromatase inhibitor Drugs 0.000 description 1
- HUZGPXBILPMCHM-IHRRRGAJSA-N Asn-Arg-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HUZGPXBILPMCHM-IHRRRGAJSA-N 0.000 description 1
- CQMQJWRCRQSBAF-BPUTZDHNSA-N Asn-Arg-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N CQMQJWRCRQSBAF-BPUTZDHNSA-N 0.000 description 1
- QRHYAUYXBVVDSB-LKXGYXEUSA-N Asn-Cys-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QRHYAUYXBVVDSB-LKXGYXEUSA-N 0.000 description 1
- PHJPKNUWWHRAOC-PEFMBERDSA-N Asn-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PHJPKNUWWHRAOC-PEFMBERDSA-N 0.000 description 1
- KMCRKVOLRCOMBG-DJFWLOJKSA-N Asn-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KMCRKVOLRCOMBG-DJFWLOJKSA-N 0.000 description 1
- PNHQRQTVBRDIEF-CIUDSAMLSA-N Asn-Leu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(=O)N)N PNHQRQTVBRDIEF-CIUDSAMLSA-N 0.000 description 1
- JLNFZLNDHONLND-GARJFASQSA-N Asn-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N JLNFZLNDHONLND-GARJFASQSA-N 0.000 description 1
- AEZCCDMZZJOGII-DCAQKATOSA-N Asn-Met-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O AEZCCDMZZJOGII-DCAQKATOSA-N 0.000 description 1
- BKZFBJYIVSBXCO-KKUMJFAQSA-N Asn-Phe-His Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC=N1)C(O)=O BKZFBJYIVSBXCO-KKUMJFAQSA-N 0.000 description 1
- AWXDRZJQCVHCIT-DCAQKATOSA-N Asn-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(N)=O AWXDRZJQCVHCIT-DCAQKATOSA-N 0.000 description 1
- UXHYOWXTJLBEPG-GSSVUCPTSA-N Asn-Thr-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UXHYOWXTJLBEPG-GSSVUCPTSA-N 0.000 description 1
- JPPLRQVZMZFOSX-UWJYBYFXSA-N Asn-Tyr-Ala Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 JPPLRQVZMZFOSX-UWJYBYFXSA-N 0.000 description 1
- QNNBHTFDFFFHGC-KKUMJFAQSA-N Asn-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QNNBHTFDFFFHGC-KKUMJFAQSA-N 0.000 description 1
- JNCRAQVYJZGIOW-QSFUFRPTSA-N Asn-Val-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JNCRAQVYJZGIOW-QSFUFRPTSA-N 0.000 description 1
- BFOYULZBKYOKAN-OLHMAJIHSA-N Asp-Asp-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BFOYULZBKYOKAN-OLHMAJIHSA-N 0.000 description 1
- VHQOCWWKXIOAQI-WDSKDSINSA-N Asp-Gln-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VHQOCWWKXIOAQI-WDSKDSINSA-N 0.000 description 1
- PDECQIHABNQRHN-GUBZILKMSA-N Asp-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O PDECQIHABNQRHN-GUBZILKMSA-N 0.000 description 1
- XDGBFDYXZCMYEX-NUMRIWBASA-N Asp-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N)O XDGBFDYXZCMYEX-NUMRIWBASA-N 0.000 description 1
- KYQNAIMCTRZLNP-QSFUFRPTSA-N Asp-Ile-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O KYQNAIMCTRZLNP-QSFUFRPTSA-N 0.000 description 1
- CLUMZOKVGUWUFD-CIUDSAMLSA-N Asp-Leu-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O CLUMZOKVGUWUFD-CIUDSAMLSA-N 0.000 description 1
- RQHLMGCXCZUOGT-ZPFDUUQYSA-N Asp-Leu-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RQHLMGCXCZUOGT-ZPFDUUQYSA-N 0.000 description 1
- YTXCCDCOHIYQFC-GUBZILKMSA-N Asp-Met-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O YTXCCDCOHIYQFC-GUBZILKMSA-N 0.000 description 1
- IDDMGSKZQDEDGA-SRVKXCTJSA-N Asp-Phe-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(N)=O)C(O)=O)CC1=CC=CC=C1 IDDMGSKZQDEDGA-SRVKXCTJSA-N 0.000 description 1
- QSFHZPQUAAQHAQ-CIUDSAMLSA-N Asp-Ser-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O QSFHZPQUAAQHAQ-CIUDSAMLSA-N 0.000 description 1
- YUELDQUPTAYEGM-XIRDDKMYSA-N Asp-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N YUELDQUPTAYEGM-XIRDDKMYSA-N 0.000 description 1
- NJLLRXWFPQQPHV-SRVKXCTJSA-N Asp-Tyr-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O NJLLRXWFPQQPHV-SRVKXCTJSA-N 0.000 description 1
- ALMIMUZAWTUNIO-BZSNNMDCSA-N Asp-Tyr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ALMIMUZAWTUNIO-BZSNNMDCSA-N 0.000 description 1
- XWKPSMRPIKKDDU-RCOVLWMOSA-N Asp-Val-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O XWKPSMRPIKKDDU-RCOVLWMOSA-N 0.000 description 1
- GYNUXDMCDILYIQ-QRTARXTBSA-N Asp-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N GYNUXDMCDILYIQ-QRTARXTBSA-N 0.000 description 1
- 244000186140 Asperula odorata Species 0.000 description 1
- BSYNRYMUTXBXSQ-UHFFFAOYSA-N Aspirin Chemical compound CC(=O)OC1=CC=CC=C1C(O)=O BSYNRYMUTXBXSQ-UHFFFAOYSA-N 0.000 description 1
- XUKUURHRXDUEBC-KAYWLYCHSA-N Atorvastatin Chemical compound C=1C=CC=CC=1C1=C(C=2C=CC(F)=CC=2)N(CC[C@@H](O)C[C@@H](O)CC(O)=O)C(C(C)C)=C1C(=O)NC1=CC=CC=C1 XUKUURHRXDUEBC-KAYWLYCHSA-N 0.000 description 1
- XUKUURHRXDUEBC-UHFFFAOYSA-N Atorvastatin Natural products C=1C=CC=CC=1C1=C(C=2C=CC(F)=CC=2)N(CCC(O)CC(O)CC(O)=O)C(C(C)C)=C1C(=O)NC1=CC=CC=C1 XUKUURHRXDUEBC-UHFFFAOYSA-N 0.000 description 1
- 238000012935 Averaging Methods 0.000 description 1
- NOWKCMXCCJGMRR-UHFFFAOYSA-N Aziridine Chemical class C1CN1 NOWKCMXCCJGMRR-UHFFFAOYSA-N 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- VGGGPCQERPFHOB-MCIONIFRSA-N Bestatin Chemical compound CC(C)C[C@H](C(O)=O)NC(=O)[C@@H](O)[C@H](N)CC1=CC=CC=C1 VGGGPCQERPFHOB-MCIONIFRSA-N 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 1
- 101150071146 COX2 gene Proteins 0.000 description 1
- 101100114534 Caenorhabditis elegans ctc-2 gene Proteins 0.000 description 1
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 1
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 description 1
- SHHKQEUPHAENFK-UHFFFAOYSA-N Carboquone Chemical compound O=C1C(C)=C(N2CC2)C(=O)C(C(COC(N)=O)OC)=C1N1CC1 SHHKQEUPHAENFK-UHFFFAOYSA-N 0.000 description 1
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 108010051109 Cell-Penetrating Peptides Proteins 0.000 description 1
- 102000020313 Cell-Penetrating Peptides Human genes 0.000 description 1
- JWBOIMRXGHLCPP-UHFFFAOYSA-N Chloditan Chemical compound C=1C=CC=C(Cl)C=1C(C(Cl)Cl)C1=CC=C(Cl)C=C1 JWBOIMRXGHLCPP-UHFFFAOYSA-N 0.000 description 1
- XCDXSSFOJZZGQC-UHFFFAOYSA-N Chlornaphazine Chemical compound C1=CC=CC2=CC(N(CCCl)CCCl)=CC=C21 XCDXSSFOJZZGQC-UHFFFAOYSA-N 0.000 description 1
- MKQWTWSXVILIKJ-LXGUWJNJSA-N Chlorozotocin Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](C=O)NC(=O)N(N=O)CCCl MKQWTWSXVILIKJ-LXGUWJNJSA-N 0.000 description 1
- 229920001268 Cholestyramine Polymers 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 229940093444 Cyclooxygenase 2 inhibitor Drugs 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- QLCPDGRAEJSYQM-LPEHRKFASA-N Cys-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CS)N)C(=O)O QLCPDGRAEJSYQM-LPEHRKFASA-N 0.000 description 1
- WDQXKVCQXRNOSI-GHCJXIJMSA-N Cys-Asp-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WDQXKVCQXRNOSI-GHCJXIJMSA-N 0.000 description 1
- BPHKULHWEIUDOB-FXQIFTODSA-N Cys-Gln-Gln Chemical compound SC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O BPHKULHWEIUDOB-FXQIFTODSA-N 0.000 description 1
- HHABWQIFXZPZCK-ACZMJKKPSA-N Cys-Gln-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N HHABWQIFXZPZCK-ACZMJKKPSA-N 0.000 description 1
- AOZBJZBKFHOYHL-AVGNSLFASA-N Cys-Glu-Tyr Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O AOZBJZBKFHOYHL-AVGNSLFASA-N 0.000 description 1
- ANPADMNVVOOYKW-DCAQKATOSA-N Cys-His-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ANPADMNVVOOYKW-DCAQKATOSA-N 0.000 description 1
- OTXLNICGSXPGQF-KBIXCLLPSA-N Cys-Ile-Glu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTXLNICGSXPGQF-KBIXCLLPSA-N 0.000 description 1
- XLLSMEFANRROJE-GUBZILKMSA-N Cys-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CS)N XLLSMEFANRROJE-GUBZILKMSA-N 0.000 description 1
- NIXHTNJAGGFBAW-CIUDSAMLSA-N Cys-Lys-Ser Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N NIXHTNJAGGFBAW-CIUDSAMLSA-N 0.000 description 1
- PGBLJHDDKCVSTC-CIUDSAMLSA-N Cys-Met-Gln Chemical compound CSCC[C@H](NC(=O)[C@@H](N)CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O PGBLJHDDKCVSTC-CIUDSAMLSA-N 0.000 description 1
- DQUWSUWXPWGTQT-DCAQKATOSA-N Cys-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CS DQUWSUWXPWGTQT-DCAQKATOSA-N 0.000 description 1
- 241000701022 Cytomegalovirus Species 0.000 description 1
- WEAHRLBPCANXCN-UHFFFAOYSA-N Daunomycin Natural products CCC1(O)CC(OC2CC(N)C(O)C(C)O2)c3cc4C(=O)c5c(OC)cccc5C(=O)c4c(O)c3C1 WEAHRLBPCANXCN-UHFFFAOYSA-N 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- SAMRUMKYXPVKPA-VFKOLLTISA-N Enocitabine Chemical compound O=C1N=C(NC(=O)CCCCCCCCCCCCCCCCCCCCC)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 SAMRUMKYXPVKPA-VFKOLLTISA-N 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 1
- OBMLHUPNRURLOK-XGRAFVIBSA-N Epitiostanol Chemical compound C1[C@@H]2S[C@@H]2C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CC[C@H]21 OBMLHUPNRURLOK-XGRAFVIBSA-N 0.000 description 1
- 229930189413 Esperamicin Natural products 0.000 description 1
- JOYRKODLDBILNP-UHFFFAOYSA-N Ethyl urethane Chemical compound CCOC(N)=O JOYRKODLDBILNP-UHFFFAOYSA-N 0.000 description 1
- 108091008794 FGF receptors Proteins 0.000 description 1
- 108010074860 Factor Xa Proteins 0.000 description 1
- 108010087819 Fc receptors Proteins 0.000 description 1
- 102000009109 Fc receptors Human genes 0.000 description 1
- 235000008526 Galium odoratum Nutrition 0.000 description 1
- HEMJJKBWTPKOJG-UHFFFAOYSA-N Gemfibrozil Chemical compound CC1=CC=C(C)C(OCCCC(C)(C)C(O)=O)=C1 HEMJJKBWTPKOJG-UHFFFAOYSA-N 0.000 description 1
- 108010072051 Glatiramer Acetate Proteins 0.000 description 1
- SOBBAYVQSNXYPQ-ACZMJKKPSA-N Gln-Asn-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SOBBAYVQSNXYPQ-ACZMJKKPSA-N 0.000 description 1
- XEYMBRRKIFYQMF-GUBZILKMSA-N Gln-Asp-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XEYMBRRKIFYQMF-GUBZILKMSA-N 0.000 description 1
- UVAOVENCIONMJP-GUBZILKMSA-N Gln-Cys-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O UVAOVENCIONMJP-GUBZILKMSA-N 0.000 description 1
- MCAVASRGVBVPMX-FXQIFTODSA-N Gln-Glu-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MCAVASRGVBVPMX-FXQIFTODSA-N 0.000 description 1
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 1
- QKCZZAZNMMVICF-DCAQKATOSA-N Gln-Leu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O QKCZZAZNMMVICF-DCAQKATOSA-N 0.000 description 1
- KPNWAJMEMRCLAL-GUBZILKMSA-N Gln-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KPNWAJMEMRCLAL-GUBZILKMSA-N 0.000 description 1
- OTQSTOXRUBVWAP-NRPADANISA-N Gln-Ser-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OTQSTOXRUBVWAP-NRPADANISA-N 0.000 description 1
- OACQOWPRWGNKTP-AVGNSLFASA-N Gln-Tyr-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O OACQOWPRWGNKTP-AVGNSLFASA-N 0.000 description 1
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 1
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 1
- OJGLIOXAKGFFDW-SRVKXCTJSA-N Glu-Arg-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N OJGLIOXAKGFFDW-SRVKXCTJSA-N 0.000 description 1
- NTBDVNJIWCKURJ-ACZMJKKPSA-N Glu-Asp-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NTBDVNJIWCKURJ-ACZMJKKPSA-N 0.000 description 1
- JPHYJQHPILOKHC-ACZMJKKPSA-N Glu-Asp-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JPHYJQHPILOKHC-ACZMJKKPSA-N 0.000 description 1
- CYHBMLHCQXXCCT-AVGNSLFASA-N Glu-Asp-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CYHBMLHCQXXCCT-AVGNSLFASA-N 0.000 description 1
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 1
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 1
- BUAKRRKDHSSIKK-IHRRRGAJSA-N Glu-Glu-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BUAKRRKDHSSIKK-IHRRRGAJSA-N 0.000 description 1
- DVLZZEPUNFEUBW-AVGNSLFASA-N Glu-His-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)O)N DVLZZEPUNFEUBW-AVGNSLFASA-N 0.000 description 1
- QNJNPKSWAHPYGI-JYJNAYRXSA-N Glu-Phe-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=CC=C1 QNJNPKSWAHPYGI-JYJNAYRXSA-N 0.000 description 1
- CAQXJMUDOLSBPF-SUSMZKCASA-N Glu-Thr-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAQXJMUDOLSBPF-SUSMZKCASA-N 0.000 description 1
- JVZLZVJTIXVIHK-SXNHZJKMSA-N Glu-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N JVZLZVJTIXVIHK-SXNHZJKMSA-N 0.000 description 1
- HVKAAUOFFTUSAA-XDTLVQLUSA-N Glu-Tyr-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O HVKAAUOFFTUSAA-XDTLVQLUSA-N 0.000 description 1
- VIPDPMHGICREIS-GVXVVHGQSA-N Glu-Val-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VIPDPMHGICREIS-GVXVVHGQSA-N 0.000 description 1
- QXUPRMQJDWJDFR-NRPADANISA-N Glu-Val-Ser Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXUPRMQJDWJDFR-NRPADANISA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- MFVQGXGQRIXBPK-WDSKDSINSA-N Gly-Ala-Glu Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFVQGXGQRIXBPK-WDSKDSINSA-N 0.000 description 1
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 1
- WKJKBELXHCTHIJ-WPRPVWTQSA-N Gly-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N WKJKBELXHCTHIJ-WPRPVWTQSA-N 0.000 description 1
- MHHUEAIBJZWDBH-YUMQZZPRSA-N Gly-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN MHHUEAIBJZWDBH-YUMQZZPRSA-N 0.000 description 1
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 1
- GNPVTZJUUBPZKW-WDSKDSINSA-N Gly-Gln-Ser Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GNPVTZJUUBPZKW-WDSKDSINSA-N 0.000 description 1
- ZQIMMEYPEXIYBB-IUCAKERBSA-N Gly-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CN ZQIMMEYPEXIYBB-IUCAKERBSA-N 0.000 description 1
- DGKBSGNCMCLDSL-BYULHYEWSA-N Gly-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN DGKBSGNCMCLDSL-BYULHYEWSA-N 0.000 description 1
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 1
- DKEXFJVMVGETOO-LURJTMIESA-N Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CN DKEXFJVMVGETOO-LURJTMIESA-N 0.000 description 1
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 1
- UHPAZODVFFYEEL-QWRGUYRKSA-N Gly-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN UHPAZODVFFYEEL-QWRGUYRKSA-N 0.000 description 1
- JBCLFWXMTIKCCB-VIFPVBQESA-N Gly-Phe Chemical compound NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-VIFPVBQESA-N 0.000 description 1
- IBYOLNARKHMLBG-WHOFXGATSA-N Gly-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 IBYOLNARKHMLBG-WHOFXGATSA-N 0.000 description 1
- YXTFLTJYLIAZQG-FJXKBIBVSA-N Gly-Thr-Arg Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YXTFLTJYLIAZQG-FJXKBIBVSA-N 0.000 description 1
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 1
- CUVBTVWFVIIDOC-YEPSODPASA-N Gly-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)CN CUVBTVWFVIIDOC-YEPSODPASA-N 0.000 description 1
- UMRIXLHPZZIOML-OALUTQOASA-N Gly-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)CN UMRIXLHPZZIOML-OALUTQOASA-N 0.000 description 1
- FULZDMOZUZKGQU-ONGXEEELSA-N Gly-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN FULZDMOZUZKGQU-ONGXEEELSA-N 0.000 description 1
- ZVXMEWXHFBYJPI-LSJOCFKGSA-N Gly-Val-Ile Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZVXMEWXHFBYJPI-LSJOCFKGSA-N 0.000 description 1
- 102100032530 Glypican-3 Human genes 0.000 description 1
- BLCLNMBMMGCOAS-URPVMXJPSA-N Goserelin Chemical compound C([C@@H](C(=O)N[C@H](COC(C)(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(=O)NNC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 BLCLNMBMMGCOAS-URPVMXJPSA-N 0.000 description 1
- 108010069236 Goserelin Proteins 0.000 description 1
- 239000012981 Hank's balanced salt solution Substances 0.000 description 1
- SKYULSWNBYAQMG-IHRRRGAJSA-N His-Leu-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SKYULSWNBYAQMG-IHRRRGAJSA-N 0.000 description 1
- UROVZOUMHNXPLZ-AVGNSLFASA-N His-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 UROVZOUMHNXPLZ-AVGNSLFASA-N 0.000 description 1
- RNAYRCNHRYEBTH-IHRRRGAJSA-N His-Met-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O RNAYRCNHRYEBTH-IHRRRGAJSA-N 0.000 description 1
- BFOGZWSSGMLYKV-DCAQKATOSA-N His-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CN=CN1)N BFOGZWSSGMLYKV-DCAQKATOSA-N 0.000 description 1
- KECFCPNPPYCGBL-PMVMPFDFSA-N His-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CC4=CN=CN4)N KECFCPNPPYCGBL-PMVMPFDFSA-N 0.000 description 1
- DMAPKBANYNZHNR-ULQDDVLXSA-N His-Val-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N DMAPKBANYNZHNR-ULQDDVLXSA-N 0.000 description 1
- 102100022893 Histone acetyltransferase KAT5 Human genes 0.000 description 1
- 241001272567 Hominoidea Species 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101001014668 Homo sapiens Glypican-3 Proteins 0.000 description 1
- VSNHCAURESNICA-UHFFFAOYSA-N Hydroxyurea Chemical compound NC(=O)NO VSNHCAURESNICA-UHFFFAOYSA-N 0.000 description 1
- MPBVHIBUJCELCL-UHFFFAOYSA-N Ibandronate Chemical compound CCCCCN(C)CCC(O)(P(O)(O)=O)P(O)(O)=O MPBVHIBUJCELCL-UHFFFAOYSA-N 0.000 description 1
- HEFNNWSXXWATRW-UHFFFAOYSA-N Ibuprofen Chemical compound CC(C)CC1=CC=C(C(C)C(O)=O)C=C1 HEFNNWSXXWATRW-UHFFFAOYSA-N 0.000 description 1
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 1
- XDXDZDZNSLXDNA-UHFFFAOYSA-N Idarubicin Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XDXDZDZNSLXDNA-UHFFFAOYSA-N 0.000 description 1
- QYZYJFXHXYUZMZ-UGYAYLCHSA-N Ile-Asn-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N QYZYJFXHXYUZMZ-UGYAYLCHSA-N 0.000 description 1
- QYOGJYIRKACXEP-SLBDDTMCSA-N Ile-Asn-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N QYOGJYIRKACXEP-SLBDDTMCSA-N 0.000 description 1
- QIHJTGSVGIPHIW-QSFUFRPTSA-N Ile-Asn-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N QIHJTGSVGIPHIW-QSFUFRPTSA-N 0.000 description 1
- TWYOYAKMLHWMOJ-ZPFDUUQYSA-N Ile-Leu-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O TWYOYAKMLHWMOJ-ZPFDUUQYSA-N 0.000 description 1
- CKRFDMPBSWYOBT-PPCPHDFISA-N Ile-Lys-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N CKRFDMPBSWYOBT-PPCPHDFISA-N 0.000 description 1
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 1
- RQJUKVXWAKJDBW-SVSWQMSJSA-N Ile-Ser-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N RQJUKVXWAKJDBW-SVSWQMSJSA-N 0.000 description 1
- WXLYNEHOGRYNFU-URLPEUOOSA-N Ile-Thr-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N WXLYNEHOGRYNFU-URLPEUOOSA-N 0.000 description 1
- PRTZQMBYUZFSFA-XEGUGMAKSA-N Ile-Tyr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)NCC(=O)O)N PRTZQMBYUZFSFA-XEGUGMAKSA-N 0.000 description 1
- YWCJXQKATPNPOE-UKJIMTQDSA-N Ile-Val-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YWCJXQKATPNPOE-UKJIMTQDSA-N 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- 102000008070 Interferon-gamma Human genes 0.000 description 1
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 1
- JLERVPBPJHKRBJ-UHFFFAOYSA-N LY 117018 Chemical compound C1=CC(O)=CC=C1C1=C(C(=O)C=2C=CC(OCCN3CCCC3)=CC=2)C2=CC=C(O)C=C2S1 JLERVPBPJHKRBJ-UHFFFAOYSA-N 0.000 description 1
- 229920001491 Lentinan Polymers 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 1
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 1
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 1
- WQWSMEOYXJTFRU-GUBZILKMSA-N Leu-Glu-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O WQWSMEOYXJTFRU-GUBZILKMSA-N 0.000 description 1
- OYQUOLRTJHWVSQ-SRVKXCTJSA-N Leu-His-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O OYQUOLRTJHWVSQ-SRVKXCTJSA-N 0.000 description 1
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 1
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 1
- KYIIALJHAOIAHF-KKUMJFAQSA-N Leu-Leu-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 KYIIALJHAOIAHF-KKUMJFAQSA-N 0.000 description 1
- REPBGZHJKYWFMJ-KKUMJFAQSA-N Leu-Lys-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N REPBGZHJKYWFMJ-KKUMJFAQSA-N 0.000 description 1
- ZDJQVSIPFLMNOX-RHYQMDGZSA-N Leu-Thr-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZDJQVSIPFLMNOX-RHYQMDGZSA-N 0.000 description 1
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 1
- 108010000817 Leuprolide Proteins 0.000 description 1
- 102000004895 Lipoproteins Human genes 0.000 description 1
- 108090001030 Lipoproteins Proteins 0.000 description 1
- GQYIWUVLTXOXAJ-UHFFFAOYSA-N Lomustine Chemical compound ClCCN(N=O)C(=O)NC1CCCCC1 GQYIWUVLTXOXAJ-UHFFFAOYSA-N 0.000 description 1
- BTSXLXFPMZXVPR-DLOVCJGASA-N Lys-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCCN)N BTSXLXFPMZXVPR-DLOVCJGASA-N 0.000 description 1
- YVSHZSUKQHNDHD-KKUMJFAQSA-N Lys-Asn-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N YVSHZSUKQHNDHD-KKUMJFAQSA-N 0.000 description 1
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 1
- IBQMEXQYZMVIFU-SRVKXCTJSA-N Lys-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCCN)N IBQMEXQYZMVIFU-SRVKXCTJSA-N 0.000 description 1
- GJJQCBVRWDGLMQ-GUBZILKMSA-N Lys-Glu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O GJJQCBVRWDGLMQ-GUBZILKMSA-N 0.000 description 1
- KZOHPCYVORJBLG-AVGNSLFASA-N Lys-Glu-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N KZOHPCYVORJBLG-AVGNSLFASA-N 0.000 description 1
- VEGLGAOVLFODGC-GUBZILKMSA-N Lys-Glu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VEGLGAOVLFODGC-GUBZILKMSA-N 0.000 description 1
- FHIAJWBDZVHLAH-YUMQZZPRSA-N Lys-Gly-Ser Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FHIAJWBDZVHLAH-YUMQZZPRSA-N 0.000 description 1
- VLMNBMFYRMGEMB-QWRGUYRKSA-N Lys-His-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CNC=N1 VLMNBMFYRMGEMB-QWRGUYRKSA-N 0.000 description 1
- SVSQSPICRKBMSZ-SRVKXCTJSA-N Lys-Pro-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O SVSQSPICRKBMSZ-SRVKXCTJSA-N 0.000 description 1
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 1
- YSZNURNVYFUEHC-BQBZGAKWSA-N Lys-Ser Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(O)=O YSZNURNVYFUEHC-BQBZGAKWSA-N 0.000 description 1
- UWHCKWNPWKTMBM-WDCWCFNPSA-N Lys-Thr-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O UWHCKWNPWKTMBM-WDCWCFNPSA-N 0.000 description 1
- QVTDVTONTRSQMF-WDCWCFNPSA-N Lys-Thr-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CCCCN QVTDVTONTRSQMF-WDCWCFNPSA-N 0.000 description 1
- SUZVLFWOCKHWET-CQDKDKBSSA-N Lys-Tyr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O SUZVLFWOCKHWET-CQDKDKBSSA-N 0.000 description 1
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 1
- 108020002496 Lysophospholipase Proteins 0.000 description 1
- VJRAUFKOOPNFIQ-UHFFFAOYSA-N Marcellomycin Natural products C12=C(O)C=3C(=O)C4=C(O)C=CC(O)=C4C(=O)C=3C=C2C(C(=O)OC)C(CC)(O)CC1OC(OC1C)CC(N(C)C)C1OC(OC1C)CC(O)C1OC1CC(O)C(O)C(C)O1 VJRAUFKOOPNFIQ-UHFFFAOYSA-N 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- IVDYZAAPOLNZKG-KWHRADDSSA-N Mepitiostane Chemical compound O([C@@H]1[C@]2(CC[C@@H]3[C@@]4(C)C[C@H]5S[C@H]5C[C@@H]4CC[C@H]3[C@@H]2CC1)C)C1(OC)CCCC1 IVDYZAAPOLNZKG-KWHRADDSSA-N 0.000 description 1
- FVKRQMQQFGBXHV-QXEWZRGKSA-N Met-Asp-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FVKRQMQQFGBXHV-QXEWZRGKSA-N 0.000 description 1
- HLYIDXAXQIJYIG-CIUDSAMLSA-N Met-Gln-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HLYIDXAXQIJYIG-CIUDSAMLSA-N 0.000 description 1
- BKIFWLQFOOKUCA-DCAQKATOSA-N Met-His-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CO)C(=O)O)N BKIFWLQFOOKUCA-DCAQKATOSA-N 0.000 description 1
- RRIHXWPHQSXHAQ-XUXIUFHCSA-N Met-Ile-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(O)=O RRIHXWPHQSXHAQ-XUXIUFHCSA-N 0.000 description 1
- DBXMFHGGHMXYHY-DCAQKATOSA-N Met-Leu-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O DBXMFHGGHMXYHY-DCAQKATOSA-N 0.000 description 1
- XDGFFEZAZHRZFR-RHYQMDGZSA-N Met-Leu-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XDGFFEZAZHRZFR-RHYQMDGZSA-N 0.000 description 1
- VSJAPSMRFYUOKS-IUCAKERBSA-N Met-Pro-Gly Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O VSJAPSMRFYUOKS-IUCAKERBSA-N 0.000 description 1
- 102100026907 Mitogen-activated protein kinase kinase kinase 8 Human genes 0.000 description 1
- 101710164353 Mitogen-activated protein kinase kinase kinase 8 Proteins 0.000 description 1
- 229930192392 Mitomycin Natural products 0.000 description 1
- PCZOHLXUXFIOCF-UHFFFAOYSA-N Monacolin X Natural products C12C(OC(=O)C(C)CC)CC(C)C=C2C=CC(C)C1CCC1CC(O)CC(=O)O1 PCZOHLXUXFIOCF-UHFFFAOYSA-N 0.000 description 1
- 102000007474 Multiprotein Complexes Human genes 0.000 description 1
- 108010085220 Multiprotein Complexes Proteins 0.000 description 1
- 102000047918 Myelin Basic Human genes 0.000 description 1
- 101710107068 Myelin basic protein Proteins 0.000 description 1
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 1
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- 230000004988 N-glycosylation Effects 0.000 description 1
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 1
- BLXXJMDCKKHMKV-UHFFFAOYSA-N Nabumetone Chemical compound C1=C(CCC(C)=O)C=CC2=CC(OC)=CC=C21 BLXXJMDCKKHMKV-UHFFFAOYSA-N 0.000 description 1
- CMWTZPSULFXXJA-UHFFFAOYSA-N Naproxen Natural products C1=C(C(C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-UHFFFAOYSA-N 0.000 description 1
- SYNHCENRCUAUNM-UHFFFAOYSA-N Nitrogen mustard N-oxide hydrochloride Chemical compound Cl.ClCC[N+]([O-])(C)CCCl SYNHCENRCUAUNM-UHFFFAOYSA-N 0.000 description 1
- KGTDRFCXGRULNK-UHFFFAOYSA-N Nogalamycin Natural products COC1C(OC)(C)C(OC)C(C)OC1OC1C2=C(O)C(C(=O)C3=C(O)C=C4C5(C)OC(C(C(C5O)N(C)C)O)OC4=C3C3=O)=C3C=C2C(C(=O)OC)C(C)(O)C1 KGTDRFCXGRULNK-UHFFFAOYSA-N 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 102100034925 P-selectin glycoprotein ligand 1 Human genes 0.000 description 1
- 101710137390 P-selectin glycoprotein ligand 1 Proteins 0.000 description 1
- 239000012826 P38 inhibitor Substances 0.000 description 1
- 101150000187 PTGS2 gene Proteins 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 108010057150 Peplomycin Proteins 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- FSPGBMWPNMRWDB-AVGNSLFASA-N Phe-Cys-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N FSPGBMWPNMRWDB-AVGNSLFASA-N 0.000 description 1
- YEEFZOKPYOUXMX-KKUMJFAQSA-N Phe-Gln-Met Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O YEEFZOKPYOUXMX-KKUMJFAQSA-N 0.000 description 1
- FXPZZKBHNOMLGA-HJWJTTGWSA-N Phe-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N FXPZZKBHNOMLGA-HJWJTTGWSA-N 0.000 description 1
- KBVJZCVLQWCJQN-KKUMJFAQSA-N Phe-Leu-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O KBVJZCVLQWCJQN-KKUMJFAQSA-N 0.000 description 1
- KDYPMIZMXDECSU-JYJNAYRXSA-N Phe-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 KDYPMIZMXDECSU-JYJNAYRXSA-N 0.000 description 1
- KLXQWABNAWDRAY-ACRUOGEOSA-N Phe-Lys-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 KLXQWABNAWDRAY-ACRUOGEOSA-N 0.000 description 1
- VHDNDCPMHQMXIR-IHRRRGAJSA-N Phe-Met-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC1=CC=CC=C1 VHDNDCPMHQMXIR-IHRRRGAJSA-N 0.000 description 1
- MMJJFXWMCMJMQA-STQMWFEESA-N Phe-Pro-Gly Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)NCC(O)=O)C1=CC=CC=C1 MMJJFXWMCMJMQA-STQMWFEESA-N 0.000 description 1
- ZLAKUZDMKVKFAI-JYJNAYRXSA-N Phe-Pro-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O ZLAKUZDMKVKFAI-JYJNAYRXSA-N 0.000 description 1
- ZTVSVSFBHUVYIN-UFYCRDLUSA-N Phe-Tyr-Met Chemical compound C([C@@H](C(=O)N[C@@H](CCSC)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CC=C(O)C=C1 ZTVSVSFBHUVYIN-UFYCRDLUSA-N 0.000 description 1
- KMSKQZKKOZQFFG-HSUXVGOQSA-N Pirarubicin Chemical compound O([C@H]1[C@@H](N)C[C@@H](O[C@H]1C)O[C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1CCCCO1 KMSKQZKKOZQFFG-HSUXVGOQSA-N 0.000 description 1
- RVGRUAULSDPKGF-UHFFFAOYSA-N Poloxamer Chemical compound C1CO1.CC1CO1 RVGRUAULSDPKGF-UHFFFAOYSA-N 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 229920001219 Polysorbate 40 Polymers 0.000 description 1
- 229920001214 Polysorbate 60 Polymers 0.000 description 1
- TUZYXOIXSAXUGO-UHFFFAOYSA-N Pravastatin Natural products C1=CC(C)C(CCC(O)CC(O)CC(O)=O)C2C(OC(=O)C(C)CC)CC(O)C=C21 TUZYXOIXSAXUGO-UHFFFAOYSA-N 0.000 description 1
- HFVNWDWLWUCIHC-GUPDPFMOSA-N Prednimustine Chemical compound O=C([C@@]1(O)CC[C@H]2[C@H]3[C@@H]([C@]4(C=CC(=O)C=C4CC3)C)[C@@H](O)C[C@@]21C)COC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 HFVNWDWLWUCIHC-GUPDPFMOSA-N 0.000 description 1
- OCSACVPBMIYNJE-GUBZILKMSA-N Pro-Arg-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O OCSACVPBMIYNJE-GUBZILKMSA-N 0.000 description 1
- SSSFPISOZOLQNP-GUBZILKMSA-N Pro-Arg-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSFPISOZOLQNP-GUBZILKMSA-N 0.000 description 1
- GDXZRWYXJSGWIV-GMOBBJLQSA-N Pro-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 GDXZRWYXJSGWIV-GMOBBJLQSA-N 0.000 description 1
- FKLSMYYLJHYPHH-UWVGGRQHSA-N Pro-Gly-Leu Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O FKLSMYYLJHYPHH-UWVGGRQHSA-N 0.000 description 1
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 1
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 1
- DWGFLKQSGRUQTI-IHRRRGAJSA-N Pro-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 DWGFLKQSGRUQTI-IHRRRGAJSA-N 0.000 description 1
- FYKUEXMZYFIZKA-DCAQKATOSA-N Pro-Pro-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FYKUEXMZYFIZKA-DCAQKATOSA-N 0.000 description 1
- VBZXFFYOBDLLFE-HSHDSVGOSA-N Pro-Trp-Thr Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H]([C@H](O)C)C(O)=O)C(=O)[C@@H]1CCCN1 VBZXFFYOBDLLFE-HSHDSVGOSA-N 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- AHHFEZNOXOZZQA-ZEBDFXRSSA-N Ranimustine Chemical compound CO[C@H]1O[C@H](CNC(=O)N(CCCl)N=O)[C@@H](O)[C@H](O)[C@H]1O AHHFEZNOXOZZQA-ZEBDFXRSSA-N 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- RYMZZMVNJRMUDD-UHFFFAOYSA-N SJ000286063 Natural products C12C(OC(=O)C(C)(C)CC)CC(C)C=C2C=CC(C)C1CCC1CC(O)CC(=O)O1 RYMZZMVNJRMUDD-UHFFFAOYSA-N 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- YMEXHZTVKDAKIY-GHCJXIJMSA-N Ser-Asn-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO)C(O)=O YMEXHZTVKDAKIY-GHCJXIJMSA-N 0.000 description 1
- OHKLFYXEOGGGCK-ZLUOBGJFSA-N Ser-Asp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OHKLFYXEOGGGCK-ZLUOBGJFSA-N 0.000 description 1
- KMWFXJCGRXBQAC-CIUDSAMLSA-N Ser-Cys-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N KMWFXJCGRXBQAC-CIUDSAMLSA-N 0.000 description 1
- MPPHJZYXDVDGOF-BWBBJGPYSA-N Ser-Cys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CO MPPHJZYXDVDGOF-BWBBJGPYSA-N 0.000 description 1
- HVKMTOIAYDOJPL-NRPADANISA-N Ser-Gln-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVKMTOIAYDOJPL-NRPADANISA-N 0.000 description 1
- SQBLRDDJTUJDMV-ACZMJKKPSA-N Ser-Glu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SQBLRDDJTUJDMV-ACZMJKKPSA-N 0.000 description 1
- UOLGINIHBRIECN-FXQIFTODSA-N Ser-Glu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UOLGINIHBRIECN-FXQIFTODSA-N 0.000 description 1
- JFWDJFULOLKQFY-QWRGUYRKSA-N Ser-Gly-Phe Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JFWDJFULOLKQFY-QWRGUYRKSA-N 0.000 description 1
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 1
- HBTCFCHYALPXME-HTFCKZLJSA-N Ser-Ile-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HBTCFCHYALPXME-HTFCKZLJSA-N 0.000 description 1
- JURQXQBJKUHGJS-UHFFFAOYSA-N Ser-Ser-Ser-Ser Chemical compound OCC(N)C(=O)NC(CO)C(=O)NC(CO)C(=O)NC(CO)C(O)=O JURQXQBJKUHGJS-UHFFFAOYSA-N 0.000 description 1
- WUXCHQZLUHBSDJ-LKXGYXEUSA-N Ser-Thr-Asp Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WUXCHQZLUHBSDJ-LKXGYXEUSA-N 0.000 description 1
- KKKVOZNCLALMPV-XKBZYTNZSA-N Ser-Thr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KKKVOZNCLALMPV-XKBZYTNZSA-N 0.000 description 1
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 1
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 1
- FHXGMDRKJHKLKW-QWRGUYRKSA-N Ser-Tyr-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 FHXGMDRKJHKLKW-QWRGUYRKSA-N 0.000 description 1
- MFQMZDPAZRZAPV-NAKRPEOUSA-N Ser-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CO)N MFQMZDPAZRZAPV-NAKRPEOUSA-N 0.000 description 1
- RCOUFINCYASMDN-GUBZILKMSA-N Ser-Val-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O RCOUFINCYASMDN-GUBZILKMSA-N 0.000 description 1
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- 230000006052 T cell proliferation Effects 0.000 description 1
- CGMTUJFWROPELF-UHFFFAOYSA-N Tenuazonic acid Natural products CCC(C)C1NC(=O)C(=C(C)/O)C1=O CGMTUJFWROPELF-UHFFFAOYSA-N 0.000 description 1
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 1
- XVNZSJIKGJLQLH-RCWTZXSCSA-N Thr-Arg-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCSC)C(=O)O)N)O XVNZSJIKGJLQLH-RCWTZXSCSA-N 0.000 description 1
- JVTHIXKSVYEWNI-JRQIVUDYSA-N Thr-Asn-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JVTHIXKSVYEWNI-JRQIVUDYSA-N 0.000 description 1
- JEDIEMIJYSRUBB-FOHZUACHSA-N Thr-Asp-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O JEDIEMIJYSRUBB-FOHZUACHSA-N 0.000 description 1
- UZJDBCHMIQXLOQ-HEIBUPTGSA-N Thr-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O UZJDBCHMIQXLOQ-HEIBUPTGSA-N 0.000 description 1
- RKDFEMGVMMYYNG-WDCWCFNPSA-N Thr-Gln-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O RKDFEMGVMMYYNG-WDCWCFNPSA-N 0.000 description 1
- XPNSAQMEAVSQRD-FBCQKBJTSA-N Thr-Gly-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)NCC(O)=O XPNSAQMEAVSQRD-FBCQKBJTSA-N 0.000 description 1
- LCCSEJSPBWKBNT-OSUNSFLBSA-N Thr-Ile-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N LCCSEJSPBWKBNT-OSUNSFLBSA-N 0.000 description 1
- XYFISNXATOERFZ-OSUNSFLBSA-N Thr-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N XYFISNXATOERFZ-OSUNSFLBSA-N 0.000 description 1
- ODXKUIGEPAGKKV-KATARQTJSA-N Thr-Leu-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)O)N)O ODXKUIGEPAGKKV-KATARQTJSA-N 0.000 description 1
- MECLEFZMPPOEAC-VOAKCMCISA-N Thr-Leu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MECLEFZMPPOEAC-VOAKCMCISA-N 0.000 description 1
- PRNGXSILMXSWQQ-OEAJRASXSA-N Thr-Leu-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PRNGXSILMXSWQQ-OEAJRASXSA-N 0.000 description 1
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 1
- MGJLBZFUXUGMML-VOAKCMCISA-N Thr-Lys-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MGJLBZFUXUGMML-VOAKCMCISA-N 0.000 description 1
- KDGBLMDAPJTQIW-RHYQMDGZSA-N Thr-Met-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)O)N)O KDGBLMDAPJTQIW-RHYQMDGZSA-N 0.000 description 1
- KPNSNVTUVKSBFL-ZJDVBMNYSA-N Thr-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KPNSNVTUVKSBFL-ZJDVBMNYSA-N 0.000 description 1
- VGYVVSQFSSKZRJ-OEAJRASXSA-N Thr-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@H](O)C)CC1=CC=CC=C1 VGYVVSQFSSKZRJ-OEAJRASXSA-N 0.000 description 1
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 1
- OLFOOYQTTQSSRK-UNQGMJICSA-N Thr-Pro-Phe Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OLFOOYQTTQSSRK-UNQGMJICSA-N 0.000 description 1
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 1
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 1
- AKHDFZHUPGVFEJ-YEPSODPASA-N Thr-Val-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AKHDFZHUPGVFEJ-YEPSODPASA-N 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- IWEQQRMGNVVKQW-OQKDUQJOSA-N Toremifene citrate Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O.C1=CC(OCCN(C)C)=CC=C1C(\C=1C=CC=CC=1)=C(\CCCl)C1=CC=CC=C1 IWEQQRMGNVVKQW-OQKDUQJOSA-N 0.000 description 1
- 102000007238 Transferrin Receptors Human genes 0.000 description 1
- 108010033576 Transferrin Receptors Proteins 0.000 description 1
- FYAMXEPQQLNQDM-UHFFFAOYSA-N Tris(1-aziridinyl)phosphine oxide Chemical compound C1CN1P(N1CC1)(=O)N1CC1 FYAMXEPQQLNQDM-UHFFFAOYSA-N 0.000 description 1
- MHCLIYHJRXZBGJ-AAEUAGOBSA-N Trp-Gly-Cys Chemical compound N[C@@H](CC1=CNC2=CC=CC=C12)C(=O)NCC(=O)N[C@@H](CS)C(=O)O MHCLIYHJRXZBGJ-AAEUAGOBSA-N 0.000 description 1
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 1
- SAKLWFSRZTZQAJ-GQGQLFGLSA-N Trp-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N SAKLWFSRZTZQAJ-GQGQLFGLSA-N 0.000 description 1
- YDTKYBHPRULROG-LTHWPDAASA-N Trp-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N YDTKYBHPRULROG-LTHWPDAASA-N 0.000 description 1
- OGZRZMJASKKMJZ-XIRDDKMYSA-N Trp-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N OGZRZMJASKKMJZ-XIRDDKMYSA-N 0.000 description 1
- RERRMBXDSFMBQE-ZFWWWQNUSA-N Trp-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N RERRMBXDSFMBQE-ZFWWWQNUSA-N 0.000 description 1
- UJGDFQRPYGJBEH-AAEUAGOBSA-N Trp-Ser-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N UJGDFQRPYGJBEH-AAEUAGOBSA-N 0.000 description 1
- BVOCLAPFOBSJHR-KKUMJFAQSA-N Tyr-Cys-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O BVOCLAPFOBSJHR-KKUMJFAQSA-N 0.000 description 1
- UMXSDHPSMROQRB-YJRXYDGGSA-N Tyr-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O UMXSDHPSMROQRB-YJRXYDGGSA-N 0.000 description 1
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 1
- GGXUDPQWAWRINY-XEGUGMAKSA-N Tyr-Ile-Gly Chemical compound OC(=O)CNC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GGXUDPQWAWRINY-XEGUGMAKSA-N 0.000 description 1
- CDKZJGMPZHPAJC-ULQDDVLXSA-N Tyr-Leu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDKZJGMPZHPAJC-ULQDDVLXSA-N 0.000 description 1
- GITNQBVCEQBDQC-KKUMJFAQSA-N Tyr-Lys-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O GITNQBVCEQBDQC-KKUMJFAQSA-N 0.000 description 1
- GYBVHTWOQJMYAM-HRCADAONSA-N Tyr-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N GYBVHTWOQJMYAM-HRCADAONSA-N 0.000 description 1
- RWOKVQUCENPXGE-IHRRRGAJSA-N Tyr-Ser-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RWOKVQUCENPXGE-IHRRRGAJSA-N 0.000 description 1
- TYFLVOUZHQUBGM-IHRRRGAJSA-N Tyr-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 TYFLVOUZHQUBGM-IHRRRGAJSA-N 0.000 description 1
- RZAGEHHVNYESNR-RNXOBYDBSA-N Tyr-Trp-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RZAGEHHVNYESNR-RNXOBYDBSA-N 0.000 description 1
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 1
- WYOBRXPIZVKNMF-IRXDYDNUSA-N Tyr-Tyr-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)NCC(O)=O)C1=CC=C(O)C=C1 WYOBRXPIZVKNMF-IRXDYDNUSA-N 0.000 description 1
- NMPXRFYMZDIBRF-ZOBUZTSGSA-N Val-Asn-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N NMPXRFYMZDIBRF-ZOBUZTSGSA-N 0.000 description 1
- CGGVNFJRZJUVAE-BYULHYEWSA-N Val-Asp-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CGGVNFJRZJUVAE-BYULHYEWSA-N 0.000 description 1
- PWRITNSESKQTPW-NRPADANISA-N Val-Gln-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N PWRITNSESKQTPW-NRPADANISA-N 0.000 description 1
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 1
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 1
- FEXILLGKGGTLRI-NHCYSSNCSA-N Val-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N FEXILLGKGGTLRI-NHCYSSNCSA-N 0.000 description 1
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 1
- DAVNYIUELQBTAP-XUXIUFHCSA-N Val-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N DAVNYIUELQBTAP-XUXIUFHCSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- YMTOEGGOCHVGEH-IHRRRGAJSA-N Val-Lys-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O YMTOEGGOCHVGEH-IHRRRGAJSA-N 0.000 description 1
- CXWJFWAZIVWBOS-XQQFMLRXSA-N Val-Lys-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N CXWJFWAZIVWBOS-XQQFMLRXSA-N 0.000 description 1
- VPGCVZRRBYOGCD-AVGNSLFASA-N Val-Lys-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O VPGCVZRRBYOGCD-AVGNSLFASA-N 0.000 description 1
- MJFSRZZJQWZHFQ-SRVKXCTJSA-N Val-Met-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(=O)O)N MJFSRZZJQWZHFQ-SRVKXCTJSA-N 0.000 description 1
- BCBFMJYTNKDALA-UFYCRDLUSA-N Val-Phe-Phe Chemical compound N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O BCBFMJYTNKDALA-UFYCRDLUSA-N 0.000 description 1
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 1
- DVLWZWNAQUBZBC-ZNSHCXBVSA-N Val-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N)O DVLWZWNAQUBZBC-ZNSHCXBVSA-N 0.000 description 1
- RLVTVHSDKHBFQP-ULQDDVLXSA-N Val-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 RLVTVHSDKHBFQP-ULQDDVLXSA-N 0.000 description 1
- IECQJCJNPJVUSB-IHRRRGAJSA-N Val-Tyr-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CO)C(O)=O IECQJCJNPJVUSB-IHRRRGAJSA-N 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 1
- 101710090398 Viral interleukin-10 homolog Proteins 0.000 description 1
- SPJCRMJCFSJKDE-ZWBUGVOYSA-N [(3s,8s,9s,10r,13r,14s,17r)-10,13-dimethyl-17-[(2r)-6-methylheptan-2-yl]-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1h-cyclopenta[a]phenanthren-3-yl] 2-[4-[bis(2-chloroethyl)amino]phenyl]acetate Chemical compound O([C@@H]1CC2=CC[C@H]3[C@@H]4CC[C@@H]([C@]4(CC[C@@H]3[C@@]2(C)CC1)C)[C@H](C)CCCC(C)C)C(=O)CC1=CC=C(N(CCCl)CCCl)C=C1 SPJCRMJCFSJKDE-ZWBUGVOYSA-N 0.000 description 1
- IFJUINDAXYAPTO-UUBSBJJBSA-N [(8r,9s,13s,14s,17s)-17-[2-[4-[4-[bis(2-chloroethyl)amino]phenyl]butanoyloxy]acetyl]oxy-13-methyl-6,7,8,9,11,12,14,15,16,17-decahydrocyclopenta[a]phenanthren-3-yl] benzoate Chemical compound C([C@@H]1[C@@H](C2=CC=3)CC[C@]4([C@H]1CC[C@@H]4OC(=O)COC(=O)CCCC=1C=CC(=CC=1)N(CCCl)CCCl)C)CC2=CC=3OC(=O)C1=CC=CC=C1 IFJUINDAXYAPTO-UUBSBJJBSA-N 0.000 description 1
- IHGLINDYFMDHJG-UHFFFAOYSA-N [2-(4-methoxyphenyl)-3,4-dihydronaphthalen-1-yl]-[4-(2-pyrrolidin-1-ylethoxy)phenyl]methanone Chemical compound C1=CC(OC)=CC=C1C(CCC1=CC=CC=C11)=C1C(=O)C(C=C1)=CC=C1OCCN1CCCC1 IHGLINDYFMDHJG-UHFFFAOYSA-N 0.000 description 1
- XZSRRNFBEIOBDA-CFNBKWCHSA-N [2-[(2s,4s)-4-[(2r,4s,5s,6s)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-2,5,12-trihydroxy-7-methoxy-6,11-dioxo-3,4-dihydro-1h-tetracen-2-yl]-2-oxoethyl] 2,2-diethoxyacetate Chemical compound O([C@H]1C[C@](CC2=C(O)C=3C(=O)C4=CC=CC(OC)=C4C(=O)C=3C(O)=C21)(O)C(=O)COC(=O)C(OCC)OCC)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 XZSRRNFBEIOBDA-CFNBKWCHSA-N 0.000 description 1
- SMKNMQUEAGCCMW-UHFFFAOYSA-N [N].C(O)NC1=NC(=NC(=N1)NCO)NCO Chemical compound [N].C(O)NC1=NC(=NC(=N1)NCO)NCO SMKNMQUEAGCCMW-UHFFFAOYSA-N 0.000 description 1
- 108010076089 accutase Proteins 0.000 description 1
- ZOZKYEHVNDEUCO-XUTVFYLZSA-N aceglatone Chemical compound O1C(=O)[C@H](OC(C)=O)[C@@H]2OC(=O)[C@@H](OC(=O)C)[C@@H]21 ZOZKYEHVNDEUCO-XUTVFYLZSA-N 0.000 description 1
- 229950002684 aceglatone Drugs 0.000 description 1
- 229960001138 acetylsalicylic acid Drugs 0.000 description 1
- 229930188522 aclacinomycin Natural products 0.000 description 1
- USZYSDMBJDPRIF-SVEJIMAYSA-N aclacinomycin A Chemical compound O([C@H]1[C@@H](O)C[C@@H](O[C@H]1C)O[C@H]1[C@H](C[C@@H](O[C@H]1C)O[C@H]1C[C@]([C@@H](C2=CC=3C(=O)C4=CC=CC(O)=C4C(=O)C=3C(O)=C21)C(=O)OC)(O)CC)N(C)C)[C@H]1CCC(=O)[C@H](C)O1 USZYSDMBJDPRIF-SVEJIMAYSA-N 0.000 description 1
- 229960004176 aclarubicin Drugs 0.000 description 1
- 229930183665 actinomycin Natural products 0.000 description 1
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 1
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 150000001299 aldehydes Chemical group 0.000 description 1
- 229940045714 alkyl sulfonate alkylating agent Drugs 0.000 description 1
- 150000008052 alkyl sulfonates Chemical class 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- SHGAZHPCJJPHSC-YCNIQYBTSA-N all-trans-retinoic acid Chemical compound OC(=O)\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-YCNIQYBTSA-N 0.000 description 1
- 208000026935 allergic disease Diseases 0.000 description 1
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 1
- 229960000473 altretamine Drugs 0.000 description 1
- 230000001668 ameliorated effect Effects 0.000 description 1
- 230000006229 amino acid addition Effects 0.000 description 1
- 229960003437 aminoglutethimide Drugs 0.000 description 1
- ROBVIMPUHSLWNV-UHFFFAOYSA-N aminoglutethimide Chemical compound C=1C=C(N)C=CC=1C1(CC)CCC(=O)NC1=O ROBVIMPUHSLWNV-UHFFFAOYSA-N 0.000 description 1
- 229960002749 aminolevulinic acid Drugs 0.000 description 1
- 229960003896 aminopterin Drugs 0.000 description 1
- 229960001220 amsacrine Drugs 0.000 description 1
- XCPGHVQEEXUHNC-UHFFFAOYSA-N amsacrine Chemical compound COC1=CC(NS(C)(=O)=O)=CC=C1NC1=C(C=CC=C2)C2=NC2=CC=CC=C12 XCPGHVQEEXUHNC-UHFFFAOYSA-N 0.000 description 1
- BBDAGFIXKZCXAH-CCXZUQQUSA-N ancitabine Chemical compound N=C1C=CN2[C@@H]3O[C@H](CO)[C@@H](O)[C@@H]3OC2=N1 BBDAGFIXKZCXAH-CCXZUQQUSA-N 0.000 description 1
- 229950000242 ancitabine Drugs 0.000 description 1
- 239000003098 androgen Substances 0.000 description 1
- 229940030486 androgens Drugs 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000002280 anti-androgenic effect Effects 0.000 description 1
- 229940046836 anti-estrogen Drugs 0.000 description 1
- 230000001833 anti-estrogenic effect Effects 0.000 description 1
- 229940124599 anti-inflammatory drug Drugs 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 239000000051 antiandrogen Substances 0.000 description 1
- 229940030495 antiandrogen sex hormone and modulator of the genital system Drugs 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 239000003529 anticholesteremic agent Substances 0.000 description 1
- 229940127226 anticholesterol agent Drugs 0.000 description 1
- 210000000612 antigen-presenting cell Anatomy 0.000 description 1
- 239000013059 antihormonal agent Substances 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 229940045687 antimetabolites folic acid analogs Drugs 0.000 description 1
- 239000008365 aqueous carrier Substances 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 239000007900 aqueous suspension Substances 0.000 description 1
- 150000008209 arabinosides Chemical class 0.000 description 1
- 108010062796 arginyllysine Proteins 0.000 description 1
- 239000003886 aromatase inhibitor Substances 0.000 description 1
- 108010077245 asparaginyl-proline Proteins 0.000 description 1
- 229940009098 aspartate Drugs 0.000 description 1
- 108010047857 aspartylglycine Proteins 0.000 description 1
- 238000002820 assay format Methods 0.000 description 1
- 208000006673 asthma Diseases 0.000 description 1
- 229960005370 atorvastatin Drugs 0.000 description 1
- 230000001363 autoimmune Effects 0.000 description 1
- 229960002756 azacitidine Drugs 0.000 description 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 1
- 229950011321 azaserine Drugs 0.000 description 1
- 150000001541 aziridines Chemical class 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 230000008033 biological extinction Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 229950008548 bisantrene Drugs 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 229960002092 busulfan Drugs 0.000 description 1
- 108700002839 cactinomycin Proteins 0.000 description 1
- 229950009908 cactinomycin Drugs 0.000 description 1
- 229930195731 calicheamicin Natural products 0.000 description 1
- HXCHCVDVKSCDHU-LULTVBGHSA-N calicheamicin Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-LULTVBGHSA-N 0.000 description 1
- 229960004117 capecitabine Drugs 0.000 description 1
- 229960004562 carboplatin Drugs 0.000 description 1
- 229960002115 carboquone Drugs 0.000 description 1
- 229930188550 carminomycin Natural products 0.000 description 1
- XREUEWVEMYWFFA-CSKJXFQVSA-N carminomycin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=C(O)C=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XREUEWVEMYWFFA-CSKJXFQVSA-N 0.000 description 1
- XREUEWVEMYWFFA-UHFFFAOYSA-N carminomycin I Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=C(O)C=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XREUEWVEMYWFFA-UHFFFAOYSA-N 0.000 description 1
- 229960005243 carmustine Drugs 0.000 description 1
- 229950001725 carubicin Drugs 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 229960005395 cetuximab Drugs 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 229960004630 chlorambucil Drugs 0.000 description 1
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 1
- 229950008249 chlornaphazine Drugs 0.000 description 1
- 229960001480 chlorozotocin Drugs 0.000 description 1
- 230000001906 cholesterol absorption Effects 0.000 description 1
- ZYVSOIYQKUDENJ-WKSBCEQHSA-N chromomycin A3 Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@@H]1OC(C)=O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@@H](O)[C@H](O[C@@H]3O[C@@H](C)[C@H](OC(C)=O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@@H]1C[C@@H](O)[C@@H](OC)[C@@H](C)O1 ZYVSOIYQKUDENJ-WKSBCEQHSA-N 0.000 description 1
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- 238000011260 co-administration Methods 0.000 description 1
- 238000002648 combination therapy Methods 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 238000010668 complexation reaction Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 229940038717 copaxone Drugs 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 229960000684 cytarabine Drugs 0.000 description 1
- 229960003901 dacarbazine Drugs 0.000 description 1
- 229960000640 dactinomycin Drugs 0.000 description 1
- 229960000975 daunorubicin Drugs 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 229950003913 detorubicin Drugs 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 239000000032 diagnostic agent Substances 0.000 description 1
- 229940039227 diagnostic agent Drugs 0.000 description 1
- WVYXNIXAMZOZFK-UHFFFAOYSA-N diaziquone Chemical compound O=C1C(NC(=O)OCC)=C(N2CC2)C(=O)C(NC(=O)OCC)=C1N1CC1 WVYXNIXAMZOZFK-UHFFFAOYSA-N 0.000 description 1
- 229950002389 diaziquone Drugs 0.000 description 1
- 229960001259 diclofenac Drugs 0.000 description 1
- DCOPUUMXTXDBNB-UHFFFAOYSA-N diclofenac Chemical compound OC(=O)CC1=CC=CC=C1NC1=C(Cl)C=CC=C1Cl DCOPUUMXTXDBNB-UHFFFAOYSA-N 0.000 description 1
- 229960000616 diflunisal Drugs 0.000 description 1
- HUPFGZXOMWLGNK-UHFFFAOYSA-N diflunisal Chemical compound C1=C(O)C(C(=O)O)=CC(C=2C(=CC(F)=CC=2)F)=C1 HUPFGZXOMWLGNK-UHFFFAOYSA-N 0.000 description 1
- MCWXGJITAZMZEV-UHFFFAOYSA-N dimethoate Chemical compound CNC(=O)CSP(=S)(OC)OC MCWXGJITAZMZEV-UHFFFAOYSA-N 0.000 description 1
- XEYBRNLFEZDVAW-ARSRFYASSA-N dinoprostone Chemical compound CCCCC[C@H](O)\C=C\[C@H]1[C@H](O)CC(=O)[C@@H]1C\C=C/CCCC(O)=O XEYBRNLFEZDVAW-ARSRFYASSA-N 0.000 description 1
- 229960002986 dinoprostone Drugs 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- NOTIQUSPUUHHEH-UXOVVSIBSA-N dromostanolone propionate Chemical compound C([C@@H]1CC2)C(=O)[C@H](C)C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H](OC(=O)CC)[C@@]2(C)CC1 NOTIQUSPUUHHEH-UXOVVSIBSA-N 0.000 description 1
- 229950004683 drostanolone propionate Drugs 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- VLCYCQAOQCDTCN-UHFFFAOYSA-N eflornithine Chemical compound NCCCC(N)(C(F)F)C(O)=O VLCYCQAOQCDTCN-UHFFFAOYSA-N 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 229950011487 enocitabine Drugs 0.000 description 1
- 229940088598 enzyme Drugs 0.000 description 1
- 229960001904 epirubicin Drugs 0.000 description 1
- 229950002973 epitiostanol Drugs 0.000 description 1
- 229950002017 esorubicin Drugs 0.000 description 1
- ITSGNOIFAJAQHJ-BMFNZSJVSA-N esorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)C[C@H](C)O1 ITSGNOIFAJAQHJ-BMFNZSJVSA-N 0.000 description 1
- LJQQFQHBKUKHIS-WJHRIEJJSA-N esperamicin Chemical compound O1CC(NC(C)C)C(OC)CC1OC1C(O)C(NOC2OC(C)C(SC)C(O)C2)C(C)OC1OC1C(\C2=C/CSSSC)=C(NC(=O)OC)C(=O)C(OC3OC(C)C(O)C(OC(=O)C=4C(=CC(OC)=C(OC)C=4)NC(=O)C(=C)OC)C3)C2(O)C#C\C=C/C#C1 LJQQFQHBKUKHIS-WJHRIEJJSA-N 0.000 description 1
- 229960001842 estramustine Drugs 0.000 description 1
- FRPJXPJMRWBBIH-RBRWEJTLSA-N estramustine Chemical compound ClCCN(CCCl)C(=O)OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 FRPJXPJMRWBBIH-RBRWEJTLSA-N 0.000 description 1
- 239000000328 estrogen antagonist Substances 0.000 description 1
- QSRLNKCNOLVZIR-KRWDZBQOSA-N ethyl (2s)-2-[[2-[4-[bis(2-chloroethyl)amino]phenyl]acetyl]amino]-4-methylsulfanylbutanoate Chemical compound CCOC(=O)[C@H](CCSC)NC(=O)CC1=CC=C(N(CCCl)CCCl)C=C1 QSRLNKCNOLVZIR-KRWDZBQOSA-N 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- 229960005293 etodolac Drugs 0.000 description 1
- XFBVBWWRPKNWHW-UHFFFAOYSA-N etodolac Chemical compound C1COC(CC)(CC(O)=O)C2=N[C]3C(CC)=CC=CC3=C21 XFBVBWWRPKNWHW-UHFFFAOYSA-N 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 229940043168 fareston Drugs 0.000 description 1
- 229960002297 fenofibrate Drugs 0.000 description 1
- YMTINGFKWWXKFG-UHFFFAOYSA-N fenofibrate Chemical compound C1=CC(OC(C)(C)C(=O)OC(C)C)=CC=C1C(=O)C1=CC=C(Cl)C=C1 YMTINGFKWWXKFG-UHFFFAOYSA-N 0.000 description 1
- 102000052178 fibroblast growth factor receptor activity proteins Human genes 0.000 description 1
- 239000012467 final product Substances 0.000 description 1
- 229960000961 floxuridine Drugs 0.000 description 1
- ODKNJVUHOIMIIZ-RRKCRQDMSA-N floxuridine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(F)=C1 ODKNJVUHOIMIIZ-RRKCRQDMSA-N 0.000 description 1
- 229960000390 fludarabine Drugs 0.000 description 1
- GIUYCYHIANZCFB-FJFJXFQQSA-N fludarabine phosphate Chemical compound C1=NC=2C(N)=NC(F)=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@@H]1O GIUYCYHIANZCFB-FJFJXFQQSA-N 0.000 description 1
- 229960002074 flutamide Drugs 0.000 description 1
- MKXKFYHWDHIYRV-UHFFFAOYSA-N flutamide Chemical compound CC(C)C(=O)NC1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 MKXKFYHWDHIYRV-UHFFFAOYSA-N 0.000 description 1
- 229960003765 fluvastatin Drugs 0.000 description 1
- 229940014144 folate Drugs 0.000 description 1
- 108020005243 folate receptor Proteins 0.000 description 1
- 102000006815 folate receptor Human genes 0.000 description 1
- 229960000304 folic acid Drugs 0.000 description 1
- 150000002224 folic acids Chemical class 0.000 description 1
- 229960004783 fotemustine Drugs 0.000 description 1
- YAKWPXVTIGTRJH-UHFFFAOYSA-N fotemustine Chemical compound CCOP(=O)(OCC)C(C)NC(=O)N(CCCl)N=O YAKWPXVTIGTRJH-UHFFFAOYSA-N 0.000 description 1
- 108010090623 galactose binding protein Proteins 0.000 description 1
- 102000021529 galactose binding proteins Human genes 0.000 description 1
- 229940044658 gallium nitrate Drugs 0.000 description 1
- 229960005277 gemcitabine Drugs 0.000 description 1
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 1
- 229960003627 gemfibrozil Drugs 0.000 description 1
- 108010078144 glutaminyl-glycine Proteins 0.000 description 1
- 229930182470 glycoside Natural products 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 229960002913 goserelin Drugs 0.000 description 1
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 1
- UUVWYPNAQBNQJQ-UHFFFAOYSA-N hexamethylmelamine Chemical compound CN(C)C1=NC(N(C)C)=NC(N(C)C)=N1 UUVWYPNAQBNQJQ-UHFFFAOYSA-N 0.000 description 1
- 231100000086 high toxicity Toxicity 0.000 description 1
- 230000003054 hormonal effect Effects 0.000 description 1
- 102000046699 human CD14 Human genes 0.000 description 1
- 102000051957 human ERBB2 Human genes 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 229960001330 hydroxycarbamide Drugs 0.000 description 1
- 229940015872 ibandronate Drugs 0.000 description 1
- 229960001680 ibuprofen Drugs 0.000 description 1
- 229960000908 idarubicin Drugs 0.000 description 1
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Substances C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 1
- 230000002519 immonomodulatory effect Effects 0.000 description 1
- 210000002865 immune cell Anatomy 0.000 description 1
- 230000036737 immune function Effects 0.000 description 1
- 102000027596 immune receptors Human genes 0.000 description 1
- 108091008915 immune receptors Proteins 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 230000002163 immunogen Effects 0.000 description 1
- 230000003308 immunostimulating effect Effects 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- DBIGHPPNXATHOF-UHFFFAOYSA-N improsulfan Chemical compound CS(=O)(=O)OCCCNCCCOS(C)(=O)=O DBIGHPPNXATHOF-UHFFFAOYSA-N 0.000 description 1
- 229950008097 improsulfan Drugs 0.000 description 1
- 238000000099 in vitro assay Methods 0.000 description 1
- 238000012606 in vitro cell culture Methods 0.000 description 1
- 229960000905 indomethacin Drugs 0.000 description 1
- 210000004969 inflammatory cell Anatomy 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 229960003130 interferon gamma Drugs 0.000 description 1
- 108010074109 interleukin-22 Proteins 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 230000002601 intratumoral effect Effects 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- DKYWVDODHFEZIM-UHFFFAOYSA-N ketoprofen Chemical compound OC(=O)C(C)C1=CC=CC(C(=O)C=2C=CC=CC=2)=C1 DKYWVDODHFEZIM-UHFFFAOYSA-N 0.000 description 1
- 229960000991 ketoprofen Drugs 0.000 description 1
- 229960004752 ketorolac Drugs 0.000 description 1
- OZWKMVRBQXNZKK-UHFFFAOYSA-N ketorolac Chemical compound OC(=O)C1CCN2C1=CC=C2C(=O)C1=CC=CC=C1 OZWKMVRBQXNZKK-UHFFFAOYSA-N 0.000 description 1
- 229940115286 lentinan Drugs 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 231100000518 lethal Toxicity 0.000 description 1
- 230000001665 lethal effect Effects 0.000 description 1
- GFIJNRVAKGFPGQ-LIJARHBVSA-N leuprolide Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 GFIJNRVAKGFPGQ-LIJARHBVSA-N 0.000 description 1
- 229960004338 leuprorelin Drugs 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 229960002247 lomustine Drugs 0.000 description 1
- 229960004844 lovastatin Drugs 0.000 description 1
- PCZOHLXUXFIOCF-BXMDZJJMSA-N lovastatin Chemical compound C([C@H]1[C@@H](C)C=CC2=C[C@H](C)C[C@@H]([C@H]12)OC(=O)[C@@H](C)CC)C[C@@H]1C[C@@H](O)CC(=O)O1 PCZOHLXUXFIOCF-BXMDZJJMSA-N 0.000 description 1
- QLJODMDSTUBWDW-UHFFFAOYSA-N lovastatin hydroxy acid Natural products C1=CC(C)C(CCC(O)CC(O)CC(O)=O)C2C(OC(=O)C(C)CC)CC(C)C=C21 QLJODMDSTUBWDW-UHFFFAOYSA-N 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 239000008176 lyophilized powder Substances 0.000 description 1
- 108010038320 lysylphenylalanine Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 210000002652 macrocyte Anatomy 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- MQXVYODZCMMZEM-ZYUZMQFOSA-N mannomustine Chemical compound ClCCNC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CNCCCl MQXVYODZCMMZEM-ZYUZMQFOSA-N 0.000 description 1
- 229950008612 mannomustine Drugs 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 235000019988 mead Nutrition 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 229960004961 mechlorethamine Drugs 0.000 description 1
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 1
- 229950009246 mepitiostane Drugs 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 206010061289 metastatic neoplasm Diseases 0.000 description 1
- 108010085203 methionylmethionine Proteins 0.000 description 1
- VJRAUFKOOPNFIQ-TVEKBUMESA-N methyl (1r,2r,4s)-4-[(2r,4s,5s,6s)-5-[(2s,4s,5s,6s)-5-[(2s,4s,5s,6s)-4,5-dihydroxy-6-methyloxan-2-yl]oxy-4-hydroxy-6-methyloxan-2-yl]oxy-4-(dimethylamino)-6-methyloxan-2-yl]oxy-2-ethyl-2,5,7,10-tetrahydroxy-6,11-dioxo-3,4-dihydro-1h-tetracene-1-carboxylat Chemical compound O([C@H]1[C@@H](O)C[C@@H](O[C@H]1C)O[C@H]1[C@H](C[C@@H](O[C@H]1C)O[C@H]1C[C@]([C@@H](C2=CC=3C(=O)C4=C(O)C=CC(O)=C4C(=O)C=3C(O)=C21)C(=O)OC)(O)CC)N(C)C)[C@H]1C[C@H](O)[C@H](O)[C@H](C)O1 VJRAUFKOOPNFIQ-TVEKBUMESA-N 0.000 description 1
- HPNSFSBZBAHARI-UHFFFAOYSA-N micophenolic acid Natural products OC1=C(CC=C(C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-UHFFFAOYSA-N 0.000 description 1
- 239000011325 microbead Substances 0.000 description 1
- 108010038232 microsomal triglyceride transfer protein Proteins 0.000 description 1
- 239000003595 mist Substances 0.000 description 1
- 229960003539 mitoguazone Drugs 0.000 description 1
- MXWHMTNPTTVWDM-NXOFHUPFSA-N mitoguazone Chemical compound NC(N)=N\N=C(/C)\C=N\N=C(N)N MXWHMTNPTTVWDM-NXOFHUPFSA-N 0.000 description 1
- VFKZTMPDYBFSTM-GUCUJZIJSA-N mitolactol Chemical compound BrC[C@H](O)[C@@H](O)[C@@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-GUCUJZIJSA-N 0.000 description 1
- 229950010913 mitolactol Drugs 0.000 description 1
- 229960000350 mitotane Drugs 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 229960000951 mycophenolic acid Drugs 0.000 description 1
- HPNSFSBZBAHARI-RUDMXATFSA-N mycophenolic acid Chemical compound OC1=C(C\C=C(/C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-RUDMXATFSA-N 0.000 description 1
- 210000000066 myeloid cell Anatomy 0.000 description 1
- NJSMWLQOCQIOPE-OCHFTUDZSA-N n-[(e)-[10-[(e)-(4,5-dihydro-1h-imidazol-2-ylhydrazinylidene)methyl]anthracen-9-yl]methylideneamino]-4,5-dihydro-1h-imidazol-2-amine Chemical compound N1CCN=C1N\N=C\C(C1=CC=CC=C11)=C(C=CC=C2)C2=C1\C=N\NC1=NCCN1 NJSMWLQOCQIOPE-OCHFTUDZSA-N 0.000 description 1
- 229960004270 nabumetone Drugs 0.000 description 1
- 239000002105 nanoparticle Substances 0.000 description 1
- 229960002009 naproxen Drugs 0.000 description 1
- CMWTZPSULFXXJA-VIFPVBQESA-N naproxen Chemical compound C1=C([C@H](C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-VIFPVBQESA-N 0.000 description 1
- 229940086322 navelbine Drugs 0.000 description 1
- 230000024717 negative regulation of secretion Effects 0.000 description 1
- 229960002653 nilutamide Drugs 0.000 description 1
- XWXYUMMDTVBTOU-UHFFFAOYSA-N nilutamide Chemical compound O=C1C(C)(C)NC(=O)N1C1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 XWXYUMMDTVBTOU-UHFFFAOYSA-N 0.000 description 1
- 229960001420 nimustine Drugs 0.000 description 1
- VFEDRRNHLBGPNN-UHFFFAOYSA-N nimustine Chemical compound CC1=NC=C(CNC(=O)N(CCCl)N=O)C(N)=N1 VFEDRRNHLBGPNN-UHFFFAOYSA-N 0.000 description 1
- YMVWGSQGCWCDGW-UHFFFAOYSA-N nitracrine Chemical compound C1=CC([N+]([O-])=O)=C2C(NCCCN(C)C)=C(C=CC=C3)C3=NC2=C1 YMVWGSQGCWCDGW-UHFFFAOYSA-N 0.000 description 1
- 229950008607 nitracrine Drugs 0.000 description 1
- 229950009266 nogalamycin Drugs 0.000 description 1
- KGTDRFCXGRULNK-JYOBTZKQSA-N nogalamycin Chemical compound CO[C@@H]1[C@@](OC)(C)[C@@H](OC)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=C(O)C=C4[C@@]5(C)O[C@H]([C@H]([C@@H]([C@H]5O)N(C)C)O)OC4=C3C3=O)=C3C=C2[C@@H](C(=O)OC)[C@@](C)(O)C1 KGTDRFCXGRULNK-JYOBTZKQSA-N 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- 239000000346 nonvolatile oil Substances 0.000 description 1
- 229950011093 onapristone Drugs 0.000 description 1
- OFPXSFXSNFPTHF-UHFFFAOYSA-N oxaprozin Chemical compound O1C(CCC(=O)O)=NC(C=2C=CC=CC=2)=C1C1=CC=CC=C1 OFPXSFXSNFPTHF-UHFFFAOYSA-N 0.000 description 1
- 229960002739 oxaprozin Drugs 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 230000006320 pegylation Effects 0.000 description 1
- 229960002340 pentostatin Drugs 0.000 description 1
- FPVKHBSQESCIEP-JQCXWYLXSA-N pentostatin Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC[C@H]2O)=C2N=C1 FPVKHBSQESCIEP-JQCXWYLXSA-N 0.000 description 1
- QIMGFXOHTOXMQP-GFAGFCTOSA-N peplomycin Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCCN[C@@H](C)C=1C=CC=CC=1)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1NC=NC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C QIMGFXOHTOXMQP-GFAGFCTOSA-N 0.000 description 1
- 229950003180 peplomycin Drugs 0.000 description 1
- 210000003024 peritoneal macrophage Anatomy 0.000 description 1
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 1
- 230000000704 physical effect Effects 0.000 description 1
- 239000002504 physiological saline solution Substances 0.000 description 1
- 229960000952 pipobroman Drugs 0.000 description 1
- NJBFOOCLYDNZJN-UHFFFAOYSA-N pipobroman Chemical compound BrCCC(=O)N1CCN(C(=O)CCBr)CC1 NJBFOOCLYDNZJN-UHFFFAOYSA-N 0.000 description 1
- NUKCGLDCWQXYOQ-UHFFFAOYSA-N piposulfan Chemical compound CS(=O)(=O)OCCC(=O)N1CCN(C(=O)CCOS(C)(=O)=O)CC1 NUKCGLDCWQXYOQ-UHFFFAOYSA-N 0.000 description 1
- 229950001100 piposulfan Drugs 0.000 description 1
- 229960001221 pirarubicin Drugs 0.000 description 1
- 229960002702 piroxicam Drugs 0.000 description 1
- QYSPLQLAKJAUJT-UHFFFAOYSA-N piroxicam Chemical compound OC=1C2=CC=CC=C2S(=O)(=O)N(C)C=1C(=O)NC1=CC=CC=N1 QYSPLQLAKJAUJT-UHFFFAOYSA-N 0.000 description 1
- 150000003057 platinum Chemical class 0.000 description 1
- 229910052697 platinum Inorganic materials 0.000 description 1
- 229960000502 poloxamer Drugs 0.000 description 1
- 229920001983 poloxamer Polymers 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 239000000244 polyoxyethylene sorbitan monooleate Substances 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 239000000249 polyoxyethylene sorbitan monopalmitate Substances 0.000 description 1
- 235000010483 polyoxyethylene sorbitan monopalmitate Nutrition 0.000 description 1
- 239000001818 polyoxyethylene sorbitan monostearate Substances 0.000 description 1
- 235000010989 polyoxyethylene sorbitan monostearate Nutrition 0.000 description 1
- 229940068977 polysorbate 20 Drugs 0.000 description 1
- 229940101027 polysorbate 40 Drugs 0.000 description 1
- 229940113124 polysorbate 60 Drugs 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- 229940068968 polysorbate 80 Drugs 0.000 description 1
- 229960002965 pravastatin Drugs 0.000 description 1
- TUZYXOIXSAXUGO-PZAWKZKUSA-N pravastatin Chemical compound C1=C[C@H](C)[C@H](CC[C@@H](O)C[C@@H](O)CC(O)=O)[C@H]2[C@@H](OC(=O)[C@@H](C)CC)C[C@H](O)C=C21 TUZYXOIXSAXUGO-PZAWKZKUSA-N 0.000 description 1
- 229960004694 prednimustine Drugs 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 1
- 229960000624 procarbazine Drugs 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- XEYBRNLFEZDVAW-UHFFFAOYSA-N prostaglandin E2 Natural products CCCCCC(O)C=CC1C(O)CC(=O)C1CC=CCCCC(O)=O XEYBRNLFEZDVAW-UHFFFAOYSA-N 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- WOLQREOUPKZMEX-UHFFFAOYSA-N pteroyltriglutamic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(=O)NC(CCC(=O)NC(CCC(O)=O)C(O)=O)C(O)=O)C(O)=O)C=C1 WOLQREOUPKZMEX-UHFFFAOYSA-N 0.000 description 1
- 150000003212 purines Chemical class 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 229960002185 ranimustine Drugs 0.000 description 1
- 239000000018 receptor agonist Substances 0.000 description 1
- 229940044601 receptor agonist Drugs 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 210000003289 regulatory T cell Anatomy 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 229930002330 retinoic acid Natural products 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 229950004892 rodorubicin Drugs 0.000 description 1
- 229960000371 rofecoxib Drugs 0.000 description 1
- RZJQGNCSTQAWON-UHFFFAOYSA-N rofecoxib Chemical compound C1=CC(S(=O)(=O)C)=CC=C1C1=C(C=2C=CC=CC=2)C(=O)OC1 RZJQGNCSTQAWON-UHFFFAOYSA-N 0.000 description 1
- 229960000672 rosuvastatin Drugs 0.000 description 1
- BPRHUIZQVSMCRT-VEUZHWNKSA-N rosuvastatin Chemical compound CC(C)C1=NC(N(C)S(C)(=O)=O)=NC(C=2C=CC(F)=CC=2)=C1\C=C\[C@@H](O)C[C@@H](O)CC(O)=O BPRHUIZQVSMCRT-VEUZHWNKSA-N 0.000 description 1
- VHXNKPBCCMUMSW-FQEVSTJZSA-N rubitecan Chemical compound C1=CC([N+]([O-])=O)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VHXNKPBCCMUMSW-FQEVSTJZSA-N 0.000 description 1
- 238000007423 screening assay Methods 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 239000003352 sequestering agent Substances 0.000 description 1
- 229960002855 simvastatin Drugs 0.000 description 1
- RYMZZMVNJRMUDD-HGQWONQESA-N simvastatin Chemical compound C([C@H]1[C@@H](C)C=CC2=C[C@H](C)C[C@@H]([C@H]12)OC(=O)C(C)(C)CC)C[C@@H]1C[C@@H](O)CC(=O)O1 RYMZZMVNJRMUDD-HGQWONQESA-N 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 239000002002 slurry Substances 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 238000009987 spinning Methods 0.000 description 1
- 229950006315 spirogermanium Drugs 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 229960001052 streptozocin Drugs 0.000 description 1
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 229960000894 sulindac Drugs 0.000 description 1
- MLKXDPUZXIRXEP-MFOYZWKCSA-N sulindac Chemical compound CC1=C(CC(O)=O)C2=CC(F)=CC=C2\C1=C/C1=CC=C(S(C)=O)C=C1 MLKXDPUZXIRXEP-MFOYZWKCSA-N 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 208000011580 syndromic disease Diseases 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- RCINICONZNJXQF-XAZOAEDWSA-N taxol® Chemical compound O([C@@H]1[C@@]2(CC(C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3(C21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-XAZOAEDWSA-N 0.000 description 1
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 description 1
- 229960001278 teniposide Drugs 0.000 description 1
- BPEWUONYVDABNZ-DZBHQSCQSA-N testolactone Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)(OC(=O)CC4)[C@@H]4[C@@H]3CCC2=C1 BPEWUONYVDABNZ-DZBHQSCQSA-N 0.000 description 1
- 229960005353 testolactone Drugs 0.000 description 1
- UDEJEOLNSNYQSX-UHFFFAOYSA-J tetrasodium;2,4,6,8-tetraoxido-1,3,5,7,2$l^{5},4$l^{5},6$l^{5},8$l^{5}-tetraoxatetraphosphocane 2,4,6,8-tetraoxide Chemical compound [Na+].[Na+].[Na+].[Na+].[O-]P1(=O)OP([O-])(=O)OP([O-])(=O)OP([O-])(=O)O1 UDEJEOLNSNYQSX-UHFFFAOYSA-J 0.000 description 1
- 238000011287 therapeutic dose Methods 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- 239000010409 thin film Substances 0.000 description 1
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- YFTWHEBLORWGNI-UHFFFAOYSA-N tiamiprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC(N)=NC2=C1NC=N2 YFTWHEBLORWGNI-UHFFFAOYSA-N 0.000 description 1
- 229950011457 tiamiprine Drugs 0.000 description 1
- 229960001017 tolmetin Drugs 0.000 description 1
- UPSPUYADGBWSHF-UHFFFAOYSA-N tolmetin Chemical compound C1=CC(C)=CC=C1C(=O)C1=CC=C(CC(O)=O)N1C UPSPUYADGBWSHF-UHFFFAOYSA-N 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- 229960005026 toremifene Drugs 0.000 description 1
- XFCLJVABOIYOMF-QPLCGJKRSA-N toremifene Chemical compound C1=CC(OCCN(C)C)=CC=C1C(\C=1C=CC=CC=1)=C(\CCCl)C1=CC=CC=C1 XFCLJVABOIYOMF-QPLCGJKRSA-N 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 238000002054 transplantation Methods 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- 229950001353 tretamine Drugs 0.000 description 1
- IUCJMVBFZDHPDX-UHFFFAOYSA-N tretamine Chemical compound C1CN1C1=NC(N2CC2)=NC(N2CC2)=N1 IUCJMVBFZDHPDX-UHFFFAOYSA-N 0.000 description 1
- 229960001727 tretinoin Drugs 0.000 description 1
- 229960004560 triaziquone Drugs 0.000 description 1
- PXSOHRWMIRDKMP-UHFFFAOYSA-N triaziquone Chemical compound O=C1C(N2CC2)=C(N2CC2)C(=O)C=C1N1CC1 PXSOHRWMIRDKMP-UHFFFAOYSA-N 0.000 description 1
- 229960001670 trilostane Drugs 0.000 description 1
- KVJXBPDAXMEYOA-CXANFOAXSA-N trilostane Chemical compound OC1=C(C#N)C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CC[C@@]32O[C@@H]31 KVJXBPDAXMEYOA-CXANFOAXSA-N 0.000 description 1
- NOYPYLRCIDNJJB-UHFFFAOYSA-N trimetrexate Chemical compound COC1=C(OC)C(OC)=CC(NCC=2C(=C3C(N)=NC(N)=NC3=CC=2)C)=C1 NOYPYLRCIDNJJB-UHFFFAOYSA-N 0.000 description 1
- 229960001099 trimetrexate Drugs 0.000 description 1
- 229950000212 trioxifene Drugs 0.000 description 1
- 229960000875 trofosfamide Drugs 0.000 description 1
- UMKFEPPTGMDVMI-UHFFFAOYSA-N trofosfamide Chemical compound ClCCN(CCCl)P1(=O)OCCCN1CCCl UMKFEPPTGMDVMI-UHFFFAOYSA-N 0.000 description 1
- HDZZVAMISRMYHH-LITAXDCLSA-N tubercidin Chemical compound C1=CC=2C(N)=NC=NC=2N1[C@@H]1O[C@@H](CO)[C@H](O)[C@H]1O HDZZVAMISRMYHH-LITAXDCLSA-N 0.000 description 1
- 230000004614 tumor growth Effects 0.000 description 1
- 108010020532 tyrosyl-proline Proteins 0.000 description 1
- 229950009811 ubenimex Drugs 0.000 description 1
- 230000003827 upregulation Effects 0.000 description 1
- 229960001055 uracil mustard Drugs 0.000 description 1
- 230000002792 vascular Effects 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 229960003048 vinblastine Drugs 0.000 description 1
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 1
- 229960004528 vincristine Drugs 0.000 description 1
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 1
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 1
- 229960004355 vindesine Drugs 0.000 description 1
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 description 1
- GBABOYUKABKIAF-IELIFDKJSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-IELIFDKJSA-N 0.000 description 1
- 229960002066 vinorelbine Drugs 0.000 description 1
- CILBMBUYJCWATM-PYGJLNRPSA-N vinorelbine ditartrate Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O.OC(=O)[C@H](O)[C@@H](O)C(O)=O.C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC CILBMBUYJCWATM-PYGJLNRPSA-N 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 230000003442 weekly effect Effects 0.000 description 1
- 229940053867 xeloda Drugs 0.000 description 1
- 229960000641 zorubicin Drugs 0.000 description 1
- FBTUMDXHSRTGRV-ALTNURHMSA-N zorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(\C)=N\NC(=O)C=1C=CC=CC=1)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 FBTUMDXHSRTGRV-ALTNURHMSA-N 0.000 description 1
Images

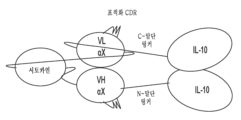














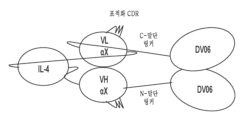








Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/54—Interleukins [IL]
- C07K14/5428—IL-10
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/06—Immunosuppressants, e.g. drugs for graft rejection
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/54—Interleukins [IL]
- C07K14/5406—IL-4
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/54—Interleukins [IL]
- C07K14/55—IL-2
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from RNA viruses
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from RNA viruses
- C07K16/1036—Retroviridae, e.g. leukemia viruses
- C07K16/1045—Lentiviridae, e.g. HIV, FIV, SIV
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2896—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against molecules with a "CD"-designation, not provided for elsewhere
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/461—Igs containing Ig-regions, -domains or -residues form different species
- C07K16/464—Igs containing CDR-residues from one specie grafted between FR-residues from another
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/545—Medicinal preparations containing antigens or antibodies characterised by the dose, timing or administration schedule
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/53—Hinge
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2318/00—Antibody mimetics or scaffolds
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Virology (AREA)
- Gastroenterology & Hepatology (AREA)
- Zoology (AREA)
- Toxicology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Pharmacology & Pharmacy (AREA)
- Engineering & Computer Science (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Oncology (AREA)
- Transplantation (AREA)
- AIDS & HIV (AREA)
- Hematology (AREA)
- Epidemiology (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicinal Preparation (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
Abstract
본 출원은 단일 쇄 가변 단편 스캐폴딩 시스템에 융합된 IL-10 또는 IL-10 변이체 분자, 및 scFv의 힌지 영역에 연결된 제2 시토카인을 포함하는 이중 시토카인 융합 단백질 조성물, 그의 제약 조성물, 및/또는 제제에 관한 것이다. 본 출원은 또한 암, 염증성 질환 또는 장애, 및 면역 및 면역 매개 질환 또는 장애를 치료하기 위해 이중 시토카인 융합 단백질 조성물을 사용하는 방법에 관한 것이다.
Description
관련 출원에 대한 상호 참조
본 출원은 2020년 7월 20일 출원된 미국 가출원 번호 63/054,208에 대한 우선권을 주장하며, 상기 우선권 출원의 개시내용은 그 전문이 본원에서 참조로 포함된다.
본 발명의 기술분야
본 개시내용은 생명공학 분야, 더욱 구체적으로 다른 염증 및 면역 조절 시토카인과 조합된 인터류킨-10 ("IL-10")을 포함하는 신규한 이중 시토카인 융합 단백질, 염증성 및 면역 질환 또는 병태를 치료하는 방법, 및/또는 암을 치료하는 방법에 관한 것이다.
원래 시토카인 합성 억제 인자로 명명된 IL-10 (Malefyt, Interleukin 10 inhbits cytokine synthesis by human monocytes: An autoreglatory role of IL-10 produced by monocytes, 1991)은 염증 반응을 억제시키고 (Fedorak, 2000), 더욱 최근에는 CD8+ T 세포를 활성화시켜 인터페론γ ("IFNγ") 의존성 항-종양 면역 반응을 유도하는 것 (Mumm J., 2011) 둘 모두로 공지된 다면발현성 시토카인이다. IL-10은 IFNγ와 구조적 유사성을 갖는 비공유 동종이량체 시토카인이다. IL-10은 IL10 수용체 1 (IL10R1)의 두 서브유닛과 IL-10 수용체 2 (IL10R2)의 두 서브유닛으로 이루어진 IL-10 수용체에 결합한다 (Moore, 2001). IL-10 수용체 복합체는 대부분의 조혈 세포의 표면 상에서 발현되고, 대식세포 및 T 세포에서 가장 높게 발현된다. IL-10은 면역억제 시토카인 (Schreiber, 2000) 및 면역자극 시토카인 (Mumm, 2011) 둘 모두로 보고되었지만, 크론병 환자의 IL-10 치료에 대한 임상 평가에서는 그 결과로 역 용량 반응을 얻은 반면 (Fedorak, 2000; Schreiber, 2000), PEG화된 IL-10을 이용한 암 환자 치료에서는 그 결과로 용량 적정가능한 강력한 항-종양 반응을 얻었다 (Naing, 2018). PEG화된 IL-10 항-종양 반응은 내인성 CD8+ T 세포 및 IFNγ를 필요로 한다 (Mumm, 2011). 종양 보유 동물을 PEG화된 IL-10으로 치료하면 종양내 CD8+ T 세포는 증가하고, 세포당 기준으로 IFNγ는 증가한다. 그러나, 가장 최근에는 PEG화된 IL-10으로 치료받은 암 환자는 면역 자극의 증거는 보였지만, 항-종양 반응 증가의 증거는 나타내지 않았다 (Spigel, 2020).
인터류킨-2 ("IL-2")는 항-종양 면역 반응을 유도할 뿐만 아니라 (Jiang, 2016), 자연 살해 ("NK") 세포 및 CD4+ T 세포의 비제어된 활성화 및 그에 의한 IFNγ 분비 및 T 조절 세포의 확장에 기인하여 높은 독성을 보이는 것으로 공지된 (Chinen, 2016) 4-나선형 번들 다면발현성 시토카인이다. 이러한 이유로 많은 그룹들이 IL-2의 독성을 감소시키기 위한 노력의 일환으로 고친화성 수용체에 대한 그의 결합을 감소시키기 위해 IL-2를 돌연변이화시키는 시도를 해 왔다 (Chen, 2018). 상기 뮤테인은 실질적인 임상적 성공을 거두지 못했다 (Bentebibe, 2019). 이는 IL-2의 잠재적으로 치명적인 독성을 감소시키기 위해서는 다른 메커니즘을 사용하여야 한다는 것을 시사한다.
IL-10은 NK 및 CD4+ T 세포 둘 모두에 의해 분비되는 IL-2 유도된 IFNγ 생산을 억제하는 것으로 보고되었지만 (Scott, 2006), IL-2 유도된 CD8+ T 세포 증식에 대한 보조인자로서 작용하는 것으로도 또한 보고되었다 (Groux, 1998). 따라서, IL-2 및 IL-10이 면역계의 세포를 공동 활성화시키는지 또는 서로 상쇄시키는지 여부는 알려져 있지 않다.
인터류킨-4 ("IL-4")는 대부분 대식세포에 의한 대체 활성화를 유도하는 것과 연관된 (Balce, 2011), 본질적인 Th2 유도 시토카인으로 간주되는 (McGuirk, 2000), 4-나선형 번들 다면발현성 시토카인이다. IL-4는 우세하게 알레르기 반응 및 천식과 연관된 염증 유도와 관련이 있다 ([Steinke, 2001]; [Ryan, 1997]). 추가로, 일부 암세포 증식을 억제시킬 수 있는 IL-4의 능력에 기인하여 ([Lee, 2016]; [Gooch, 1998]), 암 환자는 IL-4로 안전하게 치료되었다 (Davis, 2009). IL-4는 염증유발성 시토카인의 단핵구 분비를 억제하는 것으로 보고되었지만 (Woodward, 2012), 항원 제시 세포를 프라이밍하고, 박테리아에 노출된 단핵구에 의한 염증유발성 시토카인 분비를 유도하는 그의 능력에 기인하여 강력한 항-염증성 시토카인으로 간주되지 않는다 (Varin, 2010).
놀랍게도, 주요 IL-10 수용체 결합 도메인 영역에 (서열식별번호(SEQ ID No.) 3의 성숙한 EBV IL-10 아미노산 서열의 아미노산 위치 31, 75, 또는 둘 모두에서) 하나 이상의 아미노산 치환을 갖는 엡스타인-바(Epstein-Barr) 바이러스 ("EBV") IL-10 변이체가 IL-10 수용체에 결합하고 이를 활성화시키는 EBV IL-10의 능력을 변경시켰다는 것이 발견되었다. 이러한 변형에는 IL-10 수용체에 대한 EBV IL-10의 친화성을 증가시키는 능력이 포함되었다. 본 발명자는 EBV IL-10 변이체 분자가 면역 질환, 염증성 질환 또는 병태를 치료할 수 있고, 암을 치료하는 데에서 IL-10 수용체 효능제로 작용한다는 것을 발견하였다. 본 발명자는 또한 단량체 EBV IL-10 변이체를 비-면역원성 가변 중쇄 ("VH") 및 가변 경쇄 ("VL") 영역을 포함하는 스캐폴딩 시스템에 도입함으로써 생성된 EBV IL-10 변이체 분자는 반감기가 연장되었고, 적절하게 폴딩되었고, 기능적으로 활성을 보였다는 것을 발견하였다. 스캐폴딩 시스템 내로 도입된 EBV IL-10 변이체는 염증성 세포 (예컨대, 단핵구/대식세포/수지상 세포) 및 면역 세포 (예컨대, CD8+ T 세포) 둘 모두 상에서 증진된 IL-10 기능을 보였다. 2020년 3월 6일 미국 출원 16/811,718로 출원된 미국 특허 10,858,412 (그 전문이 본원에서 참조로 포함)를 참조한다. 염증성 질환, 면역 질환, 및/또는 암을 치료하기 위해 IL-10 생물학적 성질을 상가적으로 또는 상승작용적으로 증진시키는 새로운 융합 단백질 구조의 일부로서 IL-10 및 또 다른 시토카인 둘 모두를 전달하는 이전에 기술된 EBV IL-10 스캐폴딩 시스템에 대한 변형에 초점을 두고 있다.
본 개시내용은 일반적으로 이중 시토카인 융합 단백질에 관한 것이다.
따라서, 제1 측면에서, 본 개시내용은 제1 시토카인으로서 모노클로날 항체의 항원 결합 단편 또는 가변 중쇄 ("VH") 및 가변 경쇄 ("VL") 영역에 융합된 IL-10 또는 IL-10 변이체, 및 항원 결합 단편의 VH와 VL 영역 사이에 연결된 제2 시토카인을 포함하는 이중 시토카인 융합 단백질에 관한 것이다. 특정 실시양태에서, 제1 시토카인은 IL-10, 예컨대 비제한적으로 인간, 마우스, 시토메갈로바이러스 ("CMV"), 또는 EBV IL-10 형태 또는 IL-10 변이체 분자이며, 여기서, IL-10 변이체는 IL-10 수용체 결합 도메인에 영향을 미치는 하나 이상의 아미노산 치환(들)을 갖는다. 융합 단백질은 또한 제1 시토카인과 상이한 시토카인으로서, IL-10 또는 IL-10 변이체 분자와 함께 작용하여 제1 및 제2 시토카인이 융합 단백질에 의해 특정 항원에 표적화되었을 때, 또는 항원 결합 단편의 VH 및 VL 영역에 의해 반감기가 연장되었을 때, 상가적 또는 상승작용적 효과가 있도록 하는 제2 시토카인을 포함한다. 융합 단백질은 또한 이중 시토카인 융합 단백질을 항체, 항체 단편, 또는 그의 항원 결합 부분의 VH 및 VL 영역에 의해 인식되는 표적 항원에 지시하는 VH 및 VL 영역을 포함하는 항체, 항체 단편, 또는 항원 결합 부분을 포함한다. 특정 실시양태에서, 항원 결합 단편은 scFv이다.
추가의 또 다른 측면에서, 본 개시내용은 하기 화학식 (I)의 이중 시토카인 융합 단백질에 관한 것이다:
NH2-(IL10)-(X1)-(Zn)-(X2)-(IL10)-COOH;
상기 식에서,
"IL10"은 IL-10의 단량체이고, 여기서, IL-10은 인간, 마우스, CMV, 또는 EBV IL-10, 또는 그의 변이체이고, 더욱 바람직하게, IL10은 서열식별번호 1, 3, 9, 10, 11, 12, 14, 또는 16으로부터 선택되는 서열을 포함하는 단량체이고;
"X1"은 제1 모노클로날 항체로부터 수득된 VL 또는 VH 영역이고; "X2"는 제1 모노클로날 항체로부터 수득된 VH 또는 VL 영역이고; 여기서, X1이 VL일 때, X2는 VH이거나, 또는 X1이 VH일 때, X2는 VL이고;
"Z"는 IL-10 이외의 다른 시토카인이고;
"n"은 0-2로부터 선택되는 정수이다.
추가의 또 다른 측면에서, 본 개시내용은 하기 화학식 (II)의 IL-10 융합 단백질에 관한 것이다:
NH2-(IL10)-(L)-(X1)-(L)-(Zn)-(L)-(X2)-(L)-(IL10)-COOH;
상기 식에서,
"IL-10"은 서열식별번호 1, 3, 9, 10, 11, 12, 14, 또는 16으로부터 선택되는 단량체 서열이고;
"L"은 임의의 링커이고, 더욱 바람직하게, 링커는 서열식별번호 39, 40, 또는 41로부터 선택되고;
X1"은 제1 모노클로날 항체로부터 수득된 VL 또는 VH 영역이고; "X2"는 제1 모노클로날 항체로부터 수득된 VH 또는 VL 영역이고; 여기서, X1이 VL일 때, X2는 VH이거나, 또는 X1이 VH일 때, X2는 VL이고;
"Z"는 IL-6, IL-4, IL-1, IL-2, IL-3, IL-5, IL-7, IL-8, IL-9, IL-15, IL-21 IL-26, IL-27, IL-28, IL-29, GM-CSF, G-CSF, 인터페론-α, -β, -γ, TGF-β, 또는 종양 괴사 인자-α, -β, 염기성 FGF, EGF, PDGF, IL-4, IL-11, 또는 IL-13으로부터 선택되는 시토카인이고;
"n"은 0-2로부터 선택되는 정수이다.
다른 측면에서, 본 개시내용은 이중 시토카인 융합 단백질을 코딩하는 핵산 분자에 관한 것이다.
다른 측면에서, 본 개시내용은 이중 시토카인 융합 단백질을 제조 및 정제하는 방법에 관한 것이다. 한 실시양태에서, 이중 시토카인 융합 단백질을 제조하는 방법은 이중 시토카인 융합 단백질을 코딩하는 핵산을 재조합적으로 발현시키는 단계를 포함한다.
다른 측면에서, 본 개시내용은 암 치료를 필요로 하는 대상체에게 유효량의 이중 시토카인 융합 단백질을 투여하는 단계를 포함하는 암을 치료하는 방법에 관한 것이다.
다른 측면에서, 본 개시내용은 염증성 질환 또는 병태 치료를 필요로 하는 대상체에게 유효량의 이중 시토카인 융합 단백질을 투여하는 단계를 포함하는, 염증성 질환 또는 병태를 치료하는 방법에 관한 것이다. 바람직하게, 염증성 질환은 크론병, 건선, 및/또는 류마티스 관절염이다.
다른 측면에서, 본 개시내용은 면역 질환 또는 병태 치료를 필요로 하는 대상체에게 유효량의 이중 시토카인 융합 단백질을 투여하는 단계를 포함하는, 면역 질환 또는 병태를 치료하는 방법에 관한 것이다.
다른 측면에서, 본 개시내용은 패혈증 및/또는 패혈성 쇼크 및 이의 연관 증상을 치료, 억제 및/또는 완화시키는 방법에 관한 것이다.
상기 대표적인 측면의 단순화된 요약은 본 개시내용의 기본적인 이해를 제공하는 역할을 한다. 이 요약은 모든 고려된 측면의 광범위한 개요가 아니며, 모든 측면의 주요 또는 중요한 요소를 확인하는 것으로도 본 개시내용의 임의의 또는 모든 측면의 범주를 설명하는 것으로도 의도되지 않는다. 그의 유일한 목적은 하기 본 개시내용의 더욱 상세한 설명에 대한 서두로서 단순화된 형태로 하나 이상의 측면을 제시하는 것이다. 전술한 것을 달성하기 위해, 본 개시내용의 하나 이상의 측면은 청구범위에서 설명되고, 예시적으로 지적된 특징을 포함한다.
도 1은 미국 특허 10,858,412에 기술된 IL-10 시토카인 융합 단백질의 개략도이다.
도 2는 이중 시토카인 융합 단백질이 말단 연결된 IL-10 단량체 (또는 IL-10 변이체)를 포함하고, 여기서, 제2 시토카인은 scFv의 VH와 VL 사이의 링커 내로 도입된 것인, 본 개시내용에서 구현된 이중 시토카인 융합 단백질의 개략도이다.
도 3은 scFv의 VH 및 VL에 연결된 DV07 (EBV IL-10의 IL-10 수용체 고친화성 변이체), 및 최극단의 C-말단 IL-10 단량체의 카르복시 말단에 융합된 IL-2를 포함하는 ("SLP-IL-2"로 명명되는) 대안적 형태의 2개의 시토카인을 포함하는 융합 단백질의 개략도이다.
도 4는 단핵구/대식세포로부터의 TNFα 분비 감소율(%)에 대해 SLP-IL-2를 IL-10, IL-2, 및 IL-10과 IL-2의 조합과 비교하는 적정 연구이다.
도 5는 단핵구로부터의 TNFα 분비 감소율(%)에 대해 DK210을 IL-10 및 DegfrDV07 (SLP 변이체 3; 서열식별번호 31)과 비교하는 적정 연구이다.
도 6은 SLP 및 DK210을 비교한 T 세포 IFNγ 강화 검정이다. 진한 회색 막대는 두 시토카인의 혈청 최저 치료 농도를 나타내고, 옅은 회색 막대는 DK210에 대한 예상 치료 농도 요건을 나타낸다.
도 7은 NK 세포, CD4+ T 세포 및 CD8+ T 세포 상의 IL-10이 IL-2 매개 IFNγ 유도에 대한 효과를 결정하는 검정이다. 진한 회색 막대는 두 시토카인의 혈청 최저 치료 농도를 나타내고, 옅은 회색 막대는 DK210에 대한 예상 치료 농도 요건을 나타낸다.
도 8은 T 세포에서 모델 항원 제시에 대한 시토카인의 효과를 측정하는 검정이다.
도 9는 항원 노출 후 CD4+ 및 CD8+ T 세포에서의 IFNγ의 유도를 측정하는 검정이다.
도 10은 Degfr:DV07 또는 DK210으로 처리된 마우스에서 항종양 효과를 비교하는 생체내 CT26 (hEGFR+) 종양 마우스 모델 연구이다.
도 11은 Degfr:DV07 또는 DK210으로 처리된 마우스의 체중을 비교한 생체내 CT 26 (hEGFR+) 종양 마우스 모델 연구이다.
도 12는 Degfr:DV07 및 DK210으로 처리된 마우스의 생존을 비교한 생체내 CT26 (hEGFR+) 종양 마우스 모델 연구이다.
도 13은 단핵구로부터의 TNFα 분비 감소율(%)에 대한 IL-10, IL-4, 및 IL-10 및 IL-4에 대한 적정 연구이다.
도 14는 단핵구로부터의 TNFα 분비 감소율(%)에 대한 IL-10, IL-4, IL-4 및 DeboWtEBV, 및 DeboWtEBV 단독에 대한 적정 연구이다.
도 15는 DeboWtEBV 단독에 비해 DeboWtEBV 및 IL-4를 비교하는 T 세포 IFNγ 강화 검정이다.
도 16은 단핵구/대식세포에 의한 LPS 유도된 TNFα 분비 억제에 대한 IL-10, IL-4, DeboDV06, 및 IL-4와 조합된 DeboDV06을 평가하는 적정 연구이다.
도 17은 DK410 형태로 지정된 분자 부류의 개략도이다.
도 18은 단핵구/대식세포에 의한 LPS 유도된 TNFα 분비 억제에 대한 IL-10, IL-4, DeboDV06, 및 IL-4와 조합된 IL-10을 비교하여 DK410 형태의 IL-4DeboDV06 (이는 또한 "4DeboDV06"으로 공지)을 평가하는 적정 연구이다.
도 19는 CD8+ T 세포 상에서 IL-10, IL-4, DeboDV06, 및 IL-4와 조합된 DeboDV06과 비교하여 DK410 형태의 IL-4DeboDV06 (이는 또한 "4DeboDV06"으로도 공지)을 평가하는 적정 연구이다.
도 20은 비-글리코실화 (N38A) 및 고친화성 (T13D) 형태의 인간 IL-4를 포함하는 DK410 분자 부류의 구성원인 IL-4HADeglymCD14DV06 및 IL-4HADeglymCD14DV07을 대식세포/단핵구에 의한 LPS 유도된 TNFα 분비 억제에 대해 IL-10, IL-4, 및 DK410 형태의 IL-4DeboDV06 (이는 또한 "4DeboDV06"으로도 공지)과 비교하여 평가하는 적정 연구이다.
도 21은 N38A에 단일 치환을 포함하여 비-글리코실화된 형태의 IL4로 생성된 DK410 분자 부류의 구성원인 IL-4ngDmCD14DV06 및 IL-4ngDmCD14DV07을 단핵구/대식세포에 의한 LPS 유도된 TNFα 분비 억제에 대해 IL-10과 비교하여 평가하는 적정 연구이다.
도 22는 N38A에 단일 치환을 포함하여 비-글리코실화된 형태의 IL4로 생성된 DK410 분자 부류의 구성원인 IL-4ngDmCD14DV06 및 IL-4ngDmCD14DV07을 CD8+ T 세포에 의한 IFNγ 유도 매개에 대해 IL-10과 비교하여 평가하는 적정 연구이다.
도 23은 N38A에 단일 치환을 포함하여 비-글리코실화된 형태의 IL4로 생성된 DK410 분자 부류의 구성원인 IL-4ngDmMAdCAMDV06을 단핵구/대식세포에 의한 LPS 유도된 TNFα 분비 억제에 대해 IL-10과 비교하여 평가하는 적정 연구이다.
도 24는 N38A에 단일 치환을 포함하여 비-글리코실화된 형태의 IL4로 생성된 DK410 분자 부류의 구성원인 IL-4ngDmMAdCAMDV06을 CD8+ T 세포에 의한 IFNγ 유도 매개에 대해 IL-10과 비교하여 평가하는 적정 연구이다.
도 25는 LPS 투여 이전 및 이후에 IL-4ngDmMAdCAMDV06으로 처리된 마우스의 생존을 비교한 생체내 패혈증 마우스 모델 연구이다.
도 2는 이중 시토카인 융합 단백질이 말단 연결된 IL-10 단량체 (또는 IL-10 변이체)를 포함하고, 여기서, 제2 시토카인은 scFv의 VH와 VL 사이의 링커 내로 도입된 것인, 본 개시내용에서 구현된 이중 시토카인 융합 단백질의 개략도이다.
도 3은 scFv의 VH 및 VL에 연결된 DV07 (EBV IL-10의 IL-10 수용체 고친화성 변이체), 및 최극단의 C-말단 IL-10 단량체의 카르복시 말단에 융합된 IL-2를 포함하는 ("SLP-IL-2"로 명명되는) 대안적 형태의 2개의 시토카인을 포함하는 융합 단백질의 개략도이다.
도 4는 단핵구/대식세포로부터의 TNFα 분비 감소율(%)에 대해 SLP-IL-2를 IL-10, IL-2, 및 IL-10과 IL-2의 조합과 비교하는 적정 연구이다.
도 5는 단핵구로부터의 TNFα 분비 감소율(%)에 대해 DK210을 IL-10 및 DegfrDV07 (SLP 변이체 3; 서열식별번호 31)과 비교하는 적정 연구이다.
도 6은 SLP 및 DK210을 비교한 T 세포 IFNγ 강화 검정이다. 진한 회색 막대는 두 시토카인의 혈청 최저 치료 농도를 나타내고, 옅은 회색 막대는 DK210에 대한 예상 치료 농도 요건을 나타낸다.
도 7은 NK 세포, CD4+ T 세포 및 CD8+ T 세포 상의 IL-10이 IL-2 매개 IFNγ 유도에 대한 효과를 결정하는 검정이다. 진한 회색 막대는 두 시토카인의 혈청 최저 치료 농도를 나타내고, 옅은 회색 막대는 DK210에 대한 예상 치료 농도 요건을 나타낸다.
도 8은 T 세포에서 모델 항원 제시에 대한 시토카인의 효과를 측정하는 검정이다.
도 9는 항원 노출 후 CD4+ 및 CD8+ T 세포에서의 IFNγ의 유도를 측정하는 검정이다.
도 10은 Degfr:DV07 또는 DK210으로 처리된 마우스에서 항종양 효과를 비교하는 생체내 CT26 (hEGFR+) 종양 마우스 모델 연구이다.
도 11은 Degfr:DV07 또는 DK210으로 처리된 마우스의 체중을 비교한 생체내 CT 26 (hEGFR+) 종양 마우스 모델 연구이다.
도 12는 Degfr:DV07 및 DK210으로 처리된 마우스의 생존을 비교한 생체내 CT26 (hEGFR+) 종양 마우스 모델 연구이다.
도 13은 단핵구로부터의 TNFα 분비 감소율(%)에 대한 IL-10, IL-4, 및 IL-10 및 IL-4에 대한 적정 연구이다.
도 14는 단핵구로부터의 TNFα 분비 감소율(%)에 대한 IL-10, IL-4, IL-4 및 DeboWtEBV, 및 DeboWtEBV 단독에 대한 적정 연구이다.
도 15는 DeboWtEBV 단독에 비해 DeboWtEBV 및 IL-4를 비교하는 T 세포 IFNγ 강화 검정이다.
도 16은 단핵구/대식세포에 의한 LPS 유도된 TNFα 분비 억제에 대한 IL-10, IL-4, DeboDV06, 및 IL-4와 조합된 DeboDV06을 평가하는 적정 연구이다.
도 17은 DK410 형태로 지정된 분자 부류의 개략도이다.
도 18은 단핵구/대식세포에 의한 LPS 유도된 TNFα 분비 억제에 대한 IL-10, IL-4, DeboDV06, 및 IL-4와 조합된 IL-10을 비교하여 DK410 형태의 IL-4DeboDV06 (이는 또한 "4DeboDV06"으로 공지)을 평가하는 적정 연구이다.
도 19는 CD8+ T 세포 상에서 IL-10, IL-4, DeboDV06, 및 IL-4와 조합된 DeboDV06과 비교하여 DK410 형태의 IL-4DeboDV06 (이는 또한 "4DeboDV06"으로도 공지)을 평가하는 적정 연구이다.
도 20은 비-글리코실화 (N38A) 및 고친화성 (T13D) 형태의 인간 IL-4를 포함하는 DK410 분자 부류의 구성원인 IL-4HADeglymCD14DV06 및 IL-4HADeglymCD14DV07을 대식세포/단핵구에 의한 LPS 유도된 TNFα 분비 억제에 대해 IL-10, IL-4, 및 DK410 형태의 IL-4DeboDV06 (이는 또한 "4DeboDV06"으로도 공지)과 비교하여 평가하는 적정 연구이다.
도 21은 N38A에 단일 치환을 포함하여 비-글리코실화된 형태의 IL4로 생성된 DK410 분자 부류의 구성원인 IL-4ngDmCD14DV06 및 IL-4ngDmCD14DV07을 단핵구/대식세포에 의한 LPS 유도된 TNFα 분비 억제에 대해 IL-10과 비교하여 평가하는 적정 연구이다.
도 22는 N38A에 단일 치환을 포함하여 비-글리코실화된 형태의 IL4로 생성된 DK410 분자 부류의 구성원인 IL-4ngDmCD14DV06 및 IL-4ngDmCD14DV07을 CD8+ T 세포에 의한 IFNγ 유도 매개에 대해 IL-10과 비교하여 평가하는 적정 연구이다.
도 23은 N38A에 단일 치환을 포함하여 비-글리코실화된 형태의 IL4로 생성된 DK410 분자 부류의 구성원인 IL-4ngDmMAdCAMDV06을 단핵구/대식세포에 의한 LPS 유도된 TNFα 분비 억제에 대해 IL-10과 비교하여 평가하는 적정 연구이다.
도 24는 N38A에 단일 치환을 포함하여 비-글리코실화된 형태의 IL4로 생성된 DK410 분자 부류의 구성원인 IL-4ngDmMAdCAMDV06을 CD8+ T 세포에 의한 IFNγ 유도 매개에 대해 IL-10과 비교하여 평가하는 적정 연구이다.
도 25는 LPS 투여 이전 및 이후에 IL-4ngDmMAdCAMDV06으로 처리된 마우스의 생존을 비교한 생체내 패혈증 마우스 모델 연구이다.
상세한 설명
본원에서는 IL-10을 포함하는 이중 시토카인 융합 단백질, IL-10을 포함하는 이중 시토카인 융합 단백질의 제조 방법, 및 염증성 질환 또는 병태, 면역 질환 또는 병태를 치료하기 위해, 암을 치료 및/또는 예방하기 위해 IL-10을 포함하는 이중 시토카인 융합 단백질을 사용하는 방법과 관련하여 예시적인 측면을 기술한다. 관련 기술분야의 통상의 기술자는 하기 설명이 단지 예시적인 것이며, 어떤 식으로든 제한하려는 것으로 의도되지 않는다는 것을 이해할 것이다. 본 개시내용의 이점을 갖는 다른 측면이 관련 기술분야의 통상의 기술자에게 쉽게 제안될 것이다. 이제 첨부된 도면에 예시된 바와 같은 예시적인 측면의 구현에 대해 상세히 참조될 것이다. 동일한 참조 인디케이터는 동일하거나 유사한 항목을 참조하기 위해 도면 및 하기 설명 전체에 걸쳐 가능한 한도까지 사용될 것이다.
본원에 기술된 것과 유사하거나, 또는 등가인 다수의 방법 및 물질이 기술된 다양한 실시양태의 실시에 사용될 수 있지만, 바람직한 물질 및 방법이 본원에서 기술된다.
달리 명시되지 않는 한, 본원에 기술된 실시양태는 관련 기술분야의 통상의 기술자에게 널리 공지된 분자 생물학, 생화학, 약리학, 화학 및 면역학의 통상적인 방법 및 기술을 이용한다. 인간, 마우스, CMV 및/또는 EBV 형태의 IL-10을 포함하나, 이에 제한되지 않는, IL-10 변이체를 디자인하고 제작하기 위한 여러 일반 기술 뿐만 아니라, IL-10 변이체를 시험하기 위한 검정법은 관련 기술분야에서 용이하게 입수가능하고 상세하게 설명된 널리 공지된 방법이다. 예컨대, 문헌 [Sambrook, et al., Molecular Cloning: A Laboratory Manual (2nd Edition, 1989)]; [Methods In Enzymology (S. Colowick and N. Kaplan eds., Academic Press, Inc.)]; [Handbook of Experimental Immunology, Vols. I-IV (D. M. Weir and C. C. Blackwell eds., Blackwell Scientific Publications)]; [A. L. Lehninger, Biochemistry (Worth Publishers, Inc., current addition)]을 참조한다. N-말단 알데히드 기반 PEG화 화학이 또한 관련 기술분야에 널리 공지되어 있다.
정의
하기 용어를 사용하여 본원에서 논의된 다양한 실시양태를 기술할 것이고, 하기 나타낸 바와 같이 정의되는 것으로 의도된다.
다양한 실시양태를 기술하는 데 본원에서 사용된 바, 단수 형태 "하나"는 내용상 명백히 달리 지시되지 않는 한, 복수의 지시 대상을 포함한다.
"약"이라는 용어는 명시된 수치 또는 수치 범위로부터 0.0001-5%의 편차를 나타낸다. 한 실시양태에서, "약"이라는 용어는 명시된 수치 또는 수치 범위로부터 1-10%의 편차를 나타낸다. 한 실시양태에서, "약"이라는 용어는 명시된 수치 또는 수치 범위로부터 최대 25%의 편차를 나타낸다. 더욱 구체적인 실시양태에서, "약"이라는 용어는 야생형 서열과 비교할 때 뉴클레오티드 서열 상동성 또는 아미노산 서열 상동성의 측면에서 1-25%의 차이를 지칭한다.
용어 "인터류킨-10" 또는 "IL-10"은 동종이량체를 형성하기 위해 비공유적으로 연결된 2개의 서브유닛을 포함하는 단백질을 지칭하며, 여기서, IL-10은 2개의 6개 나선 번들 (나선 A-F)의 삽입된 이량체이다. 본원에서 사용된 바, 달리 명시되지 않는한, "인터류킨-10" 및 "IL-10"은 인간 IL-10 ("hIL-10"; 진뱅크 수탁 번호(Genbank Accession No.) NP_000563; 또는 미국 특허 번호 6,217,857) 단백질 (서열식별번호 1) 또는 핵산 (서열식별번호 2); 마우스 IL-10 ("mIL-10"; 진뱅크 수탁 번호: M37897; 또는 미국 특허 번호 6,217,857) 단백질 (서열식별번호 7) 또는 핵산 (서열식별번호 8); 또는 바이러스 IL-10 ("vIL-10")을 포함하나, 이에 제한되지 않는 임의 형태의 IL-10을 지칭한다. 바이러스 IL-10 상동체는 EBV 또는 CMV (각각 진뱅크 수탁 번호 NC_007605 및 DQ367962)로부터 유래될 수 있다. 용어 EBV-IL10은 EBV IL-10 단백질 상동체 (서열식별번호 3) 또는 핵산 상동체 (서열식별번호 4)를 지칭한다. 용어 CMV-IL10은 CMV IL-10 단백질 상동체 (서열식별번호 5) 또는 핵산 상동체 (서열식별번호 6)를 지칭한다. 본원에서 사용되는 바, "단량체(monomeric)" IL-10 또는 IL-10의 "단량체"라는 용어는 비공유적으로 연결될 때, IL-10 또는 변이체 IL-10의 동종이량체를 형성하는 IL-10 또는 변이체 IL-10의 개별 서브유닛을 지칭한다. "야생형," "wt" 및 "본래의"이라는 용어는 본원에서 상호교환적으로 사용되며, 해당하는 특정 IL-10의 기원의 종에서 자연상에서 흔히 발견되는 단백질 (예컨대, IL-10, CMV-IL10 또는 EBV IL-10)의 서열을 지칭한다. 따라서, 예를 들어, 용어 "야생형" 또는 "본래의" EBV IL-10은 자연상에서 가장 흔히 발견되는 아미노산 서열에 상응할 것이다.
용어 "변이체," "유사체" 및 "뮤테인"은 원하는 활성, 예컨대, 예를 들어 항-염증 활성을 유지하는 참조 분자의 생물학적으로 활성인 유도체를 지칭한다. 일반적으로, 용어 "변이체," "변이체들," "유사체" 및 "뮤테인"이 폴리펩티드와 관련이 있는 경우, 이는 본래의 분자와 비교하여 하나 이상의 아미노산 부가, 치환 (본질적으로 보존적일 수 있다) 및/또는 결실을 갖는 본래의 폴리펩티드 서열 및 구조를 가진 화합물 또는 화합물들을 지칭한다. 따라서, 용어 "IL-10 변이체," "변이체 IL-10," "IL-10 변이체 분자," 및 그의 문법적 변형어 및 복수 형태는 모두 서열 동일성 또는 상동성이 야생형 IL-10과 1-25% 차이가 나는 IL-10 아미노산 (또는 핵산) 서열을 지칭하는 등가의 용어인 것으로 의도된다. 따라서, 예를 들어, EBV IL-10 변이체 분자는 하나 이상의 아미노산 (또는 아미노산을 코딩하는 뉴클레오티드 서열) 부가, 치환 및/또는 결실을 가짐으로써 야생형 EBV IL-10과 상이한 것이다. 따라서, 한 형태에서, EBV IL-10 변이체는 약 1-42개 아미노산 차이에 해당하는 서열 상동성에서의 약 1% 내지 25% 차이를 가짐으로써 서열식별번호 3의 야생형 서열과 상이한 것이다. 한 실시양태에서, IL-10 변이체는 V31L 아미노산 돌연변이 ("DV05"; 서열식별번호 12), A75I 아미노산 돌연변이 ("DV06"; 서열식별번호 14), 또는 V31L 및 A75I 아미노산 돌연변이 둘 모두 ("DV07"; 서열식별번호 16)를 포함하는 EBV IL-10이다.
용어 "융합 단백질"은 자연적으로는 일반적으로 존재하지 않는 단백질의 신규한 배열을 생성하는 둘 이상의 단백질 또는 폴리펩티드의 조합 또는 접합을 지칭한다. 융합 단백질은 둘 이상의 단백질 또는 폴리펩티드의 공유적인 연결의 결과이다. 융합 단백질을 구성하는 둘 이상의 단백질은 아미노-말단 단부 ("NH2")에서부터 카르복시-말단 단부 ("COOH")까지 임의의 배치로 배열될 수 있다. 따라서, 예를 들어, 한 단백질의 카르복시-말단 단부는 또 다른 단백질의 카르복시 말단 단부 또는 아미노 말단 단부에 공유적으로 연결될 수 있다. 예시적인 융합 단백질은 단량체 IL-10 또는 단량체 변이체 IL-10 분자와 하나 이상의 항체 가변 도메인 (즉, VH 및/또는 VL) 또는 단일 쇄 가변 영역 ("scFv")의 조합을 포함할 수 있다. 융합 단백질은 또한 이량체를 형성하거나, 또는 동일한 유형의 다른 융합 단백질과 회합하여 융합 단백질 복합체를 생성할 수 있다. 융합 단백질의 복합체화는 일부 경우에 복합체화되지 않은 융합 단백질과 비교할 때 융합 단백질의 기능성을 활성화시키거나, 또는 증가시킬 수 있다. 예를 들어, 하나 이상의 항체 가변 도메인을 갖는 단량체 IL-10 또는 단량체 변이체 IL-10 분자는 IL-10 수용체와 결합하는 데 있어서 제한된 또는 감소된 능력을 가질 수 있지만; 융합 단백질이 복합체화될 때, IL-10 또는 변이체 IL-10 분자의 단량체 형태는 동종이량체가 되고, 가변 도메인은 기능적 디아바디와 회합한다.
"상동체," "상동성," "상동성인" 또는 "실질적으로 상동성인"이라는 용어는 적어도 2개의 폴리뉴클레오티드 서열 또는 적어도 2개의 폴리펩티드 서열 사이의 동일성(%)을 지칭한다. 서열이 정의된 길이의 분자에 걸쳐 적어도 약 50%, 바람직하게 적어도 약 75%, 더욱 바람직하게, 적어도 약 80%-85%, 바람직하게 적어도 약 90%, 및 가장 바람직하게 적어도 약 95%-98%의 서열 동일성을 보일 때, 서열은 서로 상동성인 것이다.
용어 "서열 동일성"은 정확한 뉴클레오티드-대-뉴클레오티드 또는 아미노산-대-아미노산 대응을 지칭한다. 서열 동일성은 100%의 서열 동일성 내지 50%의 서열 동일성 범위일 수 있다. 서열 동일성(%)은 서열을 정렬시키고, 정렬된 두 서열 사이의 정확한 매칭 개수를 카운팅하고, 참조 서열의 길이로 나누고, 결과에 100을 곱함으로써 두 분자 (참조 서열, 및 참조 서열과의 동일성(%)이 공지되지 않은 서열) 사이의 서열 정보를 직접적으로 비교하는 것을 포함하나, 이에 제한되지 않는 다양한 방법을 이용하여 결정될 수 있다. 용이하게 이용가능한 컴퓨터 프로그램을 이용하여 동일성(%) 확인을 지원할 수 있다.
"대상체," "개체" 또는 "환자"라는 용어는 본원에서 상호교환적으로 사용되며, 이는 척추동물, 바람직하게, 포유동물을 지칭한다. 포유동물은 뮤린, 설치류, 유인원, 인간, 농장 동물, 스포츠 동물, 및 특정 애완동물을 포함하나, 이에 제한되지 않는다.
"투여하는"이라는 용어는 본 출원의 활성 성분이 그의 의도된 기능을 수행하도록 하는 투여 경로를 포함한다.
예를 들어, 본원에 기술된 EBV IL-10 변이체 또는 그의 융합 단백질의 투여와 관련하여 "치료 유효량"은 특정 생물학적 활성을 촉진시키는 데 충분한 EBV IL-10 변이체 또는 그의 융합 단백질의 양을 지칭한다. 이는 예를 들어, 골수 세포 기능의 억제, 증강된 쿠퍼 세포 활성, 및/또는 CD8+ T 세포에 대한 임의의 효과의 결여, 또는 증강된 CD8+ T 세포 활성 뿐만 아니라, Fc 수용체의 비만 세포 상향조절의 차단, 또는 탈과립화의 예방을 포함할 수 있다. 따라서, "유효량"은 의학적 병태의 증상 또는 징후를 호전시키거나, 또는 예방할 것이다. 유효량은 또한 진단을 가능하게 하거나, 또는 용이하게 하는 데 충분한 양을 의미한다.
"치료하다" 또는 "치료"라는 용어는 질환 또는 병태의 효과를 감소시키는 방법을 지칭한다. 치료는 또한 단지 증상이 아니라, 질환 또는 병태 자체의 근본적인 원인을 감소시키는 방법을 지칭할 수 있다. 치료는 본래의 수준으로부터 임의의 감소일 수 있고, 질환, 병태, 또는 질환 또는 병태의 증상의 완전한 제거일 수 있지만, 이로 제한되지 않는다.
하기 표는 본 개시내용에서 참조되는 IL-10을 포함하는 다양한 IL-10 융합 단백질 및 이중 시토카인 융합 단백질에 대한 정의를 제공한다:




이중
시토카인
융합 단백질 구조
본 개시내용은 이전에 미국 특허 10,858,412 (미국 출원 번호 16/811,718로 출원) (이는 그 전문이 본원에서 참조로 포함)에서 기술된 IL-10 융합 단백질의 실시양태에 대한 개선을 제공한다. IL-10 융합 단백질에 대한 개선은 이전에 기술된 IL-10 융합 단백질에 제2 시토카인 분자를 도입하는 것을 포함한다. 도 1은 미국 특허 10,858,412에 기술된, 이전에 개시된 IL-10 융합 단백질 구축물들 중 하나를 나타내는 개략도이다. 이 IL-10 융합 단백질은 각 말단에 2개의 IL-10 단량체 (즉, 아미노 말단 단부 상의 제1 IL-10 단량체 및 카르복시 말단 단부 상의 제2 IL-10 단량체)를 특징으로 하는 VH 및 VL scFv 스캐폴딩에서 구축된다. 1차 스캐폴딩 시스템은 인간 항-에볼라 항체로부터 수득된 scFv를 포함한다. 미국 특허 10,858,412에 기술된 IL-10 융합 단백질은 VH에 상보성 결정 영역 ("CDR") 1-3 및 VL에 CDR 1-3을 갖는 6개의 CDR을 포함한다. 임의적으로, VH 및 VL 영역은 IL-10 융합 단백질을 특정 항원에 표적화할 수 있다. 이는 VH 및 VL 쌍의 6개의 CDR 영역 (VH에 3개의 CDR 및 VL에 3개의 CDR)을 수용체 또는 항원 표적화 항체 또는 그의 항원 결합 단편의 VH 및 VL로부터의 6개의 CDR 영역으로 치환함으로써 달성된다. 6개의 CDR 및 프레임워크 영역을 치환 및 최적화하고, 이들 CDR을 본원에 기술된 scFv 스캐폴딩으로 인그라프팅할 수 있는 능력은 관련 기술분야의 통상의 기술자에 널리 공지되어 있고, 그에 의해 실시된다. 어느 통상의 기술자라도 관심 특정 표적에 기초하여 결정할 수 있을 임의의 모노클로날 항체로부터의 6개의 CDR로 상기 6개의 CDR 영역은 치환될 수 있다.
제1 측면에서, 본 출원은 IL-10 및 적어도 하나의 다른 시토카인을 포함하는 이중 시토카인 융합 단백질로서, 이에 의해 이중 시토카인 융합 단백질은 이전에 미국 특허 10,858,412에 기술된 IL-10 융합 단백질과 비교하여 조합된 또는 상승작용적 기능성을 갖는 것인, 이중 시토카인 융합 단백질에 관한 것이다. 도 2는 IL-10을 포함하는 개선된 이중 시토카인 융합 단백질의 대표도이다. 특히, 개선된 이중 시토카인 융합 단백질은 IL-10의 두 단량체가 아미노 및 카르복시 말단 단부에서 이중 융합 단백질을 종결하도록 VH 및 VL scFv로 구성된 동일하거나, 또는 실질적으로 동일한 스캐폴딩 시스템을 적합화시킨다. 제2 시토카인은 scFv의 힌지 영역인 scFv의 VH와 VL 영역 사이에 융합됨으로써 IL-10 융합 단백질에 접합된다. 이중 시토카인 융합 단백질은 IL-10 단량체가 기능성 IL-10 분자로 동종이량체화되고, VH 및 VL 영역은, 함께 회합하여 항원 결합 및 인식을 허용하는 scFv 복합체를 형성하는 쌍을 형성하도록 기능성 단백질 복합체를 형성할 수 있다.
특정 실시양태에서, IL-10을 포함하는 이중 시토카인 융합 단백질은 하기 화학식 I을 갖는 구조이다
NH
2
-(IL10)-(X
1
)-(Z
n
)-(X
2
)-(IL10)-COOH
상기 식에서,
"IL-10"은 임의의 IL-10 단량체, 예컨대 비제한적으로 인간, 마우스, CMV 또는 EBV IL-10, 또는 IL-10 변이체 분자이고;
"X1"은 제1 모노클로날 항체로부터 수득된 VL 또는 VH 영역이고;
"X2"는 제1 모노클로날 항체로부터 수득된 VH 또는 VL 영역이고;
여기서, X1이 VL일 때, X2는 VH이거나, 또는 X1이 VH일 때, X2는 VL이고;
"Z"는 제2 시토카인으로, 여기서, 제2 시토카인은 IL-10 이외의 다른 시토카인이고;
"n"은 0-2로부터 선택되는 정수이다.
또 다른 실시양태에서, IL-10을 포함하는 이중 시토카인 융합 단백질은 하기 화학식 II를 갖는 구조이다
NH
2
-(IL10)-(L)-(X
1
)-(L)-(Z
n
)-(L)-(X
2
)-(L)-(IL10)-COOH
상기 식에서,
"IL-10"은 IL-10 단량체이고;
"L"은 링커, 바람직하게, 서열식별번호 39, 40, 또는 41의 링커이고;
"X1"은 제1 모노클로날 항체로부터 수득된 VL 또는 VH 영역이고;
"X2"는 제1 모노클로날 항체로부터 수득된 VH 또는 VL 영역이고;
여기서, X1이 VL일 때, X2는 VH이거나, 또는 X1이 VH일 때, X2는 VL이고;
"Z"는 제2 시토카인이고;
"n"은 0-2로부터 선택되는 정수이다.
한 실시양태에서, IL-10 단량체는 인간 (서열식별번호 1), CMV (서열식별번호 5), EBV (서열식별번호 3), 또는 마우스 (서열식별번호 7)를 비롯한, 임의 형태의 IL-10을 포함한다. 또 다른 실시양태에서, IL-10 단량체는 미국 특허 10,858,412에 기술된 것을 비롯한, EBV IL-10 (서열식별번호 3)의 변형된 형태 또는 변이체 형태이다. 바람직한 실시양태에서, EBV IL-10은 서열식별번호 3 중 아미노산 위치 31 (본원에서 "DV05"로 명명), 75 (본원에서 "DV06"으로 명명), 또는 둘 모두 (본원에서 "DV07"로 명명)에 하나 이상의 치환을 포함한다. 추가의 또 다른 실시양태에서, IL-10 단량체는 서열식별번호 9, 10, 11, 12, 14, 또는 16의 서열이다. IL-10 또는 IL-10 변이체 분자의 제1 및 제2 단량체는 각각 도 1에 제시되어 있는 바와 같이 융합 단백질의 말단 단부에 위치해 있다 (즉, 제1 단량체는 아미노 말단 단부에 위치해 있고, 제2 단량체는 카르복시 말단 단부에 위치해 있다).
또 다른 실시양태에서, VH 및 VL 영역은 항체, 항체 단편, 또는 그의 항원 결합 단편으로부터의 것이다. 항원 결합 단편은 scFv, Fab, F(ab')2, V-NAR, 디아바디 또는 나노바디를 포함하나, 이에 제한되지 않는다. 바람직하게, VH 및 VL은 단일 쇄 가변 단편 ("scFv")으로부터의 것이다.
또 다른 실시양태에서, IL-10을 포함하는 이중 시토카인 융합 단백질은 단일 항체로부터의 VH 및 VL 쌍을 포함한다. VH 및 VL 쌍은 IL-10 또는 그의 변이체의 단량체가 부착되어 IL-10 또는 그의 변이체의 단량체가 기능성 IL-10 분자로 동종이량체화될 수 있도록 하는 스캐폴딩으로서 작용할 수 있다. 따라서, 관련 기술분야의 통상의 기술자는 융합 단백질에 사용되는 VH 및 VL 스캐폴딩은 IL-10 단량체 또는 IL-10 단량체 변이체의 적절한 동종이량체화에 필요한 원하는 물리적 속성 및 VH 및 VL 표적화 능력을 유지시키기 위한 요구에 기초하여 선택될 수 있다는 것을 이해할 것이다. 유사하게, 통상의 기술자는 또한 VH 및 VL 쌍 내의 6개의 CDR (VH로부터의 3개의 CDR 및 VL로부터의 3개의 CDR) 또한 특이적으로 표적화된 융합 단백질을 수득하기 위해 다른 항체로부터의 6개의 CDR로 치환될 수 있다는 것을 이해할 것이다. 한 실시양태에서, 임의의 모노클로날 항체의 VH로부터의 3개의 CDR 및 VL로부터의 3개의 CDR (즉, VH 및 VL 쌍)은 서열식별번호 18, 20, 21, 23, 24, 또는 25를 포함하는 스캐폴딩 시스템 내로 인그라프팅될 수 있다. 융합 단백질이 임의의 특정 항원을 표적화하는 것으로 의도되지 않는 경우, VH 및 VL 쌍은 예컨대, 항-HIV 및/또는 항-에볼라 항체의 VH 및 VL 쌍과 같이, 임의의 특정 항원을 표적화하지 않는 (또는 생체내에서 존재비가 낮은 항원인) 스캐폴딩으로서 선택될 수 있다는 것 또한 구상된다. 따라서, 한 실시양태에서, 본 출원의 IL-10 융합 단백질은 인간 항-에볼라 항체로부터의 VH 및 VL 쌍, 더욱 바람직하게, 서열식별번호 18, 21, 또는 25의 서열을 포함할 수 있다. 융합 단백질은 1-4개 범위의 가변 영역을 포함할 수 있다. 또 다른 실시양태에서, 가변 영역은 동일한 항체로부터 또는 적어도 2개의 상이한 항체로부터의 것일 수 있다.
또 다른 실시양태에서, 항체 가변 쇄 또는 VH 및 VL 쌍 또는 VH 및 VL 쌍의 6개의 CDR의 표적 특이성은 단백질, 세포 수용체 및/또는 종양 연관 항원을 표적화하는 것을 포함할 수 있지만, 이에 제한되지 않는다. 또 다른 실시양태에서, 임의의 VH 및 VL 쌍으로부터의 CDR 영역은 상기 기술된 스캐폴딩 시스템 내로 인그라프팅될 수 있고, 이로써, 스캐폴딩은 바람직하게, IL-10 단량체가 인간 항-에볼라 항체의 VH 및 VL 영역을 포함하는 scFv에 연결되어 있고, 제2 시토카인은 scFv의 힌지 영역에 연결되어 있는 (도 2에 개략적으로 제시), Debo로 명명되는 시스템 (도 1에 개략적으로 제시)을 포함한다. 더욱 바람직하게, Debo 스캐폴딩 시스템 내로의 인그라프트먼트는 서열식별번호 18, 20, 21, 23, 24, 또는 25의 서열을 포함하는 스캐폴딩에서 이루어진다. 추가의 또 다른 실시양태에서, 예를 들어, EGFR, PDGFR, VEGFR1, VEGFR2, Her2Neu, FGFR, GPC3, 또는 다른 종양 연관 항원, MAdCam, ICAM, VCAM, CD14 또는 다른 염증 연관 세포 표면 단백질, HIV 및/또는 에볼라에 대한 항체로부터의 가변 영역과 같이, 가변 영역 또는 VH 및 VL 쌍 또는 VH 및 VL 쌍의 6개의 CDR은 각종 질환 (예컨대, 암)과 연관된 항원, 또는 건강한 대상체의 혈청에서는 전형적으로는 발견되지 않거나, 또는 드물게 발견이 되는 항원을 표적화하는 항체로부터 수득된다. 따라서, 한 실시양태에서, 가변 영역은 예를 들어, 항-EGFR, 항-MAdCam, 항-HIV (Chan et al., J. Virol, 2018, 92(18):e006411-19), 항-ICAM, 항-VCAM, 항-CD14, 또는 항-에볼라 (미국 공개 출원 2018/0180614 (그 전문이 참조로 포함), 특히, 표 2, 3, 및 4에 기술된 mAb) 항체로부터 수득되거나, 또는 유래된다. 또 다른 실시양태에서, 가변 영역은 IL-10이 그의 생물학적 효과를 유도할 수 있도록 특정한 표적 영역에 대해 시토카인, 예컨대 IL-10의 농도를 농축시킬 수 있는 항체로부터 수득되거나, 또는 유래된다. 이러한 항체는 특정 이환 영역에서 과다발현되거나, 또는 상향조절된 수용체 또는 항원을 표적화하는 것 또는 영향을 받은 특정한 부위에서 특이적으로 발현되는 것을 포함할 수 있다. 예를 들어, 가변 영역은 표피 성장 인자 수용체 (EGFR); CD52; CD14; 다양한 면역 체크포인트 표적, 예컨대 비제한적으로 몇 가지 예를 들면, PD-L1, PD-1, TIM3, BTLA, LAG3 또는 CTLA4; CD20; CD47; GD-2; VEGFR1; VEGFR2; HER2; PDGFR; EpCAM; ICAM (ICAM-1, -2, -3, -4, -5), VCAM, FAPα; 5T4; Trop2; EDB-FN; TGFβ 트랩; MAdCam, β7 인테그린 서브유닛; α4β7 인테그린; α4 인테그린 SR-A1; SR-A3; SR-A4; SR-A5; SR-A6; SR-B; dSR-C1; SR-D1; SR-E1; SR-F1; SR-F2; SR-G; SR-H1; SR-H2; SR-I1; 및 SR-J1에 대해 특이적인 항체로부터 수득될 수 있다. IL-10 (예컨대, 인간, CMV, 또는 EBV) 또는 변이체 IL-10 분자 (본원에 기술됨)의 단량체는 가변 영역 (VH 또는 VL)의 아미노 말단 단부 또는 카르복시 말단 단부에 접합되고, 이로써, 단량체 IL-10 또는 변이체 IL-10 분자는 서로 이량체화할 수 있다. 바람직한 실시양태에서, IL-10 (또는 변이체 IL-10)의 단량체는 화학식 I 또는 II에 따라 VH 및 VL 쌍에 융합되고, 여기서, IL-10 단량체는 EBV IL-10, DV05, DV06, 또는 DV07 형태의 IL-10이다.
이중 시토카인 융합 단백질 또는 이중 시토카인 융합 단백질 복합체는 또한 항원 표적화 기능을 가질 수 있다. 이중 시토카인 융합 단백질 또는 이중 시토카인 융합 단백질 복합체는 함께 회합하여 항원 결합 부위 또는 ABS를 형성할 수 있는 VH 및 VL 쌍을 포함할 것이다. 일부 배치에서, IL-10 단량체 또는 그의 IL-10 변이체 단량체는 항원 결합 부위를 포함하는 단부에 공유 결합될 것이다. 가변 영역은 대상체에서 항원성을 감소시키는 하나 이상의 아미노산을 변경함으로써 (예컨대, 부가, 차감 또는 치환에 의해) 추가로 변형될 수 있다. 가변 영역에 대한 다른 변형은 VH 및 VL 영역의 6개 CDR 영역 외부에서 발견되고, scFv의 VH 및 VL 영역의 안정성 및 발현을 증가시키는 역할을 하는 아미노산 치환, 결실 또는 부가를 포함할 수 있다. 예를 들어, 변형은 서열식별번호 27, 29, 31, 또는 33에 기술된 변형을 포함할 수 있으며, 여기서, CDR 영역은 항-EGFR 항체의 VH 및 VL 영역으로부터 수득되고, CDR 외부 영역은 scFv를 안정화시키도록 최적화되고/거나, 발현을 증가시키기 위해 최적화되며, 이는 scFv의 VH 및 VL 영역 사이에 제2 시토카인을 연결하기 위한 기초로서 사용될 수 있다. 이러한 유형의 변형이 통상의 기술자의 범위 내에 있음을 입증하기 위해, DV07을 포함하고, 인간 HER2를 표적화하는 DK210 형태의 분자 (즉, DK210her2), 예컨대, 서열식별번호 52-54, 또는 55, 더욱 바람직하게, 서열식별번호 54 (변이체 4) 또는 55 (변이체 5)에 기술된 것에 CDR 영역 및 CDR 외부 영역에 대하여 유사하게 변형시켰다. 또한, DV06을 포함하고, 인간 CD14를 표적화하는 DK410 형태의 분자 (즉, DK410CD14DV06), 예컨대, 서열식별번호 56-58, 또는 59, 더욱 바람직하게, 서열식별번호 56 (변이체 2)에 기술된 것에 CDR 영역 및 CDR 외부 영역에 대해서도 유사하게 변형시켰다. 상기 및 다른 변형은 또한 DV07을 포함하고, 인간 VEGFR1 또는 VEGFR2를 표적화하는 DK210 형태의 분자; 또는 DV06을 포함하고, 인간 VEGFR1 또는 VEGFR2를 표적화하는 DK410 형태의 분자에 대해서도 이루어질 수 있다. 관련 기술분야의 통상의 기술자는 scFv를 안정화하고/거나, 발현 목적을 위해 서열을 최적화하는 다른 변형을 결정할 수 있을 것이다.
VH 및 VL 쌍은 다수의 항체에 대해 수득된 CDR 영역이 그라프팅 또는 인그라프팅될 수 있는 스캐폴딩을 형성한다. 이러한 항체 CDR 영역은 상기 공지되고, 기술된 항체를 포함한다. 상기 기술된 VH 및 VL 스캐폴딩의 CDR 영역은 CDR 인그라프트먼트/삽입을 위해 이용가능한 하기 개수의 아미노산 위치를 포함할 것이다:

바람직한 실시양태에서, IL-10을 포함하는 이중 시토카인 융합 단백질은 VH 및 VL 쌍이 항-에볼라 항체 (예컨대, 서열식별번호 19, 27, 29, 31, 및 33에 기술된 것)로부터 유래되고, 이로써, 항-에볼라 항체로부터의 6개의 CDR 영역은 제거되고, 예컨대 비제한적으로 EGFR; CD52; CD14; 다양한 면역 체크포인트 표적, 예컨대 비제한적으로 PD-L1, PD-1, TIM3, BTLA, LAG3 또는 CTLA4; CD20; CD47; GD-2; VEGFR1; VEGFR2; HER2; PDGFR; EpCAM; ICAM (ICAM-1, -2, -3, -4, -5), VCAM, CD14, FAPα; 5T4; Trop2; EDB-FN; TGFβ 트랩; MAdCam, β7 인테그린 서브유닛; α4β7 인테그린; α4 인테그린 SR-A1; SR-A3; SR-A4; SR-A5; SR-A6; SR-B; dSR-C1; SR-D1; SR-E1; SR-F1; SR-F2; SR-G; SR-H1; SR-H2; SR-I1; 및 SR-J1에 대한 것과 같은, 특정 표적화 항체의 VH 및 VL 쌍이 인그라프팅된 것인 상기 기술된 스캐폴딩 IL-10 융합 단백질을 포함할 것이다. 한 실시양태에서, 6개의 항-에볼라 CDR 영역은 항-EGFR, 항-MAdCAM, 항-VEGFR1, 항-VEGFR2, 항-PDGFR, 또는 항-CD14로부터의 6개의 CDR 영역으로 치환된다. 바람직한 실시양태에서, IL-10 융합 단백질은 상기 기술된 항체로부터의 CDR 중 임의의 것이 인그라프팅될 수 있는 서열식별번호 18, 20, 21, 23, 24, 또는 25의 서열이다. 더욱 바람직한 실시양태에서, IL-10 융합 단백질은 서열식별번호 19, 22, 또는 26의 서열이다. 바람직한 실시양태에서, 제2 시토카인, 예컨대 비제한적으로 IL-2, IL-4, IFNα는 서열식별번호 18-27, 29, 31, 또는 33의 서열을 갖는 IL-10 융합 단백질로부터의 인간 항-에볼라 항체로부터 수득된 scFv의 VH와 VL 사이의 힌지 영역에 연결된다.
추가의 또 다른 실시양태에서, 제2 시토카인은 도 2에 도시된 바와 같이, scFv의 VH와 VL 사이에 융합된다. 제2 시토카인은 제2 시토카인이 그의 기능적 특성을 유지하도록 VH 또는 VL 영역 사이에 접합된다. 한 실시양태에서, 제2 시토카인은 IL-10 단량체와 상이한 것이다. 또 다른 측면에서 제2 시토카인은 IL-10이다. 한 실시양태에서, 제2 시토카인은 IL-6, IL-4, IL-1, IL-2, IL-3, IL-5, IL-7, IL-8, IL-9, IL-15, IL-21, IL-26, IL-27, IL-28, IL-29, GM-CSF, G-CSF, 인터페론-α, -β, -γ, TGF-β, 또는 종양 괴사 인자-α, -β, 염기성 FGF, EGF, PDGF, IL-4, IL-11, 또는 IL-13이다. 바람직한 실시양태에서, 이중 시토카인 융합 단백질 중 제2 시토카인은 IL-10 및 IL-2 또는 IL-4를 포함한다. 더욱 바람직한 실시양태에서, 이중 시토카인 융합 단백질은 서열식별번호 35, 46-58 또는 59의 서열이다. 추가의 또 다른 실시양태에서, 이중 시토카인 융합 단백질은 DV05, DV06, 또는 DV07로부터 선택되는 IL-10 변이체 분자로서; IL-10 변이체 분자는 인간 항-에볼라 항체로부터의 VH 및 VL 영역을 포함하는 스캐폴딩 시스템 (즉, Debo)에 연결되고, 여기서, 항-EGFR, 항-HER2, 항-CD14, 항-VEGFR1, 항-VEGFR2, 항-MAdCAM, 또는 항-PDGFR로부터 선택된 항체의 CDR이 함께 Debo 내로 인그라프팅되고; IL-2, IL-4, IFNα로부터 선택된 제2 시토카인이 VH 및 VL 쌍의 힌지 영역에 연결되는 것인 IL-10 변이체 분자를 포함할 것이다. 가장 바람직한 실시양태에서, 이중 시토카인은 서열식별번호 35, 46-58, 또는 59의 융합 단백질이다.
추가의 다른 실시양태에서, IL-10을 포함하는 이중 시토카인 융합 단백질은 링커를 포함한다. 관련 기술분야의 통상의 기술자는 다양한 융합 단백질 부분의 적절한 공간 배치를 달성하기 위해 링커 또는 스페이서가 사용되고, 따라서, IL-10을 포함하는 이중 시토카인 융합 단백질의 형성에 사용할 적절한 링커를 선택할 수 있다는 것을 알고 있다. 더욱 바람직한 실시양태에서, 링커 또는 스페이서는 무작위 아미노산 서열 (예컨대, SSGGGGS (서열식별번호 39), GGGGSGGGGSGGGGS (서열식별번호 40) 또는 SSGGGGSGGGGSGGGGS (서열식별번호 41)) 항체의 불변 영역일 수 있다. 불변 영역은 비제한적으로 IgG1, IgG2, IgG3, IgG4, IgA, IgM, IgD 또는 IgE로부터 유도될 수 있다. 한 실시양태에서, 링커 또는 스페이서는 불변 중쇄 ("CH") 영역 1, CH2, 또는 CH3이다. 더욱 바람직한 실시양태에서, 링커 또는 스페이서는 서열식별번호 40의 무작위 아미노산 서열이다. 또 다른 측면에서, 링커 또는 스페이서는 적어도 2개의 쇄간 디술피드 결합을 추가로 포함할 수 있다.
다른 측면에서, 본 개시내용은 IL-10 및 제2 시토카인을 포함하는 이중 시토카인 융합 단백질을 코딩하는 핵산 분자에 관한 것이다. 따라서, 한 실시양태는 서열식별번호 35, 46-58, 또는 59에 기술된 단백질을 코딩하는 핵산 서열을 포함한다. 바람직한 실시양태에서, 핵산 서열은 DK210egfr (서열식별번호 60), DK210her2 (서열식별번호 62 또는 63), DK410CD14DV06 또는 DK410ngDV06CD14 (서열식별번호 61), 또는 그와 70% 내지 99% 서열 상동성을 공유하는 핵산 서열을 포함한다. 또 다른 실시양태에서, 핵산 서열은 DV07을 포함하고, 인간 VEGFR1 또는 VEGFR2를 표적화하는 DK210 형태; 또는 DV06을 포함하고, 인간 VEGFR1 또는 VEGFR2를 표적화하는 DK410 형태의 분자를 코딩한다. IL-10 및 제2 시토카인을 포함하는 이중 시토카인 융합 단백질을 코딩하는 폴리뉴클레오티드 서열은 또한 기술된 이중 시토카인 융합 단백질의 기능적 특성을 변경시키지 않는 변형을 포함할 수 있다. 상기 변형은 통상적인 재조합 DNA 기술 및 방법을 사용할 것이다. 예를 들어, 특정 아미노산 서열의 부가 또는 치환은 합성 올리고뉴클레오티드를 사용하는 부위 지정 돌연변이유발 방법을 사용하여 핵산 (DNA) 수준에서 IL-10 서열에 도입될 수 있으며, 이 방법 또한 관련 기술분야에 널리 공지되어 있다. 바람직한 실시양태에서, IL-10 및 제2 시토카인을 포함하는 이중 시토카인 융합 단백질을 코딩하는 핵산 분자는 IL-10 변이체 분자의 기능성을 변경시키지 않는 삽입, 결실 또는 치환 (예컨대, 축퇴 코드)을 포함할 수 있다. 본원에 기술된 IL-10 변이체 및 융합 단백질을 코딩하는 뉴클레오티드 서열은 유전자 코드의 축퇴성에 기인하여 아미노산 서열과 상이할 수 있으며, 상기 언급된 서열과 70-99%, 바람직하게 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 또는 99% 상동성일 수 있다. 따라서, 본 개시내용의 실시양태는 서열식별번호 35, 46-58, 또는 59의 단백질을 코딩하되, 유전자 코드의 축퇴성에 기인하여 70-99%만큼 상이한 핵산 서열을 포함한다.
본원에 기술된 이중 시토카인 융합 단백질을 코딩하는 뉴클레오티드 서열은 예를 들어, 단백질의 발현, 생성 또는 분비에 도움이 되는 널리 공지된 서열을 추가로 포함할 수 있다. 이러한 서열로는 예를 들어, 리더 서열, 신호 펩티드 및/또는 번역 개시 부위/서열 (예컨대, 코작 컨센서스 서열)을 포함할 수 있다. 본원에 기술된 뉴클레오티드 서열은 또한 다양한 발현 시스템/벡터로의 삽입을 가능하게 하는 하나 이상의 제한 효소 부위를 포함할 수 있다.
또 다른 실시양태에서, 이중 시토카인 융합 단백질을 코딩하는 뉴클레오티드 서열은 유전자 요법에 직접 사용될 수 있다. 한 실시양태에서, 본 출원의 변이체 IL-10 분자 또는 융합 단백질은 돌연변이체 IL-10 단백질의 직접적인 투여, 및 돌연변이체 IL-10 단백질을 코딩하는 벡터에 의한 유전자 요법을 비롯한 관련 기술분야에 공지된 임의의 방법에 의해 전달될 수 있다. 유전자 요법은 플라스미드 DNA 또는 바이러스 벡터, 예컨대 아데노-관련 바이러스 벡터, 아데노바이러스 벡터, 레트로바이러스 벡터 등을 이용하여 달성될 수 있다. 일부 실시양태에서, 본 출원의 바이러스 벡터는 바이러스 입자로서 투여되고, 다르게는 이들은 플라스미드로서 (예컨대, "네이키드" DNA로서) 투여된다.
뉴클레오티드 서열의 전달을 위한 다른 방법으로는 관련 기술분야에 이미 공지된 것들을 포함한다. 이는 세포 투과 펩티드, 소수성 모이어티, 정전기 복합체, 리포솜, 리간드, 리포솜 나노입자, 지단백질 (바람직하게, HDL 또는 LDL), 폴레이트 표적화된 리포솜, 항체 (예컨대, 폴레이트 수용체, 트랜스페린 수용체), 표적화 펩티드에 의해, 또는 압타머에 의해 IL-10 또는 IL-10 변이체 분자를 코딩하는 뉴클레오티드 서열, 예컨대 비제한적으로 DNA, RNA, siRNA, mRNA, 올리고뉴클레오티드, 또는 그의 변이체의 전달을 포함한다. IL-10 변이체 분자를 코딩하는 뉴클레오티드 서열은 직접적인 주사, 주입, 패치, 붕대, 미스트 또는 에어로졸에 의해, 또는 박막 전달에 의해 대상체에게 전달될 수 있다. 뉴클레오티드 (또는 단백질)는 시토카인 자극의 표적화된 전달을 위해 필요한 임의의 영역으로 지시될 수 있다. 이는 예를 들어 폐, GI 관, 피부, 간, 두개뇌 주사를 통한 뇌, 초음파 유도된 주사를 통한 심재성 전이성 종양 병변을 포함한다.
또 다른 측면에서, 본 개시내용은 IL-10을 포함하는 이중 시토카인 융합 단백질을 제조하고, 정제하는 방법에 관한 것이다. 예를 들어, 본원에 기술된 이중 시토카인 융합 단백질을 코딩하는 핵산 서열은 융합 단백질을 재조합적으로 생성하는 데 사용될 수 있다. 예를 들어, 통상적인 분자 생물학 및 단백질 발현 기술을 사용하여, 본원에 기술된 이중 시토카인 융합 단백질을 포유동물 세포 시스템으로부터 발현 및 정제할 수 있다. 상기 시스템은 널리 공지된 진핵 세포 발현 벡터 시스템 및 숙주 세포를 포함한다. 변이체 IL-10 분자 및 융합 단백질의 발현 및 도입에 사용될 수 있는 다양한 적합한 발현 벡터가 사용될 수 있고, 관련 기술분야의 통상의 기술자에게 널리 공지되어 있다. 이들 벡터로는 예를 들어, pUC-타입 벡터, pBR-타입 벡터, pBI-타입 벡터, pGA-타입, pBinl9, pBI121, pGreen 시리즈, pCAMBRIA 시리즈, pPZP 시리즈, pPCV001, pGA482, pCLD04541, pBIBAC 시리즈, pYLTAC 시리즈, pSB11, pSB1, pGPTV 시리즈, 및 바이러스 벡터 등을 포함하며, 사용될 수 있다. 널리 공지된 숙주 세포 시스템은 CHO 세포에서의 발현을 포함하나, 이에 제한되지 않는다.
이중 시토카인 융합 단백질을 보유하는 발현 벡터는 또한 벡터 기능성을 위해 필요한 다른 벡터 성분도 포함할 수 있다. 예를 들어, 벡터는 이중 시토카인 융합 단백질의 적절한 복제 및 발현을 위해 필요한 신호 서열, 태그 서열, 프로테아제 식별 서열, 선별 마커 및 다른 서열 조절 서열, 예컨대, 프로모터를 포함할 수 있다. 벡터에서 사용되는 특정 프로모터는 다양한 숙주 세포 유형에서 이중 시토카인 융합 단백질의 발현을 유도할 수 있는 한, 특별히 제한되지 않는다. 유사하게, 태그 서열이 발현된 변이체 IL-10 분자의 정제를 더욱 간단하게 또는 용이하게 만드는 한, 태그 프로모터의 유형은 제한되지 않는다. 이는 예를 들어, 6-히스티딘, GST, MBP, HAT, HN, S, TF, Trx, Nus, 비오틴, FLAG, myc, RCFP, GFP 등을 포함하고, 사용될 수 있다. 프로테아제 인식 서열은 특별히 제한되지 않고, 예를 들어, 인식 서열, 예컨대, 인자 Xa, 트롬빈, HRV, 3C 프로테아제가 사용될 수 있다. 선택된 마커는 형질전환된 벼 식물 세포를 검출할 수 있는 한, 특별히 제한되지 않고, 예를 들어, 네오마이신-내성 유전자, 카나마이신-내성 유전자, 히그로마이신-내성 유전자 등이 사용될 수 있다.
상기 기술된 이중 시토카인 융합 단백질은 또한 제조 프로세스 동안에 융합 단백질의 회수 또는 정제에 도움이 되는 추가의 아미노산 서열을 포함할 수 있다. 이는 다양한 서열 변형 또는 친화성 태그, 예컨대 비제한적으로 단백질 A, 알부민-결합 단백질, 알칼리성 포스파타제, FLAG 에피토프, 갈락토스-결합 단백질, 히스티딘 태그, 및 관련 기술분야에 널리 공지된 임의의 다른 태그를 포함할 수 있다. 예컨대, 문헌 [Kimple et al. (Curr. Protoc. Protein Sci., 2013, 73: Unit 9.9, Table 9.91 (그 전문이 참조로 포함)]을 포함할 수 있다. 한 측면에서, 친화성 태그는 HHHHHH (서열식별번호 42)의 아미노산 서열을 갖는 히스티딘 태그이다. 히스티딘 태그는 최종 생성물로부터 제거되거나, 또는 무손상 상태 그대로 남아 있을 수 있다. 또 다른 실시양태에서, 친화성 태그는 융합 단백질에 (예컨대, 본원에 기술된 융합 단백질의 VH 영역에) 포함된 단백질 A 변형이다. 관련 기술분야의 통상의 기술자는 본원에 기술된 임의의 이중 시토카인 융합 단백질 서열이 관련 기술분야에 기술된 바와 같이, 항체 프레임워크 영역 내에 아미노산 점 치환을 삽입시킴으로써 단백질 A 변형을 포함하도록 변형될 수 있다는 것을 이해할 것이다.
또 다른 측면에서, 이중 시토카인 융합 단백질을 코딩하는 단백질 및 핵산 분자는 치료 유효량의 이중 시토카인 융합 단백질 및 제약 담체 및/또는 제약상 허용되는 부형제를 포함하는 제약 조성물로서 제제화될 수 있다. 제약 조성물은 일반적으로 사용되는 완충제, 부형제, 보존제, 안정화제로 제제화될 수 있다. 이중 시토카인 융합 단백질을 포함하는 제약 조성물은 제약상 허용되는 담체 또는 부형제와 혼합된다. 다양한 제약 담체가 관련 기술분야에 공지되어 있고, 제약 조성물에 사용될 수 있다. 예를 들어, 담체는 본 출원의 이중 시토카인 융합 단백질 조성물을 환자에게 전달하기에 적합한 임의의 상용성 비독성 물질일 수 있다. 적합한 담체의 예로는 생리식염수, 링거액, 덱스트로스 용액, 및 행크스 용액을 포함한다. 담체로는 또한 분자량이 2900 (L64), 3400 (P65), 4200 (P84), 4600 (P85), 11,400 (F88), 4950 (P103), 5900 (P104), 6500 (P105), 14,600 (F108), 5750 (P123), 및 12,600 (F127)인 것을 포함하나, 이에 제한되지 않는, 관련 기술분야의 통상의 기술자에게 일반적으로 공지된 임의의 폴록사머를 포함할 수 있다. 담체로는 또한 몇 가지 예를 들면, 폴리소르베이트 20, 폴리소르베이트 40, 폴리소르베이트 60, 및 폴리소르베이트 80을 포함하나, 이에 제한되지 않는, 유화제를 포함할 수 있다. 비수성 담체, 예컨대, 고정유 및 에틸 올레에이트 또한 사용될 수 있다. 담체로는 또한 첨가제, 예컨대, 등장성 및 화학적 안정성을 증강시키는 물질, 예컨대, 완충제 및 보존제를 포함할 수 있으며, 예컨대, 문헌 [Remington's Pharmaceutical Sciences and U.S. Pharmacopeia: National Formulary, Mack Publishing Company, Easton, Pa. (1984)]를 참조한다. 치료제 및 진단제의 제제는 예를 들어, 동결건조된 분말, 슬러리, 수성 용액 또는 현탁액의 형태로 생리학적으로 허용가능한 담체, 부형제 또는 안정화제와 혼합함으로써 제조될 수 있다.
제약 조성물은 원하는 치료 결과를 제공하는 데 충분한 치료 유효량으로 환자에게 투여하기 위해 제제화될 것이다. 바람직하게는, 상기 양은 최소한의 부정적인 부작용을 갖는다. 한 실시양태에서, 이중 시토카인 융합 단백질의 투여량은 염증성 질환 또는 병태를 치료하는 데 충분할 것이다. 또 다른 실시양태에서, 이중 시토카인 융합 단백질의 투여량은 면역 질환 또는 장애를 치료 또는 예방하는 데 충분할 것이다. 추가의 또 다른 실시양태에서, 이중 시토카인 융합 단백질의 투여량은 암을 치료 또는 예방하는 데 충분할 것이다. 투여량은 환자마다 다를 수 있고, 대상체 또는 환자의 질환 또는 병태, 환자의 전반적인 건강, 투여 방법, 부작용의 중증도 등을 고려하여 결정되어야 할 것이다.
특정 환자에 대한 유효량은 예컨대, 치료할 병태, 환자의 전반적인 건강, 투여 방법의 경로 및 용량, 및 부작용의 중증도와 같은 인자에 따라 달라질 수 있다. 환자에게 투여되는 적절한 용량은 전형적으로 치료에 영향을 미치는 것으로 관련 기술분야에서 공지되거나, 의심되거나, 또는 치료에 영향을 미치는 것으로 예측되는 파라미터 또는 인자를 이용하여 임상의에 의해 결정된다. 일반적으로, 용량은 최적 용량보다 다소 적은 양으로 시작하고, 그 후에 임의의 부정적인 부작용에 비해 원하는 또는 최적의 효과가 달성될 때까지 소량씩 증가된다. 중요한 진단 척도로는 예컨대, 염증의 증상 또는 생성된 염증성 시토카인의 수준을 포함한다.
본원에 기술된 이중 시토카인 융합 단백질의 투여를 결정하는 방법은 미국 특허 10,858,412에 기술된 것과 실질적으로 유사할 것이다. 일반적으로, 본원에 기술된 이중 시토카인 융합 단백질의 투여는 0.5 ㎍/㎏ 내지 100 ㎍/㎏ 범위가 될 것이다. 이중 시토카인 융합 단백질은 매일, 주 3회, 주 2회, 매주, 격월 또는 매월 투여될 수 있다. 유효량의 치료제는 증상을 완화시킴으로써 염증 또는 질환 또는 병태의 수준에 영향을 줄 것이다. 예를 들어, 영향은 적어도 10%; 적어도 20%; 적어도 약 30%; 적어도 40%; 적어도 50%; 또는 그 초과의 영향 수준을 포함할 수 있으며, 이로써, 질환 또는 병태는 완화되거나, 또는 완전히 치료된다.
본 출원의 조성물은 경구적으로 투여되거나, 또는 체내로 주사될 수 있다. 경구용 제제는 위장관에서 프로테아제로부터 변이체 IL-10 분자를 추가로 보호하기 위한 화합물 또한 포함할 수 있다. 주사는 일반적으로 근육내, 피하, 피내 또는 정맥내이다. 대안적으로, 적절한 상황에서 관절내 주사 또는 다른 경로가 이용될 수 있다. 비경구적으로 투여되는 이중 시토카인 융합 단백질은 바람직하게는 제약 담체 및/또는 제약상 허용되는 부형제와 함께 회합된 단위 투여량 주사가능한 형태 (액제, 현탁제, 에멀젼)로 제제화된다. 다른 실시양태에서, 본 출원의 조성물은 이식가능한 또는 주사가능한 약물 전달 시스템에 의해 환자의 체내로 도입될 수 있다.
이중
시토카인
융합 단백질 시험
원하는 생물학적 기능을 시험하기 위한 다수의 스크리닝 검정법이 관련 기술분야의 통상의 기술자에게 공지되어 있고, 이용가능하다. 한 실시양태에서, 원하는 생물학적 기능으로는 항-염증 반응 감소, T 세포 자극 감소, T 세포 기능 증강, 쿠퍼 세포 기능성 증강 및 비만 세포 탈과립화 감소를 포함하나, 이에 제한되지 않는다.
예를 들어, IL-10 노출이 T 세포 수용체 자극시에 T 세포가 더 많은 IFNγ를 생성하고 분비하도록 프라이밍한다는 것이 공지되어 있다. 동시에, IL-10 노출은 LPS에 대한 반응으로 단핵구/대식세포로부터 분비되는 TNFα, IL-6 및 다른 염증유발성 시토카인의 분비를 방지한다. IL-10은 또한 FoxP3+CD4+ Treg 증식을 억제시킨다. 한 실시양태에서, 자극성 및 억제성 반응, 그 둘 모두를 비롯하여 단핵구/대식세포 억제를 최대화시키지만, T 세포 효과는 결여된 이중 시토카인 융합 단백질은 양성으로 선택될 것이다. 한 실시양태에서, 증가된 항-염증성 효과를 갖는 이중 시토카인 융합 단백질에 대한 스크리닝은 자가면역, 항-염증성 질환, 또는 그 둘 모두의 치료를 위해 양성으로 선택될 것이다. 또 다른 실시양태에서, 쿠퍼 세포 스캐빈징을 증강시키고, Treg 억제가 결여된 이중 시토카인 융합 단백질 또한 비알콜성 지방간염 (NASH) 및/또는 비알콜성 지방간 질환 (NAFLD)의 치료를 위해 개발되도록 선택될 것이다. 추가의 또 다른 실시양태에서, 자극성 및 억제성 반응, 그 둘 모두를 비롯하여 T 세포 생물학적 성질을 최대화시키고, 증강된 쿠퍼 세포 스캐빈징 또한 갖는 이중 시토카인 융합 단백질은 암의 치료를 위해 개발되도록 선택될 것이다. 이중 시토카인 융합 단백질을 스크리닝하는 다양한 검정법 및 방법은 동시 계류 중인 미국 특허 10,858,412 (이는 그 전문이 참조로 포함된다)에서 이전에 기술된 바 있다. 미국 출원 16/811,718의 명세서 39-42 페이지를 참조한다.
이중
시토카인을
이용한 치료 및/또는 예방 방법
다른 측면에서, 본 개시내용은 악성 질환 또는 병태 또는 암 치료 및/또는 예방을 필요로 하는 대상체에게 치료 유효량의, IL-10 및 제2 시토카인을 포함하는 이중 시토카인 융합 단백질을 투여하는 단계를 포함하는, 악성 질환 또는 병태 또는 암을 치료 및/또는 예방하는 방법에 관한 것이다. 상기 단백질은 DK210 형태가 될 것이며, 여기서, 융합 단백질은 VH와 VL의 힌지 영역 사이에 연결된 제2 시토카인인 IL-2와 함께, 종양 연관 항원 ("TAA")을 표적화하는 임의의 항체로부터의 CDR이 인그라프팅된 인간 항-에볼라 항체로부터 수득된 VH 및 VL 스캐폴딩 시스템에 연결된 DV07의 단량체를 포함할 것이다. 바람직한 실시양태에서, 이중 시토카인 융합 단백질은 DV07의 EBV IL-10 단량체를 포함한다. 더욱 바람직한 실시양태에서, EBV IL-10 단량체는 서열식별번호 3의 EBV IL-10의 아미노산 위치 31 (V31L) 및 75 (A75I) 둘 모두에 치환을 포함한다. 더욱 바람직한 실시양태에서, EBV IL-10은 서열식별번호 11 또는 16이다. 바람직한 실시양태에서, 이중 시토카인 융합 단백질은 항-에볼라 항체로부터의 VH 및 VL 쌍을 포함하고, 여기서, CDR은 임의의 TAA 표적화 항체로부터의 6개의 CDR로 치환된다. 바람직한 실시양태에서, 이중 시토카인 융합 단백질의 VH 및 VL 영역은 서열식별번호 37의 VH 및 서열식별번호 38의 VL을 포함한다. 더욱 바람직한 실시양태에서, 이중 시토카인 융합 단백질은 항-에볼라 항체로부터의 VH 및 VL 쌍을 포함하고, 여기서, CDR은 항-EGFR 항체 (서열식별번호 27, 29, 31, 또는 33)로부터의 6개의 CDR로 치환되고, 여기서, 제2 시토카인은 scFv의 VH와 VL 영역 사이에 연결된다. 다른 실시양태에서, 6개의 CDR 영역은 항-Her2 Neu; 항-PDGFR; 항-VEGFR1 및 항-VEGFR2, 항-FGFR; 항-HER3; 또는 항-GPC3으로부터의 6개의 CDR로 치환된다. 바람직하게, 6개의 CDR은 항-EGFR, 또는 항-HER2로부터 수득된다. 또 다른 바람직한 실시양태에서, 제2 시토카인은 IL-2이다. 가장 바람직한 실시양태에서, 서열식별번호 35 (EGFR 표적화) 또는 52-55 (HER2 표적화)의 이중 시토카인 융합 단백질은 암을 치료하는 데 사용된다.
추가의 다른 측면에서, 본 개시내용은 염증성 질환 또는 병태 치료 및/또는 예방을 필요로 하는 대상체에게 치료 유효량의, IL-10 (또는 그의 변이체, 예컨대, DV06) 및 제2 시토카인 (예컨대, IL-4)을 포함하는 이중 시토카인 융합 단백질을 투여하는 단계를 포함하는, 염증성 질환 또는 병태를 치료 및/또는 예방하는 방법에 관한 것이다. 바람직한 실시양태에서, 염증성 질환 또는 장애는 크론병, 건선, 및 류마티스 관절염 ("RA")을 포함하나, 이에 제한되지 않는다. 상기 단백질은 DK410 형태가 될 것이며, 여기서, 융합 단백질은 VH와 VL의 힌지 영역 사이에 연결된 제2 시토카인인 IL-4 (서열식별번호 43) 또는 비-글리코실화된 형태의 IL-4 (서열식별번호 44)와 함께, 각종 염증성/면역 수용체 또는 단백질을 표적화하는 임의의 항체 (예컨대, 항-CD14, 항-VEGFR2, 항-MAdCAM)로부터의 CDR이 인그라프팅된 인간 항-에볼라 항체로부터 수득된 VH 및 VL 스캐폴딩 시스템에 연결된 DV06의 단량체를 포함할 것이다. 한 실시양태에서, IL-10 단량체는 야생형 EBV IL-10, EBV IL-10의 위치 75에 단일 아미노산 치환을 갖는 EBV IL-10 변이체 (DV06), 또는 EBV IL-10의 위치 31 및 75에 2개의 아미노산 치환을 갖는 EBV IL-10 변이체 (DV07)를 포함한다. 바람직한 실시양태에서, EBV IL-10 단량체는 야생형 EBV IL-10 또는 DV06이다. 더욱 바람직한 실시양태에서, EBV IL-10은 서열식별번호 3, 9, 10, 11, 14 또는 16이다. 바람직한 실시양태에서, 이중 시토카인 융합 단백질은 인간 항-에볼라 항체로부터의 VH 및 VL 쌍을 갖는 스캐폴딩 시스템을 포함한다. 더욱 바람직한 실시양태에서, 염증성 질환 또는 병태를 치료하는 데 사용되는 이중 시토카인 융합 단백질은 인간 항-에볼라 항체로부터의 VH 및 VL 쌍을 포함하고, 여기서, CDR은 항-MAdCAM 항체 (바람직하게, 인간 항-MAdCAM 항체) 또는 항-CD14 항체 (바람직하게, 인간 항-CD14 항체) 또는 항-VEGFR2 (바람직하게, 인간 항-VEGFR2 항체)의 VH 및 VL로부터의 6개의 CDR로 치환된다. 또 다른 바람직한 실시양태에서, 제2 시토카인은 IL-4, 바람직하게, N38A 치환을 갖는 IL-4 변이체 (서열식별번호 44)이다. 가장 바람직한 실시양태에서, 염증성 질환은 패혈증 및/또는 패혈성 쇼크를 포함하며, 이는 DV06 또는 DV07 단량체 및 IL-4를 포함하는 이중 시토카인 융합 단백질로서, 여기서, 항-CD14 항체로부터의 CDR이 항-에볼라 VH 및 VL scFv 스캐폴딩 시스템으로 인그라프팅된 것인 이중 시토카인 융합 단백질로 치료된다. 바람직한 실시양태에서, 이중 시토카인 융합 단백질은 서열식별번호 56-58, 또는 59, 더욱 바람직하게, 서열식별번호 56의 DK410 형태이다. 또 다른 바람직한 실시양태에서, 염증성 질환은 IBD를 포함하며, 이는 DV06 단량체 및 IL-4를 포함하는 이중 시토카인 융합 단백질로서, 여기서, 항-MAdCAM 항체로부터의 CDR이 항-에볼라 VH 및 VL scFv 스캐폴딩 시스템으로 인그라프팅된 것인 이중 시토카인 융합 단백질로 치료된다. 추가의 또 다른 바람직한 실시양태에서, 염증성 질환은 건선 또는 RA를 포함하며, 이는 DV06 단량체 및 IL-4를 포함하는 이중 시토카인 융합 단백질로서, 여기서, 항-VEGFR2 항체로부터의 CDR이 인간 항-에볼라 VH 및 VL scFv 스캐폴딩 시스템으로 인그라프팅된 것인 이중 시토카인 융합 단백질로 치료된다. 가장 바람직한 실시양태에서, 서열식별번호 46-50, 56-58, 또는 59 (CD14 표적화) 또는 51 (MAdCAM 표적화)의 이중 시토카인 융합 단백질이 염증 또는 패혈증을 감소시키는 데 사용된다.
추가의 또 다른 측면에서, 본 개시내용은 면역 질환 또는 병태 치료 및/또는 예방을 필요로 하는 대상체에게 치료 유효량의, IL-10을 포함하는 이중 시토카인 융합 단백질을 투여하는 단계를 포함하는, 면역 질환 또는 병태를 치료 및/또는 예방하는 방법에 관한 것이다.
다른 실시양태에서, 본 개시내용은 또한 관련 기술분야에 널리 공지된, 제2 치료제, 예컨대, 시토카인, 스테로이드, 화학요법제, 항생제, 항염증제, 또는 방사선을 이용한 공동 투여 또는 치료 방법을 고려한다. 이는 다른 치료제, 예컨대 비제한적으로 하기 중 하나 이상의 것과의 조합 치료를 포함할 수 있다: 화학요법제, 인터페론-β, 예를 들어, IFNβ-1α 및 IFN-β-1β; 미엘린 염기성 단백질을 모방하는 단백질; 코르티코스테로이드; IL-1 억제제; TNF 억제제; 항-TNFα 항체, 항-IL-6 항체, IL-1br-Ig 융합, 항-IL-23 항체, CD40 리간드 및 CD80에 대한 항체; IL-12 및 IL-23의 길항제, 예컨대, IL-12 및 IL-23의 p40 서브유닛의 길항제 (예를 들어, p40 서브유닛에 대한 억제성 항체); IL-22 길항제; 소분자 억제제, 예컨대, 메토트렉세이트, 레플루노미드, 시롤리무스 (라파마이신) 및 그의 유사체, 예컨대, CCI-779; Cox-2 및 cPLA2 억제제; NSAID; p38 억제제; TPL-2; Mk-2; NFkβ 억제제; RAGE 또는 가용성 RAGE; P-셀렉틴 또는 PSGL-1 억제제 (예컨대, 소분자 억제제, 그에 대한 항체, 예컨대, P-셀렉틴에 대한 항체); 에스트로겐 수용체 베타 (ERB) 효능제 또는 ERB-NFkβ 길항제.
추가로, 이중 시토카인 융합 단백질과의 투여에 유용한 조합 치료는 TNF 억제제, 예컨대, TNF에 결합하는 키메라, 인간화, 효과적으로 인간, 인간 또는 시험관내 생성된 항체, 또는 그의 항원-결합 단편; TNF 수용체의 가용성 단편, 예컨대, p55 또는 p75 인간 TNF 수용체 또는 그의 유도체, 예컨대, 75 kdTNFR-IgG (75 kD TNF 수용체-IgG 융합 단백질, 엔브렐(ENBREL)™), p55 kD TNF 수용체-IgG 융합 단백질; 및 TNF 효소 길항제, 예컨대, TNFα 전환 효소 (TACE) 억제제를 포함할 수 있다. 항염증제/약물과의 다른 조합 치료는 표준 비스테로이드성 항염증 약물 (NSAID) 및 시클로-옥시게나제-2 억제제를 포함하나, 이에 제한되지 않는다. NSAID로는 아스피린, 셀레콕시브, 디클로페낙, 디플루니살, 에토돌락, 이부프로펜, 인도메타신, 케토프로펜, 케토롤락, 나부메톤, 나프록센, 옥사프로진, 피록시캄, 살사레이트, 술린닥, 및/또는 톨메틴을 포함할 수 있다. 본 출원에 따른 조성물에서 사용되는 시클로-옥시게나제-2 억제제는 예를 들어, 셀레콕시브 또는 로페콕시브일 수 있다.
이중 시토카인 융합 단백질과 공동 투여될 수 있고/거나, 공동 제제화될 수 있는 추가의 치료제로는 하기 중 하나 이상의 것을 포함한다: 인터페론-β, 예를 들어, IFN β-1α 및 IFN β-1β; 코팍손(COPAXONE)®; 코르티코스테로이드; IL-1 억제제; TNF 길항제 (예컨대, TNF 수용체의 가용성 단편, 예컨대, p55 또는 p75 인간 TNF 수용체 또는 그의 유도체, 예컨대, 75 kdTNFR-IgG; CD40 리간드 및 CD80에 대한 항체; 및 IL-12 및/또는 IL-23의 길항제, 예컨대, IL-12 및 IL-23의 p40 서브유닛의 길항제 (예컨대, IL-12 및 IL-23의 p40 서브유닛에 결합하는 억제성 항체); 메토트렉세이트, 레플루노미드, 및 시롤리무스 (라파마이신) 또는 그의 유사체, 예컨대, CCI-779. 다른 치료제로는 임핌지(Imfimzi) 또는 아테졸리줌브(Atezolizumb)를 포함할 수 있다.
NASH를 치료하기 위해, 예를 들어, 이중 시토카인 융합 단백질을 콜레스테롤 강하제, 예컨대, 스타틴 및 비-스타틴 약물과 조합할 수 있다. 이들 작용제는 심바스타틴, 아토르바스타틴, 로수바스타틴, 로바스타틴, 프라바스타틴, 겜피브로질, 플루바스타틴, 콜레스티라민, 페노피브레이트, 콜레스테롤 흡수 억제제, 담즙산-결합 수지 또는 격리제, 및/또는 마이크로솜 트리글리세리드 전달 단백질 (MTP) 억제제를 포함하나, 이에 제한되지 않는다.
본원에 기술된 이중 시토카인 융합 단백질과 함께 공동 투여될 수 있는 대표적인 화학요법제로는 하기 완전하지 않은 목록을 포함할 수 있다: 알킬화제, 예컨대, 티오테파 및 시클로스포스파미드 (시톡산(CYTOXAN)™); 알킬 술포네이트, 예컨대, 부술판, 임프로술판 및 피포술판; 아지리딘, 예컨대, 벤조도파, 카르보쿠온, 메투레도파, 및 우레도파; 에틸엔이민 및 메틸아멜라민, 예컨대, 알트레타민, 트리에틸렌멜라민, 트리에틸렌포스포르아미드, 트리에틸렌티오포스파오라미드 및 트리메틸올멜라밈 질소 머스타드, 예컨대, 키오람부실, 클로르나파진, 콜로포스파미드, 에스트라무스틴, 이포스파미드, 메클로레타민, 메클로레타민 옥시드 히드로클로라이드, 멜팔란, 노벰비킨, 펜에스테린, 프레드니무스틴, 트로포스파미드, 우라실 머스타드; 니트로스우레아, 예컨대, 카르무스틴, 클로로조토신, 포테무스틴, 로무스틴, 니무스틴, 라니무스틴; 항생제, 예컨대, 아클라시노미신, 악티노마이신, 아우트라마이신, 아자세린, 블레오마이신, 칵티노마이신, 칼리케아미신, 카라비신, 카르미노마이신, 카르지노필린, 크로모마이신, 닥티노마이신, 다우노루비신, 데토루비신, 6-디아조-5-옥소-L-노르류신, 독소루비신, 에피루비신, 에소루비신, 이다루비신, 마르셀로마이신, 미토마이신, 미코페놀산, 노갈라마이신, 올리보마이신, 페플로마이신, 포트피로마이신, 퓨로마이신, 쿠엘라마이신, 로도루비신, 스트렙토니그린, 스트렙토조신, 투베르시딘, 우베니멕스, 지노스타틴, 조루비신; 항대사산물, 예컨대, 메토트렉세이트 및 5-플루오로우라실 (5-FU); 엽산 유사체, 예컨대, 데노프테린, 메토트렉세이트, 프테로프테린, 트리메트렉세이트; 퓨린 유사체, 예컨대, 플루다라빈, 6-메르캅토퓨린, 티아미프린, 티오구아닌; 피리미딘 유사체, 예컨대, 안시타빈, 아자시티딘, 6-아자우리딘, 카르모푸르, 시타라빈, 디데옥시우리딘, 독시플루리딘, 에노시타빈, 플록수리딘, 5-FU; 안드로겐, 예컨대, 칼루스테론, 드로모스타놀론 프로피오네이트, 에피티오스탄올, 메피티오스탄, 테스토락톤; 항부신제, 예컨대, 아미노글루테티미드, 미토탄, 트릴로스탄; 엽산 보충제, 예컨대, 프롤린산; 아세글라톤; 알도포스파미드 글리코시드; 아미노레불린산; 암사크린; 베스트라부실; 비산트렌; 에다트락세이트; 데포파민; 데메콜신; 디아지쿠온; 엘포르니틴; 엘리프티늄 아세테이트; 에토글루시드; 갈륨 니트레이트; 히드록시우레아; 렌티난; 로니다민; 미토구아존; 미톡산트론; 모피다몰; 니트라크린; 펜토스타틴; 페나메트; 피라루비신; 포도필린산; 2-에틸히드라지드; 프로카르바진; PSK®; 라족산; 시조피란; 스피로게르마늄; 테누아존산; 트리아지쿠온; 2,2',2"-트리클로로트리에틸아민; 우레탄; 빈데신; 다카르바진; 만노무스틴; 미토프로니톨; 미토락톨; 피포브로만; 가시토신; 아라비노시드 (Ara-C); 시클로포스파미드; 티오테파; 탁소이드, 예컨대, 파클리탁셀 (탁솔(TAXOL)® 브리스톨-마이어스 스큅 온콜로지(Bristol-Myers Squibb Oncology: 미국 뉴저지주 프린스톤)) 및 독세탁셀 (탁소테레(Taxotere)™, 롱-프랑 로리(Rhone-Poulenc Rorer: 프랑스 앙토니)); 클로람부실; 겜시타빈; 6-티오구아닌; 메르캅토퓨린; 메토트렉세이트; 백금 유사체, 예컨대, 시스플라틴 및 카르보플라틴; 빈블라스틴; 백금; 에토포시드 (VP-16); 이포스파미드; 미토미신 C; 미톡산트론; 빈크리스틴; 비노렐빈; 나벨빈; 노반트론; 테니포시드; 다우노마이신; 아미노프테린; 젤로다(Xeloda)® 로슈(Roche: 스위스); 이반드로네이트; CPT11; 토포이소머라제 억제제 RFS 2000; 디플루오로메틸오르니틴 (DMFO); 레티노산; 에스페라미신; 카페시타빈; 및 상기 중 임의의 것의 제약상 허용되는 염, 산 또는 유도체를 포함한다. 종양에 대한 호르몬 작용을 조절하거나, 억제하도록 작용하는 항호르몬제, 예컨대, 항에스트로겐, 예를 들어, 타목시펜, 랄록시펜, 아로마타제 억제 4(5)-이미다졸, 4-히드록시타목시펜, 트리옥시펜, 케옥시펜, LY117018, 오나프리스톤, 및 토레미펜 (파레스톤(Fareston)); 및 항안드로겐, 예컨대, 플루타미드, 닐루타미드, 비칼루타미드, 류프롤리드, 및 고세렐린; 및 상기 중 임의의 것의 제약상 허용되는 염, 산 또는 유도체 또한 본 정의에 포함된다.
실시예
실시예
1: IL-10 및 IL-2 이중
시토카인
융합 단백질
시험관내
연구
2개의 시토카인을 종양에 표적화하는 시험관내 효과를 평가하기 위해, 하기 구성요소로부터 DK210 (서열식별번호 35) (구조의 대표도로서 도 2 참조)으로 명명되는 이중 시토카인 융합 단백질을 구축하였다:
(a) EGFR을 표적화하는 VH 및 VL 쌍을 포함하는 scFv에 커플링된 (고친화성 IL-10 수용체 결합, EBV IL-10 변이체인) 2개의 DV07 단량체 (서열식별번호 31의 "SLP"로 명명되는 IL-10 융합 단백질); 및
(b) IL-2 시토카인 (서열식별번호 36);
여기서, IL-2 시토카인은 EGFR을 표적화하는 scFv의 VH (서열식별번호 37)와 VL (서열식별번호 38) 사이의 힌지 (또는 링커) 영역에 접합 또는 연결된다 (서열식별번호 31의 SLP 변이체).
NK, CD4+ 및 CD8+ T 세포로부터 IFNγ의 IL-2 유도에 대한 상기 두 시토카인의 조합 효과를 평가하기 위해 상기 이중 시토카인 융합 단백질을 생성하였다. 상기 기술된 SLP 구축물의 최극단 C-말단 DV07 단량체의 C-말단에 IL-2를 연결하여 "SLP-IL-2"로 명명되는 구축물 (도 3)을 생성하는 비교 구축물 또한 디자인하였다.
SLP-IL-2 (도 3) 및 DK210 (서열식별번호 35, 도 2에 개략적으로 제시)이 면역계에 미치는 효과를 시험하기 위하여, DV07 기능 평가를 위해 자기 비드 양성 선택에 의해 말초 혈액 단핵구를 단리시킨 후, 시험관내 시험을 위해 NK, CD4+ 및 CD8+ T 세포를 유사하게 단리시켰다. 인체에 피하 주사된 분자의 노출 주기 중 상이한 시점에서의 면역학적 기능을 모델링하기 위해 일련의 세포 시험관내 검정법을 셋업하였다.
먼저, IL-10, IL-2, IL-10과 IL-2의 조합, 및 SLP-IL-2가 단핵구/대식세포에 미치는 효과를 시험하였다. 본 시험은 IL-2 단독으로는 LPS에 대한 반응으로 염증유발성 시토카인인 TNFα 분비를 억제시키지 못하지만, DV07을 포함하는 SLP:IL-2 구축물은 염증유발성 시토카인 분비를 억제시킬 수 있었다는 것을 보여준다. IL-10, IL-2, IL-10과 IL-2의 조합, 및 SLP-IL-2의 적정을 수행하였다 (도 4). 예상외로, 이들 데이터는 또한 DV07 함유 구축물의 기능이 IL-10 단량체의 C-말단에의 IL-2 시토카인 부가 (즉, SLP-IL-2; 도 3)에 의해 손상된다는 것을 시사한다.
(도 2에 개략적으로 제시된) 인간 항-에볼라 항체로부터 수득된 scFv의 VH와 VL 사이의 링커 내로 IL-2가 도입된, DV07 함유 변이체로서 디자인된 DK210이 단핵구/대식세포에 미치는 효과 또한 평가하여 구축물이 IL-10 기능을 유지하는지 여부를 결정하였다. IL-10, SLP (서열식별번호 31의 DegfrDV07의 최적화된 변이체), 및 DK210egfr (서열식별번호 35)의 적정을 수행하였고 (도 5), 데이터는 IL-2를 최극단 C-말단 IL-10 단량체의 C-말단에 연결시킨 것 (SLP-IL-2)과 달리, 예상외로 IL-2를 scFv의 VH와 VL 사이의 링커 내로 도입하는 것이 SLP (서열식별번호 31의 IL-10 융합 단백질을 함유하는 DV07)의 기능을 손상시키지 않는다는 것을 시사한다.
DK210egfr이 T 세포에 미치는 직접적인 효과를 평가하기 위해, 우세하게 오직 T 세포 수용체 인게이지먼트시에만 방출되는 IFNγ 강화인, CD8+ T 세포에 대한 IL-10의 주요 기능을 직접적으로 설명하는 것으로 보고된 검정법 ([Chan, 2015]; [Mumm J., 2011]; [Emmerich, 2012])을 수행하였다.
전신 순환에서 PEG-rHuIL-10의 필요한 치료 농도는 2-5 ng/mL인 것으로 밝혀졌다 ([Mumm J., 2011]; [Naing A., 2018]; [Naing A., 2016]). CD8+ T 세포 IFNγ 검정은 1-10 ng/mL에서 최대 T 세포 IFNγ 강화를 나타내며, 이는 암 적용을 위한 IL-10의 특정 효능을 평가하기 위한 적절한 모델 검정 시스템임을 시사한다.
고용량 IL-2 요법은 5일 동안 매 8시간마다 600,000 내지 720,000 U/kg IL-2 (37 - 45 ug/kg의 등가량 (1.1 mg = 18x106 IU (IL-2)))를 투여하는 것이다 (Buchbinder, 2019). 고용량 IL-2에 대한 전신 순환에서의 C최대 농도는 37 내지 45 ng/mL이고 (Kirchner, 1998), 여기서, 최저 노출은 약 10 ng/ml이다. 이 데이터는 항원 특이적 T 세포 기능의 최대 IL-2 자극이 시험관내에서 대략 10 ng/ml이기 때문에, 본 검정법을 사용하는 것이 또한 IL-2에 대한 T 세포 반응을 평가하는 데 적합하다는 것을 시사한다. 따라서, 본 발명자들은 본 검정 포맷에서 IL-10, IL-2, IL-10과 IL-2의 조합, SLP 및 DK210에 대한 CD8+ 및 CD4+ T 세포 반응을 평가하였다 (도 6). 예상외로, IL-2와 DV07을 함께 테더링 (즉, IL-2를 scFv의 VH와 VL 사이의 링커로 SLP에 테더링)함에 따라 어느 한 분자가 단독으로 보여주는 효능을 100배만큼 증가시켰다 (~1-10 ng/mL에서 0.01 ng/mL). 예상외로, 상기 농도에서 테더링되지 않은 IL-2 및 IL-10를 부가하였을 때, IFNγ 분비는 증진되지 않았고, 이는 IL-2와 DV07을 함께 테더링하는 것이 T 세포 기능에 미치는 효과가 상가적 또는 상승작용적 효과보다 유의적으로 더 크다는 것을 시사하는 것이다.
IL-2 독성 (혈관 누출 증후군)은 NK (Assier, 2004), 및 CD4+ T 세포 (Sivakumar, 2013), 염증유발성 시토카인 분비 ([Guan, 2007]; [Baluna, 1997])와 연관이 있다. 그러므로, 본 발명자들은 IL-10이 혈액으로부터 직접 단리된 NK 세포에 대한 IL-2의 염증유발성 효과를 뮤팅할 수 있는지 여부를 평가하였다. (1) 혈액으로부터 직접 단리된 CD4+ 및 CD8+ T 세포, (2) 항원 프라이밍을 모델링하기 위해 항-CD3/항-CD28과 시토카인에 노출된 CD4+ 및 CD8+ T 세포, (3) 종양에서의 노출을 모델링하기 위해 항원 프라이밍 후 시토카인에 노출된 CD4+ 및 CD8+ T 세포 및 (4) 동족 항원과의 인게이지먼트시 노출이 항원 프라이밍된 T 세포 기능에 미치는 효과 (도 7). 말초 혈액으로부터 직접 단리된 NK 세포, CD4+ 및 CD8+ T 세포를 4일 동안 IL-10, IL-2, IL-10과 IL-2의 조합, SLP (서열식별번호 31의 DegfrDV07의 최적화된 변이체), 및 DK210egfr의 적정으로 처리하였다 (도 7). DK210egfr에 대한 예상 투여 요건은 4일마다 1회이며, 이러한 시험관내 노출이 4일 동안 예상 C최대 노출을 훨씬 초과하는 고농도의 시토카인 (최대 100 ng/mL)을 모델링한다는 것을 시사한다. 본 데이터는 IL-10을 IL-2에 개별 시토카인으로 부가하거나, 또는 DK210egfr로 함께 테더링하면 NK, CD4+ 및 CD8+ T 세포로부터의 IL-2 매개 IFNγ 분비 유도를 5-10 ng/mL에서 각각 ~50%, ~80% 및 ~50%만큼 억제시킨다는 것을 나타낸다. 0.01 ng/mL의 예상 치료 용량에서, 조합된 시토카인 DK210egfr에 의해서는 IFNγ이 거의 유도되지 않거나, 또는 전혀 유도되지 않는다.
모델 항원 제시 (고정화된 10 ng/mL 항-CD3/2 ng/mL 항-CD28) 동안 시토카인 노출의 효과 (Chan, 2015)도 조사하였다 (도 8). 데이터에 따르면, IL-2에 IL-10을 추가하였을 때, 특히, DK210egfr을 통해 테더링된 IL-2 및 IL-10을 추가하였을 때, 10 ng/mL에서 CD4+ 및 CD8+ IFNγ 유도는 각각 ~75% 및 ~90%만큼 억제된 것으로 나타났고, 0.01 ng/mL에서는 어떤 IFNγ 유도도 보이지 않는 것으로 나타났다.
마지막으로, 동족 종양 항원과의 인게이지먼트 전 종양에서의 T 세포 수송을 모델링하기 위해 항원 노출 후 CD4+ 및 CD8+ T 세포에서의 IFNγ 유도를 조사하였다 (도 9). 예상외로, 데이터에 따르면, DK210egfr 대비 IL-2, 개별적으로 적용된 IL-10 및 IL-2의 효과는 항원 프라이밍된 CD4+ 및 CD8+ T 세포에 대하여 상이한 기능을 발휘하는 것으로 나타났다. DK210egfr 경우, 예상 치료 농도에서, DK210egfr이 IL-2, 또는 개별적으로 적용된 IL-10 및 IL-2보다 더 많이 IFNγ 분비를 강화시킨다. IL-10 및 IL-2 경우, 예상 치료 농도에서, DK210egfr, IL-2 및 개별적으로 적용된 IL-10 및 IL-2는 CD4+ 및 CD8+ T 세포로부터의 IFNγ 분비를 등가적으로 유도한다. 상기 데이터는 일괄하여 IL-2 및 IL-10을 (DK210 형태로) 함께 테더링하는 것이 IL-2 독성과 연관된 염증유발성 시토카인 분비를 억제시키면서, 항원 특이적 CD4+ 및 CD8+ T 세포 반응을 강화시킨다는 것을 나타낸다. 특히, 이러한 효과는 항-에볼라 scFv 스캐폴딩으로의 항-EGFR CDR의 인그라프트먼트에 의해 영향을 받지 않았다.
실시예
2: IL-10 및 IL-2 이중
시토카인
융합 단백질
생체내
연구
안정적으로 발현된 인간 EGFR CT26 뮤린 결장직장 종양 세포주를 생성함으로써 종양 미세환경으로 DV07을 항-EGFR scFv를 통해 표적화하는 것 (여기서, DV07은 6개의 인그라프팅된 항-EGFR CDR을 포함하는, 인간 항-에볼라 ScFv 스캐폴딩으로부터 수득된 VH 및 VL을 포함하는 scFv에 융합되어 있다; 서열식별번호 31의 "Degfr:DV07")이 PEG-rHuIL-10과 비교하였을 때 우수한 항-종양 기능을 보이는 것으로 이전에 밝혀졌다. 미국 특허 10,858,412를 참조한다. 동일한 생체내 종양 연구를 이용하여, 인간 EGFR 발현 CT26 세포 뮤린 종양 세포주에서 DK210egfr을 평가하고, Degfr:DV07과 비교하였다.
종양이 평균 100 ㎣인 CT26 (hEGFR+) 종양 보유 B 세포 k.o. Balb/C 마우스를 표 1에 제시된 바와 같이 제공되는 시험 물품, 용량 및 빈도로 처리하였다. 시험 물품을 목덜미에 피하 투여하였다. 모든 물품을 15일 동안 매일 투여하였다.

전자 캘리퍼로 3일마다 종양의 길이와 너비를 측정하고, 종양 부피를 계산하였다 ((LxW2)/2)). 본 실시예에서, "Degfr:DV07"이라는 용어는 인간 EGFR 표적화된 DV07이고; DK210egfr은 "DK210"으로 약칭되고, 세툭시맙 CDR 그라프팅된 항-에볼라 scFv 스캐폴드를 통해 DV07과 커플링된 인간 IL-2이다.
방법
시험관내 세포 배양: CT26( hEGFR +) 종양 세포 (ATCC)를 완전 RPMI, 10% FCS, 및 10 ug/mL 퓨로마이신 중에서 전면생장률이 70%가 될 때까지 성장시켰다. 세포를 이식 전 시험관내에서 3회 이하의 계대배양 동안 계대시켰다. 아큐타제(Accutase) (바이오레전드(Biolegend))를 이용하여 세포 배양 플레이트로부터 세포를 꺼내고, 4℃에서 400 g로 10분 동안 스피닝하면서 완전 RPMI 중에서 세척하였다.
종양 이식: 종양 세포를 B 세포 녹아웃 마우스의 우측 옆구리에 피하로 50% 성장 인자 감소된 마트리겔(Matrigel), 50% RPMI에서 100 ㎕ 중 1 x105개의 세포/마우스로 이식하였다.
결과
종양 성장에 대한 Degfr:DV07 및 DK2 10 비교: 안정적으로 형질감염된 종양 세포 상에 존재하는 EGFR에의 결합을 통한 DV07의 종양 미세환경으로의 표적화는 효과적인 것으로 이전에 밝혀졌다. 미국 특허 10,858,412를 참조한다. 동일한 종양 시스템을 사용하여, Degfr:DV07 대 DK210을 비교하였다.
종양을 주 3회 측정하였다 (표 2). 75 ㎣ CT26( hEGFR +) 종양을 보유하는 암컷 Balb/C B 세포 녹아웃 마우스를 표 2에 예시된 시험 물품 및 투여 빈도로 피하 처리하였다.


본 실험을 위해, 종양 항원에 대한 마우스의 면역화를 제한하기 위해 CT26(hEGFR+) 세포를 50% 성장 인자 감소된 마트리겔에서 1x105개의 세포로 이식하였다.
1 mg/kg에서의 Degfr:DV07의 항-종양 효과를 동일 용량의 DK210 뿐만 아니라, 2 및 4 mg/kg 용량과도 비교하였다 (도 10). Degfr:DV07을 1 mg/kg으로 매일 투여하는 것과 비교하여 DK210을 1 mg/kg으로 매일 투여하는 것이 더 우수한 항-종양 기능을 발휘한다. 2 및 4 mg/kg 용량의 DK210은 1 mg/kg보다 더 큰 항-종양 기능을 발휘한다.
DK2 10 의 안전성 평가 : DK210 투여의 안전성을 시험하기 위해, Degfr:DV07 및 DK210으로 처리된 종양 보유 마우스의 체중을 평가하였다 (도 11). Degfr:DV07 또는 DK210 투여가 마우스의 체중에 미치는 뚜렷한 효과는 없다.
Degfr:DV07 및 DK2 10 투여가 생존에 미치는 효과 : DK210에 대한 CT26(hegfr+) 종양 보유 마우스의 생존성을 평가하였다 (도 12).
비히클 처리 마우스의 모든 종양은 17일째까지 IAACUC 규정에 의하면 너무 컸다. 30일째 4 mg/kg, 2 mg/kg 및 1 mg/kg DK210 및 Degfr:DV07 1 mg/kg 처리군에서 각각 100%, 80%, 80% 및 60%의 마우스가 살아 있었다.
본 데이터는 일괄하여 고친화성 IL-10 변이체 (DV07)의 IL-2에의 커플링 및 상기 두 분자를 모두 (DK210egfr을 통해) 종양 미세환경으로 표적화하는 것이 치료상 유효 용량에서 명백한 IL-2 매개 독성을 방지한다는 것을 시사한다. 인간 항-에볼라 스캐폴딩으로부터 수득된 VH 및 VL 영역을 포함하는 scFv 스캐폴딩으로 항-EGFR CDR을 인그라프팅하는 것은 IL-10 및 IL-2의 조합 효과에 영향을 주지 않고, 오히려 항-EGFR CDR은 DK210 분자를 종양 미세환경에 집중시키는 수단으로서 작용한다. 본 발명자들은 종양 미세환경을 표적화하는 (적절히 최적화된) 임의의 항체로부터의 CDR을 인그라프팅하면, 그 결과로 동일하거나, 또는 유사한 효과가 관찰될 것으로 여기고 있다.
실시예
3: IL-10 및 IL-4 이중
시토카인
융합 단백질
크론병 환자에서, 고용량 IL-10은 IFNγ 증가와 함께 항-염증 반응을 감소시켰다. 시토카인과 IL-10의 조합이 IL-10의 항-염증 기능을 증강시키고, IL-10의 자극 (IFNγ 강화) 기능을 억제시키는지 여부를 결정하기 위해, IL-10 및 IL-4 이중 시토카인 융합 단백질을 생성하였다. 본 발명자는 예상외로 단핵구에 대한 IL-10 및 IL-4의 조합 처리가 IL-10 또는 IL-4 단독 처리보다 LPS 유도된 염증 반응을 더 강력하게 억제시킨다는 것을 발견하게 되었다 (하기에서 더욱 상세하게 논의). 추가로, IL-4는 CD8+ T 세포에서 IL-10 매개 IFNγ 강화를 억제시켰다. (상기 실시예 1 및 2에서 기술된) DK210egfr을 디자인하기 위해 유사한 방법 및 원리를 이용하여, IL-4 또는 다양한 IL-4 변이체를 융합 구축물로서 IL-10 또는 IL-10 변이체에 커플링시켜 (대표도로서 도 17 참조) IL-10의 억제 기능을 증강시켰다. 생성된 분자 부류를 DK410으로 명명하였다.
표 3은 시토카인 및 다양한 DK410 융합 분자를 비롯한, 연구된 다양한 분자 요약을 제공한다.


건강한 공여자로부터의 말초 혈액 단핵 세포 (PBMC) 제제로부터 유래된, 자기 비드 양성 선택에 의해 단리된 단핵구/대식세포 및 CD8+ T 세포에 대해 하기 분자 및 분자 조합이 미치는 효과에 대하여 그를 시험하였다:
1. IL-4;
2. IL-10;
3. IL-10과 함께 조합된 IL-4;
4. DeboWtEBV;
5. IL-4와 함께 조합된 DeboWtEBV;
6. DeboDV06;
7. IL-4와 함께 조합된 DeboDV06;
8. DeboDV07;
9. IL-4와 함께 조합된 DeboDV07;
10. 야생형 IL-4 및 DV06을 포함하는 DK410 ("4DeboDV06");
11. 고친화성, 비-글리코실화된 IL-4 (T13D) 및 mCD14로 표적화되는 DV06을 포함하는 DK410;
12. 고친화성, 비-글리코실화된 IL-4 (T13D) 및 mCD14로 표적화되는 DV07을 포함하는 DK410;
13. mCD14로 표적화되는 DV06과 함께 비-글리코실화된 IL-4 (N38A)를 포함하는 DK410;
14. mCD14로 표적화되는 DV07과 함께 비-글리코실화된 IL-4 (N38A)를 포함하는 DK410; 및
15. mMAdCAM으로 표적화되는 DV06과 함께 비-글리코실화된 IL-4를 포함하는 DK410.
방법
PBMC 및 CD8+ T 세포 단리 : 자석 보조형 세포 분류에 의해 항-CD14 (단핵구) 또는 항-CD8 (CD8+ T 세포) 자기 마이크로비드를 사용하여 PBMC 또는 류코팩으로부터 대식세포 및 CD8+ T 세포 둘 모두를 단리시켰다.
세포 검정 - 시토카인 및 지질다당류 ( LPS )에 대한 단핵구/대식세포 세포 반응 : 본 검정에서, PMBC 유래 단핵구를 CD14 양성 선택 비드로 단리시키고, 2x105개의 세포/웰로 플레이팅하고, 적정 시토카인 및 10 ng/mL LPS에 노출시킨다. 18시간 후, 분비된 염증유발성 시토카인에 대한 ELISA에 의해 상청액을 평가한다. TNFα 감소율(%)을 플롯팅하여 시토카인 또는 시험 물품이 LPS에 미치는 영향을 나타낸다. 본 검정이 말초 혈액에서의 시토카인 및 박테리아 유래 염증유발성 생성물에 대한 단핵구의 반응을 가장 적절하게 모방한다.
세포 검정 - CD8+ T 세포 . 다중 CD8+ T 세포 검정법을 이용하였다.
먼저, CD8+ 양성 자기 선택 비드를 이용하여 PBMC로부터 유래된 CD8+ T 세포를 수득하고, 2x105개의 세포/웰로 플레이팅하고, 하기 조건하에 적정 시토카인 또는 시험 물품에 노출시켰다:
(i) 단독으로 4일 동안,
(ii) 본 분자가 동족 항원 제시에 대한 세포 반응에 주는 영향 방식을 모방하기 위해 시토카인의 존재하에 플레이트 결합된 항-CD3/항-CD28에 3일 동안,
(iii) 항원 자극된 세포가, 세포가 종양에 진입함에 따라 본 시토카인 및 신규 인자에 반응하는 방식을 모방하기 위해 항-CD3/항-CD28 후 3일 동안, 및
(iv) 종양 미세환경에서 T 세포가 동족 항원 노출에 반응하는 방식을 모방하기 위해 시험관내에서 노출된 세포로부터 4시간 후에 T 세포 수용체 유발 IFNγ 분비를 평가하였다.
단핵구/대식세포 및 CD8+ T 세포 둘 모두를 언급된 바와 같이 밤새도록 또는 3-4일 동안 0.1, 1, 10, 100 ng/mL 또는 0.001, 0.01, 0.1, 1 및 10 ng/mL (또는 몰 당량)의 적정 인간 IL-4, IL-10, DeboWtEBV, DeboDV06 및 다양한 DK410 융합 분자에 노출시켰고, 모든 조건은 이중으로 수행하였다. 상기 분자의 항-염증성 (단핵구/대식세포) 및 자극 효과 (CD8+ T 세포)를 이용하여 가장 효과적인 항-염증성 시토카인 쌍을 결정하였다.
단백질 측정 : 대식세포 세포 배양 배지를 ELISA에 의해 TNFα에 대하여 검정하고, CD8+ T 세포 배양 배지를 ELISA에 의해 IFNγ에 대하여 검정하였다. DeboDV06, 4DeboDV06 및 다양한 DK410 융합 분자는 각 단백질의 각각의 흡광 계수를 사용하여 나노드롭(Nanodrop) OD280 nM에 의해 평가하고, 농도는 쿠마시(Coomassie) 염색된 SDS-PAGE 겔 밴드 강도에 의해 제공하였다.
결과
IL-10 및 IL-4 조합에 대한 이론적 근거 전개 : IL-10은 LPS에 대한 반응으로 대식세포에 의한 TNFα 분비를 억제시키는 것으로 보고되었다 ([Interleukin 10 Inhibits Cytokine Synthesis by Human Monocytes An Autoregulatory Role of IL-10 Produced by Monocytes, 1991]; [Moore, 2001]). IL-4는 인간 단핵구 (Hart, Potential antiinflammatory effects of interleukin 4: Suppression of human monocyte tumor necrosis factor ca, interleukin 1, and prostaglandin E2, 1989) 및 인간 복막 대식세포 (Hart, 1991)로부터의 LPS 유도된 TNFα 분비를 억제시키는 것으로 보고되었다.
염증 자극으로 LPS에 반응하여 나타나는 단핵구 염증유발성 시토카인 분비 억제에 대해 IL-4 및 IL-10 조합이 미치는 효과를 결정하기 위해, 자기 비드 양성 선택에 의해 말초 혈액 단핵구를 건강한 공여자 PBMC로부터 단리시켰다. 단리된 단핵구를 적정 IL-10, IL-4, 및 IL-10과 IL-4의 조합에 노출시켰다 (도 13). 적정 (0.1, 1, 10, 100 ng/mL) 인간 IL-10, IL-4, 및 IL-10과 IL-4의 조합에 대한 건강한 인간 대식세포 반응을 평가함으로써 IL-10 단독 및 IL-4 단독 둘 모두가 LPS 유도된 TNFα 분비를 억제시킬 수 있다는 것이 입증된다. 그러나, IL-10과 IL-4를 함께 조합한 것이 TNFα 분비를 억제시키는 데 있어서 어느 시토카인이든 그 단독인 것보다 우수하다.
IL-4 및 DeboWtEBV가 단핵구/대식세포에 미치는 효과 : DeboWtEBV는 (이전에 미국 특허 10,858,412에 기술된) 인간 항-에볼라 항체로부터 유래된 반감기가 연장된 VH 및 VL 스캐폴딩 시스템에 커플링된 야생형 EBV IL-10으로 구성된다. DeboWtEBV는 TNFα 분비를 억제시키는 것으로 밝혀졌다. 단리된 단핵구를 적정 IL-10, IL-4, DeboWtEBV, 및 IL-4와 조합된 DeboWtEBV에 노출시켰다 (도 14). DeboWtEBV와 함께 IL-4의 조합은 IL-4 또는 DeboWtEBV 단독인 것보다 우수한 방식으로 단핵구로부터의 LPS 유도된 TNFα 분비를 억제시킨다.
IL-4 및 DeboWtEBV가 T 세포에 미치는 효과 : IL-10 및 IL-4가 단핵구/대식세포에 미치는 조합된 억제 효과를 평가하는 것 이외에도, IL-4 및 DeboWtEBV가 T 세포에 미치는 조합 효과를 또한 조사하였다 (도 15). DeboWtEBV는 동일한 몰 농도의 IL-10과 비교하여 CD8+ T 세포로부터 더 적은 IFNγ를 유도한다. DeboWtEBV와 IL-4의 조합은 100 ng/mL에서 DeboWtEBV 단독인 것에 의해 유도된 것보다 더 많이 IFNγ를 감소시킨다.
IL-4 및 DeboDV06이 단핵구/대식세포에 미치는 효과 : IL-10의 억제 효과가 증가될 수 있는지를 여부를 결정하기 위해, DV06으로 표시되는, 더 높은 고친화성 EBV IL-10 변이체를 평가하였다. DV06은 점 돌연변이 (A75I)를 함유하고, 야생형 EBV IL-10을 DV06으로 치환함으로써 (이전에 미국 특허 10,858,412에 기술된) 인간 항-에볼라 항체로부터 유래된 반감기가 연장된 VH 및 VL 스캐폴딩 시스템에 커플링된다. 단리된 단핵구를 적정 IL-10, IL-4, DeboDV06, 및 IL-4와 함께 조합된 DeboDV06에 노출시켰다 (도 16). DeboDV06은 (도 15와 비교하여) DeboWtEBV 대비 증가된 억제 기능을 보이고, IL-4와 DeboDV06의 조합은 유사하게 LPS에의 단핵구/대식세포 반응에 대한 억제 기능을 증가시킨다. DeboDV06과 IL-4의 조합은 IL-4 또는 DeboDV06 단독인 것보다 우수한 방식으로 단핵구로부터의 LPS 유도된 TNFα 분비를 억제시킨다.
(DK4 10 형태의) DeboDV06과 커플링된 IL-4 평가: 본 데이터는 IL-10 변이체인 DV06 (친화성이 증진된 야생형 EBV IL-10의 변이체)과 IL-4의 조합이 어느 분자이든 그 단독인 것보다 우수한 방식으로 LPS 매개 단핵구 염증 반응을 억제시킨다는 것을 시사한다. 따라서, 반감기가 연장된 스캐폴드 분자의 VH와 VL 사이의 링커에서 IL-4를 발현시킴으로써 IL-4를 DeboDV06 분자에 커플링시켜 (도 17), 이중 시토카인 융합 단백질의 비-표적화 형태인 (즉, 항-에볼라 항체로부터의 6개의 CDR 영역을 포함하는), "IL-4DeboDV06" 또는 "4DeboDV06"으로 표시되는 DK410 분자 부류의 제1 구성원을 생성하였다.
(DK4 10 형태의) IL- 4DeboDV06이 단핵구/대식세포에 미치는 효과 : DK410 형태의 IL-4DeboDV06이 LPS 유도된 염증 반응을 억제시키는지 여부를 결정하기 위해, 단리된 단핵구를 적정 IL-10, IL-4, DeboDV06, IL-4와 함께 조합된 IL-10, 및 IL-4DeboDV06에 노출시켰다 (도 18). DK410 형태의 IL-4DeboDV06은 IL-4 또는 DeboDV06 단독인 것보다 우수한 방식으로 단핵구로부터의 LPS 유도된 TNFα 분비를 억제시키지만, 특히, 더 낮은 농도에서는 IL-4 + IL-10만큼은 아니다.
(DK4 10 형태의) IL- 4DeboDV06이 CD8+ T 세포에 미치는 효과 : IFNγ를 강화시키고, CD8+ T 세포로부터 IFNγ를 유도할 수 있는 IL-4DeboDV06의 능력을 조사하고, IL-10, IL-4, DeboDV06, 및 IL-4와 함께 조합된 DeboDV06과 비교하였다 (도 19). DK410 형태의 IL-4DeboDV06은 DeboDV06 + IL-4의 조합과 유사하게 CD8+ T 세포로부터의 IFNγ 분비를 억제시킨다.
(DK4 10 형태의) IL- 4HADeglyDmCD14DV06 및 IL- 4HADeglyDmCD14DV07이 단핵구/대식세포에 미치는 효과: DK410 형태의 IL-4DeboDV06을 제조하는 데 사용된 IL-4 아미노산 서열이 글리코실화된 것으로 나타난 것으로 결정되었다. 서열 분석 결과, 추정 N-연결 글리코실화 변이가 아미노산 위치 N38에 존재하지만, 글리코실화가 기능에는 필요하지 않다는 것이 확인되었다 (Li, 2013). 추가 연구는 아미노산 T13을 아스파르테이트 (D)로 치환하였을 때, 고친화성 IL-4 변이체가 생성되었다는 것을 시사하였다 (미국 특허 6,028,176). N38A 및 T13D에서 치환을 갖는 두 점 돌연변이 모두 IL-4에 도입되었고, 뮤린 CD14로부터의 6개 CDR이 인그라프팅된 Debo 스캐폴딩에 연결되고, 도입되었다 (도 20). 본 데이터는 고친화성, 비-글리코실화된 IL-4 변이체 (즉, N38A 및 T13D 점 돌연변이 둘 모두를 포함하는 것)가 DK410 커플링된 포맷에서는 동일한 포맷의 야생형 IL-4와 비교하였을 때, 열등한 기능을 나타낸다는 것을 시사한다.
(DK4 10 형태의) IL- 4ngDmCD14DV06 및 IL- 4ngDmCD14DV07 이 단핵구/대식세포에 미치는 효과: 단리된 단핵구를 적정 IL-10, IL-4ngDmCD14DV06 ("DK410mCD14DV06"으로도 또한 공지), 및 IL-4ngDmCD14DV07 ("DK410mCD14DV07"로도 또한 공지)에 노출시켜 LPS 유도된 염증 반응의 억제에 대해 검정함으로써 N38A 치환을 포함하는 IL-4 변이체를 포함하는, DK410 형태의 IL-4ngDmCD14DV06 및 IL-4ngDmCD14DV07을 평가하였다 (도 21). "IL-4ng"로 명명되는 IL-4 변이체는 본 발명자들이 제조가능성을 개선시키기 위해 도입한 비-글리코실화된 형태의 IL-4 (N38A 치환 포함, 서열식별번호 44)이고, "mCD14"는 항-mCD14 항체로부터의 6개의 CDR이 Debo 스캐폴딩으로 인그라프팅된 것을 나타낸다. (DV06 및 DV07의 IL-10 변이체를 포함하는) 두 DK410 분자 모두 LPS 유도된 TNFα 분비를 억제시킨다.
(DK4 10 형태의) IL- 4ngDmCD14DV06 및 IL- 4ngDmCD14DV07이 T 세포에 미치는 효과: IL-10, (상기 기술된 바와 같은) DK410 형태의 IL-4ngDmCD14DV06 및 IL-4ngDmCD14DV07의 자극 효과를 T 세포에 대해 평가하였다 (도 22). (DV06 및 DV07의 IL-10 변이체를 포함하는) 두 DK410 분자 모두 CD8+ T 세포로부터의 IFNγ 분비를 IL-10만큼 유도하지 못한다. IL-4ngDmCD14DV06은 IL-4ngDmCD14DV07과 비교하였을 때 1 - 100 ng 등가 몰에의 노출시 약간 더 적은 IFNγ 분비를 유도한다.
(DK4 10 형태의) IL- 4ngDmDMAdCAMDV06이 단핵구/대식세포에 미치는 효과: 단핵구/대식세포에 대한 LPS 유도된 염증 반응 억제를 검정함으로써 DK410 형태의 IL-4ngDmMAdCAMDV06이 미치는 효과를 평가하였다. IL-4ngDmMAdCAMDV06은 (1) (N38A 치환을 포함하는) 비-글리코실화된 IL-4ng 변이체; (2) 마우스 항-MAdCAM 항체로부터의 6개의 CDR의 Debo 스캐폴딩으로의 인그라프트먼트; 및 (3) IL-10 변이체 DV06을 포함하는 DK410 형태의 이중 시토카인 융합체이다. 단리된 단핵구/대식세포를 IL-10 또는 IL-4ngDmMAdCAMDV06으로 적정하였다 (도 23). IL-4ngDmMAdCAMDV06은 단핵구/대식세포에서 LPS 유도된 TNFα 분비를 억제시킨다.
(DK4 10 형태의) IL- 4ngDmMAdCAMDV06이 T 세포에 미치는 효과: 본 발명자들은 또한 IL-10 및 IL-4ngDmMAdCAMDV06 (DK410 포맷)이 T 세포에 미치는 자극 효과도 평가하였다 (도 24). IL-4ngDmMAdCAMDV06은 IL-10과 달리 CD8+ T 세포로부터의 IFNγ 분비를 유도하지 않는다.
결론
본 데이터는 IL-4 변이체 및 IL-10 변이체가 상기 두 시토카인을 인간 항-에볼라 유래 VH/VL 스캐폴드 시스템에 커플링시킴으로써 (즉, DK410 형태로) 공동-발현될 수 있다는 것을 시사한다. IL-4 및 IL-10 변이체의 조합은 단핵구/대식세포에 의한 LPS 유도된 염증 반응을 억제시키면서, 동시에 VH 및 VL 스캐폴딩 시스템 내에 존재하는 표적화 CDR에 관계없이 CD8+ T 세포로부터의 IFNγ 유도를 억제시킨다 (4DeboDV06을 항-mCD14 및 항-mMAdCAM으로부터의 CDR을 포함하는 인그라프팅된 버전의 DK410과 비교).
항-에볼라 유래 VH 및 VL 스캐폴드는 IL-4 및 IL-10 변이체 시토카인을 효과적으로 커플링시키고, 다수의 표적화 CDR의 그라프트를 수용할 수 있다. IL-4ng (N38A 치환에 의해 비-글리코실화된 IL-4를 생성하는 IL-4 변이체)와 DV06의 조합은 0.1 - 100 ng/mL에서 LPS 매개 TNFα 분비를 효과적으로 억제시키고, 동일한 용량 범위에서 CD8+ T 세포로부터 유의적인 IFNγ를 유도하지 못한다.
실시예
4: 패혈증 치료에서의 DK4
10
("DK410mCD14DV06"으로도 공지된) IL-4ngDmCD14DV06이 LPS 유도된 TNFα 분비를 억제시킬 수 있었고, CD8+ T 세포로부터의 IFNγ 유도를 둔화시켰다는 것이 결정되었는 바 (도 21 및 도 22 참조), 상기 분자를 널리 공지되고, 통상적인 패혈증 모델에서 조사하였다.
간략하면, 야생형 Balb/C 마우스를 입수하고, 표준 IACUCU 프로토콜에 따라 적응시켰다. 마우스를 12시간 명/암 주기로 표준 사료 및 수분을 자유롭게 섭취하게 하면서 유지시켰다.
LPS의 복강내 투여 (350 mg/마우스) 전 ("이전") 또는 후 ("이후") 언급된 시점에 100 ml의 비히클 중 언급된 용량으로 비히클, DK410mCD14DV06을 동물에서 피하로 투여하였다.
적응 4일 후, 군당 마우스 다섯 (5)마리씩 하기의 것으로 처리하였다:
(1) LPS 투여 30분 전 1 mg/kg DK410mCD14DV06; 및
(2) LPS 투여 30분 후 1 mg/kg DK410mCD14DV06.
LPS 투여 48시간 후 마우스를 생존에 대해 평가하였다. LPS 투여 30분 전에 DK410mCD14DV06으로 마우스를 처리하였을 때, 그 결과로 생존율은 100%인 반면, LPS 투여 30분 후 DK410mCD14DV06으로 처리하였을 때에는 패혈성 쇼크에 대한 보호 효과가 입증되었다 (도 25).
본 데이터는 IL-10 변이체를 IL-4 변이체 (IL-4ng)에 커플링시키고, (예컨대, DK410mCD14DV06을 이용하여) 마우스 항-CD14 항체로부터의 6개의 CDR을 갖는 Debo 스캐폴딩 시스템을 통해 두 분자를 표적화하는 것이 염증 반응을 유의적으로 약화시키고, 패혈성 쇼크를 치료한다는 것을 시사한다.
본 서면 설명은 예를 사용하여 바람직한 실시양태를 비롯한, 본 개시내용의 측면을 개시하고, 또한 관련 기술분야의 통상의 기술자가 임의의 장치 또는 시스템을 제조하고, 사용하고, 임의의 통합된 방법을 수행하는 것을 포함하는 그의 측면을 실시할 수 있게 한다. 이러한 측면의 특허가능한 범주는 청구범위에 의해 정의되며, 관련 기술분야의 통상의 기술자가 착안하는 다른 예를 포함할 수 있다. 그러한 다른 예들은 그들이 청구범위의 문자 그대로의 언어와 다르지 않은 구조적 요소를 갖거나, 청구범위의 문자 그대로의 언어와 실질적이지 않은 차이가 있는 등가의 구조 요소를 포함한다면, 청구범위의 범주 내에 있는 것으로 의도된다. 기술된 다양한 실시양태로부터의 측면 뿐만 아니라 이러한 각각의 측면에 대한 다른 공지된 등가물은 본 출원의 원리에 따라 추가적인 실시양태 및 기술을 구축하기 위해 관련 기술분야의 통상의 기술자에 의해 혼합 및 매칭될 수 있다.
참고문헌


SEQUENCE LISTING
<110> DEKA BIOSCIENCES, INC.
<120> Dual Cytokine Fusion Proteins Comprising IL-10
<130> 039451.00032
<140>
<141>
<160> 63
<170> PatentIn version 3.5
<210> 1
<211> 178
<212> PRT
<213> Homo sapiens
<220>
<223> Human IL-10 Amino Acid Sequence
<400> 1
Met His Ser Ser Ala Leu Leu Cys Cys Leu Val Leu Leu Thr Gly Val
1 5 10 15
Arg Ala Ser Pro Gly Gln Gly Thr Gln Ser Glu Asn Ser Cys Thr His
20 25 30
Phe Pro Gly Asn Leu Pro Asn Met Leu Arg Asp Leu Arg Asp Ala Phe
35 40 45
Ser Arg Val Lys Thr Phe Phe Gln Met Lys Asp Gln Leu Asp Asn Leu
50 55 60
Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu Gly Cys
65 70 75 80
Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val Met Pro
85 90 95
Gln Ala Glu Asn Gln Asp Pro Asp Ile Lys Ala His Val Asn Ser Leu
100 105 110
Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys His Arg
115 120 125
Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Val Lys Asn
130 135 140
Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met Ser Glu
145 150 155 160
Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Met Lys Ile
165 170 175
Arg Asn
<210> 2
<211> 1629
<212> DNA
<213> Homo sapiens
<220>
<223> Human IL-10 Nucleic Acid Sequence
<400> 2
acacatcagg ggcttgctct tgcaaaacca aaccacaaga cagacttgca aaagaaggca 60
tgcacagctc agcactgctc tgttgcctgg tcctcctgac tggggtgagg gccagcccag 120
gccagggcac ccagtctgag aacagctgca cccacttccc aggcaacctg cctaacatgc 180
ttcgagatct ccgagatgcc ttcagcagag tgaagacttt ctttcaaatg aaggatcagc 240
tggacaactt gttgttaaag gagtccttgc tggaggactt taagggttac ctgggttgcc 300
aagccttgtc tgagatgatc cagttttacc tggaggaggt gatgccccaa gctgagaacc 360
aagacccaga catcaaggcg catgtgaact ccctggggga gaacctgaag accctcaggc 420
tgaggctacg gcgctgtcat cgatttcttc cctgtgaaaa caagagcaag gccgtggagc 480
aggtgaagaa tgcctttaat aagctccaag agaaaggcat ctacaaagcc atgagtgagt 540
ttgacatctt catcaactac atagaagcct acatgacaat gaagatacga aactgagaca 600
tcagggtggc gactctatag actctaggac ataaattaga ggtctccaaa atcggatctg 660
gggctctggg atagctgacc cagccccttg agaaacctta ttgtacctct cttatagaat 720
atttattacc tctgatacct caacccccat ttctatttat ttactgagct tctctgtgaa 780
cgatttagaa agaagcccaa tattataatt tttttcaata tttattattt tcacctgttt 840
ttaagctgtt tccatagggt gacacactat ggtatttgag tgttttaaga taaattataa 900
gttacataag ggaggaaaaa aaatgttctt tggggagcca acagaagctt ccattccaag 960
cctgaccacg ctttctagct gttgagctgt tttccctgac ctccctctaa tttatcttgt 1020
ctctgggctt ggggcttcct aactgctaca aatactctta ggaagagaaa ccagggagcc 1080
cctttgatga ttaattcacc ttccagtgtc tcggagggat tcccctaacc tcattcccca 1140
accacttcat tcttgaaagc tgtggccagc ttgttattta taacaaccta aatttggttc 1200
taggccgggc gcggtggctc acgcctgtaa tcccagcact ttgggaggct gaggcgggtg 1260
gatcacttga ggtcaggagt tcctaaccag cctggtcaac atggtgaaac cccgtctcta 1320
ctaaaaatac aaaaattagc cgggcatggt ggcgcgcacc tgtaatccca gctacttggg 1380
aggctgaggc aagagaattg cttgaaccca ggagatggaa gttgcagtga gctgatatca 1440
tgcccctgta ctccagcctg ggtgacagag caagactctg tctcaaaaaa taaaaataaa 1500
aataaatttg gttctaatag aactcagttt taactagaat ttattcaatt cctctgggaa 1560
tgttacattg tttgtctgtc ttcatagcag attttaattt tgaataaata aatgtatctt 1620
attcacatc 1629
<210> 3
<211> 147
<212> PRT
<213> Human gammaherpesvirus 4
<220>
<223> EBV IL-10 Amino Acid Sequence
<400> 3
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Val Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ala Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg
145
<210> 4
<211> 632
<212> DNA
<213> Human gammaherpesvirus 4
<220>
<223> EBV IL-10 Nucleic Acid Sequence
<400> 4
tataaatcac ttccctatct caggtaggcc tgcacacctt aggtatggag cgaaggttag 60
tggtcactct gcagtgcctg gtgctgcttt acctggcacc tgagtgtgga ggtacagacc 120
aatgtgacaa ttttccccaa atgttgaggg acctaagaga tgccttcagt cgtgttaaaa 180
cctttttcca gacaaaggac gaggtagata accttttgct caaggagtct ctgctagagg 240
actttaaggg ctaccttgga tgccaggccc tgtcagaaat gatccaattc tacctggagg 300
aagtcatgcc acaggctgaa aaccaggacc ctgaagccaa agaccatgtc aattctttgg 360
gtgaaaatct aaagacccta cggctccgcc tgcgcaggtg ccacaggttc ctgccgtgtg 420
agaacaagag taaagctgtg gaacagataa aaaatgcctt taacaagctg caggaaaaag 480
gaatttacaa agccatgagt gaatttgaca tttttattaa ctacatagaa gcatacatga 540
caattaaagc caggtgataa ttccataccc tggaagcagg agatgggtgc atttcacccc 600
aaccccccct ttcgactgtc atttacaata aa 632
<210> 5
<211> 177
<212> PRT
<213> Human betaherpesvirus 5
<220>
<223> CMV IL-10 Amino Acid Sequence
<400> 5
Met Leu Ser Val Met Val Ser Ser Ser Leu Val Leu Ile Val Phe Phe
1 5 10 15
Leu Gly Ala Ser Glu Glu Ala Lys Pro Ala Ala Thr Thr Thr Thr Ile
20 25 30
Lys Asn Thr Lys Pro Gln Cys Arg Pro Glu Asp Tyr Ala Ser Arg Leu
35 40 45
Gln Asp Leu Arg Val Thr Phe His Arg Val Lys Pro Thr Leu Gln Arg
50 55 60
Glu Asp Asp Tyr Ser Val Trp Leu Asp Gly Thr Val Val Lys Gly Cys
65 70 75 80
Trp Gly Cys Ser Val Met Asp Trp Leu Leu Arg Arg Tyr Leu Glu Ile
85 90 95
Val Phe Pro Ala Gly Asp His Val Tyr Pro Gly Leu Lys Thr Glu Leu
100 105 110
His Ser Met Arg Ser Thr Leu Glu Ser Ile Tyr Lys Asp Met Arg Gln
115 120 125
Cys Pro Leu Leu Gly Cys Gly Asp Lys Ser Val Ile Ser Arg Leu Ser
130 135 140
Gln Glu Ala Glu Arg Lys Ser Asp Asn Gly Thr Arg Lys Gly Leu Ser
145 150 155 160
Glu Leu Asp Thr Leu Phe Ser Arg Leu Glu Glu Tyr Leu His Ser Arg
165 170 175
Lys
<210> 6
<211> 693
<212> DNA
<213> Human betaherpesvirus 5
<220>
<223> CMV IL-10 Nucleic Acid Sequence
<400> 6
atgctgtcgg tgatggtctc ttcctctctg gtcctgatcg tcttttttct aggcgcttcc 60
gaggaggcga agccggcggc gacgacgacg acgataaaga atacaaagcc gcagtgtcgt 120
ccggaggatt acgcgagcag attgcaagat ctccgcgtca cctttcatcg agtaaaacct 180
acgttggtag gtcatgtagg tacggtttat tgcgacggtc tttcttttcc gcgtgtcggg 240
tgacgtagtt ttcctcttgt agcaacgtga ggacgactac tccgtgtggc tcgacggtac 300
ggtggtcaaa ggctgttggg gatgcagcgt catggactgg ttgttgaggc ggtatctgga 360
gatcgtgttc cccgcaggcg accacgtcta tcctggactt aagacggaat tgcatagtat 420
gcgctcgacg ctagaatcca tctacaaaga catgcggcaa tgcgtaagtg tctctgtggc 480
ggcgctgtcc gcgcagaggt aacaacgtgt tcatagcacg ctgttttact tttgtcgggc 540
tcccagcctc tgttaggttg cggagataag tccgtgatta gtcggctgtc tcaggaggcg 600
gaaaggaaat cggataacgg cacgcggaaa ggtctcagcg agttggacac gttgtttagc 660
cgtctcgaag agtatctgca ctcgagaaag tag 693
<210> 7
<211> 178
<212> PRT
<213> Mus musculus
<220>
<223> Mouse IL-10 Amino Acid Sequence
<400> 7
Met Pro Gly Ser Ala Leu Leu Cys Cys Leu Leu Leu Leu Thr Gly Met
1 5 10 15
Arg Ile Ser Arg Gly Gln Tyr Ser Arg Glu Asp Asn Asn Cys Thr His
20 25 30
Phe Pro Val Gly Gln Ser His Met Leu Leu Glu Leu Arg Thr Ala Phe
35 40 45
Ser Gln Val Lys Thr Phe Phe Gln Thr Lys Asp Gln Leu Asp Asn Ile
50 55 60
Leu Leu Thr Asp Ser Leu Met Gln Asp Phe Lys Gly Tyr Leu Gly Cys
65 70 75 80
Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Val Glu Val Met Pro
85 90 95
Gln Ala Glu Lys His Gly Pro Glu Ile Lys Glu His Leu Asn Ser Leu
100 105 110
Gly Glu Lys Leu Lys Thr Leu Arg Met Arg Leu Arg Arg Cys His Arg
115 120 125
Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Val Lys Ser
130 135 140
Asp Phe Asn Lys Leu Gln Asp Gln Gly Val Tyr Lys Ala Met Asn Glu
145 150 155 160
Phe Asp Ile Phe Ile Asn Cys Ile Glu Ala Tyr Met Met Ile Lys Met
165 170 175
Lys Ser
<210> 8
<211> 1314
<212> DNA
<213> Mus musculus
<220>
<223> Mouse IL-10 Nucleic Acid Sequence
<400> 8
gggggggggg atttagagac ttgctcttgc actaccaaag ccacaaagca gccttgcaga 60
aaagagagct ccatcatgcc tggctcagca ctgctatgct gcctgctctt actgactggc 120
atgaggatca gcaggggcca gtacagccgg gaagacaata actgcaccca cttcccagtc 180
ggccagagcc acatgctcct agagctgcgg actgccttca gccaggtgaa gactttcttt 240
caaacaaagg accagctgga caacatactg ctaaccgact ccttaatgca ggactttaag 300
ggttacttgg gttgccaagc cttatcggaa atgatccagt tttacctggt agaagtgatg 360
ccccaggcag agaagcatgg cccagaaatc aaggagcatt tgaattccct gggtgagaag 420
ctgaagaccc tcaggatgcg gctgaggcgc tgtcatcgat ttctcccctg tgaaaataag 480
agcaaggcag tggagcaggt gaagagtgat tttaataagc tccaagacca aggtgtctac 540
aaggccatga atgaatttga catcttcatc aactgcatag aagcatacat gatgatcaaa 600
atgaaaagct aaaacacctg cagtgtgtat tgagtctgct ggactccagg acctagacag 660
agctctctaa atctgatcca gggatcttag ctaacggaaa caactccttg gaaaacctcg 720
tttgtacctc tctccgaaat atttattacc tctgatacct cagttcccat tctatttatt 780
cactgagctt ctctgtgaac tatttagaaa gaagcccaat attataattt tacagtattt 840
attattttta acctgtgttt aagctgtttc cattggggac actttatagt atttaaaggg 900
agattatatt atatgatggg aggggttctt ccttgggaag caattgaagc ttctattcta 960
aggctggcca cacttgagag ctgcagggcc ctttgctatg gtgtcctttc aattgctctc 1020
atccctgagt tcagagctcc taagagagtt gtgaagaaac tcatgggtct tgggaagaga 1080
aaccagggag atcctttgat gatcattcct gcagcagctc agagggttcc cctactgtca 1140
tcccccagcc gcttcatccc tgaaaactgt ggccagtttg ttatttataa ccacctaaaa 1200
ttagttctaa tagaactcat ttttaactag aagtaatgca attcctctgg gaatggtgta 1260
ttgtttgtct gcctttgtag cagcatctaa ttttgaataa atggatctta ttcg 1314
<210> 9
<211> 170
<212> PRT
<213> Artificial Sequence
<220>
<223> Artificial Sequence DVLP5
<400> 9
Met Asp Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp
1 5 10 15
Leu Arg Gly Ala Arg Cys Gly Thr Asp Gln Cys Asp Asn Phe Pro Gln
20 25 30
Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe
35 40 45
Gln Thr Lys Asp Glu Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu
50 55 60
Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile
65 70 75 80
Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro
85 90 95
Glu Ala Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu
100 105 110
Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys
115 120 125
Ser Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu
130 135 140
Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr
145 150 155 160
Ile Glu Ala Tyr Met Thr Ile Lys Ala Arg
165 170
<210> 10
<211> 170
<212> PRT
<213> Artificial Sequence
<220>
<223> Artificial Sequence DVLP6
<400> 10
Met Asp Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp
1 5 10 15
Leu Arg Gly Ala Arg Cys Gly Thr Asp Gln Cys Asp Asn Phe Pro Gln
20 25 30
Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe
35 40 45
Gln Thr Lys Asp Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu
50 55 60
Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile
65 70 75 80
Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro
85 90 95
Glu Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu
100 105 110
Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys
115 120 125
Ser Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu
130 135 140
Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr
145 150 155 160
Ile Glu Ala Tyr Met Thr Ile Lys Ala Arg
165 170
<210> 11
<211> 170
<212> PRT
<213> Artificial Sequence
<220>
<223> Artificial Sequence DVLP7
<400> 11
Met Asp Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp
1 5 10 15
Leu Arg Gly Ala Arg Cys Gly Thr Asp Gln Cys Asp Asn Phe Pro Gln
20 25 30
Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe
35 40 45
Gln Thr Lys Asp Glu Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu
50 55 60
Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile
65 70 75 80
Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro
85 90 95
Glu Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu
100 105 110
Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys
115 120 125
Ser Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu
130 135 140
Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr
145 150 155 160
Ile Glu Ala Tyr Met Thr Ile Lys Ala Arg
165 170
<210> 12
<211> 147
<212> PRT
<213> Artificial Sequence
<220>
<223> DV05 Amino Acid Sequence
<400> 12
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ala Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg
145
<210> 13
<211> 441
<212> DNA
<213> Artificial Sequence
<220>
<223> DV05 Nucleic Acid Sequence
<220>
<221> misc_feature
<222> (225)..(225)
<223> n is a, c, g, or t
<400> 13
accgaccagt gcgacaactt ccctcagatg ctgcgggacc tgagagatgc cttctccaga 60
gtgaaaacat tcttccagac caaggacgag ctggacaacc tgctgctgaa agagtccctg 120
ctggaagatt tcaagggcta cctgggctgt caggccctgt ccgagatgat ccagttctac 180
ctggaagaag tgatgcccca ggccgagaat caggaccccg aggcnaagga ccacgtgaac 240
tccctgggcg agaacctgaa aaccctgcgg ctgagactgc ggcggtgcca cagatttctg 300
ccctgcgaga acaagtccaa ggccgtggaa cagatcaaga acgccttcaa caagctgcaa 360
gagaagggca tctacaaggc catgagcgag ttcgacatct tcatcaacta catcgaggcc 420
tacatgacca tcaaggccag a 441
<210> 14
<211> 147
<212> PRT
<213> Artificial Sequence
<220>
<223> DV06 Amino Acid Sequence
<400> 14
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Val Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg
145
<210> 15
<211> 441
<212> DNA
<213> Artificial Sequence
<220>
<223> DV06 Nucleic Acid Sequence
<220>
<221> misc_feature
<222> (93)..(93)
<223> n is a, c, g, or t
<400> 15
accgaccagt gcgacaactt ccctcagatg ctgcgggacc tgagagatgc cttctccaga 60
gtgaaaacat tcttccagac caaggacgag gtngacaacc tgctgctgaa agagtccctg 120
ctggaagatt tcaagggcta cctgggctgt caggccctgt ccgagatgat ccagttctac 180
ctggaagaag tgatgcccca ggccgagaat caggaccccg agatcaagga ccacgtgaac 240
tccctgggcg agaacctgaa aaccctgcgg ctgagactgc ggcggtgcca cagatttctg 300
ccctgcgaga acaagtccaa ggccgtggaa cagatcaaga acgccttcaa caagctgcaa 360
gagaagggca tctacaaggc catgagcgag ttcgacatct tcatcaacta catcgaggcc 420
tacatgacca tcaaggccag a 441
<210> 16
<211> 147
<212> PRT
<213> Artificial Sequence
<220>
<223> DV07 Amino Acid Sequence
<400> 16
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg
145
<210> 17
<211> 441
<212> DNA
<213> Artificial Sequence
<220>
<223> DV07 Nucleic Acid Sequence
<400> 17
accgaccagt gcgacaactt ccctcagatg ctgcgggacc tgagagatgc cttctccaga 60
gtgaaaacat tcttccagac caaggacgag ctggacaacc tgctgctgaa agagtccctg 120
ctggaagatt tcaagggcta cctgggctgt caggccctgt ccgagatgat ccagttctac 180
ctggaagaag tgatgcccca ggccgagaat caggaccccg agatcaagga ccacgtgaac 240
tccctgggcg agaacctgaa aaccctgcgg ctgagactgc ggcggtgcca cagatttctg 300
ccctgcgaga acaagtccaa ggccgtggaa cagatcaaga acgccttcaa caagctgcaa 360
gagaagggca tctacaaggc catgagcgag ttcgacatct tcatcaacta catcgaggcc 420
tacatgacca tcaaggccag a 441
<210> 18
<211> 567
<212> PRT
<213> Artificial Sequence
<220>
<223> DV07 Ebo
<400> 18
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Thr
180 185 190
Thr Thr Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
195 200 205
Trp Ile Gly Glu Val Asn Tyr Ser Gly Asn Ala Asn Tyr Asn Pro Ser
210 215 220
Leu Lys Gly Arg Val Ala Ile Ser Val Asp Thr Ser Lys Asn Gln Phe
225 230 235 240
Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
245 250 255
Cys Thr Ser Arg Ile Arg Ser His Ile Ala Tyr Ser Trp Lys Gly Asp
260 265 270
Val Trp Gly Lys Gly Thr Thr Val Thr Val Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser
290 295 300
Pro Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys
305 310 315 320
Arg Ala Ser Gln Ser Val Pro Arg Asn Tyr Ile Gly Trp Phe Gln Gln
325 330 335
Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Gly Ala Ser Ser Arg
340 345 350
Ala Ala Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
355 360 365
Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala Met Tyr
370 375 380
Tyr Cys His Gln Tyr Asp Arg Leu Pro Tyr Thr Phe Gly Gln Gly Thr
385 390 395 400
Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
405 410 415
Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg
420 425 430
Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys
435 440 445
Asp Glu Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe
450 455 460
Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr
465 470 475 480
Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys
485 490 495
Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg
500 505 510
Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala
515 520 525
Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile
530 535 540
Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala
545 550 555 560
Tyr Met Thr Ile Lys Ala Arg
565
<210> 19
<211> 561
<212> PRT
<213> Artificial Sequence
<220>
<223> DV07 Ebo EGF
<400> 19
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Arg Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Thr
180 185 190
Asn Tyr Gly Val His Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
195 200 205
Trp Ile Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro
210 215 220
Phe Thr Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe
225 230 235 240
Ser Leu Gln Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
245 250 255
Cys Thr Ser Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Trp Gly Lys Gly
260 265 270
Thr Thr Val Thr Val Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser Pro Gly Thr Leu Ser
290 295 300
Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser
305 310 315 320
Ile Gly Thr Asn Ile His Trp Phe Gln Gln Lys Pro Gly Gln Ala Pro
325 330 335
Arg Leu Leu Ile Tyr Tyr Ala Ser Glu Ser Ile Ser Gly Phe Pro Asp
340 345 350
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Thr
355 360 365
Arg Leu Glu Pro Glu Asp Phe Ala Met Tyr Tyr Cys Gln Gln Asn Asn
370 375 380
Asn Trp Pro Thr Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Gly
385 390 395 400
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Thr Asp
405 410 415
Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp Ala Phe
420 425 430
Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp Asn Leu
435 440 445
Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu Gly Cys
450 455 460
Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val Met Pro
465 470 475 480
Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn Ser Leu
485 490 495
Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys His Arg
500 505 510
Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile Lys Asn
515 520 525
Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met Ser Glu
530 535 540
Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile Lys Ala
545 550 555 560
Arg
<210> 20
<211> 581
<212> PRT
<213> Artificial Sequence
<220>
<223> DV06 EboX
<220>
<221> MOD_RES
<222> (193)..(199)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (193)..(199)
<223> This region may encompass 3-7 residues
<220>
<221> MOD_RES
<222> (214)..(231)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (214)..(231)
<223> This region may encompass 14-18 residues
<220>
<221> MOD_RES
<222> (264)..(274)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (264)..(274)
<223> This region may encompass 7-11 residues
<220>
<221> MOD_RES
<222> (329)..(342)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (329)..(342)
<223> This region may encompass 9-14 residues
<220>
<221> MOD_RES
<222> (358)..(366)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (358)..(366)
<223> This region may encompass 5-9 residues
<220>
<221> MOD_RES
<222> (399)..(409)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (399)..(409)
<223> This region may encompass 7-11 residues
<220>
<223> See specification as filed for detailed description of
substitutions and preferred embodiments
<400> 20
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Val Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Thr
180 185 190
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Trp Ile Arg Gln Pro Pro Gly Lys Gly
195 200 205
Leu Glu Trp Ile Gly Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
210 215 220
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Arg Val Ala Ile Ser Val Asp Thr Ser
225 230 235 240
Lys Asn Gln Phe Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr
245 250 255
Ala Ile Tyr Tyr Cys Thr Ser Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
260 265 270
Xaa Xaa Trp Lys Gly Asp Val Trp Gly Lys Gly Thr Thr Val Thr Val
275 280 285
Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
290 295 300
Ser Glu Ile Val Met Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro
305 310 315 320
Gly Glu Arg Ala Thr Leu Ser Cys Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
325 330 335
Xaa Xaa Xaa Xaa Xaa Xaa Trp Phe Gln Gln Lys Pro Gly Gln Ala Pro
340 345 350
Arg Leu Leu Ile Tyr Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Gly Phe
355 360 365
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
370 375 380
Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala Met Tyr Tyr Cys Xaa Xaa
385 390 395 400
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Phe Gly Gln Gly Thr Lys Leu
405 410 415
Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
420 425 430
Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu
435 440 445
Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu
450 455 460
Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly
465 470 475 480
Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu
485 490 495
Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His
500 505 510
Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg
515 520 525
Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu
530 535 540
Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys
545 550 555 560
Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met
565 570 575
Thr Ile Lys Ala Arg
580
<210> 21
<211> 569
<212> PRT
<213> Artificial Sequence
<220>
<223> DV06 Ebo
<400> 21
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Val Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Thr
180 185 190
Thr Thr Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
195 200 205
Trp Ile Gly Glu Val Asn Tyr Ser Gly Asn Ala Asn Tyr Asn Pro Ser
210 215 220
Leu Lys Gly Arg Val Ala Ile Ser Val Asp Thr Ser Lys Asn Gln Phe
225 230 235 240
Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
245 250 255
Cys Thr Ser Arg Ile Arg Ser His Ile Ala Tyr Ser Trp Lys Gly Asp
260 265 270
Val Trp Gly Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly
275 280 285
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr
290 295 300
Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu
305 310 315 320
Ser Cys Arg Ala Ser Gln Ser Val Pro Arg Asn Tyr Ile Gly Trp Phe
325 330 335
Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Gly Ala Ser
340 345 350
Ser Arg Ala Ala Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
355 360 365
Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala
370 375 380
Met Tyr Tyr Cys His Gln Tyr Asp Arg Leu Pro Tyr Thr Phe Gly Gln
385 390 395 400
Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly
405 410 415
Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met
420 425 430
Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln
435 440 445
Thr Lys Asp Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu
450 455 460
Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln
465 470 475 480
Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu
485 490 495
Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg
500 505 510
Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser
515 520 525
Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys
530 535 540
Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile
545 550 555 560
Glu Ala Tyr Met Thr Ile Lys Ala Arg
565
<210> 22
<211> 575
<212> PRT
<213> Artificial Sequence
<220>
<223> DV06 MadCam
<400> 22
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Val Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro
165 170 175
Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr
180 185 190
Ser Tyr Gly Ile Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu
195 200 205
Trp Met Gly Trp Ile Ser Val Tyr Ser Gly Asn Thr Asn Tyr Ala Gln
210 215 220
Lys Val Gln Gly Arg Val Thr Met Thr Ala Asp Thr Ser Thr Ser Thr
225 230 235 240
Ala Tyr Met Asp Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr
245 250 255
Tyr Cys Ala Arg Glu Gly Ser Ser Ser Ser Gly Asp Tyr Tyr Tyr Gly
260 265 270
Met Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Gly Gly
275 280 285
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val
290 295 300
Met Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro Ala
305 310 315 320
Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Leu His Thr Asp Gly Thr
325 330 335
Thr Tyr Leu Tyr Trp Tyr Leu Gln Lys Pro Gly Gln Pro Pro Gln Leu
340 345 350
Leu Ile Tyr Glu Val Ser Asn Arg Phe Ser Gly Val Pro Asp Arg Phe
355 360 365
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg Val
370 375 380
Glu Ala Glu Asp Val Gly Ile Tyr Tyr Cys Met Gln Asn Ile Gln Leu
385 390 395 400
Pro Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Gly Gly Gly
405 410 415
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys
420 425 430
Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg
435 440 445
Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Val Asp Asn Leu Leu Leu
450 455 460
Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala
465 470 475 480
Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala
485 490 495
Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn Ser Leu Gly Glu
500 505 510
Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu
515 520 525
Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile Lys Asn Ala Phe
530 535 540
Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp
545 550 555 560
Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile Lys Ala Arg
565 570 575
<210> 23
<211> 573
<212> PRT
<213> Artificial Sequence
<220>
<223> DV07 EboX
<220>
<221> MOD_RES
<222> (193)..(199)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (193)..(199)
<223> This region may encompass 3-7 residues
<220>
<221> MOD_RES
<222> (213)..(230)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (213)..(230)
<223> This region may encompass 14-18 residues
<220>
<221> MOD_RES
<222> (263)..(273)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (263)..(273)
<223> This region may encompass 7-11 residues
<220>
<221> MOD_RES
<222> (321)..(334)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (321)..(334)
<223> This region may encompass 9-14 residues
<220>
<221> MOD_RES
<222> (350)..(358)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (350)..(358)
<223> This region may encompass 5-9 residues
<220>
<221> MOD_RES
<222> (391)..(401)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (391)..(401)
<223> This region may encompass 7-11 residues
<220>
<223> See specification as filed for detailed description of
substitutions and preferred embodiments
<400> 23
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Arg Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Thr
180 185 190
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Trp Ile Arg Gln Pro Pro Gly Lys Gly
195 200 205
Leu Glu Trp Ile Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
210 215 220
Xaa Xaa Xaa Xaa Xaa Xaa Arg Val Thr Ile Ser Val Asp Thr Ser Lys
225 230 235 240
Asn Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Ala Ala Asp Thr Ala
245 250 255
Ile Tyr Tyr Cys Thr Ser Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
260 265 270
Xaa Trp Gly Lys Gly Thr Thr Val Thr Val Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser
290 295 300
Pro Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys
305 310 315 320
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Trp Phe
325 330 335
Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Xaa Xaa Xaa
340 345 350
Xaa Xaa Xaa Xaa Xaa Xaa Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly
355 360 365
Ser Gly Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp
370 375 380
Phe Ala Met Tyr Tyr Cys Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
385 390 395 400
Xaa Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser
405 410 415
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn
420 425 430
Phe Pro Gln Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys
435 440 445
Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp Asn Leu Leu Leu Lys Glu
450 455 460
Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser
465 470 475 480
Glu Met Ile Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn
485 490 495
Gln Asp Pro Glu Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu
500 505 510
Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys
515 520 525
Glu Asn Lys Ser Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys
530 535 540
Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe
545 550 555 560
Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile Lys Ala Arg
565 570
<210> 24
<211> 573
<212> PRT
<213> Artificial Sequence
<220>
<223> DV05 EboX
<220>
<221> MOD_RES
<222> (193)..(199)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (193)..(199)
<223> This region may encompass 3-7 residues
<220>
<221> MOD_RES
<222> (213)..(230)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (213)..(230)
<223> This region may encompass 14-18 residues
<220>
<221> MOD_RES
<222> (263)..(273)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (263)..(273)
<223> This region may encompass 7-11 residues
<220>
<221> MOD_RES
<222> (321)..(334)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (321)..(334)
<223> This region may encompass 9-14 residues
<220>
<221> MOD_RES
<222> (350)..(358)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (350)..(358)
<223> This region may encompass 5-9 residues
<220>
<221> MOD_RES
<222> (391)..(401)
<223> Any amino acid
<220>
<221> MISC_FEATURE
<222> (391)..(401)
<223> This region may encompass 7-11 residues
<220>
<223> See specification as filed for detailed description of
substitutions and preferred embodiments
<400> 24
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ala Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Arg Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Thr
180 185 190
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Trp Ile Arg Gln Pro Pro Gly Lys Gly
195 200 205
Leu Glu Trp Ile Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
210 215 220
Xaa Xaa Xaa Xaa Xaa Xaa Arg Val Thr Ile Ser Val Asp Thr Ser Lys
225 230 235 240
Asn Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Ala Ala Asp Thr Ala
245 250 255
Ile Tyr Tyr Cys Thr Ser Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
260 265 270
Xaa Trp Gly Lys Gly Thr Thr Val Thr Val Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser
290 295 300
Pro Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys
305 310 315 320
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Trp Phe
325 330 335
Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Xaa Xaa Xaa
340 345 350
Xaa Xaa Xaa Xaa Xaa Xaa Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly
355 360 365
Ser Gly Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp
370 375 380
Phe Ala Met Tyr Tyr Cys Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
385 390 395 400
Xaa Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser
405 410 415
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn
420 425 430
Phe Pro Gln Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys
435 440 445
Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp Asn Leu Leu Leu Lys Glu
450 455 460
Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser
465 470 475 480
Glu Met Ile Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn
485 490 495
Gln Asp Pro Glu Ala Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu
500 505 510
Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys
515 520 525
Glu Asn Lys Ser Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys
530 535 540
Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe
545 550 555 560
Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile Lys Ala Arg
565 570
<210> 25
<211> 569
<212> PRT
<213> Artificial Sequence
<220>
<223> DV07 EboL3
<400> 25
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Thr
180 185 190
Thr Thr Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
195 200 205
Trp Ile Gly Glu Val Asn Tyr Ser Gly Asn Ala Asn Tyr Asn Pro Ser
210 215 220
Leu Lys Gly Arg Val Ala Ile Ser Val Asp Thr Ser Lys Asn Gln Phe
225 230 235 240
Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
245 250 255
Cys Thr Ser Arg Ile Arg Ser His Ile Ala Tyr Ser Trp Lys Gly Asp
260 265 270
Val Trp Gly Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly
275 280 285
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr
290 295 300
Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu
305 310 315 320
Ser Cys Arg Ala Ser Gln Ser Val Pro Arg Asn Tyr Ile Gly Trp Phe
325 330 335
Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Gly Ala Ser
340 345 350
Ser Arg Ala Ala Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
355 360 365
Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala
370 375 380
Met Tyr Tyr Cys His Gln Tyr Asp Arg Leu Pro Tyr Thr Phe Gly Gln
385 390 395 400
Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly
405 410 415
Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met
420 425 430
Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln
435 440 445
Thr Lys Asp Glu Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu
450 455 460
Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln
465 470 475 480
Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu
485 490 495
Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg
500 505 510
Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser
515 520 525
Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys
530 535 540
Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile
545 550 555 560
Glu Ala Tyr Met Thr Ile Lys Ala Arg
565
<210> 26
<211> 563
<212> PRT
<213> Artificial Sequence
<220>
<223> DV07 EboEGFL3
<400> 26
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Arg Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Thr
180 185 190
Asn Tyr Gly Val His Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
195 200 205
Trp Ile Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro
210 215 220
Phe Thr Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe
225 230 235 240
Ser Leu Gln Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
245 250 255
Cys Thr Ser Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Trp Gly Lys Gly
260 265 270
Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
275 280 285
Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser Pro Gly Thr
290 295 300
Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser
305 310 315 320
Gln Ser Ile Gly Thr Asn Ile His Trp Phe Gln Gln Lys Pro Gly Gln
325 330 335
Ala Pro Arg Leu Leu Ile Tyr Tyr Ala Ser Glu Ser Ile Ser Gly Phe
340 345 350
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
355 360 365
Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala Met Tyr Tyr Cys Gln Gln
370 375 380
Asn Asn Asn Trp Pro Thr Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile
385 390 395 400
Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
405 410 415
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
420 425 430
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
435 440 445
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
450 455 460
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
465 470 475 480
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
485 490 495
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
500 505 510
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
515 520 525
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
530 535 540
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
545 550 555 560
Lys Ala Arg
<210> 27
<211> 565
<212> PRT
<213> Artificial Sequence
<220>
<223> DEboegfrDV07 Variant 1 Amino Acid Sequence
<400> 27
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Ser Gly Phe Ser Leu Thr
180 185 190
Asn Tyr Gly Val Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
195 200 205
Trp Ile Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Pro Ser
210 215 220
Leu Lys Gly Arg Val Ala Ile Ser Val Asp Thr Ser Lys Asn Gln Phe
225 230 235 240
Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
245 250 255
Cys Ala Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly
260 265 270
Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
275 280 285
Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser Pro
290 295 300
Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg
305 310 315 320
Ala Ser Gln Ser Ile Gly Thr Asn Ile Gly Trp Phe Gln Gln Lys Pro
325 330 335
Gly Gln Ala Pro Arg Leu Leu Ile Lys Tyr Ala Ser Glu Arg Ala Ala
340 345 350
Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
355 360 365
Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala Met Tyr Tyr Cys
370 375 380
Gln Gln Asn Asn Asn Trp Pro Thr Thr Phe Gly Gln Gly Thr Lys Leu
385 390 395 400
Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
405 410 415
Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu
420 425 430
Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu
435 440 445
Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly
450 455 460
Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu
465 470 475 480
Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His
485 490 495
Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg
500 505 510
Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu
515 520 525
Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys
530 535 540
Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met
545 550 555 560
Thr Ile Lys Ala Arg
565
<210> 28
<211> 1698
<212> DNA
<213> Artificial Sequence
<220>
<223> DEboegfrDV07 Variant 1 Nucleic Acid Sequence
<400> 28
accgaccagt gcgacaactt ccctcagatg ctgcgggacc tgagagatgc cttctccaga 60
gtgaaaacat tcttccagac caaggacgag ctggacaacc tgctgctgaa agagtccctg 120
ctggaagatt tcaagggcta cctgggctgt caggccctgt ccgagatgat ccagttctac 180
ctggaagaag tgatgcccca ggccgagaat caggaccccg agatcaagga ccacgtgaac 240
tccctgggcg agaacctgaa aaccctgcgg ctgagactgc ggcggtgcca cagatttctg 300
ccctgcgaga acaagtccaa ggccgtggaa cagatcaaga acgccttcaa caagctgcaa 360
gagaagggca tctacaaggc catgagcgag ttcgacatct tcatcaacta catcgaggcc 420
tacatgacca tcaaggccag aggcggcgga ggatctggcg gaggtggaag cggaggcggt 480
ggatctcagg ttcagttgca gcaatggggc gctggcctgc tgaagccttc tgagacactg 540
tctctgacct gcgccgtgtc cggcttctct ctgaccaatt acggcgtgaa ctggattcgg 600
cagcctcctg gcaaaggcct ggaatggatc ggagtgattt ggagcggcgg caacaccgac 660
tacaacccca gtctgaaggg cagagtggcc atctccgtgg acacctccaa gaaccagttc 720
tccctgagac tgaactccgt gaccgccgct gataccgcca tctactactg tgctagagcc 780
ctgacctact acgactacga gttcgcctat tggggcaagg gcaccaccgt gactgttagt 840
agtggtggtg gcggtagtgg cggaggcggc tcaggcggtg gtggatctga aatcgtgatg 900
acccagtctc ctggcactct gtctctgtct cccggcgaga gagctaccct gtcttgtaga 960
gcctctcagt ccatcggcac caacatcggc tggttccagc agaagcctgg acaggctccc 1020
cggctgctga ttaagtacgc ctctgagaga gccgctggct tccctgacag attctccggc 1080
tctggctctg gcaccgactt caccctgacc atcaccagac tggaacccga ggacttcgct 1140
atgtactact gccagcagaa caacaactgg cccaccacct ttggccaggg caccaagctg 1200
gaaatcaaag gtggcggtgg ttcaggtggc ggaggaagcg gcggaggcgg atctacagat 1260
cagtgtgaca attttcccca aatgctgagg gatctgcggg acgccttcag ccgggtcaag 1320
acattttttc agacaaagga tgaactcgat aacctcttgc tcaaagagag cctgctcgag 1380
gactttaagg gatatctggg atgccaggct ctgagcgaaa tgattcagtt ttatctcgag 1440
gaagtcatgc ctcaagcaga gaaccaggat ccagagatta aggatcatgt gaatagcctc 1500
ggggagaacc tcaagacact gagactccgg ctgagaagat gccaccggtt tctgccttgt 1560
gaaaacaaaa gcaaggctgt cgagcagatt aagaatgctt ttaacaaact ccaagaaaaa 1620
gggatctata aggctatgtc tgagtttgat atctttatca attatatcga agcttatatg 1680
actattaagg cccggtag 1698
<210> 29
<211> 565
<212> PRT
<213> Artificial Sequence
<220>
<223> DEboegfrDV07 Variant 2 Amino Acid Sequence
<400> 29
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Phe Ser Leu Thr
180 185 190
Asn Tyr Gly Val His Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
195 200 205
Trp Ile Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro
210 215 220
Phe Thr Ser Arg Val Ala Ile Ser Val Asp Thr Ser Lys Asn Gln Phe
225 230 235 240
Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
245 250 255
Cys Thr Ser Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly
260 265 270
Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
275 280 285
Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser Pro
290 295 300
Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg
305 310 315 320
Ala Ser Gln Ser Ile Gly Thr Asn Ile His Trp Phe Gln Gln Lys Pro
325 330 335
Gly Gln Ala Pro Arg Leu Leu Ile Tyr Tyr Ala Ser Glu Ser Ile Ser
340 345 350
Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
355 360 365
Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala Met Tyr Tyr Cys
370 375 380
Gln Gln Asn Asn Asn Trp Pro Thr Thr Phe Gly Gln Gly Thr Lys Leu
385 390 395 400
Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
405 410 415
Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu
420 425 430
Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu
435 440 445
Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly
450 455 460
Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu
465 470 475 480
Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His
485 490 495
Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg
500 505 510
Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu
515 520 525
Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys
530 535 540
Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met
545 550 555 560
Thr Ile Lys Ala Arg
565
<210> 30
<211> 1770
<212> DNA
<213> Artificial Sequence
<220>
<223> DEboegfrDV07 Variant 2 Nucleic Acid Sequence
<400> 30
gctagcgccg ccaccatggg atggtctttg atcctgctgt tcctggtggc cgtggctacc 60
agagtgcatt ctaccgacca gtgcgacaac ttccctcaga tgctgcggga cctgagagat 120
gccttctcca gagtgaaaac attcttccag accaaggacg agctggacaa cctgctgctg 180
aaagagtccc tgctggaaga tttcaagggc tacctgggct gtcaggccct gtccgagatg 240
atccagttct acctggaaga agtgatgccc caggccgaga atcaggaccc cgagatcaag 300
gaccacgtga actccctggg cgagaacctg aaaaccctgc ggctgagact gcggcggtgc 360
cacagatttc tgccctgcga gaacaagtcc aaggccgtgg aacagatcaa gaacgccttc 420
aacaagctgc aagagaaggg catctacaag gccatgagcg agttcgacat cttcatcaac 480
tacatcgagg cctacatgac catcaaggcc agaggcggcg gaggatctgg cggaggtgga 540
agcggaggcg gtggatctca ggttcagttg cagcaatggg gcgctggcct gctgaagcct 600
tctgagacac tgtctctgac ctgcgccgtg tacggcttct ccctgaccaa ttatggcgtg 660
cactggatca gacagcctcc aggcaaaggc ctggaatgga tcggagtgat ttggagcggc 720
ggcaacaccg actacaacac ccctttcacc tctagagtgg ccatctccgt ggacacctcc 780
aagaaccagt tcagcctgag actgaactcc gtgaccgccg ctgataccgc catctactac 840
tgcacctccg ctctgaccta ctacgactac gagttcgcct actggggcaa gggcaccaca 900
gtgactgtta gtagtggtgg cggaggtagc ggtggtggtg gtagtggcgg tggcggatct 960
gagatcgtga tgacccaatc tcctggcact ctgtctctgt ctcccggcga gagagctacc 1020
ctgtcttgta gagcctctca gtccatcggc accaacatcc actggttcca gcagaagcct 1080
ggacaggccc ctagactgct gatctactac gcctccgaga gcatcagcgg cttccctgac 1140
agattctccg gctctggctc tggcaccgac ttcaccctga caatcacccg gctggaacct 1200
gaggacttcg ctatgtacta ctgccagcag aacaacaact ggcccaccac ctttggccag 1260
ggcaccaagc tggaaatcaa aggcggaggc ggcagtggcg gcggtggctc cggcggaggc 1320
ggatctacag atcagtgtga caattttccc caaatgctga gggatctgcg ggacgccttc 1380
agccgggtca agacattttt tcagacaaag gatgaactcg ataacctctt gctcaaagag 1440
agcctgctcg aggacttcaa aggatatctg ggatgccagg ctctgagcga aatgattcag 1500
ttttatctcg aggaagtcat gccacaagca gagaaccagg atccagagat taaggatcat 1560
gtgaatagcc tcggggagaa cctcaagaca ctgagactcc ggctgagaag atgccaccgg 1620
tttctgcctt gtgaaaacaa aagcaaggct gtcgagcaga ttaagaatgc ttttaacaaa 1680
ctccaagaaa aagggatcta taaggctatg tctgagtttg atatctttat caattatatc 1740
gaagcttata tgactattaa ggcccggtag 1770
<210> 31
<211> 565
<212> PRT
<213> Artificial Sequence
<220>
<223> DEboegfrDV07 Variant 3 (SLP) Amino Acid Sequence
<400> 31
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Phe Ser Leu Thr
180 185 190
Asn Tyr Gly Val His Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
195 200 205
Trp Leu Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro
210 215 220
Phe Thr Ser Arg Val Ala Ile Ser Lys Asp Asn Ser Lys Asn Gln Val
225 230 235 240
Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
245 250 255
Cys Ala Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly
260 265 270
Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
275 280 285
Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Leu Thr Gln Ser Pro
290 295 300
Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg
305 310 315 320
Ala Ser Gln Ser Ile Gly Thr Asn Ile His Trp Tyr Gln Gln Lys Pro
325 330 335
Gly Gln Ala Pro Arg Leu Leu Ile Lys Tyr Ala Ser Glu Ser Ile Ser
340 345 350
Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
355 360 365
Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala Met Tyr Tyr Cys
370 375 380
Gln Gln Asn Asn Asn Trp Pro Thr Thr Phe Gly Gln Gly Thr Lys Leu
385 390 395 400
Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
405 410 415
Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu
420 425 430
Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu
435 440 445
Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly
450 455 460
Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu
465 470 475 480
Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His
485 490 495
Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg
500 505 510
Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu
515 520 525
Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys
530 535 540
Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met
545 550 555 560
Thr Ile Lys Ala Arg
565
<210> 32
<211> 1698
<212> DNA
<213> Artificial Sequence
<220>
<223> DEboegfrDV07 Variant 3 (SLP) Nucleic Acid Sequence
<400> 32
accgaccagt gcgacaactt ccctcagatg ctgcgggacc tgagagatgc cttctccaga 60
gtgaaaacat tcttccagac caaggacgag ctggacaacc tgctgctgaa agagtccctg 120
ctggaagatt tcaagggcta cctgggctgt caggccctgt ccgagatgat ccagttctac 180
ctggaagaag tgatgcccca ggccgagaat caggaccccg agatcaagga ccacgtgaac 240
tccctgggcg agaacctgaa aaccctgcgg ctgagactgc ggcggtgcca cagatttctg 300
ccctgcgaga acaagtccaa ggccgtggaa cagatcaaga acgccttcaa caagctgcaa 360
gagaagggca tctacaaggc catgagcgag ttcgacatct tcatcaacta catcgaggcc 420
tacatgacca tcaaggccag aggcggcgga ggatctggcg gaggtggaag cggaggcggt 480
ggatctcagg ttcagttgca gcaatggggc gctggcctgc tgaagccttc tgagacactg 540
tctctgacct gcgccgtgta cggcttctcc ctgaccaatt atggcgtgca ctggatcaga 600
cagcctccag gcaaaggcct ggaatggctg ggagtgattt ggagcggcgg caacaccgac 660
tacaacaccc ctttcacctc tagagtggcc atctccaagg acaactccaa gaaccaggtg 720
tccctgagac tgaactccgt gaccgctgcc gataccgcca tctactactg tgctagagcc 780
ctgacctact acgactacga gttcgcctat tggggcaagg gcaccaccgt gactgttagt 840
agtggtggtg gcggtagtgg cggaggcggc tcaggcggtg gtggatctga aattgtgctg 900
acccagtctc ctggcactct gtctttgagc cctggcgaga gagctaccct gtcctgtaga 960
gcctctcagt ccatcggcac caacatccac tggtatcagc agaagcctgg acaggcccct 1020
cggctgctga ttaagtacgc ctccgagtcc atcagcggct tccctgacag attctccggc 1080
tctggctctg gcaccgactt caccctgaca atcacccggc tggaacctga ggacttcgct 1140
atgtactact gccagcagaa caacaactgg cccaccacct ttggccaggg caccaagctg 1200
gaaatcaaag gtggcggtgg ttcaggtggc ggaggaagcg gcggaggcgg atctacagat 1260
cagtgtgaca attttcccca aatgctgagg gatctgcggg acgccttcag ccgggtcaag 1320
acattttttc agacaaagga tgaactcgat aacctcttgc tcaaagagag cctgctcgag 1380
gacttcaaag gatatctggg atgccaggct ctgagcgaaa tgattcagtt ttatctcgag 1440
gaagtcatgc ctcaagcaga gaaccaggat ccagagatta aggatcatgt gaatagcctc 1500
ggggagaacc tcaagacact gagactccgg ctgagaagat gccaccggtt tctgccttgt 1560
gaaaacaaaa gcaaggctgt cgagcagatt aagaatgctt ttaacaaatt gcaagaaaaa 1620
gggatctata aggctatgtc tgagtttgat atctttatca attatatcga agcttatatg 1680
actattaagg cccggtag 1698
<210> 33
<211> 565
<212> PRT
<213> Artificial Sequence
<220>
<223> DEboegfrDV07 Variant 4 Amino Acid Sequence
<400> 33
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Thr
180 185 190
Asn Tyr Gly Val His Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu
195 200 205
Trp Leu Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro
210 215 220
Phe Thr Ser Arg Val Ala Ile Ser Lys Asp Asn Ser Lys Asn Gln Val
225 230 235 240
Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
245 250 255
Cys Ala Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly
260 265 270
Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
275 280 285
Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Leu Thr Gln Ser Pro
290 295 300
Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg
305 310 315 320
Ala Ser Gln Ser Ile Gly Thr Asn Ile His Trp Tyr Gln Gln Lys Pro
325 330 335
Gly Gln Ala Pro Arg Leu Leu Ile Lys Tyr Ala Ser Glu Ser Ile Ser
340 345 350
Gly Ile Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
355 360 365
Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala Asp Tyr Tyr Cys
370 375 380
Gln Gln Asn Asn Asn Trp Pro Thr Thr Phe Gly Gln Gly Thr Lys Leu
385 390 395 400
Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
405 410 415
Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu
420 425 430
Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu
435 440 445
Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly
450 455 460
Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu
465 470 475 480
Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His
485 490 495
Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg
500 505 510
Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu
515 520 525
Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys
530 535 540
Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met
545 550 555 560
Thr Ile Lys Ala Arg
565
<210> 34
<211> 1695
<212> DNA
<213> Artificial Sequence
<220>
<223> DEboegfrDV07 Variant 4 Nucleic Acid Sequence
<400> 34
accgaccagt gcgacaactt ccctcagatg ctgcgggacc tgagagatgc cttctccaga 60
gtgaaaacat tcttccagac caaggacgag ctggacaacc tgctgctgaa agagtccctg 120
ctggaagatt tcaagggcta cctgggctgt caggccctgt ccgagatgat ccagttctac 180
ctggaagaag tgatgcccca ggccgagaat caggaccccg agatcaagga ccacgtgaac 240
tccctgggcg agaacctgaa aaccctgcgg ctgagactgc ggcggtgcca cagatttctg 300
ccctgcgaga acaagtccaa ggccgtggaa cagatcaaga acgccttcaa caagctgcaa 360
gagaagggca tctacaaggc catgagcgag ttcgacatct tcatcaacta catcgaggcc 420
tacatgacca tcaaggccag aggcggcgga ggatctggcg gaggtggaag cggaggcggt 480
ggatctcagg ttcagttgca gcaatggggc gctggcctgc tgaagccttc tgagacactg 540
tctctgacct gcaccgtgtc cggcttctcc ctgaccaatt atggcgtgca ctgggtccga 600
cagcctccag gcaaaggatt ggaatggctg ggagtgattt ggagcggcgg caacaccgac 660
tacaacaccc ctttcacctc tagagtggcc atctccaagg acaactccaa gaaccaggtg 720
tccctgagac tgaactccgt gaccgctgcc gataccgcca tctactactg tgctagagcc 780
ctgacctact acgactacga gttcgcctat tggggcaagg gcaccaccgt gactgttagt 840
agtggtggtg gcggtagtgg cggaggcggc tcaggcggtg gtggatctga aattgtgctg 900
acccagtctc ctggcactct gtctttgagc cctggcgaga gagctaccct gtcctgtaga 960
gcctctcagt ccatcggcac caacatccac tggtatcagc agaagcctgg acaggcccct 1020
cggctgctga ttaagtacgc ctccgagtcc atcagcggca tccctgacag attctccggc 1080
tctggctctg gcaccgactt caccctgaca atcacccggc tggaacctga ggacttcgcc 1140
gactactact gccagcagaa caacaactgg cccaccacct ttggccaggg caccaagctg 1200
gaaatcaaag gtggcggtgg ttcaggtggc ggaggaagcg gcggaggcgg atctacagat 1260
cagtgtgaca attttcccca aatgctgagg gatctgcggg acgccttcag ccgggtcaag 1320
acattttttc agacaaagga tgaactcgat aacctcttgc tcaaagagag cctgctcgag 1380
gacttcaaag gatatctggg atgccaggct ctgagcgaaa tgattcagtt ttatctcgag 1440
gaagtcatgc ctcaagcaga gaaccaggat ccagagatta aggatcatgt gaatagcctc 1500
ggggagaacc tcaagacact gagactccgg ctgagaagat gccaccggtt tctgccttgt 1560
gaaaacaaaa gcaaggctgt cgagcagatt aagaatgctt ttaacaaatt gcaagaaaaa 1620
gggatctata aggctatgtc tgagtttgat atctttatca attatatcga agcttatatg 1680
actattaagg cccgg 1695
<210> 35
<211> 713
<212> PRT
<213> Artificial Sequence
<220>
<223> DK210egfr Amino Acid Sequence
<400> 35
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Phe Ser Leu Thr
180 185 190
Asn Tyr Gly Val His Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
195 200 205
Trp Leu Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro
210 215 220
Phe Thr Ser Arg Val Ala Ile Ser Lys Asp Asn Ser Lys Asn Gln Val
225 230 235 240
Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
245 250 255
Cys Ala Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly
260 265 270
Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
275 280 285
Gly Gly Ser Gly Gly Gly Gly Ser Ala Pro Thr Ser Ser Ser Thr Lys
290 295 300
Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp Leu Gln Met Ile
305 310 315 320
Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu Thr Arg Met Leu
325 330 335
Thr Phe Lys Phe Tyr Met Pro Lys Lys Ala Thr Glu Leu Lys His Leu
340 345 350
Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu Val Leu Asn Leu
355 360 365
Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp Leu Ile Ser Asn
370 375 380
Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu Thr Thr Phe Met
385 390 395 400
Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu Phe Leu Asn Arg
405 410 415
Trp Ile Thr Phe Cys Gln Ser Ile Ile Ser Thr Leu Thr Gly Gly Gly
420 425 430
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Leu
435 440 445
Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr
450 455 460
Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn Ile His Trp Tyr
465 470 475 480
Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Lys Tyr Ala Ser
485 490 495
Glu Ser Ile Ser Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
500 505 510
Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala
515 520 525
Met Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr Thr Phe Gly Gln
530 535 540
Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly
545 550 555 560
Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met
565 570 575
Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln
580 585 590
Thr Lys Asp Glu Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu
595 600 605
Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln
610 615 620
Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu
625 630 635 640
Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg
645 650 655
Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser
660 665 670
Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys
675 680 685
Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile
690 695 700
Glu Ala Tyr Met Thr Ile Lys Ala Arg
705 710
<210> 36
<211> 133
<212> PRT
<213> Homo sapiens
<220>
<223> Human IL-2 Amino Acid Sequence
<400> 36
Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
1 5 10 15
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
20 25 30
Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys
35 40 45
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
50 55 60
Pro Leu Glu Glu Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu
65 70 75 80
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
85 90 95
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
100 105 110
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile
115 120 125
Ile Ser Thr Leu Thr
130
<210> 37
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified VH region of anti-EGFR antibody
<400> 37
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr
50 55 60
Ser Arg Val Ala Ile Ser Lys Asp Asn Ser Lys Asn Gln Val Ser Leu
65 70 75 80
Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Lys Gly
100 105 110
Thr Thr Val Thr Val Ser Ser
115
<210> 38
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified VL region of anti-EGFR antibody
<400> 38
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Phe Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Met Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 39
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Artificial Sequence Linker 1
<400> 39
Ser Ser Gly Gly Gly Gly Ser
1 5
<210> 40
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Artificial Sequence Linker 2
<400> 40
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 41
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Artificial Sequence Linker 3
<400> 41
Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 42
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Artificial Sequence 6xHis tag
<400> 42
His His His His His His
1 5
<210> 43
<211> 129
<212> PRT
<213> Homo sapiens
<220>
<223> Human IL-4 Amino Acid Sequence
<400> 43
His Lys Cys Asp Ile Thr Leu Gln Glu Ile Ile Lys Thr Leu Asn Ser
1 5 10 15
Leu Thr Glu Gln Lys Thr Leu Cys Thr Glu Leu Thr Val Thr Asp Ile
20 25 30
Phe Ala Ala Ser Lys Asn Thr Thr Glu Lys Glu Thr Phe Cys Arg Ala
35 40 45
Ala Thr Val Leu Arg Gln Phe Tyr Ser His His Glu Lys Asp Thr Arg
50 55 60
Cys Leu Gly Ala Thr Ala Gln Gln Phe His Arg His Lys Gln Leu Ile
65 70 75 80
Arg Phe Leu Lys Arg Leu Asp Arg Asn Leu Trp Gly Leu Ala Gly Leu
85 90 95
Asn Ser Cys Pro Val Lys Glu Ala Asn Gln Ser Thr Leu Glu Asn Phe
100 105 110
Leu Glu Arg Leu Lys Thr Ile Met Arg Glu Lys Tyr Ser Lys Cys Ser
115 120 125
Ser
<210> 44
<211> 129
<212> PRT
<213> Artificial Sequence
<220>
<223> hIL4 (N38A)
<400> 44
His Lys Cys Asp Ile Thr Leu Gln Glu Ile Ile Lys Thr Leu Asn Ser
1 5 10 15
Leu Thr Glu Gln Lys Thr Leu Cys Thr Glu Leu Thr Val Thr Asp Ile
20 25 30
Phe Ala Ala Ser Lys Ala Thr Thr Glu Lys Glu Thr Phe Cys Arg Ala
35 40 45
Ala Thr Val Leu Arg Gln Phe Tyr Ser His His Glu Lys Asp Thr Arg
50 55 60
Cys Leu Gly Ala Thr Ala Gln Gln Phe His Arg His Lys Gln Leu Ile
65 70 75 80
Arg Phe Leu Lys Arg Leu Asp Arg Asn Leu Trp Gly Leu Ala Gly Leu
85 90 95
Asn Ser Cys Pro Val Lys Glu Ala Asn Gln Ser Thr Leu Glu Asn Phe
100 105 110
Leu Glu Arg Leu Lys Thr Ile Met Arg Glu Lys Tyr Ser Lys Cys Ser
115 120 125
Ser
<210> 45
<211> 129
<212> PRT
<213> Artificial Sequence
<220>
<223> hIL4 (T13D)
<400> 45
His Lys Cys Asp Ile Thr Leu Gln Glu Ile Ile Lys Asp Leu Asn Ser
1 5 10 15
Leu Thr Glu Gln Lys Thr Leu Cys Thr Glu Leu Thr Val Thr Asp Ile
20 25 30
Phe Ala Ala Ser Lys Ala Thr Thr Glu Lys Glu Thr Phe Cys Arg Ala
35 40 45
Ala Thr Val Leu Arg Gln Phe Tyr Ser His His Glu Lys Asp Thr Arg
50 55 60
Cys Leu Gly Ala Thr Ala Gln Gln Phe His Arg His Lys Gln Leu Ile
65 70 75 80
Arg Phe Leu Lys Arg Leu Asp Arg Asn Leu Trp Gly Leu Ala Gly Leu
85 90 95
Asn Ser Cys Pro Val Lys Glu Ala Asn Gln Ser Thr Leu Glu Asn Phe
100 105 110
Leu Glu Arg Leu Lys Thr Ile Met Arg Glu Lys Tyr Ser Lys Cys Ser
115 120 125
Ser
<210> 46
<211> 713
<212> PRT
<213> Artificial Sequence
<220>
<223> DK410DV06 (non targeting)
<400> 46
Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp Leu Arg Asp
1 5 10 15
Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp Glu Val Asp
20 25 30
Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu
35 40 45
Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val
50 55 60
Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp His Val Asn
65 70 75 80
Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys
85 90 95
His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Ile
100 105 110
Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met
115 120 125
Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile
130 135 140
Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro
165 170 175
Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Thr
180 185 190
Thr Thr Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
195 200 205
Trp Ile Gly Glu Val Asn Tyr Ser Gly Asn Ala Asn Tyr Asn Pro Ser
210 215 220
Leu Lys Gly Arg Val Ala Ile Ser Val Asp Thr Ser Lys Asn Gln Phe
225 230 235 240
Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
245 250 255
Cys Thr Ser Arg Ile Arg Ser His Ile Ala Tyr Ser Trp Lys Gly Asp
260 265 270
Val Trp Gly Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly
275 280 285
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser His Lys Cys Asp Ile
290 295 300
Thr Leu Gln Glu Ile Ile Lys Thr Leu Asn Ser Leu Thr Glu Gln Lys
305 310 315 320
Thr Leu Cys Thr Glu Leu Thr Val Thr Asp Ile Phe Ala Ala Ser Lys
325 330 335
Asn Thr Thr Glu Lys Glu Thr Phe Cys Arg Ala Ala Thr Val Leu Arg
340 345 350
Gln Phe Tyr Ser His His Glu Lys Asp Thr Arg Cys Leu Gly Ala Thr
355 360 365
Ala Gln Gln Phe His Arg His Lys Gln Leu Ile Arg Phe Leu Lys Arg
370 375 380
Leu Asp Arg Asn Leu Trp Gly Leu Ala Gly Leu Asn Ser Cys Pro Val
385 390 395 400
Lys Glu Ala Asn Gln Ser Thr Leu Glu Asn Phe Leu Glu Arg Leu Lys
405 410 415
Thr Ile Met Arg Glu Lys Tyr Ser Lys Cys Ser Ser Gly Gly Gly Gly
420 425 430
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr
435 440 445
Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu
450 455 460
Ser Cys Arg Ala Ser Gln Ser Val Pro Arg Asn Tyr Ile Gly Trp Phe
465 470 475 480
Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Gly Ala Ser
485 490 495
Ser Arg Ala Ala Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
500 505 510
Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala
515 520 525
Met Tyr Tyr Cys His Gln Tyr Asp Arg Leu Pro Tyr Thr Phe Gly Gln
530 535 540
Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly
545 550 555 560
Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met
565 570 575
Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln
580 585 590
Thr Lys Asp Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu
595 600 605
Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln
610 615 620
Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu
625 630 635 640
Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg
645 650 655
Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser
660 665 670
Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys
675 680 685
Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile
690 695 700
Glu Ala Tyr Met Thr Ile Lys Ala Arg
705 710
<210> 47
<211> 729
<212> PRT
<213> Artificial Sequence
<220>
<223> DK410HADeglyDV06mCD14
<400> 47
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Ser Gly Phe
195 200 205
Ser Leu Thr Thr Tyr Tyr Met Asn Trp Ile Arg Gln Pro Pro Gly Lys
210 215 220
Gly Leu Glu Trp Ile Gly Phe Ile Arg Ser Gly Gly Ser Thr Glu Tyr
225 230 235 240
Asn Pro Ser Leu Lys Gly Arg Val Ala Ile Ser Val Asp Thr Ser Lys
245 250 255
Asn Gln Phe Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala
260 265 270
Ile Tyr Tyr Cys Ala Arg Gly Asp Tyr Tyr Asn Phe Asp Tyr Trp Gly
275 280 285
Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser His Lys Cys Asp Ile Thr Leu Gln
305 310 315 320
Glu Ile Ile Lys Asp Leu Asn Ser Leu Thr Glu Gln Lys Thr Leu Cys
325 330 335
Thr Glu Leu Thr Val Thr Asp Ile Phe Ala Ala Ser Lys Ala Thr Thr
340 345 350
Glu Lys Glu Thr Phe Cys Arg Ala Ala Thr Val Leu Arg Gln Phe Tyr
355 360 365
Ser His His Glu Lys Asp Thr Arg Cys Leu Gly Ala Thr Ala Gln Gln
370 375 380
Phe His Arg His Lys Gln Leu Ile Arg Phe Leu Lys Arg Leu Asp Arg
385 390 395 400
Asn Leu Trp Gly Leu Ala Gly Leu Asn Ser Cys Pro Val Lys Glu Ala
405 410 415
Asn Gln Ser Thr Leu Glu Asn Phe Leu Glu Arg Leu Lys Thr Ile Met
420 425 430
Arg Glu Lys Tyr Ser Lys Cys Ser Ser Gly Gly Gly Gly Ser Gly Gly
435 440 445
Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser Pro
450 455 460
Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg
465 470 475 480
Ala Ser Gln Ser Leu Val His Ser Asn Gly Lys Thr Tyr Val Gly Trp
485 490 495
Phe Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Arg Val
500 505 510
Ser Asn Arg Ala Ala Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser
515 520 525
Gly Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe
530 535 540
Ala Met Tyr Tyr Cys Leu Gln Ser Thr His Phe Pro Arg Thr Phe Gly
545 550 555 560
Gln Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly
565 570 575
Gly Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln
580 585 590
Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe
595 600 605
Gln Thr Lys Asp Glu Val Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu
610 615 620
Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln
625 630 635 640
Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu
645 650 655
Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg
660 665 670
Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser
675 680 685
Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys
690 695 700
Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile
705 710 715 720
Glu Ala Tyr Met Thr Ile Lys Ala Arg
725
<210> 48
<211> 729
<212> PRT
<213> Artificial Sequence
<220>
<223> DK410HADeglyDV07mCD14
<400> 48
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Ser Gly Phe
195 200 205
Ser Leu Thr Thr Tyr Tyr Met Asn Trp Ile Arg Gln Pro Pro Gly Lys
210 215 220
Gly Leu Glu Trp Ile Gly Phe Ile Arg Ser Gly Gly Ser Thr Glu Tyr
225 230 235 240
Asn Pro Ser Leu Lys Gly Arg Val Ala Ile Ser Val Asp Thr Ser Lys
245 250 255
Asn Gln Phe Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala
260 265 270
Ile Tyr Tyr Cys Ala Arg Gly Asp Tyr Tyr Asn Phe Asp Tyr Trp Gly
275 280 285
Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser His Lys Cys Asp Ile Thr Leu Gln
305 310 315 320
Glu Ile Ile Lys Asp Leu Asn Ser Leu Thr Glu Gln Lys Thr Leu Cys
325 330 335
Thr Glu Leu Thr Val Thr Asp Ile Phe Ala Ala Ser Lys Ala Thr Thr
340 345 350
Glu Lys Glu Thr Phe Cys Arg Ala Ala Thr Val Leu Arg Gln Phe Tyr
355 360 365
Ser His His Glu Lys Asp Thr Arg Cys Leu Gly Ala Thr Ala Gln Gln
370 375 380
Phe His Arg His Lys Gln Leu Ile Arg Phe Leu Lys Arg Leu Asp Arg
385 390 395 400
Asn Leu Trp Gly Leu Ala Gly Leu Asn Ser Cys Pro Val Lys Glu Ala
405 410 415
Asn Gln Ser Thr Leu Glu Asn Phe Leu Glu Arg Leu Lys Thr Ile Met
420 425 430
Arg Glu Lys Tyr Ser Lys Cys Ser Ser Gly Gly Gly Gly Ser Gly Gly
435 440 445
Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser Pro
450 455 460
Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg
465 470 475 480
Ala Ser Gln Ser Leu Val His Ser Asn Gly Lys Thr Tyr Val Gly Trp
485 490 495
Phe Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Arg Val
500 505 510
Ser Asn Arg Ala Ala Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser
515 520 525
Gly Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe
530 535 540
Ala Met Tyr Tyr Cys Leu Gln Ser Thr His Phe Pro Arg Thr Phe Gly
545 550 555 560
Gln Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly
565 570 575
Gly Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln
580 585 590
Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe
595 600 605
Gln Thr Lys Asp Glu Leu Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu
610 615 620
Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln
625 630 635 640
Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu
645 650 655
Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg
660 665 670
Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser
675 680 685
Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys
690 695 700
Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile
705 710 715 720
Glu Ala Tyr Met Thr Ile Lys Ala Arg
725
<210> 49
<211> 729
<212> PRT
<213> Artificial Sequence
<220>
<223> DK410ngDV06CmD14
<400> 49
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Ser Gly Phe
195 200 205
Ser Leu Thr Thr Tyr Tyr Met Asn Trp Ile Arg Gln Pro Pro Gly Lys
210 215 220
Gly Leu Glu Trp Ile Gly Phe Ile Arg Ser Gly Gly Ser Thr Glu Tyr
225 230 235 240
Asn Pro Ser Leu Lys Gly Arg Val Ala Ile Ser Val Asp Thr Ser Lys
245 250 255
Asn Gln Phe Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala
260 265 270
Ile Tyr Tyr Cys Ala Arg Gly Asp Tyr Tyr Asn Phe Asp Tyr Trp Gly
275 280 285
Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser His Lys Cys Asp Ile Thr Leu Gln
305 310 315 320
Glu Ile Ile Lys Thr Leu Asn Ser Leu Thr Glu Gln Lys Thr Leu Cys
325 330 335
Thr Glu Leu Thr Val Thr Asp Ile Phe Ala Ala Ser Lys Ala Thr Thr
340 345 350
Glu Lys Glu Thr Phe Cys Arg Ala Ala Thr Val Leu Arg Gln Phe Tyr
355 360 365
Ser His His Glu Lys Asp Thr Arg Cys Leu Gly Ala Thr Ala Gln Gln
370 375 380
Phe His Arg His Lys Gln Leu Ile Arg Phe Leu Lys Arg Leu Asp Arg
385 390 395 400
Asn Leu Trp Gly Leu Ala Gly Leu Asn Ser Cys Pro Val Lys Glu Ala
405 410 415
Asn Gln Ser Thr Leu Glu Asn Phe Leu Glu Arg Leu Lys Thr Ile Met
420 425 430
Arg Glu Lys Tyr Ser Lys Cys Ser Ser Gly Gly Gly Gly Ser Gly Gly
435 440 445
Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser Pro
450 455 460
Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg
465 470 475 480
Ala Ser Gln Ser Leu Val His Ser Asn Gly Lys Thr Tyr Val Gly Trp
485 490 495
Phe Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Arg Val
500 505 510
Ser Asn Arg Ala Ala Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser
515 520 525
Gly Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe
530 535 540
Ala Met Tyr Tyr Cys Leu Gln Ser Thr His Phe Pro Arg Thr Phe Gly
545 550 555 560
Gln Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly
565 570 575
Gly Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln
580 585 590
Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe
595 600 605
Gln Thr Lys Asp Glu Val Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu
610 615 620
Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln
625 630 635 640
Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu
645 650 655
Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg
660 665 670
Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser
675 680 685
Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys
690 695 700
Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile
705 710 715 720
Glu Ala Tyr Met Thr Ile Lys Ala Arg
725
<210> 50
<211> 729
<212> PRT
<213> Artificial Sequence
<220>
<223> DK410ngDV07CmD14
<400> 50
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Ser Gly Phe
195 200 205
Ser Leu Thr Thr Tyr Tyr Met Asn Trp Ile Arg Gln Pro Pro Gly Lys
210 215 220
Gly Leu Glu Trp Ile Gly Phe Ile Arg Ser Gly Gly Ser Thr Glu Tyr
225 230 235 240
Asn Pro Ser Leu Lys Gly Arg Val Ala Ile Ser Val Asp Thr Ser Lys
245 250 255
Asn Gln Phe Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala
260 265 270
Ile Tyr Tyr Cys Ala Arg Gly Asp Tyr Tyr Asn Phe Asp Tyr Trp Gly
275 280 285
Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser His Lys Cys Asp Ile Thr Leu Gln
305 310 315 320
Glu Ile Ile Lys Thr Leu Asn Ser Leu Thr Glu Gln Lys Thr Leu Cys
325 330 335
Thr Glu Leu Thr Val Thr Asp Ile Phe Ala Ala Ser Lys Ala Thr Thr
340 345 350
Glu Lys Glu Thr Phe Cys Arg Ala Ala Thr Val Leu Arg Gln Phe Tyr
355 360 365
Ser His His Glu Lys Asp Thr Arg Cys Leu Gly Ala Thr Ala Gln Gln
370 375 380
Phe His Arg His Lys Gln Leu Ile Arg Phe Leu Lys Arg Leu Asp Arg
385 390 395 400
Asn Leu Trp Gly Leu Ala Gly Leu Asn Ser Cys Pro Val Lys Glu Ala
405 410 415
Asn Gln Ser Thr Leu Glu Asn Phe Leu Glu Arg Leu Lys Thr Ile Met
420 425 430
Arg Glu Lys Tyr Ser Lys Cys Ser Ser Gly Gly Gly Gly Ser Gly Gly
435 440 445
Gly Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser Pro
450 455 460
Gly Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg
465 470 475 480
Ala Ser Gln Ser Leu Val His Ser Asn Gly Lys Thr Tyr Val Gly Trp
485 490 495
Phe Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Arg Val
500 505 510
Ser Asn Arg Ala Ala Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser
515 520 525
Gly Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe
530 535 540
Ala Met Tyr Tyr Cys Leu Gln Ser Thr His Phe Pro Arg Thr Phe Gly
545 550 555 560
Gln Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly
565 570 575
Gly Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln
580 585 590
Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe
595 600 605
Gln Thr Lys Asp Glu Leu Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu
610 615 620
Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln
625 630 635 640
Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu
645 650 655
Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg
660 665 670
Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser
675 680 685
Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys
690 695 700
Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile
705 710 715 720
Glu Ala Tyr Met Thr Ile Lys Ala Arg
725
<210> 51
<211> 729
<212> PRT
<213> Artificial Sequence
<220>
<223> DK410ngDV06mMAdCAM
<400> 51
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Phe
195 200 205
Thr Phe Thr Asp Phe Tyr Met Asn Trp Ile Arg Gln Pro Pro Gly Lys
210 215 220
Gly Leu Glu Trp Ile Gly Leu Ile Arg Asn Lys Ala Asn Ala Tyr Thr
225 230 235 240
Thr Glu Tyr Asn Pro Ser Val Lys Gly Arg Val Ala Ile Ser Val Asp
245 250 255
Thr Ser Lys Asn Gln Phe Ser Leu Arg Leu Asn Ser Val Thr Ala Ala
260 265 270
Asp Thr Ala Ile Tyr Tyr Cys Thr Ser Asp Asp His Trp Gly Lys Gly
275 280 285
Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
290 295 300
Ser Gly Gly Gly Gly Ser His Lys Cys Asp Ile Thr Leu Gln Glu Ile
305 310 315 320
Ile Lys Thr Leu Asn Ser Leu Thr Glu Gln Lys Thr Leu Cys Thr Glu
325 330 335
Leu Thr Val Thr Asp Ile Phe Ala Ala Ser Lys Ala Thr Thr Glu Lys
340 345 350
Glu Thr Phe Cys Arg Ala Ala Thr Val Leu Arg Gln Phe Tyr Ser His
355 360 365
His Glu Lys Asp Thr Arg Cys Leu Gly Ala Thr Ala Gln Gln Phe His
370 375 380
Arg His Lys Gln Leu Ile Arg Phe Leu Lys Arg Leu Asp Arg Asn Leu
385 390 395 400
Trp Gly Leu Ala Gly Leu Asn Ser Cys Pro Val Lys Glu Ala Asn Gln
405 410 415
Ser Thr Leu Glu Asn Phe Leu Glu Arg Leu Lys Thr Ile Met Arg Glu
420 425 430
Lys Tyr Ser Lys Cys Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
435 440 445
Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser Pro Gly Thr
450 455 460
Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Lys Ser Ser
465 470 475 480
Gln Ser Leu Leu Tyr Asn Glu Asn Lys Lys Asn Tyr Leu Ala Trp Phe
485 490 495
Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Trp Ala Ser
500 505 510
Thr Arg Glu Ser Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
515 520 525
Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala
530 535 540
Met Tyr Tyr Cys Gln Gln Tyr Tyr Asn Phe Pro Tyr Thr Phe Gly Gln
545 550 555 560
Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly
565 570 575
Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met
580 585 590
Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln
595 600 605
Thr Lys Asp Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu
610 615 620
Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln
625 630 635 640
Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu
645 650 655
Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg
660 665 670
Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser
675 680 685
Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys
690 695 700
Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile
705 710 715 720
Glu Ala Tyr Met Thr Ile Lys Ala Arg
725
<210> 52
<211> 733
<212> PRT
<213> Artificial Sequence
<220>
<223> DK210her2 (Variant 2)
<400> 52
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Phe
195 200 205
Asn Ile Lys Asp Thr Tyr Ile His Trp Ile Arg Gln Pro Pro Gly Lys
210 215 220
Gly Leu Glu Trp Ile Gly Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg
225 230 235 240
Tyr Ala Asp Ser Val Lys Gly Arg Val Ala Ile Ser Val Asp Thr Ser
245 250 255
Lys Asn Gln Phe Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr
260 265 270
Ala Ile Tyr Tyr Cys Thr Ser Trp Gly Gly Asp Gly Phe Tyr Ala Met
275 280 285
Asp Tyr Trp Gly Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly
290 295 300
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ala Pro Thr Ser
305 310 315 320
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
325 330 335
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
340 345 350
Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys Lys Ala Thr Glu
355 360 365
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
370 375 380
Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
385 390 395 400
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
405 410 415
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
420 425 430
Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile Ile Ser Thr Leu
435 440 445
Thr Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
450 455 460
Glu Ile Val Met Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
465 470 475 480
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Asp Val Asn Thr Ala
485 490 495
Val Ala Trp Phe Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
500 505 510
Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Phe Pro Asp Arg Phe Ser Gly
515 520 525
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro
530 535 540
Glu Asp Phe Ala Met Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro
545 550 555 560
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser
565 570 575
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn
580 585 590
Phe Pro Gln Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys
595 600 605
Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp Asn Leu Leu Leu Lys Glu
610 615 620
Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser
625 630 635 640
Glu Met Ile Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn
645 650 655
Gln Asp Pro Glu Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu
660 665 670
Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys
675 680 685
Glu Asn Lys Ser Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys
690 695 700
Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe
705 710 715 720
Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile Lys Ala Arg
725 730
<210> 53
<211> 733
<212> PRT
<213> Artificial Sequence
<220>
<223> DK210her2 (Variant 3)
<400> 53
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Phe
195 200 205
Asn Ile Lys Asp Thr Tyr Ile His Trp Ile Arg Gln Pro Pro Gly Lys
210 215 220
Gly Leu Glu Trp Val Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg
225 230 235 240
Tyr Ala Asp Ser Val Lys Gly Arg Phe Ala Ile Ser Ala Asp Thr Ser
245 250 255
Lys Asn Gln Ala Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr
260 265 270
Ala Ile Tyr Tyr Cys Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met
275 280 285
Asp Tyr Trp Gly Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly
290 295 300
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ala Pro Thr Ser
305 310 315 320
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
325 330 335
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
340 345 350
Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys Lys Ala Thr Glu
355 360 365
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
370 375 380
Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
385 390 395 400
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
405 410 415
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
420 425 430
Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile Ile Ser Thr Leu
435 440 445
Thr Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
450 455 460
Glu Ile Val Met Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
465 470 475 480
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Asp Val Asn Thr Ala
485 490 495
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
500 505 510
Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Phe Pro Asp Arg Phe Ser Gly
515 520 525
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro
530 535 540
Glu Asp Phe Ala Met Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro
545 550 555 560
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser
565 570 575
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn
580 585 590
Phe Pro Gln Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys
595 600 605
Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp Asn Leu Leu Leu Lys Glu
610 615 620
Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser
625 630 635 640
Glu Met Ile Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn
645 650 655
Gln Asp Pro Glu Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu
660 665 670
Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys
675 680 685
Glu Asn Lys Ser Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys
690 695 700
Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe
705 710 715 720
Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile Lys Ala Arg
725 730
<210> 54
<211> 733
<212> PRT
<213> Artificial Sequence
<220>
<223> DK210her2 (Variant 4)
<400> 54
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Glu Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Ala Ala Ser Gly Phe
195 200 205
Asn Ile Lys Asp Thr Tyr Ile His Trp Val Arg Gln Pro Pro Gly Lys
210 215 220
Gly Leu Glu Trp Val Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg
225 230 235 240
Tyr Ala Asp Ser Val Lys Gly Arg Phe Ala Ile Ser Ala Asp Thr Ser
245 250 255
Lys Asn Gln Ala Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr
260 265 270
Ala Val Tyr Tyr Cys Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met
275 280 285
Asp Tyr Trp Gly Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly
290 295 300
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ala Pro Thr Ser
305 310 315 320
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
325 330 335
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
340 345 350
Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys Lys Ala Thr Glu
355 360 365
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
370 375 380
Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
385 390 395 400
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
405 410 415
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
420 425 430
Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile Ile Ser Thr Leu
435 440 445
Thr Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
450 455 460
Glu Ile Val Met Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
465 470 475 480
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Asp Val Asn Thr Ala
485 490 495
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
500 505 510
Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Val Pro Asp Arg Phe Ser Gly
515 520 525
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro
530 535 540
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro
545 550 555 560
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser
565 570 575
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn
580 585 590
Phe Pro Gln Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys
595 600 605
Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp Asn Leu Leu Leu Lys Glu
610 615 620
Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser
625 630 635 640
Glu Met Ile Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn
645 650 655
Gln Asp Pro Glu Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu
660 665 670
Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys
675 680 685
Glu Asn Lys Ser Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys
690 695 700
Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe
705 710 715 720
Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile Lys Ala Arg
725 730
<210> 55
<211> 733
<212> PRT
<213> Artificial Sequence
<220>
<223> DK210her2 (Variant 5)
<400> 55
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Leu Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Glu Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Ala Ala Ser Gly Phe
195 200 205
Asn Ile Lys Asp Thr Tyr Ile His Trp Val Arg Gln Pro Pro Gly Lys
210 215 220
Gly Leu Glu Trp Val Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg
225 230 235 240
Tyr Ala Asp Ser Val Lys Gly Arg Phe Ala Ile Ser Ala Asp Thr Ser
245 250 255
Lys Asn Gln Ala Ser Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr
260 265 270
Ala Val Tyr Tyr Cys Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met
275 280 285
Asp Tyr Trp Gly Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly
290 295 300
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ala Pro Thr Ser
305 310 315 320
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
325 330 335
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
340 345 350
Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys Lys Ala Thr Glu
355 360 365
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
370 375 380
Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
385 390 395 400
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
405 410 415
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
420 425 430
Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile Ile Ser Thr Leu
435 440 445
Thr Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
450 455 460
Glu Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Leu Ser Pro Gly
465 470 475 480
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Asp Val Asn Thr Ala
485 490 495
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
500 505 510
Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Val Pro Asp Arg Phe Ser Gly
515 520 525
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
530 535 540
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro
545 550 555 560
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser
565 570 575
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn
580 585 590
Phe Pro Gln Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys
595 600 605
Thr Phe Phe Gln Thr Lys Asp Glu Leu Asp Asn Leu Leu Leu Lys Glu
610 615 620
Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser
625 630 635 640
Glu Met Ile Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn
645 650 655
Gln Asp Pro Glu Ile Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu
660 665 670
Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys
675 680 685
Glu Asn Lys Ser Lys Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys
690 695 700
Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe
705 710 715 720
Ile Asn Tyr Ile Glu Ala Tyr Met Thr Ile Lys Ala Arg
725 730
<210> 56
<211> 728
<212> PRT
<213> Artificial Sequence
<220>
<223> DK410ngDV06CD14 (Variant 2)
<400> 56
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Tyr
195 200 205
Ser Ile Thr Ser Asp Ser Ala Trp Asn Trp Ile Arg Gln Pro Pro Gly
210 215 220
Lys Gly Leu Glu Trp Ile Gly Tyr Ile Ser Tyr Ser Gly Ser Thr Ser
225 230 235 240
Tyr Asn Pro Ser Leu Lys Ser Arg Val Ala Ile Ser Val Asp Thr Ser
245 250 255
Lys Asn Gln Phe Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr
260 265 270
Ala Ile Tyr Tyr Cys Thr Ser Gly Leu Arg Phe Ala Tyr Trp Gly Lys
275 280 285
Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
290 295 300
Gly Ser Gly Gly Gly Gly Ser His Lys Cys Asp Ile Thr Leu Gln Glu
305 310 315 320
Ile Ile Lys Thr Leu Asn Ser Leu Thr Glu Gln Lys Thr Leu Cys Thr
325 330 335
Glu Leu Thr Val Thr Asp Ile Phe Ala Ala Ser Lys Ala Thr Thr Glu
340 345 350
Lys Glu Thr Phe Cys Arg Ala Ala Thr Val Leu Arg Gln Phe Tyr Ser
355 360 365
His His Glu Lys Asp Thr Arg Cys Leu Gly Ala Thr Ala Gln Gln Phe
370 375 380
His Arg His Lys Gln Leu Ile Arg Phe Leu Lys Arg Leu Asp Arg Asn
385 390 395 400
Leu Trp Gly Leu Ala Gly Leu Asn Ser Cys Pro Val Lys Glu Ala Asn
405 410 415
Gln Ser Thr Leu Glu Asn Phe Leu Glu Arg Leu Lys Thr Ile Met Arg
420 425 430
Glu Lys Tyr Ser Lys Cys Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
435 440 445
Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Met Thr Gln Ser Pro Gly
450 455 460
Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala
465 470 475 480
Ser Glu Ser Val Asp Ser Tyr Val Asn Ser Phe Leu His Trp Phe Gln
485 490 495
Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Arg Ala Ser Asn
500 505 510
Leu Gln Ser Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr
515 520 525
Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala Met
530 535 540
Tyr Tyr Cys Gln Gln Ser Asn Glu Asp Pro Thr Thr Phe Gly Gln Gly
545 550 555 560
Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
565 570 575
Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu
580 585 590
Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr
595 600 605
Lys Asp Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp
610 615 620
Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe
625 630 635 640
Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile
645 650 655
Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu
660 665 670
Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys
675 680 685
Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly
690 695 700
Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu
705 710 715 720
Ala Tyr Met Thr Ile Lys Ala Arg
725
<210> 57
<211> 728
<212> PRT
<213> Artificial Sequence
<220>
<223> DK410ngDV06CD14 (Variant 3)
<400> 57
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Tyr
195 200 205
Ser Ile Thr Ser Asp Ser Ala Trp Asn Trp Ile Arg Gln Pro Pro Gly
210 215 220
Lys Gly Leu Glu Trp Met Gly Tyr Ile Ser Tyr Ser Gly Ser Thr Ser
225 230 235 240
Tyr Asn Pro Ser Leu Lys Ser Arg Ile Ala Ile Ser Arg Asp Thr Ser
245 250 255
Lys Asn Gln Phe Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr
260 265 270
Ala Ile Tyr Tyr Cys Val Arg Gly Leu Arg Phe Ala Tyr Trp Gly Lys
275 280 285
Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
290 295 300
Gly Ser Gly Gly Gly Gly Ser His Lys Cys Asp Ile Thr Leu Gln Glu
305 310 315 320
Ile Ile Lys Thr Leu Asn Ser Leu Thr Glu Gln Lys Thr Leu Cys Thr
325 330 335
Glu Leu Thr Val Thr Asp Ile Phe Ala Ala Ser Lys Ala Thr Thr Glu
340 345 350
Lys Glu Thr Phe Cys Arg Ala Ala Thr Val Leu Arg Gln Phe Tyr Ser
355 360 365
His His Glu Lys Asp Thr Arg Cys Leu Gly Ala Thr Ala Gln Gln Phe
370 375 380
His Arg His Lys Gln Leu Ile Arg Phe Leu Lys Arg Leu Asp Arg Asn
385 390 395 400
Leu Trp Gly Leu Ala Gly Leu Asn Ser Cys Pro Val Lys Glu Ala Asn
405 410 415
Gln Ser Thr Leu Glu Asn Phe Leu Glu Arg Leu Lys Thr Ile Met Arg
420 425 430
Glu Lys Tyr Ser Lys Cys Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
435 440 445
Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Leu Thr Gln Ser Pro Gly
450 455 460
Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala
465 470 475 480
Ser Glu Ser Val Asp Ser Tyr Val Asn Ser Phe Leu His Trp Tyr Gln
485 490 495
Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Arg Ala Ser Asn
500 505 510
Leu Gln Ser Gly Phe Pro Asp Arg Phe Ser Gly Ser Gly Ser Arg Thr
515 520 525
Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala Met
530 535 540
Tyr Tyr Cys Gln Gln Ser Asn Glu Asp Pro Thr Thr Phe Gly Gln Gly
545 550 555 560
Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
565 570 575
Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu
580 585 590
Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr
595 600 605
Lys Asp Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp
610 615 620
Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe
625 630 635 640
Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile
645 650 655
Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu
660 665 670
Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys
675 680 685
Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly
690 695 700
Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu
705 710 715 720
Ala Tyr Met Thr Ile Lys Ala Arg
725
<210> 58
<211> 728
<212> PRT
<213> Artificial Sequence
<220>
<223> DK410ngDV06CD14 (Variant 4)
<400> 58
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Thr Val Thr Gly Tyr
195 200 205
Ser Ile Thr Ser Asp Ser Ala Trp Asn Trp Ile Arg Gln Pro Pro Gly
210 215 220
Lys Gly Leu Glu Trp Met Gly Tyr Ile Ser Tyr Ser Gly Ser Thr Ser
225 230 235 240
Tyr Asn Pro Ser Leu Lys Ser Arg Ile Ala Ile Ser Arg Asp Thr Ser
245 250 255
Lys Asn Gln Phe Ser Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr
260 265 270
Ala Thr Tyr Tyr Cys Val Arg Gly Leu Arg Phe Ala Tyr Trp Gly Lys
275 280 285
Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
290 295 300
Gly Ser Gly Gly Gly Gly Ser His Lys Cys Asp Ile Thr Leu Gln Glu
305 310 315 320
Ile Ile Lys Thr Leu Asn Ser Leu Thr Glu Gln Lys Thr Leu Cys Thr
325 330 335
Glu Leu Thr Val Thr Asp Ile Phe Ala Ala Ser Lys Ala Thr Thr Glu
340 345 350
Lys Glu Thr Phe Cys Arg Ala Ala Thr Val Leu Arg Gln Phe Tyr Ser
355 360 365
His His Glu Lys Asp Thr Arg Cys Leu Gly Ala Thr Ala Gln Gln Phe
370 375 380
His Arg His Lys Gln Leu Ile Arg Phe Leu Lys Arg Leu Asp Arg Asn
385 390 395 400
Leu Trp Gly Leu Ala Gly Leu Asn Ser Cys Pro Val Lys Glu Ala Asn
405 410 415
Gln Ser Thr Leu Glu Asn Phe Leu Glu Arg Leu Lys Thr Ile Met Arg
420 425 430
Glu Lys Tyr Ser Lys Cys Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
435 440 445
Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Leu Thr Gln Ser Pro Gly
450 455 460
Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala
465 470 475 480
Ser Glu Ser Val Asp Ser Tyr Val Asn Ser Phe Leu His Trp Tyr Gln
485 490 495
Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Arg Ala Ser Asn
500 505 510
Leu Gln Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser Gly Ser Arg Thr
515 520 525
Asp Phe Thr Leu Thr Ile Thr Arg Leu Glu Pro Glu Asp Phe Ala Thr
530 535 540
Tyr Tyr Cys Gln Gln Ser Asn Glu Asp Pro Thr Thr Phe Gly Gln Gly
545 550 555 560
Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
565 570 575
Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu
580 585 590
Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr
595 600 605
Lys Asp Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp
610 615 620
Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe
625 630 635 640
Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile
645 650 655
Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu
660 665 670
Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys
675 680 685
Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly
690 695 700
Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu
705 710 715 720
Ala Tyr Met Thr Ile Lys Ala Arg
725
<210> 59
<211> 728
<212> PRT
<213> Artificial Sequence
<220>
<223> DK410ngDV06CD14 (Variant 5)
<400> 59
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val His Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu Arg Asp
20 25 30
Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr Lys Asp
35 40 45
Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp Phe Lys
50 55 60
Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe Tyr Leu
65 70 75 80
Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile Lys Asp
85 90 95
His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu Arg Leu
100 105 110
Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys Ala Val
115 120 125
Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly Ile Tyr
130 135 140
Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu Ala Tyr
145 150 155 160
Met Thr Ile Lys Ala Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
165 170 175
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu
180 185 190
Leu Lys Pro Ser Glu Thr Leu Ser Leu Thr Cys Thr Val Thr Gly Tyr
195 200 205
Ser Ile Thr Ser Asp Ser Ala Trp Asn Trp Ile Arg Gln Pro Pro Gly
210 215 220
Lys Gly Leu Glu Trp Met Gly Tyr Ile Ser Tyr Ser Gly Ser Thr Ser
225 230 235 240
Tyr Asn Pro Ser Leu Lys Ser Arg Ile Ala Ile Ser Arg Asp Thr Ser
245 250 255
Lys Asn Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Thr Glu Asp Thr
260 265 270
Ala Thr Tyr Tyr Cys Val Arg Gly Leu Arg Phe Ala Tyr Trp Gly Lys
275 280 285
Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
290 295 300
Gly Ser Gly Gly Gly Gly Ser His Lys Cys Asp Ile Thr Leu Gln Glu
305 310 315 320
Ile Ile Lys Thr Leu Asn Ser Leu Thr Glu Gln Lys Thr Leu Cys Thr
325 330 335
Glu Leu Thr Val Thr Asp Ile Phe Ala Ala Ser Lys Ala Thr Thr Glu
340 345 350
Lys Glu Thr Phe Cys Arg Ala Ala Thr Val Leu Arg Gln Phe Tyr Ser
355 360 365
His His Glu Lys Asp Thr Arg Cys Leu Gly Ala Thr Ala Gln Gln Phe
370 375 380
His Arg His Lys Gln Leu Ile Arg Phe Leu Lys Arg Leu Asp Arg Asn
385 390 395 400
Leu Trp Gly Leu Ala Gly Leu Asn Ser Cys Pro Val Lys Glu Ala Asn
405 410 415
Gln Ser Thr Leu Glu Asn Phe Leu Glu Arg Leu Lys Thr Ile Met Arg
420 425 430
Glu Lys Tyr Ser Lys Cys Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
435 440 445
Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Leu Thr Gln Ser Pro Gly
450 455 460
Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala
465 470 475 480
Ser Glu Ser Val Asp Ser Tyr Val Asn Ser Phe Leu His Trp Tyr Gln
485 490 495
Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Arg Ala Ser Asn
500 505 510
Leu Gln Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser Gly Ser Arg Thr
515 520 525
Asp Phe Thr Leu Thr Ile Asn Arg Val Glu Pro Glu Asp Phe Ala Thr
530 535 540
Tyr Tyr Cys Gln Gln Ser Asn Glu Asp Pro Thr Thr Phe Gly Gln Gly
545 550 555 560
Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
565 570 575
Gly Gly Gly Gly Ser Thr Asp Gln Cys Asp Asn Phe Pro Gln Met Leu
580 585 590
Arg Asp Leu Arg Asp Ala Phe Ser Arg Val Lys Thr Phe Phe Gln Thr
595 600 605
Lys Asp Glu Val Asp Asn Leu Leu Leu Lys Glu Ser Leu Leu Glu Asp
610 615 620
Phe Lys Gly Tyr Leu Gly Cys Gln Ala Leu Ser Glu Met Ile Gln Phe
625 630 635 640
Tyr Leu Glu Glu Val Met Pro Gln Ala Glu Asn Gln Asp Pro Glu Ile
645 650 655
Lys Asp His Val Asn Ser Leu Gly Glu Asn Leu Lys Thr Leu Arg Leu
660 665 670
Arg Leu Arg Arg Cys His Arg Phe Leu Pro Cys Glu Asn Lys Ser Lys
675 680 685
Ala Val Glu Gln Ile Lys Asn Ala Phe Asn Lys Leu Gln Glu Lys Gly
690 695 700
Ile Tyr Lys Ala Met Ser Glu Phe Asp Ile Phe Ile Asn Tyr Ile Glu
705 710 715 720
Ala Tyr Met Thr Ile Lys Ala Arg
725
<210> 60
<211> 2208
<212> DNA
<213> Artificial Sequence
<220>
<223> DK210egfr Nucleic Acid Sequence
<400> 60
gccgccacca tgggatggtc tttgatcctg ctgttcctgg tggccgtggc taccagagtg 60
cattctaccg accagtgcga caacttccct cagatgctgc gggacctgag ggacgccttc 120
tccagagtga aaacattctt ccagaccaag gacgagctgg acaacctgct gctgaaagag 180
tccctgctgg aagatttcaa gggctacctg ggctgtcagg ccctgtccga gatgatccag 240
ttctacctgg aagaagtgat gccccaggcc gagaatcagg accctgagat caaggaccat 300
gtgaactccc tgggcgagaa cctgaaaacc ctgcggctga gactgcggcg gtgtcacaga 360
tttctgccct gcgagaacaa gtccaaggcc gtggaacaga tcaagaacgc cttcaacaag 420
ctgcaagaga agggcatcta caaggccatg agcgagttcg acatcttcat caactacatc 480
gaggcctaca tgaccatcaa ggctagaggt ggcggaggat ctggcggtgg tggttctggc 540
ggaggcggat ctcaggttca gttgcaacaa tggggcgctg gcctgctgaa gccttctgag 600
acactgtctc tgacctgcgc cgtgtacggc ttctctctga ccaattacgg cgtgcactgg 660
atccggcagc cacctggaaa aggactggaa tggctgggag tgatttggag cggcggcaac 720
accgactaca acaccccttt tacctctaga gtggccatct ccaaggacaa ctccaagaac 780
caggtgtccc tgagactgaa ctctgtgacc gccgctgata ccgccatcta ctactgtgct 840
agagccctga cctactacga ctacgagttc gcttattggg gcaagggcac caccgtgaca 900
gtttcatctg gcggcggagg aagcggtggc ggcggtagcg gaggtggtgg atctgctcct 960
acctcctcca gcaccaagaa aacccagctg cagttggagc atctgctgct ggacctccag 1020
atgatcctga acggcatcaa caactacaag aatcccaagc tgacccggat gctgaccttc 1080
aagttctaca tgcccaagaa ggccaccgag ctgaaacatc tgcagtgcct ggaagaggaa 1140
ctgaagcccc tcgaggaagt gctgaatctg gcccagtcca agaacttcca cctgaggcct 1200
agggacctga tctccaacat caacgtgatc gtgctcgagc tgaagggctc cgagacaacc 1260
tttatgtgcg agtacgccga cgagacagcc accatcgtgg aatttctgaa ccggtggatc 1320
accttctgcc agtccatcat ctctacattg accggtggtg gcggatcagg cggtggcgga 1380
agcggaggcg gaggttctga aattgtgctg acccagtctc ctggcactct gtctttgagt 1440
cctggcgaga gagctaccct gtcctgcaga gcttctcagt ccatcggcac caacatccac 1500
tggtatcagc agaagcctgg acaggcccct cggctgctga ttaagtacgc ctctgagtcc 1560
atcagcggct tccctgacag attctctggc tctggatctg gcaccgactt caccctgacc 1620
atcaccagac tggaacccga ggacttcgct atgtactact gccagcagaa caacaactgg 1680
cccaccacct ttggccaggg caccaagttg gaaatcaaag gtggcggtgg aagtggcggc 1740
ggtggctcag gcggcggtgg atctacagac cagtgtgata attttccaca gatgctcagg 1800
gatctccgcg acgcctttag ccgggtcaag acattttttc agacaaagga tgaactcgat 1860
aatctcctgc tcaaagagag cctgctcgag gactttaaag gatacctggg atgccaggct 1920
ctcagcgaaa tgattcagtt ttatttggag gaagtcatgc ctcaagctga aaaccaggat 1980
ccagagatta aggatcacgt caacagcctc ggcgagaatc tcaagacact gcgcctgagg 2040
ctgagaagat gccaccggtt tctgccttgt gaaaacaaga gcaaggctgt cgagcagatt 2100
aagaatgctt ttaacaaatt gcaagaaaaa gggatctata aggctatgtc tgagtttgat 2160
atctttatca attatatcga agcttatatg actattaagg cccggtga 2208
<210> 61
<211> 2288
<212> DNA
<213> Artificial Sequence
<220>
<223> DK410ngDV06CD14 Variant 2 Nucleic Acid Sequence
<400> 61
atcgaaatta atacgactca ctatagggag acccaagctg gctagcgccg ccaccatggg 60
atggtctttg atcctgctgt tcctggtggc cgtggctacc agagtgcatt ctaccgacca 120
gtgcgacaac ttccctcaga tgctgcggga cctgagagat gccttctcca gagtgaaaac 180
attcttccag accaaggacg aggtggacaa cctgctgctg aaagagtccc tgctggaaga 240
tttcaagggc tacctgggct gtcaggccct gtccgagatg atccagttct acctggaaga 300
agtgatgccc caggccgaga atcaggaccc cgagatcaag gaccacgtga actccctggg 360
cgagaacctg aaaaccctgc ggctgagact gcggcggtgc cacagatttc tgccctgcga 420
gaacaagtcc aaggccgtgg aacagatcaa gaacgccttc aacaagctgc aagagaaggg 480
catctacaag gccatgagcg agttcgacat cttcatcaac tacatcgagg cctacatgac 540
catcaaggcc agaggcggcg gaggatctgg cggaggtgga agcggaggcg gtggatctca 600
ggttcagttg cagcaatggg gcgctggcct gctgaagcct tctgagacac tgtctctgac 660
ctgcgccgtg tacggctact ccatcacctc tgactctgcc tggaattgga tccggcagcc 720
tcctggcaaa ggactggaat ggatcggcta catctcctac tccggctcca ccagctacaa 780
ccccagcctg aagtctagag tggccatctc cgtggacacc tccaagaacc agttctccct 840
gagactgaac tccgtgaccg ccgctgatac cgccatctac tactgcacct ccggcctgag 900
atttgcctac tggggcaagg gcaccaccgt gactgttagt agtggtggtg gcggtagtgg 960
cggaggcggc tcaggcggtg gcggatctca taagtgcgac atcaccctgc aagaaatcat 1020
caagaccctg aacagcctga ccgagcagaa aacactgtgc accgagctga ccgtgaccga 1080
tatctttgcc gcctctaagg ccacaaccga gaaagagaca ttctgcagag ccgccaccgt 1140
gctgcggcag ttttactctc accacgagaa ggacaccaga tgcctgggcg ctaccgctca 1200
gcagttccac agacacaagc agctgatccg gttcctgaag cggctggaca gaaacctgtg 1260
gggactcgcc ggcctgaact cttgccctgt gaaagaggcc aaccagtcta ccctggaaaa 1320
cttcctggaa cggctcaaga ccatcatgcg cgagaagtac tccaagtgct ccagcggtgg 1380
cggtggttca ggtggcggtg gctctggcgg cggaggtagt gaaattgtga tgacccagtc 1440
tcctggcact ctgtctctgt ctcccggcga gagagctacc ctgtcttgta gagcctccga 1500
gtccgtggac tcctacgtga acagcttcct gcactggttc cagcagaagc ctggacaggc 1560
tcccagactg ctgatctaca gagcctccaa cctgcagagc ggcttccctg acagattttc 1620
cggctctggc tccggcaccg acttcaccct gacaatcacc agactggaac ccgaggactt 1680
cgctatgtac tactgccagc agtccaacga ggaccccacc acatttggcc agggcaccaa 1740
gctggaaatc aaaggtggcg gaggaagtgg tggcggaggc tccggcggag gcggttctac 1800
agatcagtgt gataattttc cacagatgct ccgcgatctg cgggacgcct ttagccgggt 1860
caagacattt tttcagacaa aggatgaagt cgataacctc ttgctcaaag agagcctgct 1920
cgaggacttt aagggatatc tgggatgcca ggctctgagc gaaatgattc agttttatct 1980
cgaggaagtc atgcctcaag cagagaacca ggatccagag attaaggatc atgtgaatag 2040
cctcggggag aacctcaaga cactgagact ccggctgaga agatgccacc ggtttctgcc 2100
ttgtgaaaac aaaagcaagg ctgtcgagca gattaagaat gcttttaaca aactccaaga 2160
aaaagggatc tataaggcta tgtctgagtt tgatatcttt atcaattata tcgaagctta 2220
tatgactatt aaggctcgct aggggcccgt ttaaacccgc tgatcagcct cgactgtgcc 2280
ttctagtt 2288
<210> 62
<211> 2303
<212> DNA
<213> Artificial Sequence
<220>
<223> DK210her2 Variant 4 Nucleic Acid Sequence
<400> 62
atcgaaatta atacgactca ctatagggag acccaagctg gctagcgccg ccaccatggg 60
atggtctttg atcctgctgt tcctggtggc cgtggctacc agagtgcatt ctaccgacca 120
gtgcgacaac ttccctcaga tgctgcggga cctgagagat gccttctcca gagtgaaaac 180
attcttccag accaaggacg agctggacaa cctgctgctg aaagagtccc tgctggaaga 240
tttcaagggc tacctgggct gtcaggccct gtccgagatg atccagttct acctggaaga 300
agtgatgccc caggccgaga atcaggaccc cgagatcaag gaccacgtga actccctggg 360
cgagaacctg aaaaccctgc ggctgagact gcggcggtgc cacagatttc tgccctgcga 420
gaacaagtcc aaggccgtgg aacagatcaa gaacgccttc aacaagctgc aagagaaggg 480
catctacaag gccatgagcg agttcgacat cttcatcaac tacatcgagg cctacatgac 540
catcaaggcc agaggcggcg gaggatctgg cggaggtgga agcggaggcg gtggatctca 600
ggtgcagttg caagaatggg gcgctggcct gctgaagcct tccgaaacac tgtctctgac 660
ctgcgccgcc agcggcttca acatcaagga cacctacatc cactgggtcc gacagcctcc 720
aggcaaagga ctggaatggg tcgccagaat ctaccccacc aacggctaca ccagatacgc 780
cgactctgtg aagggcagat tcgccatctc tgccgacacc tccaagaacc aggccagcct 840
gagactgaac tctgtgaccg ctgctgacac cgccgtgtac tactgctcta gatggggcgg 900
agatggcttc tacgccatgg actattgggg caagggcacc accgtgacag ttagtagtgg 960
tggtggcggt agtggcggag gcggctcagg cggtggtgga tctgctccta catcctccag 1020
caccaagaaa acccagctgc agttggagca tctgctgctg gacctccaga tgatcctgaa 1080
cggcatcaac aactacaaga accccaagct gacccggatg ctgaccttca agttctacat 1140
gcccaagaag gccaccgagc tgaaacatct gcagtgcctg gaagaggaac tgaagcccct 1200
cgaggaagtg ctgaatctgg cccagtccaa gaacttccac ctgaggccta gggacctgat 1260
ctccaacatc aacgtgatcg tgctcgagct gaagggctcc gagacaacct tcatgtgcga 1320
gtacgccgac gagacagcta ccatcgtgga atttctgaac cggtggatca ccttctgcca 1380
gtccatcatc tctaccctga ctggtggcgg aggaagcggc ggaggcggat ctggcggcgg 1440
aggctctgaa attgtgatga cccagtctcc tggcactctg tctctgtctc ccggcgagag 1500
agctaccctg tcttgtagag ccagccagga cgtgaacacc gctgtggctt ggtatcagca 1560
gaagcctgga caggcccctc ggctgctgat ctactctgcc tcctttctgt actccggcgt 1620
gcccgacaga ttctccggct ctagatctgg caccgacttc accctgacca tcaccagact 1680
ggaacccgag gacttcgcca cctactactg ccagcagcac tacaccacac cacctacctt 1740
tggccagggc accaagctgg aaatcaaagg tggtggcgga tcaggcggtg gcggtagcgg 1800
tggcggaggt tctacagacc agtgtgataa ttttccccaa atgctgaggg atctgcggga 1860
cgccttctct agggtcaaga cattttttca gacaaaggat gaactcgata acctcttgct 1920
caaagagagc ctgctcgagg actttaaggg atatctggga tgccaggctc tgagcgaaat 1980
gattcagttt tatttggagg aagtcatgcc tcaagcagaa aaccaggatc cagagattaa 2040
ggatcatgtc aacagcctcg gcgagaatct caagacactg cgcctgaggc tgagaagatg 2100
ccaccggttt ctgccttgtg aaaacaaaag caaggctgtc gagcagatta agaatgcttt 2160
taacaaactc caagaaaaag ggatctataa ggctatgtct gagtttgata tctttatcaa 2220
ttatatcgaa gcttatatga ctattaaggc tcgctagggg cccgtttaaa cccgctgatc 2280
agcctcgact gtgccttcta gtt 2303
<210> 63
<211> 2303
<212> DNA
<213> Artificial Sequence
<220>
<223> DK210her2 Variant 5 Nucleic Acid Sequence
<400> 63
atcgaaatta atacgactca ctatagggag acccaagctg gctagcgccg ccaccatggg 60
atggtctttg atcctgctgt tcctggtggc cgtggctacc agagtgcatt ctaccgacca 120
gtgcgacaac ttccctcaga tgctgcggga cctgagagat gccttctcca gagtgaaaac 180
attcttccag accaaggacg agctggacaa cctgctgctg aaagagtccc tgctggaaga 240
tttcaagggc tacctgggct gtcaggccct gtccgagatg atccagttct acctggaaga 300
agtgatgccc caggccgaga atcaggaccc cgagatcaag gaccacgtga actccctggg 360
cgagaacctg aaaaccctgc ggctgagact gcggcggtgc cacagatttc tgccctgcga 420
gaacaagtcc aaggccgtgg aacagatcaa gaacgccttc aacaagctgc aagagaaggg 480
catctacaag gccatgagcg agttcgacat cttcatcaac tacatcgagg cctacatgac 540
catcaaggcc agaggcggcg gaggatctgg cggaggtgga agcggaggcg gtggatctca 600
ggtgcagttg caagaatggg gcgctggcct gctgaagcct tccgaaacac tgtctctgac 660
ctgcgccgcc agcggcttca acatcaagga cacctacatc cactgggtcc gacagcctcc 720
aggcaaagga ctggaatggg tcgccagaat ctaccccacc aacggctaca ccagatacgc 780
cgactctgtg aagggcagat tcgccatctc tgccgacacc tccaagaacc aggccagcct 840
gcagatgaac agcctgagag ctgaggacac cgccgtgtac tactgctcta gatggggcgg 900
agatggcttc tacgccatgg actattgggg caagggcacc accgtgacag ttagtagtgg 960
tggtggcggt agtggcggag gcggctcagg cggtggtgga tctgctccta catcctccag 1020
caccaagaaa acccagctgc agttggagca tctgctgctg gacctccaga tgatcctgaa 1080
cggcatcaac aactacaaga accccaagct gacccggatg ctgaccttca agttctacat 1140
gcccaagaag gccaccgagc tgaaacatct gcagtgcctg gaagaggaac tgaagcccct 1200
cgaggaagtg ctgaatctgg cccagtccaa gaacttccac ctgaggccta gggacctgat 1260
ctccaacatc aacgtgatcg tgctcgagct gaagggctcc gagacaacct tcatgtgcga 1320
gtacgccgac gagacagcta ccatcgtgga atttctgaac cggtggatca ccttctgcca 1380
gtccatcatc tctaccctga ctggtggcgg aggaagcggc ggaggcggat ctggcggcgg 1440
aggctctgaa attcagatga cccagtctcc ttccagcctg tctctgtccc ctggcgagag 1500
agctaccctg tcttgtagag ccagccagga cgtgaacacc gctgtggctt ggtatcagca 1560
gaagcctgga caggcccctc ggctgctgat ctactctgcc tcctttctgt actccggcgt 1620
gcccgacaga ttctccggct ctagatctgg caccgacttt accctgacaa tcagctccct 1680
gcagcctgag gacttcgcca cctactactg ccagcagcac tacaccacac cacctacctt 1740
tggccagggc accaagctgg aaatcaaagg tggtggcgga tcaggcggtg gcggtagcgg 1800
tggcggaggt tctacagacc agtgtgataa ttttccccaa atgctgaggg atctgcggga 1860
cgccttctct agggtcaaga cattttttca gacaaaggat gaactcgata acctcttgct 1920
caaagagagc ctgctcgagg acttcaaagg atatctggga tgccaggctc tgagcgaaat 1980
gattcagttt tatttggagg aagtcatgcc tcaagcagaa aaccaggatc cagagattaa 2040
ggatcatgtc aacagcctcg gcgagaatct caagacactg agactgaggc tgcggagatg 2100
tcaccggttt ctgccttgtg aaaacaagag caaggctgtc gagcagatta agaatgcttt 2160
taacaaactc caagaaaaag ggatctataa ggctatgtct gagtttgata tctttatcaa 2220
ttatatcgaa gcttatatga ctattaaggc tcgctagggg cccgtttaaa cccgctgatc 2280
agcctcgact gtgccttcta gtt 2303
Claims (39)
- 모노클로날 항체의 단일 쇄 가변 영역 (scFv) 또는 항원 결합 단편에 융합된 IL-10의 단량체 및 제2 시토카인을 포함하는 이중 시토카인 융합 단백질로서, 여기서, 제2 시토카인은 scFv 또는 항원 결합 단편의 VH와 VL 영역 사이에 융합된 것인 이중 시토카인 융합 단백질.
- 하기 화학식 (I)의 이중 시토카인 융합 단백질:
NH2-(IL10)-(X1)-(Zn)-(X2)-(IL10)-COOH (화학식 I);
상기 식에서,
"IL-10"은 서열식별번호 1, 3, 9, 10, 11, 12, 14, 또는 16으로부터 선택되는 단량체 서열이고;
"X1"은 제1 모노클로날 항체로부터 수득된 VL 또는 VH 영역이고;
"X2"는 제1 모노클로날 항체로부터 수득된 VH 또는 VL 영역이고;
여기서, X1이 VL일 때, X2는 VH이거나, 또는 X1이 VH일 때, X2는 VL이고
"Z"는 IL-10 이외의 다른 시토카인이고;
"n"은 0-2로부터 선택되는 정수이다. - 제2항에 있어서, X1 및 X2가 표피 성장 인자 수용체 (EGFR); CD14; CD52; 다양한 면역 체크포인트 표적, 예컨대 비제한적으로 PD-L1, PD-1, TIM3, BTLA, LAG3 또는 CTLA4; CD20; CD47; GD-2; VEGFR1, VEGFR2; HER2; PDGFR; EpCAM; ICAM (ICAM-1, -2, -3, -4, -5), VCAM, FAPα; 5T4; Trop2; EDB-FN; TGFβ 트랩; MAdCam, β7 인테그린 서브유닛; α4β7 인테그린; α4 인테그린 SR-A1; SR-A3; SR-A4; SR-A5; SR-A6; SR-B; dSR-C1; SR-D1; SR-E1; SR-F1; SR-F2; SR-G; SR-H1; SR-H2; SR-I1; SR-J1; HIV, 또는 에볼라(Ebola)에 대해 특이적인 제1 모노클로날 항체로부터 수득되는 것인 이중 시토카인 융합 단백질.
- 제2항에 있어서, VL 및 VH가 항-HIV 또는 항-에볼라 항체인 제1 모노클로날 항체로부터 수득되는 것인 이중 시토카인 융합 단백질.
- 제4항에 있어서, 항-HIV 또는 항-에볼라 모노클로날 항체로부터의 VL 및 VH가 제2 항체로부터의 6개의 CDR이 인그라프팅된 (그로 치환된) 6개의 CDR을 포함하는 것인 이중 시토카인 융합 단백질.
- 제5항에 있어서, 제2 항체가 표피 성장 인자 수용체 (EGFR); CD14; CD52; 다양한 면역 체크포인트 표적, 예컨대 비제한적으로 PD-L1, PD-1, TIM3, BTLA, LAG3 또는 CTLA4; CD20; CD47;GD-2; VEGFR1; VEGFR2; HER2; PDGFR; EpCAM; ICAM (ICAM-1, -2, -3, -4, -5), VCAM, FAPα; 5T4; Trop2; EDB-FN; TGFβ 트랩; MAdCam, β7 인테그린 서브유닛; α4β7 인테그린; α4 인테그린 SR-A1; SR-A3; SR-A4; SR-A5; SR-A6; SR-B; dSR-C1; SR-D1; SR-E1; SR-F1; SR-F2; SR-G; SR-H1; SR-H2; SR-I1; 또는 SR-J1로부터 선택되는 모노클로날 항체인 이중 시토카인 융합 단백질.
- 제5항에 있어서, 제2 모노클로날 항체로부터의 6개의 인그라프팅된 CDR이 항-EGFR 항체, 항-HER2 항체, 항-VEGFR1 항체, 또는 항-VEGFR2 항체로부터의 6개의 CDR을 포함하고, 여기서, 6개의 CDR이 VL로부터의 CDR 1-3 및 VH로부터의 CDR 1-3을 포함하는 것인 이중 시토카인 융합 단백질.
- 제2항에 있어서, Z가 IL-6, IL-4, IL-1, IL-2, IL-3, IL-5, IL-7, IL-8, IL-9, IL-15, IL-21, IL-26, IL-27, IL-28, IL-29, GM-CSF, G-CSF, 인터페론-α, -β, -γ, TGF-β, 또는 종양 괴사 인자-α, -β, 염기성 FGF, EGF, PDGF, IL-4, IL-11, 또는 IL-13으로부터 선택되는 시토카인인 이중 시토카인 융합 단백질.
- 제2항에 있어서, Z가 IL-2, IL-4, 또는 IL-15인 이중 시토카인 융합 단백질.
- 제2항에 있어서, Z가 정수 1인 이중 시토카인 융합 단백질.
- 제2항에 있어서, 링커를 추가로 포함하는 이중 시토카인 융합 단백질.
- 제2항에 있어서, IL-10이 서열식별번호 3, 12, 14, 16인 이중 시토카인 융합 단백질.
- 제2항에 있어서, 이중 시토카인 융합 단백질이 서열식별번호 35, 46-58, 또는 59인 이중 시토카인 융합 단백질.
- 하기 화학식 (II)의 IL-10 융합 단백질:
NH2-(IL10)-(L)-(X1)-(L)-(Zn)-(L)-(X2)-(L)-(IL10)-COOH (화학식 II);
상기 식에서,
"IL-10"은 서열식별번호 1, 3, 9, 10, 11, 12, 14, 또는 16으로부터 선택되는 단량체 서열이고;
"L"은 서열식별번호 39, 40, 또는 41의 링커이고;
"X1"은 제1 모노클로날 항체로부터 수득된 VL 또는 VH 영역이고;
"X2"는 제1 모노클로날 항체로부터 수득된 VH 또는 VL 영역이고;
여기서, X1이 VL일 때, X2는 VH이거나, 또는 X1이 VH일 때, X2는 VL이고;
"Z"는 IL-6, IL-4, IL-1, IL-2, IL-3, IL-5, IL-7, IL-8, IL-9, IL-15, IL-21, IL-26, IL-27, IL-28, IL-29, GM-CSF, G-CSF, 인터페론-α, -β, -γ, TGF-β, 또는 종양 괴사 인자-α, -β, 염기성 FGF, EGF, PDGF, IL-4, IL-11, 또는 IL-13으로부터 선택되는 시토카인이고;
"n"은 0-2로부터 선택되는 정수이다. - 제14항에 있어서, VL 및 VH가 표피 성장 인자 수용체 (EGFR); CD14; CD52; 다양한 면역 체크포인트 표적, 예컨대 비제한적으로 PD-L1, PD-1, TIM3, BTLA, LAG3 또는 CTLA4; CD20; CD47;GD-2; VEGFR1; VEGFR2; HER2; PDGFR; EpCAM; ICAM (ICAM-1, -2, -3, -4, -5), VCAM, FAPα; 5T4; Trop2; EDB-FN; TGFβ 트랩; MAdCam, β7 인테그린 서브유닛; α4β7 인테그린; α4 인테그린 SR-A1; SR-A3; SR-A4; SR-A5; SR-A6; SR-B; dSR-C1; SR-D1; SR-E1; SR-F1; SR-F2; SR-G; SR-H1; SR-H2; SR-I1; SR-J1; HIV, 또는 에볼라에 대해 특이적인 제1 항체로부터 수득되는 것인 IL-10 융합 단백질.
- 제15항에 있어서, VL 및 VH가 HIV 또는 에볼라에 대해 특이적인 제1 항체로부터 수득되는 것인 IL-10 융합 단백질.
- 제16항에 있어서, 항-HIV 또는 항-에볼라로부터의 VL 및 VH가 제2 항체로부터의 6개의 CDR이 그라프팅된 (그로 치환된) 6개의 CDR을 포함하는 것인 IL-10 융합 단백질.
- 제17항에 있어서, 제2 항체가 표피 성장 인자 수용체 (EGFR); CD14; CD52; 다양한 면역 체크포인트 표적, 예컨대 비제한적으로 PD-L1, PD-1, TIM3, BTLA, LAG3 또는 CTLA4; CD20; CD47;GD-2; VEGFR1; VEGFR2; HER2; PDGFR; EpCAM; ICAM (ICAM-1, -2, -3, -4, -5), VCAM, FAPα; 5T4; Trop2; EDB-FN; TGFβ 트랩; MAdCam, β7 인테그린 서브유닛; α4β7 인테그린; α4 인테그린 SR-A1; SR-A3; SR-A4; SR-A5; SR-A6; SR-B; dSR-C1; SR-D1; SR-E1; SR-F1; SR-F2; SR-G; SR-H1; SR-H2; SR-I1; 또는 SR-J1로부터 선택되는 항체인 IL-10 융합 단백질.
- 제17항에 있어서, 제2 항체로부터의 6개의 인그라프팅된 CDR이 항-EGFR 항체로부터의 6개의 CDR을 포함하고, 여기서, 6개의 CDR이 VL로부터의 CDR 1-3 및 VH로부터의 CDR 1-3을 포함하는 것인 IL-10 융합 단백질.
- 제14항에 있어서, 융합 단백질이 서열식별번호 35, 46-58, 또는 59인 IL-10 융합 단백질.
- 암 치료를 필요로 하는 대상체에게 유효량의, 제1항, 제2항 및 제14항 중 어느 한 항에 따른 융합 단백질을 투여하는 단계를 포함하는, 암을 치료하는 방법.
- 제21항에 있어서, 융합 단백질이 항-HIV 또는 항-에볼라로부터 선택되는 제1 항체로부터의 VL 및 VH 영역을 포함하고, 여기서, 제1 항체의 6개의 CDR 영역은 항-EGFR 항체, 항-HER2 항체, 항-VEGFR1 항체, 또는 항-VEGFR2 항체로부터 선택되는 제2 항체로부터의 6개의 CDR 영역이 인그라프팅된 것인 방법.
- 제22항에 있어서, 제1 항체가 항-에볼라 항체이고, 제2 항체가 항-EGFR 항체, 항-HER2 항체, 항-VEGFR1 항체, 또는 항-VEGFR2 항체로부터 선택되는 것인 방법.
- 제21항에 있어서, 시토카인 또는 "Z"가 IL-2인 방법.
- 제24항에 있어서, "Z"의 "n" 값이 1인 방법.
- 제21항에 있어서, 융합 단백질이 0.01 ng/ml 내지 100 ng/ml로 투여되는 것인 방법.
- 제21항에 있어서, 융합 단백질이 0.01 ng/ml 내지 10 ng/ml로 투여되는 것인 방법.
- 제21항에 있어서, 융합 단백질이 서열식별번호 35 52-54, 또는 55인 방법.
- 염증성 질환 치료를 필요로 하는 대상체에게 유효량의 제1항, 제2항 및 제14항 중 어느 한 항에 따른 융합 단백질을 투여하는 단계를 포함하는, 염증성 질환을 치료하는 방법.
- 제29항에 있어서, 융합 단백질이 항-HIV 또는 항-에볼라로부터 선택되는 제1 항체로부터의 VL 및 VH 영역을 포함하고, 여기서, 제1 항체의 6개의 CDR 영역은 항-CD14 항체, 항-MAdCam 항체, 항-VEGFR1, 또는 항-VEGFR2 항체로부터의 6개의 CDR 영역이 인그라프팅된 것인 방법.
- 제29항 또는 제30항에 있어서, 시토카인 "Z"가 IL-4인 방법.
- 제29항에 있어서, "Z"의 "n" 값이 1인 방법.
- 제29항에 있어서, 융합 단백질이 0.01 ng/ml 내지 100 ng/ml로 투여되는 것인 방법.
- 제29항에 있어서, 염증성 질환이 패혈증, 크론병, 류마티스 관절염, 건선, 및/또는 염증성 장 질환 (IBD)인 방법.
- 제34항에 있어서, IL-10 단량체가 서열식별번호 14의 DV06인 방법.
- 제29항에 있어서, 융합 단백질이 항-에볼라 항체로부터 선택되는 제1 항체로부터의 VL 및 VH 영역을 포함하고, 여기서, 제1 항체의 6개의 CDR 영역은 항-CD14 항체, 항-MAdCAM 항체, 항-VEGFR1 항체, 또는 항-VEGFR2 항체로부터 선택되는 제2 항체로부터의 6개의 CDR 영역이 인그라프팅된 것인 방법.
- 제34항에 있어서, IL-10 단량체가 서열식별번호 16의 DV07인 방법.
- 제29항에 있어서, 융합 단백질이 서열식별번호 46-51, 56-58, 또는 59의 단백질인 방법.
- 패혈증, 패혈성 쇼크, 및/또는 그와 연관된 증상 치료를 필요로 하는 대상체에게 유효량의, 제1항, 제2항 및 제14항 중 어느 한 항에 따른 융합 단백질을 투여하는 단계를 포함하는, 패혈증, 패혈성 쇼크, 및/또는 그와 연관된 증상을 치료하는 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063054208P | 2020-07-20 | 2020-07-20 | |
| US63/054,208 | 2020-07-20 | ||
| PCT/US2020/062907 WO2022019945A1 (en) | 2020-07-20 | 2020-12-02 | Dual cytokine fusion proteins comprising il-10 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230096959A true KR20230096959A (ko) | 2023-06-30 |
Family
ID=79291996
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237005848A KR20230096959A (ko) | 2020-07-20 | 2020-12-02 | Il-10을 포함하는 이중 시토카인 융합 단백질 |
Country Status (11)
| Country | Link |
|---|---|
| US (18) | US11292822B2 (ko) |
| EP (1) | EP4181957A1 (ko) |
| JP (1) | JP2023534847A (ko) |
| KR (1) | KR20230096959A (ko) |
| CN (1) | CN116322785A (ko) |
| AU (1) | AU2020459746A1 (ko) |
| BR (1) | BR112023001187A2 (ko) |
| CA (1) | CA3186753A1 (ko) |
| IL (1) | IL300062A (ko) |
| MX (1) | MX2023000948A (ko) |
| WO (1) | WO2022019945A1 (ko) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116322785A (zh) * | 2020-07-20 | 2023-06-23 | 德卡生物科学公司 | 包含il-10的双细胞因子融合蛋白 |
| WO2023115033A2 (en) * | 2021-12-16 | 2023-06-22 | Deka Biosciences, Inc. | Use of dual cytokine fusion proteins comprising il-10 and adoptive cell therapies or bispecific t-cell engagers to treat cancer |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| MXPA02001417A (es) * | 1999-08-09 | 2002-08-12 | Lexigen Pharm Corp | Complejos multiples de citosina-anticuerpo. |
| AU2003265866A1 (en) * | 2002-09-03 | 2004-03-29 | Vit Lauermann | Targeted release |
| ES2606490T3 (es) | 2006-05-08 | 2017-03-24 | Philogen S.P.A. | Citocinas dirigidas por anticuerpos para terapia |
| US8920808B2 (en) | 2006-10-31 | 2014-12-30 | East Carolina University | Cytokine-based fusion proteins for treatment of multiple sclerosis |
| EP3783019A1 (en) | 2007-10-30 | 2021-02-24 | Philogen S.p.A. | An antigen associated with rheumatoid arthritis |
| US9249225B2 (en) * | 2010-05-26 | 2016-02-02 | Regents Of The University Of Minnesota | Single chain variable fragment anti-CD133 antibodies and uses thereof |
| WO2014023673A1 (en) | 2012-08-08 | 2014-02-13 | Roche Glycart Ag | Interleukin-10 fusion proteins and uses thereof |
| BR112015023212A2 (pt) | 2013-03-14 | 2017-11-21 | Gill Parkash | tratamento do câncer utilizando anticorpos que se ligam à grp78 da superfície celular |
| BR112016016658A2 (pt) | 2014-02-06 | 2018-01-23 | F. Hoffmann-La Roche Ag | proteína de fusão de um anticorpo, polinucleotídeo, vetor, célula hospedeira, composição farmacêutica, métodos para produzir uma proteína de fusão e de tratamento de uma doença em um indivíduo e uso da proteína de fusão |
| CA2949081C (en) | 2014-05-16 | 2023-03-07 | Baylor Research Institute | Methods and compositions for treating autoimmune and inflammatory conditions |
| EP3625253A4 (en) * | 2017-05-16 | 2021-03-24 | Scalmibio, Inc. | ACTIVABLE ANTIBODIES AND THEIR METHODS OF USE |
| WO2019201866A1 (en) * | 2018-04-16 | 2019-10-24 | Swedish Orphan Biovitrum Ab (Publ) | Fusion protein |
| EP3934681A4 (en) * | 2019-03-06 | 2023-12-20 | Deka Biosciences, Inc. | IL-10 VARIANT MOLECULES AND METHODS OF TREATMENT OF INFLAMMATORY DISEASE AND ONCOLOGY |
| KR20230034928A (ko) * | 2020-01-09 | 2023-03-10 | 데카 바이오사이언시즈, 인크. | 유전자 마커, snp 및/또는 indel을 사용하여 il-10 치료에 대한 반응성을 결정하는 방법 |
| CN116322785A (zh) * | 2020-07-20 | 2023-06-23 | 德卡生物科学公司 | 包含il-10的双细胞因子融合蛋白 |
| US20230287075A1 (en) * | 2021-12-13 | 2023-09-14 | Deka Biosciences, Inc. | Dual cytokine fusion proteins comprising multi-subunit cytokines |
| WO2023115033A2 (en) * | 2021-12-16 | 2023-06-22 | Deka Biosciences, Inc. | Use of dual cytokine fusion proteins comprising il-10 and adoptive cell therapies or bispecific t-cell engagers to treat cancer |
| WO2023164503A2 (en) * | 2022-02-22 | 2023-08-31 | Deka Biosciences, Inc. | Method of reducing bispecific t cell engager or chimeric antigen receptor t cell mediated cytokine release syndrome using interleukins-4, -10, or a fusion protein thereof |
-
2020
- 2020-12-02 CN CN202080105253.9A patent/CN116322785A/zh active Pending
- 2020-12-02 AU AU2020459746A patent/AU2020459746A1/en active Pending
- 2020-12-02 MX MX2023000948A patent/MX2023000948A/es unknown
- 2020-12-02 WO PCT/US2020/062907 patent/WO2022019945A1/en unknown
- 2020-12-02 JP JP2023504420A patent/JP2023534847A/ja active Pending
- 2020-12-02 KR KR1020237005848A patent/KR20230096959A/ko unknown
- 2020-12-02 BR BR112023001187A patent/BR112023001187A2/pt unknown
- 2020-12-02 CA CA3186753A patent/CA3186753A1/en active Pending
- 2020-12-02 EP EP20946024.5A patent/EP4181957A1/en active Pending
- 2020-12-02 IL IL300062A patent/IL300062A/en unknown
-
2021
- 2021-03-11 US US17/199,239 patent/US11292822B2/en active Active
-
2022
- 2022-03-01 US US17/684,205 patent/US11608368B2/en active Active
- 2022-03-01 US US17/684,290 patent/US20220380428A1/en active Pending
- 2022-03-01 US US17/684,151 patent/US11613563B2/en active Active
- 2022-03-01 US US17/684,106 patent/US11572397B2/en active Active
- 2022-03-01 US US17/684,272 patent/US11618775B2/en active Active
- 2022-03-01 US US17/684,229 patent/US20220380427A1/en active Pending
- 2022-03-01 US US17/684,243 patent/US11629178B2/en active Active
-
2023
- 2023-11-03 US US18/501,581 patent/US20240076336A1/en active Pending
- 2023-11-03 US US18/501,856 patent/US20240076337A1/en active Pending
- 2023-11-03 US US18/501,762 patent/US20240059750A1/en active Pending
- 2023-11-03 US US18/501,584 patent/US20240059748A1/en active Pending
- 2023-11-03 US US18/501,741 patent/US20240059749A1/en active Pending
- 2023-11-03 US US18/501,850 patent/US20240067688A1/en active Pending
- 2023-11-03 US US18/501,914 patent/US20240076339A1/en active Pending
- 2023-11-03 US US18/501,561 patent/US20240076335A1/en active Pending
- 2023-11-03 US US18/501,571 patent/US20240067687A1/en active Pending
- 2023-11-03 US US18/501,884 patent/US20240076338A1/en active Pending
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10975134B2 (en) | Antibody-IL-10 fusion proteins | |
| US20240076337A1 (en) | Dual cytokine fusion proteins comprising il-10 | |
| JP2023538518A (ja) | IL10Rb結合分子および使用方法 |