KR20190117652A - 압축된 게놈 서열 리드로부터 게놈 참조 서열의 복원 방법 및 시스템 - Google Patents
압축된 게놈 서열 리드로부터 게놈 참조 서열의 복원 방법 및 시스템 Download PDFInfo
- Publication number
- KR20190117652A KR20190117652A KR1020197026863A KR20197026863A KR20190117652A KR 20190117652 A KR20190117652 A KR 20190117652A KR 1020197026863 A KR1020197026863 A KR 1020197026863A KR 20197026863 A KR20197026863 A KR 20197026863A KR 20190117652 A KR20190117652 A KR 20190117652A
- Authority
- KR
- South Korea
- Prior art keywords
- descriptor
- mismatch
- sequence
- binarization
- genomic
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 112
- 238000007906 compression Methods 0.000 claims abstract description 68
- 230000006835 compression Effects 0.000 claims abstract description 67
- 239000002773 nucleotide Substances 0.000 claims description 70
- 125000003729 nucleotide group Chemical group 0.000 claims description 70
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 5
- 230000011664 signaling Effects 0.000 claims description 4
- 230000008569 process Effects 0.000 description 47
- 238000013507 mapping Methods 0.000 description 36
- 238000013459 approach Methods 0.000 description 19
- 238000012163 sequencing technique Methods 0.000 description 17
- 241000170567 Gollum Species 0.000 description 10
- 238000012545 processing Methods 0.000 description 10
- 108020004414 DNA Proteins 0.000 description 9
- 102000053602 DNA Human genes 0.000 description 9
- 230000008901 benefit Effects 0.000 description 7
- 238000006467 substitution reaction Methods 0.000 description 6
- 230000005540 biological transmission Effects 0.000 description 5
- 238000006243 chemical reaction Methods 0.000 description 5
- 210000000349 chromosome Anatomy 0.000 description 5
- 238000012165 high-throughput sequencing Methods 0.000 description 5
- 238000007481 next generation sequencing Methods 0.000 description 5
- 229920002477 rna polymer Polymers 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 4
- 238000013144 data compression Methods 0.000 description 4
- 238000003780 insertion Methods 0.000 description 4
- 230000037431 insertion Effects 0.000 description 4
- 229910052757 nitrogen Inorganic materials 0.000 description 4
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 4
- 230000009466 transformation Effects 0.000 description 4
- 108010038083 amyloid fibril protein AS-SAM Proteins 0.000 description 3
- 238000010276 construction Methods 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 238000011331 genomic analysis Methods 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 229910052698 phosphorus Inorganic materials 0.000 description 3
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical group O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- 230000000712 assembly Effects 0.000 description 2
- 238000000429 assembly Methods 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 235000019506 cigar Nutrition 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 230000006837 decompression Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 238000012268 genome sequencing Methods 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 102000054765 polymorphisms of proteins Human genes 0.000 description 2
- 108090000623 proteins and genes Proteins 0.000 description 2
- 229940113082 thymine Drugs 0.000 description 2
- 238000000844 transformation Methods 0.000 description 2
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- 101100437998 Arabidopsis thaliana BZIP2 gene Proteins 0.000 description 1
- 102000020897 Formins Human genes 0.000 description 1
- 108091022623 Formins Proteins 0.000 description 1
- 101150071882 US17 gene Proteins 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 125000003275 alpha amino acid group Chemical group 0.000 description 1
- 150000001413 amino acids Chemical class 0.000 description 1
- 230000001174 ascending effect Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 210000004027 cell Anatomy 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 239000012634 fragment Substances 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 239000011368 organic material Substances 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 238000003752 polymerase chain reaction Methods 0.000 description 1
- 238000007781 pre-processing Methods 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- 238000010200 validation analysis Methods 0.000 description 1
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2282—Tablespace storage structures; Management thereof
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/23—Updating
- G06F16/2365—Ensuring data consistency and integrity
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/28—Databases characterised by their database models, e.g. relational or object models
- G06F16/284—Relational databases
- G06F16/285—Clustering or classification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/602—Providing cryptographic facilities or services
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/62—Protecting access to data via a platform, e.g. using keys or access control rules
- G06F21/6218—Protecting access to data via a platform, e.g. using keys or access control rules to a system of files or objects, e.g. local or distributed file system or database
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/62—Protecting access to data via a platform, e.g. using keys or access control rules
- G06F21/6218—Protecting access to data via a platform, e.g. using keys or access control rules to a system of files or objects, e.g. local or distributed file system or database
- G06F21/6245—Protecting personal data, e.g. for financial or medical purposes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/048—Interaction techniques based on graphical user interfaces [GUI]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/10—Ploidy or copy number detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/20—Allele or variant detection, e.g. single nucleotide polymorphism [SNP] detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/10—Sequence alignment; Homology search
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/20—Sequence assembly
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
- G16B40/10—Signal processing, e.g. from mass spectrometry [MS] or from PCR
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B45/00—ICT specially adapted for bioinformatics-related data visualisation, e.g. displaying of maps or networks
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
- G16B50/10—Ontologies; Annotations
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
- G16B50/30—Data warehousing; Computing architectures
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
- G16B50/40—Encryption of genetic data
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
- G16B50/50—Compression of genetic data
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B99/00—Subject matter not provided for in other groups of this subclass
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/3084—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction using adaptive string matching, e.g. the Lempel-Ziv method
- H03M7/3086—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction using adaptive string matching, e.g. the Lempel-Ziv method employing a sliding window, e.g. LZ77
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/70—Type of the data to be coded, other than image and sound
Abstract
본 개시에 기술된 방법 및 장치는 참조 게놈과 이전에 정렬된 게놈 서열 사이의 차이점을 기술하는 신택스 엘리먼트의 관점에서 상기 참조 게놈을 표현하는 것을 포함한다. 각각의 정렬된 게놈 서열은 신택스 엘리먼트의 부분 집합에 의해 기술된다. 모든 게놈 서열을 기술하는 신택스 엘리먼트는 이들의 통계적 특성에 따라서 블록에 분할된다. 신택스 엘리먼트의 각 블록은 엔트로피 코딩된다. 그런 다음에, 엔트로피 코딩된 블록은 연접되어 압축된 비트 스트림을 형성한다. 참조 게놈 및 정렬된 서열 사이의 차이점은 신택스 엘리먼트의 관점에서 표현되고, 이는 정렬된 리드를 기술하는 신택스 엘리먼트의 코딩된 블록의 비트 스트림에 내장(embedding)된다. 개시된 방법은 압축된 게놈 서열을 디코딩하는 경우에, 압축된 데이터에 대한 랜덤 액세스의 상이한 옵션을 유지하고, 효율적 압축을 가능하게 하면서, 정렬에 이용된 참조 게놈의 복원을 가능하게 한다.
Description
관련출원의 상호 참조
본 출원은 2017년 7월 11일자 특허 출원 PCT/US2017/041579 및 2017년 2월 14일자 특허 출원 PCT/US17/17842를 우선권으로 주장한다.
기술분야
본 개시는 정렬된 게놈 서열 리드(read)와 상기 게놈 서열의 정렬에 이용된, 연관된 정렬 정보 및 참조 게놈, 또는 이의 부분의 무손실 압축(lossless compression)에 관한 것이다. 게놈 서열은 일반적으로 뉴클레오티드라고 하는 분자의 연접(concatenation)으로 고안되어, 데옥시리보핵산 (deoxyribonucleic acid, DNA) 또는 리보핵산(Ribonucleic acid, RNA)의 단편을 형성한다. 본 발명은 동일한 알파벳을 이용하는 더 짧은 서열(shorter sequence)의 정렬에 이용되는 기호의 임의의 참조 서열에 적용될 수 있다.
본 발명은 참조-없는 압축법(reference-less compression method)에 의해 압축된, 정렬된 게놈 서열에 적용된다. 이 방면에서 초기의 시도는 Voges, J., Munderloh, M., Ostermann, J.의 "Predictive Coding of Aligned Next-Generation Sequencing Dat"(2016 Data Compression Conference (DCC)) 또는 Benoit, G.등의 "Reference-free compression of high throughput sequencing data with a probabilistic de Bruijn graph" (BMC Bioinformatics. 2015; 16: 288.)에 기술된 것이나, 본 발명에서 다루는 몇몇 한계점들을 지닌다.
본 개시의 맥락에서, 정렬된 게놈 서열의 참조-없는 압축은 정렬에 이용된 참조 게놈의 인접한 영역 또는 중첩된 영역에서 매핑된 게놈 서열을 중첩 및 연접하여 빌딩된 "컨티그(contig)"라고 명명되는 하나 이상의 로컬 참조 서열의 기준을 포함한다. 컨티그의 총 망라하는 기술(exhaustive description)은 https://en.wikipedia.org/wiki/Contig를 참고한다. 상기 컨티그는 디코딩 프로세스의 일부로서, 디코딩의 말단부(end)에서 복원되기 때문에, 이들은 압축된 비트 스트림에 포함될 필요가 없다. 컨티그가 하나 이상의 게놈 서열이 매핑된 게놈 영역에 대해서 빌딩되면, 참조-기반 압축은 이들을 게놈 디스크립터의 관점에서 기술하고, 동일한 유형의 게놈 디스크립터의 각 블록을 특정한 엔트로피 코더(entropy coder)로 압축함으로써 상기 게놈 서열에 적용된다. 이 접근법은 GZIP, LZMA, BZ와 같은 범용 압축 체계 (general purpose compression scheme)보다 더 나은 압축률에 도달하는 것을 가능하게 하고, 랜덤 액세스를 보존한다.
정렬된 게놈 서열의 참조-기반 압축은 정렬에 이용된 하나 이상의 참조 서열에 대한 상기 정렬된 서열의 매핑 위치 및 차이점의 관점에서 이들을 표현하는 것과 상기 위치 및 차이점만을 인코딩하는 것에 기초한다. 이러한 접근법이 매우 높은 압축률에 도달하는 것을 허용하는 반면 [대략적으로, 커버리지(coverage)와 함께 선형으로 증가하는데, 여기서 용어 커버리지는 참조 게놈의 각 뉴클레오티드를 포함하는, 리드의 평균 수를 의미한다], 인코딩 프로세스와 디코딩 프로세스 모두가 정렬 및 압축에 이용되는 특정한 참조 서열의 가용성(availability)을 필요로 한다. 이 접근법의 결점은 정렬 및 압축에 이용된 참조 서열이 디코딩 측에서 입수 불가한 경우에 (예를 들어, 참조 게놈의 고유 식별자 또는 이의 버전의 결핍으로 인하거나, 또는 본래의 데이터 소스가 더 이상 입수 불가능한 경우에), 압축된 컨텐트는 복원될 수 없다는 것이다. 저장 또는 전송을 위한 압축된 표현의 참조 게놈을 포함하는 것에 기초하는 해결 방안은 압축 효율의 관점에서 해로울 것이다.
이러한 문제를 다루기 위해, 정렬에 이용된 참조 게놈을 이용하지 않고 정렬된 게놈 서열 리드의 압축 및 압축 해제(decompression)를 가능하게 하는 참조-없는 압축법이 존재한다. 이들 방법의 일부는 GZIP, BZIP2, LZMA와 같은 법용 압축기를 채택하고, 순서대로 3:1의 좋지 못한 압축률에 달한다. 더욱 효율적인 방법은 "조립(assembly)"이라고 하는 프로세스에 의해 정렬된 리드 자체로부터 하나 이상의 참조 서열의 제작에 기초하는데, 이 "조립"에서, 정렬에 이용된 참조 게놈의 인접한 게놈 구간(genomic interval)에 대해서 매핑된 리드는 공유된 서브 서열(subsequence)을 찾고, 이들은 연접시킴으로써 더 긴 서열(longer sequence)의 빌딩에 이용된다. 더 짧은 서열의 연접 또는 병합(merge)으로부터 획득된 더 긴 서열은 "컨티그"라고 한다. 이러한 방법은 Voges, J., Munderloh, M., Ostermann, J.의 "Predictive Coding of Aligned Next-Generation Sequencing Data"(2016 Data Compression Conference (DCC))로부터 이미 인용된 간행물과 Benoit, G.등의 "Reference-free compression of high throughput sequencing data with a probabilistic de Bruijn graph"(BMC Bioinformatics. 2015; 16: 288.)로부터의 논문을 포함한다.
본 개시는 게놈 서열의 참조-없는 압축을 공동으로 적용(jointly applying)하는 경우에, 게놈 서열 리드의 정렬에 이용된 참조 게놈의 효율적인 압축의 문제점을 다룬다.
아래 청구 범위의 구성은 게놈 서열의 참조-없는 압축인 경우에 참조 게놈의 무손실 압축법을 제공함으로써 기존의 선행 기술 해결 방안의 문제점을 해결하며, 상기 방법은 하기의 단계를 포함한다:
· 상기 리드를 하나 이상의 참조 서열에 대해 정렬시켜, 정렬된 리드를 생성하는 단계;
· 상기 정렬된 리드를 조립하여, 컨티그(contig)를 생성하는 단계;
· 상기 참조 서열과 상기 컨티그를 비교하여, 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 획득하는 단계; 및
· 상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 엔트로피 코딩하는 단계.
압축법의 다른 측면에서, 상기 정렬된 리드를 조립하는 단계는 참조 서열상의 각 위치에 대해서, 이 위치에서 정렬된 리드 중 가장 빈도가 높게 존재하는 뉴클레오티드를 선택하는 단계를 포함한다.
압축법의 다른 측면에서, 상기 미스매치의 위치 및 미스매치 유형에 관련된 정보는 각각 제1 디스크립터 (203) 및 제2 디스크립터 (204)를 이용하여 표시된다.
압축법의 다른 측면에서, 상기 제1 디스크립터 및 제2 디스크립터는 동일한 액세스 유닛에서 캡슐화되어(encapsulating), 디코딩 디바이스에서 정렬에 이용된 참조 서열의 선택적 복원(selective reconstruction)을 가능하게 한다.
압축법의 다른 측면에서, 상기 컨티그의 길이는 인풋 파라미터로서 인코더에 정의되거나, 또는 인코더에 의해 동적으로 조정된다.
압축법의 다른 측면에서, 상기 제1 디스크립터는 스플릿 유닛-와이즈 절삭형 단항 이진화(Split Unit-wise Truncated Unary binarization)를 이용하여 이진화되고, 상기 스플릿 유닛-와이즈 절삭형 단항은 반복 절삭형 단항 이진화(repeated truncated unary binarization)의 연접(concatenation)이며, 각각의 절삭형 단항 이진화는 길이가 N 비트인, 이진화될 값의 부분에 적용되며, N은 미리 선택된 파라미터이다.
압축법의 다른 측면에서, 상기 제2 디스크립터는 절삭형 단항 이진화를 이용하여 이진화되고, 상기 제2 디스크립터의 값 다음에 0이 이어지며, 상기 값이 이진화될 가능한 최댓값과 동일한 경우에, 후행 0-비트(trailing 0-bit)는 버려진다.
압축법의 다른 측면에서, 상기 방법은 특정한 참조 게놈의 사용(usage)을 시그널링하는 정보를 인코딩하지 않는다.
압축법의 다른 측면에서, 상기 컨티그의 상기 길이는 신택스 헤더에 포함된다.
게놈 서열 데이터를 인코딩하는 장치로서, 상기 게놈 서열 데이터는 뉴클레오티드 서열의 리드를 포함하고, 상기 장치는 하기 수단을 포함하는 것인, 게놈 서열 데이터를 인코딩하는 장치:
· 상기 리드를 하나 이상의 참조 서열에 대해 정렬하여, 정렬된 리드를 생성하는 수단;
· 상기 정렬된 리드를 조립하여, 컨티그를 생성하는 수단;
· 상기 참조 서열과 상기 컨티그를 비교하여, 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 획득하는 수단; 및
· 상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 엔트로피 코딩하는 수단.
게놈 서열 데이터를 인코딩하는 장치로서, 상기 정렬된 리드를 조립하는 상기 수단은 참조 서열상의 각 위치에 대해서, 이 위치에서 정렬된 리드 중 가장 높은 빈도로 존재하는 뉴클레오티드를 선택하는 수단을 더 포함한다.
게놈 서열 데이터를 인코딩하는 장치로서, 상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 각각 제1 디스크립터 (203) 및 제2 디스크립터 (204)에 의해 표시하는 수단을 더 포함한다.
게놈 서열 데이터를 인코딩하는 장치로서, 상기 제1 디스크립터 및 제2 디스크립터를 동일한 액세스 유닛에서 캡슐화하여, 디코딩 디바이스에서 정렬에 이용되는 참조 서열의 선택적 복원을 가능하게 하는 수단을 더 포함한다.
게놈 서열 데이터를 인코딩하는 장치로서, 상기 컨티그의 길이를 인풋 파라미터로서 수신하는 수단 및 상기 컨티그의 길이를 동적으로 조정하는(dynamically adapting) 수단을 더 포함한다.
게놈 서열 데이터를 인코딩하는 장치로서, 상기 제1 디스크립터를 스플릿 유닛-와이즈 절삭형 단항 이진화를 이용하여 이진화하는 이진화 수단을 더 포함하나, 상기 스플릿 유닛-와이즈 절삭형 단항은 반복 절삭형 단항 이진화의 연접이고, 각각의 절삭형 단항 이진화는 길이가 N 비트인, 이진화될 값의 부분에 적용되며, N은 미리 선택된 파라미터이다.
게놈 서열 데이터를 인코딩하는 장치로서, 상기 제2 디스크립터를 절삭형 단항 이진화를 이용함으로써 이진화하는 이진화 수단을 더 포함하나, 상기 제2 디스크립터의 값 다음에 0이 이어지고, 상기 값이 이진화될 가능한 최댓값과 동일한 경우에, 후행 0-비트(trailing 0-bit)는 버려진다.
게놈 서열 데이터를 인코딩하는 장치로서, 상기 컨티그의 상기 길이를 신택스 헤더에서 코딩하는 수단을 더 포함한다.
하기 단계를 포함하는, 인코딩된 게놈 서열 데이터를 디코딩하는 방법:
· 인코딩된 인풋 파일을 파싱하여(parsing), 컨티그 서열을 획득하는 단계;
· 컨티그 내 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 엔트로피 디코딩하는 단계; 및
· 컨티그 내 상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 이용해 컨티그를 변형하여, 뉴클레오티드의 게놈 서열을 획득하는 단계.
디코딩하는 방법의 다른 측면에서, 컨티그 내 상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 이용해 컨티그를 변형하여, 상기 뉴클레오티드의 게놈 서열을 획득하는 단계는 제1 디스크립터 (203) 및 제2 디스크립터 (204)를 엔트로피 디코딩하는 단계를 더 포함한다.
다른 측면에서, 디코딩하는 방법은 동일한 액세스 유닛으로부터 상기 제1 디스크립터 및 제2 디스크립터를 역캡슐화하여(decapsulating), 상기 뉴클레오티드의 게놈 서열의 선택적 복원을 획득하는 단계를 더 포함한다.
다른 측면에서, 디코딩하는 방법은 상기 컨티그의 길이를 인풋 파일에 포함된 신택스 헤더로부터 디코딩하는 단계를 더 포함한다.
다른 측면에서, 디코딩하는 방법은 상기 제1 디스크립터의 역이진화(reverse binarization)를 더 포함하나, 상기 제1 디스크립터는 스플릿 유닛-와이즈 절삭형 단항 이진화를 이용하여 이진화되고, 상기 스플릿 유닛-와이즈 절삭형 단항은 반복 절삭형 단항 이진화의 연접이며, 각각의 절삭형 단항 이진화는 길이가 N 비트인, 이진화될 값의 부분에 적용되고, N은 미리 선택된 파라미터이다.
다른 측면에서, 디코딩하는 방법은 상기 제2 디스크립터의 역이진화를 더 포함하되, 상기 제2 디스크립터는 절삭형 단항 이진화를 이용하여 이진화되고, 상기 제2 디스크립터의 값 다음에 0이 이어지며, 상기 값이 이진화될 가능한 최댓값과 동일한 경우에, 후행 0-비트는 버려진다.
디코딩하는 방법의 다른 측면에서, 상기 인풋 파일은 특정한 참조 게놈의 사용을 시그널링하는 정보를 포함하지 않는다.
하기 수단을 포함하는, 인코딩된 게놈 서열 데이터를 디코딩하는 장치:
· 인코딩된 인풋 데이터를 파싱하여, 컨티그 서열을 획득하는 수단;
· 컨티그 내 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 엔트로피 디코딩하는 수단; 및
· 컨티그 내 상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 이용해 컨티그를 변형하여, 뉴클레오티드의 게놈 서열을 획득하는 수단.
인코딩된 게놈 서열 데이터를 디코딩하는 장치로서, 컨티그 내 상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 이용해 컨티그를 변형하여, 뉴클레오티드의 게놈 서열을 획득하는 상기 수단은 제1 디스크립터 (203) 및 제2 디스크립터 (204)를 엔트로피 디코딩하는 수단을 더 포함한다.
인코딩된 게놈 서열 데이터를 디코딩하는 장치로서, 동일한 액세스 유닛으로부터 상기 제1 디스크립터 및 제2 디스크립터를 역캡슐화함으로써(decapsulating), 뉴클레오티드의 게놈 서열을 선택적으로 복원하는 수단을 더 포함한다.
인코딩된 게놈 서열 데이터를 디코딩하는 장치로서, 인풋 파일에 포함된 신택스 헤더로부터 상기 컨티그의 길에에 관한 정보를 디코딩하는 수단을 더 포함한다.
인코딩된 게놈 서열 데이터를 디코딩하는 장치로서, 상기 제1 디스크립터를 역이진화하는 수단을 더 포함하되, 상기 제1 디스크립터는 스플릿 유닛-와이즈 절삭형 단항 이진화를 이용하여 이진화되고, 상기 스플릿 유닛-와이즈 절삭형 단항은 반복 절삭형 단항 이진화의 연접이며, 각각의 절삭형 단항 이진화는 길이가 N 비트인 이진화될 값의 부분에 적용되고, N은 미리 선택된 파라미터이다.
인코딩된 게놈 서열 데이터를 디코딩하는 장치로서, 상기 제2 디스크립터를 역이진화하는 수단을 더 포함하되, 상기 제2 디스크립터는 절삭형 단항 이진화를 이용하여 이진화되고, 상기 제2 디스크립터의 값 다음에 0이 이어지며, 상기 값이 이진화될 가능한 최댓값과 동일한 경우에, 후행 0-비트는 버려진다.
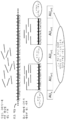
도 1은 게놈 서열이 어떻게 참조 서열에 대해서 매핑된 다음에, 병합 및 연접 작업에 의한 조립체의 빌딩에 이용되는지에 대해서 나타낸다. 제작된 조립체는 정렬된 게놈 서열이 참조 서열에 존재하는 뉴클레오티드와 상이한 뉴클레오티드를 표현하는 위치에서 참조 서열과 상이할 수 있다.
도 2는 참조 서열과 컨티그 사이의 미스매치가 어떻게 미스매치의 위치 및 유형의 관점에서 표현된 다음에, 본 개시에서 정의되는 상이한 이진화 및 변환을 구현하는 엔트로피 코더를 이용하여 인코딩되는지에 대해서 나타낸다.
도 3은 게놈 서열을 참조 게놈에 대해서 정렬하는 단계, 상기 정렬된 서열을 병합 및 연접시킴으로써 컨티그를 제작하는 단계, 컨티그에 대해서 게놈 서열을 표현하는 디스크립터를 생성하는 단계, 디스크립터의 각 블록을 전용 엔트로피 코더로 압축하는 단계를 포함하는 인코더 장치를 묘사한다.
도 4는 압축된 비트 스트림의 디코딩 프로세스를 나타내며, 이 프로세스는 입력된 비트스트림을 역다중화하여(demultiplexing) 엔트로피 코딩된 디스크립터를 추출하는 단계, 디스크립터의 각 유형을 엔트로피 디코딩하는 단계, 컨티그를 제작하는 단계, 정렬된 서열 리드를 제작된 컨티그를 이용하여 디코딩하는 단계, 컨티그 및 컨티그 미스매치 위치와 유형을 이용한 참조 게놈을 복원하는 단계를 포함한다.
도 5는 참조 서열상의 좌표 N과 좌표 M 사이에서 매핑된 서열 리드가 길이가 M-N개의 뉴클레오티드인 컨티그를 빌딩하는 데 어떻게 이용되는지에 대해서 타나낸다. 그런 다음에, 참조-기반 압축은 매핑된 서열 리드에 제작된 컨티그를 이용하여 적용된다. 매핑된 서열 리드를 표현하는 게놈 디스크립터는 엔트로피 코딩되고, 엔트로피 코딩된 게놈 디스크립터가 정렬에 이용된 참조 서열과 제작된 컨티그 사이의 차이점을 표현함에 따라, 동일한 액세스 유닛에서 다중화된다.
도 6은 액세스 유닛(Access Unit)이 참조 서열의 인접한 구간(contiguous interval)에서 매핑된 서열 리드를 표현하는 압축된 디스크립터(descriptor)를 어떻게 캡슐화(encapsulation)하는지에 대해 나타낸다. 헤더 정보(Header information)는 압축된 디스크립터의 앞에 붙어서(prepending) 데이터 파싱(data parsing)을 가능하게 한다.
도 7은 P형의 액세스 유닛이 헤더와 리드 매핑 위치(pos), 역상보(reverse complement) 정보(rcomp), 페어드 엔드 리드인 경우의 페어링 정보 (pair), 가변적인 리드 길이(variable read length)인 경우의 리드 길이 (rlen) 및 매핑 플래그(flags)를 표현하는 디스크립터의 블록의 다중화(multiplexing)로 어떻게 구성되었는지에 대해서 나타낸다. 이는 클래스 P의 리드를 인코딩하는 데 이용된다.
도 8은 참조 서열상의 좌표계, 및 참조 서열에 대한 리드와 리드 페어의 매핑를 나타낸다.
도 9는 리드 페어에서 매핑되지 않은 메이트가 어떻게 조립되어 참조 서열 내 갭을 채울 수 있는 컨티그를 빌딩할 수 있는지에 대해서 나타낸다. 또한, 그런 다음에, 이전에 매핑되지 않은 리드 페어가 새롭게 조립된 컨티그에 매핑될 수 있다.
도 10은 참조 게놈과 조립된 컨티그 사이의 다섯 개의 미스매치의 변환 및 이진화의 예시를 나타낸다.
도 11은 매핑된 서열 리드가 존재하지 않는, 정렬에 이용된 참조 게놈의 영역이 어떻게 전용 액세스 유닛에서 코딩되어, 디코딩의 말단부(end)에서 참조 게놈의 완전한 복원을 가능하게 할 수 있는지에 대해서 나타낸다.
도 2는 참조 서열과 컨티그 사이의 미스매치가 어떻게 미스매치의 위치 및 유형의 관점에서 표현된 다음에, 본 개시에서 정의되는 상이한 이진화 및 변환을 구현하는 엔트로피 코더를 이용하여 인코딩되는지에 대해서 나타낸다.
도 3은 게놈 서열을 참조 게놈에 대해서 정렬하는 단계, 상기 정렬된 서열을 병합 및 연접시킴으로써 컨티그를 제작하는 단계, 컨티그에 대해서 게놈 서열을 표현하는 디스크립터를 생성하는 단계, 디스크립터의 각 블록을 전용 엔트로피 코더로 압축하는 단계를 포함하는 인코더 장치를 묘사한다.
도 4는 압축된 비트 스트림의 디코딩 프로세스를 나타내며, 이 프로세스는 입력된 비트스트림을 역다중화하여(demultiplexing) 엔트로피 코딩된 디스크립터를 추출하는 단계, 디스크립터의 각 유형을 엔트로피 디코딩하는 단계, 컨티그를 제작하는 단계, 정렬된 서열 리드를 제작된 컨티그를 이용하여 디코딩하는 단계, 컨티그 및 컨티그 미스매치 위치와 유형을 이용한 참조 게놈을 복원하는 단계를 포함한다.
도 5는 참조 서열상의 좌표 N과 좌표 M 사이에서 매핑된 서열 리드가 길이가 M-N개의 뉴클레오티드인 컨티그를 빌딩하는 데 어떻게 이용되는지에 대해서 타나낸다. 그런 다음에, 참조-기반 압축은 매핑된 서열 리드에 제작된 컨티그를 이용하여 적용된다. 매핑된 서열 리드를 표현하는 게놈 디스크립터는 엔트로피 코딩되고, 엔트로피 코딩된 게놈 디스크립터가 정렬에 이용된 참조 서열과 제작된 컨티그 사이의 차이점을 표현함에 따라, 동일한 액세스 유닛에서 다중화된다.
도 6은 액세스 유닛(Access Unit)이 참조 서열의 인접한 구간(contiguous interval)에서 매핑된 서열 리드를 표현하는 압축된 디스크립터(descriptor)를 어떻게 캡슐화(encapsulation)하는지에 대해 나타낸다. 헤더 정보(Header information)는 압축된 디스크립터의 앞에 붙어서(prepending) 데이터 파싱(data parsing)을 가능하게 한다.
도 7은 P형의 액세스 유닛이 헤더와 리드 매핑 위치(pos), 역상보(reverse complement) 정보(rcomp), 페어드 엔드 리드인 경우의 페어링 정보 (pair), 가변적인 리드 길이(variable read length)인 경우의 리드 길이 (rlen) 및 매핑 플래그(flags)를 표현하는 디스크립터의 블록의 다중화(multiplexing)로 어떻게 구성되었는지에 대해서 나타낸다. 이는 클래스 P의 리드를 인코딩하는 데 이용된다.
도 8은 참조 서열상의 좌표계, 및 참조 서열에 대한 리드와 리드 페어의 매핑를 나타낸다.
도 9는 리드 페어에서 매핑되지 않은 메이트가 어떻게 조립되어 참조 서열 내 갭을 채울 수 있는 컨티그를 빌딩할 수 있는지에 대해서 나타낸다. 또한, 그런 다음에, 이전에 매핑되지 않은 리드 페어가 새롭게 조립된 컨티그에 매핑될 수 있다.
도 10은 참조 게놈과 조립된 컨티그 사이의 다섯 개의 미스매치의 변환 및 이진화의 예시를 나타낸다.
도 11은 매핑된 서열 리드가 존재하지 않는, 정렬에 이용된 참조 게놈의 영역이 어떻게 전용 액세스 유닛에서 코딩되어, 디코딩의 말단부(end)에서 참조 게놈의 완전한 복원을 가능하게 할 수 있는지에 대해서 나타낸다.
본 발명에서 언급된 게놈 서열 또는 프로테오믹스 서열(proteomic sequence)은, 예를 들어, 뉴클레오티드 서열, 데옥시리보핵산(Deoxyribonucleic acid, DNA) 서열, 리보핵산 (Ribonucleic acid, RNA) 서열, 및 아미노산 서열을 포함하나, 이에 한정되는 것은 아니다. 본원의 기술(description)이 뉴클레오티드 서열의 형태인 게놈 정보에 대해서 상당히 자세하나, 압축방법 및 시스템이 다른 게놈 또는 프로테오믹스 서열에 대해서도, 몇몇 변형을 수반할 수 있으나, 실시될 수 있다는 것이 이해될 것이며, 이는 통상의 기술자에 의해 이해될 것이다.
게놈 시퀀싱 정보는 고 처리량 시퀀싱 (High Throughput Sequencing, HTS) 기기에 의해, 정의된 용어로부터 비롯된 문자의 스트링(string of letters)으로 표현되는, 뉴클레오티드("염기"라고도 알려져 있음) 서열의 형태로 생성된다. 가장 작은 용어는 DNA에 존재하는 4가지 유형의 뉴클레오티드, 즉, 아데닌, 시토신, 구아닌, 및 티민을 표현하는 다섯 개의 기호: {A, C, G, T, N}에 의해 표현된다. RNA에서, 티민은 우라실(U)로 대체된다. N은 시퀀싱 기기가 임의의 염기를 호출할 수 없어서, 그 위치에서 뉴클레오티드의 본질이 정해지지 않는다는 것을 나타낸다. 시퀀싱 기기에 의해 IUPAC 다의성 코드(IUPAC ambiguity code)가 용어로서 채택되는 경우, 기호로 이용되는 알파벳은 다음의 기호로 구성된다: {A, C, G, T, U, W, S, M, K, R, Y, B, D, H, V, N 또는 -}. 아미노산인 경우, 지원되는 기호는 다음과 같다: {A, C, D, E, F, G, H, I, K, L, M, N, P, Q, R, S, T, V, W, Y}.
전문 용어
본 개시의 맥락에서, 시퀀싱 기기에 의해 생성된 뉴클레오티드 서열은 리드(read)라고 한다. 서열 리드(sequence read)는 그 수가 수십 내지 수천 사이의 범위에 이르는 뉴클레오티드로 구성될 수 있다. 일부 시퀀싱 기술은 페어(pair)로 구성된 서열 리드를 생성하며, 이의 한 리드는 한 DNA 가닥으로부터 비롯되고, 다른 리드는 다른 가닥으로부터 비롯된다. 페어를 생성하는 시퀀싱 프로세스에서 다른 리드와 연관된 리드는 이의 메이트(mate)라고 한다.
게놈 서열 리드 압축에 대한 효율적인 접근법의 통상적인 요소는 참조 서열에 대한 서열 데이터의 상관관계(correlation)의 개척이다. 인간 집단의 체세포 프로파일(somatic profile)이 극도로 다양화되었음에도, 사람과 사람 간에 상이한 뉴클레오티드의 수의 실제 부분은 전체 게놈을 구성하는 뉴클레오티드의 전체 수의 약 0.1%에 불과하다. 그러므로, 각 개인의 특성을 나타내는 특정한 게놈 정보는 전체 게놈이 지니는 전체 정보에 대해서 매우 한정되어 있다. 이미 존재하는 참조 게놈이 이전의 시퀀싱에 대해서든 또는 공개된 "평균" 공통 참조 (consensus reference)로서든 입수 가능한 경우에, 정보를 인코딩하는 오늘날 가장 통상적인 방식은 참조 게놈에 대한 차이점만을 식별 및 인코딩하는 것이다.
FASTQ 데이터 파일의 형식으로 일반적으로 표현되는, 로 서열 리드(raw sequence read)로 그렇게 하기 위해서는, 예비 전-처리 단계(preliminary pre-processing step) 참조 게놈에 대해서 매핑. 적합한 참조 게놈이 입수 불가능한 경우, 또는 특정한 참조의 사용에 의해 도입된 편향(bias)이 바람직하지 않은 경우에, 가까이에 있는 서열 리드들의 더 긴 서열 - 컨티그 ( contig ) 라고 하는 - 로의 조립에 의한 새로운 참조 서열의 제작은 가능한 대안이다.
본 개시의 전반에 걸쳐, 참조 서열(reference sequence)은 각 정수 좌표(integer coordinate)가 단일 뉴클레오티드와 연관된, 단차원 정수 좌표계(mono-dimensional integer coordinate system)와 연관된 뉴클레오티드 서열이다. 좌표값은 0 이상일 수만 있다. 본 발명의 맥락에서 이 좌표계는 제로-베이스(즉, 제1 뉴클레오티드는 좌표 0을 가지며, 위치 0에 있다고 말함)이고, 왼쪽에서 오른쪽으로 선형 증가(linearly increasing)한다.
참조 서열에 서열 리드를 매핑하는 경우에, 상기 참조 서열은 가장 왼쪽의 위치를 위치 0으로 나타낸, 단차원 좌표계의 축으로 이용된다. 참조 서열에 매핑된 각 서열 리드에 대해서, 가장 작은 좌표 번호(coordinate number)에 의해 식별된 참조 서열 위치에서 매핑된 뉴클레오티드는 대개 "가장 왼쪽의" 뉴클레오티드라고 하는 반면, 가장 큰 좌표 번호에 의해 식별된 참조 서열에서 매핑된 뉴클레오티드는 "가장 오른쪽의" 뉴클레오티드라고 한다. 이는 도 8에 도시되어 있다. 본 개시 전반에 걸쳐, 뉴클레오티드는 또한 염기(base)라고 한다.
서열 리드가 참조 서열에 매핑되는 경우에, 가장 왼쪽에 매핑된 염기의 좌표는 참조 서열상에서 리드의 매핑 위치(mapping position)를 표현한다고 말한다.
정렬된 리드에 존재하고, 참조 서열에는 존재하지 않는 염기 (삽입이라고도 함), 및 정렬 프로세스에 의해 보존되나, 참조 서열에 대해 매핑되지 않는 염기 [소프트 클립(soft clip)이라고도 함]는 매핑 위치를 갖지 않는다.
지정된 매칭 규칙에 따라서, 서열 리드가 이용된 참조 서열의 임의의 매핑된 위치에 매핑될 수 없는 경우에, 매핑되지 않음(unmapped)이라고 한다.
서열 리드들 중에서 중첩 영역(overlapping region)을 탐색함으로써 더 긴 게놈 서열을 빌딩하는 프로세스를 조립(assembly)라고 한다.
더 짧은 리드를 조립하여 빌딩된 더 긴 게놈 서열은 컨티그 ( contig ) 라고 한다 (https://en.wikipedia.org/wiki/Contig를 참고).
조립 프로세스 동안에, 임의의 컨티그의 빌딩에 실패한 서열 리드는 정렬되지 않음(unaligned)이라고 한다.
참조 게놈은 하나 이상의 참조 서열로 구성되고, 이는 과학자에 의해 종의 유전자 세트의 대표적인 예시로 조립된다. 예를 들어, 게놈 참조 컨소시엄 인간 게놈(build 37)인, GRCh37은 뉴욕주, 버팔로 소재의 13명의 익명의 자원자로부터 유래된다. 그러나, 참조 서열은 또한 이들의 추가 프로세싱을 고려하여, 리드의 압축률(compressibility)을 개선시키기 위해 착안 및 단지 제작된 합성 서열로 이루어질 수 있다.
본 개시에서, 참조 서열상의 가장 작은 좌표에 매핑하는 염기를 갖는 리드 페어를 구성하는 리드는 "리드 1"이라고 하는 반면, 이의 메이트는 "리드 2"라고 한다.
현재 선행 시퀀싱 기술을 이용하는 시퀀싱 기기에 의해 페어로 생성된 두 리드를 분리하는 거리 - 뉴클레오티드 (또는 염기)의 수로 표현됨 - 는 알려져있지 않고, 이는 페어를 구성하는 두 리드 모두를 참조 서열에 매핑함으로써 결정된다 (즉, 적절한 매칭 함수 (matching function)를 최소화함).
본 개시의 전반에 걸쳐서, 액세스 유닛(Access Unit, AU)은 비트 스트림 액세스(bit stream access) 및 조작(manipulation)을 용이하게 하기 위해, 게놈 정보 또는 관련된 메타 데이터의 코딩된 표현을 포함하는, 논리 데이터 구조(logical data structure)로서 정의된다. 이는 본 개시에 기술된 발명을 실시하는 디코딩 장치에 의해 디코딩될 수 있는 가장 작은 데이터 조직(data organization)이다.
코딩된 정보의 유형에 따라서, AU는 임의의 다른 AU 또는 다른 AU에 포함된 정보를 이용하는 것과는 독립적으로 디코딩될 수 있다.
AU는 코딩된 서열 데이터의 본질에 따라 다양한 유형으로 분류될 수 있다. 액세스 유닛은 참조 서열, 또는 이의 일부, 또는 데이터의 단일 클래스에 속하는 인코딩된 리드 또는 리드 페어를 포함한다. 임의의 단일 AU는 둘 이상의 유형의 서열 데이터를 포함할 수 없다. 예를 들어, 액세스 유닛은 게놈 참조 컨소시엄 인간 게놈 (빌드 37)인, GRCh37의 염색체 1 전체를 포함할 수 있다. 다른 액세스 유닛은 좌표 50'000과 150'000 사이에 위치한 GRCh37의 염색체 1의 뉴클레오티드의 코딩된 표현을 포함할 수 있다. 다른 액세스 유닛은 임의의 미스매치가 없는 참조 서열에 대해서 완전히 매핑하는 리드 또는 리드 페어만 포함할 수 있다. 다른 액세스 유닛은 참조 서열에 대한 미스매치로서, "N" 기호만 포함할 수 있는 리드 또는 리드 페어를 포함할 수 있다. 다른 액세스 유닛은 임의의 유형의 치환(예, 리드 또는 리드 페어에 존재하는 한 염기가 참조 서열 내 대응하는 매핑 위치의 염기와 상이함)을 포함하는 리드 또는 리드 페어를 포함할 수 있다. 다른 액세스 유닛은 미스매치, 삽입, 결실 및 소프트 클리핑된 염기(soft clipped base)를 포함하는, 리드 또는 리드 페어를 포함할 수 있다. 다른 액세스 유닛은 참조 서열에 대해 매핑하지 않는 리드 또는 리드 페어만 포함할 수 있다. 다른 액세스 유닛은 한 리드는 참조 서열에 대해 매핑되고, 다른 리드는 매핑되지 않는, 리드 페어만 포함할 수 있다. 다른 유형의 액세스 유닛은 하나 이상의 참조 서열(예를 들어, 염색체)에 의해 구성된 참조 게놈의 인코딩된 세그먼트만 포함할 수 있다.
액세스 유닛의 본질적인 특징은 서열 리드 또는 리드 페어의 정렬 정보 및 메타 데이터와 연관된, 서열 리드 또는 리드 페어, 참조 서열의 게놈 정보의 복원에 필요한 모든 요소를 액세스 유닛이 압축된 형태로 포함하는 것이다. 달리 말하면, 액세스 유닛이 지니는 리드, 또는 리드 페어 또는 참조 서열 및 연관된 정보의 완전한 복원을 위해, 액세스 유닛 자체와, 입수 가능한 경우에, 액세스 유닛이 참조하는 참조 서열을 포함하는 액세스 유닛들을 검색(retrieving) 및 압축 해제(decompress)하는 것만이 필요하다.
각 액세스 유닛에서, 다음 섹션에서 열거되고, 인코딩된 리드 또는 리드 페어에 대한 정보를 표현하는 디스크립터는 별도의 데이터 블록에 집합되어(aggregating) - 유형 당 하나 - 고성능 엔트로피 코딩(high performance entropy coding)을 달성하기 위한 이들의 동질적인 통계적 특성(homogeneous statistical properties)을 활용한다.
각 액세스 유닛은 참조 서열상의 게놈 영역에 매핑된 동일한 데이터 클래스에 속하는 서열 리드 또는 리드 페어를 표현하는 디스크립터의 압축된 부분-집합을 포함한다. 이러한 참조 서열상의 게놈 영역은 시작 좌표 (또는 시작 위치) 및 종료 좌표 (또는 종료 위치)에 의해 정의된다.
액세스 유닛의 예시가 도 6에 도시된다. 액세스 유닛은 다음 섹션에서 기술되는, 인코딩된 게놈 디스크립터의 블록으로 구성된다. 네트워크를 통한 전송을 가능하게 하기 위해, 블록들은 패킷(packet)으로 더 분해된다(decomposing). 게놈 서열 리드를 압축하는 경우에, 각 액세스 유닛은 참조 서열상의 게놈 구간(genomic interval)에 매핑된 서열 리드 또는 매핑되지 않은 서열 리드를 표현하는 압축된 디스크립터를 포함한다. 액세스 유닛은 참조 게놈 또는 이의 일부를 지니는데 이용될 수 있다. 참조 서열은 단일의 긴 뉴클레오티드 서열로서 인코딩될 수 있거나, 또는 매핑되지 않은 게놈 서열 리드로서 인코딩된 더 짧은 서열로 나뉠 수 있다(splitting).
본 개시의 맥락에서, 게놈 디스크립터는 코딩된 참조 서열, 서열 리드 및 연관된 매핑 정보의 복원 (즉, 디코딩)에 필요한 정보의 일부를 표현하는 신택스 엘리먼트 (및 비트 스트림 및/또는 파일 형식의 신택스 구조의 엘리먼트)이다.
본 발명에 개시된 게놈 디스크립터는 표 1에서 열거된다.
[표 1. 게놈
디스크립터
및 이들의 의미]


본 발명에 개시된 방법에 따르면, 참조 서열 또는 이의 일부, 서열 리드 및 연관된 정렬 정보는 상기 열거된 디스크립터의 부분-집합을 이용하여 코딩된 다음에, 다수의 엔트로피 코더(entropy coder)를 이용하여, 각각의 디스크립터 특이 통계적 특성 (descriptor specific statistical property)에 따라 엔트로피 코딩된다. 동질적인 통계적 특성을 갖는 압축된 디스크립터의 블록은 본 개시에 기술된 발명을 실시하는 장치에 의해 조작될 수 있는 하나 이상의 게놈 서열의 가장 작은 코딩된 표현을 표현하는, 액세스 유닛으로 구조화된다.
본 개시에 기술된 발명은 게놈 디스크립터의 관점에서 게놈 서열 리드의 정렬에 이용되는 참조 서열을 표현하는 방법을 정의한다. 이러한 게놈 디스크립터는 특정한 엔트로피 코더를 이용하여 압축된다. 그런 다음에, 압축된 디스크립터의 블록은 상기 참조 서열에 대해서 매핑된 서열 리드의 복원을 가능하게 하는 압축된 게놈 디스크립터를 포함하는 동일한 액세스 유닛에서 캡슐화되어, 효율적인 전송 및 선택적 액세스를 가능하게 한다.
양태에서, 본 발명의 원리는 정렬 정보와 연관된 게놈 서열 리드 및 정렬에 이용된 참조 서열 모두의 무손실 압축에 관한 것이다. 효율적인 압축은 참조 서열의 인접한 영역(contiguous region)에서 매핑된 서열 리드를 병합 또는 연접함으로써 컨티그라고 하는 더 긴 서열을 빌딩한 다음에, 제작된 컨티그에 대한 서열 리드의 참조-기반 압축을 수행함으로써 획득된다. 더 나은 압축은 참조 서열에 대해서 매핑된 게놈 서열 리드를 특성화하는 모든 특징을 표현하기 위한 "게놈 디스크립터"라고 하는 별도의 신택스 엘리먼트를 이용함으로써 획득된다. SAM 형식은 뉴클레오티드 서열 및 염기 페어와 연관된 품질 점수, 페어드 엔드 리드인 경우에 페어링 정보 등과 같은 다른 메타 데이터와 정렬 정보를 저장한다. 본 발명의 원리에 따르면, 매핑된 게놈 서열 리드 또는 매핑되지 않은 게놈 서열 리드와 연관된 각각의 특징은 게놈 디스크립터에 의에 표현된다. 동일한 유형의 게놈 디스크립터는 상이한 엔트로피 코더를 이용하여 압축되는 블록에서 연접된다. 본 발명이 시가 스트링, 매핑 플래그, 뉴클레오티드 스트링 또는 품질 값 스트링과 같은 SAM 필드 중 임의의 필드를 압축하지 않으나, 16개의 게놈 디스크립터 또는 이들의 특정한 부분-집합을 이용하여 동일한 유형의 정보를 표현한다는 것을 인식해야 한다. SAM으로/으로부터 라운드-트립 트랜스코딩(Round-trip transcoding) 및 표현된 형식은 SAM의 11개의 필수적인 필드(mandatory field)에 대해서 가능하다.
선행기술의 해결방안은 조립된 게놈을 각 참조 서열(예, 유전자)이 4개의 뉴클레오티드를 표현하는 일련의 기호로서 저장된, 압축된 FASTA 파일의 형태로 저장한다. 각 참조 서열은 데이터 베이스에서 압축 및 저장된 참조 게놈의 일부이다(게놈 조립체로도 알려짐). 개체 또는 동일한 유기체에 속하는 유기체 물질(organic material)로부터 상이한 시점에서 획득된 몇몇 게놈 조립체들이 저장되어 이의 유전적 히스토리(genetic history)를 표현한다. 게놈 분석이 게놈 서열 데이터를 기존의 참조 게놈과 비교하는 것을 필요로 하는 경우에, 게놈 분석 응용 프로그램은 퀘리(query)를 데이터 베이스에 대해서 수행하여 하나 이상의 관심 있는 참조 게놈을 검색하고, 게놈 분석을 수행한다.
바람직한 양태에서, 본 발명에서 개시된 원리는 압축된 게놈을 별도의 리소스(separate resource)로서 저장할 필요없이, 압축된 게놈 서열 데이터에 내장된 참조 게놈의 집합(collection)의 효율적인 저장을 구현하는 데 적용될 수 있다. 게놈 조립체(genome assembly)를 게놈 서열 데이터로부터 별도의 데이터 구조로서 저장하는 것 대신에, 본 발명에 개시된 방법 및 원리는 정렬에 이용되는 게놈의 복원을 가능하게 하는 게놈 서열 데이터만을 저장하는 것을 허용한다.
게놈 서열 리드 및 참조 서열의 압축된 표현
서열 리드가 이미-존재하는 또는 제작된 참조 서열에 대해서 매핑된 경우에, 각각의 서열 리드는 본 개시에서 "게놈 디스크립터" 또는 단순히 "디스크립터"로서 나타낸 다수의 엘리먼트에 의해 완전히 표현될 수 있다.
예를 들어, 참조 서열의 세그먼트와 완전히 매치하는 서열 리드인 경우에, 서열 리드의 표현에 필요한 디스크립터의 부분-집합만 참조상의 매핑 위치의 좌표(대개, 서열 리드의 가장-왼쪽의 염기의 매핑 위치의 좌표), 서열 리드 자체의 길이 및 리드가 참조 서열 가닥에 대해서, 직접적인 DNA 가닥에 대해서 매핑되었는지 또는 역방향 DNA 가닥에 대해서 매핑되었는지를 나타내는 정보로 구성된다.
서열 리드의 모든 염기가 참조 서열의 모든 염기와 매칭하는, 임의의 매핑 위치를 찾는 것이 불가능한 경우에, 미스매치의 수가 최소인 매핑(또는 매핑들)이 유지된다. 이러한 경우에, 디스크립터의 상이한 부분-집합이 미스매치의 수가 최소인, 또는 최소에 가까운 매핑 위치에 대응하여 발생할 수 있는 치환, 삽입, 결실 및 클리핑된 염기의 표현에도 또한 필요하다. 이러한 디스크립터의 부분-집합으로, 서열 리드는 디스크립터에 의해 운반되는 정보 및 참조 서열에 의해 운반되는 정보를 이용하여 복원될 수 있다.
게놈 시퀀싱 프로세스는 다음의 두 가지 주요한 물리적 이유로 인해, 리드 복제물(즉, 동일한 게놈 서열의 둘 이상의 똑같은 카피)을 생성할 수 있다:
· 중합효소 연쇄반응 복제물(Polymerase Chain Reaction duplicate)의 발생
· 데이터 습득 프로세스(data acquisition process)에서 광학적 복제물의 발생. 리드의 페어가 모두 동일한 타일(tile)상에 존재하고, 리드 사이의 거리가 실험에 따라 주어진 구성 파라미터 미만인 경우에, 리드는 광학적 복제물이라고 한다.
또한, 매핑 프로세스는 다음과 같은 다른 유형의 정보를 생성할 수 있다: 가능한 다중 매핑 위치 및 관련된 점수, 매핑의 품질, 스플라이싱된 리드의 사양(specification), 페어에 속하는 리드의 두 개의 상이한 참조(대개, 염색체)에 대한 매핑, 시퀀싱 프로세스의 특징 (예, PCR 또는 광학적 복제물). 이러한 정보 모두는 각각의 부분-집합을 확장한 다음에, 디스크립터의 각 부분-집합에 적절한 엔트로피 코딩 알고리즘을 적용함으로써 압축되는 특정한 추가 디스크립터를 필요로 한다.
그러므로, 각각의 리드 또는 리드 페어는 매핑 프로세스의 결과에 따라서 디스크립터의 특정한 부분-집합에 의해 고유하게 표현될 수 있다.
매칭 규칙에 따른 서열 리드의 분류
하나 이상의 "이미-존재하는" 참조 서열에 대한 정렬의 매칭 결과에 따라, 시퀀싱 기기에 의해 생성된 서열 리드는 개시된 본 발명에 의해 6개의 상이한 "클래스"로 분류된다.
참조 서열에 대해 DNA 뉴클레오티드 서열을 정렬하는 경우에, 다음의 경우가 식별될 수 있다:
· 참조 서열 내 영역이 임의의 에러 없이 서열 리드와 매칭되는 것으로 판명된다 (즉, 완전한 매핑). 이러한 뉴클레오티드 서열은 "완전히 매칭한 리드"로 언급되거나 또는 "클래스 P"로 나타낸다.
· 참조 서열 내 영역이 리드를 생성하는 시퀀싱 기기가 임의의 염기 (또는 뉴클레오티드)를 호출(calling)할 수 없는, 위치의 수에 의해서만 결정되는 미스매치의 유형과 수를 갖는 서열 리드와 매칭되는 것으로 판명된다. 이러한 유형의 미스매치는 "N"으로 나타내는데, 이 문자는 정의되지 않은 뉴클레오티드 염기를 나타내는 데 이용된다. 본 문서에서, 이 유형의 미스매치는 "n 형" 미스매치로 지칭된다. 이러한 서열은 "클래스 N" 리드에 속한다. 리드가 "클래스 N"에 속하는 것으로 분류되는 경우에, 매칭 부정확도(degree of matching inaccuracy)를 소정의 상한(upper bound)으로 한정하고, 유효한 매칭(valid matching)으로 고려되는 것과 그렇지 않은 것 사이에서 경계(boundary)를 설정하는 것이 유용하다. 그러므로, 클래스 N으로 할당된 리드는 또한 리드가 포함할 수 있는 정의되지 않은 염기(즉, "N"으로 호출되는 염기)의 최대 수를 정의하는, 임계 (MAXN)를 설정함으로써 제한된다. 이러한 분류는 압축된 데이터에 선택적 데이터 검색의 적용에 대해서 유용한 기준을 구성하는, 대응하는 참조 서열에 참조되는 경우에, 클래스 N에 속하는 모든 리드가 공유하는, 요구되는 최소 매칭 정확성 (또는 미스매치의 최대 정도)을 내재적으로 정의한다. 예시로서, 일부 분석 응용프로그램은 추가 분석에 대한 허용 가능한 후보로 고려될 참조 게놈에 대해서 매핑되는 경우에, 매핑된 리드가 결정되지 않은("N") 염기를 최대 3개만 포함하는 것을 요구할 수 있으나, 이에 한정되는 것은 아니다. SAM/BAM과 같은 기존의 형식으로는, 추가 분석을 진행하기 전에, 프로세싱 파이프라인(processing pipeline)이 전체 데이터 세트를 압축 해제해야 하고, 모든 압축해제된 레코드를 파싱(parsing)하여 3개가 넘는 "N"을 갖는 리드를 제거하고, 3개 미만의 "N" 기호를 갖는 리드만 유지해야 한다. 본 발명의 원리의 측면에 따라서, 인코딩 응용프로그램은 3개 이하의 "N" 기호를 갖는 리드를 별도로 압축하는 것이 가능해서, 프로세싱 파이프라인이 임의의 추가 프로세싱 또는 저장 필요성 없이 이들을 디코딩하고 이용할 수 있도록 한다.
· 참조 서열 내 영역이 리드를 생성하는 시퀀싱 기기가 임의의 뉴클레오티드 염기를 호출할 수 없는, 위치의 수에 의해 결정되는 미스매치의 유형과 이의 수(number) - 존재하는 경우에 (즉, "n 형" 미스 매칭) - 뿐만 아니라, 참조에 존재하는 염기와 상이한 염기가 호출됐었던 미스매치의 수를 갖는 서열 리드와 매칭하는 것으로 판명된다. "치환"으로 나타낸 이러한 유형의 미스매치는 단일 뉴클레오티드 변이 (Single Nucleotide Variation, SNV) 또는 단일 뉴클레오티드 다형성 (Single Nucleotide Polymorphism, SNP)이라고도 한다. 본 문서에서, 이 유형의 미스매치는 "s 형" 미스매치라고도 나타낸다. 그러면, 서열 리드는 "M 미스 매칭 리드"로서 참조되고, "클래스 M"에 할당된다. "클래스 N"의 경우와 같이, "클래스 M"에 속하는 모든 리드에 대해서도, 매칭 부정확도를 주어진 상한으로 한정하고, 유효한 매칭(valid matching)으로 고려되는 것과 그렇지 않은 것 사이에 경계를 설정하는 것이 유용하다. 그러므로, 클래스 M으로 할당된 리드는 또한 임계의 세트 - 존재하는 경우에, 하나는 "n 형" 미스매치의 수인 "n"에 대한 것(MAXN) 이고, 다른 하나는 치환의 수인 "s"에 대한 것(MAXS)임 - 를 정의함으로써 제한된다. 제3 제약조건은 두 수 "n"과 "s"의 임의의 함수인 f(n,s)에 의해 정의된 임계이다. 이러한 제3 제약조건은 임의의 의미 있는 선택적 액세스 기준에 따라, 미스 매칭 부정확성의 상한을 갖는 클래스의 생성을 가능하게 한다. 예를 들어, f(n,s)는 "클래스 M"에 속하는 리드에 대해 허용된 최대 매칭 부정확성 수준에 경계를 설정하는 (n+s)1/2 또는 (n+s) 또는 임의의 선형 또는 비-선형 수식일 수 있으나, 이에 한정되는 것은 아니다. 다양한 목적으로 서열 리드를 분석하는 경우에, 이러한 경계는 복잡한 선택적 데이터 검색을 압축된 데이터에 대해 실시하는, 매우 강력한 기준을 구성한다. 예시로서, 한 유형 또는 다른 유형에 적용된 단순 임계 (simple threshold)를 넘어서, "n 형" 미스매치의 수와 "s 형" 미스매치(치환)의 수의 임의의 가능한 조합을 포함하는 압축된 게놈 리드의 선택을 가능하게 하나, 이에 한정하는 것은 아니다. SAM/BAM 형식과 같은 기존의 해결방안은 참조 게놈에 대해 사용자-정의된 미스매치의 수를 갖는 정렬된 서열 리드의 선택을 기본적으로 지원하지 않는다. 참조 게놈에 대한 치환을 최대 "N"개 갖는 게놈 서열 리드를 선택하는 것은 하기를 요구할 것이다:
1. 전체 BAM 파일을 텍스트 SAM 파일(textual SAM file)로 압축 해제하는 것.
2. 목적하는 리드를 선택하도록 구성된 텍스트 파서 (text parser)를 이용한 디코딩된 SAM 파일의 파싱.
이 접근법은 30x 커버리지에 대해서, 매우 큰 저장 공간(SAM 텍스트는 BAM보다 약 2.5배 더 큼) 및 대략 수 시간의 긴 프로세싱 시간을 필요로 할 것이다.
본 발명의 원리의 측면에 따라서, 임의의 사용자-정의된 미스매치의 수를 표현하는 게놈 서열 리드는 별도로 압축되어, 전체 데이터 세트를 압축 해제할 필요 없이 압축 해제될 수 있다.
· 제4 클래스는 "삽입", "결실" [인델(indel)로도 알려짐] 및 "클리핑된-" 중에서, 임의의 유형의 적어도 하나의 미스매치뿐만 아니라, 존재하는 경우에, 클래스 N 또는 M에 속하는 임의의 미스매치 유형을 표현하는 시퀀싱 리드로 구성된다. 이러한 서열은 "I 미스 매칭 리드"로 나타내고, "클래스 I"에 할당된다. 삽입은 참조에 존재하지 않지만, 리드 서열에는 존재하는 하나 이상의 뉴클레오티드의 추가 서열로 구성된다. 본 문서에서, 이 유형의 미스매치는 "i 형" 미스매치로 나타낸다. 문헌에서, 삽입된 서열이 서열의 가장자리(edge)에 존재하는 경우에, 이는 "소프트 클리핑된-"으로 또한 나타낸다 (즉, 뉴클레오티드가 참조와 매칭하는 것은 아니나, 버려지는 "하드 클리핑된" 뉴클레오티드와는 반대로, 정렬된 리드에서 유지된다). 본 문서에서, 이 유형의 미스매치는 "c 형" 미스매치로 나타낸다. 결실은 참조 서열에 대한 리드 내 "공백" (없어진 뉴클레오티드)이다. 본 문서에서, 이 유형의 미스매치는 "d 형" 미스매치로 나타낸다. 클래스 "N"과 클래스 "M"의 경우와 같이, 매칭 부정확성에 한계를 정의하는 것이 가능하며, 적합하다. "클래스 I"에 대한 제약조건 세트의 정의는 "클래스 M"에 이용된 동일한 원칙에 기초하며, 표 1에서, 이 표의 마지막 행에서 보고된다. 클래스 I 데이터에 허용될 수 있는 미스매치의 각 유형에 대한 임계 외에도, 미스매치 "n", "s", "d", "i" 및 "c"의 수에 대한 임의의 함수인 w(n,s,d,i,c)에 의해 결정된 임계에 의해서, 추가의 제약조건이 정의된다. 이러한 추가 제약조건은 임의의 의미 있는 사용자 정의된 선택적 액세스 기준(user defined selective access criterion)에 따라, 매칭 부정확성의 상한을 갖는 클래스의 생성을 가능하게 한다. 예를 들어, w(n,s,d,i,c)는 "클래스 I"에 속하는 리드에 대해 허용된 최대 매칭 부정확성 수준에 대한 경계를 설정하는 (n+s+d+i+c)1/5 또는 (n+s+d+i+c) 또는 임의의 선형 또는 비-선형 수식일 수 있으나, 이에 한정되는 것은 아니다. 각 유형의 허용할 수 있는 미스매치에 적용된 단순 임계 (simple threshold)를 넘어서, "클래스 I" 리드에서 허용할 수 있는 미스매치의 수의 임의의 가능한 조합에 추가의 경계를 설정하는 것을 가능하게 하기 때문에, 서열 리드를 다양한 목적으로 분석하는 경우에, 이러한 경계는 목적하는 선택적 데이터 검색을 압축된 데이터에 적용하는 것에 대한 매우 유용한 기준을 구성한다.
· 제5 클래스는 참조 서열을 참조하는 경우에, 각 데이터 클래스에 대해서 유효한 것으로 고려된 임의의 매핑을 찾지 못한 모든 리드(즉, 표 1에서 지정된, 최대 매칭 부정확성에 대한 상한을 정의하는 매칭 규칙의 세트를 충족시키지 못함)를 포함한다. 참조 서열을 참조하고, "클래스 U"에 속하는 것으로 분류되는 경우에, 이러한 서열은 "매핑되지 않음"이라고 한다.
매칭 규칙에 따른 리드 페어의 분류
이전의 섹션에서 지정된 분류는 단일 서열 리드와 관련 있다. 리드를 페어 - 두 리드가 가변적 길이(variable length)의 알려지지 않은 서열에 의해 분리되는 것으로 알려져 있는 - 로 생성하는 시퀀싱 기술 (즉, Illumina Inc.)의 경우에, 전체 페어의 분류를 단일 데이터 클래스로 여기는 것이 적절하다. 다른 리드와 커플링(coupling)되는 리드는 이의 "메이트"라고 한다.
두 페어링된 리드(paired read) 모두가 동일한 클래스에 속하는 경우에, 전체 페어를 클래스로 할당하는 것은 자명하다: 전체 페어는 임의의 클래스 (즉, P, N, M, I, U)에 대해서 동일한 클래스에 할당된다. 두 리드가 상이한 클래스에 속하나, 이들 중 어떠한 리드도 "클래스 U"에는 속하지 않는 경우라면, 전체 페어는 하기 식 1에 따라 정의된, 가장 높은 우선권(priority)을 갖는 클래스에 할당된다:
[식 1]
P < N < M < I
상기 식 1에서, "클래스 P"는 가장 낮은 우선권을 갖고, "클래스 I"는 가장 높은 우선권을 갖는다.
리드 중 단 하나만 "클래스 U"에 속하고, 이의 메이트가 클래스 P, N, M, I 중 임의의 클래스에 속하는 경우에, 제6 클래스는 "Half Mapped (하프 매핑됨)"를 의미하는 "클래스 HM"으로 정의된다.
리드의 이러한 특정한 클래스의 정의는 이것이 참조 게놈에 존재하는 갭(gap) 또는 알려지지 않은 영역(거의 알려지지 않은 또는 알려지지 않은 영역이라고도 함)을 결정하는 시도에 이용된다는 사실 때문이다. 이러한 영역은 알려진 영역에 매핑될 수 있는 페어 리드를 이용하여, 페어를 가장자리(edge)에 매핑함으로써 복원된다. 그러면, 매핑되지 않은 메이트는 알려지지 않은 영역의 소위 "컨티그"의 빌딩에 이용되는데, 이는 도 9에 제시된다. 그러므로, 이러한 유형의 리드 페어에 대해서만 선택적 액세스를 제공하는 것은 연관된 연산 부하(computation burden)를 대단히 감소시키며, 전체적으로 조사되는 것을 필요로 하는, 선행기술의 해결방안을 이용하는 것보다, 많은 양의 데이터 세트에 의해 비롯된 이러한 데이터의 훨씬 효율적인 프로세싱을 가능하게 한다.
아래의 표는 각 리드가 속하는 데이터의 클래스를 정의하기 위해 리드에 적용된 매칭 규칙을 요약한 것이다. 이 규칙은 미스매치의 유형(n, s, d, i 및 c 형 미스매치)의 존재 또는 부재의 관점에서, 하기 표의 처음의 다섯 열에 정의되어 있다. 여섯 번째 열은 각 미스매치 유형에 대한 최대 임계 및 가능한 미스매치 유형의 임의의 함수인 f(n,s) 및 w(n,s,d,i,c)의 관점에서 규칙을 제공한다.
[표 2. 미스매치의 유형 및 본 개시에서 정의된 데이터 클래스로 분류되기 위해 각 서열 리드가 충족시켜야 하는 제약조건의 세트]
선행기술 접근법과의 비교
SAM 및 CRAM과 같은 통상적으로 이용되는 접근법은 이들의 매핑 정보를 표현하는데 필요한 디스크립터의 특정한 부분-집합에 따라서 리드 또는 리드 페어를 인코딩하지 않는다. SAM 및 CRAM은 서열 리드를 이들이 매핑된 참조 서열에 대해서 이들이 포함하는 미스매치의 수 및 유형에 따라서 데이터 클래스로 분류하지 않는다. 더욱이, 이들 형식은 단일 데이터 클래스에 속하는 서열 리드를 압축된 형태로 서열 리드만을 포함하는 액세스 유닛으로 별도로 코딩하지 않는다. 페어로 생성된 서열 리드인 경우에, 선행기술 접근법은 이들을 참조 서열에 대한 이들의 매핑 정확성에 따라서 클래스로 분할되는 단일 요소로서 코딩하지 않는다. 이러한 선행기술 접근법은 다음의 한계점 및 결점을 특징으로 한다:
1. 참조 서열에 대한 매핑 결과에 따라 서열 리드를 별도의 데이터 클래스로 분류하지 않는, 리드 또는 리드 페어의 코딩 및 디스크립터의 고유의 초-집합(unique super-set)의 이용은 좋지 못한 압축 성능을 수득하는 비효율적인 접근법이다.
2. 압축된 데이터에 대한 소스 모델링의 결핍 및 ZIP, GZIP, LZMA와 같은 범용 압축기의 이용은 좋지 못한 압축률을 생성한다.
3. 별도의 서열로서 리드 페어를 코딩하는 것은 예를 들어, 리드 식별자[리드 명칭(read name)이라고도 함]와 같은 동일한 정보를 운반하는 몇몇 디스크립터들의 복제를 필요로해서, 비효율적이고 좋지 못한 압축 성능을 야기한다.
4. 리드 페어의 복원에 필요한 정보의 검색은 과정이 차세대 시퀀싱 (Next-Generation Sequencing, NGS) 기술인 경우에 극도로 클 수 있는 전체 - 가능한 한 - 데이터 세트에서 부르트-포스 순차 검색(brute-force sequential search)을 필요로 하기 때문에, 복잡하고 비효율적이다.
5. 특정한 게놈 영역에 매핑된 리드 또는 리드 페어에 대한 선택적 액세스는 전체 데이터 세트를 검색하여 모든 리드 또는 리드 페어가 검색되었다는 것을 보증하는 것을 필요로 한다.
디스크립터의 단일 부분-집합에 의해 리드 페어를 코딩하는 경우에, 다음의 기술적 이점은 통상의 기술자에게 명백하다:
1. 명백히 불필요한, 두 리드에 공통적인 정보는 페어를 단일 요소로 코딩함으로써 복제되지 않는다 (예, 리드 페어 식별자, 매핑 거리, 매핑 참조 식별자, SAM 파일 형식에서 특정한 플래그에 의해 현재 인코딩된 다양한 매핑 품질 정보).
2. 상호간의 페어링 정보(mutual pairing information) (즉, 어떤 리드가 가까이에 있는 임의의 리드의 메이트인지에 대해서 제공하는 정보)의 검색은 복잡하지 않고, 임의의 추가 프로세싱을 필요로 하지 않는다. 역으로, 선행기술 접근법은 데이터의 전체 볼륨(volume)을 파싱하는 것을 필요로 할 수 있다.
시퀀싱 데이터의 특정 부분에 대한 효율적인 선택적 액세스를 가능하게 하고, 이들을 디지털 네트워크상에서 전송하는 것이 가능하게 되기 위해, 참조에 대해 정렬된 서열 리드를 표현하는 데 이용되는 디스크립터의 세트는 액세스 유닛(Access Unit, AU)이라고 하는, 논리적으로 별개이고 독립적인 데이터 블록으로 구조화된다. 각각의 액세스 유닛은 단일 데이터 클래스의 압축된 표현만을 포함하고, 임의의 다른 액세스 유닛과 상관없이 또는 매핑에 이용된 참조 서열 영역의 코딩된 표현을 운반하는 액세스 유닛만을 이용하여 디코딩될 수 있다. 이는 선택적 액세스와 비순차 전송 능력(out-of-order transport capability)을 가능하게 한다.
압축 효율을 증가시키기 위해, 본 발명은 "매핑 참조 식별자" 디스크립터를 동일한 참조 서열에 대해서 매핑된 두 페어를 갖는 각 리드 페어에 대해서 지정할 필요성을 제거한다. 각 액세스 유닛은 동일한 참조 서열에 대해서 매핑하는 리드 또는 페어만 포함할 수 있다. 이러한 해결방안을 이용하여, 참조 서열 식별자를 표현하는 디스크립터는 각 액세스 유닛 또는 액세스 유닛의 세트 당 단 한번만 인코딩될 필요가 있다 (SAM/BAM 형식에서 현재 수행되는 것처럼, 각 리드 별로 반복되지 않는다).
상기 표현된 규칙의 유일한 예외는 리드 페어가 상이한 참조 서열(예, 염색체)에 대해서 매핑된 두 리드를 갖는 경우이다. 이 경우에, 페어는 스플릿되고, 두 리드는 두 개의 별도의 게놈 레코드로서 인코딩되며, 각각의 인코딩된 리드는 이의 메이트가 매핑된 참조 서열의 식별자를 포함한다.
실험 데이터는 게놈 디스크립터의 통계적인 특성에 적합한 개발중인 엔트로피 코더가 데이터의 이질적인 세트(heterogeneous set)에 적용된 범용 압축기(예, LZ형 알고리즘)의 사용에 대해서 더 나은 압축 성능을 제공한다는 것을 입증했다. 결과적으로, 페어를 이루는 게놈 서열 리드를 디스크립터의 특정한 부분-집합에 의해 인코딩하는 경우에, 더 높은 압축이 디스크립터의 각각의 별도의 부분-집합을 특징으로 하는 더 낮은 엔트로피 덕분에 달성되고, 리드 페어를 복원 및 검색하는 경우에, 더 높은 압축 효율이 달성된다.
본 발명에 개시된 접근법에 의해 제공되는 달성 가능한 압축률의 관점에서의 이점은 다음 섹션에서 기술되며, 이 섹션에서 엔트로피 코딩 이전에 게놈 디스크립터의 상이한 블록에 적용된 상이한 이진화 및 변환이 관련 성능과 함께 기술된다.
서열 데이터와 참조 게놈의 인코딩
양태에서, 본 발명의 원리는 정렬된 서열 데이터의 참조-없는 압축이 수행되는 경우에, 참조 게놈 또는 게놈 조립체와 같은 참조 서열의 무손실 압축에 대한 것이다. Voges, J., Munderloh, M., Ostermann, J.의 "Predictive Coding of Aligned Next-Generation Sequencing Data" (2016 Data Compression Conference (DCC))에 따른, 정렬된 서열 데이터의 참조-없는 압축은 본 개시의 표 1에서 정의된 1 내지 12의 게놈 디스크립터를 이용하여 구현될 수 있다. Voges는 원형 버퍼(circular buffer)를 이용하여 인코딩된 서열 리드를 계속해서 저장하고, 각각의 정렬된 리드에 연관된 SAM 시가 스트링을 이용하여 관련 컨티그를 빌딩할 수 있다. 이 언급된 접근법이 참조 서열 (100)에 대해서 매핑된 게놈 시퀀싱 데이터 (101)의 효율적인 압축을 달성할 수 있으나, 이는 참조 서열 (100) 자체의 표현 및 압축을 지원하지 않는데, 그 이유는 디코딩 엔진(decoding engine)은 컨티그와 압축된 게놈 서열 리드를 복원하는 것만 가능할 것이나, 정렬에 이용된 본래의 참조 게놈은 압축된 데이터에 포함되지 않기 때문이다. 본 개시는 참조-없는 압축이 게놈 서열 데이터에 적용되는 경우에, 표 1의 13번 및 14번 게놈 디스크립터를 사용하여 정렬에 이용된 참조 게놈의 효율적인 압축을 달성하는 것을 목표로 한다. 이는 압축된 데이터에 압축 프로세스 동안에 조립된 컨티그와 정렬에 이용된 참조 게놈 사이의 차이점을 저장함으로써 달성된다. 디코딩의 말단부에서, 디코딩 프로세스는 게놈 서열 리드 압축 해제에 이용되는 컨티그를 복원할 것이고 - 13번 및 14번 디스크립터에 의해 - 정렬에 이용된 참조 게놈의 복원이 가능해질 것이다.
도 1은 정렬된 서열 리드 (101)가 참조-기반 압축의 수행에 이용될 더 긴 서열(102) - 컨티그라고 함 - 의 빌딩에 어떻게 이용될 수 있는가에 대해서 나타낸다. 컨티그는 참조 서열상의 각 위치 당, 이 위치에서 정렬된 리드에서 가장 높은 빈도로 존재하는 뉴클레오티드를 선택함으로써 조립된다. 이러한 뉴클레오티드가 참조 서열의 뉴클레오티드와 동일한 경우에, 이는 "매치"되었다고 하고, 그렇지 않고, 이러한 뉴클레오티드가 참조 서열의 뉴클레오티드와 상이한 경우라면, "미스매치"라고 한다. 또한 미리 정의된 설계 선택(design choice)으로 인한, 버퍼가 연역적으로(a priori) 고정되어야 하는 Voges의 접근법에서 이는 가능하지 않다.
더욱이, 본 발명에서, 컨티그의 길이는 사용자에 의해(예를 들어, 인풋 파라미터 파일에서) 정의될 수 있거나, 또는 인코더에 의해 동적으로 업데이트될 수 있다. 컨티그의 길이에 대한 정보는 표 18에 나타낸 것과 같은 압축된 게놈 정보의 저장 또는 전송에 이용된 파일 형식에 포함된 데이터 구조에서, 인코더로부터 디코더로 보낼 수 있다. 이러한 새로운 특징은 이것이 파라미터에 의해 정의되고, 이것이 다양한 인코더 및 디코더 아키텍처와 이들의 관련 한계에 대해서 적응될 수 있으며, 이것이 또한 게놈 서열의 인코딩 및 디코딩에 이용될 다양한 아키텍처의 진화(evolution) 및 코딩될 서열의 계산 복잡도(computational complexity)에 적응 가능하다(adaptable)는 상당한 이점을 갖는다.
컨티그 길이는 인코딩 및 디코딩 프로세스에서 이용된 뉴클레오티드의 수 및/또는 리드의 수의 두 관점 모두에서 표현될 수 있다. 이 프로세는 도면에 제시된다.
또한, 도 2는 상기 참조 서열 (200)과 컨티그 (201) 사이의 "미스매치" (202)가 표 1의 13번 및 14번 디스크립터를 이용하여 어떻게 코딩되는지에 대해서 나타낸다. 이러한 디스크립터를 엔트로피 코딩하는 것 및 이들을 정렬된 서열 리드의 압축에 이용된 디스크립터를 포함하는 동일한 액세스 유닛에서 캡슐화하는 것은 정렬에 이용된 참조 게놈을 디코딩 디바이스에서 복원하는 것을 가능하게 한다.
본 발명의 다른 양태에서, 임의의 매핑된 리드에 의해 커버되지 않은 정렬에 이용된 참조 게놈의 영역은 특정한 액세스 유닛에서 압축(즉, 엔트로피 코딩)될 수 있고, 캡슐화 및 운반될 수 있다. 이러한 액세스 유닛은 정렬에 이용되는 참조 게놈의 압축된 표현만 포함하고, 매핑된 서열 리드가 없는 게놈 영역을 커버한다. 이는 정렬에 이용되나, 이에 대해서 매핑된 리드가 존재하지 않는 참조 게놈의 영역이 특정한 액세스 유닛에서 코딩되는 도 11에 제시된다. 이러한 발명의 기술적 이점은 참조 게놈의 완전한 볼륨에 대응하는 상당량의 데이터를 저장할 필요없이, 디코딩 말단부에서 정렬에 이용된 참조 게놈의 완전한 복원이 가능하다는 것이다.
본원에 인용된 Voges 등의 해결방안에 대한 이러한 접근법의 기술적 이점은 다음과 같다:
1. 정렬에 이용된 참조 게놈은 추가 데이터[예, 외부 저장소(external repository)에 대한 임의의 다른 참조 또는 압축된 게놈]의 임의의 오프-밴드 전송(off-band transmission) 없이 디코딩 디바이스에서 입수 가능하다.
2. 참조 게놈은 액세스 유닛에 의해 커버되는 게놈 영역과 동일한 입상도(granularity)로 디코딩 디바이스에서 선택적으로 복원될 수 있다. 참조 게놈의 부분적 영역은 랜덤 액세스 메커니즘과 액세스될 수 있다. 이는 분석이 훨씬 더 작은 게놈 영역으로 제한되는 경우에도, 인간 참조 게놈을 구성하는 전체 32억 개의 뉴클레오티드의 압축 해제 및 조작(manipulation)을 필요로 하는 기존의 해결방안에 대해서 훨씬 더 효율적인 데이터 프로세싱을 가능하게 한다.
3. 본 발명에 개시된 rftp 및 rftt 디스크립터는 게놈 분석 파이프라인(genome analysis pipeline)에 의해서, 정렬에 이용된 참조 게놈이 압축된 서열 데이터가 속하는 동일한 개체에 속하는 경우에, 압축된 서열 데이터에 존재하는 새로운 단일 뉴클레오티드 다형성(SNP로도 알려짐, https://en.wikipedia.org/wiki/Single-nucleotide_polymorphism를 참고)의 지표(indicator)로서 이용될 수 있다. 매우 높은 (30x 보다 큰) 커버리지에서, 참조-없는 압축의 프로세스 동안에 빌딩된 컨티그(102)는 개체의 게놈의 새로운 조립체로서 고려될 수 있다는 것을 인식해야 할 것이다. 컨티그가 동일한 개체에 속하는 이전에 획득된 참조 게놈(100)과 비교되는 경우에, 발견된 차이점은 단일 뉴클레오티드 다형성(SNP로도 알려짐, https://en.wikipedia.org/wiki/Single-nucleotide_polymorphism를 참고)의 가능한 존재의 표시(indication)이다.
게놈
디스크립터의
엔트로피 코딩
본 개시에 정의된 게놈 디스크립터의 부분-집합은 본 발명의 원리에 따라 정의된 6개의 클래스에 속하는 게놈 데이터의 표현에 이용된다. 도 6 및 도 7은 참조 서열의 인접한 영역에 매핑된 게놈 서열 리드가 하나의 액세스 유닛에서 캡슐화된 게놈 디스크립터의 블록에 의해 표현되는 것을 나타낸다. 상기 디스크립터의 블록은 각 디스크립터의 통계적 특성에 대해서 특정하게 조정된 상이한 엔트로피 코더를 이용하여 엔트로피 코딩된다. 이 접근법은 게놈 디스크립터의 각 블록이 SAM 또는 CRAM 레코드보다 더욱 효율적으로 모델링될 수 있는 정보의 소스를 표현하기 때문에, SAM/BAM 또는 CRAM과 같은 다른 접근법보다 더 나은 압축률을 제공한다. SAM과 CRAM 레코드는 본 개시에서 정의된 게놈 디스크립터로서 동일한 통계학적 특성을 공유하지 않는 이질적인 엘리먼트(heterogeneous element)의 그룹이다.
선행기술 해결방안보다 더 나은 압축률을 제공하는 상기 디스크립터의 엔트로피 코더에 필요한 구성 파라미터와 함께 디스크립터에 적용된 변환 및 이진화는 아래에 보고되는 본 발명에서 개시된다.
디스크립터의
변환
디스크립터의 변환은 게놈 서열내에서 미스매치 위치 또는 미스매치 유형과 같은 게놈 특징을 표현하는 디스크립터의 값이 상이한 대응하는 값으로 변환되어 더 나은 압축 성능을 달성하는 프로세스이다. 양태에서, 본 개시의 원리에 따라서, rftp 디스크립터에 의해 표현되는 미스매치 위치는 다음의 단계에 따라 변환된다:
1. 변환 프로세스에 대한 인풋은 두번째 리드의 첫번째 뉴클레오티드로부터의 뉴클레오티드의 거리로서 표현되는 미스매치의 위치이다. 이는 참조 서열에 대한 조립된 컨티그의 4개의 미스매치(203)가 위치 4, 6, 10, 및 13에서 존재하는, 도 2에 제시된다.
2. 다음에, 각각의 절대 위치는 이전의 미스매치에 대한 상이한 위치로 변환된다. 첫번째 미스매치는 동일한 값을 유지한다. 그런 다음에, 4개의 위치 값은 4, 2, 4, 3으로 변환된다. 이들 값은 아래에 기술된 rftp 디스크립터의 이진화 프로세스에 대한 인풋이다.
양태에서, 본 개시의 원리에 따라, rftt 디스크립터에 의해 표현되는 미스매치 유형은 다음의 단계에 따라서 변환된다:
1. 변환 프로세스에 대한 인풋은 뉴클레오티드 기호로서 표현되는 미스매치의 유형이다. 이는 참조 서열에 대한 조립된 컨티그의 4개의 미스매치(204)가 유형 A, A, G, A인, 도 2에 제시된다.
2. 그런 다음에, 각각의 뉴클레오티드는 모든 가능한 기호를 포함하는 벡터(209)에서 뉴클레오티드의 위치를 표현하는 정수 값으로 변환된다. 이는 도 10에서 제시된다. 다음에, 4개의 미스매치 유형은 0, 0, 2, 0으로 변환된다. 이들 값은 아래에 기술된 rftt 디스크립터의 이진화 프로세스에 대한 인풋이다.
디스크립터의
이진화 (
Binarization
)
양태에서, 본 발명은 컨텍스트-적응 이진 산술 코딩(context-adaptive binary arithmetic coding, CABAC)을 게놈 디스크립터의 압축에 이용한다. CABAC는 먼저 이진 표현으로 인코딩될 모든 기호를 전환한다. 이진화의 프로세스는 산술 코딩에 앞서, 비-이진-값 기호(non-binary-valued symbol) (예, 매핑 위치, 매핑된 리드 길이 또는 미스매치 유형)를 이진 코드(binary code)로 전환한다.
각 디스크립터의 통계학적 특성에 대해 적응된 적절한 이진화의 선택은 이질적인 엘리먼트(heterogeneous element)들의 블록에 적용된 범용 압축기(general purpose compressor)에 기초한 기존의 형식보다 더 나은 압축률을 제공한다.
다음 섹션에서, 이들 변수들이 정의된다:
· symVal : 이진화될 게놈 디스크립터의 비-이진 값.
· cLength : 값이 이진화되는 비트의 수를 표현함.
· cMax : 이진화될 가능한 최댓값. 더 큰 값은 절삭(truncating)될 것이다.
다음의 이진화 표가 이러한 변수의 고정값에 대해서 계산되는 동안, 본 발명의 원리가 이들 값에 한정되는 것이 아니므로, 본 발명의 원리의 정신이 유지되면서도, 다른 값들이 본 원리에 따라서 또한 이용될 수 있다는 것이 인식되어야 한다.
본 개시에 이용된 각각의 이진화 알고리즘은 표 3에 나타낸 식별자에 의해 식별된다.
[표 3. 이진화의 유형과 각 식별자]

이진 코딩 (Binary Coding, BI)
이는 각 수치가 이의 이진 표현에 코딩되는, 표준 이진 표현(standard binary representation)이다. 변수 cLength - 표 15에 나타낸, binarization_id = 0인 경우 - 는 값이 표현될 비트의 수를 나타낸다.
절삭형 단항(Truncated Unary, TU) 이진화
TU 이진화 스트링은 1이 먼저오고, 하나의 0이 이어지는 symVal 의 연접(concatenation)이다. symVal == cMax라면, 후행 0-비트(trailing 0-bit)는 버려진다. 표 4는 cMax = 3인, 이 절삭형 단항 이진화의 이진 스트링(bin string)을 도시한다.
[표 4.
cMax
==3인, 절삭형 단항 이진화의 이진 스트링]

산술 디코딩 (arithmetic decoding)에 따른 이 이진화 프로세스에 대한 신택스가 아래에 기술된다.

binValue는 0 또는 1일 수 있는, 이진화된 값이다.
지수
골룸
(Exponential
Golomb
, EG) 이진화
이 기법을 이용하여 이진화된 게놈 디스크립터에 대한 파싱 프로세스는 첫번째 0이 아닌 비트(non-zero bit)까지 포함하는 비트 스트림 내 현재 위치에서 시작하고, 0과 동일한 선행 비트 (leading bit)의 수를 계수하는, 비트를 리딩(reading)하는 것으로 시작한다.
이 프로세스는 다음과 같이 지정된다:

다음에, 변수 symVal은 다음과 같이 할당된다:
여기서, read bits 라고 하는 함수가 인풋(input)으로서 전달된 파라미터와 동일한 저장 매체로부터 비트의 수를 리딩한다. read_bits(leadingZeroBits)로부터 반환된 값은 먼저 쓰여진 최상위 비트 (most significant bit)와 부호화되지 않은 정수의 이진 표현으로 해석된다.
표 5는 비트 스트링을 "접두(prefix)" 비트와 "접미(suffix)" 비트로 분리시킴으로써 지수-골룸 코드(Exp-Golomb code)의 구조를 도시한다. "접두" 비트는 leadingZeroBits의 계산(computation)에 대해서 상기 지정된 대로 파싱되는 비트이고, 표 5의 비트 스트링 열(bit string column)에서 0 또는 1로 나타냈다. "접미" 비트는 symVal의 계산에서 파싱되는 비트이고, 표 5에 xi로 나타냈으며, i는 0 내지 leadingZeroBits - 1까지의 범위내에 있다. 각각의 xi는 0 또는 1과 같다.
[표 5. 0 내지 62의
symVal의
값에
대한 이진 표현
]

표 6은 symVal 값으로의 비트 스트링의 명시적 할당(explicit assignment)을 도시한다.
[표 6. 명시적 형식의 지수-
골룸
비트 스트링과
symVal
]

게놈 디스크립터에 따라서, 이진화된 신택스 엘리먼트의 값은 다음의 방법들 중 하나를 이용하여 디코딩된다:
1. 디코딩된 게놈 디스크립터의 값은 이진화된 디스크립터에 대응하는 symVal 값과 동일하다.
2. 디코딩된 게놈 디스크립터의 값은, 예를 들어, https://en.wikipedia.org/wiki/Exponential-Golomb_coding 에 정의된 대로, symVal을 인풋으로 하여, 부호화된 0-차 지수-골룸 디코딩(signed 0-order Exponential-Golomb decoding)을 적용함으로써 계산된다.
부호화된 지수
골룹
(Signed Exponential
Golomb
,
SEG
) 이진화
이진화 방법에 따라서, 게놈 디스크립터는 신택스 엘리먼트를 오름차순인 이의 절댓값에 의해 배열하고(ordering), 더 낮은 symVal을 갖는 주어진 절댓값에 대한 양수 값을 표현함으로써 symVal에 연관된다. 표 7은 할당 규칭을 나타낸다.
[표 7. 부호화된 지수-
골룸
코딩된 게놈
디스크립터에
대한
symVal로의
신택스
엘리먼트의
할당]

절삭형 지수
골룸
(Truncated Exponential
Golomb
,
TEG
) 이진화
이진화 프로세스는 이진화가 어떻게 계산되는지에 대해서 정의하는 추가의 인풋 파라미터 tegParam 의 이용을 필요로 한다.
이 프로세스의 아웃풋은 신택스 엘리먼트의 TEG 이진화이다.
TEG 이진 스트링(TEG bin string)은 이진화의 유형 1(symVal == 0인 경우) 또는 2(symVal > 0인 경우)의 연접이다:
1. Min(symVal, tegParam) 값에 대한 cMax = tegParam인, 절삭형 단항 이진화
2. symVal !=0인 경우, Abs(symVal) - tegParam 값에 대한 지수 골룸 이진화
표 8은 tegParam ==2인, 이 절삭형 지수 골룸 이진화의 이진 스트링을 도시한다.
[표 8.
tegParam
=2인, 절삭형 지수
골룸
이진화의 이진 스트링]

부호화된 절삭형 지수
골룸
(Signed Truncated Exponential
Golomb
,
STEG
) 이진화
이 이진화 프로세스는 추가의 인풋 파라미터 stegParam의 이용을 필요로 한다.
STEG 이진 스트링은 1(symVal == 0인 경우) 또는 2(다른 경우) 이진화의 연접이다:
1. Abs(symVal)에 대한 절삭형 지수 골룸 이진화.
2. symVal !=0인 경우, 1-비트 플래그 (one-bit flag)는 1과 같거나(symVal<0인 경우) 또는 0과 같다(symVal>0인 경우).
표 9는 stegParam = 2인, 부호화된 절삭형 지수 골룸 이진화의 이진 스트링을 도시한다.
[표 9.
stegParam
= 2인, 부호화된 절삭형 지수
골룸
이진화의 이진 스트링]

스플릿
유닛-
와이즈
절삭형 단항 (Split Unit-wise Truncated Unary, SUTU) 이진화
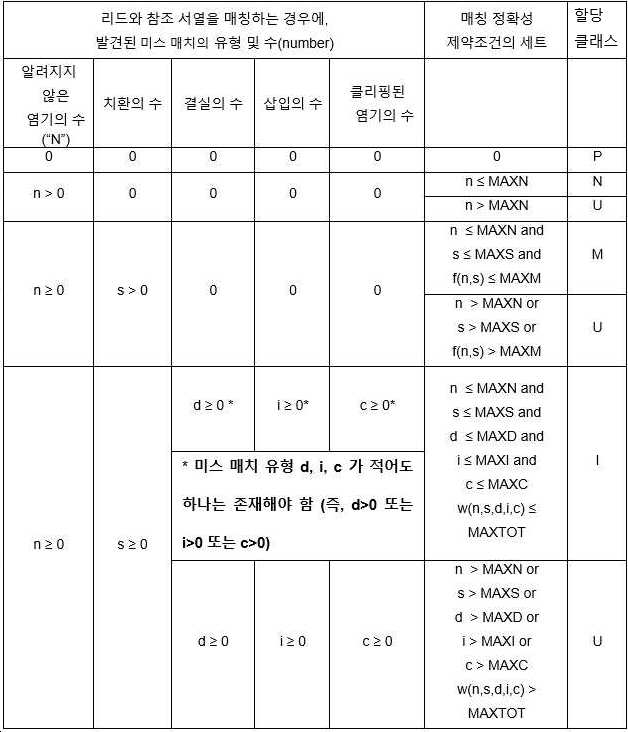
이 이진화 프로세스는 두 개의 인풋 파라미터 splitUnitSize와 outputSymSize의 이용을 필요로 한다. outputSymSize는 항상 splitUnitSize의 배수(multiple)이어야 한다.
SUTU 이진 스트링은 반복되는 TU 이진화의 연접인데, 각 TU 이진화는 길이가splitUnitSize 비트인, symVal의 일부에 적용된다. 달리 말하면, symVal은 TU 이진화로 획득된 x 이진 스트링으로 표현되는데, 여기서 x = outputSymSize/splitUnitSize이다. 각 이진 스트링에 대한 cMax 파라미터는 cMax = (1<<splitUnitSize) - 1로 정의된다.
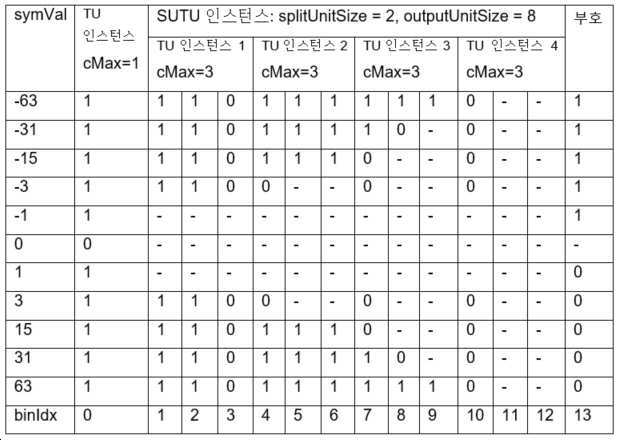
표 10은 splitUnitSize = 2이고, outputSymbSize = 8인, 스플릿 유닛-와이즈 절삭형 단항 이진화의 이진 스트링을 도시한다.
[표 10.
splitUnitSize
= 2이고,
outputSymbSize
= 8인,
스플릿
유닛-
와이즈
절삭형 단항 이진화의 이진 스트링]

이 이진화 프로세스에 대한 신택스는 아래에 기술된다.
[표 11. TU 이진화에 대한
CABAC
디코딩 프로세스]

부호화된
스플릿
유닛-
와이즈
절삭형 단항(Signed Split Unit-wise Truncated Unary, SSUTU) 이진화
이 이진화 프로세스는 두 개의 인풋 파라미터 splitUnitSize와 outputSymSize의 이용을 필요로 한다.
SSUTU 이진 스트링은 별도의 플래그로 코딩된 symVal의 부호로 SUTU 이진화 프로세스의 확장에 의해 획득된다.
· Abs(symVal) 값에 대한 SUTU 이진화.
· symVal !=0인 경우, 1-비트 플래그는 1과 동일하거나 (symVal<0 경우) 또는 0과 동일하다 (symVal>0인 경우).
표 12는 splitUnitSize = 2, outputSymbSize = 8인, 부호화된 스플릿 유닛-와이즈 절삭형 단항 이진화의 이진 스트링을 도시한다.
[표 12.
splitUnitSize
= 2,
outputSymbSize
= 8인, 부호화된
스플릿
유닛-와이즈 절삭형 단항 이진화의 이진 스트링]
이 이진화 프로세스에 대한 신택스는 아래에 기술된다.

sign_flag는 ctxIdx에 의해 식별된 컨텍스트 변수 (context variable)에 대한 비트의 cabac 디코딩을 표현한다.
decode_ cabac _ SUTU()는 SUTU 이진화에 대한 cabac 디코딩 프로세스를 표현한다.
이중 절삭형 단항(Double Truncated Unary,
DTU
) 이진화
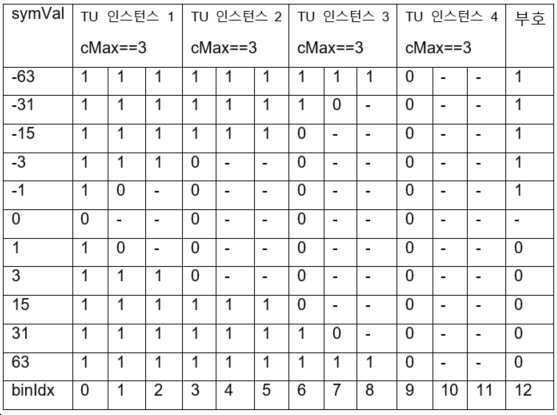
이 이진화 프로세스는 두 개의 인풋 파라미터 splitUnitSize와 outputSymSize의 이용을 필요로 한다.
DTU 이진 스트링은 두 이진화, 즉, TU 이진화와 SUTU 이진화의 연접이다. 파라미터 cMax는 TU 이진화에 이용되고, 파라미터 splitUnitSize와 outputSymSize는 SUTU 이진화에 이용된다 (이의 cMax는 내부적으로 유래된다).
· Min(Abs(symVal), cMax) 값에 대한 TU 이진화의 제1 인스턴스.
· Abs(symVal) > cMax인 경우, Abs(symVal) - cMax 값에 대한 SUTU 이진화의 제2 인스턴스.
표 13은 cMax = 1, splitUnitSize = 2, outputSymSize = 8인, 이중 절삭형 단항 이진화의 이진 스트링을 도시한다.
[표 13.
cMax
= 1,
splitUnitSize
= 2,
outputSymSize
= 8인, 이중 절삭형 단항 이진화의 이진 스트링]
이진화 프로세스는 아래에 기술된다.

decode_cabac_TU()는 TU 이진화에 대한 cabac 디코딩 프로세스를 표현한다.
decode_ cabac _ SUTU()는 SUTU 이진화에 대한 cabac 디코딩 프로세스를 표현한다.
부호화된 이중 절삭형 단항 (Signed Double Truncated Unary,
SDTU
) 이진화
이 이진화 프로세스는 두 개의 추가의 인풋 파라미터 splitUnitSize와 outputSymSize의 이용을 필요로 한다.
SDTU 이진 스트링은 플래그로서 코딩된 symVal의 부호로 DTU 이진화 프로세스의 연장에 의해 획득된다.
· Abs(symVal) 값에 대한 DTU 이진화.
· symVal !=0인 경우, 1-비트 플래그는 1과 동일하거나 (symVal<0인 경우) 또는 0과 동일하다 (symVal>0인 경우).
표 14는 cMax = 1, splitUnitSize = 2, outputSymSize = 8인 이중 절삭형 단항 이진화의 이진 스트링을 도시한다.
[표 14.
cMax
= 1,
splitUnitSize
= 2,
outputSymSize
= 8인, 부호화된 이중 절삭형 단항 이진화의 이진 스트링]
이 이진화 프로세스에 대한 신택스는 아래에 기술된다.

sign_flag는 ctxIdx에 의해 식별된된 컨텍스트 변수에 대한 비트의 cabac 디코딩을 표현한다.
decode_ cabac _ DTU()는 DTU 이진화와 cabac 디코딩을 표현한다.
이진화 파라미터
이전의 섹션에서 소개된 각각의 이진화 알고리즘은 인코딩 말단부(encoding ends)와 디코딩 말단부(decoding ends)에서 구성 파라미터를 필요로 한다. 양태에서, 상기 구성 파라미터는 표 15에 기술된 데이터 구조에서 캡슐화된다. 각각의 이진화 알고리즘은 표 3에 열거된 식별자에 의해 식별된다.
[표 15. 이진화 파라미터 구조]
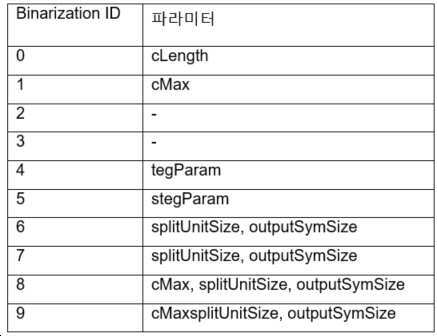
표 15에서, 다음의 시멘틱스가 적용한다:
cMax는 이진화될 가장 큰 값을 표현한다. 더 큰 값은 절삭될 것이다.
cLength는 값이 이진화되는 비트의 수를 표현한다.
tegParam는 TEG 이진화에 대해서 본 문서에서 정의된 tegParam 변수를 표현한다.
stegParam는 STEG 이진화에 대해서 본 문서에서 정의된 stegParam 변수를 표현한다.
splitUnitSize는 SUTU, SSUTU 및 DTU 이진화에 대해서 본 문서에서 정의된 splitUnitSize 변수를 표현한다.
outputSymSize는 SUTU, SSUTU DTU 및 SDTU 이진화에 대해서 본 문서에 정의된 outputSymSize 변수를 표현한다.
본 발명의 기술적 이점에 대한 증거
나타낸 CABAC 이진화를 표 16에 나타낸 각각의 게놈 디스크립터에 적용함으로써, 표 17 (* 본 개시의 원리에 따라서, 이미 압축된 표현으로 입수 가능하기 때문에, 필요한 추가 정보는 없다)에서 보고된 압축 성능이 획득될 수 있다.
본 개시에 기술된 방법의 압축 성능의 개선은 BAM 및 CRAM 접근법 및 DeeZ로 공지된 문헌의 최선의 압축기 중 하나의 대응하는 파일 크기와의 비교에 의해 인식될 수 있다 (Numanagic, I., et al "Comparison of high-throughput sequencing data compression tools", Nature Methods (ISSN: 1548-7091), vol. 13, p. 1005-1008 London: Nature Publishing Group, 2016을 참고). DeeZ, BAM 및 CRAM 압축 성능은 정렬에 이용되는 압축된 참조 게놈의 크기를 압축된 게놈 서열 데이터의 크기에 추가함으로써 계산된다는 것이 인식되어야 한다. 본 개시의 원리에 따라서, 참조 게놈은 압축된 파일에 내장된다. 오늘날 실제로, 상기 압축된 참조 게놈은 GZIP, LZMA, Bzip2와 같은 범용 압축기를 이용하여 압축된 FASTA (ASCII 텍스트) 파일이다. 제안된 비교에서, 참조 게놈 hs37d5.fa가 최대 압축의 옵션(-9)을 수반한 xz 리눅스 명령어(Linux command)를 이용하여 압축되었다.
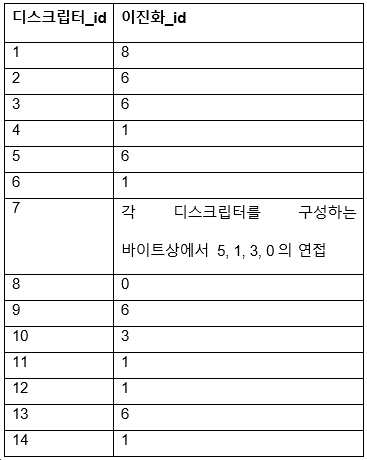
[표 16. 각 게놈
디스크립터에
연관된 이진화]
디스크립터
rftp
및
rftt에
적용된 이진화
rftp와 rftt의 이진화의 예시는 본 섹션에서 제공되며, 도 10에 도시된다.
정렬에 이용된 컨티그와 참조 게놈 사이의 다섯 미스 매칭과 연관된 디스크립터를 아래에 나타낸다:

각 뉴클레오티드 기호는 정수 코드와 연관된다.

변환 후에, 값은 다음과 같이 된다:

rftp에 대한 이진화된 값은 다음과 같이 계산된다:
1. 종결자 값은 0 또는 1로서 이진화될 수 있다. 본원에서, 이 예시에 대해서, 0이 선택된다.
2. 종결자 = 0인 경우에, splitUnitSize = 4, outputSymbolSize = 12인, 이진화 no. 6이 이용되고, 다음의 이진 스트링이 rftp의 값과 연관된다.

rftt에 대한 이진화된 값은 다음과 같이 계산된다:
1. 참조 게놈에 존재하는 뉴클레오티드를 알면, 인코딩될 가능한 기호로부터 대응하는 기호를 제거한다. 즉, 예시의 제1 미스 매칭에 대해서, 참조 서열에서 대응하는 기호가 'G'인 경우에, 인코딩될 가능한 기호의 공백(space)은 0, 1, 3, 4이다.
2. 인코딩될 데이터에 대한 미스매치 유형의 기호의 빈도가 측정되고, 0 내지 3으로 인덱싱된다. 인덱스 0은 가장 빈번한 미스매치에 영향을 미치고, 인덱스 3은 덜 빈번한 미스매치에 영향을 미친다. 이 예시에서, 인덱싱은 { 0 => 3, 1=> 0, 2=>4, 3=>1}일 수 있다.
3. 주어진 예시에서, 다섯 미스매치는 TU 이진화를 이용하여 이진화될 수 있다:

상기에 나타낸 이진화 접근법으로, 다음의 압축 결과가 달성된다:
[표 17. 선행기술 해결
방안에 대한 압축 성능
(바이트 크기)]

* 본 개시의 원리에 따라서, 이미 압축된 표현으로 입수 가능하기 때문에, 필요한 추가 정보는 없다.
코딩 파라미터
양태에서, 각 액세스 유닛의 인코딩 및 디코딩에 필요한 파라미터는 표 18에서 정의된 명명된 데이터 구조에서 캡슐화된다.
[표 18. 게놈
디스크립터에
대한 코딩 파라미터]



인코딩 장치
도 3은 본 발명의 원리에 따른 인코딩 장치를 나타낸다. 인코딩 장치는, 예를 들어, 게놈 시퀀싱 장치에 의해 생성된 정렬되지 않은 게놈 서열들(300)과 참조 게놈 (302)을 인풋으로 수신한다. Illumina사의 HiSeq 2500, Thermo-Fisher사의 Ion Torrent 디바이스 또는 Oxford의 Nanopore MinION과 같은 게놈 시퀀싱 장치가 당해 분야에 공지되어 있다. 정렬되지 않은 서열 데이터 (300)는 참조 게놈 (302)에 대해서 서열을 매핑하는 리드 정렬 유닛 (301)으로 입력된다. 다음에, 정렬된 게놈 서열(303)은 조립 장치 (304)에 의해 이용되어 하나 이상의 컨티그 (305)를 빌딩한다. 컨티그의 제작은 각 컨티그의 빌딩에 이용된 서열 리드의 수 또는 컨티그 길이와 같은 코딩 파라미터 (313)에 의해 구성될 수 있다. 그런 다음에, 제작된 컨티그 (305)는 정렬된 게놈 서열 (303)상에서 참조 기반 압축의 수행에 이용된다. 참조 기반 압축기 (306)는 매핑된 게놈 서열과 매핑되지 않은 게놈 서열 모두를 표현하는 디스크립터로 명명된 신택스 엘리먼트를 생성한다. 정렬에 이용된 참조 게놈(302) 및 제작된 컨티그 (305)는 참조 게놈(302)과 컨티그(305) 사이의 미스매치의 위치 및 유형을 표현하는 디스크립터를 생성하는 참조 게놈 차등 코딩 장치 (307)로 입력된다. 참조 기반 압축기 (306) 및 참조 게놈 차등 코더 (307)에 의해 생성된 게놈 디스크립터 (308)는 몇몇 이진화 유닛들(312)에 의해 먼저 이진화된 다음에, 몇몇 엔트로피 코더들(309)에 의해 엔트로피 코딩된다. 그런 다음에, 엔트로피 코딩된 게놈 디스크립터들은 다중화 장치(310)로 입력되어, 압축된 비트 스트림 (311)을 구성하는 하나 이상의 액세스 유닛을 빌딩한다. 다중화된 비트 스트림은 코딩 파라미터 인코더 (314)에 의해 빌딩된 코딩 파라미터 구조체들 (313)을 또한 포함한다. 각각의 액세스 유닛은 본 개시에 정의된 데이터의 한 클래스에 속하는 서열 리드와 정렬 정보를 표현하는 엔트로피 코딩된 디스크립터를 포함한다.
디코딩 장치
도 4는 본 개시의 원리에 따른 디코딩 장치를 나타낸다. 역다중화 유닛(401)은 네트워크 또는 저장 소자(storage element)로부터 다중화된 비트 스트림 (400)을 수신하고, 상기 비트 스트림을 구성하는 액세스 유닛의 엔트로피 코딩된 페이로드 (entropy coded payload)를 추출한다. 엔트로피 디코더들 (402)은 추출된 페이로드들을 수신하고, 상이한 유형의 게놈 디스크립터들을 이들의 이진 표현(binary representation)으로 디코딩한다. 그런 다음에, 상기 이진 표현은 게놈 디스크립터(403) 및 게놈 디스크립터(409)를 생성하는 몇몇 이진 디코더들(410)로 입력된다. 코딩 파라미터 디코더 (411)는 게놈 정보와 함께 다중화된 코딩 파라미터를 수신하고, 이들을 서열 리드 디코딩을 위한 컨티그의 제작을 담당하는 유닛 (404)에 입력한다. 게놈 서열 리드(409)를 표현하는 게놈 디스크립터는 디코딩 프로세스의 일환으로서 하나 이상의 컨티그 (405)를 빌딩하고, 정렬된 게놈 서열(407)을 복원하는 서열 리드 복원 유닛 (404)에 입력된다. 그런 다음에, 컨티그 (405), 및 정렬에 이용된 참조 게놈과 컨티그 사이의 차이점을 표현하는 엔트로피 디코딩된 디스크립터 (403)는 정렬에 이용된 참조 게놈 (408)을 복원하는 참조 게놈 본원 유닛(406)에 입력된다.
본원에 개시된 본 발명의 기법은 하드웨어, 소프트웨어, 펌웨어 또는 이들의 임의의 조합에서 시행될 수 있다. 소프트웨어에서 시행되는 경우에, 이들은 컴퓨터 매체에 저장될 수 있고, 하드웨어 프로세싱 유닛에 의해 실행될 수 있다. 하드웨어 프로세싱 유닛은 하나 이상의 프로세서, 디지털 시그널 프로세서, 범용 마이크로 프로세서(general purpose microprocessor), 주문형 반도체 (application specific integrated circuit) 또는 다른 이산 논리 회로(discrete logic circuitry)를 포함할 수 있다.
본 개시의 기법은 핸드폰, 데스크탑 컴퓨터, 서버, 태블릿 및 비슷한 디바이스를 비롯한, 다양한 디바이스 또는 장치에서 시행될 수 있다.
Claims (30)
- 게놈 서열 데이터를 인코딩하는 방법으로서, 상기 게놈 서열 데이터는 뉴클레오티드 서열의 리드를 포함하고, 상기 방법은 하기 단계를 포함하는 것인, 게놈 서열 데이터를 인코딩하는 방법:
· 상기 리드를 하나 이상의 참조 서열에 대해 정렬시켜, 정렬된 리드를 생성하는 단계;
· 상기 정렬된 리드를 조립하여, 컨티그(contig)를 생성하는 단계;
· 상기 참조 서열과 상기 컨티그를 비교하여, 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 획득하는 단계; 및
· 상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 엔트로피 코딩하는 단계.
- 제1항에 있어서,
상기 정렬된 리드를 조립하는 단계는 참조 서열상의 각 위치에 대해서, 이 위치에서 정렬된 리드 중 가장 빈도가 높게 존재하는 뉴클레오티드를 선택하는 단계를 포함하는 것인, 게놈 서열 데이터를 인코딩하는 방법.
- 제2항에 있어서,
상기 미스매치의 위치 및 미스매치 유형에 관련된 정보는 각각 제1 디스크립터 (203) 및 제2 디스크립터 (204)를 이용하여 표시되는 것인, 게놈 서열 데이터를 인코딩하는 방법.
- 제3항에 있어서,
상기 제1 디스크립터 및 제2 디스크립터는 동일한 액세스 유닛에서 캡슐화되어(encapsulating), 디코딩 디바이스에서 정렬에 이용된 참조 서열의 선택적 복원(selective reconstruction)을 가능하게 하는 것인, 게놈 서열 데이터를 인코딩하는 방법.
- 제4항에 있어서,
상기 컨티그의 길이는 인풋 파라미터로서 인코더에 정의되거나, 또는 인코더에 의해 동적으로 조정되는(dynamically adapted) 것인, 게놈 서열 데이터를 인코딩하는 방법.
- 제5항에 있어서,
상기 제1 디스크립터는 스플릿 유닛-와이즈 절삭형 단항 이진화(Split Unit-wise Truncated Unary binarization)를 이용하여 이진화되고, 상기 스플릿 유닛-와이즈 절삭형 단항은 반복 절삭형 단항 이진화(repeated truncated unary binarization)의 연접(concatenation)이며, 각각의 절삭형 단항 이진화는 길이가 N 비트인, 이진화될 값의 부분에 적용되며, N은 미리 선택된 파라미터인, 게놈 서열 데이터를 인코딩하는 방법.
- 제5항에 있어서,
상기 제2 디스크립터는 절삭형 단항 이진화를 이용하여 이진화되고, 상기 제2 디스크립터의 값 다음에 0이 이어지며, 상기 값이 이진화될 가능한 최댓값과 동일한 경우에, 후행 0-비트(trailing 0-bit)는 버려지는 것인, 게놈 서열 데이터를 인코딩하는 방법.
- 제5항에 있어서,
상기 방법은 특정한 참조 게놈의 사용(usage)을 시그널링하는 정보를 인코딩하지 않는 것인, 게놈 서열 데이터를 인코딩하는 방법.
- 제6항에 있어서,
상기 컨티그의 상기 길이는 신택스 헤더에 포함되는 것인, 게놈 서열 데이터를 인코딩하는 방법.
- 게놈 서열 데이터를 인코딩하는 장치로서, 상기 게놈 서열 데이터는 뉴클레오티드 서열의 리드를 포함하고, 상기 장치는 하기 수단을 포함하는 것인, 게놈 서열 데이터를 인코딩하는 장치:
· 상기 리드를 하나 이상의 참조 서열에 대해 정렬하여, 정렬된 리드를 생성하는 수단;
· 상기 정렬된 리드를 조립하여, 컨티그를 생성하는 수단;
· 상기 참조 서열과 상기 컨티그를 비교하여, 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 획득하는 수단; 및
· 상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 엔트로피 코딩하는 수단.
- 제10항에 있어서,
상기 정렬된 리드를 조립하는 상기 수단은 참조 서열상의 각 위치에 대해서, 이 위치에서 정렬된 리드 중 가장 높은 빈도로 존재하는 뉴클레오티드를 선택하는 수단을 더 포함하는 것인, 게놈 서열 데이터를 인코딩하는 장치.
- 제11항에 있어서,
상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 각각 제1 디스크립터 (203) 및 제2 디스크립터 (204)에 의해 표시되는 수단을 더 포함하는 것인, 게놈 서열 데이터를 인코딩하는 장치.
- 제12항에 있어서,
상기 제1 디스크립터 및 제2 디스크립터를 동일한 액세스 유닛에서 캡슐화하여, 디코딩 디바이스에서 정렬에 이용되는 참조 서열의 선택적 복원을 가능하게 하는 수단을 더 포함하는 것인, 게놈 서열 데이터를 인코딩하는 장치.
- 제13항에 있어서,
상기 컨티그의 길이를 인풋 파라미터로서 수신하는 수단 및 상기 컨티그의 길이를 동적으로 조정하는(dynamically adapting) 수단을 더 포함하는 것인, 게놈 서열 데이터를 인코딩하는 장치.
- 제14항에 있어서,
상기 제1 디스크립터를 스플릿 유닛-와이즈 절삭형 단항 이진화를 이용하여 이진화하는 이진화 수단을 더 포함하나, 상기 스플릿 유닛-와이즈 절삭형 단항은 반복 절삭형 단항 이진화의 연접이고, 각각의 절삭형 단항 이진화는 길이가 N 비트인, 이진화될 값의 부분에 적용되며, N은 미리 선택된 파라미터인, 게놈 서열 데이터를 인코딩하는 장치.
- 제14항에 있어서,
상기 제2 디스크립터를 절삭형 단항 이진화를 이용함으로써 이진화하는 이진화 수단을 더 포함하나, 상기 제2 디스크립터의 값 다음에 0이 이어지고, 상기 값이 이진화될 가능한 최댓값과 동일한 경우에, 후행 0-비트(trailing 0-bit)는 버려지는 것인, 게놈 서열 데이터를 인코딩하는 방법.
- 제16항에 있어서,
상기 컨티그의 상기 길이를 신택스 헤더에서 코딩하는 수단을 더 포함하는 것인, 게놈 서열 데이터를 인코딩하는 장치.
- 하기 단계를 포함하는, 인코딩된 게놈 서열 데이터를 디코딩하는 방법:
인코딩된 인풋 파일을 파싱하여(parsing), 컨티그 서열을 획득하는 단계;
컨티그 내 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 엔트로피 디코딩하는 단계; 및
상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 이용해 컨티그를 변형하여, 압축 전에 정렬에 이용된 참조 게놈을 표현하는 뉴클레오티드의 게놈 서열을 획득하는 단계.
- 제18항에 있어서,
상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 이용해 컨티그를 변형하여, 상기 뉴클레오티드의 게놈 서열을 획득하는 단계는 제1 디스크립터 (203) 및 제2 디스크립터 (204)를 엔트로피 디코딩하는 단계를 더 포함하는 것인, 인코딩된 게놈 서열 데이터를 디코딩하는 방법.
- 제19항에 있어서,
동일한 액세스 유닛으로부터 상기 제1 디스크립터 및 제2 디스크립터를 역캡슐화하여(decapsulating), 상기 뉴클레오티드의 게놈 서열의 선택적 복원을 획득하는 단계를 더 포함하는 것인, 인코딩된 게놈 서열 데이터를 디코딩하는 방법.
- 제20항에 있어서,
상기 컨티그의 길이를 인풋 파일에 포함된 신택스 헤더로부터 디코딩하는 단계를 더 포함하는 것인, 인코딩된 게놈 서열 데이터를 디코딩하는 방법.
- 제19항에 있어서,
상기 제1 디스크립터의 역이진화(reverse binarization)를 더 포함하나, 상기 제1 디스크립터는 스플릿 유닛-와이즈 절삭형 단항 이진화를 이용하여 이진화되고, 상기 스플릿 유닛-와이즈 절삭형 단항은 반복 절삭형 단항 이진화의 연접이며, 각각의 절삭형 단항 이진화는 길이가 N 비트인, 이진화될 값의 부분에 적용되고, N은 미리 선택된 파라미터인, 인코딩된 게놈 서열 데이터를 디코딩하는 방법.
- 제19항에 있어서,
상기 제2 디스크립터의 역이진화를 더 포함하되, 상기 제2 디스크립터는 절삭형 단항 이진화를 이용하여 이진화되고, 상기 제2 디스크립터의 값 다음에 0이 이어지며, 상기 값이 이진화될 가능한 최댓값과 동일한 경우에, 후행 0-비트는 버려지는 것인, 인코딩된 게놈 서열 데이터를 디코딩하는 방법.
- 제19항에 있어서,
상기 인풋 파일은 특정한 참조 게놈의 사용을 시그널링하는 정보를 포함하지 않는 것인, 인코딩된 게놈 서열 데이터를 디코딩하는 방법.
- 하기 수단을 포함하는, 인코딩된 게놈 서열 데이터를 디코딩하는 장치:
인코딩된 인풋 데이터를 파싱하여, 컨티그 서열을 획득하는 수단;
컨티그 내 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 엔트로피 디코딩하는 수단; 및
상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 이용해 컨티그를 변형하여, 압축 전에 정렬에 이용된 참조 게놈을 표현하는 뉴클레오티드의 게놈 서열을 획득하는 수단.
- 제25항에 있어서,
컨티그 내 상기 미스매치의 위치 및 미스매치의 유형에 관련된 정보를 이용해 컨티그를 변형하여, 뉴클레오티드의 게놈 서열을 획득하는 상기 수단은 제1 디스크립터 (203) 및 제2 디스크립터 (204)를 엔트로피 디코딩하는 수단을 더 포함하는 것인, 인코딩된 게놈 서열 데이터를 디코딩하는 장치.
- 제26항에 있어서,
동일한 액세스 유닛으로부터 상기 제1 디스크립터 및 제2 디스크립터를 역캡슐화함으로써(decapsulating), 뉴클레오티드의 게놈 서열을 선택적으로 복원하는 수단을 더 포함하는 것인, 인코딩된 게놈 서열 데이터를 디코딩하는 장치.
- 제27항에 있어서,
인풋 파일에 포함된 신택스 헤더로부터 상기 컨티그의 길에에 관한 정보를 디코딩하는 수단을 더 포함하는 것인, 인코딩된 게놈 서열 데이터를 디코딩하는 장치.
- 제26항에 있어서,
상기 제1 디스크립터를 역이진화하는 수단을 더 포함하되, 상기 제1 디스크립터는 스플릿 유닛-와이즈 절삭형 단항 이진화를 이용하여 이진화되고, 상기 스플릿 유닛-와이즈 절삭형 단항은 반복 절삭형 단항 이진화의 연접이며, 각각의 절삭형 단항 이진화는 길이가 N 비트인 이진화될 값의 부분에 적용되고, N은 미리 선택된 파라미터인, 인코딩된 게놈 서열 데이터를 디코딩하는 장치.
- 제26항에 있어서,
상기 제2 디스크립터를 역이진화하는 수단을 더 포함하되, 상기 제2 디스크립터는 절삭형 단항 이진화를 이용하여 이진화되고, 상기 제2 디스크립터의 값 다음에 0이 이어지며, 상기 값이 이진화될 가능한 최댓값과 동일한 경우에, 후행 0-비트는 버려지는 것인, 인코딩된 게놈 서열 데이터를 디코딩하는 장치.
Applications Claiming Priority (9)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/EP2016/074307 WO2018068829A1 (en) | 2016-10-11 | 2016-10-11 | Method and apparatus for compact representation of bioinformatics data |
| PCT/EP2016/074301 WO2018068828A1 (en) | 2016-10-11 | 2016-10-11 | Method and system for storing and accessing bioinformatics data |
| PCT/EP2016/074297 WO2018068827A1 (en) | 2016-10-11 | 2016-10-11 | Efficient data structures for bioinformatics information representation |
| PCT/EP2016/074311 WO2018068830A1 (en) | 2016-10-11 | 2016-10-11 | Method and system for the transmission of bioinformatics data |
| USPCT/US2017/017842 | 2017-02-14 | ||
| PCT/US2017/017842 WO2018071055A1 (en) | 2016-10-11 | 2017-02-14 | Method and apparatus for the compact representation of bioinformatics data |
| PCT/US2017/041579 WO2018071078A1 (en) | 2016-10-11 | 2017-07-11 | Method and apparatus for the access to bioinformatics data structured in access units |
| USPCT/US2017/041579 | 2017-07-11 | ||
| PCT/US2017/066458 WO2018151786A1 (en) | 2016-10-11 | 2017-12-14 | Method and systems for the reconstruction of genomic reference sequences from compressed genomic sequence reads |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20190117652A true KR20190117652A (ko) | 2019-10-16 |
Family
ID=61905752
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020197013567A KR20190073426A (ko) | 2016-10-11 | 2017-02-14 | 저장 또는 전송된 생물정보학 데이터의 선택적 액세스를 위한 방법 및 시스템 |
| KR1020197013418A KR20190062541A (ko) | 2016-10-11 | 2017-07-11 | 참조 서열을 사용한 생물정보학 데이터의 표현 및 처리를 위한 방법 및 시스템 |
| KR1020197013419A KR20190069469A (ko) | 2016-10-11 | 2017-07-11 | 생물정보학 데이터의 인덱싱을 위한 방법 및 시스템 |
| KR1020197026863A KR20190117652A (ko) | 2016-10-11 | 2017-12-14 | 압축된 게놈 서열 리드로부터 게놈 참조 서열의 복원 방법 및 시스템 |
Family Applications Before (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020197013567A KR20190073426A (ko) | 2016-10-11 | 2017-02-14 | 저장 또는 전송된 생물정보학 데이터의 선택적 액세스를 위한 방법 및 시스템 |
| KR1020197013418A KR20190062541A (ko) | 2016-10-11 | 2017-07-11 | 참조 서열을 사용한 생물정보학 데이터의 표현 및 처리를 위한 방법 및 시스템 |
| KR1020197013419A KR20190069469A (ko) | 2016-10-11 | 2017-07-11 | 생물정보학 데이터의 인덱싱을 위한 방법 및 시스템 |
Country Status (17)
| Country | Link |
|---|---|
| US (6) | US20200042735A1 (ko) |
| EP (3) | EP3526694A4 (ko) |
| JP (4) | JP2020505702A (ko) |
| KR (4) | KR20190073426A (ko) |
| CN (6) | CN110168651A (ko) |
| AU (3) | AU2017342688A1 (ko) |
| BR (7) | BR112019007359A2 (ko) |
| CA (3) | CA3040138A1 (ko) |
| CL (6) | CL2019000972A1 (ko) |
| CO (6) | CO2019003639A2 (ko) |
| EA (2) | EA201990916A1 (ko) |
| IL (3) | IL265879B2 (ko) |
| MX (2) | MX2019004130A (ko) |
| PE (7) | PE20191058A1 (ko) |
| PH (6) | PH12019550059A1 (ko) |
| SG (3) | SG11201903270RA (ko) |
| WO (4) | WO2018071054A1 (ko) |
Families Citing this family (27)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB2526598B (en) | 2014-05-29 | 2018-11-28 | Imagination Tech Ltd | Allocation of primitives to primitive blocks |
| US11574287B2 (en) | 2017-10-10 | 2023-02-07 | Text IQ, Inc. | Automatic document classification |
| US11030324B2 (en) * | 2017-11-30 | 2021-06-08 | Koninklijke Philips N.V. | Proactive resistance to re-identification of genomic data |
| WO2019191083A1 (en) * | 2018-03-26 | 2019-10-03 | Colorado State University Research Foundation | Apparatuses, systems and methods for generating and tracking molecular digital signatures to ensure authenticity and integrity of synthetic dna molecules |
| BR112020024028A2 (pt) * | 2018-05-31 | 2021-02-23 | Koninklijke Philips N.V. | método e sistema para gerar um genoma de referência baseado em grafo anotado e genoma de referência baseado em grafo anotado |
| CN108753765B (zh) * | 2018-06-08 | 2020-12-08 | 中国科学院遗传与发育生物学研究所 | 一种构建超长连续dna序列的基因组组装方法 |
| US20200058379A1 (en) * | 2018-08-20 | 2020-02-20 | The Board Of Trustees Of The Leland Stanford Junior University | Systems and Methods for Compressing Genetic Sequencing Data and Uses Thereof |
| GB2585816A (en) * | 2018-12-12 | 2021-01-27 | Univ York | Proof-of-work for blockchain applications |
| US20210074381A1 (en) * | 2019-09-11 | 2021-03-11 | Enancio | Method for the compression of genome sequence data |
| CN110797087B (zh) * | 2019-10-17 | 2020-11-03 | 南京医基云医疗数据研究院有限公司 | 测序序列处理方法及装置、存储介质、电子设备 |
| EP4046279A1 (en) * | 2019-10-18 | 2022-08-24 | Koninklijke Philips N.V. | System and method for effective compression, representation and decompression of diverse tabulated data |
| CN111243663B (zh) * | 2020-02-26 | 2022-06-07 | 西安交通大学 | 一种基于模式增长算法的基因变异检测方法 |
| CN111370070B (zh) * | 2020-02-27 | 2023-10-27 | 中国科学院计算技术研究所 | 一种针对大数据基因测序文件的压缩处理方法 |
| US20210295949A1 (en) * | 2020-03-17 | 2021-09-23 | Western Digital Technologies, Inc. | Devices and methods for locating a sample read in a reference genome |
| US11837330B2 (en) | 2020-03-18 | 2023-12-05 | Western Digital Technologies, Inc. | Reference-guided genome sequencing |
| EP3896698A1 (en) * | 2020-04-15 | 2021-10-20 | Genomsys SA | Method and system for the efficient data compression in mpeg-g |
| CN111459208A (zh) * | 2020-04-17 | 2020-07-28 | 南京铁道职业技术学院 | 针对地铁供电系统电能的操纵系统及其方法 |
| WO2022056293A1 (en) * | 2020-09-14 | 2022-03-17 | Illumina Software, Inc. | Custom data files for personalized medicine |
| CN112836355B (zh) * | 2021-01-14 | 2023-04-18 | 西安科技大学 | 一种预测采煤工作面顶板来压概率的方法 |
| ES2930699A1 (es) * | 2021-06-10 | 2022-12-20 | Veritas Intercontinental S L | Metodo de analisis genomico en una plataforma bioinformatica |
| CN113670643B (zh) * | 2021-08-30 | 2023-05-12 | 四川虹美智能科技有限公司 | 智能空调测试方法及系统 |
| CN113643761B (zh) * | 2021-10-13 | 2022-01-18 | 苏州赛美科基因科技有限公司 | 一种用于解读二代测序结果所需数据的提取方法 |
| US20230187020A1 (en) * | 2021-12-15 | 2023-06-15 | Illumina Software, Inc. | Systems and methods for iterative and scalable population-scale variant analysis |
| CN115391284B (zh) * | 2022-10-31 | 2023-02-03 | 四川大学华西医院 | 基因数据文件快速识别方法、系统和计算机可读存储介质 |
| CN116541348B (zh) * | 2023-03-22 | 2023-09-26 | 河北热点科技股份有限公司 | 数据智能存储方法及终端查询一体机 |
| CN116739646B (zh) * | 2023-08-15 | 2023-11-24 | 南京易联阳光信息技术股份有限公司 | 网络交易大数据分析方法及分析系统 |
| CN117153270B (zh) * | 2023-10-30 | 2024-02-02 | 吉林华瑞基因科技有限公司 | 一种基因二代测序数据处理方法 |
Family Cites Families (54)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6303297B1 (en) * | 1992-07-17 | 2001-10-16 | Incyte Pharmaceuticals, Inc. | Database for storage and analysis of full-length sequences |
| JP3429674B2 (ja) | 1998-04-28 | 2003-07-22 | 沖電気工業株式会社 | 多重通信システム |
| EP1410301A4 (en) * | 2000-04-12 | 2008-01-23 | Cleveland Clinic Foundation | SYSTEM FOR IDENTIFYING AND ANALYZING GENE EXPRESSION CONTAINING ELEMENTS RICH IN ADENYLATE URIDYLATE (ARE) |
| FR2820563B1 (fr) * | 2001-02-02 | 2003-05-16 | Expway | Procede de compression/decompression d'un document structure |
| US20040153255A1 (en) * | 2003-02-03 | 2004-08-05 | Ahn Tae-Jin | Apparatus and method for encoding DNA sequence, and computer readable medium |
| DE10320711A1 (de) * | 2003-05-08 | 2004-12-16 | Siemens Ag | Verfahren und Anordnung zur Einrichtung und Aktualisierung einer Benutzeroberfläche zum Zugriff auf Informationsseiten in einem Datennetz |
| US8280640B2 (en) | 2003-08-11 | 2012-10-02 | Eloret Corporation | System and method for pattern recognition in sequential data |
| WO2005094363A2 (en) * | 2004-03-30 | 2005-10-13 | New York University | System, method and software arrangement for bi-allele haplotype phasing |
| US8340914B2 (en) * | 2004-11-08 | 2012-12-25 | Gatewood Joe M | Methods and systems for compressing and comparing genomic data |
| US20130332133A1 (en) * | 2006-05-11 | 2013-12-12 | Ramot At Tel Aviv University Ltd. | Classification of Protein Sequences and Uses of Classified Proteins |
| SE531398C2 (sv) | 2007-02-16 | 2009-03-24 | Scalado Ab | Generering av en dataström och identifiering av positioner inuti en dataström |
| KR101369745B1 (ko) * | 2007-04-11 | 2014-03-07 | 삼성전자주식회사 | 비동기화된 비트스트림들의 다중화 및 역다중화 방법 및장치 |
| US8832112B2 (en) * | 2008-06-17 | 2014-09-09 | International Business Machines Corporation | Encoded matrix index |
| WO2010056131A1 (en) * | 2008-11-14 | 2010-05-20 | Real Time Genomics, Inc. | A method and system for analysing data sequences |
| US20100217532A1 (en) * | 2009-02-25 | 2010-08-26 | University Of Delaware | Systems and methods for identifying structurally or functionally significant amino acid sequences |
| AU2010313247A1 (en) * | 2009-10-30 | 2012-05-24 | Synthetic Genomics, Inc. | Encoding text into nucleic acid sequences |
| EP2362657B1 (en) * | 2010-02-18 | 2013-04-24 | Research In Motion Limited | Parallel entropy coding and decoding methods and devices |
| US20140228223A1 (en) * | 2010-05-10 | 2014-08-14 | Andreas Gnirke | High throughput paired-end sequencing of large-insert clone libraries |
| KR101952965B1 (ko) * | 2010-05-25 | 2019-02-27 | 더 리젠츠 오브 더 유니버시티 오브 캘리포니아 | Bambam:고처리율 서열분석 데이터의 병렬 비교 분석 |
| EP2666115A1 (en) * | 2011-01-19 | 2013-11-27 | Koninklijke Philips N.V. | Method for processing genomic data |
| WO2012122546A2 (en) * | 2011-03-09 | 2012-09-13 | Lawrence Ganeshalingam | Biological data networks and methods therefor |
| JP6027608B2 (ja) * | 2011-06-06 | 2016-11-16 | コーニンクレッカ フィリップス エヌ ヴェKoninklijke Philips N.V. | 核酸配列データのアセンブリに関する方法 |
| RS64604B1 (sr) * | 2011-06-16 | 2023-10-31 | Ge Video Compression Llc | Entropijsko kodiranje razlika vektora kretanja |
| US8707289B2 (en) * | 2011-07-20 | 2014-04-22 | Google Inc. | Multiple application versions |
| WO2013050612A1 (en) * | 2011-10-06 | 2013-04-11 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Entropy coding buffer arrangement |
| WO2013070634A1 (en) * | 2011-11-07 | 2013-05-16 | Ingenuity Systems, Inc. | Methods and systems for identification of causal genomic variants |
| KR101922129B1 (ko) * | 2011-12-05 | 2018-11-26 | 삼성전자주식회사 | 차세대 시퀀싱을 이용하여 획득된 유전 정보를 압축 및 압축해제하는 방법 및 장치 |
| CA2858686C (en) * | 2011-12-08 | 2018-10-02 | Five3 Genomics, Llc | Distributed system providing dynamic indexing and visualization of genomic data |
| EP2608096B1 (en) * | 2011-12-24 | 2020-08-05 | Tata Consultancy Services Ltd. | Compression of genomic data file |
| US9600625B2 (en) * | 2012-04-23 | 2017-03-21 | Bina Technologies, Inc. | Systems and methods for processing nucleic acid sequence data |
| CN103049680B (zh) * | 2012-12-29 | 2016-09-07 | 深圳先进技术研究院 | 基因测序数据读取方法及系统 |
| US9679104B2 (en) * | 2013-01-17 | 2017-06-13 | Edico Genome, Corp. | Bioinformatics systems, apparatuses, and methods executed on an integrated circuit processing platform |
| WO2014145503A2 (en) * | 2013-03-15 | 2014-09-18 | Lieber Institute For Brain Development | Sequence alignment using divide and conquer maximum oligonucleotide mapping (dcmom), apparatus, system and method related thereto |
| JP6054790B2 (ja) | 2013-03-28 | 2016-12-27 | 三菱スペース・ソフトウエア株式会社 | 遺伝子情報記憶装置、遺伝子情報検索装置、遺伝子情報記憶プログラム、遺伝子情報検索プログラム、遺伝子情報記憶方法、遺伝子情報検索方法及び遺伝子情報検索システム |
| GB2512829B (en) * | 2013-04-05 | 2015-05-27 | Canon Kk | Method and apparatus for encoding or decoding an image with inter layer motion information prediction according to motion information compression scheme |
| WO2014186604A1 (en) | 2013-05-15 | 2014-11-20 | Edico Genome Corp. | Bioinformatics systems, apparatuses, and methods executed on an integrated circuit processing platform |
| KR101522087B1 (ko) * | 2013-06-19 | 2015-05-28 | 삼성에스디에스 주식회사 | 미스매치를 고려한 염기 서열 정렬 시스템 및 방법 |
| CN103336916B (zh) * | 2013-07-05 | 2016-04-06 | 中国科学院数学与系统科学研究院 | 一种测序序列映射方法及系统 |
| US20150032711A1 (en) * | 2013-07-06 | 2015-01-29 | Victor Kunin | Methods for identification of organisms, assigning reads to organisms, and identification of genes in metagenomic sequences |
| KR101493982B1 (ko) * | 2013-09-26 | 2015-02-23 | 대한민국 | 품종인식 코드화 시스템 및 이를 이용한 코드화 방법 |
| CN104699998A (zh) * | 2013-12-06 | 2015-06-10 | 国际商业机器公司 | 用于对基因组进行压缩和解压缩的方法和装置 |
| US10902937B2 (en) * | 2014-02-12 | 2021-01-26 | International Business Machines Corporation | Lossless compression of DNA sequences |
| US9916313B2 (en) * | 2014-02-14 | 2018-03-13 | Sap Se | Mapping of extensible datasets to relational database schemas |
| US9886561B2 (en) * | 2014-02-19 | 2018-02-06 | The Regents Of The University Of California | Efficient encoding and storage and retrieval of genomic data |
| US9354922B2 (en) * | 2014-04-02 | 2016-05-31 | International Business Machines Corporation | Metadata-driven workflows and integration with genomic data processing systems and techniques |
| US20150379195A1 (en) * | 2014-06-25 | 2015-12-31 | The Board Of Trustees Of The Leland Stanford Junior University | Software haplotying of hla loci |
| GB2527588B (en) | 2014-06-27 | 2016-05-18 | Gurulogic Microsystems Oy | Encoder and decoder |
| US20160019339A1 (en) * | 2014-07-06 | 2016-01-21 | Mercator BioLogic Incorporated | Bioinformatics tools, systems and methods for sequence assembly |
| US10230390B2 (en) * | 2014-08-29 | 2019-03-12 | Bonnie Berger Leighton | Compressively-accelerated read mapping framework for next-generation sequencing |
| US10116632B2 (en) * | 2014-09-12 | 2018-10-30 | New York University | System, method and computer-accessible medium for secure and compressed transmission of genomic data |
| US20160125130A1 (en) * | 2014-11-05 | 2016-05-05 | Agilent Technologies, Inc. | Method for assigning target-enriched sequence reads to a genomic location |
| US20180181706A1 (en) * | 2015-06-16 | 2018-06-28 | Gottfried Wilhelm Leibniz Universitaet Hannover | Method for Compressing Genomic Data |
| CN105956417A (zh) * | 2016-05-04 | 2016-09-21 | 西安电子科技大学 | 云环境下基于编辑距离的相似碱基序列查询方法 |
| CN105975811B (zh) * | 2016-05-09 | 2019-03-15 | 管仁初 | 一种智能比对的基因序列分析装置 |
-
2017
- 2017-02-14 AU AU2017342688A patent/AU2017342688A1/en not_active Abandoned
- 2017-02-14 PE PE2019000804A patent/PE20191058A1/es unknown
- 2017-02-14 MX MX2019004130A patent/MX2019004130A/es unknown
- 2017-02-14 KR KR1020197013567A patent/KR20190073426A/ko unknown
- 2017-02-14 BR BR112019007359A patent/BR112019007359A2/pt not_active IP Right Cessation
- 2017-02-14 CN CN201780062919.5A patent/CN110168651A/zh active Pending
- 2017-02-14 WO PCT/US2017/017841 patent/WO2018071054A1/en active Search and Examination
- 2017-02-14 WO PCT/US2017/017842 patent/WO2018071055A1/en active Application Filing
- 2017-02-14 SG SG11201903270RA patent/SG11201903270RA/en unknown
- 2017-02-14 US US16/341,426 patent/US20200042735A1/en not_active Abandoned
- 2017-02-14 CA CA3040138A patent/CA3040138A1/en not_active Abandoned
- 2017-02-14 JP JP2019540510A patent/JP2020505702A/ja not_active Withdrawn
- 2017-02-14 EP EP17859972.6A patent/EP3526694A4/en not_active Withdrawn
- 2017-07-11 CN CN201780063013.5A patent/CN110506272B/zh active Active
- 2017-07-11 CA CA3040147A patent/CA3040147A1/en not_active Abandoned
- 2017-07-11 AU AU2017341684A patent/AU2017341684A1/en not_active Abandoned
- 2017-07-11 BR BR112019007360A patent/BR112019007360A2/pt not_active Application Discontinuation
- 2017-07-11 PE PE2019000803A patent/PE20191057A1/es unknown
- 2017-07-11 WO PCT/US2017/041585 patent/WO2018071079A1/en active Search and Examination
- 2017-07-11 US US16/337,642 patent/US11404143B2/en active Active
- 2017-07-11 PE PE2019000805A patent/PE20191227A1/es unknown
- 2017-07-11 EA EA201990916A patent/EA201990916A1/ru unknown
- 2017-07-11 KR KR1020197013418A patent/KR20190062541A/ko active Search and Examination
- 2017-07-11 SG SG11201903272XA patent/SG11201903272XA/en unknown
- 2017-07-11 WO PCT/US2017/041591 patent/WO2018071080A2/en unknown
- 2017-07-11 SG SG11201903271UA patent/SG11201903271UA/en unknown
- 2017-07-11 EA EA201990917A patent/EA201990917A1/ru unknown
- 2017-07-11 MX MX2019004128A patent/MX2019004128A/es unknown
- 2017-07-11 KR KR1020197013419A patent/KR20190069469A/ko not_active Application Discontinuation
- 2017-07-11 PE PE2019000802A patent/PE20191056A1/es unknown
- 2017-07-11 EP EP17860868.3A patent/EP3526707A4/en not_active Withdrawn
- 2017-07-11 IL IL265879A patent/IL265879B2/en unknown
- 2017-07-11 JP JP2019540512A patent/JP2019537172A/ja not_active Withdrawn
- 2017-07-11 EP EP17860980.6A patent/EP3526657A4/en active Pending
- 2017-07-11 BR BR112019007363A patent/BR112019007363A2/pt not_active Application Discontinuation
- 2017-07-11 JP JP2019540513A patent/JP2020500383A/ja not_active Withdrawn
- 2017-07-11 AU AU2017341685A patent/AU2017341685A1/en not_active Abandoned
- 2017-07-11 CN CN201780063014.XA patent/CN110121577B/zh active Active
- 2017-07-11 BR BR112019007357A patent/BR112019007357A2/pt not_active Application Discontinuation
- 2017-07-11 US US16/337,639 patent/US20190214111A1/en not_active Abandoned
- 2017-07-11 CA CA3040145A patent/CA3040145A1/en not_active Abandoned
- 2017-07-11 CN CN201780062885.XA patent/CN110114830B/zh active Active
- 2017-07-11 JP JP2019540511A patent/JP7079786B2/ja active Active
- 2017-12-14 KR KR1020197026863A patent/KR20190117652A/ko not_active Application Discontinuation
- 2017-12-14 US US16/485,623 patent/US20190385702A1/en active Pending
- 2017-12-14 CN CN201780086529.1A patent/CN110603595B/zh active Active
- 2017-12-14 PE PE2019001667A patent/PE20200323A1/es unknown
- 2017-12-14 BR BR112019016230A patent/BR112019016230A2/pt not_active Application Discontinuation
- 2017-12-15 PE PE2019001669A patent/PE20200226A1/es unknown
- 2017-12-15 BR BR112019016232A patent/BR112019016232A2/pt not_active Application Discontinuation
- 2017-12-15 CN CN201780086770.4A patent/CN110678929B/zh active Active
- 2017-12-15 US US16/485,649 patent/US20200051667A1/en active Pending
-
2018
- 2018-02-14 US US16/485,670 patent/US20200051665A1/en active Pending
- 2018-02-14 PE PE2019001668A patent/PE20200227A1/es unknown
- 2018-02-14 BR BR112019016236A patent/BR112019016236A2/pt unknown
-
2019
- 2019-04-08 IL IL265928A patent/IL265928B/en active IP Right Grant
- 2019-04-10 CL CL2019000972A patent/CL2019000972A1/es unknown
- 2019-04-10 CL CL2019000973A patent/CL2019000973A1/es unknown
- 2019-04-10 CL CL2019000968A patent/CL2019000968A1/es unknown
- 2019-04-11 PH PH12019550059A patent/PH12019550059A1/en unknown
- 2019-04-11 CO CONC2019/0003639A patent/CO2019003639A2/es unknown
- 2019-04-11 PH PH12019550060A patent/PH12019550060A1/en unknown
- 2019-04-11 CO CONC2019/0003595A patent/CO2019003595A2/es unknown
- 2019-04-11 CO CONC2019/0003638A patent/CO2019003638A2/es unknown
- 2019-04-11 PH PH12019550057A patent/PH12019550057A1/en unknown
- 2019-04-11 IL IL265972A patent/IL265972A/en unknown
- 2019-04-11 PH PH12019550058A patent/PH12019550058A1/en unknown
- 2019-04-15 CO CONC2019/0003842A patent/CO2019003842A2/es unknown
- 2019-08-12 CL CL2019002277A patent/CL2019002277A1/es unknown
- 2019-08-12 CL CL2019002275A patent/CL2019002275A1/es unknown
- 2019-08-12 CL CL2019002276A patent/CL2019002276A1/es unknown
- 2019-08-13 PH PH12019501879A patent/PH12019501879A1/en unknown
- 2019-08-13 PH PH12019501881A patent/PH12019501881A1/en unknown
- 2019-09-12 CO CONC2019/0009920A patent/CO2019009920A2/es unknown
- 2019-09-12 CO CONC2019/0009922A patent/CO2019009922A2/es unknown
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20190117652A (ko) | 압축된 게놈 서열 리드로부터 게놈 참조 서열의 복원 방법 및 시스템 | |
| KR101969848B1 (ko) | 유전자 데이터를 압축하는 방법 및 장치 | |
| EP3583249B1 (en) | Method and systems for the reconstruction of genomic reference sequences from compressed genomic sequence reads | |
| CA3039688C (en) | Efficient data structures for bioinformatics information representation | |
| CN110168652B (zh) | 用于存储和访问生物信息学数据的方法和系统 | |
| JP2020509474A (ja) | 圧縮されたゲノムシーケンスリードからゲノムリファレンスシーケンスを再構築するための方法とシステム | |
| KR20190113971A (ko) | 다중 게놈 디스크립터를 이용한 생명정보학 데이터의 압축 표현 방법 및 장치 | |
| KR20190071741A (ko) | 생물 정보학 데이터의 간략 표현 방법 및 장치 | |
| CA3052772A1 (en) | Method and systems for the reconstruction of genomic reference sequences from compressed genomic sequence reads | |
| JP7324145B2 (ja) | ゲノムシーケンスリードの効率的圧縮のための方法及びシステム | |
| WO2018071078A1 (en) | Method and apparatus for the access to bioinformatics data structured in access units | |
| CN110663022B (zh) | 使用基因组描述符紧凑表示生物信息学数据的方法和设备 | |
| NZ757185B2 (en) | Method and apparatus for the compact representation of bioinformatics data using multiple genomic descriptors | |
| EA043338B1 (ru) | Способ и устройство для компактного представления биоинформационных данных с помощью нескольких геномных дескрипторов |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| WITB | Written withdrawal of application |