KR20230058074A - Ilt2에 대한 항체 및 이의 용도 - Google Patents
Ilt2에 대한 항체 및 이의 용도 Download PDFInfo
- Publication number
- KR20230058074A KR20230058074A KR1020237008527A KR20237008527A KR20230058074A KR 20230058074 A KR20230058074 A KR 20230058074A KR 1020237008527 A KR1020237008527 A KR 1020237008527A KR 20237008527 A KR20237008527 A KR 20237008527A KR 20230058074 A KR20230058074 A KR 20230058074A
- Authority
- KR
- South Korea
- Prior art keywords
- antibody
- seq
- ilt2
- ser
- leu
- Prior art date
Links
- 108010017736 Leukocyte Immunoglobulin-like Receptor B1 Proteins 0.000 title claims description 382
- 102000004569 Leukocyte Immunoglobulin-like Receptor B1 Human genes 0.000 title claims description 18
- 230000027455 binding Effects 0.000 claims abstract description 287
- 239000000427 antigen Substances 0.000 claims abstract description 235
- 102000036639 antigens Human genes 0.000 claims abstract description 235
- 108091007433 antigens Proteins 0.000 claims abstract description 235
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 219
- 239000012634 fragment Substances 0.000 claims abstract description 192
- 201000011510 cancer Diseases 0.000 claims abstract description 160
- 238000000034 method Methods 0.000 claims abstract description 117
- 239000008194 pharmaceutical composition Substances 0.000 claims abstract description 23
- 210000004027 cell Anatomy 0.000 claims description 201
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 148
- 239000003795 chemical substances by application Substances 0.000 claims description 114
- 108010024164 HLA-G Antigens Proteins 0.000 claims description 95
- 230000001965 increasing effect Effects 0.000 claims description 88
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 86
- 102100028967 HLA class I histocompatibility antigen, alpha chain G Human genes 0.000 claims description 83
- 230000014509 gene expression Effects 0.000 claims description 79
- 210000002540 macrophage Anatomy 0.000 claims description 76
- 230000000694 effects Effects 0.000 claims description 73
- 241000282414 Homo sapiens Species 0.000 claims description 71
- 206010057249 Phagocytosis Diseases 0.000 claims description 62
- 230000008782 phagocytosis Effects 0.000 claims description 62
- 230000003993 interaction Effects 0.000 claims description 54
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 54
- 108010081355 beta 2-Microglobulin Proteins 0.000 claims description 53
- 102000015736 beta 2-Microglobulin Human genes 0.000 claims description 53
- 210000004443 dendritic cell Anatomy 0.000 claims description 53
- 238000002560 therapeutic procedure Methods 0.000 claims description 48
- 210000000822 natural killer cell Anatomy 0.000 claims description 46
- 238000011282 treatment Methods 0.000 claims description 43
- 150000007523 nucleic acids Chemical class 0.000 claims description 41
- 230000035772 mutation Effects 0.000 claims description 36
- 229920001184 polypeptide Polymers 0.000 claims description 32
- 230000003013 cytotoxicity Effects 0.000 claims description 31
- 231100000135 cytotoxicity Toxicity 0.000 claims description 31
- 238000004519 manufacturing process Methods 0.000 claims description 30
- 230000003571 opsonizing effect Effects 0.000 claims description 23
- 101000984190 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily B member 1 Proteins 0.000 claims description 21
- 230000002757 inflammatory effect Effects 0.000 claims description 19
- 102000054957 human LILRB1 Human genes 0.000 claims description 17
- 108090000623 proteins and genes Proteins 0.000 claims description 16
- 238000009169 immunotherapy Methods 0.000 claims description 14
- 102000039446 nucleic acids Human genes 0.000 claims description 14
- 108020004707 nucleic acids Proteins 0.000 claims description 14
- 102000004169 proteins and genes Human genes 0.000 claims description 14
- 230000002401 inhibitory effect Effects 0.000 claims description 10
- 230000005867 T cell response Effects 0.000 claims description 7
- 230000005764 inhibitory process Effects 0.000 claims description 7
- 229960002621 pembrolizumab Drugs 0.000 claims description 7
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 7
- 230000020411 cell activation Effects 0.000 claims description 6
- 229960005395 cetuximab Drugs 0.000 claims description 6
- 239000003814 drug Substances 0.000 claims description 6
- 230000002829 reductive effect Effects 0.000 claims description 6
- 230000006052 T cell proliferation Effects 0.000 claims description 5
- 229940121647 egfr inhibitor Drugs 0.000 claims description 5
- 230000001939 inductive effect Effects 0.000 claims description 5
- 230000000259 anti-tumor effect Effects 0.000 claims description 4
- 239000002773 nucleotide Substances 0.000 claims description 4
- 125000003729 nucleotide group Chemical group 0.000 claims description 4
- 238000012258 culturing Methods 0.000 claims description 3
- 239000013604 expression vector Substances 0.000 claims description 2
- 230000006698 induction Effects 0.000 claims 1
- 239000000203 mixture Substances 0.000 abstract description 25
- 238000002360 preparation method Methods 0.000 abstract description 4
- 238000010187 selection method Methods 0.000 abstract description 3
- 102100025584 Leukocyte immunoglobulin-like receptor subfamily B member 1 Human genes 0.000 description 372
- 210000001744 T-lymphocyte Anatomy 0.000 description 61
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 50
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 50
- 210000002865 immune cell Anatomy 0.000 description 47
- 102000008096 B7-H1 Antigen Human genes 0.000 description 36
- 108010074708 B7-H1 Antigen Proteins 0.000 description 36
- 108091054437 MHC class I family Proteins 0.000 description 35
- 102000043129 MHC class I family Human genes 0.000 description 35
- 230000000903 blocking effect Effects 0.000 description 35
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 34
- 230000028327 secretion Effects 0.000 description 34
- 241000699670 Mus sp. Species 0.000 description 29
- 108091028043 Nucleic acid sequence Proteins 0.000 description 27
- 230000008629 immune suppression Effects 0.000 description 26
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 25
- 230000001404 mediated effect Effects 0.000 description 24
- 210000004881 tumor cell Anatomy 0.000 description 21
- 235000001014 amino acid Nutrition 0.000 description 20
- 210000001616 monocyte Anatomy 0.000 description 19
- 238000012360 testing method Methods 0.000 description 19
- 238000003556 assay Methods 0.000 description 18
- 241000880493 Leptailurus serval Species 0.000 description 17
- 150000001413 amino acids Chemical class 0.000 description 17
- 231100000673 dose–response relationship Toxicity 0.000 description 17
- 102000040430 polynucleotide Human genes 0.000 description 17
- 108091033319 polynucleotide Proteins 0.000 description 17
- 239000002157 polynucleotide Substances 0.000 description 17
- 102000004127 Cytokines Human genes 0.000 description 16
- 108090000695 Cytokines Proteins 0.000 description 16
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 16
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 16
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 16
- 108010073969 valyllysine Proteins 0.000 description 16
- 108010061238 threonyl-glycine Proteins 0.000 description 15
- BVLIJXXSXBUGEC-SRVKXCTJSA-N Asn-Asn-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BVLIJXXSXBUGEC-SRVKXCTJSA-N 0.000 description 14
- 108060003951 Immunoglobulin Proteins 0.000 description 14
- 210000003690 classically activated macrophage Anatomy 0.000 description 14
- 108010050848 glycylleucine Proteins 0.000 description 14
- 102000018358 immunoglobulin Human genes 0.000 description 14
- 108010051242 phenylalanylserine Proteins 0.000 description 14
- 230000000770 proinflammatory effect Effects 0.000 description 14
- DNAZKGFYFRGZIH-QWRGUYRKSA-N Gly-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 DNAZKGFYFRGZIH-QWRGUYRKSA-N 0.000 description 13
- 210000004322 M2 macrophage Anatomy 0.000 description 13
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 13
- 108010068265 aspartyltyrosine Proteins 0.000 description 13
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 13
- 239000013641 positive control Substances 0.000 description 13
- 108010031719 prolyl-serine Proteins 0.000 description 13
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 12
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 12
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 12
- 241000699666 Mus <mouse, genus> Species 0.000 description 12
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 12
- 108010003137 tyrosyltyrosine Proteins 0.000 description 12
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 11
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 11
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 11
- 108010092854 aspartyllysine Proteins 0.000 description 11
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 11
- 235000018102 proteins Nutrition 0.000 description 11
- 230000004044 response Effects 0.000 description 11
- 102100025137 Early activation antigen CD69 Human genes 0.000 description 10
- 101000934374 Homo sapiens Early activation antigen CD69 Proteins 0.000 description 10
- 208000008839 Kidney Neoplasms Diseases 0.000 description 10
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 10
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 10
- 102000009571 Macrophage Inflammatory Proteins Human genes 0.000 description 10
- 108010009474 Macrophage Inflammatory Proteins Proteins 0.000 description 10
- 241001529936 Murinae Species 0.000 description 10
- 206010038389 Renal cancer Diseases 0.000 description 10
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 10
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 10
- 108010087924 alanylproline Proteins 0.000 description 10
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 10
- 230000009918 complex formation Effects 0.000 description 10
- 238000000684 flow cytometry Methods 0.000 description 10
- 238000009472 formulation Methods 0.000 description 10
- 108010078144 glutaminyl-glycine Proteins 0.000 description 10
- 108010064235 lysylglycine Proteins 0.000 description 10
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 9
- QPTAGIPWARILES-AVGNSLFASA-N Asn-Gln-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QPTAGIPWARILES-AVGNSLFASA-N 0.000 description 9
- GMUOCGCDOYYWPD-FXQIFTODSA-N Asn-Pro-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O GMUOCGCDOYYWPD-FXQIFTODSA-N 0.000 description 9
- UPAGTDJAORYMEC-VHWLVUOQSA-N Asn-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)N)N UPAGTDJAORYMEC-VHWLVUOQSA-N 0.000 description 9
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 9
- MFDPBZAFCRKYEY-LAEOZQHASA-N Asp-Val-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MFDPBZAFCRKYEY-LAEOZQHASA-N 0.000 description 9
- 108020004414 DNA Proteins 0.000 description 9
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 9
- WLRJHVNFGAOYPS-HJPIBITLSA-N Ile-Ser-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N WLRJHVNFGAOYPS-HJPIBITLSA-N 0.000 description 9
- WCNWGAUZWWSYDG-SVSWQMSJSA-N Ile-Thr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)O)N WCNWGAUZWWSYDG-SVSWQMSJSA-N 0.000 description 9
- 108010002350 Interleukin-2 Proteins 0.000 description 9
- 102000000588 Interleukin-2 Human genes 0.000 description 9
- DPWGZWUMUUJQDT-IUCAKERBSA-N Leu-Gln-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O DPWGZWUMUUJQDT-IUCAKERBSA-N 0.000 description 9
- BGZCJDGBBUUBHA-KKUMJFAQSA-N Leu-Lys-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O BGZCJDGBBUUBHA-KKUMJFAQSA-N 0.000 description 9
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 9
- DNEJSAIMVANNPA-DCAQKATOSA-N Lys-Asn-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DNEJSAIMVANNPA-DCAQKATOSA-N 0.000 description 9
- BCRQJDMZQUHQSV-STQMWFEESA-N Met-Gly-Tyr Chemical compound [H]N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BCRQJDMZQUHQSV-STQMWFEESA-N 0.000 description 9
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 9
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 9
- IQPWNQRRAJHOKV-KATARQTJSA-N Thr-Ser-Lys Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN IQPWNQRRAJHOKV-KATARQTJSA-N 0.000 description 9
- 102000004142 Trypsin Human genes 0.000 description 9
- 108090000631 Trypsin Proteins 0.000 description 9
- FZADUTOCSFDBRV-RNXOBYDBSA-N Tyr-Tyr-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=C(O)C=C1 FZADUTOCSFDBRV-RNXOBYDBSA-N 0.000 description 9
- 108010047857 aspartylglycine Proteins 0.000 description 9
- 210000004369 blood Anatomy 0.000 description 9
- 239000008280 blood Substances 0.000 description 9
- 201000010099 disease Diseases 0.000 description 9
- 230000006870 function Effects 0.000 description 9
- 238000001727 in vivo Methods 0.000 description 9
- 201000010982 kidney cancer Diseases 0.000 description 9
- 239000003446 ligand Substances 0.000 description 9
- 210000004072 lung Anatomy 0.000 description 9
- 238000010186 staining Methods 0.000 description 9
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 9
- 239000012588 trypsin Substances 0.000 description 9
- OKEWAFFWMHBGPT-XPUUQOCRSA-N Ala-His-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CN=CN1 OKEWAFFWMHBGPT-XPUUQOCRSA-N 0.000 description 8
- LLZXKVAAEWBUPB-KKUMJFAQSA-N Arg-Gln-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LLZXKVAAEWBUPB-KKUMJFAQSA-N 0.000 description 8
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 8
- 101001023379 Homo sapiens Lysosome-associated membrane glycoprotein 1 Proteins 0.000 description 8
- HJDZMPFEXINXLO-QPHKQPEJSA-N Ile-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N HJDZMPFEXINXLO-QPHKQPEJSA-N 0.000 description 8
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 8
- 102100035133 Lysosome-associated membrane glycoprotein 1 Human genes 0.000 description 8
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 8
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 8
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 8
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 8
- MDXLPNRXCFOBTL-BZSNNMDCSA-N Tyr-Ser-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MDXLPNRXCFOBTL-BZSNNMDCSA-N 0.000 description 8
- 230000004913 activation Effects 0.000 description 8
- 238000004458 analytical method Methods 0.000 description 8
- 230000000875 corresponding effect Effects 0.000 description 8
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 8
- 108010087823 glycyltyrosine Proteins 0.000 description 8
- 210000004408 hybridoma Anatomy 0.000 description 8
- 108010054155 lysyllysine Proteins 0.000 description 8
- 239000000463 material Substances 0.000 description 8
- 239000012528 membrane Substances 0.000 description 8
- 108010077112 prolyl-proline Proteins 0.000 description 8
- 230000002195 synergetic effect Effects 0.000 description 8
- NCXTYSVDWLAQGZ-ZKWXMUAHSA-N Asn-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O NCXTYSVDWLAQGZ-ZKWXMUAHSA-N 0.000 description 7
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 7
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 7
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 7
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 7
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 7
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 7
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 7
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 7
- 229960002685 biotin Drugs 0.000 description 7
- 239000011616 biotin Substances 0.000 description 7
- 238000011284 combination treatment Methods 0.000 description 7
- 230000003247 decreasing effect Effects 0.000 description 7
- 201000004101 esophageal cancer Diseases 0.000 description 7
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 7
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 7
- 201000001441 melanoma Diseases 0.000 description 7
- 238000006467 substitution reaction Methods 0.000 description 7
- 230000001225 therapeutic effect Effects 0.000 description 7
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 6
- 238000002965 ELISA Methods 0.000 description 6
- AQPZYBSRDRZBAG-AVGNSLFASA-N Gln-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N AQPZYBSRDRZBAG-AVGNSLFASA-N 0.000 description 6
- 108010065920 Insulin Lispro Proteins 0.000 description 6
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 6
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 6
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 6
- 241001465754 Metazoa Species 0.000 description 6
- JDMKQHSHKJHAHR-UHFFFAOYSA-N Phe-Phe-Leu-Tyr Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)CC1=CC=CC=C1 JDMKQHSHKJHAHR-UHFFFAOYSA-N 0.000 description 6
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 6
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 6
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 6
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 6
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 6
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 6
- 125000000539 amino acid group Chemical group 0.000 description 6
- 230000001093 anti-cancer Effects 0.000 description 6
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 6
- 239000000872 buffer Substances 0.000 description 6
- 230000001419 dependent effect Effects 0.000 description 6
- 239000012636 effector Substances 0.000 description 6
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 6
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 6
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 6
- 208000014829 head and neck neoplasm Diseases 0.000 description 6
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 6
- 208000020816 lung neoplasm Diseases 0.000 description 6
- 230000004048 modification Effects 0.000 description 6
- 238000012986 modification Methods 0.000 description 6
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 6
- 210000004981 tumor-associated macrophage Anatomy 0.000 description 6
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 6
- 108010051110 tyrosyl-lysine Proteins 0.000 description 6
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 5
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 5
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 5
- WQLJRNRLHWJIRW-KKUMJFAQSA-N Asn-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N)O WQLJRNRLHWJIRW-KKUMJFAQSA-N 0.000 description 5
- NYGILGUOUOXGMJ-YUMQZZPRSA-N Asn-Lys-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O NYGILGUOUOXGMJ-YUMQZZPRSA-N 0.000 description 5
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 5
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 5
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 5
- 108020004705 Codon Proteins 0.000 description 5
- 206010009944 Colon cancer Diseases 0.000 description 5
- SMEYEQDCCBHTEF-FXQIFTODSA-N Cys-Pro-Ala Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O SMEYEQDCCBHTEF-FXQIFTODSA-N 0.000 description 5
- ALTQTAKGRFLRLR-GUBZILKMSA-N Cys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N ALTQTAKGRFLRLR-GUBZILKMSA-N 0.000 description 5
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 5
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 5
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 5
- YHOJJFFTSMWVGR-HJGDQZAQSA-N Glu-Met-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YHOJJFFTSMWVGR-HJGDQZAQSA-N 0.000 description 5
- AAJHGGDRKHYSDH-GUBZILKMSA-N Glu-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O AAJHGGDRKHYSDH-GUBZILKMSA-N 0.000 description 5
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 5
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 5
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 5
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 5
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 5
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 5
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 5
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 5
- WSXTWLJHTLRFLW-SRVKXCTJSA-N Lys-Ala-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O WSXTWLJHTLRFLW-SRVKXCTJSA-N 0.000 description 5
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 5
- 102000007651 Macrophage Colony-Stimulating Factor Human genes 0.000 description 5
- 108010046938 Macrophage Colony-Stimulating Factor Proteins 0.000 description 5
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 5
- 101001043827 Mus musculus Interleukin-2 Proteins 0.000 description 5
- 108010079364 N-glycylalanine Proteins 0.000 description 5
- HQVPQXMCQKXARZ-FXQIFTODSA-N Pro-Cys-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O HQVPQXMCQKXARZ-FXQIFTODSA-N 0.000 description 5
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 5
- UEJYSALTSUZXFV-SRVKXCTJSA-N Rigin Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O UEJYSALTSUZXFV-SRVKXCTJSA-N 0.000 description 5
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 5
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 5
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 5
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 5
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 5
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 5
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 5
- 208000005718 Stomach Neoplasms Diseases 0.000 description 5
- 230000006044 T cell activation Effects 0.000 description 5
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 5
- LAFLAXHTDVNVEL-WDCWCFNPSA-N Thr-Gln-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O LAFLAXHTDVNVEL-WDCWCFNPSA-N 0.000 description 5
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 5
- SSSDKJMQMZTMJP-BVSLBCMMSA-N Trp-Tyr-Val Chemical compound C([C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CC=C(O)C=C1 SSSDKJMQMZTMJP-BVSLBCMMSA-N 0.000 description 5
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 5
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 5
- BGTDGENDNWGMDQ-KJEVXHAQSA-N Val-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N)O BGTDGENDNWGMDQ-KJEVXHAQSA-N 0.000 description 5
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 5
- 230000035508 accumulation Effects 0.000 description 5
- 238000009825 accumulation Methods 0.000 description 5
- 230000000996 additive effect Effects 0.000 description 5
- 238000002648 combination therapy Methods 0.000 description 5
- 238000012217 deletion Methods 0.000 description 5
- 230000037430 deletion Effects 0.000 description 5
- 239000003937 drug carrier Substances 0.000 description 5
- 230000002708 enhancing effect Effects 0.000 description 5
- 229940082789 erbitux Drugs 0.000 description 5
- 238000002474 experimental method Methods 0.000 description 5
- 206010017758 gastric cancer Diseases 0.000 description 5
- 108010049041 glutamylalanine Proteins 0.000 description 5
- 108010077515 glycylproline Proteins 0.000 description 5
- 108010037850 glycylvaline Proteins 0.000 description 5
- 201000010536 head and neck cancer Diseases 0.000 description 5
- 238000011534 incubation Methods 0.000 description 5
- 210000004698 lymphocyte Anatomy 0.000 description 5
- 238000013507 mapping Methods 0.000 description 5
- 210000005259 peripheral blood Anatomy 0.000 description 5
- 239000011886 peripheral blood Substances 0.000 description 5
- 108010070643 prolylglutamic acid Proteins 0.000 description 5
- 238000012216 screening Methods 0.000 description 5
- 238000009097 single-agent therapy Methods 0.000 description 5
- 201000011549 stomach cancer Diseases 0.000 description 5
- 230000001629 suppression Effects 0.000 description 5
- 210000001519 tissue Anatomy 0.000 description 5
- 108700004896 tripeptide FEG Proteins 0.000 description 5
- 108010044292 tryptophyltyrosine Proteins 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 4
- VHEVVUZDDUCAKU-FXQIFTODSA-N Ala-Met-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O VHEVVUZDDUCAKU-FXQIFTODSA-N 0.000 description 4
- QQJSJIBESHAJPM-IHRRRGAJSA-N Arg-Cys-Tyr Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QQJSJIBESHAJPM-IHRRRGAJSA-N 0.000 description 4
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 4
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 4
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 4
- OHLLDUNVMPPUMD-DCAQKATOSA-N Cys-Leu-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N OHLLDUNVMPPUMD-DCAQKATOSA-N 0.000 description 4
- KSMSFCBQBQPFAD-GUBZILKMSA-N Cys-Pro-Pro Chemical compound SC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 KSMSFCBQBQPFAD-GUBZILKMSA-N 0.000 description 4
- JILRMFFFCHUUTJ-ACZMJKKPSA-N Gln-Ser-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O JILRMFFFCHUUTJ-ACZMJKKPSA-N 0.000 description 4
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 4
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 4
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 4
- GLYJPWIRLBAIJH-UHFFFAOYSA-N Ile-Lys-Pro Natural products CCC(C)C(N)C(=O)NC(CCCCN)C(=O)N1CCCC1C(O)=O GLYJPWIRLBAIJH-UHFFFAOYSA-N 0.000 description 4
- 108090001005 Interleukin-6 Proteins 0.000 description 4
- 102000004889 Interleukin-6 Human genes 0.000 description 4
- -1 K250 Substances 0.000 description 4
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 4
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 4
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 4
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 4
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 4
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 4
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 4
- UZVWDRPUTHXQAM-FXQIFTODSA-N Met-Asp-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O UZVWDRPUTHXQAM-FXQIFTODSA-N 0.000 description 4
- 206010027476 Metastases Diseases 0.000 description 4
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 4
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 4
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 4
- SJRQWEDYTKYHHL-SLFFLAALSA-N Phe-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O SJRQWEDYTKYHHL-SLFFLAALSA-N 0.000 description 4
- 239000004698 Polyethylene Substances 0.000 description 4
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 4
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 4
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 4
- 108010076504 Protein Sorting Signals Proteins 0.000 description 4
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 4
- GHPQVUYZQQGEDA-BIIVOSGPSA-N Ser-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N)C(=O)O GHPQVUYZQQGEDA-BIIVOSGPSA-N 0.000 description 4
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 4
- ZOPISOXXPQNOCO-SVSWQMSJSA-N Ser-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CO)N ZOPISOXXPQNOCO-SVSWQMSJSA-N 0.000 description 4
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 4
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 4
- OQSQCUWQOIHECT-YJRXYDGGSA-N Ser-Tyr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OQSQCUWQOIHECT-YJRXYDGGSA-N 0.000 description 4
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 4
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 4
- QOIKZODVIPOPDD-AVGNSLFASA-N Tyr-Cys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOIKZODVIPOPDD-AVGNSLFASA-N 0.000 description 4
- RMRFSFXLFWWAJZ-HJOGWXRNSA-N Tyr-Tyr-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 RMRFSFXLFWWAJZ-HJOGWXRNSA-N 0.000 description 4
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 4
- 239000004480 active ingredient Substances 0.000 description 4
- 239000013543 active substance Substances 0.000 description 4
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 4
- 108010005233 alanylglutamic acid Proteins 0.000 description 4
- 108010047495 alanylglycine Proteins 0.000 description 4
- 239000005557 antagonist Substances 0.000 description 4
- 230000005888 antibody-dependent cellular phagocytosis Effects 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 235000018417 cysteine Nutrition 0.000 description 4
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 4
- 230000029087 digestion Effects 0.000 description 4
- 239000000539 dimer Substances 0.000 description 4
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 4
- 208000035475 disorder Diseases 0.000 description 4
- 238000009826 distribution Methods 0.000 description 4
- 239000002158 endotoxin Substances 0.000 description 4
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 4
- 235000013922 glutamic acid Nutrition 0.000 description 4
- 239000004220 glutamic acid Substances 0.000 description 4
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 4
- 230000028993 immune response Effects 0.000 description 4
- 238000003364 immunohistochemistry Methods 0.000 description 4
- 230000001506 immunosuppresive effect Effects 0.000 description 4
- 239000004615 ingredient Substances 0.000 description 4
- 230000002601 intratumoral effect Effects 0.000 description 4
- 238000001990 intravenous administration Methods 0.000 description 4
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 4
- 238000002372 labelling Methods 0.000 description 4
- 230000000670 limiting effect Effects 0.000 description 4
- 201000005202 lung cancer Diseases 0.000 description 4
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 4
- 239000003550 marker Substances 0.000 description 4
- 230000009401 metastasis Effects 0.000 description 4
- 231100000252 nontoxic Toxicity 0.000 description 4
- 230000003000 nontoxic effect Effects 0.000 description 4
- 201000002528 pancreatic cancer Diseases 0.000 description 4
- 208000008443 pancreatic carcinoma Diseases 0.000 description 4
- 239000002953 phosphate buffered saline Substances 0.000 description 4
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 4
- 108010026333 seryl-proline Proteins 0.000 description 4
- 230000011664 signaling Effects 0.000 description 4
- 239000007787 solid Substances 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- 239000002904 solvent Substances 0.000 description 4
- 230000009870 specific binding Effects 0.000 description 4
- 239000000126 substance Substances 0.000 description 4
- 108010029599 tyrosyl-glutamyl-tryptophan Proteins 0.000 description 4
- COEXAQSTZUWMRI-STQMWFEESA-N (2s)-1-[2-[[(2s)-2-amino-3-(4-hydroxyphenyl)propanoyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound C([C@H](N)C(=O)NCC(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=C(O)C=C1 COEXAQSTZUWMRI-STQMWFEESA-N 0.000 description 3
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 3
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 3
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 3
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 3
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 3
- OLGCWMNDJTWQAG-GUBZILKMSA-N Asn-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(N)=O OLGCWMNDJTWQAG-GUBZILKMSA-N 0.000 description 3
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 3
- HDHZCEDPLTVHFZ-GUBZILKMSA-N Asn-Leu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O HDHZCEDPLTVHFZ-GUBZILKMSA-N 0.000 description 3
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 3
- ODNWIBOCFGMRTP-SRVKXCTJSA-N Asp-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CN=CN1 ODNWIBOCFGMRTP-SRVKXCTJSA-N 0.000 description 3
- KTTCQQNRRLCIBC-GHCJXIJMSA-N Asp-Ile-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O KTTCQQNRRLCIBC-GHCJXIJMSA-N 0.000 description 3
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 3
- WMLFFCRUSPNENW-ZLUOBGJFSA-N Asp-Ser-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O WMLFFCRUSPNENW-ZLUOBGJFSA-N 0.000 description 3
- YUELDQUPTAYEGM-XIRDDKMYSA-N Asp-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N YUELDQUPTAYEGM-XIRDDKMYSA-N 0.000 description 3
- 206010006187 Breast cancer Diseases 0.000 description 3
- 208000026310 Breast neoplasm Diseases 0.000 description 3
- 206010008342 Cervix carcinoma Diseases 0.000 description 3
- BYALSSDCQYHKMY-XGEHTFHBSA-N Cys-Arg-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CS)N)O BYALSSDCQYHKMY-XGEHTFHBSA-N 0.000 description 3
- NDUSUIGBMZCOIL-ZKWXMUAHSA-N Cys-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N NDUSUIGBMZCOIL-ZKWXMUAHSA-N 0.000 description 3
- XKBASPWPBXNVLQ-WDSKDSINSA-N Gln-Gly-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XKBASPWPBXNVLQ-WDSKDSINSA-N 0.000 description 3
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 3
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 3
- HNVFSTLPVJWIDV-CIUDSAMLSA-N Glu-Glu-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HNVFSTLPVJWIDV-CIUDSAMLSA-N 0.000 description 3
- OAGVHWYIBZMWLA-YFKPBYRVSA-N Glu-Gly-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)NCC(O)=O OAGVHWYIBZMWLA-YFKPBYRVSA-N 0.000 description 3
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 3
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 3
- QOXDAWODGSIDDI-GUBZILKMSA-N Glu-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N QOXDAWODGSIDDI-GUBZILKMSA-N 0.000 description 3
- MFYLRRCYBBJYPI-JYJNAYRXSA-N Glu-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O MFYLRRCYBBJYPI-JYJNAYRXSA-N 0.000 description 3
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 3
- IXKRSKPKSLXIHN-YUMQZZPRSA-N Gly-Cys-Leu Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O IXKRSKPKSLXIHN-YUMQZZPRSA-N 0.000 description 3
- JUGQPPOVWXSPKJ-RYUDHWBXSA-N Gly-Gln-Phe Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JUGQPPOVWXSPKJ-RYUDHWBXSA-N 0.000 description 3
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 3
- AFWYPMDMDYCKMD-KBPBESRZSA-N Gly-Leu-Tyr Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AFWYPMDMDYCKMD-KBPBESRZSA-N 0.000 description 3
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 3
- BMWFDYIYBAFROD-WPRPVWTQSA-N Gly-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN BMWFDYIYBAFROD-WPRPVWTQSA-N 0.000 description 3
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 3
- 102000001398 Granzyme Human genes 0.000 description 3
- 108060005986 Granzyme Proteins 0.000 description 3
- 102000006354 HLA-DR Antigens Human genes 0.000 description 3
- 108010058597 HLA-DR Antigens Proteins 0.000 description 3
- 206010073073 Hepatobiliary cancer Diseases 0.000 description 3
- ZHHLTWUOWXHVQJ-YUMQZZPRSA-N His-Ser-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZHHLTWUOWXHVQJ-YUMQZZPRSA-N 0.000 description 3
- ALPXXNRQBMRCPZ-MEYUZBJRSA-N His-Thr-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ALPXXNRQBMRCPZ-MEYUZBJRSA-N 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 101000984198 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily A member 1 Proteins 0.000 description 3
- 101000984200 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily A member 3 Proteins 0.000 description 3
- 101000984189 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily B member 2 Proteins 0.000 description 3
- JODPUDMBQBIWCK-GHCJXIJMSA-N Ile-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O JODPUDMBQBIWCK-GHCJXIJMSA-N 0.000 description 3
- 108010074328 Interferon-gamma Proteins 0.000 description 3
- 108090000978 Interleukin-4 Proteins 0.000 description 3
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 3
- USTCFDAQCLDPBD-XIRDDKMYSA-N Leu-Asn-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N USTCFDAQCLDPBD-XIRDDKMYSA-N 0.000 description 3
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 3
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 3
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 3
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 3
- AUNMOHYWTAPQLA-XUXIUFHCSA-N Leu-Met-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AUNMOHYWTAPQLA-XUXIUFHCSA-N 0.000 description 3
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 3
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 3
- 102100025587 Leukocyte immunoglobulin-like receptor subfamily A member 1 Human genes 0.000 description 3
- 102100025556 Leukocyte immunoglobulin-like receptor subfamily A member 3 Human genes 0.000 description 3
- 101710145789 Leukocyte immunoglobulin-like receptor subfamily B member 1 Proteins 0.000 description 3
- 102100025583 Leukocyte immunoglobulin-like receptor subfamily B member 2 Human genes 0.000 description 3
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 3
- NTSPQIONFJUMJV-AVGNSLFASA-N Lys-Arg-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O NTSPQIONFJUMJV-AVGNSLFASA-N 0.000 description 3
- YKIRNDPUWONXQN-GUBZILKMSA-N Lys-Asn-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YKIRNDPUWONXQN-GUBZILKMSA-N 0.000 description 3
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 3
- NKKFVJRLCCUJNA-QWRGUYRKSA-N Lys-Gly-Lys Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN NKKFVJRLCCUJNA-QWRGUYRKSA-N 0.000 description 3
- PBLLTSKBTAHDNA-KBPBESRZSA-N Lys-Gly-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PBLLTSKBTAHDNA-KBPBESRZSA-N 0.000 description 3
- AFLBTVGQCQLOFJ-AVGNSLFASA-N Lys-Pro-Arg Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AFLBTVGQCQLOFJ-AVGNSLFASA-N 0.000 description 3
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 3
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 3
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 3
- CAVRAQIDHUPECU-UVOCVTCTSA-N Lys-Thr-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAVRAQIDHUPECU-UVOCVTCTSA-N 0.000 description 3
- 241000124008 Mammalia Species 0.000 description 3
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 3
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 3
- CDNPIRSCAFMMBE-SRVKXCTJSA-N Phe-Asn-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CDNPIRSCAFMMBE-SRVKXCTJSA-N 0.000 description 3
- GNRMAQSIROFNMI-IXOXFDKPSA-N Phe-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GNRMAQSIROFNMI-IXOXFDKPSA-N 0.000 description 3
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 3
- WFHYFCWBLSKEMS-KKUMJFAQSA-N Pro-Glu-Phe Chemical compound N([C@@H](CCC(=O)O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C(=O)[C@@H]1CCCN1 WFHYFCWBLSKEMS-KKUMJFAQSA-N 0.000 description 3
- FKVNLUZHSFCNGY-RVMXOQNASA-N Pro-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 FKVNLUZHSFCNGY-RVMXOQNASA-N 0.000 description 3
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 3
- KBUAPZAZPWNYSW-SRVKXCTJSA-N Pro-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KBUAPZAZPWNYSW-SRVKXCTJSA-N 0.000 description 3
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 108020004511 Recombinant DNA Proteins 0.000 description 3
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 3
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 3
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 3
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 3
- DJACUBDEDBZKLQ-KBIXCLLPSA-N Ser-Ile-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O DJACUBDEDBZKLQ-KBIXCLLPSA-N 0.000 description 3
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 3
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 3
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 3
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 3
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 3
- 208000000453 Skin Neoplasms Diseases 0.000 description 3
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 3
- ASJDFGOPDCVXTG-KATARQTJSA-N Thr-Cys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O ASJDFGOPDCVXTG-KATARQTJSA-N 0.000 description 3
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 3
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 3
- LVRFMARKDGGZMX-IZPVPAKOSA-N Thr-Tyr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=C(O)C=C1 LVRFMARKDGGZMX-IZPVPAKOSA-N 0.000 description 3
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 3
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 3
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 3
- WURLIFOWSMBUAR-SLFFLAALSA-N Tyr-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O WURLIFOWSMBUAR-SLFFLAALSA-N 0.000 description 3
- YYLHVUCSTXXKBS-IHRRRGAJSA-N Tyr-Pro-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YYLHVUCSTXXKBS-IHRRRGAJSA-N 0.000 description 3
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 3
- 208000008385 Urogenital Neoplasms Diseases 0.000 description 3
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 3
- SCBITHMBEJNRHC-LSJOCFKGSA-N Val-Asp-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N SCBITHMBEJNRHC-LSJOCFKGSA-N 0.000 description 3
- RKIGNDAHUOOIMJ-BQFCYCMXSA-N Val-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 RKIGNDAHUOOIMJ-BQFCYCMXSA-N 0.000 description 3
- FTKXYXACXYOHND-XUXIUFHCSA-N Val-Ile-Leu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O FTKXYXACXYOHND-XUXIUFHCSA-N 0.000 description 3
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 3
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 3
- KTEZUXISLQTDDQ-NHCYSSNCSA-N Val-Lys-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N KTEZUXISLQTDDQ-NHCYSSNCSA-N 0.000 description 3
- SBJCTAZFSZXWSR-AVGNSLFASA-N Val-Met-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SBJCTAZFSZXWSR-AVGNSLFASA-N 0.000 description 3
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 3
- PGBMPFKFKXYROZ-UFYCRDLUSA-N Val-Tyr-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N PGBMPFKFKXYROZ-UFYCRDLUSA-N 0.000 description 3
- 238000007792 addition Methods 0.000 description 3
- 239000000654 additive Substances 0.000 description 3
- 235000004279 alanine Nutrition 0.000 description 3
- 108010044940 alanylglutamine Proteins 0.000 description 3
- 230000008485 antagonism Effects 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 108010068380 arginylarginine Proteins 0.000 description 3
- 108010093581 aspartyl-proline Proteins 0.000 description 3
- 238000013357 binding ELISA Methods 0.000 description 3
- 229960000074 biopharmaceutical Drugs 0.000 description 3
- 230000037396 body weight Effects 0.000 description 3
- 239000000969 carrier Substances 0.000 description 3
- 239000006285 cell suspension Substances 0.000 description 3
- 201000010881 cervical cancer Diseases 0.000 description 3
- 238000011260 co-administration Methods 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 238000007796 conventional method Methods 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 108010074027 glycyl-seryl-phenylalanine Proteins 0.000 description 3
- 108010015792 glycyllysine Proteins 0.000 description 3
- TUJKJAMUKRIRHC-UHFFFAOYSA-N hydroxyl Chemical compound [OH] TUJKJAMUKRIRHC-UHFFFAOYSA-N 0.000 description 3
- 230000037451 immune surveillance Effects 0.000 description 3
- 230000005847 immunogenicity Effects 0.000 description 3
- 238000012744 immunostaining Methods 0.000 description 3
- 238000000338 in vitro Methods 0.000 description 3
- 108010053037 kyotorphin Proteins 0.000 description 3
- 230000003902 lesion Effects 0.000 description 3
- 125000001909 leucine group Chemical group [H]N(*)C(C(*)=O)C([H])([H])C(C([H])([H])[H])C([H])([H])[H] 0.000 description 3
- 108010057821 leucylproline Proteins 0.000 description 3
- 201000007270 liver cancer Diseases 0.000 description 3
- 208000014018 liver neoplasm Diseases 0.000 description 3
- 108010038320 lysylphenylalanine Proteins 0.000 description 3
- 238000004949 mass spectrometry Methods 0.000 description 3
- 230000035800 maturation Effects 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 239000002609 medium Substances 0.000 description 3
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 3
- 230000003647 oxidation Effects 0.000 description 3
- 238000007254 oxidation reaction Methods 0.000 description 3
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 3
- 108010073101 phenylalanylleucine Proteins 0.000 description 3
- 239000013612 plasmid Substances 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 108010014614 prolyl-glycyl-proline Proteins 0.000 description 3
- 108010053725 prolylvaline Proteins 0.000 description 3
- 102000005962 receptors Human genes 0.000 description 3
- 108020003175 receptors Proteins 0.000 description 3
- 201000000849 skin cancer Diseases 0.000 description 3
- 208000024891 symptom Diseases 0.000 description 3
- 238000004885 tandem mass spectrometry Methods 0.000 description 3
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 3
- 230000003614 tolerogenic effect Effects 0.000 description 3
- 238000001890 transfection Methods 0.000 description 3
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 3
- 239000013598 vector Substances 0.000 description 3
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 3
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Natural products CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 2
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 2
- CZPAHAKGPDUIPJ-CIUDSAMLSA-N Ala-Gln-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CZPAHAKGPDUIPJ-CIUDSAMLSA-N 0.000 description 2
- VBRDBGCROKWTPV-XHNCKOQMSA-N Ala-Glu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N VBRDBGCROKWTPV-XHNCKOQMSA-N 0.000 description 2
- WGDNWOMKBUXFHR-BQBZGAKWSA-N Ala-Gly-Arg Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N WGDNWOMKBUXFHR-BQBZGAKWSA-N 0.000 description 2
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 2
- OINVDEKBKBCPLX-JXUBOQSCSA-N Ala-Lys-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OINVDEKBKBCPLX-JXUBOQSCSA-N 0.000 description 2
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 2
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 2
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 2
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 2
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 2
- KMFPQTITXUKJOV-DCAQKATOSA-N Arg-Ser-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O KMFPQTITXUKJOV-DCAQKATOSA-N 0.000 description 2
- ZJBUILVYSXQNSW-YTWAJWBKSA-N Arg-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ZJBUILVYSXQNSW-YTWAJWBKSA-N 0.000 description 2
- ULBHWNVWSCJLCO-NHCYSSNCSA-N Arg-Val-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N ULBHWNVWSCJLCO-NHCYSSNCSA-N 0.000 description 2
- 206010003445 Ascites Diseases 0.000 description 2
- NUHQMYUWLUSRJX-BIIVOSGPSA-N Asn-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N NUHQMYUWLUSRJX-BIIVOSGPSA-N 0.000 description 2
- XSGBIBGAMKTHMY-WHFBIAKZSA-N Asn-Asp-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O XSGBIBGAMKTHMY-WHFBIAKZSA-N 0.000 description 2
- SRUUBQBAVNQZGJ-LAEOZQHASA-N Asn-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N SRUUBQBAVNQZGJ-LAEOZQHASA-N 0.000 description 2
- JWQWPRCDYWNVNM-ACZMJKKPSA-N Asn-Ser-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N JWQWPRCDYWNVNM-ACZMJKKPSA-N 0.000 description 2
- HNXWVVHIGTZTBO-LKXGYXEUSA-N Asn-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O HNXWVVHIGTZTBO-LKXGYXEUSA-N 0.000 description 2
- JZLFYAAGGYMRIK-BYULHYEWSA-N Asn-Val-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O JZLFYAAGGYMRIK-BYULHYEWSA-N 0.000 description 2
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 2
- JSNWZMFSLIWAHS-HJGDQZAQSA-N Asp-Thr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O JSNWZMFSLIWAHS-HJGDQZAQSA-N 0.000 description 2
- QOJJMJKTMKNFEF-ZKWXMUAHSA-N Asp-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O QOJJMJKTMKNFEF-ZKWXMUAHSA-N 0.000 description 2
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 2
- KEBJBKIASQVRJS-WDSKDSINSA-N Cys-Gln-Gly Chemical compound C(CC(=O)N)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N KEBJBKIASQVRJS-WDSKDSINSA-N 0.000 description 2
- OZHXXYOHPLLLMI-CIUDSAMLSA-N Cys-Lys-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OZHXXYOHPLLLMI-CIUDSAMLSA-N 0.000 description 2
- BNCKELUXXUYRNY-GUBZILKMSA-N Cys-Lys-Glu Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CS)N BNCKELUXXUYRNY-GUBZILKMSA-N 0.000 description 2
- NDNZRWUDUMTITL-FXQIFTODSA-N Cys-Ser-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NDNZRWUDUMTITL-FXQIFTODSA-N 0.000 description 2
- KXHAPEPORGOXDT-UWJYBYFXSA-N Cys-Tyr-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O KXHAPEPORGOXDT-UWJYBYFXSA-N 0.000 description 2
- BOMGEMDZTNZESV-QWRGUYRKSA-N Cys-Tyr-Gly Chemical compound SC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 BOMGEMDZTNZESV-QWRGUYRKSA-N 0.000 description 2
- 102000001301 EGF receptor Human genes 0.000 description 2
- 108060006698 EGF receptor Proteins 0.000 description 2
- 238000012286 ELISA Assay Methods 0.000 description 2
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 2
- LLQPHQFNMLZJMP-UHFFFAOYSA-N Fentrazamide Chemical compound N1=NN(C=2C(=CC=CC=2)Cl)C(=O)N1C(=O)N(CC)C1CCCCC1 LLQPHQFNMLZJMP-UHFFFAOYSA-N 0.000 description 2
- DTMLKCYOQKZXKZ-HJGDQZAQSA-N Gln-Arg-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DTMLKCYOQKZXKZ-HJGDQZAQSA-N 0.000 description 2
- FJAYYNIXQNERSO-ACZMJKKPSA-N Gln-Cys-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N FJAYYNIXQNERSO-ACZMJKKPSA-N 0.000 description 2
- RBWKVOSARCFSQQ-FXQIFTODSA-N Gln-Gln-Ser Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O RBWKVOSARCFSQQ-FXQIFTODSA-N 0.000 description 2
- CGVWDTRDPLOMHZ-FXQIFTODSA-N Gln-Glu-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CGVWDTRDPLOMHZ-FXQIFTODSA-N 0.000 description 2
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 2
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 2
- HGBHRZBXOOHRDH-JBACZVJFSA-N Gln-Tyr-Trp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HGBHRZBXOOHRDH-JBACZVJFSA-N 0.000 description 2
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 2
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 2
- WATXSTJXNBOHKD-LAEOZQHASA-N Glu-Asp-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O WATXSTJXNBOHKD-LAEOZQHASA-N 0.000 description 2
- RFDHKPSHTXZKLL-IHRRRGAJSA-N Glu-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)O)N RFDHKPSHTXZKLL-IHRRRGAJSA-N 0.000 description 2
- HVYWQYLBVXMXSV-GUBZILKMSA-N Glu-Leu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HVYWQYLBVXMXSV-GUBZILKMSA-N 0.000 description 2
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 2
- HRBYTAIBKPNZKQ-AVGNSLFASA-N Glu-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O HRBYTAIBKPNZKQ-AVGNSLFASA-N 0.000 description 2
- MFNUFCFRAZPJFW-JYJNAYRXSA-N Glu-Lys-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFNUFCFRAZPJFW-JYJNAYRXSA-N 0.000 description 2
- JWNZHMSRZXXGTM-XKBZYTNZSA-N Glu-Ser-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JWNZHMSRZXXGTM-XKBZYTNZSA-N 0.000 description 2
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 2
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 2
- BPCLDCNZBUYGOD-BPUTZDHNSA-N Glu-Trp-Glu Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 BPCLDCNZBUYGOD-BPUTZDHNSA-N 0.000 description 2
- DXMOIVCNJIJQSC-QEJZJMRPSA-N Glu-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N DXMOIVCNJIJQSC-QEJZJMRPSA-N 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- QIZJOTQTCAGKPU-KWQFWETISA-N Gly-Ala-Tyr Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 QIZJOTQTCAGKPU-KWQFWETISA-N 0.000 description 2
- WKJKBELXHCTHIJ-WPRPVWTQSA-N Gly-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N WKJKBELXHCTHIJ-WPRPVWTQSA-N 0.000 description 2
- KTSZUNRRYXPZTK-BQBZGAKWSA-N Gly-Gln-Glu Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KTSZUNRRYXPZTK-BQBZGAKWSA-N 0.000 description 2
- STVHDEHTKFXBJQ-LAEOZQHASA-N Gly-Glu-Ile Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O STVHDEHTKFXBJQ-LAEOZQHASA-N 0.000 description 2
- KMSGYZQRXPUKGI-BYPYZUCNSA-N Gly-Gly-Asn Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(N)=O KMSGYZQRXPUKGI-BYPYZUCNSA-N 0.000 description 2
- QPTNELDXWKRIFX-YFKPBYRVSA-N Gly-Gly-Gln Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O QPTNELDXWKRIFX-YFKPBYRVSA-N 0.000 description 2
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 2
- HAXARWKYFIIHKD-ZKWXMUAHSA-N Gly-Ile-Ser Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HAXARWKYFIIHKD-ZKWXMUAHSA-N 0.000 description 2
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 2
- LOEANKRDMMVOGZ-YUMQZZPRSA-N Gly-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O LOEANKRDMMVOGZ-YUMQZZPRSA-N 0.000 description 2
- GMTXWRIDLGTVFC-IUCAKERBSA-N Gly-Lys-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMTXWRIDLGTVFC-IUCAKERBSA-N 0.000 description 2
- GGAPHLIUUTVYMX-QWRGUYRKSA-N Gly-Phe-Ser Chemical compound OC[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)C[NH3+])CC1=CC=CC=C1 GGAPHLIUUTVYMX-QWRGUYRKSA-N 0.000 description 2
- OOCFXNOVSLSHAB-IUCAKERBSA-N Gly-Pro-Pro Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OOCFXNOVSLSHAB-IUCAKERBSA-N 0.000 description 2
- OHUKZZYSJBKFRR-WHFBIAKZSA-N Gly-Ser-Asp Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O OHUKZZYSJBKFRR-WHFBIAKZSA-N 0.000 description 2
- ZLCLYFGMKFCDCN-XPUUQOCRSA-N Gly-Ser-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CO)NC(=O)CN)C(O)=O ZLCLYFGMKFCDCN-XPUUQOCRSA-N 0.000 description 2
- SYOJVRNQCXYEOV-XVKPBYJWSA-N Gly-Val-Glu Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SYOJVRNQCXYEOV-XVKPBYJWSA-N 0.000 description 2
- FULZDMOZUZKGQU-ONGXEEELSA-N Gly-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN FULZDMOZUZKGQU-ONGXEEELSA-N 0.000 description 2
- 102100028966 HLA class I histocompatibility antigen, alpha chain F Human genes 0.000 description 2
- 102000012153 HLA-B27 Antigen Human genes 0.000 description 2
- 108010061486 HLA-B27 Antigen Proteins 0.000 description 2
- AWHJQEYGWRKPHE-LSJOCFKGSA-N His-Ala-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AWHJQEYGWRKPHE-LSJOCFKGSA-N 0.000 description 2
- DCRODRAURLJOFY-XPUUQOCRSA-N His-Ala-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)NCC(O)=O DCRODRAURLJOFY-XPUUQOCRSA-N 0.000 description 2
- TTYKEFZRLKQTHH-MELADBBJSA-N His-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O TTYKEFZRLKQTHH-MELADBBJSA-N 0.000 description 2
- 101000986080 Homo sapiens HLA class I histocompatibility antigen, alpha chain F Proteins 0.000 description 2
- 101001002657 Homo sapiens Interleukin-2 Proteins 0.000 description 2
- 101000984192 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily B member 3 Proteins 0.000 description 2
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 description 2
- 101000818543 Homo sapiens Tyrosine-protein kinase ZAP-70 Proteins 0.000 description 2
- MKWSZEHGHSLNPF-NAKRPEOUSA-N Ile-Ala-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O)N MKWSZEHGHSLNPF-NAKRPEOUSA-N 0.000 description 2
- QYZYJFXHXYUZMZ-UGYAYLCHSA-N Ile-Asn-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N QYZYJFXHXYUZMZ-UGYAYLCHSA-N 0.000 description 2
- DFJJAVZIHDFOGQ-MNXVOIDGSA-N Ile-Glu-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N DFJJAVZIHDFOGQ-MNXVOIDGSA-N 0.000 description 2
- GLYJPWIRLBAIJH-FQUUOJAGSA-N Ile-Lys-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N GLYJPWIRLBAIJH-FQUUOJAGSA-N 0.000 description 2
- 206010061598 Immunodeficiency Diseases 0.000 description 2
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 2
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 2
- 102000008070 Interferon-gamma Human genes 0.000 description 2
- 108010002352 Interleukin-1 Proteins 0.000 description 2
- 102000000589 Interleukin-1 Human genes 0.000 description 2
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 2
- HXWALXSAVBLTPK-NUTKFTJISA-N Leu-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(C)C)N HXWALXSAVBLTPK-NUTKFTJISA-N 0.000 description 2
- DXYBNWJZJVSZAE-GUBZILKMSA-N Leu-Gln-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N DXYBNWJZJVSZAE-GUBZILKMSA-N 0.000 description 2
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 2
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 2
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 2
- SVBJIZVVYJYGLA-DCAQKATOSA-N Leu-Ser-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O SVBJIZVVYJYGLA-DCAQKATOSA-N 0.000 description 2
- UCRJTSIIAYHOHE-ULQDDVLXSA-N Leu-Tyr-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UCRJTSIIAYHOHE-ULQDDVLXSA-N 0.000 description 2
- VUBIPAHVHMZHCM-KKUMJFAQSA-N Leu-Tyr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 VUBIPAHVHMZHCM-KKUMJFAQSA-N 0.000 description 2
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 2
- NTBFKPBULZGXQL-KKUMJFAQSA-N Lys-Asp-Tyr Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTBFKPBULZGXQL-KKUMJFAQSA-N 0.000 description 2
- RFQATBGBLDAKGI-VHSXEESVSA-N Lys-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCCCN)N)C(=O)O RFQATBGBLDAKGI-VHSXEESVSA-N 0.000 description 2
- LOGFVTREOLYCPF-RHYQMDGZSA-N Lys-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN LOGFVTREOLYCPF-RHYQMDGZSA-N 0.000 description 2
- SJDQOYTYNGZZJX-SRVKXCTJSA-N Met-Glu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SJDQOYTYNGZZJX-SRVKXCTJSA-N 0.000 description 2
- RKIIYGUHIQJCBW-SRVKXCTJSA-N Met-His-Glu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O RKIIYGUHIQJCBW-SRVKXCTJSA-N 0.000 description 2
- FWAHLGXNBLWIKB-NAKRPEOUSA-N Met-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCSC FWAHLGXNBLWIKB-NAKRPEOUSA-N 0.000 description 2
- 230000006051 NK cell activation Effects 0.000 description 2
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 2
- PXHVJJICTQNCMI-UHFFFAOYSA-N Nickel Chemical compound [Ni] PXHVJJICTQNCMI-UHFFFAOYSA-N 0.000 description 2
- 206010033128 Ovarian cancer Diseases 0.000 description 2
- 206010061535 Ovarian neoplasm Diseases 0.000 description 2
- YYKZDTVQHTUKDW-RYUDHWBXSA-N Phe-Gly-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N YYKZDTVQHTUKDW-RYUDHWBXSA-N 0.000 description 2
- QTVUPXHPSXZJKH-ULQDDVLXSA-N Phe-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N QTVUPXHPSXZJKH-ULQDDVLXSA-N 0.000 description 2
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 2
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 2
- JFNPBBOGGNMSRX-CIUDSAMLSA-N Pro-Gln-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O JFNPBBOGGNMSRX-CIUDSAMLSA-N 0.000 description 2
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 2
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 2
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 2
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 2
- FDMCIBSQRKFSTJ-RHYQMDGZSA-N Pro-Thr-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O FDMCIBSQRKFSTJ-RHYQMDGZSA-N 0.000 description 2
- FZXSYIPVAFVYBH-KKUMJFAQSA-N Pro-Tyr-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O FZXSYIPVAFVYBH-KKUMJFAQSA-N 0.000 description 2
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 2
- FIODMZKLZFLYQP-GUBZILKMSA-N Pro-Val-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FIODMZKLZFLYQP-GUBZILKMSA-N 0.000 description 2
- 239000012979 RPMI medium Substances 0.000 description 2
- 206010070308 Refractory cancer Diseases 0.000 description 2
- HZWAHWQZPSXNCB-BPUTZDHNSA-N Ser-Arg-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HZWAHWQZPSXNCB-BPUTZDHNSA-N 0.000 description 2
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 2
- RDFQNDHEHVSONI-ZLUOBGJFSA-N Ser-Asn-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDFQNDHEHVSONI-ZLUOBGJFSA-N 0.000 description 2
- SFZKGGOGCNQPJY-CIUDSAMLSA-N Ser-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N SFZKGGOGCNQPJY-CIUDSAMLSA-N 0.000 description 2
- BQWCDDAISCPDQV-XHNCKOQMSA-N Ser-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N)C(=O)O BQWCDDAISCPDQV-XHNCKOQMSA-N 0.000 description 2
- HVKMTOIAYDOJPL-NRPADANISA-N Ser-Gln-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVKMTOIAYDOJPL-NRPADANISA-N 0.000 description 2
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 2
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 2
- QJKPECIAWNNKIT-KKUMJFAQSA-N Ser-Lys-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QJKPECIAWNNKIT-KKUMJFAQSA-N 0.000 description 2
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 2
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 2
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 2
- ZSDXEKUKQAKZFE-XAVMHZPKSA-N Ser-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N)O ZSDXEKUKQAKZFE-XAVMHZPKSA-N 0.000 description 2
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 2
- OSFZCEQJLWCIBG-BZSNNMDCSA-N Ser-Tyr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OSFZCEQJLWCIBG-BZSNNMDCSA-N 0.000 description 2
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 2
- 235000021355 Stearic acid Nutrition 0.000 description 2
- BSNZTJXVDOINSR-JXUBOQSCSA-N Thr-Ala-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BSNZTJXVDOINSR-JXUBOQSCSA-N 0.000 description 2
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 2
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 2
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 2
- JMBRNXUOLJFURW-BEAPCOKYSA-N Thr-Phe-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N)O JMBRNXUOLJFURW-BEAPCOKYSA-N 0.000 description 2
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 2
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 2
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 2
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 2
- 208000024770 Thyroid neoplasm Diseases 0.000 description 2
- VISUNEBASWEMCU-SZMVWBNQSA-N Trp-Glu-His Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N VISUNEBASWEMCU-SZMVWBNQSA-N 0.000 description 2
- YDTKYBHPRULROG-LTHWPDAASA-N Trp-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N YDTKYBHPRULROG-LTHWPDAASA-N 0.000 description 2
- XGFGVFMXDXALEV-XIRDDKMYSA-N Trp-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N XGFGVFMXDXALEV-XIRDDKMYSA-N 0.000 description 2
- UIDJDMVRDUANDL-BVSLBCMMSA-N Trp-Tyr-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UIDJDMVRDUANDL-BVSLBCMMSA-N 0.000 description 2
- UOXPLPBMEPLZBW-WDSOQIARSA-N Trp-Val-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 UOXPLPBMEPLZBW-WDSOQIARSA-N 0.000 description 2
- CDRYEAWHKJSGAF-BPNCWPANSA-N Tyr-Ala-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O CDRYEAWHKJSGAF-BPNCWPANSA-N 0.000 description 2
- SEFNTZYRPGBDCY-IHRRRGAJSA-N Tyr-Arg-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N)O SEFNTZYRPGBDCY-IHRRRGAJSA-N 0.000 description 2
- QYSBJAUCUKHSLU-JYJNAYRXSA-N Tyr-Arg-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O QYSBJAUCUKHSLU-JYJNAYRXSA-N 0.000 description 2
- AZGZDDNKFFUDEH-QWRGUYRKSA-N Tyr-Gly-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AZGZDDNKFFUDEH-QWRGUYRKSA-N 0.000 description 2
- NSGZILIDHCIZAM-KKUMJFAQSA-N Tyr-Leu-Ser Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N NSGZILIDHCIZAM-KKUMJFAQSA-N 0.000 description 2
- GZUIDWDVMWZSMI-KKUMJFAQSA-N Tyr-Lys-Cys Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CS)C(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GZUIDWDVMWZSMI-KKUMJFAQSA-N 0.000 description 2
- XJPXTYLVMUZGNW-IHRRRGAJSA-N Tyr-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O XJPXTYLVMUZGNW-IHRRRGAJSA-N 0.000 description 2
- SZEIFUXUTBBQFQ-STQMWFEESA-N Tyr-Pro-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SZEIFUXUTBBQFQ-STQMWFEESA-N 0.000 description 2
- QFHRUCJIRVILCK-YJRXYDGGSA-N Tyr-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O QFHRUCJIRVILCK-YJRXYDGGSA-N 0.000 description 2
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 2
- 102100021125 Tyrosine-protein kinase ZAP-70 Human genes 0.000 description 2
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 2
- BMGOFDMKDVVGJG-NHCYSSNCSA-N Val-Asp-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BMGOFDMKDVVGJG-NHCYSSNCSA-N 0.000 description 2
- OACSGBOREVRSME-NHCYSSNCSA-N Val-His-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](CC(N)=O)C(O)=O OACSGBOREVRSME-NHCYSSNCSA-N 0.000 description 2
- YMTOEGGOCHVGEH-IHRRRGAJSA-N Val-Lys-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O YMTOEGGOCHVGEH-IHRRRGAJSA-N 0.000 description 2
- QTPQHINADBYBNA-DCAQKATOSA-N Val-Ser-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN QTPQHINADBYBNA-DCAQKATOSA-N 0.000 description 2
- SDHZOOIGIUEPDY-JYJNAYRXSA-N Val-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 SDHZOOIGIUEPDY-JYJNAYRXSA-N 0.000 description 2
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 2
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- 239000002671 adjuvant Substances 0.000 description 2
- 108010041407 alanylaspartic acid Proteins 0.000 description 2
- 230000030741 antigen processing and presentation Effects 0.000 description 2
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 2
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 2
- 229950002916 avelumab Drugs 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 210000001124 body fluid Anatomy 0.000 description 2
- 210000001185 bone marrow Anatomy 0.000 description 2
- OSGAYBCDTDRGGQ-UHFFFAOYSA-L calcium sulfate Chemical compound [Ca+2].[O-]S([O-])(=O)=O OSGAYBCDTDRGGQ-UHFFFAOYSA-L 0.000 description 2
- 230000006041 cell recruitment Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 208000029742 colonic neoplasm Diseases 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 230000009260 cross reactivity Effects 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 108010069495 cysteinyltyrosine Proteins 0.000 description 2
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 229950009791 durvalumab Drugs 0.000 description 2
- 230000006862 enzymatic digestion Effects 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 230000002496 gastric effect Effects 0.000 description 2
- 210000004602 germ cell Anatomy 0.000 description 2
- 235000011187 glycerol Nutrition 0.000 description 2
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 2
- 108010010147 glycylglutamine Proteins 0.000 description 2
- 239000003102 growth factor Substances 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 238000003119 immunoblot Methods 0.000 description 2
- 230000002163 immunogen Effects 0.000 description 2
- 230000016784 immunoglobulin production Effects 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 230000001976 improved effect Effects 0.000 description 2
- 230000028709 inflammatory response Effects 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 229960003130 interferon gamma Drugs 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 150000002500 ions Chemical class 0.000 description 2
- 108010091871 leucylmethionine Proteins 0.000 description 2
- 208000032839 leukemia Diseases 0.000 description 2
- 210000000265 leukocyte Anatomy 0.000 description 2
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 2
- 208000037841 lung tumor Diseases 0.000 description 2
- 108010057952 lysyl-phenylalanyl-lysine Proteins 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- 238000006386 neutralization reaction Methods 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 2
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 2
- 229960001972 panitumumab Drugs 0.000 description 2
- 229960002087 pertuzumab Drugs 0.000 description 2
- 210000000680 phagosome Anatomy 0.000 description 2
- 230000000144 pharmacologic effect Effects 0.000 description 2
- 239000008363 phosphate buffer Substances 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 229920005862 polyol Polymers 0.000 description 2
- 150000003077 polyols Chemical class 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 108010029020 prolylglycine Proteins 0.000 description 2
- 108010015796 prolylisoleucine Proteins 0.000 description 2
- 238000011321 prophylaxis Methods 0.000 description 2
- 230000007115 recruitment Effects 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 208000016691 refractory malignant neoplasm Diseases 0.000 description 2
- 229960004641 rituximab Drugs 0.000 description 2
- CXMXRPHRNRROMY-UHFFFAOYSA-N sebacic acid Chemical compound OC(=O)CCCCCCCCC(O)=O CXMXRPHRNRROMY-UHFFFAOYSA-N 0.000 description 2
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 241000894007 species Species 0.000 description 2
- 206010041823 squamous cell carcinoma Diseases 0.000 description 2
- 238000007619 statistical method Methods 0.000 description 2
- 239000008117 stearic acid Substances 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 108010031491 threonyl-lysyl-glutamic acid Proteins 0.000 description 2
- 201000002510 thyroid cancer Diseases 0.000 description 2
- 108010080629 tryptophan-leucine Proteins 0.000 description 2
- 108010038745 tryptophylglycine Proteins 0.000 description 2
- 108010017949 tyrosyl-glycyl-glycine Proteins 0.000 description 2
- 108010071635 tyrosyl-prolyl-arginine Proteins 0.000 description 2
- 108010052774 valyl-lysyl-glycyl-phenylalanyl-tyrosine Proteins 0.000 description 2
- 239000000080 wetting agent Substances 0.000 description 2
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- YHOPXCAOTRUGLV-XAMCCFCMSA-N Ala-Ala-Asp-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O YHOPXCAOTRUGLV-XAMCCFCMSA-N 0.000 description 1
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 1
- JAMAWBXXKFGFGX-KZVJFYERSA-N Ala-Arg-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JAMAWBXXKFGFGX-KZVJFYERSA-N 0.000 description 1
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 1
- WXERCAHAIKMTKX-ZLUOBGJFSA-N Ala-Asp-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O WXERCAHAIKMTKX-ZLUOBGJFSA-N 0.000 description 1
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 1
- WCBVQNZTOKJWJS-ACZMJKKPSA-N Ala-Cys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O WCBVQNZTOKJWJS-ACZMJKKPSA-N 0.000 description 1
- BLGHHPHXVJWCNK-GUBZILKMSA-N Ala-Gln-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BLGHHPHXVJWCNK-GUBZILKMSA-N 0.000 description 1
- WKOBSJOZRJJVRZ-FXQIFTODSA-N Ala-Glu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WKOBSJOZRJJVRZ-FXQIFTODSA-N 0.000 description 1
- FBHOPGDGELNWRH-DRZSPHRISA-N Ala-Glu-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O FBHOPGDGELNWRH-DRZSPHRISA-N 0.000 description 1
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 1
- WMYJZJRILUVVRG-WDSKDSINSA-N Ala-Gly-Gln Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O WMYJZJRILUVVRG-WDSKDSINSA-N 0.000 description 1
- BTBUEVAGZCKULD-XPUUQOCRSA-N Ala-Gly-His Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CN=CN1 BTBUEVAGZCKULD-XPUUQOCRSA-N 0.000 description 1
- NIZKGBJVCMRDKO-KWQFWETISA-N Ala-Gly-Tyr Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NIZKGBJVCMRDKO-KWQFWETISA-N 0.000 description 1
- IVKWMMGFLAMMKJ-XVYDVKMFSA-N Ala-His-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N IVKWMMGFLAMMKJ-XVYDVKMFSA-N 0.000 description 1
- NMXKFWOEASXOGB-QSFUFRPTSA-N Ala-Ile-His Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NMXKFWOEASXOGB-QSFUFRPTSA-N 0.000 description 1
- QCTFKEJEIMPOLW-JURCDPSOSA-N Ala-Ile-Phe Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QCTFKEJEIMPOLW-JURCDPSOSA-N 0.000 description 1
- DYJJJCHDHLEFDW-FXQIFTODSA-N Ala-Pro-Cys Chemical compound C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)O)N DYJJJCHDHLEFDW-FXQIFTODSA-N 0.000 description 1
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 1
- MSWSRLGNLKHDEI-ACZMJKKPSA-N Ala-Ser-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O MSWSRLGNLKHDEI-ACZMJKKPSA-N 0.000 description 1
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 1
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 1
- YCTIYBUTCKNOTI-UWJYBYFXSA-N Ala-Tyr-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCTIYBUTCKNOTI-UWJYBYFXSA-N 0.000 description 1
- GCTANJIJJROSLH-GVARAGBVSA-N Ala-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C)N GCTANJIJJROSLH-GVARAGBVSA-N 0.000 description 1
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 1
- LYILPUNCKACNGF-NAKRPEOUSA-N Ala-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C)N LYILPUNCKACNGF-NAKRPEOUSA-N 0.000 description 1
- XCIGOVDXZULBBV-DCAQKATOSA-N Ala-Val-Lys Chemical compound CC(C)[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CCCCN)C(O)=O XCIGOVDXZULBBV-DCAQKATOSA-N 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- PEFFAAKJGBZBKL-NAKRPEOUSA-N Arg-Ala-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O PEFFAAKJGBZBKL-NAKRPEOUSA-N 0.000 description 1
- JTKLCCFLSLCCST-SZMVWBNQSA-N Arg-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(O)=O)=CNC2=C1 JTKLCCFLSLCCST-SZMVWBNQSA-N 0.000 description 1
- TTXYKSADPSNOIF-IHRRRGAJSA-N Arg-Asp-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O TTXYKSADPSNOIF-IHRRRGAJSA-N 0.000 description 1
- JUWQNWXEGDYCIE-YUMQZZPRSA-N Arg-Gln-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O JUWQNWXEGDYCIE-YUMQZZPRSA-N 0.000 description 1
- ZEAYJGRKRUBDOB-GARJFASQSA-N Arg-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ZEAYJGRKRUBDOB-GARJFASQSA-N 0.000 description 1
- HPKSHFSEXICTLI-CIUDSAMLSA-N Arg-Glu-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HPKSHFSEXICTLI-CIUDSAMLSA-N 0.000 description 1
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 1
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 1
- YBIAYFFIVAZXPK-AVGNSLFASA-N Arg-His-Arg Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O YBIAYFFIVAZXPK-AVGNSLFASA-N 0.000 description 1
- GNYUVVJYGJFKHN-RVMXOQNASA-N Arg-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N GNYUVVJYGJFKHN-RVMXOQNASA-N 0.000 description 1
- WMEVEPXNCMKNGH-IHRRRGAJSA-N Arg-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N WMEVEPXNCMKNGH-IHRRRGAJSA-N 0.000 description 1
- YVTHEZNOKSAWRW-DCAQKATOSA-N Arg-Lys-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O YVTHEZNOKSAWRW-DCAQKATOSA-N 0.000 description 1
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 1
- BECXEHHOZNFFFX-IHRRRGAJSA-N Arg-Ser-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BECXEHHOZNFFFX-IHRRRGAJSA-N 0.000 description 1
- INOIAEUXVVNJKA-XGEHTFHBSA-N Arg-Thr-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O INOIAEUXVVNJKA-XGEHTFHBSA-N 0.000 description 1
- ZUVMUOOHJYNJPP-XIRDDKMYSA-N Arg-Trp-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZUVMUOOHJYNJPP-XIRDDKMYSA-N 0.000 description 1
- WAEWODAAWLGLMK-OYDLWJJNSA-N Arg-Trp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N WAEWODAAWLGLMK-OYDLWJJNSA-N 0.000 description 1
- QMQZYILAWUOLPV-JYJNAYRXSA-N Arg-Tyr-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)CC1=CC=C(O)C=C1 QMQZYILAWUOLPV-JYJNAYRXSA-N 0.000 description 1
- CPTXATAOUQJQRO-GUBZILKMSA-N Arg-Val-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O CPTXATAOUQJQRO-GUBZILKMSA-N 0.000 description 1
- XYOVHPDDWCEUDY-CIUDSAMLSA-N Asn-Ala-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O XYOVHPDDWCEUDY-CIUDSAMLSA-N 0.000 description 1
- GXMSVVBIAMWMKO-BQBZGAKWSA-N Asn-Arg-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N GXMSVVBIAMWMKO-BQBZGAKWSA-N 0.000 description 1
- HUZGPXBILPMCHM-IHRRRGAJSA-N Asn-Arg-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HUZGPXBILPMCHM-IHRRRGAJSA-N 0.000 description 1
- JRVABKHPWDRUJF-UBHSHLNASA-N Asn-Asn-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N JRVABKHPWDRUJF-UBHSHLNASA-N 0.000 description 1
- HCAUEJAQCXVQQM-ACZMJKKPSA-N Asn-Glu-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HCAUEJAQCXVQQM-ACZMJKKPSA-N 0.000 description 1
- WONGRTVAMHFGBE-WDSKDSINSA-N Asn-Gly-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N WONGRTVAMHFGBE-WDSKDSINSA-N 0.000 description 1
- BKFXFUPYETWGGA-XVSYOHENSA-N Asn-Phe-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BKFXFUPYETWGGA-XVSYOHENSA-N 0.000 description 1
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 1
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 1
- HPNDKUOLNRVRAY-BIIVOSGPSA-N Asn-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N)C(=O)O HPNDKUOLNRVRAY-BIIVOSGPSA-N 0.000 description 1
- JBDLMLZNDRLDIX-HJGDQZAQSA-N Asn-Thr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O JBDLMLZNDRLDIX-HJGDQZAQSA-N 0.000 description 1
- LGCVSPFCFXWUEY-IHPCNDPISA-N Asn-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N LGCVSPFCFXWUEY-IHPCNDPISA-N 0.000 description 1
- JNCRAQVYJZGIOW-QSFUFRPTSA-N Asn-Val-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JNCRAQVYJZGIOW-QSFUFRPTSA-N 0.000 description 1
- XOQYDFCQPWAMSA-KKHAAJSZSA-N Asn-Val-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XOQYDFCQPWAMSA-KKHAAJSZSA-N 0.000 description 1
- HPNDBHLITCHRSO-WHFBIAKZSA-N Asp-Ala-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)NCC(O)=O HPNDBHLITCHRSO-WHFBIAKZSA-N 0.000 description 1
- SOYOSFXLXYZNRG-CIUDSAMLSA-N Asp-Arg-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O SOYOSFXLXYZNRG-CIUDSAMLSA-N 0.000 description 1
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 1
- LKIYSIYBKYLKPU-BIIVOSGPSA-N Asp-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N)C(=O)O LKIYSIYBKYLKPU-BIIVOSGPSA-N 0.000 description 1
- NZJDBCYBYCUEDC-UBHSHLNASA-N Asp-Cys-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N NZJDBCYBYCUEDC-UBHSHLNASA-N 0.000 description 1
- XAJRHVUUVUPFQL-ACZMJKKPSA-N Asp-Glu-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O XAJRHVUUVUPFQL-ACZMJKKPSA-N 0.000 description 1
- HSWYMWGDMPLTTH-FXQIFTODSA-N Asp-Glu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HSWYMWGDMPLTTH-FXQIFTODSA-N 0.000 description 1
- QCLHLXDWRKOHRR-GUBZILKMSA-N Asp-Glu-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N QCLHLXDWRKOHRR-GUBZILKMSA-N 0.000 description 1
- VIRHEUMYXXLCBF-WDSKDSINSA-N Asp-Gly-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O VIRHEUMYXXLCBF-WDSKDSINSA-N 0.000 description 1
- TVIZQBFURPLQDV-DJFWLOJKSA-N Asp-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC(=O)O)N TVIZQBFURPLQDV-DJFWLOJKSA-N 0.000 description 1
- RKNIUWSZIAUEPK-PBCZWWQYSA-N Asp-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC(=O)O)N)O RKNIUWSZIAUEPK-PBCZWWQYSA-N 0.000 description 1
- KYQNAIMCTRZLNP-QSFUFRPTSA-N Asp-Ile-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O KYQNAIMCTRZLNP-QSFUFRPTSA-N 0.000 description 1
- UJGRZQYSNYTCAX-SRVKXCTJSA-N Asp-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UJGRZQYSNYTCAX-SRVKXCTJSA-N 0.000 description 1
- UZFHNLYQWMGUHU-DCAQKATOSA-N Asp-Lys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UZFHNLYQWMGUHU-DCAQKATOSA-N 0.000 description 1
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 1
- YRZIYQGXTSBRLT-AVGNSLFASA-N Asp-Phe-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O YRZIYQGXTSBRLT-AVGNSLFASA-N 0.000 description 1
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 1
- YFGUZQQCSDZRBN-DCAQKATOSA-N Asp-Pro-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O YFGUZQQCSDZRBN-DCAQKATOSA-N 0.000 description 1
- XXAMCEGRCZQGEM-ZLUOBGJFSA-N Asp-Ser-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O XXAMCEGRCZQGEM-ZLUOBGJFSA-N 0.000 description 1
- ZVGRHIRJLWBWGJ-ACZMJKKPSA-N Asp-Ser-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZVGRHIRJLWBWGJ-ACZMJKKPSA-N 0.000 description 1
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 1
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 1
- OZBXOELNJBSJOA-UBHSHLNASA-N Asp-Ser-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N OZBXOELNJBSJOA-UBHSHLNASA-N 0.000 description 1
- XYPJXLLXNSAWHZ-SRVKXCTJSA-N Asp-Ser-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XYPJXLLXNSAWHZ-SRVKXCTJSA-N 0.000 description 1
- MJJIHRWNWSQTOI-VEVYYDQMSA-N Asp-Thr-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O MJJIHRWNWSQTOI-VEVYYDQMSA-N 0.000 description 1
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 1
- 206010005003 Bladder cancer Diseases 0.000 description 1
- 206010005949 Bone cancer Diseases 0.000 description 1
- 208000018084 Bone neoplasm Diseases 0.000 description 1
- 108700031361 Brachyury Proteins 0.000 description 1
- 102100021943 C-C motif chemokine 2 Human genes 0.000 description 1
- 101710155857 C-C motif chemokine 2 Proteins 0.000 description 1
- 241000282465 Canis Species 0.000 description 1
- 201000009030 Carcinoma Diseases 0.000 description 1
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 description 1
- YZFCGHIBLBDZDA-ZLUOBGJFSA-N Cys-Asp-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YZFCGHIBLBDZDA-ZLUOBGJFSA-N 0.000 description 1
- HHABWQIFXZPZCK-ACZMJKKPSA-N Cys-Gln-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N HHABWQIFXZPZCK-ACZMJKKPSA-N 0.000 description 1
- VIRYODQIWJNWNU-NRPADANISA-N Cys-Glu-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N VIRYODQIWJNWNU-NRPADANISA-N 0.000 description 1
- SSNJZBGOMNLSLA-CIUDSAMLSA-N Cys-Leu-Asn Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O SSNJZBGOMNLSLA-CIUDSAMLSA-N 0.000 description 1
- SWJYSDXMTPMBHO-FXQIFTODSA-N Cys-Pro-Ser Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SWJYSDXMTPMBHO-FXQIFTODSA-N 0.000 description 1
- ZKAUCGZIIXXWJQ-BZSNNMDCSA-N Cys-Tyr-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)NC(=O)[C@H](CS)N)O ZKAUCGZIIXXWJQ-BZSNNMDCSA-N 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 238000008157 ELISA kit Methods 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- 241000283074 Equus asinus Species 0.000 description 1
- 108010087819 Fc receptors Proteins 0.000 description 1
- 102000009109 Fc receptors Human genes 0.000 description 1
- 208000022072 Gallbladder Neoplasms Diseases 0.000 description 1
- 201000003741 Gastrointestinal carcinoma Diseases 0.000 description 1
- 206010062878 Gastrooesophageal cancer Diseases 0.000 description 1
- 201000010915 Glioblastoma multiforme Diseases 0.000 description 1
- WUAYFMZULZDSLB-ACZMJKKPSA-N Gln-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O WUAYFMZULZDSLB-ACZMJKKPSA-N 0.000 description 1
- HHWQMFIGMMOVFK-WDSKDSINSA-N Gln-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O HHWQMFIGMMOVFK-WDSKDSINSA-N 0.000 description 1
- RGXXLQWXBFNXTG-CIUDSAMLSA-N Gln-Arg-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O RGXXLQWXBFNXTG-CIUDSAMLSA-N 0.000 description 1
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 1
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 1
- DHNWZLGBTPUTQQ-QEJZJMRPSA-N Gln-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N DHNWZLGBTPUTQQ-QEJZJMRPSA-N 0.000 description 1
- ALUBSZXSNSPDQV-WDSKDSINSA-N Gln-Cys-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O ALUBSZXSNSPDQV-WDSKDSINSA-N 0.000 description 1
- UVAOVENCIONMJP-GUBZILKMSA-N Gln-Cys-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O UVAOVENCIONMJP-GUBZILKMSA-N 0.000 description 1
- LOJYQMFIIJVETK-WDSKDSINSA-N Gln-Gln Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(O)=O LOJYQMFIIJVETK-WDSKDSINSA-N 0.000 description 1
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 1
- PNENQZWRFMUZOM-DCAQKATOSA-N Gln-Glu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O PNENQZWRFMUZOM-DCAQKATOSA-N 0.000 description 1
- JHPFPROFOAJRFN-IHRRRGAJSA-N Gln-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O JHPFPROFOAJRFN-IHRRRGAJSA-N 0.000 description 1
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 1
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 1
- NXPXQIZKDOXIHH-JSGCOSHPSA-N Gln-Gly-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N NXPXQIZKDOXIHH-JSGCOSHPSA-N 0.000 description 1
- IULKWYSYZSURJK-AVGNSLFASA-N Gln-Leu-Lys Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O IULKWYSYZSURJK-AVGNSLFASA-N 0.000 description 1
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 1
- OZEQPCDLCDRCGY-SOUVJXGZSA-N Gln-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)N)N)C(=O)O OZEQPCDLCDRCGY-SOUVJXGZSA-N 0.000 description 1
- ZVQZXPADLZIQFF-FHWLQOOXSA-N Gln-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@H](CCC(N)=O)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 ZVQZXPADLZIQFF-FHWLQOOXSA-N 0.000 description 1
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 1
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 1
- VNTGPISAOMAXRK-CIUDSAMLSA-N Gln-Pro-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O VNTGPISAOMAXRK-CIUDSAMLSA-N 0.000 description 1
- RONJIBWTGKVKFY-HTUGSXCWSA-N Gln-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O RONJIBWTGKVKFY-HTUGSXCWSA-N 0.000 description 1
- ZZLDMBMFKZFQMU-NRPADANISA-N Gln-Val-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O ZZLDMBMFKZFQMU-NRPADANISA-N 0.000 description 1
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 1
- RUFHOVYUYSNDNY-ACZMJKKPSA-N Glu-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O RUFHOVYUYSNDNY-ACZMJKKPSA-N 0.000 description 1
- FYBSCGZLICNOBA-XQXXSGGOSA-N Glu-Ala-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FYBSCGZLICNOBA-XQXXSGGOSA-N 0.000 description 1
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 1
- PCBBLFVHTYNQGG-LAEOZQHASA-N Glu-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N PCBBLFVHTYNQGG-LAEOZQHASA-N 0.000 description 1
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 1
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 1
- CLROYXHHUZELFX-FXQIFTODSA-N Glu-Gln-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CLROYXHHUZELFX-FXQIFTODSA-N 0.000 description 1
- PXHABOCPJVTGEK-BQBZGAKWSA-N Glu-Gln-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O PXHABOCPJVTGEK-BQBZGAKWSA-N 0.000 description 1
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 1
- KASDBWKLWJKTLJ-GUBZILKMSA-N Glu-Glu-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O KASDBWKLWJKTLJ-GUBZILKMSA-N 0.000 description 1
- PHONAZGUEGIOEM-GLLZPBPUSA-N Glu-Glu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PHONAZGUEGIOEM-GLLZPBPUSA-N 0.000 description 1
- OGNJZUXUTPQVBR-BQBZGAKWSA-N Glu-Gly-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OGNJZUXUTPQVBR-BQBZGAKWSA-N 0.000 description 1
- OPAINBJQDQTGJY-JGVFFNPUSA-N Glu-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCC(=O)O)N)C(=O)O OPAINBJQDQTGJY-JGVFFNPUSA-N 0.000 description 1
- VXQOONWNIWFOCS-HGNGGELXSA-N Glu-His-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)O)N VXQOONWNIWFOCS-HGNGGELXSA-N 0.000 description 1
- VGOFRWOTSXVPAU-SDDRHHMPSA-N Glu-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCC(=O)O)N)C(=O)O VGOFRWOTSXVPAU-SDDRHHMPSA-N 0.000 description 1
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 1
- KRRFFAHEAOCBCQ-SIUGBPQLSA-N Glu-Ile-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KRRFFAHEAOCBCQ-SIUGBPQLSA-N 0.000 description 1
- YGLCLCMAYUYZSG-AVGNSLFASA-N Glu-Lys-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 YGLCLCMAYUYZSG-AVGNSLFASA-N 0.000 description 1
- QDMVXRNLOPTPIE-WDCWCFNPSA-N Glu-Lys-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QDMVXRNLOPTPIE-WDCWCFNPSA-N 0.000 description 1
- ZQYZDDXTNQXUJH-CIUDSAMLSA-N Glu-Met-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(=O)O)N ZQYZDDXTNQXUJH-CIUDSAMLSA-N 0.000 description 1
- JDUKCSSHWNIQQZ-IHRRRGAJSA-N Glu-Phe-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O JDUKCSSHWNIQQZ-IHRRRGAJSA-N 0.000 description 1
- QNJNPKSWAHPYGI-JYJNAYRXSA-N Glu-Phe-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=CC=C1 QNJNPKSWAHPYGI-JYJNAYRXSA-N 0.000 description 1
- CBWKURKPYSLMJV-SOUVJXGZSA-N Glu-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CBWKURKPYSLMJV-SOUVJXGZSA-N 0.000 description 1
- CQAHWYDHKUWYIX-YUMQZZPRSA-N Glu-Pro-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O CQAHWYDHKUWYIX-YUMQZZPRSA-N 0.000 description 1
- DCBSZJJHOTXMHY-DCAQKATOSA-N Glu-Pro-Pro Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DCBSZJJHOTXMHY-DCAQKATOSA-N 0.000 description 1
- VNCNWQPIQYAMAK-ACZMJKKPSA-N Glu-Ser-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O VNCNWQPIQYAMAK-ACZMJKKPSA-N 0.000 description 1
- MWTGQXBHVRTCOR-GLLZPBPUSA-N Glu-Thr-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MWTGQXBHVRTCOR-GLLZPBPUSA-N 0.000 description 1
- NTHIHAUEXVTXQG-KKUMJFAQSA-N Glu-Tyr-Arg Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O NTHIHAUEXVTXQG-KKUMJFAQSA-N 0.000 description 1
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 1
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 1
- PYTZFYUXZZHOAD-WHFBIAKZSA-N Gly-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)CN PYTZFYUXZZHOAD-WHFBIAKZSA-N 0.000 description 1
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 1
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 1
- JRDYDYXZKFNNRQ-XPUUQOCRSA-N Gly-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN JRDYDYXZKFNNRQ-XPUUQOCRSA-N 0.000 description 1
- GWCRIHNSVMOBEQ-BQBZGAKWSA-N Gly-Arg-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O GWCRIHNSVMOBEQ-BQBZGAKWSA-N 0.000 description 1
- XUORRGAFUQIMLC-STQMWFEESA-N Gly-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN)O XUORRGAFUQIMLC-STQMWFEESA-N 0.000 description 1
- GRIRDMVMJJDZKV-RCOVLWMOSA-N Gly-Asn-Val Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O GRIRDMVMJJDZKV-RCOVLWMOSA-N 0.000 description 1
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 1
- JLJLBWDKDRYOPA-RYUDHWBXSA-N Gly-Gln-Tyr Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 JLJLBWDKDRYOPA-RYUDHWBXSA-N 0.000 description 1
- DHDOADIPGZTAHT-YUMQZZPRSA-N Gly-Glu-Arg Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DHDOADIPGZTAHT-YUMQZZPRSA-N 0.000 description 1
- FIQQRCFQXGLOSZ-WDSKDSINSA-N Gly-Glu-Asp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FIQQRCFQXGLOSZ-WDSKDSINSA-N 0.000 description 1
- BIRKKBCSAIHDDF-WDSKDSINSA-N Gly-Glu-Cys Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O BIRKKBCSAIHDDF-WDSKDSINSA-N 0.000 description 1
- LHRXAHLCRMQBGJ-RYUDHWBXSA-N Gly-Glu-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)CN LHRXAHLCRMQBGJ-RYUDHWBXSA-N 0.000 description 1
- FSPVILZGHUJOHS-QWRGUYRKSA-N Gly-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CNC=N1 FSPVILZGHUJOHS-QWRGUYRKSA-N 0.000 description 1
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 1
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 1
- UUYBFNKHOCJCHT-VHSXEESVSA-N Gly-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN UUYBFNKHOCJCHT-VHSXEESVSA-N 0.000 description 1
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 1
- SSFWXSNOKDZNHY-QXEWZRGKSA-N Gly-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN SSFWXSNOKDZNHY-QXEWZRGKSA-N 0.000 description 1
- GLACUWHUYFBSPJ-FJXKBIBVSA-N Gly-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN GLACUWHUYFBSPJ-FJXKBIBVSA-N 0.000 description 1
- CSMYMGFCEJWALV-WDSKDSINSA-N Gly-Ser-Gln Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O CSMYMGFCEJWALV-WDSKDSINSA-N 0.000 description 1
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 1
- ABPRMMYHROQBLY-NKWVEPMBSA-N Gly-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)CN)C(=O)O ABPRMMYHROQBLY-NKWVEPMBSA-N 0.000 description 1
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 1
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- FOKISINOENBSDM-WLTAIBSBSA-N Gly-Thr-Tyr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O FOKISINOENBSDM-WLTAIBSBSA-N 0.000 description 1
- CUVBTVWFVIIDOC-YEPSODPASA-N Gly-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)CN CUVBTVWFVIIDOC-YEPSODPASA-N 0.000 description 1
- KOYUSMBPJOVSOO-XEGUGMAKSA-N Gly-Tyr-Ile Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KOYUSMBPJOVSOO-XEGUGMAKSA-N 0.000 description 1
- LYZYGGWCBLBDMC-QWHCGFSZSA-N Gly-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)CN)C(=O)O LYZYGGWCBLBDMC-QWHCGFSZSA-N 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- VPZXBVLAVMBEQI-VKHMYHEASA-N Glycyl-alanine Chemical compound OC(=O)[C@H](C)NC(=O)CN VPZXBVLAVMBEQI-VKHMYHEASA-N 0.000 description 1
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 1
- 102100028972 HLA class I histocompatibility antigen, A alpha chain Human genes 0.000 description 1
- 108010075704 HLA-A Antigens Proteins 0.000 description 1
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 1
- JWTKVPMQCCRPQY-SRVKXCTJSA-N His-Asn-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JWTKVPMQCCRPQY-SRVKXCTJSA-N 0.000 description 1
- HIAHVKLTHNOENC-HGNGGELXSA-N His-Glu-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HIAHVKLTHNOENC-HGNGGELXSA-N 0.000 description 1
- AIPUZFXMXAHZKY-QWRGUYRKSA-N His-Leu-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AIPUZFXMXAHZKY-QWRGUYRKSA-N 0.000 description 1
- SKOKHBGDXGTDDP-MELADBBJSA-N His-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N SKOKHBGDXGTDDP-MELADBBJSA-N 0.000 description 1
- TVMNTHXFRSXZGR-IHRRRGAJSA-N His-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O TVMNTHXFRSXZGR-IHRRRGAJSA-N 0.000 description 1
- ZVKDCQVQTGYBQT-LSJOCFKGSA-N His-Pro-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O ZVKDCQVQTGYBQT-LSJOCFKGSA-N 0.000 description 1
- XJFITURPHAKKAI-SRVKXCTJSA-N His-Pro-Gln Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(N)=O)C(O)=O)C1=CN=CN1 XJFITURPHAKKAI-SRVKXCTJSA-N 0.000 description 1
- YEKYGQZUBCRNGH-DCAQKATOSA-N His-Pro-Ser Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CN=CN2)N)C(=O)N[C@@H](CO)C(=O)O YEKYGQZUBCRNGH-DCAQKATOSA-N 0.000 description 1
- FHKZHRMERJUXRJ-DCAQKATOSA-N His-Ser-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 FHKZHRMERJUXRJ-DCAQKATOSA-N 0.000 description 1
- PZAJPILZRFPYJJ-SRVKXCTJSA-N His-Ser-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O PZAJPILZRFPYJJ-SRVKXCTJSA-N 0.000 description 1
- PFOUFRJYHWZJKW-NKIYYHGXSA-N His-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O PFOUFRJYHWZJKW-NKIYYHGXSA-N 0.000 description 1
- WSXNWASHQNSMRX-GVXVVHGQSA-N His-Val-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N WSXNWASHQNSMRX-GVXVVHGQSA-N 0.000 description 1
- 101000937544 Homo sapiens Beta-2-microglobulin Proteins 0.000 description 1
- 101100220044 Homo sapiens CD34 gene Proteins 0.000 description 1
- 101001009603 Homo sapiens Granzyme B Proteins 0.000 description 1
- 101001033249 Homo sapiens Interleukin-1 beta Proteins 0.000 description 1
- 101000984197 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily A member 2 Proteins 0.000 description 1
- 101000984186 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily B member 4 Proteins 0.000 description 1
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 1
- 101100048372 Human cytomegalovirus (strain AD169) H301 gene Proteins 0.000 description 1
- 101100048373 Human cytomegalovirus (strain Merlin) UL18 gene Proteins 0.000 description 1
- 108010073807 IgG Receptors Proteins 0.000 description 1
- 102000009490 IgG Receptors Human genes 0.000 description 1
- GAZGFPOZOLEYAJ-YTFOTSKYSA-N Ile-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N GAZGFPOZOLEYAJ-YTFOTSKYSA-N 0.000 description 1
- PHRWFSFCNJPWRO-PPCPHDFISA-N Ile-Leu-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N PHRWFSFCNJPWRO-PPCPHDFISA-N 0.000 description 1
- NZGTYCMLUGYMCV-XUXIUFHCSA-N Ile-Lys-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N NZGTYCMLUGYMCV-XUXIUFHCSA-N 0.000 description 1
- FHPZJWJWTWZKNA-LLLHUVSDSA-N Ile-Phe-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N FHPZJWJWTWZKNA-LLLHUVSDSA-N 0.000 description 1
- FGBRXCZYVRFNKQ-MXAVVETBSA-N Ile-Phe-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N FGBRXCZYVRFNKQ-MXAVVETBSA-N 0.000 description 1
- BATWGBRIZANGPN-ZPFDUUQYSA-N Ile-Pro-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BATWGBRIZANGPN-ZPFDUUQYSA-N 0.000 description 1
- CAHCWMVNBZJVAW-NAKRPEOUSA-N Ile-Pro-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)O)N CAHCWMVNBZJVAW-NAKRPEOUSA-N 0.000 description 1
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 1
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 1
- AGGIYSLVUKVOPT-HTFCKZLJSA-N Ile-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N AGGIYSLVUKVOPT-HTFCKZLJSA-N 0.000 description 1
- VGSPNSSCMOHRRR-BJDJZHNGSA-N Ile-Ser-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N VGSPNSSCMOHRRR-BJDJZHNGSA-N 0.000 description 1
- NAFIFZNBSPWYOO-RWRJDSDZSA-N Ile-Thr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N NAFIFZNBSPWYOO-RWRJDSDZSA-N 0.000 description 1
- KWHFUMYCSPJCFQ-NGTWOADLSA-N Ile-Thr-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N KWHFUMYCSPJCFQ-NGTWOADLSA-N 0.000 description 1
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 1
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 206010062016 Immunosuppression Diseases 0.000 description 1
- 102100037850 Interferon gamma Human genes 0.000 description 1
- 102100039065 Interleukin-1 beta Human genes 0.000 description 1
- 102000013462 Interleukin-12 Human genes 0.000 description 1
- 108010065805 Interleukin-12 Proteins 0.000 description 1
- 102000003812 Interleukin-15 Human genes 0.000 description 1
- 108090000172 Interleukin-15 Proteins 0.000 description 1
- 102000003810 Interleukin-18 Human genes 0.000 description 1
- 108090000171 Interleukin-18 Proteins 0.000 description 1
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 1
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 1
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 1
- CNNQBZRGQATKNY-DCAQKATOSA-N Leu-Arg-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N CNNQBZRGQATKNY-DCAQKATOSA-N 0.000 description 1
- UCOCBWDBHCUPQP-DCAQKATOSA-N Leu-Arg-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O UCOCBWDBHCUPQP-DCAQKATOSA-N 0.000 description 1
- DBVWMYGBVFCRBE-CIUDSAMLSA-N Leu-Asn-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DBVWMYGBVFCRBE-CIUDSAMLSA-N 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- KTFHTMHHKXUYPW-ZPFDUUQYSA-N Leu-Asp-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KTFHTMHHKXUYPW-ZPFDUUQYSA-N 0.000 description 1
- CLVUXCBGKUECIT-HJGDQZAQSA-N Leu-Asp-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CLVUXCBGKUECIT-HJGDQZAQSA-N 0.000 description 1
- QKIBIXAQKAFZGL-GUBZILKMSA-N Leu-Cys-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QKIBIXAQKAFZGL-GUBZILKMSA-N 0.000 description 1
- NHHKSOGJYNQENP-SRVKXCTJSA-N Leu-Cys-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N NHHKSOGJYNQENP-SRVKXCTJSA-N 0.000 description 1
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 1
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 1
- BABSVXFGKFLIGW-UWVGGRQHSA-N Leu-Gly-Arg Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N BABSVXFGKFLIGW-UWVGGRQHSA-N 0.000 description 1
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 1
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 1
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 1
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 1
- BTNXKBVLWJBTNR-SRVKXCTJSA-N Leu-His-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O BTNXKBVLWJBTNR-SRVKXCTJSA-N 0.000 description 1
- DBSLVQBXKVKDKJ-BJDJZHNGSA-N Leu-Ile-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O DBSLVQBXKVKDKJ-BJDJZHNGSA-N 0.000 description 1
- ORWTWZXGDBYVCP-BJDJZHNGSA-N Leu-Ile-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC(C)C ORWTWZXGDBYVCP-BJDJZHNGSA-N 0.000 description 1
- KUIDCYNIEJBZBU-AJNGGQMLSA-N Leu-Ile-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O KUIDCYNIEJBZBU-AJNGGQMLSA-N 0.000 description 1
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 1
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 1
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 1
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 1
- YRRCOJOXAJNSAX-IHRRRGAJSA-N Leu-Pro-Lys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N YRRCOJOXAJNSAX-IHRRRGAJSA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- AKVBOOKXVAMKSS-GUBZILKMSA-N Leu-Ser-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O AKVBOOKXVAMKSS-GUBZILKMSA-N 0.000 description 1
- AMSSKPUHBUQBOQ-SRVKXCTJSA-N Leu-Ser-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N AMSSKPUHBUQBOQ-SRVKXCTJSA-N 0.000 description 1
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 1
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 1
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 1
- DAYQSYGBCUKVKT-VOAKCMCISA-N Leu-Thr-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O DAYQSYGBCUKVKT-VOAKCMCISA-N 0.000 description 1
- CNWDWAMPKVYJJB-NUTKFTJISA-N Leu-Trp-Ala Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 CNWDWAMPKVYJJB-NUTKFTJISA-N 0.000 description 1
- YLMIDMSLKLRNHX-HSCHXYMDSA-N Leu-Trp-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YLMIDMSLKLRNHX-HSCHXYMDSA-N 0.000 description 1
- RIHIGSWBLHSGLV-CQDKDKBSSA-N Leu-Tyr-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O RIHIGSWBLHSGLV-CQDKDKBSSA-N 0.000 description 1
- BTEMNFBEAAOGBR-BZSNNMDCSA-N Leu-Tyr-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BTEMNFBEAAOGBR-BZSNNMDCSA-N 0.000 description 1
- 102100025586 Leukocyte immunoglobulin-like receptor subfamily A member 2 Human genes 0.000 description 1
- 102100025578 Leukocyte immunoglobulin-like receptor subfamily B member 4 Human genes 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 1
- SWWCDAGDQHTKIE-RHYQMDGZSA-N Lys-Arg-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWWCDAGDQHTKIE-RHYQMDGZSA-N 0.000 description 1
- FLCMXEFCTLXBTL-DCAQKATOSA-N Lys-Asp-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N FLCMXEFCTLXBTL-DCAQKATOSA-N 0.000 description 1
- MWVUEPNEPWMFBD-SRVKXCTJSA-N Lys-Cys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCCCN MWVUEPNEPWMFBD-SRVKXCTJSA-N 0.000 description 1
- GCMWRRQAKQXDED-IUCAKERBSA-N Lys-Glu-Gly Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)N[C@@H](CCC([O-])=O)C(=O)NCC([O-])=O GCMWRRQAKQXDED-IUCAKERBSA-N 0.000 description 1
- ODUQLUADRKMHOZ-JYJNAYRXSA-N Lys-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)O ODUQLUADRKMHOZ-JYJNAYRXSA-N 0.000 description 1
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 1
- CTBMEDOQJFGNMI-IHPCNDPISA-N Lys-His-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC3=CN=CN3)NC(=O)[C@H](CCCCN)N CTBMEDOQJFGNMI-IHPCNDPISA-N 0.000 description 1
- YUAXTFMFMOIMAM-QWRGUYRKSA-N Lys-Lys-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O YUAXTFMFMOIMAM-QWRGUYRKSA-N 0.000 description 1
- WGILOYIKJVQUPT-DCAQKATOSA-N Lys-Pro-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O WGILOYIKJVQUPT-DCAQKATOSA-N 0.000 description 1
- MIROMRNASYKZNL-ULQDDVLXSA-N Lys-Pro-Tyr Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 MIROMRNASYKZNL-ULQDDVLXSA-N 0.000 description 1
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 1
- PLOUVAYOMTYJRG-JXUBOQSCSA-N Lys-Thr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O PLOUVAYOMTYJRG-JXUBOQSCSA-N 0.000 description 1
- YKBSXQFZWFXFIB-VOAKCMCISA-N Lys-Thr-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O YKBSXQFZWFXFIB-VOAKCMCISA-N 0.000 description 1
- YFQSSOAGMZGXFT-MEYUZBJRSA-N Lys-Thr-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YFQSSOAGMZGXFT-MEYUZBJRSA-N 0.000 description 1
- PELXPRPDQRFBGQ-KKUMJFAQSA-N Lys-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N)O PELXPRPDQRFBGQ-KKUMJFAQSA-N 0.000 description 1
- XATKLFSXFINPSB-JYJNAYRXSA-N Lys-Tyr-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O XATKLFSXFINPSB-JYJNAYRXSA-N 0.000 description 1
- RQILLQOQXLZTCK-KBPBESRZSA-N Lys-Tyr-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O RQILLQOQXLZTCK-KBPBESRZSA-N 0.000 description 1
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 1
- HMZPYMSEAALNAE-ULQDDVLXSA-N Lys-Val-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O HMZPYMSEAALNAE-ULQDDVLXSA-N 0.000 description 1
- 241000282567 Macaca fascicularis Species 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- DZTDEZSHBVRUCQ-FXQIFTODSA-N Met-Asp-Cys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N DZTDEZSHBVRUCQ-FXQIFTODSA-N 0.000 description 1
- TZLYIHDABYBOCJ-FXQIFTODSA-N Met-Asp-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O TZLYIHDABYBOCJ-FXQIFTODSA-N 0.000 description 1
- MCNGIXXCMJAURZ-VEVYYDQMSA-N Met-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCSC)N)O MCNGIXXCMJAURZ-VEVYYDQMSA-N 0.000 description 1
- VOOINLQYUZOREH-SRVKXCTJSA-N Met-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCSC)N VOOINLQYUZOREH-SRVKXCTJSA-N 0.000 description 1
- NDJSSFWDYDUQID-YTWAJWBKSA-N Met-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N)O NDJSSFWDYDUQID-YTWAJWBKSA-N 0.000 description 1
- 101100508544 Mus musculus Il2 gene Proteins 0.000 description 1
- 101001034843 Mus musculus Interferon-induced transmembrane protein 1 Proteins 0.000 description 1
- AUEJLPRZGVVDNU-UHFFFAOYSA-N N-L-tyrosyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CC1=CC=C(O)C=C1 AUEJLPRZGVVDNU-UHFFFAOYSA-N 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 1
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- 108090000284 Pepsin A Proteins 0.000 description 1
- 241000009328 Perro Species 0.000 description 1
- HXSUFWQYLPKEHF-IHRRRGAJSA-N Phe-Asn-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HXSUFWQYLPKEHF-IHRRRGAJSA-N 0.000 description 1
- CSYVXYQDIVCQNU-QWRGUYRKSA-N Phe-Asp-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O CSYVXYQDIVCQNU-QWRGUYRKSA-N 0.000 description 1
- CUMXHKAOHNWRFQ-BZSNNMDCSA-N Phe-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CUMXHKAOHNWRFQ-BZSNNMDCSA-N 0.000 description 1
- FSPGBMWPNMRWDB-AVGNSLFASA-N Phe-Cys-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N FSPGBMWPNMRWDB-AVGNSLFASA-N 0.000 description 1
- FIRWJEJVFFGXSH-RYUDHWBXSA-N Phe-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 FIRWJEJVFFGXSH-RYUDHWBXSA-N 0.000 description 1
- BIYWZVCPZIFGPY-QWRGUYRKSA-N Phe-Gly-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CO)C(O)=O BIYWZVCPZIFGPY-QWRGUYRKSA-N 0.000 description 1
- BWTKUQPNOMMKMA-FIRPJDEBSA-N Phe-Ile-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BWTKUQPNOMMKMA-FIRPJDEBSA-N 0.000 description 1
- RSPUIENXSJYZQO-JYJNAYRXSA-N Phe-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RSPUIENXSJYZQO-JYJNAYRXSA-N 0.000 description 1
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 1
- IIEOLPMQYRBZCN-SRVKXCTJSA-N Phe-Ser-Cys Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O IIEOLPMQYRBZCN-SRVKXCTJSA-N 0.000 description 1
- MVIJMIZJPHQGEN-IHRRRGAJSA-N Phe-Ser-Val Chemical compound CC(C)[C@@H](C([O-])=O)NC(=O)[C@H](CO)NC(=O)[C@@H]([NH3+])CC1=CC=CC=C1 MVIJMIZJPHQGEN-IHRRRGAJSA-N 0.000 description 1
- RAGOJJCBGXARPO-XVSYOHENSA-N Phe-Thr-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RAGOJJCBGXARPO-XVSYOHENSA-N 0.000 description 1
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 1
- BAONJAHBAUDJKA-BZSNNMDCSA-N Phe-Tyr-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=CC=C1 BAONJAHBAUDJKA-BZSNNMDCSA-N 0.000 description 1
- JTKGCYOOJLUETJ-ULQDDVLXSA-N Phe-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 JTKGCYOOJLUETJ-ULQDDVLXSA-N 0.000 description 1
- 229920001054 Poly(ethylene‐co‐vinyl acetate) Polymers 0.000 description 1
- 229920002732 Polyanhydride Polymers 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- LNLNHXIQPGKRJQ-SRVKXCTJSA-N Pro-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 LNLNHXIQPGKRJQ-SRVKXCTJSA-N 0.000 description 1
- SSSFPISOZOLQNP-GUBZILKMSA-N Pro-Arg-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSFPISOZOLQNP-GUBZILKMSA-N 0.000 description 1
- ZSKJPKFTPQCPIH-RCWTZXSCSA-N Pro-Arg-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZSKJPKFTPQCPIH-RCWTZXSCSA-N 0.000 description 1
- TUYWCHPXKQTISF-LPEHRKFASA-N Pro-Cys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N2CCC[C@@H]2C(=O)O TUYWCHPXKQTISF-LPEHRKFASA-N 0.000 description 1
- PZSCUPVOJGKHEP-CIUDSAMLSA-N Pro-Gln-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PZSCUPVOJGKHEP-CIUDSAMLSA-N 0.000 description 1
- SNIPWBQKOPCJRG-CIUDSAMLSA-N Pro-Gln-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O SNIPWBQKOPCJRG-CIUDSAMLSA-N 0.000 description 1
- UPJGUQPLYWTISV-GUBZILKMSA-N Pro-Gln-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UPJGUQPLYWTISV-GUBZILKMSA-N 0.000 description 1
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 1
- LGSANCBHSMDFDY-GARJFASQSA-N Pro-Glu-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O LGSANCBHSMDFDY-GARJFASQSA-N 0.000 description 1
- UUHXBJHVTVGSKM-BQBZGAKWSA-N Pro-Gly-Asn Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O UUHXBJHVTVGSKM-BQBZGAKWSA-N 0.000 description 1
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 1
- PEYNRYREGPAOAK-LSJOCFKGSA-N Pro-His-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C([O-])=O)NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 PEYNRYREGPAOAK-LSJOCFKGSA-N 0.000 description 1
- AUQGUYPHJSMAKI-CYDGBPFRSA-N Pro-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 AUQGUYPHJSMAKI-CYDGBPFRSA-N 0.000 description 1
- CLJLVCYFABNTHP-DCAQKATOSA-N Pro-Leu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O CLJLVCYFABNTHP-DCAQKATOSA-N 0.000 description 1
- FKYKZHOKDOPHSA-DCAQKATOSA-N Pro-Leu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FKYKZHOKDOPHSA-DCAQKATOSA-N 0.000 description 1
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 1
- WIPAMEKBSHNFQE-IUCAKERBSA-N Pro-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@@H]1CCCN1 WIPAMEKBSHNFQE-IUCAKERBSA-N 0.000 description 1
- HWLKHNDRXWTFTN-GUBZILKMSA-N Pro-Pro-Cys Chemical compound C1C[C@H](NC1)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CS)C(=O)O HWLKHNDRXWTFTN-GUBZILKMSA-N 0.000 description 1
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 1
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 1
- SEZGGSHLMROBFX-CIUDSAMLSA-N Pro-Ser-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O SEZGGSHLMROBFX-CIUDSAMLSA-N 0.000 description 1
- ITUDDXVFGFEKPD-NAKRPEOUSA-N Pro-Ser-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ITUDDXVFGFEKPD-NAKRPEOUSA-N 0.000 description 1
- SNGZLPOXVRTNMB-LPEHRKFASA-N Pro-Ser-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N2CCC[C@@H]2C(=O)O SNGZLPOXVRTNMB-LPEHRKFASA-N 0.000 description 1
- RMJZWERKFFNNNS-XGEHTFHBSA-N Pro-Thr-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O RMJZWERKFFNNNS-XGEHTFHBSA-N 0.000 description 1
- XNJVJEHDZPDPQL-BZSNNMDCSA-N Pro-Trp-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@@H]1CCCN1)C(O)=O XNJVJEHDZPDPQL-BZSNNMDCSA-N 0.000 description 1
- YHUBAXGAAYULJY-ULQDDVLXSA-N Pro-Tyr-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O YHUBAXGAAYULJY-ULQDDVLXSA-N 0.000 description 1
- QKWYXRPICJEQAJ-KJEVXHAQSA-N Pro-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@@H]2CCCN2)O QKWYXRPICJEQAJ-KJEVXHAQSA-N 0.000 description 1
- IMNVAOPEMFDAQD-NHCYSSNCSA-N Pro-Val-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IMNVAOPEMFDAQD-NHCYSSNCSA-N 0.000 description 1
- FHJQROWZEJFZPO-SRVKXCTJSA-N Pro-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 FHJQROWZEJFZPO-SRVKXCTJSA-N 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 238000001190 Q-PCR Methods 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 208000015634 Rectal Neoplasms Diseases 0.000 description 1
- 208000006265 Renal cell carcinoma Diseases 0.000 description 1
- MMGJPDWSIOAGTH-ACZMJKKPSA-N Ser-Ala-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MMGJPDWSIOAGTH-ACZMJKKPSA-N 0.000 description 1
- DWUIECHTAMYEFL-XVYDVKMFSA-N Ser-Ala-His Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 DWUIECHTAMYEFL-XVYDVKMFSA-N 0.000 description 1
- BRKHVZNDAOMAHX-BIIVOSGPSA-N Ser-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N BRKHVZNDAOMAHX-BIIVOSGPSA-N 0.000 description 1
- GXXTUIUYTWGPMV-FXQIFTODSA-N Ser-Arg-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O GXXTUIUYTWGPMV-FXQIFTODSA-N 0.000 description 1
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 1
- OOKCGAYXSNJBGQ-ZLUOBGJFSA-N Ser-Asn-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OOKCGAYXSNJBGQ-ZLUOBGJFSA-N 0.000 description 1
- UBRXAVQWXOWRSJ-ZLUOBGJFSA-N Ser-Asn-Asp Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)C(=O)N UBRXAVQWXOWRSJ-ZLUOBGJFSA-N 0.000 description 1
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 1
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 1
- KNZQGAUEYZJUSQ-ZLUOBGJFSA-N Ser-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N KNZQGAUEYZJUSQ-ZLUOBGJFSA-N 0.000 description 1
- FTVRVZNYIYWJGB-ACZMJKKPSA-N Ser-Asp-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FTVRVZNYIYWJGB-ACZMJKKPSA-N 0.000 description 1
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 1
- BGOWRLSWJCVYAQ-CIUDSAMLSA-N Ser-Asp-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BGOWRLSWJCVYAQ-CIUDSAMLSA-N 0.000 description 1
- XWCYBVBLJRWOFR-WDSKDSINSA-N Ser-Gln-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O XWCYBVBLJRWOFR-WDSKDSINSA-N 0.000 description 1
- VMVNCJDKFOQOHM-GUBZILKMSA-N Ser-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N VMVNCJDKFOQOHM-GUBZILKMSA-N 0.000 description 1
- BRIZMMZEYSAKJX-QEJZJMRPSA-N Ser-Glu-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N BRIZMMZEYSAKJX-QEJZJMRPSA-N 0.000 description 1
- MIJWOJAXARLEHA-WDSKDSINSA-N Ser-Gly-Glu Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O MIJWOJAXARLEHA-WDSKDSINSA-N 0.000 description 1
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 1
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 1
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 1
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 1
- OQPNSDWGAMFJNU-QWRGUYRKSA-N Ser-Gly-Tyr Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OQPNSDWGAMFJNU-QWRGUYRKSA-N 0.000 description 1
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 1
- ZIFYDQAFEMIZII-GUBZILKMSA-N Ser-Leu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZIFYDQAFEMIZII-GUBZILKMSA-N 0.000 description 1
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 1
- KCGIREHVWRXNDH-GARJFASQSA-N Ser-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N KCGIREHVWRXNDH-GARJFASQSA-N 0.000 description 1
- PPNPDKGQRFSCAC-CIUDSAMLSA-N Ser-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPNPDKGQRFSCAC-CIUDSAMLSA-N 0.000 description 1
- QPPYAWVLAVXISR-DCAQKATOSA-N Ser-Pro-His Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CO)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O QPPYAWVLAVXISR-DCAQKATOSA-N 0.000 description 1
- XGQKSRGHEZNWIS-IHRRRGAJSA-N Ser-Pro-Tyr Chemical compound N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O XGQKSRGHEZNWIS-IHRRRGAJSA-N 0.000 description 1
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 1
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 1
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 1
- JCLAFVNDBJMLBC-JBDRJPRFSA-N Ser-Ser-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JCLAFVNDBJMLBC-JBDRJPRFSA-N 0.000 description 1
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 1
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 1
- PCJLFYBAQZQOFE-KATARQTJSA-N Ser-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N)O PCJLFYBAQZQOFE-KATARQTJSA-N 0.000 description 1
- ZKOKTQPHFMRSJP-YJRXYDGGSA-N Ser-Thr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKOKTQPHFMRSJP-YJRXYDGGSA-N 0.000 description 1
- AXKJPUBALUNJEO-UBHSHLNASA-N Ser-Trp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O AXKJPUBALUNJEO-UBHSHLNASA-N 0.000 description 1
- FHXGMDRKJHKLKW-QWRGUYRKSA-N Ser-Tyr-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 FHXGMDRKJHKLKW-QWRGUYRKSA-N 0.000 description 1
- LLSLRQOEAFCZLW-NRPADANISA-N Ser-Val-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LLSLRQOEAFCZLW-NRPADANISA-N 0.000 description 1
- JZRYFUGREMECBH-XPUUQOCRSA-N Ser-Val-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O JZRYFUGREMECBH-XPUUQOCRSA-N 0.000 description 1
- MFQMZDPAZRZAPV-NAKRPEOUSA-N Ser-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CO)N MFQMZDPAZRZAPV-NAKRPEOUSA-N 0.000 description 1
- RCOUFINCYASMDN-GUBZILKMSA-N Ser-Val-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O RCOUFINCYASMDN-GUBZILKMSA-N 0.000 description 1
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 1
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 1
- 208000032383 Soft tissue cancer Diseases 0.000 description 1
- 241000191940 Staphylococcus Species 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 1
- 101150037769 TRX2 gene Proteins 0.000 description 1
- 208000024313 Testicular Neoplasms Diseases 0.000 description 1
- 206010057644 Testis cancer Diseases 0.000 description 1
- TYVAWPFQYFPSBR-BFHQHQDPSA-N Thr-Ala-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)NCC(O)=O TYVAWPFQYFPSBR-BFHQHQDPSA-N 0.000 description 1
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 1
- GLQFKOVWXPPFTP-VEVYYDQMSA-N Thr-Arg-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O GLQFKOVWXPPFTP-VEVYYDQMSA-N 0.000 description 1
- MQBTXMPQNCGSSZ-OSUNSFLBSA-N Thr-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)O)CCCN=C(N)N MQBTXMPQNCGSSZ-OSUNSFLBSA-N 0.000 description 1
- VXMHQKHDKCATDV-VEVYYDQMSA-N Thr-Asp-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VXMHQKHDKCATDV-VEVYYDQMSA-N 0.000 description 1
- ODSAPYVQSLDRSR-LKXGYXEUSA-N Thr-Cys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O ODSAPYVQSLDRSR-LKXGYXEUSA-N 0.000 description 1
- DSLHSTIUAPKERR-XGEHTFHBSA-N Thr-Cys-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O DSLHSTIUAPKERR-XGEHTFHBSA-N 0.000 description 1
- VUVCRYXYUUPGSB-GLLZPBPUSA-N Thr-Gln-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O VUVCRYXYUUPGSB-GLLZPBPUSA-N 0.000 description 1
- UHBPFYOQQPFKQR-JHEQGTHGSA-N Thr-Gln-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O UHBPFYOQQPFKQR-JHEQGTHGSA-N 0.000 description 1
- GKWNLDNXMMLRMC-GLLZPBPUSA-N Thr-Glu-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O GKWNLDNXMMLRMC-GLLZPBPUSA-N 0.000 description 1
- CYVQBKQYQGEELV-NKIYYHGXSA-N Thr-His-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O CYVQBKQYQGEELV-NKIYYHGXSA-N 0.000 description 1
- YUOCMLNTUZAGNF-KLHWPWHYSA-N Thr-His-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N)O YUOCMLNTUZAGNF-KLHWPWHYSA-N 0.000 description 1
- JRAUIKJSEAKTGD-TUBUOCAGSA-N Thr-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N JRAUIKJSEAKTGD-TUBUOCAGSA-N 0.000 description 1
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 1
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 1
- ISLDRLHVPXABBC-IEGACIPQSA-N Thr-Leu-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ISLDRLHVPXABBC-IEGACIPQSA-N 0.000 description 1
- BDGBHYCAZJPLHX-HJGDQZAQSA-N Thr-Lys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BDGBHYCAZJPLHX-HJGDQZAQSA-N 0.000 description 1
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 1
- XSEPSRUDSPHMPX-KATARQTJSA-N Thr-Lys-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O XSEPSRUDSPHMPX-KATARQTJSA-N 0.000 description 1
- KKPOGALELPLJTL-MEYUZBJRSA-N Thr-Lys-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KKPOGALELPLJTL-MEYUZBJRSA-N 0.000 description 1
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 1
- WNQJTLATMXYSEL-OEAJRASXSA-N Thr-Phe-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O WNQJTLATMXYSEL-OEAJRASXSA-N 0.000 description 1
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 1
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 1
- GVMXJJAJLIEASL-ZJDVBMNYSA-N Thr-Pro-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O GVMXJJAJLIEASL-ZJDVBMNYSA-N 0.000 description 1
- IWAVRIPRTCJAQO-HSHDSVGOSA-N Thr-Pro-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O IWAVRIPRTCJAQO-HSHDSVGOSA-N 0.000 description 1
- FWTFAZKJORVTIR-VZFHVOOUSA-N Thr-Ser-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O FWTFAZKJORVTIR-VZFHVOOUSA-N 0.000 description 1
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 1
- UQCNIMDPYICBTR-KYNKHSRBSA-N Thr-Thr-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UQCNIMDPYICBTR-KYNKHSRBSA-N 0.000 description 1
- ZMYCLHFLHRVOEA-HEIBUPTGSA-N Thr-Thr-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ZMYCLHFLHRVOEA-HEIBUPTGSA-N 0.000 description 1
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 1
- KHTIUAKJRUIEMA-HOUAVDHOSA-N Thr-Trp-Asp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O)=CNC2=C1 KHTIUAKJRUIEMA-HOUAVDHOSA-N 0.000 description 1
- XGUAUKUYQHBUNY-SWRJLBSHSA-N Thr-Trp-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(O)=O XGUAUKUYQHBUNY-SWRJLBSHSA-N 0.000 description 1
- LXXCHJKHJYRMIY-FQPOAREZSA-N Thr-Tyr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O LXXCHJKHJYRMIY-FQPOAREZSA-N 0.000 description 1
- KAJRRNHOVMZYBL-IRIUXVKKSA-N Thr-Tyr-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAJRRNHOVMZYBL-IRIUXVKKSA-N 0.000 description 1
- QNXZCKMXHPULME-ZNSHCXBVSA-N Thr-Val-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O QNXZCKMXHPULME-ZNSHCXBVSA-N 0.000 description 1
- 208000003721 Triple Negative Breast Neoplasms Diseases 0.000 description 1
- PXYJUECTGMGIDT-WDSOQIARSA-N Trp-Arg-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 PXYJUECTGMGIDT-WDSOQIARSA-N 0.000 description 1
- TWJDQTTXXZDJKV-BPUTZDHNSA-N Trp-Arg-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O TWJDQTTXXZDJKV-BPUTZDHNSA-N 0.000 description 1
- OFCKFBGRYHOKFP-IHPCNDPISA-N Trp-Asp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N OFCKFBGRYHOKFP-IHPCNDPISA-N 0.000 description 1
- UDCHKDYNMRJYMI-QEJZJMRPSA-N Trp-Glu-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UDCHKDYNMRJYMI-QEJZJMRPSA-N 0.000 description 1
- NLWCSMOXNKBRLC-WDSOQIARSA-N Trp-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLWCSMOXNKBRLC-WDSOQIARSA-N 0.000 description 1
- VOCHZIJXPRBVSI-XIRDDKMYSA-N Trp-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N VOCHZIJXPRBVSI-XIRDDKMYSA-N 0.000 description 1
- FBGDDUKYOBNZJL-WDSOQIARSA-N Trp-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N FBGDDUKYOBNZJL-WDSOQIARSA-N 0.000 description 1
- BOBZBMOTRORUPT-XIRDDKMYSA-N Trp-Ser-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 BOBZBMOTRORUPT-XIRDDKMYSA-N 0.000 description 1
- ZGTKIODEJMUQOT-WIRXVTQYSA-N Trp-Trp-Tyr Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=C(O)C=C1 ZGTKIODEJMUQOT-WIRXVTQYSA-N 0.000 description 1
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 1
- NOXKHHXSHQFSGJ-FQPOAREZSA-N Tyr-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NOXKHHXSHQFSGJ-FQPOAREZSA-N 0.000 description 1
- KSVMDJJCYKIXTK-IGNZVWTISA-N Tyr-Ala-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 KSVMDJJCYKIXTK-IGNZVWTISA-N 0.000 description 1
- HTHCZRWCFXMENJ-KKUMJFAQSA-N Tyr-Arg-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HTHCZRWCFXMENJ-KKUMJFAQSA-N 0.000 description 1
- ADBDQGBDNUTRDB-ULQDDVLXSA-N Tyr-Arg-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O ADBDQGBDNUTRDB-ULQDDVLXSA-N 0.000 description 1
- CKKFTIQYURNSEI-IHRRRGAJSA-N Tyr-Asn-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CKKFTIQYURNSEI-IHRRRGAJSA-N 0.000 description 1
- VTFWAGGJDRSQFG-MELADBBJSA-N Tyr-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O VTFWAGGJDRSQFG-MELADBBJSA-N 0.000 description 1
- JWHOIHCOHMZSAR-QWRGUYRKSA-N Tyr-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JWHOIHCOHMZSAR-QWRGUYRKSA-N 0.000 description 1
- VFJIWSJKZJTQII-SRVKXCTJSA-N Tyr-Asp-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O VFJIWSJKZJTQII-SRVKXCTJSA-N 0.000 description 1
- QHEGAOPHISYNDF-XDTLVQLUSA-N Tyr-Gln-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QHEGAOPHISYNDF-XDTLVQLUSA-N 0.000 description 1
- HZZKQZDUIKVFDZ-AVGNSLFASA-N Tyr-Gln-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)O HZZKQZDUIKVFDZ-AVGNSLFASA-N 0.000 description 1
- SLCSPPCQWUHPPO-JYJNAYRXSA-N Tyr-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SLCSPPCQWUHPPO-JYJNAYRXSA-N 0.000 description 1
- OSMTVLSRTQDWHJ-JBACZVJFSA-N Tyr-Glu-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=C(O)C=C1 OSMTVLSRTQDWHJ-JBACZVJFSA-N 0.000 description 1
- CNLKDWSAORJEMW-KWQFWETISA-N Tyr-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O CNLKDWSAORJEMW-KWQFWETISA-N 0.000 description 1
- FNWGDMZVYBVAGJ-XEGUGMAKSA-N Tyr-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC1=CC=C(C=C1)O)N FNWGDMZVYBVAGJ-XEGUGMAKSA-N 0.000 description 1
- WSFXJLFSJSXGMQ-MGHWNKPDSA-N Tyr-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N WSFXJLFSJSXGMQ-MGHWNKPDSA-N 0.000 description 1
- QARCDOCCDOLJSF-HJPIBITLSA-N Tyr-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QARCDOCCDOLJSF-HJPIBITLSA-N 0.000 description 1
- YMUQBRQQCPQEQN-CXTHYWKRSA-N Tyr-Ile-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N YMUQBRQQCPQEQN-CXTHYWKRSA-N 0.000 description 1
- HSBZWINKRYZCSQ-KKUMJFAQSA-N Tyr-Lys-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O HSBZWINKRYZCSQ-KKUMJFAQSA-N 0.000 description 1
- SINRIKQYQJRGDQ-MEYUZBJRSA-N Tyr-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SINRIKQYQJRGDQ-MEYUZBJRSA-N 0.000 description 1
- LMKKMCGTDANZTR-BZSNNMDCSA-N Tyr-Phe-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 LMKKMCGTDANZTR-BZSNNMDCSA-N 0.000 description 1
- AUZADXNWQMBZOO-JYJNAYRXSA-N Tyr-Pro-Arg Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C1=CC=C(O)C=C1 AUZADXNWQMBZOO-JYJNAYRXSA-N 0.000 description 1
- RWOKVQUCENPXGE-IHRRRGAJSA-N Tyr-Ser-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RWOKVQUCENPXGE-IHRRRGAJSA-N 0.000 description 1
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 1
- LDKDSFQSEUOCOO-RPTUDFQQSA-N Tyr-Thr-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LDKDSFQSEUOCOO-RPTUDFQQSA-N 0.000 description 1
- WQOHKVRQDLNDIL-YJRXYDGGSA-N Tyr-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O WQOHKVRQDLNDIL-YJRXYDGGSA-N 0.000 description 1
- YMZYSCDRTXEOKD-IHPCNDPISA-N Tyr-Trp-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N YMZYSCDRTXEOKD-IHPCNDPISA-N 0.000 description 1
- QRCBQDPRKMYTMB-IHPCNDPISA-N Tyr-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N QRCBQDPRKMYTMB-IHPCNDPISA-N 0.000 description 1
- GZWPQZDVTBZVEP-BZSNNMDCSA-N Tyr-Tyr-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O GZWPQZDVTBZVEP-BZSNNMDCSA-N 0.000 description 1
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 1
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 1
- JFAWZADYPRMRCO-UBHSHLNASA-N Val-Ala-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JFAWZADYPRMRCO-UBHSHLNASA-N 0.000 description 1
- ZLFHAAGHGQBQQN-AEJSXWLSSA-N Val-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZLFHAAGHGQBQQN-AEJSXWLSSA-N 0.000 description 1
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 1
- JLFKWDAZBRYCGX-ZKWXMUAHSA-N Val-Asn-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N JLFKWDAZBRYCGX-ZKWXMUAHSA-N 0.000 description 1
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 1
- ZQGPWORGSNRQLN-NHCYSSNCSA-N Val-Asp-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N ZQGPWORGSNRQLN-NHCYSSNCSA-N 0.000 description 1
- YODDULVCGFQRFZ-ZKWXMUAHSA-N Val-Asp-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YODDULVCGFQRFZ-ZKWXMUAHSA-N 0.000 description 1
- LHADRQBREKTRLR-DCAQKATOSA-N Val-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N LHADRQBREKTRLR-DCAQKATOSA-N 0.000 description 1
- AGKDVLSDNSTLFA-UMNHJUIQSA-N Val-Gln-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N AGKDVLSDNSTLFA-UMNHJUIQSA-N 0.000 description 1
- OXVPMZVGCAPFIG-BQFCYCMXSA-N Val-Gln-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N OXVPMZVGCAPFIG-BQFCYCMXSA-N 0.000 description 1
- MHAHQDBEIDPFQS-NHCYSSNCSA-N Val-Glu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C MHAHQDBEIDPFQS-NHCYSSNCSA-N 0.000 description 1
- OQWNEUXPKHIEJO-NRPADANISA-N Val-Glu-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N OQWNEUXPKHIEJO-NRPADANISA-N 0.000 description 1
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 1
- ZIGZPYJXIWLQFC-QTKMDUPCSA-N Val-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N)O ZIGZPYJXIWLQFC-QTKMDUPCSA-N 0.000 description 1
- UKEVLVBHRKWECS-LSJOCFKGSA-N Val-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](C(C)C)N UKEVLVBHRKWECS-LSJOCFKGSA-N 0.000 description 1
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 1
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 1
- AJNUKMZFHXUBMK-GUBZILKMSA-N Val-Ser-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N AJNUKMZFHXUBMK-GUBZILKMSA-N 0.000 description 1
- RYHUIHUOYRNNIE-NRPADANISA-N Val-Ser-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RYHUIHUOYRNNIE-NRPADANISA-N 0.000 description 1
- TVGWMCTYUFBXAP-QTKMDUPCSA-N Val-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N)O TVGWMCTYUFBXAP-QTKMDUPCSA-N 0.000 description 1
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 1
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 1
- YLBNZCJFSVJDRJ-KJEVXHAQSA-N Val-Thr-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O YLBNZCJFSVJDRJ-KJEVXHAQSA-N 0.000 description 1
- DFQZDQPLWBSFEJ-LSJOCFKGSA-N Val-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N DFQZDQPLWBSFEJ-LSJOCFKGSA-N 0.000 description 1
- ZLNYBMWGPOKSLW-LSJOCFKGSA-N Val-Val-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLNYBMWGPOKSLW-LSJOCFKGSA-N 0.000 description 1
- ZHWZDZFWBXWPDW-GUBZILKMSA-N Val-Val-Cys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O ZHWZDZFWBXWPDW-GUBZILKMSA-N 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 108010081404 acein-2 Proteins 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 108010011559 alanylphenylalanine Proteins 0.000 description 1
- 108010070783 alanyltyrosine Proteins 0.000 description 1
- 238000009175 antibody therapy Methods 0.000 description 1
- 238000011319 anticancer therapy Methods 0.000 description 1
- 239000002246 antineoplastic agent Substances 0.000 description 1
- 229940041181 antineoplastic drug Drugs 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 239000012736 aqueous medium Substances 0.000 description 1
- 108010008355 arginyl-glutamine Proteins 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- 108010038633 aspartylglutamate Proteins 0.000 description 1
- 229960003852 atezolizumab Drugs 0.000 description 1
- 229920000249 biocompatible polymer Polymers 0.000 description 1
- 238000007622 bioinformatic analysis Methods 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 210000002798 bone marrow cell Anatomy 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 235000011132 calcium sulphate Nutrition 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 231100000504 carcinogenesis Toxicity 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 208000006990 cholangiocarcinoma Diseases 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 238000011198 co-culture assay Methods 0.000 description 1
- 201000010897 colon adenocarcinoma Diseases 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 238000009096 combination chemotherapy Methods 0.000 description 1
- 230000002301 combined effect Effects 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 238000004132 cross linking Methods 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 108010016616 cysteinylglycine Proteins 0.000 description 1
- 108010060199 cysteinylproline Proteins 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 239000003405 delayed action preparation Substances 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 230000002939 deleterious effect Effects 0.000 description 1
- 229910052805 deuterium Inorganic materials 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000002405 diagnostic procedure Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- POULHZVOKOAJMA-UHFFFAOYSA-M dodecanoate Chemical compound CCCCCCCCCCCC([O-])=O POULHZVOKOAJMA-UHFFFAOYSA-M 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 238000004836 empirical method Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 235000019441 ethanol Nutrition 0.000 description 1
- 125000004494 ethyl ester group Chemical group 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- 208000024519 eye neoplasm Diseases 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- BDAGIHXWWSANSR-UHFFFAOYSA-N formic acid Substances OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 1
- 230000005714 functional activity Effects 0.000 description 1
- 201000010175 gallbladder cancer Diseases 0.000 description 1
- 201000006974 gastroesophageal cancer Diseases 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 208000005017 glioblastoma Diseases 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 150000002334 glycols Chemical class 0.000 description 1
- 108010051307 glycyl-glycyl-proline Proteins 0.000 description 1
- 108010089804 glycyl-threonine Proteins 0.000 description 1
- 230000002489 hematologic effect Effects 0.000 description 1
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 1
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 1
- 229940022353 herceptin Drugs 0.000 description 1
- 108010040030 histidinoalanine Proteins 0.000 description 1
- 108010025306 histidylleucine Proteins 0.000 description 1
- 108010085325 histidylproline Proteins 0.000 description 1
- 108010018006 histidylserine Proteins 0.000 description 1
- 102000047279 human B2M Human genes 0.000 description 1
- 238000011577 humanized mouse model Methods 0.000 description 1
- 239000000017 hydrogel Substances 0.000 description 1
- 229940031574 hydroxymethyl cellulose Drugs 0.000 description 1
- 229920003063 hydroxymethyl cellulose Polymers 0.000 description 1
- 230000005934 immune activation Effects 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 230000003308 immunostimulating effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000000126 in silico method Methods 0.000 description 1
- 238000007901 in situ hybridization Methods 0.000 description 1
- 210000004969 inflammatory cell Anatomy 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 238000011081 inoculation Methods 0.000 description 1
- 201000002313 intestinal cancer Diseases 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 108010078274 isoleucylvaline Proteins 0.000 description 1
- 238000012004 kinetic exclusion assay Methods 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 229940070765 laurate Drugs 0.000 description 1
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 1
- 108010000761 leucylarginine Proteins 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- 108010009298 lysylglutamic acid Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 238000002705 metabolomic analysis Methods 0.000 description 1
- 230000001431 metabolomic effect Effects 0.000 description 1
- 230000001394 metastastic effect Effects 0.000 description 1
- 206010061289 metastatic neoplasm Diseases 0.000 description 1
- 239000004530 micro-emulsion Substances 0.000 description 1
- 238000002493 microarray Methods 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 239000003094 microcapsule Substances 0.000 description 1
- 239000004005 microsphere Substances 0.000 description 1
- 239000003607 modifier Substances 0.000 description 1
- 238000003032 molecular docking Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- 210000000066 myeloid cell Anatomy 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 230000025020 negative regulation of T cell proliferation Effects 0.000 description 1
- 201000011682 nervous system cancer Diseases 0.000 description 1
- 230000003472 neutralizing effect Effects 0.000 description 1
- 229910052759 nickel Inorganic materials 0.000 description 1
- 229960003301 nivolumab Drugs 0.000 description 1
- 238000001668 nucleic acid synthesis Methods 0.000 description 1
- 201000008106 ocular cancer Diseases 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 230000000174 oncolytic effect Effects 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 229940043515 other immunoglobulins in atc Drugs 0.000 description 1
- 230000001590 oxidative effect Effects 0.000 description 1
- 239000006179 pH buffering agent Substances 0.000 description 1
- 230000000242 pagocytic effect Effects 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 210000004976 peripheral blood cell Anatomy 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 230000003285 pharmacodynamic effect Effects 0.000 description 1
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 1
- 108010025488 pinealon Proteins 0.000 description 1
- 229920001200 poly(ethylene-vinyl acetate) Polymers 0.000 description 1
- 229920001223 polyethylene glycol Polymers 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 238000007639 printing Methods 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 238000004393 prognosis Methods 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- 238000012514 protein characterization Methods 0.000 description 1
- 230000004853 protein function Effects 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 206010038038 rectal cancer Diseases 0.000 description 1
- 201000001275 rectum cancer Diseases 0.000 description 1
- 201000010174 renal carcinoma Diseases 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 235000010356 sorbitol Nutrition 0.000 description 1
- 208000017572 squamous cell neoplasm Diseases 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 239000007858 starting material Substances 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 210000002084 suppressor macrophage Anatomy 0.000 description 1
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 229940066453 tecentriq Drugs 0.000 description 1
- 201000003120 testicular cancer Diseases 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 125000003396 thiol group Chemical group [H]S* 0.000 description 1
- 210000001685 thyroid gland Anatomy 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 206010044412 transitional cell carcinoma Diseases 0.000 description 1
- 238000002054 transplantation Methods 0.000 description 1
- 229960000575 trastuzumab Drugs 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- 208000022679 triple-negative breast carcinoma Diseases 0.000 description 1
- 108010045269 tryptophyltryptophan Proteins 0.000 description 1
- 230000005740 tumor formation Effects 0.000 description 1
- 230000004614 tumor growth Effects 0.000 description 1
- 230000005760 tumorsuppression Effects 0.000 description 1
- 108010078580 tyrosylleucine Proteins 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 201000005112 urinary bladder cancer Diseases 0.000 description 1
- 208000037964 urogenital cancer Diseases 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 238000009736 wetting Methods 0.000 description 1
- 108010027345 wheylin-1 peptide Proteins 0.000 description 1
- 238000002424 x-ray crystallography Methods 0.000 description 1
Images


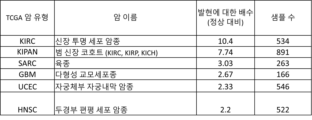








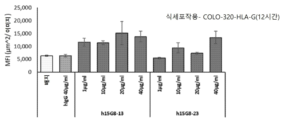
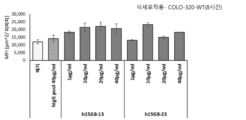
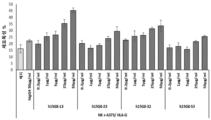




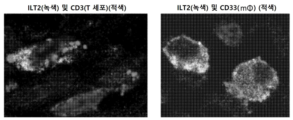
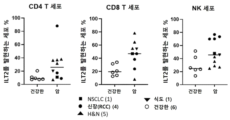
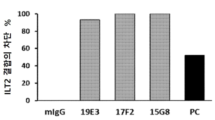


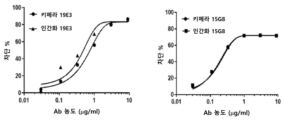


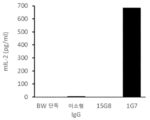

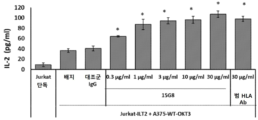
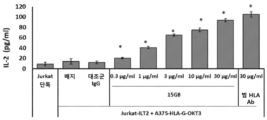


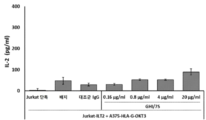







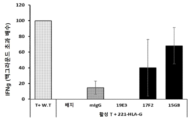











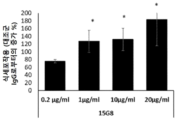

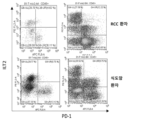








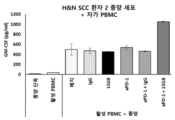








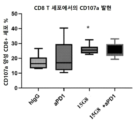

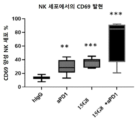







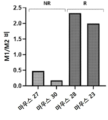



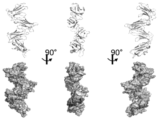




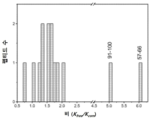










Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6854—Immunoglobulins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
- A61K2039/507—Comprising a combination of two or more separate antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/71—Decreased effector function due to an Fc-modification
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Veterinary Medicine (AREA)
- Hematology (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Biomedical Technology (AREA)
- Urology & Nephrology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Microbiology (AREA)
- Cell Biology (AREA)
- Biotechnology (AREA)
- Food Science & Technology (AREA)
- Physics & Mathematics (AREA)
- Analytical Chemistry (AREA)
- General Physics & Mathematics (AREA)
- Pathology (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Peptides Or Proteins (AREA)
- Acyclic And Carbocyclic Compounds In Medicinal Compositions (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
본 개시는 단일클론 항-ILT2 항체 또는 이의 항원 결합 단편뿐만 아니라 이를 포함하는 약학적 조성물 및 이의 제조 방법을 제공한다. 또한 본 개시의 항체 또는 조성물을 사용하여 암을 치료하는 방법이 제공된다. 또한 환자 선택 방법이 제공된다.
Description
기술분야
본 발명은 단일클론 항체 및 암에 대한 면역 반응의 조절 분야에 관한 것이다.
관련 출원에 대한 상호 참조
본 출원은 2020년 8월 12일에 출원된 PCT 특허출원 PCT/IL2020/050889, 2021년 2월 4일에 출원된 미국 특허 가출원 제63/145,604호, 및 2021년 2월 15일에 출원된 미국 특허 가출원 제63/149,371호의 우선권 이익을 주장한다. 이들 우선권 출원의 개시는 그 전체가 본원에 참조로 포함된다.
서열 목록
본 출원에는 ASCII 형식으로 전자 제출되었고 그 전체가 본원에 참조로 포함되는 서열 목록이 포함된다. 2021년 8월 10일에 생성된 서열 목록의 전자 사본은 022548_WO091_SL.txt로 명명되며 105,080킬로바이트 크기이다.
백혈구 면역글로불린 유사 수용체 서브패밀리 B 구성원 1(LILRB1), LIR1, 및 CD85j로도 알려져 있는 면역글로불린 유사 전사체 2(ILT2)는 면역 세포에서 발현되는 세포 표면 단백질로, 면역반응을 억제하는 것으로 알려져 있다. 이 단백질은 세포외 영역에 4개의 IgC 도메인 및 4개의 세포내 ITIM 도메인을 함유한다. 이는 ILT1, ILT2, ILT3, 및 ILT4로 구성된 ILT 패밀리의 구성원이다. ILT2는 약 80% 상동성을 갖는 ILT4와 가장 유사하다. ILT2의 알려진 리간드에는 MHC-I뿐만 아니라 비전형적 MHC 분자, 예컨대 HLA-F, HLA-G, HLA-B27, 및 UL18(인간 CMV)이 포함된다. 인간에서 ILT2의 알려진 가장 강력한 상호작용인자는 HLA-G1이다.
HLA-G1은 유방암, 자궁경부암, 결장직장암(CRC), 폐암, 위암, 췌장암, 갑상선암, 및 난소암 세포뿐만 아니라 다형성 교모세포종 세포 및 흑색종 세포를 포함한, 다양한 암세포의 표면에서 광범위하게 발현된다. 이 발현은 좋지 않은 임상 결과와 연관된다. 또한 종양 미세환경에서 면역 세포 상의 ILT2 발현은, HLA-G1이 존재하지 않는 경우에도, 종양분해 면역 요법에 대한 임상 반응이 좋지 않은 것과 관련이 있다. 암에 대한 무기로서 그리고 암 감시를 위해 면역 반응을 활용하는 것은 암 예방 및 치료를 위한 유망한 방법이다. 그러나 ILT2는 효과적인 면역 요법에 대한 장애물을 제시한다. ILT2의 HLA-G1-독립적 기능뿐만 아니라 ILT2-HLA-G1 축을 우회할 수 있는 치료 방식이 크게 요구된다.
본 개시는 ILT2에 결합하여 ILT2-매개 면역 억제를 억제하는 단일클론 항체 및 이를 포함하는 약학적 조성물을 제공한다. 또한 본원에 기재된 조성물을 투여하는 단계를 포함하는 암 치료 방법, 본원에 기재된 항체, 항원 결합 단편, 및 조성물을 생성하는 방법, 및 PD-1/PD-L1 기반 요법의 효능을 증가시키는 방법이 제공된다.
일 양태에 따르면, 서열번호 41 내지 44 및 68 내지 70으로부터 선택된 인간 면역글로불린-유사 수용체 서브패밀리 B 구성원 1(ILT2)의 서열에 결합하는 단일클론 항체 또는 항원 결합 단편이 제공된다.
일부 구현예에 따르면, 서열은 서열번호 68 내지 70으로부터 선택된다.
일부 구현예에 따르면, 서열은 서열번호 71 또는 72이다.
일부 구현예에 따르면, 항체 또는 항원 결합 단편은 서열번호 71 및 72에 결합한다.
일부 구현예에 따르면, 본 개시의 항체 또는 항원 결합 단편은 ILT2에 결합하고 ILT2와 베타-2-마이크로글로불린(B2M) 사이의 직접적인 상호작용을 억제한다.
일부 구현예에 따르면, 항체 또는 항원 결합 단편은 ILT2의 B2M과의 직접적인 상호작용의 억제를 통해 ILT2와 HLA 단백질 또는 MHC-I 단백질의 상호작용을 억제한다.
일부 구현예에 따르면, HLA는 HLA-G이다.
일부 구현예에 따르면, 항체는 IgG4 항체이고, S228P 및 L235E 돌연변이(Eu 넘버링)를 포함하는 인간 IgG4 항체의 중쇄 불변 영역을 포함한다.
일 양태에 따르면, 3개의 중쇄 CDR(CDR-H1-3) 및 3개의 경쇄 CDR(CDR-L1-3)을 포함하는 단일클론 항-ILT2 IgG4 항체로서, CDR-H1-3 및 CDR-L1-3는
a.
각각 서열번호 13 내지 18,
b.
각각 서열번호 1 내지 6, 또는
c.
각각 서열번호 7 내지 12
를 포함하고,
항체는 인간 IgG4 항체의 중쇄 불변 영역을 포함하고, 중쇄 불변 영역에 S228P 및 L235E 돌연변이(Eu 넘버링) 중 하나 또는 둘 모두를 포함하는, 단일클론 항-ILT2 IgG4 항체가 제공된다.
일부 구현예에 따르면, 본 개시의 항체는 서열번호 19, 21, 및 23으로부터 선택된 아미노산 서열, 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 중쇄 가변 도메인을 포함한다.
일부 구현예에 따르면, 본 개시의 항체는 서열번호 20, 22, 24, 및 45로부터 선택된 아미노산 서열, 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 경쇄 가변 도메인을 포함한다.
일부 구현예에 따르면, 서열번호 15에서 X는 A이고, 중쇄는 서열번호 28 및 56 내지 59로부터 선택된 가변 도메인 서열, 또는 이와 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에 따르면, 경쇄는 서열번호 24 및 60 내지 62로부터 선택된 가변 도메인 서열, 또는 이와 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에 따르면, 중쇄 불변 영역은 서열번호 55, 또는 이와 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에 따르면, 중쇄는 서열번호 48 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 경쇄는 서열번호 49 또는 이와 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에 따르면, 중쇄는 서열번호 51 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 경쇄는 서열번호 49 또는 이와 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에 따르면, 중쇄는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 경쇄는 서열번호 49 또는 이와 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에 따르면, 중쇄는 서열번호 64 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 경쇄는 서열번호 49 또는 이와 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에 따르면, 중쇄는 서열번호 65의 아미노산 서열 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 경쇄는 서열번호 66 또는 이와 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에 따르면, 중쇄는 서열번호 67 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 경쇄는 서열번호 49 또는 이와 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에 따르면, 중쇄는 서열번호 53 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 경쇄는 서열번호 54 또는 이와 적어도 95% 동일한 아미노산 서열을 포함한다.
일 양태에 따르면, 각각 서열번호 48 및 49를 포함하는 중쇄 및 경쇄를 포함하는 단일클론 항체가 제공된다.
일부 구현예에 따르면, 본 개시의 항체 또는 항체 결합 단편은 ILT2의 결합, 항-종양 T 세포 반응의 유도/강화, T 세포 증식 증가, 암 유발 억제인자 골수 활성 감소, 자연 살해 세포 세포독성 증가, 대식세포 식세포작용 증가, M1 염증성 대식세포 생성 증가, M2 억제인자 대식세포 생성 감소, 종양 미세 환경에서의 수지상 세포 수 증가, 수지상 세포 활성화 증가, HLA-G 발현 암 치료, 및 MHC-I 발현 암 치료 중 적어도 하나에 사용하기 위한 것이다.
일부 구현예에 따르면, 본 개시의 항체 또는 항체 결합 단편은 HLA-G 또는 MHC-I 발현 암의 치료를 위해 옵소닌화제와 조합하여 사용하기 위한 것이다.
일부 구현예에 따르면, 본 개시의 항체 또는 항체 결합 단편은 HLA-G 또는 MHC-I 발현 암의 치료를 위해 항-PD-L1/PD-1 기반 요법(예를 들어 면역요법)과 조합하여 사용하기 위한 것이다. 특정 구현예에서, 항-PD-L1/PD-1 기반 요법은 펨브롤리주맙 요법이다.
일 양태에 따르면, 본 개시의 항체 또는 항원 결합 단편을 포함하는 약학적 조성물이 제공된다.
일 양태에 따르면, HLA-G 또는 MHC-I 발현 암의 치료를 필요로 하는 대상체에서 이를 치료하는 방법으로서, 본 개시의 약학적 조성물 또는 본 개시의 항체 또는 항원 결합 단편을 대상체에게 투여하는 단계를 포함하는 방법이 제공된다.
일 양태에 따르면, HLA-G 또는 MHC-I을 발현하는 암세포에 대한 항-PD-L1/PD-1 기반 요법의 효능 증가를 필요로 하는 대상체에서 이의 효능을 증가시키는 방법으로서, 항-PD-L1/PD-1 기반 요법을 받는 대상체에게 본 개시의 약학적 조성물 또는 본 개시의 항체 또는 항원 결합 단편을 투여하는 단계를 포함하는 방법이 제공된다.
일부 구현예에 따르면, 해당 방법은 대상체에게 옵소닌화제를 투여하는 단계를 추가로 포함한다.
일부 구현예에 따르면, 옵소닌화제는 EGFR 억제제이고, 임의로 EGFR 억제제는 세툭시맙이다.
일부 구현예에 따르면, 해당 방법은 대상체에게 항-PD-L1/PD-1 기반 요법(예를 들어 면역요법)을 투여하는 단계를 추가로 포함한다. 특정 구현예에서, 항-PD-L1/PD-1 기반 면역요법은 펨브롤리주맙 요법이다.
일 양태에 따르면, ILT2에 대한 결합에 대해, 중쇄 및 경쇄가 각각 서열번호 48 및 49를 포함하는 기준 항체와 경쟁하는 항체를 확인하는 방법으로서, 항체 라이브러리를 서열번호 41 내지 44 및 68 내지 70으로부터 선택된 ILT2 서열을 포함하는 폴리펩티드 서열과 접촉시키는 단계, 및 라이브러리로부터 ILT2 서열에 결합하는 항체를 선택하여 ILT2에 대한 결합에 대해 상기 기준 항체와 경쟁하는 항체를 수득하는 단계를 포함하는 방법을 제공한다.
일 양태에 따르면, 제제(예를 들어 ILT2-결합 단백질 또는 분자)를 생성하는 방법으로서, 서열번호 41 내지 44 및 68 내지 70으로부터 선택된 인간 ILT2의 서열에 결합하는 제제를 수득하는 단계, 또는 서열번호 41 내지 44 및 68 내지 70으로부터 선택된 인간 ILT2의 서열에 결합하는 제제를 암호화하는 하나 이상의 뉴클레오티드 서열을 포함하는 숙주 세포를 수득하는 단계, 및 제제의 발현이 가능한 조건 하에서 숙주 세포를 배양하여 제제를 생성하는 단계를 포함하는 방법이 제공된다. 일부 구현예에 따르면, 제제는 서열번호 68 내지 70으로부터 선택된 서열에 결합한다. 일부 구현예에 따르면, 분자는 서열번호 71 및 72 중 하나 또는 둘 모두에 결합한다. 일부 구현예에 따르면, 제제는 서열번호 71 및 72에 결합한다.
일 양태에 따르면, 본 개시의 방법에 의해 생성된 제제가 제공된다.
일 양태에 따르면, 본 개시의 항체 또는 항원 결합 단편을 암호화하는 단리된 핵산 분자가 제공된다. 일부 구현예에서, 핵산 분자는 발현 벡터이다.
일 양태에 따르면, 본 개시의 단리된 핵산 분자를 포함하는 숙주 세포가 제공된다.
본 개시의 추가 구현예 및 적용가능 전체 범위는 이하 제공되는 상세한 설명으로부터 명백해질 것이다. 그러나 본 개시의 사상 및 범위 내의 다양한 변경 및 수정이 이 상세한 설명으로부터 당업자에게 명백해질 것이므로, 상세한 설명 및 특정 실시예는 본 개시의 바람직한 구현예를 나타내지만, 단지 예시로서만 제공되는 것으로 이해되어야 한다.
도 1. 림프구 상에서 ILT2의 발현을 나타낸 히스토그램. 5 μg/mL 최종 농도의 상용 항체 #1을 사용하였다. 결합은 검은색 히스토그램으로 표시된 반면 이소형 대조군 염색은 밝은 회색 히스토그램으로 표시되었다.
도 2. 다양한 면역 세포 상에서 ILT2의 발현을 나타낸 히스토그램. 5 μg/mL 최종 농도의 상용 항체 #1을 사용하였다. 결합은 검은색 히스토그램으로 표시된 반면 이소형 대조군 염색은 밝은 회색 히스토그램으로 표시되어 있다.
도 3a 내지 도 3c. (도 3a) ILT2 RNA가 과발현되는 TCGA 데이터베이스로부터의 암 적응증 표. (도 3b) 종양에서의 골수 유래 억제 세포(MDSC) 강화와 ILT2 발현 사이의 상관관계 점 도표. 또한, M2 강화와 ILT2 발현 사이의 상관 관계를 나타낸 막대 그래프 제공. (도 3c) 상이한 종양에서 ILT2를 발현하는 다양한 면역 세포의 백분율 산점도.
도 4a 및 4b. (도 4a) 면역조직화학(IHC)에 의해 확인된 바에 따른 HLA-G 양성인 다양한 암에 대한 사례 백분율의 막대 그래프. (도 4b) 다양한 암에 대한 HLA-G IHC 점수의 산점도.
도 5. 다양한 암에서 가용성 HLA-G 수준의 산점도.
도 6a 내지 6h. (도 6a) 3개의 항-ILT2 항체의 중쇄 및 경쇄의 서열. KABAT 시스템에 따라 결정된 CDR은 밑줄로 표시하였다. (도 6b) 인간 ILT2로 형질감염된 BW 세포의 표면 상에 발현된 ILT2에 대한 인간화 15G8 항체의 결합을 나타낸 선 그래프. 해당 그래프는 2차 항체 단독과 비교하여, 상이한 시험 항체의 FAB(fold above background) 수준을 나타낸 것이다. (도 6c 내지 6f) 15G8 항체의 존재 하에 대식세포와 함께 배양된 (도 6c) A375-HLA-G, (도 6d) COLO-320-WT, (도 6e) COLO-320-WT, 및 (도 6f) COLO-320-HLA-G에 대한 식세포 사례의 평균 형광 강도(MFI)로서 식세포작용을 측정한 막대 그래프. (6g 내지 6h) 15G8 항체의 존재 하에 (도 6g) A375-HLA-G 및 (도 6h) A253 WT를 발현하는 다양한 암 세포주와 공동배양된 NK 세포주 세포로부터의 세포독성 백분율을 나타낸 막대 그래프.
도 7a 내지 7e. (도 7a) ILT2 및 ILT2 패밀리 구성원에 대한 항체 결합값의 표. (도 7b) 인간 ILT2로 형질감염된 BW 세포의 세포 표면 상의 ILT2에 대한 항체 결합을 나타낸 히스토그램 (도 7c) 인간 ILT2로 형질감염된 BW 세포의 표면 상에 발현된 ILT2에 대한 키메라 및 인간화 19E3(좌측 패널) 및 키메라 및 인간화 15G8(우측 패널)의 결합을 나타낸 선 그래프. (도 7d) 19E3 항체를 사용한 위암 샘플 상의 면역염색. (도 7e) 15G8 인간화 항체를 사용하여, 건강한 대조군 및 암 환자로부터의 PBMC 샘플에서 ILT2를 발현하는 다양한 면역 세포의 백분율을 나타낸 산점도.
도 8a 내지 8p. (도 8a) 각각의 ILT2 항체 및 양성 대조군(PC, GHI/75 항체)에 대한 차단 백분율의 막대 그래프. (도 8b) ILT2 차단 항체의 존재 하에 HLA-G를 발현하는 세포에 대한 ILT2-비오틴 결합을 나타낸 히스토그램. 세포에 대한 ILT2-비오틴의 결합은 Streptavidin-PE를 사용하여 유세포 분석으로 확인하였다. 항체 없음(회색선), 15G8(밝은 회색선), 이소형 대조군(검은색선). (도 8c) HLA-G를 발현하는 세포에 대한 ILT2-비오틴 결합에 의해 결정된 15G8 인간화 항체의 차단 활성의 선 그래프. (도 8d) 항체의 존재 하에 HLA-G를 발현하는 세포에 대한 ILT2-비오틴의 결합에 의해 결정된 키메라 및 인간화 19E3(좌측 패널) 및 키메라 및 인간화 15G8(우측 패널)의 차단 활성의 선 그래프. (도 8e) HLA-G-발현 세포의 존재 하에 및 ILT2 차단 항체의 존재 또는 부재 하에 ILT2 신호전달 리포터 구성체를 발현하는 세포로부터의 마우스 IL-2 분비의 막대 그래프. PC = 양성 대조군(GHI/75 항체). (도 8f) 리포터 분석에 의해 확인된 15G8 인간화 항체의 차단 활성의 선 그래프. (도 8g) ILT2 차단 항체 및 양성 대조군 항체의 존재 또는 부재 하에 ILT2 신호전달 리포터 구성체를 발현하는 세포로부터의 마우스 IL-2 분비의 막대 그래프. (도 8h 내지 8k) (도 8h) ILT2가 없거나, (도 8i 내지 8k) (도 8i) MHC-I 발현만을 갖거나, (도 8j 내지 8k) ILT2 차단 항체 및 양성 대조군 (도 8i 내지 8j) 범-HLA 항체 또는 (도 8k) HLA-G 특이적 항체의 존재 또는 부재 하에 MHC-I 및 외인성 HLA-G를 모두 발현하는, A375 암세포와 공동 배양된 ILT2를 발현하는, Jurkat 세포로부터의 인간 IL-2 분비의 막대 그래프. (도 8l 내지 8n) (도 8l) 15G8 항체, (도 8m) GHI/75 항체, 및 (도 8n) HP-F1 항체의 존재 또는 부재 하에 HLA-G를 발현하는 A375 암세포와 배양된 ILT2를 발현하는 Jurakt 세포로부터의 인간 IL-2 분비의 막대 그래프. (도 8o 내지 8p) 15G8 항체의 존재 및 존재 없이 HLA-G-양성 암세포와 인큐베이션된, 각각 TIL 세포 및 NK 세포에서의, 활성화 마커 (도 8o) 인산화된 ZAP70 및 (도 8p) 인산화된 Syk의 발현의 점 도표.
도 9a 내지 9d. (도 9a) FACS 기반 방법에 의해 결정된 ILT2 항체의 존재 하에 대식세포와 공동배양된 HLA-G 발현 암세포의 대조군으로부터의 백분율로서 식세포작용을 측정한 막대 그래프. (도 9b) Incucyte® 시스템에 의해 결정된 ILT2 항체의 존재 하에 대식세포에 의한 암세포의 실시간 식세포작용의 선 그래프. (도 9c) ILT2 항체 15G8의 존재 하에 대식세포와 공동배양된 다양한 HLA-G 및 MHC-I 발현 암세포의 대조군으로부터의 백분율로서 식세포작용을 측정한 막대 그래프. (도 9d) ILT2 항체, 세툭시맙(Erbitux®), hIgG 대조군, 또는 이들의 조합의 존재 하에 A253-HLA-G 세포와 공동배양된 대식세포에 의한 식세포작용의 막대 그래프.
도 10a 및 10b. ILT2 항체의 존재 하에 (도 10a) 야생형 721.221 세포 또는 HLA-G 발현 721.221 세포 또는 (도 10b) HLA-G 발현 A375 세포와 공동배양된 활성화된 CD8 T 세포로부터의 IFNγ 분비 및 그랜자임 B 분비의 막대 그래프.
도 11a 내지 11h. (도 11a 및 11b) ILT2 항체의 존재 하에 (도 11a) HLA-G 및 (도 11b) MHC-I를 발현하는 다양한 암 세포주와 공동배양된 NK 세포주 세포로부터의 세포독성 백분율의 막대 그래프. (도 11c 및 11d) 15G8 ILT2 항체의 존재 하에 각각 H&N 암 및 흑색종 세포와 공동배양된 NK 세포주 세포로부터의 (도 11c) 그랜자임 B 및 (도 11d) IFNγ 분비의 막대 그래프. (도 11e 및 11f) ILT2 항체의 존재 하에 표적 암세포와 인큐베이션된 ILT2 양성 1차 NK 세포에서의 (도 11e) IFNγ 발현 및 (도 11f) CD107A 발현의 막대 그래프. (도 11g 및 11h) ILT2 항체에 반응하는 ILT2 양성 세포와 (도 11g) IFNγ 발현 및 (도 11h) CD107A 발현의 상관관계를 보여주는 개별 발현의 산점도.
도 12. IgG 또는 항-ILT2 항체의 존재 하에 건강한 공여자로부터 단리된 단핵구로부터 M0, M1, 또는 M2 대식세포로 분화된 대식세포에서의 유세포 분석으로 확인된 HLA-DR 및 CD80 발현(MFI)의 선 그래프. 대조군 IgG 대비, 특정 마커의 발현의 증가를 나타낸 환자의 수를 시험한 각 조건에 대해 나타내었다.
도 13a 내지 13c. (도 13a) 다양한 원발성 종양 세포와 공동배양된 대식세포에 의한 식세포작용의 막대 그래프. (도 13b 및 13c) 본 개시의 인간화 항체의 존재 하에 자가 대식세포에 의한 (도 13b) RCC 환자 및 (도 13c) H&N 환자로부터 단리된 원발성 종양 세포의 용량 의존적 식세포작용의 막대 그래프.
도 14a 내지 14l. (도 14a) RCC 및 식도암 환자의 종양 세포(좌측 패널) 및 PBMC(우측 패널)에서의 ILT2 및 PD-1 발현의 점 도표. (도 14b 및 14c) CRC 환자의 TME에서 CD8 T 세포 집단에서 (도 14b) PD-1 및 (도 14c) ILT2 RNA 발현의 박스 및 휘스커 플롯. (도 14d 및 14e) 건강한 공여자의 말초 혈액으로부터의 CD8 T 세포에서 (도 14d) ILT2 발현 및 식도암으로부터의 TIL에서 (도 14e) ILT2 및 PD-1 발현의 점 도표. (도 14f) 15G8, 항-PD-1 항체 또는 이 둘의 조합의 존재 하에 스타필로코커스 내독소 B(SEB)로 활성화된 10명의 건강한 공여자로부터의 PBMC 상에서 막 CD107a에서의 증가 산점도. (도 14g) 3명의 공여자로부터의 예시적 PBMC에서의 발현에서 CD107a 증가의 막대 그래프. (도 14h 내지 14j) 항-PD-1 항체, 인간화 항-ILT2 항체, 또는 둘 다의 존재 하에 다양한 원발성 암세포와 공동배양된 활성화된 PBMC로부터의 염증성 사이토카인 (도 14h) IFNγ, (도 14i) TNFα, (도 14j) GM-CSF 분비 수준의 막대 차트. (도 14k 및 14l). 혼합 림프구 반응에서 (도 14k) 수지상 세포 또는 (도 14l) 대식세포와 공동배양된 T 세포로부터의 IFNγ 분비 수준의 막대 차트.
도 15a 내지 15f. (도 15a) 인간 대식세포 및 항-ILT2 항체가 보충된 면역 손상된 마우스에서 성장시킨 HLA-G 및 MHC-I 발현 종양의 종양 부피의 선 그래프. (도 15b). 폐 종양 예방을 위한 마우스 치료 일정 예시. (도 15c) 인간 PBMC 및 ILT2 항체를 포함하거나 포함하지 않는 HLA-G 양성 암세포가 접종된 면역 손상된 마우스의 폐 사진. (도 15d) 도 15c의 데이터를 요약한 산점도. (도 15e) 이미 확립된 폐 종양을 치료하기 위한 마우스 치료 일정의 예시. (도 15f) 종양 중량의 박스 및 휘스커 플롯.
도 16a 내지 16f. (도 16a 내지 16f) (도 16a) 전체 CD8 T 세포에서의 CD107A 발현, (도 16b) TEMRA 세포에서의 CD107A 발현, (도 16c) NK 세포에서의 CD69 발현, (도 16d) 전체 CD8 T 세포에서의 CD69 발현, (도 16e) TEMRA 세포에서의 CD107 발현, 및 (도 16f) 각각 이의 TEMRA 세포 또는 NK 세포에서 저수준 또는 고수준의 ILT2를 갖는 공여자로부터의 PBMC를 투여받은 마우스에서 조합 처리된 NK 세포에서의 CD69 발현의 상자 및 휘스커 플롯. *은 P가 0.005미만이다. **은 P가 0.0005미만이다. ***은 P가 0.0001미만이다.
도 17a 내지 17h. (도 17a) 두경부암이 접종되고 항-ILT2 또는 대조군 항체로 처치된 인간화 NSG 마우스에 대한 치료 일정의 예시. (도 17b) IgG 및 항-ILT2로 처치된 마우스로부터의 종양 중량의 선 그래프. (도 17c 내지 17e) BND-22 처치에 반응하거나(R) 반응하지 않은(NR) 마우스의 말초 CD8 T 세포에서의 (도 17c) 기준선 ILT2 수준의 막대 그래프. 종양-내 처치-후 항-ILT2 항체로 처치된 4마리의 마우스에서의 (도 17d) CD107A 발현, (도 17e) M1/M2 비율, 및 (도 17f) 총 CD80 양성 수지상 세포 수.
도 18a 내지 18f. (도 18a) 유의미한 예측 결합을 갖는 잔기를 나타내는 ILT2의 부분 서열. 이들 잔기는 에피토프에 속할 원시 확률의 함수로서 4개의 범주로 나뉜다. 별표는 선택된 돌연변이의 위치를 나타낸다. (도 18b 및 18c) (도 18b) 18a로부터의 잔기의 위치 및 (도 18c) ILT2 상의 4개의 주요 상호작용 영역을 나타내는 ILT2 표면 구조의 3D 렌더링. (도 18d 내지 18f) (도 18d) 15G8 항체의 에피토프 및 WO2020/136145로부터의 3H5, 12D12, 및 27H5 항체의 에피토프(좌측 상단 원), 뿐만 아니라 3H5 항체의 이차 에피토프(우측 상단 원) 및 (도 18e 및18f) (도 18e) HLA-A 또는 (도 18f) HLA-G와 복합체를 이루는 B2M과 ILT2 상의 15G8 에피토프의 상호작용을 나타내는 ILT2의 3D 리본 또는 표면 다이어그램.
도 19a 내지 19g. ILT2-15G8 복합체에 대한 유리 ILT2의 보호 비율 분포. (도 19a) ILT2 단백질의 트립신 분해로부터 도출된 데이터의 막대 차트. 분포의 중앙값은 1.5이고 평균은 1.37이다. (도 19b) ILT2 단백질의 트립신 및 Asp-N 분해로부터 도출된 데이터의 막대 차트. 분포의 중앙값은 1.58이고 평균은 1.48이다. 선택된 보호 영역을 표시하였다. (도 19c 내지 19g) 복합체에 대한 유리 ILT2 펩티드의 용량-반응 플롯 비교. 사각형과 원이 있는 선은 각각 대조군 및 복합체를 나타낸다. (도 19c) 펩티드 56 내지 71: 유리 ILT2 K = 9.09 s-1, 복합체 K = 2.31 s-1은 복합체 형성의 결과로서 3.94배 감소를 나타냄. (도 19d) 펩티드 57 내지 71: 유리 ILT2 K = 6.93 s-1, 복합체 K = 1.97 s-1은 복합체 형성의 결과로서 3.52배 감소를 나타냄. (도 19e) 펩티드 84 내지 100: 유리 ILT2 K = 1.26 s-1, 복합체 K = 0.37 s-1은 복합체 형성의 결과로서 3.41배 감소를 나타냄. (도 19f) 펩티드 57 내지 66: 유리 ILT2 K = 4.32 s-1, 복합체 K = 0.72 s-1은 복합체 형성의 결과로서 6배 감소를 나타냄. (도 19g) 펩티드 91 내지 100: 유리 ILT2 K = 0.7 s-1, 복합체 K = 0.14 s-1은 복합체 형성의 결과로서 5배 감소를 나타냄.
도 20. ELISA 분석에서 15G8 또는 비관련 항체의 존재 하에 인간 B2M에 대한 ILT2-Fc의 결합 그래프.
도 21a 내지 21d. (도 21a 및 21b) 다양한 항-ILT2 항체의 존재 하에 대식세포와 공동배양된 (도 21a) A375-HLA-G 및 (도 21b) SKMEL28-HLA-G 암세포의 IgG 대조군 대비 식세포작용의 백분율(%) 증가 막대 그래프. (도 21c 및 21d) 경쟁하는 비-비오틴화 (도 21c) GHI/75, HP-F1, 및 (도 21d) MAB20172, 및 15G8 항체의 존재 하에 비오틴화 15G8 항체를 사용한 경쟁 ILT2 결합 ELISA의 선 그래프.
도 2. 다양한 면역 세포 상에서 ILT2의 발현을 나타낸 히스토그램. 5 μg/mL 최종 농도의 상용 항체 #1을 사용하였다. 결합은 검은색 히스토그램으로 표시된 반면 이소형 대조군 염색은 밝은 회색 히스토그램으로 표시되어 있다.
도 3a 내지 도 3c. (도 3a) ILT2 RNA가 과발현되는 TCGA 데이터베이스로부터의 암 적응증 표. (도 3b) 종양에서의 골수 유래 억제 세포(MDSC) 강화와 ILT2 발현 사이의 상관관계 점 도표. 또한, M2 강화와 ILT2 발현 사이의 상관 관계를 나타낸 막대 그래프 제공. (도 3c) 상이한 종양에서 ILT2를 발현하는 다양한 면역 세포의 백분율 산점도.
도 4a 및 4b. (도 4a) 면역조직화학(IHC)에 의해 확인된 바에 따른 HLA-G 양성인 다양한 암에 대한 사례 백분율의 막대 그래프. (도 4b) 다양한 암에 대한 HLA-G IHC 점수의 산점도.
도 5. 다양한 암에서 가용성 HLA-G 수준의 산점도.
도 6a 내지 6h. (도 6a) 3개의 항-ILT2 항체의 중쇄 및 경쇄의 서열. KABAT 시스템에 따라 결정된 CDR은 밑줄로 표시하였다. (도 6b) 인간 ILT2로 형질감염된 BW 세포의 표면 상에 발현된 ILT2에 대한 인간화 15G8 항체의 결합을 나타낸 선 그래프. 해당 그래프는 2차 항체 단독과 비교하여, 상이한 시험 항체의 FAB(fold above background) 수준을 나타낸 것이다. (도 6c 내지 6f) 15G8 항체의 존재 하에 대식세포와 함께 배양된 (도 6c) A375-HLA-G, (도 6d) COLO-320-WT, (도 6e) COLO-320-WT, 및 (도 6f) COLO-320-HLA-G에 대한 식세포 사례의 평균 형광 강도(MFI)로서 식세포작용을 측정한 막대 그래프. (6g 내지 6h) 15G8 항체의 존재 하에 (도 6g) A375-HLA-G 및 (도 6h) A253 WT를 발현하는 다양한 암 세포주와 공동배양된 NK 세포주 세포로부터의 세포독성 백분율을 나타낸 막대 그래프.
도 7a 내지 7e. (도 7a) ILT2 및 ILT2 패밀리 구성원에 대한 항체 결합값의 표. (도 7b) 인간 ILT2로 형질감염된 BW 세포의 세포 표면 상의 ILT2에 대한 항체 결합을 나타낸 히스토그램 (도 7c) 인간 ILT2로 형질감염된 BW 세포의 표면 상에 발현된 ILT2에 대한 키메라 및 인간화 19E3(좌측 패널) 및 키메라 및 인간화 15G8(우측 패널)의 결합을 나타낸 선 그래프. (도 7d) 19E3 항체를 사용한 위암 샘플 상의 면역염색. (도 7e) 15G8 인간화 항체를 사용하여, 건강한 대조군 및 암 환자로부터의 PBMC 샘플에서 ILT2를 발현하는 다양한 면역 세포의 백분율을 나타낸 산점도.
도 8a 내지 8p. (도 8a) 각각의 ILT2 항체 및 양성 대조군(PC, GHI/75 항체)에 대한 차단 백분율의 막대 그래프. (도 8b) ILT2 차단 항체의 존재 하에 HLA-G를 발현하는 세포에 대한 ILT2-비오틴 결합을 나타낸 히스토그램. 세포에 대한 ILT2-비오틴의 결합은 Streptavidin-PE를 사용하여 유세포 분석으로 확인하였다. 항체 없음(회색선), 15G8(밝은 회색선), 이소형 대조군(검은색선). (도 8c) HLA-G를 발현하는 세포에 대한 ILT2-비오틴 결합에 의해 결정된 15G8 인간화 항체의 차단 활성의 선 그래프. (도 8d) 항체의 존재 하에 HLA-G를 발현하는 세포에 대한 ILT2-비오틴의 결합에 의해 결정된 키메라 및 인간화 19E3(좌측 패널) 및 키메라 및 인간화 15G8(우측 패널)의 차단 활성의 선 그래프. (도 8e) HLA-G-발현 세포의 존재 하에 및 ILT2 차단 항체의 존재 또는 부재 하에 ILT2 신호전달 리포터 구성체를 발현하는 세포로부터의 마우스 IL-2 분비의 막대 그래프. PC = 양성 대조군(GHI/75 항체). (도 8f) 리포터 분석에 의해 확인된 15G8 인간화 항체의 차단 활성의 선 그래프. (도 8g) ILT2 차단 항체 및 양성 대조군 항체의 존재 또는 부재 하에 ILT2 신호전달 리포터 구성체를 발현하는 세포로부터의 마우스 IL-2 분비의 막대 그래프. (도 8h 내지 8k) (도 8h) ILT2가 없거나, (도 8i 내지 8k) (도 8i) MHC-I 발현만을 갖거나, (도 8j 내지 8k) ILT2 차단 항체 및 양성 대조군 (도 8i 내지 8j) 범-HLA 항체 또는 (도 8k) HLA-G 특이적 항체의 존재 또는 부재 하에 MHC-I 및 외인성 HLA-G를 모두 발현하는, A375 암세포와 공동 배양된 ILT2를 발현하는, Jurkat 세포로부터의 인간 IL-2 분비의 막대 그래프. (도 8l 내지 8n) (도 8l) 15G8 항체, (도 8m) GHI/75 항체, 및 (도 8n) HP-F1 항체의 존재 또는 부재 하에 HLA-G를 발현하는 A375 암세포와 배양된 ILT2를 발현하는 Jurakt 세포로부터의 인간 IL-2 분비의 막대 그래프. (도 8o 내지 8p) 15G8 항체의 존재 및 존재 없이 HLA-G-양성 암세포와 인큐베이션된, 각각 TIL 세포 및 NK 세포에서의, 활성화 마커 (도 8o) 인산화된 ZAP70 및 (도 8p) 인산화된 Syk의 발현의 점 도표.
도 9a 내지 9d. (도 9a) FACS 기반 방법에 의해 결정된 ILT2 항체의 존재 하에 대식세포와 공동배양된 HLA-G 발현 암세포의 대조군으로부터의 백분율로서 식세포작용을 측정한 막대 그래프. (도 9b) Incucyte® 시스템에 의해 결정된 ILT2 항체의 존재 하에 대식세포에 의한 암세포의 실시간 식세포작용의 선 그래프. (도 9c) ILT2 항체 15G8의 존재 하에 대식세포와 공동배양된 다양한 HLA-G 및 MHC-I 발현 암세포의 대조군으로부터의 백분율로서 식세포작용을 측정한 막대 그래프. (도 9d) ILT2 항체, 세툭시맙(Erbitux®), hIgG 대조군, 또는 이들의 조합의 존재 하에 A253-HLA-G 세포와 공동배양된 대식세포에 의한 식세포작용의 막대 그래프.
도 10a 및 10b. ILT2 항체의 존재 하에 (도 10a) 야생형 721.221 세포 또는 HLA-G 발현 721.221 세포 또는 (도 10b) HLA-G 발현 A375 세포와 공동배양된 활성화된 CD8 T 세포로부터의 IFNγ 분비 및 그랜자임 B 분비의 막대 그래프.
도 11a 내지 11h. (도 11a 및 11b) ILT2 항체의 존재 하에 (도 11a) HLA-G 및 (도 11b) MHC-I를 발현하는 다양한 암 세포주와 공동배양된 NK 세포주 세포로부터의 세포독성 백분율의 막대 그래프. (도 11c 및 11d) 15G8 ILT2 항체의 존재 하에 각각 H&N 암 및 흑색종 세포와 공동배양된 NK 세포주 세포로부터의 (도 11c) 그랜자임 B 및 (도 11d) IFNγ 분비의 막대 그래프. (도 11e 및 11f) ILT2 항체의 존재 하에 표적 암세포와 인큐베이션된 ILT2 양성 1차 NK 세포에서의 (도 11e) IFNγ 발현 및 (도 11f) CD107A 발현의 막대 그래프. (도 11g 및 11h) ILT2 항체에 반응하는 ILT2 양성 세포와 (도 11g) IFNγ 발현 및 (도 11h) CD107A 발현의 상관관계를 보여주는 개별 발현의 산점도.
도 12. IgG 또는 항-ILT2 항체의 존재 하에 건강한 공여자로부터 단리된 단핵구로부터 M0, M1, 또는 M2 대식세포로 분화된 대식세포에서의 유세포 분석으로 확인된 HLA-DR 및 CD80 발현(MFI)의 선 그래프. 대조군 IgG 대비, 특정 마커의 발현의 증가를 나타낸 환자의 수를 시험한 각 조건에 대해 나타내었다.
도 13a 내지 13c. (도 13a) 다양한 원발성 종양 세포와 공동배양된 대식세포에 의한 식세포작용의 막대 그래프. (도 13b 및 13c) 본 개시의 인간화 항체의 존재 하에 자가 대식세포에 의한 (도 13b) RCC 환자 및 (도 13c) H&N 환자로부터 단리된 원발성 종양 세포의 용량 의존적 식세포작용의 막대 그래프.
도 14a 내지 14l. (도 14a) RCC 및 식도암 환자의 종양 세포(좌측 패널) 및 PBMC(우측 패널)에서의 ILT2 및 PD-1 발현의 점 도표. (도 14b 및 14c) CRC 환자의 TME에서 CD8 T 세포 집단에서 (도 14b) PD-1 및 (도 14c) ILT2 RNA 발현의 박스 및 휘스커 플롯. (도 14d 및 14e) 건강한 공여자의 말초 혈액으로부터의 CD8 T 세포에서 (도 14d) ILT2 발현 및 식도암으로부터의 TIL에서 (도 14e) ILT2 및 PD-1 발현의 점 도표. (도 14f) 15G8, 항-PD-1 항체 또는 이 둘의 조합의 존재 하에 스타필로코커스 내독소 B(SEB)로 활성화된 10명의 건강한 공여자로부터의 PBMC 상에서 막 CD107a에서의 증가 산점도. (도 14g) 3명의 공여자로부터의 예시적 PBMC에서의 발현에서 CD107a 증가의 막대 그래프. (도 14h 내지 14j) 항-PD-1 항체, 인간화 항-ILT2 항체, 또는 둘 다의 존재 하에 다양한 원발성 암세포와 공동배양된 활성화된 PBMC로부터의 염증성 사이토카인 (도 14h) IFNγ, (도 14i) TNFα, (도 14j) GM-CSF 분비 수준의 막대 차트. (도 14k 및 14l). 혼합 림프구 반응에서 (도 14k) 수지상 세포 또는 (도 14l) 대식세포와 공동배양된 T 세포로부터의 IFNγ 분비 수준의 막대 차트.
도 15a 내지 15f. (도 15a) 인간 대식세포 및 항-ILT2 항체가 보충된 면역 손상된 마우스에서 성장시킨 HLA-G 및 MHC-I 발현 종양의 종양 부피의 선 그래프. (도 15b). 폐 종양 예방을 위한 마우스 치료 일정 예시. (도 15c) 인간 PBMC 및 ILT2 항체를 포함하거나 포함하지 않는 HLA-G 양성 암세포가 접종된 면역 손상된 마우스의 폐 사진. (도 15d) 도 15c의 데이터를 요약한 산점도. (도 15e) 이미 확립된 폐 종양을 치료하기 위한 마우스 치료 일정의 예시. (도 15f) 종양 중량의 박스 및 휘스커 플롯.
도 16a 내지 16f. (도 16a 내지 16f) (도 16a) 전체 CD8 T 세포에서의 CD107A 발현, (도 16b) TEMRA 세포에서의 CD107A 발현, (도 16c) NK 세포에서의 CD69 발현, (도 16d) 전체 CD8 T 세포에서의 CD69 발현, (도 16e) TEMRA 세포에서의 CD107 발현, 및 (도 16f) 각각 이의 TEMRA 세포 또는 NK 세포에서 저수준 또는 고수준의 ILT2를 갖는 공여자로부터의 PBMC를 투여받은 마우스에서 조합 처리된 NK 세포에서의 CD69 발현의 상자 및 휘스커 플롯. *은 P가 0.005미만이다. **은 P가 0.0005미만이다. ***은 P가 0.0001미만이다.
도 17a 내지 17h. (도 17a) 두경부암이 접종되고 항-ILT2 또는 대조군 항체로 처치된 인간화 NSG 마우스에 대한 치료 일정의 예시. (도 17b) IgG 및 항-ILT2로 처치된 마우스로부터의 종양 중량의 선 그래프. (도 17c 내지 17e) BND-22 처치에 반응하거나(R) 반응하지 않은(NR) 마우스의 말초 CD8 T 세포에서의 (도 17c) 기준선 ILT2 수준의 막대 그래프. 종양-내 처치-후 항-ILT2 항체로 처치된 4마리의 마우스에서의 (도 17d) CD107A 발현, (도 17e) M1/M2 비율, 및 (도 17f) 총 CD80 양성 수지상 세포 수.
도 18a 내지 18f. (도 18a) 유의미한 예측 결합을 갖는 잔기를 나타내는 ILT2의 부분 서열. 이들 잔기는 에피토프에 속할 원시 확률의 함수로서 4개의 범주로 나뉜다. 별표는 선택된 돌연변이의 위치를 나타낸다. (도 18b 및 18c) (도 18b) 18a로부터의 잔기의 위치 및 (도 18c) ILT2 상의 4개의 주요 상호작용 영역을 나타내는 ILT2 표면 구조의 3D 렌더링. (도 18d 내지 18f) (도 18d) 15G8 항체의 에피토프 및 WO2020/136145로부터의 3H5, 12D12, 및 27H5 항체의 에피토프(좌측 상단 원), 뿐만 아니라 3H5 항체의 이차 에피토프(우측 상단 원) 및 (도 18e 및18f) (도 18e) HLA-A 또는 (도 18f) HLA-G와 복합체를 이루는 B2M과 ILT2 상의 15G8 에피토프의 상호작용을 나타내는 ILT2의 3D 리본 또는 표면 다이어그램.
도 19a 내지 19g. ILT2-15G8 복합체에 대한 유리 ILT2의 보호 비율 분포. (도 19a) ILT2 단백질의 트립신 분해로부터 도출된 데이터의 막대 차트. 분포의 중앙값은 1.5이고 평균은 1.37이다. (도 19b) ILT2 단백질의 트립신 및 Asp-N 분해로부터 도출된 데이터의 막대 차트. 분포의 중앙값은 1.58이고 평균은 1.48이다. 선택된 보호 영역을 표시하였다. (도 19c 내지 19g) 복합체에 대한 유리 ILT2 펩티드의 용량-반응 플롯 비교. 사각형과 원이 있는 선은 각각 대조군 및 복합체를 나타낸다. (도 19c) 펩티드 56 내지 71: 유리 ILT2 K = 9.09 s-1, 복합체 K = 2.31 s-1은 복합체 형성의 결과로서 3.94배 감소를 나타냄. (도 19d) 펩티드 57 내지 71: 유리 ILT2 K = 6.93 s-1, 복합체 K = 1.97 s-1은 복합체 형성의 결과로서 3.52배 감소를 나타냄. (도 19e) 펩티드 84 내지 100: 유리 ILT2 K = 1.26 s-1, 복합체 K = 0.37 s-1은 복합체 형성의 결과로서 3.41배 감소를 나타냄. (도 19f) 펩티드 57 내지 66: 유리 ILT2 K = 4.32 s-1, 복합체 K = 0.72 s-1은 복합체 형성의 결과로서 6배 감소를 나타냄. (도 19g) 펩티드 91 내지 100: 유리 ILT2 K = 0.7 s-1, 복합체 K = 0.14 s-1은 복합체 형성의 결과로서 5배 감소를 나타냄.
도 20. ELISA 분석에서 15G8 또는 비관련 항체의 존재 하에 인간 B2M에 대한 ILT2-Fc의 결합 그래프.
도 21a 내지 21d. (도 21a 및 21b) 다양한 항-ILT2 항체의 존재 하에 대식세포와 공동배양된 (도 21a) A375-HLA-G 및 (도 21b) SKMEL28-HLA-G 암세포의 IgG 대조군 대비 식세포작용의 백분율(%) 증가 막대 그래프. (도 21c 및 21d) 경쟁하는 비-비오틴화 (도 21c) GHI/75, HP-F1, 및 (도 21d) MAB20172, 및 15G8 항체의 존재 하에 비오틴화 15G8 항체를 사용한 경쟁 ILT2 결합 ELISA의 선 그래프.
본 개시는 ILT2에 결합하고 ILT2-매개 면역 억제를 억제하는 단일클론 항체 또는 항원 결합 단편 및 약학적 조성물에 관한 것이다. 또한, 암을 치료하는 방법 및 PD-1/PD-L1 면역요법을 강화하는 방법이 제공된다.
본 발명은 적어도 부분적으로 ILT2 길항작용이 암세포에 대항하기 위해 PD-1 및 PD-L1 기반 면역요법과 상승적으로 작용한다는 놀라운 발견에 기반한다. 구체적으로, 항-PD-1 항체와 조합된 ILT2 차단 항체가 면역 세포에 의한 전염증성 사이토카인 분비를 증가시킨다는 것이 확인되었다. 이러한 증가는 단순히 부가적인 것이 아니라, 오히려 개별적으로 각 제제의 효과의 합보다 컸다. 실제로, 적어도 하나의 사이토카인에 있어서 신규한(de novo) 증가가 관찰되었고, 제제 단독으로는 임의의 효과를 갖지 않았다. 이러한 조합 치료를 통해 PD-1/PD-L1 불응성 암의 PD-1/PD-L1 반응성 암으로의 전환이 가능하다.
또한 놀랍게도 환자의 면역 세포에서 ILT2 발현 수준이 ILT2 차단 요법의 효과와 상관관계가 있다는 것이 확인되었다. 요법에 대한 반응자는 ILT2 수준이 높은 반면, 비-반응자는 ILT2 수준이 낮았다. 특히, 순환 CD8 양성 T 세포의 ILT2 수준으로 치료 결과가 예측되었다.
마지막으로, 본 개시의 항체는 D1 및 D2 도메인 사이의 ILT2 인터도메인 내의 고유한 에피토프에 결합하는 것으로 확인되었다. 이 영역은 ILT2와 베타-2-마이크로글로불린(B2M) 사이의 상호작용 도메인으로 알려져 있다. 본 개시의 항체는 이러한 상호작용을 직접적으로 차단하는 것으로 알려진 최초의 항체이다. 또한, 본 발명의 항체는 다른 항-ILT2 항체에서 보고되지 않은 면역 자극 효과가 있는 것으로 확인되었다. 본 항체는 MHC-I(예를 들어 HLA-G) 발현 암세포에 대한 T 세포, NK 세포, 수지상 세포, 및 대식세포의 면역감시를 조절할 수 있었다. 특히, 최초로, 단일 요법으로서 사용된 항-ILT2 항체는 암세포의 식세포작용을 강화시키는 것으로 나타났다.
항체
제1 양태에서, 본 개시는 3개의 중쇄 CDR(CDR-H) 및 3개의 경쇄 CDR(CDR-L)을 포함하는 항체로서, CDR-H1은 서열번호 1(DHTIH)에 기재된 아미노산 서열을 포함하고, CDR-H2는 서열번호 2(YIYPRDGSTKYNEKFKG)에 기재된 아미노산 서열을 포함하고, CDR-H3은 서열번호 3(TWDYFDY)에 기재된 아미노산 서열을 포함하고, CDR-L1은 서열번호 4(RASESVDSYGNSFMH)에 기재된 아미노산 서열을 포함하고, CDR-L2는 서열번호 5(RASNLES)에 기재된 아미노산 서열을 포함하고, CDR-L3은 서열번호 6(QQSNEDPYT)에 기재된 아미노산 서열을 포함하는, 항체를 제공한다. 일부 구현예에서, 항체는 IgG4 항체(예를 들어 인간 IgG4)의 중쇄 불변 영역을 추가로 포함한다.
다른 양태에서, 본 개시는 3개의 중쇄 CDR(CDR-H) 및 3개의 경쇄 CDR(CDR-L)을 포함하는 항체 또는 항원 결합 단편으로서, CDR-H1은 서열번호 7(GYTFTSYGIS)에 기재된 아미노산 서열을 포함하고, CDR-H2는 서열번호 8(EIYPGSGNSYYNEKFKG)에 기재된 아미노산 서열을 포함하고, CDR-H3은 서열번호 9(SNDGYPDY)에 기재된 아미노산 서열을 포함하고, CDR-L1은 서열번호 10(KASDHINNWLA)에 기재된 아미노산 서열을 포함하고, CDR-L2는 서열번호 11(GATSLET)에 기재된 아미노산 서열을 포함하고, CDR-L3은 서열번호 12(QQYWSTPWT)에 기재된 아미노산 서열을 포함하는, 항체 또는 항원 결합 단편을 제공한다. 일부 구현예에서, 항체는 IgG4 항체(예를 들어 인간 IgG4)의 중쇄 불변 영역을 추가로 포함한다.
다른 양태에서, 본 개시는 3개의 중쇄 CDR(CDR-H) 및 3개의 경쇄 CDR(CDR-L)을 포함하는 항체 또는 항원 결합 단편으로서, CDR-H1은 서열번호 13(SGYYWN)에 기재된 아미노산 서열을 포함하고, CDR-H2는 서열번호 14(YISYDGSNNYNPSLKN)에 기재된 아미노산 서열을 포함하고, CDR-H3은 서열번호 15(GYSYYYAMDX)에 기재된 아미노산 서열을 포함하고, CDR-L1은 서열번호 16(RTSQDISNYLN)에 기재된 아미노산 서열을 포함하고, CDR-L2는 서열번호 17(YTSRLHS)에 기재된 아미노산 서열을 포함하고, CDR-L3은 서열번호 18(QQGNTLPT)에 기재된 아미노산 서열을 포함하는, 항체 또는 항원 결합 단편을 제공한다. 일부 구현예에서, 항체는 IgG4 항체(예를 들어 인간 IgG4)의 중쇄 불변 영역을 추가로 포함한다.
일부 구현예에서, 서열번호 15는 GYSYYYAMDA(서열번호 25)이다. 일부 구현예에서, 서열번호 15는 서열번호 25이고, 항체 또는 항원 결합 단편은 인간화 항체이다. 일부 구현예에서, 서열번호 15는 GYSYYYAMDS(서열번호 26)이다. 일부 구현예에서, 서열번호 15는 서열번호 26이고, 항체 또는 항원 결합 단편은 인간화 항체이다. 일부 구현예에서, 서열번호 15는 GYSYYYAMDC(서열번호 27)이다. 일부 구현예에서, 서열번호 16는 서열번호 27이고, 항체 또는 항원 결합 단편은 뮤린 항체이다.
다른 양태에서, 도메인 D1 및 D2 사이의 인간 백혈구 면역글로불린-유사 수용체 서브패밀리 B 구성원 1(ILT2) 인터도메인에 결합하는 항체 또는 항원 결합 단편이 제공된다
다른 양태에서, VKKGQFPIPSITWEH(서열번호 41), LELVVTGAYIKPTLS(서열번호 42), VILQCDSQVAFDGFS(서열번호 43), WYRCYAYDSNSPYEW(서열번호 44), KGQFPIPSITWEHAGR(서열번호 68), GQFPIPSITWEHAGR(서열번호 69), 및 SESSDPLELVVTGAYIK(서열번호 70)로부터 선택된 ILT2의 서열에 결합하는 항체 또는 항원 결합 단편이 제공된다. 일부 구현예에서, 항체 또는 항원 결합 단편은 상기 서열의 1, 2, 3, 4, 5, 6, 또는 7개 모두에 결합할 수 있다.
다른 양태에서, ILT2에 결합하고 ILT2와 베타-2-마이크로글로불린(B2M) 사이의 상호작용을 억제하는 항체 또는 항원 결합 단편이 제공된다.
일부 구현예에서, 항체는 단일클론 항체이다. 일부 구현예에서, 항체는 다클론 항체이다. 일부 구현예에서, 항체는 뮤린 항체이다. 일부 구현예에서, 항체는 인간화 항체이다. 본원에서 사용되는 "인간화" 항체는 인간 골격을 갖지만, 비-인간 항체로부터 유래되거나 취해지는 CDR을 갖는 항체를 지칭한다. 일부 구현예에서, 인간화 동안 CDR은 변경될 수 있지만 일반적으로 여전히 비-인간 모 항체의 CDR로부터 유래된다. 일부 구현예에서, 항원 결합 단편은 단일쇄 항체이다. 일부 구현예에서, 항원 결합 단편은 단일 도메인 항체이다.
일부 구현예에서, 항체는 IgG4 불변 영역을 포함한다. 일부 구현예에서, 항체는 인간 IgG4 불변 영역을 포함하는 인간화 항체이다. 일부 구현예에서, IgG4 불변 영역은 조작된 IgG4 불변 영역이고, 야생형 IgG4 불변 영역에 비해 돌연변이를 함유한다. 일부 구현예에서, 인간 IgG4 불변 영역은 다음과 같은 아미노산 서열을 포함한다:

일부 구현예에서, 인간 IgG4 불변 영역은 서열번호 50으로 구성된다. 일부 구현예에서, 인간 IgG4 불변 영역은 서열번호 50에 대해 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100%의 동일성을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 인간 IgG4 불변 영역은 서열번호 50에 대해 적어도 95%의 동일성을 포함한다. 일부 구현예에서, 인간 IgG4 불변 영역은 서열번호 50에 대해 적어도 97%의 동일성을 포함한다. 일부 구현예에서, 인간 IgG4 불변 영역은 서열번호 50에 대해 적어도 99%의 동일성을 포함한다.
일부 구현예에서, IgG4 불변 영역은 적어도 하나의 돌연변이를 포함한다. 일부 구현예에서, 돌연변이는 Fc 감마 수용체(FcγR)와 같은 Fc 수용체에 대한 결합을 감소시키거나, IgG4 항체의 Fab-암 교환을 감소시킨다. 일부 구현예에서, 돌연변이는 세린 108의 돌연변이이다. 일부 구현예에서, 세린은 프롤린으로 돌연변이된다. 일부 구현예에서, 세린 108은 서열번호 50의 세린 108(또는 Eu 넘버링에 따른 S228)이다. 세린 108에서 프롤린으로의 돌연변이는 S228P 돌연변이로도 알려져 있다. 일부 구현예에서, 돌연변이는 류신 115(또는 Eu 넘버링에 따른 L235)의 돌연변이이다. 일부 구현예에서, 류신은 글루탐산으로 돌연변이된다. 일부 구현예에서, 류신 115는 서열번호 50의 류신 115이다. 류신 115에서 글루탐산으로의 돌연변이는 L235E 돌연변이로도 알려져 있다. 중쇄의 불변 영역에서 임의의 아미노산의 정확한 수치적 위치는 중쇄의 가변 영역의 길이에 따라 달라짐을 당업자는 이해할 것이다. 이와 같이, 세린의 위치는 불변 영역 내에서 108로 제공되고, 류신의 위치는 115로 제공된다(예를 들어 서열번호 50 참조). 불변 영역에 대한 변형(예를 들어 염기의 추가 또는 결실)은 또한 수치적 위치를 변경할 수 있지만, 인용된 돌연변이를 포함하는 한 IgG4의 임의의 유사체 또는 유도체도 고려된다는 것을 추가로 이해해야 한다. 일부 구현예에서, IgG4 불변 영역은 복수의 돌연변이를 포함한다. 일부 구현예에서, IgG4 불변 영역은 세린 108 및 류신 115의 돌연변이를 포함한다. 일부 구현예에서, IgG4 불변 영역은 S108P 및 L115E 돌연변이(또는 Eu 넘버링에 따른 S228P 및 L235E 돌연변이)를 포함한다.
일부 구현예에서, IgG4 불변 영역은 하기 아미노산 서열을 포함하고, 야생형 인간 IgG4 불변 영역에 대한 돌연변이(S228P 및 L235E; Eu 넘버링)는 박스 표시되어 있다:

일부 구현예에서, 인간 IgG4 불변 영역은 서열번호 55를 포함하거나 이로 구성된다. 일부 구현예에서, 본 개시의 항체는 서열번호 55를 포함한다. 일부 구현예에서, 본 개시의 항체의 중쇄 불변 영역은 서열번호 55를 포함한다. 일부 구현예에서, 본 개시의 항체의 중쇄 불변 영역은 서열번호 55로 구성된다. 일부 구현예에서, IgG4 불변 영역은 예를 들어 항체의 제조가능성을 개선하거나 면역원성을 감소시키는 추가 돌연변이를 함유하는 서열번호 55의 유사체 또는 유도체이다. 일부 구현예에서, IgG4 불변 영역은 서열번호 55에 대해 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100%의 동일성을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, IgG4 불변 영역은 서열번호 55에 대해 적어도 95%의 동일성을 포함한다. 일부 구현예에서, IgG4 불변 영역은 서열번호 55에 대해 적어도 97%의 동일성을 포함한다. 일부 구현예에서, IgG4 불변 영역은 서열번호 55에 대해 적어도 99%의 동일성을 포함한다.
일부 구현예에서, IgG4 불변 영역의 유사체는 적어도 하나의 다른 돌연변이를 추가로 포함한다. 일부 구현예에서, 적어도 하나의 다른 돌연변이는 서열번호 55이다. 일부 구현예에서, 적어도 하나의 다른 돌연변이는 108번 위치에 존재하지 않는다. 일부 구현예에서, 적어도 하나의 다른 돌연변이는 115번 위치에 존재하지 않는다. 일부 구현예에서, 적어도 하나의 다른 돌연변이는 108번 위치 또는 115번 위치에 존재하지 않는다. IgG4의 다른 돌연변이는 당업계에 잘 알려져 있으며 이들 중 임의의 것이 사용될 수 있다. 다른 돌연변이의 예로는E233P, F234A, L235A, G237A, P239G, F243L, T250Q, T250E, M252Y, S254T, T256E, E258F, D259I, V264A, D265A, F296Y, T307A, T307Q, V308W, V308Y, V308F, Q311V, K317Q, A330R, E356K, K370Q, K370E, E380A, R409K, V427T, M428L, M428F, H434K, N434S, N434A, N434H, N434F, H435R, Y436H, K439E, L445, G236의 결실, G446의 결실, 및 K447의 결실(숫자는 Eu 넘버링에 따라 부여됨)을 포함하지만, 이제 한정되지 않는다. 거듭해서 말하면, 이러한 돌연변이에 대해 주어진 수치적 위치는 일반적인 표기법(Eu 넘버링)이지만 중쇄 가변 영역의 길이에 따라 달라진다. 서열번호 50 내에서, 이러한 위치는 E113, F114, L115, G117, P119, F123, T130, M132, S134, T136, E138, D139, V144, D145, F176, T187, V188, Q191, K197, A210, E236, K250, E260, R289, V307, M308, H313, N314, H315, Y316, K319, L325, G326, 및 K327에 해당한다. E233P/F234A/L235A/G236del/G237A 또는 S228P/F234A/L235A/G237A/P238S와 같은, 돌연변이의 특정 조합이 사용될 수 있음이 또한 이해될 것이다.
일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2에 결합한다. 일부 구현예에서, ILT2는 인간 ILT2이다. 일부 구현예에서, ILT2는 포유류 ILT2이다. 일부 구현예에서, ILT2는 영장류 ILT2(예를 들어 시노몰구스 원숭이 ILT2)이다. 일부 구현예에서, ILT2는 뮤린 ILT2이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2의 세포외 도메인에 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2의 리간드 포켓에 결합한다. 일부 구현예에서, 리간드는 B2M이다. 일부 구현예에서, 리간드는 HLA가 아니다. 일부 구현예에서, 리간드는 HLA이다. 일부 구현예에서, HLA는 HLA-G이다. 일부 구현예에서, 리간드는 MHC가 아니다. 일부 구현예에서, 리간드는 MHC이다. 일부 구현예에서, MHC는 MHC 클래스 I(MHC-I)이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2 인터도메인에 결합한다. 일부 구현예에서, 인터도메인은 D1 및 D2 도메인 사이의 인터페이스이다. 일부 구현예에서, 인터도메인은 D1과 D2 도메인 사이의 힌지 도메인이다. 일부 구현예에서, 인터도메인은 D1의 N-말단 도메인을 포함하지 않는다. 일부 구현예에서, 인터도메인은 서열번호 31의 아미노산 54 내지 184로부터 존재한다. 일부 구현예에서, 서열번호 31의 아미노산 54 내지 184는 인터도메인을 포함한다. 일부 구현예에서, 인터도메인은 서열번호 31의 아미노산 90 내지 184로부터 존재한다. 일부 구현예에서, 아미노산 90 내지 184는 인터도메인을 포함한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 인터도메인 내의 에피토프에 결합한다. 일부 구현예에서, 에피토프는 인터도메인의 적어도 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 97, 99, 또는 100%를 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 에피토프는 D2 내에 있다. 일부 구현예에서, 항체 또는 항원 결합 도메인은 D2에서 에피토프에 결합한다. 일부 구현예에서, 에피토프는 적어도 부분적으로 D2에 있다. 일부 구현예에서, 항체 또는 항원 결합 도메인은 적어도 부분적으로 D2에서 에피토프에 결합한다. 일부 구현예에서, 에피토프는 D1 및 D2에 걸쳐있다. 일부 구현예에서, 항체 또는 항원 결합 단편은 HLA-G의 α3 도메인과 상호작용하는 ILT2 도메인에 결합하지 않는다.
일부 구현예에서, ILT2는 포유류 ILT2이다. 일부 구현예에서, ILT2는 인간 ILT2이다. 일부 구현예에서, ILT2는 NCBI 참조 서열 NP_006660.4에서 제공되는 아미노산 서열을 갖는다. 일부 구현예에서, ILT2는 다음과 같은 아미노산 서열을 갖는다:

일부 구현예에서, ILT2는 NCBI 참조 서열 NP_001075106.2에서 제공되는 아미노산 서열을 갖는다. 일부 구현예에서, ILT2는 NCBI 참조 서열 NP_001075107.2에서 제공되는 아미노산 서열을 갖는다. 일부 구현예에서, ILT2는 NCBI 참조 서열 NP_001075108.2에서 제공되는 아미노산 서열을 갖는다. 일부 구현예에서, ILT2는 NCBI 참조 서열 NP_001265328.2에서 제공되는 아미노산 서열을 갖는다.
일부 구현예에서, ILT2의 D1 도메인은 아미노산 서열

을 포함하거나 이로 구성된다.
일부 구현예에서, ILT2의 D1 도메인은 서열번호 31의 아미노산 24 내지 121을 포함하거나 이로 구성된다. 일부 구현예에서, ILT2의 D2 도메인은 아미노산 서열

을 포함하거나 이로 구성된다.
일부 구현예에서, ILT2의 D2 도메인은 서열번호 31의 아미노산 122 내지 222를 포함하거나 이로 구성된다. 일부 구현예에서, ILT2의 인터도메인은 서열번호 31의 아미노산 Gln41, Lys65, Trp90, Gly120, Ala121, Val122, Ile123, Gln148, Val149, Ala150, Phe151, Asp201, Asn203, 및 Glu207을 포함한다. 일부 구현예에서, 에피토프는 서열번호 31의 아미노산 Gln41, Lys65, Trp90, Gly120, Ala121, Val122, Ile123, Gln148, Val149, Ala150, Phe151, Asp201, Asn203, 및 Glu207을 포함한다. 일부 구현예에서, 에피토프는 서열번호 31의 아미노산 Gln41, Lys65, Trp90, Gly120, Ala121, Val122, Ile123, Gln148, Val149, Ala150, Phe151, Asp201, Asn203, 및 Glu207로부터 선택된 적어도 5개, 6개, 7개, 8개, 9개, 10개, 11개, 12개, 13개, 또는 14개 아미노산을 포함한다.
일부 구현예에서, 에피토프는 서열번호 31의 아미노산 Gln41, Lys65, Trp90, Gly120, Ala121, Val122, Ile123, Gln148, Val149, Ala150, Phe151, Asp201, Asn203, 및 Glu207로부터 선택된 적어도 10개 아미노산을 포함한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 41에서 제공되는 ILT2 에피토프에 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 42에서 제공되는 ILT2 에피토프에 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 43에서 제공되는 ILT2 에피토프에 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 44에서 제공되는 ILT2 에피토프에 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 41, 42, 43, 및 44 중 적어도 2개로부터의 잔기를 포함하는 3차원 에피토프(예를 들어 서열번호 41, 42, 43, 및 44 중 적어도 2개를 포함하는 3차원 에피토프)에 결합한다. 일부 구현예에서, 3차원 에피토프는 서열번호 41, 42, 43, 및 44 중 적어도 3개로부터의 잔기를 포함한다(예를 들어 서열번호 41, 42, 43, 및 44 중 적어도 3개를 포함하는 3차원 에피토프). 일부 구현예에서, 3차원 에피토프는 서열번호 41, 42, 43, 및 44로부터의 잔기를 포함한다(예를 들어 서열번호 41, 42, 43, 및 44를 포함하는 3차원 에피토프).
일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 41에(예를 들어 서열번호 41을 포함하거나 그 내에 있는 ILT2 에피토프에) 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 42에(예를 들어 서열번호 42을 포함하거나 그 내에 있는 ILT2 에피토프에) 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 43에(예를 들어 서열번호 43을 포함하거나 그 내에 있는 ILT2 에피토프에) 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 44에(예를 들어 서열번호 44을 포함하거나 그 내에 있는 ILT2 에피토프에) 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 68에(예를 들어 서열번호 68을 포함하거나 그 내에 있는 ILT2 에피토프에) 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 69에(예를 들어 서열번호 69을 포함하거나 그 내에 있는 ILT2 에피토프에) 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 70에(예를 들어 서열번호 70을 포함하거나 그 내에 있는 ILT2 에피토프에) 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 41 내지 44 및 68 내지 70 중 적어도 2개로부터의 잔기를 포함하는 3차원 에피토프(예를 들어 서열번호 41 내지 44 및 68 내지 70 중 적어도 2개를 포함하는 3차원 에피토프)에 결합한다. 일부 구현예에서, 3차원 에피토프는 서열번호 41 내지 44 및 68 내지 70 중 적어도 3개로부터의 잔기를 포함한다(예를 들어 3차원 에피토프는 서열번호 41 내지 44 및 68 내지 70 중 적어도 3개를 포함함). 일부 구현예에서, 3차원 에피토프는 서열번호 41 내지 44 및 68 내지 70 중 적어도 4개로부터의 잔기를 포함한다(예를 들어 3차원 에피토프는 서열번호 41 내지 44 및 68 내지 70 중 적어도 4개를 포함함). 일부 구현예에서, 3차원 에피토프는 서열번호 41, 42, 및 68 내지 70로부터의 잔기를 포함한다(예를 들어 3차원 에피토프는 서열번호 41, 42, 및 68 내지 70을 포함함). 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 68 내지 70에(예를 들어 서열번호 68 내지 70을 포함하거나 그 내에 있는 에피토프에) 결합한다.
일부 구현예에서, 항체 또는 항원 결합 단편은 서열 GQFPIPSITW(서열번호 71)(예를 들어 상기 서열을 포함하거나 그 내에 있는 ILT2 에피토프)에 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열 ELVVTGAYIK(서열번호 72)(예를 들어 상기 서열을 포함하거나 그 내에 있는 ILT2 에피토프)에 결합한다. 특정 구현예에서, 항체 또는 항원 결합 단편은 서열번호 71 및 72에(예를 들어 서열번호 71 및 72를 포함하거나 그 내에 있는 에피토프에) 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 68 내지 72로부터 선택된 서열에(예를 들어 상기 서열을 포함하거나 그 내에 있는 에피토프에) 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 41 내지 44 및 68 내지 72로부터 선택된 서열에(예를 들어 상기 서열을 포함하거나 그 내에 있는 에피토프)에 결합한다. 일부 구현예에서, 서열번호 71은 서열번호 41 내의 에피토프이다. 일부 구현예에서, 서열번호 71은 서열번호 68 내의 에피토프이다. 일부 구현예에서, 서열번호 71은 서열번호 69 내의 에피토프이다. 일부 구현예에서, 서열번호 72는 서열번호 42 내의 에피토프이다. 일부 구현예에서, 서열번호 72는 서열번호 70 내의 에피토프이다.
일부 구현예에서, 항체 또는 항원 결합 단편은 Q18, G19, K42, L45, S64, I65, T66, W67, E68, G97, A98, Y99, I100, Q125, V126, A127, F128, D178, N180, S181, 및 E184로부터 선택된 ILT2의 잔기를 포함하는 ILT2 에피토프에 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 G97, A98, Y99, I100, Q125, 및 V126으로부터 선택된 ILT2의 잔기를 포함하는 ILT2 에피토프에 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 Q18, G19, K42, L45, S64, I65, T66, W67, E68, G97, A98, Y99, I100, Q125, V126, A127, F128, D178, N180, S181, 및 E184로부터 선택된 ILT2의 복수의 잔기를 포함하는 ILT2 에피토프에 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 G97, A98, Y99, I100, Q125, 및 V126으로부터 선택된 ILT2의 복수의 잔기를 포함하는 ILT2 에피토프에 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 Q18, G19, K42, L45, S64, I65, T66, W67, E68, G97, A98, Y99, I100, Q125, V126, A127, F128, D178, N180, S181, 및 E184로부터 선택된 적어도 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개, 11개, 12개, 13개, 14개, 15개, 16개, 17개, 18개, 19개, 20개, 또는 21개 잔기에 결합한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 항체 또는 항원 결합 단편은 G97, A98, Y99, I100, Q125, 및 V126으로부터 선택된 적어도 1개, 2개, 3개, 4개, 5개, 또는 6개 잔기에 결합한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 항체 또는 항원 결합 단편은 G97, A98, Y99, I100, Q125, 및 V126에 결합한다. 본원에서 사용되는 숫자는 서열번호 31에 대한 것임이 이해될 것이다.
일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2 길항제이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2 작용제가 아니다. 일부 구현예에서, 길항작용은 ILT2-매개 면역 억제의 길항작용이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2-매개 면역 억제를 억제한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2 신호전달을 억제한다.
일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2와 B2M 사이의 상호작용을 억제한다. 일부 구현예에서, 상호작용은 직접적 상호작용이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2의 B2M과의 접촉을 억제한다. 일부 구현예에서, 접촉은 직접적 접촉이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2와 HLA 사이의 상호작용을 억제한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2와 MHC 사이의 상호작용을 억제한다. 일부 구현예에서, MHC는 HLA이다. 일부 구현예에서, HLA은 HLA-G이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2와 HLA, MHC, 또는 둘 다와의 상호작용을 억제한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2의 B2M과의 상호작용을 억제하여 ILT2와 HLA, MHC, 또는 둘 다와의 상호작용을 억제한다. 일부 구현예에서, 상호작용은 B2M에 의해 매개된다. 일부 구현예에서, 항체는 B2M과의 상호작용을 억제하여 HLA, MHC, 또는 둘 다와의 상호작용을 간접적으로 억제한다. 일부 구현예에서, 상호작용은 B2M 매개 상호작용이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2와 B2M/HLA 복합체 사이의 상호작용을 억제한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2와 B2M/MHC 복합체 사이의 상호작용을 억제한다. 일부 구현예에서, 복합체는 B2M 단량체를 포함한다. 일부 구현예에서, 복합체는 HLA 또는 MHC 단량체를 포함한다. 일부 구현예에서, 복합체는 B2M 이량체를 포함한다. 일부 구현예에서, 복합체는 HLA 또는 MHC 이량체를 포함한다.
일부 구현예에서, ILT2-매개 면역 억제는 면역 세포의 억제이다. 일부 구현예에서, 면역 세포는 T 세포, 대식세포, 수지상 세포, 및 자연 살해(NK) 세포로부터 선택된다. 일부 구현예에서, ILT2-매개 면역 억제는 T 세포, 대식세포, 수지상 세포, 및 NK 세포의 억제이다. 일부 구현예에서, ILT2-매개 면역 억제는 T 세포, 대식세포, 및 NK 세포의 억제이다. 일부 구현예에서, T 세포는 CD8 양성 T 세포이다. 일부 구현예에서, T 세포는 TEMRA 세포(CD45RA를 재발현하는 말단 분화된 효과기 메모리 세포)이다. 일부 구현예에서, 면역 세포는 CD8 양성 T 세포, TEMRA 세포, 수지상 세포, 대식세포, 및 자연 살해(NK) 세포로부터 선택된다. 일부 구현예에서, 면역 세포는 T 세포이다. 일부 구현예에서, 면역 세포는 NK 세포이다. 일부 구현예에서, 면역 세포는 대식세포이다. 일부 구현예에서, 대식세포는 종양-연관 대식세포(TAM)이다. 일부 구현예에서, 면역 세포는 수지상 세포이다. 일부 구현예에서, 수지상 세포는 관용성 수지상 세포이다. 일부 구현예에서, 면역 세포는 말초 혈액 면역 세포이다. 일부 구현예에서, 면역 세포는 말초 혈액 단핵 세포(PBMC)이다. 일부 구현예에서, 면역 세포는 종양내 면역 세포이다. 일부 구현예에서, 면역 세포는 종양 미세환경(TME) 내 면역 세포이다. 일부 구현예에서, ILT2-매개 면역 억제는 대식세포 식세포작용의 억제이다. 일부 구현예에서, ILT2-매개 면역 억제는 NK 세포 세포독성의 억제이다. 일부 구현예에서, ILT2-매개 면역 억제는 T 세포 세포독성의 억제이다. 일부 구현예에서, ILT2-매개 면역 억제는 T 세포 증식의 억제이다. 일부 구현예에서, ILT2-매개 면역 억제는 면역 세포 증식의 억제이다.
일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2 이외의 백혈구 면역글로불린-유사 수용체 서브패밀리 B의 구성원에 결합하지 않는다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2에 특이적이다. KD가 1 μM 이하, 바람직하게는 100 nM 이하 또는 10 nM 이하인 경우 항체가 항원에 특이적으로 결합한다고 말한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2에 우선적으로 결합한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 ILT2 이외의 백혈구 면역글로불린-유사 수용체 서브패밀리 B의 구성원을 억제하지 않는다.
본원에서 사용되는 "결합 효능의 증가"는 이소형 대조군의 결합보다 큰, 표적 또는 항원에 대한 특이적 결합을 나타낸다. 일부 구현예에서, 결합의 증가는 결합 효능의 적어도 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 200%, 300%, 400%, 500%, 600%, 700%, 800%, 900%, 또는 1000% 증가이다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 결합의 증가는 결합이 없는 이소형 대조군 대비 결합의 존재를 나타낸다. 특정 도메인에 대한 항체의 결합은 당업자에게 잘 알려져 있을 것이다. 항체 결합은 x-선 결정학, 면역침전, 면역블로팅, 경쟁 분석, 표면 플라즈몬 공명, 및 동역학 배제 분석을 포함하는 당업자에게 알려진 임의의 방식으로 분석될 수 있지만, 이에 한정되지 않는다. 일부 구현예에서, 결합 효능의 증가는 특이적 결합이다.
본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 103 M-1초-1, 5 X 103 M-1초sec-1, 104 M-1sec-1, 또는 5 X 104 M-1sec-1 이상의 온 속도(k(on))로 표적 항원, 예를 들어 ILT2에 결합한다고 말할 수 있다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-6 M 이상의 KD로 표적 항원에 결합한다고 말할 수 있는 반면, 대부분의 항체는 적어도 10-9 M의 전형적인 KD를 갖는다. 일부 구현예에서, KD는 친화도의 척도이다. 당업자는 친화도가 더 높은 더 강한 결합이 더 낮은 KD를 갖는 결합임을 이해할 것이다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-6 M 내지 10-12 M의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-6 M 내지 10-11의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-6 M 내지 10-10의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-6 M 내지 10-9의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-7 M 내지 10-12의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-8 M 내지 10-12의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-9 M 내지 10-12의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-7 M 내지 10-11의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-8 M 내지 10-11의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-9 M 내지 10-11의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-7 M 내지 10-10의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-8 M 내지 10-10의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-9 M 내지 10-10의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-7 M 내지 10-9의 KD로 표적 항원에 결합한다. 일부 구현예에서, 본원에서 개시된 항체 또는 항원 결합 단편, 변이체, 또는 유도체는 10-8 M 내지 10-9의 KD로 표적 항원에 결합한다.
일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 19(QVQLQQSDAELVKPGASVKISCKVSGYTFTDHTIHWMKQRPEQGLEWIGYIYPRDGSTKYNEKFKGKATLTADKSSSTAYMQLNSLTSEDSAVYFCARTWDYFDYWGQGTTLTVSS)의 아미노산 서열을 포함하는 중쇄를 포함한다. 일부 구현예에서, 중쇄는 서열번호 19와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 19와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 21(QVQLQQSGAELARPGASVKLSCKASGYTFTSYGISWVKQRTGQGLEWVGEIYPGSGNSYYNEKFKGKATLTADKSSSTAYMELRSLTSEDSAVYFCARSNDGYPDYWGQGTTLTVSS)의 아미노산 서열을 포함하는 중쇄를 포함한다. 일부 구현예에서, 중쇄는 서열번호 21과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 21과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 23(DVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQFPGKKLEWMGYISYDGSNNYNPSLKNRITISRDTSKNQFSLKLNSVTAADTATYYCAHGYSYYYAMDXWGQGTSVTVSS)의 아미노산 서열을 포함하는 중쇄를 포함하고, X는 A, C, 및 S로부터 선택된다. 일부 구현예에서, 중쇄는 서열번호 23과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 23과 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 20(DIVLTQSPASLAVSLGQRATISCRASESVDSYGNSFMHWYQQKPGQPPKLLIYRASNLESGIPARFSGSGSRTDFTLTINPVEADDVATYYCQQSNEDPYTFGGGTKLEIK)의 아미노산 서열을 포함하는 경쇄를 포함한다. 일부 구현예에서, 경쇄는 서열번호 20과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 20과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 22(DIQMTQSSSYLSVSLGGRVTITCKASDHINNWLAWYQQKPGNAPRLLISGATSLETGVPSRFSGSGSGKDYTLSITSLQTEDVATYYCQQYWSTPWTFGGGTKLEIK)의 아미노산 서열을 포함하는 경쇄를 포함한다. 일부 구현예에서, 경쇄는 서열번호 22와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 22와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 24(DIQMTQSPSSLSASVGDRVTITCRTSQDISNYLNWYQQKPGKAVKLLISYTSRLHSGVPSRFSGSGSGTDYTLTISSLQPEDFATYYCQQGNTLPTFGQGTKLEIK)의 아미노산 서열을 포함하는 경쇄를 포함한다. 일부 구현예에서, 경쇄는 서열번호 24와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 24와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 서열번호 45(DIQMTQTTSSLSASLGDRVTISCRTSQDISNYLNWYQQKPDGTVKLLISYTSRLHSGVPSRFSGSGSGTDYSLTISNLEQEDIATYFCQQGNTLPTFGSGTKLEIK)의 아미노산 서열을 포함하는 경쇄를 포함한다. 일부 구현예에서, 경쇄는 서열번호 45와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 45와 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에서, 서열번호 23은 DVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQFPGKKLEWMGYISYDGSNNYNPSLKNRITISRDTSKNQFSLKLNSVTAADTATYYCAHGYSYYYAMDAWGQGTSVTVSS(서열번호 28)이다. 일부 구현예에서, 서열번호 23은 서열번호 28이고, 항체 또는 항원 결합 단편은 인간화된다. 일부 구현예에서, 중쇄는 서열번호 28과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 28과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 서열번호 23은 DVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQFPGKKLEWMGYISYDGSNNYNPSLKNRITISRDTSKNQFSLKLNSVTAADTATYYCAHGYSYYYAMDSWGQGTSVTVSS(서열번호 29)이다. 일부 구현예에서, 서열번호 23은 서열번호 29이고, 항체 또는 항원 결합 단편은 인간화된다. 일부 구현예에서, 중쇄는 서열번호 29와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 29와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 서열번호 23은 DVQLQGSGPGLVKPSQSLSLTCSVTGYSITSGYYWNWIRQFPGNKLEWMGYISYDGSNNYNPSLKNRISITRDTSKNQFFLKLNSVTSEDTATYYCAHGYSYYYAMDCWGQGTSVTVSS(서열번호 30)이다. 일부 구현예에서, 서열번호 23은 서열번호 30이고, 항체 또는 항원 결합 단편은 뮤린이다. 일부 구현예에서, 중쇄는 서열번호 30과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 30과 적어도 95% 동일한 아미노산 서열을 포함한다.
일부 구현예에서, 서열번호 15는 서열번호 25이고, 중쇄는 서열번호 28을 포함하거나 이로 구성된다. 일부 구현예에서, 서열번호 15는 서열번호 25이고, 중쇄는 DVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQFPGKKLEWMGYISYDGSNNYNPSLKNRITISRDTSKNQFSLKLSSVTAADTATYYCAHGYSYYYAMDAWGQGTTVTVSS(서열번호 56)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 56과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 56과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄 가변 영역은 서열번호 56으로 구성된다. 일부 구현예에서, 중쇄 가변 영역은 서열번호 56에 대해 적어도 95% 동일성을 갖는 서열로 구성된다. 일부 구현예에서, 서열번호 15는 서열번호 25이고, 중쇄는 DVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQPPGKGLEWMGYISYDGSNNYNPSLKNRITISRDTSKNQFSLKLSSVTAADTATYYCAHGYSYYYAMDAWGQGTTVTVSS (서열번호 57)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 57과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 57과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄 가변 영역은 서열번호 57로 구성된다. 일부 구현예에서, 중쇄 가변 영역은 서열번호 57과 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 서열번호 15는 서열번호 25이고, 중쇄는 QVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQPPGKGLEWMGYISYDGSNNYNPSLKNRVTISRDTSKNQFSLKLSSVTAADTATYYCAHGYSYYYAMDAWGQGTTVTVSS(서열번호 58)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 58과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 58과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄 가변 영역은 서열번호 58로 구성된다. 일부 구현예에서, 중쇄 가변 영역은 서열번호 58과 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 서열번호 15는 서열번호 25이고, 중쇄는 QVQLQGSGPGLVKPSETLSLTCTVTGYSITSGYYWNWIRQPPGKGLEWIGYISYDGSNNYNPSLKNRVTISRDTSKNQFSLKLSSVTAADTATYYCAHGYSYYYAMDAWGQGTTVTVSS(서열번호 59)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 59와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 59와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄 가변 영역은 서열번호 59로 구성된다. 일부 구현예에서, 중쇄 가변 영역은 서열번호 59와 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 중쇄는 서열번호 28 및 56 내지 59로부터 선택된 서열을 포함한다. 일부 구현예에서, 중쇄는 서열번호 56 내지59로부터 선택된 서열을 포함한다. 일부 구현예에서, 중쇄 가변 영역은 서열번호 28 및 56 내지 59로부터 선택된 서열로 구성된다. 일부 구현예에서, 중쇄 가변 영역은 서열번호 56 내지 59로부터 선택된 서열로 구성된다.
일부 구현예에서, 중쇄는 DVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQFPGKKLEWMGYISYDGSNNYNPSLKNRITISRDTSKNQFSLKLNSVTAADTATYYCAHGYSYYYAMDAWGQGTSVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFEGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(서열번호 48)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 48과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 48과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄는 서열번호 48로 구성된다. 일부 구현예에서, 중쇄는 서열번호 48과 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 중쇄는 DVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQFPGKKLEWMGYISYDGSNNYNPSLKNRITISRDTSKNQFSLKLNSVTAADTATYYCAHGYSYYYAMDSWGQGTSVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFEGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(서열번호 51)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 51과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 51과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄는 서열번호 51로 구성된다. 일부 구현예에서, 중쇄는 서열번호 51과 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 중쇄는 DVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQFPGKKLEWMGYISYDGSNNYNPSLKNRITISRDTSKNQFSLKLNSVTAADTATYYCAHGYSYYYAMDCWGQGTSVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFEGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(서열번호 52)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 52와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 52와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄는 서열번호 52로 구성된다. 일부 구현예에서, 중쇄는 서열번호 52와 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 중쇄는 DVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQFPGKKLEWMGYISYDGSNNYNPSLKNRITISRDTSKNQFSLKLSSVTAADTATYYCAHGYSYYYAMDAWGQGTTVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFEGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(서열번호 64)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 64와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 64와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄는 서열번호 64로 구성된다. 일부 구현예에서, 중쇄는 서열번호 64와 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 중쇄는 DVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQPPGKGLEWMGYISYDGSNNYNPSLKNRITISRDTSKNQFSLKLSSVTAADTATYYCAHGYSYYYAMDAWGQGTTVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFEGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(서열번호 65)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 65와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 65와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄는 서열번호 65로 구성된다. 일부 구현예에서, 중쇄는 서열번호 65와 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 중쇄는 QVQLQGSGPGLVKPSETLSLTCTVTGYSITSGYYWNWIRQPPGKGLEWIGYISYDGSNNYNPSLKNRVTISRDTSKNQFSLKLSSVTAADTATYYCAHGYSYYYAMDAWGQGTTVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFEGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(서열번호 67)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 67과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 67과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄는 서열번호 67로 구성된다. 일부 구현예에서, 중쇄는 서열번호 67과 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 중쇄는 QVQLQGSGPGLVKPSETLSLTCSVTGYSITSGYYWNWIRQPPGKGLEWMGYISYDGSNNYNPSLKNRVTISRDTSKNQFSLKLSSVTAADTATYYCAHGYSYYYAMDAWGQGTTVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFEGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(서열번호 106)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 106과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 106과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄는 서열번호 106으로 구성된다. 일부 구현예에서, 중쇄는 서열번호 106과 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 중쇄는 QVQLQQSGAELARPGASVKLSCKASGYTFTSYGISWVKQRTGQGLEWVGEIYPGSGNSYYNEKFKGKATLTADKSSSTAYMELRSLTSEDSAVYFCARSNDGYPDYWGQGTTLTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFEGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(서열번호 53)를 포함한다. 일부 구현예에서, 중쇄는 서열번호 53과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 중쇄는 서열번호 53과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 중쇄는 서열번호 53으로 구성된다. 일부 구현예에서, 중쇄는 서열번호 53과 적어도 95% 동일한 서열로 구성된다.
일부 구현예에서, 항체는 카파 경쇄를 포함한다. 일부 구현예에서, 경쇄의 불변 영역은 카파 불변 영역이다. 일부 구현예에서, 카파 불변 영역은 RTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(서열번호 63)를 포함한다. 일부 구현예에서, 카파 불변 영역은 서열번호 63으로 구성된다. 일부 구현예에서, 카파 불변 영역은 서열번호 63의 유사체 또는 유도체이다. 일부 구현예에서, 카파 불변 영역은 서열번호 63에 대해 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100%의 동일성을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 카파 불변 영역은 서열번호 63에 대해 적어도 95%의 동일성을 포함한다. 일부 구현예에서, 카파 불변 영역은 서열번호 63에 대해 적어도 97%의 동일성을 포함한다. 일부 구현예에서, 카파 불변 영역은 서열번호 63에 대해 적어도 99%의 동일성을 포함한다.
일부 구현예에서, 경쇄는 DIQMTQSTSSLSASVGDRVTITCRTSQDISNYLNWYQQKPGKAVKLLISYTSRLHSGVPSRFSGSGSGTDYTLTISSLQQEDFATYFCQQGNTLPTFGQGTKLEIK(서열번호 60)를 포함한다. 일부 구현예에서, 경쇄는 서열번호 60과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 60과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 경쇄 가변 영역은 서열번호 60으로 구성된다. 일부 구현예에서, 경쇄 가변 영역은 서열번호 60과 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 경쇄는 DIQMTQSPSSLSASVGDRVTITCRTSQDISNYLNWYQQKPGKAVKLLISYTSRLHSGVPSRFSGSGSGTDYTLTISSLQPEDFATYFCQQGNTLPTFGQGTKLEIK(서열번호 61)를 포함한다. 일부 구현예에서, 경쇄는 서열번호 61과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 61과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 경쇄 가변 영역은 서열번호 61로 구성된다. 일부 구현예에서, 경쇄 가변 영역은 서열번호 61과 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 경쇄는 DIQMTQSPSSLSASVGDRVTITCRTSQDISNYLNWYQQKPGKAVKLLISYTSRLHSGVPSRFSGSGSGTDYTLTISSLQPEDFATYYCQQGNTLPTFGQGTKLEIK(서열번호 24)를 포함한다. 일부 구현예에서, 경쇄는 서열번호 24와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 24와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 경쇄 가변 영역은 서열번호 24로 구성된다. 일부 구현예에서, 경쇄 가변 영역은 서열번호 24와 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 경쇄는 DIQMTQSPSSLSASVGDRVTITCRTSQDISNYLNWYQQKPGKAPKLLISYTSRLHSGVPSRFSGSGSGTDYTLTISSLQPEDFATYFCQQGNTLPTFGQGTKLEIK(서열번호 62)를 포함한다. 일부 구현예에서, 경쇄는 서열번호 62와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 62와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 경쇄 가변 영역은 서열번호 62로 구성된다. 일부 구현예에서, 경쇄 가변 영역은 서열번호 62와 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 경쇄는 서열번호 24 및 60 내지 62로부터 선택된 서열을 포함한다. 일부 구현예에서, 경쇄는 서열번호 60 내지 62로부터 선택된 서열을 포함한다. 일부 구현예에서, 경쇄 가변 영역은 서열번호 24 및 60 내지 62로부터 선택된 서열로 구성된다. 일부 구현예에서, 경쇄는 서열번호 60 내지 62로부터 선택된 서열을 포함한다. 일부 구현예에서, 경쇄 가변 영역은 서열번호 60 내지 62로부터 선택된 서열로 구성된다.
일부 구현예에서, 경쇄는 DIQMTQSPSSLSASVGDRVTITCRTSQDISNYLNWYQQKPGKAVKLLISYTSRLHSGVPSRFSGSGSGTDYTLTISSLQPEDFATYYCQQGNTLPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(서열번호 49)를 포함한다. 일부 구현예에서, 경쇄는 서열번호 49와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 49와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 경쇄는 서열번호 49로 구성된다. 일부 구현예에서, 경쇄는 서열번호 49와 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 경쇄는 DIQMTQSPSSLSASVGDRVTITCRTSQDISNYLNWYQQKPGKAVKLLISYTSRLHSGVPSRFSGSGSGTDYTLTISSLQPEDFATYFCQQGNTLPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(서열번호 66)를 포함한다. 일부 구현예에서, 경쇄는 서열번호 66과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 66과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 경쇄는 서열번호 66으로 구성된다. 일부 구현예에서, 경쇄는 서열번호 66과 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 경쇄는 DIQMTQSSSYLSVSLGGRVTITCKASDHINNWLAWYQQKPGNAPRLLISGATSLETGVPSRFSGSGSGKDYTLSITSLQTEDVATYYCQQYWSTPWTFGGGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(서열번호 54)를 포함한다. 일부 구현예에서, 경쇄는 서열번호 54와 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 54와 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 경쇄는 서열번호 54로 구성된다. 일부 구현예에서, 경쇄는 서열번호 54와 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 경쇄는 DIQMTQSTSSLSASVGDRVTITCRTSQDISNYLNWYQQKPGKAVKLLISYTSRLHSGVPSRFSGSGSGTDYTLTISSLQQEDFATYFCQQGNTLPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(서열번호 107)를 포함한다. 일부 구현예에서, 경쇄는 서열번호 107과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 107과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 경쇄는 서열번호 107로 구성된다. 일부 구현예에서, 경쇄는 서열번호 107과 적어도 95% 동일한 서열로 구성된다. 일부 구현예에서, 경쇄는 DIQMTQSPSSLSASVGDRVTITCRTSQDISNYLNWYQQKPGKAPKLLISYTSRLHSGVPSRFSGSGSGTDYTLTISSLQPEDFATYFCQQGNTLPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(서열번호 108)를 포함한다. 일부 구현예에서, 경쇄는 서열번호 108과 적어도 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100% 동일한 아미노산 서열을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 경쇄는 서열번호 108과 적어도 95% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 경쇄는 서열번호 108로 구성된다. 일부 구현예에서, 경쇄는 서열번호 108과 적어도 95% 동일한 서열로 구성된다.
일부 구현예에서, 항체는 서열번호 48을 포함하는 중쇄 및 서열번호 49를 포함하는 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 48로 구성된 중쇄 및 서열번호 49로 구성된 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 48을 포함하는 중쇄 및 서열번호 49를 포함하는 경쇄로 구성된다. 일부 구현예에서, 항체는 서열번호 48로 구성된 중쇄 및 서열번호 49로 구성된 경쇄로 구성된다. 일부 구현예에서, 항체는 15G8-13이다.
일부 구현예에서, 항체는 서열번호 51을 포함하는 중쇄 및 서열번호 49를 포함하는 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 51로 구성된 중쇄 및 서열번호 49로 구성된 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 51을 포함하는 중쇄 및 서열번호 49를 포함하는 경쇄로 구성된다. 일부 구현예에서, 항체는 서열번호 51로 구성된 중쇄 및 서열번호 49로 구성된 경쇄로 구성된다. 일부 구현예에서, 항체는 108번 위치에 세린이 있는 15G8-13이다.
상기 기재된 중쇄 및 경쇄의 임의의 조합을 갖는 항체는 본 개시에 의해 고려된다.
일부 구현예에서, 항체는 서열번호 52를 포함하는 중쇄 및 서열번호 49를 포함하는 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 52로 구성된 중쇄 및 서열번호 49로 구성된 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 52를 포함하는 중쇄 및 서열번호 49를 포함하는 경쇄로 구성된다. 일부 구현예에서, 항체는 서열번호 52로 구성된 중쇄 및 서열번호 49로 구성된 경쇄로 구성된다. 일부 구현예에서, 항체는 108번 위치에 시스테인이 있는 15G8-13이다.
일부 구현예에서, 항체는 서열번호 64를 포함하는 중쇄 및 서열번호 49를 포함하는 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 64로 구성된 중쇄 및 서열번호 49로 구성된 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 64를 포함하는 중쇄 및 서열번호 49를 포함하는 경쇄로 구성된다. 일부 구현예에서, 항체는 서열번호 64로 구성된 중쇄 및 서열번호 49로 구성된 경쇄로 구성된다. 일부 구현예에서, 항체는 15G8-23이다.
일부 구현예에서, 항체는 서열번호 65를 포함하는 중쇄 및 서열번호 66을 포함하는 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 65로 구성된 중쇄 및 서열번호 66으로 구성된 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 65를 포함하는 중쇄 및 서열번호 66을 포함하는 경쇄로 구성된다. 일부 구현예에서, 항체는 서열번호 65로 구성된 중쇄 및 서열번호 66으로 구성된 경쇄로 구성된다. 일부 구현예에서, 항체는 15G8-32이다.
일부 구현예에서, 항체는 서열번호 67을 포함하는 중쇄 및 서열번호 49를 포함하는 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 67로 구성된 중쇄 및 서열번호 49로 구성된 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 67을 포함하는 중쇄 및 서열번호 49를 포함하는 경쇄로 구성된다. 일부 구현예에서, 항체는 서열번호 67로 구성된 중쇄 및 서열번호 49로 구성된 경쇄로 구성된다. 일부 구현예에서, 항체는 15G8-53이다.
일부 구현예에서, 항체는 서열번호 53을 포함하는 중쇄 및 서열번호 54를 포함하는 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 53으로 구성된 중쇄 및 서열번호 54로 구성된 경쇄를 포함한다. 일부 구현예에서, 항체는 서열번호 53을 포함하는 중쇄 및 서열번호 54를 포함하는 경쇄로 구성된다. 일부 구현예에서, 항체는 서열번호 53으로 구성된 중쇄 및 서열번호 54로 구성된 경쇄로 구성된다. 일부 구현예에서, 항체는 19E3이다.
일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 암의 치료 또는 완화를 필요로 하는 대상체에서 이를 치료 또는 완화하는 데 사용하기 위한 것이다. 일부 구현예에서, 암은 HLA-G 양성 암이다. 일부 구현예에서, 암은 MHC-I 양성 암이다. 일부 구현예에서, 암은 HLA-G 발현 암이다. 일부 구현예에서, 암은 MHC-I 발현 암이다. 일부 구현예에서, 암은 고형암이다. 일부 구현예에서, 암은 종양이다. 일부 구현예에서, 암은 간담도암, 자궁경부암, 비뇨생식기암(예를 들어 요로상피암), 고환암, 전립선암, 갑상선암, 난소암, 신경계암, 안구암, 폐암, 연조직암, 골암, 췌장암, 방광암, 피부암, 장암, 간암, 직장암, 결장직장암, 식도암, 위암, 위식도암, 유방암(예를 들어 삼중 음성 유방암), 신장암(예를 들어 신장 암종), 두경부암, 백혈병, 및 림프종으로부터 선택된다. 일부 구현예에서, 암은 유방암, 간담도암, 자궁경부암, 결장직장암, 식도암, 위암, 두경부암, 간암, 폐암(예를 들어 비소세포 폐암), 신장암, 피부암(예를 들어 흑색종 또는 편평 세포 암종), 비뇨생식기암, 및 췌장암으로부터 선택된다. 일부 구현예에서, 암은 유방암, 간담도암(예를 들어 간세포 암종, 담낭암, 담관암종 등), 자궁경부암, 결장직장암(예를 들어 KRAS 야생형 결장직장암), 식도암, 위암, 두경부암, 간암, 폐암, 신장암, 피부암, 비뇨생식기암, 췌장암, 및 백혈병으로부터 선택된다.
일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 종양 미세환경을 면역억제성에서 면역자극성으로 전환시키는 데 사용하기 위한 것이다. 일부 구현예에서, 상기 종양 미세환경의 전환은 항-종양 T 세포 반응의 유도/강화, T 세포 증식 증가, 암 유발 억제인자 골수 활성 감소, 수지상 세포(DC) 활성화 증가, 종양에 대한 수지상 세포 귀소 증가, 대식세포 식세포작용 증가, M1 대식세포 생성 증가, M2 대식세포 생성 감소, 및 NK 세포 활성 증가 중 하나 이상을 포함한다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 암세포에 대한 T 세포 반응을 증가시키는 데 사용하기 위한 것이다. 일부 구현예에서, T 세포 반응은 전염증성 사이토카인 분비의 증가를 포함한다. 일부 구현예에서, T 세포 반응은 세포독성의 증가를 포함한다. 일부 구현예에서, T 세포 반응은 T 세포 증식의 증가를 포함한다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 암세포의 대식세포 식세포작용을 증가시키는 데 사용하기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 종양 또는 암으로의 수지상 세포 귀소를 증가시키는 데 사용하기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 대식세포 식세포작용을 증가시키는 데 사용하기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 암의 대식세포 식세포작용을 증가시키는 데 사용하기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 M1 대식세포의 생성을 증가시키는 데 사용하기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 M2 대식세포의 생성을 감소시키는 데 사용하기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 암세포에 대한 NK 세포 세포독성을 증가시키는 데 사용하기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 암 유발 억제인자 골수 활성을 감소시키는 데 사용하기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 관용성 수지상 세포(DC) 활성을 감소시키는 데 사용하기 위한 것이다. 일부 구현예에서, 본 발명의 항체 또는 항원 결합 단편은 M1 단핵구 활성 또는 수를 증가시키기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 M2 단핵구 활성 또는 수를 감소시키기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 M1 대식세포의 생성을 증가시키기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 M2 대식세포의 생성을 감소시키기 위한 것이다. 일부 구현예에서, M1 단핵구/대식세포는 염증성 대식세포/단핵구이다. 일부 구현예에서, M2 단핵구/대식세포는 억제인자 대식세포/단핵구이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 종양에서 DC 수를 증가시키기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 종양으로의 DC 모집을 증가시키기 위한 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 종양으로의 DC 모집을 증가시키기 위한 것이다. 일부 구현예에서, 종양에 모집된다는 것은 종양 미세환경(TME)에 모집되는 것이다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 DC 활성화를 증가시키기 위한 것이다. 일부 구현예에서, DC 활성화 증가는 관용성 수지상 세포 활성 감소를 포함한다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 항원 제시를 증가시키기 위한 것이다.
일부 구현예에서, 항체 또는 항원 결합 단편은 대상체에서 적어도 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10가지 항암 효과를 유도한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 항체 또는 항원 결합 단편은 대상체에서 적어도 2가지 효과를 유도한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 대상체에서 적어도 3가지 효과를 유도한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 대상체에서 적어도 4가지 효과를 유도한다. 일부 구현예에서, 효과는 NK 세포 세포독성 증가, T 세포 세포독성 증가, T 세포 증식 증가, 대식세포 식세포작용 증가, M1 대식세포 생성 증가, M2 대식세포 생성 감소, 암 종양으로의 수지상 세포 귀소 증가, 및 수지상 세포 활성화 증가로부터 선택된다. 일부 구현예에서, 효과는 a) NK 세포 세포독성 증가; b) T 세포 세포독성 증가, 증식 또는 둘 다; c) 대식세포 식세포작용 증가, M1 대식세포 생성 증가, M2 대식세포 생성 감소, 또는 이들의 조합; 및 d) 암 종양으로의 수지상 세포 귀소 증가, 수지상 세포 활성화 증가, 및 이들의 조합으로부터 선택된다. 일부 구현예에서, 세포독성은 암에 대한 세포독성이다. 일부 구현예에서, 식세포작용은 암 또는 암세포의 식세포작용이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 대상체에서 T 세포, NK 세포, 수지상 세포, 및 대식세포에 대한 항암 효과를 유도한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 대상체에서 T 세포, NK 세포, 수지상 세포, 및 대식세포 중 적어도 3개에 대한 항암 효과를 유도한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 단일요법으로서 효과를 유도한다. 일부 구현예에서, 항체 또는 항원 결합 단편은 조합 없이 효과를 유도한다.
일부 구현예에서, 세포독성의 증가는 전염증성 사이토카인 분비의 증가를 포함한다. 전염증성 사이토카인은 당업계에 잘 알려져 있으며, IL-1, IL-1B, IL-6, TNFα, IFNγ, MCP-1, IL-12, IL-18, IL-2, IL-15, IL-17, IL-21, 및 과립구-대식세포 콜로니 자극 인자(GM-CSF)를 포함하지만, 이에 한정되지 않는다. 일부 구현예에서, 전염증성 사이토카인은 IL-6, 인터페론 감마(IFNγ), 및 GM-CSF로부터 선택된다. 일부 구현예에서, 전염증성 사이토카인은 GM-CSF이다.
"항-ILT2 항체", "ILT2를 인식하는 항체", 또는 "ILT2에 대한 항체"는 충분한 친화도 및 특이성을 가지고 ILT2에 결합하는 항체이다. 일부 구현예에서, 항-ILT2 항체는 이 항체가 결합하는 항원으로서 ILT2를 갖는다.
"항원"은 항체 형성을 유발할 수 있고 항체에 의해 결합될 수 있는 분자 또는 분자의 일부이다. 항원은 하나 이상의 에피토프를 가질 수 있다. 위에서 언급한 특이적 반응은 항원이 고도로 선택적 방식으로, 그 대응하는 항체와 반응하고 다른 항원에 의해 유발될 수 있는 여러 다른 항체와는 반응하지 않을 것임을 시사하는 것을 의미한다.
본 발명에 따른 용어 "항원 결정기" 또는 "에피토프"는 특정 항체와 특이적으로 반응하는 항원 분자의 영역을 나타낸다. 에피토프로부터 유래된 펩티드 서열은 동물을 면역화하고 추가적인 다클론 또는 단일클론 항체를 생성하기 위해 당업계에 알려진 방법을 적용하여 단독으로 또는 담체 모이어티와 함께 사용될 수 있다. 면역글로불린 가변 도메인은 또한 CDR을 포함하는 가변 영역 세그먼트를 확인하기 위해 IMGT 정보 시스템(www://imgt. cines.fr/)(IMGT® V-Quest)을 사용하여 분석할 수 있다. 예를 들어 문헌[Brochet et al., Nucl Acids Res. (2008) J6:W503-508] 참조.
문헌[Kabat et al.] 또한 모든 항체에 적용 가능한 가변 도메인 서열에 대한 넘버링 시스템을 정의하였다. 당업자는 서열 자체를 넘어서는 임의의 실험 데이터에 의존하지 않고 이 "Kabat 넘버링" 시스템을 임의의 가변 도메인 서열에 명확하게 대입할 수 있다. 본원에서 사용되는 바와 같이, "Kabat 넘버링"은 문헌[Kabat et al., U.S. Dept. of Health and Human Services, “Sequence of Proteins of Immunological Interest” (1983)]에 의해 제시된 넘버링 시스템을 나타낸다.
일부 구현예에서, 항체 또는 항원 결합 단편은 다른 제제와 조합하여 사용하기 위한 것이다. 일부 구현예에서, 다른 제제와의 조합 사용은 HLA-G 및/또는 MHC-I 발현 암을 치료하기 위한 것이다. 일부 구현예에서, 제제는 옵소닌화제이다. 일부 구현예에서, 제제는 항-PD-1 및/또는 항-PD-L1 제제이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 항-PD-1/PD-L1 기반 요법과 조합하여 사용하기 위한 것이다.
본원에서 사용되는 바와 같이, "옵소닌화제"는 표적 세포(예를 들어 암세포, 세포내 병원체를 보유하는 세포 등)에 결합하고 표적 세포를 옵소닌화할 수 있는 임의의 제제이다. 예를 들어, 항체가 Fc 영역을 갖는, 표적 세포에 결합할 수 있는 임의의 항체는 표적 세포를 옵소닌화하는 제제로 간주된다. 일부 구현예에서, 옵소닌화제는 항체 의존적 세포 식세포작용(ADCP)을 유도하는 항체이다. 옵소닌화제의 예로는 항-CD47 항체, 항-CD20 항체, 항-HER2 항체, 항-EGFR 항체, 항-CD52 항체, 및 항-CD30 항체를 포함하지만, 이에 한정되지 않는다. 일부 구현예에서, 옵소닌화제는 리툭시맙(Rituxan®), 트라스투주맙(Herceptin®), 페르투주맙(Perjeta®), 세툭시맙(Erbitux®), 및 파니투무맙(Vectibix®)으로부터 선택된다. 일부 구현예에서, 옵소닌화제는 항-EGFR 항체이다. 일부 구현예에서, 옵소닌화제는 세툭시맙이다.
본원에서 사용되는 바와 같이, "항-PD-1/PD-L1 요법" 및 "PD-1/PD-L1 요법"은 동의어이고 상호교환적으로 사용되며 PD-1 및 PD-L1 신호전달 축의 차단을 포함하는 치료 요법을 나타낸다. 일부 구현예에서, 암은 PD-L1 양성 암이다. 일부 구현예에서, PD-1/PD-L1 요법은 PD-1/PD-L1 면역요법이다. 일부 구현예에서, PD-1/PD-L1 요법은 PD-1/PD-L1 차단이다. 일부 구현예에서, PD-1/PD-L1 요법은 PD-1 기반 면역 억제를 차단하는 제제이다. 일부 구현예에서, PD-1/PD-L1 요법은 항-PD-1 차단 항체(예를 들어 니볼루맙(Optivo®), 펨브롤리주맙(Keytruda®), 및 세미플리맙(Lybtayo®)으로부터 선택됨)를 포함한다. 일부 구현예에서, PD-1/PD-L1 요법은 항-PD-L1 차단 항체(예를 들어 아테졸리주맙(Tecentriq®), 아벨루맙(Bavencio®), 및 더발루맙(Imfinzi®)으로부터 선택됨)를 포함한다. 일부 구현예에서, PD-1/PD-L1 요법은 면역 감시를 증가시킨다. 일부 구현예에서, PD-1/PD-L1 요법은 항암 요법이다. 일부 구현예에서, PD-1/PD-L1 요법은 종양 면역 감시를 증가시킨다. 달리 나타내지 않는 한, 용어 "항체"("면역글로불린"이라고도 함)는 목적하는 생물학적 활성을 나타내는 한 단일클론 항체 및 항체 단편(또한 본원에서 항체 부분이라고도 함)을 포함한다. 특정 구현예에서, 키메라 항체 또는 인간화 항체의 사용 또한 본 개시에 포함된다. "항체 또는 이의 항원 결합 단편"과 관련하여 용어 "항체"는 2개의 중쇄 및 2개의 경쇄를 갖는 완전한 항체를 의미한다.
자연 발생 항체 구조의 기본 단위는 약 150,000 달톤의 이종사량체 당단백질 복합체로, 두 개의 동일한 경(L)쇄 및 두 개의 동일한 중(H)쇄로 구성되며 비공유 결합 및 이황화 결합에 의해 함께 연결된다. 각각의 중쇄 및 경쇄는 또한 규칙적으로 이격된 사슬 내 이황화 가교를 갖는다. 5개의 인간 항체 클래스(IgG, IgA, IgM, IgD, 및 IgE)가 존재하며, 이러한 클래스 내에서 다양한 하위클래스(예를 들어 IgG1, IgG2, IgG3, 및 IgG4)가 구조적 차이, 예컨대 단일 항체 분자의 면역글로불린 단위의 수, 개별 단위의 이황화 가교 구조, 및 사슬 길이 및 서열의 차이에 기반하여 인식된다. 항체의 클래스 및 하위클래스는 이의 이소형이다.
중쇄 및 경쇄의 아미노 말단 영역은 카복시 말단 영역보다 서열이 더 다양하므로 가변 도메인이라고 한다. 항체 구조의 해당 부분은 항체의 항원 결합 특이성을 부여한다. 중쇄 가변(VH) 도메인 및 경쇄 가변(VL) 도메인이 함께 단일 항원 결합 부위를 형성하므로 기본 면역글로불린 단위는 2개의 항원 결합 부위를 갖는다. 특정 아미노산 잔기는 경쇄 및 중쇄 가변 도메인 사이의 인터페이스를 형성하는 것으로 여겨진다(Chothia et al., J Mol Biol. (1985) 186, 651-63; Novotny and Haber, Proc Natl Acad Sci USA (1985) 82:4592-6).
중쇄 및 경쇄의 카복시 말단부는 불변 도메인, 즉 CH1, CH2, CH3, CL을 형성한다. 이러한 도메인에서는 다양성이 훨씬 더 적지만, 동물 종마다 차이가 있고, 또한 동일한 개체 내에, 각각 다른 기능을 갖는 여러 가지 상이한 이소형 항체가 있다.
용어 "프레임워크 영역" 또는 "FR"은 본원에 정의된 바와 같은 초가변 영역 아미노산 잔기가 아닌 항체의 가변 도메인 내 아미노산 잔기를 나타한다. 본원에서 사용되는 용어 "초가변 영역"은 항원 결합을 담당하는 항체의 가변 도메인 내 아미노산 잔기를 나타낸다. 초가변 영역은 "상보성 결정 영역" 또는 "CDR"로부터의 아미노산 잔기를 포함한다. CDR은 주로 항원의 에피토프에 대한 결합을 담당한다. FR 및 CDR의 범위는 정확하게 정의되어 있다(문헌[Kabat et al.] 참조). 일부 구현예에서, CDR은 KABAT 시스템을 사용하여 결정된다. 일부 구현예에서, CDR은 Chothia 시스템을 사용하여 결정된다. 일부 구현예에서, Chothia 시스템은 강화된 Chothia 시스템(Martin 시스템)이다.
구체적으로 본원에서 단일클론 항체는 중쇄 및/또는 경쇄의 일부분이 특정 종으로부터 유래되거나 특정 항체 클래스 또는 하위클래스에 속하는 항체에서의 상응하는 서열과 동일하거나 상동성인 한편, 상기 사슬(들)의 나머지는 또 다른 종으로부터 유래되거나 또 다른 항체 클래스 또는 하위클래스에 속하는 항체에서의 상응하는 서열과 동일하거나 상동성인 "키메라" 항체를 포함하고, 목적하는 생물학적 활성을 나타낸다는 전제 하에 그러한 항체의 단편 또한 포함한다(미국 특허 4,816,567호; 및 문헌[Morrison et al., Proc Natl Acad Sci USA (1984) 57:6851-5]). 또한, 친화도 또는 특이성을 비롯한, 항체 분자의 특정 특성을 변경시키기 위해 상보성 결정 영역 (CDR) 이식을 수행할 수 있다. CDR 이식에 대한 비제한적인 예는 미국 특허 제5,225,539호에 개시되어 있다.
키메라 항체는, 상이한 동물 종으로부터 상이한 부분이 유래된 분자, 예컨대 뮤린 mAb로부터 유래된 가변 영역 및 인간 면역글로불린 불변 영역을 갖는 분자이다. 실질적으로 인간 항체(수용자 항체로 명명됨)로부터의 가변 영역 프레임워크 잔기 및 실질적으로 마우스 항체(공여자 항체로 명명됨)로부터의 상보성 결정 영역을 갖는 항체를 또한 인간화 항체로 지칭된다. 예를 들어, 뮤린 mAb는 하이브리도마로부터의 수율은 더 높지만, 인간에서 면역원성이 더 높기 때문에, 인간/뮤린 키메라 mAb가 사용되는 경우와 같이, 키메라 항체는 주로 적용 시 면역원성을 감소시키고 생성 수율을 증가시키는 데 사용된다. 키메라 항체 및 이의 생성 방법은 당업계에 알려져 있다 (예를 들어 PCT 특허 출원 WO 86/01533, WO 97/02671, WO 90/07861, WO 92/22653, 및 미국 특허 제5,693,762호, 제5,693,761호, 제5,585,089호, 제5,530,101호, 및 제5,225,539호). 본원에서 사용되는 바와 같이, 용어 "인간화 항체"는 인간 항체로부터의 프레임워크 영역 및 비-인간(보통 마우스 또는 래트) 면역글로불린으로부터의 하나 이상의 CDR을 포함하는 항체를 나타낸다. 가능하게는 CDR을 제외한, 인간화 면역글로불린의 일부는 천연 인간 면역글로불린 서열의 대응하는 부분과 실질적으로 동일하다. 그러나 일부 경우에, 예를 들어 프레임워크 영역에서의, 특정 아미노산 잔기는 인간화 항체의 성능을 최적화하기 위해 변형될 수 있다. 중요하게는, 인간화 항체는 CDR을 제공하는 공여자 항체와 동일한 항원에 결합할 것으로 예상된다. 추가 상세사항에 대해서는, 예를 들어 Medical Research Council(UK)에 배속된 미국 특허 제5,225,539호를 참고한다. 용어 "수용자 인간 면역글로불린으로부터의 프레임워크 영역" 및 "수용자 인간 면역글로불린으로부터 유래된 프레임워크 영역", 및 유사한 문법적 표현은 본원에서 상호 교환적으로 사용되어 수용자 인간 면역글로불린의 동일한 아미노산 서열을 갖는 프레임워크 영역 또는 이의 일부를 나타낸다.
본원에서 사용되는 바와 같이, 용어 "단일클론 항체" 또는 "mAb"는 실질적으로 동종성 항체 집단으로부터 수득된 항체를, 즉 단일클론 항체의 생성 동안 발생할 수 있는 가능한 변이체를 제외하고, 집단을 이루는 개별 항체가 동일하고/하거나 동일한 에피토프에 결합함을 나타내며, 이러한 변이체는 일반적으로 소량으로 존재한다. 전형적으로 상이한 결정기(에피토프)에 대해 유도된 상이한 항체를 포함하는 다클론 항체 제제와는 대조적으로, 각각의 단일클론 항체는 항원 상의 단일 결정기에 대해 유도된다. 이의 특이성 외에도, 단일클론 항체는 다른 면역글로불린으로 오염되지 않는다는 점에서 유리하다. 수식어 "단일클론"은 실질적으로 동종성 항체 집단으로부터 수득되는 항체의 특징을 시사한다. 본원에서 제공되는 방법에 따라 사용될 단일클론 항체는 문헌[Kohler et al., Nature (1975) 256:495]에서 최초로 기재된 하이브리도마 방법에 의해 생성될 수 있거나 재조합 DNA 방법(예를 들어 미국 특허 제4,816,567호 참조)에 의해 생성될 수 있다. "단일클론 항체"는 또한, 예를 들어 문헌[Clackson et al., Nature (1991) 352:624-8 and Marks et al., J Mol Biol. (1991) 222:581-97]에 기재된 기법을 사용하여 파지 항체 라이브러리로부터 단리될 수 있다.
본 개시의 mAb는 IgG, IgM, IgE, 또는 IgA를 포함하는 임의의 면역글로불린 클래스의 것일 수 있다 mAb를 생성하는 하이브리도마는 시험관내 또는 생체내 배양될 수 있다. 고역가의 mAb는, 개별 하이브리도마로부터의 세포가 프리스틴-프라이밍된 Balb/c 마우스 내로 복강내 주사되어 고농도의 목적하는 mAb를 함유하는 복수를 생성하는 생체내 생성으로부터 수득될 수 있다. 이소형 IgM 또는 IgG의 mAb는 이러한 복수로부터 또는 배양 상청액으로부터, 당업자에게 잘 알려진 칼럼 크로마토그래피 방법을 사용하여 정제될 수 있다.
"항체 단편", "항원 결합 단편", 및 "항원 결합 부분"은 동의어로 사용되며, 바람직하게는 이의 항원 결합 영역을 포함하는, 온전한 항체의 일부를 포함한다. 항체 단편의 예로는 Fab, Fab’, F(ab’)2, 및 Fv 단편, scFvs, 디아바디, 탠덤 디아바디(taDb), 선형 항체(예를 들어 미국 특허 제5,641,870호, 실시예 2; 문헌[Zapata et al., Protein Eng. (1995) 8(10):1057-62)]); 1-암 항체, 단일 가변 도메인 항체, 미니바디, 단일쇄 항체 분자, 항체 단편으로부터 형성된 다중특이적 항체(예를 들어 비제한적으로 Db- Fc, taDb-Fc, taDb-CH3, (scFV)4-Fc, 디-scFv, 비-scFv, 또는 탠덤(디,트리)-scFv 포함), 및 이중 특이적 T 세포 관여자(BiTE)가 포함된다.
항체의 파파인 분해는 각각 단일 항원 결합 부위를 갖는 "Fab" 단편이라고 하는 2개의 동일한 항원 결합 단편, 및 잔기 "Fc" 단편(용이하게 결정화되는 능력이 반영된 명칭임)을 생성한다. 펩신 처리는 2개의 항원 결합 부위를 가지면서도 항원을 가교시킬 수 있는 F(ab’)2 단편을 도출한다.
"Fv"는 완전한 항원 인식 및 항원 결합 부위를 함유하는 최소 항체 단편이다. 이 영역은 단단히, 비-공유 연합된 하나의 중쇄 및 하나의 경쇄 가변 도메인의 이량체로 구성된다. 전체적으로, 6개의 초가변 영역이 항체에 항원 결합 특이성을 부여한다. 그러나 단일 가변 도메인(또는 항원에 특이적인 3개의 초가변 영역만을 포함하는 Fv의 절반)도, 전체 결합 부위보다 친화도가 더 낮긴 하지만, 항원을 인식하고 결합하는 능력을 가지고 있다.
Fab 단편은 또한 경쇄의 불변 도메인 및 중쇄의 제1 불변 도메인(CH1)을 함유한다. Fab' 단편은 항체 힌지 영역으로부터의 하나 이상의 시스테인을 포함하는 중쇄 CH1 도메인의 카복시 말단에 소수의 잔기가 추가된다는 점에서 Fab 단편과 다르다. Fab'-SH는 본원에서 불변 도메인의 시스테인 잔기가 적어도 하나의 유리 티올기를 보유하는 Fab'에 대한 명칭이다. F(ab’)2 항체 단편은 원래 이들 사이에 힌지 시스테인을 갖는 Fab' 단편 쌍으로 생성되었다. 항체 단편의 다른 화학적 결합이 또한 알려져 있다.
임의의 척추동물 종으로부터의 항체(면역글로불린)의 "경쇄"는 이의 불변 도메인의 아미노산 서열에 기반하여, 카파 및 람다로 명명되는 2개의 명확히 구별되는 유형 중 하나로 지정될 수 있다.
이의 중쇄의 불변 도메인의 아미노산 서열에 따라, 항체는 상이한 클래스로 지정될 수 있다. 온전한 항체에는 5개의 주요 클래스, 즉 IgA, IgD, IgE, IgG, 및 IgM이 존재하며, 이들 중 일부는 하위클래스(이소형), 예를 들어 IgG, IgG2, IgG3, IgG4, IgA1, 및 IgA2로 추가 구분될 수 있다. 상이한 클래스의 항체에 대응하는 중쇄 불변 도메인은 각각 a, 델타, e, 감마, 및 마이크로로 불린다. 상이한 클래스의 면역글로불린의 서브유닛 구조 및 3차원 구성은 잘 알려져 있다.
"단일쇄 Fv" 또는 "scFv" 항체 단편은 항체의 VH 및 VL 도메인을 포함하며, 이들 도메인은 단일 폴리펩티드쇄에 존재한다. 일부 구현예에서, Fv 폴리펩티드는 scFv가 항원 결합을 위해 목적하는 구조를 형성할 수 있도록 하는 VH 및 VL 도메인 간 폴리펩티드 링커를 추가로 포함한다. scFv에 대한 리뷰는 문헌[Pluckthun in The Pharmacology of Monoclonal Antibodies, vol. 113, Rosenburg and Moore eds., Springer- Verlag, New York, pp. 269-315 (1994)]을 참조한다.
용어 "디아바디"는 2개의 항원 결합 부위를 갖는 작은 항체 단편으로서, 동일한 폴리펩티드 사슬(VH- VL) 내에 경쇄 가변 도메인(VL)에 연결된 중쇄 가변 도메인(VH)을 포함하는 단편을 지칭한다. 이 도메인은 동일한 사슬의 두 도메인 간에 쌍을 형성시킬 수 없을 정도로 짧은 링커를 사용하기 때문에, 다른 사슬의 상보적 도메인과 쌍을 이루어 2개의 항원 결합 부위를 생성하게 된다. 디아바디는 문헌[Natl. Acad. Sci. USA, 90:6444-6448 (1993)]에 나와 있다.
용어 "다중특이적 항체"는 가장 넓은 의미로 사용되며 구체적으로 다중에피토프 특이성을 갖는 항체에 해당된다. 이러한 다중특이적 항체에는 비제한적으로 중쇄 가변 도메인(VH) 및 경쇄 가변 도메인(VL)을 포함하며, VH/VL 단위가 다중에피토프 특이성을 갖는 항체, 2개 이상의 VL 및 VH 도메인을 가지며 각각의 VH/VL 단위가 상이한 에피토프에 결합하는 항체, 2개 이상의 단일 가변 도메인을 가지며 각각의 단일 가변 도메인이 상이한 에피토프에 결합하는 항체, 전장 항체, 항체 단편, 예컨대 Fab, Fv, dsFv, scFv, 디아바디, 이중특이적 디아바디, 트리아바디, 삼중기능적 항체, 공유 또는 비-공유 연결된 항체 단편이 포함된다. "다중에피토프 특이성"은 동일하거나 상이한 표적 상에서 2개 이상의 상이한 에피토프에 특이적으로 결합하는 능력을 나타낸다.
본 개시는 또한 본원에 기재된 항-ILT2 항체의 결합 특이성(예를 들어 6개의 CDR 또는 VH 및 VL과 같은 항원 결합 부분을 포함함)을 갖는 다중특이적 항체(예를 들어 이중특이적 항체)를 제공한다. 일부 구현예에서, 다중특이적 항체는 ILT2 또는 다른 단백질, 예컨대 암 항원, 또는 활성이 암과 같은 질환 병태를 매개하는 또 다른 세포 표면 분자를 표적화할 수 있는 또 다른 별개 항체의 결합 특이성을 추가로 갖는다. 다중특이적 항체 및 이의 제조물은 당업계에 알려져 있다. 일부 구현예, 본원에 기재된 다중특이적 항체는 본원에 기재된 치료 방법, 키트, 또는 제조 물품에서 본원에 기재된 항-ILT2 항체 대신 사용된다.
본 개시의 단일클론 항체는 당업계에 잘 알려진 방법을 사용하여 제조될 수 있다. 예로는 다양한 기법, 예컨대 문헌[Kohler, G. and Milstein, C, Nature 256: 495-497 (1975); Kozbor et al., Immunology Today (1983) 4:72; Cole et al., pg. 77-96 in Monoclonal Antibodies and Cancer Therapy, Alan R. Liss, Inc. (1985)]에서의 기법이 포함된다.
생체내 항체를 유도하는 통상적 방법에 더하여, 항체는 파지 디스플레이 기술을 사용하여 시험관내 생성될 수 있다. 이러한 재조합 항체의 생성은 통상적인 항체 생성에 비해 훨씬 빠르고, 수많은 항원에 대해 생성될 수 있다. 또한, 통상적 방법을 사용하는 경우, 여러 항원은 비면역원성이거나 극도로 독성이 있는 것으로 입증되어, 동물에서 항체를 생성하는 데 사용될 수 없다. 또한, 재조합 항체의 친화도 성숙(즉, 친화도 및 특이성 증가)은 매우 간단하고 비교적 빠르다. 마지막으로, 특정 항원에 대한 많은 수의 상이한 항체가 한 번의 선택 절차로 생성될 수 있다. 재조합 단일클론 항체를 생성하기 위해, 모두 디스플레이 라이브러리에 기반한 다양한 방법을 사용하여 상이한 항원 인식 부위를 갖는 대규모 항체 풀을 생성할 수 있다. 이러한 라이브러리는 여러 방식으로 제조될 수 있다: 중쇄 생식계열 유전자 풀에서 합성 CDR3 영역을 클로닝하여 대규모 항체 레퍼토리를 생성함으로써 합성 레퍼토리를 생성할 수 있고, 이로부터 다양한 특이성을 갖는 재조합 항체 단편이 선택될 수 있다. 항체 라이브러리 구성을 위한 출발 물질로서 인간의 림프구 풀을 사용할 수 있다. 인간 IgM 항체의 나이브 레퍼토리를 구성하여 매우 다양한 인간 라이브러리를 생성하는 것이 가능하다. 이 방법은 상이한 항원에 대한 다수의 수의 항체를 선택하는 데 성공적으로 널리 사용되어 왔다. 박테리오파지 라이브러리 구성 및 재조합 항체의 선택을 위한 프로토콜은 잘 알려진 참조 문서[Current Protocols in Immunology, Colligan et al. (Eds.), John Wiley & Sons, Inc. (1992-2000), Chapter 17, Section 17.1]에 제공되어 있다.
비-인간 항체는 당업계에 알려진 임의의 방법에 의해 인간화될 수 있다. 일 방법에서, 비-인간 상보성 결정 영역(CDR)은 인간 항체 또는 공통 항체 프레임워크 서열에 삽입된다. 이어서 친화도 또는 면역원성을 조절하기 위해 추가적인 변화를 항체 프레임워크에 도입할 수 있다.
일부 구현예에서, 본원에 기재된 항체는 중화 항체이다. 본원에서 논의되는 "중화"는 본 개시의 항체에 의한 단백질 기능의 감소로 정의된다. 일 구현예에서, 본원에서 논의되는 바와 같이, "중화"는 항체가 면역 세포의 표면, 바람직하게는 미성숙 및 성숙 골수 계통 유래 세포, T 세포, 및 NK 세포에 결합하여 이들 세포 내부의 억제 신호의 전파를 차단하고 억제성이 더 적은 표현형과 기능을 부여한다.
일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편은 본 개시의 제제이다.
일부 구현예에서, 본 개시는 본 개시의 항체를 암호화하는 핵산 서열을 제공한다. 일 구현예에서, 본원에 기재된 바와 같은 항체는 본원에 기재된 바와 같은 뉴클레오티드 서열에 대해 적어도 75% 동일성을 갖는 뉴클레오티드 서열을 포함하는 핵산 분자에 의해 암호화된다. 일 구현예에서, 본원에 기재된 바와 같은 항체는 본원에 기재된 바와 같은 핵산 서열에 대해 적어도 80% 동일성을 갖는 핵산 서열을 포함하는 핵산 분자에 의해 암호화된다. 일 구현예에서, 본원에 기재된 바와 같은 항체는 본원에 기재된 바와 같은 핵산 서열에 대해 적어도 85% 동일성을 갖는 핵산 서열을 포함하는 핵산 분자에 의해 암호화된다. 일 구현예에서, 본원에 기재된 바와 같은 항체는 본원에 기재된 바와 같은 핵산 서열에 대해 적어도 90% 동일성을 갖는 핵산 서열을 포함하는 핵산에 의해 암호화된다. 일 구현예에서, 본원에 기재된 바와 같은 항체는 본원에 기재된 바와 같은 핵산 서열에 대해 적어도 95% 동일성을 갖는 핵산 서열을 포함하는 핵산에 의해 암호화된다.
다른 양태에 따르면, 본 개시의 항체 또는 항원 결합 단편을 암호화하는 핵산 서열이 제공된다.
다른 양태에 따르면, 본 개시의 항체 또는 항원 결합 단편을 암호화하는 핵산 분자가 제공된다.
일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편의 중쇄의 가변 영역을 암호화하는 핵산 서열은 다음의 서열로부터 선택된 핵산 서열을 포함한다:
caggttcagctgcagcagtctggagctgagctggcgaggcctggggcttcagtgaagctgtcctgcaaggcttctggctacaccttcacaagctatggtataagctgggtgaagcagagaactggacagggccttgagtgggttggagagatttatcctggaagtggtaattcttactacaatgagaagttcaagggcaaggccacactgactgcagacaaatcctccagcacagcgtacatggagctccgcagcctgacatctgaggactctgcggtctatttctgtgcaagatcgaatgatggttaccctgactactggggccaaggcaccactctcacagtctcctca(서열번호 32),
gatgtacagcttcaggggtcaggacctggcctcgtgaaaccttctcagtctctgtctctcacctgctctgtcactggctactccatcaccagtggttattactggaactggatccggcagtttccaggaaacaaactggaatggatgggctacataagctacgatggtagcaataactacaacccatctctcaaaaatcgaatctccatcactcgtgacacatctaagaaccagtttttcctgaagttgaattctgtgacttctgaggacacagccacatattactgtgcccatggttactcatattactatgctatggactgctggggtcaaggaacctcagtcaccgtctcctca(서열번호 33),
gatgtccagctgcaaggctctggccctggactggttaagccttccgagacactgtccctgacctgctctgtgaccggctactctatcacctccggctactactggaactggatcagacagttccccggcaagaaactggaatggatgggctacatctcctacgacggctccaacaactacaaccccagcctgaagaaccggatcaccatctctcgggacacctccaagaaccagttctccctgaagctgaactccgtgaccgctgccgataccgctacctactactgtgctcacggctactcctactactacgccatggatgcttggggccagggcacatctgtgacagtgtcctct(서열번호 34), 및
caggttcagctgcaacagtctgacgctgagttggtgaaacctggagcttcagtgaagatatcctgcaaggtttctggctacaccttcactgaccatactattcactggatgaagcagaggcctgaacagggcctggaatggattggatatatttatcctagagatggtagtactaagtacaatgagaagttcaagggcaaggccacattgactgcagacaaatcctccagcacagcctacatgcagctcaacagcctgacatctgaggactctgcagtctatttctgtgcaagaacctgggactactttgactactggggccaaggcaccactctcacagtctcctca(서열번호 35).
일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편의 경쇄의 가변 영역을 암호화하는 핵산 서열은 다음의 서열로부터 선택된 핵산 서열을 포함한다:
gacattgtgctgacccaatctccagcttctttggctgtgtctctagggcagagggccaccatatcctgcagagccagtgaaagtgttgatagttatggcaatagttttatgcactggtaccagcagaaaccaggacagccacccaaactcctcatctatcgtgcatccaacctagaatctgggatccctgccaggttcagtggcagtgggtctaggacagacttcaccctcaccattaatcctgtggaggctgatgatgttgcaacctattactgtcagcaaagtaatgaggatccgtacacgttcggaggggggaccaagctggaaataaaa(서열번호 36),
gatatccagatgacacagactacatcctccctgtctgcctctctgggagacagagtcaccatcagttgcaggacaagtcaggacattagcaattatttaaactggtatcagcagaaaccagatggaactgttaaactcctgatctcctacacatcaagattgcactcaggagtcccatcaaggttcagtggcagtgggtctggaacagattattctctcaccattagcaacctggagcaagaagatattgccacttacttttgccaacagggtaatacgcttcccacgttcggctcggggacaaagttggaaataaaa(서열번호 37),
gacatccagatgacccagtctccatcctctctgtctgcctctgtgggcgacagagtgaccatcacctgtcggacctctcaggacatctccaactacctgaactggtatcagcagaaacccggcaaggccgtgaagctgctgatctcctacacctccagactgcactctggcgtgccctccagattttctggctctggatctggcaccgactacaccctgaccatcagttctctgcagcctgaggacttcgccacctactactgtcagcagggcaacaccctgcctacctttggccagggcaccaagctggaaatcaag(서열번호 38),
및gacatccagatgacacaatcttcatcctacttgtctgtatctctaggaggcagagtcaccattacttgcaaggcaagtgaccacattaataattggttagcctggtatcagcagaaaccaggaaatgctcctaggctcttaatatctggtgcaaccagtttggaaactggggttccttcaagattcagtggcagtggatctggaaaggattacactctcagcattaccagtcttcagactgaagatgttgctacttattactgtcaacagtattggagtactccgtggacgttcggtggaggcaccaagctggaaatcaaa(서열번호 39).
일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편의 중쇄를 암호화하는 핵산 서열은 gatgtccagctgcaaggctctggccctggactggttaagccttccgagacactgtccctgacctgctctgtgaccggctactctatcacctccggctactactggaactggatcagacagttccccggcaagaaactggaatggatgggctacatctcctacgacggctccaacaactacaaccccagcctgaagaaccggatcaccatctctcgggacacctccaagaaccagttctccctgaagctgaactccgtgaccgctgccgataccgctacctactactgtgctcacggctactcctactactacgccatggatgcttggggccagggcacatctgtgacagtgtcctctgcttccaccaagggaccctctgtgttccctctggctccttgctccagatccacctctgagtctaccgctgctctgggctgcctggtcaaggattactttcctgagcctgtgaccgtgtcttggaactctggtgctctgacctccggcgtgcacacatttccagctgtgctgcagtcctccggcctgtactctctgtcctctgtcgtgaccgtgccttctagctctctgggcaccaagacctacacctgtaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggaatctaagtacggccctccttgtcctccatgtcctgctccagaattcgaaggcggcccttccgtgttcctgtttcctccaaagcctaaggacaccctgatgatctctcggacccctgaagtgacctgcgtggtggtggatgtgtctcaagaggaccccgaggtgcagttcaattggtacgtggacggcgtggaagtgcacaacgccaagaccaagcctagagaggaacagttcaactccacctacagagtggtgtccgtgctgaccgtgctgcaccaggattggctgaacggcaaagagtacaagtgcaaggtgtccaacaagggcctgcctagctccatcgaaaagaccatctccaaggctaagggccagcctcgggaacctcaggtttacaccctgcctccaagccaagaggaaatgaccaagaatcaggtgtcactgacatgcctcgtgaagggcttctacccctccgatatcgccgtggaatgggagtctaatggccagccagagaacaattacaagacaacccctcctgtgctggactccgacggctctttcttcctgtattcccgcctgaccgtggacaagtccagatggcaagagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaatcactacacccagaagtccctgtctctgtccctgggcaaa(서열번호 109)를 포함하거나 이로 구성된다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편의 중쇄를 암호화하는 핵산 서열은 신호 펩티드를 암호화하는 서열을 추가로 포함한다. 일부 구현예에서, 신호 펩티드를 암호화하는 서열은 N-말단 서열이다. 일부 구현예에서, 신호 펩티드를 암호화하는 서열은 atggatctgctgcacaagaacatgaagcacctgtggttctttctgctgctggtggccgctcctagatgggtgttgtct(서열번호 110)를 포함하거나 이로 구성된다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편의 중쇄를 암호화하는 서열은 정지 코돈을 추가로 포함한다. 일부 구현예에서, 정지 코돈은 다수의 정지 코돈이다. 일부 구현예에서, 정지 코돈은 tga, tag, 및 taa로부터 선택된다.
일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편의 경쇄를 암호화하는 핵산 서열은 gacatccagatgacccagtctccatcctctctgtctgcctctgtgggcgacagagtgaccatcacctgtcggacctctcaggacatctccaactacctgaactggtatcagcagaaacccggcaaggccgtgaagctgctgatctcctacacctccagactgcactctggcgtgccctccagattttctggctctggatctggcaccgactacaccctgaccatcagttctctgcagcctgaggacttcgccacctactactgtcagcagggcaacaccctgcctacctttggccagggcaccaagctggaaatcaagagaaccgtggctgccccttccgtgttcatcttcccaccatctgacgagcagctgaagtccggcacagcttctgtcgtgtgcctgctgaacaacttctaccctcgggaagccaaggtgcagtggaaggtggacaatgccctgcagtccggcaactcccaagagtctgtgaccgagcaggactccaaggactctacctacagcctgtcctccacactgaccctgtctaaggccgactacgagaagcacaaggtgtacgcctgtgaagtgacccaccagggactgtctagccccgtgaccaagtctttcaacagaggcgagtgc(서열번호 111)를 포함하거나 이로 구성된다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편의 경쇄를 암호화하는 핵산 서열은 신호 펩티드를 암호화하는 서열을 추가로 포함한다. 일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편의 경쇄를 암호화하는 서열은 정지 코돈을 추가로 포함한다.
일부 구현예에서, 항체 또는 항원 결합 단편은 뮤린이고 중쇄를 암호화하는 서열은 서열번호 32, 33, 및 35로부터 선택된다. 일부 구현예에서, 항체 또는 항원 결합 단편은 뮤린이고 경쇄를 암호화하는 서열은 서열번호 36, 37, 및 39로부터 선택된다. 일부 구현예에서, 항체 또는 항원 결합 단편은 인간화되고 중쇄를 암호화하는 서열은 서열번호 34이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 인간화되고 경쇄를 암호화하는 서열은 서열번호 38이다.
본 명세서에서 상호교환 가능하게 사용되는 "폴리뉴클레오티드" 또는 "핵산"은 임의의 길이의 뉴클레오티드의 중합체를 지칭하며, DNA 및 RNA를 포함한다.
폴리펩티드를 암호화하는 폴리뉴클레오티드는 비제한적으로 폴리펩티드 mRNA를 보유하고 이를 검출 가능한 수준으로 발현하는 것으로 여겨지는 조직으로부터 제조되는 cDNA 라이브러리를 포함하는 임의의 공급원으로부터 수득할 수 있다. 따라서, 폴리펩티드를 암호화하는 폴리뉴클레오티드는 인간 조직으로부터 제조된 cDNA 라이브러리로부터 편리하게 수득할 수 있다. 폴리펩티드-암호화 유전자는 또한 게놈 라이브러리로부터 또는 알려진 합성 절차(예를 들어 자동화된 핵산 합성)를 통해 수득할 수 있다.
예를 들어, 폴리뉴클레오티드는 경쇄 또는 중쇄와 같은 전체 면역글로불린 분자쇄를 암호화할 수 있다. 전체 중쇄에는 중쇄 가변 영역(VH)뿐만 아니라 일반적으로 3개의 불변 도메인, 즉 CH1, CH2, 및 CH3을 포함할 중쇄 불변 영역(CH), 및 "힌지" 영역이 포함된다. 일부 경우에, 불변 영역의 존재가 바람직하다.
폴리뉴클레오타이드에 의해 암호화될 수 있는 다른 폴리펩티드에는 항원 결합 항체 단편, 예컨대 단일 도메인 항체("dAb"), Fv, scFv, Fab', 및 CHI가 포함되며 CK 또는 CL 도메인은 절제되었다. 미니바디는 통상적 항체보다 작으므로 임상/진단 사용에서 더 나은 조직 침투를 달성할 수 있지만 2가이기 때문에 dAb와 같은 1가 항체 단편보다 높은 결합 친화도를 보유할 것이다. 따라서, 문맥상 달리 지시하지 않는 한, 본원에서 사용되는 용어 "항체"는 전체 항체 분자뿐만 아니라 상기 논의된 유형의 항원 결합 항체 단편도 포함한다. 암호화된 폴리펩티드에 존재하는 각각의 프레임워크 영역은 상응하는 인간 수용자 프레임워크 대비 적어도 하나의 아미노산 치환을 포함할 수 있다. 따라서, 예를 들어 프레임워크 영역은 수용자 프레임워크 영역 대비 총 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개, 11개, 12개, 13개, 14개, 또는 15개 아미노산 치환을 포함할 수 있다. 개시된 단백질 생성물을 포함하는 개별 아미노산의 특성에 기반하여, 일부 합리적인 치환은 당업자에 의해 인식될 것이다. 아미노산 치환, 즉 "보존적 치환"은, 예를 들어, 관련된 잔기의 극성, 전하, 용해도, 소수성, 친수성, 및/또는 양친매성 성질의 유사성에 기초하여 이루어질 수 있다.
적합하게는, 본원에 기재된 폴리뉴클레오티드는 단리되고/되거나 정제될 수 있다. 일부 구현예에서, 폴리뉴클레오타이드는 단리된 폴리뉴클레오타이드이다.
본원에서 사용되는 바와 같이, 용어 "비자연 발생" 성분, 조성물, 물체, 및/또는 성분, 조성물, 또는 물체의 임의의 조합, 또는 이의 임의의 문법적 변형은, 당업자가 "자연 발생"한 것으로 잘 이해하고 있거나 임의의 시점에 판사 또는 행정부 또는 재판부에 의해 "자연 발생"인 것으로 결정 또는 해석되거나 결정 또는 해석될 수도 있는 성분, 조성물, 물체 형태, 및/또는 성분, 조성물, 또는 물체의 임의의 조합을 명시적으로 배제하되 이에 한정하여 배제하는 조건적 용어이다.
치료 및 진단 방법
다른 양태에 따르면, HLA, MHC-I, 또는 둘 다의 치료를 필요로 하는 대상체에서 이를 치료하는 방법으로서, 본 개시의 항체 또는 항원 결합 단편을 대상체에게 투여하는 단계를 포함하는 방법이 제공된다.
다른 양태에 따르면, 암의 치료를 필요로 하는 대상체에서 이를 치료하는 방법으로서, 대상체에서 ILT2의 발현이 소정의 역치를 초과하는지 확인하고 ILT2 기반 면역 억제를 억제하는 제제를 대상체에게 투여하는 단계를 포함하는 대상체에서 암을 치료하는 방법이 제공된다.
다른 양태에 따르면, 암의 치료를 필요로 하는 대상체에서 이를 치료하는 방법으로서, ILT2-매개 면역 억제를 억제하는 제제를 대상에게 투여하는 단계; 및 대상체에게 PD-1/PD-L1 기반 요법을 투여하는 단계를 포함하는 대상체에서 암을 치료하는 방법이 제공된다.
다른 양태에 따르면, 암세포에 대한 항-PD-L1/PD-1 기반 요법의 효능 증가를 필요로 하는 대상체에서 이의 효능을 증가시키는 방법으로서, 암세포를 ILT2-매개 면역 억제를 억제하는 제제와 접촉시키는 단계를 포함하는 방법이 제공된다.
다른 양태에 따르면, 암을 앓고 있는 대상체의 치료를 위해 항-PD-L1/PD-1 기반 요법과 조합하여 사용하기 위한 ILT2에 결합하고 ILT2 매개 면역 세포 억제를 억제하는 제제가 제공된다.
본원에서 사용되는 바와 같이, 용어 질환, 장애, 또는 병태의 "치료" 또는 "치료하는"은 이의 적어도 하나의 증상 경감, 이의 중증도 감소, 또는 이의 진행(예를 들어 암 전이)의 억제를 포함한다. 치료는 질환, 장애, 또는 병태가 완전히 완치되었음을 의미할 필요는 없다. 효과적인 치료가 되기 위해, 본원에서 유용한 조성물은 질환, 장애, 또는 병태의 중증도를 감소시키거나, 이와 관련된 증상의 중증도를 감소시키거나, 환자 또는 대상체의 삶의 질에 대한 개선을 제공할 수 있으면 된다.
본원에서 사용되는 바와 같이, 용어 "치료"는 치료받는 개체에서 질환의 경과를 변경하려는 시도에서의 임상적 개입을 의미하며 예방을 위해 또는 임상 병리 경과 동안 수행될 수 있다. 치료의 바람직한 효과에는 질환의 발병 또는 재발 방지, 증상 완화, 질환의 병리적 결과 감소, 질환 진행 속도 감소, 질환 병태의 완화, 관해, 또는 개선된 예후가 포함된다. 용어 "치료"는 또한 배양 중인 세포 또는 조직에 영향을 미치는 생체외 절차를 포함할 수 있다.
일부 구현예에서, 항체 또는 항원 결합 단편은 단일요법으로 투여된다. 일부 구현예에서, 항체 또는 항원 결합 단편은 PD-1/PD-L1 요법과 조합하여 투여된다. 일부 구현예에서, 항체 또는 항원 결합 단편은 옵소닌화제와 조합하여 투여된다. 일부 구현예에서, 옵소닌화제는 항-CD47 제제가 아니다. 일부 구현예에서, 항-CD47 제제는 항-CD47 항체이다. 일부 구현예에서, 항체 또는 항원 결합 단편은 항-CD47 제제 또는 요법과 조합하여 투여되지 않는다. 일부 구현예에서, 항체 또는 항원 결합 단편은 항-CD47 제제 또는 요법과 조합되지 않는다.
일부 구현예에서, 치료는 면역 감시의 증가를 포함한다. 일부 구현예에서, 치료는 면역 반응의 증가를 포함한다. 일부 구현예에서, 치료는 종양 부담의 감소를 포함한다. 일부 구현예에서, 치료는 암 전이의 감소를 포함한다. 일부 구현예에서, 치료는 암에 대한 세포독성의 증가를 포함한다. 일부 구현예에서, 치료는 암에 대한 염증 반응의 증가를 포함한다. 일부 구현예에서, 치료는 암 식세포작용의 증가를 포함한다.
본원에서 사용되는 바와 같이, 용어 "대상체"는 척추동물, 예를 들어 포유동물, 특히 인간을 포함하는 개체 또는 환자를 나타낸다. 일부 구현예에서, 대상체는 인간이다. 일부 구현예에서, 대상체는 포유류(예를 들어 마우스, 래트, 개, 토끼, 또는 비-인간 영장류)이다. 일부 구현예에서, 대상체는 암이 있다.
일부 구현예에서, 암은 HLA 발현 암이다. 일부 구현예에서, HLA는 HLA-G1와 같은 HLA-G 및 HLA-G의 다른 이소형이다. 일부 구현예에서, 암은 MHC-I 발현 암이다. 일부 구현예에서, 암은 PD-L1 발현 암이다. 일부 구현예에서, 암은 고형암이다. 일부 구현예에서, 암은 혈액암이다. 일부 구현예에서, 암은 PD-1 및/또는 PD-L1 기반 요법에 대해 불응성이다. 일부 구현예에서, 암은 PD-1 및/또는 PD-L1 기반 요법에 전혀 반응하지 않았다. 일부 구현예에서, 암은 PD-1 및/또는 PD-L1 기반 요법에 반응성이었으나 불응성이 되었다. 일부 구현예에서, 본 개시의 방법은 불응성 암을 반응성 암으로 전환시킨다.
일부 구현예에서, 암은 절제불가능하거나, 전이성이거나, 승인된 표준 요법 또는 상기의 임의의 조합에 대해 불응성이거나 이의 대상이 아니다.
일부 구현예에서, 해당 방법은 암이 HLA, MHC-I, 또는 둘 모두를 발현하는지 확인하는 단계를 포함한다. 일부 구현예에서, 해당 방법은 암이 HLA를 발현하는지 확인하는 단계를 포함한다. 일부 구현예에서, 해당 방법은 암이 MHC-I을 발현하는지 확인하는 단계를 포함한다. 일부 구현예에서, 해당 방법은 암이 MHC-I(즉, 인간에서 클래스 I HLA)을 발현하는지 확인하는 단계를 포함한다. 일부 구현예에서, 확인은 암에서의 발현 측정을 포함한다. 일부 구현예에서, 확인은 암의 표면 상에서의 발현 측정을 포함한다. 일부 구현예에서, 암 내 및/또는 상은 암세포 내 및/또는 상이다. 일부 구현예에서, 확인은 암에 의해 분비된 HLA-G의 측정을 포함한다. 일부 구현예에서, 확인은 가용성 HLA-G의 측정을 포함한다. 일부 구현예에서, 가용성 HLA-G는 체액에 존재한다. 일부 구현예에서, 체액은 혈액이다.
일부 구현예에서, 해당 방법은 대상체에서 ILT2의 발현을 확인하는 단계를 포함한다. 일부 구현예에서, 해당 방법은 대상체에서 ILT2의 발현이 소정의 역치를 초과하는지 확인하는 단계를 포함한다. 일부 구현예에서, 확인은 대상체에서 ILT2의 발현 측정을 포함한다. 일부 구현예에서, 확인은 투여 전에 이루어진다. 일부 구현예에서, 측정은 투여 전에 이루어진다. 일부 구현예에서, ILT2의 발현은 면역 세포에서의 발현이다. 일부 구현예에서, ILT2의 발현은 대상체의 면역 세포에서의 발현이다. 일부 구현예에서, 면역 세포는 말초 혈액 면역 세포이다. 일부 구현예에서, 면역 세포는 말초 혈액 단핵 세포(PBMC)이다. 일부 구현예에서, 면역 세포는 종양내 면역 세포이다. 일부 구현예에서, 면역 세포는 종양 미세환경(TME) 내 면역 세포이다. 일부 구현예에서, 면역 세포는 CD8 양성 T 세포, 대식세포, NK 세포, 및 TEMRA 세포로부터 선택된다. 일부 구현예에서, 면역 세포는 CD8 양성 T 세포이다. 일부 구현예에서, 면역 세포는 말초 혈액 CD8 양성 T 세포이다.
일부 구현예에서, 본 개시의 항체 또는 항원 결합 단편의 투여는 본 개시의 항체 또는 항원 결합 단편을 포함하는 약학적 조성물을 투여하는 단계를 포함한다. 일부 구현예에서, 치료적 유효량의 항체 또는 항원 결합 단편이 투여된다. 일부 구현예에서, 약학적 조성물은 담체, 부형제, 또는 보조제를 추가로 포함한다. 일부 구현예에서, 담체는 약학적으로 허용가능한 담체이다.
본원에서 사용되는 바와 같이, 용어 "담체", "부형제", 또는 "보조제"는 활성 제제가 아닌 약학적 조성물의 임의의 성분을 나타낸다. 본원에서 사용되는 바와 같이, 용어 "약학적으로 허용가능한 담체"는 비독성, 불활성 고체, 반고체 액체 충전제, 희석제, 캡슐화 물질, 임의 유형의 제형 보조제, 또는 단순히 식염수와 같은 멸균 수성 매질을 나타낸다. 약학적으로 허용가능한 담체로 작용할 수 있는 물질의 일부 예로는 락토스, 글루코스, 및 수크로스와 같은 당, 프로필렌 글리콜과 같은 글리콜, 글리세린, 소르비톨, 만니톨, 및 폴리에틸렌 글리콜과 같은 폴리올, 에틸 올레이트 및 에틸 라우레이트와 같은 에스테르, 발열원 비함유수, 등장성 식염수, 링거 용액, 에틸알코올 및 포스페이트 완충 용액뿐만 아니라 약학적 제형에 사용되는 기타 무독성 호환 물질이 있다. 본원에서 담체로 작용할 수 있는 물질의 일부 비제한적 예에는 당, 스테아르산, 스테아르산마그네슘, 황산칼슘, 폴리올, 발열원 비함유수, 등장성 식염수, 포스페이트 완충 용액, 및 다른 약학적 제형에 사용되는 기타 무독성 약학적 호환 물질이 포함된다. 라우릴황산나트륨과 같은 습윤제 및 윤활제뿐만 아니라 부형제, 안정화제, 항산화제, 및 보존제 또한 존재할 수 있다. 임의의 비독성, 불활성, 및 효과적인 담체를 사용하여 본원에서 고려되는 조성물을 제형화할 수 있다.
담체는 본원에 제시된 약학적 조성물의 총 중량의 약 0.1% 내지 약 99.99999%를 포함할 수 있다.
용어 "치료적 유효량"은 포유류에서 질환 또는 장애를 치료하는 데 효과적인 약물의 양을 나타낸다. 용어 "치료적 유효량"은 목적하는 치료적 또는 예방적 결과를 달성하기 위해 필요한 기간 및 투여량에 있어 효과적인 양을 나타낸다. 정확한 투여 형태와 요법은 환자의 병태에 따라 의사가 결정한다.
일부 구현예에서, 해당 방법은 대상체에게 옵소닌화제를 투여하는 단계를 추가로 포함한다. 일부 구현예에서, 해당 방법은 세포를 옵소닌화제와 접촉시키는 단계를 추가로 포함한다. 일부 구현예에서, 옵소닌화제는 표피 성장 인자 수용체(EGFR) 억제제이다. 일부 구현예에서, EGFR 억제제는 세툭시맙이다. 일부 구현예에서, 옵소닌화제는 항-CD47 제제가 아니다. 일부 구현예에서, 해당 방법은 대상체에게 PD-1/PD-L1 기반 요법을 투여하는 단계를 추가로 포함한다. 일부 구현예에서, 해당 방법은 세포를 PD-1/PD-L1 기반 요법과 접촉시키는 단계를 추가로 포함한다. 일부 구현예에서, 해당 방법은 PD-1/PD-L1 기반 요법의 존재 하에 세포를 성장시키는 단계를 추가로 포함한다. 일부 구현예에서, PD-1/PD-L1 기반 요법은 PD-1 또는 PD-L1 차단 항체(예를 들어 펨브롤리주맙)이다. 일부 구현예에서, 해당 방법은 항-CD47 제제 또는 요법을 투여하는 단계를 포함하지 않는다. 일부 구현예에서, 해당 방법은 항-CD47 제제 또는 요법의 투여가 없다. 일부 구현예에서, 해당 방법은 항-CD47 제제 또는 요법을 투여하는 단계를 추가로 포함한다.
일부 구현예에서, ILT2 기반 면역 억제를 억제하는 제제는 ILT2에 결합한다. 일부 구현예에서, 제제는 ILT2 세포외 도메인에 결합한다. 일부 구현예에서, 제제는 ILT2 길항제이다. 일부 구현예에서, 제제는 ILT2 차단 항체이다. 일부 구현예에서, 제제는 ILT2와 B2M의 상호작용을 억제한다. 일부 구현예에서, 제제는 본 개시의 항체이다.
일부 구현예에서, ILT2 기반 면역 억제를 억제하는 제제는 옵소닌화제 전, 후, 또는 이와 동시에 투여된다. 일부 구현예에서, ILT2 기반 면역 억제를 억제하는 제제 및 옵소닌화제는 단일 조성물로 투여된다. 일부 구현예에서, ILT2 기반 면역 억제를 억제하는 제제 및 옵소닌화제는 별개의 조성물로 투여된다.
일부 구현예에서, ILT2 기반 면역 억제를 억제하는 제제는 PD-1/PD-L1 요법 전, 후, 또는 이와 동시에 투여된다. 일부 구현예에서, ILT2 기반 면역 억제를 억제하는 제제 및 PD-1/PD-L1 요법은 단일 조성물로 투여된다. 일부 구현예에서, ILT2 기반 면역 억제를 억제하는 제제 및 PD-1/PD-L1 요법은 별개의 조성물로 투여된다. 일부 구현예에서, 제제 또는 요법 중 적어도 하나는 공동 투여에 적합하다.
본원에서 사용되는 바와 같이, 용어 "공동 투여에 적합"은 대상체에게 안전하고 용이하게 투여될 수 있는 형태로 존재하는 항체를 의미한다. 일부 비제한적 구현예에서, 공동 투여는 주사, 즉 종양내 주사, 정맥내 주사 또는 주입, 또는 피하 주사, 또는 경구 투여 또는 흡입과 같은 기타 알려진 방법에 의해 수행될 수 있다. 일부 구현예에서, 항체는 대상체에게 안전하고 용이하게 투여될 수 있는 약학적 조성물 내에 포함될 것이다. 일부 구현예에서, 약학적 조성물은 항체 및 약학적으로 허용가능한 담체 또는 부형제를 포함한다.
일부 구현예에서, HLA는 HLA-G이다. 일부 구현예에서, HLA는 비정규 HLA이다. 일부 구현예에서, HLA는 정규 HLA이다. 일부 구현예에서, mRNA 발현이 확인된다. 일부 구현예에서, 단백질 발현이 확인된다. 일부 구현예에서, 단백질의 표면 발현이 확인된다. 발현을 측정하는 방법은 당업계에 잘 알려져 있고, PCR, Q-PCR, 노던 블롯, 면역블롯, 제자리 혼성화, 면역염색, 및 FACS를 포함한다. 일부 구현예에서, 해당 방법은 표면 발현을 확인하기 위한 암의 FACS 분석을 포함한다.
본 개시의 항체 또는 항원 결합 단편 및 약학적 조성물은 본원에 기재된 바와 같은 치료 방법에 사용될 수 있고, 본원에 기재된 바와 같은 치료에 사용될 수 있고/있거나 본원에 기재된 바와 같은 치료를 위한 의약의 제조에 사용될 수 있음이 이해된다. 본 개시는 또한 본원에 기재된 항체 또는 항원 결합 단편 또는 약학적 조성물을 포함하는 키트 및 제조 물품을 제공한다.
제형
본 개시는 또한 본원에 다양하게 기재된 병태의 치료, 진단, 또는 예방을 위한 치료 조성물의 제조를 위한, ILT2를 인식하는 적어도 하나의 항체를 활성 제제로서 포함하는, 인간 의료용 약학적 제형을 고려한다.
이러한 약학적 및 약제 제형에서, 활성 제제는 바람직하게는 하나 이상의 약학적으로 허용가능한 담체 및 임의로 임의의 다른 치료 성분과 조합하여 사용된다. 담체는 제제의 다른 성분과 상용성이고 이의 수용자에게 과도하게 유해하지 않은 관점에서 약학적으로 허용가능해야 한다. 활성 제제는 상기 기재된 바와 같은 목적하는 약리학적 효과를 달성하기에 효과적인 양 및 목적하는 1일 용량을 달성하기에 적절한 양으로 제공된다.
전형적으로, 항체의 항원 결합 부분을 포함하는 본 개시의 분자는 치료 용도를 위해 멸균 식염수 용액에 현탁될 것이다. 약학적 조성물은 대안적으로 활성 성분(항체의 항원 결합 부분을 포함하는 분자)의 방출을 제어하거나 환자의 시스템에서 활성 성분의 존재를 연장하기 위해 제형화될 수 있다. 다수의 적합한 약물 전달 시스템이 알려져 있고, 예를 들어 이식가능한 약물 방출 시스템, 하이드로겔, 하이드록시메틸셀룰로스, 마이크로캡슐, 리포솜, 마이크로에멀젼, 마이크로스피어 등이 포함된다. 제어 방출 제조물은 본 개시에 따른 분자를 복합체화하거나 흡착시키기 위한 중합체의 사용을 통해 제조될 수 있다. 예를 들어, 생체적합성 중합체에는 폴리(에틸렌-코-비닐 아세테이트)의 매트릭스 및 스테아르산 이량체 및와 세바신산의 폴리무수물 공중합체의 매트릭스가 포함된다. 이러한 매트릭스로부터의 본 발명에 따른 분자, 즉 항체 또는 항체 단편의 방출 속도는 분자의 분자량, 매트릭스 내 분자의 양, 및 분산된 입자의 크기에 따라 달라진다.
본 발명의 약학적 조성물은 경구, 국소, 비강내, 피하, 근육내, 정맥내, 동맥내, 관절내, 병변내, 또는 비경구와 같은 임의의 적합한 방식으로 투여될 수 있다. 일반적으로 정맥내(IV) 또는 관절내 투여가 바람직할 것이다.
본 개시에 따른 분자의 치료적 유효량이 특히 투여 일정, 투여되는 분자의 단위 용량, 분자가 다른 치료제와의 조합으로 투여되는지 여부, 환자의 면역 상태 및 건강, 투여되는 분자의 치료 활성 및 치료의의 판단에 따라 달라질 것이라는 점은 당업자에게 자명할 것이다.
본 발명의 분자(항체 또는 이의 단편)의 적절한 투여량은 투여 경로, 분자(폴리펩티드, 폴리뉴클레오티드, 유기 분자 등)의 유형, 환자의 연령, 체중, 성별, 또는 병태에 따라 달라지며, 결국 의사에 의해 결정되어야 하지만, 경구 투여의 경우, 1일 투여량은 일반적으로 체중 ㎏ 당 약 0.01 mg 내지 약 500 mg, 바람직하게는 약 0.01 mg 내지 약 50 mg, 보다 바람직하게는 약 0.1 mg 내지 약 10 mg일 수 있다. 비경구 투여의 경우, 1일 투여량은 일반적으로 체중 kg 당 약 0.001 mg 내지 약 100 mg, 바람직하게는 약 0.001 mg 내지 약 10 mg, 보다 바람직하게는 약 0.01 mg 내지 약 1 mg일 수 있다. 1일 투여량은 예를 들어 1일 1회 내지 4회 개별 투여의 전형적 요법으로 투여될 수 있다. 다른 바람직한 투여 방법에는 체중 kg 당 약 0.01 mg 내지 약 100 mg의 관절내 투여가 포함된다. 유효량에 도달하는 데 있어서의 다양한 고려 사항은, 예를 들어 문헌[Goodman and Gilman’s: The Pharmacological Bases of Therapeutics, 8th ed., Pergamon Press, 1990; and Remington’s Pharmaceutical Sciences, 17th ed., Mack Publishing Co., Easton, Pa., 1990]에 기재되어 있다.
조합 화학요법의 적합한 투여 요법은 당업계에 알려져 있고, 예를 들어 문헌[Saltz et al., Proc ASCO (1999) 18:233a and Douillard et al., Lancet (2000) 355:1041-7]에 기재되어 있다.
활성 성분으로서 본 개시의 분자는 잘 알려진 바와 같이 약학적으로 허용가능하고 활성 성분과 상용성인 부형제에 용해되거나, 분산되거나, 혼합된다. 적합한 부형제는, 예를 들어 물, 식염수, 포스페이트 완충 식염수(PBS), 덱스트로스, 글리세롤 등 및 이들의 조합이다. 다른 적합한 담체는 당업자에게 잘 알려져 있다. 또한, 요망되는 경우, 조성물은 습윤제 또는 유화제, pH 완충제와 같은 보조 물질을 소량 함유할 수 있다.
제조 방법
다른 양태에 따르면, 제제의 제조 방법으로서,
ILT2 세포외 도메인 또는 이의 단편에 결합하는 제제를 수득하는 단계, ILT2와 B2M 사이의 상호작용을 억제하는 상기 제제의 능력을 시험하고, ILT2와 B2M 사이의 상호작용을 억제하는 적어도 하나의 제제를 선택하는 단계를 포함하는 제제를 제조하는 방법이 제공된다. 본원에서 사용되는 바와 같이, 제제는 예를 들어 분자 또는 단백질일 수 있다.
다른 양태에 따르면, 제제의 제조 방법으로서,
제제를 암호화하는 핵산 서열을 포함하는 하나 이상의 벡터를 포함하는 숙주 세포를 배양하는 단계(여기서, 핵산 서열은 다음의 단계를 통해 선택된 제제의 서열임:
i.
ILT2 세포외 도메인 또는 이의 단편에 결합하는 제제를 수득하는 단계;
ii.
ILT2와 B2M 사이의 상호작용을 억제하는 상기 제제의 능력을 시험하는 단계; 및
iii.
ILT2와 B2M 사이의 상호작용을 억제하는 적어도 하나의 제제를 선택하는 단계)
를 포함하는 제제를 제조하는 방법이 제공된다.
다른 양태에 따르면, 제제의 제조 방법으로서, 서열번호 41 내지 44 및 68 내지 70으로부터 선택된 인간 ILT2의 서열에 결합하는 제제를 수득하는 단계를 포함하는 제제를 제조하는 방법이 제공된다.
다른 양태에 따르면, ILT2에 대한 결합에 대해, 중쇄 및 경쇄가 각각 서열번호 48 및 49를 포함하는 기준 항체와 경쟁하는 항체를 확인하는 방법으로서, 항체 라이브러리를 서열번호 41 내지 44 및 68 내지 70으로부터 선택된 ILT2 서열을 포함하는 폴리펩티드 서열과 접촉시키는 단계, 및 라이브러리로부터 ILT2 서열에 결합하는 항체를 선택하여 ILT2에 대한 결합에 대해 기준 항체와 경쟁하는 항체를 수득하는 단계를 포함하는 방법을 제공한다.
다른 양태에 따르면, 제제의 제조 방법으로서, 제제를 암호화하는 핵산 서열을 포함하는 하나 이상의 벡터를 포함하는 숙주 세포를 배양하는 단계(여기서, 핵산 서열은 서열번호 41 내지 44 및 68 내지 70으로부터 선택된 인간 ILT2 서열에 결합하는 제제를 수득하여 선택된 제제의 서열임)를 포함하는 제제를 제조하는 방법이 제공된다.
일부 구현예에서, 해당 방법은 서열번호 41 내지 44 및 68 내지 70으로부터 선택된 서열에 결합하는 제제를 수득하는 단계를 포함한다. 일부 구현예에서, 핵산 서열은 서열번호 41 내지 44 및 68 내지 70으로부터 선택된 서열에 결합하는 제제를 수득하여 선택된 제제의 서열이다. 일부 구현예에서, 해당 방법은 서열번호 68 내지 70으로부터 선택된 서열에 결합하는 제제를 수득하는 단계를 포함한다. 일부 구현예에서, 핵산 서열은 서열번호 68 내지 70으로부터 선택된 서열에 결합하는 제제를 수득하여 선택된 제제의 서열이다. 일부 구현예에서, 해당 방법은 서열번호 71 및 내지 72로부터 선택된 서열에 결합하는 제제를 수득하는 단계를 포함한다. 일부 구현예에서, 핵산 서열은 서열번호 71 및 내지 72로부터 선택된 서열에 결합하는 제제를 수득하여 선택된 제제의 서열이다. 일부 구현예에서, 해당 방법은 서열번호 71 및 72의 서열에 결합하는 제제를 수득하는 단계를 포함한다. 일부 구현예에서, 핵산 서열은 서열번호 71 및 72의 서열에 결합하는 제제를 수득하여 선택된 제제의 서열이다. 일부 구현예에서, 기준 항체는 15G8이다. 일부 구현예에서, 기준 항체는 15G8-13이다.
일부 구현예에서, 해당 방법은 ILT2 매개 면역 억제를 억제하는 제제의 능력을 시험하고 ILT2 매개 면역 억제를 억제하는 적어도 하나의 제제를 선택하는 단계를 추가로 포함한다. 일부 구현예에서, 핵산 서열은 ILT2 매개 면역 억제를 억제하는 제제의 능력을 시험하고 ILT2 매개 면역 억제를 억제하는 제제를 선택하여 선택된 제제의 서열이다. 일부 구현예에서, 해당 방법은, 대식세포에 의한 암세포의 식세포작용 증가, 암세포에 대한 T 세포 활성 증가, M1 대식세포 생성 증가, M2 대식세포 생성 감소, 종양 미세환경으로의 수지상 세포 모집 증가, 수지상 세포 활성화 증가, 및 자연 살해(NK) 세포 세포독성 증가 중 적어도 3개를 유도하는 상기 제제의 능력을 시험하고, 적어도 3개를 유도하는 적어도 하나의 제제를 선택하는 단계를 포함한다. 일부 구현예에서, 해당 방법은 T 세포, NK 세포, 수지상 세포, 및 대식세포 중 적어도 3개에서 효과를 유도하는 제제의 능력을 시험하는 단계를 포함한다. 일부 구현예에서, 해당 방법은 T 세포, NK 세포, 수지상 세포, 및 대식세포에서 효과를 유도하는 제제의 능력을 시험하는 단계를 포함한다.
일부 구현예에서, 효능 증가는 항암 효과의 상승적 증가를 포함한다. 일부 구현예에서, 항암 효과는 전염증성 사이토카인 분비이다. 일부 구현예에서, 전염증성 사이토카인은 GM-CSF, IL-6, 및 IFNγ로부터 선택된다. 일부 구현예에서, 전염증성 사이토카인은 GM-CSF, IL-6, 또는 IFNγ이다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 전염증성 사이토카인은 GM-CSF이다. 일부 구현예에서, 효능 증가는 T 세포 활성화의 상승적 증가를 포함한다. 일부 구현예에서, 효능 증가는 T 세포 세포독성의 상승적 증가를 포함한다. 일부 구현예에서, 효능 증가는 T 세포 활성화 및 세포독성 모두에서의 상승적 증가를 포함한다. 일부 구현예에서, 증가는 막 CD107a 발현의 증가를 포함한다. 일부 구현예에서, 증가는 막 CD107a 발현의 증가를 특징으로 한다. 일부 구현예에서, 증가는 제제가 투여되거나 접촉되지 않은 경우의 효능과 비교된다. 일부 구현예에서, 효능 증가는 PD-1/PD-L1 기반 요법에 불응성인 암을 해당 요법에 반응하는 암으로 전환시키는 것을 포함한다. 일부 구현예에서, 암은 HLA를 발현한다. 일부 구현예에서, 암은 MHC-I을 발현한다.
일부 구현예에서, 대식세포 염증 활성의 증가는 대식세포에 의한 암세포의 식세포작용의 증가를 포함한다. 일부 구현예에서, 대식세포 염증 활성의 증가는 M1 대식세포의 생성 증가를 포함한다. 일부 구현예에서, 대식세포 염증 활성의 증가는 M2 대식세포의 생성 감소를 포함한다. 일부 구현예에서, 대식세포 염증 활성의 증가는 대식세포 상의 M1 표현형의 증가를 포함한다. 일부 구현예에서, 대식세포 염증 활성의 증가는 대식세포 상의 M2 표현형의 감소를 포함한다.
일부 구현예에서, 수지상 세포 활성은 수지상 세포 활성화를 포함한다. 일부 구현예에서, 수지상 세포 활성은 종양으로의 수지상 세포 모집을 포함한다. 일부 구현예에서, 수지상 세포 활성은 암세포에 대한 활성이다. 일부 구현예에서, 암세포에 대한 활성은 TME에서의 활성이다. 일부 구현예에서, 종양은 TME이다. 일부 구현예에서, 종양은 TME를 포함한다. 일부 구현예에서, 종양은 종양 및 이의 TME를 포함한다. 일부 구현예에서, 수지상 세포 활성은 항원 제시를 포함한다.
일부 구현예에서, 제제의 능력을 시험하는 단계는 암세포에 대한 T 세포 활성, 대식세포 염증 활성, 수지상 세포 활성, 및 암세포에 대한 자연 살해(NK) 세포 세포독성 중 적어도 1개, 2개, 3개, 4개, 5개, 또는 전체를 증가시키는 제제의 능력을 포함한다. 각각의 가능성은 본 개시의 별도의 구현예를 나타낸다. 일부 구현예에서, 적어도 하나의 제제를 선택하는 단계는 암세포에 대한 T 세포 활성, 대식세포 염증 활성, 수지상 세포 활성, 및 암세포에 대한 자연 살해(NK) 세포 세포독성 중 적어도 1개, 2개, 3개, 4개, 5개, 또는 전체를 증가시키는 제제의 선택을 포함한다. 일부 구현예에서, 대식세포 염증 활성의 증가는 M1 대식세포의 생성을 증가시키고/시키거나 대식세포에 의한 암세포의 식세포작용을 증가시키는 것이다. 일부 구현예에서, 대식세포 염증 활성의 증가는 M2 대식세포의 생성을 감소시키는 것이다. 일부 구현예에서, 제제의 능력을 시험하는 단계는 대식세포 염증 활성을 증가시키는 제제의 능력을 포함한다. 일부 구현예에서, 제제의 능력을 시험하는 단계는 수지상 세포 활성을 증가시키는 제제의 능력을 포함한다. 일부 구현예에서, 종양에 대한 것은 TME에 대한 것이다. 일부 구현예에서, 제제의 능력을 시험하는 단계는 암세포에 대한 NK 세포 세포독성을 증가시키는 제제의 능력을 포함한다.
일부 구현예에서, 해당 방법은 ILT2와 B2M의 상호작용을 억제하는 제제의 능력을 시험하는 단계를 추가로 포함한다. 일부 구현예에서, 상호작용은 직접적 상호작용이다. 일부 구현예에서, 해당 방법은 ILT2와 B2M의 접촉을 억제하는 제제의 능력을 시험하는 단계를 추가로 포함한다. 일부 구현예에서, 상호작용은 결합이다. 일부 구현예에서, 접촉은 결합이다. 일부 구현예에서, 해당 방법은 에피토프에 결합하는 제제의 능력을 시험하는 단계를 추가로 포함한다.
하기 실시예는 본 발명의 화합물 및 방법을 제조하고 사용하는 방법을 예시하기 위한 것이며 결코 제한으로 해석되어서는 안 된다. 본 개시는 이제 이의 구체적 구현예와 함께 설명될 것이지만, 여러 수정 및 변형이 당업자에게 자명할 것임이 명백하다. 따라서, 첨부된 청구범위의 정신 및 넓은 범위에 속하는 모든 수정 및 변형을 포함하는 것으로 의도된다.
실시예
일반적으로, 본원에서 사용되는 명명법 및 본 개시에서 사용되는 실험실 절차는 분자, 생화학, 미생물, 및 재조합 DNA 기법을 포함한다. 이러한 기법은 문헌에 충분히 기재되어 있다. 예를 들어, 본원에 참조로 포함되는 문헌[Molecular Cloning: A laboratory Manual” Sambrook et al., (1989); “Current Protocols in Molecular Biology” Volumes I-III Ausubel, R. M., ed. (1994); Ausubel et al., “Current Protocols in Molecular Biology,” John Wiley and Sons, Baltimore, Maryland (1989); Perbal, “A Practical Guide to Molecular Cloning,” John Wiley & Sons, New York (1988); Watson et al., “Recombinant DNA,” Scientific American Books, New York; Birren et al. (eds) “Genome Analysis: A Laboratory Manual Series,” Vols. 1-4, Cold Spring Harbor Laboratory Press, New York (1998); 미국 특허 제4,666,828호; 제4,683,202호; 제4,801,531호; 제5,192,659호, 및 제5,272,057호에 기재된 방법론; “Cell Biology: A Laboratory Handbook,” Volumes I-III Cellis, J. E., ed. (1994); “Culture of Animal Cells - A Manual of Basic Technique” by Freshney, Wiley-Liss, N. Y. (1994), Third Edition; “Current Protocols in Immunology” Volumes I-III Coligan J. E., ed. (1994); Stites et al. (eds), “Basic and Clinical Immunology” (8th Edition), Appleton & Lange, Norwalk, CT (1994); Mishell and Shiigi (eds), “Strategies for Protein Purification and Characterization - A Laboratory Course Manual” CSHL Press (1996); “Monoclonal Antibodies: Methods and Protocols.” Vincent Ossipow, Nicolas Fischer. Humana Press (2014); “Monoclonal Antibodies: Methods and Protocols.” Maher Albitar. Springer Science & Business Media (2007)] 참조. 기타 일반 참조는 본 문서 전반에 걸쳐 제공된다.
물질 및 방법
항체 - 상용 항-ILT2 mAb는 다음과 같다: 클론 #1 - GHI/75(BioLegend, Cat. No. 333704), 클론 #2 - HP-F1(eBioscience, Cat. No. 16-5129). 추가적으로 사용된 mAb: HLA-G(MEM-G/9; Abcam, Cat. No. ab7758; G-0031,), ILT4(42D1, Biolegend, Cat. No. 338704), ILT6(Sino Biological, Cat No. 13549-MM06), LILRA1(R&D systems, Cat. No. MAB30851), 범-HLA(W6/22; eBioscience, Cat. No. 16-9983-85), 및 His(Proteintech, Cat. No. 10001-0-AP).
유세포 분석 - 일반적으로 세포는 모든 단계에서 얼음 상에서 또는 4°C에서 보관하였다. 염색 전, 5X105 세포를 FACS 완충액(0.1% BSA 함유 PBS) 중 50 μg/mL 인간 IgG(Sigma, Cat. No. I4506)로 15분 동안 차단하였다. 항체를 제조사에서 권장하는 농도로 사용하고 암실에서 30분 동안 인큐베이션하였다. 인큐베이션을 96웰 U자형 바닥 플레이트에서 100μL 중에 수행하였고, 세포를 200 μL FACS 완충제로 2회 세척하고 분석을 위해 150 μL FACS 완충제 중 FACS 튜브로 옮겼다. Gallios Flow Cytometry Acquisition Software용 Kaluza를 사용하여 Gallios Flow Cytometer(Beckman coulter) 상에서 세포를 분석하였다.
골수 세포 분화 - 단핵구를 음성 선택 방법으로 EasySep™ Human Monocyte Enrichment Kit(STEMCELL, Cat. No. 19059)를 사용하여 건강한 공여자의 신선한 혈액 샘플로부터 단리하였다. 상이한 세포 집단을 관련 마커의 FACS 분석 및 특징적인 사이토카인의 분비 분석에 의해 나타낸 표현형에 대해 시험하였다. 성숙을 위해, 단핵구를 성장인자를 함유하는 RPMI 배지 중 0.8X106/mL의 밀도로 배양하였고, 성장인자는 3일차 및 6일차에 교체되었다. 염증성 M1 대식세포를 50 ng/mL GM-CSF(M1 표현형)의 존재 하에 6일 동안 성숙시키고, 이어서 20 ng/mL IFN-감마 및 50 ng/mL LPS의 존재 하에 48시간 동안 성숙시켰다. 억제성 M2 대식세포를 50 ng/mL의 M-CSF를 6일 동안 사용한 후 10 ng/mL M-CSF 및 20 ng/mL IL-4 및 IL-10을 48시간 동안 사용하여 분화시켰다. 수지상 세포를 50 ng/mL GM-CSF 및 20 ng/mL IL-4로 6일 동안 유도하고, 성숙(100 ng/mL LPS) 또는 관용성(IL-10(100 U/mL) 및 IFN-a2b(1000 U/mL)) 수지상 세포로 추가 분화시켰다.
형질감염 - HLA-G1 cDNA를 PCDNA3.1 벡터에 클로닝하여 HLA-G1(전장 HLA-G 전사체를 암호화함) 플라스미드를 생성하였다. jetPEI® Transfection 시약(PolyPlus Transfections)을 사용하여 형질감염을 수행하였다. 인간 ILT2 단백질의 세포외 부분을 마우스 CD3 유전자의 막관통 및 세포질 잔기와 프레임 내 조합하여 ILT2/CD3z 플라스미드를 생성하였다. 제조사가 기술한 바와 같이, Nucleofector II(Lonza)를 사용하여 플라스미드를 마우스 BW5417.3 T 세포주로 핵감염시켰다. 안정한 형질감염체를 G418 함유 배지에서 선별하였다.
NK 및 암 세포주 공동배양 분석 - NK 세포를 항-ILT2 항체 및 매칭되는 이소형 대조군의 존재 하에 표시된 세포주와 함께 37℃에서 5시간 동안 배양하였다. 세포독성 수준을 형광측정 LDH 검출 키트(Promega)를 사용하여 측정하였다.
유세포 분석 차단 분석 - N 말단에서 인간 IgG1의 Fc 부분과 융합된 재조합 인간 ILT2 단백질을 비오틴(Innova bioscience)과 접합하였다. 총 5X105개의 A375/HLA-G1 세포를 항-ILT2 클론 #1 또는 이소형 매칭된 대조군 mAb 및 비오틴(10 μg/mL)과 접합된 ILT2-Fc의 존재 하에 100 μL의 부피로 실온에서 30분 동안 인큐베이션하였다. 몇 번의 세척 단계 후, streptavidin-PE를 0.2 μg/mL의 최종 농도로 첨가하고 얼음 상에서 30분 동안 인큐베이션한 후 FACS 분석을 수행하였다.
BW ILT2/CD3z-쇄 키메라 분석 - 3X104개의 BW/ILT2z를 동등한 수의 A375/WT 또는 A375/HLA-G1 세포와 24시간 동안 혼합하였다. 기능적 mAbs를 지시된 농도로 매칭되는 이소형 대조군에서 사용하였다. 분비된 마우스 IL2의 양을 상용 ELISA 키트(BioLegend)로 평가하였다.
식세포작용 분석 - 단핵구를 인간 단핵구 농축 키트를 사용하여 건강한 혈액 은행 공여자로부터 수득한 버피 코트 샘플로부터 분리하였다. 대식세포를 생성하기 위해 6~7일 동안 10% 인간 혈청 및 M-CSF(50 ng/ml) 가 보충된 RPMI 배지에서 단핵구를 성장시켰다. 성숙한 대식세포를 단리하여 96웰 플레이트(15K 세포/웰)에 재시딩하고 5% CO2로 37c에서 O.N 인큐베이션하였다. 표적 1차 암세포 또는 다양한 적응증의 세포주를 pHrodo Red Cell Labeling Dye로 표지하고, 세척하고, 대식세포에 첨가하였다(1:5의 이펙터:표적 비율 달성을 위한 75K 세포/웰). 분석 플레이트를 IncuCyte S3 기기로 분석하였다.
IncuCyte pHrodo Red Cell Labeling Dye의 형광은 포식소체에 상주하는 것과 같은 산성 환경에서 증가하므로 형광 측정을 통해 식세포작용을 정량화할 수 있다. IncuCyte 기기로 형광 적색 신호 강도 및 위상 이미지에 대해 30분마다 분석 플레이트(4개 이미지/웰, X10 배율)를 샘플링하였다. 식세포작용 사례를 적색 형광 신호의 축적으로서 반영하고, 식세포작용 속도를 적색 형광 신호 축적의 동역학으로부터 반영하였다.
실시예 1: ILT2 및 HLA-G가 암세포 및 암 관련 면역 세포 상에서 발견됨
ILT2는 건강한 면역 세포뿐만 아니라 많은 종양 세포의 표면에서도 발견되는 알려진 면역억제 분자이다. ILT2는 HLA 클래스 분자(HLA-G뿐만 아니라 HLA-F, 및 HLA-B27)뿐만 아니라 MHC-1과도 결합하고 CD8과 경쟁하여 T 세포 활성화를 억제하는 것으로 나타났다. ILT2를 발현하는 세포의 범위에 대한 추가적인 이해를 위해 다양한 면역 세포 상에서 상용 항체(항체 #1)를 사용하여 유세포 분석을 수행하였다. 문헌에 보고된 바와 같이, 자연 살해(NK) 세포뿐만 아니라 흑색종 환자로부터 유래된 세포독성 T 세포(CTL)도 ILT2의 표면 발현에 대해 양성이었다(도 1). 또한, 건강한 공여자의 혈액에서 수득한 단핵구를 조사한 결과 ILT2를 높게 발현하는 것으로 나타났다(도 2, 좌측 끝 패널). 단핵구가 다른 골수 세포 집단(수지상 세포 및 대식세포)으로 분화되면, 미성숙, 염증, 또는 관용성 여부에 관계없이 ILT2 발현이 유지되었다(도 2, 우측 패널).
상이한 암 적응증에서의 ILT2 발현을 TCGA 데이터베이스의 생물정보학 분석으로 조사하였다(도 3a). 흥미롭게도, TCGA에 제공된 샘플의 종양에서, ILT2 RNA 발현 수준과 골수 유래 억제인자 세포(MDSC) 및 억제성 M2 종양 관련 대식세포(TAM) 존재 사이의 상관관계가 관찰되었다(도 3b). 유세포 분석에 의한 상이한 고형 종양으로부터의 신선 종양 샘플의 분석은 종양 미세환경(TME)에서 선천성 및 적응성 면역 세포에 의한 ILT2의 발현을 입증하였다. 비소세포 폐암(NSCLC), 신장암(RCC), 두경부암, 식도암, 및 결장암 환자의 종양 샘플을 수집하고, 효소 분해를 통해 단일 세포 현탁액을 생성하였다. 총 면역 세포, 종양 관련 대식세포(TAM), CD4 양성 T 세포, CD8 양성 T 세포, 및 자연 살해 세포(NK)에 대한 ILT2 양성 세포의 백분율이 도 3c에 제시되어 있다. 따라서, ILT2가 항암 활성을 갖는 세포(염증 세포)뿐만 아니라 암 촉진 및 면역 억제 활성을 갖는 세포(관용성 및 MDSC) 상에서 모두 발현된다는 것이 명백하다.
또한 HLA-G 발현을 다양한 암에서 조사하였다. 상이한 적응증으로부터의 암 샘플의 조직 마이크로어레이(TMA)를 면역-조직화학에 의해 상용 다클론성 HLA-G 항체로 염색하였다. 각각의 암 유형에 대한 양성 사례의 백분율이 제공되어 있다(도 4a). 또한 몇몇 적응증에 대해 확장된 TMA를 조사하였다. HLA-G 염색 점수는 염색 강도와 양성 세포의 백분율을 곱하여 계산하였다. 100 초과의 높은 HLA-G 염색 점수가 높은 비율의 식도암, 위암, 두경부암, 및 신장암에서 검출되었다(도 4b). 표 1은 각 적응증의 양성 사례 백분율을 나타낸 것이다.

HLA-G는 가용성 분비 형태뿐만 아니라 보다 일반적인 막 형태 또한 갖는다. 암 환자에서 가용성 HLA-G의 발현 수준을 조사하기 위해 상용 ELISA를 사용하여 HLA-G의 존재에 대해 혈장 샘플을 조사하였다. HLA-G는 정상(건강한) 대조군 대비, 몇몇 암 적응증에서 과발현되는 것으로 확인되었다(도 5). 또한 특정 암 유형에서 유의미하게 더 높은 수준을 갖는 환자 집단을 검출할 수 있었다.
실시예 2: ILT2 차단 항체의 생성
하이브리도마 기술을 사용하여 단일클론 ILT2 길항제 항체를 생성하였다. 69개의 ILT2-특이적 하이브리도마를 처음에 생성하였다. 조사된 다양한 분석에서 바람직한 결합, 교차 반응성 프로파일, 및 기능적 활성에 따라 3개의 리드 항체를 선택하였다. 선택된 항체는 19E3, 15G8, 및 17F2였다. 이 항체를 통상적인 방법을 사용하여 시퀀싱하였다. 선택된 항체의 가변 영역의 서열을 도 6a에 나타내었다. CDR을 KABAT 시스템에 따라 결정하였다. 일반적인 CDR 이식 접근법을 사용하여 15G8 및 19E3을 인간화하였다. 간략하게, 원래의 하이브리도마 유래 항체로부터의 필수 CDR 및 프레임워크 잔기를 확인하고 생식계열 인간 항체의 가변 및 불변 영역에 이식하였다. 최종 인간화 항체는 IgG4 항체이다.
이식에 사용된 IgG4 중쇄 불변 영역은 FcγR에 대한 결합을 감소시키는 것으로 알려진 두 개의 점 돌연변이를 함유하였다. 이러한 돌연변이는 통상적으로 S228P 및 L235E로 알려져 있지만 이의 정확한 위치는 중쇄 가변 영역의 길이에 따라 다르다. 15G8 항체의 경우 227번 위치의 세린이 프롤린으로 돌연변이되었고 234번 위치의 류신이 글루탐산으로 돌연변이되었다. 19E3의 경우 225번 위치의 세린이 프롤린으로 돌연변이되었고 232번 위치의 류신이 글루탐산으로 돌연변이되었다. 최종 인간화 15G8은 또한 CDR-H3에서의 시스테인을 제거하고 이를 알라닌 또는 세린으로 대체하는, 단일 아미노산 변경을 포함하였다. 개발 가능성을 개선하기 위해 이러한 변경을 가했다. 생성된 두 항체의 결합이 확인되었고, 추가 시험을 위해 알라닌을 갖는 15G8 항체를 선택하였다. 인간화 15G8에 대한 모든 향후 언급은 알라닌 변이체를 나타낸다.
15G8 CDR의 이식 시, 5개의 중쇄 및 4개의 카파 경쇄를 생성하였다. 이 쇄는 VH1-5 및 Vk1-4로 지정되었다. 표 2에 이 쇄의 서열이 제공되어 있다. 각각의 중쇄를 각각의 경쇄와 조합하면 20개의 상이한 생성 항체가 가능하다. 20개의 모든 가능한 항체를 HEK EBNA 세포에서 일시적으로 발현시켰고, 상청액을 Biacore T200을 사용하여 재조합 ILT2 펩티드에 대한 결합에 대해 시험하였다. 키메라 15G8 항체를 대조군으로 사용하였다. 결합 결과는 표 3에 요약되어 있다.


20개의 조합 중 7개를 추가 연구에서 선택하였다. 경쇄 Vk1을 포함하는 항체는 중쇄에 관계없이 일정하게 가장 낮은 수율의 항체를 생성하므로, Vk1 함유 항체는 선택에서 제외되었다. Vk4는 일정하게 가장 높은 수율의 항체를 생성하므로, VH3, VH4 및 VH5의 조합을 선택하였다. Vk4와 VH1 및 VH2의 조합도 높은 발현을 나타내었지만, 이들 항체의 대조군 항체보다 KD가 좋지 않았고, VH1 및 VH2를 함유하는 모든 항체에 대해서는 가장 좋지 않았다. VH1/Vk3, VH2/Vk3, 및 VH3/Vk2는 모두 상대적 KD 값이 가장 낮아 선택되었다. VH5/Vk3는 또한 높은 발현 및 낮은 상대적 KD 값의 조합을 위해 선택되었다.
이 7개의 항체를 단백질 A 크로마토그래피로 정제하고 농도를 계산하였다. 선택된 항체의 기능적 능력을 특성화하기 위해 여러 분석을 수행하였다.
먼저, 막 ILT2에 대한 결합에 대해 7개의 15G8 항체를 시험하였다. BW 세포를 인간 ILT2로 형질감염시키고 5x105 BW-ILT2를 7개의 항체 또는 염색 완충제(PBS 중 0.05% BSA) 중 10 μg/ml의 대조군 IgG와 30분 동안 인큐베이션하고, 이어서 염색 완충제로 세척하고 2차 PE-접합 당나귀 항 마우스 항체로 인큐베이션하였다. 이어서, 세포를 염색 완충제를 사용하여 두 번 세척하고 Cytoflex 유세포 분석기(Beckman Coulter)를 사용하여 분석하고 데이터를 CytExpert 소프트웨어(Ver 2.3)를 사용하여 분석하였다. 도 6b에서 알 수 있듯이, 전체 결합 동역학은 7개의 항체 간에 유사했지만, EC50 값을 계산했을 때(표 4), 4개의 항체가 다른 3개보다 우수하였다. 추가적으로 이 4개의 항체를 기능에 대해 시험하였다.

종양 세포의 식세포작용을 향상시키는 인간화 15G8 항체의 능력을 여러 암 유형에 대해 시험하였다. 대식세포에 의한 종양 세포주의 식세포작용에 대해 실시간 모니터링을 수행하였다(재료 및 방법 참조). 도 6c 내지 6d에서 알 수 있듯이, 시험된 상이한 인간화 ILT2 차단 항체는 HLA-G 양성 종양 세포(도 6c) 및 MHC-I 단독 양성 종양 세포(도 6d) 둘 다의 식세포작용을 향상시킬 수 있었다. 변이체 15G8-13, 15G8-23, 및 15G8-34는 A375-HLA-G의 식세포작용에서 다른 변이체보다 다소 더 높은 효능을 보였다(도 6c). 따라서 15G8-13 및 15G8-23를 추가적인 식세포작용 실험에서 추가로 평가하였다. 도 6e 내지 6f에서 나타난 바와 같이, 두 항체 모두 시험된 세포주의 식세포작용을 향상시킬 수 있었지만, 15G8-13은 특히 저농도에서 다소 더 우수한 활성을 나타냈다.
이어서, NK 세포가 표적 암 세포주와 인큐베이션된 후 LDH 수준을 측정하여 세포독성을 평가하는 시스템에서, NK 세포 효과기 활성을 향상시키는 인간화 15G8 변이체의 능력을 시험하였다. 도 6g 내지 6h에서 알 수 있듯이, 상이한 변이체는 모두 용량 의존적 방식으로 HLA-G-양성(도 6g) 및 MHC-I 단독 세포(도 6h) 둘 다에 대한 NK 세포의 세포독성을 유의하게 향상시킬 수 있었다. 변이체 15G8-13은 이번에는 NK 세포 세포독성의 강화에서 다소 우수한 활성을 재차 입증하였다. 다소지만 일관된 우월성으로 인해 15G8-13을 모든 향후 분석을 위해 선택하였고, 이하에서 간단히 15G8 인간화 항체로 지칭된다.
실시예 3: ILT2 차단 항체의 비교
3개의 상이한 시스템을 사용하여 ILT2에 결합하는, CDR이 다른 3개의 항-ILT2 항체의 능력을 시험하였다. ELISA를 사용하여 재조합 ILT2에 대한 결합을 시험하고(도 7a), ILT2로 형질감염된 BW 세포를 사용하여 막 ILT2에 대한 결합을 시험하였다(도 7b 및 7c). 키메라 및 인간화 항체는 유사한 결합을 나타냈다(도 7c 및 7d). 상용 마우스 항인간 ILT2 항체(Biolegend; Clone GHI/75)를 양성 대조군으로 사용하였다. 3개의 시험된 항체는, 용액(도 7a) 중에서건 세포의 표면(도 7b) 상에서건 ILT2에 성공적으로 결합하였다. 몇몇 유사한 ILT 패밀리 구성원인 PIRB, ILT6, 및 LILRA1에 대한 교차 반응성을 또한 바인딩 ELISA를 사용하여 조사하였다(도 7a). 이들 단백질에 대한 항체를 양성 대조군으로서 사용하였다. 어느 항체도 PIRB, ILT6, 및 LILRA1과 교차 반응하지 않았다. 항체는 또한 면역염색에도 효과적이었다(도 7d). 흥미롭게도, 암 환자의 혈액에서 PBMC를 단리하면, 건강한 대조군보다 암 환자에서 더 많은 T 세포 및 NK 세포 상에서 ILT2가 발현됨을 확인하였다(도 7e).
실시예 4: ILT2 항체가 ILT2-HLA-G 상호작용을 차단함
생성된 항-ILT2 항체가 HLA-G와 ILT2 사이의 상호작용을 차단하는 능력을 4가지 다른 분석을 사용하여 시험하였다. 먼저 차단 유세포 분석 분석을 수행하였다. HLA-G 형질감염된 A375 세포를 본 개시의 항체 및 양성 대조군 항체의 존재 하에 비오틴화된 ILT2와 인큐베이션하였다. 상업적으로 이용 가능한 항-ILT2 항체 GHI/75(BioLegend, Cat. 333704)를 양성 대조군으로서 사용하였다. 세포에 대한 ILT2-비오틴의 결합은 Streptavidin-PE를 사용하여 유세포 분석으로 확인하였다(도 8a). 차단 백분율은 음성 대조군(대조군 IgG의 존재 하에 ILT2 결합)에 대해 정규화하여 측정하였다. 항체 부재(회색선), 15G8 존재(밝은 회색선), 및 이소형 대조군 존재(검은색선) 하의 ILT2 결합을 나타내는 대표적 FACS 분석을 도 8b에 나타내었다. 다양한 농도의 항체로 차단 백분율을 계산하였다(도 8c). 키메라 뮤린 및 인간화 항체는 유사한 차단 능력을 나타내었다(도 8d).
또한, HLA-G와 ILT2 사이의 상호작용을 기능적으로 차단하는 ILT2 항체의 능력을 BW ILT2/마우스 Z-쇄 키메라 리포터 분석에서 조사하였다. BW 세포를 마우스 T 세포 제타쇄에 융합된 인간 ILT2(BW-ILT2)로 형질감염시켰다. 이어서 세포를 선택된 ILT2 항체의 존재 하에 A375-HLA-G 세포와 인큐베이션하였다. 기능적 ILT2-HLA-G 상호작용 시 BW 세포는 리포터 사이토카인인 마우스 IL-2를 분비한다. 상호작용을 차단하면 리포터 사이토카인의 분비가 감소할 것이다. 인큐베이션 24시간 후 마우스 IL-2의 분비를 ELISA로 확인하였다. 결과는 처치 당 3중 웰로부터의 mIL-2 수준의 평균 ±SE를 나타낸다(도 8e). 상용 마우스 항-인간 ILT2 항체(Biolegend; 클론 GHI/75)를 두 분석 모두에 대해 양성 대조군(PC)으로서 사용하였다. 다양한 농도의 항체로 차단 백분율을 계산하였다(도 8f). 동일한 BW ILT2/마우스 Z-쇄 키메라 리포터 분석을 사용하여 새로운 항체가 자체적으로 ILT2 활성화 효과를 가질 수 있는 가능성을 배제하였다. 세포를 암세포 없이 ILT2 항체와 인큐베이션하고 마우스 IL-2 분비를 다시 측정하였다(도 8g). 새로운 ILT2 항체는 작용 효과가 없는 것으로 확인되었지만, 동일한 하이브리도마 공정에 의해 생성된 다른 항체(1G7)는 ILT2에 결합하고 그 활성을 유도할 수 있다.
또한, 기능 차단을 인간 Jurkat 세포(T 세포)에서 조사하였다. HLA-G 및 단일쇄 항-CD3(OKT3)을 외인성으로 발현하는 A375 암 세포를 포함하거나 포함하지 않고 Jurkat 세포를 인큐베이션하였다. 전염증성 인간 IL-2의 분비를 측정하였다. 변형되지 않은 Jurkat 세포(ILT2 음성인 세포)가 사용된 경우, Jurkat 세포를 암세포와 공동배양했을 때 높은 수준의 IL-2가 분비되었다(도 8h). 당연히, 차단할 ILT2가 없었기 때문에 15G8 항체의 첨가는 IL-2 분비에 영향을 미치지 않았다. 따라서 Jurkat 세포를 인간 ILT2를 발현하도록 형질감염시켰다. 먼저, ILT2-양성 Jurkat 세포를 OKT3를 외인성으로 발현하는 A375 암세포와 포함하거나 포함하지 않고 배양하였다. 이 암세포는 자연적으로 MHC-I 양성이다. 암세포로부터의 MHC-I는 IL-2 분비를 강력히 억제하였다(도 8i). 이 경우, 15G8 항체의 첨가는 ILT2/MHC-I 상호작용을 차단하고 IL-2 분비를 용량 의존적으로 증가시켰다. 범-HLA 항체를 양성 대조군으로서 사용하였고, 동일한 농도에서 15G8 항체는 pan-HLA 항체와 유사하였다(도 8i). 억제 효과를 높이기 위해, A375 세포를 또한 HLA-G로 형질감염시켜 이를 MHC-I 및 HLA-G 양성으로 만들었다. 이들 세포는 ILT2 양성 세포에 대해 훨씬 더 강력한 억제 효과를 나타내어 IL-2 분비를 단독 배양된 Jurkat 세포의 분비만큼 감소시켰다(도 8j). 용량 의존적 효과가 15G8 항체가 투여되었을 때 다시 관찰되었으며, 다시, 동일한 투여량에서 15G8 항체 및 범-HLA 항체가 동등하게 효과적이었다(도 8j). 특히, 범-HLA 대신에 HLA-G 특이적 항체만을 사용한 경우, 효과가 크게 감소하였고 1/100th 농도로 사용된 15G8 항체와 유사하였다(도 8k).
또한 이 Jurkat 시스템을 사용하여 15G8 항체를 2개의 상업적으로 이용 가능한 항체인 GHI/75 및 HP-F1과 비교하였다. 인간 ILT2를 발현하는 Jurkat 세포를 다양한 농도의 15G8, GHI/75, 및 HP-F1의 존재 및 부재 하에 HLA-G/OKT3를 발현하는 A375 세포와 함께 배양하였다. 이미 관찰된 바와 같이, 15G8은 IL-2 분비에서 통계적으로 유의한, 용량 의존적 증가를 야기하였다(도 8l). GHI/75는 배지 단독에 비해 IL2 분비에 영향을 미치지 않았지만 IgG 대조군에 비해 약간 증가하였다(도 8m). HP-F1은 작지만 유의미한 증가를 나타내고 정체를 보여 투여량의 증가에 따라 증가하지 않았다(도 8n). 20 μg/ml의 HP-F1 경우에도 단지 4 μg/ml의 15G8에 비해 열등하였다.
마지막으로 활성화를 TIL 및 NK 세포에서 직접 측정하였다. TIL을 A375-HLA-G-OKT3 세포와 함께 5분 동안 인큐베이션한 후 T 세포 활성화 마커인 인산화된 ZAP70을 검출하였다. NK 세포를 A253-HLA-G 세포와 함께 2분 동안 인큐베이션한 후 NK 세포 활성화 마커인 인산화된 Syk를 검출하였다. 활성화는 암세포와 공동배양되었을 때 두 세포 유형 모두에서 관찰되었지만, 이 활성화는 ILT2 항체의 존재 하에 강화되었다(도 8o 내지 8p). 이러한 결과는 ILT2 항체가 ILT2-HLA-G 상호작용을 효율적으로 차단하여 T 세포 및 NK 세포 활성화를 향상시킬 수 있음을 입증한다.
실시예 5: ILT2 항체가 HLA-G 및 MHC-I 양성 종양 세포의 식세포작용을 향상시킴
생성된 항-ILT2 항체가 종양 세포의 식세포작용을 향상시키는 능력을 2개의 다른 시스템을 사용하여 시험하였다. 건강한 공여자의 혈액에서 단핵구를 단리하고 M-CSF의 존재 하에 6~7일 동안 인큐베이션하여 대식세포를 생성하였다. 먼저, 유세포 분석 기반 분석을 사용하였다. PKH67-FITC로 염색된 상이한 암 세포주를 지시된 항체의 존재 하에 eFluor 670-APC로 염색된 대식세포와 인큐베이션하였다. 식세포작용 수준을 표적 세포의 포식을 나타내는 이중 염색된 대식세포의 백분율로 측정하였다. 식세포작용 수준은 대조군(배지 단독)으로부터의 백분율로 표시된다. 도 9a에서 입증된 바와 같이, 상이한 ILT2 차단 항체는 대식세포에 의한 HLA-G 양성 A375 세포의 식세포작용을 향상시킬 수 있었다. 또한 실시간 IncuCyte® 분석 시스템을 사용하여 종양 세포의 식세포작용을 향상시키는 대식세포의 능력을 조사하였다. 표적 세포주를 pHrodo™ Red Cell Labeling Dye로 표지하고 세척하고 다양한 처치와 함께 대식세포에 반복하여 첨가하였다. IncuCyte® pHrodo™ Red Cell Labeling Dye의 형광은 포식소체에 상주하는 것과 같은 산성 환경에서 증가하므로 형광 측정을 통해 식세포작용을 정량화할 수 있다. IncuCyte 기기로 형광 적색 신호 강도 및 위상 이미지에 대해 30분마다 분석 플레이트를 샘플링하였다. 식세포작용 사례를 적색 형광 신호의 축적으로서 반영하고, 식세포작용 속도를 적색 형광 신호 축적의 동역학으로부터 반영하였다. 이 실시간 시스템을 사용하여 인간화 항-ILT2 항체가 HLA-G 양성 A375 세포의 식세포작용을 향상시키는 능력을 확인하였다(도 9b). 또한 IncuCyte® 시스템을 사용하여, 생성된 차단 ILT2 항체가 HLA-G 양성뿐만 아니라 다양한 MHC-I 양성(WT) 암 세포주 모두의 식세포작용을 향상시킬 수 있음이 입증되었다(도 9c).
암 세포의 식세포작용에 대한, 생성된 ILT2 항체와 항체 의존적 세포성 식세포작용(ADCP) 유도 항체인 에르비툭스의 조합 효과를 전술한 IncuCyte® 실시간 시스템을 사용하여 조사하였다. ILT2 차단 항체와 에르비툭스의 조합은 각각의 항체 단독의 활성에 비해, HLA-G를 과발현하는 암 세포주의 식세포작용을 유의미하게 증가시켰다(도 9d). 실제로, 에르비툭스와 15G8 인간화 항체의 조합은 상승적 효과가 있었고, 조합 처치 시의 식세포작용 증가는 단순히 부가적인 것 이상이었다.
실시예 6: 선택된 ILT2 항체가 HLA-G에 의해 억제되는 T 세포 활성을 회복시킬 수 있음
생성된 항-ILT2 항체가 HLA-G에 의해 억제된 T 세포 활성을 회복시키는 능력을 조사하기 위해, 인간 CD8 T 세포를 야생형 721.221 세포(221 WT) 또는 가용성 HLA-G5(221-HLA-G)를 과발현하는 721.221 세포와 공동인큐베이션하였다. 표준 ELISA를 사용하여 5일 후에 T 세포로부터의 IFNγ 분비 수준을 측정하였다. 결과는 221-HLA-G 단독의 효과를 초과하는 배수 비율로 입증되었으며 4회의 독립적 실험의 평균을 나타낸다. 도 10a에 나타낸 결과는 몇몇 ILT2 항체가 HLA-G-억제된 T 세포 활성을 회복시킬 수 있음을 입증한다. 이를 또한 A375-HLA-G-OKT3 세포와의 인큐베이션으로 시험하였다. 72시간 후 인간 그랜자임 B의 분비를 또한 측정하였고, 용량 의존적 방식으로 15G8 항체의 존재 하에 증가됨을 확인하였다(도 10b).
실시예 7: 선택된 ILT2 항체가 HLA-G 및 MHC-I 양성 종양 세포에 대한 NK 세포독성을 향상시킬 수 있음.
NK 세포를 다양한 표적 암 세포주와 인큐베이션하는 시스템에서, 생성된 항-ILT2 항체가 NK 세포 효과기 활성을 향상시키는 능력을 시험하였다. 세포를 7.5:1의 효과기 대 표적 비율로 5시간 동안 공동인큐베이션한 후, 형광측정 LDH 검출 키트를 사용하여 세포독성 수준을 검출하였다. 특이적 세포독성의 백분율을 다음과 같이 계산하였다.

도 11a에서 입증된 바와 같이, 본 개시의 ILT2 항체는 용량 의존적 방식으로 HLA-G 양성 세포 및 다양한 MHC-I-양성 암 세포주(도 11b) 모두에 대한 NK 세포의 세포독성을 유의미하게 향상시킬 수 있었다. 그랜자임 B(도 11c) 및 인터페론 감마(도 11d) 분비를 또한 측정하여 용량 의존적 방식으로 증가하는 것을 확인하였다. 1차 NK 세포를 표적 HLA-G+ 흑색종 세포와 공동배양한 후 IFNγ, ILT2, CD56, 및 CD107A의 발현에 대해 FACS로 분석하였다. ILT2 양성, CD56 양성, NK 세포 집단을 구체적으로 분석하고 IFNγ 발현 및 막 CD107A 발현의 용량 의존적 증가를 관찰하였다(도 11e 내지 11f). 각각의 실험을 개별적으로 플롯팅하였을 때, ILT2 양성 세포 백분율(%) 와 IFNγ 및 CD107A의 발현 증가 사이의 상관관계가 분명히 명백하였다(도 11g 내지 11h).
실시예 8: ILT2 항체가 염증성 대식세포의 생성을 증가시킴
차단 ILT2가 대식세포의 성숙에 미치는 영향을 시험관내 조사하였다. 건강한 공여자로부터 단리된 단핵구를 5일 동안 M-CSF(50 mg/mL)의 존재에서 분화시켜 인간화 차단 ILT2 항체 또는 대조군 IgG의 존재 하에 성숙한 대식세포(M0)를 생성하였다. 대식세포를 LPS(50 ng/mL)의 존재 하에 추가 분화시켜 M1 대식세포를 생성하거나 IL-4(25 ng/mL)와 추가 분화시켜 M2 대식세포를 생성하였다. 도 12에서 입증된 바와 같이, 대식세포의 성숙 과정 동안 ILT2 차단 항체의 존재는 이들이 M0, M1, 또는 M2 대식세포로 분화되었는지와 무관하게, 시험된 대부분의 공여자의 대식세포에서 HLA-DR(M1 염증성 대식세포의 마커)의 발현을 증가시켰다. 또한, M1 대식세포로 분화된 대식세포도 시험된 대부분의 공여자에서 CD80 수준이 증가하였다. 종합하면, 이러한 결과는 선택된 ILT2 길항제 항체가 더 높은 수준의 HLA-DR 및 CD80을 나타내는 대식세포를 유도할 수 있음을 입증하며, 이는 보다 염증성 M1 표현형을 갖는 대식세포를 나타낸다.
실시예 9: ILT2 차단 항체가 환자의 종양 세포에 대한 면역 세포의 활성을 향상시킴
생성된 항-ILT2 항체의 활성을 암 환자(RCC 및 H&N)의 종양 샘플을 사용하여 생체외 시스템에서 조사하였다. 환자로부터 종양 세포의 식세포작용을 증가시키는 항체의 능력을 시험하기 위해, 단핵구로부터 생성된 대식세포를 종양 샘플로부터 단리된 종양 세포와 인큐베이션하였다. 식세포작용 수준을 위에 상세히 설명된 IncuCyte® 실시간 분석 시스템을 사용하여 조사하였다. 도 13a에서 입증된 바와 같이, ILT2 항체는 상이한 암 적응증을 가진 환자로부터의 종양 세포의 식세포작용을 향상시킬 수 있었다. 또한, 효과는 용량 의존적이었고 자가 대식세포에도 존재했으며 RCC(도 13b) 및 H&N의 편평 세포 암종(도 13c) 모두에서 나타났다. 또한 ILT2 항체가 PBMC의 활성을 높이는 효과를 조사하였다. 환자로부터 얻은 종양 샘플의 단일 세포 현탁액을 IL-2의 존재 하에 동일한 환자로부터 단리된 PBMC(활성화된 PBMC)와 인큐베이션하였다. 도 14g에서 입증된 바와 같이, 종양 세포의 존재 하에 전염증성 TNF-α 사이토카인의 PBMC 분비는 ILT2 항체의 존재 하에 상승하였다. 종합하면, 이러한 결과는 다양한 암 적응증의 종양 세포에 대한 면역 세포의 활성을 증가시키는 차단 ILT2 항체의 능력을 입증한다.
실시예 10: ILT2 차단 항체가 PD-1/PD-L1 요법과 조합될 수 있음
ILT2 및 PD-1은 대부분 말초 혈액 세포 및 종양 미세환경 상주 면역 세포를 모두 포함하는 상이한 면역 세포에서 발현된다(도 14a). CRC 환자의 종양내 CD8 양성 T 세포에서 ILT2 및 PD-1 발현의 분석은 T 중추 메모리 세포(Tcm) 및 소진된 T 세포(Tex) 모두 높은 수준의 PD-1(도 14b)을, 그러나 낮은 수준의 ILT2(도 14c)를 발현함을 확인하였다. CD45RA 재발현 T 세포(TEMRA)는 높은 수준의 ILT2 및 낮은 수준의 PD-1을 발현하는 정반대의 패턴을 보였다. 이러한 이분법은 암 특이적 현상이 아니었으며, 건강한 공여자의 혈액에서 얻은 TEMRA 세포의 높은 백분율(83%)이 ILT2 양성인 반면 전체 CD8 양성 T 세포의 낮은 백분율(17%)만이 양성인 것으로 확인되었다(도 14d). 그럼에도 불구하고, ILT2 발현은 TME의 T 세포에서 강화되었다. 식도암 환자로부터 단리된 종양의 효소 분해를 통해 단일 세포 현탁액을 생성하였다. FACS 분석은 높은 비율의 CD8 양성 종양 침윤 림프구(TIL)가 TEMRA 세포(50%)이고 이들 TEMRA 세포는 100% ILT2 양성이지만, 거의 완전히 PD-1 음성(95%)임을 나타내었다(도 14e).
본 개시의 항-ILT2 항체 및 항-PD-1의 조합의 효과를 10명의 건강한 공여자로부터의 SEB-활성화(10 ng/ml) PBMC에서 시험하였다. 막 CD107a의 발현을 증가된 세포독성에 대한 마커로 사용하였다. 전반적으로, 15G8 항체는 표면 CD107a에서 평균적으로 약간의 증가를 나타낸 반면, 항-PD-1은 공여자 의존적인 다소 더 큰 반응을 나타냈다(도 14f). 두 항체의 조합은 평균적으로 CD107a 수준을 증가시켰지만 이러한 변화는 특정 공여자 샘플에 따라 가변적이었다. 도 14g는 3개의 예시적인 샘플을 제시한다. 첫 번째 공여자는 항-PD-1이 15G8과 조합된 경우 부가적 효과를 보였고, 전체 CD107a 수준은 각각의 항체 단독 효과의 합과 거의 동일하였다. 두 번째 공여자는 항-ILT2보다 항-PD-1에 더 강한 반응을 보였지만, 예상외로 두 항체의 조합은 부가적 효과 이상이었다. 항-PD-1은 발현이 19% 증가했고, 항-ILT2는 3.7% 증가했지만, 조합 처치는 33.2% 증가했다. 이러한 상승적 효과는 공여자 #3의 세포에서 더욱 두드러졌다. 공여자 #3에서 15G8은 항-PD-1보다 더 효과적이었고(13.1% 증가 대 9.3% 증가), 조합 요법은 훨씬 더 효과적(41%)으로 단순히 부가적 조합으로부터 예측되는 것보다 거의 두 배의 효과를 나타냈다.
PD-1 차단 항체 및 생성된 ILT2 항체를 사용한 환자 종양 세포의 조합 처치를 다음과 같이 평가하였다. 다양한 환자 암세포를 항-PD1 항체, 본 개시의 항체 및 이의 조합의 존재 하에 자가 PBMC와 인큐베이션하였다. IgG를 대조군으로서 사용하고 전염증성 분자의 분비를 판독값으로 측정하였다. 전염증성 사이토카인의 향상된 분비가 조합 처치에서 관찰되었다(도 14h 내지 14j). 인간화 항체 15G8에 의한 첫 번째 환자로부터의 결장 선암종 세포의 처치는 IgG 대조군에 비해, IFNγ 분비를 전혀 향상시키지 않은 반면, 항-PD-1은 사이토카인 분비를 강력하게 증가시켰다(도 14h). 그러나 예상외로 항-PD-1과 ILT2 항체의 조합은 분비를 50% 초과만큼 증가시켰다. 두 번째 환자는 ILT2 항체 또는 항-PD-1에 의해 유도된 약간의 증가 및 두 항체가 조합 사용되었을 때 존재하는 강화된 상승적 증가로, 유사한 경향을 나타내었다(도 14i). GM-CSF 발현은 대조군 대비, 항체 단독으로는 변경되지 않았지만, 놀랍게도 두 항체의 조합은 대조군 GM-CSF 수준의 거의 100%의 강력한 증가를 나타내었다(도 14j).
이어서, 혼합 림프구 반응을 사용하여 조합 요법을 평가하였다. 수지상 세포 및 CD8 양성 T 세포를 상이한 건강한 공여자로부터 단리하고 H&N 암 환자로부터 단리된 단핵구로부터 대식세포를 생성하였다. 세포를 지시된 처리(각각 20 ug/mg)로, 5:1의 효과기 세포 대 표적 비율로 조합하였다. T 세포에 의한 IFNγ 분비는 항-ILT2 항체 또는 항-PD-1 항체가 존재할 때 강화되었고, 이 효과는 두 항체의 조합을 사용함으로써 증가되었다(도 14k 내지 14l). 수지상 세포 배양(도 14k) 대비 대식세포 배양(도 14l)에서 더 큰 축적 효과가 관찰되었다. 이러한 결과는 항-ILT2 및 항-PD-1 요법이 면역 세포 염증 반응을 강화하는 데 상승적이며 신규한(de novo) 효과가 있음을 분명히 보여준다.
실시예 11: ILT2 차단 항체가 생체내 종양 부하를 감소시킴
항-ILT2 항체의 효능을 생체내 이종이식 모델에서 조사하였다. 면역 손상된 SCID-NOD 또는 NSG 마우스에 암 세포주(A375-HLA-G, A375-WT, COLO-320-HLA-G)를 접종하고 건강한 공여자의 혈액에서 생성된 인간 대식세포를 ILT2 항체의 존재 하에 마우스에 주사하였다. 도 15a에서 입증된 바와 같이, 생성된 ILT2 항체의 투여는 이 모델에서 유의미한 종양 억제를 야기하였고, 이는 이 시스템에서 인간 대식세포의 활성에 의해 매개될 가능성이 가장 높다. 또한, HLA-G 양성 및 MHC-I 양성 종양세포에서도 항종양 효능이 관찰되었다.
항-ILT2 항체의 효능을 또한 폐 병변 흑색종 이종이식 생체내 모델에서 조사하였다. 면역 손상된 SCID-NOD 마우스에 흑색종 세포(MEL526-HLA-G)를 접종하였다. 건강한 공여자의 혈액으로부터 단리된 인간 PBMC를 선택 ILT2 항체의 존재 하에 접종 1일 후 시작하여 2일차, 10일차, 18일차에 반복하여 마우스에 주사하였다(도 15b). ILT2 항체는 1일차, 4일차, 8일차, 11일차, 15일차, 18일차, 22일차, 및 25일차에 투여하였다. 도 15c에서 입증된 바와 같이, 생성된 ILT2 항체의 투여는 종양 세포의 전이를 현저하게 감소시켰고, 이는 마우스의 폐에서 흑색 병변의 형성으로 나타난다. ILT2 항체로 처치된 마우스의 폐는 대조군 IgG로 처치된 마우스에 비해 이러한 병변이 거의 없다. 이 효과는 또한 이들 마우스에서 폐의 중량의 감소로 입증되며(도 15d), 투여된 항체에 의한 ILT2의 억제와 조합되어 마우스에 투여된 인간 림프구에 의해 매개되었을 가능성이 가장 높다. 따라서, 항-ILT2 항체는 전이 및 종양 형성을 예방하는 데 효과적이었다.
다음으로, 이미 형성된 종양의 치료에서 새로운 항체의 효과를 동일한 생체내 마우스 모델에서 시험하였다. SCID-NOD 마우스를 이전과 같이 MEL526-HLA-G 세포로 IV 투여에 의해 생착하였다. 15일 후, 건강한 공여자로부터 단리된 인간 PBMC를 관련 마우스 군에 투여하고 이 투여를 25일차, 35일차, 및 51일차에 반복하였다(도 15e 참조). 항체(ILT2 항체, 항-PD-1 항체, 또는 둘의 조합)를 14일차, 17일차, 20일차, 24일차, 27일차, 30일차, 34일차, 37일차, 및 50일차에 투여하였다(도 15e 참조). 53일차에 마우스를 희생시키고 폐를 칭량하였다. 시험 마우스의 폐 중량에서 나이브 마우스의 폐 중량을 제하여 종양 중량을 계산하였다. 항-PD-1 항체는 유의하지는 않지만 종양 중량을 감소시킨 반면, ILT2 항체 및 조합 처치는 유의한 효과를 나타냈다(도 15f).
종양 유래 CD8 T 세포, TEMRA, 세포 및 NK 세포를 CD107A 및 CD69 발현에 대해 시험하였다. 전체 CD8 T 세포에서, 항-PD-1 항체는 CD107A 발현에서 유의하지 않은 증가를 유도한 반면, 조합 요법이 아닌 ILT2 항체는 유의한 변화를 유도하였다(도 16a). TEMRA 세포에서 ILT2 항체 및 조합 요법 모두 유의미한 증가를 유도하였다(도 16b). NK 세포에서, 항-PD1 및 항-ILT2 항체 모두 CD69 양성 세포의 백분율을 유의미하게 증가시켰지만, 놀랍게도 조합 요법은 크게 향상된 효과를 보여, CD69 양성 세포의 총 백분율이 단독 요법의 조합보다 더 컸다(도 16c). 놀랍게도, CD69 발현을 CD8 T 세포에서 조사하였을 때, 항-PD1도 항-ILT2도 발현을 증가시키지 않았지만, 조합 처치는 CD69 발현에서 매우 유의미한 증가를 유도하였(도 16d). 또한, ILT2 항체의 효과는 ILT2 발현과 상관관계가 있는 것으로 확인되었다. ILT2 발현이 낮거나 높은 PBMC를 투여받은 마우스로 나누어 실험을 진행한 결과 활성화 마커에서 상당한 차이가 관찰되었다. TEMRA 세포에서 높은 ILT2 발현 PBMC는 낮은 ILT2 발현 PBMC와 비교하여 두 배를 초과하는 CD107A 발현을 포함하였다(도 16e). 마찬가지로, NK 세포를 조사하였을 때, 높은 ILT2 발현 PBMC는 조합 처치가 투여된 경우 거의 90%의 세포가 CD69를 발현하도록 유도한 반면 낮은 ILT2 발현 PBMC는 40% 미만의 NK 세포가 CD69를 발현하도록 유도하였다(도 16f). 따라서 PBMC에서 ILT2의 발현 수준은 항체가 가장 강력한 효과를 내는 데 있어 필수적이다.
실시예 12: 생체내 인간화 H&N 모델
두 번째 생체내 모델에서 인간화 마우스(인간 CD34+ 생착 마우스)에 A253-HLA-G 세포를 접종하였다. 종양이 80 입방 밀리미터의 크기에 도달했을 때 마우스를 대조군 IgG 또는 ILT2 항체(15G8, 둘 다 10 mg/kg)로 처치하였다. 처치를 43일차까지 주 2회 반복하고(도 17a), 종양을 다양한 시점에 캘리퍼로 측정하여 종양 크기를 확인하였다. ILT2 항체는 마우스 4마리 중 2마리(마우스 # 23 및 28)에서 종양 성장을 완전히 지연시켰고, 43일차에 종양이 제거되었다(도 17b). 처치에 대한 다른 반응이 마우스의 면역 세포에서 ILT2의 발현 수준이 다르기 때문인지 확인하기 위해 말초 혈액의 CD8 T 세포를 기준선에서 ILT2 발현에 대해 분석하였다. 실제로, 완전한 반응을 보인 두 마우스 모두 ILT2의 높은 발현을 가진 T 세포를 가졌고, 다른 두 마우스는 상당히 낮은 발현 수준을 보였다(도 17c). 또한, 처치 후 TME를 조사하여, 반응자를 비반응자와 구별하는 반응의 3개의 다른 약력학적 마커인, T 세포에서의 CD107A 발현(도 17d), M1/M2 대식세포 비율(도 17e), 및 총 CD80 양성 수지상 세포(도 17f)를 입증하였다. 이러한 결과는 항-ILT2가 종양 미세환경의 골수 및 림프 구획에서 변화를 생성하고 또한 항원을 제시하고 종양에 더 많은 T 세포를 모집하는 수지상 세포의 능력을 증가시킬 수 있다는 사실을 시사한다.
실시예 13: 15G8 인간화 항체의 에피토프 맵핑
15G8 항체를 에피토프 맵핑을 위해 발송하여 이것이 결합하는 ILT2 상의 위치를 확인하였다. 맵핑은 MAbSilico사에서 수행하였다. 사용된 ILT2의 구조는 다음의 구조, 즉 6AEE(4개의 Ig 유사 도메인, 일부 루프는 소실됨), 1VDG(미공개, 도메인 1 및 2), 1G0X(도메인 1 및 2), 및 4LL9(도메인 3 및 4)를 사용하여 모델링하였다. 6AEE 및 1G0X 구조는 문헌[Wang et al., Cell Mol Immunol. (2020) 17(9):966-75, and the 4LL9 structure was taken from Chapman et al., Immunity (2000) 13(5):727-36]에서 취했다. 영역 D1은 ILT2의 잔기 24 내지 121로 정의되었다. 영역 D2는 ILT2의 잔기 122 내지 222로 정의되었다. 영역 D3은 ILT2의 잔기 223 내지 321로 정의되었다. 영역 D4는 ILT2의 잔기 322 내지 409로 정의되었다. 항체의 3D 모델은 MODELLER를 사용하여 구축하였다.
상위 30개의 도킹 포즈에 근거하여, 표적의 잔기를 이들이 에피토프에 속할 확률에 대해 점수를 매겼다. 에피토프에 속할 가능성이 있는 잔기는 도 18a에서의 서열과 도 18b에서의 표적 구조에 나타나 있다. 이들 잔기로부터, 4개의 주요 상호작용 영역이 표적 상에 정의된다(도 18c). 이러한 상호작용 영역 4개 모두 ILT2의 인터도메인 섹션, 즉 D1과 D2 사이의 힌지 섹션에서 확인된다.
대부분의 ILT2 항체의 결합 에피토프는 알려져 있지 않지만, 국제 특허 공개 WO2020/136145는 다양한 항체에 대한 에피토프 정보를 개시하고 있다. 하나는 D1 영역 내에서 그리고 다른 하나는 D4 영역 내에서, 2개의 일반적 결합 영역이 확인되었다. 특히, 3H5, 12D12, 및 27H5로 명명된 3개의 항체는 D1에서의 E34, R36, Y76, A82, 및 R84에서 치환을 갖는 돌연변이에 대한 결합 소실을 특징으로 하였다. 이들 항체 중 하나인 3H5는 D1의 G29, Q30, T32, Q33, 및 D80에서 치환을 갖는 돌연변이에 대한 결합의 감소를 보였다. 이들 잔기는 D1 영역에만 있으며, 모두 15G8 항체의 결합 에피토프로서 정의된 4개 영역(모두 인터도메인 내)의 밖에 있다.(도 18a에서 서열은 하나의 아미노산 뒤에서 시작하므로, 예를 들어 WO2020/136145의 E34는 도 18a에서 E33임에 유의). 따라서, 항체 15G8은 WO2020/136145 공개의 항체와 상이한 3차원 에피토프에 결합한다(도 18d).
다음으로, 15G8 항체에 의해 결합된 특정 에피토프를 경험적으로 시험하였다. 경험적 맵핑은 하이드록실 라디칼 풋프린팅(HRF) 및 질량 분석 기술(재료 및 방법 참조)을 사용하여 Neoproteomics Inc.에서 수행하였다. 트립신과 이중 트립신, 및 Asp-N 분해 모두에서 수득한 ILT2 단백질의 전체 서열 범위는 약 90.7%였다. 트립신으로 분해된 ILT2 단백질의 경우 LCMS 및 MS/MS 분석을 통해 총 23개의 펩티드를 검출하였다. 이 23개의 펩티드 중, 20개가 표지된 것으로 관찰되었다(표 5; 가장 높은 정규화 보호 비율(NR) 값은 굵게 표시됨). 펩티드 위치 및 해당 서열은 열 1 및 2에 표시되어 있다. 트립신 및 Asp-N에 의해 분해된 ILT2 단백질의 경우, LCMS 및 MS/MS 분석을 통해 총 15개의 펩티드를 검출하였다. 이 15개의 펩티드 중, 14개가 표지된 것으로 관찰되었다(표 6; 가장 높은 정규화 보호 비율(NR) 값은 굵게 표시됨). 굵게 표시된 잔기는 변형된 것으로 확인되었다.


HRF 프로세스는 탠덤 질량 분석 데이터에서 확인된 특정 질량 변화를 초래하는 안정적인 측쇄 산화 변형을 도입한다. 선택된 이온 크로마토그램(SIC)을 비산화된 형태와 모든 산화된 형태의 펩티드 이온에 대해 (특정 m/z로) 추출 및 통합하였다. 이러한 피크 면적 값을 하이드록실 라디칼 노출의 함수로서 변형되지 않은 펩티드의 손실을 측정하는 용량 반응(DR) 플롯의 형태로 반응 동역학을 특성화하는 데 사용하였다. 복합체의 용매 보호 영역은 유리 단백질의 동일한 영역에 비해 감소된 산화 반응을 나타낸다. 산화 속도의 차이(속도 상수, K라고 함)는 결합 인터페이스의 잠재적 위치를 나타낸다.
하나의 복제 실험에서 얻은 MS 데이터를 사용하여 각 펩티드 및 특정 잔기에 대한 K 값을 계산하였다. 오류를 포함한 모든 검출된 펩티드에 대한 전체 적합도 결과는 표 5 및 6에 제공되어 있다. 세 번째 및 네 번째 열은 각각 유리 ILT2 및 이의 복합물에 대한 K 값을 나타낸다. 적합 오류를 나타내는 오류 막대를 각 K 값 옆에 나타내었다. 다섯 번째 열은 R(=K유리/K복합체) 비율을 나타낸다. 여섯 번째 열은 R/((평균 + 중앙값)/2)로 계산된 정규화 비율(NR)을 나타낸다. 주어진 펩티드에 대한 R 값이 1 미만이면 해당 영역이 복합체 형성 중 도입된 구조적 변화로 인해 용매 접근성이 증가했음을 시사한다. R 값이 1에 가까운 경우, 해당 영역의 용매 접근성이 변경되지 않은 상태로 유지됨을 나타내는 반면, R값이 1을 초과하는 경우, 해당 영역이 복합체 형성의 함수로서 용매로부터 보호됨을 나타낸다. 그러나 대부분의 펩티드에 대한 R 값(표 5의 5열)은 0.49와 3.94 사이에 속하며 평균값은 1.37이고 중앙값은 1.5이다(3.41, 3.52. 및 3.94 값은 통계 분석에서 제외됨). 대부분의 펩티드에 대한 R 값(표 6의 5열)은 0.78과 6 사이에 속하며 평균값은 1.48이고 중앙값은 1.58이다(5 및 6 값은 통계 분석에서 제외됨). 또한, 각각 ILT2 내의 모든 트립신 펩티드 및 트립신/Asp-N 펩티드에 대한 R 값의 분포를 보여주는 도 19a 및 19b는 또한 ILT2 내의 대부분의 펩티드가 1보다 큰 복합체 형성 시 변형의 변화를 나타냄을 시사한다. 샘플 간의 비생물학적 변이를 보정하기 위해 대사체학에서 사용되는 것과 유사한 전략을 사용하여(평균 스케일링, 중심 경향으로 나누기), 평균과 중앙값의 평균을 사용하여 비율을 1의 값으로 정규화하였다. 1.44 및 1.53의 정규화 계수를 각각 트립신 및 트립신/Asp-N 실험에서 도출된 R 값에 대한 정규화 비율(NR)에 대해 사용하였다. 2+의 NR은 이러한 연구에서 복합체 형성 시, 산화에서 상당한 보호로 간주된다.
전체적으로, 표 5는 56 내지 71, 57 내지 71, 및 84 내지 100의 ILT2 영역을 커버하고 ILT2-15G8 복합체 대 ILT2 단독에서 각각 2.74, 2.44, 및 2.35의 가장 높은 보호를 나타내는, ILT2로부터의 3개의 펩티드를 나타낸 것이다. 표 6은 각각 3.92 및 3.27의 가장 높은 보호를 나타내는 아미노산 57 내지 66 및 91 내지 100을 커버하는 2개의 펩티드를 나타낸 것이다. 이 영역은 15G8 mAb와의 결합 인터페이스의 일부이다.
5개의 중요 펩티드에 대한 개별 DR 플롯을 도 19c 내지 도 19g에 나타내었다. 이들은 복합체 형성의 결과로 가장 보호된 5개의 펩티드에 대한 비교 DR 플롯을 예시한다. 유리 ILT2 형태 및 ILT2-15G8 복합체에 대한 DR 플롯은 각각 파란색과 빨간색으로 표시하였다. 빨간색과 파란색 실선은 이론적인 1차 방정식에 가장 잘 맞는 것을 보여준다. 표 5 및 6, 및 도 19c 내지 19g는 ILT2의 잔기 56 내지 71(서열번호 3), 57 내지 71(서열번호 4), 84 내지 100(서열번호 5), 57 내지 66(서열번호 6), 및 91 내지 100(서열번호 7)을 커버하는 5개의 펩티드에 대한 용매 접근성의 가장 큰 감소/보호를 나타낸 것이다. 57 내지 66(NR=3.92), 91 내지 100(NR=3.27), 56 내지 71(NR=2.74), 57 내지 71(NR=2.44), 및 84 내지 100(NR=2.35) 펩티드에 대한 전반적인 보호 수준은 이러한 영역이 15G8과의 결합 인터페이스의 일부임을 입증한다.
흥미롭게도, 15G8 에피토프로 정의된 영역, 즉 D1과 D2 사이의 인터도메인이 HLA와의 복합체인 경우, 베타-2-마이크로글로불린(B2M)과 결합하는 ILT2의 주요 상호작용 영역으로 확인되었다(문헌[Kuroki et al., J Immuno. (2019) 203(12):3386-94] 참조). (도 18e 및 18f). 실제로 잔기 G97, A98, Y99, I100, Q125, 및 V126은 문헌[Kuroki et al.](문헌[Kuroki]에서 보충도 S2)에 의해 B2M과 상호작용하는 것으로 구체적으로 확인되었다. 표 5 및 6의 잔기 96 내지 99에 해당하는 문헌[Kuroki]의 잔기 97 내지 100은 15G8에 대한 2개의 상호작용 펩티드에 속하므로 15G8 에피토프의 잔기이다. 이는 15G8이 B2M 의존적 방식으로 HLA에 대한 ILT2의 결합을 억제하고 실제로B2M으로의 직접적인 ILT2 결합을 차단함을 강력하게 시사한다. 대조적으로, 다른 보고된 항체(3H5, 12D12, 및 27H5)는 HLA-G의 α3 도메인과 상호작용하는 ILT2의 N-말단 D1 영역에 결합한(문헌[Kuroki]에서 보충도 S2 참조). 이는 문헌[Kuroki et al.]이 ILT2에 대한 주요 상호작용 부위가 B2M 부위이며 α3 도메인에 대한 결합은 부가적이고 가요성임을 확인했다는 점에서 매우 중요하다. 이는 T 세포, NK 세포, 및 대식세포/수지상 세포 기능에 영향을 미치는 15G8의 고유한 능력을 설명할 수 있다. 이는 ILT2의 이차 부위가 아닌 ILT2의 주요 상호작용 부위를 차단한다.
15G8이 ILT2와 B2M 사이의 상호작용을 차단할 수 있는지 시험하기 위해 B2M 차단 ELISA를 수행하였다. 96웰 니켈 플레이트를 재조합 인간 B2M-His 태그(3 μg/ml; Sino Biologics, 11976-H08H)로 밤새 코팅하였다. 비오틴화된 ILT2-Fc(20 μg/ml; Sino Biologics, 1614-H02H; Innova Biosciences, 370-0010)를 37°C에서 2시간 동안 첨가하여, 적정된 BND-22 또는 무관한 항체(항 인간 CD28, Biolegend, 302934)(Ab 범위 80~0.1 μg/ml, X3 배)의 존재 또는 부재 하에 ILT2가 B2M에 결합하도록 하였다. B2M에 대한 ILT2 결합을 HRP 접합된 스트렙타비딘(R&D Systems, DY998)으로 검출하였다. ELISA Reader(Biotek Synergy-H1 플레이트 판독기)를 사용하여 흡광도를 측정하였다.
도 20에 나타낸 바와 같이, 15G8은 특히 더 높은 항체 농도에서 ILT2-B2M 상호작용을 차단하였다. 대조적으로, 이 시스템에 영향을 미치지 않는 비관련 항체는 해당 상호작용을 차단하지 않았다. 15G8이 ILT2와 B2M 사이의 결합을 방해할 수 있음을 직접적으로 입증함으로써, 이러한 결과는 15G8 에피토프가 ILT2와 B2M의 상호작용에 특이적으로 관여하는 것으로 알려진 잔기를 포함한다는 이전의 관찰을 입증한다.
식세포작용에 영향을 미치는 것으로 확인된 유일한 ILT2 항체는 GHI/75이며, 이는 항-CD47 차단 매개 암세포 식세포작용을 향상시키는 것으로 나타났지만 그 자체로는 영향을 미치지 않는 것으로 나타났다(문헌[Barkal et al., Nat Immunol. (2018) 19(1):76-84] 참조). 조합된 GHI/75 및 항-CD47 효과는 B2M의 결실이 식세포작용의 증가에 영향을 미치지 않았기 때문에 B2M 의존적이지 않은 것으로 확인되었다. 따라서, 식세포작용에 대한 15G8 단독의 효과(도 13a 내지 13c)는 B2M 의존적일 수 있으며, 이는 이 항체의 고유한 능력을 설명해줄 것이다. 이와 관련하여 15G8 항체의 우월성을 직접 시험하였다. A375 또는 외인성 HLA-G를 발현하는 SKMEL28 암 세포를 IgG 대조군, 15G8, 또는 GHI/75의 존재 하에 대식세포와 공동배양하였다. 또한 HP-F1 항체를 A375 세포에서 시험하였다. PKH67-FITC로 염색된 암 세포주를 지시된 항체의 존재 하에 eFluor 670-APC로 염색된 대식세포와 인큐베이션하였다. 식세포작용 수준을 표적 세포의 포식을 나타내는 이중 염색된 대식세포의 백분율로 측정하였다. IgG 대조군 대비 식세포작용의 증가 백분율(%)을 계산하였다. 15G8은 두 세포 유형 모두에서 대조군에 비해 식세포작용을 증가시켰다(도 21a 내지 21b). 예상대로 GHI/75와 HP-F1 모두 식세포작용에 영향을 미치지 않았다. 이는 15G8이 단일요법으로서 식세포작용을 향상시킬 수 있는 최초의 항-ILT2 항체임을 확인시켜준다.
이는 GHI/75 및 기타 상용 항체의 에피토프에 대한 의문을 제기한다. 이들 항체의 에피토프는 공개되지 않았지만, 경쟁 ELISA 분석을 수행하여 15G8 및 상업적으로 이용가능한 항체 GHI/75, HP-F1, 및 MAB20172(R&D Systems, 클론 292319)가 ILT2에 동시에 결합할 수 있는지 확인하였다. 비오틴화된 15G8 항체를 ILT2 결합 ELISA에서 일정한 농도(1 μg/mL)로 사용하였다. GHI/75, HP-F1, 또는 MAB20172를 증가하는 농도로 첨가하고 경쟁을 평가하였다. 이들 3개의 항체의 첨가된 양에 관계없이, 이들 중 어느 것도 ILT2에 대한 결합에 대해 15G8과 경쟁하지 않았다(도 21c 내지 21d). 대조적으로, 네이키드(비오틴화되지 않은) 15G8을 첨가한 경우, 결합은 예상한 바와 같이 용량 의존적 방식으로 감소하였다. 이는 GHI/75, HP-F1, 및 MAB20172가 15G8과 상이한 에피토프에 결합함을 나타낸다. 이는 이 에피토프에 결합하고, B2M과의 상호작용을 특이적으로 차단하고, 암에 대항하여 T 세포, NK 세포, 및 대식세포/수지상 세포를 동시에 활성화/모집할 수 있는 것으로 확인된 최초의 항-ILT2 항체가 15G8임을 말해준다.
실시예 14: ILT2와 B2M 사이의 상호작용을 억제할 수 있는 항체를 확인하기 위한 스크리닝 방법
B2M은 HLA-G 및 기타 ILT2 리간드의 일부를 형성하는 단백질이다. 실시예 13에 나타낸 바와 같이, 15G8은 ILT2와 B2M 사이의 상호작용을 담당하는 특정 영역에서 ILT2에 결합하는 고유한 특성을 갖는다. 이 결합을 통해 15G8은 리간드(예를 들어 HLA-G)에 대한 ILT2의 결합을 억제하거나 차단하여 면역 활성화 효과를 나타낼 수 있다. 상기 실시예 13에 기재된 바와 같이, 특이적 결합 영역은 ILT2 D1 및 D2 도메인의 인터페이스 내에 존재하는 것으로 특성화되었고, 경험적 방법을 사용하여 서열번호 68, 69, 70, 71, 및 72 내의 잔기를 포함하는 것으로 추가로 확인되었다. 15G8 결합 영역은 또한 인실리코 방법을 사용하여 확증되었다(도 18a).
유사한 에피토프에 대한 결합을 특징으로 하고 ILT2와 B2M 사이의 상호작용을 특이적으로 차단하는 능력을 갖는 다른 항체가 생성될 수 있는 것으로 고려된다. 이러한 항체는 완전한 재조합 ILT2, 또는 D1-D2 인터페이스 영역을 포함하는 단지 D1 및 D2 도메인, 또는 서열번호 68, 서열번호 69, 서열번호 70, 서열번호 71, 및/또는 서열번호 72와 유사한(예를 들어 이를 포함하거나, 이의 내에 있거나, 이와 동일한) 선형 펩티드로 동물을 면역화하는 것을 포함하는 방법에 의해 유도될 수 있다. 모든 경우에, 유도된 항체는 ILT2-B2M 결합을 차단하는 능력에 대해 추가로 스크리닝된다. 유도된 항체는 예를 들어 상기의 "재료 및 방법"에서 설명한 하이드록실 라디칼 풋 프린팅(HRF) 및 질량 분석 기술과 같은 경험적 기술 또는 질량 분석법에 추가로 결합된 수소-중수소 교환(HDX)과 같은 에피토프 결합 측정을 위한 기타 유사한 알려진 기술을 사용하여, ILT2의 B2M 결합 영역에 대한 특이적 결합에 대해 스크리닝할 수 있다.
마찬가지로 나이브 항체 라이브러리는 재조합 ILT2 또는 세포에서 발현된 ILT2에 결합하는 항체에 대해 스크리닝할 수 있다. 예를 들어, D1~D2 인터페이스 영역을 포함하는 D1 및 D2 도메인으로 구성된 ILT2 단편에 대한 결합에 대해 스크리닝을 수행할 수 있다. 또한 서열번호 68, 서열번호 69, 서열번호 70, 서열번호 71, 및/또는 서열번호 72와 유사한(예를 들어, 이를 포함하거나, 이의 내에 있거나, 이와 동일한) 선형 펩티드, 또는 ILT2 서열에서 이들 두 펩티드와 이들 사이에 존재하는 아미노산으로 구성된 폴리펩티드에 대한 결합에 대해 스크리닝을 수행할 수 있다. 이들 서열에 대한 결합을 나타내는 항체는 상이한 경험적 에피토프 맵핑 기법을 사용하여, 상기 기재된 바와 같이, 추가로 스크리닝될 수 있다.
일부 경우에 스크리닝은, B2M 또는 B2M 모이어티를 포함하는 재조합 또는 세포-발현된 상이한 단백질에 대한 ILT2 결합의 차단을 검출하기 위한 분석을 사용하여, ILT2-B2M 상호작용을 특이적으로 차단하는 능력에 대한 후보 항체의 평가를 포함할 수 있다. 일부 경우에 스크리닝은 B2M에 대한 ILT2의 결합을 차단하는 것으로 나타난 15G8 항체와 특이적으로 경쟁하는 능력에 대한 후보 항체의 평가를 포함할 수 있다.
구체적 구현예의 상기 설명은 다른 연구자가, 현재의 지식을 적용함으로써, 과도한 실험 없이 그리고 일반적 개념에서 벗어나지 않고 이러한 구체적 구현예를 다양한 적용을 위해 용이하게 변형하고/하거나 적응시킬 수 있는 본 개시의 일반적 성질을 매우 충분히 드러낼 것이며, 이에 따라, 이러한 적응 및 변형이 개시되는 구현예의 균등부의 의미 및 범위 내에서 이해되어야 하며 그렇게 의도된다. 본원에서 채택된 어법 또는 용어는 설명을 위한 것이며 제한을 위한 것이 아님이 이해되어야 한다. 개시된 다양한 기능을 수행하기 위한 수단, 물질, 및 단계는 본 개시에서 벗어나지 않고 다양한 대안적 형태를 취할 수 있다.
본 명세서 및 구현예 전반에 걸쳐, 단어 "가지다" 및 "포함하다", 또는 "갖다", "가지고 있는", "포함한다", 또는 "포함하는"과 같은 변형은 언급된 정수 또는 정수군을 포함하되, 임의의 기타 정수 또는 정수군을 배제하지 않는다는 것을 의미하는 것으로 이해될 것이다. 측정 가능한 값, 예컨대 양, 기간 등을 지칭할 때, "약"은, 명시된 값으로부터 ±20%, 또는 일부 경우에 ±10%, 또는 일부 경우에 ±5%, 또는 일부 경우에 ±1%, 또는 일부 경우에 ±0.1%의 편차를 포괄하는 의미이며, 이러한 편차는 개시된 방법의 수행에 적절하다. 또한, 문맥상 달리 요구되지 않는 한, 단수 용어는 복수를 포함하고 복수 용어는 단수를 포함한다.

SEQUENCE LISTING
<110> BIOND BIOLOGICS LTD.
<120> ANTIBODIES AGAINST ILT2 AND USE THEREOF
<130> 022548.WO091
<140>
<141>
<150> 63/149,371
<151> 2021-02-15
<150> 63/145,604
<151> 2021-02-04
<150> PCT/IL2020/050889
<151> 2020-08-12
<160> 116
<170> PatentIn version 3.5
<210> 1
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 1
Asp His Thr Ile His
1 5
<210> 2
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 2
Tyr Ile Tyr Pro Arg Asp Gly Ser Thr Lys Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 3
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 3
Thr Trp Asp Tyr Phe Asp Tyr
1 5
<210> 4
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 4
Arg Ala Ser Glu Ser Val Asp Ser Tyr Gly Asn Ser Phe Met His
1 5 10 15
<210> 5
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 5
Arg Ala Ser Asn Leu Glu Ser
1 5
<210> 6
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 6
Gln Gln Ser Asn Glu Asp Pro Tyr Thr
1 5
<210> 7
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 7
Gly Tyr Thr Phe Thr Ser Tyr Gly Ile Ser
1 5 10
<210> 8
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 8
Glu Ile Tyr Pro Gly Ser Gly Asn Ser Tyr Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 9
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 9
Ser Asn Asp Gly Tyr Pro Asp Tyr
1 5
<210> 10
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 10
Lys Ala Ser Asp His Ile Asn Asn Trp Leu Ala
1 5 10
<210> 11
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 11
Gly Ala Thr Ser Leu Glu Thr
1 5
<210> 12
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 12
Gln Gln Tyr Trp Ser Thr Pro Trp Thr
1 5
<210> 13
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 13
Ser Gly Tyr Tyr Trp Asn
1 5
<210> 14
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 14
Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu Lys Asn
1 5 10 15
<210> 15
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> VARIANT
<222> (10)..(10)
<223> /replace="Cys" or "Ser"
<220>
<221> SITE
<222> (1)..(10)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 15
Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala
1 5 10
<210> 16
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 16
Arg Thr Ser Gln Asp Ile Ser Asn Tyr Leu Asn
1 5 10
<210> 17
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 17
Tyr Thr Ser Arg Leu His Ser
1 5
<210> 18
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 18
Gln Gln Gly Asn Thr Leu Pro Thr
1 5
<210> 19
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 19
Gln Val Gln Leu Gln Gln Ser Asp Ala Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Val Ser Gly Tyr Thr Phe Thr Asp His
20 25 30
Thr Ile His Trp Met Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Pro Arg Asp Gly Ser Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Asn Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala Arg Thr Trp Asp Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu
100 105 110
Thr Val Ser Ser
115
<210> 20
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 20
Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Ser Tyr
20 25 30
Gly Asn Ser Phe Met His Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Arg Thr Asp Phe Thr Leu Thr Ile Asn
65 70 75 80
Pro Val Glu Ala Asp Asp Val Ala Thr Tyr Tyr Cys Gln Gln Ser Asn
85 90 95
Glu Asp Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 21
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 21
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Lys Gln Arg Thr Gly Gln Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Tyr Pro Gly Ser Gly Asn Ser Tyr Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala Arg Ser Asn Asp Gly Tyr Pro Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 22
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 22
Asp Ile Gln Met Thr Gln Ser Ser Ser Tyr Leu Ser Val Ser Leu Gly
1 5 10 15
Gly Arg Val Thr Ile Thr Cys Lys Ala Ser Asp His Ile Asn Asn Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Asn Ala Pro Arg Leu Leu Ile
35 40 45
Ser Gly Ala Thr Ser Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Lys Asp Tyr Thr Leu Ser Ile Thr Ser Leu Gln Thr
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Tyr Trp Ser Thr Pro Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 23
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (108)..(108)
<223> /replace="Cys" or "Ser"
<220>
<221> SITE
<222> (1)..(119)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 23
Asp Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Phe Pro Gly Lys Lys Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 24
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 24
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Val Lys Leu Leu Ile
35 40 45
Ser Tyr Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Asn Thr Leu Pro Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 25
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 25
Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala
1 5 10
<210> 26
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 26
Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ser
1 5 10
<210> 27
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 27
Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Cys
1 5 10
<210> 28
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 28
Asp Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Phe Pro Gly Lys Lys Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 29
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 29
Asp Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Phe Pro Gly Lys Lys Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ser Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 30
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 30
Asp Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Ser Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Phe Pro Gly Asn Lys Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Ile Ser Ile Thr Arg Asp Thr Ser Lys Asn Gln Phe Phe
65 70 75 80
Leu Lys Leu Asn Ser Val Thr Ser Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Cys Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 31
<211> 650
<212> PRT
<213> Homo sapiens
<400> 31
Met Thr Pro Ile Leu Thr Val Leu Ile Cys Leu Gly Leu Ser Leu Gly
1 5 10 15
Pro Arg Thr His Val Gln Ala Gly His Leu Pro Lys Pro Thr Leu Trp
20 25 30
Ala Glu Pro Gly Ser Val Ile Thr Gln Gly Ser Pro Val Thr Leu Arg
35 40 45
Cys Gln Gly Gly Gln Glu Thr Gln Glu Tyr Arg Leu Tyr Arg Glu Lys
50 55 60
Lys Thr Ala Leu Trp Ile Thr Arg Ile Pro Gln Glu Leu Val Lys Lys
65 70 75 80
Gly Gln Phe Pro Ile Pro Ser Ile Thr Trp Glu His Ala Gly Arg Tyr
85 90 95
Arg Cys Tyr Tyr Gly Ser Asp Thr Ala Gly Arg Ser Glu Ser Ser Asp
100 105 110
Pro Leu Glu Leu Val Val Thr Gly Ala Tyr Ile Lys Pro Thr Leu Ser
115 120 125
Ala Gln Pro Ser Pro Val Val Asn Ser Gly Gly Asn Val Ile Leu Gln
130 135 140
Cys Asp Ser Gln Val Ala Phe Asp Gly Phe Ser Leu Cys Lys Glu Gly
145 150 155 160
Glu Asp Glu His Pro Gln Cys Leu Asn Ser Gln Pro His Ala Arg Gly
165 170 175
Ser Ser Arg Ala Ile Phe Ser Val Gly Pro Val Ser Pro Ser Arg Arg
180 185 190
Trp Trp Tyr Arg Cys Tyr Ala Tyr Asp Ser Asn Ser Pro Tyr Glu Trp
195 200 205
Ser Leu Pro Ser Asp Leu Leu Glu Leu Leu Val Leu Gly Val Ser Lys
210 215 220
Lys Pro Ser Leu Ser Val Gln Pro Gly Pro Ile Val Ala Pro Glu Glu
225 230 235 240
Thr Leu Thr Leu Gln Cys Gly Ser Asp Ala Gly Tyr Asn Arg Phe Val
245 250 255
Leu Tyr Lys Asp Gly Glu Arg Asp Phe Leu Gln Leu Ala Gly Ala Gln
260 265 270
Pro Gln Ala Gly Leu Ser Gln Ala Asn Phe Thr Leu Gly Pro Val Ser
275 280 285
Arg Ser Tyr Gly Gly Gln Tyr Arg Cys Tyr Gly Ala His Asn Leu Ser
290 295 300
Ser Glu Trp Ser Ala Pro Ser Asp Pro Leu Asp Ile Leu Ile Ala Gly
305 310 315 320
Gln Phe Tyr Asp Arg Val Ser Leu Ser Val Gln Pro Gly Pro Thr Val
325 330 335
Ala Ser Gly Glu Asn Val Thr Leu Leu Cys Gln Ser Gln Gly Trp Met
340 345 350
Gln Thr Phe Leu Leu Thr Lys Glu Gly Ala Ala Asp Asp Pro Trp Arg
355 360 365
Leu Arg Ser Thr Tyr Gln Ser Gln Lys Tyr Gln Ala Glu Phe Pro Met
370 375 380
Gly Pro Val Thr Ser Ala His Ala Gly Thr Tyr Arg Cys Tyr Gly Ser
385 390 395 400
Gln Ser Ser Lys Pro Tyr Leu Leu Thr His Pro Ser Asp Pro Leu Glu
405 410 415
Leu Val Val Ser Gly Pro Ser Gly Gly Pro Ser Ser Pro Thr Thr Gly
420 425 430
Pro Thr Ser Thr Ser Gly Pro Glu Asp Gln Pro Leu Thr Pro Thr Gly
435 440 445
Ser Asp Pro Gln Ser Gly Leu Gly Arg His Leu Gly Val Val Ile Gly
450 455 460
Ile Leu Val Ala Val Ile Leu Leu Leu Leu Leu Leu Leu Leu Leu Phe
465 470 475 480
Leu Ile Leu Arg His Arg Arg Gln Gly Lys His Trp Thr Ser Thr Gln
485 490 495
Arg Lys Ala Asp Phe Gln His Pro Ala Gly Ala Val Gly Pro Glu Pro
500 505 510
Thr Asp Arg Gly Leu Gln Trp Arg Ser Ser Pro Ala Ala Asp Ala Gln
515 520 525
Glu Glu Asn Leu Tyr Ala Ala Val Lys His Thr Gln Pro Glu Asp Gly
530 535 540
Val Glu Met Asp Thr Arg Ser Pro His Asp Glu Asp Pro Gln Ala Val
545 550 555 560
Thr Tyr Ala Glu Val Lys His Ser Arg Pro Arg Arg Glu Met Ala Ser
565 570 575
Pro Pro Ser Pro Leu Ser Gly Glu Phe Leu Asp Thr Lys Asp Arg Gln
580 585 590
Ala Glu Glu Asp Arg Gln Met Asp Thr Glu Ala Ala Ala Ser Glu Ala
595 600 605
Pro Gln Asp Val Thr Tyr Ala Gln Leu His Ser Leu Thr Leu Arg Arg
610 615 620
Glu Ala Thr Glu Pro Pro Pro Ser Gln Glu Gly Pro Ser Pro Ala Val
625 630 635 640
Pro Ser Ile Tyr Ala Thr Leu Ala Ile His
645 650
<210> 32
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 32
caggttcagc tgcagcagtc tggagctgag ctggcgaggc ctggggcttc agtgaagctg 60
tcctgcaagg cttctggcta caccttcaca agctatggta taagctgggt gaagcagaga 120
actggacagg gccttgagtg ggttggagag atttatcctg gaagtggtaa ttcttactac 180
aatgagaagt tcaagggcaa ggccacactg actgcagaca aatcctccag cacagcgtac 240
atggagctcc gcagcctgac atctgaggac tctgcggtct atttctgtgc aagatcgaat 300
gatggttacc ctgactactg gggccaaggc accactctca cagtctcctc a 351
<210> 33
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 33
gatgtacagc ttcaggggtc aggacctggc ctcgtgaaac cttctcagtc tctgtctctc 60
acctgctctg tcactggcta ctccatcacc agtggttatt actggaactg gatccggcag 120
tttccaggaa acaaactgga atggatgggc tacataagct acgatggtag caataactac 180
aacccatctc tcaaaaatcg aatctccatc actcgtgaca catctaagaa ccagtttttc 240
ctgaagttga attctgtgac ttctgaggac acagccacat attactgtgc ccatggttac 300
tcatattact atgctatgga ctgctggggt caaggaacct cagtcaccgt ctcctca 357
<210> 34
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 34
gatgtccagc tgcaaggctc tggccctgga ctggttaagc cttccgagac actgtccctg 60
acctgctctg tgaccggcta ctctatcacc tccggctact actggaactg gatcagacag 120
ttccccggca agaaactgga atggatgggc tacatctcct acgacggctc caacaactac 180
aaccccagcc tgaagaaccg gatcaccatc tctcgggaca cctccaagaa ccagttctcc 240
ctgaagctga actccgtgac cgctgccgat accgctacct actactgtgc tcacggctac 300
tcctactact acgccatgga tgcttggggc cagggcacat ctgtgacagt gtcctct 357
<210> 35
<211> 348
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 35
caggttcagc tgcaacagtc tgacgctgag ttggtgaaac ctggagcttc agtgaagata 60
tcctgcaagg tttctggcta caccttcact gaccatacta ttcactggat gaagcagagg 120
cctgaacagg gcctggaatg gattggatat atttatccta gagatggtag tactaagtac 180
aatgagaagt tcaagggcaa ggccacattg actgcagaca aatcctccag cacagcctac 240
atgcagctca acagcctgac atctgaggac tctgcagtct atttctgtgc aagaacctgg 300
gactactttg actactgggg ccaaggcacc actctcacag tctcctca 348
<210> 36
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 36
gacattgtgc tgacccaatc tccagcttct ttggctgtgt ctctagggca gagggccacc 60
atatcctgca gagccagtga aagtgttgat agttatggca atagttttat gcactggtac 120
cagcagaaac caggacagcc acccaaactc ctcatctatc gtgcatccaa cctagaatct 180
gggatccctg ccaggttcag tggcagtggg tctaggacag acttcaccct caccattaat 240
cctgtggagg ctgatgatgt tgcaacctat tactgtcagc aaagtaatga ggatccgtac 300
acgttcggag gggggaccaa gctggaaata aaa 333
<210> 37
<211> 318
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 37
gatatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca ggacaagtca ggacattagc aattatttaa actggtatca gcagaaacca 120
gatggaactg ttaaactcct gatctcctac acatcaagat tgcactcagg agtcccatca 180
aggttcagtg gcagtgggtc tggaacagat tattctctca ccattagcaa cctggagcaa 240
gaagatattg ccacttactt ttgccaacag ggtaatacgc ttcccacgtt cggctcgggg 300
acaaagttgg aaataaaa 318
<210> 38
<211> 318
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 38
gacatccaga tgacccagtc tccatcctct ctgtctgcct ctgtgggcga cagagtgacc 60
atcacctgtc ggacctctca ggacatctcc aactacctga actggtatca gcagaaaccc 120
ggcaaggccg tgaagctgct gatctcctac acctccagac tgcactctgg cgtgccctcc 180
agattttctg gctctggatc tggcaccgac tacaccctga ccatcagttc tctgcagcct 240
gaggacttcg ccacctacta ctgtcagcag ggcaacaccc tgcctacctt tggccagggc 300
accaagctgg aaatcaag 318
<210> 39
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 39
gacatccaga tgacacaatc ttcatcctac ttgtctgtat ctctaggagg cagagtcacc 60
attacttgca aggcaagtga ccacattaat aattggttag cctggtatca gcagaaacca 120
ggaaatgctc ctaggctctt aatatctggt gcaaccagtt tggaaactgg ggttccttca 180
agattcagtg gcagtggatc tggaaaggat tacactctca gcattaccag tcttcagact 240
gaagatgttg ctacttatta ctgtcaacag tattggagta ctccgtggac gttcggtgga 300
ggcaccaagc tggaaatcaa a 321
<210> 40
<211> 393
<212> PRT
<213> Homo sapiens
<400> 40
His Leu Pro Lys Pro Thr Leu Trp Ala Glu Pro Gly Ser Val Ile Thr
1 5 10 15
Gln Gly Ser Pro Val Thr Leu Arg Cys Gln Gly Gly Gln Glu Thr Gln
20 25 30
Glu Tyr Arg Leu Tyr Arg Glu Lys Lys Thr Ala Leu Trp Ile Thr Arg
35 40 45
Ile Pro Gln Glu Leu Val Lys Lys Gly Gln Phe Pro Ile Pro Ser Ile
50 55 60
Thr Trp Glu His Ala Gly Arg Tyr Arg Cys Tyr Tyr Gly Ser Asp Thr
65 70 75 80
Ala Gly Arg Ser Glu Ser Ser Asp Pro Leu Glu Leu Val Val Thr Gly
85 90 95
Ala Tyr Ile Lys Pro Thr Leu Ser Ala Gln Pro Ser Pro Val Val Asn
100 105 110
Ser Gly Gly Asn Val Ile Leu Gln Cys Asp Ser Gln Val Ala Phe Asp
115 120 125
Gly Phe Ser Leu Cys Lys Glu Gly Glu Asp Glu His Pro Gln Cys Leu
130 135 140
Asn Ser Gln Pro His Ala Arg Gly Ser Ser Arg Ala Ile Phe Ser Val
145 150 155 160
Gly Pro Val Ser Pro Ser Arg Arg Trp Trp Tyr Arg Cys Tyr Ala Tyr
165 170 175
Asp Ser Asn Ser Pro Tyr Glu Trp Ser Leu Pro Ser Asp Leu Leu Glu
180 185 190
Leu Leu Val Leu Gly Val Ser Lys Lys Pro Ser Leu Ser Val Gln Pro
195 200 205
Gly Pro Ile Val Ala Pro Glu Glu Thr Leu Thr Leu Gln Cys Gly Ser
210 215 220
Asp Ala Gly Tyr Asn Arg Phe Val Leu Tyr Lys Asp Gly Glu Arg Asp
225 230 235 240
Phe Leu Gln Leu Ala Gly Ala Gln Pro Gln Ala Gly Leu Ser Gln Ala
245 250 255
Asn Phe Thr Leu Gly Pro Val Ser Arg Ser Tyr Gly Gly Gln Tyr Arg
260 265 270
Cys Tyr Gly Ala His Asn Leu Ser Ser Glu Trp Ser Ala Pro Ser Asp
275 280 285
Pro Leu Asp Ile Leu Ile Ala Gly Gln Phe Tyr Asp Arg Val Ser Leu
290 295 300
Ser Val Gln Pro Gly Pro Thr Val Ala Ser Gly Glu Asn Val Thr Leu
305 310 315 320
Leu Cys Gln Ser Gln Gly Trp Met Gln Thr Phe Leu Leu Thr Lys Glu
325 330 335
Gly Ala Ala Asp Asp Pro Trp Arg Leu Arg Ser Thr Tyr Gln Ser Gln
340 345 350
Lys Tyr Gln Ala Glu Phe Pro Met Gly Pro Val Thr Ser Ala His Ala
355 360 365
Gly Thr Tyr Arg Cys Tyr Gly Ser Gln Ser Ser Lys Pro Tyr Leu Leu
370 375 380
Thr His Pro Ser Asp Pro Leu Glu Leu
385 390
<210> 41
<211> 15
<212> PRT
<213> Homo sapiens
<400> 41
Val Lys Lys Gly Gln Phe Pro Ile Pro Ser Ile Thr Trp Glu His
1 5 10 15
<210> 42
<211> 15
<212> PRT
<213> Homo sapiens
<400> 42
Leu Glu Leu Val Val Thr Gly Ala Tyr Ile Lys Pro Thr Leu Ser
1 5 10 15
<210> 43
<211> 15
<212> PRT
<213> Homo sapiens
<400> 43
Val Ile Leu Gln Cys Asp Ser Gln Val Ala Phe Asp Gly Phe Ser
1 5 10 15
<210> 44
<211> 15
<212> PRT
<213> Homo sapiens
<400> 44
Trp Tyr Arg Cys Tyr Ala Tyr Asp Ser Asn Ser Pro Tyr Glu Trp
1 5 10 15
<210> 45
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 45
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Arg Thr Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Asp Gly Thr Val Lys Leu Leu Ile
35 40 45
Ser Tyr Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Leu Glu Gln
65 70 75 80
Glu Asp Ile Ala Thr Tyr Phe Cys Gln Gln Gly Asn Thr Leu Pro Thr
85 90 95
Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 46
<211> 98
<212> PRT
<213> Homo sapiens
<400> 46
Gly His Leu Pro Lys Pro Thr Leu Trp Ala Glu Pro Gly Ser Val Ile
1 5 10 15
Thr Gln Gly Ser Pro Val Thr Leu Arg Cys Gln Gly Gly Gln Glu Thr
20 25 30
Gln Glu Tyr Arg Leu Tyr Arg Glu Lys Lys Thr Ala Leu Trp Ile Thr
35 40 45
Arg Ile Pro Gln Glu Leu Val Lys Lys Gly Gln Phe Pro Ile Pro Ser
50 55 60
Ile Thr Trp Glu His Ala Gly Arg Tyr Arg Cys Tyr Tyr Gly Ser Asp
65 70 75 80
Thr Ala Gly Arg Ser Glu Ser Ser Asp Pro Leu Glu Leu Val Val Thr
85 90 95
Gly Ala
<210> 47
<211> 101
<212> PRT
<213> Homo sapiens
<400> 47
Tyr Ile Lys Pro Thr Leu Ser Ala Gln Pro Ser Pro Val Val Asn Ser
1 5 10 15
Gly Gly Asn Val Ile Leu Gln Cys Asp Ser Gln Val Ala Phe Asp Gly
20 25 30
Phe Ser Leu Cys Lys Glu Gly Glu Asp Glu His Pro Gln Cys Leu Asn
35 40 45
Ser Gln Pro His Ala Arg Gly Ser Ser Arg Ala Ile Phe Ser Val Gly
50 55 60
Pro Val Ser Pro Ser Arg Arg Trp Trp Tyr Arg Cys Tyr Ala Tyr Asp
65 70 75 80
Ser Asn Ser Pro Tyr Glu Trp Ser Leu Pro Ser Asp Leu Leu Glu Leu
85 90 95
Leu Val Leu Gly Val
100
<210> 48
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 48
Asp Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Phe Pro Gly Lys Lys Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Phe Glu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val
260 265 270
Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 49
<211> 213
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 49
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Val Lys Leu Leu Ile
35 40 45
Ser Tyr Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Asn Thr Leu Pro Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys
210
<210> 50
<211> 327
<212> PRT
<213> Homo sapiens
<400> 50
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Ser Cys Pro Ala Pro
100 105 110
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
130 135 140
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly Lys
325
<210> 51
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 51
Asp Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Phe Pro Gly Lys Lys Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ser Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Phe Glu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val
260 265 270
Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 52
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 52
Asp Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Phe Pro Gly Lys Lys Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Cys Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Phe Glu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val
260 265 270
Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 53
<211> 444
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 53
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Lys Gln Arg Thr Gly Gln Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Tyr Pro Gly Ser Gly Asn Ser Tyr Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala Arg Ser Asn Asp Gly Tyr Pro Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro
210 215 220
Pro Cys Pro Ala Pro Glu Phe Glu Gly Gly Pro Ser Val Phe Leu Phe
225 230 235 240
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
245 250 255
Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe
260 265 270
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
275 280 285
Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
290 295 300
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
305 310 315 320
Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala
325 330 335
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln
340 345 350
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
355 360 365
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
370 375 380
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
385 390 395 400
Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu
405 410 415
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
420 425 430
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440
<210> 54
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 54
Asp Ile Gln Met Thr Gln Ser Ser Ser Tyr Leu Ser Val Ser Leu Gly
1 5 10 15
Gly Arg Val Thr Ile Thr Cys Lys Ala Ser Asp His Ile Asn Asn Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Asn Ala Pro Arg Leu Leu Ile
35 40 45
Ser Gly Ala Thr Ser Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Lys Asp Tyr Thr Leu Ser Ile Thr Ser Leu Gln Thr
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Tyr Trp Ser Thr Pro Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 55
<211> 327
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 55
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
100 105 110
Glu Phe Glu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
130 135 140
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly Lys
325
<210> 56
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 56
Asp Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Phe Pro Gly Lys Lys Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser
115
<210> 57
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 57
Asp Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser
115
<210> 58
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 58
Gln Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Val Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser
115
<210> 59
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 59
Gln Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Val Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser
115
<210> 60
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 60
Asp Ile Gln Met Thr Gln Ser Thr Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Val Lys Leu Leu Ile
35 40 45
Ser Tyr Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Gln
65 70 75 80
Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Gly Asn Thr Leu Pro Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 61
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 61
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Val Lys Leu Leu Ile
35 40 45
Ser Tyr Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Gly Asn Thr Leu Pro Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 62
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 62
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Ser Tyr Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Gly Asn Thr Leu Pro Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 63
<211> 107
<212> PRT
<213> Homo sapiens
<400> 63
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 64
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 64
Asp Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Phe Pro Gly Lys Lys Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Phe Glu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val
260 265 270
Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 65
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 65
Asp Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Phe Glu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val
260 265 270
Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 66
<211> 213
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 66
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Val Lys Leu Leu Ile
35 40 45
Ser Tyr Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Gly Asn Thr Leu Pro Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys
210
<210> 67
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 67
Gln Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Val Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Phe Glu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val
260 265 270
Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 68
<211> 16
<212> PRT
<213> Homo sapiens
<400> 68
Lys Gly Gln Phe Pro Ile Pro Ser Ile Thr Trp Glu His Ala Gly Arg
1 5 10 15
<210> 69
<211> 15
<212> PRT
<213> Homo sapiens
<400> 69
Gly Gln Phe Pro Ile Pro Ser Ile Thr Trp Glu His Ala Gly Arg
1 5 10 15
<210> 70
<211> 17
<212> PRT
<213> Homo sapiens
<400> 70
Ser Glu Ser Ser Asp Pro Leu Glu Leu Val Val Thr Gly Ala Tyr Ile
1 5 10 15
Lys
<210> 71
<211> 10
<212> PRT
<213> Homo sapiens
<400> 71
Gly Gln Phe Pro Ile Pro Ser Ile Thr Trp
1 5 10
<210> 72
<211> 10
<212> PRT
<213> Homo sapiens
<400> 72
Glu Leu Val Val Thr Gly Ala Tyr Ile Lys
1 5 10
<210> 73
<211> 20
<212> PRT
<213> Homo sapiens
<400> 73
Pro Thr Leu Trp Ala Glu Pro Gly Ser Val Ile Thr Gln Gly Ser Pro
1 5 10 15
Val Thr Leu Arg
20
<210> 74
<211> 11
<212> PRT
<213> Homo sapiens
<400> 74
Cys Gln Gly Gly Gln Glu Thr Gln Glu Tyr Arg
1 5 10
<210> 75
<211> 7
<212> PRT
<213> Homo sapiens
<400> 75
Thr Ala Leu Trp Ile Thr Arg
1 5
<210> 76
<211> 7
<212> PRT
<213> Homo sapiens
<400> 76
Ile Pro Gln Glu Leu Val Lys
1 5
<210> 77
<211> 10
<212> PRT
<213> Homo sapiens
<400> 77
Cys Tyr Tyr Gly Ser Asp Thr Ala Gly Arg
1 5 10
<210> 78
<211> 34
<212> PRT
<213> Homo sapiens
<400> 78
Pro Thr Leu Ser Ala Gln Pro Ser Pro Val Val Asn Ser Gly Gly Asn
1 5 10 15
Val Ile Leu Gln Cys Asp Ser Gln Val Ala Phe Asp Gly Phe Ser Leu
20 25 30
Cys Lys
<210> 79
<211> 17
<212> PRT
<213> Homo sapiens
<400> 79
Glu Gly Glu Asp Glu His Pro Gln Cys Leu Asn Ser Gln Pro His Ala
1 5 10 15
Arg
<210> 80
<211> 12
<212> PRT
<213> Homo sapiens
<400> 80
Ala Ile Phe Ser Val Gly Pro Val Ser Pro Ser Arg
1 5 10
<210> 81
<211> 13
<212> PRT
<213> Homo sapiens
<400> 81
Ala Ile Phe Ser Val Gly Pro Val Ser Pro Ser Arg Arg
1 5 10
<210> 82
<211> 5
<212> PRT
<213> Homo sapiens
<400> 82
Arg Trp Trp Tyr Arg
1 5
<210> 83
<211> 28
<212> PRT
<213> Homo sapiens
<400> 83
Cys Tyr Ala Tyr Asp Ser Asn Ser Pro Tyr Glu Trp Ser Leu Pro Ser
1 5 10 15
Asp Leu Leu Glu Leu Leu Val Leu Gly Val Ser Lys
20 25
<210> 84
<211> 30
<212> PRT
<213> Homo sapiens
<400> 84
Lys Pro Ser Leu Ser Val Gln Pro Gly Pro Ile Val Ala Pro Glu Glu
1 5 10 15
Thr Leu Thr Leu Gln Cys Gly Ser Asp Ala Gly Tyr Asn Arg
20 25 30
<210> 85
<211> 30
<212> PRT
<213> Homo sapiens
<220>
<221> MOD_RES
<222> (22)..(22)
<223> /note="potential glycosylation site"
<400> 85
Asp Gly Glu Arg Asp Phe Leu Gln Leu Ala Gly Ala Gln Pro Gln Ala
1 5 10 15
Gly Leu Ser Gln Ala Asn Phe Thr Leu Gly Pro Val Ser Arg
20 25 30
<210> 86
<211> 26
<212> PRT
<213> Homo sapiens
<220>
<221> MOD_RES
<222> (18)..(18)
<223> /note="potential glycosylation site"
<400> 86
Asp Phe Leu Gln Leu Ala Gly Ala Gln Pro Gln Ala Gly Leu Ser Gln
1 5 10 15
Ala Asn Phe Thr Leu Gly Pro Val Ser Arg
20 25
<210> 87
<211> 26
<212> PRT
<213> Homo sapiens
<400> 87
Asp Phe Leu Gln Leu Ala Gly Ala Gln Pro Gln Ala Gly Leu Ser Gln
1 5 10 15
Ala Asn Phe Thr Leu Gly Pro Val Ser Arg
20 25
<210> 88
<211> 7
<212> PRT
<213> Homo sapiens
<400> 88
Ser Tyr Gly Gly Gln Tyr Arg
1 5
<210> 89
<211> 29
<212> PRT
<213> Homo sapiens
<400> 89
Cys Tyr Gly Ala His Asn Leu Ser Ser Glu Trp Ser Ala Pro Ser Asp
1 5 10 15
Pro Leu Asp Ile Leu Ile Ala Gly Gln Phe Tyr Asp Arg
20 25
<210> 90
<211> 9
<212> PRT
<213> Homo sapiens
<400> 90
Glu Gly Ala Ala Asp Asp Pro Trp Arg
1 5
<210> 91
<211> 19
<212> PRT
<213> Homo sapiens
<400> 91
Tyr Gln Ala Glu Phe Pro Met Gly Pro Val Thr Ser Ala His Ala Gly
1 5 10 15
Thr Tyr Arg
<210> 92
<211> 8
<212> PRT
<213> Homo sapiens
<400> 92
Cys Tyr Gly Ser Gln Ser Ser Lys
1 5
<210> 93
<211> 20
<212> PRT
<213> Homo sapiens
<400> 93
Pro Thr Leu Trp Ala Glu Pro Gly Ser Val Ile Thr Gln Gly Ser Pro
1 5 10 15
Val Thr Leu Arg
20
<210> 94
<211> 15
<212> PRT
<213> Homo sapiens
<400> 94
Glu Pro Gly Ser Val Ile Thr Gln Gly Ser Pro Val Thr Leu Arg
1 5 10 15
<210> 95
<211> 7
<212> PRT
<213> Homo sapiens
<400> 95
Thr Ala Leu Trp Ile Thr Arg
1 5
<210> 96
<211> 7
<212> PRT
<213> Homo sapiens
<400> 96
Ile Pro Gln Glu Leu Val Lys
1 5
<210> 97
<211> 15
<212> PRT
<213> Homo sapiens
<400> 97
Glu Asp Glu His Pro Gln Cys Leu Asn Ser Gln Pro His Ala Arg
1 5 10 15
<210> 98
<211> 12
<212> PRT
<213> Homo sapiens
<400> 98
Ala Ile Phe Ser Val Gly Pro Val Ser Pro Ser Arg
1 5 10
<210> 99
<211> 6
<212> PRT
<213> Homo sapiens
<400> 99
Glu Trp Ser Leu Pro Ser
1 5
<210> 100
<211> 12
<212> PRT
<213> Homo sapiens
<400> 100
Asp Leu Leu Glu Leu Leu Val Leu Gly Val Ser Lys
1 5 10
<210> 101
<211> 9
<212> PRT
<213> Homo sapiens
<400> 101
Glu Leu Leu Val Leu Gly Val Ser Lys
1 5
<210> 102
<211> 7
<212> PRT
<213> Homo sapiens
<400> 102
Ser Tyr Gly Gly Gln Tyr Arg
1 5
<210> 103
<211> 9
<212> PRT
<213> Homo sapiens
<400> 103
Asp Ile Leu Ile Ala Gly Gln Phe Tyr
1 5
<210> 104
<211> 19
<212> PRT
<213> Homo sapiens
<400> 104
Tyr Gln Ala Glu Phe Pro Met Gly Pro Val Thr Ser Ala His Ala Gly
1 5 10 15
Thr Tyr Arg
<210> 105
<211> 16
<212> PRT
<213> Homo sapiens
<400> 105
Glu Phe Pro Met Gly Pro Val Thr Ser Ala His Ala Gly Thr Tyr Arg
1 5 10 15
<210> 106
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 106
Gln Val Gln Leu Gln Gly Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Val Thr Gly Tyr Ser Ile Thr Ser Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Asp Gly Ser Asn Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Asn Arg Val Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala His Gly Tyr Ser Tyr Tyr Tyr Ala Met Asp Ala Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Phe Glu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val
260 265 270
Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 107
<211> 213
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 107
Asp Ile Gln Met Thr Gln Ser Thr Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Val Lys Leu Leu Ile
35 40 45
Ser Tyr Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Gln
65 70 75 80
Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Gly Asn Thr Leu Pro Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys
210
<210> 108
<211> 213
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 108
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Ser Tyr Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Gly Asn Thr Leu Pro Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys
210
<210> 109
<211> 1338
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 109
gatgtccagc tgcaaggctc tggccctgga ctggttaagc cttccgagac actgtccctg 60
acctgctctg tgaccggcta ctctatcacc tccggctact actggaactg gatcagacag 120
ttccccggca agaaactgga atggatgggc tacatctcct acgacggctc caacaactac 180
aaccccagcc tgaagaaccg gatcaccatc tctcgggaca cctccaagaa ccagttctcc 240
ctgaagctga actccgtgac cgctgccgat accgctacct actactgtgc tcacggctac 300
tcctactact acgccatgga tgcttggggc cagggcacat ctgtgacagt gtcctctgct 360
tccaccaagg gaccctctgt gttccctctg gctccttgct ccagatccac ctctgagtct 420
accgctgctc tgggctgcct ggtcaaggat tactttcctg agcctgtgac cgtgtcttgg 480
aactctggtg ctctgacctc cggcgtgcac acatttccag ctgtgctgca gtcctccggc 540
ctgtactctc tgtcctctgt cgtgaccgtg ccttctagct ctctgggcac caagacctac 600
acctgtaacg tggaccacaa gccttccaac accaaggtgg acaagcgcgt ggaatctaag 660
tacggccctc cttgtcctcc atgtcctgct ccagaattcg aaggcggccc ttccgtgttc 720
ctgtttcctc caaagcctaa ggacaccctg atgatctctc ggacccctga agtgacctgc 780
gtggtggtgg atgtgtctca agaggacccc gaggtgcagt tcaattggta cgtggacggc 840
gtggaagtgc acaacgccaa gaccaagcct agagaggaac agttcaactc cacctacaga 900
gtggtgtccg tgctgaccgt gctgcaccag gattggctga acggcaaaga gtacaagtgc 960
aaggtgtcca acaagggcct gcctagctcc atcgaaaaga ccatctccaa ggctaagggc 1020
cagcctcggg aacctcaggt ttacaccctg cctccaagcc aagaggaaat gaccaagaat 1080
caggtgtcac tgacatgcct cgtgaagggc ttctacccct ccgatatcgc cgtggaatgg 1140
gagtctaatg gccagccaga gaacaattac aagacaaccc ctcctgtgct ggactccgac 1200
ggctctttct tcctgtattc ccgcctgacc gtggacaagt ccagatggca agagggcaac 1260
gtgttctcct gctccgtgat gcacgaggcc ctgcacaatc actacaccca gaagtccctg 1320
tctctgtccc tgggcaaa 1338
<210> 110
<211> 78
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 110
atggatctgc tgcacaagaa catgaagcac ctgtggttct ttctgctgct ggtggccgct 60
cctagatggg tgttgtct 78
<210> 111
<211> 639
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 111
gacatccaga tgacccagtc tccatcctct ctgtctgcct ctgtgggcga cagagtgacc 60
atcacctgtc ggacctctca ggacatctcc aactacctga actggtatca gcagaaaccc 120
ggcaaggccg tgaagctgct gatctcctac acctccagac tgcactctgg cgtgccctcc 180
agattttctg gctctggatc tggcaccgac tacaccctga ccatcagttc tctgcagcct 240
gaggacttcg ccacctacta ctgtcagcag ggcaacaccc tgcctacctt tggccagggc 300
accaagctgg aaatcaagag aaccgtggct gccccttccg tgttcatctt cccaccatct 360
gacgagcagc tgaagtccgg cacagcttct gtcgtgtgcc tgctgaacaa cttctaccct 420
cgggaagcca aggtgcagtg gaaggtggac aatgccctgc agtccggcaa ctcccaagag 480
tctgtgaccg agcaggactc caaggactct acctacagcc tgtcctccac actgaccctg 540
tctaaggccg actacgagaa gcacaaggtg tacgcctgtg aagtgaccca ccagggactg 600
tctagccccg tgaccaagtc tttcaacaga ggcgagtgc 639
<210> 112
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 112
gatgttcagc tgcaaggctc tggacctggc ctggtcaagc cttccgaaac actgtccctg 60
acctgctccg tgaccggcta ctctatcacc tccggctact actggaactg gatcagacag 120
ttccccggca agaaactgga atggatgggc tacatctcct acgacggctc caacaactac 180
aaccccagcc tgaagaaccg gatcaccatc tctcgggaca cctccaagaa ccagttctcc 240
ctgaagctgt ccagcgtgac cgctgctgat accgccacct actactgtgc tcacggctac 300
tcctactact acgccatgga tgcttggggc cagggaacaa ccgttacagt ctcctca 357
<210> 113
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 113
gatgttcagc tgcaaggctc tggacctggc ctggtcaagc cttccgaaac actgtccctg 60
acctgctccg tgaccggcta ctctatcacc tccggctact actggaactg gatcagacag 120
cctcctggca agggccttga gtggatgggc tacatctcct acgacggctc caacaactac 180
aaccccagcc tgaagaaccg gatcaccatc tctcgggaca cctccaagaa ccagttctcc 240
ctgaagctgt ccagcgtgac cgctgctgat accgccacct actactgtgc tcacggctac 300
tcctactact acgccatgga tgcttggggc cagggaacaa ccgttacagt ctcctca 357
<210> 114
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 114
caagttcagc tgcaaggctc tggacctggc ctggtcaagc cttccgaaac actgtctctg 60
acctgcaccg tgaccggcta ctctatcacc tccggctact actggaactg gatcagacag 120
cctcctggca agggcctcga gtggatcggc tacatctctt acgacggctc caacaactac 180
aaccccagcc tgaagaacag agtgaccatc agccgggaca cctccaagaa ccagttctcc 240
ctgaagctgt cctccgtgac cgctgctgat accgccacct actactgtgc tcacggctac 300
tcctactact acgccatgga tgcttggggc cagggaacaa ccgttacagt ctcctca 357
<210> 115
<211> 318
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 115
gacattcaga tgacccagtc tccatccagc ctgtccgcct ctgtgggcga cagagtgacc 60
atcacctgtc ggacctctca ggacatctcc aactacctga actggtatca gcagaaaccc 120
ggcaaggccg tgaagctgct gatctcctac acctctagac tgcactccgg cgtgccctcc 180
agattttctg gctctggatc tggcaccgac tataccctga caatctccag cctgcagcct 240
gaggacttcg ctacctactt ctgccagcaa ggcaacaccc tgcctacctt tggccagggc 300
acaaagttgg agatcaaa 318
<210> 116
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 116
gatgtacagc ttcaggggtc aggacctggc ctcgtgaaac cttctcagtc tctgtctctc 60
acctgctctg tcactggcta ctccatcacc agtggttatt actggaactg gatccggcag 120
tttccaggaa acaaactgga atggatgggc tacataagct acgatggtag caataactac 180
aacccatctc tcaaaaatcg aatctccatc actcgtgaca catctaagaa ccagtttttc 240
ctgaagttga attctgtgac ttctgaggac acagccacat attactgtgc ccatggttac 300
tcatattact atgctatgga cagctggggt caaggaacct cagtcaccgt ctcctca 357
Claims (42)
- 서열번호 41 내지 44 및 68 내지 70으로부터 선택된 인간 ILT2의 서열에 결합하는 단일클론 항체 또는 이의 항원 결합 단편.
- 제1항에 있어서, 서열은 서열번호 68 내지 70으로부터 선택되는, 항체 또는 항원 결합 단편.
- 서열번호 71 및 72로부터 선택된 인간 ILT2의 서열에 결합하는 단일클론 항체 또는 이의 항원 결합 단편.
- 제3항에 있어서, 항체 또는 항원 결합 단편은 서열번호 71 및 72에 결합하는, 항체 또는 항원 결합 단편.
- 제1항 내지 제4항 중 어느 한 항에 있어서, 상기 항체 또는 항원 결합 단편은 ILT2에 결합하고, 상기 ILT2와 베타-2-마이크로글로불린(B2M) 사이의 직접적인 상호작용을 억제하는, 항체 또는 항원 결합 단편.
- 제5항에 있어서, 상기 항체 또는 항원 결합 단편은 상기 ILT2의 B2M과의 직접적인 상호작용의 억제를 통해 상기 ILT2와 HLA 단백질 또는 MHC-I 단백질의 상호작용을 억제하는, 항체 또는 항원 결합 단편.
- 제6항에 있어서, 상기 HLA는 HLA-G인, 항체 또는 항원 결합 단편.
- 제1항 내지 제7항 중 어느 한 항에 있어서, 상기 항체는 IgG4 항체이고, S228P 및 L235E 돌연변이(Eu 넘버링)를 포함하는 인간 IgG4 항체의 중쇄 불변 영역을 포함하는, 항체.
- 3개의 중쇄 CDR(CDR-H1-3) 및 3개의 경쇄 CDR(CDR-L1-3)을 포함하는 단일클론 항-ILT2 IgG4 항체로서, CDR-H1-3 및 CDR-L1-3는
a. 각각 서열번호 13 내지 18,
b. 각각 서열번호 1 내지 6, 또는
c. 각각 서열번호 7 내지 12
를 포함하고,
항체는 인간 IgG4 항체의 중쇄 불변 영역을 포함하고, 중쇄 불변 영역에 S228P 및 L235E 돌연변이(Eu 넘버링) 중 하나 또는 둘 모두를 포함하는, 단일클론 항-ILT2 IgG4 항체. - 제9항에 있어서, 서열번호 19, 21, 및 23으로부터 선택된 아미노산 서열, 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 중쇄 가변 도메인을 포함하는, IgG4 항체.
- 제9항 또는 제10항에 있어서, 서열번호 20, 22, 24, 및 45로부터 선택된 아미노산 서열, 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 경쇄 가변 도메인을 포함하는, IgG4 항체.
- 제9항 내지 제11항 중 어느 한 항에 있어서,
CDR-H1-3 및 CDR-L1-3은 각각 서열번호 13 내지 18을 포함하고,
서열번호 15에서 X는 A이고,
상기 중쇄는 서열번호 28 및 56 내지 59로부터 선택된 가변 도메인 서열, 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는, IgG4 항체. - 제12항에 있어서, 상기 경쇄는 서열번호 24 및 60 내지 62로부터 선택된 가변 도메인 서열, 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는, IgG4 항체.
- 제9항 내지 제13항 중 어느 한 항에 있어서, 상기 중쇄 불변 영역은 서열번호 55, 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는, IgG4 항체.
- 제14항에 있어서, 상기 중쇄는 서열번호 48 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 상기 경쇄는 서열번호 49 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는, IgG4 항체.
- 제14항에 있어서, 상기 중쇄는 서열번호 51 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 상기 경쇄는 서열번호 49 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는, IgG4 항체.
- 제14항에 있어서, 상기 중쇄는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 상기 경쇄는 서열번호 49의 아미노산 서열 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는, IgG4 항체.
- 제14항에 있어서, 상기 중쇄는 서열번호 64 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 상기 경쇄는 서열번호 49 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는, IgG4 항체.
- 제14항에 있어서, 상기 중쇄는 서열번호 65의 아미노산 서열 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 상기 경쇄는 서열번호 66 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는, IgG4 항체.
- 제14항에 있어서, 상기 중쇄는 서열번호 67 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 상기 경쇄는 서열번호 49 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는, IgG4 항체.
- 제14항에 있어서, 상기 중쇄는 서열번호 53 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하고, 상기 경쇄는 서열번호 54 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는, IgG4 항체.
- 중쇄 및 경쇄를 포함하는 단일클론 항체로서, 중쇄 및 경쇄는 각각 서열번호 48 및 49를 포함하는, 단일클론 항체.
- ILT2의 결합, 항-종양 T 세포 반응의 유도/강화, T 세포 증식 증가, 암 유발 억제인자 골수 활성 감소, 자연 살해 세포 세포독성 증가, 대식세포 식세포작용 증가, M1 염증성 대식세포 생성 증가, M2 억제인자 대식세포 생성 감소, 종양 미세 환경에서의 수지상 세포 수 증가, 수지상 세포 활성화 증가, HLA-G 발현 암 치료, 및 MHC-I 발현 암 치료 중 적어도 하나에 사용하기 위한 제1항 내지 제22항 중 어느 한 항의 항체 또는 항원 결합 단편.
- HLA-G 또는 MHC-I 발현 암의 치료를 위해 옵소닌화제와 조합하여 사용하기 위한 제1항 내지 제23항 중 어느 한 항의 항체 또는 항원 결합 단편.
- HLA-G 또는 MHC-I 발현 암의 치료를 위해 항-PD-L1/PD-1 기반 면역요법과 조합하여 사용하기 위한 제1항 내지 제24항 중 어느 한 항의 항체 또는 항원 결합 단편으로서, 임의로 항-PD-L1/PD-1 기반 면역요법은 펨브롤리주맙 면역요법인, 항체 또는 항원 결합 단편.
- 제1항 내지 제25항 중 어느 한 항의 항체 또는 항원 결합 단편 및 약학적으로 허용가능한 부형제를 포함하는 약학적 조성물.
- HLA-G 또는 MHC-I 발현 암의 치료를 필요로 하는 대상체에서 이를 치료하는 방법으로서, 제26항의 약학적 조성물 또는 제1항 내지 제25항 중 어느 한 항의 항체 또는 항원 결합 단편을 상기 대상체에게 투여하는 단계를 포함하는 방법.
- 제27항에 있어서, 상기 대상체에게 항-PD-L1/PD-1 기반 면역요법을 투여하는 단계를 추가로 포함하고, 임의로 항-PD-L1/PD-1 기반 면역요법은 펨브롤리주맙 면역요법인, 방법.
- HLA-G 또는 MHC-I을 발현하는 암세포에 대한 항-PD-L1/PD-1 기반 요법의 효능 증가를 필요로 하는 대상체에서 이의 효능을 증가시키는 방법으로서, 항-PD-L1/PD-1 기반 요법을 받는 대상체에게 제26항의 약학적 조성물 또는 제1항 내지 제25항 중 어느 한 항의 항체 또는 항원 결합 단편을 투여하는 단계를 포함하는 방법.
- 제27항 내지 제29항 중 어느 한 항에 있어서, 상기 대상체에게 옵소닌화제를 투여하는 단계를 추가로 포함하는 방법.
- 제30항에 있어서, 상기 옵소닌화제는 EGFR 억제제이고, 임의로 상기 EGFR 억제제는 세툭시맙인, 방법.
- 제23항 내지 제25항 중 어느 한 항에서의 의약의 제조를 위한 또는 제27항 내지 제31항 중 어느 한 항의 방법에 사용하기 위한 제1항 내지 제22항 중 어느 한 항의 항체 또는 항원 결합 단편의 용도.
- 제27항 내지 제31항 중 어느 한 항의 방법에 사용하기 위한 제1항 내지 제22항 중 어느 한 항의 항체 또는 항원 결합 단편.
- ILT2에 대한 결합에 대해, 중쇄 및 경쇄가 각각 서열번호 48 및 49를 포함하는 기준 항체와 경쟁하는 항체를 확인하는 방법으로서,
항체 라이브러리를 서열번호 41 내지 44 및 68 내지 70으로부터 선택된 ILT2 서열을 포함하는 폴리펩티드 서열과 접촉시키는 단계, 및
라이브러리로부터 ILT2 서열에 결합하는 항체를 선택하여 ILT2에 대한 결합에 대해 상기 기준 항체와 경쟁하는 항체를 수득하는 단계
를 포함하는 방법. - ILT2-결합 분자를 생성하는 방법으로서,
서열번호 41 내지 44 및 68 내지 70으로부터 선택된 인간 ILT2의 서열에 결합하는 분자를 암호화하는 하나 이상의 뉴클레오티드 서열을 포함하는 숙주 세포를 수득하는 단계,
분자의 발현이 가능한 조건 하에서 숙주 세포를 배양하여 ILT2-결합 분자를 생성하는 단계
를 포함하는 방법. - 제35항에 있어서, 분자는 서열번호 68 내지 70으로부터 선택된 서열에 결합하는, 방법.
- 제34항 내지 제36항 중 어느 한 항에 있어서, 분자는 서열번호 71 및 72 중 하나 또는 둘 모두에 결합하는, 방법.
- 제37항에 있어서, 분자는 서열번호 71 및 72에 결합하는, 방법.
- 제35항 내지 제38항 중 어느 한 항의 방법에 의해 생성된 ILT2-결합 분자.
- 제1항 내지 제25항 중 어느 한 항의 항체 또는 항원 결합 단편을 암호화하는 단리된 핵산 분자.
- 제40항에 있어서, 상기 핵산 분자는 발현 벡터인, 단리된 핵산 분자.
- 제40항 또는 제41항의 단리된 핵산 분자를 포함하는 숙주 세포.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/IL2020/050889 WO2021028921A1 (en) | 2019-08-12 | 2020-08-12 | Antibodies against ilt2 and use thereof |
| ILPCT/IL2020/050889 | 2020-08-12 | ||
| US202163145604P | 2021-02-04 | 2021-02-04 | |
| US63/145,604 | 2021-02-04 | ||
| US202163149371P | 2021-02-15 | 2021-02-15 | |
| US63/149,371 | 2021-02-15 | ||
| PCT/IB2021/057414 WO2022034524A2 (en) | 2020-08-12 | 2021-08-11 | Antibodies against ilt2 and use thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230058074A true KR20230058074A (ko) | 2023-05-02 |
Family
ID=80223922
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237008527A KR20230058074A (ko) | 2020-08-12 | 2021-08-11 | Ilt2에 대한 항체 및 이의 용도 |
Country Status (13)
| Country | Link |
|---|---|
| US (1) | US20220048991A1 (ko) |
| EP (1) | EP4196227A2 (ko) |
| JP (1) | JP2023537396A (ko) |
| KR (1) | KR20230058074A (ko) |
| CN (1) | CN116096756A (ko) |
| AU (1) | AU2021325430A1 (ko) |
| BR (1) | BR112023002301A2 (ko) |
| CA (1) | CA3190634A1 (ko) |
| CO (1) | CO2023002375A2 (ko) |
| IL (1) | IL300588A (ko) |
| MX (1) | MX2023001776A (ko) |
| TW (1) | TW202221035A (ko) |
| WO (1) | WO2022034524A2 (ko) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023170434A1 (en) * | 2022-03-11 | 2023-09-14 | Macomics Limited | Compositions and methods for modulation of macrophage activity |
| CN116082500B (zh) * | 2022-12-09 | 2023-08-22 | 珠海重链生物科技有限公司 | 抗SARS-CoV-2抗体nCoV1和nCoV2及其应用 |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US4666828A (en) | 1984-08-15 | 1987-05-19 | The General Hospital Corporation | Test for Huntington's disease |
| GB8422238D0 (en) | 1984-09-03 | 1984-10-10 | Neuberger M S | Chimeric proteins |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US4801531A (en) | 1985-04-17 | 1989-01-31 | Biotechnology Research Partners, Ltd. | Apo AI/CIII genomic polymorphisms predictive of atherosclerosis |
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| US5272057A (en) | 1988-10-14 | 1993-12-21 | Georgetown University | Method of detecting a predisposition to cancer by the use of restriction fragment length polymorphism of the gene for human poly (ADP-ribose) polymerase |
| IL162181A (en) | 1988-12-28 | 2006-04-10 | Pdl Biopharma Inc | A method of producing humanized immunoglubulin, and polynucleotides encoding the same |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US5192659A (en) | 1989-08-25 | 1993-03-09 | Genetype Ag | Intron sequence analysis method for detection of adjacent and remote locus alleles as haplotypes |
| CA2103059C (en) | 1991-06-14 | 2005-03-22 | Paul J. Carter | Method for making humanized antibodies |
| US5641870A (en) | 1995-04-20 | 1997-06-24 | Genentech, Inc. | Low pH hydrophobic interaction chromatography for antibody purification |
| US5719867A (en) | 1995-06-30 | 1998-02-17 | Scientific-Atlanta, Inc. | Plural telephony channel baseband signal demodulator for a broadband communications system |
| CA2959821A1 (en) * | 2014-10-24 | 2016-04-28 | The Board Of Trustees Of The Leland Stanford Junior University | Compositions and methods for inducing phagocytosis of mhc class i positive cells and countering anti-cd47/sirpa resistance |
| EP3868787A1 (en) * | 2016-01-21 | 2021-08-25 | Innate Pharma | Neutralization of inhibitory pathways in lymphocytes |
| EP3740224A4 (en) * | 2018-01-18 | 2022-05-04 | Adanate, Inc. | ANTI-LILRB ANTIBODIES AND THEIR USES |
| EP3902829A2 (en) | 2018-12-26 | 2021-11-03 | Innate Pharma | Leucocyte immunoglobulin-like receptor 2 neutralizing antibodies |
-
2021
- 2021-08-11 IL IL300588A patent/IL300588A/en unknown
- 2021-08-11 CN CN202180056995.1A patent/CN116096756A/zh active Pending
- 2021-08-11 AU AU2021325430A patent/AU2021325430A1/en active Pending
- 2021-08-11 KR KR1020237008527A patent/KR20230058074A/ko unknown
- 2021-08-11 TW TW110129661A patent/TW202221035A/zh unknown
- 2021-08-11 BR BR112023002301A patent/BR112023002301A2/pt unknown
- 2021-08-11 WO PCT/IB2021/057414 patent/WO2022034524A2/en active Application Filing
- 2021-08-11 MX MX2023001776A patent/MX2023001776A/es unknown
- 2021-08-11 CA CA3190634A patent/CA3190634A1/en active Pending
- 2021-08-11 JP JP2023509679A patent/JP2023537396A/ja active Pending
- 2021-08-11 US US17/399,971 patent/US20220048991A1/en active Pending
- 2021-08-11 EP EP21763407.0A patent/EP4196227A2/en active Pending
-
2023
- 2023-02-28 CO CONC2023/0002375A patent/CO2023002375A2/es unknown
Also Published As
| Publication number | Publication date |
|---|---|
| CO2023002375A2 (es) | 2023-03-27 |
| EP4196227A2 (en) | 2023-06-21 |
| IL300588A (en) | 2023-04-01 |
| US20220048991A1 (en) | 2022-02-17 |
| MX2023001776A (es) | 2023-03-10 |
| JP2023537396A (ja) | 2023-08-31 |
| TW202221035A (zh) | 2022-06-01 |
| WO2022034524A2 (en) | 2022-02-17 |
| CA3190634A1 (en) | 2022-02-17 |
| CN116096756A (zh) | 2023-05-09 |
| BR112023002301A2 (pt) | 2023-10-03 |
| WO2022034524A3 (en) | 2022-04-28 |
| AU2021325430A1 (en) | 2023-04-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7366543B2 (ja) | Bcma結合分子及びその使用方法 | |
| AU2017302668B9 (en) | Combination therapies of chimeric antigen receptors and PD-1 inhibitors | |
| KR20190039421A (ko) | 항-tigit 항체, 항-pvrig 항체 및 이들의 조합 | |
| JP2020514363A (ja) | 腫瘍特異的細胞枯渇のためのFc最適化抗CD25 | |
| CA3020373A1 (en) | New anti-sirpa antibodies and their therapeutic applications | |
| KR102433076B1 (ko) | Ilt2에 대한 항체 및 이의 용도 | |
| JP2021524278A (ja) | 抗メソテリン抗体 | |
| KR20230058074A (ko) | Ilt2에 대한 항체 및 이의 용도 | |
| CN114901364A (zh) | 用于治疗实体癌和血液癌的组合疗法 | |
| WO2022256563A1 (en) | Anti-ccr8 antibodies and uses thereof | |
| JP2022553927A (ja) | Ilt-2阻害剤での癌の処置 | |
| KR20220030937A (ko) | 항체 및 사용 방법 | |
| JP2021014449A (ja) | Pd−1/cd3二重特異性タンパク質による血液がん治療 | |
| WO2023040940A1 (zh) | Pvrig/tigit结合蛋白联合免疫检查点抑制剂用于治疗癌症 | |
| JP2024514255A (ja) | 増強された抗hvem抗体及びその使用 | |
| WO2023091512A2 (en) | Antibodies to anti-siglec-9 and multispecific antibodies targeting siglec-7 and siglec-9 | |
| CN117177770A (zh) | 使用抗tigit抗体与抗pd1抗体组合治疗癌症的方法 | |
| CN116199777A (zh) | 抗hNKG2D抗体及其应用 |