KR20230025941A - 비-erk mapk 경로 억제제-내성 암을 치료하기 위한 방법 및 조성물 - Google Patents
비-erk mapk 경로 억제제-내성 암을 치료하기 위한 방법 및 조성물 Download PDFInfo
- Publication number
- KR20230025941A KR20230025941A KR1020237004648A KR20237004648A KR20230025941A KR 20230025941 A KR20230025941 A KR 20230025941A KR 1020237004648 A KR1020237004648 A KR 1020237004648A KR 20237004648 A KR20237004648 A KR 20237004648A KR 20230025941 A KR20230025941 A KR 20230025941A
- Authority
- KR
- South Korea
- Prior art keywords
- bvd
- braf
- inhibitor
- cancer
- cells
- Prior art date
Links
- 239000003112 inhibitor Substances 0.000 title claims abstract description 144
- 238000000034 method Methods 0.000 title claims abstract description 84
- 239000000203 mixture Substances 0.000 title claims description 47
- 230000037361 pathway Effects 0.000 title abstract description 80
- 208000016691 refractory malignant neoplasm Diseases 0.000 title description 3
- 101150024075 Mapk1 gene Proteins 0.000 title 1
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 178
- 201000011510 cancer Diseases 0.000 claims abstract description 85
- KSERXGMCDHOLSS-LJQANCHMSA-N n-[(1s)-1-(3-chlorophenyl)-2-hydroxyethyl]-4-[5-chloro-2-(propan-2-ylamino)pyridin-4-yl]-1h-pyrrole-2-carboxamide Chemical group C1=NC(NC(C)C)=CC(C=2C=C(NC=2)C(=O)N[C@H](CO)C=2C=C(Cl)C=CC=2)=C1Cl KSERXGMCDHOLSS-LJQANCHMSA-N 0.000 claims description 393
- BFSMGDJOXZAERB-UHFFFAOYSA-N dabrafenib Chemical compound S1C(C(C)(C)C)=NC(C=2C(=C(NS(=O)(=O)C=3C(=CC=CC=3F)F)C=CC=2)F)=C1C1=CC=NC(N)=N1 BFSMGDJOXZAERB-UHFFFAOYSA-N 0.000 claims description 275
- 229960002465 dabrafenib Drugs 0.000 claims description 272
- 238000011282 treatment Methods 0.000 claims description 159
- 239000003795 chemical substances by application Substances 0.000 claims description 106
- 229940124647 MEK inhibitor Drugs 0.000 claims description 102
- 230000035772 mutation Effects 0.000 claims description 95
- 102000043136 MAP kinase family Human genes 0.000 claims description 89
- 108091054455 MAP kinase family Proteins 0.000 claims description 89
- 230000000694 effects Effects 0.000 claims description 85
- LIRYPHYGHXZJBZ-UHFFFAOYSA-N trametinib Chemical group CC(=O)NC1=CC=CC(N2C(N(C3CC3)C(=O)C3=C(NC=4C(=CC(I)=CC=4)F)N(C)C(=O)C(C)=C32)=O)=C1 LIRYPHYGHXZJBZ-UHFFFAOYSA-N 0.000 claims description 79
- 229960004066 trametinib Drugs 0.000 claims description 78
- 229940125431 BRAF inhibitor Drugs 0.000 claims description 74
- 239000002829 mitogen activated protein kinase inhibitor Substances 0.000 claims description 69
- 108090000744 Mitogen-Activated Protein Kinase Kinases Proteins 0.000 claims description 65
- 102000004232 Mitogen-Activated Protein Kinase Kinases Human genes 0.000 claims description 64
- 201000001441 melanoma Diseases 0.000 claims description 46
- 102200055464 rs113488022 Human genes 0.000 claims description 46
- 150000003839 salts Chemical class 0.000 claims description 39
- 102220197841 rs1057519729 Human genes 0.000 claims description 36
- 241000282414 Homo sapiens Species 0.000 claims description 30
- GPXBXXGIAQBQNI-UHFFFAOYSA-N vemurafenib Chemical group CCCS(=O)(=O)NC1=CC=C(F)C(C(=O)C=2C3=CC(=CN=C3NC=2)C=2C=CC(Cl)=CC=2)=C1F GPXBXXGIAQBQNI-UHFFFAOYSA-N 0.000 claims description 30
- 229960003862 vemurafenib Drugs 0.000 claims description 27
- 239000003981 vehicle Substances 0.000 claims description 21
- 241001465754 Metazoa Species 0.000 claims description 20
- 206010009944 Colon cancer Diseases 0.000 claims description 15
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims description 15
- 206010061289 metastatic neoplasm Diseases 0.000 claims description 10
- 230000001394 metastastic effect Effects 0.000 claims description 9
- 239000002671 adjuvant Substances 0.000 claims description 7
- 229960002271 cobimetinib Drugs 0.000 claims description 7
- 208000002154 non-small cell lung carcinoma Diseases 0.000 claims description 7
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 claims description 7
- RESIMIUSNACMNW-BXRWSSRYSA-N cobimetinib fumarate Chemical compound OC(=O)\C=C\C(O)=O.C1C(O)([C@H]2NCCCC2)CN1C(=O)C1=CC=C(F)C(F)=C1NC1=CC=C(I)C=C1F.C1C(O)([C@H]2NCCCC2)CN1C(=O)C1=CC=C(F)C(F)=C1NC1=CC=C(I)C=C1F RESIMIUSNACMNW-BXRWSSRYSA-N 0.000 claims description 6
- 102000008203 CTLA-4 Antigen Human genes 0.000 claims description 5
- 108010021064 CTLA-4 Antigen Proteins 0.000 claims description 5
- 101100519207 Mus musculus Pdcd1 gene Proteins 0.000 claims description 5
- 239000003937 drug carrier Substances 0.000 claims description 5
- 206010033701 Papillary thyroid cancer Diseases 0.000 claims description 4
- 208000030045 thyroid gland papillary carcinoma Diseases 0.000 claims description 4
- 241000288906 Primates Species 0.000 claims description 3
- 244000144972 livestock Species 0.000 claims description 3
- 229960005386 ipilimumab Drugs 0.000 claims description 2
- 229960003301 nivolumab Drugs 0.000 claims description 2
- 229960002621 pembrolizumab Drugs 0.000 claims description 2
- 101000984753 Homo sapiens Serine/threonine-protein kinase B-raf Proteins 0.000 claims 2
- 102100027103 Serine/threonine-protein kinase B-raf Human genes 0.000 claims 2
- 239000012275 CTLA-4 inhibitor Substances 0.000 claims 1
- 229940045513 CTLA4 antagonist Drugs 0.000 claims 1
- 239000012270 PD-1 inhibitor Substances 0.000 claims 1
- 239000012668 PD-1-inhibitor Substances 0.000 claims 1
- 229940121655 pd-1 inhibitor Drugs 0.000 claims 1
- 108010007457 Extracellular Signal-Regulated MAP Kinases Proteins 0.000 abstract description 82
- 238000002560 therapeutic procedure Methods 0.000 abstract description 56
- 230000026731 phosphorylation Effects 0.000 abstract description 53
- 238000006366 phosphorylation reaction Methods 0.000 abstract description 53
- 239000012824 ERK inhibitor Substances 0.000 abstract description 29
- 239000008194 pharmaceutical composition Substances 0.000 abstract description 26
- 230000008901 benefit Effects 0.000 abstract description 21
- 230000002401 inhibitory effect Effects 0.000 abstract description 12
- 102000007665 Extracellular Signal-Regulated MAP Kinases Human genes 0.000 abstract 2
- 210000004027 cell Anatomy 0.000 description 340
- 102100024193 Mitogen-activated protein kinase 1 Human genes 0.000 description 108
- 102000019149 MAP kinase activity proteins Human genes 0.000 description 100
- 108040008097 MAP kinase activity proteins Proteins 0.000 description 100
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 95
- 230000005764 inhibitory process Effects 0.000 description 95
- 239000003814 drug Substances 0.000 description 88
- 230000004044 response Effects 0.000 description 58
- 150000001875 compounds Chemical class 0.000 description 57
- 229940079593 drug Drugs 0.000 description 54
- 102100031480 Dual specificity mitogen-activated protein kinase kinase 1 Human genes 0.000 description 53
- 101710146526 Dual specificity mitogen-activated protein kinase kinase 1 Proteins 0.000 description 52
- 230000001965 increasing effect Effects 0.000 description 50
- 230000011664 signaling Effects 0.000 description 45
- 238000001516 cell proliferation assay Methods 0.000 description 44
- 108090000623 proteins and genes Proteins 0.000 description 44
- 102000004169 proteins and genes Human genes 0.000 description 39
- 102100033479 RAF proto-oncogene serine/threonine-protein kinase Human genes 0.000 description 36
- 239000011159 matrix material Substances 0.000 description 34
- 101000744436 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Trans-acting factor D Proteins 0.000 description 31
- 230000002829 reductive effect Effects 0.000 description 27
- 210000004369 blood Anatomy 0.000 description 24
- 239000008280 blood Substances 0.000 description 24
- 101000876610 Dictyostelium discoideum Extracellular signal-regulated kinase 2 Proteins 0.000 description 23
- 101001052493 Homo sapiens Mitogen-activated protein kinase 1 Proteins 0.000 description 23
- 239000000523 sample Substances 0.000 description 23
- 238000001262 western blot Methods 0.000 description 22
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 21
- 241000282320 Panthera leo Species 0.000 description 21
- 239000012091 fetal bovine serum Substances 0.000 description 21
- 102000016914 ras Proteins Human genes 0.000 description 21
- 238000003556 assay Methods 0.000 description 20
- 238000000338 in vitro Methods 0.000 description 20
- 230000004083 survival effect Effects 0.000 description 20
- 101150040459 RAS gene Proteins 0.000 description 19
- 230000004913 activation Effects 0.000 description 19
- 238000001994 activation Methods 0.000 description 19
- 238000003570 cell viability assay Methods 0.000 description 19
- 102100039788 GTPase NRas Human genes 0.000 description 18
- 101000744505 Homo sapiens GTPase NRas Proteins 0.000 description 18
- 101150076031 RAS1 gene Proteins 0.000 description 18
- 238000004458 analytical method Methods 0.000 description 18
- 238000012054 celltiter-glo Methods 0.000 description 18
- 230000035899 viability Effects 0.000 description 18
- 108010017324 STAT3 Transcription Factor Proteins 0.000 description 17
- 102100024040 Signal transducer and activator of transcription 3 Human genes 0.000 description 17
- 230000001419 dependent effect Effects 0.000 description 17
- 230000006870 function Effects 0.000 description 17
- 230000035945 sensitivity Effects 0.000 description 17
- 230000003213 activating effect Effects 0.000 description 16
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 16
- 231100000371 dose-limiting toxicity Toxicity 0.000 description 16
- -1 Vx11e (Vx) Chemical compound 0.000 description 15
- 238000006243 chemical reaction Methods 0.000 description 15
- 201000010099 disease Diseases 0.000 description 15
- 230000014509 gene expression Effects 0.000 description 15
- 238000012360 testing method Methods 0.000 description 15
- 230000003827 upregulation Effects 0.000 description 15
- ZKHQWZAMYRWXGA-KQYNXXCUSA-J ATP(4-) Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](COP([O-])(=O)OP([O-])(=O)OP([O-])([O-])=O)[C@@H](O)[C@H]1O ZKHQWZAMYRWXGA-KQYNXXCUSA-J 0.000 description 14
- ZKHQWZAMYRWXGA-UHFFFAOYSA-N Adenosine triphosphate Natural products C1=NC=2C(N)=NC=NC=2N1C1OC(COP(O)(=O)OP(O)(=O)OP(O)(O)=O)C(O)C1O ZKHQWZAMYRWXGA-UHFFFAOYSA-N 0.000 description 14
- PHEDXBVPIONUQT-UHFFFAOYSA-N Cocarcinogen A1 Natural products CCCCCCCCCCCCCC(=O)OC1C(C)C2(O)C3C=C(C)C(=O)C3(O)CC(CO)=CC2C2C1(OC(C)=O)C2(C)C PHEDXBVPIONUQT-UHFFFAOYSA-N 0.000 description 14
- 231100000682 maximum tolerated dose Toxicity 0.000 description 14
- PHEDXBVPIONUQT-RGYGYFBISA-N phorbol 13-acetate 12-myristate Chemical compound C([C@]1(O)C(=O)C(C)=C[C@H]1[C@@]1(O)[C@H](C)[C@H]2OC(=O)CCCCCCCCCCCCC)C(CO)=C[C@H]1[C@H]1[C@]2(OC(C)=O)C1(C)C PHEDXBVPIONUQT-RGYGYFBISA-N 0.000 description 14
- 229940124597 therapeutic agent Drugs 0.000 description 14
- 239000000654 additive Substances 0.000 description 13
- 230000000259 anti-tumor effect Effects 0.000 description 13
- 239000003085 diluting agent Substances 0.000 description 13
- 238000002474 experimental method Methods 0.000 description 13
- 239000002609 medium Substances 0.000 description 13
- 230000036961 partial effect Effects 0.000 description 13
- 239000000758 substrate Substances 0.000 description 13
- 230000005723 MEK inhibition Effects 0.000 description 12
- 108091000080 Phosphotransferase Proteins 0.000 description 12
- 230000000996 additive effect Effects 0.000 description 12
- 239000012636 effector Substances 0.000 description 12
- 238000009472 formulation Methods 0.000 description 12
- 230000012010 growth Effects 0.000 description 12
- 230000007246 mechanism Effects 0.000 description 12
- 102000020233 phosphotransferase Human genes 0.000 description 12
- 102000027426 receptor tyrosine kinases Human genes 0.000 description 12
- 108091008598 receptor tyrosine kinases Proteins 0.000 description 12
- 230000008685 targeting Effects 0.000 description 12
- 102100033536 Ribosomal protein S6 kinase alpha-1 Human genes 0.000 description 11
- 238000001727 in vivo Methods 0.000 description 11
- 230000003285 pharmacodynamic effect Effects 0.000 description 11
- 230000003389 potentiating effect Effects 0.000 description 11
- 230000002035 prolonged effect Effects 0.000 description 11
- 238000009097 single-agent therapy Methods 0.000 description 11
- 230000004614 tumor growth Effects 0.000 description 11
- 238000011144 upstream manufacturing Methods 0.000 description 11
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 10
- 241000699670 Mus sp. Species 0.000 description 10
- 102000038030 PI3Ks Human genes 0.000 description 10
- 108091007960 PI3Ks Proteins 0.000 description 10
- 238000002648 combination therapy Methods 0.000 description 10
- 230000018109 developmental process Effects 0.000 description 10
- 239000006166 lysate Substances 0.000 description 10
- 238000005259 measurement Methods 0.000 description 10
- 210000002381 plasma Anatomy 0.000 description 10
- 230000007420 reactivation Effects 0.000 description 10
- 230000002441 reversible effect Effects 0.000 description 10
- 230000019491 signal transduction Effects 0.000 description 10
- 239000000243 solution Substances 0.000 description 10
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 10
- 102100030708 GTPase KRas Human genes 0.000 description 9
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 9
- 101000584612 Homo sapiens GTPase KRas Proteins 0.000 description 9
- 101000944909 Homo sapiens Ribosomal protein S6 kinase alpha-1 Proteins 0.000 description 9
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 9
- 239000004480 active ingredient Substances 0.000 description 9
- 230000003321 amplification Effects 0.000 description 9
- 239000000872 buffer Substances 0.000 description 9
- 238000011161 development Methods 0.000 description 9
- 231100000673 dose–response relationship Toxicity 0.000 description 9
- 239000012634 fragment Substances 0.000 description 9
- 230000002068 genetic effect Effects 0.000 description 9
- 239000004615 ingredient Substances 0.000 description 9
- 230000003993 interaction Effects 0.000 description 9
- 238000003199 nucleic acid amplification method Methods 0.000 description 9
- 238000012163 sequencing technique Methods 0.000 description 9
- 239000000126 substance Substances 0.000 description 9
- 230000001225 therapeutic effect Effects 0.000 description 9
- RZUOCXOYPYGSKL-GOSISDBHSA-N 1-[(1s)-1-(4-chloro-3-fluorophenyl)-2-hydroxyethyl]-4-[2-[(2-methylpyrazol-3-yl)amino]pyrimidin-4-yl]pyridin-2-one Chemical compound CN1N=CC=C1NC1=NC=CC(C2=CC(=O)N([C@H](CO)C=3C=C(F)C(Cl)=CC=3)C=C2)=N1 RZUOCXOYPYGSKL-GOSISDBHSA-N 0.000 description 8
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 8
- 230000004075 alteration Effects 0.000 description 8
- 239000012472 biological sample Substances 0.000 description 8
- 239000000969 carrier Substances 0.000 description 8
- 239000003153 chemical reaction reagent Substances 0.000 description 8
- 238000012790 confirmation Methods 0.000 description 8
- 239000000499 gel Substances 0.000 description 8
- 239000003550 marker Substances 0.000 description 8
- 239000000463 material Substances 0.000 description 8
- 239000003921 oil Substances 0.000 description 8
- 239000000843 powder Substances 0.000 description 8
- 238000012216 screening Methods 0.000 description 8
- 239000000725 suspension Substances 0.000 description 8
- 238000002626 targeted therapy Methods 0.000 description 8
- 230000001988 toxicity Effects 0.000 description 8
- 231100000419 toxicity Toxicity 0.000 description 8
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 8
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 7
- 206010012735 Diarrhoea Diseases 0.000 description 7
- 229940126656 GS-4224 Drugs 0.000 description 7
- 101001057587 Homo sapiens Dual specificity protein phosphatase 6 Proteins 0.000 description 7
- 108091008611 Protein Kinase B Proteins 0.000 description 7
- 238000010521 absorption reaction Methods 0.000 description 7
- 239000012298 atmosphere Substances 0.000 description 7
- 229910002091 carbon monoxide Inorganic materials 0.000 description 7
- 239000002552 dosage form Substances 0.000 description 7
- 238000011156 evaluation Methods 0.000 description 7
- 230000003902 lesion Effects 0.000 description 7
- 230000001404 mediated effect Effects 0.000 description 7
- 201000005962 mycosis fungoides Diseases 0.000 description 7
- 229940002612 prodrug Drugs 0.000 description 7
- 239000000651 prodrug Substances 0.000 description 7
- 230000009467 reduction Effects 0.000 description 7
- 230000002195 synergetic effect Effects 0.000 description 7
- 229950008878 ulixertinib Drugs 0.000 description 7
- 102000011727 Caspases Human genes 0.000 description 6
- 108010076667 Caspases Proteins 0.000 description 6
- 108020004414 DNA Proteins 0.000 description 6
- 102100027274 Dual specificity protein phosphatase 6 Human genes 0.000 description 6
- 208000010201 Exanthema Diseases 0.000 description 6
- 229930012538 Paclitaxel Natural products 0.000 description 6
- 229940122907 Phosphatase inhibitor Drugs 0.000 description 6
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 6
- 108010029485 Protein Isoforms Proteins 0.000 description 6
- 102000001708 Protein Isoforms Human genes 0.000 description 6
- 101710141955 RAF proto-oncogene serine/threonine-protein kinase Proteins 0.000 description 6
- 108020004459 Small interfering RNA Proteins 0.000 description 6
- BPEGJWRSRHCHSN-UHFFFAOYSA-N Temozolomide Chemical compound O=C1N(C)N=NC2=C(C(N)=O)N=CN21 BPEGJWRSRHCHSN-UHFFFAOYSA-N 0.000 description 6
- 239000001768 carboxy methyl cellulose Substances 0.000 description 6
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 6
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 6
- 230000022131 cell cycle Effects 0.000 description 6
- 230000008859 change Effects 0.000 description 6
- DDRJAANPRJIHGJ-UHFFFAOYSA-N creatinine Chemical compound CN1CC(=O)NC1=N DDRJAANPRJIHGJ-UHFFFAOYSA-N 0.000 description 6
- 230000001086 cytosolic effect Effects 0.000 description 6
- 229940127089 cytotoxic agent Drugs 0.000 description 6
- 201000005884 exanthem Diseases 0.000 description 6
- 229940088597 hormone Drugs 0.000 description 6
- 239000005556 hormone Substances 0.000 description 6
- 238000011835 investigation Methods 0.000 description 6
- 239000012139 lysis buffer Substances 0.000 description 6
- 235000019198 oils Nutrition 0.000 description 6
- 229960001592 paclitaxel Drugs 0.000 description 6
- 239000008188 pellet Substances 0.000 description 6
- 230000036515 potency Effects 0.000 description 6
- 206010037844 rash Diseases 0.000 description 6
- 230000008261 resistance mechanism Effects 0.000 description 6
- CYOHGALHFOKKQC-UHFFFAOYSA-N selumetinib Chemical compound OCCONC(=O)C=1C=C2N(C)C=NC2=C(F)C=1NC1=CC=C(Br)C=C1Cl CYOHGALHFOKKQC-UHFFFAOYSA-N 0.000 description 6
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 6
- 229960004964 temozolomide Drugs 0.000 description 6
- 210000004881 tumor cell Anatomy 0.000 description 6
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 5
- 108700028369 Alleles Proteins 0.000 description 5
- 102000001765 Bcl-2-Like Protein 11 Human genes 0.000 description 5
- 108010040168 Bcl-2-Like Protein 11 Proteins 0.000 description 5
- 239000007995 HEPES buffer Substances 0.000 description 5
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 5
- 241000124008 Mammalia Species 0.000 description 5
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 5
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 5
- 230000001154 acute effect Effects 0.000 description 5
- 208000037844 advanced solid tumor Diseases 0.000 description 5
- 230000006907 apoptotic process Effects 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 239000000090 biomarker Substances 0.000 description 5
- 238000005119 centrifugation Methods 0.000 description 5
- 238000000576 coating method Methods 0.000 description 5
- 230000000875 corresponding effect Effects 0.000 description 5
- 239000002254 cytotoxic agent Substances 0.000 description 5
- 231100000599 cytotoxic agent Toxicity 0.000 description 5
- 238000001514 detection method Methods 0.000 description 5
- 239000007789 gas Substances 0.000 description 5
- 239000008103 glucose Substances 0.000 description 5
- 238000009396 hybridization Methods 0.000 description 5
- 238000011534 incubation Methods 0.000 description 5
- 239000007788 liquid Substances 0.000 description 5
- 230000036210 malignancy Effects 0.000 description 5
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 5
- 238000004949 mass spectrometry Methods 0.000 description 5
- 230000000869 mutational effect Effects 0.000 description 5
- 229940127084 other anti-cancer agent Drugs 0.000 description 5
- 201000002528 pancreatic cancer Diseases 0.000 description 5
- 208000008443 pancreatic carcinoma Diseases 0.000 description 5
- 229920001223 polyethylene glycol Polymers 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 108090000765 processed proteins & peptides Proteins 0.000 description 5
- 230000035755 proliferation Effects 0.000 description 5
- 150000003384 small molecules Chemical class 0.000 description 5
- 239000007787 solid Substances 0.000 description 5
- 239000003826 tablet Substances 0.000 description 5
- 210000002700 urine Anatomy 0.000 description 5
- 102000047934 Caspase-3/7 Human genes 0.000 description 4
- 108700037887 Caspase-3/7 Proteins 0.000 description 4
- 108010058546 Cyclin D1 Proteins 0.000 description 4
- 206010061818 Disease progression Diseases 0.000 description 4
- 238000002965 ELISA Methods 0.000 description 4
- 102100024165 G1/S-specific cyclin-D1 Human genes 0.000 description 4
- 101000771237 Homo sapiens Serine/threonine-protein kinase A-Raf Proteins 0.000 description 4
- 102100026907 Mitogen-activated protein kinase kinase kinase 8 Human genes 0.000 description 4
- 101100523539 Mus musculus Raf1 gene Proteins 0.000 description 4
- 206010028813 Nausea Diseases 0.000 description 4
- 108091034117 Oligonucleotide Proteins 0.000 description 4
- 229930182555 Penicillin Natural products 0.000 description 4
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 4
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 4
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 4
- 102000001253 Protein Kinase Human genes 0.000 description 4
- 102000018471 Proto-Oncogene Proteins B-raf Human genes 0.000 description 4
- 108010091528 Proto-Oncogene Proteins B-raf Proteins 0.000 description 4
- 238000011529 RT qPCR Methods 0.000 description 4
- 229940078123 Ras inhibitor Drugs 0.000 description 4
- 102100029437 Serine/threonine-protein kinase A-Raf Human genes 0.000 description 4
- 229920002472 Starch Polymers 0.000 description 4
- 206010047700 Vomiting Diseases 0.000 description 4
- 230000002411 adverse Effects 0.000 description 4
- 230000003281 allosteric effect Effects 0.000 description 4
- 238000003236 bicinchoninic acid assay Methods 0.000 description 4
- 239000002775 capsule Substances 0.000 description 4
- 230000010261 cell growth Effects 0.000 description 4
- 230000004663 cell proliferation Effects 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 238000002591 computed tomography Methods 0.000 description 4
- 210000000805 cytoplasm Anatomy 0.000 description 4
- 230000029087 digestion Effects 0.000 description 4
- 230000005750 disease progression Effects 0.000 description 4
- 239000000839 emulsion Substances 0.000 description 4
- 235000019441 ethanol Nutrition 0.000 description 4
- 238000002509 fluorescent in situ hybridization Methods 0.000 description 4
- 239000008187 granular material Substances 0.000 description 4
- 230000009036 growth inhibition Effects 0.000 description 4
- 230000002519 immonomodulatory effect Effects 0.000 description 4
- 239000003701 inert diluent Substances 0.000 description 4
- 238000004020 luminiscence type Methods 0.000 description 4
- 208000020816 lung neoplasm Diseases 0.000 description 4
- 239000012528 membrane Substances 0.000 description 4
- 230000008693 nausea Effects 0.000 description 4
- 150000007523 nucleic acids Chemical group 0.000 description 4
- 239000012188 paraffin wax Substances 0.000 description 4
- 239000006072 paste Substances 0.000 description 4
- 229940049954 penicillin Drugs 0.000 description 4
- 239000000546 pharmaceutical excipient Substances 0.000 description 4
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 4
- 239000013641 positive control Substances 0.000 description 4
- 239000003755 preservative agent Substances 0.000 description 4
- 108060006633 protein kinase Proteins 0.000 description 4
- 150000003856 quaternary ammonium compounds Chemical class 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 210000003705 ribosome Anatomy 0.000 description 4
- 239000011780 sodium chloride Substances 0.000 description 4
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 4
- 230000006641 stabilisation Effects 0.000 description 4
- 238000011105 stabilization Methods 0.000 description 4
- 235000019698 starch Nutrition 0.000 description 4
- 210000001519 tissue Anatomy 0.000 description 4
- 239000003053 toxin Substances 0.000 description 4
- 231100000765 toxin Toxicity 0.000 description 4
- 108700012359 toxins Proteins 0.000 description 4
- 230000008673 vomiting Effects 0.000 description 4
- 239000001993 wax Substances 0.000 description 4
- 230000003442 weekly effect Effects 0.000 description 4
- 239000000080 wetting agent Substances 0.000 description 4
- JNYAEWCLZODPBN-JGWLITMVSA-N (2r,3r,4s)-2-[(1r)-1,2-dihydroxyethyl]oxolane-3,4-diol Chemical class OC[C@@H](O)[C@H]1OC[C@H](O)[C@H]1O JNYAEWCLZODPBN-JGWLITMVSA-N 0.000 description 3
- VBICKXHEKHSIBG-UHFFFAOYSA-N 1-monostearoylglycerol Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(O)CO VBICKXHEKHSIBG-UHFFFAOYSA-N 0.000 description 3
- 238000010176 18-FDG-positron emission tomography Methods 0.000 description 3
- KISWVXRQTGLFGD-UHFFFAOYSA-N 2-[[2-[[6-amino-2-[[2-[[2-[[5-amino-2-[[2-[[1-[2-[[6-amino-2-[(2,5-diamino-5-oxopentanoyl)amino]hexanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]pyrrolidine-2-carbonyl]amino]-3-hydroxypropanoyl]amino]-5-oxopentanoyl]amino]-5-(diaminomethylideneamino)p Chemical compound C1CCN(C(=O)C(CCCN=C(N)N)NC(=O)C(CCCCN)NC(=O)C(N)CCC(N)=O)C1C(=O)NC(CO)C(=O)NC(CCC(N)=O)C(=O)NC(CCCN=C(N)N)C(=O)NC(CO)C(=O)NC(CCCCN)C(=O)NC(C(=O)NC(CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 KISWVXRQTGLFGD-UHFFFAOYSA-N 0.000 description 3
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 3
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 3
- WVDDGKGOMKODPV-UHFFFAOYSA-N Benzyl alcohol Chemical compound OCC1=CC=CC=C1 WVDDGKGOMKODPV-UHFFFAOYSA-N 0.000 description 3
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 3
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 3
- 102100023272 Dual specificity mitogen-activated protein kinase kinase 5 Human genes 0.000 description 3
- 239000012591 Dulbecco’s Phosphate Buffered Saline Substances 0.000 description 3
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 3
- 101710165567 Extracellular signal-regulated kinase 1 Proteins 0.000 description 3
- 241000282326 Felis catus Species 0.000 description 3
- 230000010190 G1 phase Effects 0.000 description 3
- 102100029974 GTPase HRas Human genes 0.000 description 3
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 3
- 101000584633 Homo sapiens GTPase HRas Proteins 0.000 description 3
- 101000950687 Homo sapiens Mitogen-activated protein kinase 7 Proteins 0.000 description 3
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 3
- 108010055717 JNK Mitogen-Activated Protein Kinases Proteins 0.000 description 3
- 206010069755 K-ras gene mutation Diseases 0.000 description 3
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 3
- 206010027480 Metastatic malignant melanoma Diseases 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 108700015928 Mitogen-activated protein kinase 13 Proteins 0.000 description 3
- 102100037805 Mitogen-activated protein kinase 7 Human genes 0.000 description 3
- 102000003993 Phosphatidylinositol 3-kinases Human genes 0.000 description 3
- 108090000430 Phosphatidylinositol 3-kinases Proteins 0.000 description 3
- 101710179684 Poly [ADP-ribose] polymerase Proteins 0.000 description 3
- 102100023712 Poly [ADP-ribose] polymerase 1 Human genes 0.000 description 3
- 229920000776 Poly(Adenosine diphosphate-ribose) polymerase Polymers 0.000 description 3
- ATUOYWHBWRKTHZ-UHFFFAOYSA-N Propane Chemical compound CCC ATUOYWHBWRKTHZ-UHFFFAOYSA-N 0.000 description 3
- PLXBWHJQWKZRKG-UHFFFAOYSA-N Resazurin Chemical compound C1=CC(=O)C=C2OC3=CC(O)=CC=C3[N+]([O-])=C21 PLXBWHJQWKZRKG-UHFFFAOYSA-N 0.000 description 3
- 108010034782 Ribosomal Protein S6 Kinases Proteins 0.000 description 3
- 102000009738 Ribosomal Protein S6 Kinases Human genes 0.000 description 3
- 229930006000 Sucrose Natural products 0.000 description 3
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 3
- 208000031673 T-Cell Cutaneous Lymphoma Diseases 0.000 description 3
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 3
- 208000024770 Thyroid neoplasm Diseases 0.000 description 3
- 102000004142 Trypsin Human genes 0.000 description 3
- 108090000631 Trypsin Proteins 0.000 description 3
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 3
- 239000013543 active substance Substances 0.000 description 3
- 230000003044 adaptive effect Effects 0.000 description 3
- 150000001413 amino acids Chemical class 0.000 description 3
- 230000003042 antagnostic effect Effects 0.000 description 3
- 230000002238 attenuated effect Effects 0.000 description 3
- 230000009286 beneficial effect Effects 0.000 description 3
- 235000012216 bentonite Nutrition 0.000 description 3
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 3
- 239000011230 binding agent Substances 0.000 description 3
- 229920002988 biodegradable polymer Polymers 0.000 description 3
- 239000004621 biodegradable polymer Substances 0.000 description 3
- 238000001574 biopsy Methods 0.000 description 3
- 239000001506 calcium phosphate Substances 0.000 description 3
- 238000012512 characterization method Methods 0.000 description 3
- 239000011248 coating agent Substances 0.000 description 3
- 239000003086 colorant Substances 0.000 description 3
- 230000002860 competitive effect Effects 0.000 description 3
- 239000006071 cream Substances 0.000 description 3
- 229940109239 creatinine Drugs 0.000 description 3
- 201000007241 cutaneous T cell lymphoma Diseases 0.000 description 3
- 229940063582 dabrafenib 50 mg Drugs 0.000 description 3
- 230000007423 decrease Effects 0.000 description 3
- 230000003111 delayed effect Effects 0.000 description 3
- 238000010790 dilution Methods 0.000 description 3
- 239000012895 dilution Substances 0.000 description 3
- 239000007884 disintegrant Substances 0.000 description 3
- 239000002270 dispersing agent Substances 0.000 description 3
- 239000006185 dispersion Substances 0.000 description 3
- 238000004090 dissolution Methods 0.000 description 3
- 239000003995 emulsifying agent Substances 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 3
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 3
- 239000000945 filler Substances 0.000 description 3
- 239000000796 flavoring agent Substances 0.000 description 3
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 3
- 231100000226 haematotoxicity Toxicity 0.000 description 3
- 201000005787 hematologic cancer Diseases 0.000 description 3
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 3
- 239000003906 humectant Substances 0.000 description 3
- 230000001976 improved effect Effects 0.000 description 3
- 230000006872 improvement Effects 0.000 description 3
- 238000010874 in vitro model Methods 0.000 description 3
- 229960004768 irinotecan Drugs 0.000 description 3
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 3
- 239000008101 lactose Substances 0.000 description 3
- 239000002502 liposome Substances 0.000 description 3
- 239000000314 lubricant Substances 0.000 description 3
- 201000005202 lung cancer Diseases 0.000 description 3
- 230000002503 metabolic effect Effects 0.000 description 3
- 239000002207 metabolite Substances 0.000 description 3
- 208000021039 metastatic melanoma Diseases 0.000 description 3
- 238000002552 multiple reaction monitoring Methods 0.000 description 3
- KSERXGMCDHOLSS-UHFFFAOYSA-N n-[1-(3-chlorophenyl)-2-hydroxyethyl]-4-[5-chloro-2-(propan-2-ylamino)pyridin-4-yl]-1h-pyrrole-2-carboxamide Chemical compound C1=NC(NC(C)C)=CC(C=2C=C(NC=2)C(=O)NC(CO)C=2C=C(Cl)C=CC=2)=C1Cl KSERXGMCDHOLSS-UHFFFAOYSA-N 0.000 description 3
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 3
- 239000013642 negative control Substances 0.000 description 3
- 229930027945 nicotinamide-adenine dinucleotide Natural products 0.000 description 3
- BOPGDPNILDQYTO-NNYOXOHSSA-N nicotinamide-adenine dinucleotide Chemical compound C1=CCC(C(=O)N)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OC[C@@H]2[C@H]([C@@H](O)[C@@H](O2)N2C3=NC=NC(N)=C3N=C2)O)O1 BOPGDPNILDQYTO-NNYOXOHSSA-N 0.000 description 3
- 102000039446 nucleic acids Human genes 0.000 description 3
- 108020004707 nucleic acids Proteins 0.000 description 3
- 239000002674 ointment Substances 0.000 description 3
- 238000003305 oral gavage Methods 0.000 description 3
- 108010068338 p38 Mitogen-Activated Protein Kinases Proteins 0.000 description 3
- 102000002574 p38 Mitogen-Activated Protein Kinases Human genes 0.000 description 3
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 3
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 3
- 239000002935 phosphatidylinositol 3 kinase inhibitor Substances 0.000 description 3
- 239000006187 pill Substances 0.000 description 3
- 230000036470 plasma concentration Effects 0.000 description 3
- 229920000642 polymer Polymers 0.000 description 3
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 3
- 230000001323 posttranslational effect Effects 0.000 description 3
- 208000025638 primary cutaneous T-cell non-Hodgkin lymphoma Diseases 0.000 description 3
- 208000037821 progressive disease Diseases 0.000 description 3
- 230000002062 proliferating effect Effects 0.000 description 3
- 239000002534 radiation-sensitizing agent Substances 0.000 description 3
- 102000009929 raf Kinases Human genes 0.000 description 3
- 108010077182 raf Kinases Proteins 0.000 description 3
- 238000003753 real-time PCR Methods 0.000 description 3
- 239000012898 sample dilution Substances 0.000 description 3
- 229950010746 selumetinib Drugs 0.000 description 3
- RMAQACBXLXPBSY-UHFFFAOYSA-N silicic acid Chemical compound O[Si](O)(O)O RMAQACBXLXPBSY-UHFFFAOYSA-N 0.000 description 3
- CDBYLPFSWZWCQE-UHFFFAOYSA-L sodium carbonate Substances [Na+].[Na+].[O-]C([O-])=O CDBYLPFSWZWCQE-UHFFFAOYSA-L 0.000 description 3
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 3
- 239000000600 sorbitol Substances 0.000 description 3
- 239000007921 spray Substances 0.000 description 3
- 239000008107 starch Substances 0.000 description 3
- 229940032147 starch Drugs 0.000 description 3
- 229960005322 streptomycin Drugs 0.000 description 3
- 239000005720 sucrose Substances 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 239000004094 surface-active agent Substances 0.000 description 3
- 239000000375 suspending agent Substances 0.000 description 3
- 230000002459 sustained effect Effects 0.000 description 3
- 230000009044 synergistic interaction Effects 0.000 description 3
- 239000006188 syrup Substances 0.000 description 3
- 235000020357 syrup Nutrition 0.000 description 3
- 238000009121 systemic therapy Methods 0.000 description 3
- 239000000454 talc Substances 0.000 description 3
- 235000012222 talc Nutrition 0.000 description 3
- 229910052623 talc Inorganic materials 0.000 description 3
- 201000002510 thyroid cancer Diseases 0.000 description 3
- 230000036964 tight binding Effects 0.000 description 3
- YNJBWRMUSHSURL-UHFFFAOYSA-N trichloroacetic acid Chemical compound OC(=O)C(Cl)(Cl)Cl YNJBWRMUSHSURL-UHFFFAOYSA-N 0.000 description 3
- 239000012588 trypsin Substances 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- PUPZLCDOIYMWBV-UHFFFAOYSA-N (+/-)-1,3-Butanediol Chemical compound CC(O)CCO PUPZLCDOIYMWBV-UHFFFAOYSA-N 0.000 description 2
- SRLVNYDXMUGOFI-XBXARRHUSA-N (5e)-5-[(2,2-difluoro-1,3-benzodioxol-5-yl)methylidene]-1,3-thiazolidine-2,4-dione Chemical compound C1=C2OC(F)(F)OC2=CC=C1\C=C1\SC(=O)NC1=O SRLVNYDXMUGOFI-XBXARRHUSA-N 0.000 description 2
- ZKZXNDJNWUTGDK-NSCUHMNNSA-N (E)-N-[2-(4-bromocinnamylamino)ethyl]isoquinoline-5-sulfonamide Chemical compound C1=CC(Br)=CC=C1\C=C\CNCCNS(=O)(=O)C1=CC=CC2=CN=CC=C12 ZKZXNDJNWUTGDK-NSCUHMNNSA-N 0.000 description 2
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 2
- LFWGZXMTCUOPFI-UHFFFAOYSA-N 2,3-diphenyl-6-quinoxalinecarboxylic acid Chemical compound C=1C=CC=CC=1C1=NC2=CC(C(=O)O)=CC=C2N=C1C1=CC=CC=C1 LFWGZXMTCUOPFI-UHFFFAOYSA-N 0.000 description 2
- QFWCYNPOPKQOKV-UHFFFAOYSA-N 2-(2-amino-3-methoxyphenyl)chromen-4-one Chemical compound COC1=CC=CC(C=2OC3=CC=CC=C3C(=O)C=2)=C1N QFWCYNPOPKQOKV-UHFFFAOYSA-N 0.000 description 2
- RZIDZIGAXXNODG-UHFFFAOYSA-N 4-[(4-chlorophenyl)methyl]-1-(7h-pyrrolo[2,3-d]pyrimidin-4-yl)piperidin-4-amine Chemical compound C1CN(C=2C=3C=CNC=3N=CN=2)CCC1(N)CC1=CC=C(Cl)C=C1 RZIDZIGAXXNODG-UHFFFAOYSA-N 0.000 description 2
- BYWWNRBKPCPJMG-UHFFFAOYSA-N 4-dodecyl-n-(1,3,4-thiadiazol-2-yl)benzenesulfonamide Chemical compound C1=CC(CCCCCCCCCCCC)=CC=C1S(=O)(=O)NC1=NN=CS1 BYWWNRBKPCPJMG-UHFFFAOYSA-N 0.000 description 2
- JYCQQPHGFMYQCF-UHFFFAOYSA-N 4-tert-Octylphenol monoethoxylate Chemical compound CC(C)(C)CC(C)(C)C1=CC=C(OCCO)C=C1 JYCQQPHGFMYQCF-UHFFFAOYSA-N 0.000 description 2
- FYVOJZAKVSEZOA-UHFFFAOYSA-N 5-(1H-pyrrol-2-yl)-1H-pyrazole Chemical compound C1=CNC(C2=NNC=C2)=C1 FYVOJZAKVSEZOA-UHFFFAOYSA-N 0.000 description 2
- NGFFVZQXSRKHBM-FKBYEOEOSA-N 5-[[(1r,1as,6br)-1-[6-(trifluoromethyl)-1h-benzimidazol-2-yl]-1a,6b-dihydro-1h-cyclopropa[b][1]benzofuran-5-yl]oxy]-3,4-dihydro-1h-1,8-naphthyridin-2-one Chemical compound N1C(=O)CCC2=C1N=CC=C2OC(C=C1[C@@H]23)=CC=C1O[C@@H]3[C@H]2C1=NC2=CC=C(C(F)(F)F)C=C2N1 NGFFVZQXSRKHBM-FKBYEOEOSA-N 0.000 description 2
- HBAQYPYDRFILMT-UHFFFAOYSA-N 8-[3-(1-cyclopropylpyrazol-4-yl)-1H-pyrazolo[4,3-d]pyrimidin-5-yl]-3-methyl-3,8-diazabicyclo[3.2.1]octan-2-one Chemical class C1(CC1)N1N=CC(=C1)C1=NNC2=C1N=C(N=C2)N1C2C(N(CC1CC2)C)=O HBAQYPYDRFILMT-UHFFFAOYSA-N 0.000 description 2
- HWUHTJIKQZZBRA-UHFFFAOYSA-N 8-[4-(1-aminocyclobutyl)phenyl]-9-phenyl-2h-[1,2,4]triazolo[3,4-f][1,6]naphthyridin-3-one;dihydrochloride Chemical compound Cl.Cl.C=1C=C(C=2C(=CC=3C=4N(C(NN=4)=O)C=CC=3N=2)C=2C=CC=CC=2)C=CC=1C1(N)CCC1 HWUHTJIKQZZBRA-UHFFFAOYSA-N 0.000 description 2
- 208000002874 Acne Vulgaris Diseases 0.000 description 2
- 229920001817 Agar Polymers 0.000 description 2
- 102000004625 Aspartate Aminotransferases Human genes 0.000 description 2
- 108010003415 Aspartate Aminotransferases Proteins 0.000 description 2
- 241000416162 Astragalus gummifer Species 0.000 description 2
- 241000193738 Bacillus anthracis Species 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- 208000003174 Brain Neoplasms Diseases 0.000 description 2
- 206010006187 Breast cancer Diseases 0.000 description 2
- 208000026310 Breast neoplasm Diseases 0.000 description 2
- VTYYLEPIZMXCLO-UHFFFAOYSA-L Calcium carbonate Chemical compound [Ca+2].[O-]C([O-])=O VTYYLEPIZMXCLO-UHFFFAOYSA-L 0.000 description 2
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 2
- 208000005623 Carcinogenesis Diseases 0.000 description 2
- 108010081668 Cytochrome P-450 CYP3A Proteins 0.000 description 2
- 102100039205 Cytochrome P450 3A4 Human genes 0.000 description 2
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 2
- 239000012623 DNA damaging agent Substances 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- 102100023275 Dual specificity mitogen-activated protein kinase kinase 3 Human genes 0.000 description 2
- 206010014733 Endometrial cancer Diseases 0.000 description 2
- 206010014759 Endometrial neoplasm Diseases 0.000 description 2
- 239000004606 Fillers/Extenders Substances 0.000 description 2
- VWUXBMIQPBEWFH-WCCTWKNTSA-N Fulvestrant Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3[C@H](CCCCCCCCCS(=O)CCCC(F)(F)C(F)(F)F)CC2=C1 VWUXBMIQPBEWFH-WCCTWKNTSA-N 0.000 description 2
- KGPGFQWBCSZGEL-ZDUSSCGKSA-N GSK690693 Chemical compound C=12N(CC)C(C=3C(=NON=3)N)=NC2=C(C#CC(C)(C)O)N=CC=1OC[C@H]1CCCNC1 KGPGFQWBCSZGEL-ZDUSSCGKSA-N 0.000 description 2
- 108010010803 Gelatin Proteins 0.000 description 2
- 241000206672 Gelidium Species 0.000 description 2
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 2
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 2
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 2
- 101710113864 Heat shock protein 90 Proteins 0.000 description 2
- 102100034051 Heat shock protein HSP 90-alpha Human genes 0.000 description 2
- 241000282412 Homo Species 0.000 description 2
- 101001115394 Homo sapiens Dual specificity mitogen-activated protein kinase kinase 3 Proteins 0.000 description 2
- 101001050288 Homo sapiens Transcription factor Jun Proteins 0.000 description 2
- 108060003951 Immunoglobulin Proteins 0.000 description 2
- 102000013462 Interleukin-12 Human genes 0.000 description 2
- 108010065805 Interleukin-12 Proteins 0.000 description 2
- 102000019145 JUN kinase activity proteins Human genes 0.000 description 2
- ZHEHVZXPFVXKEY-RUAOOFDTSA-N KT 5720 Chemical compound C12=C3N4C5=CC=CC=C5C3=C3CNC(=O)C3=C2C2=CC=CC=C2N1[C@@H]1C[C@](C(=O)OCCCCCC)(O)[C@@]4(C)O1 ZHEHVZXPFVXKEY-RUAOOFDTSA-N 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- 206010025323 Lymphomas Diseases 0.000 description 2
- 229940126560 MAPK inhibitor Drugs 0.000 description 2
- KPQQGHGDBBJGFA-QNGWXLTQSA-N MK-8353 Chemical compound C([C@@](C1)(SC)C(=O)NC=2C=C3C(C=4C=NC(OC(C)C)=CC=4)=NNC3=CC=2)CN1CC(=O)N(CC=1)CCC=1C(C=C1)=CC=C1C=1N=CN(C)N=1 KPQQGHGDBBJGFA-QNGWXLTQSA-N 0.000 description 2
- 229930195725 Mannitol Natural products 0.000 description 2
- 208000003445 Mouth Neoplasms Diseases 0.000 description 2
- 102000047918 Myelin Basic Human genes 0.000 description 2
- 101710107068 Myelin basic protein Proteins 0.000 description 2
- 201000003793 Myelodysplastic syndrome Diseases 0.000 description 2
- FCKJZIRDZMVDEM-UHFFFAOYSA-N N-(7,8-dimethoxy-2,3-dihydro-1H-imidazo[1,2-c]quinazolin-5-ylidene)pyridine-3-carboxamide Chemical compound COC1=C(C2=NC(=NC(=O)C3=CN=CC=C3)N4CCNC4=C2C=C1)OC FCKJZIRDZMVDEM-UHFFFAOYSA-N 0.000 description 2
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 2
- 206010061309 Neoplasm progression Diseases 0.000 description 2
- 208000034176 Neoplasms, Germ Cell and Embryonal Diseases 0.000 description 2
- 208000033383 Neuroendocrine tumor of pancreas Diseases 0.000 description 2
- 206010052399 Neuroendocrine tumour Diseases 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- 206010033128 Ovarian cancer Diseases 0.000 description 2
- 206010061535 Ovarian neoplasm Diseases 0.000 description 2
- 239000002033 PVDF binder Substances 0.000 description 2
- 239000002202 Polyethylene glycol Substances 0.000 description 2
- RJKFOVLPORLFTN-LEKSSAKUSA-N Progesterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)C)[C@@]1(C)CC2 RJKFOVLPORLFTN-LEKSSAKUSA-N 0.000 description 2
- 108010057464 Prolactin Proteins 0.000 description 2
- 102000003946 Prolactin Human genes 0.000 description 2
- 102000013009 Pyruvate Kinase Human genes 0.000 description 2
- 108020005115 Pyruvate Kinase Proteins 0.000 description 2
- 239000012083 RIPA buffer Substances 0.000 description 2
- 101710119197 Ribosomal protein S6 kinase alpha-1 Proteins 0.000 description 2
- 239000008156 Ringer's lactate solution Substances 0.000 description 2
- HDAJDNHIBCDLQF-RUZDIDTESA-N SCH772984 Chemical compound O=C([C@@H]1CCN(C1)CC(=O)N1CCN(CC1)C=1C=CC(=CC=1)C=1N=CC=CN=1)NC(C=C12)=CC=C1NN=C2C1=CC=NC=C1 HDAJDNHIBCDLQF-RUZDIDTESA-N 0.000 description 2
- 208000000453 Skin Neoplasms Diseases 0.000 description 2
- 108091027967 Small hairpin RNA Proteins 0.000 description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 description 2
- VWMJHAFYPMOMGF-ZCFIWIBFSA-N TAK-580 Chemical compound N([C@H](C)C=1SC(=CN=1)C(=O)NC=1N=CC(Cl)=C(C=1)C(F)(F)F)C(=O)C1=NC=NC(N)=C1Cl VWMJHAFYPMOMGF-ZCFIWIBFSA-N 0.000 description 2
- MUMGGOZAMZWBJJ-DYKIIFRCSA-N Testostosterone Chemical compound O=C1CC[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 MUMGGOZAMZWBJJ-DYKIIFRCSA-N 0.000 description 2
- 102000002938 Thrombospondin Human genes 0.000 description 2
- 108060008245 Thrombospondin Proteins 0.000 description 2
- 229920001615 Tragacanth Polymers 0.000 description 2
- 102000040945 Transcription factor Human genes 0.000 description 2
- 108091023040 Transcription factor Proteins 0.000 description 2
- 102100023132 Transcription factor Jun Human genes 0.000 description 2
- DTQVDTLACAAQTR-UHFFFAOYSA-N Trifluoroacetic acid Chemical compound OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 description 2
- 239000007983 Tris buffer Substances 0.000 description 2
- DVEXZJFMOKTQEZ-JYFOCSDGSA-N U0126 Chemical compound C=1C=CC=C(N)C=1SC(\N)=C(/C#N)\C(\C#N)=C(/N)SC1=CC=CC=C1N DVEXZJFMOKTQEZ-JYFOCSDGSA-N 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 2
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 2
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- XLOMVQKBTHCTTD-UHFFFAOYSA-N Zinc monoxide Chemical compound [Zn]=O XLOMVQKBTHCTTD-UHFFFAOYSA-N 0.000 description 2
- 230000001594 aberrant effect Effects 0.000 description 2
- 238000002835 absorbance Methods 0.000 description 2
- 239000002250 absorbent Substances 0.000 description 2
- 230000002745 absorbent Effects 0.000 description 2
- 238000009825 accumulation Methods 0.000 description 2
- 206010000496 acne Diseases 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 235000010419 agar Nutrition 0.000 description 2
- 235000010443 alginic acid Nutrition 0.000 description 2
- 229920000615 alginic acid Polymers 0.000 description 2
- 229940100198 alkylating agent Drugs 0.000 description 2
- 239000002168 alkylating agent Substances 0.000 description 2
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 2
- 229940024606 amino acid Drugs 0.000 description 2
- YBBLVLTVTVSKRW-UHFFFAOYSA-N anastrozole Chemical compound N#CC(C)(C)C1=CC(C(C)(C#N)C)=CC(CN2N=CN=C2)=C1 YBBLVLTVTVSKRW-UHFFFAOYSA-N 0.000 description 2
- 239000004037 angiogenesis inhibitor Substances 0.000 description 2
- 238000010171 animal model Methods 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 230000000340 anti-metabolite Effects 0.000 description 2
- 229940044684 anti-microtubule agent Drugs 0.000 description 2
- 230000001028 anti-proliverative effect Effects 0.000 description 2
- 230000006023 anti-tumor response Effects 0.000 description 2
- 229940088710 antibiotic agent Drugs 0.000 description 2
- 239000000427 antigen Substances 0.000 description 2
- 108091007433 antigens Proteins 0.000 description 2
- 102000036639 antigens Human genes 0.000 description 2
- 229940100197 antimetabolite Drugs 0.000 description 2
- 239000002256 antimetabolite Substances 0.000 description 2
- 239000003963 antioxidant agent Substances 0.000 description 2
- 230000001640 apoptogenic effect Effects 0.000 description 2
- 230000005756 apoptotic signaling Effects 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 238000011717 athymic nude mouse Methods 0.000 description 2
- 230000035578 autophosphorylation Effects 0.000 description 2
- 239000000440 bentonite Substances 0.000 description 2
- 229910000278 bentonite Inorganic materials 0.000 description 2
- SVPXDRXYRYOSEX-UHFFFAOYSA-N bentoquatam Chemical compound O.O=[Si]=O.O=[Al]O[Al]=O SVPXDRXYRYOSEX-UHFFFAOYSA-N 0.000 description 2
- SESFRYSPDFLNCH-UHFFFAOYSA-N benzyl benzoate Chemical compound C=1C=CC=CC=1C(=O)OCC1=CC=CC=C1 SESFRYSPDFLNCH-UHFFFAOYSA-N 0.000 description 2
- 229960000397 bevacizumab Drugs 0.000 description 2
- ACWZRVQXLIRSDF-UHFFFAOYSA-N binimetinib Chemical compound OCCONC(=O)C=1C=C2N(C)C=NC2=C(F)C=1NC1=CC=C(Br)C=C1F ACWZRVQXLIRSDF-UHFFFAOYSA-N 0.000 description 2
- 230000000903 blocking effect Effects 0.000 description 2
- 230000036952 cancer formation Effects 0.000 description 2
- 235000011089 carbon dioxide Nutrition 0.000 description 2
- 231100000504 carcinogenesis Toxicity 0.000 description 2
- 239000004359 castor oil Substances 0.000 description 2
- 235000019438 castor oil Nutrition 0.000 description 2
- 238000010370 cell cloning Methods 0.000 description 2
- 230000030833 cell death Effects 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 229920002678 cellulose Polymers 0.000 description 2
- 239000001913 cellulose Substances 0.000 description 2
- 235000010980 cellulose Nutrition 0.000 description 2
- 229940110456 cocoa butter Drugs 0.000 description 2
- 235000019868 cocoa butter Nutrition 0.000 description 2
- 238000004040 coloring Methods 0.000 description 2
- 238000011284 combination treatment Methods 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 238000013270 controlled release Methods 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 235000005687 corn oil Nutrition 0.000 description 2
- 239000002285 corn oil Substances 0.000 description 2
- 235000012343 cottonseed oil Nutrition 0.000 description 2
- 239000002385 cottonseed oil Substances 0.000 description 2
- 239000013078 crystal Substances 0.000 description 2
- 230000001186 cumulative effect Effects 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 231100000433 cytotoxic Toxicity 0.000 description 2
- 230000001472 cytotoxic effect Effects 0.000 description 2
- 229960003901 dacarbazine Drugs 0.000 description 2
- 238000007405 data analysis Methods 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 238000012350 deep sequencing Methods 0.000 description 2
- 230000018044 dehydration Effects 0.000 description 2
- 238000006297 dehydration reaction Methods 0.000 description 2
- 229960003964 deoxycholic acid Drugs 0.000 description 2
- 238000006471 dimerization reaction Methods 0.000 description 2
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 2
- 239000008298 dragée Substances 0.000 description 2
- 238000001962 electrophoresis Methods 0.000 description 2
- 230000005284 excitation Effects 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 206010017758 gastric cancer Diseases 0.000 description 2
- 230000002496 gastric effect Effects 0.000 description 2
- 239000008273 gelatin Substances 0.000 description 2
- 229920000159 gelatin Polymers 0.000 description 2
- 235000019322 gelatine Nutrition 0.000 description 2
- 235000011852 gelatine desserts Nutrition 0.000 description 2
- 238000010363 gene targeting Methods 0.000 description 2
- 230000008303 genetic mechanism Effects 0.000 description 2
- ZEMPKEQAKRGZGQ-XOQCFJPHSA-N glycerol triricinoleate Natural products CCCCCC[C@@H](O)CC=CCCCCCCCC(=O)OC[C@@H](COC(=O)CCCCCCCC=CC[C@@H](O)CCCCCC)OC(=O)CCCCCCCC=CC[C@H](O)CCCCCC ZEMPKEQAKRGZGQ-XOQCFJPHSA-N 0.000 description 2
- JYGXADMDTFJGBT-VWUMJDOOSA-N hydrocortisone Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 JYGXADMDTFJGBT-VWUMJDOOSA-N 0.000 description 2
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 2
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 2
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 2
- UFVKGYZPFZQRLF-UHFFFAOYSA-N hydroxypropyl methyl cellulose Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(OC3C(C(O)C(O)C(CO)O3)O)C(CO)O2)O)C(CO)O1 UFVKGYZPFZQRLF-UHFFFAOYSA-N 0.000 description 2
- 229960003445 idelalisib Drugs 0.000 description 2
- YKLIKGKUANLGSB-HNNXBMFYSA-N idelalisib Chemical compound C1([C@@H](NC=2[C]3N=CN=C3N=CN=2)CC)=NC2=CC=CC(F)=C2C(=O)N1C1=CC=CC=C1 YKLIKGKUANLGSB-HNNXBMFYSA-N 0.000 description 2
- 102000018358 immunoglobulin Human genes 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 230000005917 in vivo anti-tumor Effects 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- FABUFPQFXZVHFB-PVYNADRNSA-N ixabepilone Chemical compound C/C([C@@H]1C[C@@H]2O[C@]2(C)CCC[C@@H]([C@@H]([C@@H](C)C(=O)C(C)(C)[C@@H](O)CC(=O)N1)O)C)=C\C1=CSC(C)=N1 FABUFPQFXZVHFB-PVYNADRNSA-N 0.000 description 2
- 229940043355 kinase inhibitor Drugs 0.000 description 2
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical compound CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 2
- HPJKCIUCZWXJDR-UHFFFAOYSA-N letrozole Chemical compound C1=CC(C#N)=CC=C1C(N1N=CN=C1)C1=CC=C(C#N)C=C1 HPJKCIUCZWXJDR-UHFFFAOYSA-N 0.000 description 2
- 208000032839 leukemia Diseases 0.000 description 2
- 239000003446 ligand Substances 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 208000012987 lip and oral cavity carcinoma Diseases 0.000 description 2
- 238000001294 liquid chromatography-tandem mass spectrometry Methods 0.000 description 2
- 239000008297 liquid dosage form Substances 0.000 description 2
- 208000014018 liver neoplasm Diseases 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 239000000594 mannitol Substances 0.000 description 2
- 235000010355 mannitol Nutrition 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 2
- 230000010534 mechanism of action Effects 0.000 description 2
- 238000002844 melting Methods 0.000 description 2
- 230000008018 melting Effects 0.000 description 2
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 2
- 230000004060 metabolic process Effects 0.000 description 2
- 239000004530 micro-emulsion Substances 0.000 description 2
- 238000002493 microarray Methods 0.000 description 2
- 239000004005 microsphere Substances 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 238000000465 moulding Methods 0.000 description 2
- RDSACQWTXKSHJT-NSHDSACASA-N n-[3,4-difluoro-2-(2-fluoro-4-iodoanilino)-6-methoxyphenyl]-1-[(2s)-2,3-dihydroxypropyl]cyclopropane-1-sulfonamide Chemical compound C1CC1(C[C@H](O)CO)S(=O)(=O)NC=1C(OC)=CC(F)=C(F)C=1NC1=CC=C(I)C=C1F RDSACQWTXKSHJT-NSHDSACASA-N 0.000 description 2
- 230000009826 neoplastic cell growth Effects 0.000 description 2
- 208000016065 neuroendocrine neoplasm Diseases 0.000 description 2
- 201000011519 neuroendocrine tumor Diseases 0.000 description 2
- 208000026878 nongerminomatous germ cell tumor Diseases 0.000 description 2
- 230000009437 off-target effect Effects 0.000 description 2
- 239000004006 olive oil Substances 0.000 description 2
- 235000008390 olive oil Nutrition 0.000 description 2
- 201000008968 osteosarcoma Diseases 0.000 description 2
- 208000021010 pancreatic neuroendocrine tumor Diseases 0.000 description 2
- YBYRMVIVWMBXKQ-UHFFFAOYSA-N phenylmethanesulfonyl fluoride Chemical compound FS(=O)(=O)CC1=CC=CC=C1 YBYRMVIVWMBXKQ-UHFFFAOYSA-N 0.000 description 2
- 239000002953 phosphate buffered saline Substances 0.000 description 2
- 229930029653 phosphoenolpyruvate Natural products 0.000 description 2
- DTBNBXWJWCWCIK-UHFFFAOYSA-N phosphoenolpyruvic acid Chemical compound OC(=O)C(=C)OP(O)(O)=O DTBNBXWJWCWCIK-UHFFFAOYSA-N 0.000 description 2
- 239000003757 phosphotransferase inhibitor Substances 0.000 description 2
- 230000006461 physiological response Effects 0.000 description 2
- 210000004180 plasmocyte Anatomy 0.000 description 2
- 229910052697 platinum Inorganic materials 0.000 description 2
- 229920001296 polysiloxane Polymers 0.000 description 2
- 230000001124 posttranscriptional effect Effects 0.000 description 2
- 230000007015 preclinical effect Effects 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 230000000750 progressive effect Effects 0.000 description 2
- 229940097325 prolactin Drugs 0.000 description 2
- BDERNNFJNOPAEC-UHFFFAOYSA-N propan-1-ol Chemical compound CCCO BDERNNFJNOPAEC-UHFFFAOYSA-N 0.000 description 2
- 239000003380 propellant Substances 0.000 description 2
- 229960004063 propylene glycol Drugs 0.000 description 2
- 238000010814 radioimmunoprecipitation assay Methods 0.000 description 2
- 108010014186 ras Proteins Proteins 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 229960004641 rituximab Drugs 0.000 description 2
- 210000003296 saliva Anatomy 0.000 description 2
- 239000012723 sample buffer Substances 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 239000008159 sesame oil Substances 0.000 description 2
- 235000011803 sesame oil Nutrition 0.000 description 2
- 235000012239 silicon dioxide Nutrition 0.000 description 2
- 210000003491 skin Anatomy 0.000 description 2
- 201000000849 skin cancer Diseases 0.000 description 2
- FHHPUSMSKHSNKW-SMOYURAASA-M sodium deoxycholate Chemical compound [Na+].C([C@H]1CC2)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC([O-])=O)C)[C@@]2(C)[C@@H](O)C1 FHHPUSMSKHSNKW-SMOYURAASA-M 0.000 description 2
- 239000007909 solid dosage form Substances 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 230000000638 stimulation Effects 0.000 description 2
- 201000011549 stomach cancer Diseases 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 239000000829 suppository Substances 0.000 description 2
- 239000003765 sweetening agent Substances 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- LBTVHXHERHESKG-UHFFFAOYSA-N tetrahydrocurcumin Chemical compound C1=C(O)C(OC)=CC(CCC(=O)CC(=O)CCC=2C=C(OC)C(O)=CC=2)=C1 LBTVHXHERHESKG-UHFFFAOYSA-N 0.000 description 2
- 239000002562 thickening agent Substances 0.000 description 2
- 238000004448 titration Methods 0.000 description 2
- 238000000954 titration curve Methods 0.000 description 2
- 230000000699 topical effect Effects 0.000 description 2
- 235000010487 tragacanth Nutrition 0.000 description 2
- 239000000196 tragacanth Substances 0.000 description 2
- 229940116362 tragacanth Drugs 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 238000002054 transplantation Methods 0.000 description 2
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical class [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 2
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 2
- 230000005751 tumor progression Effects 0.000 description 2
- 231100000402 unacceptable toxicity Toxicity 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- 239000013598 vector Substances 0.000 description 2
- 238000013389 whole blood assay Methods 0.000 description 2
- 229940034727 zelboraf Drugs 0.000 description 2
- DNXHEGUUPJUMQT-UHFFFAOYSA-N (+)-estrone Natural products OC1=CC=C2C3CCC(C)(C(CC4)=O)C4C3CCC2=C1 DNXHEGUUPJUMQT-UHFFFAOYSA-N 0.000 description 1
- PROQIPRRNZUXQM-UHFFFAOYSA-N (16alpha,17betaOH)-Estra-1,3,5(10)-triene-3,16,17-triol Natural products OC1=CC=C2C3CCC(C)(C(C(O)C4)O)C4C3CCC2=C1 PROQIPRRNZUXQM-UHFFFAOYSA-N 0.000 description 1
- ASGMFNBUXDJWJJ-JLCFBVMHSA-N (1R,3R)-3-[[3-bromo-1-[4-(5-methyl-1,3,4-thiadiazol-2-yl)phenyl]pyrazolo[3,4-d]pyrimidin-6-yl]amino]-N,1-dimethylcyclopentane-1-carboxamide Chemical compound BrC1=NN(C2=NC(=NC=C21)N[C@H]1C[C@@](CC1)(C(=O)NC)C)C1=CC=C(C=C1)C=1SC(=NN=1)C ASGMFNBUXDJWJJ-JLCFBVMHSA-N 0.000 description 1
- UAOUIVVJBYDFKD-XKCDOFEDSA-N (1R,9R,10S,11R,12R,15S,18S,21R)-10,11,21-trihydroxy-8,8-dimethyl-14-methylidene-4-(prop-2-enylamino)-20-oxa-5-thia-3-azahexacyclo[9.7.2.112,15.01,9.02,6.012,18]henicosa-2(6),3-dien-13-one Chemical compound C([C@@H]1[C@@H](O)[C@@]23C(C1=C)=O)C[C@H]2[C@]12C(N=C(NCC=C)S4)=C4CC(C)(C)[C@H]1[C@H](O)[C@]3(O)OC2 UAOUIVVJBYDFKD-XKCDOFEDSA-N 0.000 description 1
- ABJSOROVZZKJGI-OCYUSGCXSA-N (1r,2r,4r)-2-(4-bromophenyl)-n-[(4-chlorophenyl)-(2-fluoropyridin-4-yl)methyl]-4-morpholin-4-ylcyclohexane-1-carboxamide Chemical compound C1=NC(F)=CC(C(NC(=O)[C@H]2[C@@H](C[C@@H](CC2)N2CCOCC2)C=2C=CC(Br)=CC=2)C=2C=CC(Cl)=CC=2)=C1 ABJSOROVZZKJGI-OCYUSGCXSA-N 0.000 description 1
- SZUVGFMDDVSKSI-WIFOCOSTSA-N (1s,2s,3s,5r)-1-(carboxymethyl)-3,5-bis[(4-phenoxyphenyl)methyl-propylcarbamoyl]cyclopentane-1,2-dicarboxylic acid Chemical compound O=C([C@@H]1[C@@H]([C@](CC(O)=O)([C@H](C(=O)N(CCC)CC=2C=CC(OC=3C=CC=CC=3)=CC=2)C1)C(O)=O)C(O)=O)N(CCC)CC(C=C1)=CC=C1OC1=CC=CC=C1 SZUVGFMDDVSKSI-WIFOCOSTSA-N 0.000 description 1
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 1
- IUSARDYWEPUTPN-OZBXUNDUSA-N (2r)-n-[(2s,3r)-4-[[(4s)-6-(2,2-dimethylpropyl)spiro[3,4-dihydropyrano[2,3-b]pyridine-2,1'-cyclobutane]-4-yl]amino]-3-hydroxy-1-[3-(1,3-thiazol-2-yl)phenyl]butan-2-yl]-2-methoxypropanamide Chemical compound C([C@H](NC(=O)[C@@H](C)OC)[C@H](O)CN[C@@H]1C2=CC(CC(C)(C)C)=CN=C2OC2(CCC2)C1)C(C=1)=CC=CC=1C1=NC=CS1 IUSARDYWEPUTPN-OZBXUNDUSA-N 0.000 description 1
- AXFMEGAFCUULFV-BLFANLJRSA-N (2s)-2-[[(2s)-1-[(2s,3r)-2-amino-3-methylpentanoyl]pyrrolidine-2-carbonyl]amino]pentanedioic acid Chemical compound CC[C@@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AXFMEGAFCUULFV-BLFANLJRSA-N 0.000 description 1
- WWTBZEKOSBFBEM-SPWPXUSOSA-N (2s)-2-[[2-benzyl-3-[hydroxy-[(1r)-2-phenyl-1-(phenylmethoxycarbonylamino)ethyl]phosphoryl]propanoyl]amino]-3-(1h-indol-3-yl)propanoic acid Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)O)C(=O)C(CP(O)(=O)[C@H](CC=1C=CC=CC=1)NC(=O)OCC=1C=CC=CC=1)CC1=CC=CC=C1 WWTBZEKOSBFBEM-SPWPXUSOSA-N 0.000 description 1
- STBLNCCBQMHSRC-BATDWUPUSA-N (2s)-n-[(3s,4s)-5-acetyl-7-cyano-4-methyl-1-[(2-methylnaphthalen-1-yl)methyl]-2-oxo-3,4-dihydro-1,5-benzodiazepin-3-yl]-2-(methylamino)propanamide Chemical compound O=C1[C@@H](NC(=O)[C@H](C)NC)[C@H](C)N(C(C)=O)C2=CC(C#N)=CC=C2N1CC1=C(C)C=CC2=CC=CC=C12 STBLNCCBQMHSRC-BATDWUPUSA-N 0.000 description 1
- IWZSHWBGHQBIML-ZGGLMWTQSA-N (3S,8S,10R,13S,14S,17S)-17-isoquinolin-7-yl-N,N,10,13-tetramethyl-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1H-cyclopenta[a]phenanthren-3-amine Chemical compound CN(C)[C@H]1CC[C@]2(C)C3CC[C@@]4(C)[C@@H](CC[C@@H]4c4ccc5ccncc5c4)[C@@H]3CC=C2C1 IWZSHWBGHQBIML-ZGGLMWTQSA-N 0.000 description 1
- HUWSZNZAROKDRZ-RRLWZMAJSA-N (3r,4r)-3-azaniumyl-5-[[(2s,3r)-1-[(2s)-2,3-dicarboxypyrrolidin-1-yl]-3-methyl-1-oxopentan-2-yl]amino]-5-oxo-4-sulfanylpentane-1-sulfonate Chemical compound OS(=O)(=O)CC[C@@H](N)[C@@H](S)C(=O)N[C@@H]([C@H](C)CC)C(=O)N1CCC(C(O)=O)[C@H]1C(O)=O HUWSZNZAROKDRZ-RRLWZMAJSA-N 0.000 description 1
- IUGRBTCJEYEDIY-VZUCSPMQSA-N (e)-2-(3,4-dihydroxybenzoyl)-3-(2-oxo-3h-1,3-benzoxazol-5-yl)prop-2-enenitrile Chemical compound C1=C(O)C(O)=CC=C1C(=O)C(\C#N)=C\C1=CC=C(OC(=O)N2)C2=C1 IUGRBTCJEYEDIY-VZUCSPMQSA-N 0.000 description 1
- 229940058015 1,3-butylene glycol Drugs 0.000 description 1
- KSJVAYBCXSURMQ-UHFFFAOYSA-N 1-(3-chloro-4-methylphenyl)-3-[2,6-dinitro-4-(trifluoromethyl)anilino]thiourea Chemical compound C1=C(Cl)C(C)=CC=C1NC(=S)NNC1=C([N+]([O-])=O)C=C(C(F)(F)F)C=C1[N+]([O-])=O KSJVAYBCXSURMQ-UHFFFAOYSA-N 0.000 description 1
- KQZLRWGGWXJPOS-NLFPWZOASA-N 1-[(1R)-1-(2,4-dichlorophenyl)ethyl]-6-[(4S,5R)-4-[(2S)-2-(hydroxymethyl)pyrrolidin-1-yl]-5-methylcyclohexen-1-yl]pyrazolo[3,4-b]pyrazine-3-carbonitrile Chemical compound ClC1=C(C=CC(=C1)Cl)[C@@H](C)N1N=C(C=2C1=NC(=CN=2)C1=CC[C@@H]([C@@H](C1)C)N1[C@@H](CCC1)CO)C#N KQZLRWGGWXJPOS-NLFPWZOASA-N 0.000 description 1
- WZZBNLYBHUDSHF-DHLKQENFSA-N 1-[(3s,4s)-4-[8-(2-chloro-4-pyrimidin-2-yloxyphenyl)-7-fluoro-2-methylimidazo[4,5-c]quinolin-1-yl]-3-fluoropiperidin-1-yl]-2-hydroxyethanone Chemical compound CC1=NC2=CN=C3C=C(F)C(C=4C(=CC(OC=5N=CC=CN=5)=CC=4)Cl)=CC3=C2N1[C@H]1CCN(C(=O)CO)C[C@@H]1F WZZBNLYBHUDSHF-DHLKQENFSA-N 0.000 description 1
- NNPBSITXCGPXJC-UHFFFAOYSA-N 1-[2,6-dinitro-4-(trifluoromethyl)anilino]-3-(4-fluorophenyl)thiourea Chemical compound [O-][N+](=O)C1=CC(C(F)(F)F)=CC([N+]([O-])=O)=C1NNC(=S)NC1=CC=C(F)C=C1 NNPBSITXCGPXJC-UHFFFAOYSA-N 0.000 description 1
- ONBQEOIKXPHGMB-VBSBHUPXSA-N 1-[2-[(2s,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]oxy-4,6-dihydroxyphenyl]-3-(4-hydroxyphenyl)propan-1-one Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1OC1=CC(O)=CC(O)=C1C(=O)CCC1=CC=C(O)C=C1 ONBQEOIKXPHGMB-VBSBHUPXSA-N 0.000 description 1
- UNILWMWFPHPYOR-KXEYIPSPSA-M 1-[6-[2-[3-[3-[3-[2-[2-[3-[[2-[2-[[(2r)-1-[[2-[[(2r)-1-[3-[2-[2-[3-[[2-(2-amino-2-oxoethoxy)acetyl]amino]propoxy]ethoxy]ethoxy]propylamino]-3-hydroxy-1-oxopropan-2-yl]amino]-2-oxoethyl]amino]-3-[(2r)-2,3-di(hexadecanoyloxy)propyl]sulfanyl-1-oxopropan-2-yl Chemical compound O=C1C(SCCC(=O)NCCCOCCOCCOCCCNC(=O)COCC(=O)N[C@@H](CSC[C@@H](COC(=O)CCCCCCCCCCCCCCC)OC(=O)CCCCCCCCCCCCCCC)C(=O)NCC(=O)N[C@H](CO)C(=O)NCCCOCCOCCOCCCNC(=O)COCC(N)=O)CC(=O)N1CCNC(=O)CCCCCN\1C2=CC=C(S([O-])(=O)=O)C=C2CC/1=C/C=C/C=C/C1=[N+](CC)C2=CC=C(S([O-])(=O)=O)C=C2C1 UNILWMWFPHPYOR-KXEYIPSPSA-M 0.000 description 1
- YABJJWZLRMPFSI-UHFFFAOYSA-N 1-methyl-5-[[2-[5-(trifluoromethyl)-1H-imidazol-2-yl]-4-pyridinyl]oxy]-N-[4-(trifluoromethyl)phenyl]-2-benzimidazolamine Chemical compound N=1C2=CC(OC=3C=C(N=CC=3)C=3NC(=CN=3)C(F)(F)F)=CC=C2N(C)C=1NC1=CC=C(C(F)(F)F)C=C1 YABJJWZLRMPFSI-UHFFFAOYSA-N 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- WNWHHMBRJJOGFJ-UHFFFAOYSA-N 16-methylheptadecan-1-ol Chemical class CC(C)CCCCCCCCCCCCCCCO WNWHHMBRJJOGFJ-UHFFFAOYSA-N 0.000 description 1
- NVKAWKQGWWIWPM-ABEVXSGRSA-N 17-β-hydroxy-5-α-Androstan-3-one Chemical compound C1C(=O)CC[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CC[C@H]21 NVKAWKQGWWIWPM-ABEVXSGRSA-N 0.000 description 1
- VOXZDWNPVJITMN-ZBRFXRBCSA-N 17β-estradiol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 VOXZDWNPVJITMN-ZBRFXRBCSA-N 0.000 description 1
- UEJJHQNACJXSKW-UHFFFAOYSA-N 2-(2,6-dioxopiperidin-3-yl)-1H-isoindole-1,3(2H)-dione Chemical compound O=C1C2=CC=CC=C2C(=O)N1C1CCC(=O)NC1=O UEJJHQNACJXSKW-UHFFFAOYSA-N 0.000 description 1
- GFMMXOIFOQCCGU-UHFFFAOYSA-N 2-(2-chloro-4-iodoanilino)-N-(cyclopropylmethoxy)-3,4-difluorobenzamide Chemical compound C=1C=C(I)C=C(Cl)C=1NC1=C(F)C(F)=CC=C1C(=O)NOCC1CC1 GFMMXOIFOQCCGU-UHFFFAOYSA-N 0.000 description 1
- JCTJISIFGZHOFY-UHFFFAOYSA-N 2-(4,6-dichloro-2-methyl-1h-indol-3-yl)ethanamine Chemical compound ClC1=CC(Cl)=C2C(CCN)=C(C)NC2=C1 JCTJISIFGZHOFY-UHFFFAOYSA-N 0.000 description 1
- SCSSXJVRZMQUKA-UHFFFAOYSA-N 2-(9h-fluoren-9-ylmethoxycarbonylamino)-3-pyridin-4-ylpropanoic acid Chemical compound C12=CC=CC=C2C2=CC=CC=C2C1COC(=O)NC(C(=O)O)CC1=CC=NC=C1 SCSSXJVRZMQUKA-UHFFFAOYSA-N 0.000 description 1
- PUYVJBBSBPUKBT-AWEZNQCLSA-N 2-[(1s)-1-[(2-amino-7h-purin-6-yl)amino]ethyl]-5-methyl-3-(2-methylphenyl)quinazolin-4-one Chemical compound C1([C@@H](NC=2C=3NC=NC=3N=C(N)N=2)C)=NC2=CC=CC(C)=C2C(=O)N1C1=CC=CC=C1C PUYVJBBSBPUKBT-AWEZNQCLSA-N 0.000 description 1
- VHVPQPYKVGDNFY-DFMJLFEVSA-N 2-[(2r)-butan-2-yl]-4-[4-[4-[4-[[(2r,4s)-2-(2,4-dichlorophenyl)-2-(1,2,4-triazol-1-ylmethyl)-1,3-dioxolan-4-yl]methoxy]phenyl]piperazin-1-yl]phenyl]-1,2,4-triazol-3-one Chemical compound O=C1N([C@H](C)CC)N=CN1C1=CC=C(N2CCN(CC2)C=2C=CC(OC[C@@H]3O[C@](CN4N=CN=C4)(OC3)C=3C(=CC(Cl)=CC=3)Cl)=CC=2)C=C1 VHVPQPYKVGDNFY-DFMJLFEVSA-N 0.000 description 1
- RTQWWZBSTRGEAV-PKHIMPSTSA-N 2-[[(2s)-2-[bis(carboxymethyl)amino]-3-[4-(methylcarbamoylamino)phenyl]propyl]-[2-[bis(carboxymethyl)amino]propyl]amino]acetic acid Chemical compound CNC(=O)NC1=CC=C(C[C@@H](CN(CC(C)N(CC(O)=O)CC(O)=O)CC(O)=O)N(CC(O)=O)CC(O)=O)C=C1 RTQWWZBSTRGEAV-PKHIMPSTSA-N 0.000 description 1
- XJFPXLWGZWAWRQ-UHFFFAOYSA-N 2-[[2-[[2-[[2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]acetyl]amino]acetate Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)NCC(=O)NCC(O)=O XJFPXLWGZWAWRQ-UHFFFAOYSA-N 0.000 description 1
- YSUIQYOGTINQIN-UZFYAQMZSA-N 2-amino-9-[(1S,6R,8R,9S,10R,15R,17R,18R)-8-(6-aminopurin-9-yl)-9,18-difluoro-3,12-dihydroxy-3,12-bis(sulfanylidene)-2,4,7,11,13,16-hexaoxa-3lambda5,12lambda5-diphosphatricyclo[13.2.1.06,10]octadecan-17-yl]-1H-purin-6-one Chemical compound NC1=NC2=C(N=CN2[C@@H]2O[C@@H]3COP(S)(=O)O[C@@H]4[C@@H](COP(S)(=O)O[C@@H]2[C@@H]3F)O[C@H]([C@H]4F)N2C=NC3=C2N=CN=C3N)C(=O)N1 YSUIQYOGTINQIN-UZFYAQMZSA-N 0.000 description 1
- TVTJUIAKQFIXCE-HUKYDQBMSA-N 2-amino-9-[(2R,3S,4S,5R)-4-fluoro-3-hydroxy-5-(hydroxymethyl)oxolan-2-yl]-7-prop-2-ynyl-1H-purine-6,8-dione Chemical compound NC=1NC(C=2N(C(N(C=2N=1)[C@@H]1O[C@@H]([C@H]([C@H]1O)F)CO)=O)CC#C)=O TVTJUIAKQFIXCE-HUKYDQBMSA-N 0.000 description 1
- NPRYCHLHHVWLQZ-TURQNECASA-N 2-amino-9-[(2R,3S,4S,5R)-4-fluoro-3-hydroxy-5-(hydroxymethyl)oxolan-2-yl]-7-prop-2-ynylpurin-8-one Chemical compound NC1=NC=C2N(C(N(C2=N1)[C@@H]1O[C@@H]([C@H]([C@H]1O)F)CO)=O)CC#C NPRYCHLHHVWLQZ-TURQNECASA-N 0.000 description 1
- NMYLSLKWQQWWSC-GWTDSMLYSA-N 2-amino-9-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-3h-purin-6-one;phosphoric acid Chemical compound OP(O)(O)=O.C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NMYLSLKWQQWWSC-GWTDSMLYSA-N 0.000 description 1
- AOYNUTHNTBLRMT-SLPGGIOYSA-N 2-deoxy-2-fluoro-aldehydo-D-glucose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](F)C=O AOYNUTHNTBLRMT-SLPGGIOYSA-N 0.000 description 1
- JNODDICFTDYODH-UHFFFAOYSA-N 2-hydroxytetrahydrofuran Chemical compound OC1CCCO1 JNODDICFTDYODH-UHFFFAOYSA-N 0.000 description 1
- CQOQDQWUFQDJMK-SSTWWWIQSA-N 2-methoxy-17beta-estradiol Chemical compound C([C@@H]12)C[C@]3(C)[C@@H](O)CC[C@H]3[C@@H]1CCC1=C2C=C(OC)C(O)=C1 CQOQDQWUFQDJMK-SSTWWWIQSA-N 0.000 description 1
- FIMYFEGKMOCQKT-UHFFFAOYSA-N 3,4-difluoro-2-(2-fluoro-4-iodoanilino)-n-(2-hydroxyethoxy)-5-[(3-oxooxazinan-2-yl)methyl]benzamide Chemical compound FC=1C(F)=C(NC=2C(=CC(I)=CC=2)F)C(C(=O)NOCCO)=CC=1CN1OCCCC1=O FIMYFEGKMOCQKT-UHFFFAOYSA-N 0.000 description 1
- QBWKPGNFQQJGFY-QLFBSQMISA-N 3-[(1r)-1-[(2r,6s)-2,6-dimethylmorpholin-4-yl]ethyl]-n-[6-methyl-3-(1h-pyrazol-4-yl)imidazo[1,2-a]pyrazin-8-yl]-1,2-thiazol-5-amine Chemical compound N1([C@H](C)C2=NSC(NC=3C4=NC=C(N4C=C(C)N=3)C3=CNN=C3)=C2)C[C@H](C)O[C@H](C)C1 QBWKPGNFQQJGFY-QLFBSQMISA-N 0.000 description 1
- RCLQNICOARASSR-SECBINFHSA-N 3-[(2r)-2,3-dihydroxypropyl]-6-fluoro-5-(2-fluoro-4-iodoanilino)-8-methylpyrido[2,3-d]pyrimidine-4,7-dione Chemical compound FC=1C(=O)N(C)C=2N=CN(C[C@@H](O)CO)C(=O)C=2C=1NC1=CC=C(I)C=C1F RCLQNICOARASSR-SECBINFHSA-N 0.000 description 1
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 1
- SGOOQMRIPALTEL-UHFFFAOYSA-N 4-hydroxy-N,1-dimethyl-2-oxo-N-phenyl-3-quinolinecarboxamide Chemical compound OC=1C2=CC=CC=C2N(C)C(=O)C=1C(=O)N(C)C1=CC=CC=C1 SGOOQMRIPALTEL-UHFFFAOYSA-N 0.000 description 1
- SDGWAUUPHUBJNQ-UHFFFAOYSA-N 5-(1,3-benzodioxol-5-ylmethylidene)-1,3-thiazolidine-2,4-dione Chemical compound S1C(=O)NC(=O)C1=CC1=CC=C(OCO2)C2=C1 SDGWAUUPHUBJNQ-UHFFFAOYSA-N 0.000 description 1
- IDPUKCWIGUEADI-UHFFFAOYSA-N 5-[bis(2-chloroethyl)amino]uracil Chemical compound ClCCN(CCCl)C1=CNC(=O)NC1=O IDPUKCWIGUEADI-UHFFFAOYSA-N 0.000 description 1
- XAUDJQYHKZQPEU-KVQBGUIXSA-N 5-aza-2'-deoxycytidine Chemical compound O=C1N=C(N)N=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 XAUDJQYHKZQPEU-KVQBGUIXSA-N 0.000 description 1
- LVRVABPNVHYXRT-BQWXUCBYSA-N 52906-92-0 Chemical compound C([C@H](N)C(=O)N[C@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)C(C)C)C1=CC=CC=C1 LVRVABPNVHYXRT-BQWXUCBYSA-N 0.000 description 1
- DOCINCLJNAXZQF-LBPRGKRZSA-N 6-fluoro-3-phenyl-2-[(1s)-1-(7h-purin-6-ylamino)ethyl]quinazolin-4-one Chemical compound C1([C@@H](NC=2C=3N=CNC=3N=CN=2)C)=NC2=CC=C(F)C=C2C(=O)N1C1=CC=CC=C1 DOCINCLJNAXZQF-LBPRGKRZSA-N 0.000 description 1
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 1
- HFDKKNHCYWNNNQ-YOGANYHLSA-N 75976-10-2 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(N)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@@H](NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](C)N)C(C)C)[C@@H](C)O)C1=CC=C(O)C=C1 HFDKKNHCYWNNNQ-YOGANYHLSA-N 0.000 description 1
- SJVQHLPISAIATJ-ZDUSSCGKSA-N 8-chloro-2-phenyl-3-[(1S)-1-(7H-purin-6-ylamino)ethyl]-1-isoquinolinone Chemical compound C1([C@@H](NC=2C=3N=CNC=3N=CN=2)C)=CC2=CC=CC(Cl)=C2C(=O)N1C1=CC=CC=C1 SJVQHLPISAIATJ-ZDUSSCGKSA-N 0.000 description 1
- 208000002008 AIDS-Related Lymphoma Diseases 0.000 description 1
- 102100033793 ALK tyrosine kinase receptor Human genes 0.000 description 1
- 101710168331 ALK tyrosine kinase receptor Proteins 0.000 description 1
- 229960005531 AMG 319 Drugs 0.000 description 1
- 108010076365 Adiponectin Proteins 0.000 description 1
- 102000011690 Adiponectin Human genes 0.000 description 1
- 239000000275 Adrenocorticotropic Hormone Substances 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 1
- VBRDBGCROKWTPV-XHNCKOQMSA-N Ala-Glu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N VBRDBGCROKWTPV-XHNCKOQMSA-N 0.000 description 1
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 1
- VWEWCZSUWOEEFM-WDSKDSINSA-N Ala-Gly-Ala-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(=O)NCC(O)=O VWEWCZSUWOEEFM-WDSKDSINSA-N 0.000 description 1
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 1
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 1
- PQSUYGKTWSAVDQ-ZVIOFETBSA-N Aldosterone Chemical compound C([C@@]1([C@@H](C(=O)CO)CC[C@H]1[C@@H]1CC2)C=O)[C@H](O)[C@@H]1[C@]1(C)C2=CC(=O)CC1 PQSUYGKTWSAVDQ-ZVIOFETBSA-N 0.000 description 1
- PQSUYGKTWSAVDQ-UHFFFAOYSA-N Aldosterone Natural products C1CC2C3CCC(C(=O)CO)C3(C=O)CC(O)C2C2(C)C1=CC(=O)CC2 PQSUYGKTWSAVDQ-UHFFFAOYSA-N 0.000 description 1
- 201000004384 Alopecia Diseases 0.000 description 1
- 239000005995 Aluminium silicate Substances 0.000 description 1
- 108091093088 Amplicon Proteins 0.000 description 1
- 206010061424 Anal cancer Diseases 0.000 description 1
- 102400000068 Angiostatin Human genes 0.000 description 1
- 108010079709 Angiostatins Proteins 0.000 description 1
- 102000004881 Angiotensinogen Human genes 0.000 description 1
- 108090001067 Angiotensinogen Proteins 0.000 description 1
- 102000015427 Angiotensins Human genes 0.000 description 1
- 108010064733 Angiotensins Proteins 0.000 description 1
- 208000007860 Anus Neoplasms Diseases 0.000 description 1
- 206010073360 Appendix cancer Diseases 0.000 description 1
- 101100455868 Arabidopsis thaliana MKK2 gene Proteins 0.000 description 1
- 244000105624 Arachis hypogaea Species 0.000 description 1
- 241001415342 Ardea Species 0.000 description 1
- YWLDTBBUHZJQHW-KKUMJFAQSA-N Asp-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N YWLDTBBUHZJQHW-KKUMJFAQSA-N 0.000 description 1
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 1
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 1
- MLDQJTXFUGDVEO-UHFFFAOYSA-N BAY-43-9006 Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=CC(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 MLDQJTXFUGDVEO-UHFFFAOYSA-N 0.000 description 1
- 238000009020 BCA Protein Assay Kit Methods 0.000 description 1
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 1
- 206010004593 Bile duct cancer Diseases 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 206010005949 Bone cancer Diseases 0.000 description 1
- 208000018084 Bone neoplasm Diseases 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 102400000667 Brain natriuretic peptide 32 Human genes 0.000 description 1
- 101800000407 Brain natriuretic peptide 32 Proteins 0.000 description 1
- 101800002247 Brain natriuretic peptide 45 Proteins 0.000 description 1
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 1
- 102100021935 C-C motif chemokine 26 Human genes 0.000 description 1
- 101100026251 Caenorhabditis elegans atf-2 gene Proteins 0.000 description 1
- 235000021318 Calcifediol Nutrition 0.000 description 1
- 108060001064 Calcitonin Proteins 0.000 description 1
- 102000055006 Calcitonin Human genes 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 description 1
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 201000009030 Carcinoma Diseases 0.000 description 1
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 1
- 108090000397 Caspase 3 Proteins 0.000 description 1
- 108090000567 Caspase 7 Proteins 0.000 description 1
- 238000003731 Caspase Glo 3/7 Assay Methods 0.000 description 1
- 102100029855 Caspase-3 Human genes 0.000 description 1
- 102100038902 Caspase-7 Human genes 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 206010007953 Central nervous system lymphoma Diseases 0.000 description 1
- 208000003569 Central serous chorioretinopathy Diseases 0.000 description 1
- 206010008342 Cervix carcinoma Diseases 0.000 description 1
- 101800001982 Cholecystokinin Proteins 0.000 description 1
- 102100025841 Cholecystokinin Human genes 0.000 description 1
- 102000011022 Chorionic Gonadotropin Human genes 0.000 description 1
- 108010062540 Chorionic Gonadotropin Proteins 0.000 description 1
- 208000033379 Chorioretinopathy Diseases 0.000 description 1
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 229940126639 Compound 33 Drugs 0.000 description 1
- 229940127007 Compound 39 Drugs 0.000 description 1
- 208000032170 Congenital Abnormalities Diseases 0.000 description 1
- 206010010356 Congenital anomaly Diseases 0.000 description 1
- 206010010774 Constipation Diseases 0.000 description 1
- 102400000739 Corticotropin Human genes 0.000 description 1
- 101800000414 Corticotropin Proteins 0.000 description 1
- 108010022152 Corticotropin-Releasing Hormone Proteins 0.000 description 1
- 102000012289 Corticotropin-Releasing Hormone Human genes 0.000 description 1
- 239000000055 Corticotropin-Releasing Hormone Substances 0.000 description 1
- 229920002785 Croscarmellose sodium Polymers 0.000 description 1
- 102000016736 Cyclin Human genes 0.000 description 1
- 108050006400 Cyclin Proteins 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 1
- 108010074922 Cytochrome P-450 CYP1A2 Proteins 0.000 description 1
- 108010001237 Cytochrome P-450 CYP2D6 Proteins 0.000 description 1
- 102100026533 Cytochrome P450 1A2 Human genes 0.000 description 1
- 102100021704 Cytochrome P450 2D6 Human genes 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- 239000012624 DNA alkylating agent Substances 0.000 description 1
- 230000004544 DNA amplification Effects 0.000 description 1
- 230000004543 DNA replication Effects 0.000 description 1
- 108010092160 Dactinomycin Proteins 0.000 description 1
- 208000005156 Dehydration Diseases 0.000 description 1
- FMGSKLZLMKYGDP-UHFFFAOYSA-N Dehydroepiandrosterone Natural products C1C(O)CCC2(C)C3CCC(C)(C(CC4)=O)C4C3CC=C21 FMGSKLZLMKYGDP-UHFFFAOYSA-N 0.000 description 1
- 101710088194 Dehydrogenase Proteins 0.000 description 1
- 235000019739 Dicalciumphosphate Nutrition 0.000 description 1
- 102000016607 Diphtheria Toxin Human genes 0.000 description 1
- 108010053187 Diphtheria Toxin Proteins 0.000 description 1
- 101100015729 Drosophila melanogaster drk gene Proteins 0.000 description 1
- 206010059866 Drug resistance Diseases 0.000 description 1
- 102100023274 Dual specificity mitogen-activated protein kinase kinase 4 Human genes 0.000 description 1
- 102100023332 Dual specificity mitogen-activated protein kinase kinase 7 Human genes 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 102000001301 EGF receptor Human genes 0.000 description 1
- 108060006698 EGF receptor Proteins 0.000 description 1
- 238000008157 ELISA kit Methods 0.000 description 1
- 101150029707 ERBB2 gene Proteins 0.000 description 1
- 229940125929 ERK1/2 kinase inhibitor Drugs 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- 101150033452 Elk1 gene Proteins 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 102400001047 Endostatin Human genes 0.000 description 1
- 108010079505 Endostatins Proteins 0.000 description 1
- 108050009340 Endothelin Proteins 0.000 description 1
- 102000002045 Endothelin Human genes 0.000 description 1
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 108090000394 Erythropoietin Proteins 0.000 description 1
- 102000003951 Erythropoietin Human genes 0.000 description 1
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 1
- DNXHEGUUPJUMQT-CBZIJGRNSA-N Estrone Chemical compound OC1=CC=C2[C@H]3CC[C@](C)(C(CC4)=O)[C@@H]4[C@@H]3CCC2=C1 DNXHEGUUPJUMQT-CBZIJGRNSA-N 0.000 description 1
- 101150031329 Ets1 gene Proteins 0.000 description 1
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 229940123414 Folate antagonist Drugs 0.000 description 1
- 108010079345 Follicle Stimulating Hormone Proteins 0.000 description 1
- 102000012673 Follicle Stimulating Hormone Human genes 0.000 description 1
- 230000006370 G0 arrest Effects 0.000 description 1
- 230000037057 G1 phase arrest Effects 0.000 description 1
- 230000004668 G2/M phase Effects 0.000 description 1
- RFWVETIZUQEJEF-UHFFFAOYSA-N GDC-0623 Chemical compound OCCONC(=O)C=1C=CC2=CN=CN2C=1NC1=CC=C(I)C=C1F RFWVETIZUQEJEF-UHFFFAOYSA-N 0.000 description 1
- DEZZLWQELQORIU-RELWKKBWSA-N GDC-0879 Chemical compound N=1N(CCO)C=C(C=2C=C3CCC(/C3=CC=2)=N\O)C=1C1=CC=NC=C1 DEZZLWQELQORIU-RELWKKBWSA-N 0.000 description 1
- 108700012941 GNRH1 Proteins 0.000 description 1
- 102400001370 Galanin Human genes 0.000 description 1
- 101800002068 Galanin Proteins 0.000 description 1
- 208000022072 Gallbladder Neoplasms Diseases 0.000 description 1
- 102400000921 Gastrin Human genes 0.000 description 1
- 108010052343 Gastrins Proteins 0.000 description 1
- 208000018522 Gastrointestinal disease Diseases 0.000 description 1
- 208000021309 Germ cell tumor Diseases 0.000 description 1
- 101800001586 Ghrelin Proteins 0.000 description 1
- 102400000442 Ghrelin-28 Human genes 0.000 description 1
- LZRMPXRYLLTAJX-GUBZILKMSA-N Gln-Arg-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O LZRMPXRYLLTAJX-GUBZILKMSA-N 0.000 description 1
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 1
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 1
- NJPQBTJSYCKCNS-HVTMNAMFSA-N Glu-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)O)N NJPQBTJSYCKCNS-HVTMNAMFSA-N 0.000 description 1
- DXVOKNVIKORTHQ-GUBZILKMSA-N Glu-Pro-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O DXVOKNVIKORTHQ-GUBZILKMSA-N 0.000 description 1
- IDEODOAVGCMUQV-GUBZILKMSA-N Glu-Ser-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IDEODOAVGCMUQV-GUBZILKMSA-N 0.000 description 1
- XIJOPMSILDNVNJ-ZVZYQTTQSA-N Glu-Val-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O XIJOPMSILDNVNJ-ZVZYQTTQSA-N 0.000 description 1
- 102400000321 Glucagon Human genes 0.000 description 1
- 108060003199 Glucagon Proteins 0.000 description 1
- GGEJHJIXRBTJPD-BYPYZUCNSA-N Gly-Asn-Gly Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GGEJHJIXRBTJPD-BYPYZUCNSA-N 0.000 description 1
- ZRZILYKEJBMFHY-BQBZGAKWSA-N Gly-Asp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN ZRZILYKEJBMFHY-BQBZGAKWSA-N 0.000 description 1
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 1
- GDOZQTNZPCUARW-YFKPBYRVSA-N Gly-Gly-Glu Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O GDOZQTNZPCUARW-YFKPBYRVSA-N 0.000 description 1
- 108010051696 Growth Hormone Proteins 0.000 description 1
- 239000000095 Growth Hormone-Releasing Hormone Substances 0.000 description 1
- 208000012766 Growth delay Diseases 0.000 description 1
- 206010053759 Growth retardation Diseases 0.000 description 1
- 102100032606 Heat shock factor protein 1 Human genes 0.000 description 1
- 101710190344 Heat shock factor protein 1 Proteins 0.000 description 1
- 206010019695 Hepatic neoplasm Diseases 0.000 description 1
- BYTORXDZJWWIKR-UHFFFAOYSA-N Hinokiol Natural products CC(C)c1cc2CCC3C(C)(CO)C(O)CCC3(C)c2cc1O BYTORXDZJWWIKR-UHFFFAOYSA-N 0.000 description 1
- OBTMRGFRLJBSFI-GARJFASQSA-N His-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O OBTMRGFRLJBSFI-GARJFASQSA-N 0.000 description 1
- 102100033636 Histone H3.2 Human genes 0.000 description 1
- 108010033040 Histones Proteins 0.000 description 1
- 208000017604 Hodgkin disease Diseases 0.000 description 1
- 208000021519 Hodgkin lymphoma Diseases 0.000 description 1
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 1
- 238000010867 Hoechst staining Methods 0.000 description 1
- 101000897493 Homo sapiens C-C motif chemokine 26 Proteins 0.000 description 1
- 101000721661 Homo sapiens Cellular tumor antigen p53 Proteins 0.000 description 1
- 101001014196 Homo sapiens Dual specificity mitogen-activated protein kinase kinase 1 Proteins 0.000 description 1
- 101001115395 Homo sapiens Dual specificity mitogen-activated protein kinase kinase 4 Proteins 0.000 description 1
- 101001115390 Homo sapiens Dual specificity mitogen-activated protein kinase kinase 5 Proteins 0.000 description 1
- 101000624594 Homo sapiens Dual specificity mitogen-activated protein kinase kinase 7 Proteins 0.000 description 1
- 101000599056 Homo sapiens Interleukin-6 receptor subunit beta Proteins 0.000 description 1
- 101000628949 Homo sapiens Mitogen-activated protein kinase 10 Proteins 0.000 description 1
- 101000950695 Homo sapiens Mitogen-activated protein kinase 8 Proteins 0.000 description 1
- 101000950669 Homo sapiens Mitogen-activated protein kinase 9 Proteins 0.000 description 1
- 101001018145 Homo sapiens Mitogen-activated protein kinase kinase kinase 3 Proteins 0.000 description 1
- 101001018196 Homo sapiens Mitogen-activated protein kinase kinase kinase 5 Proteins 0.000 description 1
- 101001055085 Homo sapiens Mitogen-activated protein kinase kinase kinase 9 Proteins 0.000 description 1
- 101000947178 Homo sapiens Platelet basic protein Proteins 0.000 description 1
- 101000617830 Homo sapiens Sterol O-acyltransferase 1 Proteins 0.000 description 1
- 101000997835 Homo sapiens Tyrosine-protein kinase JAK1 Proteins 0.000 description 1
- 206010021042 Hypopharyngeal cancer Diseases 0.000 description 1
- 206010056305 Hypopharyngeal neoplasm Diseases 0.000 description 1
- 208000001953 Hypotension Diseases 0.000 description 1
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 1
- XDXDZDZNSLXDNA-UHFFFAOYSA-N Idarubicin Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XDXDZDZNSLXDNA-UHFFFAOYSA-N 0.000 description 1
- PNTWNAXGBOZMBO-MNXVOIDGSA-N Ile-Lys-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PNTWNAXGBOZMBO-MNXVOIDGSA-N 0.000 description 1
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 description 1
- 102000002746 Inhibins Human genes 0.000 description 1
- 108010004250 Inhibins Proteins 0.000 description 1
- 108091008026 Inhibitory immune checkpoint proteins Proteins 0.000 description 1
- 102000037984 Inhibitory immune checkpoint proteins Human genes 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 108090000723 Insulin-Like Growth Factor I Proteins 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 108010002350 Interleukin-2 Proteins 0.000 description 1
- 102100037795 Interleukin-6 receptor subunit beta Human genes 0.000 description 1
- 108010002586 Interleukin-7 Proteins 0.000 description 1
- 102000036770 Islet Amyloid Polypeptide Human genes 0.000 description 1
- 108010041872 Islet Amyloid Polypeptide Proteins 0.000 description 1
- 101150093335 KIN1 gene Proteins 0.000 description 1
- 208000007766 Kaposi sarcoma Diseases 0.000 description 1
- 208000008839 Kidney Neoplasms Diseases 0.000 description 1
- 229930182816 L-glutamine Natural products 0.000 description 1
- 102000003855 L-lactate dehydrogenase Human genes 0.000 description 1
- 108700023483 L-lactate dehydrogenases Proteins 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- 239000005511 L01XE05 - Sorafenib Substances 0.000 description 1
- 239000003798 L01XE11 - Pazopanib Substances 0.000 description 1
- 201000005099 Langerhans cell histiocytosis Diseases 0.000 description 1
- 206010023825 Laryngeal cancer Diseases 0.000 description 1
- 108010092277 Leptin Proteins 0.000 description 1
- 102000016267 Leptin Human genes 0.000 description 1
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 1
- BIZNDKMFQHDOIE-KKUMJFAQSA-N Leu-Phe-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(N)=O)C(O)=O)CC1=CC=CC=C1 BIZNDKMFQHDOIE-KKUMJFAQSA-N 0.000 description 1
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 1
- 240000007472 Leucaena leucocephala Species 0.000 description 1
- 235000010643 Leucaena leucocephala Nutrition 0.000 description 1
- 206010062038 Lip neoplasm Diseases 0.000 description 1
- GQYIWUVLTXOXAJ-UHFFFAOYSA-N Lomustine Chemical compound ClCCN(N=O)C(=O)NC1CCCCC1 GQYIWUVLTXOXAJ-UHFFFAOYSA-N 0.000 description 1
- 108010073521 Luteinizing Hormone Proteins 0.000 description 1
- 102000009151 Luteinizing Hormone Human genes 0.000 description 1
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 1
- 206010025312 Lymphoma AIDS related Diseases 0.000 description 1
- MUXNCRWTWBMNHX-SRVKXCTJSA-N Lys-Leu-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O MUXNCRWTWBMNHX-SRVKXCTJSA-N 0.000 description 1
- 108010068305 MAP Kinase Kinase 5 Proteins 0.000 description 1
- 108010075654 MAP Kinase Kinase Kinase 1 Proteins 0.000 description 1
- 108010075656 MAP Kinase Kinase Kinase 2 Proteins 0.000 description 1
- 101150015464 MAP2K5 gene Proteins 0.000 description 1
- 230000037364 MAPK/ERK pathway Effects 0.000 description 1
- 108700012928 MAPK14 Proteins 0.000 description 1
- 101150020862 MKK5 gene Proteins 0.000 description 1
- 208000030070 Malignant epithelial tumor of ovary Diseases 0.000 description 1
- 206010073059 Malignant neoplasm of unknown primary site Diseases 0.000 description 1
- 208000032271 Malignant tumor of penis Diseases 0.000 description 1
- 240000003183 Manihot esculenta Species 0.000 description 1
- 235000016735 Manihot esculenta subsp esculenta Nutrition 0.000 description 1
- 239000000637 Melanocyte-Stimulating Hormone Substances 0.000 description 1
- 108010007013 Melanocyte-Stimulating Hormones Proteins 0.000 description 1
- 208000002030 Merkel cell carcinoma Diseases 0.000 description 1
- MCNGIXXCMJAURZ-VEVYYDQMSA-N Met-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCSC)N)O MCNGIXXCMJAURZ-VEVYYDQMSA-N 0.000 description 1
- RRIHXWPHQSXHAQ-XUXIUFHCSA-N Met-Ile-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(O)=O RRIHXWPHQSXHAQ-XUXIUFHCSA-N 0.000 description 1
- 206010059282 Metastases to central nervous system Diseases 0.000 description 1
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 1
- 102000044589 Mitogen-Activated Protein Kinase 1 Human genes 0.000 description 1
- 102000046795 Mitogen-Activated Protein Kinase 3 Human genes 0.000 description 1
- 108700027649 Mitogen-Activated Protein Kinase 3 Proteins 0.000 description 1
- 102100026931 Mitogen-activated protein kinase 10 Human genes 0.000 description 1
- 102000054819 Mitogen-activated protein kinase 14 Human genes 0.000 description 1
- 102100037808 Mitogen-activated protein kinase 8 Human genes 0.000 description 1
- 102100037809 Mitogen-activated protein kinase 9 Human genes 0.000 description 1
- 102100033115 Mitogen-activated protein kinase kinase kinase 1 Human genes 0.000 description 1
- 102100033058 Mitogen-activated protein kinase kinase kinase 2 Human genes 0.000 description 1
- 102100033059 Mitogen-activated protein kinase kinase kinase 3 Human genes 0.000 description 1
- 102100033127 Mitogen-activated protein kinase kinase kinase 5 Human genes 0.000 description 1
- 102100026909 Mitogen-activated protein kinase kinase kinase 9 Human genes 0.000 description 1
- 229930192392 Mitomycin Natural products 0.000 description 1
- 101800002372 Motilin Proteins 0.000 description 1
- 102000002419 Motilin Human genes 0.000 description 1
- 208000034578 Multiple myelomas Diseases 0.000 description 1
- 108010085220 Multiprotein Complexes Proteins 0.000 description 1
- 102000007474 Multiprotein Complexes Human genes 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 241000699666 Mus <mouse, genus> Species 0.000 description 1
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 1
- 201000007224 Myeloproliferative neoplasm Diseases 0.000 description 1
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 1
- 108010079364 N-glycylalanine Proteins 0.000 description 1
- OPFJDXRVMFKJJO-ZHHKINOHSA-N N-{[3-(2-benzamido-4-methyl-1,3-thiazol-5-yl)-pyrazol-5-yl]carbonyl}-G-dR-G-dD-dD-dD-NH2 Chemical compound S1C(C=2NN=C(C=2)C(=O)NCC(=O)N[C@H](CCCN=C(N)N)C(=O)NCC(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC(O)=O)C(N)=O)=C(C)N=C1NC(=O)C1=CC=CC=C1 OPFJDXRVMFKJJO-ZHHKINOHSA-N 0.000 description 1
- 108010018525 NFATC Transcription Factors Proteins 0.000 description 1
- 102000002673 NFATC Transcription Factors Human genes 0.000 description 1
- 208000001894 Nasopharyngeal Neoplasms Diseases 0.000 description 1
- 206010061306 Nasopharyngeal cancer Diseases 0.000 description 1
- 206010029260 Neuroblastoma Diseases 0.000 description 1
- 206010029266 Neuroendocrine carcinoma of the skin Diseases 0.000 description 1
- 244000061176 Nicotiana tabacum Species 0.000 description 1
- 235000002637 Nicotiana tabacum Nutrition 0.000 description 1
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 1
- 208000010505 Nose Neoplasms Diseases 0.000 description 1
- MSHZHSPISPJWHW-UHFFFAOYSA-N O-(chloroacetylcarbamoyl)fumagillol Chemical compound O1C(CC=C(C)C)C1(C)C1C(OC)C(OC(=O)NC(=O)CCl)CCC21CO2 MSHZHSPISPJWHW-UHFFFAOYSA-N 0.000 description 1
- CTQNGGLPUBDAKN-UHFFFAOYSA-N O-Xylene Chemical compound CC1=CC=CC=C1C CTQNGGLPUBDAKN-UHFFFAOYSA-N 0.000 description 1
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 1
- 102000002512 Orexin Human genes 0.000 description 1
- 206010031096 Oropharyngeal cancer Diseases 0.000 description 1
- 206010057444 Oropharyngeal neoplasm Diseases 0.000 description 1
- 208000007571 Ovarian Epithelial Carcinoma Diseases 0.000 description 1
- 206010061328 Ovarian epithelial cancer Diseases 0.000 description 1
- 102400000050 Oxytocin Human genes 0.000 description 1
- 101800000989 Oxytocin Proteins 0.000 description 1
- XNOPRXBHLZRZKH-UHFFFAOYSA-N Oxytocin Natural products N1C(=O)C(N)CSSCC(C(=O)N2C(CCC2)C(=O)NC(CC(C)C)C(=O)NCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(CCC(N)=O)NC(=O)C(C(C)CC)NC(=O)C1CC1=CC=C(O)C=C1 XNOPRXBHLZRZKH-UHFFFAOYSA-N 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 229940118166 PI3 kinase delta inhibitor Drugs 0.000 description 1
- 229940116355 PI3 kinase inhibitor Drugs 0.000 description 1
- YZDJQTHVDDOVHR-UHFFFAOYSA-N PLX-4720 Chemical compound CCCS(=O)(=O)NC1=CC=C(F)C(C(=O)C=2C3=CC(Cl)=CN=C3NC=2)=C1F YZDJQTHVDDOVHR-UHFFFAOYSA-N 0.000 description 1
- 102000014160 PTEN Phosphohydrolase Human genes 0.000 description 1
- 108010011536 PTEN Phosphohydrolase Proteins 0.000 description 1
- 208000002193 Pain Diseases 0.000 description 1
- 102000018886 Pancreatic Polypeptide Human genes 0.000 description 1
- 108020002230 Pancreatic Ribonuclease Proteins 0.000 description 1
- 102000005891 Pancreatic ribonuclease Human genes 0.000 description 1
- 208000000821 Parathyroid Neoplasms Diseases 0.000 description 1
- 102000003982 Parathyroid hormone Human genes 0.000 description 1
- 108090000445 Parathyroid hormone Proteins 0.000 description 1
- 206010034133 Pathogen resistance Diseases 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- 208000002471 Penile Neoplasms Diseases 0.000 description 1
- 206010034299 Penile cancer Diseases 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 241000233805 Phoenix Species 0.000 description 1
- 208000007913 Pituitary Neoplasms Diseases 0.000 description 1
- 102000004576 Placental Lactogen Human genes 0.000 description 1
- 108010003044 Placental Lactogen Proteins 0.000 description 1
- 239000000381 Placental Lactogen Substances 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- 102100036154 Platelet basic protein Human genes 0.000 description 1
- 102000004211 Platelet factor 4 Human genes 0.000 description 1
- 108090000778 Platelet factor 4 Proteins 0.000 description 1
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 1
- 239000004952 Polyamide Substances 0.000 description 1
- 229920001710 Polyorthoester Polymers 0.000 description 1
- ITUDDXVFGFEKPD-NAKRPEOUSA-N Pro-Ser-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ITUDDXVFGFEKPD-NAKRPEOUSA-N 0.000 description 1
- 108010087786 Prolactin-Releasing Hormone Proteins 0.000 description 1
- 102100028850 Prolactin-releasing peptide Human genes 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 1
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 1
- 108010071563 Proto-Oncogene Proteins c-fos Proteins 0.000 description 1
- 102000007568 Proto-Oncogene Proteins c-fos Human genes 0.000 description 1
- 208000003251 Pruritus Diseases 0.000 description 1
- 206010037660 Pyrexia Diseases 0.000 description 1
- 241000219492 Quercus Species 0.000 description 1
- 108091082327 RAF family Proteins 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 101150062264 Raf gene Proteins 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 101100287693 Rattus norvegicus Kcnh4 gene Proteins 0.000 description 1
- 101100287705 Rattus norvegicus Kcnh8 gene Proteins 0.000 description 1
- 208000015634 Rectal Neoplasms Diseases 0.000 description 1
- 108090000103 Relaxin Proteins 0.000 description 1
- 102000003743 Relaxin Human genes 0.000 description 1
- 206010038389 Renal cancer Diseases 0.000 description 1
- 208000006265 Renal cell carcinoma Diseases 0.000 description 1
- 102100028255 Renin Human genes 0.000 description 1
- 108090000783 Renin Proteins 0.000 description 1
- 230000018199 S phase Effects 0.000 description 1
- 108010040181 SF 1126 Proteins 0.000 description 1
- 208000004337 Salivary Gland Neoplasms Diseases 0.000 description 1
- 206010061934 Salivary gland cancer Diseases 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 101100225046 Schizosaccharomyces pombe (strain 972 / ATCC 24843) ecl2 gene Proteins 0.000 description 1
- 108010086019 Secretin Proteins 0.000 description 1
- 102100037505 Secretin Human genes 0.000 description 1
- 229940124639 Selective inhibitor Drugs 0.000 description 1
- ZUGXSSFMTXKHJS-ZLUOBGJFSA-N Ser-Ala-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O ZUGXSSFMTXKHJS-ZLUOBGJFSA-N 0.000 description 1
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 1
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 1
- 108010034546 Serratia marcescens nuclease Proteins 0.000 description 1
- 208000009359 Sezary Syndrome Diseases 0.000 description 1
- 208000021388 Sezary disease Diseases 0.000 description 1
- PNUZDKCDAWUEGK-CYZMBNFOSA-N Sitafloxacin Chemical compound C([C@H]1N)N(C=2C(=C3C(C(C(C(O)=O)=CN3[C@H]3[C@H](C3)F)=O)=CC=2F)Cl)CC11CC1 PNUZDKCDAWUEGK-CYZMBNFOSA-N 0.000 description 1
- 208000021712 Soft tissue sarcoma Diseases 0.000 description 1
- 235000002595 Solanum tuberosum Nutrition 0.000 description 1
- 244000061456 Solanum tuberosum Species 0.000 description 1
- 101710142969 Somatoliberin Proteins 0.000 description 1
- 102100022831 Somatoliberin Human genes 0.000 description 1
- 102000013275 Somatomedins Human genes 0.000 description 1
- 108010056088 Somatostatin Proteins 0.000 description 1
- 102000005157 Somatostatin Human genes 0.000 description 1
- 102100038803 Somatotropin Human genes 0.000 description 1
- SSZBUIDZHHWXNJ-UHFFFAOYSA-N Stearinsaeure-hexadecylester Natural products CCCCCCCCCCCCCCCCCC(=O)OCCCCCCCCCCCCCCCC SSZBUIDZHHWXNJ-UHFFFAOYSA-N 0.000 description 1
- 102100021993 Sterol O-acyltransferase 1 Human genes 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 101000697584 Streptomyces lavendulae Streptothricin acetyltransferase Proteins 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 101000983124 Sus scrofa Pancreatic prohormone precursor Proteins 0.000 description 1
- OJFKUJDRGJSAQB-UHFFFAOYSA-N TAK-632 Chemical compound C1=C(NC(=O)CC=2C=C(C=CC=2)C(F)(F)F)C(F)=CC=C1OC(C(=C1S2)C#N)=CC=C1N=C2NC(=O)C1CC1 OJFKUJDRGJSAQB-UHFFFAOYSA-N 0.000 description 1
- 208000024313 Testicular Neoplasms Diseases 0.000 description 1
- 206010057644 Testis cancer Diseases 0.000 description 1
- KRPKYGOFYUNIGM-XVSYOHENSA-N Thr-Asp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O KRPKYGOFYUNIGM-XVSYOHENSA-N 0.000 description 1
- LKEKWDJCJSPXNI-IRIUXVKKSA-N Thr-Glu-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LKEKWDJCJSPXNI-IRIUXVKKSA-N 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 102000036693 Thrombopoietin Human genes 0.000 description 1
- 108010041111 Thrombopoietin Proteins 0.000 description 1
- 108010046075 Thymosin Proteins 0.000 description 1
- 102000007501 Thymosin Human genes 0.000 description 1
- 208000033781 Thyroid carcinoma Diseases 0.000 description 1
- 102000011923 Thyrotropin Human genes 0.000 description 1
- 108010061174 Thyrotropin Proteins 0.000 description 1
- 206010044407 Transitional cell cancer of the renal pelvis and ureter Diseases 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- 229940122618 Trypsin inhibitor Drugs 0.000 description 1
- 101710162629 Trypsin inhibitor Proteins 0.000 description 1
- WVRUKYLYMFGKAN-IHRRRGAJSA-N Tyr-Glu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 WVRUKYLYMFGKAN-IHRRRGAJSA-N 0.000 description 1
- KSCVLGXNQXKUAR-JYJNAYRXSA-N Tyr-Leu-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KSCVLGXNQXKUAR-JYJNAYRXSA-N 0.000 description 1
- WQOHKVRQDLNDIL-YJRXYDGGSA-N Tyr-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O WQOHKVRQDLNDIL-YJRXYDGGSA-N 0.000 description 1
- 206010046431 Urethral cancer Diseases 0.000 description 1
- 206010046458 Urethral neoplasms Diseases 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 208000002495 Uterine Neoplasms Diseases 0.000 description 1
- OFTXTCGQJXTNQS-XGEHTFHBSA-N Val-Thr-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N)O OFTXTCGQJXTNQS-XGEHTFHBSA-N 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- GXBMIBRIOWHPDT-UHFFFAOYSA-N Vasopressin Natural products N1C(=O)C(CC=2C=C(O)C=CC=2)NC(=O)C(N)CSSCC(C(=O)N2C(CCC2)C(=O)NC(CCCN=C(N)N)C(=O)NCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(CCC(N)=O)NC(=O)C1CC1=CC=CC=C1 GXBMIBRIOWHPDT-UHFFFAOYSA-N 0.000 description 1
- 108010004977 Vasopressins Proteins 0.000 description 1
- 102000002852 Vasopressins Human genes 0.000 description 1
- 229940122803 Vinca alkaloid Drugs 0.000 description 1
- 206010047741 Vulval cancer Diseases 0.000 description 1
- 208000004354 Vulvar Neoplasms Diseases 0.000 description 1
- 208000033559 Waldenström macroglobulinemia Diseases 0.000 description 1
- 208000008383 Wilms tumor Diseases 0.000 description 1
- LNUFLCYMSVYYNW-ZPJMAFJPSA-N [(2r,3r,4s,5r,6r)-2-[(2r,3r,4s,5r,6r)-6-[(2r,3r,4s,5r,6r)-6-[(2r,3r,4s,5r,6r)-6-[[(3s,5s,8r,9s,10s,13r,14s,17r)-10,13-dimethyl-17-[(2r)-6-methylheptan-2-yl]-2,3,4,5,6,7,8,9,11,12,14,15,16,17-tetradecahydro-1h-cyclopenta[a]phenanthren-3-yl]oxy]-4,5-disulfo Chemical compound O([C@@H]1[C@@H](COS(O)(=O)=O)O[C@@H]([C@@H]([C@H]1OS(O)(=O)=O)OS(O)(=O)=O)O[C@@H]1[C@@H](COS(O)(=O)=O)O[C@@H]([C@@H]([C@H]1OS(O)(=O)=O)OS(O)(=O)=O)O[C@@H]1[C@@H](COS(O)(=O)=O)O[C@H]([C@@H]([C@H]1OS(O)(=O)=O)OS(O)(=O)=O)O[C@@H]1C[C@@H]2CC[C@H]3[C@@H]4CC[C@@H]([C@]4(CC[C@@H]3[C@@]2(C)CC1)C)[C@H](C)CCCC(C)C)[C@H]1O[C@H](COS(O)(=O)=O)[C@@H](OS(O)(=O)=O)[C@H](OS(O)(=O)=O)[C@H]1OS(O)(=O)=O LNUFLCYMSVYYNW-ZPJMAFJPSA-N 0.000 description 1
- SMNRFWMNPDABKZ-WVALLCKVSA-N [[(2R,3S,4R,5S)-5-(2,6-dioxo-3H-pyridin-3-yl)-3,4-dihydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl] [[[(2R,3S,4S,5R,6R)-4-fluoro-3,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-hydroxyphosphoryl]oxy-hydroxyphosphoryl] hydrogen phosphate Chemical compound OC[C@H]1O[C@H](OP(O)(=O)OP(O)(=O)OP(O)(=O)OP(O)(=O)OC[C@H]2O[C@H]([C@H](O)[C@@H]2O)C2C=CC(=O)NC2=O)[C@H](O)[C@@H](F)[C@@H]1O SMNRFWMNPDABKZ-WVALLCKVSA-N 0.000 description 1
- WREOTYWODABZMH-DTZQCDIJSA-N [[(2r,3s,4r,5r)-3,4-dihydroxy-5-[2-oxo-4-(2-phenylethoxyamino)pyrimidin-1-yl]oxolan-2-yl]methoxy-hydroxyphosphoryl] phosphono hydrogen phosphate Chemical compound O[C@@H]1[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O[C@H]1N(C=C\1)C(=O)NC/1=N\OCCC1=CC=CC=C1 WREOTYWODABZMH-DTZQCDIJSA-N 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 239000003655 absorption accelerator Substances 0.000 description 1
- 239000003070 absorption delaying agent Substances 0.000 description 1
- 229930183665 actinomycin Natural products 0.000 description 1
- 239000008186 active pharmaceutical agent Substances 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 230000008649 adaptation response Effects 0.000 description 1
- 102000035181 adaptor proteins Human genes 0.000 description 1
- 108091005764 adaptor proteins Proteins 0.000 description 1
- 230000001464 adherent effect Effects 0.000 description 1
- 208000020990 adrenal cortex carcinoma Diseases 0.000 description 1
- 208000007128 adrenocortical carcinoma Diseases 0.000 description 1
- 208000014619 adult acute lymphoblastic leukemia Diseases 0.000 description 1
- 229960002478 aldosterone Drugs 0.000 description 1
- KDGFLJKFZUIJMX-UHFFFAOYSA-N alectinib Chemical compound CCC1=CC=2C(=O)C(C3=CC=C(C=C3N3)C#N)=C3C(C)(C)C=2C=C1N(CC1)CCC1N1CCOCC1 KDGFLJKFZUIJMX-UHFFFAOYSA-N 0.000 description 1
- 239000000783 alginic acid Substances 0.000 description 1
- 229960001126 alginic acid Drugs 0.000 description 1
- 150000004781 alginic acids Chemical class 0.000 description 1
- 231100000360 alopecia Toxicity 0.000 description 1
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 235000012211 aluminium silicate Nutrition 0.000 description 1
- XCPGHVQEEXUHNC-UHFFFAOYSA-N amsacrine Chemical compound COC1=CC(NS(C)(=O)=O)=CC=C1NC1=C(C=CC=C2)C2=NC2=CC=CC=C12 XCPGHVQEEXUHNC-UHFFFAOYSA-N 0.000 description 1
- 229960001220 amsacrine Drugs 0.000 description 1
- 229960002932 anastrozole Drugs 0.000 description 1
- AEMFNILZOJDQLW-QAGGRKNESA-N androst-4-ene-3,17-dione Chemical compound O=C1CC[C@]2(C)[C@H]3CC[C@](C)(C(CC4)=O)[C@@H]4[C@@H]3CCC2=C1 AEMFNILZOJDQLW-QAGGRKNESA-N 0.000 description 1
- 229960003473 androstanolone Drugs 0.000 description 1
- 229960005471 androstenedione Drugs 0.000 description 1
- AEMFNILZOJDQLW-UHFFFAOYSA-N androstenedione Natural products O=C1CCC2(C)C3CCC(C)(C(CC4)=O)C4C3CCC2=C1 AEMFNILZOJDQLW-UHFFFAOYSA-N 0.000 description 1
- 208000007502 anemia Diseases 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 150000008064 anhydrides Chemical class 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 230000001772 anti-angiogenic effect Effects 0.000 description 1
- 230000001093 anti-cancer Effects 0.000 description 1
- 239000000868 anti-mullerian hormone Substances 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 239000002246 antineoplastic agent Substances 0.000 description 1
- 201000011165 anus cancer Diseases 0.000 description 1
- 208000021780 appendiceal neoplasm Diseases 0.000 description 1
- KBZOIRJILGZLEJ-LGYYRGKSSA-N argipressin Chemical compound C([C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSC[C@@H](C(N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N1)=O)N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(N)=O)C1=CC=CC=C1 KBZOIRJILGZLEJ-LGYYRGKSSA-N 0.000 description 1
- 229940078010 arimidex Drugs 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- FZCSTZYAHCUGEM-UHFFFAOYSA-N aspergillomarasmine B Natural products OC(=O)CNC(C(O)=O)CNC(C(O)=O)CC(O)=O FZCSTZYAHCUGEM-UHFFFAOYSA-N 0.000 description 1
- 239000012131 assay buffer Substances 0.000 description 1
- XRWSZZJLZRKHHD-WVWIJVSJSA-N asunaprevir Chemical compound O=C([C@@H]1C[C@H](CN1C(=O)[C@@H](NC(=O)OC(C)(C)C)C(C)(C)C)OC1=NC=C(C2=CC=C(Cl)C=C21)OC)N[C@]1(C(=O)NS(=O)(=O)C2CC2)C[C@H]1C=C XRWSZZJLZRKHHD-WVWIJVSJSA-N 0.000 description 1
- 229940120638 avastin Drugs 0.000 description 1
- 210000003050 axon Anatomy 0.000 description 1
- KLNFSAOEKUDMFA-UHFFFAOYSA-N azanide;2-hydroxyacetic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OCC(O)=O KLNFSAOEKUDMFA-UHFFFAOYSA-N 0.000 description 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 1
- 239000002774 b raf kinase inhibitor Substances 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 239000003855 balanced salt solution Substances 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 150000001556 benzimidazoles Chemical class 0.000 description 1
- 235000019445 benzyl alcohol Nutrition 0.000 description 1
- 229960002903 benzyl benzoate Drugs 0.000 description 1
- KGNDCEVUMONOKF-UGPLYTSKSA-N benzyl n-[(2r)-1-[(2s,4r)-2-[[(2s)-6-amino-1-(1,3-benzoxazol-2-yl)-1,1-dihydroxyhexan-2-yl]carbamoyl]-4-[(4-methylphenyl)methoxy]pyrrolidin-1-yl]-1-oxo-4-phenylbutan-2-yl]carbamate Chemical compound C1=CC(C)=CC=C1CO[C@H]1CN(C(=O)[C@@H](CCC=2C=CC=CC=2)NC(=O)OCC=2C=CC=CC=2)[C@H](C(=O)N[C@@H](CCCCN)C(O)(O)C=2OC3=CC=CC=C3N=2)C1 KGNDCEVUMONOKF-UGPLYTSKSA-N 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 230000007698 birth defect Effects 0.000 description 1
- OWMVSZAMULFTJU-UHFFFAOYSA-N bis-tris Chemical compound OCCN(CCO)C(CO)(CO)CO OWMVSZAMULFTJU-UHFFFAOYSA-N 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 210000004204 blood vessel Anatomy 0.000 description 1
- 230000036760 body temperature Effects 0.000 description 1
- 210000001185 bone marrow Anatomy 0.000 description 1
- 101150048834 braF gene Proteins 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- 239000006172 buffering agent Substances 0.000 description 1
- 229960002092 busulfan Drugs 0.000 description 1
- 239000001273 butane Substances 0.000 description 1
- 235000019437 butane-1,3-diol Nutrition 0.000 description 1
- JWUBBDSIWDLEOM-DTOXIADCSA-N calcidiol Chemical compound C1(/[C@@H]2CC[C@@H]([C@]2(CCC1)C)[C@@H](CCCC(C)(C)O)C)=C\C=C1\C[C@@H](O)CCC1=C JWUBBDSIWDLEOM-DTOXIADCSA-N 0.000 description 1
- 229960004361 calcifediol Drugs 0.000 description 1
- 229960004015 calcitonin Drugs 0.000 description 1
- BBBFJLBPOGFECG-VJVYQDLKSA-N calcitonin Chemical compound N([C@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(N)=O)C(C)C)C(=O)[C@@H]1CSSC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1 BBBFJLBPOGFECG-VJVYQDLKSA-N 0.000 description 1
- 229960005084 calcitriol Drugs 0.000 description 1
- GMRQFYUYWCNGIN-NKMMMXOESA-N calcitriol Chemical compound C1(/[C@@H]2CC[C@@H]([C@]2(CCC1)C)[C@@H](CCCC(C)(C)O)C)=C\C=C1\C[C@@H](O)C[C@H](O)C1=C GMRQFYUYWCNGIN-NKMMMXOESA-N 0.000 description 1
- 235000020964 calcitriol Nutrition 0.000 description 1
- 239000011612 calcitriol Substances 0.000 description 1
- 229910000019 calcium carbonate Inorganic materials 0.000 description 1
- 235000010216 calcium carbonate Nutrition 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 239000000378 calcium silicate Substances 0.000 description 1
- 229910052918 calcium silicate Inorganic materials 0.000 description 1
- CJZGTCYPCWQAJB-UHFFFAOYSA-L calcium stearate Chemical compound [Ca+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O CJZGTCYPCWQAJB-UHFFFAOYSA-L 0.000 description 1
- 235000013539 calcium stearate Nutrition 0.000 description 1
- 239000008116 calcium stearate Substances 0.000 description 1
- HUSUHZRVLBSGBO-UHFFFAOYSA-L calcium;dihydrogen phosphate;hydroxide Chemical compound O.[Ca+2].OP([O-])([O-])=O HUSUHZRVLBSGBO-UHFFFAOYSA-L 0.000 description 1
- OYACROKNLOSFPA-UHFFFAOYSA-N calcium;dioxido(oxo)silane Chemical compound [Ca+2].[O-][Si]([O-])=O OYACROKNLOSFPA-UHFFFAOYSA-N 0.000 description 1
- BPKIGYQJPYCAOW-FFJTTWKXSA-I calcium;potassium;disodium;(2s)-2-hydroxypropanoate;dichloride;dihydroxide;hydrate Chemical compound O.[OH-].[OH-].[Na+].[Na+].[Cl-].[Cl-].[K+].[Ca+2].C[C@H](O)C([O-])=O BPKIGYQJPYCAOW-FFJTTWKXSA-I 0.000 description 1
- BMLSTPRTEKLIPM-UHFFFAOYSA-I calcium;potassium;disodium;hydrogen carbonate;dichloride;dihydroxide;hydrate Chemical compound O.[OH-].[OH-].[Na+].[Na+].[Cl-].[Cl-].[K+].[Ca+2].OC([O-])=O BMLSTPRTEKLIPM-UHFFFAOYSA-I 0.000 description 1
- 230000004611 cancer cell death Effects 0.000 description 1
- 230000005880 cancer cell killing Effects 0.000 description 1
- 229960004117 capecitabine Drugs 0.000 description 1
- 229960004562 carboplatin Drugs 0.000 description 1
- 208000002458 carcinoid tumor Diseases 0.000 description 1
- 229960005243 carmustine Drugs 0.000 description 1
- 210000000845 cartilage Anatomy 0.000 description 1
- 230000001364 causal effect Effects 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000025084 cell cycle arrest Effects 0.000 description 1
- 238000010822 cell death assay Methods 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 230000032823 cell division Effects 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 230000003833 cell viability Effects 0.000 description 1
- 230000030570 cellular localization Effects 0.000 description 1
- 230000005754 cellular signaling Effects 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 229960005395 cetuximab Drugs 0.000 description 1
- 229960000541 cetyl alcohol Drugs 0.000 description 1
- AOXOCDRNSPFDPE-UKEONUMOSA-N chembl413654 Chemical compound C([C@H](C(=O)NCC(=O)N[C@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@H](CCSC)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC=1C=CC=CC=1)C(N)=O)NC(=O)[C@@H](C)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)[C@@H](N)CCC(O)=O)C1=CC=C(O)C=C1 AOXOCDRNSPFDPE-UKEONUMOSA-N 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 208000018805 childhood acute lymphoblastic leukemia Diseases 0.000 description 1
- 201000011633 childhood acute lymphocytic leukemia Diseases 0.000 description 1
- 201000002687 childhood acute myeloid leukemia Diseases 0.000 description 1
- 229960004630 chlorambucil Drugs 0.000 description 1
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 1
- 150000005827 chlorofluoro hydrocarbons Chemical class 0.000 description 1
- 208000006990 cholangiocarcinoma Diseases 0.000 description 1
- 229940107137 cholecystokinin Drugs 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 1
- 239000004927 clay Substances 0.000 description 1
- 238000011260 co-administration Methods 0.000 description 1
- BSMCAPRUBJMWDF-KRWDZBQOSA-N cobimetinib Chemical compound C1C(O)([C@H]2NCCCC2)CN1C(=O)C1=CC=C(F)C(F)=C1NC1=CC=C(I)C=C1F BSMCAPRUBJMWDF-KRWDZBQOSA-N 0.000 description 1
- 208000029742 colonic neoplasm Diseases 0.000 description 1
- 201000010989 colorectal carcinoma Diseases 0.000 description 1
- 230000001447 compensatory effect Effects 0.000 description 1
- 229940125773 compound 10 Drugs 0.000 description 1
- 229940126543 compound 14 Drugs 0.000 description 1
- 229940125758 compound 15 Drugs 0.000 description 1
- 229940126142 compound 16 Drugs 0.000 description 1
- 229940125810 compound 20 Drugs 0.000 description 1
- 229940126086 compound 21 Drugs 0.000 description 1
- 229940126208 compound 22 Drugs 0.000 description 1
- 229940125833 compound 23 Drugs 0.000 description 1
- 229940125961 compound 24 Drugs 0.000 description 1
- 229940125846 compound 25 Drugs 0.000 description 1
- 229940125851 compound 27 Drugs 0.000 description 1
- 229940125877 compound 31 Drugs 0.000 description 1
- 229940125878 compound 36 Drugs 0.000 description 1
- 229940125807 compound 37 Drugs 0.000 description 1
- 229940127573 compound 38 Drugs 0.000 description 1
- 230000002508 compound effect Effects 0.000 description 1
- 239000007891 compressed tablet Substances 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 239000003246 corticosteroid Substances 0.000 description 1
- 229960001334 corticosteroids Drugs 0.000 description 1
- IDLFZVILOHSSID-OVLDLUHVSA-N corticotropin Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)NC(=O)[C@@H](N)CO)C1=CC=C(O)C=C1 IDLFZVILOHSSID-OVLDLUHVSA-N 0.000 description 1
- 229960000258 corticotropin Drugs 0.000 description 1
- 229940041967 corticotropin-releasing hormone Drugs 0.000 description 1
- KLVRDXBAMSPYKH-RKYZNNDCSA-N corticotropin-releasing hormone (human) Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(N)=O)[C@@H](C)CC)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](C)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1N(CCC1)C(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CO)[C@@H](C)CC)C(C)C)C(C)C)C1=CNC=N1 KLVRDXBAMSPYKH-RKYZNNDCSA-N 0.000 description 1
- 239000001767 crosslinked sodium carboxy methyl cellulose Substances 0.000 description 1
- 235000010947 crosslinked sodium carboxy methyl cellulose Nutrition 0.000 description 1
- NISPVUDLMHQFRQ-MKIKIEMVSA-N cucurbitacin I Chemical compound C([C@H]1[C@]2(C)C[C@@H](O)[C@@H]([C@]2(CC(=O)[C@]11C)C)[C@@](C)(O)C(=O)/C=C/C(C)(O)C)C=C2[C@H]1C=C(O)C(=O)C2(C)C NISPVUDLMHQFRQ-MKIKIEMVSA-N 0.000 description 1
- NISPVUDLMHQFRQ-ILFSFOJUSA-N cucurbitacin I Natural products CC(C)(O)C=CC(=O)[C@](C)(O)[C@H]1[C@H](O)C[C@@]2(C)[C@@H]3CC=C4[C@@H](C=C(O)C(=O)C4(C)C)[C@]3(C)C(=O)C[C@]12C NISPVUDLMHQFRQ-ILFSFOJUSA-N 0.000 description 1
- 230000006341 curative response Effects 0.000 description 1
- 208000035250 cutaneous malignant susceptibility to 1 melanoma Diseases 0.000 description 1
- 208000030381 cutaneous melanoma Diseases 0.000 description 1
- 208000017763 cutaneous neuroendocrine carcinoma Diseases 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 210000004292 cytoskeleton Anatomy 0.000 description 1
- 238000011393 cytotoxic chemotherapy Methods 0.000 description 1
- YKGMKSIHIVVYKY-UHFFFAOYSA-N dabrafenib mesylate Chemical compound CS(O)(=O)=O.S1C(C(C)(C)C)=NC(C=2C(=C(NS(=O)(=O)C=3C(=CC=CC=3F)F)C=CC=2)F)=C1C1=CC=NC(N)=N1 YKGMKSIHIVVYKY-UHFFFAOYSA-N 0.000 description 1
- 229960000975 daunorubicin Drugs 0.000 description 1
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 229960003603 decitabine Drugs 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- FMGSKLZLMKYGDP-USOAJAOKSA-N dehydroepiandrosterone Chemical compound C1[C@@H](O)CC[C@]2(C)[C@H]3CC[C@](C)(C(CC4)=O)[C@@H]4[C@@H]3CC=C21 FMGSKLZLMKYGDP-USOAJAOKSA-N 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 239000008356 dextrose and sodium chloride injection Substances 0.000 description 1
- 239000008355 dextrose injection Substances 0.000 description 1
- NEFBYIFKOOEVPA-UHFFFAOYSA-K dicalcium phosphate Chemical compound [Ca+2].[Ca+2].[O-]P([O-])([O-])=O NEFBYIFKOOEVPA-UHFFFAOYSA-K 0.000 description 1
- 229940038472 dicalcium phosphate Drugs 0.000 description 1
- 229910000390 dicalcium phosphate Inorganic materials 0.000 description 1
- 235000014113 dietary fatty acids Nutrition 0.000 description 1
- 230000009699 differential effect Effects 0.000 description 1
- 238000002022 differential scanning fluorescence spectroscopy Methods 0.000 description 1
- UGMCXQCYOVCMTB-UHFFFAOYSA-K dihydroxy(stearato)aluminium Chemical compound CCCCCCCCCCCCCCCCCC(=O)O[Al](O)O UGMCXQCYOVCMTB-UHFFFAOYSA-K 0.000 description 1
- RMDMBHQVNHQDDD-VFWKRBOSSA-L disodium;(2e,4e,6e,8e,10e,12e,14e)-2,6,11,15-tetramethylhexadeca-2,4,6,8,10,12,14-heptaenedioate Chemical compound [Na+].[Na+].[O-]C(=O)C(/C)=C/C=C/C(/C)=C/C=C/C=C(\C)/C=C/C=C(\C)C([O-])=O RMDMBHQVNHQDDD-VFWKRBOSSA-L 0.000 description 1
- HXINDCTZKGGRDE-JPKZNVRTSA-L disodium;[3-[5-[2-[[(3r)-1-(1-methylpyrazol-3-yl)sulfonylpiperidin-3-yl]amino]pyrimidin-4-yl]imidazo[2,1-b][1,3]oxazol-6-yl]phenoxy]methyl phosphate Chemical compound [Na+].[Na+].CN1C=CC(S(=O)(=O)N2C[C@@H](CCC2)NC=2N=C(C=CN=2)C=2N3C=COC3=NC=2C=2C=C(OCOP([O-])([O-])=O)C=CC=2)=N1 HXINDCTZKGGRDE-JPKZNVRTSA-L 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 238000001647 drug administration Methods 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 238000002651 drug therapy Methods 0.000 description 1
- 238000001035 drying Methods 0.000 description 1
- 230000002900 effect on cell Effects 0.000 description 1
- 229950007919 egtazic acid Drugs 0.000 description 1
- 229910001651 emery Inorganic materials 0.000 description 1
- 230000001804 emulsifying effect Effects 0.000 description 1
- 210000004696 endometrium Anatomy 0.000 description 1
- 230000010595 endothelial cell migration Effects 0.000 description 1
- ZUBDGKVDJUIMQQ-UBFCDGJISA-N endothelin-1 Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)NC(=O)[C@H]1NC(=O)[C@H](CC=2C=CC=CC=2)NC(=O)[C@@H](CC=2C=CC(O)=CC=2)NC(=O)[C@H](C(C)C)NC(=O)[C@H]2CSSC[C@@H](C(N[C@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N2)=O)NC(=O)[C@@H](CO)NC(=O)[C@H](N)CSSC1)C1=CNC=N1 ZUBDGKVDJUIMQQ-UBFCDGJISA-N 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- HKSZLNNOFSGOKW-UHFFFAOYSA-N ent-staurosporine Natural products C12=C3N4C5=CC=CC=C5C3=C3CNC(=O)C3=C2C2=CC=CC=C2N1C1CC(NC)C(OC)C4(C)O1 HKSZLNNOFSGOKW-UHFFFAOYSA-N 0.000 description 1
- 239000002702 enteric coating Substances 0.000 description 1
- 238000009505 enteric coating Methods 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 238000001952 enzyme assay Methods 0.000 description 1
- 229960001904 epirubicin Drugs 0.000 description 1
- 238000011067 equilibration Methods 0.000 description 1
- 229940082789 erbitux Drugs 0.000 description 1
- 229940105423 erythropoietin Drugs 0.000 description 1
- 201000004101 esophageal cancer Diseases 0.000 description 1
- 229960005309 estradiol Drugs 0.000 description 1
- 229930182833 estradiol Natural products 0.000 description 1
- 229960001348 estriol Drugs 0.000 description 1
- PROQIPRRNZUXQM-ZXXIGWHRSA-N estriol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H]([C@H](O)C4)O)[C@@H]4[C@@H]3CCC2=C1 PROQIPRRNZUXQM-ZXXIGWHRSA-N 0.000 description 1
- 229960003399 estrone Drugs 0.000 description 1
- 229940093499 ethyl acetate Drugs 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- DEFVIWRASFVYLL-UHFFFAOYSA-N ethylene glycol bis(2-aminoethyl)tetraacetic acid Chemical compound OC(=O)CN(CC(O)=O)CCOCCOCCN(CC(O)=O)CC(O)=O DEFVIWRASFVYLL-UHFFFAOYSA-N 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- 229960005420 etoposide Drugs 0.000 description 1
- LIQODXNTTZAGID-OCBXBXKTSA-N etoposide phosphate Chemical compound COC1=C(OP(O)(O)=O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 LIQODXNTTZAGID-OCBXBXKTSA-N 0.000 description 1
- 229960000752 etoposide phosphate Drugs 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 230000029142 excretion Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 238000010195 expression analysis Methods 0.000 description 1
- 201000008819 extrahepatic bile duct carcinoma Diseases 0.000 description 1
- 238000013213 extrapolation Methods 0.000 description 1
- 208000024519 eye neoplasm Diseases 0.000 description 1
- 125000004030 farnesyl group Chemical group [H]C([*])([H])C([H])=C(C([H])([H])[H])C([H])([H])C([H])([H])C([H])=C(C([H])([H])[H])C([H])([H])C([H])([H])C([H])=C(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 229940087861 faslodex Drugs 0.000 description 1
- 239000000194 fatty acid Substances 0.000 description 1
- 229930195729 fatty acid Natural products 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 229940087476 femara Drugs 0.000 description 1
- 238000007667 floating Methods 0.000 description 1
- 229960000390 fludarabine Drugs 0.000 description 1
- GIUYCYHIANZCFB-FJFJXFQQSA-N fludarabine phosphate Chemical compound C1=NC=2C(N)=NC(F)=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@@H]1O GIUYCYHIANZCFB-FJFJXFQQSA-N 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- 230000004907 flux Effects 0.000 description 1
- 239000006260 foam Substances 0.000 description 1
- 229940028334 follicle stimulating hormone Drugs 0.000 description 1
- 230000037406 food intake Effects 0.000 description 1
- 238000007672 fourth generation sequencing Methods 0.000 description 1
- 229960002258 fulvestrant Drugs 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 201000010175 gallbladder cancer Diseases 0.000 description 1
- 210000001035 gastrointestinal tract Anatomy 0.000 description 1
- 239000007903 gelatin capsule Substances 0.000 description 1
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 1
- 229960005277 gemcitabine Drugs 0.000 description 1
- 238000011223 gene expression profiling Methods 0.000 description 1
- 238000003205 genotyping method Methods 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- 201000003115 germ cell cancer Diseases 0.000 description 1
- 201000007116 gestational trophoblastic neoplasm Diseases 0.000 description 1
- BGHSOEHUOOAYMY-JTZMCQEISA-N ghrelin Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)CN)C1=CC=CC=C1 BGHSOEHUOOAYMY-JTZMCQEISA-N 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- MASNOZXLGMXCHN-ZLPAWPGGSA-N glucagon Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)C(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 MASNOZXLGMXCHN-ZLPAWPGGSA-N 0.000 description 1
- 229960004666 glucagon Drugs 0.000 description 1
- 235000001727 glucose Nutrition 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 108010049041 glutamylalanine Proteins 0.000 description 1
- YQEMORVAKMFKLG-UHFFFAOYSA-N glycerine monostearate Natural products CCCCCCCCCCCCCCCCCC(=O)OC(CO)CO YQEMORVAKMFKLG-UHFFFAOYSA-N 0.000 description 1
- SVUQHVRAGMNPLW-UHFFFAOYSA-N glycerol monostearate Natural products CCCCCCCCCCCCCCCCC(=O)OCC(O)CO SVUQHVRAGMNPLW-UHFFFAOYSA-N 0.000 description 1
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 1
- 108010089804 glycyl-threonine Proteins 0.000 description 1
- 108010050848 glycylleucine Proteins 0.000 description 1
- 238000005469 granulation Methods 0.000 description 1
- 230000003179 granulation Effects 0.000 description 1
- 101150098203 grb2 gene Proteins 0.000 description 1
- 239000000122 growth hormone Substances 0.000 description 1
- JAXFJECJQZDFJS-XHEPKHHKSA-N gtpl8555 Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)N[C@H](B1O[C@@]2(C)[C@H]3C[C@H](C3(C)C)C[C@H]2O1)CCC1=CC=C(F)C=C1 JAXFJECJQZDFJS-XHEPKHHKSA-N 0.000 description 1
- 201000009277 hairy cell leukemia Diseases 0.000 description 1
- 201000010536 head and neck cancer Diseases 0.000 description 1
- 208000014829 head and neck neoplasm Diseases 0.000 description 1
- 230000035876 healing Effects 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 230000004217 heart function Effects 0.000 description 1
- 230000002008 hemorrhagic effect Effects 0.000 description 1
- ZFGMDIBRIDKWMY-PASTXAENSA-N heparin Chemical compound CC(O)=N[C@@H]1[C@@H](O)[C@H](O)[C@@H](COS(O)(=O)=O)O[C@@H]1O[C@@H]1[C@@H](C(O)=O)O[C@@H](O[C@H]2[C@@H]([C@@H](OS(O)(=O)=O)[C@@H](O[C@@H]3[C@@H](OC(O)[C@H](OS(O)(=O)=O)[C@H]3O)C(O)=O)O[C@@H]2O)CS(O)(=O)=O)[C@H](O)[C@H]1O ZFGMDIBRIDKWMY-PASTXAENSA-N 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- BXWNKGSJHAJOGX-UHFFFAOYSA-N hexadecan-1-ol Chemical compound CCCCCCCCCCCCCCCCO BXWNKGSJHAJOGX-UHFFFAOYSA-N 0.000 description 1
- 238000013537 high throughput screening Methods 0.000 description 1
- 231100000171 higher toxicity Toxicity 0.000 description 1
- FVYXIJYOAGAUQK-UHFFFAOYSA-N honokiol Chemical compound C1=C(CC=C)C(O)=CC=C1C1=CC(CC=C)=CC=C1O FVYXIJYOAGAUQK-UHFFFAOYSA-N 0.000 description 1
- VVOAZFWZEDHOOU-UHFFFAOYSA-N honokiol Natural products OC1=CC=C(CC=C)C=C1C1=CC(CC=C)=CC=C1O VVOAZFWZEDHOOU-UHFFFAOYSA-N 0.000 description 1
- 229940084986 human chorionic gonadotropin Drugs 0.000 description 1
- 229930195733 hydrocarbon Natural products 0.000 description 1
- 150000002430 hydrocarbons Chemical class 0.000 description 1
- 229960000890 hydrocortisone Drugs 0.000 description 1
- 230000003463 hyperproliferative effect Effects 0.000 description 1
- 201000006866 hypopharynx cancer Diseases 0.000 description 1
- 230000036543 hypotension Effects 0.000 description 1
- 229960001001 ibritumomab tiuxetan Drugs 0.000 description 1
- 229960000908 idarubicin Drugs 0.000 description 1
- 229960001101 ifosfamide Drugs 0.000 description 1
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 229960002751 imiquimod Drugs 0.000 description 1
- DOUYETYNHWVLEO-UHFFFAOYSA-N imiquimod Chemical compound C1=CC=CC2=C3N(CC(C)C)C=NC3=C(N)N=C21 DOUYETYNHWVLEO-UHFFFAOYSA-N 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 description 1
- 238000003364 immunohistochemistry Methods 0.000 description 1
- 239000002955 immunomodulating agent Substances 0.000 description 1
- 229940121354 immunomodulator Drugs 0.000 description 1
- 230000002584 immunomodulator Effects 0.000 description 1
- 239000000411 inducer Substances 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 239000000893 inhibin Substances 0.000 description 1
- ZPNFWUPYTFPOJU-LPYSRVMUSA-N iniprol Chemical compound C([C@H]1C(=O)NCC(=O)NCC(=O)N[C@H]2CSSC[C@H]3C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC=4C=CC=CC=4)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC2=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC=2C=CC=CC=2)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H]2N(CCC2)C(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N2[C@@H](CCC2)C(=O)N2[C@@H](CCC2)C(=O)N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N2[C@@H](CCC2)C(=O)N3)C(=O)NCC(=O)NCC(=O)N[C@@H](C)C(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@H](C(=O)N1)C(C)C)[C@@H](C)O)[C@@H](C)CC)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 ZPNFWUPYTFPOJU-LPYSRVMUSA-N 0.000 description 1
- 239000007972 injectable composition Substances 0.000 description 1
- 229940102223 injectable solution Drugs 0.000 description 1
- 230000000266 injurious effect Effects 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 239000000138 intercalating agent Substances 0.000 description 1
- 229940047124 interferons Drugs 0.000 description 1
- 230000035987 intoxication Effects 0.000 description 1
- 231100000566 intoxication Toxicity 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000010255 intramuscular injection Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- OMEUGRCNAZNQLN-UHFFFAOYSA-N isis 5132 Chemical compound O=C1NC(=O)C(C)=CN1C1OC(COP(O)(=S)OC2C(OC(C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=S)OC2C(OC(C2)N2C3=NC=NC(N)=C3N=C2)COP(O)(=S)OC2C(OC(C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)OC2C(OC(C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=S)OC2C(OC(C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=S)OC2C(OC(C2)N2C3=NC=NC(N)=C3N=C2)COP(O)(=S)OC2C(OC(C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)OC2C(OC(C2)N2C3=NC=NC(N)=C3N=C2)COP(O)(=S)OC2C(OC(C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(S)(=O)OC2C(OC(C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=S)OC2C(OC(C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=S)OC2C(OC(C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=S)OC2C(OC(C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)OC2C(OC(C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)OC2C(OC(C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=S)OC2C(OC(C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)OC2C(OC(C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)OC2C(OC(C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)OC2C(OC(C2)N2C(NC(=O)C(C)=C2)=O)CO)C(O)C1 OMEUGRCNAZNQLN-UHFFFAOYSA-N 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 1
- 239000007951 isotonicity adjuster Substances 0.000 description 1
- 229960004130 itraconazole Drugs 0.000 description 1
- 229960002014 ixabepilone Drugs 0.000 description 1
- 229940111707 ixempra Drugs 0.000 description 1
- 229940126401 izorlisib Drugs 0.000 description 1
- ZLVXBBHTMQJRSX-VMGNSXQWSA-N jdtic Chemical compound C1([C@]2(C)CCN(C[C@@H]2C)C[C@H](C(C)C)NC(=O)[C@@H]2NCC3=CC(O)=CC=C3C2)=CC=CC(O)=C1 ZLVXBBHTMQJRSX-VMGNSXQWSA-N 0.000 description 1
- NLYAJNPCOHFWQQ-UHFFFAOYSA-N kaolin Chemical compound O.O.O=[Al]O[Si](=O)O[Si](=O)O[Al]=O NLYAJNPCOHFWQQ-UHFFFAOYSA-N 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 201000010982 kidney cancer Diseases 0.000 description 1
- 230000002147 killing effect Effects 0.000 description 1
- 239000004310 lactic acid Substances 0.000 description 1
- 235000014655 lactic acid Nutrition 0.000 description 1
- 206010023841 laryngeal neoplasm Diseases 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 229940039781 leptin Drugs 0.000 description 1
- NRYBAZVQPHGZNS-ZSOCWYAHSA-N leptin Chemical compound O=C([C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC(C)C)CCSC)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CS)C(O)=O NRYBAZVQPHGZNS-ZSOCWYAHSA-N 0.000 description 1
- 231100000518 lethal Toxicity 0.000 description 1
- 230000001665 lethal effect Effects 0.000 description 1
- 229960003881 letrozole Drugs 0.000 description 1
- 150000002617 leukotrienes Chemical class 0.000 description 1
- CMJCXYNUCSMDBY-ZDUSSCGKSA-N lgx818 Chemical compound COC(=O)N[C@@H](C)CNC1=NC=CC(C=2C(=NN(C=2)C(C)C)C=2C(=C(NS(C)(=O)=O)C=C(Cl)C=2)F)=N1 CMJCXYNUCSMDBY-ZDUSSCGKSA-N 0.000 description 1
- 201000006721 lip cancer Diseases 0.000 description 1
- 239000006194 liquid suspension Substances 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 201000007270 liver cancer Diseases 0.000 description 1
- 238000007449 liver function test Methods 0.000 description 1
- 229960002247 lomustine Drugs 0.000 description 1
- 229950001750 lonafarnib Drugs 0.000 description 1
- DHMTURDWPRKSOA-RUZDIDTESA-N lonafarnib Chemical compound C1CN(C(=O)N)CCC1CC(=O)N1CCC([C@@H]2C3=C(Br)C=C(Cl)C=C3CCC3=CC(Br)=CN=C32)CC1 DHMTURDWPRKSOA-RUZDIDTESA-N 0.000 description 1
- 239000006210 lotion Substances 0.000 description 1
- 208000037841 lung tumor Diseases 0.000 description 1
- 229940040129 luteinizing hormone Drugs 0.000 description 1
- 238000012792 lyophilization process Methods 0.000 description 1
- 201000000564 macroglobulinemia Diseases 0.000 description 1
- UEGPKNKPLBYCNK-UHFFFAOYSA-L magnesium acetate Chemical compound [Mg+2].CC([O-])=O.CC([O-])=O UEGPKNKPLBYCNK-UHFFFAOYSA-L 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 230000036244 malformation Effects 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 208000016035 malignant germ cell tumor of ovary Diseases 0.000 description 1
- 208000006178 malignant mesothelioma Diseases 0.000 description 1
- 208000026045 malignant tumor of parathyroid gland Diseases 0.000 description 1
- 201000006512 mast cell neoplasm Diseases 0.000 description 1
- 229960004961 mechlorethamine Drugs 0.000 description 1
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 1
- 229940126601 medicinal product Drugs 0.000 description 1
- 229940083118 mekinist Drugs 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 1
- 229960001428 mercaptopurine Drugs 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 108010056582 methionylglutamic acid Proteins 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 229960000282 metronidazole Drugs 0.000 description 1
- VAOCPAMSLUNLGC-UHFFFAOYSA-N metronidazole Chemical compound CC1=NC=C([N+]([O-])=O)N1CCO VAOCPAMSLUNLGC-UHFFFAOYSA-N 0.000 description 1
- 238000012775 microarray technology Methods 0.000 description 1
- 239000003094 microcapsule Substances 0.000 description 1
- 229940016286 microcrystalline cellulose Drugs 0.000 description 1
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 1
- 239000008108 microcrystalline cellulose Substances 0.000 description 1
- 229960003775 miltefosine Drugs 0.000 description 1
- PQLXHQMOHUQAKB-UHFFFAOYSA-N miltefosine Chemical compound CCCCCCCCCCCCCCCCOP([O-])(=O)OCC[N+](C)(C)C PQLXHQMOHUQAKB-UHFFFAOYSA-N 0.000 description 1
- 229950010514 misonidazole Drugs 0.000 description 1
- OBBCSXFCDPPXOL-UHFFFAOYSA-N misonidazole Chemical compound COCC(O)CN1C=CN=C1[N+]([O-])=O OBBCSXFCDPPXOL-UHFFFAOYSA-N 0.000 description 1
- CFCUWKMKBJTWLW-BKHRDMLASA-N mithramycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@H](O)[C@H](O[C@@H]3O[C@H](C)[C@@H](O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@@H](O)[C@H](O)[C@@H](C)O1 CFCUWKMKBJTWLW-BKHRDMLASA-N 0.000 description 1
- 239000003226 mitogen Substances 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- 229960001156 mitoxantrone Drugs 0.000 description 1
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 239000007932 molded tablet Substances 0.000 description 1
- SLZIZIJTGAYEKK-CIJSCKBQSA-N molport-023-220-247 Chemical compound C([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(N)=O)NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)CN)[C@@H](C)O)C1=CNC=N1 SLZIZIJTGAYEKK-CIJSCKBQSA-N 0.000 description 1
- CQDGTJPVBWZJAZ-UHFFFAOYSA-N monoethyl carbonate Chemical compound CCOC(O)=O CQDGTJPVBWZJAZ-UHFFFAOYSA-N 0.000 description 1
- 201000006462 myelodysplastic/myeloproliferative neoplasm Diseases 0.000 description 1
- 208000025113 myeloid leukemia Diseases 0.000 description 1
- KWRYMZHCQIOOEB-LBPRGKRZSA-N n-[(1s)-1-(7-fluoro-2-pyridin-2-ylquinolin-3-yl)ethyl]-7h-purin-6-amine Chemical compound C1([C@@H](NC=2C=3N=CNC=3N=CN=2)C)=CC2=CC=C(F)C=C2N=C1C1=CC=CC=N1 KWRYMZHCQIOOEB-LBPRGKRZSA-N 0.000 description 1
- IJDNQMDRQITEOD-UHFFFAOYSA-N n-butane Chemical compound CCCC IJDNQMDRQITEOD-UHFFFAOYSA-N 0.000 description 1
- OHDXDNUPVVYWOV-UHFFFAOYSA-N n-methyl-1-(2-naphthalen-1-ylsulfanylphenyl)methanamine Chemical compound CNCC1=CC=CC=C1SC1=CC=CC2=CC=CC=C12 OHDXDNUPVVYWOV-UHFFFAOYSA-N 0.000 description 1
- OFBQJSOFQDEBGM-UHFFFAOYSA-N n-pentane Natural products CCCCC OFBQJSOFQDEBGM-UHFFFAOYSA-N 0.000 description 1
- 229950006238 nadide Drugs 0.000 description 1
- 208000037830 nasal cancer Diseases 0.000 description 1
- 229950007221 nedaplatin Drugs 0.000 description 1
- 230000007524 negative regulation of DNA replication Effects 0.000 description 1
- 230000017095 negative regulation of cell growth Effects 0.000 description 1
- HPNRHPKXQZSDFX-OAQDCNSJSA-N nesiritide Chemical compound C([C@H]1C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CSSC[C@@H](C(=O)N1)NC(=O)CNC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](CCSC)NC(=O)[C@H](CCCCN)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CO)C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1N=CNC=1)C(O)=O)=O)[C@@H](C)CC)C1=CC=CC=C1 HPNRHPKXQZSDFX-OAQDCNSJSA-N 0.000 description 1
- 229940085033 nolvadex Drugs 0.000 description 1
- 231100000344 non-irritating Toxicity 0.000 description 1
- 239000012457 nonaqueous media Substances 0.000 description 1
- 230000005937 nuclear translocation Effects 0.000 description 1
- 238000010899 nucleation Methods 0.000 description 1
- 239000002773 nucleotide Substances 0.000 description 1
- 125000003729 nucleotide group Chemical group 0.000 description 1
- 201000008106 ocular cancer Diseases 0.000 description 1
- PIDFDZJZLOTZTM-KHVQSSSXSA-N ombitasvir Chemical compound COC(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@H]1C(=O)NC1=CC=C([C@H]2N([C@@H](CC2)C=2C=CC(NC(=O)[C@H]3N(CCC3)C(=O)[C@@H](NC(=O)OC)C(C)C)=CC=2)C=2C=CC(=CC=2)C(C)(C)C)C=C1 PIDFDZJZLOTZTM-KHVQSSSXSA-N 0.000 description 1
- 231100000590 oncogenic Toxicity 0.000 description 1
- 230000002246 oncogenic effect Effects 0.000 description 1
- 230000004650 oncogenic pathway Effects 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 108060005714 orexin Proteins 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 210000003463 organelle Anatomy 0.000 description 1
- 150000002895 organic esters Chemical class 0.000 description 1
- 201000006958 oropharynx cancer Diseases 0.000 description 1
- 201000008042 ovarian germ cell cancer Diseases 0.000 description 1
- 229960001756 oxaliplatin Drugs 0.000 description 1
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 description 1
- 229940094443 oxytocics prostaglandins Drugs 0.000 description 1
- XNOPRXBHLZRZKH-DSZYJQQASA-N oxytocin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSC[C@H](N)C(=O)N1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(N)=O)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 XNOPRXBHLZRZKH-DSZYJQQASA-N 0.000 description 1
- 229960001723 oxytocin Drugs 0.000 description 1
- 238000004806 packaging method and process Methods 0.000 description 1
- 238000012856 packing Methods 0.000 description 1
- 201000002530 pancreatic endocrine carcinoma Diseases 0.000 description 1
- 239000000199 parathyroid hormone Substances 0.000 description 1
- 229960001319 parathyroid hormone Drugs 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 235000010603 pastilles Nutrition 0.000 description 1
- 230000009428 pathway alteration Effects 0.000 description 1
- 229960000639 pazopanib Drugs 0.000 description 1
- CUIHSIWYWATEQL-UHFFFAOYSA-N pazopanib Chemical compound C1=CC2=C(C)N(C)N=C2C=C1N(C)C(N=1)=CC=NC=1NC1=CC=C(C)C(S(N)(=O)=O)=C1 CUIHSIWYWATEQL-UHFFFAOYSA-N 0.000 description 1
- 235000020232 peanut Nutrition 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- WBXPDJSOTKVWSJ-ZDUSSCGKSA-N pemetrexed Chemical compound C=1NC=2NC(N)=NC(=O)C=2C=1CCC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 WBXPDJSOTKVWSJ-ZDUSSCGKSA-N 0.000 description 1
- 239000002304 perfume Substances 0.000 description 1
- SZFPYBIJACMNJV-UHFFFAOYSA-N perifosine Chemical compound CCCCCCCCCCCCCCCCCCOP([O-])(=O)OC1CC[N+](C)(C)CC1 SZFPYBIJACMNJV-UHFFFAOYSA-N 0.000 description 1
- 229950010632 perifosine Drugs 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- 239000002831 pharmacologic agent Substances 0.000 description 1
- WVDDGKGOMKODPV-ZQBYOMGUSA-N phenyl(114C)methanol Chemical compound O[14CH2]C1=CC=CC=C1 WVDDGKGOMKODPV-ZQBYOMGUSA-N 0.000 description 1
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 1
- 201000002511 pituitary cancer Diseases 0.000 description 1
- 238000007747 plating Methods 0.000 description 1
- 230000036178 pleiotropy Effects 0.000 description 1
- 229960003171 plicamycin Drugs 0.000 description 1
- 231100000614 poison Toxicity 0.000 description 1
- 239000002574 poison Substances 0.000 description 1
- 229920002647 polyamide Polymers 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 229920001184 polypeptide Polymers 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 description 1
- 229960002847 prasterone Drugs 0.000 description 1
- 208000016800 primary central nervous system lymphoma Diseases 0.000 description 1
- 102000004196 processed proteins & peptides Human genes 0.000 description 1
- 229960003387 progesterone Drugs 0.000 description 1
- 239000000186 progesterone Substances 0.000 description 1
- 230000002250 progressing effect Effects 0.000 description 1
- 239000002877 prolactin releasing hormone Substances 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 239000001294 propane Substances 0.000 description 1
- 235000013772 propylene glycol Nutrition 0.000 description 1
- 150000003815 prostacyclins Chemical class 0.000 description 1
- 150000003180 prostaglandins Chemical class 0.000 description 1
- 238000003498 protein array Methods 0.000 description 1
- 238000002731 protein assay Methods 0.000 description 1
- 239000003528 protein farnesyltransferase inhibitor Substances 0.000 description 1
- 239000003531 protein hydrolysate Substances 0.000 description 1
- 230000009145 protein modification Effects 0.000 description 1
- 230000007026 protein scission Effects 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 239000000649 purine antagonist Substances 0.000 description 1
- 239000003790 pyrimidine antagonist Substances 0.000 description 1
- 125000000714 pyrimidinyl group Chemical group 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 238000007420 radioactive assay Methods 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 239000000941 radioactive substance Substances 0.000 description 1
- 239000012132 radioimmunoprecipitation assay buffer Substances 0.000 description 1
- 238000001959 radiotherapy Methods 0.000 description 1
- 206010038038 rectal cancer Diseases 0.000 description 1
- 201000001275 rectum cancer Diseases 0.000 description 1
- 229950008933 refametinib Drugs 0.000 description 1
- 238000000611 regression analysis Methods 0.000 description 1
- 230000029865 regulation of blood pressure Effects 0.000 description 1
- 208000015347 renal cell adenocarcinoma Diseases 0.000 description 1
- 208000030859 renal pelvis/ureter urothelial carcinoma Diseases 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 230000000284 resting effect Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 208000004644 retinal vein occlusion Diseases 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 201000009410 rhabdomyosarcoma Diseases 0.000 description 1
- 229960003522 roquinimex Drugs 0.000 description 1
- 102200006659 rs104894226 Human genes 0.000 description 1
- 102200006614 rs104894229 Human genes 0.000 description 1
- 102200006648 rs28933406 Human genes 0.000 description 1
- 102200010052 rs730881014 Human genes 0.000 description 1
- 239000010979 ruby Substances 0.000 description 1
- 229910001750 ruby Inorganic materials 0.000 description 1
- YGSDEFSMJLZEOE-UHFFFAOYSA-M salicylate Chemical compound OC1=CC=CC=C1C([O-])=O YGSDEFSMJLZEOE-UHFFFAOYSA-M 0.000 description 1
- 229960001860 salicylate Drugs 0.000 description 1
- WUILNKCFCLNXOK-CFBAGHHKSA-N salirasib Chemical compound CC(C)=CCC\C(C)=C\CC\C(C)=C\CSC1=CC=CC=C1C(O)=O WUILNKCFCLNXOK-CFBAGHHKSA-N 0.000 description 1
- 229950008669 salirasib Drugs 0.000 description 1
- 238000007480 sanger sequencing Methods 0.000 description 1
- 229960005399 satraplatin Drugs 0.000 description 1
- 190014017285 satraplatin Chemical compound 0.000 description 1
- 238000003345 scintillation counting Methods 0.000 description 1
- 229960002101 secretin Drugs 0.000 description 1
- OWMZNFCDEHGFEP-NFBCVYDUSA-N secretin human Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(N)=O)[C@@H](C)O)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)C1=CC=CC=C1 OWMZNFCDEHGFEP-NFBCVYDUSA-N 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- WUWDLXZGHZSWQZ-WQLSENKSSA-N semaxanib Chemical compound N1C(C)=CC(C)=C1\C=C/1C2=CC=CC=C2NC\1=O WUWDLXZGHZSWQZ-WQLSENKSSA-N 0.000 description 1
- 229950003647 semaxanib Drugs 0.000 description 1
- 238000010206 sensitivity analysis Methods 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 108010071207 serylmethionine Proteins 0.000 description 1
- 208000012201 sexual and gender identity disease Diseases 0.000 description 1
- 208000015891 sexual disease Diseases 0.000 description 1
- 230000007781 signaling event Effects 0.000 description 1
- 150000004760 silicates Chemical class 0.000 description 1
- IZTQOLKUZKXIRV-YRVFCXMDSA-N sincalide Chemical compound C([C@@H](C(=O)N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(N)=O)NC(=O)[C@@H](N)CC(O)=O)C1=CC=C(OS(O)(=O)=O)C=C1 IZTQOLKUZKXIRV-YRVFCXMDSA-N 0.000 description 1
- 238000011125 single therapy Methods 0.000 description 1
- 208000037968 sinus cancer Diseases 0.000 description 1
- 206010040882 skin lesion Diseases 0.000 description 1
- 231100000444 skin lesion Toxicity 0.000 description 1
- 201000003708 skin melanoma Diseases 0.000 description 1
- 201000002314 small intestine cancer Diseases 0.000 description 1
- 229910000029 sodium carbonate Inorganic materials 0.000 description 1
- 239000008354 sodium chloride injection Substances 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 239000008109 sodium starch glycolate Substances 0.000 description 1
- 229940079832 sodium starch glycolate Drugs 0.000 description 1
- 229920003109 sodium starch glycolate Polymers 0.000 description 1
- 239000008247 solid mixture Substances 0.000 description 1
- 229960000553 somatostatin Drugs 0.000 description 1
- NHXLMOGPVYXJNR-ATOGVRKGSA-N somatostatin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CSSC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(=O)N1)[C@@H](C)O)NC(=O)CNC(=O)[C@H](C)N)C(O)=O)=O)[C@H](O)C)C1=CC=CC=C1 NHXLMOGPVYXJNR-ATOGVRKGSA-N 0.000 description 1
- 229960003787 sorafenib Drugs 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 230000009126 specific adaptive response Effects 0.000 description 1
- PFNFFQXMRSDOHW-UHFFFAOYSA-N spermine Chemical compound NCCCNCCCCNCCCN PFNFFQXMRSDOHW-UHFFFAOYSA-N 0.000 description 1
- 238000005507 spraying Methods 0.000 description 1
- HKSZLNNOFSGOKW-FYTWVXJKSA-N staurosporine Chemical compound C12=C3N4C5=CC=CC=C5C3=C3CNC(=O)C3=C2C2=CC=CC=C2N1[C@H]1C[C@@H](NC)[C@@H](OC)[C@]4(C)O1 HKSZLNNOFSGOKW-FYTWVXJKSA-N 0.000 description 1
- CGPUWJWCVCFERF-UHFFFAOYSA-N staurosporine Natural products C12=C3N4C5=CC=CC=C5C3=C3CNC(=O)C3=C2C2=CC=CC=C2N1C1CC(NC)C(OC)C4(OC)O1 CGPUWJWCVCFERF-UHFFFAOYSA-N 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 229960001052 streptozocin Drugs 0.000 description 1
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 1
- 230000004960 subcellular localization Effects 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 230000008093 supporting effect Effects 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 229960005314 suramin Drugs 0.000 description 1
- FIAFUQMPZJWCLV-UHFFFAOYSA-N suramin Chemical compound OS(=O)(=O)C1=CC(S(O)(=O)=O)=C2C(NC(=O)C3=CC=C(C(=C3)NC(=O)C=3C=C(NC(=O)NC=4C=C(C=CC=4)C(=O)NC=4C(=CC=C(C=4)C(=O)NC=4C5=C(C=C(C=C5C(=CC=4)S(O)(=O)=O)S(O)(=O)=O)S(O)(=O)=O)C)C=CC=3)C)=CC=C(S(O)(=O)=O)C2=C1 FIAFUQMPZJWCLV-UHFFFAOYSA-N 0.000 description 1
- 238000013268 sustained release Methods 0.000 description 1
- 208000011580 syndromic disease Diseases 0.000 description 1
- 230000005737 synergistic response Effects 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- 229950001899 tasquinimod Drugs 0.000 description 1
- ONDYALNGTUAJDX-UHFFFAOYSA-N tasquinimod Chemical compound OC=1C=2C(OC)=CC=CC=2N(C)C(=O)C=1C(=O)N(C)C1=CC=C(C(F)(F)F)C=C1 ONDYALNGTUAJDX-UHFFFAOYSA-N 0.000 description 1
- RCINICONZNJXQF-XAZOAEDWSA-N taxol® Chemical compound O([C@@H]1[C@@]2(CC(C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3(C21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-XAZOAEDWSA-N 0.000 description 1
- 229940063683 taxotere Drugs 0.000 description 1
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 description 1
- 229960001278 teniposide Drugs 0.000 description 1
- 201000003120 testicular cancer Diseases 0.000 description 1
- 229960003604 testosterone Drugs 0.000 description 1
- CXVCSRUYMINUSF-UHFFFAOYSA-N tetrathiomolybdate(2-) Chemical compound [S-][Mo]([S-])(=S)=S CXVCSRUYMINUSF-UHFFFAOYSA-N 0.000 description 1
- 101150081717 tfs gene Proteins 0.000 description 1
- 229960003433 thalidomide Drugs 0.000 description 1
- 230000004797 therapeutic response Effects 0.000 description 1
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 1
- 206010043554 thrombocytopenia Diseases 0.000 description 1
- 150000003595 thromboxanes Chemical class 0.000 description 1
- 208000008732 thymoma Diseases 0.000 description 1
- LCJVIYPJPCBWKS-NXPQJCNCSA-N thymosin Chemical compound SC[C@@H](N)C(=O)N[C@H](CO)C(=O)N[C@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@H](C(C)C)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](C(C)C)C(=O)N[C@H](CO)C(=O)N[C@H](CO)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@H]([C@@H](C)CC)C(=O)N[C@H]([C@H](C)O)C(=O)N[C@H](C(C)C)C(=O)N[C@H](CCCCN)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@H](CCCCN)C(=O)N[C@H](CCCCN)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@H](C(C)C)C(=O)N[C@H](C(C)C)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@H](CCC(O)=O)C(O)=O LCJVIYPJPCBWKS-NXPQJCNCSA-N 0.000 description 1
- 210000001685 thyroid gland Anatomy 0.000 description 1
- 208000013077 thyroid gland carcinoma Diseases 0.000 description 1
- 230000036962 time dependent Effects 0.000 description 1
- 229950002376 tirapazamine Drugs 0.000 description 1
- QVMPZNRFXAKISM-UHFFFAOYSA-N tirapazamine Chemical compound C1=CC=C2[N+]([O-])=NC(=N)N(O)C2=C1 QVMPZNRFXAKISM-UHFFFAOYSA-N 0.000 description 1
- 238000003325 tomography Methods 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 229960000303 topotecan Drugs 0.000 description 1
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 238000010967 transthoracic echocardiography Methods 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- 150000003626 triacylglycerols Chemical class 0.000 description 1
- 229940078499 tricalcium phosphate Drugs 0.000 description 1
- 235000019731 tricalcium phosphate Nutrition 0.000 description 1
- 229910000391 tricalcium phosphate Inorganic materials 0.000 description 1
- 229950003873 triciribine Drugs 0.000 description 1
- HOGVTUZUJGHKPL-HTVVRFAVSA-N triciribine Chemical compound C=12C3=NC=NC=1N(C)N=C(N)C2=CN3[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O HOGVTUZUJGHKPL-HTVVRFAVSA-N 0.000 description 1
- 229950002860 triplatin tetranitrate Drugs 0.000 description 1
- 190014017283 triplatin tetranitrate Chemical compound 0.000 description 1
- 239000002753 trypsin inhibitor Substances 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 230000009750 upstream signaling Effects 0.000 description 1
- 229960001055 uracil mustard Drugs 0.000 description 1
- 230000036325 urinary excretion Effects 0.000 description 1
- 206010046766 uterine cancer Diseases 0.000 description 1
- 206010046885 vaginal cancer Diseases 0.000 description 1
- 208000013139 vaginal neoplasm Diseases 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 229960000653 valrubicin Drugs 0.000 description 1
- ZOCKGBMQLCSHFP-KQRAQHLDSA-N valrubicin Chemical compound O([C@H]1C[C@](CC2=C(O)C=3C(=O)C4=CC=CC(OC)=C4C(=O)C=3C(O)=C21)(O)C(=O)COC(=O)CCCC)[C@H]1C[C@H](NC(=O)C(F)(F)F)[C@H](O)[C@H](C)O1 ZOCKGBMQLCSHFP-KQRAQHLDSA-N 0.000 description 1
- 229960003726 vasopressin Drugs 0.000 description 1
- 235000019871 vegetable fat Nutrition 0.000 description 1
- 231100000611 venom Toxicity 0.000 description 1
- 239000002435 venom Substances 0.000 description 1
- 210000001048 venom Anatomy 0.000 description 1
- 231100000747 viability assay Toxicity 0.000 description 1
- 238000003026 viability measurement method Methods 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
- 201000005102 vulva cancer Diseases 0.000 description 1
- 239000008215 water for injection Substances 0.000 description 1
- 239000012224 working solution Substances 0.000 description 1
- 239000008096 xylene Substances 0.000 description 1
- 239000011787 zinc oxide Substances 0.000 description 1
Images
































































































































































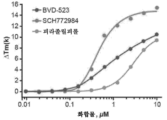






























Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/33—Heterocyclic compounds
- A61K31/395—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins
- A61K31/435—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having six-membered rings with one nitrogen as the only ring hetero atom
- A61K31/4353—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having six-membered rings with one nitrogen as the only ring hetero atom ortho- or peri-condensed with heterocyclic ring systems
- A61K31/437—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having six-membered rings with one nitrogen as the only ring hetero atom ortho- or peri-condensed with heterocyclic ring systems the heterocyclic ring system containing a five-membered ring having nitrogen as a ring hetero atom, e.g. indolizine, beta-carboline
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/33—Heterocyclic compounds
- A61K31/395—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins
- A61K31/435—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having six-membered rings with one nitrogen as the only ring hetero atom
- A61K31/44—Non condensed pyridines; Hydrogenated derivatives thereof
- A61K31/4427—Non condensed pyridines; Hydrogenated derivatives thereof containing further heterocyclic ring systems
- A61K31/4439—Non condensed pyridines; Hydrogenated derivatives thereof containing further heterocyclic ring systems containing a five-membered ring with nitrogen as a ring hetero atom, e.g. omeprazole
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/33—Heterocyclic compounds
- A61K31/395—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins
- A61K31/435—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having six-membered rings with one nitrogen as the only ring hetero atom
- A61K31/44—Non condensed pyridines; Hydrogenated derivatives thereof
- A61K31/445—Non condensed piperidines, e.g. piperocaine
- A61K31/4523—Non condensed piperidines, e.g. piperocaine containing further heterocyclic ring systems
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/33—Heterocyclic compounds
- A61K31/395—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins
- A61K31/495—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having six-membered rings with two or more nitrogen atoms as the only ring heteroatoms, e.g. piperazine or tetrazines
- A61K31/505—Pyrimidines; Hydrogenated pyrimidines, e.g. trimethoprim
- A61K31/506—Pyrimidines; Hydrogenated pyrimidines, e.g. trimethoprim not condensed and containing further heterocyclic rings
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/33—Heterocyclic compounds
- A61K31/395—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins
- A61K31/495—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having six-membered rings with two or more nitrogen atoms as the only ring heteroatoms, e.g. piperazine or tetrazines
- A61K31/505—Pyrimidines; Hydrogenated pyrimidines, e.g. trimethoprim
- A61K31/519—Pyrimidines; Hydrogenated pyrimidines, e.g. trimethoprim ortho- or peri-condensed with heterocyclic rings
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/04—Antineoplastic agents specific for metastasis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/04—Immunostimulants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/06—Immunosuppressants, e.g. drugs for graft rejection
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/10—Drugs for disorders of the cardiovascular system for treating ischaemic or atherosclerotic diseases, e.g. antianginal drugs, coronary vasodilators, drugs for myocardial infarction, retinopathy, cerebrovascula insufficiency, renal arteriosclerosis
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57484—Immunoassay; Biospecific binding assay; Materials therefor for cancer involving compounds serving as markers for tumor, cancer, neoplasia, e.g. cellular determinants, receptors, heat shock/stress proteins, A-protein, oligosaccharides, metabolites
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2300/00—Mixtures or combinations of active ingredients, wherein at least one active ingredient is fully defined in groups A61K31/00 - A61K41/00
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/106—Pharmacogenomics, i.e. genetic variability in individual responses to drugs and drug metabolism
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/156—Polymorphic or mutational markers
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Immunology (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Epidemiology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Oncology (AREA)
- Molecular Biology (AREA)
- Urology & Nephrology (AREA)
- Analytical Chemistry (AREA)
- Pathology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biomedical Technology (AREA)
- Cell Biology (AREA)
- Hematology (AREA)
- Biotechnology (AREA)
- Physics & Mathematics (AREA)
- Hospice & Palliative Care (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- Food Science & Technology (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Biophysics (AREA)
- Transplantation (AREA)
- Virology (AREA)
Abstract
본 발명은 특히 비-ERK MAPK 경로 억제제 치료법에 대해 저항성이거나 내성이 있는 암의 작용을 치료하거나 개선시키기 위한 방법, 약제학적 조성물 및 키트를 제공한다. 또한, ERK 억제제 치료법으로부터 이득을 얻을 수 있는 암을 갖는 대상체를 확인하는 방법, 비-ERK MAPK 경로 억제제에 대해 저항성이거나 내성이 있는 암세포에서 RSK의 인산화를 억제하는 방법을 제공한다.
Description
관련 출원에 대한 교차 참조
본 출원은, 미국 특허출원 61/919,551 (2013.12.20)의 우선권을 주장하는 PCT 국제 출원 PCT/US2014/071749 (2014. 12.19)의 부분 연속출원인 미국 특허출원 15/161,137 (2016.5.20)에 대한 이권을 주장하며, 이들 모두는 본원에 전체가 인용되는 것처럼, 이들 전체가 참조로서 본원에 포함된다.
본 발명은, 특히, 대상체에서, 비-ERK MAPK 경로 억제제 치료법에 대해 저항성이거나 내성이 있는 암의 작용을 치료하거나 개선시키기 위한 방법, 약제학적 조성물 및 키트를 제공한다.
참조로 포함된 서열 리스트
본 출원은, 2016년 5월 20일자로 생성된, 전체 크기 351 KB의 "0398850pct.txt"의 서열 리스트 텍스트 파일로서 본원 출원시 동시에 제출된 아미노산 및/또는 핵산 서열에 대한 참조를 함유한다. 상기한 서열 리스트는 37 C.F.R. § 1.52(e)(5)에 따라 그 전체가 참조로서 본원에 포함된다.
미토겐-활성화된 단백질 키나아제(MAPK) 신호전달 경로의 성분들을 표적화하는 약물 억제제들은 다양한 암, 특히 BRAF 단백질 키나아제에 돌연변이를 갖는 암에 대한 임상적 효능을 나타낸다. RAF 및 MEK 억제제 둘다는 진행된 전이성 BRAF 돌연변이체 흑색종에서의 단일 제제 용도로 허가되었다. BRAF 및 MEK 억제제 활성은, 단독 또는 병용으로도 기타 암에서 예측할 수 없었고, BRAF 돌연변이 갑상선 및 폐암에서 효능이 유력하고, BRAF 돌연변이 결장직장암에서는 단지 주변 활성만 갖는다.
다른 표적화된 치료법에서와 같이, RAF 및 MEK 억제제에 대한 질환 반응의 패턴은, 약물이 사용되는 암에 존재하는 내인성 유전자 이종성에 의해 영향받는 것으로 보인다. 예를 들면, PTEN 및 PI3K 세포 성장 신호전달 경로를 활성화시키는 다른 변이를 포함한 특정 유전자 변화들은, RAF 억제제 베무라페닙을 사용하여 치료된 BRAF 돌연변이 흑색종에서 불량한 초기 반응 및/또는 비교적 빠른 진행을 예측할 수 있는 것으로 나타났다. 마찬가지로, MEK 유전자 좌(loci)에서의 직접적인 돌연변이는 BRAF, MEK 또는 병용된 약물 치료 이후 진행되는 종양에서 드러나는 것으로 보인다. RAS 및 RAF 유전자 증폭 및 스플라이싱 돌연변이들로부터의 몇몇 추가 예들은, 종양원성 다면발현이 표적화된 약물 치료의 선택압과 직면하게 되는 경우 획득된 약물 내성(acquired durg resistance)이 생긴다는 것을 시사한다.
상기와 같은 측면에서, 종양원성 경로의 다양한 교점들(nodes)을 이상적으로 억제하고, 다양한 암 게놈의 적응적(adaptive) 능력을 뛰어넘는 선택압의 부과를 유도함에 의해 병용제로 효과적인 신규한 표적화된 제제에 대한 필요성이 존재하였다. 본 출원은 상기 및 기타 필요성을 충족하는 것이다.
발명의 요지
본원 발명의 한 실시형태는, 비-ERK MAPK 경로 억제제 치료법에 대해 저항성이거나 내성이 있는 암의 작용을 대상체에서 치료하거나 개선시키기 위한 방법이다. 상기 방법은 상기 대상체에게 BVD-523 또는 이의 약제학적으로 허용되는 염의 유효량을 투여함을 포함한다.
본원 발명의 또다른 실시형태는 암의 작용을 대상체에서 치료하거나 개선시키기 위한 방법이다. 상기 방법은:
(a) BRAF 억제제 치료법, MEK 억제제 치료법 또는 BRAF 및 MEK 억제제 치료법에 대해 저항성이거나 내성이 된 암이 있는 대상체를 확인하는 단계; 및
(b) 상기 저항성 또는 내성 암이 있는 대상체에게 BVD-523 또는 이의 약제학적으로 허용되는 염인 ERK 억제제의 유효량을 투여함을 포함한다.
본원 발명의 추가의 실시형태는, BRAF 억제제 치료법, MEK 억제제 치료법 또는 이들 둘 다에 대해 저항성이거나 내성이 있는 암의 작용을 대상체에서 치료하거나 개선시키기 위한 방법이다. 상기 방법은 상기 대상체에게 BVD-523 또는 이의 약제학적으로 허용되는 염의 유효량을 투여함을 포함한다.
본원 발명의 또다른 실시형태는 ERK 억제제를 사용한 치료법으로 혜택을 보는 암을 갖는 대상체를 확인하기 위한 방법이다. 상기 방법은:
(a) 상기 대상체로부터 생물학적 샘플을 수득하는 단계; 및
(b) 상기 대상체가 하기 마커들:
(i) RAF 이소형들간의 전환,
(ii) 수용체 티로신 키나아제 (RTK) 또는 NRAS 신호전달의 상향조절,
(iii) 미토겐 활성화된 단백질 키나아제(MAPK) 신호전달의 재활성화,
(iv) MEK 활성화 돌연변이의 존재,
(v) 돌연변이 BRAF의 증폭,
(vi) STAT3 상향조절,
(vii) MEK에 대한 억제제의 결합을 직접 차단하거나 구성적 MEK 활성을 초래하는 MEK의 알로스테릭 포켓에서의 돌연변이
중 하나 또는 그 이상을 갖는지를 결정하기 위해 상기 샘플을 스크리닝하는 단계를 포함하고, 여기서, 상기 마커들 중 하나 또는 그 이상의 존재는, 상기 대상체의 암이 BRAF 및/또는 MEK 억제제 치료법에 대해 저항성 또는 내성이며 상기 대상체가 BVD-523 또는 이의 약제학적으로 허용되는 염인 ERK 억제제를 사용한 치료법으로 혜택을 보게 될 것임을 확인시켜준다.
본원 발명의 추가의 실시형태는, 비-ERK MAPK 경로 치료법에 대해 저항성이거나 내성이 있는 암의 작용을 대상체에서 치료하거나 개선시키기 위한 약제학적 조성물이다. 상기 조성물은 약제학적으로 허용되는 담체 또는 희석제 및 BVD-523 또는 이의 약제학적으로 허용되는 염의 유효량을 포함한다.
본원 발명의 또다른 실시형태는, 비-ERK MAPK 경로 치료법에 대해 저항성이거나 내성이 있는 암의 작용을 대상체에서 치료하거나 개선시키기 위한 키트이다. 상기 키트는 본원 발명에 따른 상기 약제학적 조성물들 중 임의의 것을 이의 사용 지침서와 함께 포장하여 포함한다.
본원 발명의 또다른 실시형태는, 비-ERK MAPK 경로 억제제에 대해 저항성이거나 내성인 암 세포에서 RSK의 인산화를 억제하기 위한 방법이다. 상기 방법은 상기 암 세포 내에서 RSK의 인산화가 억제되기에 충분한 시간동안 상기 암 세포를 BVD-523 또는 이의 약제학적으로 허용되는 염의 유효량과 접촉시킴을 포함한다.
본원 발명의 또다른 실시형태는, 비절제성 또는 전이성 BRAF600 돌연변이-양성 흑색종을 갖는 대상체를 치료하는 방법으로서, 상기 방법은 상기 대상체에게 600 mg BID의 BVD-523 또는 이의 약제학적으로 허용되는 염을 투여함을 포함한다.
본원 발명의 또다른 실시형태는, 비절제성 또는 전이성 BRAF600 돌연변이-양성 흑색종을 갖는 대상체를 치료하기 위한 조성물로서, 상기 조성물은 600 mg의 BVD-523 또는 이의 약제학적으로 허용되는 염 및 임의로 약제학적으로 허용되는 담체, 보조제 또는 비히클을 포함한다.
특허 또는 출원 파일은 컬러로 작성된 적어도 하나의 도면을 함유한다. 컬러 도면(들)이 있는 이같은 특허 또는 특허 출원 공보의 사본은 필요한 비용의 지불과 함께 요청이 있을 경우 청에 의해 제공될 것이다.
도 1a 내지 도 1c는 제1 달 동안 사람 악성 흑색종 세포주 (A375 세포)에서 용량 상승 연구의 진행과정을 보여준다. 다양한 처리들 (트라메티닙 (2형 MEK 억제제), 다브라페닙 (BRAF 억제제), 및 BVD-523 (ERK1/2 억제제))은 표시된 바와 같다.
도 2a 내지 도 2h는 제1 달에 증가된 제제(들)에 대한 민감성에서의 변화를 추적하는 증식 검정의 결과를 보여준다. 다양한 처리들 (트라메티닙, 다브라페닙, BVD-523 및 파시탁셀)은 그래프의 상단에 표시된 바와 같다. 그래프의 우측 해설은 용량 상승 연구에서 나타난 다양한 세포 유형을 보여준다. 예를 들면, "다브라페닙"은 용량 상승 연구의 제1 달로부터 다브라페닙의 최고 용량으로 처리된 세포를 지칭한다. 모세포(parental)는 약물로 처리되지 않은 대조군 세포(control cells)를 지칭한다. 도 2a, 도 2c 및 도 2g는 대조군에 대해 정규화된 것이고, 도 2d, 도 2f 및 도 2h는 원데이터(raw data)를 나타낸다.
도 3a 내지 도 3d는 제2 달 동안 A375 세포에서의 용량 상승 연구의 진행과정을 보여준다. 다양한 처리들 (트라메티닙, 다브라페닙 및 BVD-523)은 표시된 바와 같다.
도 4a 내지 도 4h는 제2 달에 증가된 제제(들)에 대한 민감성에서의 변화를 추적하는 증식 검정의 결과를 보여준다. 다양한 처리들 (트라메티닙, 다브라페닙, BVD-523 및 파시탁셀)은 그래프의 상단에 표시된 바와 같다. 그래프의 우측 해설은 용량 상승 연구에서 나타난 다양한 세포 유형을 보여준다. 예를 들면, "다브라페닙"은 용량 상승 연구의 제2 달로부터 다브라페닙의 최고 용량으로 처리된 세포를 지칭한다. 모세포는 약물로 처리되지 않은 대조군 세포를 지칭한다. 도 4a, 도 4c 및 도 4g는 대조군에 대해 정규화된 것이고, 도 4d, 도 4f 및 도 4h는 원데이터를 나타낸다.
도 5a 내지 도 5h는 도 4a 내지 도 4h로부터의 단지 모세포 및 BVD-523 세포주 데이터만을 보여준다. 다양한 처리들 (트라메티닙, 다브라페닙, BVD-523 및 파시탁셀)은 표시된 바와 같다. 도 5a, 도 5c 및 도 5g는 대조군에 대해 정규화된 것이고, 도 5d, 도 5f 및 도 5h는 원데이터를 나타낸다.
도 6a 내지 도 6d는 제3 달 동안 사람 악성 세포주 (A375 세포)에서 용량 상승 연구의 진행과정을 보여준다. 다양한 처리들 (트라메티닙, 다브라페닙 및 BVD-523)은 표시된 바와 같다.
도 7은 용량 상승 검정으로부터의 DMSO 대조군 웰에서 성장시킨 세포에 적용된 증식 검정의 결과를 보여주는 히스토그램이다.
도 8a 내지 도 8d는 당해 연구의 제3 달 동안의 증식 검정을 보여주는 일련의 선 그래프이다. 다양한 처리들 (트라메티닙, 다브라페닙, BVD-523 및 파시탁셀)은 그래프의 상단에 표시된 바와 같다. 그래프의 우측 해설은 용량 상승 연구에서 나타난 다양한 세포 유형을 보여준다. 예를 들면, "다브라페닙"은 용량 상승 연구의 제3 달로부터 다브라페닙의 최고 용량으로 처리된 세포를 지칭한다. 모세포는 약물로 처리되지 않은 대조군 세포를 지칭한다.
도 9a 내지 도 9d는 도 8a 내지 도 8d로부터의 모세포, 다브라페닙 및 BVD-523 세포주 데이터만을 보여준다.
도 10a는 알라마 블루 (Alamar Blue) 세포 생존성 검정을 사용한 A375 세포에서 트라메티닙/다브라페닙 병용의 억제율%를 나타내는 용량 매트릭스이다. 도 10b는 트라메티닙/다브라페닙 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 10c 및 도 10d는 알라마 블루 (Alamar Blue) 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 트라메티닙 단일 제제 처리에 대한 생존율(viability) %를 보여준다. 도 10e는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 트라메티닙 병용 처리에 대한 생존율 %를 보여준다.
도 11a는 셀타이터-글로 (CellTiter-Glo) 세포 생존성 검정을 사용하여 A375 세포에서 트라메티닙/다브라페닙 병용의 억제율 %를 보여주는 용량 매트릭스이다. 도 11b는 트라메티닙/다브라페닙 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 11c 및 도 11d는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 트라메티닙 단일 제제 처리에 대한 생존율 %를 보여준다. 도 11e는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 트라메티닙 병용 처리에 대한 생존율 %를 보여준다.
도 12a는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 BVD-523/다브라페닙 병용의 억제율 %를 나타내는 용량 매트릭스이다. 도 12b는 BVD-523/다브라페닙 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 12c 및 도 12d는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 BVD-523 단일 제제 처리에 대한 생존율 %를 보여준다. 도 12e는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 BVD-523 병용 처리에 대한 생존율 %를 보여준다.
도 13a는 셀타이터-글로 세포 생존성 검정을 사용하여 A375 세포에서 BVD-523/다브라페닙 병용의 억제율 %를 보여주는 용량 매트릭스이다. 도 13b는 BVD-523/다브라페닙 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 13c 및 도 13d는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 BVD-523 단일 제제 처리에 대한 생존율 %를 보여준다. 도 13e는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 BVD-523 병용 처리에 대한 생존율 %를 보여준다.
도 14a는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 트라메티닙/BVD-523 병용의 억제율 %를 나타내는 용량 매트릭스이다. 도 14b는 트라메티닙/BVD-523 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 14c 및 도 14d는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 BVD-523 및 트라메티닙 단일 제제 처리에 대한 생존율 %를 보여준다. 도 14e는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 BVD-523 및 트라메티닙 병용 처리에 대한 생존율 %를 보여준다.
도 15a는 셀타이터-글로 세포 생존성 검정을 사용하여 A375 세포에서 트라메티닙/BVD-523 병용의 억제 %를 보여주는 용량 매트릭스이다. 도 15b는 트라메티닙/BVD-523 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 15c 및 도 15d는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 BVD-523 및 트라메티닙 단일 제제 처리에 대한 생존율 %를 보여준다. 도 15e는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 BVD-523 및 트라메티닙 병용 처리에 대한 생존율 %를 보여준다.
도 16a 내지 도 16d는 다양한 농도(nM)의 BVD-523, 다브라페닙 (Dab) 및 트라메티닙(Tram)으로 4시간 처리한 후 A375 세포에서 MAPK 신호전달의 웨스턴 블롯 분석을 보여주는 일련의 영상이다. 별도로 지시되는 경우를 제외하곤 각각의 레인에 40 μg의 총 단백질을 로딩하였다. 이 실험에서, 이중 샘플을 수거하였다. 도 16a 및 도 16b는 이중 샘플로부터의 결과를 나타낸다. 유사하게, 도 16c 및 도 16d는 또한 이중 샘플로부터의 결과를 나타낸다. 도 16a 및 도 16b에서, pRSK1는 A375 세포에서 다른 마커들에 비해 비교적 약한 신호를 나타냈다. 셀 시그날링(Cell Signaling (cat. #11989))으로부터의 상이한 pRSK1-S380 항체를 시험하였으나 검출가능한 신호를 나타내지 않았다 (데이터 도시안됨). 도 16c 및 도 16d에서, pCRAF-338은 최소의 신호를 나타냈다.
도 17a 내지 도 17d는 다양한 농도(nM)의 BVD-523, 다브라페닙 (Dab) 및 트라메티닙(Tram)으로 4시간 처리한 후 사람 결장직장암종 세포주 (HCT116 세포)에서 MAPK 신호전달의 웨스턴 블롯 분석을 보여주는 일련의 영상이다. 별도로 지시되는 경우를 제외하곤 각각의 레인에 40 μg의 총 단백질을 로딩하였다. 이 실험에서, 이중 샘플을 수거하였다. 도 17a 및 도 17b는 이중 샘플로부터의 결과를 나타낸다. 유사하게, 도 17c 및 도 17d는 또한 이중 샘플로부터의 결과를 나타낸다. 도 17a 및 도 17b에서, pRSK1 수준은 HCT116 세포에서 매우 낮은 것으로 보이고, 도 17c 및 도 17d에서, pCRAF-338 신호 또한 매우 약하였다.
도 18a 내지 도 18d는 다양한 농도(nM)의 표시한 것과 같은 BVD-523 ("BVD523"), 트라메티닙("tram") 및/또는 다브라페닙 ("Dab")으로 24시간 처리한 후 A375 흑색종 세포에서 세포 주기 및 아폽토시스 신호전달의 웨스턴 블롯 분석을 보여주는 일련의 영상이다. 별도로 지시되는 경우를 제외하곤 각각의 레인에 50 μg의 총 단백질을 로딩하였다. 이 실험에서, 이중 샘플을 수거하였다. 도 18a 및 도 18b는 이중 샘플로부터의 결과를 나타낸다. 유사하게, 도 18c 및 도 18d는 또한 이중 샘플로부터의 결과를 나타낸다. 도 18a 및 도 18b에서, 절단된 PARP (89kDa)에 상응하는 크기의 밴드는 나타나지 않았다.
도 19는 BVD-523이 표적화된 약물에 대한 획득된 내성을 생체내에서 치료할 수 있음을 보여준다. 환자 유래의 세포주 ST052C를, MAPK-경로 유도된 치료법으로 10개월 동안 치료한 후 진행된 BRAFV600E 흑색종 환자로부터 분리하였다. 생체외 처리된 ST052C는 50 mg/kg BID의 다브라페닙에 대한 획득된 교차 내성을 나타냈다. 한편, BVD-523은 100 mg/kg BID로 단일 제제로서 ST052C에 효과적이었다.
도 20은 본원에 사용된 용량 상승 프로토콜을 나타내는 플로우차트이다.
도 21은 미토겐-활성화된 단백질 키나아제 (MAPK) 경로의 도식을 보여준다.
도 22a 내지 도 22e는 단일 제제 증식 검정의 결과를 보여준다. 증식 결과는 BVD-523 (도 22a), SCH772984 (도 22b), 다브라페닙 (도 22c), 트라메티닙 (도 22d) 및 파클리탁셀 (도 22e)로의 처리에 대해 도시되어 있다.
도 23a 내지 도 23o는 BVD-523과 다브라페닙 병용의 결과를 보여준다. 도 23a는 RKO 모세포(parental cell)에서 상기 병용제에 대한 억제율(%)을 나타내는 용량 매트릭스를 도시한다. 도 23b 및 도 23c는 도23a의 상기 병용제에서의 단일 제제 증식 검정 결과를 도시한다. 도 23d는 도 23a의 상기 병용제에 대한 로에베(Loewe) 초과를 보여주고, 도 23e는 도 23a의 상기 병용제에 대한 블리스 초과를 보여준다. 도 23f는 RKO MEK1 (Q56P/+) - 클론 1 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 23g 및 도 23h는 도 23f의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 23i는 도 23f의 상기 병용제에 대한 로에베 초과를 보여주고, 도 23j는 도 23f의 상기 병용제에 대한 블리스 초과를 보여준다. 도 23k는 RKO MEK1 (Q56P/+) - 클론 2 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 23l 및 도 23m은 도 23k의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 23n은 도 23k의 상기 병용제에 대한 로에베 초과를 보여주고, 도 23o는 도 23k의 상기 병용제에 대한 블리스 초과를 보여준다.
도 24a 내지 도 24o는 SCH772984과 다브라페닙 병용의 결과를 보여준다. 도 24a는 RKO 모세포에서 상기 병용제에 대한 억제율(%)을 나타내는 용량 매트릭스를 도시한다. 도 24b 및 도 24c는 도24a의 상기 병용제에서의 단일 제제 증식 검정 결과를 도시한다. 도 24d는 도 24a의 상기 병용제에 대한 로에베 초과를 보여주고, 도 24e는 도 24a의 상기 병용제에 대한 블리스 초과를 보여준다. 도 24f는 RKO MEK1 (Q56P/+) - 클론 1 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 24g 및 도 24h는 도 24f의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 24i는 도 24f의 상기 병용제에 대한 로에베 초과를 보여주고, 도 24j는 도 24f의 상기 병용제에 대한 블리스 초과를 보여준다. 도 24k는 RKO MEK1 (Q56P/+) - 클론 2 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 24l 및 도 24m은 도 24k의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 24n은 도 24k의 상기 병용제에 대한 로에베 초과를 보여주고, 도 24o는 도 24k의 상기 병용제에 대한 블리스 초과를 보여준다.
도 25a 내지 도 25o는 트라메티닙과 다브라페닙 병용의 결과를 보여준다. 도 25a는 RKO 모세포에서 상기 병용제에 대한 억제율(%)을 나타내는 용량 매트릭스를 도시한다. 도 25b 및 도 25c는 도 25a의 상기 병용제에서의 단일 제제 증식 검정 결과를 도시한다. 도 25d는 도 25a의 상기 병용제에 대한 로에베 초과를 보여주고, 도 25e는 도 25a의 상기 병용제에 대한 블리스 초과를 보여준다. 도 25f는 RKO MEK1 (Q56P/+) - 클론 1 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 25g 및 도 25h는 도 25f의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 25i는 도 25f의 상기 병용제에 대한 로에베 초과를 보여주고, 도 25j는 도 25f의 상기 병용제에 대한 블리스 초과를 보여준다. 도 25k는 RKO MEK1 (Q56P/+) - 클론 2 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 25l 및 도 25m은 도 25k의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 25n은 도 25k의 상기 병용제에 대한 로에베 초과를 보여주고, 도 25o는 도 25k의 상기 병용제에 대한 블리스 초과를 보여준다.
도 26a는 시험된 병용제에 대한 로베(Lowe) 용적을 도시한다. 도 26b는 시험된 병용제에 대한 블리스(Bliss) 용적을 도시한다. 도 26c는 시험된 병용제에 대한 상승작용 스코어를 도시한다.
도 27a 내지 도 27i는 MEK 획득된 내성에서 MAPK 및 이펙터 경로 신호전달에서의 변화를 도시한다. 동질유전자 RKO 모세포 및 MEK1 (Q56P/+) 세포를 화합물로 4 또는 24 시간 처리한 후 지시된 항체로 면역블롯팅한다. 다브라페닙은 BRAF 억제제였고 트라메티닙은 MEK 억제제였다. 도 27a는 RKO MEK1 (Q56P/+) 세포에서의 증가된 신호전달을 도시한다. 도 27b 및 도 27c는 RKO 모세포 (27b) 및 RKO MEK1 (Q56P/+) (27c) 세포에서의 실험 1 (실시예 7 참고)에서와 같이 4시간 처리한 결과를 도시한다. 도 27d 및 도 27e는 RKO 모세포 (27d) 및 RKO MEK1 (Q56P/+) (27e) 세포에서의 실험 2 (실시예 7 참고)에서와 같이 4시간 처리한 결과를 도시한다. 도 27f 및 도 27g는 RKO 모세포 (27f) 및 RKO MEK1 (Q56P/+) (27g) 세포에서의 실험 2 (실시예 7 참고)에서와 같이 4시간 처리한 결과를 도시한다. 도 27h 및 도 27i는 RKO 모세포 (27h) 및 RKO MEK1 (Q56P/+) (27i) 세포에서의 결과의 요약을 도시한다.
도 28a 및 도 28e는 BVD-523 및 SCH772984 병용의 결과를 도시한다. 도 28a는 A375 세포에서 상기 병용제에 대한 억제율(%)을 나타내는 용량 매트릭스를 도시한다. 도 28b 및 도 28c는 도 28a의 상기 병용제에서의 단일 제제 증식 검정 결과를 도시한다. 도 28d는 도 28a의 상기 병용제에 대한 로에베 초과를 보여주고, 도 28e는 도 28a의 상기 병용제에 대한 블리스 초과를 보여준다.
도 29a 내지 도 29f는 신규한 ERK1/2 억제제 BVD-523 (울릭서티닙)의 발견 및 특징분석을 나타낸다. 도 29a는 BVD-523가 가역적 ATP-경쟁적 방식의 억제를 나타냄을 증명한다. 이것은 도 29b에 도시된 바와 같이 ATP 농도가 증가함에 따라 ERK2의 억제에 대한 IC50 값의 선형 증가에 의해 입증된다. 도 29c는 용량-반응 곡선의 대표적인 플롯을 도시하고 도 29d는 시간에 따른 IC50 플롯을 도시한다. 도 29e는 음성 대조 단백질 p38과 비교한, ERK2 및 포스포-ERK2 (pERK2)에 대한 BVD-523의 결합을 도시한다. 도 29f는 ERK 억제제 SCH772984 및 피라졸릴피롤과 비교한, ERK2에 대한 BVD-523 결합을 도시한다.
도 30a 내지 도 30d는 BVD 523이 시험관내에서 세포 증식을 억제하고 카스파제 3 및 카스파제 7 활성을 증가시킴을 보여준다. 도 30a는, RAS 패밀리 구성원 및 RAF의 존재에 의해 정의되는 것과 같이, MAPK 경로 돌연변이를 갖는 세포에서 BVD-523이 우선적 활성을 나타냄을 입증한다. 또한, 도 30b에 도시된 것과 같이, BVD-523은 세포 주기의 G1기에서 민감성 세포주를 차단한다. 도 30c는 BVD-523이 A375, WM266 및 LS411N 암세포주에서 72시간 노출 후 카스파제 활성의 농도 및 시간 의존적 증가를 유도하였음을 보여준다. 도 30d는 MAPK 경로 및 이펙터 단백질이 BRAF V600E-돌연변이 A375 세포에서 급성 (4시간) 및 지속적 (24시간) BVD-523 처리에 의해 조절됨을 보여준다.
도 31a 내지 도 31c는 생체내 BVD-523 항-종양 활성을 도시한다. BVD-523 단일치료로, A375(도 31a) 및 Colo205 세포주 (도 31b) 이종이식 모델에서 종양 성장을 억제함을 보여준다 (a P<0.0001, 비히클 대조군과 비교; 14일 및 18일째 CPT-11만 투여). 약어: BID, 1일 2회; CMC, 카복시메틸셀룰로즈; QD, 매일; Q4D, 4일마다. 도 31c는 Colo205 이종이식편에서, 증가된 ERK1/2 포스포릴화가 BVD-523 농도와 상호관련있음을 보여준다.
도 32a는 ERK1/2 억제제의 신호전달 효과를 도시한다. RPPA를 사용하여, 단백질에 대한 효과를 세포주 (A375, AN3Ca, Colo205, HCT116, HT29 및 MIAPaca2)에서 ERK1/2 억제제 BVD-523 (BVD), Vx11e (Vx), GDC-0994 (GDC), 또는 SCH722984 (SCH)로 처리한 후 측정한다. 도 32b는 ERK 억제제 BVD-523, GDC-0994, 및 Vx11e가 SCH722984와 비교하여 포스포-ERK (ERK 1/2 T202 Y204)에 대해 차별적 효과를 가짐을 보여준다; 포스포-RSK (p90 RSK 380) 및 사이클린 D1은 시험된 ERK 억제제에 의해 억제된다. 약어: BRAFi, BRAF 억제제; MEKi, MEK 억제제. 도 32c는 BVD-523, 트라메티닙, SCH722984, 또는 다브라페닙으로 처리 후 RKO 세포주로부터의 세포 및 핵 분획에 대한 웨스턴 블롯 검정을 도시한다. 히스톤 H3 (핵 편재된 단백질) 및 HSP90 (세포질 편재된 단백질)을 양성 대조군으로 포함시켜 핵 및 세포질 분획이 적절히 향상되었는지를 확인한다; 핵 분획은 높은 H3를 갖고 세포질 분획은 보다 높은 HSP90을 갖는다.
도 33은 ERK 억제제 BVD-523, Vx11, GDC-0994 및 SCH772984 (SCH)가 포스포-ATK 수준에서 세포주-의존적 변화를 나타냄을 보여준다. 약어: DMSO, 디메틸 설폭사이드.
도 34a 내지 도 34d는 BRAF/MEK 억제에 대한 내성 모델에서 BVD-523이 활성을 나타냄을 보여준다. 증가된 약물 농도로의 노출 후 BRAF V600E A375 세포에서 BVD-523, 다브라페닙 또는 트라메티닙에 대한 내성의 발현을 표시한다. 처리들간에 내성 획득의 동력학(kinetics)이 확실히 비교될 수 있도록 하기 위하여 언제 용량이 증가될 수 있는지 결정하기 위한 엄격한 세트의 "기준"이 적용되었다 (참고, 실시예 1). 시간은 IC50의 승수에 대하여 나타난다; 플롯팅된 선의 각각의 포인트는 배지의 변화 또는 세포 분열을 나타낸다. 도 34a는 BVD-523의 존재하에 세포를 성장에 적응시키는 것이 다브라페닙 또는 트라메티닙을 사용하는 경우에서 보다 더 도전적임(challenging)을 나타낸다. 도 34b는 병용된 BRAF (다브라페닙) + MEK (트라메티닙) 억제에 대한 내성을 획득하기 위해 배양된 A375 세포에 BVD-523 민감성이 보유됨을 도시한다. 도 34c에서, 세포를 96 시간 동안 화합물로 처리하고 CellTiter-Glo®로 생존성을 평가하였다. BVD-523 활성은, MEK1 Q56P의 내인성 이형접합 녹-인(knock-in)으로 인해 BRAF (다브라페닙) 및 MEK (트라메티닙) 억제제에 대한 교차 내성인 BRAF V600E RKO 세포 내에서 보유된다. 도 34d는 BRAF V600E-돌연변이 세포주 RKO 내에서 pRSK의 BVD-523 억제가 MEK1 Q56P (MEK 및 BRAF 억제에 대한 내성 부여)의 존재하에 유지됨을 보여준다. SW48 세포주 내로의 KRAS 돌연변이 대립유전자의 녹-인 (knock-in)으로 MEK 억제제 트라메티닙 및 셀루메티닙에 대한 민감성이 상당히 사라지지만, BVD-523 에 대한 민감성은 상대적으로 유지된다.
도 35a는 베무라페닙-재발된 환자로부터 유래된 이종이식편에서 BVD-523의 생체내 활성을 도시한다. 평균 종양 용적 (± SEM)이 BVD-523 100 mg/kg BID 단독, 다브라페닙 50 mg/kg BID 단독, 및 BVD-523 100 mg/kg BID 플러스 다브라페닙 50 mg/kg BID에 대해 도시되어 있다. 약어: BID, 1일 2회; SEM, 평균의 표준 오차.
도 36a 내지 도 36d는 병용된 BVD-523 및 BRAF 억제의 이점을 도시한다. 도 36a 및 도 36b는, 75-144 mm3의 초기 종양 용적을 갖는 A375 BRAF V600E-돌연변이 흑색종 세포주 이종이식 모델에서, BVD-523 플러스 다브라페닙의 병용이 각각의 제제 단독으로의 치료에 비해 우수한 항종양 활성을 나타냈음을 보여준다. 도 36c 및 도 36d는 투약 초기에 거대 종양 용적 (700 내지 800 mm3)을 갖는 동일 모델로부터의 유사한 데이터를 보여준다. 평균 종양 성장 (좌측 패널) 및 카플린-마이어 생존 (우측 패널)의 플롯이 각각의 연구에 대해 제시된다. 약어: BID, 1일 2회; QD, 1일 1회.
도 37a는, KRAS 대립유전자로 엔지니어링된 SW48 결장직장 세포에서 파클리탁셀에 대한 반응이 대조군에 비해 변화되지 않았음을 보여준다. 도 37b는 BVD-523 및 베무라페닙 사이의 병용 상호작용을 도시하는데, 이는 로에베 합 공식 및 블리스 독립 모델 (Loewe Additivity and Bliss Independence Models)을 사용하여 농도의 8 Х 10 매트릭스를 사용하여 평가하고 호리즌 챌리스 (Horizon's Chalice, Bioinformatics Software)로 분석하였다. 챌리스는, 용량 매트릭스를 가로지르는 부가치(additive)로서의 예상값을 초과하는 계산된 억제 초과값을 히트맵(heat map)으로 디스플레이하고, 로에베 모델에 기초하여 정량적 "상승작용 스코어"를 리포팅함으로써, 잠재적 상승적 상호작용을 식별가능하게 한다. 그 결과는, BVD-523 및 베무라페닙 사이의 상호작용이 적어도 상가적이고, 일부의 경우, BRAF V600E 돌연변이를 함유하는 흑색종 세포주에서 상승적임을 시사한다. 도 37c는 BVD-523과 다브라페닙의 병용이 A375 BRAF V600E 흑색종 세포에서 획득된 내성의 개시를 현저히 지연시킴을 보여준다. 다브라페닙 단독 또는 BVD-523 또는 트라메티닙과 병용된 다브라페닙의 농도 상승에 반응한 일시적인 내성의 획득을 평가하였다. 처리들간에 적응의 동력학(kinetics)이 확실히 비교될 수 있도록 하기 위하여 언제 용량이 증가될 수 있는지에 대한 엄격한 세트의 "기준"이 적용되었다 (참고, 실시예 1).
도 38은 사람 전혈에서 BVD-523이 생체외에서 PMA-자극된 RSK1/2 포스포릴화를 억제함을 보여준다. 평균 BVD-523 농도 데이터 세트를 (―)로 표시한다. BVD-523의 각각의 농도에 대해 n = 20이다. 약어: PBMC, 말초혈 단핵 세포; RSK, 리보솜 S6 키나아제.
도 39a는 정상 상태 BVD-523 약동학을 도시한다 (사이클 1, 제15일). 빨간 점선은 EC50 200 ng/mL HWB를 나타낸다. 약어: AUC, 곡선하 면적; BID, 1일 2회; Cmax, 최대 농도; EC50, 50% 최대 유효 농도; HWB, 사람 전혈; SD, 표준 편차. 도 39b는 사람 전혈에서 BVD-523에 의한 ERK 포스포릴화의 약력학적 억제를 도시한다. 약어: BID, 1일 2회; pRSK, 포스포-RSK; RSK, 리보솜 S6 키나아제.
도 40a는 BVD-523으로 치료한 환자에서의 최고의 방사선촬영 반응을 도시한다. 연구 치료의 ≥1 용량을 투여받고 >1 치료시 종양 평가를 받은 (25/27; 2는 표적 병소의 스캔 둘다를 받지 않았다), RECIST v1.1 에 의해 측정된 질환을 갖는 모든 환자들을 포함시켰다. 반응은, 각각의 표적 병소의 최장 직경의 합에서 기준선으로부터의 변화로 측정하였다. 나타낸 용량은 반응 시점에 환자가 받은 용량이다. 점선은 RECIST v1.1에 따른 부분 반응에 대한 역치를 나타낸다. 약어: CRC, 직장결장암; NET, 신경내분비 종양; NSCLC, 비-소세포 폐암; NSGCT, 비정상피종성배세포종양; PNET, 췌장 NET; PTC, 유두갑상선암; RECIST v1.1, 고형 종양에서의 반응 평가 기준 버전 1.1; SLD, 최장 직경의 합. 도 40b는 BVD-523으로 치료된 BRAF-돌연변이 흑색종을 갖는 61세 환자에서 확인된 부분 반응의 컴퓨터 단층촬영 스캔을 나타낸다.
도 41은 종양 반응 및 종양 진행을 도시한다. BVD-523으로 치료된 반응-측정가능한 환자에서의 종양 반응, 종양 진행 및 치료 지속기간의 스위머 플롯이 도시되어 있다. 종축의 원점은 랜덤화 날짜 또는 참조 개시일에 상응한다. 분석 종료일: 2015년 12월 1일. 약어: BID, 1일 2회.
도 1a 내지 도 1c는 제1 달 동안 사람 악성 흑색종 세포주 (A375 세포)에서 용량 상승 연구의 진행과정을 보여준다. 다양한 처리들 (트라메티닙 (2형 MEK 억제제), 다브라페닙 (BRAF 억제제), 및 BVD-523 (ERK1/2 억제제))은 표시된 바와 같다.
도 2a 내지 도 2h는 제1 달에 증가된 제제(들)에 대한 민감성에서의 변화를 추적하는 증식 검정의 결과를 보여준다. 다양한 처리들 (트라메티닙, 다브라페닙, BVD-523 및 파시탁셀)은 그래프의 상단에 표시된 바와 같다. 그래프의 우측 해설은 용량 상승 연구에서 나타난 다양한 세포 유형을 보여준다. 예를 들면, "다브라페닙"은 용량 상승 연구의 제1 달로부터 다브라페닙의 최고 용량으로 처리된 세포를 지칭한다. 모세포(parental)는 약물로 처리되지 않은 대조군 세포(control cells)를 지칭한다. 도 2a, 도 2c 및 도 2g는 대조군에 대해 정규화된 것이고, 도 2d, 도 2f 및 도 2h는 원데이터(raw data)를 나타낸다.
도 3a 내지 도 3d는 제2 달 동안 A375 세포에서의 용량 상승 연구의 진행과정을 보여준다. 다양한 처리들 (트라메티닙, 다브라페닙 및 BVD-523)은 표시된 바와 같다.
도 4a 내지 도 4h는 제2 달에 증가된 제제(들)에 대한 민감성에서의 변화를 추적하는 증식 검정의 결과를 보여준다. 다양한 처리들 (트라메티닙, 다브라페닙, BVD-523 및 파시탁셀)은 그래프의 상단에 표시된 바와 같다. 그래프의 우측 해설은 용량 상승 연구에서 나타난 다양한 세포 유형을 보여준다. 예를 들면, "다브라페닙"은 용량 상승 연구의 제2 달로부터 다브라페닙의 최고 용량으로 처리된 세포를 지칭한다. 모세포는 약물로 처리되지 않은 대조군 세포를 지칭한다. 도 4a, 도 4c 및 도 4g는 대조군에 대해 정규화된 것이고, 도 4d, 도 4f 및 도 4h는 원데이터를 나타낸다.
도 5a 내지 도 5h는 도 4a 내지 도 4h로부터의 단지 모세포 및 BVD-523 세포주 데이터만을 보여준다. 다양한 처리들 (트라메티닙, 다브라페닙, BVD-523 및 파시탁셀)은 표시된 바와 같다. 도 5a, 도 5c 및 도 5g는 대조군에 대해 정규화된 것이고, 도 5d, 도 5f 및 도 5h는 원데이터를 나타낸다.
도 6a 내지 도 6d는 제3 달 동안 사람 악성 세포주 (A375 세포)에서 용량 상승 연구의 진행과정을 보여준다. 다양한 처리들 (트라메티닙, 다브라페닙 및 BVD-523)은 표시된 바와 같다.
도 7은 용량 상승 검정으로부터의 DMSO 대조군 웰에서 성장시킨 세포에 적용된 증식 검정의 결과를 보여주는 히스토그램이다.
도 8a 내지 도 8d는 당해 연구의 제3 달 동안의 증식 검정을 보여주는 일련의 선 그래프이다. 다양한 처리들 (트라메티닙, 다브라페닙, BVD-523 및 파시탁셀)은 그래프의 상단에 표시된 바와 같다. 그래프의 우측 해설은 용량 상승 연구에서 나타난 다양한 세포 유형을 보여준다. 예를 들면, "다브라페닙"은 용량 상승 연구의 제3 달로부터 다브라페닙의 최고 용량으로 처리된 세포를 지칭한다. 모세포는 약물로 처리되지 않은 대조군 세포를 지칭한다.
도 9a 내지 도 9d는 도 8a 내지 도 8d로부터의 모세포, 다브라페닙 및 BVD-523 세포주 데이터만을 보여준다.
도 10a는 알라마 블루 (Alamar Blue) 세포 생존성 검정을 사용한 A375 세포에서 트라메티닙/다브라페닙 병용의 억제율%를 나타내는 용량 매트릭스이다. 도 10b는 트라메티닙/다브라페닙 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 10c 및 도 10d는 알라마 블루 (Alamar Blue) 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 트라메티닙 단일 제제 처리에 대한 생존율(viability) %를 보여준다. 도 10e는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 트라메티닙 병용 처리에 대한 생존율 %를 보여준다.
도 11a는 셀타이터-글로 (CellTiter-Glo) 세포 생존성 검정을 사용하여 A375 세포에서 트라메티닙/다브라페닙 병용의 억제율 %를 보여주는 용량 매트릭스이다. 도 11b는 트라메티닙/다브라페닙 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 11c 및 도 11d는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 트라메티닙 단일 제제 처리에 대한 생존율 %를 보여준다. 도 11e는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 트라메티닙 병용 처리에 대한 생존율 %를 보여준다.
도 12a는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 BVD-523/다브라페닙 병용의 억제율 %를 나타내는 용량 매트릭스이다. 도 12b는 BVD-523/다브라페닙 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 12c 및 도 12d는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 BVD-523 단일 제제 처리에 대한 생존율 %를 보여준다. 도 12e는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 BVD-523 병용 처리에 대한 생존율 %를 보여준다.
도 13a는 셀타이터-글로 세포 생존성 검정을 사용하여 A375 세포에서 BVD-523/다브라페닙 병용의 억제율 %를 보여주는 용량 매트릭스이다. 도 13b는 BVD-523/다브라페닙 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 13c 및 도 13d는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 BVD-523 단일 제제 처리에 대한 생존율 %를 보여준다. 도 13e는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 다브라페닙 및 BVD-523 병용 처리에 대한 생존율 %를 보여준다.
도 14a는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 트라메티닙/BVD-523 병용의 억제율 %를 나타내는 용량 매트릭스이다. 도 14b는 트라메티닙/BVD-523 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 14c 및 도 14d는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 BVD-523 및 트라메티닙 단일 제제 처리에 대한 생존율 %를 보여준다. 도 14e는 알라마 블루 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 BVD-523 및 트라메티닙 병용 처리에 대한 생존율 %를 보여준다.
도 15a는 셀타이터-글로 세포 생존성 검정을 사용하여 A375 세포에서 트라메티닙/BVD-523 병용의 억제 %를 보여주는 용량 매트릭스이다. 도 15b는 트라메티닙/BVD-523 병용에 대한 블리스 초과를 보여주는 용량 매트릭스이다. 도 15c 및 도 15d는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 BVD-523 및 트라메티닙 단일 제제 처리에 대한 생존율 %를 보여준다. 도 15e는 셀타이터-글로 세포 생존성 검정을 사용한 A375 세포에서 DMSO만으로 처리한 대조군에 비해 BVD-523 및 트라메티닙 병용 처리에 대한 생존율 %를 보여준다.
도 16a 내지 도 16d는 다양한 농도(nM)의 BVD-523, 다브라페닙 (Dab) 및 트라메티닙(Tram)으로 4시간 처리한 후 A375 세포에서 MAPK 신호전달의 웨스턴 블롯 분석을 보여주는 일련의 영상이다. 별도로 지시되는 경우를 제외하곤 각각의 레인에 40 μg의 총 단백질을 로딩하였다. 이 실험에서, 이중 샘플을 수거하였다. 도 16a 및 도 16b는 이중 샘플로부터의 결과를 나타낸다. 유사하게, 도 16c 및 도 16d는 또한 이중 샘플로부터의 결과를 나타낸다. 도 16a 및 도 16b에서, pRSK1는 A375 세포에서 다른 마커들에 비해 비교적 약한 신호를 나타냈다. 셀 시그날링(Cell Signaling (cat. #11989))으로부터의 상이한 pRSK1-S380 항체를 시험하였으나 검출가능한 신호를 나타내지 않았다 (데이터 도시안됨). 도 16c 및 도 16d에서, pCRAF-338은 최소의 신호를 나타냈다.
도 17a 내지 도 17d는 다양한 농도(nM)의 BVD-523, 다브라페닙 (Dab) 및 트라메티닙(Tram)으로 4시간 처리한 후 사람 결장직장암종 세포주 (HCT116 세포)에서 MAPK 신호전달의 웨스턴 블롯 분석을 보여주는 일련의 영상이다. 별도로 지시되는 경우를 제외하곤 각각의 레인에 40 μg의 총 단백질을 로딩하였다. 이 실험에서, 이중 샘플을 수거하였다. 도 17a 및 도 17b는 이중 샘플로부터의 결과를 나타낸다. 유사하게, 도 17c 및 도 17d는 또한 이중 샘플로부터의 결과를 나타낸다. 도 17a 및 도 17b에서, pRSK1 수준은 HCT116 세포에서 매우 낮은 것으로 보이고, 도 17c 및 도 17d에서, pCRAF-338 신호 또한 매우 약하였다.
도 18a 내지 도 18d는 다양한 농도(nM)의 표시한 것과 같은 BVD-523 ("BVD523"), 트라메티닙("tram") 및/또는 다브라페닙 ("Dab")으로 24시간 처리한 후 A375 흑색종 세포에서 세포 주기 및 아폽토시스 신호전달의 웨스턴 블롯 분석을 보여주는 일련의 영상이다. 별도로 지시되는 경우를 제외하곤 각각의 레인에 50 μg의 총 단백질을 로딩하였다. 이 실험에서, 이중 샘플을 수거하였다. 도 18a 및 도 18b는 이중 샘플로부터의 결과를 나타낸다. 유사하게, 도 18c 및 도 18d는 또한 이중 샘플로부터의 결과를 나타낸다. 도 18a 및 도 18b에서, 절단된 PARP (89kDa)에 상응하는 크기의 밴드는 나타나지 않았다.
도 19는 BVD-523이 표적화된 약물에 대한 획득된 내성을 생체내에서 치료할 수 있음을 보여준다. 환자 유래의 세포주 ST052C를, MAPK-경로 유도된 치료법으로 10개월 동안 치료한 후 진행된 BRAFV600E 흑색종 환자로부터 분리하였다. 생체외 처리된 ST052C는 50 mg/kg BID의 다브라페닙에 대한 획득된 교차 내성을 나타냈다. 한편, BVD-523은 100 mg/kg BID로 단일 제제로서 ST052C에 효과적이었다.
도 20은 본원에 사용된 용량 상승 프로토콜을 나타내는 플로우차트이다.
도 21은 미토겐-활성화된 단백질 키나아제 (MAPK) 경로의 도식을 보여준다.
도 22a 내지 도 22e는 단일 제제 증식 검정의 결과를 보여준다. 증식 결과는 BVD-523 (도 22a), SCH772984 (도 22b), 다브라페닙 (도 22c), 트라메티닙 (도 22d) 및 파클리탁셀 (도 22e)로의 처리에 대해 도시되어 있다.
도 23a 내지 도 23o는 BVD-523과 다브라페닙 병용의 결과를 보여준다. 도 23a는 RKO 모세포(parental cell)에서 상기 병용제에 대한 억제율(%)을 나타내는 용량 매트릭스를 도시한다. 도 23b 및 도 23c는 도23a의 상기 병용제에서의 단일 제제 증식 검정 결과를 도시한다. 도 23d는 도 23a의 상기 병용제에 대한 로에베(Loewe) 초과를 보여주고, 도 23e는 도 23a의 상기 병용제에 대한 블리스 초과를 보여준다. 도 23f는 RKO MEK1 (Q56P/+) - 클론 1 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 23g 및 도 23h는 도 23f의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 23i는 도 23f의 상기 병용제에 대한 로에베 초과를 보여주고, 도 23j는 도 23f의 상기 병용제에 대한 블리스 초과를 보여준다. 도 23k는 RKO MEK1 (Q56P/+) - 클론 2 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 23l 및 도 23m은 도 23k의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 23n은 도 23k의 상기 병용제에 대한 로에베 초과를 보여주고, 도 23o는 도 23k의 상기 병용제에 대한 블리스 초과를 보여준다.
도 24a 내지 도 24o는 SCH772984과 다브라페닙 병용의 결과를 보여준다. 도 24a는 RKO 모세포에서 상기 병용제에 대한 억제율(%)을 나타내는 용량 매트릭스를 도시한다. 도 24b 및 도 24c는 도24a의 상기 병용제에서의 단일 제제 증식 검정 결과를 도시한다. 도 24d는 도 24a의 상기 병용제에 대한 로에베 초과를 보여주고, 도 24e는 도 24a의 상기 병용제에 대한 블리스 초과를 보여준다. 도 24f는 RKO MEK1 (Q56P/+) - 클론 1 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 24g 및 도 24h는 도 24f의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 24i는 도 24f의 상기 병용제에 대한 로에베 초과를 보여주고, 도 24j는 도 24f의 상기 병용제에 대한 블리스 초과를 보여준다. 도 24k는 RKO MEK1 (Q56P/+) - 클론 2 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 24l 및 도 24m은 도 24k의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 24n은 도 24k의 상기 병용제에 대한 로에베 초과를 보여주고, 도 24o는 도 24k의 상기 병용제에 대한 블리스 초과를 보여준다.
도 25a 내지 도 25o는 트라메티닙과 다브라페닙 병용의 결과를 보여준다. 도 25a는 RKO 모세포에서 상기 병용제에 대한 억제율(%)을 나타내는 용량 매트릭스를 도시한다. 도 25b 및 도 25c는 도 25a의 상기 병용제에서의 단일 제제 증식 검정 결과를 도시한다. 도 25d는 도 25a의 상기 병용제에 대한 로에베 초과를 보여주고, 도 25e는 도 25a의 상기 병용제에 대한 블리스 초과를 보여준다. 도 25f는 RKO MEK1 (Q56P/+) - 클론 1 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 25g 및 도 25h는 도 25f의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 25i는 도 25f의 상기 병용제에 대한 로에베 초과를 보여주고, 도 25j는 도 25f의 상기 병용제에 대한 블리스 초과를 보여준다. 도 25k는 RKO MEK1 (Q56P/+) - 클론 2 세포에서의 상기 병용제의 억제율(%)을 보여주는 용량 매트릭스를 도시한다. 도 25l 및 도 25m은 도 25k의 상기 병용제에서의 단일 제제 증식 검정의 결과를 도시한다. 도 25n은 도 25k의 상기 병용제에 대한 로에베 초과를 보여주고, 도 25o는 도 25k의 상기 병용제에 대한 블리스 초과를 보여준다.
도 26a는 시험된 병용제에 대한 로베(Lowe) 용적을 도시한다. 도 26b는 시험된 병용제에 대한 블리스(Bliss) 용적을 도시한다. 도 26c는 시험된 병용제에 대한 상승작용 스코어를 도시한다.
도 27a 내지 도 27i는 MEK 획득된 내성에서 MAPK 및 이펙터 경로 신호전달에서의 변화를 도시한다. 동질유전자 RKO 모세포 및 MEK1 (Q56P/+) 세포를 화합물로 4 또는 24 시간 처리한 후 지시된 항체로 면역블롯팅한다. 다브라페닙은 BRAF 억제제였고 트라메티닙은 MEK 억제제였다. 도 27a는 RKO MEK1 (Q56P/+) 세포에서의 증가된 신호전달을 도시한다. 도 27b 및 도 27c는 RKO 모세포 (27b) 및 RKO MEK1 (Q56P/+) (27c) 세포에서의 실험 1 (실시예 7 참고)에서와 같이 4시간 처리한 결과를 도시한다. 도 27d 및 도 27e는 RKO 모세포 (27d) 및 RKO MEK1 (Q56P/+) (27e) 세포에서의 실험 2 (실시예 7 참고)에서와 같이 4시간 처리한 결과를 도시한다. 도 27f 및 도 27g는 RKO 모세포 (27f) 및 RKO MEK1 (Q56P/+) (27g) 세포에서의 실험 2 (실시예 7 참고)에서와 같이 4시간 처리한 결과를 도시한다. 도 27h 및 도 27i는 RKO 모세포 (27h) 및 RKO MEK1 (Q56P/+) (27i) 세포에서의 결과의 요약을 도시한다.
도 28a 및 도 28e는 BVD-523 및 SCH772984 병용의 결과를 도시한다. 도 28a는 A375 세포에서 상기 병용제에 대한 억제율(%)을 나타내는 용량 매트릭스를 도시한다. 도 28b 및 도 28c는 도 28a의 상기 병용제에서의 단일 제제 증식 검정 결과를 도시한다. 도 28d는 도 28a의 상기 병용제에 대한 로에베 초과를 보여주고, 도 28e는 도 28a의 상기 병용제에 대한 블리스 초과를 보여준다.
도 29a 내지 도 29f는 신규한 ERK1/2 억제제 BVD-523 (울릭서티닙)의 발견 및 특징분석을 나타낸다. 도 29a는 BVD-523가 가역적 ATP-경쟁적 방식의 억제를 나타냄을 증명한다. 이것은 도 29b에 도시된 바와 같이 ATP 농도가 증가함에 따라 ERK2의 억제에 대한 IC50 값의 선형 증가에 의해 입증된다. 도 29c는 용량-반응 곡선의 대표적인 플롯을 도시하고 도 29d는 시간에 따른 IC50 플롯을 도시한다. 도 29e는 음성 대조 단백질 p38과 비교한, ERK2 및 포스포-ERK2 (pERK2)에 대한 BVD-523의 결합을 도시한다. 도 29f는 ERK 억제제 SCH772984 및 피라졸릴피롤과 비교한, ERK2에 대한 BVD-523 결합을 도시한다.
도 30a 내지 도 30d는 BVD 523이 시험관내에서 세포 증식을 억제하고 카스파제 3 및 카스파제 7 활성을 증가시킴을 보여준다. 도 30a는, RAS 패밀리 구성원 및 RAF의 존재에 의해 정의되는 것과 같이, MAPK 경로 돌연변이를 갖는 세포에서 BVD-523이 우선적 활성을 나타냄을 입증한다. 또한, 도 30b에 도시된 것과 같이, BVD-523은 세포 주기의 G1기에서 민감성 세포주를 차단한다. 도 30c는 BVD-523이 A375, WM266 및 LS411N 암세포주에서 72시간 노출 후 카스파제 활성의 농도 및 시간 의존적 증가를 유도하였음을 보여준다. 도 30d는 MAPK 경로 및 이펙터 단백질이 BRAF V600E-돌연변이 A375 세포에서 급성 (4시간) 및 지속적 (24시간) BVD-523 처리에 의해 조절됨을 보여준다.
도 31a 내지 도 31c는 생체내 BVD-523 항-종양 활성을 도시한다. BVD-523 단일치료로, A375(도 31a) 및 Colo205 세포주 (도 31b) 이종이식 모델에서 종양 성장을 억제함을 보여준다 (a P<0.0001, 비히클 대조군과 비교; 14일 및 18일째 CPT-11만 투여). 약어: BID, 1일 2회; CMC, 카복시메틸셀룰로즈; QD, 매일; Q4D, 4일마다. 도 31c는 Colo205 이종이식편에서, 증가된 ERK1/2 포스포릴화가 BVD-523 농도와 상호관련있음을 보여준다.
도 32a는 ERK1/2 억제제의 신호전달 효과를 도시한다. RPPA를 사용하여, 단백질에 대한 효과를 세포주 (A375, AN3Ca, Colo205, HCT116, HT29 및 MIAPaca2)에서 ERK1/2 억제제 BVD-523 (BVD), Vx11e (Vx), GDC-0994 (GDC), 또는 SCH722984 (SCH)로 처리한 후 측정한다. 도 32b는 ERK 억제제 BVD-523, GDC-0994, 및 Vx11e가 SCH722984와 비교하여 포스포-ERK (ERK 1/2 T202 Y204)에 대해 차별적 효과를 가짐을 보여준다; 포스포-RSK (p90 RSK 380) 및 사이클린 D1은 시험된 ERK 억제제에 의해 억제된다. 약어: BRAFi, BRAF 억제제; MEKi, MEK 억제제. 도 32c는 BVD-523, 트라메티닙, SCH722984, 또는 다브라페닙으로 처리 후 RKO 세포주로부터의 세포 및 핵 분획에 대한 웨스턴 블롯 검정을 도시한다. 히스톤 H3 (핵 편재된 단백질) 및 HSP90 (세포질 편재된 단백질)을 양성 대조군으로 포함시켜 핵 및 세포질 분획이 적절히 향상되었는지를 확인한다; 핵 분획은 높은 H3를 갖고 세포질 분획은 보다 높은 HSP90을 갖는다.
도 33은 ERK 억제제 BVD-523, Vx11, GDC-0994 및 SCH772984 (SCH)가 포스포-ATK 수준에서 세포주-의존적 변화를 나타냄을 보여준다. 약어: DMSO, 디메틸 설폭사이드.
도 34a 내지 도 34d는 BRAF/MEK 억제에 대한 내성 모델에서 BVD-523이 활성을 나타냄을 보여준다. 증가된 약물 농도로의 노출 후 BRAF V600E A375 세포에서 BVD-523, 다브라페닙 또는 트라메티닙에 대한 내성의 발현을 표시한다. 처리들간에 내성 획득의 동력학(kinetics)이 확실히 비교될 수 있도록 하기 위하여 언제 용량이 증가될 수 있는지 결정하기 위한 엄격한 세트의 "기준"이 적용되었다 (참고, 실시예 1). 시간은 IC50의 승수에 대하여 나타난다; 플롯팅된 선의 각각의 포인트는 배지의 변화 또는 세포 분열을 나타낸다. 도 34a는 BVD-523의 존재하에 세포를 성장에 적응시키는 것이 다브라페닙 또는 트라메티닙을 사용하는 경우에서 보다 더 도전적임(challenging)을 나타낸다. 도 34b는 병용된 BRAF (다브라페닙) + MEK (트라메티닙) 억제에 대한 내성을 획득하기 위해 배양된 A375 세포에 BVD-523 민감성이 보유됨을 도시한다. 도 34c에서, 세포를 96 시간 동안 화합물로 처리하고 CellTiter-Glo®로 생존성을 평가하였다. BVD-523 활성은, MEK1 Q56P의 내인성 이형접합 녹-인(knock-in)으로 인해 BRAF (다브라페닙) 및 MEK (트라메티닙) 억제제에 대한 교차 내성인 BRAF V600E RKO 세포 내에서 보유된다. 도 34d는 BRAF V600E-돌연변이 세포주 RKO 내에서 pRSK의 BVD-523 억제가 MEK1 Q56P (MEK 및 BRAF 억제에 대한 내성 부여)의 존재하에 유지됨을 보여준다. SW48 세포주 내로의 KRAS 돌연변이 대립유전자의 녹-인 (knock-in)으로 MEK 억제제 트라메티닙 및 셀루메티닙에 대한 민감성이 상당히 사라지지만, BVD-523 에 대한 민감성은 상대적으로 유지된다.
도 35a는 베무라페닙-재발된 환자로부터 유래된 이종이식편에서 BVD-523의 생체내 활성을 도시한다. 평균 종양 용적 (± SEM)이 BVD-523 100 mg/kg BID 단독, 다브라페닙 50 mg/kg BID 단독, 및 BVD-523 100 mg/kg BID 플러스 다브라페닙 50 mg/kg BID에 대해 도시되어 있다. 약어: BID, 1일 2회; SEM, 평균의 표준 오차.
도 36a 내지 도 36d는 병용된 BVD-523 및 BRAF 억제의 이점을 도시한다. 도 36a 및 도 36b는, 75-144 mm3의 초기 종양 용적을 갖는 A375 BRAF V600E-돌연변이 흑색종 세포주 이종이식 모델에서, BVD-523 플러스 다브라페닙의 병용이 각각의 제제 단독으로의 치료에 비해 우수한 항종양 활성을 나타냈음을 보여준다. 도 36c 및 도 36d는 투약 초기에 거대 종양 용적 (700 내지 800 mm3)을 갖는 동일 모델로부터의 유사한 데이터를 보여준다. 평균 종양 성장 (좌측 패널) 및 카플린-마이어 생존 (우측 패널)의 플롯이 각각의 연구에 대해 제시된다. 약어: BID, 1일 2회; QD, 1일 1회.
도 37a는, KRAS 대립유전자로 엔지니어링된 SW48 결장직장 세포에서 파클리탁셀에 대한 반응이 대조군에 비해 변화되지 않았음을 보여준다. 도 37b는 BVD-523 및 베무라페닙 사이의 병용 상호작용을 도시하는데, 이는 로에베 합 공식 및 블리스 독립 모델 (Loewe Additivity and Bliss Independence Models)을 사용하여 농도의 8 Х 10 매트릭스를 사용하여 평가하고 호리즌 챌리스 (Horizon's Chalice, Bioinformatics Software)로 분석하였다. 챌리스는, 용량 매트릭스를 가로지르는 부가치(additive)로서의 예상값을 초과하는 계산된 억제 초과값을 히트맵(heat map)으로 디스플레이하고, 로에베 모델에 기초하여 정량적 "상승작용 스코어"를 리포팅함으로써, 잠재적 상승적 상호작용을 식별가능하게 한다. 그 결과는, BVD-523 및 베무라페닙 사이의 상호작용이 적어도 상가적이고, 일부의 경우, BRAF V600E 돌연변이를 함유하는 흑색종 세포주에서 상승적임을 시사한다. 도 37c는 BVD-523과 다브라페닙의 병용이 A375 BRAF V600E 흑색종 세포에서 획득된 내성의 개시를 현저히 지연시킴을 보여준다. 다브라페닙 단독 또는 BVD-523 또는 트라메티닙과 병용된 다브라페닙의 농도 상승에 반응한 일시적인 내성의 획득을 평가하였다. 처리들간에 적응의 동력학(kinetics)이 확실히 비교될 수 있도록 하기 위하여 언제 용량이 증가될 수 있는지에 대한 엄격한 세트의 "기준"이 적용되었다 (참고, 실시예 1).
도 38은 사람 전혈에서 BVD-523이 생체외에서 PMA-자극된 RSK1/2 포스포릴화를 억제함을 보여준다. 평균 BVD-523 농도 데이터 세트를 (―)로 표시한다. BVD-523의 각각의 농도에 대해 n = 20이다. 약어: PBMC, 말초혈 단핵 세포; RSK, 리보솜 S6 키나아제.
도 39a는 정상 상태 BVD-523 약동학을 도시한다 (사이클 1, 제15일). 빨간 점선은 EC50 200 ng/mL HWB를 나타낸다. 약어: AUC, 곡선하 면적; BID, 1일 2회; Cmax, 최대 농도; EC50, 50% 최대 유효 농도; HWB, 사람 전혈; SD, 표준 편차. 도 39b는 사람 전혈에서 BVD-523에 의한 ERK 포스포릴화의 약력학적 억제를 도시한다. 약어: BID, 1일 2회; pRSK, 포스포-RSK; RSK, 리보솜 S6 키나아제.
도 40a는 BVD-523으로 치료한 환자에서의 최고의 방사선촬영 반응을 도시한다. 연구 치료의 ≥1 용량을 투여받고 >1 치료시 종양 평가를 받은 (25/27; 2는 표적 병소의 스캔 둘다를 받지 않았다), RECIST v1.1 에 의해 측정된 질환을 갖는 모든 환자들을 포함시켰다. 반응은, 각각의 표적 병소의 최장 직경의 합에서 기준선으로부터의 변화로 측정하였다. 나타낸 용량은 반응 시점에 환자가 받은 용량이다. 점선은 RECIST v1.1에 따른 부분 반응에 대한 역치를 나타낸다. 약어: CRC, 직장결장암; NET, 신경내분비 종양; NSCLC, 비-소세포 폐암; NSGCT, 비정상피종성배세포종양; PNET, 췌장 NET; PTC, 유두갑상선암; RECIST v1.1, 고형 종양에서의 반응 평가 기준 버전 1.1; SLD, 최장 직경의 합. 도 40b는 BVD-523으로 치료된 BRAF-돌연변이 흑색종을 갖는 61세 환자에서 확인된 부분 반응의 컴퓨터 단층촬영 스캔을 나타낸다.
도 41은 종양 반응 및 종양 진행을 도시한다. BVD-523으로 치료된 반응-측정가능한 환자에서의 종양 반응, 종양 진행 및 치료 지속기간의 스위머 플롯이 도시되어 있다. 종축의 원점은 랜덤화 날짜 또는 참조 개시일에 상응한다. 분석 종료일: 2015년 12월 1일. 약어: BID, 1일 2회.
발명의 상세한 설명
본 발명의 하나의 실시형태는 대상체에서 암의 작용의 치료 또는 개선 방법이고, 여기서, 암은 비-ERK MAPK 경로 억제제 치료법에 대해 저항성 또는 내성이다. 상기 방법은 대상체에게 BVD-523 또는 약제학적으로 허용되는 이의 염의 유효량을 투여함을 포함한다.
본원에 사용된 용어 "치료하다(treat)", "치료하는(treating)", "치료(treatment)" 및 이의 문법적인 변형은 개별적인 대상체에게 프로토콜, 용법, 프로세스 또는 치료법을 수행함을 의미하고, 여기서, 대상체, 예를 들면, 환자에서 생리적인 반응 또는 극복을 획득하는 것이 바람직하다. 특히, 본 발명의 방법 및 조성물은 질환 증상의 발병을 느리게 하거나 질환 또는 상태의 개시를 지연시키거나 질환 발달의 진행을 멈추는데 사용될 수 있다. 그러나, 모든 치료된 대상체는 특정 치료 프로토콜, 용법, 프로세스 또는 치료법에 반응하지 않을 수 있기 때문에, 치료는 각각의 모든 대상체 또는 대상체 집단, 예를 들면, 환자 집단에서 목적하는 생리적인 반응 또는 극복이 성취되는 것을 요구하지 않는다. 따라서, 제공된 대상체 또는 대상체 집단, 예를 들면, 환자 집단은 치료에 반응하는데 실패하거나 치료에 부적합하게 반응한다.
본원에 사용된 용어 "개선하다(ameliorate)", "개선하는(ameliorating)" 및 이의 문법적인 변형은 대상체에서 질환의 증상의 중증도를 감소시킴을 의미한다.
본원에 사용된 "대상체(subject)"는 포유동물, 바람직하게는, 사람이다. 사람 이외에, 본 발명의 범위 내에 포유동물의 범주는, 예를 들면, 농장 동물, 가축 동물, 실험실용 동물 등을 포함한다. 농장 동물의 일부 예는 소, 돼지, 말, 염소 등을 포함한다. 가축 동물의 일부 예는 개, 고양이 등을 포함한다. 실험실 동물의 일부 예는 영장류, 래트, 마우스, 토끼, 기니피그 등을 포함한다.
본 발명에서, BVD-523은 화학식 (I)에 따른 화합물 및 약제학적으로 허용되는 이의 염에 상응한다:
화학식 (I)

BVD-523은, 예를 들면, 미국 특허 제7,354,939호에 개시된 방법에 따라서 합성할 수 있다. BVD-523의 둘 다의 에난티오머 에난티오머 및 라세미 혼합물은 또한 본 발명의 범위 내에 고려된다. BVD-523은, 문헌[참조: Hatzivassiliou et al. (2012)]에 사용된 SCH772984 및 피리미딘 구조와 같은 특정의 다른 ERK1/2 억제제와 고유하고 별개인 것으로 여겨지는, 작용 기전을 갖는 ERK1/2 억제제이다. 예를 들면, SCH772984와 같은 다른 ERK1/2 억제제는, ERK의 자동인산화를 억제하고[참조: Morris et al., 2013], 반면 BVD-523은 ERK의 자동인산화를 가능하게 하면서 여전히 ERK를 억제한다. [참조: 예를 들면, 도 18).
본원에 사용된 단어 "내성(resistant)" 및 "저항성(refractory)"은 상호교환적으로 사용된다. 비-ERK MAPK 경로 억제제 치료법 치료에 대한 "내성"이 있음은 비-ERK MAPK 억제제가 암 치료시 감소된 효능을 갖는다는 것을 의미한다.
본원에 사용된 "비-ERK MAPK 억제제"는 ERK1/2 억제제를 제외하고 세포 성장의 감소 또는 세포 사멸 증가를 야기하는 MAPK 경로의 단백질 또는 다른 구성원의 활성, 발현 또는 인산화를 감소시키는 임의의 물질을 의미한다. 본원에 사용된 "ERK1/2 억제제" (i) 예를 들면, ERK1/2에 결합하여 ERK1 및/또는 ERK2와 직접적으로 상호작용하고, (ii) ERK1 및/또는 ERK2 단백질 키나아제의 발현 또는 활성을 감소시키는 물질을 의미한다. 따라서, MEK 억제제 및 RAF 억제제와 같은 ERK1/2의 업스트림에서 작용하는 억제제는, 본 발명에 따른 ERK1/2 억제제가 아니다(그러나 이들은 비-ERK MAPK 억제제이다). 본 발명에 따른 ERK1/2 억제제의 비-제한적 예는 AEZS-131 (Aeterna Zentaris), AEZS-136 (Aeterna Zentaris), BVD-523 (BioMed Valley Discoveries, Inc.), SCH-722984 (Merck & Co.), SCH-772984 (Merck & Co.), SCH-900353 (MK-8353) (Merck & Co.), 약제학적으로 허용되는 이의 염, 및 이의 조합을 포함한다.
포유동물 MAPK 케스케이드의 개요를 도 21에 나타낸다. MAPK 경로는 예를 들면, 문헌[참조: Akinleye et al., 2013]에서 검토된다. 간단히, 도 21에서 ERK1/2 모듈에 대해(연자색 박스, MAPK 1/2 신호전달 케스케이드는 수용체 티로신 키나아제 (RTK)로의 리간드 결합에 의해 활성화된다. 활성화된 수용체는 어댑터 단백질 Grb2 및 SOS를 동원하고 인산화하고, 이는 이어서 막-결합 GTPase Ras와 상호작용하고, 이의 활성화를 야기한다. 이의 활성화된 GTP-결합 형태에서, Ras는 RAF 키나아제 (A-RAF, B-RAF, 및 C-RAF/RAF-1)를 동원하고 활성화한다. 활성화된 RAF 키나아제는 MAPK 1/2 (MKK1/2)를 활성화시키고, 이는 차례로 ERK1/2의 활성화 서열 Thr-Glu-Tyr에서 트레오닌 및 티로신 잔기의 인산화를 촉매화한다. JNK/p38 모듈에 대해(도 21에서 황색 박스), 업스트림 키나아제, MAP3Ks, 예를 들면, MEKK1/4, ASK1/2, 및 MLK1/2/3은, MAP2K3/6 (MKK3/6), MAP2K4 (MKK4), 및 MAP2K7 (MKK7)을 활성화시킨다. 이들 MAP2K는 이어서 JNK1, JNK2, 및 JNK3, 뿐만 아니라 p38 α/β/γ/δ를 포함하는 JNK 단백질 키나아제를 활성화시킨다. 이의 기능을 실행하기 위해, JNKs는 c-Jun, ATF-2, NF-ATc1, HSF-1 및 STAT3을 포함하는 수개의 전사 인자를 활성화시킨다. ERK5 모듈에 대해(도 21에서 청색 박스), MAP2K5 (MKK5)의 키나아제 업스트림은 MEKK2 및 MEKK3이다. MEK5의 최고 특성화된 다운스트림 표적은 ERK5이고, 이는 또한 큰 MAP 키나아제 1 (BMK1)로서 공지되어 있는데, 다른 MAPKs의 크기의 2배이기 때문이다.
본 발명에 따른 비-ERK MAPK 경로 억제제의 비-제한적 예는 RAS 억제제, RAF 억제제 (예를 들면, A-RAF, B-RAF, C-RAF (RAF-1)의 억제제), MEK 억제제, 및 이의 조합을 포함한다. 바람직하게는, 비-ERK MAPK 경로 억제제는 BRAF 억제제, MEK 억제제, 및 이의 조합이다.
본원에 사용된 "RAS 억제제"는 (i) 예를 들면, RAS에 결합하여 RAS와 직접적으로 상호작용하고, (ii) RAS의 발현 또는 활성을 감소시키는 물질을 의미한다. 비-제한적 예시적인 RAS 억제제는, 이에 제한되는 것은 아니지만, 파르네실 트랜스퍼라제 억제제 (예를 들면, 티피파르닙 및 로나파르닙), 파르네실 그룹-함유 소분자(예를 들면, 살리라시브 및 TLN-4601), 마우러(Maurer)에 의해 개시된 DCAI [참조: Maurer et al., 2012], 시마(Shima)에 의해 개시된 Kobe0065 및 Kobe2602 [참조: Shima et al., 2013], HBS 3 [참조: Patgiri et al., 2011], 및 AIK-4 (Allinky)를 포함한다.
본원에 사용된 "RAF 억제제"는 (i) 예를 들면, RAF에 결합하여 RAF와 직접적으로 상호작용하고, (ii) A-RAF, B-RAF, 및 C-RAF (RAF-1)와 같은 RAF의 발현 또는 활성을 감소시키는 물질을 의미한다. BRAF 억제제를 포함하는 비-제한적 예시적인 RAF 억제제는 다음을 포함한다:
화합물 7  (리(Li) 등),
(리(Li) 등),
화합물 9  (Id.),
(Id.),
화합물 10  (Id.),
(Id.),
화합물 13  (Id.),
(Id.),
화합물 14  (Id.),
(Id.),
화합물 15  (Id.),
(Id.),
화합물 16  (Id.),
(Id.),
화합물 18  (Id.),
(Id.),
화합물 19  (Id.),
(Id.),
화합물 20  (Id.),
(Id.),
화합물 21  (Id.),
(Id.),
화합물 22  (Id.),
(Id.),
화합물 23  (Id.),
(Id.),
화합물 24  (Id.),
(Id.),
화합물 25  (Id.),
(Id.),
화합물 26  (Id.),
(Id.),
화합물 27  (Id.),
(Id.),
화합물 28  (Id.),
(Id.),
화합물 30  (Id.),
(Id.),
화합물 31  (Id.),
(Id.),
화합물 32  (Id.),
(Id.),
화합물 33  (Id.),
(Id.),
화합물 34  (Id.),
(Id.),
화합물 35  (Id.),
(Id.),
화합물 36  (Id.),
(Id.),
화합물 37  (Id.),
(Id.),
화합물 38  (Id.),
(Id.),
화합물 39  (Id.),
(Id.),
화합물 40  (Id.),
(Id.),
AAL881 (Novartis); AB-024 (Ambit Biosciences), ARQ-736 (ArQule), ARQ-761 (ArQule), AZ628 (Axon Medchem BV), BeiGene-283 (BeiGene), BIIB-024 (MLN 2480) (Sunesis & Takeda), b-raf 억제제 (Sareum), BRAF 키나아제 억제제 (Selexagen Therapeutics), BRAF siRNA 313 (tacaccagcaagctagatgca) 및 523 (cctatcgttagagtcttcctg) [참조: Liu et al., 2007], CTT239065 (Institute of Cancer Research), 다브라페닙 (GSK2118436), DP-4978 (Deciphera Pharmaceuticals), HM-95573 (Hanmi), GDC-0879 (Genentech), GW-5074 (Sigma Aldrich), ISIS 5132 (Novartis), L779450 (Merck), LBT613 (Novartis), LErafAON (NeoPharm, Inc.), LGX-818 (Novartis), 파조파닙 (GlaxoSmithKline), PLX3202 (Plexxikon), PLX4720 (Plexxikon), PLX5568 (Plexxikon), RAF-265 (Novartis), RAF-365 (Novartis), 레고라페닙 (Bayer Healthcare Pharmaceuticals, Inc.), RO 5126766 (Hoffmann-La Roche), SB 590885 (GlaxoSmithKline), SB699393 (GlaxoSmithKline), 소라페닙 (Onyx Pharmaceuticals), TAK 632 (Takeda), TL-241 (Teligene), 베무라페닙 (RG7204 또는 PLX4032) (Daiichi Sankyo), XL-281 (Exelixis), ZM-336372 (AstraZeneca), 약제학적으로 허용되는 이의 염, 및 이의 조합.
본원에 사용된 "MEK 억제제"는 (i) 예를 들면, MEK에 결합하여 MEK와 직접적으로 상호작용하고, (ii) MEK의 발현 또는 활성을 감소시키는 물질을 의미한다. 따라서, RAS 억제제 및 RAF 억제제와 같은 MEK의 업스트림에서 작용하는 억제제는, 본 발명에 따른 MEF 억제제가 아니다. MEK 억제제의 비-제한적 예는 탄저병 독소, 안트로퀴노놀 (Golden Biotechnology), ARRY-142886 (6-(4-브로모-2-클로로-페닐아미노)-7-플루오로-3-메틸-3H-벤조이미다졸-5-카복실산 (2-하이드록시-에톡시)-아미드) (Array BioPharma), ARRY-438162 (Array BioPharma), AS-1940477 (Astellas), AS-703988 (Merck KGaA), 벤타마피모드 (Merck KGaA), BI-847325 (Boehringer Ingelheim), E-6201 (Eisai), GDC-0623 (Hoffmann-La Roche), GDC-0973 (코비메티닙) (Hoffmann-La Roche), L783277 (Merck), 탄저병 독소의 치명적 인자 부분, MEK162 (Array BioPharma), PD 098059 (2-(2'-아미노-3'-메톡시페닐)-옥사나프탈렌-4-온) (Pfizer), PD 184352 (CI-1040) (Pfizer), PD-0325901 (Pfizer), 피마세르팁 (Santhera Pharmaceuticals), RDEA119 (Ardea Biosciences/Bayer), 레파메티닙 (AstraZeneca), RG422 (Chugai Pharmaceutical Co.), RO092210 (Roche), RO4987655 (Hoffmann-La Roche), RO5126766 (Hoffmann-La Roche), 셀루메티닙 (AZD6244) (AstraZeneca), SL327 (Sigma), TAK-733 (Takeda), 트라메티닙 (Japan Tobacco), U0126 (1,4-디아미노-2,3-디시아노-1,4-비스(2-아미노페닐티오)부타디엔) (Sigma), WX-554 (Wilex), YopJ 폴리펩타이드 [참조: Mittal et al., 2010], 약제학적으로 허용되는 이의 염, 및 이의 조합을 포함한다.
이러한 실시형태의 하나의 양상에서, 리보솜 s6 키나아제 (RSK)의 실질적으로 모든 인산화는 BVD-523 또는 약제학적으로 허용되는 이의 염의 투여 후 억제된다. RSK 인산화의 정황에서 본원에 사용된, "실질적으로 모두"는 50% 초과의 감소, 바람직하게는 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 초과의 감소를 의미한다.
이러한 실시형태의 또다른 양상에서, 암은 MAPK 활성을 갖는다. 본원에 사용된 "MAPK 활성"을 갖는다는 것은, ERK의 단백질 업스트림이 활성일 아닐 수 있지만 ERK의 단백질 다운스트림이 여전히 활성임을 의미한다. 이러한 암은 고형 종양 암 또는 혈액 암일 수 있다.
본 발명에서, 암은 고형 암 및 혈액 암 둘 다를 포함한다. 고형 암의 비-제한적 예는 부신피질 암종, 항문 암, 방광 암, 골 암 (예를 들면, 골육종), 뇌 암, 유방 암, 카르시노이드 암, 암종, 자궁경부 암, 결장 암, 자궁내막 암, 식도 암, 간외 담관 암, 암의 유잉 부류(Ewing family of cancers), 두개외 배아 세포 암, 안 암, 담낭 암, 위 암, 배아 세포 종양, 임신 영양막 종양, 두경부암 암, 하인두 암, 섬 세포 암종, 신장 암, 대장 암, 후두 암, 백혈병, 입술 및 구강 암, 간 종양/암, 폐 종양/암, 림프종, 악성 중피종, 메르켈 세포 암종, 균상식육종, 골수형성이상 증후군, 골수증식성 장애, 코인두 암, 신경모세포종, 경구 암, 입인두 암, 골육종, 난소 상피 암, 난소 배아 세포 암, 췌장 암, 부비동 및 비강 암, 부갑상선 암, 음경 암, 뇌하수체 암, 혈장 세포 신생물, 전립선 암, 횡문근육종, 직장 암, 신장 세포 암, 신장 골반 및 요관의 이행 세포 암, 침샘 암, 세자리(Sezary) 증후군, 피부 암(예를 들면, 피부 t-세포 림프종, 카포시 육종, 비만 세포 종양, 및 흑색종), 소장 암, 연조직 육종, 위 암, 고환암, 가슴샘종, 갑상선 암, 요도 암, 자궁 암, 질 암, 외음부 암, 및 윌름스 종양을 포함한다.
혈액 암의 예는, 이에 제한되는 것은 아니지만, 백혈병, 예를 들면, 성인/소아 급성 림프모구 백혈병, 성인/소아 급성 골수성 백혈병, 만성 림프성 백혈병, 만성 골수성 백혈병, 및 털 세포 백혈병, 림프종, 예를 들면, AIDS-관련 림프종, 피부 T-세포 림프종, 성인/소아 호지킨 림프종, 균상식육종, 성인/소아 비-호지킨 림프종, 원발성 중추 신경계 림프종, 세자리 증후군, 피부 T-세포 림프종, 및 발덴스트롬 마크로글로불린혈증, 뿐만 아니라 다른 증식성 장애, 예를 들면, 만성 골수증식성 장애, 랑게르한스 세포 조직구증, 다발성 골수종/혈장 세포 신생물, 골수형성이상 증후군, 및 골수형성이상/골수증식성 신생물을 포함한다.
바람직하게는, 암은 대장 암, 유방 암, 췌장 암, 피부 암, 및 자궁내막 암으로 이루어진 그룹으로부터 선택된다. 보다 바람직하게는, 암은 흑색종이다.
이러한 실시형태의 또다른 양상에서, 상기 방법은 추가로 대상체에게 암의 작용을 치료 또는 개선하기에 효과적인 적어도 하나의 추가 치료학적 제제 투여함을 포함한다. 추가 치료학적 제제는 항체 또는 이의 단편, 세포독성 제제, 독소, 방사성핵종, 면역조절제, 광활성 치료학적 제제, 방사선민감성 제제, 호르몬, 항-혈관 신생 제제, 및 이의 조합으로 이루어진 그룹으로부터 선택될 수 있다.
본원에 사용된 "항체"는 천연 발생 면역글로불린 뿐만 아니라 비-천연 발생 면역글로불린을 포함하고, 예를 들면, 단일 쇄 항체, 키메라 항체 (예를 들면, 사람화 뮤린 항체), 및 이종접합(heteroconjugate) 항체 (예를 들면, 이중특이성 항체)를 포함한다. 항체의 단편은 항원에 결합하는 것들, (예를 들면, Fab', F(ab')2, Fab, Fv, 및 rIgG)을 포함한다. 또한 예를 들면, 문헌을 참조한다[참조: Pierce Catalog and Handbook, 1994-1995 (Pierce Chemical Co., Rockford, Ill.); Kuby, J., Immunology, 3rd Ed., W.H. Freeman & Co., New York (1998)]. 용어 항체는 또한 이가 또는 이중특이성 분자, 디아바디(diabodies), 트리아바디(triabodies), 및 테트라바디(tetrabodies)를 포함한다. 용어 "항체"는 추가로 폴리클로날 및 모노클로날 항체 둘 다를 포함한다.
본 발명에서 사용할 수 있는 치료학적 항체의 예는 리툭시맙 (Rituxan), 세툭시맙 (Erbitux), 베바시주맙 (Avastin), 및 이브리투모맙 (Zevalin)을 포함한다.
본 발명에 따른 세포독성 제제는 DNA 손상제, 항대사물질, 항-미세관 제제, 항생제 등을 포함한다. DNA 손상제는 알킬화 제제, 백금-기반 제제, 중격 제제(intercalating agents), 및 DNA 복제의 억제제를 포함한다. DNA 알킬화 제제의 비-제한적 예는 사이클로포스파미드, 메클로레타민, 우라무스틴, 멜팔란, 클로람부실, 이포스파미드, 카르무스틴, 로무스틴, 스트렙토조신, 부설판, 테모졸로마이드, 약제학적으로 허용되는 이의 염, 프로드럭, 및 이의 조합을 포함한다. 백금-기반 제제의 비-제한적 예는 시스플라틴, 카보플라틴, 옥살리플라틴, 네다플라틴, 사트라플라틴, 트리플라틴 테트라니트레이트, 약제학적으로 허용되는 이의 염, 프로드럭, 및 이의 조합을 포함한다. 중격 제제의 비-제한적 예는 독소루비신, 다우노루비신, 이다루비신, 미톡산트론, 약제학적으로 허용되는 이의 염, 프로드럭, 및 이의 조합을 포함한다. DNA 복제 억제제의 비-제한적 예는 이리노테칸, 토포테칸, 암사크린, 에토포사이드, 에토포사이드 포스페이트, 테니포사이드, 약제학적으로 허용되는 이의 염, 프로드럭, 및 이의 조합을 포함한다. 항대사물질은 폴레이트 길항제, 예를 들면, 메토트렉세이트 및 프레메트렉세드, 퓨린 길항제, 예를 들면, 6-머캅토퓨린, 다카르바진, 및 플루다라빈, 및 피리미딘 길항제, 예를 들면, 5-플루오로우라실, 아라비노실시토신, 카페시타빈, 겜시타빈, 데시타빈, 약제학적으로 허용되는 이의 염, 프로드럭, 및 이의 조합을 포함한다. 항-미세관 제제는 제한없이 빈카 알칼로이드, 파클리탁셀 (Taxol®), 도세탁셀 (Taxotere®), 및 익사베필론 (Ixempra®)을 포함한다. 항생제는 제한없이 악티노마이신, 안트라사이클린, 발루비신, 에피루비신, 블레오마이신, 플리카마이신, 미토마이신, 약제학적으로 허용되는 이의 염, 프로드럭, 및 이의 조합을 포함한다.
본 발명에 따른 세포독성 제제는 또한 PI3K/Akt 경로의 억제제를 포함한다. PI3K/Akt 경로의 억제제의 비-제한적 예는 A-674563 (CAS # 552325-73-2), AGL 2263, AMG-319 (Amgen, Thousand Oaks, CA), AS-041164 (5-벤조[1,3]디옥솔-5-일메틸렌-티아졸리딘-2,4-디온), AS-604850 (5-(2,2-디플루오로-벤조[1,3]디옥솔-5-일메틸렌)-티아졸리딘-2,4-디온), AS-605240 (5-퀴녹실린-6-메틸렌-1,3-티아졸리딘-2,4-디온), AT7867 (CAS # 857531-00-1), 벤즈이미다졸 시리즈, 게네테크(Genentech) (Roche Holdings Inc., South San Francisco, CA), BML-257 (CAS # 32387-96-5), CAL-120 (Gilead Sciences, Foster City, CA), CAL-129 (Gilead Sciences), CAL-130 (Gilead Sciences), CAL-253 (Gilead Sciences), CAL-263 (Gilead Sciences), CAS # 612847-09-3, CAS # 681281-88-9, CAS # 75747-14-7, CAS # 925681-41-0, CAS # 98510-80-6, CCT128930 (CAS # 885499-61-6), CH5132799 (CAS # 1007207-67-1), CHR-4432 (Chroma Therapeutics, Ltd., Abingdon, UK), FPA 124 (CAS # 902779-59-3), GS-1101 (CAL-101) (Gilead Sciences), GSK 690693 (CAS # 937174-76-0), H-89 (CAS # 127243-85-0), Honokiol, IC87114 (Gilead Science), IPI-145 (Intellikine Inc.), KAR-4139 (Karus Therapeutics, Chilworth, UK), KAR-4141 (Karus Therapeutics), KIN-1 (Karus Therapeutics), KT 5720 (CAS # 108068-98-0), 밀테포신(Miltefosine), MK-2206 디하이드로클로라이드 (CAS # 1032350-13-2), ML-9 (CAS # 105637-50-1), 날트린돌 하이드로클로라이드, OXY-111A (NormOxys Inc., Brighton, MA), 페리포신, PHT-427 (CAS # 1191951-57-1), PI3 키나아제 델타 억제제, Merck KGaA (Merck & Co., Whitehouse Station, NJ), PI3 키나아제 델타 억제제, 게네테크 (Roche Holdings Inc.), PI3 키나아제 델타 억제제, 인코젠(Incozen) (Incozen Therapeutics, Pvt. Ltd., Hydrabad, India), PI3 키나아제 델타 억제제-2, 인코젠 (Incozen Therapeutics), PI3 키나아제 억제제, 로쉐(Roche)-4 (Roche Holdings Inc.), PI3 키나아제 억제제, 로쉐(Roche) (Roche Holdings Inc.), PI3 키나아제 억제제, 로쉐-5 (Roche Holdings Inc.), PI3-알파/델타 억제제, 패스웨이 테라퓨틱스(Pathway Therapeutics) (Pathway Therapeutics Ltd., South San Francisco, CA), PI3-델타 억제제, 셀좀 (Cellzome) (Cellzome AG, Heidelberg, Germany), PI3-델타 억제제, 인텔리킨(Intellikine) (Intellikine Inc., La Jolla, CA), PI3-델타 억제제, 패스웨이 테라퓨틱스-1 (Pathway Therapeutics Ltd.), PI3-델타 억제제, 패스웨이 테라퓨틱스-2 (Pathway Therapeutics Ltd.), PI3-델타/감마 억제제, 셀좀 (Cellzome AG), PI3-델타/감마 억제제, 셀좀 (Cellzome AG), PI3-델타/감마 억제제, 인텔리킨 (Intellikine Inc.), PI3-델타/감마 억제제, 인텔리킨 (Intellikine Inc.), PI3-델타/감마 억제제, 패스웨이 테라퓨틱스 (Pathway Therapeutics Ltd.), PI3-델타/감마 억제제, 패스웨이 테라퓨틱스 (Pathway Therapeutics Ltd.), PI3-감마 억제제 에보테크 (Evotec), PI3-감마 억제제, 셀좀 (Cellzome AG), PI3-감마 억제제, 패스웨이 테라퓨틱스 (Pathway Therapeutics Ltd.), PI3K 델타/감마 억제제, 인텔리킨-1 (Intellikine Inc.), PI3K 델타/감마 억제제, 인텔리킨-1 (Intellikine Inc.), 픽틸리시브 (Roche Holdings Inc.), PIK-90 (CAS # 677338-12-4), SC-103980 (Pfizer, New York, NY), SF-1126 (Semafore Pharmaceuticals, Indianapolis, IN), SH-5, SH-6, 테트라하이드로 쿠르쿠민, TG100-115 (Targegen Inc., San Diego, CA), 트리시리빈, X-339 (Xcovery, West Palm Beach, FL), XL-499 (Evotech, Hamburg, Germany), 약제학적으로 허용되는 이의 염, 및 이의 조합을 포함한다.
본 발명에서, 용어 "독소"는 식물 또는 동물 기원의 항원 독(poison) 또는 독(venom)을 의미한다. 예는 디프테리아 독소 또는 이의 단편이다.
본 발명에서, 용어 "방사성핵종"은 환자에게, 예를 들면, 정맥내 또는 경구 투여된 후, 환자의 정상 대사를 통해 표적 기관 또는 조직 내로 침투되고 국소 방사선을 단시간 동안 전달하는 방사성활성 물질을 의미한다. 방사성핵종의 예는, 이에 제한되는 것은 아니지만, I-125, At-211, Lu-177, Cu-67, I-131, Sm-153, Re-186, P-32, Re-188, In-114m, 및 Y 90을 포함한다.
본 발명에서, 용어 "면역조절제"는 이의 생성을 개시한 항원을 인지하고 반응하여 항체 또는 민감화된 세포를 생성하는 면역계의 능력을 증강 또는 감소시켜 면역 반응을 변경시키는 물질을 의미한다. 면역조절제는 재조합, 합성, 또는 천연 제제일 수 있고, 시토킨, 코르티코스테로이드, 세포독성 제제, 티모신, 및 면역글로불린을 포함한다. 일부 면역조절제는 신체에 천연으로 존재하고, 이들 중 일부는 약리학적 제제로 이용가능하다. 면역조절제의 예는, 이에 제한되는 것은 아니지만, 과립구 콜로니-자극 인자 (G-CSF), 인터페론, 이미퀴모드 및 박테리아의 세포 막 부분, IL-2, IL-7, IL-12, CCL3, CCL26, CXCL7, 및 합성 시토신 포스페이트-구아노신 (CpG)을 포함한다.
본 발명에서, 용어 "광활성 치료학적 제제"는 광(light)에 노출시 활성이 되는 화합물 및 조성물을 의미한다. 광활성 치료학적 제제의 특정 예는, 예를 들면, 미국 특허 출원 연속 제2011/0152230 A1호에, "Photoactive Metal Nitrosyls For Blood Pressure Regulation And Cancer Therapy" 표제로 개지되어 있다.
본 발명에서, 용어 "방사선민감성 제제"는 방사선 치료법에 대해 종양 세포를 더 민감성으로 만드는 화합물을 의미한다. 방사선민감성 제제의 예는 미소니다졸, 메트로니다졸, 티라파자민, 및 트랜스 나트륨 크로세티네이트를 포함한다.
본 발명에서, 용어 "호르몬"은 또다른 신체 부분에 영향을 미치는 신체 일부에서 세포에 의해 방출된 물질을 의미한다. 호르몬의 예는, 이에 제한되는 것은 아니지만, 프로스타글란딘, 류코트리엔, 프로스타사이클린, 트롬복산, 아밀린, 안티물레리안(antimullerian) 호르몬, 아디포넥틴, 부신피질자극 호르몬, 안지오텐시노겐, 안지오텐신, 바소프레신, 아트리오펩틴, 뇌 나트륨이뇨 펩타이드, 칼시토닌, 콜레시스토키닌, 코르티코트로핀-방출 호르몬, 엔세팔린, 엔도텔린, 에리트로포이에틴, 여포-자극 호르몬, 갈라닌, 가스트린, 그렐린, 글루카곤, 고나도트로핀-방출 호르몬, 성장 호르몬-방출 호르몬, 사람 융모막 고나도트로핀, 사람 태반 락토겐, 성장 호르몬, 인히빈, 인슐린, 소마토메딘, 렙틴, 립트로핀, 황체형성 호르몬, 멜라닌세포 자극 호르몬, 모틸린, 오렉신, 옥시토신, 췌장 폴리펩타이드, 부갑상선 호르몬, 프롤락틴, 프롤락틴 방출 호르몬, 렐락신, 레닌, 세크레틴, 소마토스타틴, 트롬보포이에틴, 갑상선-자극 호르몬, 테스토스테론, 데하이드로에피안드로스테론, 안드로스테네디온, 디하이드로테스토스테론, 알도스테론, 에스트라디올, 에스트론, 에스트리올, 코르티솔, 프로게스테론, 칼시트리올, 및 칼시디올을 포함한다.
일부 화합물은 특정 호르몬의 활성을 간섭하거나, 특정 호르몬의 생성을 정지시킨다. 이들 호르몬-간섭 화합물은, 이에 제한되는 것은 아니지만, 타목시펜 (Nolvadex®), 아나스트로졸 (Arimidex®), 레트로졸 (Femara®), 및 풀베스트란트 (Faslodex®)를 포함한다. 이러한 화합물은 또한 본 발명의 호르몬의 의미 내에 있다.
본원에 사용된 "항-혈관 신생" 제제는 신규 혈관의 성장을 감소 또는 억제하는 물질을 의미하고, 예를 들면, 혈관 내피 성장 인자 (VEGF)의 억제제 및 내피 세포 이주의 억제제이다. 항-혈관 신생 제제는 제한없이 2-메톡시에스트라디올, 안지오스타틴, 베바시주맙, 연골-유도 혈관 신생 억제 인자, 엔도스타틴, IFN-α, IL-12, 이트라코나졸, 리노미드, 혈소판 인자-4, 프롤락틴, SU5416, 수라민, 타스퀴니모드, 테코갈란, 테트라티오몰리브데이트, 탈리도미드, 트롬보스폰딘, 트롬보스폰딘, TNP-470, ziv-아플리베르셉트, 약제학적으로 허용되는 이의 염, 프로드럭, 및 이의 조합을 포함한다.
본 발명의 또다른 실시형태는 대상체에서 암의 작용의 치료 또는 개선 방법이다. 상기 방법은 다음을 포함한다:
(a) BRAF 억제제 치료법, MEK 억제제 치료법, 또는 BRAF 및 MEK 억제제 치료법에 대해 저항성이거나 내성이 된 암을 갖는 대상체를 확인하는 단계;
(b) 상기 저항성 또는 내성 암을 갖는 대상체에게 BVD-523인 ERK 억제제 또는 약제학적으로 허용되는 이의 염의 유효량을 투여하는 단계.
적합하고 바람직한 대상체는 본원에 개시된 바와 같다. 이러한 실시형태에서, 상기 방법은 상기 개시된 암을 치료하는데 사용될 수 있다. 본 발명에 따라서, 암은 MAPK 활성을 가질 수 있다.
이러한 실시형태의 하나의 양상에서, BRAF 및/또는 MEK 억제제 치료법에 대해 저항성이거나 내성인 암을 갖는 대상체를 확인하는 단계는 다음을 포함한다:
(a) 대상체로부터 생물학적 샘플을 입수하고;
(b) 대상체가 BRAF 억제제 치료법, MEK 억제제 치료법, 및 이의 조합으로 이루어진 그룹으로부터 선택된 억제제 치료법에 내성이 되었는지 결정하기 위해 샘플을 스크리닝한다.
본 발명에서, 생물학적 샘플은, 이에 제한되는 것은 아니지만, 혈액, 혈장, 소변, 피부, 타액, 및 생검을 포함한다. 생물학적 샘플은 당해 기술 분야에 공지되어 있는 일상적 절차 및 방법에 의해 대상체로부터 입수한다.
바람직하게는, BRAF 억제제 치료법에 대해 저항성이거나 내성인 암을 스크리닝하는 것은, 예를 들면, (i) RAF 이소형 간의 전환, (ii) RTK 또는 NRAS 신호전달의 상향조절, (iii) 미토겐 활성화된 단백질 키나아제 (MAPK) 신호전달의 재활성화, (iv) MEK 활성화 돌연변이의 존재, 및 이의 조합을 확인하는 것을 포함할 수 있다.
RAF 이소형 간의 전환은 BRAF 억제제 치료법에 획득된 내성을 갖는 대상체에서 일어날 수 있다. 이러한 전환을 검출하기 위해, BRAF 억제제-내성 종양 세포는 환자로부터 회수(retrieve)될 수 있고, 웨스턴 블롯팅을 통해 BRAF 억제제의 존재하에 ERK 및 포스포-ERK 수준에 대해 분석할 수 있다. BRAF 억제제로 치료된 BRAF 억제제-민감성 세포와의 비교는 BRAF 억제제-내성 종양 세포에서 더 높은 수준의 포스포-ERK를 나타낼 수 있고, 이는 RAF 이소형이 BRAF 대신에 ERK를 인산화시키는 전환이 일어남을 암시한다. RAF 이소형이 대체되었는지 확인은 BRAF 억제제에 노출된 BRAF 억제제-내성 세포에서 개별적으로 ARAF 및 CRAF의 sh/siRNA-매개된 녹다운(knockdown), 이어서, 후속적인 ERK 및 포스포-ERK 수준을 위한 웨스턴 블롯팅을 포함할 수 있다. 예를 들면, BRAF 억제제에 노출된 BRAF 억제제-내성 세포에서 ARAF 녹다운이 높은 수준의 포스포-ERK를 여전히 야기하는 경우, CRAF가 인산화 ERK를 대체하였음을 나타낸다. 마찬가지로, CRAF가 BRAF 억제제에 노출된 BRAF 억제제-내성 세포에서 녹다운되고, ERK가 여전히 고도로 인산화된 경우, ARAF가 ERK 인산화를 대체함을 의미한다. RAF 이소형 전환은 또한 BRAF 억제제의 존재하에 BRAF 억제제-내성 세포에서 동시에 일어나는 ARAF 및 CRAF의 녹다운을 포함할 수 있고, 효과적으로 모든 RAF-매개된 인산화를 차단한다. 결과적인 ERK 인산화의 감소는, BRAF 억제제-내성 세포가 ERK를 인산화시키기 위한 RAF 이소형 간의 전환 능력을 갖는다는 것을 나타낸다 [참조: Villanueva, et al., 2010].
RTK 또는 NRAS 신호전달의 상향조절은 또한 BRAF 억제제 내성의 원인일 수 있다. 검출은, 예를 들면, 먼저 다운스트림 RAF 이펙터 MEK1/2 및 ERK1/2의 활성화를 분석하기 위해 포스포-특이적 항체로 웨스턴 블롯팅 프로토콜을 사용함을 포함할 수 있다. BRAF 억제제-내성 세포가 BRAF 억제제의 존재하에 이들 단백질의 높은 활성화 수준을 나타내는 경우, RTK 또는 NRAS 상향조절이 원인일 수 있다. BRAF 억제제의 존재하에 BRAF 억제제-내성 세포의 유전자 발현 프로파일링 (또는 다른 관련 방법)은 BRAF 억제제-민감성 세포와 비교하여 더 높은 발현 수준의 KIT, MET, EGFR, 및 PDGFRβ RTKs를 나타낼 수 있다. 실시간 정량적 폴리머라제 쇄 반응 실험, 또는 이들 유전자 중 어느 것에 초점을 맞추는 다른 유사한 절차는, 더 높은 발현 수준을 확인할 수 있고, 동시에 포스포-RTK 어레이 (R&D Systems, Minneapolis, MN)는 상승된 활성화-관련 티로신 인산화를 나타낼 수 있다. 대안적으로, NRAS 활성화는 다양한 유전자 서열분석 프로토콜에 의해 검출할 수 있다. NRAS 중 활성화 돌연변이, 특히 Q61K는, B-RAF 신호전달이 바이패스(bypass)되었음을 나타낼 수 있다. 흑색종 세포에서, 활성화된 NRAS는 C-RAF를 사용하여 MEK-ERK로 신호화한다. 따라서, 활성화된 NRAS는 BRAF 억제제에 노출된 BRAF 억제제-내성 세포에서 유사한 바이패스 경로를 가능하게 한다. 제공된 BRAF 억제제-내성 샘플에서 이들 기전의 추가 확인이, 예를 들면, BRAF 억제제의 존재하에 상향조절된 RTKs 또는 활성화된 NRAS의 sh/siRNA-매개된 녹다운을 사용하여 수행될 수 있다. 성장 억제의 임의의 유의한 수준은 RTK 또는 NRAS 신호전달의 상향조절이 이러한 특정 샘플에서 BRAF 억제의 원인임을 나타낼 수 있다[참조: Nazarian, et al., 2010].
BRAF 억제제-내성 세포에서 MAPK 신호전달의 재활성화 검출은 BRAF 억제제 내성에 대한 또다른 바이패스 기전을 나타낼 수 있다. COT 및 C-RAF는 BRAF 억제제에 노출된 BRAF V600E 배경에서 상향조절됨을 나타내었다. 정량적 실시간 RT-PCR은, 예를 들면, BRAF 억제제의 존재하에 BRAF 억제제-내성 세포에서 증가된 COT 발현을 나타낼 수 있다. 추가로, BRAF 억제제의 존재하에 BRAF 억제제-내성 세포에서 COT의 sh/siRNA-매개된 녹다운은 BRAF 억제제-내성 세포의 생존력을 감소시킬 수 있고, 이는 이들 특정 세포가 COT 억제 및/또는 병용 BRAF 억제제/MEK 억제제 치료에 대해 민감성일 수 있음을 나타낸다 [참조: Johannessen, et al., 2010].
MAPK 신호전달의 재활성화는 또한 MEK1에서 돌연변이를 활성화시킴에 의해 BRAF 억제제-내성 배경에서 수행될 수 있다. BRAF 억제제-내성 종양으로부터 표적화된, 유전체 DNA의 대량 병렬 서열분석은 MEK1, 예를 들면, 다른 것들 중에서 C121S, G128D, N122D, 및 Y130에서 돌연변이 활성화를 나타낼 수 있다. MEK1에서 다른, 문서화되지 않은 돌연변이는 예를 들면, A375와 같은 BRAF 억제제-민감성 세포주에서 특정 돌연변이 발현에 의해 분석될 수 있다. BRAF 억제제에 노출시 이들 세포에서 성장 억제 수준의 측정은, MEK1 돌연변이가 BRAF 억제 치료법에 대해 내성을 야기하는 경우 나타날 수 있다. 이러한 발견을 확인하기 위해, MEK1 돌연변이를 이소성 발현하는 세포에서 상승된 수준의 포스포-ERK1/2를 위한 웨스턴 블롯팅은 MEK1 돌연변이가, BRAF 억제제-내성 종양이 BRAF를 바이패스하고 MEK1을 통한 ERK의 인산화를 촉진할 수 있게 함을 나타낼 수 있다[참조: Wagle, et al., 2011].
본 발명에 따라서, MEK 억제제 치료법에 대해 저항성이거나 내성인 암의 스크리닝은, 예를 들면, (i) 돌연변이 BRAF의 증폭, (ii) STAT3 상향조절, (iii) 억제제의 MEK로의 결합을 직접적으로 차단시키거나 구성적 MEK 활성을 야기하는 MEK의 알로스테리 포켓에서 돌연변이, 및 이의 조합을 확인함을 포함할 수 있다.
돌연변이 BRAF의 증폭은 MEK 억제제 내성을 야기할 수 있다. MEK 억제제 내성은 전형적으로 MEK 억제제의 존재하에 높은 수준의 인산화된 ERK 및 MEK에 관련되고, 이는 예를 들면, 웨스턴 블롯팅으로 검정될 수 있다. MEK 억제제-내성 세포주에서 돌연변이 BRAF의 증폭은, 예를 들면, 형광성 동일계내 하이브리드화 (FISH) 또는 내성 세포주의 유전체 DNA로부터 정량적 PCR에 의해 검출될 수 있다. BRAF 증폭이 MEK 억제제 내성의 1차 원인인지의 확인은 내성 세포에서 BRAF-표적화된 sh/siRNAs를 사용하여 수반될 수 있다. MEK 또는 ERK 인산화에서 유의한 감소가 관찰되는 경우, BRAF 증폭은 추가 치료학적 접근을 위한 적합한 표적일 수 있다. [참조: Corcoran, et al., 2010].
STAT3 상향조절을 확인하는 것은 특정 종양 샘플이 MEK 억제제 치료법에 저항성임을 나타낼 수 있다. 전장-유전체(Genome-wide) 발현 프로파일링은 STAT3 경로가 종양에서 상향조절됨을 나타낼 수 있다. 다른 기술, 예를 들면, 포스포-STAT3을 위한 웨스턴 블롯팅 및 STAT 경로-관련 유전자 JAK1 및 IL6ST를 위한 실시간 qPCR은 상향조절된 STAT3을 나타낼 수 있다. STAT3 상향조절이 특정 샘플에서 MEK 억제제 내성을 야기하는지의 추가 확인은 샘플에서 STAT3에 대한 sh/siRNAs의 사용, 이어서, MEK 및 ERK 활성화 뿐만 아니라 포스포-STAT3 및 전체 STAT3을 위한 적합한 웨스턴 블롯팅을 포함할 수 있다. 성장 억제 연구는 STAT3 녹다운이 MEK 억제에 대해 이전 MEK 억제제-내성 세포를 민감화시킴을 나타낼 수 있다. 유사한 결과는 샘플이 JSI-124와 같은 STAT3 억제제에 노출되는 경우 나타날 수 있다. STAT3 상향조절이 특정 종양에서 MEK 억제제 내성의 원인인지의 추가 확인은 BIM-EL, BIM-L, 및 BIM-SL을 포함하는 BIM 발현을 위한 웨스턴 블롯팅으로부터 일어날 수 있다. BIM 발현은 MEK 억제제-유도 아폽토시스를 야기하고, 이에 따라, STAT3 상향조절은 BIM 수준을 낮출 수 있다. STAT3은 miR 17-92의 발현을 조절하는 것으로 공지되어 있고, 이는 BIM 발현을 억압한다. 상향조절된 STAT3은 더 높은 수준의 miR 17-92을 야기할 수 있고, 이는 BIM 수준을 낮출 것이고, MEK 억제에 대한 저항을 촉진할 것이다. 따라서, miR 17-92 수준의 실시간 qPCR은 또한 STAT3 상향조절이 특정 샘플에서 MEK 억제 저항을 야기하는지의 검정을 지원할 수 있다. [참조: Dai, et al., 2011].
억제제의 MEK로의 결합을 직접적으로 차단할 수 있고 구성적 MEK 활성을 야기할 수 있는 MEK의 알로스테리 포켓에서 돌연변이는 하기 개시된 방법에 의해 검출할 수 있다. 이러한 돌연변이는 에머리(Emery) 및 동료들[참조: Emery, et al., 2009] 뿐만 아니라 왕(Wang) 및 동료들[참조: Wang et al., 2011]에 의해 이전에 확인되었다. 다른 돌연변이는 N-말단 네가티브 조절 나선, 예를 들면, P124L 및 Q56P. (Id.)에 내부에 또는 맞닿게 위치한 MEK1 코돈에 영향을 줄 수 있다.
핵산, 예를 들면, 상기 확인된 MEK 유전자에서 돌연변이를 확인하는 방법은, 당해 기술 분야에 공지되어 있다. 핵산은 생물학적 샘플로부터 입수할 수 있다.본 발명에서, 생물학적 샘플은, 이에 제한되는 것은 아니지만, 혈액, 혈장, 소변, 피부, 타액, 및 생검을 포함한다. 생물학적 샘플은 당해 기술 분야에 공지된 일상적 절차 및 방법에 의해 대상체로부터 입수된다.
돌연변이를 확인하는 방법의 비-제한적 예는 PCR, 서열분석, 하이브리드 포획, 용액-내 포획, 분자 역전 프로브, 형광성 동일계내 하이브리드화 (FISH) 검정, 및 이의 조합을 포함한다.
다양한 서열분석 방법은 당해 기술 분야에 공지되어 있다. 이들은, 이에 제한되는 것은 아니지만, Sanger 서열분석 (또한 디데옥시 서열분석으로 언급됨) 및, 예를 들면, 문헌[참조: Metzker 2005]에 개시된 다양한 합성에 의한 서열분석(SBS) 방법, 하이브리드화, 결찰(예를 들면, WO 2005021786), 분해(예를 들면, 미국 특허 제5,622,824호 및 제6,140,053호)에 의한 서열분석 및 나노포어 서열분석 (제조원: Oxford Nanopore Technologies, UK)을 포함한다. 심층 서열분석 기술에서, 서열에서 제공된 뉴클레이타이드는 서열분석 프로세스 동안 1회 초과로 판독된다. 심층 서열분석 기술은 예를 들면, 미국 특허 공보 제20120264632호 및 국제 특허 공보 제WO2012125848호에 개시된다.
돌연변이 검출을 위한 PCR-기반 방법은 당해 기술 분야에 공지되어 있고, PCR 증폭을 이용하고, 여기서, 샘플에서 각각의 표적 서열은 상응하는 쌍의 독특한, 서열-특이적 프라이머를 갖는다. 예를 들면, 폴리머라제 쇄 반응-제한 단편 길이 다형성 (PCR-RFLP) 방법은 유전체 서열이 PCR에 의해 증폭된 후 돌연변이의 신속한 검출을 가능하게 한다. 돌연변이는 특이적 제한 엔도뉴클레아제로의 소화에 의해 구별되고, 전기 영동에 의해 확인된다. 예를 들면, 문헌을 참조한다[참조: Ota et al., 2007]. 돌연변이는 또한 실시간 PCR을 사용하여 검출될 수 있다. 예를 들면, 국제 출원 공보 제WO2012046981호를 참조한다.
하이브리드 포획 방법은 당해 기술 분야에 공지되어 있고, 예를 들면, 미국 특허 공보 제20130203632호 및 미국 특허 제8,389,219호 및 제8,288,520호에 개시된다. 이들 방법은 사용자-설계된 올리고뉴클레오타이드로의 표적 유전체 영역의 선택적 하이브리드화를 기초로 한다. 하이브리드화는 높은 또는 낮은 밀도 미세어레이 상 부동화된 올리고뉴클레오타이드 (온-에레이 포획)에 대한 것일 수 있거나, 리간드 (예를 들면, 비오틴)로 개질된 올리고뉴클레오타이드에 대한 용액-상 하이브리드화일 수 있고, 이는 후속적으로 고체 표면, 예를 들면, 비드에 부동화될 수 있다 (용액-내 포획).
분자 역전 프로브 (MIP) 기술은 당해 기술 분야에 공지되어 있고, 예를 들면, 문헌[참조: Absalan et al., 2008]에 개시되어 있다. 이 방법은 MIP 분자를 사용하고, 이는 유전자형에 대한 특정한 "자물쇠" 프로브이다[참조: Nilsson et al, 1994]. MIP 분자는, 특이적 영역, 범용 서열, 제한 위치 및 Tag (index) 서열 (16-22 bp)을 포함하는 선형 올리고뉴클레오타이드이다. MIP는 관심 대상 유전적 마커/SNP 주위에 직접적으로 하이브리드화한다. MIP 방법은 또한, 유전체 DNA에 대해 병행하여(in parallel) 하이브리드화되는 다수의 "자물쇠" 프로브 세트를 사용할 수 있다 [참조: Hardenbol et al., 2003]. 완벽한 일치의 경우, 유전체 상동성 영역은 배치에서 역전을 겪고(기술의 이름으로 제안된 바와 같이) 원형 분자를 만들어서 결찰된다. 첫번째 제한 후, 모든 분자는 범용 프라이머로 증폭된다. 앰플리콘은 미세어레이 상에서 하이브리드화를 위한 짧은 단편을 보장하기 위해 다시 제한된다. 생성된 짧은 단편은 표지화되고, Tag 서열을 통해, 어레이 상에서 cTag (인덱스를 위한 상보적 스트랜드)로 하이브리드화된다. Tag-cTag 듀플렉스 형성 후, 신호가 검출된다.
하기 표 1, 2, 및 3은 서열 목록에서 다양한 동물로부터의 야생형 BRAF, N-RAS, 및 MEK1의 대표적인 핵산 및 아미노 산 서열의 서열 번호를 나타낸다. 이들 서열은 돌연변이 BRAF, N-RAS, 및 MEK1 유전자형을 갖는 대상체를 확인하기 위한 방법에서 사용될 수 있다.
표 1 - BRAF 서열


표 2 - N-RAS 서열

표 3 - MEK1 서열

이러한 실시형태의 또다른 양상에서, 상기 방법은 추가로 적어도 하나의 추가 치료학적 제제, 바람직하게는 PI3K/Akt 경로의 억제제를, 본원에 개시된 바와 같이, 투여함을 포함한다.
본 발명의 추가의 실시형태는, 암이 BRAF 억제제 치료법, MEK 억제제 치료법, 또는 둘 다에 대해 저항성이거나 내성인 대상체에서 암의 작용의 치료 또는 개선 방법이다. 상기 방법은 대상체에게 BVD-523 또는 약제학적으로 허용되는 이의 염의 유효량을 투여함을 포함한다.
적합하고 바람직한 대상체는 본원에 개시된 바와 같다. 이러한 실시형태에서, 상기 방법은 돌연변이 배경, 내성 프로파일, 및 상기 확인된 MAPK 활성을 갖는 암을 포함하는 상기 포함하는 개시된 암을 치료하는데 사용될 수 있다. 이러한 돌연변이의 확인 방법은 또한 상기 열거된 바와 같다.
이러한 실시형태의 추가의 양상에서, 상기 방법은 추가로 대상체에게 적어도 하나의 추가 치료학적 제제, 바람직하게는 본원에 개시된 바와 같은 PI3K/Akt 경로의 억제제를 투여함을 포함한다.
본 발명의 또다른 실시형태는 ERK 억제제를 사용한 치료법으로 이득을 볼 수 있는 암을 갖는 대상체의 확인 방법이다. 상기 방법은 다음을 포함한다:
(a) 대상체로부터 생물학적 샘플을 입수하고;
(b) 대상체가 하기 마커 중 하나 이상을 갖는지를 결정하기 위해 샘플을 스크리닝하고:
(i) RAF 이소형 간의 전환,
(ii) RTK 또는 NRAS 신호전달의 상향조절,
(iii) 미토겐 활성화된 단백질 키나아제 (MAPK) 신호전달의 재활성화,
(iv) MEK 활성화 돌연변이의 존재,
(v) 돌연변이 BRAF의 증폭,
(vi) STAT3 상향조절,
(vii) 억제제의 MEK로의 결합을 직접적으로 차단하거나 구성적 MEK 활성을 야기하는 MEK의 알로스테리 포켓에서 돌연변이,
여기서, 마커 중 하나 이상의 존재는 대상체의 암이 BRAF 및/또는 MEK 억제제 치료법에 대해 저항성 또는 내성이고 대상체가 BVD-523 또는 약제학적으로 허용되는 이의 염인 ERK 억제제를 사용하는 치료법으로부터 이득을 얻을 수 있음을 확실하게 한다.
적합하고 바람직한 대상체는 본원에 개시된 바와 같다. 이러한 실시형태에서, 상기 방법은 돌연변이 배경, 내성 프로파일, 및 상기 확인된 MAPK 활성을 갖는 암을 포함하는 상기 개시된 암을 갖는 대상체를 확인하는데 사용할 수 있다. 이러한 돌연변이의 확인 방법은 또한 상기 열거된 바와 같다.
이러한 실시형태의 하나의 양상에서, 상기 방법은 추가로 BVD-523 또는 약제학적으로 허용되는 이의 염을 상기 마커 중 하나 이상을 갖는 대상체에게 투여함을 포함한다. 바람직하게는, 상기 방법은 추가로 마커 중 하나 이상을 갖는 대상체에게 적어도 하나의 추가 치료학적 제제, 바람직하게는 본원에 개시된 바와 같은 PI3K/Akt 경로의 억제제를 투여함을 포함한다.
본 발명의 추가 실시형태는 암이 비-ERK MAPK 경로 치료법에 대해 저항성이거나 내성인 대상체에서 암의 작용을 치료 또는 개선하기 위한 약제학적 조성물이다. 상기 조성물은 약제학적으로 허용되는 담체 또는 희석제 및 BVD-523 또는 약제학적으로 허용되는 이의 염의 유효량을 포함한다.
적합하고 바람직한 대상체 및 비-ERK MAPK 경로 억제제 치료법의 유형은 본원에 개시된 바와 같다. 이러한 실시형태에서, 약제학적 조성물은 돌연변이 배경, 내성 프로파일, 및 상기 확인된 MAPK 활성을 갖는 암을 포함하는 상기 개시된 암의 치료를 위해 사용될 수 있다. 이러한 돌연변이의 확인 방법은 또한 상기 열거된 바와 같다.
이러한 실시형태의 하나의 양상에서, 약제학적 조성물은 추가로 적어도 하나의 추가 치료학적 제제, 바람직하게는 본원에 개시된 바와 같은 PI3K/Akt 경로의 억제제를 포함한다.
본 발명의 또다른 실시형태는 대상체에서 비-ERK MAPK 경로 치료법에 대해 저항성 또는 내성인 암의 작용을 치료 또는 개선을 위한 키트이다. 이들 키트는 이의 사용을 위한 지침서와 함께 패키징된 본 발명에 따른 임의의 약제학적 조성물을 포함한다.
키트는 또한 약제학적 조성물을 대상체에게 투여하는데 사용하기 위한 각각의 약제학적 조성물 및 다른 시약, 예를 들면, 완충제, 밸런싱된 염 용액 등을 위해 적합한 저장 컨테이너, 예를 들면, 앰풀, 바이알, 관 등을 포함할 수 있다. 약제학적 조성물 및 다른 시약은 용액 또는 분말 형태와 같은 임의의 용이한 형태로키트에 존재할 수 있다. 키트는 추가로 약제학적 조성물 및 다른 임의의 시약을 하우징하기 위한 하나 이상의 칸막이를 임의로 갖는 패키징 컨테이너를 포함할 수 있다.
적합하고 바람직한 대상체 및 비-ERK MAPK 경로 억제제 치료법의 유형은 본원에 개시된 바와 같다. 이러한 실시형태에서, 키트는 돌연변이 배경, 내성 프로파일, 및 본원에서 확인된 MAPK 활성을 갖는 이들 암을 포함하는 상기 개시된 암을 치료하는데 사용할 수 있다. 이러한 돌연변이의 확인 방법은 상기 열거된 바와 같다.
이러한 실시형태의 하나의 양상에서, 키트는 추가로 적어도 하나의 추가 치료학적 제제, 바람직하게는 본원에 개시된 바와 같은 PI3K/Akt 경로의 억제제를 포함한다.
본 발명의 또다른 실시형태는 비-ERK MAPK 경로 억제제에 대해 저항성이거나 내성인 암 세포에서 RSK의 인산화의 억제 방법이다. 상기 방법은 억제될 암 세포에서 암 세포를 BVD-523 또는 약제학적으로 허용되는 이의 염의 유효량과 RSK의 인산화를 위해 충분한 기간 동안 접촉시킴을 포함한다. 이러한 실시형태에서, "접촉"은 BVD-523 또는 약제학적으로 허용되는 이의 염 및 임의의 하나 이상의 추가 치료학적 제제를 암 세포에 근접시킴을 의미한다. 이는 포유동물로의 약물 전달의 종래의 기술을 사용하여, 또는 시험관내 상황에서, 예를 들면, BVD-523 또는 약제학적으로 허용되는 이의 염 및 임의의 다른 치료학적 제제를 암 세포가 위치하는 배양 배지에 제공하여 수행할 수 있다. 생체외 상황에서, 접촉은, 예를 들면, BVD-523 또는 약제학적으로 허용되는 이의 염 및 임의의 다른 치료학적 제제를 암성 조직에 제공하여 수행할 수 있다.
비-ERK MAPK 경로 억제제의 적합하고 바람직한 유형은 본원에 개시된 바와 같다. 이러한 실시형태에서, 암 세포 사멸의 수행은 다양한 돌연변이 배경, 내성 프로파일, 및 상기 개시된 MAPK 활성을 갖는 암 세포에서 수행할 수 있다. 이러한 돌연변이의 확인 방법은 또한 상기 열거된 바와 같다.
시험관내, 생체외, 또는 생체내 수행될 수 있는 이러한 실시형태의 방법을, 예를 들면, 본원에 기재된 암 유형의 세포에서 암 세포를 사멸시켜 암 세포 사멸을 수행하는데 사용될 수 있다.
이러한 실시형태의 하나의 양상에서, 50% 초과의 RSK 인산화가 억제된다. 이러한 실시형태의 또다른 양상에서, 75% 초과의 RSK 인산화가 억제된다. 이러한 실시형태의 추가 양상에서, 90% 초과의 RSK 인산화가 억제된다. 이러한 실시형태의 추가의 양상에서, 95% 초과의 RSK 인산화가 억제된다. 이러한 실시형태의 또다른 양상에서, 99% 초과의 RSK 인산화가 억제된다. 이러한 실시형태의 추가 양상에서, 100%의 RSK 인산화가 억제된다.
이러한 실시형태의 추가의 양상에서, 암 세포는 포유동물 암 세포이다. 바람직하게는, 포유동물 암 세포는 사람, 영장류, 농장 동물, 및 가축 동물로 이루어진 그룹으로부터 선택된 포유동물로부터 입수된다. 보다 바람직하게는, 포유동물 암 세포는 사람 암 세포이다.
이러한 실시형태의 추가의 양상에서, 접촉 단계는 BVD-523 또는 약제학적으로 허용되는 염을 암 세포가 입수된 대상체에게 투여함을 포함한다.
본 발명에서, 본원에 개시된 화합물 또는 조성물의 "유효량" 또는 "치료학적 유효량"은 대상체에게 투여되는 경우 유익하거나 목적하는 결과를 가져오는데 충분한 이러한 화합물 또는 조성물의 양이다. 효과적인 용량 형태(dosage forms), 투여 방식, 및 용량의 양은 경험적으로 결정할 수 있고, 이러한 결정은 당해 기술분야의 숙련가의 재량 내이다. 용량의 양은 투여 경로, 배설 속도, 치료 기간, 투여된 임의의 다른 약물의 확인, 연령, 사이즈, 및 포유동물의 종, 예를 들면, 사람 환자 등 의학 및 수의학 기술 분야에 잘 공지된 인자에 따라 가변적인 것은 당해 기술 분야의 숙련가가 이해할 수 있다. 일반적으로, 본 발명에 따른 화합물 또는 조성물의 적합한 투약(dose)은 목적하는 효과를 제공하는데 효과적인 최저 투약인 조성물의 양일 것이다. 본 발명의 화합물 또는 조성물의 효과적인 투약은 2, 3, 4, 5, 6 이상의 서브-투약으로 투여될 수 있고, 하루 동안 적합한 간격으로 개별적으로 투여될 수 있다.
본원에 개시된 BVD-523 및 다른 항-암 제제의 용량의 적합한, 비-제한적 예는 1일 약 1 mg/kg 내지 약 2400 mg/kg, 예를 들면, 1일 약 1 mg/kg 내지 약 1200 mg/kg, 1일 75 mg/kg 내지 1일 약 300 mg/kg이고, 1일 약 1 mg/kg 내지 약 100 mg/kg을 포함한다. 이러한 제제의 다른 대표적인 용량은 1일 약 1 mg/kg, 5 mg/kg, 10 mg/kg, 15 mg/kg, 20 mg/kg, 25 mg/kg, 30 mg/kg, 35 mg/kg, 40 mg/kg, 45 mg/kg, 50 mg/kg, 60 mg/kg, 70 mg/kg, 75 mg/kg, 80 mg/kg, 90 mg/kg, 100 mg/kg, 125 mg/kg, 150 mg/kg, 175 mg/kg, 200 mg/kg, 250 mg/kg, 300 mg/kg, 400 mg/kg, 500 mg/kg, 600 mg/kg, 700 mg/kg, 800 mg/kg, 900 mg/kg, 1000 mg/kg, 1100 mg/kg, 1200 mg/kg, 1300 mg/kg, 1400 mg/kg, 1500 mg/kg, 1600 mg/kg, 1700 mg/kg, 1800 mg/kg, 1900 mg/kg, 2000 mg/kg, 2100 mg/kg, 2200 mg/kg, 및 2300 mg/kg을 포함한다. 본원에 기재된 BVD-523 및 다른 항-암 제제의 효과적인 투약은, 2, 3, 4, 5, 6 이상의 서브-투약으로 투여될 수 있고, 하루 동안 적합한 간격으로 개별적으로 투여될 수 있다.
본원에 기재된 BVD-523, 다른 억제제, 및 다양한 다른 항-암 제제, 또는 본 발명의 약제학적 조성물은 임의의 목적하고 효과적인 방식으로 경구 섭취, 또는 눈으로 국소 투여를 위한 연고 또는 점적제로서, 또는 비경구 또는 복강내, 피하, 국부, 피내, 흡입, 폐내, 직장, 질내, 설하, 근육내, 정맥내, 동맥내, 척수강내, 또는 림프내와 같은 임의의 적합한 방식으로 다른 투여를 위해 투여될 수 있다. 추가로, 본원에 기재된 BVD-523, 다른 억제제, 및 다양한 다른 항-암 제제, 또는 본 발명의 약제학적 조성물은 다른 치료제와 함께 투여할 수 있다. 본원에 기재된 BVD-523, 다른 억제제, 및 다양한 다른 항-암 제제, 또는 본 발명의 약제학적 조성물은 캡슐화되거나 그렇지 않으면 목적하는 경우 위 또는 기타 분비물에 대해 보호될 수 있다.
본 발명의 약제학적 조성물은 하나 이상의 활성 성분을 하나 이상의 약제학적으로-허용되는 희석제 또는 담체 및, 임의의, 하나 이상의 다른 화합물, 약물, 성분 및/또는 물질과 혼합하여 포함한다. 선택된 투여 경로에 상관없이, 본 발명의 제제/화합물은 당해 기술 분야의 숙련가들에게 공지된 종래의 방법에 의해 약제학적으로-허용되는 용량 형태(dosage forms)로 제형화된다. 예를 들면, 문헌[참조: Remington, The Science and Practice of Pharmacy (21st Edition, Lippincott Williams and Wilkins, Philadelphia, PA.)]을 참조한다.
약제학적으로 허용되는 희석제 또는 담체는 당해 기술 분야에 잘 공지되어 있고[참조: 예를 들면, Remington, The Science and Practice of Pharmacy (21st Edition, Lippincott Williams and Wilkins, Philadelphia, PA.) and The National Formulary (American Pharmaceutical Association, Washington, D.C.)], 당 (예를 들면, 락토스, 수크로스, 만니톨, 및 소르비톨), 전분, 셀룰로오스 제제, 칼슘 포스페이트 (예를 들면, 디칼슘 포스페이트, 트리칼슘 포스페이트 및 칼슘 산소 포스페이트), 나트륨 시트레이트, 물, 수성 용액 (예를 들면, 염수, 염화나트륨 주사, 링거 주사, 덱스트로스 주사, 덱스트로스 및 염화나트륨 주사, 락테이트화 링거 주사), 알코올 (예를 들면, 에틸 알코올, 프로필 알코올, 및 벤질 알코올), 폴리올 (예를 들면, 글리세롤, 프로필렌 글리콜, 및 폴리에틸렌 글리콜), 유기 에스테르 (예를 들면, 에틸 올레에이트 및 트리글리세라이드), 생분해성 중합체 (예를 들면, 폴리락타이드-폴리글리라이드, 폴리(오르토에스테르), 및 다가(무수물)), 엘라스토머성 매트리스, 리포좀, 미세구, 오일 (예를 들면, 옥수수유, 배아유, 올리브유, 피마자유, 참기름, 면실유, 및 땅콩유), 코코아 버터, 왁스 (예를 들면, 좌제 왁스), 파라핀, 실리콘, 탈크, 실리실레이트 등을 포함한다. 본 발명의 약제학적 조성물에 사용되는 약제학적으로 허용되는 희석제 또는 담체 각각은 제형의 다른 성분과 적합성의 관점에서 "허용"되어야 하고, 대상체에게 해롭지 않아야 한다. 선택된 용량 형태 및 의도된 투여 경로를 위해 적합한 희석제 또는 담체는 당해 기술 분야에 잘 공지되어 있고, 선택된 용량 형태 및 투여 방법을 위해 허용되는 희석제 또는 담체는 당해 기술분야의 일반적인 기술을 사용하여 결정할 수 있다.
본 발명의 약제학적 조성물은, 임의로, 약제학적 조성물에서 통상 사용되는 성분 및/또는 물질을 포함할 수 있다. 이들 성분 및 물질은 당해 기술 분야에 잘 공지되어 있고, 다음을 포함한다: (1) 필러 또는 증량제, 예를 들면, 전분, 락토스, 수크로스, 글루코오스, 만니톨, 및 규산; (2) 결합제, 예를 들면, 카복시메틸셀룰로오스, 알기네이트, 젤라틴, 폴리비닐 피롤리돈, 하이드록시프로필메틸 셀룰로오스, 수크로스 및 아카시아; (3) 보습제, 예를 들면, 글리세롤; (4) 붕해제, 예를 들면, 아가-아가, 탄산칼슘, 감자 또는 타피오카 전분, 알긴산, 특정 실리케이트, 나트륨 전분 글리콜레이트, 가교결합된 나트륨 카복시메틸 셀룰로오스 및 탄산나트륨; (5) 용해 지연제, 예를 들면, 파라핀; (6) 흡수 촉진제, 예를 들면, 4급 암모늄 화합물; (7) 습윤 제제, 예를 들면, 세틸 알코올 및 글리세롤 모노스테아레이트; (8) 흡수제, 예를 들면, 카올린 및 벤토나이트 점토; (9) 윤활제, 예를 들면, 탈크, 칼슘 스테아레이트, 마그네슘 스테아레이트, 고체 폴리에틸렌 글리콜, 및 나트륨 라우릴 설페이트; (10) 현탁 제제, 예를 들면, 에톡시화된 이소스테아릴 알코올, 폴리옥시에틸렌 소르비톨 및 소르비탄 에스테르, 미세결정성 셀룰로오스, 알루미늄 메타하이드록사이드, 벤토나이트, 아가-아가 및 트라가칸트; (11) 완충 제제; (12) 부형제, 예를 들면, 락토스, 유당, 폴리에틸렌 글리콜, 동물성 및 식물성 지방, 오일, 왁스, 파라핀, 코코아 버터, 전분, 트라가칸트, 셀룰로오스 유도체, 폴리에틸렌 글리콜, 실리콘, 벤토나이트, 규산, 탈크, 살리실레이트, 아연 옥사이드, 알루미늄 하이드록사이드, 칼슘 실리케이트, 및 폴리아미드 분말; (13) 불활성 희석제, 예를 들면, 물 또는 다른 용매; (14) 보존제; (15) 표면-활성 제제; (16) 분산 제제; (17) 제어-방출 또는 흡수-지연 제제, 예를 들면, 하이드록시프로필메틸 셀룰로오스, 다른 중합체 매트리스, 생분해성 중합체, 리포좀, 미세구, 알루미늄 모노스테아레이트, 젤라틴, 및 왁스; (18) 불투명화 제제; (19) 보조제; (20) 습윤 제제; (21) 유화 및 현탁 제제; (22) 가용화 제제 및 유화제, 예를 들면, 에틸 알코올, 이소프로필 알코올, 에틸 카보네이트, 에틸 아세테이트, 벤질 알코올, 벤질 벤조에이트, 프로필렌 글리콜, 1,3-부틸렌 글리콜, 오일 (특히, 면실유, 땅콩유, 옥수수유, 배아유, 올리브유, 피마자유 및 참기름), 글리세롤, 테트라하이드로푸릴 알코올, 폴리에틸렌 글리콜 및 소르비탄의 지방산 에스테르; (23) 추진체, 예를 들면, 클로로플루오로탄화수소 및 휘발성 비치환된 탄화수소, 예를 들면, 부탄 및 프로판; (24) 항산화제; (25) 제형을 의도된 수령자의 혈액과 등장성이 되게 하는 제제, 예를 들면, 당 및 염화나트륨; (26) 농후화 제제; (27) 코팅 물질, 예를 들면, 레시틴; 및 (28) 감미제, 향미제, 착색제, 방향제 및 보존제. 이러한 성분 또는 물질 각각은 제형의 다른 성분과 적합성의 관점에서 "허용"되어야 하고, 대상체에게 해롭지 않아야 한다. 선택된 용량 형태 및 의도된 투여 경로를 위해 적합한 성분 및 물질은 당해 기술 분야에 잘 공지되어 있고, 선택된 용량 형태 및 투여 방법을 위해 허용되는 성분 및 물질은 당해 기술분야의 일반적인 기술을 사용하여 결정할 수 있다.
경구 투여를 위해 적합한 본 발명의 약제학적 조성물은 캡슐, 샤쉐, 알약, 정제, 분말제, 과립제, 수성 또는 비-수성 액체의 용액 또는 현탁액, 수중유(oil-in-water) 또는 유중수(water-in-oil) 액체 에멀젼, 엘릭서제 또는 시럽, 파스틸, 볼루스(bolus), 연약 또는 페이스트의 형태일 수 있다. 이들 제형은 당해 기술 분야에 공지된 방법으로 예를 들면, 종래의 팬-코팅, 혼합, 과립화 또는 동결건조 공정를 통해 제조할 수 있다.
경구 투여를 위한 고체 용량 형태(캡슐, 정제, 알약, 드라제, 분말제, 과립제 등)를, 예를 들면, 활성 성분(들)을 하나 이상의 약제학적으로-허용되는 희석제 또는 담체 및, 임의의, 하나 이상의 필러, 증량제, 결합제, 보습제, 붕해제, 용해 지연제, 흡수 촉진제, 습윤제, 흡수제, 윤활제, 및/또는 착색제와 함께 혼합하여 제조할 수 있다. 유사한 유형의 고체 조성물이 적합한 부형제를 사용하여 연질 및 경질-충전 젤라틴 캡슐 내에 필러로서 사용될 수 있다. 정제는 임의의 하나 이상의 보조 성분과 함께 압축 또는 성형으로 제조될 수 있다. 압축 정제는 적합한 결합제, 윤활제, 불활성 희석제, 보존제, 붕해제, 표면-활성 또는 분산제를 사용하여 제조할 수 있다. 성형 정제는 적합한 기계에서 성형에 의해 제조될 수 있다. 정제, 및 드라제, 캡슐, 알약 및 과립제와 같은 다른 고체 용량 형태가 임의로 약제학적-제형 기술에서 잘 공지된 장용 코팅 및 다른 코팅과 같은 코팅 및 쉘로 등급화 또는 제조될 수 있다. 이들은 또한 본원의 활성 성분의 서방출 또는 제어 방출을 제공하기 위해 제형화될 수 있다. 이들은, 예를 들면, 박테리아-보유 필터를 통해 여과하여 살균될 수 있다. 이들 조성물은 또한 임의로 불투명화 제제를 포함할 수 있고, 이들이 활성 성분을 단독으로 또는, 우선적으로, 위장관의 특정 부분에, 임의로, 지연된 방식으로 방출하는 조성물일 수 있다. 활성 성분은 또한 미세캡슐화 형태일 수 있다.
경구 투여용 액체 용량 형태는 약제학적으로-허용되는 에멀젼, 미세에멀젼, 용액, 현탁액, 시럽 및 엘릭서제를 포함한다. 액체 용량 형태는 당해 기술에 통상 사용되는 적합한 불활성 희석제를 포함할 수 있다. 불활성 희석제 이외에, 경구 조성물은 또한 습윤제, 유화제 및 현탁제, 감미제, 향미제, 착색제, 방향제 및 보존제와 같은 보조제를 포함할 수 있다. 현탁액은 현탁 제제를 포함할 수 있다.
직장 또는 질내 투여를 위한 본 발명의 약제학적 조성물은 좌제로 존재할 수 있고, 이는 하나 이상의 활성 성분(들)을, 실온에서 고체이지만 체온에서 액체이고, 따라서, 직장 또는 질 강 내에서 용융되고 활성 화합물을 방출할 수 있는 하나 이상의 적합한 비자극 희석제 또는 담체와 혼합하여 제조할 수 있다. 질내 투여에 적합한 본 발명의 약제학적 조성물은 또한 적합한 것으로 당해 기술 분야에 공지된 이러한 약제학적으로-허용되는 희석제 또는 담체를 포함하는 페서리, 탐폰, 크림, 겔, 페이스트, 포움 또는 스프레이 제형을 포함한다.
국부 또는 경피 투여를 위한 용량 형태는 분말제, 스프레이, 연고, 페이스트, 크림, 로션, 겔, 용액, 패치, 점적제 및 흡입제를 포함한다. 활성 제제(들)/화합물(들)은 멸균 상태하에 적합한 약제학적으로-허용되는 희석제 또는 담체와 혼합할 수 있다. 연고, 페이스트, 크림 및 겔은 부형제를 포함할 수 있다. 분말제 및 시럽은 부형제 및 추진체를 포함할 수 있다.
비경구 투여에 적합한 본 발명의 약제학적 조성물은 하나 이상의 제제(들)/화합물(들)을 사용 직전에 멸균 주사 가능 용액 또는 분산액으로 재구성될 수 있는 하나 이상의 약제학적으로-허용되는 멸균 등장성 수성 또는 비-수성 용액, 분산액, 현탁액 또는 에멀젼, 또는 멸균 분말과 함께 포함할 수 있고, 이는 적합한 항산화제, 완충제, 제형을 의도된 수령자의 혈액에 등장성이 되게 하는 용질, 또는 현탁 또는 농후화 제제를 포함할 수 있다. 적합한 유동성은, 예를 들면, 코팅 물질을 사용함에 의해, 분산액의 경우 요구되는 입자 크기를 유지함에 의해, 및 계면활성제의 사용에 의해 유지될 수 있다. 이들 약제학적 조성물은 또한 습윤제, 유화제 및 분산제와 같은 적합한 보조제를 포함할 수 있다. 또한 등장성 제제를 포함하는 것이 바람직할 수 있다. 게다가, 주사 가능 약제학적 형태의 연장된 흡수는 흡수를 지연시키는 제제를 포함하여 수행될 수 있다.
일부 경우, 약물(예를 들면, 약제학적 제형)의 효과를 연장시키기 위해, 피하 또는 근육내 주사로부터 이의 흡수를 느리게 하는 것이 바람직하다. 이는 열악한 수용해도를 갖는 결정성 또는 무정형 물질의 액체 현탁액의 사용에 의해 수행될 수 있다.
활성 제제/약물의 흡수 속도는 이에 이의 용해 속도를 좌우하고, 이는 차례로, 결정 크기 및 결정 형태를 좌우할 수 있다. 대안적으로, 비경구-투여된 제제/약물의 지연된 흡수는 활성 제제/약물을 오일 비히클 중에 용해 또는 현탁시켜 수행할 수 있다. 주사 가능 데포(depot) 형태는 생분해성 중합체 중 활성 성분의 미세캡슐 매트리스를 형성하여 제조할 수 있다. 활성 성분 대 중합체의 비, 및 사용된 특정 중합체의 성질에 좌우되어, 활성 성분 방출 속도가 제어될 수 있다. 데포 주사 가능 제형은 또한 약물을 체 조직에 적합성인 리포좀 또는 미세에멀젼 중에 포획하여 제조한다. 주사 가능 물질을 예를 들면, 박테리아-보유 필터를 통한 여과에 의해 살균할 수 있다.
제형은 유닛-투약 또는 다중-투약 밀봉된 컨테이너, 예를 들면, 앰풀 및 바이알로 존재할 수 있고, 사용 직전에 멸균 액체 희석제 또는 담체, 예를 들면, 주사용수의 첨가만을 필요로 하는 동결건조된 상태로 저장될 수 있다. 즉석 주사 용액 및 현탁액을 상기한 유형의 멸균 분말제, 과립제 및 정제로부터 제조할 수 있다.
본 발명은 비-ERK MAPK 경로 억제제 요법에 대해 저항성 또는 내성인 암의 치료를 제공하고, ERK 억제제의 효과를 증진시키기 위해 나타낸 조합을 개시한다. 본원에서, 본 출원인은 또한 상이한 ERK 억제제의 조합이 마찬가지로 상승 효과가 있음을 보여주었다. 따라서, 본원에 기술된 조합의 효과가 하나 이상의 추가의 ERK 억제제의 사용에 의해 추가로 개선될 수 있다는 것이 고려된다. 따라서, 본 발명의 일부 실시형태는 하나 이상의 추가의 ERK 억제제를 포함한다.
본 발명은 또한 BVD-523 600 ㎎ BID 또는 약제학적으로 허용되는 이의 염을 대상체에게 투여하는 것을 포함하는, 절제불가능하거나 전이성인 BRAF600 돌연변이 양성 흑색종을 갖는 대상체의 치료 방법을 제공한다.
본 발명의 일부 실시형태에서, 돌연변이는 BRAFV600E 돌연변이이다.
본 발명은 또한 BVD-523 600 ㎎ 또는 약제학적으로 허용되는 이의 염 및 임의로 약제학적으로 허용되는 담체, 보조제, 또는 비히클을 포함하는, 절제불가능하거나 전이성인 BRAF600 돌연변이 양성 흑색종을 갖는 대상체를 치료하기 위한 조성물을 제공한다.
하기 실시예는 본 발명의 방법을 추가로 설명하기 위해 제공된다. 이들 실시예는 단지 예시적인 것이며 어떤 식으로든 본 발명의 범위를 제한하려는 것은 아니다.
실시예
실시예 1
재료 및 방법
암 세포주를 표준 배지 및 혈청 조건 하의 세포 배양에서 유지시켰다. 용량 증가 연구(dose escalation study)를 위해, A375 세포를 분할하고, 약 40-60%의 컨플루언스(confluence)로 성장시킨 후 특정 약물의 초기 용량으로 처리하였다. 표 4는 증가된 약물 처리의 요약을 나타낸다.
표 4- 증가된 치료의 요약

단일 제제 용량 증가는 문헌[참조: Little et al., 2011]에 기초하여 수행하였으며, 도 20에 개략적으로 설명되어 있다. 이어서, 세포를 70-90%의 컨플루언스가 될 때까지 성장시키고 분할시켰다. 분할 비율은 가능한 한 "정상"으로 유지되었고 치료들 간에 합리적으로 일치시켰다(예: 부모의 정상 분할 비율의 최소 50%). 배지는 3-4일 마다 새로 교체하였다. 세포가 다시 약 40-60% 컨플루언스에 도달했을 때, 용량을 증가시켰다. 40-60% 창(window)를 놓친 경우, 세포를 다시 분할시키고 이들이 40-60% 컨플루언스에 도달하면 투여하였다. 다시, 배지는 3-4일 마다 새로 교체하였다. 이 과정을 필요에 따라 반복하였다(도 20).
단일 제제 처리의 경우, 시작 농도 및 용량 증가는 대략 IC50으로 시작하여 작은 증분(increment)으로 상승시키거나, 또는 초기 4-5회 용량에 대해, 완만하게 용량을 두 배로 증가시키고, 다음 4회 용량에 대해 동일 증분만큼 증가시킨 후, 이후 용량의 농도를 1.5배 증가시킴으로써 수행하였다.
병용 치료의 경우, 시작 농도 및 용량 증가는 각 화합물의 대략 IC50의 절반으로 시작하여(병용 검정은 이것이 약 40-70% 억제 범위를 초래할 것이라고 시사한다), 단일 제제에 따라 증가(즉, 처음 두배로 증가시킨 후 다음 4회 용량에 대해 동일 증분만큼 증가시킨 다음, 농도를 1.5배로 증가시킴)시킴으로써 수행하였다. 표 5는 이러한 계획을 사용한 계획된 용량 증가를 나타낸다.
표 5 - 계획된 용량 증가 - 1개월

클론 내성 세포 집단은 한계 희석(limiting dilution)에 의해 내성 세포 풀로부터 유도되었다.
증식 분석은 적절한 시간 간격(예컨대 매 달, 그러나 타이밍은 이용가능한 적절한 세포 수에 의존적임)으로 증가된 약제에 대한 민감도의 변화를 추적하는데 사용되었다. 증식 분석을 위해, 세포가 10% FBS를 함유하는 약물이 없는 DMEM 배지에서 웰 당 3000 세포로 96-웰 플레이트에 씨딩(seed)하였고, 화합물 또는 비히클 대조군을 첨가하기 전에 밤새도록 부착(adhere)시켰다. 화합물을 DMSO 스톡으로부터 제조하여 도 2a 내지 도 2h에 나타낸 최종 농도 범위를 얻었다. 최종 DMSO 농도는 0.1%로 일정하였다. 시험 화합물을 가습 대기에서 37℃ 및 5% CO2에서 96 시간 동안 세포와 함께 인큐베이팅하였다. 그 후, 알라머 블루(Alamar Blue) 10%(v/v)를 첨가하고 4 시간 동안 인큐베이팅하고, BMG FLUOstar 플레이트 판독기를 사용하여 형광 물질을 검출하였다. 평균 배지 전용 배경 값(average media only background value)을 빼고 GraphPad Prism에서 4-파라미터 로지스틱 방정식(4-parameter logistic equation)을 사용하여 데이터를 분석하였다. 파클리탁셀을 양성 대조군으로 사용하였다.
표 6에 나타낸 각 제제의 농도로 성장하는 세포를 사용하여 28 일째에 1 개월째의 증식 분석을 개시하였다.
표 6 - 증식 분석에서 사용된 약물의 초기 농도 - 1 개월 째

표 7에 나타낸 각 제제의 농도로 성장하는 세포를 사용하여 56 일째에 2 개월 째의 증식 분석을 개시하였다.
표 7 - 증식 분석에서 사용된 약물의 초기 농도 - 2 개월 째

3 개월의 증가 기간의 말에, 증식 분석의 최종 라운드 및 잠재적 단일 세포 복제 전에 2 주 동안 배양물을 최고 농도에서 유지시켰다. 증식 분석/단일 세포 복제는 활발하게 증식하는 세포를 필요로 함에 따라, 세포가 최고 농도에서 매우 천천히 증식하거나 단지 최근에 증가된 처리의 경우, 백업 배양물 또한 낮은 농도에서 유지시켰다(표 8). 세포가 거의 완전히 성장을 멈추고 최고 농도(1.8μM)에서 특히 취약해 보인 BVD-523 치료의 경우, 배양물을 2 주의 기간 동안 더 낮은 농도에서 유지시켰다.
표 8 - 고정 농도에서 2주 동안 배양된 처리의 상세 사항

3개월 째의 증식 분석은 표 9에 나타낸 각 약제의 농도에서 성장한 세포를 사용하였다.
표 9 - 증식 분석에서 사용된 약물의 초기 농도 - 3 개월 째

병용 연구를 위해, A375 세포(ATCC)를 DMEM + 10% FBS에서 3000 세포/웰의 세포 밀도로 96-웰 플레이트에 삼중으로 씨딩하고, 시험 화합물 또는 비히클 대조군을 첨가하기 전에 밤새도록 부착시켰다. 최종 DMSO의 농도가 0.2 %인 10 x 8 용량 매트릭스를 사용하여 병용을 테스트하였다. 96 시간 분석 배양에 이어 형광 플레이트 판독기에서 판독하기 전에 알라머 블루 10 % (v/v)의 후속적인 첨가 및 4 시간의 배양이 이어졌다. 알라머 블루를 판독한 후, 배지/알라머 블루 혼합물을 털어내고(flick off), 100 μl의 CellTiter-Glo/PBS (1:1)을 첨가하고, 플레이트를 제조사 지침 (Promega)에 따라 처리하였다. 데이터를 분석하기 전에 배지 전용 배경 값을 뺐다. 그 후 블리스 가산성(Bliss additivity) 모델을 적용하였다.
요약하면, 조합 억제에 대해 예측된 분획 억제 값(fractional inhibition values)은 방정식 Cbliss = A + B - (A x B)를 사용하여 계산하였고, 여기서 A 및 B는 특정 농도에서 약물 A 단독 또는 약물 B 단독으로 수득된 분획 억제이다. Cbliss는 두 약물의 조합이 정확히 가산적인(additive) 경우 예상되는 분획 억제이다. 실험적으로 관찰된 분획 억제 값에서 Cbliss 값을 빼서 "Bliss 초과(excess over bliss)" 값을 얻는다. 0 보다 큰 블리스 초과 값은 상승작용 효과를 나타내지만, 0 보다 작은 값은 길항작용을 나타낸다. 블리스 초과 값은 히트 맵 ± SD로 플롯팅(plot)하였다.
단일 및 조합 데이터는 또한 GraphPad Prism에서 생성된 용량-반응 곡선으로 표시된다 (DMSO만 처리한 대조군과 비교하여 % 생존능을 사용하여 플롯팅됨).
집중적인 조합 연구를 위해, 알라머 블루 생존능 분석을 조합 연구에 대해 상기 기술된 바와 같이 수행하였다. 추가적으로, Caspase-Glo 3/7 분석을 수행하였다. 요약하면, HCT116 세포를 McCoy's 5A + 10% FBS에서 5000 세포/웰의 세포 밀도로 백색 96-웰 플레이트에서 삼중으로 씨딩하였다. A375 세포를 DMEM + 10% FBS에서 5000 세포/웰의 밀도로 씨딩하였다. 시험 화합물 또는 비히클 대조군을 첨가하기 전에 세포를 밤새도록 부착시켰다. DMSO의 최종 농도는 0.2 %이고, 800 nM 스타우로스포린(staurosporine)을 양성 대조군으로 포함시켰다. 24 시간 및 48 시간의 분석 배양 기간을 사용하였다. 그 다음, Caspase-Glo® 3/7 50 % (v/v)를 첨가하고, 플레이트를 오비탈 쉐이커에서 5 분간 혼합시키고, 형광 플레이트 판독기에서 판독하기 전에 실온에서 1 시간 동안 배양시켰다. 데이터를 분석하기 전에 배지 전용 배경 값을 뺐다.
시차 주사 형광측정법(Differential Scanning Fluorimetry)에 대해, SYPRO Orange(5,000 x 용액, Invitrogen)를 완충 용액(10 mM HEPES, 150 mM NaCl, pH 7.5)에서 희석(1:1,000)시켰다. HisX6 태그된 단백질은 1μM의 최종 농도에서 비활성 ERK2, 활성 ERK2 (ppERK2), 또는 p38α를 포함하였다. 단백질/염료 용액 및 100% DMSO 중의 화합물을 원하는 최종 농도를 달성하도록 웰 (2 % v/v 최종 DMSO 농도)에 첨가하고, 혼합하고, RT-PCR 기기에 넣었다. 다음으로, 용융 곡선을 1 분당 1 ℃의 속도로 25-95 ℃에서 작동시키고, 화합물의 부재 또는 존재 하에서 각 단백질에 대해 용융 온도(Tm)를 측정하였다. 다양한 약물 농도의 존재 하에서 Tm의 변화(ΔTm)가 제시된다.
ERK1의 Ki 측정을 위해, 활성화된 ERK1(10 nM)을 0.1 M HEPES 완충액(pH 7.5), 10 mM MgCl2, 2.5 mM 포스포에놀피루베이트, 200 μM 니코틴아미드 아데닌 디뉴클레오타이드(NADH), 150 μg/mL 피루베이트 키나아제, 50 μg/mL 락테이트 데하이드로게나제, 및 200 μM 에르크티드(Erktide) 펩타이드에서 30 ℃에서 10 분 동안 2.5% (v/v) DMSO 중의 다양한 농도의 화합물과 함께 배양하였다. 65 μM의 ATP를 첨가하여 반응을 개시하였다. 감소된 흡광도(340nm)를 모니터링하고, IC50을 억제제 농도의 함수로서 측정하였다.
ERK2의 Ki 측정을 위해, 방사성 분석을 사용하여 BVD-523의 ERK2에 대한 억제 활성을 측정하였고, 성분들의 최종 농도는 100 mM HEPES (pH 7.5), 10 mM MgCl2, 1 mM 디티오트레이톨(DTT), 0.12 nM ERK2, 10 μM 미엘린 염기성 단백질 (MBP), 및 50 μM 33P-γ-ATP이었다. ATP 및 MBP를 제외한 모든 반응 성분들을 미리 혼합하고, 96-웰 플레이트에 분액 (33 μL)하였다. DMSO 중의 화합물의 스톡 용액을 사용하여 500 배까지 희석시켰다; DMSO의 1.5 μL 분액 또는 DMSO 중의 억제제를 각각의 웰에 첨가하였다. 반응은 기질 33P-γ-ATP 및 MBP (33 μL)를 첨가함으로써 개시하였다. 20분 후, 반응을 4 mM ATP를 함유하는 20% (w/v) 트라이클로로아세트산 (TCA) (55 μL)으로 급냉시키고, GF/B 필터 플레이트로 옮기고, 5% (w/v) TCA로 3번 세척하였다. Ultimate Gold ™ 신틸란트 (50 μL)를 첨가한 후, 샘플을 Packard TopCount에서 계수하였다. 활성 대 농도 적정 곡선으로부터, Prism software, version 3.0을 사용하여 경쟁적 밀접 결합 억제 반응속도(competitive tight binding inhibition kinetics)를 위한 방정식에 데이터를 피팅시켜 Ki 값을 측정하였다.
ERK2의 IC50 측정을 위해, 표준 결합 효소 분석법으로 활성을 분석하였다. 최종 농도는 다음과 같았다: 0.1 M HEPES (pH 7.5), 10 mM MgCl2, 1 mM DTT, 2.5 mM 포스포에놀피루베이트, 200 μM NADH, 50 μg/mL 피루베이트 키나아제, 10 μg/mL 락테이트 데하이드로게나제, 65 μM ATP, 및 800 μM 펩타이드(ATGPLSPGPFGRR). ATP를 제외한 모든 반응 성분들을 ERK와 미리 혼합하여 분석 플레이트 웰에 분액하였다. 웰 당 DMSO의 농도를 일정하게 유지하면서, DMSO 중의 BVD-523을 각 웰에 넣었다. BVD-523 농도는 각각의 적정에 대해 500 배 범위에 걸쳐 있다. ATP를 첨가하여 반응을 개시하기 전에 분석 플레이트를 분광 광도계(분자 장치(molecular devices))의 플레이트 판독기 구획에서 30 ℃에서 10분 동안 배양하였다. 340 nm에서의 흡광도 변화를 시간의 함수로서 모니터링하였다; 초기 기울기는 반응 속도에 상응한다. BVD-523 적정 곡선의 속도 대 농도를, Prism software, version 3.0을 사용하여 경쟁적 밀접 결합 억제 반응 속도를 위한 방정식에 피팅하여 Ki의 값을 측정하거나 3-파라미터 피트(3-parameter fit)에 피팅하여 IC50을 측정하였다.
세포 사멸 분석을 위해, 세포를 96-웰 플레이트에 웰 당 2 Х 104 세포로 도말하고 밤새도록 부착시키거나 50% 컨플루언스로 성장시켰다. 세포를 배지(최종 부피 200 μL, 농도 범위 4-0.25 μM)에서 BVD-523의 연속 희석액으로 처리하고, 37 ℃ CO2 배양기에서 48 시간 동안 배양하였다. 세포를 100 μL의 PBS로 세척하고, 60 μL 의 방사면역침강 분석(radioimmunoprecipitation assay) 완충액 (50 mM Tris-HCl, pH 8.0, 150 mM NaCl, 1.0% [w/v] NP-40, 0.5% [w/v] 나트륨 디옥시콜레이트, 1% [w/v] SDS)을 첨가한 다음, 4 ℃에서 10 분간 배양하여 세포를 용해시켰다. 30 μL 용해물(lysate)의 분액을 100 μL의 카스파제 분석 완충액 (120 mM HEPES, 12 mM EDTA, 20 mM 디티오트레이톨, 12.5 μg/mL AC-DEVD-AMC 카스파제 기질)에 첨가하고, 실온에서 4 시간 내지 밤새 배양하였다. 플레이트를 형광측정기 (여기 파장(excitation wavelength) 360 nm, 방출 파장 460 mm)에서 판독하였다. 나머지 30 μL의 용해물은 BioRad 단백질 분석 키트(시료 대 작업시약 비 1:8)를 사용하여 총 단백질 함량을 분석하였다. 최종 정규화된 카스파제 활성은 μg 단백질 당 형광 단위로 유도하였고, DMSO 대조군과 비교할 때 카스파제 활성의 배수 증가로 전환하였다.
A375 이종이식편(xenografts)에서의 항종양 활성의 측정을 위해, 암컷 흉선 누드 마우스에서 연속 피하 이식에 의해 유지된 A375 세포로 이종이식을 개시하였다. 각 시험 마우스는 오른쪽 옆구리에 피하로 이식된 A375 종양 단편(1 mm3)을 투여받았다. 일단 종양이 목표 크기 (80-120 mm3)에 도달하면, 동물을 처리군과 대조군으로 무작위 추출하여 약물 치료를 시작하였다.
BVD-523 단일요법을 평가하기 위해, 1% (w/v) 카복시메틸셀룰로오스 (CMC) 중의 BVD-523을 5, 25, 50, 100, 또는 150 mg/kg의 용량으로 BID 경구 투여하였다. 경구용 테모졸로마이드는 양성 기준 화합물로서 1 일 1 회 (QD) 75 또는 175 mg/kg을 총 5 회 처리 (QD × 5) 동안 투여하였다.
다브라페닙과 병용한 BVD-523의 효능을 15 그룹 중 9 그룹 및 10 그룹 중 1그룹(그룹 10)으로 무작위한 마우스에서 평가하였다. 다브라페닙은 50 또는 100 mg/kg QD로 p.o. 투여하였고, BVD-523은 50 또는 100 mg/kg BID 단독 및 병용하여 연구 종료시까지 p.o. 투여하였다; 비히클 처리 및 테모졸로마이드 처리(150 mg/kg QD × 5)된 대조군도 포함시켰다. 20 일 째에 병용 투여를 중지하여 종양의 재성장을 관찰하였다. 동물들을 개별적으로 모니터링하고, 각 종양이 2000 mm3의 종말점 부피, 또는 최종일(45 일) 중 먼저 오는 시점에 도달했을 때, 동물들을 안락사시키고, 종말점까지의 중앙값 시간 (TTE)을 계산하였다. 이 병용 요법은 또한 228-1008 mm3 범위의 큰 종양이 평가되는 병기 상향(upstaged)된 A375 모델에서 평가하였다. 여기에서, 마우스를 14 그룹 중 1 그룹 (그룹 1) 및 20 그룹 중 4 그룹 (그룹 2-5)으로 무작위 추출하였다. 투약은 1 일 째에 다브라페닙 + BVD-523 (25 mg/kg 다브라페닙 + 50 mg/kg BVD-523 또는 50 mg/kg 다브라페닙 + 100 mg/kg BVD-523)으로 시작하였고, 각 약제는 연구가 끝날 때까지 p.o. BID 투여되었다. 이 연구에는 비히클 처리된 대조군 뿐만 아니라 50 mg/kg 다브라페닙과 100 mg/kg BVD-523 단일요법 군도 포함되었다. 종양은 매주 2 회 측정하였다. 42 일 째에 병용 투여를 중단하여 연구 종료 (60 일 째)에 걸쳐 종양 재성장을 모니터링하였다. 치료 결과는 로그 순위(long rank) 생존 분석을 통해 분석된 그룹 간의 차이를 갖는, 치료된 마우스 대 대조 마우스에 대한 중앙(median) TTE의 백분율 증가로 정의되는 % TGD로부터 결정되었다. TGI 분석을 위해, 공식 % TGI=1-Tf-Ti/Cf-C에 기초하여 초기(i) 및 최종(f) 종양 측정치를 사용하여 각 처리군(T) 대 대조군(C)에 대해 % TGI 값을 계산하고 보고하였다. 또한, CR 및 PR 반응에 대해 마우스를 모니터링하였다. 연구 종료 시에 CR이 있는 동물을 TFS로 분류하였다.
Colo205 이종이식편에서의 BVD-523 활성의 측정을 위해, 인간 Colo205 세포를 10% (v/v) 태아 소 혈청 (FBS), 100 유닛/mL 페니실린, 100 μg/mL 스트렙토마이신 (Invitrogen), 및 2 mM L-글루타민을 함유하는 RPMI 1640에서 배양하였다. 세포를 이식하기 전에 4 회 미만의 계대로 배양하였다. 0 일 째에, 암컷 흉선 누드 마우스 (19-23 g)에게 2 Х 106 Colo205 세포를 우측 등 액축 부위(dorsal axillary region)에 피하주사하였다.
대략 200 mm3의 종양 부피를 가진 마우스를 6 개의 실험군으로 무작위 추출 하였다. 1% CMC (w/v)의 비히클 대조군을 매주 제조하였다. BVD-523을 목적하는 농도에서 1% (w/v) CMC에 현탁시키고, 얼음 상에서 6,500 rpm으로 50 분 동안 균질화시켰다. BVD-523 현탁액을 매주 제조하고, 13 일 동안 8 시간 또는 16 시간 투약 일정으로 50, 100, 150 및 200 mg/kg (n = 12/그룹)의 총 일일 투여량을 BID p.o. 투여하였다. 비히클 대조군 (n = 12)을 동일한 투여 요법을 사용하여 투여하였다. CPT-11을 양성 기준 화합물 (n = 12)로 투여하였다. CPT-11 주사의 각 1 mL는 20 mg의 이리노테칸, 45 mg의 소르비톨 및 0.9 mg의 젖산을 함유하였다. CPT-11은 100 mg/kg/day로 4 일마다 2 회 연속 복강 투여하였다.
Colo205 이종이식편에서 ERK1/2 동위원소-태그된 내부 표준 (ITIS) 질량분광법의 측정을 위해, 냉동된 종양을 빙냉(ice cold) 용해 완충액 (10 mM TRIS-HCl, pH 8.0, 10 mM MgCl2, 1% (v/v) Triton X-100, CompleteTM 프로테아제 억제제 칵테일 [Roche, cat. No. 1836170], 포스파타제 억제제 칵테일 I [Sigma, cat. No. P-2850], 포스파타제 억제제 칵테일 II [Sigma cat. No. 5726], 및 벤조나제 [Novagen cat. No. 70664]) 10 부피에서 용해시켰다. 용해물을 원심분리 (4 ℃에서 60 분 동안 100,000 × g)하여 정제하고, 상청액을 용해 완충액으로 2 mg/mL로 조정하였다. ERK1은 아가로스-커플링된 pan-anti-ERK1 (Santa Cruz Biotechnology 카탈로그 번호 sc-93ac) 항체를 사용하여 면역침강시켰다. 면역침강된 단백질을 SDS-PAGE로 분석하고, SYPRO Ruby (Invitrogen)로 염색하고, ERK 밴드를 면도기로 절제하였다. 겔 슬라이스를 300 μL의 20 mM NH4HCO3로 세척하고, 작은 조각으로 절단하고, Page Eraser Tip (The Nest Group cat no. SEM0007)에 넣었다. 겔 조각은 트립신 소화 전에 환원되고 알킬화되었다. 트립신 조각은 75 μL의 50% (v/v) 아세토니트릴, 0.2 % (v/v) 트리플루오로아세트산에서 분리시키고, 결과 샘플은 SpeedVac에서 0-10 μL로 농축시켰다.
ITIS 분석을 위해, 소화된 시료에 중(heavy)-원자 표지된 펩타이드 표준 물질을 첨가하고, 분획 인산화를 커플링된 액체 크로마토그래피-탠덤 질량 분석 (MS)에 의해 정량화하였다. 나노모세관(Nanocapillary) 크로마토그래피는 1:750 분할(splitting) 후 나노스케일 유동을 전달하는 Flux Instruments의 Rheos 2000 바이너리 펌프, 전자방출 이온화 (ESI) 에미터 역할도 하는 LC Packings Inertsil 나노 프레칼럼 (C18, 5 mm, 100Å, 30 mm ID Х 1 mm), 및 New Objective PicoFrit AQUASIL 분해 칼럼 (C18, 5 mm, 75/15 mm ID Х 10 cm)을 사용하여 수행하였다. 나노-ESI 소스와 결합된 Applied Biosystem API 3000 질량 분석기를 MS 분석에 사용하였다. 분무 가스 공급원에 연결된 사내(in-house-made) 가스 노즐은 안정적인 나노 흐름 스프레이를 돕기 위해 사용되었다. 데이터는 다중 반응 모니터링 (MRM) 모드에서 획득되었다: 분무 가스(nebulizing gas) 3; 커튼 가스(curtain gas) 7; 콜리전 가스(collision gas) 5; 이온 스프레이 전압(ion spray voltage) 2150 볼트, 출구 전위(exit potential) 10 볼트; Q1/Q3 해상도 Low/Unit; 및 모든 MRM 채널에 대한 체류 시간 65 msec. 모든 로우 MS 데이터는 Applied Biosystem의 Analyst 소프트웨어 스위트와 맞춤형 도구(custom tool)의 조합을 사용하여 처리하였다.
획득된 내성의 세포주 모델에서 약물 감응성(drug sensitivity)을 평가하기 위해, 용량 증가된 A375 세포 및 동질유전자(isogenic) RKO 세포의 약물 감응성을 96 시간 증식 분석에서 평가하였다. RKO 동질유전자 세포 (10% [v/v] FBS 함유 McCoy's 5A) 또는 용량 증가된 A375 세포 (10 % FBS 함유 DMEM)를 96-웰 플레이트에 씨딩하고, 화합물 또는 비히클 대조군을 첨가하기 전에 밤새도록 부착시켰다. 용량 증가된 A375 세포는 억제제가 없을때 씨딩함에 주목한다. 화합물을 0.1 % (v/v) DMSO 스톡에서 제조하여 표시된 바와 같은 최종 농도를 얻었다. 시험 화합물을 5 % CO2 가습 대기에서 37 ℃에서 96 시간 동안 세포와 함께 배양하였다. RKO 세포의 경우, CellTiter-Glo® 시약 (Promega)을 제조업체의 지침에 따라 첨가하고, BMG FLUOstar 플레이트 판독기를 사용하여 발광을 검출하였다. A375 분석을 위해, 알라머블루 (ThermoFisher) 10 % (v/v)를 첨가하고 4 시간 동안 배양한 후, 형광 물질을 BMG FLUOstar를 사용하여 검출하였다. 평균 배지 전용 배경 값을 빼고 GraphPad Prism에서 4-파라미터 로지스틱 방정식을 사용하여 데이터를 분석하였다.
ERK1의 IC50 측정은 25 μL의 최종 반응 부피에서 측정되었다. ERK1 (인간) (5-10 mU)를 25 mM Tris (pH 7.5), 0.02 mM 에틸렌글리콜테트라아세트산, 250 μM 펩타이드, 10 mM Mg 아세테이트 및 γ-33P-ATP(대략 500 cpm/pmol의 특이적 활성, 농도는 필요에 따라)와 함께 배양하였다. Mg ATP 첨가는 반응을 개시시켰다. 실온 (RT)에서 40 분 동안 배양한 후, 5 μL의 3 % (w/v) 인산 용액을 첨가하여 반응을 중단시켰다. 이어서, 반응물 10 μL를 P30 필터매트 상에 스폿팅하고, 건조 및 신틸레이션 계수 전에 75 mM 인산에서 5 분 동안 3 회 세척 한 후 메탄올에서 1 회 세척하였다.
RKO MEK1 Q56P 동질유전자 세포는 재조합 AAV-매개 유전자 타겟팅 전략을 사용하여 Horizon Discovery (Cambridge, UK; #HD 106-019)에 의해 생산하였다. 간략하게, rAAV 바이러스는 HEK293T 세포에서 적절한 표적 벡터 및 헬퍼 벡터의 형질감염 후 생성되고, AAV 정제 키트 (Virapur, San Diego, USA)를 사용하여 정제되고, qPCR을 사용하여 적정된다. 그 후, 부모 동형접합성(homozygous) RKO 세포 (MEK1의 동형접합성 야생형)를 rAAV 바이러스로 감염시키고, 스크리닝 카세트를 통합 한 클론을 G418 스크리닝에 의해 확인하고 확장시켰다. 단일 대립유전자로의 MEK1 Q56P 점 돌연변이의 녹-인(knock-in)에 대해 이형접합성(heterozygous)인 올바르게 표적화된 클론을 PCR 및 서열분석으로 확인하였다.
돌연변이체 KRAS (De Roock et al 2010, JAMA, 304, 1812-1820)의 녹-인에 대해 이형접합성인 동질유전자 SW48 세포주는 Horizon Discovery (카탈로그 넘버 HD 103-002, HD 103-006 HD 103-007, HD 103-009, HD 103-010, HD 103-011, HD 103-013)에서 수득하였다. 증식 분석을 위해, 세포를 10 % FBS를 함유하는 McCoy's 5A 배지에서 96-웰 플레이트에 씨딩하고, 화합물 또는 비히클 대조군을 첨가하기 전에 밤새도록 부착시켰다. 시험 화합물을 5% CO2 대기에서 37 ℃에서 96 시간 동안 세포와 함께 배양하였다. 그 후, 알라머 블루를 사용하여 생존능을 평가하였다.
전매 KinaseProfiler 분석은 Upstate Discovery에서 수행하였고, 데이비스(Davies) 등이 사용한 것과 유사한 방사성 검출을 사용하여 70개의 키나아제 패널에 대한 BVD-523의 선택성을 분석하였다.
약물 감응성 분석은 이전에 기술된 바와 같이 (Yang et al., 2013), 고 처리량 스크리닝을 사용하는 암 프로젝트에서 약물 감응성의 유전체학 (The Genomics of Drug Sensitivity in Cancer Project)의 일부로서 수행하였다.
웨스턴 블롯 분석을 위해, A375 세포를 둘베코 변형 이글 배지(Dulbecco's Modified Eagle's Medium) + 10 % (v/v) FBS의 10cm 접시 위에 씨딩하였다. 시험 화합물 또는 비히클을 첨가하기 전에 세포를 밤새도록 부착시켰다. RKO 세포 실험을 위해, 이들 세포를 McCoy's 5A + 10 % (v/v) FBS의 6-웰 플레이트 또는 10cm 접시에 씨딩하였다. 이어서, 세포를 원하는 농도 및 기간으로 처리하였다. 세포를 트립신 처리에 의해 수확하고, 펠렛화하고, 동결시켰다. 용해물은 프로테아제 및 포스파타제 억제제 칵테일 (Roche)을 함유하는 RIPA 완충액으로 제조하고, 11,000 rpm에서 10 분간 원심분리하여 정제시키고, 비신코닌산 분석법으로 정량하였다. 샘플을 SDS-PAGE로 분석하고, 폴리비닐리덴 디플루오라이드 막에 블로팅하고, 지시된 표적에 대한 항체 (즉, pRB [Ser780], 카탈로그 넘버 9307; CCND1, 카탈로그 넘버 ab6152; BCL-xL, 카탈로그 넘버 2762; PARP, 카탈로그 넘버 9542; DUSP6, 카탈로그 넘버 3058S)를 사용하여 프로빙하였다.
역상 단백질 분석(RPPA)의 경우, A375, MIAPaCa-2, HCT116, Colo205, HT-29 및 AN3Ca 세포 (ATCC)를 80 % 컨플루언스로 도말하여 밤새 회복시킨 후 (MIAPaCa-2 세포는 30 % 컨플루언스로 도말하고, 3 일 동안 회복시켰다), 37 ℃에서 6 시간 동안 10 μM의 각 화합물 (즉, BVD-523, SCH722984, GDC-0994 또는 Vx-11e)로 처리하였다. 대조군 웰을 세포 용해물 생성 전에 6 시간 동안 0.1 % (v/v) DMSO로 처리하였다. 샘플은 그 후 역상 단백질 마이크로어레이 기술 (Theranostics Health)을 사용하여 분석하였다.
Colo205 이종이식편에서의 pERK IHC의 분석을 위해, 이종이식 종양을 70 % 에서 100 %의 단계적 에탄올에서 밤새 처리하고, 크실렌의 2 변화에서 제거하고, 파라핀으로 침투시키고, 파라핀 블록에 봉매시켰다. 그 다음, 5-μm 단면을 잘라 내고 양으로 하전된 유리 슬라이드 위에 놓고, 60 ℃에서 30 분 이상 1 시간 이하로 구웠다. 각 동물 및 투여군의 단일 섹션을 항-포스포 p42/p44 MAPK 항체 (pERK [1:100], CST; Cat no. 9101; Lot no. 16)로 프로빙하고, 헤마톡실린으로 대조염색 한 다음, Zeiss Axioplan 2 현미경을 사용하여 미시적으로(microscopically) 분석하였다. 이소타입 대조군 (토끼, Zymed laboratories, catalog no. 08-6199, lot no. 40186458)을 음성 대조군으로 사용하였다.
FACS 분석을 위해, 세포를 긁어내어 1,500 rpm으로 5 분간 펠렛화 한 다음 1 mL의 완충액에 재현탁시키고 -70 ℃에서 냉동시켰다. 냉동된 세포를 해동하고 다시 원심분리 한 후, 0.25 mL의 완충액 A (스페르민 테트라하이드로클로라이드 세제 완충액의 트립신)에서 10 분간 재현탁시켜 세포 덩어리를 분해하고 세포막과 세포 골격을 분해하였다. 완충액 B (완충제 중 트립신 저해제 및 리보뉴클레아제 I, 0.2 mL)를 암부(dark)에서 10 분 동안 첨가하였다. 생성된 DNA 염색된 핵을 여과시키고 FACS로 분석하였다. 히스토그램을 분석하여, n 및 2n DNA (또는 그 이상) 함량의 존재에 기초하여 세포 주기의 G1, S 및 G2/M 단계에서의 세포의 비율을 확정하였다.
시험관내 조합 활성의 측정을 위해, 5,000 개의 G-361 세포를 10 % (v/v) FBS를 함유한 McCoy's 5A를 함유하는 96-웰 플레이트에 삼중으로 씨딩하고 밤새도록 부착시켰다. 베무라페닙/BVD-523 조합은 10 x 8 용량 매트릭스를 사용하여 테스트하였다. 화합물을 5 % CO2 가습 대기에서 37 ℃에서 72 시간 동안 세포와 함께 배양하였다. CellTiter-Glo 시약을 제조업체의 지시에 따라 첨가하고, MBG FLUOstar 플레이트 판독기를 사용하여 발광을 검출하였다. 용량 매트릭스에 걸친 상호 작용은 Horizon의 Chalice 조합 분석 소프트웨어(Horizon's Chalice Combination Analysis Software)를 사용하여 로오베 가산성 및 블리스 독립성 모델(Loewe Additivity and Bliss independence model)에 의해 결정하였다.
시험관내에서 용량 증가에 의한 화합물 내성을 생성하기 위해, A375 부모 세포 (ATCC CRL-1619)를 10% 열-불활성화된 FBS와 페니실린/스트렙토마이신을 함유하는 둘베코 변형 이글 배지 (DMEM)에서 ~40-60 % 컨플루언스로 성장시킨 후, BVD-523, 트라메티닙, 또는 다브라페닙의 초기 용량을 단독으로 또는 조합하여 각 화합물의 IC50 이하에서 처리하였다; 조합 연구에서 초기 투여량은 각 화합물의 IC50의 절반이었다. 세포를 ~70-90 %의 컨플루언스까지 성장시키고 분열시켰다; 배지를 3-4 일마다 새로 교체하였다. 세포가 다시 ~40-60 %의 컨플루언스에 도달하면, 동일 증분 (초기 농도와 동등)으로 용량을 증가시킨 다음 농도를 1.5 배 증가시킨 후, 세포가 계속 빠르게 적응하는 경우, 2 배로 추가 증가시킨다(예를 들어, 다브라페닙 증가의 첫 6 회 투여량은: 5, 10, 15, 20, 25, 및 37.5 nM). 이 과정은 필요에 따라 반복하였다.
고 포도당 조건 하에서 완전 혈청에서 약물 5 일 후 Resazurin (Alamar Blue) 대사 분석에 의해 세포 생존능 분석을 수행하였다. 세포를 10 % FBS 및 페니실린/스트렙타비딘 + 고 포도당 (18-25 mM)을 함유하는 배지에서 ~15%-50% 컨플루언스로 384-웰 마이크로플레이트에 씨딩하였다. 각 세포주에 대한 최적 세포수를 결정하여 약물 복용 중 성장을 최적화하였다. 부착성 세포주의 경우, 밤새 배양 한 후, 액체 처리 로봇을 사용하여 각 화합물 9 배 농도 (2 배 희석 계단)로 세포를 처리하고, 96 시간 시점에서 분석을 위해 배양기로 되돌려놓았다. 현탁 세포주의 경우, 세포를 도말 직후에 화합물로 처리하고, 96 시간 시점에 배양기로 되돌려 놓았다. 그 후, 세포를 글루타티온이 없는(glutathione-free) 배지에서 제조된 55 μg/ml Resazurin (Sigma)으로 4 시간 동안 염색시켰다. 형광 신호 강도의 정량은 Resazurin에 대해 535/595 nm의 여기 파장 및 방출 파장에서 형광 플레이트 판독기를 사용하여 수행하였다. 모든 스크리닝 플레이트는 엄격한 품질 관리 조치를 받았다. 세포 생존능에 대한 효과를 측정하고, 곡선 피팅(curve-fitting) 알고리즘을 로우 데이터 세트에 적용하여 반 최고치(half maximal) 억제 농도 (IC50)를 포함한, 약물 반응의 다중 매개변수 기재를 유도하였다. IC50은 μM 단위의 IC50의 자연 로그로 표시된다 (LN_IC50, EXP는 IC50을 μM으로 표시). IC50의 외삽법(Extrapolation)은 매우 높은 값을 산출하는 곳에서 허용된다. 원하는 경우, 시험된 최대 농도 (및 낮은 값에 대해서는 시험된 최소 농도)에서 IC50 값을 캡핑(capping)하여 시험된 농도 범위로 데이터를 제한시켰다.
베무라페닙에 임상적으로 저항성이었던 BRAFV600E 환자로부터의 흑색종을 나타내는 환자 유래 이종이식편 (AT052C)에서 BVD-523의 효능 시험을 위해, 종양 단편을 숙주 동물로부터 수확하고, 면역-결핍 마우스에 이식하였다. 이 연구는 대략 170 mm3의 평균 종양 부피에서 시작되었으며, 이 시점에서 동물들은 대조군 (1% [v/v] CMC p.o., BIDХ31)과 3 개의 처리군 (BVD-523 [100 mg/kg], 다브라페닙 [50 mg/kg], 또는 BVD-523/다브라페닙 [100/50 mg/kg], n = 10/그룹)을 포함한 4 개의 그룹으로 무작위 추출되었다; 모든 치료 약물은 BID × 31 일정으로 p.o. 투여되었다.
인간 전혈 샘플에서 BVD-523에 의한 PMA-자극된 RSK1 인산화의 억제에 대한 IC50 측정을 위해, BVD-523에 의한 PMA 자극된 RSK1 인산화의 억제에 대한 IC50 값을 10 명의 건강한 공여자 (22-61 세)에 대해 BVD-523 10μM 내지 5nM 범위에 이르는 8 포인트 농도 곡선을 사용하여 측정하였다. 대조군은 각각의 공여자에 대해 3 개의 자극받지 않은 샘플 및 3 개의 PMA-자극된 샘플로 구성되었다. 발광-RSK (pRSK) 및 총 RSK 수준 모두를 측정하고, 데이터를 각 샘플에 대해 pRSK/RSK 수준을 사용하여 계산하였다.
각 공여자로부터의 30 밀리리터의 혈액을 나트륨 헤파린 베큐테이너(vacutainers)에 넣었다. 공여자 당 22 개의 2 mL 마이크로튜브 각각에 1 mL의 전혈을 첨가하였다. 마이크로튜브는 공여자 번호 (1 내지 10) 및 후속 처리 지정(subsequent treatment designation)으로 표시되었다: 오직 PMA 자극에 대한 "A" (최대), PMA 자극을 받은 BVD-523 함유 샘플에 대한 "B"; 및 자극되지 않은 샘플에 대한 "C" (최소). 디메틸 설폭사이드 (DMSO)를 A 군 및 C 군의 모든 튜브에 0.1 %의 최종 농도로 첨가하였다. 그 후, 샘플을 실온에서 부드럽게 흔들었다.
BVD-523 (100 % DMSO 중 10 mM)을 100 % DMSO로 3 배 희석하여 연속 희석하였다. 100 % DMSO에서 연속적으로 희석된 BVD-523 샘플을 10 % 태아 소 혈청 및 페니실린/스트렙토마이신/글루타민을 함유한 둘베코 변형 이글 배지에서 10 배로 희석하고, 이들 각각의 작업 용액 10 μL를 각각 지정된 BVD-523 농도에 대해 혈액 1mL당 첨가하였다. BVD-523의 각 농도는 2 개의 1 mL 혈액 샘플로 각각 2 회 실시하여 8 포인트 농도 곡선 전체에 대해 16 개의 총 샘플을 얻었다. 그 후 샘플을 실온에서 최소 2 시간 내지 최대 3 시간 동안 부드럽게 흔들었다.
모든 공여자에 대한 A 군 및 B 군에서의 인간 전혈 샘플을 실온에서 20 분 동안 100 nM의 최종 농도에서 PMA로 자극시켰다. C 군의 샘플은 PMA로 처리하지 않았지만 다른 모든 샘플과 마찬가지로 흔들어 처리하였다.
각 샘플에 대한 PMA 처리가 완료되면, 인간의 전혈로부터 말초 혈액 단핵 세포를 분리하였다. 각 샘플에서 1 mL의 혈액을 2 mL 미세원심분리 튜브(microcentrifuge tube)에서 0.75 mL의 실온 Histopaque 1077 위에 조심스럽게 덮어씌웠다. 샘플을 에펜도르프 (Eppendorf) 미세 원심분리기에서 16,000 x g에서 2 분간 원심분리 하였다. 계면 및 상층부를 제거하고, 차가운 둘베코(Dulbecco's) 인산 완충된 생리식염수 (DPBS) 1 mL를 함유하는 튜브에 첨가하였다. 이후, 이 샘플을 16,000 x g에서 30 초 동안 원심분리하여 세포를 펠렛화하였다. 완충액 상청액을 흡인 제거하고, 펠렛을 1 mL의 차가운 DPBS에 재현탁시켰다. 각 샘플로부터의 펠렛을 상기와 같이 재-펠렛화하였다. 완충액을 흡인 제거하고, 펠렛을 하기에 나타낸 바와 같이 용해시켰다.
완전한 용해 완충액은 Meso Scale Discovery Tris 용해 완충액, 1X Halt 프로테아제 억제제 칵테일, 1X 포스파타제 억제제 칵테일 2, 1X 포스파타제 억제제 칵테일 3, 2mM 페닐메탄설포닐 플루오라이드, 및 0.1 % 나트륨 도데실 설페이트로 구성되었다. 용해 완충액을 얼음 상에 유지시켜, 각 샘플 그룹에 대해 신선한 상태를 만들었다. 최종 세포 펠렛은 120 μL의 완전한 용해 완충액을 첨가하여 용해시켰다. 세포 펠렛이 사라질 때까지 샘플을 섞은 후(vortexed) 드라이아이스로 동결시켰다. 샘플은 ELISA에 의한 pRSK 및 총 RSK의 측정 전에 -20 ℃에서 보관하였다.
pRSK ELISA (PathScan)의 경우, 해동된 용해물을 시료 희석액 (ELISA 키트에서 제공됨)과 1:1로 조합시켰다: 120 μL의 용해물을 둥근 바닥 96-웰 플레이트에서 120 μL의 시료 희석액에 첨가하였다. 그 후, 조합물을 pRSK 마이크로웰에 웰 당 100 μL로 옮겼다. 총 RSK ELISA (PathScan)의 경우, 샘플 희석액에서 이미 1:1로 희석된 용해물 20 μL를 둥근 바닥 96-웰 플레이트에서 200 μL의 샘플 희석액으로 추가 희석시켰다. 그 후, 조합물을 웰 당 100 μL로 총 RSK 마이크로웰에 옮겼다. 플레이트를 플레이트 씰로 밀봉하고, 4 ℃에서 표적 단백질을 가장 잘 검출하는 것으로 나타난 시간인 16 내지 18 시간 동안 배양하였다. 두 ELISA는 키트 지침에 따라 개발되었습니다.
18 세 이상의 환자는 만약 이들이 치유불가능한(noncurable), 조직학적으로 확인된 전이성 또는 진행성 악성 종양; ECOG 성능 상태 0 또는 1; 적절한 신장, 간, 골수 및 심장 기능; 및 3 개월 이상의 평균 수명을 갖는 경우, 참여 자격이 있었다. 환자들은 전이성 질환에 대해 화학 요법의 2개 이하의 선험 라인(prior line)을 받을 수 있다. 제외 기준은 공지된 제어되지 않는 뇌 전이; 연구 약제의 흡수를 저해 할 수 있는 위장 장애; 망막 정맥 폐색(retinal vein occlusion) 또는 중심장액망막병(central serous retinopathy)의 과거 또는 현재의 징후(evidence)/위험; 및 CYP1A2, CYP2D6 및 CYP3A4의 강력한 억제제 또는 CYP3A4의 강력한 유도제로 알려진 약제의 병용 요법이었다. 모든 참가자는 연구 절차 시작 전에 사전 동의를 제공하였다.
BVD-523을 1 회 이상 투여받은 환자는 SAS (버전 9.3) 소프트웨어를 사용하는 분석에 포함시켰다. 데이터 컷오프는 2016 년 12 월 1 일이었다. 이 연구는 ClinicalTrials.gov, number NCT01781429에 등록되어 있다.
본 발명은 진행성 악성 종양 환자에서 BVD-523의 용량을 증가시키는 것에 대한 안전성, 약동학 및 약력학을 평가하기 위해 공개형(open-label), 다기관(multicenter) 제1 상 연구로부터의 데이터를 제시한다. 투약 요법은 진행성 고형 종양을 갖는 환자에서 BVD-523의 MTD 및 RP2D를 확인하기 위해 공동으로 사용 되는 가속화된 적정(accelerated titration) 및 표준 코호트 3 + 3 용량 증가 계획을 모두를 결합하였다. 치료 코호트 당 1 내지 6 명의 환자가 10mg BID의 용량으로 시작하여, 21 일 주기로 BID 일정 (12 시간 간격)으로 BVD-523의 순차적으로 더 높은 경구 용량을 할당받았다. BVD-523을 다음과 같은 용량으로 21 일 주기로 연속적으로 BID 투여하였다 : 10 mg (n = 1); 20 mg (n = 1); 40 mg (n = 1); 75 mg (n = 1); 150 mg (n = 1); 300 mg (n = 4); 600 mg (n = 7); 750 mg (n = 4); 및 900 mg (n = 7).
환자는 질병의 진행, 허용 불가능한 독성, 또는 다른 철회 기준을 만족시키는 임상적 관찰에 이르기까지 BID 경구 용량을 투여받았다. 용량 증가는 한 환자가 2 등급 이상의 독성 (탈모 또는 설사 제외)을 경험할 때까지 단일 환자 코호트에서 최대 100 % 증분되었다. 그 후 코호트를 각각 적어도 3 명의 환자로 확대시키고, 이후의 용량 증가 증분을 최대 100 %에서 최대 50 %까지 감소시켰다. 3 환자 코호트에서 적어도 1 명의 환자가 DLT를 경험했을 때, 최대 3 명의 추가 환자가 이러한 용량 수준으로 치료되었다. 6 명 이하의 환자에서 DLT가 1 건 이상 발생했을 때, 이러한 용량 수준을 용인되지 않는(nontolerated) 용량으로 정의하고 용량 증가를 중단하였다. 가장 높은 현재 용량을 투여 받은 환자를 최소 3 주 동안 관찰하고, 용량-제한 부작용이 주어진 용량을 할당받은 6 명 중 2 명 미만에서 보고되었다면, 환자내 용량 증가를 허용하였다. DLT 또는 허용되지 않는 독성을 겪고 있는 환자는 독성이 1 등급 이하로 회복될 때까지 치료를 중단하였다. BVD-523 치료의 재개는 시험되었던 수준의 다음의 더 낮은 용량 수준에서 또는 20 % 내지 30 % 용량 감소에서 시작되어, 캡슐 용량과 일치시켰다.
제1 상 연구의 주된 목표는 용량 제한 독성, MTD 및 RP2D를 결정하여 BVD-523의 안전성과 내약성을 정의하는 것이다. 부차적인 목표는 진행성 악성 종양 환자에서 BVD-523의 약동학 프로파일의 결정 및 RECIST v1.1을 사용한 물리적 또는 방사선 검사로 평가한 종양 반응에 대한 임의의 예비 임상 효과에 대한 조사를 포함하였다. 탐색적 목표는 약력학 마커 (biomarker) 측정법의 평가와 표시된 대로 18F-FDG-PET에 의해 평가된 종양 반응에 대한 예비 임상 효과의 조사를 포함하였다.
MTD, DLT 및 RP2D를 측정하기 위해, MTD를 치료의 첫 21 일 동안 환자 중 33 % 이하가 BVD-523 관련 DLT를 경험한 최고 용량 코호트로 정의하였다. DLT는 치료의 첫 21 일 중의 1 일 초과 동안 4 등급 이상의 혈액 독성: 합병증(예: 출혈이 있는 혈소판 감소증)을 동반한 3 등급의 혈액 독성; 메스꺼움, 구토, 변비, 통증 및 발진(적절한 치료에도 불구하고 AE가 지속되면 이들도 DLT가 된다)을 제외한 3 등급 이상의 비-혈액학적 독성; 또는 BVD-523 관련 독성으로 인한 사이클 1에서 3일을 초과하는 치료 중단(또는 사이클 2가 7 일 넘게 지속될 수 없는 경우)을 초래하는 BVD 관련 독성으로 정의하였다.
RP2D는 MTD 만큼 높을 수 있으며, 임상 연구자, 의료용 모니터 및 스폰서의 의견을 토대로 결정되었다. 약동학, 약력학 및 다중 사이클 후에 관찰된 누적된 독성과 관련된 관찰이 RP2D를 뒷받침하는 근거에 포함되었다.
안전성 평가와 관련하여, AE는 반드시 BVD-523과 인과관계를 갖는 것은 아닌 의약품을 투여받은 환자에서의 임의의 바람직하지 않은 의료 사건(untoward medical occurrence)으로 정의되고, MedDRA 코딩 사전을 사용하여 코딩되었다. SAE는 사망을 초래하거나, 생명을 위협하거나, 입원 환자의 병원 입원(inpatient hospitalization) 또는 기존 입원 기간의 연장을 요구하거나; 지속적 또는 현저한 장애/무능력 또는 선천적인 기형/출생 결함을 초래한 모든 용량에서 발생하는 바람직하지 않은 의료 사건이다. AE의 중증도는 the National Cancer Institute Common Terminology Criteria for Adverse Events, Grading Scale, version 4에 따라 등급이 매겨졌다.
안전성 평가는 3주 마다 또는 그후로 임상적으로 지시된 경우, 치료를 계속한 환자에서 8, 15, 22, 29, 36, 43 일째에 기준선에서 수행되었다. 각 평가에는 신체 검사와 임상 검사가 포함되었다. 임상 적으로 의미가 있고 조사자의 재량에 따라 심전도를 반복하였다. 조사관은 AE가 연구 약물과 관련이 있는지 여부를 판단하고, 해결 또는 안정화될 때까지 추적 조사를 실시하거나, AE가 더 이상 임상적으로 중요하지 않다고 판단하였다.
약동학 분석에서, 약동학 집단은 BVD-523을 1 회 이상 투여받고, 혈장 및/또는 소변에 대한 평가 가능한 약동학 데이터를 갖는 환자들로 구성되었다. 혈액 샘플은 투약하기 전, 그리고 나서 1일 째 (방문 2, 치료의 기준선/개시) 및 15일 째 (방문 4; 안정 상태)에 아침 투약 이후 0.5 (± 5 분), 1 (± 5 분), 2 (± 10 분), 4 (± 10 분), 6 (± 10 분), 8 (± 10 분), 및 12 (± 2 시간) 시간에 수집하였다. 22 일째, 투약 전, 최종 혈액 샘플을 약동학 분석을 위해 수집하였다. 소변 샘플은 예비 투여(predose)시 및 1 일 및 15 일 째에 투약 후 1 내지 6 시간 및 6 내지 12 시간 ± 2 시간 간격으로 수집하였다. 검증된 LC/MS/MS 방법을 사용하여 BVD-523 및 대사 산물에 대한 혈장 및 소변 샘플을 분석하였다. 비구획적 방법(noncompartmental method)으로 Phoenix WinNonlin (Pharsight)을 사용하여 표준 약동학 파라미터를 얻었다. 용량 및 노출량(exposure) 사이의 관계는 표준 최소 자승 회귀 분석을 사용하여 계산하였다.
BVD-523에 의한 표적 억제의 약동학적 확인을 위해, BVD-523에 의한 표적화 된 ERK 억제를, 제1 상 연구 동안에 상이한 용량의 BVD-523 (10-900 mg BID)를 투여받은 진행성 고형 종양 (N = 27)을 갖는 환자로부터 수득한 인간 전혈 샘플에서 표적 바이오마커로서 pRSK를 검사하여 측정하였다. 4개 시점 (예비 투여 기준선 (baseline predose), 투여 후 4 시간 기준선 (baseline 4 hours postdose), 15일 째 예비 투여 (Day 15 predose); 및 15일 째 투여 후 4 시간 (Day 15 4 hours postdose))으로부터의 BVD-523 활성은 BVD-523으로 배양된 PMA-자극된 혈액의 백분율 활성 (pRSK)으로 표현하였다.
항 종양 반응의 측정을 위해, 종양 측정은 기준선에서 발생한 신체 검사 및 각 치료 사이클의 첫 날에 근거하였다. CT 및 기타 평가는 2 내지 3 사이클마다 이루어졌다. 결과는 RECIST v1.1에 따라 평가되었다: CR은 모든 표적 병변의 소실로 정의되었다; PR은 기준선 측정을 참조로 하여, 표적 병변의 가장 긴 직경의 합계가 30 % 이상 감소한 것으로 정의되었다; 안정된 질환은 기준선 측정을 참조로 하여, PR에 대한 자격을 갖추기에 충분한 수축이 아니고, 진행성 질환에 대한 자격을 갖추기에 충분한 증가가 아닌 것으로 정의되었다. 대사 반응은 BVD-523의 첫 번째 용량을 투여하기 전 및 15일 째 (방문 4)에 18F-FDG-PET 스캐닝을 통해 18F-포도당의 종양 흡수를 시각화하여 평가되었다.
실시예 2
용량 증가 및 증식 분석 - 1 개월 째
용량 증가 진행 - 1 개월 째
A375 세포는 BVD-523, 다브라페닙 및 트라메티닙을 단일 약제로 사용하거나 또는 조합하여 사용하여 용량을 증가시켰다. 첫 달 동안 용량은 작은 증분(small increment)으로 증가시켰다. 성장률에서의 현저한 감소 외에, 세포는 일반적으로 용량 증가를 잘 견뎠고, 용량은 2 개월 째에 보다 큰 증분을 사용하여 보다 적극적으로 증가시키기로 계획되었다. 도 1a - 도 1c는 용량 증가 연구에 대한 1 개월 째의 진행을 보여준다.
증식 분석 결과 - 1 개월 째
BVD-523, 다브라페닙 및 트라메티닙 치료에 대한 증가된 세포주 대 부모 세포주의 반응을 평가하기 위해 증식 분석을 수행하였다.
도 2a - 도 2h는 연구 1 개월 째의 정규화된(nomalized) 및 로우 증식 분석 결과를 나타낸다. 상이한 치료 (도 2d, 도 2f 및 도 2h) 간의 DMSO 대조군에서의 최대 신호의 차이는 치료 간의 상이한 성장 속도를 시사함에 주목한다. 이러한 차이는 증식 분석에서 억제제에 대한 세포주의 반응에 영향을 줄 수 있다
표 10은 연구의 1 개월 째의 IC50 데이터를 보여준다.
표 10 - IC50 데이터 - 1개월 째

* Par= 부모 세포주
다브라페닙 또는 트라메티닙 단일 약제 또는 병용의 용량 증가 존재 하에서 성장한 세포가 증식 분석에서 이들 두 약제에 대한 감소된 반응을 나타낸다는 초기 암시가 있었다.
2 개월 째의 초기 단계에서, 다브라페닙 단독 치료에서의 세포 성장률이 1 개월 째의 초기 단계에 비해 현저히 증가하였다. 이는 진행 속도의 증가를 가능하게 했고, 내성이 분명해짐을 시사하였다.
실시예 3
용량 단계적 상승(escalation) 및 증식 검정 - 2개월째
용량 단계적 상승 진행 - 2개월째
연구 2개월째에 대부분의 치료가 초기의 완만한 단계적 상승 페이즈와 비교하여 용량이 더 큰 증분(increment)(1.5배)으로 증가된 페이즈(phase)로 이동하는 것을 알았다. 다브라페닙 및 트라메티닙의 단일 제제 단계적 상승은 100x 모 세포 IC50과 동등한 농도로 성장하는 세포가 가장 빨랐다(도 3a 및 도 3b). BVD-523의 단일 제제 단계적 상승은 다브라페닙 및 트라메티닙과 비교하여 더 서서히 진행되었다(도 3c). 단일 제제 단계적 상승의 비교에 관해서는 도 3d를 참조한다. BVD-523 단계적 상승된 세포는 보다 "취약한" 외형을 가졌고 다브라페닙 및 트라메티닙 단계적 상승된 집단과 비교하여 더 많은 수의 부유(floating) 세포가 존재하였다.
조합된 제제 단계적 상승은 단일 제제 처리보다 더 서서히 진행되었다. BVD-523/트라베티닙 조합은 세포가 진행되는 것을 예방하는데 특히 효과적이었다.
증식 검정 결과 - 2개월째
단일 제제 단계적 상승된 다브라페닙 및 트라메티닙 세포 집단에 대한 증식 검정은 용량 반응 곡선에서 완만한 변화(shift)를 나타냈고, 이는 추가적 기간의 단계적 상승은 내성 세포를 더 농축시키는데 유익할 것임을 시사한다. 흥미롭게도, 증식 검정에서, BVD-523에 노출된 세포는 억제제 중단(withdrawal)시 잘 성장하지 않고, 이는 중독 수준을 나타낼 수도 있음을 시사하는 증거가 있었다.
도 4a 내지 도 4h는 연구 2개월째로부터의 정규화된 로우(raw) 증식 검정 결과를 보여준다. 상이한 치료제들(도 4d, 도 4f 및 도 4h) 사이에 DMSO 대조군에서의 최대 신호 차이가 치료제들 사이의 상이한 성장 속도를 시사함에 주목한다. 이들 차이는 증식 검정에서 억제제에 대한 세포주의 반응에 영향을 미칠 수 있다.
도 5a 내지 도 5h는 모세포주 및 BVD-523 세포주 데이터에만 초점을 맞춘 연구 2개월째로부터의 정규화된 로우 증식 검정 결과를 보여준다.
표 11은 연구 2개월째에 관한 IC50 데이터를 보여준다. 상대적 IC50은 프리즘(Prism)에서의 4-매개변수 곡선 맞춤으로부터 결정되었다.
표 11 IC50 데이터 - 2개월째

실시예 4
용량 단계적 상승 및 증식 검정 - 3개월째
용량 단계적 상승 진행 - 3개월째
도 6a 내지 도 6c는 연구 3개월째에 관한 단일 및 조합 제제 단계적 상승을 보여준다. 도 6d는 단일 제제 단계적 상승의 비교를 보여준다.
증식 검정 결과 - 3개월째
도 7은 DMSO 대조군 웰에서의 증식 검정 동안의 성장의 평가를 보여준다. 도 8a 내지 도 8d는 연구 3개월째로부터의 결과를 보여준다. 도 9a 내지 도 9d는 단일 치료 세포주에 초점을 맞춘 연구 3개월째로부터의 결과를 보여준다.
표 12는 연구 3개월째에 관한 IC50 데이터를 보여준다. 상대적 IC50은 프리즘에서의 4-매개변수 곡선 맞춤으로부터 결정되었다. 트라메티닙이 단계적 상승된 세포주에 대해서는 검정 동안 성장의 결여로 인하여 IC50 값이 측정되지 않았다(ND: 실행되지 않음).
표 12 IC50 데이터 - 3개월째

도 19는 연구 3개월째에 관한 단일 및 조합 제제 단계적 상승을 보여준다. 모 A375 세포에서 이들 제제의 IC50의 100배 초과의 농도로의 다브라페닙 또는 트라베티닙의 존재 하에 성장할 수 있는 세포주 변이체가 수득되었다. 대조적으로, BVD-523에 대해 내성인 세포주는 모세포 IC50 농도의 10X 미만에서만 유지될 수 있다. 민감성 시험은 다브라페닙 및 트라메티닙-내성 세포주가 BVD-523에 대해 상대적으로 민감성을 유지하였고; 내성 세포주에서 BVD-523에 대한 증가된 IC50 "변화"는 다브라페닙 또는 트라메티닙 치료에 따른 이들 상응하는 IC50 증가보다 더 완만하였음을 시사하였다. 유사하게, 다브라페닙 또는 트라메티닙 치료와 비교하여, 내성 세포주가 모 A375 세포주에서 이의 IC50의 10배 초과의 농도로의 BVD-523으로 치료된 경우에 세포 성장의 보다 완전한 억제가 관찰되었다. 전체적으로, 내성 및 교차-민감성의 패턴은 BVD-523이 획득된 내성의 설정에서 효과적임을 유지할 수 있음을 시사한다.
실시예 5
조합 연구 결과
예상한 바와 같이, BRAF(V600E) 돌연변이를 지닌 A375 세포는 다브라페닙에 대해 민감성이었다. 알라마 블루(Alamar Blue)를 이용하여 계산된 단일 제제 IC50 값(도 10a 내지 도 10e, 도 12a 내지 도 12e 및 도 14a 내지 도 14e)은 일반적으로 CellTiter-Glo를 이용하여 유도된 값(도 11a 내지 도 11e, 도 13a 내지 도 13e 및 도 15a 내지 도 15e)들과 비교하여 다브라페닙 및 BVD-523에 대해 약간 더 낮았다. 72시간 CellTiter-Glo 검정에서 다브라페닙 및 트라메티닙에 관한 공개된 IC50 값은 각각 28 ± 16nM 및 5 ± 3nM이었다(Greger et al., 2012; King et al., 2013) - 여기에 보고된 단일 제제 결과는 이들 값과 일치한다. 모든 치료에서 상승작용(synergy)의 윈도우(window)에 대한 몇몇의 증거가 존재하였다. 삼중 실험 사이의 편차는 낮았지만, 무 약물 대조군에 비해 일부 치료에서 관찰된 분명한(예를 들면, 트라메티닙/BVD-523 조합에서 특히 분명한) 향상된 성장을 설명할 가능성이 있는 에지(edge) 효과의 몇몇의 증거가 존재하였다. 이는 일부 치료에서 상승작용의 수준의 인공적인 향상을 초래할 수 있었으므로 블리스(Bliss) 분석의 해석을 더 힘들게 한다.
A375 세포에 대해 조합 검정을 반복하였다. 단일 제제 BVD-523, 트라메티닙 및 다브라페닙 효력은 본원에 개시된 이전 연구에서 보고된 효력과 일치하였다.
요약하면, 종합하여 데이터는 MEK 및 BRAF 내성 세포가 ERK 억제제인 BVD-523을 이용한 치료에 의해 극복될 수 있음을 보여준다.
실시예 6
MAPK 키나제 활성 및 이펙터 기능의 BVD-523 변경된 마커
웨스턴 블롯 연구를 위해, HCT116 세포(5 x 106)를 McCoy's 5A + 10% FBS의 10cm 디쉬에 씨딩하였다. A375 세포(2.5 x 106)를 DMEM + 10% FBS의 10cm 디쉬에 씨딩하였다. 명시된 양의 시험 화합물(BVD-523) 또는 비히클 대조군을 부가하기 전에 세포를 밤새 부착되도록 하였다. 하기에 구체화되는 바와 같이 전체 세포 단백질 용해물을 단리하기 전에 세포를 4시간 또는 24시간 동안 처리하였다. 세포를 트립신처리(trypsinisation)에 의해 수확하였고, 펠렛화(pelleted)하고, 스냅 동결시켰다(snap frozen). 용해물은 RIPA(Radio-Immunoprecipitation Assay: 방사선-면역침전 검정) 완충액을 이용하여 조제하였고, 원심분리에 의해 청징화하였고, 바이신코닉산 검정(BCA: bicinchoninic acid assay)에 의해 정량하였다. 20 내지 50㎍의 단백질을 SDS-PAGE 전기영동에 의해 해상하였고, PVDF 멤브레인에 블롯팅하였고, 하기 표 13(4시간 처리) 및 표 14(24시간 처리)에 상술한 항체를 이용하여 프로빙하였다.
표 13 항체 상세설명

표 14 항체 상세설명

도 16a 내지 도 16d, 도 17a 내지 도 17d, 및 도 18a 내지 도 18d는 하기에 대한 각종 농도의 BVD-523을 이용하여 치료한 세포의 웨스턴 블롯 분석을 보여준다: 1) 4시간 후 A375 세포 내의 MAPK 신호전달 구성원; 2) 각종 양의 BVD-523을 이용한 A375 24시간 치료에서의 세포 주기 및 아폽토시스 신호전달; 및 3) 4시간 동안 치료한 HCT-116 세포에서의 MAPK 신호전달. 그 결과는 시험관내에서 RAF 및 RAS 돌연변이체 암 세포에서 BVD-523을 이용한 급성 및 연장된 치료가 기질 인산화 및 ERK 키나제의 이펙터 표적 둘 다에 영향을 미친다는 것을 보여준다. 이들 변화를 유도하는데 요구되는 BVD-523의 농도는 전형적으로 저 마이크로몰(μM) 범위 내이다.
몇몇의 비활성(specific activity) 마커의 변화는 주목할 만하다. 우선, BVD-523 치료 후 서서히 이동하는 ERK 키나제의 이소형의 존재도(abundance)가 증가하고; 완만한 변화가 급성으로 관찰될 수 있고, 연장된 치료 후에도 증가한다. 이는 효소적으로 활성인 인산화된 형태의 ERK의 증가를 나타낼 수 있지만, ERK에 의한 직접적 및 간접적 조절 둘 다를 행한 다수의 단백질이 BVD-523 치료 후에 "오프(off)"로 남아 있다는 것은 여전히 주목할 만하다. 첫째, RSK1/2 단백질은 단백질 변형을 위해 ERK에 엄격하게 의존하는 잔기에서 감소된 인산화를 나타낸다(T359/S363). 둘째, BVD-523 치료는 MAPK 피드백 포스파타제, DUSP6에서의 복잡한 변화를 유도한다: 급성 치료 후에 서서히 이동하는 단백질 이소형은 감소되지만, 총 단백질 수준은 연장된 BVD-523 치료 후에 크게 감소된다. 이들 발견 둘 다는 ERK 키나제의 감소된 활성과 일치하고, 이는 번역-후 및 전사 메커니즘 둘 다를 통해 DUSP6 기능을 제어한다. 전반적으로, 전형적으로 활성인 것으로 생각되는 세포 형태의 ERK의 증가에도 불구하고, 세포 ERK 효소 활성은 BVD-523을 이용한 급성 또는 연장된 치료 후에 완전히 억제될 가능성이 있는 것으로 밝혀진다.
이들 관찰과 일치하여, MAPK 경로 신호전달을 필요로 하는 이펙터 유전자는 BVD-523을 이용한 치료 후에 변경된다. G1/S 세포-주기 장치는 MAPK 신호전달에 의해 번역-후 및 전사 수준 둘 다에서 조절되고, 사이클린-D1 단백질 수준은 연장된 BVD-523 치료 후에 크게 감소한다. 유사하게, 아폽토시스 이펙터의 단백질 존재도 및 유전자 발현은 흔히 온전한(intact) MAPK 신호전달을 요구하고, Bim-EL의 전체 수준은 연장된 BVD-523 치료 후에 증가한다. 그러나, 상기 언급된 바와 같이, PARP 단백질 절단 및 증가된 아폽토시스는 A375 세포 백그라운드에서 주목되지 않았고; 이는 추가의 인자들이 BVD-523/ERK-의존적 이펙터 신호전달의 변화가 세포 사멸 및 세포 주기 정지와 같은 결정적인 사건으로 번역되는지 여부에 영향을 미칠 수 있음을 시사한다.
BVD-523의 세포 활성과 일치하여, 마커 분석은 ERK 억제가 암 세포에서의 각종 분자 신호전달 사건을 변경시켜 이들을 감소된 세포 증식 및 생존 둘 다에 감수성이 되게 함을 시사한다.
요약하면, 도 16a 내지 도 16d, 도 17a 내지 도 17d 및 도 18a 내지 도 18d는 BVD-523이 MAPK 신호전달 경로를 억제하고 이러한 설정에서 RAF 또는 MEK 억제와 비교하여 보다 유리할 수 있음을 보여준다.
마지막으로, BVD-523의 특성은 이를 유사한 활성을 갖는 다른 제제와 비교하여 ERK 억제제로서 사용하기에 바람직한 제제로 만들 수 있다. 키나제 억제제 약물은 이들의 효소 표적과의 고유하고 특이적인 상호작용을 나타내고, 약물 효능은 직접적 억제 방식뿐만 아니라 치료 후에 발생하는 적응성 변화에 대한 감수성 둘 다에 의해 크게 영향을 받는다는 것이 공지되어 있다. 예를 들면, ABL, KIT, EGFR 및 ALK 키나제의 억제제는 이들의 동족(cognate) 표적이 활성 또는 불활성 입체배치(configuration)에서 발견되는 경우에만 효과적이다. 마찬가지로, 소정의 이들 억제제는 단백질 표적의 2차 유전적 돌연변이 또는 번역-후 적응성 변화 중 어느 하나에 고유하게 민감성이다. 마지막으로, RAF 억제제는 소정 단백질 복합체 및/또는 준세포 국재화(subcellular localization)에 존재하는 RAF 키나제에 대해 상이한 효력을 나타낸다. 요약하면, ERK 키나제가 마찬가지로 다양하고 가변성이며 복잡한 생화학적 상태로 존재하는 것으로 공지되어 있으므로, BVD-523은 다른 제제와 별개이고 고도로 바람직한 방식으로 이들 표적과 상호작용하고 이들 표적을 억제할 수 있을 가능성이 있는 것으로 밝혀진다.
실시예 7
생존력 및 MAPK 신호전달에 대한 BVD-523 및 표준(benchmark) ERK BRAF 및 MEK 억제제의 영향
단일 제제 증식 검정
세포를 10% FBS을 함유하는 McCoy's 5A에 표 15에 표시된 밀도로 96웰 플레이트에 씨딩하였고, 화합물 또는 비히클 대조군을 부가하기 전에 세포를 밤새 부착되도록 하였다. 화합물은 DMSO 스톡으로부터 조제하여 원하는 최종 농도로 제공하였다. 최종 DMSO 농도는 0.1%로 일정하였다. 시험 화합물을 습윤화된 분위기에서 37℃, 5% CO2에서 96h 동안 상기 세포와 함께 인큐베이션하였다. CellTiter-Glo® 시약(Promega, Madison, WI)을 제조업자의 지침에 따라 부가하였고, BMG FLUOstar 플레이트 판독기(BMG Labtech, Ortenberg, Germany)를 이용하여 발광성을 검출하였다. 평균 배지 전용 백그라운드 값을 감하고 GraphPad Prism(GraphPad Software, La Jolla, CA)에서 4-매개변수 로지스틱 방정식(logistic equation)을 이용하여 데이터를 분석하였다.
조합 증식 검정
세포를 10% FBS을 함유하는 McCoy's 5A에 표 15에 표시된 밀도로 96웰 플레이트에 삼중으로 씨딩하였고, 시험 화합물 또는 비히클 대조군을 부가하기 전에 세포를 밤새 부착되도록 하였다. 10x8 용량 매트릭스를 이용하여 조합을 시험하였다. 최종 DMSO 농도는 0.2%에서 일정하였다.
시험 화합물을 습윤화된 분위기에서 37℃, 5% CO2에서 96h 동안 상기 세포와 함께 인큐베이션하였다. 회흐스트(Hoechst) 염색으로 세포를 염색하였고, 상기 기술된 바와 같이 형광성을 검출하였다. 평균 배지 전용 백그라운드 값을 감하고 데이터를 분석하였다.
용량 매트릭스에 걸친 조합 상호작용은 사용자 매뉴얼(chalice.horizondiscovery.com/chalice-portal/documentation/analyzer/home.jsp에서 입수가능함)에 개요되어 있는 바와 같이 Chalice™ 조합 분석 소프트웨어(Horizon Discovery Group, Cambridge, MA)를 이용하여 로에베 가산성(Loewe Additivity) 및 블리스 독립 모델에 의해 측정되었다. 상승작용은 가산성에 대해 예측된 값과 각각의 조합점에서 실험적으로 관찰된 수준의 억제를 비교함으로써 측정되고, 이는 매트릭스의 에지(edge)에 따른 단일-제제 반응으로부터 유도된다. 잠재적인 상승작용적 상호작용은 예측된 것을 초과하는 계산된 과량의 억제를 용량 매트릭스에 걸친 히트 맵으로서 부가제로 표시함으로써 그리고 로에베 모델에 기초하여 정량적 "상승작용 점수'를 보고함으로써 확인되었다. 조합 검정 플레이트로부터 유도된 단일 제제 데이터는 Chalice™에서 생성된 용량-반응 국선으로서 제시되었다.
표 15 세포주 씨딩 밀도

웨스턴 블롯팅
세포를 10% FBS을 함유하는 McCoy's 5A에 표 15에 표시된 밀도로 6웰 플레이트(실험 1) 또는 10cm 디쉬(실험 2)에 씨딩하였고, 화합물 또는 비히클 대조군을 부가하기 전에 세포를 밤새 부착되도록 하였다. 시험 화합물을 부가하였고, 습윤화된 분위기에서 37℃, 5% CO2에서 4 또는 24h 동안 상기 세포와 함께 인큐베이션하였다. 세포를 트립신처리에 의해 수확하였고, 원심분리에 의해 펠렛화하였고, 드라이 아이스 상에서 스냅 동결시켰다.
용해물은 RIPA 완충액(50mM Tris-하이드로클로라이드, pH 8.0; 150mM 나트륨 클로라이드; 1.0% Igepal CA-630(NP-40); 0.5% 나트륨 데옥시콜레이트; 0.1% ㄴ나나트륨 도데실 설페이트; 1x완전 EDTA-불포함 프로테아제 억제제 칵테일(Roche, Nutley, NJ; cat 05 892 791 001); 1xphosSTOP 포스파타제 억제제 칵테일(Roche, Nutley, NJ; cat. 04 906 837 001))을 이용하여 조제하였고, 벤치-탑(bench-top) 원심분리기에서 10분 동안 11,000rpm으로의 원심분리에 의해 청징화하였다.
용해물 중의 전체 단백질은 제조업자의 지침(Pierce™, BCA 단백질 검정 키트; Thermo Scientific, Waltham, MA; cat/ 23225)에 따라 BCA 검정에 의해 정량하였고 샘플 완충액(NuPAGE LDS 샘플 완충액; (Invitrogen, Carlsbad, CA; cat. NP0007))에서 끓였고 -80℃에서 보관하였다.
등량의 단백질(40μg)을 NuPAGE 4-12% Bis-Tris 겔(Invitrogen, Carlsbad, CA; cat. WG1402BOX) 상에 해상하였고, 제조업자의 지침에 따라 iBlot 겔 전달 장치(Invitrogen, Carlsbad, CA)에 iBlot 겔 전달 스택(stack)(Invitrogen Carlsbad, CA; cat. IB4010-01)을 사용하여 PVDF 멤브레인 상에 블롯팅하였다.
블롯은 표 16에 상술한 항체 및 차단 조건을 이용하여 프로빙하였다. 웨스턴 블롯은 Pierce™ ECL2 웨스턴 블롯팅 기질(Thermo Scientific, Waltham, MA; cat. 80196)을 이용하여 전개시켰고, FluorChem M 웨스턴 블롯 이미저(imager)(ProteinSimple, San Jose, CA)를 이용하여 촬상하였다.
표 16 항체 및 웨스턴 블롯팅 조건

MEK1(Q56P) 돌연변이는 MAPK 경로를 상향-조절하고 BRAF 또는 MEK 억제제에 대한 획득된 내성을 유도하는 것으로 공지되어 있는 임상학적으로 관련된 MEK1/2 활성화 돌연변이의 한 부류를 예시한다.
이러한 연구는 MEK1(Q56P) 활성화 돌연변이의 존재 또는 부재에 대해 동질유전자인 1쌍의 RKO BRAF(V600E) 세포주를 사용하여 활성화 MEK 돌연변이가 신규한 ERK 억제제 BVD-523 대 다른 벤치마크 MAPK 억제제에 반응하여 생기는 영향을 평가하였다.
세포 생존력에 대한 영향은 96h 후에 CellTiter-Glo®를 이용하여 세포 ATP 수준을 정량함으로써 평가하였다. 단일 제제 검정은 이중 돌연변이 BRAF(V600E)::MEK1(Q56P) 세포가 모 BRAF(V600E) 세포에 비하여 벤치마크 임상학적 BRAF(다브라페닙에 의해 예시됨) 또는 MEK(트라메티닙에 의해 예시됨) 억제제를 이용한 억제에 대해 현저히 감소된 민감성을 나타냈음을 입증하였고, 이는 진료소에서 이러한 부류의 돌연변이와 관련된 것으로 공지되어 있는 획득된 내성을 재현하기 위한 이러한 동질유전자 모델의 적합성을 입증한다(표 17).
표 17 단일 제제 IC50 값

대조적으로, BVD-523에 대한 반응은 모세포 및 이중 돌연변이 세포 둘 다에서 동일하였고, 이는 BVD-523이 획득된 내성의 이러한 메커니즘에 대해 감수성이 아님을 나타낸다.
이들 결과는 2개의 독립적으로 유도된 이중 돌연변이 BRAF(V600E)::MEK1(Q56P) 세포주 클론에서 동일하였고, 이는 모세포에 대한 이들 반응의 차이는 관련되어 있지 않은 클론 인공물보다 오히려 MEK1 돌연변이의 존재에 구체적으로 관련되어 있음을 확인시켜 준다(도 22a 내지 도 22e). 또한, 제2 기계론적으로 구별되는 벤치마크 ERK 억제제(SCH772984)를 이용하여 유사한 결과가 관찰되었고, 이는 이들 관찰이 특히 ERK의 억제와 관련되어 있고 오프-표적(off-target) 효과로 인한 것이 아니라는 개념을 지지한다.
BVD-523을 BRAF 억제제(다브라페닙에 의해 예시됨)와 조합하는 것의 효과는 또한 Horizon의 Chalice™ 조합 분석 소프트웨어와 함께 로에베 가산성 또는 블리스 독립 모델을 이용하여 농도의 매트릭스에 걸쳐 이들 세포주에서 평가하였다(도 23 내지 도 23o 및 도 24 내지 도 24o). 이어서, 잠재적으로 상승작용적인 상호작용의 존재는 예측된 것을 초과하는 계산된 과량의 억제를 히트 맵으로서 용량 매트릭스에 걸친 부가제로 표시함으로써 그리고 조합에 대한 전체 반응이 상승작용적(양의 값), 길항작용적(음의 값) 또는 부가적(약 0)인지 여부를 나타내는 '용적 점수'로서 계산함으로써 평가하였다.
해당 결과는 BVD-523::다브라페닙 조합이 주로 모세포주 및 돌연변이 세포주에서 부가적이었음을 시사한다. 대조적으로, MEK 억제제(트라메티닙) + 다브라페닙의 조합은 대부분 모세포주에서 부가적이면서 이중 돌연변이체 BRAF(V600E)::MEK1(Q56P) 세포주에서 강한 상승작용을 나타냈다(도 25a 내지 도 25o). 시험된 조합들에 대한 로에베 용적, 블리스 용적 및 상승작용 점수는 각각 표 18 내지 표 20에 나타내고, 도 26a 내지 도 26c에 그래프로 나타낸다.
표 18 로에베 용적

표 19 블리스 용적

표 20 상승작용 점수

MAPK 경로에 대한 신호적 영향을 웨스턴 블롯팅에 의해 평가하였다. 기저 ERK 인산화(DMSO 샘플의 수준은 모세포주에 비해 MEK1(Q56P)-발현 세포주에서 현저하게 상향-조절되어 이러한 동질유전자 모델이 MEK 활성화 획득된 내성 돌연변이의 발현에 대해 예측된 표현형을 충실하게 재현함을 추가로 확인하였다.
모 BRAF(V600E) RKO 세포에서, 약리학적 활성 농도의 RAF, MEK 및 ERK 키나제 억제제제를 이용한 급성 치료 후에 RSK1/2 인산화의 감소된 수준이 관찰되었다. 대조적으로 동질유전자 이중 돌연변이체 BRAFV600E::MEK1Q56P 세포는 BRAF 또는 MEK 억제제 치료 후 감소된 RSK 인산화를 나타내지 않고, 한편 BVD-523은 유사한 농도에서 여젼히 효과적이다(도 27a 내지 도 27i). 점선은 트라메티닙-치료된 샘플(+ 매칭된 DMSO 대조군) 및 블롯이 BRAFi 및 BVD-523 치료된 샘플에 대한 별도의 실험으로부터 유도됨을 나타낸다.
세포 성장 억제 패턴과 일치하는 이펙터 유전자 신호전달의 변화는 연장된 억제제 치료 후에 관찰된다. 모 RKO 세포주에서, 인산화된 pRB의 감소된 수준은 연장된 MEK 및 ERK 억제제 치료 후에 관찰된다. pRB 조절 수준에서, MEK1 돌연변이체 세포주는 저농도 MEK 억제제 치료에 대해 비민감성인 것으로 밝혀지고, 한편 보다 높은 농도는 여전히 효과적이다. 결정적으로, pRB 활성에 대한 BVD-523 효력은 MEK 돌연변이에 의해 강하게 영향을 받지 않는 것으로 밝혀진다. 놀랍게도, RAF 억제제 치료는 업스트림 신호전달의 강력한 억제에도 불구하고 모세포 및 MEK 돌연변이체 백그라운드 둘 다에서 pRB 상태에 영향을 미치지 않는다.
요약하면, 이들 결과는 BVD-523이 MEK1(Q56P)과 같은 MEK 활성화 돌연변이에 의해 유도된 획득된 내성에 대해 감수성이 아님을 보여준다. 또한, 이들은 BVD-523과 BRAFi(다브라페닙에 의해 예시됨) 사이의 상호작용과 조합하여 MEK 활성화 돌연변이의 존재와 관계없이 부가적임을 시사한다.
실시예 8
ERK 억제제들 사이의 조합 상호작용
RAF 돌연변이체 흑색종 세포주 A375 세포를 10% FBS를 갖는 DMEM에서 배양하였고, 96-웰 플레이트에 2000개 세포/웰의 초기 밀도로 삼중으로 씨딩하였다. 실시예 4에 상기 기술된 바와 같이 72시간 후에 ERK 억제제 BVD-523과 SCH772984 사이의 조합 상호작용을 분석하였다. 제조업자의 지침에 따라 CellTiter-Glo® 시약(Promega, Madison, WI)을 이용하여 생존력을 측정하였고 BMG FLUOstar 플레이트 판독기(BMG Labtech, Ortenberg, Germany)를 이용하여 발광성을 검출하였다.
로에베 및 블리스 '과량 억제' 히트 맵의 가시화는 BVD-523 및 SCH772984의 조합이 중간-범위 용량에서 잠재적인 상승작용의 윈도우를 이용하여 주로 부가적이었음을 시사하였다(도 28a 내지 도 28e).
요약하면, 이들 결과는 BVD-523과 SCH772984 사이의 상호작용이 적어도 부가적이고 몇몇의 경우에는 상승작용적임을 시사한다.
실시예 9
암에서의 MAPK 신호전달 경로의 표적화: 신규한 선택적 ERK1/2 억제제 BVD-523(울릭세르티닙)을 이용한 유망한 활성
암에 대한 치료 전략은 종양 증식 및 생존에 필수적인 비정상적 신호전달을 유도하는 유전적 병변의 영향에 대응하는 제제에 대한 전형적인 세포독성-기반 접근법으로부터 발전하였다. 미토겐-활성화된 단백질 키나제(MAPK) 신호전달 캐스케이드(RAS-RAF-MEK-ERK)(Cargnello and Rouxx 2011)의 ERK 모듈은 RAS 및 BRAF와 같은 경로 구성원의 구성적으로 활성화된 돌연변이 이외에도 몇몇의 수용체 티로신 키나제(예를 들면, EGFR 및 ErbB-2)와 결합될 수 있다(Gollob et al. 2006). ERK 신호전달의 비정상적 활성화를 통해, RAS 또는 BRAF에서의 유전적 변화는 신속한 종양 성장, 증가된 세포 생존 및 아폽토시스에 대한 내성을 초래한다(Poulikakos et al. 2011, Corcoran et al. 2010, Nazarian et al. 2010, Shi et al. 2014, Wagle et al. 2011). RAS 패밀리 구성원 KRAS 및 NRAS의 활성화 돌연변이는 모든 사람 암의 약 30%에서 발견되고, 특히 췌장(Kanda et al. 2012)과 결장직장암((Arrington et al. 2014)에서 높은 발생률로 발견된다. 보통 아미노산 600의 발린을 암호화하는 BRAF 유전자의 구성적 활성화 돌연변이는 흑색종, 갑상선 암종, 결장직장암 및 비-소세포 폐암에서 관찰되었다(Hall et al. 2014). 다운스트림 구성원 ERK 및 MEK의 변화를 초래하는 유전적 돌연변이를 지닌 암도 보고되어 있다(Ojesina et al. 2014, Arcila et al. 2015). MAPK 경로를 활성화시키는 변경은 또한 표적화된 치료법에 대한 내성의 설정에서 일반적이다(Groenendijk et al. 2014). 따라서, MAPK 경로 말단 마스터 키나제(ERK1/2)의 표적화는 이러한 경로 활성화 변경(예를 들면, BRAF, NRAS 및 KRAS)을 갖는 종양에 대한 유망한 전략이다.
BRAF V600 돌연변이를 갖는 절제불가능 또는 전이성 피부 흑색종의 단일-제제 치료를 위한 3종의 MAPK 경로-표적화 약물: BRAF 억제제들 베무라페닙 및 다브라페닙 및 MEK 억제제 트라메티닙이 미국 식약청(FDA: Food and Drug Administration)에 의해 승인되어 있다. 또한, 다브라페닙 및 트라메티닙의 조합도 이러한 징후에서 승인되어 있다(Queirolo et al. 2015 and Massey et al. 2015). 추가의 MEK 억제제 코비메티닙은 이러한 징후에서 BRAF 억제제와의 조합 용법의 일부로서 승인되어 있다. 이들 약물을 이용한 임상학적 경험은 MAPK 경로를 치료학적 표적으로서 입증한다. BRAF V600-돌연변이체 흑색종을 지닌 환자의 페이즈 III 시험에서, 단일 제제 베무라페닙 및 다브라페닙은 세포독성 화학치료법(다카르바진)에 비해 우수한 반응률(대략 50% 대 5 내지 19%) 및 중간값 무진행 생존(PFS, 5.1 내지 5.3개월 대 1.6 내지 2.7개월)을 입증하였다(Chapman et al. 2011 and Hauschild et al. 2012). 또한, 동시발생적(concomitant) BRAF- + MEK-표적화된 치료법의 임상학적 사용은 MAPK 경로에서의 상이한 노드(node)들의 동시 표적화가 반응의 규모(magnitude) 및 지속기간을 향상시킬 수 있음을 입증하였다. BRAF + MEK-표적화된 제제(다브라페닙/트라메티닙 또는 코비메티닙/베무라페닙)의 제1선 사용은 단일 제제 BRAF 억제와 비교하여 중간값 전체 생존을 추가로 개선시켰다(Robert et al. 2015, Long et al. 2015, Larkin et al. 2014). 따라서, 조합된 BRAF-/MEK-표적화된 치료법은 BRAF V600 돌연변이를 갖는 전이성 흑색종을 지닌 환자에게 유용한 치료 옵션이다.
BRAF-/MEK-억제제 조합 치료법으로 보여지는 임상학적 결과에서의 개선에도 불구하고, 지속가능한 이점은 대략 9 내지 11개월의 범위의 중간값 PFS로, 획득된 내성 및 후속적 질환 진행의 궁극적인 발달에 의해 제한된다. (Robert et al. 2015, Long et al. 2015, Larkin et al. 2014, and Flaherty et al. 2012). 단일 제제 BRAF 억제에 대한 획득된 내성의 유전적 메커니즘이 열심히 연구되어 왔고, 내성 메커니즘의 동정으로는 BRAF의 스플라이스 변이체(Poulikakos et al. 2011), BRAF V600E 증폭(Corcoran et al. 2010), MEK 돌연변이(Wagle et al. 2014), NRAS 돌연변이, 및 RTK 활성화(Nazarian et al. 2010 and Shi et al. 2014)가 포함된다. BRAF-/MEK-억제제 조합 치료법의 설정에서 내성 메커니즘이 나타나기 시작하고 BRAF 단일 제제 내성의 메커니즘을 반영한다(Wagle et al. 2014 and Long et al. 2014). 이들 유전적 사건은 모두 공통으로 ERK 신호전달을 재활성화하는 능력을 공유한다. 실제로, ERK 전사 표적에 의해 측정된 바와 같은 재활성화된 MAPK 경로 신호전달은 BRAF 억제제-내성 환자로부터의 종양 생검에서 흔하다(Rizos et al., 2014). 또한, ERK1/2 재활성화는 내성의 유전적 메커니즘의 부재 하에 관찰되었다(Carlino et al. 2015). 따라서, 지속가능한 임상학적 이점을 달성하기 위한 탐구는 연구자들이 다운스트림 MAPK 구성원인 ERK1/2를 표적으로 하는 추가의 제제를 평가하는데 초점을 맞추도록 하였다. ERK의 억제는 BRAF/MEK 억제에 대한 내성을 갖는 환자에게 중요한 임상학적 이점을 제공할 수 있다. ERK 패밀리 키나제는 BRAF 또는 MEK 억제제에 대해 내성인 이들 암을 포함하는 전임상학적 암 모델에서 치료학적 표적으로서의 가능성을 보여주었다(Morris et al. 2013 and Hatzivassiliou et al. 2012). 그러나, 이러한 ERK1/2 억제제의 잠재적 사용은 흑색종에서 획득된 내성을 넘어 확대된다.
ERK1/2의 표적화는 BRAF/MEK 치료법-재발 환자뿐만 아니라 MAPK의 공지의 동인(driver)을 갖는 임의의 종양 유형에서 합리적인 전략이다. ERK1 및 ERK2는 해당 경로의 다운스트림에 존재하므로, 이들은 업스트림 내성 메커니즘을 회피할 수 있는 MAPK 캐스케이드 내에서 특히 매력적인 치료 전략을 나타낸다. 여기서, MAPK 경로-의존적 암의 모델에서 BVD-523(울릭세르티닙)의 전임상학적 특성확인이 약물-나이브(naive) 및 BRAF/MEK 치료법 획득된-내성 모델을 포함하여 보고된다. BVD-523의 페이즈 I 용량-조사 연구의 결과는 본 저널에 동반 공개로서 포함된다. 실시예 17 내지 실시예 24를 참조한다.
본 발명에서, BVD-523은 시험관내 및 생체내 항암 활성을 갖는 ERK1/2의 강력한 고도로 선택적인 가역적 소분자 ATP-경쟁적 억제제인 것으로 밝혀졌다.
BVD-523(울릭세르티닙)은 높은 효력 및 ERK1/2 선택성을 지닌 신규한 가역적 ATP-경쟁적 ERK1/2 억제제로서 동정되었고 특성확인되었다. BVD-523은 MAPK(RAS-RAF-MEK) 경로 돌연변이를 갖는 세포에서 가장 현저하게 감소된 증식 및 향상된 카스파제 활성을 야기하였다. 생체내 BRAF V600E 이종이식 연구에서, BVD-523은 용량-의존적 성장 억제 및 종양 퇴행을 나타내었다. 흥미롭게도, BVD-523은 ERK1/2의 증가된 인산화에도 불구하고 표적 기질의 인산화를 억제하였다. BVD-523은 또한 단일 제제 및 조합 BRAF/MEK 표적화된 치료법에 대한 획득된 내성의 모델에서 항종양 활성을 입증하였다. BRAF V600E-돌연변이체 흑색종 세포주 이종이식 모델에서의 상승작용적 항증식 효과는 또한 BVD-523이 BRAF 억제와 조합으로 사용된 경우에 입증되었다. 이들 연구는 BVD-523이 이의 종양이 MAPK 경로의 업스트림 노드를 표적으로 하는 다른 치료법에 대해 획득된 내성을 갖는 암을 포함하는 ERK-의존성 암에 대한 치료제로서의 가능성이 있음을 시사한다.
실시예 10
신규한 ERK1/2 억제제인 BVD-523(울릭세르티닙)의 발견 및 초기 특성확인
고출력 소분자 스크린을 사용하여 최초로 동정된 리드(lead)의 광범위한 최적화(Aronov et al. 2009)에 따라, 신규한 아데노신 트리포스페이트(ATP)-경쟁적 ERK1/2 억제제인 BVD-523(울릭세르티닙)이 동정되었다(도 29a). BVD-523은 ERK2에 대해 0.04 ± 0.02nM의 Ki를 갖는 강력한 ERK 억제제이다. 이는 ERK2 억제에 대한 IC50 값이 증가하는 ATP 농도에 따라 선형적으로 증가함에 따라, ATP의 가역적인 경쟁적 억제제인 것으로 밝혀졌다(도 29b 및 도 29c). IC50은 10분 이상의 인큐베이션 시간 동안 거의 일정하게 유지되었고, 이는 BVD-523과 ERK2의 신속한 평형 및 결합을 시사한다(도 29d). BVD-523은 또한 0.3nM 미만의 Ki를 나타내는 재조합 ERK1(Rudolph et al. 2015)의 단단히 결합하는 억제제이다.
ERK2에 대한 BVD-523의 결합은 열량측정 연구를 사용하여 입증하였고, ERK 억제제 SCH772984 및 피라졸릴피롤을 사용하여 생성된 데이터와 비교하였다(Arovov et al. 2007). 양성 ΔTm 값(도 29e)에 의해 나타낸 바와 같이, 모든 화합물은 증가하는 농도에 따라 불활성 ERK2에 결합하여 이를 안정화시켰다. BVD-523 및 SCH-772984를 이용하여 관찰된 ΔTm의 10 내지 15도 변화는 저-나노몰 결합 친화성을 갖는 화합물과 일치한다(Fedorov et al. 2012). BVD-523은 인산화된 활성 ERK2(pERK2) 및 불활성 ERK2 둘 다에 대해 강한 결합 친화성을 입증하였다(도 29f). 불활성 ERK2와 비교하여 pERK2에 대해 더 강한 친화성이 관찰되었다. BVD-523은 음성 대조군 단백질 p38α MAP 키나제와 상호작용하지 않았다(도 29f).
BVD-523은 ERK1 및 ERK2 이외에도 75개의 키나제에 대한 생화학적 카운터-스크린(counter-screen)에 기초하여 우수한 ERK1/2 키나제 선택성을 입증하였다. ATP 농도는 모든 검정에서 Km과 거의 동일하였다. 2μM BVD-523에 의해 50% 초과로 억제된 키나제는 Ki 값(또는 겉보기 Ki; 표 21)을 생성하도록 재시험되었다. 14개의 키나제들 중 12개는 1μM 미만의 Ki를 가졌다. ERK2에 대한 BVD-523의 선택성은 0.3nM 미만의 Ki로 억제된(10배) ERK1을 제외한 시험된 모든 키나제에 대해 7000배 초과였다. 따라서, BVD-523은 ERK1/2의 매우 강력하고 선택적인 억제제이다.
표 21 BVD-523은 ERK1 및 ERK2 키나아제에 대한 선택성을 나타낸다.

실시예 11
BVD-523은 세포 증식을 우선적으로 억제하고 MAPK 경로-활성화 돌연변이를 갖는 암 세포주에서 시험관내 카스파제-3/7 활성을 향상시킨다
BVD-523 세포 활성은 다양한 계통 및 유전적 배경의 대략 1,000개의 암 세포주의 패널에서 평가되었다(도 30a 및 표 22). 세포주는 RAS 패밀리 구성원과 BRAF에서의 돌연변이 부재 또는 존재에 따라 MAPK 야생형(wt) 또는 돌연변이체로 분류되었다. 일부 MAPK-wt 세포주는 BVD-523에 민감성이었지만, 일반적으로 BVD-523은 MAPK 경로 변경을 갖는 세포에서 우선적으로 증식을 억제하였다.
이어서, 민감성 세포에 대한 BVD-523 치료의 성장 및 생존 영향을 특성확인하였다. 24시간 동안의 500nM 또는 2000nM의 BVD-523을 이용한 치료 후 BRAF V600E-돌연변이 흑색종 세포주 UACC-62에 대해 형광성 활성화 세포 분류(FACS: Fluorescence activated cell sorting) 분석을 수행하였다. 치료된 세포는 농도-의존적 방식으로 세포 주기의 G1 페이즈에 정지되었다(도 30b).
또한, 카스파제-3/7 활성을 다중 사람 암세포주에서의 아폽토시스의 척도로서 분석하였다. 72시간 동안의 BVD-523을 이용한 치료 후, 카스파제 3/7에서 농도- 및 세포주-의존적 증가가 관찰되었다(도 30c). BVD-523 치료는 BRAF V600 돌연변이(A375, WM266 및 LS411N)를 갖는 MAPK-활성화된 세포주의 서브세트에서 확연한 카스파제-3/7 유도를 초래하였다. 이는 MAPK 경로-돌연변이 암 세포주에서의 BVD-523에 의한 증식의 우선적 억제에 대한 초기 관찰과 일치한다(도 30a).
BVD-523에 의해 유발된 신호전달에 대한 효과 및 작용의 메커니즘을 추가로 특성확인하기 위해, 다양한 이펙터 및 MAPK-관련 단백질의 수준을 BVD-523-치료된 BRAF V600E-돌연변이 A375 흑색종 세포에서 평가하였다(도 30d). BVD-523 치료의 4시간 및 24시간 후 포스포(Phospho)-ERK1/2 수준이 농도-의존적 방식으로 증가하였다. 2μM의 BVD-523 치료로 관찰된 pERK1/2의 우세한 농도-의존적 증가에도 불구하고, ERK1/2 표적 RSK1/2의 인산화는 4시간째 및 24시간째 둘 다에서 감소되었고, 이는 지속적 억제와 일치한다. ERK1/2 활성의 원위 마커인 DUSP6의 전체 단백질 수준도 4시간째 및 24시간째에 약화되었다. BVD-523을 이용한 24시간의 치료 후, 아폽토시스성 마커 BIM-EL은 용량-의존적 방식으로 증가하였고, 한편 사이클린 D-1 및 pRB는 2μM에서 약화되었다. 모든 효과는 온-표적(on-target) ERK1/2 억제와 일치한다.
실시예 12
BVD-523은
BRAF
V600E
-돌연변이 암세포주 이종이식 모델에서의 생체내 항종양 활성을 입증한다
BVD-523이 농도-의존적 방식으로 증식을 감소시켰고 아폽토시스를 유도하였다는 본 발명자들의 시험관내 발견에 기초하여, MAPK/ERK-경로 의존성을 이용한 모델에서 생체내 항-종양 활성을 입증하기 위해 경구 위관영양법(oral gavage)에 의해 BVD-523을 투여하였다. 흑색종(세포주 A375) 및 결장직장암(세포주 Colo205)의 이종이식 모델을 이용하였고, 이의 둘 다는 BRAF V600E 돌연변이를 지닌다.
A375 세포주의 이종이식편에서, BVD-523 효능을 치료 14일 후에 대조군 세포독성 알킬화제인 테모졸로마이드와 비교하였다. BVD-523은 1일 2회 50mg/kg(BID)에서 시작하여 유의한 용량-의존적 항종양 활성을 입증하였다(도 31a). 50 및 100mg/kg BID의 용량은 종양 성장을 유의하게 약화시켰고, 종양 성장 억제(TGI)는 각각 71%(P=0.004) 및 99%(P<0.001)였다. 100mg/kg BID 그룹에서 7개의 부분적 퇴행(PR: partial regression)이 나타났고; 임의의 다른 그룹에서는 퇴행 반응이 나타나지 않았다. 관찰된 효능은 바람직하게는 테모졸로마이드의 효능과 비교하였고, 이는 75mg/kg 및 175mg/kg으로 투여했을 때 각각 34%(P>0.05) 및 78%(P=0.005)의 경미한 용량-의존적 TGI를 초래하였다.
추가로, BVD-523은 Colo205 사람 결장직장암 세포주 이종이식 모델에서 항종양 효능을 입증하였다(도 31b). BVD-523은 50, 75 및 100mg/kg BID의 용량에서 유의한 용량-의존적 종양 퇴행을 재차 나타내었고, -48.2%, -77.2%, 그리고 -92.3%의 평균 종양 퇴행 T/Ti(T = 치료 종료, Ti = 치료 개시)이 수득되었다(모두 P<0.0001). 최소 용량의 BVD-523(25mg/kg BID)에서는 퇴행이 관찰되지 않았지만; 25.2%(P <0.0001)의 T/C(T = 치료, C = 대조군)로 유의한 종양 성장 억제가 관찰되었다. 잘 허용되지는 않지만, 양성 대조군 화학 치료학적 제제 이리노테칸(CPT-11)은 유의한 항종양 활성을 나타내었고, 6.4%의 T/C로 Colo205 종양 성장을 억제하였다(P<0.0001). 그러나 CPT-11은 마우스에서의 이의 최대 허용 용량에서도 50, 75 또는 100mg/kg BID의 용량의 BVD-523만큼 효과적이지 못하였다.
약동학 및 약력학 사이의 관계를 확립하기 위해, 단일 100mg/kg 경구 투약 후 24-시간 기간에 걸친 면역조직화학 및 동위원소-태그된 내부 표준 질량 분광광도법에 의해 BVD-523 혈장 농도를 종양에서 측정된 pERK1/2 수준과 비교하였다(도 31c). ERK1/2의 인산화는 치료되지 않은 종양(0시간째)에서 낮았다. BVD-523을 이용한 치료 후, ERK1/2 인산화는 투약-후 1시간째부터 투약-후 8시간째의 최대 수준까지 꾸준히 증가하였고, 이어서 24시간째까지 투약-전 수준으로 회복되었다. pERK1/2의 이러한 증가는 BVD-523 약물 혈장 농도와 상관관계가 있었다. BVD-523 치료로 증가된 pERK1/2의 생체내 관찰은 초기의 시험관내 발견과 일치한다(도 30d).
실시예 13
BVD-523은 증가된 ERK1/2 인산화에도 불구하고 ERK1/2 기질 억제를 초래한다
다른 공지의 ERK1/2 억제제(SCH772984, GDC-0994 및 Vx-11e)(Morris et al. 2013 및 Liu et al. 2015)에 비교하여 신호전달에 대한 BVD-523의 영향을 조사하기 위해, ERK 억제에 대한 민감성을 갖는 다양한 세포주에서 대략 40개의 단백질의 대규모 역상 단백질 어레이(RPPA: reverse phase protein array)를 사용하였다. BRAF 및 RAS에서 공통적 변경을 갖는 세포주를 검정하였다: BRAF V600E 돌연변이 세포주 A375, Colo205 및 HT29; KRAS G12C-돌연변이 세포주 MIAPACa-2; KRAS G13D-돌연변이 세포주 HCT116; 및 비정형(atypical) HRAS F82L 돌연변이를 갖는 AN3Ca. 단백질 수준의 변화는 디메틸 설폭사이드(DMSO)-처리된 모세포 대조군으로부터의 백분율 변화로서 나타낸다(도 32a 및 표 23). 모든 ERK 억제제는 ERK1/2(pERK1/2[ERK1/2-T202, -Y204])의 인산화를 제외하고는 정성적으로 유사한 단백질 효과를 유발하였고; SCH7722984는 모든 세포주에서 pERK1/2를 억제하였고, 한편 BVD-523, GDC-0994 및 Vx-11e는 pERK1/2를 현저하게 증가시켰다. pERK1/2의 근위 및 원위 표적인 포스포-p90 RSK(pRSK1) 및 사이클린 D1은 ERK1/2 인산화의 정도에 관계없이 시험된 모든 억제제에 의해 유사하게 억제되었다(도 32b). BVD-523에 대한 이들 독립적인 결과는 A375 세포에서의 웨스턴 블롯에 의해 현저하게 상승된 pERK1/2에도 불구하고, pERK1/2 및 불활성 ERK1/2의 BVD-523 결합 및 안정화를 입증하는 단백질-결합 연구(도 29e 및 도 29f) 이외에도 ERK1/2 기질인 RSK1/2의 인산화가 여전히 억제되어 있었음을 보여주는 연구(도 32d)와 일치한다. 따라서 증가된 pERK1/2 수준을 측정하는 것은 BVD-523에 대한 임상학적 약력학적 바이오마커로서 간주될 수 있고, 한편 pRSK1 및 DUSP6와 같은 ERK1/2 표적의 억제를 정량하는 것도 또한 유사한 목적을 제공할 수 있다.
RPPA 데이터세트(도 32a)에서 추가적인 단백질 변화가 주목된다. 감소된 pS6-리보솜 단백질은 모든 화합물을 갖는 모든 세포주에서 입증되는 바와 같이 ERK1/2 억제의 다른 약력학적 마커인 것으로 나타난다(도 32b). 또한, pAKT의 현저한 유도는 각각의 ERK1/2 억제제가 세포주 A375 및 AN3CA 세포에서 pAKT를 유도한 경우 세포주-의존적 관찰인 것으로 나타난다(도 33). 흥미롭게도, 생존 마커 인 pBAD의 억제 정도는 시험된 다른 ERK1/2 억제제와 비교하여 GDC-0994에 의한 pBAD의 적당한 억제만으로 화합물들 사이에 상이한 것으로 나타난다(도 32a).
이어서, BVD-523이 BRAF V600E-돌연변이 RKO 결장직장 세포주(도 32c)에서 ERK1/2 및 다운스트림 표적 pRSK의 세포 국재화에 영향을 미치는 방법을 조사하였다. 나머지 세포에서, ERK1/2는 세포질에 국재하고, 1회 자극된 pERK1/2는 표적 세포소기관, 특히 전사 표적이 활성화된 핵으로 이동한다(Wainstein et al. 2016). DMSO-치료된 대조군 세포에서, pERK1/2는 핵 및 세포질 분획 둘 다에서 분명하고, 이는 이러한 세포주에서 BRAF V600E의 존재로 인하여 MAPK 경로 활성을 반영할 가능성이 있다. BVD-523를 이용한 치료는 핵 및 세포질에서 상승된 pERK1/2를 초래하였고, DMSO-치료된 세포와 비교하여 핵의 총 ERK1/2의 완만한 증가도 초래하였고, 이는 pERK1/2의 화합물-유도된 안정화가 일부 핵 전좌(translocation)를 자극한다는 것을 시사한다. 상기 구획 둘 다에서 pERK1/2가 증가했음에도 불구하고, pRSK 수준은 DMSO 대조군에 비해 세포질 및 핵 구획에서 더 낮다. 비교인자 MAPK 신호전달 억제제(즉, 트라메티닙, SCH7722984, 다브라페닙)는 핵 및 세포질 구획에서의 낮은 수준에 의해 반영되는 바와 같이 ERK1/2 및 RSK의 인산화를 억제하였다. 이들 데이터는 재차 pERK1/2의 BVD-523-관련된 증가가 세포질 및 핵 둘 다에서 분명함을 시사하지만; 이는 표적 기질의 활성화로 해석되지 않는다. 이는 도 30d 및 도 32a에 제시된 데이터와 일치한다.
실시예 14
BVD-523은 BRAF 및 MEK 억제제 내성의 시험관내 모델에서 활성을 나타냈다
BRAF 및 MEK 억제제에 대한 내성의 출현은 이들의 임상학적 효능을 제한한다. 여기서, 실험은 시험관내 BRAF(다브라페닙), MEK(트라메티닙) 및 ERK1/2(BVD-523) 억제에 대한 내성의 발달을 모델링하고 비교하고자 하였다. 수개월에 걸쳐, BRAF V600E-돌연변이 A375 세포를 점차 증가하는 농도의 각각 억제제에서 배양하였다. 약물-내성 A375 세포주는 고농도의 트라메티닙 또는 다브라페닙에서의 성장 후에 용이하게 수득되었고, BVD-523에 대한 내성을 갖는 세포주를 개발하는 것은 어려운 것으로 판명되었다(도 34a). 전반적으로, 이들 시험관내 데이터는 유사한 표적 억제를 수득하는 농도에서 BVD-523에 대한 내성이 다브라페닙 또는 트라메티닙에 비해 지연되고, 진료소에서의 지속가능한 반응으로 해석될 수 있음을 시사한다.
ERK1/2 신호전달에 대한 재활성화 및 의존성은 BRAF/MEK 억제에 대한 획득된 내성의 공통의 특성이고(Morris et al. 2013 및 Hatzivassiliou et al. 2012); 따라서, 획득된 내성의 시험관내 모델에서 BVD-523의 활성을 평가하였다. 우선, 기술된 증가된 농도 방법을 사용하여 다브라페닙 및 트라메티닙 조합-내성 A375 집단을 얻었다. BRAF/MEK 조합-내성 집단에서의 다브라페닙, 트라메티닙 및 BVD-523에 대한 모세포 A375로부터의 IC50 및 IC50-배수 변화를 표 24에 나타낸다. BVD-523 IC50은 완만하게 변화하였고(2.5배), 한편 다브라페닙 및 트라메티닙은 보다 유의하게 변화하였다(각각 8.5배 및 13.5배)(표 24). 세포독성제 파클리탁셀을 대조군으로서 시험하였고, 효력의 완만한 변화만이 관찰되었다. 이들 데이터는 BRAF/MEK 치료법 내성의 설정에서 BVD-523의 조사를 지지하지만, 이 세포 집단에서의 내성의 메커니즘은 여전히 특성확인되어야 한다.
표 24 BRAF/MEK 억제 모델에서의 BVD-523 활성

BRAF 억제제 내성의 공지의 메커니즘을 갖는 모델에서 ERK1/2 억제의 취급용이성(tractability)을 추가로 조사하기 위해, AAV-매개된 유전자 표적화를 사용하여 MEK1 Q56P-활성화 돌연변이의 조작된 이형접합성 녹-인(knock-in)의 존재 또는 부재에 대해 동질유전자인 1쌍의 RKO BRAF V600E-돌연변이 세포주를 생성하였다(Trunzer et al. 2013 및 Emery et al. 2009). MEK1 Q56P를 포함하는 MEK1/2 돌연변이는 환자에서 단일 제제 BRAF 및 조합 BRAF/MEK 치료법-획득된 내성 둘 다에 연루되었다(Wagle et al. 2011, Wagle et al. 2014, Emery et al. 2009 및 Johnson et al. 2015). 단일-제제 검정은 모 BRAF V600E::MEK1 wt 세포와 비교하여, 이중-돌연변이 BRAF V600E::MEK1 Q56P 세포가 BRAF 억제제인 베무라페닙 및 다브라페닙 및 MEK 억제제인 트라메티닙에 대해 현저하게 감소된 민감성을 나타내었음을 입증하였다(도 34b). 대조적으로, BVD-523에 대한 반응은 모세포 및 MEKQ56P-돌연변이 세포 둘 다에서 본질적으로 동일하고, 이는 BVD-523이 이러한 획득된 내성의 메커니즘에 감수성이지 않음을 나타낸다. 이들 결과는 2개의 독립적으로 유도된 이중-돌연변이 BRAF V600E::MEK1 Q56P 세포주 클론에서 확인되었고, 이로써 결과는 관련되어 있지 않은 클론 인공물보다는 오히려 MEK1 Q56P 돌연변이의 존재와 구체적으로 관련되어 있음을 확인하였다. 또한, 제2의 기계론적으로 구별되는 ERK1/2 억제제(SCH772984)를 이용하여 유사한 결과가 관찰되었고, 이는 이들 관찰이 특히 ERK1/2의 기계론적 억제와 관련되어 있고 오프-표적 화합물 효과로 인한 것이 아니라는 개념을 지지한다.
BRAF V600E::MEK1 Q56P 세포주에서의 MAPK 경로 신호전달에 대한 BVD-523의 기계론적 영향을 추가로 특성확인하기 위해, 단백질 수준을 웨스턴 블롯에 의해 평가하였다(도 34c). 모 BRAF V600E RKO 세포에서 BRAF(베무라페닙), MEK(트라메티닙) 또는 ERK1/2(BVD-523) 억제제를 약리학적 활성 농도로 4시간 치료한 후 감소된 수준의 pRSK1/2가 관찰되었다. 대조적으로, 동질유전자 이중 돌연변이 BRAF V600E::MEK1 Q56P 세포는 BRAF 또는 MEK 억제제 치료 후 감소된 RSK 인산화를 나타내지 않았고, 한편 BVD-523은 모세포 RKO에 필적하는 수준으로 pRSK1/2를 억제하는데 여전히 효과적이었다. 유사하게, 모세포 RKO 및 BRAF V600E::MEK1 Q56P 둘 다에서의 BVD-523 치료 24시간까지 pRB가 감소되어 G0/G1 정지를 나타낸다.
획득된 KRAS 돌연변이는 또한 MAPK 경로 억제제에 대한 내성의 공지의 동인이다. 이러한 내성 메커니즘에 대한 BVD-523의 감수성을 이해하기 위해, 결장직장암 세포주 SW48에서 임상적으로 관련되어 있는 KRAS 돌연변이의 동질유전자 패널을 사용하였다. BVD-523에 대한 민감성을 MEK 억제제 셀루메티닙 및 트라메티닙과 비교하였다(도 34d). 파클리탁셀에 대한 민감성은 변경되지 않았다(도 37a). 몇몇의 돌연변이 KRAS 대립유전자는가 MEK 억제에 대한 강한 수준 내지 중간 정도 수준의 내성을 부여하였지만, BVD-523에 대한 민감성은 대다수의 대립유전자에 따라 변경되지 않았고, 민감성의 변화가 관찰된 경우, 이는 트라메티닙 또는 셀루메티닙을 이용하여 관찰된 정도가 아니었다. 전반적으로, 이들 데이터는 BVD-523이 MEK 억제제보다 이 문맥에서 더 효능성임을 시사한다.
실시예 15
BVD-523은 BRAF 억제제-내성 환자-유도된 흑색종 이종이식 모델에서의 생체내 활성을 입증한다
BRAF-/MEK-획득된 내성의 시험관내 모델에서 관찰된 BVD-523의 항종양 효과를 확인하고 확장시키기 위해, 베무라페닙에 대한 내성을 갖는 환자로부터 유도된 BRAF-내성 이종이식 모델을 이용하였다. BVD-523은 단독으로 그리고 50mg/kg BID의 다브라페닙과의 조합으로 28일 동안 100mg/kg BID의 경구 위관영양법에 의해 투약되었다(도 35). 예측된 바와 같이, 단일 제제 다브라페닙(22% TGI)에 대해 최소 항종양 활성이 입증되었다. BVD-523 활성은 비히클 대조군과 비교하여 유의하였고(P≤0.05), TGI는 78%였다. 이 모델에서, BVD-523을 다브라페닙과 조합하는 것은 76%의 TGI를 초래하였고(P≤0.05); 따라서, BRAF-획득된 내성의 이러한 모델에서 단일 제제 BVD-523와 비교하여 상기 조합에 대해 추가의 이점이 얻어지지 않았다.
실시예 16
BVD-523 및 BRAF 억제제를 이용한 조합 치료법은 유망한 항종양 활성을 제공한다
BRAF-돌연변이 암을 지닌 환자는 조합된 BRAF/MEK 치료법에 대한 내성을 획득할 수 있고(Wagle et al. 2014), 이는 MAPK 경로 내의 다른 조합 접근법의 고려를 보장한다. BRAF V600E-돌연변이 흑색종 세포주 G-361에서 BVD-523을 BRAF 억제제인 베무라페닙과 조합하는 것의 항-증식성 효과를 평가하였다. 예상한 바와 같이, 단일 제제 BVD-523 및 베무라페닙은 둘 다 활성이었고, 조합시 완만한 상승작용이 관찰되었다(도 37b). 이는 BRAF 억제제와 조합된 BVD-523이 BRAF V600E 돌연변이를 갖는 흑색종 세포주에서 적어도 부가적이고 잠재적으로 상승작용적임을 나타낸다. 또한, BRAF 억제제 + BVD-523에서 BRAF V600E 돌연변이 세포주(A375)의 연속 배양 후 시험관내에서 획득된 내성을 생성하는 것은 어려웠다. 대조적으로, 다브라페닙에 대한 내성의 생성만이 상대적으로 신속하게 발생하였다(도 37c). 심지어 다브라페닙 + 트라메티닙 전에 조합된 다브라페닙 및 트라메티닙에 대한 내성이 발생하였다.
조합된 BRAF 및 ERK 억제의 이점은 농도가 내약성에 의해 제한되지 않는 경우 시험관내 조합 연구에서 완전히 실현되지 않을 수 있다. 조합의 이점을 이해하기 위해, BRAF V600E-돌연변이 사람 흑색종 세포주 A375의 이종이식을 이용하여 생체 내에서 효능을 평가하였다. 조합 치료에 대한 주목할만한 반응으로 인하여, 조합 그룹에서의 투약은 종양 재성장을 모니터링하기 위해 20일째에 중단하였고, 42일째에 재개시하였다(도 36a). 45일째에 연구가 종결될 때까지 종양을 매주 2회 측정하였다. 대조군에 대한 종점까지의 중간값 시간(TTE: time to endpoint)은 9.2일이었고, 35.8일의 가능한 최대 종양 성장 지연(TGD)이 100%로서 정의되었다. 테모졸로마이드 치료는 1.3일의 TGD(4 %)를 초래하였고, 퇴행을 초래하지 않았다. 50 및 100mg/kg 다브라페닙 단독 치료법은 각각 6.9일(19%) 및 19.3일(54%)의 TGD, 유의한 생존 이점(P<0.001), 및 100mg/kg 그룹에서의 1 PR을 산출하였다. 100mg/kg BVD 523 단독 치료법은 9.3일(26 %)의 TGD, 유의 한 생존 이점(P<0.001) 및 2개의 지속가능한 완전 반응을 초래하였다. 다브라페닙의 BVD-523과의 조합은 각각 주목할만한 퇴행 반응을 갖는 최대 가능한 100% TGD 및 이들의 상응하는 단독 치료법과 비교하여 통계학적으로 우수한 전반적 생존(P<0.001)을 산출하였다. 최저 용량 조합은 주목할만한 7/15 무-종양 생존자(TFS)를 산출하였고, 3개의 보다 높은-용량 조합은 치유적(curative) 또는 준-치유적(near-curative) 활성과 일치하는 총 43/44 TFS를 산출하였다(도 36b). 요약하면, 다브라페닙의 BVD-523과의 조합은 둘 중 어느 하나의 단일 제제에 비해 더 많은 수의 TFS와 우수한 효능을 산출하였다.
개시 종양 용적이 대략 75 내지 144㎣인 A375 이종이식 모델에서의 BVD-523 + 다브라페닙의 활성에 기초하여, 추적(follow-up) 실험을 수행하여 "단계상향된(upstaged)" A375 이종이식편(평균 종양 개시 용적, 700 내지 800㎣)에서 조합 치료법의 효능을 측정하였다(도 36c). 대조군에 대한 중간값 TTE는 6.2일이었고, 이는 53.8일의 최대 가능한 TGD를 확립하였고, 이는 60일 연구 동안 100% TGD로서 정의되었다. BVD-523 100mg/kg 단독 치료법은 무시할만한 TGD(0.7일, 1%)를 산출하였고, 대조군으로부터의 유의한 생존 차이를 산출하지 않았다(P>0.05). TTE들 및 2개의 PR의 분포는 BVD-523 단독을 이용한 치료에 대한 반응자들의 서브세트가 존재할 수 있었음을 시사하였다. 다브라페닙 50mg/kg 단독 치료법은 효과적이었고, 이는 46.2일(86 %)의 TGD 및 대조군과 비교하여 유의한 생존 이점(P<0.001)을 수득하였다. 이 그룹은 11마리의 평가가능한 마우스들 중에서 3마리의 TFS를 포함하여 5마리의 CR 및 5마리의 PR을 가졌다(도 36d). 다브라페닙의 BVD-523과의 조합 둘 다는 대조군에 비해 최대 100% TGD 및 유의한 생존 이점을 산출하였다(P<0.001). 각각의 조합은 퇴행 활성에 있어서 분석에서 구별이 있었지만 평가가능한 마우스들 중에서 100% 퇴행 반응을 산출하였다. 25mg/kg 다브라페닙 및 50mg/kg BVD-523 조합은 2마리의 PR 및 8마리의 CR, 6/10 TFS를 가졌고, 반면 50mg/kg 다브라페닙 및 100mg/kg BVD-523 조합은 60일째에 11/11TFS를 가졌다(도 36d). 전반적으로, 이들 데이터는 BRAF V600-돌연변이 흑색종에서 BVD-523의 BRAF-표적화 치료법과의 최전선 조합에 대한 이론적 근거를 지지하고, 이러한 변경을 갖는 다른 종양 유형으로 확장될 가능성이 있다.
논의
BVD-523은 생체내 및 시험관내 암 모델에서 활성을 갖는 ERK1/2의 강력한 고도로 선택적인 가역적 소분자 ATP-경쟁적 억제제이다. 시험관내에서, BVD-523은 몇몇의 사람 종양 세포주, 특히 이의 작용 메커니즘과 일치하는 MAPK 신호전달 경로에서 활성화 돌연변를 지닌 종양 세포주들에 대한 강력한 억제를 입증하였다. BVD-523은 ERK1/2, pRSK 및 총 DUSP6 단백질 수준의 직접적 기질의 억제를 포함하는 다운스트림 표적 및 이펙터 단백질의 변화를 유발하였다. 이들 발견은 다른 ERK1/2 억제제에 대한 이전 연구의 발견과 일치하고, 이는 ERK1/2 억제를 이용한 pRSK의 효과적 억압을 입증하였다(Morris et al. 2013 및 Hatzivassiliou et al., 2012). 흥미롭게도, BVD-523 치료는 시험관내에서 그리고 생체내에서 ERK1/2 인산화의 현저한 증가를 초래하였다. 본 발명자들의 발견과 유사하게, pERK1/2의 증가가 ERK1/2 억제제 Vx11e에서 보고되었고; 반대로, SCH772984를 이용하여 pERK1/2 억제가 발생한다(Morris et al. 2013). 시험된 다양한 ERK1/2 억제제들 중에서 pERK1/2 수준의 차이가 관찰되었지만, 다운스트림 이펙터(즉, pRSK1 및 총 DUSP6)는 유사하게 억제되었다. 이들 발견은 pRSK1과 같은 ERK1/2 표적 기질을 정량하는 것이 ERK1/2 활성의 BVD-523-매개된 억제에 대한 신뢰할 수 있는 약동학적 바이오마커로서 작용할 수 있음을 시사한다.
BRAF(다브라페닙, 베무라페닙) 및 MEK(트라메티닙, 코비메티닙) 억제제는 MAPK 경로를 특히 BRAF V600 돌연변이를 갖는 환자에서의 치료 표적으로서 입증하지만, 항종양 반응은 획득된 내성의 출현 및 후속적 질환 진행에 의해 제한된다. 내성은 보상 신호전달 분자의 상향조절 및 활성화(Nazarian et al. 2010, Villanueva et al. 2010, Johannessen et al. 2010 and Wang et al. 2011), 표적 유전자의 증폭(Corcoran et al. 2010) 및 경로 구성원의 활성화 돌연변이(예를 들면, RAS, MEK)에 기인하였다(Wagle et al. 2011, Emery et al. 2009 and Wang et al. 2011). ERK1/2 경로의 재활성화는 획득된 내성 메커니즘의 한 공통의 결과이다. BRAF V600E-돌연변이 흑색종 세포주 A375에 도입되었을 때, MEK Q56P는 MEK 및 BRAF 억제에 대한 내성을 부여하였다(Wagle et al., 2011). 대조적으로, BVD-523은 조작된 MEK Q56P 세포주에서 강력한 저해 활성을 보유하였고, 이는 ERK1/2 억제가 BRAF/MEK 치료에 반응하여 발생할 수 있는 업스트림 활성화 변경의 설정에 효과적임을 나타낸다. 획득된 내성의 맥락에서 BVD-523에 대한 역할의 추가의 증거로서, BVD-523의 효능은 베무라페닙에 대해 질환이 진행된 환자로부터의 종양 샘플로부터 유도된 이종이식 모델에서 분명하였고; BRAF 억제제인 다브라페닙은 이 모델에서 효과적이지 않았다. 이들 데이터는 BRAF/MEK 내성의 설정에서 ERK1/2을 표적화하기 위한 역할을 지지하고, 이전에 발표된 결과를 보완한다(Morris et al. 2013 및 Hatzivassiliou et al. 2012). MAPK 경로의 억제제에 대한 내성을 추가로 특성확인하기 위해, BVD-523에 대한 내성의 출현이 조사되었다. BVD-523을 이용한 암세포의 단일 제제 처리는 지속가능하였고 업스트림 MAPK 신호전달 구성원을 표적으로 하는 다른 제제(즉, 다브라페닙, 트라메티닙)와 비교하여 내성을 발현하는 것이 더 어렵다는 것이 밝혀졌다. 이는 잠재적으로 BVD-523이 ATP 결합 부위의 보다 보존된 활성 확인을 우선적으로 표적으로 한다는 사실로 인하여, ERK1/2-표적화제에 대한 내성을 획득하는 것은 BRAF 또는 MEK 치료법에 대한 내성을 획득하는 것보다 달성하기 어려움을 시사할 수 있다. 그러나, 다른 ERK1/2 억제제에 대한 시험관내 연구는 내성을 유도하는 ERK1/2의 특정 돌연변이체를 확인하였고(Jha et al. 2016 및 Goetz et al. 2014); 이러한 특정 돌연변이는 ERK1/2 억제제-재발 환자로부터의 임상학적 샘플에서 아직 확인되지 않았다.
BVD-523을 이용한 ERK1/2 억제의 잠재적인 임상학적 이점은 BRAF/MEK 치료법-내성 환자의 설정을 넘어 확대된다. ERK1/2는 이러한 MAPK 경로 내에서 다운스트림 마스터 노드이므로, 종양 성장이 MAPK 신호전달에 의존하는 다수의 암 설정에서 이의 억제가 매력적이다. 모든 암의 대략 30%는 RAS 돌연변이를 갖고; 따라서 BVD-523을 이용한 다운스트림 ERK1/2의 표적화는 이들 암에 대한 합리적인 치료법이다. 또한, Hayes et al.에 의한 연구로부터의 결과는 KRAS-돌연변이 췌장암에서 연장된 ERK1/2 억제가 노화-유사 성장 억압과 관련되어 있음을 나타낸다(Hayes et al., 2016). 그러나, RAS 돌연변이의 설정에서 MAPK 신호전달의 최대 및 지속가능한 약화를 위해 조합 접근법이 필요할 수 있다. 예를 들면, KRAS-돌연변이 결장직장암 세포의 MEK 억제는 MEK 억제에 대한 반응을 약화시키는 ErbB 패밀리 활성화의 적응성 반응을 초래한다(Sun et al., 2014). BVD-523을 이용한 ERK1/2 억제 후 유사한 상황-특이적 적응 반응이 발생할 수 있다. 다양한 유전적 프로파일 및 암 조직학을 위한 최적의 치료법 조합이 진행중인 연구의 주제이다. BRAF V600 및 RAS 돌연변이 이외에도, MAPK를 유도하는 다른 변경이 발생하고 있다. 예를 들면, RAF 이량체화를 촉진시키는 신규한 RAF 융합 및 비정형 비-V600 BRAF 돌연변이는 MAPK 경로를 활성화시킨다(Yao et al. 2015). BRAF V600-돌연변이 단량체 단백질을 억제하는 베무라페닙 및 다브라페닙과 같은 BRAF 억제제는 이량체화-의존적 방식으로 MAPK 신호전달을 유도하는 비정형 RAF 변경에서 불활성인 것으로 나타났다(Yao et al. 2015). 그러나, 이들 종양에서 다운스트림 ERK1/2를 표적으로 하는 BVD-523을 이용한 치료는 충족되지 않은 의학적 요구를 해소하는 신규 접근법일 수 있다.
BRAF V600-돌연변이 흑색종 종양의 설정에서, 조합된 BRAF 및 MEK 억제는 동일한 경로의 상이한 노드를 표적으로 하는 제제가 치료 반응 및 지속기간을 향상시킬 수 있는 방법을 예시한다. 사람 흑색종 세포주 A375의 BRAF V600E-돌연변이 이종이식편에서의 본 발명자들의 조합 연구는 BVD-523 및 BRAF 억제제와의 조합 치료법을 지지한다. 상기 조합은 치유 반응과 일치하는 결과를 포함하는 단일 제제 처리에 비해 우수한 이점을 입증하였다. 조합된 BRAF/BVD-523 치료법의 임상학적 효능 및 내약성은 여전히 측정되어야 한다. BRAF/ERK1/2 조합이 적어도 표적화된 BRAF/MEK 조합에 대한 효능에서 비교될 것으로 기대하는 것은 무리일 수 있다. 또한, BVD-523에 대한 획득된 내성이 다른 MAPK 경로 억제제와 비교하여 달성하기가 더 어렵다는 시험관내 관찰은 BRAF/BVD-523 억제제 조합이 보다 지속가능한 반응을 제공할 가능성이 있음을 시사한다.
또한, 흑색종에 대한 면역 치료법을 사용하여 유의한 진전이 이루어졌다. 미국 FDA는 세포독성 T-림프구 항원-4 표적화된 제제 이필리무맙 및 프로그래밍된 사멸-1 억제제 펨브롤리주맙 및 니볼루맙을 포함하는 진행성 흑색종의 치료를 위한 다양한 면역 체크포인트(checkpoint) 억제제를 승인하였다. BVD-523을 이러한 면역 치료법과 조합하는 것은 매력적인 치료학적 옵션이고; 투약 스케쥴을 탐구하기 위해 그리고 상승작용적 반응이 달성될 수 있는지 여부를 평가하기 위해 추가의 조사가 보장된다.
전임상학적 데이터에 기초하여, BVD-523은 환자의 종양이 다른 치료법에 대해 획득된 내성을 갖는 환자들을 포함하는 MAPK 신호전달에 의존하는 악성 종양을 지닌 환자의 치료에 대한 가능성을 가질 수 있다. BVD-523의 임학적 개발은 하기에 설명되어 있다. 실시예 17 내지 실시예 24를 참조한다.
실시예 17
진행성 고형 종양을 지닌 환자에서의 혁신 신약(First-in-Class) 신규한 경구 ERK1/2 키나제 억제제 BVD-523(울릭세르티닙)의 페이즈 I 용량-단계적상승 연구
본 발명은 진행성 고형 종양을 지닌 환자의 치료를 위한 ERK1/2 억제제의 혁신 신약 용량-단계적 상승 연구를 기술한다. BVD-523은 유리한 약동학 및 임상학적 활성의 초기 증거와 함께 허용가능한 안전성 프로필을 갖는다.
RAS-RAF-MEK-ERK 캐스케이드를 통한 미토겐-활성화된 단백질 키나제(MAPK) 신호전달은 종양형성에 중요한 역할을 하고; 따라서 치료학적 표적으로서 유의한 관심을 끌고 있다. 이러한 유비쿼터스(ubiquitous) 경로는 단백질 키나제 RAF, MEK1/2 및 ERK1/2의 캐스케이드 업스트림의 RAS로 구성된다. RAS는 GTP 결합에 의해 활성화되고, 결국 순차적으로 각각의 단백질 키나제의 활성화를 초래한다. 이들은 MEK1/2에 대한 유일한 생리학적 기질인 것으로 밝혀지지만, ERK1/2는 전사 인자 Elk1, c-Fos, p53, Ets1/2 및 c-Jun을 포함하여 세포질 및 핵에 다수의 표적을 갖는다(Shaul et al. 2007). ERK1/2 활성화 및 키나제 활성은 리보솜 S6 키나제(RSK) 패밀리 구성원의 활성화를 포함하는 각종 메커니즘을 통해 세포 증식, 분화 및 생존에 영향을 미친다(Romeo et al. 2012).
RAS-RAF-MEK1/2-ERK1/2 신호전달 경로의 구성적이고 비정상적인 활성화가 확인되었고 다수의 암의 발달 또는 유지에 연루되어 있다(Schubbert et al. 2007 및 Gollob et al. 2006). KRAS, NRAS 및 HRAS와 같은 RAS 패밀리 유전자 내의 돌연변이가 가장 흔하며, 사람 암의 30%에서 활성화 RAS 돌연변이가 발생한다(Schubbert et al. 2007). KRAS 돌연변이는 췌장암(>90%)(Kanda et al. 2012), 담관암(3% 내지 50%)(Hezel et al. 2014), 결장직장암(30% 내지 50%)(Arrington et al. 2012), 폐암(27%)(Pennycuick et al. 2012), 난소암(15% 내지 39%)(Dobrzycka et al. 2009), 및 자궁내막양 자궁내막암(18%)(O'Hara and Bell 2012)에서 우세하고; NRAS 돌연변이는 흑색종(20%)(Khattak et al. 2013) 및 골수성 백혈병(8% 내지 13%)(Yohe 2015)에서 우세하고; HRAS 돌연변이는 방광암(12%)(Fernandez-Medarde and Santos 2011)에서 우세하다. 특히 흑색종에서 RAF 패밀리 유전자 내의 돌연변이, 가장 현저하게는 BRAF가 빈번하다. BRAF 돌연변이는 악성 흑색종의 66%에서 그리고 광범위의 다른 암의 약 7%(Davies et al. 2002)에서 확인되었고, 한편 MEK 돌연변이는 흑색종에서 전체 빈도 8%로 드물게 발생한다(Nikolaev et. al. 2012). 대조적으로, 종양형성을 초래하는 ERK 돌연변이는 현재까지 드물게만 보고되어 왔다(Deschenes-Simard et al. 2014).
미국 식약청(FDA)은 BRAF V600-돌연변이 전이성 흑색종을 갖는 환자를 위한 단일 치료법으로서 2개의 선택적 BRAF 억제제인 베무라페닙 및 다브라페닙을 승인하였다(Taflinar[패키지 삽입물] 및 Zelboraf[패키지 삽입물]). 이들 표적화된 치료법에 관한 반응률은 BRAF V600 돌연변이를 갖는 환자에서 50% 만큼 높을 수 있지만, 반응의 지속기간은 보통 수년이 아닌 수개월로 측정된다(Hauschild et al. 2012 and McArthur et al. 2014). MEK1/억제제 트라메티닙은 또한 이러한 설정에서의 단독 치료법으로서 승인되어 있지만(Mekinist[패키지 삽입물]), 보다 흔하게는 BRAF 억제제 다브라페닙과 조합으로 사용된다. 다브라페닙과 조합하여 투여된 트라메티닙의 제1선 사용은 전반적인 독성을 증가시키지 않고 베무라페닙 단독 치료법과 비교하여 전반적인 생존을 훨씬 더 향상시키고(Robert et al. 2015), 이는 이러한 MAPK 신호전달 경로의 다중 단백질을 동시에 표적화하는 것의 잠재적 유용성을 강조한다. 이러한 치료학적 조합은 또한 각각의 단일 제제 단독과 비교하여 MEK 억제제-관련된 발진 및 BRAF 억제제-유도된 과증식성 피부 병변의 보다 낮은 발생률과 관련되어 있었다(Flaherty et al. 2012). 최근, 페이즈 III 시험은 또한 BRAF V600E/K 돌연변이-양성 흑색종을 지닌 환자에서 다브라페닙 + 트라메티닙 대 다브라페닙 단독을 이용하여 전반적 생존의 유의한 향상(25.1 대 18.7개월, 위험비[HR] 0.71, P=0.0107), 무진행 생존(PFS)(11.0 대 8.8개월, HR 0.6, P=0.0004) 및 전반적 반응(69% 대 53%; P=0.0014)을 입증하였다(Long et al. 2015). 유사하게, PFS의 유의한 향상(9.9 대 6.2개월, HR 0.51, P<0.001) 및 완전 반응(CR) 또는 부분 반응(PR)의 비율(68% 대 45%; P<0.001)은 코비메티닙 + 베무라페닙의 조합을 베무라페닙 단독과 함께 이용하여 입증되었다(Larkin et al. 2014). 이를 위해, BRAF V600E/K-돌연변이된 흑색종에 대한 베무라페닙 및 코베메티닙의 조합에 대해 최근에 FDA 승인이 인정되었다. 이들 및 관련 발견에 기초하여, BRAF 억제제 + MEK 억제제의 조합은 BRAF V600E/K 돌연변이를 함유하는 전이성 흑색종을 지닌 환자에 대한 표준 표적화된 치료 옵션이 되었다.
BRAF/MEK-표적화된 조합 치료법은 단일 제제 옵션을 초과하여 유의한 추가의 이점을 제공하는 것으로 입증되었지만, 대부분의 환자들은 궁극적으로는 약 12개월 후에 내성 및 질환 진행을 발달시킨다(Robert et al. 2015, Flaherty et al. 2012 및 Long et al. 2015). BRAF 스플라이싱 변이체의 생성, BRAF 증폭, NRAS 또는 MEK 돌연변이의 발달, 및 우회 경로의 상향조절을 포함하는 단일 제제 또는 조합 치료법 중 어느 하나 후에 획득된 내성의 몇몇의 메커니즘이 확인되었다(Poulikakos et al. 2011, Corcoran et al. 2010, Nazarian et al. 2010, Shi et al. 2014, Johannessen et al. 2010, Wagle et al. 2011, Wagle et al. 2014 및 Ahronian et al.). 이들 내성 메커니즘들 중 다수는 MAPK 경로 신호전달의 신속한 회복 및 단일 제제 BRAF 또는 조합 BRAF/MEK 억제제 치료법으로부터의 종양 세포의 도피를 가능하게 하는 ERK 신호전달의 재활성화가 중요하다(Paraiso et al. 2010). ERK 억제는 이러한 MAPK 신호전달 경로의 가장 원위의 마스터 키나제이므로 업스트림 메커니즘으로부터의 내성을 회피하거나 극복할 기회를 제공할 수 있다. 이는 소분자 억제제에 의한 ERK의 억제가 BRAF 및 MEK 억제제에 대한 내성의 출현을 억제하고 또한 이들 억제제에 대한 획득된 내성을 극복하도록 작용하였다는 전임상학적 증거에 의해 지지된다(Morris et al. 2013 and Hatzivassiliou et al. 2012).
BVD-523은 BRAF 및 RAS 돌연변이체 이종이식 모델에서 종양 성장을 감소시키고 종양 퇴행를 유도하는 것으로 밝혀진, 매우 강력하고 선택적이며 가역적인 ATP-경쟁적 ERK1/2 억제제이다. 또한, 단일 제제 BVD-523은 BRAF 및 MEK 억제제 둘 다에 대해 교차-내성인 사람 이종이식 모델을 억제하였다. 실시예 9 내지 실시예 16을 참조한다. 따라서, 최대 내약 용량 및 추가의 연구를 위한 권장 용량 둘 다를 확인하기 위해 경구 BVD-523의 개방-표지 최초 사람(first-in-human) 연구(Clinicaltrials.gov identifier, NCT01781429)가 수행되었다. 또한 본 연구는 진행성 암을 지닌 환자의 약동학적 특성 및 약력학적 특성 및 예비 효능을 평가하는 것을 목적으로 하였다.
실시예 18
환자 특성
총 27명의 환자가 등록되었고, 2013년 4월 4일부터 2015년 12월 1일까지 적어도 1회 용량의 연구 약물을 투여받았다. 기저선 인구통계 및 질환 특성은 표 25에 나타낸다. 중간값 환자 연령은 61세(범위, 33 내지 86세)였다. 환자들의 52%(14/27)는 남성이었고 63%(17/27)는 ECOG(Eastern Cooperative Oncology Group) 수행 상태가 1이었다. 흑색종이 가장 흔한 암이었다(30%; 이들 환자의 7/8에서 BRAF 돌연변이가 나타남). 나머지 환자들은 결장직장암(19%; 5/27), 유두상 갑상선암(15%; 4/27) 또는 비-소세포 폐암(NSCLC)(7%; 2/27)을 가졌고, 8명(30%)은 기타 암(2명 췌장암, 1명 충수암, 1명 비정상피종 생식 세포, 1명 난소암 3명 미지의 원발성 암)으로서 분류되었다. 대다수의 환자들은 2선 또는 보다 이전의 치료선의 전신 치료법을 투여받았고, 41%(11/27)는 2 내지 3선을 투여받았고, 48%(13/27)는 3선 초과의 전신 치료법을 투여받았다.
표 25 환자들의 기저선 인구통계 및 임상학적 특성


실시예 19
RSK1/2 인산화에 대한 BVD-523의 생체외 영향
임상학적 연구를 지원하기 위해 사용될 수 있는 생체외 바이오마커 검정은 ERK 활성에 대한 BVD-523의 억제 효과를 입증하기 위해 개발되었다. 상기 검정은 BVD-523, 다브라페닙, 트라메티닙 및 베무라페닙과 같은 MAPK 신호전달의 억제제가 BRAF 돌연변이 암 세포주에서 억제제 농도의 함수로서 RSK 인산화를 억제하는 것으로 밝혀진 경우 전임상 세포 데이터를 확장한다. 실시예 9 내지 실시예 16을 참조한다. 구체적으로, 전혈에서 ERK 기질인 RSK1의 포르볼 12-미리스테이트 13-아세테이트(PMA: phorbol 12-myristate 13-acetate)-자극된 인산화의 ERK 억제제-의존적 억제를 표적 마커로서 사용하였다. BVD-523이 건강한 지원자 유래의 전혈에 직접 부가된 경우, PMA-자극된 RSK 인산화는 증가하는 농도의 BVD-523에 따라 감소하였다(도 38). 누적 데이터에 대한 평균 IC50은 BVD-523의 경우 461±20nM이었고, 10μM BVD-523에서 75.8±2.7%의 최대 억제를 가졌다. 최대 억제는 10μM BVD-523의 존재 하에 측정된 RSK 인산화로서 정의되었다. BVD-523 투약 직전에 또는 BVD-523 투약 후에 정의된 시점에서 수집한 환자-유도된 전혈 샘플을 유사하게 처리하였고 RSK 인산화 수준을 정량하였다.
실시예 20
용량 단계적상승, 용량-제한 독성(DLT), 최대 내약 용량(MTD) 및 권고 페이즈 II 용량(RP2D)
프로토콜에 따라, 5명의 단일 환자 코호트(10 내지 150mg 1일 2회[BID])는 DLT의 증거없이 진행되었다. BVD-523 노출을 보다 완전하게 특성확인하기 위해 300mg BID 코호트를 확장하였다. 600mg BID가 제공된 6명의 환자들 중 1명은 3등급 발진의 DLT를 경험하였다. 900mg BID 용량은 MTD를 초과하였고, 1명의 환자는 3등급 가려움증 및 상승된 아스파테이트 아미노트랜스퍼라제(AST)를 경험하였고, 다른 환자는 3등급 설사, 구토, 탈수 및 상승된 크레아티닌을 경험하였다(표 26). 750mg BID의 후속적 중간 용량도 MTD를 초과하였고, 1명의 환자에서의 3등급 발진 및 다른 환자에서의 2등급 설사의 DLT, 2등급 저혈압, 상승된 크레아티닌 및 빈혈이 있었다. 따라서, MTD와 RP2D는 600mg BID로 결정되었다.
표 26 주기 1(21일)에서의 용량-제한 독성

약어: AST, 아스파르테이트 트랜스아미나제, BID, 1일 2회; DLT, 용량-제한 독성; N/A, 이용불가
실시예 21
유해 사건(AE)
임의의 등급의 조사자-평가된 치료-관련 AE는 27명 중 26명(96 %)에서 나타났다. 가장 흔한 치료-관련 AE(30% 초과)는 발진(주로 여드름)(70%), 피로(59%), 설사(52%) 및 구역(52%)이었다(표 27). 치료-관련 AE로 인하여 4등급 또는 5등급의 치료 관련 AE 또는 중단된 치료를 경험한 환자는 없었다. 대부분의 사건은 1등급 내지 2등급이었고, 치료-관련 3등급 사건은 27명 중 13명(48%)에서 나타났다. 환자의 10% 이상에서 나타나는 3등급 치료-관련된 유일한 사건은 설사(15%) 및 증가된 간 기능 검사(11%)였고, 이의 전부는 600mg BID 용량 초과로 발생되었다.
표 27 환자들의 10% 이상에서의 BVD-523에 관련되어 있을 가능성이 있는/BVD-523에 확실히 관련되어 있는 유해 사건

14명의 환자는 총 28개의 중증의 AE(SAE)를 경험하였다. 이들 중 9개는 조사자에 의해 BVD-523에 관련되어 있거나 이와 관련되어 있을 가능성이 있는 것으로 간주되었고, 이는 탈수, 설사, 또는 상승된 크레아티닌(각각 2명), 구토, 구역 및 발열(각각 1명)을 포함하였다. 모든 다른 SAE는 BVD-523을 이용한 치료와 관련되어 있지 않은 것으로 간주되었다. 연구 동안 3명의 환자들에서 AE로부터 초래되는 용량 감소가 발생하였다: 1명의 환자는 600mg BID에서 300mg BID로 감소되었고, 2명의 환자는 900mg BID에서 600mg BID로 감소되었다.
실시예 22
약동학
BVD-523의 단일-용량 및 정상-상태 약동학은 도 39a 및 표 28에 요약되어 있다. 일반적으로, 경구 투여된 BVD-523은 진행성 악성 종양을 지닌 환자에서 서서히 흡수되었다. 최대 농도(Cmax)에 도달한 후, 혈장 BVD-523 수준은 약 2 내지 4시간 동안 지속되었다. 후속적으로, 혈장 약물 농도는 서서히 감소하였다. 혈장 약물 농도는 아침 투약 후 최대 12시간째까지만 측정되었으므로, 유효 또는 말단 페이즈 제거율을 계산할 수 없었다. BVD-523 약동학은 600mg BID까지 투여했을 때 Cmax 및 곡선 아래 면적(AUC) 둘 다의 관점에서 선형이었고 용량 비례적이었다. 용량이 600에서 900mg BID로 증가함에 따라 노출의 추가의 증가는 관찰되지 않았다. Cmax는 20mg BID 초과의 모든 용량에 대한 생체외 전혈 검정(약 200ng/mL)에 기초하여 EC50의 수준에 도달하였다. 부가적으로, 정상-상태 노출은 투약 기간에 걸쳐 150mg BID 이상의 용량 수준에 대해 표적 EC50으로 또는 표적 EC50 초과를 유지하였다. BVD-523 및 이의 대사물질의 최소 혈장 축적은 15일째에 보다 낮은 용량 수준(<75mg BID)으로 관찰되었고, 반면 보다 높은 용량 수준에 대한 축적은 대략 1.3-배 내지 4.0-배 범위였다. 22일째의 투약전 농도는 일반적으로 15일째와 유사하였고, 이는 15일째까지 정상 상태가 이미 얻어졌음을 나타낸다(데이터는 표시하지 않음). BVD-523 및 이의 대사물질에 대한 혈장 노출의 환자간 가변성의 정도는 중간정도이고 문제가 없는 것으로 간주되었다.
표 28 정상-상태 BVD-523 약동학 (주기 1, 15일째)

BVD-523의 제1 투약 후 및 정상 상태에서의 소변 배설은 투약 후 12시간 이내에 모든 용량 수준에서 무시할만하였고(용량의 0.2% 미만), 이러한 매우 낮은 백분율 범위 내에서 용량-관련되어 있지 않았다. 신장 청소율(clearance)은 용량-독립적인 것으로 밝혀졌다. 개별 신장 청소율 값은 0.128 내지 0.0895L/hr(여기서, n = 1/용량 수준)의 범위였고 평균 값은 0.0149 내지 0.0300L/hr(여기서, n ≥ 3)의 범위였다.
실시예 23
BVD-523에 의한 표적 억제의 약력학적 확인
BVD-523에 의한 온-표적 및 경로 억제를 확인하기 위해, BVD-523을 투여받은 고형 종양을 지닌 환자로부터의 사람 전혈 샘플에서 RSK-1 인산화를 표적 바이오 마커로서 조사하였다. BVD-523-치료된 환자들로부터 투약 15일째 직전에 수집된 정상 상태 전혈 샘플은 10mg BID로의 BVD-523 투약을 이용한 0% ERK 억제 내지 900mg BID로 투약을 이용한 93±8% ERK 억제의 범위인 PMA 자극된 ERK 활성의 농도-의존적 억제를 나타내었다(도 39b). ERK 인산화의 50% 억제를 수득한 BVD-523의 혈장 농도는 BVD-523이 건강한 지원자 혈장에 직접 스파이크(spike)되었거나 환자의 경구 투약 후에 존재하였는지 여부와 유사하였다.
실시예 24
항종양 효과
고형 종양 버전 1.1의 반응 평가 기준(Response Evaluation Criteria in Solid Tumors version 1.1 (RECIST v1.1))을 사용하여 25명의 평가가능한 환자들에서 BVD-523에 대한 종양 반응을 평가하였고; 2명의 환자는 둘 다 표적 병변의 스캔을 받지 않았고, 따라서 RECIST v1.1을 이용하여 평가하지 않았다. 완전한 반응을 달성한 환자는 없었지만, 3명의 환자(BRAF V600 돌연변이를 갖는 흑색종을 지닌 모든 환자)은 부분 반응을 달성하였다(129일[BRAF/MEK-억제제 나이브], 294일 진행중[이전의 BRAF/MEK 억제제에 불응], 데이터 컷오프 날짜까지 313일 진행중[다른 BRAF/MEK 억제제에 불내성(intolerant)])(도 40a). 흥미롭게도, 3명의 부분 반응자들은 모두 BRAF-돌연변이 흑색종을 가졌다. BVD-523을 450mg BID의 용량으로 투여받았던 1명의 부분 반응자는 기저선으로부터 표적 병변의 총합의 대략 70%의 감소를 가졌고, 한편 다른 부분 반응자들은 47.0% 및 33.6%의 감소를 보였다. 안정한 질환은 18명의 환자에서 입증되었고, 6명은 6개월 초과 동안 안정한 질환을 가졌고, 6명의 부가적 환자들은 3개월 초과 동안 안정한 질환을 가졌다. 이러한 연구에서, 첫번째 평가에서 4명의 환자가 진행성 질환을 나타냈다.
도 40b는 이전의 베무라페닙 및 후속적 다브라페닙/트라메티닙 치료를 진행하였던 3명의 부분 반응자(RECIST v1.1)들 중 1명의 컴퓨터 단층촬영(CT) 스캔을 도시하고; 300일 초과 동안 BVD-523 600mg BID 투약 후에 지속가능한 부분 반응이 관찰되었다. BVD-523은 16명의 평가가능한 환자들 중 5명에서 플루오로데옥시글루코스-양성 방출 단층촬영(18F-FDG-PET)을 사용한 대사 반응과 관련이 있었다.
도 41은 연구 집단에서의 반응까지의 시간 및 반응 지속기간을 도시한다. BVD-523에 대한 반응을 입증한 2명의 환자는 연구를 유지하였고, 연구 컷오프 날짜(500일 초과)로 BVD-523 치료를 계속하였고; 부가적으로 기관지폐포성 NSCLC를 지닌 1명의 환자(분자 프로파일링을 위한 조직이 충분하지 않음)는 안정한 질환으로 700일 초과 동안 치료중이었다. 27명의 환자들 중 24명(90 %)이 진행성 질환(22/27, 82%) 또는 다른 이유(2/27, 7%)로 치료를 중단하였다. 중단 전 BVD-523 치료의 평균 지속기간은 4.7개월이었다.
논의
본 발명은 진행성 고형 종양을 지닌 27명의 환자에서 BVD-523의 안전성, 약동학, 약력학 및 예비 효능을 평가하는 최초 사람 연구로부터의 결과를 제시한다. 이러한 용량-단계적 상승 연구에서, BVD-523을 이용한 경구 치료는 RECIST v1.1에 의한 방사선사진 반응(3명의 부분 반응) 및 몇몇의 환자들에서의 연장된 질환 안정화 둘 다를 초래하였고, 이들의 대다수는 2개 이상의 이전의 전신 치료법으로 치료되었다. 종양에서의 대사 반응의 BVD-523-의존적 억제의 증거는 18F-글루코스의 종양 흡수를 영상화함으로써 환자들의 서브세트에서 확립되었다. 약물 노출은 600mg BID까지 증가하는 용량에 따라 선형으로 증가하였고, 600mg BID로의 노출은 생체외 전혈 검정에서 ERK-의존적 기질(RSK-1) 인산화의 거의 완전한 24/7 억제를 제공하였다. 또한, BVD-523에 대한 내약성은 600mg BID인 것으로 결정되는 이의 MTD 및 RP2D까지 투여할 때 관리가능하였다.
BVD-523은 일반적으로 관리가능하고 가역적인 독성으로 내약성이 우수하였다. 가장 흔한 AE는 발진(일반적으로 여드름 모양), 피로, 및 구역, 구토 및 설사를 포함하는 위장 부작용이었다. BVD-523의 안전성 프로파일은 MAPK 경로의 선택적 억제와 일치하고; AE 프로파일은 MEK 억제제 경험과 상당한 중첩을 보인다. 그러나, 임의의 표적화된 치료법과 관련된 독성은 특정 메커니즘 및 표적 억제 정도 및 임의의 오프-표적 효과 둘 다에 대한 의존성을 포함할 수 있다(Zelboraf[패키지 삽입물] 및 Hauschild et al. 2012). 진행중인 조사 및 장래의 조사는 이러한 용량-단계적 상승 연구에서 입증된 효능 및 안전성 프로파일 둘 다를 확장시킬 것이고, ERK 억제제 BVD-523의 고유한 프로파일이 단일 제제로서 또는 다른 제제와의 조합으로 사용될 수 있는 방법을 안내할 것이다.
RAF와 MEK 억제제에 의한 지속가능한 반응은 흔히 ERK 경로의 재활성화에 관여하는 공통의 특징과 함께 내인적인 그리고 궁극적인 획득된 내성에 의해 제한된다(Poulikakos et al. 2011, Corcoran et al. 2010, Nazarian et al. 2010, Shi et al. 2014, Johannessen et al. 2010, Wagle et al. 2011, Wagle et al. 2014, Ahronian et al. 2015 및 Paraiso et al. 2010). 따라서, BVD-523 단독 또는 다른 MAPK 신호전달 경로 억제제와 조합으로의 ERK 억제는 기존 치료법에 대한 내성의 발달을 지연시키고 광범위한 환자 집단에게 이익을 주는 잠재성을 가질 수 있다. BVD-523을 포함하는 해당 ERK 억제제는 BRAF- 및 MEK-내성 세포주에서의 이들의 효력을 유지하고, 치료 기준(standard of care)(BRAF/MEK 조합 치료법)에 대한 획득된 내성을 갖는 환자에서 ERK 억제제를 사용하기 위한 전임상학적 증거를 제공한다. 예를 들면, 실시예 9 내지 실시예 16을 참조한다. 중요하게도, 이러한 연구에서 처음에는 BRAF 억제제(베무라페닙)로 치료하고 후속적으로 BRAF 및 MEK 억제제(다브라페닙/트라메티닙)의 조합으로 치료한 경우 안정한 질환을 경험한 후 환자의 암이 진행된 환자는 단일 제제 BVD-523을 투여받을 때 부분 반응을 가졌다. 이러한 환자는 본원에 보고된 연구의 컷오프 날짜로 총 708일 동안 연구를 유지하였다. 이 환자에서 관찰된 항종양 효과에 부분적으로 기초하여, FDA는 BRAF 및/또는 MEK 억제제(들)을 이용한 치료 후 이에 대해 불응이거나 이를 진행한 절제불가능한 또는 전이성 BRAF V600 돌연변이-양성 흑색종을 지닌 환자의 치료를 위한 BVD-523의 조사를 패스트 트랙(Fast Track) 개발 프로그램으로서 명명하였다. BVD-523이 환자 치유(예를 들면, 단일 제제로서 또는 다양한 조합으로)를 가장 잘 지원할 수 있는 정확한 방법에 대한 세밀한 정의는 추가의 임상학적 연구를 필요로 한다.
요약하면, 본 실시예는 진행성 암을 지닌 환자에 대한 치료로서 신규한 혁신 신약 ERK 억제제인 BVD-523을 평가하는 페이즈 I 연구의 용량 단계적상승 부분으로부터의 초기 데이터 유래의 데이터를 제시한다. BVD-523을 이용한 1일 2회 경구 치료는 이용가능한 MAPK 경로-표적화된 치료법에 대해 나이브이거나 이를 진행한 환자들을 포함하는 몇몇의 환자들에서 항종양 효과를 초래하였다. BVD-523은 일반적으로 이러한 진행성 암 환자 집단에서 내약성이 우수하였고, 독성은 관리가능하였으며; MTD와 RP2D는 600mg BID였다. BVD-523 노출은 RP2D까지 선형으로 증가하였고 이 용량 수준에서 강력한 약력학 효과가 나타났다. 이러한 페이즈 I 임상학적 연구의 확장은 현재 용량-단계적 상승 페이즈에서 이루어진 관찰을 확인하고 확대하기 위해 진행중이다. 구체적으로, 환자는 다양한 종양 조직학에 걸쳐 분자 분류된 확장 코호트(예를 들면, NRAS, BRAF, MEK 또는 ERK 변경)에 등록되어 있다. 또한, 확장 코호트는 이용가능한 MAPK 경로 치료법에 나이브하거나 또는 이러한 치료에서 질환이 진행된 암을 지닌 환자에서의 BVD-523의 사용을 평가하고 있다.
문헌











본원에 인용된 모든 문헌은 본원에 전문이 인용된 것과 같이 참조로 본원에 포함된다.
본 발명의 예시적인 실시형태가 본원에 기재되어 있지만, 본 발명은 기재된 것들에 제한되지 않고, 다양한 다른 변경 및 변형이 본 발명의 범위 또는 취지에 벗어나지 않으면서 당해 기술분야의 숙련가에 의해 이루어질 수 있다.
SEQUENCE LISTING
<110> BIOMED VALLEY DISCOVERIES, INC.
<120> METHODS AND COMPOSITIONS FOR TREATING NON-ERK MAPK PATHWAY
INHIBITOR-RESISTANT CANCERS
<130> C065272/0398850pct
<150> US 15/161,137
<151> 2016-05-20
<160> 82
<170> KopatentIn 1.7
<210> 1
<211> 2949
<212> DNA
<213> Homo sapiens
<400> 1
cgcctccctt ccccctcccc gcccgacagc ggccgctcgg gccccggctc tcggttataa 60
gatggcggcg ctgagcggtg gcggtggtgg cggcgcggag ccgggccagg ctctgttcaa 120
cggggacatg gagcccgagg ccggcgccgg cgccggcgcc gcggcctctt cggctgcgga 180
ccctgccatt ccggaggagg tgtggaatat caaacaaatg attaagttga cacaggaaca 240
tatagaggcc ctattggaca aatttggtgg ggagcataat ccaccatcaa tatatctgga 300
ggcctatgaa gaatacacca gcaagctaga tgcactccaa caaagagaac aacagttatt 360
ggaatctctg gggaacggaa ctgatttttc tgtttctagc tctgcatcaa tggataccgt 420
tacatcttct tcctcttcta gcctttcagt gctaccttca tctctttcag tttttcaaaa 480
tcccacagat gtggcacgga gcaaccccaa gtcaccacaa aaacctatcg ttagagtctt 540
cctgcccaac aaacagagga cagtggtacc tgcaaggtgt ggagttacag tccgagacag 600
tctaaagaaa gcactgatga tgagaggtct aatcccagag tgctgtgctg tttacagaat 660
tcaggatgga gagaagaaac caattggttg ggacactgat atttcctggc ttactggaga 720
agaattgcat gtggaagtgt tggagaatgt tccacttaca acacacaact ttgtacgaaa 780
aacgtttttc accttagcat tttgtgactt ttgtcgaaag ctgcttttcc agggtttccg 840
ctgtcaaaca tgtggttata aatttcacca gcgttgtagt acagaagttc cactgatgtg 900
tgttaattat gaccaacttg atttgctgtt tgtctccaag ttctttgaac accacccaat 960
accacaggaa gaggcgtcct tagcagagac tgccctaaca tctggatcat ccccttccgc 1020
acccgcctcg gactctattg ggccccaaat tctcaccagt ccgtctcctt caaaatccat 1080
tccaattcca cagcccttcc gaccagcaga tgaagatcat cgaaatcaat ttgggcaacg 1140
agaccgatcc tcatcagctc ccaatgtgca tataaacaca atagaacctg tcaatattga 1200
tgacttgatt agagaccaag gatttcgtgg tgatggagga tcaaccacag gtttgtctgc 1260
taccccccct gcctcattac ctggctcact aactaacgtg aaagccttac agaaatctcc 1320
aggacctcag cgagaaagga agtcatcttc atcctcagaa gacaggaatc gaatgaaaac 1380
acttggtaga cgggactcga gtgatgattg ggagattcct gatgggcaga ttacagtggg 1440
acaaagaatt ggatctggat catttggaac agtctacaag ggaaagtggc atggtgatgt 1500
ggcagtgaaa atgttgaatg tgacagcacc tacacctcag cagttacaag ccttcaaaaa 1560
tgaagtagga gtactcagga aaacacgaca tgtgaatatc ctactcttca tgggctattc 1620
cacaaagcca caactggcta ttgttaccca gtggtgtgag ggctccagct tgtatcacca 1680
tctccatatc attgagacca aatttgagat gatcaaactt atagatattg cacgacagac 1740
tgcacagggc atggattact tacacgccaa gtcaatcatc cacagagacc tcaagagtaa 1800
taatatattt cttcatgaag acctcacagt aaaaataggt gattttggtc tagctacagt 1860
gaaatctcga tggagtgggt cccatcagtt tgaacagttg tctggatcca ttttgtggat 1920
ggcaccagaa gtcatcagaa tgcaagataa aaatccatac agctttcagt cagatgtata 1980
tgcatttgga attgttctgt atgaattgat gactggacag ttaccttatt caaacatcaa 2040
caacagggac cagataattt ttatggtggg acgaggatac ctgtctccag atctcagtaa 2100
ggtacggagt aactgtccaa aagccatgaa gagattaatg gcagagtgcc tcaaaaagaa 2160
aagagatgag agaccactct ttccccaaat tctcgcctct attgagctgc tggcccgctc 2220
attgccaaaa attcaccgca gtgcatcaga accctccttg aatcgggctg gtttccaaac 2280
agaggatttt agtctatatg cttgtgcttc tccaaaaaca cccatccagg cagggggata 2340
tggtgcgttt cctgtccact gaaacaaatg agtgagagag ttcaggagag tagcaacaaa 2400
aggaaaataa atgaacatat gtttgcttat atgttaaatt gaataaaata ctctcttttt 2460
ttttaaggtg aaccaaagaa cacttgtgtg gttaaagact agatataatt tttccccaaa 2520
ctaaaattta tacttaacat tggattttta acatccaagg gttaaaatac atagacattg 2580
ctaaaaattg gcagagcctc ttctagaggc tttactttct gttccgggtt tgtatcattc 2640
acttggttat tttaagtagt aaacttcagt ttctcatgca acttttgttg ccagctatca 2700
catgtccact agggactcca gaagaagacc ctacctatgc ctgtgtttgc aggtgagaag 2760
ttggcagtcg gttagcctgg gttagataag gcaaactgaa cagatctaat ttaggaagtc 2820
agtagaattt aataattcta ttattattct taataatttt tctataacta tttcttttta 2880
taacaatttg gaaaatgtgg atgtctttta tttccttgaa gcaataaact aagtttcttt 2940
ttataaaaa 2949
<210> 2
<211> 765
<212> PRT
<213> Homo sapiens
<400> 2
Ala Ala Leu Ser Gly Gly Gly Gly Gly Gly Ala Glu Pro Gly Gln Ala
1 5 10 15
Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala Gly Ala Gly Ala
20 25 30
Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn
35 40 45
Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu
50 55 60
Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala
65 70 75 80
Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln
85 90 95
Gln Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser
100 105 110
Ser Ala Ser Met Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser
115 120 125
Val Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ala
130 135 140
Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
145 150 155 160
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
165 170 175
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
180 185 190
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
195 200 205
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
210 215 220
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr
225 230 235 240
Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln
245 250 255
Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser
260 265 270
Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu
275 280 285
Phe Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala
290 295 300
Ser Leu Ala Glu Thr Ala Leu Thr Ser Gly Ser Ser Pro Ser Ala Pro
305 310 315 320
Ala Ser Asp Ser Ile Gly Pro Gln Ile Leu Thr Ser Pro Ser Pro Ser
325 330 335
Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His
340 345 350
Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val
355 360 365
His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp
370 375 380
Gln Gly Phe Arg Gly Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr
385 390 395 400
Pro Pro Ala Ser Leu Pro Gly Ser Leu Thr Asn Val Lys Ala Leu Gln
405 410 415
Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu
420 425 430
Asp Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp
435 440 445
Trp Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser
450 455 460
Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala
465 470 475 480
Val Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala
485 490 495
Phe Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile
500 505 510
Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr
515 520 525
Gln Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu
530 535 540
Thr Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala
545 550 555 560
Gln Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu
565 570 575
Lys Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly
580 585 590
Asp Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln
595 600 605
Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile
610 615 620
Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala
625 630 635 640
Phe Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser
645 650 655
Asn Ile Asn Asn Arg Asp Gln Ile Ile Phe Met Val Gly Arg Gly Tyr
660 665 670
Leu Ser Pro Asp Leu Ser Lys Val Arg Ser Asn Cys Pro Lys Ala Met
675 680 685
Lys Arg Leu Met Ala Glu Cys Leu Lys Lys Lys Arg Asp Glu Arg Pro
690 695 700
Leu Phe Pro Gln Ile Leu Ala Ser Ile Glu Leu Leu Ala Arg Ser Leu
705 710 715 720
Pro Lys Ile His Arg Ser Ala Ser Glu Pro Ser Leu Asn Arg Ala Gly
725 730 735
Phe Gln Thr Glu Asp Phe Ser Leu Tyr Ala Cys Ala Ser Pro Lys Thr
740 745 750
Pro Ile Gln Ala Gly Gly Tyr Gly Ala Phe Pro Val His
755 760 765
<210> 3
<211> 3906
<212> DNA
<213> Rattus norvegicus
<400> 3
atggcggcgc tgagtggcgg cggtggcagc agcagcggtg gcggtggcgg cggcggcggc 60
ggcggtggtg gcggcggcgg cggcggcgcc gaacagggac aggctctgtt caatggcgac 120
atggagccgg aggccggcgc tggcgccgcg gcctcttcgg ccgcggaccc ggccattcct 180
gaagaggtgt ggaatatcaa gcaaatgatt aagttgacac aggaacatat agaggcccta 240
ttggacaagt ttggtgggga gcataaccca ccgtcaatat acctggaggc ctatgaagag 300
tacaccagca agctagatgc ccttcagcag agagagcagc agctgttgga atccctggtt 360
tttcaaactc ccacagatgt atcacggaac aaccccaagt caccacagaa acctatcgtt 420
cgtgtcttcc tgcccaacaa acagaggaca gtggtgcccg caagatgtgg tgtaacggtc 480
cgagacagtc taaagaaagc actaatgatg aggggtctca tcccagagtg ctgtgctgtt 540
tacagaattc aggacggaga gaagaaacca attggctggg acactgacat ttcctggctt 600
actggagagg agctacatgt tgaagtacta gagaatgttc ctctgacaac ccacaacttc 660
gtacggaaaa cttttttcac cttagcattt tgtgactttt gccgaaagct gcttttccag 720
ggtttccgct gtcaaacatg tggttataag tttcaccagc gttgtagtac agaggttcca 780
ctgatgtgtg ttaattatga ccaacttgat ttgctgtttg tctccaagtt ctttgagcat 840
cacccagtac cacaggagga ggccttctca gcagagacta cccttccatc tggatgctct 900
tccgcacccc cctcagactc tattgggccc caaatcctca ccagtccatc tccttcaaaa 960
tccattccaa ttccacagcc cttccggcca gcagatgaag atcatcgcaa tcagtttggg 1020
caacgagacc gctcctcctc cgctcccaat gttcatataa acacaatcga acctgtcaat 1080
attgatgaaa aattcccaga agtggaatta caggatcaaa gggatttgat tagagaccag 1140
gggtttcgtg gggatggagc ccctttgaac cagctgatgc gctgtcttcg gaaataccaa 1200
tcccggactc ccagccccct cctccattct gtccccagtg aaatagtgtt tgattttgag 1260
cctggcccag tgttcagagg gtcaaccaca ggcttgtcgg ccaccccacc tgcctcatta 1320
cctggctcac tcactaacgt gaaagcctta cagaaatctc caggacctca gcgggaaagg 1380
aagtcctcct cctcctcctc ctccacggaa gacagaagtc ggatgaaaac acttggtaga 1440
agagattcaa gtgatgattg ggagattcct gatggacaga ttacagtggg acagagaatt 1500
ggatctgggt cctttggaac tgtctacaag ggaaagtggc atggcgacgt ggcagtgaaa 1560
atgctgaatg tgacagcacc cacacctcag cagttacagg ccttcaaaaa cgaagtcgga 1620
gtactcagga aaactcgaca tgtgaacatc ctccttttca tgggctattc tacaaagcca 1680
cagctggcta ttgttacaca gtggtgtgaa ggctccagct tatatcacca tctccacatc 1740
attgagacca aatttgagat gatcaaactt atagatattg cacggcagac tgcacagggc 1800
atggattact tacacgccaa gtcaatcatc cacagagacc tcaagagtaa taatatattt 1860
cttcatgaag acctcacggt aaaaataggt gactttggtt tagccacagt gaagtcccga 1920
tggagtgggt cccatcagtt tgaacagttg tctggatcta ttttgtggat ggcacccgaa 1980
gtaatcagaa tgcaagataa aaacccatat agctttcagt cagacgtgta tgcatttggg 2040
attgttctgt atgaactgat gactggtcag ctaccttatt caaacatcaa caacagggat 2100
cagataattt ttatggtggg acgaggatac ctatctccag atctcagtaa ggtacggagt 2160
aactgtccaa aagccatgaa gagattaatg gcagagtgcc tcaaaaagaa aagagacgag 2220
agaccactct ttccccaaat tctcgcctct attgagctgc tggcccgctc attgccaaaa 2280
attcaccgca gtgcatcaga accctccttg aatcgggctg gtttccaaac agaagatttt 2340
agtctgtatg cttgtgcttc tccaaaaaca cccatccaag cagggggata tggagaattt 2400
gcagccttca agtagccact ccatcatggc agcatctact ctttatttct taagtcttgt 2460
gttcatacaa tttgttaaca tcaaaacaca gttctgttcc tcaaattttt tttaaagata 2520
caaaattttc aatgcataag ctcgtgtgga acagaatgga atttcctatt caacaaaaga 2580
gggaagaatg ttttaggaac cagaattctc tgctgcccgt gtttcttctt caacacaaat 2640
atcatgtgca tacaactctg cccattccca agaagaaaga ggagagaccc cgaattctgc 2700
ccttttggtg gtcaggcatg atggaaagaa tttgctgctg cagcttggga aaaattgcta 2760
tggaaagtct gccagtcaac tttgcccttc taaccaccag atccatttgt ggctggtcat 2820
ctgatggggc gatttcaatc accaagcatc gttcttgcct gttgtgggat tatgtcgtgg 2880
agcactttcc ctatccacca ccgttaattt ccgagggatg gagtaaatgc agcataccct 2940
ttgtgtagca cctgtccagt cctcaaccaa tgctatcaca gtgaagctct ttaaatttaa 3000
gtggtgggtg agtgttgagg agagactgcc ttgggggcag agaaaagggg atgctgcatc 3060
ttcttcctca cctccagctc tctcacctcg ggttgccttg cacactgggc tccgcctaac 3120
cactcgggct gggcagtgct ggcacacatt gccgcctttt ctcattgggt ccagcaattg 3180
agcagagggt tgggggattg tttcctccac aatgtagcaa attctcagga aaatacagtc 3240
catatcttcc tctcagctct tccagtcacc aaatacttac gtggctcctt tgtccaggac 3300
ataaaacacc gtggacaaca cctaattaaa agcctacaaa actgcttact gacagttttg 3360
aatgtgagac atttgtgtaa tttaaatgta aggtacaggt cttaatttct tctattaagt 3420
ttcttctatt tttatttaaa cgaagaaaat aattttcagg tttaattgga ataaacgaat 3480
acttcccaaa agactatata ccctgaaaat tatatttttg ttaattgtaa acaactttta 3540
aaaaatggtt attatccttt tctctaccta aaattatggg aaatcttagc ataatgacaa 3600
ttatttatac tttttaaata aatggtactt gctggatcca cactaacatc tttgctaaca 3660
ttcccattgt ttcttccaac ttcactccta cactacatcc tccatcctct ttctagtctt 3720
ttatctataa tatgcaacct aaaataaaag tggtggtgtc tccattcatt cttcttcttc 3780
cttttttccc caagcctggt cttcaaaagg ttgggtaatt tagtagctga gttccctagg 3840
tagaaataga actattaggg acattggggt tgtaggaaag cgtgaggcct gtcaccagtt 3900
gttctt 3906
<210> 4
<211> 804
<212> PRT
<213> Rattus norvegicus
<400> 4
Met Ala Ala Leu Ser Gly Gly Gly Gly Ser Ser Ser Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Glu Gln
20 25 30
Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala Gly
35 40 45
Ala Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp
50 55 60
Asn Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu
65 70 75 80
Leu Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu
85 90 95
Ala Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu
100 105 110
Gln Gln Leu Leu Glu Ser Leu Val Phe Gln Thr Pro Thr Asp Val Ser
115 120 125
Arg Asn Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
130 135 140
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
145 150 155 160
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
165 170 175
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
180 185 190
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
195 200 205
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr
210 215 220
Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln
225 230 235 240
Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser
245 250 255
Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu
260 265 270
Phe Val Ser Lys Phe Phe Glu His His Pro Val Pro Gln Glu Glu Ala
275 280 285
Phe Ser Ala Glu Thr Thr Leu Pro Ser Gly Cys Ser Ser Ala Pro Pro
290 295 300
Ser Asp Ser Ile Gly Pro Gln Ile Leu Thr Ser Pro Ser Pro Ser Lys
305 310 315 320
Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His Arg
325 330 335
Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val His
340 345 350
Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Glu Lys Phe Pro Glu Val
355 360 365
Glu Leu Gln Asp Gln Arg Asp Leu Ile Arg Asp Gln Gly Phe Arg Gly
370 375 380
Asp Gly Ala Pro Leu Asn Gln Leu Met Arg Cys Leu Arg Lys Tyr Gln
385 390 395 400
Ser Arg Thr Pro Ser Pro Leu Leu His Ser Val Pro Ser Glu Ile Val
405 410 415
Phe Asp Phe Glu Pro Gly Pro Val Phe Arg Gly Ser Thr Thr Gly Leu
420 425 430
Ser Ala Thr Pro Pro Ala Ser Leu Pro Gly Ser Leu Thr Asn Val Lys
435 440 445
Ala Leu Gln Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser
450 455 460
Ser Ser Ser Ser Thr Glu Asp Arg Ser Arg Met Lys Thr Leu Gly Arg
465 470 475 480
Arg Asp Ser Ser Asp Asp Trp Glu Ile Pro Asp Gly Gln Ile Thr Val
485 490 495
Gly Gln Arg Ile Gly Ser Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys
500 505 510
Trp His Gly Asp Val Ala Val Lys Met Leu Asn Val Thr Ala Pro Thr
515 520 525
Pro Gln Gln Leu Gln Ala Phe Lys Asn Glu Val Gly Val Leu Arg Lys
530 535 540
Thr Arg His Val Asn Ile Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro
545 550 555 560
Gln Leu Ala Ile Val Thr Gln Trp Cys Glu Gly Ser Ser Leu Tyr His
565 570 575
His Leu His Ile Ile Glu Thr Lys Phe Glu Met Ile Lys Leu Ile Asp
580 585 590
Ile Ala Arg Gln Thr Ala Gln Gly Met Asp Tyr Leu His Ala Lys Ser
595 600 605
Ile Ile His Arg Asp Leu Lys Ser Asn Asn Ile Phe Leu His Glu Asp
610 615 620
Leu Thr Val Lys Ile Gly Asp Phe Gly Leu Ala Thr Val Lys Ser Arg
625 630 635 640
Trp Ser Gly Ser His Gln Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp
645 650 655
Met Ala Pro Glu Val Ile Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe
660 665 670
Gln Ser Asp Val Tyr Ala Phe Gly Ile Val Leu Tyr Glu Leu Met Thr
675 680 685
Gly Gln Leu Pro Tyr Ser Asn Ile Asn Asn Arg Asp Gln Ile Ile Phe
690 695 700
Met Val Gly Arg Gly Tyr Leu Ser Pro Asp Leu Ser Lys Val Arg Ser
705 710 715 720
Asn Cys Pro Lys Ala Met Lys Arg Leu Met Ala Glu Cys Leu Lys Lys
725 730 735
Lys Arg Asp Glu Arg Pro Leu Phe Pro Gln Ile Leu Ala Ser Ile Glu
740 745 750
Leu Leu Ala Arg Ser Leu Pro Lys Ile His Arg Ser Ala Ser Glu Pro
755 760 765
Ser Leu Asn Arg Ala Gly Phe Gln Thr Glu Asp Phe Ser Leu Tyr Ala
770 775 780
Cys Ala Ser Pro Lys Thr Pro Ile Gln Ala Gly Gly Tyr Gly Glu Phe
785 790 795 800
Ala Ala Phe Lys
<210> 5
<211> 9728
<212> DNA
<213> Mus musculus
<400> 5
ccctcaggct cggctgcgcc ggggccgccg gcgggttcca gaggtggcct ccgccccggc 60
cgctccgccc acgccccccg cgcctccgcg cccgcctccg cccgccctgc gcctcccttc 120
cccctccccg ccccgcggcg gccgctcggc ccggctcgcg cttcgaagat ggcggcgctg 180
agtggcggcg gtggcagcag cagcggtggc ggcggcggcg gtggcggcgg cggtggcggt 240
ggcgacggcg gcggcggcgc cgagcagggc caggctctgt tcaatggcga catggagccg 300
gaggccggcg ctggcgccgc ggcctcttcg gctgcggacc cggccattcc tgaagaggta 360
tggaatatca agcaaatgat taagttgaca caggaacata tagaggccct attggacaaa 420
tttggtggag agcataaccc accatcaata tacctggagg cctatgaaga gtacaccagc 480
aagctagatg cccttcagca aagagaacag cagcttttgg aatccctggt ttttcaaact 540
cccacagatg catcacggaa caaccccaag tcaccacaga aacctatcgt tagagtcttc 600
ctgcccaaca aacagaggac agtggtaccc gcaagatgtg gtgttacagt tcgagacagt 660
ctaaagaaag cactgatgat gagaggtctc atcccagaat gctgtgctgt ttacagaatt 720
caggatggag agaagaaacc aattggctgg gacacggaca tttcctggct tactggagag 780
gagttacatg ttgaagtact ggagaatgtc ccacttacaa cacacaactt tgtacggaaa 840
acttttttca ccttagcatt ttgtgacttt tgccgaaagc tgcttttcca gggtttccgt 900
tgtcaaacat gtggttataa atttcaccag cgttgtagta cagaggttcc actgatgtgt 960
gtaaattatg accaacttga tttgctgttt gtctccaagt tctttgagca tcacccagta 1020
ccacaggagg aggcctcctt cccagagact gcccttccat ctggatcctc ttccgcaccc 1080
ccctcagact ctactgggcc ccaaatcctc accagtccat ctccttcaaa atccattcca 1140
attccacagc ccttccgacc agcagatgaa gatcatcgca atcagtttgg gcaacgagac 1200
cggtcctcct cagctcccaa tgttcatata aacacaattg agcctgtgaa tatcgatgaa 1260
aaattcccag aagtggaatt acaggatcaa agggatttga ttagagacca ggggtttcgt 1320
ggtgatggag cccccttgaa ccaactgatg cgctgtcttc ggaaatacca atcccggact 1380
cccagccccc tcctccattc tgtccccagt gaaatagtgt ttgattttga gcctggccca 1440
gtgttcagag ggtcaaccac aggcttgtcc gccaccccgc ctgcctcatt acctggctca 1500
ctcactaacg tgaaagcctt acagaaatct ccaggtcctc agcgggaaag gaagtcatct 1560
tcttcctcat cctcggagga cagaagtcgg atgaaaacac ttggtagaag agattcaagt 1620
gatgactggg agattcctga tggacagatt acagtgggac agagaattgg atctgggtca 1680
tttggaactg tctacaaggg aaagtggcat ggtgatgtgg cagtgaaaat gttgaatgtg 1740
acagcaccca cacctcaaca gctacaggcc ttcaaaaatg aagtaggagt gctcaggaaa 1800
actcgacatg tgaatatcct ccttttcatg ggctattcta caaagccaca actggcaatt 1860
gttacacagt ggtgtgaggg ctccagctta tatcaccatc tccacatcat tgagaccaaa 1920
tttgagatga tcaaacttat agatattgct cggcagactg cacagggcat ggattactta 1980
cacgccaagt caatcatcca cagagacctc aagagtaata atatatttct tcatgaagac 2040
ctcacggtaa aaataggtga ctttggtcta gccacagtga aatctcggtg gagtgggtcc 2100
catcagtttg aacagttgtc tggatctatt ttgtggatgg caccagaagt aatcagaatg 2160
caagataaaa acccgtatag ctttcagtca gacgtgtatg cgtttgggat tgttctgtac 2220
gaactgatga ccggccagct accttattca aacatcaaca acagggatca gataattttt 2280
atggtgggac gaggatacct atctccagat ctcagtaagg tacggagtaa ctgtccaaaa 2340
gccatgaaga gattaatggc agagtgcctc aaaaagaaaa gagacgagag accactcttt 2400
ccccaaattc tcgcctccat tgagctgctg gcccgctcat tgccaaaaat tcaccgcagt 2460
gcatcagaac cttccttgaa tcgggctggt ttccaaacag aagattttag tctgtatgct 2520
tgtgcttctc cgaaaacacc catccaagca gggggatatg gagaatttgc agccttcaag 2580
tagccagtcc atcatggcag catctactct ttatttctta agtcttgtgt tcatacagtt 2640
tgttaacatc aaaacacagt tctgttcctc aaaaaatttt ttaaagatac aaaattttca 2700
atgcataagt tcatgtggaa cagaatggaa tttcctattc aacaaaagag ggaagaatgt 2760
tttaggaacc agaattctct gctgcccgtg tttcttcttc aacataacta tcacgtgcat 2820
acaagtctgc ccattcccaa gaagaaagag gagagaccct gaattctgcc cttttggtgg 2880
tcaggcatga tggaaagaat ttgctgctgc agcttgggaa aattgctatg gaaagtctgc 2940
cagtcgactt tgcccttcta accaccagat cagcctgtgg ctggtcatct gatggggcga 3000
tttccatcac caagcatcgt tcttgcctat tctgggatta tgttgtggag cactttccct 3060
gtccagcacc gttcatttct gagggatgga gtaaatgcag cattcccttg tgtagcgcct 3120
gttcagtcct cagcagctgc tgtcacagcg aagcttttta cagttaagtg gtgggggaga 3180
gttgaggaga gcctgcctcg gggcagagaa aagggggtgc tgcatcttct tcctcacctc 3240
cagctctctc acctcgggtt gccttgctca ctgggctccg cctaaccact caggctgctc 3300
agtgctggca cacattgcct tcttttctca ttgggtccag caattgagga gagggttggg 3360
ggattgtttc ctcctcaatg tagcaaattc tcaggaaaat acagtccata tcttcctctc 3420
agctcttcca gtcaccaaat acttacgtgg ctcctttgtc caggacataa aacaccgtgg 3480
acaacaccta attaaaagcc tacaaaactg cttactgaca gttttgaatg tgagacactt 3540
gtgtaattta aatgtaaggt acaggtttta atttctgagt ttcttctatt tttatttaaa 3600
agaagaaaat aattttcagt tttaattgga ataaatgagt acttcccaca agactatata 3660
ccctgaaaat tatatttttg ttaattgtaa acaactttta aagaataatt attatccttt 3720
tctctaccta aaaattatgg ggaatcttag cataatgaca attatttata ctttttaaat 3780
aaatggtact tgctggatcc acactaacat ctttgctaac aatcccattg tttcttccaa 3840
cttaactcct acactacatc ctacatcctc tttctagtct tttatctata atatgcaacc 3900
taaaataaac gtggtggcgt ctccattcat tctccctctt cctgttttcc ccaagcctgg 3960
tcttcaaaag gttgggtaat cggtccctga gctccctagc tggcaatgca actattaggg 4020
acattggagt tgcaggagag caggaagcct gtccccagct gttcttctag aaccctaaat 4080
cttatctttg cacagatcaa aagtatcacc tcgtcacagt tctccttagc ctttacttac 4140
aggtaatata aataaaaatc accatagtag taaagaaaac aactggatgg attgatgacc 4200
agtacctctc agagccagga atcttgaatc tccaggattt atacgtgcaa atttaaggag 4260
atgtacttag caacttcaag ccaagaactt ccaaaatact agcgaatcta aaataaaatg 4320
gaattttgag ttatttttaa agttcaaatt ataattgata ccactatgta tttaagccta 4380
ctcacagcaa gttagatgga ttttgctaaa ctcattgcca gactgtggtg gtggtggtgg 4440
tagtgtgcac ctttaatcca agcaactcag caatcagaat gaggtaaatc tctgtgaata 4500
caaggcctgc ctagtctgca gcgctagttc caggatagcc agggctacac acacaaaaac 4560
cctctctcaa aaaaaacaaa attaattagt tgataataaa aaataactaa agtatcatca 4620
aaggaaggcc tactggaagt tttatatatt cccagtaaat tgaaaaatat tctgaagtta 4680
ttaaccagtt agcaacaatg tgtttttaag tcttacataa acagagcaaa gtcttcaaat 4740
gtttcagagc tgagaagata attgtgcttg atatgaaaaa tagcctctcc atatgatgtg 4800
ccacattgaa aggcgtcatt acccttttaa atacttctta atgtggcttt gttcccttta 4860
cccaggatta gctagaaaga gctaggtagg cttcggccac agttgcacat ttcgggcctg 4920
ctgaagaatg ggagctttga aggctggcct tggtggagga gcccctcagt gctggagggt 4980
ggggcgtgta cgcagcatgg aagtggtcta gacagagtgc aaagggacag acttctttct 5040
cattttagta tagggtgatg tctcacttga aatgagaaag tagagttgat attaaacgaa 5100
gctgtgccca gaaaccaggc tcagggtatt gtgagatttt ctttttaaat agagaatata 5160
aaagatagaa ataaatattt aaaccttcct tcttattttc tatcaaatag atttttttta 5220
tcatttgcaa acaacataaa aaaaggtttc ttttgtgggg ttttctttcc ttcttttttt 5280
tttttttttt tttttaagac tgcagataat cttgttgagc tcctcggaaa atacaaggaa 5340
gtccgtgttt gtgcagagcg ctttatgagt aactgtatag acagtgtggc tgcttcactc 5400
atcccagagg gctgcagctg tcggcccatg aagtggctgc agtgcctcgt gagatctgct 5460
ttgttttgtt tggagtgaag tctttgaaag gtttgagtgc aactatatag gactgttttt 5520
aaataagtag tattcctcat gaactttctc attgttaagc tacaggaccc aaactctacc 5580
actaagatat tattaacctc aaaatgtagt ttatagaagg aatttgcaaa tagaatatcc 5640
agttcgtact tatatgcatc ttcaacaaag attctctgtg acttgttgga tttggttcct 5700
gaacagccca tttctgtatt tgaggttagg agggcataat gaggcatcct aaaagacaat 5760
ctgatataaa ctgtatgcta gatgtatgct ggtaggggag aaagcattct gtaaagacat 5820
gatttaagac ttcagctctg tcaaccagaa accttgtaaa tacttcctgt cttggtgcag 5880
ccccgcccct ttgatcacac gatgttgtct tgtgcttgtc agacactgtc agagctgctg 5940
ttcgtccctc tgcagatctc acctgtcccc actgcacacc cacctcctgc ctcttgcaga 6000
cctcagcatc tagctttagt tggaaacagt tcagggttca ggtgacttct taaaaaaaaa 6060
aaaaaaccct acctcctcag aatgaggtaa tgaatagtta tttatttaaa gtatgaagag 6120
tcaggagcgc tcgaacatga aggtgattta agatggttcc tttcgtgtgt attgtagctg 6180
agcacttgtt tttgtcctaa agggcattat acatttaagc agtgattctg tttaaagatg 6240
tttttcttta aaggtgtagc tcagagtatc tgttgttgga attggtgcca gagtctgctt 6300
aatagatttc agaatcctaa gcttaagtca gtcgcatgaa gttaagtagt tatggtaaca 6360
ctttgctagc catgatataa ttctactttt taggagtagg tttggcaaaa ctgtatgcct 6420
tcaaagtgag ttggccacag ctttgtcaca tgcacagata ctcatctgaa gagactgccc 6480
agctaagagg gcggaaggat accctttttt cctacgattc gcttctttgt ccacgttggc 6540
attgttagta ctagtttatc agcaccttga ccagcagatg tcaaccaata agctattttt 6600
aaaaccatag ccagagatgg agaggtcact gtgagtagaa acagcaggac gcttacagga 6660
gtgaaatggt gtagggaggc tctagaaaaa tatcttgaca atttgccaaa tgatcttact 6720
gtgccttcat gatgcaataa aaaagctaac attttagcag aaatcagtga tttacgaaga 6780
gagtggccag tctggtttaa ctcagctggg ataatatttt tagagtgcaa tttagactgc 6840
gaagataaat gcactaaaga gtttatagcc aattcacatt tgaaaaataa gaaaatggta 6900
aattttcagt gaaatatttt tttaaagcac ataatcccta gtgtagccag aaatatttac 6960
cacatagagc agctaggctg agatacagtc cagtgacatt tctagagaaa ccttttctac 7020
tcccacgggc tcctcaaagc atggaaattt tatacaaaat gtttgacatt ttaagatact 7080
gctgtagttt agttttgaaa tagtatgtgc tgagcagcaa tcatgtacta actcagagag 7140
agaaaacaac aacaaattgt gcatctgatt tgttttcaga gaaatgctgc caacttagat 7200
actgagttct cagagcttca agtgtaaact tgcctcccaa gtcctgtttg caaatgaagt 7260
tggctagtgc tactgactgc tccagcacat gatggaaggc agggggctgt ctctgaagtg 7320
tcttctataa agggacaata gaatagtgag agacctggtc agtgtgtgtc agctggacac 7380
tccatgctat gggacttgca tcttctgtcc tcaccatccc caagacattg tgctttcctc 7440
agttgtcctc tagctgtttc actcagacac caagatgaat tactgatgcc agaaggggcc 7500
aaaatggcca gtgtgttttg ggggttgtat cagttgactg gacaataact ttaatagttt 7560
cagatcattt atttttactt ccattttgac agacatttaa atggaaattt agtcctaact 7620
tttgtcattt gaaaggaaaa attaacagtt cctataagat acttttgagg tggaatctga 7680
catcctaatt ttttttcttt tcagtgggtt tgcagcgagg gtcttgtatg cactaggcaa 7740
gggttctacc actaagccac atttcccagg aaataaaatg ttaacagtta aaacatacac 7800
acaaatacac aaacacctta ttaccacttt agtaaagtga gagatgtgcg tcctttgtct 7860
cagtctccac gatttcagct gccccttgta tgaataactc agtctcgcta aactgtttac 7920
ttttatttac ctggtttgac tagttgcagc tatataacca gttgtgcatg aggacaacag 7980
ccagtgtgtt tgttttgttt ttggtttttt gtggtacatt ttttgtaaag aattctgtag 8040
attgaagtgc tctttgaaaa cagaactgag atatatttat tcttgttagc atcaaaaaac 8100
attttgtgca aatgatttgc ttttcctggc aggctgagta ccatatccag cgcccacaat 8160
tgcgggttcc catctaccat gtccacaggg gagacagacg ggaagcacat gaggggtgtg 8220
tttacagagt tgtaggagtt atgtagttct cttgttgcct tggaaatcac tgttgtttta 8280
agactgttga acccgtgtgt ttggctgggc tgtgagttac atgaagaaac tgcaaactag 8340
catatgcaga caaagctcac agactaggcg taaatggagg aaaatggacc aaaataaggc 8400
agggtgacac ataaaccttg ggcttcggag aaaactaagg gtggagatga actataatca 8460
cctgaataca atgtaagagt gcaataagtg tgcttattct aagctgtgaa cttcttttaa 8520
atcattcctt tctaatacat ttatgtatgt tccattgctg actaaaacca gctatgagaa 8580
catatgcctt tttattcatg ttaactacca gtttaagtgg ctaaccttaa tgtcttattt 8640
atcttcattt tgtattagtt tacataccag gtatgtgtgt gtgctgtact cttcttccct 8700
ttatttgaaa acacttttca ctgggtcatc tccttggcca ttccacaaca caactttggt 8760
ttggctttca atgtcacctt atttgatggc ctgtgtccca gtagcagaat ttatggtatt 8820
cccattgctg gctgctcttc cgaccctttg cttctacagc acttgtctct cctaagatag 8880
tcagaaacta actgatcagg ggatggactt caccattcat cgtgtctctt caattctatt 8940
aaatagacca ctcttgggct ttagaccagg aaaaaggaga cagctctagc catctaccaa 9000
gcctcaccct aaaaggtcac ccgtacttct tggtctgagg acaagtctcc actccagtaa 9060
gggagagggg aggaaatgct tcctgtttga aatgcagtga attcctatgg ctcctgtttc 9120
accacccgca cctatggcaa cccatataca ttcctcttgt ctgtaactgc caaaggttgg 9180
gtttatgtca cttcagttcc actcaagcat tgaaaaggtt ctcatggagt ctggggtgtg 9240
cccagtgaaa agatggggac tttttcatta tccacagacc tctctatacc tgctttgcaa 9300
aaattataat ggagtaacta tttttaaagc ttatttttca attcataaga aaaagacatt 9360
tattttcaat caaatggatg atgtctctta tcccttatcc ctcaatgttt gcttgaattt 9420
tgtttgttcc ctatacctac tccctaattc tttagttcct tcctgctcag gtcccttcat 9480
ttgtactttg gagtttttct catgtaaatt tgtataatgg aaaatattgt tcagtttgga 9540
tagaaagcat ggagaaataa ataaaaaaag atagctgaaa atcaaattga agaaatttat 9600
ttctgtgtaa agttatttaa aaactctgta ttatatttaa agaaaaaagc ccaacccccc 9660
aaaaagtgct atgtaattga tgtgaatatg cgaatactgc tataataaag attgactgca 9720
tggagaaa 9728
<210> 6
<211> 804
<212> PRT
<213> Mus musculus
<400> 6
Met Ala Ala Leu Ser Gly Gly Gly Gly Ser Ser Ser Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Gly Gly Gly Gly Gly Asp Gly Gly Gly Gly Ala Glu
20 25 30
Gln Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala
35 40 45
Gly Ala Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val
50 55 60
Trp Asn Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala
65 70 75 80
Leu Leu Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu
85 90 95
Glu Ala Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg
100 105 110
Glu Gln Gln Leu Leu Glu Ser Leu Val Phe Gln Thr Pro Thr Asp Ala
115 120 125
Ser Arg Asn Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe
130 135 140
Leu Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr
145 150 155 160
Val Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro
165 170 175
Glu Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile
180 185 190
Gly Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val
195 200 205
Glu Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys
210 215 220
Thr Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe
225 230 235 240
Gln Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys
245 250 255
Ser Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu
260 265 270
Leu Phe Val Ser Lys Phe Phe Glu His His Pro Val Pro Gln Glu Glu
275 280 285
Ala Ser Phe Pro Glu Thr Ala Leu Pro Ser Gly Ser Ser Ser Ala Pro
290 295 300
Pro Ser Asp Ser Thr Gly Pro Gln Ile Leu Thr Ser Pro Ser Pro Ser
305 310 315 320
Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His
325 330 335
Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val
340 345 350
His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Glu Lys Phe Pro Glu
355 360 365
Val Glu Leu Gln Asp Gln Arg Asp Leu Ile Arg Asp Gln Gly Phe Arg
370 375 380
Gly Asp Gly Ala Pro Leu Asn Gln Leu Met Arg Cys Leu Arg Lys Tyr
385 390 395 400
Gln Ser Arg Thr Pro Ser Pro Leu Leu His Ser Val Pro Ser Glu Ile
405 410 415
Val Phe Asp Phe Glu Pro Gly Pro Val Phe Arg Gly Ser Thr Thr Gly
420 425 430
Leu Ser Ala Thr Pro Pro Ala Ser Leu Pro Gly Ser Leu Thr Asn Val
435 440 445
Lys Ala Leu Gln Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser
450 455 460
Ser Ser Ser Ser Ser Glu Asp Arg Ser Arg Met Lys Thr Leu Gly Arg
465 470 475 480
Arg Asp Ser Ser Asp Asp Trp Glu Ile Pro Asp Gly Gln Ile Thr Val
485 490 495
Gly Gln Arg Ile Gly Ser Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys
500 505 510
Trp His Gly Asp Val Ala Val Lys Met Leu Asn Val Thr Ala Pro Thr
515 520 525
Pro Gln Gln Leu Gln Ala Phe Lys Asn Glu Val Gly Val Leu Arg Lys
530 535 540
Thr Arg His Val Asn Ile Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro
545 550 555 560
Gln Leu Ala Ile Val Thr Gln Trp Cys Glu Gly Ser Ser Leu Tyr His
565 570 575
His Leu His Ile Ile Glu Thr Lys Phe Glu Met Ile Lys Leu Ile Asp
580 585 590
Ile Ala Arg Gln Thr Ala Gln Gly Met Asp Tyr Leu His Ala Lys Ser
595 600 605
Ile Ile His Arg Asp Leu Lys Ser Asn Asn Ile Phe Leu His Glu Asp
610 615 620
Leu Thr Val Lys Ile Gly Asp Phe Gly Leu Ala Thr Val Lys Ser Arg
625 630 635 640
Trp Ser Gly Ser His Gln Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp
645 650 655
Met Ala Pro Glu Val Ile Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe
660 665 670
Gln Ser Asp Val Tyr Ala Phe Gly Ile Val Leu Tyr Glu Leu Met Thr
675 680 685
Gly Gln Leu Pro Tyr Ser Asn Ile Asn Asn Arg Asp Gln Ile Ile Phe
690 695 700
Met Val Gly Arg Gly Tyr Leu Ser Pro Asp Leu Ser Lys Val Arg Ser
705 710 715 720
Asn Cys Pro Lys Ala Met Lys Arg Leu Met Ala Glu Cys Leu Lys Lys
725 730 735
Lys Arg Asp Glu Arg Pro Leu Phe Pro Gln Ile Leu Ala Ser Ile Glu
740 745 750
Leu Leu Ala Arg Ser Leu Pro Lys Ile His Arg Ser Ala Ser Glu Pro
755 760 765
Ser Leu Asn Arg Ala Gly Phe Gln Thr Glu Asp Phe Ser Leu Tyr Ala
770 775 780
Cys Ala Ser Pro Lys Thr Pro Ile Gln Ala Gly Gly Tyr Gly Glu Phe
785 790 795 800
Ala Ala Phe Lys
<210> 7
<211> 2232
<212> DNA
<213> Oryctolagus cuniculus
<400> 7
atggggaatg tgtggaatat caaacaaatg attaagttga cacaggagca tatagaggcc 60
ctattggaca aatttggtgg ggagcataat ccaccatcaa tatatctgga ggcctacgaa 120
gaatacacca gcaagctaga tgccctccaa caaagagaac agcagttatt ggaatcccta 180
gtttttcaaa atcccacaga tgtgtcacgg agcaacccca agtcaccaca aaaacctatt 240
gttagagtct tcctgcccaa caaacagagg acagtggtac ctgcaagatg tggagttacg 300
gttcgagaca gtctaaagaa agcgctgatg atgagaggtc tgatcccaga atgctgtgct 360
gtttacagaa ttcaggatgg agagaagaag ccaattggct gggacactga tatttcctgg 420
ctcactggag aagagctgca tgtggaagtg ttagagaatg tcccactcac cacacataac 480
tttgtacgga aaactttttt caccttagca ttttgtgact tctgtagaaa gctgcttttc 540
cagggtttcc gctgtcaaac atgtggctac aaatttcacc agcgttgtag tacggaagtt 600
ccactgatgt gtgttaatta tgaccaactt gatttgctgt ttgtctccaa gttctttgaa 660
caccacccag taccacagga ggaggcctcc ttagcagaga ctgccctcac atctgggtca 720
tcgccttccg cacctccctc agactctatt gggcaccaaa ttctcaccag tccgtcccct 780
tcaaaatcca ttccgattcc acagtccttc cgaccagcag atgaagatca tcgaaatcag 840
tttgggcaac gagaccggtc ttcatcagcg cctaatgttc acattaacac aatagaacct 900
gtcaatattg atgaaaaatt cccagaagtg gaattacagg atcaaaggga cttgattaga 960
gaccaagggt ttcgtggtga tggagcccct ttgaaccagc tgatgcgctg tcttcggaaa 1020
taccaatccc ggactcccag tcccctccta ccttctgtcc ccagtgacat agtgtttgat 1080
tttgagcctg gcccagtgtt cagaggatcg accacgggtt tgtctgccac tccccctgcc 1140
tcattacctg gctcactcac tagtgtgaaa gctgtacaga gatccccagg acctcagcga 1200
gagaggaagt cgtcttcctc ctcagaagac aggaatcgaa tgaaaactct tggtagacgg 1260
gattcaagtg atgattggga gattcctgat gggcagatca ccgtgggaca gagaattgga 1320
tctggatcat ttggaaccgt ctacaaggga aaatggcacg gtgatgtggc agtaaaaatg 1380
ttgaatgtga cagcacctac acctcagcag ttacaggcct tcaaaaatga agtaggagta 1440
ctcaggaaaa cacgacatgt gaatatccta cttttcatgg gctattccac aaagccacag 1500
ctggctattg ttacccagtg gtgtgagggc tccagtttat atcaccatct ccacatcatt 1560
gagaccaaat tcgagatgat caaacttata gatattgcac ggcagactgc acagggcatg 1620
gattacttac acgccaagtc aatcatccac agagacctca agagtaataa tatatttctt 1680
catgaagacc tcacagtaaa aataggtgat tttggtctag ccacagtgaa atctcgatgg 1740
agtgggtccc atcagtttga acaattgtct ggatccattt tgtggatggc accagaagta 1800
atcagaatgc aagacaaaaa cccatatagc tttcagtcag atgtatatgc atttgggatt 1860
gttctgtatg aattgatgac tgggcagtta ccttactcaa acatcaacaa cagggaccag 1920
atcattttta tggtgggacg tggctacctg tctccagacc tcagtaaggt acggagtaac 1980
tgtccgaaag ccatgaagag attaatggca gagtgcctca aaaagaaaag agatgagaga 2040
ccactctttc cccaaattct cgcctccatt gagctgctgg cccgctcatt gccaaaaatc 2100
caccgcagtg catcagaacc ctccttgaat cgggctggtt tccagacaga ggattttagt 2160
ctatatgctt gtgcttctcc aaaaacaccc atccaggcag ggggatatgg agaatttgca 2220
gccttcaagt ag 2232
<210> 8
<211> 743
<212> PRT
<213> Oryctolagus cuniculus
<400> 8
Met Gly Asn Val Trp Asn Ile Lys Gln Met Ile Lys Leu Thr Gln Glu
1 5 10 15
His Ile Glu Ala Leu Leu Asp Lys Phe Gly Gly Glu His Asn Pro Pro
20 25 30
Ser Ile Tyr Leu Glu Ala Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala
35 40 45
Leu Gln Gln Arg Glu Gln Gln Leu Leu Glu Ser Leu Val Phe Gln Asn
50 55 60
Pro Thr Asp Val Ser Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile
65 70 75 80
Val Arg Val Phe Leu Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg
85 90 95
Cys Gly Val Thr Val Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg
100 105 110
Gly Leu Ile Pro Glu Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu
115 120 125
Lys Lys Pro Ile Gly Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu
130 135 140
Glu Leu His Val Glu Val Leu Glu Asn Val Pro Leu Thr Thr His Asn
145 150 155 160
Phe Val Arg Lys Thr Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg
165 170 175
Lys Leu Leu Phe Gln Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe
180 185 190
His Gln Arg Cys Ser Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp
195 200 205
Gln Leu Asp Leu Leu Phe Val Ser Lys Phe Phe Glu His His Pro Val
210 215 220
Pro Gln Glu Glu Ala Ser Leu Ala Glu Thr Ala Leu Thr Ser Gly Ser
225 230 235 240
Ser Pro Ser Ala Pro Pro Ser Asp Ser Ile Gly His Gln Ile Leu Thr
245 250 255
Ser Pro Ser Pro Ser Lys Ser Ile Pro Ile Pro Gln Ser Phe Arg Pro
260 265 270
Ala Asp Glu Asp His Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser
275 280 285
Ser Ala Pro Asn Val His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp
290 295 300
Glu Lys Phe Pro Glu Val Glu Leu Gln Asp Gln Arg Asp Leu Ile Arg
305 310 315 320
Asp Gln Gly Phe Arg Gly Asp Gly Ala Pro Leu Asn Gln Leu Met Arg
325 330 335
Cys Leu Arg Lys Tyr Gln Ser Arg Thr Pro Ser Pro Leu Leu Pro Ser
340 345 350
Val Pro Ser Asp Ile Val Phe Asp Phe Glu Pro Gly Pro Val Phe Arg
355 360 365
Gly Ser Thr Thr Gly Leu Ser Ala Thr Pro Pro Ala Ser Leu Pro Gly
370 375 380
Ser Leu Thr Ser Val Lys Ala Val Gln Arg Ser Pro Gly Pro Gln Arg
385 390 395 400
Glu Arg Lys Ser Ser Ser Ser Ser Glu Asp Arg Asn Arg Met Lys Thr
405 410 415
Leu Gly Arg Arg Asp Ser Ser Asp Asp Trp Glu Ile Pro Asp Gly Gln
420 425 430
Ile Thr Val Gly Gln Arg Ile Gly Ser Gly Ser Phe Gly Thr Val Tyr
435 440 445
Lys Gly Lys Trp His Gly Asp Val Ala Val Lys Met Leu Asn Val Thr
450 455 460
Ala Pro Thr Pro Gln Gln Leu Gln Ala Phe Lys Asn Glu Val Gly Val
465 470 475 480
Leu Arg Lys Thr Arg His Val Asn Ile Leu Leu Phe Met Gly Tyr Ser
485 490 495
Thr Lys Pro Gln Leu Ala Ile Val Thr Gln Trp Cys Glu Gly Ser Ser
500 505 510
Leu Tyr His His Leu His Ile Ile Glu Thr Lys Phe Glu Met Ile Lys
515 520 525
Leu Ile Asp Ile Ala Arg Gln Thr Ala Gln Gly Met Asp Tyr Leu His
530 535 540
Ala Lys Ser Ile Ile His Arg Asp Leu Lys Ser Asn Asn Ile Phe Leu
545 550 555 560
His Glu Asp Leu Thr Val Lys Ile Gly Asp Phe Gly Leu Ala Thr Val
565 570 575
Lys Ser Arg Trp Ser Gly Ser His Gln Phe Glu Gln Leu Ser Gly Ser
580 585 590
Ile Leu Trp Met Ala Pro Glu Val Ile Arg Met Gln Asp Lys Asn Pro
595 600 605
Tyr Ser Phe Gln Ser Asp Val Tyr Ala Phe Gly Ile Val Leu Tyr Glu
610 615 620
Leu Met Thr Gly Gln Leu Pro Tyr Ser Asn Ile Asn Asn Arg Asp Gln
625 630 635 640
Ile Ile Phe Met Val Gly Arg Gly Tyr Leu Ser Pro Asp Leu Ser Lys
645 650 655
Val Arg Ser Asn Cys Pro Lys Ala Met Lys Arg Leu Met Ala Glu Cys
660 665 670
Leu Lys Lys Lys Arg Asp Glu Arg Pro Leu Phe Pro Gln Ile Leu Ala
675 680 685
Ser Ile Glu Leu Leu Ala Arg Ser Leu Pro Lys Ile His Arg Ser Ala
690 695 700
Ser Glu Pro Ser Leu Asn Arg Ala Gly Phe Gln Thr Glu Asp Phe Ser
705 710 715 720
Leu Tyr Ala Cys Ala Ser Pro Lys Thr Pro Ile Gln Ala Gly Gly Tyr
725 730 735
Gly Glu Phe Ala Ala Phe Lys
740
<210> 9
<211> 2186
<212> DNA
<213> Cavia porcellus
<400> 9
atggcggcgc tcagcggcgg cggtggcgcg gagcagggcc aggctctgtt caacggggac 60
atggagctcg aggccggcgc cggcgccgca gcctcttcgg ctgcagaccc tgccattccc 120
gaggaggtat ggaatatcaa acaaatgatt aagttgacgc aggaacacat agaggcccta 180
ttggacaaat ttggtggaga gcataatcca ccatcaatat acctggaggc ctatgaagaa 240
tacaccagca aactagatgc cctccaacaa agagaacagc agttactgga atccctcggg 300
aatggaactg atttttctgt ttctagctct gcatcactgg acaccgttac atcttcttct 360
tcttctagcc tttcagtact accttcatct ctttcagttt ttcaaaatcc tacagatgtg 420
tcacggagca accccaaatc accacaaaaa cctattgtta gagtcttcct gcccaacaaa 480
cagaggacag tggtacctgc aaggtgtgga gttacagtcc gagacagtct gaagaaagca 540
ctcatgatga gaggtcttat cccagagtgc tgtgctgtgt acagaattca ggatggagaa 600
aagaaaccaa ttggctggga cactgacatt tcctggctta ctggggaaga attacatgta 660
gaagtattgg agaatgttcc acttacaaca cacaattttg tatgtatctt tatatttttt 720
ttgctgtttg tctccaagtt ctttgaacac cacccaatac cacaggagga ggcttcctta 780
gcagagacca cccttacatc tggatcatcc ccttctgcac ccccctcaga gtccattggg 840
cccccaattc tcaccagccc atctccttca aaatccattc caattccaca gcctttccgg 900
ccaggagagg aagatcatcg aaatcaattt gggcagcgag accggtcctc atctgctccc 960
aatgtgcata taaacacaat agaacctgtc aatattgatg atttgattag agaccaaggg 1020
tttcgtagtg atggaggatc aactacaggt ttgtctgcca ccccacctgc ctcattacct 1080
ggctcactca ctaatgtgaa agccttacag aaatctccag gacctcagcg agaaaggaag 1140
tcatcttcat cctcagaaga cagaaatcga atgaaaacgc ttggtagacg ggactcaagt 1200
gatgattggg agattcctga tgggcagatt acagtgggac aaagaattgg atctgggtca 1260
tttggaacag tctacaaggg gaagtggcat ggtgacgtgg cagtgaaaat gttgaatgtg 1320
acagcaccca cacctcaaca gttacaggcc ttcaaaaatg aagtaggagt actcaggaaa 1380
acacgacatg tgaatatcct actcttcatg ggctattcca caaagccaca gctagctatt 1440
gttacccagt ggtgtgaggg ctccagctta taccaccatc tccacatcat cgagaccaaa 1500
tttgagatga tcaaacttat agatattgca cgacagactg cccagggcat ggattactta 1560
cacgccaagt caatcatcca cagagacctc aagagtaata atatatttct tcacgaagac 1620
ctcacggtta aaataggtga ttttggtcta gccacagtga aatctcgatg gagtgggtcc 1680
catcagtttg aacagttgtc tggatccatt ttgtggatgg caccagaagt aatcagaatg 1740
cgagataaaa acccatacag ttttcagtcc gatgtatatg catttgggat tgttctatat 1800
gaattgatga ctgggcagtt accctattca aatatcaaca acagggacca gataattttt 1860
atggtgggac gaggatatct atctccagat ctcagcaagg tacggagtaa ctgtccaaaa 1920
gccatgaaga ggttaatggc ggagtgcctc aaaaagaaaa gagatgagag accactcttt 1980
ccccaaattc tcgcctctat tgagctgctg gcccgctcat tgccaaaaat tcaccgcagt 2040
gcatcagaac cctccttgaa tcgggctggt ttccaaacag aggattttag tctctatgct 2100
tgtgcttctc caaaaacacc catccaggca gggggatatg gtgcgtttcc tgtccactga 2160
tgcaaattaa atgagtgaga aataaa 2186
<210> 10
<211> 719
<212> PRT
<213> Cavia porcellus
<400> 10
Met Ala Ala Leu Ser Gly Gly Gly Gly Ala Glu Gln Gly Gln Ala Leu
1 5 10 15
Phe Asn Gly Asp Met Glu Leu Glu Ala Gly Ala Gly Ala Ala Ala Ser
20 25 30
Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn Ile Lys Gln
35 40 45
Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu Asp Lys Phe
50 55 60
Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala Tyr Glu Glu
65 70 75 80
Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln Gln Leu Leu
85 90 95
Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser Ser Ala Ser
100 105 110
Leu Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser Val Leu Pro
115 120 125
Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser Arg Ser Asn
130 135 140
Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu Pro Asn Lys
145 150 155 160
Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val Arg Asp Ser
165 170 175
Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu Cys Cys Ala
180 185 190
Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly Trp Asp Thr
195 200 205
Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu Val Leu Glu
210 215 220
Asn Val Pro Leu Thr Thr His Asn Phe Val Cys Ile Phe Ile Phe Phe
225 230 235 240
Leu Leu Phe Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu
245 250 255
Glu Ala Ser Leu Ala Glu Thr Thr Leu Thr Ser Gly Ser Ser Pro Ser
260 265 270
Ala Pro Pro Ser Glu Ser Ile Gly Pro Pro Ile Leu Thr Ser Pro Ser
275 280 285
Pro Ser Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Gly Glu Glu
290 295 300
Asp His Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro
305 310 315 320
Asn Val His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile
325 330 335
Arg Asp Gln Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser
340 345 350
Ala Thr Pro Pro Ala Ser Leu Pro Gly Ser Leu Thr Asn Val Lys Ala
355 360 365
Leu Gln Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser
370 375 380
Ser Glu Asp Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser
385 390 395 400
Asp Asp Trp Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile
405 410 415
Gly Ser Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp
420 425 430
Val Ala Val Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu
435 440 445
Gln Ala Phe Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val
450 455 460
Asn Ile Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile
465 470 475 480
Val Thr Gln Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile
485 490 495
Ile Glu Thr Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln
500 505 510
Thr Ala Gln Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg
515 520 525
Asp Leu Lys Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys
530 535 540
Ile Gly Asp Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser
545 550 555 560
His Gln Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu
565 570 575
Val Ile Arg Met Arg Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val
580 585 590
Tyr Ala Phe Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro
595 600 605
Tyr Ser Asn Ile Asn Asn Arg Asp Gln Ile Ile Phe Met Val Gly Arg
610 615 620
Gly Tyr Leu Ser Pro Asp Leu Ser Lys Val Arg Ser Asn Cys Pro Lys
625 630 635 640
Ala Met Lys Arg Leu Met Ala Glu Cys Leu Lys Lys Lys Arg Asp Glu
645 650 655
Arg Pro Leu Phe Pro Gln Ile Leu Ala Ser Ile Glu Leu Leu Ala Arg
660 665 670
Ser Leu Pro Lys Ile His Arg Ser Ala Ser Glu Pro Ser Leu Asn Arg
675 680 685
Ala Gly Phe Gln Thr Glu Asp Phe Ser Leu Tyr Ala Cys Ala Ser Pro
690 695 700
Lys Thr Pro Ile Gln Ala Gly Gly Tyr Gly Ala Phe Pro Val His
705 710 715
<210> 11
<211> 3229
<212> DNA
<213> Canis familiaris
<400> 11
gtaatgctgg attttcatgg aataagtttg acctgtgctg cagtggcctc cagcaaggta 60
cccgcaagat gtggagttac agtccgggac agtctaaaga aagctctgat gatgagaggt 120
ctaatcccag agtgctgtgc tgtttacaga attcaggatg gagagaagaa accgattggc 180
tgggacactg atatttcctg gctcactgga gaggaattgc atgtagaagt gttggaaaat 240
gttccgctta ccacacacaa ctttgtacgg aaaacttttt tcaccttagc attttgtgac 300
ttttgtcgaa agctgctttt ccagggtttt cgctgtcaaa catgtggtta taaatttcac 360
cagcgttgta gtacagaggt tccactgatg tgtgttaatt atgaccaact tgatttgctg 420
tttgtctcca agttctttga acaccaccca ataccacagg aggaggcctc catagcagag 480
actgccctta cgtctggatc atccccttct gctcccccct ccgattctcc tgggccccca 540
attctgacca gtccgtctcc ttcaaaatcc attccaattc cacagccttt ccgaccagca 600
gatgaagatc atcgaaatca gtttggacaa cgagaccggt cctcatcagc tccaaatgtg 660
catataaaca caatagaacc cgtcaacatt gatgacttga ttagagacca agggtttcgt 720
agtgatggag gatcaaccac aggtttgtct gccacccccc ctgcctcatt gcctggctca 780
ctcactaatg taaaagcatt acagaaatct ccaggacctc agcgggaaag aaaatcatct 840
tcatcctcag aagataggaa tcgaatgaaa acacttggta gacgggattc aagtgatgat 900
tgggagatac ctgatgggca gatcacagtg ggacagagaa ttggatccgg gtcatttggg 960
acagtctaca agggaaagtg gcatggtgac gtggcagtga aaatgttgaa tgtgacagca 1020
cccacacctc agcagttaca ggccttcaaa aatgaagtag gagtactcag gaaaactcga 1080
catgtgaata tcctactctt tatgggctat tcaacaaagc cccaactggc tattgttacc 1140
cagtggtgtg agggctccag cttatatcac catctccaca tcattgagac caaatttgag 1200
atgataaagc ttatagatat tgcacggcag actgcacagg gcatggatta cttacacgcc 1260
aagtcaatca tccacagaga cctcaagagt aataatattt ttcttcatga agacctcaca 1320
gtaaaaatag gtgattttgg tctagccaca gtgaaatctc gatggagtgg gtcccatcag 1380
tttgaacagt tgtctggatc cattttgtgg atggcaccag aagtgatccg aatgcaagac 1440
aaaaacccat atagcttcca gtcagatgta tacgcatttg ggattgttct atatgaattg 1500
atgacagggc agttacctta ttcaaacatc aacaacaggg accagataat ttttatggtg 1560
ggacgaggat atctttctcc agatctcagt aaggtacgga gtaactgtcc aaaagccatg 1620
aagagattga tggcagagtg cctaaaaaag aaaagagatg agaggccact ctttccccaa 1680
attctcgcct ctattgagct gctggcccgc tcattgccaa aaattcaccg cagtgcatca 1740
gaaccctcct tgaatcgggc tggcttccaa acagaggatt ttagtctcta tgcttgcgct 1800
tctccaaaaa cacccatcca ggcaggggga tacggagaat ttgcagcctt caagtagcca 1860
caccatcatg gcaacaacta ctcttatttc ttaagtcttg tgttcgtaca atttgttaac 1920
atcaaaacac agttctgttc ctcaaatctt tttttaaaga tacagaattt tcaatgcata 1980
agctggtgtg gaacagaatg gaatttccca tccaacaaaa gagggaagaa tgttttagga 2040
accagaattc tctgctgcca gtgtttcttc ttcaacacaa ataccacgtg catacaagtc 2100
tgcccactcc caggaaggaa gaggagagcc tgagttctga ccttttgatg gtcaggcatg 2160
atggaaagaa actgctgcta cagcttggga gattggctgt ggagagcctg cccgtcagct 2220
ctgcccttct aaccgccaga tgagtgtgtg gctggtcacc tgacagggca gctgcaatcg 2280
ccaagcatcg ttctctttcc tgtcctggga ttttgtcgtg gagctctttc cccctagtca 2340
ccaccggttc atttctgagg gatggaacaa aaatgcagca tggcctttct gtgtggtgca 2400
tgtccggtct ttgacaaatt tttatcaagt gaagctcttg tatttaaatg gagaatgaga 2460
ggcgaggggg ggggatcacg ttttggtgta ggggcaaagg gaatgctgca tctttttcct 2520
gacccactgg gtttctggcc tttgtttcct tgctcactga gggtgtctgc ctataaccac 2580
gcaggctgga aagtgctggc acacattgcc ttctcttctc actgggtcca gcaatgaaga 2640
caagtgttgg ggattttttt ttttgccctc cacaatgtag caagttctca ggaaaataca 2700
gttaatatct tcctcctaag ctcttccagt catcaagtac ttatgtggct actttgtcca 2760
gggcacaaaa tgccatggcg gtatccaatt aaaagcctac aaaactgctt gataacagtt 2820
ttgaatgtgt gagacattta tgtaatttaa atgtaaggta caagttttaa tttctgagtt 2880
tctctattat atttttatta aaaagaaaat aattttcaga tttaattgaa ttggaataaa 2940
ataatacttc ccaccagaat tatatatcct ggaaaattgt atttttgtta tataaacaac 3000
ttttaaagaa agatcattat ccttttctct acctaaatat ggggagtctt agcataatga 3060
cagatattta taatttttaa attaatggta cttgctggat ccacactaac atctttgcta 3120
atatctcatg ttttcctcca acttactcct acactacatc ctccatcctc tttccagtct 3180
tttatctaga atatgcaacc taaaataaaa atggtggtgt ctccattca 3229
<210> 12
<211> 617
<212> PRT
<213> Canis familiaris
<400> 12
Met Leu Asp Phe His Gly Ile Ser Leu Thr Cys Ala Ala Val Ala Ser
1 5 10 15
Ser Lys Val Pro Ala Arg Cys Gly Val Thr Val Arg Asp Ser Leu Lys
20 25 30
Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu Cys Cys Ala Val Tyr
35 40 45
Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly Trp Asp Thr Asp Ile
50 55 60
Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu Val Leu Glu Asn Val
65 70 75 80
Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr Phe Phe Thr Leu Ala
85 90 95
Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln Gly Phe Arg Cys Gln
100 105 110
Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser Thr Glu Val Pro Leu
115 120 125
Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu Phe Val Ser Lys Phe
130 135 140
Phe Glu His His Pro Ile Pro Gln Glu Glu Ala Ser Ile Ala Glu Thr
145 150 155 160
Ala Leu Thr Ser Gly Ser Ser Pro Ser Ala Pro Pro Ser Asp Ser Pro
165 170 175
Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser Lys Ser Ile Pro Ile
180 185 190
Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His Arg Asn Gln Phe Gly
195 200 205
Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val His Ile Asn Thr Ile
210 215 220
Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp Gln Gly Phe Arg Ser
225 230 235 240
Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr Pro Pro Ala Ser Leu
245 250 255
Pro Gly Ser Leu Thr Asn Val Lys Ala Leu Gln Lys Ser Pro Gly Pro
260 265 270
Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu Asp Arg Asn Arg Met
275 280 285
Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp Trp Glu Ile Pro Asp
290 295 300
Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser Gly Ser Phe Gly Thr
305 310 315 320
Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala Val Lys Met Leu Asn
325 330 335
Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala Phe Lys Asn Glu Val
340 345 350
Gly Val Leu Arg Lys Thr Arg His Val Asn Ile Leu Leu Phe Met Gly
355 360 365
Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr Gln Trp Cys Glu Gly
370 375 380
Ser Ser Leu Tyr His His Leu His Ile Ile Glu Thr Lys Phe Glu Met
385 390 395 400
Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala Gln Gly Met Asp Tyr
405 410 415
Leu His Ala Lys Ser Ile Ile His Arg Asp Leu Lys Ser Asn Asn Ile
420 425 430
Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly Asp Phe Gly Leu Ala
435 440 445
Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln Phe Glu Gln Leu Ser
450 455 460
Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile Arg Met Gln Asp Lys
465 470 475 480
Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala Phe Gly Ile Val Leu
485 490 495
Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser Asn Ile Asn Asn Arg
500 505 510
Asp Gln Ile Ile Phe Met Val Gly Arg Gly Tyr Leu Ser Pro Asp Leu
515 520 525
Ser Lys Val Arg Ser Asn Cys Pro Lys Ala Met Lys Arg Leu Met Ala
530 535 540
Glu Cys Leu Lys Lys Lys Arg Asp Glu Arg Pro Leu Phe Pro Gln Ile
545 550 555 560
Leu Ala Ser Ile Glu Leu Leu Ala Arg Ser Leu Pro Lys Ile His Arg
565 570 575
Ser Ala Ser Glu Pro Ser Leu Asn Arg Ala Gly Phe Gln Thr Glu Asp
580 585 590
Phe Ser Leu Tyr Ala Cys Ala Ser Pro Lys Thr Pro Ile Gln Ala Gly
595 600 605
Gly Tyr Gly Glu Phe Ala Ala Phe Lys
610 615
<210> 13
<211> 1889
<212> DNA
<213> Canis familiaris
<400> 13
ggaatatcaa acaaatgatt aagttgacac aggaacatat agaagcccta ttggacaagt 60
ttggtgggga gcataatcca ccatcaatat atctggaggc ctatgaagaa tacaccagca 120
aactagatgc cctccaacag cgagaacaac agttattgga atccctgggg aatggaactg 180
atttttctgt ttctagctct gcatcaacgg acaccgttac atcttcttcc tcttctagcc 240
tttcagtgct accttcatct ctttcagttt ttcaaaatcc cacagatata tcacggagca 300
atcccaagtc accacaaaaa cctatcgtta gagtcttcct gcccaataaa cagaggacgg 360
tggtacccgc aagatgtgga gttacagtcc gggacagtct aaagaaagct ctgatgatga 420
gaggtctaat cccagagtgc tgtgctgttt acagaattca ggatggagag aagaaaccga 480
ttggctggga cactgatatt tcctggctca ctggagagga attgcatgta gaagtgttgg 540
aaaatgttcc gcttaccaca cacaactttg tacggaaaac ttttttcacc ttagcatttt 600
gtgacttttg tcgaaagctg cttttccagg gttttcgctg tcaaacatgt ggttataaat 660
ttcaccagcg ttgtagtaca gaggttccac tgatgtgtgt taattatgac caacttgatt 720
tgctgtttgt ctccaagttc tttgaacacc acccaatacc acaggaggag gcctccatag 780
cagagactgc ccttacgtct ggatcatccc cttctgctcc cccctccgat tctcctgggc 840
ccccaattct gaccagtccg tctccttcaa aatccattcc aattccacag cctttccgac 900
cagcagatga agatcatcga aatcagtttg gacaacgaga ccggtcctca tcagctccaa 960
atgtgcatat aaacacaata gaacccgtca acattgatga cttgattaga gaccaagggt 1020
ttcgtagtga tggaggatca accacaggtt tgtctgccac cccccctgcc tcattgcctg 1080
gctcactcac taatgtaaaa gcattacaga aatctccagg acctcagcgg gaaagaaaat 1140
catcttcatc ctcagaagat aggaatcgaa tgaaaacact tggtagacgg gattcaagtg 1200
atgattggga gatacctgat gggcagatca cagtgggaca gagaattgga tccgggtcat 1260
ttgggacagt ctacaaggga aagtggcatg gtgacgtggc agtgaaaatg ttgaatgtga 1320
cagcacccac acctcagcag ttacaggcct tcaaaaatga agtaggagta ctcaggaaaa 1380
ctcgacatgt gaatatccta ctctttatgg gctattcaac aaagccccaa ctggctattg 1440
ttacccagtg gtgtgagggc tccagcttat atcaccatct ccacatcatt gagaccaaat 1500
ttgagatgat aaagcttata gatattgcac ggcagactgc acagggcatg gattacttac 1560
acgccaagtc aatcatccac agagacctca agagtaataa tatttttctt catgaagacc 1620
tcacagtaaa aataggtgat tttggtctag ccacagtgaa atctcgatgg agtgggtccc 1680
atcagtttga acagttgtct ggatccattt tgtggatggc accagaagtg atccgaatgc 1740
aagacaaaaa cccatatagc ttccagtcag atgtatacgc atttgggatt gttctatatg 1800
aattgatgac agggcagtta ccttattcaa acatcaacaa cagggaccag ctcagatcat 1860
gatcacggtg tcatgagatc aagccccac 1889
<210> 14
<211> 615
<212> PRT
<213> Canis familiaris
<400> 14
Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu Asp Lys Phe
1 5 10 15
Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala Tyr Glu Glu
20 25 30
Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln Gln Leu Leu
35 40 45
Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser Ser Ala Ser
50 55 60
Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser Val Leu Pro
65 70 75 80
Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Ile Ser Arg Ser Asn
85 90 95
Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu Pro Asn Lys
100 105 110
Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val Arg Asp Ser
115 120 125
Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu Cys Cys Ala
130 135 140
Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly Trp Asp Thr
145 150 155 160
Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu Val Leu Glu
165 170 175
Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr Phe Phe Thr
180 185 190
Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln Gly Phe Arg
195 200 205
Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser Thr Glu Val
210 215 220
Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu Phe Val Ser
225 230 235 240
Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala Ser Ile Ala
245 250 255
Glu Thr Ala Leu Thr Ser Gly Ser Ser Pro Ser Ala Pro Pro Ser Asp
260 265 270
Ser Pro Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser Lys Ser Ile
275 280 285
Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His Arg Asn Gln
290 295 300
Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val His Ile Asn
305 310 315 320
Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp Gln Gly Phe
325 330 335
Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr Pro Pro Ala
340 345 350
Ser Leu Pro Gly Ser Leu Thr Asn Val Lys Ala Leu Gln Lys Ser Pro
355 360 365
Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu Asp Arg Asn
370 375 380
Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp Trp Glu Ile
385 390 395 400
Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser Gly Ser Phe
405 410 415
Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala Val Lys Met
420 425 430
Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala Phe Lys Asn
435 440 445
Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile Leu Leu Phe
450 455 460
Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr Gln Trp Cys
465 470 475 480
Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu Thr Lys Phe
485 490 495
Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala Gln Gly Met
500 505 510
Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu Lys Ser Asn
515 520 525
Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly Asp Phe Gly
530 535 540
Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln Phe Glu Gln
545 550 555 560
Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile Arg Met Gln
565 570 575
Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala Phe Gly Ile
580 585 590
Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser Asn Ile Asn
595 600 605
Asn Arg Asp Gln Leu Arg Ser
610 615
<210> 15
<211> 3521
<212> DNA
<213> Felis catus
<220>
<221> misc_feature
<222> (630)..(649)
<223> n is a, c, g, or t
<400> 15
atgcctaacc tcagtctctg ccaccacggc caatttgctc atgtgcccac tgtgtcggca 60
ctgggatatt ttgtgatttg ccttggccat tgtccactgt ccttgacatt gcctgaagga 120
gaaccactga tgctaatgtt gaaggtgacc tttgcaggct ctccactact cataccaaag 180
atgcggcccc ctgataatcc cagagccact gtctgcacat gggcaaaaca ggctacattc 240
tgtgcagact ggggagaaag gttccaagaa cacagtgcca tagttttggg cagagagttt 300
caacacagca tagtgtctat ggcagtatct ggatttggcc gggggaagtg cccaagagga 360
gacagtcagg ctgtgtccta cggccaagga cctgcactta tttttgcatg cagtggttta 420
gcacagggaa gagaacgaag taggaaatcg gagccatgga aacggcagag cggaggaaac 480
gtgcacgcgc gagggtgggc acgaaaggaa agaaccctcc ccagaagact gcgcgagggc 540
gctcctagga ttacgtcacg caccccgcga aaactgaaat gtactgtgtg tggtctttta 600
attgaactat cttccttatg tgcacttaan nnnnnnnnnn nnnnnnnnng cggcggcggc 660
ggtggcgcgg agcagggcca ggctctgttc aacggggaca tggagcccga agccggcgcc 720
gcggcctctt cggctgcgga ccctgccatt cccgaggagg tgtggaatat caaacaaatg 780
attaagttga cacaggaaca tatagaggcc ctattggaca aatttggtgg ggagcataat 840
ccaccatcaa tatatctaga ggcctatgaa gaatacacca gcaagctaga tgccctccaa 900
cagagagaac aacagttatt ggaatccctg gggaatggaa ctgatttttc tgtttctagc 960
tctgcatcaa cagacaccgt tacatcttcc tcctcttcta gcctttcagt gctaccttca 1020
tctctttcag tttttcaaaa ccccacagat gtgtcacgga gcaatcccaa gtcaccacag 1080
aaacctatcg ttagagtctt cctgcctaat aaacagagga cagtggtacc tgcaagatgt 1140
ggagttacag tccgggacag tctaaagaaa gctctgatga tgagaggtct aatccctgag 1200
tgctgtgctg tttacagaat tcaggatgga gagaagaaac caattggctg ggacactgat 1260
atctcctggc tcaccggaga ggaattgcat gtagaagtgt tggaaaatgt tccacttaca 1320
actcacaact ttgtatgtac ggaaaacgtt ttcaccttag cattttgtga cttttgtcga 1380
aagctgcttt tccaaggttt tcgctgtcaa acgtgtggtt ataaatttca ccagcgttgt 1440
agtacagagg ttccactgat gtgtgttaat tatgaccaac ttgatttgct gtttgtctcc 1500
aagttctttg aacaccaccc aataccacag gaggaggcct ccatagcaga gactgcccta 1560
acgtctggat cgtccccttc tgcccccccc tccgattcta ctgggcccca aattctcacc 1620
agtccgtctc cttcaaaatc cattccaatt ccacagcctt tccgaccagc agatgaagat 1680
catcgaaatc aatttggaca gcgagaccgg tcctcatcag ctccaaatgt gcatataaat 1740
acaatagaac ctgtcaatat tgatgacttg attagagacc aggggtttcg tagtgatgga 1800
ggatcaacca caggcttgtc tgccaccccc cctgcctcat tgccgggctc tctcactaat 1860
gtaaaagcat tacagaaatc tccagggcct cagcgggaaa ggaaatcttc ttcatcctca 1920
gaagatagga atcgaatgaa aacacttggt agaagggatt caagtgatga ttgggagatt 1980
cctgatgggc agatcacagt gggacagaga attggatccg ggtcatttgg gacagtctac 2040
aagggaaagt ggcatggtga tgtggcagtg aaaatgttga atgtgacagc acccacacct 2100
cagcagttac aggccttcaa aaatgaagta ggagtactca ggaaaactcg gcatgtgaac 2160
atcctgctct tcatgggcta ttcaacaaag ccccagctgg ctattgtcac ccagtggtgt 2220
gagggctcca gcttatacca ccatctccac atcatcgaga ccaaattcga gatgatcaag 2280
ctgatagata ttgctcggca gactgcgcag ggcatggatt acttacacgc caagtcaatc 2340
atccacagag acctcaagag taataatatt tttcttcacg aagacctcac agtaaaaata 2400
ggtgattttg gtctagccac agtgaaatct cgatggagtg ggtcccatca gtttgaacag 2460
ttgtctggat ccattttgtg gatggcacca gaagtaattc gaatgcaaga taaaaaccca 2520
tatagctttc agtcagatgt atatgcattt gggattgttc tatatgaatt gatgactgga 2580
cagttacctt attcaaacat caacaacagg gaccagataa tttttatggt gggacgagga 2640
tatctttctc cagatctcag taaggtacga agtaactgtc caaaagccat gaagagattg 2700
atggcagagt gcctaaaaaa gaaaagagat gagaggccac tgtttcccca aattcttgcc 2760
tctattgagc tgctggcccg ctcattgcca aaaattcacc gcagtgcatc agaaccctcc 2820
ttgaatcggg ctggcttcca gacagaggat tttagtctct atgcttgtgc ttctccaaaa 2880
acacccatcc aggcaggggg atatggtgcg tttcccgtcc actgagataa gttagatgag 2940
tgcgcgagtg cagggggccg gggccaagga ggtggaaatg tgcgtgcttc tgtactaagt 3000
tggatagcat cttctttttt aaaaaaagat gaaccaaaga atgtgtatgt ttttaaagac 3060
tagatataat tatttcctga tctaaaatgt atacttagct ttggattttc aatatccaag 3120
ggttttcaaa atgcacagac attgctgaac atttgcagta cctcttctgg aggctttact 3180
tcctgttaca aattggtttt gtttactggc ttatcctaat tattaaactt caattaaact 3240
tttctcctgc accttttgtt atgagctatc acatgtccct tagggactcg caagagcagt 3300
actgcccccg tgtacgggct tgcaggtaga aaggggatga cgggttttaa cacctgtgtg 3360
aggcaaggca gtccgaacag atctcattta ggaagccacg agagttgaat aagttatttt 3420
tattcttagt attttttctg taactacttt ttattataac ttggaaaata tggatgtcct 3480
ttatacacct tagcaataga ctgaatttct ttttataaat t 3521
<210> 16
<211> 974
<212> PRT
<213> Felis catus
<220>
<221> misc_feature
<222> (210)..(217)
<223> Xaa can be any naturally occurring amino acid
<400> 16
Met Pro Asn Leu Ser Leu Cys His His Gly Gln Phe Ala His Val Pro
1 5 10 15
Thr Val Ser Ala Leu Gly Tyr Phe Val Ile Cys Leu Gly His Cys Pro
20 25 30
Leu Ser Leu Thr Leu Pro Glu Gly Glu Pro Leu Met Leu Met Leu Lys
35 40 45
Val Thr Phe Ala Gly Ser Pro Leu Leu Ile Pro Lys Met Arg Pro Pro
50 55 60
Asp Asn Pro Arg Ala Thr Val Cys Thr Trp Ala Lys Gln Ala Thr Phe
65 70 75 80
Cys Ala Asp Trp Gly Glu Arg Phe Gln Glu His Ser Ala Ile Val Leu
85 90 95
Gly Arg Glu Phe Gln His Ser Ile Val Ser Met Ala Val Ser Gly Phe
100 105 110
Gly Arg Gly Lys Cys Pro Arg Gly Asp Ser Gln Ala Val Ser Tyr Gly
115 120 125
Gln Gly Pro Ala Leu Ile Phe Ala Cys Ser Gly Leu Ala Gln Gly Arg
130 135 140
Glu Arg Ser Arg Lys Ser Glu Pro Trp Lys Arg Gln Ser Gly Gly Asn
145 150 155 160
Val His Ala Arg Gly Trp Ala Arg Lys Glu Arg Thr Leu Pro Arg Arg
165 170 175
Leu Arg Glu Gly Ala Pro Arg Ile Thr Ser Arg Thr Pro Arg Lys Leu
180 185 190
Lys Cys Thr Val Cys Gly Leu Leu Ile Glu Leu Ser Ser Leu Cys Ala
195 200 205
Leu Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Gly Gly Gly Gly Gly Ala Glu
210 215 220
Gln Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala
225 230 235 240
Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn
245 250 255
Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu
260 265 270
Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala
275 280 285
Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln
290 295 300
Gln Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser
305 310 315 320
Ser Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser
325 330 335
Val Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser
340 345 350
Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
355 360 365
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
370 375 380
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
385 390 395 400
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
405 410 415
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
420 425 430
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Cys Thr Glu
435 440 445
Asn Val Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe
450 455 460
Gln Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys
465 470 475 480
Ser Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu
485 490 495
Leu Phe Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu
500 505 510
Ala Ser Ile Ala Glu Thr Ala Leu Thr Ser Gly Ser Ser Pro Ser Ala
515 520 525
Pro Pro Ser Asp Ser Thr Gly Pro Gln Ile Leu Thr Ser Pro Ser Pro
530 535 540
Ser Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp
545 550 555 560
His Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn
565 570 575
Val His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg
580 585 590
Asp Gln Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala
595 600 605
Thr Pro Pro Ala Ser Leu Pro Gly Ser Leu Thr Asn Val Lys Ala Leu
610 615 620
Gln Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser
625 630 635 640
Glu Asp Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp
645 650 655
Asp Trp Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly
660 665 670
Ser Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val
675 680 685
Ala Val Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln
690 695 700
Ala Phe Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn
705 710 715 720
Ile Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val
725 730 735
Thr Gln Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile
740 745 750
Glu Thr Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr
755 760 765
Ala Gln Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp
770 775 780
Leu Lys Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile
785 790 795 800
Gly Asp Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His
805 810 815
Gln Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val
820 825 830
Ile Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr
835 840 845
Ala Phe Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr
850 855 860
Ser Asn Ile Asn Asn Arg Asp Gln Ile Ile Phe Met Val Gly Arg Gly
865 870 875 880
Tyr Leu Ser Pro Asp Leu Ser Lys Val Arg Ser Asn Cys Pro Lys Ala
885 890 895
Met Lys Arg Leu Met Ala Glu Cys Leu Lys Lys Lys Arg Asp Glu Arg
900 905 910
Pro Leu Phe Pro Gln Ile Leu Ala Ser Ile Glu Leu Leu Ala Arg Ser
915 920 925
Leu Pro Lys Ile His Arg Ser Ala Ser Glu Pro Ser Leu Asn Arg Ala
930 935 940
Gly Phe Gln Thr Glu Asp Phe Ser Leu Tyr Ala Cys Ala Ser Pro Lys
945 950 955 960
Thr Pro Ile Gln Ala Gly Gly Tyr Gly Ala Phe Pro Val His
965 970
<210> 17
<211> 3853
<212> DNA
<213> Bos taurus
<400> 17
ctcagctgcg ccgggtctca caagacggtt cccgaggtgg cccaggcgcc gtcccaccgc 60
cgacgccgcc cgggccgccc gggccgtccc tccccgctgc cccccgtcct ccgcctccgc 120
ctccccccgc cctcagcctc ccttccccct ccccgcccag cagcggtcgc tcgggcccgg 180
ctctcggtta taagatggcg gcgctgagtg gcggcggcgg cggcggcggc ggtggcgcgg 240
agcagggcca ggctctgttc aacggggaca tggagcccga ggccggcgcc gcggcctctt 300
cggctgcgga ccccgccatt cccgaggagg tgtggaatat caaacaaatg attaagttga 360
cacaggagca tatagaggcc ctattggaca aatttggtgg ggagcataat ccaccatcaa 420
tatatctgga ggcctatgaa gaatacacca gcaagctaga tgccctccaa caaagagaac 480
aacagttatt ggaatccctg gggaatggaa ctgatttttc tgtttctagc tctgcatcaa 540
cggacaccgt tacatcttct tcctcttcta gcctttcagt gctgccttca tctctttcag 600
tttttcaaaa tcccacagat gtgtcacgga gcaaccccaa gtcaccacaa aaacctatcg 660
ttagagtctt cctgcccaat aaacagagga cagtggtacc tgcacggtgt ggagtcacag 720
tccgggacag cctgaagaag gcactgatga tgagaggtct aatcccagag tgctgtgctg 780
tttacagaat tcaggatggg gagaagaaac caattggctg ggacactgat atttcctggc 840
ttactggaga ggagttgcat gtagaagtgt tggagaatgt tccacttaca acacacaact 900
ttgtacggaa aacttttttc accttagcat tttgtgactt ctgtagaaag ctgcttttcc 960
agggattccg ctgtcaaaca tgtggttata aatttcacca gcgttgtagt acagaggttc 1020
cactgatgtg tgttaattat gaccaactag atttgctgtt tgtctccaag ttctttgaac 1080
accacccaat accacaggag gaggcctcct tagcagagac tacccttcca tgtggctcat 1140
ccccttctgc acccccctcc gattctattg ggcccccaat tctcaccagt ccatctcctt 1200
caaaatccat tccaattcca cagcctttcc gaccagcaga tgaagatcat cgaaatcagt 1260
ttggacaacg agaccggtcc tcatcagctc caaatgtgca tataaacaca atagaacccg 1320
tcaatattga tgacttgatt agagaccaag ggtttcgtag tgatggagga tcaaccacag 1380
gtttatccgc cacaccccct gcctcattac ctggctcact ctctaatgtg aaagcattgc 1440
agaaatctcc aggacctcag cgagaaagaa agtcctcttc atcctcagaa gacaggaatc 1500
gaatgaaaac gcttggtaga cgggattcaa gtgacgattg ggagattcct gatggacaga 1560
tcacagtggg acaaagaatt ggatcagggt catttgggac agtctacaag ggaaagtggc 1620
atggtgatgt ggcagtgaaa atgttgaatg tgacagcacc cacacctcag cagttacagg 1680
ccttcaaaaa tgaagtagga gtactcagga aaacgcgaca tgtgaatatc ctcctcttca 1740
tgggttattc aacaaagcca caactggcta ttgttaccca gtggtgtgag ggctccagtt 1800
tatatcatca tctccacatc attgagacca aattcgagat gatcaaactt atagatattg 1860
cacggcagac tgcacagggc atggattact tacacgccaa gtcaatcatc cacagagacc 1920
tcaagagtaa taatattttt cttcatgaag acctcacagt aaaaataggt gattttggtc 1980
tagccacagt gaaatctcga tggagtgggt cccatcagtt tgaacagttg tctggatcca 2040
ttttgtggat ggcaccagaa gtaatcagaa tgcaagataa aaacccatat agctttcagt 2100
cagatgtata tgcatttggg attgttctgt atgaattgat gaccggacag ttaccttatt 2160
caaatatcaa caacagggac cagataattt ttatggtggg acgaggatat ctgtctccag 2220
atctcagtaa ggtacggagt aactgtccaa aagccatgaa gagattaatg gcagagtgcc 2280
taaaaaagaa aagagatgaa agaccactct ttccccaaat tctcgcctct attgagctgc 2340
tggcccgctc attgccaaaa attcaccgca gtgcatcaga accctccttg aatcgggctg 2400
gcttccaaac agaggatttt agtctatatg cttgtgcttc tccaaaaaca cccattcagg 2460
cagggggata tggtacgttt cctgttcact gaaacaaacc gagtgagtga cagcatgtag 2520
gagggtaggg acaaaagaaa gtgaacaaat gtttgcttat atatttgtta aattgaatag 2580
gattttcttt ttctttaaag gtgaacaaga gaacatgtgt gtttttaaag tttggatata 2640
gttttcttcc cagtctaaaa cccatagtta gcattacatt ttcaacatcg aatttttttt 2700
taattcatag acattgctga aaatttataa taccttttcc agaggcttta cttcccattc 2760
caagtttgtt ttgtttactt ggttagtcta atcattaaac tttaaacttt ccccacctac 2820
cttttgctgt tagctatccc gcatccatta ggggctccaa gaacagcact gtctgcgtgt 2880
gtgtgttggc aggtgggaag ctgatggtaa gttaggctgt gttagtgaag gtaaactgac 2940
caggtctaat taggagtcac tagaattgaa taagcttatt tttattaata ttttttctta 3000
taactatttc tttttgtaat aatttagaaa atataattgt tctttattcc cttacagcag 3060
tataaattat tggtgcaggt aaccaaagat attactgagg agtggcatgt ttgacatgag 3120
tgacatggtt taactttgga tttttagtta atatttcttt atatattaag gatgtcttac 3180
acattataga agtcaaattt actgacaaag gtattgcctc ctcttcctcc ccaaaaacac 3240
agcaaaattc tctgggaact cgtagcattg ttggttttct tttggatgac tatggttgcc 3300
aaacaaccaa gtaattgatt ttttttaaat tattattgct ttagattata ctcacctctc 3360
atgatgcctg ttagcaatca cctttatcca tgtgtcttgt aaaatatctt tcctccttat 3420
attctttgcc caacaagagt ctacttgtta tgaatgagta ctattttctt tttttgattc 3480
cccagtataa ttagtatgtt tagtgctttc taggacttcc actttcttat gttaaaaaaa 3540
aaaacaaact aatgtggcag tcagtatatt cttactgtga atcagagtct ttactgggaa 3600
tcaaagtgaa agaagcagct gttctgactt cagagtcagc ctagggacca aaaccagcct 3660
cttaaataca ccttcattta ttcagtttgg atttgtgatg attttcatta tagctgacag 3720
ttcaaggtta ttcagtggca cacagatagc atctgcataa atgcctttct tcttgaaaat 3780
aaaggagaaa attgggaaga ctttacacca atagtttagt ctttaagtac cacagataac 3840
acacaccata aat 3853
<210> 18
<211> 764
<212> PRT
<213> Bos taurus
<400> 18
Ala Ala Leu Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Glu Gln
1 5 10 15
Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala Ala
20 25 30
Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn Ile
35 40 45
Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu Asp
50 55 60
Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala Tyr
65 70 75 80
Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln Gln
85 90 95
Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser Ser
100 105 110
Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser Val
115 120 125
Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser Arg
130 135 140
Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu Pro
145 150 155 160
Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val Arg
165 170 175
Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu Cys
180 185 190
Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly Trp
195 200 205
Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu Val
210 215 220
Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr Phe
225 230 235 240
Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln Gly
245 250 255
Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser Thr
260 265 270
Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu Phe
275 280 285
Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala Ser
290 295 300
Leu Ala Glu Thr Thr Leu Pro Cys Gly Ser Ser Pro Ser Ala Pro Pro
305 310 315 320
Ser Asp Ser Ile Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser Lys
325 330 335
Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His Arg
340 345 350
Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val His
355 360 365
Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp Gln
370 375 380
Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr Pro
385 390 395 400
Pro Ala Ser Leu Pro Gly Ser Leu Ser Asn Val Lys Ala Leu Gln Lys
405 410 415
Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu Asp
420 425 430
Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp Trp
435 440 445
Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser Gly
450 455 460
Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala Val
465 470 475 480
Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala Phe
485 490 495
Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile Leu
500 505 510
Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr Gln
515 520 525
Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu Thr
530 535 540
Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala Gln
545 550 555 560
Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu Lys
565 570 575
Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly Asp
580 585 590
Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln Phe
595 600 605
Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile Arg
610 615 620
Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala Phe
625 630 635 640
Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser Asn
645 650 655
Ile Asn Asn Arg Asp Gln Ile Ile Phe Met Val Gly Arg Gly Tyr Leu
660 665 670
Ser Pro Asp Leu Ser Lys Val Arg Ser Asn Cys Pro Lys Ala Met Lys
675 680 685
Arg Leu Met Ala Glu Cys Leu Lys Lys Lys Arg Asp Glu Arg Pro Leu
690 695 700
Phe Pro Gln Ile Leu Ala Ser Ile Glu Leu Leu Ala Arg Ser Leu Pro
705 710 715 720
Lys Ile His Arg Ser Ala Ser Glu Pro Ser Leu Asn Arg Ala Gly Phe
725 730 735
Gln Thr Glu Asp Phe Ser Leu Tyr Ala Cys Ala Ser Pro Lys Thr Pro
740 745 750
Ile Gln Ala Gly Gly Tyr Gly Thr Phe Pro Val His
755 760
<210> 19
<211> 4936
<212> DNA
<213> Bos taurus
<400> 19
ctcagctgcg ccgggtctca caagacggtt cccgaggtgg cccaggcgcc gtcccaccgc 60
cgacgccgcc cgggccgccc gggccgtccc tccccgctgc cccccgtcct ccgcctccgc 120
ctccccccgc cctcagcctc ccttccccct ccccgcccag cagcggtcgc tcgggcccgg 180
ctctcggtta taagatggcg gcgctgagtg gcggcggcgg cggcggcggc ggtggcgcgg 240
agcagggcca ggctctgttc aacggggaca tggagcccga ggccggcgcc gcggcctctt 300
cggctgcgga ccccgccatt cccgaggagg tgtggaatat caaacaaatg attaagttga 360
cacaggagca tatagaggcc ctattggaca aatttggtgg ggagcataat ccaccatcaa 420
tatatctgga ggcctatgaa gaatacacca gcaagctaga tgccctccaa caaagagaac 480
aacagttatt ggaatccctg gggaatggaa ctgatttttc tgtttctagc tctgcatcaa 540
cggacaccgt tacatcttct tcctcttcta gcctttcagt gctgccttca tctctttcag 600
tttttcaaaa tcccacagat gtgtcacgga gcaaccccaa gtcaccacaa aaacctatcg 660
ttagagtctt cctgcccaat aaacagagga cagtggtacc tgcacggtgt ggagtcacag 720
tccgggacag cctgaagaag gcactgatga tgagaggtct aatcccagag tgctgtgctg 780
tttacagaat tcaggatggg gagaagaaac caattggctg ggacactgat atttcctggc 840
ttactggaga ggagttgcat gtagaagtgt tggagaatgt tccacttaca acacacaact 900
ttgtacggaa aacttttttc accttagcat tttgtgactt ctgtagaaag ctgcttttcc 960
agggattccg ctgtcaaaca tgtggttata aatttcacca gcgttgtagt acagaggttc 1020
cactgatgtg tgttaattat gaccaactag atttgctgtt tgtctccaag ttctttgaac 1080
accacccaat accacaggag gaggcctcct tagcagagac tacccttcca tgtggctcat 1140
ccccttctgc acccccctcc gattctattg ggcccccaat tctcaccagt ccatctcctt 1200
caaaatccat tccaattcca cagcctttcc gaccagcaga tgaagatcat cgaaatcagt 1260
ttggacaacg agaccggtcc tcatcagctc caaatgtgca tataaacaca atagaacccg 1320
tcaatattga tgacttgatt agagaccaag ggtttcgtag tgatggagga tcaaccacag 1380
gtttatccgc cacaccccct gcctcattac ctggctcact ctctaatgtg aaagcattgc 1440
agaaatctcc aggacctcag cgagaaagaa agtcctcttc atcctcagaa gacaggaatc 1500
gaatgaaaac gcttggtaga cgggattcaa gtgacgattg ggagattcct gatggacaga 1560
tcacagtggg acaaagaatt ggatcagggt catttgggac agtctacaag ggaaagtggc 1620
atggtgatgt ggcagtgaaa atgttgaatg tgacagcacc cacacctcag cagttacagg 1680
ccttcaaaaa tgaagtagga gtactcagga aaacgcgaca tgtgaatatc ctcctcttca 1740
tgggttattc aacaaagcca caactggcta ttgttaccca gtggtgtgag ggctccagtt 1800
tatatcatca tctccacatc attgagacca aattcgagat gatcaaactt atagatattg 1860
cacggcagac tgcacagggc atggattact tacacgccaa gtcaatcatc cacagagacc 1920
tcaagagtaa taatattttt cttcatgaag acctcacagt aaaaataggt gattttggtc 1980
tagccacagt gaaatctcga tggagtgggt cccatcagtt tgaacagttg tctggatcca 2040
ttttgtggat ggcaccagaa gtaatcagaa tgcaagataa aaacccatat agctttcagt 2100
cagatgtata tgcatttggg attgttctgt atgaattgat gaccggacag ttaccttatt 2160
caaatatcaa caacagggac cagataattt ttatggtggg acgaggatat ctgtctccag 2220
atctcagtaa ggtacggagt aactgtccaa aagccatgaa gagattaatg gcagagtgcc 2280
taaaaaagaa aagagatgaa agaccactct ttccccaagt aggaaagact ctcctaagca 2340
agagacaaaa ttcagaagtt atcagggaaa aagataagca gattctcgcc tctattgagc 2400
tgctggcccg ctcattgcca aaaattcacc gcagtgcatc agaaccctcc ttgaatcggg 2460
ctggcttcca aacagaggat tttagtctat atgcttgtgc ttctccaaaa acacccattc 2520
aggcaggggg atatgaagca gatttggctc ttacatcaaa taaaaataga gtagaagttg 2580
ggatttagag atttcctgac atgcaagaag gaataagcaa gaaaaaaagg tttgttttcc 2640
ccaaatcata tctattgtct tttacttcta ttttttctta aattttttgt gatttcagag 2700
acatgtagag ttttattgat acctaaacta tgagttcttt tttttttttt tttttcatta 2760
ttttgatttt tttggccaag aggcatatgg gatcttagct tgagaaagca acaattttct 2820
tgatgtcatt ttgggtgagg gcacatattg ctgtgaacag tgtggtgata gccaccaggg 2880
accaaactca cacccgctgc attgaaaggt gaagtcttaa acactggacc agcagagaaa 2940
ttcctactct atgagttctt tttgtcatcc cctccccgca ccctccaccc ccaacctaaa 3000
gtctgatgat gaaatcaaca actattccat tagaagcagt agattctggt agcatgatct 3060
ttagtttgtt agtaagattt tgtgctttgt ggggttgtgt cgttttaagg ctaatattta 3120
agtttgtcaa atagaatgct gttcagattg taaaaatgag taataaacat ctgaagtttt 3180
ttttaagtta tttttaacat ggtatataca gttgagctta gagtttatca ttttctgata 3240
ttctcttact tagtagatga attctagcca ttttttataa agatttctgt taagcaaatc 3300
ctgttttcac atgggcttcc tttaagggat tttagattct gctggatatg gtgactgctc 3360
ataagactgt tgaaaattac ttttaagatg tattagaata cttctgaaaa aaaatagcaa 3420
ccttaaaacc ataagcaaaa gtagtaaggg tgtttataca tttctagagt ccctgtttag 3480
gtaatagcct cctatgattg tactttaaat gttttgctct ccaaggtttt agtaacttgg 3540
ctttttttct aatcagtgcc aaactccccc agttttttta actttaaata tgaggtaata 3600
aatcttttac ccttccttga tcttttgact tataatacct tggtcagttg tttcttaaaa 3660
ggaatcctta aatggaaaga gacaatatca ctgtctgcag ttctgattag tagttttatt 3720
cagaatggaa aaacagatta ttcatttttg aaaattgttc aggggtatgt tcattgttag 3780
gaccttggac tttggagtca gtgcctagct atgcattcca ggtctgccat tttctggctg 3840
tgaaattttg gacaagttac ttaaccactt taaaccccag ctttaagaag taaattaacc 3900
ccagtaaatt aagaagtaat agcagccact tcgtagagtt gttatgaggc tcagatgcag 3960
tgcaaatgtg tataaagtat tcagggagtc acctggtata ctataataga cactagaata 4020
gttgccaata ttatcagcat acaatctgag gattctgtca gccaatcatt agcaatctgt 4080
tgtttgttgg gacatgccag tgttctccag ttgaaatcag tagcaatcta aaaatggata 4140
gattattcct catttaaata gtgtgttcat ataagtgatt gcttggatcc ttatcagaag 4200
ttgctgttac tgaaaaatga taaggctgac taaattgtga tagttgtcag ttactaacca 4260
actcccagaa atgaataaga ggaacctatc tctagttcct agtagaaggt atggacaaaa 4320
tagtaggtga aaaataatgt cttgaacccc caaattaagt aagctttaaa gagtacaata 4380
cctcaaaggg tctttgcggt ttaaaatttg tatgctgaga atgatgttca ttgacatgtg 4440
cctatatgta attttttgat agtttaaaag gtgaaatgaa ctacagatgg gagaggtctg 4500
aattttcttg ccttcagtca aatgtgtaat gtggacatat tatttgacct gtgaatttta 4560
tcttttaaaa aagattaatt cctgcttctt ccttcctaat agttgcatta taataatgaa 4620
aatgagttga taatttgggg ggaaagtatt ctacaaatca accttattat tttaccattg 4680
gtttctgaga aattttgttc atttgaaccg tttatagctt gattagaatc atagcatgta 4740
aaacccaact gagggattat ctgcagactt aatgtagtat tatgtaagtt gtcttctttc 4800
atttcgacct tttttgcttt tgttgttgct agatctgtag tatgtagcta gtcacctttc 4860
agcgaggttt cagcgaggct tttctgtgtc tctaggttat ttgagataac ttttttaaaa 4920
ttagctcttg tcctcc 4936
<210> 20
<211> 797
<212> PRT
<213> Bos taurus
<400> 20
Met Ala Ala Leu Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Glu
1 5 10 15
Gln Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala
20 25 30
Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn
35 40 45
Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu
50 55 60
Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala
65 70 75 80
Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln
85 90 95
Gln Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser
100 105 110
Ser Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser
115 120 125
Val Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser
130 135 140
Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
145 150 155 160
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
165 170 175
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
180 185 190
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
195 200 205
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
210 215 220
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr
225 230 235 240
Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln
245 250 255
Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser
260 265 270
Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu
275 280 285
Phe Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala
290 295 300
Ser Leu Ala Glu Thr Thr Leu Pro Cys Gly Ser Ser Pro Ser Ala Pro
305 310 315 320
Pro Ser Asp Ser Ile Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser
325 330 335
Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His
340 345 350
Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val
355 360 365
His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp
370 375 380
Gln Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr
385 390 395 400
Pro Pro Ala Ser Leu Pro Gly Ser Leu Ser Asn Val Lys Ala Leu Gln
405 410 415
Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu
420 425 430
Asp Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp
435 440 445
Trp Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser
450 455 460
Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala
465 470 475 480
Val Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala
485 490 495
Phe Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile
500 505 510
Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr
515 520 525
Gln Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu
530 535 540
Thr Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala
545 550 555 560
Gln Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu
565 570 575
Lys Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly
580 585 590
Asp Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln
595 600 605
Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile
610 615 620
Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala
625 630 635 640
Phe Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser
645 650 655
Asn Ile Asn Asn Arg Asp Gln Ile Ile Phe Met Val Gly Arg Gly Tyr
660 665 670
Leu Ser Pro Asp Leu Ser Lys Val Arg Ser Asn Cys Pro Lys Ala Met
675 680 685
Lys Arg Leu Met Ala Glu Cys Leu Lys Lys Lys Arg Asp Glu Arg Pro
690 695 700
Leu Phe Pro Gln Val Gly Lys Thr Leu Leu Ser Lys Arg Gln Asn Ser
705 710 715 720
Glu Val Ile Arg Glu Lys Asp Lys Gln Ile Leu Ala Ser Ile Glu Leu
725 730 735
Leu Ala Arg Ser Leu Pro Lys Ile His Arg Ser Ala Ser Glu Pro Ser
740 745 750
Leu Asn Arg Ala Gly Phe Gln Thr Glu Asp Phe Ser Leu Tyr Ala Cys
755 760 765
Ala Ser Pro Lys Thr Pro Ile Gln Ala Gly Gly Tyr Glu Ala Asp Leu
770 775 780
Ala Leu Thr Ser Asn Lys Asn Arg Val Glu Val Gly Ile
785 790 795
<210> 21
<211> 4154
<212> DNA
<213> Bos taurus
<400> 21
ctcagctgcg ccgggtctca caagacggtt cccgaggtgg cccaggcgcc gtcccaccgc 60
cgacgccgcc cgggccgccc gggccgtccc tccccgctgc cccccgtcct ccgcctccgc 120
ctccccccgc cctcagcctc ccttccccct ccccgcccag cagcggtcgc tcgggcccgg 180
ctctcggtta taagatggcg gcgctgagtg gcggcggcgg cggcggcggc ggtggcgcgg 240
agcagggcca ggctctgttc aacggggaca tggagcccga ggccggcgcc gcggcctctt 300
cggctgcgga ccccgccatt cccgaggagg tgtggaatat caaacaaatg attaagttga 360
cacaggagca tatagaggcc ctattggaca aatttggtgg ggagcataat ccaccatcaa 420
tatatctgga ggcctatgaa gaatacacca gcaagctaga tgccctccaa caaagagaac 480
aacagttatt ggaatccctg gggaatggaa ctgatttttc tgtttctagc tctgcatcaa 540
cggacaccgt tacatcttct tcctcttcta gcctttcagt gctgccttca tctctttcag 600
tttttcaaaa tcccacagat gtgtcacgga gcaaccccaa gtcaccacaa aaacctatcg 660
ttagagtctt cctgcccaat aaacagagga cagtggtacc tgcacggtgt ggagtcacag 720
tccgggacag cctgaagaag gcactgatga tgagaggtct aatcccagag tgctgtgctg 780
tttacagaat tcaggatggg gagaagaaac caattggctg ggacactgat atttcctggc 840
ttactggaga ggagttgcat gtagaagtgt tggagaatgt tccacttaca acacacaact 900
ttgtacggaa aacttttttc accttagcat tttgtgactt ctgtagaaag ctgcttttcc 960
agggattccg ctgtcaaaca tgtggttata aatttcacca gcgttgtagt acagaggttc 1020
cactgatgtg tgttaattat gaccaactag atttgctgtt tgtctccaag ttctttgaac 1080
accacccaat accacaggag gaggcctcct tagcagagac tacccttcca tgtggctcat 1140
ccccttctgc acccccctcc gattctattg ggcccccaat tctcaccagt ccatctcctt 1200
caaaatccat tccaattcca cagcctttcc gaccagcaga tgaagatcat cgaaatcagt 1260
ttggacaacg agaccggtcc tcatcagctc caaatgtgca tataaacaca atagaacccg 1320
tcaatattga tgacttgatt agagaccaag ggtttcgtag tgatggagga tcaaccacag 1380
gtttatccgc cacaccccct gcctcattac ctggctcact ctctaatgtg aaagcattgc 1440
agaaatctcc aggacctcag cgagaaagaa agtcctcttc atcctcagaa gacaggaatc 1500
gaatgaaaac gcttggtaga cgggattcaa gtgacgattg ggagattcct gatggacaga 1560
tcacagtggg acaaagaatt ggatcagggt catttgggac agtctacaag ggaaagtggc 1620
atggtgatgt ggcagtgaaa atgttgaatg tgacagcacc cacacctcag cagttacagg 1680
ccttcaaaaa tgaagtagga gtactcagga aaacgcgaca tgtgaatatc ctcctcttca 1740
tgggttattc aacaaagcca caactggcta ttgttaccca gtggtgtgag ggctccagtt 1800
tatatcatca tctccacatc attgagacca aattcgagat gatcaaactt atagatattg 1860
cacggcagac tgcacagggc atggattact tacacgccaa gtcaatcatc cacagagacc 1920
tcaagagtaa taatattttt cttcatgaag acctcacagt aaaaataggt gattttggtc 1980
tagccacagt gaaatctcga tggagtgggt cccatcagtt tgaacagttg tctggatcca 2040
ttttgtggat ggcaccagaa gtaatcagaa tgcaagataa aaacccatat agctttcagt 2100
cagatgtata tgcatttggg attgttctgt atgaattgat gaccggacag ttaccttatt 2160
caaatatcaa caacagggac cagataattt ttatggtggg acgaggatat ctgtctccag 2220
atctcagtaa ggtacggagt aactgtccaa aagccatgaa gagattaatg gcagagtgcc 2280
taaaaaagaa aagagatgaa agaccactct ttccccaagt aggaaagact ctcctaagca 2340
agagacaaaa ttcagaagtt atcagggaaa aagataagca gattctcgcc tctattgagc 2400
tgctggcccg ctcattgcca aaaattcacc gcagtgcatc agaaccctcc ttgaatcggg 2460
ctggcttcca aacagaggat tttagtctat atgcttgtgc ttctccaaaa acacccattc 2520
aggcaggggg atatggctga gcacattgtc catcacccac aagtggctgg ttctcatcgc 2580
agaatctacg tagggaatcg ggcgtgaaat tcacttaaga gatagagcag aggaagtgtt 2640
ctgtttacag gaatggagat gagagttatg agtaagttgc ttagtcagtt ggctttgttt 2700
tgaaaattat tgtgttatat ttgtgttaac ctacttgtgt tttgacagta tatgtcacat 2760
aggaagaaac ctcagactag cataataaca aagctcagac taggcacaga tgtacacaga 2820
atggaccaaa atgggatggg ggaaggtatg ggaataagtc taggggtagg gaaaaattga 2880
tgtgagggtg ggaaataaac tgtaattacc tgaaataaaa tgtaagagtg caataagtgt 2940
gctttttatt ctaagctgtg aatgggtttt ttaaaaaaag cattccttcc caatgcattt 3000
gcctatgttc catagctgat taaaaccagc tatataaaca tatgcctttt tattcatgtt 3060
aattaccaat ataaatggct aacctttacg tcttatttat cttcatgtta tgttagttta 3120
catacaggga tgtgtgtgtg tgtgtatgct ataaattttc cctccttcgt ttaaaaacgc 3180
gtttgttgga tcctctctgt ttccttaggc catgccacag ctcatagtct cagcttggcc 3240
ttcctgtcac ctgatctgaa ggactatcac agtgacgtag ctcgttcatt ggttgtacac 3300
actctaaccc ttttccttgc tcagcaatta ctgtgtcttc taaaacagga gtgtacaacc 3360
atgagattgc aattaattgt ttgacatatg tccctttgaa ttctatttat tagttatgat 3420
tgattgctct ttggtttgga ccaagaaaaa cgaaatccca cctccccacc ttttcactta 3480
tttcttactt tgaggacaat tctgtaagag agaggaaagg gaactccttc atgttttaac 3540
tgcagcaagt taatggccct ggtttacacc aaacattatg gtgattcaca ttcacattcc 3600
tctcctctct tgctgccaga ggtttgggtt ttgttcagtt ctgctcaagc actgaaaaag 3660
ttttcatgga gtctggagag tgcccagtga aaagatggtt tttaattgtc cacagacctt 3720
tctgttcctg ctttgcaaaa attacaaagg agtaactatt tttaaagctt atttttcaat 3780
tcataaaaaa gacatttatt ttcagtcaga tgatgtctcc ttgtccctta atcctcaatg 3840
tttgcttgaa tctttttttt ttttctgatt ttctcccatc cccacttctt gatacttctt 3900
gagttctctt tcctgctcag gtcctttcat ttgtactttg gagttttttc tcatgtaaat 3960
ttgtacaatg gaaaatattg ttcagtttgg atagaacgca tggagaatta aataaaaaag 4020
atagctgaaa ttcagattga aatttatttg tgtaaagtta tttaaaaact ctgtactata 4080
taaaaggcaa aaaaagttct atgtacttga tgtgaatatg cgaatactgc tataataaag 4140
attgactgca tgga 4154
<210> 22
<211> 781
<212> PRT
<213> Bos taurus
<400> 22
Met Ala Ala Leu Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Glu
1 5 10 15
Gln Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala
20 25 30
Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn
35 40 45
Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu
50 55 60
Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala
65 70 75 80
Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln
85 90 95
Gln Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser
100 105 110
Ser Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser
115 120 125
Val Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser
130 135 140
Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
145 150 155 160
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
165 170 175
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
180 185 190
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
195 200 205
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
210 215 220
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr
225 230 235 240
Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln
245 250 255
Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser
260 265 270
Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu
275 280 285
Phe Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala
290 295 300
Ser Leu Ala Glu Thr Thr Leu Pro Cys Gly Ser Ser Pro Ser Ala Pro
305 310 315 320
Pro Ser Asp Ser Ile Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser
325 330 335
Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His
340 345 350
Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val
355 360 365
His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp
370 375 380
Gln Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr
385 390 395 400
Pro Pro Ala Ser Leu Pro Gly Ser Leu Ser Asn Val Lys Ala Leu Gln
405 410 415
Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu
420 425 430
Asp Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp
435 440 445
Trp Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser
450 455 460
Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala
465 470 475 480
Val Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala
485 490 495
Phe Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile
500 505 510
Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr
515 520 525
Gln Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu
530 535 540
Thr Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala
545 550 555 560
Gln Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu
565 570 575
Lys Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly
580 585 590
Asp Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln
595 600 605
Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile
610 615 620
Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala
625 630 635 640
Phe Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser
645 650 655
Asn Ile Asn Asn Arg Asp Gln Ile Ile Phe Met Val Gly Arg Gly Tyr
660 665 670
Leu Ser Pro Asp Leu Ser Lys Val Arg Ser Asn Cys Pro Lys Ala Met
675 680 685
Lys Arg Leu Met Ala Glu Cys Leu Lys Lys Lys Arg Asp Glu Arg Pro
690 695 700
Leu Phe Pro Gln Val Gly Lys Thr Leu Leu Ser Lys Arg Gln Asn Ser
705 710 715 720
Glu Val Ile Arg Glu Lys Asp Lys Gln Ile Leu Ala Ser Ile Glu Leu
725 730 735
Leu Ala Arg Ser Leu Pro Lys Ile His Arg Ser Ala Ser Glu Pro Ser
740 745 750
Leu Asn Arg Ala Gly Phe Gln Thr Glu Asp Phe Ser Leu Tyr Ala Cys
755 760 765
Ala Ser Pro Lys Thr Pro Ile Gln Ala Gly Gly Tyr Gly
770 775 780
<210> 23
<211> 7914
<212> DNA
<213> Bos taurus
<400> 23
ctcagctgcg ccgggtctca caagacggtt cccgaggtgg cccaggcgcc gtcccaccgc 60
cgacgccgcc cgggccgccc gggccgtccc tccccgctgc cccccgtcct ccgcctccgc 120
ctccccccgc cctcagcctc ccttccccct ccccgcccag cagcggtcgc tcgggcccgg 180
ctctcggtta taagatggcg gcgctgagtg gcggcggcgg cggcggcggc ggtggcgcgg 240
agcagggcca ggctctgttc aacggggaca tggagcccga ggccggcgcc gcggcctctt 300
cggctgcgga ccccgccatt cccgaggagg tgtggaatat caaacaaatg attaagttga 360
cacaggagca tatagaggcc ctattggaca aatttggtgg ggagcataat ccaccatcaa 420
tatatctgga ggcctatgaa gaatacacca gcaagctaga tgccctccaa caaagagaac 480
aacagttatt ggaatccctg gggaatggaa ctgatttttc tgtttctagc tctgcatcaa 540
cggacaccgt tacatcttct tcctcttcta gcctttcagt gctgccttca tctctttcag 600
tttttcaaaa tcccacagat gtgtcacgga gcaaccccaa gtcaccacaa aaacctatcg 660
ttagagtctt cctgcccaat aaacagagga cagtggtacc tgcacggtgt ggagtcacag 720
tccgggacag cctgaagaag gcactgatga tgagaggtct aatcccagag tgctgtgctg 780
tttacagaat tcaggatggg gagaagaaac caattggctg ggacactgat atttcctggc 840
ttactggaga ggagttgcat gtagaagtgt tggagaatgt tccacttaca acacacaact 900
ttgtacggaa aacttttttc accttagcat tttgtgactt ctgtagaaag ctgcttttcc 960
agggattccg ctgtcaaaca tgtggttata aatttcacca gcgttgtagt acagaggttc 1020
cactgatgtg tgttaattat gaccaactag atttgctgtt tgtctccaag ttctttgaac 1080
accacccaat accacaggag gaggcctcct tagcagagac tacccttcca tgtggctcat 1140
ccccttctgc acccccctcc gattctattg ggcccccaat tctcaccagt ccatctcctt 1200
caaaatccat tccaattcca cagcctttcc gaccagcaga tgaagatcat cgaaatcagt 1260
ttggacaacg agaccggtcc tcatcagctc caaatgtgca tataaacaca atagaacccg 1320
tcaatattga tgacttgatt agagaccaag ggtttcgtag tgatggagga tcaaccacag 1380
gtttatccgc cacaccccct gcctcattac ctggctcact ctctaatgtg aaagcattgc 1440
agaaatctcc aggacctcag cgagaaagaa agtcctcttc atcctcagaa gacaggaatc 1500
gaatgaaaac gcttggtaga cgggattcaa gtgacgattg ggagattcct gatggacaga 1560
tcacagtggg acaaagaatt ggatcagggt catttgggac agtctacaag ggaaagtggc 1620
atggtgatgt ggcagtgaaa atgttgaatg tgacagcacc cacacctcag cagttacagg 1680
ccttcaaaaa tgaagtagga gtactcagga aaacgcgaca tgtgaatatc ctcctcttca 1740
tgggttattc aacaaagcca caactggcta ttgttaccca gtggtgtgag ggctccagtt 1800
tatatcatca tctccacatc attgagacca aattcgagat gatcaaactt atagatattg 1860
cacggcagac tgcacagggc atggattact tacacgccaa gtcaatcatc cacagagacc 1920
tcaagagtaa taatattttt cttcatgaag acctcacagt aaaaataggt gattttggtc 1980
tagccacagt gaaatctcga tggagtgggt cccatcagtt tgaacagttg tctggatcca 2040
ttttgtggat ggcaccagaa gtaatcagaa tgcaagataa aaacccatat agctttcagt 2100
cagatgtata tgcatttggg attgttctgt atgaattgat gaccggacag ttaccttatt 2160
caaatatcaa caacagggac cagataattt ttatggtggg acgaggatat ctgtctccag 2220
atctcagtaa ggtacggagt aactgtccaa aagccatgaa gagattaatg gcagagtgcc 2280
taaaaaagaa aagagatgaa agaccactct ttccccaaat tctcgcctct attgagctgc 2340
tggcccgctc attgccaaaa attcaccgca gtgcatcaga accctccttg aatcgggctg 2400
gcttccaaac agaggatttt agtctatatg cttgtgcttc tccaaaaaca cccattcagg 2460
cagggggata tggagaattt gcagccttca agtagccaca ccatcatgac agcatctact 2520
cttatttctt aagtcttgtg ttcgtacaat ttgttaacat caaaacacag ttctgttcct 2580
caactctttt taaagttaaa atttttcagt gcataagctg gtgtggaaca gaaggaaatt 2640
tcccatccaa caaaagaggg aagaatgttt taggaaccag aattctctgc tgccagtgtt 2700
tcttcttcaa cacaaatatc acaagtctgc ccactcccag gaagaaagag gagagaccct 2760
gagttctgac cttttgatgg tcaggcatga tggaaagaaa ctgctgctac agcttgggag 2820
atttgctctg ggaagtctgc cagtcaactt tgcccttcta accaccagat caatatgtgg 2880
ctgatcatct gatggggcag ttgcaatcac caagccttgt tctctttcct gttctgggat 2940
tgtgttgtgg aacccttttc cctagccacc accagttcat ttctgaggga tggaacaaaa 3000
atgcagcatg cccttcctgt gtggtgcatg ttcagtcctt gacaaatttt taccaaaatg 3060
aagctacttt atttaaaagg agggtgagag gtgaggaggt cactttgggt gtggcggaaa 3120
gggaatgctg catctttttc ctgggctgct ggggctctgg ccttggcttg ccagccggaa 3180
gcgctggcac gcatcgcctt cttttcccat tgggtccagc aatgaagacg agtgtttggg 3240
gttttttttt tctccaccat gtagcaagtt ctcaggaaaa tacaattgat atcttcctcc 3300
taagctcttc caatcagtca ccaagtactt atgtggttac tttgtccagg gcacaaaatg 3360
cctgtatcta attaaaagcc tacaaaactg cttgataaca gttttgaatg tgagacattt 3420
atgtaattta aatgtaaggt acaagtttta atttctgagt ttcttctatt atatttttat 3480
taaaaaaaga aaataatttt cagattgaat tggagtaaaa taatattact tcccactaga 3540
attatatatc ctggaaaatt gtatttttgt tacataagca gcttttaaag aaagatcatt 3600
acccttttct ctacataaat atatggggag tcttagccta atgacaaata tttataattt 3660
ttaaattaat ggtacttgct ggatccatac taacatcttt actaatacct cattgtttct 3720
tccaacttac tcctacacta catcctacat cttcttccta gtcttttatc tagaatatgc 3780
aacctcaaat aaaaatggtg gtgtcctcat tcattctcct ccttcctttt ttcccaagcc 3840
tgatcttcaa aaggttggtt aatttggcag ctgagttcct ccccaggcag agaatagacc 3900
aattttaggt gtattgggac tgagggagga tgtgtaaaga ttaacatcag taaagaaccg 3960
ctgtggagta attaagaact ttgttcttta taactggaga atataaccta accctaacat 4020
ccctcagcct ttactaaagt gtggcgtaaa tcacagtagt agcaaagaaa gtgactctgg 4080
atgtgttcct ggccagtacc tcccttatca tgaatgtaga ctctctcatc aagatttagg 4140
aatataaatc aaatcaaatg tgcccagcca agctatgtag taagggactt gaacaatatt 4200
aggcagaacc tataaaataa atcagggaat tagaaattat ttaaagtttt caaattgtaa 4260
attgccccgg tgtctttcag cctactgcca ttatttttgc tacaatacct acatttcaga 4320
ggagggccta ctgaaaattc catgcaagtg gaaaataatc ctcaagttat taatgagttt 4380
gaaaagcaat gagttcttaa gtctttgtga gtagagcaag atcctacaaa attcagaaat 4440
agtaaaaatg gattcatgct gatttgaaga gcatctgtgt gcataatata atgctgcatc 4500
tcttttaaaa gcagtctatt tttcttttta aatttgtccc catagatgct tttgaacatg 4560
aacatgctta tgttaccttt tccgaggttg ggaagagcca ggagctctca ggcagggccc 4620
cctccctcag ctgggcagga gctgctcagg aggagctagt tatagaggaa gcttagcgtt 4680
ggcattttca aaattcaagg tgataacgct ttcttcttcc tttctgtttt agaatagatt 4740
gctgtctgat ttgaaaaagg gaaatagatt tgatctcaaa tgaatctgtg cccagaagcc 4800
aggctcaggg tattcagaga tttgtatagt gccctcaaaa aataacaaaa ttttagcttt 4860
ccttttttct tcttttctcc atcaaattct tttttctcta gtttacaaat gacatggaaa 4920
aggaatttcc cctgagtttt gtatgccttt ttttttttgg cttagactat agataggcgt 4980
gttgagctcc taagaaaata caaggaggaa ctctttgttg tgcagagcac tttatgagta 5040
gtttgtgtgg ataatatgtg actgcttccc tgacgagctt gtgaggctgt acttatgtct 5100
ttcctgtaag gcagcttcag tgccttctgt agtgtatata aggaaagatt acgccttctg 5160
aaaaatctca gagcaaccat aagattattt taaaatatgt agtatgactg atggactttt 5220
tcatcattaa attagtctag catctaaact tttaccactg aaataatatt gaccaaaaag 5280
caatttataa aaggtatttg tgaatagaaa atacaatgtg atcatttgta cttatgtgca 5340
ccttaaaaga ggaattctgt ctagctgtca aattctggtt ccttaacatc cagtccttga 5400
ttgtgattga gatctggtag gacgtgctgg ggcacgctag cagataaaat cccgtatact 5460
ttaggataga tgttacattt atgtcagtgt tggcaaagag cattgtgtag taataaagaa 5520
ttcaagactt cagcaatgtc aacctgaaac tttgtaaata tttcctagat tgttatttga 5580
tgcagtcaca gctctttatc acacaatgtt gtctttccct catcaggcaa ttttagaact 5640
gctgcacacc cctcctcaga tctcacctgc ccctcctgta cattcacctc tccagccttg 5700
tgcacacctc atttagcttt agtttgaaac acattgcagg gttcaggtga cctcttcaaa 5760
aactacctcc tcagaatgag gtaatgaata gttatttatt ttaaaatatg aaaagtcagg 5820
agctctagaa tatgaagatg atctaagatt ttaactttta tgtatacttg ttgagcactc 5880
tccttttgtc ctaaagggca ttatacattt aagcagtaat actgaaaaat gtagctcaga 5940
gtaactgaat gttgttgaaa gtggtgccag aatctgtttt aggggtacgt atcagaatct 6000
taatcttaaa tcggttacat gaaattaaat agttaatggt aacacttgac taacagatat 6060
aattttaatt ttcggtaggc ttttagcaag acagtaagta catcttcata atgagttagc 6120
cacagcttca tcacatgcac agattttcct gttgagagac tgcccagtta agagggtaga 6180
atgatgaacc atttttcagg attctcttct ttgtccaaac tggcattgtg agtgctagaa 6240
tatcagcact ttcaaactag tgattccaac tattaggcta ttaaaaagca aaacaaacca 6300
aacaaaccat agccagacat gggaagttta ctatgagtat aaacagcaaa tagcttacag 6360
gtcatacatt gaaatggtgt aggtaaggcg ttagaaaaat accttgacaa tttgccaaat 6420
gatcttactg tgccttcatg atgcaataaa aaaaaaaaaa atttagcata aatcagtgat 6480
ttgtgaagag agcagccacc ctggtctaac tcagctgtgt taatattttt tagcgtgcaa 6540
tttagactgc aaagataaat gcactaaaga gtttatagcc aaaatcacat ttaaaaaatg 6600
agagaaaaca caggtaaatt ttcagtgaac aaaattattt ttttaaagta cataatccct 6660
agtatagtca gatatattta tcacatagag caaataggtt gaaatcacaa ttcagtgaca 6720
tttctagaga aactttttct actcccatag gttcttcaaa gcatggaact tttatataac 6780
agaaatgtgt gacggtcatt ttaaattgct gtagtttggg gctgaagtac tgtgtgctgg 6840
gcagcaatca catgtattaa ctagtgagaa aggagaaatt aagatatagg acagaatttg 6900
attttcttgt tcccagatta ctgctgccaa cctagacact gagtttccag aggctgaaac 6960
gtaaacttgc agctcagcaa ctgttttgca aagttagtgg gactgtcctg cttatgctgt 7020
tcaaaaatgc tctgagggcc aggtggggcc tccaggggct cctctctgag gggacatcag 7080
actagctaac gacctggcgg gcggatgtga accggacaca ctccatggtg tgcttcttgt 7140
atcggtccct cgccaccctc aagaaaggct tcagcgggtt ctctagacgt ctccactaag 7200
gtgtgttact aacagccatg ggttgttgag cacccgagga gtgcaatagc atctctgcat 7260
gattgtatat tggcccgaag agaatgaagt ggccagtgta ctcatgttcc atgttgctag 7320
ctctggtaaa ctgaaaatac tggtaagatt tttgttttat cagtacacta gagagtaagc 7380
tttgttttgt tgtttttaga taatgttttc acttccattt ggaaagacat ttaaattgag 7440
tttcagtcct aaattttgcc agtcatggta attagcagtt tctatcaggt atttttaagg 7500
tagaagagga tagaaacata agttctaaaa gcttaaggta accgtggttt attttaaaat 7560
gtttaggggt ggttagtctc tacctcaaaa aaagtgagtg aatcttttat ttcagcattc 7620
acaagttcgg ctgttgtttt tgtaatacat ttttttttta accttttgac ccccctttac 7680
ctaagtgtca atgtagtttt attaattact aagtcagttt cattaaaatg tttatttagc 7740
agttttgact aattgcaatg attaatatag ccagttgtgc atgaggacac agccagtgag 7800
tatatctggg ttttttttgt gatgcttttt ttcttaagac ttctgtagat ttatgaagta 7860
ctcattgaaa acaactaaaa tacgtttatt cgtgttaata tggaaaaaaa aaaa 7914
<210> 24
<211> 766
<212> PRT
<213> Bos taurus
<400> 24
Met Ala Ala Leu Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Glu
1 5 10 15
Gln Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala
20 25 30
Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn
35 40 45
Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu
50 55 60
Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala
65 70 75 80
Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln
85 90 95
Gln Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser
100 105 110
Ser Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser
115 120 125
Val Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser
130 135 140
Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
145 150 155 160
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
165 170 175
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
180 185 190
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
195 200 205
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
210 215 220
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr
225 230 235 240
Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln
245 250 255
Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser
260 265 270
Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu
275 280 285
Phe Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala
290 295 300
Ser Leu Ala Glu Thr Thr Leu Pro Cys Gly Ser Ser Pro Ser Ala Pro
305 310 315 320
Pro Ser Asp Ser Ile Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser
325 330 335
Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His
340 345 350
Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val
355 360 365
His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp
370 375 380
Gln Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr
385 390 395 400
Pro Pro Ala Ser Leu Pro Gly Ser Leu Ser Asn Val Lys Ala Leu Gln
405 410 415
Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu
420 425 430
Asp Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp
435 440 445
Trp Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser
450 455 460
Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala
465 470 475 480
Val Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala
485 490 495
Phe Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile
500 505 510
Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr
515 520 525
Gln Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu
530 535 540
Thr Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala
545 550 555 560
Gln Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu
565 570 575
Lys Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly
580 585 590
Asp Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln
595 600 605
Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile
610 615 620
Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala
625 630 635 640
Phe Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser
645 650 655
Asn Ile Asn Asn Arg Asp Gln Ile Ile Phe Met Val Gly Arg Gly Tyr
660 665 670
Leu Ser Pro Asp Leu Ser Lys Val Arg Ser Asn Cys Pro Lys Ala Met
675 680 685
Lys Arg Leu Met Ala Glu Cys Leu Lys Lys Lys Arg Asp Glu Arg Pro
690 695 700
Leu Phe Pro Gln Ile Leu Ala Ser Ile Glu Leu Leu Ala Arg Ser Leu
705 710 715 720
Pro Lys Ile His Arg Ser Ala Ser Glu Pro Ser Leu Asn Arg Ala Gly
725 730 735
Phe Gln Thr Glu Asp Phe Ser Leu Tyr Ala Cys Ala Ser Pro Lys Thr
740 745 750
Pro Ile Gln Ala Gly Gly Tyr Gly Glu Phe Ala Ala Phe Lys
755 760 765
<210> 25
<211> 4670
<212> DNA
<213> Bos taurus
<400> 25
ggtgtgtcat agtgcagcag attgaatgca gaagatatga aaattcagat gtcttctgtt 60
aaggtgtgga atatcaaaca aatgattaag ttgacacagg agcatataga ggccctattg 120
gacaaatttg gtggggagca taatccacca tcaatatatc tggaggccta tgaagaatac 180
accagcaagc tagatgccct ccaacaaaga gaacaacagt tattggaatc cctggggaat 240
ggaactgatt tttctgtttc tagctctgca tcaacggaca ccgttacatc ttcttcctct 300
tctagccttt cagtgctgcc ttcatctctt tcagtttttc aaaatcccac agatgtgtca 360
cggagcaacc ccaagtcacc acaaaaacct atcgttagag tcttcctgcc caataaacag 420
aggacagtgg tacctgcacg gtgtggagtc acagtccggg acagcctgaa gaaggcactg 480
atgatgagag gtctaatccc agagtgctgt gctgtttaca gaattcagga tggggagaag 540
aaaccaattg gctgggacac tgatatttcc tggcttactg gagaggagtt gcatgtagaa 600
gtgttggaga atgttccact tacaacacac aactttgtac ggaaaacttt tttcacctta 660
gcattttgtg acttctgtag aaagctgctt ttccagggat tccgctgtca aacatgtggt 720
tataaatttc accagcgttg tagtacagag gttccactga tgtgtgttaa ttatgaccaa 780
ctagatttgc tgtttgtctc caagttcttt gaacaccacc caataccaca ggaggaggcc 840
tccttagcag agactaccct tccatgtggc tcatcccctt ctgcaccccc ctccgattct 900
attgggcccc caattctcac cagtccatct ccttcaaaat ccattccaat tccacagcct 960
ttccgaccag cagatgaaga tcatcgaaat cagtttggac aacgagaccg gtcctcatca 1020
gctccaaatg tgcatataaa cacaatagaa cccgtcaata ttgatgactt gattagagac 1080
caagggtttc gtagtgatgg aggatcaacc acaggtttat ccgccacacc ccctgcctca 1140
ttacctggct cactctctaa tgtgaaagca ttgcagaaat ctccaggacc tcagcgagaa 1200
agaaagtcct cttcatcctc agaagacagg aatcgaatga aaacgcttgg tagacgggat 1260
tcaagtgacg attgggagat tcctgatgga cagatcacag tgggacaaag aattggatca 1320
gggtcatttg ggacagtcta caagggaaag tggcatggtg atgtggcagt gaaaatgttg 1380
aatgtgacag cacccacacc tcagcagtta caggccttca aaaatgaagt aggagtactc 1440
aggaaaacgc gacatgtgaa tatcctcctc ttcatgggtt attcaacaaa gccacaactg 1500
gctattgtta cccagtggtg tgagggctcc agtttatatc atcatctcca catcattgag 1560
accaaattcg agatgatcaa acttatagat attgcacggc agactgcaca gggcatggat 1620
tacttacacg ccaagtcaat catccacaga gacctcaaga gtaataatat ttttcttcat 1680
gaagacctca cagtaaaaat aggtgatttt ggtctagcca cagtgaaatc tcgatggagt 1740
gggtcccatc agtttgaaca gttgtctgga tccattttgt ggatggcacc agaagtaatc 1800
agaatgcaag ataaaaaccc atatagcttt cagtcagatg tatatgcatt tgggattgtt 1860
ctgtatgaat tgatgaccgg acagttacct tattcaaata tcaacaacag ggaccagata 1920
atttttatgg tgggacgagg atatctgtct ccagatctca gtaaggtacg gagtaactgt 1980
ccaaaagcca tgaagagatt aatggcagag tgcctaaaaa agaaaagaga tgaaagacca 2040
ctctttcccc aagtaggaaa gactctccta agcaagagac aaaattcaga agttatcagg 2100
gaaaaagata agcagattct cgcctctatt gagctgctgg cccgctcatt gccaaaaatt 2160
caccgcagtg catcagaacc ctccttgaat cgggctggct tccaaacaga ggattttagt 2220
ctatatgctt gtgcttctcc aaaaacaccc attcaggcag ggggatatga agcagatttg 2280
gctcttacat caaataaaaa tagagtagaa gttgggattt agagatttcc tgacatgcaa 2340
gaaggaataa gcaagaaaaa aaggtttgtt ttccccaaat catatctatt gtcttttact 2400
tctatttttt cttaaatttt ttgtgatttc agagacatgt agagttttat tgatacctaa 2460
actatgagtt cttttttttt tttttttttc attattttga tttttttggc caagaggcat 2520
atgggatctt agcttgagaa agcaacaatt ttcttgatgt cattttgggt gagggcacat 2580
attgctgtga acagtgtggt gatagccacc agggaccaaa ctcacacccg ctgcattgaa 2640
aggtgaagtc ttaaacactg gaccagcaga gaaattccta ctctatgagt tctttttgtc 2700
atcccctccc cgcaccctcc acccccaacc taaagtctga tgatgaaatc aacaactatt 2760
ccattagaag cagtagattc tggtagcatg atctttagtt tgttagtaag attttgtgct 2820
ttgtggggtt gtgtcgtttt aaggctaata tttaagtttg tcaaatagaa tgctgttcag 2880
attgtaaaaa tgagtaataa acatctgaag ttttttttaa gttattttta acatggtata 2940
tacagttgag cttagagttt atcattttct gatattctct tacttagtag atgaattcta 3000
gccatttttt ataaagattt ctgttaagca aatcctgttt tcacatgggc ttcctttaag 3060
ggattttaga ttctgctgga tatggtgact gctcataaga ctgttgaaaa ttacttttaa 3120
gatgtattag aatacttctg aaaaaaaata gcaaccttaa aaccataagc aaaagtagta 3180
agggtgttta tacatttcta gagtccctgt ttaggtaata gcctcctatg attgtacttt 3240
aaatgttttg ctctccaagg ttttagtaac ttggcttttt ttctaatcag tgccaaactc 3300
ccccagtttt tttaacttta aatatgaggt aataaatctt ttacccttcc ttgatctttt 3360
gacttataat accttggtca gttgtttctt aaaaggaatc cttaaatgga aagagacaat 3420
atcactgtct gcagttctga ttagtagttt tattcagaat ggaaaaacag attattcatt 3480
tttgaaaatt gttcaggggt atgttcattg ttaggacctt ggactttgga gtcagtgcct 3540
agctatgcat tccaggtctg ccattttctg gctgtgaaat tttggacaag ttacttaacc 3600
actttaaacc ccagctttaa gaagtaaatt aaccccagta aattaagaag taatagcagc 3660
cacttcgtag agttgttatg aggctcagat gcagtgcaaa tgtgtataaa gtattcaggg 3720
agtcacctgg tatactataa tagacactag aatagttgcc aatattatca gcatacaatc 3780
tgaggattct gtcagccaat cattagcaat ctgttgtttg ttgggacatg ccagtgttct 3840
ccagttgaaa tcagtagcaa tctaaaaatg gatagattat tcctcattta aatagtgtgt 3900
tcatataagt gattgcttgg atccttatca gaagttgctg ttactgaaaa atgataaggc 3960
tgactaaatt gtgatagttg tcagttacta accaactccc agaaatgaat aagaggaacc 4020
tatctctagt tcctagtaga aggtatggac aaaatagtag gtgaaaaata atgtcttgaa 4080
cccccaaatt aagtaagctt taaagagtac aatacctcaa agggtctttg cggtttaaaa 4140
tttgtatgct gagaatgatg ttcattgaca tgtgcctata tgtaattttt tgatagttta 4200
aaaggtgaaa tgaactacag atgggagagg tctgaatttt cttgccttca gtcaaatgtg 4260
taatgtggac atattatttg acctgtgaat tttatctttt aaaaaagatt aattcctgct 4320
tcttccttcc taatagttgc attataataa tgaaaatgag ttgataattt ggggggaaag 4380
tattctacaa atcaacctta ttattttacc attggtttct gagaaatttt gttcatttga 4440
accgtttata gcttgattag aatcatagca tgtaaaaccc aactgaggga ttatctgcag 4500
acttaatgta gtattatgta agttgtcttc tttcatttcg accttttttg cttttgttgt 4560
tgctagatct gtagtatgta gctagtcacc tttcagcgag gtttcagcga ggcttttctg 4620
tgtctctagg ttatttgaga taactttttt aaaattagct cttgtcctcc 4670
<210> 26
<211> 761
<212> PRT
<213> Bos taurus
<400> 26
Met Lys Ile Gln Met Ser Ser Val Lys Val Trp Asn Ile Lys Gln Met
1 5 10 15
Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu Asp Lys Phe Gly
20 25 30
Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala Tyr Glu Glu Tyr
35 40 45
Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln Gln Leu Leu Glu
50 55 60
Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser Ser Ala Ser Thr
65 70 75 80
Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser Val Leu Pro Ser
85 90 95
Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser Arg Ser Asn Pro
100 105 110
Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu Pro Asn Lys Gln
115 120 125
Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val Arg Asp Ser Leu
130 135 140
Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu Cys Cys Ala Val
145 150 155 160
Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly Trp Asp Thr Asp
165 170 175
Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu Val Leu Glu Asn
180 185 190
Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr Phe Phe Thr Leu
195 200 205
Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln Gly Phe Arg Cys
210 215 220
Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser Thr Glu Val Pro
225 230 235 240
Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu Phe Val Ser Lys
245 250 255
Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala Ser Leu Ala Glu
260 265 270
Thr Thr Leu Pro Cys Gly Ser Ser Pro Ser Ala Pro Pro Ser Asp Ser
275 280 285
Ile Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser Lys Ser Ile Pro
290 295 300
Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His Arg Asn Gln Phe
305 310 315 320
Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val His Ile Asn Thr
325 330 335
Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp Gln Gly Phe Arg
340 345 350
Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr Pro Pro Ala Ser
355 360 365
Leu Pro Gly Ser Leu Ser Asn Val Lys Ala Leu Gln Lys Ser Pro Gly
370 375 380
Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu Asp Arg Asn Arg
385 390 395 400
Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp Trp Glu Ile Pro
405 410 415
Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser Gly Ser Phe Gly
420 425 430
Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala Val Lys Met Leu
435 440 445
Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala Phe Lys Asn Glu
450 455 460
Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile Leu Leu Phe Met
465 470 475 480
Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr Gln Trp Cys Glu
485 490 495
Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu Thr Lys Phe Glu
500 505 510
Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala Gln Gly Met Asp
515 520 525
Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu Lys Ser Asn Asn
530 535 540
Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly Asp Phe Gly Leu
545 550 555 560
Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln Phe Glu Gln Leu
565 570 575
Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile Arg Met Gln Asp
580 585 590
Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala Phe Gly Ile Val
595 600 605
Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser Asn Ile Asn Asn
610 615 620
Arg Asp Gln Ile Ile Phe Met Val Gly Arg Gly Tyr Leu Ser Pro Asp
625 630 635 640
Leu Ser Lys Val Arg Ser Asn Cys Pro Lys Ala Met Lys Arg Leu Met
645 650 655
Ala Glu Cys Leu Lys Lys Lys Arg Asp Glu Arg Pro Leu Phe Pro Gln
660 665 670
Val Gly Lys Thr Leu Leu Ser Lys Arg Gln Asn Ser Glu Val Ile Arg
675 680 685
Glu Lys Asp Lys Gln Ile Leu Ala Ser Ile Glu Leu Leu Ala Arg Ser
690 695 700
Leu Pro Lys Ile His Arg Ser Ala Ser Glu Pro Ser Leu Asn Arg Ala
705 710 715 720
Gly Phe Gln Thr Glu Asp Phe Ser Leu Tyr Ala Cys Ala Ser Pro Lys
725 730 735
Thr Pro Ile Gln Ala Gly Gly Tyr Glu Ala Asp Leu Ala Leu Thr Ser
740 745 750
Asn Lys Asn Arg Val Glu Val Gly Ile
755 760
<210> 27
<211> 4816
<212> DNA
<213> Bos taurus
<400> 27
ctcagctgcg ccgggtctca caagacggtt cccgaggtgg cccaggcgcc gtcccaccgc 60
cgacgccgcc cgggccgccc gggccgtccc tccccgctgc cccccgtcct ccgcctccgc 120
ctccccccgc cctcagcctc ccttccccct ccccgcccag cagcggtcgc tcgggcccgg 180
ctctcggtta taagatggcg gcgctgagtg gcggcggcgg cggcggcggc ggtggcgcgg 240
agcagggcca ggctctgttc aacggggaca tggagcccga ggccggcgcc gcggcctctt 300
cggctgcgga ccccgccatt cccgaggagg tgtggaatat caaacaaatg attaagttga 360
cacaggagca tatagaggcc ctattggaca aatttggtgg ggagcataat ccaccatcaa 420
tatatctgga ggcctatgaa gaatacacca gcaagctaga tgccctccaa caaagagaac 480
aacagttatt ggaatccctg gggaatggaa ctgatttttc tgtttctagc tctgcatcaa 540
cggacaccgt tacatcttct tcctcttcta gcctttcagt gctgccttca tctctttcag 600
tttttcaaaa tcccacagat gtgtcacgga gcaaccccaa gtcaccacaa aaacctatcg 660
ttagagtctt cctgcccaat aaacagagga cagtggtacc tgcacggtgt ggagtcacag 720
tccgggacag cctgaagaag gcactgatga tgagaggtct aatcccagag tgctgtgctg 780
tttacagaat tcaggatggg gagaagaaac caattggctg ggacactgat atttcctggc 840
ttactggaga ggagttgcat gtagaagtgt tggagaatgt tccacttaca acacacaact 900
ttgtacggaa aacttttttc accttagcat tttgtgactt ctgtagaaag ctgcttttcc 960
agggattccg ctgtcaaaca tgtggttata aatttcacca gcgttgtagt acagaggttc 1020
cactgatgtg tgttaattat gaccaactag agcccccaat tctcaccagt ccatctcctt 1080
caaaatccat tccaattcca cagcctttcc gaccagcaga tgaagatcat cgaaatcagt 1140
ttggacaacg agaccggtcc tcatcagctc caaatgtgca tataaacaca atagaacccg 1200
tcaatattga tgacttgatt agagaccaag ggtttcgtag tgatggagga tcaaccacag 1260
gtttatccgc cacaccccct gcctcattac ctggctcact ctctaatgtg aaagcattgc 1320
agaaatctcc aggacctcag cgagaaagaa agtcctcttc atcctcagaa gacaggaatc 1380
gaatgaaaac gcttggtaga cgggattcaa gtgacgattg ggagattcct gatggacaga 1440
tcacagtggg acaaagaatt ggatcagggt catttgggac agtctacaag ggaaagtggc 1500
atggtgatgt ggcagtgaaa atgttgaatg tgacagcacc cacacctcag cagttacagg 1560
ccttcaaaaa tgaagtagga gtactcagga aaacgcgaca tgtgaatatc ctcctcttca 1620
tgggttattc aacaaagcca caactggcta ttgttaccca gtggtgtgag ggctccagtt 1680
tatatcatca tctccacatc attgagacca aattcgagat gatcaaactt atagatattg 1740
cacggcagac tgcacagggc atggattact tacacgccaa gtcaatcatc cacagagacc 1800
tcaagagtaa taatattttt cttcatgaag acctcacagt aaaaataggt gattttggtc 1860
tagccacagt gaaatctcga tggagtgggt cccatcagtt tgaacagttg tctggatcca 1920
ttttgtggat ggcaccagaa gtaatcagaa tgcaagataa aaacccatat agctttcagt 1980
cagatgtata tgcatttggg attgttctgt atgaattgat gaccggacag ttaccttatt 2040
caaatatcaa caacagggac cagataattt ttatggtggg acgaggatat ctgtctccag 2100
atctcagtaa ggtacggagt aactgtccaa aagccatgaa gagattaatg gcagagtgcc 2160
taaaaaagaa aagagatgaa agaccactct ttccccaagt aggaaagact ctcctaagca 2220
agagacaaaa ttcagaagtt atcagggaaa aagataagca gattctcgcc tctattgagc 2280
tgctggcccg ctcattgcca aaaattcacc gcagtgcatc agaaccctcc ttgaatcggg 2340
ctggcttcca aacagaggat tttagtctat atgcttgtgc ttctccaaaa acacccattc 2400
aggcaggggg atatgaagca gatttggctc ttacatcaaa taaaaataga gtagaagttg 2460
ggatttagag atttcctgac atgcaagaag gaataagcaa gaaaaaaagg tttgttttcc 2520
ccaaatcata tctattgtct tttacttcta ttttttctta aattttttgt gatttcagag 2580
acatgtagag ttttattgat acctaaacta tgagttcttt tttttttttt tttttcatta 2640
ttttgatttt tttggccaag aggcatatgg gatcttagct tgagaaagca acaattttct 2700
tgatgtcatt ttgggtgagg gcacatattg ctgtgaacag tgtggtgata gccaccaggg 2760
accaaactca cacccgctgc attgaaaggt gaagtcttaa acactggacc agcagagaaa 2820
ttcctactct atgagttctt tttgtcatcc cctccccgca ccctccaccc ccaacctaaa 2880
gtctgatgat gaaatcaaca actattccat tagaagcagt agattctggt agcatgatct 2940
ttagtttgtt agtaagattt tgtgctttgt ggggttgtgt cgttttaagg ctaatattta 3000
agtttgtcaa atagaatgct gttcagattg taaaaatgag taataaacat ctgaagtttt 3060
ttttaagtta tttttaacat ggtatataca gttgagctta gagtttatca ttttctgata 3120
ttctcttact tagtagatga attctagcca ttttttataa agatttctgt taagcaaatc 3180
ctgttttcac atgggcttcc tttaagggat tttagattct gctggatatg gtgactgctc 3240
ataagactgt tgaaaattac ttttaagatg tattagaata cttctgaaaa aaaatagcaa 3300
ccttaaaacc ataagcaaaa gtagtaaggg tgtttataca tttctagagt ccctgtttag 3360
gtaatagcct cctatgattg tactttaaat gttttgctct ccaaggtttt agtaacttgg 3420
ctttttttct aatcagtgcc aaactccccc agttttttta actttaaata tgaggtaata 3480
aatcttttac ccttccttga tcttttgact tataatacct tggtcagttg tttcttaaaa 3540
ggaatcctta aatggaaaga gacaatatca ctgtctgcag ttctgattag tagttttatt 3600
cagaatggaa aaacagatta ttcatttttg aaaattgttc aggggtatgt tcattgttag 3660
gaccttggac tttggagtca gtgcctagct atgcattcca ggtctgccat tttctggctg 3720
tgaaattttg gacaagttac ttaaccactt taaaccccag ctttaagaag taaattaacc 3780
ccagtaaatt aagaagtaat agcagccact tcgtagagtt gttatgaggc tcagatgcag 3840
tgcaaatgtg tataaagtat tcagggagtc acctggtata ctataataga cactagaata 3900
gttgccaata ttatcagcat acaatctgag gattctgtca gccaatcatt agcaatctgt 3960
tgtttgttgg gacatgccag tgttctccag ttgaaatcag tagcaatcta aaaatggata 4020
gattattcct catttaaata gtgtgttcat ataagtgatt gcttggatcc ttatcagaag 4080
ttgctgttac tgaaaaatga taaggctgac taaattgtga tagttgtcag ttactaacca 4140
actcccagaa atgaataaga ggaacctatc tctagttcct agtagaaggt atggacaaaa 4200
tagtaggtga aaaataatgt cttgaacccc caaattaagt aagctttaaa gagtacaata 4260
cctcaaaggg tctttgcggt ttaaaatttg tatgctgaga atgatgttca ttgacatgtg 4320
cctatatgta attttttgat agtttaaaag gtgaaatgaa ctacagatgg gagaggtctg 4380
aattttcttg ccttcagtca aatgtgtaat gtggacatat tatttgacct gtgaatttta 4440
tcttttaaaa aagattaatt cctgcttctt ccttcctaat agttgcatta taataatgaa 4500
aatgagttga taatttgggg ggaaagtatt ctacaaatca accttattat tttaccattg 4560
gtttctgaga aattttgttc atttgaaccg tttatagctt gattagaatc atagcatgta 4620
aaacccaact gagggattat ctgcagactt aatgtagtat tatgtaagtt gtcttctttc 4680
atttcgacct tttttgcttt tgttgttgct agatctgtag tatgtagcta gtcacctttc 4740
agcgaggttt cagcgaggct tttctgtgtc tctaggttat ttgagataac ttttttaaaa 4800
ttagctcttg tcctcc 4816
<210> 28
<211> 757
<212> PRT
<213> Bos taurus
<400> 28
Met Ala Ala Leu Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Glu
1 5 10 15
Gln Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala
20 25 30
Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn
35 40 45
Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu
50 55 60
Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala
65 70 75 80
Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln
85 90 95
Gln Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser
100 105 110
Ser Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser
115 120 125
Val Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser
130 135 140
Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
145 150 155 160
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
165 170 175
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
180 185 190
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
195 200 205
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
210 215 220
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr
225 230 235 240
Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln
245 250 255
Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser
260 265 270
Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Glu Pro Pro
275 280 285
Ile Leu Thr Ser Pro Ser Pro Ser Lys Ser Ile Pro Ile Pro Gln Pro
290 295 300
Phe Arg Pro Ala Asp Glu Asp His Arg Asn Gln Phe Gly Gln Arg Asp
305 310 315 320
Arg Ser Ser Ser Ala Pro Asn Val His Ile Asn Thr Ile Glu Pro Val
325 330 335
Asn Ile Asp Asp Leu Ile Arg Asp Gln Gly Phe Arg Ser Asp Gly Gly
340 345 350
Ser Thr Thr Gly Leu Ser Ala Thr Pro Pro Ala Ser Leu Pro Gly Ser
355 360 365
Leu Ser Asn Val Lys Ala Leu Gln Lys Ser Pro Gly Pro Gln Arg Glu
370 375 380
Arg Lys Ser Ser Ser Ser Ser Glu Asp Arg Asn Arg Met Lys Thr Leu
385 390 395 400
Gly Arg Arg Asp Ser Ser Asp Asp Trp Glu Ile Pro Asp Gly Gln Ile
405 410 415
Thr Val Gly Gln Arg Ile Gly Ser Gly Ser Phe Gly Thr Val Tyr Lys
420 425 430
Gly Lys Trp His Gly Asp Val Ala Val Lys Met Leu Asn Val Thr Ala
435 440 445
Pro Thr Pro Gln Gln Leu Gln Ala Phe Lys Asn Glu Val Gly Val Leu
450 455 460
Arg Lys Thr Arg His Val Asn Ile Leu Leu Phe Met Gly Tyr Ser Thr
465 470 475 480
Lys Pro Gln Leu Ala Ile Val Thr Gln Trp Cys Glu Gly Ser Ser Leu
485 490 495
Tyr His His Leu His Ile Ile Glu Thr Lys Phe Glu Met Ile Lys Leu
500 505 510
Ile Asp Ile Ala Arg Gln Thr Ala Gln Gly Met Asp Tyr Leu His Ala
515 520 525
Lys Ser Ile Ile His Arg Asp Leu Lys Ser Asn Asn Ile Phe Leu His
530 535 540
Glu Asp Leu Thr Val Lys Ile Gly Asp Phe Gly Leu Ala Thr Val Lys
545 550 555 560
Ser Arg Trp Ser Gly Ser His Gln Phe Glu Gln Leu Ser Gly Ser Ile
565 570 575
Leu Trp Met Ala Pro Glu Val Ile Arg Met Gln Asp Lys Asn Pro Tyr
580 585 590
Ser Phe Gln Ser Asp Val Tyr Ala Phe Gly Ile Val Leu Tyr Glu Leu
595 600 605
Met Thr Gly Gln Leu Pro Tyr Ser Asn Ile Asn Asn Arg Asp Gln Ile
610 615 620
Ile Phe Met Val Gly Arg Gly Tyr Leu Ser Pro Asp Leu Ser Lys Val
625 630 635 640
Arg Ser Asn Cys Pro Lys Ala Met Lys Arg Leu Met Ala Glu Cys Leu
645 650 655
Lys Lys Lys Arg Asp Glu Arg Pro Leu Phe Pro Gln Val Gly Lys Thr
660 665 670
Leu Leu Ser Lys Arg Gln Asn Ser Glu Val Ile Arg Glu Lys Asp Lys
675 680 685
Gln Ile Leu Ala Ser Ile Glu Leu Leu Ala Arg Ser Leu Pro Lys Ile
690 695 700
His Arg Ser Ala Ser Glu Pro Ser Leu Asn Arg Ala Gly Phe Gln Thr
705 710 715 720
Glu Asp Phe Ser Leu Tyr Ala Cys Ala Ser Pro Lys Thr Pro Ile Gln
725 730 735
Ala Gly Gly Tyr Glu Ala Asp Leu Ala Leu Thr Ser Asn Lys Asn Arg
740 745 750
Val Glu Val Gly Ile
755
<210> 29
<211> 2499
<212> DNA
<213> Bos taurus
<400> 29
ctcagctgcg ccgggtctca caagacggtt cccgaggtgg cccaggcgcc gtcccaccgc 60
cgacgccgcc cgggccgccc gggccgtccc tccccgctgc cccccgtcct ccgcctccgc 120
ctccccccgc cctcagcctc ccttccccct ccccgcccag cagcggtcgc tcgggcccgg 180
ctctcggtta taagatggcg gcgctgagtg gcggcggcgg cggcggcggc ggtggcgcgg 240
agcagggcca ggctctgttc aacggggaca tggagcccga ggccggcgcc gcggcctctt 300
cggctgcgga ccccgccatt cccgaggagg tgtggaatat caaacaaatg attaagttga 360
cacaggagca tatagaggcc ctattggaca aatttggtgg ggagcataat ccaccatcaa 420
tatatctgga ggcctatgaa gaatacacca gcaagctaga tgccctccaa caaagagaac 480
aacagttatt ggaatccctg gggaatggaa ctgatttttc tgtttctagc tctgcatcaa 540
cggacaccgt tacatcttct tcctcttcta gcctttcagt gctgccttca tctctttcag 600
tttttcaaaa tcccacagat gtgtcacgga gcaaccccaa gtcaccacaa aaacctatcg 660
ttagagtctt cctgcccaat aaacagagga cagtggtacc tgcacggtgt ggagtcacag 720
tccgggacag cctgaagaag gcactgatga tgagaggtct aatcccagag tgctgtgctg 780
tttacagaat tcaggatggg gagaagaaac caattggctg ggacactgat atttcctggc 840
ttactggaga ggagttgcat gtagaagtgt tggagaatgt tccacttaca acacacaact 900
ttgtacggaa aacttttttc accttagcat tttgtgactt ctgtagaaag ctgcttttcc 960
agggattccg ctgtcaaaca tgtggttata aatttcacca gcgttgtagt acagaggttc 1020
cactgatgtg tgttaattat gaccaactag atttgctgtt tgtctccaag ttctttgaac 1080
accacccaat accacaggag gaggcctcct tagcagagac tacccttcca tgtggctcat 1140
ccccttctgc acccccctcc gattctattg ggcccccaat tctcaccagt ccatctcctt 1200
caaaatccat tccaattcca cagcctttcc gaccagcaga tgaagatcat cgaaatcagt 1260
ttggacaacg agaccggtcc tcatcagctc caaatgtgca tataaacaca atagaacccg 1320
tcaatattga tgacttgatt agagaccaag ggtttcgtag tgatggagga tcaaccacag 1380
gtttatccgc cacaccccct gcctcattac ctggctcact ctctaatgtg aaagcattgc 1440
agaaatctcc aggacctcag cgagaaagaa agtcctcttc atcctcagaa gacaggaatc 1500
gaatgaaaac gcttggtaga cgggattcaa gtgacgattg ggagattcct gatggacaga 1560
tcacagtggg acaaagaatt ggatcagggt catttgggac agtctacaag ggaaagtggc 1620
atggtgatgt ggcagtgaaa atgttgaatg tgacagcacc cacacctcag cagttacagg 1680
ccttcaaaaa tgaagtagga gtactcagga aaacgcgaca tgtgaatatc ctcctcttca 1740
tgggttattc aacaaagcca caactggcta ttgttaccca gtggtgtgag ggctccagtt 1800
tatatcatca tctccacatc attgagacca aattcgagat gatcaaactt atagatattg 1860
cacggcagac tgcacagggc atggattact tacacgccaa gtcaatcatc cacagagacc 1920
tcaagagtaa taatattttt cttcatgaag acctcacagt aaaaataggt gattttggtc 1980
tagccacagt gaaatctcga tggagtgggt cccatcagtt tgaacagttg tctggatcca 2040
ttttgtggat ggcaccagaa gtaatcagaa tgcaagataa aaacccatat agctttcagt 2100
cagatgtata tgcatttggg attgttctgt atgaattgat gaccggacag ttaccttatt 2160
caaatatcaa caacagggac cagataattt ttatggtggg acgaggatat ctgtctccag 2220
atctcagtaa ggtacggagt aactgtccaa aagccatgaa gagattaatg gcagagtgcc 2280
taaaaaagaa aagagatgaa agaccactct ttccccaagt aggaaagact ctcctaagca 2340
agagacaaaa ttcagaagtt atcagggaaa aagataagca ggaaaagtat gtttctttag 2400
tacattccag gcatttggga ttacagtaaa aacaatattc tcgcctctat tgagctgctg 2460
gcccgctcat tgccaaaaat tcaccgcagt gcatcagaa 2499
<210> 30
<211> 744
<212> PRT
<213> Bos taurus
<400> 30
Met Ala Ala Leu Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Glu
1 5 10 15
Gln Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala
20 25 30
Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn
35 40 45
Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu
50 55 60
Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala
65 70 75 80
Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln
85 90 95
Gln Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser
100 105 110
Ser Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser
115 120 125
Val Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser
130 135 140
Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
145 150 155 160
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
165 170 175
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
180 185 190
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
195 200 205
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
210 215 220
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr
225 230 235 240
Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln
245 250 255
Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser
260 265 270
Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu
275 280 285
Phe Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala
290 295 300
Ser Leu Ala Glu Thr Thr Leu Pro Cys Gly Ser Ser Pro Ser Ala Pro
305 310 315 320
Pro Ser Asp Ser Ile Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser
325 330 335
Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His
340 345 350
Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val
355 360 365
His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp
370 375 380
Gln Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr
385 390 395 400
Pro Pro Ala Ser Leu Pro Gly Ser Leu Ser Asn Val Lys Ala Leu Gln
405 410 415
Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu
420 425 430
Asp Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp
435 440 445
Trp Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser
450 455 460
Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala
465 470 475 480
Val Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala
485 490 495
Phe Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile
500 505 510
Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr
515 520 525
Gln Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu
530 535 540
Thr Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala
545 550 555 560
Gln Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu
565 570 575
Lys Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly
580 585 590
Asp Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln
595 600 605
Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile
610 615 620
Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala
625 630 635 640
Phe Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser
645 650 655
Asn Ile Asn Asn Arg Asp Gln Ile Ile Phe Met Val Gly Arg Gly Tyr
660 665 670
Leu Ser Pro Asp Leu Ser Lys Val Arg Ser Asn Cys Pro Lys Ala Met
675 680 685
Lys Arg Leu Met Ala Glu Cys Leu Lys Lys Lys Arg Asp Glu Arg Pro
690 695 700
Leu Phe Pro Gln Val Gly Lys Thr Leu Leu Ser Lys Arg Gln Asn Ser
705 710 715 720
Glu Val Ile Arg Glu Lys Asp Lys Gln Glu Lys Tyr Val Ser Leu Val
725 730 735
His Ser Arg His Leu Gly Leu Gln
740
<210> 31
<211> 2404
<212> DNA
<213> Bos taurus
<400> 31
ctcagctgcg ccgggtctca caagacggtt cccgaggtgg cccaggcgcc gtcccaccgc 60
cgacgccgcc cgggccgccc gggccgtccc tccccgctgc cccccgtcct ccgcctccgc 120
ctccccccgc cctcagcctc ccttccccct ccccgcccag cagcggtcgc tcgggcccgg 180
ctctcggtta taagatggcg gcgctgagtg gcggcggcgg cggcggcggc ggtggcgcgg 240
agcagggcca ggctctgttc aacggggaca tggagcccga ggccggcgcc gcggcctctt 300
cggctgcgga ccccgccatt cccgaggagg tgtggaatat caaacaaatg attaagttga 360
cacaggagca tatagaggcc ctattggaca aatttggtgg ggagcataat ccaccatcaa 420
tatatctgga ggcctatgaa gaatacacca gcaagctaga tgccctccaa caaagagaac 480
aacagttatt ggaatccctg gggaatggaa ctgatttttc tgtttctagc tctgcatcaa 540
cggacaccgt tacatcttct tcctcttcta gcctttcagt gctgccttca tctctttcag 600
tttttcaaaa tcccacagat gtgtcacgga gcaaccccaa gtcaccacaa aaacctatcg 660
ttagagtctt cctgcccaat aaacagagga cagtggtacc tgcacggtgt ggagtcacag 720
tccgggacag cctgaagaag gcactgatga tgagaggtct aatcccagag tgctgtgctg 780
tttacagaat tcaggatggg gagaagaaac caattggctg ggacactgat atttcctggc 840
ttactggaga ggagttgcat gtagaagtgt tggagaatgt tccacttaca acacacaact 900
ttgtacggaa aacttttttc accttagcat tttgtgactt ctgtagaaag ctgcttttcc 960
agggattccg ctgtcaaaca tgtggttata aatttcacca gcgttgtagt acagaggttc 1020
cactgatgtg tgttaattat gaccaactag atttgctgtt tgtctccaag ttctttgaac 1080
accacccaat accacaggag gaggcctcct tagcagagac tacccttcca tgtggctcat 1140
ccccttctgc acccccctcc gattctattg ggcccccaat tctcaccagt ccatctcctt 1200
caaaatccat tccaattcca cagcctttcc gaccagcaga tgaagatcat cgaaatcagt 1260
ttggacaacg agaccggtcc tcatcagctc caaatgtgca tataaacaca atagaacccg 1320
tcaatattga tgacttgatt agagaccaag ggtttcgtag tgatggagga tcaaccacag 1380
gtttatccgc cacaccccct gcctcattac ctggctcact ctctaatgtg aaagcattgc 1440
agaaatctcc aggacctcag cgagaaagaa agtcctcttc atcctcagaa gacaggaatc 1500
gaatgaaaac gcttggtaga cgggattcaa gtgacgattg ggagattcct gatggacaga 1560
tcacagtggg acaaagaatt ggatcagggt catttgggac agtctacaag ggaaagtggc 1620
atggtgatgt ggcagtgaaa atgttgaatg tgacagcacc cacacctcag cagttacagg 1680
ccttcaaaaa tgaagtagga gtactcagga aaacgcgaca tgtgaatatc ctcctcttca 1740
tgggttattc aacaaagcca caactggcta ttgttaccca gtggtgtgag ggctccagtt 1800
tatatcatca tctccacatc attgagacca aattcgagat gatcaaactt atagatattg 1860
cacggcagac tgcacagggc atggattact tacacgccaa gtcaatcatc cacagagacc 1920
tcaagagtaa taatattttt cttcatgaag acctcacagt aaaaataggt gattttggtc 1980
tagccacagt gaaatctcga tggagtgggt cccatcagtt tgaacagttg tctggatcca 2040
ttttgtggat ggcaccagaa gtaatcagaa tgcaagataa aaacccatat agctttcagt 2100
cagatgtata tgcatttggg attgttctgt atgaattgat gaccggacag ttaccttatt 2160
caaatatcaa caacagggac cagataattt ttatggtggg acgaggatat ctgtctccag 2220
atctcagtaa ggtacggagt aactgtccaa aagccatgaa gagattaatg gcagagtgcc 2280
taaaaaagaa aagagatgaa agaccactct ttccccaaga tctctcttcc caccatagac 2340
acaaaaattt cagatggcta caggtttaca tgtaaaaaac agaattataa caaatgattt 2400
ttat 2404
<210> 32
<211> 726
<212> PRT
<213> Bos taurus
<400> 32
Met Ala Ala Leu Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Glu
1 5 10 15
Gln Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala
20 25 30
Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn
35 40 45
Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu
50 55 60
Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala
65 70 75 80
Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln
85 90 95
Gln Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser
100 105 110
Ser Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser
115 120 125
Val Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser
130 135 140
Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
145 150 155 160
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
165 170 175
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
180 185 190
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
195 200 205
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
210 215 220
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr
225 230 235 240
Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln
245 250 255
Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser
260 265 270
Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu
275 280 285
Phe Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala
290 295 300
Ser Leu Ala Glu Thr Thr Leu Pro Cys Gly Ser Ser Pro Ser Ala Pro
305 310 315 320
Pro Ser Asp Ser Ile Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser
325 330 335
Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His
340 345 350
Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val
355 360 365
His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp
370 375 380
Gln Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr
385 390 395 400
Pro Pro Ala Ser Leu Pro Gly Ser Leu Ser Asn Val Lys Ala Leu Gln
405 410 415
Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu
420 425 430
Asp Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp
435 440 445
Trp Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser
450 455 460
Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala
465 470 475 480
Val Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala
485 490 495
Phe Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile
500 505 510
Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr
515 520 525
Gln Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu
530 535 540
Thr Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala
545 550 555 560
Gln Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu
565 570 575
Lys Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly
580 585 590
Asp Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln
595 600 605
Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile
610 615 620
Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala
625 630 635 640
Phe Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser
645 650 655
Asn Ile Asn Asn Arg Asp Gln Ile Ile Phe Met Val Gly Arg Gly Tyr
660 665 670
Leu Ser Pro Asp Leu Ser Lys Val Arg Ser Asn Cys Pro Lys Ala Met
675 680 685
Lys Arg Leu Met Ala Glu Cys Leu Lys Lys Lys Arg Asp Glu Arg Pro
690 695 700
Leu Phe Pro Gln Asp Leu Ser Ser His His Arg His Lys Asn Phe Arg
705 710 715 720
Trp Leu Gln Val Tyr Met
725
<210> 33
<211> 2331
<212> DNA
<213> Bos taurus
<400> 33
ctcagctgcg ccgggtctca caagacggtt cccgaggtgg cccaggcgcc gtcccaccgc 60
cgacgccgcc cgggccgccc gggccgtccc tccccgctgc cccccgtcct ccgcctccgc 120
ctccccccgc cctcagcctc ccttccccct ccccgcccag cagcggtcgc tcgggcccgg 180
ctctcggtta taagatggcg gcgctgagtg gcggcggcgg cggcggcggc ggtggcgcgg 240
agcagggcca ggctctgttc aacggggaca tggagcccga ggccggcgcc gcggcctctt 300
cggctgcgga ccccgccatt cccgaggagg tgtggaatat caaacaaatg attaagttga 360
cacaggagca tatagaggcc ctattggaca aatttggtgg ggagcataat ccaccatcaa 420
tatatctgga ggcctatgaa gaatacacca gcaagctaga tgccctccaa caaagagaac 480
aacagttatt ggaatccctg gggaatggaa ctgatttttc tgtttctagc tctgcatcaa 540
cggacaccgt tacatcttct tcctcttcta gcctttcagt gctgccttca tctctttcag 600
tttttcaaaa tcccacagat gtgtcacgga gcaaccccaa gtcaccacaa aaacctatcg 660
ttagagtctt cctgcccaat aaacagagga cagtggtacc tgcacggtgt ggagtcacag 720
tccgggacag cctgaagaag gcactgatga tgagaggtct aatcccagag tgctgtgctg 780
tttacagaat tcaggatggg gagaagaaac caattggctg ggacactgat atttcctggc 840
ttactggaga ggagttgcat gtagaagtgt tggagaatgt tccacttaca acacacaact 900
ttgtacggaa aacttttttc accttagcat tttgtgactt ctgtagaaag ctgcttttcc 960
agggattccg ctgtcaaaca tgtggttata aatttcacca gcgttgtagt acagaggttc 1020
cactgatgtg tgttaattat gaccaactag atttgctgtt tgtctccaag ttctttgaac 1080
accacccaat accacaggag gaggcctcct tagcagagac tacccttcca tgtggctcat 1140
ccccttctgc acccccctcc gattctattg ggcccccaat tctcaccagt ccatctcctt 1200
caaaatccat tccaattcca cagcctttcc gaccagcaga tgaagatcat cgaaatcagt 1260
ttggacaacg agaccggtcc tcatcagctc caaatgtgca tataaacaca atagaacccg 1320
tcaatattga tgacttgatt agagaccaag ggtttcgtag tgatggagga tcaaccacag 1380
gtttatccgc cacaccccct gcctcattac ctggctcact ctctaatgtg aaagcattgc 1440
agaaatctcc aggacctcag cgagaaagaa agtcctcttc atcctcagaa gacaggaatc 1500
gaatgaaaac gcttggtaga cgggattcaa gtgacgattg ggagattcct gatggacaga 1560
tcacagtggg acaaagaatt ggatcagggt catttgggac agtctacaag ggaaagtggc 1620
atggtgatgt ggcagtgaaa atgttgaatg tgacagcacc cacacctcag cagttacagg 1680
ccttcaaaaa tgaagtagga gtactcagga aaacgcgaca tgtgaatatc ctcctcttca 1740
tgggttattc aacaaagcca caactggcta ttgttaccca gtggtgtgag ggctccagtt 1800
tatatcatca tctccacatc attgagacca aattcgagat gatcaaactt atagatattg 1860
cacggcagac tgcacagggc atggattact tacacgccaa gtcaatcatc cacagagacc 1920
tcaagagtaa taatattttt cttcatgaag acctcacagt aaaaataggt gattttggtc 1980
tagccacagt gaaatctcga tggagtgggt cccatcagtt tgaacagttg tctggatcca 2040
ttttgtggat ggcaccagaa gtaatcagaa tgcaagataa aaacccatat agctttcagt 2100
cagatgtata tgcatttggg attgttctgt atgaattgat gaccggacag ttaccttatt 2160
caaatatcaa caacagggac caggtgcttt gtcctccatg ggagtgtaat aaatgctgtg 2220
caagggctta cttcccatga gagaagtgag tgaccaacag aaggataatt tttatggtgg 2280
gacgaggata tctgtctcca gatctcagta aggtacggag taactgtcca a 2331
<210> 34
<211> 681
<212> PRT
<213> Bos taurus
<400> 34
Met Ala Ala Leu Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Glu
1 5 10 15
Gln Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala
20 25 30
Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn
35 40 45
Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu
50 55 60
Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala
65 70 75 80
Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln
85 90 95
Gln Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser
100 105 110
Ser Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser
115 120 125
Val Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser
130 135 140
Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
145 150 155 160
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
165 170 175
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
180 185 190
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
195 200 205
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
210 215 220
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr
225 230 235 240
Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln
245 250 255
Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser
260 265 270
Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu
275 280 285
Phe Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala
290 295 300
Ser Leu Ala Glu Thr Thr Leu Pro Cys Gly Ser Ser Pro Ser Ala Pro
305 310 315 320
Pro Ser Asp Ser Ile Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser
325 330 335
Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His
340 345 350
Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val
355 360 365
His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp
370 375 380
Gln Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr
385 390 395 400
Pro Pro Ala Ser Leu Pro Gly Ser Leu Ser Asn Val Lys Ala Leu Gln
405 410 415
Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu
420 425 430
Asp Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp
435 440 445
Trp Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser
450 455 460
Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala
465 470 475 480
Val Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala
485 490 495
Phe Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile
500 505 510
Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr
515 520 525
Gln Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu
530 535 540
Thr Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala
545 550 555 560
Gln Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu
565 570 575
Lys Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly
580 585 590
Asp Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln
595 600 605
Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile
610 615 620
Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala
625 630 635 640
Phe Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser
645 650 655
Asn Ile Asn Asn Arg Asp Gln Val Leu Cys Pro Pro Trp Glu Cys Asn
660 665 670
Lys Cys Cys Ala Arg Ala Tyr Phe Pro
675 680
<210> 35
<211> 2319
<212> DNA
<213> Bos taurus
<400> 35
ctcagctgcg ccgggtctca caagacggtt cccgaggtgg cccaggcgcc gtcccaccgc 60
cgacgccgcc cgggccgccc gggccgtccc tccccgctgc cccccgtcct ccgcctccgc 120
ctccccccgc cctcagcctc ccttccccct ccccgcccag cagcggtcgc tcgggcccgg 180
ctctcggtta taagatggcg gcgctgagtg gcggcggcgg cggcggcggc ggtggcgcgg 240
agcagggcca ggctctgttc aacggggaca tggagcccga ggccggcgcc gcggcctctt 300
cggctgcgga ccccgccatt cccgaggagg tgtggaatat caaacaaatg attaagttga 360
cacaggagca tatagaggcc ctattggaca aatttggtgg ggagcataat ccaccatcaa 420
tatatctgga ggcctatgaa gaatacacca gcaagctaga tgccctccaa caaagagaac 480
aacagttatt ggaatccctg gggaatggaa ctgatttttc tgtttctagc tctgcatcaa 540
cggacaccgt tacatcttct tcctcttcta gcctttcagt gctgccttca tctctttcag 600
tttttcaaaa tcccacagat gtgtcacgga gcaaccccaa gtcaccacaa aaacctatcg 660
ttagagtctt cctgcccaat aaacagagga cagtggtacc tgcacggtgt ggagtcacag 720
tccgggacag cctgaagaag gcactgatga tgagaggtct aatcccagag tgctgtgctg 780
tttacagaat tcaggatggg gagaagaaac caattggctg ggacactgat atttcctggc 840
ttactggaga ggagttgcat gtagaagtgt tggagaatgt tccacttaca acacacaact 900
ttgtacggaa aacttttttc accttagcat tttgtgactt ctgtagaaag ctgcttttcc 960
agggattccg ctgtcaaaca tgtggttata aatttcacca gcgttgtagt acagaggttc 1020
cactgatgtg tgttaattat gaccaactag atttgctgtt tgtctccaag ttctttgaac 1080
accacccaat accacaggag gaggcctcct tagcagagac tacccttcca tgtggctcat 1140
ccccttctgc acccccctcc gattctattg ggcccccaat tctcaccagt ccatctcctt 1200
caaaatccat tccaattcca cagcctttcc gaccagcaga tgaagatcat cgaaatcagt 1260
ttggacaacg agaccggtcc tcatcagctc caaatgtgca tataaacaca atagaacccg 1320
tcaatattga tgacttgatt agagaccaag ggtttcgtag tgatggagga tcaaccacag 1380
gtttatccgc cacaccccct gcctcattac ctggctcact ctctaatgtg aaagcattgc 1440
agaaatctcc aggacctcag cgagaaagaa agtcctcttc atcctcagaa gacaggaatc 1500
gaatgaaaac gcttggtaga cgggattcaa gtgacgattg ggagattcct gatggacaga 1560
tcacagtggg acaaagaatt ggatcagggt catttgggac agtctacaag ggaaagtggc 1620
atggtgatgt ggcagtgaaa atgttgaatg tgacagcacc cacacctcag cagttacagg 1680
ccttcaaaaa tgaagtagga gtactcagga aaacgcgaca tgtgaatatc ctcctcttca 1740
tgggttattc aacaaagcca caactggcta ttgttaccca gtggtgtgag ggctccagtt 1800
tatatcatca tctccacatc attgagacca aattcgagat gatcaaactt atagatattg 1860
cacggcagac tgcacagggc atggattact tacacgccaa gtcaatcatc cacagagacc 1920
tcaagagtaa taatattttt cttcatgaag acctcacagt aaaaataggt gattttggtc 1980
tagccacagt gaaatctcga tggagtgggt cccatcagtt tgaacagttg tctggatcca 2040
ttttgtggat ggcaccagaa gtaatcagaa tgcaagataa aaacccatat agctttcagt 2100
cagatgtata tgcatttggg attgttctgt atgaattgat gaccggacag ttaccttatt 2160
caaatatcaa caacagggac caggtgcttt gtcctccatg ggagtgtaat aaatgctgtg 2220
caagggctta cttcccatga gagaagtgag tgaccaacag aaggtctgtg caaggaaaag 2280
agacaaagcc acggatcaga agcacatggc cataactga 2319
<210> 36
<211> 681
<212> PRT
<213> Bos taurus
<400> 36
Met Ala Ala Leu Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Glu
1 5 10 15
Gln Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala
20 25 30
Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn
35 40 45
Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu
50 55 60
Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala
65 70 75 80
Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln
85 90 95
Gln Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser
100 105 110
Ser Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser
115 120 125
Val Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser
130 135 140
Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
145 150 155 160
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
165 170 175
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
180 185 190
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
195 200 205
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
210 215 220
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr
225 230 235 240
Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln
245 250 255
Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser
260 265 270
Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu
275 280 285
Phe Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala
290 295 300
Ser Leu Ala Glu Thr Thr Leu Pro Cys Gly Ser Ser Pro Ser Ala Pro
305 310 315 320
Pro Ser Asp Ser Ile Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser
325 330 335
Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His
340 345 350
Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val
355 360 365
His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp
370 375 380
Gln Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr
385 390 395 400
Pro Pro Ala Ser Leu Pro Gly Ser Leu Ser Asn Val Lys Ala Leu Gln
405 410 415
Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu
420 425 430
Asp Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp
435 440 445
Trp Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser
450 455 460
Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala
465 470 475 480
Val Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala
485 490 495
Phe Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile
500 505 510
Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr
515 520 525
Gln Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu
530 535 540
Thr Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala
545 550 555 560
Gln Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu
565 570 575
Lys Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly
580 585 590
Asp Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln
595 600 605
Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile
610 615 620
Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala
625 630 635 640
Phe Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser
645 650 655
Asn Ile Asn Asn Arg Asp Gln Val Leu Cys Pro Pro Trp Glu Cys Asn
660 665 670
Lys Cys Cys Ala Arg Ala Tyr Phe Pro
675 680
<210> 37
<211> 2661
<212> DNA
<213> Bos taurus
<400> 37
tcagctgcgc cgggtctcac aagacggttc ccgaggtggc ccaggcgccg tcccaccgcc 60
gacgccgccc gggccgcccg ggccgtccct ccccgctgcc ccccgtcctc cgcctccgcc 120
tccccccgcc ctcagcctcc cttccccctc cccgcccagc agcggtcgct cgggcccggc 180
tctcggttat aagatggcgg cgctgagtgg cggcggcggc ggcggcggcg gtggcgcgga 240
gcagggccag gctctgttca acggggacat ggagcccgag gccggcgccg cggcctcttc 300
ggctgcggac cccgccattc ccgaggaggt gtggaatatc aaacaaatga ttaagttgac 360
acaggagcat atagaggccc tattggacaa atttggtggg gagcataatc caccatcaat 420
atatctggag gcctatgaag aatacaccag caagctagat gccctccaac aaagagaaca 480
acagttattg gaatccctgg ggaatggaac tgatttttct gtttctagct ctgcatcaac 540
ggacaccgtt acatcttctt cctcttctag cctttcagtg ctgccttcat ctctttcagt 600
ttttcaaaat cccacagatg tgtcacggag caaccccaag tcaccacaaa aacctatcgt 660
tagagtcttc ctgcccaata aacagaggac agtggtacct gcacggtgtg gagtcacagt 720
ccgggacagc ctgaagaagg cactgatgat gagaggtcta atcccagagt gctgtgctgt 780
ttacagaatt caggatgggg agaagaaacc aattggctgg gacactgata tttcctggct 840
tactggagag gagttgcatg tagaagtgtt ggagaatgtt ccacttacaa cacacaactt 900
tgtacggaaa acttttttca ccttagcatt ttgtgacttc tgtagaaagc tgcttttcca 960
gggattccgc tgtcaaacat gtggttataa atttcaccag cgttgtagta cagaggttcc 1020
actgatgtgt gttaattatg accaactaga tttgctgttt gtctccaagt tctttgaaca 1080
ccacccaata ccacaggagg aggcctcctt agcagagact acccttccat gtggctcatc 1140
cccttctgca cccccctccg attctattgg gcccccaatt ctcaccagtc catctccttc 1200
aaaatccatt ccaattccac agcctttccg accagcagat gaagatcatc gaaatcagtt 1260
tggacaacga gaccggtcct catcagctcc aaatgtgcat ataaacacaa tagaacccgt 1320
caatattgat gacttgatta gagaccaagg gtttcgtagt gatggaggat caaccacagg 1380
tttatccgcc acaccccctg cctcattacc tggctcactc tctaatgtga aagcattgca 1440
gaaatctcca ggacctcagc gagaaagaaa gtcctcttca tcctcagaag acaggaatcg 1500
aatgaaaacg cttggtagac gggattcaag tgacgattgg gagattcctg atggacagat 1560
cacagtggga caaagaattg gatcagggtc atttgggaca gtctacaagg gaaagtggca 1620
tggtgatgtg gcagtgaaaa tgttgaatgt gacagcaccc acacctcagc agttacaggc 1680
cttcaaaaat gaagtaggag tactcaggaa aacgcgacat gtgaatatcc tcctcttcat 1740
gggttattca acaaagccac aactggctat tgttacccag tggtgtgagg gctccagttt 1800
atatcatcat ctccacatca ttgagaccaa attcgagatg atcaaactta tagatattgc 1860
acggcagact gcacagggca tggattactt acacgccaag tcaatcatcc acagagacct 1920
caagagtaat aatatttttc ttcatgaaga cctcacagta aaaataggtg attttggtct 1980
agccacagtg aaatctcgat ggagtgggtc ccatcagttt gaacagttgt ctggatccat 2040
tttgtggatg gcaccagaag taatcagaat gcaagataaa aacccatata gctttcagtc 2100
agatgtatat gcatttggga ttgttctgta tgaattgatg accggacagt taccttattc 2160
aaatatcaac aacagggacc agtctgtgca aggaaaagag acaaagccac ggatcagaag 2220
cacatggcca taactgaaga ttttgtgaac tctcacaagg aaaaaatttg ctctttgaac 2280
aataagaagg aactcactaa aatgtaactg agaactgttc aacaggttga aagctgaaag 2340
atgccattgg aactgacaaa atgtttctta aacataaatg atgaaacagt gaaactacat 2400
aatatctcct ctggctgaaa cattcaagaa gtttaaaatg cttaagttaa aaataaaatc 2460
ctagtaaaca atggacttac tgtgcaacat agagaatatc ttacgataac ctgtaatgga 2520
aaagaatctg aaaaagaatg tatataactg aatcactttg ctgtaaacta gaatctgaca 2580
caacactgta aatcactaca cttttctgtt gcatgccaaa gattatttaa taacgtcatt 2640
aaaaaattat tttaataatt a 2661
<210> 38
<211> 679
<212> PRT
<213> Bos taurus
<400> 38
Met Ala Ala Leu Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Glu
1 5 10 15
Gln Gly Gln Ala Leu Phe Asn Gly Asp Met Glu Pro Glu Ala Gly Ala
20 25 30
Ala Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn
35 40 45
Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu
50 55 60
Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala
65 70 75 80
Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln
85 90 95
Gln Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser
100 105 110
Ser Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser
115 120 125
Val Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser
130 135 140
Arg Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu
145 150 155 160
Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val
165 170 175
Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu
180 185 190
Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly
195 200 205
Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu
210 215 220
Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr
225 230 235 240
Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln
245 250 255
Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser
260 265 270
Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu
275 280 285
Phe Val Ser Lys Phe Phe Glu His His Pro Ile Pro Gln Glu Glu Ala
290 295 300
Ser Leu Ala Glu Thr Thr Leu Pro Cys Gly Ser Ser Pro Ser Ala Pro
305 310 315 320
Pro Ser Asp Ser Ile Gly Pro Pro Ile Leu Thr Ser Pro Ser Pro Ser
325 330 335
Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His
340 345 350
Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val
355 360 365
His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp
370 375 380
Gln Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr
385 390 395 400
Pro Pro Ala Ser Leu Pro Gly Ser Leu Ser Asn Val Lys Ala Leu Gln
405 410 415
Lys Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu
420 425 430
Asp Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp
435 440 445
Trp Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser
450 455 460
Gly Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala
465 470 475 480
Val Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala
485 490 495
Phe Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile
500 505 510
Leu Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr
515 520 525
Gln Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu
530 535 540
Thr Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala
545 550 555 560
Gln Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu
565 570 575
Lys Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly
580 585 590
Asp Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln
595 600 605
Phe Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile
610 615 620
Arg Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala
625 630 635 640
Phe Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser
645 650 655
Asn Ile Asn Asn Arg Asp Gln Ser Val Gln Gly Lys Glu Thr Lys Pro
660 665 670
Arg Ile Arg Ser Thr Trp Pro
675
<210> 39
<211> 7434
<212> DNA
<213> Bos taurus
<400> 39
acaccgttac atcttcttcc tcttctagcc tttcagtgct gccttcatct ctttcagttt 60
ttcaaaatcc cacagatgtg tcacggagca accccaagtc accacaaaaa cctatcgtta 120
gagtcttcct gcccaataaa cagaggacag tggtacctgc acggtgtgga gtcacagtcc 180
gggacagcct gaagaaggca ctgatgatga gaggtctaat cccagagtgc tgtgctgttt 240
acagaattca ggatggggag aagaaaccaa ttggctggga cactgatatt tcctggctta 300
ctggagagga gttgcatgta gaagtgttgg agaatgttcc acttacaaca cacaactttg 360
tacggaaaac ttttttcacc ttagcatttt gtgacttctg tagaaagctg cttttccagg 420
gattccgctg tcaaacatgt ggttataaat ttcaccagcg ttgtagtaca gaggttccac 480
tgatgtgtgt taattatgac caactagatt tgctgtttgt ctccaagttc tttgaacacc 540
acccaatacc acaggaggag gcctccttag cagagactac ccttccatgt ggctcatccc 600
cttctgcacc cccctccgat tctattgggc ccccaattct caccagtcca tctccttcaa 660
aatccattcc aattccacag cctttccgac cagcagatga agatcatcga aatcagtttg 720
gacaacgaga ccggtcctca tcagctccaa atgtgcatat aaacacaata gaacccgtca 780
atattgatga cttgattaga gaccaagggt ttcgtagtga tggaggatca accacaggtt 840
tatccgccac accccctgcc tcattacctg gctcactctc taatgtgaaa gcattgcaga 900
aatctccagg acctcagcga gaaagaaagt cctcttcatc ctcagaagac aggaatcgaa 960
tgaaaacgct tggtagacgg gattcaagtg acgattggga gattcctgat ggacagatca 1020
cagtgggaca aagaattgga tcagggtcat ttgggacagt ctacaaggga aagtggcatg 1080
gtgatgtggc agtgaaaatg ttgaatgtga cagcacccac acctcagcag ttacaggcct 1140
tcaaaaatga agtaggagta ctcaggaaaa cgcgacatgt gaatatcctc ctcttcatgg 1200
gttattcaac aaagccacaa ctggctattg ttacccagtg gtgtgagggc tccagtttat 1260
atcatcatct ccacatcatt gagaccaaat tcgagatgat caaacttata gatattgcac 1320
ggcagactgc acagggcatg gattacttac acgccaagtc aatcatccac agagacctca 1380
agagtaataa tatttttctt catgaagacc tcacagtaaa aataggtgat tttggtctag 1440
ccacagtgaa atctcgatgg agtgggtccc atcagtttga acagttgtct ggatccattt 1500
tgtggatggc accagaagta atcagaatgc aagataaaaa cccatatagc tttcagtcag 1560
atgtatatgc atttgggatt gttctgtatg aattgatgac cggacagtta ccttattcaa 1620
atatcaacaa cagggaccag ataattttta tggtgggacg aggatatctg tctccagatc 1680
tcagtaaggt acggagtaac tgtccaaaag ccatgaagag attaatggca gagtgcctaa 1740
aaaagaaaag agatgaaaga ccactctttc cccaagtagg aaagactctc ctaagcaaga 1800
gacaaaattc agaagttatc agggaaaaag ataagcagat tctcgcctct attgagctgc 1860
tggcccgctc attgccaaaa attcaccgca gtgcatcaga accctccttg aatcgggctg 1920
gcttccaaac agaggatttt agtctatatg cttgtgcttc tccaaaaaca cccattcagg 1980
cagggggata tggagaattt gcagccttca agtagccaca ccatcatgac agcatctact 2040
cttatttctt aagtcttgtg ttcgtacaat ttgttaacat caaaacacag ttctgttcct 2100
caactctttt taaagttaaa atttttcagt gcataagctg gtgtggaaca gaaggaaatt 2160
tcccatccaa caaaagaggg aagaatgttt taggaaccag aattctctgc tgccagtgtt 2220
tcttcttcaa cacaaatatc acaagtctgc ccactcccag gaagaaagag gagagaccct 2280
gagttctgac cttttgatgg tcaggcatga tggaaagaaa ctgctgctac agcttgggag 2340
atttgctctg ggaagtctgc cagtcaactt tgcccttcta accaccagat caatatgtgg 2400
ctgatcatct gatggggcag ttgcaatcac caagccttgt tctctttcct gttctgggat 2460
tgtgttgtgg aacccttttc cctagccacc accagttcat ttctgaggga tggaacaaaa 2520
atgcagcatg cccttcctgt gtggtgcatg ttcagtcctt gacaaatttt taccaaaatg 2580
aagctacttt atttaaaagg agggtgagag gtgaggaggt cactttgggt gtggcggaaa 2640
gggaatgctg catctttttc ctgggctgct ggggctctgg ccttggcttg ccagccggaa 2700
gcgctggcac gcatcgcctt cttttcccat tgggtccagc aatgaagacg agtgtttggg 2760
gttttttttt tctccaccat gtagcaagtt ctcaggaaaa tacaattgat atcttcctcc 2820
taagctcttc caatcagtca ccaagtactt atgtggttac tttgtccagg gcacaaaatg 2880
cctgtatcta attaaaagcc tacaaaactg cttgataaca gttttgaatg tgagacattt 2940
atgtaattta aatgtaaggt acaagtttta atttctgagt ttcttctatt atatttttat 3000
taaaaaaaga aaataatttt cagattgaat tggagtaaaa taatattact tcccactaga 3060
attatatatc ctggaaaatt gtatttttgt tacataagca gcttttaaag aaagatcatt 3120
acccttttct ctacataaat atatggggag tcttagccta atgacaaata tttataattt 3180
ttaaattaat ggtacttgct ggatccatac taacatcttt actaatacct cattgtttct 3240
tccaacttac tcctacacta catcctacat cttcttccta gtcttttatc tagaatatgc 3300
aacctcaaat aaaaatggtg gtgtcctcat tcattctcct ccttcctttt ttcccaagcc 3360
tgatcttcaa aaggttggtt aatttggcag ctgagttcct ccccaggcag agaatagacc 3420
aattttaggt gtattgggac tgagggagga tgtgtaaaga ttaacatcag taaagaaccg 3480
ctgtggagta attaagaact ttgttcttta taactggaga atataaccta accctaacat 3540
ccctcagcct ttactaaagt gtggcgtaaa tcacagtagt agcaaagaaa gtgactctgg 3600
atgtgttcct ggccagtacc tcccttatca tgaatgtaga ctctctcatc aagatttagg 3660
aatataaatc aaatcaaatg tgcccagcca agctatgtag taagggactt gaacaatatt 3720
aggcagaacc tataaaataa atcagggaat tagaaattat ttaaagtttt caaattgtaa 3780
attgccccgg tgtctttcag cctactgcca ttatttttgc tacaatacct acatttcaga 3840
ggagggccta ctgaaaattc catgcaagtg gaaaataatc ctcaagttat taatgagttt 3900
gaaaagcaat gagttcttaa gtctttgtga gtagagcaag atcctacaaa attcagaaat 3960
agtaaaaatg gattcatgct gatttgaaga gcatctgtgt gcataatata atgctgcatc 4020
tcttttaaaa gcagtctatt tttcttttta aatttgtccc catagatgct tttgaacatg 4080
aacatgctta tgttaccttt tccgaggttg ggaagagcca ggagctctca ggcagggccc 4140
cctccctcag ctgggcagga gctgctcagg aggagctagt tatagaggaa gcttagcgtt 4200
ggcattttca aaattcaagg tgataacgct ttcttcttcc tttctgtttt agaatagatt 4260
gctgtctgat ttgaaaaagg gaaatagatt tgatctcaaa tgaatctgtg cccagaagcc 4320
aggctcaggg tattcagaga tttgtatagt gccctcaaaa aataacaaaa ttttagcttt 4380
ccttttttct tcttttctcc atcaaattct tttttctcta gtttacaaat gacatggaaa 4440
aggaatttcc cctgagtttt gtatgccttt ttttttttgg cttagactat agataggcgt 4500
gttgagctcc taagaaaata caaggaggaa ctctttgttg tgcagagcac tttatgagta 4560
gtttgtgtgg ataatatgtg actgcttccc tgacgagctt gtgaggctgt acttatgtct 4620
ttcctgtaag gcagcttcag tgccttctgt agtgtatata aggaaagatt acgccttctg 4680
aaaaatctca gagcaaccat aagattattt taaaatatgt agtatgactg atggactttt 4740
tcatcattaa attagtctag catctaaact tttaccactg aaataatatt gaccaaaaag 4800
caatttataa aaggtatttg tgaatagaaa atacaatgtg atcatttgta cttatgtgca 4860
ccttaaaaga ggaattctgt ctagctgtca aattctggtt ccttaacatc cagtccttga 4920
ttgtgattga gatctggtag gacgtgctgg ggcacgctag cagataaaat cccgtatact 4980
ttaggataga tgttacattt atgtcagtgt tggcaaagag cattgtgtag taataaagaa 5040
ttcaagactt cagcaatgtc aacctgaaac tttgtaaata tttcctagat tgttatttga 5100
tgcagtcaca gctctttatc acacaatgtt gtctttccct catcaggcaa ttttagaact 5160
gctgcacacc cctcctcaga tctcacctgc ccctcctgta cattcacctc tccagccttg 5220
tgcacacctc atttagcttt agtttgaaac acattgcagg gttcaggtga cctcttcaaa 5280
aactacctcc tcagaatgag gtaatgaata gttatttatt ttaaaatatg aaaagtcagg 5340
agctctagaa tatgaagatg atctaagatt ttaactttta tgtatacttg ttgagcactc 5400
tccttttgtc ctaaagggca ttatacattt aagcagtaat actgaaaaat gtagctcaga 5460
gtaactgaat gttgttgaaa gtggtgccag aatctgtttt aggggtacgt atcagaatct 5520
taatcttaaa tcggttacat gaaattaaat agttaatggt aacacttgac taacagatat 5580
aattttaatt ttcggtaggc ttttagcaag acagtaagta catcttcata atgagttagc 5640
cacagcttca tcacatgcac agattttcct gttgagagac tgcccagtta agagggtaga 5700
atgatgaacc atttttcagg attctcttct ttgtccaaac tggcattgtg agtgctagaa 5760
tatcagcact ttcaaactag tgattccaac tattaggcta ttaaaaagca aaacaaacca 5820
aacaaaccat agccagacat gggaagttta ctatgagtat aaacagcaaa tagcttacag 5880
gtcatacatt gaaatggtgt aggtaaggcg ttagaaaaat accttgacaa tttgccaaat 5940
gatcttactg tgccttcatg atgcaataaa aaaaaaaaaa atttagcata aatcagtgat 6000
ttgtgaagag agcagccacc ctggtctaac tcagctgtgt taatattttt tagcgtgcaa 6060
tttagactgc aaagataaat gcactaaaga gtttatagcc aaaatcacat ttaaaaaatg 6120
agagaaaaca caggtaaatt ttcagtgaac aaaattattt ttttaaagta cataatccct 6180
agtatagtca gatatattta tcacatagag caaataggtt gaaatcacaa ttcagtgaca 6240
tttctagaga aactttttct actcccatag gttcttcaaa gcatggaact tttatataac 6300
agaaatgtgt gacggtcatt ttaaattgct gtagtttggg gctgaagtac tgtgtgctgg 6360
gcagcaatca catgtattaa ctagtgagaa aggagaaatt aagatatagg acagaatttg 6420
attttcttgt tcccagatta ctgctgccaa cctagacact gagtttccag aggctgaaac 6480
gtaaacttgc agctcagcaa ctgttttgca aagttagtgg gactgtcctg cttatgctgt 6540
tcaaaaatgc tctgagggcc aggtggggcc tccaggggct cctctctgag gggacatcag 6600
actagctaac gacctggcgg gcggatgtga accggacaca ctccatggtg tgcttcttgt 6660
atcggtccct cgccaccctc aagaaaggct tcagcgggtt ctctagacgt ctccactaag 6720
gtgtgttact aacagccatg ggttgttgag cacccgagga gtgcaatagc atctctgcat 6780
gattgtatat tggcccgaag agaatgaagt ggccagtgta ctcatgttcc atgttgctag 6840
ctctggtaaa ctgaaaatac tggtaagatt tttgttttat cagtacacta gagagtaagc 6900
tttgttttgt tgtttttaga taatgttttc acttccattt ggaaagacat ttaaattgag 6960
tttcagtcct aaattttgcc agtcatggta attagcagtt tctatcaggt atttttaagg 7020
tagaagagga tagaaacata agttctaaaa gcttaaggta accgtggttt attttaaaat 7080
gtttaggggt ggttagtctc tacctcaaaa aaagtgagtg aatcttttat ttcagcattc 7140
acaagttcgg ctgttgtttt tgtaatacat ttttttttta accttttgac ccccctttac 7200
ctaagtgtca atgtagtttt attaattact aagtcagttt cattaaaatg tttatttagc 7260
agttttgact aattgcaatg attaatatag ccagttgtgc atgaggacac agccagtgag 7320
tatatctggg ttttttttgt gatgcttttt ttcttaagac ttctgtagat ttatgaagta 7380
ctcattgaaa acaactaaaa tacgtttatt cgtgttaata tggaaaaaaa aaaa 7434
<210> 40
<211> 603
<212> PRT
<213> Bos taurus
<400> 40
Met Met Arg Gly Leu Ile Pro Glu Cys Cys Ala Val Tyr Arg Ile Gln
1 5 10 15
Asp Gly Glu Lys Lys Pro Ile Gly Trp Asp Thr Asp Ile Ser Trp Leu
20 25 30
Thr Gly Glu Glu Leu His Val Glu Val Leu Glu Asn Val Pro Leu Thr
35 40 45
Thr His Asn Phe Val Arg Lys Thr Phe Phe Thr Leu Ala Phe Cys Asp
50 55 60
Phe Cys Arg Lys Leu Leu Phe Gln Gly Phe Arg Cys Gln Thr Cys Gly
65 70 75 80
Tyr Lys Phe His Gln Arg Cys Ser Thr Glu Val Pro Leu Met Cys Val
85 90 95
Asn Tyr Asp Gln Leu Asp Leu Leu Phe Val Ser Lys Phe Phe Glu His
100 105 110
His Pro Ile Pro Gln Glu Glu Ala Ser Leu Ala Glu Thr Thr Leu Pro
115 120 125
Cys Gly Ser Ser Pro Ser Ala Pro Pro Ser Asp Ser Ile Gly Pro Pro
130 135 140
Ile Leu Thr Ser Pro Ser Pro Ser Lys Ser Ile Pro Ile Pro Gln Pro
145 150 155 160
Phe Arg Pro Ala Asp Glu Asp His Arg Asn Gln Phe Gly Gln Arg Asp
165 170 175
Arg Ser Ser Ser Ala Pro Asn Val His Ile Asn Thr Ile Glu Pro Val
180 185 190
Asn Ile Asp Asp Leu Ile Arg Asp Gln Gly Phe Arg Ser Asp Gly Gly
195 200 205
Ser Thr Thr Gly Leu Ser Ala Thr Pro Pro Ala Ser Leu Pro Gly Ser
210 215 220
Leu Ser Asn Val Lys Ala Leu Gln Lys Ser Pro Gly Pro Gln Arg Glu
225 230 235 240
Arg Lys Ser Ser Ser Ser Ser Glu Asp Arg Asn Arg Met Lys Thr Leu
245 250 255
Gly Arg Arg Asp Ser Ser Asp Asp Trp Glu Ile Pro Asp Gly Gln Ile
260 265 270
Thr Val Gly Gln Arg Ile Gly Ser Gly Ser Phe Gly Thr Val Tyr Lys
275 280 285
Gly Lys Trp His Gly Asp Val Ala Val Lys Met Leu Asn Val Thr Ala
290 295 300
Pro Thr Pro Gln Gln Leu Gln Ala Phe Lys Asn Glu Val Gly Val Leu
305 310 315 320
Arg Lys Thr Arg His Val Asn Ile Leu Leu Phe Met Gly Tyr Ser Thr
325 330 335
Lys Pro Gln Leu Ala Ile Val Thr Gln Trp Cys Glu Gly Ser Ser Leu
340 345 350
Tyr His His Leu His Ile Ile Glu Thr Lys Phe Glu Met Ile Lys Leu
355 360 365
Ile Asp Ile Ala Arg Gln Thr Ala Gln Gly Met Asp Tyr Leu His Ala
370 375 380
Lys Ser Ile Ile His Arg Asp Leu Lys Ser Asn Asn Ile Phe Leu His
385 390 395 400
Glu Asp Leu Thr Val Lys Ile Gly Asp Phe Gly Leu Ala Thr Val Lys
405 410 415
Ser Arg Trp Ser Gly Ser His Gln Phe Glu Gln Leu Ser Gly Ser Ile
420 425 430
Leu Trp Met Ala Pro Glu Val Ile Arg Met Gln Asp Lys Asn Pro Tyr
435 440 445
Ser Phe Gln Ser Asp Val Tyr Ala Phe Gly Ile Val Leu Tyr Glu Leu
450 455 460
Met Thr Gly Gln Leu Pro Tyr Ser Asn Ile Asn Asn Arg Asp Gln Ile
465 470 475 480
Ile Phe Met Val Gly Arg Gly Tyr Leu Ser Pro Asp Leu Ser Lys Val
485 490 495
Arg Ser Asn Cys Pro Lys Ala Met Lys Arg Leu Met Ala Glu Cys Leu
500 505 510
Lys Lys Lys Arg Asp Glu Arg Pro Leu Phe Pro Gln Val Gly Lys Thr
515 520 525
Leu Leu Ser Lys Arg Gln Asn Ser Glu Val Ile Arg Glu Lys Asp Lys
530 535 540
Gln Ile Leu Ala Ser Ile Glu Leu Leu Ala Arg Ser Leu Pro Lys Ile
545 550 555 560
His Arg Ser Ala Ser Glu Pro Ser Leu Asn Arg Ala Gly Phe Gln Thr
565 570 575
Glu Asp Phe Ser Leu Tyr Ala Cys Ala Ser Pro Lys Thr Pro Ile Gln
580 585 590
Ala Gly Gly Tyr Gly Glu Phe Ala Ala Phe Lys
595 600
<210> 41
<211> 2295
<212> DNA
<213> Equus caballus
<220>
<221> misc_feature
<222> (79)..(79)
<223> n is a, c, g, or t
<400> 41
atgaagacgc tgagcggcgg cggcggcggc gcggagcagg gccaggctct gttcaacggg 60
gacatggaac ccggaggcnc cgcgccggcg cccgcggcct cgtcggccgc ggaccctgcc 120
attcccgagg aggtatggaa tatcaaacaa atgattaaat tgacacagga acatatagag 180
gccctattgg acaaatttgg tggggagcat aatccaccat caatatatct ggaggcctat 240
gaagaataca ccagcaagct agatgccctc caacaaagag aacaacagtt attggaatcc 300
ctggggaatg gaactgattt ttctgtttct agttctgcat caacggacac cgttacatct 360
tcttcctctt ctagcctttc agtgctacct tcatctcttt cagtttttca aaatcccaca 420
gatgtgtcac ggagcaaccc taagtcacca caaaaaccta tcgttagagt cttcctgccc 480
aacaaacaga ggacagtggt acctgcaagg tgtggcgtta cagtccggga cagtctaaag 540
aaagcactga tgatgagagg tctaatccca gagtgctgtg ctgtttacag aattcaggat 600
ggagagaaga aaccaattgg ctgggacact gatatttcct ggctcactgg agaggaattg 660
catgtagaag tgttggagaa tgttccactt acaacacaca actttgtacg gaaaactttt 720
ttcaccttag cattttgtga cttttgtcga aagctgcttt tccagggttt ccgctgtcaa 780
acatgtggtt ataaatttca ccagcgttgt agtacagagg ttccactgat gtgtgttaat 840
tatgaccaac ttgatttgct gtttgtctcc aagttctttg aacaccaccc agtatcacag 900
gaggaggcct ccttagcaga gactgccctt acatctggat catccccttc tgcacccccc 960
tccgattcca ttgggcccca aattctcacc agtccatctc cttcaaaatc cattccaatt 1020
ccacagcctt tccgaccagc agatgaagat catcgaaatc agtttggaca acgagaccgg 1080
tcctcatcag ctccaaatgt acatataaac acaatagaac ctgtcaatat tgatgacttg 1140
attagagacc aagggtttcg tagtgatgga ggatcaacca caggtttatc tgccaccccc 1200
cctgcctcat tacctggctc actcactaat gtgaaggcat tacagaaatc tccaggacct 1260
caacgggaaa ggaaatcatc ttcatcctca gaagacagga atcgaatgaa aactcttggt 1320
agacgggatt caagtgacga ttgggagatt cctgatgggc agatcacagt gggacaaaga 1380
attggatctg ggtcatttgg gacagtctac aagggaaagt ggcatggtga tgtggcagtg 1440
aaaatgttga atgtgacagc acccacacct cagcagttac aggccttcaa aaatgaagta 1500
ggagtactca ggaaaactcg acatgtgaat atcctactct tcatgggcta ttcaacaaag 1560
ccacaactgg ctattgttac ccagtggtgt gagggctcca gcttatatca ccatctccac 1620
atcattgaga ccaaatttga gatgatcaaa cttatagata ttgctcggca aactgcacag 1680
ggcatggatt acttacacgc caagtcaatc atccacagag acctcaagag taataatatt 1740
tttcttcatg aagacctcac agtaaaaata ggtgattttg gtctagccac agtgaaatct 1800
cgatggagtg ggtcccatca gtttgaacag ttgtctggat ccattttgtg gatggcacca 1860
gaagtaatca gaatgcaaga taaaaacccg tatagctttc aatcagatgt atatgccttt 1920
gggattgttc tgtatgaatt gatgactgga cagttacctt attcaaacat caacaacagg 1980
gaccagataa tttttatggt gggaagagga tatctatctc cagatctcag taaggtacgg 2040
agtaactgtc caaaagccat gaagagatta atggcagagt gcctaaaaaa gaaaagagac 2100
gagagaccac tcttccccca aattctcgcc tctattgagc tgctggcccg ctcattgcca 2160
aaaattcacc gcagtgcatc agagccctcc ttgaatcggg ctggcttcca gacagaggat 2220
tttagtctat atgcttgtgc ttctccgaaa acacccatcc aggcaggggg atatggtgcg 2280
tttcctgtcc actga 2295
<210> 42
<211> 764
<212> PRT
<213> Equus caballus
<220>
<221> misc_feature
<222> (27)..(27)
<223> Xaa can be any naturally occurring amino acid
<400> 42
Met Lys Thr Leu Ser Gly Gly Gly Gly Gly Ala Glu Gln Gly Gln Ala
1 5 10 15
Leu Phe Asn Gly Asp Met Glu Pro Gly Gly Xaa Ala Pro Ala Pro Ala
20 25 30
Ala Ser Ser Ala Ala Asp Pro Ala Ile Pro Glu Glu Val Trp Asn Ile
35 40 45
Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu Leu Asp
50 55 60
Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu Ala Tyr
65 70 75 80
Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu Gln Gln
85 90 95
Leu Leu Glu Ser Leu Gly Asn Gly Thr Asp Phe Ser Val Ser Ser Ser
100 105 110
Ala Ser Thr Asp Thr Val Thr Ser Ser Ser Ser Ser Ser Leu Ser Val
115 120 125
Leu Pro Ser Ser Leu Ser Val Phe Gln Asn Pro Thr Asp Val Ser Arg
130 135 140
Ser Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe Leu Pro
145 150 155 160
Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr Val Arg
165 170 175
Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro Glu Cys
180 185 190
Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile Gly Trp
195 200 205
Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val Glu Val
210 215 220
Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys Thr Phe
225 230 235 240
Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe Gln Gly
245 250 255
Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys Ser Thr
260 265 270
Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu Leu Phe
275 280 285
Val Ser Lys Phe Phe Glu His His Pro Val Ser Gln Glu Glu Ala Ser
290 295 300
Leu Ala Glu Thr Ala Leu Thr Ser Gly Ser Ser Pro Ser Ala Pro Pro
305 310 315 320
Ser Asp Ser Ile Gly Pro Gln Ile Leu Thr Ser Pro Ser Pro Ser Lys
325 330 335
Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp His Arg
340 345 350
Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn Val His
355 360 365
Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg Asp Gln
370 375 380
Gly Phe Arg Ser Asp Gly Gly Ser Thr Thr Gly Leu Ser Ala Thr Pro
385 390 395 400
Pro Ala Ser Leu Pro Gly Ser Leu Thr Asn Val Lys Ala Leu Gln Lys
405 410 415
Ser Pro Gly Pro Gln Arg Glu Arg Lys Ser Ser Ser Ser Ser Glu Asp
420 425 430
Arg Asn Arg Met Lys Thr Leu Gly Arg Arg Asp Ser Ser Asp Asp Trp
435 440 445
Glu Ile Pro Asp Gly Gln Ile Thr Val Gly Gln Arg Ile Gly Ser Gly
450 455 460
Ser Phe Gly Thr Val Tyr Lys Gly Lys Trp His Gly Asp Val Ala Val
465 470 475 480
Lys Met Leu Asn Val Thr Ala Pro Thr Pro Gln Gln Leu Gln Ala Phe
485 490 495
Lys Asn Glu Val Gly Val Leu Arg Lys Thr Arg His Val Asn Ile Leu
500 505 510
Leu Phe Met Gly Tyr Ser Thr Lys Pro Gln Leu Ala Ile Val Thr Gln
515 520 525
Trp Cys Glu Gly Ser Ser Leu Tyr His His Leu His Ile Ile Glu Thr
530 535 540
Lys Phe Glu Met Ile Lys Leu Ile Asp Ile Ala Arg Gln Thr Ala Gln
545 550 555 560
Gly Met Asp Tyr Leu His Ala Lys Ser Ile Ile His Arg Asp Leu Lys
565 570 575
Ser Asn Asn Ile Phe Leu His Glu Asp Leu Thr Val Lys Ile Gly Asp
580 585 590
Phe Gly Leu Ala Thr Val Lys Ser Arg Trp Ser Gly Ser His Gln Phe
595 600 605
Glu Gln Leu Ser Gly Ser Ile Leu Trp Met Ala Pro Glu Val Ile Arg
610 615 620
Met Gln Asp Lys Asn Pro Tyr Ser Phe Gln Ser Asp Val Tyr Ala Phe
625 630 635 640
Gly Ile Val Leu Tyr Glu Leu Met Thr Gly Gln Leu Pro Tyr Ser Asn
645 650 655
Ile Asn Asn Arg Asp Gln Ile Ile Phe Met Val Gly Arg Gly Tyr Leu
660 665 670
Ser Pro Asp Leu Ser Lys Val Arg Ser Asn Cys Pro Lys Ala Met Lys
675 680 685
Arg Leu Met Ala Glu Cys Leu Lys Lys Lys Arg Asp Glu Arg Pro Leu
690 695 700
Phe Pro Gln Ile Leu Ala Ser Ile Glu Leu Leu Ala Arg Ser Leu Pro
705 710 715 720
Lys Ile His Arg Ser Ala Ser Glu Pro Ser Leu Asn Arg Ala Gly Phe
725 730 735
Gln Thr Glu Asp Phe Ser Leu Tyr Ala Cys Ala Ser Pro Lys Thr Pro
740 745 750
Ile Gln Ala Gly Gly Tyr Gly Ala Phe Pro Val His
755 760
<210> 43
<211> 2678
<212> DNA
<213> Gallus gallus
<400> 43
tccccctccc tcgccccagc gcttcgatcc aagatggcgg cgctgagcag cggcagcagc 60
gccgaggggg cctcgctctt caacggggac atggagcccg agccgccgcc gcccgtgctg 120
ggcgcctgct acgccgggag cggcggcggc gacccggcca tcccggagga ggtgtggaat 180
atcaaacaga tgattaaatt aacacaagaa catatagaag cgctgttaga caagtttgga 240
ggagagcata acccaccatc aatatattta gaggcctatg aggagtacac cagcaaacta 300
gatgctctac agcagagaga acagcagtta ttggaatcca tgggaaatgg aactgatttc 360
tctgtttcca gttcagcttc aacggacaca gttgcatcat cttcctcctc tagcctctct 420
gtagcacctt catccctttc agtttatcaa aatcctactg atatgtcgcg gaataaccct 480
aagtctccac agaagcctat tgttagagtc ttcctgccca acaagcaaag gactgtggtt 540
ccggcaagat gtggggtgac agtccgagac agcctgaaga aagctctgat gatgagaggt 600
cttattccag aatgctgtgc tgtttacaga atacaggatg gagagaagaa gccaattggc 660
tgggacactg acatttcctg gctaaccgga gaggagttac acgtggaggt cttggagaat 720
gtgccactca caacacacaa ttttgtacga aaaacattct tcacgttagc gttctgcgac 780
ttctgtcgaa agctgctttt ccagggattc cgatgccaga catgtggcta caaatttcac 840
cagcgctgta gcacagaagt gccactgatg tgtgttaact acgaccaact cgatttgctg 900
tttgtctcca agttctttga acatcacccc atatcgcagg aggagaccac cttaggagag 960
accaccccgg catcgggatc gtacccctca gtgcccccat cagattctgt tggaccacca 1020
attctcccta gtccttctcc ttcaaaatcc attccaatcc cacagccctt ccgaccagca 1080
gatgaagacc atcggaatca gtttgggcaa cgcgaccgat cctcttcagc tcccaatgtt 1140
cacatcaata caattgagcc agtcaatatt gatgacttga ttagagacca gggtgtacga 1200
ggagagggag cccctttgaa ccagctgatg cgctgtcttc ggaaatacca atcccggact 1260
cccagtcccc tccttcattc tgtccccagt gaaatagtgt ttgattttga gcctggccca 1320
gtgttcagag gttcaactgc aggtttgtct gcaacacctc ctgcatcttt gcctgggtca 1380
cttaccaatg tgaaagcatt acagaaatca ccaggccccc aacgggaaag gaaatcatcc 1440
tcatcctcag aagacagaaa taggatgaaa acccttggtc gacgagattc aagtgatgat 1500
tgggaaatac cagatgggca gatcacagtt ggacaaagga taggatctgg atcatttgga 1560
acagtctaca aaggaaagtg gcatggtgac gtggcagtga aaatgttgaa tgttacagca 1620
cccacacctc aacagttaca ggctttcaaa aatgaagtag gagtgctcag gaaaacacgg 1680
catgtgaata tcctactttt tatgggttat tcaacaaaac ctcagttggc tattgttaca 1740
cagtggtgtg aggggtccag cttatatcac catctgcaca taattgagac caagtttgaa 1800
atgatcaaac taattgatat tgcacgacag actgcacaag gcatggatta tttgcatgcc 1860
aagtcaatca tccacagaga cctcaagagt aataatattt ttcttcatga agacctcaca 1920
gtaaaaatag gtgacttcgg tctggctaca gtgaaatcac gatggagtgg atctcatcaa 1980
tttgaacagt tatctggatc aattctatgg atggcaccgg aagtgatcag gatgcaagac 2040
aaaaacccat atagctttca gtcagatgtg tatgcattcg ggattgtgct ttatgaactg 2100
atgactggac agttaccata ctcaaacatc aacaacaggg accagataat ttttatggtg 2160
ggacgaggat atctatctcc agacctcagt aaagtaagaa gtaactgtcc aaaagctatg 2220
aagagactaa tggcagaatg cttgaaaaag aaaagagatg agagacctct ttttccacag 2280
attcttgcct ccattgagct tctggcccgg tcgttgccaa aaattcaccg cagtgcatct 2340
gagccgtcac taaaccgggc tggcttccag accgaggatt tcagtctgta tgcttgtgct 2400
tctccaaaaa cgcccatcca agcaggggga tacggtgggt ttccagtaca ctgaaaagaa 2460
atgtgaaagc gtgtgcctgt ttgctcatgt gctggtgtgt tcctgtgtgt gcaacgcata 2520
cgtacgttct cagttcctac cagcgacttt ttaaggttta ctgagggaat gaagactcat 2580
ttcctaacat ggggcattga acgtcctgag cacaagtcag tgctggtaag gaatgtcttg 2640
ggaacagctg gcaagaagaa ttagaaggta cttaaagg 2678
<210> 44
<211> 806
<212> PRT
<213> Gallus gallus
<400> 44
Met Ala Ala Leu Ser Ser Gly Ser Ser Ala Glu Gly Ala Ser Leu Phe
1 5 10 15
Asn Gly Asp Met Glu Pro Glu Pro Pro Pro Pro Val Leu Gly Ala Cys
20 25 30
Tyr Ala Gly Ser Gly Gly Gly Asp Pro Ala Ile Pro Glu Glu Val Trp
35 40 45
Asn Ile Lys Gln Met Ile Lys Leu Thr Gln Glu His Ile Glu Ala Leu
50 55 60
Leu Asp Lys Phe Gly Gly Glu His Asn Pro Pro Ser Ile Tyr Leu Glu
65 70 75 80
Ala Tyr Glu Glu Tyr Thr Ser Lys Leu Asp Ala Leu Gln Gln Arg Glu
85 90 95
Gln Gln Leu Leu Glu Ser Met Gly Asn Gly Thr Asp Phe Ser Val Ser
100 105 110
Ser Ser Ala Ser Thr Asp Thr Val Ala Ser Ser Ser Ser Ser Ser Leu
115 120 125
Ser Val Ala Pro Ser Ser Leu Ser Val Tyr Gln Asn Pro Thr Asp Met
130 135 140
Ser Arg Asn Asn Pro Lys Ser Pro Gln Lys Pro Ile Val Arg Val Phe
145 150 155 160
Leu Pro Asn Lys Gln Arg Thr Val Val Pro Ala Arg Cys Gly Val Thr
165 170 175
Val Arg Asp Ser Leu Lys Lys Ala Leu Met Met Arg Gly Leu Ile Pro
180 185 190
Glu Cys Cys Ala Val Tyr Arg Ile Gln Asp Gly Glu Lys Lys Pro Ile
195 200 205
Gly Trp Asp Thr Asp Ile Ser Trp Leu Thr Gly Glu Glu Leu His Val
210 215 220
Glu Val Leu Glu Asn Val Pro Leu Thr Thr His Asn Phe Val Arg Lys
225 230 235 240
Thr Phe Phe Thr Leu Ala Phe Cys Asp Phe Cys Arg Lys Leu Leu Phe
245 250 255
Gln Gly Phe Arg Cys Gln Thr Cys Gly Tyr Lys Phe His Gln Arg Cys
260 265 270
Ser Thr Glu Val Pro Leu Met Cys Val Asn Tyr Asp Gln Leu Asp Leu
275 280 285
Leu Phe Val Ser Lys Phe Phe Glu His His Pro Ile Ser Gln Glu Glu
290 295 300
Thr Thr Leu Gly Glu Thr Thr Pro Ala Ser Gly Ser Tyr Pro Ser Val
305 310 315 320
Pro Pro Ser Asp Ser Val Gly Pro Pro Ile Leu Pro Ser Pro Ser Pro
325 330 335
Ser Lys Ser Ile Pro Ile Pro Gln Pro Phe Arg Pro Ala Asp Glu Asp
340 345 350
His Arg Asn Gln Phe Gly Gln Arg Asp Arg Ser Ser Ser Ala Pro Asn
355 360 365
Val His Ile Asn Thr Ile Glu Pro Val Asn Ile Asp Asp Leu Ile Arg
370 375 380
Asp Gln Gly Val Arg Gly Glu Gly Ala Pro Leu Asn Gln Leu Met Arg
385 390 395 400
Cys Leu Arg Lys Tyr Gln Ser Arg Thr Pro Ser Pro Leu Leu His Ser
405 410 415
Val Pro Ser Glu Ile Val Phe Asp Phe Glu Pro Gly Pro Val Phe Arg
420 425 430
Gly Ser Thr Ala Gly Leu Ser Ala Thr Pro Pro Ala Ser Leu Pro Gly
435 440 445
Ser Leu Thr Asn Val Lys Ala Leu Gln Lys Ser Pro Gly Pro Gln Arg
450 455 460
Glu Arg Lys Ser Ser Ser Ser Ser Glu Asp Arg Asn Arg Met Lys Thr
465 470 475 480
Leu Gly Arg Arg Asp Ser Ser Asp Asp Trp Glu Ile Pro Asp Gly Gln
485 490 495
Ile Thr Val Gly Gln Arg Ile Gly Ser Gly Ser Phe Gly Thr Val Tyr
500 505 510
Lys Gly Lys Trp His Gly Asp Val Ala Val Lys Met Leu Asn Val Thr
515 520 525
Ala Pro Thr Pro Gln Gln Leu Gln Ala Phe Lys Asn Glu Val Gly Val
530 535 540
Leu Arg Lys Thr Arg His Val Asn Ile Leu Leu Phe Met Gly Tyr Ser
545 550 555 560
Thr Lys Pro Gln Leu Ala Ile Val Thr Gln Trp Cys Glu Gly Ser Ser
565 570 575
Leu Tyr His His Leu His Ile Ile Glu Thr Lys Phe Glu Met Ile Lys
580 585 590
Leu Ile Asp Ile Ala Arg Gln Thr Ala Gln Gly Met Asp Tyr Leu His
595 600 605
Ala Lys Ser Ile Ile His Arg Asp Leu Lys Ser Asn Asn Ile Phe Leu
610 615 620
His Glu Asp Leu Thr Val Lys Ile Gly Asp Phe Gly Leu Ala Thr Val
625 630 635 640
Lys Ser Arg Trp Ser Gly Ser His Gln Phe Glu Gln Leu Ser Gly Ser
645 650 655
Ile Leu Trp Met Ala Pro Glu Val Ile Arg Met Gln Asp Lys Asn Pro
660 665 670
Tyr Ser Phe Gln Ser Asp Val Tyr Ala Phe Gly Ile Val Leu Tyr Glu
675 680 685
Leu Met Thr Gly Gln Leu Pro Tyr Ser Asn Ile Asn Asn Arg Asp Gln
690 695 700
Ile Ile Phe Met Val Gly Arg Gly Tyr Leu Ser Pro Asp Leu Ser Lys
705 710 715 720
Val Arg Ser Asn Cys Pro Lys Ala Met Lys Arg Leu Met Ala Glu Cys
725 730 735
Leu Lys Lys Lys Arg Asp Glu Arg Pro Leu Phe Pro Gln Ile Leu Ala
740 745 750
Ser Ile Glu Leu Leu Ala Arg Ser Leu Pro Lys Ile His Arg Ser Ala
755 760 765
Ser Glu Pro Ser Leu Asn Arg Ala Gly Phe Gln Thr Glu Asp Phe Ser
770 775 780
Leu Tyr Ala Cys Ala Ser Pro Lys Thr Pro Ile Gln Ala Gly Gly Tyr
785 790 795 800
Gly Gly Phe Pro Val His
805
<210> 45
<211> 4454
<212> DNA
<213> Homo sapiens
<400> 45
gaaacgtccc gtgtgggagg ggcgggtctg ggtgcggcct gccgcatgac tcgtggttcg 60
gaggcccacg tggccggggc ggggactcag gcgcctgggg cgccgactga ttacgtagcg 120
ggcggggccg gaagtgccgc tccttggtgg gggctgttca tggcggttcc ggggtctcca 180
acatttttcc cggctgtggt cctaaatctg tccaaagcag aggcagtgga gcttgaggtt 240
cttgctggtg tgaaatgact gagtacaaac tggtggtggt tggagcaggt ggtgttggga 300
aaagcgcact gacaatccag ctaatccaga accactttgt agatgaatat gatcccacca 360
tagaggattc ttacagaaaa caagtggtta tagatggtga aacctgtttg ttggacatac 420
tggatacagc tggacaagaa gagtacagtg ccatgagaga ccaatacatg aggacaggcg 480
aaggcttcct ctgtgtattt gccatcaata atagcaagtc atttgcggat attaacctct 540
acagggagca gattaagcga gtaaaagact cggatgatgt acctatggtg ctagtgggaa 600
acaagtgtga tttgccaaca aggacagttg atacaaaaca agcccacgaa ctggccaaga 660
gttacgggat tccattcatt gaaacctcag ccaagaccag acagggtgtt gaagatgctt 720
tttacacact ggtaagagaa atacgccagt accgaatgaa aaaactcaac agcagtgatg 780
atgggactca gggttgtatg ggattgccat gtgtggtgat gtaacaagat acttttaaag 840
ttttgtcaga aaagagccac tttcaagctg cactgacacc ctggtcctga cttccctgga 900
ggagaagtat tcctgttgct gtcttcagtc tcacagagaa gctcctgcta cttccccagc 960
tctcagtagt ttagtacaat aatctctatt tgagaagttc tcagaataac tacctcctca 1020
cttggctgtc tgaccagaga atgcacctct tgttactccc tgttattttt ctgccctggg 1080
ttcttccaca gcacaaacac acctctgcca ccccaggttt ttcatctgaa aagcagttca 1140
tgtctgaaac agagaaccaa accgcaaacg tgaaattcta ttgaaaacag tgtcttgagc 1200
tctaaagtag caactgctgg tgattttttt tttcttttta ctgttgaact tagaactatg 1260
ctaatttttg gagaaatgtc ataaattact gttttgccaa gaatatagtt attattgctg 1320
tttggtttgt ttataatgtt atcggctcta ttctctaaac tggcatctgc tctagattca 1380
taaatacaaa aatgaatact gaattttgag tctatcctag tcttcacaac tttgacgtaa 1440
ttaaatccaa ctttcacagt gaagtgcctt tttcctagaa gtggtttgta gacttccttt 1500
ataatatttc agtggaatag atgtctcaaa aatccttatg catgaaatga atgtctgaga 1560
tacgtctgtg acttatctac cattgaagga aagctatatc tatttgagag cagatgccat 1620
tttgtacatg tatgaaattg gttttccaga ggcctgtttt ggggctttcc caggagaaag 1680
atgaaactga aagcacatga ataatttcac ttaataattt ttacctaatc tccacttttt 1740
tcataggtta ctacctatac aatgtatgta atttgtttcc cctagcttac tgataaacct 1800
aatattcaat gaacttccat ttgtattcaa atttgtgtca taccagaaag ctctacattt 1860
gcagatgttc aaatattgta aaactttggt gcattgttat ttaatagctg tgatcagtga 1920
ttttcaaacc tcaaatatag tatattaaca aattacattt tcactgtata tcatggtatc 1980
ttaatgatgt atataattgc cttcaatccc cttctcaccc caccctctac agcttccccc 2040
acagcaatag gggcttgatt atttcagttg agtaaagcat ggtgctaatg gaccagggtc 2100
acagtttcaa aacttgaaca atccagttag catcacagag aaagaaattc ttctgcattt 2160
gctcattgca ccagtaactc cagctagtaa ttttgctagg tagctgcagt tagccctgca 2220
aggaaagaag aggtcagtta gcacaaaccc tttaccatga ctggaaaact cagtatcacg 2280
tatttaaaca tttttttttc ttttagccat gtagaaactc taaattaagc caatattctc 2340
atttgagaat gaggatgtct cagctgagaa acgttttaaa ttctctttat tcataatgtt 2400
ctttgaaggg tttaaaacaa gatgttgata aatctaagct gatgagtttg ctcaaaacag 2460
gaagttgaaa ttgttgagac aggaatggaa aatataatta attgatacct atgaggattt 2520
ggaggcttgg cattttaatt tgcagataat accctggtaa ttctcatgaa aaatagactt 2580
ggataacttt tgataaaaga ctaattccaa aatggccact ttgttcctgt ctttaatatc 2640
taaatactta ctgaggtcct ccatcttcta tattatgaat tttcatttat taagcaaatg 2700
tcatattacc ttgaaattca gaagagaaga aacatatact gtgtccagag tataatgaac 2760
ctgcagagtt gtgcttctta ctgctaattc tgggagcttt cacagtactg tcatcatttg 2820
taaatggaaa ttctgctttt ctgtttctgc tccttctgga gcagtgctac tctgtaattt 2880
tcctgaggct tatcacctca gtcatttctt ttttaaatgt ctgtgactgg cagtgattct 2940
ttttcttaaa aatctattaa atttgatgtc aaattaggga gaaagatagt tactcatctt 3000
gggctcttgt gccaatagcc cttgtatgta tgtacttaga gttttccaag tatgttctaa 3060
gcacagaagt ttctaaatgg ggccaaaatt cagacttgag tatgttcttt gaatacctta 3120
agaagttaca attagccggg catggtggcc cgtgcctgta gtcccagcta cttgagaggc 3180
tgaggcagga gaatcacttc aacccaggag gtggaggtta cagtgagcag agatcgtgcc 3240
actgcactcc agcctgggtg acaagagaga cttgtctcca aaaaaaaagt tacacctagg 3300
tgtgaatttt ggcacaaagg agtgacaaac ttatagttaa aagctgaata acttcagtgt 3360
ggtataaaac gtggttttta ggctatgttt gtgattgctg aaaagaattc tagtttacct 3420
caaaatcctt ctctttcccc aaattaagtg cctggccagc tgtcataaat tacatattcc 3480
ttttggtttt tttaaaggtt acatgttcaa gagtgaaaat aagatgttct gtctgaaggc 3540
taccatgccg gatctgtaaa tgaacctgtt aaatgctgta tttgctccaa cggcttacta 3600
tagaatgtta cttaatacaa tatcatactt attacaattt ttactatagg agtgtaatag 3660
gtaaaattaa tctctatttt agtgggccca tgtttagtct ttcaccatcc tttaaactgc 3720
tgtgaatttt tttgtcatga cttgaaagca aggatagaga aacactttag agatatgtgg 3780
ggttttttta ccattccaga gcttgtgagc ataatcatat ttgctttata tttatagtca 3840
tgaactccta agttggcagc tacaaccaag aaccaaaaaa tggtgcgttc tgcttcttgt 3900
aattcatctc tgctaataaa ttataagaag caaggaaaat tagggaaaat attttatttg 3960
gatggtttct ataaacaagg gactataatt cttgtacatt atttttcatc tttgctgttt 4020
ctttgagcag tctaatgtgc cacacaatta tctaaggtat ttgttttcta taagaattgt 4080
tttaaaagta ttcttgttac cagagtagtt gtattatatt tcaaaacgta agatgatttt 4140
taaaagcctg agtactgacc taagatggaa ttgtatgaac tctgctctgg agggagggga 4200
ggatgtccgt ggaagttgta agacttttat ttttttgtgc catcaaatat aggtaaaaat 4260
aattgtgcaa ttctgctgtt taaacaggaa ctattggcct ccttggccct aaatggaagg 4320
gccgatattt taagttgatt attttattgt aaattaatcc aacctagttc tttttaattt 4380
ggttgaatgt tttttcttgt taaatgatgt ttaaaaaata aaaactggaa gttcttggct 4440
tagtcataat tctt 4454
<210> 46
<211> 189
<212> PRT
<213> Homo sapiens
<400> 46
Met Thr Glu Tyr Lys Leu Val Val Val Gly Ala Gly Gly Val Gly Lys
1 5 10 15
Ser Ala Leu Thr Ile Gln Leu Ile Gln Asn His Phe Val Asp Glu Tyr
20 25 30
Asp Pro Thr Ile Glu Asp Ser Tyr Arg Lys Gln Val Val Ile Asp Gly
35 40 45
Glu Thr Cys Leu Leu Asp Ile Leu Asp Thr Ala Gly Gln Glu Glu Tyr
50 55 60
Ser Ala Met Arg Asp Gln Tyr Met Arg Thr Gly Glu Gly Phe Leu Cys
65 70 75 80
Val Phe Ala Ile Asn Asn Ser Lys Ser Phe Ala Asp Ile Asn Leu Tyr
85 90 95
Arg Glu Gln Ile Lys Arg Val Lys Asp Ser Asp Asp Val Pro Met Val
100 105 110
Leu Val Gly Asn Lys Cys Asp Leu Pro Thr Arg Thr Val Asp Thr Lys
115 120 125
Gln Ala His Glu Leu Ala Lys Ser Tyr Gly Ile Pro Phe Ile Glu Thr
130 135 140
Ser Ala Lys Thr Arg Gln Gly Val Glu Asp Ala Phe Tyr Thr Leu Val
145 150 155 160
Arg Glu Ile Arg Gln Tyr Arg Met Lys Lys Leu Asn Ser Ser Asp Asp
165 170 175
Gly Thr Gln Gly Cys Met Gly Leu Pro Cys Val Val Met
180 185
<210> 47
<211> 1326
<212> DNA
<213> Rattus norvegicus
<400> 47
gccgttcatg gcggtttcgg ggtctccaac agcttctcag gttgaaatcc aaaagcctcc 60
cgaggcgggg tctgcggagt ttgagatttt tgcaggtgtg aaatgactga gtacaaactg 120
gtggtggttg gagcaggtgg cgttgggaaa agtgctttga caatccagct aatccagaac 180
cactttgtgg atgaatatga tcccaccata gaggattctt accgaaaaca agtggtgatt 240
gacggtgaga cctgtctact ggacatactg gacacagctg gacaagagga gtacagtgcc 300
atgagagacc aatacatgag gacaggcgaa gggttcctct gtgtgtttgc catcaataat 360
agcaaatcct ttgcagatat taacctctac agggagcaaa ttaagcgcgt gaaagactct 420
gatgatgtac ccatggtgct ggtagggaac aagtgtgact tgccaacaag gacagttgac 480
acaaagcaag cccacgagct ggccaagagt tatggaattc cattcattga aacctcagcc 540
aagacccgac agggtgtgga ggatgccttt tacacgcttg taagggagat acgccagtac 600
cggatgaaga agctcaacag cagtgaggat ggcactcaag gctgtatggg gctgccctgt 660
gtggtgatgt agtaagaccc tttaaaagtt ctgtcatcag aaacgagcca ctttcaagcc 720
tcactgatgc cctggttctg acatccctgg aggagacgtg tttctgctgc tctctgcatc 780
tcagagaagc tcctgcttcc tgcttcccca acttagttac tgagcacagc catctaacct 840
gagacctctt cagaataact acctcctcac tcggctgtcc gaccagagaa atgaacctgt 900
ttctccccag tagttctctg ccctgggttt cccctagaaa caaacacacc tgccagctgg 960
ctttgtcctc cgaaaagcag tttacattga tgcagagaac caaactatag acaagcaatt 1020
ctgttgtcaa cagtttctta agctctaagg taacaattgc tggtgatttc cccctttgcc 1080
cccaactgtt gaacttggcc ttgttagttt tgggggaaat gtcaaaaatt aatctcttcc 1140
cgagaataga attagtgttg ctgattgcct gatttgcaat gtgatcagct atattctata 1200
agctggcgtc tgctctgtat tcataaatgc aaacatgagt actgacgtaa gtgcatccct 1260
agtcttctca gctgcatgca attaaatcca acgttcacaa caaaaaaaaa aaaaaaaaaa 1320
aaaaaa 1326
<210> 48
<211> 189
<212> PRT
<213> Rattus norvegicus
<400> 48
Met Thr Glu Tyr Lys Leu Val Val Val Gly Ala Gly Gly Val Gly Lys
1 5 10 15
Ser Ala Leu Thr Ile Gln Leu Ile Gln Asn His Phe Val Asp Glu Tyr
20 25 30
Asp Pro Thr Ile Glu Asp Ser Tyr Arg Lys Gln Val Val Ile Asp Gly
35 40 45
Glu Thr Cys Leu Leu Asp Ile Leu Asp Thr Ala Gly Gln Glu Glu Tyr
50 55 60
Ser Ala Met Arg Asp Gln Tyr Met Arg Thr Gly Glu Gly Phe Leu Cys
65 70 75 80
Val Phe Ala Ile Asn Asn Ser Lys Ser Phe Ala Asp Ile Asn Leu Tyr
85 90 95
Arg Glu Gln Ile Lys Arg Val Lys Asp Ser Asp Asp Val Pro Met Val
100 105 110
Leu Val Gly Asn Lys Cys Asp Leu Pro Thr Arg Thr Val Asp Thr Lys
115 120 125
Gln Ala His Glu Leu Ala Lys Ser Tyr Gly Ile Pro Phe Ile Glu Thr
130 135 140
Ser Ala Lys Thr Arg Gln Gly Val Glu Asp Ala Phe Tyr Thr Leu Val
145 150 155 160
Arg Glu Ile Arg Gln Tyr Arg Met Lys Lys Leu Asn Ser Ser Glu Asp
165 170 175
Gly Thr Gln Gly Cys Met Gly Leu Pro Cys Val Val Met
180 185
<210> 49
<211> 4470
<212> DNA
<213> Mus musculus
<400> 49
gggactgggg cgccttgggc gcctagtgat tacgtagcgg gtggggccgg aagtgccgct 60
ccctggcggg ggctgttcat ggcggtttcg gggtctccaa cagcttctca ggttgaagtc 120
caaaagcctc ccgaggcggg gtctgcggag tttgaggttt ttgctggtgt gaaatgactg 180
agtacaaact ggtggtggtt ggagcaggtg gtgttgggaa aagcgccttg acgatccagc 240
taatccagaa ccactttgtg gatgaatatg atcccaccat agaggattct taccgaaagc 300
aagtggtgat tgatggtgag acctgcctgc tggacatact ggacacagct ggacaagagg 360
agtacagtgc catgagagac cagtacatga ggacaggcga agggttcctc tgtgtatttg 420
ccatcaataa tagcaaatca tttgcagata ttaacctcta cagggagcaa attaagcgtg 480
tgaaagattc tgatgatgtc cccatggtgc tggtaggcaa caagtgtgac ttgccaacaa 540
ggacagttga cacaaagcaa gcccacgaac tggccaagag ttacggaatt ccattcattg 600
agacctcagc caagacccga cagggtgtgg aggatgcctt ttacacactg gtaagggaga 660
tacgccagta ccgaatgaaa aagctcaaca gcagtgacga tggcactcaa ggttgtatgg 720
ggctgccctg tgtgctgatg tagtaagaca ctttgaaagt tctgtcatca gaaaagagcc 780
actttgaagc tgcactgatg ccctggttct gacatccctg gaggagacct gttcctgctg 840
ctctctgcat ctcagagaag ctcctgcttc ctgcttcccc gactcagtta ctgagcacag 900
ccatctaacc tgagacctct tcagaataac tacctcctca ctcggctgtc tgaccagaga 960
aatagacctg tctctcccgg tcgttctctg ccctgggttc ccctagaaac agacacagcc 1020
tccagctggc tttgtcctct gaaaagcagt ttacattgat gcagagaacc aaactagaca 1080
tgccattctg ttgacaacag tttcttatac tctaaggtaa caactgctgg tgattttccc 1140
ctgcccccaa ctgttgaact tggccttgtt ggtttggggg gaaaatgtca taaattactt 1200
tcttcccaaa atataattag tgttgctgat tgatttgtaa tgtgatcagc tatattccat 1260
aaactggcat ctgctctgta ttcataaatg caaacacgaa tactctcaac tgcatgcaat 1320
taaatccaac attcacaaca aagtgccttt ttcctaaaag tgctctgtag gctccattac 1380
agtttgtaat tggaatagat gtgtcaagaa ccattgtata ggaaagtgac tctgagccat 1440
ctacctttga gggaaaggtg tatgtacctg atggcagatg ctttgtgtat gcacatgaag 1500
atagtttccc tgtctgggat tctcccagga gaaagatgga actgaaacaa ttacaagtaa 1560
tttcatttaa ttctagctaa tctttttttt tttttttttt ttttttggta gactatcacc 1620
tataaatatt tggaatatct tctagcttac tgataatcta ataattaatg agcttccatt 1680
ataatgaatt ggttcatacc aggaagccct ccatttatag tatagatact gtaaaaattg 1740
gcatgttgtt actttatagc tgtgattaat gattcctcag accttgctga gatatagtta 1800
ttagcagaca ggttatatct ttgctgcata gtttcttcat ggaatatata tctatctgta 1860
tgtggagaga acgtggccct cagttccctt ctcagcatcc ctcatctctc agcctagaga 1920
agttcgagca tcctagaggg gcttgaacag ttatctcggt taaaccatgg tgctaatgga 1980
ccgggtcatg gtttcaaaac ttgaacaagc cagttagcat cacagagaaa cagtccatcc 2040
atatttgctc cctgcctatt attcctgctt acagactttt gcctgatgcc tgctgttagt 2100
gctacaagga taaagcttgt gtggttctca ccaggactgg aagtacctgg tgagctctgg 2160
ggtaagccta gatatcttta cattttcaga cccttattct tagccacgtg gaaactgaag 2220
ccagagtcca tacctccatc tccttccccc cccaaaaaaa ttagattaat gttctttata 2280
tagctttttt aaagtattta aaacatgtct ataagttagg ctgccaacta acaaaagctg 2340
atgtgtttgt tcaaataaag aggtatcctt cgctactcga gagaagaatg taaaatgcca 2400
ttgattgttg tcacttggag gcttgatgtt tgccctgata attcattagt gggttttgtt 2460
tgtcacatga tacctaagat gtaactcagc tcagtaattc taatgaaaac ataaattgga 2520
taccttaatt gaaaaaagca aacctaattc caaaatggcc attttctctt ctgatcttgt 2580
aatacctaaa attctgaggt ccttgggatt cttttgttta taacaggatc ttgctgtgta 2640
gtcctagctg gcctcaaact cacaatactc ttcctggatc aatctcccaa gtgctgggat 2700
tacaggcaca ttccaccaca cacacctgac tgagctcgtt cctaatgagt tttcattaag 2760
caaattcccc atcaccttga aactaatcag aagggggaag aaacatttgc tatgctcctg 2820
agtgctaaca ctgggatcat tcacatgggg tttgcattcc taggcaaact aaactgctgc 2880
cttttacaac aaggctcagt catcttcctg aagctgctga gaccagcact tggtcttgtt 2940
ttgttttaat atgtctatat gactggtggt ggatccctaa atagtttatt aattaaactc 3000
cagttaagga gaaagttact caccttgacc cgtttgacca tatcccgtgt gtgtgtgtgt 3060
gtgtgtgtgt gtgtgtgtgt gtgtgtgtgt gtgcacgcgt atgtacgtac gtatgtatgt 3120
aggtatgtag gtggtttcca gtataaacac agaaacaaat ggagccaatt caggtttcag 3180
atgcccttac taacatatat tcccacgggg tgtgggtttt ggcacaacag tgacaaactt 3240
aaaagccaag taagagccgg gcgtggtggc gcacgccttt aatcccagca cttgggaggc 3300
agaggcaggc ggatttctga gttctaggcc atcctggtct acagtgagtt ccaggacagc 3360
cagtgctaca cagagaaacc ctgtctcgaa aagccaaaaa aaaaaaaaaa aaaaaaaaaa 3420
aaaagccaag taggtccagt tggtatagta tcaaagtgtt tttagagtaa ttagtgaagg 3480
tctgctttac ctcaaagttg cagagcctct cttcctgagt ttaagtgcct ggccggcagt 3540
cacaaattaa catgttgctg taaggcagtt agttgaagct ttgttcacac attggagagt 3600
atgaaaataa agtgttctaa gagcgctgat actggatctg tgtaaacctg gtaaatgccg 3660
tttgtccagg acttagcgtg tgtgagttgg tagctcagta cgagtttact agttccgcag 3720
tgtgtacaat ggaggcgggt ttgttttagc tggccacctg tagaatcagc ctttaaactg 3780
ctgtgaactt tgtcatgact tgaatatgaa gatagacaaa aactctgtaa agacaaatgt 3840
ttgttttccc ccttacagaa cgtgtgagct tggttttatc ttcctttgta tttagtcata 3900
acctctcaag ctggcagctc cgaccaagga tcagaagctg tgtgcgttcc acctggtgga 3960
attagctcag ctctatatga gaagtggagt taatggaaaa cgtgttgact gggtggtttc 4020
tatttaaaag agtgatgata attcttgaac agtagttttt attttgctat ttctttaagc 4080
tgactgatgt gccacaaaat tattttaagg tatttgtgtt ttaagagtgt tctcatgaga 4140
ttagttgtag atatttttta aaatacaact ggtttttaaa atctgagtat tgctctaagc 4200
aagtgtttag actcttacgg gaaggtgggt ggaagttgtt tggcttccgt atttccatgc 4260
gtgccgtcag acataggtca gaacgccaac tgtgcatcct gctgtttaaa gacctcttgg 4320
cctctgtgac cctcatgaag gggctgatat tttaagttga ctgtttgatt gtaaattaat 4380
cctttctaat ttttaaagac ttgcttgact gttttccttg ttaaataatt ttaaaaaaat 4440
aaaaaactgg aagttctttg cttaactgta 4470
<210> 50
<211> 189
<212> PRT
<213> Mus musculus
<400> 50
Met Thr Glu Tyr Lys Leu Val Val Val Gly Ala Gly Gly Val Gly Lys
1 5 10 15
Ser Ala Leu Thr Ile Gln Leu Ile Gln Asn His Phe Val Asp Glu Tyr
20 25 30
Asp Pro Thr Ile Glu Asp Ser Tyr Arg Lys Gln Val Val Ile Asp Gly
35 40 45
Glu Thr Cys Leu Leu Asp Ile Leu Asp Thr Ala Gly Gln Glu Glu Tyr
50 55 60
Ser Ala Met Arg Asp Gln Tyr Met Arg Thr Gly Glu Gly Phe Leu Cys
65 70 75 80
Val Phe Ala Ile Asn Asn Ser Lys Ser Phe Ala Asp Ile Asn Leu Tyr
85 90 95
Arg Glu Gln Ile Lys Arg Val Lys Asp Ser Asp Asp Val Pro Met Val
100 105 110
Leu Val Gly Asn Lys Cys Asp Leu Pro Thr Arg Thr Val Asp Thr Lys
115 120 125
Gln Ala His Glu Leu Ala Lys Ser Tyr Gly Ile Pro Phe Ile Glu Thr
130 135 140
Ser Ala Lys Thr Arg Gln Gly Val Glu Asp Ala Phe Tyr Thr Leu Val
145 150 155 160
Arg Glu Ile Arg Gln Tyr Arg Met Lys Lys Leu Asn Ser Ser Asp Asp
165 170 175
Gly Thr Gln Gly Cys Met Gly Leu Pro Cys Val Leu Met
180 185
<210> 51
<211> 570
<212> DNA
<213> Cavia porcellus
<400> 51
atgactgagt ataaactggt ggtggttgga gcaggtggtg tcgggaaaag tgcactgacc 60
atccagctaa ttcagaacca ctttgtcgat gaatatgatc ccaccataga ggattcttac 120
cgaaaacagg tggttataga tggtgaaact tgtctgttgg atattctgga tacagctgga 180
caagaggagt acagtgccat gagagaccaa tacatgagga caggcgaagg cttcctctgt 240
gtgtttgcca tcaataatag caaatcattt gcagatatta acctctacag ggagcagatt 300
aaacgagtaa aagactcaga tgatgtacct atggtgctgg tagggaacaa gtgtgatttg 360
ccaacaagga ctgttgacac aaaacaagcc catgaactgg ccaagagtta cgggattcca 420
ttcattgaaa cctcagccaa gaccagacag ggtgttgaag atgcatttta cacactcgta 480
agagaaatac gccagtacag aatgaaaaaa ctcaacagca atgatgatgg gactcaaggt 540
tgtatggggt tgccatgtgt ggtgatgtaa 570
<210> 52
<211> 189
<212> PRT
<213> Cavia porcellus
<400> 52
Met Thr Glu Tyr Lys Leu Val Val Val Gly Ala Gly Gly Val Gly Lys
1 5 10 15
Ser Ala Leu Thr Ile Gln Leu Ile Gln Asn His Phe Val Asp Glu Tyr
20 25 30
Asp Pro Thr Ile Glu Asp Ser Tyr Arg Lys Gln Val Val Ile Asp Gly
35 40 45
Glu Thr Cys Leu Leu Asp Ile Leu Asp Thr Ala Gly Gln Glu Glu Tyr
50 55 60
Ser Ala Met Arg Asp Gln Tyr Met Arg Thr Gly Glu Gly Phe Leu Cys
65 70 75 80
Val Phe Ala Ile Asn Asn Ser Lys Ser Phe Ala Asp Ile Asn Leu Tyr
85 90 95
Arg Glu Gln Ile Lys Arg Val Lys Asp Ser Asp Asp Val Pro Met Val
100 105 110
Leu Val Gly Asn Lys Cys Asp Leu Pro Thr Arg Thr Val Asp Thr Lys
115 120 125
Gln Ala His Glu Leu Ala Lys Ser Tyr Gly Ile Pro Phe Ile Glu Thr
130 135 140
Ser Ala Lys Thr Arg Gln Gly Val Glu Asp Ala Phe Tyr Thr Leu Val
145 150 155 160
Arg Glu Ile Arg Gln Tyr Arg Met Lys Lys Leu Asn Ser Asn Asp Asp
165 170 175
Gly Thr Gln Gly Cys Met Gly Leu Pro Cys Val Val Met
180 185
<210> 53
<211> 1220
<212> DNA
<213> Cavia porcellus
<400> 53
gttccggggt cctcaacgtt tctcagggtt gagattctat atccttttga agctggggcg 60
gcagagcttg aggttcttgc tggtgtgaaa tgactgagta taaactggtg gtggttggag 120
caggtggtgt cgggaaaagt gcactgacca tccagctaat tcagaaccac tttgtcgatg 180
aatatgatcc caccatagag gattcttacc gaaaacaggt ggttatagat ggtgaaactt 240
gtctgttgga tattctggat acagctggac aagaggagta cagtgccatg agagaccaat 300
acatgaggac aggcgaaggc ttcctctgtg tgtttgccat caataatagc aaatcatttg 360
cagatattaa cctctacagg gagcagatta aacgagtaaa agactcagat gatgtaccta 420
tggtgctggt agggaacaag tgtgatttgc caacaaggac tgttgacaca aaacaagccc 480
atgaactggc caagagttac gggattccat tcattgaaac ctcagccaag accagacagg 540
gtgttgaaga tgcattttac acactcgtaa gagaaatacg ccagtacaga atgaaaaaac 600
tcaacagcaa tgatgatggg actcaaggtt gtatggggtt gccatgtgtg gtgatgtaac 660
aagatattta acaaagttct atcagaaaag agccactttc aagctgcact gataccctgg 720
tcctgacttc cctggaggag aagtatccct gttgctctct tcatctcaga gaagctcctg 780
ctgtttgtcc acctctcagt gtatgagcac agtctctgct tgagaacttc tcagaataac 840
tacctcctca cttggttgtc tgaccagaga aatgcacctc ttgttaattc cccaataatt 900
ttctgccctg ggctctcccc aacaaaaaac aaacacttct gccatccaaa aagcaacttg 960
gtctgaaaca gaaccaaact gtagattgaa attctcttaa aaagtcttga gctctaaagt 1020
tagcaaccgc tggtgatttt tattttcctt tttatttttg aacttggaac tgacctatgt 1080
tagattttgg agaaatgtca taaagtactg ttgtgccaag aagataatta tgttgctgaa 1140
tggttgattt atagtgttat cagctatatt ttacaaactg gcatctgctc tgtattcata 1200
aatacaaaaa tgaagccagg 1220
<210> 54
<211> 189
<212> PRT
<213> Cavia porcellus
<400> 54
Met Thr Glu Tyr Lys Leu Val Val Val Gly Ala Gly Gly Val Gly Lys
1 5 10 15
Ser Ala Leu Thr Ile Gln Leu Ile Gln Asn His Phe Val Asp Glu Tyr
20 25 30
Asp Pro Thr Ile Glu Asp Ser Tyr Arg Lys Gln Val Val Ile Asp Gly
35 40 45
Glu Thr Cys Leu Leu Asp Ile Leu Asp Thr Ala Gly Gln Glu Glu Tyr
50 55 60
Ser Ala Met Arg Asp Gln Tyr Met Arg Thr Gly Glu Gly Phe Leu Cys
65 70 75 80
Val Phe Ala Ile Asn Asn Ser Lys Ser Phe Ala Asp Ile Asn Leu Tyr
85 90 95
Arg Glu Gln Ile Lys Arg Val Lys Asp Ser Asp Asp Val Pro Met Val
100 105 110
Leu Val Gly Asn Lys Cys Asp Leu Pro Thr Arg Thr Val Asp Thr Lys
115 120 125
Gln Ala His Glu Leu Ala Lys Ser Tyr Gly Ile Pro Phe Ile Glu Thr
130 135 140
Ser Ala Lys Thr Arg Gln Gly Val Glu Asp Ala Phe Tyr Thr Leu Val
145 150 155 160
Arg Glu Ile Arg Gln Tyr Arg Met Lys Lys Leu Asn Ser Asn Asp Asp
165 170 175
Gly Thr Gln Gly Cys Met Gly Leu Pro Cys Val Val Met
180 185
<210> 55
<211> 1307
<212> DNA
<213> Canis familiaris
<400> 55
tgattacgta gcgggcgggg ccggaagtgc cgctccctag tgggggctgt tcatggcggt 60
tccggggtct ccaacctttc tcctagttgt ggtcctaaat acgtcggaag cggaggcggc 120
gaagcttgag gttcttgctg gtgtgaaatg actgagtaca aactggtggt ggttggagca 180
ggtggtgttg ggaaaagcgc actgacaatc cagctaatcc agaaccactt tgtagatgaa 240
tatgatccca ccatagagga ttcttaccga aaacaggtgg ttatagacgg tgaaacctgt 300
ctgttggata tactggatac agctggtcaa gaagagtaca gtgccatgag agaccaatac 360
atgaggacag gcgaaggctt cctctgtgta tttgccatca ataatagcaa atcatttgca 420
gacattaacc tctacaggga acagattaag cgagtaaaag attcagatga tgtacctatg 480
gtgctagtag gaaacaagtg tgatttgcca acaaggacag ttgacacaaa acaagcccat 540
gaactggcca agagttatgg gattccattc attgaaacct cagccaagac cagacagggt 600
gtcgaggatg ccttttacac actggtaaga gaaatacgtc agtaccgaat gaagaaactc 660
aacagcagtg atgatgggac tcaaggttgt atggggttac catgtgtggt gatgtaacaa 720
gacactttta aagttctagc atcagaaaag agccactgtc aagctgcact gacaccctgg 780
tcctgacttc cctggaggag aagtattcct gttgctatct tcagtctcac aaagaagctc 840
ctgctacttc cccaactctc agtagatcag tacaatgttc tctatttgag aagttctccg 900
aacaactacc tcctcacttg gttgtctgac cagagaaatg aacctcttgt tccttcccgc 960
tgtttttcca ccctgaattc tcccccaaca cacataaaca aacctctgcc atcccaggtt 1020
tttcatctga aaaataattc atgctctgaa acagagaaca aaactgtaga catgaaattc 1080
tgtaggaaac aaggtcttga gctcaaaagt agcaactgct ggtgaccttt ttttcccccc 1140
tttttactgt tgaacttgga actatgttgg tttttggaga aatgtcataa gttactgttt 1200
tgctgagaat atagttaagt tgacatttgg tttgtttgta atatcattag ctattttcta 1260
taaattggca tctgctctgc attcataaat acacgagtga attctga 1307
<210> 56
<211> 189
<212> PRT
<213> Canis familiaris
<400> 56
Met Thr Glu Tyr Lys Leu Val Val Val Gly Ala Gly Gly Val Gly Lys
1 5 10 15
Ser Ala Leu Thr Ile Gln Leu Ile Gln Asn His Phe Val Asp Glu Tyr
20 25 30
Asp Pro Thr Ile Glu Asp Ser Tyr Arg Lys Gln Val Val Ile Asp Gly
35 40 45
Glu Thr Cys Leu Leu Asp Ile Leu Asp Thr Ala Gly Gln Glu Glu Tyr
50 55 60
Ser Ala Met Arg Asp Gln Tyr Met Arg Thr Gly Glu Gly Phe Leu Cys
65 70 75 80
Val Phe Ala Ile Asn Asn Ser Lys Ser Phe Ala Asp Ile Asn Leu Tyr
85 90 95
Arg Glu Gln Ile Lys Arg Val Lys Asp Ser Asp Asp Val Pro Met Val
100 105 110
Leu Val Gly Asn Lys Cys Asp Leu Pro Thr Arg Thr Val Asp Thr Lys
115 120 125
Gln Ala His Glu Leu Ala Lys Ser Tyr Gly Ile Pro Phe Ile Glu Thr
130 135 140
Ser Ala Lys Thr Arg Gln Gly Val Glu Asp Ala Phe Tyr Thr Leu Val
145 150 155 160
Arg Glu Ile Arg Gln Tyr Arg Met Lys Lys Leu Asn Ser Ser Asp Asp
165 170 175
Gly Thr Gln Gly Cys Met Gly Leu Pro Cys Val Val Met
180 185
<210> 57
<211> 3104
<212> DNA
<213> Felis catus
<400> 57
aaaaaataaa taaatttaag aaaccatttt aaaattatgc acagttgcag cctggaaaac 60
ttaaggtggc gccttatagt atcaatctta ggagctttat ttggtgcatt taacgcaact 120
ggtaattgca aaatccactt cgcctgtgta agtgaaaaat atagactgtt atcttgttgg 180
ccctatgaaa ttctgcactt ggtatttagc atatactcta ccttcattac tatctggcaa 240
gatgttctgc cttagcactc agttgcattc ttttcctttt ctttcctgtt cattatgctt 300
taattctgag gaccatatga gggtagaata tattaaaaat tacaaaaatt ataaaaattt 360
gtataggcaa accatttcct taagttgatg gccaaatgtt aaaatgttat ttttcatatc 420
atttataatc ttgtcacagt ccacttaacg aagtttggtt agatttcagt gaaaattatc 480
ttccagagta gttttttttt ttttttcctg ggattaggga ggggggtaac tttactgcaa 540
ttagtatgta tggtgcagaa tttcatgcaa atgaggtgtg ccagcagtgt ggtaatttaa 600
tcgtatttaa acaaaaacaa acaaaaaaaa aacgaatgca caaacttgct gctgcttaga 660
tcactgcagc ttctaggacc cagtttcttt tactgatttc aaaacaaaac aaaacaaaaa 720
aataaaaaaa gttgtgcctg aaatgaatct tgtttttttt ataagtagcc gcctggttcc 780
tgtgtcctgt gaaatacagg cacttgaccc ttggtgtagc ttctgttcga ctttatatca 840
cgggaatgga ttggtctgat ttcttggccc tcatcttgaa ttggccacat ccagggtccc 900
tggccagtgg actgaaggct ttgtctaaga ggacaagggc agctcagggg atgtggggga 960
gggcgctttt atcttccccg ttgtcgtttg aggttttgat cttctctggg taaagaggcc 1020
gtttatcttt gtaaacacaa aacatttttg ctttctccag ttttctgtta atggcgaaag 1080
aatggaagcg aataaagttt tactgatttt tgagactcta gcacctagcg ctttcatttt 1140
tgaaacgtcc tgtgtgggag gggcgggtct gggtgcggcc cgccgcgtga ctcctgagtc 1200
gggggcccac gtggctgggg cggggactcg gacgccccgg gcgccgactg attacgtagc 1260
gggcggggcc ggaagtgccg ctccctagtg ggggctgttc atggcggttc cggggtctcc 1320
atcctttttc ccagttgttc taaatcagtc ggaagcggag gcagcgaagt ttgaggttct 1380
cgctggtgtg aaatgactga gtacaaactg gtggtggttg gagcaggtgg tgttgggaaa 1440
agcgcactga caatccagct aatccagaac cactttgtag atgaatatga tcccaccata 1500
gaggattctt accgaaaaca ggtggttata gacggtgaaa cctgtctgtt ggacatactg 1560
gatacagctg gtcaagaaga gtacagtgcc atgagagacc aatacatgag gacaggcgaa 1620
ggcttcctct gtgtatttgc catcaacaat agcaaatcat ttgcagatat taacctttac 1680
agggaacaga ttaagcgagt aaaagactcc gatgatgtac ctatggtgct agtaggaaac 1740
aagtgtgatt tgccaacaag gaccgtcgac acaaaacaag cccacgaact ggccaagagt 1800
tatgggattc cattcattga aacctcagcc aagaccagac agggtgttga agatgccttt 1860
tacacactgg taagagaaat acgtcagtac cgaatgaaga aactcaacag cagtgatgac 1920
gggactcaag gttgtatggg gttaccgtgt gtggtgatgt aacaagatac ttttaaagtt 1980
ctagcatcag aaaagagcca ctgtcaagct gcactgacac cctggtcctg acttccctgg 2040
aggagaagcg ttcctgttgc tattttcagt ttcacaaaga agctcctgct atttccccaa 2100
ctctccgtag atcagtacat tattctctgt ttgagaagtt ctccgaataa ctacctcctc 2160
acttggttgt ctgaccagag aaatgaacct cttgttactc cccactgttt ttccaccctg 2220
gttctccccc agcacatata aacaaacctc ccaggttttt catctgaaaa gtaattcatg 2280
ctctgaaaca gagaaccaaa ctgtagacat gaaattctgt aggaaacaat gtcttgagct 2340
ctaaagtagc aactgctggt gacttttttt tttttttttt cctttttact gttgaacttg 2400
gaactatgtt ggtttttgga gaaatgtcgt aagttactgt tttgctgagt atatagttaa 2460
gtttaccatt cggtttgttt gtaatgtcat tggctatact ctgtacctgg catctgctct 2520
gcattcataa atacaaaagt gaattctgac ttttgagtct atcctagtgt tctcaacttc 2580
cacataatta aatctaactt ttgcagcaaa gtgccttttt cctagaagtg gtttgtagat 2640
ttgctttata atactttggt ggaatagatg tctcaaaaac cattatacat gaaaatgaat 2700
gtctgagata cgtctatgat ctgtctacct ttgagggaaa aatataccga cataatagca 2760
gatgccatgt cttacgtgta tgaagttgga tttccagaga cctgatttgg gtctcttcca 2820
agagaaagat gaaactggaa acaattatga ataacttcac ttaattttta cctaatctct 2880
acttcggggt gggagggcag ggagtaggtt accacttaca aaatatatgc aatttgtttc 2940
ttctagctta ctgataatga acttccattc ttatttaaat ttaggtcata tcctaaagct 3000
ttacatttgc aggtgttcga aattgtaagt ttaatgcagt tttatttaat agctatgatc 3060
aatgattttc aagcctcaga tgtattaacg gacacatttt cact 3104
<210> 58
<211> 189
<212> PRT
<213> Felis catus
<400> 58
Met Thr Glu Tyr Lys Leu Val Val Val Gly Ala Gly Gly Val Gly Lys
1 5 10 15
Ser Ala Leu Thr Ile Gln Leu Ile Gln Asn His Phe Val Asp Glu Tyr
20 25 30
Asp Pro Thr Ile Glu Asp Ser Tyr Arg Lys Gln Val Val Ile Asp Gly
35 40 45
Glu Thr Cys Leu Leu Asp Ile Leu Asp Thr Ala Gly Gln Glu Glu Tyr
50 55 60
Ser Ala Met Arg Asp Gln Tyr Met Arg Thr Gly Glu Gly Phe Leu Cys
65 70 75 80
Val Phe Ala Ile Asn Asn Ser Lys Ser Phe Ala Asp Ile Asn Leu Tyr
85 90 95
Arg Glu Gln Ile Lys Arg Val Lys Asp Ser Asp Asp Val Pro Met Val
100 105 110
Leu Val Gly Asn Lys Cys Asp Leu Pro Thr Arg Thr Val Asp Thr Lys
115 120 125
Gln Ala His Glu Leu Ala Lys Ser Tyr Gly Ile Pro Phe Ile Glu Thr
130 135 140
Ser Ala Lys Thr Arg Gln Gly Val Glu Asp Ala Phe Tyr Thr Leu Val
145 150 155 160
Arg Glu Ile Arg Gln Tyr Arg Met Lys Lys Leu Asn Ser Ser Asp Asp
165 170 175
Gly Thr Gln Gly Cys Met Gly Leu Pro Cys Val Val Met
180 185
<210> 59
<211> 4283
<212> DNA
<213> Bos taurus
<400> 59
ggccgctccc tagtgggggc tgttcatggc ggttccgggg tctcccaaca attttcccgg 60
ttgtggtcgt aatctatccg aagtggaggc agtggagcta gaggttcttg ctggtgtgaa 120
atgactgagt acaaactggt ggtggttgga gcaggtggtg ttgggaaaag tgcactgaca 180
atccagctaa tccagaacca ctttgtagat gaatatgatc ccaccataga ggattcctac 240
cgaaaacagg tggttataga tggtgaaacc tgtctgttgg acatactgga tacagctgga 300
caagaggagt acagtgccat gagagaccaa tacatgagga caggcgaagg cttcctttgt 360
gtgtttgcca tcaataatag caaatcattt gcagatatta acctctacag ggaacagata 420
aagcgtgtaa aggactcgga tgatgtacct atggtgctag taggaaacaa gtgtgatttg 480
ccaacaagga cagttgacac aaaacaagcc catgaactgg ccaaaagtta tgggattcca 540
ttcattgaaa cctcagccaa gaccagacag ggtgttgaag atgcctttta cacactggta 600
agagaaatac gtcagtaccg aatgaaaaag ctcaacagca gtgatgatgg cactcaaggc 660
tgtatggggt tgccgtgtgt ggtgatgtaa caagatactt ttaaagttct cacatcagaa 720
aagagccact gtcaagctgc actgacaccc tggtcctgac ttccctggag gagaagtatt 780
cctgttgcta tcttcagttt caaaaagaag ctcctgctat ttccccaact ctcagtagat 840
caatataata ttctctattt gagaagttct caagaataac tacctcctca cttggttgtc 900
tgaccagaga attgaacctc ttgttactcc cagtattttt ccaccctggg ttctccccca 960
gcacacacaa acgcacctct gccacccagg tttttcatct gaaaagcaat taatactctg 1020
aaacagagaa ccaaactgta gaaacatgaa attctgtaga aaacaatgtc ttgagctcta 1080
aagtagcaac tgctggtgat tttttttttt tttttttcct ttttattgtt gaacttggaa 1140
ctatgttggt ttgtggagaa atgtcataaa ttactgtttt gctgagaata tagttaatgt 1200
tgctctctgg tttgtttgta atgttatcag ctatattcta taaactggca tctactctgt 1260
atttagaaat acaaaaatga atactgacct tttgagtcta ccctcatctt ctcgactttc 1320
ttgtaattaa atgtaacttt cacgatgaag tgccttttgc ctgggagtga ctcgtagact 1380
tcctttaaaa tacttcagtg gaatagatgt ctcagaaact gttatacata agaataaatg 1440
tctgagatat gtctatgacc catctagctt tgagggaaag atataccaat atgatagcag 1500
atgccatttc ttacatctat aacgttgatt ttctggagac ctattttggg gctctccgag 1560
agaaagatga gactataaat gattaggaat aatttcactt aatttttaca taacctccac 1620
tttttgtttt gtagtttact acctgcaaaa catataattt gattcctttt agcttacaga 1680
taatctaatg ttaaatgaac ttccattcat attttaattt ggatcatatc aggaagtcta 1740
catttgcagg tgttcaaaaa ttgtaaaagt gtgatgcagt tttatttaat agctgtgatc 1800
aatgattttc aagcctcaaa tatgttaata gacacatttt cactgtatat catggtatta 1860
ataattattg atgtatataa ttgtccttgg tccccttctc tgttcatcac ctcatggcaa 1920
tggcttgatt aattatttca gctgagtaaa gcatggtgct aatagaccag ggtcacagtg 1980
tcaaaacttc agtgagccag taagcatcac agagaaagaa attctttcac atttgctcac 2040
cattaactcc agctaatagt tttgccagat gtgtgtggtt agtcctgcaa ggaaaggaga 2100
agtcagttaa tacaaattct taaccaggac tggaaaaact tgttttcctg agaagggtca 2160
gcttagaagt ctttatctgg actctatttt tagccacatg gaaatcaaat taagctgatc 2220
ttttttctca agtttttgag agtgaggatg cctcagatca acatttttaa aatattcttt 2280
attcttacgt tcttttaagg gtttaaaaca acgttgagta attagtctgg gcataccagg 2340
taacaagctg ataagtttgt gctgaacaag aagtagcctt tggattgaaa ttgctgtttt 2400
gagaagggat agaaaatata attaataatt atgagacttg acttttctat ttgcagataa 2460
tatcctgata attctgatga aaatagactt ggataatttt tgataaaaga atcgttccaa 2520
aatggccact tgctgttctt gtcttctaat gtgtaaatac ttactgaggt cctcttctaa 2580
tatgagttgt catttattaa gcaaattcca cattgccttg aaatgaattc ggaagagaag 2640
aaaaagtcat agtataccca gagaatgaaa aatccagaga attgtgctcc ttagtgttaa 2700
ttctgaagcc ttcgtagtcc acacccatag acagaaactc tctgccactt tgcttctgct 2760
cctcttggag cattgcgctg tcatttcctt gaggatagat tgaggcttgt caactcagtt 2820
gtattgtctt cctcctcttc ctcttgtctg tgtgactgac agtgtgactc ttactaatgt 2880
cagatgcggg gatgcgggga ggtggggggg agtagctcat tttaggctct tgcacccttt 2940
accgttgtat gtgtgtgtct tttagttttc tcaagaatgt tctaagcaca gaagtatcta 3000
aatggggcca aaattcagac ttgaaaatgt tcttttaata gcttcttaaa aagttacact 3060
ttggtgtgaa ttttggcagg atagagtgac aaactcttaa acgctgaata acttcagtta 3120
gtgtgttata gtttttagaa tatgtttgtg attgctgaaa acaattatag tttacctcaa 3180
aatctgaaag tctctttccc caagttaagt gcctggccag ctgtcaaaga ttacatatta 3240
ctttatgttt gtttgttttt taaaggttgc acattcaaga ttgtgaaaat aaggtgttct 3300
gtctgaaagc taccatgcct gtctgtaaat gaatccactg agtgctgtac ttgttccaac 3360
agcttactac agaatgctac ttggtaatat catactcgtt acagttttca cttcaggagt 3420
gtactaggta gaatgatcct gtgtgtattg tagtgggctc catgtttagt cttttcagca 3480
tcctttaaac tgctgtgaat ttttgtcttg acttgaaagc aaggatagag aaacacttta 3540
aagagatact ttgggttttt ttccattcca gaattggtga gcatagttag attttgcttt 3600
acatttacag tcatgaactc ttaagctggc agctacaacc aagaaccaaa agagggtgca 3660
ttctgcttct tgtaattcat ctttgctaat aaattatgag aagcaaagat aattaattag 3720
agaaactatt ttatttgggt ggtttctata aacaagggac tataattctt aaacattatt 3780
tttcattttt gctgtttctt taagaaacct aatgtgccac aacattattt taaggtgttt 3840
cttaaaagaa ttgtttttaa aagtgttctc attttcagag taattgtaga tatatttcaa 3900
aatataactg ataattttta aaggcctgag tactgaccta agaagcagtt gtatgaattc 3960
tctgggggga agggaggagc tcagtgaaag ttgtatgact tttatatttc tgtgccatca 4020
aataaaggta aaaatgtctt ttgtgcagtt ttgctgttca aacagaaact attggcctcc 4080
ttggccctaa atgaaagggc tggtatttta agttgactat tttattgtaa attaatccat 4140
cttaattttt ttaaatttgg ttgaatgttc tcttgttaaa tgtttaaaaa ataaaaactg 4200
gaagttcttt gcttagtcat aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 4260
aaaaaaataa aaaaaaaaaa aaa 4283
<210> 60
<211> 189
<212> PRT
<213> Bos taurus
<400> 60
Met Thr Glu Tyr Lys Leu Val Val Val Gly Ala Gly Gly Val Gly Lys
1 5 10 15
Ser Ala Leu Thr Ile Gln Leu Ile Gln Asn His Phe Val Asp Glu Tyr
20 25 30
Asp Pro Thr Ile Glu Asp Ser Tyr Arg Lys Gln Val Val Ile Asp Gly
35 40 45
Glu Thr Cys Leu Leu Asp Ile Leu Asp Thr Ala Gly Gln Glu Glu Tyr
50 55 60
Ser Ala Met Arg Asp Gln Tyr Met Arg Thr Gly Glu Gly Phe Leu Cys
65 70 75 80
Val Phe Ala Ile Asn Asn Ser Lys Ser Phe Ala Asp Ile Asn Leu Tyr
85 90 95
Arg Glu Gln Ile Lys Arg Val Lys Asp Ser Asp Asp Val Pro Met Val
100 105 110
Leu Val Gly Asn Lys Cys Asp Leu Pro Thr Arg Thr Val Asp Thr Lys
115 120 125
Gln Ala His Glu Leu Ala Lys Ser Tyr Gly Ile Pro Phe Ile Glu Thr
130 135 140
Ser Ala Lys Thr Arg Gln Gly Val Glu Asp Ala Phe Tyr Thr Leu Val
145 150 155 160
Arg Glu Ile Arg Gln Tyr Arg Met Lys Lys Leu Asn Ser Ser Asp Asp
165 170 175
Gly Thr Gln Gly Cys Met Gly Leu Pro Cys Val Val Met
180 185
<210> 61
<211> 4825
<212> DNA
<213> Gallus gallus
<400> 61
gcgccgggac cggaagccgg aagctttgca gaagggtgtt ccgcgttcgc ggtgcgggag 60
cggtcagccg gggtggcggg gctggggccg gccggggcag gcggctccgc gctccgcact 120
gggccgctgg gagggcgatg actgaataca agctggtggt ggtgggagct ggcggcgtcg 180
ggaagagcgc gttgaccatc cagctcatcc agaaccactt cgtggacgag tacgacccca 240
ccatcgagga ttcgtacaga aagcaggttg tcatcgatgg agagacgtgc ttgttggaca 300
ttctggacac tgcaggacag gaagaataca gtgctatgcg tgatcagtac atgagaactg 360
gggaaggatt cctttgtgtg tttgccatta acaacagtaa atcattcgct gatattaacc 420
tttacagaga gcaaatcaag agagtgaaag attcagacga tgtgccaatg gtgctggtgg 480
ggaataagtg cgatttgcca acaaggacag tagacaccaa acaggctcaa gagttagcaa 540
aaagctacgg cattcccttc atagagacat cagccaaaac gagacagggt gtggaagatg 600
cgttttacac actggtgagg gagattcggc agtaccggat gaaaaagctc aacagcaacg 660
aagatgggaa tcagggctgt atggggttgt cctgcattgt gatgtgataa gatgccaggt 720
tcagatgtag ctgctggaca agtctcgatg ctactgtatt gtgtctcatg ctgatgccct 780
gcagtatttt ggtgccagcg accagactct tggtaccagt taattagctc aggatccttt 840
cctgtgctcc atctgaagaa aacatctctg gtatctacct ccttgctcag ctcacagagc 900
agtcatatct cttggtgtac tgggattctt ttctagctgt gttgtctggg tttgttcaag 960
aagaaaacca gtcacaagaa aagtgaatta cagagactaa atgctgtgaa aaagatcaca 1020
ctttacctcc agagtaaaag ctagaagtgg cgtttgaccc ctttgcattg gattcagatt 1080
tgcggtgttg tcagaggagt ggcagaagta attttgccat tacaaaggtt tctgtcacca 1140
gtcggattgg tatctgctgt ctgtgcaccc acacagtgta tctgcaacat ctgcattgtg 1200
ccagaagtat cacttaactg atgaactgat cctttatttt tctgtaataa aaaggagata 1260
tctttgctaa cttaagtgcc tgtttgctca gaaggttgga ggttgtatgc tgttcccttg 1320
ggctgaggag aaccccaagg atgaatttct tgggtgctca ttgtcttgag caggcaagtt 1380
ttgtgtgggt gatctctttt catggcagga tattaaaatg ggaatttgta gtctggaaga 1440
tggagcagct gtttgtgaga ctcttgagtt agggagagaa atgtatacca cgtctgttct 1500
cgatccatca gaatggatcc atccacctct ttgtgtgtgg aactgtgtat agtctgtatt 1560
ggttttctac agcacttgga tctctttgga ccaaattagc gagctgttca ttttaacata 1620
actgccagta tttatagaca atttcttacg gacagataat gaatttagaa actggaggtt 1680
actttgggca gctgttcctc agctctgtct gtaacttgca aattattctg agttattttc 1740
tgcagaacct ccttccttat cacgggagga gcctgggagt tgaggttgac tgtaattggg 1800
tcaatggttg tcacagactt aaggtgtcca ggctgattgg aggaggcact gagccctaac 1860
agagcactga gctgacttct aattgcagca tccttgcaaa atgaggaagg gagttcagtg 1920
atgtctgcac tgaagatgta tgatacactg atagcagttc tgggtatgtt gtaacagctt 1980
caaagtagaa ccgcagtact gcgtgagctg tgtgacttct tcctagaaca cagcactgtc 2040
accccatatg gttgggacgt gcaggtgaga ccaacaccta ccaggttccc tggcgtaccg 2100
tggccttctc agttcttgtg ccagtgatac tgggttctgt tctgtggtgt cagacagcgt 2160
cctgtagcaa agctgaattc ccacttagtc tggtgagaga ataaagagcc atcagccaac 2220
agagggagcg ttcattctgc tggagcagtg cgagctgtaa gcattacgag aggcgtagtt 2280
tcagtttgtt gcagtcaggt tcctatattt tcaaagctga aatcagaaat aagtaaatac 2340
ggagaaaata agctgttgct tttaatgctc tttcctccac taattgtact cttaattttc 2400
ttcttgggag gccgaggatc catctgcata actttagctg tgatgctcca gataagtgtt 2460
tagaattcat tttatctttg actgatggga ctgataagaa gttaacgcac aatattttta 2520
catacaacat cgttttccag tgacctcctg agcggtggga agcattatgg gatagcaccg 2580
gctgtgactc gagttcattt gaaggcgatc tcttgcctgc aggttaaatg ggacggagtc 2640
agaatcactg tgagccgtct gtaatcagca aacagtctgt gggcttttct tactgtgttc 2700
tctctgtttg ccttagtttg gtgcaggaag agttccttgt gacagcgtcc tttgaggtgt 2760
gttgcaggag ctgaccattt gctccttgag ctgtgtgatg aactgttgtc cacttaatgg 2820
agttacagaa gcagcttctg ggagtcgcat ctggtcgcat acattcagtg ttttgggaag 2880
ctgtcagtgt ggtgtttgca ctgtgtttga atggtgttca tggtgggtct gttatgctcc 2940
tggatgattt ggggagatgt ggggctgctt ccgtggcaga caggatcagc tcagggcgct 3000
gctgcctatg gctgtgggaa acctcacagt tggtgtttga atagtggcca agtatgtcaa 3060
ttaaaaatac attttgaagg gaggtttgtc atagctctgt actttggcat gctctgctta 3120
ctgaaaacat actagctgta gctcaaaaaa agttgtgaat cctcagaata atacaggagc 3180
tggcaattgt ggctgctttc tctttgtgtt ccttttctct tgggttggat gaagctttaa 3240
aaaggaagga gccctggtga gggttggtca gtgtgcattt cattcttgga accagagagg 3300
aagttgcatc aactttcagg acgctgcaga gctcacttgc acaggtggtg ctccagtcta 3360
tgtgattttt ggggtcaaat cttgagatga tcttacaaaa tcagattttg tacccatcat 3420
gagcatgagg tgagtggttg tgctcggttt ctagctgcat gtatgtatac agacacgtgt 3480
atgcagacat gtctatgtgt gagtagttcg agtcagtcaa ggttactggc agcacctaaa 3540
gcgtatgcac cacataatgc atgcaggcaa aagtcctatc ttaggagcca tctcttcatg 3600
ggtttgggtt tatataggca gtatttttaa acagaatatc cgaagcactt tctggagttc 3660
tgtggtaatg cagtgacacc tatttggatg aaggaagatg tgtctgagga gcacgtaagc 3720
agatttgctg ccctaacaga gaggttttgg taaccgtgga aaaggttttc tcctggatct 3780
gtgtgtgctc ttggtgagct gcaatccatg acagggcaca accagatgag aaggaaaccc 3840
ggccatccca tgcttgagca cagctctgac tcagtagttc caccagatgt gccctttcag 3900
tcaaagtgtt ctgatctctt agagctttct gtagttcaag ttaccactca ctctccagct 3960
tgctcggtta atgtctgttg gcggcgttga gttggacttg ggaaaggtgt gtgtggtagg 4020
aacaagcaga gtgtgatgtg cttctgttat caggacttaa gctagagtgg ttggcagata 4080
ggaaatgcag ctattccttg aaagcaagca gatcatggat ggtcagccaa actgccctgg 4140
ctttggtggg agctgcactg cagaaggacc aaaccccaac aagatttggc acatttgttt 4200
agaagataag cacagatggt tttgcacaag gcagctcctc ataatggtgg ctttgtagat 4260
ttagtccaaa tgttcttatt tagatctagc agcacatcac tgtgtccgtg cccatctaac 4320
ctcgctatcc taagtagagc agaccccaaa caaccttgtt caaaaactac cagtgcaaat 4380
aactgaacta aatatttgtt actgctgact gagaacagct gttcgagtgt agcattgtgg 4440
cttgttaatg tgagtgcccc aactctatgg tcttattaaa gaaacccaaa cattgctcag 4500
attttgttct tattgtcatc ataagacttg aatagtgatg gtaatgctta cgtagacgtg 4560
tcttgtgagt gcacttcagt gatttagaaa gaactggatt tcaagcaact ttggacctgt 4620
ggggggaggg agattaatga aggtttgaat cacattctaa ttctatgtac agtccttcat 4680
tactccacaa gcctaaatcc tatacagcct ccaggatagc tggaaactgt tgagatctgg 4740
actttttttt tttaatccaa gggctaactt gttgtaactt ggtataatta tctgctttcg 4800
gaaatgcatc tctgttggtt tgaaa 4825
<210> 62
<211> 189
<212> PRT
<213> Gallus gallus
<400> 62
Met Thr Glu Tyr Lys Leu Val Val Val Gly Ala Gly Gly Val Gly Lys
1 5 10 15
Ser Ala Leu Thr Ile Gln Leu Ile Gln Asn His Phe Val Asp Glu Tyr
20 25 30
Asp Pro Thr Ile Glu Asp Ser Tyr Arg Lys Gln Val Val Ile Asp Gly
35 40 45
Glu Thr Cys Leu Leu Asp Ile Leu Asp Thr Ala Gly Gln Glu Glu Tyr
50 55 60
Ser Ala Met Arg Asp Gln Tyr Met Arg Thr Gly Glu Gly Phe Leu Cys
65 70 75 80
Val Phe Ala Ile Asn Asn Ser Lys Ser Phe Ala Asp Ile Asn Leu Tyr
85 90 95
Arg Glu Gln Ile Lys Arg Val Lys Asp Ser Asp Asp Val Pro Met Val
100 105 110
Leu Val Gly Asn Lys Cys Asp Leu Pro Thr Arg Thr Val Asp Thr Lys
115 120 125
Gln Ala Gln Glu Leu Ala Lys Ser Tyr Gly Ile Pro Phe Ile Glu Thr
130 135 140
Ser Ala Lys Thr Arg Gln Gly Val Glu Asp Ala Phe Tyr Thr Leu Val
145 150 155 160
Arg Glu Ile Arg Gln Tyr Arg Met Lys Lys Leu Asn Ser Asn Glu Asp
165 170 175
Gly Asn Gln Gly Cys Met Gly Leu Ser Cys Ile Val Met
180 185
<210> 63
<211> 2603
<212> DNA
<213> Homo sapiens
<400> 63
aggcgaggct tccccttccc cgcccctccc ccggcctcca gtccctccca gggccgcttc 60
gcagagcggc taggagcacg gcggcggcgg cactttcccc ggcaggagct ggagctgggc 120
tctggtgcgc gcgcggctgt gccgcccgag ccggagggac tggttggttg agagagagag 180
aggaagggaa tcccgggctg ccgaaccgca cgttcagccc gctccgctcc tgcagggcag 240
cctttcggct ctctgcgcgc gaagccgagt cccgggcggg tggggcgggg gtccactgag 300
accgctaccg gcccctcggc gctgacggga ccgcgcgggg cgcacccgct gaaggcagcc 360
ccggggcccg cggcccggac ttggtcctgc gcagcgggcg cggggcagcg cagcgggagg 420
aagcgagagg tgctgccctc cccccggagt tggaagcgcg ttacccgggt ccaaaatgcc 480
caagaagaag ccgacgccca tccagctgaa cccggccccc gacggctctg cagttaacgg 540
gaccagctct gcggagacca acttggaggc cttgcagaag aagctggagg agctagagct 600
tgatgagcag cagcgaaagc gccttgaggc ctttcttacc cagaagcaga aggtgggaga 660
actgaaggat gacgactttg agaagatcag tgagctgggg gctggcaatg gcggtgtggt 720
gttcaaggtc tcccacaagc cttctggcct ggtcatggcc agaaagctaa ttcatctgga 780
gatcaaaccc gcaatccgga accagatcat aagggagctg caggttctgc atgagtgcaa 840
ctctccgtac atcgtgggct tctatggtgc gttctacagc gatggcgaga tcagtatctg 900
catggagcac atggatggag gttctctgga tcaagtcctg aagaaagctg gaagaattcc 960
tgaacaaatt ttaggaaaag ttagcattgc tgtaataaaa ggcctgacat atctgaggga 1020
gaagcacaag atcatgcaca gagatgtcaa gccctccaac atcctagtca actcccgtgg 1080
ggagatcaag ctctgtgact ttggggtcag cgggcagctc atcgactcca tggccaactc 1140
cttcgtgggc acaaggtcct acatgtcgcc agaaagactc caggggactc attactctgt 1200
gcagtcagac atctggagca tgggactgtc tctggtagag atggcggttg ggaggtatcc 1260
catccctcct ccagatgcca aggagctgga gctgatgttt gggtgccagg tggaaggaga 1320
tgcggctgag accccaccca ggccaaggac ccccgggagg ccccttagct catacggaat 1380
ggacagccga cctcccatgg caatttttga gttgttggat tacatagtca acgagcctcc 1440
tccaaaactg cccagtggag tgttcagtct ggaatttcaa gattttgtga ataaatgctt 1500
aataaaaaac cccgcagaga gagcagattt gaagcaactc atggttcatg cttttatcaa 1560
gagatctgat gctgaggaag tggattttgc aggttggctc tgctccacca tcggccttaa 1620
ccagcccagc acaccaaccc atgctgctgg cgtctaagtg tttgggaagc aacaaagagc 1680
gagtcccctg cccggtggtt tgccatgtcg cttttgggcc tccttcccat gcctgtctct 1740
gttcagatgt gcatttcacc tgtgacaaag gatgaagaac acagcatgtg ccaagattct 1800
actcttgtca tttttaatat tactgtcttt attcttatta ctattattgt tcccctaagt 1860
ggattggctt tgtgcttggg gctatttgtg tgtatgctga tgatcaaaac ctgtgccagg 1920
ctgaattaca gtgaaatttt ggtgaatgtg ggtagtcatt cttacaattg cactgctgtt 1980
cctgctccat gactggctgt ctgcctgtat tttcgggatt ctttgacatt tggtggtact 2040
ttattcttgc tgggcatact ttctctctag gagggagcct tgtgagatcc ttcacaggca 2100
gtgcatgtga agcatgcttt gctgctatga aaatgagcat cagagagtgt acatcatgtt 2160
attttattat tattatttgc ttttcatgta gaactcagca gttgacatcc aaatctagcc 2220
agagcccttc actgccatga tagctggggc ttcaccagtc tgtctactgt ggtgatctgt 2280
agacttctgg ttgtatttct atatttattt tcagtatact gtgtgggata cttagtggta 2340
tgtctcttta agttttgatt aatgtttctt aaatggaatt attttgaatg tcacaaattg 2400
atcaagatat taaaatgtcg gatttatctt tccccatatc caagtaccaa tgctgttgta 2460
aacaacgtgt atagtgccta aaattgtatg aaaatccttt taaccatttt aacctagatg 2520
tttaacaaat ctaatctctt attctaataa atatactatg aaataaaaaa aaaaggatga 2580
aagctaaaaa aaaaaaaaaa aaa 2603
<210> 64
<211> 393
<212> PRT
<213> Homo sapiens
<400> 64
Met Pro Lys Lys Lys Pro Thr Pro Ile Gln Leu Asn Pro Ala Pro Asp
1 5 10 15
Gly Ser Ala Val Asn Gly Thr Ser Ser Ala Glu Thr Asn Leu Glu Ala
20 25 30
Leu Gln Lys Lys Leu Glu Glu Leu Glu Leu Asp Glu Gln Gln Arg Lys
35 40 45
Arg Leu Glu Ala Phe Leu Thr Gln Lys Gln Lys Val Gly Glu Leu Lys
50 55 60
Asp Asp Asp Phe Glu Lys Ile Ser Glu Leu Gly Ala Gly Asn Gly Gly
65 70 75 80
Val Val Phe Lys Val Ser His Lys Pro Ser Gly Leu Val Met Ala Arg
85 90 95
Lys Leu Ile His Leu Glu Ile Lys Pro Ala Ile Arg Asn Gln Ile Ile
100 105 110
Arg Glu Leu Gln Val Leu His Glu Cys Asn Ser Pro Tyr Ile Val Gly
115 120 125
Phe Tyr Gly Ala Phe Tyr Ser Asp Gly Glu Ile Ser Ile Cys Met Glu
130 135 140
His Met Asp Gly Gly Ser Leu Asp Gln Val Leu Lys Lys Ala Gly Arg
145 150 155 160
Ile Pro Glu Gln Ile Leu Gly Lys Val Ser Ile Ala Val Ile Lys Gly
165 170 175
Leu Thr Tyr Leu Arg Glu Lys His Lys Ile Met His Arg Asp Val Lys
180 185 190
Pro Ser Asn Ile Leu Val Asn Ser Arg Gly Glu Ile Lys Leu Cys Asp
195 200 205
Phe Gly Val Ser Gly Gln Leu Ile Asp Ser Met Ala Asn Ser Phe Val
210 215 220
Gly Thr Arg Ser Tyr Met Ser Pro Glu Arg Leu Gln Gly Thr His Tyr
225 230 235 240
Ser Val Gln Ser Asp Ile Trp Ser Met Gly Leu Ser Leu Val Glu Met
245 250 255
Ala Val Gly Arg Tyr Pro Ile Pro Pro Pro Asp Ala Lys Glu Leu Glu
260 265 270
Leu Met Phe Gly Cys Gln Val Glu Gly Asp Ala Ala Glu Thr Pro Pro
275 280 285
Arg Pro Arg Thr Pro Gly Arg Pro Leu Ser Ser Tyr Gly Met Asp Ser
290 295 300
Arg Pro Pro Met Ala Ile Phe Glu Leu Leu Asp Tyr Ile Val Asn Glu
305 310 315 320
Pro Pro Pro Lys Leu Pro Ser Gly Val Phe Ser Leu Glu Phe Gln Asp
325 330 335
Phe Val Asn Lys Cys Leu Ile Lys Asn Pro Ala Glu Arg Ala Asp Leu
340 345 350
Lys Gln Leu Met Val His Ala Phe Ile Lys Arg Ser Asp Ala Glu Glu
355 360 365
Val Asp Phe Ala Gly Trp Leu Cys Ser Thr Ile Gly Leu Asn Gln Pro
370 375 380
Ser Thr Pro Thr His Ala Ala Gly Val
385 390
<210> 65
<211> 2151
<212> DNA
<213> Rattus norvegicus
<400> 65
cggccgcgcg ctccctgctg agttgcaggc tgtttcccgg ctgcaagatg cccaagaaga 60
agccgacgcc catccagctg aacccggccc ccgatggctc cgcggttaac gggaccagct 120
cggccgagac caacctggag gccttgcaga agaagctgga ggagctggag ctggacgagc 180
agcagcggaa gcgccttgag gcctttctga cgcagaagca gaaggtggga gagttgaagg 240
atgatgactt tgagaagatc agtgaactgg gggctggcaa tggtggagtg gtgttcaagg 300
tctcccacaa gccatctggc ctggttatgg ctaggaagct aattcacctg gagatcaaac 360
ccgcaatccg gaaccagatc atccgggagc tgcaggtgct gcatgagtgc aactccccgt 420
acatagtggg cttctacggg gccttctaca gtgacggcga gatcagcatc tgcatggagc 480
acatggatgg tgggtccttg gatcaagtgc tgaagaaagc tggaagaatt cctgagcaaa 540
ttttaggaaa agtcagcatc gctgtgataa aaggcctgac atatctacga gagaagcaca 600
agattatgca cagagatgtc aagccttcca acattctagt gaactcacgt ggggagatca 660
aactctgcga ttttggggtc agcgggcagc taattgactc catggccaac tccttcgtgg 720
gaacaaggtc ctacatgtcg cctgagagac tccaggggac tcactactct gtgcagtcgg 780
acatctggag catggggctc tctctggtgg agatggcagt tggaagatac cccattcctc 840
ctcctgatgc caaggagctg gagctgctgt ttggatgcca ggtggaagga gacgcggccg 900
aaacgccacc caggccaagg acccctggga ggcccctcag ctcatatgga atggatagcc 960
gacctcccat ggcaattttt gagttgttgg attacatcgt caatgagcct cctccaaaac 1020
tgcccagtgg agtattcagt ctggaatttc aggattttgt gaataagtgc ttaataaaga 1080
accctgcaga gagagcagat ctgaagcagc tcatggtaca tgctttcatc aagagatctg 1140
atgccgagga ggtagacttc gcaggctggc tctgctccac cattgggctt aaccagccca 1200
gcacaccaac ccacgctgcc agcatctgag cctttgggaa gcagcagaga ggaatcctct 1260
gcccagtggc atgccatgtt gctttcaggc ctctcccatg cttgtctatg ttcagatgtg 1320
catctcatct gtgacaaagg atgaagaaca cagcatgtgc caaatcgtac ttgtgtcatt 1380
tttaatattg tctttatcgc tatggttact cccctaagtg gattggcttt gtgcttgggg 1440
ctatttgtct gttcatcaaa tacatgccag gttgaactac agtgaaaccc tggtgacctg 1500
ggtggtcttc ttactgatgt ttgcgctgct gttcatcgtg actcactagc tggctgcctg 1560
tattgtcagg attctcggac ccttggtact tcactcttgc tggtgacctc tcagtctgag 1620
gagagggggc cttctgagac ccttcacagg cagtgcatgc atgaaaagca tgctttgctg 1680
ctactgaaat gagcaccaga acgtgtacat catggtattt tatttttgct tttggtatag 1740
aactcagcag ttcccattta aaaaaaaaat ctaaccagag cccatcactg ccatgatagc 1800
tggggcttca gtctgtctac tgtggtgatt tttagacttc tggttgtatt tctatattta 1860
tttttaaata tactgtgtgg gatacttagt ggtatatgtc tctgagtttg gattagtgtt 1920
tctaaattgg tagttatttt gaatgtcaca aatggattaa ggaatcaacg tatcaagagt 1980
tctatctttc ttccagtcta agtaccaatg ctattgtaaa cgtgtatagt gcctacaaat 2040
tgtatgaaaa cccttttaac cactttactc aagatgttta tcaaatctaa tctcttattc 2100
taataaaaat actatcaagt taaagtaaaa aaaaaaaaaa aaaaaaaaaa a 2151
<210> 66
<211> 393
<212> PRT
<213> Rattus norvegicus
<400> 66
Met Pro Lys Lys Lys Pro Thr Pro Ile Gln Leu Asn Pro Ala Pro Asp
1 5 10 15
Gly Ser Ala Val Asn Gly Thr Ser Ser Ala Glu Thr Asn Leu Glu Ala
20 25 30
Leu Gln Lys Lys Leu Glu Glu Leu Glu Leu Asp Glu Gln Gln Arg Lys
35 40 45
Arg Leu Glu Ala Phe Leu Thr Gln Lys Gln Lys Val Gly Glu Leu Lys
50 55 60
Asp Asp Asp Phe Glu Lys Ile Ser Glu Leu Gly Ala Gly Asn Gly Gly
65 70 75 80
Val Val Phe Lys Val Ser His Lys Pro Ser Gly Leu Val Met Ala Arg
85 90 95
Lys Leu Ile His Leu Glu Ile Lys Pro Ala Ile Arg Asn Gln Ile Ile
100 105 110
Arg Glu Leu Gln Val Leu His Glu Cys Asn Ser Pro Tyr Ile Val Gly
115 120 125
Phe Tyr Gly Ala Phe Tyr Ser Asp Gly Glu Ile Ser Ile Cys Met Glu
130 135 140
His Met Asp Gly Gly Ser Leu Asp Gln Val Leu Lys Lys Ala Gly Arg
145 150 155 160
Ile Pro Glu Gln Ile Leu Gly Lys Val Ser Ile Ala Val Ile Lys Gly
165 170 175
Leu Thr Tyr Leu Arg Glu Lys His Lys Ile Met His Arg Asp Val Lys
180 185 190
Pro Ser Asn Ile Leu Val Asn Ser Arg Gly Glu Ile Lys Leu Cys Asp
195 200 205
Phe Gly Val Ser Gly Gln Leu Ile Asp Ser Met Ala Asn Ser Phe Val
210 215 220
Gly Thr Arg Ser Tyr Met Ser Pro Glu Arg Leu Gln Gly Thr His Tyr
225 230 235 240
Ser Val Gln Ser Asp Ile Trp Ser Met Gly Leu Ser Leu Val Glu Met
245 250 255
Ala Val Gly Arg Tyr Pro Ile Pro Pro Pro Asp Ala Lys Glu Leu Glu
260 265 270
Leu Leu Phe Gly Cys Gln Val Glu Gly Asp Ala Ala Glu Thr Pro Pro
275 280 285
Arg Pro Arg Thr Pro Gly Arg Pro Leu Ser Ser Tyr Gly Met Asp Ser
290 295 300
Arg Pro Pro Met Ala Ile Phe Glu Leu Leu Asp Tyr Ile Val Asn Glu
305 310 315 320
Pro Pro Pro Lys Leu Pro Ser Gly Val Phe Ser Leu Glu Phe Gln Asp
325 330 335
Phe Val Asn Lys Cys Leu Ile Lys Asn Pro Ala Glu Arg Ala Asp Leu
340 345 350
Lys Gln Leu Met Val His Ala Phe Ile Lys Arg Ser Asp Ala Glu Glu
355 360 365
Val Asp Phe Ala Gly Trp Leu Cys Ser Thr Ile Gly Leu Asn Gln Pro
370 375 380
Ser Thr Pro Thr His Ala Ala Ser Ile
385 390
<210> 67
<211> 2387
<212> DNA
<213> Mus musculus
<400> 67
agtccctcac tgggacgtct gtgcgcggcg tctcggagcg ccggagcagc ggtggccgca 60
ctttctccaa gctggggctg tagctgagct gtgggtagtg cgcagggagc cgtccgagcc 120
cgaggaaccg gtgtgctgag gcgagagttc ccggccggcg agcgcgcgca gctggttctc 180
cgcgtgggtt gggcggaggg tcccaggagc gcggcgttga tcgagccgcc ccgactctgg 240
gcagagccga gggaggaagc gagaagcggc cgcgcgctcc ctgctgagtt gcaggctctt 300
tcccggctgc aagatgccca agaagaagcc gacgcccatc cagctgaacc cggcccccga 360
tggctcggcg gttaacggga ccagctcggc cgagaccaac ctggaggcct tgcagaagaa 420
gctggaggag ctggagcttg acgagcagca gcggaagcgg ctcgaggcct ttctgacgca 480
gaagcagaag gtgggggaac tgaaggatga tgactttgag aagatcagcg aactgggagc 540
tggcaacggt ggagtggtct tcaaggtctc ccacaagcca tctggcctgg ttatggctag 600
aaagctgatc cacctggaga tcaaacccgc aatccggaac cagatcatcc gggagctgca 660
ggtactgcac gagtgcaact ccccgtacat cgtgggcttc tacggggcct tctacagcga 720
cggcgagatc agcatctgca tggagcacat ggatggtggg tccttggatc aagttctgaa 780
gaaagctgga agaattcctg agcaaatttt aggaaaagtt agcattgctg tgataaaagg 840
cctgacctat cttcgggaga agcacaagat tatgcacaga gatgtcaagc catccaacat 900
tctagtgaac tcacgtgggg agatcaaact ctgtgatttt ggggtcagcg ggcagctaat 960
tgactctatg gccaactcct tcgtgggcac gagatcctac atgtcgcctg agagactcca 1020
ggggactcac tactctgtgc agtcggacat ctggagcatg gggctctctc tggtggagat 1080
ggcagttggg agatacccca ttcctcctcc tgatgccaag gagctggagc tactgtttgg 1140
atgccatgtg gaaggagacg cagccgaaac accacccagg ccaaggaccc ctgggaggcc 1200
tctcagctca tatggaatgg acagccgacc tcccatggca atttttgagt tgttggatta 1260
cattgtcaat gagcctcctc caaaactgcc cagtggagta ttcagtctgg agtttcagga 1320
ttttgtgaat aaatgcttaa taaagaaccc tgcagagaga gcagatctga agcagctcat 1380
ggtacatgct ttcatcaaaa gatctgacgc cgaggaggta gacttcgcag gctggctctg 1440
ctccaccatt gggcttaacc agcccagcac accaacccac gctgccagca tctgagcctt 1500
taggaagcag caaagaggaa ttctctgccc agtggcatgc catgttgctt tcaggcctct 1560
cccatgcttg tctatgttca gacgtgcatc tcatctgtga caaaggatga agaacacagc 1620
atgtgccaaa ttgtacttgt gtcattttta atatcattgt ctttatcact atggttactc 1680
ccctaagtgg attggctttg tgcttggggc tatttgtctg ttcatcaaac acatgccagg 1740
ctgaactaca gtgaaaccct agtgacctgg gtggtcgttc ttactgatgt ttgcactgct 1800
gttcatcgtg actcactagc tggctgcctg tattgtcagg attctcggac cttggtactt 1860
cactcttgct ggtgacctct cagtctgaga gggagccttg tgagaccctt cacaggcagt 1920
gcatgcatgg aaagcatgct ttgctgctac tgaaatgagc atcagaacgt gtacgtcatg 1980
gtatttttat tttttgcttt tggtatagaa ctcagcaatt cccatcaaaa aaacctaagc 2040
agagcccatc actgccatga tagctgggct tcagtctgtc tactgtggtg atttttagac 2100
ttctggttgt atttctatat ttatttttaa atatacagtg tgggatactt agtggtgtgt 2160
gtctctaagt ttggattagt gtttctaaat tggtggttat tttgaatgtc acaaatggat 2220
taaagcatca atgtatcaag agttctatct ttcttccagt ctaagtacca atgctattgt 2280
aaacaacgtg tatagtgcct acaaattgta tgaaacccct tttaaccact ttaatcaaga 2340
tgtttatcaa atctaatctc ttattctaat aaaaatacta tcaagtt 2387
<210> 68
<211> 393
<212> PRT
<213> Mus musculus
<400> 68
Met Pro Lys Lys Lys Pro Thr Pro Ile Gln Leu Asn Pro Ala Pro Asp
1 5 10 15
Gly Ser Ala Val Asn Gly Thr Ser Ser Ala Glu Thr Asn Leu Glu Ala
20 25 30
Leu Gln Lys Lys Leu Glu Glu Leu Glu Leu Asp Glu Gln Gln Arg Lys
35 40 45
Arg Leu Glu Ala Phe Leu Thr Gln Lys Gln Lys Val Gly Glu Leu Lys
50 55 60
Asp Asp Asp Phe Glu Lys Ile Ser Glu Leu Gly Ala Gly Asn Gly Gly
65 70 75 80
Val Val Phe Lys Val Ser His Lys Pro Ser Gly Leu Val Met Ala Arg
85 90 95
Lys Leu Ile His Leu Glu Ile Lys Pro Ala Ile Arg Asn Gln Ile Ile
100 105 110
Arg Glu Leu Gln Val Leu His Glu Cys Asn Ser Pro Tyr Ile Val Gly
115 120 125
Phe Tyr Gly Ala Phe Tyr Ser Asp Gly Glu Ile Ser Ile Cys Met Glu
130 135 140
His Met Asp Gly Gly Ser Leu Asp Gln Val Leu Lys Lys Ala Gly Arg
145 150 155 160
Ile Pro Glu Gln Ile Leu Gly Lys Val Ser Ile Ala Val Ile Lys Gly
165 170 175
Leu Thr Tyr Leu Arg Glu Lys His Lys Ile Met His Arg Asp Val Lys
180 185 190
Pro Ser Asn Ile Leu Val Asn Ser Arg Gly Glu Ile Lys Leu Cys Asp
195 200 205
Phe Gly Val Ser Gly Gln Leu Ile Asp Ser Met Ala Asn Ser Phe Val
210 215 220
Gly Thr Arg Ser Tyr Met Ser Pro Glu Arg Leu Gln Gly Thr His Tyr
225 230 235 240
Ser Val Gln Ser Asp Ile Trp Ser Met Gly Leu Ser Leu Val Glu Met
245 250 255
Ala Val Gly Arg Tyr Pro Ile Pro Pro Pro Asp Ala Lys Glu Leu Glu
260 265 270
Leu Leu Phe Gly Cys His Val Glu Gly Asp Ala Ala Glu Thr Pro Pro
275 280 285
Arg Pro Arg Thr Pro Gly Arg Pro Leu Ser Ser Tyr Gly Met Asp Ser
290 295 300
Arg Pro Pro Met Ala Ile Phe Glu Leu Leu Asp Tyr Ile Val Asn Glu
305 310 315 320
Pro Pro Pro Lys Leu Pro Ser Gly Val Phe Ser Leu Glu Phe Gln Asp
325 330 335
Phe Val Asn Lys Cys Leu Ile Lys Asn Pro Ala Glu Arg Ala Asp Leu
340 345 350
Lys Gln Leu Met Val His Ala Phe Ile Lys Arg Ser Asp Ala Glu Glu
355 360 365
Val Asp Phe Ala Gly Trp Leu Cys Ser Thr Ile Gly Leu Asn Gln Pro
370 375 380
Ser Thr Pro Thr His Ala Ala Ser Ile
385 390
<210> 69
<211> 1182
<212> DNA
<213> Oryctolagus cuniculus
<400> 69
atgccaaaga agaagcccac ccccatccag ctgaatcctg cccctgacgg ctcggcggtg 60
aatggtacca gctcggcgga gaccaacctg gaggccttgc agaagaagct ggaggagctg 120
gagcttgacg agcagcagcg gaagcgcctg gaggccttcc tcacccagaa gcagaaagtg 180
ggagagctga aggacgatga cttcgagaag atcagtgagc tgggagccgg caacggcggc 240
gtggtgttca aggtctccca caagcccagt ggcctggtga tggccagaaa gcttattcac 300
ctggagatca aacctgctat ccggaaccag atcataaggg agctgcaggt tctgcacgag 360
tgcaactccc cgtacatcgt gggcttctac ggggcattct acagcgatgg cgagatcagc 420
atctgcatgg agcacatgga cgggggttcc ttggatcaag tcctgaagaa agctggacgg 480
attcccgagc aaattttggg gaaagttagc attgctgtga tcaagggcct gacgtatctg 540
agggagaagc acaagatcat gcacagagat gtgaagccct ccaacatcct ggtcaactcc 600
cgcggggaga tcaagctctg tgacttcggg gtcagtgggc agctcatcga ctccatggcc 660
aactccttcg tgggcaccag gtcttatatg tcgcccgaga gactccaggg gacacactac 720
tctgtgcagt cggacatctg gagcatgggg ctgtccctgg tggagatggc ggtggggcgg 780
taccccatcc cgccccccga cgccaaggag ctggagctga tgtttgggtg ccaggtggag 840
ggcgatgcgg ccgagactcc gcccaggccc aggacccctg ggcggcccct cagctcgtat 900
ggaatggata gccggcctcc catggcgatt tttgagctgc tggattacat cgtcaatgag 960
cctcctccga aactccccag cgcagtcttc agcctggagt ttcaagattt tgtgaataaa 1020
tgcttaataa aaaaccccgc cgagagagca gacttgaagc agctcatggt tcatgctttt 1080
atcaagaggt ctgatgccga ggaggtggat tttgctggtt ggctgtgctc caccatcggc 1140
cttaaccagc ccagcacgcc gacgcacgcg gccggtgtgt ga 1182
<210> 70
<211> 393
<212> PRT
<213> Oryctolagus cuniculus
<400> 70
Met Pro Lys Lys Lys Pro Thr Pro Ile Gln Leu Asn Pro Ala Pro Asp
1 5 10 15
Gly Ser Ala Val Asn Gly Thr Ser Ser Ala Glu Thr Asn Leu Glu Ala
20 25 30
Leu Gln Lys Lys Leu Glu Glu Leu Glu Leu Asp Glu Gln Gln Arg Lys
35 40 45
Arg Leu Glu Ala Phe Leu Thr Gln Lys Gln Lys Val Gly Glu Leu Lys
50 55 60
Asp Asp Asp Phe Glu Lys Ile Ser Glu Leu Gly Ala Gly Asn Gly Gly
65 70 75 80
Val Val Phe Lys Val Ser His Lys Pro Ser Gly Leu Val Met Ala Arg
85 90 95
Lys Leu Ile His Leu Glu Ile Lys Pro Ala Ile Arg Asn Gln Ile Ile
100 105 110
Arg Glu Leu Gln Val Leu His Glu Cys Asn Ser Pro Tyr Ile Val Gly
115 120 125
Phe Tyr Gly Ala Phe Tyr Ser Asp Gly Glu Ile Ser Ile Cys Met Glu
130 135 140
His Met Asp Gly Gly Ser Leu Asp Gln Val Leu Lys Lys Ala Gly Arg
145 150 155 160
Ile Pro Glu Gln Ile Leu Gly Lys Val Ser Ile Ala Val Ile Lys Gly
165 170 175
Leu Thr Tyr Leu Arg Glu Lys His Lys Ile Met His Arg Asp Val Lys
180 185 190
Pro Ser Asn Ile Leu Val Asn Ser Arg Gly Glu Ile Lys Leu Cys Asp
195 200 205
Phe Gly Val Ser Gly Gln Leu Ile Asp Ser Met Ala Asn Ser Phe Val
210 215 220
Gly Thr Arg Ser Tyr Met Ser Pro Glu Arg Leu Gln Gly Thr His Tyr
225 230 235 240
Ser Val Gln Ser Asp Ile Trp Ser Met Gly Leu Ser Leu Val Glu Met
245 250 255
Ala Val Gly Arg Tyr Pro Ile Pro Pro Pro Asp Ala Lys Glu Leu Glu
260 265 270
Leu Met Phe Gly Cys Gln Val Glu Gly Asp Ala Ala Glu Thr Pro Pro
275 280 285
Arg Pro Arg Thr Pro Gly Arg Pro Leu Ser Ser Tyr Gly Met Asp Ser
290 295 300
Arg Pro Pro Met Ala Ile Phe Glu Leu Leu Asp Tyr Ile Val Asn Glu
305 310 315 320
Pro Pro Pro Lys Leu Pro Ser Ala Val Phe Ser Leu Glu Phe Gln Asp
325 330 335
Phe Val Asn Lys Cys Leu Ile Lys Asn Pro Ala Glu Arg Ala Asp Leu
340 345 350
Lys Gln Leu Met Val His Ala Phe Ile Lys Arg Ser Asp Ala Glu Glu
355 360 365
Val Asp Phe Ala Gly Trp Leu Cys Ser Thr Ile Gly Leu Asn Gln Pro
370 375 380
Ser Thr Pro Thr His Ala Ala Gly Val
385 390
<210> 71
<211> 1872
<212> DNA
<213> Cavia porcellus
<400> 71
cgtgtcttcg tcgggaccgc cctcctcctt gagtcctccc cccaccggga cggccgagtg 60
gagaggccgg acgaaggcgg cggccccggc ggcggctttt cctcggcttc gctgtgcagc 120
gtgcgcggcg aggttgaccg cccgcgagcg cccgtgactg agggaacagg gagagagctc 180
gggcggccga gcgcgcagcc ctccgtgggc attgccgcct ggacctcccg gaaggcaccc 240
cgggccgcgg ccgccacccg tcccgccctc gttcggagct gagacgccgt cgccgcgcaa 300
gatgcccaag aagaagccga cgcccatcca gctgaacccg gcccccgacg gctcggcggt 360
gaacgggacc agctcggccg agaccaacct agaggctttg cagaagaagc tggaggagct 420
ggagctggat gagcagcagc ggaagcgcct cgaagctttc ctgacacaga agcagaaggt 480
gggcgagctg aaggacgatg actttgagaa gatcagtgag ctgggtgccg gcaatggcgg 540
tgtggtgttc aaggtctccc acaagccatc tggcctggtc atggcccgaa agcttatcca 600
cctggagatc aagccagcca tccgcaatca gatcatccgt gagctgcagg ttctgcacga 660
gtgcaactcg ccctacattg tgggcttcta tggggccttc tacagtgatg gcgagatcag 720
catctgcatg gagcacatgg atggaggttc cttggatcaa gtcctgaaga aagctggaag 780
aattcctgag caaattttag gaaaagttag cattgctgtg atcaaaggcc tgacatacct 840
gagggagaag cacaagatta tgcacagaga tgtcaagccc tccaacatcc tggtcaactc 900
ccgcggggag atcaagctct gtgactttgg ggtcagcggg cagctcatcg attccatggc 960
caactccttc gtgggcaccc ggtcctacat gtcgccagag agactgcagg gcacacacta 1020
ctcagtgcag tcggacatct ggagcatggg actgtcactg gtggagatgg cggttgggag 1080
gtaccccatc ccccctccag atgccaagga gctggagctg gtgttcgggt gccaggtgga 1140
aggagatgca gctgagatgc cgcccaggcc caggaccccc ggaagacccc tgagctcata 1200
tggaatggac agccggcctc ccatggcgat tttcgagctg ttggattaca tagtcaacga 1260
gccacctccc aaactgccca gtggagtctt cagtctggaa ttccaggact ttgtaaataa 1320
atgcttaata aagaaccctg cggagagagc agacttgaag cagctcatgg ttcatgcctt 1380
catcaagcgc tctgatgctg aggaggtgga cttcgcaggt tggctctgtg ccaccatcgg 1440
ccttaaccag cccagtaccc cgacccacgt ggccagcatc tgagctgcgg cccggcccag 1500
acgtgctctg ccagcagccg ctatgctctg gcctctccct cgcttctctt cagacgtgcg 1560
tttcacctcc gaccagggtg cagacacagc atgtgccaag ctgtatttgt gttccttttc 1620
agtctttatt gccaccgtgt cacccgagtg gatttgcttt gtgcttaggg ctgtttgtgc 1680
tgatgatcac acacacgctg agctgaacag tgacacttgg tgatgtggtt gtcactgttc 1740
tcactccatg tggctggcct gttgcctcca gtgtctccag acttggggat gtctggtggc 1800
acttcccctg ccagggcatc tcctcagcag agagggaggc ctctgggccc ttgtccttgg 1860
cagtgcaagt ga 1872
<210> 72
<211> 393
<212> PRT
<213> Cavia porcellus
<400> 72
Met Pro Lys Lys Lys Pro Thr Pro Ile Gln Leu Asn Pro Ala Pro Asp
1 5 10 15
Gly Ser Ala Val Asn Gly Thr Ser Ser Ala Glu Thr Asn Leu Glu Ala
20 25 30
Leu Gln Lys Lys Leu Glu Glu Leu Glu Leu Asp Glu Gln Gln Arg Lys
35 40 45
Arg Leu Glu Ala Phe Leu Thr Gln Lys Gln Lys Val Gly Glu Leu Lys
50 55 60
Asp Asp Asp Phe Glu Lys Ile Ser Glu Leu Gly Ala Gly Asn Gly Gly
65 70 75 80
Val Val Phe Lys Val Ser His Lys Pro Ser Gly Leu Val Met Ala Arg
85 90 95
Lys Leu Ile His Leu Glu Ile Lys Pro Ala Ile Arg Asn Gln Ile Ile
100 105 110
Arg Glu Leu Gln Val Leu His Glu Cys Asn Ser Pro Tyr Ile Val Gly
115 120 125
Phe Tyr Gly Ala Phe Tyr Ser Asp Gly Glu Ile Ser Ile Cys Met Glu
130 135 140
His Met Asp Gly Gly Ser Leu Asp Gln Val Leu Lys Lys Ala Gly Arg
145 150 155 160
Ile Pro Glu Gln Ile Leu Gly Lys Val Ser Ile Ala Val Ile Lys Gly
165 170 175
Leu Thr Tyr Leu Arg Glu Lys His Lys Ile Met His Arg Asp Val Lys
180 185 190
Pro Ser Asn Ile Leu Val Asn Ser Arg Gly Glu Ile Lys Leu Cys Asp
195 200 205
Phe Gly Val Ser Gly Gln Leu Ile Asp Ser Met Ala Asn Ser Phe Val
210 215 220
Gly Thr Arg Ser Tyr Met Ser Pro Glu Arg Leu Gln Gly Thr His Tyr
225 230 235 240
Ser Val Gln Ser Asp Ile Trp Ser Met Gly Leu Ser Leu Val Glu Met
245 250 255
Ala Val Gly Arg Tyr Pro Ile Pro Pro Pro Asp Ala Lys Glu Leu Glu
260 265 270
Leu Val Phe Gly Cys Gln Val Glu Gly Asp Ala Ala Glu Met Pro Pro
275 280 285
Arg Pro Arg Thr Pro Gly Arg Pro Leu Ser Ser Tyr Gly Met Asp Ser
290 295 300
Arg Pro Pro Met Ala Ile Phe Glu Leu Leu Asp Tyr Ile Val Asn Glu
305 310 315 320
Pro Pro Pro Lys Leu Pro Ser Gly Val Phe Ser Leu Glu Phe Gln Asp
325 330 335
Phe Val Asn Lys Cys Leu Ile Lys Asn Pro Ala Glu Arg Ala Asp Leu
340 345 350
Lys Gln Leu Met Val His Ala Phe Ile Lys Arg Ser Asp Ala Glu Glu
355 360 365
Val Asp Phe Ala Gly Trp Leu Cys Ala Thr Ile Gly Leu Asn Gln Pro
370 375 380
Ser Thr Pro Thr His Val Ala Ser Ile
385 390
<210> 73
<211> 1257
<212> DNA
<213> Canis familiaris
<400> 73
ggagagcgag acacgggccg ctctccgctc ggagccggac gcgccttccc gcgtccaaaa 60
tgcccaagaa gaagccgacg cccatccagc tgaacccggc ccccgacggc tcggcggtga 120
acgggaccag ctcggcggag accaacctgg aggccttgca gaagaagctg gaggagctgg 180
agcttgatga gcagcagcgg aagcgccttg aggcctttct cacccagaag cagaaggtcg 240
gggaactgaa ggatgacgac ttcgagaaga tcagtgagct gggtgctggc aacggtggcg 300
tggtgttcaa ggtctcccac aagccgtccg gcctagtcat ggccagaaag ctaattcacc 360
tggagatcaa acctgcaatc cggaaccaga tcataaggga gctacaggtt ctacatgagt 420
gcaactcccc gtacatcgtg ggcttctatg gtgcattcta cagcgatggc gagatcagta 480
tctgcatgga gcacatggat gggggttcct tggatcaagt cctgaagaaa gctggaagaa 540
ttcctgaaca aattctagga aaagttagca tcgctgtaat aaaaggtctg acatacctga 600
gagagaagca caagattatg cacagagatg tcaagccttc caacatcctc gtgaactccc 660
gtggggagat caagctctgt gactttgggg tcagcgggca gctcattgac tccatggcca 720
actccttcgt gggcacaagg tcctacatgt cgccagaaag actccagggg actcattact 780
ccgtgcagtc ggacatctgg agcatggggc tctctctggt ggagatggca gttgggaggt 840
atcccatccc tcctccggat gccaaggagc tggagctgat gtttgggtgc caagtggagg 900
gagacgtggc tgagacccca cccagaccaa ggaccccggg aagacccctt agctcttatg 960
gaatggacag ccgaccgccc atggcaattt ttgagctgtt ggattacata gtcaacgagc 1020
cccctccaaa actgcccagt ggagtattca gtctggaatt tcaagatttt gtgaataaat 1080
gcttaataaa aaacccagca gagagagcag atctgaagca actcatggtt catgccttca 1140
tcaagagatc tgacggtgaa gaagtggatt ttgcaggttg gctctgctcc ccccattggc 1200
cttaaccagc ccagcacgcc gacccacgca gctggcgtct aactcgagtc tagagat 1257
<210> 74
<211> 381
<212> PRT
<213> Canis familiaris
<400> 74
Met Pro Lys Lys Lys Pro Thr Pro Ile Gln Leu Asn Pro Ala Pro Asp
1 5 10 15
Gly Ser Ala Val Asn Gly Thr Ser Ser Ala Glu Thr Asn Leu Glu Ala
20 25 30
Leu Gln Lys Lys Leu Glu Glu Leu Glu Leu Asp Glu Gln Gln Arg Lys
35 40 45
Arg Leu Glu Ala Phe Leu Thr Gln Lys Gln Lys Val Gly Glu Leu Lys
50 55 60
Asp Asp Asp Phe Glu Lys Ile Ser Glu Leu Gly Ala Gly Asn Gly Gly
65 70 75 80
Val Val Phe Lys Val Ser His Lys Pro Ser Gly Leu Val Met Ala Arg
85 90 95
Lys Leu Ile His Leu Glu Ile Lys Pro Ala Ile Arg Asn Gln Ile Ile
100 105 110
Arg Glu Leu Gln Val Leu His Glu Cys Asn Ser Pro Tyr Ile Val Gly
115 120 125
Phe Tyr Gly Ala Phe Tyr Ser Asp Gly Glu Ile Ser Ile Cys Met Glu
130 135 140
His Met Asp Gly Gly Ser Leu Asp Gln Val Leu Lys Lys Ala Gly Arg
145 150 155 160
Ile Pro Glu Gln Ile Leu Gly Lys Val Ser Ile Ala Val Ile Lys Gly
165 170 175
Leu Thr Tyr Leu Arg Glu Lys His Lys Ile Met His Arg Asp Val Lys
180 185 190
Pro Ser Asn Ile Leu Val Asn Ser Arg Gly Glu Ile Lys Leu Cys Asp
195 200 205
Phe Gly Val Ser Gly Gln Leu Ile Asp Ser Met Ala Asn Ser Phe Val
210 215 220
Gly Thr Arg Ser Tyr Met Ser Pro Glu Arg Leu Gln Gly Thr His Tyr
225 230 235 240
Ser Val Gln Ser Asp Ile Trp Ser Met Gly Leu Ser Leu Val Glu Met
245 250 255
Ala Val Gly Arg Tyr Pro Ile Pro Pro Pro Asp Ala Lys Glu Leu Glu
260 265 270
Leu Met Phe Gly Cys Gln Val Glu Gly Asp Val Ala Glu Thr Pro Pro
275 280 285
Arg Pro Arg Thr Pro Gly Arg Pro Leu Ser Ser Tyr Gly Met Asp Ser
290 295 300
Arg Pro Pro Met Ala Ile Phe Glu Leu Leu Asp Tyr Ile Val Asn Glu
305 310 315 320
Pro Pro Pro Lys Leu Pro Ser Gly Val Phe Ser Leu Glu Phe Gln Asp
325 330 335
Phe Val Asn Lys Cys Leu Ile Lys Asn Pro Ala Glu Arg Ala Asp Leu
340 345 350
Lys Gln Leu Met Val His Ala Phe Ile Lys Arg Ser Asp Gly Glu Glu
355 360 365
Val Asp Phe Ala Gly Trp Leu Cys Ser Pro His Trp Pro
370 375 380
<210> 75
<211> 2095
<212> DNA
<213> Felis catus
<400> 75
agccggcaag gagttgagcg tgcggggtgc ataggcgcgg gtcgtgggag atgaagctgg 60
agaggaccaa cctggaggcc ttgcagaaga agctggagga gctggagctc gatgagcagc 120
aacggaagcg cctggaggcc tttcttaccc agaagcagaa ggtcggggaa ttgaaggatg 180
acgacttcga gaagatcagc gagctgggcg ctggcaacgg tggtgtggtg ttcaaggtct 240
cccataagcc gtctggcctg gtcatggcca gaaagctaat tcacctggag atcaaacctg 300
caatccggaa ccagatcata agggagctgc aggttctaca tgagtgcaac tccccataca 360
tcgtgggctt ctatggcgcg ttctacagcg acggcgagat cagtatctgt atggagcaca 420
tggatggggg ttccttggat caagtcctga agaaagctgg aagaattcct gaacaaattt 480
taggaaaagt tagcattgct gtaataaaag gtctgacata cctgagggag aagcacaaga 540
ttatgcacag agatgtcaag ccttccaaca tcctagtgaa ctctcgtggg gagatcaagc 600
tctgtgactt tggggtcagc gggcagctca tcgactccat ggccaactcc ttcgtgggca 660
caaggtccta catgtcgcca gaaagactcc aggggactca ttactccgtg cagtcggaca 720
tctggagcat ggggctatct ctggttgaga tggcagtcgg gaggtatccc atccctcctc 780
ccgatgccaa ggagctggag ctgatgtttg ggtgccaagt ggagggagat gcggctgaga 840
cgccacccag gccgaggacc cccggaaggc ccctcagctc gtatggaatg gacagccgac 900
ctcccatggc aatttttgag ttgttggatt acatagtcaa cgagcctcct ccaaagctgc 960
ccagtggagt attcagtctg gaatttcaag attttgtgaa taaatgcctc ataaaaaacc 1020
cagcagagag agcagatctg aaacaactca tggttcatgc ctttatcaag agatctgatg 1080
gtgaggaagt ggattttgca ggttggctct gctccaccat cggccttaac cagcccagca 1140
caccgaccca cgcggccggc gtctaagtat ctgggaagca gcaaagagcg agtcccctgc 1200
ccagtggtgt gccattgtcg ctttcaggcc tctttgccat gcctgtctcc gttcagacgt 1260
gcatttcgcc tacgacaaag gatgaagaac acagcatgtg ccaaaattct atttgtgtct 1320
tttttaatat tactgtcatt tattctgtta tttccctaag tggattggct ttgtgcttgg 1380
ggctattttt gtgtatgttg atccaaacat gcgcaacgtt cagttacagt gaaaccttgg 1440
tgactgtggg tagtcattct tactgaaaat tgcactgctc ttcccccacc gtgactggct 1500
agctgcctgt agttttggga ttcttttgac acttggtggt actgcattct tgccgggcgc 1560
accttccttc tgttggggta ggagccttgt aagatccttc acaggcactg catgtgaagc 1620
atgctttgct gctatgaaaa agaacatcag aaagtataga tcttgttatt ttattatatt 1680
tttgcttttg gtgtagaatg aagcaatttc tgtcaaaatc tagccagagc ccttcactgc 1740
cacgatagct ggggcttcac cagtctgtct actgtgatga tttgtagact tctggttgta 1800
tttctatatt tattttaaaa tatattatgt gggatattta gtggtatgtg tctctttaag 1860
tttgaattag tgtttctaaa atgatggtta ctttgaatgt tacaaatgga tcaaggcatt 1920
aaaatgtatg agatttatct ttccccaaat ccaagtaccg atgctattgt aaacaacagt 1980
gtgtatagtg cctaagaatt gtatgaaaat ccttttaacc atttcaaccc agatgtttaa 2040
caaatctaat ctcttattct aataaatata ctatcaagtt aaaaggatga aaaaa 2095
<210> 76
<211> 371
<212> PRT
<213> Felis catus
<400> 76
Met Lys Leu Glu Arg Thr Asn Leu Glu Ala Leu Gln Lys Lys Leu Glu
1 5 10 15
Glu Leu Glu Leu Asp Glu Gln Gln Arg Lys Arg Leu Glu Ala Phe Leu
20 25 30
Thr Gln Lys Gln Lys Val Gly Glu Leu Lys Asp Asp Asp Phe Glu Lys
35 40 45
Ile Ser Glu Leu Gly Ala Gly Asn Gly Gly Val Val Phe Lys Val Ser
50 55 60
His Lys Pro Ser Gly Leu Val Met Ala Arg Lys Leu Ile His Leu Glu
65 70 75 80
Ile Lys Pro Ala Ile Arg Asn Gln Ile Ile Arg Glu Leu Gln Val Leu
85 90 95
His Glu Cys Asn Ser Pro Tyr Ile Val Gly Phe Tyr Gly Ala Phe Tyr
100 105 110
Ser Asp Gly Glu Ile Ser Ile Cys Met Glu His Met Asp Gly Gly Ser
115 120 125
Leu Asp Gln Val Leu Lys Lys Ala Gly Arg Ile Pro Glu Gln Ile Leu
130 135 140
Gly Lys Val Ser Ile Ala Val Ile Lys Gly Leu Thr Tyr Leu Arg Glu
145 150 155 160
Lys His Lys Ile Met His Arg Asp Val Lys Pro Ser Asn Ile Leu Val
165 170 175
Asn Ser Arg Gly Glu Ile Lys Leu Cys Asp Phe Gly Val Ser Gly Gln
180 185 190
Leu Ile Asp Ser Met Ala Asn Ser Phe Val Gly Thr Arg Ser Tyr Met
195 200 205
Ser Pro Glu Arg Leu Gln Gly Thr His Tyr Ser Val Gln Ser Asp Ile
210 215 220
Trp Ser Met Gly Leu Ser Leu Val Glu Met Ala Val Gly Arg Tyr Pro
225 230 235 240
Ile Pro Pro Pro Asp Ala Lys Glu Leu Glu Leu Met Phe Gly Cys Gln
245 250 255
Val Glu Gly Asp Ala Ala Glu Thr Pro Pro Arg Pro Arg Thr Pro Gly
260 265 270
Arg Pro Leu Ser Ser Tyr Gly Met Asp Ser Arg Pro Pro Met Ala Ile
275 280 285
Phe Glu Leu Leu Asp Tyr Ile Val Asn Glu Pro Pro Pro Lys Leu Pro
290 295 300
Ser Gly Val Phe Ser Leu Glu Phe Gln Asp Phe Val Asn Lys Cys Leu
305 310 315 320
Ile Lys Asn Pro Ala Glu Arg Ala Asp Leu Lys Gln Leu Met Val His
325 330 335
Ala Phe Ile Lys Arg Ser Asp Gly Glu Glu Val Asp Phe Ala Gly Trp
340 345 350
Leu Cys Ser Thr Ile Gly Leu Asn Gln Pro Ser Thr Pro Thr His Ala
355 360 365
Ala Gly Val
370
<210> 77
<211> 2405
<212> DNA
<213> Bos taurus
<400> 77
ccggttgact gagggagagt gggagggaat cccgggctgc cgagctgcgc cggcggggaa 60
gcccttcggt tccctgtgca ctgagcaagt gggccggggg gttcccccag accgccactg 120
gccctttggc cctgacggga ccgcgcaggg cgcgcccccc gaaggcagcc ttcgggcttg 180
cggcccagac ttggccccgc gaggccggcg cggggcagct cagagggagg aagctagagg 240
ggccgccctc agagttggga gcgcctttcc tgggtccaaa atgcccaaga agaagccgac 300
gcccatccag ctgaacccgg ccccggacgg ctccgcggtt aacgggacca gctcggcgga 360
gaccaacctg gaggccttgc agaagaagct ggaggagctg gagctcgatg aacagcagcg 420
gaagcgcctc gaggcctttc tgacccagaa gcagaaggtg ggggaactga aggatgatga 480
ctttgagaag atcagtgagc tgggtgccgg caatggaggt gtggtgttca aggtctccca 540
caagccgtcc ggacttgtta tggccagaaa gctaattcac ctggagatca aacctgccat 600
ccggaaccag atcataaggg agctgcaggt tctccatgag tgcaactcgc cttatatcgt 660
gggcttctac ggggcgttct acagcgacgg cgagatcagc atctgcatgg agcacatgga 720
tgggggttcc ttggatcaag ttctgaagaa agctggaaga attcctgaac aaattttagg 780
aaaagttagc attgctgtaa taaaaggcct gacatacctg agggagaagc acaagattat 840
gcacagagat gtcaagccgt ccaacatcct agtgaacagc cgtggagaga tcaagctctg 900
tgactttggg gtcagcgggc agctcatcga ctccatggcc aactccttcg tgggcaccag 960
gtcctacatg tcgccagagc gactccaggg gacccattac tccgtgcagt cggacatctg 1020
gagcatgggg ctctctctgg ttgagatggc tgtcgggagg tatcccatcc ctcctccaga 1080
tgccaaggag ctggagctga tgtttgggtg ccaggtggag ggagatgcgg ctgagacccc 1140
gcccaggcca aggacccccg ggaggcccct cagctcttat ggaatggaca gccgacctcc 1200
aatggcaatt tttgagttgt tggattacat agtcaatgag cctcctccaa aactgcccag 1260
tggagtattc agtctggaat ttcaagattt tgtgaataaa tgcttaataa aaaaccccgc 1320
agagagagca gatttgaagc aactcatggt tcatgctttt atcaagagat ctgatgctga 1380
ggaagtggat tttgcaggtt ggctctgctc caccatcggc cttaaccaac ccagcacacc 1440
cacccatgcg gctggcgtct aagtggttgg gaagcagcag tccctgccca agggcatgca 1500
ctgttgcttc cgggcagcct tcccatgcct gtctctgttc agacgtgcat ttcacctatg 1560
acaaaggatg aagaacacag catgtgccaa aattctattt gtgtcatttt caatattatc 1620
atctttactc ttattactat tgttattccc ctaagtggat tggctttgtg cttggggcta 1680
tttttgtgta tattgatgat gaagacatgt gcaatgtaga attacagtga aactctggtg 1740
actgtgggta gtcattctta ctgaaaactg cactgctttc ccacaccatg aactggctgg 1800
tcgcctctat tttcgggatt ctttgacact tggtggtact tcattcttgc caggcatacc 1860
ttctaactga gtaggaagga gccttgtaag atccttcaca ggcagtgcat gtgaagcatg 1920
ctttgctgct ataaaaatga gcatcagaaa gtgtgtatca tgttatttta ttatgttctt 1980
gcttttggtg tagaattcag caaattttca tcaaaatcta gccagagccc ttcactgcca 2040
tgatagctgg ggcttcacca gtctgtctac tgtgatgatt tgtagacttc tggttgtatt 2100
tctgtattta tttttaaatc taccgtgtgg atatttagtg ctatgtctct ttaagtttgg 2160
attagtgttt ctaaaatggt ggagttgctc tgaatgttac aaatggatca aggcattaaa 2220
atgaatgaga tctacctttc accaagtact gatgctattg taaacaacag tgtgtatagt 2280
gcctaacaac tgtatgaaaa tccttttacc attttaatcc agatgtttaa caagcctaat 2340
ctcttactct aataaatata ctatcaaatt caaaggaaaa aaaaaaaaaa aaaaaaaaaa 2400
aaaaa 2405
<210> 78
<211> 393
<212> PRT
<213> Bos taurus
<400> 78
Met Pro Lys Lys Lys Pro Thr Pro Ile Gln Leu Asn Pro Ala Pro Asp
1 5 10 15
Gly Ser Ala Val Asn Gly Thr Ser Ser Ala Glu Thr Asn Leu Glu Ala
20 25 30
Leu Gln Lys Lys Leu Glu Glu Leu Glu Leu Asp Glu Gln Gln Arg Lys
35 40 45
Arg Leu Glu Ala Phe Leu Thr Gln Lys Gln Lys Val Gly Glu Leu Lys
50 55 60
Asp Asp Asp Phe Glu Lys Ile Ser Glu Leu Gly Ala Gly Asn Gly Gly
65 70 75 80
Val Val Phe Lys Val Ser His Lys Pro Ser Gly Leu Val Met Ala Arg
85 90 95
Lys Leu Ile His Leu Glu Ile Lys Pro Ala Ile Arg Asn Gln Ile Ile
100 105 110
Arg Glu Leu Gln Val Leu His Glu Cys Asn Ser Pro Tyr Ile Val Gly
115 120 125
Phe Tyr Gly Ala Phe Tyr Ser Asp Gly Glu Ile Ser Ile Cys Met Glu
130 135 140
His Met Asp Gly Gly Ser Leu Asp Gln Val Leu Lys Lys Ala Gly Arg
145 150 155 160
Ile Pro Glu Gln Ile Leu Gly Lys Val Ser Ile Ala Val Ile Lys Gly
165 170 175
Leu Thr Tyr Leu Arg Glu Lys His Lys Ile Met His Arg Asp Val Lys
180 185 190
Pro Ser Asn Ile Leu Val Asn Ser Arg Gly Glu Ile Lys Leu Cys Asp
195 200 205
Phe Gly Val Ser Gly Gln Leu Ile Asp Ser Met Ala Asn Ser Phe Val
210 215 220
Gly Thr Arg Ser Tyr Met Ser Pro Glu Arg Leu Gln Gly Thr His Tyr
225 230 235 240
Ser Val Gln Ser Asp Ile Trp Ser Met Gly Leu Ser Leu Val Glu Met
245 250 255
Ala Val Gly Arg Tyr Pro Ile Pro Pro Pro Asp Ala Lys Glu Leu Glu
260 265 270
Leu Met Phe Gly Cys Gln Val Glu Gly Asp Ala Ala Glu Thr Pro Pro
275 280 285
Arg Pro Arg Thr Pro Gly Arg Pro Leu Ser Ser Tyr Gly Met Asp Ser
290 295 300
Arg Pro Pro Met Ala Ile Phe Glu Leu Leu Asp Tyr Ile Val Asn Glu
305 310 315 320
Pro Pro Pro Lys Leu Pro Ser Gly Val Phe Ser Leu Glu Phe Gln Asp
325 330 335
Phe Val Asn Lys Cys Leu Ile Lys Asn Pro Ala Glu Arg Ala Asp Leu
340 345 350
Lys Gln Leu Met Val His Ala Phe Ile Lys Arg Ser Asp Ala Glu Glu
355 360 365
Val Asp Phe Ala Gly Trp Leu Cys Ser Thr Ile Gly Leu Asn Gln Pro
370 375 380
Ser Thr Pro Thr His Ala Ala Gly Val
385 390
<210> 79
<211> 2146
<212> DNA
<213> Equus caballus
<400> 79
caagtgggaa agcttgggat gcgtggagga gccagctact agtttagtgt gctgggtgcg 60
tcggtgcagg tcgcaggaga tgaagccgga gaggaccaac ctggaggcct tgcagaagaa 120
gctggaggag ctggagctcg atgaacagca gcgaaagcgc cttgaggcct ttcttactca 180
gaagcagaag gttggggaac tgaaggatga tgactttgag aagatcagtg agctgggtgc 240
tggcaatggt ggtgtggtat tcaaggttgc ccacaaaccg tctggtttgg tcatggccag 300
aaagctaatt cacctggaga tcaagcctgc aatccggaac cagatcataa gggagctgca 360
ggttctacat gagtgcaact ccccatatat tgtgggcttc tatggcgcat tctacagcga 420
tggtgagatc agcatctgca tggagcacat ggatgggggt tccttggatc aagtcctaaa 480
gaaagctgga agaattcctg agcaaatttt aggaaaagtt agcattgctg taataaaagg 540
cctgacgtat ctgagggaga agcacaagat tatgcacaga gatgtcaagc cctccaacat 600
cctagtgaac tcccgtgggg agatcaagct gtgtgatttt ggggtcagcg ggcagctcat 660
cgactccatg gccaactcct tcgtgggcac aaggtcttac atgtcgccgg aaagactcca 720
ggggactcat tattcagtgc agtcggacat ctggagcatg gggctctctc tggttgagat 780
ggcggtcggg aggtatccca tccctcctcc agatgccaag gagctggagc tgatgtttgg 840
gtgccaagtg gagggagatg cggctgagac tccgcctagg ccaaggaccc ctggaagacc 900
cctcagctct tatggaatgg acagccgacc tcctatggca atttttgagt tactggatta 960
catagtcaac gagcctcctc ccaagctgcc cagtggagta ttcagtctgg aatttcagga 1020
ttttgtgaat aaatgcttaa tcaaaaaccc tgcagagaga gcagatttga agcaactcat 1080
ggttcacgct tttatcaaga gatctgatgc cgaggaagtg gattttgcag gttggctctg 1140
ctccaccatt ggccttaacc agcccagcac accaacccac gcggctggcg tctaagcgtt 1200
tgggaagcag caaaaagcga gccccctgcc gcgtggtgtg ccatgttgct ttcgggcctc 1260
cttcccatgc ctgtctgttc acacgtgcat ttcacctgtg acaaaggatg aagaacacag 1320
catgtgccaa aattctattt gtgtcatttt taatagtact gtctttattc ttattactat 1380
tgttattccc ctaagtggat tggctttgtg cttgggacta ttttgtgtat gttgatgatc 1440
aaaacatgcg caatgttgaa ttaccgtgaa actggtgact gtgggtagtc cttcttattg 1500
aaaattgcac tgctcttccc tccctgtcac tggctggctg cctgtatttc tggggttctt 1560
tgacacttgg tggtacttca ttcttgcagg gcatacctcc tattcgagta ggaaggagcc 1620
tttaagatcc ttcacaggca gtgcatgtga agcatgcttt gctgctatga aaatgagcat 1680
cagaaagtgt atatcatgtt attttattat tattatgttt ttgcttttgg tgtagaattc 1740
agcaatttcc atcaagatct agccagagcc cttcactgcc atgatagctg gggcttcacc 1800
agtctgccta ctgtgatgat ttgtagactt ctggttgtat ttctatattt atttttaaat 1860
atactgtgtg ggatatttag tggtatatgt ctctctaagt ttggagtggt gtttctaaaa 1920
tggagttact ttgaatgtta tagatggatc aaggcataaa atgtatgaga tttatttttc 1980
cccaaatcca aatactgatg ctattgtaaa caacaaacag tgtgtatagt gcctaaaaat 2040
tgtatgaaag tccttttaac cattttaatc cagatgttta acaaatctaa tctcttattc 2100
taataaatat actatcaagt taaacggaca aaagatttct actttc 2146
<210> 80
<211> 371
<212> PRT
<213> Equus caballus
<400> 80
Met Lys Pro Glu Arg Thr Asn Leu Glu Ala Leu Gln Lys Lys Leu Glu
1 5 10 15
Glu Leu Glu Leu Asp Glu Gln Gln Arg Lys Arg Leu Glu Ala Phe Leu
20 25 30
Thr Gln Lys Gln Lys Val Gly Glu Leu Lys Asp Asp Asp Phe Glu Lys
35 40 45
Ile Ser Glu Leu Gly Ala Gly Asn Gly Gly Val Val Phe Lys Val Ala
50 55 60
His Lys Pro Ser Gly Leu Val Met Ala Arg Lys Leu Ile His Leu Glu
65 70 75 80
Ile Lys Pro Ala Ile Arg Asn Gln Ile Ile Arg Glu Leu Gln Val Leu
85 90 95
His Glu Cys Asn Ser Pro Tyr Ile Val Gly Phe Tyr Gly Ala Phe Tyr
100 105 110
Ser Asp Gly Glu Ile Ser Ile Cys Met Glu His Met Asp Gly Gly Ser
115 120 125
Leu Asp Gln Val Leu Lys Lys Ala Gly Arg Ile Pro Glu Gln Ile Leu
130 135 140
Gly Lys Val Ser Ile Ala Val Ile Lys Gly Leu Thr Tyr Leu Arg Glu
145 150 155 160
Lys His Lys Ile Met His Arg Asp Val Lys Pro Ser Asn Ile Leu Val
165 170 175
Asn Ser Arg Gly Glu Ile Lys Leu Cys Asp Phe Gly Val Ser Gly Gln
180 185 190
Leu Ile Asp Ser Met Ala Asn Ser Phe Val Gly Thr Arg Ser Tyr Met
195 200 205
Ser Pro Glu Arg Leu Gln Gly Thr His Tyr Ser Val Gln Ser Asp Ile
210 215 220
Trp Ser Met Gly Leu Ser Leu Val Glu Met Ala Val Gly Arg Tyr Pro
225 230 235 240
Ile Pro Pro Pro Asp Ala Lys Glu Leu Glu Leu Met Phe Gly Cys Gln
245 250 255
Val Glu Gly Asp Ala Ala Glu Thr Pro Pro Arg Pro Arg Thr Pro Gly
260 265 270
Arg Pro Leu Ser Ser Tyr Gly Met Asp Ser Arg Pro Pro Met Ala Ile
275 280 285
Phe Glu Leu Leu Asp Tyr Ile Val Asn Glu Pro Pro Pro Lys Leu Pro
290 295 300
Ser Gly Val Phe Ser Leu Glu Phe Gln Asp Phe Val Asn Lys Cys Leu
305 310 315 320
Ile Lys Asn Pro Ala Glu Arg Ala Asp Leu Lys Gln Leu Met Val His
325 330 335
Ala Phe Ile Lys Arg Ser Asp Ala Glu Glu Val Asp Phe Ala Gly Trp
340 345 350
Leu Cys Ser Thr Ile Gly Leu Asn Gln Pro Ser Thr Pro Thr His Ala
355 360 365
Ala Gly Val
370
<210> 81
<211> 2274
<212> DNA
<213> Gallus gallus
<400> 81
ctaaccaggc gggagctgtc ggtgcggagc tcggtgtcgc tccgccgggc aggccgggtc 60
gacggccgcg ctgtgccgga gcggcagcgt cgcgggctcg gctccttctc ggggaggcgg 120
ccgcgcgctg ctccggcgct gaggggcggc cccgaagttt gcttcgcgtc gggaagtccg 180
tcggacctgg ccgaagtggg gccgcggccg ctccgtccgt cacgctctgc gctggccggg 240
gggcaacatg cccaagaaga agccagggcc gatccagctc aaccccgctc cggatggctc 300
cgccgtcaac gggaccagct ctgccgagac aaacttggaa gctcttcaga agaagctgga 360
agagctagag ctggatgaac agcaaaggaa gcgccttgaa gctttcctta cccagaaaca 420
aaaagttggg gagctgaagg atgatgactt cgagaagatc agtgagctgg gagcagggaa 480
tggcggggtg gtgttcaaag tatctcacaa gccttctggc ctcatcatgg caagaaaatt 540
gattcatcta gaaatcaagc cagctattcg aaaccagatc atccgtgagc tgcaggttct 600
acatgagtgc aattcaccat acatagtggg cttttatgga gctttttaca gtgatgggga 660
aatcagcatt tgcatggaac acatggatgg tggctcattg gatcaagtgc tgaaaaaggc 720
tggaagaatt ccagagcaga tactgggcaa agtcagcatt gcagtaataa aaggactcac 780
atatctgaga gaaaagcata aaataatgca cagagatgtt aaaccatcta acatcttggt 840
aaactctaga ggtgagatca agctttgtga ttttggtgtc agtggacaac tgatagattc 900
tatggcaaac tcatttgttg gcacgcgctc ctacatgtct ccggaaagac tgcagggaac 960
tcattattca gtgcagtcag atatatggag tatggggctg tctctggtag aaatggccat 1020
tggcagatac ccgattcctc ctcctgactc taaggagctc gagttgatgt ttggctgccc 1080
ggtagaggga gattctccag tcacagagac ctcacccagg caaagaacac ctggtcgacc 1140
aatgagctcc tatggaccag acagcagacc cccgatggca atctttgaac ttctggatta 1200
catcgtcaat gagccacctc caaaactgcc caatggtgtc tttggttctg aatttcaaga 1260
ttttgttaac aaatgtttaa ttaaaaatcc tgctgagaga gctgatttga agcagctgat 1320
gattcacgct ttcattaaga gatctgaagc agaggaggtg gattttgcag gatggctttg 1380
ctcaaccata ggccttaacc aaccgagtac acccacgcat gctgctggag tctgaatgtg 1440
gaagagcaaa tcctgtcccg tacatctgtt aacagcgcta ctttggtcct atttcctaag 1500
cttgtacctg ttcaaacatg tatttcacct cttaaggaag aatgtcttta tagcatgtgc 1560
caaattgttt tcaattttgt catcaactaa ttggtattgt actgggttac atttgtttgc 1620
tgaccaaaat gtaaaatgtt taagttacag tgcttgctga ttttaagtga ttatggaatt 1680
atggatattc tttcttaatg aaaatatcac tgggggggaa tttacccctg gattgtttga 1740
actttatcaa gactctttgt aaactgttgg tacttcagtc atgcttacct aatctcccat 1800
gcaaaaaaag gggtagggat gctccaaaac tgtatctgtt gagcatgctt ttgctgctgc 1860
caaactgtat cttggaagtt aggcctaatg gttccaattt ggtgttgtgt agagatcact 1920
ctttccaggt aaagaaggta agagctctgc attccttggg atggacaggg cagtatccta 1980
cttgtagact tgttcatatt tctatattta tttttaaaat gtatcatcat acttggattt 2040
agtgatatat gtctttccaa ttgattttta aaggttagct ctcagaagcg tcctacagaa 2100
tcatgacaaa gatctgggct ttcttttaac cttaagattc atgacagctg tgtttggtgt 2160
ctaaaatgta tgaagatcct ctattgtttt attctctcag atgtttagca atggtttctc 2220
ttaataaata tattatcaag taaaaaaaaa aaaaaaataa aaaaaaaaaa aaaa 2274
<210> 82
<211> 395
<212> PRT
<213> Gallus gallus
<400> 82
Met Pro Lys Lys Lys Pro Gly Pro Ile Gln Leu Asn Pro Ala Pro Asp
1 5 10 15
Gly Ser Ala Val Asn Gly Thr Ser Ser Ala Glu Thr Asn Leu Glu Ala
20 25 30
Leu Gln Lys Lys Leu Glu Glu Leu Glu Leu Asp Glu Gln Gln Arg Lys
35 40 45
Arg Leu Glu Ala Phe Leu Thr Gln Lys Gln Lys Val Gly Glu Leu Lys
50 55 60
Asp Asp Asp Phe Glu Lys Ile Ser Glu Leu Gly Ala Gly Asn Gly Gly
65 70 75 80
Val Val Phe Lys Val Ser His Lys Pro Ser Gly Leu Ile Met Ala Arg
85 90 95
Lys Leu Ile His Leu Glu Ile Lys Pro Ala Ile Arg Asn Gln Ile Ile
100 105 110
Arg Glu Leu Gln Val Leu His Glu Cys Asn Ser Pro Tyr Ile Val Gly
115 120 125
Phe Tyr Gly Ala Phe Tyr Ser Asp Gly Glu Ile Ser Ile Cys Met Glu
130 135 140
His Met Asp Gly Gly Ser Leu Asp Gln Val Leu Lys Lys Ala Gly Arg
145 150 155 160
Ile Pro Glu Gln Ile Leu Gly Lys Val Ser Ile Ala Val Ile Lys Gly
165 170 175
Leu Thr Tyr Leu Arg Glu Lys His Lys Ile Met His Arg Asp Val Lys
180 185 190
Pro Ser Asn Ile Leu Val Asn Ser Arg Gly Glu Ile Lys Leu Cys Asp
195 200 205
Phe Gly Val Ser Gly Gln Leu Ile Asp Ser Met Ala Asn Ser Phe Val
210 215 220
Gly Thr Arg Ser Tyr Met Ser Pro Glu Arg Leu Gln Gly Thr His Tyr
225 230 235 240
Ser Val Gln Ser Asp Ile Trp Ser Met Gly Leu Ser Leu Val Glu Met
245 250 255
Ala Ile Gly Arg Tyr Pro Ile Pro Pro Pro Asp Ser Lys Glu Leu Glu
260 265 270
Leu Met Phe Gly Cys Pro Val Glu Gly Asp Ser Pro Val Thr Glu Thr
275 280 285
Ser Pro Arg Gln Arg Thr Pro Gly Arg Pro Met Ser Ser Tyr Gly Pro
290 295 300
Asp Ser Arg Pro Pro Met Ala Ile Phe Glu Leu Leu Asp Tyr Ile Val
305 310 315 320
Asn Glu Pro Pro Pro Lys Leu Pro Asn Gly Val Phe Gly Ser Glu Phe
325 330 335
Gln Asp Phe Val Asn Lys Cys Leu Ile Lys Asn Pro Ala Glu Arg Ala
340 345 350
Asp Leu Lys Gln Leu Met Ile His Ala Phe Ile Lys Arg Ser Glu Ala
355 360 365
Glu Glu Val Asp Phe Ala Gly Trp Leu Cys Ser Thr Ile Gly Leu Asn
370 375 380
Gln Pro Ser Thr Pro Thr His Ala Ala Gly Val
385 390 395
Claims (19)
- (i) BRAF 억제제인 제1 제제, (ii) MEK 억제제인 제2 제제, 및 (iii) BVD-523 또는 이의 약제학적으로 허용되는 염인 제3 제제, 및 임의로 약제학적으로 허용되는 담체, 보조제 또는 비히클을 포함하는, 대상체에서 암을 치료하기 위한 조성물.
- 제1항에 있어서, 상기 BRAF 억제제가 베무라페닙, 다브라페닙, 또는 이의 약제학적으로 허용되는 염으로부터 선택되는, 조성물.
- 제1항에 있어서, 상기 MEK 억제제가 트라메티닙, 코비메티닙, 또는 이의 약제학적으로 허용되는 염으로부터 선택되는, 조성물.
- 제1항에 있어서, 상기 BVD-523 또는 이의 약제학적으로 허용되는 염이 450 내지 600 mg BID의 용량으로 사람 대상체에게 투여되는, 조성물.
- 제1항에 있어서, 상기 암이 흑색종, 결장직장암, 유두상 갑상선암(papillary thyroid cancer), 및 비-소세포 폐암으로 이루어진 그룹으로부터 선택되는, 조성물.
- 제1항에 있어서, 상기 암이 흑색종인, 조성물.
- 제1항에 있어서, 상기 암이 진행된(advanced) 것인, 조성물.
- 제1항에 있어서, 상기 암이 비절제성 또는 전이성인, 조성물.
- 제1항에 있어서, 상기 암이 MAPK 활성을 갖는, 조성물.
- 제1항에 있어서, 상기 대상체가 영장류, 농장 동물, 및 가축 동물로 이루어진 그룹으로부터 선택되는, 조성물.
- 제1항에 있어서, 상기 대상체가 사람인, 조성물.
- 제1항에 있어서, 암을 갖는 상기 대상체가 BRAFV600 및/또는 MEKQ56에 돌연변이를 갖는, 조성물.
- 제12항에 있어서, 상기 돌연변이가 BRAFV600E, BRAFV600K, MEKQ56P, 또는 BRAFV600E::MEKQ56P로부터 선택되는, 조성물.
- 제1항에 있어서, 상기 대상체가 BRAF 억제제 치료, MEK 억제제 치료, 또는 병용된 BRAF 및 MEK 억제제 치료에 불응인, 조성물.
- 제1항에 있어서, 프로그래밍된 사멸-1 (PD-1) 억제제, 세포독성 T-림프구 항원-4 (CTLA-4) 억제제, 또는 이들의 조합으로 이루어진 그룹으로부터 선택되는 적어도 하나의 추가 제제를 더 포함하는, 조성물.
- 제15항에 있어서, 상기 PD-1 억제제가 펨브롤리주맙, 니볼루맙, 또는 이들의 조합으로부터 선택되는, 조성물.
- 제15항에 있어서, 상기 CTLA-4 억제제가 이필리무맙인, 조성물.
- (i) BRAF 억제제인 제1 제제, (ii) MEK 억제제인 제2 제제, 및 (iii) BVD-523 또는 이의 약제학적으로 허용되는 염인 제3 제제, 및 임의로 약제학적으로 허용되는 담체, 보조제 또는 비히클을 포함하는, 대상체에서 암을 치료하기 위한 키트.
- 제18항에 있어서, 프로그래밍된 사멸-1 (PD-1) 억제제, 세포독성 T-림프구 항원-4 (CTLA-4) 억제제, 또는 이들의 조합으로 이루어진 그룹으로부터 선택되는 적어도 하나의 추가 제제를 더 포함하는, 키트.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201361919551P | 2013-12-20 | 2013-12-20 | |
| US15/161,137 | 2016-05-20 | ||
| US15/161,137 US20160317519A1 (en) | 2013-12-20 | 2016-05-20 | Methods and compositions for treating non-erk mapk pathway inhibitor-resistant cancers |
| KR1020187037187A KR20190009804A (ko) | 2013-12-20 | 2017-05-22 | 비-erk mapk 경로 억제제-내성 암을 치료하기 위한 방법 및 조성물 |
| PCT/US2017/033843 WO2017201532A1 (en) | 2013-12-20 | 2017-05-22 | Methods and compositions for treating non-erk mapk pathway inhibitor-resistant cancers |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187037187A Division KR20190009804A (ko) | 2013-12-20 | 2017-05-22 | 비-erk mapk 경로 억제제-내성 암을 치료하기 위한 방법 및 조성물 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230025941A true KR20230025941A (ko) | 2023-02-23 |
Family
ID=53403903
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187037187A KR20190009804A (ko) | 2013-12-20 | 2017-05-22 | 비-erk mapk 경로 억제제-내성 암을 치료하기 위한 방법 및 조성물 |
| KR1020237004648A KR20230025941A (ko) | 2013-12-20 | 2017-05-22 | 비-erk mapk 경로 억제제-내성 암을 치료하기 위한 방법 및 조성물 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187037187A KR20190009804A (ko) | 2013-12-20 | 2017-05-22 | 비-erk mapk 경로 억제제-내성 암을 치료하기 위한 방법 및 조성물 |
Country Status (15)
| Country | Link |
|---|---|
| US (5) | US20160317519A1 (ko) |
| EP (1) | EP3458056A4 (ko) |
| JP (2) | JP7427212B2 (ko) |
| KR (2) | KR20190009804A (ko) |
| CN (1) | CN109475541A (ko) |
| AU (2) | AU2017267804B2 (ko) |
| BR (1) | BR112018073786A2 (ko) |
| CA (1) | CA3024703A1 (ko) |
| CL (1) | CL2018003282A1 (ko) |
| IL (2) | IL263108B (ko) |
| MX (2) | MX2018014231A (ko) |
| RU (1) | RU2018145048A (ko) |
| SG (1) | SG11201810287RA (ko) |
| WO (2) | WO2015095842A2 (ko) |
| ZA (2) | ZA201808480B (ko) |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8193182B2 (en) | 2008-01-04 | 2012-06-05 | Intellikine, Inc. | Substituted isoquinolin-1(2H)-ones, and methods of use thereof |
| KR101897881B1 (ko) | 2008-01-04 | 2018-09-12 | 인텔리카인, 엘엘씨 | 특정 화학 물질, 조성물 및 방법 |
| KR101875720B1 (ko) | 2011-01-10 | 2018-07-09 | 인피니티 파마슈티칼스, 인코포레이티드 | 이소퀴놀린온 및 이의 고체 형태의 제조 방법 |
| US8828998B2 (en) | 2012-06-25 | 2014-09-09 | Infinity Pharmaceuticals, Inc. | Treatment of lupus, fibrotic conditions, and inflammatory myopathies and other disorders using PI3 kinase inhibitors |
| WO2015095842A2 (en) | 2013-12-20 | 2015-06-25 | Biomed Valley Discoveries, Inc. | Methods and compositions for treating non-erk mapk pathway inhibitor-resistant cancers |
| US20150320755A1 (en) | 2014-04-16 | 2015-11-12 | Infinity Pharmaceuticals, Inc. | Combination therapies |
| BR112018012255A2 (pt) * | 2015-12-18 | 2018-12-04 | Ignyta Inc | método para tratar câncer |
| WO2017180581A1 (en) * | 2016-04-15 | 2017-10-19 | Genentech, Inc. | Diagnostic and therapeutic methods for cancer |
| WO2017180817A1 (en) * | 2016-04-15 | 2017-10-19 | Musc Foundation For Research Development | Treatment of septicemia and ards with erk inhibitors |
| CN109640999A (zh) | 2016-06-24 | 2019-04-16 | 无限药品股份有限公司 | 组合疗法 |
| WO2018134254A1 (en) | 2017-01-17 | 2018-07-26 | Heparegenix Gmbh | Protein kinase inhibitors for promoting liver regeneration or reducing or preventing hepatocyte death |
| CA3063614A1 (en) * | 2017-05-16 | 2018-11-22 | Biomed Valley Discoveries, Inc. | Compositions and methods for treating cancer with atypical braf mutations |
| KR20210006365A (ko) * | 2018-04-09 | 2021-01-18 | 쥐원 쎄라퓨틱스, 인크. | 구동 종양원성 돌연변이를 갖는 암의 치료 |
| CN110656172A (zh) * | 2019-01-14 | 2020-01-07 | 南方医科大学珠江医院 | 一种预测小细胞肺癌对ep化疗方案敏感性的分子标志物及试剂盒 |
| WO2021118924A2 (en) * | 2019-12-12 | 2021-06-17 | Ting Therapeutics Llc | Compositions and methods for the prevention and treatment of hearing loss |
| CN115177622A (zh) * | 2022-07-19 | 2022-10-14 | 中南大学湘雅二医院 | 多个化合物在制备治疗骨髓增殖性肿瘤的药物中的应用 |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2376299C2 (ru) * | 2004-05-14 | 2009-12-20 | Вертекс Фармасьютикалз, Инкорпорейтед | Пиррольные соединения в качестве ингибиторов erk протеинкиназ, их синтез и промежуточные соединения |
| CA2609387A1 (en) * | 2005-05-27 | 2006-11-30 | Bayer Healthcare Ag | Combination therapy comprising diaryl ureas for treating diseases |
| SI2884979T1 (sl) * | 2012-08-17 | 2019-10-30 | Hoffmann La Roche | Kombinirana zdravljenja melanoma, ki vključujejo dajanje kobimetiniba in vemurafeniba |
| EP2953622B1 (en) * | 2013-02-11 | 2021-03-24 | Abraxis BioScience, LLC | Methods of treating melanoma |
| CN104994879A (zh) * | 2013-02-22 | 2015-10-21 | 霍夫曼-拉罗奇有限公司 | 治疗癌症和预防药物抗性的方法 |
| EP3082800B1 (en) | 2013-12-20 | 2022-02-02 | Biomed Valley Discoveries, Inc. | Cancer treatment using combinations of erk and raf inhibitors |
| WO2015095833A1 (en) * | 2013-12-20 | 2015-06-25 | Biomed Valley Discoveries, Inc. | Treatment of hematologic cancers |
| WO2015095842A2 (en) * | 2013-12-20 | 2015-06-25 | Biomed Valley Discoveries, Inc. | Methods and compositions for treating non-erk mapk pathway inhibitor-resistant cancers |
| WO2015095834A2 (en) * | 2013-12-20 | 2015-06-25 | Biomed Valley Discoveries, Inc. | Cancer treatments using erk1/2 and bcl-2 family inhibitors |
| WO2016025649A1 (en) * | 2014-08-13 | 2016-02-18 | Celgene Avilomics Research, Inc. | Combinations of an erk inhibitor and a dot1l inhibitor and related methods |
-
2014
- 2014-12-19 WO PCT/US2014/071749 patent/WO2015095842A2/en active Application Filing
-
2016
- 2016-05-20 US US15/161,137 patent/US20160317519A1/en not_active Abandoned
-
2017
- 2017-05-22 AU AU2017267804A patent/AU2017267804B2/en active Active
- 2017-05-22 CA CA3024703A patent/CA3024703A1/en active Pending
- 2017-05-22 US US16/302,955 patent/US11246859B2/en active Active
- 2017-05-22 KR KR1020187037187A patent/KR20190009804A/ko not_active IP Right Cessation
- 2017-05-22 MX MX2018014231A patent/MX2018014231A/es unknown
- 2017-05-22 EP EP17800334.9A patent/EP3458056A4/en active Pending
- 2017-05-22 KR KR1020237004648A patent/KR20230025941A/ko not_active Application Discontinuation
- 2017-05-22 IL IL263108A patent/IL263108B/en unknown
- 2017-05-22 IL IL294056A patent/IL294056A/en unknown
- 2017-05-22 JP JP2018560887A patent/JP7427212B2/ja active Active
- 2017-05-22 WO PCT/US2017/033843 patent/WO2017201532A1/en active Application Filing
- 2017-05-22 RU RU2018145048A patent/RU2018145048A/ru not_active Application Discontinuation
- 2017-05-22 CN CN201780044255.XA patent/CN109475541A/zh active Pending
- 2017-05-22 BR BR112018073786-0A patent/BR112018073786A2/pt unknown
- 2017-05-22 SG SG11201810287RA patent/SG11201810287RA/en unknown
- 2017-10-30 US US15/797,593 patent/US10881646B2/en active Active
-
2018
- 2018-11-19 CL CL2018003282A patent/CL2018003282A1/es unknown
- 2018-11-20 MX MX2022005473A patent/MX2022005473A/es unknown
- 2018-12-14 ZA ZA2018/08480A patent/ZA201808480B/en unknown
-
2020
- 2020-10-23 US US17/078,255 patent/US20210038587A1/en active Pending
- 2020-12-11 ZA ZA2020/07734A patent/ZA202007734B/en unknown
-
2021
- 2021-12-23 US US17/561,076 patent/US20220117950A1/en active Pending
- 2021-12-28 JP JP2021214205A patent/JP2022034068A/ja active Pending
-
2023
- 2023-07-11 AU AU2023204587A patent/AU2023204587A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| KR20190009804A (ko) | 2019-01-29 |
| US20180104228A1 (en) | 2018-04-19 |
| MX2018014231A (es) | 2019-05-15 |
| US20210038587A1 (en) | 2021-02-11 |
| ZA202007734B (en) | 2022-04-28 |
| IL263108B (en) | 2022-08-01 |
| BR112018073786A2 (pt) | 2019-02-26 |
| US20160317519A1 (en) | 2016-11-03 |
| WO2015095842A2 (en) | 2015-06-25 |
| JP2022034068A (ja) | 2022-03-02 |
| IL263108A (en) | 2018-12-31 |
| JP7427212B2 (ja) | 2024-02-05 |
| MX2022005473A (es) | 2022-06-02 |
| RU2018145048A (ru) | 2020-06-22 |
| US20190201387A1 (en) | 2019-07-04 |
| CA3024703A1 (en) | 2017-11-23 |
| US20220117950A1 (en) | 2022-04-21 |
| AU2017267804A1 (en) | 2019-01-17 |
| SG11201810287RA (en) | 2018-12-28 |
| CN109475541A (zh) | 2019-03-15 |
| IL294056A (en) | 2022-08-01 |
| EP3458056A4 (en) | 2020-01-08 |
| CL2018003282A1 (es) | 2019-10-18 |
| US11246859B2 (en) | 2022-02-15 |
| ZA201808480B (en) | 2022-04-28 |
| US10881646B2 (en) | 2021-01-05 |
| WO2015095842A3 (en) | 2015-08-20 |
| AU2017267804B2 (en) | 2023-04-27 |
| WO2017201532A1 (en) | 2017-11-23 |
| JP2019519519A (ja) | 2019-07-11 |
| AU2023204587A1 (en) | 2023-08-17 |
| EP3458056A1 (en) | 2019-03-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20230025941A (ko) | 비-erk mapk 경로 억제제-내성 암을 치료하기 위한 방법 및 조성물 | |
| RU2722784C2 (ru) | Лечение злокачественных опухолей с применением комбинаций ингибиторов erk и raf | |
| CN110799245B (zh) | 用于治疗具有非典型braf突变的癌症的组合物和方法 | |
| AU2014368927B2 (en) | Cancer treatments using combinations of CDK and ERK inhibitors | |
| JP2023100682A (ja) | Egfrまたはher2のエクソン20変異を有するがん細胞に対する抗腫瘍活性を有する化合物 | |
| US20210189342A1 (en) | Compositions and methods for modulating monocyte and macrophage inflammatory phenotypes and immunotherapy uses thereof | |
| KR102027394B1 (ko) | 탈모 질환의 치료 방법 | |
| KR102619197B1 (ko) | Hsd17b13 변종 및 이것의 용도 | |
| KR20210030947A (ko) | Nlrp3 길항제를 사용한 tnf 억제제 저항성 대상체를 위한 치료 방법 또는 치료제의 선택 방법 | |
| JP6678583B2 (ja) | 2型mek阻害剤およびerk阻害剤の組み合わせを用いるがん処置 | |
| WO2015066452A2 (en) | Methods of treating pediatric cancers | |
| CN111514283A (zh) | 使用抗cd19嵌合抗原受体治疗癌症 | |
| KR20140147797A (ko) | 암 및 자가면역 질환의 치료 방법 및 조성물 | |
| US20220313700A1 (en) | Methods for treating map3k8 positive cancers | |
| WO2017106189A1 (en) | Compositions and methods for treating ras/mapk mutant lung cancer | |
| RU2812706C2 (ru) | Композиции и способы для лечения злокачественной опухоли с атипичными мутациями braf | |
| WO2020115261A1 (en) | Methods and compositions for treating melanoma | |
| TW200904466A (en) | Methods of treating inflammatory disorders using isoforms of receptor tyrosine kinases |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A107 | Divisional application of patent | ||
| E902 | Notification of reason for refusal |