KR20200045006A - 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 - Google Patents
신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 Download PDFInfo
- Publication number
- KR20200045006A KR20200045006A KR1020207011552A KR20207011552A KR20200045006A KR 20200045006 A KR20200045006 A KR 20200045006A KR 1020207011552 A KR1020207011552 A KR 1020207011552A KR 20207011552 A KR20207011552 A KR 20207011552A KR 20200045006 A KR20200045006 A KR 20200045006A
- Authority
- KR
- South Korea
- Prior art keywords
- weight
- cell
- input
- cells
- register
- Prior art date
Links
- 238000013528 artificial neural network Methods 0.000 title claims abstract description 63
- 239000011159 matrix material Substances 0.000 claims description 64
- 238000000034 method Methods 0.000 claims description 33
- 230000004044 response Effects 0.000 claims description 9
- 238000004891 communication Methods 0.000 claims description 7
- 230000009471 action Effects 0.000 claims description 3
- 230000004913 activation Effects 0.000 abstract description 95
- 238000001994 activation Methods 0.000 description 94
- 230000008569 process Effects 0.000 description 12
- 238000004260 weight control Methods 0.000 description 11
- 238000004590 computer program Methods 0.000 description 10
- 238000004364 calculation method Methods 0.000 description 9
- 230000009467 reduction Effects 0.000 description 8
- 230000006870 function Effects 0.000 description 4
- 230000003287 optical effect Effects 0.000 description 4
- 238000009825 accumulation Methods 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 2
- 238000013527 convolutional neural network Methods 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 238000013515 script Methods 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 230000037396 body weight Effects 0.000 description 1
- 230000020411 cell activation Effects 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 238000003062 neural network model Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000001953 sensory effect Effects 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/80—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors
- G06F15/8007—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors single instruction multiple data [SIMD] multiprocessors
- G06F15/8023—Two dimensional arrays, e.g. mesh, torus
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/80—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors
- G06F15/8046—Systolic arrays
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/16—Matrix or vector computation, e.g. matrix-matrix or matrix-vector multiplication, matrix factorization
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/002—Biomolecular computers, i.e. using biomolecules, proteins, cells
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/04—Inference or reasoning models
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biophysics (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- Computer Hardware Design (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Neurology (AREA)
- Mathematical Analysis (AREA)
- Computational Mathematics (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Databases & Information Systems (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Algebra (AREA)
- Image Processing (AREA)
- Complex Calculations (AREA)
- Image Analysis (AREA)
- Design And Manufacture Of Integrated Circuits (AREA)
- Multi Processors (AREA)
Abstract
신경망에 대한 신경망 컴퓨테이션들을 수행하기 위한 회로가 개시되며, 회로는 복수의 셀들을 포함하는 시스톨릭 어레이; 가중치 페처 유닛 ―가중치 페처 유닛은, 복수의 신경망 계층들의 각각에 대해, 복수의 가중치 입력들을 신경망 계층에 대한 시스톨릭 어레이의 제 1 차원을 따라 셀들에 전송하도록 구성됨―; 및 복수의 가중치 시퀀서 유닛들을 포함하고, 각각의 가중치 시퀀서 유닛은 시스톨릭 어레이의 제 1 차원을 따라 별개의 셀에 커플링되고, 복수의 가중치 시퀀서 유닛들은, 복수의 신경망 계층들 각각에 대해, 복수의 클록 사이클들을 통해 복수의 가중치 입력들을 신경망 계층에 대한 시스톨릭 어레이의 제 2 차원을 따라 셀들로 시프트하도록 구성되고, 각각의 셀은 곱셈 회로를 사용하여 활성화 입력 및 각각의 가중치 입력의 곱을 컴퓨팅하도록 구성된다.
Description
이 명세서는 하드웨어에서의 신경망 추론들을 컴퓨팅하는 것에 관한 것이다.
신경망들은 수신된 입력에 대한 출력(예를 들어, 분류)을 생성하기 위해 모델들의 하나 또는 그 초과의 계층들을 활용하는 기계 학습 모델들이다. 일부 신경망들은 출력 계층 이외에도 하나 또는 그 초과의 숨겨진 계층들을 포함한다. 각각의 숨겨진 계층의 출력은 네트워크의 다음 계층, 즉 네트워크의 다음 숨겨진 계층 또는 출력 계층에 대한 입력으로 사용된다. 네트워크의 각각의 계층은 파라미터들의 각각의 세트의 현재 값들에 따라, 수신된 입력으로부터 출력을 생성한다.
일부 신경망들은 하나 또는 그 초과의 컨벌루셔널 신경망 계층들을 포함한다. 각각의 컨벌루셔널 신경망 계층은 커넬(kernel)들의 연관된 세트를 갖는다. 각각의 커넬은 사용자에 의해 생성된 신경망 모델에 의해 확립된 값들을 포함한다. 일부 구현들에서, 커넬들은 특정 이미지 컨투어들, 형상들 또는 컬러들을 식별한다. 커넬들은 가중치 입력들의 매트릭스 구조로 나타내어질 수 있다. 각각의 컨벌루셔널 계층은 또한 활성화 입력들의 세트를 프로세싱할 수 있다. 활성화 입력들의 세트는 매트릭스 구조로도 나타내어질 수 있다.
일부 기존 시스템들은 소프트웨어에서, 주어진 컨벌루셔널 계층에 대한 컴퓨테이션들을 수행한다. 예를 들어, 소프트웨어는 계층에 대한 각각의 커넬을 활성화 입력들의 세트에 적용할 수 있다. 즉, 각각의 커넬에 대해, 소프트웨어는 다차원적으로 표현될 수 있는 커넬을, 다차원적으로 표현될 수 있는 활성화 입력들의 제 1 부분 위로 오버레이할 수 있다. 그런다음, 소프트웨어는 중첩된 엘리먼트(overlapped element)들로부터 도트 곱(dot product)을 컴퓨팅할 수 있다. 도트 곱은 단일 활성화 입력, 예를 들어, 중첩된 다차원 공간에서 상부-좌측 포지션을 갖는 활성화 입력 엘리먼트에 대응할 수 있다. 예를 들어, 슬라이딩 윈도우를 사용하여, 이후 소프트웨어는 커넬을 시프트시켜 활성화 입력들의 제 2 부분을 오버레이하고 다른 활성화 입력에 대응하는 다른 도트 곱을 계산할 수 있다. 소프트웨어는, 각각의 활성화 입력이, 대응하는 도트 곱을 가질 때까지 이 프로세스를 반복적으로 수행할 수 있다. 일부 구현들에서, 도트 곱들은 활성화 값들을 생성하는 활성화 함수에 입력된다. 활성화 값들은, 신경망의 후속 계층으로 전송되기 전에 결합, 예를 들어, 풀링될 수 있다.
컨벌루션 계산들을 컴퓨팅하는 한 가지 방법은 큰 차원 공간에서 다수의 매트릭스 곱셈들을 요구한다. 프로세서는 억지 방법(brute force method)을 통해 매트릭스 곱셈들을 컴퓨팅할 수 있다. 예를 들어, 계산 집약적이고 시간 집약적이긴 하지만, 프로세서는 컨벌루션 계산들을 위해 개개의 합산들 및 곱들을 반복적으로 계산할 수 있다. 프로세서가 계산들을 병렬화하는 정도는, 자신의 아키텍처로 인해 제한된다.
일반적으로, 본 명세서는 신경망 추론을 컴퓨팅하는 특수 목적 하드웨어 회로를 설명한다.
일반적으로, 본 명세서에서 설명된 요지의 일 혁신적인 양상은 복수의 계층들을 포함하는 신경망에 대한 신경망 컴퓨테이션들을 수행하기 위한 회로에서 구현될 수 있으며, 회로는 복수의 셀들을 포함하는 시스톨릭 어레이; 가중치 페처 유닛 ―가중치 페처 유닛은, 복수의 가중치 입력들을 신경망 계층에 대한 시스톨릭 어레이의 제 1 차원을 따라 셀들에 전송하도록, 복수의 신경망 계층들의 각각에 대해 구성됨―; 및 복수의 가중치 시퀀서 유닛들을 포함하고, 각각의 가중치 시퀀서 유닛은 시스톨릭 어레이의 제 1 차원을 따라 별개의 셀에 커플링되고, 복수의 가중치 시퀀서 유닛들은, 복수의 클록 사이클들을 통해 복수의 가중치 입력들을 신경망 계층에 대한 시스톨릭 어레이의 제 2 차원을 따라 셀들로 시프트하도록, 복수의 신경망 계층들 각각에 대해 구성되고, 각각의 가중치 입력은 제 2 차원을 따라 각각의 셀 내부에 저장되고, 각각의 셀은 곱셈 회로를 사용하여 활성화 입력 및 각각의 가중치 입력의 곱을 컴퓨팅하도록 구성된다.
구현들은 다음 중 하나 또는 그 초과의 것을 포함할 수 있다. 값 시퀀서 유닛은, 복수의 신경망 계층들 각각에 대해, 복수의 활성화 입력들을 신경망 계층에 대한 시스톨릭 어레이의 제 2 차원을 따라 셀들에 전송하도록 구성된다. 시스톨릭 어레이의 제 1 차원은 시스톨릭 어레이의 로우들에 대응하고, 시스톨릭 어레이의 제 2 차원은 시스톨릭 어레이의 컬럼들에 대응한다. 각각의 셀은 인접 셀에 가중치 제어 신호를 전달하도록 구성되고, 가중치 제어 신호는 인접 셀의 회로가 인접 셀에 대한 가중치 입력을 시프트하게 하거나 또는 로딩하게 한다. 각각의 셀은, 셀로 시프트된 가중치 입력을 저장하도록 구성된 가중치 경로 레지스터; 가중치 경로 레지스터에 커플링된 가중치 레지스터; 가중치 입력을 가중치 레지스터에 저장할지 여부를 결정하도록 구성된 가중치 제어 레지스터; 활성화 입력을 저장하도록 구성되고 그리고 활성화 입력을 제 1 차원을 따라 제 1 인접 셀의 다른 활성화 레지스터에 전송하도록 구성되는 활성화 레지스터; 가중치 레지스터 및 활성화 레지스터에 커플링되는 곱셈 회로 ―곱셈 회로는 가중치 입력 및 활성화 입력의 곱을 출력하도록 구성됨―; 곱셈 회로에 커플링되고 제 2 차원을 따라 제 2 인접 셀로부터 제 1 부분 합 및 곱을 수신하도록 구성되는 합산 회로 ―합산 회로는 제 1 부분 합 및 곱의 제 2 부분 합을 출력하도록 구성됨―; 및 합산 회로에 커플링되고 그리고 제 2 부분 합을 저장하도록 구성되는 부분 합 레지스터를 포함하고, 부분 합 레지스터는 제 2 부분 합을 제 2 차원을 따라 제 3 인접 셀의 다른 합산 회로에 전송하도록 구성된다. 각각의 가중치 시퀀서 유닛은, 가중치 시퀀서 유닛에 커플링된 대응하는 셀 내의 가중치 제어 레지스터에 대응하는 일시정지 카운터; 및 감소 회로를 포함하고, 감소 회로는 감소된 출력을 생성하기 위해 가중치 시퀀서 유닛에 대한 입력을 감소시키고 감소된 출력을 일시정지 카운터에 전송하도록 구성된다. 각각의 일시정지 카운터의 값들이 동일하고, 각각의 가중치 시퀀서 유닛은 대응하는 가중치 입력을 시스톨릭 어레이의 대응하는 별개의 셀에 로딩하도록 구성되고, 로딩하는 것은 가중치 입력을 곱셈 회로에 전송하는 것을 포함한다. 각각의 일시정지 카운터의 값들이 미리결정된 값에 도달하면, 복수의 가중치 시퀀서 유닛들은 제 2 차원을 따르는 복수의 가중치 입력들의 시프트를 일시정지한다. 시스톨릭 어레이는, 복수의 신경망 계층들 각각에 대해, 각각의 곱으로부터 신경망 계층에 대한 누산 출력을 생성하도록 구성된다.
본 명세서에 설명된 요지의 특정 실시예들은, 다음의 이점들 중 하나 또는 그 초과의 것을 실현하기 위해서 구현될 수 있다. 가중치를 프리페칭하는 것은, 신경망 프로세서가 보다 효율적으로 컴퓨테이션들을 수행할 수 있게 한다. 프로세서는 가중치 페처 유닛 및 가중치 시퀀서 유닛을 사용하여 가중치 입력들을 시스톨릭 어레이에 로딩하는 것을 조정할 수 있음으로써, 외부 메모리 유닛을 시스톨릭 어레이 내의 각각의 셀에 커플링시키는 와이어의 필요성을 없앤다. 프로세서는 다수개의 컨벌루션 컴퓨테이션들의 수행을 동기화하기 위해서 가중치 입력들을 시프트시키는 것을 일시정지, 즉 "프리징(freeze)"시킬 수 있다.
본 명세서의 요지의 하나 또는 그 초과의 실시예들의 상세들은 첨부된 도면들 및 아래의 설명에 제시된다. 요지의 다른 특징들, 양상들 및 이점들은 설명, 도면들 및 청구항들로부터 명백해질 것이다.
도 1은 신경망의 주어진 계층에 대한 컴퓨테이션을 수행하기 위한 예시적인 방법의 흐름도이다.
도 2는 예시적인 신경망 프로세싱 시스템을 도시한다.
도 3은 매트릭스 컴퓨테이션 유닛을 포함하는 예시적인 아키텍처를 도시한다.
도 4는 시스톨릭 어레이 내부의 셀의 예시적인 아키텍처를 도시한다.
도 5는 공간 차원들 및 특징 차원을 갖는 예시적인 매트릭스 구조를 도시한다.
도 6은 커넬 매트릭스 구조가 시스톨릭 어레이에 전송되는 방법을 예시하는 예를 도시한다.
도 7은 3개의 클록 사이클들 이후 셀들 내부의 가중치 입력들을 예시하는 예를 도시한다.
도 8은 제어 신호들이 활성화 입력들을 시프트시키거나 또는 로딩시키는 방법을 예시하는 예이다.
다양한 도면들에서의 동일한 참조 번호들 및 표기들은 동일한 엘리먼트들을 표시한다.
도 2는 예시적인 신경망 프로세싱 시스템을 도시한다.
도 3은 매트릭스 컴퓨테이션 유닛을 포함하는 예시적인 아키텍처를 도시한다.
도 4는 시스톨릭 어레이 내부의 셀의 예시적인 아키텍처를 도시한다.
도 5는 공간 차원들 및 특징 차원을 갖는 예시적인 매트릭스 구조를 도시한다.
도 6은 커넬 매트릭스 구조가 시스톨릭 어레이에 전송되는 방법을 예시하는 예를 도시한다.
도 7은 3개의 클록 사이클들 이후 셀들 내부의 가중치 입력들을 예시하는 예를 도시한다.
도 8은 제어 신호들이 활성화 입력들을 시프트시키거나 또는 로딩시키는 방법을 예시하는 예이다.
다양한 도면들에서의 동일한 참조 번호들 및 표기들은 동일한 엘리먼트들을 표시한다.
다수개의 계층들을 갖는 신경망은 추론들을 컴퓨팅하기 위해 사용될 수 있다. 예를 들어, 입력이 주어지면, 신경망은 입력에 대한 추론을 컴퓨팅할 수 있다. 신경망은 신경망의 계층들 각각을 통해 입력을 프로세싱함으로써 이 추론을 컴퓨팅한다. 특히, 신경망의 계층들은, 가중치들의 각각의 세트를 각각 가지고 시퀀스로 배열된다. 각각의 계층은 입력을 수신하고 계층에 대한 가중치들의 세트에 따라 입력을 프로세싱하여 출력을 생성한다.
따라서, 수신된 입력으로부터 추론을 컴퓨팅하기 위해서, 신경망이 입력을 수신하고 시퀀스에서 신경망 계층들 각각을 통해 입력을 프로세싱하여 추론을 생성하며, 하나의 신경망 계층으로부터의 출력이 다음 신경망 계층에 대한 입력으로서 제공된다. 신경망 계층에 대한 데이터 입력들, 예를 들어, 신경망으로의 입력, 또는 시퀀스에서 계층 밑의 계층의, 신경망 계층으로의 출력들이 계층에 대한 활성화 입력들로 지칭될 수 있다.
일부 구현들에서, 신경망의 계층들은 방향 그래프로 배열된다. 즉, 임의의 특정 계층은 다수개의 입력들, 다수개의 출력들, 또는 둘 모두를 수신할 수 있다. 신경망의 계층들은 또한, 계층의 출력이 이전 계층에 대한 입력으로서 다시 되돌려 보내질 수 있도록 배열될 수 있다.
도 1은 특수 목적 하드웨어 회로를 사용하여 신경망의 주어진 계층에 대한 컴퓨테이션을 수행하기 위한 일 예시적인 프로세스(100)의 흐름도이다. 편의상, 방법(100)은, 방법(100)을 수행하는 하나 또는 그 초과의 회로들을 갖는 시스템과 관련하여 설명될 것이다. 방법(100)은, 수신된 입력으로부터 추론을 컴퓨팅하기 위해 신경망의 각각의 계층에 대해 수행될 수 있다.
시스템은 주어진 계층에 대한 가중치 입력들의 세트들을 수신하고(단계 102) 활성화 입력들의 세트들을 수신한다(단계 104). 가중치 입력들의 세트들 및 활성화 입력들의 세트들은, 특수 목적 하드웨어 회로의 동적 메모리 및 통합 버퍼로부터 각각 수신될 수 있다. 일부 구현들에서, 가중치 입력들의 세트들 및 활성화 입력들의 세트들 둘 모두가 통합 버퍼로부터 수신될 수 있다.
시스템은 특수 목적 하드웨어 회로의 매트릭스 곱셈 유닛을 사용하여 가중치 입력들 및 활성화 입력들으로부터 누산 값들을 생성한다(단계 106). 일부 구현들에서, 누산 값들은 가중치 입력들의 세트들과 활성화 입력들의 세트들의 도트 곱들이다. 즉, 가중치들의 하나의 세트의 경우, 시스템은 각각의 가중치 입력을 각각의 활성화 입력과 곱셈하고 그 곱들을 함께 합산하여 누산 값을 형성할 수 있다. 그런 다음, 시스템은 가중치들의 다른 세트와 활성화 입력들의 다른 세트들과의 도트 곱을 컴퓨팅할 수 있다.
시스템은 특수 목적 하드웨어 회로의 벡터 계산 유닛을 사용하여 누산 값들로부터 계층 출력을 생성할 수 있다(단계 108). 일부 구현들에서, 벡터 컴퓨테이션 유닛은 누산 값들에 활성화 함수를 적용한다. 계층의 출력은 신경망의 후속 계층에 대한 입력으로 사용하기 위해 통합 버퍼에 저장될 수 있거나 또는 추론을 결정하는데 사용될 수 있다. 시스템은, 수신된 입력이 신경망의 각각의 계층을 통해 프로세싱되어 수신된 입력에 대한 추론이 생성되었을 경우 신경망의 프로세싱을 종료한다.
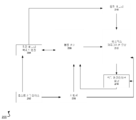
도 2는 신경망 컴퓨테이션들을 수행하기 위한 예시적인 특수 목적 통합 회로(200)를 도시한다. 시스템(200)은 호스트 인터페이스(202)를 포함한다. 호스트 인터페이스(202)는 신경망 컴퓨테이션에 대한 파라미터들을 포함하는 명령들을 수신할 수 있다. 파라미터들은 다음: 얼마나 많은 계층들이 프로세싱되어야하는지, 계층의 각각의 계층에 대한 가중치 입력들의 대응하는 세트들, 활성화 입력들의 초기 세트, 즉, 추론이 컴퓨팅되는 신경망에 대한 입력, 각각의 계층의 대응하는 입력 및 출력 사이즈들, 신경망 컴퓨테이션을 위한 스트라이드 값, 및 프로세싱될 계층의 타입, 예를 들어, 컨벌루셔널 계층 또는 완전 연결된 계층 중 적어도 하나 또는 그 초과의 것을 포함할 수 있다.
호스트 인터페이스(202)는, 명령들을 시퀀서(206)로 전송할 수 있으며, 시퀀서(206)는 명령들을, 신경망 컴퓨테이션들을 수행하도록 회로를 제어하는 저 레벨 제어 신호들로 변환한다. 일부 구현들에서, 제어 신호들은 회로에서의 데이터 흐름을 조절하는데, 예를 들어 가중치 입력들의 세트들 및 활성화 입력들의 세트들이 회로를 통해 흐르는 방법을 조절한다. 시퀀서(206)는 제어 신호들을 통합 버퍼(208), 매트릭스 컴퓨테이션 유닛(212), 및 벡터 컴퓨테이션 유닛(214)에 전송할 수 있다. 일부 구현에서, 시퀀서(206)는 또한 직접 메모리 액세스 엔진(204) 및 동적 메모리(210)에 제어 신호들을 전송한다. 일부 구현들에서, 시퀀서(206)는 클록 신호들을 생성하는 프로세서이다. 시퀀서(206)는, 적절한 시간들에, 클록 신호들을 회로(200)의 각각의 컴포넌트에 전송하기 위해 클록 신호들의 타이밍을 사용할 수 있다. 일부 다른 구현들에서, 호스트 인터페이스(202)는 외부 프로세서로부터의 클록 신호를 전달한다.
호스트 인터페이스(202)는 가중치 입력들의 세트들 및 활성 입력들의 초기 세트들을 직접 메모리 액세스 엔진(204)에 전송할 수 있다. 직접 메모리 액세스 엔진(204)은 통합 버퍼(208)에 활성화 입력들의 세트들을 저장할 수 있다. 일부 구현들에서, 직접 메모리 액세스는 메모리 유닛일 수 있는 동적 메모리(210)에 가중치들의 세트들을 저장한다. 일부 구현들에서, 동적 메모리는 회로로부터 떨어져 위치된다.
통합 버퍼(208)는 메모리 버퍼이다. 이는, 직접 메모리 액세스 엔진(204)으로부터의 활성화 입력들의 세트 및 벡터 컴퓨테이션 유닛(214)의 출력들을 저장하는데 사용될 수 있다. 직접 메모리 액세스 엔진(204)은 또한 통합 버퍼(208)로부터 벡터 컴퓨테이션 유닛(214)의 출력들을 판독할 수 있다.
동적 메모리(210) 및 통합 버퍼(208)는, 가중치 입력들의 세트들 및 활성화 입력들의 세트들을 각각 매트릭스 컴퓨테이션 유닛(212)에 전송할 수 있다. 일부 구현들에서, 매트릭스 컴퓨테이션 유닛(212)은 2차원 시스톨릭 어레이이다. 매트릭스 컴퓨테이션 유닛(212)은 또한, 1차원 시스톨릭 어레이이거나 또는 수학적 연산들, 예를 들어, 곱셈 및 덧셈을 수행할 수 있는 다른 회로일 수 있다. 일부 구현들에서, 매트릭스 컴퓨테이션 유닛(212)은 범용 매트릭스 프로세서이다.
매트릭스 컴퓨테이션 유닛(212)은 가중치 입력들 및 활성화 입력들을 프로세싱하고 벡터 컴퓨테이션 유닛(214)에 출력들의 벡터를 제공할 수 있다. 몇몇 구현들에서, 매트릭스 컴퓨테이션 유닛은 출력들의 벡터를 통합 버퍼(208)에 전송하며, 통합 버퍼(208)는 출력들의 벡터를 벡터 컴퓨테이션 유닛(214)으로 전송한다. 벡터 컴퓨테이션 유닛은 출력들의 벡터를 프로세싱하고 프로세싱된 출력들의 벡터를 통합 버퍼(208)에 저장할 수 있다. 예를 들어, 벡터 컴퓨테이션 유닛(214)은 비선형 함수를 매트릭스 컴퓨테이션 유닛의 출력들, 예를 들어, 누산 값들의 벡터에 적용하여 활성화된 값들을 생성할 수 있다. 일부 구현들에서, 벡터 컴퓨테이션 유닛(214)은 정규화된 값들, 풀링된 값들, 또는 둘 모두를 생성한다. 프로세싱된 출력들의 벡터는, 예를 들어, 신경망의 후속 계층에서 사용하기 위해, 매트릭스 컴퓨테이션 유닛(212)에 대한 활성화 입력들로서 사용될 수 있다. 매트릭스 컴퓨테이션 유닛(212)은 도 3 및 도 4를 참조하여 아래에 더욱 상세히 설명될 것이다.
도 3은 매트릭스 컴퓨테이션 유닛을 포함하는 예시적인 아키텍처(300)를 도시한다. 매트릭스 컴퓨테이션 유닛은 2차원 시스톨릭 어레이(306)이다. 어레이(306)는 다수개의 셀들(304)을 포함한다. 일부 구현들에서, 시스톨릭 어레이(306)의 제 1 차원(320)은 셀들의 컬럼들에 대응하고 시스톨릭 어레이(306)의 제 2 차원(322)은 셀들의 로우들에 대응한다. 시스톨릭 어레이는 컬럼들보다 더 많은 로우들을 갖거나, 로우들보다 더 많은 컬럼들을 갖거나, 또는 같은 수의 컬럼들 및 로우들을 가질 수 있다.
예시된 예에서, 값 로더들(302)은 어레이(306)의 로우들에 활성화 입력들을 전송하고, 가중치 페처 인터페이스(308)는 가중치 입력들을 어레이(306)의 컬럼들에 전송한다. 그러나, 다른 구현들에서, 활성화 입력들이 컬럼들로 전달되고 가중치 입력들이 어레이(306)의 로우들로 전달된다.
값 로더들(302)은 통합 버퍼, 예컨대, 도 2의 통합 버퍼(208)로부터 활성화 입력들을 수신할 수 있다. 각각의 값 로더는 대응하는 활성화 입력을 어레이(306)의 별개의 제일 좌측 셀에 전송할 수 있다. 제일 좌측 셀은 어레이(306)의 제일 좌측 컬럼을 따라 있는 셀일 수 있다. 예를 들어, 값 로더(312)는 활성화 입력을 셀(314)에 전송할 수 있다. 또한, 값 로더는 인접한 값 로더에 활성화 입력을 전송할 수 있으며, 활성화 입력은 어레이(306)의 다른 제일 좌측 셀에서 사용될 수 있다. 이는, 활성화 입력들이 어레이(306)의 다른 특정 셀에서의 사용을 위해 시프트되도록 허용한다.
가중치 페처 인터페이스(308)는, 메모리 유닛, 예를 들어, 도 2의 동적 메모리(210)로부터 가중치 입력을 수신할 수 있다. 가중치 페처 인터페이스(308)는 대응하는 가중치 입력을 어레이(306)의 별개의 제일 상부 셀에 전송할 수 있다. 제일 상부 셀은 어레이(306)의 제일 상부 로우를 따라 있는 셀일 수 있다. 예를 들어, 가중치 페처 인터페이스(308)는 가중치 입력들을 셀들(314 및 316)에 전송할 수 있다.
일부 구현들에서, 호스트 인터페이스, 예를 들어, 도 2의 호스트 인터페이스(202)는 어레이(306) 전체에 걸친 활성화 입력들을 하나의 차원을 따라, 예를 들어, 우측으로 시프트하는 반면, 어레이(306) 전체에 걸친 가중치 입력들을 다른 차원을 따라, 예를 들어, 하부로 시프트한다. 예를 들어, 1 클록 사이클 동안, 셀(314)에서의 활성화 입력이, 셀(314)의 우측에 있는 셀(316)의 활성화 레지스터로 시프트할 수 있다. 유사하게, 셀(316)에서의 가중치 입력은 셀(314) 아래의 셀(318)의 가중치 레지스터로 시프트할 수 있다.
각각의 클록 사이클에서, 각각의 셀은 주어진 가중치 입력, 및 주어진 활성화 입력을 프로세싱하여 누산 출력을 생성할 수 있다. 누산 출력은 또한, 주어진 가중치 입력과 동일한 차원을 따라 인접 셀로 전달될 수 있다. 개개의 셀이 도 4를 참조하여 아래에서 추가로 설명된다.
일부 구현들에서, 가중치들 및 활성화들은, 하나의 컨벌루션 계산에서 다른 계산으로 천이하기 위해 주어진 클록 사이클 동안 1개 초과의 셀만큼 시프트된다.
누산 출력이 가중치 입력과 동일한 컬럼을 따라 전달될 수 있는데, 예를 들어, 어레이(306)의 컬럼의 하부를 향하여 전달될 수 있다. 일부 구현들에서, 각각의 컬럼의 하부에서, 어레이(306)는, 컬럼들보다 더 많은 가중치 입력들을 갖는 계층들 또는 로우들보다 더 많은 활성화 입력들을 갖는 계층들과 함께 계산들을 수행할 경우 각각의 컬럼으로부터의 각각의 누산 출력을 저장하고 누산하는 누산기 유닛(310)을 포함할 수 있다. 일부 구현들에서, 각각의 누산기 유닛은 다수개의 병렬 누산들을 저장한다. 이는 도 6을 참조하여 아래에서 추가로 설명될 것이다. 누산기 유닛들(310)은 각각의 누산 출력을 누산하여 최종 누산 값을 생성할 수 있다. 최종 누산 값은 벡터 컴퓨테이션 유닛으로 전달될 수 있다. 일부 다른 구현들에서, 누산기 유닛들(310)은, 컬럼들보다 더 적은 수의 가중치 입력들을 갖는 계층들 또는 로우들보다 더 적은 수의 활성화 입력들을 갖는 계층들을 프로세싱할 경우 어떠한 누산들도 수행하지 않고 누산 값들을 벡터 계산 유닛으로 전달한다.
활성화 입력들 및 가중치 입력들이 회로를 통해 흐를 때, 회로는 누산 값들을 정확하게 계산하기 위해서 흐름으로부터 가중치 입력들의 세트를 "프리징"하거나 일시정지할 수 있다. 즉, 회로가 가중치 입력들의 세트를 일시정지할 수 있으므로 가중치 입력들의 특정 세트가 활성화 입력들의 특정 세트에 적용될 수 있다.
일부 구현들에서, 가중치 시퀀서들(324)은, 가중치 입력들이 인접 셀들로 시프트할지 여부를 구성한다. 가중치 시퀀서(326)는 호스트, 예를 들어, 도 2의 호스트 인터페이스(202)로부터, 또는 외부 프로세서로부터 제어 값을 수신할 수 있다. 각각의 체중 시퀀서는 어레이(306) 내의 대응하는 셀에 제어 값을 전달할 수 있다. 특히, 제어 값은 셀 내의 가중치 제어 레지스터, 예를 들어, 도 4의 가중치 제어 레지스터(414)에 저장될 수 있다. 제어 값은, 가중치 입력들이 어레이의 차원을 따라 시프트될지 또는 로딩될지 여부를 결정할 수 있으며, 이는 도 8과 관련하여 아래에 설명될 것이다. 또한, 가중치 시퀀서는 제어 값을 인접한 가중치 시퀀서에 전송할 수 있으며, 이 가중치 시퀀서는 대응하는 셀에 대한 대응하는 가중치 입력을 시프트시키는 것 또는 로딩하는 것을 조절할 수 있다.
일부 구현들에서, 제어 값은 정수로 표현된다. 각각의 가중치 시퀀서는 정수를 저장하는 일시정지 카운터 레지스터를 포함할 수 있다. 또한, 가중치 시퀀서는 제어 값을 일시정지 카운터 레지스터에 저장하기 전에 정수를 감소시킬 수 있다. 일시정지 카운터 레지스터에 제어 값을 저장한 후, 가중치 시퀀서가 정수를 인접한 가중치 시퀀서로 전송하고 그 정수를 대응하는 셀에 전송할 수 있다. 예를 들어, 각각의 가중치 시퀀서는, 감소된 정수를 제어 값으로부터 생성하도록 구성된 감소 회로를 구비할 수 있다. 감소된 정수는 일시정지 카운터 레지스터에 저장될 수 있다. 저장된 제어 값들은 어레이의 전체 컬럼에 걸쳐 시프트의 동시 일시정지를 조정하기 위해 사용될 수 있으며, 이는 도 8과 관련하여 아래에 추가로 설명될 것이다.
일부 구현들에서, 회로에서 가중치들을 일시정지하는 것은 개발자가 회로를 디버깅할 수 있게 한다.
가중치들을 일시정지하는 다른 방법들이 가능하다. 예를 들어, 일시정지 카운터 레지스터들 내부의 값들을 인접한 일시정지 카운터 레지스터들로 전달하는 대신, 트리를 사용하여 제어 값이 전달될 수 있다. 즉, 주어진 셀에서, 신호는 모든 인접 셀들로 전달될 수 있고, 하나의 인접 셀에만 전달되지 않음으로써, 신호가 시스톨릭 어레이 전체에 걸쳐 신속하게 확산될 수 있게 한다.
도 4는 시스톨릭 어레이, 예를 들어, 도 3의 시스톨릭 어레이(306) 내부의 셀의 예시적인 아키텍처(400)를 도시한다.
셀은 활성화 입력을 저장하는 활성화 레지스터(406)를 포함할 수 있다. 활성화 레지스터는, 시스톨릭 어레이 내의 셀의 포지션에 따라, 좌측 인접 셀, 즉, 주어진 셀의 좌측에 위치되는 인접 셀로부터, 또는 통합 버퍼로부터 활성화 입력을 수신할 수 있다. 셀은 가중치 입력을 저장하는 가중치 레지스터(402)를 포함할 수 있다. 가중치 입력은, 시스톨릭 어레이 내의 셀의 포지션에 따라, 상부 인접 셀로부터 또는 가중치 페처 인터페이스로부터 전달될 수 있다. 셀은 또한 레지스터의 합(404)을 포함할 수 있다. 레지스터의 합(404)은 상부 인접 셀로부터의 누산 값을 저장할 수 있다. 곱셈 회로(408)는 가중치 레지스터(402)로부터의 가중치 입력을 활성화 레지스터(406)로부터의 활성화 입력과 곱하기 위해 사용될 수 있다. 곱셈 회로(408)는 곱을 합산 회로(410)로 출력할 수 있다.
합산 회로는 레지스터의 합(404)으로부터의 누산 값을 곱과 합산하여 새로운 누산 값을 생성할 수 있다. 그런 다음, 합산 회로(410)는 새로운 누산 값을 하부 인접 셀에 위치된 레지스터 내의 다른 합으로 전송할 수 있다. 새로운 누산 값은 하부 인접 셀에서의 합산을 위한 피연산자로서 사용될 수 있다.
일부 구현들에서, 셀은 또한 일반 제어 레지스터를 포함한다. 제어 레지스터는, 셀이 가중치 입력 또는 활성화 입력을 인접 셀들로 시프트해야 하는지 여부를 결정하는 제어 신호를 저장할 수 있다. 일부 구현들에서, 가중치 입력 또는 활성화 입력을 시프트하는 것은 2 이상의 클록 사이클이 걸린다. 제어 신호는 또한, 활성화 입력 또는 가중치 입력들이 곱셈 회로(408)로 전달되는지 여부를 결정할 수 있거나, 또는 곱셈 회로(408)가 활성화 입력 및 가중치 입력에 대해 연산하는지를 여부를 결정할 수 있다. 제어 신호는 또한, 예를 들어, 와이어를 사용하여, 하나 또는 그 초과의 인접 셀들로 전달될 수 있다.
일부 구현들에서, 가중치들은 가중치 경로 레지스터(412)로 프리-시프트된다. 가중치 경로 레지스터(412)는, 예를 들어, 상부 인접 셀로부터 가중치 입력을 수신할 수 있고, 제어 신호에 기초하여 가중치 입력을 가중치 레지스터(402)에 전달할 수 있다. 가중치 레지스터(402)는, 활성화 입력들이, 예를 들어, 활성화 레지스터(406)를 통해 다수개의 클록 사이클들 동안 셀로 전달될 때, 가중치 입력이 셀 내에 유지되고 인접 셀로 전달되지 않도록 가중치 입력을 정적으로 저장할 수 있다. 따라서, 가중치 입력은, 예를 들어, 곱셈 회로(408)를 사용하여 다수개의 활성화 입력들에 적용될 수 있고, 각각의 누산 값들이 인접 셀로 전달될 수 있다.
일부 구현들에서, 가중치 제어 레지스터(414)는, 가중치 입력이 가중치 레지스터(402)에 저장되는지 여부를 제어한다. 예를 들어, 가중치 제어 레지스터(414)가 0의 제어 값을 저장하는 경우, 가중치 레지스터(402)는 가중치 경로 레지스터(412)에 의해 전송된 가중치 입력을 저장할 수 있다. 일부 구현들에서, 가중치 입력을 가중치 레지스터(402)에 저장하는 것은 가중치 입력을 로딩하는 것으로 지칭된다. 일단 가중치 입력이 로딩되면, 가중치 입력은 프로세싱을 위해 곱셈 회로(408)로 전송될 수 있다. 가중치 제어 레지스터(414)가 넌-제로 제어 값을 저장하는 경우, 가중치 레지스터(402)는 가중치 경로 레지스터(412)에 의해 전송된 가중치 입력을 무시할 수 있다. 가중치 제어 레지스터(414)에 저장된 제어 값은, 하나 또는 그 초과의 인접 셀들로 전달될 수 있고, 예를 들어, 주어진 셀의 경우, 제어 값이 그 주어진 셀의 우측에 위치된 셀의 가중치 제어 레지스터로 전송될 수 있다.
셀은 또한, 가중치 입력 및 활성화 입력을 인접 셀들로 시프트시킬 수 있다. 예를 들어, 가중치 경로 레지스터(412)는 가중치 입력을 하부 인접 셀 내의 다른 가중치 경로 레지스터에 전송할 수 있다. 활성화 레지스터(406)는 활성화 입력을 우측 인접 셀 내의 다른 활성화 레지스터에 전송할 수 있다. 따라서, 가중치 입력 및 활성화 입력 둘 모두는, 후속 클록 사이클에서 어레이 내의 다른 셀들에 의해 재사용될 수 있다.
도 5는 공간 차원들 및 특징 차원을 갖는 예시적인 매트릭스 구조(500)를 도시한다. 매트릭스 구조(500)는 활성화 입력들의 세트 또는 가중치 입력들의 세트를 나타낼 수 있다. 활성화 입력들의 세트에 대한 매트릭스 구조는 본 명세서에서 활성화 매트릭스 구조로 지칭될 것이고, 가중치 입력들의 세트에 대한 매트릭스 구조는 본 명세서에서 커넬 매트릭스 구조로 지칭될 것이다. 매트릭스 구조(500)는 3개 차원들: 2개의 공간 차원들 및 1개의 특징 차원을 갖는다.
일부 구현들에서, 공간 차원들은 활성화 입력들의 세트의 공간 또는 포지션에 대응한다. 예를 들어, 신경망이 2개의 차원들을 갖는 이미지를 프로세싱하고 있는 경우, 매트릭스 구조들은 이미지의 공간 좌표들, 즉 XY 좌표들에 대응하는 2개의 공간 차원들을 가질 수 있다.
특징 차원은 활성화 입력으로부터의 특징들에 대응한다. 각각의 특징 차원은 깊이 레벨들을 가질 수 있다: 예를 들어, 매트릭스 구조(500)는 깊이 레벨들(502, 504 및 506)을 갖는다. 예시로서, 매트릭스 구조(500)가 활성화 입력들의 세트로서 제 1 계층에 전송된 3 × 3 × 3 이미지를 나타내는 경우, 이미지(3 × 3)의 X 및 Y 차원들은 공간 차원들이 될 수 있고, Z 차원(3)은 R, G 및 B 값들에 대응하는 특징 차원이 될 수 있다. 즉, 깊이 레벨(502)은, 9개의 '1' 활성화 입력들의 특징, 예를 들어, 적색 값들에 대응할 수 있고, 깊이 레벨(504)은 9개의 '2' 활성화 입력들의 특징, 예를 들어, 녹색 값들에 대응할 수 있고, 깊이 레벨(506)은 9개의 '3' 활성화 입력들의 특징, 예를 들어 청색 값들에 대응할 수 있다.
도 5의 예에서 특징 차원에 대해 3개의 깊이 레벨들만이 도시되어 있지만, 주어진 특징 차원은 많은 수, 예를 들어, 수백 개의 특징 차원들을 가질 수 있다. 유사하게, 하나의 특징 차원만이 예시되어 있지만, 주어진 매트릭스 구조는 다수개의 특징 차원들을 가질 수 있다.
매트릭스 구조(500)를 사용하여, 컨벌루셔널 계층에 대한 컴퓨테이션을 수행하기 위해, 시스템은 컨벌루셔널 컴퓨테이션을 2-차원 매트릭스 곱셈으로 변환해야 한다.
도 6은 도 5의 매트릭스 구조(500)가 주어진 컨벌루셔널 계층에서 시스톨릭 어레이(606)에 의해 프로세싱되는 방법을 예시하는 예를 도시한다. 매트릭스 구조(600)는 활성화 입력들의 세트일 수 있다. 일반적으로, 신경망 프로세서는 활성화 입력들, 예를 들어, 매트릭스 구조(600) 내의 엘리먼트들, 및 가중치 입력들, 예를 들어, 커넬들 A-D(610)를, 각각 어레이의 로우들 및 컬럼들에 전송할 수 있다. 활성화 및 가중치 입력들은 시스톨릭 어레이의 우측 및 하부로 각각 시프트될 수 있고, 특정 포지션, 예를 들어, 특정 셀의 특정 레지스터에 도달해야 한다. 예를 들어, 제어 신호를 검사함으로써 입력들이 제자리에 있는 것으로 결정되면, 프로세서는 셀들 내에 저장된 입력들을 사용하여 계산들을 수행하여 주어진 계층의 출력을 생성할 수 있다.
신경망 프로세서는, 상술된 바와 같이, 구조(600)의 부분들을 시스톨릭 어레이의 로우들로 전송하기 전에 매트릭스 구조(600)를 "평탄화(flatten)"한다. 즉, 신경망 프로세서는 매트릭스 구조(600)의 깊이 계층들(602), 예를 들어, 도 6의 깊이 계층들(602, 604 및 606)을 분할하고, 각각의 깊이 계층을 별개의 셀로 전송할 수 있다. 일부 구현들에서, 각각의 깊이 계층은 시스톨릭 어레이(606)의 상이한 로우 상의 셀로 전송된다. 예를 들어, 프로세서는 제 1 깊이 계층으로부터의 활성화 입력들, 예를 들어, 9개의 '1' 활성화 입력들의 매트릭스를 시스톨릭 어레이(606)의 제 1 로우에 있는 제일 좌측 셀로, 제 2 깊이 계층으로부터의 활성화 입력들, 예를 들어, 9개의 '2' 활성화 입력들의 매트릭스를 제 2 로우에 있는 제일 좌측 셀로, 제 3 깊이 계층으로부터의 활성화 입력들, 예를 들어, 9개의 '3' 활성화 입력들의 매트릭스를 제 3 로우에 있는 제일 좌측 셀로 전송하는 식이다.
주어진 계층은 다수의 커넬들, 예를 들어, 커넬들 A-D(610)를 가질 수 있다. 커넬들 A-D(610)는 차원 3 × 3 × 10의 매트릭스 구조들을 가질 수 있다. 프로세서는 각각의 커넬 매트릭스 구조를 시스톨릭 어레이(606)의 별개의 컬럼에 있는 셀에 전송할 수 있다. 예를 들어, 커넬 A는 제 1 컬럼의 상부 셀로 전송될 수 있고, 커넬 B는 제 2 컬럼의 상부 셀로 전송될 수 있는 식이다.
매트릭스 구조가 셀로 전송될 경우, 매트릭스의 제 1 엘리먼트는 1 클록 사이클 동안 셀에 저장될 수 있다. 다음 클록 사이클에서, 다음 엘리먼트가 셀에 저장될 수 있다. 저장된 제 1 엘리먼트는, 도 4를 참조하여 상술된 바와 같이 인접 셀로 시프트될 수 있다. 입력들을 시프트하는 것은 매트릭스 구조의 모든 엘리먼트들이 시스톨릭 어레이(606)에 저장될 때까지 계속될 수 있다. 활성화 입력들 및 가중치 입력들 둘 모두는 하나 또는 그 초과의 클록 사이클들 이후에 각각의 셀 전체에 걸쳐 시프트될 수 있다. 시스톨릭 어레이 내부의 입력들을 시프트시키는 것이 도 7과 관련하여 아래에서 추가로 설명될 것이다.
도 7은 3개 클록 사이클들 이후의 예시적인 3 × 3 시스톨릭 어레이의 셀들 내부의 가중치 입력들을 예시하는 예(700)를 도시한다. 각각의 셀은, 도 5를 참조하여 상술된 바와 같이 가중치 입력 및 활성화 입력을 저장할 수 있다. 가중치 입력들은, 도 7과 관련하여 상술된 바와 같이, 컨벌루션 계산들을 위해 시스톨릭 어레이의 별개의 컬럼들에 있는 셀들로 전송될 수 있다. 예로서, 시스템은 1, 2 및 4의 가중치 입력들을 갖는 제 1 커넬 매트릭스 구조를 시스톨릭 어레이의 제 1 컬럼에 전송한다. 시스템은 3, 5 및 7의 가중치 입력들을 갖는 제 2 커넬 구조를 제 2 컬럼으로 전송한다. 시스템은 6, 8 및 10의 가중치들을 갖는 제 3 커넬 구조를 제 3 컬럼으로 전송한다. 모든 각각의 클록 사이클 이후, 가중치 입력들이 1 차원으로 시프트될 수 있는데, 예를 들어, 상부에서 하부로 시프트될 수 있는 반면, 활성화 입력들은 다른 차원으로 시프트될 수 있으며, 예를 들어 좌측에서 우측으로 시프트될 수 있다(예시안됨).
가중치 입력들이 스태거식 방식으로 셀들 내에 저장될 수 있다. 즉, 제 1 클록 사이클(702) 이후의 시스톨릭 어레이의 상태는 상부-좌측 셀 내부에 '1'을 나타낸다. '1'은 셀에 저장된 '1'의 가중치 입력을 나타낸다. 다음 클록 사이클(704)에서, '1'은 상부-좌측 셀 아래의 셀으로 시프트되고, 커넬로부터의 다른 가중치 입력인 '2'가 상부-좌측 셀에 저장될뿐만 아니라, '3'의 가중치 입력이 제 2 컬럼에 있는 제일 상부 셀에 저장된다.
제 3 클록 사이클(706)에서, 각각의 가중치가 다시 시프트된다. 제 1 컬럼에서, 제일 하부 셀은 '1'의 가중치 입력을 저장하고, '2'의 가중치 입력이, 이전 사이클에서 '1'의 가중치 입력이 저장되었던 위치에 저장되며, '4'의 가중치 입력이 상부-제일 좌측 셀에 저장된다. 유사하게, 제 2 컬럼에서, '3'이 아래로 시프트되고 '5' 가중치 입력이 상부-중간 셀에 저장된다. 제 3 컬럼에서, '6' 가중치 입력이 상부-제일 우측 셀에 저장된다.
일부 구현들에서, 가중치 입력들이 시프트되어야하는지 여부를 결정하는 가중치 입력들에 대한 제어 신호가 또한 가중치 입력들과 함께 시프트된다.
활성화 입력들이 유사한 방식으로 다른 차원에서 시프트될 수 있는데, 예를 들어, 좌측에서 우측으로 시프트될 수 있다.
일단 활성화 입력들 및 가중치 입력들이 제자리에 있으면, 프로세서는, 예를 들어, 셀들 내부의 곱셈 및 합산 회로들을 사용함으로써 컨벌루션 계산을 수행하여 벡터 컴퓨테이션 유닛에서 사용될 누산 값의 세트를 생성할 수 있다.
이 시스템은 가중치 입력들이 어레이의 컬럼들로 전송되고 활성화 입력들이 어레이의 로우들로 전송되는 것으로 설명되었지만, 일부 구현들에서는, 가중치 입력들이 어레이의 로우들로 전송되고 활성화 입력들이 어레이의 컬럼들로 전송된다.
도 8은 제어 값들이 가중치 입력들을 시프트시키거나 또는 로딩시키는 방법을 예시하는 예이다. 제어 값들(806)은, 도 3과 관련하여 상술된 바와 같이, 호스트에 의해 전송될 수 있고 가중치 시퀀서들에 의해 저장될 수 있다. 그래프 내의 값들은, 시스톨릭 어레이의 로우들 1 내지 4(804)에 각각 대응하는 가중치 시퀀서들(808-814)에 저장된 제어 값들을, 클록 사이클 단위(802)로 나타낸다.
일부 구현들에서, 주어진 가중치 시퀀서의 제어 값이 넌-제로인 경우, 시스톨릭 어레이의 대응하는 셀에서의 가중치 입력이 인접 셀로 시프트될 것이다. 주어진 가중치 시퀀서의 제어 값이 제로인 경우, 가중치 입력은, 대응하는 셀로 로딩되고 셀의 활성화 입력과의 곱을 컴퓨팅하기 위해 사용될 수 있다.
예시로서, 호스트는, 4개의 가중치 입력들이 로딩되기 전에 이들이 시프트되어야 한다고 결정할 수 있다. 클록 사이클 0에서, 호스트는 5의 제어 값을 가중치 시퀀서(808), 즉, 로우 1에 대응하는 가중치 시퀀서에 전송할 수 있다. 가중치 시퀀서(808)는 감소 회로를 포함하며, 감소 회로는 1 클록 사이클을 소요하여 5의 제어 값에 기초하여 4의 제어 값을 출력한다. 따라서, 4의 제어 값이, 후속 클록 사이클, 즉 클록 사이클 1에서 가중치 시퀀서(808)에 저장된다.
클록 사이클 1에서, 호스트는 4의 제어 값을 가중치 시퀀서(808)로 전송한다. 따라서, 클록 사이클 2에서, 가중치 시퀀서(808)는, 예를 들어, 감소 회로를 사용하여 3의 제어 값을 저장한다. 클록 사이클 1에서, 가중치 시퀀서(808)는 4의 제어 값을 가중치 시퀀서(810)에 전송할 수 있다. 따라서, 클록 사이클 2에서, 4의 제어 값이 가중치 시퀀서(810)의 감소 회로에 의해 프로세싱된 후, 가중치 시퀀서(810)는 3의 제어 값을 저장할 수 있다.
유사하게, 호스트는 3, 2 및 1의 제어 값들을, 각각 클록 사이클들 2, 3 및 4에서 전송할 수 있다. 각각의 가중치 시퀀서(808-814) 내의 감소 회로는, 제어 값들이 감소할 경우, 지연을 야기하기 때문에, 각각의 클록 사이클에서 제어 값들(806)을 감소시키는 것은 결국, 각각의 가중치 시퀀서로 하여금, 동일한 제어 값, 즉 클록 사이클 4에서 1의 제어 값들을 그리고 클록 사이클 5에서 0의 제어 값들을 저장하게 할 수 있다.
일부 구현들에서, 각각의 가중치 시퀀서가 0의 제어 값을 출력할 경우, 시스톨릭 어레이는 가중치 입력들의 시프트를 일시정지하고 각각의 셀에 가중치 입력들을 로딩한다. 즉, 가중치 입력들을 로딩함으로써, 시스톨릭 어레이는, 가중치 입력들이 도트 곱 컴퓨테이션들에서 피연산자로서 사용될 수 있게 함으로써, 신경망의 계층을 프로세싱하기 시작한다.
일부 구현들에서, 컴퓨테이션이 완료된 후, 가중치들을 시프트시키는 것을 다시 시작하기 위해서, 호스트는 제어 값들을 넌-제로의 수로 변경하는데, 예를 들어, 클록 사이클 7 동안 5의 제어 값을 전송한다. 시프트 프로세스는 클록 사이클 0과 관련하여 상술된 바와 같이 반복될 수 있다.
일부 구현들에서, 제어 값들이 다른 오프셋, 예를 들어, 1에서 시작한다.
본 명세서에서 설명한 기능적 동작들 및 요지의 실시예들은 디지털 전자 회로에서, 유형적으로 구현된 컴퓨터 소프트웨어 또는 펌웨어에서, 본 명세서에 개시된 구조들 및 이들의 구조적 등가물들을 포함하는 컴퓨터 하드웨어에서, 또는 이들 중 하나 또는 그 초과의 것의 결합들에서 구현될 수 있다. 본 명세서에서 설명한 요지의 실시예들은 하나 또는 그 초과의 컴퓨터 프로그램들, 즉 데이터 프로세싱 장치에 의한 실행을 위해 또는 데이터 프로세싱 장치의 동작을 제어하기 위해 유형의 비일시적 프로그램 캐리어 상에 인코딩되는 컴퓨터 프로그램 명령들의 하나 또는 그 초과의 모듈들로서 구현될 수 있다. 대안으로 또는 추가로, 프로그램 명령들은 데이터 프로세싱 장치에 의한 실행을 위해 적절한 수신기 장치로의 송신을 위한 정보를 인코딩하기 위해 발생되는 인공적으로 발생한 전파 신호, 예를 들어 기계 발생 전기, 광학 또는 전자기 신호에 대해 인코딩될 수 있다. 컴퓨터 저장 매체는 기계 판독 가능 저장 디바이스, 기계 판독 가능 저장 기판, 랜덤 또는 직렬 액세스 메모리 디바이스, 또는 이들 중 하나 또는 그 초과의 것의 결합일 수 있다.
"데이터 프로세싱 장치"라는 용어는 예로서 프로그래밍 가능 프로세서, 컴퓨터 또는 다수개의 프로세서들이나 컴퓨터들을 포함하여, 데이터를 프로세싱하기 위한 모든 종류들의 장치, 디바이스들 및 기계들을 포괄한다. 장치는 특수 목적 로직 회로, 예를 들어, FPGA(field programmable gate array) 또는 ASIC(application specific integrated circuit)을 포함할 수 있다. 장치는 또한 하드웨어뿐만 아니라, 해당 컴퓨터 프로그램에 대한 실행 환경을 생성하는 코드, 예를 들어 프로세서 펌웨어, 프로토콜 스택, 데이터베이스 관리 시스템, 운영 시스템, 또는 이들 중 하나 또는 그 초과의 것에 대한 결합을 구성하는 코드를 포함할 수 있다.
(프로그램, 소프트웨어, 소프트웨어 애플리케이션, 모듈, 소프트웨어 모듈, 스크립트 또는 코드로 또한 지칭되거나 이로서 설명될 수 있는) 컴퓨터 프로그램은 컴파일링된 또는 해석된 언어들, 또는 순수-기능적 또는 서술적 또는 절차적 언어들을 포함하는 임의의 형태의 프로그래밍 언어로 기록될 수 있고, 이는 독립형 프로그램으로서 또는 모듈, 컴포넌트, 서브루틴, 또는 컴퓨팅 환경에 사용하기에 적절한 다른 유닛으로서의 형태를 포함하는 임의의 형태로 전개될 수 있다. 컴퓨터 프로그램은 파일 시스템 내의 파일에 대응할 수도 있지만 반드시 그런 것은 아니다. 프로그램은 다른 프로그램들 또는 데이터, 예를 들어 마크업 언어 문서에 저장된 하나 또는 그 초과의 스크립트들을 보유하는 파일의 일부에, 해당 프로그램에 전용된 단일 파일에, 또는 다수개의 조정된 파일들, 예를 들어 하나 또는 그 초과의 모듈들, 하위 프로그램들, 또는 코드의 부분들을 저장하는 파일들에 저장될 수 있다. 컴퓨터 프로그램은 하나의 컴퓨터 상에서 또는 한 사이트에 로케이팅되거나 다수개의 사이트들에 걸쳐 분포되어 통신 네트워크에 의해 상호 접속되는 다수개의 컴퓨터들 상에서 실행되도록 전개될 수 있다.
본 명세서에서 설명한 프로세스들 및 로직 흐름들은 입력 데이터에 대해 동작하여 출력을 발생시킴으로써 기능들을 수행하기 위해 하나 또는 그 초과의 컴퓨터 프로그램들을 실행하는 하나 또는 그 초과의 프로그래밍 가능 컴퓨터들에 의해 수행될 수 있다. 프로세스들 및 로직 흐름들은 또한 특수 목적 로직 회로, 예를 들어 FPGA(field programmable gate array) 또는 ASIC(application specific integrated circuit)에 의해 수행될 수 있으며, 장치가 또한 이로서 구현될 수 있다.
컴퓨터 프로그램의 실행에 적합한 컴퓨터들은 범용 또는 특수 목적 마이크로프로세서들 또는 이 둘 모두, 또는 임의의 다른 종류의 중앙 프로세싱 유닛을 포함하며, 예로서 이에 기반할 수 있다. 일반적으로, 중앙 프로세싱 유닛은 판독 전용 메모리 또는 랜덤 액세스 메모리 또는 이 둘 모두로부터 명령들 및 데이터를 수신할 것이다. 컴퓨터의 필수 엘리먼트들은 명령들을 수행 또는 실행하기 위한 중앙 프로세싱 유닛 그리고 명령들 및 데이터를 저장하기 위한 하나 또는 그 초과의 메모리 디바이스들이다. 일반적으로, 컴퓨터는 또한 데이터를 저장하기 위한 하나 또는 그 초과의 대용량 저장 디바이스들, 예를 들어, 자기, 마그네토 광 디스크들, 또는 광 디스크들을 포함하거나, 이들로부터 데이터를 수신하고 또는 이들에 데이터를 전송하도록, 또는 이 둘 모두를 위해 동작 가능하게 연결될 것이다. 그러나 컴퓨터가 이러한 디바이스들을 가질 필요는 없다. 더욱이, 컴퓨터는 다른 디바이스, 몇 가지만 예로 들자면, 예를 들어 모바일 전화, PDA(personal digital assistant), 모바일 오디오 또는 비디오 플레이어, 게임 콘솔, GPS(Global Positioning System) 수신기, 또는 휴대용 저장 디바이스, 예를 들어 USB(universal serial bus) 플래시 드라이브에 내장될 수 있다.
컴퓨터 프로그램 명령들 및 데이터를 저장하기에 적합한 컴퓨터 판독 가능 매체들은, 예로서 반도체 메모리 디바이스들, 예를 들어 EPROM, EEPROM, 및 플래시 메모리 디바이스들; 자기 디스크들, 예를 들어 내부 하드 디스크들 또는 착탈식 디스크들; 마그네토 광 디스크들; 그리고 CD ROM 및 DVD-ROM 디스크들을 포함하는 모든 형태들의 비휘발성 메모리, 매체들 및 메모리 디바이스들을 포함한다. 프로세서 및 메모리는 특수 목적 로직 회로에 의해 보완되거나 특수 목적 로직 회로에 포함될 수 있다.
사용자와의 상호 작용을 전송하기 위해, 본 명세서에서 설명한 요지의 실시예들은 사용자에게 정보를 디스플레이하기 위한 디스플레이 디바이스, 예를 들어 CRT(cathode ray tube) 또는 LCD(liquid crystal display) 모니터, 및 사용자가 컴퓨터에 입력을 전송할 수 있게 하는 키보드와 포인팅 디바이스, 예를 들어 마우스 또는 트랙볼을 갖는 컴퓨터 상에 구현될 수 있다. 다른 종류들의 디바이스들이 사용자와의 상호 작용을 전송하기 위해 또한 사용될 수 있는데; 예를 들어, 사용자에게 제공되는 피드백은 임의의 형태의 감각 피드백, 예를 들어 시각 피드백, 청각 피드백 또는 촉각 피드백일 수 있고; 사용자로부터의 입력은 음향, 음성 또는 촉각 입력을 포함하는 임의의 형태로 수신될 수 있다. 추가로, 컴퓨터는 사용자에 의해 사용되는 디바이스에 문서들을 전송하고 이러한 디바이스로부터 문서들을 수신함으로써; 예를 들어, 웹 브라우저로부터 수신된 요청들에 대한 응답으로 사용자의 클라이언트 디바이스 상의 웹 브라우저에 웹 페이지들을 전송함으로써 사용자와 상호 작용할 수 있다.
본 명세서에서 설명한 요지의 실시예들은 예를 들어, 데이터 서버로서 백엔드 컴포넌트를 포함하는, 또는 미들웨어 컴포넌트, 예를 들어, 애플리케이션 서버를 포함하는, 또는 프론트엔드 컴포넌트, 예를 들어, 본 명세서에서 설명한 요지의 구현과 사용자가 상호 작용할 수 있게 하는 그래픽 사용자 인터페이스 또는 웹 브라우저를 갖는 클라이언트 컴퓨터를 포함하는 컴퓨팅 시스템으로, 또는 이러한 하나 또는 그 초과의 백엔드, 미들웨어 또는 프론트엔드 컴포넌트들의 임의의 결합으로 구현될 수 있다. 시스템의 컴포넌트들은 임의의 형태 또는 매체의 디지털 데이터 통신, 예를 들어 통신 네트워크에 의해 상호 접속될 수 있다. 통신 네트워크들의 예들은 "LAN"(local area network) 및 "WAN"(wide area network), 예를 들어 인터넷을 포함한다.
컴퓨팅 시스템은 클라이언트들 및 서버들을 포함할 수 있다. 클라이언트 및 서버는 일반적으로 서로로부터 원거리이며 일반적으로 통신 네트워크를 통해 상호 작용한다. 클라이언트와 서버의 관계는 각각의 컴퓨터들 상에서 실행되며 서로 클라이언트-서버 관계를 갖는 컴퓨터 프로그램들에 의해 발생한다.
본 명세서는 많은 특정 구현 세부사항들을 포함하지만, 이들은 청구될 수 있는 것의 또는 임의의 발명의 범위에 대한 한정들로서가 아니라, 그보다는 특정 발명들의 특정 실시예들에 특정할 수 있는 특징들의 설명으로서 해석되어야 한다. 개별 실시예들과 관련하여 본 명세서에 설명되는 특정 특징들은 또한 단일 실시예로 결합하여 구현될 수 있다. 반대로, 단일 실시예와 관련하여 설명되는 다양한 특징들은 또한 다수개의 실시예들로 개별적으로 또는 임의의 적절한 하위 결합으로 구현될 수 있다. 더욱이, 특징들이 특정한 결합들로 작용하는 것으로 앞서 설명되고 심지어 초기에 이와 같이 청구될 수 있다 하더라도, 어떤 경우들에는 청구된 결합으로부터의 하나 또는 그 초과의 특징들이 그 결합으로부터 삭제될 수 있고, 청구된 결합은 하위 결합 또는 하위 결합의 변형에 관련될 수 있다.
유사하게, 동작들이 특정 순서로 도면들에 도시되지만, 이는 바람직한 결과들을 달성하기 위해 이러한 동작들이 도시된 특정 순서로 또는 순차적인 순서로 수행될 것을, 또는 예시된 모든 동작들이 수행될 것을 요구하는 것으로 이해되지 않아야 한다. 특정 상황들에서는, 다중 작업 및 병렬 프로세싱이 유리할 수도 있다. 더욱이, 앞서 설명한 실시예들에서 다양한 시스템 모듈들 및 컴포넌트들의 분리는 모든 실시예들에서 이러한 분리를 필요로 하는 것으로 이해되지 않아야 하며, 설명한 프로그램 컴포넌트들 및 시스템들은 일반적으로 단일 소프트웨어 제품으로 함께 통합되거나 다수개의 소프트웨어 제품들로 패키지화될 수 있다는 것이 이해되어야 한다.
요지의 특정 실시예들이 설명되었다. 다른 실시예들이 다음의 청구항들의 범위 내에 있다. 예를 들어, 청구항들에서 언급되는 동작들은 다른 순서로 수행되며 여전히 바람직한 결과들을 달성할 수 있다. 일례로, 첨부 도면들에 도시된 프로세스들은 바람직한 결과들을 달성하기 위해 반드시 도시된 특정 순서 또는 순차적인 순서를 필요로 하는 것은 아니다. 특정 구현들에서는, 다중 작업 및 병렬 프로세싱이 유리할 수 있다.
Claims (19)
- 복수의 계층들을 포함하는 신경망에 대한 신경망 컴퓨테이션들을 수행하기 위한 회로로서,
제 1 셀 및 제 2 셀을 포함하는 매트릭스 컴퓨테이션 유닛; 및
가중치 회로를 포함하고, 상기 가중치 회로는:
상기 제 1 및 제 2 셀들 각각 내의 각각의 가중치 레지스터 ― 상기 각각의 가중치 레지스터는 외부 소스(source)로부터 수신되는 가중치 입력을 저장하기 위해 구성됨 ―;
적어도 상기 제 1 셀에 가중치 입력을 전송하도록 구성된 가중치 페처; 및
상기 제 1 셀로부터 상기 제 2 셀에 상기 가중치 입력을 시프트하도록 구성된 가중치 시퀀서를 포함하고,
상기 매트릭스 컴퓨테이션 유닛은, 상기 가중치 입력과 계층 입력의 곱을 컴퓨팅하는 것을 포함하는 신경망 컴퓨테이션을 수행하기 위해 상기 제 1 셀, 상기 제 2 셀 및 상기 가중치 회로를 사용하는,
회로. - 제 1 항에 있어서,
상기 제 1 및 제 2 셀들 각각 내의 각각의 제어 레지스터를 더 포함하고,
상기 각각의 제어 레지스터는 상기 가중치 시퀀서로부터 각각의 제어 값을 수신하도록 구성되며,
상기 각각의 제어 레지스터는, 상기 각각의 제어 레지스터가 상기 가중치 레지스터에 상기 가중치 입력을 저장하지 않는다고 결정하는 것에 대한 응답으로 상기 제 2 셀을 저장할지 여부를 결정하도록 구성되는,
회로. - 제 2 항에 있어서,
상기 제 1 셀에서 상기 각각의 제어 레지스터에 의해 수신되는 상기 각각의 제어 값은, 상기 각각의 제어 레지스터가 상기 가중치 레지스터에 상기 가중치 입력을 저장하지 않는다고 결정하는 것에 대한 응답으로 상기 제 1 셀로부터 상기 제 2 셀에 상기 가중치 입력을 시프트하기 위해 사용되는,
회로. - 제 1 항에 있어서,
상기 가중치 페처는:
상기 외부 소스와 통신하는 동적 메모리 유닛을 통해 상기 외부 소스로부터 상기 가중치 입력을 수신하고; 그리고
상기 매트릭스 컴퓨테이션 유닛의 제 1 차원을 따라 적어도 상기 제 1 셀에 상기 가중치 입력을 전송하는,
회로. - 제 4 항에 있어서,
상기 가중치 페처가 상기 매트릭스 컴퓨테이션 유닛의 제 1 차원을 따라 적어도 상기 제 1 셀에 상기 가중치 입력을 전송하는 것에 대한 응답으로, 상기 가중치 입력은 상기 제 1 셀의 각각의 가중치 레지스터에 저장되는,
회로. - 제 1 항에 있어서,
상기 제 1 셀 및 상기 제 2 셀 각각은 상기 셀의 각각의 가중치 레지스터에 커플링되는 각각의 곱셈 회로를 포함하고, 그리고
상기 곱셈 회로는 상기 계층 입력과 상기 가중치 입력을 곱한 곱을 출력하도록 구성되는,
회로. - 제 1 항에 있어서,
상기 매트릭스 컴퓨테이션 유닛은 셀들의 어레이을 포함하고, 상기 셀들의 어레이는 상기 제 1 및 제 2 셀들을 포함하고 적어도 2개의 차원들을 가지고,
상기 가중치 페처는 상기 셀들의 어레이의 제 1 차원을 따라 다수의 셀들 각각에 커플링되며, 그리고
상기 가중치 시퀀서는 상기 셀들의 어레이의 제 2 차원을 따라 다수의 셀들 각각에 커플링되는,
회로. - 제 7 항에 있어서,
상기 셀들의 어레이의 제 2 차원을 따라 다수의 셀들 각각에 커플링되는 값 로더를 더 포함하고,
상기 값 로더는:
상기 외부 소스로부터 하나 이상의 계층 입력들을 수신하고; 그리고
상기 셀들의 어레이의 제 2 차원을 따라, 적어도 상기 제 1 또는 제 2 셀들에 상기 하나 이상의 계층 입력들을 전송하도록 구성되는,
회로. - 가중치 회로 및 매트릭스 컴퓨테이션 유닛을 포함하는 회로를 사용하고 복수의 계층들을 포함하는 신경망에 대한 신경망 컴퓨테이션들을 수행하기 위한 방법으로서,
상기 가중치 회로의 가중치 페처를 사용하여, 상기 매트릭스 컴퓨테이션 유닛의 셀에 가중치 입력을 전송하는 단계 ― 상기 가중치 입력은 외부 소스로부터 수신됨 ―;
상기 셀의 제어 레지스터에 의해, 상기 제어 레지스터에 의해 수신된 제어 값에 기초하여 상기 셀의 가중치 레지스터에 상기 가중치 입력을 저장할지 여부를 결정하는 단계;
상기 제어 레지스터가 상기 가중치 입력이 상기 가중치 레지스터에 저장되어야 한다고 결정하는 것에 대한 응답으로 상기 셀의 가중치 레지스터에 상기 가중치 입력을 저장하는 단계;
상기 셀에 의해, 상기 외부 소스에 의해 제공된 계층 입력을 수신하는 단계; 및
상기 셀의 가중치 레지스터에 커플링된 곱셈 회로를 사용하여, 상기 가중치 입력과 상기 계층 입력을 곱한 곱을 생성하는 단계를 포함하는,
방법. - 제 9 항에 있어서,
상기 매트릭스 컴퓨테이션 유닛은 다수의 셀들의 어레이를 포함하고, 상기 어레이는 적어도 두개의 차원들을 가지며,
상기 방법은:
상기 매트릭스 컴퓨테이션 유닛의 셀들에 의해, 상기 가중치 페처에 의해 전송된 상기 가중치 입력을 수신하는 단계; 및
상기 어레이의 제 1 차원을 따라, 상기 어레이의 인접 셀에 상기 가중치 입력을 시프트하는 단계를 더 포함하고,
상기 가중치 입력은, 상기 셀의 제어 레지스터가 상기 셀의 가중치 레지스터에 상기 가중치 입력을 저장하지 않는다고 결정하는 것에 대한 응답으로 상기 인접 셀로 시프트되는,
방법. - 제 10 항에 있어서,
상기 회로의 가중치 시퀀서에 의해, 상기 셀의 제어 레지스터에 의해 수신된 상기 제어 값을 제공하는 단계; 및
상기 제어 값에 기초하여, 복수의 클록 사이클들에 걸쳐 상기 어레이의 제 1 차원을 따라 하나 이상의 셀들에 하나 이상의 가중치 입력들을 시프트하는 단계를 더 포함하는,
방법. - 제 11 항에 있어서,
상기 가중치 페처는 상기 어레이의 제 1 차원을 따라 다수의 셀들 각각에 커플링되며, 그리고
상기 가중치 시퀀서는 상기 어레이의 제 2 차원을 따라 다수의 셀들 각각에 커플링되는,
방법. - 제 12 항에 있어서,
상기 회로는 상기 어레이의 제 2 차원을 따라 다수의 셀들 각각에 커플링되는 값 로더를 더 포함하며, 그리고
상기 방법은:
상기 값 로더에 의해, 상기 외부 소스로부터 하나 이상의 계층 입력들을 수신하는 단계; 및
상기 값 로더에 의해 그리고 상기 어레이의 제 2 차원을 따라, 상기 어레이의 제 2 차원을 따라 배열된 하나 이상의 셀들에 상기 하나 이상의 계층 입력들을 전송하는 단계를 더 포함하는,
방법. - 제 13 항에 있어서,
상기 셀의 가중치 레지스터에 상기 가중치 입력을 저장하는 단계는:
상기 셀에 계층 입력들이 제공될 때, 상기 값 로더를 사용하여 그리고 다수의 클록 사이클들에 걸쳐, 상기 가중치 입력이 셀 내에 저장된 채 남아있고 인접 셀로 시프트되지 않도록, 상기 가중치 입력을 정적으로 저장하는 단계를 포함하는,
방법. - 제 10 항에 있어서,
상기 가중치 페처에 의해, 상기 외부 소스와 통신하는 동적 메모리를 통해 상기 외부 소스로부터 상기 가중치 입력을 수신하는 단계; 및
상기 가중치 페처에 의해, 상기 매트릭스 컴퓨테이션 유닛의 다수의 셀들의 어레이의 제 1 차원을 따라 적어도 제 1 셀에 상기 가중치 입력을 전송하는 단계를 더 포함하는,
방법. - 제 15 항에 있어서,
상기 가중치 페처가 상기 매트릭스 컴퓨테이션 유닛의 제 1 차원을 따라 적어도 상기 제 1 셀에 상기 가중치 입력을 전송하는 것에 대한 응답으로, 상기 가중치 입력은 상기 제 1 셀의 가중치 레지스터에 저장되는,
방법. - 제 9 항에 있어서,
상기 셀의 합산 회로에 의해, 상기 곱셈 회로에 의해 생성된 상기 곱 및 상기 매트릭스 컴퓨테이션 유닛의 인접한 셀로부터의 제 1 부분 합을 수신하는 단계; 및
상기 합산 회로에 의해, 상기 곱과 상기 제 1 부분 합을 더한 합인 제 2 부분 합을 생성하는 단계를 더 포함하는,
방법. - 다중 계층 신경망에 대한 신경망 컴퓨테이션들을 수행하기 위해 사용되는 명령들을 저장하고 가중치 회로 및 매트릭스 컴퓨테이션 유닛을 사용하기 위한 비일시적 기계-판독가능한 저장 장치로서,
상기 명령들은 동작들을 수행시키기 위해 프로세싱 장치에 의해 실행될 수 있고, 그리고
상기 동작들은:
상기 가중치 회로의 가중치 페처를 사용하여, 상기 매트릭스 컴퓨테이션 유닛의 셀에 가중치 입력을 전송하는 동작 ― 상기 가중치 입력은 외부 소스로부터 수신됨 ―;
상기 셀의 제어 레지스터에 의해, 상기 제어 레지스터에 의해 수신된 제어 값에 기초하여 상기 셀의 가중치 레지스터에 상기 가중치 입력을 저장할지 여부를 결정하는 동작;
상기 제어 레지스터가 상기 가중치 입력이 상기 가중치 레지스터에 저장되어야 한다고 결정하는 것에 대한 응답으로 상기 셀의 가중치 레지스터에 상기 가중치 입력을 저장하는 동작;
상기 셀에 의해, 상기 외부 소스에 의해 제공된 계층 입력을 수신하는 동작; 및
상기 셀의 가중치 레지스터에 커플링된 곱셈 회로를 사용하여, 상기 가중치 입력과 상기 계층 입력을 곱한 곱을 생성하는 동작을 포함하는,
비일시적 기계-판독가능한 저장 장치. - 제 18 항에 있어서,
상기 매트릭스 컴퓨테이션 유닛은 다수의 셀들의 어레이를 포함하고, 상기 셀들의 어레이는 적어도 2개의 차원들을 가지며, 그리고
상기 동작들은:
상기 매트릭스 컴퓨테이션 유닛의 셀들에 의해, 상기 가중치 페처에 의해 전송된 상기 가중치 입력을 수신하는 동작; 및
상기 어레이의 제 1 차원을 따라, 상기 어레이의 인접 셀에 상기 가중치 입력을 시프트하는 동작을 더 포함하고,
상기 가중치 입력은, 상기 셀의 제어 레지스터가 상기 셀의 가중치 레지스터에 상기 가중치 입력을 저장하지 않는다고 결정하는 것에 대한 응답으로 상기 인접 셀로 시프트되는,
비일시적 기계-판독가능한 저장 장치.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020227021145A KR102641283B1 (ko) | 2015-05-21 | 2016-04-29 | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 |
Applications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562164981P | 2015-05-21 | 2015-05-21 | |
| US62/164,981 | 2015-05-21 | ||
| US14/844,670 US10049322B2 (en) | 2015-05-21 | 2015-09-03 | Prefetching weights for use in a neural network processor |
| US14/844,670 | 2015-09-03 | ||
| PCT/US2016/029965 WO2016186810A1 (en) | 2015-05-21 | 2016-04-29 | Prefetching weights for use in a neural network processor |
| KR1020177028188A KR102105128B1 (ko) | 2015-05-21 | 2016-04-29 | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020177028188A Division KR102105128B1 (ko) | 2015-05-21 | 2016-04-29 | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227021145A Division KR102641283B1 (ko) | 2015-05-21 | 2016-04-29 | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200045006A true KR20200045006A (ko) | 2020-04-29 |
| KR102413522B1 KR102413522B1 (ko) | 2022-06-24 |
Family
ID=56081550
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020177028188A KR102105128B1 (ko) | 2015-05-21 | 2016-04-29 | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 |
| KR1020247005904A KR20240029112A (ko) | 2015-05-21 | 2016-04-29 | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 |
| KR1020207011552A KR102413522B1 (ko) | 2015-05-21 | 2016-04-29 | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 |
| KR1020227021145A KR102641283B1 (ko) | 2015-05-21 | 2016-04-29 | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 |
Family Applications Before (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020177028188A KR102105128B1 (ko) | 2015-05-21 | 2016-04-29 | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 |
| KR1020247005904A KR20240029112A (ko) | 2015-05-21 | 2016-04-29 | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227021145A KR102641283B1 (ko) | 2015-05-21 | 2016-04-29 | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 |
Country Status (11)
| Country | Link |
|---|---|
| US (6) | US10049322B2 (ko) |
| EP (2) | EP3298546B1 (ko) |
| JP (5) | JP6689878B2 (ko) |
| KR (4) | KR102105128B1 (ko) |
| CN (2) | CN112465132A (ko) |
| DE (2) | DE202016107439U1 (ko) |
| DK (1) | DK3298546T3 (ko) |
| GB (2) | GB2553052B (ko) |
| HK (1) | HK1245462A1 (ko) |
| TW (1) | TWI636368B (ko) |
| WO (1) | WO2016186810A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021246818A1 (ko) * | 2020-06-05 | 2021-12-09 | 주식회사 퓨리오사에이아이 | 뉴럴 네트워크 프로세싱 방법 및 이를 위한 장치 |
Families Citing this family (125)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10846591B2 (en) * | 2015-12-29 | 2020-11-24 | Synopsys, Inc. | Configurable and programmable multi-core architecture with a specialized instruction set for embedded application based on neural networks |
| US10360496B2 (en) * | 2016-04-01 | 2019-07-23 | Intel Corporation | Apparatus and method for a digital neuromorphic processor |
| KR20180034853A (ko) * | 2016-09-28 | 2018-04-05 | 에스케이하이닉스 주식회사 | 합성곱 신경망의 연산 장치 및 방법 |
| IE87469B1 (en) * | 2016-10-06 | 2024-01-03 | Google Llc | Image processing neural networks with separable convolutional layers |
| US10521488B1 (en) | 2016-12-30 | 2019-12-31 | X Development Llc | Dynamic partitioning |
| EP3998539A1 (en) * | 2016-12-30 | 2022-05-18 | INTEL Corporation | Deep learning hardware |
| US10146768B2 (en) * | 2017-01-25 | 2018-12-04 | Google Llc | Automatic suggested responses to images received in messages using language model |
| JP6823495B2 (ja) * | 2017-02-27 | 2021-02-03 | 株式会社日立製作所 | 情報処理装置および画像認識装置 |
| US10896367B2 (en) * | 2017-03-07 | 2021-01-19 | Google Llc | Depth concatenation using a matrix computation unit |
| US10909447B2 (en) | 2017-03-09 | 2021-02-02 | Google Llc | Transposing neural network matrices in hardware |
| US10241972B2 (en) | 2017-03-16 | 2019-03-26 | International Business Machines Corporation | Matrix multiplication on a systolic array |
| KR102414583B1 (ko) * | 2017-03-23 | 2022-06-29 | 삼성전자주식회사 | 머신 러닝을 수행하는 전자 장치 및 머신 러닝 수행 방법 |
| US10331999B2 (en) * | 2017-04-03 | 2019-06-25 | Gyrfalcon Technology Inc. | Memory subsystem in CNN based digital IC for artificial intelligence |
| US10552733B2 (en) | 2017-04-03 | 2020-02-04 | Gyrfalcon Technology Inc. | Memory subsystem in CNN based digital IC for artificial intelligence |
| US10534996B2 (en) | 2017-04-03 | 2020-01-14 | Gyrfalcon Technology Inc. | Memory subsystem in CNN based digital IC for artificial intelligence |
| US10546234B2 (en) | 2017-04-03 | 2020-01-28 | Gyrfalcon Technology Inc. | Buffer memory architecture for a CNN based processing unit and creation methods thereof |
| US10824938B2 (en) * | 2017-04-24 | 2020-11-03 | Intel Corporation | Specialized fixed function hardware for efficient convolution |
| US10698974B2 (en) * | 2017-05-17 | 2020-06-30 | Google Llc | Low latency matrix multiply unit |
| US10019668B1 (en) * | 2017-05-19 | 2018-07-10 | Google Llc | Scheduling neural network processing |
| US11328037B2 (en) * | 2017-07-07 | 2022-05-10 | Intel Corporation | Memory-size- and bandwidth-efficient method for feeding systolic array matrix multipliers |
| CN109284827A (zh) | 2017-07-19 | 2019-01-29 | 阿里巴巴集团控股有限公司 | 神经网络计算方法、设备、处理器及计算机可读存储介质 |
| US11893393B2 (en) | 2017-07-24 | 2024-02-06 | Tesla, Inc. | Computational array microprocessor system with hardware arbiter managing memory requests |
| US10671349B2 (en) | 2017-07-24 | 2020-06-02 | Tesla, Inc. | Accelerated mathematical engine |
| US11409692B2 (en) | 2017-07-24 | 2022-08-09 | Tesla, Inc. | Vector computational unit |
| US11157441B2 (en) | 2017-07-24 | 2021-10-26 | Tesla, Inc. | Computational array microprocessor system using non-consecutive data formatting |
| US11157287B2 (en) | 2017-07-24 | 2021-10-26 | Tesla, Inc. | Computational array microprocessor system with variable latency memory access |
| US11360934B1 (en) | 2017-09-15 | 2022-06-14 | Groq, Inc. | Tensor streaming processor architecture |
| US11868804B1 (en) | 2019-11-18 | 2024-01-09 | Groq, Inc. | Processor instruction dispatch configuration |
| US11243880B1 (en) | 2017-09-15 | 2022-02-08 | Groq, Inc. | Processor architecture |
| US11114138B2 (en) | 2017-09-15 | 2021-09-07 | Groq, Inc. | Data structures with multiple read ports |
| US11170307B1 (en) | 2017-09-21 | 2021-11-09 | Groq, Inc. | Predictive model compiler for generating a statically scheduled binary with known resource constraints |
| CN111149090B (zh) * | 2017-09-21 | 2023-12-01 | 华为技术有限公司 | 多线程脉动阵列 |
| CN107832839B (zh) * | 2017-10-31 | 2020-02-14 | 南京地平线机器人技术有限公司 | 执行卷积神经网络中的运算的方法和装置 |
| GB2568086B (en) | 2017-11-03 | 2020-05-27 | Imagination Tech Ltd | Hardware implementation of convolution layer of deep neutral network |
| EP3480747A1 (en) | 2017-11-06 | 2019-05-08 | Imagination Technologies Limited | Single plane filters |
| KR102424962B1 (ko) | 2017-11-15 | 2022-07-25 | 삼성전자주식회사 | 병렬 연산 처리를 수행하는 메모리 장치 및 이를 포함하는 메모리 모듈 |
| CN107909148B (zh) * | 2017-12-12 | 2020-10-20 | 南京地平线机器人技术有限公司 | 用于执行卷积神经网络中的卷积运算的装置 |
| US10803379B2 (en) | 2017-12-12 | 2020-10-13 | Amazon Technologies, Inc. | Multi-memory on-chip computational network |
| WO2019118363A1 (en) * | 2017-12-12 | 2019-06-20 | Amazon Technologies, Inc. | On-chip computational network |
| CN111105033B (zh) * | 2017-12-14 | 2024-01-12 | 中科寒武纪科技股份有限公司 | 神经网络处理器板卡及相关产品 |
| US11119677B2 (en) * | 2017-12-15 | 2021-09-14 | Samsung Electronics Co., Ltd. | HBM based memory lookup engine for deep learning accelerator |
| KR102637735B1 (ko) * | 2018-01-09 | 2024-02-19 | 삼성전자주식회사 | 근사 곱셈기를 구비하는 뉴럴 네트워크 처리 장치 및 이를 포함하는 시스템온 칩 |
| CN109416756A (zh) * | 2018-01-15 | 2019-03-01 | 深圳鲲云信息科技有限公司 | 卷积器及其所应用的人工智能处理装置 |
| CN108364063B (zh) * | 2018-01-24 | 2019-09-27 | 福州瑞芯微电子股份有限公司 | 一种基于权值分配资源的神经网络训练方法和装置 |
| US11561791B2 (en) | 2018-02-01 | 2023-01-24 | Tesla, Inc. | Vector computational unit receiving data elements in parallel from a last row of a computational array |
| CN108416434B (zh) * | 2018-02-07 | 2021-06-04 | 复旦大学 | 针对神经网络的卷积层与全连接层进行加速的电路结构 |
| US10796198B2 (en) | 2018-02-08 | 2020-10-06 | Western Digital Technologies, Inc. | Adjusting enhancement coefficients for neural network engine |
| US11164072B2 (en) | 2018-02-08 | 2021-11-02 | Western Digital Technologies, Inc. | Convolution engines for systolic neural network processor |
| DE102018202095A1 (de) * | 2018-02-12 | 2019-08-14 | Robert Bosch Gmbh | Verfahren und Vorrichtung zum Überprüfen einer Neuronenfunktion in einem neuronalen Netzwerk |
| US11468302B2 (en) * | 2018-03-13 | 2022-10-11 | Recogni Inc. | Efficient convolutional engine |
| US11475306B2 (en) | 2018-03-22 | 2022-10-18 | Amazon Technologies, Inc. | Processing for multiple input data sets |
| EP3738081A1 (en) * | 2018-03-22 | 2020-11-18 | Amazon Technologies Inc. | Processing for multiple input data sets |
| CN110210610B (zh) * | 2018-03-27 | 2023-06-20 | 腾讯科技(深圳)有限公司 | 卷积计算加速器、卷积计算方法及卷积计算设备 |
| US10621489B2 (en) * | 2018-03-30 | 2020-04-14 | International Business Machines Corporation | Massively parallel neural inference computing elements |
| US11188814B2 (en) * | 2018-04-05 | 2021-11-30 | Arm Limited | Systolic convolutional neural network |
| US20190332924A1 (en) * | 2018-04-27 | 2019-10-31 | International Business Machines Corporation | Central scheduler and instruction dispatcher for a neural inference processor |
| US11537838B2 (en) * | 2018-05-04 | 2022-12-27 | Apple Inc. | Scalable neural network processing engine |
| CA3100495A1 (en) | 2018-05-16 | 2019-11-21 | Benevis Informatics, Llc | Systems and methods for review of computer-aided detection of pathology in images |
| CA3101026A1 (en) * | 2018-06-05 | 2019-12-12 | Lightelligence, Inc. | Optoelectronic computing systems |
| US12099912B2 (en) | 2018-06-22 | 2024-09-24 | Samsung Electronics Co., Ltd. | Neural processor |
| US10839894B2 (en) * | 2018-06-29 | 2020-11-17 | Taiwan Semiconductor Manufacturing Company Ltd. | Memory computation circuit and method |
| US20200019836A1 (en) * | 2018-07-12 | 2020-01-16 | International Business Machines Corporation | Hierarchical parallelism in a network of distributed neural network cores |
| CN110751276A (zh) * | 2018-07-24 | 2020-02-04 | 闪迪技术有限公司 | 在nand存储器阵列中实现具有三值输入和二值权重的神经网络 |
| US10643119B2 (en) * | 2018-07-24 | 2020-05-05 | Sandisk Technologies Llc | Differential non-volatile memory cell for artificial neural network |
| US11954573B2 (en) * | 2018-09-06 | 2024-04-09 | Black Sesame Technologies Inc. | Convolutional neural network using adaptive 3D array |
| CN109543816B (zh) * | 2018-09-20 | 2022-12-06 | 中国科学院计算技术研究所 | 一种基于权重捏合的卷积神经网络计算方法和系统 |
| US10817042B2 (en) * | 2018-09-27 | 2020-10-27 | Intel Corporation | Power savings for neural network architecture with zero activations during inference |
| US11443185B2 (en) * | 2018-10-11 | 2022-09-13 | Powerchip Semiconductor Manufacturing Corporation | Memory chip capable of performing artificial intelligence operation and method thereof |
| US11636325B2 (en) | 2018-10-24 | 2023-04-25 | Macronix International Co., Ltd. | In-memory data pooling for machine learning |
| KR102637733B1 (ko) | 2018-10-31 | 2024-02-19 | 삼성전자주식회사 | 뉴럴 네트워크 프로세서 및 그것의 컨볼루션 연산 방법 |
| JP7315317B2 (ja) * | 2018-11-09 | 2023-07-26 | 株式会社Preferred Networks | プロセッサおよびプロセッサのデータ転送方法 |
| US11455370B2 (en) | 2018-11-19 | 2022-09-27 | Groq, Inc. | Flattened input stream generation for convolution with expanded kernel |
| US11562229B2 (en) * | 2018-11-30 | 2023-01-24 | Macronix International Co., Ltd. | Convolution accelerator using in-memory computation |
| US11494645B2 (en) | 2018-12-06 | 2022-11-08 | Egis Technology Inc. | Convolutional neural network processor and data processing method thereof |
| CN111291874B (zh) * | 2018-12-06 | 2023-12-01 | 神盾股份有限公司 | 卷积神经网络处理器及其数据处理方法 |
| US11100193B2 (en) * | 2018-12-07 | 2021-08-24 | Samsung Electronics Co., Ltd. | Dataflow accelerator architecture for general matrix-matrix multiplication and tensor computation in deep learning |
| US11934480B2 (en) | 2018-12-18 | 2024-03-19 | Macronix International Co., Ltd. | NAND block architecture for in-memory multiply-and-accumulate operations |
| CN109919321A (zh) * | 2019-02-01 | 2019-06-21 | 京微齐力(北京)科技有限公司 | 单元具有本地累加功能的人工智能模块及系统芯片 |
| CN109933371A (zh) * | 2019-02-01 | 2019-06-25 | 京微齐力(北京)科技有限公司 | 其单元可访问本地存储器的人工智能模块和系统芯片 |
| CN109857024B (zh) * | 2019-02-01 | 2021-11-12 | 京微齐力(北京)科技有限公司 | 人工智能模块的单元性能测试方法和系统芯片 |
| CN109902064A (zh) * | 2019-02-01 | 2019-06-18 | 京微齐力(北京)科技有限公司 | 一种二维脉动阵列的芯片电路 |
| US11507662B2 (en) | 2019-02-04 | 2022-11-22 | Sateesh Kumar Addepalli | Systems and methods of security for trusted artificial intelligence hardware processing |
| US11544525B2 (en) | 2019-02-04 | 2023-01-03 | Sateesh Kumar Addepalli | Systems and methods for artificial intelligence with a flexible hardware processing framework |
| US11150720B2 (en) | 2019-02-04 | 2021-10-19 | Sateesh Kumar Addepalli | Systems and methods for power management of hardware utilizing virtual multilane architecture |
| US20200249996A1 (en) * | 2019-02-04 | 2020-08-06 | Pathtronic Inc. | Systems and methods for artificial intelligence hardware processing |
| US11423454B2 (en) | 2019-02-15 | 2022-08-23 | Sateesh Kumar Addepalli | Real-time customizable AI model collaboration and marketplace service over a trusted AI model network |
| JP7297468B2 (ja) | 2019-02-28 | 2023-06-26 | キヤノン株式会社 | データ処理装置及びその方法 |
| KR20200107295A (ko) * | 2019-03-07 | 2020-09-16 | 에스케이하이닉스 주식회사 | 시스톨릭 어레이 및 프로세싱 시스템 |
| JP7107482B2 (ja) | 2019-03-15 | 2022-07-27 | インテル・コーポレーション | ハイブリッド浮動小数点フォーマットのドット積累算命令を有するグラフィックスプロセッサ及びグラフィックス処理ユニット |
| US10929058B2 (en) | 2019-03-25 | 2021-02-23 | Western Digital Technologies, Inc. | Enhanced memory device architecture for machine learning |
| US11783176B2 (en) | 2019-03-25 | 2023-10-10 | Western Digital Technologies, Inc. | Enhanced storage device memory architecture for machine learning |
| US11671111B2 (en) | 2019-04-17 | 2023-06-06 | Samsung Electronics Co., Ltd. | Hardware channel-parallel data compression/decompression |
| US11880760B2 (en) | 2019-05-01 | 2024-01-23 | Samsung Electronics Co., Ltd. | Mixed-precision NPU tile with depth-wise convolution |
| CN111985628B (zh) * | 2019-05-24 | 2024-04-30 | 澜起科技股份有限公司 | 计算装置及包括所述计算装置的神经网络处理器 |
| KR102351087B1 (ko) | 2019-06-04 | 2022-01-14 | 주식회사 딥엑스 | 인공신경망의 데이터 로컬리티 기반의 데이터 캐슁을 이용하여 고속의 인공신경망 오퍼레이션을 지원하는 데이터 관리 장치 |
| US11233049B2 (en) | 2019-06-14 | 2022-01-25 | Macronix International Co., Ltd. | Neuromorphic computing device |
| TWI698810B (zh) * | 2019-06-14 | 2020-07-11 | 旺宏電子股份有限公司 | 類神經計算裝置 |
| US11514300B2 (en) | 2019-06-14 | 2022-11-29 | Macronix International Co., Ltd. | Resistor circuit, artificial intelligence chip and method for manufacturing the same |
| CN110210615B (zh) * | 2019-07-08 | 2024-05-28 | 中昊芯英(杭州)科技有限公司 | 一种用于执行神经网络计算的脉动阵列系统 |
| CN110543934B (zh) * | 2019-08-14 | 2022-02-01 | 北京航空航天大学 | 一种用于卷积神经网络的脉动阵列计算结构及方法 |
| US20220318638A1 (en) * | 2019-08-22 | 2022-10-06 | Google Llc | Propagation latency reduction |
| US11501145B1 (en) * | 2019-09-17 | 2022-11-15 | Amazon Technologies, Inc. | Memory operation for systolic array |
| US11842169B1 (en) | 2019-09-25 | 2023-12-12 | Amazon Technologies, Inc. | Systolic multiply delayed accumulate processor architecture |
| EP4066170A4 (en) * | 2019-11-26 | 2024-01-17 | Groq, Inc. | LOADING OPERANDS AND DELIVERING RESULTS FROM A MULTI-DIMENSIONAL ARRAY USING ONLY ONE SIDE |
| KR20210065605A (ko) | 2019-11-27 | 2021-06-04 | 한국전자통신연구원 | 선인출 정보를 이용한 메모리 제어 방법 및 장치 |
| US11467806B2 (en) | 2019-11-27 | 2022-10-11 | Amazon Technologies, Inc. | Systolic array including fused multiply accumulate with efficient prenormalization and extended dynamic range |
| US11816446B2 (en) | 2019-11-27 | 2023-11-14 | Amazon Technologies, Inc. | Systolic array component combining multiple integer and floating-point data types |
| US12112141B2 (en) | 2019-12-12 | 2024-10-08 | Samsung Electronics Co., Ltd. | Accelerating 2D convolutional layer mapping on a dot product architecture |
| US11586889B1 (en) * | 2019-12-13 | 2023-02-21 | Amazon Technologies, Inc. | Sensory perception accelerator |
| US11669733B2 (en) | 2019-12-23 | 2023-06-06 | Marvell Asia Pte. Ltd. | Processing unit and method for computing a convolution using a hardware-implemented spiral algorithm |
| TWI733334B (zh) * | 2020-02-15 | 2021-07-11 | 財團法人工業技術研究院 | 卷積神經網路運算裝置及其運算的方法 |
| KR20210105053A (ko) * | 2020-02-18 | 2021-08-26 | 에스케이하이닉스 주식회사 | 연산 회로 및 그것을 포함하는 딥 러닝 시스템 |
| US12073310B2 (en) * | 2020-04-01 | 2024-08-27 | Microsoft Technology Licensing, Llc | Deep neural network accelerator with independent datapaths for simultaneous processing of different classes of operations |
| CN113496117B (zh) * | 2020-04-02 | 2024-03-12 | 北京庖丁科技有限公司 | 交叉检查表格中单元格数字内容的方法和电子设备 |
| US11507817B2 (en) | 2020-04-17 | 2022-11-22 | Samsung Electronics Co., Ltd. | System and method for performing computations for deep neural networks |
| JP7537213B2 (ja) | 2020-09-30 | 2024-08-21 | セイコーエプソン株式会社 | 情報処理装置、演算方法、及び、コンピュータープログラム |
| US11308027B1 (en) | 2020-06-29 | 2022-04-19 | Amazon Technologies, Inc. | Multiple accumulate busses in a systolic array |
| US11422773B1 (en) | 2020-06-29 | 2022-08-23 | Amazon Technologies, Inc. | Multiple busses within a systolic array processing element |
| CN111737193B (zh) * | 2020-08-03 | 2020-12-08 | 深圳鲲云信息科技有限公司 | 数据存储方法、装置、设备和存储介质 |
| US12008469B1 (en) | 2020-09-01 | 2024-06-11 | Amazon Technologies, Inc. | Acceleration of neural networks with stacks of convolutional layers |
| CN112580787B (zh) * | 2020-12-25 | 2023-11-17 | 北京百度网讯科技有限公司 | 神经网络加速器的数据处理方法、装置、设备及存储介质 |
| TWI788128B (zh) * | 2021-04-16 | 2022-12-21 | 旺宏電子股份有限公司 | 記憶體裝置及其操作方法 |
| TWI847030B (zh) | 2021-05-05 | 2024-07-01 | 創鑫智慧股份有限公司 | 矩陣乘法器及其操作方法 |
| US11880682B2 (en) | 2021-06-30 | 2024-01-23 | Amazon Technologies, Inc. | Systolic array with efficient input reduction and extended array performance |
| US20230004523A1 (en) * | 2021-06-30 | 2023-01-05 | Amazon Technologies, Inc. | Systolic array with input reduction to multiple reduced inputs |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0422348A2 (en) * | 1989-10-10 | 1991-04-17 | Hnc, Inc. | Two-dimensional systolic array for neural networks, and method |
| JPH07141454A (ja) * | 1993-11-18 | 1995-06-02 | G D S:Kk | シストリックアレイプロセサー |
| KR100189195B1 (ko) * | 1996-04-04 | 1999-06-01 | 박래홍 | 단일화된 시스톨릭어레이 구조에 의한 2차원 dct/dst/dht의 수행장치 |
| KR20030082255A (ko) * | 2002-04-17 | 2003-10-22 | 한국전자통신연구원 | 향상된 선형 궤환 시프트 레지스터 구조의 유한체 승산기 |
| JP2004157756A (ja) * | 2002-11-06 | 2004-06-03 | Canon Inc | 階層処理装置 |
| US20040117710A1 (en) * | 2002-12-17 | 2004-06-17 | Srinivas Patil | Weight compression/decompression system |
Family Cites Families (41)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU8698582A (en) | 1981-08-14 | 1983-02-17 | Rca Corp. | Digital air filter |
| JPS6028345A (ja) | 1983-07-26 | 1985-02-13 | Fujitsu Ltd | 並列計算機における通信方式 |
| JPS63293668A (ja) | 1987-05-27 | 1988-11-30 | Matsushita Electric Ind Co Ltd | 並列計算機の通信方法 |
| US5014235A (en) | 1987-12-15 | 1991-05-07 | Steven G. Morton | Convolution memory |
| US5136717A (en) | 1988-11-23 | 1992-08-04 | Flavors Technology Inc. | Realtime systolic, multiple-instruction, single-data parallel computer system |
| US5146543A (en) | 1990-05-22 | 1992-09-08 | International Business Machines Corp. | Scalable neural array processor |
| US5337395A (en) | 1991-04-08 | 1994-08-09 | International Business Machines Corporation | SPIN: a sequential pipeline neurocomputer |
| US5274832A (en) * | 1990-10-04 | 1993-12-28 | National Semiconductor Corporation | Systolic array for multidimensional matrix computations |
| JP2760170B2 (ja) | 1990-11-29 | 1998-05-28 | 松下電器産業株式会社 | 学習機械 |
| JP2749725B2 (ja) | 1991-03-18 | 1998-05-13 | 富士通株式会社 | 並列計算機の通信方法 |
| JPH04290155A (ja) | 1991-03-19 | 1992-10-14 | Fujitsu Ltd | 並列データ処理方式 |
| US5903454A (en) | 1991-12-23 | 1999-05-11 | Hoffberg; Linda Irene | Human-factored interface corporating adaptive pattern recognition based controller apparatus |
| JPH05346914A (ja) | 1992-06-16 | 1993-12-27 | Matsushita Electron Corp | ニューロプロセッサ |
| US5465041A (en) | 1993-09-17 | 1995-11-07 | Penberthy, Inc. | Bipolar tracking current source/sink with ground clamp |
| DE4414821A1 (de) | 1994-04-28 | 1995-11-02 | Vorwerk Co Interholding | Küchenmaschine mit einem Rührgefäß und einem Antrieb für ein Rührwerk in dem Rührgefäß |
| US5583964A (en) * | 1994-05-02 | 1996-12-10 | Motorola, Inc. | Computer utilizing neural network and method of using same |
| US5799134A (en) | 1995-03-13 | 1998-08-25 | Industrial Technology Research Institute | One dimensional systolic array architecture for neural network |
| US5812993A (en) | 1996-03-07 | 1998-09-22 | Technion Research And Development Foundation Ltd. | Digital hardware architecture for realizing neural network |
| US6038337A (en) | 1996-03-29 | 2000-03-14 | Nec Research Institute, Inc. | Method and apparatus for object recognition |
| JPH11177399A (ja) | 1997-12-15 | 1999-07-02 | Mitsubishi Electric Corp | クロック遅延回路およびこれを用いた発振回路、位相同期回路、クロック生成回路 |
| GB9902115D0 (en) | 1999-02-01 | 1999-03-24 | Axeon Limited | Neural networks |
| FR2853424B1 (fr) * | 2003-04-04 | 2005-10-21 | Atmel Corp | Architecture de multiplicateurs polynomial et naturel combines |
| US7245767B2 (en) | 2003-08-21 | 2007-07-17 | Hewlett-Packard Development Company, L.P. | Method and apparatus for object identification, classification or verification |
| US7634137B2 (en) | 2005-10-14 | 2009-12-15 | Microsoft Corporation | Unfolded convolution for fast feature extraction |
| WO2008067676A1 (en) | 2006-12-08 | 2008-06-12 | Medhat Moussa | Architecture, system and method for artificial neural network implementation |
| US8184696B1 (en) | 2007-09-11 | 2012-05-22 | Xilinx, Inc. | Method and apparatus for an adaptive systolic array structure |
| TW200923803A (en) | 2007-11-26 | 2009-06-01 | Univ Nat Taipei Technology | Hardware neural network learning and recall architecture |
| TWI417798B (zh) | 2008-11-21 | 2013-12-01 | Nat Taipei University Oftechnology | High - speed reverse transfer neural network system with elastic structure and learning function |
| JP5376920B2 (ja) | 2008-12-04 | 2013-12-25 | キヤノン株式会社 | コンボリューション演算回路、階層的コンボリューション演算回路及び物体認識装置 |
| US8442927B2 (en) | 2009-07-30 | 2013-05-14 | Nec Laboratories America, Inc. | Dynamically configurable, multi-ported co-processor for convolutional neural networks |
| US9141386B2 (en) * | 2010-09-24 | 2015-09-22 | Intel Corporation | Vector logical reduction operation implemented using swizzling on a semiconductor chip |
| TWI525558B (zh) | 2011-01-17 | 2016-03-11 | Univ Nat Taipei Technology | Resilient high - speed hardware reverse transfer and feedback type neural network system |
| US8924455B1 (en) | 2011-02-25 | 2014-12-30 | Xilinx, Inc. | Multiplication of matrices using systolic arrays |
| US9111222B2 (en) * | 2011-11-09 | 2015-08-18 | Qualcomm Incorporated | Method and apparatus for switching the binary state of a location in memory in a probabilistic manner to store synaptic weights of a neural network |
| TW201331855A (zh) | 2012-01-19 | 2013-08-01 | Univ Nat Taipei Technology | 具自由回饋節點的高速硬體倒傳遞及回饋型類神經網路 |
| US9477925B2 (en) | 2012-11-20 | 2016-10-25 | Microsoft Technology Licensing, Llc | Deep neural networks training for speech and pattern recognition |
| US9811775B2 (en) | 2012-12-24 | 2017-11-07 | Google Inc. | Parallelizing neural networks during training |
| US9190053B2 (en) | 2013-03-25 | 2015-11-17 | The Governing Council Of The Univeristy Of Toronto | System and method for applying a convolutional neural network to speech recognition |
| CN104035751B (zh) | 2014-06-20 | 2016-10-12 | 深圳市腾讯计算机系统有限公司 | 基于多图形处理器的数据并行处理方法及装置 |
| EP3064130A1 (en) | 2015-03-02 | 2016-09-07 | MindMaze SA | Brain activity measurement and feedback system |
| US20160267111A1 (en) | 2015-03-11 | 2016-09-15 | Microsoft Technology Licensing, Llc | Two-stage vector reduction using two-dimensional and one-dimensional systolic arrays |
-
2015
- 2015-09-03 US US14/844,670 patent/US10049322B2/en active Active
-
2016
- 2016-04-29 GB GB1715437.8A patent/GB2553052B/en active Active
- 2016-04-29 KR KR1020177028188A patent/KR102105128B1/ko active IP Right Grant
- 2016-04-29 KR KR1020247005904A patent/KR20240029112A/ko not_active Application Discontinuation
- 2016-04-29 CN CN202011278833.6A patent/CN112465132A/zh active Pending
- 2016-04-29 DE DE202016107439.8U patent/DE202016107439U1/de active Active
- 2016-04-29 CN CN201680020202.XA patent/CN107454966B/zh active Active
- 2016-04-29 GB GB2112401.1A patent/GB2597611B/en active Active
- 2016-04-29 DK DK16725266.7T patent/DK3298546T3/da active
- 2016-04-29 EP EP16725266.7A patent/EP3298546B1/en active Active
- 2016-04-29 DE DE112016002298.0T patent/DE112016002298T5/de not_active Ceased
- 2016-04-29 EP EP21205423.3A patent/EP3968232A1/en active Pending
- 2016-04-29 KR KR1020207011552A patent/KR102413522B1/ko active IP Right Grant
- 2016-04-29 KR KR1020227021145A patent/KR102641283B1/ko active IP Right Grant
- 2016-04-29 WO PCT/US2016/029965 patent/WO2016186810A1/en active Application Filing
- 2016-04-29 JP JP2017550913A patent/JP6689878B2/ja active Active
- 2016-05-20 TW TW105115866A patent/TWI636368B/zh active
- 2016-12-22 US US15/389,273 patent/US9805304B2/en active Active
-
2018
- 2018-04-03 HK HK18104415.9A patent/HK1245462A1/zh unknown
- 2018-08-02 US US16/053,305 patent/US11281966B2/en active Active
-
2020
- 2020-03-23 US US16/826,466 patent/US10878316B2/en active Active
- 2020-04-08 JP JP2020069854A patent/JP6953577B2/ja active Active
- 2020-12-28 US US17/134,936 patent/US11853865B2/en active Active
-
2021
- 2021-09-29 JP JP2021159352A patent/JP7071577B2/ja active Active
-
2022
- 2022-05-06 JP JP2022076581A patent/JP7383757B2/ja active Active
-
2023
- 2023-11-01 US US18/386,037 patent/US20240062055A1/en active Pending
- 2023-11-08 JP JP2023190654A patent/JP2024016196A/ja active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0422348A2 (en) * | 1989-10-10 | 1991-04-17 | Hnc, Inc. | Two-dimensional systolic array for neural networks, and method |
| JPH07141454A (ja) * | 1993-11-18 | 1995-06-02 | G D S:Kk | シストリックアレイプロセサー |
| KR100189195B1 (ko) * | 1996-04-04 | 1999-06-01 | 박래홍 | 단일화된 시스톨릭어레이 구조에 의한 2차원 dct/dst/dht의 수행장치 |
| KR20030082255A (ko) * | 2002-04-17 | 2003-10-22 | 한국전자통신연구원 | 향상된 선형 궤환 시프트 레지스터 구조의 유한체 승산기 |
| JP2004157756A (ja) * | 2002-11-06 | 2004-06-03 | Canon Inc | 階層処理装置 |
| US20040117710A1 (en) * | 2002-12-17 | 2004-06-17 | Srinivas Patil | Weight compression/decompression system |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021246818A1 (ko) * | 2020-06-05 | 2021-12-09 | 주식회사 퓨리오사에이아이 | 뉴럴 네트워크 프로세싱 방법 및 이를 위한 장치 |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102105128B1 (ko) | 신경망 프로세서에서 사용하기 위한 가중치들의 프리페칭 | |
| US11361051B1 (en) | Dynamic partitioning | |
| KR102127524B1 (ko) | 신경망 프로세서의 벡터 컴퓨테이션 유닛 | |
| EP3539059B1 (en) | Performing kernel striding in hardware | |
| KR102106144B1 (ko) | 신경망 프로세서에서의 배치 프로세싱 | |
| US20200057942A1 (en) | Neural Network Processor | |
| WO2016186811A1 (en) | Computing convolutions using a neural network processor | |
| TWI851499B (zh) | 用於執行類神經網路計算之電路、方法及非暫時性機器可讀儲存裝置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A107 | Divisional application of patent | ||
| A201 | Request for examination | ||
| AMND | Amendment | ||
| E902 | Notification of reason for refusal | ||
| AMND | Amendment | ||
| E601 | Decision to refuse application | ||
| AMND | Amendment | ||
| X701 | Decision to grant (after re-examination) | ||
| GRNT | Written decision to grant |