KR20230051208A - 신규 aav 캡시드 및 이를 함유하는 조성물 - Google Patents
신규 aav 캡시드 및 이를 함유하는 조성물 Download PDFInfo
- Publication number
- KR20230051208A KR20230051208A KR1020237007585A KR20237007585A KR20230051208A KR 20230051208 A KR20230051208 A KR 20230051208A KR 1020237007585 A KR1020237007585 A KR 1020237007585A KR 20237007585 A KR20237007585 A KR 20237007585A KR 20230051208 A KR20230051208 A KR 20230051208A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- acid sequence
- aav
- protein
- capsid
- Prior art date
Links
- 210000000234 capsid Anatomy 0.000 title claims abstract description 242
- 239000000203 mixture Substances 0.000 title description 16
- 239000013598 vector Substances 0.000 claims abstract description 302
- 239000013607 AAV vector Substances 0.000 claims abstract description 80
- 238000010361 transduction Methods 0.000 claims abstract description 70
- 230000026683 transduction Effects 0.000 claims abstract description 70
- 241000702421 Dependoparvovirus Species 0.000 claims abstract description 22
- 230000001965 increasing effect Effects 0.000 claims abstract description 14
- 108090000623 proteins and genes Proteins 0.000 claims description 265
- 108700019146 Transgenes Proteins 0.000 claims description 234
- 235000018102 proteins Nutrition 0.000 claims description 183
- 102000004169 proteins and genes Human genes 0.000 claims description 183
- 210000004027 cell Anatomy 0.000 claims description 153
- 235000001014 amino acid Nutrition 0.000 claims description 148
- 230000014509 gene expression Effects 0.000 claims description 147
- 150000007523 nucleic acids Chemical group 0.000 claims description 146
- 229940024606 amino acid Drugs 0.000 claims description 128
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 124
- 238000000034 method Methods 0.000 claims description 120
- 150000001413 amino acids Chemical class 0.000 claims description 119
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 92
- 239000002773 nucleotide Substances 0.000 claims description 81
- 125000003729 nucleotide group Chemical group 0.000 claims description 81
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 79
- 241001655883 Adeno-associated virus - 1 Species 0.000 claims description 76
- 108090000565 Capsid Proteins Proteins 0.000 claims description 73
- 102100023321 Ceruloplasmin Human genes 0.000 claims description 73
- 210000004185 liver Anatomy 0.000 claims description 58
- 238000012384 transportation and delivery Methods 0.000 claims description 52
- 210000003169 central nervous system Anatomy 0.000 claims description 45
- 230000006240 deamidation Effects 0.000 claims description 40
- 230000004048 modification Effects 0.000 claims description 38
- 238000012986 modification Methods 0.000 claims description 38
- 238000006467 substitution reaction Methods 0.000 claims description 38
- 238000002347 injection Methods 0.000 claims description 35
- 239000007924 injection Substances 0.000 claims description 35
- 238000004519 manufacturing process Methods 0.000 claims description 35
- 230000001105 regulatory effect Effects 0.000 claims description 31
- 102000039446 nucleic acids Human genes 0.000 claims description 30
- 108020004707 nucleic acids Proteins 0.000 claims description 30
- 210000002569 neuron Anatomy 0.000 claims description 27
- 241001164825 Adeno-associated virus - 8 Species 0.000 claims description 24
- 239000004471 Glycine Substances 0.000 claims description 21
- 238000007913 intrathecal administration Methods 0.000 claims description 20
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 claims description 18
- 230000006870 function Effects 0.000 claims description 18
- 238000004806 packaging method and process Methods 0.000 claims description 16
- 230000002829 reductive effect Effects 0.000 claims description 16
- 230000008859 change Effects 0.000 claims description 15
- 210000001130 astrocyte Anatomy 0.000 claims description 14
- 231100000304 hepatotoxicity Toxicity 0.000 claims description 14
- 241000972680 Adeno-associated virus - 6 Species 0.000 claims description 12
- 230000007056 liver toxicity Effects 0.000 claims description 12
- 235000009582 asparagine Nutrition 0.000 claims description 10
- 238000007910 systemic administration Methods 0.000 claims description 10
- 210000002987 choroid plexus Anatomy 0.000 claims description 9
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 claims description 9
- 210000001320 hippocampus Anatomy 0.000 claims description 8
- 230000001976 improved effect Effects 0.000 claims description 8
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 claims description 7
- 229960001230 asparagine Drugs 0.000 claims description 7
- 210000003734 kidney Anatomy 0.000 claims description 7
- 230000005100 tissue tropism Effects 0.000 claims description 7
- 101150066583 rep gene Proteins 0.000 claims description 6
- 210000001577 neostriatum Anatomy 0.000 claims description 5
- 230000005101 cell tropism Effects 0.000 claims description 4
- 210000004738 parenchymal cell Anatomy 0.000 claims description 4
- 238000012258 culturing Methods 0.000 claims description 2
- 238000010253 intravenous injection Methods 0.000 claims description 2
- 102100021244 Integral membrane protein GPR180 Human genes 0.000 claims 2
- 150000001508 asparagines Chemical class 0.000 claims 1
- 208000002267 Anti-neutrophil cytoplasmic antibody-associated vasculitis Diseases 0.000 abstract description 16
- 241001465754 Metazoa Species 0.000 description 72
- 210000001519 tissue Anatomy 0.000 description 72
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 61
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 61
- 239000005090 green fluorescent protein Substances 0.000 description 57
- 239000000047 product Substances 0.000 description 53
- 108090000765 processed proteins & peptides Proteins 0.000 description 48
- 108020004414 DNA Proteins 0.000 description 41
- 238000001990 intravenous administration Methods 0.000 description 40
- 101000834253 Gallus gallus Actin, cytoplasmic 1 Proteins 0.000 description 38
- 108010048367 enhanced green fluorescent protein Proteins 0.000 description 38
- 102000004196 processed proteins & peptides Human genes 0.000 description 38
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 35
- 241000700605 Viruses Species 0.000 description 31
- 210000004556 brain Anatomy 0.000 description 31
- 241000282560 Macaca mulatta Species 0.000 description 30
- 229920001184 polypeptide Polymers 0.000 description 28
- 239000013612 plasmid Substances 0.000 description 26
- 210000002027 skeletal muscle Anatomy 0.000 description 26
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 25
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 24
- 239000000427 antigen Substances 0.000 description 24
- 108091007433 antigens Proteins 0.000 description 24
- 102000036639 antigens Human genes 0.000 description 24
- 238000011282 treatment Methods 0.000 description 22
- 101710132601 Capsid protein Proteins 0.000 description 21
- 101710197658 Capsid protein VP1 Proteins 0.000 description 21
- 101710118046 RNA-directed RNA polymerase Proteins 0.000 description 21
- 101710108545 Viral protein 1 Proteins 0.000 description 21
- 239000012634 fragment Substances 0.000 description 21
- 238000004458 analytical method Methods 0.000 description 19
- 201000010099 disease Diseases 0.000 description 18
- 230000003612 virological effect Effects 0.000 description 18
- 241000699670 Mus sp. Species 0.000 description 17
- 108091029500 miR-183 stem-loop Proteins 0.000 description 17
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 16
- 210000002966 serum Anatomy 0.000 description 16
- 241000699666 Mus <mouse, genus> Species 0.000 description 15
- 230000000694 effects Effects 0.000 description 15
- 210000002216 heart Anatomy 0.000 description 15
- 108091070501 miRNA Proteins 0.000 description 15
- 239000002679 microRNA Substances 0.000 description 15
- 238000012546 transfer Methods 0.000 description 15
- 238000003364 immunohistochemistry Methods 0.000 description 14
- 108091023796 miR-182 stem-loop Proteins 0.000 description 14
- 210000003205 muscle Anatomy 0.000 description 14
- 238000002560 therapeutic procedure Methods 0.000 description 14
- 108091026890 Coding region Proteins 0.000 description 13
- 108020004705 Codon Proteins 0.000 description 13
- 125000000010 L-asparaginyl group Chemical group O=C([*])[C@](N([H])[H])([H])C([H])([H])C(=O)N([H])[H] 0.000 description 13
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 13
- 230000000903 blocking effect Effects 0.000 description 13
- 239000003623 enhancer Substances 0.000 description 13
- -1 i.e. Chemical compound 0.000 description 13
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 12
- 108091008874 T cell receptors Proteins 0.000 description 12
- 239000000872 buffer Substances 0.000 description 12
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 12
- 239000002245 particle Substances 0.000 description 12
- 239000000523 sample Substances 0.000 description 12
- 241001164823 Adeno-associated virus - 7 Species 0.000 description 11
- 101000805768 Banna virus (strain Indonesia/JKT-6423/1980) mRNA (guanine-N(7))-methyltransferase Proteins 0.000 description 11
- 101000686790 Chaetoceros protobacilladnavirus 2 Replication-associated protein Proteins 0.000 description 11
- 101000864475 Chlamydia phage 1 Internal scaffolding protein VP3 Proteins 0.000 description 11
- 101000803553 Eumenes pomiformis Venom peptide 3 Proteins 0.000 description 11
- 101000583961 Halorubrum pleomorphic virus 1 Matrix protein Proteins 0.000 description 11
- 238000011887 Necropsy Methods 0.000 description 11
- 239000002253 acid Substances 0.000 description 11
- 238000001415 gene therapy Methods 0.000 description 11
- 238000010362 genome editing Methods 0.000 description 11
- 230000028993 immune response Effects 0.000 description 11
- 239000002953 phosphate buffered saline Substances 0.000 description 11
- 125000006850 spacer group Chemical group 0.000 description 11
- 210000000278 spinal cord Anatomy 0.000 description 11
- 102100026189 Beta-galactosidase Human genes 0.000 description 10
- 238000002965 ELISA Methods 0.000 description 10
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 10
- 101710081079 Minor spike protein H Proteins 0.000 description 10
- 101710149951 Protein Tat Proteins 0.000 description 10
- 125000000539 amino acid group Chemical group 0.000 description 10
- 238000003556 assay Methods 0.000 description 10
- 238000006243 chemical reaction Methods 0.000 description 10
- 230000000295 complement effect Effects 0.000 description 10
- 230000035772 mutation Effects 0.000 description 10
- 238000011002 quantification Methods 0.000 description 10
- 241000701022 Cytomegalovirus Species 0.000 description 9
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 9
- 238000011529 RT qPCR Methods 0.000 description 9
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 9
- 238000010171 animal model Methods 0.000 description 9
- 108010005774 beta-Galactosidase Proteins 0.000 description 9
- 239000004220 glutamic acid Substances 0.000 description 9
- 210000004072 lung Anatomy 0.000 description 9
- 230000001717 pathogenic effect Effects 0.000 description 9
- 230000008488 polyadenylation Effects 0.000 description 9
- 102000005962 receptors Human genes 0.000 description 9
- 108020003175 receptors Proteins 0.000 description 9
- 238000012163 sequencing technique Methods 0.000 description 9
- 238000012360 testing method Methods 0.000 description 9
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 8
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 8
- 241000702423 Adeno-associated virus - 2 Species 0.000 description 8
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 8
- 101000600434 Homo sapiens Putative uncharacterized protein encoded by MIR7-3HG Proteins 0.000 description 8
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 8
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 8
- 206010028980 Neoplasm Diseases 0.000 description 8
- 101710163270 Nuclease Proteins 0.000 description 8
- 102100037401 Putative uncharacterized protein encoded by MIR7-3HG Human genes 0.000 description 8
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Chemical compound CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 8
- 235000003704 aspartic acid Nutrition 0.000 description 8
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 8
- 238000011156 evaluation Methods 0.000 description 8
- 238000013467 fragmentation Methods 0.000 description 8
- 238000006062 fragmentation reaction Methods 0.000 description 8
- 230000002209 hydrophobic effect Effects 0.000 description 8
- 150000002500 ions Chemical class 0.000 description 8
- 238000002955 isolation Methods 0.000 description 8
- 239000002904 solvent Substances 0.000 description 8
- 210000003594 spinal ganglia Anatomy 0.000 description 8
- 238000010186 staining Methods 0.000 description 8
- 230000009885 systemic effect Effects 0.000 description 8
- 230000008685 targeting Effects 0.000 description 8
- 239000013603 viral vector Substances 0.000 description 8
- 238000011740 C57BL/6 mouse Methods 0.000 description 7
- 102000004190 Enzymes Human genes 0.000 description 7
- 108090000790 Enzymes Proteins 0.000 description 7
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 7
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 7
- 108060001084 Luciferase Proteins 0.000 description 7
- 108091034117 Oligonucleotide Proteins 0.000 description 7
- 241000288906 Primates Species 0.000 description 7
- 230000007812 deficiency Effects 0.000 description 7
- 238000010790 dilution Methods 0.000 description 7
- 239000012895 dilution Substances 0.000 description 7
- 208000035475 disorder Diseases 0.000 description 7
- 239000003814 drug Substances 0.000 description 7
- 229940088598 enzyme Drugs 0.000 description 7
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 7
- 201000006417 multiple sclerosis Diseases 0.000 description 7
- 230000007935 neutral effect Effects 0.000 description 7
- 239000008194 pharmaceutical composition Substances 0.000 description 7
- 238000002360 preparation method Methods 0.000 description 7
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 6
- 108091093088 Amplicon Proteins 0.000 description 6
- 108090000994 Catalytic RNA Proteins 0.000 description 6
- 102000053642 Catalytic RNA Human genes 0.000 description 6
- 241000282693 Cercopithecidae Species 0.000 description 6
- 102000053602 DNA Human genes 0.000 description 6
- 241000282324 Felis Species 0.000 description 6
- 102000053171 Glial Fibrillary Acidic Human genes 0.000 description 6
- 101710193519 Glial fibrillary acidic protein Proteins 0.000 description 6
- 241000282412 Homo Species 0.000 description 6
- 241000725303 Human immunodeficiency virus Species 0.000 description 6
- 108060003951 Immunoglobulin Proteins 0.000 description 6
- 102000004877 Insulin Human genes 0.000 description 6
- 108091092195 Intron Proteins 0.000 description 6
- 102100024640 Low-density lipoprotein receptor Human genes 0.000 description 6
- 208000002678 Mucopolysaccharidoses Diseases 0.000 description 6
- 241000283973 Oryctolagus cuniculus Species 0.000 description 6
- 210000001744 T-lymphocyte Anatomy 0.000 description 6
- 238000008050 Total Bilirubin Reagent Methods 0.000 description 6
- DTQVDTLACAAQTR-UHFFFAOYSA-N Trifluoroacetic acid Chemical compound OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 description 6
- 108090000631 Trypsin Proteins 0.000 description 6
- 102000004142 Trypsin Human genes 0.000 description 6
- 230000002950 deficient Effects 0.000 description 6
- 238000012217 deletion Methods 0.000 description 6
- 238000001514 detection method Methods 0.000 description 6
- 210000005046 glial fibrillary acidic protein Anatomy 0.000 description 6
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 6
- 108010050848 glycylleucine Proteins 0.000 description 6
- 102000018358 immunoglobulin Human genes 0.000 description 6
- 238000001727 in vivo Methods 0.000 description 6
- 229940125396 insulin Drugs 0.000 description 6
- 210000005228 liver tissue Anatomy 0.000 description 6
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 6
- 206010028093 mucopolysaccharidosis Diseases 0.000 description 6
- 210000004165 myocardium Anatomy 0.000 description 6
- 230000003472 neutralizing effect Effects 0.000 description 6
- 239000002243 precursor Substances 0.000 description 6
- 239000013608 rAAV vector Substances 0.000 description 6
- 108091092562 ribozyme Proteins 0.000 description 6
- 241000894007 species Species 0.000 description 6
- 239000003053 toxin Substances 0.000 description 6
- 231100000765 toxin Toxicity 0.000 description 6
- 108700012359 toxins Proteins 0.000 description 6
- VCSABYLVNWQYQE-SRVKXCTJSA-N Ala-Lys-Lys Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O VCSABYLVNWQYQE-SRVKXCTJSA-N 0.000 description 5
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 5
- 208000023275 Autoimmune disease Diseases 0.000 description 5
- 241000282465 Canis Species 0.000 description 5
- 102100034746 Cyclin-dependent kinase-like 5 Human genes 0.000 description 5
- 102000003951 Erythropoietin Human genes 0.000 description 5
- 108090000394 Erythropoietin Proteins 0.000 description 5
- 241000282326 Felis catus Species 0.000 description 5
- 108090001061 Insulin Proteins 0.000 description 5
- 125000003412 L-alanyl group Chemical group [H]N([H])[C@@](C([H])([H])[H])(C(=O)[*])[H] 0.000 description 5
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 5
- 239000005089 Luciferase Substances 0.000 description 5
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 5
- 108010079364 N-glycylalanine Proteins 0.000 description 5
- 102000010175 Opsin Human genes 0.000 description 5
- 108050001704 Opsin Proteins 0.000 description 5
- APJPXSFJBMMOLW-KBPBESRZSA-N Phe-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 APJPXSFJBMMOLW-KBPBESRZSA-N 0.000 description 5
- 108010038512 Platelet-Derived Growth Factor Proteins 0.000 description 5
- 102000010780 Platelet-Derived Growth Factor Human genes 0.000 description 5
- NMCBVGFGWSIGSB-NUTKFTJISA-N Trp-Ala-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N NMCBVGFGWSIGSB-NUTKFTJISA-N 0.000 description 5
- 101150110932 US19 gene Proteins 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 201000011510 cancer Diseases 0.000 description 5
- 239000003153 chemical reaction reagent Substances 0.000 description 5
- 230000037430 deletion Effects 0.000 description 5
- 230000029087 digestion Effects 0.000 description 5
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 229940105423 erythropoietin Drugs 0.000 description 5
- 238000002474 experimental method Methods 0.000 description 5
- 238000010195 expression analysis Methods 0.000 description 5
- 238000013412 genome amplification Methods 0.000 description 5
- 235000004554 glutamine Nutrition 0.000 description 5
- 210000005003 heart tissue Anatomy 0.000 description 5
- 238000010166 immunofluorescence Methods 0.000 description 5
- 238000000338 in vitro Methods 0.000 description 5
- 230000001939 inductive effect Effects 0.000 description 5
- 208000015181 infectious disease Diseases 0.000 description 5
- 238000004949 mass spectrometry Methods 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 230000007170 pathology Effects 0.000 description 5
- 230000002093 peripheral effect Effects 0.000 description 5
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 description 5
- 238000012545 processing Methods 0.000 description 5
- 206010039073 rheumatoid arthritis Diseases 0.000 description 5
- 210000000952 spleen Anatomy 0.000 description 5
- 239000000758 substrate Substances 0.000 description 5
- 230000002463 transducing effect Effects 0.000 description 5
- 239000012588 trypsin Substances 0.000 description 5
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 4
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 4
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 4
- UHFUZWSZQKMDSX-DCAQKATOSA-N Arg-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UHFUZWSZQKMDSX-DCAQKATOSA-N 0.000 description 4
- 108090001008 Avidin Proteins 0.000 description 4
- 241000193738 Bacillus anthracis Species 0.000 description 4
- 108010035563 Chloramphenicol O-acetyltransferase Proteins 0.000 description 4
- 241000711573 Coronaviridae Species 0.000 description 4
- 241000283074 Equus asinus Species 0.000 description 4
- 102000001690 Factor VIII Human genes 0.000 description 4
- 108010054218 Factor VIII Proteins 0.000 description 4
- 241000287828 Gallus gallus Species 0.000 description 4
- 102100033295 Glial cell line-derived neurotrophic factor Human genes 0.000 description 4
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 4
- 241000701024 Human betaherpesvirus 5 Species 0.000 description 4
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 4
- ZXEUFAVXODIPHC-GUBZILKMSA-N Lys-Glu-Asn Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZXEUFAVXODIPHC-GUBZILKMSA-N 0.000 description 4
- 102400000058 Neuregulin-1 Human genes 0.000 description 4
- 108700026244 Open Reading Frames Proteins 0.000 description 4
- 102100028200 Ornithine transcarbamylase, mitochondrial Human genes 0.000 description 4
- 102000035195 Peptidases Human genes 0.000 description 4
- 108091005804 Peptidases Proteins 0.000 description 4
- 108010071690 Prealbumin Proteins 0.000 description 4
- 102100037632 Progranulin Human genes 0.000 description 4
- 108091027967 Small hairpin RNA Proteins 0.000 description 4
- 102000009190 Transthyretin Human genes 0.000 description 4
- JAIZPWVHPQRYOU-ZJDVBMNYSA-N Val-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O JAIZPWVHPQRYOU-ZJDVBMNYSA-N 0.000 description 4
- 238000009825 accumulation Methods 0.000 description 4
- ZSLZBFCDCINBPY-ZSJPKINUSA-N acetyl-CoA Chemical compound O[C@@H]1[C@H](OP(O)(O)=O)[C@@H](COP(O)(=O)OP(O)(=O)OCC(C)(C)[C@@H](O)C(=O)NCCC(=O)NCCSC(=O)C)O[C@H]1N1C2=NC=NC(N)=C2N=C1 ZSLZBFCDCINBPY-ZSJPKINUSA-N 0.000 description 4
- 108010050122 alpha 1-Antitrypsin Proteins 0.000 description 4
- 102000015395 alpha 1-Antitrypsin Human genes 0.000 description 4
- 229940024142 alpha 1-antitrypsin Drugs 0.000 description 4
- 206010002026 amyotrophic lateral sclerosis Diseases 0.000 description 4
- 125000000613 asparagine group Chemical class N[C@@H](CC(N)=O)C(=O)* 0.000 description 4
- 229960000074 biopharmaceutical Drugs 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 4
- 229960002685 biotin Drugs 0.000 description 4
- 235000020958 biotin Nutrition 0.000 description 4
- 239000011616 biotin Substances 0.000 description 4
- 239000000969 carrier Substances 0.000 description 4
- 239000003795 chemical substances by application Substances 0.000 description 4
- 239000002299 complementary DNA Substances 0.000 description 4
- 230000000875 corresponding effect Effects 0.000 description 4
- 238000013461 design Methods 0.000 description 4
- 229940079593 drug Drugs 0.000 description 4
- 238000001493 electron microscopy Methods 0.000 description 4
- 229960000301 factor viii Drugs 0.000 description 4
- 125000000524 functional group Chemical group 0.000 description 4
- 238000001476 gene delivery Methods 0.000 description 4
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 4
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 4
- 108010087823 glycyltyrosine Proteins 0.000 description 4
- 239000003102 growth factor Substances 0.000 description 4
- 229960000789 guanidine hydrochloride Drugs 0.000 description 4
- PJJJBBJSCAKJQF-UHFFFAOYSA-N guanidinium chloride Chemical compound [Cl-].NC(N)=[NH2+] PJJJBBJSCAKJQF-UHFFFAOYSA-N 0.000 description 4
- 229940072221 immunoglobulins Drugs 0.000 description 4
- 238000011534 incubation Methods 0.000 description 4
- 238000003780 insertion Methods 0.000 description 4
- 230000037431 insertion Effects 0.000 description 4
- 238000007914 intraventricular administration Methods 0.000 description 4
- PGLTVOMIXTUURA-UHFFFAOYSA-N iodoacetamide Chemical compound NC(=O)CI PGLTVOMIXTUURA-UHFFFAOYSA-N 0.000 description 4
- 210000003140 lateral ventricle Anatomy 0.000 description 4
- 239000000463 material Substances 0.000 description 4
- 239000012528 membrane Substances 0.000 description 4
- 108010016686 methionyl-alanyl-serine Proteins 0.000 description 4
- 210000002161 motor neuron Anatomy 0.000 description 4
- 208000005340 mucopolysaccharidosis III Diseases 0.000 description 4
- 229940053128 nerve growth factor Drugs 0.000 description 4
- 238000005457 optimization Methods 0.000 description 4
- 210000000056 organ Anatomy 0.000 description 4
- 108010051242 phenylalanylserine Proteins 0.000 description 4
- 230000026731 phosphorylation Effects 0.000 description 4
- 238000006366 phosphorylation reaction Methods 0.000 description 4
- 108010015796 prolylisoleucine Proteins 0.000 description 4
- 201000004012 propionic acidemia Diseases 0.000 description 4
- 238000003127 radioimmunoassay Methods 0.000 description 4
- 230000004044 response Effects 0.000 description 4
- 239000004055 small Interfering RNA Substances 0.000 description 4
- 238000001228 spectrum Methods 0.000 description 4
- 208000002320 spinal muscular atrophy Diseases 0.000 description 4
- KZNICNPSHKQLFF-UHFFFAOYSA-N succinimide Chemical group O=C1CCC(=O)N1 KZNICNPSHKQLFF-UHFFFAOYSA-N 0.000 description 4
- 230000004083 survival effect Effects 0.000 description 4
- 230000002123 temporal effect Effects 0.000 description 4
- 108010061238 threonyl-glycine Proteins 0.000 description 4
- 230000001988 toxicity Effects 0.000 description 4
- 231100000419 toxicity Toxicity 0.000 description 4
- 238000001890 transfection Methods 0.000 description 4
- 238000013519 translation Methods 0.000 description 4
- 239000003981 vehicle Substances 0.000 description 4
- 102100038837 2-Hydroxyacid oxidase 1 Human genes 0.000 description 3
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 3
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 3
- CCDFBRZVTDDJNM-GUBZILKMSA-N Ala-Leu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CCDFBRZVTDDJNM-GUBZILKMSA-N 0.000 description 3
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 3
- YCTIYBUTCKNOTI-UWJYBYFXSA-N Ala-Tyr-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCTIYBUTCKNOTI-UWJYBYFXSA-N 0.000 description 3
- JQFJNGVSGOUQDH-XIRDDKMYSA-N Arg-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCN=C(N)N)N)C(O)=O)=CNC2=C1 JQFJNGVSGOUQDH-XIRDDKMYSA-N 0.000 description 3
- GMFAGHNRXPSSJS-SRVKXCTJSA-N Arg-Leu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GMFAGHNRXPSSJS-SRVKXCTJSA-N 0.000 description 3
- WIDVAWAQBRAKTI-YUMQZZPRSA-N Asn-Leu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O WIDVAWAQBRAKTI-YUMQZZPRSA-N 0.000 description 3
- XEDQMTWEYFBOIK-ACZMJKKPSA-N Asp-Ala-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XEDQMTWEYFBOIK-ACZMJKKPSA-N 0.000 description 3
- UGKZHCBLMLSANF-CIUDSAMLSA-N Asp-Asn-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O UGKZHCBLMLSANF-CIUDSAMLSA-N 0.000 description 3
- UGIBTKGQVWFTGX-BIIVOSGPSA-N Asp-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N)C(=O)O UGIBTKGQVWFTGX-BIIVOSGPSA-N 0.000 description 3
- PGUYEUCYVNZGGV-QWRGUYRKSA-N Asp-Gly-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PGUYEUCYVNZGGV-QWRGUYRKSA-N 0.000 description 3
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 3
- 102000007370 Ataxin2 Human genes 0.000 description 3
- 108010032951 Ataxin2 Proteins 0.000 description 3
- 238000011746 C57BL/6J (JAX™ mouse strain) Methods 0.000 description 3
- 241000283707 Capra Species 0.000 description 3
- 102000014914 Carrier Proteins Human genes 0.000 description 3
- 102100022641 Coagulation factor IX Human genes 0.000 description 3
- 101710178912 Cyclin-dependent kinase-like 5 Proteins 0.000 description 3
- 102000004127 Cytokines Human genes 0.000 description 3
- 108090000695 Cytokines Proteins 0.000 description 3
- 108010069091 Dystrophin Proteins 0.000 description 3
- 102000001039 Dystrophin Human genes 0.000 description 3
- 201000011240 Frontotemporal dementia Diseases 0.000 description 3
- 206010017533 Fungal infection Diseases 0.000 description 3
- ULXXDWZMMSQBDC-ACZMJKKPSA-N Gln-Asp-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N ULXXDWZMMSQBDC-ACZMJKKPSA-N 0.000 description 3
- KVXVVDFOZNYYKZ-DCAQKATOSA-N Gln-Gln-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KVXVVDFOZNYYKZ-DCAQKATOSA-N 0.000 description 3
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 3
- VOLVNCMGXWDDQY-LPEHRKFASA-N Gln-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O VOLVNCMGXWDDQY-LPEHRKFASA-N 0.000 description 3
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 3
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 3
- CUXJIASLBRJOFV-LAEOZQHASA-N Glu-Gly-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUXJIASLBRJOFV-LAEOZQHASA-N 0.000 description 3
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 3
- YTSVAIMKVLZUDU-YUMQZZPRSA-N Gly-Leu-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YTSVAIMKVLZUDU-YUMQZZPRSA-N 0.000 description 3
- PNUFMLXHOLFRLD-KBPBESRZSA-N Gly-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 PNUFMLXHOLFRLD-KBPBESRZSA-N 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 3
- 108091005904 Hemoglobin subunit beta Proteins 0.000 description 3
- BDHUXUFYNUOUIT-SRVKXCTJSA-N His-Asp-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BDHUXUFYNUOUIT-SRVKXCTJSA-N 0.000 description 3
- 101000887201 Homo sapiens Polyamine-transporting ATPase 13A2 Proteins 0.000 description 3
- 208000000563 Hyperlipoproteinemia Type II Diseases 0.000 description 3
- 108010065920 Insulin Lispro Proteins 0.000 description 3
- 102000015696 Interleukins Human genes 0.000 description 3
- 108010063738 Interleukins Proteins 0.000 description 3
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 3
- 108010001831 LDL receptors Proteins 0.000 description 3
- BMVFXOQHDQZAQU-DCAQKATOSA-N Leu-Pro-Asp Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N BMVFXOQHDQZAQU-DCAQKATOSA-N 0.000 description 3
- MPOHDJKRBLVGCT-CIUDSAMLSA-N Lys-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N MPOHDJKRBLVGCT-CIUDSAMLSA-N 0.000 description 3
- XFIHDSBIPWEYJJ-YUMQZZPRSA-N Lys-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN XFIHDSBIPWEYJJ-YUMQZZPRSA-N 0.000 description 3
- LCMWVZLBCUVDAZ-IUCAKERBSA-N Lys-Gly-Glu Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CCC([O-])=O LCMWVZLBCUVDAZ-IUCAKERBSA-N 0.000 description 3
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 3
- 102100026001 Lysosomal acid lipase/cholesteryl ester hydrolase Human genes 0.000 description 3
- YRAWWKUTNBILNT-FXQIFTODSA-N Met-Ala-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YRAWWKUTNBILNT-FXQIFTODSA-N 0.000 description 3
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 3
- 108010025020 Nerve Growth Factor Proteins 0.000 description 3
- 108090000556 Neuregulin-1 Proteins 0.000 description 3
- 101710198224 Ornithine carbamoyltransferase, mitochondrial Proteins 0.000 description 3
- 102100038551 Peptide-N(4)-(N-acetyl-beta-glucosaminyl)asparagine amidase Human genes 0.000 description 3
- UNLYPPYNDXHGDG-IHRRRGAJSA-N Phe-Gln-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 UNLYPPYNDXHGDG-IHRRRGAJSA-N 0.000 description 3
- 108010069013 Phenylalanine Hydroxylase Proteins 0.000 description 3
- 102100038223 Phenylalanine-4-hydroxylase Human genes 0.000 description 3
- 102100039917 Polyamine-transporting ATPase 13A2 Human genes 0.000 description 3
- VGVCNKSUVSZEIE-IHRRRGAJSA-N Pro-Phe-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O VGVCNKSUVSZEIE-IHRRRGAJSA-N 0.000 description 3
- IMNVAOPEMFDAQD-NHCYSSNCSA-N Pro-Val-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IMNVAOPEMFDAQD-NHCYSSNCSA-N 0.000 description 3
- 239000004365 Protease Substances 0.000 description 3
- 208000035977 Rare disease Diseases 0.000 description 3
- 241000283984 Rodentia Species 0.000 description 3
- 206010039710 Scleroderma Diseases 0.000 description 3
- XKFJENWJGHMDLI-QWRGUYRKSA-N Ser-Phe-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O XKFJENWJGHMDLI-QWRGUYRKSA-N 0.000 description 3
- 241000700584 Simplexvirus Species 0.000 description 3
- 108020004682 Single-Stranded DNA Proteins 0.000 description 3
- 108010039203 Tripeptidyl-Peptidase 1 Proteins 0.000 description 3
- 102100034197 Tripeptidyl-peptidase 1 Human genes 0.000 description 3
- VPRHDRKAPYZMHL-SZMVWBNQSA-N Trp-Leu-Glu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 VPRHDRKAPYZMHL-SZMVWBNQSA-N 0.000 description 3
- 206010067584 Type 1 diabetes mellitus Diseases 0.000 description 3
- 206010045261 Type IIa hyperlipidaemia Diseases 0.000 description 3
- CYDVHRFXDMDMGX-KKUMJFAQSA-N Tyr-Asn-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O CYDVHRFXDMDMGX-KKUMJFAQSA-N 0.000 description 3
- QSFJHIRIHOJRKS-ULQDDVLXSA-N Tyr-Leu-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QSFJHIRIHOJRKS-ULQDDVLXSA-N 0.000 description 3
- DWAMXBFJNZIHMC-KBPBESRZSA-N Tyr-Leu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O DWAMXBFJNZIHMC-KBPBESRZSA-N 0.000 description 3
- DMWNPLOERDAHSY-MEYUZBJRSA-N Tyr-Leu-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DMWNPLOERDAHSY-MEYUZBJRSA-N 0.000 description 3
- 108091000117 Tyrosine 3-Monooxygenase Proteins 0.000 description 3
- 102000048218 Tyrosine 3-monooxygenases Human genes 0.000 description 3
- QPZMOUMNTGTEFR-ZKWXMUAHSA-N Val-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N QPZMOUMNTGTEFR-ZKWXMUAHSA-N 0.000 description 3
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 3
- ZHQWPWQNVRCXAX-XQQFMLRXSA-N Val-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZHQWPWQNVRCXAX-XQQFMLRXSA-N 0.000 description 3
- UZFNHAXYMICTBU-DZKIICNBSA-N Val-Phe-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N UZFNHAXYMICTBU-DZKIICNBSA-N 0.000 description 3
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 3
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 3
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 3
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 3
- 230000009435 amidation Effects 0.000 description 3
- 238000007112 amidation reaction Methods 0.000 description 3
- 125000003277 amino group Chemical group 0.000 description 3
- 230000003321 amplification Effects 0.000 description 3
- 108010092854 aspartyllysine Proteins 0.000 description 3
- 244000052616 bacterial pathogen Species 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 230000027455 binding Effects 0.000 description 3
- 108091008324 binding proteins Proteins 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 239000007979 citrate buffer Substances 0.000 description 3
- 230000001086 cytosolic effect Effects 0.000 description 3
- 230000007547 defect Effects 0.000 description 3
- 230000001419 dependent effect Effects 0.000 description 3
- 210000000188 diaphragm Anatomy 0.000 description 3
- 238000009826 distribution Methods 0.000 description 3
- 238000011304 droplet digital PCR Methods 0.000 description 3
- 210000002889 endothelial cell Anatomy 0.000 description 3
- 230000002255 enzymatic effect Effects 0.000 description 3
- 201000001386 familial hypercholesterolemia Diseases 0.000 description 3
- 235000019253 formic acid Nutrition 0.000 description 3
- 208000024386 fungal infectious disease Diseases 0.000 description 3
- 108020001507 fusion proteins Proteins 0.000 description 3
- 102000037865 fusion proteins Human genes 0.000 description 3
- 102000034356 gene-regulatory proteins Human genes 0.000 description 3
- 108091006104 gene-regulatory proteins Proteins 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 108010059898 glycyl-tyrosyl-lysine Proteins 0.000 description 3
- 210000002064 heart cell Anatomy 0.000 description 3
- 108010040030 histidinoalanine Proteins 0.000 description 3
- 230000003463 hyperproliferative effect Effects 0.000 description 3
- 210000000987 immune system Anatomy 0.000 description 3
- 230000036039 immunity Effects 0.000 description 3
- 229940047122 interleukins Drugs 0.000 description 3
- 239000000543 intermediate Substances 0.000 description 3
- 108010034529 leucyl-lysine Proteins 0.000 description 3
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 3
- 108010057821 leucylproline Proteins 0.000 description 3
- 239000007788 liquid Substances 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 239000011159 matrix material Substances 0.000 description 3
- 108020004999 messenger RNA Proteins 0.000 description 3
- 238000007431 microscopic evaluation Methods 0.000 description 3
- 201000006938 muscular dystrophy Diseases 0.000 description 3
- 210000004498 neuroglial cell Anatomy 0.000 description 3
- 238000003199 nucleic acid amplification method Methods 0.000 description 3
- 230000003647 oxidation Effects 0.000 description 3
- 238000007254 oxidation reaction Methods 0.000 description 3
- 239000012188 paraffin wax Substances 0.000 description 3
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 3
- 108091008695 photoreceptors Proteins 0.000 description 3
- 230000001124 posttranscriptional effect Effects 0.000 description 3
- 239000002244 precipitate Substances 0.000 description 3
- 238000003753 real-time PCR Methods 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 238000005070 sampling Methods 0.000 description 3
- 230000028327 secretion Effects 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 208000011580 syndromic disease Diseases 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- JGVWCANSWKRBCS-UHFFFAOYSA-N tetramethylrhodamine thiocyanate Chemical compound [Cl-].C=12C=CC(N(C)C)=CC2=[O+]C2=CC(N(C)C)=CC=C2C=1C1=CC=C(SC#N)C=C1C(O)=O JGVWCANSWKRBCS-UHFFFAOYSA-N 0.000 description 3
- 230000001225 therapeutic effect Effects 0.000 description 3
- 230000009258 tissue cross reactivity Effects 0.000 description 3
- GPRLSGONYQIRFK-MNYXATJNSA-N triton Chemical compound [3H+] GPRLSGONYQIRFK-MNYXATJNSA-N 0.000 description 3
- 108010015666 tryptophyl-leucyl-glutamic acid Proteins 0.000 description 3
- 108010045269 tryptophyltryptophan Proteins 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 3
- 239000003643 water by type Substances 0.000 description 3
- 239000008096 xylene Substances 0.000 description 3
- PQFMROVJTOPVDF-JBDRJPRFSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-amino-3-carboxypropanoyl]amino]-3-carboxypropanoyl]amino]-4-carboxybutanoyl]amino]butanedioic acid Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PQFMROVJTOPVDF-JBDRJPRFSA-N 0.000 description 2
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 2
- HSTOKWSFWGCZMH-UHFFFAOYSA-N 3,3'-diaminobenzidine Chemical compound C1=C(N)C(N)=CC=C1C1=CC=C(N)C(N)=C1 HSTOKWSFWGCZMH-UHFFFAOYSA-N 0.000 description 2
- 108020003589 5' Untranslated Regions Proteins 0.000 description 2
- OPIFSICVWOWJMJ-AEOCFKNESA-N 5-bromo-4-chloro-3-indolyl beta-D-galactoside Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1OC1=CNC2=CC=C(Br)C(Cl)=C12 OPIFSICVWOWJMJ-AEOCFKNESA-N 0.000 description 2
- 208000034012 Acid sphingomyelinase deficiency Diseases 0.000 description 2
- 208000005452 Acute intermittent porphyria Diseases 0.000 description 2
- FJVAQLJNTSUQPY-CIUDSAMLSA-N Ala-Ala-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN FJVAQLJNTSUQPY-CIUDSAMLSA-N 0.000 description 2
- GSCLWXDNIMNIJE-ZLUOBGJFSA-N Ala-Asp-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GSCLWXDNIMNIJE-ZLUOBGJFSA-N 0.000 description 2
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 2
- FBHOPGDGELNWRH-DRZSPHRISA-N Ala-Glu-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O FBHOPGDGELNWRH-DRZSPHRISA-N 0.000 description 2
- CBCCCLMNOBLBSC-XVYDVKMFSA-N Ala-His-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O CBCCCLMNOBLBSC-XVYDVKMFSA-N 0.000 description 2
- BHTBAVZSZCQZPT-GUBZILKMSA-N Ala-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N BHTBAVZSZCQZPT-GUBZILKMSA-N 0.000 description 2
- NHWYNIZWLJYZAG-XVYDVKMFSA-N Ala-Ser-His Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N NHWYNIZWLJYZAG-XVYDVKMFSA-N 0.000 description 2
- MMLHRUJLOUSRJX-CIUDSAMLSA-N Ala-Ser-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN MMLHRUJLOUSRJX-CIUDSAMLSA-N 0.000 description 2
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 2
- LSMDIAAALJJLRO-XQXXSGGOSA-N Ala-Thr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LSMDIAAALJJLRO-XQXXSGGOSA-N 0.000 description 2
- XSLGWYYNOSUMRM-ZKWXMUAHSA-N Ala-Val-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XSLGWYYNOSUMRM-ZKWXMUAHSA-N 0.000 description 2
- VHAQSYHSDKERBS-XPUUQOCRSA-N Ala-Val-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O VHAQSYHSDKERBS-XPUUQOCRSA-N 0.000 description 2
- 241000710929 Alphavirus Species 0.000 description 2
- ATRRKUHOCOJYRX-UHFFFAOYSA-N Ammonium bicarbonate Chemical compound [NH4+].OC([O-])=O ATRRKUHOCOJYRX-UHFFFAOYSA-N 0.000 description 2
- 229910000013 Ammonium bicarbonate Inorganic materials 0.000 description 2
- 108020005544 Antisense RNA Proteins 0.000 description 2
- ASQYTJJWAMDISW-BPUTZDHNSA-N Arg-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N ASQYTJJWAMDISW-BPUTZDHNSA-N 0.000 description 2
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 2
- FVBZXNSRIDVYJS-AVGNSLFASA-N Arg-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N FVBZXNSRIDVYJS-AVGNSLFASA-N 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- 102100022146 Arylsulfatase A Human genes 0.000 description 2
- AYZAWXAPBAYCHO-CIUDSAMLSA-N Asn-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N AYZAWXAPBAYCHO-CIUDSAMLSA-N 0.000 description 2
- KXFCBAHYSLJCCY-ZLUOBGJFSA-N Asn-Asn-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O KXFCBAHYSLJCCY-ZLUOBGJFSA-N 0.000 description 2
- PIWWUBYJNONVTJ-ZLUOBGJFSA-N Asn-Asp-Asn Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)C(=O)N PIWWUBYJNONVTJ-ZLUOBGJFSA-N 0.000 description 2
- XSGBIBGAMKTHMY-WHFBIAKZSA-N Asn-Asp-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O XSGBIBGAMKTHMY-WHFBIAKZSA-N 0.000 description 2
- GNKVBRYFXYWXAB-WDSKDSINSA-N Asn-Glu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O GNKVBRYFXYWXAB-WDSKDSINSA-N 0.000 description 2
- FTSAJSADJCMDHH-CIUDSAMLSA-N Asn-Lys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N FTSAJSADJCMDHH-CIUDSAMLSA-N 0.000 description 2
- BKFXFUPYETWGGA-XVSYOHENSA-N Asn-Phe-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BKFXFUPYETWGGA-XVSYOHENSA-N 0.000 description 2
- GKKUBLFXKRDMFC-BQBZGAKWSA-N Asn-Pro-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O GKKUBLFXKRDMFC-BQBZGAKWSA-N 0.000 description 2
- VCJCPARXDBEGNE-GUBZILKMSA-N Asn-Pro-Pro Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 VCJCPARXDBEGNE-GUBZILKMSA-N 0.000 description 2
- VHQSGALUSWIYOD-QXEWZRGKSA-N Asn-Pro-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O VHQSGALUSWIYOD-QXEWZRGKSA-N 0.000 description 2
- WLVLIYYBPPONRJ-GCJQMDKQSA-N Asn-Thr-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O WLVLIYYBPPONRJ-GCJQMDKQSA-N 0.000 description 2
- RDLYUKRPEJERMM-XIRDDKMYSA-N Asn-Trp-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(C)C)C(O)=O RDLYUKRPEJERMM-XIRDDKMYSA-N 0.000 description 2
- ZLGKHJHFYSRUBH-FXQIFTODSA-N Asp-Arg-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLGKHJHFYSRUBH-FXQIFTODSA-N 0.000 description 2
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 2
- UFAQGGZUXVLONR-AVGNSLFASA-N Asp-Gln-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N)O UFAQGGZUXVLONR-AVGNSLFASA-N 0.000 description 2
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 2
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 2
- SFJUYBCDQBAYAJ-YDHLFZDLSA-N Asp-Val-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SFJUYBCDQBAYAJ-YDHLFZDLSA-N 0.000 description 2
- 206010003591 Ataxia Diseases 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 2
- 102100022548 Beta-hexosaminidase subunit alpha Human genes 0.000 description 2
- 102000007350 Bone Morphogenetic Proteins Human genes 0.000 description 2
- 108010007726 Bone Morphogenetic Proteins Proteins 0.000 description 2
- 108030001720 Bontoxilysin Proteins 0.000 description 2
- 102000004219 Brain-derived neurotrophic factor Human genes 0.000 description 2
- 108090000715 Brain-derived neurotrophic factor Proteins 0.000 description 2
- 241000589562 Brucella Species 0.000 description 2
- 108010009575 CD55 Antigens Proteins 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 101150044789 Cap gene Proteins 0.000 description 2
- 102100026422 Carbamoyl-phosphate synthase [ammonia], mitochondrial Human genes 0.000 description 2
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 2
- 102100032219 Cathepsin D Human genes 0.000 description 2
- 102100025064 Cellular tumor antigen p53 Human genes 0.000 description 2
- 108010036867 Cerebroside-Sulfatase Proteins 0.000 description 2
- 108091006146 Channels Proteins 0.000 description 2
- 206010061041 Chlamydial infection Diseases 0.000 description 2
- 102000011022 Chorionic Gonadotropin Human genes 0.000 description 2
- 108010062540 Chorionic Gonadotropin Proteins 0.000 description 2
- 108010005939 Ciliary Neurotrophic Factor Proteins 0.000 description 2
- 102100031614 Ciliary neurotrophic factor Human genes 0.000 description 2
- 208000025809 Citrullinemia type II Diseases 0.000 description 2
- 108091035707 Consensus sequence Proteins 0.000 description 2
- 201000007336 Cryptococcosis Diseases 0.000 description 2
- HBHMVBGGHDMPBF-GARJFASQSA-N Cys-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CS)N HBHMVBGGHDMPBF-GARJFASQSA-N 0.000 description 2
- 201000003883 Cystic fibrosis Diseases 0.000 description 2
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 2
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 2
- 108010053770 Deoxyribonucleases Proteins 0.000 description 2
- 102000016911 Deoxyribonucleases Human genes 0.000 description 2
- 108090000204 Dipeptidase 1 Proteins 0.000 description 2
- 102100031675 DnaJ homolog subfamily C member 5 Human genes 0.000 description 2
- 208000004232 Enteritis Diseases 0.000 description 2
- 241000709661 Enterovirus Species 0.000 description 2
- 241000991587 Enterovirus C Species 0.000 description 2
- 108010076282 Factor IX Proteins 0.000 description 2
- 241000713800 Feline immunodeficiency virus Species 0.000 description 2
- 102000003971 Fibroblast Growth Factor 1 Human genes 0.000 description 2
- 108090000386 Fibroblast Growth Factor 1 Proteins 0.000 description 2
- 102000003974 Fibroblast growth factor 2 Human genes 0.000 description 2
- 108090000379 Fibroblast growth factor 2 Proteins 0.000 description 2
- 102000012673 Follicle Stimulating Hormone Human genes 0.000 description 2
- 108010079345 Follicle Stimulating Hormone Proteins 0.000 description 2
- 102100028496 Galactocerebrosidase Human genes 0.000 description 2
- 208000003098 Ganglion Cysts Diseases 0.000 description 2
- 208000005577 Gastroenteritis Diseases 0.000 description 2
- 108091010837 Glial cell line-derived neurotrophic factor Proteins 0.000 description 2
- PRBLYKYHAJEABA-SRVKXCTJSA-N Gln-Arg-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O PRBLYKYHAJEABA-SRVKXCTJSA-N 0.000 description 2
- LJEPDHWNQXPXMM-NHCYSSNCSA-N Gln-Arg-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O LJEPDHWNQXPXMM-NHCYSSNCSA-N 0.000 description 2
- IVCOYUURLWQDJQ-LPEHRKFASA-N Gln-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O IVCOYUURLWQDJQ-LPEHRKFASA-N 0.000 description 2
- NSORZJXKUQFEKL-JGVFFNPUSA-N Gln-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCC(=O)N)N)C(=O)O NSORZJXKUQFEKL-JGVFFNPUSA-N 0.000 description 2
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 2
- MFORDNZDKAVNSR-SRVKXCTJSA-N Gln-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O MFORDNZDKAVNSR-SRVKXCTJSA-N 0.000 description 2
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 2
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 2
- SGVGIVDZLSHSEN-RYUDHWBXSA-N Gln-Tyr-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O SGVGIVDZLSHSEN-RYUDHWBXSA-N 0.000 description 2
- UBRQJXFDVZNYJP-AVGNSLFASA-N Gln-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UBRQJXFDVZNYJP-AVGNSLFASA-N 0.000 description 2
- WATXSTJXNBOHKD-LAEOZQHASA-N Glu-Asp-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O WATXSTJXNBOHKD-LAEOZQHASA-N 0.000 description 2
- AUTNXSQEVVHSJK-YVNDNENWSA-N Glu-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O AUTNXSQEVVHSJK-YVNDNENWSA-N 0.000 description 2
- VGUYMZGLJUJRBV-YVNDNENWSA-N Glu-Ile-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O VGUYMZGLJUJRBV-YVNDNENWSA-N 0.000 description 2
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 2
- UMZHHILWZBFPGL-LOKLDPHHSA-N Glu-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O UMZHHILWZBFPGL-LOKLDPHHSA-N 0.000 description 2
- PMSDOVISAARGAV-FHWLQOOXSA-N Glu-Tyr-Phe Chemical compound C([C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 PMSDOVISAARGAV-FHWLQOOXSA-N 0.000 description 2
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 2
- 101800000224 Glucagon-like peptide 1 Proteins 0.000 description 2
- 102400000322 Glucagon-like peptide 1 Human genes 0.000 description 2
- DTHNMHAUYICORS-KTKZVXAJSA-N Glucagon-like peptide 1 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 DTHNMHAUYICORS-KTKZVXAJSA-N 0.000 description 2
- 102000053187 Glucuronidase Human genes 0.000 description 2
- 108010060309 Glucuronidase Proteins 0.000 description 2
- OGCIHJPYKVSMTE-YUMQZZPRSA-N Gly-Arg-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O OGCIHJPYKVSMTE-YUMQZZPRSA-N 0.000 description 2
- CIMULJZTTOBOPN-WHFBIAKZSA-N Gly-Asn-Asn Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CIMULJZTTOBOPN-WHFBIAKZSA-N 0.000 description 2
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 2
- BEQGFMIBZFNROK-JGVFFNPUSA-N Gly-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)CN)C(=O)O BEQGFMIBZFNROK-JGVFFNPUSA-N 0.000 description 2
- VEPBEGNDJYANCF-QWRGUYRKSA-N Gly-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN VEPBEGNDJYANCF-QWRGUYRKSA-N 0.000 description 2
- QSQXZZCGPXQBPP-BQBZGAKWSA-N Gly-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)CN)C(=O)N[C@@H](CS)C(=O)O QSQXZZCGPXQBPP-BQBZGAKWSA-N 0.000 description 2
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 2
- MUGLKCQHTUFLGF-WPRPVWTQSA-N Gly-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)CN MUGLKCQHTUFLGF-WPRPVWTQSA-N 0.000 description 2
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 2
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 2
- 206010018691 Granuloma Diseases 0.000 description 2
- 108010051696 Growth Hormone Proteins 0.000 description 2
- 239000000095 Growth Hormone-Releasing Hormone Substances 0.000 description 2
- 108010010234 HDL Lipoproteins Proteins 0.000 description 2
- 102000015779 HDL Lipoproteins Human genes 0.000 description 2
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 2
- 101710154606 Hemagglutinin Proteins 0.000 description 2
- 208000009292 Hemophilia A Diseases 0.000 description 2
- 241000700721 Hepatitis B virus Species 0.000 description 2
- 102000003745 Hepatocyte Growth Factor Human genes 0.000 description 2
- 108090000100 Hepatocyte Growth Factor Proteins 0.000 description 2
- 206010019851 Hepatotoxicity Diseases 0.000 description 2
- AASLOGQZZKZWKH-SRVKXCTJSA-N His-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N AASLOGQZZKZWKH-SRVKXCTJSA-N 0.000 description 2
- HVCRQRQPIIRNLY-IUCAKERBSA-N His-Gln-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)NCC(=O)O)N HVCRQRQPIIRNLY-IUCAKERBSA-N 0.000 description 2
- VUUFXXGKMPLKNH-BZSNNMDCSA-N His-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N VUUFXXGKMPLKNH-BZSNNMDCSA-N 0.000 description 2
- 101001031589 Homo sapiens 2-Hydroxyacid oxidase 1 Proteins 0.000 description 2
- 101000855412 Homo sapiens Carbamoyl-phosphate synthase [ammonia], mitochondrial Proteins 0.000 description 2
- 101000869010 Homo sapiens Cathepsin D Proteins 0.000 description 2
- 101000945692 Homo sapiens Cyclin-dependent kinase-like 5 Proteins 0.000 description 2
- 101000845893 Homo sapiens DnaJ homolog subfamily C member 5 Proteins 0.000 description 2
- 101000575454 Homo sapiens Major facilitator superfamily domain-containing protein 8 Proteins 0.000 description 2
- 101001027324 Homo sapiens Progranulin Proteins 0.000 description 2
- 101000841498 Homo sapiens UDP-glucuronosyltransferase 1A1 Proteins 0.000 description 2
- 108010000521 Human Growth Hormone Proteins 0.000 description 2
- 102000002265 Human Growth Hormone Human genes 0.000 description 2
- 239000000854 Human Growth Hormone Substances 0.000 description 2
- 108010056651 Hydroxymethylbilane synthase Proteins 0.000 description 2
- 108091054729 IRF family Proteins 0.000 description 2
- LQSBBHNVAVNZSX-GHCJXIJMSA-N Ile-Ala-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N LQSBBHNVAVNZSX-GHCJXIJMSA-N 0.000 description 2
- QYZYJFXHXYUZMZ-UGYAYLCHSA-N Ile-Asn-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N QYZYJFXHXYUZMZ-UGYAYLCHSA-N 0.000 description 2
- DFFTXLCCDFYRKD-MBLNEYKQSA-N Ile-Gly-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N DFFTXLCCDFYRKD-MBLNEYKQSA-N 0.000 description 2
- UAELWXJFLZBKQS-WHOFXGATSA-N Ile-Phe-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](Cc1ccccc1)C(=O)NCC(O)=O UAELWXJFLZBKQS-WHOFXGATSA-N 0.000 description 2
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 2
- JTBFQNHKNRZJDS-SYWGBEHUSA-N Ile-Trp-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](C)C(=O)O)N JTBFQNHKNRZJDS-SYWGBEHUSA-N 0.000 description 2
- 206010061598 Immunodeficiency Diseases 0.000 description 2
- 102000016854 Interferon Regulatory Factors Human genes 0.000 description 2
- 102000004388 Interleukin-4 Human genes 0.000 description 2
- 108010038486 Interleukin-4 Receptors Proteins 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- 108010007622 LDL Lipoproteins Proteins 0.000 description 2
- 102000007330 LDL Lipoproteins Human genes 0.000 description 2
- 241000700563 Leporipoxvirus Species 0.000 description 2
- STAVRDQLZOTNKJ-RHYQMDGZSA-N Leu-Arg-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STAVRDQLZOTNKJ-RHYQMDGZSA-N 0.000 description 2
- IGUOAYLTQJLPPD-DCAQKATOSA-N Leu-Asn-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IGUOAYLTQJLPPD-DCAQKATOSA-N 0.000 description 2
- DBVWMYGBVFCRBE-CIUDSAMLSA-N Leu-Asn-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DBVWMYGBVFCRBE-CIUDSAMLSA-N 0.000 description 2
- ZURHXHNAEJJRNU-CIUDSAMLSA-N Leu-Asp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZURHXHNAEJJRNU-CIUDSAMLSA-N 0.000 description 2
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 2
- ARRIJPQRBWRNLT-DCAQKATOSA-N Leu-Met-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ARRIJPQRBWRNLT-DCAQKATOSA-N 0.000 description 2
- FLNPJLDPGMLWAU-UWVGGRQHSA-N Leu-Met-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC(C)C FLNPJLDPGMLWAU-UWVGGRQHSA-N 0.000 description 2
- PTRKPHUGYULXPU-KKUMJFAQSA-N Leu-Phe-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O PTRKPHUGYULXPU-KKUMJFAQSA-N 0.000 description 2
- UCBPDSYUVAAHCD-UWVGGRQHSA-N Leu-Pro-Gly Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UCBPDSYUVAAHCD-UWVGGRQHSA-N 0.000 description 2
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 2
- YIRIDPUGZKHMHT-ACRUOGEOSA-N Leu-Tyr-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YIRIDPUGZKHMHT-ACRUOGEOSA-N 0.000 description 2
- 102000009151 Luteinizing Hormone Human genes 0.000 description 2
- 108010073521 Luteinizing Hormone Proteins 0.000 description 2
- 108010074338 Lymphokines Proteins 0.000 description 2
- 102000008072 Lymphokines Human genes 0.000 description 2
- KNKHAVVBVXKOGX-JXUBOQSCSA-N Lys-Ala-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KNKHAVVBVXKOGX-JXUBOQSCSA-N 0.000 description 2
- GNLJXWBNLAIPEP-MELADBBJSA-N Lys-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCCCN)N)C(=O)O GNLJXWBNLAIPEP-MELADBBJSA-N 0.000 description 2
- IZJGPPIGYTVXLB-FQUUOJAGSA-N Lys-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IZJGPPIGYTVXLB-FQUUOJAGSA-N 0.000 description 2
- ALEVUGKHINJNIF-QEJZJMRPSA-N Lys-Phe-Ala Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 ALEVUGKHINJNIF-QEJZJMRPSA-N 0.000 description 2
- IPTUBUUIFRZMJK-ACRUOGEOSA-N Lys-Phe-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 IPTUBUUIFRZMJK-ACRUOGEOSA-N 0.000 description 2
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 2
- GIKFNMZSGYAPEJ-HJGDQZAQSA-N Lys-Thr-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O GIKFNMZSGYAPEJ-HJGDQZAQSA-N 0.000 description 2
- 102100033448 Lysosomal alpha-glucosidase Human genes 0.000 description 2
- 101150078498 MYB gene Proteins 0.000 description 2
- 102100025613 Major facilitator superfamily domain-containing protein 8 Human genes 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- 241000489861 Maximus Species 0.000 description 2
- 102400001132 Melanin-concentrating hormone Human genes 0.000 description 2
- 101800002739 Melanin-concentrating hormone Proteins 0.000 description 2
- 102000050019 Membrane Cofactor Human genes 0.000 description 2
- 101710146216 Membrane cofactor protein Proteins 0.000 description 2
- WXHHTBVYQOSYSL-FXQIFTODSA-N Met-Ala-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O WXHHTBVYQOSYSL-FXQIFTODSA-N 0.000 description 2
- IUYCGMNKIZDRQI-BQBZGAKWSA-N Met-Gly-Ala Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O IUYCGMNKIZDRQI-BQBZGAKWSA-N 0.000 description 2
- HZLSUXCMSIBCRV-RVMXOQNASA-N Met-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N HZLSUXCMSIBCRV-RVMXOQNASA-N 0.000 description 2
- GGXZOTSDJJTDGB-GUBZILKMSA-N Met-Ser-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O GGXZOTSDJJTDGB-GUBZILKMSA-N 0.000 description 2
- OTKQHDPECKUDSB-SZMVWBNQSA-N Met-Val-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 OTKQHDPECKUDSB-SZMVWBNQSA-N 0.000 description 2
- 102000006890 Methyl-CpG-Binding Protein 2 Human genes 0.000 description 2
- 108010072388 Methyl-CpG-Binding Protein 2 Proteins 0.000 description 2
- 102000019010 Methylmalonyl-CoA Mutase Human genes 0.000 description 2
- 108010051862 Methylmalonyl-CoA mutase Proteins 0.000 description 2
- 206010028095 Mucopolysaccharidosis IV Diseases 0.000 description 2
- 241000711386 Mumps virus Species 0.000 description 2
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 2
- 206010028851 Necrosis Diseases 0.000 description 2
- 102000015336 Nerve Growth Factor Human genes 0.000 description 2
- 201000000788 Niemann-Pick disease type C1 Diseases 0.000 description 2
- CTQNGGLPUBDAKN-UHFFFAOYSA-N O-Xylene Chemical compound CC1=CC=CC=C1C CTQNGGLPUBDAKN-UHFFFAOYSA-N 0.000 description 2
- 208000022873 Ocular disease Diseases 0.000 description 2
- 241000713112 Orthobunyavirus Species 0.000 description 2
- 241000150452 Orthohantavirus Species 0.000 description 2
- 101710093908 Outer capsid protein VP4 Proteins 0.000 description 2
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 description 2
- 238000012408 PCR amplification Methods 0.000 description 2
- 102000005327 Palmitoyl protein thioesterase Human genes 0.000 description 2
- 108020002591 Palmitoyl protein thioesterase Proteins 0.000 description 2
- 241000935974 Paralichthys dentatus Species 0.000 description 2
- 102000003982 Parathyroid hormone Human genes 0.000 description 2
- 108090000445 Parathyroid hormone Proteins 0.000 description 2
- 101710086247 Peptide-N(4)-(N-acetyl-beta-glucosaminyl)asparagine amidase Proteins 0.000 description 2
- HXSUFWQYLPKEHF-IHRRRGAJSA-N Phe-Asn-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HXSUFWQYLPKEHF-IHRRRGAJSA-N 0.000 description 2
- KIEPQOIQHFKQLK-PCBIJLKTSA-N Phe-Asn-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KIEPQOIQHFKQLK-PCBIJLKTSA-N 0.000 description 2
- YYKZDTVQHTUKDW-RYUDHWBXSA-N Phe-Gly-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N YYKZDTVQHTUKDW-RYUDHWBXSA-N 0.000 description 2
- QPVFUAUFEBPIPT-CDMKHQONSA-N Phe-Gly-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O QPVFUAUFEBPIPT-CDMKHQONSA-N 0.000 description 2
- DOXQMJCSSYZSNM-BZSNNMDCSA-N Phe-Lys-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O DOXQMJCSSYZSNM-BZSNNMDCSA-N 0.000 description 2
- QSWKNJAPHQDAAS-MELADBBJSA-N Phe-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O QSWKNJAPHQDAAS-MELADBBJSA-N 0.000 description 2
- BPIMVBKDLSBKIJ-FCLVOEFKSA-N Phe-Thr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BPIMVBKDLSBKIJ-FCLVOEFKSA-N 0.000 description 2
- 108010011964 Phosphatidylcholine-sterol O-acyltransferase Proteins 0.000 description 2
- 102100031538 Phosphatidylcholine-sterol acyltransferase Human genes 0.000 description 2
- 208000005746 Phosphoenolpyruvate carboxykinase deficiency Diseases 0.000 description 2
- 241000709664 Picornaviridae Species 0.000 description 2
- 102100034391 Porphobilinogen deaminase Human genes 0.000 description 2
- 206010036182 Porphyria acute Diseases 0.000 description 2
- 208000010291 Primary Progressive Nonfluent Aphasia Diseases 0.000 description 2
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 2
- ICTZKEXYDDZZFP-SRVKXCTJSA-N Pro-Arg-Pro Chemical compound N([C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(O)=O)C(=O)[C@@H]1CCCN1 ICTZKEXYDDZZFP-SRVKXCTJSA-N 0.000 description 2
- YFNOUBWUIIJQHF-LPEHRKFASA-N Pro-Asp-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O YFNOUBWUIIJQHF-LPEHRKFASA-N 0.000 description 2
- BRJGUPWVFXKBQI-XUXIUFHCSA-N Pro-Leu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRJGUPWVFXKBQI-XUXIUFHCSA-N 0.000 description 2
- WLJYLAQSUSIQNH-GUBZILKMSA-N Pro-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@@H]1CCCN1 WLJYLAQSUSIQNH-GUBZILKMSA-N 0.000 description 2
- GNADVDLLGVSXLS-ULQDDVLXSA-N Pro-Phe-His Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC=N1)C(O)=O GNADVDLLGVSXLS-ULQDDVLXSA-N 0.000 description 2
- ZVEQWRWMRFIVSD-HRCADAONSA-N Pro-Phe-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N3CCC[C@@H]3C(=O)O ZVEQWRWMRFIVSD-HRCADAONSA-N 0.000 description 2
- SNGZLPOXVRTNMB-LPEHRKFASA-N Pro-Ser-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N2CCC[C@@H]2C(=O)O SNGZLPOXVRTNMB-LPEHRKFASA-N 0.000 description 2
- GZNYIXWOIUFLGO-ZJDVBMNYSA-N Pro-Thr-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZNYIXWOIUFLGO-ZJDVBMNYSA-N 0.000 description 2
- VVAWNPIOYXAMAL-KJEVXHAQSA-N Pro-Thr-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VVAWNPIOYXAMAL-KJEVXHAQSA-N 0.000 description 2
- DMNANGOFEUVBRV-GJZGRUSLSA-N Pro-Trp-Gly Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)O)C(=O)[C@@H]1CCCN1 DMNANGOFEUVBRV-GJZGRUSLSA-N 0.000 description 2
- 108010012809 Progranulins Proteins 0.000 description 2
- 101710176177 Protein A56 Proteins 0.000 description 2
- 101710149136 Protein Vpr Proteins 0.000 description 2
- 102100027378 Prothrombin Human genes 0.000 description 2
- 108010094028 Prothrombin Proteins 0.000 description 2
- 241000125945 Protoparvovirus Species 0.000 description 2
- 201000004681 Psoriasis Diseases 0.000 description 2
- 206010037688 Q fever Diseases 0.000 description 2
- 108010079005 RDV peptide Proteins 0.000 description 2
- 206010037742 Rabies Diseases 0.000 description 2
- 241000702263 Reovirus sp. Species 0.000 description 2
- 108091081062 Repeated sequence (DNA) Proteins 0.000 description 2
- 108700008625 Reporter Genes Proteins 0.000 description 2
- 241000714474 Rous sarcoma virus Species 0.000 description 2
- 101100368917 Schizosaccharomyces pombe (strain 972 / ATCC 24843) taz1 gene Proteins 0.000 description 2
- MWMKFWJYRRGXOR-ZLUOBGJFSA-N Ser-Ala-Asn Chemical compound N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)O)CC(N)=O)C)CO MWMKFWJYRRGXOR-ZLUOBGJFSA-N 0.000 description 2
- MMGJPDWSIOAGTH-ACZMJKKPSA-N Ser-Ala-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MMGJPDWSIOAGTH-ACZMJKKPSA-N 0.000 description 2
- JPIDMRXXNMIVKY-VZFHVOOUSA-N Ser-Ala-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPIDMRXXNMIVKY-VZFHVOOUSA-N 0.000 description 2
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 2
- CRZRTKAVUUGKEQ-ACZMJKKPSA-N Ser-Gln-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CRZRTKAVUUGKEQ-ACZMJKKPSA-N 0.000 description 2
- YMAWDPHQVABADW-CIUDSAMLSA-N Ser-Gln-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O YMAWDPHQVABADW-CIUDSAMLSA-N 0.000 description 2
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 2
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 2
- HBTCFCHYALPXME-HTFCKZLJSA-N Ser-Ile-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HBTCFCHYALPXME-HTFCKZLJSA-N 0.000 description 2
- NNFMANHDYSVNIO-DCAQKATOSA-N Ser-Lys-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NNFMANHDYSVNIO-DCAQKATOSA-N 0.000 description 2
- LRZLZIUXQBIWTB-KATARQTJSA-N Ser-Lys-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LRZLZIUXQBIWTB-KATARQTJSA-N 0.000 description 2
- KZPRPBLHYMZIMH-MXAVVETBSA-N Ser-Phe-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KZPRPBLHYMZIMH-MXAVVETBSA-N 0.000 description 2
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 2
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 2
- OQSQCUWQOIHECT-YJRXYDGGSA-N Ser-Tyr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OQSQCUWQOIHECT-YJRXYDGGSA-N 0.000 description 2
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 2
- 102000004446 Serum Response Factor Human genes 0.000 description 2
- 108010042291 Serum Response Factor Proteins 0.000 description 2
- 241000710960 Sindbis virus Species 0.000 description 2
- 102100022831 Somatoliberin Human genes 0.000 description 2
- 101710142969 Somatoliberin Proteins 0.000 description 2
- 102100038803 Somatotropin Human genes 0.000 description 2
- 208000009415 Spinocerebellar Ataxias Diseases 0.000 description 2
- 201000003622 Spinocerebellar ataxia type 2 Diseases 0.000 description 2
- 229930006000 Sucrose Natural products 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- 241000282898 Sus scrofa Species 0.000 description 2
- 208000005400 Synovial Cyst Diseases 0.000 description 2
- 208000022292 Tay-Sachs disease Diseases 0.000 description 2
- GFDUZZACIWNMPE-KZVJFYERSA-N Thr-Ala-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O GFDUZZACIWNMPE-KZVJFYERSA-N 0.000 description 2
- LVHHEVGYAZGXDE-KDXUFGMBSA-N Thr-Ala-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(=O)O)N)O LVHHEVGYAZGXDE-KDXUFGMBSA-N 0.000 description 2
- WFUAUEQXPVNAEF-ZJDVBMNYSA-N Thr-Arg-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CCCN=C(N)N WFUAUEQXPVNAEF-ZJDVBMNYSA-N 0.000 description 2
- YBXMGKCLOPDEKA-NUMRIWBASA-N Thr-Asp-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O YBXMGKCLOPDEKA-NUMRIWBASA-N 0.000 description 2
- JEDIEMIJYSRUBB-FOHZUACHSA-N Thr-Asp-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O JEDIEMIJYSRUBB-FOHZUACHSA-N 0.000 description 2
- GCXFWAZRHBRYEM-NUMRIWBASA-N Thr-Gln-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O GCXFWAZRHBRYEM-NUMRIWBASA-N 0.000 description 2
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 2
- VYEHBMMAJFVTOI-JHEQGTHGSA-N Thr-Gly-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O VYEHBMMAJFVTOI-JHEQGTHGSA-N 0.000 description 2
- ZMYCLHFLHRVOEA-HEIBUPTGSA-N Thr-Thr-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ZMYCLHFLHRVOEA-HEIBUPTGSA-N 0.000 description 2
- QGVBFDIREUUSHX-IFFSRLJSSA-N Thr-Val-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O QGVBFDIREUUSHX-IFFSRLJSSA-N 0.000 description 2
- 102000036693 Thrombopoietin Human genes 0.000 description 2
- 108010041111 Thrombopoietin Proteins 0.000 description 2
- 102000006601 Thymidine Kinase Human genes 0.000 description 2
- 108020004440 Thymidine kinase Proteins 0.000 description 2
- 108020004566 Transfer RNA Proteins 0.000 description 2
- 101800004564 Transforming growth factor alpha Proteins 0.000 description 2
- QNTBGBCOEYNAPV-CWRNSKLLSA-N Trp-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O QNTBGBCOEYNAPV-CWRNSKLLSA-N 0.000 description 2
- YXONONCLMLHWJX-SZMVWBNQSA-N Trp-Glu-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 YXONONCLMLHWJX-SZMVWBNQSA-N 0.000 description 2
- NOFFAYIYPAUNRM-HKUYNNGSSA-N Trp-Gly-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC2=CNC3=CC=CC=C32)N NOFFAYIYPAUNRM-HKUYNNGSSA-N 0.000 description 2
- YRSOERSDNRSCBC-XIRDDKMYSA-N Trp-His-Cys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CN=CN3)C(=O)N[C@@H](CS)C(=O)O)N YRSOERSDNRSCBC-XIRDDKMYSA-N 0.000 description 2
- UJRIVCPPPMYCNA-HOCLYGCPSA-N Trp-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N UJRIVCPPPMYCNA-HOCLYGCPSA-N 0.000 description 2
- SEXRBCGSZRCIPE-LYSGOOTNSA-N Trp-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O SEXRBCGSZRCIPE-LYSGOOTNSA-N 0.000 description 2
- 208000034784 Tularaemia Diseases 0.000 description 2
- ZWZOCUWOXSDYFZ-CQDKDKBSSA-N Tyr-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 ZWZOCUWOXSDYFZ-CQDKDKBSSA-N 0.000 description 2
- HKIUVWMZYFBIHG-KKUMJFAQSA-N Tyr-Arg-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O HKIUVWMZYFBIHG-KKUMJFAQSA-N 0.000 description 2
- AYHSJESDFKREAR-KKUMJFAQSA-N Tyr-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AYHSJESDFKREAR-KKUMJFAQSA-N 0.000 description 2
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 2
- BYAKMYBZADCNMN-JYJNAYRXSA-N Tyr-Lys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O BYAKMYBZADCNMN-JYJNAYRXSA-N 0.000 description 2
- LMKKMCGTDANZTR-BZSNNMDCSA-N Tyr-Phe-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 LMKKMCGTDANZTR-BZSNNMDCSA-N 0.000 description 2
- OKDNSNWJEXAMSU-IRXDYDNUSA-N Tyr-Phe-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(O)=O)C1=CC=C(O)C=C1 OKDNSNWJEXAMSU-IRXDYDNUSA-N 0.000 description 2
- LUMQYLVYUIRHHU-YJRXYDGGSA-N Tyr-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUMQYLVYUIRHHU-YJRXYDGGSA-N 0.000 description 2
- LVFZXRQQQDTBQH-IRIUXVKKSA-N Tyr-Thr-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LVFZXRQQQDTBQH-IRIUXVKKSA-N 0.000 description 2
- WQOHKVRQDLNDIL-YJRXYDGGSA-N Tyr-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O WQOHKVRQDLNDIL-YJRXYDGGSA-N 0.000 description 2
- HZWPGKAKGYJWCI-ULQDDVLXSA-N Tyr-Val-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(C)C)C(O)=O HZWPGKAKGYJWCI-ULQDDVLXSA-N 0.000 description 2
- 102100029152 UDP-glucuronosyltransferase 1A1 Human genes 0.000 description 2
- 102100030434 Ubiquitin-protein ligase E3A Human genes 0.000 description 2
- 101710188886 Ubiquitin-protein ligase E3A Proteins 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- 108010062497 VLDL Lipoproteins Proteins 0.000 description 2
- 206010046865 Vaccinia virus infection Diseases 0.000 description 2
- SZTTYWIUCGSURQ-AUTRQRHGSA-N Val-Glu-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SZTTYWIUCGSURQ-AUTRQRHGSA-N 0.000 description 2
- JTWIMNMUYLQNPI-WPRPVWTQSA-N Val-Gly-Arg Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N JTWIMNMUYLQNPI-WPRPVWTQSA-N 0.000 description 2
- NXRAUQGGHPCJIB-RCOVLWMOSA-N Val-Gly-Asn Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O NXRAUQGGHPCJIB-RCOVLWMOSA-N 0.000 description 2
- XBRMBDFYOFARST-AVGNSLFASA-N Val-His-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C(C)C)C(=O)O)N XBRMBDFYOFARST-AVGNSLFASA-N 0.000 description 2
- IJGPOONOTBNTFS-GVXVVHGQSA-N Val-Lys-Glu Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O IJGPOONOTBNTFS-GVXVVHGQSA-N 0.000 description 2
- MGVYZTPLGXPVQB-CYDGBPFRSA-N Val-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N MGVYZTPLGXPVQB-CYDGBPFRSA-N 0.000 description 2
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 2
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 2
- JXWGBRRVTRAZQA-ULQDDVLXSA-N Val-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N JXWGBRRVTRAZQA-ULQDDVLXSA-N 0.000 description 2
- 241000700647 Variola virus Species 0.000 description 2
- 101710201961 Virion infectivity factor Proteins 0.000 description 2
- 241001492404 Woodchuck hepatitis virus Species 0.000 description 2
- 108010017070 Zinc Finger Nucleases Proteins 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 2
- 239000000910 agglutinin Substances 0.000 description 2
- 235000004279 alanine Nutrition 0.000 description 2
- 108010070944 alanylhistidine Proteins 0.000 description 2
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 2
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 2
- 125000003368 amide group Chemical group 0.000 description 2
- 235000012538 ammonium bicarbonate Nutrition 0.000 description 2
- 239000001099 ammonium carbonate Substances 0.000 description 2
- 239000005557 antagonist Substances 0.000 description 2
- 230000000692 anti-sense effect Effects 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 2
- 108010066988 asparaginyl-alanyl-glycyl-alanine Proteins 0.000 description 2
- 108010077245 asparaginyl-proline Proteins 0.000 description 2
- 108010021908 aspartyl-aspartyl-glutamyl-aspartic acid Proteins 0.000 description 2
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 2
- 230000003416 augmentation Effects 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 102000006635 beta-lactamase Human genes 0.000 description 2
- 239000003124 biologic agent Substances 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 210000000601 blood cell Anatomy 0.000 description 2
- 229940112869 bone morphogenetic protein Drugs 0.000 description 2
- 229940053031 botulinum toxin Drugs 0.000 description 2
- 108010006025 bovine growth hormone Proteins 0.000 description 2
- 229940077737 brain-derived neurotrophic factor Drugs 0.000 description 2
- 238000007623 carbamidomethylation reaction Methods 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 235000011089 carbon dioxide Nutrition 0.000 description 2
- 230000000747 cardiac effect Effects 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 239000003184 complementary RNA Substances 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 238000011262 co‐therapy Methods 0.000 description 2
- 230000001351 cycling effect Effects 0.000 description 2
- 108010069495 cysteinyltyrosine Proteins 0.000 description 2
- 230000007850 degeneration Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 206010012601 diabetes mellitus Diseases 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 2
- 206010013023 diphtheria Diseases 0.000 description 2
- 210000000981 epithelium Anatomy 0.000 description 2
- 210000001508 eye Anatomy 0.000 description 2
- 229960004222 factor ix Drugs 0.000 description 2
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 2
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 2
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 2
- 229940028334 follicle stimulating hormone Drugs 0.000 description 2
- 235000013305 food Nutrition 0.000 description 2
- 230000002496 gastric effect Effects 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 230000007614 genetic variation Effects 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 2
- HPAIKDPJURGQLN-UHFFFAOYSA-N glycyl-L-histidyl-L-phenylalanine Natural products C=1C=CC=CC=1CC(C(O)=O)NC(=O)C(NC(=O)CN)CC1=CN=CN1 HPAIKDPJURGQLN-UHFFFAOYSA-N 0.000 description 2
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 2
- 108010077435 glycyl-phenylalanyl-glycine Proteins 0.000 description 2
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 2
- 108010089804 glycyl-threonine Proteins 0.000 description 2
- 108010010147 glycylglutamine Proteins 0.000 description 2
- 108010077515 glycylproline Proteins 0.000 description 2
- 239000000122 growth hormone Substances 0.000 description 2
- 238000003306 harvesting Methods 0.000 description 2
- 230000002440 hepatic effect Effects 0.000 description 2
- 208000006454 hepatitis Diseases 0.000 description 2
- 231100000283 hepatitis Toxicity 0.000 description 2
- 230000007686 hepatotoxicity Effects 0.000 description 2
- 108010025306 histidylleucine Proteins 0.000 description 2
- 108010092114 histidylphenylalanine Proteins 0.000 description 2
- 108010085325 histidylproline Proteins 0.000 description 2
- 229940088597 hormone Drugs 0.000 description 2
- 239000005556 hormone Substances 0.000 description 2
- 229940084986 human chorionic gonadotropin Drugs 0.000 description 2
- 230000000984 immunochemical effect Effects 0.000 description 2
- 230000002163 immunogen Effects 0.000 description 2
- 238000010324 immunological assay Methods 0.000 description 2
- 230000002458 infectious effect Effects 0.000 description 2
- 206010022000 influenza Diseases 0.000 description 2
- 238000001802 infusion Methods 0.000 description 2
- 230000003601 intercostal effect Effects 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 238000005468 ion implantation Methods 0.000 description 2
- 238000006317 isomerization reaction Methods 0.000 description 2
- 230000000155 isotopic effect Effects 0.000 description 2
- 230000003902 lesion Effects 0.000 description 2
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 2
- 238000001294 liquid chromatography-tandem mass spectrometry Methods 0.000 description 2
- 210000003141 lower extremity Anatomy 0.000 description 2
- 238000009593 lumbar puncture Methods 0.000 description 2
- 229940040129 luteinizing hormone Drugs 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- ORRDHOMWDPJSNL-UHFFFAOYSA-N melanin concentrating hormone Chemical compound N1C(=O)C(C(C)C)NC(=O)C(CCCNC(N)=N)NC(=O)CNC(=O)C(C(C)C)NC(=O)C(CCSC)NC(=O)C(NC(=O)C(CCCNC(N)=N)NC(=O)C(NC(=O)C(NC(=O)C(N)CC(O)=O)C(C)O)CCSC)CSSCC(C(=O)NC(CC=2C3=CC=CC=C3NC=2)C(=O)NC(CCC(O)=O)C(=O)NC(C(C)C)C(O)=O)NC(=O)C2CCCN2C(=O)C(CCCNC(N)=N)NC(=O)C1CC1=CC=C(O)C=C1 ORRDHOMWDPJSNL-UHFFFAOYSA-N 0.000 description 2
- 108091005601 modified peptides Proteins 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- 238000002887 multiple sequence alignment Methods 0.000 description 2
- 201000009240 nasopharyngitis Diseases 0.000 description 2
- 230000017074 necrotic cell death Effects 0.000 description 2
- 230000007830 nerve conduction Effects 0.000 description 2
- 230000001537 neural effect Effects 0.000 description 2
- 238000007481 next generation sequencing Methods 0.000 description 2
- 230000000771 oncological effect Effects 0.000 description 2
- 210000000496 pancreas Anatomy 0.000 description 2
- 239000000199 parathyroid hormone Substances 0.000 description 2
- 229960001319 parathyroid hormone Drugs 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 210000000062 pectoralis major Anatomy 0.000 description 2
- 238000012510 peptide mapping method Methods 0.000 description 2
- 210000000578 peripheral nerve Anatomy 0.000 description 2
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 2
- GCYXWQUSHADNBF-AAEALURTSA-N preproglucagon 78-108 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 GCYXWQUSHADNBF-AAEALURTSA-N 0.000 description 2
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 2
- 108010077112 prolyl-proline Proteins 0.000 description 2
- 235000019419 proteases Nutrition 0.000 description 2
- 230000001681 protective effect Effects 0.000 description 2
- 229940039716 prothrombin Drugs 0.000 description 2
- 210000003314 quadriceps muscle Anatomy 0.000 description 2
- 238000004725 rapid separation liquid chromatography Methods 0.000 description 2
- 230000006798 recombination Effects 0.000 description 2
- 238000005215 recombination Methods 0.000 description 2
- 210000001139 rectus abdominis Anatomy 0.000 description 2
- 108010054624 red fluorescent protein Proteins 0.000 description 2
- 230000002787 reinforcement Effects 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 108020004418 ribosomal RNA Proteins 0.000 description 2
- 238000002864 sequence alignment Methods 0.000 description 2
- 210000002460 smooth muscle Anatomy 0.000 description 2
- 230000003997 social interaction Effects 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 238000007811 spectroscopic assay Methods 0.000 description 2
- 229910001220 stainless steel Inorganic materials 0.000 description 2
- 239000010935 stainless steel Substances 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 210000002330 subarachnoid space Anatomy 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 239000005720 sucrose Substances 0.000 description 2
- 230000001629 suppression Effects 0.000 description 2
- 208000006379 syphilis Diseases 0.000 description 2
- 230000001839 systemic circulation Effects 0.000 description 2
- 238000012385 systemic delivery Methods 0.000 description 2
- 238000004885 tandem mass spectrometry Methods 0.000 description 2
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 2
- 210000001103 thalamus Anatomy 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 230000005026 transcription initiation Effects 0.000 description 2
- 238000003151 transfection method Methods 0.000 description 2
- 230000032258 transport Effects 0.000 description 2
- 210000004881 tumor cell Anatomy 0.000 description 2
- 208000035408 type 1 diabetes mellitus 1 Diseases 0.000 description 2
- 208000001072 type 2 diabetes mellitus Diseases 0.000 description 2
- 241000701161 unidentified adenovirus Species 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- 208000007089 vaccinia Diseases 0.000 description 2
- 210000003462 vein Anatomy 0.000 description 2
- 230000000007 visual effect Effects 0.000 description 2
- NMWKYTGJWUAZPZ-WWHBDHEGSA-N (4S)-4-[[(4R,7S,10S,16S,19S,25S,28S,31R)-31-[[(2S)-2-[[(1R,6R,9S,12S,18S,21S,24S,27S,30S,33S,36S,39S,42R,47R,53S,56S,59S,62S,65S,68S,71S,76S,79S,85S)-47-[[(2S)-2-[[(2S)-4-amino-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-amino-3-methylbutanoyl]amino]-3-methylbutanoyl]amino]-3-hydroxypropanoyl]amino]-3-(1H-imidazol-4-yl)propanoyl]amino]-3-phenylpropanoyl]amino]-4-oxobutanoyl]amino]-3-carboxypropanoyl]amino]-18-(4-aminobutyl)-27,68-bis(3-amino-3-oxopropyl)-36,71,76-tribenzyl-39-(3-carbamimidamidopropyl)-24-(2-carboxyethyl)-21,56-bis(carboxymethyl)-65,85-bis[(1R)-1-hydroxyethyl]-59-(hydroxymethyl)-62,79-bis(1H-imidazol-4-ylmethyl)-9-methyl-33-(2-methylpropyl)-8,11,17,20,23,26,29,32,35,38,41,48,54,57,60,63,66,69,72,74,77,80,83,86-tetracosaoxo-30-propan-2-yl-3,4,44,45-tetrathia-7,10,16,19,22,25,28,31,34,37,40,49,55,58,61,64,67,70,73,75,78,81,84,87-tetracosazatetracyclo[40.31.14.012,16.049,53]heptaoctacontane-6-carbonyl]amino]-3-methylbutanoyl]amino]-7-(3-carbamimidamidopropyl)-25-(hydroxymethyl)-19-[(4-hydroxyphenyl)methyl]-28-(1H-imidazol-4-ylmethyl)-10-methyl-6,9,12,15,18,21,24,27,30-nonaoxo-16-propan-2-yl-1,2-dithia-5,8,11,14,17,20,23,26,29-nonazacyclodotriacontane-4-carbonyl]amino]-5-[[(2S)-1-[[(2S)-1-[[(2S)-3-carboxy-1-[[(2S)-1-[[(2S)-1-[[(1S)-1-carboxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxopropan-2-yl]amino]-1-oxopropan-2-yl]amino]-3-(1H-imidazol-4-yl)-1-oxopropan-2-yl]amino]-5-oxopentanoic acid Chemical compound CC(C)C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](Cc1c[nH]cn1)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CSSC[C@H](NC(=O)[C@@H](NC(=O)[C@@H]2CSSC[C@@H]3NC(=O)[C@H](Cc4ccccc4)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](Cc4c[nH]cn4)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]4CCCN4C(=O)[C@H](CSSC[C@H](NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](Cc4c[nH]cn4)NC(=O)[C@H](Cc4ccccc4)NC3=O)[C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](Cc3ccccc3)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N3CCC[C@H]3C(=O)N[C@@H](C)C(=O)N2)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](Cc2ccccc2)NC(=O)[C@H](Cc2c[nH]cn2)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)C(C)C)[C@@H](C)O)C(C)C)C(=O)N[C@@H](Cc2c[nH]cn2)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](Cc2ccc(O)cc2)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1)C(=O)N[C@@H](C)C(O)=O NMWKYTGJWUAZPZ-WWHBDHEGSA-N 0.000 description 1
- NCYCYZXNIZJOKI-IOUUIBBYSA-N 11-cis-retinal Chemical compound O=C/C=C(\C)/C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C NCYCYZXNIZJOKI-IOUUIBBYSA-N 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- KISWVXRQTGLFGD-UHFFFAOYSA-N 2-[[2-[[6-amino-2-[[2-[[2-[[5-amino-2-[[2-[[1-[2-[[6-amino-2-[(2,5-diamino-5-oxopentanoyl)amino]hexanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]pyrrolidine-2-carbonyl]amino]-3-hydroxypropanoyl]amino]-5-oxopentanoyl]amino]-5-(diaminomethylideneamino)p Chemical compound C1CCN(C(=O)C(CCCN=C(N)N)NC(=O)C(CCCCN)NC(=O)C(N)CCC(N)=O)C1C(=O)NC(CO)C(=O)NC(CCC(N)=O)C(=O)NC(CCCN=C(N)N)C(=O)NC(CO)C(=O)NC(CCCCN)C(=O)NC(C(=O)NC(CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 KISWVXRQTGLFGD-UHFFFAOYSA-N 0.000 description 1
- 108020005345 3' Untranslated Regions Proteins 0.000 description 1
- 108010046716 3-Methyl-2-Oxobutanoate Dehydrogenase (Lipoamide) Proteins 0.000 description 1
- 101710169336 5'-deoxyadenosine deaminase Proteins 0.000 description 1
- 101150079978 AGRN gene Proteins 0.000 description 1
- 102100020973 ATP-binding cassette sub-family D member 3 Human genes 0.000 description 1
- 241000208140 Acer Species 0.000 description 1
- 208000013824 Acidemia Diseases 0.000 description 1
- 208000010444 Acidosis Diseases 0.000 description 1
- 108010059616 Activins Proteins 0.000 description 1
- 102000005606 Activins Human genes 0.000 description 1
- 102000002735 Acyl-CoA Dehydrogenase Human genes 0.000 description 1
- 108010001058 Acyl-CoA Dehydrogenase Proteins 0.000 description 1
- 241000202702 Adeno-associated virus - 3 Species 0.000 description 1
- 241000580270 Adeno-associated virus - 4 Species 0.000 description 1
- 241001634120 Adeno-associated virus - 5 Species 0.000 description 1
- 102100036664 Adenosine deaminase Human genes 0.000 description 1
- 102100040026 Agrin Human genes 0.000 description 1
- 108700019743 Agrin Proteins 0.000 description 1
- OINVDEKBKBCPLX-JXUBOQSCSA-N Ala-Lys-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OINVDEKBKBCPLX-JXUBOQSCSA-N 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 108010080691 Alcohol O-acetyltransferase Proteins 0.000 description 1
- 102100035028 Alpha-L-iduronidase Human genes 0.000 description 1
- 102100034561 Alpha-N-acetylglucosaminidase Human genes 0.000 description 1
- 102100026277 Alpha-galactosidase A Human genes 0.000 description 1
- 241000700587 Alphaherpesvirinae Species 0.000 description 1
- 208000024827 Alzheimer disease Diseases 0.000 description 1
- 208000031277 Amaurotic familial idiocy Diseases 0.000 description 1
- 208000004881 Amebiasis Diseases 0.000 description 1
- 206010001980 Amoebiasis Diseases 0.000 description 1
- 241000024188 Andala Species 0.000 description 1
- 108010048154 Angiopoietin-1 Proteins 0.000 description 1
- 102000009088 Angiopoietin-1 Human genes 0.000 description 1
- 102000009840 Angiopoietins Human genes 0.000 description 1
- 108010009906 Angiopoietins Proteins 0.000 description 1
- 102400000068 Angiostatin Human genes 0.000 description 1
- 108010079709 Angiostatins Proteins 0.000 description 1
- 206010002556 Ankylosing Spondylitis Diseases 0.000 description 1
- 201000003126 Anuria Diseases 0.000 description 1
- 108010071619 Apolipoproteins Proteins 0.000 description 1
- 102000007592 Apolipoproteins Human genes 0.000 description 1
- 102000018655 Apolipoproteins C Human genes 0.000 description 1
- 108010027070 Apolipoproteins C Proteins 0.000 description 1
- 102000013918 Apolipoproteins E Human genes 0.000 description 1
- 108010025628 Apolipoproteins E Proteins 0.000 description 1
- 241000607305 Arctica Species 0.000 description 1
- 241000712891 Arenavirus Species 0.000 description 1
- NGYHSXDNNOFHNE-AVGNSLFASA-N Arg-Pro-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O NGYHSXDNNOFHNE-AVGNSLFASA-N 0.000 description 1
- CGWVCWFQGXOUSJ-ULQDDVLXSA-N Arg-Tyr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O CGWVCWFQGXOUSJ-ULQDDVLXSA-N 0.000 description 1
- 102000004452 Arginase Human genes 0.000 description 1
- 108700024123 Arginases Proteins 0.000 description 1
- 102000053640 Argininosuccinate synthases Human genes 0.000 description 1
- 108700024106 Argininosuccinate synthases Proteins 0.000 description 1
- 206010058298 Argininosuccinate synthetase deficiency Diseases 0.000 description 1
- KDZOASGQNOPSCU-WDSKDSINSA-N Argininosuccinic acid Chemical compound OC(=O)[C@@H](N)CCC\N=C(/N)N[C@H](C(O)=O)CC(O)=O KDZOASGQNOPSCU-WDSKDSINSA-N 0.000 description 1
- 108090000121 Aromatic-L-amino-acid decarboxylases Proteins 0.000 description 1
- 102000003823 Aromatic-L-amino-acid decarboxylases Human genes 0.000 description 1
- 206010003267 Arthritis reactive Diseases 0.000 description 1
- 102100031491 Arylsulfatase B Human genes 0.000 description 1
- PCKRJVZAQZWNKM-WHFBIAKZSA-N Asn-Asn-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O PCKRJVZAQZWNKM-WHFBIAKZSA-N 0.000 description 1
- HYQYLOSCICEYTR-YUMQZZPRSA-N Asn-Gly-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O HYQYLOSCICEYTR-YUMQZZPRSA-N 0.000 description 1
- WUQXMTITJLFXAU-JIOCBJNQSA-N Asn-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N)O WUQXMTITJLFXAU-JIOCBJNQSA-N 0.000 description 1
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 1
- BRRPVTUFESPTCP-ACZMJKKPSA-N Asp-Ser-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O BRRPVTUFESPTCP-ACZMJKKPSA-N 0.000 description 1
- 108010023546 Aspartylglucosylaminase Proteins 0.000 description 1
- 201000002909 Aspergillosis Diseases 0.000 description 1
- 208000036641 Aspergillus infections Diseases 0.000 description 1
- 201000001320 Atherosclerosis Diseases 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- 241000711404 Avian avulavirus 1 Species 0.000 description 1
- 241000700663 Avipoxvirus Species 0.000 description 1
- 208000003950 B-cell lymphoma Diseases 0.000 description 1
- 238000009020 BCA Protein Assay Kit Methods 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 206010044583 Bartonella Infections Diseases 0.000 description 1
- 101000742334 Bdellovibrio phage phiMH2K Replication-associated protein VP4 Proteins 0.000 description 1
- 102100026031 Beta-glucuronidase Human genes 0.000 description 1
- 241000701021 Betaherpesvirinae Species 0.000 description 1
- 206010005098 Blastomycosis Diseases 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 241000712005 Bovine respirovirus 3 Species 0.000 description 1
- 206010006500 Brucellosis Diseases 0.000 description 1
- 241000722910 Burkholderia mallei Species 0.000 description 1
- 206010069748 Burkholderia pseudomallei infection Diseases 0.000 description 1
- 208000011691 Burkitt lymphomas Diseases 0.000 description 1
- 125000001433 C-terminal amino-acid group Chemical group 0.000 description 1
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 1
- 102000002110 C2 domains Human genes 0.000 description 1
- 108050009459 C2 domains Proteins 0.000 description 1
- 101710186200 CCAAT/enhancer-binding protein Proteins 0.000 description 1
- 102100022002 CD59 glycoprotein Human genes 0.000 description 1
- 101710172824 CRISPR-associated endonuclease Cas9 Proteins 0.000 description 1
- 101100190541 Caenorhabditis elegans pink-1 gene Proteins 0.000 description 1
- 241001517013 Calidris pugnax Species 0.000 description 1
- 208000008889 California Encephalitis Diseases 0.000 description 1
- 241000222122 Candida albicans Species 0.000 description 1
- 206010007134 Candida infections Diseases 0.000 description 1
- 241000711506 Canine coronavirus Species 0.000 description 1
- 241000712083 Canine morbillivirus Species 0.000 description 1
- 241000701931 Canine parvovirus Species 0.000 description 1
- 241000700664 Capripoxvirus Species 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 102000004031 Carboxy-Lyases Human genes 0.000 description 1
- 108090000489 Carboxy-Lyases Proteins 0.000 description 1
- 206010007559 Cardiac failure congestive Diseases 0.000 description 1
- 108700004991 Cas12a Proteins 0.000 description 1
- 102100025953 Cathepsin F Human genes 0.000 description 1
- 241000700199 Cavia porcellus Species 0.000 description 1
- 102000004201 Ceramidases Human genes 0.000 description 1
- 108090000751 Ceramidases Proteins 0.000 description 1
- 206010053684 Cerebrohepatorenal syndrome Diseases 0.000 description 1
- 208000026368 Cestode infections Diseases 0.000 description 1
- 108010035848 Channelrhodopsins Proteins 0.000 description 1
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 description 1
- 206010008631 Cholera Diseases 0.000 description 1
- 241000700628 Chordopoxvirinae Species 0.000 description 1
- 108090000317 Chymotrypsin Proteins 0.000 description 1
- 108091062157 Cis-regulatory element Proteins 0.000 description 1
- 201000011297 Citrullinemia Diseases 0.000 description 1
- 241001112696 Clostridia Species 0.000 description 1
- 241000193155 Clostridium botulinum Species 0.000 description 1
- 241000193468 Clostridium perfringens Species 0.000 description 1
- 102100026735 Coagulation factor VIII Human genes 0.000 description 1
- 241000223205 Coccidioides immitis Species 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 206010009900 Colitis ulcerative Diseases 0.000 description 1
- 208000009802 Colorado tick fever Diseases 0.000 description 1
- 206010010356 Congenital anomaly Diseases 0.000 description 1
- 206010010904 Convulsion Diseases 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 102100027591 Copper-transporting ATPase 2 Human genes 0.000 description 1
- 101710139375 Corneodesmosin Proteins 0.000 description 1
- 241000186216 Corynebacterium Species 0.000 description 1
- 241001445332 Coxiella <snail> Species 0.000 description 1
- 241000709687 Coxsackievirus Species 0.000 description 1
- 208000011231 Crohn disease Diseases 0.000 description 1
- 241000221204 Cryptococcus neoformans Species 0.000 description 1
- 241000195493 Cryptophyta Species 0.000 description 1
- 108010045171 Cyclic AMP Response Element-Binding Protein Proteins 0.000 description 1
- 102000005636 Cyclic AMP Response Element-Binding Protein Human genes 0.000 description 1
- 102100023580 Cyclic AMP-dependent transcription factor ATF-4 Human genes 0.000 description 1
- 206010011732 Cyst Diseases 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- NBSCHQHZLSJFNQ-QTVWNMPRSA-N D-Mannose-6-phosphate Chemical compound OC1O[C@H](COP(O)(O)=O)[C@@H](O)[C@H](O)[C@@H]1O NBSCHQHZLSJFNQ-QTVWNMPRSA-N 0.000 description 1
- LEVWYRKDKASIDU-QWWZWVQMSA-N D-cystine Chemical compound OC(=O)[C@H](N)CSSC[C@@H](N)C(O)=O LEVWYRKDKASIDU-QWWZWVQMSA-N 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 241000252212 Danio rerio Species 0.000 description 1
- 206010012289 Dementia Diseases 0.000 description 1
- 208000001490 Dengue Diseases 0.000 description 1
- 206010012310 Dengue fever Diseases 0.000 description 1
- 241000710829 Dengue virus group Species 0.000 description 1
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 1
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 1
- 201000004624 Dermatitis Diseases 0.000 description 1
- 206010012438 Dermatitis atopic Diseases 0.000 description 1
- 206010012504 Dermatophytosis Diseases 0.000 description 1
- 208000000655 Distemper Diseases 0.000 description 1
- 101150002621 EPO gene Proteins 0.000 description 1
- 241001115402 Ebolavirus Species 0.000 description 1
- 241001466953 Echovirus Species 0.000 description 1
- 241000588877 Eikenella Species 0.000 description 1
- 208000005189 Embolism Diseases 0.000 description 1
- 206010014561 Emphysema Diseases 0.000 description 1
- 206010014596 Encephalitis Japanese B Diseases 0.000 description 1
- 206010014584 Encephalitis california Diseases 0.000 description 1
- 206010014614 Encephalitis western equine Diseases 0.000 description 1
- 102100031780 Endonuclease Human genes 0.000 description 1
- 108010042407 Endonucleases Proteins 0.000 description 1
- 102000004533 Endonucleases Human genes 0.000 description 1
- 102100030013 Endoribonuclease Human genes 0.000 description 1
- 101710199605 Endoribonuclease Proteins 0.000 description 1
- 241000588921 Enterobacteriaceae Species 0.000 description 1
- 241000700572 Entomopoxvirinae Species 0.000 description 1
- 206010066919 Epidemic polyarthritis Diseases 0.000 description 1
- 108050004280 Epsilon toxin Proteins 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 208000000832 Equine Encephalomyelitis Diseases 0.000 description 1
- 241000710803 Equine arteritis virus Species 0.000 description 1
- 241000713730 Equine infectious anemia virus Species 0.000 description 1
- 208000025127 Erdheim-Chester disease Diseases 0.000 description 1
- 241000186810 Erysipelothrix rhusiopathiae Species 0.000 description 1
- 101000867232 Escherichia coli Heat-stable enterotoxin II Proteins 0.000 description 1
- OTMSDBZUPAUEDD-UHFFFAOYSA-N Ethane Chemical compound CC OTMSDBZUPAUEDD-UHFFFAOYSA-N 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 108091029865 Exogenous DNA Proteins 0.000 description 1
- 208000024720 Fabry Disease Diseases 0.000 description 1
- 201000003542 Factor VIII deficiency Diseases 0.000 description 1
- 206010016202 Familial Amyloidosis Diseases 0.000 description 1
- 241000725579 Feline coronavirus Species 0.000 description 1
- 241000711475 Feline infectious peritonitis virus Species 0.000 description 1
- 241000714165 Feline leukemia virus Species 0.000 description 1
- 241000701915 Feline panleukopenia virus Species 0.000 description 1
- 241000701925 Feline parvovirus Species 0.000 description 1
- 102000018233 Fibroblast Growth Factor Human genes 0.000 description 1
- 108050007372 Fibroblast Growth Factor Proteins 0.000 description 1
- 201000006353 Filariasis Diseases 0.000 description 1
- 241000711950 Filoviridae Species 0.000 description 1
- 108090000331 Firefly luciferases Proteins 0.000 description 1
- 241000710781 Flaviviridae Species 0.000 description 1
- 208000007212 Foot-and-Mouth Disease Diseases 0.000 description 1
- 241000710198 Foot-and-mouth disease virus Species 0.000 description 1
- 208000001914 Fragile X syndrome Diseases 0.000 description 1
- 241000589602 Francisella tularensis Species 0.000 description 1
- 102000003869 Frataxin Human genes 0.000 description 1
- 108090000217 Frataxin Proteins 0.000 description 1
- 102100029115 Fumarylacetoacetase Human genes 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 108091006027 G proteins Proteins 0.000 description 1
- 108010088742 GATA Transcription Factors Proteins 0.000 description 1
- 102000004610 GATA3 Transcription Factor Human genes 0.000 description 1
- 108010003338 GATA3 Transcription Factor Proteins 0.000 description 1
- 102000030782 GTP binding Human genes 0.000 description 1
- 108091000058 GTP-Binding Proteins 0.000 description 1
- 101710177291 Gag polyprotein Proteins 0.000 description 1
- 208000027472 Galactosemias Diseases 0.000 description 1
- 108010042681 Galactosylceramidase Proteins 0.000 description 1
- 241000701047 Gallid alphaherpesvirus 2 Species 0.000 description 1
- 241000701046 Gammaherpesvirinae Species 0.000 description 1
- 208000015872 Gaucher disease Diseases 0.000 description 1
- ZBKUIQNCRIYVGH-SDDRHHMPSA-N Gln-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZBKUIQNCRIYVGH-SDDRHHMPSA-N 0.000 description 1
- 208000010055 Globoid Cell Leukodystrophy Diseases 0.000 description 1
- 102000051325 Glucagon Human genes 0.000 description 1
- 108060003199 Glucagon Proteins 0.000 description 1
- 102000003676 Glucocorticoid Receptors Human genes 0.000 description 1
- 108090000079 Glucocorticoid Receptors Proteins 0.000 description 1
- 102000003638 Glucose-6-Phosphatase Human genes 0.000 description 1
- 108010086800 Glucose-6-Phosphatase Proteins 0.000 description 1
- 102000004547 Glucosylceramidase Human genes 0.000 description 1
- 108010017544 Glucosylceramidase Proteins 0.000 description 1
- 102000016354 Glucuronosyltransferase Human genes 0.000 description 1
- 108010092364 Glucuronosyltransferase Proteins 0.000 description 1
- 108010015451 Glutaryl-CoA Dehydrogenase Proteins 0.000 description 1
- 102100028603 Glutaryl-CoA dehydrogenase, mitochondrial Human genes 0.000 description 1
- 102000004327 Glycine dehydrogenase (decarboxylating) Human genes 0.000 description 1
- 108090000826 Glycine dehydrogenase (decarboxylating) Proteins 0.000 description 1
- 108010001483 Glycogen Synthase Proteins 0.000 description 1
- 208000032007 Glycogen storage disease due to acid maltase deficiency Diseases 0.000 description 1
- 206010053185 Glycogen storage disease type II Diseases 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 244000060234 Gmelina philippensis Species 0.000 description 1
- 201000005569 Gout Diseases 0.000 description 1
- 108060003393 Granulin Proteins 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 206010072579 Granulomatosis with polyangiitis Diseases 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 241000606790 Haemophilus Species 0.000 description 1
- 206010061192 Haemorrhagic fever Diseases 0.000 description 1
- 108010050754 Halorhodopsins Proteins 0.000 description 1
- 101000852023 Halorubrum pleomorphic virus 1 Envelope protein Proteins 0.000 description 1
- 208000030836 Hashimoto thyroiditis Diseases 0.000 description 1
- 206010019280 Heart failures Diseases 0.000 description 1
- 208000031220 Hemophilia Diseases 0.000 description 1
- 208000005176 Hepatitis C Diseases 0.000 description 1
- 208000005331 Hepatitis D Diseases 0.000 description 1
- 208000002972 Hepatolenticular Degeneration Diseases 0.000 description 1
- 241000709721 Hepatovirus A Species 0.000 description 1
- 208000007514 Herpes zoster Diseases 0.000 description 1
- 201000002563 Histoplasmosis Diseases 0.000 description 1
- 101150068639 Hnf4a gene Proteins 0.000 description 1
- 101000783770 Homo sapiens ATP-binding cassette sub-family D member 3 Proteins 0.000 description 1
- 101000765010 Homo sapiens Beta-galactosidase Proteins 0.000 description 1
- 101000933465 Homo sapiens Beta-glucuronidase Proteins 0.000 description 1
- 101000897400 Homo sapiens CD59 glycoprotein Proteins 0.000 description 1
- 101000933218 Homo sapiens Cathepsin F Proteins 0.000 description 1
- 101000721661 Homo sapiens Cellular tumor antigen p53 Proteins 0.000 description 1
- 101000911390 Homo sapiens Coagulation factor VIII Proteins 0.000 description 1
- 101000936280 Homo sapiens Copper-transporting ATPase 2 Proteins 0.000 description 1
- 101000974934 Homo sapiens Cyclic AMP-dependent transcription factor ATF-2 Proteins 0.000 description 1
- 101000905743 Homo sapiens Cyclic AMP-dependent transcription factor ATF-4 Proteins 0.000 description 1
- 101000860395 Homo sapiens Galactocerebrosidase Proteins 0.000 description 1
- 101000997829 Homo sapiens Glial cell line-derived neurotrophic factor Proteins 0.000 description 1
- 101001122174 Homo sapiens Lipoamide acyltransferase component of branched-chain alpha-keto acid dehydrogenase complex, mitochondrial Proteins 0.000 description 1
- 101001032837 Homo sapiens Metabotropic glutamate receptor 6 Proteins 0.000 description 1
- 101000986595 Homo sapiens Ornithine transcarbamylase, mitochondrial Proteins 0.000 description 1
- 101000603761 Homo sapiens Peptide-N(4)-(N-acetyl-beta-glucosaminyl)asparagine amidase Proteins 0.000 description 1
- 101000595674 Homo sapiens Pituitary homeobox 3 Proteins 0.000 description 1
- 101001098868 Homo sapiens Proprotein convertase subtilisin/kexin type 9 Proteins 0.000 description 1
- 101000629622 Homo sapiens Serine-pyruvate aminotransferase Proteins 0.000 description 1
- 101000785978 Homo sapiens Sphingomyelin phosphodiesterase Proteins 0.000 description 1
- 101000837845 Homo sapiens Transcription factor E3 Proteins 0.000 description 1
- 101000837829 Homo sapiens Transcription factor IIIA Proteins 0.000 description 1
- 101001104102 Homo sapiens X-linked retinitis pigmentosa GTPase regulator Proteins 0.000 description 1
- 102000008100 Human Serum Albumin Human genes 0.000 description 1
- 108091006905 Human Serum Albumin Proteins 0.000 description 1
- 241001207270 Human enterovirus Species 0.000 description 1
- 241000726041 Human respirovirus 1 Species 0.000 description 1
- 241000712003 Human respirovirus 3 Species 0.000 description 1
- 241001559187 Human rubulavirus 2 Species 0.000 description 1
- 241001559186 Human rubulavirus 4 Species 0.000 description 1
- 208000023105 Huntington disease Diseases 0.000 description 1
- 108010003272 Hyaluronate lyase Proteins 0.000 description 1
- 102000001974 Hyaluronidases Human genes 0.000 description 1
- 102000004157 Hydrolases Human genes 0.000 description 1
- 108090000604 Hydrolases Proteins 0.000 description 1
- 208000001021 Hyperlipoproteinemia Type I Diseases 0.000 description 1
- 201000001916 Hypochondriasis Diseases 0.000 description 1
- 108010091358 Hypoxanthine Phosphoribosyltransferase Proteins 0.000 description 1
- 102100029098 Hypoxanthine-guanine phosphoribosyltransferase Human genes 0.000 description 1
- 108010053927 Iduronate Sulfatase Proteins 0.000 description 1
- 102000004627 Iduronidase Human genes 0.000 description 1
- 108010003381 Iduronidase Proteins 0.000 description 1
- GAZGFPOZOLEYAJ-YTFOTSKYSA-N Ile-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N GAZGFPOZOLEYAJ-YTFOTSKYSA-N 0.000 description 1
- 208000029462 Immunodeficiency disease Diseases 0.000 description 1
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 1
- 208000035343 Infantile neurovisceral acid sphingomyelinase deficiency Diseases 0.000 description 1
- 241000711450 Infectious bronchitis virus Species 0.000 description 1
- 102000002746 Inhibins Human genes 0.000 description 1
- 108010004250 Inhibins Proteins 0.000 description 1
- 108090000723 Insulin-Like Growth Factor I Proteins 0.000 description 1
- 102000004218 Insulin-Like Growth Factor I Human genes 0.000 description 1
- 108090001117 Insulin-Like Growth Factor II Proteins 0.000 description 1
- 102000048143 Insulin-Like Growth Factor II Human genes 0.000 description 1
- 101710092928 Insulin-like peptide-1 Proteins 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 102000003996 Interferon-beta Human genes 0.000 description 1
- 108090000467 Interferon-beta Proteins 0.000 description 1
- 102000008070 Interferon-gamma Human genes 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- 108010002352 Interleukin-1 Proteins 0.000 description 1
- 102000000589 Interleukin-1 Human genes 0.000 description 1
- 108010065805 Interleukin-12 Proteins 0.000 description 1
- 102000004559 Interleukin-13 Receptors Human genes 0.000 description 1
- 108010017511 Interleukin-13 Receptors Proteins 0.000 description 1
- 108090000171 Interleukin-18 Proteins 0.000 description 1
- 108010002350 Interleukin-2 Proteins 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 102000010787 Interleukin-4 Receptors Human genes 0.000 description 1
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 1
- 108010013792 Isovaleryl-CoA Dehydrogenase Proteins 0.000 description 1
- 102100025392 Isovaleryl-CoA dehydrogenase, mitochondrial Human genes 0.000 description 1
- 101150008942 J gene Proteins 0.000 description 1
- 201000005807 Japanese encephalitis Diseases 0.000 description 1
- 241000710843 Japanese encephalitis virus group Species 0.000 description 1
- 206010023126 Jaundice Diseases 0.000 description 1
- 208000028226 Krabbe disease Diseases 0.000 description 1
- 238000012313 Kruskal-Wallis test Methods 0.000 description 1
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- 201000009908 La Crosse encephalitis Diseases 0.000 description 1
- 206010023927 Lassa fever Diseases 0.000 description 1
- 201000003533 Leber congenital amaurosis Diseases 0.000 description 1
- 208000004554 Leishmaniasis Diseases 0.000 description 1
- 241000713666 Lentivirus Species 0.000 description 1
- 206010024229 Leprosy Diseases 0.000 description 1
- 206010024238 Leptospirosis Diseases 0.000 description 1
- 208000009625 Lesch-Nyhan syndrome Diseases 0.000 description 1
- HNDWYLYAYNBWMP-AJNGGQMLSA-N Leu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N HNDWYLYAYNBWMP-AJNGGQMLSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 108090000581 Leukemia inhibitory factor Proteins 0.000 description 1
- 102000004058 Leukemia inhibitory factor Human genes 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 102100027064 Lipoamide acyltransferase component of branched-chain alpha-keto acid dehydrogenase complex, mitochondrial Human genes 0.000 description 1
- 241000186779 Listeria monocytogenes Species 0.000 description 1
- 102000004317 Lyases Human genes 0.000 description 1
- 108090000856 Lyases Proteins 0.000 description 1
- 241000701043 Lymphocryptovirus Species 0.000 description 1
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 1
- ZJWIXBZTAAJERF-IHRRRGAJSA-N Lys-Lys-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZJWIXBZTAAJERF-IHRRRGAJSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 208000015439 Lysosomal storage disease Diseases 0.000 description 1
- 241000711828 Lyssavirus Species 0.000 description 1
- 241000282553 Macaca Species 0.000 description 1
- 241000282567 Macaca fascicularis Species 0.000 description 1
- 101710125418 Major capsid protein Proteins 0.000 description 1
- 241001115401 Marburgvirus Species 0.000 description 1
- 241000283923 Marmota monax Species 0.000 description 1
- 101710085938 Matrix protein Proteins 0.000 description 1
- 201000005505 Measles Diseases 0.000 description 1
- 101710127721 Membrane protein Proteins 0.000 description 1
- 102100038300 Metabotropic glutamate receptor 6 Human genes 0.000 description 1
- 102000010750 Metalloproteins Human genes 0.000 description 1
- 108010063312 Metalloproteins Proteins 0.000 description 1
- 108010085747 Methylmalonyl-CoA Decarboxylase Proteins 0.000 description 1
- 241001460074 Microsporum distortum Species 0.000 description 1
- 101710169105 Minor spike protein Proteins 0.000 description 1
- 241000588621 Moraxella Species 0.000 description 1
- 241000712045 Morbillivirus Species 0.000 description 1
- 241000701034 Muromegalovirus Species 0.000 description 1
- 101100335081 Mus musculus Flt3 gene Proteins 0.000 description 1
- 208000023178 Musculoskeletal disease Diseases 0.000 description 1
- 241000204031 Mycoplasma Species 0.000 description 1
- 206010028470 Mycoplasma infections Diseases 0.000 description 1
- 241000202934 Mycoplasma pneumoniae Species 0.000 description 1
- 102100032970 Myogenin Human genes 0.000 description 1
- 108010056785 Myogenin Proteins 0.000 description 1
- 102100030626 Myosin-binding protein H Human genes 0.000 description 1
- 101710139548 Myosin-binding protein H Proteins 0.000 description 1
- 102100021003 N(4)-(beta-N-acetylglucosaminyl)-L-asparaginase Human genes 0.000 description 1
- 108010027520 N-Acetylgalactosamine-4-Sulfatase Proteins 0.000 description 1
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 1
- 108010023320 N-acetylglucosamine-6-sulfatase Proteins 0.000 description 1
- 102000056067 N-acetylglucosamine-6-sulfatases Human genes 0.000 description 1
- NSTPXGARCQOSAU-VIFPVBQESA-N N-formyl-L-phenylalanine Chemical compound O=CN[C@H](C(=O)O)CC1=CC=CC=C1 NSTPXGARCQOSAU-VIFPVBQESA-N 0.000 description 1
- 208000006007 Nairobi Sheep Disease Diseases 0.000 description 1
- 241000588653 Neisseria Species 0.000 description 1
- 102000007072 Nerve Growth Factors Human genes 0.000 description 1
- 208000012902 Nervous system disease Diseases 0.000 description 1
- 108010074223 Netrin-1 Proteins 0.000 description 1
- 102000009065 Netrin-1 Human genes 0.000 description 1
- 102000014413 Neuregulin Human genes 0.000 description 1
- 108050003475 Neuregulin Proteins 0.000 description 1
- 208000029726 Neurodevelopmental disease Diseases 0.000 description 1
- 102100029268 Neurotrophin-3 Human genes 0.000 description 1
- 201000000794 Niemann-Pick disease type A Diseases 0.000 description 1
- 208000001140 Night Blindness Diseases 0.000 description 1
- 102000007999 Nuclear Proteins Human genes 0.000 description 1
- 108010089610 Nuclear Proteins Proteins 0.000 description 1
- 102000007399 Nuclear hormone receptor Human genes 0.000 description 1
- 108020005497 Nuclear hormone receptor Proteins 0.000 description 1
- 108090001074 Nucleocapsid Proteins Proteins 0.000 description 1
- 101710141454 Nucleoprotein Proteins 0.000 description 1
- 102000043276 Oncogene Human genes 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- 241000702259 Orbivirus Species 0.000 description 1
- 208000000599 Ornithine Carbamoyltransferase Deficiency Disease Diseases 0.000 description 1
- 206010052450 Ornithine transcarbamoylase deficiency Diseases 0.000 description 1
- 208000035903 Ornithine transcarbamylase deficiency Diseases 0.000 description 1
- 241000150218 Orthonairovirus Species 0.000 description 1
- 241000700629 Orthopoxvirus Species 0.000 description 1
- 102000014160 PTEN Phosphohydrolase Human genes 0.000 description 1
- 108010011536 PTEN Phosphohydrolase Proteins 0.000 description 1
- 102100025824 Palmitoyl-protein thioesterase 1 Human genes 0.000 description 1
- 241001631646 Papillomaviridae Species 0.000 description 1
- 241001537205 Paracoccidioides Species 0.000 description 1
- 241000700639 Parapoxvirus Species 0.000 description 1
- 208000018737 Parkinson disease Diseases 0.000 description 1
- 241000606860 Pasteurella Species 0.000 description 1
- 102000007079 Peptide Fragments Human genes 0.000 description 1
- 108010033276 Peptide Fragments Proteins 0.000 description 1
- 201000011252 Phenylketonuria Diseases 0.000 description 1
- 241000713137 Phlebovirus Species 0.000 description 1
- 108010064071 Phosphorylase Kinase Proteins 0.000 description 1
- 102000014750 Phosphorylase Kinase Human genes 0.000 description 1
- 108010073135 Phosphorylases Proteins 0.000 description 1
- 102000009097 Phosphorylases Human genes 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 241000364051 Pima Species 0.000 description 1
- 102100036088 Pituitary homeobox 3 Human genes 0.000 description 1
- 102100024616 Platelet endothelial cell adhesion molecule Human genes 0.000 description 1
- 241000233872 Pneumocystis carinii Species 0.000 description 1
- 241000711902 Pneumovirus Species 0.000 description 1
- 241001505332 Polyomavirus sp. Species 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 241000156302 Porcine hemagglutinating encephalomyelitis virus Species 0.000 description 1
- 241000702619 Porcine parvovirus Species 0.000 description 1
- 241001135989 Porcine reproductive and respiratory syndrome virus Species 0.000 description 1
- 108010035004 Prephenate Dehydrogenase Proteins 0.000 description 1
- WGAQWMRJUFQXMF-ZPFDUUQYSA-N Pro-Gln-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WGAQWMRJUFQXMF-ZPFDUUQYSA-N 0.000 description 1
- FYKUEXMZYFIZKA-DCAQKATOSA-N Pro-Pro-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FYKUEXMZYFIZKA-DCAQKATOSA-N 0.000 description 1
- ZMLRZBWCXPQADC-TUAOUCFPSA-N Pro-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 ZMLRZBWCXPQADC-TUAOUCFPSA-N 0.000 description 1
- 102100021191 Probable G-protein coupled receptor 179 Human genes 0.000 description 1
- 108091011158 Probable G-protein coupled receptor 179 Proteins 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 102100038955 Proprotein convertase subtilisin/kexin type 9 Human genes 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 101710150344 Protein Rev Proteins 0.000 description 1
- 229940096437 Protein S Drugs 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 108010001267 Protein Subunits Proteins 0.000 description 1
- 102000002067 Protein Subunits Human genes 0.000 description 1
- 241000589516 Pseudomonas Species 0.000 description 1
- 241000287531 Psittacidae Species 0.000 description 1
- 206010037660 Pyrexia Diseases 0.000 description 1
- 239000013614 RNA sample Substances 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 238000011530 RNeasy Mini Kit Methods 0.000 description 1
- 230000010799 Receptor Interactions Effects 0.000 description 1
- 208000001647 Renal Insufficiency Diseases 0.000 description 1
- 241001068295 Replication defective viruses Species 0.000 description 1
- 241000725643 Respiratory syncytial virus Species 0.000 description 1
- 101710137010 Retinol-binding protein 3 Proteins 0.000 description 1
- 102100038247 Retinol-binding protein 3 Human genes 0.000 description 1
- 208000006289 Rett Syndrome Diseases 0.000 description 1
- 241000701037 Rhadinovirus Species 0.000 description 1
- 206010051497 Rhinotracheitis Diseases 0.000 description 1
- 102100040756 Rhodopsin Human genes 0.000 description 1
- 108090000820 Rhodopsin Proteins 0.000 description 1
- 108010039491 Ricin Proteins 0.000 description 1
- 235000004443 Ricinus communis Nutrition 0.000 description 1
- 240000000528 Ricinus communis Species 0.000 description 1
- 241000606701 Rickettsia Species 0.000 description 1
- 208000034712 Rickettsia Infections Diseases 0.000 description 1
- 206010061495 Rickettsiosis Diseases 0.000 description 1
- 208000000705 Rift Valley Fever Diseases 0.000 description 1
- 206010039207 Rocky Mountain Spotted Fever Diseases 0.000 description 1
- 241000710942 Ross River virus Species 0.000 description 1
- 241000702670 Rotavirus Species 0.000 description 1
- 241000710799 Rubella virus Species 0.000 description 1
- 241000710801 Rubivirus Species 0.000 description 1
- 241000607142 Salmonella Species 0.000 description 1
- 208000021811 Sandhoff disease Diseases 0.000 description 1
- 102100027732 Sarcoplasmic/endoplasmic reticulum calcium ATPase 2 Human genes 0.000 description 1
- 101710109123 Sarcoplasmic/endoplasmic reticulum calcium ATPase 2 Proteins 0.000 description 1
- 208000018642 Semantic dementia Diseases 0.000 description 1
- 102000014105 Semaphorin Human genes 0.000 description 1
- 108050003978 Semaphorin Proteins 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- WBINSDOPZHQPPM-AVGNSLFASA-N Ser-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)O WBINSDOPZHQPPM-AVGNSLFASA-N 0.000 description 1
- 102100026842 Serine-pyruvate aminotransferase Human genes 0.000 description 1
- 101710113029 Serine/threonine-protein kinase Proteins 0.000 description 1
- 241000607768 Shigella Species 0.000 description 1
- 208000021386 Sjogren Syndrome Diseases 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- 208000001203 Smallpox Diseases 0.000 description 1
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical group [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 1
- 108010061312 Sphingomyelin Phosphodiesterase Proteins 0.000 description 1
- 102000011971 Sphingomyelin Phosphodiesterase Human genes 0.000 description 1
- 102100026263 Sphingomyelin phosphodiesterase Human genes 0.000 description 1
- 101710198474 Spike protein Proteins 0.000 description 1
- 241000605008 Spirillum Species 0.000 description 1
- 241000589970 Spirochaetales Species 0.000 description 1
- 206010041896 St. Louis Encephalitis Diseases 0.000 description 1
- 241000710888 St. Louis encephalitis virus Species 0.000 description 1
- 241000295644 Staphylococcaceae Species 0.000 description 1
- 241000191940 Staphylococcus Species 0.000 description 1
- 108091081024 Start codon Proteins 0.000 description 1
- 108010055297 Sterol Esterase Proteins 0.000 description 1
- 241001478880 Streptobacillus moniliformis Species 0.000 description 1
- 101000910035 Streptococcus pyogenes serotype M1 CRISPR-associated endonuclease Cas9/Csn1 Proteins 0.000 description 1
- 241000700568 Suipoxvirus Species 0.000 description 1
- 101001062859 Sus scrofa Fatty acid-binding protein, adipocyte Proteins 0.000 description 1
- 206010042971 T-cell lymphoma Diseases 0.000 description 1
- 208000027585 T-cell non-Hodgkin lymphoma Diseases 0.000 description 1
- 102100040347 TAR DNA-binding protein 43 Human genes 0.000 description 1
- 101710150875 TAR DNA-binding protein 43 Proteins 0.000 description 1
- 206010043376 Tetanus Diseases 0.000 description 1
- 208000002903 Thalassemia Diseases 0.000 description 1
- 241001189642 Theroa Species 0.000 description 1
- GZYNMZQXFRWDFH-YTWAJWBKSA-N Thr-Arg-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O GZYNMZQXFRWDFH-YTWAJWBKSA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 102100026966 Thrombomodulin Human genes 0.000 description 1
- 108010079274 Thrombomodulin Proteins 0.000 description 1
- 108010000499 Thromboplastin Proteins 0.000 description 1
- 208000007536 Thrombosis Diseases 0.000 description 1
- 208000002474 Tinea Diseases 0.000 description 1
- 102100030859 Tissue factor Human genes 0.000 description 1
- 208000035317 Total hypoxanthine-guanine phosphoribosyl transferase deficiency Diseases 0.000 description 1
- 241000223997 Toxoplasma gondii Species 0.000 description 1
- 101001023030 Toxoplasma gondii Myosin-D Proteins 0.000 description 1
- 201000005485 Toxoplasmosis Diseases 0.000 description 1
- 108010018242 Transcription Factor AP-1 Proteins 0.000 description 1
- 102000040945 Transcription factor Human genes 0.000 description 1
- 102100028507 Transcription factor E3 Human genes 0.000 description 1
- 102000006747 Transforming Growth Factor alpha Human genes 0.000 description 1
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 1
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 1
- 102400001320 Transforming growth factor alpha Human genes 0.000 description 1
- 241000869417 Trematodes Species 0.000 description 1
- 241000589886 Treponema Species 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 102000044209 Tumor Suppressor Genes Human genes 0.000 description 1
- 108700025716 Tumor Suppressor Genes Proteins 0.000 description 1
- 102100031988 Tumor necrosis factor ligand superfamily member 6 Human genes 0.000 description 1
- 108050002568 Tumor necrosis factor ligand superfamily member 6 Proteins 0.000 description 1
- 208000007824 Type A Niemann-Pick Disease Diseases 0.000 description 1
- TWAVEIJGFCBWCG-JYJNAYRXSA-N Tyr-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N TWAVEIJGFCBWCG-JYJNAYRXSA-N 0.000 description 1
- 208000032001 Tyrosinemia type 1 Diseases 0.000 description 1
- 108010058532 UTP-hexose-1-phosphate uridylyltransferase Proteins 0.000 description 1
- 102000006321 UTP-hexose-1-phosphate uridylyltransferase Human genes 0.000 description 1
- 201000006704 Ulcerative Colitis Diseases 0.000 description 1
- CGGVNFJRZJUVAE-BYULHYEWSA-N Val-Asp-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CGGVNFJRZJUVAE-BYULHYEWSA-N 0.000 description 1
- HHSILIQTHXABKM-YDHLFZDLSA-N Val-Asp-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](Cc1ccccc1)C(O)=O HHSILIQTHXABKM-YDHLFZDLSA-N 0.000 description 1
- XGJLNBNZNMVJRS-NRPADANISA-N Val-Glu-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O XGJLNBNZNMVJRS-NRPADANISA-N 0.000 description 1
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 1
- 241000701067 Varicellovirus Species 0.000 description 1
- 206010047115 Vasculitis Diseases 0.000 description 1
- 241000711975 Vesicular stomatitis virus Species 0.000 description 1
- 241000711970 Vesiculovirus Species 0.000 description 1
- 101800001476 Viral genome-linked protein Proteins 0.000 description 1
- 208000028227 Viral hemorrhagic fever Diseases 0.000 description 1
- 206010047642 Vitiligo Diseases 0.000 description 1
- 208000005466 Western Equine Encephalomyelitis Diseases 0.000 description 1
- 201000005806 Western equine encephalitis Diseases 0.000 description 1
- 241000710951 Western equine encephalitis virus Species 0.000 description 1
- 102100022748 Wilms tumor protein Human genes 0.000 description 1
- 101710127857 Wilms tumor protein Proteins 0.000 description 1
- 208000018839 Wilson disease Diseases 0.000 description 1
- 208000026589 Wolman disease Diseases 0.000 description 1
- 102100040092 X-linked retinitis pigmentosa GTPase regulator Human genes 0.000 description 1
- 208000003152 Yellow Fever Diseases 0.000 description 1
- 241000120645 Yellow fever virus group Species 0.000 description 1
- 241000607734 Yersinia <bacteria> Species 0.000 description 1
- 241000607479 Yersinia pestis Species 0.000 description 1
- 201000004525 Zellweger Syndrome Diseases 0.000 description 1
- 208000036813 Zellweger spectrum disease Diseases 0.000 description 1
- 206010061418 Zygomycosis Diseases 0.000 description 1
- 241000606834 [Haemophilus] ducreyi Species 0.000 description 1
- 108020002494 acetyltransferase Proteins 0.000 description 1
- 102000005421 acetyltransferase Human genes 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 201000007691 actinomycosis Diseases 0.000 description 1
- 239000000488 activin Substances 0.000 description 1
- 208000012873 acute gastroenteritis Diseases 0.000 description 1
- 229960005305 adenosine Drugs 0.000 description 1
- 102000030621 adenylate cyclase Human genes 0.000 description 1
- 108060000200 adenylate cyclase Proteins 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 238000005804 alkylation reaction Methods 0.000 description 1
- 208000006682 alpha 1-Antitrypsin Deficiency Diseases 0.000 description 1
- SHZGCJCMOBCMKK-PHYPRBDBSA-N alpha-D-fucose Chemical compound C[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O SHZGCJCMOBCMKK-PHYPRBDBSA-N 0.000 description 1
- 108010030291 alpha-Galactosidase Proteins 0.000 description 1
- 108010028144 alpha-Glucosidases Proteins 0.000 description 1
- 102000012086 alpha-L-Fucosidase Human genes 0.000 description 1
- 108010061314 alpha-L-Fucosidase Proteins 0.000 description 1
- 102000019199 alpha-Mannosidase Human genes 0.000 description 1
- 108010012864 alpha-Mannosidase Proteins 0.000 description 1
- 108010009380 alpha-N-acetyl-D-glucosaminidase Proteins 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 238000000540 analysis of variance Methods 0.000 description 1
- 208000007502 anemia Diseases 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 210000004960 anterior grey column Anatomy 0.000 description 1
- 208000026753 anterior segment dysgenesis Diseases 0.000 description 1
- 238000011394 anticancer treatment Methods 0.000 description 1
- 229940009098 aspartate Drugs 0.000 description 1
- FZCSTZYAHCUGEM-UHFFFAOYSA-N aspergillomarasmine B Natural products OC(=O)CNC(C(O)=O)CNC(C(O)=O)CC(O)=O FZCSTZYAHCUGEM-UHFFFAOYSA-N 0.000 description 1
- 238000000429 assembly Methods 0.000 description 1
- 230000000712 assembly Effects 0.000 description 1
- 201000008937 atopic dermatitis Diseases 0.000 description 1
- 230000005784 autoimmunity Effects 0.000 description 1
- 201000008680 babesiosis Diseases 0.000 description 1
- 229940065181 bacillus anthracis Drugs 0.000 description 1
- 239000003855 balanced salt solution Substances 0.000 description 1
- 206010004145 bartonellosis Diseases 0.000 description 1
- 102000012740 beta Adrenergic Receptors Human genes 0.000 description 1
- 108010079452 beta Adrenergic Receptors Proteins 0.000 description 1
- 102000006995 beta-Glucosidase Human genes 0.000 description 1
- 108010047754 beta-Glucosidase Proteins 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 210000004204 blood vessel Anatomy 0.000 description 1
- 208000003836 bluetongue Diseases 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- 210000000133 brain stem Anatomy 0.000 description 1
- 210000005013 brain tissue Anatomy 0.000 description 1
- 238000000339 bright-field microscopy Methods 0.000 description 1
- 239000007975 buffered saline Substances 0.000 description 1
- 229940074375 burkholderia mallei Drugs 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 201000003984 candidiasis Diseases 0.000 description 1
- 208000014058 canine distemper Diseases 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 125000003917 carbamoyl group Chemical group [H]N([H])C(*)=O 0.000 description 1
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 210000001638 cerebellum Anatomy 0.000 description 1
- 210000003710 cerebral cortex Anatomy 0.000 description 1
- 201000004559 cerebral degeneration Diseases 0.000 description 1
- 230000002490 cerebral effect Effects 0.000 description 1
- 210000004289 cerebral ventricle Anatomy 0.000 description 1
- 208000031406 ceroid lipofuscinosis, neuronal, 4 (Kufs type) Diseases 0.000 description 1
- 201000000902 chlamydia Diseases 0.000 description 1
- 208000012538 chlamydia trachomatis infectious disease Diseases 0.000 description 1
- CRQQGFGUEAVUIL-UHFFFAOYSA-N chlorothalonil Chemical compound ClC1=C(Cl)C(C#N)=C(Cl)C(C#N)=C1Cl CRQQGFGUEAVUIL-UHFFFAOYSA-N 0.000 description 1
- 235000012000 cholesterol Nutrition 0.000 description 1
- 208000020832 chronic kidney disease Diseases 0.000 description 1
- 229960002376 chymotrypsin Drugs 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 238000011260 co-administration Methods 0.000 description 1
- 230000004186 co-expression Effects 0.000 description 1
- 230000015271 coagulation Effects 0.000 description 1
- 238000005345 coagulation Methods 0.000 description 1
- 201000003486 coccidioidomycosis Diseases 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 239000002872 contrast media Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 230000001054 cortical effect Effects 0.000 description 1
- 239000003246 corticosteroid Substances 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 208000031513 cyst Diseases 0.000 description 1
- ILRYLPWNYFXEMH-UHFFFAOYSA-N cystathionine Chemical compound OC(=O)C(N)CCSCC(N)C(O)=O ILRYLPWNYFXEMH-UHFFFAOYSA-N 0.000 description 1
- 229960003067 cystine Drugs 0.000 description 1
- 238000004163 cytometry Methods 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 230000006735 deficit Effects 0.000 description 1
- 208000025729 dengue disease Diseases 0.000 description 1
- 201000001981 dermatomyositis Diseases 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 238000009792 diffusion process Methods 0.000 description 1
- 238000007847 digital PCR Methods 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 231100000676 disease causative agent Toxicity 0.000 description 1
- BFMYDTVEBKDAKJ-UHFFFAOYSA-L disodium;(2',7'-dibromo-3',6'-dioxido-3-oxospiro[2-benzofuran-1,9'-xanthene]-4'-yl)mercury;hydrate Chemical compound O.[Na+].[Na+].O1C(=O)C2=CC=CC=C2C21C1=CC(Br)=C([O-])C([Hg])=C1OC1=C2C=C(Br)C([O-])=C1 BFMYDTVEBKDAKJ-UHFFFAOYSA-L 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 230000005782 double-strand break Effects 0.000 description 1
- 239000003937 drug carrier Substances 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 230000002526 effect on cardiovascular system Effects 0.000 description 1
- 206010014599 encephalitis Diseases 0.000 description 1
- 230000002124 endocrine Effects 0.000 description 1
- 239000012645 endogenous antigen Substances 0.000 description 1
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 1
- 108010078428 env Gene Products Proteins 0.000 description 1
- 238000002641 enzyme replacement therapy Methods 0.000 description 1
- YQGOJNYOYNNSMM-UHFFFAOYSA-N eosin Chemical compound [Na+].OC(=O)C1=CC=CC=C1C1=C2C=C(Br)C(=O)C(Br)=C2OC2=C(Br)C(O)=C(Br)C=C21 YQGOJNYOYNNSMM-UHFFFAOYSA-N 0.000 description 1
- 102000012803 ephrin Human genes 0.000 description 1
- 108060002566 ephrin Proteins 0.000 description 1
- 208000028104 epidemic louse-borne typhus Diseases 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 102000015694 estrogen receptors Human genes 0.000 description 1
- 108010038795 estrogen receptors Proteins 0.000 description 1
- 238000013401 experimental design Methods 0.000 description 1
- 239000011536 extraction buffer Substances 0.000 description 1
- 229940126864 fibroblast growth factor Drugs 0.000 description 1
- 239000012467 final product Substances 0.000 description 1
- 108700014844 flt3 ligand Proteins 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- 238000000799 fluorescence microscopy Methods 0.000 description 1
- 238000002594 fluoroscopy Methods 0.000 description 1
- 229960000304 folic acid Drugs 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 229940118764 francisella tularensis Drugs 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 108010022687 fumarylacetoacetase Proteins 0.000 description 1
- 244000053095 fungal pathogen Species 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 229930182830 galactose Natural products 0.000 description 1
- QPJBWNIQKHGLAU-IQZHVAEDSA-N ganglioside GM1 Chemical compound O[C@@H]1[C@@H](O)[C@H](OC[C@H](NC(=O)CCCCCCCCCCCCCCCCC)[C@H](O)\C=C\CCCCCCCCCCCCC)O[C@H](CO)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@]2(O[C@H]([C@H](NC(C)=O)[C@@H](O)C2)[C@H](O)[C@H](O)CO)C(O)=O)[C@@H](O[C@H]2[C@@H]([C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O3)O)[C@@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](CO)O1 QPJBWNIQKHGLAU-IQZHVAEDSA-N 0.000 description 1
- GIVLTTJNORAZON-HDBOBKCLSA-N ganglioside GM2 (18:0) Chemical compound O[C@@H]1[C@@H](O)[C@H](OC[C@H](NC(=O)CCCCCCCCCCCCCCCCC)[C@H](O)\C=C\CCCCCCCCCCCCC)O[C@H](CO)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@]2(O[C@H]([C@H](NC(C)=O)[C@@H](O)C2)[C@H](O)[C@H](O)CO)C(O)=O)[C@@H](O[C@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](CO)O1 GIVLTTJNORAZON-HDBOBKCLSA-N 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 230000009395 genetic defect Effects 0.000 description 1
- 201000006592 giardiasis Diseases 0.000 description 1
- MASNOZXLGMXCHN-ZLPAWPGGSA-N glucagon Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)C(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 MASNOZXLGMXCHN-ZLPAWPGGSA-N 0.000 description 1
- 229960004666 glucagon Drugs 0.000 description 1
- 150000002307 glutamic acids Chemical class 0.000 description 1
- 150000002333 glycines Chemical class 0.000 description 1
- 208000007345 glycogen storage disease Diseases 0.000 description 1
- 201000004502 glycogen storage disease II Diseases 0.000 description 1
- 108010062584 glycollate oxidase Proteins 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 244000000013 helminth Species 0.000 description 1
- 208000009429 hemophilia B Diseases 0.000 description 1
- 108010089932 heparan sulfate sulfatase Proteins 0.000 description 1
- 208000029570 hepatitis D virus infection Diseases 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 208000017105 hereditary amyloidosis Diseases 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 238000007489 histopathology method Methods 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 229960002773 hyaluronidase Drugs 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 125000001165 hydrophobic group Chemical group 0.000 description 1
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 1
- 238000010191 image analysis Methods 0.000 description 1
- 208000026278 immune system disease Diseases 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 230000007813 immunodeficiency Effects 0.000 description 1
- 238000010820 immunofluorescence microscopy Methods 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 230000008676 import Effects 0.000 description 1
- 238000000099 in vitro assay Methods 0.000 description 1
- 230000003960 inflammatory cascade Effects 0.000 description 1
- 208000027866 inflammatory disease Diseases 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 239000000893 inhibin Substances 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- ZPNFWUPYTFPOJU-LPYSRVMUSA-N iniprol Chemical compound C([C@H]1C(=O)NCC(=O)NCC(=O)N[C@H]2CSSC[C@H]3C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC=4C=CC=CC=4)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC2=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC=2C=CC=CC=2)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H]2N(CCC2)C(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N2[C@@H](CCC2)C(=O)N2[C@@H](CCC2)C(=O)N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N2[C@@H](CCC2)C(=O)N3)C(=O)NCC(=O)NCC(=O)N[C@@H](C)C(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@H](C(=O)N1)C(C)C)[C@@H](C)O)[C@@H](C)CC)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 ZPNFWUPYTFPOJU-LPYSRVMUSA-N 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000000185 intracerebroventricular administration Methods 0.000 description 1
- NBQNWMBBSKPBAY-UHFFFAOYSA-N iodixanol Chemical compound IC=1C(C(=O)NCC(O)CO)=C(I)C(C(=O)NCC(O)CO)=C(I)C=1N(C(=O)C)CC(O)CN(C(C)=O)C1=C(I)C(C(=O)NCC(O)CO)=C(I)C(C(=O)NCC(O)CO)=C1I NBQNWMBBSKPBAY-UHFFFAOYSA-N 0.000 description 1
- 229960004359 iodixanol Drugs 0.000 description 1
- NTHXOOBQLCIOLC-UHFFFAOYSA-N iohexol Chemical compound OCC(O)CN(C(=O)C)C1=C(I)C(C(=O)NCC(O)CO)=C(I)C(C(=O)NCC(O)CO)=C1I NTHXOOBQLCIOLC-UHFFFAOYSA-N 0.000 description 1
- 229960001025 iohexol Drugs 0.000 description 1
- 208000023589 ischemic disease Diseases 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 150000004715 keto acids Chemical class 0.000 description 1
- 208000017169 kidney disease Diseases 0.000 description 1
- 201000006370 kidney failure Diseases 0.000 description 1
- 210000005240 left ventricle Anatomy 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- 208000036546 leukodystrophy Diseases 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 238000004811 liquid chromatography Methods 0.000 description 1
- 210000005229 liver cell Anatomy 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 238000011068 loading method Methods 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 230000033001 locomotion Effects 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 230000002132 lysosomal effect Effects 0.000 description 1
- 201000004792 malaria Diseases 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 210000005171 mammalian brain Anatomy 0.000 description 1
- 201000004015 melioidosis Diseases 0.000 description 1
- 208000030159 metabolic disease Diseases 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 201000003694 methylmalonic acidemia Diseases 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 230000002438 mitochondrial effect Effects 0.000 description 1
- 238000009126 molecular therapy Methods 0.000 description 1
- 210000001616 monocyte Anatomy 0.000 description 1
- 210000000337 motor cortex Anatomy 0.000 description 1
- 208000012253 mucopolysaccharidosis IVA Diseases 0.000 description 1
- 208000022018 mucopolysaccharidosis type 2 Diseases 0.000 description 1
- 208000025919 mucopolysaccharidosis type 7 Diseases 0.000 description 1
- 208000027333 mucopolysaccharidosis type IIID Diseases 0.000 description 1
- 208000012091 mucopolysaccharidosis type IVB Diseases 0.000 description 1
- 201000007524 mucormycosis Diseases 0.000 description 1
- 210000000663 muscle cell Anatomy 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 210000000107 myocyte Anatomy 0.000 description 1
- 210000000653 nervous system Anatomy 0.000 description 1
- 108010081726 netrin-2 Proteins 0.000 description 1
- 208000015122 neurodegenerative disease Diseases 0.000 description 1
- 230000001272 neurogenic effect Effects 0.000 description 1
- 230000000926 neurological effect Effects 0.000 description 1
- 201000007605 neuronal ceroid lipofuscinosis 11 Diseases 0.000 description 1
- 201000007659 neuronal ceroid lipofuscinosis 13 Diseases 0.000 description 1
- 201000007640 neuronal ceroid lipofuscinosis 7 Diseases 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 125000004433 nitrogen atom Chemical group N* 0.000 description 1
- 108700007229 noggin Proteins 0.000 description 1
- 102000045246 noggin Human genes 0.000 description 1
- 108020004017 nuclear receptors Proteins 0.000 description 1
- 238000012758 nuclear staining Methods 0.000 description 1
- 230000000269 nucleophilic effect Effects 0.000 description 1
- 238000001543 one-way ANOVA Methods 0.000 description 1
- 210000001328 optic nerve Anatomy 0.000 description 1
- 201000011278 ornithine carbamoyltransferase deficiency Diseases 0.000 description 1
- 201000008482 osteoarthritis Diseases 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 235000006408 oxalic acid Nutrition 0.000 description 1
- 150000002913 oxalic acids Chemical class 0.000 description 1
- 210000004923 pancreatic tissue Anatomy 0.000 description 1
- 208000003154 papilloma Diseases 0.000 description 1
- 230000001769 paralizing effect Effects 0.000 description 1
- 244000045947 parasite Species 0.000 description 1
- 230000003071 parasitic effect Effects 0.000 description 1
- 230000001936 parietal effect Effects 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- YVBBRRALBYAZBM-UHFFFAOYSA-N perfluorooctane Chemical compound FC(F)(F)C(F)(F)C(F)(F)C(F)(F)C(F)(F)C(F)(F)C(F)(F)C(F)(F)F YVBBRRALBYAZBM-UHFFFAOYSA-N 0.000 description 1
- 230000009984 peri-natal effect Effects 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 102000005681 phospholamban Human genes 0.000 description 1
- 108010059929 phospholamban Proteins 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 238000005498 polishing Methods 0.000 description 1
- 208000005987 polymyositis Diseases 0.000 description 1
- 102000040430 polynucleotide Human genes 0.000 description 1
- 108091033319 polynucleotide Proteins 0.000 description 1
- 239000002157 polynucleotide Substances 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 238000011176 pooling Methods 0.000 description 1
- 238000012805 post-processing Methods 0.000 description 1
- 230000001323 posttranslational effect Effects 0.000 description 1
- 244000144977 poultry Species 0.000 description 1
- OIGNJSKKLXVSLS-VWUMJDOOSA-N prednisolone Chemical compound O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 OIGNJSKKLXVSLS-VWUMJDOOSA-N 0.000 description 1
- 229960005205 prednisolone Drugs 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 230000000750 progressive effect Effects 0.000 description 1
- 108010053725 prolylvaline Proteins 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 230000000272 proprioceptive effect Effects 0.000 description 1
- 235000019833 protease Nutrition 0.000 description 1
- 239000012460 protein solution Substances 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 238000004445 quantitative analysis Methods 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 208000002574 reactive arthritis Diseases 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 208000023504 respiratory system disease Diseases 0.000 description 1
- 230000000284 resting effect Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 210000003660 reticulum Anatomy 0.000 description 1
- 230000002207 retinal effect Effects 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 210000005241 right ventricle Anatomy 0.000 description 1
- 230000000630 rising effect Effects 0.000 description 1
- 201000000306 sarcoidosis Diseases 0.000 description 1
- 102000014452 scavenger receptors Human genes 0.000 description 1
- 108010078070 scavenger receptors Proteins 0.000 description 1
- 201000004409 schistosomiasis Diseases 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 210000001044 sensory neuron Anatomy 0.000 description 1
- 208000002491 severe combined immunodeficiency Diseases 0.000 description 1
- 210000002363 skeletal muscle cell Anatomy 0.000 description 1
- 210000001032 spinal nerve Anatomy 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 108020003113 steroid hormone receptors Proteins 0.000 description 1
- 102000005969 steroid hormone receptors Human genes 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 210000001977 striatum neuron Anatomy 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 229960002317 succinimide Drugs 0.000 description 1
- 239000004094 surface-active agent Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 238000010257 thawing Methods 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 210000000115 thoracic cavity Anatomy 0.000 description 1
- 241001147422 tick-borne encephalitis virus group Species 0.000 description 1
- 230000008467 tissue growth Effects 0.000 description 1
- 231100000041 toxicology testing Toxicity 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 208000003982 trichinellosis Diseases 0.000 description 1
- 230000010415 tropism Effects 0.000 description 1
- 201000002311 trypanosomiasis Diseases 0.000 description 1
- 239000002753 trypsin inhibitor Substances 0.000 description 1
- 201000008827 tuberculosis Diseases 0.000 description 1
- 102000003390 tumor necrosis factor Human genes 0.000 description 1
- 206010061393 typhus Diseases 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 201000011296 tyrosinemia Diseases 0.000 description 1
- 238000004704 ultra performance liquid chromatography Methods 0.000 description 1
- 241000724775 unclassified viruses Species 0.000 description 1
- 241001148471 unidentified anaerobic bacterium Species 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241000712461 unidentified influenza virus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 238000012762 unpaired Student’s t-test Methods 0.000 description 1
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 201000006266 variola major Diseases 0.000 description 1
- 230000002861 ventricular Effects 0.000 description 1
- 210000002845 virion Anatomy 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
- 102000009310 vitamin D receptors Human genes 0.000 description 1
- 108050000156 vitamin D receptors Proteins 0.000 description 1
- 101150040614 vpx gene Proteins 0.000 description 1
- 150000003738 xylenes Chemical class 0.000 description 1
- 201000009482 yaws Diseases 0.000 description 1
- 208000018878 young-onset Parkinson disease Diseases 0.000 description 1
Images









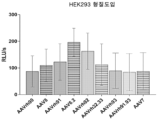




















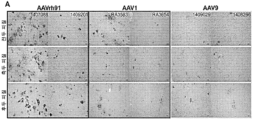
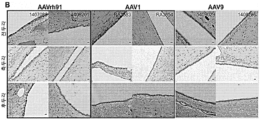



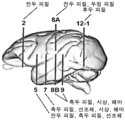




























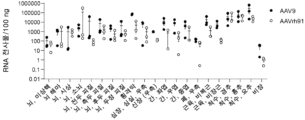







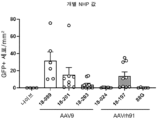



























Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/0008—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition
- A61K48/0016—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition wherein the nucleic acid is delivered as a 'naked' nucleic acid, i.e. not combined with an entity such as a cationic lipid
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/005—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/0012—Galenical forms characterised by the site of application
- A61K9/0019—Injectable compositions; Intramuscular, intravenous, arterial, subcutaneous administration; Compositions to be administered through the skin in an invasive manner
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/0075—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the delivery route, e.g. oral, subcutaneous
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14122—New viral proteins or individual genes, new structural or functional aspects of known viral proteins or genes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14141—Use of virus, viral particle or viral elements as a vector
- C12N2750/14143—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14141—Use of virus, viral particle or viral elements as a vector
- C12N2750/14145—Special targeting system for viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14151—Methods of production or purification of viral material
- C12N2750/14152—Methods of production or purification of viral material relating to complementing cells and packaging systems for producing virus or viral particles
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14171—Demonstrated in vivo effect
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- Molecular Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Zoology (AREA)
- General Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Biochemistry (AREA)
- Wood Science & Technology (AREA)
- Medicinal Chemistry (AREA)
- Virology (AREA)
- Biophysics (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Epidemiology (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Microbiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Gastroenterology & Hepatology (AREA)
- Dermatology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
신규 AAV 캡시드 및 이를 포함하는 재조합 AAV 벡터가 본원에서 제공된다. 일 구현예에서, 신규 AAV 캡시드를 이용하는 벡터는 종래 기술의 AAV와 비교하여 선택된 표적 조직의 증가된 형질도입을 나타낸다.
Description
아데노-연관 바이러스(AAV) 벡터는 여러 임상 적응증에 사용되는 안전하고 효과적인 유전자 전달 비히클이다. AAV 벡터를 기반으로 한 치료 접근법은 레베르 선천성 흑암시(Leber congenital amaurosis), 지질단백질 리파아제 결핍 및 척수성 근위축증의 치료를 위해 미국 식품의약국 및 기타 전세계 규제 당국의 승인을 받았다. 이러한 승인된 유전자 치료제는 천연 공급원으로부터 단리된 AAV 캡시드를 전달 비히클로 사용한다. AAV 캡시드 유전자의 서열 및 구조적 다양성은 바이러스 클레드 간에 관찰되는 바이러스 친화성, 항원성 및 패키징 효율의 가변성에 기여한다. 유전자 치료 플랫폼을 발전시키고 확장하기 위해서는 일련의 조직 친화성이 있는 신규 캡시드를 발견하는 것이 필요하다.
지난 20년 동안, 특정 조직 유형에 증가된 친화성을 부여하거나 항-AAV 중화 항체를 회피하기 위해 캡시드 단백질의 변형을 통한 AAV 공학이 캡시드 개발의 주요 방안이었다. 그러나, 천연 공급원 유래, 예컨대 다른 동물 유래의 조직, 혈액 또는 배양된 바이러스 제제로부터 AAV의 단리는 임상 적용에 적합한 신규 AAV를 식별하기 위한 주요 방법으로 남아 있다. 항-AAV 항체는 AAV 저장소가 방대하다는 것을 나타내는 다양한 포유동물 공급원에서 발견되었다.
AAV는 이들의 낮은 면역원성과 비-병원성 특성으로 인해 유전자 치료에 가장 효과적인 벡터 후보 중 하나이다. 그러나, 효율적인 유전자 전달을 허용함에도 불구하고, 현재 임상에서 사용되는 AAV 벡터는 바이러스에 대한 기존 면역 및 제한된 조직 친화성에 의해 방해받을 수 있다. 새롭고 더 효과적인 AAV 벡터가 필요하다.
일 측면에서, AAVrh91 캡시드 및 CNS의 표적 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함하는 재조합 아데노-연관 바이러스 (AAV) 벡터를 대상체에게 투여하는 단계를 포함하는, 대상체의 중추신경계(CNS)의 하나 이상의 표적 세포에 전이유전자를 전달하는 방법이 본원에서 제공된다. 특정 구현예에서, 상기 CNS의 표적 세포는 실질 세포, 맥락막총의 세포, 뇌실막 세포, 성상교세포, 및/또는 및 뉴런, 선택적으로 피질, 해마, 및/또는 선조체의 뉴런이다. 특정 구현예에서, 상기 전이유전자는 분비된 유전자 산물을 암호화한다. 특정 구현예에서, 상기 AAV 벡터는 선택적으로 대조내(intra-cisterna magna, ICM) 주사를 통해 척수강내로 전달된다. 특정 구현예에서, 상기 AAV 벡터는 뇌실질내 투여를 통해 전달된다.
일 측면에서, AAVrh91 캡시드 및 간의 표적 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함하는 재조합 AAV 벡터를 ICM 주사를 통해 대상체에게 투여하는 단계를 포함하는, 전이유전자를 포함하는 AAV 벡터의 척수강내 투여 후 대상체의 간으로 전이유전자의 전달을 개선하는 방법이 본원에서 제공되며, 상기 간의 형질도입 수준은 AAV1, AAV9, 및/또는 AAV6.2 캡시드를 갖는 AAV 벡터로 달성되는 수준에 비해 증가된다.
일 측면에서, AAVrh91 캡시드 및 간의 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함하는 재조합 AAV 벡터를 정맥내 주사를 통해 대상체에게 투여하는 단계를 포함하는, 대상체에게 AAV 벡터를 전신 투여한 후 간을 탈표적화하고/하거나 간 독성을 감소시키는 방법이 본원에서 제공되며, 상기 AAV 벡터의 투여 후 관찰되는 간의 형질도입 수준 및/또는 간 독성은 AAV1, AAV8, 및/또는 AAV9 캡시드를 갖는 AAV 벡터에 비해 감소된다. 특정 구현예에서, 상기 AAVrh91 캡시드는 서열번호 2의 아미노산 서열을 포함하는 캡시드 단백질을 포함한다. 특정 구현예에서, 상기 AAVrh91 캡시드는 서열번호 1 또는 3의 뉴클레오티드 서열, 또는 서열번호 1 또는 3의 뉴클레오티드 서열을 적어도 90%, 적어도 95%, 적어도 97%, 적어도 98% 또는 적어도 99% 공유하는 서열의 발현에 의해 생성되는 캡시드 단백질을 포함한다. 특정 구현예에서, 상기 AAVrh91 캡시드는 캡시드 단백질을 포함하고, 상기 캡시드 단백질은 서열번호 1 또는 3의 뉴클레오티드 서열에 의해 암호화된다. 특정 구현예에서, 상기 AAVrh91 캡시드는 (1) 서열번호 2의 1 내지 736번의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp1 단백질, 서열번호 1 또는 3으로부터 생성되는 vp1 단백질, 또는 서열번호 2의 1 내지 736번의 예상되는 아미노산 서열을 암호화하는 서열번호 1 또는 3과 적어도 70% 동일한 핵산 서열로부터 생성되는 vp1 단백질로부터 선택되는 AAVrh91 vp1 단백질의 이종 집단, 서열번호 2의 적어도 약 138 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp2 단백질, 서열번호 1 또는 3의 적어도 412 내지 2208번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp2 단백질, 또는 서열번호 2의 적어도 약 138 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 서열번호 1 또는 3의 적어도 412 내지 2208번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp2 단백질로부터 선택되는 AAVrh91 vp2 단백질의 이종 집단, 서열번호 2의 적어도 약 203 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp3 단백질, 서열번호 1 또는 3의 적어도 607 내지 2208번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp3 단백질, 또는 서열번호 2의 적어도 약 203 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 서열번호 1 또는 3의 적어도 607 내지 2208번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp3 단백질로부터 선택되는 AAVrh91 vp3 단백질의 이종 집단; 및/또는 (2) 서열번호 2의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp1 단백질의 이종 집단, 서열번호 2의 적어도 약 138 내지 736번 아미노산의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp2 단백질의 이종 집단, 및 서열번호 2의 적어도 203 내지 736번 아미노산을 암호화하는 핵산 서열의 산물인 vp3 단백질의 이종 집단으로서, 상기 vp1, vp2 및 vp3 단백질은 서열번호 2의 아스파라긴-글리신 쌍에서 적어도 2개의 고도로 탈아미드화된 아스파라긴(N)을 포함하고 선택적으로 다른 탈아미드화된 아미노산을 포함하는 하위집단을 더 포함하는 아미노산 변형을 갖는 하위집단을 포함하고, 상기 탈아미드화는 아미노산 변화를 초래하는, 상기 vp1 단백질의 이종 집단, 상기 vp2 단백질의 이종 집단 및 상기 vp3 단백질의 이종 집단:을 포함하는 캡시드 단백질을 포함한다.
일 측면에서, 재조합 AAV를 생성하는 데 유용한 재조합 AAV 생산 시스템이 본원에서 제공되며, 상기 생산 시스템은 (a) 위치 418, 547, 584, 588, 598, 및/또는 642번 중 하나 이상에서 아미노산 치환을 갖는 AAV 캡시드 단백질을 암호화하는 뉴클레오티드 서열(서열번호 2와 정렬되는 경우); (b) AAV 캡시드 내로 패키징하기에 적합한 핵산 분자로서, 상기 핵산 분자는 적어도 하나의 AAV 반전 말단 반복부(ITR) 및 숙주 세포에서 산물의 발현을 지시하는 서열에 작동가능하게 연결된 유전자 산물을 암호화하는 비-AAV 핵산 서열을 포함하는, 핵산 분자; 및 (c) AAV 캡시드 내로 핵산 분자의 패키징을 허용하기에 충분한 AAV rep 기능 및 헬퍼 기능:을 포함한다. 특정 구현예에서, 상기 (a)의 뉴클레오티드 서열은 나열된 위치 중 하나 이상에서 치환을 갖는 클레드 A 캡시드 단백질을 암호화한다. 특정 구현예에서, 상기 (a)의 뉴클레오티드 서열은 나열된 위치 중 하나 이상에서 아미노산 치환을 갖는 AAV1, AAVhu48R3, AAVhu48, AAVhu44, AAV.VR-355, AAV.VR-195, AAV6, 또는 AAV6.2 캡시드 단백질을 암호화한다. 특정 구현예에서, 상기 (a)의 뉴클레오티드 서열은 418번 위치에서의 Asp, 547번 위치에서의 Asn, 584번 위치에서의 Leu, 588번 위치에서의 Asn, 598번 위치에서의 Val, 및 642번 위치에서의 His로부터 선택되는 하나 이상의 아미노 치환을 갖는 캡시드 단백질의 아미노산 서열을 암호화한다. 특정 구현예에서, 상기 (a)의 뉴클레오티드 서열은 Glu418, Ser547, Phe584, Ser588, Ala598, 및/또는 Asn642에서 아미노산 치환을 갖는 서열번호 8(AAV1)의 아미노산 서열을 암호화하고, 상기 암호화된 아미노산 서열은 서열번호 8과 적어도 95% 동일하거나 적어도 99% 동일하다. 특정 구현예에서, 상기 (a)의 뉴클레오티드 서열은 418번 위치에서의 Asp, 547번 위치에서의 Asn, 584번 위치에서의 Leu, 588번 위치에서의 Asn, 598번 위치에서의 Val, 및 642번 위치에서의 His로부터 선택되는 하나 이상의 아미노 치환을 갖는 서열번호 8(AAV1)의 아미노산 서열을 암호화하고, 상기 암호화된 아미노산 서열은 서열번호 8과 적어도 95% 동일하거나 적어도 99% 동일하다. 특정 구현예에서, 상기 생산 시스템은 인간 배아 신장 293 세포를 포함한다.
일 측면에서, 재조합 AAV를 생성하는 방법이 본원에서 제공되며, (a) 위치 418, 547, 584, 588, 598, 및 642번 중 하나 이상에서 아미노산 치환을 갖는 AAV 캡시드 단백질을 암호화하는 핵산 분자(서열번호 2와 정렬되는 경우); (b) 기능성 rep 유전자; (c) AAV 5' ITR, AAV 3' ITR, 및 전이유전자를 포함하는 미니유전자; 및 (d) AAV 캡시드 내로 미니유전자의 패키징을 허용하기에 충분한 헬퍼 기능을 포함하는 숙주 세포를 배양하는 단계를 포함한다. 특정 구현예에서, 상기 생성된 재조합 AAV는 비변형 캡시드 단백질에 비해 개선된 생산 수율 및/또는 변경된 세포 또는 조직 친화성을 갖는다. 특정 구현예에서, 상기 생성된 재조합 AAV는 비변형 캡시드 단백질에 비해 더 높은 수준으로 CNS의 세포를 형질도입한다. 특정 구현예에서, 상기 (a)의 뉴클레오티드 서열은 나열된 위치 중 하나 이상에서 치환을 갖는 클레드 A 캡시드 단백질을 암호화한다. 특정 구현예에서, 상기 (a)의 뉴클레오티드 서열은 나열된 치환 중 하나 이상을 갖는 AAV1, AAVhu48R3, AAVhu48, AAVhu44, AAV.VR-355, AAV.VR-195, AAV6, 또는 AAV6.2 캡시드를 암호화한다. 특정 구현예에서, 상기 (a)의 뉴클레오티드 서열은 418번 위치에서의 Asp, 547번 위치에서의 Asn, 584번 위치에서의 Leu, 588번 위치에서의 Asn, 598번 위치에서의 Val, 및 642번 위치에서의 His로부터 선택되는 하나 이상의 아미노 치환을 갖는 캡시드 단백질의 아미노산 서열을 암호화한다. 특정 구현예에서, 상기 (a)의 뉴클레오티드 서열은 Glu418, Ser547, Phe584, Ser588, Ala598, 및/또는 Asn642에서 아미노산 치환을 갖는 서열번호 8(AAV1)의 아미노산 서열을 암호화하고, 상기 암호화된 아미노산 서열은 서열번호 8과 적어도 95% 동일하거나 적어도 99% 동일하다. 특정 구현예에서, 상기 (a)의 뉴클레오티드 서열은 418번 위치에서의 Asp, 547번 위치에서의 Asn, 584번 위치에서의 Leu, 588번 위치에서의 Asn, 598번 위치에서의 Val, 및 642번 위치에서의 His로부터 선택되는 하나 이상의 아미노 치환을 갖는 서열번호 8(AAV1)의 아미노산 서열을 암호화하고, 상기 암호화된 아미노산 서열은 서열번호 8과 적어도 95% 동일하거나 적어도 99% 동일하다.
일 측면에서, 대상체의 중추신경계(CNS)의 하나 이상의 표적 세포에 전이유전자를 전달하는 데 사용하기 위한 재조합 AAV 벡터가 본원에서 제공되며, 상기 재조합 AAV 벡터는 AAVrh91 캡시드 및 CNS의 표적 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함한다. 특정 구현예에서, 상기 CNS의 표적 세포는 실질 세포, 맥락막총의 세포, 뇌실막 세포, 성상교세포, 및/또는 및 뉴런, 선택적으로 피질, 해마, 및/또는 선조체의 뉴런이다. 특정 구현예에서, 상기 전이유전자는 분비된 유전자 산물을 암호화한다. 특정 구현예에서, 상기 AAV 벡터는 선택적으로 대조내(ICM) 주사를 통해 척수강내로 투여된다. 특정 구현예에서, 상기 AAV 벡터는 뇌실질내 투여를 통해 전달된다.
일 측면에서, 전이유전자를 포함하는 AAV 벡터의 척수강내 투여 후 대상체의 간으로 전이유전자를 전달하는 데 사용하기 위한 재조합 AAV 벡터가 본원에서 제공되며, 상기 재조합 AAV 벡터는 AAVrh91 캡시드 및 간의 표적 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함하고, 상기 간의 트랜잭션(transaction) 수준은 AAV1, AAV9, 및/또는 AAV6.2 캡시드를 갖는 AAV 벡터로 달성되는 수준에 비해 증가된다.
일 측면에서, 대상체에게 AAV 벡터를 전신 투여한 후 간을 탈표적화하고/하거나 간 독성을 감소시키는 데 사용하기 위한 재조합 AAV 벡터가 본원에서 제공되며, 상기 재조합 AAV 벡터는 AAVrh91 캡시드 및 간의 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함하고, 상기 AAV 벡터의 투여 후 관찰되는 간의 형질도입 수준 및/또는 간 독성은 AAV1, AAV8, 및/또는 AAV9 캡시드를 갖는 AAV 벡터에 비해 감소된다.
이들 조성물 및 방법의 다른 측면 및 이점은 하기 상세한 설명에서 추가로 기술된다.
도 1은 AAV-SGA 작업 흐름에 대한 다이어그램을 도시한다. 게놈 DNA를 히말라야 원숭이(rhesus macaque) 조직 샘플로부터 단리하고 AAV 캡시드 유전자의 존재에 대해 스크리닝하였다. AAV-양성 DNA를 종점 희석시키고 추가 라운드의 PCR에 적용하였다. 푸아송 분포(Poisson distribution)에 따르면, 웰의 30% 이하에서 PCR 산물을 산출하는 DNA 희석은 시간의 80%에서 양성 PCR당 하나의 증폭 가능한 DNA 주형을 포함한다. Illumina MiSeq 2×150 또는 2×250쌍 말단 시퀀싱 플랫폼을 사용하여 양성 앰플리콘을 시퀀싱하고, 결과 판독물을 SPAdes 어셈블러를 사용하여 새로 조립하였다.
도 2는 신규 AAV 자연 분리주 및 대표적인 클레드 대조군의 DNA 게놈 서열의 이웃-결합 계통발생을 나타내는 다이어그램이다.
도 3a 내지 도 3d는 AAVrh91(서열번호 1), AAVrh91eng(서열번호 3), AAV6.2(서열번호 5) 및 AAV1(서열번호 7) 캡시드에 대한 핵산 서열에 대한 정렬을 나타낸다.
도 4a 내지 도 4b는 AAVrh91(서열번호 2), AAV6.2(서열번호 6) 및 AAV1(서열번호 8) 캡시드에 대한 아미노산 서열의 정렬을 나타낸다.
도 5a 내지 도 5b는 벡터 수율을 평가하기 위한 Huh7(도 15a) 및 HEK293 세포(도 15b)의 시험관내 형질도입의 분석을 나타낸다. AAV.CB7.CI.ffLuc 전이유전자 발현을 루시퍼라제 활성 분석으로 분석하였다. 벡터는 1x1010 GC/mL의 농도로 세포에 투여하였다. n = 3. 평균 및 SD로 표시된 데이터; * p < 0.01.
도 6a 내지 도 6b는 정제 후 벡터 생산 수율의 분석을 나타낸다. (도 6a) 캡시드를 기반으로 한 평균 벡터 수율. (도 6b) 전이유전자를 기반으로 한 클레드 A 캡시드 벡터 수율. 평균 및 SD로 표시된 데이터; * p < 0.01.
도 7a 내지 도 7c는 AAVrh91 벡터 제제의 질량 분석기 분석 결과를 나타낸다.
도 8a 내지 도 8d는 주사 후 14일째 마우스 조직에서 eGFP 전이유전자 생체분포를 나타낸다. (도 8a 및 도 8b) C57BL/6 마우스에 CB7.CI.eGFP.WPRE.RBG를 포함하는 AAV 캡시드를 마우스당 1 x 1012 GC의 용량으로 IV 주사하였다(n=5). (도 8c 및 도 8d) C57BL/6 마우스에 CB7.CI.eGFP.WPRE.RBG를 포함하는 다양한 AAV 캡시드(6.9x1010 GC/마우스에서 투약된 클레드 A 벡터)를 마우스당 1x1011 GC의 용량으로 뇌실내로 ICV 주사하였다(n=5). 값은 평균±SD로 표현되어 있으며; * p < 0.01, ** p < 0.001.
도 9a 내지 도 9b는 AAV 벡터의 IM 전달 후 골격근에서 β-갈락토시다제 발현의 분석을 나타낸다. 다양한 캡시드를 갖고 pAAV.CMV.LacZ 전이유전자를 포함하는 벡터의 3x109 GC를 마우스에 투여하였다. 20일째에, 근육 조직을 수확하고, X-gal 염색(어두운 염색)에 의해 전이유전자 발현을 평가하였다.
도 10은 다양한 AAV 벡터의 IM 전달 후 혈청 내 mAb의 수준을 나타낸다. B6 마우스에 tMCK 프로모터 하에서 3D6 항체를 발현하는 벡터의 1x1011 GC를 투여하였다.
도 11은 3D6 또는 LacZ 전이유전자를 발현하는 벡터에 대한 (AAV8에 대한) 수율을 나타낸다.
도 12는 NHP에서 풀링된 바코딩된 벡터 연구에 대한 실험 설계를 나타낸다 (데이터는 도 13a 내지 도 13d에 나타냄). 5개의 신규 캡시드 및 5개의 대조군(AAVrh.90, AAVrh91, AAVrh.92, AAVrh.93, AAVrh91.93, AAV8, AAV6.2, AAVrh32.33, AAV7 및 AAV9)을 고유한 6 bp 바코드가 있는 변형된 ATG-결핍 GFP 전이유전자로 패키징하였다. 벡터를 동일한 양으로 풀링하고 필리핀 원숭이(cynomologus macaque)에 IV 또는 ICM 주사하였다(총 용량: 2x1013 GC/kg IV 및 3x1013 GC ICM). IV 주사한 동물은 기준선에서 AAV6, AAV8, 및 AAVrh32.33에 대해 혈청음성이었고 중화 항체 역가가 AAV7 및 AAV9에 대하여 각각 1:5 및 1:10이었다.
도 13a 내지 도 13d는 IV 전달(도 13a 및 도 13b) 및 ICM 전달(도 13c 및 도 13d) 후 바코딩된 캡시드의 RNA 발현 분석을 나타내는 그래프이다. IV 투여 - 2x1013 GC/kg 총 용량, 30일째 부검. ICM 투여 - 3x1013 GC/kg GC/동물, 30일째 부검. 각각의 조직 RNA 샘플에서 바코드 빈도를 각각의 바코드가 혼합물에서 동등한 표현(10%)을 갖도록 주사 주입 물질의 빈도로 정규화하였다. 10개 벡터의 주입량은 8.5 내지 12%의 범위였다. 값은 평균±SEM으로 표현되어 있으며, ** p < 0.001이다.
도 14는 14 dpi에서 마우스 내 AAVrh91 및 AAV6.2 벡터의 IV 전달 후 GFP 발현 현미경 분석을 나타낸다. C57BL/6 마우스에 pAAV.CB7.CI.eGFP.WPRE.RBG 전이유전자를 포함하는 벡터를 1x1012 GC/마우스, n=5의 용량으로 IV 주사하였다. 간, 심장, 뇌 및 근육의 대표 이미지는 직접 형광에 의한 GFP 전이유전자 발현을 나타낸다.
도 15는 14dpi에서 마우스 내 ICV 전달 후 신규 AAV 벡터의 GFP 발현 현미경 분석을 나타낸다. C57BL/6 마우스에 pAAV.CB7.CI.eGFP.WPRE.RBG 전이유전자를 포함하는 벡터, n=5를 주사하였다. 클레드 A 벡터 형질도입된 뇌실막 세포 및 맥락막총에 대한 GFP 형광의 대표 이미지를 나타낸다. 스케일 바: 100 μm.
도 16a 내지 도 16c는 히말라야 원숭이의 CNS 조직 내 ICM 전달 후 GFP 전이유전자 발현에 대한 면역화학염색을 나타낸다. 동물에게 pAAV.CB7.CI.eGFP.WPRE.rBG 전이유전자를 포함하는 벡터 1.6x1013 GC를 ICM 주사를 통해 투여하였다. 뇌(도 16a), 측뇌실(도 16b) 및 척수(도 16c) 내 벡터의 형질도입은 28-31 dpi로 평가하였다. n = 그룹당 2마리. 동물 ID는 우측 상단 모서리에 있음. 스케일 바: 100 μm.
도 17은 히말라야 원숭이의 간 및 심장 조직 내 ICM 전달 후 GFP 전이유전자 발현에 대한 면역화학염색을 나타낸다. 동물에게 pAAV.CB7.CI.eGFP.WPRE.rBG 전이유전자를 포함하는 벡터 1.6x1013 GC를 ICM 주사를 통해 투여하였다. 간 및 심장 내 벡터의 형질도입은 28-31 dpi로 평가하였다. n = 그룹당 2마리. 동물 ID는 우측 상단 모서리에 있음. 스케일 바: 100 μm.
도 18a 내지 도 18e는 NHP 내 ICM 전달 후 신규 벡터 AAVrh91의 세포 친화성에 대한 분석을 나타낸다. 동물에게 pAAV.CB7.CI.eGFP.WPRE.rBG 전이유전자를 포함하는 벡터 1.6x1013 GC를 ICM 주사를 통해 제공하였다. 벡터의 형질도입은 28-31 dpi로 평가하였다. n = 캡시드당 2 NHP. 도 18a 및 도 18b에서 확인된 뇌 절편 내 성상교세포(도 18c) 및 뉴런(도 18d)에서 AAV9에 대한 평균 GFP 발현의 정량화. (도 18e) 뇌의 하위영역에서 AAVrh91 및 AAV9 뉴런 형질도입의 정량화. Ctx.: 피질, Fr.: 전두, Temp.: 측두, Par.: 두정, Occ.: 후두, Str.: 선조체, Thal.: 시상, Hip.: 해마. AAVrh91은 ICM 전달 후 NHP 뇌에서 AAV9보다 더 높은 비율의 뉴런 및 성상교세포를 형질도입한다.
도 19a 내지 도 19c는 AAVrh91, AAV1, 및 AAV9 캡시드를 NHP로 ICM 전달 후 벡터 전이유전자의 생체분포를 나타낸다. 동물에게 pAAV.CB7.CI.eGFP.WPRE.rBG 전이유전자를 포함하는 벡터 1.6x1013 GC를 투여하였다. n = 캡시드 당 2 NHP. 벡터의 생체분포는 피질(도 19a) 및 뇌의 비피질 영역(도 19b) 및 척수(도 19c)에서 qPCR 28-31 dpi로 평가하였다. 평균 및 SEM으로 보고된 값. 동물: AAVrh91 (1409201 및 1407088), AAV1 (RA3654 및 RA3583), AAV9 (1408266 및 1409029).
도 20은 동물로 그룹화된 도 19a 내지 도 19c에 보고된 모든 CNS 조직에서 평균 GC 수준을 나타낸다. *p < 0.05, **p < 0.01, ****p < 0.0001. 동물: AAVrh91 (1409201 및 1407088), AAV1 (RA3654 및 RA3583), AAV9 (1408266 및 1409029).
도 21a 내지 도 21b는 인간 개체군에서 AAVrh91의 혈청 유병률을 나타낸다. AAV2, AAV8, AAVrh32.33 및 AAVrh91에 대한 항-캡시드 중화 항체(NAb)는 50개의 무작위 인간 혈청 샘플에 대해 평가하였다. (도 21a) 다양한 캡시드에 대한 NAb의 혈청 유병률 및 (도 21b) NAb 반응의 크기.
도 22a 내지 도 22f는 C57BL/6J 마우스에서 IV 투여 후 AAV1, AAV8, AAV9, 및 AAVrh91의 생체분포를 나타낸다. 성체 C57BL/6J 마우스 (n=5/그룹)에 CB7 프로모터로부터 GFP를 발현하는 AAV1, AAV8, AAV9 또는 AAVrh91의 1011 또는 1012 GC/마우스를 IV로 주사하였다. 벡터 투여 후 21일째에 마우스를 부검하였다. 간(도 22a), 비장(도 22b), 심장(도 22c), 골격근(비복근; 도 22d), 뇌(도 22e) 및 척수(도 22f)를 qPCR로 벡터 게놈 복제물 및 벡터-유래 RNA 전사물 평가를 위해 수확하였다.
도 23a 내지 도 23d는 히말라야 원숭이에서 AAV9와 비교하여 AAVrh91의 유전자 발현이 강화된 심장 및 골격근과 감소된 간을 나타낸다. 히말라야 원숭이에게 5x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 IV로 투여하였다. 벡터 투여 후 21일째에 동물을 부검하였다. (도 23a) DNA 및 (도 23b) RNA를 추출하고 벡터-유래 서열을 qPCR로 정량하였다. GFP 단백질 발현은 정량화된 이미지와 함께 ELISA(도 23c) 또는 IHC(도 23d)에 의해 결정되었다.
도 24a 내지 도 24c는 히말라야 원숭이의 대부분의 근육 그룹에 걸쳐 AAVrh91의 형질도입으로 강화된 골격근을 나타낸다. 히말라야 원숭이에게 5x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 IV로 투여하였다. 벡터 투여 후 21일째에 동물을 부검하고, 13개의 골격근 그룹으로부터 샘플을 수확하였다. (도 24a) DNA 및 (도 24b) RNA를 추출하고 벡터-유래 서열을 qPCR로 정량하였다. GFP 단백질 발현은 ELISA(도 24c)에 의해 결정되었다. 각 근육 그룹에 대해 좌측 점 세트는 AAV9이고 우측 점 세트는 AAVrh91이다.
도 25는 AAV9 및 AAVrh91을 IV 투여한 후의 간 변성 및 개별 세포 괴사를 나타낸다. 히말라야 원숭이에게 5x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 IV로 투여하였다.
도 26a 내지 도 26b는 AAV9 및 AAVrh91을 IV로 투여한 후 히말라야 원숭이의 임상 병리 평가를 나타낸다. 히말라야 원숭이에게 5x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 IV로 투여하였다. (도 26a) ALT, AST, 알칼리 포스파타제, GGT, 총 빌리루빈, (도 26b) 프로트롬빈 시간(PT), APTT 및 혈소판 수의 평가를 위한 혈액 샘플을 본 연구의 생존 단계에 걸쳐 채취하였다. 벡터 투여 후 21일째에 동물을 부검하였다.
도 27a 내지 도 27b는 AAV9 및 AAVrh91을 ICM 투여한 후 히말라야 원숭이의 임상 병리 평가를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 ICM 투여하였다. (도 27a) AST, ALT, 알칼리 포스파타제, GGT, 총 빌리루빈, (도 27b) 프로트롬빈 시간(PT), APTT, 혈소판 수, CSF 백혈구 수의 평가를 위한 혈액 샘플을 본 연구의 생존 단계에 걸쳐 채취하였다. 벡터 투여 후 14일째에 동물을 부검하였다.
도 28a 내지 도 28c는 AAV9 및 AAVrh91을 ICM 투여한 후의 생체분포를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP를 ICM 투여하였다. 부검은 14일째에 수행하였다.
도 29a 내지 도 29i는 DRG에서 GFP 양성 감각 뉴런의 정량화를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 ICM 투여하였다. (도 29a) 조직 절편에서 GFP를 검출하기 위해 면역조직화학을 수행하였고, 이미징 소프트웨어를 사용하여 슬라이드를 평가하였다. 경추 분절 DRG의 분석을 위한 데이터는 GFP+ 세포/mm2(도 29b 및 도 29c) 및 GFP 양성 면적%(도 29d 및 도 29e)로 나타낸다. 요추 분절 DRG의 분석을 위한 데이터는 GFP+ 세포/mm2(도 29f 및 도 29g) 및 GFP 양성 면적%(도 29h 및 도 29i)으로 나타낸다.
도 30a 내지 도 30g는 척수 분절에서 GFP 양성 운동 뉴런의 정량화를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 ICM 투여하였다. (도 30a) 조직 절편에서 GFP를 검출하기 위해 면역조직화학을 수행하였고, 이미징 소프트웨어를 사용하여 슬라이드를 평가하였다. GFP 양성 뉴런은 경추 분절의 전각(ventral horn) (도 30b 및 도 30c), 흉부 분절의 전각(도 30d 및 도 30e) 및 요추 분절의 전각(도 30f 및 도 30g)에서 수동으로 계수하였다.
도 31a 내지 도 31c는 후두 피질의 뉴런에서 GFP 양성 세포의 정량화를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 ICM 투여하였다. (도 31a) 조직 절편에서 GFP를 검출하기 위해 면역조직화학을 수행하였고, 이미징 소프트웨어를 사용하여 슬라이드를 평가하였다. GFP 양성 뉴런을 수동으로 계수하였다(도 31b 및 도 31c).
도 32는 AAV9 및 AAVrh91의 ICM 투여 후 신경 전도 속도 평가를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.2.10mAb(n=3/그룹)를 ICM 투여하였다. 평가는 기준선과 생존 단계 동안 수행되었다.
도 33a 내지 도 33b는 AAV9 및 AAVrh91의 ICM 투여 후 CSF 및 혈청 내 전이유전자의 농도를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.2.10mAb(n=3/그룹)를 ICM 투여하였다. 혈청(도 33a) 및 CSF(도 33b)를 2.10mAb 발현에 대해 모니터링하였다.
도 34a 내지 도 34b는 AAV9 및 AAVrh91의 ICM 투여 후 생체분포를 나타낸다.히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.2.10mAb (n=3/그룹)를 ICM 투여하였다. 벡터 투여 후 90일째에 부검을 수행하였다.
도 35a 내지 도 35f는 AAVrh91과 AAV1 캡시드 간의 구조적 차이를 나타낸다. AAVrh91의 구조는 저온EM을 사용하여 2.33 Å의 분해능으로 해석하였고, AAV1(6JCR)에 대해 공개된 구조와 비교하였다. 2개의 캡시드 간에 상이한 VP3의 아미노산은 위치 (도 35a) 418, (도 35b) 547, (도 35c) 584, (도 35d) 588, (도 35e) 598 및 (도 35f) 642에 위치하며, 이들의 구조적 맥락에서 제시된다. 지정된 위치의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 지정된 잔기와 밀접한 접촉을 형성하는 아미노산은 텍스트로 표시된다. 각 잔기에 대한 사슬-내 및 사슬-간 접촉은 A 또는 B의 문자 지정으로 표시된다. 도 35a는 동일한 위치의 AAV1 Glu 418과 비교하여, 이의 구조적 맥락에서 AAVrh91 Asp 418 아미노산 잔기를 나타낸다. 위치 418의 잔기에 매우 근접한 아미노산 Arg 308, Lys 310 및 Glu 686도 표시되어 있다. 위치 418의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 표지된 모든 아미노산은 동일한 폴리펩티드 사슬에 위치하며, 위치 418의 잔기와 사슬-내 접촉을 형성한다. 도 35b는 동일한 위치의 AAV1 Ser 547과 비교하여 구조적 맥락에서 AAVrh91 Asn 547 아미노산 잔기를 나타낸다. 위치 547의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 도 35c는 동일한 위치의 AAV1 Phe 584와 비교하여 이의 구조적 맥락에서 AAVrh91 Leu 584 아미노산 잔기를 나타낸다. 위치 584의 잔기에 매우 근접한 아미노산 Arg 485, Arg 488, Lys 528, Glu 531, Phe 534, Thr 574 및 Glu575도 표시되어 있다. 위치 584의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 체인-간 접촉은 A 또는 B의 문자 지정으로 표시된다. 위치 584의 아미노산은 A로 표시되고, B로 표시되는 주변 잔기는 인접한 폴리펩티드 사슬에서 발견된다. 도 35d는 동일한 위치에 있는 AAV1 Ser 588과 비교하여, 3-중 스파이크 구조의 끝에 있는 AAVrh91 Asn 588 아미노산 잔기를 나타낸다. 위치 588의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 도 35e는 동일한 위치의 AAV1 Ala 598과 비교하여, 이의 구조적 맥락에서 AAVrh91 Val 598 아미노산 잔기를 나타낸다. 위치 598의 잔기에 매우 근접한 아미노산 Tyr 484, Val 580, Val 596, Met 599 및 Leu 602도 표시되어 있다. 위치 598의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 각 잔기에 대한 사슬-내 및 사슬-간 접촉은 A 또는 B의 문자 지정으로 표시된다. A로 표시된 아미노산은 위치 598의 아미노산과 동일한 폴리펩티드 사슬에 있고, B로 표시된 아미노산은 인접한 사슬에 있다. 도 35f는 동일한 위치의 AAV1 Asn 642와 비교하여 이의 구조적 맥락에서 AAVrh91 His 642 아미노산 잔기를 나타낸다. 위치 642의 잔기에 매우 근접한 아미노산 Tyr 349, Tyr 414, Glu 417 및 Lys 641도 표지되어 있다. 위치 642의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 표지된 모든 아미노산은 동일한 폴리펩티드 사슬에 위치하며, 위치 642의 잔기와 사슬-내 접촉을 형성한다.
도 36a 내지 도 36b는 AAVrh91 암호화 서열 및 조작된 AAVrh91 암호화 서열(AAVrh91eng)을 갖는 전이 플라스미드(trans plasmid)에 대한 AAV 벡터 수율 비교를 나타낸다. 각각의 작제물에 대해, 플라스미드를 재-형질전환하고, 12-웰 플레이트에서 개별 삼중-형질감염을 위해 4개의 클론을 무작위로 선발하였다. 벡터 수율은 두 가지 방법으로 결정하였다 - (도 36a) 생산 역가의 경우 qPCR (도 36b) 감염성 역가의 경우 Huh7 형질도입. 각 실험은 2회 - 반복 1 및 반복 2를 수행하였다.
도 37a 내지 도 37c는 추가 조절 요소를 갖는 전이 플라스미드에 대한 AAV 벡터 수율 비교를 나타낸다. WPRE 및/또는 bGH 폴리A를 포함하는 전이 플라스미드를 생성하였다(도 37a). 벡터 수율은 생산 역가에 대한 qPCR(도 37b) 및 감염성 역가에 대한 Huh7(도 37c) 형질도입의 두 가지 방법으로 결정되었다. 각 실험은 2회 - 반복 1 및 반복 2를 수행하였다.
도 2는 신규 AAV 자연 분리주 및 대표적인 클레드 대조군의 DNA 게놈 서열의 이웃-결합 계통발생을 나타내는 다이어그램이다.
도 3a 내지 도 3d는 AAVrh91(서열번호 1), AAVrh91eng(서열번호 3), AAV6.2(서열번호 5) 및 AAV1(서열번호 7) 캡시드에 대한 핵산 서열에 대한 정렬을 나타낸다.
도 4a 내지 도 4b는 AAVrh91(서열번호 2), AAV6.2(서열번호 6) 및 AAV1(서열번호 8) 캡시드에 대한 아미노산 서열의 정렬을 나타낸다.
도 5a 내지 도 5b는 벡터 수율을 평가하기 위한 Huh7(도 15a) 및 HEK293 세포(도 15b)의 시험관내 형질도입의 분석을 나타낸다. AAV.CB7.CI.ffLuc 전이유전자 발현을 루시퍼라제 활성 분석으로 분석하였다. 벡터는 1x1010 GC/mL의 농도로 세포에 투여하였다. n = 3. 평균 및 SD로 표시된 데이터; * p < 0.01.
도 6a 내지 도 6b는 정제 후 벡터 생산 수율의 분석을 나타낸다. (도 6a) 캡시드를 기반으로 한 평균 벡터 수율. (도 6b) 전이유전자를 기반으로 한 클레드 A 캡시드 벡터 수율. 평균 및 SD로 표시된 데이터; * p < 0.01.
도 7a 내지 도 7c는 AAVrh91 벡터 제제의 질량 분석기 분석 결과를 나타낸다.
도 8a 내지 도 8d는 주사 후 14일째 마우스 조직에서 eGFP 전이유전자 생체분포를 나타낸다. (도 8a 및 도 8b) C57BL/6 마우스에 CB7.CI.eGFP.WPRE.RBG를 포함하는 AAV 캡시드를 마우스당 1 x 1012 GC의 용량으로 IV 주사하였다(n=5). (도 8c 및 도 8d) C57BL/6 마우스에 CB7.CI.eGFP.WPRE.RBG를 포함하는 다양한 AAV 캡시드(6.9x1010 GC/마우스에서 투약된 클레드 A 벡터)를 마우스당 1x1011 GC의 용량으로 뇌실내로 ICV 주사하였다(n=5). 값은 평균±SD로 표현되어 있으며; * p < 0.01, ** p < 0.001.
도 9a 내지 도 9b는 AAV 벡터의 IM 전달 후 골격근에서 β-갈락토시다제 발현의 분석을 나타낸다. 다양한 캡시드를 갖고 pAAV.CMV.LacZ 전이유전자를 포함하는 벡터의 3x109 GC를 마우스에 투여하였다. 20일째에, 근육 조직을 수확하고, X-gal 염색(어두운 염색)에 의해 전이유전자 발현을 평가하였다.
도 10은 다양한 AAV 벡터의 IM 전달 후 혈청 내 mAb의 수준을 나타낸다. B6 마우스에 tMCK 프로모터 하에서 3D6 항체를 발현하는 벡터의 1x1011 GC를 투여하였다.
도 11은 3D6 또는 LacZ 전이유전자를 발현하는 벡터에 대한 (AAV8에 대한) 수율을 나타낸다.
도 12는 NHP에서 풀링된 바코딩된 벡터 연구에 대한 실험 설계를 나타낸다 (데이터는 도 13a 내지 도 13d에 나타냄). 5개의 신규 캡시드 및 5개의 대조군(AAVrh.90, AAVrh91, AAVrh.92, AAVrh.93, AAVrh91.93, AAV8, AAV6.2, AAVrh32.33, AAV7 및 AAV9)을 고유한 6 bp 바코드가 있는 변형된 ATG-결핍 GFP 전이유전자로 패키징하였다. 벡터를 동일한 양으로 풀링하고 필리핀 원숭이(cynomologus macaque)에 IV 또는 ICM 주사하였다(총 용량: 2x1013 GC/kg IV 및 3x1013 GC ICM). IV 주사한 동물은 기준선에서 AAV6, AAV8, 및 AAVrh32.33에 대해 혈청음성이었고 중화 항체 역가가 AAV7 및 AAV9에 대하여 각각 1:5 및 1:10이었다.
도 13a 내지 도 13d는 IV 전달(도 13a 및 도 13b) 및 ICM 전달(도 13c 및 도 13d) 후 바코딩된 캡시드의 RNA 발현 분석을 나타내는 그래프이다. IV 투여 - 2x1013 GC/kg 총 용량, 30일째 부검. ICM 투여 - 3x1013 GC/kg GC/동물, 30일째 부검. 각각의 조직 RNA 샘플에서 바코드 빈도를 각각의 바코드가 혼합물에서 동등한 표현(10%)을 갖도록 주사 주입 물질의 빈도로 정규화하였다. 10개 벡터의 주입량은 8.5 내지 12%의 범위였다. 값은 평균±SEM으로 표현되어 있으며, ** p < 0.001이다.
도 14는 14 dpi에서 마우스 내 AAVrh91 및 AAV6.2 벡터의 IV 전달 후 GFP 발현 현미경 분석을 나타낸다. C57BL/6 마우스에 pAAV.CB7.CI.eGFP.WPRE.RBG 전이유전자를 포함하는 벡터를 1x1012 GC/마우스, n=5의 용량으로 IV 주사하였다. 간, 심장, 뇌 및 근육의 대표 이미지는 직접 형광에 의한 GFP 전이유전자 발현을 나타낸다.
도 15는 14dpi에서 마우스 내 ICV 전달 후 신규 AAV 벡터의 GFP 발현 현미경 분석을 나타낸다. C57BL/6 마우스에 pAAV.CB7.CI.eGFP.WPRE.RBG 전이유전자를 포함하는 벡터, n=5를 주사하였다. 클레드 A 벡터 형질도입된 뇌실막 세포 및 맥락막총에 대한 GFP 형광의 대표 이미지를 나타낸다. 스케일 바: 100 μm.
도 16a 내지 도 16c는 히말라야 원숭이의 CNS 조직 내 ICM 전달 후 GFP 전이유전자 발현에 대한 면역화학염색을 나타낸다. 동물에게 pAAV.CB7.CI.eGFP.WPRE.rBG 전이유전자를 포함하는 벡터 1.6x1013 GC를 ICM 주사를 통해 투여하였다. 뇌(도 16a), 측뇌실(도 16b) 및 척수(도 16c) 내 벡터의 형질도입은 28-31 dpi로 평가하였다. n = 그룹당 2마리. 동물 ID는 우측 상단 모서리에 있음. 스케일 바: 100 μm.
도 17은 히말라야 원숭이의 간 및 심장 조직 내 ICM 전달 후 GFP 전이유전자 발현에 대한 면역화학염색을 나타낸다. 동물에게 pAAV.CB7.CI.eGFP.WPRE.rBG 전이유전자를 포함하는 벡터 1.6x1013 GC를 ICM 주사를 통해 투여하였다. 간 및 심장 내 벡터의 형질도입은 28-31 dpi로 평가하였다. n = 그룹당 2마리. 동물 ID는 우측 상단 모서리에 있음. 스케일 바: 100 μm.
도 18a 내지 도 18e는 NHP 내 ICM 전달 후 신규 벡터 AAVrh91의 세포 친화성에 대한 분석을 나타낸다. 동물에게 pAAV.CB7.CI.eGFP.WPRE.rBG 전이유전자를 포함하는 벡터 1.6x1013 GC를 ICM 주사를 통해 제공하였다. 벡터의 형질도입은 28-31 dpi로 평가하였다. n = 캡시드당 2 NHP. 도 18a 및 도 18b에서 확인된 뇌 절편 내 성상교세포(도 18c) 및 뉴런(도 18d)에서 AAV9에 대한 평균 GFP 발현의 정량화. (도 18e) 뇌의 하위영역에서 AAVrh91 및 AAV9 뉴런 형질도입의 정량화. Ctx.: 피질, Fr.: 전두, Temp.: 측두, Par.: 두정, Occ.: 후두, Str.: 선조체, Thal.: 시상, Hip.: 해마. AAVrh91은 ICM 전달 후 NHP 뇌에서 AAV9보다 더 높은 비율의 뉴런 및 성상교세포를 형질도입한다.
도 19a 내지 도 19c는 AAVrh91, AAV1, 및 AAV9 캡시드를 NHP로 ICM 전달 후 벡터 전이유전자의 생체분포를 나타낸다. 동물에게 pAAV.CB7.CI.eGFP.WPRE.rBG 전이유전자를 포함하는 벡터 1.6x1013 GC를 투여하였다. n = 캡시드 당 2 NHP. 벡터의 생체분포는 피질(도 19a) 및 뇌의 비피질 영역(도 19b) 및 척수(도 19c)에서 qPCR 28-31 dpi로 평가하였다. 평균 및 SEM으로 보고된 값. 동물: AAVrh91 (1409201 및 1407088), AAV1 (RA3654 및 RA3583), AAV9 (1408266 및 1409029).
도 20은 동물로 그룹화된 도 19a 내지 도 19c에 보고된 모든 CNS 조직에서 평균 GC 수준을 나타낸다. *p < 0.05, **p < 0.01, ****p < 0.0001. 동물: AAVrh91 (1409201 및 1407088), AAV1 (RA3654 및 RA3583), AAV9 (1408266 및 1409029).
도 21a 내지 도 21b는 인간 개체군에서 AAVrh91의 혈청 유병률을 나타낸다. AAV2, AAV8, AAVrh32.33 및 AAVrh91에 대한 항-캡시드 중화 항체(NAb)는 50개의 무작위 인간 혈청 샘플에 대해 평가하였다. (도 21a) 다양한 캡시드에 대한 NAb의 혈청 유병률 및 (도 21b) NAb 반응의 크기.
도 22a 내지 도 22f는 C57BL/6J 마우스에서 IV 투여 후 AAV1, AAV8, AAV9, 및 AAVrh91의 생체분포를 나타낸다. 성체 C57BL/6J 마우스 (n=5/그룹)에 CB7 프로모터로부터 GFP를 발현하는 AAV1, AAV8, AAV9 또는 AAVrh91의 1011 또는 1012 GC/마우스를 IV로 주사하였다. 벡터 투여 후 21일째에 마우스를 부검하였다. 간(도 22a), 비장(도 22b), 심장(도 22c), 골격근(비복근; 도 22d), 뇌(도 22e) 및 척수(도 22f)를 qPCR로 벡터 게놈 복제물 및 벡터-유래 RNA 전사물 평가를 위해 수확하였다.
도 23a 내지 도 23d는 히말라야 원숭이에서 AAV9와 비교하여 AAVrh91의 유전자 발현이 강화된 심장 및 골격근과 감소된 간을 나타낸다. 히말라야 원숭이에게 5x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 IV로 투여하였다. 벡터 투여 후 21일째에 동물을 부검하였다. (도 23a) DNA 및 (도 23b) RNA를 추출하고 벡터-유래 서열을 qPCR로 정량하였다. GFP 단백질 발현은 정량화된 이미지와 함께 ELISA(도 23c) 또는 IHC(도 23d)에 의해 결정되었다.
도 24a 내지 도 24c는 히말라야 원숭이의 대부분의 근육 그룹에 걸쳐 AAVrh91의 형질도입으로 강화된 골격근을 나타낸다. 히말라야 원숭이에게 5x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 IV로 투여하였다. 벡터 투여 후 21일째에 동물을 부검하고, 13개의 골격근 그룹으로부터 샘플을 수확하였다. (도 24a) DNA 및 (도 24b) RNA를 추출하고 벡터-유래 서열을 qPCR로 정량하였다. GFP 단백질 발현은 ELISA(도 24c)에 의해 결정되었다. 각 근육 그룹에 대해 좌측 점 세트는 AAV9이고 우측 점 세트는 AAVrh91이다.
도 25는 AAV9 및 AAVrh91을 IV 투여한 후의 간 변성 및 개별 세포 괴사를 나타낸다. 히말라야 원숭이에게 5x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 IV로 투여하였다.
도 26a 내지 도 26b는 AAV9 및 AAVrh91을 IV로 투여한 후 히말라야 원숭이의 임상 병리 평가를 나타낸다. 히말라야 원숭이에게 5x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 IV로 투여하였다. (도 26a) ALT, AST, 알칼리 포스파타제, GGT, 총 빌리루빈, (도 26b) 프로트롬빈 시간(PT), APTT 및 혈소판 수의 평가를 위한 혈액 샘플을 본 연구의 생존 단계에 걸쳐 채취하였다. 벡터 투여 후 21일째에 동물을 부검하였다.
도 27a 내지 도 27b는 AAV9 및 AAVrh91을 ICM 투여한 후 히말라야 원숭이의 임상 병리 평가를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 ICM 투여하였다. (도 27a) AST, ALT, 알칼리 포스파타제, GGT, 총 빌리루빈, (도 27b) 프로트롬빈 시간(PT), APTT, 혈소판 수, CSF 백혈구 수의 평가를 위한 혈액 샘플을 본 연구의 생존 단계에 걸쳐 채취하였다. 벡터 투여 후 14일째에 동물을 부검하였다.
도 28a 내지 도 28c는 AAV9 및 AAVrh91을 ICM 투여한 후의 생체분포를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP를 ICM 투여하였다. 부검은 14일째에 수행하였다.
도 29a 내지 도 29i는 DRG에서 GFP 양성 감각 뉴런의 정량화를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 ICM 투여하였다. (도 29a) 조직 절편에서 GFP를 검출하기 위해 면역조직화학을 수행하였고, 이미징 소프트웨어를 사용하여 슬라이드를 평가하였다. 경추 분절 DRG의 분석을 위한 데이터는 GFP+ 세포/mm2(도 29b 및 도 29c) 및 GFP 양성 면적%(도 29d 및 도 29e)로 나타낸다. 요추 분절 DRG의 분석을 위한 데이터는 GFP+ 세포/mm2(도 29f 및 도 29g) 및 GFP 양성 면적%(도 29h 및 도 29i)으로 나타낸다.
도 30a 내지 도 30g는 척수 분절에서 GFP 양성 운동 뉴런의 정량화를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 ICM 투여하였다. (도 30a) 조직 절편에서 GFP를 검출하기 위해 면역조직화학을 수행하였고, 이미징 소프트웨어를 사용하여 슬라이드를 평가하였다. GFP 양성 뉴런은 경추 분절의 전각(ventral horn) (도 30b 및 도 30c), 흉부 분절의 전각(도 30d 및 도 30e) 및 요추 분절의 전각(도 30f 및 도 30g)에서 수동으로 계수하였다.
도 31a 내지 도 31c는 후두 피질의 뉴런에서 GFP 양성 세포의 정량화를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.eGFP(n=3/그룹)를 ICM 투여하였다. (도 31a) 조직 절편에서 GFP를 검출하기 위해 면역조직화학을 수행하였고, 이미징 소프트웨어를 사용하여 슬라이드를 평가하였다. GFP 양성 뉴런을 수동으로 계수하였다(도 31b 및 도 31c).
도 32는 AAV9 및 AAVrh91의 ICM 투여 후 신경 전도 속도 평가를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.2.10mAb(n=3/그룹)를 ICM 투여하였다. 평가는 기준선과 생존 단계 동안 수행되었다.
도 33a 내지 도 33b는 AAV9 및 AAVrh91의 ICM 투여 후 CSF 및 혈청 내 전이유전자의 농도를 나타낸다. 히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.2.10mAb(n=3/그룹)를 ICM 투여하였다. 혈청(도 33a) 및 CSF(도 33b)를 2.10mAb 발현에 대해 모니터링하였다.
도 34a 내지 도 34b는 AAV9 및 AAVrh91의 ICM 투여 후 생체분포를 나타낸다.히말라야 원숭이에게 3x1013 GC/kg의 AAV9 또는 AAVrh91.CB7.2.10mAb (n=3/그룹)를 ICM 투여하였다. 벡터 투여 후 90일째에 부검을 수행하였다.
도 35a 내지 도 35f는 AAVrh91과 AAV1 캡시드 간의 구조적 차이를 나타낸다. AAVrh91의 구조는 저온EM을 사용하여 2.33 Å의 분해능으로 해석하였고, AAV1(6JCR)에 대해 공개된 구조와 비교하였다. 2개의 캡시드 간에 상이한 VP3의 아미노산은 위치 (도 35a) 418, (도 35b) 547, (도 35c) 584, (도 35d) 588, (도 35e) 598 및 (도 35f) 642에 위치하며, 이들의 구조적 맥락에서 제시된다. 지정된 위치의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 지정된 잔기와 밀접한 접촉을 형성하는 아미노산은 텍스트로 표시된다. 각 잔기에 대한 사슬-내 및 사슬-간 접촉은 A 또는 B의 문자 지정으로 표시된다. 도 35a는 동일한 위치의 AAV1 Glu 418과 비교하여, 이의 구조적 맥락에서 AAVrh91 Asp 418 아미노산 잔기를 나타낸다. 위치 418의 잔기에 매우 근접한 아미노산 Arg 308, Lys 310 및 Glu 686도 표시되어 있다. 위치 418의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 표지된 모든 아미노산은 동일한 폴리펩티드 사슬에 위치하며, 위치 418의 잔기와 사슬-내 접촉을 형성한다. 도 35b는 동일한 위치의 AAV1 Ser 547과 비교하여 구조적 맥락에서 AAVrh91 Asn 547 아미노산 잔기를 나타낸다. 위치 547의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 도 35c는 동일한 위치의 AAV1 Phe 584와 비교하여 이의 구조적 맥락에서 AAVrh91 Leu 584 아미노산 잔기를 나타낸다. 위치 584의 잔기에 매우 근접한 아미노산 Arg 485, Arg 488, Lys 528, Glu 531, Phe 534, Thr 574 및 Glu575도 표시되어 있다. 위치 584의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 체인-간 접촉은 A 또는 B의 문자 지정으로 표시된다. 위치 584의 아미노산은 A로 표시되고, B로 표시되는 주변 잔기는 인접한 폴리펩티드 사슬에서 발견된다. 도 35d는 동일한 위치에 있는 AAV1 Ser 588과 비교하여, 3-중 스파이크 구조의 끝에 있는 AAVrh91 Asn 588 아미노산 잔기를 나타낸다. 위치 588의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 도 35e는 동일한 위치의 AAV1 Ala 598과 비교하여, 이의 구조적 맥락에서 AAVrh91 Val 598 아미노산 잔기를 나타낸다. 위치 598의 잔기에 매우 근접한 아미노산 Tyr 484, Val 580, Val 596, Met 599 및 Leu 602도 표시되어 있다. 위치 598의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 각 잔기에 대한 사슬-내 및 사슬-간 접촉은 A 또는 B의 문자 지정으로 표시된다. A로 표시된 아미노산은 위치 598의 아미노산과 동일한 폴리펩티드 사슬에 있고, B로 표시된 아미노산은 인접한 사슬에 있다. 도 35f는 동일한 위치의 AAV1 Asn 642와 비교하여 이의 구조적 맥락에서 AAVrh91 His 642 아미노산 잔기를 나타낸다. 위치 642의 잔기에 매우 근접한 아미노산 Tyr 349, Tyr 414, Glu 417 및 Lys 641도 표지되어 있다. 위치 642의 아미노산은 검은색으로 표시되고, 다른 모든 아미노산은 회색으로 표시된다. 표지된 모든 아미노산은 동일한 폴리펩티드 사슬에 위치하며, 위치 642의 잔기와 사슬-내 접촉을 형성한다.
도 36a 내지 도 36b는 AAVrh91 암호화 서열 및 조작된 AAVrh91 암호화 서열(AAVrh91eng)을 갖는 전이 플라스미드(trans plasmid)에 대한 AAV 벡터 수율 비교를 나타낸다. 각각의 작제물에 대해, 플라스미드를 재-형질전환하고, 12-웰 플레이트에서 개별 삼중-형질감염을 위해 4개의 클론을 무작위로 선발하였다. 벡터 수율은 두 가지 방법으로 결정하였다 - (도 36a) 생산 역가의 경우 qPCR (도 36b) 감염성 역가의 경우 Huh7 형질도입. 각 실험은 2회 - 반복 1 및 반복 2를 수행하였다.
도 37a 내지 도 37c는 추가 조절 요소를 갖는 전이 플라스미드에 대한 AAV 벡터 수율 비교를 나타낸다. WPRE 및/또는 bGH 폴리A를 포함하는 전이 플라스미드를 생성하였다(도 37a). 벡터 수율은 생산 역가에 대한 qPCR(도 37b) 및 감염성 역가에 대한 Huh7(도 37c) 형질도입의 두 가지 방법으로 결정되었다. 각 실험은 2회 - 반복 1 및 반복 2를 수행하였다.
천연 포유동물 숙주에서 AAV의 유전적 변이는 바이러스 집단 내에서 개별 AAV 게놈을 정확하게 단리하는 데 사용되는 기법인 AAV 단일 게놈 증폭을 사용하여 조사하였다(도 1). 다양한 클레드에서 분류될 수 있는 히말라야 원숭이 조직으로부터 신규 AAV 서열의 단리가 본원에 기술된다. 기술된 신규 캡시드 서열을 사용하여 유전자 전달 벡터를 생산하였다. 본 발명자들은 정맥내(IV) 및 뇌실내(ICV) 전달 후 마우스에서, 그리고 IV 및 대조내(ICM) 전달 후 NHP에서 자연 분리주-유래 AAV 벡터의 생물학적 특성을 평가하였다. 결과는 프로토타입 클레드 구성원 대조군과 비교할 때 새로운 AAV 변이체의 클레드-특이적 및 가변적 형질도입 패턴을 모두 확인하였다.
대상체에게 전달된 후 발현을 지시하는 조절 서열의 제어 하에 AAVrh91 캡시드 및 전이유전자를 암호화하는 핵산을 갖는 재조합 AAVrh91 벡터가 본원에서 제공된다. rAAVrh91 캡시드는 서열번호 2의 아미노산 서열을 독립적으로 갖는 단백질을 포함한다. 이들 벡터를 포함하는 조성물이 제공된다. 본원에 기술된 방법은 다양한 병태의 치료를 위해 관심 조직을 표적화하기 위한 rAAV의 용도에 관한 것이다.
특정 구현예에서, 중추신경계로 전이유전자를 전달하기에 매우 적합한 AAVrh91 캡시드를 포함하는 벡터가 본원에서 제공된다. 특정 구현예에서, 예를 들어 ICM 전달을 통해 뇌로의 전달을 포함하는 척수강내 전달이 바람직하다. 특정 구현예에서, AAVrh91 캡시드를 포함하는 벡터는 평활근으로의 전이유전자 전달에 매우 적합하다. 특정 구현예에서, AAVrh91 캡시드를 포함하는 벡터는 심장 조직으로의 전이유전자 전달에 매우 적합하다. 다른 구현예에서, AAVrh91 캡시드를 포함하는 벡터는 골격(줄무늬) 근육으로의 전달에 매우 적합하다. 특정 구현예에서, AAVrh91 벡터는 이들 조직을 표적화하는 데 적합한 투여 경로를 통해 전신적으로 전달되거나 표적화될 수 있다. 특정 구현예에서, CNS에 대한 AAVrh91 벡터의 투여는 또한 하나 이상의 주변 기관 (예를 들어, 심장 및/또는 간을 포함함)으로의 전이유전자 전달을 초래한다.
달리 정의되지 않는 한, 본원에서 사용되는 기술적 및 과학적 용어는 본 발명이 속하는 기술분야의 통상의 기술자에 의해 그리고 당업자에게 본 출원에서 사용되는 다수의 용어에 대한 일반적인 지침을 제공하는 공개된 텍스트를 참조하여 일반적으로 이해되는 바와 동일한 의미를 가진다. 하기 정의는 단지 명확성을 위해 제공되며 청구된 발명을 제한하는 것으로 의도되지 않는다. 본원에 사용된 바와 같이, 용어 "한(a)" 또는 "하나(an)"는 하나 이상을 지칭하며, 예를 들어 "숙주 세포"는 하나 이상의 숙주 세포를 표현하는 것으로 이해된다. 이와 같이, 용어 "한" (또는 "하나"), "하나 이상", 및 "적어도 하나"는 본원에서 상호교환적으로 사용된다. 본원에 사용된 바와 같이, 용어 "약"은 달리 명시되지 않는 한, 주어진 참조값으로부터 10%의 가변성을 의미한다. 본 명세서의 다양한 구현예는 "포함하는" 언어를 사용하여 제시되어 있지만, 다른 상황 하에서, 관련 구현예는 또한 "로 이루어진" 또는 "로 본질적으로 이루어진" 언어를 사용하여 해석되고 기술되는 것으로 의도된다.
하기 설명과 관련하여, 본원에 기술된 각각의 조성물은 또 다른 구현예에서 본 발명의 방법에 유용한 것으로 의도된다. 추가적으로, 상기 방법에 유용한 것으로 본원에 기술된 각각의 조성물은 또 다른 구현예에서 그 자체가 본 발명의 구현예인 것으로 또한 의도된다.
"재조합 AAV" 또는 "rAAV"는 2개의 요소, AAV 캡시드 및 AAV 캡시드 내에 패키징된 적어도 비-AAV 암호화 서열을 포함하는 벡터 게놈을 포함하는 DNAse-저항성 바이러스 입자이다. 달리 명시되지 않는 한, 이 용어는 어구 "rAAV 벡터"와 상호 교환 가능하게 사용될 수 있다. rAAV는 임의의 기능성 AAV rep 유전자 또는 기능성 AAV cap 유전자가 결여되어 있고 자손을 생성할 수 없기 때문에, "복제-결함 바이러스" 또는 "바이러스 벡터"이다. 특정 구현예에서, 유일한 AAV 서열은, 반전 말단 반복부 서열(ITR) 사이에 위치하는 유전자 및 조절 서열이 AAV 캡시드 내에 패키징될 수 있도록 하기 위해 전형적으로 벡터 게놈의 5' 및 3' 제일 말단에 위치하는 AAV 반전 말단 반복부 서열(ITR)이다.
본원에 사용된 바와 같이, "벡터 게놈"은 바이러스 입자를 형성하는 rAAV 캡시드 내부에 패키징된 핵산 서열을 지칭한다. 이와 같은 핵산 서열은 AAV 반전 말단 반복부 서열(ITR)을 포함한다. 본원의 예에서, 벡터 게놈은 최소한 5'에서 3'으로, AAV 5' ITR, 암호화 서열(들), 및 AAV 3' ITR을 포함한다. 특정 구현예에서, ITR은 AAV2 유래이고, 캡시드와 상이한 공급원의 AAV, 또는 또 다른 전장 ITR이 선택될 수 있다. 특정 구현예에서, ITR은 생성 동안 rep 기능을 제공하는 AAV 또는 트랜스상보성(transcomplementing) AAV와 동일한 AAV 공급원 유래이다. 또한, 다른 ITR이 사용될 수 있다. 또한, 벡터 게놈은 유전자 산물의 발현을 지시하는 조절 서열을 포함한다. 벡터 게놈의 적합한 성분은 본원에서 보다 상세하게 논의된다. 벡터 게놈은 때때로 "미니유전자"로 본원에서 지칭된다.
용어 "발현 카세트"는 전이유전자 서열 및 이에 따른 조절 서열(예컨대, 프로모터, 인핸서, 폴리A)를 포함하는 핵산 분자를 지칭하며, 상기 카세트는 바이러스 벡터(예를 들어, 바이러스 입자)의 캡시드 내로 패키징될 수 있다. 전형적으로, 바이러스 벡터를 생성하기 위한 이와 같은 발현 카세트는 바이러스 게놈의 패키징 신호가 측면에 있는 전이유전자 서열 및 본원에 기술된 바와 같은 다른 발현 제어 서열을 포함한다. 예를 들어, AAV 바이러스 벡터의 경우, 패키징 신호는 5' 반전 말단 반복부(ITR) 및 3' ITR에 있다. 특정 구현예에서, 용어 "전이유전자"는 "발현 카세트"와 상호교환적으로 사용될 수 있다. 다른 구현예에서, 용어 "전이유전자"는 선택된 유전자에 대한 암호화 서열만을 지칭한다.
rAAV는 AAV 캡시드 및 벡터 게놈으로 구성된다. AAV 캡시드는 vp1의 이종 집단, vp2의 이종 집단, 및 vp3 단백질의 이종 집단의 조합체이다. 본원에 사용된 바와 같이 vp 캡시드 단백질을 지칭하는 데 사용되는 경우, 용어 "이종" 또는 이의 임의의 문법적 변형은, 예를 들어, 상이한 변형된 아미노산 서열이 있는 vp1, vp2 또는 vp3 단량체 (단백질)를 가지는, 동일하지 않은 요소로 이루어진 집단을 지칭한다.
본원에 사용된 바와 같이, vp1, vp2 및 vp3 단백질 (대안적으로 동종형으로 칭해짐)과 관련하여 사용될 때 용어 "이종 집단"은 캡시드 내 vp1, vp2 및 vp3 단백질의 아미노산 서열의 차이를 지칭한다. AAV 캡시드는 vp1 단백질 내, vp2 단백질 내 및 vp3 단백질 내에 예상되는 아미노산 잔기로부터 변형이 있는 하위집단을 포함한다. 이러한 하위집단은, 최소한 특정 탈아미드화된 아스파라긴(N 또는 Asn) 잔기를 포함한다. 예를 들어, 특정 하위집단은 아스파라긴-글리신 쌍에서 적어도 1개, 2개, 3개 또는 4개의 고도로 탈아미드화된 아스파라긴(N) 위치를 포함하고 선택적으로 다른 탈아미드화된 아미노산을 더 포함하며, 상기 탈아미드화는 아미노산 변화 및 다른 선택적인 변형을 초래한다.
본원에 사용된 바와 같이, vp 단백질의 "하위집단"은 달리 명시되지 않는 한, 공통적으로 적어도 하나의 정의된 특징을 갖고, 적어도 하나의 그룹 구성원 내지 참조 그룹의 모든 구성원보다 더 적은 수의 그룹 구성원으로 이루어진 vp 단백질의 그룹을 지칭한다. 예를 들어, vp1 단백질의 "하위집단"은 달리 명시되지 않는 한, 조립된 AAV 캡시드 내에 적어도 하나(1)의 vp1 단백질이 있고 모든 vp1 단백질보다 더 적은 수의 vp1 단백질이 있을 수 있다. vp3 단백질의 "하위집단"은 달리 명시되지 않는 한, 조립된 AAV 캡시드 내에 하나(1)의 vp3 단백질 내지 모든 vp3 단백질보다 더 적은 수의 vp3 단백질이 있을 수 있다. 예를 들어, vp1 단백질은 vp 단백질의 하위집단일 수 있고; vp2 단백질은 vp 단백질의 별개의 하위집단일 수 있으며, vp3은 또한 조립된 AAV 캡시드 내의 vp 단백질의 추가의 하위집단이다. 또 다른 예에서, vp1, vp2 및 vp3 단백질은, 예를 들어, 아스파라긴-글리신 쌍에서 상이한 변형, 예를 들어 적어도 1개, 2개, 3개 또는 4개의 고도로 탈아미드화된 아스파라긴을 가지는 하위집단을 포함할 수 있다. 2019년 2월 27일에 출원된 PCT/US19/019804호 및 2019년 2월 27일에 출원된 PCT/US19/019861호를 참조하며, 이들 각각은 본원에 참조로 포함된다.
달리 명시되지 않는 한, 고도로 탈아미드화된 것은 참조 아미노산 위치에서 예상되는 아미노산 서열과 비교하여, 참조된 아미노산 위치에서 적어도 45% 탈아미드화된, 적어도 50% 탈아미드화된, 적어도 60% 탈아미드화된, 적어도 65% 탈아미드화된, 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 99%, 또는 최대 약 100%의 탈아미드화된 것을 지칭한다. 이와 같은 백분율은 2D-겔, 질량 분석 기법, 또는 다른 적합한 기법을 사용하여 결정될 수 있다.
이론에 구속시키고자 하는 것은 아니지만, AAV 캡시드 내의 vp 단백질에서 적어도 고도로 탈아미드화된 잔기의 탈아미드화는 사실상 주로 비-효소적인 것으로 여겨지는데, 이는 선택된 아스파라긴, 그리고 더 적은 정도로는 글루타민 잔기를 탈아미드화시키는 캡시드 단백질 내의 기능기에 의해 유발된다. 대부분의 탈아미드화 vp1 단백질의 효율적인 캡시드 조합체는, 이러한 이벤트가 캡시드 조립 이후에 일어나거나 개별적인 단량체(vp1, vp2 또는 vp3)의 탈아미드화가 구조적으로 잘 용인되고, 조립 동역학에 크게 영향을 미치지 않음을 나타낸다. 일반적으로 세포 유입 이전에 내부에 위치될 것으로 간주되는 VP1-고유(VP1-u) 영역(~ aa 1 내지 137)에서의 광범위한 탈아미드화는, VP 탈아미드화가 캡시드 조립 이전에 일어날 수 있음을 시사한다.
이론에 구속시키고자 하는 것은 아니지만, N의 탈아미드화는 이의 C-말단 잔기의 백본 질소 원자가 Asn 측쇄 아미드기 탄소 원자에 대한 친핵성 공격을 수행함으로써 일어날 수 있다. 중간체 폐환(ring-closed) 석신이미드 잔기가 형성되는 것으로 여겨진다. 이후 석신이미드 잔기에 신속한 가수분해가 수행되어 최종 산물인 아스파트산(Asp) 또는 이소 아스파트산(IsoAsp)이 생성된다. 따라서, 특정 구현예에서, 아스파라긴(N 또는 Asn)의 탈아미드화는 Asp 또는 IsoAsp를 생성하고, 이는 하기에 예시된 바와 같이, 예를 들어 석신이미드 중간체를 통해서 상호전환될 수 있다.

본원에 제공된 바와 같이, VP1, VP2 또는 VP3에서 각각의 탈아미드화된 N은 독립적으로 아스파트산(Asp), 이소아스파트산(isoAsp), 아스파테이트, 및/또는 Asp 및 isoAsp의 상호전환 블렌드, 또는 이들의 조합일 수 있다. α- 및 이소아스파트산의 임의의 적합한 비율이 존재할 수 있다. 예를 들어, 특정 구현예에서, 비율은 10:1 내지 1:10의 아스파트산 대 이소아스파트산, 약 50:50의 아스파트산:이소아스파트산, 또는 약 1:3의 아스파트산:이소아스파트산, 또는 또 다른 선택된 비율일 수 있다.
특정 구현예에서, 하나 이상의 글루타민(Q)은 글루탐산(Glu), 즉, α-글루탐산, γ-글루탐산(Glu), 또는 α- 및 γ-글루탐산의 블렌드로 탈아미드화될 수 있으며, 이는 일반적인 글루타리마이드 중간체를 통해 상호전환될 수 있다. α- 및 γ-글루탐산의 임의의 적합한 비율이 존재할 수 있다. 예를 들어, 특정 구현예에서, 비율은 10:1 내지 1:10의 α 대 γ, 약 50:50의 α:γ, 또는 약 1:3의 α:γ, 또는 또 다른 선택된 비율일 수 있다.

따라서, rAAV는, 최소한 적어도 하나의 고도로 탈아미드화된 아스파라긴을 포함하는 적어도 하나의 하위집단을 포함하는, 탈아미드화된 아미노산이 있는 vp1, vp2 및/또는 vp3 단백질의 rAAV 캡시드 내의 하위집단을 포함한다. 추가적으로, 다른 변형은 특히 선택된 아스파트산(D 또는 Asp) 잔기 위치에서 이성질체화를 포함할 수 있다. 또 다른 구현예에서, 변형은 Asp 위치에서의 아미드화를 포함할 수 있다.
특정 구현예에서, AAV 캡시드는 적어도 1개, 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5개 내지 적어도 약 25개의 탈아미드화된 아미노산 잔기 위치를 갖는 vp1, vp2 및 vp3의 하위집단을 포함하며, 이의 적어도 1 내지 10%, 적어도 10 내지 25%, 적어도 25 내지 50%, 적어도 50 내지 70%, 적어도 70 내지 100%, 적어도 75 내지 100%, 적어도 80 내지 100% 또는 적어도 90 내지 100%는 vp 단백질의 암호화된 아미노산 서열과 비교하여 탈아미드화된다. 이들 대부분은 N 잔기일 수 있다. 그러나, Q 잔기가 또한 탈아미드화될 수 있다.
본원에 사용된 바와 같이, "암호화된 아미노산 서열"은 아미노산으로 번역되는 참조된 핵산 서열의 공지된 DNA 코돈의 번역을 기반으로 예상되는 아미노산을 지칭한다. 하기 표는 단일 문자 암호(SLC) 및 세 문자 암호(3LC) 둘 다를 나타내는, DNA 코돈 및 20개의 일반적인 아미노산을 예시한다.

특정 구현예에서, rAAV는 본원에 제공되고 본원에 참조로 포함된 표에 제시된 위치에서 2개, 3개, 4개, 5개, 또는 그 이상의 탈아미드화된 잔기를 포함하는 하위집단을 갖는 vp1, vp2 및 vp3 단백질을 갖는 AAV 캡시드를 갖는다.
rAAV의 탈아미드화는 2D 겔 전기영동법, 및/또는 질량 분석법, 및/또는 단백질 모델링 기법을 사용하여 결정될 수 있다. 온라인 크로마토그래피는 Acclaim PepMap 컬럼 및 NanoFlex 소스가 있는 Q Exactive HF(Thermo Fisher Scientific)에 커플링된 Thermo UltiMate 3000 RSLC 시스템(Thermo Fisher Scientific)을 이용하여 수행될 수 있다. MS 데이터는 조사 스캔(200 내지 2000 m/z)으로부터의 가장 풍부한 시퀀싱전(not-yet-sequenced) 전구체 이온을 동력학적으로 선택하는 Q Exactive HF에 대한 데이터 의존적인 상위 20 방법을 사용하여 획득된다. 시퀀싱은 예측된 자동 이득 제어로 결정된 1e5 이온의 목표 값을 이용한 고 에너지 충돌 분열 단편화를 통해서 수행되고, 전구체의 단리는 4 m/z의 윈도우로 수행되었다. 조사 스캔은 m/z 200에서 120,000의 분해능으로 획득되었다. HCD 스펙트럼에 대한 분해능은 50 ms의 최대 이온 주입 시간 및 30의 정규화된 충돌 에너지를 이용하여 m/z 200에서 30,000으로 설정될 수 있다. S-렌즈 RF 수준은 50에서 설정되어, 소화로부터 펩티드에 의해서 점유된 m/z 영역의 최적의 전달을 제공할 수 있다. 전구체 이온은 단편화 선택으로부터 단일, 미배정, 또는 6 및 더 높은 전하 상태로 제외될 수 있다. BioPharma Finder 1.0 소프트웨어(Thermo Fischer Scientific)가 획득된 데이터의 분석에 사용될 수 있다. 펩티드 맵핑을 위해서, 고정된 변형으로서 설정된 카바마이도메틸화; 및 가변 변형으로서 설정된 산화, 탈아미드화, 및 인산화, 10-ppm 질량 정확도, 높은 프로테아제 특이성, 및 MS/MS 스펙트럼에 대한 0.8의 신뢰 수준을 가지는 단기식 단백질 FASTA 데이터베이스를 사용하여 검색을 수행한다. 적합한 프로테아제의 예는, 예를 들어 트립신 또는 키모트립신을 포함할 수 있다. 탈아미드화된 펩티드의 질량 분석법적 식별은 비교적 간단한데, 그 이유는 탈아미드화가 무손상 분자 +0.984 Da의 질량(-OH와 -NH2 기 간의 질량 차이)에 추가되기 때문이다. 특정 펩티드의 탈아미드화 백분율은 탈아미드화된 펩티드의 질량 면적을, 탈아미드화된 펩티드와 천연 펩티드의 면적의 합으로 나눔으로써 결정된다. 가능한 탈아미드화 부위의 수를 고려하여, 상이한 부위에서 탈아미드화된 동중 원소종(isobaric species)이 단일 피크에서 동시에 이동할 수 있다. 결론적으로, 다수의 잠재적인 탈아미드화 부위가 있는 펩티드로부터 기원한 단편 이온을 사용하여 탈아미드화의 다수의 부위를 위치시키거나 구별할 수 있다. 이러한 경우에, 관찰된 동위원소 패턴 내의 상대 강도를 사용하여 상이한 탈아미드화된 펩티드 이성질체의 상대 풍부도를 구체적으로 결정할 수 있다. 이러한 방법은, 모든 이성질체 종에 대한 단편화 효율성이 동일하고, 탈아미드화 부위에 독립적이라고 가정한다. 이러한 예시적인 방법에 대한 다수의 변경이 사용될 수 있음을 당업자는 이해할 것이다. 예를 들어, 적합한 질량 분석기는, 예를 들어 사중극자 비행 시간 질량 분석기(quadrupole time of flight mass spectrometer: QTOF), 예컨대, Waters Xevo 또는 Agilent 6530 또는 오비트랩 기기(orbitrap instrument), 예컨대, Orbitrap Fusion 또는 Orbitrap Velos(Thermo Fisher)를 포함할 수 있다. 적합하게 액체 크로마토그래피 시스템은, 예를 들어, Waters 또는 Agilent 시스템으로부터의 Acquity UPLC 시스템(1100 또는 1200 시리즈)을 포함한다. 적합한 데이터 분석 소프트웨어는, 예를 들어 MassLynx(Waters), Pinpoint 및 Pepfinder(Thermo Fischer Scientific), Mascot(Matrix Science), Peaks DB(Bioinformatics Solutions)를 포함할 수 있다. 또 다른 기법은, 예를 들어, X. Jin 등, Hu Gene Therapy Methods, Vol. 28, No. 5, pp. 255-267 (2017년 6월 16일자로 온라인 공개됨)에 기술된 것일 수 있다.
탈아미드화에 이외에, 다른 변형이 일어날 수 있는데, 이는 하나의 아미노산이 상이한 아미노산 잔기로의 전환을 초래하지 않는다. 이와 같은 변형은 아세틸화된 잔기, 이성질체화, 인산화, 또는 산화를 포함할 수 있다.
탈아미드화의 조절: 특정 구현예서, AAV는 아스파라긴-글리신 쌍에서 글리신을 변화시키도록 변형되어, 탈아미드화를 감소시킨다. 다른 구현예에서, 아스파라긴은 상이한 아미노산, 예를 들어 더 느린 속도로 탈아미드화시키는 글루타민으로; 또는 아미드기가 결여된 아미노산(예를 들어, 글루타민 및 아스파라긴은 아미드기를 포함함)으로; 및/또는 아민기가 결여된 아미노산(예를 들어, 라이신, 아르기닌 및 히스티딘은 아민기를 포함함)으로 변경된다. 본원에 사용된 바와 같이, 아미드 또는 아민 측기가 결여된 아미노산은, 예를 들어, 글리신, 알라닌, 발린, 류신, 이소류신, 세린, 트레오닌, 시스틴, 페닐알라닌, 타이로신, 또는 트립토판, 및/또는 프롤린을 지칭한다. 예컨대, 기술된 변형은 암호화된 AAV 아미노산 서열에서 발견되는 아스파라긴-글리신 쌍 중 1개, 2개 또는 3개에 존재할 수 있다. 특정 구현예에서, 이와 같은 변형은 아스파라긴-글리신 쌍 중 4개 모두에서 일어나지는 않는다. 따라서, AAV 및/또는 조작된 AAV 변이체의 탈아미드화를 감소시키는 방법은 더 낮은 탈아미드화 속도를 갖는다. 추가적으로, 또는 대안적으로 하나 이상의 다른 아미드 아미노산은 비-아미드 아미노산으로 변화되어 AAV의 탈아미드화를 감소시킬 수 있다. 특정 구현예에서, 본원에 기술된 바와 같은 돌연변이체 AAV 캡시드는 아스파라긴-글리신 쌍에서 돌연변이를 포함하여, 글리신은 알라닌 또는 세린으로 변화된다. 돌연변이체 AAV 캡시드는 1개, 2개 또는 3개의 돌연변이체를 포함할 수 있고, 이때 참조 AAV는 본래 4개의 NG 쌍을 포함한다. 특정 구현예에서, AAV 캡시드는 1개, 2개, 3개 또는 4개의 이와 같은 돌연변이체를 포함할 수 있고, 이때 참조 AAV는 본래 5개의 NG 쌍을 포함한다. 특정 구현예에서, 돌연변이체 AAV 캡시드는 NG 쌍 내에 단일 돌연변이만을 포함한다. 특정 구현예에서, 돌연변이체 AAV 캡시드는 2개의 상이한 NG 쌍 내에 돌연변이를 포함한다. 특정 구현예에서, 돌연변이체 AAV 캡시드는 2개의 상이한 NG 쌍인 돌연변이를 포함하며, 이는 AAV 캡시드에서 구조적으로 분리된 위치에 위치한다. 특정 구현예에서, 돌연변이는 VP1-고유 영역에 존재하지 않는다. 특정 구현예에서, 돌연변이 중 하나는 VP1-고유 영역에 존재한다. 선택적으로, 돌연변이체 AAV 캡시드는 NG 쌍 내에 변형을 포함하지 않지만, NG 쌍의 위부에 위치한 하나 이상의 아스파라긴 또는 글루타민에서 탈아미드화를 최소화하거나 제거하기 위한 돌연변이를 포함한다.
특정 구현예에서, 야생형 AAV 캡시드에서 하나 이상의 NG를 제거하는 AAV 캡시드를 조작하는 단계를 포함하는 rAAV 벡터의 효능을 증가시키는 방법이 제공된다. 특정 구현예에서, "NG"의 "G"에 대한 암호화 서열은 또 다른 아미노산을 암호화하도록 조작된다. 하기 소정의 예에서, "S" 또는 "A"가 치환된다. 그러나, 다른 적합한 아미노산 암호화 서열이 선택될 수 있다.
이러한 아미노산 변형은 통상적인 유전 공학 기법에 의해 이루어질 수 있다. 예를 들어, 아스파라긴-글리신 쌍에서 글리신을 암호화하는 코돈 중 1개 내지 3개가 글리신 이외의 아미노산을 암호화하도록 변형되는, 변형된 AAV vp 코돈을 포함하는 핵산 서열이 생성될 수 있다. 특정 구현예에서, 변형된 아스파라긴 코돈을 포함하는 핵산 서열은 변형된 코돈이 아르기닌 이외의 아미노산을 암호화하도록, 아스파라긴-글리신 쌍 중 1개 내지 3개에서 조작될 수 있다. 각각의 변형된 코돈은 상이한 아미노산을 암호화할 수 있다. 대안적으로, 변경된 코돈 중 하나 이상은 동일한 아미노산을 암호화할 수 있다. 특정 구현예에서, 변형된 AAVrh91 핵산 서열은 천연 AAVrh91 캡시드보다 탈아미드화가 더 낮은 캡시드를 갖는 돌연변이체 rAAV를 생성하는데 사용된다. 이와 같은 돌연변이체 rAAV는 감소된 면역성을 갖고/갖거나 저장, 특히 현탁액 형태로의 저장 시 안정성을 증가시킬 수 있다.
또한, 탈아미드화가 감소된 AAV 캡시드를 암호화하는 핵산 서열이 본원에서 제공된다. DNA(게놈 또는 cDNA), 또는 RNA(예를 들어, mRNA)를 포함하여, 이러한 AAV 캡시드를 암호화하는 핵산 서열을 설계하는 것은 당업계의 기술 내에 있다. 이와 같은 핵산 서열은 선택된 시스템(즉, 세포 유형)에서의 발현에 대하여 코돈-최적화될 수 있고 다양한 방법에 의해 설계될 수 있다. 이러한 최적화는 이용 가능한 온라인 (예를 들어, GeneArt), 공개된 방법, 또는 코돈 최적화 서비스를 제공하는 회사, 예를 들어, DNA2.0 (Menlo Park, CA)을 사용하여 수행될 수 있다. 하나의 코돈 최적화 방법은, 예를 들어, 국제 공개 특허 WO 제2015/012924호에 기술되어 있으며, 이는 그 전체가 참조로 본원에 포함된다. 또한, 예를 들어 미국 공개 특허 제2014/0032186호 및 미국 공개 특허 제2006/0136184호를 참조한다. 적합하게는, 산물에 대한 오픈 리딩 프레임(ORF)의 전체 길이가 변형된다. 그러나, 일부 구현예에서, 단지 ORF의 단편만이 변경될 수 있다. 이러한 방법 중 하나를 사용함으로써, 임의의 주어진 폴리펩티드 서열에 빈도를 적용할 수 있고, 폴리펩티드를 암호화하는 코돈-최적화된 암호화 영역의 핵산 단편을 생성할 수 있다. 코돈에 대한 실제 변화를 수행하기 위해 또는 본원에 기술된 바와 같이 설계된 코돈-최적화된 암호화 영역을 합성하기 위해 다수의 옵션이 이용 가능하다. 이와 같은 변형 또는 합성은 당업계의 통상의 기술자에게 잘 알려진 표준 및 정례적인 분자 생물학적 조작을 사용하여 수행될 수 있다. 한 접근법에서, 각각 80 내지 90개 뉴클레오티드 길이의 일련의 상보성 올리고뉴클레오티드 쌍 및 원하는 서열의 길이의 스패닝은 표준 방법에 의해서 합성된다. 이러한 올리고뉴클레오티드 쌍은, 어닐링 시, 이것이 응집성(cohesive) 말단을 포함하는, 80 내지 90개 염기쌍의 이중 가닥 단편을 형성하도록 합성되고, 예를 들어 쌍 내의 각각의 올리고뉴클레오티드는 쌍 내의 다른 올리고뉴클레오티드와 상보성인 영역을 넘어서 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개 또는 그 이상의 염기를 연장하도록 합성된다. 올리고뉴클레오티드의 각각의 쌍의 단일-가닥 말단은 올리고뉴클레오티드의 또 다른 쌍의 단일-가닥 말단과 어닐링하도록 설계된다. 올리고뉴클레오티드 쌍은 어닐링되는 것이 허용되며, 그 다음 이러한 이중-가닥 단편의 대략 5개 내지 6개는 응집성 단일 가닥 말단을 통해 함께 어닐링되는 것이 허용되고, 그 다음 이는 함께 결찰되고, 표준 박테리아 클로닝 벡터, 예를 들어, Invitrogen Corporation, 미국 캘리포니아주 칼스배드 소재로부터 입수 가능한 TOPO® 벡터 내로 클로닝된다. 그 다음, 작제물은 표준 방법에 의해서 시퀀싱된다. 함께 결찰된 80개 내지 90개 염기 쌍 단편의 5개 내지 6개의 단편, 즉, 약 500개 염기 쌍의 단편으로 이루어진 이러한 작제물 중 몇몇이 제조되어, 전체 원하는 서열이 일련의 플라스미드 작제물에서 표현된다. 그 다음, 이러한 플라스미드의 삽입물은 적절한 제한 효소로 절단되고, 함께 결찰되어 최종 작제물을 형성한다. 그 다음, 최종 작제물은 표준 박테리아 클로닝 벡터 내로 클로닝되고, 시퀀싱된다. 추가 방법은 당업자에게 즉시 명백할 것이다. 추가적으로, 유전자 합성은 상업적으로 용이하게 입수 가능하다.
특정 구현예에서, 다수의 고도로 탈아미드화된 "NG" 위치를 포함하는 AAV 캡시드 동종형(즉, VP1, VP2, VP3)의 이종 집단을 갖는 AAV 캡시드가 제공된다. 특정 구현예에서, 고도로 탈아미드화된 위치는 예상되는 전장 VP1 아미노산 서열을 참조하여 하기 확인된 위치에 있다. 다른 구현예에서, 캡시드 유전자는 참조된 "NG"가 제거되고 돌연변이체 "NG"가 또 다른 위치로 조작되도록 변형된다.
본원에 사용된 바와 같이, 용어 "표적 세포" 및 "표적 조직"은 대상 AAV 벡터에 의해 형질도입되도록 의도된 임의의 세포 또는 조직을 지칭할 수 있다. 상기 용어는 근육, 간, 폐, 기도 상피, 중추신경계, 뉴런, 눈(안구 세포), 또는 심장 중 임의의 하나 이상을 지칭할 수 있다. 일 구현예에서, 표적 조직은 간이다. 또 다른 구현예에서, 표적 조직은 심장이다. 또 다른 구현예에서, 표적 조직은 뇌이다. 특정 구현예에서, 상기 표적 세포는 CNS의 하나 이상의 세포 유형이며, 이는 성상교세포, 뉴런, 뇌실막 세포 및 맥락막총의 세포를 포함하나 이에 제한되지 않는다. 또 다른 구현예에서, 표적 조직은 근육이다.
본원에 사용된 바와 같이, 용어 "포유동물 대상체" 또는 "대상체"는 특히 인간을 비롯하여 본원에 기술된 치료 또는 예방 방법을 필요로 하는 임의의 포유동물을 포함한다. 이와 같은 치료 또는 예방을 필요로 하는 다른 포유동물은 비-인간 영장류 등을 비롯하여, 개, 고양이, 또는 기타 가축동물, 말, 가축, 실험 동물을 포함한다. 대상체는 수컷 또는 암컷일 수 있다.
본원에 사용된 바와 같이, rAAV의 "스톡"은 rAAV의 집단을 지칭한다. 탈아미드화로 인한 캡시드 단백질의 이질성에도 불구하고, 스톡의 rAAV는 동일한 벡터 게놈을 공유할 것으로 예상된다. 스톡은 예를 들어 선택된 AAV 캡시드 단백질 및 선택된 생산 시스템의 특징인 이종 탈아미드화 패턴을 갖는 캡시드를 가지는 rAAV를 포함할 수 있다. 스톡은 단일 생산 시스템으로부터 생산되거나 생산 시스템의 여러 실행으로부터 풀링될 수 있다. 본원에 기술된 것을 포함하나, 이에 제한되지 않는 다양한 생산 시스템이 선택될 수 있다.
본원에 사용된 바와 같이, 용어 "숙주 세포"는 rAAV가 플라스미드로부터 생성되는 패키징 세포주를 지칭할 수 있다. 대안적으로, 용어 "숙주 세포"는 전이유전자의 발현이 바람직한 표적 세포를 지칭할 수 있다.
A. AAV 캡시드
서열번호 2에 제시된 vp1 서열을 갖는 신규한 AAV 캡시드 단백질이 본원에서 제공된다. AAV 캡시드는 3개의 중첩 암호화 서열로 이루어지며, 이는 대안적인 시작 코돈 사용으로 인해 길이가 다양하다. 이러한 가변 단백질은 VP1, VP2 및 VP3으로 지칭되며, 이때 VP1이 가장 길고 VP3이 가장 짧다. AAV 입자는 ~1:1:10 (VP1:VP2:VP3)의 비율로 3가지 캡시드 단백질 전부로 이루어진다. N-말단에서 VP1 및 VP2에 포함되는 VP3은 입자를 구축하는 주요 구조 성분이다. 캡시드 단백질은 여러 가지 상이한 넘버링 시스템을 사용하여 지칭될 수 있다. 편의상, 본원에 사용된 바와 같이, AAV 서열은, VP1의 첫 번째 잔기에 대해 aa 1로 시작하는 VP1 넘버링을 사용하여 지칭된다. 그러나, 본원에 기술된 캡시드 단백질은 VP1, VP2 및 VP3 (본원에서 vp1, vp2 및 vp3으로 상호교환적으로 사용됨)을 포함한다. 캡시드의 가변 단백질의 넘버링은 하기와 같다:
뉴클레오티드(nt)
AAVrh91: 서열번호 1의 vp1 - nt 1 내지 2208번; vp2 - nt 412 내지 2208번; vp3 - nt 607 내지 2208번
AAVrh91eng: 서열번호 3의 vp1 - nt 1 내지 2208번; vp2 - nt 412 내지 2208번; vp3 - nt 607 내지 2208번
본원에 기술된 캡시드에 대한 핵산 서열의 정렬은 도 3a 내지 도 3d에 도시되어 있다.
아미노산(aa)
AAVrh91 및 AAVrh91eng: 서열번호 2의 aa vp1 - 1 내지 736번; vp2 - aa 138 내지 736번; vp3 - aa 203 내지 736번.
본원에 기술된 캡시드에 대한 아미노산 서열의 정렬은 도 4a 내지 도 4b에 도시되어 있다.
AAVrh91(서열번호 2)의 vp1, vp2 및 vp3 중 적어도 하나를 포함하는 rAAV가 본원에 포함된다. 또한, AAVrh91(서열번호 1) 또는 AAVrh91eng(서열번호 3)의 vp1, vp2 및 vp3 중 적어도 하나에 의해 암호화된 AAV 캡시드를 포함하는 rAAV가 본원에서 제공된다.
일 구현예에서, 재조합 아데노-연관 바이러스(rAAV)의 혼합 집단을 포함하는 조성물이 제공되며, 상기 rAAV 각각은 하기를 포함한다: (a) vp1 단백질, vp2 단백질 및 vp3 단백질로 구성되는 약 60개의 캡시드 단백질을 포함하는 AAV 캡시드로서, 상기 vp1, vp2 및 vp3 단백질은 선택된 AAV vp1 아미노산 서열을 암호화는 핵산 서열로부터 생성되는 vp1 단백질의 이종 집단, 선택된 AAV vp2 아미노산 서열을 암호화하는 핵산 서열로부터 생성되는 vp2 단백질의 이종 집단, 선택된 AAV vp3 아미노산 서열을 암호화하는 핵산 서열로부터 생성되는 vp3 단백질의 이종 집단이고, 상기 vp1, vp2 및 vp3 단백질은 AAV 캡시드의 아스파라긴-글리신 쌍에서 적어도 2개의 고도로 탈아미드화된 아스파라긴(N)을 포함하고 선택적으로 다른 탈아미드화된 아미노산을 포함하는 하위집단을 더 포함하는 아미노산 변형이 있는 하위집단을 포함하며, 상기 탈아미드화는 아미노산 변화를 초래하는, AAV 캡시드; 및 (b) AAV 캡시드 내의 벡터 게놈으로서, AAV 반전 말단 반복부 서열을 포함하는 핵산 분자 및 숙주 세포에서 산물의 발현을 지시하는 서열에 작동가능하게 연결된 산물을 암호화하는 비-AAV 핵산 서열을 포함하는, 벡터 게놈.
특정 구현예에서, 탈아미드화된 아스파라긴은 아스파트산, 이소아스파트산, 상호전환 아스파트산/이소아스파트산 쌍, 또는 이들의 조합으로 탈아미드화된다. 특정 구현예에서, 캡시드는 (α)-글루탐산, γ-글루탐산, 상호전환 (α)-글루탐산/γ-글루탐산 쌍, 또는 이들의 조합으로 탈아미드화된 탈아미드화된 글루타민(들)을 더 포함한다.
특정 구현예에서, 신규한 단리된 AAVrh91 캡시드가 제공된다. AAVrh91 캡시드를 암호화하는 핵산 서열은 서열번호 1에서 제공되고 암호화된 아미노산 서열은 서열번호 2에서 제공된다. AAVrh91 (서열번호 2)의 vp1, vp2 및 vp3 중 적어도 하나를 포함하는 rAAV가 본원에서 제공된다. 또한, AAVrh91 (서열번호 1)의 vp1, vp2 및 vp3 중 적어도 하나에 의해 암호화된 AAV 캡시드를 포함하는 rAAV가 본원에서 제공된다. 또 다른 구현예에서, AAVrh91 아미노산 서열을 암호화하는 핵산 서열은 서열번호 3에서 제공되고 암호화된 아미노산 서열은 서열번호 2에서 제공된다. 또한, AAVrh91eng (서열번호 3)의 vp1, vp2 및 vp3 중 적어도 하나에 의해 암호화된 AAV 캡시드를 포함하는 rAAV가 본원에서 제공된다. 특정 구현예에서, vp1, vp2 및/또는 vp3은 AAVrh91 (서열번호 2)의 전장 캡시드 단백질이다. 다른 구현예에서, vp1, vp2 및/또는 vp3은 N-말단 및/또는 C-말단 절단부(예를 들어, 약 1개 내지 약 10개 아미노산의 절단부(들))를 갖는다.
추가의 측면에서, 하기를 포함하는 재조합 아데노-연관 바이러스(rAAV)가 제공된다: (A) (1) 서열번호 2의 1 내지 736번의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp1 단백질, 서열번호 1로부터 생성되는 vp1 단백질, 또는 서열번호 2의 1 내지 736번의 예상되는 아미노산 서열을 암호화하는 서열번호 1과 적어도 70% 동일한 핵산 서열로부터 생성되는 vp1 단백질로부터 선택되는 AAVrh91 vp1 단백질의 이종 집단, 서열번호 2의 적어도 약 138 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp2 단백질, 서열번호 1의 적어도 412 내지 2208번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp2 단백질, 또는 서열번호 2의 적어도 약 138 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 서열번호 1의 적어도 412 내지 2208번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp2 단백질로부터 선택되는 AAVrh91 vp2 단백질의 이종 집단, 서열번호 2의 적어도 약 203 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp3 단백질, 서열번호 1의 적어도 607 내지 2208번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp3 단백질, 또는 서열번호 1의 적어도 약 203 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 서열번호 1의 적어도 607 내지 2208번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp3 단백질로부터 선택되는 AAVrh91 vp3 단백질의 이종 집단:을 포함하는 AAVrh91 캡시드 단백질; 및/또는 (2) 서열번호 2의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp1 단백질의 이종 집단, 서열번호 2의 적어도 약 138 내지 736번 아미노산의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp2 단백질의 이종 집단, 및 서열번호 2의 적어도 203 내지 736번 아미노산을 암호화하는 핵산 서열의 산물인 vp3 단백질의 이종 집단으로서, 상기 vp1, vp2 및 vp3 단백질은 서열번호 2의 아스파라긴-글리신 쌍에서 적어도 2개의 고도로 탈아미드화된 아스파라긴(N)을 포함하고 선택적으로 다른 탈아미드화된 아미노산을 포함하는 하위집단을 더 포함하는 아미노산 변형을 갖는 하위집단을 포함하고, 상기 탈아미드화는 아미노산 변화를 초래하는, 상기 vp1 단백질의 이종 집단, 상기 vp2 단백질의 이종 집단 및 상기 vp3 단백질의 이종 집단: 중 하나 이상을 포함하는 AAVrh91 캡시드; 및 (B) AAVrh91 캡시드 내 벡터 게놈으로서, AAV 반전 말단 반복부 서열을 포함하는 핵산 분자 및 숙주 세포에서 산물의 발현을 지시하는 서열에 작동가능하게 연결된 산물을 암호화하는 비-AAV 핵산 서열을 포함하는 벡터 게놈.
또 다른 측면에서, 하기를 포함하는 재조합 아데노-연관 바이러스(rAAV)가 제공된다: (A) (1) 서열번호 2의 1 내지 736번의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp1 단백질, 서열번호 3으로부터 생성되는 vp1 단백질, 또는 서열번호 2의 1 내지 736번의 예상되는 아미노산 서열을 암호화하는 서열번호 3과 적어도 70% 동일한 핵산 서열로부터 생성되는 vp1 단백질로부터 선택되는 AAVrh91 vp1 단백질의 이종 집단, 서열번호 2의 적어도 약 138 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp2 단백질, 서열번호 3의 적어도 412 내지 2208번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp2 단백질, 또는 서열번호 2의 적어도 약 138 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 서열번호 3의 적어도 412 내지 2208번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp2 단백질로부터 선택되는 AAVrh91 vp2 단백질의 이종 집단, 서열번호 2의 적어도 약 203 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp3 단백질, 서열번호 3의 적어도 607 내지 2208번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp3 단백질, 또는 서열번호 2의 적어도 약 203 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 서열번호 3의 적어도 607 내지 2208번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp3 단백질로부터 선택되는 AAVrh91 vp3 단백질의 이종 집단:을 포함하는 AAVrh91 캡시드 단백질; 및/또는 (2) 서열번호 2의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp1 단백질의 이종 집단, 서열번호 2의 적어도 약 138 내지 736번 아미노산의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp2 단백질의 이종 집단, 및 서열번호 2의 적어도 203 내지 736번 아미노산을 암호화하는 핵산 서열의 산물인 vp3 단백질의 이종 집단으로서, 상기 vp1, vp2 및 vp3 단백질은 서열번호 2의 아스파라긴-글리신 쌍에서 적어도 2개의 고도로 탈아미드화된 아스파라긴(N)을 포함하고 선택적으로 다른 탈아미드화된 아미노산을 포함하는 하위집단을 더 포함하는 아미노산 변형을 갖는 하위집단을 포함하고, 상기 탈아미드화는 아미노산 변화를 초래하는, 상기 vp1 단백질의 이종 집단, 상기 vp2 단백질의 이종 집단 및 상기 vp3 단백질의 이종 집단: 중 하나 이상을 포함하는 AAVrh91 캡시드; 및 (B) AAVrh91 캡시드 내 벡터 게놈으로서, AAV 반전 말단 반복부 서열을 포함하는 핵산 분자 및 숙주 세포에서 산물의 발현을 지시하는 서열에 작동가능하게 연결된 산물을 암호화하는 비-AAV 핵산 서열을 포함하는 벡터 게놈.
특정 구현예에서, AAVrh91 vp1, vp2 및 vp3 단백질은 서열번호 2의 아스파라긴-글리신 쌍에서 적어도 2개의 고도로 탈아미드화된 아스파라긴(N)을 포함하고 선택적으로 다른 탈아미드화된 아미노산을 포함하는 하위집단을 더 포함하는 아미노산 변형을 갖는 하위집단을 포함하고, 상기 탈아미드화는 아미노산 변화를 초래한다. 서열번호 2의 수에 비해, N-G 쌍 N57, N383 및/또는 N512에서 높은 수준의 탈아미드화가 관찰된다. 하기 표 및 도 7b 및 도 7c에 나타낸 바와 같이, 다른 잔기에서 탈아미드화가 관찰되었다. 특정 구현예에서, AAVrh91은 예를 들어, 전형적으로 10% 미만으로 탈아미드화된 다른 잔기를 가질 수 있고/있거나 (예를 들어, S149에서의) 인산화 (예를 들어, 존재하는 경우, 약 2 내지 약 30%, 또는 약 2 내지 약 20%, 또는 약 2 내지 약 10%의 범위) 또는 (예를 들어, ~W22, ~M211, W247, M403, M435, M471, W478, W503, ~M537, ~M541, ~M559, ~M599, M635 및/또는 W695 중 하나 이상에서의) 산화를 포함하는 다른 변형을 가질 수 있다. 선택적으로 W는 키뉴레인으로 산화될 수 있다.
표 - AAVrh91 탈아미드화

특정 구현예에서, AAVrh91 캡시드는 트립신 효소를 이용한 질량 분석법을 사용하여 결정된 바와 같이, 선행하는 표에서 확인된 위치 중 하나 이상에서 제공된 범위로 변형된다. 특정 구현예에서, 위치 중 하나 이상, 또는 N 다음의 글리신은 본원에 기술된 바와 같이 변형된다. 잔기 번호는 본원에서 제공된 AAVrh91 서열을 기반으로 한다. 서열번호 2를 참조한다.
특정 구현예에서, AAVrh91 캡시드는, 서열번호 2의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp1 단백질의 이종 집단, 서열번호 2의 적어도 약 138 내지 736번 아미노산의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp2 단백질의 이종 집단, 및 서열번호 2의 적어도 203 내지 736번 아미노산을 암호화하는 핵산 서열의 산물인 vp3 단백질의 이종 집단을 포함한다.
특정 구현예에서, AAVrh91 vp1 캡시드 단백질을 암호화하는 핵산 서열은 서열번호 1에서 제공된다. 다른 구현예에서, 서열번호 1과 70% 내지 99.9% 동일성, 또는 서열번호 1과 100% 동일한 핵산 서열이 AAVrh91 캡시드 단백질을 발현하도록 선택될 수 있다. 다른 특정 구현예에서, 핵산 서열은 서열번호 1과 적어도 약 75% 동일, 적어도 80% 동일, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97% 동일, 적어도 99%, 또는 100% 동일하다. 그러나, 서열번호 2의 아미노산 서열을 암호화하는 다른 핵산 서열은 rAAV 캡시드를 생성하는 데 사용하기 위해 선택될 수 있다. 특정 구현예에서, 핵산 서열은 서열번호 1의 핵산 서열, 또는 서열번호 2를 암호화하는 서열번호 1과 적어도 70% 내지 99.9% 동일, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 99%, 또는 100% 동일한 서열을 갖는다. 특정 구현예에서, 핵산 서열은 서열번호 1의 핵산 서열, 또는 서열번호 2의 vp2 캡시드 단백질(약 aa 138 내지 736번)을 암호화하는 서열번호 1의 약 nt 412 내지 약 nt 2208번과 적어도 70% 내지 99.9%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 99% 또는 100% 동일한 서열을 갖는다. 특정 구현예에서, 핵산 서열은 서열번호 1의 약 nt 607 내지 약 nt 2208번의 핵산 서열 또는 서열번호 2의 vp3 캡시드 단백질(약 aa 203 내지 736번)을 암호화하는 서열번호 1의 nt 607 내지 약 nt 2208번과 적어도 70% 내지 99.9%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 99%, 또는 100% 동일한 서열을 갖는다.
특정 구현예에서, AAVrh91 vp1 캡시드 단백질을 암호화하는 핵산 서열은 서열번호 3에서 제공된다. 다른 구현예에서, 서열번호 3과 70% 내지 99.9% 동일성, 또는 서열번호 3과 100% 동일한 핵산 서열이 AAVrh91 캡시드 단백질을 발현하도록 선택될 수 있다. 다른 특정 구현예에서, 핵산 서열은 서열번호 3과 적어도 약 75% 동일, 적어도 80% 동일, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97% 동일, 적어도 99% 내지 99.9% 동일, 또는 100% 동일하다. 그러나, 서열번호 2의 아미노산 서열을 암호화하는 다른 핵산 서열은 rAAV 캡시드를 생성하는 데 사용하기 위해 선택될 수 있다. 특정 구현예에서, 핵산 서열은 서열번호 3의 핵산 서열, 또는 서열번호 2를 암호화하는 서열번호 3과 적어도 70% 내지 99.9% 동일, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 99%, 또는 100% 동일한 서열을 갖는다. 특정 구현예에서, 핵산 서열은 서열번호 3의 핵산 서열, 또는 서열번호 2의 vp2 캡시드 단백질(약 aa 138 내지 736번)을 암호화하는 서열번호 3의 약 nt 412 내지 약 nt 2208번과 적어도 70% 내지 99.9%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 99% 또는 100% 동일한 서열을 갖는다. 특정 구현예에서, 핵산 서열은 서열번호 3의 약 nt 607 내지 약 nt 2208번의 핵산 서열 또는 서열번호 2의 vp3 캡시드 단백질(약 aa 203 내지 736번)을 암호화하는 서열번호 3의 nt 607 내지 약 nt 2208번과 적어도 70% 내지 99.9%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 99% 동일, 또는 100% 동일한 서열을 갖는다.
본 발명은 또한 AAVrh91 캡시드 서열(서열번호 2) 또는 돌연변이체 AAVrh91을 암호화하는 핵산 서열을 포함하며, 여기서 하나 이상의 잔기는 탈아미드화, 또는 본원에서 확인된 다른 변형을 감소시키기 위해 변경된다. 이와 같은 핵산 서열은 돌연변이체 AAVrh91 캡시드의 생산에 사용될 수 있다.
특정 구현예에서, 서열번호 1의 서열, 또는 본원에 기술된 바와 같은 변형(예를 들어, 탈아미드화된 아미노산)을 가진 서열번호 2의 vp1 아미노산 서열을 암호화하는 서열번호 1과 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 99%, 또는 100% 동일한 서열을 갖는 핵산 분자가 본원에서 제공된다. 특정 구현예에서, 서열번호 3의 서열, 또는 본원에 기술된 바와 같은 변형(예를 들어, 탈아미드화된 아미노산)을 가진 서열번호 2의 vp1 아미노산 서열을 암호화하는 서열번호 3과 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 99%, 또는 100% 동일한 서열을 갖는 핵산 분자가 본원에서 제공된다. 특정 구현예에서, vp1 아미노산 서열은 서열번호 2에서 재현된다. 특정 구현예에서, 본원에 기술된 핵산 서열을 갖는 플라스미드가 제공된다. 이와 같은 플라스미드는 AAVrh91 (서열번호 1)의 vp1, vp2 및 vp3 중 적어도 하나를 암호화하는 핵산 서열, 또는 서열번호 1의 vp1, vp2 및/또는 vp3 서열과 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99% 동일성을 공유하는 서열을 포함한다. 추가의 구현예에서, 플라스미드는 비-AAV 서열을 포함한다. 특정 구현예에서, 플라스미드는 WPRE 및/또는 bGH-폴리A 신호를 포함한다. 본원에 기술된 플라스미드를 포함하는 배양된 숙주 세포가 또한 제공된다.
또한, 예를 들어, 표적 세포에 대한 캡시드 기능/유전자 전달을 개선하고/하거나 수율을 증가시켜 AAV 벡터의 제조를 개선하기 위해, 하나 이상의 아미노산 치환을 도입함으로써 변형된 AAV 캡시드 단백질이 본원에서 제공된다. 기술된 바와 같이, 캡시드 간의 차이는 벡터 패키징의 차이를 초래할 수 있다. 예를 들어, VP1 단백질 서열이 단지 1.1% 상이함에도 불구하고, 벡터 수율에 기초하여, AAVrh91 벡터는 AAV6.2 기반 벡터보다 상당히 더 높은 수준으로 전이유전자를 패키징하는 것으로 밝혀졌다. AAVrh91은 또한 AAV1보다 높은 수준으로 전이유전자를 패키징한다.
기술된 바와 같이, 캡시드 구조의 비교는 AAVrh91과 AAV1 캡시드 간에 상이한 잔기의 위치에 대한 확인으로 이어졌다. 잔기 중 6개는 AAVrh91 vp3 단백질 - Asp418, Asn547, Leu584, Asn588, Val598 및 His642에 위치한다. AAVrh91 캡시드에서 확인된 것과 비교하여 이러한 아미노산 치환 또는 보존적 아미노산 치환을 포함하도록, 다른 클레드 A 벡터를 포함한 AAV 벡터의 변형은 변경된 친화성 및 개선된 수율을 포함하여 개선된 특성을 가진 신규 캡시드를 생성할 수 있다. 따라서, 특정 구현예에서, 하기로부터 선택되는 하나 이상의 아미노 치환을 포함하도록 변형된 캡시드 단백질을 갖는 AAV가 본원에서 제공된다: 위치 418번에서 Asp, 위치 547번에서 Asn, 위치 584번에서 Leu, 위치 588번에서 Asn, 위치 598번에서 Val, 위치 642번에서 His. 특정 구현예에서, 캡시드 단백질은 벡터에 대한 제조 수율을 증가시키기 위해 위치 584번에서 Leu(예를 들어, Leu로부터)를 포함하도록 변형된다. 특정 구현예에서, 위치 598번에서의 Ala 또는 Val 치환은 벡터의 제조 수율을 개선시킨다. 특정 구현예에서, 캡시드 단백질은 위치 418, 547, 584, 588, 598 및 642번으로부터 선택된 하나 이상의 잔기에서 아미노산 치환을 포함하도록 변형된다. 아미노산 치환은 보존적 아미노산 치환, 즉 AAVrh91 캡시드 단백질의 위치 418, 547, 584, 588, 598 및/또는 642에서 관찰된 치환과 유사한 특성을 가질 것으로 예상되는 다른 잔기로 AAV 캡시드 단백질의 아미노산 잔기를 대체하는 것일 수 있다. 특정 구현예에서, 캡시드 단백질은 위치 584에 Leu 및 위치 547에 Asn을 포함하도록 변형된다. 위치의 넘버링은 캡시드 단백질 서열을 AAVrh91 아미노산 서열(서열번호 2) 또는 AAV1 아미노산 서열(서열번호 8)과 정렬함으로써 결정될 수 있다. 특정 구현예에서, 변형된 캡시드 단백질은 AAV1 캡시드 단백질이다. 추가의 구현예에서, 변형된 캡시드 단백질은 서열번호 8과 적어도 95% 동일하거나 적어도 99% 동일한 서열을 갖는다. 다른 구현예에서, 변형된 캡시드는 클레드 A AAV 캡시드 단백질이다. 추가 구현예에서, 변형된 캡시드 단백질은 AAVhu48R3, AAVhu48, AAVhu44, AAV.VR-355, AAV.VR-195, AAV6 또는 AAV6.2 캡시드 단백질이다.
본원에 사용된 바와 같이, "보존적 아미노산 대체" 또는 "보존적 아미노산 치환"은 아미노산을 유사한 생화학적 특성(예를 들어, 전하, 소수성 및 크기)을 갖는 다른 아미노산으로의 변화, 대체 또는 치환을 지칭하며, 이는 당업계의 종사자들에게 알려져 있다. 또한, 예를 들어, FRENCH 등, What is a conservative substitution? Journal of Molecular Evolution, March 1983, Volume 19, Issue 2, pp 171-175 및 YAMPOLSKY 등, The Exchangeability of Amino Acids in Proteins, Genetics. 2005 Aug; 170(4): 1459-1472를 참조하며, 이들 각각은 그 전체가 참조로 본원에 포함된다.
용어 "실질적인 상동성" 또는 "실질적인 유사성"은 핵산 또는 이의 단편을 지칭하는 경우, 또 다른 핵산 (또는 이의 상보적 가닥)과 적절한 뉴클레오티드 삽입 또는 결실이 있도록 최적으로 정렬될 때, 정렬된 서열의 적어도 약 95 내지 99%에 뉴클레오티드 서열 동일성이 존재한다는 것을 나타낸다. 바람직하게는, 상동성은 전장 서열, 또는 이의 오픈 리딩 프레임, 또는 길이가 적어도 15개의 뉴클레오티드인 또 다른 적합한 단편에 걸친 것이다. 적합한 단편의 예가 본원에 기술되어 있다.
핵산 서열과 관련하여 용어 "동일성 백분율(%)", "서열 동일성", "서열 동일성 백분율", 또는 "동일한 백분율"은 관련성을 위해 정렬되는 경우 동일한 2개의 서열에서의 잔기를 지칭한다. 서열 동일성 비교의 길이는 게놈의 전장, 유전자 암호화 서열의 전장, 또는 적어도 약 500개 내지 5000개 뉴클레오티드의 단편에 걸친 것일 수 있으며, 이것이 바람직하다. 그러나, 예를 들어, 적어도 약 9개의 뉴클레오티드, 보통 적어도 약 20개 내지 24개의 뉴클레오티드, 적어도 약 28개 내지 32개의 뉴클레오티드, 적어도 약 36개 이상의 뉴클레오티드의 더 작은 단편 간의 동일성이 또한 바람직할 수 있다.
동일성 백분율은 단백질, 폴리펩티드, 약 32개의 아미노산, 약 330개의 아미노산, 또는 이들의 펩티드 단편 또는 상응하는 핵산 서열 암호화 서열의 전장에 걸쳐 아미노산 서열에 대하여 용이하게 결정될 수 있다. 적합한 아미노산 단편은 적어도 약 8개의 아미노산 길이일 수 있고, 최대 약 700개의 아미노산일 수 있다. 일반적으로, 2개의 상이한 서열 간의 "동일성", "상동성", 또는 "유사성"을 지칭하는 경우, "동일성", "상동성" 또는 "유사성"은 "정렬된" 서열을 참조로 결정된다. "정렬된" 서열 또는 "정렬"은, 종종 참조 서열과 비교하여 누락되거나 추가적인 염기 또는 아미노산에 대한 수정을 포함하는, 다수의 핵산 서열 또는 단백질(아미노산) 서열을 지칭한다.
동일성은 서열의 정렬을 준비함으로써 그리고 당업계에 공지되어 있거나 상업적으로 이용 가능한 다양한 알고리즘 및/또는 컴퓨터 프로그램의 사용을 통해 결정될 수 있다[예를 들어, BLAST, ExPASy; ClustalO; FASTA; 예를 들어, Needleman-Wunsch 알고리즘, Smith-Waterman 알고리즘을 사용함]. 정렬은 다양한 공공 또는 상업적으로 이용 가능한 다중 서열 정렬 프로그램 중 임의의 것을 사용하여 수행된다. 서열 정렬 프로그램, 예를 들어 "Clustal Omega", "Clustal X", "MAP", "PIMA", "MSA", "BLOCKMAKER", "MEME", 및 "Match-Box" 프로그램이 아미노산 서열에 이용 가능하다. 일반적으로, 이들 프로그램 중 임의의 것은 디폴트 설정으로 사용되지만, 당업자는 필요에 따라 이러한 설정을 변경할 수 있다. 대안적으로, 당업자는 적어도 참조된 알고리즘 및 프로그램에 의해 제공되는 것과 같은 동일성 또는 정렬의 수준을 제공하는 또 다른 알고리즘 또는 컴퓨터 프로그램을 이용할 수 있다. 예를 들어, J. D. Thomson 등, Nucl. Acids. Res., "A comprehensive comparison of multiple sequence alignments", 27(13):2682-2690 (1999)을 참조한다.
다중 서열 정렬 프로그램은 또한 핵산 서열에 대해 이용 가능하다. 이와 같은 프로그램의 예는 "Clustal Omega", "Clustal W", "CAP Sequence Assembly", "BLAST", "MAP" 및 "MEME"를 포함하며, 이들은 인터넷 상의 웹 서버를 통해 접근 가능하다. 이와 같은 프로그램에 대한 다른 공급원은 당업자에게 공지되어 있다. 대안적으로, Vector NTI 유틸리티가 또한 사용된다. 또한 상기 기술된 프로그램에 포함된 것을 포함하여, 뉴클레오티드 서열 동일성을 측정하는 데 사용될 수 있는 당업계에 공지된 다수의 알고리즘이 있다. 또 다른 예로서, 폴리뉴클레오티드 서열은 GCG 버전 6.1의 프로그램인 Fasta™을 사용하여 비교될 수 있다. Fasta™은 질의 서열과 검색 서열 간의 최상의 중복 영역의 정렬 및 서열 동일성 백분율을 제공한다. 예를 들어, 핵산 서열 간의 서열 동일성 백분율은 GCG 버전 6.1에서 제공되는 바와 같이 디폴트 파라미터(단어 크기 6, 득점 매트릭스에 대한 NOPAM 인자)와 함께 Fasta™를 사용하여 결정될 수 있으며, 이는 본원에 참조로 포함된다.
B. rAAV 벡터 및 조성물
또 다른 측면에서, 이종 유전자 또는 다른 핵산 서열을 표적 세포에 전달하는 데 유용한 바이러스 벡터의 생산을 위해, 이의 단편을 포함하여, 본원에 기술된 AAV 캡시드 서열을 이용하는 분자가 본원에 기술된다. 일 구현예에서, 본원에 기술된 조성물 및 방법에 유용한 벡터는, 최소한, 본원에 기술된 바와 같은 AAV 캡시드, 예를 들어, AVrh91 캡시드를 암호화하는 서열, 또는 이의 단편을 포함한다. 또 다른 구현예에서, 유용한 벡터는, 최소한, 선택된 AAV 혈청형 rep 단백질을 암호화하는 서열, 또는 이의 단편을 포함한다. 선택적으로, 이와 같은 벡터는 AAV cap 및 rep 단백질을 둘 다 포함할 수 있다. AAV rep 및 cap이 둘 다 제공되는 벡터에서, AAV rep 및 AAV cap 서열은 둘 다 하나의 혈청형 기원, 예를 들어, 모두 AAVrh91 기원일 수 있다. 대안적으로, rep 서열이 cap 서열을 제공하는 야생형 AAV와 상이한 AAV 유래인 벡터가 사용될 수 있다. 일 구현예에서, rep 및 cap 서열은 별개의 공급원 (예를 들어, 별개의 벡터, 또는 숙주 세포 및 벡터)으로부터 발현된다. 또 다른 구현예에서, 이러한 rep 서열은 상이한 AAV 혈청형의 cap 서열에 프레임 내에서 융합되어 키메라 AAV 벡터, 예컨대 미국 특허 제7,282,199호에 기술된 AAV2/8을 형성하며, 이는 본원에 참조로 포함된다. 선택적으로, 벡터는 AAV 5' ITR 및 AAV 3' ITR이 측면에 있는 선택된 전이유전자를 포함하는 미니유전자를 더 포함한다. 또 다른 구현예에서, AAV는 자가-상보성 AAV(sc-AAV)이다(본원에 참조로 포함되는 US 제2012/0141422호 참조). 자가-상보성 벡터는 DNA 합성 또는 다중 벡터 게놈 간의 염기쌍 형성에 대한 필요 없이 dsDNA로 접힐 수 있는 역반복 게놈을 패키징한다. scAAV는 발현 이전에 단일-가닥 DNA(ssDNA) 게놈을 이중-가닥 DNA(dsDNA)로 전환할 필요가 없기 때문에, 이들은 보다 효율적인 벡터이다. 그러나, 이러한 효율성에 대한 절충점은 벡터의 암호화 능력의 절반이 손실된다는 것이다. ScAAV는 소형 단백질-암호화 유전자(최대 ~55 kd) 및 현재 이용 가능한 임의의 RNA-기반 요법에 유용하다.
하나의 AAV의 캡시드가 이종 캡시드 단백질로 대체된 위형(Pseudotyped) 벡터가 본원에서 유용하다. 예시적인 목적으로, AAV2 ITR과 함께 본원에 기술된 바와 같은 AAVrh91 캡시드를 이용하는 AAV 벡터가 하기 기술된 실시예에서 사용된다. 상기 인용한 Mussolino 등을 참조한다. 달리 명시되지 않는 한, AAV ITR, 및 본원에 기술된 다른 선택된 AAV 성분은 AAV1, AAV2, AAV3, AAV4, AAV5, AAV6, AAV7, AAV8, AAV9 또는 다른 공지되고 공지되지 않은 AAV 혈청형을 포함하나 이에 제한되지 않는 임의의 AAV 혈청형 중에서 개별적으로 선택될 수 있다. 바람직한 일 구현예에서, AAV 혈청형 2의 ITR이 사용된다. 그러나, 다른 적합한 혈청형 유래의 ITR이 선택될 수 있다. 이러한 ITR 또는 다른 AAV 성분은 당업자에게 이용 가능한 기법을 사용하여 AAV 혈청형으로부터 용이하게 단리될 수 있다. 이와 같은 AAV는 학문적, 상업적, 또는 공공 출처 (예를 들어, American Type Culture Collection, Manassas, VA)로부터 단리되거나 얻을 수 있다. 대안적으로, AAV 서열은, 예를 들어, GenBank, PubMed 등과 같은 문헌 또는 데이터베이스에서 이용 가능한 것과 같은 공개된 서열을 참조하여 합성 또는 다른 적합한 수단을 통해 얻을 수 있다.
본원에 기술된 rAAV는 또한 벡터 게놈을 포함한다. 벡터 게놈은 최소한 하기 기술된 바와 같은 비-AAV 또는 이종 핵산 서열 (전이유전자)과 이의 조절 서열, 및 5' 및 3' AAV 반전 말단 반복부(ITR)로 구성된다. 캡시드 단백질 내로 패키징되어 선택된 표적 세포에 전달되는 것이 이러한 미니유전자이다.
전이유전자는 전이유전자 측면에 있는 벡터 서열에 대해 이종인 핵산 서열이며, 이는 관심이 있는 폴리펩티드, 단백질, 또는 다른 산물을 암호화한다. 핵산 암호화 서열은 표적 세포에서 전이유전자 전사, 번역, 및/또는 발현을 허용하는 방식으로 조절 성분에 작동가능하게 연결된다. 이종 핵산 서열(전이유전자)은 임의의 유기체로부터 유래될 수 있다. AAV는 하나 이상의 전이유전자를 포함할 수 있다.
특정 구현예에서, 에리트로포이에틴(EPO)을 암호화하는 서열을 포함하는 전이유전자를 포함하는 rAAVrh91 벡터가 본원에서 제공된다. 특정 구현예에서, 전이유전자는 개 또는 고양이 EPO 유전자를 암호화한다. 이와 같은 재조합 벡터는, 예를 들어 순환 적혈구 양의 감소를 특징으로 하는 대상체에서 만성 신장 질환 및 다른 병태를 치료하기 위한 요법에서 사용하기에 적합하다.
특정 구현예에서, 항-신경 성장 인자(NGF) 항체를 암호화하는 서열을 포함하는 전이유전자를 포함하는 rAAVrh91 벡터가 본원에서 제공된다. 특정 구현예에서, 전이유전자는 개 또는 고양이 항-NGF 항체를 암호화한다. 이와 같은 재조합 벡터는, 예를 들어 대상체에서 골관절염 통증을 치료하기 위한 요법에서 사용하기에 적합하다.
특정 구현예에서, 글루카곤-유사 펩티드 1(GLP-1)을 암호화하는 서열을 포함하는 전이유전자를 포함하는 rAAVrh91 벡터가 본원에서 제공된다. 특정 구현예에서, 전이유전자는 개 또는 고양이 GLP-1을 암호화한다. 이와 같은 재조합 벡터는, 예를 들어 대상체에서 II형 당뇨병을 치료하기 위한 요법에서 사용하기에 적합하다.
특정 구현예에서, 인슐린을 암호화하는 서열을 포함하는 전이유전자를 포함하는 rAAVrh91 벡터가 본원에서 제공된다. 특정 구현예에서, 전이유전자는 개 또는 고양이 인슐린을 암호화한다. 이와 같은 재조합 벡터는, 예를 들어 대상체에서 I형 당뇨병 또는 II형 당뇨병을 치료하기 위한 요법에서 사용하기에 적합하다.
특정 구현예에서, CLN(세로이드 리포푸신증, 신경원) 유전자를 포함하는 전이유전자를 포함하는 rAAVrh91 벡터가 본원에서 제공된다. 특정 구현예에서, 전이유전자는 팔미토일-단백질 티오에스테라제 1 - PPT1(CLN1)을 암호화한다. 특정 구현예에서, 전이유전자는 트리펩티딜 펩티다제 1 - TPP1(CLN2)을 암호화한다. 특정 구현예에서, 전이유전자는 CLN3(CLN3)을 암호화한다. 특정 구현예에서, 전이유전자는 DNAJC5(CLN4)를 암호화한다. 특정 구현예에서, 전이유전자는 CLN5(CLN5)를 암호화한다. 특정 구현예에서, 전이유전자는 CLN6(CLN6)을 암호화한다. 특정 구현예에서, 전이유전자 MFSD8(CLN7)을 암호화한다. 특정 구현예에서, 전이유전자는 CLN8(CLN8)을 암호화한다. 특정 구현예에서, 전이유전자는 CTSD(CLN10)를 암호화한다. 특정 구현예에서, 전이유전자는 GRN(CLN11)을 암호화한다. 특정 구현예에서, 전이유전자는 ATP13A2(CLN12)를 암호화한다. 특정 구현예에서, 전이유전자는 ATP13A2(CLN13.)를 암호화한다. 이와 같은 재조합 벡터는, 예를 들어 대상체에서 바텐병 또는 신경원 세로이드 리포푸신증(NCL)을 치료하기 위한 요법에서 사용하기에 적합하다.
특정 구현예에서, PINK1 유전자에 의해 암호화되는 미토콘드리아 세린/트레오닌-단백질 키나아제인, PTEN-유도 키나아제 1을 암호화하는 서열을 포함하는 전이유전자를 포함하는 rAAVrh91 벡터가 본원에서 제공된다. 이와 같은 재조합 벡터는, 예를 들어 젊은 나이에 발병한 파킨슨병(Young-onset Parkinson's disease)을 치료하기 위한 요법에서 사용하기에 적합하다.
특정 구현예에서, IgE, IL-32, 또는 예를 들어 항체 및 수용체-IgG 융합 단백질을 비롯한, IL-4/IL-13 수용체의 인터류킨-4 수용체 알파(IL-4Rα) 서브유닛에 대한 길항제를 암호화하는 서열을 포함하는 전이유전자를 포함하는 rAAVrh91 벡터가 본원에서 제공된다. 특정 구현예에서, 전이유전자는 개 또는 고양이 IgE, IL-32, 또는 IL-4Rα 서브유닛에 대한 길항제를 암호화한다. 이와 같은 재조합 벡터는, 예를 들어 대상체에서 아토피성 피부염을 치료하기 위한 요법에서 사용하기에 적합하다.
전이유전자 서열의 조성은 생성된 벡터가 사용될 용도에 따라 달라질 것이다. 예를 들어, 전이유전자 서열의 한 가지 유형은, 발현 시 검출 가능한 신호를 생성하는 리포터 서열을 포함한다. 이와 같은 리포터 서열은, β-락타마제, β-갈락토시다제(LacZ), 알칼리 포스파타제, 티미딘 키나제, 녹색 형광 단백질(GFP), 강화된 GFP(EGFP), 클로람페니콜 아세틸트랜스퍼라제(CAT), 루시퍼라제, 예를 들어 CD2, CD4, CD8, 인플루엔자 혈구응집소 단백질, 및 고친화성 항체가 존재하거나 통상적인 수단에 의해 생성될 수 있는, 당업계에 잘 알려진 다른 것을 포함하는 막 결합 단백질, 및 특히 혈구응집소 또는 Myc 유래의 항원 tag 도메인에 적절하게 융합된 막 결합 단백질을 포함하는 융합 단백질을 암호화하는 DNA 서열을 포함하나, 이에 제한되지 않는다.
이들 암호화 서열은 이의 발현을 구동시키는 조절 요소와 연관될 때 효소, 방사선, 비색, 형광 또는 다른 분광 분석, 형광 활성화 세포 분류 분석 및 효소 결합 면역흡착 분석(ELISA), 방사면역측정법(RIA) 및 면역조직화학을 포함하는 면역학적 분석을 포함하는 통상적인 수단에 의해 검출 가능한 신호를 제공한다. 예를 들어, 마커 서열이 LacZ 유전자인 경우, 신호를 보유하는 벡터의 존재는 베타-갈락토시다제 활성에 대한 분석에 의해 검출된다. 전이유전자가 녹색 형광 단백질 또는 루시퍼라제인 경우, 신호를 보유하는 벡터는 광도계에서 색상 또는 광 생성에 의해 시각적으로 측정될 수 있다.
그러나, 바람직하게는, 전이유전자는 단백질, 펩티드, RNA, 효소, 우성 음성 돌연변이체, 또는 촉매 RNA와 같은 생물학 및 의학에서 유용한 산물을 암호화하는 비-마커 서열이다. 바람직한 RNA 분자는 tRNA, dsRNA, 리보솜 RNA, 촉매 RNA, siRNA, 작은 헤어핀 RNA, 트랜스-스플라이싱 RNA, 및 안티센스 RNA를 포함한다. 유용한 RNA 서열의 일 예는 처리된 동물에서 표적화된 핵산 서열의 발현을 억제하거나 소멸시키는 서열이다. 전형적으로, 적합한 표적 서열은 종양학적 표적 및 바이러스 질환을 포함한다. 이와 같은 표적의 예를 들어, 면역원과 관련된 섹션에서 하기 확인된 종양학적 표적 및 바이러스를 참조한다.
전이유전자는 정상 유전자가 정상 수준 보다 적게 발현되는 결함 또는 기능성 유전자 산물이 발현되지 않는 결함을 포함할 수 있는 유전자 결함을 교정하거나 개선시키는 데 사용될 수 있다. 대안적으로, 전이유전자는 세포 유형 또는 숙주에서 천연적으로 발현되지 않는 산물을 세포에 제공할 수 있다. 바람직한 전이유전자 서열의 유형은 숙주 세포에서 발현되는 치료용 단백질 또는 폴리펩티드를 암호화한다. 본 발명은 다수의 전이유전자를 사용하는 것을 더 포함한다. 특정 상황에서, 상이한 전이유전자는 단백질의 각각의 서브유닛을 암호화하거나, 상이한 펩티드 또는 단백질을 암호화하는 데 사용될 수 있다. 이는, 단백질 서브유닛을 암호화하는 DNA의 크기가 큰 경우, 예를 들어 면역글로불린, 혈소판-유래 성장 인자, 또는 디스트로핀 단백질의 경우에 바람직하다. 세포가 다중-서브유닛 단백질을 생성하기 위해, 세포는 각각의 상이한 서브유닛을 포함하는 재조합 바이러스로 감염된다. 대안적으로, 단백질의 상이한 서브유닛은 동일한 전이유전자에 의해 암호화될 수 있다. 이 경우에, 단일 전이유전자는 내부 리보자임 진입 부위(internal ribozyme entry site, IRES)에 의해 분리된 각각의 서브유닛에 대한 DNA와 더불어, 각각의 서브유닛을 암호화하는 DNA를 포함한다. 이는, 각각의 서브유닛을 암호화하는 DNA의 크기가 작은 경우, 예를 들어 서브유닛을 암호화하는 DNA의 총 크기 및 IRES가 5 킬로베이스 미만인 경우에 바람직하다. IRES에 대한 대안으로서, DNA는 번역 후 이벤트에서 자가 절단하는 2A 펩티드를 암호화하는 서열에 의해 분리될 수 있다. 예를 들어, M.L. Donnelly 등, J. Gen. Virol., 78(Pt 1):13-21 (1997년 1월); Furler, S. 등, Gene Ther., 8(11):864-873 (2001년 6월); Klump H. 등, Gene Ther., 8(10):811-817 (2001년 5월)을 참조한다. 이러한 2A 펩티드는 IRES보다 상당히 작으며, 이는 공간이 제한 인자인 경우에 사용하기에 매우 적합하다. 더 자주, 전이유전자가 크거나, 다중-서브유닛으로 이루어지거나, 2개의 전이유전자가 공동-전달되는 경우, 원하는 전이유전자(들) 또는 서브유닛을 보유하는 rAAV는 공동-투여되어 이를 생체내에서 콘카타머화(concatamerize)되는 것을 가능하게 하여 단일 벡터 게놈을 형성한다. 이와 같은 구현예에서, 제1 AAV는 단일 전이유전자를 발현하는 발현 카세트를 보유할 수 있고, 제2 AAV는 숙주 세포에서 공동-발현을 위해 상이한 전이유전자를 발현하는 발현 카세트를 보유할 수 있다. 그러나, 선택된 전이유전자는 임의의 생물학적 활성 산물 또는 다른 산물, 예를 들어 연구에 바람직한 산물을 암호화할 수 있다.
적합한 전이유전자 또는 유전자 산물의 예는 가족성 고콜레스테롤혈증, 근이영양증, 낭포성 섬유증, 및 희귀 질환과 연관된 것을 포함한다. 이와 같은 희귀 질환의 예는 특히 척수성 근위축증(SMA), 헌팅턴병, 레트 증후군(예를 들어, 메틸-CpG-결합 단백질 2(MeCP2); UniProtKB - P51608), 근위축성 측삭 경화증(ALS), 듀센형 근이영양증, 프리드리히 운동실조증(예를 들어, 프라탁신), 척수소뇌 운동실조증 2형(SCA2)/ALS와 연관된 ATXN2; ALS와 연관된 TDP-43, 프로그래뉼린(PRGN)(전두측두엽 치매(FTD), 진행형 비-유창성 실어증(PNFA) 및 의미 치매를 포함하는, 비-알츠하이머 뇌 변성과 연관됨), CDKL5 결핍증, 엔젤만 증후군, N-글리카나제 1 결핍증, 알츠하이머병, 취약 X 증후군, 니만픽병(A형 및 B형(ASMD 또는 산성 스핑고미엘리나제 결핍증), c형(NPC)을 포함함), 점액다당류증(MPS), 월만병, 테이-삭스병을 포함할 수 있다. 예를 들어, www.orpha.net/consor/cgi-bin/Disease_Search_List.php; rarediseases.info.nih.gov/diseases를 참조한다.
전이유전자에 의해 암호화되는 유용한 치료제는, 인슐린, 글루카곤, 글루카곤-유사 펩티드 1(GLP-1), 성장 호르몬(GH), 부갑상선 호르몬(PTH), 성장 호르몬 방출 인자(GRF), 여포 자극 호르몬(FSH), 황체 형성 호르몬(LH), 인간 융모성 생식선 자극 호르몬(hCG), 혈관 내피 성장 인자(VEGF), 안지오포이에틴, 안지오스타틴, 과립구 집락 자극 인자(GCSF), 에리트로포이에틴(EPO), 결합 조직 성장 인자(CTGF), 염기성 섬유아세포 성자 인자(bFGF), 산성 섬유아세포 성장 인자(aFGF), 표피 성장 인자(EGF), 형질전환 성장 인자 α(TGFα), 혈소판-유래 성장 인자(PDGF), 인슐린 성장 인자 I 및 II(IGF-I 및 IGF-II), TGF β, 액티빈, 인히빈, 또는 골형성 단백질(BMP) BMP 1 내지 15를 포함하는, 형질전환 성장 인자 β 슈퍼패밀리 중 임의의 하나, 헤레귤린/뉴레귤린/ARIA/성장 인자의 neu 분화 인자(NDF) 패밀리 중 임의의 하나, 신경 성장 인자(NGF), 뇌-유래 신경영양 인자(BDNF), 뉴로트로핀 NT-3 및 NT-4/5, 섬모 신경영양 인자(CNTF), 신경아교 세포주 유래 신경영양 인자(GDNF), 리소좀산 리파아제(LIPA 또는 LAL), 뉴투린, 아그린, 세마포린/콜랩신의 패밀리 중 임의의 하나, 네트린-1 및 네트린-2, 간세포 성장 인자(HGF), 에프린, 노긴, 음향 고슴도치 및 타이로신 하이드록실라제를 포함하나, 이에 제한되지 않는 호르몬과 성장 및 분화 인자를 포함한다. 다른 유용한 전이유전자는 α-L-이두로니다제(MPSI), 이두로네이트 설파타제(MPSII), 헤파란 N-설파타제(설파미니다제)(MPS IIIA, 산필리포 A), α-N-아세틸-글루코사미니다제(MPS IIIB, 산필리포 B), 아세틸-CoA: α-글루코사미나이드 아세틸트랜스퍼라제(MPS IIIC, 산필리포 C), N-아세틸글루코사민 6-설파타제(MPS IIID, 산필리포 D), 갈락토스 6-설파타제(MPS IVA, 모르키오 A), β-갈락토시다제(MPS IVB, 모르키오 B), N-아세틸-갈락토사민 4-설파타제(MPS VI, 마로토-라미(Maroteaux-Lamy)), β-글루쿠로니다제(MPS VII, Sly) 및 히알루로니다제(MPS IX)을 포함하는, 점액다당류증(MPS)을 유발하는 리소좀 효소를 암호화한다.
다른 유용한 전이유전자 산물은, 트롬보포이에틴(TPO), 인터류킨(IL) IL-1 내지 IL-25(IL-2, IL-4, IL-12, 및 IL-18을 포함함), 단핵구 화학주성 단백질, 백혈병 억제 인자, 과립구-대식세포 집락 자극 인자, Fas 리간드, 종양 괴사 인자 α 및 β, 인터페론 α, β 및 γ, 줄기 세포 인자, flk-2/flt3 리간드와 같은 사이토카인 및 림포카인을 포함하나, 이에 제한되지 않는 면역체계를 조절하는 단백질을 포함한다. 면역체계에 의해 생성되는 유전자 산물도 또한 본 발명에 유용하다. 이는 면역글로불린 IgG, IgM, IgA, IgD 및 IgE, 키메라 면역글로불린, 인간화 항체, 단일 사슬 항체, T 세포 수용체, 키메라 T 세포 수용체, 단일 사슬 T 세포 수용체, 클래스 I 및 클래스 II MHC 분자뿐만 아니라, 조작된 면역글로불린 및 MHC 분자를 포함하나, 이에 제한되지 않는다. 유용한 유전자 산물은 또한 보체 조절 단백질, 예컨대, 보체 조절 단백질, 막 보조인자 단백질(MCP), 붕괴 촉진 인자(DAF), CR1, CF2 및 CD59를 포함한다.
또 다른 유용한 유전자 산물은 호르몬, 성장 인자, 사이토카인, 림포카인, 조절 단백질 및 면역체계 단백질에 대한 수용체 중 임의의 하나를 포함한다. 본 발명은 저밀도 지질단백질(LDL) 수용체, 고밀도 지질단백질(HDL) 수용체, 초저밀도 지질단백질(VLDL) 수용체, 및 스캐빈저 수용체를 포함하여, 콜레스테롤 조절을 위한 수용체를 포함한다. 본 발명은 또한 글루코코르티코이드 수용체 및 에스트로겐 수용체, 비타민 D 수용체 및 다른 핵 수용체를 포함하는 스테로이드 호르몬 수용체 슈퍼패밀리의 구성원과 같은 유전자 산물을 포함한다. 추가적으로, 유용한 유전자 산물은 jun, fos, max, mad, 혈청 반응 인자(SRF), AP-1, AP2, myb, MyoD 및 미오게닌, ETS-박스 포함 단백질, TFE3, E2F, ATF1, ATF2, ATF3, ATF4, ZF5, NFAT, CREB, HNF-4, C/EBP, SP1, CCAAT-박스 결합 단백질, 인터페론 조절 인자(IRF-1), 윌름스 종양 단백질, ETS-결합 단백질, STAT, GATA-박스 결합 단백질, 예를 들어, GATA-3, 및 익상 나선형 단백질(winged helix protein)의 포크헤드 패밀리와 같은 전사 인자를 포함한다.
다른 유용한 유전자 산물은 카바모일 합성효소 I, 오르니틴 트랜스카바밀라제, 아르기노석시네이트 합성효소, 아르기노석시네이트 분해효소, 아르기나제, 푸마릴아세트아세테이트 가수분해효소, 페닐알라닌 하이드록실라제, 알파-1 항트립신, 글루코스-6-포스파타제, 포르포빌리노겐 데아미나제, 인자 VIII, 인자 IX, 시스타티온 베타-신타제, 분지쇄 케토산 데카복실라제, 알부민, 이소발레릴-coA 탈수소효소, 프로피오닐 CoA 카복실라제, 메틸 말로닐 CoA 뮤타제, 글루타릴 CoA 탈수소효소, 인슐린, 베타-글루코시다제, 피루베이트 카복실레이트, 간 포스포릴라제, 포스포릴라제 키나제, 글리신 데카복실라제, H-단백질, T-단백질, 낭포성 섬유증 막관통 조절인자(CFTR) 서열, 및 디스트로핀 서열 또는 이들의 기능성 단편을 포함한다. 또 다른 유용한 유전자 산물은 효소 대체 요법에 유용할 수 있는 효소를 포함하며, 이는 효소의 활성 결핍으로 인한 다양한 병태에 유용하다. 예를 들어, 만노스-6-포스페이트를 포함하는 효소는 리소좀 축적 질환에 대한 치료에 이용될 수 있다 (예를 들어, 적합한 유전자는 β-글루쿠로니다제(GUSB)를 암호화하는 것을 포함함). 또 다른 예에서, 유전자 산물은 유비퀴틴 단백질 리가제 E3A(UBE3A)이다. 또한 유용한 유전자 산물은 UDP 글루쿠로노실트랜스퍼라제 패밀리 1 구성원 A1(UGT1A1)을 포함한다.
다른 유용한 유전자 산물은 삽입, 결실 또는 아미노산 치환을 포함하는 비-천연 발생 아미노산 서열을 갖는 키메라 또는 하이브리드 폴리펩티드와 같은 비-천연 발생 폴리펩티드를 포함한다. 예를 들어, 단일-사슬 조작된 면역글로불린은 특정 면역저하 환자에서 유용할 수 있다. 비-천연 발생 유전자 서열의 다른 유형은 표적의 과발현을 감소시키는 데 사용될 수 있는 리보자임과 같은 안티센스 분자 및 촉매 핵산을 포함한다.
유전자 발현의 감소 및/또는 조절은 특히 암 및 건선과 같은 과증식 세포를 특징으로 하는 과증식성 병태의 치료에 바람직하다. 표적 폴리펩티드는 정상 세포와 비교하여 과증식성 세포에서 독점적으로 또는 더 높은 수준으로 생성되는 폴리펩티드를 포함한다. 표적 항원은 myb, myc, fyn과 같은 종양 유전자, 및 전좌 유전자 bcr/abl, ras, src, P53, neu, trk 및 EGRF에 의해 암호화되는 폴리펩티드를 포함한다. 표적 항원으로서 종양 유전자 산물에 추가적으로, 항암 치료 및 보호 요법을 위한 표적 폴리펩티드는 B 세포 림프종에 의해 만들어진 항체의 가변 영역 및 T 세포 림프종의 T 세포 수용체의 가변 영역을 포함하며, 이들은 일부 구현예에서 또한 자가면역 질환에 대한 표적 항원으로서 사용된다. 다른 종양-연관 폴리펩티드는 모노클로널 항체 17-1A에 의해 인식되는 폴리펩티드 및 엽산 결합 폴리펩티드를 포함하여 종양 세포에서 더 높은 수준으로 발견되는 폴리펩티드와 같은 표적 폴리펩티드로서 사용될 수 있다.
다른 적합한 치료용 폴리펩티드 및 단백질은 자가-지시 항체를 생성하는 세포 및 세포 수용체를 포함하는 자가면역과 연관된 표적에 대한 광범위한 보호 면역 반응을 부여함으로써 자가면역 질환 및 장애를 앓고 있는 개체를 치료하는 데 유용할 수 있는 것을 포함한다. T 세포 매개 자가면역 질환은 류카티스 관절염(RA), 다발성 경화증(MS), 쇼그렌 증후군, 사르코이드증, 인슐린 의존성 당뇨병(IDDM), 자가면역성 갑상선염, 반응성 관절염, 강직성 척추염, 피부경화증, 다발성근염, 피부근염, 건선, 혈관염, 베게너 육아종증, 크론병 및 궤양성 대장염을 포함한다. 이들 질환 각각은 내인성 항원에 결합하고 자가면역 질환과 연관된 염증 캐스케이드를 개시하는 T 세포 수용체(TCR)를 특징으로 한다.
또 다른 유용한 유전자 산물은 혈우병 B(인자 IX를 포함함) 및 혈우병 A(인자 VIII 및 이의 변이체, 예컨대, B-결실 도메인 및 이종이량체의 경쇄 및 중쇄를 포함함; 미국 특허 제6,200,560호 및 미국 특허 제6,221,349호)를 포함하는, 혈우병의 치료에 사용되는 것을 포함한다. 일부 구현예에서, 미니유전자는 10개 아미노산 신호 서열뿐만 아니라 인간 성장 호르몬(hGH) 폴리아데닐화 서열을 암호화하는 인자 VIII 중쇄의 처음 57개 염기쌍을 포함한다. 대안적인 구현예에서, 미니유전자는 A1 및 A2 도메인뿐만 아니라, B 도메인 N-말단으로부터 5개 아미노산, 및/또는 B 도메인 C-말단의 85개 아미노산뿐만 아니라, A3, C1 및 C2 도메인을 포함한다. 또 다른 구현예에서, 인자 VIII 중쇄 및 경쇄를 암호화하는 핵산은 B 도메인의 14개 아미노산을 암호화하는 42개 핵산에 의해 분리된 단일 미니유전자로 제공된다[미국 특허 제6,200,560호].
rAAV를 통해 전달될 수 있는 추가의 예시적인 유전자는, 글리코겐 축적 질환 또는 결핍 유형 1A(GSD1)와 연관된 글루코스-6-포스포타제, PEPCK 결핍과 연관된 포스포에놀피루베이트-카복시키나제(PEPCK); 발작 및 심각한 신경발달 장애와 연관된 세린/트레오닌 키나제 9(STK9)로도 공지된 사이클린-의존성 키나제-유사 5(CDKL5); (NGLY1) N-글리카나제 1; 갈락토스혈증과 연관된 갈락토스-1-포스페이트 우리딜 트랜스퍼라제; 페닐케톤뇨증(PKU)과 연관된 페닐알라닌 하이드록실라제(PAH); 단풍당뇨증과 연관된 BCKDH, BCKDH-E2, BAKDH-E1a, 및 BAKDH-E1b를 포함하는, 분지쇄 알파-케토산 탈수소효소, 하이드록시산 옥시다제 1(GO/HAO1) 및 AGXT를 포함하는 원발성 옥살산뇨증 1형과 연관된 유전자 산물; 타이로신혈증 1형과 연관된 푸마릴아세토아세테이트 가수분해효소; 메틸말론산혈증과 연관된 메틸말로닐-CoA 뮤타제; 중쇄 아세틸 CoA 결핍과 연관된 중쇄 아실 CoA 탈수소효소; 오르니틴 트랜스카바밀라제 결핍과 연관된 오르니틴 트랜스카바밀라제(OTC); 시트룰린혈증과 연관된 아르기니노숙신산 합성효소(ASS1); 레시틴-콜레스테롤 아실트랜스퍼라제(LCAT) 결핍; 아메틸말론산혈증(MMA); 니만-픽병 유형 C1과 연관된 NPC1; 프로피온산혈증(PA); 트랜스타이레틴(TTR)-관련 유전성 아밀로이드증과 연관된 TTR; 가족성 고콜레스테롤혈증(FH)과 연관된 저밀도 지질단백질 수용체(LDLR) 단백질, LDLR 변이체, 예컨대 WO 2015/164778호에 기술된 것; PCSK9; 치매와 연관된 ApoE 및 ApoC 단백질; 크리글러-나자르병과 연관된 UDP-글루쿠로노실트랜스퍼라제; 중증 복합 면역결핍 질환과 연관된 아데노신 데아미나제; 통풍 및 레쉬-니한 증후군과 연관된 하이포크산틴 구아닌 포스포리보실 트랜스퍼라제; 바이오티미다제 결핍과 연관된 바이오티미다제; 파브리병과 연관된 알파-갈락토시다제 A(a-Gal A); GM1 강글리오사이드 축적증과 연관된 베타-갈락토시다제(GLB1); 윌슨병과 연관된 ATP7B; 고셰병 2형 및 3형과 연관된 베타-글루코세레브로시다제; 젤웨거 증후군과 연관된 퍼옥시좀 막 단백질 70 kDa; 이염성 백질이영양증과 연관된 아릴설파타제 A(ARSA), 크라베병과 연관된 갈락토세레브로시다제(GALC) 효소, 폼페병과 연관된 알파-글루코시다제(GAA); 니만-픽병 A형과 연관된 스핑고미엘리나제(SMPD1) 유전자; 성인 발병 II형 시트룰린혈증(CTLN2)과 연관된 아르기니노숙시네이트 신타제; 요소 회로 장애와 연관된 카바모일-포스페이트 신타제 1(CPS1); 척수성 근위축과 연관된 생존 운동 뉴런(SMN) 단백질; 파아버 지방육아종증과 연관된 세라미다제; GM2 강글리오사이드 축적증 및 테이-삭스병 및 샌드호프병과 연관된 b-헥소사미니다제; 아스파틸-글루코사민뇨증과 연관된 아스파틸글루코사미니다제; 푸코사이드 축적증과 연관된 α-푸코시다제; 알파-만노사이드 축적증과 연관된 α-만노시다제; 급성 간헐성 포르피린증(AIP)과 연관된 포르포빌리노겐 데아미나제; 알파-1 항트립신 결핍(폐기종)의 치료를 위한 알파-1 항트립신; 지중해빈혈 또는 신부전으로 인한 빈혈의 치료를 위한 에리트로포이에틴; 허혈성 질환의 치료를 위한 혈관 내피 성장 인자, 안지오포이에틴-1, 및 섬유아세포 성장 인자; 예를 들어 죽상동맥경화증, 혈전증, 또는 색전증에서 보이는 바와 같은 폐색된 혈관의 치료를 위한 트롬보모듈린 및 조직 인자 경로 억제제; 파킨스병의 치료를 위한 방향족 아미노산 데카복실라제(AADC), 및 타이로신 하이드록실라제(TH); 울혈성 심부전의 치료를 위한 포스포람반, 근소포체(소포체) 아데노신 트라이포스파타제-2(SERCA2), 및 심장 아데닐릴 사이클라제의 베타 아드레날린성 수용체, 이에 대한 안티센스, 또는 이의 돌연변이체 형태; 다양한 암의 치료를 위한 p53과 같은 종양 억제 유전자; 염증 및 면역 장애 및 암의 치료를 위한 다양한 인터류킨 중 하나와 같은 사이토카인; 근이영양증의 치료를 위한 디스트로핀 또는 미니디스트로핀 및 유트로핀 또는 미니유트로핀; 및 당뇨병의 치료를 위한 인슐린 또는 GLP-1을 포함하나, 이에 제한되지 않는다.
특정 구현예에서, rAAV는 유전자 편집 시스템에서 사용될 수 있으며, 상기 시스템은 하나의 rAAV 또는 다수의 rAAV 스톡의 공동-투여를 수반할 수 있다. 예를 들어, rAAV는 SpCas9, SaCas9, ARCUS, Cpf1(Cas12a로도 알려짐), CjCas9 및 기타 적절한 유전자 편집 작제물을 전달하도록 조작될 수 있다.
특정 구현예에서, rAAV-기반 유전자 편집 뉴클레아제 시스템이 본원에서 제공된다. 상기 유전자 편집 뉴클레아제는 질병-관련 유전자, 즉 관심 유전자 내 부위를 표적화한다.
특정 구현예에서, AAV-기반 유전자 편집 뉴클레아제 시스템은 AAVrh91 캡시드 및 그 내부에 봉입된 벡터 게놈을 포함하는 rAAV를 포함하고, 상기 벡터 게놈은 AAV 5' 반전 말단 반복부 (ITR), 관심 유전자의 인식 부위를 인식하고 절단하는 유전자 편집 뉴클레아제를 암호화하는 핵산 서열을 포함하는 발현 카세트로서, 여기서 상기 유전자 편집 뉴클레아제 암호화 서열은 관심 유전자를 포함하는 세포에서 이의 발현을 지시하는 발현 제어 서열에 작동가능하게 연결되는 발현 카세트, 및 AAV 3' ITR을 포함한다. rAAV-기반 유전자 편집 뉴클레아제 시스템을 사용하여 치료하는 방법이 또한 본원에 제공된다.
일부 구현예에서, rAAV-기반 유전자 편집 메가뉴클레아제 시스템은 질병, 장애, 증후군 및/또는 병태를 치료하기 위해 사용된다. 일부 구현예에서, 유전자 편집 뉴클레아제는 관심 유전자를 표적으로 하고, 상기 관심 유전자는 질병, 장애, 증후군 및/또는 병태와 연관 및/또는 연루된 하나 이상의 유전적 돌연변이, 결실, 삽입 및/또는 결함을 갖는다. 일부 구현예에서, 장애는 심혈관, 간, 내분비 또는 대사, 근골격, 신경학적 및/또는 신장 장애로 선택되나 이에 제한되지 않는다.
대안적으로, 또는 추가적으로, 본 발명의 벡터는 본 발명의 AAV 서열 및 선택된 면역원에 대한 면역 반응을 유도하는 펩티드, 폴리펩타이드 또는 단백질을 암호화하는 전이유전자를 포함할 수 있다. 예를 들어, 면역원은 다양한 바이러스 패밀리로부터 선택될 수 있다. 면역 반응이 바람직한 바이러스 패밀리의 예는, 일반 감기 사례의 약 50%를 차지하는 리노바이러스(rhinovirus) 속을 포함하는 피코나바이러스(picornavirus) 과; 폴리오바이러스(poliovirus), 콕사키바이러스(coxsackievirus), 에코바이러스(echovirus), 및 인간 엔테로바이러스(enterovirus), 예컨대, A형 간염 바이러스를 포함하는 엔테로바이러스(enterovirus) 속; 및 주로 비-인간 동물에서 구제역의 원인이 되는 압소바이러스(apthovirus) 속을 포함한다. 바이러스 중 피코나바이러스 과 내에서, 표적 항원은 VP1, VP2, VP3, VP4, 및 VPG를 포함한다. 또 다른 바이러스 과는, 유행성 위장염의 중요한 원인 물질인 노워크(Norwalk) 그룹의 바이러스를 포함하는 칼시바이러스(calcivirus) 과를 포함한다. 인간 및 비-인간 동물에서 면역 반응을 유도하기 위해 항원을 표적화하는 데 사용하기에 바람직한 또 다른 바이러스 과는 알파바이러스(alphavirus) 속을 포함하는 토가바이러스(togavirus) 과이며, 이는 신드비스 바이러스(Sindbis virus), 로스리버 바이러스(RossRiver virus), 및 베네수엘라, 동부 및 서부 말 뇌염(Venezuelan, Eastern & Western Equine encephalitis), 및 루벨라 바이러스(Rubella virus)를 포함하는 루비바이러스(rubivirus) 속을 포함한다. 플라비비리대(flaviviridae) 과는 뎅기, 황열, 일본 뇌염, 세인트루이스 뇌염 및 진드기 매개 뇌염 바이러스를 포함한다. 다른 표적 항원은 C형 간염 또는 코로나바이러스(coronavirus) 과로부터 생성될 수 있으며, 이는 다수의 비-인간 바이러스, 예컨대, 감염성 기관지염 바이러스(가금류), 돼지 전염성 위장 바이러스(돼지), 돼지 혈구응집성 뇌척수염 바이러스(돼지), 고양이 감염성 복막염 바이러스(고양이), 고양이 장 코로나바이러스(고양이), 개 코로나바이러스(개), 및 인간 호흡기 코로나바이러스를 포함하며, 이는 일반 감기 및/또는 비-A, B 또는 C형 간염을 유발할 수 있다. 코로나바이러스 과 내에서, 표적 항원은 E1 (M 또는 기질 단백질이라고도 함), E2(S 또는 스파이크 단백질이라고도 함), E3(HE 또는 혈구응집소-엘테로스라고도 함) 당단백질(모든 코로나바이러스에 존재하지는 않음), 또는 N(뉴클레오캡시드)를 포함한다. 또 다른 항원은 랍도바이러스(rhabdovirus) 과에 대하여 표적화될 수 있으며, 이는 베시큘로바이러스(vesiculovirus) 속(예를 들어, 수포성 구내염 바이러스), 및 리사바이러스(lyssavirus) 속(예를 들어, 광견병)을 포함한다. 랍도바이러스 과 내에서, 적합한 항원은 G 단백질 또는 N 단백질로부터 유래될 수 있다. 출혈열 바이러스, 예컨대, 마르부르그(Marburg) 및 에볼라 바이러스(Ebola virus)를 포함하는 필로비리대(filoviridae) 과는 항원의 적합한 공급원일 수 있다. 파라믹소바이러스(paramyxovirus) 과는 파라인플루엔자(parainfluenza) 바이러스 1형, 파라인플루엔자 바이러스 3형, 소 파라인플루엔자 바이러스 3형, 이하선염 바이러스(멈프스 바이러스), 파라인플루엔자 바이러스 2형, 파라인플루엔자 바이러스 4형, 뉴캐슬병 바이러스(Newcastle disease virus)(닭), 우역, 홍역 및 개홍역을 포함하는 모르빌리바이러스(morbillivirus), 및 호흡기 세포융합 바이러스를 포함하는 폐렴바이러스(pneumovirus)를 포함한다. 인플루엔자 바이러스는 오쏘믹소바이러스(orthomyxovirus) 과 내에서 분류되며, 항원(예를 들어, HA 단백질, N1 단백질)의 적합한 공급원이다. 분야바이러스(bunyavirus) 과는 분야바이러스(캘리포니아 뇌염, 라크로스), 플레보바이러스(phlebovirus)(리프트 계곡열), 한타바이러스(hantavirus)(푸레말라는 헤마하긴 열 바이러스임), 나이로바이러스(nairovirus)(나이로비 양 병) 속 및 다양한 비지정 분가바이러스(bungavirus)를 포함한다. 아레나바이러스(arenavirus) 과는 LCM 및 랏사열 바이러스(Lassa fever virus)에 대한 항원의 공급원을 제공한다. 레오바이러스(reovirus) 과는 레오바이러스, 로타바이러스(rotavirus)(소아에서 급성 위장염을 유발함), 오르비바이러스(orbivirus), 및 컬티바이러스(cultivirus)(콜로라도 진드기 열, 레봄보(인간), 말 뇌염, 청설병) 속을 포함한다.
레트로바이러스(retrovirus) 과는 고양이 백혈병 바이러스, HTLVI 및 HTLVII, 렌티바이러스(인간 면역결핍 바이러스(HIV), 원숭이 면역결핍 바이러스(SIV), 고양이 면역결핍 바이러스(FIV), 말 감염성 빈혈 바이러스, 및 스푸마바이러스(spumavirinal)를 포함함)와 같은 인간 및 수의학적 질환을 포함하는 온코리바이러스(oncorivirinal) 아과를 포함한다. HIV와 SIV 사이에, 많은 적합한 항원이 기술되어 있으며 용이하게 선택될 수 있다. 적합한 HIV 및 SIV 항원의 예는 gag, pol, Vif, Vpx, VPR, Env, Tat 및 Rev 단백질뿐만 아니라 이들의 다양한 단편을 포함하나, 이에 제한되지 않는다. 추가적으로, 이들 항원에 대한 다양한 변형이 기술된 바 있다. 이러한 목적에 적합한 항원이 당업자에게 공지되어 있다. 예를 들어, 다른 단백질 중에서, gag, pol, Vif, 및 Vpr, Env, Tat 및 Rev를 암호화하는 서열을 선택할 수 있다. 예를 들어, 미국 특허 제5,972,596호에 기술된 변형된 gag 단백질을 참조한다. 또한, D.H. Barouch 등, J. Virol., 75(5):2462-2467 (2001년 3월), 및 R.R. Amara 등, Science, 292:69-74 (2001년 4월 6일)에 기술된 HIV 및 SIV 단백질을 참조한다. 이들 단백질 또는 이들의 서브유닛은 단독으로, 또는 별개의 벡터를 통해 또는 단일 벡터로부터 조합되어 전달될 수 있다.
파포바바이러스(papovavirus) 과는 폴리오마바이러스(polyomavirus) 아과(BKU 및 JCU 바이러스) 및 파필로마바이러스(papillomavirus) 아과(유두종의 악성 진행 또는 암과 연관됨)를 포함한다. 아데노바이러스(adenovirus) 과는 호흡기 질환 및/또는 장염을 유발하는 바이러스(EX, AD7, ARD, O.B.)를 포함한다. 파보바이러스(parvovirus) 과는 고양이 파보바이러스(고양이 장염), 고양이 범백혈구감소증 바이러스, 개 파보바이러스, 및 돼지 파보바이러스. 헤르페스바이러스(herpesvirus) 과는, 단순바이러스(simplexvirus)(HSVI, HSVII), 바리셀로바이러스(varicellovirus)(위광견병, 수두 대상포진) 속을 포함하는 알파헤르페스비리내(alphaherpesvirinae) 아과, 및 거대세포바이러스(cytomegalovirus) 속(HCMV, 뮤로메갈로바이러스(muromegalovirus))을 포함하는 베타헤르페스비리내(betaherpesvirinae) 아과, 및 림포크립토바이러스(lymphocryptovirus), EBV(버킷 림프종), 감염성 비강기관염, 마레크병 바이러스(Marek's disease virus), 및 라디노바이러스(rhadinovirus) 속을 포함하는 감마헤르페스비리내(gammaherpesvirinae) 아과를 포함한다. 폭스바이러스(poxvirus) 과는 오쏘폭스바이러스(orthopoxvirus)(두창(천연두) 및 백시니아(우두)), 파라폭스바이러스(parapoxvirus), 아비폭스바이러스(avipoxvirus), 카프리폭스바이러스(capripoxvirus), 레포리폭스바이러스(leporipoxvirus), 수이폭스바이러스(suipoxvirus) 속을 포함하는 코르도폭스비리내(chordopoxvirinae) 아과, 및 엔테모폭스비리내(entomopoxvirinae) 아과를 포함한다. 헤파드나바이러스(hepadnavirus) 과는 B형 간염 바이러스를 포함한다. 항원의 적합한 공급원일 수 있는 한 가지 미분류 바이러스는 델타 간염 바이러스이다. 또 다른 바이러스 공급원은 조류 감염성 낭병 바이러스 및 돼지 호흡기 및 생식 증후군 바이러스를 포함할 수 있다. 알파바이러스(alphavirus) 과는 말 동맥염 바이러스 및 다양한 뇌염 바이러스를 포함한다.
본 발명은 또한 인간 및 비-인간 척추동물을 감염시키는 박테리아, 진균, 기생 미생물 또는 다세포 기생충을 포함하는 다른 병원체에 대하여, 또는 암 세포 또는 종양 세포로부터 인간 또는 비-인간 동물을 면역화시키는 데 유용한 면역원을 포함할 수 있다. 박테리아 병원체의 예는 폐렴구균(pneumococci); 포도상구균(staphylococci); 및 연쇄구균(streptococci)을 포함하는 병원성 그람-양성 구균(cocci)을 포함한다. 병원성 그람-음성 구균은 수막염균(meningococcus); 임균(gonococcus)을 포함한다. 병원성 장내 그람-음성 간균(bacillus)은 장내세균과(enterobacteriaceae); 슈도모나스(pseudomonas); 아시네토박테리아(acinetobacteria) 및 아이케넬라(eikenella); 멜리오이도시스(melioidosis); 살모넬라(salmonella); 시겔라(shigella); 헤모필루스(haemophilus); 모락셀라(moraxella); H. 듀크레이(H. ducreyi)(연성하감을 유발함); 브루셀라(brucella); 프라니셀라 투라렌시스(Franisella tularensis)(야토병을 유발함); 예르시니아(yersinia)(파스퇴렐라(pasteurella)); 스트렙토바실러스 모닐리포르미스(streptobacillus moniliformis) 및 스피릴룸(spirillum)을 포함하고; 그람-양성 간균은 리스테리아 모노사이토게네스(listeria monocytogenes); 에리시펠로트릭스 루시오패티에(erysipelothrix rhusiopathiae); 코리네박테리움 디프테리아(Corynebacterium diphtheria)(디프테리아); 콜레라; B. 안트라시스(B. anthracis)(탄저병); 도너반증(서혜부 육아종); 및 바르토넬라증을 포함한다. 병원성 혐기성 박테리아에 의해 유발되는 질환은 파상풍; 보툴리눔독소증; 다른 클로스트리디아; 결핵; 한센병; 및 다른 마이코박테리아를 포함한다. 병원성 스피로헤타병은 매독, 트레포네마증; 요오스(yaws), 열대백반피부염 및 지방유행성 매독; 및 렙토스피라증을 포함한다. 더 고등의 병원체 박테리아 및 병원성 진균에 의해 유발되는 다른 감염증은 방선균증; 노카르디아증; 크립토코커스증, 분아균증, 히스토플라스마증 및 콕시디오이데스 진균증; 칸디다증, 아스페르길루스증, 및 모균증; 스포로트릭스증; 파라콕시디오이드 진균증, 페트리엘리디오시스(petriellidiosis), 토룰롭시스증, 진균종 및 색소진균증; 및 피부사상균증을 포함한다. 리케차 감염은 발진티푸스, 록키산 홍반열, Q열, 및 리케치아두를 포함한다. 마이코플라스마 및 클라미디아 감염의 예는 폐렴 마이코플라스마; 성병성 림프 육아종; 앵무새병; 및 주산기 클라미디아 감염을 포함한다. 병원성 진핵생물은 병원성 원생동물 및 연충을 포함하고 이에 의해 생성되는 감염은 아메바증; 말라리아; 리슈만편모충증; 트리파노소마증; 톡소플라스마증; 뉴모시스티스 카리니(Pneumocystis carinii); 트라이칸스(Trichans); 톡소플라스마 곤디(Toxoplasma gondii); 바베시아증; 지아디아증; 트리키넬라증; 필라리아증; 주혈흡충증; 선충; 흡충(trematodes 또는 fluke); 및 조충(촌충) 감염을 포함한다.
다수의 이들 유기체 및/또는 이에 의해 생성되는 독소는 질병통제센터[Centers for Disease Control(CDC), 보건사회복지부, USA]에 의해 생물학적 공격에 사용될 가능성이 있는 작용제로 확인되었다. 예를 들어, 이들 생물학적 작용제의 일부는 바실러스 안트라시스(Bacillus anthracis)(탄저병), 클로스트리듐 보툴리눔(Clostridium botulinum) 및 이의 독소(보툴리눔독소증), 예르시니아 페스티스(Yersinia pestis)(페스트), 바리올라 메이저(variola major)(천연두), 프란시셀라 툴라렌시스(Francisella tularensis)(야토병), 및 바이러스성 출혈열 (이들 모두는 현재 카테고리 A 작용제로 분류됨); 콕시엘라 부르네티(Coxiella burnetti)(Q열); 브루셀라 종(브루셀라병), 부르크홀데리아 말레이(Burkholderia mallei)(마비저), 리시누스 코뮤니스(Ricinus communis) 및 이의 독소(리신 독소), 클로스트리듐 퍼프린젠스(Clostridium perfringens) 및 이의 독소(엡실론 독소), 스타필로코커스(Staphylococcus) 종 및 이의 독소(엔테로톡신 B) (이들 모두는 현재 카테고리 B 작용제로 분류됨); 니판 바이러스(Nipan virus) 및 한타바이러스 (이들은 현재 카테고리 C 작용제로 분류됨)를 포함한다. 추가적으로, 그렇게 분류되거나 상이하게 분류되는 다른 유기체가 장래에 이와 같은 목적으로 식별되고/거나 사용될 수 있다. 본원에 기술된 바이러스 벡터 및 다른 작제물은 이들 유기체, 바이러스, 이의 독소 또는 다른 부산물로부터 항원을 전달하는 데 유용하며, 이는 이들 생물학적 작용제로 감염 또는 다른 부작용을 예방 및/또는 치료할 것임을 용이하게 이해할 것이다.
T 세포의 가변 영역에 대한 면역원을 전달하기 위한 본 발명의 벡터의 투여는 이러한 T 세포를 제거하기 위한 CTL을 포함하는 면역 반응을 유발한다. 류마티스 관절염(RA)에서, 질환과 관련된 T 세포 수용체(TCR)의 여러 특정 가변 영역이 특성화되었다. 이러한 TCR은 V-3, V-14, V-17 및 Vα-17을 포함한다. 따라서, 이들 폴리펩티드 중 적어도 하나를 암호화하는 핵산 서열의 전달은 RA에 관련된 T 세포를 표적화할 면역 반응을 유발할 것이다. 다발성 경화증(MS)에서, 질환과 관련된 TCR의 여러 특정 가변 영역이 특성화되었다. 이러한 TCR은 V-7 및 Vα-10을 포함한다. 따라서, 이들 폴리펩티드 중 적어도 하나를 암호화하는 핵산 서열의 전달은 MS에 관련된 T 세포를 표적화할 면역 반응을 유발할 것이다. 피부경화증에서, 질환과 관련된 TCR의 여러 특정 가변 영역이 특성화되었다. 이러한 TCR은 V-6, V-8, V-14 및 Vα-16, Vα-3C, Vα-7, Vα-14, Vα-15, Vα-16, Vα-28 및 Vα-12를 포함한다. 따라서, 이들 폴리펩티드 중 적어도 하나를 암호화하는 핵산 분자의 전달은 피부경화증에 관련된 T 세포를 표적화할 면역 반응을 유발할 것이다.
일 구현예에서, 전이유전자는 광유전자적 요법을 제공하도록 선택된다. 광유전자적 요법에서, 인공 광수용체는 나머지 망막 회로에 있는 생존 세포 유형으로 광-활성화 채널 또는 펌프의 유전자 전달에 의해 작제된다. 이는 상당한 양의 광수용체 기능을 상실했지만 신경절 세포 및 시신경에 대한 양극 세포 회로가 손상되지 않은 상태인 환자에게 특히 유용하다. 일 구현예에서, 이종 핵산 서열(전이유전자)은 옵신이다. 옵신 서열은 인간, 조류 및 박테리아를 포함하는 임의의 적합한 단일- 또는 다세포-유기체로부터 유래될 수 있다. 일 구현예에서, 옵신은 로돕신, 포톱신, L/M 파장(적색/녹색)-옵신, 또는 단파장(S) 옵신(청색)이다. 또 다른 구현예에서, 옵신은 채널로돕신 또는 할로로돕신이다.
또 다른 구현예에서, 전이유전자는 유전자 증대 요법에 사용하기 위해, 즉, 결손되거나 결함이 있는 유전자의 대체 복제물을 제공하기 위해 선택된다. 이러한 구현예에서, 전이유전자는 필요한 대체 유전자를 제공하기 위해 당업자에 의해 용이하게 선택될 수 있다. 일 구현예에서, 결손/결함 유전자는 안구 장애와 관련이 있다. 또 다른 구현예에서, 전이유전자는 NYX, GRM6, TRPM1L 또는 GPR179이고, 안구 장애는 선천성 정지형 야맹증이다. 예를 들어, Zeitz 등, Am J Hum Genet. 2013 Jan 10;92(1):67-75. Epub 2012 Dec 13을 참조하며, 이는 본원에 참조로 포함된다. 또 다른 구현예에서, 전이유전자는 RPGR이다.
또 다른 구현예에서, 전이유전자는 유전자 억제 요법에 사용하기 위해 선택되며, 즉, 하나 이상의 천연 유전자의 발현은 전사 또는 번역 수준에서 중단되거나 억제된다. 이는 짧은 헤어핀 RNA(shRNA) 또는 당업계에 잘 알려진 다른 기법을 사용하여 달성될 수 있다. 예를 들어, Sun 등, Int J Cancer. 2010 Feb 1;126(3):764-74 및 O'Reilly M 등, Am J Hum Genet. 2007 Jul;81(1):127-35을 참조하며, 이들은 본원에 참조로 포함된다. 이 구현예에서, 전이유전자는 침묵시키고자 하는 유전자를 기반으로 하여 당업자에 의해 용이하게 선택될 수 있다.
또 다른 구현예에서, 전이유전자는 하나 이상의 전이유전자를 포함한다. 이는 2개 이상의 이종 서열을 보유하는 단일 벡터를 사용하여, 또는 각각 하나 이상의 이종 서열을 보유하는 2개 이상의 AAV를 사용하여 달성될 수 있다. 일 구현예에서, AAV는 유전자 억제 (또는 녹다운) 및 유전자 증대 공동-요법에 사용된다. 녹다운/증대 공동-요법에서, 관심이 있는 유전자의 결함 복제물은 침묵되고 돌연변이되지 않은 복제물이 제공된다. 일 구현예에서, 이는 2개 이상의 공동-투여된 벡터를 사용하여 달성된다. Millington-Ward 등, Molecular Therapy, April 2011, 19(4):642-649을 참조하며, 이는 본원에 참조로 포함된다. 전이유전자는 원하는 결과를 기반으로 하여 당업자에 의해 용이하게 선택될 수 있다.
또 다른 구현예에서, 전이유전자는 유전자 교정 요법에 사용하기 위해 선택된다. 이는, 예를 들어 외인성 DNA 공여체 기질과 함께 아연-핑거 뉴클레아제(ZFN)-유도 DNA 이중-가닥 절단을 사용하여 달성될 수 있다. 예를 들어, Ellis 등, Gene Therapy (epub January 2012) 20:35-42를 참조하며, 이는 본원에 참조로 포함된다. 전이유전자는 원하는 결과를 기반으로 하여 당업자에 의해 용이하게 선택될 수 있다.
일 구현예에서, 본원에 기술된 캡시드는 미국 특허 가출원 제61/153,470호, 제62/183,825호, 제62/254,225호 및 제62/287,511호에 기술된 CRISPR-Cas 이중 벡터 시스템에 유용하며, 이들 각각은 본원에 참조로 포함된다. 캡시드는 또한 호밍 엔도뉴클레아제 또는 다른 메가뉴클레아제의 전달에 유용하다.
또 다른 구현예에서, 본원에서 유용한 전이유전자는 발현시 검출 가능한 신호를 생성하는 리포터 서열을 포함한다. 이와 같은 리포터 서열은, β-락타마제, β-갈락토시다제(LacZ), 알칼리 포스파타제, 티미딘 키나제, 녹색 형광 단백질(GFP), 적색 형광 단백질(RFP), 클로람페니콜 아세틸트랜스퍼라제(CAT), 루시퍼라제, 예를 들어 CD2, CD4, CD8, 인플루엔자 혈구응집소 단백질, 및 고친화성 항체가 존재하거나 통상적인 수단에 의해 생성될 수 있는, 당업계에 잘 알려진 다른 것을 포함하는 막 결합 단백질, 및 특히 혈구응집소 또는 Myc 유래의 항원 tag 도메인에 적절하게 융합된 막 결합 단백질을 포함하는 융합 단백질을 암호화하는 DNA 서열을 포함하나, 이에 제한되지 않는다.
이들 암호화 서열은 이의 발현을 구동시키는 조절 요소와 연관되어 있을 때 효소, 방사선, 비색, 형광 또는 다른 분광 사진 분석, 형광 활성화 세포 분류 분석 및 효소 결합 면역흡착 분석(ELISA), 방사면역측정법(RIA) 및 면역조직화학을 포함하는 면역학적 분석을 포함하는 통상적인 수단에 의해 검출 가능한 신호를 제공한다. 예를 들어, 마커 서열이 LacZ 유전자인 경우, 신호를 보유하는 벡터의 존재는 베타-갈락토시다제 활성에 대한 분석에 의해 검출된다. 전이유전자가 녹색 형광 단백질 또는 루시퍼라제인 경우, 신호를 보유하는 벡터는 광도계에서 색상 또는 광 생성에 의해 시각적으로 측정될 수 있다.
바람직하게는, 전이유전자는 단백질, 펩티드, RNA, 효소, 또는 촉매 RNA와 같은 생물학 및 의학에서 유용한 산물을 암호화한다. 바람직한 RNA 분자는 shRNA, tRNA, dsRNA, 리보솜 RNA, 촉매 RNA, 및 안티센스 RNA를 포함한다. 유용한 RNA 서열의 일 예는 처리된 동물에서 표적화된 핵산 서열의 발현을 소멸시키는 서열이다.
조절 서열은 본원에 기술된 바와 같이 생성된 벡터로 형질감염되거나 바이러스로 감염된 세포에서 전사, 번역 및/또는 발현을 허용하는 방식으로 전이유전자에 작동가능하게 연결된 통상적인 제어 요소를 포함한다. 본원에 사용된 바와 같이, "작동가능하게 연결된" 서열은 관심 유전자와 인접한 발현 제어 서열 및 관심 유전자를 제어하기 위해 전이(trans)로 또는 일정 거리에서 작용하는 발현 제어 서열을 둘 다 포함한다.
단백질 또는 핵산과 관련하여 사용되는 용어 "이종"은 단백질 또는 핵산이 자연에서 서로 동일한 관계로 발견되지 않는 2개 이상의 서열 또는 하위 서열을 포함함을 나타낸다. 예를 들어, 핵산은 전형적으로 새로운 기능성 핵산을 만들기 위해 배열된 관련 없는 유전자의 2개 이상의 서열을 갖는 재조합 방식으로 생산된다. 예를 들어, 일 구현예에서, 핵산은 상이한 유전자로부터의 암호화 서열의 발현을 지시하도록 배열된 하나의 유전자로부터의 프로모터를 갖는다. 따라서, 암호화 서열과 관련하여 프로모터는 이종이다.
발현 제어 서열은 적절한 전사 개시, 종결, 프로모터 및 인핸서 서열; 효율적인 RNA 처리 신호, 예컨대, 스플라이싱 및 폴리아데닐화(폴리A) 신호; 세포질 mRNA를 안정화시키는 서열; 번역 효율을 향상시키는 서열(즉, 코작 컨센서스 서열); 단백질 안정성을 향상시키는 서열; 및 원하는 경우, 암호화된 산물의 분비를 향상시키는 서열을 포함한다. 프로모터를 포함하여 다수의 발현 제어 서열이 당업계에 공지되어 있고 이용될 수 있다.
본원에서 제공되는 작제물에 유용한 조절 서열은 또한, 바람직하게는 프로모터/인핸서 서열과 유전자 사이에 위치한 인트론을 포함할 수 있다. 바람직한 한 가지 인트론 서열은 SV-40에서 유래한 것이며, SD-SA로 지칭되는 100 bp 미니-인트론 스플라이스 공여체/스플라이스 수용체이다. 또 다른 적합한 서열은 우드척 간염 바이러스(woodchuck hepatitis virus) 전사후 요소를 포함한다. (예를 들어, L. Wang 및 I. Verma, 1999 Proc. Natl. Acad. Sci., USA, 96:3906-3910 참조). 폴리A 신호는 SV-40, 인간 및 소를 포함하나, 이에 제한되지 않는 많은 적합한 종에서 유래할 수 있다.
본원에 기술된 방법에 유용한 rAAV의 또 다른 조절 성분은 내부 리보솜 유입 부위(internal ribosome entry site, IRES)이다. IRES 서열, 또는 다른 적합한 시스템은 단일 유전자 전사물로부터 하나 이상의 폴리펩티드를 생성하는 데 사용될 수 있다. IRES (또는 다른 적합한 서열)는 하나 이상의 폴리펩티드 사슬을 포함하는 단백질을 생성하는 데 또는 동일한 세포로부터 또는 동일한 세포 내에서 2가지 상이한 단백질을 발현시키는 데 사용된다. 예시적인 IRES는, 광수용체, RPE 및 신경절 세포에서 전이유전자 발현을 지원하는 폴리오바이러스 내부 리보솜 유입 서열이다. 바람직하게는 IRES는 rAAV 벡터에서 전이유전자에 대해 3'에 위치한다.
일 구현예에서, 발현 카세트 또는 벡터 게놈은 프로모터 (또는 프로모터의 기능성 단편)를 포함한다. rAAV에서 이용될 프로모터의 선택은 원하는 표적 세포에서 선택된 전이유전자를 발현할 수 있는 광범위한 구성적 또는 유도성 프로모터 중에서 이루어질 수 있다. 일 구현예에서, 표적 세포는 안구 세포이다. 프로모터는 인간을 포함하는 임의의 종으로부터 유래될 수 있다. 바람직하게는, 일 구현예에서, 프로모터는 "세포 특이적"이다. 용어 "세포-특이적"은 재조합 벡터에 대해 선택된 특정 프로모터가 특정 세포 조직에서 선택된 전이유전자의 발현을 지시할 수 있음을 의미한다. 일 구현예에서, 프로모터는 근육 세포에서 전이유전자의 발현에 특이적이다. 또 다른 구현예에서, 프로모터는 폐에서의 발현에 특이적이다. 또 다른 구현예에서, 프로모터는 간 세포에서 전이유전자의 발현에 특이적이다. 또 다른 구현예에서, 프로모터는 기도 상피에서 전이유전자의 발현에 특이적이다. 또 다른 구현예에서, 프로모터는 뉴런에서 전이유전자의 발현에 특이적이다. 또 다른 구현예에서, 프로모터는 심장에서 전이유전자의 발현에 특이적이다.
발현 카세트는 전형적으로, 예를 들어 선택된 5' ITR 서열 및 면역글로불린 작제물 암호화 서열 사이에 위치한 발현 제어 서열의 일부로서 프로모터 서열을 포함한다. 일 구현예에서, 간에서의 발현이 바람직하다. 따라서, 일 구현예에서, 간-특이적 프로모터가 사용된다. 조직 특이적 프로모터, 구성적 프로모터, 조절 가능 프로모터[예를 들어, WO 2011/126808호 및 WO 2013/04943호 참조], 또는 생리학적 신호에 반응성인 프로모터가 본원에 기술된 벡터에 사용되고 이용될 수 있다. 또 다른 구현예에서, 근육에서의 발현이 바람직하다. 따라서, 일 구현예에서, 근육-특이적 프로모터가 사용된다. 일 구현예에서, 프로모터는 MCK 기반 프로모터, 예컨대, dMCK(509-bp) 또는 tMCK(720-bp) 프로모터이다(예컨대, Wang 등, Gene Ther. 2008 Nov;15(22):1489-99. doi: 10.1038/gt.2008.104. Epub 2008 Jun 19 참조, 이는 본원에 참조로 포함됨). 또 다른 유용한 프로모터는 SPc5-12 프로모터이다(Rasowo 등, European Scientific Journal June 2014 edition vol.10, No.18 참조, 이는 본원에 참조로 포함됨). 일 구현예에서, 프로모터는 CMV 프로모터이다. 또 다른 구현예에서, 프로모터는 TBG 프로모터이다. 또 다른 구현예에서, CB7 프로모터 또는 CAG 프로모터가 사용된다. CB7은 거대세포바이러스 인핸서 요소가 있는 닭 β-액틴 프로모터이다. 대안적으로, 다른 간-특이적 프로모터가 사용될 수 있다[예를 들어, The Liver Specific Gene Promoter Database, Cold Spring Harbor, rulai.schl.edu/LSPD, alpha 1 anti-trypsin (A1AT); human albumin Miyatake 등, J. Virol., 71:5124 32 (1997), humAlb; 및 hepatitis B virus core promoter, Sandig 등, Gene Ther., 3:1002 9 (1996) 참조]. TTR 최소 인핸서/프로모터, 알파-항트립신 프로모터, LSP(845 nt)25는 인트론이 없는 scAAV를 필요로 한다.
프로모터(들)는 상이한 공급원, 예를 들어 인간 거대세포바이러스(CMV), 급초기 인핸서/프로모터, SV40 초기 인핸서/프로모터, JC 폴리모바이러스 프로모터, 수초 염기성 단백질(MBP) 또는 신경교 섬유질 산성 단백질(GFAP) 프로모터, 단순 헤르페스 바이러스(HSV-1) 잠복기 연관 프로모터(LAP), 라우스 육종 바이러스(RSV) 긴 말단 반복부(LTR) 프로모터, 뉴런-특이적 프로모터(NSE), 혈소판 유래 성장 인자(PDGF) 프로모터, hSYN, 멜라닌-농축 호르몬(MCH) 프로모터, CBA, 기질 금속단백질 프로모터(MPP), 및 닭 베타-액틴 프로모터로부터 선택될 수 있다.
발현 카세트는 적어도 하나의 인핸서, 즉, CMV 인핸서를 포함할 수 있다. 또 다른 인핸서 요소는, 예를 들어 아포지질단백질 인핸서, 제브라피시 인핸서, GFAP 인핸서 요소, 및 WO 2013/1555222호에 기술된 바와 같은 뇌 특이적 인핸서, 우드척 간염 전사후 (WPRE) 조절 요소를 포함할 수 있다. 추가적으로, 또는 대안적으로, 다른 것, 예를 들어 하이브리드 인간 거대세포바이러스(HCMV)-급초기(IE)-PDGR 프로모터 또는 다른 프로모터-인핸서 요소가 선택될 수 있다. 본원에서 유용한 다른 인핸서 서열은 IRBP 인핸서(Nicoud 2007, J Gene Med. 2007 Dec;9(12):1015-23), 급초기 거대세포바이러스 인핸서, 면역글로불린 유전자 또는 SV40 인핸서로부터 유래된 것, 마우스 근위 프로모터에서 확인된 시스-작용 요소 등을 포함한다.
프로모터에 추가적으로, 발현 카세트 및/또는 벡터는 다른 적절한 전사 개시, 종결, 인핸서 서열, 효율적인 RNA 처리 신호, 예컨대, 스플라이싱 및 폴리아데닐화(폴리A) 신호; 세포질 mRNA를 안정화시키는 서열; 번역 효율을 향상시키는 서열(즉, 코작 컨센서스 서열); 단백질 안정성을 향상시키는 서열; 및 원하는 경우, 암호화된 산물의 분비를 향상시키는 서열을 포함할 수 있다. 다양한 적합한 폴리A가 공지되어 있다. 일 예에서, 폴리A는 토기 베타 글로빈, 예컨대, 127 bp 토끼 베타-글로빈 폴리아데닐화 신호(GenBank # V00882.1)이다. 다른 구현예에서, SV40 폴리A 신호가 선택된다. 특정 구현예에서, 폴리 A는 소 성장 호르몬 폴리아데닐화(bGH-폴리A) 신호이다.
또 다른 적합한 폴리A 서열이 선택될 수 있다. 특정 구현예에서, 인트론이 포함된다. 한 가지 적합한 인트론은 닭 베타-액틴 인트론이다. 일 구현예에서, 인트론은 875 bp(GenBank # X00182.1)이다. 또 다른 구현예에서, Promega로부터 입수 가능한 키메라 인트론이 사용된다. 그러나, 다른 적합한 인트론이 선택될 수 있다. 일 구현예에서, 벡터 게놈이 천연 AAV 벡터 게놈(예를 들어, 4.1 내지 5.2 kb)과 대략 동일한 크기를 가지도록 스페이서가 포함된다. 일 구현예에서, 벡터 게놈이 대략 4.7 kb가 되도록 스페이서가 포함된다. Wu 등, Effect of Genome Size on AAV Vector Packaging, Mol Ther. 2010 Jan; 18(1): 80-86을 참조하며, 이는 본원에 참조로 포함된다.
이들 및 다른 공통 벡터 및 조절 요소의 선택은 통상적이며, 다수의 이와 같은 서열이 이용 가능하다. 예를 들어, Sambrook 등 및 예를 들어 페이지 3.18 내지 3.26 및 16.17 내지 16.27에 인용된 참조문헌 및 Ausubel 등, Current Protocols in Molecular Biology, John Wiley & Sons, New York, 1989을 참조한다. 물론, 모든 벡터 및 발현 제어 서열이 본원에 기술된 바와 같은 모든 전이유전자를 발현하도록 동등하게 잘 기능하지는 않을 것이다. 그러나, 당업자는 본 발명의 범주를 벗어나지 않으면서 이들 및 다른 발현 제어 서열 중에서 선택할 수 있다.
특정 구현예에서, 발현 카세트는 miR-183 표적 서열인 적어도 하나의 miRNA 표적 서열을 포함한다. 특정 구현예에서, 벡터 게놈 또는 발현 카세트는 AGTGAATTCTACCAGTGCCATA (서열번호 13)를 포함하는 miR-183 표적 서열을 포함하며, 여기서 miR-183 시드 서열에 상보적인 서열은 밑줄이 그어져 있다. 특정 구현예에서, 벡터 게놈 또는 발현 카세트는 miR-183 시드 서열에 100% 상보적인 서열의 하나 이상의 복제물(예를 들어, 2개 또는 3개 복제물)을 포함한다. 특정 구현예에서, miR-183 표적 서열은 길이가 약 7개의 뉴클레오티드 내지 약 28개의 뉴클레오티드이고 miR-183 시드 서열에 적어도 100% 상보적인 적어도 하나의 영역을 포함한다. 특정 구현예에서, miR-183 표적 서열은 서열번호 13에 부분 상보성을 갖는 서열을 포함하고, 따라서 서열번호 13에 대해 정렬될 때 하나 이상의 미스매치가 존재한다. 특정 구현예에서, miR-183 표적 서열은 서열번호 13에 대해 정렬될 때 적어도 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개 또는 10개의 미스매치를 갖는 서열을 포함하며, 이때 미스매치는 비-연속적일 수 있다. 특정 구현예에서, miR-183 표적 서열은 miR-183 표적 서열 길이의 적어도 30%를 또한 포함하는 100% 상보성의 영역을 포함한다. 특정 구현예에서, 100% 상보성의 영역은 miR-183 시드 서열에 100% 상보성을 갖는 서열을 포함한다. 특정 구현예에서, miR-183 표적 서열의 나머지는 miR-183에 적어도 약 80% 내지 약 99% 상보성을 갖는다. 특정 구현예에서, 발현 카세트 또는 벡터 게놈은 절단된 서열번호 13, 즉, 서열번호 13의 5' 또는 3' 말단 중 어느 하나 또는 둘 다에서 적어도 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개 또는 10개의 뉴클레오티드가 결여된 서열을 포함하는 miR-183 표적 서열을 포함한다. 특정 구현예에서, 발현 카세트 또는 벡터 게놈은 전이유전자 및 1개의 miR-183 표적 서열을 포함한다. 또 다른 구현예에서, 발현 카세트 또는 벡터 게놈은 적어도 2개, 3개 또는 4개의 miR-183 표적 서열을 포함한다.
특정 구현예에서, 발현 카세트는 miR-182 표적 서열인 적어도 하나의 miRNA 표적 서열을 포함한다. 특정 구현예에서, 벡터 게놈 또는 발현 카세트는 AGTGTGAGTTCTACCATTGCCAAA(서열번호 14)를 포함하는 miR-182 표적 서열을 포함한다. 특정 구현예에서, 벡터 게놈 또는 발현 카세트는 miR-182 시드 서열에 100% 상보적인 서열의 하나 초과의 복제물(예를 들어, 2개 또는 3개 복제물)을 포함한다. 특정 구현예에서, miR-182 표적 서열은 길이가 약 7개의 뉴클레오티드 내지 약 28개 뉴클레오티드이고 miR-182 시드 서열에 적어도 100% 상보적인 적어도 하나의 영역을 포함한다. 특정 구현예에서, miR-182 표적 서열은 서열번호 14에 부분 상보성을 가지는 서열을 포함하고, 따라서 서열번호 14에 대해 정렬될 때 하나 이상의 미스매치가 존재한다. 특정 구현예에서, miR-183 표적 서열은 서열번호 14에 대해 정렬될 때 적어도 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개 또는 10개의 미스매치를 가지는 서열을 포함하며, 이때 미스매치는 비-연속적일 수 있다. 특정 구현예에서, miR-182 표적 서열은 miR-182 표적 서열 길이의 적어도 30%를 또한 포함하는 100% 상보성의 영역을 포함한다. 특정 구현예에서, 100% 상보성의 영역은 miR-182 시드 서열에 100% 상보성을 갖는 서열을 포함한다. 특정 구현예에서, miR-182 표적 서열의 나머지는 miR-182에 적어도 약 80% 내지 약 99% 상보성을 갖는다. 특정 구현예에서, 발현 카세트 또는 벡터 게놈은 절단된 서열번호 14, 즉, 서열번호 14의 5' 또는 3' 말단 중 어느 하나 또는 둘 다에서 적어도 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개 또는 10개의 뉴클레오티드가 결여된 서열을 포함하는 miR-182 표적 서열을 포함한다. 특정 구현예에서, 발현 카세트 또는 벡터 게놈은 전이유전자 및 1개의 miR-182 표적 서열을 포함한다. 또 다른 구현예에서, 발현 카세트 또는 벡터 게놈은 적어도 2개, 3개 또는 4개의 miR-182 표적 서열을 포함한다.
용어 "탠덤 반복부"는 본원에서 2개 이상의 연속적인 miRNA 표적 서열의 존재를 지칭하는 데 사용된다. 이러한 miRNA 표적 서열은 연속적일 수 있으며, 즉, 하나의 3' 말단이 개재 서열 없이 다음의 5' 말단의 바로 상류에 있거나 그 반대이도록 서로 바로 뒤에 위치할 수 있다. 또 다른 구현예에서, 2개 이상의 miRNA 표적 서열은 짧은 스페이서 서열에 의해 분리된다.
본원에 사용된 바와 같이, "스페이서"는 2개 이상의 연속적인 miRNA 표적 서열 사이에 위치한, 예를 들어 길이가 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개 또는 10개의 뉴클레오티드인 임의의 선택된 핵산 서열이다. 특정 구현예에서, 스페이서는 길이가 1개 내지 8개의 뉴클레오티드, 길이가 2개 내지 7개의 뉴클레오티드, 길이가 3개 내지 6개의 뉴클레오티드, 길이가 4개의 뉴클레오티드, 4개 내지 9개의 뉴클레오티드, 3개 내지 7개의 뉴클레오티드, 또는 더 긴 값이다. 적합하게는, 스페이서는 비-암호화 서열이다. 특정 구현예에서, 스페이서는 네(4) 개의 뉴클레오티드를 가질 수 있다. 특정 구현예에서, 스페이서는 GGAT이다. 특정 구현예에서, 스페이서는 여섯(6) 개의 뉴클레오티드이다. 특정 구현예에서, 스페이서는 CACGTG 또는 GCATGC이다.
특정 구현예에서, 탠덤 반복부는 2개, 3개, 4개 또는 그 이상의 동일한 miRNA 표적 서열을 포함한다. 특정 구현예에서, 탠덤 반복부는 적어도 2개의 상이한 miRNA 표적 서열, 적어도 3개의 상이한 miRNA 표적 서열, 또는 적어도 4개의 상이한 miRNA 표적 서열 등을 포함한다. 특정 구현예에서, 탠덤 반복부는 2개 또는 3개의 동일한 miRNA 표적 서열 및 상이한 제4 miRNA 표적 서열을 포함할 수 있다.
특정 구현예에서, 발현 카세트에 탠덤 반복부의 적어도 2개의 상이한 세트가 있을 수 있다. 예를 들어, 3' UTR은 전이유전자의 바로 하류에 탠덤 반복부, UTR 서열, 및 UTR의 3' 말단에 더 가까운 2개 이상의 탠덤 반복부를 포함할 수 있다. 또 다른 예에서, 5' UTR은 1개, 2개 또는 그 이상의 miRNA 표적 서열을 포함할 수 있다. 또 다른 예에서, 3'은 탠덤 반복부를 포함할 수 있고 5' UTR은 적어도 1개의 miRNA 표적 서열을 포함할 수 있다.
특정 구현예에서, 발현 카세트는 전이유전자에 대한 정지 코돈의 약 0개 내지 20개 뉴클레오티드 내에서 시작하는 2개, 3개, 4개 또는 그 이상의 탠덤 반복부를 포함한다. 다른 구현예에서, 발현 카세트는 전이유전자에 대한 정지 코돈으로부터 적어도 100개 내지 약 4000개 뉴클레오티드의 miRNA 탠덤 반복부를 포함한다.
본원에 참조로 포함되는 2019년 12월 20일자로 출원된 PCT/US19/67872호를 참조하고, 2018년 12월 21일자로 출원된 미국 특허 가출원 제62/783,956호에 대해 우선권을 주장하며, 이는 본원에 참조로 포함된다. 2020년 5월 12일자로 출원된 미국 특허 가출원 제63/023,593호, 2020년 6월 12일자로 출원된 미국 특허 가출원 제63/038,488호 및 2020년 6월 24일자로 출원된 미국 특허 가출원 제63/043,562호 또한 참조로 포함된다.
또 다른 구현예에서, 재조합 아데노-연관 바이러스를 생성하는 방법이 제공된다. 적합한 재조합 아데노-연관 바이러스(AAV)는 본원에 기술된 바와 같은 AAV 캡시드 단백질을 암호화하는 핵산 서열, 또는 이의 단편; 기능성 rep 유전자; 최소한 AAV 반전 말단 반복부(ITR) 및 바람직한 전이유전자를 암호화하는 이종 핵산 서열로 구성된 미니유전자; 및 AAV 캡시드 단백질 내로 미니유전자의 패키징을 허용하기에 충분한 헬퍼 기능을 포함하는 숙주 세포를 배양함으로써 생성된다. AAV 캡시드에 AAV 미니유전자를 패키징하기 위해 숙주 세포에서 배양되는 데 필요한 구성요소는 숙주 세포에 트랜스로 제공될 수 있다. 대안적으로, 필요한 구성요소(예를 들어, 미니유전자, rep 서열, cap 서열 및/또는 헬퍼 기능) 중 임의의 하나 이상은 당업자에게 공지된 방법을 사용하여 필요한 구성요소 중 하나 이상을 포함하도록 조작된 안정적인 숙주 세포에 의해 제공될 수 있다. 캡시드를 생성하는 방법, 이에 따른 암호화 서열, 및 rAAV 바이러스 벡터의 생산 방법이 기술되어 있다. 예를 들어, Gao 등, Proc. Natl. Acad. Sci. U.S.A. 100 (10), 6081-6086 (2003) 및 US 제2013/0045186A1호를 참조하며, 이는 본원에 참조로 포함된다.
또한 본원에 기술된 바와 같은 rAAV로 형질도입된 숙주 세포가 본원에서 제공된다. 가장 적합하게는, 이와 같은 안정적인 숙주 세포는 유도성 프로모터의 제어 하에서 필요한 구성요소(들)를 포함할 것이다. 그러나, 필요한 구성요소(들)는 구성적 프로모터의 제어 하에 있을 수 있다. 적합한 유도성 및 구성적 프로모터의 예는 본원의 전이유전자와 함께 사용하기에 적합한 조절 요소의 하기 논의에서 제공된다. 또 다른 대안에서, 선택되는 안정적인 숙주 세포는 구성적 프로모터의 제어 하에 선택된 구성요소(들) 및 하나 이상의 유도성 프로모터의 제어 하에 다른 선택된 구성요소(들)를 포함할 수 있다. 예를 들어, 293 세포(구성적 프로모터의 제어 하에 E1 헬퍼 기능을 포함함)로부터 유래되지만, 유도성 프로모터의 제어 하에 rep 및/또는 cap 단백질을 포함하는 안정적인 숙주 세포가 생성될 수 있다. 또 다른 안정적인 숙주 세포는 당업자에 의해 생성될 수 있다. 또 다른 구현예에서, 숙주 세포는 본원에 기술된 바와 같은 핵산 분자를 포함한다. 특정 구현예에서, 기술된 신규 벡터는 공지된 캡시드와 비교하여 개선된 생산(즉, 더 높은 수율)을 갖는다. 예를 들어, AAVrh91 벡터의 생산은 AAV1 및 AAV6에 비해 개선된 수율을 입증하였다.
본원에 기술된 rAAV를 생성하는 데 필요한 미니유전자, rep 서열, cap 서열, 및 헬퍼 기능은 운반되는 서열을 전달하는 임의의 유전적 요소의 형태로 패키징 숙주 세포에 전달될 수 있다. 선택된 유전적 요소는 본원에 기술된 것을 포함하여 임의의 적합한 방법에 의해 전달될 수 있다. 본 발명의 임의의 구현예를 작제하는 데 사용되는 방법은 핵산 조작의 숙련자에게 공지되어 있고 유전 공학, 재조합 공학, 및 합성 기법을 포함한다. 예를 들어, Sambrook 등, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Press, Cold Spring Harbor, NY을 참조한다. 유사하게, rAAV 비리온을 생성하는 방법이 잘 알려져 있으며 적합한 방법의 선택은 본 발명에 대하여 제한되지 않는다. 예를 들어, 특히 K. Fisher 등, 1993 J. Virol., 70:520-532 및 미국 특허 제5,478,745호를 참조한다. 이들 간행물은 본원에 참조로 포함된다.
C. 약제학적 조성물 및 투여
일 구현예에서, 상기 상세히 기술된 바와 같은 표적 세포에서 사용하기 위한 원하는 전이유전자 및 프로모터를 포함하는 재조합 AAV는 선택적으로 통상적인 방법에 의해 오염에 대해 평가된 다음, 이를 필요로 하는 대상체에게 투여하기 위한 약제학적 조성물로 제형화된다. 이와 같은 제형은 적절한 생리학적 수준에서 pH를 유지하기 위한 약제학적으로 및/또는 생리학적으로 허용 가능한 비히클 또는 담체, 예컨대, 완충 식염수 또는 다른 완충제, 예를 들어 HEPES의 사용, 및 선택적으로 다른 약물, 약제, 안정화제, 완충제, 담체, 아쥬반트, 희석제 등을 포함한다. 주사의 경우, 담체는 전형적으로 액체일 것이다. 예시적인 생리학적으로 허용 가능한 담체는 멸균된 무-발열원 물 및 멸균된 무-발열원 인산염 완충 식염수를 포함한다. 이와 같은 공지된 다양한 담체는 본원에 참조로 포함되는 미국 공개 특허 제7,629,322호에 제공되어 있다. 일 구현예에서, 담체는 등장성 염화나트륨 용액이다. 또 다른 구현예에서, 담체는 평형 염액이다. 일 구현예에서, 담체는 트윈을 포함한다. 바이러스가 장기간 보관되어야 하는 경우, 글리세롤 또는 트윈20의 존재 하에 동결될 수 있다. 또 다른 구현예에서, 약제학적으로 허용 가능한 담체는 계면활성제, 예컨대, 퍼플루오로옥탄(퍼플루오론 액체)을 포함한다. 벡터는 인간 대상체에서의 주입에 적합한 완충제/담체 중에서 제형화된다. 완충제/담체는 rAAV가 주입 튜브에 달라붙는 것을 방지하지만 생체내에서 rAAV 결합 활성을 방해하지 않는 구성요소를 포함해야 한다.
본원에 기술된 방법의 특정 구현예에서, 상기 기술된 약제학적 조성물은 대상체에게 근육내(IM)로 투여된다. 다른 구현예에서, 약제학적 조성물은 정맥내(IV)로 투여된다. 다른 구현예에서, 약제학적 조성물은 뇌실내(ICV) 주사에 의해 투여된다. 다른 구현예에서, 약제학적 조성물은 대조내(ICM) 주사에 의해 투여된다. 다른 구현예에서, 약제학적 조성물은 뇌실질내 주사에 의해 투여된다. 본원에 기술된 방법에 유용할 수 있는 다른 투여 형태는, 망막하 또는 유리체내 전달을 포함하여 원하는 기관(예를 들어, 눈)으로의 직접 전달, 경구, 흡입, 비강내, 기관내, 정맥내, 근육내, 피하, 피내, 및 다른 비경구 투여 경로를 포함하나, 이에 제한되지 않는다. 원하는 경우 투여 경로는 조합될 수 있다.
본원에 사용된 바와 같이, 용어 "척추강내 전달" 또는 "척추강내 투여"는 뇌척수액(CSF)에 도달하도록 주사를 통해 척추관으로, 보다 구체적으로는 지주막하 공간으로의 투여 경로를 지칭한다. 척추강내 전달은 요추 천자, 뇌실내(intraventricular)(뇌실내(ICV)를 포함함), 후두하/수조내, 및/또는 C1-2 천자를 포함할 수 있다. 예를 들어, 물질은 요추 천자에 의해 지주막하 공간 전체에 확산을 위해 도입될 수 있다. 또 다른 예에서, 주사는 대조 내로 이루어질 수 있다.
본원에 사용된 바와 같이, 용어 "수조내 전달" 또는 "수조내 투여"는 소뇌연수 대조의 뇌척수액으로, 보다 구체적으로는 후두하 천자를 통해 또는 대조 내로의 직접 주사에 의해 또는 영구적으로 위치한 튜브를 통해 직접 투여하는 경로를 지칭한다.
조성물은 치료할 영역의 크기, 사용되는 바이러스 역가, 투여 경로, 및 방법의 원하는 효과에 따라, 범위 내의 모든 숫자를 포함하여 약 0.1 μL 내지 약 10 mL의 부피로 전달될 수 있다. 일 구현예에서, 부피는 약 50 μL이다. 또 다른 구현예에서, 부피는 약 70 μL이다. 또 다른 구현예에서, 부피는 약 100 μL이다. 또 다른 구현예에서, 부피는 약 125 μL이다. 또 다른 구현예에서, 부피는 약 150 μL이다. 또 다른 구현예에서, 부피는 약 175 μL이다. 또 다른 구현예에서, 부피는 약 200 μL이다. 또 다른 구현예에서, 부피는 약 250 μL이다. 또 다른 구현예에서, 부피는 약 300 μL이다. 또 다른 구현예에서, 부피는 약 450 μL이다. 또 다른 구현예에서, 부피는 약 500 μL이다. 또 다른 구현예에서, 부피는 약 600 μL이다. 또 다른 구현예에서, 부피는 약 750 μL이다. 또 다른 구현예에서, 부피는 약 850 μL이다. 또 다른 구현예에서, 부피는 약 1000 μL이다. 또 다른 구현예에서, 부피는 약 1.5 mL이다. 또 다른 구현예에서, 부피는 약 2 mL이다. 또 다른 구현예에서, 부피는 약 2.5 mL이다. 또 다른 구현예에서, 부피는 약 3 mL이다. 또 다른 구현예에서, 부피는 약 3.5 mL이다. 또 다른 구현예에서, 부피는 약 4 mL이다. 또 다른 구현예에서, 부피는 약 5 mL이다. 또 다른 구현예에서, 부피는 약 5.5 mL이다. 또 다른 구현예에서, 부피는 약 6 mL이다. 또 다른 구현예에서, 부피는 약 6.5 mL이다. 또 다른 구현예에서, 부피는 약 7 mL이다. 또 다른 구현예에서, 부피는 약 8 mL이다. 또 다른 구현예에서, 부피는 약 8.5 mL이다. 또 다른 구현예에서, 부피는 약 9 mL이다. 또 다른 구현예에서, 부피는 약 9.5 mL이다. 또 다른 구현예에서, 부피는 약 10 mL이다.
조절 서열의 제어 하에 원하는 전이유전자를 암호화하는 핵산 서열을 보유하는 재조합 아데노-연관 바이러스의 유효 농도는 바람직하게는 밀리리터당 약 107 내지 1014개 벡터 게놈(vg/mL)(또한, 게놈 복제물/mL(GC/mL)로도 불림)의 범위이다. 일 구현예에서, rAAV 벡터 게놈은 실시간 PCR에 의해 측정된다. 또 다른 구현예에서, rAAV 벡터 게놈은 디지털 PCR에 의해 측정된다. Lock 등, Absolute determination of single-stranded and self-complementary adeno-associated viral vector genome titers by droplet digital PCR, Hum Gene Ther Methods. 2014 Apr;25(2):115-25. doi: 10.1089/hgtb.2013.131. Epub 2014 Feb 14를 참조하며, 이는 본원에 참조로 포함된다. 또 다른 구현예에서, rAAV 감염성 단위는 S.K. McLaughlin 등, 1988 J. Virol., 62:1963에 기재된 바와 같이 측정되며, 이는 본원에 참조로 포함된다.
바람직하게는, 농도는 약 1.5×109 vg/mL 내지 약 1.5×1013 vg/mL, 더 바람직하게는 약 1.5×109 vg/mL 내지 약 1.5×1011 vg/mL이다. 일 구현예에서, 유효 농도는 약 1.4×108 vg/mL이다. 일 구현예에서, 유효 농도는 약 3.5×1010 vg/mL이다. 또 다른 구현예에서, 유효 농도는 약 5.6×1011 vg/mL이다. 또 다른 구현예에서, 유효 농도는 약 5.3×1012 vg/mL이다. 또 다른 구현예에서, 유효 농도는 약 1.5×1012 vg/mL이다. 또 다른 구현예에서, 유효 농도는 약 1.5×1013 vg/mL이다. 본원에 기재된 모든 범위는 종점을 포함한다.
일 구현예에서, 투여량은 약 1.5×109 vg/체중 ㎏ 내지 약 1.5×1013 vg/㎏, 더 바람직하게는 약 1.5×109 vg/㎏ 내지 약 1.5×1011 vg/㎏이다. 일 구현예에서, 투여량은 약 1.4×108 vg/㎏이다. 일 구현예에서, 투여량은 약 3.5×1010 vg/㎏이다. 또 다른 구현예에서, 투여량은 약 5.6×1011 vg/㎏이다. 또 다른 구현예에서, 투여량은 약 5.3×1012 vg/㎏이다. 또 다른 구현예에서, 투여량은 약 1.5×1012 vg/㎏이다. 또 다른 구현예에서, 투여량은 약 1.5×1013 vg/㎏이다. 또 다른 구현예에서, 투여량은 약 3.0×1013 vg/㎏이다. 또 다른 구현예에서, 투여량은 약 1.0×1014 vg/㎏이다. 본원에 기술된 모든 범위는 종점을 포함한다.
일 구현예에서, 유효 투여량 (전달되는 총 게놈 복제물)은 약 107 내지 1013개의 벡터 게놈이다. 일 구현예에서, 총 투여량은 약 108개의 게놈 복제물이다. 일 구현예에서, 총 투여량은 약 109개의 게놈 복제물이다. 일 구현예에서, 총 투여량은 약 1010개의 게놈 복제물이다. 일 구현예에서, 총 투여량은 약 1011개의 게놈 복제물이다. 일 구현예에서, 총 투여량은 약 1012개의 게놈 복제물이다. 일 구현예에서, 총 투여량은 약 1013개의 게놈 복제물이다. 일 구현예에서, 총 투여량은 약 1014개의 게놈 복제물이다. 일 구현예에서, 총 투여량은 약 1015개의 게놈 복제물이다.
독성과 같은 바람직하지 않은 영향의 위험을 감소시키기 위해 가장 낮은 유효 농도의 바이러스를 이용하는 것이 바람직하다. 이들 범위의 또 다른 투여량 및 투여 부피는 치료될 대상체, 바람직하게는 인간의 신체 상태, 대상체의 연령, 특정 장애 및 진행성인 경우 장애의 발달 정도를 고려하여 주치의에 의해 선택될 수 있다. 예를 들어 정맥내 전달은 약 1.5×1013개 vg/㎏ 정도의 용량이 필요할 수 있다.
D. 방법
또 다른 측면에서, 표적 조직에 형질도입하는 방법이 제공된다. 일 구현예에서, 방법은 본원에 기술된 바와 같은 AAVrh91 캡시드를 갖는 rAAV를 투여하는 단계를 포함한다. 하기 실시예에 나타낸 바와 같이, 본 발명자들은 AAVrh91로 명명된 AAV가 심장 (평활근), CNS 세포, 및 골격 (줄무늬) 근육에 효과적으로 형질도입한다는 것을 제시하였다. 본원에 기술된 바와 같이, AAVrh91 캡시드를 갖는 벡터는 다양한 세포 및 조직 유형을 형질도입할 수 있고 투여 경로에 따라 고유한 친화성을 나타낸다. 특정 구현예에서, 방법은 AAVrh91 벡터의 전신 투여를 포함한다. 특정 구현예에서, AAVrh91 벡터는 특정 세포 또는 조직 유형을 표적화하기에 적합한 투여 경로를 통해 전달된다. 예를 들어, AAVrh91 벡터는 척수강내 투여 후 폐 및 췌장과 같은 조직에서 AAV6.2보다 더 높은 전이유전자 발현 수준을 갖는다. 유사하게, 척수강내 투여 후 AAVrh91에 대해 AAV6.2에 비해 근육 조직에서 향상된 발현이 관찰되었다.
특정 구현예에서, AAVrh91 캡시드를 갖는 rAAV를 투여하는 단계를 포함하는 CNS의 세포 (예를 들어, 하나 이상의 뉴런, 내피 세포, 신경아교세포 및 뇌실막 세포)를 형질도입하는 방법이 본원에서 제공된다. 일 구현예에서, 정맥내 투여가 사용된다. 다른 구현예에서, ICV 투여가 사용된다. 또 다른 구현예에서, ICM 투여가 사용된다. 특정 구현예에서, 척수, 해마, 운동 피질, 소뇌 및 운동 뉴런 중 임의의 것을 포함하나 이에 제한되지 않는 CNS의 세포로 전이유전자를 전달하는 방법이 본원에서 제공된다. 상기 방법은 세포를 AAVrh91 캡시드를 갖는 rAAV와 접촉시키는 단계를 포함하며, 여기서 상기 rAAV는 전이유전자를 포함한다. 또 다른 측면에서, AAVrh91 캡시드를 갖는 rAAV의 용도는 전이유전자를 CNS로 전달하기 위해 제공된다. 특정 구현예에서, AAVrh91 캡시드를 갖는 rAAV의 용도는 뇌실막 세포 또는 맥락막총에 전이유전자를 전달하기 위해 제공된다. 특정 구현예에서, 뇌실막 세포 및/또는 맥락막총의 형질도입은 CNS에서 전이유전자의 향상된 분비 수준을 초래한다.
특정 구현예에서, AAVrh91은 AAV1 또는 AAV6.2 캡시드를 갖는 벡터로 관찰된 것보다 더 높은 수준으로 CNS의 세포에 전이유전자를 전달한다. 특정 구현예에서, 더 높은 수준의 형질도입은 하나 이상의 뇌실막 세포, 뉴런 및/또는 성상교세포에서 관찰된다. 특정 구현예에서, 뇌 실질에 전이유전자를 전달하기 위한 AAVrh91 캡시드를 갖는 rAAV의 용도가 제공된다. AAV9 벡터를 사용하여 달성된 것보다 더 높은 수준의 형질도입에 있어서, 성상교세포와 같은 뇌의 세포를 표적화하기 위한 AAVrh91 벡터의 용도가 본원에서 제공된다. 특정 구현예에서, 더 높은 형질도입 수준은 전두 및 측두 피질을 포함하는 뇌의 미측(caudal) 절편에서 달성된다. 특정 구현예에서, AAVrh91 벡터는 예를 들어 AAV9에 비해 피질, 해마 및/또는 선조체에서 뉴런의 더 높은 수준의 형질도입을 달성한다.
본원에 논의된 바와 같이, 본원에 기술된 AAV 캡시드를 포함하는 벡터는 높은 수준으로 심장 조직을 형질도입할 수 있다. 심장 세포에 전이유전자를 전달하는 방법이 본원에서 제공된다. 상기 방법은 심장 세포를 AAVrh91 캡시드를 갖는 rAAV와 접촉시키는 단계를 포함하며, 여기서 상기 rAAV는 전이유전자를 포함한다. 또 다른 측면에서, 전이유전자를 심장으로 전달하기 위해 AAVrh91 캡시드를 갖는 rAAV의 용도가 제공된다. 특정 구현예에서, 전이유전자를 심장 세포로 전달하는 방법은 AAVrh91 캡시드를 갖는 rAVV의 전신 전달 (예를 들어, IV 투여)을 포함한다.
특정 구현예에서, AAVrh91 캡시드를 갖는 rAAV를 투여하는 단계를 포함하는 골격근을 형질도입하는 방법이 본원에서 제공된다. AAVrh91은 AAV9와 비교하여 골격근의 형질도입이 증가하지 않더라도 유사하다. 특정 구현예에서, 방법은 AAVrh91 캡시드를 골격 (줄무늬) 근육에 전달하는 단계를 포함한다. 특정 구현예에서, 골격근에 전이유전자를 전달하는 방법이 제공된다. 상기 방법은 AAVrh91 캡시드를 갖는 rAAV와 골격근을 접촉시키는 단계를 포함하며, 여기서 상기 rAAV는 전이유전자를 포함한다. 특정 구현예에서, 전이유전자를 골격근으로 전달하는 방법은 AAVrh91 캡시드를 갖는 rAAV의 전신 전달(예를 들어, IV 투여)을 포함한다.
특정 구현예에서, AAVrh91 벡터는 대상체의 간에서 탈표적 발현의 형질도입을 감소시키는 용도로 기술된다. 따라서, 잠재적인 간 독성을 피하거나 간 조직의 AAV 표적화와 관련된 간 독성을 감소시키기 위해 AAVrh91이 사용된다. 특정 구현예에서, 감소된 간 독성은 전신 주사, 특히 정맥내 투여 후에 관찰된다. 특정 구현예에서, 독성의 감소는 AAV9 캡시드를 갖는 벡터와 같은 또 다른 캡시드를 갖는 벡터의 전달에 상대적이다.
단일 게놈 증폭
AAV 게놈은 전통적으로 PCR 기반 방법을 사용하여 전체 포유동물 게놈 DNA 내로부터 단리되었으며: 프라이머는 다양한 VP1(캡시드) 유전자 대부분의 측면에 있는 보존된 영역을 검출하는 데 사용된다. 그 다음 PCR 산물은 플라스미드 백본으로 클로닝되고 개별 클론은 Sanger 방법을 사용하여 시퀀싱된다. 전통적인 PCR 및 분자 클로닝 기반 바이러스 단리 방법은 신규 AAV 게놈을 회수하는 데 효과적이지만 회수된 게놈은 PCR-매개 재조합 및 중합효소 오류에 의해 영향을 받을 수 있다. 추가적으로, 현재 이용 가능한 차세대 시퀀싱 기술은 이전에 사용된 Sanger 기술과 비교하여 견줄 데 없는 정확도로 바이러스 게놈의 시퀀싱을 가능하게 하였다. 바이러스 집단 내로부터 개별 AAV 게놈을 정확하게 단리하는 신규하고 고-처리량의 PCR 및 차세대 시퀀싱 기반 방법이 본원에서 제공된다. 이 방법, 즉 AAV-단일 게놈 증폭(AAV-SGA)은 포유동물 숙주 내에서 AAV 다양성에 대한 지식을 개선시키는 데 사용될 수 있다. 더욱이, 유전자 치료용 벡터로서 사용하기 위한 신규 캡시드를 식별하는 것을 가능하게 하였다.
AAV-SGA는 검증되고 최적화되어 게놈 집단을 포함하는 샘플로부터 개별 AAV 서열을 효과적으로 회수하였다. 이 기법은 이전에 인간 및 비인간 영장류 숙주 내로부터 단일 HIV 및 HCV 게놈을 단리하는 데 사용되었다. 캡시드 검출 PCR에 의해 AAV에 대해 양성인 것을 스크리닝하는 게놈 DNA 샘플은 종점-희석된다. 푸아송 분포에 따르면, 80% 신뢰도로 PCR 증폭이 30% 미만의 양성 반응을 산출하는 희석은 단일 증폭 가능한 AAV 게놈을 포함한다. 이러한 절차는 중합효소의 주형 전환에 의해 유발된 PCR-매개 재조합의 가능성이 감소된 바이러스 게놈의 PCR 증폭을 허용한다. AAV-SGA PCR 앰플리콘은 2X150 또는 2X250 쌍-말단 시퀀싱을 사용하는 Illumina MiSeq 플랫폼을 사용하여 시퀀싱된다. 이 방법은 높은 상동성 영역을 갖는 여러 바이러스를 포함하는 단일 샘플로부터 시퀀싱 판독물의 수렴에 대한 염려 없이 전장 AAV VP1 서열의 정확한 새로운 조합체를 허용한다.
AAV-SGA 기법은 히말라야 원숭이 조직으로부터 다수의 신규 AAV 캡시드 서열을 단리하는 데 성공하였다. AAV의 상이한 클레드 유래의 다수 바이러스가 단일 샘플로부터 확인되었으며; 이는 AAV의 집단이 숙주 조직에 존재할 수 있음을 입증한다. 예를 들어, 클레드 D, E, 및 외부 "프린지" 바이러스와 서열 유사성을 갖는 캡시드가 단일 간 조직 샘플에서 단리되었다.
AAV 발견에 대한 SGA의 적용은 이전에 기술되지 않았다. 이 접근법은 유효하지 않은 AAV 게놈 서열을 생성할 수 있는 주형 전환 및 중합효소 오류 문제를 해결한다. 추가적으로, 단리된 게놈의 품질은 단일 단리물과 동일한 숙주 샘플로부터 동일한 서열이 반복적으로 회수될 때 자명하다.
하기 실시예는 본 발명의 다양한 구현예를 예시하기 위해 제공된다. 실시예는 어떤 식으로든 본 발명을 제한하는 것으로 의도되지 않는다.
E. 실시예
실시예 1: 물질 및 방법
AAV 서열의 검출 및 단리
비인간 영장류 조직 공급원
펜실베니아 대학교 콜로니 유래의 히말라야 원숭이를 인공적으로 번식시켰으며, 이들은 중국 또는 인도 기원이었다.
신규 AAV 단리
게놈 DNA를 추출하고(QIAmp DNA Mini Kit, QIAGEN), NHP 간 조직 표본으로부터 3.1 kb 전장 Cap 단편을 증폭시키는 PCR 전fir을 사용함으로써 AAV DNA의 존재에 대해 분석하였다. AAV Rep 유전자의 보존된 영역 내 5' 프라이머(AV1NS, 5'-GCTGCGTCAACTGGACCAATGAGAAC-3')(서열번호 9)를 전장 AAV Cap 앰플리콘의 증폭을 위해 AAV Cap 유전자 하류에 있는 보존된 영역에 위치한 3' 프라이머(AV2CAS, 5'-CGCAGAGACCAAAGTTCAACTGAAACGA-3')(서열번호 10)와 조합하여 사용하였다. Q5 High-Fidelity Hot Start DNA Polymerase(New England Biolabs)를 사용하여 하기 사이클링 조건을 사용하여 AAV DNA를 증폭시켰다: 98℃에서 30초; 98℃에서 10초, 59℃에서 10초, 72℃에서 93초, 50 사이클; 및 72℃에서 120초 동안 연장.
양성 PCR 반응을 초래한 주형 게놈 DNA 샘플에 AAV-단일 게놈 증폭(AAV-SGA)을 적용하였다. 상기에서 언급한 동일한 프라이머를 사용하여, 96개 중 29개 미만의 PCR 반응이 증폭 산물을 산출하도록 96-웰 플레이트에서 게놈 DNA를 종점 희석하였다. 푸아송 분포에 따르면, 웰의 30% 이하에서 PCR 산물을 산출하는 DNA 희석은 시간의 80% 초과에서 양성 PCR당 하나의 증폭 가능한 DNA 주형을 포함한다. Illumina MiSeq 2×150 또는 2×250쌍 말단 시퀀싱 플랫폼을 사용하여 양성 PCR 반응으로부터 AAV DNA 앰플리콘을 시퀀싱하고, 결과 판독물을 SPAdes 어셈블러(cab.spbu.ru/software/spades)를 사용하여 새로 조립하였다. NCBI BLASTn(blast.ncbi.nlm.nih.gov) 및 Vector NTI AlignX 소프트웨어(Thermo Fisher)를 사용하여 서열 분석을 수행하였다.
AAV 생산 및 역가 결정
시험관내 분석에 사용된 AAV 벡터는 HEK293 세포에서 삼중 형질감염 방법으로 생산하였다. 벡터는 이전에 기술된 1 세포 스택 스케일 HEK293 삼중 형질감염 방법으로부터 채용된 프로토콜을 사용하여 6-웰 플레이트 스케일에서 벡터를 생산하였다. 감소된 배양 면적에 기초하여 하기와 같은 변형이 이루어졌다: 1) 사용된 플라스미드 비율은 2:1:0.1(헬퍼 플라스미드: 전이 플라스미드(trans plasmid): 시스 플라스미드(cis plasmid), 질량 기준); 및 2) 수확 시 동결/해동 이외의 다른 처리는 수행하지 않았다(Lock, M. 등, Human gene therapy, 2010. 21: p. 1259-71). 벡터는 CB7.ffluciferase.rBG 전이유전자와 함께 패키징하였다. 세포 용해물을 수집하고 전이유전자 카세트에 암호화된 토끼 β-글로빈 폴리아데닐화 신호에 대한 프라이머 및 프로브를 사용하여, TaqMan qPCR 증폭(Applied Biosystems, Foster City, CA)에 의해 DNase I- 및 프로테이나제 K-저항성 벡터 게놈을 적정하였다.
시험관내 형질도입 분석
삼중 형질감염 및 벡터 용해물 수확 후, 1x1010 GC/mL의 각 벡터를 신선한 완전 배지로 연속 희석한 다음 하루 전에 각각 1x105개 세포/웰 또는 1.5 x 106개 세포/웰로 시딩된 Huh7 또는 HEK293 세포를 형질도입하는 데 사용하였다. 루시퍼라제 활성은 D-루시페린 처리(Promega, Madison, WI) 후 루미노미터(Biotek, Winooski, VT)로 검출하였다.
설치류에서 신규 AAV 캡시드의 생체내 특성화
동물
모든 동물 프로토콜은 펜실베니아 대학교의 동물실험 위원회(Institutional Animal Care and Use Committee)의 승인을 받았다. C56BL/6J 마우스는 Jackson Laboratory에서 구입하였다. GFP 리포터 유전자 실험을 위해, 성체(6 내지 8주령) 수컷에게 주사하였다. 동물을 케이지당 2 내지 5마리 동물의 표준 케이지에 수용하였다. 케이지, 물병, 및 침구 기재는 차단 시설에서 고압멸균처리하고, 케이지는 1주일에 1회 교체하였다. 자동으로 제어되는 12시간 명 또는 암 사이클을 유지하였다. 각각의 암(dark) 기간은 오후 7:00(±30분)에 시작되었다. 방사선조사된 실험실 설치류 먹이는 임의로 제공되었다.
시험 물품 및 연구 설계
마우스에게 측면 꼬리 정맥을 통해 0.1 mL의 각 벡터를 마우스당 1×1012개 GC를 정맥내로(IV) 투여하거나 마우스당 5 uL로 1×1011개 GC의 용량으로 뇌의 측뇌실 내에 뇌실내(ICV)로 주사하였다. 각 그룹에 대해 3 또는 5마리의 마우스에 투약하였다.
주사 후 14일째에 CO2의 흡입에 의해 마우스를 안락사시켰다. 조직을 수집하고, 생체분포 분석을 위해 드라이 아이스에서 급속-동결하거나 10% 중성 포르말린에 침지-고정시키고, 수크로스에 저온-보존하고, OCT에서 동결한 다음, GFP 직접 관찰을 위해 크라이오스탯을 이용하여 절편화하였다. 내피 세포 형질도입 분석에 사용된 조직을 부검 후 파라핀으로 포매하였다.
리포터 유전자 시각화
직접적인 GFP 형광을 관찰하기 위해, 조직 샘플을 약 24시간 동안 포르말린에 고정시키고, PBS에서 잠시 세척한 다음, 최대 밀도에 도달할 때까지 PBS 중 15% 및 30% 수크로스에서 순차적으로 평형화한 다음, 동결절편의 준비를 위해 OCT 포매 배지에서 동결시켰다. 절편을 핵 대조염색으로서 DAPI를 포함하는 Fluoromount G(Electron Microscopy Sciences, Hatfield, PA)에 장착하였다.
GFP 면역조직화학을 파라핀-포매 조직 샘플에서 수행하였다. 에탄올 및 자일렌을 이용하여 절편을 탈파라핀화하고, 항원 복구를 위해 10 mM 시트레이트 완충액(pH 6.0)에서 6분 동안 끓인 다음, 2% H2O2로 15분 동안, 아비딘/비오틴 차단 시약(Vector Laboratories)으로 각각 15분 동안, 그리고 차단 완충액(PBS 중 1% 당나귀 혈청+0.2% 트리톤)으로 10분 동안 순차적으로 처리하였다. 이후 1차 항체와 함께 1시간 동안 인큐베이션하고 차단 완충액에서 45분 동안 비오틴화된 2차 항체와 함께 인큐베이션하였다(Jackson Immunoresearch). 1차 항체, 닭 항-GFP(Abcam ab13970) 및 토끼 항-CD31(Abcam ab28364) 내피 세포 마커를 사용하였다. DAB를 기질로서 이용하여 제조업체의 지침에 따라 Vectastain Elite ABC 키트(Vector Laboratories)를 사용하여 결합된 항체를 갈색 침전물로 시각화하였다.
면역형광의 경우, 파라핀 절편을 탈파라핀화하고 15분 동안 PBS+0.2% Triton에서 1% 당나귀 혈청으로 항원 복구 후 차단시킨 다음, 차단 완충액에서 희석된 1차(1시간) 및 형광-표지 2차 항체(45분, Jackson Immunoresearch)와 함께 순차적으로 인큐베이션하였다. 사용된 항체는 닭 항-GFP(Abcam ab13970), 토끼 항-CD31(Abcam ab28364), 및 마우스 항-NF-200(클론 RT97, Millipore CBL212)이었다. 1차 항체를 함께 혼합하고 GFP 및 NF-200 항체를 각각 FITC- 및 TRITC-표지된 2차 항체를 통해 검출하였다. 제조업체의 프로토콜(Vector Labs)에 따라 VectaFluor™ Excel Amplified DyLight® 488 Anti-Rabbit IgG 키트를 사용하여 CD31에 대한 토끼 항체에 대한 신호를 향상시켰다. X-gal 염색에 기반한 LacZ 유전자 발현 검출은 이전에 입증된 프로토콜을 사용하여 골격근 조직 절편에 대해 수행하였다(Bell, P. 등, Histochemistry and Cell Biology, 2005. 124: p. 77-85). 형광 및 명시야 현미경 이미지는 Nikon Eclipse TiE 현미경으로 촬영하였다.
바코딩된 벡터 전이유전자의 비인간 영장류 형질도입 평가
시험 물품 및 연구 설계
5개의 신규 캡시드 및 5개의 대조군 캡시드(AAVrh.90, AAVrh91, AAVrh.92, AAVrh.93, AAVrh91.93, AAV8, AAV6.2, AAVrh32.33, AAV7 및 AAV9)를 사용하여 변형된 ATG-결핍 자가-상보성 eGFP(dGFP) 전이유전자를 패키징하였다. 각각의 고유한 캡시드 제제는 벡터 게놈의 폴리아데닐화 서열 이전에 상응하는 고유한 6 bp 바코드가 있는 dGFP 전이유전자를 포함하였다. 전이유전자는 CB8 프로모터 및 SV40 폴리아데닐화 서열(AAVsc.CB8.dGFP.바코드.SV40)을 포함하였다. 앞서 기술된 바와 같이 Penn Vector Core에 의해 AAV 벡터를 생성하고 적정하였다(예를 들어, Lock, M. 등, (2010) Hum. Gene Ther. 21:1259-71 참조). HEK293 세포를 삼중 형질감염시킨 다음, 세포 배양 상층액을 수확하고, 농축시킨 다음, 이오딕사놀 구배를 이용하여 정제하였다. 정제된 벡터를 앞서 기술된 바와 같이 SV40 폴리A 서열을 표적화하는 프라이머를 사용하여 액적 디지털 PCR로 적정하였다(예를 들어, Lock, M. 등, (2014) Hum. Gene Ther. Methods 25:115-25 참조).
10개의 정제된 벡터를 2마리의 개별 동물에 주사하기 위해 동일한 게놈 복제물 양으로 풀링하였고: 전달된 총 용량은 IV 전달을 통한 2x1013 GC/㎏ 및 척추강내 공간으로 대조내(ICM) 전달을 통한 3x1013 GC/동물이었다. 주사 후 30일째에 동물을 희생시켰고 하류 전이유전자 RNA 발현 분석을 위해 RNAlater(QIAGEN)에서 모든 조직을 수확하였다.
동물
모든 동물 절차는 펜실베니아 대학교의 동물실험 위원회의 승인을 받았다. 필리핀 원숭이(마카카 파시쿨라리스(Macaca fascicularis))를 Bristol Meyers Squibb(USA)에서 기증받았다. 동물을 스테인리스-강 압착 백 케이지가 있는, 펜실베니아주 필라델피아 소재 필라델피아 아동 병원의 실험실 동물 관리 국제 인증 비인간 영장류 연구 프로그램 시설의 평가 및 인증 협회(Association for Assessment and Accreditation of Laboratory Animal Care International-accredited Nonhuman Primate Research Program facility)에 수용하였다. 동물은 음식 취급, 시각 및 청각 자극, 조종, 및 사회적 상호작용과 같은 다양한 강화를 받았다.
10세 수컷 8 kg 동물을 ICM 연구에 사용하였다. 6세 수컷 6.98 kg 동물을 IV 연구에 사용하였다. 이 동물을 AAV-중화 항체의 존재에 대해 스크리닝하였고, 기준선에서 AAV6, AAV8, 및 AAVrh32.33에 대해 혈청음성이었다. 기준선에서, 이 동물은 중화 항체 역가가 AAV7 및 AAV9에 대해 각각 1:5 및 1:10이었다.
ICM 주사 절차
마취된 원숭이를 머리를 앞으로 구부린 상태에서 측와위 자세로 X-선 테이블 위에 놓았다. 무균 기법을 사용하여 CSF 흐름이 관찰될 때까지 21 G 내지 27 G, 1 인치 내지 1.5 인치 퀸케(Quincke) 척추 바늘(Becton Dickinson, Franklin Lakes, NJ, USA)을 후두하 공간으로 전진시켰다. 기준선 분석을 위해 1 mL의 CSF를 수집하였다. 뇌간의 잠재적인 손상을 피하기 위해 형광 투시경(OEC 9800 C-arm; GE Healthcare, Little Chalfont, UK)으로 바늘의 올바른 위치를 확인하였다. CSF 수집 후, 루어(Luer) 접근 연장 또는 소구경 T 포트 연장 세트 카테터를 척추 바늘에 연결하여 180 mg/mL 이오헥솔 조영제(GE Healthcare, Little Chalfont, UK)의 투약을 용이하게 하였다. 바늘 위치를 확인한 후, 시험 물품을 포함하는 주사기(1 mL에 해당하는 부피+주사기 부피 및 링커 사강(dead space))를 가요성 링커에 연결하고 30±5초에 걸쳐 주사하였다. 바늘을 제거하고, 천자 부위에 직접 압력을 가하였다.
IV 주사 절차
주입 펌프(Harvard Apparatus, Holliston, MA)를 통해 1 mL/분의 속도로 말초 정맥 내로 10 mL의 벡터 시험 물품을 원숭이에게 투여하였다.
전이유전자 발현 분석
제조업체의 사양(Life Technologies)에 따라 TRIzol을 사용하여 모든 RNALater-처리된 조직으로부터 전체 조직 RNA를 추출하였다. 추출한 RNA를 제조업체의 프로토콜(Roche, Basel, Switzerland)에 따라 DNase I로 처리하였다. RNeasy Mini Kit(QIAGEN)를 사용하여 RNA를 정제하였다. Applied Biosystems High Capacity cDNA Reverse Transcriptase Kit(Life Technologies)를 사용하여 cDNA의 역전사 합성을 수행하였다. 6 bp 고유 바코드 측면에 있는 프라이머 표적화 영역을 사용하여 117 bp 앰플리콘(정방향 프라이머: GGCGAACAGCGGACACCGATATGAA(서열번호 11), 역방향 프라이머: GGCTCTCGTCGCGTGAGAATGAGAA(서열번호 12))을 PCR 증폭시켰고, Q5High-Fidelity Hot Start DNA Polymerase(New England Biolabs)를 사용하여 하기 사이클링 조건을 사용하여 반응을 수행하였다: 98℃에서 30초; 98℃에서 10초, 72℃에서 17초, 25 사이클; 및 72℃에서 120초 동안 연장. MiSeq Standard 2×150 bp 시퀀싱 플랫폼(Illumina)을 사용하여 앰플리콘을 시퀀싱하였다.
발현 분석 패키지(github.com/ExpressionAnalysis/ea-utils), cutadapt(cutadapt.readthedocs.io/en/stable/), fastx toolkit 패키지(hannonlab.cshl.edu/fastx_toolkit/) 및 R 버전 3.3.1.(cran.r-project.org/bin/windows/base/old/3.3.1/)의 fastq-join 프로그램을 사용하여 바코드 판독물을 분석하였다. 조직 샘플 유래의 바코드 발현 카운트 데이터를 각각의 동물에 대한 시퀀싱된 주사 벡터 물질 유래의 바코드 카운트에 대하여 정규화하고 GraphPad Prism 버전 7.04를 사용하여 각각의 조직 샘플 유래의 바코드 비율을 플롯팅하였다.
NHP에서 ICM AAVrh91 형질도입 특성화 연구
동물 및 연구 설계
모든 동물 절차는 펜실베니아 대학교의 동물실험 위원회의 승인을 받았다. 동물을 스테인리스-강 압착 백 케이지가 있는, 펜실베니아주 필라델피아 소재 필라델피아 아동 병원의 실험실 동물 관리 국제 인증 비인간 영장류 연구 프로그램 시설의 평가 및 인증 협회에 수용하였다. 동물은 음식 취급, 시각 및 청각 자극, 조종, 및 사회적 상호작용과 같은 다양한 강화를 받았다.
AAVrh91, AAV1, AAV8, 및 AAV9 캡시드를 이전에 기술된 방법을 사용하여 닭 베타 액틴 (CB7) 프로모터 (AAV.CB7.CI.eGFP.WPRE.rBG)의 강화된 녹색 형광 단백질(eGFP)을 발현하는 플라스미드로 패키징하였다(예를 들어, Lock, M. 등, (2010) Hum. Gene Ther. 21:1259-71 및 Lock, M. 등, (2014) Hum. Gene Ther. Methods 25:115-25 참조). 1.557x1013 GC의 용량을 각각의 동물에 ICM으로 주사하였다. ICM 주사 방법은 상기에 기술되어 있다. 주사 후 28 내지 31일째에 동물을 희생시키고 DNA 벡터 생체분포 연구를 위해 조직을 드라이아이스 상에서 수확하였다. Recommended Practices for Sampling and Processing the Nervous System (Brain, Spinal Cord, Nerve, and Eye) during Nonclinical General Toxicity Studies. Pardo 등, (2012). STP Position Paper에 따라 뇌를 전체 수집하고, 다듬고, 뇌 몰드를 사용하여 절편화하였다. 조직을 또한 수집하고, 포르말린으로 고정한 다음, 조직병리학적 분석을 위해 파라핀으로 포매하였다.
벡터 형질도입의 조직학적 분석
GFP 면역조직화학(IHC)의 경우, 에탄올 및 자일렌을 이용하여 절편을 탈파라핀화하고, 항원 복구를 위해 10 mM 시트레이트 완충액(pH 6.0)에서 6분 동안 끓인 다음, 2% H2O2로 15분 동안, 아비딘/비오틴 차단 시약(Vector Laboratories)으로 각각 15분 동안, 그리고 차단 완충액(PBS 중 1% 당나귀 혈청+0.2% 트리톤)으로 10분 동안 순차적으로 처리하였다. 그 다음 차단 완충액에서 GFP에 대한 염소 항체(Novus Biologicals, NB100-1770, 1:500)와 함께 4℃에서 하룻밤 인큐베이션하고, PBS에서 세척한 후, 차단 완충액에서 비오틴화된 2차 항-염소 항체(Jackson ImmunoResearch, 1:500)와 함께 45분 동안 인큐베이션하였다. PBS에서 세척한 후, DAB를 기질로서 이용하여 제조업체의 지침에 따라 Vectastain Elite ABC 키트(Vector Laboratories)를 적용하여 결합된 항체를 갈색 침전물로 시각화하였다.
면역형광(IF)의 경우, H2O2 및 아비딘/비오틴 차단 없이 유사하게 파라핀 절편을 전처리하였다. 하기 1차 항체를 조합하고 절편을 37℃에서 1시간 동안 인큐베이션하였다: 염소 항-GFP(Novus Biologicals, NB100-1770; 1:300-500), 기니 피그 항-NeuN(Millipore, ABN90; 1:500), 닭 항-GFAP(Abcam, ab4674; 1:1000). 이후, 이는 형광색소-표지된 2차 항체(FITC 항-염소, Cy5 항-기니 피그, TRITC 항-GFAP; Jackson ImmunoResearch, 실온에서 1시간, 1:200)와 인큐베이션하여 PBS에서 세척하였다. PBS로 세척한 후, 절편을 핵 대조염색으로서 DAPI를 포함하는 Fluoromount G(Electron Microscopy Sciences)에 장착하였다.
벡터 생체분포 분석
조직 게놈 DNA를 QIAamp DNA Mini Kit(QIAGEN)를 이용하여 추출하고, AAV 벡터 게놈을 벡터의 EGFP 서열을 표적화하는 프라이머/프로브와 함께 Taqman 시약(Applied Biosystems, Life Technologies)을 사용하여 실시간 PCR에 의해 정량화하였다.
중추신경계 조직(CNS)의 세포 형질도입 정량화 분석
IF 슬라이드는 상기 기술한 바와 같이 준비하고 Aperio VERSA 스캐닝 시스템을 사용하여 스캐닝하였다. 관심 영역을 정의하기 위해 먼저 전체 슬라이드를 저배율(1.25x)로 스캐닝하였다. 초기 1.25x 스캔 후, 슬라이드를 4개의 상이한 채널 DAPI, FITC, TRITC 및 Cy5를 사용하여 20x 배율로 스캐닝하였다. 형질도입된 뉴런 및 성상교세포는 Visiopharm 이미지 분석 소프트웨어 v.2019.07로 개발된 공동-염색 검출 알고리즘을 사용하여 최종 20x 스캔으로부터 정량화하였다.
AAVrh91에 대한 저온-전자 현미경검사 (cryoEM)
AAVrh91의 CryoEM은 매사추세츠 대학교 의과대학 Cryo-EM 코어 시설에서 수행하였다. 3 μl의 벡터를 희석 없이 (3.37x1013 GC/ml), 2 nm 두께의 연속 탄소 필름(Quantifoil)이 있는 발광-하전된(glow-charged) R2/1 구리 그리드에 추가하였다. 22℃ 및 95% 상대 습도에서 여과지로 7 내지 8초 동안 블롯팅한 후, 그리드를 Vitrobot Mark IV(Thermo Fisher Scientific)를 사용하여 액체 에탄 슬러시에서 동결하였다. 얼음 두께가 약간 상이한 2개의 그리드를 얻었다. Gatan K3 직접 검출기(Gatan, Pleasanton, USA)가 포함된 200 kV에서 작동하는 Talos Arctica 전자 현미경(Thermo Fisher Scientific)을 사용하여 그리드 1 상에서 1584개의 동영상을 수집하고, 그리드 2 상에서 3675개의 동영상을 수집하였다. SerialEM 소프트웨어를 사용하여 데이터를 획득하였다. 픽셀 크기는 0.435 Å/pix (bin=0.5)이고, 총 선량은 동영상 당 26개의 프레임으로 36.984 전자/Å2이었다. 이미지는 -0.5 내지 -1.5 μm 범위에서 디포커스(defocus)로 수집하였다.
AAVrh91 구조 결정, 모델 구축 및 개량
그리드 1 및 그리드 2의 경우, 동영상은 MotionCor2의 Relion 3.0 구현을 사용하여 동작-보정되었으며, 최종 픽셀 크기는 0.87 Å으로 비닝(binning)되었다. 동작 보정 후, ctffind4를 사용하여 현미경 사진의 디포커스를 추정하고 Relion 3.0을 사용하여 처리하였다. 그런 다음 그리드 1의 모든 처리된 이미지와 그리드 2의 3664개의 처리된 이미지를 총 5248개의 이미지에 대해 단일 데이터 세트로 결합시켰다. 이 세트로부터 본 발명자들은 2차원(2D) 분류를 위해 대략 1,000개의 입자를 선택하고 분류하였다. 최상의 클래스는 자동 선택을 위한 주형으로 사용하였다. 자동 선택에서 총 283,818개의 입자가 2D 분류의 한 라운드를 통해 분류되어 거짓 양성 및 최적이 아닌 입자를 제거하여 254,442개의 입자를 생성하였다. 초기 모델은 Relion으로 ab initio 모델 생성을 통해 C1 대칭으로 생성하였다. 본 발명자들은 C1 대칭 및 각도 샘플링을 사용하여 3차원(3D) 분류를 통해 입자를 5개 클래스로 분류하였다. 총 173,558개의 입자에 대해 3개의 최상의 클래스를 선택하였다. 이러한 입자를 사용하여, 본 발명자들은 C1 대칭에서 3D 자동-개량을 수행하고, 20면체 대칭을 적용한 다음 20면체 대칭이 적용된 또 다른 3D 자동-개량을 수행하였다. 본 발명자들은 그런 다음 개량된 입자에 대해 CTF 개량 및 입자 연마를 수행하였다. 최종 3D 자동-개량 및 후-처리는 0.143의 푸리에 쉘 상관 최적-표준(gold-standard) 컷오프를 기준으로 AAVrh91의 구조를 2.33 Å으로 산출하였다.
초기 모델은 AAV1(6JCR)의 이전에 공개된 구조로부터 생성되었다. 이러한 모델은 전자 밀도에 맞추어 COOT에서 AAVrh91 서열을 반영하도록 변형되었다. 초기 구축 단계 후, 본 발명자들은 PHENIX 소프트웨어 패키지에 포함된 phenix.real_space_refinement 프로그램을 사용하여 전자 밀도 맵에 대해 모델을 개량하였다. 본 발명자들은 20면체 비결정학적 대칭으로 전체 모델을 생성하였다. 본 발명자들은 강체(rigid-body) 피팅, 전역 최소화, 로컬 그리드 검색 및 이방성 변위 매개변수(ADP) 개량을 사용하여 2차 구조 및 비결정학적 대칭(NCS) 제약 조건 하에서 개량을 수행하였다.
AAV 캡시드의 아미노산 변형에 대한 질량 분석기(MS) 분석
시약
중탄산암모늄, 디티오트레이톨(DTT), 요오도아세트아미드(IAM)를 Sigma(St. Louis, MO)로부터 구입하였다. 아세토니트릴, 포름산, 및 트리플루오로아세트산(TFA), 8 M 구아니딘 하이드로클로라이드(GndHCl), 및 트립신을 Thermo Fisher Scientific(Rockford, IL)으로부터 구입하였다.
트립신 소화
1 M DTT 및 1.0 M 요오도아세트아미드의 스톡 용액을 준비하였다. 10 mM DTT 및 2 M GndHCl의 존재 하에 90℃에서 10분 동안 캡시드 단백질을 변성시키고 환원시켰다. 샘플을 실온까지 냉각시킨 다음, 암실에서 실온으로 30분 동안 30 mM IAM으로 알킬화시켰다. 1 mL DTT를 첨가하여 알킬화 반응을 켄칭하였다. 변성된 단백질 용액에 최종 GndHCl 농도를 200 mM로 희석시키는 부피로 20 mM 중탄산암모늄(pH 7.5 내지 8)을 첨가한다. 트립신 대 단백질 비율이 1:20이 되도록 트립신 용액을 첨가하고 37℃에서 4시간 동안 인큐베이션시킨다. 소화 후, 최종 0.5%로 TFA를 첨가하여 소화 반응을 켄칭시킨다.
LC-MS/MS
NanoFlex 공급원이 있는 Q Exactive HF(Thermo Fisher Scientific)에 결합된 Thermo UltiMate 3000 RSLC 시스템(Thermo Fisher Scientific)과 Acclaim PepMap 컬럼(길이 15 cm, 내경 300-μm)을 이용하여 온라인 크로마토그래피를 수행하였다. 온라인 분석 동안, 컬럼 온도를 35℃의 온도로 조절하였다. 이동상 A(0.1% 포름산을 포함하는 MilliQ 물) 및 이동상 B(0.1% 포름산을 포함하는 아세토니트릴)의 구배를 이용하여 펩티드를 분리하였다. 구배를 15분에 걸쳐 4% B에서 6% B로, 그 다음 25분 동안 10% B로(총 40분), 그 다음 46분 동안 30% B로(총 86분) 실행하였다. 샘플을 컬럼에 직접 로딩한다. 컬럼 크기는 75 cm×내경 15 um이고 2 미크론 C18 매질(Acclaim PepMap)로 패킹한다. 로딩, 도입, 및 세척 단계로 인해, LC-MS/MS 실행에 대한 총 시간은 약 2시간이었다.
조사 스캔(200 내지 2000 m/z)으로부터의 가장 풍부한 시퀀싱전 전구체 이온을 동력학적으로 선택하는 Q Exactive HF에 대한 데이터 의존적인 상위 20 방법을 사용하여 MS 데이터를 획득하였다. 예측된 자동 이득 제어로 결정된 1e5 이온의 목표 값을 이용한 고 에너지 충돌 분열 단편화를 통해서 시퀀싱을 수행하였고, 4 m/z의 윈도우로 전구체의 단리를 수행하였다. m/z 200에서 120,000의 분해능으로 조사 스캔을 획득하였다. 50 ms의 최대 이온 주입 시간 및 30의 정규화된 충돌 에너지를 이용하여 m/z 200에서 30,000으로 HCD 스펙트럼에 대한 분해능을 설정하였다. S-렌즈 RF 수준을 50에서 설정하여, 소화로부터 펩티드에 의해서 점유된 m/z 영역의 최적의 전달을 제공하였다. 단편화 선택으로부터 단일, 미배정, 또는 6 및 더 높은 전하 상태를 갖는 전구체 이온을 제외하였다.
데이터 처리
BioPharma Finder 1.0 소프트웨어(Thermo Fischer Scientific)를 획득된 모든 데이터의 분석에 사용하였다. 펩티드 맵핑을 위해, 고정된 변형으로서 설정된 카바마이도메틸화; 및 가변 변형으로서 설정된 산화, 탈아미드화, 및 인산화, 10 ppm 질량 정확도, 높은 프로테아제 특이성 및 MS/MS 스펙트럼에 대한 0.8의 신뢰 수준을 가지는 단기식 단백질 FASTA 데이터베이스를 사용하여 검색을 수행하였다. 변형된 펩티드의 질량 면적을, 변형된 펩티드와 천연 펩티드의 면적의 합으로 나눔으로써 펩티드의 변형 백분율을 결정하였다. 가능한 변형 부위의 수를 고려하여, 상이한 부위에서 변형된 동중 원소종이 단일 피크에서 동시에 이동할 수 있다. 결론적으로, 다수의 잠재적인 변형 부위가 있는 펩티드로부터 기원한 단편 이온을 사용하여 다수의 변형 부위를 위치시키거나 구별할 수 있다. 이러한 경우에, 관찰된 동위원소 패턴 내의 상대 강도를 사용하여 상이한 변형된 펩티드 이성질체의 상대 풍부도를 구체적으로 결정할 수 있다. 이러한 방법은, 모든 이성질체 종에 대한 단편화 효율성이 동일하고, 변형 부위에 독립적이라고 가정한다. 이러한 접근법은 변형된 구체적인 부위 및 또한 관련된 잠재적인 조합의 정의를 가능하게 한다.
통계 분석
모든 통계 분석은 Prism(GraphPad Software, San Diego, CA, USA) 버전 7.04를 사용하여 완료하였다. 두 그룹 간의 비교는 독립표본 스튜던츠 t-검정(unpaired Student's t-test)을 사용하여 수행되었으며, 여러 그룹 간의 비교는 일원 분산 분석(ANOVA, 크루스칼-윌리스(Kruskal-Wallis) 검정 및 던(Dunn) 다중 비교 검정)을 사용하여 수행하였다.
조직병리학
테스트 항목 그룹에 대해 맹검된 면허가 있는 수의 병리학자는 병소가 없는 경우 0, 최소의 경우 1(<10%), 경도의 경우 2(10-25%), 중등도의 경우 3(25-50%), 중증의 경우 4(50-95%), 및 극심한 경우 5(>95%)로 정의된 병리 심각도 점수를 확립하였다. 점수는 헤마톡실린 및 에오신(H&E)-염색된 조직의 현미경 평가를 기반으로 하며, 평균 고배율 현미경 시야에서 병변에 의해 영향을 받는 조직의 비율을 나타낸다.
벡터 게놈 복제물 및 전이유전자 RNA 분석
부검 시 조직 샘플을 급속 동결하고, QIAamp DNA Mini Kit (Qiagen, Valencia, CA)를 사용하여 DNA를 추출하였다. DNase 처리된 총 RNA를 100 mg의 조직으로부터 분리하였다. 분광광도법으로 RNA를 정량화하고, 분취량을 랜덤 프라이머를 사용하여 cDNA로 역전사시켰다. 추출된 DNA에서의 벡터 GC의 검출 및 정량화와 추출된 RNA에서의 상대적인 뉴클레아제 HAO1 전사물의 발현은 실시간 PCR로 수행하였다. 간략하게, 벡터 GC 및 RNA 수준은 각각 벡터의 폴리A 서열 및 전이유전자-특이적 서열에 대해 설계된 프라이머/프로브를 사용하여 정량화하였다.
GFP 단백질 발현의 정량화
횡경막, 심장, 신장, 간, 폐, 골격근(상완이두근, 대퇴이두근, 삼각근, 요측수근신근, 비복근, 대둔근, 늑간, 대흉근, 복직근, 비장근, 전경골근, 승모근, 및 외측광근을 포함함) 및 비장의 샘플을 균질화하고 GFP 단백질 수준을 제조업체의 지침에 따라 효소-결합 면역흡착 분석(ELISA; abcam ab171581)으로 결정하였다. 간략하게, 조직 샘플을 500 μl의 1X 세포 추출 완충액에서 균질화하고, 원심분리하고, 상층액을 추출하였다. 각 샘플에 대해 희석된 상층액을 ELISA 플레이트에 이중으로 첨가하고 제조업체의 지침에 따라 분석을 수행하였다. 또한, 상층액의 단백질 농도는 비씨코닌산(BCA) 분석(Pierce™ BCA Protein Assay Kit, ThermoFisher)으로 결정하였다. GFP 단백질 수준은 샘플당 총 단백질 수준으로 정규화하였다(pg 단백질당 μg GFP 발현).
면역조직화학
조직 샘플을 10% 중성 완충 포르말린에 고정하여, 표준 프로토콜에 따라 파라핀-포매하고, 면역조직화학에 의한 eGFP 발현 측정에 사용하였다. 절편은 에탄올 및 자일렌 시리즈를 통해 탈파라핀화하고, 항원 복구를 수행하기 위해 10 mM 시트레이트 완충액(pH 6.0)에서 6분 동안 끓인 다음, 2% H2O2(15분), 아비딘/비오틴 차단 시약(각각 15분; Vector Laboratories), 그리고 차단 완충액(10분 동안 PBS 중 1% 당나귀 혈청+0.2% Triton X-100)로 순차적으로 차단하고, 이후 GFP에 대한 1차 항체(염소 항체 NB100-1770, Novus Biologicals; 희석 1:500)와 함께 4℃에서 밤새 인큐베이션하였다. 절편을 차단 완충액에 희석된 비오티닐화된 항-토끼 2차 항체(1:500 희석, 45분; Jackson ImmunoResearch)와 함께 인큐베이션하였다. 3,3'-디아미노벤지딘(DAB)를 기질로 사용하는 Vectastain Elite ABC 키트(Vector Laboratories)는 결합된 항체를 갈색 침전물로 시각화하였다.
IHC 이미지 분석에 의한 GFP 발현의 정량화
GFP 발현은 심장, 간 및 비복근 골격근으로부터의 항-GFP 항체 면역표지된 절편으로부터 정량화하였다. 동물당 최대 3개의 면역표지된 절편을 Aperio AT2 스캐너(Leica Biosystems) 상에서 스캐닝하고, ImageJ 소프트웨어(버전 1.53c)를 사용하여 GFP 신호 정량화를 위해 5 내지 10개의 관심 영역을 선택하였다. GFP 신호 백그라운드는 나이브(naive) 대조군을 사용하여 설정하였으며; GFP 신호를 초과하는 백그라운드를 정량화한 다음 절편 영역으로 정규화하였다.
인간 개체군에서 AAVrh91의 혈청 유병률
Lee Biosolutions(Maryland Heights, MO)로부터 100개의 무작위 인간 혈청 샘플을 획득하였다. AAV2, AAV8, AAV9, AAVrh32.33 및 AAVrh91에 대한 NAb 역가는 이전에 기술된 바와 같이 결정하였다(Calcedo 등, 2009).
실시예 2: AAV-단일 게놈 증폭 (AAV-SGA)
아데노-연관 바이러스(AAV)는 이를 유전자 요법을 위한 벡터로서 효과적인 후보로 만드는 비-병원성이고 면역원성이 약한 단일-가닥 DNA 파보바이러스이다. 1세대 AAV(AAV1 내지 6)의 발견 이래로, 본 발명자들의 실험실은 다양한 고등 영장류 종으로부터 다수의 바이러스를 단리하는 노력을 주도하여 왔다. 여기에서 확인된 이러한 2세대 AAV는 영장류-유래 AAV 게놈에 특이적인 보존 영역에 대한 프라이머를 사용하는 벌크 PCR-기반 기법을 사용하여 단리되었다. AAV-SGA를 사용하여, 본 발명자들은 천연 포유동물 숙주에서 AAV의 유전적 변이를 탐구하였다(도 1).
AAV-SGA는 혼합 집단 내로부터 단일 바이러스 게놈을 높은 정확도로 단리하는 데 사용될 수 있는 강력한 기법이다. 본 연구에서, 본 발명자들은 AAV-SGA를 사용하여 히말라야 원숭이 조직 표본으로부터 신규 AAV 게놈을 동정하였다. 신규 바이러스 분리주는 유전적으로 다양하고 클레드 D, E, 및 프린지 클레드로 분류될 수 있다(도 2).
벡터 수율 및 시험관내 형질도입의 분석
모든 신규 캡시드 서열을 사용하여 유전자 전달 벡터를 생산하였다. 각각의 캡시드 VP1 서열을 표준 AAV2 Rep 유전자를 포함하는 전이 플라스미드로 클로닝하였다. 상기 전이 플라스미드는 HEK293 세포 삼중 형질주입 벡터 생산 방법을 위해 벡터 전이유전자 뿐만 아니라 아데노바이러스 헬퍼 플라스미드를 포함하는 다양한 시스 플라스미드와 조합하여 사용하였다. 정제된 벡터 역가는 DNAse I 처리 후 액적 디지털 PCR로 측정하여 벡터-캡시드화 전이유전자의 양을 결정하였다.
유비쿼터스 프로모터(CB7)의 제어 하에 반딧불이 루시퍼라제 전이유전자를 포함하는 벡터를 사용하여, 본 발명자들은 두 가지 인간 세포 유형에서 신규 캡시드의 시험관내 형질도입 능력을 테스트하였다: 간-유래 세포주인 Huh7 및 신장-유래 세포주인 HEK293. 벡터는 HEK293 세포보다 더 높은 효율로 Huh7 세포를 크게 형질도입하였다. Huh7 세포에서, AAV6.2 및 AAV7은 둘 다 그들의 신규 캡시드 대응물보다 상당히 더 높은 루시퍼라제 활성, 형질도입 수준의 직접적인 판독을 나타내었다(도 5a). 모든 캡시드는 사용된 용량에서 유사하게 낮은 수준으로 HEK293 세포에 형질도입되었다(도 5b).
신규 캡시드는 AAVrh91을 제외하고 이들의 클레드 대조군과 유사한 효율로 전이유전자를 패키징하였다(도 6a). AAVrh91-기반 벡터는 AAV6-기반 벡터보다 상당히 높은 수율로 벡터를 생산하였다. AAVrh91 및 AAV1 캡시드에서 벡터 생산에 대한 패키징된 전이유전자 유형의 영향을 고려할 때, 본 발명자들은 낮은 복제 수로 인해 모든 그룹에서 통계적 유의성에 대한 테스트를 수행할 수 없었지만, 동일한 전이유전자를 포함하는 AAV1 제제보다 AAVrh91 제제의 역가가 동일하거나 1 내지 2배 더 높은 것을 관찰하였다(도 6b).
AAVrh91 캡시드를 이전에 기술된 바와 같이 탈아미드화 및 기타 변형에 대해 분석하였다(PCT/US19/019804호 및 PCT/US19/2019/019861호 참조). 도 7a, 도 7b, 및 도 7c에 나타낸 바와 같이, 결과는 AAVrh91이 고도로 탈아미드화된 3개의 아미노산(N57, N383 및 N512)을 갖는다는 것을 나타내었고, 이는 아스파라긴-글리신 쌍(서열번호 2에서 AAVrh91의 넘버링)의 아스파라긴에 해당한다. 더 낮은 탈아미드화 비율은 잔기 N303, N497 및 N691 뿐만 아니라 S149에서의 인산화에서도 일관되게 관찰되었다.
설치류에서 신규 AAV 캡시드의 생체내 형질도입
다음으로, 본 발명자들은 마우스에서 5개의 새로운 캡시드의 조직 친화성을 특성화하였다. 모든 캡시드는 3가지 마우스 실험에 테스트하기 위한 유비쿼터스 프로모터, CB7 또는 CMV, 및 강화된 녹색 형광 단백질(eGFP) 또는 β-갈락토시다제(LacZ) 리포터 전이유전자를 포함하는 유전자 전달 벡터로서 생산되었다.
전신 형질도입 능력에 대한 벡터를 테스트하기 위해, 본 발명자들은 정맥(IV) 꼬리 정맥내 투여 경로(ROA)를 통해 성체 C57BL/6 마우스에 주입하였다. 벡터는 CB7.eGFP 전이유전자를 포함하고, 마우스당 1012개의 게놈 복제물(GC) 용량으로 주사하였다. 간, 심장, 뇌 및 골격근의 면역형광 현미경검사는 AAVrh91 및 AAV6.2 벡터에 대한 eGFP 발현에서 유사한 경향을 나타내었다(도 14).
BBB를 우회하고 CNS 조직에서 형질도입을 촉진하기 위해, 본 발명자들은 성체 C57BL/6 마우스의 CSF 함유 측뇌실에 각 CB7.eGFP 벡터를 ICV ROA로 주사하였다. 클레드 A 벡터를 제외한 모든 캡시드를 마우스당 1x1011 GC 용량으로 투여하였다. 클레드 A 벡터를 마우스당 6.9x1010 GC로 투여하였다. AAV6.2의 낮은 제조 수율로 인해, 본 발명자들은 이 그룹에 대한 적절한 벡터 농도를 달성할 수 없었다.
주사 후 14일째, 본 발명자들은 간, 심장, 골격근, 그리고 가장 중요하게는 뇌에서 벡터 게놈의 생체분포를 분석하였다(도 8d). 평균적으로, AAV6.2 및 AAV7의 뇌 GC 수준은 각각 신규 캡시드 대응물인 AAVrh91, 그리고 AAVrh93 및 AAVrh91.93보다 높았으나; 이러한 데이터는 통계적으로 유의하지 않았다. 본 발명자들은 또한 간에서 발견되는 더 많은 양의 AAVrh91 벡터 게놈에 의해 표시되는 바와 같이, 대조군 캡시드인 AAV6.2보다 더 많은 AAVrh91의 GC가 전달 후 주변부로 빠져나갔음을 관찰하였다(도 8d).
본 발명자들은 직접 형광에 의해 ICV 주입된 뇌에서 전이유전자 발현을 정성적으로 분석하고, 신규 캡시드와 대조군 간의 다양한 형질도입 수준을 관찰하였다. 클레드 A 벡터, AAVrh91 및 AAV6.2는 심실의 맥락막총 및 뇌실막 세포의 현저한 형질도입을 나타내었다(도 15).
마지막으로, 본 발명자들은 골격근 세포의 형질도입을 위해 근육내 ROA에 의한 벡터 전달을 테스트하였다. 본 연구를 위해, 본 발명자들은 성체 C57BL/6 마우스당 3x109 GC의 용량으로 벡터를 포함하는 CMV.LacZ 전이유전자를 주사하였다. β-갈락토시다제 검출 후 조직의 현미경검사는 클레드 A 벡터, AAVrh91, AAV1 및 AAV6에 의한 균일하게 강한 근세포 형질도입을 나타냈다. 대조적으로, 이 용량에서, AAV8은 근육 조직의 열악한 형질도입을 보였다(도 9b). AAVrh91을 통한 IM 전달은 또한 혈청에서 높은 수준의 검출 가능한 mAb를 초래하였다(도 10). 도 11은 mAb 및 LacZ 벡터의 다양한 제제에 대한 수율을 나타낸다. 두 전이유전자에 대해, AAVrh91은 AAV1 및 AAV6에 비해 더 높은 수율을 보였다.
전반적으로, 이들 연구는 신규 AAVrh91 캡시드가 마우스에서 다양한 세포 및 조직 유형을 형질도입할 수 있고, ROA에 의존하는 고유한 친화성을 나타낸다는 것을 보여주었다.
실시예 3: 바코딩된 전이유전자 시스템을 사용한 비인간 영장류에서 신규 AAV 자연 분리주의 형질도입 평가
AAV 벡터는 임상 적용에서 안전하고 효과적인 유전자 전달 비히클인 것으로 나타났지만, 바이러스에 대한 기존 면역력에 의해 방해받을 수 있고 제한된 조직 친화성을 가질 수 있다. 본 발명자들은 바코딩된 전이유전자 방법이 다수의 AAV 혈청형에 의해 단일 동물에서 다양한 조직의 형질도입을 동시에 비교하는 데 효과적임을 입증하였다. 이러한 기법은 사용되는 동물의 수를 감소시키고 외래 전이유전자-관련 면역 반응을 방지한다. 따라서, 신규 캡시드 및 이의 각각의 원형 클레드 구성원 대조군(AAV6.2, AAV7, AAV8, AAVrh32.33, 및 AAV9)을 전사물의 폴리A 신호 이전에 변형된 eGFP 전이유전자 및 고유한 6개 염기쌍 바코드를 포함하는 벡터로 만들었다(도 12). ATG 서열 모티프의 결실에 의해 전이유전자를 변형시켜 폴리펩티드 번역과 그 결과에 따른 외래 단백질에 대한 면역 반응을 방지하였다. 동일한 양으로 벡터를 풀링하고 필리핀 원숭이에 IV 또는 ICM 주사하여(총 용량: 2x1013 GC/㎏ IV 및 3x1013 GC ICM) 신규 캡시드의 전신 및 중추신경계 형질도입 패턴을 평가하였다. 모든 발현 데이터는 실제 입력 비율로 정규화하여 풀링된 비율의 이러한 약간의 변화를 제어하였다.
본 발명자들은 두 개의 서로 다른 ROA를 사용하여 풀링된 벡터를 두 마리의 필리핀 원숭이에 투여하였다. 신규 AAV 캡시드의 전신 형질도입을 분석하기 위해, 본 발명자들은 풀링된 벡터 혼합물의 총 용량 2x1013 GC/kg을 첫 번째 동물에게 정맥내로 주사하였다. 본 발명자들은 CNS 조직의 직접적인 표적화를 위해 두 번째 NHP의 CSF에 3x1013 GC의 벡터 용량을 전달하기 위해 대조내(ICM) 주사를 통한 척수강내(IT) 전달 접근법을 추가로 활용하였다. 벡터 전달 후 30일째, 전이유전자 발현은 전이유전자 RNA를 추출하고 이어서 주입 물질에 상대적인 각 샘플로부터 각 벡터에 해당하는 바코드 빈도를 정량화함으로써 각 동물의 다양한 조직에서 분석되었다.
흥미롭게도, 폐 및 췌장 조직에서 AAVrh91은 AAV6.2보다 더 높은 전이유전자 발현 수준을 가졌다(도 13a). 본 발명자들은 또한 AAVrh91이 AAV6.2보다 더 높은 수준에서 근육 조직을 형질도입하는 것을 관찰했지만, 이는 췌장 또는 폐에서의 형질도입 향상만큼 유의미하지 않았다. 이 동물은 주사 시점에 AAV7 및 AAV9에 대한 낮은 수준의 기존 중화 항체(각각 역가 1:5 및 1:10)를 가지고 있기 때문에, 모든 조직에서 클레드 D 및 F 캡시드에 대한 바코드 빈도는 매우 낮았다. 평균적으로, 모든 바코드의 0.3 내지 7%만이 AAV7, AAV9, AAVrh93 및 AAVrh91.93 전이유전자에서 유래하였다.
ICM ROA에 의해 벡터가 투여된 동물에서, 클레드 A 벡터 AAVrh91 및 AAV6.2는 CNS의 두 조직 뿐만 아니라 말초 조직에서 상대적으로 높은 형질도입 빈도를 나타냈고, 이는 벡터의 ICM 전달 후 일부가 체순환으로 진입했음을 나타낸다(도 13c 및 도 13d). 이 동물은 또한 각각 1:10, 1:5 및 1:5의 역가에서 AAV7, AAV8 및 AAV9에 대한 낮은 수준의 기존 혈청 중화 항체를 가졌다.
이러한 연구는 개별 NHP에서 신규 AAV 캡시드의 상대적인 조직 친화성을 효율적으로 평가할 수 있었고, AAVrh91을 전신 및 CNS 표적 유전자 치료 적용을 위한 잠재적인 벡터로 강조하였다.
실시예 4: AAVrh91은 척수강내 전달 후 강력한 CNS 형질도입 프로파일을 나타낸다
전체 AAV 벡터 조직 형질도입을 분석하기 위해 분자 바코딩된 전이유전자 방법을 사용하는 것은 다양한 기관에서 상대적인 발현 수준을 스크리닝하는 효과적인 방법이다. 그러나, 동일한 세포를 전달하는 많은 다른 벡터가 있으므로 조직 내에서 세포 친화성을 평가하는 것은 기술적으로 복잡할 수 있다. 또한, 여러 벡터를 풀링할 때 개별 벡터의 용량을 준임상 수준으로 줄일 수 있으므로, 이는 번역 응용 프로그램에 대한 캡시드의 유용성을 평가하기 어렵다.
AAVrh91 벡터의 CNS 내에서 세포 친화성을 완전히 평가하기 위해, 본 발명자들은 HEK293 세포에서 삼중 형질도입 방법에 의해 CB7.eGFP 전이유전자를 포함하는 벡터를 생성하고 1.6x1013 GC의 벡터를 ICM 주사를 통해 히말라야 원숭이에 주사하였다. 동일한 전이유전자를 포함하는 AAV1 및 AAV9 벡터는 또한 두 벡터가 잘 연구되었기 때문에 대조군으로서 두 개의 추가 그룹에 투여되었으며; AAV1은 AAVrh91과 동일한 클레드에 있으며 AAV9는 현재 최적-표준 CNS 트로픽 벡터이다. 따라서, 본 발명자들은 번역 관련 모델 유기체에서 3개의 캡시드의 형질도입 효율을 비교하고자 하였다.
ICM 주사 후 대략 4주째, 본 발명자들은 GFP 면역조직화학에 의해 전이유전자 발현을 평가하였다. 본 발명자들은 AAV9보다 더 높은 수준으로 뇌의 전두, 측두 및 후두 피질에서 광범위한 수준의 AAVrh91 벡터-매개 유전자 발현을 관찰하였다(도 16a). 측뇌실의 CSF-생성 뇌실막 세포는 클레드 A 벡터, AAVrh91 및 AAV1 모두에 의해 강력하게 형질도입되었다. 대조적으로, 본 발명자들은 AAV9 벡터가 투여된 동물에서 이 세포 유형의 상당한 형질도입을 볼 수 없었다(도 16b). 척수의 운동 뉴런에서의 GFP 발현은 요추 분절에 존재하는 더 강한 GFP 염색으로 3개의 벡터 모두에 의해 유사하게 형질도입되었다(도 16c). 흥미롭게도, AAVrh91 및 AAV1을 투여한 동물의 간 및 심장 조직에서 GFP 발현의 현저한 염색이 관찰되었으며, 이는 벡터의 일부가 CSF로부터 체순환으로 유입되었음을 나타낸다. 이들 말초 조직의 형질도입은 AAV9 동물에서 더 약했다(도 17).
다음으로, 본 발명자들은 면역형광 세포 정량 분석을 사용하여 AAV1 및 AAV9와 비교하여 AAVrh91의 세포 친화성을 평가하였다. 포유류의 뇌는 두 가지 주요 세포 유형으로 구성된다: 뉴런 및 교세포. 신경교 섬유질 산성 단백질(GFAP) 및 신경 핵 단백질(NeuN) 마커를 사용하여, 본 발명자들은 뇌 조직 절편에서 각각 성상교세포(주요 유형의 신경교 세포) 및 뉴런에 대해 염색할 수 있었다(도 18a 및 도 18b). 본 발명자들은 DAPI 핵 염색으로 염색된 세포를 정량화하고, GFAP 또는 NeuN과 함께 GFP를 형질도입하여 뇌에 존재하는 형질도입된 성상교세포 및 뉴런의 수를 결정하였다.
본 발명자들은 평균적으로 AAVrh91이 뇌의 대부분의 영역에서 AAV9보다 대략 2 내지 4배 더 높은 속도로 성상교세포에 형질도입되고, 문측(rostral)에서 미측(caudal) 영역으로의 형질도입이 현저하게 증가함을 발견하였다. AAV1은 미측 절편 8B, 9 및 12-1에서 AAV9보다 약 2배 더 높은 수준으로 성상교세포를 형질도입했지만, 수준은 주로 전두 및 측두 피질을 포함하는 절편 2, 5 및 7에서 AAV9와 더 유사하였다(도 18c). 대조적으로, AAVrh91과 AAV9 뉴런 형질도입 간의 차이는 전자가 후자보다 1.5 내지 2.5배 더 높은 수준으로 형질도입되는 경우 더 적었다(도 18d). 특정 뇌 영역으로 계층화될 때, 본 발명자들은 AAVrh91에 의해 형질도입된 피질, 해마 및 선조체 내 뉴런의 약 1% 및 AAV9에 의해 0.25 내지 0.7% 형질도입으로 전반적으로 유사한 경향을 관찰하였다. 흥미롭게도, 시상은 평가된 나머지 뇌 영역에서보다 두 벡터에 의해 훨씬 더 높은 수준의 형질도입을 보였다(도 18d).
모든 그룹에서 벡터 게놈의 생체 분포는 qPCR로 분석하였다. 본 발명자들은 CNS로부터 스크리닝된 대부분의 조직에서 AAVrh91이 가장 높은 GC 수준을 보임을 발견하였다. AAV9 형질도입된 조직은 모든 그룹에서 유사한 GC 존재를 나타낸 척수를 제외하고 대부분의 조직에서 대략 1로그의 GC 양의 감소를 보였다(도 19a 내지 도 19c). 스크리닝된 모든 CNS 조직에서 GC의 평균 생체분포를 고려할 때, AAVrh91 및 AAV1을 받은 동물은 AAV9 벡터를 받은 동물보다 상당히 더 높은 형질도입 수준을 보였다(도 20).
흥미롭게도, 클레드 A GFP-발현 벡터를 받은 4마리의 동물은 AAV-매개 DRG 독성을 나타내는 부검에서 DRG 및 말초 신경 병리를 나타냈다. 본 발명자들은 AAVrh91 및 AAV1의 형질도입 수준이 가장 높은 동물이 다양한 말초 신경, DRG, 척수 영역 및 간에서 전반적으로 높은 등급의 병리 측면을 보임을 발견하였다. 특히, 하나의 AAV1 투여된 NHP, RA3654는 연구 21일째에 경미한 임상 소견을 나타냈다: 뒷다리와 뒷다리 운동 실조증 모두에서 의식적인 고유 감각 결손. 이러한 임상 결과는 코르티코스테로이드(프레드니솔론)를 투여한 후 연구의 나머지 기간(22일 내지 30일) 동안 해결되었다.
상기 기술된 연구는 천연 공급원으로부터 단리되고 시험관내 및 생체내 유전자 전달 벡터로 테스트된 신규 AAV 캡시드에 대한 포괄적인 분석을 제공한다. 본 발명자들의 신규 캡시드는 표면-노출된 HVR 뿐만 아니라 구조적으로 내부 VP1 및 VP2 고유 영역 모두에서 대조군 캡시드로부터 아미노산 서열 변이를 가졌다. 이러한 서열의 다양성은 숙주 세포 수용체에 대한 차별적 결합을 허용할 수 있으며, 이는 상이한 캡시드 간의 조직 친화성의 변화를 초래한다. 또한, VP1 및 VP2 고유 영역 내에서 서열의 차이는 이러한 영역이 핵으로의 전이유전자 전달을 매개하는 다양한 세포질 성분과 상호작용하는 것으로 기인하므로, 상기 벡터의 트래피킹(trafficking) 불일치에 기여할 수 있다. 캡시드 돌연변이 유발 기술을 사용한 추가 연구는 AAV 친화성 및 트래피킹에 대한 아미노산 변이의 효과를 밝혀낼 수 있다.
신규 캡시드와 대조군 간의 차이는 벡터 패키징의 차이로 이어질 수도 있다. 흥미롭게도, VP1 단백질 서열이 1.1%만 상이함에도 불구하고, 본 발명자들은 벡터 수율에 기초하여 AAVrh91 벡터가 AAV6.2 기반 벡터보다 상당히 더 높은 수준으로 전이유전자를 패키징한다는 것을 발견하였다. 본 발명자들은 또한 AAVrh91이 AAV1보다 높은 수준의 전이유전자를 패키징함을 확인하였다.
AAV9는 CNS 트로픽 벡터로서의 유용성을 위해 가장 잘 연구된 AAV 캡시드 중 하나이며, CNS 유전자 요법을 위한 최적-표준으로 간주된다. 마우스에서, BBB를 가로질러 정맥내 전달 후 높은 효율로 뇌와 척수의 세포를 형질도입할 수 있는 것으로 나타났다. 또한, 뇌에서의 형질도입은 확산되지만 소형 및 대형 동물 모델 모두에서 CSF로 IT 전달 후 국소화된 CNS 형질도입에서 그 효과를 입증하는 수많은 연구가 있었다. 여기서, 본 발명자들은 영장류 CNS인 AAVrh91을 효과적으로 표적으로 하는 신규 AAV 캡시드를 확인하였다. 고유한 뇌실막 세포 형질도입 표현형은 이 세포 유형이 전이유전자를 CSF로 방출하여 전체 심실 시스템을 통해 순환할 수 있기 때문에 분비된 전이유전자가 필요한 장애를 치료하는 데 매우 유용할 수 있다. 본 발명자들은 또한 AAV1을 사용하여 이 뇌실막 세포 형질도입 패턴을 관찰했지만, AAVrh91은 전체 뇌 형질도입 수준이 더 높았고 제조 프로파일이 더 우수하였다. 흥미롭게도, 본 발명자들은 AAV9 그룹과 비교하여 AAVrh91 및 AAV1 그룹의 간 및 심장 조직에서 형질도입된 세포의 더 높은 빈도를 관찰하였다. AAVrh91은 또한 적어도 AAV9에 필적하는 효율적인 실질 형질도입을 나타낸다. 전반적으로, 시험된 대부분의 뇌 영역에서 AAV9의 것보다 더 큰 GC 생체분포 및 형질도입 수준으로, AAVrh91은 AAV9를 대신하여 번역 유전자 요법 연구를 위한 치료적 전이유전자의 IT 전달에 강력하게 고려되어야 한다.
실시예 5: 인간 개체군에서 AAVrh91의 혈청 유병률
본 발명자들은 최대 100개의 무작위 인간 혈청 샘플을 사용하여 인간 개체군에서 AAVrh91에 대한 항-캡시드 NAb의 혈청 유병률을 평가하였다(도 21a). 본 발명자들은 또한 비교를 위해 적어도 50개의 동일한 샘플에서 AAV2, AAV8, AAV9 및 AAVrh32.33에 대한 NAb를 평가하였다. AAVrh91은 본원에서 평가된 인간 샘플에서 AAV8(42%)과 유사한 혈청 유병률(37%)을 가지며, 이는 AAV9(60%)에 비해 감소하였다. 본 발명자들이 NAb 반응의 크기를 조사했을 때, AAVrh91에 대해 양성인 극소수의 샘플이 낮은 양성 범위(NAb 역가 1/5-1/10)에 있었다. 비교해 보면, 다른 캡시드에 대한 NAb 반응 크기의 확산은 낮은 양성 범위에서 보고된 증가된 샘플과 함께 더 확산되었다(도 21b).
실시예 6: 전신 투여 후 AAVrh91의 생체분포
본 발명자들은 동물 모델에 전신 투여 후 AAV 벡터로서 AAVrh91 캡시드의 생물학적 특성을 특성화하고자 하였다. 다양한 조직 형질도입 특성은 마우스 및 히말라야 원숭이 둘 다에 IV 전달 후 생체내에서 관찰하였다.
AAV1, AAV8 및 AAV9와 비교하여 전신 투여 후 마우스에서 AAVrh91의 생체분포
소형 동물 모델에서 AAVrh91의 생체분포 및 형질도입 프로파일을 평가하기 위해, 본 발명자들은 CB7 프로모터로부터 eGFP를 발현하는 벡터 1011 또는 1012 GC를 C57BL/6J 마우스에 IV 투여하였다. 또한, 마우스에 동일한 용량의 AAV1, AAV8 및 AAV9 벡터를 투여하였다. 벡터 투여 후 21일째에 마우스를 부검하고, 간, 심장 및 골격근(비복근)을 수확하였다. DNA 및 RNA의 단리 후, 샘플을 벡터 게놈 복제물 및 벡터-유래 RNA 전사물 수준에 대해 각각 평가하였다(도 22a 내지 도 22f).
평가된 모든 조직 (간, 심장 및 골격근)의 경우, 평가된 4개의 모든 캡시드에 대해 벡터 게놈 복제물의 용량-의존적 증가가 있었다. AAV8 벡터의 투여는 간에서 가장 높은 벡터 게놈 복제물 및 전이유전자 발현을 초래하였다. 흥미롭게도, AAV1에 비해 고용량(1012 GC/동물)에서 간 내 AAVrh91 게놈 복제물의 수가 감소한 것으로 나타났으며, 이는 간에서 이 캡시드의 잠재적 탈-표적화를 시사한다. AAV9 및 AAVrh91 벡터에 대한 전이유전자 RNA 수준에서 용량 효과가 검출되지 않았다.
심장 및 골격근에서, 본 발명자들은 평가된 다른 벡터보다 AAVrh91을 사용하여 더 높은 게놈 복제물을 관찰하였다. AAVrh91은 심장에서 AAV9만큼 고도로 발현되지 않았지만, 이는 AAV8과 유사하였다. 흥미롭게도, 전이유전자 발현은 골격근에서 AAV1, AAV9 및 AAVrh91에 대해 유사하였다. 형광에 의한 GFP 발현의 평가를 위해 부검 시 조직 샘플을 또한 수확하였다. 전이유전자 단백질 발현은 간, 심장 및 골격근(비복근)에 걸친 RNA 수준과 상관관계가 있었다.
전신 투여 후 히말라야 원숭이에서 AAVrh91의 평가
대형 동물 모델에서 전신 투여 후 AAVrh91의 생체분포 및 형질도입 프로파일을 평가하기 위해, 본 발명자들은 5x1013 GC/kg의 AAVrh91.CB7.eGFP를 3마리의 히말라야 원숭이에 투여하였다. AAVrh91을 현재 동급 최고 벡터의 전신 생체분포와 직접 비교하기 위해 동량의 AAV9를 추가 3마리의 히말라야 원숭이에 투여하였다.
IV 벡터 투여 후, 임상 병리학의 변화에 대해 모든 NHP를 모니터링하였다(도 26a 및 도 28b). 기록된 변화 중 어느 것도 통계적 유의성에 도달하지 않았지만, 3일째에 ALT, AST 및 총 빌리루빈의 상승이 있었으며, 이는 AAV9를 투여한 동물에서 더 컸다. 이러한 상승은 AAVrh91을 투여한 NHP에서 14일째에 ALT 및 AST에서 더 작은 상승이 발생하면서 7일째부터 기준선 수준으로 빠르게 되돌아갔다. 총 빌리루빈 수준은 또한 14일째에 많은 동물에서 두 번째로 정점을 찍었고, AAV9를 받은 한 동물은 5.8 mg/dl(18-017)로 상승하였다. 이 동물은 황달을 보였고 피하 수액을 투여받았지만 그 외에는 안정적이었다. 총 빌리루빈의 이차 증가는 간에서 GFP의 발현과 비-자가 단백질에 대한 후속 반응에 기인하였다. 3일째에 평가된 두 캡시드에 걸친 응고 시간 (PT 및 APTT)에 약간의 연장이 있었고, AAVrh91을 투여한 동물에서 혈소판 수의 약간의 감소가 나타났다.
NHP를 벡터 투여 후 21일째에 부검하고 조직을 수확하였다. 샘플링 문제로 인한 변화를 감소시키기 위해, 본 발명자들은 NHP당 하나의 샘플만 평가된 횡경막, 신장 및 비장을 제외하고 각 조직의 여러 샘플을 평가하였다. 좌심실과 우심실 모두 심장에서 평가하였고, 간 3엽(좌측, 중간, 우측), 좌측 및 우측 폐, 및 13개의 골격근(상완이두근, 대퇴이두근, 삼각근, 요측수근신근, 비복근, 대둔근, 늑간, 대흉근, 복직근, 비장근, 전경골근, 승모근, 및 외측광근)을 캡시드당 3개의 NHP에서 평가하였다.
AAV9 및 AAVrh91은 간에서 검출되는 대부분의 벡터 게놈과 함께, 전신 주사 후 상당히 유사한 벡터 생체분포 프로파일을 갖는 것으로 나타났다(도 23a). 캡시드 간의 차이는 통계적으로 유의하지 않았지만, AAV9를 투여한 NHP는 간에서 2.5배 더 높은 벡터 게놈 복제물을 가졌다(AAVrh91을 투여한 NHP의 경우 평균 81.6 GC/이배체 게놈 대 32.6 GC/이배체 게놈). 다른 말초 기관(심장, 신장, 폐, 골격근 및 비장)의 게놈 복제물은 간보다 최대 2로그 낮았지만, AAVrh91의 값은 AAV9보다 약간 더 높았다.
전이유전자가 정맥내 투여 후 발현되는 위치를 추가로 평가하기 위해, 본 발명자들은 전이유전자 RNA 복제물 및 GFP 단백질 발현을 평가하였다(도 23b, 도 23c 및 도 23d). AAV9는 신장, 간, 폐 및 비장에서 더 높은 전이유전자 RNA 수준을 갖는 반면, AAVrh91은 횡경막, 심장 및 골격근에서 AAV9로 RNA 수준을 초과하였다(도 23b). 이러한 경향은 GFP 단백질 발현이 ELISA(도 23c) 또는 IHC에 의해 검출된 GFP 발현의 이미지 정량화(도 23d)로 평가되었을 때 유지되었다. AAV9 벡터를 받고 14일째에 혈청 총 빌리루빈 수준이 확연히 상승한 동물 18-017은 지속적으로 낮은 벡터 게놈 복제물, 전이유전자 RNA 수준 및 간에서 거의 없는 GFP 단백질 발현을 보였다. 이것은 결핍된 전이유전자 발현 및 형질도입된 간세포의 제거를 초래하는 비-자가 전이유전자에 대한 면역 반응을 나타낸다. 조직병리학은 동물 18-017 및 18-022(2/3, AAV9)에서 가장 심각한 간 독성(간세포 변성 및 개별 세포 괴사)이 관찰되었음을 밝혔다. 그룹 간 비교 시, AAVrh91 벡터(최소 내지 경도)를 받은 동물에 비해 AAV9 벡터(중등도 내지 중증)를 받은 동물에서 간 독성의 심각도가 증가하였다(도 25).
NHP당 수확된 13개의 골격근 샘플 각각에서 벡터 게놈 복제물, 전이유전자 RNA 수준 및 GFP 발현의 추가 분석은 AAVrh91 유전자 전달 및 전이유전자 발현의 일관성을 나타내었다. 평가된 골격근 그룹에 걸친 벡터 게놈 복제물은 AAV9에 비해 AAVrh91의 투여 후 지속적으로 0.5 내지 4.6배 증가했지만, 결합된 데이터의 차이는 통계적 유의성에 도달하지 않았다(도 24a). 전이유전자 RNA(도 24b) 및 GFP 발현(도 24c)의 증가된 가변성은 또한 AAVrh91로 강화된 전이유전자 발현 경향이 통계적으로 유의미한 수준에 도달하는 것을 가능하게 하지 않았다.
소형 및 대형 동물 모델 둘 다에 대한 이러한 연구는 천연 공급원에서 단리되고 유전자 전달 벡터로 평가된 신규 AAV 캡시드인 AAVrh91에 대한 포괄적인 분석을 제공한다. 마우스와 히말라야 원숭이 모두에서 AAVrh91은 AAV9와 비교하여 골격근의 형질도입이 증가하지는 않더라도 유사하다. 본 발명자들은 또한 AAVrh91 벡터가 평가된 다른 AAV 캡시드보다 간에서 더 적은 전이유전자를 발현함을 관찰하였다. AAVrh91 캡시드에 의한 간의 이러한 잠재적 탈표적화는 AAVrh91 벡터가 전신 주사 후 간 독성 측면에서 캡시드에 비해 간에서 전이유전자의 발현이 적어 장점이 있음을 시사할 수 있다.
실시예 7: 비-인간 영장류에 대한 ICM 투여 후 AAVrh91의 생체분포
히말라야 원숭이에 대조내(ICM) 투여 후 AAVrh91 캡시드를 사용한 전이유전자 전달을 평가하기 위해 추가 연구를 수행하였다.
첫 번째 연구에서, eGFP 전이유전자, AAVrh91.CB7.eGFP 또는 AAV9.CB7.eGFP를 운반하는 3x1013 GC/kg의 벡터를 NHP(n=3/그룹)에 전달하였다. 투여 후 14일째에 부검을 수행하였다. 신경 전도 속도 평가는 기준선에서 그리고 14일째 부검 전에 수행하였다(도 32). 생체분포 및 형질도입 프로파일의 비교는 도 28a 내지 도 28c에 도시되어 있다. 뇌(도 31a 내지 도 31c), 척수(도 30a 내지 도 30g) 및 후근 신경절(DRG)(도 29a 내지 도 29i)에서 GFP 양성 뉴런을 정량화하기 위해 면역조직화학을 수행하였다. (AAV9와 비교하여) AAVrh91이 투여된 NHP 내 DRG에서 더 적은 전이유전자 발현이 관찰되었다(도 29a 내지 도 29i). 이러한 결과는 ICM 경로를 통한 AAVrh91 유전자 전달이 AAV9보다 적은 DRG 독성과 연관될 가능성이 있음을 시사한다.
추가의 연구에서, 항체 전이유전자(2.10A mAb), AAVrh91.CB7. 2.10A 또는 AAV9.CB7.2.10A을 운반하는 3x1013GC/kg의 벡터를 NHP(n=3/그룹)에 전달하였다. 혈청 및 CSF를 2.10A mAb 발현에 대해 모니터링하였다(도 33a 및 도 33b). 벡터 투여 후 90일째에 부검을 수행하고, 벡터 생체분포 분석을 위해 조직을 수집하였다(도 34a 및 도 34b).
실시예 8: AAVrh91 및 AAV1 캡시드를 비교하는 저온-EM 구조적 데이터
AAVrh91 벡터의 개선된 특성에 대한 기계적 통찰력을 제공하기 위해, 본 발명자들은 저온(cryo)-전자 현미경을 사용하여 2.33 Å 분해능에서 이 벡터의 구조를 해석하였다. 본 발명자들은 본 발명의 구조를 임상 시험에서 가장 널리 사용되는 클레드 A 벡터인 AAV1에 대해 이전에 공개된 구조와 비교하였다. AAVrh91은 11개의 아미노산 위치에서 AAV1과 상이하며, 그 중 6개가 캡시드의 VP3 단백질에 위치하고 표면에 노출된다. 도 35a 내지 도 35f를 참조한다.
결과
AAVrh91의 Asp 418 및 AAV1의 Glu 418은 AAV 캡시드의 내부 표면에 위치한 용매-노출된 잔기이며, 다른 하전된 잔기 Arg 308, Lys 310 및 Glu 686에 아주 근접하다(도 35a). Asp 및 Glu는 둘 다 중성 pH에서 음전하를 띠는 산성 잔기이며, 두 구조에서 유사한 확인을 채택하는 것으로 볼 수 있다. 위치 418 주변의 하전된 잔기에 대한 구조적 변화는 관찰되지 않았다. 전반적으로 Glu 418에서 Asp 418로의 변화는 매우 보수적이며, 캡시드 기능에 무시해도 될 정도의 영향을 미칠 것이다.
AAVrh91의 Asn 547 및 AAV1의 Ser 547은 AAV 캡시드의 외부 표면 상의 HVR VII에 위치한 용매-노출된 잔기이며, 이는 다른 아미노산에 아주 근접하지 않았다(도 35b). 둘 다 중성 pH에서 전하를 띠지 않는 극성 아미노산이지만, 상이한 기능기를 보유한다. Asn은 측쇄에 카르보닐 및 아민 기능기를 포함하고, Ser은 단일 하이드록실기를 포함한다. 캡시드 외부의 용매 노출은 이들 잔기가 세포 수용체와 상호작용할 수 있지만, 현재까지 이 위치의 잔기에 대해 정의된 AAV 구조-기능 관계가 없음을 의미한다. 전반적으로, 이 변화는 또한 보수적이지만, 아미노산 사이의 기능기의 차이는 캡시드 기능에 영향을 미칠 가능성이 있다.
AAVrh91의 Leu 584 및 AAV1의 Phe 584는 AAV 캡시드의 외부 표면 상의 HVR VIII에 위치한 용매-노출된 잔기이며, Arg 485, Arg 488, Lys 528, Glu 531, Phe 534, Thr 574, 및 Glu575에 아주 근접하고, 이는 모두 인접 사슬에 위치한다(도 35c). Leu는 작은 소수성 아미노산이고, Phe는 큰 소수성 아미노산이다. 위치 584에 아주 근접한 잔기는 Phe 534(소수성) 및 Thr 574(극성)를 제외하고, 모두 하전된 아미노산이다. AAVrh91에서 더 작은 Leu 잔기는 AAV1에서 더 큰 Phe보다 이들 근위 하전된 잔기에 덜 파괴적일 수 있다. 이 하전된 포켓에 대한 감소된 파괴는 캡시드 안정성을 증가시키는 기능을 할 수 있다. 이 위치에서 사슬간 접촉의 우세를 고려할 때, 위치 584에서 Phe에서 Leu로의 변화는 AAV1에 비해 AAVrh91에 대해 관찰된 증가된 제조 수율을 부분적으로 설명할 수 있다.
AAVrh91의 Asn 588 및 AAV1의 Ser 588은 AAV의 3중 스파이크 구조 끝에 있는 AAV 캡시드의 외부 표면 상의 HVR VIII에 위치한 용매-노출된 잔기이며, 이는 다른 아미노산에 아주 근접하지 않았다(도 35d). 상기 언급된 바와 같이, 두 잔기는 중성 pH에서 하전되지 않은 극성 아미노산이지만, 캡시드/수용체 상호작용에 영향을 미칠 수 있는 상이한 기능기를 보유한다. 위치 588은 AAV 친화성을 변경하기 위한 단백질 공학 결실에서 펩티드 삽입에 사용되는 일반적인 위치라는 점에서 유의하다. 중요한 위치 및 높은 수준의 용매 노출이 세포 수용체와 상호작용할 가능성을 증가시키기 때문이다. 향상된 노출로 인해, 이 Ser에서 Asn으로의 돌연변이는 위치 547에서 관찰된 동일한 돌연변이보다 캡시드 기능에 더 영향을 미칠 가능성이 높다.
AAVrh91의 Val 598 및 AAV1의 Ala 598은 또한 HVR VIII에 위치하나, 용매에 고도로 노출된 위치에 있지 않다. 대신, 이러한 작은 소수성 잔기는 인접한 잔기 Tyr 484, Val 580, Val 596, Met 599 및 Leu 602와 함께 소수성 포켓의 형성에 참여한다(도 35e). 이들 잔기는 3개의 VP3 단백질이 모이는 AAV의 3중 축 중앙에 위치하며, 인접한 펩티드 사슬과 많은 접촉을 한다. AAV1의 598번 위치에서 발견되는 Ala는 가장 작은 소수성 아미노산인 반면, AAVrh91의 Val 598은 약간 더 크고 더 소수성이다. Val 잔기는 더 작은 Ala 대응물보다 이 소수성 포켓 내의 공간을 더 잘 채우는 것으로 보이며, 이는 캡시드 안정성을 개선시킬 수 있다. 이 소수성 포켓의 중앙 위치와 이의 사슬간 접촉의 수를 고려할 때, 위치 598에서 이 Ala/Val 치환은 AAVrh91를 이용하여 관찰된 제조상의 이점에 대해 가장 가능성 있는 설명이다.
AAVrh91의 His 642 및 AAV1의 Asn 642는 AAV 캡시드의 내부 표면에 위치한 용매-노출된 잔기이며, 이는 극성 잔기 Tyr349 및 Tyr414, 및 하전된 잔기 Glu417 및 Lys641에 근접하다(도 35f). His는 중성 pH에서 양전하를 띠는 염기성 잔기이고, Asn은 중성 pH에서 전하를 띠지 않는 극성 잔기이다. 위치 642에서 Asn/His 치환은 친수성 잔기 주변에서 관찰 가능한 구조적 변화를 유도하지 않는다. 전반적으로, Asn 642에서 His 642로의 변화는 국소 양전하의 증가를 초래하지만, 캡시드 내부의 위치와 주변 캡시드 구조에 대한 최소한의 영향은 이러한 변화가 캡시드 기능을 극적으로 변경시키지 않을 것임을 시사한다.
실시예 9: AAVrh91 벡터 생산 최적화
AAVrh91 벡터 수율을 개선시키기 위해 AAVrh91에 대한 전이 생산 플라스미드를 변경하기 위해 여러 전략을 활용하였다.
한 가지 전략은 코돈 사용 최적화를 포함하여 AAVrh91 캡시드 유전자 서열을 조작하는 것이었다. 생성된 서열(rh91M113, AAVrh91eng, 서열번호 3)은 113개의 뉴클레오티드에서 천연 AAVrh91 암호화 서열과 상이하지만 동일한 아미노산 서열을 암호화한다. 각 버전에 대해, 본 발명자들은 플라스미드를 재-형질전환하고, 12-웰 플레이트에서 개별 삼중-형질감염을 위해 4개의 클론을 무작위로 선발하였다. 벡터 수율은 두 가지 방법으로 결정하였다: 생산 역가의 경우 qPCR(도 36a) 및 감염성 역가의 경우 Huh7 형질도입(도 36b). 본 발명자들은 그 차이가 통계적으로 유의하지 않았지만, rh91M113이 두 측정을 사용한 반복 실험에서 수율을 개선시켰음을 관찰하였다 (p 값 중 어느 것도 0.05 미만이 아님).
두 번째 전략은 전이 플라스미드에 조절 요소를 추가하는 것이었다. 본 발명자들은 우드척 간염 바이러스 전사 후 조절 요소(WPRE) 및 소 성장 호르몬 폴리아데닐화(bGH 폴리A) 신호 중 하나 또는 모두를 포함하는 플라스미드를 생성하였다(도 37a). 벡터 수율은 상기 기술한 방법을 사용하여 평가하였다. 결과는 조절자 요소(WPRE 및 bGH 폴리A, WPRE 단독 및 bGH 폴리A 단독)의 포함이 벡터 수율을 개선시킬 수 있음을 나타낸다(도 37b 및 도 37c).
(서열목록 자유 텍스트)
숫자 식별자 <223> 하에 자유 텍스트를 포함하는 서열에 대해 하기 정보가 제공된다.

본 명세서에 인용된 모든 문헌은 본원에 참조로 포함된다. 2019년 4월 29일자로 출원된 미국 특허 가출원 제62/840,1840호, 2019년 10월 10일자로 출원된 미국 특허 가출원 제62/913,314호, 2019년 10월 21일자로 출원된 미국 특허 가출원 제62/924,095호, 2020년 8월 14일자로 출원된 미국 특허 가출원 제63/065,616호, 2020년 11월 4일자로 출원된 미국 특허 가출원 제63/109,734호, 및 2020년 4월 20일자로 출원된 국제 특허 출원 PCT/US2020/030266호는 서열목록과 함께 전문이 참조로 포함된다. 본원에 "21-9545PCT_ST25"로 표시된 서열목록 및 그 안의 서열 및 텍스트는 참조로 포함된다. 본 발명이 특정 구현예를 참조하여 기술되었지만, 본 발명의 사상을 벗어나지 않으면서 변형이 이루어질 수 있음이 이해될 것이다. 이와 같은 변형은 첨부된 청구범위의 범주 내에 속하는 것으로 의도된다.
SEQUENCE LISTING
<110> The Trustees of the University of Pennsylvania
<120> NOVEL AAV CAPSIDS AND COMPOSITIONS CONTAINING SAME
<130> 21-9545.PCT
<150> US 63/065,616
<151> 2020-08-14
<150> US 63/109,734
<151> 2020-11-04
<160> 14
<170> PatentIn version 3.5
<210> 1
<211> 2211
<212> DNA
<213> adeno-associated virus rh.91
<220>
<221> CDS
<222> (1)..(2211)
<400> 1
atg gct gcc gat ggt tat ctt cca gat tgg ctc gag gac aac ctc tct 48
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
gag ggc att cgc gag tgg tgg gcg ctg aaa cct gga gcc ccg aaa ccc 96
Glu Gly Ile Arg Glu Trp Trp Ala Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
aaa gcc aac cag caa aag cag gac gac ggc cgg ggt ctg gtg ctt cct 144
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
ggc tac aag tac ctc gga ccc ttc aac gga ctc gac aag ggg gag ccc 192
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
gtc aac gcg gcg gac gca gcg gcc ctc gag cac gac aag gcc tac gac 240
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
cag cag ctc aaa gcg ggt gac aat ccg tac ctg cgg tat aac cac gcc 288
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
gac gcc gag ttt cag gag cgt ctg caa gaa gat acg tct ttt ggg ggc 336
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
aac ctc ggg cga gca gtc ttc cag gcc aag aag cgg gtt ctc gaa cct 384
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
ttt ggt ctg gtt gag gaa gca gct aag acg gct cct gga aag aaa cgt 432
Phe Gly Leu Val Glu Glu Ala Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
ccg gta gag cag tcg ccc caa gaa cca gac tcc tcc tcg ggc att ggc 480
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
aaa tca ggc cag cag ccc gcc aaa aag aga ctc aat ttc ggt cag act 528
Lys Ser Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
ggc gac tca gag tca gtc ccc gac cct caa cct ctc gga gaa cct cca 576
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
gaa acc ccc gct gct gtg gga cct act aca atg gct tca ggc ggt ggc 624
Glu Thr Pro Ala Ala Val Gly Pro Thr Thr Met Ala Ser Gly Gly Gly
195 200 205
gca cca atg gca gac aat aac gaa ggc gcc gac gga gtg ggt aat gcc 672
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ala
210 215 220
tca gga aat tgg cat tgc gat tcc aca tgg ctg ggc gac aga gtc atc 720
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
acc acc agc acc cga acc tgg gcc ctt cct acc tac aac aac cac ctc 768
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
tac aag caa atc tcc agc gct tca acg ggg gcc agt aac gac aac cac 816
Tyr Lys Gln Ile Ser Ser Ala Ser Thr Gly Ala Ser Asn Asp Asn His
260 265 270
tac ttt ggc tac agc acc ccc tgg ggg tat ttt gat ttc aac aga ttc 864
Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe
275 280 285
cac tgc cac ttc tca cca cgt gac tgg cag cga ctc att aac aac aac 912
His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn
290 295 300
tgg gga ttc cgg ccc aag aga ctc aac ttc aag ctc ttc aac atc cag 960
Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln
305 310 315 320
gtc aag gag gtc acg acg aat gat ggc gtc aca acc atc gct aat aac 1008
Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn Asn
325 330 335
ctt acc agc acg gtt caa gtg ttc tcg gac tcg gag tac cag ctg ccg 1056
Leu Thr Ser Thr Val Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu Pro
340 345 350
tac gtc ctc ggt tct gcg cac cag ggc tgc ctc cct ccg ttc ccg gcg 1104
Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala
355 360 365
gac gta ttc atg att cct cag tac ggc tac cta acg ctc aac aat ggc 1152
Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly
370 375 380
agc cag gcc gta gga cgt tca tcc ttt tat tgc ctg gaa tat ttc cca 1200
Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro
385 390 395 400
tct caa atg ctg aga acg ggc aac aac ttt acc ttc agc tac acc ttt 1248
Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe
405 410 415
gaa gat gtg cct ttc cac agc agt tac gcg cac agc cag agc ctg gac 1296
Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp
420 425 430
agg cta atg aat cct cta atc gac cag tac ctg tat tac cta aac aga 1344
Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg
435 440 445
act cag aat caa tcc gga agt gca caa aac aag gac ttg ctg ttt agc 1392
Thr Gln Asn Gln Ser Gly Ser Ala Gln Asn Lys Asp Leu Leu Phe Ser
450 455 460
cgg ggg tct cca gct ggc atg tct gtt cag ccc aaa aac tgg cta ccc 1440
Arg Gly Ser Pro Ala Gly Met Ser Val Gln Pro Lys Asn Trp Leu Pro
465 470 475 480
ggg ccc tgt tac cga cag cag cgt gtt tct aaa aca aaa aca gac aac 1488
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Lys Thr Asp Asn
485 490 495
aac aac agc aac ttt acc tgg act ggt gcc tcc aaa tac aat ctg aac 1536
Asn Asn Ser Asn Phe Thr Trp Thr Gly Ala Ser Lys Tyr Asn Leu Asn
500 505 510
gga cgt gaa tcc atc att aac cct ggc acc gct atg gca tcc cac aag 1584
Gly Arg Glu Ser Ile Ile Asn Pro Gly Thr Ala Met Ala Ser His Lys
515 520 525
gac gac gaa gac aaa ttt ttt ccc atg agc ggt gtt atg att ttt ggc 1632
Asp Asp Glu Asp Lys Phe Phe Pro Met Ser Gly Val Met Ile Phe Gly
530 535 540
aaa gaa aat gca gga gca tca aac act gca tta gac aat gtt atg att 1680
Lys Glu Asn Ala Gly Ala Ser Asn Thr Ala Leu Asp Asn Val Met Ile
545 550 555 560
aca gat gaa gag gaa att aaa gct acc aac ccc gtg gcc acc gag aga 1728
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Arg
565 570 575
ttt gga act gtg gca gtc aat ctc caa agc agc aat aca gac cct gca 1776
Phe Gly Thr Val Ala Val Asn Leu Gln Ser Ser Asn Thr Asp Pro Ala
580 585 590
aca gga gac gtg cat gtc atg ggg gct tta cct ggc atg gtg tgg caa 1824
Thr Gly Asp Val His Val Met Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
gac aga gac gtg tac ctg cag ggt ccc att tgg gcc aag att cct cac 1872
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
acg gat gga cac ttt cac ccg tct cct ctt atg ggc ggc ttt gga ctt 1920
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
aag cac ccg cct cct cag atc ctc atc aaa aac acg cct gtt cct gcg 1968
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
aat cct ccg gca gag ttt tcg gct aca aag ttt gct tca ttc atc acc 2016
Asn Pro Pro Ala Glu Phe Ser Ala Thr Lys Phe Ala Ser Phe Ile Thr
660 665 670
cag tac tcc aca gga caa gtg agc gtg gaa att gaa tgg gag ctg cag 2064
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
aaa gaa aac agt aag cgc tgg aat cct gaa gtg cag tac acc tcc aac 2112
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Val Gln Tyr Thr Ser Asn
690 695 700
tac gcg aaa tct gcc aac gtt gat ttc act gtg gac aac aat gga ctt 2160
Tyr Ala Lys Ser Ala Asn Val Asp Phe Thr Val Asp Asn Asn Gly Leu
705 710 715 720
tat act gag cct cgc ccc att ggc acc cgt tac ctt acc cgt ccc ctt 2208
Tyr Thr Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Pro Leu
725 730 735
taa 2211
<210> 2
<211> 736
<212> PRT
<213> adeno-associated virus rh.91
<400> 2
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Ala Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Phe Gly Leu Val Glu Glu Ala Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
Lys Ser Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
Glu Thr Pro Ala Ala Val Gly Pro Thr Thr Met Ala Ser Gly Gly Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ala
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Ala Ser Thr Gly Ala Ser Asn Asp Asn His
260 265 270
Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe
275 280 285
His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn
290 295 300
Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln
305 310 315 320
Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn Asn
325 330 335
Leu Thr Ser Thr Val Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu Pro
340 345 350
Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala
355 360 365
Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly
370 375 380
Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro
385 390 395 400
Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe
405 410 415
Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp
420 425 430
Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg
435 440 445
Thr Gln Asn Gln Ser Gly Ser Ala Gln Asn Lys Asp Leu Leu Phe Ser
450 455 460
Arg Gly Ser Pro Ala Gly Met Ser Val Gln Pro Lys Asn Trp Leu Pro
465 470 475 480
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Lys Thr Asp Asn
485 490 495
Asn Asn Ser Asn Phe Thr Trp Thr Gly Ala Ser Lys Tyr Asn Leu Asn
500 505 510
Gly Arg Glu Ser Ile Ile Asn Pro Gly Thr Ala Met Ala Ser His Lys
515 520 525
Asp Asp Glu Asp Lys Phe Phe Pro Met Ser Gly Val Met Ile Phe Gly
530 535 540
Lys Glu Asn Ala Gly Ala Ser Asn Thr Ala Leu Asp Asn Val Met Ile
545 550 555 560
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Arg
565 570 575
Phe Gly Thr Val Ala Val Asn Leu Gln Ser Ser Asn Thr Asp Pro Ala
580 585 590
Thr Gly Asp Val His Val Met Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
Asn Pro Pro Ala Glu Phe Ser Ala Thr Lys Phe Ala Ser Phe Ile Thr
660 665 670
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Val Gln Tyr Thr Ser Asn
690 695 700
Tyr Ala Lys Ser Ala Asn Val Asp Phe Thr Val Asp Asn Asn Gly Leu
705 710 715 720
Tyr Thr Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Pro Leu
725 730 735
<210> 3
<211> 2211
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic construct
<220>
<221> CDS
<222> (1)..(2211)
<400> 3
atg gct gct gac ggt tat ctt cca gat tgg ctc gag gac aac ctt tct 48
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
gaa ggc att cgt gag tgg tgg gct ctg aaa cct gga gcc cct aaa ccc 96
Glu Gly Ile Arg Glu Trp Trp Ala Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
aaa gcg aac caa caa aag cag gac gac ggc cgg ggt ctt gtg ctt ccg 144
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
ggt tac aaa tac ctc gga ccc ttc aac gga ctc gac aaa gga gag ccg 192
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
gtc aac gcg gcg gac gcg gca gcc ctc gaa cac gac aaa gct tac gac 240
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
cag cag ctc aag gcc ggt gac aac ccg tac ctc cgg tac aac cac gcc 288
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
gac gcc gag ttt cag gag cgt ctt caa gaa gat acg tct ttt ggg ggc 336
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
aac ctt ggc aga gca gtc ttc cag gcc aaa aag agg gtt ctt gag cct 384
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
ttt ggt ctg gtt gag gaa gca gct aaa acg gct cct gga aag aag agg 432
Phe Gly Leu Val Glu Glu Ala Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
cct gta gag cag tct cct cag gaa ccg gac tca tca tct ggt att ggc 480
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
aaa tcg ggc cag cag cct gcc aaa aaa aga cta aat ttc ggt cag act 528
Lys Ser Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
ggc gac tca gag tca gtc ccc gac cct caa cct ctc gga gaa cct cca 576
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
gaa acc ccc gct gct gtg gga cct act aca atg gct tca ggc ggt ggc 624
Glu Thr Pro Ala Ala Val Gly Pro Thr Thr Met Ala Ser Gly Gly Gly
195 200 205
gca cca atg gca gac aat aac gaa ggc gcc gac gga gtg ggt aat gcc 672
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ala
210 215 220
tca gga aat tgg cat tgc gat tcc aca tgg ctg ggc gac aga gtc atc 720
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
acc acc agc acc cga acc tgg gcc ctt cct acc tac aac aac cac ctc 768
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
tac aag caa atc tcc agc gct tca acg ggg gcc agt aac gac aac cac 816
Tyr Lys Gln Ile Ser Ser Ala Ser Thr Gly Ala Ser Asn Asp Asn His
260 265 270
tac ttt ggc tac agc acc ccc tgg ggg tat ttt gat ttc aac aga ttc 864
Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe
275 280 285
cac tgc cac ttc tca cca cgt gac tgg cag cga ctc att aac aac aac 912
His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn
290 295 300
tgg gga ttc cgg ccc aag aga ctc aac ttc aag ctc ttc aac atc cag 960
Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln
305 310 315 320
gtc aag gag gtc acg acg aat gat ggc gtc aca acc atc gct aat aac 1008
Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn Asn
325 330 335
ctt acc agc acg gtt caa gtg ttc tcg gac tcg gag tac cag ctg ccg 1056
Leu Thr Ser Thr Val Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu Pro
340 345 350
tac gtc ctc ggt tct gcg cac cag ggc tgc ctc cct ccg ttc ccg gcg 1104
Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala
355 360 365
gac gta ttc atg att cct cag tat gga tac ctc acc ctg aac aac gga 1152
Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly
370 375 380
agt caa gcg gtg gga cgc tca tcc ttt tac tgc ctg gag tac ttc cct 1200
Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro
385 390 395 400
tcg cag atg cta agg act gga aat aac ttc acc ttc agc tat acc ttc 1248
Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe
405 410 415
gag gat gta cct ttt cac agc agc tac gct cac agc cag agt ttg gat 1296
Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp
420 425 430
cgc ttg atg aat cct ctt att gat cag tat ctg tac tac ctg aac aga 1344
Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg
435 440 445
acg caa aat caa tct gga agt gca caa aac aag gac ctg ctt ttt agc 1392
Thr Gln Asn Gln Ser Gly Ser Ala Gln Asn Lys Asp Leu Leu Phe Ser
450 455 460
cgg ggg tct cct gct ggc atg tct gtt cag ccc aaa aat tgg cta cct 1440
Arg Gly Ser Pro Ala Gly Met Ser Val Gln Pro Lys Asn Trp Leu Pro
465 470 475 480
ggg ccc tgc tac cgg caa cag aga gtt tca aag act aaa aca gac aac 1488
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Lys Thr Asp Asn
485 490 495
aac aac agt aac ttt acc tgg aca ggt gcc agc aaa tat aat ctc aat 1536
Asn Asn Ser Asn Phe Thr Trp Thr Gly Ala Ser Lys Tyr Asn Leu Asn
500 505 510
ggc cgc gaa tcg atc att aat cca gga acc gct atg gcc agt cac aag 1584
Gly Arg Glu Ser Ile Ile Asn Pro Gly Thr Ala Met Ala Ser His Lys
515 520 525
gac gat gaa gac aaa ttt ttc cct atg agc ggc gtt atg ata ttt ggc 1632
Asp Asp Glu Asp Lys Phe Phe Pro Met Ser Gly Val Met Ile Phe Gly
530 535 540
aaa gaa aat gca gga gca agt aac act gca tta gat aat gta atg att 1680
Lys Glu Asn Ala Gly Ala Ser Asn Thr Ala Leu Asp Asn Val Met Ile
545 550 555 560
acg gat gaa gaa gag att aaa gct acc aat cct gtg gca aca gag aga 1728
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Arg
565 570 575
ttt gga act gtg gca gtc aac ttg cag agc tca aat aca gac ccc gca 1776
Phe Gly Thr Val Ala Val Asn Leu Gln Ser Ser Asn Thr Asp Pro Ala
580 585 590
act gga gac gtc cat gtc atg ggg gcc tta cct ggc atg gtg tgg caa 1824
Thr Gly Asp Val His Val Met Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
gat cgt gac gtg tac ctt caa gga cct atc tgg gca aag att cct cac 1872
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
acg gat gga cac ttt cat cct tct cct ctg atg gga ggc ttt gga ctg 1920
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
aaa cat ccg cct cct caa atc ctc atc aaa aat act ccg gta ccg gca 1968
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
aat cct ccg gca gag ttc agc gct aca aag ttt gct tca ttt atc act 2016
Asn Pro Pro Ala Glu Phe Ser Ala Thr Lys Phe Ala Ser Phe Ile Thr
660 665 670
cag tac tcc act gga cag gtc agc gtg gaa att gag tgg gag cta cag 2064
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
aaa gaa aac agc aaa cgt tgg aat cca gag gtg cag tac act tcc aac 2112
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Val Gln Tyr Thr Ser Asn
690 695 700
tac gcg aag tct gcc aat gtg gac ttt act gta gac aac aat ggt ctt 2160
Tyr Ala Lys Ser Ala Asn Val Asp Phe Thr Val Asp Asn Asn Gly Leu
705 710 715 720
tat act gaa cct cgc cct att gga acc cgg tat ctc aca cga ccc ttg 2208
Tyr Thr Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Pro Leu
725 730 735
taa 2211
<210> 4
<211> 736
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 4
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Ala Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Phe Gly Leu Val Glu Glu Ala Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
Lys Ser Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
Glu Thr Pro Ala Ala Val Gly Pro Thr Thr Met Ala Ser Gly Gly Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ala
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Ala Ser Thr Gly Ala Ser Asn Asp Asn His
260 265 270
Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe
275 280 285
His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn
290 295 300
Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln
305 310 315 320
Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn Asn
325 330 335
Leu Thr Ser Thr Val Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu Pro
340 345 350
Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala
355 360 365
Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly
370 375 380
Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro
385 390 395 400
Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe
405 410 415
Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp
420 425 430
Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg
435 440 445
Thr Gln Asn Gln Ser Gly Ser Ala Gln Asn Lys Asp Leu Leu Phe Ser
450 455 460
Arg Gly Ser Pro Ala Gly Met Ser Val Gln Pro Lys Asn Trp Leu Pro
465 470 475 480
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Lys Thr Asp Asn
485 490 495
Asn Asn Ser Asn Phe Thr Trp Thr Gly Ala Ser Lys Tyr Asn Leu Asn
500 505 510
Gly Arg Glu Ser Ile Ile Asn Pro Gly Thr Ala Met Ala Ser His Lys
515 520 525
Asp Asp Glu Asp Lys Phe Phe Pro Met Ser Gly Val Met Ile Phe Gly
530 535 540
Lys Glu Asn Ala Gly Ala Ser Asn Thr Ala Leu Asp Asn Val Met Ile
545 550 555 560
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Arg
565 570 575
Phe Gly Thr Val Ala Val Asn Leu Gln Ser Ser Asn Thr Asp Pro Ala
580 585 590
Thr Gly Asp Val His Val Met Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
Asn Pro Pro Ala Glu Phe Ser Ala Thr Lys Phe Ala Ser Phe Ile Thr
660 665 670
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Val Gln Tyr Thr Ser Asn
690 695 700
Tyr Ala Lys Ser Ala Asn Val Asp Phe Thr Val Asp Asn Asn Gly Leu
705 710 715 720
Tyr Thr Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Pro Leu
725 730 735
<210> 5
<211> 2211
<212> DNA
<213> Artificial Sequence
<220>
<223> AAV6 mutant
<220>
<221> CDS
<222> (1)..(2211)
<400> 5
atg gct gcc gat ggt tat ctt cca gat tgg ctc gag gac aac ctc tct 48
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
gag ggc att cgc gag tgg tgg gac ttg aaa cct gga gcc ccg aaa ccc 96
Glu Gly Ile Arg Glu Trp Trp Asp Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
aaa gcc aac cag caa aag cag gac gac ggc cgg ggt ctg gtg ctt cct 144
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
ggc tac aag tac ctc gga ccc ttc aac gga ctc gac aag ggg gag ccc 192
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
gtc aac gcg gcg gat gca gcg gcc ctc gag cac gac aag gcc tac gac 240
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
cag cag ctc aaa gcg ggt gac aat ccg tac ctg cgg tat aac cac gcc 288
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
gac gcc gag ttt cag gag cgt ctg caa gaa gat acg tct ttt ggg ggc 336
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
aac ctc ggg cga gca gtc ttc cag gcc aag aag agg gtt ctc gaa cct 384
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
ctt ggt ctg gtt gag gaa ggt gct aag acg gct cct gga aag aaa cgt 432
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
ccg gta gag cag tcg cca caa gag cca gac tcc tcc tcg ggc att ggc 480
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
aag aca ggc cag cag ccc gct aaa aag aga ctc aat ttt ggt cag act 528
Lys Thr Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
ggc gac tca gag tca gtc ccc gac cca caa cct ctc gga gaa cct cca 576
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
gca acc ccc gct gct gtg gga cct act aca atg gct tca ggc ggt ggc 624
Ala Thr Pro Ala Ala Val Gly Pro Thr Thr Met Ala Ser Gly Gly Gly
195 200 205
gca cca atg gca gac aat aac gaa ggc gcc gac gga gtg ggt aat gcc 672
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ala
210 215 220
tca gga aat tgg cat tgc gat tcc aca tgg ctg ggc gac aga gtc atc 720
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
acc acc agc acc cga aca tgg gcc ttg ccc acc tat aac aac cac ctc 768
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
tac aag caa atc tcc agt gct tca acg ggg gcc agc aac gac aac cac 816
Tyr Lys Gln Ile Ser Ser Ala Ser Thr Gly Ala Ser Asn Asp Asn His
260 265 270
tac ttc ggc tac agc acc ccc tgg ggg tat ttt gat ttc aac aga ttc 864
Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe
275 280 285
cac tgc cat ttc tca cca cgt gac tgg cag cga ctc atc aac aac aat 912
His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn
290 295 300
tgg gga ttc cgg ccc aag aga ctc aac ttc aag ctc ttc aac atc caa 960
Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln
305 310 315 320
gtc aag gag gtc acg acg aat gat ggc gtc acg acc atc gct aat aac 1008
Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn Asn
325 330 335
ctt acc agc acg gtt caa gtc ttc tcg gac tcg gag tac cag ttg ccg 1056
Leu Thr Ser Thr Val Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu Pro
340 345 350
tac gtc ctc ggc tct gcg cac cag ggc tgc ctc cct ccg ttc ccg gcg 1104
Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala
355 360 365
gac gtg ttc atg att ccg cag tac ggc tac cta acg ctc aac aat ggc 1152
Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly
370 375 380
agc cag gca gtg gga cgg tca tcc ttt tac tgc ctg gaa tat ttc cca 1200
Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro
385 390 395 400
tcg cag atg ctg aga acg ggc aat aac ttt acc ttc agc tac acc ttc 1248
Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe
405 410 415
gag gac gtg cct ttc cac agc agc tac gcg cac agc cag agc ctg gac 1296
Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp
420 425 430
cgg ctg atg aat cct ctc atc gac cag tac ctg tat tac ctg aac aga 1344
Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg
435 440 445
act cag aat cag tcc gga agt gcc caa aac aag gac ttg ctg ttt agc 1392
Thr Gln Asn Gln Ser Gly Ser Ala Gln Asn Lys Asp Leu Leu Phe Ser
450 455 460
cgg ggg tct cca gct ggc atg tct gtt cag ccc aaa aac tgg cta cct 1440
Arg Gly Ser Pro Ala Gly Met Ser Val Gln Pro Lys Asn Trp Leu Pro
465 470 475 480
gga ccc tgt tac cgg cag cag cgc gtt tct aaa aca aaa aca gac aac 1488
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Lys Thr Asp Asn
485 490 495
aac aac agc aac ttt acc tgg act ggt gct tca aaa tat aac ctt aat 1536
Asn Asn Ser Asn Phe Thr Trp Thr Gly Ala Ser Lys Tyr Asn Leu Asn
500 505 510
ggg cgt gaa tct ata atc aac cct ggc act gct atg gcc tca cac aaa 1584
Gly Arg Glu Ser Ile Ile Asn Pro Gly Thr Ala Met Ala Ser His Lys
515 520 525
gac gac aaa gac aag ttc ttt ccc atg agc ggt gtc atg att ttt gga 1632
Asp Asp Lys Asp Lys Phe Phe Pro Met Ser Gly Val Met Ile Phe Gly
530 535 540
aag gag agc gcc gga gct tca aac act gca ttg gac aat gtc atg atc 1680
Lys Glu Ser Ala Gly Ala Ser Asn Thr Ala Leu Asp Asn Val Met Ile
545 550 555 560
aca gac gaa gag gaa atc aaa gcc act aac ccc gtg gcc acc gaa aga 1728
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Arg
565 570 575
ttt ggg act gtg gca gtc aat ctc cag agc agc agc aca gac cct gcg 1776
Phe Gly Thr Val Ala Val Asn Leu Gln Ser Ser Ser Thr Asp Pro Ala
580 585 590
acc gga gat gtg cat gtt atg gga gcc tta cct gga atg gtg tgg caa 1824
Thr Gly Asp Val His Val Met Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
gac aga gac gta tac ctg cag ggt cct att tgg gcc aaa att cct cac 1872
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
acg gat gga cac ttt cac ccg tct cct ctc atg ggc ggc ttt gga ctt 1920
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
aag cac ccg cct cct cag atc ctc atc aaa aac acg cct gtt cct gcg 1968
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
aat cct ccg gca gag ttt tcg gct aca aag ttt gct tca ttc atc acc 2016
Asn Pro Pro Ala Glu Phe Ser Ala Thr Lys Phe Ala Ser Phe Ile Thr
660 665 670
cag tat tcc aca gga caa gtg agc gtg gag att gaa tgg gag ctg cag 2064
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
aaa gaa aac agc aaa cgc tgg aat ccc gaa gtg cag tat aca tct aac 2112
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Val Gln Tyr Thr Ser Asn
690 695 700
tat gca aaa tct gcc aac gtt gat ttc act gtg gac aac aat gga ctt 2160
Tyr Ala Lys Ser Ala Asn Val Asp Phe Thr Val Asp Asn Asn Gly Leu
705 710 715 720
tat act gag cct cgc ccc att ggc acc cgt tac ctc acc cgt ccc ctg 2208
Tyr Thr Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Pro Leu
725 730 735
taa 2211
<210> 6
<211> 736
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 6
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Asp Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
Lys Thr Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
Ala Thr Pro Ala Ala Val Gly Pro Thr Thr Met Ala Ser Gly Gly Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ala
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Ala Ser Thr Gly Ala Ser Asn Asp Asn His
260 265 270
Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe
275 280 285
His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn
290 295 300
Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln
305 310 315 320
Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn Asn
325 330 335
Leu Thr Ser Thr Val Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu Pro
340 345 350
Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala
355 360 365
Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly
370 375 380
Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro
385 390 395 400
Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe
405 410 415
Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp
420 425 430
Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg
435 440 445
Thr Gln Asn Gln Ser Gly Ser Ala Gln Asn Lys Asp Leu Leu Phe Ser
450 455 460
Arg Gly Ser Pro Ala Gly Met Ser Val Gln Pro Lys Asn Trp Leu Pro
465 470 475 480
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Lys Thr Asp Asn
485 490 495
Asn Asn Ser Asn Phe Thr Trp Thr Gly Ala Ser Lys Tyr Asn Leu Asn
500 505 510
Gly Arg Glu Ser Ile Ile Asn Pro Gly Thr Ala Met Ala Ser His Lys
515 520 525
Asp Asp Lys Asp Lys Phe Phe Pro Met Ser Gly Val Met Ile Phe Gly
530 535 540
Lys Glu Ser Ala Gly Ala Ser Asn Thr Ala Leu Asp Asn Val Met Ile
545 550 555 560
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Arg
565 570 575
Phe Gly Thr Val Ala Val Asn Leu Gln Ser Ser Ser Thr Asp Pro Ala
580 585 590
Thr Gly Asp Val His Val Met Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
Asn Pro Pro Ala Glu Phe Ser Ala Thr Lys Phe Ala Ser Phe Ile Thr
660 665 670
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Val Gln Tyr Thr Ser Asn
690 695 700
Tyr Ala Lys Ser Ala Asn Val Asp Phe Thr Val Asp Asn Asn Gly Leu
705 710 715 720
Tyr Thr Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Pro Leu
725 730 735
<210> 7
<211> 2211
<212> DNA
<213> adeno-associated virus 1
<220>
<221> CDS
<222> (1)..(2211)
<400> 7
atg gct gcc gat ggt tat ctt cca gat tgg ctc gag gac aac ctc tct 48
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
gag ggc att cgc gag tgg tgg gac ttg aaa cct gga gcc ccg aag ccc 96
Glu Gly Ile Arg Glu Trp Trp Asp Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
aaa gcc aac cag caa aag cag gac gac ggc cgg ggt ctg gtg ctt cct 144
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
ggc tac aag tac ctc gga ccc ttc aac gga ctc gac aag ggg gag ccc 192
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
gtc aac gcg gcg gac gca gcg gcc ctc gag cac gac aag gcc tac gac 240
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
cag cag ctc aaa gcg ggt gac aat ccg tac ctg cgg tat aac cac gcc 288
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
gac gcc gag ttt cag gag cgt ctg caa gaa gat acg tct ttt ggg ggc 336
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
aac ctc ggg cga gca gtc ttc cag gcc aag aag cgg gtt ctc gaa cct 384
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
ctc ggt ctg gtt gag gaa ggc gct aag acg gct cct gga aag aaa cgt 432
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
ccg gta gag cag tcg cca caa gag cca gac tcc tcc tcg ggc atc ggc 480
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
aag aca ggc cag cag ccc gct aaa aag aga ctc aat ttt ggt cag act 528
Lys Thr Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
ggc gac tca gag tca gtc ccc gat cca caa cct ctc gga gaa cct cca 576
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
gca acc ccc gct gct gtg gga cct act aca atg gct tca ggc ggt ggc 624
Ala Thr Pro Ala Ala Val Gly Pro Thr Thr Met Ala Ser Gly Gly Gly
195 200 205
gca cca atg gca gac aat aac gaa ggc gcc gac gga gtg ggt aat gcc 672
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ala
210 215 220
tca gga aat tgg cat tgc gat tcc aca tgg ctg ggc gac aga gtc atc 720
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
acc acc agc acc cgc acc tgg gcc ttg ccc acc tac aat aac cac ctc 768
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
tac aag caa atc tcc agt gct tca acg ggg gcc agc aac gac aac cac 816
Tyr Lys Gln Ile Ser Ser Ala Ser Thr Gly Ala Ser Asn Asp Asn His
260 265 270
tac ttc ggc tac agc acc ccc tgg ggg tat ttt gat ttc aac aga ttc 864
Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe
275 280 285
cac tgc cac ttt tca cca cgt gac tgg cag cga ctc atc aac aac aat 912
His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn
290 295 300
tgg gga ttc cgg ccc aag aga ctc aac ttc aaa ctc ttc aac atc caa 960
Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln
305 310 315 320
gtc aag gag gtc acg acg aat gat ggc gtc aca acc atc gct aat aac 1008
Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn Asn
325 330 335
ctt acc agc acg gtt caa gtc ttc tcg gac tcg gag tac cag ctt ccg 1056
Leu Thr Ser Thr Val Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu Pro
340 345 350
tac gtc ctc ggc tct gcg cac cag ggc tgc ctc cct ccg ttc ccg gcg 1104
Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala
355 360 365
gac gtg ttc atg att ccg caa tac ggc tac ctg acg ctc aac aat ggc 1152
Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly
370 375 380
agc caa gcc gtg gga cgt tca tcc ttt tac tgc ctg gaa tat ttc cct 1200
Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro
385 390 395 400
tct cag atg ctg aga acg ggc aac aac ttt acc ttc agc tac acc ttt 1248
Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe
405 410 415
gag gaa gtg cct ttc cac agc agc tac gcg cac agc cag agc ctg gac 1296
Glu Glu Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp
420 425 430
cgg ctg atg aat cct ctc atc gac caa tac ctg tat tac ctg aac aga 1344
Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg
435 440 445
act caa aat cag tcc gga agt gcc caa aac aag gac ttg ctg ttt agc 1392
Thr Gln Asn Gln Ser Gly Ser Ala Gln Asn Lys Asp Leu Leu Phe Ser
450 455 460
cgt ggg tct cca gct ggc atg tct gtt cag ccc aaa aac tgg cta cct 1440
Arg Gly Ser Pro Ala Gly Met Ser Val Gln Pro Lys Asn Trp Leu Pro
465 470 475 480
gga ccc tgt tat cgg cag cag cgc gtt tct aaa aca aaa aca gac aac 1488
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Lys Thr Asp Asn
485 490 495
aac aac agc aat ttt acc tgg act ggt gct tca aaa tat aac ctc aat 1536
Asn Asn Ser Asn Phe Thr Trp Thr Gly Ala Ser Lys Tyr Asn Leu Asn
500 505 510
ggg cgt gaa tcc atc atc aac cct ggc act gct atg gcc tca cac aaa 1584
Gly Arg Glu Ser Ile Ile Asn Pro Gly Thr Ala Met Ala Ser His Lys
515 520 525
gac gac gaa gac aag ttc ttt ccc atg agc ggt gtc atg att ttt gga 1632
Asp Asp Glu Asp Lys Phe Phe Pro Met Ser Gly Val Met Ile Phe Gly
530 535 540
aaa gag agc gcc gga gct tca aac act gca ttg gac aat gtc atg att 1680
Lys Glu Ser Ala Gly Ala Ser Asn Thr Ala Leu Asp Asn Val Met Ile
545 550 555 560
aca gac gaa gag gaa att aaa gcc act aac cct gtg gcc acc gaa aga 1728
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Arg
565 570 575
ttt ggg acc gtg gca gtc aat ttc cag agc agc agc aca gac cct gcg 1776
Phe Gly Thr Val Ala Val Asn Phe Gln Ser Ser Ser Thr Asp Pro Ala
580 585 590
acc gga gat gtg cat gct atg gga gca tta cct ggc atg gtg tgg caa 1824
Thr Gly Asp Val His Ala Met Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
gat aga gac gtg tac ctg cag ggt ccc att tgg gcc aaa att cct cac 1872
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
aca gat gga cac ttt cac ccg tct cct ctt atg ggc ggc ttt gga ctc 1920
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
aag aac ccg cct cct cag atc ctc atc aaa aac acg cct gtt cct gcg 1968
Lys Asn Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
aat cct ccg gcg gag ttt tca gct aca aag ttt gct tca ttc atc acc 2016
Asn Pro Pro Ala Glu Phe Ser Ala Thr Lys Phe Ala Ser Phe Ile Thr
660 665 670
caa tac tcc aca gga caa gtg agt gtg gaa att gaa tgg gag ctg cag 2064
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
aaa gaa aac agc aag cgc tgg aat ccc gaa gtg cag tac aca tcc aat 2112
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Val Gln Tyr Thr Ser Asn
690 695 700
tat gca aaa tct gcc aac gtt gat ttt act gtg gac aac aat gga ctt 2160
Tyr Ala Lys Ser Ala Asn Val Asp Phe Thr Val Asp Asn Asn Gly Leu
705 710 715 720
tat act gag cct cgc ccc att ggc acc cgt tac ctt acc cgt ccc ctg 2208
Tyr Thr Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Pro Leu
725 730 735
taa 2211
<210> 8
<211> 736
<212> PRT
<213> adeno-associated virus 1
<400> 8
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Asp Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
Lys Thr Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
Ala Thr Pro Ala Ala Val Gly Pro Thr Thr Met Ala Ser Gly Gly Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ala
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Ala Ser Thr Gly Ala Ser Asn Asp Asn His
260 265 270
Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe
275 280 285
His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn
290 295 300
Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln
305 310 315 320
Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn Asn
325 330 335
Leu Thr Ser Thr Val Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu Pro
340 345 350
Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala
355 360 365
Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly
370 375 380
Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro
385 390 395 400
Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe
405 410 415
Glu Glu Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp
420 425 430
Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg
435 440 445
Thr Gln Asn Gln Ser Gly Ser Ala Gln Asn Lys Asp Leu Leu Phe Ser
450 455 460
Arg Gly Ser Pro Ala Gly Met Ser Val Gln Pro Lys Asn Trp Leu Pro
465 470 475 480
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Lys Thr Asp Asn
485 490 495
Asn Asn Ser Asn Phe Thr Trp Thr Gly Ala Ser Lys Tyr Asn Leu Asn
500 505 510
Gly Arg Glu Ser Ile Ile Asn Pro Gly Thr Ala Met Ala Ser His Lys
515 520 525
Asp Asp Glu Asp Lys Phe Phe Pro Met Ser Gly Val Met Ile Phe Gly
530 535 540
Lys Glu Ser Ala Gly Ala Ser Asn Thr Ala Leu Asp Asn Val Met Ile
545 550 555 560
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Arg
565 570 575
Phe Gly Thr Val Ala Val Asn Phe Gln Ser Ser Ser Thr Asp Pro Ala
580 585 590
Thr Gly Asp Val His Ala Met Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
Lys Asn Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
Asn Pro Pro Ala Glu Phe Ser Ala Thr Lys Phe Ala Ser Phe Ile Thr
660 665 670
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Val Gln Tyr Thr Ser Asn
690 695 700
Tyr Ala Lys Ser Ala Asn Val Asp Phe Thr Val Asp Asn Asn Gly Leu
705 710 715 720
Tyr Thr Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Pro Leu
725 730 735
<210> 9
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<223> primer sequence
<400> 9
gctgcgtcaa ctggaccaat gagaac 26
<210> 10
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<223> primer sequence
<400> 10
cgcagagacc aaagttcaac tgaaacga 28
<210> 11
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> primer sequence
<400> 11
ggcgaacagc ggacaccgat atgaa 25
<210> 12
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> primer sequence
<400> 12
ggctctcgtc gcgtgagaat gagaa 25
<210> 13
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> miRNA target sequence
<400> 13
agtgaattct accagtgcca ta 22
<210> 14
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> miRNA target sequence
<400> 14
agtgtgagtt ctaccattgc caaa 24
Claims (41)
- 대상체의 중추신경계(CNS)의 하나 이상의 표적 세포에 전이유전자를 전달하는 방법으로서, 상기 방법은 AAVrh91 캡시드 및 CNS의 표적 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함하는 재조합 아데노-연관 바이러스 (AAV) 벡터를 대상체에게 투여하는 단계를 포함하는 방법.
- 제1항에 있어서, 상기 CNS의 표적 세포는 실질 세포, 맥락막총의 세포, 뇌실막 세포, 성상교세포, 및/또는 및 뉴런, 선택적으로 피질, 해마, 및/또는 선조체의 뉴런인, 방법.
- 제1항 또는 제2항에 있어서, 상기 전이유전자는 분비된 유전자 산물을 암호화하는 것인, 방법.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 상기 AAV 벡터는 선택적으로 대조내(intra-cisterna magna, ICM) 주사를 통해 척수강내로 전달되는 것인, 방법.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 상기 AAV 벡터는 뇌실질내 투여를 통해 전달되는 것인, 방법.
- 전이유전자를 포함하는 AAV 벡터의 척수강내 투여 후 대상체의 간으로 전이유전자의 전달을 개선하는 방법으로서, 상기 방법은 AAVrh91 캡시드 및 간의 표적 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함하는 재조합 AAV 벡터를 ICM 주사를 통해 대상체에게 투여하는 단계를 포함하며, 상기 간의 형질도입 수준은 AAV1, AAV9, 및/또는 AAV6.2 캡시드를 갖는 AAV 벡터로 달성되는 수준에 비해 증가되는 것인, 방법.
- 대상체에게 AAV 벡터를 전신 투여한 후 간을 탈표적화하고/하거나 간 독성을 감소시키는 방법으로서, 상기 방법은 AAVrh91 캡시드 및 간의 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함하는 재조합 AAV 벡터를 정맥내 주사를 통해 대상체에게 투여하는 단계를 포함하며, 상기 AAV 벡터의 투여 후 관찰되는 간의 형질도입 수준 및/또는 간 독성은 AAV1, AAV8, 및/또는 AAV9 캡시드를 갖는 AAV 벡터에 비해 감소되는 것인, 방법.
- 제1항 내지 제7항 중 어느 한 항에 있어서, 상기 AAVrh91 캡시드는 서열번호 2의 아미노산 서열을 포함하는 캡시드 단백질을 포함하는 것인, 방법.
- 제1항 내지 제8항 중 어느 한 항에 있어서, 상기 AAVrh91 캡시드는 서열번호 1 또는 3의 뉴클레오티드 서열, 또는 서열번호 1 또는 3의 뉴클레오티드 서열을 적어도 90%, 적어도 95%, 적어도 97%, 적어도 98% 또는 적어도 99% 공유하는 서열의 발현에 의해 생성되는 캡시드 단백질을 포함하는 것인, 방법.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 AAVrh91 캡시드는 캡시드 단백질을 포함하며, 상기 캡시드 단백질은 서열번호 1 또는 3의 뉴클레오티드 서열에 의해 암호화되는 것인, 방법.
- 제1항 내지 제10항 중 어느 한 항에 있어서, 상기 AAVrh91 캡시드는,
(1) 서열번호 2의 1 내지 736번의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp1 단백질, 서열번호 1 또는 3으로부터 생성되는 vp1 단백질, 또는 서열번호 2의 1 내지 736번의 예상되는 아미노산 서열을 암호화하는 서열번호 1 또는 3과 적어도 70% 동일한 핵산 서열로부터 생성되는 vp1 단백질로부터 선택되는 AAVrh91 vp1 단백질의 이종 집단,
서열번호 2의 적어도 약 138 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp2 단백질, 서열번호 1 또는 3의 적어도 412 내지 2208번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp2 단백질, 또는 서열번호 2의 적어도 약 138 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 서열번호 1 또는 3의 적어도 412 내지 2208번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp2 단백질로부터 선택되는 AAVrh91 vp2 단백질의 이종 집단,
서열번호 2의 적어도 약 203 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp3 단백질, 서열번호 1 또는 3의 적어도 607 내지 2208번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp3 단백질, 또는 서열번호 2의 적어도 약 203 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 서열번호 1 또는 3의 적어도 607 내지 2208번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp3 단백질로부터 선택되는 AAVrh91 vp3 단백질의 이종 집단; 및/또는
(2) 서열번호 2의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp1 단백질의 이종 집단, 서열번호 2의 적어도 약 138 내지 736번 아미노산의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp2 단백질의 이종 집단, 및 서열번호 2의 적어도 203 내지 736번 아미노산을 암호화하는 핵산 서열의 산물인 vp3 단백질의 이종 집단으로서, 상기 vp1, vp2 및 vp3 단백질은 서열번호 2의 아스파라긴-글리신 쌍에서 적어도 2개의 고도로 탈아미드화된 아스파라긴(N)을 포함하고 선택적으로 다른 탈아미드화된 아미노산을 포함하는 하위집단을 더 포함하는 아미노산 변형을 갖는 하위집단을 함유하고, 상기 탈아미드화는 아미노산 변화를 초래하는, vp1 단백질의 이종 집단, vp2 단백질의 이종 집단 및 vp3 단백질의 이종 집단
을 포함하는 캡시드 단백질을 포함하는 것인, 방법. - 제11항에 있어서, 상기 캡시드 단백질을 암호화하는 핵산 서열은 서열번호 1 또는 3, 또는 서열번호 2의 아미노산 서열을 암호화하는 서열번호 1 또는 3과 적어도 80% 내지 적어도 99% 동일한 서열인, 방법.
- 제11항 또는 제12항에 있어서, 상기 핵산 서열은 서열번호 1 또는 3과 적어도 80% 동일한 것인, 방법.
- 재조합 AAV를 생성하는 데 유용한 재조합 AAV 생산 시스템으로서, 상기 생산 시스템은,
(a) 위치 418, 547, 584, 588, 598, 및/또는 642번 중 하나 이상에서 아미노산 치환을 갖는 AAV 캡시드 단백질을 암호화하는 뉴클레오티드 서열(서열번호 2와 정렬되는 경우);
(b) AAV 캡시드 내로 패키징하기에 적합한 핵산 분자로서, 상기 핵산 분자는 적어도 하나의 AAV 반전 말단 반복부(ITR) 및 숙주 세포에서 산물의 발현을 지시하는 서열에 작동가능하게 연결된 유전자 산물을 암호화하는 비-AAV 핵산 서열을 포함하는, 핵산 분자; 및
(c) AAV 캡시드 내로 핵산 분자의 패키징을 허용하기에 충분한 AAV rep 기능 및 헬퍼 기능
을 포함하는, 시스템. - 제15항에 있어서, 상기 (a)의 뉴클레오티드 서열은 나열된 위치 중 하나 이상에서 치환을 갖는 클레드 A 캡시드 단백질을 암호화하는 것인, 시스템.
- 제14항 또는 제15항에 있어서, 상기 (a)의 뉴클레오티드 서열은 나열된 위치 중 하나 이상에서 아미노산 치환을 갖는 AAV1, AAVhu48R3, AAVhu48, AAVhu44, AAV.VR-355, AAV.VR-195, AAV6, 또는 AAV6.2 캡시드 단백질을 암호화하는 것인, 시스템.
- 제14항 내지 제16항 중 어느 한 항에 있어서, 상기 (a)의 뉴클레오티드 서열은 418번 위치에서의 Asp, 547번 위치에서의 Asn, 584번 위치에서의 Leu, 588번 위치에서의 Asn, 598번 위치에서의 Val, 및 642번 위치에서의 His로부터 선택되는 하나 이상의 아미노 치환을 갖는 캡시드 단백질의 아미노산 서열을 암호화하는 것인, 시스템.
- 제14항 내지 제16항 중 어느 한 항에 있어서, 상기 (a)의 뉴클레오티드 서열은 Glu418, Ser547, Phe584, Ser588, Ala598, 및/또는 Asn642에서 아미노산 치환을 갖는 서열번호 8(AAV1)의 아미노산 서열을 암호화하고, 상기 암호화된 아미노산 서열은 서열번호 8과 적어도 95% 동일하거나 적어도 99% 동일한 것인, 시스템.
- 제14항 내지 제16항 중 어느 한 항에 있어서, 상기 (a)의 뉴클레오티드 서열은 418번 위치에서의 Asp, 547번 위치에서의 Asn, 584번 위치에서의 Leu, 588번 위치에서의 Asn, 598번 위치에서의 Val, 및 642번 위치에서의 His로부터 선택되는 하나 이상의 아미노 치환을 갖는 서열번호 8(AAV1)의 아미노산 서열을 암호화하고, 상기 암호화된 아미노산 서열은 서열번호 8과 적어도 95% 동일하거나 적어도 99% 동일한 것인, 시스템.
- 제14항 내지 제19항 중 어느 한 항에 있어서, 상기 생산 시스템은 인간 배아 신장 293 세포를 포함하는 것인, 시스템.
- 재조합 AAV를 생성하는 방법으로서, (a) 위치 418, 547, 584, 588, 598, 및 642번 중 하나 이상에서 아미노산 치환을 갖는 AAV 캡시드 단백질을 암호화하는 핵산 분자(서열번호 2와 정렬되는 경우); (b) 기능성 rep 유전자; (c) AAV 5' ITR, AAV 3' ITR, 및 전이유전자를 포함하는 미니유전자; 및 (d) AAV 캡시드 내로 미니유전자의 패키징을 허용하기에 충분한 헬퍼 기능을 함유하는 숙주 세포를 배양하는 단계를 포함하는, 방법.
- 제21항에 있어서, 상기 생성된 재조합 AAV는 비변형 캡시드 단백질에 비해 개선된 생산 수율 및/또는 변경된 세포 또는 조직 친화성을 갖는 것인, 방법.
- 제21항 또는 제22항에 있어서, 상기 생성된 재조합 AAV는 비변형 캡시드 단백질에 비해 더 높은 수준으로 CNS의 세포를 형질도입하는 것인, 방법.
- 제21항 내지 제23항 중 어느 한 항에 있어서, 상기 (a)의 뉴클레오티드 서열은 나열된 위치 중 하나 이상에서 치환을 갖는 클레드 A 캡시드 단백질을 암호화하는 것인, 방법.
- 제21항 내지 제24항 중 어느 한 항에 있어서, 상기 (a)의 뉴클레오티드 서열은 나열된 치환 중 하나 이상을 갖는 AAV1, AAVhu48R3, AAVhu48, AAVhu44, AAV.VR-355, AAV.VR-195, AAV6, 또는 AAV6.2 캡시드를 암호화하는 것인, 방법.
- 제21항 내지 제25항 중 어느 한 항에 있어서, 상기 (a)의 뉴클레오티드 서열은 418번 위치에서의 Asp, 547번 위치에서의 Asn, 584번 위치에서의 Leu, 588번 위치에서의 Asn, 598번 위치에서의 Val, 및 642번 위치에서의 His로부터 선택되는 하나 이상의 아미노 치환을 갖는 캡시드 단백질의 아미노산 서열을 암호화하는 것인, 방법.
- 제21항 내지 제26항 중 어느 한 항에 있어서, 상기 (a)의 뉴클레오티드 서열은 Glu418, Ser547, Phe584, Ser588, Ala598, 및/또는 Asn642에서 아미노산 치환을 갖는 서열번호 8(AAV1)의 아미노산 서열을 암호화하고, 상기 암호화된 아미노산 서열은 서열번호 8과 적어도 95% 동일하거나 적어도 99% 동일한 것인, 방법.
- 제21항 내지 제27항 중 어느 한 항에 있어서, 상기 (a)의 뉴클레오티드 서열은 418번 위치에서의 Asp, 547번 위치에서의 Asn, 584번 위치에서의 Leu, 588번 위치에서의 Asn, 598번 위치에서의 Val, 및 642번 위치에서의 His로부터 선택되는 하나 이상의 아미노 치환을 갖는 서열번호 8(AAV1)의 아미노산 서열을 암호화하고, 상기 암호화된 아미노산 서열은 서열번호 8과 적어도 95% 동일하거나 적어도 99% 동일한 것인, 방법.
- 대상체의 중추신경계(CNS)의 하나 이상의 표적 세포에 전이유전자를 전달하는 데 사용하기 위한 재조합 AAV 벡터로서, 상기 재조합 AAV 벡터는 AAVrh91 캡시드 및 CNS의 표적 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함하는 것인, 사용하기 위한 재조합 AAV 벡터.
- 제29항에 있어서, 상기 CNS의 표적 세포는 실질 세포, 맥락막총의 세포, 뇌실막 세포, 성상교세포, 및/또는 및 뉴런, 선택적으로 피질, 해마, 및/또는 선조체의 뉴런인, 사용하기 위한 재조합 AAV 벡터.
- 제29항 또는 에 있어서, 상기 전이유전자는 분비된 유전자 산물을 암호화하는 것인, 사용하기 위한 재조합 AAV 벡터.
- 제28항 내지 제30항 중 어느 한 항에 있어서, 상기 AAV 벡터는 선택적으로 대조내(ICM) 주사를 통해 척수강내로 투여되는 것인, 사용하기 위한 재조합 AAV 벡터.
- 제28항 내지 제31항 중 어느 한 항에 있어서, 상기 AAV 벡터는 뇌실질내 투여를 통해 전달되는 것인, 사용하기 위한 재조합 AAV 벡터.
- 전이유전자를 포함하는 AAV 벡터의 척수강내 투여 후 대상체의 간으로 전이유전자를 전달하는 데 사용하기 위한 재조합 AAV 벡터로서, 상기 재조합 AAV 벡터는 AAVrh91 캡시드 및 간의 표적 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함하고, 상기 간의 트랜잭션 수준은 AAV1, AAV9, 및/또는 AAV6.2 캡시드를 갖는 AAV 벡터로 달성되는 수준에 비해 증가되는 것인, 사용하기 위한 재조합 AAV 벡터.
- 대상체에게 AAV 벡터를 전신 투여한 후 간을 탈표적화하고/하거나 간 독성을 감소시키는 데 사용하기 위한 재조합 AAV 벡터로서, 상기 재조합 AAV 벡터는 AAVrh91 캡시드 및 간의 세포에서 전이유전자의 발현을 지시하는 조절 서열에 작동가능하게 연결된 전이유전자를 포함하는 벡터 게놈을 포함하며, 상기 AAV 벡터의 투여 후 관찰되는 간의 형질도입 수준 및/또는 간 독성은 AAV1, AAV8, 및/또는 AAV9 캡시드를 갖는 AAV 벡터에 비해 감소되는 것인, 사용하기 위한 재조합 AAV 벡터.
- 제34항 또는 제35항 중 어느 한 항에 있어서, 상기 AAV 캡시드는 서열번호 2의 아미노산 서열을 포함하는 캡시드 단백질(AAVrh91)을 포함하는 것인, 사용하기 위한 재조합 AAV 벡터.
- 제34항 내지 제36항 중 어느 한 항에 있어서, 상기 AAV 캡시드는 서열번호 1 또는 3의 뉴클레오티드 서열, 또는 서열번호 1 또는 3과 적어도 적어도 90%, 적어도 95%, 적어도 97%, 적어도 98% 또는 적어도 99% 동일성을 공유하는 서열의 발현에 의해 생성되는 캡시드 단백질을 포함하고, 상기 캡시드에 이종 핵산 서열을 포함하는 벡터 게놈을 패키징한, 사용하기 위한 재조합 AAV 벡터.
- 제34항 내지 제37항 중 어느 한 항에 있어서, 상기 AAV 캡시드는 캡시드 단백질을 포함하며, 상기 캡시드 단백질은 서열번호 1 또는 3의 뉴클레오티드 서열에 의해 암호화되는 것인, 사용하기 위한 재조합 AAV 벡터.
- 제34항 내지 제38항 중 어느 한 항에 있어서, 상기 AAV 캡시드는,
(1) 서열번호 2의 1 내지 736번의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp1 단백질, 서열번호 1 또는 3으로부터 생성되는 vp1 단백질, 또는 서열번호 2의 1 내지 736번의 예상되는 아미노산 서열을 암호화하는 서열번호 1 또는 3과 적어도 70% 동일한 핵산 서열로부터 생성되는 vp1 단백질로부터 선택되는 AAVrh91 vp1 단백질의 이종 집단,
서열번호 2의 적어도 약 138 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp2 단백질, 서열번호 1 또는 3의 적어도 412 내지 2208번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp2 단백질, 또는 서열번호 2의 적어도 약 138 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 서열번호 1 또는 3의 적어도 412 내지 2208번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp2 단백질로부터 선택되는 AAVrh91 vp2 단백질의 이종 집단,
서열번호 2의 적어도 약 203 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 핵산 서열로부터의 발현에 의해 생성되는 vp3 단백질, 서열번호 1 또는 3의 적어도 607 내지 2208번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp3 단백질, 또는 서열번호 2의 적어도 약 203 내지 736번 아미노산의 예상되는 아미노산 서열을 암호화하는 서열번호 1 또는 3의 적어도 607 내지 2208번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp3 단백질로부터 선택되는 AAVrh91 vp3 단백질의 이종 집단; 및/또는
(2) 서열번호 2의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp1 단백질의 이종 집단, 서열번호 2의 적어도 약 138 내지 736번 아미노산의 아미노산 서열을 암호화하는 핵산 서열의 산물인 vp2 단백질의 이종 집단, 및 서열번호 2의 적어도 203 내지 736번 아미노산을 암호화하는 핵산 서열의 산물인 vp3 단백질의 이종 집단으로서, 상기 vp1, vp2 및 vp3 단백질은 서열번호 2의 아스파라긴-글리신 쌍에서 적어도 2개의 고도로 탈아미드화된 아스파라긴(N)을 포함하고 선택적으로 다른 탈아미드화된 아미노산을 포함하는 하위집단을 더 포함하는 아미노산 변형을 갖는 하위집단을 함유하며, 상기 탈아미드화는 아미노산 변화를 초래하는, vp1 단백질의 이종 집단, vp2 단백질의 이종 집단 및 vp3 단백질의 이종 집단
을 포함하는 AAV 캡시드 단백질을 포함하는 것인, 사용하기 위한 재조합 AAV 벡터. - 제39항 중 어느 한 항에 있어서, 상기 단백질을 암호화하는 핵산 서열은 서열번호 1 또는 3, 또는 서열번호 2의 아미노산 서열을 암호화하는 서열번호 1 또는 3과 적어도 80% 내지 적어도 99% 동일한 서열인, 사용하기 위한 재조합 AAV 벡터.
- 제39항 또는 제40항에 있어서, 상기 핵산 서열은 서열번호 1 또는 3과 적어도 80% 동일한 것인, 사용하기 위한 재조합 AAV 벡터.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063065616P | 2020-08-14 | 2020-08-14 | |
| US63/065,616 | 2020-08-14 | ||
| US202063109734P | 2020-11-04 | 2020-11-04 | |
| US63/109,734 | 2020-11-04 | ||
| PCT/US2021/045945 WO2022036220A1 (en) | 2020-08-14 | 2021-08-13 | Novel aav capsids and compositions containing same |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230051208A true KR20230051208A (ko) | 2023-04-17 |
Family
ID=77595666
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237007585A KR20230051208A (ko) | 2020-08-14 | 2021-08-13 | 신규 aav 캡시드 및 이를 함유하는 조성물 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US20230287451A1 (ko) |
| EP (1) | EP4196170A1 (ko) |
| JP (1) | JP2023537625A (ko) |
| KR (1) | KR20230051208A (ko) |
| CN (1) | CN116209769A (ko) |
| AU (1) | AU2021325954A1 (ko) |
| CA (1) | CA3188956A1 (ko) |
| IL (1) | IL300410A (ko) |
| MX (1) | MX2023001863A (ko) |
| TW (1) | TW202221127A (ko) |
| WO (1) | WO2022036220A1 (ko) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240207452A1 (en) | 2021-04-23 | 2024-06-27 | The Trustees Of The University Of Pennsylvania | Novel compositions with brain-specific targeting motifs and compositions containing same |
| IL315256A (en) * | 2022-03-03 | 2024-10-01 | The Trustees Of The Univ Of Pennsylvania | AAV vectors for delivery of GLP-1 receptor agonist fusions |
| WO2024015966A2 (en) * | 2022-07-15 | 2024-01-18 | The Trustees Of The University Of Pennsylvania | Recombinant aav having aav clade d and clade e capsids and compositions containing same |
| CN117801116A (zh) * | 2022-09-30 | 2024-04-02 | 上海玮美基因科技有限责任公司 | 一种融合型新型腺相关病毒及其应用 |
| WO2024130067A2 (en) | 2022-12-17 | 2024-06-20 | The Trustees Of The University Of Pennsylvania | Recombinant aav mutant vectors with cardiac and skeletal muscle-specific targeting motifs and compositions containing same |
| WO2024130070A2 (en) | 2022-12-17 | 2024-06-20 | The Trustees Of The University Of Pennsylvania | Recombinant aav capsids with cardiac- and skeletal muscle- specific targeting motifs and uses thereof |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6174666B1 (en) | 1992-03-27 | 2001-01-16 | The United States Of America As Represented By The Department Of Health And Human Services | Method of eliminating inhibitory/instability regions from mRNA |
| US5478745A (en) | 1992-12-04 | 1995-12-26 | University Of Pittsburgh | Recombinant viral vector system |
| US6221349B1 (en) | 1998-10-20 | 2001-04-24 | Avigen, Inc. | Adeno-associated vectors for expression of factor VIII by target cells |
| US6200560B1 (en) | 1998-10-20 | 2001-03-13 | Avigen, Inc. | Adeno-associated virus vectors for expression of factor VIII by target cells |
| NZ578982A (en) | 2001-11-13 | 2011-03-31 | Univ Pennsylvania | A method of detecting and/or identifying adeno-associated virus (AAV) sequences and isolating novel sequences identified thereby |
| ES2975413T3 (es) | 2001-12-17 | 2024-07-05 | Univ Pennsylvania | Secuencias de serotipo 8 de virus adenoasociado (AAV), vectores que las contienen y usos de las mismas |
| EP1486567A1 (en) * | 2003-06-11 | 2004-12-15 | Deutsches Krebsforschungszentrum Stiftung des öffentlichen Rechts | Improved adeno-associated virus (AAV) vector for gene therapy |
| US8005620B2 (en) | 2003-08-01 | 2011-08-23 | Dna Twopointo Inc. | Systems and methods for biopolymer engineering |
| EP2434420A3 (en) | 2003-08-01 | 2012-07-25 | Dna Twopointo Inc. | Systems and methods for biopolymer engineering |
| EP2287323A1 (en) | 2009-07-31 | 2011-02-23 | Association Institut de Myologie | Widespread gene delivery to the retina using systemic administration of AAV vectors |
| CA2793633A1 (en) | 2010-03-29 | 2011-10-13 | The Trustees Of The University Of Pennsylvania | Pharmacologically induced transgene ablation system |
| FR2977562B1 (fr) | 2011-07-06 | 2016-12-23 | Gaztransport Et Technigaz | Cuve etanche et thermiquement isolante integree dans une structure porteuse |
| WO2013155222A2 (en) | 2012-04-10 | 2013-10-17 | The Regents Of The University Of California | Brain-specific enhancers for cell-based therapy |
| WO2015012924A2 (en) | 2013-04-29 | 2015-01-29 | The Trustees Of The University Of Pennsylvania | Tissue preferential codon modified expression cassettes, vectors containing same, and use thereof |
| JP6741590B2 (ja) | 2014-04-25 | 2020-08-19 | ザ・トラステイーズ・オブ・ザ・ユニバーシテイ・オブ・ペンシルベニア | コレステロールレベルを低下させるためのldlr変異体および組成物中でのそれらの使用 |
-
2021
- 2021-08-13 AU AU2021325954A patent/AU2021325954A1/en active Pending
- 2021-08-13 TW TW110129927A patent/TW202221127A/zh unknown
- 2021-08-13 EP EP21763485.6A patent/EP4196170A1/en active Pending
- 2021-08-13 US US18/040,648 patent/US20230287451A1/en active Pending
- 2021-08-13 CN CN202180070175.8A patent/CN116209769A/zh active Pending
- 2021-08-13 JP JP2023511556A patent/JP2023537625A/ja active Pending
- 2021-08-13 IL IL300410A patent/IL300410A/en unknown
- 2021-08-13 CA CA3188956A patent/CA3188956A1/en active Pending
- 2021-08-13 KR KR1020237007585A patent/KR20230051208A/ko active Search and Examination
- 2021-08-13 MX MX2023001863A patent/MX2023001863A/es unknown
- 2021-08-13 WO PCT/US2021/045945 patent/WO2022036220A1/en active Application Filing
Also Published As
| Publication number | Publication date |
|---|---|
| EP4196170A1 (en) | 2023-06-21 |
| JP2023537625A (ja) | 2023-09-04 |
| WO2022036220A1 (en) | 2022-02-17 |
| US20230287451A1 (en) | 2023-09-14 |
| AU2021325954A1 (en) | 2023-03-02 |
| IL300410A (en) | 2023-04-01 |
| MX2023001863A (es) | 2023-06-13 |
| CA3188956A1 (en) | 2022-02-17 |
| TW202221127A (zh) | 2022-06-01 |
| CN116209769A (zh) | 2023-06-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220204990A1 (en) | Novel aav capsids and compositions containing same | |
| JP7140683B2 (ja) | 新規なaav8変異カプシド及びそれを含有する組成物 | |
| JP7498665B2 (ja) | 新規アデノ随伴ウイルス(aav)ベクター、低減されたカプシド脱アミド化を有するaavベクター、およびその使用 | |
| US20230287451A1 (en) | Novel aav capsids and compositions containing same | |
| WO2018200419A1 (en) | Viral vectors comprising engineered aav capsids and compositions containing the same | |
| JP2023550581A (ja) | Aavカプシド及びそれを含有する組成物 | |
| US20230383313A1 (en) | Improved adeno-associated virus (aav) vector and uses therefor |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination |