KR20150088869A - 활성화 단백질 C(aPC)에 대한 모노클로날 항체 - Google Patents
활성화 단백질 C(aPC)에 대한 모노클로날 항체 Download PDFInfo
- Publication number
- KR20150088869A KR20150088869A KR1020157017008A KR20157017008A KR20150088869A KR 20150088869 A KR20150088869 A KR 20150088869A KR 1020157017008 A KR1020157017008 A KR 1020157017008A KR 20157017008 A KR20157017008 A KR 20157017008A KR 20150088869 A KR20150088869 A KR 20150088869A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- gly
- amino acid
- seq
- acid sequence
- Prior art date
Links
Images



















Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/40—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against enzymes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/3955—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against proteinaceous materials, e.g. enzymes, hormones, lymphokines
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P7/00—Drugs for disorders of the blood or the extracellular fluid
- A61P7/04—Antihaemorrhagics; Procoagulants; Haemostatic agents; Antifibrinolytic agents
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y304/00—Hydrolases acting on peptide bonds, i.e. peptidases (3.4)
- C12Y304/21—Serine endopeptidases (3.4.21)
- C12Y304/21069—Protein C activated (3.4.21.69)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2299/00—Coordinates from 3D structures of peptides, e.g. proteins or enzymes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Immunology (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Genetics & Genomics (AREA)
- Epidemiology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Microbiology (AREA)
- Mycology (AREA)
- Endocrinology (AREA)
- Diabetes (AREA)
- Hematology (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- General Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Investigating Or Analysing Biological Materials (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
본 발명은 자이모겐 단백질 C (PC)와 최소한 결합하는 인간 활성화 단백질 C (aPC)에 대한, 항체, 항원 결합 항체 단편(Fab), 및 다른 단백질 스캐폴드를 제공한다. 또한, 이러한 aPC 결합 단백질은 aPC의 항응고 활성을 잠재적으로 차단하여 응고를 유도할 수 있다. 이러한 바인더의 치료적 용도는 특이적 항체를 패닝(panning) 및 스크리닝하는 방법으로, 본 명세서에 기술하였다.
Description
본 원은 2012년 11월 29일자로 출원된 미국 가특허출원 제61/731,294호와 2013년 3월 15일자로 출원된 미국 가특허출원 제61/786,472호에 대해 우선권을 주장하며, 이 출원들의 내용은 본 원에 그 전체가 참조로 포함되었다.
서열 목록 제출
본 출원과 관련한 서열 목록이 EFS-Web을 통해 전자 포맷으로 제출되었고, 본 명세서에 그 전문이 참조로 포함되었다.
구체예의 분야
인간 단백질 C의 활성 형태(aPC)에 우선적으로 결합하는 단리된 모노클로날 항체 및 그의 단편이 제공된다.
인간 단백질 C (PC) 자이모겐(zymogen)은 간에서 461-아미노산 잔기 전구체로서 합성되어 혈액 내로 분비된다(서열번호: 1에 기재). 분비 전에 단일사슬 폴리펩티드 전구체는 디펩티드(Lys156-Arg157)와 42-aa 잔기 프리프로리더 (prepro-leader)를 제거하여 헤테로다이머로 전환된다. 헤테로다이머 형태(417 잔기)는 디설파이드 결합으로 연결된 경쇄(155aa, 21 kDa)와 중쇄(262aa, 41 kDa)로 구성되어 있다(서열번호: 2에 기재). PC 자이모겐은 트롬빈 절단부위를 함유하여, "활성화 펩티드"의 제거 및 서열번호: 3에 나타낸 활성화된 PC (aPC) 형태 (405 잔기)로 PC의 활성화를 유도한다. 도 1에 인간 PC와 그의 활성형태, aPC의 카툰식 그림을 제공하였다. 인간 PC는 9 Gla-잔기와 N-결합 글리코실화를 위한 4개의 잠재적 부위를 함유한다. 경쇄는 Gla 도메인과 2 EGF형 도메인을 함유한다. 중쇄는 활성 세린 프로테아제 도메인을 갖는다.
PC는 일반적으로 건강한 인간 혈액에서 3-5ug/ml (~65 nM)로 순환하며 그의 반감기는 6-8시간이다. 순환하는 PC 자이모겐의 지배적 형태는 헤테로다이머 형태이다. PC의 경쇄는 하나의 감마-카복시 글루탐산(Gla)이 많은 도메인(45aa), 2개의 EGF형 도메인 (46aa) 및 링커(linker) 서열을 함유한다. PC의 중쇄는 12-aa 고도 극성 "활성화 펩티드"와 전형적인 세린 프로테아제 촉매 트리아드(triad)를 갖는 촉매 도메인을 갖고 있다.
인간 PC는 광범위한 번역후 변성, 예를 들어 글리코실화, 비타민 K 의존성 감마 카복실화 및 감마 하이드록실화를 수행한다(1-2). 이것은 23%의 탄수화물(중량 기준) 및 4개의 잠재적 N-결합 글리코실화 부위(경쇄 중 1개 Asn97과 중쇄 중 3개 Asn248/313/329)를 함유한다. 그의 Gla 도메인은 9 Gla 잔기를 함유하고 음으로 하전된 인지질 막에 PC의 칼슘 의존성 결합을 담당한다. Gla 도메인은 또한 내피 단백질 C 리셉터(EPCR)에 결합할 수 있고, 이것은 PC 활성화에서 내피 막에 트롬빈과 트롬보모듈린(thrombomodulin)을 정렬한다.
단백질 C 자이모겐은 전형적으로 그의 활성 효소 --- 생물학적 능력을 갖는 활성화된 단백질 C (aPC)로 전환된다. PC 경로의 활성은 PC 활성화와 aPC 불활성화의 속도로 조절된다. PC 활성화는 내피세포 표면에서 2단계 공정으로 발생한다. 이것은 트롬빈/트롬보모듈린 컴플렉스에 의한 PC의 단백질 가수분해 활성화 전에 내피세포에서 EPCR과 PC의 결합(Gla 도메인 경유)을 필요로 한다. 내피세포 표면 상에서 트롬빈/트롬보모듈린으로 촉매되는 인간 PC 중쇄의 Arg12에서의 단일 절단으로 12-aa AP가 유리되고 자이모겐 PC가 aPC, 활성 세린 프로테아제로 전환된다. 따라서, PC와 aPC의 아미노산 서열 간 주요 차이는 APC 내에 없는 PC 내 12-aa 활성 펩티드의 존재이다. PC가 aPC로 활성화되는 것은 또한 구조적 변화를 유발하여; 결과적으로 PC가 아니라 aPC만이 벤즈아미딘 또는 클로로메틸케톤(CMK) 펩티드 저해제로 그의 효소활성부위에서 표지될 수 있다. CMK-저해제와의 컴플렉스 내에서 Gla-도메인이 없는 aPC의 결정 구조가 최근 밝혀졌다. 인간 혈장 내의 주요 aPC 불활성화 물질은 세르핀 상과(serpin superfamily)의 성분인, 인간 혈장 내에서 100 nM로 존재하는 단백질 C 저해제(PCI)이다. 생리적 조건하에서, aPC는 20-30분의 반감기로 인간 혈액 내에서 매우 낮은 농도(1-2 ng/ml 또는 40 pM)로 순환한다.
단백질 C 경로는 혈전증에 대한 자연적인 방어 메카니즘으로 작용한다. 이것은 응고제 반응이 증가할 때 항응고제 반응을 증폭시킬 수 있는 온디맨드(on-demand) 시스템이라는 점에서 다른 항응고제와는 차이가 있다. 다쳤을 때, 응고를 위해 트롬빈이 생성된다. 동시에, 트롬빈은 또한 혈관 표면에 있는 트롬보모듈린에 결합하여 항응고 반응을 촉발하며, 이것은 단백질 C 활성화를 촉진한다. 따라서, aPC 생성은 대략 트롬빈 농도와 PC 수준에 비례한다.
응고과정의 중요한 조절인자로서 단백질 C 경로의 생리적 중요성은 3가지 임상적 발견에 의해 입증된다: (a) 단백질 C 결핍과 연관된 심각한 혈전성 합병증과 결함을 단백질 C 보충물로 교정하는 능력; (b) 단백질 C 코팩터(단백질 S)의 결함과 연관된 가족력 혈전성향증(thrombophilia); 및 (c) aPC에 의한 절단에 저항하도록 하는 그의 기질(Factor V Leiden R506Q) 내 유전적 돌연변이와 연관된 혈전증 위험(Bernard, GR et.al. N Engl J Med 2001, 344:699-709 참조).
다른 비타민 K-의존성 응고인자와 비교하여 aPC는 2개의 응고 코팩터, Factor Va와 VIIIa의 단백질 가수분해 불활성화에 의한 항응고제로서 작용하여 트롬빈의 생성을 저해한다. 감소된 트롬빈 농도로 인하여, 트롬빈으로 유발된 염증성, 전구응고성 항-피브린용해성 반응이 감소한다. aPC는 또한 플라스미노겐 활성체 저해제(PAI)와 컴플렉스를 형성하여 강화된 피브린용해 반응에 직접 기여한다.
항응고제 작용 이외에도, aPC는 세포보호 효과, 예를 들어 항염증 및 항세포사멸 활성, 및 내피 장벽 작용의 보호를 유도한다. 세포에서 aPC의 직접적 세포보호 작용은 EPCR과 G-단백질 결합 리셉터, 프로테아제 활성화 리셉터-1(PAR-1)을 필요로 한다. 따라서, aPC는 피브린용해를 촉진하고 혈전증과 염증을 저해한다. aPC의 항응고제와 세포보호 작용은 별개인 것으로 보인다. 대부분의 세포보호 효과는 주로 aPC와 aPC 돌연변이체의 항응고 활성과 무관하면서 최소한의 항응고 활성과 정상 세포보호 활성이 발생된다. 마찬가지로, 과다 항응고성이나 비세포보호성 aPC 돌연변이체 또한 보고되었다.
aPC 경쇄의 C-말단은 또한 프로테아제 도메인 활성부위의 반대쪽에 Gly142-Leu155 잔기를 포함하는 고도로 하전된 영역이다. E149A-aPC는 야생형 aPC와 구분할 수 없는 아미드분해 활성을 갖지만, 단백질 S 코팩터 활성에 대한 증가된 민감성으로 인해 활성화된 부분 트롬보플라스틴 시간(aPTT) 응고 어세이에서 항응고 활성이 3배 이상 증가하였다. E149A-aPC는 생체 내 과잉활성 항혈전성 포텐시뿐만 아니라 혈장응고 어세이에서 과잉활성 항응고 활성을 나타냈다. 이 돌연변이체는 또한 LPS로 유도된 치사 내독소혈증 쥐 모델에서 감소된 세포보호와 사망율 감소 활성을 나타냈다. 이것은 aPC의 세포보호 활성이 쥐 모델에서 사망율을 감소하는데 필요한 것을 시사한다. 이에 비하여, aPC의 항응고 활성은 사망율 감소에 필수적이 아니거나 충분하지 않다. aPC는 패혈증, 과응고와 연관된 생명위협 상태 및 일반화된 염증 반응을 치료하는데 사용되고 있다. 패혈증에서 aPC 요법의 심각한 부작용은 2% 환자에서 발생하는 대출혈(major bleeding)이다. 이러한 심각한 부작용이 그의 임상적 사용을 제한하고 있다.
인간의 활성화 단백질 C(aPC)에 대한 모노클로날 항체를 제공한다. 적어도 하나의 구체예에서, 항-aPC 모노클로날 항체는 단백질 C에 대해 최소한의 결합을 나타내며, 이것이 aPC의 자이모겐이다.
일부 구체예에서, 제공된 aPC의 모노클로날 항체가 최적화되어, 예를 들어 친화도를 증가하거나, 작용적 활성을 증가하거나 생식세포계열 서열로부터의 분화를 감소시킨다.
또한, 단리된 모노클로날 항체에 의해 결합된 인간 aPC의 특이적 에피토프를 제공한다. 또한 이를 코딩하는 단리된 핵산 분자를 제공한다.
또한, 항-aPC 모노클로날 항체를 포함하는 약학 조성물과 혈우병 A와 B 같은 응고에서 유전적 및 후천적 결핍 또는 결함의 치료방법을 제공한다. 출혈시간을 단축하는 것이 필요한 환자에게 항-aPC 모노클로날 항체를 투여하여 출혈시간을 단축하는 방법을 제공한다. 인간 aPC와 결합하는 모노클로날 항체를 제조하는 방법을 제공한다.
당업자라면 이하에 기술된 도면들이 단지 예시를 위한 것임을 알 수 있다. 도면들은 어떤 측면에서도 본 발명의 범위를 제한하지 않는다.
도 1은 성숙한 헤테로다이머 형태의 인간 활성화 단백질 C의 카툰 그림을 나타낸 것이다.
도 2는 인간 Fab 항체 라이브러리에서 확인된 10 항-aPC Fab 중에서 나타난 중쇄 및 경쇄 CDR의 아미노산 서열 배열을 나타낸 것이다.
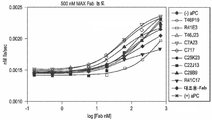
도 3은 직접 ELISA에 의해 항-APC Fab를 특성화한 그래프를 나타낸 것이다. ELISA 플레이트를 웰 당 100 ng의 인간 PC (hPC), 인간 aPC (hAPC), 개 aPC (dAPC), 마우스 aPC (mAPC)로 코팅하였다. X-축에 표시한 정제된 Fab를 플레이트에 20 nM (1 ug/ml)로 첨가하였다. 결합된 Fab를 제2 항체(항-인간 Fab-HRP), 이어서 HRP 기질 AmplexRed로 검출하였다. 정제된 Fab는 우선적으로 인간 aPC에 결합하였고, Fab R41C17을 제외하고 인간 PC에 결합하지 않거나 거의 결합하지 않았다. Fab T46J23은 또한 마우스 aPC에 대해 약간의 결합을 보였다.
도 4는 ELISA에 의한 항-aPC Fab의 결합 선택성을 나타낸 것이다.
도 5는 인간 aPC에서 스파이킹(spiking)하여 aPTT에 의한 용량 의존적 방식의 정상 인간 혈장 응혈의 저해를 나타낸 그래프이다. 50%의 통합 인간 정상 혈장은 52초 내에 응혈을 형성하였다. 100, 200, 400, 800, 또는 1600 ng/ml의 인간 aPC와 혈장의 사전 인큐베이션은 용량 의존적 방식으로 응혈 시간을 지연하였다. 재조합 인간 aPC (rh-APC)와 혈장 유도 인간 aPC (pdh-APC)에 대해 거의 동일한 포텐시가 관찰되었다.
도 6은 항-aPC Fab가 인간 aPC를 저해하고 인간 정상 혈장에서 응혈을 유도하는 것을 나타내는 그래프이다. 400ng/ml의 인간 aPC는 혈장 응고시간을 52초에서 180초까지 연장하였다. 대조용 항체(대조군) 또는 그의 Fab(대조군-Fab) 또는 선택 Fab를 0, 0.5, 1, 2, 5, 10, 또는 20ug/ml로 aPC와 인큐베이션하므로써 응고시간을 용량 의존적 방식으로 감소하였다(상부 패널). 3 Fab (R41E3, C22J13, 대조군-Fab)를 또한 더 큰 효과를 위해 40 ug/ml로 시험하였다(하부 패널).
도 7은 항-aPC Fab가 개 aPC를 저해하고 aPTT에서 응혈을 유도하는 것을 나타낸 것이다.
도 8은 aPC의 아미드분해 활성에 대한 항-aPC Fab의 효과를 나타낸 것이다. 인간 aPC 단백질(20 nM)을 먼저 동일 부피의 항-aPC Fab(1-3000 nM)와 실온에서 20분 동안 사전 인큐베이션하고, 발색성 기질 SPECTROZYME PCa를 반응 혼합물에 최대 1mM까지 첨가하였다. 최종 농도 10 nM의 인간 aPC의 아미드분해 활성을 Fab 존재 하에서 측정하였다. 가수분해 속도가 Fab의 존재하에 저해되었고 최대 80% 감소하였다.
도 9는 aPC의 Factor Va (FVa) 불활성화 활성에 대한 항-aPC Fab의 효과를 나타낸 것이다.
도 10은 ELISA에 의한 항-aPC 인간 IgG1의 종 교차 반응성과 항-aPC 인간 IgG1의 결합 특이성을 나타낸 것이다. ELISA 플레이트를 1 ug/ml의 인간 PC (hPC), 인간 aPC (hAPC), 개 aPC, 마우스 aPC, 래빗 aPC로 코팅하였다. 정제된 IgG (20nM)를 플레이트에 첨가하였다. 결합된 IgG를 제2 항체 (항-인간 IgG-HRP), 이어서 HRP 기질 AmplexRed에 의해 검출하였다. 5개의 항-aPC 인간 IgG1이 개와 래빗 aPC와 교차반응하였고, 하나의 IgG1도 마우스 aPC와 결합하였다.
도 11은 (a) 인간, (b) 래빗, (c) 개, 및 (d) 마우스 - 종 aPC의 아미드분해 활성에 대한 항-aPC IgG의 효과를 나타낸 것이다. aPC 단백질(20 nM)을 먼저 동일 부피의 항-aPC-hIgG1(1-1000 nM)과 실온에서 20분 동안 사전 인큐베이션하고, 발색성 기질 SPECTROZYME PCa를 반응 혼합물에 최대 1mM까지 첨가하였다. 최종 농도 10 nM의 aPC의 아미드분해 활성을 Fab 존재하에서 측정하였다. 가수분해 속도가 IgG의 존재 하에 저해되었다. 음성 대조용 항체(항-CTX-hIgG1)를 사용하였다.
도 12는 항-aPC-hIgG1이 응고시간을 단축하고 인간 혈장 응고 어세이(aPTT)에서 응집을 유발하는 것을 나타낸 것이다.
도 13은 중증 혈우병 환자 혈장에 대한 항-aPC-IgG1의 효과를 나타낸 것이다. 내피세포와 트롬보모듈린 존재하에, PC는 aPC로 활성화되어 트롬빈 생성을 감소한다. 대조용 Ab와 달리 항-aPC-항체는 새로 생성된 aPC를 신속하게 저해하고 트롬빈 생성을 5-10x 증가한다. 증강된 트롬빈 생성은 응고장애가 있는 환자에서 응고를 개선한다.
도 14는 항-aPC-항체 변이체의 활성 프로파일을 나타낸 것이다. 친본 (parent) 항체, C25K23과 마찬가지로, 이러한 변이체들은 (a) 높은 친화도로 aPC와 결합하고, (b) aPC 활성을 정제된 시스템에서 강력하게 저해하고, (c) 인간 혈장 응고 어세이에서 응집을 유도하는 응고시간을 단축한다.
도 15는 최종 Rwork= 0.201, Rfree = 0.241로 정련된 컴플렉스 구조를 나타낸 개략도이다. 왼쪽과 오른쪽 패널은 90°회전된 동일한 컴플렉스 구조를 나타낸다. Fab C25K23의 HCDR3 루프는 aPC의 중쇄와 광범위하게 상호작용한다.
도 16은 왼쪽 패널에 Fab C25K23 중쇄의 CDR3 루프에서 Trp104 잔기 주위에서의 상호작용에 대한 확대도를 나타내었다. 이것이 aPC 활성부위(촉매적으로 중요한 His57, Asp102, 및 Ser195 잔기)의 접근성을 차단하고 있다. 오른쪽 패널은 Trp104와 PPACK가 활성부위에서 동일한 영역을 차지하기 때문에 Fab C25K23이 PPACK 저해제와 유사한 방법으로 aPC의 활성을 저해하는 것을 나타내고 있다.
도 17은 ELISA에 의해 활성부위 차단 aPC에 결합하거나 하지 않는, Fab와 IgG 형태의 항-aPC 항체를 나타낸 그래프이다.
도 1은 성숙한 헤테로다이머 형태의 인간 활성화 단백질 C의 카툰 그림을 나타낸 것이다.
도 2는 인간 Fab 항체 라이브러리에서 확인된 10 항-aPC Fab 중에서 나타난 중쇄 및 경쇄 CDR의 아미노산 서열 배열을 나타낸 것이다.
도 3은 직접 ELISA에 의해 항-APC Fab를 특성화한 그래프를 나타낸 것이다. ELISA 플레이트를 웰 당 100 ng의 인간 PC (hPC), 인간 aPC (hAPC), 개 aPC (dAPC), 마우스 aPC (mAPC)로 코팅하였다. X-축에 표시한 정제된 Fab를 플레이트에 20 nM (1 ug/ml)로 첨가하였다. 결합된 Fab를 제2 항체(항-인간 Fab-HRP), 이어서 HRP 기질 AmplexRed로 검출하였다. 정제된 Fab는 우선적으로 인간 aPC에 결합하였고, Fab R41C17을 제외하고 인간 PC에 결합하지 않거나 거의 결합하지 않았다. Fab T46J23은 또한 마우스 aPC에 대해 약간의 결합을 보였다.
도 4는 ELISA에 의한 항-aPC Fab의 결합 선택성을 나타낸 것이다.
도 5는 인간 aPC에서 스파이킹(spiking)하여 aPTT에 의한 용량 의존적 방식의 정상 인간 혈장 응혈의 저해를 나타낸 그래프이다. 50%의 통합 인간 정상 혈장은 52초 내에 응혈을 형성하였다. 100, 200, 400, 800, 또는 1600 ng/ml의 인간 aPC와 혈장의 사전 인큐베이션은 용량 의존적 방식으로 응혈 시간을 지연하였다. 재조합 인간 aPC (rh-APC)와 혈장 유도 인간 aPC (pdh-APC)에 대해 거의 동일한 포텐시가 관찰되었다.
도 6은 항-aPC Fab가 인간 aPC를 저해하고 인간 정상 혈장에서 응혈을 유도하는 것을 나타내는 그래프이다. 400ng/ml의 인간 aPC는 혈장 응고시간을 52초에서 180초까지 연장하였다. 대조용 항체(대조군) 또는 그의 Fab(대조군-Fab) 또는 선택 Fab를 0, 0.5, 1, 2, 5, 10, 또는 20ug/ml로 aPC와 인큐베이션하므로써 응고시간을 용량 의존적 방식으로 감소하였다(상부 패널). 3 Fab (R41E3, C22J13, 대조군-Fab)를 또한 더 큰 효과를 위해 40 ug/ml로 시험하였다(하부 패널).
도 7은 항-aPC Fab가 개 aPC를 저해하고 aPTT에서 응혈을 유도하는 것을 나타낸 것이다.
도 8은 aPC의 아미드분해 활성에 대한 항-aPC Fab의 효과를 나타낸 것이다. 인간 aPC 단백질(20 nM)을 먼저 동일 부피의 항-aPC Fab(1-3000 nM)와 실온에서 20분 동안 사전 인큐베이션하고, 발색성 기질 SPECTROZYME PCa를 반응 혼합물에 최대 1mM까지 첨가하였다. 최종 농도 10 nM의 인간 aPC의 아미드분해 활성을 Fab 존재 하에서 측정하였다. 가수분해 속도가 Fab의 존재하에 저해되었고 최대 80% 감소하였다.
도 9는 aPC의 Factor Va (FVa) 불활성화 활성에 대한 항-aPC Fab의 효과를 나타낸 것이다.
도 10은 ELISA에 의한 항-aPC 인간 IgG1의 종 교차 반응성과 항-aPC 인간 IgG1의 결합 특이성을 나타낸 것이다. ELISA 플레이트를 1 ug/ml의 인간 PC (hPC), 인간 aPC (hAPC), 개 aPC, 마우스 aPC, 래빗 aPC로 코팅하였다. 정제된 IgG (20nM)를 플레이트에 첨가하였다. 결합된 IgG를 제2 항체 (항-인간 IgG-HRP), 이어서 HRP 기질 AmplexRed에 의해 검출하였다. 5개의 항-aPC 인간 IgG1이 개와 래빗 aPC와 교차반응하였고, 하나의 IgG1도 마우스 aPC와 결합하였다.
도 11은 (a) 인간, (b) 래빗, (c) 개, 및 (d) 마우스 - 종 aPC의 아미드분해 활성에 대한 항-aPC IgG의 효과를 나타낸 것이다. aPC 단백질(20 nM)을 먼저 동일 부피의 항-aPC-hIgG1(1-1000 nM)과 실온에서 20분 동안 사전 인큐베이션하고, 발색성 기질 SPECTROZYME PCa를 반응 혼합물에 최대 1mM까지 첨가하였다. 최종 농도 10 nM의 aPC의 아미드분해 활성을 Fab 존재하에서 측정하였다. 가수분해 속도가 IgG의 존재 하에 저해되었다. 음성 대조용 항체(항-CTX-hIgG1)를 사용하였다.
도 12는 항-aPC-hIgG1이 응고시간을 단축하고 인간 혈장 응고 어세이(aPTT)에서 응집을 유발하는 것을 나타낸 것이다.
도 13은 중증 혈우병 환자 혈장에 대한 항-aPC-IgG1의 효과를 나타낸 것이다. 내피세포와 트롬보모듈린 존재하에, PC는 aPC로 활성화되어 트롬빈 생성을 감소한다. 대조용 Ab와 달리 항-aPC-항체는 새로 생성된 aPC를 신속하게 저해하고 트롬빈 생성을 5-10x 증가한다. 증강된 트롬빈 생성은 응고장애가 있는 환자에서 응고를 개선한다.
도 14는 항-aPC-항체 변이체의 활성 프로파일을 나타낸 것이다. 친본 (parent) 항체, C25K23과 마찬가지로, 이러한 변이체들은 (a) 높은 친화도로 aPC와 결합하고, (b) aPC 활성을 정제된 시스템에서 강력하게 저해하고, (c) 인간 혈장 응고 어세이에서 응집을 유도하는 응고시간을 단축한다.
도 15는 최종 Rwork= 0.201, Rfree = 0.241로 정련된 컴플렉스 구조를 나타낸 개략도이다. 왼쪽과 오른쪽 패널은 90°회전된 동일한 컴플렉스 구조를 나타낸다. Fab C25K23의 HCDR3 루프는 aPC의 중쇄와 광범위하게 상호작용한다.
도 16은 왼쪽 패널에 Fab C25K23 중쇄의 CDR3 루프에서 Trp104 잔기 주위에서의 상호작용에 대한 확대도를 나타내었다. 이것이 aPC 활성부위(촉매적으로 중요한 His57, Asp102, 및 Ser195 잔기)의 접근성을 차단하고 있다. 오른쪽 패널은 Trp104와 PPACK가 활성부위에서 동일한 영역을 차지하기 때문에 Fab C25K23이 PPACK 저해제와 유사한 방법으로 aPC의 활성을 저해하는 것을 나타내고 있다.
도 17은 ELISA에 의해 활성부위 차단 aPC에 결합하거나 하지 않는, Fab와 IgG 형태의 항-aPC 항체를 나타낸 그래프이다.
상기한 바와 같이, 본 발명은 모노클로날 항체를 포함하는 항체, 및 인간 단백질 C의 활성형(aPC)에 특이적으로 결합하지만 인간 단백질 C의 자이모겐 형태 (PC)에 대해 반응성이 없거나 비교적 적은 반응성을 나타내는 다른 결합 단백질을 제공한다.
본 원의 목적에 있어서, 다음 용어들은 하기한 정의로 사용된다:
정의
적절한 경우에 단수로 사용된 용어는 복수를 포함할 수도 있고 반대의 경우도 가능하다. 이하의 어떤 정의가 다른 문헌, 예를 들어 본 원에 참조로 포함된 문헌 등에서 그 용어의 사용과 상충하는 경우, (예를 들어, 용어가 원래 사용된 문헌에서)반대 의미가 명백하게 의도되지 않는 한 이하에 기재된 정의는 본 명세서 및 관련 청구범위를 해석하기 위해 항상 조정된다. "또는"의 사용은 달리 표시되지 않는 한 "및/또는"을 의미한다. 본 원에서 "하나"는 달리 표시되지 않는 한 또는 "하나 이상"이 명백하게 적절하지 않은 한 "하나 이상"을 의미한다. "포함하다", "포함하는", "함유하다" 및 "함유하는"이란 용어는 상호교환적이며 제한적이지 않다. 예를 들어, "함유하는"이란 용어는 "포함하나, 비제한적"인 것을 의미한다.
본 원에서 사용된 "단백질 C" 또는 "PC"란 용어는 세포에 의해 자연적으로 발현되고 혈장 내에 존재하는 자이모겐 형태의 단백질 C의 변이체, 이소폼 (isoform) 및/또는 종 상동체를 지칭하고, 단백질 C의 활성형과는 다르다.
본 원에서 사용된 "활성화 단백질 C" 또는 "aPC"란 용어는 단백질 C 내에 존재하는 12 아미노산 활성화 펩티드가 없는 것을 특징으로 하는 단백질 C의 활성형을 지칭한다.
본 원에서 사용된 바와 같이, "항체"는 온전한 항체 및 그의 임의의 항원 결합 단편 (즉, "항원-결합 부분") 또는 단일사슬을 지칭한다. 상기 용어는 천연 발생이거나 정상적인 면역글로불린 유전자 단편 재조합 과정으로 형성된 전장 면역글로불린 분자 (예를 들어, IgG 항체), 또는 면역글로불린 분자에서 특이적인 결합 활성을 보유하는 면역학적 활성 부분, 예컨대 항체 단편을 포함한다. 구조에 상관없이, 항체 단편은 전장 항체에 의해 인식되는 것과 동일한 항원과 결합한다. 예를 들어, 항-aPC 모노클로날 항체 단편은 aPC의 에피토프에 결합한다. 항체의 항원-결합 작용은 전장 항체의 단편에 의해 수행될 수 있다. 항체의 "항원-결합 부분"이라는 용어에 포함되는 결합 단편의 예는 다음을 포함한다: (i) Fab 단편, VL, VH, CL 및 CH1 도메인으로 이루어진 1가 단편; (ii) F(ab')2 단편, 힌지 영역에서 디설파이드 결합에 의해 연결된 2개의 Fab 단편을 포함하는 2가 단편; (iii) VH 및 CH1 도메인으로 이루어진 Fd 단편; (iv) 항체의 단일 아암(arm)의 VL 및 VH 도메인으로 이루어진 Fv 단편; (v) VH 도메인으로 이루어진 dAb 단편 (Ward et al. (1989) Nature 341:544-546); (vi) 단리된 상보성 결정 영역 (CDR); (vii) 미니바디(minibodies), 디아바디(diabodies), 트리아바디(triabodies), 테트라바디(tetrabodies), 및 카파 바디(kappa bodies) (예를 들어, Ill et al., Protein Eng 1997; 10:949-57 참조); (viii) 카멜 IgG; 및 (ix) IgNAR. 추가로, Fv 단편의 2개 도메인, VL 및 VH는 별개의 유전자에 의해 코딩되지만, 이것들은 VL 및 VH 영역이 쌍을 이루어 1가 분자를 형성한 단일 단백질 사슬(단일사슬 Fv (scFv)로 공지; 예를 들어, 문헌 [Bird et al. (1988) Science 242:423-426] 및 [Huston et al. (1988) Proc. Natl. Acad. Sci. USA 85:5879-5883] 참조)로 제조될 수 있게 하는 합성 링커에 의해서 재조합 방법으로 결합될 수도 있다. 이러한 단일사슬 항체 역시 항체의 "항원 결합 부분"이라는 용어 내에 포함되는 것으로 한다. 이들 항체 단편은 당업자에게 공지된 통상의 기술을 이용하여 수득되며, 이 단편들은 무손상 항체와 동일한 방식으로 유용성에 대해 분석된다.
또한, 항원 결합 단편이 항체 모방체(antibody mimetic)에 포함될 수 있음을 고려하였다. 본 원에서 사용된 "항체 모방체" 또는 "모방체"란 용어는 항체에 대해 유사한 결합을 나타내지만 더 작은 대체 항체 또는 비-항체 단백질인 단백질을 의미한다. 이러한 항체 모방체는 스캐폴드(scaffold)에 포함될 수 있다. 상기 용어 "스캐폴드"는 맞춤형 작용과 특징을 갖는 새로운 생성물의 조작을 위한 폴리펩티드 플랫폼을 지칭한다.
본 원에서 사용된 "항-aPC 항체"란 용어는 aPC의 에피토프에 특이적으로 결합하는 항체를 지칭한다. 생체 내에서 aPC의 에피토프에 결합할 때 본 원에 기술된 항-aPC 항체는 혈액 응고 캐스캐이드의 하나 이상의 측면을 증강한다.
본 원에서 사용된, "결합 저해" 및 "결합 차단" (예를 들어, aPC에 대한 aPC 기질 결합의 저해/차단을 지칭함)이란 용어는 상호교환적으로 사용되고, 단백질과 그 기질의 부분적 및 완전한 저해 또는 차단 둘 다, 예컨대 적어도 약 10%, 약 20%, 약 30%, 약 40%, 약 50%, 약 60%, 약 70%, 약 80%, 약 90%, 약 95%, 약 96%, 약 97%, 약 98%, 약 99%, 또는 약 100%까지의 저해 또는 차단을 포함한다. 본 원에서 사용된 "약"이란 표시된 수치의 +/- 10%를 의미한다.
aPC와 aPC 기질 결합의 저해 및/또는 차단과 관련하여, 저해와 차단이란 용어는 또한 항-aPC 항체와 접촉하지 않는 aPC와 비교하여 항-aPC 항체와 접촉할 때 생리적 기질과 aPC의 결합 친화성의 측정가능한 감소, 예를 들어 Factor Va를 포함한 그의 기질 또는 Factor VIIIa와 aPC의 상호작용의 적어도 약 10%, 약 20%, 약 30%, 약 40%, 약 50%, 약 60%, 약 70%, 약 80%, 약 90%, 약 95%, 약 96%, 약 97%, 약 98%, 약 99%, 또는 약 100%까지의 차단을 포함한다.
본 원에서 사용된, "모노클로날 항체" 또는 "모노클로날 항체 조성물"이란 용어는 단일 분자 조성물의 항체 분자의 제제를 지칭한다. 모노클로날 항체 조성물은 특정 에피토프에 대한 단일 결합 특이성 및 친화도를 나타낸다. 따라서, "인간 모노클로날 항체"란 용어는 인간 생식세포계열 면역글로불린 서열로부터 유래된 가변 및 불변 영역을 갖는, 단일 결합 특이성을 나타내는 항체를 지칭한다. 본 발명의 인간 항체는 인간 생식세포계열 면역글로불린 서열에 의해 코딩되지 않는 아미노산 잔기(예를 들어, 시험관내 무작위 또는 부위 특이적 돌연변이유발, 또는 생체내 체세포 돌연변이에 의해 도입된 돌연변이)를 포함할 수 있다.
본 원에서 사용된 "단리된 항체"는 다른 생체 분자, 예를 들어 상이한 항원 특이성을 갖는 항체가 실질적으로 없는 항체를 지칭한다(예를 들어, aPC 이외의 항원과 결합하는 항체가 실질적으로 없는, aPC와 결합하는 단리된 항체). 일부 구체예에서, 단리된 항체는 적어도 건조 중량으로 약 75%, 약 80%, 약 90%, 약 95%, 약 97%, 약 99%, 약 99.9% 또는 약 100% 순수하다. 일부 구체예에서, 순도는 컬럼크로마토그래피, 폴리아크릴아미드 겔 전기영동 또는 HPLC 분석 같은 방법으로 측정할 수 있다. 그러나, 인간 aPC의 에피토프, 이소폼 또는 변이체에 결합하는 단리된 항체는, 예를 들어 다른 종으로부터의 다른 관련 항원(예를 들어, aPC 종 상동체)과의 교차 반응성을 가질 수 있다. 또한, 단리된 항체에는 다른 세포 물질 및/또는 화학물질이 실질적으로 없을 수 있다. 본 원에서 사용된, "특이적 결합"은 소정의 항원에 대한 항체 결합을 지칭한다. 전형적으로, "특이적 결합"을 나타내는 항체는 적어도 약 105 M-1의 친화도로 항원에 결합하고, 무관한 항원(예를 들어, BSA, 카제인)과의 결합에 대한 결합 친화도보다 더 높은, 예를 들어 적어도 2배 더 높은 친화도로 상기 소정의 항원에 결합한다. "항원을 인식하는 항체" 및 "항원에 대해 특이적인 항체"란 어구는 본 원에서 "항원에 특이적으로 결합하는 항체"란 용어와 상호교환적으로 사용된다.
본 원에서 사용된 "최소 결합"이란 용어는 특정된 항원에 결합하지 않거나/않고 친화도가 낮은 항체를 지칭한다. 전형적으로 항원에 대해 최소 결합을 갖는 항체는 약 102 M-1보다 더 낮은 친화도로 그 항원에 결합하고 무관한 항원에 결합하는 것보다 더 높은 친화도로 소정의 항원과 결합하지 않는다.
본 원에서 사용된, 항체, 예컨대 IgG 항체에 대한 "고친화도"란 용어는 적어도 약 107 M-1, 적어도 일 구체예에서는 적어도 약 108 M-1, 일부 구체예에서는 적어도 약 109 M-1, 1010 M-1, 1011 M-1 또는 그 이상, 예를 들어 최대 1013 M-1 또는 그 이상의 결합 친화도를 지칭한다. 그러나, "고친화도" 결합은 다른 항체 동종형(isotype)마다 달라질 수 있다. 예를 들어, IgM 동종형에 대한 "고친화도" 결합은 적어도 약 107 M-1의 결합 친화도를 지칭한다. 본 원에서 사용된, "동종형(isotype)"은 중쇄 불변 영역 유전자에 의해 코딩되는 항체 클래스 (예를 들어, IgM 또는 IgG1)를 지칭한다.
"상보성-결정 영역" 또는 "CDR"은 결합된 항원의 3차원 구조에 상보적인 N-터미널 항원-결합 표면을 형성하는 항체 분자의 중쇄 가변영역 또는 경쇄 가변영역 내의 3개의 초가변영역 중 하나를 지칭한다. 중쇄 또는 경쇄의 N-터미널로부터 시작하여, 이들 상보성-결정 영역은 각각 "CDR1", "CDR2" 및 "CDR3"로 표시된다[Wu TT, Kabat EA, Bilofsky H, Proc Natl Acad Sci U S A. 1975 Dec;72(12):5107 and Wu TT, Kabat EA, J Exp Med. 1970 Aug 1;132(2):211]. CDR은 항원-항체 결합에 관여하고, CDR3는 항원-항체 결합에 특이적인 고유 영역을 포함한다. 따라서, 항원-결합 부위는 중쇄 및 경쇄 V 영역 각각으로부터의 CDR 영역을 포함하는 6개의 CDR을 포함할 수 있다.
"에피토프(epitope)"란 용어는 항체가 특이적으로 결합하거나 상호작용하는 항원의 면적 또는 영역을 지칭하는 것으로, 일부 구체예에서는 항원이 항체와 물리적으로 접촉하는 곳을 나타낸다. 반면, "파라토프(paratope)"란 용어는 항원이 특이적으로 결합하는 항체 상의 면적 또는 영역을 지칭한다. 경쟁 결합으로 특징화되는 에피토프는 대응하는 항체의 결합이 상호 배타적일 경우, 즉, 어느 항체의 결합이 다른 항체의 동시 결합을 배제시키는 경우 오버래핑(overlapping)이라 한다. 에피토프는 항원이 대응하는 두 항체의 동시적인 결합을 수용할 수 있는 경우 별개(고유한)인 것으로 언급된다.
본 원에서 사용된 "경쟁하는 항체"란 용어는 본 원에 기술된 바와 같이 aPC에 대한 항체로서 대략적으로, 실질적으로 또는 필수적으로 동일한, 또는 완전 동일한 에피토프에 결합하는 항체를 지칭한다. "경쟁하는 항체"는 중복하는 에피토프 특이성을 갖는 항체를 포함한다. 따라서, 경쟁하는 항체는 aPC와의 결합에 있어서 본 원에 기술된 바와 같은 항체와 효과적으로 경쟁할 수 있다. 일부 구체예에서, 경쟁하는 항체는 본 원에 기술된 항체와 동일한 에피토프에 결합할 수 있다. 다른 관점에서, 경쟁하는 항체는 본 원에 기술된 항체와 동일한 에피토프 특이성을 갖는다.
본 원에서 사용된 "보존적 치환"이란 하나 이상의 아미노산으로 해당 폴리펩티드의 생물학적 또는 생화학적 작용의 손실을 야기하지 않는 유사한 생화학적 특성을 갖는 아미노산을 치환하는 것을 포함하는 폴리펩티드의 변성을 지칭한다. "보존적 아미노산 치환"은 아미노산 잔기를 유사한 측쇄를 갖는 아미노산 잔기로 대체시키는 치환이다. 유사한 측쇄를 갖는 아미노산 잔기 부류는 당분야에서는 규정되어 있다. 이들 부류는 염기성 측쇄를 갖는 아미노산(예를 들어, 라이신, 아르기닌, 히스티딘), 산성 측쇄를 갖는 아미노산(예를 들어, 아스파트산, 글루탐산), 비하전 극성 측쇄를 갖는 아미노산(예를 들어, 글리신, 아스파라긴, 글루타민, 세린, 트레오닌, 티로신, 시스테인), 비극성 측쇄를 갖는 아미노산(예를 들어, 알라닌, 발린, 루신, 이소루신, 프롤린, 페닐알라닌, 메티오닌, 트립토판), 베타-분지된 측쇄를 갖는 아미노산(예를 들어, 트레오닌, 발린, 이소루신) 및 방향족 측쇄를 갖는 아미노산(예를 들어, 티로신, 페닐알라닌, 트립토판, 히스티딘)을 포함한다. 본 발명의 항체는 여전히 항원 결합 활성을 유지하는, 하나 이상의 보존적 아미노산 치환을 가질 수 있다.
핵산 및 폴리펩티드의 경우, "실질적 상동성"은 2종의 핵산 또는 2종의 폴리펩티드 또는 이들의 지정된 서열이 최적으로 정렬 및 비교될 때 적절한 뉴클레오티드 또는 아미노산 삽입 또는 결실을 가지면서 뉴클레오티드 또는 아미노산의 적어도 약 80%, 통상적으로는 적어도 약 85%, 일부 구체예에서 약 90%, 91%, 92%, 93%, 94% 또는 95%, 적어도 일 구체예에서 적어도 약 96%, 97%, 98%, 99%, 99.1%, 99.2%, 99.3%, 99.4% 또는 99.5%로 동일한 것을 나타낸다. 경우에 따라, 절편이 선택적인 혼성화 조건하에 그 가닥의 상보체에 혼성화되는 경우, 핵산에 대한 실질적 상동성이 존재한다. 본 발명은 본 원에서 언급된 특이적 핵산 서열 및 아미노산 서열에 대해 실질적 상동성을 갖는 핵산 서열 및 폴리펩티드 서열을 포함한다.
2종의 서열 간 동일성 비율(%)은 그 서열들이 공유하는 동일한 위치의 수에대한 함수(즉, 상동성(%) = 동일한 위치의 수/위치의 총 수×100)로서, 2종 서열의 최적 정렬을 위해 도입되어야 하는 갭의 수 및 갭 각각의 길이를 고려한다. 두 서열 간 서열 비교 및 동일성 비율(%)의 결정은 수학적 알고리즘, 예컨대 VectorNTI™의 AlignX™ 모듈 (Invitrogen Corp., 미국 캘리포니아주 칼스배드)(이에 제한되지 않음)을 사용하여 달성될 수 있다. AlignX™의 경우, 다중 정렬의 디폴트 변수는 다음과 같다: 갭 간격 패널티(gap opening penalty): 10, 갭 연장 패널티: 0.05, 갭 분리 패널티 범위: 8, 정렬 지연에 대한 동일성(%): 40. (보다 상세한 내용은 http://www.invitrogen.com/site/us/en/home/LINNEA-Online-Guides/ LINNEA-Communities/Vector-NTI-Community/Sequence-analysis-and-data-management-software-for-PCs/AlignX-Module-for-Vector-NTI-Advance.reg.us.html 참조).
의문(query) 서열(본 발명의 서열) 및 대상 서열 간 최상의 전체 매치를 결정하는 또다른 방법은 글로벌 서열 정렬이라고도 지칭되며, 히긴스(Higgins) 등의 알고리즘(Computer Applications in the Biosciences (CABIOS), 1992, 8(2): 189-191)을 기초로 하는 CLUSTALW 컴퓨터 프로그램(Thompson et al., 핵산 Research, 1994, 2(22): 4673-4680)을 사용하여 결정할 수 있다. 서열 정렬에 있어서 의문 및 대상 서열은 둘 다 DNA 서열이다. 상기 글로벌 서열 정렬의 결과는 동일성 비율(%)로 나타낸다. 쌍별 정렬을 통한 동일성 비율(%) 계산을 위해서 DNA 서열의 CLUSTALW 정렬에 사용할 수 있는 변수는 다음과 같다: 매트릭스 = IUB, k-튜플(tuple) = 1, 탑 디아고날(Top Diagonal)의 수 = 5, 갭 패널티 = 3, 갭 오픈 패널티 = 10, 갭 연장 패널티 = 0.1. 다중 정렬의 경우, 다음 CLUSTALW 변수가 사용될 수 있다: 갭 오프닝 패널티 = 10, 갭 연장 변수 = 0.05, 갭 분리 패널티 범위 = 8, 정렬 지연에 대한 동일성(%) = 40.
핵산은 온전한 세포 중에, 세포 용해물 중에, 또는 부분적으로 정제되거나 실질적으로 순수한 형태로 존재할 수 있다. 핵산은 자연적 환경에서 통상적으로 결합된 다른 세포 성분으로부터 정제해낸 경우에 "단리된" 또는 "실질적으로 순수"한 것이다. 핵산을 단리하기 위해서, 다음과 같은 표준 기술을 사용할 수 있다: 알칼리/SDS 처리, CsCl 밴딩, 컬럼크로마토그래피, 아가로스 겔 전기영동 및 당업계 공지의 기타 기술.
활성화된 단백질 C에 대한
모노클로날
항체
aPC에 대해서는 그의 항응고 특성이 알려져 있다. 혈우병 또는 상처가 지혈의 일시적 손상을 야기한 외상 환자에서 항상성이 조절되지 않는 출혈 장애는 aPC 저해제로 치료할 수 있다. 항체, 그의 항원 결합 단편, 및 다른 aPC 특이적 단백질 스캐폴드를 사용하여 aPC 단백질 작용의 서브세트를 저해하고 나머지를 보존하기 위한 표적 특이성을 제공할 수 있다. 혈장 농도에서 aPC (<4 ng/ml) 대 PC (4 ug/ml)의 적어도 1000배 차이를 고려하면, 잠재적 aPC 저해제 치료제의 증가된 특이성은 PC의 높은 순환 초과량의 존재 하에서 aPC 작용을 차단하는데 도움이 된다.
aPC의 항응고 작용을 차단하는 aPC 특이적 항체는 출혈장애, 예를 들어 혈우병이 있는 환자, 저해제를 가진 혈우병 환자, 외상성 응고장애, aPC에 의한 패혈증 치료 중의 중증 출혈 환자, 선택 수술, 예컨대 이식, 심장 수술, 정형외과 수술로 인한 출혈, 월경과다증의 과도한 출혈의 치료제로 사용할 수 있다.
장기적인 순환 반감기를 갖는 항-aPC 항체는 혈우병 같은 만성 질환의 치료에 유용할 수 있다. aPC 항체 단편 또는 짧은 반감기를 갖는 aPC 결합 단백질 스캐폴드가 급성 용도(예를 들어, 외상 치료 용도)에서는 더 효과적일 수 있다. aPC는 다작용성 단백질이므로, 항체, 항원 결합 항체 단편을 포함하는 선택적 aPC 작용 차단제(SAFB), 친화도와 표적 특이성이 증가된 aPC 특이적 단백질 스캐폴드는 다른 aPC 작용에 영향을 주지 않고 선택적으로 단지 하나의 aPC 작용만을 차단할 수 있다.
aPC 결합 항체는 인간 aPC에 대한 인간 항체 라이브러리를 패닝(panning) 및 스크리닝하여 동정되었다. 동정된 항체는 인간 PC에 대해 최소한의 결합을 나타내거나 나타내지 않았다. 단리된 모노클로날 항체 각각의 중쇄 가변영역과 경쇄 가변영역을 서열화하였고, 그의 CDR 영역을 동정하였다. 각각의 aPC 특이적 모노클로날 항체의 중쇄 및 경쇄 영역에 해당하는 서열 식별번호("서열번호(SEQ ID NO.)")를 표 1에 요약하였다.


일 구체예에서, 인간 활성화 단백질 C (aPC)에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 단리된 모노클로날 항체를 제공하며, 여기서 항체는 서열번호: 14-23으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 중쇄 가변영역을 포함한다.
또다른 구체예에서, 인간 활성화 단백질 C (aPC)에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 단리된 모노클로날 항체를 제공하며, 여기서 항체는 서열번호: 4-13으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 경쇄 가변영역을 포함한다.
또다른 구체예에서, 인간 활성화 단백질 C (aPC)에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 단리된 모노클로날 항체를 제공하며, 여기서 항체는 서열번호: 14-23으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 중쇄 가변영역과 서열번호: 4-13으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 경쇄 가변영역을 포함한다.
다른 구체예에서, 항체는 다음을 포함하는 중쇄 및 경쇄 가변영역을 포함한다:
(a) 서열번호: 14의 아미노산 서열을 포함하는 중쇄 가변영역과 서열번호: 4의 아미노산 서열을 포함하는 경쇄 가변영역;
(b) 서열번호: 15의 아미노산 서열을 포함하는 중쇄 가변영역과 서열번호: 5의 아미노산 서열을 포함하는 경쇄 가변영역;
(c) 서열번호: 16의 아미노산 서열을 포함하는 중쇄 가변영역과 서열번호: 6의 아미노산 서열을 포함하는 경쇄 가변영역;
(d) 서열번호: 17의 아미노산 서열을 포함하는 중쇄 가변영역과 서열번호: 7의 아미노산 서열을 포함하는 경쇄 가변영역;
(e) 서열번호: 18의 아미노산 서열을 포함하는 중쇄 가변영역과 서열번호: 8의 아미노산 서열을 포함하는 경쇄 가변영역;
(f) 서열번호: 19의 아미노산 서열을 포함하는 중쇄 가변영역과 서열번호: 9의 아미노산 서열을 포함하는 경쇄 가변영역;
(g) 서열번호: 20의 아미노산 서열을 포함하는 중쇄 가변영역과 서열번호: 10의 아미노산 서열을 포함하는 경쇄 가변영역;
(h) 서열번호: 21의 아미노산 서열을 포함하는 중쇄 가변영역과 서열번호: 11의 아미노산 서열을 포함하는 경쇄 가변영역;
(i) 서열번호: 22의 아미노산 서열을 포함하는 중쇄 가변영역과 서열번호: 12의 아미노산 서열을 포함하는 경쇄 가변영역;
(j) 서열번호: 23의 아미노산 서열을 포함하는 중쇄 가변영역과 서열번호: 13의 아미노산 서열을 포함하는 경쇄 가변영역;
표 2에는 인간 aPC에 결합하는 모노클로날 항체의 중쇄 및 경쇄 각각의 CDR 영역("CDR1", "CDR2", 및 "CDR3")의 서열번호를 요약하였다.

일 구체예에서, 인간 활성화 단백질 C (aPC)에 결합하는 단리된 모노클로날 항체를 제공하며, 여기서 항체는 서열번호: 94-103으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR3를 포함한다. 이 CDR3들은 패닝과 스크리닝에서 동정된 항체의 중쇄로부터 동정되었다. 다른 구체예에서, 이 항체는 (a) 서열번호: 74-83으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1, (b) 서열번호: 84-93으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2, 또는 (c) 서열번호: 74-83으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1 및 서열번호: 84-93으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2를 추가로 포함한다.
또다른 구체예에서, 패닝과 스크리닝에서 동정된 항체의 경쇄들 중 하나로부터 유래한 CDR3를 공유하는 항체를 제공한다. 따라서, 또한 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 단리된 모노클로날 항체를 제공하며, 여기서 항체는 서열번호: 64-73으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR3를 포함한다. 다른 구체예에서, 이 항체는 (a) 서열번호: 44-53으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1, (b) 서열번호: 54-63으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2, 또는 (c) 서열번호: 44-53으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1 및 서열번호: 54-63으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2를 추가로 포함한다.
또다른 구체예에서, 항체는 스크리닝과 패닝에서 동정된 항체의 중쇄 및 경쇄로부터의 CDR3를 포함한다. 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 단리된 모노클로날 항체를 제공하며, 여기서 항체는 서열번호: 94-103으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR3 및 서열번호: 64-73으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR3를 포함한다. 다른 구체예에서, 항체는 추가로 (a) 서열번호: 74-83으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1, (b) 서열번호: 84-93으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2, (c) 서열번호: 44-53으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1, 및/또는 (d) 서열번호: 54-63으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2를 포함한다.
일부 구체예에서, 항체는 다음을 포함하는 중쇄 및 경쇄 가변영역을 포함한다:
(a) 서열번호: 44, 54, 및 64를 포함하는 아미노산 서열을 포함하는 경쇄 가변영역 및 서열번호: 74, 84, 및 94를 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(b) 서열번호: 45, 55, 및 65를 포함하는 아미노산 서열을 포함하는 경쇄 가변영역 및 서열번호: 75, 85, 및 95를 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(c) 서열번호: 46, 56, 및 66을 포함하는 아미노산 서열을 포함하는 경쇄 가변영역 및 서열번호: 76, 86, 및 96을 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(d) 서열번호: 47, 57, 및 67을 포함하는 아미노산 서열을 포함하는 경쇄 가변영역 및 서열번호: 77, 87, 및 97을 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(e) 서열번호: 48, 58, 및 68을 포함하는 아미노산 서열을 포함하는 경쇄 가변영역 및 서열번호: 78, 88, 및 98을 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(f) 서열번호: 49, 59, 및 69를 포함하는 아미노산 서열을 포함하는 경쇄 가변영역 및 서열번호: 79, 89, 및 99를 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(g) 서열번호: 50, 60, 및 70을 포함하는 아미노산 서열을 포함하는 경쇄 가변영역 및 서열번호: 80, 90, 및 100을 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(h) 서열번호: 51, 61, 및 71을 포함하는 아미노산 서열을 포함하는 경쇄 가변영역 및 서열번호: 81, 91, 및 101을 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(i) 서열번호: 52, 62, 및 72를 포함하는 아미노산 서열을 포함하는 경쇄 가변영역 및 서열번호: 82, 92, 및 102를 포함하는 아미노산 서열을 포함하는 중쇄 가변영역; 및
(j) 서열번호: 53, 63, 및 73을 포함하는 아미노산 서열을 포함하는 경쇄 가변영역 및 서열번호: 83, 93, 및 103을 포함하는 아미노산 서열을 포함하는 중쇄 가변영역.
또한, 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 단리된 모노클로날 항체를 제공하며, 여기서 항체는 서열번호: 4-13에 기재된 아미노산으로 구성되는 군에서 선택된 아미노산 서열에 대해 적어도 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 또는 99.5%의 동일성(identity)을 갖는 아미노산 서열을 포함한다.
또한, 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 단리된 모노클로날 항체를 제공하며, 여기서 항체는 서열번호: 14-23에 기재된 아미노산으로 구성되는 군에서 선택된 아미노산 서열에 대해 적어도 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 또는 99.5%의 동일성을 갖는 아미노산 서열을 포함한다.
항체는 종 특이적이거나 다수 종과 교차반응할 수 있다. 일부 구체예에서, 항체는 사람, 마우스, 래트, 래빗, 기니피그, 원숭이, 돼지, 개, 고양이 또는 다른 포유동물 종의 aPC와 특이적으로 반응하거나 교차반응할 수 있다.
항체는 다양한 부류의 항체들 중 어느 하나일 수 있으며, 예컨대 비제한적으로 IgG1, IgG2, IgG3, IgG4, IgM, IgA1, IgA2, 분비 IgA, IgD,및 IgE 항체일 수 있다.
일 구체예에서, 인간 활성화 단백질 C에 대한 단리된 전체 인간 모노클로날 항체가 제공된다.
항-aPC 항체의 최적화
변이체
일부 구체예에서, 패닝 및 스크리닝된 항체는, 예를 들어 aPC에 대한 친화도를 증가하거나, PC에 대한 친화도를 더 감소하거나, 다른 종에 대한 교차반응성을 향상하거나 aPC의 차단 활성을 향상시키기 위해 최적화할 수 있다. 이러한 최적화는, 예를 들어 CDR, 또는 항체의 CDR에 대해 최근접, 즉 CDR에 인접한 약 3 또는 4잔기의 아미노산에서 부위 포화 돌연변이유발을 이용하여 수행할 수 있다.
또한, aPC에 대해 친화도가 증가되거나 고친화도를 갖는 모노클로날 항체가 제공된다. 일부 구체예에서, 항-aPC 항체는 적어도 약 107M-1, 일부 구체예에서 적어도 약 108M-1, 일부 구체예에서 적어도 약 109M-1, 1010M-1, 1011M-1 이상, 예를 들어 최대 1013M-1 이상의 결합 친화도를 갖는다.
일부 구체예에서, 추가의 아미노산 변성은 생식세포계열 서열로부터의 분화를 감소시키기 위해 도입될 수 있다. 다른 구체예에서, 아미노산 변성은 대규모 생산공정에서 항체 생산을 촉진하기 위해 도입될 수 있다.
일부 구체예에서, 인간 활성화 단백질 C에 특이적으로 결합하는 단리된 항-aPC 모노클로날 항체가 제공되며, 항체는 하나 이상의 아미노산 변성을 포함한다. 일부 구체예에서, 항체는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 또는 20 이상의 변성을 포함한다.
따라서, 일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 항체는 서열번호: 8에 기재된 아미노산 서열을 포함하는 경쇄를 포함하고, 아미노산 서열은 하나 이상의 아미노산 변성을 포함한다. 일부 구체예에서, 경쇄의 변성은 치환, 삽입 또는 결실이다. 일부 구체예에서, 변성은 경쇄의 CDR 내에 위치한다. 다른 구체예에서, 변성은 경쇄의 CDR 외부에 위치한다.
일부 구체예에서, 서열번호: 8의 경쇄의 변성은 G52, N53, N54, R56, P57, S58, Q91, Y93, S95, S96, L97, S98, G99, S100 및 V101에서 선택된 위치에 있다. 변성은, 예를 들어 다음 치환들 중 하나일 수 있다: G52S, G52Y, G52H, G52F, N53G, N54K, N54R, R56K, P57G, P57W, P57N, S58V, S58F, S58R, Q91R, Q91G, Y93W, S95F, S95Y, S95G, S95W, S95E, S96G, S96A, S96Y, S96W, S96R, L97M, L97G, L97R, L97V, S98L, S98W, S98V, S98R, G99A, G99E, S100A, S100V, V101Y, V101L 또는 V101E. 또한, 일부 구체예에서, 항체는 다음 중 2 이상의 치환을 포함할 수 있다: G52S, G52Y, G52H, G52F, N53G, N54K, N54R, R56K, P57G, P57W, P57N, S58V, S58F, S58R, Q91R, Q91G, Y93W, S95F, S95Y, S95G, S95W, S95E, S96G, S96A, S96Y, S96W, S96R, L97M, L97G, L97R, L97V, S98L, S98W, S98V, S98R, G99A, G99E, S100A, S100V, V101Y, V101L 또는 V101E.
일부 구체예에서, 서열번호: 8의 경쇄는 추가로 A10, T13, S78, R81 및 S82에서 선택된 하나 이상의 위치에 변성을 포함한다. 일부 구체예에서, 경쇄의 A10 위치에서의 변성은 A10V이다. 일부 구체예에서, 경쇄의 T13 위치에서의 변성은 T13A이다. 일부 구체예에서, 경쇄의 S78 위치에서의 변성은 S78T이다. 일부 구체예에서, 경쇄의 R81 위치에서의 변성은 R81Q이다. 일부 구체예에서, 경쇄의 S82 위치에서의 변성은 S82A이다. 일부 구체예에서, 서열번호: 8의 경쇄는 2 이상의 변성 A10V, T13A, S78T, R81Q 및 S82A를 포함한다. 일부 구체예에서, 서열번호: 8의 경쇄는 변성 A10V, T13A, S78T, R81Q 및 S82A를 모두 포함한다.
다른 구체예에서, 단백질 C의 인간 활성화 형태에 특이적으로 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 18에 기재된 아미노산 서열을 갖는 중쇄를 포함하고, 아미노산 서열은 하나 이상의 아미노산 변성을 포함한다. 일부 구체예에서, 경쇄의 변성은 치환, 삽입 또는 결실이다.
일부 구체예에서, 서열번호: 18의 중쇄는 위치 N54 또는 S56에서의 변성을 포함한다. 일부 구체예에서, 중쇄의 위치 N54에서의 변성은 N54G, N54Q 또는 N54A이다. 일부 구체예에서, 중쇄의 위치 S56에서의 변성은 S56A 또는 S56G이다.
일부 구체예에서, 아미노산은 대규모 생산공정에서 항체 생산을 촉진하기 위해 변성될 수 있다. 예를 들어, 일부 구체예에서, 향상된 생물물리적 특성(예를 들어, 최소한의 응집/고착성)을 위해 항체의 소수성 표면 영역을 감소하도록 변성할 수 있다. 일부 구체예에서, 추가적인 변성이 서열번호: 8의 경쇄에서 이루어질 수 있다. 일부 구체예에서, 서열번호: 8의 경쇄의 변성은 위치 Y33에 있다. 일부 구체예에서, 경쇄 내 Y33에서의 변성은 Y33A, Y33K 또는 Y33D이다. 일부 구체예에서, 추가 변성은 서열번호: 18의 중쇄에서 이루어진다. 일부 구체예에서, 서열번호: 18의 중쇄의 변성은 하나 이상의 위치 Y32, W33, W53 또는 W110에 있다. 일부 구체예에서, 서열번호: 18의 중쇄에서의 변성은 Y32A, Y32K, Y32D, W33A, W33K, W33D, W53A, W53K, W53D, W110A, W110K, 또는 W110D에서 선택된다.
일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 108에 기재된 아미노산 서열을 갖는 경쇄를 포함한다. 일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 110에 기재된 아미노산 서열을 갖는 경쇄를 포함한다. 일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 112에 기재된 아미노산 서열을 갖는 경쇄를 포함한다. 일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 114에 기재된 아미노산 서열을 갖는 경쇄를 포함한다. 일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 116에 기재된 아미노산 서열을 갖는 경쇄를 포함한다. 일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 118에 기재된 아미노산 서열을 갖는 경쇄를 포함한다.
일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 109에 기재된 아미노산 서열을 갖는 중쇄를 포함한다. 일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 111에 기재된 아미노산 서열을 갖는 중쇄를 포함한다. 일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 113에 기재된 아미노산 서열을 갖는 중쇄를 포함한다. 일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 115에 기재된 아미노산 서열을 갖는 중쇄를 포함한다. 일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 117에 기재된 아미노산 서열을 갖는 중쇄를 포함한다. 일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 119에 기재된 아미노산 서열을 갖는 중쇄를 포함한다.
일부 구체예에서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체가 제공되며, 여기서 항체는 서열번호: 12에 기재된 아미노산 서열을 갖는 경쇄를 포함하며, 아미노산 서열은 하나 이상의 아미노산 변성을 포함한다. 일부 구체예에서, 경쇄의 변성은 치환, 삽입 또는 결실이다. 일부 구체예에서, 변성은 경쇄의 CDR 내에 위치한다. 다른 구체예에서, 변성은 경쇄의 CDR 외부에 위치한다.
일부 구체예에서, 서열번호: 12의 경쇄의 변성은 T25, D52, N53, N54, N55, D95, N98 또는 G99에서 선택된 위치에 있다. 변성은, 예를 들어 다음 치환들 중 하나일 수 있다: T25S, D52Y, D52F, D52L, D52G, N53C, N53K, N53G, N54S, N55K, D95G, N98S, G99H, G99L 또는 G99F. 또한, 일부 구체예에서, 항체는 다음 중 2 이상의 치환을 포함할 수 있다: T25S, D52Y, D52F, D52L, D52G, N53C, N53K, N53G, N54S, N55K, D95G, N98S, G99H, G99L 또는 G99F.
다른 구체예에서, 단백질 C의 인간 활성화 형태에 결합하는 단리된 항-aPC 모노클로날 항체를 제공하며, 여기서 항체는 서열번호: 22에 기재된 아미노산 서열을 갖는 중쇄를 포함하며, 아미노산 서열은 하나 이상의 아미노산 변성을 포함한다. 일부 구체예에서, 경쇄의 변성은 치환, 삽입 또는 결실이다.
에피토프
또한, 인간 활성화 단백질 C의 에피토프에 결합하는 단리된 모노클로날 항체를 제공하며, 에피토프는 서열번호: 3에 기재된 인간 aPC 중쇄로부터 하나 이상의 잔기를 포함한다.
일부 구체예에서, 에피토프는 인간 aPC의 활성부위를 포함할 수 있다. 일부 구체예에서, 활성부위는 인간 aPC의 아미노산 잔기 S195를 포함할 수 있다.
일부 구체예에서, 에피토프는 서열번호: 3에 기재된 인간 활성화 단백질 C의 D60, K96, S97, T98, T99, E170, V171, M172, S173, M175, A190, S195, W215, G216, E217, G218, 및 G218에서 선택된 하나 이상의 잔기를 포함할 수 있다.
또한, 인간 활성화 단백질 C에 결합하는 본 원에 기술된 어느 하나의 항체와 경쟁할 수 있는 항체가 제공된다. 예를 들어, 이같은 경쟁 항체는 상기한 에피토프 하나 이상과 결합할 수 있다.
핵산, 벡터 및 숙주세포
또한 상기한 모노클로날 항체를 코딩하는 단리된 핵산 분자가 제공된다.
따라서, 인간 활성화 단백질 C에 결합하는 항체를 코딩하는 단리된 핵산 분자가 제공된다.
일부 구체예에서, 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 항체를 코딩하는 단리된 핵산 분자를 제공하며, 여기서 항체는 서열번호: 34-43으로 구성되는 군에서 선택된 핵산 서열을 포함하는 중쇄 가변영역을 포함한다.
일부 구체예에서, 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 항체를 코딩하는 단리된 핵산 분자를 제공하며, 여기서 항체는 서열번호: 24-33으로 구성되는 군에서 선택된 핵산 서열을 포함하는 경쇄 가변영역을 포함한다.
일부 구체예에서, 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 항체를 코딩하는 단리된 핵산 분자를 제공하며, 여기서 항체는 서열번호: 14-23으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 중쇄 가변영역을 포함한다.
일부 구체예에서, 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 항체를 코딩하는 단리된 핵산 분자를 제공하며, 여기서 항체는 서열번호: 4-13으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 경쇄 가변영역을 포함한다.
또다른 구체예에서, 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는 항체를 코딩하는 단리된 핵산 분자를 제공하며, 여기서 항체는 서열번호: 14-23으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 중쇄 가변영역 또는 서열번호: 4-13으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 경쇄 가변영역, 및 중쇄 가변영역 또는 경쇄 가변영역의 하나 이상의 아미노산 변성을 포함한다.
게다가, 상기한 모노클로날 항체 중 어느 하나를 코딩하는 단리된 핵산 분자를 포함하는 벡터 및 이 벡터를 포함하는 숙주세포를 제공한다.
aPC에 대한 항체의 제조방법
모노클로날 항체는 본 구체예들 중 하나에 따른 모노클로날 항체의 가변영역을 코딩하는 뉴클레오티드 서열을 숙주세포에서 발현하여 재조합 생산할 수 있다. 발현벡터의 도움으로, 뉴클레오티드 서열을 함유하는 핵산을 형질감염하고 생산에 적합한 숙주세포에서 발현할 수 있다. 따라서, 또한 다음을 포함하는 인간 aPC와 결합하는 모노클로날 항체의 제조방법이 제공된다:
(a) 모노클로날 항체를 코딩하는 핵산 분자를 숙주세포에 형질감염하고,
(b) 모노클로날 항체를 숙주세포에서 발현하도록 숙주세포를 배양하고, 경우에 따라 생산된 모노클로날 항체를 단리 및 정제하고, 여기서 핵산 분자는 모노클로날 항체를 코딩하는 뉴클레오티드 서열을 포함한다.
일 예로, 항체, 또는 그의 항체 단편을 발현하기 위해 표준 분자생물학 방법으로 얻어진 부분적 또는 전장 경쇄 및 중쇄를 코딩하는 DNA를 발현켁터에 삽입하여 유전자를 작동적으로 전사 및 번역 조절서열에 연결한다. 본 내용에서, "작동적으로 연결"이란 용어는 전사 및 번역 조절서열이 벡터 내에서 항체 유전자의 전사 및 번역을 조절하는 이들의 의도된 작용을 하도록 항체 유전자를 벡터 내에 결찰하는 것을 의미한다. 발현벡터와 발현 조절서열은 사용된 발현 숙주세포와 화합할 수 있도록 선택된다. 항체 경쇄 유전자와 항체 중쇄 유전자를 별도 벡터에 삽입하거나, 더욱 전형적으로 두 유전자를 동일한 발현벡터에 삽입한다. 항체 유전자는 발현벡터에 표준 방법에 의해 삽입된다(예를 들어, 항체 유전자 단편 및 벡터 상의 상보성 제한부위의 결찰, 또는 제한부위가 없으면 비점착말단(blunt end) 결찰). 본 원에 기술된 항체의 경쇄 및 중쇄 가변영역을 사용하여 항체 동종형의 전장 항체 유전자를 생성하기 위해 목적하는 동종형의 중쇄 불변 및 경쇄 불변영역을 이미 코딩하는 발현벡터에 이들을 삽입하여 VH 세그먼트를 벡터 내에서 CH 세그먼트(들)에 작동적으로 연결하고 VL 세그먼트를 벡터 내에서 CL 세그먼트에 작동적으로 연결시킨다. 추가적으로 또는 선택적으로, 재조합 발현벡터는 숙주세포로부터 항체 사슬의 분비를 촉진하는 시그널 펩티드를 코딩할 수 있다. 시그널 펩티드가 항체 사슬 유전자의 아미노 말단에 프레임 내(in-frame) 연결되도록 항체 사슬 유전자를 벡터에 클론할 수 있다. 시그널 펩티드는 면역글로불린 시그널 펩티드 또는 이종 시그널 펩티드(즉, 면역글로불린이 아닌 단백질 유래의 시그널 펩티드)일 수 있다.
항체 사슬 코딩 유전자 이외에, 재조합 발현벡터는 숙주세포에서 항체 사슬 유전자의 발현을 제어하는 조절서열을 갖는다. "조절서열"이란 용어는 프로모터, 인핸서, 및 항체 사슬 유전자의 전사 또는 번역을 조절하는 다른 발현 조절성분(예를 들어, 폴리아데닐화 시그널)을 포함한다. 이러한 조절 서열은, 예를 들어 문헌 [Goeddel; Gene Expression Technology. Methods in Enzymology 185, Academic Press, San Diego, Calif. (1990)]에 기재되어 있다. 당업자는 조절 서열의 선택을 비롯한 발현벡터의 디자인이 형질전환될 숙주세포의 선택, 원하는 단백질의 발현 수준 등과 같은 인자에 따라 달라질 수 있음을 인지할 것이다. 포유동물 숙주세포 발현을 위한 조절 서열의 예는 포유동물 세포에서의 고수준 단백질 발현을 지시하는 바이러스 요소, 예컨대 사이토메갈로바이러스 (CMV), 원숭이(Simian) 바이러스 40 (SV40), 아데노바이러스 (예를 들어, 아데노바이러스 주요 후기 프로모터 (AdMLP)) 및 폴리오마로부터 유래된 프로모터 및/또는 인핸서를 포함한다. 선택적으로, 비-바이러스 조절 서열, 예를 들어 유비퀴틴 프로모터 또는 β-글로빈 프로모터를 사용할 수 있다.
항체 사슬 유전자 및 조절 서열에 추가하여, 재조합 발현벡터는 추가의 서열, 예를 들어 숙주세포에서의 벡터의 복제를 조절하는 서열 (예를 들어, 복제 기점) 및 선택가능한 마커 유전자를 보유할 수 있다. 선택가능한 마커 유전자는 벡터가 도입된 숙주세포의 선택을 용이하게 한다 (예를 들어 미국 특허 제4,399,216호, 동 제4,634,665호 및 동 제5,179,017호 (모두가 악셀(Axel) 등) 참조). 예를 들어, 전형적으로, 선택가능한 마커 유전자는 벡터를 도입시킨 숙주세포에 약물, 예컨대 G418, 히그로마이신 또는 메토트렉세이트에 대한 내성을 부여한다. 선택가능한 마커 유전자의 예는 디히드로폴레이트 리덕타제 (DHFR) 유전자 (메토트렉세이트 선택/증폭을 이용하여 dhfr- 숙주세포에서 사용하기 위함) 및 neo 유전자 (G418 선택을 위함)를 포함한다.
경쇄 및 중쇄의 발현을 위해, 중쇄 및 경쇄를 코딩하는 발현벡터(들)를 표준 기술에 의해 숙주세포로 형질감염시킨다. 용어 "형질감염"의 다양한 형태들은 원핵 또는 진핵 숙주세포 내로 외인성 DNA를 도입하는데 일반적으로 사용되는 다양한 기술, 예를 들어 전기천공, 인산칼슘 침전, DEAE-덱스트란 형질감염 등을 포함한다. 항체를 원핵 또는 진핵 숙주세포에서 발현시키는 것이 이론상 가능하긴 하지만, 항체를 진핵 세포, 예를 들어 포유동물 숙주세포에서 발현시키는 것이 일반적인데, 이는 이러한 진핵 세포, 특히 포유동물 세포가 적절하게 폴딩되고 면역학적으로 활성인 항체를 조립하고 분비하는데 있어서 원핵 세포보다 더 용이하기 때문이다.
재조합 항체를 발현시키는데 적합한 포유동물 숙주세포의 예는 차이니즈 햄스터 난소 (CHO 세포) (예를 들어 문헌 [R. J. Kaufman and P. A. Sharp (1982) Mol. Biol. 159:601-621]에 기재된 바와 같이 DHFR 선택가능한 마커와 함께 사용되는, 문헌 [Urlaub and Chasin, (1980) Proc. Natl. Acad. Sci. USA 77:4216-4220]에 기재된 dhfr- CHO 세포를 포함함), NSO 골수종 세포, COS 세포, HKB11 세포 및 SP2 세포를 포함한다. 항체 유전자를 코딩하는 재조합 발현벡터가 포유동물 숙주세포 내로 도입되는 경우, 항체는 숙주세포에서의 항체 발현 또는 숙주세포가 성장하는 배양 배지로의 항체 분비를 허용하기에 충분한 시간의 기간 동안 숙주세포를 배양함으로써 생성된다. 항체는 표준 단백질 정제 방법, 예컨대 한외여과, 크기 배제 크로마토그래피, 이온 교환 크로마토그래피 및 원심분리를 이용하여 배양 배지로부터 회수될 수 있다.
무손상
항체를 발현하기 위한 부분 항체 서열의 사용
항체는 주로 6개의 중쇄 및 경쇄 CDR에 위치한 아미노산 잔기를 통해 표적 항원과 상호작용한다. 이러한 이유로, CDR 내의 아미노산 서열은 CDR 밖의 서열보다 개개의 항체 사이에서 더 다양하다. CDR 서열이 대부분의 항체-항원 상호작용을 담당하기 때문에, 상이한 특성을 갖는 상이한 항체로부터의 프레임워크 서열에 이식된 특정 자연 발생 항체로부터의 CDR 서열을 포함하는 발현벡터를 구성하여 특정 자연 발생 항체의 특성을 모방하는 재조합 항체를 발현시키는 것이 가능하다 (예를 들어, 문헌, Riechmann, L. et al., 1998, Nature 332:323-327; Jones, P. et al., 1986, Nature 321:522-525; 및 Queen, C. et al., 1989, Proc. Natl. Acad. Sci. U.S.A. 86:10029-10033 참조). 이러한 프레임워크 서열은 생식세포계열(germline) 항체 유전자 서열을 포함하는 공개된 DNA 데이터베이스로부터 수득될 수 있다. 이들 생식세포계열 서열은 B 세포 성숙 동안의 V(D)J 연결에 의해 형성되는 완전하게 조립된 가변 유전자를 포함하지 않을 것이기 때문에 성숙 항체 유전자 서열과는 상이할 것이다. 원래의 항체와 유사한 결합 특성을 갖는 무손상 재조합 항체를 재생성하기 위해서 특정 항체의 전체 DNA 서열을 수득할 필요는 없다 (WO 99/45962 참조). 전형적으로, CDR 영역에 걸쳐 있는 부분적 중쇄 및 경쇄 서열이 이러한 목적에 충분하다. 부분적 서열을 사용하여 재조합된 항체 가변 유전자에 기여하는 생식세포계열 가변 및 연결 유전자 절편을 결정한다. 이후, 생식세포계열 서열을 사용하여 가변영역의 손실 부분을 채운다. 중쇄 및 경쇄 리더 서열은 단백질 성숙 동안에 절단되고, 최종 항체의 특성에 기여하지 않는다. 이러한 이유로, 발현 구조물을 위한 상응하는 생식세포계열 리더 서열을 이용하는 것이 필요하다. 손실된 서열을 부가하기 위해, 클로닝된 cDNA 서열을 결찰 또는 PCR 증폭에 의해 합성 올리고뉴클레오티드와 조합시킬 수 있다. 선택적으로, 전체 가변영역은 짧고 중복되는 올리고뉴클레오티드 세트로 합성되고 PCR 증폭으로 조합되어 전체적으로 합성 가변영역 클론을 생성할 수 있다. 이러한 공정은 특정 제한 부위의 제거 또는 포함, 또는 특정 코돈의 최적화와 같은 특정의 이점을 갖는다.
중쇄 및 경쇄 전사체의 뉴클레오티드 서열은 합성 올리고뉴클레오티드의 중복되는 세트를 디자인하여 천연 서열과 동일한 아미노산 코딩 능력을 갖는 합성 V 서열을 생성하는데 사용된다. 합성 중쇄 및 경쇄 서열은 천연 서열과 상이할 수 있다. 예를 들어: 올리고뉴클레오티드 합성 및 PCR 증폭을 용이하게 하기 위해서 반복된 뉴클레오티드 염기의 열(string)을 중단하고; 코작(Kozak) 규칙(Kozak, 1991, J. Biol. Chem. 266:19867-19870])에 따라 최적의 번역 개시 부위가 혼입되며; 제한 부위가 번역 개시 부위의 상류 또는 하류로 조작됨.
중쇄 및 경쇄 가변영역 둘 다의 경우에, 최적화된 코딩 및 상응하는 비-코딩 가닥 서열은 상응하는 비-코딩 올리고뉴클레오티드의 중간 정도에서 30개 내지 50개 뉴클레오티드 분절로 절단된다. 따라서, 각 사슬마다 올리고뉴클레오티드는 150개 내지 400개 뉴클레오티드의 세그먼트에 걸쳐 있는 중복된 이중 가닥 세트로 조립될 수 있다. 이후, 상기 풀(pools)을 템플레이트로 사용하여 150개 내지 400개 뉴클레오티드의 PCR 증폭 생성물을 생산한다. 전형적으로, 단일 가변영역 올리고뉴클레오티드 세트는, 별도로 증폭되어 2종의 중첩된 PCR 생성물을 생산하는 2종의 풀로 나뉠 것이다. 이후, 이들 중복 생성물은 PCR 증폭으로 조합되어 완전 가변영역을 형성한다. 또한, PCR 증폭시에 중쇄 또는 경쇄 불변 영역의 중복된 단편을 포함시켜서 발현벡터 구조물로 쉽게 클로닝될 수 있는 단편을 생성시키는 것이 바람직할 수 있다.
이후, 다시 구성된 중쇄 및 경쇄 가변영역을 클로닝된 프로모터, 번역 개시, 불변 영역, 3' 비-번역, 폴리아데닐화, 및 전사 종결 서열과 조합하여 발현벡터 구조물을 형성한다. 중쇄 및 경쇄 발현 구조물을 단일 벡터 내로 조합하여 숙주세포로 동시에 형질감염시키거나 연속 형질감염시키거나 별도로 형질감염시킬 수 있고, 이것은 이후에 융합되어 2종의 사슬 모두를 발현시키는 숙주세포를 형성한다.
따라서, 또다른 측면에서, 인간 항-aPC 항체의 구조적 특징을 사용하여 aPC에 대한 결합 작용을 보유하는, 구조적으로 연관된 인간 항-aPC 항체를 생성한다. 더욱 구체적으로, 본 발명의 모노클로날 항체의 구체적으로 확인된 중쇄 및 경쇄 영역의 1개 이상의 CDR은 공지의 인간 프레임워크 영역 및 CDR과 재조합 방식으로 조합되어 재조합 방식으로 조작된 본 발명의 추가의 인간 항-aPC 항체를 생성할 수 있다.
약학적 조성물
또한, 치료 유효량의 항-aPC 모노클로날 항체 및 약학적으로 허용되는 담체를 포함하는 약학적 조성물이 제공된다. "약학적으로 허용되는 담체"는 제제를 제제화하거나 또는 안정화시키는 것을 돕기 위해서 활성성분에 추가될 수 있는 물질이고, 환자에게 유의한 해로운 독성 효과를 야기하지 않는다. 이러한 담체의 예는 당업자에게 공지되어 있으며, 물, 당, 예컨대 말토스 또는 수크로스, 알부민, 염, 예컨대 염화나트륨 등을 포함한다. 다른 담체는 예를 들어 문헌 [Remington's Pharmaceutical Sciences (E. W. Martin)]에 기재되어 있다. 이러한 조성물은 치료 유효량의 적어도 하나의 항-TFPI 모노클로날 항체를 함유한다.
약학적으로 허용되는 담체는 멸균 주사가능한 용액제 또는 분산액제를 즉각 투여용(extemporaneous)으로 제조하기 위한 멸균 수용액 또는 분산액 및 멸균 분말을 포함한다. 약학적 활성 물질을 위한 이러한 매질 및 작용제의 사용은 당업계에 공지되어 있다. 조성물은 바람직하게는 비경구 주사용으로 제제화된다. 조성물은 용액제, 마이크로에멀젼제, 리포좀제, 또는 높은 약물 농도에 적합한 기타 주문된 구조물로서 제제화될 수 있다. 담체는 예를 들어 물, 에탄올, 폴리올 (예를 들어, 글리세롤, 프로필렌 글리콜 및 액체 폴리에틸렌 글리콜 등) 및 이것들의 적합한 혼합물을 함유하는 용매 또는 분산 매질일 수 있다. 일부 경우에, 조성물 중에 등장화제, 예를 들어 당, 폴리알코올, 예컨대 만니톨, 소르비톨 또는 염화나트륨을 포함시킬 것이다.
멸균 주사가능한 용액제는 필요한 양의 활성 화합물을 필요에 따라 상기 기재된 성분들 중 1종 또는 이것들의 조합물과 함께 적절한 용매 중에 혼입시킨 후에 멸균 마이크로여과를 수행하여 제조될 수 있다. 일반적으로, 분산액제는 활성 화합물을 기본적인 분산 매질 및 상기 기재된 것들로부터의 기타 필요한 성분을 함유하는 멸균 비히클로 혼입시켜 제조된다. 멸균 주사가능한 용액제를 제조하기 위한 멸균 분말의 경우, 일부 제조 방법은 활성성분 및 임의의 추가의 원하는 성분의 분말을 이것의 미리 멸균-여과시킨 용액으로부터 생성하는 진공 건조 및 냉동-건조 (동결건조)이다.
약학적 용도
모노클로날 항체는 응고의 유전적 및 후천적 결핍 또는 결함을 처치하기 위한 치료 목적으로 사용될 수 있다. 예를 들어, 상기한 구체예에서 모노클로날 항체는 aPC와, Factor Va 또는 Factor VIIIa를 포함할 수 있는 그의 기질과의 상호작용을 차단하는데 사용될 수 있다.
모노클로날 항체는 지혈 장애, 예컨대 혈소판감소증, 혈소판 장애 및 출혈 장애 (예를 들어, 혈우병 A 및 혈우병 B)의 치료에서 치료 용도를 갖는다. 이러한 장애는 치료 유효량의 항-aPC 모노클로날 항체를 이러한 장애의 치료가 필요한 환자에게 투여함으로써 치료될 수 있다. 모노클로날 항체는 또한 외상 및 출혈성 졸증(stroke)과 같은 적응증에서 제어되지 않는 출혈의 치료에서 치료 용도를 갖는다. 따라서, 또한, 치료 유효량의 본 발명의 항-aPC 모노클로날 항체를 출혈 시간을 단축시킬 필요가 있는 환자에게 투여하는 것을 포함하는, 출혈 시간을 단축시키는 방법이 제공된다.
다른 구체예에서, 항-aPC 항체는, 예를 들어 aPC가 패혈증 또는 출혈장애의 치료에 사용된 것을 포함하여 aPC 처치 환자를 위한 해독제로서 유용할 수 있다.
항체는 지혈 장애를 해결하기 위해 단일요법으로서 또는 다른 요법과 조합되어 사용될 수 있다. 예를 들어, 하나 이상의 항체 및 혈액 응고 인자, 예컨대 Factor VIIa, Factor VIII 또는 Factor IX의 동시 투여는 혈우병 치료에 유용하다고 여겨진다. 일 구체예에서, (a) 인간 조직 인자 경로 저해제에 결합하는, 제1 양의 모노클로날 항체, 및 (b) 제2 양의 Factor VIII 또는 Factor IX를 투여하는 것을 포함하고, 여기서 상기 제1 및 제2 양은 함께 응고에 있어서의 유전적 및 후천적 결핍 또는 결함의 치료에 효과적인, 응고에 있어서의 유전적 및 후천적 결핍 또는 결함을 치료하는 방법이 제공된다. 또다른 구체예에서, (a) 인간 조직 인자 경로 저해제에 결합하는, 제1 양의 모노클로날 항체, 및 (b) 제2 양의 Factor VIII 또는 Factor IX를 투여하는 것을 포함하고, 여기서 상기 제1 및 제2 양은 함께 응고에 있어서의 유전적 및 후천적 결핍 또는 결함의 치료에 효과적이고, 추가로 여기서 Factor VII은 동시 투여되지 않는, 응고에 있어서의 유전적 및 후천적 결핍 또는 결함을 치료하는 방법이 제공된다. 본 발명은 또한 모노클로날 항체 및 Factor VIII 또는 Factor IX의 치료 유효량의 조합물을 포함하고 Factor VII은 함유하지 않는 약학적 조성물을 포함한다. "Factor VII"는 Factor VII 및 Factor VIIa를 포함한다. 이러한 조합 요법은 혈액 응고 인자의 필요한 주입 빈도를 감소시킬 수 있다. 동시 투여 또는 조합 요법은, 각각 별도로 제제화되거나 하나의 조성물 중에 함께 제제화된 2종의 치료 약물의 투여를 의미하고, 별도로 제제화된 경우에는 대략 동일한 시간에 또는 상이한 시간이지만 동일한 치료 기간에 걸쳐서 투여된다.
일부 구체예에서, 본 원에 기술된 하나 이상의 항체들은 지혈 장애를 해결하기 위해 조합하여 사용할 수 있다. 예를 들어, 본 원에 기술된 2 이상의 항체의 동시투여는 혈우병 또는 다른 지혈 장애를 치료하는데 유용할 것이다.
약학적 조성물은 혈우병 A 또는 B로 고통받는 대상에게 출혈 증상의 중증도에 따라 달라질 수 있거나 예방 요법의 경우에는 환자의 혈액 응고 결핍의 중증도에 따라 달라질 수 있는 투여량 및 빈도로 비경구 투여될 수 있다.
상기 조성물은 필요에 따라 볼루스로서 또는 연속 주입에 의해 환자에게 투여될 수 있다. 예를 들어, Fab 단편으로 제공되는 본 발명의 항체의 볼루스 투여는 0.0025 내지 100 mg/kg 체중, 0.025 내지 0.25 mg/kg, 0.010 내지 0.10 mg/kg 또는 0.10 내지 0.50 mg/kg의 양일 수 있다. 연속 주입의 경우, Fab 단편으로 제공되는 본 발명의 항체는 0.001 내지 100 mg/kg 체중/분, 0.0125 내지 1.25 mg/kg/분, 0.010 내지 0.75 mg/kg/분, 0.010 내지 1.0 mg/kg/분 또는 0.10 내지 0.50 mg/kg/분으로 1시간 내지 24시간, 1시간 내지 12시간, 2시간 내지 12시간, 6시간 내지 12시간, 2시간 내지 8시간, 또는 1시간 내지 2시간의 기간 동안 투여될 수 있다. 전장 항체 (완전 불변 영역을 가짐)로 제공되는 본 발명의 항체를 투여하는 경우, 투여량은 약 1 내지 10 mg/kg 체중, 2 내지 8 mg/kg, 또는 5 내지 6 mg/kg일 수 있다. 이러한 전장 항체는 전형적으로 30분 내지 3시간의 기간 동안 지속되는 주입을 통해 투여된다. 투여 빈도는 상태의 중증도에 따라 달라진다. 빈도는 1주 당 3회 내지 매 2주 내지 6개월 마다 1회의 범위일 수 있다.
추가로, 조성물은 피하 주사를 통해 환자에게 투여될 수 있다. 예를 들어, 10 내지 100 mg 투여량의 항-aPC 항체가 매주, 격주 또는 매달 피하 주사를 통해 환자에게 투여될 수 있다.
본 원에서 사용된 바와 같이, "치료학적 유효량"은 생체내 혈액 응고 시간을 효과적으로 증가시키거나 또는 필요한 환자에게 생체내 측정가능한 이점을 야기하는데 요구되는, 항-aPC 모노클로날 항체 또는 이러한 항체 및 Factor VIII 또는 Factor IX의 조합물의 양을 의미한다. 정확한 양은 치료 조성물의 성분 및 물리적 특징, 의도된 환자 집단, 개개의 환자의 고려사항 등을 포함하지만 이에 제한되지 않는 수많은 인자에 따라 달라질 것이고 당업자가 쉽게 결정할 수 있다.
실시예
본 명세서의 측면은 이하의 실시예에 의해 더욱 잘 이해될 수 있으며, 실시예는 본 발명의 범위를 어떠한 방법으로도 제한하는 것으로 이해되지 않아야 한다.
실시예
1 재료 및 방법
인간 aPC 특이적 바인더의 스크리닝
마스터 플레이트의 제조: 패닝 전략 당 1880 클론을 성장 배지(2XYT/1% 글루코스/100μg/ml 카베니실린(Carbenicillin))를 함유하는 384 웰 플레이트 (ThermoFisher Scientific, Weltham, MA USA)에 Qpix2(Genetix, Boston, MA USA) 콜로니 픽커(picker)를 사용하여 채취하여 마스터 플레이트를 제조하였다. 플레이트를 밤새 37 ℃에서 진탕하면서 배양하였다.
발현 플레이트의 제조: Evolution P3 액체 핸들러(Perkin Elmer, Waltham, MA, USA)를 사용하여 마스터 플레이트의 배지 5 μl를 발현 배지(2XYT/0.1% 글루코스/100 ug/ml Carb)를 함유하는 384 웰 플레이트에 옮겨 30 ℃에서 인큐베이션하였다. 배양물의 OD 600이 0.5가 되었을 때 IPTG를 0.5 mM의 최종 농도로 첨가하였다. 이후, 플레이트를 밤새 배양에서 30 ℃로 회복하였다.
프라이머리 ELISA: Maxisorp 384 웰 플레이트(ThermoFisher Scientific, Rochester, NY USA)를 Ca/Mg를 갖는 DPBS 중의 재조합 인간 aPC 또는 인간 PC(Mol. Innovation) 1 μg/ml로 코팅하여 4 ℃에서 밤새 인큐베이션하였다. 코팅된 ELISA 플레이트를 DPBST(PBS+0.05% TWEEN)로 3회 세척하고 MDPBST(PBS+0.05% TWEEN+5% Milk)로 1hr 동안 RT에서 차단하였다. 차단된 플레이트를 흡인하고 15 μl 발현배지와 30 μl MDPBST를 각 웰에 옮겼다. ELISA 플레이트를 실온에서 1hr 동안 인큐베이션한 후 DPBST로 5회 세척하였다. 항-hFab-HRP (Jackson ImmunoResearch, 1:10,000 희석/DPBST)를 각 웰에 첨가하여 1hr 동안 실온에서 인큐베이션하였다. 이후, 플레이트를 DPBST로 5회 세척하였다. Amplex Red(Invitrogen) 기질을 첨가하고 플레이트를 485 nm의 여기와 595 nm의 방출에서 판독하였다.
확인 ELISA: Qpix2 콜로니 픽커를 사용하여, 추정 양성 클론을 마스터 플레이트로부터 1 ml 성장 배지를 함유하는 96 딥(deep)-웰 플레이트(Qiagen)에 재배열하여 밤새 37 ℃에서 배양하였다. 발현 플레이트를 마스터 플레이트로부터 접종하여 배양물의 OD600이 0.5에 이르면 IPTG로 0.5 mM의 최종 농도를 유도하였다. 이후, 위에 요약된 바와 같이 발현 배지에 대해 ELISA를 수행하였다.
비오틴화
(
biotinylated
) aPC를 사용한 라이브러리 선택(용액 중
패닝
)
두 가지 방법을 수행하였다: PC 바인더의 고갈(depletion) 및 전체 PC 및 aPC 바인더의 비고갈. Dynabeads M280 스트렙타비딘(Streptavidin)을 100 nM 비오틴-TF (조직인자, 비고갈용) 또는 100 nM 비오틴-PC (고갈)에 결합하여 마그네틱 장치로 캡쳐하였다. 1-7.5x1012 cfu Fab 라이브러리 파지(phage)를, DPBS/3%BSA/0.05% TWEEN 20으로 사전 차단하여, 비오틴-TF 또는 비오틴-PC 결합 스트렙타비딘 비즈(beads)와 함께 로테이터(rotator)에서 실온으로 2시간 동안 인큐베이션하였다. 비오틴-TF (비고갈) 또는 비오틴-PC (고갈)/스트렙타비딘 비즈를 캡쳐하여 폐기하였다. 얻어진 파지 상청액을 1ml DPBS/3%BSA/0.05% TWEEN 20/1mM CaCl2 중의 100 nM (제1 라운드), 50 nM (제2 라운드) 또는 10 nM (제3 라운드) 비오틴-aPC와 2시간 동안 RT에서 또는 40 ℃에서 밤새 인큐베이션하였다. 100ul의 스트렙타비딘 결합 마그네틱 비즈를 파지-aPC 용액에 첨가하고 30분 동안 실온에서 인큐베이션하였다. 파지-aPC 컴플렉스 비즈를 마그네틱 장치에 캡쳐하여 패닝 라운드에 따라 3% BSA 또는 0.05% TWEEN 20을 갖는 DPBS로 여러 번 세척하였다. 결합된 파지를 1mg/ml의 트립신으로 용출하고 아프로티닌(aprotinin)으로 중화하였다. 이후, 용출된 파지를 사용하여 10 ml의 기하급수적으로 성장하는 E. coli HB101F'를 감염하여 다음 라운드의 선택을 위해 증폭하였다. 파지 원액을 CFU 적정(패닝 출력물)으로 분석하였다.
고정화 aPC를 사용한 라이브러리 선택(고체상
패닝
)
5웰의 Maxi-sorp 96-웰 플레이트를 DPBS 중의 400 ng/well 재조합 aPC로 4 ℃에서 밤새 코팅하였다. 용액 중 패닝과 같은 파지 라이브러리를 비고갈용 비오틴-TF 또는 고갈용 비오틴-PC로 사전 처리하였다. 이후, 얻어진 파지를 aPC 코팅된 웰에 첨가하여 진탕기로 1-2 시간 동안 실온에서 인큐베이션하였다. 결합되지 않은 파지를 패닝 라운드에 따라 3% BSA 또는 0.05% TWEEN 20을 갖는 DPBS로 여러 번 세척하여 제거하였다. 결합된 파지를 1mg/ml의 트립신으로 용출하고 아프로티닌으로 중화하였다. 이후, 용출된 파지를 사용하여 10 ml의 기하급수적으로 성장하는 E. coli HB101F'를 감염하여 다음 라운드의 선택을 위해 증폭하였다. 파지 원액을 CFU 적정(패닝 출력물)으로 분석하였다.
선택된 파지 풀(pool)의 증폭: 용출된 파지 원액을
HB101F
'에서 선택 라운드 2, 3 및 4에서
헬퍼
파지
M13K07을
사용하여 증폭하였다.
10 ml 부피의 기하급수적으로 성장하는 HB101F'을 선택의 각 라운드로부터의 용출 파지로 감염하고 37 ℃에서 45분 동안 50 rpm으로 인큐베이션하였다. 이후 박테리아를 2xYT 배지에 재현탁하고 100 μg/ml 카보시닌(carbocinin), 15 μg/ml 테트라사이클린 및 1% 글루코스를 함유하는 2개의 15 cm 아가 플레이트에 도포하여 30 ℃에서 밤새 인큐베이션하였다. 플레이트로부터 박테리아를 총 8 ml 2xYT/carb/ tet으로 수집하였다.
약 10 μl의 세포를 10 ml의 2xYT/carb/tet (OD600은 약 0.1-0.2)에 재현탁하고 OD600이 0.5-0.7에 이를 때까지 37 ℃에서 인큐베이션하였다. 5x1010cfu의 M13K07 헬퍼 파지를 세포에 첨가하여 45분 동안 37 ℃에서 인큐베이션하였다. 이후, 감염된 세포를 15 ml의 새로운 2xYT/carb/카나마이신 (50 μg/ml)/tet에 재현탁하고 밤새 30 ℃에서 진탕하여 파지를 생산하였다. 원심분리와 0.45 μm 필터에 의한 여과로 파지 상청액을 모았다. 900 μl의 상청액을 다음 라운드의 선택에서 사용하였다.
aPC 항체의 DNA 서열화 분석
표준 분자 생물학 방법을 사용하여 플라스미드를 제조하였다. 다음 프라이머들을 선택된 항체 클론의 DNA 서열화에 사용하였다.
a)
프라이머 A: 5’ GAAACAGCTATGAAATACCTATTGC 3’
b)
프라이머 B: 5’ GCCTGAGCAGTGGAAGTCC 3’
c)
프라이머 C: 5’ TAGGTATTTCATTATGACTGTCTC 3’
d)
프라이머 D: 5’ CCCAGTCACGACGTTGTAAAACG 3’
혈장으로부터 단백질 C의 정제
1리터의 개 또는 래빗 혈장을 항응고제로서 포함된 헤파린을 갖는 20x50ml의 동결된 원액(Bioreclamation, Inc., Westbury, NY)으로 구입하였다. 정제방법은 Esmon의 랩(lab)(12)에 의해 기술되었으며, 변형을 갖는다. 혈장을 4 ℃에서 해동하고, 0.02M Tris-HCl, pH7.5, 헤파린 1U/ml(최종), 벤즈아미딘 HCl 10mM(최종)로 RT에서 1:1로 희석하여 단백질 C와 다른 비타민 K-의존성 단백질을 캡쳐하기 위한 Q-Sepharose 컬럼에 적재하였다. 컬럼을 완충된 0.15M NaCl로 세척하고, 단백질 C를 완충된 0.5M NaCl로 용출하였다. 용출액을 10mM Ca++와 100U/ml 헤파린으로 재칼슘경화(recalcify)한 다음, HCP4-Affigel-10 친화성 컬럼에 적재하였다. 컬럼을 Ca 함유 완충액으로 세척하고 EDTA 함유 완충액으로 용출하였다. 정제된 PC를 밤새 PBS 완충액에 투석하고, 급속 냉동하여 -80에서 0.5 ml 분액으로 저장하였다. 정제 수율은 1리터의 개 혈장으로부터 1.75mg이었다. 정제된 PC는 SDS-PAGE와 분석 SEC로 측정했을 때 98%의 순도를 가졌다.
Fab
발현 및 정제
Fab 발현에 있어서, 5·lsFab E. coli 글리세롤 원액을 1 ml 성장배지(LB, 1% 글루코스, 100·g/ml 암피실린)에 접종하고 배양물을 250 rpm으로 진탕하면서 37 ℃에서 밤새 배양하였다. 오버나이트 배양물 500·l를 10 ml의 예열된(37 ℃) 인덕션 배지(LB, 0.1% 글루코스, 100·g/ml 암피실린)에 접종하여 37 ℃에서 OD500 0.6-0.7까지 250 rpm으로 배양하였다. IPTG를 배양물에 0.5 mM 최종 농도로 Fab 발현을 위해 첨가하고, 배양물을 250 rpm으로 진탕하면서 30 ℃에서 밤새 배양하였다. 다음날, 오버나이트 배양물을 3,000g으로 15 분 동안 4 ℃에서 원심분리하여 배지와 세포를 분리하였다. 상청액과 펠렛을 Fab 정제를 위해 저장하였다. 상청액과 펠렛 모두에서 Fab 발현을 항-His 항체를 사용하는 웨스턴 블롯 분석으로 확인할 수 있다.
Fab 정제에 있어서, 단백질 A 컬럼(MabSure)을 BioInvent 프로토콜이 추천한 바와 같이 사용하였다. 상청액을 0.45 um 필터로 여과하여 찌꺼기를 제거하고 완전(complete) 프로테아제 저해제 정제(Roche 11873580001)와 혼합한 후, 완충액으로 평형시킨 단백질 A 컬럼에 적재하였다. Fab를 pH 2-3 완충액, 다음으로 완충액 교환 PBS, pH 7.0으로 용출하였다. Fab가 세포 펠렛에서 분리되도록 1 ml 용균 완충액을 펠렛에 첨가하였다. 혼합물을 1h 동안 용균을 위해 4℃로 로킹 플랫폼(rocking platform)에서 인큐베이션한 후, 3,000 g으로 30 분 동안 4 ℃에서 원심분리하였다. 투명한 상청액을 새로운 튜브에 옮겨서 단백질 A 컬럼에 적재하였다. 용균 완충액은 차가운 슈크로스 용액(20% 슈크로스 (w/v), 30 mM TRIS-HCL, 1 mM EDTA, pH 8.0) 중의 새로 제조된 1 mg/ml 라이소자임 (Sigma L-6876), 2.5 U/ml 벤조나제(benzonase)(Sigma E1014) (25 KU/ml, 원액 1/10.000), 및 완전 프로테아제 저해제 (Roche 11873580001) 1정을 함유한다. 정제된 Fab의 순도는 SDS-PAGE와 분석용 크기배제 크로마토그래피(SEC)로 확인하였다. 내독소 농도 또한 관찰하였다.
PC 및 aPC의
웨스턴
블롯
분석
정제된 단백질(100ng/레인)을 DTT가 있거나(환원성) DTT가 없는(비환원성) 4x SDS-PAGE 로딩 염료와 혼합하여 95 ℃에서 5분 동안 가열한 후, 4-12% NuPAGE 겔에 적재하였다. 단백질을 i-Blot (Life technologies, Carlsbad, CA)에 의해 니트로셀룰로스 막으로 옮겼다. 탐침 단계를 SNAP-id (Millipore)로 수행하였다. 5% 밀크/PBS로 10분 동안 차단한 후, 막을 다양한 시료(예를 들어, 비오틴화 aPC 검출을 위한 스트렙타비딘-HRP, 마우스 항-인간 PC 모노클로날 항체 HCP-4 및 개 aPC 검출을 위한 항-PC 염소 폴리클로날 항체)와 인큐베이션하였다. 탐침한 후, HRP 2차 항체와 10분 동안 실온에서 인큐베이션하였다. 블롯을 0.1% TWEEN-20을 갖는 PBS로 세척한 후, HRP의 시그널을 화학발광 기질(ECL) (Pierce, Rockford, IL) 및 x-선 필름 노출을 사용하여 검출하였다.
Fab
ELISA
항원 단백질(인간 PC, 인간 PC, 마우스 APC, 개 APC)을 ELISA 플레이트에 100ng/100ul/웰(PBS/Ca 완충액(Life technologies))로 밤새 4 ℃에서 코팅하였다. 다음날, 플레이트를 3x 세척하고 5% PBS/Ca/BSA/Tween20으로 1h 동안 RT에서 차단하였다. 가용성 Fab를 각 웰에 첨가하여 1 h 동안 RT에서 인큐베이션하였다. 항-인간 람다(lambda)-항체-HRP를 검출 항체로서 첨가한 후, 플레이트를 실온에서 1 hr 동안 인큐베이션하고, 충분히 세척한 후 Amplex Red 기질을 사용하여 키트 제조업체가 기술한 바에 따라 현상하였다. 시그널을 RFU로서 형광 플레이트 판독기(SpectraMax 340pc, Molecular Devices, Sunnyvale, CA)를 사용하여 측정하였다. 표준 곡선을 4-파라미터 모델에 대해 최적화하고, 미지물의 값을 곡선으로부터 추정하였다.
실시예
2. 라이브러리로부터 aPC 항체의
패닝
인간 활성화 단백질 C에 대한 전체 인간 Fab 항체 라이브러리의 패닝과 스크리닝을 실시예 1에 기술된 방법을 사용하여 수행하였다. DNA 서열화를 양성 항체 클론에 대해 수행하여 10개의 고유한 항체 서열을 얻었다. 항체의 중쇄 및 경쇄 배열을 도 2에 나타내었다. 동일한 중쇄 CDR3 서열을 5 Fab (C7I7, C7A23, T46J23, C22J13, C25K23)에서 확인하였다.
정제된 Fab를 작용성 어세이 패널로 특성화하여 다음을 평가하였다: a) 이들의 결합 특이성(aPC vs. PC); 결합 친화도(ELISA 및 Biacore); 및 종 교차 반응성(즉, 사람, 개 및 마우스를 포함한 상이한 종 기원의 aPC에 대한 결합). 래빗 aPC는 또한 나중에 IgG 포맷에서 사용하였다; b) 다른 비타민 K-의존성 응고인자(예를 들어, FIIa, FVIIa, FIXa, FXa)에 대한 이들의 결합 선택성; c) 혈장 응고 어세이 aPTT에서 aPC의 항-응고 활성을 저해하는 이들의 능력; 및 d) (작은 펩티드 기질에 대한)아미드분해 활성 어세이 및 (단백질 기질 FVa에 대한)FVa 불활성화 어세이를 사용한 완충액 중 aPC의 프로테아제 효소 활성에 대한 이들의 효과.
실시예
3 aPC 특이적 항체의 결합 친화도 및 종-교차반응성
이러한 정제된 항-aPC Fab의 항원 결합 활성을 도 3에 나타낸 바와 같이 직접 ELISA에 의해 측정하였다. 항원을 ELISA 플레이트에 직접 코팅하였다. 코팅 항원은 100ng/웰(PBS/Ca 완충액)의 인간 PC (혈장 유도성), 인간 aPC (재조합), 개 aPC (혈장 유도성), 및 마우스 aPC(재조합)를 포함하였다. 플레이트를 5% 밀크/PBS로 차단하여 PBS-Tween20으로 세척한 후, 가용성 Fab (1 ug/ml, 20 nM)를 플레이트에 첨가하고 진탕하면서 1 h 동안 RT에서 인큐베이션하였다. Fab 결합을 항-인간 Fab (람다) 항체-HRP 및 Amplex red를 기질로 사용하여 검출하였다. ELISA 데이터는 모든 Fab가 인간 PC가 아니라 인간 aPC에 특이적으로 결합하는 것임을 나타내었다. 하나의 Fab, R41C17이 인간 PC에 대해 최소한의 결합을 나타냈다. 이에 비해, R41C17은 인간 APC 및 인간 PC 모두에 결합하였다. 또한, 도 3에 ELISA에 의한 Fab의 종-교차 반응성을 나타냈다. 8개 aPC 특이적 바인더 중에서 4개(C7I7, C7A23, C25K23, T46J23)도 개 aPC와 교차 반응성을 나타냈고, 하나의 Fab, T46J23은 마우스 aPC와 어느 정도의 결합을 나타냈다.
표 3에 ELISA로 측정된 항-aPC 항체와 인간 aPC 및 개 aPC의 EC50을 기재하였다.

항-aPC Fab의 친화도를 Biacore에 의해 측정하여 표 4에 기재하였다.

실시예
4 항
-aPC
Fab의
결합 선택성
이러한 fab의 결합 선택성을 결정하기 위해 프로효소 인간 PC, 트롬빈 (FIIa), 및 활성화 Factor II (FIIa, 트롬빈), Factor VII (FVIIa), Factor IX (FIXa), 및 Factor X (FXa)에 대한 이들의 결합 활성을 ELISA로 평가하였다. 요약하면, ELISA 플레이트를 1 ug/ml의 인간 aPC, 10 ug/ml의 마우스 PC, 10 ug/ml의 개 PC, 5-10 ug/ml의 다른 응고인자들(FIIa, FVIIa, FIXa, FXa)로 코팅하였다. 항-aPC Fab를 웰에 20 nM(1 ug/ml)로 첨가하였다. 결합된 Fab를 제2 항체(항-인간 Fab-HRP), 이어서 HRP 기질 AmplexRed로 검출하였다. 양성 대조군으로서, 각 항원에 특이적인 대조용 항체를 사용하여 코팅 항원이 존재하는 것을 증명하였다.
도 4에서 보이는 바와 같이, 20 nM의 농도까지 어떠한 Fab도 Factor IIa, VIIa, IXa, 또는 Xa에 대한 결합을 나타내지 않았다. 프로효소 마우스 PC 또는 개 PC에 대한 결합 또한 검출할 수 없었다.
실시예
5 aPC를 저해하고 정상 인간 혈장에서 응혈을 유발하는 항-aPC
인간 aPC는 잠재적인 항응고제이며, 이러한 작용은 도 5에 나타낸 혈장 응고 어세이(aPTT)로 용이하게 증명할 수 있다. aPTT 어세이에서, 50% 정상 인간 혼주(pooled) 혈장은 혈장과 인지질의 혼합물에 CaCls (개시제)를 첨가했을 때 52초 내에 응집을 형성하였다. 인간 aPC를 100, 200, 400, 800, 또는 1600 ng/ml로 혈장과 사전 인큐베이션하여 응혈시간을 용량 의존적 방식으로 연장하였다. 도 5에서 보이는 바와 같이, 거의 동일한 효능이 혈장 유도성 aPC와 재조합 aPC에서 얻어졌다. Stago 기기에서 응고 시간의 최대 설정이 240초이기 때문에, 이러한 작용 어세이에서 인간 aPC의 항응고 활성은 800 ng/ml의 aPC에서 그의 최대값에 이르렀다.
aPC의 항응고 활성에 대한 항-aPC Fab의 잠재적인 저해효과를 평가하기 위해 400 ng/ml aPC를 aPTT 어세이에서 양호한 어세이 범위로 사용하였다(도 6). 혈장 응고시간은 투여된 aPC의 항응고 활성으로 인하여 52초에서 180초로 늘어났다. 툴(tool) 마우스 항-인간 APC 항체 (대조군) 또는 그의 Fab (대조용-Fab) 또는 Fab C7A23를 0, 0.5, 1, 2, 5, 10, 또는 20ug/ml로 aPC (즉, aPC보다 1.5x 내지 60x 배 과량의 Fab)와 인큐베이션하여 응고시간을 용량 의존적 방식으로 감소하였다. Fab C7A23는 인간 aPC의 항응고 활성을 반전(reverse)하는데 있어서 대조용-Fab보다 4-5배 더 강력하였다. 이에 비해, 음성 대조용 Fab(인간 Fab 람다)는 응고시간에 대한 효과를 나타내지 않았다. 도 6에서, 전장 대조용 항체(2가)는 aPTT 어세이에서 대조용-Fab (일가)보다 10배 더 강력하다. 이 결과는 직접 ELISA에서 aPC 결합에 대한 이들의 EC50값 [대조군 (0.56nM) vs. 대조용-Fab (6.56 nM)]과 일치한다(결과 미기재). 따라서, 항-aPC Fab가 IgG 포맷으로 전환되었을 때 더 강력한 분자임을 시사하였다. aPTT 결과, 항-aPC Fab가 aPC의 항응고 활성을 상당히 저해하고 응고시간을 단축하는 것으로 나타났다. 모든 시험된 Fab는 혈장 응고 어세이 aPTT에서 대조용-Fab와 비교하여 평가하였다(도 6). 도 6의 상부 그래프에서 비특이적 인간 Fab는 음성 대조군으로 사용되었고, 이것은 예상대로 응고시간에 영향을 미치지 않았다. 양성 대조군(대조군과 대조용-Fab)은 용량 의존적 방식으로 응고시간을 단축하였다.
Fab C7A23, C7I7, C25K23, T46J23, 및 T46P19 5 ug/ml(스파이크인(spiked-in) aPC에 대해 15배 몰 과량)는 인간 aPC 활성의 80-93% 저해를 유발하고 응혈을 증가하였다. 이들은 대조용-Fab보다 훨씬 더 강력하였다. 이에 비해, 동일한 조건 하에서 Fab R41E3만이 aPC 활성을 30-40% 저해하였다. aPTT에서 R41E3의 약한 활성은 마찬가지로 ELISA와 Biacore로 측정된 바와 같이 aPC 결합에 대한 그의 낮은 친화도 때문이다. R41E3 Fab 농도가 40ug/ml(aPC에 대해 100배 몰 과량)로 증가하는 것은 실제로 도 6의 하부 그래프에서 보이는 바와 같이 인간 aPC의 80% 저해를 유발하였다. 또한, 고용량(40ug/ml)의 C22J13 Fab는 인간 aPC의 80% 저해를 생성하였다. Fab C26B9는 이 어세이에서 대조용-Fab보다 더 강력하였다. 하부 그래프에서, Fab R41C17은 aPC 활성에 대해 어떤 효과도 갖지 않았는데, 왜냐하면 이것은 PC와 aPC 모두에 결합하고 인간 혈장 내에 aPC보다 1000배 이상 더 많은 PC가 있기 때문이다. 이러한 데이터는 또한 Fab R41C17이 다른 Fab 유래의 상이한 결합 에피토프를 가지는 것을 시사한다.
종 aPC ELISA 데이타로 표시된 바와 같이, 4 Fab(C7A23, C7I7, C25K23, T46J23)는 또한 개 aPC와 나노몰 친화도로 결합하며, 이러한 Fab를 aPTT에 의해 도 7에 나타낸 바와 같이 50% 혼주 인간 정상 혈장에 스파이크된 개 aPC를 사용하여 평가하였다. 개 aPC는 aPTT에 의해 인간 aPC와 동일한 항응고 활성을 나타냈다(데이터 미기재). 300 ng/ml의 개 aPC는 응고시간을 47초에서 117초로 증가시켰다. 대조용 항체 또는 대조용-Fab 0, 0.5, 1, 2, 5, 10, 또는 20 ug/ml와 개 aPC의 인큐베이션은 응고시간에 영향을 미치지 않았으며, 왜냐하면 ELISA에 의하면 이들이 개 aPC와 교차반응하지 않았기 때문이다. 그러나, Fab C7A23은 응고시간을 용량 의존적 방식으로 상당히 감소하였고 개 aPC 활성을 5 ug/ml로 80% 또는 20 ug/ml로 85%까지 저해하였다. 게다가, C7A23은 aPTT 어세이에서 인간 aPC와 개 aPC를 차단하는데 비슷한 효능을 나타냈다. Fab C7A23, C717, C25K23은 명백하게 개 aPC 활성을 용량 의존적 방식으로 저해하였다. 20 ug/ml Fab 농도에서, 3 Fab는 aPC의 80-90% 저해를 유발하였고 응고시간을 단축하였다. Fab T46J23은 고용량으로 단지 40% 저해만을 나타내었고, ELISA 및 Biacore에 의하면 C7A23, C7I7, C25K23 (KD=1-5nM)보다 개 aPC에 대한 그의 약한 결합(KD=22 nM)과 일치한다. 이에 비해, Fab T46P19와 R41E3은 예상된 바와 같이 APTT에서 개 aPC에 대해 어떤 효과도 없었으며, 왜냐하면 이들은 ELISA에 의하면 개-aPC와 결합할 수 없기 때문이다.
실시예
6 aPC의 효소활성에 대한 항-aPC
Fab의
효과
활성화 단백질 C는 세린 프로테아제이다. 그의 촉매활성은 다음 2가지 방법으로 측정할 수 있다: a) 작은 펩티드 기질을 사용한 아미드분해 활성 어세이, 및 b) 생리적 단백질 기질 FVa를 사용한 FVa 분해 어세이.
인간 aPC의 아미드분해 활성을 완충액 중 aPC의 발색성 펩티드 기질을 사용하여 조사하였다. 10 nM의 정제된 aPC 단백질을 발색성 기질 SPECTROZYME Pca (Lys-Pro-Arg-pNA, MW 773.9 Da) 1 mM과 30분 동안 인큐베이션하였다. 기질의 비색성 생성물로의 전환(즉, aPC의 효소 활성)을 매 5분마다 OD450을 동역학적으로 판독하여 관찰하였다. 재조합 인간 aPC로 표준 곡선을 생성하였다. aPC의 아미드분해 활성에 대한 항-aPC Fab의 효과를 시험하기 위해(도 8), 정제된 aPC 단백질(20 nM)을 먼저 동일 부피의 항-aPC Fab (1-1000 nM)와 RT에서 20분 동안 사전 인큐베이션한 다음, 발생성 기질 SPECTROZYME Pca를 반응 혼합물에 1 mM까지 첨가하였다. 최종 농도 10 nM의 인간 aPC의 아미드분해 활성을 Fab 존재 하에 측정하였다. 1 mM의 최종 기질 농도에서의 가수분해 속도는 Fab 존재 하에서 부분적으로 저해되어 80%의 최대 감소에 달하였다. R41C17을 제외한 모든 Fab는 aPC를 용량 의존적 방식으로 저해하였다. 고친화도 바인더(C7I7, C7A23, T46P19, T46J23, C25K23)는 이 어세이에서 나머지 약한 바인더(R41E3, C22J13, C26B9)보다 훨씬 더 빠른 저해를 나타내기 때문에 ELISA 결합 어세이에서 IC50은 EC50과 관련이 있다. 그러나, 약한 바인더에서 Fab의 농도 증가는 또한 최대 저해를 생성하였다. 예를 들어, R41E3 3,000 nM는 aPC 활성의 약 80% 저해를 생성하고, 동일 범위의 저해는 100 nM의 고친화도 바인더에 의해 얻어졌다. 따라서, 대부분의 바인더는 그의 아미드분해 활성의 저해를 유발하는 aPC의 활성부위와 상호작용하였다. 흥미롭게도, 대조용 항체는 aPC의 부분적 저해(40%)를 유발하여 100 nM 초과의 농도에서 안정기(plateau)에 이르렀다. R41C17 Fab의 농도를 증가했을 때 저해효과는 관찰되지 않았다. 인간 aPC에 대한 그의 결합 친화도가 Biacore에 의한 4.8 nM의 KD값을 갖는 고친화도 바인더와 비슷하기 때문에 이러한 데이터는 R41C17이 aPC의 효소 활성부위에서 상당히 떨어진 결합 에피토프를 가지는 것을 나타낸다.
인간 aPC의 FVa 불활성화 활성은 인간 aPC (180 pM)를 그의 생리학적 단백질 기질 FVa (1.25 nM)와 인큐베이션한 다음, FXa와 프로트롬빈을 반응 혼합물에 첨가하여 프로트롬비나제(prothrombinase) 컴플렉스를 형성하여 측정할 수 있다. 트롬빈의 발생성 펩티드 기질을 첨가하여 트롬빈 생성을 검출하였다(도 9). 판독물이 트롬빈 생성물이다(FIIa/sec). 정제된 Factor Va(1.25nM)를 Fab(1-500 nM)의 농도 범위 하에 aPC (180pM)와 인큐베이션하였고, FVa 활성을 프로트롬비나제/테나제 어세이에서 평가하였다.
생물학적 기질 FVa에 대한 aPC 활성에서 Fab의 영향을 FXa- 및 트롬빈-생성 어세이에 의해 정제된 FVa를 사용하여 측정하였다. 이 어세이에서, FVa 0.16 U/ml (1.25 nM)를 어세이 완충액(20 mM TrisHCl, 137 nM NaCl, 10 ug/ml 인지질, 5 mM CaCl2, 1 mg/ml BSA)중의 aPC 180 pM과 항체의 존재 또는 부재 하에 인큐베이션하였다. 30분 동안 인큐베이션한 후, 25 ul의 혼합물을 웰에 옮겼다. 이어서, 어세이 완충액 중의 50 ul 인간 FXa와 프로트롬빈을 웰에 첨가하고 트롬빈-매개 기질 가수분해의 동역학을 30 ℃에서 플레이트 판독기를 사용하여 관찰하였다. aPC 활성의 기저선으로서, 첨가된 Fab 부재 하에, aPC의 인큐베이션은 판독물을 0.0022 nM FIIa/sec에서 0.0015 nM FIIa/sec로 변화하였다.
Fab를 반응 혼합물에 첨가하므로써 FVa의 aPC 매개 단백질 가수분해의 거의 완전한 저해와 용량 의존적 방식의 트롬빈 생성의 급속한 증가가 발생하였다. 도 9에서 보이는 바와 같이, aPC에 의한 FVa의 단백질 가수분해 저해에 대한 IC50값은 나노몰 범위 내에 있고 시험된 모든 Fab에서 비슷하였다. 대부분의 Fab가 양성 대조용 Fab보다 더 강력하였다. R41E3는 인간 aPC에 대한 결합이 더 약하기 때문에 더 늦게 증가하였다. R41C17은 놀라웁게도 본 어세이에서 어느 정도의 활성을 나타냈다. 이 Fab는 작은 펩티드 기질을 사용했을 때 aPTT에 의한 aPC의 항응고 활성 또는 aPC의 아미드분해 활성에 대한 효과가 없었다. 이러한 데이터는 R4117 결합 에피토프가 다른 Fab와는 상당히 다르다는 것을 나타낸다.
실시예
7 항
-aPC
IgG의
발현 및 정제
모두 10개의 항-aPC Fab를 인간 IgG1으로 Fv 서열을 인간 IgG1 발현벡터에 클로닝하여 전환하였다. 플라스미드를 일과성 발현을 위한 HEK293 세포에 형질감염시켰다. 배양배지로 분비된 항체를 단백질 A 컬럼으로 정제하였다. 고수율 항체 T46J23-hIgG1은 200 ml 배양에서 10.3 mg을 생산하였다. 일부 항체는 200 ml 당 1 mg만 생산되었다. 내독소 농도 또한 관찰하였다(0.01 EU/mg 미만).
정제된 Fab와 마찬가지로, 정제된 IgG 모두를 작용성 어세이 패널로 특성화하여 다음을 평가하였다: a) 이들의 결합 특이성 및 결합 친화도; b) 종 교차 반응성(래빗 aPC를 포함한 상이한 종 기원의 aPC에 대한 결합); c) 아미드분해 활성 어세이를 사용한 종 aPC의 효소 활성에 대한 이들의 효과; 및 d) 인간 혈장과 마우스 혈장을 사용한 혈장 응고 어세이 aPTT에서 aPC의 항응고 활성을 저해하는 이들의 능력.
실시예
8 항
-aPC
IgG의
결합 특이성과 결합 친화도
도 10에 나타낸 바와 같이, ELISA에서는 대부분의 IgG 항체가 인간 PC보다 인간 aPC에 우선적으로 결합하기 때문에 Fab처럼 그의 결합 특이성을 유지하는 것으로 나타났다. 한편, R41C17과 O3E7은 인간 aPC 및 인간 PC 모두와 결합한다. 놀라웁게도, T46J23은 IgG로 Fab의 전환 후에 인간 PC 결합을 얻었다. ELISA에 의한 적정 실험에서는 또한, 일반적으로 이러한 2가 IgG1의 결합 친화도가 표 5에 나타낸 상응하는 일가 Fab와 비교하여 2-50배 증가되는 것으로 나타났다. 특히, 저친화도 Fab R41E3은 Fab-IgG 전환 후에 Fab에 대해 104 nM vs. IgG에 대해 1.76 nM의 EC50값으로 결합 친화도를 거의 50배 증가시켰다. 모든 IgG는 서브나노몰 및 낮은 나노몰 범위의 EC50값으로 인간 APC에 대한 고친화도 결합을 나타냈다. O3E7-IgG는 16.9 nM의 EC50값을 갖는 가장 약한 IgG이다.

도 10에 나타낸 바와 같이, 이러한 IgG의 종 교차반응성을 (a) 인간, (b) 래빗, (c) 개, (d) 마우스 aPC 및 PC를 사용하여 시험하였다. 10개의 항-인간 aPC IgG 중에서, 5개 IgG가 래빗 aPC에 높은 친화도(EC50 = 0.6 - 7 nM)로 결합하였으며, 래빗 PC에 대한 결합은 검출할 수 없었다. 이러한 5개 IgG는 또한 개 APC에 높은 친화도(EC50 = 1.7 - 10 nM)로 결합하였으며, 이들은 개 PC와는 결합하지 않았다. 5개 IgG 중 하나인 항체 T46J23은 또한 마우스 aPC와 6 nM의 EC50값으로 결합하였다. T46J23은 마우스 PC와는 결합하지 않았다.
실시예
9 아미드분해 활성
어세이를
사용한 완충액 중 종 APC의 효소 활성에 대한 항-APC
IgG의
효과
5개 종 교차반응성 IgG를 종 APC의 아미드분해 활성에 대한 이들의 효과에 대해 평가하였다(도 11). 인간 aPC 아미드분해 활성 어세이에서, 음성 대조용 IgG (항-CTX 항체)는 저해 효과를 갖지 않았다. 5개의 IgG는 모두 인간 aPC를 용량 의존적 방식으로 저해하였다. 이들의 IC50값은 T46J23-IgG는 18 nM; C22J13은 27 nM; C7I7은 64 nM; C7A23은 78 nM, 그리고 C25K23은 131 nM였다.
래빗 aPC 아미드분해 활성 어세이에서, 음성 대조용 IgG (항-CTX 항체)는 저해 효과를 갖지 않았다. 5개의 IgG는 모두 래빗 aPC를 용량 의존적 방식으로 저해하였다. 이들의 IC50값은 T46J23-IgG는 17 nM; C22J13은 24 nM; C7I7은 29 nM; C7A23은 25 nM, 그리고 C25K23은 74 nM였다.
개 aPC 아미드분해 활성 어세이에서, 음성 대조용 IgG (항-CTX 항체)는 저해 효과를 갖지 않았다. 5개의 IgG는 개 aPC를 용량 의존적 방식으로 약하게 저해하였다. 이들의 IC50값은 T46J23-IgG는 625 nM; C22J13은 1300 nM; C7I7은 147 nM; C7A23은 49 nM, 그리고 C25K23은 692 nM였다.
마우스 aPC 아미드분해 활성 어세이에서, T46J23만이 마우스 aPC를 저해하였으나, 고용량(1000 nM)을 필요로 하였다. C7I7과 다른 IgG는 마우스 aPC에 대해 작용하지 않았다. 이러한 항체들의 종 APC 활성에 대한 저해효과를 표 6에 요약하였다.

도 14(b)에 나타낸, 인간 aPC 아미드분해 활성 어세이에서, C25K23 IgG1의 두 개 변이체, 2310-IgG2 및 2312-IgG2는 정제 시스템에서 aPC의 강력한 저해를 나타냈다. C25K23 IgG1은 서열번호: 108에 기재한 경쇄와 서열번호: 109에 기재한 중쇄를 갖는다. TPP-2031은 변성 N54G를 포함하는 중쇄를 갖는 변성된 C25K23 IgG이다. 변이체 2310은 서열번호: 112에 기재된 변성 A10V, T13A, S78T, R81Q 및 S82A를 포함하는 경쇄 및 서열번호: 113에 기재된 변성 N54Q를 포함하는 중쇄를 갖는 변성된 C25K23 IgG이다. 변이체 2312는 서열번호: 116에 기재된 변성 A10V, T13A, S78T, R81Q 및 S82A를 포함하는 경쇄 및 서열번호: 117에 기재된 변성 S56A를 포함하는 중쇄를 갖는 변성된 C25K23 IgG이다. 이러한 변이체들은 또한 도 14(a)에 나타낸 바와 같이 aPC에 대해 높은 친화도를 보인다. TPP-2309는 서열번호: 110에 기재된 변성 A10V, T13A, S78T, R81Q 및 S82A를 포함하는 경쇄와 서열번호: 111에 기재된 변성 N54G를 포함하는 중쇄를 갖는 변성된 C25K23 IgG1이다.
실시예
10 aPC를 저해하고 정상 인간 혈장에서 응혈을 유도하는 항-aPC
IgG
aPC의 항응고 활성에 대한 항-aPC IgG의 효과를 먼저 인간 혈장 응고 어세이(aPTT)에서 시험하여 도 12에 나타내었다. 50퍼센트(50%)의 인간 혈장이 aPC 부재 하에서 50-52 초의 기저선 응고시간을 가졌다. aPC는 잘 알려진 항응고제이므로 인간 aPC를 혈장에 첨가하면 예상대로 응고시간이 190초로 증가하였다. 음성 대조용 IgG1 (항-CTX 항체)과 aPC의 사전 인큐베이션은 응고시간을 변화시키지 않았다. 이에 비해, aPC와 항-aPC 특이적 IgG의 사전 인큐베이션은 응고시간을 용량 의존적 방식으로 상당히 단축하였다. 1:1 몰 비율에서 T46J23-IgG와 C7I7-IgG 1 ug/ml은 둘 다 aPC의 ~50% 활성을 저해(400ng/ml에서)하였고 응고시간을 190초에서 114초로 단축하였다. 20ug/ml에서, 3개 항체들(T46J23, C7I7, C26B9)은 모두 aPC의 항응고 활성을 완전히 역전하였고 응고를 정상으로 회복시켰다. R41E3-IgG는 aPC를 저해하는데 있어서 3개 IgG보다 효능이 낮았다. R41E3는 부분적으로 응고시간을 75초까지 회복하였고, 163배 몰 과량에서 ~80%의 aPC 활성을 저해하였다.
항-aPC IgG의 변성된 변이체 효과를 도 14(c)에 나타낸 바와 같이 aPTT 어세이에서 시험하였다. 도 12의 결과와 마찬가지로, aPC와 변성된 항-aPC 특이적 IgG의 사전 인큐베이션은 응고시간을 용량 의존적 방식으로 상당히 단축하였다.
실시예
11 aPC를 저해하고 중증 혈우병 환자 혈장에서 응혈을 유도하는 항-aPC
IgG
aPC의 항응고 활성에 대한 항-APC IgG의 효과를 도 13에 나타낸 바와 같이 트롬빈 생성 어세이(TGA)에서 혈우병 환자 혈장을 사용하여 추가로 시험하였다. 세포 내벽 혈관(내피세포)의 손상은 외재성 응고 경로로 알려진 제한된 양의 트롬빈 생성을 유발하는 조직인자의 노출을 야기한다. 내피세포 상의 트롬보모듈린은 aPC와 그의 항응고 활성의 생성에 기여한다. 중증 혈우병 혈장은 ~50 nM의 총 트롬빈만을 생성하였다. 항-aPC-항체를 혈우병 혈장에 첨가하여 트롬빈 생성을 용량 의존적 방식으로 증가하였다.
실시예
12
공결정
(Co-crystal) 시험
항체 제조 및
QC
재조합 항-aPC 인간 Fab(C25K23와 T46J23)를 E.coli에서 발현하여 단백질 A 크로마토그래피로 균일하게 정제하였다. 정제된 Fab는 >90% 순도를 가지는 것으로 나타났고 SDS-PAGE와 분석용 크기배제 크로마토그래피에 의하면 응집은 없었다. 이들의 작용을 aPC-결합 어세이 (ELISA)로 특성화하였다. C25K23Fab와 T46J23Fab는 모두 인간 aPC 전장 및 Gla-무도메인(domainless) aPC와 ELISA로 측정된 2-4 nM의 비슷한 EC50값으로 결합하였다. 10밀리그람의 Fab가 제조되었다.
항원 제조 및
QC
혈장-유도성 인간 aPC-Gla-무도메인(aPC-GD)을 Enzyme Research Lab에서 구매하여 ELISA에 의해 특성화하여 C25K23Fab와 T46J23Fab를 모두 인식할 수 있는지 확인하였다.
컴플렉스
형성
컴플렉스 형성에 있어서, 0.9mg aPC-GD를 1.05 mg C25K23Fab와 혼합하고 반응혼합물을 4 ℃에서 5시간 동안 인큐베이션하였다. 혼합물을 겔 여과 컬럼에 적재하여 자유 Fab 또는 자유 aPC-GD를 aPC-GD-Fab 컴플렉스에서 분리하였다. 각 분획을 모아서 SDS-PAGE에 의해 비환원성 조건 하에 분석하였다. 이 과정을 3회 반복하고, aPC-GD-Fab 컴플렉스를 함유하는 분획을 모아 10 mg/ml로 농축하였다.
aPC-Fab 컴플렉스를 상이한 결정 성장 조건하에서 결정화하여 구조 결정에 적합한 결정을 제조하였다(최대 해상도 < 3 Å). 고출력 결정화 스크리닝 키트를 사용하였고 2 히트(hit)를 확인하였다:
a) 0.1% n-옥틸-β-D-글루코시드, 0.1M 시트르산나트륨 삼염기 2수화물 PH 5.5, 22% PEG 3350
b) 18% 2-프로판올, 0.1M 시트르산나트륨 삼염기 2수화물 PH 5.5, 20% PEG 4000
데이터 수집
구조 측정은 2.2 옹스트롬 해상도로 보고된 aPC 및 Fab X-선 구조를 모델로 하는 Molecular Replacement에 의한 aPC-GD-C25K23Fab 결정 회절 이미지(예를 들어, pdb code 1aut by Mather et al., 1996), 이어서 모델 구축 및 정련 (refinement)으로부터 성공하였다. 도 15에는 aPC 및 C25K23 Fab 구조의 간략도를 나타내었다. 도 15에서 보이는 바와 같이, C25K23은 aPC 촉매 도메인과 접촉하는 그의 중쇄의 CDR3 루프를 사용한다. 매우 중요하게, 도 16에서 보이는 바와 같이 C25K23으로부터 W104의 측쇄를 aPC의 촉매 포켓에 삽입하여 이전에 보고된 aPC 저해제(트리-펩티드 저해제 PPACK)와의 입체적 중첩을 얻었다.
이 구조로부터, 항체에 의해 결합된 aPC의 에피토프가 aPC의 중쇄 내에 있는 것으로 측정되었다. aPC 중쇄와 Fab 사이에서 접촉하는 잔기들은 aPC 잔기 D60, K96, S97, T98, T99, E170, V171, M172, S173, M175, A190, S195, W215, G216, E217, G218, 및 G218을 포함한다.
Fab C25K23에 대해 특이적으로, 파라토프(paratope)가 서열번호: 18에 기재된 중쇄의 잔기 S31, Y32, W53, R57, R101, W104, R106, F107, W110 및 서열번호: 8에 기재된 경쇄의 K55를 포함하는 것으로 측정되었다.
실시예
13 활성부위 결합
비가역적 활성부위 저해제, 비오틴-PPACK을 사용하여 인간 aPC의 활성부위를 채웠다(도 16 참조). 비오틴-PPACK-hAPC 또는 인간 aPC를 maxisorp 96-웰 플레이트에 코팅하였다. 항-aPC 항체(Fab 및 IgG)를 1:3 비율로 20 nM에서 0.007 nM까지 연속 희석하고 코팅 웰에 첨가하여 1h 동안 실온에서 인큐베이션하였다. 결합된 항-aPC-Fab 또는 항-aPC IgG를 HRP-컨쥬게이트 항-인간 또는 항-마우스 Fab 항체로 검출하고 형광원 기질(amplex red와 H2O2)과 인큐베이션하여 형광성 시그널(RFU)을 생성하였다. 플레이트를 Gemini EM 형광 마이크로플레이트 판독기(Molecular Devices, Sunnyvale, CA)로 판독하였다. 20 nM 항체 농도에서의 RFU를 트리플리케이트 웰(+/-SD)의 평균으로 막대 그래프에서 제공하였다.
도 17에서 보이는 바와 같이, 적어도 2가지 종류의 항체가 라이브러리로부터 확인되었다. 첫 번째는 더 이상 비오틴-PPACK-hAPC (활성부위 차단 hAPC)와 결합하지 않는 T46J23 (Fab와 hIgG) 및 C25K23 (Fab와 hIgG)을 포함하는 활성부위 관련된 것이다. 두 번째는 항-Gla-도메인 항체인 것으로 보이는 R41C17을 포함한 비활성부위 관련된 것이다. 이러한 데이터는 인간 aPC에서 T46J23 및 C25K23의 활성부위 결합에 대한 명백한 증거를 제공하고, 이러한 항체들의 작용 특성, 즉 hAPC 활성의 완전한 차단을 설명하고 있다.
본 발명의 구체예들을 특정 구체예 및 실시예와 관련하여 기술하였으나, 다양한 개질과 변경이 가능하고 등가물은 여기에 첨부된 청구범위의 요지와 범위를 벗어나지 않고 대체될 수 있음을 이해하여야 한다. 따라서, 본 명세서와 실시예는 제한적 측면에서보다 예시적인 것으로 간주되어야 한다. 또한, 본 원에서 언급된 모든 논문, 서적, 특허출원 및 특허의 내용은 그 전체가 본 원에 참조로 포함되었다.
SEQUENCE LISTING
<110> Bayer HealthCare LLC
<120> Monoclonal Antibodies against Activated Protein C (aPC)
<130> BHC 11 5 003
<160> 119
<170> PatentIn version 3.5
<210> 1
<211> 461
<212> PRT
<213> Homo sapiens
<400> 1
Met Trp Gln Leu Thr Ser Leu Leu Leu Phe Val Ala Thr Trp Gly Ile
1 5 10 15
Ser Gly Thr Pro Ala Pro Leu Asp Ser Val Phe Ser Ser Ser Glu Arg
20 25 30
Ala His Gln Val Leu Arg Ile Arg Lys Arg Ala Asn Ser Phe Leu Glu
35 40 45
Glu Leu Arg His Ser Ser Leu Glu Arg Glu Cys Ile Glu Glu Ile Cys
50 55 60
Asp Phe Glu Glu Ala Lys Glu Ile Phe Gln Asn Val Asp Asp Thr Leu
65 70 75 80
Ala Phe Trp Ser Lys His Val Asp Gly Asp Gln Cys Leu Val Leu Pro
85 90 95
Leu Glu His Pro Cys Ala Ser Leu Cys Cys Gly His Gly Thr Cys Ile
100 105 110
Asp Gly Ile Gly Ser Phe Ser Cys Asp Cys Arg Ser Gly Trp Glu Gly
115 120 125
Arg Phe Cys Gln Arg Glu Val Ser Phe Leu Asn Cys Ser Leu Asp Asn
130 135 140
Gly Gly Cys Thr His Tyr Cys Leu Glu Glu Val Gly Trp Arg Arg Cys
145 150 155 160
Ser Cys Ala Pro Gly Tyr Lys Leu Gly Asp Asp Leu Leu Gln Cys His
165 170 175
Pro Ala Val Lys Phe Pro Cys Gly Arg Pro Trp Lys Arg Met Glu Lys
180 185 190
Lys Arg Ser His Leu Lys Arg Asp Thr Glu Asp Gln Glu Asp Gln Val
195 200 205
Asp Pro Arg Leu Ile Asp Gly Lys Met Thr Arg Arg Gly Asp Ser Pro
210 215 220
Trp Gln Val Val Leu Leu Asp Ser Lys Lys Lys Leu Ala Cys Gly Ala
225 230 235 240
Val Leu Ile His Pro Ser Trp Val Leu Thr Ala Ala His Cys Met Asp
245 250 255
Glu Ser Lys Lys Leu Leu Val Arg Leu Gly Glu Tyr Asp Leu Arg Arg
260 265 270
Trp Glu Lys Trp Glu Leu Asp Leu Asp Ile Lys Glu Val Phe Val His
275 280 285
Pro Asn Tyr Ser Lys Ser Thr Thr Asp Asn Asp Ile Ala Leu Leu His
290 295 300
Leu Ala Gln Pro Ala Thr Leu Ser Gln Thr Ile Val Pro Ile Cys Leu
305 310 315 320
Pro Asp Ser Gly Leu Ala Glu Arg Glu Leu Asn Gln Ala Gly Gln Glu
325 330 335
Thr Leu Val Thr Gly Trp Gly Tyr His Ser Ser Arg Glu Lys Glu Ala
340 345 350
Lys Arg Asn Arg Thr Phe Val Leu Asn Phe Ile Lys Ile Pro Val Val
355 360 365
Pro His Asn Glu Cys Ser Glu Val Met Ser Asn Met Val Ser Glu Asn
370 375 380
Met Leu Cys Ala Gly Ile Leu Gly Asp Arg Gln Asp Ala Cys Glu Gly
385 390 395 400
Asp Ser Gly Gly Pro Met Val Ala Ser Phe His Gly Thr Trp Phe Leu
405 410 415
Val Gly Leu Val Ser Trp Gly Glu Gly Cys Gly Leu Leu His Asn Tyr
420 425 430
Gly Val Tyr Thr Lys Val Ser Arg Tyr Leu Asp Trp Ile His Gly His
435 440 445
Ile Arg Asp Lys Glu Ala Pro Gln Lys Ser Trp Ala Pro
450 455 460
<210> 2
<211> 417
<212> PRT
<213> Homo sapiens
<400> 2
Ala Asn Ser Phe Leu Glu Glu Leu Arg His Ser Ser Leu Glu Arg Glu
1 5 10 15
Cys Ile Glu Glu Ile Cys Asp Phe Glu Glu Ala Lys Glu Ile Phe Gln
20 25 30
Asn Val Asp Asp Thr Leu Ala Phe Trp Ser Lys His Val Asp Gly Asp
35 40 45
Gln Cys Leu Val Leu Pro Leu Glu His Pro Cys Ala Ser Leu Cys Cys
50 55 60
Gly His Gly Thr Cys Ile Asp Gly Ile Gly Ser Phe Ser Cys Asp Cys
65 70 75 80
Arg Ser Gly Trp Glu Gly Arg Phe Cys Gln Arg Glu Val Ser Phe Leu
85 90 95
Asn Cys Ser Leu Asp Asn Gly Gly Cys Thr His Tyr Cys Leu Glu Glu
100 105 110
Val Gly Trp Arg Arg Cys Ser Cys Ala Pro Gly Tyr Lys Leu Gly Asp
115 120 125
Asp Leu Leu Gln Cys His Pro Ala Val Lys Phe Pro Cys Gly Arg Pro
130 135 140
Trp Lys Arg Met Glu Lys Lys Arg Ser His Leu Asp Thr Glu Asp Gln
145 150 155 160
Glu Asp Gln Val Asp Pro Arg Leu Ile Asp Gly Lys Met Thr Arg Arg
165 170 175
Gly Asp Ser Pro Trp Gln Val Val Leu Leu Asp Ser Lys Lys Lys Leu
180 185 190
Ala Cys Gly Ala Val Leu Ile His Pro Ser Trp Val Leu Thr Ala Ala
195 200 205
His Cys Met Asp Glu Ser Lys Lys Leu Leu Val Arg Leu Gly Glu Tyr
210 215 220
Asp Leu Arg Arg Trp Glu Lys Trp Glu Leu Asp Leu Asp Ile Lys Glu
225 230 235 240
Val Phe Val His Pro Asn Tyr Ser Lys Ser Thr Thr Asp Asn Asp Ile
245 250 255
Ala Leu Leu His Leu Ala Gln Pro Ala Thr Leu Ser Gln Thr Ile Val
260 265 270
Pro Ile Cys Leu Pro Asp Ser Gly Leu Ala Glu Arg Glu Leu Asn Gln
275 280 285
Ala Gly Gln Glu Thr Leu Val Thr Gly Trp Gly Tyr His Ser Ser Arg
290 295 300
Glu Lys Glu Ala Lys Arg Asn Arg Thr Phe Val Leu Asn Phe Ile Lys
305 310 315 320
Ile Pro Val Val Pro His Asn Glu Cys Ser Glu Val Met Ser Asn Met
325 330 335
Val Ser Glu Asn Met Leu Cys Ala Gly Ile Leu Gly Asp Arg Gln Asp
340 345 350
Ala Cys Glu Gly Asp Ser Gly Gly Pro Met Val Ala Ser Phe His Gly
355 360 365
Thr Trp Phe Leu Val Gly Leu Val Ser Trp Gly Glu Gly Cys Gly Leu
370 375 380
Leu His Asn Tyr Gly Val Tyr Thr Lys Val Ser Arg Tyr Leu Asp Trp
385 390 395 400
Ile His Gly His Ile Arg Asp Lys Glu Ala Pro Gln Lys Ser Trp Ala
405 410 415
Pro
<210> 3
<211> 405
<212> PRT
<213> Homo sapiens
<400> 3
Ala Asn Ser Phe Leu Glu Glu Leu Arg His Ser Ser Leu Glu Arg Glu
1 5 10 15
Cys Ile Glu Glu Ile Cys Asp Phe Glu Glu Ala Lys Glu Ile Phe Gln
20 25 30
Asn Val Asp Asp Thr Leu Ala Phe Trp Ser Lys His Val Asp Gly Asp
35 40 45
Gln Cys Leu Val Leu Pro Leu Glu His Pro Cys Ala Ser Leu Cys Cys
50 55 60
Gly His Gly Thr Cys Ile Asp Gly Ile Gly Ser Phe Ser Cys Asp Cys
65 70 75 80
Arg Ser Gly Trp Glu Gly Arg Phe Cys Gln Arg Glu Val Ser Phe Leu
85 90 95
Asn Cys Ser Leu Asp Asn Gly Gly Cys Thr His Tyr Cys Leu Glu Glu
100 105 110
Val Gly Trp Arg Arg Cys Ser Cys Ala Pro Gly Tyr Lys Leu Gly Asp
115 120 125
Asp Leu Leu Gln Cys His Pro Ala Val Lys Phe Pro Cys Gly Arg Pro
130 135 140
Trp Lys Arg Met Glu Lys Lys Arg Ser His Leu Leu Ile Asp Gly Lys
145 150 155 160
Met Thr Arg Arg Gly Asp Ser Pro Trp Gln Val Val Leu Leu Asp Ser
165 170 175
Lys Lys Lys Leu Ala Cys Gly Ala Val Leu Ile His Pro Ser Trp Val
180 185 190
Leu Thr Ala Ala His Cys Met Asp Glu Ser Lys Lys Leu Leu Val Arg
195 200 205
Leu Gly Glu Tyr Asp Leu Arg Arg Trp Glu Lys Trp Glu Leu Asp Leu
210 215 220
Asp Ile Lys Glu Val Phe Val His Pro Asn Tyr Ser Lys Ser Thr Thr
225 230 235 240
Asp Asn Asp Ile Ala Leu Leu His Leu Ala Gln Pro Ala Thr Leu Ser
245 250 255
Gln Thr Ile Val Pro Ile Cys Leu Pro Asp Ser Gly Leu Ala Glu Arg
260 265 270
Glu Leu Asn Gln Ala Gly Gln Glu Thr Leu Val Thr Gly Trp Gly Tyr
275 280 285
His Ser Ser Arg Glu Lys Glu Ala Lys Arg Asn Arg Thr Phe Val Leu
290 295 300
Asn Phe Ile Lys Ile Pro Val Val Pro His Asn Glu Cys Ser Glu Val
305 310 315 320
Met Ser Asn Met Val Ser Glu Asn Met Leu Cys Ala Gly Ile Leu Gly
325 330 335
Asp Arg Gln Asp Ala Cys Glu Gly Asp Ser Gly Gly Pro Met Val Ala
340 345 350
Ser Phe His Gly Thr Trp Phe Leu Val Gly Leu Val Ser Trp Gly Glu
355 360 365
Gly Cys Gly Leu Leu His Asn Tyr Gly Val Tyr Thr Lys Val Ser Arg
370 375 380
Tyr Leu Asp Trp Ile His Gly His Ile Arg Asp Lys Glu Ala Pro Gln
385 390 395 400
Lys Ser Trp Ala Pro
405
<210> 4
<211> 113
<212> PRT
<213> Homo sapiens
<400> 4
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn
20 25 30
Tyr Val Ser Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Arg Asn Asn Gln Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Asp Leu
85 90 95
Ser Gly Pro Tyr Val Leu Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
Gly
<210> 5
<211> 111
<212> PRT
<213> Homo sapiens
<400> 5
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu
65 70 75 80
Arg Ser Glu Asp Glu Ala Ala Tyr Tyr Cys Ser Ser Tyr Val Gly Ser
85 90 95
Asp Leu Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 6
<211> 112
<212> PRT
<213> Homo sapiens
<400> 6
Gln Ser Val Leu Thr Gln Pro Pro Ser Thr Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Phe Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu
65 70 75 80
Arg Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Thr Trp Gln Asp Thr
85 90 95
Leu Thr Gly Trp Met Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 7
<211> 110
<212> PRT
<213> Homo sapiens
<400> 7
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Asp Ser Asn Ile Gly Ser Asn
20 25 30
Ala Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Asp Asn Asn Lys Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Thr Ser Ser Asn
85 90 95
Thr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 8
<211> 112
<212> PRT
<213> Homo sapiens
<400> 8
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Ala
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Asn Lys Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu
65 70 75 80
Arg Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Gly Ser Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 9
<211> 112
<212> PRT
<213> Homo sapiens
<400> 9
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Arg Ser Asn
20 25 30
Thr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser Leu
85 90 95
Ser Gly Asp Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 10
<211> 121
<212> PRT
<213> Homo sapiens
<400> 10
Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln Arg Val Thr
1 5 10 15
Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Val Val
20 25 30
His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu Ile Tyr
35 40 45
Arg Asn Asn His Arg Pro Ser Gly Val Pro Asp Arg Phe Ser Gly Ser
50 55 60
Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg Ser Glu
65 70 75 80
Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu Asn Gly
85 90 95
Arg Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln Pro Lys
100 105 110
Ala Ala Pro Ser Val Thr Leu Phe Pro
115 120
<210> 11
<211> 118
<212> PRT
<213> Homo sapiens
<400> 11
Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln Arg Val Thr
1 5 10 15
Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn Ala Val Asn
20 25 30
Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu Ile Tyr Ser
35 40 45
Asn Asn Gln Arg Pro Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Lys
50 55 60
Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg Ser Glu Asp
65 70 75 80
Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Thr Ser Ser Ser Thr His Val
85 90 95
Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln Pro Lys Ala
100 105 110
Ala Pro Ser Val Thr Leu
115
<210> 12
<211> 121
<212> PRT
<213> Homo sapiens
<400> 12
Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln Arg Val Thr
1 5 10 15
Ile Ser Cys Thr Gly Thr Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val
20 25 30
His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu Ile Tyr
35 40 45
Asp Asn Asn Asn Arg Pro Ser Gly Val Pro Asp Arg Phe Ser Gly Ser
50 55 60
Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg Ser Glu
65 70 75 80
Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu Asn Gly
85 90 95
Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln Pro Lys
100 105 110
Ala Ala Pro Ser Val Thr Leu Phe Pro
115 120
<210> 13
<211> 120
<212> PRT
<213> Homo sapiens
<400> 13
Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln Arg Val Thr
1 5 10 15
Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val
20 25 30
His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu Ile Tyr
35 40 45
Gly Asn Ile Asn Arg Pro Ser Gly Val Pro Asp Arg Phe Ser Gly Ser
50 55 60
Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg Ser Glu
65 70 75 80
Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Thr Arg Ser Ala Thr Leu
85 90 95
Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln Pro Lys Ala
100 105 110
Ala Pro Ser Val Thr Leu Phe Pro
115 120
<210> 14
<211> 124
<212> PRT
<213> Homo sapiens
<400> 14
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Gly Asn His
20 25 30
Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Val Ser Trp Asn Gly Ser Arg Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp
100 105 110
Pro Trp Gly Gln Gly Thr Leu Val Thr Val Thr Ser
115 120
<210> 15
<211> 124
<212> PRT
<213> Homo sapiens
<400> 15
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Gly Asn His
20 25 30
Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Val Ser Trp Asn Gly Ser Arg Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp
100 105 110
Pro Trp Gly Gln Gly Thr Leu Val Thr Val Thr Ser
115 120
<210> 16
<211> 122
<212> PRT
<213> Homo sapiens
<400> 16
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ser Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Arg Val Arg Gly Ile Tyr Asp Ala Phe Asp Met Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Thr Ser
115 120
<210> 17
<211> 124
<212> PRT
<213> Homo sapiens
<400> 17
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Asn
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Leu Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp
100 105 110
Pro Trp Gly Gln Gly Thr Leu Val Thr Val Thr Ser
115 120
<210> 18
<211> 124
<212> PRT
<213> Homo sapiens
<400> 18
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Val Ser Trp Asn Gly Ser Arg Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp
100 105 110
Pro Trp Gly Gln Gly Thr Leu Val Thr Val Thr Ser
115 120
<210> 19
<211> 115
<212> PRT
<213> Homo sapiens
<400> 19
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Tyr Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Met Gly Arg Ala Phe Asp Ile Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Thr Ser
115
<210> 20
<211> 126
<212> PRT
<213> Homo sapiens
<400> 20
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Ser Tyr Asp Gly Arg Glu Lys Tyr Tyr Ser Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Gly Arg Thr Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Thr Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
<210> 21
<211> 133
<212> PRT
<213> Homo sapiens
<400> 21
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Asn Tyr
20 25 30
Ala Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Val Ser Trp Asn Gly Ser Arg Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Asp Ser Ser Ser Ala Gly Arg Trp Ala Gly Ser Leu Asp
100 105 110
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Thr Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe
130
<210> 22
<211> 133
<212> PRT
<213> Homo sapiens
<400> 22
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Gly Asn His
20 25 30
Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Val Ser Trp Asn Gly Ser Arg Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp
100 105 110
Pro Trp Gly Gln Gly Thr Leu Val Thr Val Thr Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe
130
<210> 23
<211> 131
<212> PRT
<213> Homo sapiens
<400> 23
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Gly Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asn Arg Ala Thr Arg Ser Gly Tyr Tyr Tyr Phe Asp Ser Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Thr Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe
130
<210> 24
<211> 339
<212> DNA
<213> Homo sapiens
<400> 24
cagtctgtgc tgactcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcctgctctg gaagcagctc caacattggg aataattatg tatcctggta tcagcagctc 120
ccaggaacgg cccccaaact cctcatctat aggaataatc agcggccctc aggggtccct 180
gaccgattct ctggctccaa gtctggcacc tcagcctccc tggccatcag tgggctccgg 240
tccgaggatg aggctgatta ttactgccag tcctatgaca gcgacctgag tggtccctat 300
gtgcttttcg gcggaggaac caagctgacg gtcctaggt 339
<210> 25
<211> 333
<212> DNA
<213> Homo sapiens
<400> 25
cagtctgtgc tgactcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcctgcactg ggagcagctc caacatcggg gcaggttatg atgtacactg gtatcagcag 120
ctcccaggaa cggcccccaa actcctcatc tatggtaaca gcaatcggcc ctcaggggtc 180
cctgaccgat tctctggctc caagtctggc acctcagcct ccctggccat cagtgggctc 240
cggtccgagg atgaggctgc ttattactgc agctcatatg taggcagcga cctcgtggtg 300
ttcggcggag gaaccaagct gacggtccta ggt 333
<210> 26
<211> 336
<212> DNA
<213> Homo sapiens
<400> 26
cagtctgtgc tgactcagcc accctcaacg tctgggaccc ccgggcagag ggtcaccatc 60
tcctgcactg ggagcagctc caacatcggg gcaggttttg atgtacactg gtatcagcag 120
ctcccaggaa cggcccccaa actcctcatc tatggtaaca gcaatcggcc ctcaggggtc 180
cctgaccgat tctctggctc caagtctggc acctcagcct ccctggccat cagtgggctc 240
cggtccgagg atgaggctga ttattactgt gctacttggc aagacactct gactggttgg 300
atgttcggcg gaggaaccaa gctgacggtc ctaggt 336
<210> 27
<211> 330
<212> DNA
<213> Homo sapiens
<400> 27
cagtctgtgc tgactcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcttgttctg gaagcgactc caacatcgga agtaatgctg ttaattggta tcagcagctc 120
ccaggaacgg cccccaaact cctcatctat gacaataata agcgaccctc aggggtccct 180
gaccgattct ctggctccaa gtctggcacc tcagcctccc tggccatcag tgggctccgg 240
tccgaggatg aggctgatta ttactgcagc tcatatacaa gcagcaacac tgtcgtattc 300
ggcggaggaa ccaagctgac ggtcctaggt 330
<210> 28
<211> 336
<212> DNA
<213> Homo sapiens
<400> 28
cagtctgtgc tgactcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcctgcactg ggagcagctc caacatcggg gcagcttatg atgtacactg gtatcagcag 120
ctcccaggaa cggcccccaa actcctcatc tatggcaata ataagcgacc ctcaggggtc 180
cctgaccgat tctctggctc caagtctggc acctcagcct ccctggccat cagtgggctc 240
cggtccgagg atgaggctga ttattactgc cagtcctatg acagcagcct gagtggttcg 300
gtattcggcg gaggaaccaa gctgacggtc ctaggt 336
<210> 29
<211> 336
<212> DNA
<213> Homo sapiens
<400> 29
cagtctgtgc tgactcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcctgcactg ggagcagctc caacatcggg gcagcttatg atgtacactg gtatcagcag 120
ctcccaggaa cggcccccaa actcctcatc tatggcaata ataagcgacc ctcaggggtc 180
cctgaccgat tctctggctc caagtctggc acctcagcct ccctggccat cagtgggctc 240
cggtccgagg atgaggctga ttattactgc cagtcctatg acagcagcct gagtggttcg 300
gtattcggcg gaggaaccaa gctgacggtc ctaggt 336
<210> 30
<211> 336
<212> DNA
<213> Homo sapiens
<400> 30
cagtctgtgc tgactcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcctgcactg ggagcagctc caacattggg gcgggttatg ttgtacattg gtatcagcag 120
ctcccaggaa cggcccccaa actcctcatc tataggaata atcatcggcc ctcaggggtc 180
cctgaccgat tctctggctc caagtctggc acctcagcct ccctggccat cagtgggctc 240
cggtccgagg atgaggctga ttattactgt gcagcatggg atgacagcct gaatggtcgg 300
gtgttcggcg gaggaaccaa gctgacggtc ctaggt 336
<210> 31
<211> 333
<212> DNA
<213> Homo sapiens
<400> 31
cagtctgtgc tgactcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcctgttctg gaagcagctc caacatcgga aataatgctg taaactggta tcagcagctc 120
ccaggaacgg cccccaaact cctcatctat agtaataatc agcggccctc aggggtccct 180
gaccgattct ctggctccaa gtctggcacc tcagcctccc tggccatcag tgggctccgg 240
tccgaggatg aggctgatta ttactgcagc tcatatacaa gcagcagcac tcatgtggta 300
ttcggcggag gaaccaagct gacggtccta ggt 333
<210> 32
<211> 336
<212> DNA
<213> Homo sapiens
<400> 32
cagtctgtgc tgactcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcctgcactg ggaccagctc caacatcggg gcaggttatg atgtacactg gtatcagcag 120
ctcccaggaa cggcccccaa actcctcatc tatgataaca acaatcggcc ctcaggggtc 180
cctgaccgat tctctggctc caagtctggc acctcagcct ccctggccat cagtgggctc 240
cggtccgagg atgaggctga ttattactgt gcagcatggg atgacagcct gaacggtgtg 300
gtattcggcg gaggaaccaa gctgacggtc ctaggt 336
<210> 33
<211> 333
<212> DNA
<213> Homo sapiens
<400> 33
cagtctgtgc tgactcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcctgcactg ggagcagctc caacatcggg gcaggttatg atgtacactg gtatcagcag 120
ctcccaggaa cggcccccaa actcctcatc tatggtaaca tcaatcggcc ctcaggggtc 180
cctgaccgat tctctggctc caagtctggc acctcagcct ccctggccat cagtgggctc 240
cggtccgagg atgaggctga ttattactgc agctcatata caagaagcgc cactctcgtg 300
ttcggcggag gaaccaagct gacggtccta ggt 333
<210> 34
<211> 372
<212> DNA
<213> Homo sapiens
<400> 34
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttggt aatcattgga tgacctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtatcgggt gttagttgga atggcagtag gacgcactat 180
gcagactctg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac actgccgtgt attactgtgc cctgacaggg 300
agaagtggct ggatgcgctt cccaaactgg ttcgacccct ggggccaagg taccctggtc 360
accgtgacta gt 372
<210> 35
<211> 372
<212> DNA
<213> Homo sapines
<400> 35
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttggt aatcattgga tgacctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtatcgggt gttagttgga atggcagtag gacgcactat 180
gcagactctg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac actgccgtgt attactgtgc cctgacaggg 300
agaagtggct ggatgcgctt cccaaactgg ttcgacccct ggggccaagg taccctggtc 360
accgtgacta gt 372
<210> 36
<211> 366
<212> DNA
<213> Homo sapiens
<400> 36
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagt agttatagca tgaactgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac actgccgtgt attactgtgc gagagatcga 300
cgggttcggg gaatctatga tgcatttgat atgtggggcc agggtaccct ggtcaccgtg 360
actagt 366
<210> 37
<211> 372
<212> DNA
<213> Homo sapiens
<400> 37
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt agcaactaca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtggcagtt atatcatatg atggaagcaa taaatactac 180
gcagactccg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac actgccatgt attactgtgc cctgacaggg 300
agaagtggct ggatgcgctt cccaaactgg ttcgacccct ggggccaagg taccctggtc 360
accgtgacta gt 372
<210> 38
<211> 372
<212> DNA
<213> Homo sapiens
<400> 38
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagt agctattgga tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtatcgggt gttagttgga atggcagtag gacgcactat 180
gcagactctg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac actgccgtgt attactgtgc cctgacaggg 300
agaagtggct ggatgcgctt cccaaactgg ttcgacccct ggggccaggg taccctggtc 360
accgtgacta gt 372
<210> 39
<211> 345
<212> DNA
<213> Homo sapiens
<400> 39
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt agctatggca tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtctcagtt atttatagcg gtggtagcac atactacgca 180
gactccgtga agggcagatt caccatctcc agagacaatt ccaagaacac gctgtatctg 240
caaatgaaca gcctgagagc cgaggacact gccgtgtatt actgtgcgag gatgggaagg 300
gcttttgata tctggggcca aggtaccctg gtcaccgtga ctagt 345
<210> 40
<211> 351
<212> DNA
<213> Homo sapiens
<400> 40
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc aactatgcga tgagctgggt ccgccagtct 120
ccagggaagg ggctggagtg ggtggctgtt atatcatatg acggaaggga gaagtactac 180
tcagactccg tcaagggacg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac actgccgtgt attactgtgc gagagatcgg 300
ggacgtacct ttgactactg gggccaaggt accctggtca ccgtgactag t 351
<210> 41
<211> 372
<212> DNA
<213> Homo sapiens
<400> 41
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttaac aactatgcca tgacctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtatcgggt gttagttgga atggcagtag gacgcactat 180
gcagactctg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac actgccgtgt attactgtgc gagagcggat 300
agcagcagcg ccgggaggtg ggccggctca cttgactact ggggccaagg taccctggtc 360
accgtgacta gt 372
<210> 42
<211> 372
<212> DNA
<213> Homo sapiens
<400> 42
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttggt aatcattgga tgacctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtatcgggt gttagttgga atggcagtag gacgcactat 180
gcagactctg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac actgccgtgt attactgtgc cctgacaggg 300
agaagtggct ggatgcgctt cccaaactgg ttcgacccct ggggccaagg taccctggtc 360
accgtgacta gt 372
<210> 43
<211> 366
<212> DNA
<213> Homo sapiens
<400> 43
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt ggctatggca tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtctctggt attaattgga atggtggtag cacaggttat 180
gcagactctg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac actgccgtgt attactgtgc gagaaatcga 300
gccacccgca gtggctacta ttactttgac tcctggggcc agggtaccct ggtcaccgtg 360
actagt 366
<210> 44
<211> 13
<212> PRT
<213> Homo sapiens
<400> 44
Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn Tyr Val Ser
1 5 10
<210> 45
<211> 14
<212> PRT
<213> Homo sapiens
<400> 45
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 46
<211> 14
<212> PRT
<213> Homo sapiens
<400> 46
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Phe Asp Val His
1 5 10
<210> 47
<211> 13
<212> PRT
<213> Homo sapiens
<400> 47
Ser Gly Ser Asp Ser Asn Ile Gly Ser Asn Ala Val Asn
1 5 10
<210> 48
<211> 14
<212> PRT
<213> Homo sapiens
<400> 48
Thr Gly Ser Ser Ser Asn Ile Gly Ala Ala Tyr Asp Val His
1 5 10
<210> 49
<211> 13
<212> PRT
<213> Homo sapiens
<400> 49
Ser Gly Ser Ser Ser Asn Ile Arg Ser Asn Thr Val Asn
1 5 10
<210> 50
<211> 14
<212> PRT
<213> Homo sapiens
<400> 50
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Val Val His
1 5 10
<210> 51
<211> 13
<212> PRT
<213> Homo sapiens
<400> 51
Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn Ala Val Asn
1 5 10
<210> 52
<211> 14
<212> PRT
<213> Homo sapiens
<400> 52
Thr Gly Thr Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 53
<211> 14
<212> PRT
<213> Homo sapiens
<400> 53
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 54
<211> 6
<212> PRT
<213> Homo sapiens
<400> 54
Arg Asn Asn Gln Arg Pro
1 5
<210> 55
<211> 6
<212> PRT
<213> Homo sapiens
<400> 55
Gly Asn Ser Asn Arg Pro
1 5
<210> 56
<211> 6
<212> PRT
<213> Homo sapiens
<400> 56
Gly Asn Ser Asn Arg Pro
1 5
<210> 57
<211> 6
<212> PRT
<213> Homo sapiens
<400> 57
Asp Asn Asn Lys Arg Pro
1 5
<210> 58
<211> 6
<212> PRT
<213> Homo sapiens
<400> 58
Gly Asn Asn Lys Arg Pro
1 5
<210> 59
<211> 6
<212> PRT
<213> Homo sapiens
<400> 59
Gly Asn Ser Asn Arg Pro
1 5
<210> 60
<211> 6
<212> PRT
<213> Homo sapiens
<400> 60
Arg Asn Asn His Arg Pro
1 5
<210> 61
<211> 6
<212> PRT
<213> Homo sapiens
<400> 61
Ser Asn Asn Gln Arg Pro
1 5
<210> 62
<211> 6
<212> PRT
<213> Homo sapiens
<400> 62
Asp Asn Asn Asn Arg Pro
1 5
<210> 63
<211> 6
<212> PRT
<213> Homo sapiens
<400> 63
Gly Asn Ile Asn Arg Pro
1 5
<210> 64
<211> 13
<212> PRT
<213> Homo sapiens
<400> 64
Gln Ser Tyr Asp Ser Asp Leu Ser Gly Pro Tyr Val Leu
1 5 10
<210> 65
<211> 10
<212> PRT
<213> Homo sapiens
<400> 65
Ser Ser Tyr Val Gly Ser Asp Leu Val Val
1 5 10
<210> 66
<211> 11
<212> PRT
<213> Homo sapiens
<400> 66
Ala Thr Trp Gln Asp Thr Leu Thr Gly Trp Met
1 5 10
<210> 67
<211> 10
<212> PRT
<213> Homo sapiens
<400> 67
Ser Ser Tyr Thr Ser Ser Asn Thr Val Val
1 5 10
<210> 68
<211> 11
<212> PRT
<213> Homo sapiens
<400> 68
Gln Ser Tyr Asp Ser Ser Leu Ser Gly Ser Val
1 5 10
<210> 69
<211> 12
<212> PRT
<213> Homo sapiens
<400> 69
Gln Ser Tyr Asp Ser Ser Leu Ser Gly Asp Val Val
1 5 10
<210> 70
<211> 11
<212> PRT
<213> Homo sapiens
<400> 70
Ala Ala Trp Asp Asp Ser Leu Asn Gly Arg Val
1 5 10
<210> 71
<211> 11
<212> PRT
<213> Homo sapiens
<400> 71
Ser Ser Tyr Thr Ser Ser Ser Thr His Val Val
1 5 10
<210> 72
<211> 11
<212> PRT
<213> Homo sapiens
<400> 72
Ala Ala Trp Asp Asp Ser Leu Asn Gly Val Val
1 5 10
<210> 73
<211> 10
<212> PRT
<213> Homo sapiens
<400> 73
Ser Ser Tyr Thr Arg Ser Ala Thr Leu Val
1 5 10
<210> 74
<211> 5
<212> PRT
<213> Homo sapiens
<400> 74
Asn His Trp Met Thr
1 5
<210> 75
<211> 5
<212> PRT
<213> Homo sapiens
<400> 75
Asn His Trp Met Thr
1 5
<210> 76
<211> 5
<212> PRT
<213> Homo sapiens
<400> 76
Ser Tyr Ser Met Asn
1 5
<210> 77
<211> 5
<212> PRT
<213> Homo sapiens
<400> 77
Ser Asn Tyr Met Ser
1 5
<210> 78
<211> 5
<212> PRT
<213> Homo sapiens
<400> 78
Ser Tyr Trp Met Ser
1 5
<210> 79
<211> 5
<212> PRT
<213> Homo sapiens
<400> 79
Ser Tyr Gly Met His
1 5
<210> 80
<211> 5
<212> PRT
<213> Homo sapiens
<400> 80
Asn Tyr Ala Met Ser
1 5
<210> 81
<211> 5
<212> PRT
<213> Homo sapiens
<400> 81
Asn Tyr Ala Met Thr
1 5
<210> 82
<211> 5
<212> PRT
<213> Homo sapiens
<400> 82
Asn His Trp Met Thr
1 5
<210> 83
<211> 5
<212> PRT
<213> Homo sapiens
<400> 83
Gly Tyr Gly Met His
1 5
<210> 84
<211> 18
<212> PRT
<213> Homo sapiens
<400> 84
Ser Gly Val Ser Trp Asn Gly Ser Arg Thr His Tyr Ala Asp Ser Val
1 5 10 15
Lys Gly
<210> 85
<211> 18
<212> PRT
<213> Homo sapiens
<400> 85
Ser Gly Val Ser Trp Asn Gly Ser Arg Thr His Tyr Ala Asp Ser Val
1 5 10 15
Lys Gly
<210> 86
<211> 18
<212> PRT
<213> Homo sapiens
<400> 86
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
1 5 10 15
Lys Gly
<210> 87
<211> 18
<212> PRT
<213> Homo sapiens
<400> 87
Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val
1 5 10 15
Lys Gly
<210> 88
<211> 18
<212> PRT
<213> Homo sapiens
<400> 88
Ser Gly Val Ser Trp Asn Gly Ser Arg Thr His Tyr Ala Asp Ser Val
1 5 10 15
Lys Gly
<210> 89
<211> 17
<212> PRT
<213> Homo sapiens
<400> 89
Ser Val Ile Tyr Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 90
<211> 18
<212> PRT
<213> Homo sapiens
<400> 90
Ala Val Ile Ser Tyr Asp Gly Arg Glu Lys Tyr Tyr Ser Asp Ser Val
1 5 10 15
Lys Gly
<210> 91
<211> 18
<212> PRT
<213> Homo sapiens
<400> 91
Ser Gly Val Ser Trp Asn Gly Ser Arg Thr His Tyr Ala Asp Ser Val
1 5 10 15
Lys Gly
<210> 92
<211> 18
<212> PRT
<213> Homo sapiens
<400> 92
Ser Gly Val Ser Trp Asn Gly Ser Arg Thr His Tyr Ala Asp Ser Val
1 5 10 15
Lys Gly
<210> 93
<211> 18
<212> PRT
<213> Homo sapiens
<400> 93
Ser Gly Ile Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val
1 5 10 15
Lys Gly
<210> 94
<211> 15
<212> PRT
<213> Homo sapiens
<400> 94
Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp Pro
1 5 10 15
<210> 95
<211> 15
<212> PRT
<213> Homo sapiens
<400> 95
Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp Pro
1 5 10 15
<210> 96
<211> 13
<212> PRT
<213> Homo sapiens
<400> 96
Asp Arg Arg Val Arg Gly Ile Tyr Asp Ala Phe Asp Met
1 5 10
<210> 97
<211> 15
<212> PRT
<213> Homo sapiens
<400> 97
Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp Pro
1 5 10 15
<210> 98
<211> 15
<212> PRT
<213> Homo sapiens
<400> 98
Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp Pro
1 5 10 15
<210> 99
<211> 7
<212> PRT
<213> Homo sapiens
<400> 99
Met Gly Arg Ala Phe Asp Ile
1 5
<210> 100
<211> 8
<212> PRT
<213> Homo sapiens
<400> 100
Asp Arg Gly Arg Thr Phe Asp Tyr
1 5
<210> 101
<211> 15
<212> PRT
<213> Homo sapiens
<400> 101
Ala Asp Ser Ser Ser Ala Gly Arg Trp Ala Gly Ser Leu Asp Tyr
1 5 10 15
<210> 102
<211> 15
<212> PRT
<213> Homo sapiens
<400> 102
Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp Pro
1 5 10 15
<210> 103
<211> 13
<212> PRT
<213> Homo sapiens
<400> 103
Asn Arg Ala Thr Arg Ser Gly Tyr Tyr Tyr Phe Asp Ser
1 5 10
<210> 104
<211> 25
<212> DNA
<213> Artificial
<220>
<223> Primer Sequence
<400> 104
gaaacagcta tgaaatacct attgc 25
<210> 105
<211> 19
<212> DNA
<213> Artificial
<220>
<223> Primer Sequence
<400> 105
gcctgagcag tggaagtcc 19
<210> 106
<211> 24
<212> DNA
<213> Artificial
<220>
<223> Primer Sequence
<400> 106
taggtatttc attatgactg tctc 24
<210> 107
<211> 23
<212> DNA
<213> Artificial
<220>
<223> Primer Sequence
<400> 107
cccagtcacg acgttgtaaa acg 23
<210> 108
<211> 217
<212> PRT
<213> Homo sapiens
<400> 108
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Ala
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Asn Lys Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu
65 70 75 80
Arg Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Gly Ser Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 109
<211> 453
<212> PRT
<213> Homo sapiens
<400> 109
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Val Ser Trp Asn Gly Ser Arg Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp
100 105 110
Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
355 360 365
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly
450
<210> 110
<211> 217
<212> PRT
<213> Homo sapiens
<400> 110
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Ala
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Asn Lys Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Gly Ser Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 111
<211> 449
<212> PRT
<213> Homo sapiens
<400> 111
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Val Ser Trp Gly Gly Ser Arg Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp
100 105 110
Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu
130 135 140
Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn
195 200 205
Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg
210 215 220
Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg
290 295 300
Val Val Ser Val Leu Thr Val Val His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly
<210> 112
<211> 217
<212> PRT
<213> Homo sapiens
<400> 112
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Ala
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Asn Lys Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Gly Ser Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 113
<211> 449
<212> PRT
<213> Homo sapiens
<400> 113
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Val Ser Trp Gln Gly Ser Arg Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp
100 105 110
Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu
130 135 140
Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn
195 200 205
Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg
210 215 220
Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg
290 295 300
Val Val Ser Val Leu Thr Val Val His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly
<210> 114
<211> 217
<212> PRT
<213> Homo sapiens
<400> 114
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Ala
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Asn Lys Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Gly Ser Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 115
<211> 449
<212> PRT
<213> Homo sapiens
<400> 115
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Val Ser Trp Ala Gly Ser Arg Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp
100 105 110
Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu
130 135 140
Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn
195 200 205
Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg
210 215 220
Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg
290 295 300
Val Val Ser Val Leu Thr Val Val His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly
<210> 116
<211> 217
<212> PRT
<213> Homo sapiens
<400> 116
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Ala
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Asn Lys Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Gly Ser Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 117
<211> 449
<212> PRT
<213> Homo sapiens
<400> 117
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Val Ser Trp Asn Gly Ala Arg Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp
100 105 110
Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu
130 135 140
Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn
195 200 205
Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg
210 215 220
Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg
290 295 300
Val Val Ser Val Leu Thr Val Val His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly
<210> 118
<211> 217
<212> PRT
<213> Homo sapiens
<400> 118
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Ala
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Asn Lys Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Gly Ser Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
115 120 125
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
130 135 140
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
145 150 155 160
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
165 170 175
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
180 185 190
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
195 200 205
Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 119
<211> 449
<212> PRT
<213> Homo sapiens
<400> 119
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Val Ser Trp Asn Gly Gly Arg Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Thr Gly Arg Ser Gly Trp Met Arg Phe Pro Asn Trp Phe Asp
100 105 110
Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu
130 135 140
Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn
195 200 205
Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg
210 215 220
Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg
290 295 300
Val Val Ser Val Leu Thr Val Val His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly
Claims (45)
- 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하며, 서열번호: 14, 15, 17, 18, 19, 21, 22, 23, 109, 111, 113, 115, 117 및 119로 구성되는 군에서 선택된 아미노산 서열을 포함하는 중쇄 가변영역을 포함하는 단리된 모노클로날 항체.
- 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하며, 서열번호: 4, 5, 7, 8, 9, 11, 12, 13, 108, 110, 112, 114, 116 및 118로 구성되는 군에서 선택된 아미노산 서열을 포함하는 경쇄 가변영역을 포함하는 단리된 모노클로날 항체.
- 제1항에 있어서, 서열번호: 4, 5, 7, 8, 9, 11, 12, 13, 108, 110, 112, 114, 116 및 118로 구성되는 군에서 선택된 아미노산 서열을 포함하는 경쇄 가변영역을 추가로 포함하는 단리된 모노클로날 항체.
- 제3항에 있어서, 다음을 포함하는 중쇄 및 경쇄 가변영역을 포함하는 단리된 모노클로날 항체:
(a) 서열번호: 14의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 4의 아미노산 서열을 갖는 경쇄 가변영역;
(b) 서열번호: 15의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 5의 아미노산 서열을 갖는 경쇄 가변영역;
(c) 서열번호: 17의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 7의 아미노산 서열을 갖는 경쇄 가변영역;
(d) 서열번호: 18의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 8의 아미노산 서열을 갖는 경쇄 가변영역;
(e) 서열번호: 19의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 9의 아미노산 서열을 갖는 경쇄 가변영역;
(f) 서열번호: 21의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 11의 아미노산 서열을 갖는 경쇄 가변영역;
(g) 서열번호: 22의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 12의 아미노산 서열을 갖는 경쇄 가변영역;
(h) 서열번호: 23의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 13의 아미노산 서열을 갖는 경쇄 가변영역;
(i) 서열번호: 109의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 108의 아미노산 서열을 갖는 경쇄 가변영역;
(j) 서열번호: 111의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 110의 아미노산 서열을 갖는 경쇄 가변영역;
(k) 서열번호: 113의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 112의 아미노산 서열을 갖는 경쇄 가변영역;
(l) 서열번호: 115의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 114의 아미노산 서열을 갖는 경쇄 가변영역;
(m) 서열번호: 117의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 116의 아미노산 서열을 갖는 경쇄 가변영역;
(n) 서열번호: 119의 아미노산 서열을 갖는 중쇄 가변영역과 서열번호: 118의 아미노산 서열을 갖는 경쇄 가변영역. - 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하며, 서열번호: 94, 95, 97, 98, 99, 101, 102 및 103으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR3를 포함하는 단리된 모노클로날 항체.
- 제5항에 있어서, (a) 서열번호: 74, 75, 77, 78, 79, 81, 82 및 83으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1, (b) 서열번호: 84, 85, 87, 88, 89, 91, 92 및 93으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2, 또는 (c) 서열번호: 74, 75, 77, 78, 79, 81, 82 및 83으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1 및 서열번호: 84, 85, 87, 88, 89, 91, 92 및 93으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2를 추가로 포함하는 단리된 모노클로날 항체.
- 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하며, 서열번호: 64, 65, 67, 68, 69, 71, 72 및 73으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR3를 포함하는 단리된 모노클로날 항체.
- 제7항에 있어서, (a) 서열번호: 44, 45, 47, 48, 49, 51, 52 및 53으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1, (b) 서열번호: 54, 55, 57, 58, 59, 61, 62 및 63으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2, 또는 (c) 서열번호: 44, 45, 47, 48, 49, 51, 52 및 53으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1 및 서열번호: 54, 55, 57, 58, 59, 61, 62 및 63으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2를 추가로 포함하는 단리된 모노클로날 항체.
- 제5항에 있어서, 서열번호: 64, 65, 67, 68, 69, 71, 72 및 73으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR3를 추가로 포함하는 단리된 모노클로날 항체.
- 제9항에 있어서, (a) 서열번호: 74, 75, 77, 78, 79, 81, 82 및 83으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1, (b) 서열번호: 84, 85, 87, 88, 89, 91, 92 및 93으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2, (c) 서열번호: 44, 45, 47, 48, 49, 51, 52 및 53으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR1 및 (d) 서열번호: 54, 55, 57, 58, 59, 61, 62 및 63으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 CDR2를 추가로 포함하는 단리된 모노클로날 항체.
- 제4항에 있어서, 다음을 포함하는 중쇄 및 경쇄 가변영역을 포함하는 항체:
(a) 서열번호: 44, 54 및 64를 포함하는 아미노산 서열을 포함하는 경쇄 가변영역과 서열번호: 74, 84 및 94를 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(b) 서열번호: 45, 55 및 65를 포함하는 아미노산 서열을 포함하는 경쇄 가변영역과 서열번호: 75, 85 및 95를 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(c) 서열번호: 47, 57 및 67을 포함하는 아미노산 서열을 포함하는 경쇄 가변영역과 서열번호: 77, 87 및 97을 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(d) 서열번호: 48, 58 및 68을 포함하는 아미노산 서열을 포함하는 경쇄 가변영역과 서열번호: 78, 88 및 98을 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(e) 서열번호: 49, 59 및 69를 포함하는 아미노산 서열을 포함하는 경쇄 가변영역과 서열번호: 79, 89 및 99를 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(f) 서열번호: 51, 61 및 71을 포함하는 아미노산 서열을 포함하는 경쇄 가변영역과 서열번호: 81, 91 및 101을 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(g) 서열번호: 52, 62 및 72를 포함하는 아미노산 서열을 포함하는 경쇄 가변영역과 서열번호: 82, 92 및 102를 포함하는 아미노산 서열을 포함하는 중쇄 가변영역;
(h) 서열번호: 53, 63 및 73을 포함하는 아미노산 서열을 포함하는 경쇄 가변영역과 서열번호: 83, 93 및 103을 포함하는 아미노산 서열을 포함하는 중쇄 가변영역. - 제4항에 있어서, 하나 이상의 아미노산 변성을 추가로 포함하는 단리된 모노클로날 항체.
- 제11항에 있어서, 하나 이상의 아미노산 변성을 추가로 포함하는 단리된 모노클로날 항체.
- 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하며, 서열번호: 8의 아미노산 서열을 포함하는 경쇄 가변영역을 포함하고, 아미노산 서열이 하나 이상의 아미노산 변성을 포함하는, 단리된 모노클로날 항체.
- 제13항에 있어서, 변성이 치환인 단리된 모노클로날 항체.
- 제14항에 있어서, 치환이 A10, T13, G52, N53, N54, R56, P57, S58, S78, R81, S82, Q91, Y93, S95, S96, L97, S98, G99, S100 및 V101로 구성되는 군에서 선택된 위치인 단리된 모노클로날 항체.
- 제15항에 있어서, 치환이 A10V, T13A, G52S, G52Y, G52H, G52F, N53G, N54K, N54R, R56K, P57G, P57W, P57N, S58V, S58F, S58R, S78T, R81Q, S82A, Q91R, Q91G, Y93W, S95F, S95Y, S95G, S95W, S95E, S96G, S96A, S96Y, S96W, S96R, L97M, L97G, L97R, L97V, S98L, S98W, S98V, S98R, G99A, G99E, S100A, S100V, V101Y, V1OlL 및 V101E로 구성되는 군에서 선택된 단리된 모노클로날 항체.
- 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하며, 서열번호: 18의 아미노산 서열을 포함하는 중쇄 가변영역을 포함하고, 아미노산 서열이 하나 이상의 아미노산 변성을 포함하는, 단리된 모노클로날 항체.
- 제18항에 있어서, 변성이 치환인 단리된 모노클로날 항체.
- 제19항에 있어서, 치환이 N54 및 S56으로 구성되는 군에서 선택된 위치인 단리된 모노클로날 항체.
- 제20항에 있어서, 치환이 N54G, N54Q, N54A, S56A 및 S56G로 구성되는 군에서 선택된 단리된 모노클로날 항체.
- 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하며, 서열번호: 12의 아미노산 서열을 포함하는 경쇄 가변영역을 포함하고, 아미노산 서열이 하나 이상의 아미노산 변성을 포함하는, 단리된 모노클로날 항체.
- 제22항에 있어서, 변성이 치환인 단리된 모노클로날 항체.
- 제23항에 있어서, 치환이 T25, D52, N53, N54, N55, D95, N98 및 G99로 구성되는 군에서 선택된 위치인 단리된 모노클로날 항체.
- 제24항에 있어서, 치환이 T25S, D52Y, D52F, D52L, D52G, N53C, N53K, N53G, N54S, N55K, D95G, N98S, G99H, G99L 및 G99F로 구성되는 군에서 선택된 단리된 모노클로날 항체.
- 인간 활성화 단백질 C(인간 aPC, 서열번호: 3)의 에피토프에 결합하고, 에피토프가 인간 aPC 중쇄의 잔기를 포함하는 단리된 모노클로날 항체.
- 인간 활성화 단백질 C(인간 aPC, 서열번호: 3)의 에피토프에 결합하고, 에피토프가 서열번호: 3의 S195를 포함하는 단리된 모노클로날 항체.
- 인간 활성화 단백질 C의 에피토프에 결합하고, 에피토프가 D60, K96, S97, T98, T99, E170, V171, M172, S173, M175, A190, S195, W215, G216, E217, G218, 및 서열번호: 3의 G218로 구성되는 군에서 선택된 하나 이상의 잔기를 포함하는 단리된 모노클로날 항체.
- 활성화 단백질 C의 활성부위에 결합하는 단리된 모노클로날 항체.
- 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하는, 전체 인간 항체인 단리된 모노클로날 항체.
- 제1항 내지 제30항 중 어느 하나의 항에 있어서, IgGl, IgG2, IgG3, IgG4, IgM, IgAl, IgA2, 분비 IgA, IgD, IgE 항체 및 항체 단편으로 구성되는 군에서 선택된 단리된 모노클로날 항체.
- 제1항 내지 제30항 중 어느 하나의 항에 있어서, 인간 활성화 단백질 C에 결합하는 단리된 모노클로날 항체.
- 제32항에 있어서, 활성화 단백질 C의 비인간 종(species)에 추가로 결합하는 단리된 모노클로날 항체.
- 제1항 내지 제30항 중 어느 하나의 항에 있어서, 항체 존재 하에서 혈액 응고시간이 단축된 단리된 모노클로날 항체.
- 제1항 내지 제30항 중 어느 한 항의 항체와 경쟁하는 항체.
- 제1항 내지 제30항 중 어느 한 항의 모노클로날 항체의 치료적 유효량과 약학적으로 허용가능한 담체를 포함하는 약학 조성물.
- 제36항의 약학 조성물의 치료적 유효량을 환자에게 투여하는 것을 포함하는 응고의 유전적 또는 후천적 결핍 또는 결함을 치료하는 방법.
- 제36항의 약학 조성물의 치료적 유효량을 환자에게 투여하는 것을 포함하는 응고장애(coagulopathy)를 치료하는 방법.
- 제38항에 있어서, 응고장애가 혈우병 A, B 또는 C인 방법.
- 제38항에 있어서, 응고장애가 외상으로 유도된 응고장애 또는 중증 출혈 환자로 구성되는 군에서 선택된 방법.
- 제38항에 있어서, 응고인자의 투여를 추가로 포함하는 방법.
- 제41항에 있어서, 응고 인자가 Factor VIIa, Factor VIII 또는 Factor IX로 구성되는 군에서 선택된 방법.
- 제36항의 약학 조성물의 치료적 유효량을 환자에게 투여하는 것을 포함하는 출혈시간을 단축하는 방법.
- 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하며, 서열번호: 14, 15, 17, 18, 19, 21, 22 및 23으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 중쇄 가변영역을 포함하는 항체를 코딩하는, 단리된 핵산 분자.
- 활성화 단백질 C에 결합하고 항응고 활성을 저해하지만 불활성화 단백질 C에 최소한 결합하며, 서열번호: 4, 5, 7, 8, 9, 11, 12 및 13으로 구성되는 군에서 선택된 아미노산 서열을 포함하는 경쇄 가변영역을 포함하는 항체를 코딩하는, 단리된 핵산 분자.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201261731294P | 2012-11-29 | 2012-11-29 | |
| US61/731,294 | 2012-11-29 | ||
| US201361786472P | 2013-03-15 | 2013-03-15 | |
| US61/786,472 | 2013-03-15 | ||
| PCT/US2013/072243 WO2014085596A1 (en) | 2012-11-29 | 2013-11-27 | MONOCLONAL ANTIBODIES AGAISNT ACTIVATED PROTEIN C (aPC) |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20150088869A true KR20150088869A (ko) | 2015-08-03 |
Family
ID=50828462
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020157017008A KR20150088869A (ko) | 2012-11-29 | 2013-11-27 | 활성화 단백질 C(aPC)에 대한 모노클로날 항체 |
Country Status (18)
| Country | Link |
|---|---|
| US (1) | US20150307625A1 (ko) |
| EP (1) | EP2925351A4 (ko) |
| JP (1) | JP2016501230A (ko) |
| KR (1) | KR20150088869A (ko) |
| CN (1) | CN104812402A (ko) |
| AR (1) | AR093671A1 (ko) |
| AU (1) | AU2013352159A1 (ko) |
| BR (1) | BR112015012414A2 (ko) |
| CA (1) | CA2892750A1 (ko) |
| HK (1) | HK1212896A1 (ko) |
| IL (1) | IL238658A0 (ko) |
| MX (1) | MX2015006424A (ko) |
| RU (1) | RU2015125349A (ko) |
| SG (1) | SG11201503719WA (ko) |
| TW (1) | TW201429992A (ko) |
| UY (1) | UY35154A (ko) |
| WO (1) | WO2014085596A1 (ko) |
| ZA (1) | ZA201504659B (ko) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11077187B2 (en) | 2015-11-17 | 2021-08-03 | Oklahoma Medical Research Foundation | Epitope of optimized humanized monoclonal antibodies against activated protein C and uses thereof |
| EP3831843A1 (en) | 2019-12-08 | 2021-06-09 | Royal College Of Surgeons In Ireland | A hemostatic agent and uses thereof |
| CN115611986A (zh) * | 2021-07-13 | 2023-01-17 | 上海莱士血液制品股份有限公司 | 针对人活化蛋白c的单克隆抗体及其制备和应用 |
| CN116496394A (zh) * | 2022-01-26 | 2023-07-28 | 东莞市朋志生物科技有限公司 | 抗s100蛋白的抗体、检测s100蛋白的试剂和试剂盒 |
| WO2023168429A2 (en) * | 2022-03-04 | 2023-09-07 | Coagulant Therapeutics Corporation | Camelid antibodies against activated protein c and uses thereof |
Family Cites Families (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1993009804A1 (en) * | 1991-11-18 | 1993-05-27 | The Scripps Research Institute | Serine protease derived-polypeptides and anti-peptide antibodies, systems and therapeutic methods for inhibiting coagulation |
| DE69740154D1 (de) * | 1996-04-24 | 2011-05-05 | Univ Michigan | Gegen Inaktivierung resistenter Faktor VIII |
| US6989241B2 (en) * | 2000-10-02 | 2006-01-24 | Oklahoma Medical Research Foundation | Assay for rapid detection of human activated protein C and highly specific monoclonal antibody therefor |
| US20030226155A1 (en) * | 2001-08-30 | 2003-12-04 | Biorexis Pharmaceutical Corporation | Modified transferrin-antibody fusion proteins |
| US20030203355A1 (en) * | 2002-04-24 | 2003-10-30 | Los Alamos National Laboratory | Fluorobodies: binding ligands with intrinsic fluorescence |
| GB0309126D0 (en) * | 2003-04-17 | 2003-05-28 | Neutec Pharma Plc | Clostridium difficile focussed antibodies |
| CA2575791A1 (en) * | 2004-08-03 | 2006-02-16 | Dyax Corp. | Hk1-binding proteins |
| CA2591665C (en) * | 2004-12-20 | 2015-05-05 | Crucell Holland B.V. | Binding molecules capable of neutralizing west nile virus and uses thereof |
| JP5302007B2 (ja) * | 2005-12-13 | 2013-10-02 | アストラゼネカ アクチボラグ | インスリン様増殖因子に特異的な結合タンパク質およびその使用 |
| US8039597B2 (en) * | 2007-09-07 | 2011-10-18 | Agensys, Inc. | Antibodies and related molecules that bind to 24P4C12 proteins |
| AR068767A1 (es) * | 2007-10-12 | 2009-12-02 | Novartis Ag | Anticuerpos contra esclerostina, composiciones y metodos de uso de estos anticuerpos para tratar un trastorno patologico mediado por esclerostina |
| AU2008316661B2 (en) * | 2007-10-26 | 2013-05-23 | Oklahoma Medical Research Foundation | Monoclonal antibodies against activated and unactivated protein C |
| GB0903151D0 (en) * | 2009-02-25 | 2009-04-08 | Bioinvent Int Ab | Antibody uses and methods |
| US8926976B2 (en) * | 2009-09-25 | 2015-01-06 | Xoma Technology Ltd. | Modulators |
| GB201011771D0 (en) * | 2010-07-13 | 2010-08-25 | Bioinvent Int Ab | Biological material and particular uses thereof |
| GB201013989D0 (en) * | 2010-08-20 | 2010-10-06 | Univ Southampton | Biological materials and methods of using the same |
| AU2011329067A1 (en) * | 2010-11-16 | 2013-05-30 | Medimmune, Llc | Regimens for treatments using anti-IGF antibodies |
| US8440797B2 (en) * | 2010-12-06 | 2013-05-14 | Dainippon Sumitomo Pharma Co., Ltd. | Human monoclonal antibody |
| GB201020995D0 (en) * | 2010-12-10 | 2011-01-26 | Bioinvent Int Ab | Biological materials and uses thereof |
-
2013
- 2013-11-27 SG SG11201503719WA patent/SG11201503719WA/en unknown
- 2013-11-27 KR KR1020157017008A patent/KR20150088869A/ko not_active Application Discontinuation
- 2013-11-27 BR BR112015012414A patent/BR112015012414A2/pt not_active IP Right Cessation
- 2013-11-27 RU RU2015125349A patent/RU2015125349A/ru not_active Application Discontinuation
- 2013-11-27 AU AU2013352159A patent/AU2013352159A1/en not_active Abandoned
- 2013-11-27 WO PCT/US2013/072243 patent/WO2014085596A1/en active Application Filing
- 2013-11-27 CA CA2892750A patent/CA2892750A1/en not_active Abandoned
- 2013-11-27 EP EP13857869.5A patent/EP2925351A4/en not_active Withdrawn
- 2013-11-27 MX MX2015006424A patent/MX2015006424A/es unknown
- 2013-11-27 CN CN201380062159.XA patent/CN104812402A/zh active Pending
- 2013-11-27 US US14/443,710 patent/US20150307625A1/en not_active Abandoned
- 2013-11-27 JP JP2015545438A patent/JP2016501230A/ja active Pending
- 2013-11-28 TW TW102143366A patent/TW201429992A/zh unknown
- 2013-11-28 UY UY0001035154A patent/UY35154A/es not_active Application Discontinuation
- 2013-11-29 AR ARP130104417A patent/AR093671A1/es unknown
-
2015
- 2015-05-06 IL IL238658A patent/IL238658A0/en unknown
- 2015-06-26 ZA ZA2015/04659A patent/ZA201504659B/en unknown
-
2016
- 2016-01-27 HK HK16100878.9A patent/HK1212896A1/zh unknown
Also Published As
| Publication number | Publication date |
|---|---|
| SG11201503719WA (en) | 2015-06-29 |
| BR112015012414A2 (pt) | 2017-09-12 |
| RU2015125349A (ru) | 2017-01-10 |
| AR093671A1 (es) | 2015-06-17 |
| EP2925351A4 (en) | 2016-08-24 |
| JP2016501230A (ja) | 2016-01-18 |
| CN104812402A (zh) | 2015-07-29 |
| MX2015006424A (es) | 2015-08-14 |
| CA2892750A1 (en) | 2014-06-05 |
| IL238658A0 (en) | 2015-06-30 |
| AU2013352159A1 (en) | 2015-06-04 |
| EP2925351A1 (en) | 2015-10-07 |
| UY35154A (es) | 2014-06-30 |
| ZA201504659B (en) | 2017-11-29 |
| TW201429992A (zh) | 2014-08-01 |
| US20150307625A1 (en) | 2015-10-29 |
| HK1212896A1 (zh) | 2016-06-24 |
| WO2014085596A1 (en) | 2014-06-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6684369B2 (ja) | 組織因子経路インヒビター(tfpi)に対する最適化されたモノクローナル抗体 | |
| CA2933259C (en) | Monoclonal antibodies against tissue factor pathway inhibitor (tfpi) | |
| JP6696899B2 (ja) | プラスミノーゲン活性化因子阻害剤−1(pai−1)に対する抗体及びその使用 | |
| JP6170903B2 (ja) | 組織因子経路インヒビター(tfpi)に対するモノクローナル抗体 | |
| TW201802121A (zh) | 抗因子XI/XIa抗體之逆轉結合劑及其用途 | |
| KR20150088869A (ko) | 활성화 단백질 C(aPC)에 대한 모노클로날 항체 | |
| JP2018038398A (ja) | 組織因子経路インヒビター(tfpi)に対するモノクローナル抗体 | |
| AU2018271420B2 (en) | Optimized monoclonal antibodies against tissue factor pathway inhibitor (TFPI) | |
| JP6559188B2 (ja) | 組織因子経路インヒビター(tfpi)に対するモノクローナル抗体 | |
| JP6419664B2 (ja) | 組織因子経路インヒビター(tfpi)に対するモノクローナル抗体 | |
| JP2018108089A (ja) | 組織因子経路インヒビター(tfpi)に対するモノクローナル抗体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |