KR20080071190A - 델타-9 일롱가제, 및 다중불포화 지방산 생성에 있어서의이들의 용도 - Google Patents
델타-9 일롱가제, 및 다중불포화 지방산 생성에 있어서의이들의 용도 Download PDFInfo
- Publication number
- KR20080071190A KR20080071190A KR1020087015062A KR20087015062A KR20080071190A KR 20080071190 A KR20080071190 A KR 20080071190A KR 1020087015062 A KR1020087015062 A KR 1020087015062A KR 20087015062 A KR20087015062 A KR 20087015062A KR 20080071190 A KR20080071190 A KR 20080071190A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- sequence
- polypeptide
- gene
- yarrowia
- Prior art date
Links
- 235000020777 polyunsaturated fatty acids Nutrition 0.000 title abstract description 87
- 238000000034 method Methods 0.000 claims abstract description 113
- 150000007523 nucleic acids Chemical group 0.000 claims abstract description 103
- 240000004808 Saccharomyces cerevisiae Species 0.000 claims abstract description 66
- OYHQOLUKZRVURQ-IXWMQOLASA-N linoleic acid Natural products CCCCC\C=C/C\C=C\CCCCCCCC(O)=O OYHQOLUKZRVURQ-IXWMQOLASA-N 0.000 claims abstract description 9
- 235000021297 Eicosadienoic acid Nutrition 0.000 claims abstract description 8
- OYHQOLUKZRVURQ-HZJYTTRNSA-N Linoleic acid Chemical compound CCCCC\C=C/C\C=C/CCCCCCCC(O)=O OYHQOLUKZRVURQ-HZJYTTRNSA-N 0.000 claims abstract description 7
- 235000020778 linoleic acid Nutrition 0.000 claims abstract description 7
- XSXIVVZCUAHUJO-AVQMFFATSA-N (11e,14e)-icosa-11,14-dienoic acid Chemical compound CCCCC\C=C\C\C=C\CCCCCCCCCC(O)=O XSXIVVZCUAHUJO-AVQMFFATSA-N 0.000 claims abstract 4
- 230000014509 gene expression Effects 0.000 claims description 132
- 241000235013 Yarrowia Species 0.000 claims description 125
- 239000000047 product Substances 0.000 claims description 92
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 82
- 125000003729 nucleotide group Chemical group 0.000 claims description 76
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 76
- 239000002773 nucleotide Substances 0.000 claims description 75
- 229920001184 polypeptide Polymers 0.000 claims description 75
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 67
- 230000000694 effects Effects 0.000 claims description 65
- 238000009396 hybridization Methods 0.000 claims description 53
- 238000004519 manufacturing process Methods 0.000 claims description 50
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 48
- 235000013305 food Nutrition 0.000 claims description 48
- 150000001413 amino acids Chemical class 0.000 claims description 37
- 230000000813 microbial effect Effects 0.000 claims description 35
- 102000040430 polynucleotide Human genes 0.000 claims description 34
- 108091033319 polynucleotide Proteins 0.000 claims description 34
- 239000002157 polynucleotide Substances 0.000 claims description 34
- 230000000295 complement effect Effects 0.000 claims description 30
- 239000002253 acid Substances 0.000 claims description 29
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 28
- 238000005406 washing Methods 0.000 claims description 24
- 241000970807 Thermoanaerobacterales Species 0.000 claims description 23
- 108020004705 Codon Proteins 0.000 claims description 21
- 241000233866 Fungi Species 0.000 claims description 15
- 238000006467 substitution reaction Methods 0.000 claims description 14
- 241001465754 Metazoa Species 0.000 claims description 13
- 235000013350 formula milk Nutrition 0.000 claims description 13
- DTOSIQBPPRVQHS-PDBXOOCHSA-N alpha-linolenic acid Chemical compound CC\C=C/C\C=C/C\C=C/CCCCCCCC(O)=O DTOSIQBPPRVQHS-PDBXOOCHSA-N 0.000 claims description 12
- 241000195493 Cryptophyta Species 0.000 claims description 11
- 241000894006 Bacteria Species 0.000 claims description 10
- 241000235015 Yarrowia lipolytica Species 0.000 claims description 9
- 230000008569 process Effects 0.000 claims description 9
- 235000015872 dietary supplement Nutrition 0.000 claims description 8
- 235000020661 alpha-linolenic acid Nutrition 0.000 claims description 7
- 229960004488 linolenic acid Drugs 0.000 claims description 7
- 241000222120 Candida <Saccharomycetales> Species 0.000 claims description 6
- 241000223252 Rhodotorula Species 0.000 claims description 6
- 235000013365 dairy product Nutrition 0.000 claims description 6
- 241001149698 Lipomyces Species 0.000 claims description 4
- 238000009360 aquaculture Methods 0.000 claims description 4
- 244000144974 aquaculture Species 0.000 claims description 4
- 235000013622 meat product Nutrition 0.000 claims description 4
- 244000144977 poultry Species 0.000 claims description 4
- 235000011888 snacks Nutrition 0.000 claims description 4
- 241001527609 Cryptococcus Species 0.000 claims description 3
- 241000282849 Ruminantia Species 0.000 claims description 3
- 241000223230 Trichosporon Species 0.000 claims description 3
- WHXSMMKQMYFTQS-UHFFFAOYSA-N Lithium Chemical compound [Li] WHXSMMKQMYFTQS-UHFFFAOYSA-N 0.000 claims description 2
- 239000003814 drug Substances 0.000 claims description 2
- 235000011868 grain product Nutrition 0.000 claims description 2
- 229910052744 lithium Inorganic materials 0.000 claims description 2
- HJOVHMDZYOCNQW-UHFFFAOYSA-N isophorone Chemical compound CC1=CC(=O)CC(C)(C)C1 HJOVHMDZYOCNQW-UHFFFAOYSA-N 0.000 claims 2
- 240000000073 Achillea millefolium Species 0.000 claims 1
- 235000007754 Achillea millefolium Nutrition 0.000 claims 1
- 241000235575 Mortierella Species 0.000 claims 1
- 241000233671 Schizochytrium Species 0.000 claims 1
- 241000233675 Thraustochytrium Species 0.000 claims 1
- AHANXAKGNAKFSK-PDBXOOCHSA-N all-cis-icosa-11,14,17-trienoic acid Chemical compound CC\C=C/C\C=C/C\C=C/CCCCCCCCCC(O)=O AHANXAKGNAKFSK-PDBXOOCHSA-N 0.000 claims 1
- PRHHYVQTPBEDFE-UHFFFAOYSA-N eicosatrienoic acid Natural products CCCCCC=CCC=CCCCCC=CCCCC(O)=O PRHHYVQTPBEDFE-UHFFFAOYSA-N 0.000 claims 1
- 239000012634 fragment Substances 0.000 abstract description 97
- 235000020978 long-chain polyunsaturated fatty acids Nutrition 0.000 abstract description 15
- 108090000623 proteins and genes Proteins 0.000 description 295
- 108020004414 DNA Proteins 0.000 description 160
- 210000004027 cell Anatomy 0.000 description 140
- 241000196324 Embryophyta Species 0.000 description 124
- 239000013612 plasmid Substances 0.000 description 122
- 239000013615 primer Substances 0.000 description 94
- 235000010469 Glycine max Nutrition 0.000 description 74
- 239000000194 fatty acid Substances 0.000 description 74
- 235000014113 dietary fatty acids Nutrition 0.000 description 73
- 229930195729 fatty acid Natural products 0.000 description 73
- 150000004665 fatty acids Chemical class 0.000 description 71
- 239000003921 oil Substances 0.000 description 69
- 244000068988 Glycine max Species 0.000 description 67
- 235000019198 oils Nutrition 0.000 description 66
- 239000013598 vector Substances 0.000 description 63
- 239000002299 complementary DNA Substances 0.000 description 62
- 102000004169 proteins and genes Human genes 0.000 description 61
- 235000018102 proteins Nutrition 0.000 description 59
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 55
- 108090000790 Enzymes Proteins 0.000 description 53
- 101710095468 Cyclase Proteins 0.000 description 52
- 102000004190 Enzymes Human genes 0.000 description 52
- 238000006243 chemical reaction Methods 0.000 description 51
- 235000020660 omega-3 fatty acid Nutrition 0.000 description 51
- 108010022240 delta-8 fatty acid desaturase Proteins 0.000 description 50
- 239000002609 medium Substances 0.000 description 48
- 238000003752 polymerase chain reaction Methods 0.000 description 47
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 42
- 241000195619 Euglena gracilis Species 0.000 description 42
- 235000001014 amino acid Nutrition 0.000 description 39
- 239000013604 expression vector Substances 0.000 description 39
- 235000020665 omega-6 fatty acid Nutrition 0.000 description 37
- 108091026890 Coding region Proteins 0.000 description 36
- 150000002632 lipids Chemical class 0.000 description 36
- 239000000203 mixture Substances 0.000 description 36
- 230000015572 biosynthetic process Effects 0.000 description 35
- 108020004999 messenger RNA Proteins 0.000 description 35
- 239000000523 sample Substances 0.000 description 34
- 210000001519 tissue Anatomy 0.000 description 34
- 229940033080 omega-6 fatty acid Drugs 0.000 description 33
- 239000000758 substrate Substances 0.000 description 32
- 229940024606 amino acid Drugs 0.000 description 31
- 235000020673 eicosapentaenoic acid Nutrition 0.000 description 31
- 229940012843 omega-3 fatty acid Drugs 0.000 description 31
- 230000009466 transformation Effects 0.000 description 31
- 230000001105 regulatory effect Effects 0.000 description 29
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 27
- 239000007788 liquid Substances 0.000 description 27
- 241000894007 species Species 0.000 description 27
- 230000037361 pathway Effects 0.000 description 26
- 230000035897 transcription Effects 0.000 description 26
- 238000013518 transcription Methods 0.000 description 26
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 26
- MBMBGCFOFBJSGT-KUBAVDMBSA-N all-cis-docosa-4,7,10,13,16,19-hexaenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCC(O)=O MBMBGCFOFBJSGT-KUBAVDMBSA-N 0.000 description 25
- 102000039446 nucleic acids Human genes 0.000 description 25
- 108020004707 nucleic acids Proteins 0.000 description 25
- 238000003786 synthesis reaction Methods 0.000 description 25
- 230000006696 biosynthetic metabolic pathway Effects 0.000 description 24
- 238000010276 construction Methods 0.000 description 24
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 22
- 108091034117 Oligonucleotide Proteins 0.000 description 22
- 238000004458 analytical method Methods 0.000 description 22
- 235000020669 docosahexaenoic acid Nutrition 0.000 description 22
- 210000002257 embryonic structure Anatomy 0.000 description 22
- 108010075530 Kunitz Soybean Trypsin Inhibitor Proteins 0.000 description 21
- HOBAELRKJCKHQD-UHFFFAOYSA-N (8Z,11Z,14Z)-8,11,14-eicosatrienoic acid Natural products CCCCCC=CCC=CCC=CCCCCCCC(O)=O HOBAELRKJCKHQD-UHFFFAOYSA-N 0.000 description 20
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 20
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 20
- 239000002585 base Substances 0.000 description 20
- HOBAELRKJCKHQD-QNEBEIHSSA-N dihomo-γ-linolenic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/CCCCCCC(O)=O HOBAELRKJCKHQD-QNEBEIHSSA-N 0.000 description 20
- 210000001161 mammalian embryo Anatomy 0.000 description 20
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 19
- 230000003321 amplification Effects 0.000 description 19
- 238000003199 nucleic acid amplification method Methods 0.000 description 19
- 230000009261 transgenic effect Effects 0.000 description 18
- 238000013519 translation Methods 0.000 description 18
- 230000014616 translation Effects 0.000 description 18
- 241000588724 Escherichia coli Species 0.000 description 17
- 235000020664 gamma-linolenic acid Nutrition 0.000 description 17
- VZCCETWTMQHEPK-QNEBEIHSSA-N gamma-linolenic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/CCCCC(O)=O VZCCETWTMQHEPK-QNEBEIHSSA-N 0.000 description 17
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 16
- 108020004511 Recombinant DNA Proteins 0.000 description 16
- 229910052799 carbon Inorganic materials 0.000 description 16
- 239000003795 chemical substances by application Substances 0.000 description 16
- 238000002955 isolation Methods 0.000 description 16
- 238000012986 modification Methods 0.000 description 16
- YUFFSWGQGVEMMI-JLNKQSITSA-N (7Z,10Z,13Z,16Z,19Z)-docosapentaenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCCCCC(O)=O YUFFSWGQGVEMMI-JLNKQSITSA-N 0.000 description 15
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 15
- 238000010230 functional analysis Methods 0.000 description 15
- 230000012010 growth Effects 0.000 description 15
- 244000005700 microbiome Species 0.000 description 15
- 230000004048 modification Effects 0.000 description 15
- VLKZOEOYAKHREP-UHFFFAOYSA-N n-Hexane Chemical compound CCCCCC VLKZOEOYAKHREP-UHFFFAOYSA-N 0.000 description 15
- YUFFSWGQGVEMMI-UHFFFAOYSA-N (7Z,10Z,13Z,16Z,19Z)-7,10,13,16,19-docosapentaenoic acid Natural products CCC=CCC=CCC=CCC=CCC=CCCCCCC(O)=O YUFFSWGQGVEMMI-UHFFFAOYSA-N 0.000 description 14
- SEHFUALWMUWDKS-UHFFFAOYSA-N 5-fluoroorotic acid Chemical compound OC(=O)C=1NC(=O)NC(=O)C=1F SEHFUALWMUWDKS-UHFFFAOYSA-N 0.000 description 14
- 241000195620 Euglena Species 0.000 description 14
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 14
- 239000003925 fat Substances 0.000 description 14
- 235000019197 fats Nutrition 0.000 description 14
- 230000006870 function Effects 0.000 description 14
- 230000010076 replication Effects 0.000 description 14
- 230000014621 translational initiation Effects 0.000 description 14
- 238000012408 PCR amplification Methods 0.000 description 13
- 238000005984 hydrogenation reaction Methods 0.000 description 13
- 239000000543 intermediate Substances 0.000 description 13
- 238000012545 processing Methods 0.000 description 13
- WRIDQFICGBMAFQ-UHFFFAOYSA-N (E)-8-Octadecenoic acid Natural products CCCCCCCCCC=CCCCCCCC(O)=O WRIDQFICGBMAFQ-UHFFFAOYSA-N 0.000 description 12
- LQJBNNIYVWPHFW-UHFFFAOYSA-N 20:1omega9c fatty acid Natural products CCCCCCCCCCC=CCCCCCCCC(O)=O LQJBNNIYVWPHFW-UHFFFAOYSA-N 0.000 description 12
- QSBYPNXLFMSGKH-UHFFFAOYSA-N 9-Heptadecensaeure Natural products CCCCCCCC=CCCCCCCCC(O)=O QSBYPNXLFMSGKH-UHFFFAOYSA-N 0.000 description 12
- 102100027211 Albumin Human genes 0.000 description 12
- 102000000412 Annexin Human genes 0.000 description 12
- 108050008874 Annexin Proteins 0.000 description 12
- 101001091269 Escherichia coli Hygromycin-B 4-O-kinase Proteins 0.000 description 12
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 12
- 239000005642 Oleic acid Substances 0.000 description 12
- ZQPPMHVWECSIRJ-UHFFFAOYSA-N Oleic acid Natural products CCCCCCCCC=CCCCCCCCC(O)=O ZQPPMHVWECSIRJ-UHFFFAOYSA-N 0.000 description 12
- 101001091268 Streptomyces hygroscopicus Hygromycin-B 7''-O-kinase Proteins 0.000 description 12
- 108010011713 delta-15 desaturase Proteins 0.000 description 12
- 108010050848 glycylleucine Proteins 0.000 description 12
- QXJSBBXBKPUZAA-UHFFFAOYSA-N isooleic acid Natural products CCCCCCCC=CCCCCCCCCC(O)=O QXJSBBXBKPUZAA-UHFFFAOYSA-N 0.000 description 12
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 description 12
- 235000021313 oleic acid Nutrition 0.000 description 12
- 238000004114 suspension culture Methods 0.000 description 12
- 230000001131 transforming effect Effects 0.000 description 12
- 102100034542 Acyl-CoA (8-3)-desaturase Human genes 0.000 description 11
- 108010088751 Albumins Proteins 0.000 description 11
- 108010073542 Delta-5 Fatty Acid Desaturase Proteins 0.000 description 11
- 241000172147 Saprolegnia diclina Species 0.000 description 11
- 239000006227 byproduct Substances 0.000 description 11
- 238000005119 centrifugation Methods 0.000 description 11
- 238000010367 cloning Methods 0.000 description 11
- 230000004186 co-expression Effects 0.000 description 11
- 235000013372 meat Nutrition 0.000 description 11
- 239000008188 pellet Substances 0.000 description 11
- 239000000243 solution Substances 0.000 description 11
- 229920001817 Agar Polymers 0.000 description 10
- 108700010070 Codon Usage Proteins 0.000 description 10
- 241001245610 Eutreptiella Species 0.000 description 10
- 241000907999 Mortierella alpina Species 0.000 description 10
- 239000008272 agar Substances 0.000 description 10
- 235000019387 fatty acid methyl ester Nutrition 0.000 description 10
- 230000001965 increasing effect Effects 0.000 description 10
- 108010057821 leucylproline Proteins 0.000 description 10
- 238000012216 screening Methods 0.000 description 10
- 239000007787 solid Substances 0.000 description 10
- 238000011144 upstream manufacturing Methods 0.000 description 10
- 229940035893 uracil Drugs 0.000 description 10
- 241000024188 Andala Species 0.000 description 9
- 241000282326 Felis catus Species 0.000 description 9
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 9
- 108091081024 Start codon Proteins 0.000 description 9
- -1 Val) Chemical compound 0.000 description 9
- 239000000872 buffer Substances 0.000 description 9
- 235000013351 cheese Nutrition 0.000 description 9
- 235000016709 nutrition Nutrition 0.000 description 9
- 239000002245 particle Substances 0.000 description 9
- 239000002243 precursor Substances 0.000 description 9
- 238000012163 sequencing technique Methods 0.000 description 9
- 235000012424 soybean oil Nutrition 0.000 description 9
- 239000003549 soybean oil Substances 0.000 description 9
- 235000021122 unsaturated fatty acids Nutrition 0.000 description 9
- 108010000700 Acetolactate synthase Proteins 0.000 description 8
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 8
- 102000053602 DNA Human genes 0.000 description 8
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 8
- 101000912235 Rebecca salina Acyl-lipid (7-3)-desaturase Proteins 0.000 description 8
- 101000877236 Siganus canaliculatus Acyl-CoA Delta-4 desaturase Proteins 0.000 description 8
- 235000019441 ethanol Nutrition 0.000 description 8
- 238000000855 fermentation Methods 0.000 description 8
- 230000004151 fermentation Effects 0.000 description 8
- 210000003495 flagella Anatomy 0.000 description 8
- 230000002068 genetic effect Effects 0.000 description 8
- 238000002844 melting Methods 0.000 description 8
- 230000008018 melting Effects 0.000 description 8
- 230000037353 metabolic pathway Effects 0.000 description 8
- 229910052757 nitrogen Inorganic materials 0.000 description 8
- 239000006014 omega-3 oil Substances 0.000 description 8
- SECPZKHBENQXJG-FPLPWBNLSA-N palmitoleic acid Chemical compound CCCCCC\C=C/CCCCCCCC(O)=O SECPZKHBENQXJG-FPLPWBNLSA-N 0.000 description 8
- 150000003839 salts Chemical class 0.000 description 8
- 239000000126 substance Substances 0.000 description 8
- DCXXMTOCNZCJGO-UHFFFAOYSA-N tristearoylglycerol Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(OC(=O)CCCCCCCCCCCCCCCCC)COC(=O)CCCCCCCCCCCCCCCCC DCXXMTOCNZCJGO-UHFFFAOYSA-N 0.000 description 8
- 150000004670 unsaturated fatty acids Chemical class 0.000 description 8
- 235000015112 vegetable and seed oil Nutrition 0.000 description 8
- 102100034544 Acyl-CoA 6-desaturase Human genes 0.000 description 7
- 108010037138 Linoleoyl-CoA Desaturase Proteins 0.000 description 7
- 230000009471 action Effects 0.000 description 7
- 235000013339 cereals Nutrition 0.000 description 7
- 239000003153 chemical reaction reagent Substances 0.000 description 7
- 238000000605 extraction Methods 0.000 description 7
- 238000004817 gas chromatography Methods 0.000 description 7
- 230000010354 integration Effects 0.000 description 7
- 239000003550 marker Substances 0.000 description 7
- 239000000463 material Substances 0.000 description 7
- 238000010369 molecular cloning Methods 0.000 description 7
- 230000035772 mutation Effects 0.000 description 7
- 230000035764 nutrition Effects 0.000 description 7
- 239000011780 sodium chloride Substances 0.000 description 7
- 235000013343 vitamin Nutrition 0.000 description 7
- 239000011782 vitamin Substances 0.000 description 7
- 229940088594 vitamin Drugs 0.000 description 7
- 229930003231 vitamin Natural products 0.000 description 7
- UHPMCKVQTMMPCG-UHFFFAOYSA-N 5,8-dihydroxy-2-methoxy-6-methyl-7-(2-oxopropyl)naphthalene-1,4-dione Chemical compound CC1=C(CC(C)=O)C(O)=C2C(=O)C(OC)=CC(=O)C2=C1O UHPMCKVQTMMPCG-UHFFFAOYSA-N 0.000 description 6
- 108020005544 Antisense RNA Proteins 0.000 description 6
- 241000223218 Fusarium Species 0.000 description 6
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 6
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 6
- WQDUMFSSJAZKTM-UHFFFAOYSA-N Sodium methoxide Chemical compound [Na+].[O-]C WQDUMFSSJAZKTM-UHFFFAOYSA-N 0.000 description 6
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 6
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 6
- 229960000723 ampicillin Drugs 0.000 description 6
- 230000001580 bacterial effect Effects 0.000 description 6
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 6
- 125000004432 carbon atom Chemical group C* 0.000 description 6
- 210000000349 chromosome Anatomy 0.000 description 6
- 239000003184 complementary RNA Substances 0.000 description 6
- 238000012217 deletion Methods 0.000 description 6
- 230000037430 deletion Effects 0.000 description 6
- 238000011161 development Methods 0.000 description 6
- 230000018109 developmental process Effects 0.000 description 6
- XIVFQYWMMJWUCD-UHFFFAOYSA-N dihydrophaseic acid Natural products C1C(O)CC2(C)OCC1(C)C2(O)C=CC(C)=CC(O)=O XIVFQYWMMJWUCD-UHFFFAOYSA-N 0.000 description 6
- 235000021588 free fatty acids Nutrition 0.000 description 6
- 239000008103 glucose Substances 0.000 description 6
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 6
- 239000001963 growth medium Substances 0.000 description 6
- IPCSVZSSVZVIGE-UHFFFAOYSA-M hexadecanoate Chemical compound CCCCCCCCCCCCCCCC([O-])=O IPCSVZSSVZVIGE-UHFFFAOYSA-M 0.000 description 6
- 108010028295 histidylhistidine Proteins 0.000 description 6
- 230000005764 inhibitory process Effects 0.000 description 6
- 230000003389 potentiating effect Effects 0.000 description 6
- 238000000746 purification Methods 0.000 description 6
- 229920006395 saturated elastomer Polymers 0.000 description 6
- 235000003441 saturated fatty acids Nutrition 0.000 description 6
- 150000004671 saturated fatty acids Chemical class 0.000 description 6
- 239000000344 soap Substances 0.000 description 6
- 230000000392 somatic effect Effects 0.000 description 6
- ATHGHQPFGPMSJY-UHFFFAOYSA-N spermidine Chemical compound NCCCCNCCCN ATHGHQPFGPMSJY-UHFFFAOYSA-N 0.000 description 6
- 238000005809 transesterification reaction Methods 0.000 description 6
- XSXIVVZCUAHUJO-HZJYTTRNSA-N (11Z,14Z)-icosadienoic acid Chemical compound CCCCC\C=C/C\C=C/CCCCCCCCCC(O)=O XSXIVVZCUAHUJO-HZJYTTRNSA-N 0.000 description 5
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 5
- 108010073771 Soybean Proteins Proteins 0.000 description 5
- 229930006000 Sucrose Natural products 0.000 description 5
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 5
- 240000008042 Zea mays Species 0.000 description 5
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 5
- 230000000692 anti-sense effect Effects 0.000 description 5
- 108010068265 aspartyltyrosine Proteins 0.000 description 5
- 238000003556 assay Methods 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 238000010804 cDNA synthesis Methods 0.000 description 5
- 239000007795 chemical reaction product Substances 0.000 description 5
- 239000013599 cloning vector Substances 0.000 description 5
- 238000013461 design Methods 0.000 description 5
- 238000010586 diagram Methods 0.000 description 5
- 239000012153 distilled water Substances 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 238000009472 formulation Methods 0.000 description 5
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 5
- 229910052737 gold Inorganic materials 0.000 description 5
- 239000010931 gold Substances 0.000 description 5
- 230000007407 health benefit Effects 0.000 description 5
- 108010092114 histidylphenylalanine Proteins 0.000 description 5
- 230000003834 intracellular effect Effects 0.000 description 5
- 238000007726 management method Methods 0.000 description 5
- 230000002503 metabolic effect Effects 0.000 description 5
- 238000007899 nucleic acid hybridization Methods 0.000 description 5
- 230000036961 partial effect Effects 0.000 description 5
- 239000000843 powder Substances 0.000 description 5
- 239000011541 reaction mixture Substances 0.000 description 5
- 238000011069 regeneration method Methods 0.000 description 5
- 239000000725 suspension Substances 0.000 description 5
- 230000005030 transcription termination Effects 0.000 description 5
- 210000005253 yeast cell Anatomy 0.000 description 5
- 229920000936 Agarose Polymers 0.000 description 4
- 241000219198 Brassica Species 0.000 description 4
- 239000005496 Chlorsulfuron Substances 0.000 description 4
- 108091035707 Consensus sequence Proteins 0.000 description 4
- 102000036181 Fatty Acid Elongases Human genes 0.000 description 4
- 108010058732 Fatty Acid Elongases Proteins 0.000 description 4
- 108010087894 Fatty acid desaturases Proteins 0.000 description 4
- 108700037728 Glycine max beta-conglycinin Proteins 0.000 description 4
- 241001501873 Isochrysis galbana Species 0.000 description 4
- 241000880493 Leptailurus serval Species 0.000 description 4
- PTRKPHUGYULXPU-KKUMJFAQSA-N Leu-Phe-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O PTRKPHUGYULXPU-KKUMJFAQSA-N 0.000 description 4
- 241000124008 Mammalia Species 0.000 description 4
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 4
- 108700026244 Open Reading Frames Proteins 0.000 description 4
- 235000021319 Palmitoleic acid Nutrition 0.000 description 4
- CDNPIRSCAFMMBE-SRVKXCTJSA-N Phe-Asn-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CDNPIRSCAFMMBE-SRVKXCTJSA-N 0.000 description 4
- 240000004713 Pisum sativum Species 0.000 description 4
- 235000010582 Pisum sativum Nutrition 0.000 description 4
- 241000235070 Saccharomyces Species 0.000 description 4
- 241000592344 Spermatophyta Species 0.000 description 4
- NWEGIYMHTZXVBP-JSGCOSHPSA-N Tyr-Val-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O NWEGIYMHTZXVBP-JSGCOSHPSA-N 0.000 description 4
- 239000011543 agarose gel Substances 0.000 description 4
- 238000000246 agarose gel electrophoresis Methods 0.000 description 4
- YZXBAPSDXZZRGB-DOFZRALJSA-N arachidonic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/C\C=C/CCCC(O)=O YZXBAPSDXZZRGB-DOFZRALJSA-N 0.000 description 4
- 230000002567 autonomic effect Effects 0.000 description 4
- 239000001569 carbon dioxide Substances 0.000 description 4
- 229910002092 carbon dioxide Inorganic materials 0.000 description 4
- VJYIFXVZLXQVHO-UHFFFAOYSA-N chlorsulfuron Chemical compound COC1=NC(C)=NC(NC(=O)NS(=O)(=O)C=2C(=CC=CC=2)Cl)=N1 VJYIFXVZLXQVHO-UHFFFAOYSA-N 0.000 description 4
- SECPZKHBENQXJG-UHFFFAOYSA-N cis-palmitoleic acid Natural products CCCCCCC=CCCCCCCCC(O)=O SECPZKHBENQXJG-UHFFFAOYSA-N 0.000 description 4
- 239000010779 crude oil Substances 0.000 description 4
- 230000007423 decrease Effects 0.000 description 4
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 4
- 235000004626 essential fatty acids Nutrition 0.000 description 4
- 239000000499 gel Substances 0.000 description 4
- 238000007429 general method Methods 0.000 description 4
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 4
- 238000000338 in vitro Methods 0.000 description 4
- 235000020667 long-chain omega-3 fatty acid Nutrition 0.000 description 4
- 235000013310 margarine Nutrition 0.000 description 4
- 239000003264 margarine Substances 0.000 description 4
- 230000035800 maturation Effects 0.000 description 4
- 239000012528 membrane Substances 0.000 description 4
- 230000004060 metabolic process Effects 0.000 description 4
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 4
- 210000000056 organ Anatomy 0.000 description 4
- 210000003463 organelle Anatomy 0.000 description 4
- 150000003904 phospholipids Chemical class 0.000 description 4
- 230000008488 polyadenylation Effects 0.000 description 4
- NLKNQRATVPKPDG-UHFFFAOYSA-M potassium iodide Chemical compound [K+].[I-] NLKNQRATVPKPDG-UHFFFAOYSA-M 0.000 description 4
- 238000002360 preparation method Methods 0.000 description 4
- 238000007670 refining Methods 0.000 description 4
- 230000008929 regeneration Effects 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 238000012552 review Methods 0.000 description 4
- 238000004904 shortening Methods 0.000 description 4
- 239000002689 soil Substances 0.000 description 4
- 229940001941 soy protein Drugs 0.000 description 4
- 238000003756 stirring Methods 0.000 description 4
- 239000005720 sucrose Substances 0.000 description 4
- 230000002194 synthesizing effect Effects 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 230000002103 transcriptional effect Effects 0.000 description 4
- 230000001052 transient effect Effects 0.000 description 4
- JDKIKEYFSJUYJZ-OUJQXAOTSA-N (5Z,11Z,14Z,17Z)-icosatetraenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/CCCC\C=C/CCCC(O)=O JDKIKEYFSJUYJZ-OUJQXAOTSA-N 0.000 description 3
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 3
- 239000005631 2,4-Dichlorophenoxyacetic acid Substances 0.000 description 3
- TWJNQYPJQDRXPH-UHFFFAOYSA-N 2-cyanobenzohydrazide Chemical compound NNC(=O)C1=CC=CC=C1C#N TWJNQYPJQDRXPH-UHFFFAOYSA-N 0.000 description 3
- 101150090724 3 gene Proteins 0.000 description 3
- 101150001232 ALS gene Proteins 0.000 description 3
- 102000057234 Acyl transferases Human genes 0.000 description 3
- 108700016155 Acyl transferases Proteins 0.000 description 3
- PVQLRJRPUTXFFX-CIUDSAMLSA-N Ala-Met-Gln Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O PVQLRJRPUTXFFX-CIUDSAMLSA-N 0.000 description 3
- 108700028369 Alleles Proteins 0.000 description 3
- KSZHWTRZPOTIGY-AVGNSLFASA-N Asn-Tyr-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O KSZHWTRZPOTIGY-AVGNSLFASA-N 0.000 description 3
- 241000283690 Bos taurus Species 0.000 description 3
- 235000011331 Brassica Nutrition 0.000 description 3
- 229920000742 Cotton Polymers 0.000 description 3
- 239000003155 DNA primer Substances 0.000 description 3
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 3
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 3
- 241000233732 Fusarium verticillioides Species 0.000 description 3
- 244000299507 Gossypium hirsutum Species 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 206010020649 Hyperkeratosis Diseases 0.000 description 3
- HPCFRQWLTRDGHT-AJNGGQMLSA-N Ile-Leu-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O HPCFRQWLTRDGHT-AJNGGQMLSA-N 0.000 description 3
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 3
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 3
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 3
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 3
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 3
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 3
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 3
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 3
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 3
- LIINDKYIGYTDLG-PPCPHDFISA-N Leu-Ile-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LIINDKYIGYTDLG-PPCPHDFISA-N 0.000 description 3
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 3
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 235000021360 Myristic acid Nutrition 0.000 description 3
- TUNFSRHWOTWDNC-UHFFFAOYSA-N Myristic acid Natural products CCCCCCCCCCCCCC(O)=O TUNFSRHWOTWDNC-UHFFFAOYSA-N 0.000 description 3
- 108010079364 N-glycylalanine Proteins 0.000 description 3
- 206010028980 Neoplasm Diseases 0.000 description 3
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 3
- 241000209504 Poaceae Species 0.000 description 3
- 108091034057 RNA (poly(A)) Proteins 0.000 description 3
- 108020005091 Replication Origin Proteins 0.000 description 3
- 238000012300 Sequence Analysis Methods 0.000 description 3
- PLQWGQUNUPMNOD-KKUMJFAQSA-N Ser-Tyr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O PLQWGQUNUPMNOD-KKUMJFAQSA-N 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- 235000021355 Stearic acid Nutrition 0.000 description 3
- 108700005078 Synthetic Genes Proteins 0.000 description 3
- RFKVQLIXNVEOMB-WEDXCCLWSA-N Thr-Leu-Gly Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)O)N)O RFKVQLIXNVEOMB-WEDXCCLWSA-N 0.000 description 3
- 108700019146 Transgenes Proteins 0.000 description 3
- BYSKNUASOAGJSS-NQCBNZPSSA-N Trp-Ile-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N BYSKNUASOAGJSS-NQCBNZPSSA-N 0.000 description 3
- SUGRIIAOLCDLBD-ZOBUZTSGSA-N Val-Trp-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(=O)O)C(=O)O)N SUGRIIAOLCDLBD-ZOBUZTSGSA-N 0.000 description 3
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 description 3
- 108010011559 alanylphenylalanine Proteins 0.000 description 3
- 125000001931 aliphatic group Chemical group 0.000 description 3
- JAZBEHYOTPTENJ-JLNKQSITSA-N all-cis-5,8,11,14,17-icosapentaenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCCC(O)=O JAZBEHYOTPTENJ-JLNKQSITSA-N 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 3
- 230000008238 biochemical pathway Effects 0.000 description 3
- 230000001851 biosynthetic effect Effects 0.000 description 3
- 238000004422 calculation algorithm Methods 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 239000003054 catalyst Substances 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 150000001875 compounds Chemical class 0.000 description 3
- 235000009508 confectionery Nutrition 0.000 description 3
- 235000005822 corn Nutrition 0.000 description 3
- 125000004122 cyclic group Chemical group 0.000 description 3
- 238000004332 deodorization Methods 0.000 description 3
- 230000001419 dependent effect Effects 0.000 description 3
- 235000005911 diet Nutrition 0.000 description 3
- 230000029087 digestion Effects 0.000 description 3
- JAZBEHYOTPTENJ-UHFFFAOYSA-N eicosapentaenoic acid Natural products CCC=CCC=CCC=CCC=CCC=CCCCC(O)=O JAZBEHYOTPTENJ-UHFFFAOYSA-N 0.000 description 3
- 229920001971 elastomer Polymers 0.000 description 3
- 238000004520 electroporation Methods 0.000 description 3
- 239000000284 extract Substances 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- 239000011521 glass Substances 0.000 description 3
- 108010015792 glycyllysine Proteins 0.000 description 3
- 235000013402 health food Nutrition 0.000 description 3
- 239000004615 ingredient Substances 0.000 description 3
- 230000000977 initiatory effect Effects 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- 239000000787 lecithin Substances 0.000 description 3
- 229940067606 lecithin Drugs 0.000 description 3
- 235000010445 lecithin Nutrition 0.000 description 3
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 3
- 108010000761 leucylarginine Proteins 0.000 description 3
- XIXADJRWDQXREU-UHFFFAOYSA-M lithium acetate Chemical compound [Li+].CC([O-])=O XIXADJRWDQXREU-UHFFFAOYSA-M 0.000 description 3
- 108010005942 methionylglycine Proteins 0.000 description 3
- 108010068488 methionylphenylalanine Proteins 0.000 description 3
- 235000013336 milk Nutrition 0.000 description 3
- 239000008267 milk Substances 0.000 description 3
- 210000004080 milk Anatomy 0.000 description 3
- 230000003278 mimic effect Effects 0.000 description 3
- 238000002156 mixing Methods 0.000 description 3
- 235000021281 monounsaturated fatty acids Nutrition 0.000 description 3
- 230000001338 necrotic effect Effects 0.000 description 3
- 230000007935 neutral effect Effects 0.000 description 3
- 239000002853 nucleic acid probe Substances 0.000 description 3
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 3
- 238000005457 optimization Methods 0.000 description 3
- 230000002018 overexpression Effects 0.000 description 3
- 108010051242 phenylalanylserine Proteins 0.000 description 3
- 239000000049 pigment Substances 0.000 description 3
- 235000013594 poultry meat Nutrition 0.000 description 3
- 235000020991 processed meat Nutrition 0.000 description 3
- 210000001938 protoplast Anatomy 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 230000004044 response Effects 0.000 description 3
- 108091008146 restriction endonucleases Proteins 0.000 description 3
- 230000002441 reversible effect Effects 0.000 description 3
- 239000001509 sodium citrate Substances 0.000 description 3
- 229940063673 spermidine Drugs 0.000 description 3
- 239000008117 stearic acid Substances 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 238000011426 transformation method Methods 0.000 description 3
- 108010044292 tryptophyltyrosine Proteins 0.000 description 3
- 108010003137 tyrosyltyrosine Proteins 0.000 description 3
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 3
- 229940045145 uridine Drugs 0.000 description 3
- 150000003722 vitamin derivatives Chemical class 0.000 description 3
- 230000003442 weekly effect Effects 0.000 description 3
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 2
- GVJHHUAWPYXKBD-UHFFFAOYSA-N (±)-α-Tocopherol Chemical compound OC1=C(C)C(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-UHFFFAOYSA-N 0.000 description 2
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 2
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 2
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 2
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 2
- 241000589155 Agrobacterium tumefaciens Species 0.000 description 2
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 2
- FSBCNCKIQZZASN-GUBZILKMSA-N Ala-Arg-Met Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(O)=O FSBCNCKIQZZASN-GUBZILKMSA-N 0.000 description 2
- GFBLJMHGHAXGNY-ZLUOBGJFSA-N Ala-Asn-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O GFBLJMHGHAXGNY-ZLUOBGJFSA-N 0.000 description 2
- HMRWQTHUDVXMGH-GUBZILKMSA-N Ala-Glu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HMRWQTHUDVXMGH-GUBZILKMSA-N 0.000 description 2
- BEMGNWZECGIJOI-WDSKDSINSA-N Ala-Gly-Glu Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O BEMGNWZECGIJOI-WDSKDSINSA-N 0.000 description 2
- 108010076441 Ala-His-His Proteins 0.000 description 2
- QUIGLPSHIFPEOV-CIUDSAMLSA-N Ala-Lys-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O QUIGLPSHIFPEOV-CIUDSAMLSA-N 0.000 description 2
- DXTYEWAQOXYRHZ-KKXDTOCCSA-N Ala-Phe-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N DXTYEWAQOXYRHZ-KKXDTOCCSA-N 0.000 description 2
- BHTBAVZSZCQZPT-GUBZILKMSA-N Ala-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N BHTBAVZSZCQZPT-GUBZILKMSA-N 0.000 description 2
- NZGRHTKZFSVPAN-BIIVOSGPSA-N Ala-Ser-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N NZGRHTKZFSVPAN-BIIVOSGPSA-N 0.000 description 2
- YXXPVUOMPSZURS-ZLIFDBKOSA-N Ala-Trp-Leu Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@H](C)N)=CNC2=C1 YXXPVUOMPSZURS-ZLIFDBKOSA-N 0.000 description 2
- MTDDMSUUXNQMKK-BPNCWPANSA-N Ala-Tyr-Arg Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N MTDDMSUUXNQMKK-BPNCWPANSA-N 0.000 description 2
- XSLGWYYNOSUMRM-ZKWXMUAHSA-N Ala-Val-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XSLGWYYNOSUMRM-ZKWXMUAHSA-N 0.000 description 2
- DHONNEYAZPNGSG-UBHSHLNASA-N Ala-Val-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 DHONNEYAZPNGSG-UBHSHLNASA-N 0.000 description 2
- OMSKGWFGWCQFBD-KZVJFYERSA-N Ala-Val-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OMSKGWFGWCQFBD-KZVJFYERSA-N 0.000 description 2
- 241000272517 Anseriformes Species 0.000 description 2
- 241000219194 Arabidopsis Species 0.000 description 2
- 101000980980 Arabidopsis thaliana Phosphatidate cytidylyltransferase 5, chloroplastic Proteins 0.000 description 2
- MUXONAMCEUBVGA-DCAQKATOSA-N Arg-Arg-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O MUXONAMCEUBVGA-DCAQKATOSA-N 0.000 description 2
- CFGHCPUPFHWMCM-FDARSICLSA-N Arg-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N CFGHCPUPFHWMCM-FDARSICLSA-N 0.000 description 2
- NIELFHOLFTUZME-HJWJTTGWSA-N Arg-Phe-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NIELFHOLFTUZME-HJWJTTGWSA-N 0.000 description 2
- PNHQRQTVBRDIEF-CIUDSAMLSA-N Asn-Leu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(=O)N)N PNHQRQTVBRDIEF-CIUDSAMLSA-N 0.000 description 2
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 2
- JPPLRQVZMZFOSX-UWJYBYFXSA-N Asn-Tyr-Ala Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 JPPLRQVZMZFOSX-UWJYBYFXSA-N 0.000 description 2
- CBHVAFXKOYAHOY-NHCYSSNCSA-N Asn-Val-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O CBHVAFXKOYAHOY-NHCYSSNCSA-N 0.000 description 2
- NJIKKGUVGUBICV-ZLUOBGJFSA-N Asp-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O NJIKKGUVGUBICV-ZLUOBGJFSA-N 0.000 description 2
- LBOVBQONZJRWPV-YUMQZZPRSA-N Asp-Lys-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LBOVBQONZJRWPV-YUMQZZPRSA-N 0.000 description 2
- KESWRFKUZRUTAH-FXQIFTODSA-N Asp-Pro-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O KESWRFKUZRUTAH-FXQIFTODSA-N 0.000 description 2
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 2
- RKXVTTIQNKPCHU-KKHAAJSZSA-N Asp-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O RKXVTTIQNKPCHU-KKHAAJSZSA-N 0.000 description 2
- 241000972773 Aulopiformes Species 0.000 description 2
- 235000007319 Avena orientalis Nutrition 0.000 description 2
- 244000075850 Avena orientalis Species 0.000 description 2
- 208000016444 Benign adult familial myoclonic epilepsy Diseases 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 244000020518 Carthamus tinctorius Species 0.000 description 2
- 235000003255 Carthamus tinctorius Nutrition 0.000 description 2
- HEDRZPFGACZZDS-UHFFFAOYSA-N Chloroform Chemical compound ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 2
- 108020004635 Complementary DNA Proteins 0.000 description 2
- 102000012410 DNA Ligases Human genes 0.000 description 2
- 108010061982 DNA Ligases Proteins 0.000 description 2
- 108010017826 DNA Polymerase I Proteins 0.000 description 2
- 102000004594 DNA Polymerase I Human genes 0.000 description 2
- 238000007399 DNA isolation Methods 0.000 description 2
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 2
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 2
- 102100034543 Fatty acid desaturase 3 Human genes 0.000 description 2
- 102000009114 Fatty acid desaturases Human genes 0.000 description 2
- 102000001390 Fructose-Bisphosphate Aldolase Human genes 0.000 description 2
- 108010068561 Fructose-Bisphosphate Aldolase Proteins 0.000 description 2
- 241000287828 Gallus gallus Species 0.000 description 2
- GHYJGDCPHMSFEJ-GUBZILKMSA-N Gln-Gln-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N GHYJGDCPHMSFEJ-GUBZILKMSA-N 0.000 description 2
- OGMQXTXGLDNBSS-FXQIFTODSA-N Glu-Ala-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O OGMQXTXGLDNBSS-FXQIFTODSA-N 0.000 description 2
- UGSVSNXPJJDJKL-SDDRHHMPSA-N Glu-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N UGSVSNXPJJDJKL-SDDRHHMPSA-N 0.000 description 2
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 2
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 2
- LHYJCVCQPWRMKZ-WEDXCCLWSA-N Gly-Leu-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LHYJCVCQPWRMKZ-WEDXCCLWSA-N 0.000 description 2
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 2
- CLNSYANKYVMZNM-UWVGGRQHSA-N Gly-Lys-Arg Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N CLNSYANKYVMZNM-UWVGGRQHSA-N 0.000 description 2
- FHQRLHFYVZAQHU-IUCAKERBSA-N Gly-Lys-Gln Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O FHQRLHFYVZAQHU-IUCAKERBSA-N 0.000 description 2
- JPVGHHQGKPQYIL-KBPBESRZSA-N Gly-Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 JPVGHHQGKPQYIL-KBPBESRZSA-N 0.000 description 2
- GGAPHLIUUTVYMX-QWRGUYRKSA-N Gly-Phe-Ser Chemical compound OC[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)C[NH3+])CC1=CC=CC=C1 GGAPHLIUUTVYMX-QWRGUYRKSA-N 0.000 description 2
- LLWQVJNHMYBLLK-CDMKHQONSA-N Gly-Thr-Phe Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LLWQVJNHMYBLLK-CDMKHQONSA-N 0.000 description 2
- GULGDABMYTYMJZ-STQMWFEESA-N Gly-Trp-Asp Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(O)=O)C(O)=O GULGDABMYTYMJZ-STQMWFEESA-N 0.000 description 2
- SFOXOSKVTLDEDM-HOTGVXAUSA-N Gly-Trp-Leu Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)CN)=CNC2=C1 SFOXOSKVTLDEDM-HOTGVXAUSA-N 0.000 description 2
- JZNWSCPGTDBMEW-UHFFFAOYSA-N Glycerophosphorylethanolamin Natural products NCCOP(O)(=O)OCC(O)CO JZNWSCPGTDBMEW-UHFFFAOYSA-N 0.000 description 2
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 2
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 2
- 239000007995 HEPES buffer Substances 0.000 description 2
- 244000020551 Helianthus annuus Species 0.000 description 2
- 235000003222 Helianthus annuus Nutrition 0.000 description 2
- KYMUEAZVLPRVAE-GUBZILKMSA-N His-Asn-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KYMUEAZVLPRVAE-GUBZILKMSA-N 0.000 description 2
- JWTKVPMQCCRPQY-SRVKXCTJSA-N His-Asn-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JWTKVPMQCCRPQY-SRVKXCTJSA-N 0.000 description 2
- ZSKJIISDJXJQPV-BZSNNMDCSA-N His-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CN=CN1 ZSKJIISDJXJQPV-BZSNNMDCSA-N 0.000 description 2
- VGYOLSOFODKLSP-IHPCNDPISA-N His-Leu-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CN=CN1 VGYOLSOFODKLSP-IHPCNDPISA-N 0.000 description 2
- SGLXGEDPYJPGIQ-ACRUOGEOSA-N His-Phe-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N SGLXGEDPYJPGIQ-ACRUOGEOSA-N 0.000 description 2
- 240000005979 Hordeum vulgare Species 0.000 description 2
- 235000007340 Hordeum vulgare Nutrition 0.000 description 2
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 2
- WECYRWOMWSCWNX-XUXIUFHCSA-N Ile-Arg-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O WECYRWOMWSCWNX-XUXIUFHCSA-N 0.000 description 2
- FHCNLXMTQJNJNH-KBIXCLLPSA-N Ile-Cys-Gln Chemical compound N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)O FHCNLXMTQJNJNH-KBIXCLLPSA-N 0.000 description 2
- GAZGFPOZOLEYAJ-YTFOTSKYSA-N Ile-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N GAZGFPOZOLEYAJ-YTFOTSKYSA-N 0.000 description 2
- MITYXXNZSZLHGG-OBAATPRFSA-N Ile-Trp-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N MITYXXNZSZLHGG-OBAATPRFSA-N 0.000 description 2
- 208000026350 Inborn Genetic disease Diseases 0.000 description 2
- 108010065920 Insulin Lispro Proteins 0.000 description 2
- 102100034343 Integrase Human genes 0.000 description 2
- 108091092195 Intron Proteins 0.000 description 2
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 2
- 101710088879 Kunitz trypsin inhibitor 3 Proteins 0.000 description 2
- SRBFZHDQGSBBOR-HWQSCIPKSA-N L-arabinopyranose Chemical compound O[C@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-HWQSCIPKSA-N 0.000 description 2
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 2
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 2
- 101710191633 Legumin A2 Proteins 0.000 description 2
- VQPPIMUZCZCOIL-GUBZILKMSA-N Leu-Gln-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O VQPPIMUZCZCOIL-GUBZILKMSA-N 0.000 description 2
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 2
- QNTJIDXQHWUBKC-BZSNNMDCSA-N Leu-Lys-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QNTJIDXQHWUBKC-BZSNNMDCSA-N 0.000 description 2
- YESNGRDJQWDYLH-KKUMJFAQSA-N Leu-Phe-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)O)N YESNGRDJQWDYLH-KKUMJFAQSA-N 0.000 description 2
- AAKRWBIIGKPOKQ-ONGXEEELSA-N Leu-Val-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AAKRWBIIGKPOKQ-ONGXEEELSA-N 0.000 description 2
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 2
- 241000208202 Linaceae Species 0.000 description 2
- 235000004431 Linum usitatissimum Nutrition 0.000 description 2
- WSXTWLJHTLRFLW-SRVKXCTJSA-N Lys-Ala-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O WSXTWLJHTLRFLW-SRVKXCTJSA-N 0.000 description 2
- FLCMXEFCTLXBTL-DCAQKATOSA-N Lys-Asp-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N FLCMXEFCTLXBTL-DCAQKATOSA-N 0.000 description 2
- YUAXTFMFMOIMAM-QWRGUYRKSA-N Lys-Lys-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O YUAXTFMFMOIMAM-QWRGUYRKSA-N 0.000 description 2
- LNMKRJJLEFASGA-BZSNNMDCSA-N Lys-Phe-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O LNMKRJJLEFASGA-BZSNNMDCSA-N 0.000 description 2
- LTYOQGRJFJAKNA-KKIMTKSISA-N Malonyl CoA Natural products S(C(=O)CC(=O)O)CCNC(=O)CCNC(=O)[C@@H](O)C(CO[P@](=O)(O[P@](=O)(OC[C@H]1[C@@H](OP(=O)(O)O)[C@@H](O)[C@@H](n2c3ncnc(N)c3nc2)O1)O)O)(C)C LTYOQGRJFJAKNA-KKIMTKSISA-N 0.000 description 2
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 2
- QEVRUYFHWJJUHZ-DCAQKATOSA-N Met-Ala-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C QEVRUYFHWJJUHZ-DCAQKATOSA-N 0.000 description 2
- MXEASDMFHUKOGE-ULQDDVLXSA-N Met-His-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N MXEASDMFHUKOGE-ULQDDVLXSA-N 0.000 description 2
- WXXNVZMWHOLNRJ-AVGNSLFASA-N Met-Pro-Lys Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O WXXNVZMWHOLNRJ-AVGNSLFASA-N 0.000 description 2
- 101100005882 Mus musculus Cel gene Proteins 0.000 description 2
- 101100289046 Mus musculus Lias gene Proteins 0.000 description 2
- IMNFDUFMRHMDMM-UHFFFAOYSA-N N-Heptane Chemical compound CCCCCCC IMNFDUFMRHMDMM-UHFFFAOYSA-N 0.000 description 2
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 2
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 2
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 2
- XZFYRXDAULDNFX-UHFFFAOYSA-N N-L-cysteinyl-L-phenylalanine Natural products SCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XZFYRXDAULDNFX-UHFFFAOYSA-N 0.000 description 2
- 108010066427 N-valyltryptophan Proteins 0.000 description 2
- PVNIIMVLHYAWGP-UHFFFAOYSA-N Niacin Chemical compound OC(=O)C1=CC=CN=C1 PVNIIMVLHYAWGP-UHFFFAOYSA-N 0.000 description 2
- PXHVJJICTQNCMI-UHFFFAOYSA-N Nickel Chemical compound [Ni] PXHVJJICTQNCMI-UHFFFAOYSA-N 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- 241000206765 Pavlova lutheri Species 0.000 description 2
- 241000286209 Phasianidae Species 0.000 description 2
- NAOVYENZCWFBDG-BZSNNMDCSA-N Phe-His-His Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CC=CC=C1 NAOVYENZCWFBDG-BZSNNMDCSA-N 0.000 description 2
- HTXVATDVCRFORF-MGHWNKPDSA-N Phe-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N HTXVATDVCRFORF-MGHWNKPDSA-N 0.000 description 2
- OHIYMVFLQXTZAW-UFYCRDLUSA-N Phe-Met-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O OHIYMVFLQXTZAW-UFYCRDLUSA-N 0.000 description 2
- ZYNBEWGJFXTBDU-ACRUOGEOSA-N Phe-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CC=CC=C2)N ZYNBEWGJFXTBDU-ACRUOGEOSA-N 0.000 description 2
- XALFIVXGQUEGKV-JSGCOSHPSA-N Phe-Val-Gly Chemical compound OC(=O)CNC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 XALFIVXGQUEGKV-JSGCOSHPSA-N 0.000 description 2
- ZYFVNVRFVHJEIU-UHFFFAOYSA-N PicoGreen Chemical compound CN(C)CCCN(CCCN(C)C)C1=CC(=CC2=[N+](C3=CC=CC=C3S2)C)C2=CC=CC=C2N1C1=CC=CC=C1 ZYFVNVRFVHJEIU-UHFFFAOYSA-N 0.000 description 2
- JFNPBBOGGNMSRX-CIUDSAMLSA-N Pro-Gln-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O JFNPBBOGGNMSRX-CIUDSAMLSA-N 0.000 description 2
- DRKAXLDECUGLFE-ULQDDVLXSA-N Pro-Leu-Phe Chemical compound CC(C)C[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O DRKAXLDECUGLFE-ULQDDVLXSA-N 0.000 description 2
- VTFXTWDFPTWNJY-RHYQMDGZSA-N Pro-Leu-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VTFXTWDFPTWNJY-RHYQMDGZSA-N 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- LCTONWCANYUPML-UHFFFAOYSA-N Pyruvic acid Chemical compound CC(=O)C(O)=O LCTONWCANYUPML-UHFFFAOYSA-N 0.000 description 2
- 238000002123 RNA extraction Methods 0.000 description 2
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 2
- 241000209056 Secale Species 0.000 description 2
- 235000007238 Secale cereale Nutrition 0.000 description 2
- ZKBKUWQVDWWSRI-BZSNNMDCSA-N Ser-Phe-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKBKUWQVDWWSRI-BZSNNMDCSA-N 0.000 description 2
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 2
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- 108020004682 Single-Stranded DNA Proteins 0.000 description 2
- 229930182558 Sterol Natural products 0.000 description 2
- 241000282887 Suidae Species 0.000 description 2
- 108010006785 Taq Polymerase Proteins 0.000 description 2
- BSNZTJXVDOINSR-JXUBOQSCSA-N Thr-Ala-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BSNZTJXVDOINSR-JXUBOQSCSA-N 0.000 description 2
- NFMPFBCXABPALN-OWLDWWDNSA-N Thr-Ala-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N)O NFMPFBCXABPALN-OWLDWWDNSA-N 0.000 description 2
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 2
- LCCSEJSPBWKBNT-OSUNSFLBSA-N Thr-Ile-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N LCCSEJSPBWKBNT-OSUNSFLBSA-N 0.000 description 2
- MGJLBZFUXUGMML-VOAKCMCISA-N Thr-Lys-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MGJLBZFUXUGMML-VOAKCMCISA-N 0.000 description 2
- LKJCABTUFGTPPY-HJGDQZAQSA-N Thr-Pro-Gln Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O LKJCABTUFGTPPY-HJGDQZAQSA-N 0.000 description 2
- XZUBGOYOGDRYFC-XGEHTFHBSA-N Thr-Ser-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O XZUBGOYOGDRYFC-XGEHTFHBSA-N 0.000 description 2
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 2
- 235000021307 Triticum Nutrition 0.000 description 2
- 244000098338 Triticum aestivum Species 0.000 description 2
- XNRJFXBORWMIPY-DCPHZVHLSA-N Trp-Ala-Phe Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XNRJFXBORWMIPY-DCPHZVHLSA-N 0.000 description 2
- RERIQEJUYCLJQI-QRTARXTBSA-N Trp-Asp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N RERIQEJUYCLJQI-QRTARXTBSA-N 0.000 description 2
- NGALWFGCOMHUSN-AVGNSLFASA-N Tyr-Gln-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NGALWFGCOMHUSN-AVGNSLFASA-N 0.000 description 2
- QAYSODICXVZUIA-WLTAIBSBSA-N Tyr-Gly-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O QAYSODICXVZUIA-WLTAIBSBSA-N 0.000 description 2
- NXRGXTBPMOGFID-CFMVVWHZSA-N Tyr-Ile-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O NXRGXTBPMOGFID-CFMVVWHZSA-N 0.000 description 2
- BSCBBPKDVOZICB-KKUMJFAQSA-N Tyr-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BSCBBPKDVOZICB-KKUMJFAQSA-N 0.000 description 2
- DWAMXBFJNZIHMC-KBPBESRZSA-N Tyr-Leu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O DWAMXBFJNZIHMC-KBPBESRZSA-N 0.000 description 2
- CWVHKVVKAQIJKY-ACRUOGEOSA-N Tyr-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CC=C(C=C2)O)N CWVHKVVKAQIJKY-ACRUOGEOSA-N 0.000 description 2
- NHOVZGFNTGMYMI-KKUMJFAQSA-N Tyr-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NHOVZGFNTGMYMI-KKUMJFAQSA-N 0.000 description 2
- TYGHOWWWMTWVKM-HJOGWXRNSA-N Tyr-Tyr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 TYGHOWWWMTWVKM-HJOGWXRNSA-N 0.000 description 2
- FZADUTOCSFDBRV-RNXOBYDBSA-N Tyr-Tyr-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=C(O)C=C1 FZADUTOCSFDBRV-RNXOBYDBSA-N 0.000 description 2
- PQPWEALFTLKSEB-DZKIICNBSA-N Tyr-Val-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PQPWEALFTLKSEB-DZKIICNBSA-N 0.000 description 2
- 108090000848 Ubiquitin Proteins 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- VLOYGOZDPGYWFO-LAEOZQHASA-N Val-Asp-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VLOYGOZDPGYWFO-LAEOZQHASA-N 0.000 description 2
- PYPZMFDMCCWNST-NAKRPEOUSA-N Val-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N PYPZMFDMCCWNST-NAKRPEOUSA-N 0.000 description 2
- AEMPCGRFEZTWIF-IHRRRGAJSA-N Val-Leu-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O AEMPCGRFEZTWIF-IHRRRGAJSA-N 0.000 description 2
- HPOSMQWRPMRMFO-GUBZILKMSA-N Val-Pro-Cys Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)O)N HPOSMQWRPMRMFO-GUBZILKMSA-N 0.000 description 2
- QZKVWWIUSQGWMY-IHRRRGAJSA-N Val-Ser-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QZKVWWIUSQGWMY-IHRRRGAJSA-N 0.000 description 2
- CEKSLIVSNNGOKH-KZVJFYERSA-N Val-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](C(C)C)N)O CEKSLIVSNNGOKH-KZVJFYERSA-N 0.000 description 2
- WFTKOJGOOUJLJV-VKOGCVSHSA-N Val-Trp-Ile Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C([O-])=O)NC(=O)[C@@H]([NH3+])C(C)C)=CNC2=C1 WFTKOJGOOUJLJV-VKOGCVSHSA-N 0.000 description 2
- 235000016383 Zea mays subsp huehuetenangensis Nutrition 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- UDMBCSSLTHHNCD-KQYNXXCUSA-N adenosine 5'-monophosphate Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@H]1O UDMBCSSLTHHNCD-KQYNXXCUSA-N 0.000 description 2
- 108010044940 alanylglutamine Proteins 0.000 description 2
- 108010047495 alanylglycine Proteins 0.000 description 2
- 108010070783 alanyltyrosine Proteins 0.000 description 2
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 2
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 2
- 235000011130 ammonium sulphate Nutrition 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 239000008346 aqueous phase Substances 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 235000021342 arachidonic acid Nutrition 0.000 description 2
- 229940114079 arachidonic acid Drugs 0.000 description 2
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 2
- 108010062796 arginyllysine Proteins 0.000 description 2
- 108010047857 aspartylglycine Proteins 0.000 description 2
- 238000002820 assay format Methods 0.000 description 2
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 2
- 238000002869 basic local alignment search tool Methods 0.000 description 2
- 239000011324 bead Substances 0.000 description 2
- 238000004061 bleaching Methods 0.000 description 2
- 235000014121 butter Nutrition 0.000 description 2
- 244000309466 calf Species 0.000 description 2
- 201000011510 cancer Diseases 0.000 description 2
- 229940041514 candida albicans extract Drugs 0.000 description 2
- 150000001720 carbohydrates Chemical class 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 239000004464 cereal grain Substances 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- 235000013330 chicken meat Nutrition 0.000 description 2
- 239000003086 colorant Substances 0.000 description 2
- 230000001276 controlling effect Effects 0.000 description 2
- SUYVUBYJARFZHO-RRKCRQDMSA-N dATP Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 SUYVUBYJARFZHO-RRKCRQDMSA-N 0.000 description 2
- SUYVUBYJARFZHO-UHFFFAOYSA-N dATP Natural products C1=NC=2C(N)=NC=NC=2N1C1CC(O)C(COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 SUYVUBYJARFZHO-UHFFFAOYSA-N 0.000 description 2
- RGWHQCVHVJXOKC-SHYZEUOFSA-J dCTP(4-) Chemical compound O=C1N=C(N)C=CN1[C@@H]1O[C@H](COP([O-])(=O)OP([O-])(=O)OP([O-])([O-])=O)[C@@H](O)C1 RGWHQCVHVJXOKC-SHYZEUOFSA-J 0.000 description 2
- HAAZLUGHYHWQIW-KVQBGUIXSA-N dGTP Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 HAAZLUGHYHWQIW-KVQBGUIXSA-N 0.000 description 2
- NHVNXKFIZYSCEB-XLPZGREQSA-N dTTP Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C1 NHVNXKFIZYSCEB-XLPZGREQSA-N 0.000 description 2
- CYQFCXCEBYINGO-IAGOWNOFSA-N delta1-THC Chemical compound C1=C(C)CC[C@H]2C(C)(C)OC3=CC(CCCCC)=CC(O)=C3[C@@H]21 CYQFCXCEBYINGO-IAGOWNOFSA-N 0.000 description 2
- 230000000368 destabilizing effect Effects 0.000 description 2
- 150000001982 diacylglycerols Chemical class 0.000 description 2
- 230000037213 diet Effects 0.000 description 2
- 229940090949 docosahexaenoic acid Drugs 0.000 description 2
- 239000008157 edible vegetable oil Substances 0.000 description 2
- 150000002066 eicosanoids Chemical class 0.000 description 2
- 229960005135 eicosapentaenoic acid Drugs 0.000 description 2
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 210000003527 eukaryotic cell Anatomy 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 208000016427 familial adult myoclonic epilepsy Diseases 0.000 description 2
- 239000000835 fiber Substances 0.000 description 2
- 239000012467 final product Substances 0.000 description 2
- 239000012737 fresh medium Substances 0.000 description 2
- 239000013505 freshwater Substances 0.000 description 2
- 239000005350 fused silica glass Substances 0.000 description 2
- VZCCETWTMQHEPK-UHFFFAOYSA-N gamma-Linolensaeure Natural products CCCCCC=CCC=CCC=CCCCCC(O)=O VZCCETWTMQHEPK-UHFFFAOYSA-N 0.000 description 2
- 238000001502 gel electrophoresis Methods 0.000 description 2
- 208000016361 genetic disease Diseases 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 230000035784 germination Effects 0.000 description 2
- 108010078144 glutaminyl-glycine Proteins 0.000 description 2
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 2
- 102000006602 glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 2
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 2
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 2
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 description 2
- 108010089804 glycyl-threonine Proteins 0.000 description 2
- 108010087823 glycyltyrosine Proteins 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 235000001497 healthy food Nutrition 0.000 description 2
- 239000001307 helium Substances 0.000 description 2
- 229910052734 helium Inorganic materials 0.000 description 2
- SWQJXJOGLNCZEY-UHFFFAOYSA-N helium atom Chemical compound [He] SWQJXJOGLNCZEY-UHFFFAOYSA-N 0.000 description 2
- IPCSVZSSVZVIGE-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 description 2
- 150000004687 hexahydrates Chemical class 0.000 description 2
- 235000020256 human milk Nutrition 0.000 description 2
- 239000001257 hydrogen Substances 0.000 description 2
- 229910052739 hydrogen Inorganic materials 0.000 description 2
- 230000001976 improved effect Effects 0.000 description 2
- 239000012535 impurity Substances 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 238000010348 incorporation Methods 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 229910052500 inorganic mineral Inorganic materials 0.000 description 2
- 239000013067 intermediate product Substances 0.000 description 2
- PHTQWCKDNZKARW-UHFFFAOYSA-N isoamylol Chemical compound CC(C)CCO PHTQWCKDNZKARW-UHFFFAOYSA-N 0.000 description 2
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 2
- 229930027917 kanamycin Natural products 0.000 description 2
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 2
- 229960000318 kanamycin Drugs 0.000 description 2
- 229930182823 kanamycin A Natural products 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 235000020997 lean meat Nutrition 0.000 description 2
- 108010034529 leucyl-lysine Proteins 0.000 description 2
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 2
- 108010030617 leucyl-phenylalanyl-valine Proteins 0.000 description 2
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 2
- 238000007834 ligase chain reaction Methods 0.000 description 2
- 101150091094 lipA gene Proteins 0.000 description 2
- YAFQFNOUYXZVPZ-UHFFFAOYSA-N liproxstatin-1 Chemical compound ClC1=CC=CC(CNC=2C3(CCNCC3)NC3=CC=CC=C3N=2)=C1 YAFQFNOUYXZVPZ-UHFFFAOYSA-N 0.000 description 2
- 108010017391 lysylvaline Proteins 0.000 description 2
- 238000010841 mRNA extraction Methods 0.000 description 2
- 238000012423 maintenance Methods 0.000 description 2
- 235000009973 maize Nutrition 0.000 description 2
- LTYOQGRJFJAKNA-DVVLENMVSA-N malonyl-CoA Chemical compound O[C@@H]1[C@H](OP(O)(O)=O)[C@@H](COP(O)(=O)OP(O)(=O)OCC(C)(C)[C@@H](O)C(=O)NCCC(=O)NCCSC(=O)CC(O)=O)O[C@H]1N1C2=NC=NC(N)=C2N=C1 LTYOQGRJFJAKNA-DVVLENMVSA-N 0.000 description 2
- 230000013011 mating Effects 0.000 description 2
- 230000001404 mediated effect Effects 0.000 description 2
- QSHDDOUJBYECFT-UHFFFAOYSA-N mercury Chemical compound [Hg] QSHDDOUJBYECFT-UHFFFAOYSA-N 0.000 description 2
- 229910052753 mercury Inorganic materials 0.000 description 2
- 238000000520 microinjection Methods 0.000 description 2
- 235000010755 mineral Nutrition 0.000 description 2
- 239000011707 mineral Substances 0.000 description 2
- 239000006151 minimal media Substances 0.000 description 2
- 239000003068 molecular probe Substances 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 210000004940 nucleus Anatomy 0.000 description 2
- 235000015097 nutrients Nutrition 0.000 description 2
- 108010033653 omega-3 fatty acid desaturase Proteins 0.000 description 2
- 239000012074 organic phase Substances 0.000 description 2
- 230000008520 organization Effects 0.000 description 2
- 239000001301 oxygen Substances 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 235000015927 pasta Nutrition 0.000 description 2
- 239000000825 pharmaceutical preparation Substances 0.000 description 2
- 229940127557 pharmaceutical product Drugs 0.000 description 2
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 2
- 239000010452 phosphate Substances 0.000 description 2
- WTJKGGKOPKCXLL-RRHRGVEJSA-N phosphatidylcholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCC=CCCCCCCCC WTJKGGKOPKCXLL-RRHRGVEJSA-N 0.000 description 2
- 150000008104 phosphatidylethanolamines Chemical class 0.000 description 2
- 229910052698 phosphorus Inorganic materials 0.000 description 2
- 230000000243 photosynthetic effect Effects 0.000 description 2
- 230000000704 physical effect Effects 0.000 description 2
- 239000013600 plasmid vector Substances 0.000 description 2
- 229920003023 plastic Polymers 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 229920001282 polysaccharide Polymers 0.000 description 2
- SCVFZCLFOSHCOH-UHFFFAOYSA-M potassium acetate Chemical compound [K+].CC([O-])=O SCVFZCLFOSHCOH-UHFFFAOYSA-M 0.000 description 2
- 235000013324 preserved food Nutrition 0.000 description 2
- 210000001236 prokaryotic cell Anatomy 0.000 description 2
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 2
- 238000011002 quantification Methods 0.000 description 2
- 108700012830 rat Lip2 Proteins 0.000 description 2
- 238000009790 rate-determining step (RDS) Methods 0.000 description 2
- 230000002829 reductive effect Effects 0.000 description 2
- 230000001172 regenerating effect Effects 0.000 description 2
- 235000019515 salmon Nutrition 0.000 description 2
- 235000013580 sausages Nutrition 0.000 description 2
- 239000013535 sea water Substances 0.000 description 2
- 238000002864 sequence alignment Methods 0.000 description 2
- 108010048818 seryl-histidine Proteins 0.000 description 2
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 2
- 108010026333 seryl-proline Proteins 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 2
- 238000000527 sonication Methods 0.000 description 2
- 230000010473 stable expression Effects 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 150000003432 sterols Chemical class 0.000 description 2
- 235000003702 sterols Nutrition 0.000 description 2
- 238000003860 storage Methods 0.000 description 2
- 239000013589 supplement Substances 0.000 description 2
- 239000011732 tocopherol Substances 0.000 description 2
- 229930003799 tocopherol Natural products 0.000 description 2
- 125000002640 tocopherol group Chemical class 0.000 description 2
- 235000019149 tocopherols Nutrition 0.000 description 2
- 230000005026 transcription initiation Effects 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 238000000844 transformation Methods 0.000 description 2
- 150000003626 triacylglycerols Chemical class 0.000 description 2
- MDTPTXSNPBAUHX-UHFFFAOYSA-M trimethylsulfanium;hydroxide Chemical compound [OH-].C[S+](C)C MDTPTXSNPBAUHX-UHFFFAOYSA-M 0.000 description 2
- 108010080629 tryptophan-leucine Proteins 0.000 description 2
- 108010051110 tyrosyl-lysine Proteins 0.000 description 2
- 108010077037 tyrosyl-tyrosyl-phenylalanine Proteins 0.000 description 2
- 108010009962 valyltyrosine Proteins 0.000 description 2
- 239000008158 vegetable oil Substances 0.000 description 2
- 239000012138 yeast extract Substances 0.000 description 2
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 1
- TWSWSIQAPQLDBP-CGRWFSSPSA-N (7e,10e,13e,16e)-docosa-7,10,13,16-tetraenoic acid Chemical compound CCCCC\C=C\C\C=C\C\C=C\C\C=C\CCCCCC(O)=O TWSWSIQAPQLDBP-CGRWFSSPSA-N 0.000 description 1
- YZAZXIUFBCPZGB-QZOPMXJLSA-N (z)-octadec-9-enoic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O.CCCCCCCC\C=C/CCCCCCCC(O)=O YZAZXIUFBCPZGB-QZOPMXJLSA-N 0.000 description 1
- PORPENFLTBBHSG-MGBGTMOVSA-N 1,2-dihexadecanoyl-sn-glycerol-3-phosphate Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(O)=O)OC(=O)CCCCCCCCCCCCCCC PORPENFLTBBHSG-MGBGTMOVSA-N 0.000 description 1
- WRGQSWVCFNIUNZ-GDCKJWNLSA-N 1-oleoyl-sn-glycerol 3-phosphate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OC[C@@H](O)COP(O)(O)=O WRGQSWVCFNIUNZ-GDCKJWNLSA-N 0.000 description 1
- UGAGPNKCDRTDHP-UHFFFAOYSA-N 16-hydroxyhexadecanoic acid Chemical compound OCCCCCCCCCCCCCCCC(O)=O UGAGPNKCDRTDHP-UHFFFAOYSA-N 0.000 description 1
- KHWCHTKSEGGWEX-RRKCRQDMSA-N 2'-deoxyadenosine 5'-monophosphate Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(O)=O)O1 KHWCHTKSEGGWEX-RRKCRQDMSA-N 0.000 description 1
- LTFMZDNNPPEQNG-KVQBGUIXSA-N 2'-deoxyguanosine 5'-monophosphate Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1[C@H]1C[C@H](O)[C@@H](COP(O)(O)=O)O1 LTFMZDNNPPEQNG-KVQBGUIXSA-N 0.000 description 1
- IHPYMWDTONKSCO-UHFFFAOYSA-N 2,2'-piperazine-1,4-diylbisethanesulfonic acid Chemical compound OS(=O)(=O)CCN1CCN(CCS(O)(=O)=O)CC1 IHPYMWDTONKSCO-UHFFFAOYSA-N 0.000 description 1
- LMSDCGXQALIMLM-UHFFFAOYSA-N 2-[2-[bis(carboxymethyl)amino]ethyl-(carboxymethyl)amino]acetic acid;iron Chemical compound [Fe].OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O LMSDCGXQALIMLM-UHFFFAOYSA-N 0.000 description 1
- SCPRYBYMKVYVND-UHFFFAOYSA-N 2-[[2-[[1-(2-amino-4-methylpentanoyl)pyrrolidine-2-carbonyl]amino]-4-methylpentanoyl]amino]-4-methylpentanoic acid Chemical compound CC(C)CC(N)C(=O)N1CCCC1C(=O)NC(CC(C)C)C(=O)NC(CC(C)C)C(O)=O SCPRYBYMKVYVND-UHFFFAOYSA-N 0.000 description 1
- KPGXRSRHYNQIFN-UHFFFAOYSA-N 2-oxoglutaric acid Chemical compound OC(=O)CCC(=O)C(O)=O KPGXRSRHYNQIFN-UHFFFAOYSA-N 0.000 description 1
- AEDORKVKMIVLBW-BLDDREHASA-N 3-oxo-3-[[(2r,3s,4s,5r,6r)-3,4,5-trihydroxy-6-[[5-hydroxy-4-(hydroxymethyl)-6-methylpyridin-3-yl]methoxy]oxan-2-yl]methoxy]propanoic acid Chemical compound OCC1=C(O)C(C)=NC=C1CO[C@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](COC(=O)CC(O)=O)O1 AEDORKVKMIVLBW-BLDDREHASA-N 0.000 description 1
- 101710161460 3-oxoacyl-[acyl-carrier-protein] synthase Proteins 0.000 description 1
- LODRRYMGPWQCTR-UHFFFAOYSA-N 5-fluoro-2,4-dioxo-1h-pyrimidine-6-carboxylic acid;hydrate Chemical compound O.OC(=O)C=1NC(=O)NC(=O)C=1F LODRRYMGPWQCTR-UHFFFAOYSA-N 0.000 description 1
- 241000224423 Acanthamoeba castellanii Species 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- 102000004672 Acetyl-CoA C-acyltransferase Human genes 0.000 description 1
- 108010003902 Acetyl-CoA C-acyltransferase Proteins 0.000 description 1
- 101150040074 Aco2 gene Proteins 0.000 description 1
- 241000251468 Actinopterygii Species 0.000 description 1
- 102000004539 Acyl-CoA Oxidase Human genes 0.000 description 1
- 108020001558 Acyl-CoA oxidase Proteins 0.000 description 1
- 102100022089 Acyl-[acyl-carrier-protein] hydrolase Human genes 0.000 description 1
- 241000589158 Agrobacterium Species 0.000 description 1
- 241000589156 Agrobacterium rhizogenes Species 0.000 description 1
- DKJPOZOEBONHFS-ZLUOBGJFSA-N Ala-Ala-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O DKJPOZOEBONHFS-ZLUOBGJFSA-N 0.000 description 1
- HGRBNYQIMKTUNT-XVYDVKMFSA-N Ala-Asn-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N HGRBNYQIMKTUNT-XVYDVKMFSA-N 0.000 description 1
- DECCMEWNXSNSDO-ZLUOBGJFSA-N Ala-Cys-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O DECCMEWNXSNSDO-ZLUOBGJFSA-N 0.000 description 1
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 1
- WGDNWOMKBUXFHR-BQBZGAKWSA-N Ala-Gly-Arg Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N WGDNWOMKBUXFHR-BQBZGAKWSA-N 0.000 description 1
- BLIMFWGRQKRCGT-YUMQZZPRSA-N Ala-Gly-Lys Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN BLIMFWGRQKRCGT-YUMQZZPRSA-N 0.000 description 1
- NYDBKUNVSALYPX-NAKRPEOUSA-N Ala-Ile-Arg Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NYDBKUNVSALYPX-NAKRPEOUSA-N 0.000 description 1
- XCZXVTHYGSMQGH-NAKRPEOUSA-N Ala-Ile-Met Chemical compound C[C@H]([NH3+])C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCSC)C([O-])=O XCZXVTHYGSMQGH-NAKRPEOUSA-N 0.000 description 1
- LXAARTARZJJCMB-CIQUZCHMSA-N Ala-Ile-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LXAARTARZJJCMB-CIQUZCHMSA-N 0.000 description 1
- LNNSWWRRYJLGNI-NAKRPEOUSA-N Ala-Ile-Val Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O LNNSWWRRYJLGNI-NAKRPEOUSA-N 0.000 description 1
- WUHJHHGYVVJMQE-BJDJZHNGSA-N Ala-Leu-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WUHJHHGYVVJMQE-BJDJZHNGSA-N 0.000 description 1
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 1
- VCSABYLVNWQYQE-SRVKXCTJSA-N Ala-Lys-Lys Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O VCSABYLVNWQYQE-SRVKXCTJSA-N 0.000 description 1
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 1
- DHBKYZYFEXXUAK-ONGXEEELSA-N Ala-Phe-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 DHBKYZYFEXXUAK-ONGXEEELSA-N 0.000 description 1
- WEZNQZHACPSMEF-QEJZJMRPSA-N Ala-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 WEZNQZHACPSMEF-QEJZJMRPSA-N 0.000 description 1
- RNHKOQHGYMTHFR-UBHSHLNASA-N Ala-Phe-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=CC=C1 RNHKOQHGYMTHFR-UBHSHLNASA-N 0.000 description 1
- IHMCQESUJVZTKW-UBHSHLNASA-N Ala-Phe-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=CC=C1 IHMCQESUJVZTKW-UBHSHLNASA-N 0.000 description 1
- NHWYNIZWLJYZAG-XVYDVKMFSA-N Ala-Ser-His Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N NHWYNIZWLJYZAG-XVYDVKMFSA-N 0.000 description 1
- XQNRANMFRPCFFW-GCJQMDKQSA-N Ala-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C)N)O XQNRANMFRPCFFW-GCJQMDKQSA-N 0.000 description 1
- YNOCMHZSWJMGBB-GCJQMDKQSA-N Ala-Thr-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O YNOCMHZSWJMGBB-GCJQMDKQSA-N 0.000 description 1
- SAHQGRZIQVEJPF-JXUBOQSCSA-N Ala-Thr-Lys Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN SAHQGRZIQVEJPF-JXUBOQSCSA-N 0.000 description 1
- TVUFMYKTYXTRPY-HERUPUMHSA-N Ala-Trp-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(O)=O TVUFMYKTYXTRPY-HERUPUMHSA-N 0.000 description 1
- CLOMBHBBUKAUBP-LSJOCFKGSA-N Ala-Val-His Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N CLOMBHBBUKAUBP-LSJOCFKGSA-N 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- VHUUQVKOLVNVRT-UHFFFAOYSA-N Ammonium hydroxide Chemical compound [NH4+].[OH-] VHUUQVKOLVNVRT-UHFFFAOYSA-N 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- 108700002172 Arabidopsis fad3 Proteins 0.000 description 1
- 108700021822 Arabidopsis oleosin Proteins 0.000 description 1
- 235000017060 Arachis glabrata Nutrition 0.000 description 1
- 235000010777 Arachis hypogaea Nutrition 0.000 description 1
- 244000105624 Arachis hypogaea Species 0.000 description 1
- 235000018262 Arachis monticola Nutrition 0.000 description 1
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 1
- QPOARHANPULOTM-GMOBBJLQSA-N Arg-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N QPOARHANPULOTM-GMOBBJLQSA-N 0.000 description 1
- GHNDBBVSWOWYII-LPEHRKFASA-N Arg-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O GHNDBBVSWOWYII-LPEHRKFASA-N 0.000 description 1
- OCOZPTHLDVSFCZ-BPUTZDHNSA-N Arg-Asn-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N OCOZPTHLDVSFCZ-BPUTZDHNSA-N 0.000 description 1
- RWCLSUOSKWTXLA-FXQIFTODSA-N Arg-Asp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RWCLSUOSKWTXLA-FXQIFTODSA-N 0.000 description 1
- JSHVMZANPXCDTL-GMOBBJLQSA-N Arg-Asp-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JSHVMZANPXCDTL-GMOBBJLQSA-N 0.000 description 1
- PTVGLOCPAVYPFG-CIUDSAMLSA-N Arg-Gln-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PTVGLOCPAVYPFG-CIUDSAMLSA-N 0.000 description 1
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 1
- RFXXUWGNVRJTNQ-QXEWZRGKSA-N Arg-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCCN=C(N)N)N RFXXUWGNVRJTNQ-QXEWZRGKSA-N 0.000 description 1
- QEHMMRSQJMOYNO-DCAQKATOSA-N Arg-His-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N QEHMMRSQJMOYNO-DCAQKATOSA-N 0.000 description 1
- YQGZIRIYGHNSQO-ZPFDUUQYSA-N Arg-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N YQGZIRIYGHNSQO-ZPFDUUQYSA-N 0.000 description 1
- LKDHUGLXOHYINY-XUXIUFHCSA-N Arg-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N LKDHUGLXOHYINY-XUXIUFHCSA-N 0.000 description 1
- HJDNZFIYILEIKR-OSUNSFLBSA-N Arg-Ile-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HJDNZFIYILEIKR-OSUNSFLBSA-N 0.000 description 1
- OGSQONVYSTZIJB-WDSOQIARSA-N Arg-Leu-Trp Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCCN=C(N)N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O OGSQONVYSTZIJB-WDSOQIARSA-N 0.000 description 1
- CLICCYPMVFGUOF-IHRRRGAJSA-N Arg-Lys-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O CLICCYPMVFGUOF-IHRRRGAJSA-N 0.000 description 1
- VRTWYUYCJGNFES-CIUDSAMLSA-N Arg-Ser-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O VRTWYUYCJGNFES-CIUDSAMLSA-N 0.000 description 1
- KMFPQTITXUKJOV-DCAQKATOSA-N Arg-Ser-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O KMFPQTITXUKJOV-DCAQKATOSA-N 0.000 description 1
- CGWVCWFQGXOUSJ-ULQDDVLXSA-N Arg-Tyr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O CGWVCWFQGXOUSJ-ULQDDVLXSA-N 0.000 description 1
- NXVGBGZQQFDUTM-XVYDVKMFSA-N Asn-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N NXVGBGZQQFDUTM-XVYDVKMFSA-N 0.000 description 1
- JJGRJMKUOYXZRA-LPEHRKFASA-N Asn-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N)C(=O)O JJGRJMKUOYXZRA-LPEHRKFASA-N 0.000 description 1
- KXEGPPNPXOKKHK-ZLUOBGJFSA-N Asn-Asp-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KXEGPPNPXOKKHK-ZLUOBGJFSA-N 0.000 description 1
- QPTAGIPWARILES-AVGNSLFASA-N Asn-Gln-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QPTAGIPWARILES-AVGNSLFASA-N 0.000 description 1
- JREOBWLIZLXRIS-GUBZILKMSA-N Asn-Glu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JREOBWLIZLXRIS-GUBZILKMSA-N 0.000 description 1
- CTQIOCMSIJATNX-WHFBIAKZSA-N Asn-Gly-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O CTQIOCMSIJATNX-WHFBIAKZSA-N 0.000 description 1
- HYQYLOSCICEYTR-YUMQZZPRSA-N Asn-Gly-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O HYQYLOSCICEYTR-YUMQZZPRSA-N 0.000 description 1
- JQSWHKKUZMTOIH-QWRGUYRKSA-N Asn-Gly-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N JQSWHKKUZMTOIH-QWRGUYRKSA-N 0.000 description 1
- WQLJRNRLHWJIRW-KKUMJFAQSA-N Asn-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N)O WQLJRNRLHWJIRW-KKUMJFAQSA-N 0.000 description 1
- OLISTMZJGQUOGS-GMOBBJLQSA-N Asn-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N OLISTMZJGQUOGS-GMOBBJLQSA-N 0.000 description 1
- GLWFAWNYGWBMOC-SRVKXCTJSA-N Asn-Leu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GLWFAWNYGWBMOC-SRVKXCTJSA-N 0.000 description 1
- NCFJQJRLQJEECD-NHCYSSNCSA-N Asn-Leu-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O NCFJQJRLQJEECD-NHCYSSNCSA-N 0.000 description 1
- FTNRWCPWDWRPAV-BZSNNMDCSA-N Asn-Phe-Phe Chemical compound C([C@H](NC(=O)[C@H](CC(N)=O)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FTNRWCPWDWRPAV-BZSNNMDCSA-N 0.000 description 1
- ZJIFRAPZHAGLGR-MELADBBJSA-N Asn-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)N)N)C(=O)O ZJIFRAPZHAGLGR-MELADBBJSA-N 0.000 description 1
- NJSNXIOKBHPFMB-GMOBBJLQSA-N Asn-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)N)N NJSNXIOKBHPFMB-GMOBBJLQSA-N 0.000 description 1
- BYLSYQASFJJBCL-DCAQKATOSA-N Asn-Pro-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O BYLSYQASFJJBCL-DCAQKATOSA-N 0.000 description 1
- IIQIOFVDFOLCHP-UHFFFAOYSA-N Asn-Pro-Ser-Ser Chemical compound NC(=O)CC(N)C(=O)N1CCCC1C(=O)NC(CO)C(=O)NC(CO)C(O)=O IIQIOFVDFOLCHP-UHFFFAOYSA-N 0.000 description 1
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 1
- QTKYFZCMSQLYHI-UBHSHLNASA-N Asn-Trp-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O QTKYFZCMSQLYHI-UBHSHLNASA-N 0.000 description 1
- CGYKCTPUGXFPMG-IHPCNDPISA-N Asn-Tyr-Trp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O CGYKCTPUGXFPMG-IHPCNDPISA-N 0.000 description 1
- ZAESWDKAMDVHLL-RCOVLWMOSA-N Asn-Val-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O ZAESWDKAMDVHLL-RCOVLWMOSA-N 0.000 description 1
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 1
- QHAJMRDEWNAIBQ-FXQIFTODSA-N Asp-Arg-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O QHAJMRDEWNAIBQ-FXQIFTODSA-N 0.000 description 1
- ZLGKHJHFYSRUBH-FXQIFTODSA-N Asp-Arg-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLGKHJHFYSRUBH-FXQIFTODSA-N 0.000 description 1
- MFMJRYHVLLEMQM-DCAQKATOSA-N Asp-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N MFMJRYHVLLEMQM-DCAQKATOSA-N 0.000 description 1
- UGKZHCBLMLSANF-CIUDSAMLSA-N Asp-Asn-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O UGKZHCBLMLSANF-CIUDSAMLSA-N 0.000 description 1
- PXLNPFOJZQMXAT-BYULHYEWSA-N Asp-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O PXLNPFOJZQMXAT-BYULHYEWSA-N 0.000 description 1
- VHQOCWWKXIOAQI-WDSKDSINSA-N Asp-Gln-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VHQOCWWKXIOAQI-WDSKDSINSA-N 0.000 description 1
- ZSVJVIOVABDTTL-YUMQZZPRSA-N Asp-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)O)N ZSVJVIOVABDTTL-YUMQZZPRSA-N 0.000 description 1
- SVABRQFIHCSNCI-FOHZUACHSA-N Asp-Gly-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O SVABRQFIHCSNCI-FOHZUACHSA-N 0.000 description 1
- CYCKJEFVFNRWEZ-UGYAYLCHSA-N Asp-Ile-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O CYCKJEFVFNRWEZ-UGYAYLCHSA-N 0.000 description 1
- GKWFMNNNYZHJHV-SRVKXCTJSA-N Asp-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC(O)=O GKWFMNNNYZHJHV-SRVKXCTJSA-N 0.000 description 1
- RNAQPBOOJRDICC-BPUTZDHNSA-N Asp-Met-Trp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N RNAQPBOOJRDICC-BPUTZDHNSA-N 0.000 description 1
- DJCAHYVLMSRBFR-QXEWZRGKSA-N Asp-Met-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC(O)=O DJCAHYVLMSRBFR-QXEWZRGKSA-N 0.000 description 1
- LIJXJYGRSRWLCJ-IHRRRGAJSA-N Asp-Phe-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O LIJXJYGRSRWLCJ-IHRRRGAJSA-N 0.000 description 1
- UCHSVZYJKJLPHF-BZSNNMDCSA-N Asp-Phe-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O UCHSVZYJKJLPHF-BZSNNMDCSA-N 0.000 description 1
- UAXIKORUDGGIGA-DCAQKATOSA-N Asp-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O UAXIKORUDGGIGA-DCAQKATOSA-N 0.000 description 1
- LGGHQRZIJSYRHA-GUBZILKMSA-N Asp-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)O)N LGGHQRZIJSYRHA-GUBZILKMSA-N 0.000 description 1
- KGHLGJAXYSVNJP-WHFBIAKZSA-N Asp-Ser-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O KGHLGJAXYSVNJP-WHFBIAKZSA-N 0.000 description 1
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 1
- ZQFRDAZBTSFGGW-SRVKXCTJSA-N Asp-Ser-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ZQFRDAZBTSFGGW-SRVKXCTJSA-N 0.000 description 1
- CXEFNHOVIIDHFU-IHPCNDPISA-N Asp-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CC(=O)O)N CXEFNHOVIIDHFU-IHPCNDPISA-N 0.000 description 1
- PLNJUJGNLDSFOP-UWJYBYFXSA-N Asp-Tyr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PLNJUJGNLDSFOP-UWJYBYFXSA-N 0.000 description 1
- OYSYWMMZGJSQRB-AVGNSLFASA-N Asp-Tyr-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O OYSYWMMZGJSQRB-AVGNSLFASA-N 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- 241000701844 Bacillus virus phi29 Species 0.000 description 1
- 108010023063 Bacto-peptone Proteins 0.000 description 1
- 241000219310 Beta vulgaris subsp. vulgaris Species 0.000 description 1
- 239000002028 Biomass Substances 0.000 description 1
- 240000002791 Brassica napus Species 0.000 description 1
- 235000004977 Brassica sinapistrum Nutrition 0.000 description 1
- 101100289888 Caenorhabditis elegans lys-5 gene Proteins 0.000 description 1
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 1
- 101100457838 Caenorhabditis elegans mod-1 gene Proteins 0.000 description 1
- 108090000489 Carboxy-Lyases Proteins 0.000 description 1
- 240000006432 Carica papaya Species 0.000 description 1
- 235000009467 Carica papaya Nutrition 0.000 description 1
- WLYGSPLCNKYESI-RSUQVHIMSA-N Carthamin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1[C@@]1(O)C(O)=C(C(=O)\C=C\C=2C=CC(O)=CC=2)C(=O)C(\C=C\2C([C@](O)([C@H]3[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O3)O)C(O)=C(C(=O)\C=C\C=3C=CC(O)=CC=3)C/2=O)=O)=C1O WLYGSPLCNKYESI-RSUQVHIMSA-N 0.000 description 1
- 241000208809 Carthamus Species 0.000 description 1
- 241000701489 Cauliflower mosaic virus Species 0.000 description 1
- 241000282994 Cervidae Species 0.000 description 1
- 240000006162 Chenopodium quinoa Species 0.000 description 1
- 101100366760 Chlorobium chlorochromatii (strain CaD3) smpB gene Proteins 0.000 description 1
- 244000060011 Cocos nucifera Species 0.000 description 1
- 235000013162 Cocos nucifera Nutrition 0.000 description 1
- 108020004394 Complementary RNA Proteins 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 241000938605 Crocodylia Species 0.000 description 1
- MIKUYHXYGGJMLM-GIMIYPNGSA-N Crotonoside Natural products C1=NC2=C(N)NC(=O)N=C2N1[C@H]1O[C@@H](CO)[C@H](O)[C@@H]1O MIKUYHXYGGJMLM-GIMIYPNGSA-N 0.000 description 1
- 241000223233 Cutaneotrichosporon cutaneum Species 0.000 description 1
- 241000235646 Cyberlindnera jadinii Species 0.000 description 1
- 241001042096 Cyberlindnera tropicalis Species 0.000 description 1
- FWYBFUDWUUFLDN-FXQIFTODSA-N Cys-Asp-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N FWYBFUDWUUFLDN-FXQIFTODSA-N 0.000 description 1
- MUZAUPFGPMMZSS-GUBZILKMSA-N Cys-Glu-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N MUZAUPFGPMMZSS-GUBZILKMSA-N 0.000 description 1
- OWAFTBLVZNSIFO-SRVKXCTJSA-N Cys-His-His Chemical compound N[C@@H](CS)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O OWAFTBLVZNSIFO-SRVKXCTJSA-N 0.000 description 1
- BBQIWFFTTQTNOC-AVGNSLFASA-N Cys-Phe-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N BBQIWFFTTQTNOC-AVGNSLFASA-N 0.000 description 1
- SWJYSDXMTPMBHO-FXQIFTODSA-N Cys-Pro-Ser Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SWJYSDXMTPMBHO-FXQIFTODSA-N 0.000 description 1
- LKHMGNHQULEPFY-ACZMJKKPSA-N Cys-Ser-Glu Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O LKHMGNHQULEPFY-ACZMJKKPSA-N 0.000 description 1
- NYHBQMYGNKIUIF-UHFFFAOYSA-N D-guanosine Natural products C1=2NC(N)=NC(=O)C=2N=CN1C1OC(CO)C(O)C1O NYHBQMYGNKIUIF-UHFFFAOYSA-N 0.000 description 1
- 239000003298 DNA probe Substances 0.000 description 1
- 238000013382 DNA quantification Methods 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 201000004624 Dermatitis Diseases 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 235000021298 Dihomo-γ-linolenic acid Nutrition 0.000 description 1
- 235000021294 Docosapentaenoic acid Nutrition 0.000 description 1
- 235000021292 Docosatetraenoic acid Nutrition 0.000 description 1
- 101100284769 Drosophila melanogaster hemo gene Proteins 0.000 description 1
- 101710121765 Endo-1,4-beta-xylanase Proteins 0.000 description 1
- 239000004386 Erythritol Substances 0.000 description 1
- UNXHWFMMPAWVPI-UHFFFAOYSA-N Erythritol Natural products OCC(O)C(O)CO UNXHWFMMPAWVPI-UHFFFAOYSA-N 0.000 description 1
- 241001302160 Escherichia coli str. K-12 substr. DH10B Species 0.000 description 1
- 241000195623 Euglenida Species 0.000 description 1
- 101710089384 Extracellular protease Proteins 0.000 description 1
- 101150095274 FBA1 gene Proteins 0.000 description 1
- 108010039731 Fatty Acid Synthases Proteins 0.000 description 1
- 229920001917 Ficoll Polymers 0.000 description 1
- BDAGIHXWWSANSR-UHFFFAOYSA-M Formate Chemical compound [O-]C=O BDAGIHXWWSANSR-UHFFFAOYSA-M 0.000 description 1
- 229930091371 Fructose Natural products 0.000 description 1
- 239000005715 Fructose Substances 0.000 description 1
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 1
- LOJYQMFIIJVETK-WDSKDSINSA-N Gln-Gln Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(O)=O LOJYQMFIIJVETK-WDSKDSINSA-N 0.000 description 1
- MCAVASRGVBVPMX-FXQIFTODSA-N Gln-Glu-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MCAVASRGVBVPMX-FXQIFTODSA-N 0.000 description 1
- LVSYIKGMLRHKME-IUCAKERBSA-N Gln-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N LVSYIKGMLRHKME-IUCAKERBSA-N 0.000 description 1
- VGTDBGYFVWOQTI-RYUDHWBXSA-N Gln-Gly-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VGTDBGYFVWOQTI-RYUDHWBXSA-N 0.000 description 1
- GLAPJAHOPFSLKL-SRVKXCTJSA-N Gln-His-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)N)N GLAPJAHOPFSLKL-SRVKXCTJSA-N 0.000 description 1
- HHQCBFGKQDMWSP-GUBZILKMSA-N Gln-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)N)N HHQCBFGKQDMWSP-GUBZILKMSA-N 0.000 description 1
- SHAUZYVSXAMYAZ-JYJNAYRXSA-N Gln-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N SHAUZYVSXAMYAZ-JYJNAYRXSA-N 0.000 description 1
- TWIAMTNJOMRDAK-GUBZILKMSA-N Gln-Lys-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O TWIAMTNJOMRDAK-GUBZILKMSA-N 0.000 description 1
- GQTNWYFWSUFFRA-KKUMJFAQSA-N Gln-Met-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GQTNWYFWSUFFRA-KKUMJFAQSA-N 0.000 description 1
- FTTHLXOMDMLKKW-FHWLQOOXSA-N Gln-Phe-Phe Chemical compound C([C@H](NC(=O)[C@H](CCC(N)=O)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FTTHLXOMDMLKKW-FHWLQOOXSA-N 0.000 description 1
- ZVQZXPADLZIQFF-FHWLQOOXSA-N Gln-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@H](CCC(N)=O)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 ZVQZXPADLZIQFF-FHWLQOOXSA-N 0.000 description 1
- OTQSTOXRUBVWAP-NRPADANISA-N Gln-Ser-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OTQSTOXRUBVWAP-NRPADANISA-N 0.000 description 1
- RONJIBWTGKVKFY-HTUGSXCWSA-N Gln-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O RONJIBWTGKVKFY-HTUGSXCWSA-N 0.000 description 1
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 1
- CMBXOSFZCFGDLE-IHRRRGAJSA-N Gln-Tyr-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O CMBXOSFZCFGDLE-IHRRRGAJSA-N 0.000 description 1
- VCUNGPMMPNJSGS-JYJNAYRXSA-N Gln-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VCUNGPMMPNJSGS-JYJNAYRXSA-N 0.000 description 1
- UBRQJXFDVZNYJP-AVGNSLFASA-N Gln-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UBRQJXFDVZNYJP-AVGNSLFASA-N 0.000 description 1
- BBFCMGBMYIAGRS-AUTRQRHGSA-N Gln-Val-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BBFCMGBMYIAGRS-AUTRQRHGSA-N 0.000 description 1
- QGWXAMDECCKGRU-XVKPBYJWSA-N Gln-Val-Gly Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(N)=O)C(=O)NCC(O)=O QGWXAMDECCKGRU-XVKPBYJWSA-N 0.000 description 1
- SOEXCCGNHQBFPV-DLOVCJGASA-N Gln-Val-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SOEXCCGNHQBFPV-DLOVCJGASA-N 0.000 description 1
- RLZBLVSJDFHDBL-KBIXCLLPSA-N Glu-Ala-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RLZBLVSJDFHDBL-KBIXCLLPSA-N 0.000 description 1
- ATRHMOJQJWPVBQ-DRZSPHRISA-N Glu-Ala-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ATRHMOJQJWPVBQ-DRZSPHRISA-N 0.000 description 1
- NCWOMXABNYEPLY-NRPADANISA-N Glu-Ala-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O NCWOMXABNYEPLY-NRPADANISA-N 0.000 description 1
- JPHYJQHPILOKHC-ACZMJKKPSA-N Glu-Asp-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JPHYJQHPILOKHC-ACZMJKKPSA-N 0.000 description 1
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 1
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 1
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 1
- XOFYVODYSNKPDK-AVGNSLFASA-N Glu-His-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XOFYVODYSNKPDK-AVGNSLFASA-N 0.000 description 1
- ZCFNZTVIDMLUQC-SXNHZJKMSA-N Glu-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZCFNZTVIDMLUQC-SXNHZJKMSA-N 0.000 description 1
- HVYWQYLBVXMXSV-GUBZILKMSA-N Glu-Leu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HVYWQYLBVXMXSV-GUBZILKMSA-N 0.000 description 1
- FBEJIDRSQCGFJI-GUBZILKMSA-N Glu-Leu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FBEJIDRSQCGFJI-GUBZILKMSA-N 0.000 description 1
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 1
- YKBUCXNNBYZYAY-MNXVOIDGSA-N Glu-Lys-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YKBUCXNNBYZYAY-MNXVOIDGSA-N 0.000 description 1
- ZTVGZOIBLRPQNR-KKUMJFAQSA-N Glu-Met-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZTVGZOIBLRPQNR-KKUMJFAQSA-N 0.000 description 1
- KXTAGESXNQEZKB-DZKIICNBSA-N Glu-Phe-Val Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 KXTAGESXNQEZKB-DZKIICNBSA-N 0.000 description 1
- UDEPRBFQTWGLCW-CIUDSAMLSA-N Glu-Pro-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O UDEPRBFQTWGLCW-CIUDSAMLSA-N 0.000 description 1
- YQAQQKPWFOBSMU-WDCWCFNPSA-N Glu-Thr-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O YQAQQKPWFOBSMU-WDCWCFNPSA-N 0.000 description 1
- ZGXGVBYEJGVJMV-HJGDQZAQSA-N Glu-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O ZGXGVBYEJGVJMV-HJGDQZAQSA-N 0.000 description 1
- CAQXJMUDOLSBPF-SUSMZKCASA-N Glu-Thr-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAQXJMUDOLSBPF-SUSMZKCASA-N 0.000 description 1
- HJTSRYLPAYGEEC-SIUGBPQLSA-N Glu-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCC(=O)O)N HJTSRYLPAYGEEC-SIUGBPQLSA-N 0.000 description 1
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 1
- VIPDPMHGICREIS-GVXVVHGQSA-N Glu-Val-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VIPDPMHGICREIS-GVXVVHGQSA-N 0.000 description 1
- 108010060309 Glucuronidase Proteins 0.000 description 1
- 102000053187 Glucuronidase Human genes 0.000 description 1
- MFVQGXGQRIXBPK-WDSKDSINSA-N Gly-Ala-Glu Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFVQGXGQRIXBPK-WDSKDSINSA-N 0.000 description 1
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 1
- JRDYDYXZKFNNRQ-XPUUQOCRSA-N Gly-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN JRDYDYXZKFNNRQ-XPUUQOCRSA-N 0.000 description 1
- CLODWIOAKCSBAN-BQBZGAKWSA-N Gly-Arg-Asp Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O CLODWIOAKCSBAN-BQBZGAKWSA-N 0.000 description 1
- XUORRGAFUQIMLC-STQMWFEESA-N Gly-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN)O XUORRGAFUQIMLC-STQMWFEESA-N 0.000 description 1
- WKJKBELXHCTHIJ-WPRPVWTQSA-N Gly-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N WKJKBELXHCTHIJ-WPRPVWTQSA-N 0.000 description 1
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 1
- BPQYBFAXRGMGGY-LAEOZQHASA-N Gly-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)CN BPQYBFAXRGMGGY-LAEOZQHASA-N 0.000 description 1
- QSVCIFZPGLOZGH-WDSKDSINSA-N Gly-Glu-Ser Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QSVCIFZPGLOZGH-WDSKDSINSA-N 0.000 description 1
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 1
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 1
- KAJAOGBVWCYGHZ-JTQLQIEISA-N Gly-Gly-Phe Chemical compound [NH3+]CC(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KAJAOGBVWCYGHZ-JTQLQIEISA-N 0.000 description 1
- VAXIVIPMCTYSHI-YUMQZZPRSA-N Gly-His-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)CN VAXIVIPMCTYSHI-YUMQZZPRSA-N 0.000 description 1
- ADZGCWWDPFDHCY-ZETCQYMHSA-N Gly-His-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CC1=CN=CN1 ADZGCWWDPFDHCY-ZETCQYMHSA-N 0.000 description 1
- SWQALSGKVLYKDT-ZKWXMUAHSA-N Gly-Ile-Ala Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SWQALSGKVLYKDT-ZKWXMUAHSA-N 0.000 description 1
- AAHSHTLISQUZJL-QSFUFRPTSA-N Gly-Ile-Ile Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AAHSHTLISQUZJL-QSFUFRPTSA-N 0.000 description 1
- PAWIVEIWWYGBAM-YUMQZZPRSA-N Gly-Leu-Ala Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O PAWIVEIWWYGBAM-YUMQZZPRSA-N 0.000 description 1
- IUZGUFAJDBHQQV-YUMQZZPRSA-N Gly-Leu-Asn Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IUZGUFAJDBHQQV-YUMQZZPRSA-N 0.000 description 1
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 1
- VBOBNHSVQKKTOT-YUMQZZPRSA-N Gly-Lys-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O VBOBNHSVQKKTOT-YUMQZZPRSA-N 0.000 description 1
- OQQKUTVULYLCDG-ONGXEEELSA-N Gly-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)CN)C(O)=O OQQKUTVULYLCDG-ONGXEEELSA-N 0.000 description 1
- BBTCXWTXOXUNFX-IUCAKERBSA-N Gly-Met-Arg Chemical compound CSCC[C@H](NC(=O)CN)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O BBTCXWTXOXUNFX-IUCAKERBSA-N 0.000 description 1
- QGDOOCIPHSSADO-STQMWFEESA-N Gly-Met-Phe Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QGDOOCIPHSSADO-STQMWFEESA-N 0.000 description 1
- IBYOLNARKHMLBG-WHOFXGATSA-N Gly-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 IBYOLNARKHMLBG-WHOFXGATSA-N 0.000 description 1
- QAMMIGULQSIRCD-IRXDYDNUSA-N Gly-Phe-Tyr Chemical compound C([C@H](NC(=O)C[NH3+])C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C([O-])=O)C1=CC=CC=C1 QAMMIGULQSIRCD-IRXDYDNUSA-N 0.000 description 1
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 1
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 1
- UIQGJYUEQDOODF-KWQFWETISA-N Gly-Tyr-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 UIQGJYUEQDOODF-KWQFWETISA-N 0.000 description 1
- OCRQUYDOYKCOQG-IRXDYDNUSA-N Gly-Tyr-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 OCRQUYDOYKCOQG-IRXDYDNUSA-N 0.000 description 1
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 1
- MUGLKCQHTUFLGF-WPRPVWTQSA-N Gly-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)CN MUGLKCQHTUFLGF-WPRPVWTQSA-N 0.000 description 1
- UXDDRFCJKNROTO-UHFFFAOYSA-N Glycerol 1,2-diacetate Chemical compound CC(=O)OCC(CO)OC(C)=O UXDDRFCJKNROTO-UHFFFAOYSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 101001036905 Glycine max Beta-conglycinin beta subunit 1 Proteins 0.000 description 1
- 229930186217 Glycolipid Natural products 0.000 description 1
- RVKIPWVMZANZLI-UHFFFAOYSA-N H-Lys-Trp-OH Natural products C1=CC=C2C(CC(NC(=O)C(N)CCCCN)C(O)=O)=CNC2=C1 RVKIPWVMZANZLI-UHFFFAOYSA-N 0.000 description 1
- 102000015779 HDL Lipoproteins Human genes 0.000 description 1
- 108010010234 HDL Lipoproteins Proteins 0.000 description 1
- 102000002812 Heat-Shock Proteins Human genes 0.000 description 1
- 108010004889 Heat-Shock Proteins Proteins 0.000 description 1
- 241000208818 Helianthus Species 0.000 description 1
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 1
- OBTMRGFRLJBSFI-GARJFASQSA-N His-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O OBTMRGFRLJBSFI-GARJFASQSA-N 0.000 description 1
- DFHVLUKTTVTCKY-PBCZWWQYSA-N His-Asn-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N)O DFHVLUKTTVTCKY-PBCZWWQYSA-N 0.000 description 1
- ZJSMFRTVYSLKQU-DJFWLOJKSA-N His-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CN=CN1)N ZJSMFRTVYSLKQU-DJFWLOJKSA-N 0.000 description 1
- ZZLWLWSUIBSMNP-CIUDSAMLSA-N His-Asp-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZZLWLWSUIBSMNP-CIUDSAMLSA-N 0.000 description 1
- CYHWWHKRCKHYGQ-GUBZILKMSA-N His-Cys-Glu Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N CYHWWHKRCKHYGQ-GUBZILKMSA-N 0.000 description 1
- JWLWNCVBBSBCEM-NKIYYHGXSA-N His-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N)O JWLWNCVBBSBCEM-NKIYYHGXSA-N 0.000 description 1
- PQKCQZHAGILVIM-NKIYYHGXSA-N His-Glu-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O PQKCQZHAGILVIM-NKIYYHGXSA-N 0.000 description 1
- PMWSGVRIMIFXQH-KKUMJFAQSA-N His-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1NC=NC=1)C1=CN=CN1 PMWSGVRIMIFXQH-KKUMJFAQSA-N 0.000 description 1
- BZKDJRSZWLPJNI-SRVKXCTJSA-N His-His-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O BZKDJRSZWLPJNI-SRVKXCTJSA-N 0.000 description 1
- VJJSDSNFXCWCEJ-DJFWLOJKSA-N His-Ile-Asn Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O VJJSDSNFXCWCEJ-DJFWLOJKSA-N 0.000 description 1
- AIPUZFXMXAHZKY-QWRGUYRKSA-N His-Leu-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AIPUZFXMXAHZKY-QWRGUYRKSA-N 0.000 description 1
- XKIYNCLILDLGRS-QWRGUYRKSA-N His-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CC1=CN=CN1 XKIYNCLILDLGRS-QWRGUYRKSA-N 0.000 description 1
- QCBYAHHNOHBXIH-UWVGGRQHSA-N His-Pro-Gly Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)NCC(O)=O)C1=CN=CN1 QCBYAHHNOHBXIH-UWVGGRQHSA-N 0.000 description 1
- CHIAUHSHDARFBD-ULQDDVLXSA-N His-Pro-Tyr Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CN=CN1 CHIAUHSHDARFBD-ULQDDVLXSA-N 0.000 description 1
- KAXZXLSXFWSNNZ-XVYDVKMFSA-N His-Ser-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KAXZXLSXFWSNNZ-XVYDVKMFSA-N 0.000 description 1
- PLCAEMGSYOYIPP-GUBZILKMSA-N His-Ser-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 PLCAEMGSYOYIPP-GUBZILKMSA-N 0.000 description 1
- CSRRMQFXMBPSIL-SIXJUCDHSA-N His-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CN=CN3)N CSRRMQFXMBPSIL-SIXJUCDHSA-N 0.000 description 1
- YERBCFWVWITTEJ-NAZCDGGXSA-N His-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CN=CN3)N)O YERBCFWVWITTEJ-NAZCDGGXSA-N 0.000 description 1
- 108010033040 Histones Proteins 0.000 description 1
- 101001128156 Homo sapiens Nanos homolog 3 Proteins 0.000 description 1
- 101001124309 Homo sapiens Nitric oxide synthase, endothelial Proteins 0.000 description 1
- XSXIVVZCUAHUJO-UHFFFAOYSA-N Homo-gamma-linoleic acid Natural products CCCCCC=CCC=CCCCCCCCCCC(O)=O XSXIVVZCUAHUJO-UHFFFAOYSA-N 0.000 description 1
- GRRNUXAQVGOGFE-UHFFFAOYSA-N Hygromycin-B Natural products OC1C(NC)CC(N)C(O)C1OC1C2OC3(C(C(O)C(O)C(C(N)CO)O3)O)OC2C(O)C(CO)O1 GRRNUXAQVGOGFE-UHFFFAOYSA-N 0.000 description 1
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 1
- CYHYBSGMHMHKOA-CIQUZCHMSA-N Ile-Ala-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N CYHYBSGMHMHKOA-CIQUZCHMSA-N 0.000 description 1
- AZEYWPUCOYXFOE-CYDGBPFRSA-N Ile-Arg-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C(C)C)C(=O)O)N AZEYWPUCOYXFOE-CYDGBPFRSA-N 0.000 description 1
- NBJAAWYRLGCJOF-UGYAYLCHSA-N Ile-Asp-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N NBJAAWYRLGCJOF-UGYAYLCHSA-N 0.000 description 1
- NKRJALPCDNXULF-BYULHYEWSA-N Ile-Asp-Gly Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O NKRJALPCDNXULF-BYULHYEWSA-N 0.000 description 1
- DCQMJRSOGCYKTR-GHCJXIJMSA-N Ile-Asp-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O DCQMJRSOGCYKTR-GHCJXIJMSA-N 0.000 description 1
- LLHYWBGDMBGNHA-VGDYDELISA-N Ile-Cys-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N LLHYWBGDMBGNHA-VGDYDELISA-N 0.000 description 1
- CNPNWGHRMBQHBZ-ZKWXMUAHSA-N Ile-Gln Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(O)=O)CCC(N)=O CNPNWGHRMBQHBZ-ZKWXMUAHSA-N 0.000 description 1
- BALLIXFZYSECCF-QEWYBTABSA-N Ile-Gln-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N BALLIXFZYSECCF-QEWYBTABSA-N 0.000 description 1
- BEWFWZRGBDVXRP-PEFMBERDSA-N Ile-Glu-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O BEWFWZRGBDVXRP-PEFMBERDSA-N 0.000 description 1
- IXEFKXAGHRQFAF-HVTMNAMFSA-N Ile-Glu-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N IXEFKXAGHRQFAF-HVTMNAMFSA-N 0.000 description 1
- NZOCIWKZUVUNDW-ZKWXMUAHSA-N Ile-Gly-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O NZOCIWKZUVUNDW-ZKWXMUAHSA-N 0.000 description 1
- KFVUBLZRFSVDGO-BYULHYEWSA-N Ile-Gly-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O KFVUBLZRFSVDGO-BYULHYEWSA-N 0.000 description 1
- IGJWJGIHUFQANP-LAEOZQHASA-N Ile-Gly-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N IGJWJGIHUFQANP-LAEOZQHASA-N 0.000 description 1
- NYEYYMLUABXDMC-NHCYSSNCSA-N Ile-Gly-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)O)N NYEYYMLUABXDMC-NHCYSSNCSA-N 0.000 description 1
- CCYGNFBYUNHFSC-MGHWNKPDSA-N Ile-His-Phe Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O CCYGNFBYUNHFSC-MGHWNKPDSA-N 0.000 description 1
- SJLVSMMIFYTSGY-GRLWGSQLSA-N Ile-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N SJLVSMMIFYTSGY-GRLWGSQLSA-N 0.000 description 1
- AXNGDPAKKCEKGY-QPHKQPEJSA-N Ile-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N AXNGDPAKKCEKGY-QPHKQPEJSA-N 0.000 description 1
- TVYWVSJGSHQWMT-AJNGGQMLSA-N Ile-Leu-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N TVYWVSJGSHQWMT-AJNGGQMLSA-N 0.000 description 1
- PHRWFSFCNJPWRO-PPCPHDFISA-N Ile-Leu-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N PHRWFSFCNJPWRO-PPCPHDFISA-N 0.000 description 1
- PWUMCBLVWPCKNO-MGHWNKPDSA-N Ile-Leu-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PWUMCBLVWPCKNO-MGHWNKPDSA-N 0.000 description 1
- GLYJPWIRLBAIJH-UHFFFAOYSA-N Ile-Lys-Pro Natural products CCC(C)C(N)C(=O)NC(CCCCN)C(=O)N1CCCC1C(O)=O GLYJPWIRLBAIJH-UHFFFAOYSA-N 0.000 description 1
- VISRCHQHQCLODA-NAKRPEOUSA-N Ile-Pro-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)O)N VISRCHQHQCLODA-NAKRPEOUSA-N 0.000 description 1
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 1
- RQJUKVXWAKJDBW-SVSWQMSJSA-N Ile-Ser-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N RQJUKVXWAKJDBW-SVSWQMSJSA-N 0.000 description 1
- YCKPUHHMCFSUMD-IUKAMOBKSA-N Ile-Thr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCKPUHHMCFSUMD-IUKAMOBKSA-N 0.000 description 1
- NAFIFZNBSPWYOO-RWRJDSDZSA-N Ile-Thr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N NAFIFZNBSPWYOO-RWRJDSDZSA-N 0.000 description 1
- WCNWGAUZWWSYDG-SVSWQMSJSA-N Ile-Thr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)O)N WCNWGAUZWWSYDG-SVSWQMSJSA-N 0.000 description 1
- NGKPIPCGMLWHBX-WZLNRYEVSA-N Ile-Tyr-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NGKPIPCGMLWHBX-WZLNRYEVSA-N 0.000 description 1
- RQZFWBLDTBDEOF-RNJOBUHISA-N Ile-Val-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N RQZFWBLDTBDEOF-RNJOBUHISA-N 0.000 description 1
- JZBVBOKASHNXAD-NAKRPEOUSA-N Ile-Val-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N JZBVBOKASHNXAD-NAKRPEOUSA-N 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 102000008070 Interferon-gamma Human genes 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 102100024319 Intestinal-type alkaline phosphatase Human genes 0.000 description 1
- 101710184243 Intestinal-type alkaline phosphatase Proteins 0.000 description 1
- 241000235649 Kluyveromyces Species 0.000 description 1
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- 101150007280 LEU2 gene Proteins 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 101710094902 Legumin Proteins 0.000 description 1
- QPRQGENIBFLVEB-BJDJZHNGSA-N Leu-Ala-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O QPRQGENIBFLVEB-BJDJZHNGSA-N 0.000 description 1
- HXWALXSAVBLTPK-NUTKFTJISA-N Leu-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(C)C)N HXWALXSAVBLTPK-NUTKFTJISA-N 0.000 description 1
- WGNOPSQMIQERPK-GARJFASQSA-N Leu-Asn-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N WGNOPSQMIQERPK-GARJFASQSA-N 0.000 description 1
- WGNOPSQMIQERPK-UHFFFAOYSA-N Leu-Asn-Pro Natural products CC(C)CC(N)C(=O)NC(CC(=O)N)C(=O)N1CCCC1C(=O)O WGNOPSQMIQERPK-UHFFFAOYSA-N 0.000 description 1
- QKIBIXAQKAFZGL-GUBZILKMSA-N Leu-Cys-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QKIBIXAQKAFZGL-GUBZILKMSA-N 0.000 description 1
- VFQOCUQGMUXTJR-DCAQKATOSA-N Leu-Cys-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCSC)C(=O)O)N VFQOCUQGMUXTJR-DCAQKATOSA-N 0.000 description 1
- KUEVMUXNILMJTK-JYJNAYRXSA-N Leu-Gln-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KUEVMUXNILMJTK-JYJNAYRXSA-N 0.000 description 1
- LLBQJYDYOLIQAI-JYJNAYRXSA-N Leu-Glu-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LLBQJYDYOLIQAI-JYJNAYRXSA-N 0.000 description 1
- VBZOAGIPCULURB-QWRGUYRKSA-N Leu-Gly-His Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N VBZOAGIPCULURB-QWRGUYRKSA-N 0.000 description 1
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 1
- UCDHVOALNXENLC-KBPBESRZSA-N Leu-Gly-Tyr Chemical compound CC(C)C[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 UCDHVOALNXENLC-KBPBESRZSA-N 0.000 description 1
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 1
- YWYQSLOTVIRCFE-SRVKXCTJSA-N Leu-His-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(O)=O YWYQSLOTVIRCFE-SRVKXCTJSA-N 0.000 description 1
- LKXANTUNFMVCNF-IHPCNDPISA-N Leu-His-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O LKXANTUNFMVCNF-IHPCNDPISA-N 0.000 description 1
- DBSLVQBXKVKDKJ-BJDJZHNGSA-N Leu-Ile-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O DBSLVQBXKVKDKJ-BJDJZHNGSA-N 0.000 description 1
- AUBMZAMQCOYSIC-MNXVOIDGSA-N Leu-Ile-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O AUBMZAMQCOYSIC-MNXVOIDGSA-N 0.000 description 1
- HNDWYLYAYNBWMP-AJNGGQMLSA-N Leu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N HNDWYLYAYNBWMP-AJNGGQMLSA-N 0.000 description 1
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 1
- UCNNZELZXFXXJQ-BZSNNMDCSA-N Leu-Leu-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCNNZELZXFXXJQ-BZSNNMDCSA-N 0.000 description 1
- JLWZLIQRYCTYBD-IHRRRGAJSA-N Leu-Lys-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JLWZLIQRYCTYBD-IHRRRGAJSA-N 0.000 description 1
- OVZLLFONXILPDZ-VOAKCMCISA-N Leu-Lys-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OVZLLFONXILPDZ-VOAKCMCISA-N 0.000 description 1
- CPONGMJGVIAWEH-DCAQKATOSA-N Leu-Met-Ala Chemical compound CSCC[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](C)C(O)=O CPONGMJGVIAWEH-DCAQKATOSA-N 0.000 description 1
- FLNPJLDPGMLWAU-UWVGGRQHSA-N Leu-Met-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC(C)C FLNPJLDPGMLWAU-UWVGGRQHSA-N 0.000 description 1
- NJMXCOOEFLMZSR-AVGNSLFASA-N Leu-Met-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O NJMXCOOEFLMZSR-AVGNSLFASA-N 0.000 description 1
- KTOIECMYZZGVSI-BZSNNMDCSA-N Leu-Phe-His Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CC=CC=C1 KTOIECMYZZGVSI-BZSNNMDCSA-N 0.000 description 1
- SYRTUBLKWNDSDK-DKIMLUQUSA-N Leu-Phe-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SYRTUBLKWNDSDK-DKIMLUQUSA-N 0.000 description 1
- DRWMRVFCKKXHCH-BZSNNMDCSA-N Leu-Phe-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=CC=C1 DRWMRVFCKKXHCH-BZSNNMDCSA-N 0.000 description 1
- MJWVXZABPOKJJF-ACRUOGEOSA-N Leu-Phe-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MJWVXZABPOKJJF-ACRUOGEOSA-N 0.000 description 1
- YWKNKRAKOCLOLH-OEAJRASXSA-N Leu-Phe-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=CC=C1 YWKNKRAKOCLOLH-OEAJRASXSA-N 0.000 description 1
- FYPWFNKQVVEELI-ULQDDVLXSA-N Leu-Phe-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 FYPWFNKQVVEELI-ULQDDVLXSA-N 0.000 description 1
- MUCIDQMDOYQYBR-IHRRRGAJSA-N Leu-Pro-His Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N MUCIDQMDOYQYBR-IHRRRGAJSA-N 0.000 description 1
- KWLWZYMNUZJKMZ-IHRRRGAJSA-N Leu-Pro-Leu Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O KWLWZYMNUZJKMZ-IHRRRGAJSA-N 0.000 description 1
- UCXQIIIFOOGYEM-ULQDDVLXSA-N Leu-Pro-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCXQIIIFOOGYEM-ULQDDVLXSA-N 0.000 description 1
- GOFJOGXGMPHOGL-DCAQKATOSA-N Leu-Ser-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(C)C GOFJOGXGMPHOGL-DCAQKATOSA-N 0.000 description 1
- ZJZNLRVCZWUONM-JXUBOQSCSA-N Leu-Thr-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O ZJZNLRVCZWUONM-JXUBOQSCSA-N 0.000 description 1
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 1
- ODRREERHVHMIPT-OEAJRASXSA-N Leu-Thr-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ODRREERHVHMIPT-OEAJRASXSA-N 0.000 description 1
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 1
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 1
- ONHCDMBHPQIPAI-YTQUADARSA-N Leu-Trp-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N3CCC[C@@H]3C(=O)O)N ONHCDMBHPQIPAI-YTQUADARSA-N 0.000 description 1
- WBRJVRXEGQIDRK-XIRDDKMYSA-N Leu-Trp-Ser Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 WBRJVRXEGQIDRK-XIRDDKMYSA-N 0.000 description 1
- LXGSOEPHQJONMG-PMVMPFDFSA-N Leu-Trp-Tyr Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N LXGSOEPHQJONMG-PMVMPFDFSA-N 0.000 description 1
- JGKHAFUAPZCCDU-BZSNNMDCSA-N Leu-Tyr-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=C(O)C=C1 JGKHAFUAPZCCDU-BZSNNMDCSA-N 0.000 description 1
- XOEDPXDZJHBQIX-ULQDDVLXSA-N Leu-Val-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XOEDPXDZJHBQIX-ULQDDVLXSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 241000208204 Linum Species 0.000 description 1
- 108090001060 Lipase Proteins 0.000 description 1
- 239000004367 Lipase Substances 0.000 description 1
- 102000004882 Lipase Human genes 0.000 description 1
- 239000006142 Luria-Bertani Agar Substances 0.000 description 1
- 108090000856 Lyases Proteins 0.000 description 1
- 102000004317 Lyases Human genes 0.000 description 1
- 235000007688 Lycopersicon esculentum Nutrition 0.000 description 1
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 1
- NTEVEUCLFMWSND-SRVKXCTJSA-N Lys-Arg-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O NTEVEUCLFMWSND-SRVKXCTJSA-N 0.000 description 1
- CKSXSQUVEYCDIW-AVGNSLFASA-N Lys-Arg-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N CKSXSQUVEYCDIW-AVGNSLFASA-N 0.000 description 1
- DNEJSAIMVANNPA-DCAQKATOSA-N Lys-Asn-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DNEJSAIMVANNPA-DCAQKATOSA-N 0.000 description 1
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 1
- QUYCUALODHJQLK-CIUDSAMLSA-N Lys-Asp-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O QUYCUALODHJQLK-CIUDSAMLSA-N 0.000 description 1
- GJJQCBVRWDGLMQ-GUBZILKMSA-N Lys-Glu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O GJJQCBVRWDGLMQ-GUBZILKMSA-N 0.000 description 1
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 1
- SQJSXOQXJYAVRV-SRVKXCTJSA-N Lys-His-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N SQJSXOQXJYAVRV-SRVKXCTJSA-N 0.000 description 1
- ZXFRGTAIIZHNHG-AJNGGQMLSA-N Lys-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CCCCN)N ZXFRGTAIIZHNHG-AJNGGQMLSA-N 0.000 description 1
- PRSBSVAVOQOAMI-BJDJZHNGSA-N Lys-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN PRSBSVAVOQOAMI-BJDJZHNGSA-N 0.000 description 1
- OVAOHZIOUBEQCJ-IHRRRGAJSA-N Lys-Leu-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OVAOHZIOUBEQCJ-IHRRRGAJSA-N 0.000 description 1
- WVJNGSFKBKOKRV-AJNGGQMLSA-N Lys-Leu-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WVJNGSFKBKOKRV-AJNGGQMLSA-N 0.000 description 1
- XIZQPFCRXLUNMK-BZSNNMDCSA-N Lys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCCCN)N XIZQPFCRXLUNMK-BZSNNMDCSA-N 0.000 description 1
- GAHJXEMYXKLZRQ-AJNGGQMLSA-N Lys-Lys-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GAHJXEMYXKLZRQ-AJNGGQMLSA-N 0.000 description 1
- BXPHMHQHYHILBB-BZSNNMDCSA-N Lys-Lys-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BXPHMHQHYHILBB-BZSNNMDCSA-N 0.000 description 1
- QQPSCXKFDSORFT-IHRRRGAJSA-N Lys-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN QQPSCXKFDSORFT-IHRRRGAJSA-N 0.000 description 1
- WLXGMVVHTIUPHE-ULQDDVLXSA-N Lys-Phe-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O WLXGMVVHTIUPHE-ULQDDVLXSA-N 0.000 description 1
- HYSVGEAWTGPMOA-IHRRRGAJSA-N Lys-Pro-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O HYSVGEAWTGPMOA-IHRRRGAJSA-N 0.000 description 1
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 1
- TVHCDSBMFQYPNA-RHYQMDGZSA-N Lys-Thr-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O TVHCDSBMFQYPNA-RHYQMDGZSA-N 0.000 description 1
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 1
- YCJCEMKOZOYBEF-OEAJRASXSA-N Lys-Thr-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O YCJCEMKOZOYBEF-OEAJRASXSA-N 0.000 description 1
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 101150110972 ME1 gene Proteins 0.000 description 1
- OFOBLEOULBTSOW-UHFFFAOYSA-L Malonate Chemical compound [O-]C(=O)CC([O-])=O OFOBLEOULBTSOW-UHFFFAOYSA-L 0.000 description 1
- 108091027974 Mature messenger RNA Proteins 0.000 description 1
- 240000004658 Medicago sativa Species 0.000 description 1
- 235000017587 Medicago sativa ssp. sativa Nutrition 0.000 description 1
- YRAWWKUTNBILNT-FXQIFTODSA-N Met-Ala-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YRAWWKUTNBILNT-FXQIFTODSA-N 0.000 description 1
- BQVJARUIXRXDKN-DCAQKATOSA-N Met-Asn-His Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 BQVJARUIXRXDKN-DCAQKATOSA-N 0.000 description 1
- QXEVZBXTDTVPCP-GMOBBJLQSA-N Met-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCSC)N QXEVZBXTDTVPCP-GMOBBJLQSA-N 0.000 description 1
- AWOMRHGUWFBDNU-ZPFDUUQYSA-N Met-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCSC)N AWOMRHGUWFBDNU-ZPFDUUQYSA-N 0.000 description 1
- PHWSCIFNNLLUFJ-NHCYSSNCSA-N Met-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCSC)N PHWSCIFNNLLUFJ-NHCYSSNCSA-N 0.000 description 1
- OOSPRDCGTLQLBP-NHCYSSNCSA-N Met-Glu-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OOSPRDCGTLQLBP-NHCYSSNCSA-N 0.000 description 1
- LQMHZERGCQJKAH-STQMWFEESA-N Met-Gly-Phe Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 LQMHZERGCQJKAH-STQMWFEESA-N 0.000 description 1
- SXWQMBGNFXAGAT-FJXKBIBVSA-N Met-Gly-Thr Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O SXWQMBGNFXAGAT-FJXKBIBVSA-N 0.000 description 1
- BKIFWLQFOOKUCA-DCAQKATOSA-N Met-His-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CO)C(=O)O)N BKIFWLQFOOKUCA-DCAQKATOSA-N 0.000 description 1
- AFFKUNVPPLQUGA-DCAQKATOSA-N Met-Leu-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O AFFKUNVPPLQUGA-DCAQKATOSA-N 0.000 description 1
- ZRACLHJYVRBJFC-ULQDDVLXSA-N Met-Lys-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZRACLHJYVRBJFC-ULQDDVLXSA-N 0.000 description 1
- CGUYGMFQZCYJSG-DCAQKATOSA-N Met-Lys-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O CGUYGMFQZCYJSG-DCAQKATOSA-N 0.000 description 1
- KRLKICLNEICJGV-STQMWFEESA-N Met-Phe-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 KRLKICLNEICJGV-STQMWFEESA-N 0.000 description 1
- NHXXGBXJTLRGJI-GUBZILKMSA-N Met-Pro-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O NHXXGBXJTLRGJI-GUBZILKMSA-N 0.000 description 1
- SMVTWPOATVIXTN-NAKRPEOUSA-N Met-Ser-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SMVTWPOATVIXTN-NAKRPEOUSA-N 0.000 description 1
- OOXVBECOTYHTCK-WDSOQIARSA-N Met-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCSC)N OOXVBECOTYHTCK-WDSOQIARSA-N 0.000 description 1
- CULGJGUDIJATIP-STQMWFEESA-N Met-Tyr-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 CULGJGUDIJATIP-STQMWFEESA-N 0.000 description 1
- ATBJCCFCJXCNGZ-UFYCRDLUSA-N Met-Tyr-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)CCSC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 ATBJCCFCJXCNGZ-UFYCRDLUSA-N 0.000 description 1
- LPNWWHBFXPNHJG-AVGNSLFASA-N Met-Val-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN LPNWWHBFXPNHJG-AVGNSLFASA-N 0.000 description 1
- 108020005196 Mitochondrial DNA Proteins 0.000 description 1
- 108010021466 Mutant Proteins Proteins 0.000 description 1
- 102000008300 Mutant Proteins Human genes 0.000 description 1
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 description 1
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 1
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 1
- 108010087066 N2-tryptophyllysine Proteins 0.000 description 1
- 102100031893 Nanos homolog 3 Human genes 0.000 description 1
- 241000244206 Nematoda Species 0.000 description 1
- 108091093105 Nuclear DNA Proteins 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- 241000272458 Numididae Species 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 108010055012 Orotidine-5'-phosphate decarboxylase Proteins 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- 239000007990 PIPES buffer Substances 0.000 description 1
- 235000021314 Palmitic acid Nutrition 0.000 description 1
- 241000206766 Pavlova Species 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 244000046052 Phaseolus vulgaris Species 0.000 description 1
- DFEVBOYEUQJGER-JURCDPSOSA-N Phe-Ala-Ile Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O DFEVBOYEUQJGER-JURCDPSOSA-N 0.000 description 1
- GNUCSNWOCQFMMC-UFYCRDLUSA-N Phe-Arg-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 GNUCSNWOCQFMMC-UFYCRDLUSA-N 0.000 description 1
- JIYJYFIXQTYDNF-YDHLFZDLSA-N Phe-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N JIYJYFIXQTYDNF-YDHLFZDLSA-N 0.000 description 1
- WMGVYPPIMZPWPN-SRVKXCTJSA-N Phe-Asp-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N WMGVYPPIMZPWPN-SRVKXCTJSA-N 0.000 description 1
- WIVCOAKLPICYGY-KKUMJFAQSA-N Phe-Asp-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N WIVCOAKLPICYGY-KKUMJFAQSA-N 0.000 description 1
- IILUKIJNFMUBNF-IHRRRGAJSA-N Phe-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O IILUKIJNFMUBNF-IHRRRGAJSA-N 0.000 description 1
- WPTYDQPGBMDUBI-QWRGUYRKSA-N Phe-Gly-Asn Chemical compound N[C@@H](Cc1ccccc1)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O WPTYDQPGBMDUBI-QWRGUYRKSA-N 0.000 description 1
- HGNGAMWHGGANAU-WHOFXGATSA-N Phe-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HGNGAMWHGGANAU-WHOFXGATSA-N 0.000 description 1
- BEEVXUYVEHXWRQ-YESZJQIVSA-N Phe-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O BEEVXUYVEHXWRQ-YESZJQIVSA-N 0.000 description 1
- KPEIBEPEUAZWNS-ULQDDVLXSA-N Phe-Leu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 KPEIBEPEUAZWNS-ULQDDVLXSA-N 0.000 description 1
- KNYPNEYICHHLQL-ACRUOGEOSA-N Phe-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 KNYPNEYICHHLQL-ACRUOGEOSA-N 0.000 description 1
- RMKGXGPQIPLTFC-KKUMJFAQSA-N Phe-Lys-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O RMKGXGPQIPLTFC-KKUMJFAQSA-N 0.000 description 1
- WZEWCHQHNCMBEN-PMVMPFDFSA-N Phe-Lys-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N WZEWCHQHNCMBEN-PMVMPFDFSA-N 0.000 description 1
- SRILZRSXIKRGBF-HRCADAONSA-N Phe-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N SRILZRSXIKRGBF-HRCADAONSA-N 0.000 description 1
- FQUUYTNBMIBOHS-IHRRRGAJSA-N Phe-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N FQUUYTNBMIBOHS-IHRRRGAJSA-N 0.000 description 1
- OKQQWSNUSQURLI-JYJNAYRXSA-N Phe-Met-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC1=CC=CC=C1)N OKQQWSNUSQURLI-JYJNAYRXSA-N 0.000 description 1
- OWSLLRKCHLTUND-BZSNNMDCSA-N Phe-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OWSLLRKCHLTUND-BZSNNMDCSA-N 0.000 description 1
- TXJJXEXCZBHDNA-ACRUOGEOSA-N Phe-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N TXJJXEXCZBHDNA-ACRUOGEOSA-N 0.000 description 1
- GRVMHFCZUIYNKQ-UFYCRDLUSA-N Phe-Phe-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O GRVMHFCZUIYNKQ-UFYCRDLUSA-N 0.000 description 1
- JXQVYPWVGUOIDV-MXAVVETBSA-N Phe-Ser-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JXQVYPWVGUOIDV-MXAVVETBSA-N 0.000 description 1
- MVIJMIZJPHQGEN-IHRRRGAJSA-N Phe-Ser-Val Chemical compound CC(C)[C@@H](C([O-])=O)NC(=O)[C@H](CO)NC(=O)[C@@H]([NH3+])CC1=CC=CC=C1 MVIJMIZJPHQGEN-IHRRRGAJSA-N 0.000 description 1
- JHSRGEODDALISP-XVSYOHENSA-N Phe-Thr-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O JHSRGEODDALISP-XVSYOHENSA-N 0.000 description 1
- ZVJGAXNBBKPYOE-HKUYNNGSSA-N Phe-Trp-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(O)=O)C1=CC=CC=C1 ZVJGAXNBBKPYOE-HKUYNNGSSA-N 0.000 description 1
- GTMSCDVFQLNEOY-BZSNNMDCSA-N Phe-Tyr-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N GTMSCDVFQLNEOY-BZSNNMDCSA-N 0.000 description 1
- MMPBPRXOFJNCCN-ZEWNOJEFSA-N Phe-Tyr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MMPBPRXOFJNCCN-ZEWNOJEFSA-N 0.000 description 1
- KIQUCMUULDXTAZ-HJOGWXRNSA-N Phe-Tyr-Tyr Chemical compound N[C@@H](Cc1ccccc1)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O KIQUCMUULDXTAZ-HJOGWXRNSA-N 0.000 description 1
- ZOGICTVLQDWPER-UFYCRDLUSA-N Phe-Tyr-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O ZOGICTVLQDWPER-UFYCRDLUSA-N 0.000 description 1
- GOUWCZRDTWTODO-YDHLFZDLSA-N Phe-Val-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O GOUWCZRDTWTODO-YDHLFZDLSA-N 0.000 description 1
- BQMFWUKNOCJDNV-HJWJTTGWSA-N Phe-Val-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BQMFWUKNOCJDNV-HJWJTTGWSA-N 0.000 description 1
- VIIRRNQMMIHYHQ-XHSDSOJGSA-N Phe-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N VIIRRNQMMIHYHQ-XHSDSOJGSA-N 0.000 description 1
- IEIFEYBAYFSRBQ-IHRRRGAJSA-N Phe-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N IEIFEYBAYFSRBQ-IHRRRGAJSA-N 0.000 description 1
- 102000001107 Phosphatidate Phosphatase Human genes 0.000 description 1
- 108010069394 Phosphatidate Phosphatase Proteins 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 244000298647 Poinciana pulcherrima Species 0.000 description 1
- 229920002319 Poly(methyl acrylate) Polymers 0.000 description 1
- 241000201976 Polycarpon Species 0.000 description 1
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 1
- INXAPZFIOVGHSV-CIUDSAMLSA-N Pro-Asn-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1 INXAPZFIOVGHSV-CIUDSAMLSA-N 0.000 description 1
- AHXPYZRZRMQOAU-QXEWZRGKSA-N Pro-Asn-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1)C(O)=O AHXPYZRZRMQOAU-QXEWZRGKSA-N 0.000 description 1
- VJLJGKQAOQJXJG-CIUDSAMLSA-N Pro-Asp-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VJLJGKQAOQJXJG-CIUDSAMLSA-N 0.000 description 1
- GDXZRWYXJSGWIV-GMOBBJLQSA-N Pro-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 GDXZRWYXJSGWIV-GMOBBJLQSA-N 0.000 description 1
- YKQNVTOIYFQMLW-IHRRRGAJSA-N Pro-Cys-Tyr Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 YKQNVTOIYFQMLW-IHRRRGAJSA-N 0.000 description 1
- LGSANCBHSMDFDY-GARJFASQSA-N Pro-Glu-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O LGSANCBHSMDFDY-GARJFASQSA-N 0.000 description 1
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 1
- AJCRQOHDLCBHFA-SRVKXCTJSA-N Pro-His-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O AJCRQOHDLCBHFA-SRVKXCTJSA-N 0.000 description 1
- BCNRNJWSRFDPTQ-HJWJTTGWSA-N Pro-Ile-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O BCNRNJWSRFDPTQ-HJWJTTGWSA-N 0.000 description 1
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 1
- SRBFGSGDNNQABI-FHWLQOOXSA-N Pro-Leu-Trp Chemical compound N([C@@H](CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C(=O)[C@@H]1CCCN1 SRBFGSGDNNQABI-FHWLQOOXSA-N 0.000 description 1
- VWHJZETTZDAGOM-XUXIUFHCSA-N Pro-Lys-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VWHJZETTZDAGOM-XUXIUFHCSA-N 0.000 description 1
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 1
- WOIFYRZPIORBRY-AVGNSLFASA-N Pro-Lys-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O WOIFYRZPIORBRY-AVGNSLFASA-N 0.000 description 1
- ANESFYPBAJPYNJ-SDDRHHMPSA-N Pro-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 ANESFYPBAJPYNJ-SDDRHHMPSA-N 0.000 description 1
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 1
- FDMCIBSQRKFSTJ-RHYQMDGZSA-N Pro-Thr-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O FDMCIBSQRKFSTJ-RHYQMDGZSA-N 0.000 description 1
- ZYJMLBCDFPIGNL-JYJNAYRXSA-N Pro-Tyr-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@H](Cc1ccc(O)cc1)NC(=O)[C@@H]1CCCN1)C(O)=O ZYJMLBCDFPIGNL-JYJNAYRXSA-N 0.000 description 1
- VDHGTOHMHHQSKG-JYJNAYRXSA-N Pro-Val-Phe Chemical compound CC(C)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O VDHGTOHMHHQSKG-JYJNAYRXSA-N 0.000 description 1
- MTMJNKFZDQEVSY-BZSNNMDCSA-N Pro-Val-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O MTMJNKFZDQEVSY-BZSNNMDCSA-N 0.000 description 1
- 201000004681 Psoriasis Diseases 0.000 description 1
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 1
- 108010079005 RDV peptide Proteins 0.000 description 1
- 108010003201 RGH 0205 Proteins 0.000 description 1
- 108020004518 RNA Probes Proteins 0.000 description 1
- 239000003391 RNA probe Substances 0.000 description 1
- 239000013614 RNA sample Substances 0.000 description 1
- 241000825199 Rebecca salina Species 0.000 description 1
- 241001149408 Rhodotorula graminis Species 0.000 description 1
- 241000221523 Rhodotorula toruloides Species 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 240000000111 Saccharum officinarum Species 0.000 description 1
- 235000007201 Saccharum officinarum Nutrition 0.000 description 1
- 241000233673 Schizochytrium aggregatum Species 0.000 description 1
- 108010016634 Seed Storage Proteins Proteins 0.000 description 1
- IDCKUIWEIZYVSO-WFBYXXMGSA-N Ser-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C)C(O)=O)=CNC2=C1 IDCKUIWEIZYVSO-WFBYXXMGSA-N 0.000 description 1
- VQBLHWSPVYYZTB-DCAQKATOSA-N Ser-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CO)N VQBLHWSPVYYZTB-DCAQKATOSA-N 0.000 description 1
- QFBNNYNWKYKVJO-DCAQKATOSA-N Ser-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N QFBNNYNWKYKVJO-DCAQKATOSA-N 0.000 description 1
- RZUOXAKGNHXZTB-GUBZILKMSA-N Ser-Arg-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(O)=O RZUOXAKGNHXZTB-GUBZILKMSA-N 0.000 description 1
- OHKLFYXEOGGGCK-ZLUOBGJFSA-N Ser-Asp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OHKLFYXEOGGGCK-ZLUOBGJFSA-N 0.000 description 1
- WTPKKLMBNBCCNL-ACZMJKKPSA-N Ser-Cys-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N WTPKKLMBNBCCNL-ACZMJKKPSA-N 0.000 description 1
- DGHFNYXVIXNNMC-GUBZILKMSA-N Ser-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N DGHFNYXVIXNNMC-GUBZILKMSA-N 0.000 description 1
- XERQKTRGJIKTRB-CIUDSAMLSA-N Ser-His-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)N)CC1=CN=CN1 XERQKTRGJIKTRB-CIUDSAMLSA-N 0.000 description 1
- SFTZTYBXIXLRGQ-JBDRJPRFSA-N Ser-Ile-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SFTZTYBXIXLRGQ-JBDRJPRFSA-N 0.000 description 1
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 1
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 1
- NNFMANHDYSVNIO-DCAQKATOSA-N Ser-Lys-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NNFMANHDYSVNIO-DCAQKATOSA-N 0.000 description 1
- WGDYNRCOQRERLZ-KKUMJFAQSA-N Ser-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N WGDYNRCOQRERLZ-KKUMJFAQSA-N 0.000 description 1
- UPLYXVPQLJVWMM-KKUMJFAQSA-N Ser-Phe-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O UPLYXVPQLJVWMM-KKUMJFAQSA-N 0.000 description 1
- GZGFSPWOMUKKCV-NAKRPEOUSA-N Ser-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO GZGFSPWOMUKKCV-NAKRPEOUSA-N 0.000 description 1
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 1
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 1
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 1
- OJFFAQFRCVPHNN-JYBASQMISA-N Ser-Thr-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O OJFFAQFRCVPHNN-JYBASQMISA-N 0.000 description 1
- VEVYMLNYMULSMS-AVGNSLFASA-N Ser-Tyr-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VEVYMLNYMULSMS-AVGNSLFASA-N 0.000 description 1
- HKHCTNFKZXAMIF-KKUMJFAQSA-N Ser-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC1=CC=C(O)C=C1 HKHCTNFKZXAMIF-KKUMJFAQSA-N 0.000 description 1
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 1
- LSHUNRICNSEEAN-BPUTZDHNSA-N Ser-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CO)N LSHUNRICNSEEAN-BPUTZDHNSA-N 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 1
- 241000862632 Soja Species 0.000 description 1
- 240000003768 Solanum lycopersicum Species 0.000 description 1
- 244000062793 Sorghum vulgare Species 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 235000021536 Sugar beet Nutrition 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-L Sulfate Chemical compound [O-]S([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 1
- JZRWCGZRTZMZEH-UHFFFAOYSA-N Thiamine Natural products CC1=C(CCO)SC=[N+]1CC1=CN=C(C)N=C1N JZRWCGZRTZMZEH-UHFFFAOYSA-N 0.000 description 1
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 1
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 1
- CAGTXGDOIFXLPC-KZVJFYERSA-N Thr-Arg-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CCCN=C(N)N CAGTXGDOIFXLPC-KZVJFYERSA-N 0.000 description 1
- VFEHSAJCWWHDBH-RHYQMDGZSA-N Thr-Arg-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VFEHSAJCWWHDBH-RHYQMDGZSA-N 0.000 description 1
- CTONFVDJYCAMQM-IUKAMOBKSA-N Thr-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H]([C@@H](C)O)N CTONFVDJYCAMQM-IUKAMOBKSA-N 0.000 description 1
- PZVGOVRNGKEFCB-KKHAAJSZSA-N Thr-Asn-Val Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N)O PZVGOVRNGKEFCB-KKHAAJSZSA-N 0.000 description 1
- LMMDEZPNUTZJAY-GCJQMDKQSA-N Thr-Asp-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O LMMDEZPNUTZJAY-GCJQMDKQSA-N 0.000 description 1
- RKDFEMGVMMYYNG-WDCWCFNPSA-N Thr-Gln-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O RKDFEMGVMMYYNG-WDCWCFNPSA-N 0.000 description 1
- UBDDORVPVLEECX-FJXKBIBVSA-N Thr-Gly-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O UBDDORVPVLEECX-FJXKBIBVSA-N 0.000 description 1
- DJDSEDOKJTZBAR-ZDLURKLDSA-N Thr-Gly-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O DJDSEDOKJTZBAR-ZDLURKLDSA-N 0.000 description 1
- MECLEFZMPPOEAC-VOAKCMCISA-N Thr-Leu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MECLEFZMPPOEAC-VOAKCMCISA-N 0.000 description 1
- PRNGXSILMXSWQQ-OEAJRASXSA-N Thr-Leu-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PRNGXSILMXSWQQ-OEAJRASXSA-N 0.000 description 1
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 1
- NQQMWWVVGIXUOX-SVSWQMSJSA-N Thr-Ser-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NQQMWWVVGIXUOX-SVSWQMSJSA-N 0.000 description 1
- BBPCSGKKPJUYRB-UVOCVTCTSA-N Thr-Thr-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O BBPCSGKKPJUYRB-UVOCVTCTSA-N 0.000 description 1
- XGUAUKUYQHBUNY-SWRJLBSHSA-N Thr-Trp-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(O)=O XGUAUKUYQHBUNY-SWRJLBSHSA-N 0.000 description 1
- NLWDSYKZUPRMBJ-IEGACIPQSA-N Thr-Trp-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O NLWDSYKZUPRMBJ-IEGACIPQSA-N 0.000 description 1
- ZEJBJDHSQPOVJV-UAXMHLISSA-N Thr-Trp-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZEJBJDHSQPOVJV-UAXMHLISSA-N 0.000 description 1
- BGHVVGPELPHRCI-HZTRNQAASA-N Thr-Trp-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)N)O BGHVVGPELPHRCI-HZTRNQAASA-N 0.000 description 1
- BZTSQFWJNJYZSX-JRQIVUDYSA-N Thr-Tyr-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O BZTSQFWJNJYZSX-JRQIVUDYSA-N 0.000 description 1
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 1
- XGFYGMKZKFRGAI-RCWTZXSCSA-N Thr-Val-Arg Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N XGFYGMKZKFRGAI-RCWTZXSCSA-N 0.000 description 1
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 1
- SBYQHZCMVSPQCS-RCWTZXSCSA-N Thr-Val-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O SBYQHZCMVSPQCS-RCWTZXSCSA-N 0.000 description 1
- SPIFGZFZMVLPHN-UNQGMJICSA-N Thr-Val-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SPIFGZFZMVLPHN-UNQGMJICSA-N 0.000 description 1
- BTAJAOWZCWOHBU-HSHDSVGOSA-N Thr-Val-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)O)C(C)C)C(O)=O)=CNC2=C1 BTAJAOWZCWOHBU-HSHDSVGOSA-N 0.000 description 1
- 241001467333 Thraustochytriaceae Species 0.000 description 1
- BRBCKMMXKONBAA-KWBADKCTSA-N Trp-Ala-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 BRBCKMMXKONBAA-KWBADKCTSA-N 0.000 description 1
- LTLBNCDNXQCOLB-UBHSHLNASA-N Trp-Asp-Ser Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 LTLBNCDNXQCOLB-UBHSHLNASA-N 0.000 description 1
- DTPARJBMONKGGC-IHPCNDPISA-N Trp-Cys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N DTPARJBMONKGGC-IHPCNDPISA-N 0.000 description 1
- CXPJPTFWKXNDKV-NUTKFTJISA-N Trp-Leu-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 CXPJPTFWKXNDKV-NUTKFTJISA-N 0.000 description 1
- YVXIAOOYAKBAAI-SZMVWBNQSA-N Trp-Leu-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 YVXIAOOYAKBAAI-SZMVWBNQSA-N 0.000 description 1
- BOMYCJXTWRMKJA-RNXOBYDBSA-N Trp-Phe-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)NC(=O)[C@H](CC3=CNC4=CC=CC=C43)N BOMYCJXTWRMKJA-RNXOBYDBSA-N 0.000 description 1
- XOLLWQIBBLBAHQ-WDSOQIARSA-N Trp-Pro-Leu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O XOLLWQIBBLBAHQ-WDSOQIARSA-N 0.000 description 1
- YCQXZDHDSUHUSG-FJHTZYQYSA-N Trp-Thr-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 YCQXZDHDSUHUSG-FJHTZYQYSA-N 0.000 description 1
- XXJDYWYVZBHELV-TUSQITKMSA-N Trp-Trp-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)N[C@@H](CCCCN)C(=O)O)N XXJDYWYVZBHELV-TUSQITKMSA-N 0.000 description 1
- UIDJDMVRDUANDL-BVSLBCMMSA-N Trp-Tyr-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UIDJDMVRDUANDL-BVSLBCMMSA-N 0.000 description 1
- XKTWZYNTLXITCY-QRTARXTBSA-N Trp-Val-Asn Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O)=CNC2=C1 XKTWZYNTLXITCY-QRTARXTBSA-N 0.000 description 1
- 101710162629 Trypsin inhibitor Proteins 0.000 description 1
- 229940122618 Trypsin inhibitor Drugs 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- XLMDWQNAOKLKCP-XDTLVQLUSA-N Tyr-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N XLMDWQNAOKLKCP-XDTLVQLUSA-N 0.000 description 1
- CDRYEAWHKJSGAF-BPNCWPANSA-N Tyr-Ala-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O CDRYEAWHKJSGAF-BPNCWPANSA-N 0.000 description 1
- AKFLVKKWVZMFOT-IHRRRGAJSA-N Tyr-Arg-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O AKFLVKKWVZMFOT-IHRRRGAJSA-N 0.000 description 1
- GFZQWWDXJVGEMW-ULQDDVLXSA-N Tyr-Arg-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O GFZQWWDXJVGEMW-ULQDDVLXSA-N 0.000 description 1
- IIJWXEUNETVJPV-IHRRRGAJSA-N Tyr-Arg-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N)O IIJWXEUNETVJPV-IHRRRGAJSA-N 0.000 description 1
- AYHSJESDFKREAR-KKUMJFAQSA-N Tyr-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AYHSJESDFKREAR-KKUMJFAQSA-N 0.000 description 1
- UABYBEBXFFNCIR-YDHLFZDLSA-N Tyr-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UABYBEBXFFNCIR-YDHLFZDLSA-N 0.000 description 1
- RYSNTWVRSLCAJZ-RYUDHWBXSA-N Tyr-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 RYSNTWVRSLCAJZ-RYUDHWBXSA-N 0.000 description 1
- RIJPHPUJRLEOAK-JYJNAYRXSA-N Tyr-Gln-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O RIJPHPUJRLEOAK-JYJNAYRXSA-N 0.000 description 1
- UXUFNBVCPAWACG-SIUGBPQLSA-N Tyr-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N UXUFNBVCPAWACG-SIUGBPQLSA-N 0.000 description 1
- ARJASMXQBRNAGI-YESZJQIVSA-N Tyr-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N ARJASMXQBRNAGI-YESZJQIVSA-N 0.000 description 1
- HSBZWINKRYZCSQ-KKUMJFAQSA-N Tyr-Lys-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O HSBZWINKRYZCSQ-KKUMJFAQSA-N 0.000 description 1
- ZOBLBMGJKVJVEV-BZSNNMDCSA-N Tyr-Lys-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N)O ZOBLBMGJKVJVEV-BZSNNMDCSA-N 0.000 description 1
- VBFVQTPETKJCQW-RPTUDFQQSA-N Tyr-Phe-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VBFVQTPETKJCQW-RPTUDFQQSA-N 0.000 description 1
- PHKQVWWHRYUCJL-HJOGWXRNSA-N Tyr-Phe-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PHKQVWWHRYUCJL-HJOGWXRNSA-N 0.000 description 1
- XJPXTYLVMUZGNW-IHRRRGAJSA-N Tyr-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O XJPXTYLVMUZGNW-IHRRRGAJSA-N 0.000 description 1
- BIWVVOHTKDLRMP-ULQDDVLXSA-N Tyr-Pro-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O BIWVVOHTKDLRMP-ULQDDVLXSA-N 0.000 description 1
- SOAUMCDLIUGXJJ-SRVKXCTJSA-N Tyr-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O SOAUMCDLIUGXJJ-SRVKXCTJSA-N 0.000 description 1
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 1
- MDXLPNRXCFOBTL-BZSNNMDCSA-N Tyr-Ser-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MDXLPNRXCFOBTL-BZSNNMDCSA-N 0.000 description 1
- NZBSVMQZQMEUHI-WZLNRYEVSA-N Tyr-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N NZBSVMQZQMEUHI-WZLNRYEVSA-N 0.000 description 1
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 1
- NVJCMGGZHOJNBU-UFYCRDLUSA-N Tyr-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N NVJCMGGZHOJNBU-UFYCRDLUSA-N 0.000 description 1
- KYOBSHFOBAOFBF-UHFFFAOYSA-N UMP Natural products OC1C(O)C(COP(O)(O)=O)OC1N1C(=O)NC(=O)C=C1C(O)=O KYOBSHFOBAOFBF-UHFFFAOYSA-N 0.000 description 1
- 101150050575 URA3 gene Proteins 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- 108010064997 VPY tripeptide Proteins 0.000 description 1
- UEOOXDLMQZBPFR-ZKWXMUAHSA-N Val-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N UEOOXDLMQZBPFR-ZKWXMUAHSA-N 0.000 description 1
- PAPWZOJOLKZEFR-AVGNSLFASA-N Val-Arg-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N PAPWZOJOLKZEFR-AVGNSLFASA-N 0.000 description 1
- ZMDCGGKHRKNWKD-LAEOZQHASA-N Val-Asn-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZMDCGGKHRKNWKD-LAEOZQHASA-N 0.000 description 1
- QGFPYRPIUXBYGR-YDHLFZDLSA-N Val-Asn-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N QGFPYRPIUXBYGR-YDHLFZDLSA-N 0.000 description 1
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 1
- AAOPYWQQBXHINJ-DZKIICNBSA-N Val-Gln-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N AAOPYWQQBXHINJ-DZKIICNBSA-N 0.000 description 1
- BRPKEERLGYNCNC-NHCYSSNCSA-N Val-Glu-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N BRPKEERLGYNCNC-NHCYSSNCSA-N 0.000 description 1
- VLDMQVZZWDOKQF-AUTRQRHGSA-N Val-Glu-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N VLDMQVZZWDOKQF-AUTRQRHGSA-N 0.000 description 1
- VVZDBPBZHLQPPB-XVKPBYJWSA-N Val-Glu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O VVZDBPBZHLQPPB-XVKPBYJWSA-N 0.000 description 1
- BEGDZYNDCNEGJZ-XVKPBYJWSA-N Val-Gly-Gln Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O BEGDZYNDCNEGJZ-XVKPBYJWSA-N 0.000 description 1
- URIRWLJVWHYLET-ONGXEEELSA-N Val-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C URIRWLJVWHYLET-ONGXEEELSA-N 0.000 description 1
- KZKMBGXCNLPYKD-YEPSODPASA-N Val-Gly-Thr Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O KZKMBGXCNLPYKD-YEPSODPASA-N 0.000 description 1
- VXDSPJJQUQDCKH-UKJIMTQDSA-N Val-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N VXDSPJJQUQDCKH-UKJIMTQDSA-N 0.000 description 1
- BMOFUVHDBROBSE-DCAQKATOSA-N Val-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N BMOFUVHDBROBSE-DCAQKATOSA-N 0.000 description 1
- JAKHAONCJJZVHT-DCAQKATOSA-N Val-Lys-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N JAKHAONCJJZVHT-DCAQKATOSA-N 0.000 description 1
- XPKCFQZDQGVJCX-RHYQMDGZSA-N Val-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N)O XPKCFQZDQGVJCX-RHYQMDGZSA-N 0.000 description 1
- ILMVQSHENUZYIZ-JYJNAYRXSA-N Val-Met-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N ILMVQSHENUZYIZ-JYJNAYRXSA-N 0.000 description 1
- CKTMJBPRVQWPHU-JSGCOSHPSA-N Val-Phe-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)O)N CKTMJBPRVQWPHU-JSGCOSHPSA-N 0.000 description 1
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 1
- ZEBRMWPTJNHXAJ-JYJNAYRXSA-N Val-Phe-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)O)N ZEBRMWPTJNHXAJ-JYJNAYRXSA-N 0.000 description 1
- BCBFMJYTNKDALA-UFYCRDLUSA-N Val-Phe-Phe Chemical compound N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O BCBFMJYTNKDALA-UFYCRDLUSA-N 0.000 description 1
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 1
- QIVPZSWBBHRNBA-JYJNAYRXSA-N Val-Pro-Phe Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O QIVPZSWBBHRNBA-JYJNAYRXSA-N 0.000 description 1
- QWCZXKIFPWPQHR-JYJNAYRXSA-N Val-Pro-Tyr Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QWCZXKIFPWPQHR-JYJNAYRXSA-N 0.000 description 1
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 1
- VIKZGAUAKQZDOF-NRPADANISA-N Val-Ser-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O VIKZGAUAKQZDOF-NRPADANISA-N 0.000 description 1
- HWNYVQMOLCYHEA-IHRRRGAJSA-N Val-Ser-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N HWNYVQMOLCYHEA-IHRRRGAJSA-N 0.000 description 1
- MNSSBIHFEUUXNW-RCWTZXSCSA-N Val-Thr-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N MNSSBIHFEUUXNW-RCWTZXSCSA-N 0.000 description 1
- QTXGUIMEHKCPBH-FHWLQOOXSA-N Val-Trp-Lys Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 QTXGUIMEHKCPBH-FHWLQOOXSA-N 0.000 description 1
- RFZFBOQPPFCOKG-BZSNNMDCSA-N Val-Trp-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCSC)C(=O)O)N RFZFBOQPPFCOKG-BZSNNMDCSA-N 0.000 description 1
- HOZAIQIEJTWWDG-HJOGWXRNSA-N Val-Trp-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)N HOZAIQIEJTWWDG-HJOGWXRNSA-N 0.000 description 1
- VBTFUDNTMCHPII-UHFFFAOYSA-N Val-Trp-Tyr Natural products C=1NC2=CC=CC=C2C=1CC(NC(=O)C(N)C(C)C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 VBTFUDNTMCHPII-UHFFFAOYSA-N 0.000 description 1
- NLNCNKIVJPEFBC-DLOVCJGASA-N Val-Val-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O NLNCNKIVJPEFBC-DLOVCJGASA-N 0.000 description 1
- XNLUVJPMPAZHCY-JYJNAYRXSA-N Val-Val-Phe Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 XNLUVJPMPAZHCY-JYJNAYRXSA-N 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 229930003427 Vitamin E Natural products 0.000 description 1
- 239000005862 Whey Substances 0.000 description 1
- 108010046377 Whey Proteins Proteins 0.000 description 1
- 102000007544 Whey Proteins Human genes 0.000 description 1
- 241000746966 Zizania Species 0.000 description 1
- 235000002636 Zizania aquatica Nutrition 0.000 description 1
- 230000035508 accumulation Effects 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- FKNHDDTXBWMZIR-GEMLJDPKSA-N acetic acid;(2s)-1-[(2r)-2-amino-3-sulfanylpropanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(O)=O.SC[C@H](N)C(=O)N1CCC[C@H]1C(O)=O FKNHDDTXBWMZIR-GEMLJDPKSA-N 0.000 description 1
- 125000002252 acyl group Chemical group 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- TWSWSIQAPQLDBP-UHFFFAOYSA-N adrenic acid Natural products CCCCCC=CCC=CCC=CCC=CCCCCCC(O)=O TWSWSIQAPQLDBP-UHFFFAOYSA-N 0.000 description 1
- 108010045649 agarase Proteins 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 108010005233 alanylglutamic acid Proteins 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 150000001335 aliphatic alkanes Chemical class 0.000 description 1
- 239000003513 alkali Substances 0.000 description 1
- AWUCVROLDVIAJX-UHFFFAOYSA-N alpha-glycerophosphate Natural products OCC(O)COP(O)(O)=O AWUCVROLDVIAJX-UHFFFAOYSA-N 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 229940126575 aminoglycoside Drugs 0.000 description 1
- BIGPRXCJEDHCLP-UHFFFAOYSA-N ammonium bisulfate Chemical compound [NH4+].OS([O-])(=O)=O BIGPRXCJEDHCLP-UHFFFAOYSA-N 0.000 description 1
- 239000000908 ammonium hydroxide Substances 0.000 description 1
- 238000012197 amplification kit Methods 0.000 description 1
- 230000003698 anagen phase Effects 0.000 description 1
- 230000019552 anatomical structure morphogenesis Effects 0.000 description 1
- 125000000129 anionic group Chemical group 0.000 description 1
- 229920006318 anionic polymer Polymers 0.000 description 1
- 230000003466 anti-cipated effect Effects 0.000 description 1
- 229940121363 anti-inflammatory agent Drugs 0.000 description 1
- 239000002260 anti-inflammatory agent Substances 0.000 description 1
- 230000003110 anti-inflammatory effect Effects 0.000 description 1
- 239000003529 anticholesteremic agent Substances 0.000 description 1
- 229940127226 anticholesterol agent Drugs 0.000 description 1
- 229940053200 antiepileptics fatty acid derivative Drugs 0.000 description 1
- 239000000074 antisense oligonucleotide Substances 0.000 description 1
- 238000012230 antisense oligonucleotides Methods 0.000 description 1
- 108010008355 arginyl-glutamine Proteins 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 108010093581 aspartyl-proline Proteins 0.000 description 1
- 108010092854 aspartyllysine Proteins 0.000 description 1
- 208000006673 asthma Diseases 0.000 description 1
- 125000004429 atom Chemical group 0.000 description 1
- 208000010668 atopic eczema Diseases 0.000 description 1
- 235000008452 baby food Nutrition 0.000 description 1
- 235000015241 bacon Nutrition 0.000 description 1
- 230000010310 bacterial transformation Effects 0.000 description 1
- OGBUMNBNEWYMNJ-UHFFFAOYSA-N batilol Chemical class CCCCCCCCCCCCCCCCCCOCC(O)CO OGBUMNBNEWYMNJ-UHFFFAOYSA-N 0.000 description 1
- 235000013527 bean curd Nutrition 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 235000013361 beverage Nutrition 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 235000008429 bread Nutrition 0.000 description 1
- 235000012813 breadcrumbs Nutrition 0.000 description 1
- 235000015496 breakfast cereal Nutrition 0.000 description 1
- 229960001948 caffeine Drugs 0.000 description 1
- 235000012970 cakes Nutrition 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 239000011203 carbon fibre reinforced carbon Substances 0.000 description 1
- 235000014171 carbonated beverage Nutrition 0.000 description 1
- 235000021466 carotenoid Nutrition 0.000 description 1
- 239000012159 carrier gas Substances 0.000 description 1
- 230000006652 catabolic pathway Effects 0.000 description 1
- 238000009903 catalytic hydrogenation reaction Methods 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 239000003518 caustics Substances 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 238000011072 cell harvest Methods 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000030570 cellular localization Effects 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 230000003196 chaotropic effect Effects 0.000 description 1
- 235000015218 chewing gum Nutrition 0.000 description 1
- 229930002875 chlorophyll Natural products 0.000 description 1
- 235000019804 chlorophyll Nutrition 0.000 description 1
- ATNHDLDRLWWWCB-AENOIHSZSA-M chlorophyll a Chemical compound C1([C@@H](C(=O)OC)C(=O)C2=C3C)=C2N2C3=CC(C(CC)=C3C)=[N+]4C3=CC3=C(C=C)C(C)=C5N3[Mg-2]42[N+]2=C1[C@@H](CCC(=O)OC\C=C(/C)CCC[C@H](C)CCC[C@H](C)CCCC(C)C)[C@H](C)C2=C5 ATNHDLDRLWWWCB-AENOIHSZSA-M 0.000 description 1
- 210000003763 chloroplast Anatomy 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 239000013611 chromosomal DNA Substances 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 210000000078 claw Anatomy 0.000 description 1
- 229940110456 cocoa butter Drugs 0.000 description 1
- 235000019868 cocoa butter Nutrition 0.000 description 1
- 235000016213 coffee Nutrition 0.000 description 1
- 235000013353 coffee beverage Nutrition 0.000 description 1
- 235000014156 coffee whiteners Nutrition 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000009833 condensation Methods 0.000 description 1
- 230000005494 condensation Effects 0.000 description 1
- 238000006482 condensation reaction Methods 0.000 description 1
- 235000020186 condensed milk Nutrition 0.000 description 1
- 235000019841 confectionery fat Nutrition 0.000 description 1
- 238000001816 cooling Methods 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- 208000029078 coronary artery disease Diseases 0.000 description 1
- 239000006071 cream Substances 0.000 description 1
- 238000002425 crystallisation Methods 0.000 description 1
- 230000008025 crystallization Effects 0.000 description 1
- GICLSALZHXCILJ-UHFFFAOYSA-N ctk5a5089 Chemical compound NCC(O)=O.NCC(O)=O GICLSALZHXCILJ-UHFFFAOYSA-N 0.000 description 1
- 235000014048 cultured milk product Nutrition 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 108010060199 cysteinylproline Proteins 0.000 description 1
- 108010069495 cysteinyltyrosine Proteins 0.000 description 1
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical class NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 1
- GYOZYWVXFNDGLU-XLPZGREQSA-N dTMP Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)C1 GYOZYWVXFNDGLU-XLPZGREQSA-N 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 230000018044 dehydration Effects 0.000 description 1
- 238000006297 dehydration reaction Methods 0.000 description 1
- 235000011850 desserts Nutrition 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 206010012601 diabetes mellitus Diseases 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 230000000378 dietary effect Effects 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 102000038379 digestive enzymes Human genes 0.000 description 1
- 108091007734 digestive enzymes Proteins 0.000 description 1
- 239000013024 dilution buffer Substances 0.000 description 1
- 108010054813 diprotin B Proteins 0.000 description 1
- 150000002016 disaccharides Chemical class 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- 235000021186 dishes Nutrition 0.000 description 1
- NEKNNCABDXGBEN-UHFFFAOYSA-L disodium;4-(4-chloro-2-methylphenoxy)butanoate;4-(2,4-dichlorophenoxy)butanoate Chemical compound [Na+].[Na+].CC1=CC(Cl)=CC=C1OCCCC([O-])=O.[O-]C(=O)CCCOC1=CC=C(Cl)C=C1Cl NEKNNCABDXGBEN-UHFFFAOYSA-L 0.000 description 1
- ZDXLFJGIPWQALB-UHFFFAOYSA-M disodium;oxido(oxo)borane;chlorate Chemical compound [Na+].[Na+].[O-]B=O.[O-]Cl(=O)=O ZDXLFJGIPWQALB-UHFFFAOYSA-M 0.000 description 1
- CVCXSNONTRFSEH-UHFFFAOYSA-N docosa-2,4-dienoic acid Chemical compound CCCCCCCCCCCCCCCCCC=CC=CC(O)=O CVCXSNONTRFSEH-UHFFFAOYSA-N 0.000 description 1
- 235000012489 doughnuts Nutrition 0.000 description 1
- 238000011143 downstream manufacturing Methods 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 238000001035 drying Methods 0.000 description 1
- 230000008143 early embryonic development Effects 0.000 description 1
- 230000002526 effect on cardiovascular system Effects 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 230000013020 embryo development Effects 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 230000009483 enzymatic pathway Effects 0.000 description 1
- KAQKFAOMNZTLHT-VVUHWYTRSA-N epoprostenol Chemical compound O1C(=CCCCC(O)=O)C[C@@H]2[C@@H](/C=C/[C@@H](O)CCCCC)[C@H](O)C[C@@H]21 KAQKFAOMNZTLHT-VVUHWYTRSA-N 0.000 description 1
- 229960001123 epoprostenol Drugs 0.000 description 1
- UNXHWFMMPAWVPI-ZXZARUISSA-N erythritol Chemical compound OC[C@H](O)[C@H](O)CO UNXHWFMMPAWVPI-ZXZARUISSA-N 0.000 description 1
- 229940009714 erythritol Drugs 0.000 description 1
- 235000019414 erythritol Nutrition 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 150000002190 fatty acyls Chemical group 0.000 description 1
- 238000011049 filling Methods 0.000 description 1
- 235000019688 fish Nutrition 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- 235000019634 flavors Nutrition 0.000 description 1
- 235000013312 flour Nutrition 0.000 description 1
- 230000004907 flux Effects 0.000 description 1
- 238000005194 fractionation Methods 0.000 description 1
- 235000013611 frozen food Nutrition 0.000 description 1
- 235000015203 fruit juice Nutrition 0.000 description 1
- 235000013376 functional food Nutrition 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- 229940098330 gamma linoleic acid Drugs 0.000 description 1
- 229940044627 gamma-interferon Drugs 0.000 description 1
- WIGCFUFOHFEKBI-UHFFFAOYSA-N gamma-tocopherol Natural products CC(C)CCCC(C)CCCC(C)CCCC1CCC2C(C)C(O)C(C)C(C)C2O1 WIGCFUFOHFEKBI-UHFFFAOYSA-N 0.000 description 1
- 229960002733 gamolenic acid Drugs 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 239000007897 gelcap Substances 0.000 description 1
- 230000030279 gene silencing Effects 0.000 description 1
- 230000004077 genetic alteration Effects 0.000 description 1
- 231100000118 genetic alteration Toxicity 0.000 description 1
- 238000003205 genotyping method Methods 0.000 description 1
- 239000012869 germination medium Substances 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 1
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 1
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 1
- 108010081551 glycylphenylalanine Proteins 0.000 description 1
- 108010084389 glycyltryptophan Proteins 0.000 description 1
- PJJJBBJSCAKJQF-UHFFFAOYSA-N guanidinium chloride Chemical compound [Cl-].NC(N)=[NH2+] PJJJBBJSCAKJQF-UHFFFAOYSA-N 0.000 description 1
- ZJYYHGLJYGJLLN-UHFFFAOYSA-N guanidinium thiocyanate Chemical compound SC#N.NC(N)=N ZJYYHGLJYGJLLN-UHFFFAOYSA-N 0.000 description 1
- 229940029575 guanosine Drugs 0.000 description 1
- RQFCJASXJCIDSX-UUOKFMHZSA-N guanosine 5'-monophosphate Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@H]1O RQFCJASXJCIDSX-UUOKFMHZSA-N 0.000 description 1
- 150000004820 halides Chemical class 0.000 description 1
- JYDNQSLNPKOEII-CFYXSCKTSA-N hexadec-9-enoic acid;(z)-hexadec-9-enoic acid Chemical compound CCCCCCC=CCCCCCCCC(O)=O.CCCCCC\C=C/CCCCCCCC(O)=O JYDNQSLNPKOEII-CFYXSCKTSA-N 0.000 description 1
- RMMMJEMNGXIIPT-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O.CCCCCCCCCCCCCCCC(O)=O.CCCCCCCCCCCCCCCC(O)=O RMMMJEMNGXIIPT-UHFFFAOYSA-N 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 108010036413 histidylglycine Proteins 0.000 description 1
- 108010085325 histidylproline Proteins 0.000 description 1
- 238000000265 homogenisation Methods 0.000 description 1
- 238000002744 homologous recombination Methods 0.000 description 1
- 230000006801 homologous recombination Effects 0.000 description 1
- 235000019692 hotdogs Nutrition 0.000 description 1
- 101150047832 hpt gene Proteins 0.000 description 1
- 230000000887 hydrating effect Effects 0.000 description 1
- 229930195733 hydrocarbon Natural products 0.000 description 1
- 150000002430 hydrocarbons Chemical class 0.000 description 1
- 125000001165 hydrophobic group Chemical group 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- GRRNUXAQVGOGFE-NZSRVPFOSA-N hygromycin B Chemical compound O[C@@H]1[C@@H](NC)C[C@@H](N)[C@H](O)[C@H]1O[C@H]1[C@H]2O[C@@]3([C@@H]([C@@H](O)[C@@H](O)[C@@H](C(N)CO)O3)O)O[C@H]2[C@@H](O)[C@@H](CO)O1 GRRNUXAQVGOGFE-NZSRVPFOSA-N 0.000 description 1
- 229940097277 hygromycin b Drugs 0.000 description 1
- 235000015243 ice cream Nutrition 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 229960000367 inositol Drugs 0.000 description 1
- CDAISMWEOUEBRE-GPIVLXJGSA-N inositol Chemical compound O[C@H]1[C@H](O)[C@@H](O)[C@H](O)[C@H](O)[C@@H]1O CDAISMWEOUEBRE-GPIVLXJGSA-N 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 230000006525 intracellular process Effects 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 229910052742 iron Inorganic materials 0.000 description 1
- 108010027338 isoleucylcysteine Proteins 0.000 description 1
- 235000015110 jellies Nutrition 0.000 description 1
- 239000008274 jelly Substances 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 238000011005 laboratory method Methods 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 150000002617 leukotrienes Chemical class 0.000 description 1
- KQQKGWQCNNTQJW-UHFFFAOYSA-N linolenic acid Natural products CC=CCCC=CCC=CCCCCCCCC(O)=O KQQKGWQCNNTQJW-UHFFFAOYSA-N 0.000 description 1
- 235000019421 lipase Nutrition 0.000 description 1
- 230000006372 lipid accumulation Effects 0.000 description 1
- 235000014666 liquid concentrate Nutrition 0.000 description 1
- 150000004668 long chain fatty acids Chemical class 0.000 description 1
- 235000010598 long-chain omega-6 fatty acid Nutrition 0.000 description 1
- 108010003700 lysyl aspartic acid Proteins 0.000 description 1
- 108010009298 lysylglutamic acid Proteins 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- UEGPKNKPLBYCNK-UHFFFAOYSA-L magnesium acetate Chemical compound [Mg+2].CC([O-])=O.CC([O-])=O UEGPKNKPLBYCNK-UHFFFAOYSA-L 0.000 description 1
- 239000011654 magnesium acetate Substances 0.000 description 1
- 235000011285 magnesium acetate Nutrition 0.000 description 1
- 229940069446 magnesium acetate Drugs 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- WSFSSNUMVMOOMR-NJFSPNSNSA-N methanone Chemical compound O=[14CH2] WSFSSNUMVMOOMR-NJFSPNSNSA-N 0.000 description 1
- 150000004702 methyl esters Chemical class 0.000 description 1
- 238000009629 microbiological culture Methods 0.000 description 1
- 235000019713 millet Nutrition 0.000 description 1
- 210000003470 mitochondria Anatomy 0.000 description 1
- 235000013379 molasses Nutrition 0.000 description 1
- 239000006082 mold release agent Substances 0.000 description 1
- 150000004712 monophosphates Chemical group 0.000 description 1
- 150000002772 monosaccharides Chemical class 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 231100000299 mutagenicity Toxicity 0.000 description 1
- 230000007886 mutagenicity Effects 0.000 description 1
- WQEPLUUGTLDZJY-UHFFFAOYSA-N n-Pentadecanoic acid Natural products CCCCCCCCCCCCCCC(O)=O WQEPLUUGTLDZJY-UHFFFAOYSA-N 0.000 description 1
- 229910052759 nickel Inorganic materials 0.000 description 1
- 229960003512 nicotinic acid Drugs 0.000 description 1
- 235000001968 nicotinic acid Nutrition 0.000 description 1
- 239000011664 nicotinic acid Substances 0.000 description 1
- RQFLGKYCYMMRMC-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O.CCCCCCCCCCCCCCCCCC(O)=O RQFLGKYCYMMRMC-UHFFFAOYSA-N 0.000 description 1
- 235000014593 oils and fats Nutrition 0.000 description 1
- 150000002889 oleic acids Chemical class 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 229920001542 oligosaccharide Polymers 0.000 description 1
- 150000002482 oligosaccharides Chemical class 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 239000003960 organic solvent Substances 0.000 description 1
- KYOBSHFOBAOFBF-ZAKLUEHWSA-N orotidine-5'-monophosphate Chemical compound O[C@@H]1[C@@H](O)[C@H](COP(O)(O)=O)O[C@H]1N1C(=O)NC(=O)C=C1C(O)=O KYOBSHFOBAOFBF-ZAKLUEHWSA-N 0.000 description 1
- 230000001590 oxidative effect Effects 0.000 description 1
- 230000003071 parasitic effect Effects 0.000 description 1
- 235000012162 pavlova Nutrition 0.000 description 1
- 235000020232 peanut Nutrition 0.000 description 1
- 239000012466 permeate Substances 0.000 description 1
- 239000008194 pharmaceutical composition Substances 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 108010072637 phenylalanyl-arginyl-phenylalanine Proteins 0.000 description 1
- 108010084525 phenylalanyl-phenylalanyl-glycine Proteins 0.000 description 1
- 108010018625 phenylalanylarginine Proteins 0.000 description 1
- 108010012581 phenylalanylglutamate Proteins 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 230000008635 plant growth Effects 0.000 description 1
- 210000002381 plasma Anatomy 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 210000002706 plastid Anatomy 0.000 description 1
- 239000003495 polar organic solvent Substances 0.000 description 1
- 230000010152 pollination Effects 0.000 description 1
- 239000005014 poly(hydroxyalkanoate) Substances 0.000 description 1
- 229920000058 polyacrylate Polymers 0.000 description 1
- 229920000903 polyhydroxyalkanoate Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 230000001124 posttranscriptional effect Effects 0.000 description 1
- 235000011056 potassium acetate Nutrition 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 230000019525 primary metabolic process Effects 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 108010031719 prolyl-serine Proteins 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- QAQREVBBADEHPA-IEXPHMLFSA-N propionyl-CoA Chemical compound O[C@@H]1[C@H](OP(O)(O)=O)[C@@H](COP(O)(=O)OP(O)(=O)OCC(C)(C)[C@@H](O)C(=O)NCCC(=O)NCCSC(=O)CC)O[C@H]1N1C2=NC=NC(N)=C2N=C1 QAQREVBBADEHPA-IEXPHMLFSA-N 0.000 description 1
- 150000003180 prostaglandins Chemical class 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 235000011962 puddings Nutrition 0.000 description 1
- 239000012264 purified product Substances 0.000 description 1
- 235000019171 pyridoxine hydrochloride Nutrition 0.000 description 1
- 239000011764 pyridoxine hydrochloride Substances 0.000 description 1
- 229940107700 pyruvic acid Drugs 0.000 description 1
- 238000000163 radioactive labelling Methods 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 230000001850 reproductive effect Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 108091092562 ribozyme Proteins 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 238000005096 rolling process Methods 0.000 description 1
- 229910052701 rubidium Inorganic materials 0.000 description 1
- IGLNJRXAVVLDKE-UHFFFAOYSA-N rubidium atom Chemical compound [Rb] IGLNJRXAVVLDKE-UHFFFAOYSA-N 0.000 description 1
- 238000007127 saponification reaction Methods 0.000 description 1
- 235000015067 sauces Nutrition 0.000 description 1
- CDAISMWEOUEBRE-UHFFFAOYSA-N scyllo-inosotol Natural products OC1C(O)C(O)C(O)C(O)C1O CDAISMWEOUEBRE-UHFFFAOYSA-N 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 230000005562 seed maturation Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 230000001568 sexual effect Effects 0.000 description 1
- 235000015170 shellfish Nutrition 0.000 description 1
- 150000004666 short chain fatty acids Chemical class 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 235000020183 skimmed milk Nutrition 0.000 description 1
- 210000000813 small intestine Anatomy 0.000 description 1
- AWUCVROLDVIAJX-GSVOUGTGSA-N sn-glycerol 3-phosphate Chemical compound OC[C@@H](O)COP(O)(O)=O AWUCVROLDVIAJX-GSVOUGTGSA-N 0.000 description 1
- 239000001632 sodium acetate Substances 0.000 description 1
- 235000017281 sodium acetate Nutrition 0.000 description 1
- SUKJFIGYRHOWBL-UHFFFAOYSA-N sodium hypochlorite Chemical compound [Na+].Cl[O-] SUKJFIGYRHOWBL-UHFFFAOYSA-N 0.000 description 1
- 229910001415 sodium ion Inorganic materials 0.000 description 1
- BAZAXWOYCMUHIX-UHFFFAOYSA-M sodium perchlorate Chemical compound [Na+].[O-]Cl(=O)(=O)=O BAZAXWOYCMUHIX-UHFFFAOYSA-M 0.000 description 1
- 229910001488 sodium perchlorate Inorganic materials 0.000 description 1
- VGTPCRGMBIAPIM-UHFFFAOYSA-M sodium thiocyanate Chemical compound [Na+].[S-]C#N VGTPCRGMBIAPIM-UHFFFAOYSA-M 0.000 description 1
- 235000002316 solid fats Nutrition 0.000 description 1
- 238000007711 solidification Methods 0.000 description 1
- 230000008023 solidification Effects 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 238000000638 solvent extraction Methods 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 235000021262 sour milk Nutrition 0.000 description 1
- 235000013322 soy milk Nutrition 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 238000001256 steam distillation Methods 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 150000005846 sugar alcohols Chemical class 0.000 description 1
- 235000021092 sugar substitutes Nutrition 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 229910021653 sulphate ion Inorganic materials 0.000 description 1
- 238000000194 supercritical-fluid extraction Methods 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- ZTUXEFFFLOVXQE-UHFFFAOYSA-N tetradecanoic acid Chemical compound CCCCCCCCCCCCCC(O)=O.CCCCCCCCCCCCCC(O)=O ZTUXEFFFLOVXQE-UHFFFAOYSA-N 0.000 description 1
- 235000019157 thiamine Nutrition 0.000 description 1
- KYMBYSLLVAOCFI-UHFFFAOYSA-N thiamine Chemical compound CC1=C(CCO)SCN1CC1=CN=C(C)N=C1N KYMBYSLLVAOCFI-UHFFFAOYSA-N 0.000 description 1
- 229960003495 thiamine Drugs 0.000 description 1
- 239000011721 thiamine Substances 0.000 description 1
- 108010061238 threonyl-glycine Proteins 0.000 description 1
- 210000001541 thymus gland Anatomy 0.000 description 1
- 230000009772 tissue formation Effects 0.000 description 1
- 230000017423 tissue regeneration Effects 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 230000010474 transient expression Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- UFTFJSFQGQCHQW-UHFFFAOYSA-N triformin Chemical compound O=COCC(OC=O)COC=O UFTFJSFQGQCHQW-UHFFFAOYSA-N 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
- RYYVLZVUVIJVGH-UHFFFAOYSA-N trimethylxanthine Natural products CN1C(=O)N(C)C(=O)C2=C1N=CN2C RYYVLZVUVIJVGH-UHFFFAOYSA-N 0.000 description 1
- PIEPQKCYPFFYMG-UHFFFAOYSA-N tris acetate Chemical compound CC(O)=O.OCC(N)(CO)CO PIEPQKCYPFFYMG-UHFFFAOYSA-N 0.000 description 1
- HRXKRNGNAMMEHJ-UHFFFAOYSA-K trisodium citrate Chemical compound [Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O HRXKRNGNAMMEHJ-UHFFFAOYSA-K 0.000 description 1
- 229940038773 trisodium citrate Drugs 0.000 description 1
- 239000002753 trypsin inhibitor Substances 0.000 description 1
- 108010058119 tryptophyl-glycyl-glycine Proteins 0.000 description 1
- 108010029384 tryptophyl-histidine Proteins 0.000 description 1
- 108010084932 tryptophyl-proline Proteins 0.000 description 1
- 108010038745 tryptophylglycine Proteins 0.000 description 1
- 108010020532 tyrosyl-proline Proteins 0.000 description 1
- 235000013311 vegetables Nutrition 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 235000019156 vitamin B Nutrition 0.000 description 1
- 239000011720 vitamin B Substances 0.000 description 1
- 235000019165 vitamin E Nutrition 0.000 description 1
- 239000011709 vitamin E Substances 0.000 description 1
- 229940046009 vitamin E Drugs 0.000 description 1
- 229940011671 vitamin b6 Drugs 0.000 description 1
- 239000003039 volatile agent Substances 0.000 description 1
- 235000020985 whole grains Nutrition 0.000 description 1
- 235000008939 whole milk Nutrition 0.000 description 1
- 238000004804 winding Methods 0.000 description 1
- 239000002023 wood Substances 0.000 description 1
- 235000013618 yogurt Nutrition 0.000 description 1
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 1
Images
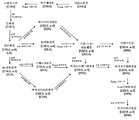















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8241—Phenotypically and genetically modified plants via recombinant DNA technology
- C12N15/8242—Phenotypically and genetically modified plants via recombinant DNA technology with non-agronomic quality (output) traits, e.g. for industrial processing; Value added, non-agronomic traits
- C12N15/8243—Phenotypically and genetically modified plants via recombinant DNA technology with non-agronomic quality (output) traits, e.g. for industrial processing; Value added, non-agronomic traits involving biosynthetic or metabolic pathways, i.e. metabolic engineering, e.g. nicotine, caffeine
- C12N15/8247—Phenotypically and genetically modified plants via recombinant DNA technology with non-agronomic quality (output) traits, e.g. for industrial processing; Value added, non-agronomic traits involving biosynthetic or metabolic pathways, i.e. metabolic engineering, e.g. nicotine, caffeine involving modified lipid metabolism, e.g. seed oil composition
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11B—PRODUCING, e.g. BY PRESSING RAW MATERIALS OR BY EXTRACTION FROM WASTE MATERIALS, REFINING OR PRESERVING FATS, FATTY SUBSTANCES, e.g. LANOLIN, FATTY OILS OR WAXES; ESSENTIAL OILS; PERFUMES
- C11B1/00—Production of fats or fatty oils from raw materials
- C11B1/02—Pretreatment
- C11B1/025—Pretreatment by enzymes or microorganisms, living or dead
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1025—Acyltransferases (2.3)
- C12N9/1029—Acyltransferases (2.3) transferring groups other than amino-acyl groups (2.3.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
- C12P7/6409—Fatty acids
- C12P7/6427—Polyunsaturated fatty acids [PUFA], i.e. having two or more double bonds in their backbone
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
- C12P7/6436—Fatty acid esters
- C12P7/6445—Glycerides
- C12P7/6458—Glycerides by transesterification, e.g. interesterification, ester interchange, alcoholysis or acidolysis
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
- C12P7/6436—Fatty acid esters
- C12P7/6445—Glycerides
- C12P7/6463—Glycerides obtained from glyceride producing microorganisms, e.g. single cell oil
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
- C12P7/6436—Fatty acid esters
- C12P7/6445—Glycerides
- C12P7/6472—Glycerides containing polyunsaturated fatty acid [PUFA] residues, i.e. having two or more double bonds in their backbone
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Oil, Petroleum & Natural Gas (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Cell Biology (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Medicinal Chemistry (AREA)
- Nutrition Science (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Breeding Of Plants And Reproduction By Means Of Culturing (AREA)
- Feed For Specific Animals (AREA)
- Fodder In General (AREA)
- Enzymes And Modification Thereof (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
- Coloring Foods And Improving Nutritive Qualities (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
본 발명은 리놀레산 [18:2, LA]을 에이코사디엔산 [20:2, EDA]으로 전환시키는 능력을 갖는 Δ9 일롱가제에 관한 것이다. Δ9 일롱가제를 코딩하는 단리된 핵산 단편 및 이러한 단편을 포함하는 재조합 구축물 및 이들 Δ9 일롱가제를 사용하여 식물 및 유질 효모에서 장쇄 다중불포화 지방산 (PUFA)을 생성하는 방법이 개시되어 있다.
리놀레산, 에이코사디엔산, Δ9 일롱가제, 핵산 단편, 재조합 구축물, 식물, 유질 효모, 장쇄 다중불포화 지방산, PUFA
Description
본 출원은 2005년 11월 23일자로 출원한 미국 가출원 제60/739,989호의 이점을 청구하며, 상기 문헌의 전문은 본원에 참고로 포함된다.
본 발명은 생명공학 분야에 속한다. 더욱 구체적으로, 본 발명은 Δ9 지방산 일롱가제(elongase) 효소를 코딩하는 핵산 단편의 동정, 및 장쇄 다중불포화 지방산 (PUFA)의 생성에 있어서 이들 일롱가제의 용도에 관한 것이다.
PUFA의 중요성은 명백하다. 예를 들어, 특정 PUFA는 건강한 세포의 중요한 생물학적 성분으로서, 포유동물에서는 드 노보(de novo) 합성될 수 없고 대신에 먹이로 구하거나 리놀레산 (LA, 18:2 ω-6) 또는 α-리놀렌산 (ALA, 18:3 ω-3)의 추가의 탈포화 및 신장에 의해 얻어야 하는 "필수" 지방산이고; 세포 세포질막의 구성성분으로서, 인지질 또는 트리아실글리세롤과 같은 형태로 존재할 수 있고; 적당한 발생 (특히, 유아(infant) 뇌의 발생) 및 조직 형성 및 복구에 필요하며; 포유동물에서 중요한 여러가지 생물학적 활성 에이코사노이드 (예컨대, 프로스타사이클린, 에이코사노이드, 류코트리엔, 프로스타글란딘)의 전구체로 인식된다. 추가로, 장쇄 ω-3 PUFA의 다량 섭취는 심혈관 보호 효과가 있다 ([Dyerberg, J. et al., Amer. J. Clin. Nutr., 28:958-966 (1975)], [Dyerberg, J. et al., Lancet, 2(8081):117-119 (July 15, 1978)], [Shimokawa, H., World Rev. Nutr. Diet, 88:100-108 (2001)], [von Schacky, C. and Dyerberg, J., World Rev. Nutr. Diet, 88:90-99 (2001)]). 수많은 다른 연구는 다양한 증상 및 질환 (예를 들어, 천식, 건선, 습진, 당뇨병, 암)에 대하여 ω-3 및/또는 ω-6 PUFA 투여가 부여하는 광범위한 범위의 건강상의 이익을 증명한다.
오늘날, 식물, 조류(algae), 진균 및 효모를 비롯한 다양한 각종 숙주가 상업적인 PUFA 생성을 위한 수단으로 조사되고 있다. 숙주 유기체의 천연 PUFA-생성 능력은 때때로 주어진 방법에 특이적이지만, 유전자 조작은 또한 몇가지 숙주의 천연 능력 (심지어는, 천연적으로 LA 및 ALA 지방산 생성으로 한정된 것들까지도 포함됨)이 실질적으로 증대되어 각종 장쇄 ω-3/ω-6 PUFA를 높은 수준으로 생성할 수 있다는 것도 입증하였다. 이러한 효과가 천연적인 능력 때문인지 또는 재조합 기술 때문인지간에, 아라키돈산 (ARA, 20:4 ω-6), 에이코사펜타엔산 (EPA, 20:5 ω-3) 및 도코사헥사엔산 (DHA, 22:6 ω-3)의 생성은 모두가 Δ9 일롱가제/Δ8 데새투라제(desaturase) 경로 (몇가지 유기체, 예컨대 녹색편모충 종에서 작용하며, 에이코사디엔산 [EDA, 20:2 ω-6] 및/또는 에이코사트리엔산 [ETrA, 20:3 ω-3]의 생성을 특징으로 함) 또는 Δ6 데새투라제/Δ6 일롱가제 경로 (주로 조류, 이끼류, 진균류, 선충류 및 인간에서 발견되고, 감마-리놀레산 [GLA, 18:3 ω-6] 및/또는 스테아리돈산 [STA, 18:4 ω-3])의 생성을 특징으로 함)의 발현을 필요로 한다 (도 1).
본원에서의 목적상, 본 출원은 Δ9 일롱가제/Δ8 데새투라제 경로의 용도, 더욱 구체적으로는 Δ9 일롱가제 효소의 용도에 초점을 맞춘다. 지금까지 동정된 대부분의 Δ9 일롱가제 효소는 LA를 EDA로 전환시키는 능력과 ALA를 ETrA로 전환시키는 능력을 둘다 보유한다 (여기서, 이후에 EDA 및 ETrA 각각으로부터 DGLA 및 ETA가 합성된 후에 Δ8 데새투라제에 의한 반응이 진행되고, 이후에는 DGLA 및 ETA 각각으로부터 ARA 및 EPA가 합성된 후에 Δ5데새투라제에 의한 반응이 진행되며, DHA 합성에는 추가의 C20 /22 일롱가제 및 Δ4 데새투라제의 추후 발현이 필요함).
ARA, EPA 및 DHA를 생성하는 새로운 방법이 필요함에도 불구하고, Δ9 일롱가제 효소는 거의 동정된 바 없다. 예를 들어, 유일한 1가지 Δ9 일롱가제가 본 출원인의 발명 이전의 최근에 공지되어 있다. 구체적으로, PCT 공개 제WO 2002/077213호, 동 제WO 2005/083093호, 동 제WO 2005/012316호 및 동 제WO 2004/057001호는 이소크리시스 갈바나(Isochrysis galbana)로부터의 Δ9 일롱가제 및 그의 용도 (또한 진뱅크(GenBank) 관리 번호 AAL37626 참조)에 관하여 기재한다. 따라서, ω-3/ω-6 지방산의 생성에 사용하기 위한 다양한 숙주 유기체에서의 이종 발현에 적합한 Δ9 일롱가제를 코딩하는 추가의 유전자를 동정 및 단리할 필요가 있다.
과거에 동정되었던 일롱가제는 작용하는 기질 면에서 상이하다. 이것들은 동물과 식물 모두에 존재한다. 포유동물에서 발견되는 것은 포화, 모노불포화 및 다중불포화 지방산에 작용할 수 있다. 그러나, 식물에서 발견되는 것은 포화 및 모노불포화 지방산에 특이적이다. 따라서, 식물에서 PUFA를 생성하기 위해서는 PUFA-특이적 일롱가제가 필요하다.
식물에서의 신장 과정은 말로네이트 및 지방산이 축합되면서 이산화탄소 분자가 방출되는 중요한 단계에 의해 개시되는 4-단계 과정을 수반한다. 지방산 신장시의 기질은 CoA-티오에스테르이다. 축합 단계는 3-케토아실 신타제에 의해 매개되며, 일반적으로 4개 반응의 전체 주기에서의 속도-제한 단계이고 약간의 기질 특이성을 제공한다. 1회 신장 주기의 생성물은 2개 탄소 원자 만큼 연장된 지방산을 재생한다 ([Browse et al., Trends in Biochemical Sciences, 27(9):467 473 (September 2002)], [Napier, Trends in Plant Sciences, 7(2):51 54 (February 2002)]).
Δ9 일롱가제와 Δ8 데새투라제를 발현하는 것과 관련한 유용성을 기초로 하여, 다양한 공급원으로부터 Δ8 데새투라를 동정하고 특징규명하려는 상당한 노력이 있었다. 지금까지의 대부분의 노력은 유글레나 그라실리스(Euglena gracilis)로부터 Δ8 데새투라제를 단리하고 특징규명하는 것에 초점을 맞추었고, 이. 그라실리스 Δ8 데새투라제의 여러가지 서열 변이가 보고된 바 있다 (예를 들어, [Wallis et al., Arch. Biochem. and Biophys., 365(2):307-316 (May 1999)], PCT 공개 제WO 2000/34439호, 미국 특허 제6,825,017호, PCT 공개 제WO 2004/057001호, 2005년 6월 24일자로 출원한 미국 출원 제11/166,003호 (PCT 공개 제WO 2006/012325호 및 동 제WO 2006/012326호, 2006년 2월 2일 공개) 참조). 보다 최 근에는, PCT 공개 제WO 2005/103253호 (2005년 4월 22일 공개)가 파블로바 살리나(Pavlova salina)의 Δ8 데새투라제 효소에 대한 아미노산 및 핵산 서열을 개시하였다. 문헌 [Sayanova et al., FEBS Lett., 580:1946-1952 (2006)]은 자유롭게 살아있는 토양 아메바인 아칸트아메바 카스텔라니이(Acanthamoeba castellanii)로부터 아라비돕시스(Arabidopsis)에서 발현되면 C20 Δ8 데새투라제를 코딩하는 cDNA를 단리하고 특징규명한 것에 대하여 기재하였다. 또한, 본원과 공동 명의이고 본원과 동시 계류 중인 출원인 가출원 제60/795810호 (2006년 4월 28일자 출원)는 파블로바 루테리(Pavlova lutheri) (CCMP459)로부터의 Δ8 데새투라제 효소에 대한 아미노산 및 핵산 서열을 개시하였고, 본원과 공동 명의이고 본원과 동시 계류 중인 출원인, 2006년 10월 23일자로 출원한 미국 가출원 제60/853563호는 녹색편모충인 테트루에트레프티아 폼퀘텐시스(Tetruetreptia pomquetensis) CCMP1491, 유트레프티엘라(Eutreptiella) 종 CCMP389 및 유트레프티엘라 짐나스티카(Eutreptiella cf_gymnastica) CCMP1594로부터의 Δ8 데새투라제를 개시하였다.
본원과 공동 명의의 하기 특허 출원서는 유질(oleaginous) 효모 (즉, 야로위아 리폴리티카(Yarrowia lipolytica)) 중에서의 PUFA 생성에 관한 것이다: PCT 공개 제WO 2004/101757호 및 PCT 공개 제WO 2004/101753호 (둘다 2004년 11월 25일자로 공개됨), 미국 출원 제11/265,761호 (2005년 11월 2일자 출원. PCT 공개 제WO 2006/052870호에 상응함), 미국 출원 제11/264,784호 (2005년 11월 1일자 출원. PCT 공개 제WO 2006/055322호에 상응함), 및 미국 출원 제11/264,737호 (2005년 11 월 1일자 출원. PCT 공개 제WO 2006/052871호에 상응함) 등.
추가로, PCT 공개 제WO 2004/071467호 (2004년 8월 26일자로 공개됨)는 식물에서의 PUFA 생성에 관한 것이며, PCT 공개 제WO 2004/071178호 (2004년 8월 26일자로 공개됨)는 안넥신 프로모터, 및 식물에서의 트랜스진(transgene) 발현에 있어서의 이들의 용도에 관한 것으로, 이들 2가지 모두가 본원과 공동 명의이며 동시 계류 중이다.
본 출원인은 유글레나 그라실리스 및 유트레프티엘라 종 CCMP389로부터 Δ9 일롱가제를 코딩하는 유전자를 단리함으로써 상술한 문제를 해결하였다.
발명의 요약
본 발명은 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 신규한 유전자 구축물, 및 식물, 조류, 박테리아, 효모 및 진균에서의 PUFA 생성을 위한 이들의 용도에 관한 것이다.
따라서, 본 발명은
(a) 클러스탈 브이(Clustal V) 정렬 방법을 기초로 하여 서열 2 또는 서열 5에 기재된 바와 같은 아미노산 서열과 비교할 때 70% 이상의 아미노산 동일성을 가지며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열,
(b) BLASTN 정렬 방법을 기초로 하여 서열 1, 서열 3, 서열 4 또는 서열 6에 기재된 바와 같은 뉴클레오티드 서열과 비교할 때 70% 이상의 서열 동일성을 가지며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하 는 단리된 핵산 서열,
(c) 0.1× SSC, 0.1% SDS 중 65℃에서의 혼성화 및 2× SSC, 0.1% SDS를 사용한 세척 및 이후 0.1× SSC, 0.1% SDS를 사용한 세척의 엄격한 혼성화 조건하에서 서열 1, 서열 3, 서열 4 또는 서열 6에 기재된 바와 같은 뉴클레오티드 서열과 혼성화하며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열, 또는
(d) 상기 (a), (b) 또는 (c)의 뉴클레오티드 서열과 동일한 수의 뉴클레오티드로 이루어지며 100% 상보적인, 상기 (a), (b) 또는 (c)의 뉴클레오티드 서열의 상보체
로 구성된 군에서 선택된 단리된 폴리뉴클레오티드를 제공한다.
추가로, 본 발명은 본 발명의 단리된 핵산 서열에 의해 코딩되는 폴리펩티드를 제공한다. 구체적으로, 본 발명은 아미노산 서열이
(a) 서열 2 또는 서열 5에 기재된 바와 같은 아미노산 서열, 및
(b) 1개 이상의 보존적 아미노산 치환으로 인해 상기 (a)에서의 아미노산 서열과 상이한 아미노산 서열
로 구성된 군에서 선택된 Δ9 일롱가제 폴리펩티드를 제공한다.
또다른 실시양태에서, 본 발명은 본 발명의 단리된 핵산 서열로 형질전환된 숙주 세포를 제공하며, 바람직한 숙주 세포는 예를 들어 조류, 박테리아, 효모, 난균 및 진균과 같은 미생물 종이다.
또다른 실시양태에서, 본 발명은
a) i) (1) 클러스탈 브이 정렬 방법을 기초로 하여 서열 2 또는 서열 5에 기재된 바와 같은 아미노산 서열과 비교할 때 70% 이상의 아미노산 동일성을 가지며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열, 및
(2) 0.1× SSC, 0.1% SDS 중 65℃에서의 혼성화 및 2× SSC, 0.1% SDS를 사용한 세척 및 이후 0.1× SSC, 0.1% SDS를 사용한 세척의 엄격한 혼성화 조건하에서 서열 1, 서열 3, 서열 4 또는 서열 6에 기재된 바와 같은 뉴클레오티드 서열과 혼성화하며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열
로 구성된 군에서 선택된, Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 단리된 폴리뉴클레오티드 서열, 및
(ii) 리놀레산의 공급원
을 포함하는 단리된 형질전환된 효모 숙주 세포를 제공하는 단계,
b) Δ9 일롱가제 폴리펩티드를 코딩하는 핵산 서열이 발현되고 리놀레산이 에이코사디엔산으로 전환되는 조건하에서 상기 단계 (a)의 효모 숙주 세포를 성장시키는 단계, 및
c) 임의로, 상기 단계 (b)의 에이코사디엔산을 회수하는 단계
를 포함하는, 에이코사디엔산의 생성 방법을 제공한다.
별법의 실시양태에서, 본 발명은
a) i) (1) 클러스탈 브이 정렬 방법을 기초로 하여 서열 2 또는 서열 5에 기 재된 바와 같은 아미노산 서열과 비교할 때 70% 이상의 아미노산 동일성을 가지며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열, 및
(2) 0.1× SSC, 0.1% SDS 중 65℃에서의 혼성화 및 2× SSC, 0.1% SDS를 사용한 세척 및 이후 0.1× SSC, 0.1% SDS를 사용한 세척의 엄격한 혼성화 조건하에서 서열 1, 서열 3, 서열 4 또는 서열 6에 기재된 바와 같은 뉴클레오티드 서열과 혼성화하며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열
로 구성된 군에서 선택된, Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 단리된 폴리뉴클레오티드 서열, 및
(ii) α-리놀렌산의 공급원
을 포함하는 단리된 형질전환된 효모 숙주 세포를 제공하는 단계,
b) Δ9 일롱가제 폴리펩티드를 코딩하는 핵산 서열이 발현되고 α-리놀렌산이 에이코사트리엔산으로 전환되는 조건하에서 상기 단계 (a)의 숙주 세포를 성장시키는 단계, 및
c) 임의로, 상기 단계 (b)의 에이코사트리엔산을 회수하는 단계
를 포함하는, 에이코사트리엔산의 생성 방법을 제공한다.
또다른 실시양태에서, 본 발명은 본 발명의 형질전환된 숙주에 의해 생성된 미생물 오일을 제공한다.
별개의 실시양태에서, 본 발명은 본 발명의 미생물 오일을 포함하는 식품을 제공한다.
또다른 실시양태에서, 본 발명은 본 발명의 오일을 포함하는 동물 사료를 제공한다.
생물학적 기탁
하기하는 플라스미드는 미국 20110-2209 버지니아주 만나사스 유니버시티 불러버드 10801에 소재하는 아메리칸 타입 컬쳐 콜렉션(American Type Culture Collection, ATCC)에 기탁되었고, 다음과 같은 명칭, 관리 번호 및 기탁일을 갖는다 (표 1):
| ATCC 기탁물 | ||
| 플라스미드 | 관리 번호 | 기탁일 |
| pKR72 | PTA-6019 | 2004년 5월 28일 |
| pKR275 | PTA-4989 | 2003년 1월 30일 |
| pKR585 | PTA-6279 | 2004년 11월 4일 |
| pKR578 | PTA-6280 | 2004년 11월 4일 |
도면의 간단한 설명 및 서열 기재
도 1은 미리스트산이 각종 중간체를 거쳐 DHA로 전환되는 ω-3/ω-6 지방산 생합성 경로를 예시한다.
도 2는 본 발명의 유글레나 그라실리스 Δ9 일롱가제의 아미노산 서열 (서열 2), 본 발명의 유트레프티엘라 종 CCMP389 Δ9 일롱가제의 아미노산 서열 (서열 5), 및 이소크리시스 갈바나 (NCBI 관리 번호: AAL37626 (GI 17226123))로부터의 장쇄 PUFA 신장 효소의 아미노산 서열 (서열 8)의 클러스탈 브이 정렬 (디폴트 파라미터 포함)을 보여준다.
도 3은 유글레나 그라실리스 세포 추출물의 지질 프로파일 크로마토그램을 보여준다 (실시예 1).
도 4는 본 발명의 유글레나 그라실리스 Δ9 일롱가제의 아미노산 서열 (서열 2), 및 이소크리시스 갈바나 (NCBI 관리 번호: AAL37626 (GI 17226123))로부터의 장쇄 PUFA 신장 효소의 아미노산 서열 (서열 8)의 클러스탈 브이 정렬 (디폴트 파라미터 포함)을 보여준다.
도 5는 플라스미드 pY119의 맵이다.
도 6은 사카로마이세스 세레비지애(Saccharomyces cerevisiae) 중 유글레나 그라실리스 Δ9 일롱가제 (EgD9e)의 기능적 분석에 대한 결과이다.
도 7A는 플라스미드 pY5-30의 맵이고, 도 7B는 플라스미드 pDMW263의 맵이며, 도 7C는 pZUF17의 플라스미드 맵이다.
도 8은 플라스미드 pY115의 맵이다.
도 9A는 야로위아 리폴리티카 게이트웨이(Gateway)® 데스티네이션 벡터(destination vector) pBY1의 맵이고, 도 9B는 플라스미드 pBY2의 맵이며, 도 9C는 플라스미드 pBY1-FAE의 맵이다.
도 10은 유글레나 그라실리스 Δ9 일롱가제 유전자의 DNA 서열 (EgD9e, 서열 1)과 야로위아 리폴리티카 중에서의 발현을 위해 코돈-최적화된 합성 유전자의 DNA 서열 (EgD9eS, 서열 3) 사이의 비교를 보여준다.
도 11A는 플라스미드 pY120의 맵이며, 도11B는 플라스미드 pKR912의 맵이다.
도 12A는 플라스미드 pKR911의 맵이며, 도 12B는 플라스미드 pKR913의 맵이다.
도 13A는 플라스미드 pKR886의 맵이며, 도 13B는 플라스미드 pKR886r의 맵이다.
도 14A는 플라스미드 pKR669의 맵이며, 도 14B는 플라스미드 pKR873의 맵이다.
도 15A는 pFBAIN-389Elo의 플라스미드 맵이며, 도 15B는 pZUFE389S의 플라스미드 맵이다.
도 16은 유트레프티엘라 종 CCMP389 Δ9 일롱가제 유전자의 DNA 서열 (E389D9e, 서열 4)과 야로위아 리폴리티카 중에서의 발현을 위해 코돈-최적화된 합성 유전자의 DNA 서열 (E389D9eS, 서열 6) 사이의 비교를 보여준다.
본 발명은 하기하는 발명의 상세한 설명 및 첨부하는 도면 및 서열 목록으로부터 보다 완벽하게 이해될 수 있으며, 이러한 기재는 본 출원서의 일부를 구성한다.
하기 서열은 37 C.F.R. §1.821 내지 1.825 ("뉴클레오티드 서열 및/또는 아미노산 서열 기재를 포함하는 특허 출원에 대한 요건 - 서열 규칙")에 따르며, 세계 지적 재산권 기구 (WIPO) 기준 ST.25 (1998) 및 EPO 및 PCT의 서열 목록 요건 (규칙 5.2 및 49.5(a-bis), 및 시행세칙의 제208항 및 부록 C)에 부합한다. 뉴클레오티드 및 아미노산 서열 데이타에 사용된 부호 및 포맷은 37 C.F.R. §1.822에 기재된 규칙에 따른다.
서열 목록에 대한 언급
서열 1 내지 서열 17, 서열 21, 서열 22, 서열 45 내지 서열 48, 서열 51 내지 서열 61, 서열 68 내지 서열 71, 서열 76 내지 서열 79, 서열 81 내지 서열 93, 서열 96 내지 서열 102 및 서열 118 내지 서열 129는 하기 표 2에 나타낸 바와 같이 유전자 또는 단백질 (또는 그의 일부)을 코딩하는 ORF 또는 플라스미드이다:




서열 18은 유글레나 그라실리스 cDNA 라이브러리 eeg1c의 서열분석에 사용된 M13F 범용 프라이머(universal primer)이다.
서열 19 및 서열 20은 클론 eeg1c.pk001.n5.f로부터의 EgD9e 증폭에 사용된 프라이머 oEugEL1-1 및 oEugEL1-2 각각에 상응한다.
서열 23 내지 서열 38은 IgD9eS의 증폭에 사용된 프라이머 IL3-1A, IL3-1B, IL3-2A, IL3-2B, IL3-3A, IL3-3B, IL3-4A, IL3-4B, IL3-5A, IL3-5B, IL3-6A, IL3-6B, IL3-7A, IL3-7B, IL3-8A 및 IL3-8B 각각에 상응한다.
서열 39 내지 서열 42는 IgD9eS의 증폭에 사용된 프라이머 IL3-1F, IL3-4R, IL3-5F 및 IL3-8R 각각에 상응한다.
서열 43은 pT9(1-4)로부터의 417 bp NcoI/PstI 단편이다.
서열 44는 pT9(5-8)로부터의 377 bp PstI/NotI 단편이다.
서열 49 및 서열 50은 벡터 pY115로부터의 IgD9eS 증폭에 사용된 프라이머 프라이머 ig-s 및 ig-as 각각에 상응한다.
서열 62 및 서열 63은 cDNA로부터의 EgD8 증폭에 사용된 프라이머 Eg5-1 및 Eg3-3 각각에 상응한다.
서열 64 내지 서열 67은 EgD8의 서열분석에 사용된 프라이머 T7, M13-28Rev, Eg3-2 및 Eg5-2 각각에 상응한다.
서열 72는 pKR457에 대한 KTi 카세트 5'-말단 다중 클로닝 부위 (MCS)의 서열이다.
서열 73은 콩 알부민 전사 3' 종결자를 포함하는, pKR457에 대한 KTi 카세트 3'-말단 다중 클로닝 부위 (MCS)의 서열이다.
서열 74 및 서열 75는 콩 게놈 DNA로부터의 콩 알부민 전사 종결자 증폭에 사용된 프라이머 oSalb-12 및 oSalb-13 각각에 상응한다.
서열 80은 pKR767 생성을 위해 pKR287에 부가된 제한 부위에 상응한다.
서열 94 및 서열 95는 pKR160의 제작 동안 제한 부위의 생성에 사용된 프라이머 oSAlb-9 및 oSAlb-2 각각에 상응한다.
서열 103 내지 서열 105는 유트레프티엘라 종 CCMP389의 cDNA 합성에 사용된 스마트(SMART)™ IV 올리고뉴클레오티드 프라이머, CDSIII/3' PCR 프라이머 및 5'-PCR 프라이머 각각에 상응한다.
서열 106은 서열 107에 기재된 펩티드를 코딩하는 동의성(degenerate) 프라이머 EuEF3의 뉴클레오티드 서열이다. 유사하게, 서열 108은 서열 109에 기재된 펩티드를 코딩하는 동의성 프라이머 EuER3의 뉴클레오티드 서열이다.
서열 110 내지 서열 113은 E389D9e를 코딩하는 cDNA의 5'-말단 PCR 증폭에 사용된 프라이머 389Elo-5-1, 389Elo-5-2, DNR CDS 5'-2 및 389Elo-5-4 각각에 상응한다.
서열 114 및 서열 115는 E389D9를 코딩하는 cDNA의 3'-말단 PCR 증폭에 사용된 프라이머 389Elo-3-1 및 389Elo-3-2 각각에 상응한다.
서열 116 및 서열 117은 E389D9e를 코딩하는 전장 cDNA의 증폭에 사용된 프라이머 389ELO-F 및 389ELO-R1 각각에 상응한다.
본원에서 언급한 모든 특허, 특허 출원 및 공개공보는 그 전문이 본원에 참고로 포함된다. 구체적으로, 여기에는 하기하는 본원과 동시 명의의 동시 계류 중인 출원들이 포함된다: 미국 특허 출원 제10/840478호, 동 제10/840579호 및 동 제10/840325호 (2004년 5월 6일자 출원), 미국 특허 출원 제10/869630호 (2004년 6월 16일자 출원), 미국 특허 출원 제10/882760호 (2004년 7월 1일자 출원), 미국 특허 출원 제10/985109호 및 동 제10/985691호 (2004년 11월 10일자 출원), 미국 특허 출원 제10/987548호 (2004년 11월 12일자 출원), 미국 특허 출원 제11/024545호 및 동 제11/024544호 (2004년 12월 29일자 출원), 미국 특허 출원 제11/166993호 (2005년 6월 24일자 출원), 미국 특허 출원 제11/183664호 (2005년 7월 18일자 출원), 미국 특허 출원 제11/185301호 (2005년 7월 20일자 출원), 미국 특허 출원 제11/190750호 (2005년 7월 27일자 출원), 미국 특허 출원 제11/198975호 (2005년 8월 8일자 출원), 미국 특허 출원 제11/225354호 (2005년 9월 13일자 출원), 미국 특허 출원 제11/251466호 (2005년 10월 14일자 출원), 미국 특허 출원 제11/254173호 및 동 제11/253882호 (2005년 10월 19일자 출원), 미국 특허 출원 제11/264784호 및 동 제11/264737호 (2005년 11월 1일자 출원), 미국 특허 출원 제11/265761호 (2005년 11월 2일자 출원), 미국 특허 출원 제60/739989호 (2005년 11월 23일자 출원), 미국 특허 출원 제60/795810호 (2006년 4월 28일자 출원), 미국 특허 출원 제60/793575호 (2006년 4월 20일자 출원), 미국 특허 출원 제60/796637호 (2006년 5월 2일자 출원), 미국 특허 출원 제60/801172호 (2006년 5월 17일자 출원), 미국 특허 출원 제60/801119호 (2006년 5월 17일자 출원), 미국 특허 출원 제60/853563호 (2006년 10월 23일자 출원), 미국 특허 출원 제60/855177호 (2006년 10월 30일자 출원). 여기에는 하기하는 본원과 동시 명의의 동시 계류 중인 출원들이 추가로 포함된다: 식물에서의 PUFA 생성에 관한 미국 특허 출원 제10/776311호, 및 안넥신 프로모터 및 식물 중 트랜스진 발현에 있어서의 이들의 용도에 관한 미국 특허 출원 제10/776889호.
본 발명은 건강상 유익한 PUFA의 생성을 위한 생화학적 경로의 조작에 사용될 수 있는 신규한 유글레나 그라실리스 및 유트레프티엘라 종 CCMP389 Δ9 일롱가제 효소, 및 이를 코딩하는 유전자를 제공한다.
본원에 개시한 방법으로 제조된 PUFA 또는 그의 유도체는 식이 대용물(dietary substitute) 또는 보조제, 및 유아용 조제식(infant formula)으로 사용될 수도 있고, 정맥내 영양보급을 받고 있는 환자에게 사용될 수도 있으며, 또는 영양불량의 예방 또는 치료용으로 사용될 수도 있다. 별법으로, 정제된 PUFA (또는 그의 유도체)는 제제화된 식용 오일, 지방 또는 마가린에 혼입되어 정상적인 사용시에는 수용자가 식이 보조용으로 원하는 양만큼 섭취할 수 있다. PUFA는 또한 유아용 조제식, 영양 보조제 또는 다른 식품에도 혼입될 수 있고, 소염제 또는 콜레스테롤 저하제로 사용될 수도 있다. 임의로, 상기 조성물은 제약 용도 (인간 또는 동물)에 사용될 수도 있다.
정의
본 명세서에서는 수많은 용어와 약어가 사용된다. 하기하는 정의가 제공된다.
"오픈 리딩 프레임"은 ORF로 약칭된다.
"폴리머라제 연쇄 반응"은 PCR로 약칭된다.
"아메리칸 타입 컬쳐 콜렉션"은 ATCC로 약칭된다.
"다중불포화 지방산(들)"은 PUFA(들)로 약칭된다.
"트리아실글리세롤"은 TAG로 약칭된다.
본원에서 사용된 바와 같이, 용어 "발명" 또는 "본 발명"은 본 발명의 임의의 한 특정 실시양태로 한정되는 것을 의미하는 것이 아니며, 일반적으로 청구의 범위 및 명세서에 기재한 바와 같은 본 발명의 임의의 실시양태 및 모든 실시양태에 적용된다.
용어 "지방산"은 약 C12 내지 C22의 다양한 쇄 길이의 장쇄 지방족 산 (알칸산)을 지칭한다 (그러나, 더 긴 쇄 길이의 산과 더 짧은 쇄 길이의 산도 둘다 공지되어 있음). 주된 쇄 길이는 C16과 C22 사이이다. "포화 지방산" vs. "불포화 지방산", "모노불포화 지방산" vs. "다중불포화 지방산" (또는 "PUFA"), 및 "오메가-6 지방산" (ω-6 또는 n-6) vs. "오메가-3 지방산" (ω-3 또는 n-3) 사이의 구별에 관한 추가의 세부사항은 PCT 공개 제WO 2004/101757호에 기재되어 있다.
본원에서 지방산은 "X:Y" (여기서, X는 특정 지방산 중 탄소 (C) 원자의 수이고, Y는 이중 결합의 수임)의 간단한 표기 시스템으로 기재된다. 지방산 표기 뒤의 수는 해당 지방산에서 카르복실 말단으로부터의 이중 결합의 위치를 나타내고, 이때 "c"는 이중 결합의 시스-배위에 대한 것 [예를 들어, 팔미트산 (16:0), 스테아르산 (18:0), 올레산 (18:1, 9c), 페트로셀린산 (18:1, 6c), LA (18:2, 9c,12c), GLA (18:3, 6c,9c,12c) 및 ALA (18:3, 9c,12c,15c)]이다. 달리 명시하지 않는 한은 18:1, 18:2 및 18:3은 올레산, LA 및 ALA 지방산을 지칭한다. 달리 구체적으로 기재하지 않는다면, 이중 결합은 시스 배위라고 가정한다. 예를 들어, 18:2 (9,12)의 이중 결합은 시스 배위로 존재한다고 가정한다.
본 명세서에서 PUFA를 기재하는데 사용된 명명법을 하기 표 3에 나타낸다. "약칭 표기"라는 제목의 컬럼에서 오메가-시스템은 탄소의 수, 이중 결합의 수, 및 오메가 탄소와 가장 가까운 이중 결합의 위치를 오메가 탄소 (이러한 목적상, 1로 번호를 매김)로부터 세어서 표시하기 위해 사용된 것이다. 표 3의 나머지 부분은 ω-3 및 ω-6 지방산의 일반명 및 이들의 전구체, 본 명세서 전반에서 사용될 약어, 및 각 화합물의 화학적 명칭을 요약한다.
| 일반명 | 약어 | 화학적 명칭 | 약칭 표기 |
| 미리스트산 | -- | 테트라데칸산 | 14:0 |
| 팔미트산 | 팔미테이트 | 헥사데칸산 | 16:0 |
| 팔미톨레산 | -- | 9-헥사데센산 | 16:1 |
| 스테아르산 | -- | 옥타데칸산 | 18:0 |
| 올레산 | -- | 시스-9-옥타데센산 | 18:1 |
| 리놀레산 | LA | 시스-9,12- 옥타데카디엔산 | 18:2 ω-6 |
| 감마-리놀렌산 | GLA | 시스-6,9,12- 옥타데카트리엔산 | 18:3 ω-6 |
| 에이코사디엔산 | EDA | 시스-11,14-에이코사디엔산 | 20:2 ω-6 |
| 디호모-감마- 리놀렌산 | DGLA | 시스-8,11,14- 에이코사트리엔산 | 20:3 ω-6 |
| 시아돈산 | SCI | 시스-5,11,14-에이코사트리엔산 | 20:3b ω-6 |
| 아라키돈산 | ARA | 시스-5,8,11,14- 에이코사테트라엔산 | 20:4 ω-6 |
| 알파-리놀렌산 | ALA | 시스-9,12,15- 옥타데카트리엔산 | 18:3 ω-3 |
| 스테아리돈산 | STA | 시스-6,9,12,15- 옥타데카테트라엔산 | 18:4 ω-3 |
| 에이코사트리엔산 | ETrA | 시스-11,14,17- 에이코사트리엔산 | 20:3 ω-3 |
| 에이코사테트라엔산 | ETA | 시스-8,11,14,17- 에이코사테트라엔산 | 20:4 ω-3 |
| 주니페론산 | JUP | 시스-5,11,14,17- 에이코사트리엔산 | 20:4b ω-3 |
| 에이코사펜타엔산 | EPA | 시스-5,8,11,14,17- 에이코사펜타엔산 | 20:5 ω-3 |
| 도코사펜타엔산 | DPA | 시스-7,10,13,16,19- 도코사펜타엔산 | 22:5 ω-3 |
| 도코사헥사엔산 | DHA | 시스-4,7,10,13,16,19- 도코사헥사엔산 | 22:6 ω-3 |
용어 "필수 지방산"은 특정 필수 지방산을 드 노보 합성할 수 없는 유기체가 생존을 위해 반드시 섭취해야 하는 상기 특정 PUFA를 지칭한다. 예를 들어, 포유동물은 필수 지방산 LA를 합성할 수 없다. 다른 필수 지방산으로는 GLA, DGLA, ARA, EPA 및 DHA 등이 있으나 이에 제한되지 않는다.
용어 "지방"은 25℃에서 고체이고 통상적으로 포화 상태인 지질 물질을 지칭한다.
용어 "오일"은 25℃에서 액체이고 통상적으로 다중불포화 상태인 지질 물질을 지칭한다. PUFA는 일부 조류, 유질 효모 및 섬유상 진균의 오일에 존재한다. "미생물 오일" 또는 "단일 세포 오일"은 미생물이 살아있는 동안에 천연적으로 생성한 오일이다.
용어 "트리아실글리세롤", "오일" 및 "TAG"는 글리세롤 분자로 에스테르화된 3개의 지방 아실 잔기로 이루어진 중성 지질을 지칭한다 (또한, 상기 용어들은 본원의 개시내용에서 구별없이 사용될 것임). 이러한 오일은 장쇄 PUFA 뿐만이 아니라 더 짧은 포화 및 불포화 지방산 및 더 긴 쇄의 포화 지방산까지도 함유할 수 있다. 따라서, "오일 생합성"은 일반적으로 세포내 TAG의 합성을 지칭한다.
"전체 지질 및 오일 분획 중 PUFA의 백분율(%)"은 그러한 분획 중 전체 지방산에 대한 PUFA의 백분율(%)을 지칭한다. 용어 "전체 지질 분획" 또는 "지질 분획"은 둘다 유질 유기체 내 모든 지질 (즉, 중성 및 극성)의 합을 지칭하며, 따라서 포스파티딜콜린 (PC) 분획, 포스파티딜에탄올아민 (PE) 분획 및 트리아실글리세롤 (TAG 또는 오일) 분획에 존재하는 지질도 포함한다. 그러나, 용어 "지질" 및 "오일"은 본 명세서에서 구별없이 사용될 것이다.
용어 "전환 효율" 및 "기질 전환율(%)"은 특정 효소 (예를 들어, 데새투라제)가 기질을 생성물로 전환시킬 수 있는 효율을 지칭한다. 전환 효율은 식 ([생성물]/[기질+생성물])×100 (여기서의 '생성물'은 그것이 유래된 경로 중의 중간 생성물 및 모든 생성물을 포함함)에 따라 결정된다.
생화학적 의미에서, 대사 경로 또는 생합성 경로는 세포 내에서 발생하는 일련의 화학 반응으로 간주될 수 있으며, 효소에 의해 촉매되어 세포에 의해 사용되거나 저장될 대사 생성물이 형성되거나 또는 또다른 대사 경로를 개시한다 (이후에는 흐름(flux) 생성 단계라 부름). 이들 경로 중 많은 것들이 정교하며, 초기 물질을 단계별로 변형시켜 원하는 정확한 화학 구조를 갖는 생성물이 형성되도록 하는 단계를 포함한다.
용어 "PUFA 생합성 경로"는 올레산을 LA, EDA, GLA, DGLA, ARA, ALA, STA, ETrA, ETA, EPA, DPA 및 DHA로 전환시키는 대사 과정을 지칭한다. 이 과정은 문헌 (예컨대, PCT 공개 제WO 2005/003322호 및 동 제WO 2006/052870호 참조)에 기재되어 있다. 간단하게 설명하자면, 이 과정은 소포체 막에 존재하는 일련의 특별한 탈포화 및 신장 효소 (즉, "PUFA 생합성 경로 효소")에 의한, 탄소 원자의 부가를 통한 탄소 쇄의 신장 및 이중 결합의 부가를 통한 분자의 탈포화를 수반한다. 더욱 구체적으로, "PUFA 생합성 경로 효소"는 PUFA의 생합성과 관련이 있는 하기 효소 (및 이러한 효소를 코딩하는 유전자) 중 임의의 것을 지칭한다: Δ4 데새투라제, Δ5 데새투라제, Δ6 데새투라제, Δ12 데새투라제, Δ15 데새투라제, Δ17 데새투라제, Δ9 데새투라제, Δ8 데새투라제, Δ9 일롱가제, C14 /16 일롱가제, C16 /18 일롱가제, C18 /20 일롱가제 및/또는 C20 /22 일롱가제.
용어 "오메가-3/오메가-6 지방산 생합성 경로"는 적절한 조건하에 발현된 경우에 ω-3 지방산 및 ω-6 지방산 중의 어느 하나 또는 둘다의 생성을 촉매하는 효소를 코딩하는 유전자 세트를 지칭한다. 전형적으로, 상기 유전자는 PUFA 생합성 경로 효소를 코딩하는 ω-3/ω-6 지방산 생합성 경로에 관여한다. 대표적인 경로가 도 1에 예시되어 있으며, 이는 미리스트산이 여러가지 중간체를 거쳐 DHA로 전환되는 것을 보여주며, ω-3 지방산과 ω-6 지방산 모두가 공통의 공급원으로부터 어떻게 생성될 수 있는지를 입증한다. 상기 경로는 자연적으로 2개 부분으로 나뉘는데, 하나는 ω-3 지방산을 생성하고 다른 것은 ω-6 지방산만을 생성한다.
ω-3/ω-6 지방산 생합성 경로와 관련하여 본원에서 사용된 바와 같이, 용어 "기능적"은 상기 경로 중의 유전자 일부 (또는 전부)가 활성 효소를 발현하여, 생체내 촉매 또는 기질 전환을 일으킨다는 것을 의미한다. "ω-3/ω-6 지방산 생합성 경로" 또는 "기능적 ω-3/ω-6 지방산 생합성 경로"는 PUFA 생합성 경로 효소 유전자가 모두 필요하다는 것을 의미하지는 않음을 이해해야 하는데, 이는 수많은 지방산 생성물에는 단지 상기 경로의 유전자 중 서브세트의 발현만이 필요할 것이기 때문이다.
용어 "Δ9 일롱가제/Δ8 데새투라제 경로"는 장쇄 PUFA를 생성하는 생합성 경로를 지칭한다. 상기 경로는 최소한 Δ9 일롱가제 및 Δ8 데새투라제를 포함하여, 이로 인해 LA 및 ALA 각각으로부터 DGLA 및/또는 ETA가 생합성될 수 있다. 다른 데새투라제 및 일롱가제가 발현되면, ARA, EPA, DPA 및 DHA도 합성될 수 있다. 이러한 경로는 GLA 및/또는 STA의 생합성이 배제되는 것과 같은 일부 실시양태에서 유리할 수 있다.
용어 "중간체 지방산"은 지방산 대사 경로 중에 생성되며, 다른 대사 경로 효소의 작용에 의해 그 경로 중의 의도된 지방산 생성물로 추가 전환될 수 있는 임의의 지방산을 지칭한다. 예를 들어, Δ9 일롱가제/Δ8 데새투라제 경로를 이용하여 EPA가 생성되는 경우에는 EDA, ETrA, DGLA, ETA 및 ARA가 생성될 수 있으며, 이들 지방산은 다른 대사 경로 효소의 작용을 통해 EPA로 추가 전환될 수 있기 때문에 "중간체 지방산"으로 간주된다.
용어 "부산물 지방산"은 지방산 대사 경로 중에 생성되며, 그 경로 중의 의도된 지방산 생성물도 아니고 그 경로의 "중간체 지방산"도 아닌 임의의 지방산을 지칭한다. 예를 들어, Δ9 일롱가제/Δ8 데새투라제 경로를 이용하여 EPA가 생성되는 경우에는, EDA 또는 ETrA 각각에 대한 Δ5 데새투라제의 작용으로 시아돈산 (SCI) 및 주니페론산 (JUP)도 생성될 수 있다. 이것들은 "부산물 지방산"으로 간주되는데, 이는 이들 중 어느 것도 다른 대사 경로 효소의 작용에 의해 EPA로 추가로 전환될 수는 없기 때문이다.
"데새투라제"는 1종 이상의 지방산을 탈포화시켜서, 즉 1종 이상의 지방산에 이중 결합을 도입하여 관심 지방산 또는 전구체를 생성할 수 있는 폴리펩티드이다. 본 명세서 전반에 걸쳐서 특정 지방산에 관한 언급시에 오메가-시스템이 사용되고는 있지만, 델타-시스템을 사용하여 기질의 카르복실 말단부터 세어서 데새투라제의 활성을 표시하는 것이 보다 편리하다. 관심 데새투라제는, 예를 들어 (1) 지방산의 카르복실-말단부로부터 번호를 매겨서 8번째 탄소 원자와 9번째 탄소 원자 사이에서 상기 분자를 탈포화시키고, 예를 들어 EDA가 DGLA로 전환되고/되거나 ETrA가 ETA로 전환되는 것을 촉매할 수 있는 Δ8 데새투라제, (2) DGLA가 ARA로 전환되고/되거나 ETA가 EPA로 전환되는 것을 촉매하는 Δ5 데새투라제, (3) LA가 GLA로 전환되고/되거나 ALA가 STA로 전환되는 것을 촉매하는 Δ6 데새투라제, (4) DPA가 DHA로 전환되는 것을 촉매하는 Δ4 데새투라제, (5) 올레산이 LA로 전환되는 것을 촉매하는 Δ12 데새투라제, (6) LA가 ALA로 전환되고/되거나 GLA가 STA로 전환되는 것을 촉매하는 Δ15 데새투라제, (7) ALA가 EPA로 전환되고/되거나 DGLA가 ETA로 전환되는 것을 촉매하는 Δ17 데새투라제, 및 (8) 팔미테이트가 팔미톨레산 (16:1)으로 전환되고/되거나 스테아레이트가 올레산 (18:1)으로 환되는 것을 촉매하는 Δ9 데새투라제를 포함한다. 당업계에서, Δ15 및 Δ17 데새투라제는 이것들이 ω-6 지방산을 이것의 ω-3 대응물로 전환시키는 능력 (예컨대, LA의 ALA로의 전환 및 ARA의 EPA로의 전환 (각각))을 기초로 하여 때때로 "오메가-3 데새투라제", "w-3 데새투라제", 및/또는 "ω-3 데새투라제"라고 지칭되기도 한다. 일부 실시양태에서, 특정 지방산 데새투라제의 특이성은 적합한 숙주를 지방산 데새투라제에 대한 유전자로 형질전환시키고 숙주의 지방산 프로파일에 미치는 효과를 결정하여 실험적으로 결정하는 것이 가장 바람직하다.
본원에서의 목적상, 용어 "EgD8"은 본원의 서열 60에 의해 코딩되는, 유글레나 그라실리스로부터 단리된 Δ8 데새투라제 효소 (서열 61)를 지칭한다. EgD8은 PCT 공개 제WO 2006/012325호 및 동 제WO 2006/012326호에 기재된 바와 같은 "Eg5" [미국 공개 제2005-0287652-A1호의 서열 2]와 100% 동일하며 기능적으로 동등하다.
유사하게, 용어 "EgD8S"는 본원에서 야로위아 리폴리티카 중에서의 발현을 위해 코돈-최적화된, 유글레나 그라실리스 유래의 합성 Δ8 데새투라제 (즉, 서열 68 및 서열 69)를 지칭한다. EgD8S는 PCT 공개 제WO 2006/012325호 및 동 제WO 2006/012326호에 기재된 바와 같은 "D8SF"와 100% 동일하며 기능적으로 동등하다.
용어 "일롱가제 시스템"은 일롱가제 시스템이 작용하는 지방산 기질보다 2개 탄소가 더 긴 지방산을 생성하는, 지방산 탄소 쇄 신장을 담당하는 4가지 효소 군을 지칭한다. 더욱 구체적으로, 신장 과정은 지방산 신타제와 관련되어 일어나는데, 여기서는 CoA가 아실 운반체이다 [Lassner et al., Plant Cell, 8:281-292 (1996)]. 기질-특이적 단계이면서 또한 속도-제한 단계인 것으로 밝혀진 제1 단계에서는 말로닐-CoA가 장쇄 아실-CoA와 축합되어 이산화탄소 (CO2) 및 β-케토아실-CoA (아실 잔기는 2개 탄소 원자만큼 신장되었음)를 생성한다. 이후의 반응은 β-히드록시아실-CoA로의 환원, 에노일-CoA로의 탈수, 및 신장된 아실-CoA를 생성하는 두번째 환원을 포함한다. 일롱가제 시스템에 의해 촉매되는 반응의 예는 GLA의 DGLA로의 전환, STA의 ETA로의 전환, 및 EPA의 DPA로의 전환이다.
본원에서의 목적상, 이러한 제1 축합 반응 (즉, 말로닐-CoA의 β-케토아실-CoA로의 전환)을 촉매하는 효소를 일반적으로 "일롱가제"로 지칭할 것이다. 일반적으로, 일롱가제의 기질 선택성은 약간 광범위하지만, 쇄 길이 및 불포화도 둘다에 의해 나뉜다. 따라서, 일롱가제는 여러가지 특이성을 보유할 수 있다. 예를 들어 C14 /16 일롱가제는 C14 기질 (예컨대, 미리스트산)을 이용할 것이고, C16 /18 일롱가제는 C16 기질 (예컨대, 팔미테이트)을 이용할 것이고, C18 /20 일롱가제 (또한 Δ6 일롱가제로도 알려져 있으며, 이들 용어는 구별없이 사용될 수 있음)는 C18 기질 (예컨대, GLA, STA)을 이용할 것이며, C20 /22 일롱가제는 C20 기질 (예컨대, EPA)을 이용할 것이다. 유사한 방식으로, 또한 본원에서 특별한 관심이 있는 것으로서, "Δ9 일롱가제"는 LA 및 ALA가 각각 EDA 및 ETrA로 전환되는 것을 촉매할 수 있다. 일부 일롱가제는 광범위한 특이성을 보유하기 때문에 단일 효소가 여러 일롱가제 반응을 촉매할 수 있다는 것을 기억하는 것은 중요하다. 따라서, 예를 들어 Δ9 일롱가제는 C16 /18 일롱가제, C18 /20 일롱가제 및/또는 C20 /22 일롱가제로도 작용할 수 있고, Δ5 및 Δ6 지방산, 예를 들어 EPA 및/또는 GLA 각각에 대하여 대안적이지만 선호되지 않는 특이성을 가질 수 있다. 바람직한 실시양태에서, 지방산 일롱가제의 특이성은 적합한 숙주를 지방산 일롱가제에 대한 유전자로 형질전환시키고 숙주의 지방산 프로파일에 미치는 효과를 결정하여 실험적으로 결정하는 것이 가장 바람직하다.
본원에서의 목적상, 용어 "EgD9e"는 서열 1에 의해 코딩되는, 유글레나 그라실리스로부터 단리된 Δ9 일롱가제 효소 (서열 2)를 지칭한다. 반대로, 용어 "EgD9eS"는 야로위아 리폴리티카 중에서의 발현을 위해 코돈-최적화된, 유글레나 그라실리스 유래의 합성 Δ9 일롱가제 (즉, 서열 3 및 서열 2)를 지칭한다.
용어 "E389D9e"는 서열 4에 의해 코딩되는, 유트레프티엘라 종 CCMP389로부터 단리된 Δ9 일롱가제 효소 (서열 5)를 지칭한다. 반대로, 용어 "E389D9eS"는 야로위아 리폴리티카 중에서의 발현을 위해 코돈-최적화된, 유트레프티엘라 종 CCMP389 유래의 합성 Δ9 일롱가제 (즉, 서열 6 및 서열 5)를 지칭한다.
용어 "IgD9e"는 이소크리시스 갈바나로부터 단리된, 서열 7에 의해 코딩되는 Δ9 일롱가제 효소 (서열 8, NCBI 관리 번호: AAL37626 [GI 17226123], 유전자좌 AAL37626, CDS AF390174, 진뱅크 관리 번호: AF390174)를 지칭한다. 반대로, 용어 "IgD9eS"는 야로위아 리폴리티카 중에서의 발현을 위해 코돈-최적화된, 이소크리시스 갈바나 유래의 합성 Δ9 일롱가제 (즉, 서열 9 및 서열 8)를 지칭한다. IgD9eS의 합성 및 기능적 분석은 PCT 공개 제WO 2006/052870호 (여기서의 IgD9eS는 그에 기재된 서열 51 및 서열 50과 동등함)에 기재되어 있다.
용어 "아미노산"은 단백질 또는 폴리펩티드의 기본적인 화학적 구조 단위를 지칭한다. 아미노산은 아미노산에 대한 1-문자 코드 또는 3-문자 코드로 표기되며, 문헌 ([Nucleic Acids Research, 13:3021-3030 (1985)] 및 [Biochemical Journal, 219 (2):345-373 (1984)])에 기재된 IUPAC-IYUB 기준에 부합되며, 상기 문헌은 본원에 참고로 포함된다.
용어 "보존적 아미노산 치환"은 주어진 단백질 중의 아미노산 잔기가 또다른 아미노산으로 치환되면서 그 단백질의 화학적 또는 기능적 성질은 변경시키지 않는 치환을 지칭한다. 예를 들어, 주어진 부위에서 화학적으로 동등한 아미노산을 생성 (그러나, 그에 의해 코딩되는 폴딩(folding)된 단백질의 구조적 및 기능적 특성에는 영향을 주지 않음)하는 유전자 변경이 일반적이라는 것은 당업계에 널리 공지되어 있다. 본 발명의 목적상, "보존적 아미노산 치환"은 하기하는 5개 군 중 하나 내에서의 교환으로 정의된다:
1. 비-극성 또는 약간 극성인 작은 지방족 잔기: Ala [A], Ser [S], Thr [T] (Pro [P], Gly [G]),
2. 음으로 대전된 극성 잔기 및 이들의 아미드: Asp [D], Asn [N], Glu [E], Gln [Q],
3. 양으로 대전된 극성 잔기: His [H], Arg [R], Lys [K],
4. 비-극성인 큰 지방족 잔기: Met [M], Leu [L], Ile [I], Val [V] (Cys [C]), 및
5. 큰 방향족 잔기: Phe [F], Tyr [Y], Trp [W].
보존적 아미노산 치환은 일반적으로 1) 치환 영역에서의 폴리펩티드 주쇄 구조, 2) 표적 부위에서 분자의 전하 또는 소수성, 또는 3) 측쇄의 크기(bulk)를 유지한다. 추가로, 많은 경우에서, 단백질 분자의 N-말단부 및 C-말단부의 변경은 그 단백질의 활성을 변경시킬 것으로 예상되지 않는다.
용어 "비-보존적 아미노산 치환"은 일반적으로 단백질 특성에 있어서 가장 큰 변화를 야기할 것으로 예상되는 아미노산 치환을 지칭한다. 따라서, 예를 들어, 비-보존적 아미노산 치환은 1) 친수성 잔기가 소수성 잔기로 치환되거나 그 반대의 경우 (예컨대, Ser 또는 Thr vs . Leu, Ile, Val), 2) Cys 또는 Pro가 임의의 다른 잔기로 치환되거나 그 반대의 경우, 3) 전기양성 측쇄를 갖는 잔기가 전기음성 잔기로 치환되거나 그 반대의 경우 (예컨대, Lys, Arg 또는 His vs . Asp 또는 Glu), 또는 4) 커다란 측쇄를 갖는 잔기가 측쇄를 갖지 않는 것으로 치환되거나 그 반대의 경우 (예컨대, Phe vs. Gly) 중 하나일 것이다. 때때로, 상기 5개 군 중 2개 사이에서의 비-보존적 아미노산 치환은 코딩되는 단백질의 활성에 영향을 주지 않을 것이다.
용어 "폴리뉴클레오티드", "폴리뉴클레오티드 서열", "핵산 서열", "핵산 단편" 및 "단리된 핵산 단편"은 본원에서 구별없이 사용된다. 이들 용어는 뉴클레오티드 서열 등을 포함한다. 폴리뉴클레오티드는 단일-가닥 또는 이중-가닥의 RNA 또는 DNA 중합체일 수 있고, 합성, 비-천연 또는 변경된 뉴클레오티드 염기를 임의로 함유한다. DNA 중합체 형태의 폴리뉴클레오티드는 1개 이상의 절편의 cDNA, 게놈 DNA, 합성 DNA, 또는 이들의 혼합물로 이루어질 수 있다. 뉴클레오티드 (통상적으로, 이의 5' 모노포스페이트 형태로 존재함)는 다음과 같은 1-문자 표시로 언급된다: 아데닐레이트 또는 데옥시아데닐레이트 (각각 RNA 또는 DNA에 대한 것)는 "A", 시티딜레이트 또는 데옥시시티딜레이트는 "C", 구아닐레이트 또는 데옥시구아닐레이트는 "G", 유리딜레이트는 "U", 데옥시티미딜레이트는 "T", 퓨린 (A 또는 G)은 "R", 피리미딘 (C 또는 T)은 "Y", G 또는 T는 "K", A 또는 C 또는 T는 "H", 이노신은 "I", 및 임의의 뉴클레오티드는 "N".
용어 "기능적으로 동등한 아단편(subfragment)" 및 "동등하게 기능적인 아단편"은 본원에서 구별없이 사용된다. 이들 용어는 단리된 핵산 단편의 일부 또는 하위서열을 지칭하며, 상기 단편 또는 아단편이 활성 효소를 코딩하든 코딩하지 않든 간에 유전자 발현을 변경시키거나 특정 표현형을 생성하는 능력을 보유한다. 예를 들어, 단편 또는 아단편은 형질전환된 식물에서 원하는 표현형을 생성하기 위한 키메라 유전자를 디자인하는데 사용될 수 있다. 키메라 유전자는 이것이 활성 효소를 코딩하든 코딩하지 않든 간에 핵산 단편 또는 그의 아단편을 식물 프로모터 서열에 대하여 센스 또는 안티센스 배향으로 연결시켜 저해하는데 사용되도록 디자인될 수 있다.
용어 "보존된 도메인" 또는 "모티프"는 진화적으로 관련된 단백질의 정렬된 서열을 따라 특정 위치에서 보존된 아미노산 세트를 의미한다. 다른 위치의 아미노산은 상동성 단백질 사이에서 달라질 수 있지만, 특정 위치에서 고도로 보존된 아미노산은 단백질의 구조, 안정성 또는 활성에 필수적인 아미노산을 나타낸다. 이것들은 단백질 상동체 과의 정렬된 서열에서의 높은 보존도로 확인되기 때문에, 새로 결정된 서열을 갖는 단백질이 이전에 확인된 단백질 과에 속하는지 여부를 결정하기 위한 식별자(identifier) 또는 "표시자(signatures)"로 사용될 수 있다. 본원에서의 목적상, 하기 표 4는 Δ9 일롱가제 활성을 갖는 단백질을 나타내는 본 발명의 모티프를 기재한다:

용어 "상동성", "상동성인", "실질적으로 유사한" 및 "실질적으로 상응하는"은 본원에서 구별없이 사용된다. 이것들은 1개 이상의 뉴클레오티드 염기에서의 변화가 핵산 단편이 유전자 발현을 매개하거나 특정 표현형을 생성하는 능력에 영향을 주지 않는 핵산 단편을 지칭한다. 이들 용어는 또한 1개 이상의 뉴클레오티드의 결실 또는 삽입과 같은 본 발명의 핵산 단편의 변형을 지칭하는데, 이것은 이로써 생성된 핵산 단편의 기능적 특성을 처음의 미변형 단편에 비해 실질적으로 변경시키지 않는다. 따라서, 당업자가 알고 있는 바와 같이, 본 발명이 특정 예시적 서열보다 더 많은 것을 포함한다는 것이 이해된다.
추가로, 당업자는 본 발명에 포함되는 실질적으로 유사한 핵산 서열이 본원에 예시한 서열, 또는 본원에 개시한 뉴클레오티드 서열의 임의의 일부이면서 본원에 개시한 임의의 핵산 서열에 기능적으로 동등한 서열과의 혼성화 (중간 정도의 엄격 조건하에서, 예를 들어, 0.5× SSC, 0.1% SDS, 60℃) 능력에 의해서도 한정된다는 것을 인식하고 있다. 엄격도 조건은 중간 정도로 유사한 단편, 예컨대 관계가 먼 유기체들로부터의 상동성 서열 내지 고도로 유사한 단편, 예컨대 밀접한 관계가 있는 유기체들로부터의 기능적 효소를 중복복제하는 유전자를 스크리닝하도록 조정될 수 있다. 혼성화후 세척이 엄격도 조건을 결정한다.
용어 "선택적으로 혼성화하다"는 주어진 핵산 서열이 엄격한 혼성화 조건하에서 명시된 핵산 표적 서열과 혼성화하는 것이 비-표적 핵산 서열과의 혼성화보다 검출가능하게 더 높은 정도 (예컨대, 백그라운드(background))보다 2배 이상 더 높음)인 것에 대한 지칭을 포함하며, 비-표적 핵산과의 혼성화는 실질적으로 배제된다. 선택적으로 혼성화하는 서열은 전형적으로 서로와 약 80% 이상의 서열 동일성 또는 90%의 서열 동일성을 가지며, 최대 100% 서열 동일성 (즉, 완전 상보적)을 포함한다.
용어 "엄격 조건" 또는 "엄격한 혼성화 조건"은 프로브가 그의 표적 서열과 선택적으로 혼성화하는 조건에 대한 지칭을 포함한다. 엄격 조건은 서열-의존적이고, 여러가지 환경에서 달라질 것이다. 혼성화 및/또는 세척 조건의 엄격도를 제어함으로써, 프로브와 100% 상보적 (상동성 프로빙(probing))인 표적 서열을 확인할 수 있다. 별법으로, 서열 내에서 약간의 미스매치가 허용되도록 엄격도 조건을 조정하여 더 낮은 정도의 유사성이 검출 (이종 프로빙)되도록 할 수도 있다. 일반적으로, 프로브는 약 1000개 미만의 뉴클레오티드길이, 임의로는 500개 미만의 뉴클레오티드 길이이다. 전형적으로, 엄격 조건은 pH 7.0 내지 8.3에서 염 농도가 약 1.5 M 미만의 Na 이온, 전형적으로는 약 0.01 내지 1.0 M의 Na 이온 농도 (또는 다른 염)이고, 짧은 프로브 (예컨대, 10개 내지 50개 뉴클레오티드)의 경우에는 온도가 약 30℃ 이상이고 긴 프로브 (예컨대, 50개 초과의 뉴클레오티드)의 경우에는 온도가 약 60℃ 이상인 조건이다. 엄격 조건은 불안정화제, 예컨대 포름아미드의 첨가로 달성될 수도 있다. 예시적인 낮은 엄격도 조건은 30% 내지 35% 포름아미드, 1 M NaCl, 1% SDS (나트륨 도데실 술페이트)의 완충액을 사용한 37℃에서의 혼성화 및 1× SSC 내지 2× SSC (20× SSC = 3.0 M NaCl/0.3 M 시트르산삼나트륨) 중 50℃ 내지 55℃에서의 세척을 포함한다. 예시적인 중간 정도의 엄격도 조건은 40% 내지 45% 포름아미드, 1 M NaCl, 1% SDS 중 37℃에서의 혼성화 및 0.5× SSC 내지 1× SSC 중 55℃ 내지 60℃에서의 세척을 포함한다. 예시적인 높은 엄격도 조건은 50% 포름아미드, 1 M NaCl, 1% SDS 중 37℃에서의 혼성화 및 0.1× SSC 중 60℃ 내지 65℃에서의 세척을 포함한다. 다른 예시적인 엄격한 혼성화 조건은 0.1× SSC, 0.1% SDS 중 65℃에서의 혼성화 및 2× SSC, 0.1% SDS를 사용한 세척 및 이후에 0.1× SSC, 0.1% SDS를 사용한 세척을 포함한다.
전형적으로, 특이성은 마지막 세척 용액의 이온 강도 및 온도가 중요한 인자인 혼성화후 세척에 대한 함수이다. DNA-DNA 하이브리드의 경우, Tm은 문헌 [Meinkoth et al., Anal. Biochem., 138:267-284 (1984)]의 하기 방정식으로 추정될 수 있다: Tm = 81.5℃ + 16.6 (log M) + 0.41 (% GC)- 0.61 (% 포름아미드)-500/L (여기서, M은 1가 양이온의 몰농도이고, % GC는 DNA 중 구아노신 및 시토신 뉴클레오티드의 백분율(%)이고, % 포름아미드는 혼성화 용액 중 포름아미드의 백분율(%)이며, L은 염기쌍 중 하이브리드의 길이이다. Tm은 상보적 표적 서열 중 50%가 완벽하게 매치된 프로브에 혼성화하는 온도 (규정된 이온 강도 및 pH 하에서)이다. Tm은 미스매치 1%마다 약 1℃씩 줄어들기 때문에, 원하는 동일성의 서열과 혼성화되도록 Tm, 혼성화 및/또는 세척 조건을 조정할 수 있다. 예를 들어, 90% 이상의 동일성을 갖는 서열을 찾는다면, Tm은 10℃ 감소될 수 있다. 일반적으로, 엄격 조건은 규정된 이온 강도 및 pH에서 특정 서열 및 그의 상보체에 대한 열 용융점 (Tm)보다 약 5℃ 더 낮도록 선택된다. 그러나, 고도의 엄격 조건은 열 용융점 (Tm)보다 1℃, 2℃, 3℃ 또는 4℃ 더 낮은 온도에서의 혼성화 및/또는 세척을 이용할 수 있고, 중간 정도의 엄격 조건은 열 용융점 (Tm)보다 6℃, 7℃, 8℃, 9℃ 또는 10℃ 더 낮은 온도에서의 혼성화 및/또는 세척을 이용할 수 있으며, 낮은 엄격도 조건은 열 용융점 (Tm)보다 11℃, 12℃, 13℃, 14℃, 15℃ 또는 20℃ 더 낮은 온도에서의 혼성화 및/또는 세척을 이용할 수 있다. 당업자는, 혼성화 및/또는 세척 용액의 엄격도에서의 변동이 본질적으로 상기 방정식, 혼성화 및 세척 조성, 및 원하는 Tm을 이용하여 기재된다는 것을 이해할 것이다. 원하는 정도의 미스매치로 인해서 Tm이 45℃ (수용액) 또는 32℃ (포름아미드 용액) 미만이 된다면, SSC 농도를 증가시켜서 더 높은 온도가 이용될 수 있도록 하는 것이 바람직하다. 핵산 혼성화에 관한 상세한 지침은 문헌 ([Tijssen, Laboratory Techniques in Biochemistry and Molecular Biology--Hybridization with Nucleic Acid Probes, Part I, Chapter 2 "Overview of principles of hybridization and the strategy of nucleic acid probe assays", Elsevier, New York (1993)] 및 [Current Protocols in Molecular Biology, Chapter 2, Ausubel et al., Eds., Greene Publishing and Wiley-Interscience, New York (1995)])에 기재되어 있다. 혼성화 및/또는 세척 조건은 적어도 10분, 30분, 60분, 90분, 120분 또는 240분 동안 적용될 수 있다.
핵산 또는 폴리펩티드 서열과 관련한 "서열 동일성" 또는 "동일성"은 2개의 서열을 명시된 비교 윈도우에서 최대로 일치하도록 정렬할 때 동일한 핵산 염기 또는 아미노산 잔기를 지칭한다.
따라서, "서열 동일성(%)"은 최적으로 정렬한 2종의 서열을 비교 윈도우에서 비교하여 결정된 값을 지칭하며, 비교 윈도우 내의 폴리뉴클레오티드 또는 폴리펩티드 서열의 일부는 상기 2종 서열을 최적으로 정렬하기 위한 기준 서열 (부가 또는 결실을 포함하지 않음)과의 비교시에 부가 또는 결실 (즉, 갭)을 포함할 수 있다. 백분율(%)은, 양쪽 서열에서 동일한 핵산 염기 또는 아미노산 잔기가 존재하는 위치의 수를 결정하여 매치되는 위치의 수를 산출하고, 매치되는 위치의 수를 비교 윈도우 내 위치의 총수로 나누고 그 결과값에 100을 곱하여 서열 동일성(%)을 산출하여 계산된다. 서열 동일성(%)의 유용한 예로는 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 또는 95%, 또는 50% 내지 100% 범위의 임의의 정수 백분율(%) 등이 있으나 이에 제한되지 않는다. 이러한 동일성은 본원에 기재한 임의의 프로그램을 이용하여 결정할 수 있다.
서열 정렬 및 동일성(%) 또는 유사성(%) 계산은 LASERGENE 바이오인포매틱스(bioInformatics) 컴퓨팅 수트의 메그얼라인(MegAlign) 프로그램 (미국 위스콘신주 매디슨 소재의 디엔에이스타, 인크.(DNASTAR, Inc.))를 포함하지만 이에 제한되지 않는, 상동성 서열을 검출하도록 디자인된 다양한 비교 방법을 이용하여 결정될 수 있다. 본 명세서의 내용에서, 서열 분석 소프트웨어를 분석에 사용한 경우, 달리 명시하지 않는 한은 그 분석 결과가 언급된 프로그램의 "디폴트 값"을 기초로 한다는 것을 이해할 것이다. 본원에서 사용된 바와 같이, "디폴트 값"은 처음 초기화시에 해당 소프트웨어에 원래 부하된 임의의 세트의 값 또는 파라미터를 의미한다.
"클러스탈 브이 정렬 방법"은 클러스탈 브이 ([Higgins and Sharp, CABIOS, 5:151-153 (1989)], [Higgins, D.G. et al., Comput. Appl. Biosci., 8:189-191 (1992)]에 기재되어 있음)로 표시되고 LASERGENE 바이오인포매틱스 컴퓨팅 수트 (상기 문헌)의 메그얼라인™ 프로그램에 기재된 정렬 방법에 상응한다. 다중 정렬의 경우, 디폴트 값은 GAP PENALTY = 10 및 GAP LENGTH PENALTY = 10에 상응한다. 클러스탈 방법을 이용한 단백질 서열의 동일성(%) 계산 및 쌍별 정렬을 위한 디폴트 파라미터는 KTUPLE = 1, GAP PENALTY = 3, WINDOW = 5 및 DIAGONALS SAVED = 5이다. 핵산의 경우, 이들 파라미터는 KTUPLE = 2, GAP PENALTY = 5, WINDOW = 4 및 DIAGONALS SAVED = 4이다. 클러스탈 브이 프로그램을 이용한 서열 정렬후, 동일 프로그램 내의 "서열 거리" 표를 참조하여 "동일성(%)"을 구할 수 있다.
"BLASTN 정렬 방법"은 디폴트 파라미터를 사용하여 뉴클레오티드 서열을 비교하는, NCBI (National Center for Biotechnology Information)가 제공하는 알고리즘이다.
당업자는 서열 동일성의 많은 수준이 다른 종으로부터 동일하거나 유사한 기능 또는 활성을 갖는 폴리펩티드를 확인하는데 유용하다는 것을 이해할 것이다. 동일성(%)의 유용한 예로는 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 또는 95%, 또는 50% 내지 100% 범위의 임의의 정수 백분율(%) 등이 있으나 이에 제한되지 않는다. 사실, 50% 내지 100% 범위의 임의의 정수, 예컨대 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%의 아미노산 동일성은 본 발명을 기재하는데 유용할 수 있다. 또한, 단리된 뉴클레오티드 단편의 임의의 전장 또는 부분적 상보체에도 관심이 있다.
용어 "게놈"이 식물 세포에 적용되는 경우에, 이것은 핵 내에 존재하는 염색체 DNA 뿐만이 아니라 세포의 세포내 성분 (예컨대, 미토콘드리아, 색소체(plastid)) 내에 존재하는 세포소기관 DNA까지도 포함한다.
"유전자"는 특정 단백질을 발현하는 핵산 단편을 지칭하며, 코딩 서열 앞쪽 (5' 비-코딩 서열) 및 뒷쪽 (3' 비-코딩 서열)의 조절 서열을 포함한다. "천연 유전자"는 자연계에서 자신의 고유 조절 서열과 함께 존재하는 유전자를 지칭한다. "키메라 유전자"는 천연 유전자가 아니고, 자연계에서는 함께 존재하지 않는 조절 서열과 코딩 서열을 포함하는 임의의 유전자를 지칭한다. 따라서, 키메라 유전자는 상이한 공급원으로부터 유래되는 조절 서열과 코딩 서열을 포함할 수도 있고, 또는 동일한 공급원으로부터 유래되지만 자연계에 존재하는 것과는 상이한 방식으로 배열된 조절 서열과 코딩 서열을 포함할 수도 있다. "외래" 유전자는 정상적으로는 숙주 유기체에 존재하지 않지만 유전자 전달에 의해 숙주 유기체 내로 도입된 유전자를 지칭한다. 외래 유전자는 비-천연 유기체 내로 삽입된 천연 유전자, 또는 키메라 유전자를 포함할 수 있다. "트랜스진"은 형질전환 절차를 통해 게놈 내로 도입된 유전자이다.
"코돈-최적화 유전자"는 숙주 세포에 의해 선호되는 코돈 사용 빈도를 모방하도록 디자인된 코돈 사용 빈도를 갖는 유전자이다.
"대립유전자"는 염색체상의 주어진 유전자좌를 차지하는 여러가지 대안적 형태의 유전자 중 하나이다. 염색체상의 주어진 유전자좌에 존재하는 모든 대립유전자가 동일한 경우, 해당 식물은 그 유전자좌에서 동형접합이다. 염색체상의 주어진 유전자좌에 존재하는 대립유전자들이 상이한 경우, 해당 식물은 그 유전자좌에서 이형접합이다.
"코딩 서열"은 특정 아미노산 서열을 코딩하는 DNA 서열을 지칭한다. "조절 서열"은 코딩 서열의 상류 (5' 비-코딩 서열), 코딩 서열 내, 또는 코딩 서열의 하류 (3' 비-코딩 서열)에 위치하고, 관련 코딩 서열의 전사, RNA 프로세싱 또는 안정성 또는 번역에 영향을 주는 뉴클레오티드 서열을 지칭한다. 조절 서열로는 프로모터, 번역 리더 서열, 인트론, 폴리아데닐화 인식 서열, RNA 프로세싱 부위, 효과기(effector) 결합 부위 및 스템-루프(stem-loop) 구조 등을 들 수 있으나 이에 제한되지 않는다.
"프로모터"는 코딩 서열 또는 기능적 RNA의 발현을 제어할 수 있는 DNA 서열을 지칭한다. 프로모터 서열은 근위 및 보다 원위의 상류 요소로 이루어지며, 후자의 요소는 흔히 인핸서라고 지칭된다. 따라서, "인핸서"는 프로모터 활성을 자극할 수 있는 DNA 서열이며, 프로모터 고유의 요소일 수도 있고, 또는 프로모터의 수준 또는 조직-특이성을 증대시키기 위해 삽입된 이종 요소일 수도 있다. 프로모터는 그 전체가 천연 유전자로부터 유래될 수도 있고, 또는 자연계에 존재하는 상이한 프로모터들로부터 유래된 여러가지 요소들로 구성될 수도 있으며, 또는 심지어는 합성 DNA 절편을 포함할 수도 있다. 당업자는 상이한 프로모터가 여러가지 조직 또는 세포 유형에서, 또는 여러 발생 단계에서, 또는 여러가지 환경적 조건에 대한 반응에서 유전자의 발현을 지시할 수 있다는 것을 이해하고 있다. 대부분의 경우에는 조절 서열의 정확한 경계가 완벽하게 규정되어 있지 않기 때문에, 약간의 차이가 있는 DNA 단편들이 동일한 프로모터 활성을 가질 수 있다는 것이 추가로 인식되고 있다. 대부분의 시기에 대부분의 세포 유형에서 유전자가 발현되도록 하는 프로모터는 통상 "구성적(constitutive) 프로모터"라고 지칭된다. 식물 세포에 유용한 여러 유형의 새로운 프로모터가 계속 발견되고 있다. 많은 예가 문헌 [Okamuro, J. K., and Goldberg, R. B. Biochemistry of Plants, 15:1-82 (1989)]에 기재되어 있다.
"번역 리더 서열"은 유전자의 프로모터 서열과 코딩 서열 사이에 위치한 폴리뉴클레오티드 서열을 지칭한다. 번역 리더 서열은 번역 출발 서열의 완전 프로세싱된 mRNA 상류에 존재한다. 번역 리더 서열은 mRNA로의 1차 전사체의 프로세싱, mRNA 안정성 또는 번역 효율에 영향을 줄 수 있다. 번역 리더 서열의 예는 문헌 [Turner, R. and Foster, G. D., Mol. Biotechnol., 3:225-236 (1995)]에 기재되어 있다.
"3' 비-코딩 서열", "전사 종결자" 또는 "종결 서열"은 코딩 서열의 하류에 위치한 DNA 서열을 지칭하며, 폴리아데닐화 인식 서열, 및 mRNA 프로세싱 또는 유전자 발현에 영향을 줄 수 있는 조절 신호를 코딩하는 기타 서열을 포함한다. 통상적으로, 폴리아데닐화 신호는 mRNA 전구체의 3'-말단에 폴리아데닐산 구역을 부가하는 것에 영향을 주는 것을 특징으로 한다. 상이한 3' 비-코딩 서열의 용도는 문헌 [Ingelbrecht, I. L., et al. Plant Cell, 1:671-680 (1989)]에 예시되어 있다.
"RNA 전사체"는 DNA 서열의 RNA 폴리머라제-촉매된 전사로 인한 생성물을 지칭한다. RNA 전사체가 DNA 서열의 완벽한 상보적 카피인 경우에는 이것을 1차 전사체라고 지칭한다. RNA 전사체가 1차 전사체의 전사후 프로세싱으로 유래된 RNA 서열인 경우에는 성숙 RNA라고 지칭한다. "메신저 RNA" 또는 "mRNA"는 인트론을 갖고 있지 않으며 세포에 의해 단백질로 번역될 수 있는 RNA를 지칭한다. "cDNA"는 mRNA 주형에 상보적이고 역전사효소를 이용하여 이로부터 합성되는 DNA를 지칭한다. cDNA는 단일-가닥일 수도 있고, 또는 DNA 폴리머라제 I의 클레나우(Klenow) 단편을 이용하여 이중-가닥 형태로 전환될 수도 있다. "센스" RNA는 mRNA를 포함하며 세포 내에서 또는 시험관내에서 단백질로 번역될 수 있는 RNA 전사체를 지칭한다. "안티센스 RNA"는 표적 1차 전사체 또는 mRNA의 전부 또는 일부에 상보적이고, 표적 유전자의 발현을 차단시키는 RNA 전사체를 지칭한다 (미국 특허 제5,107,065호). 안티센스 RNA는 특정 유전자 전사체의 임의의 일부, 즉 5' 비-코딩 서열, 3' 비-코딩 서열, 인트론, 또는 코딩 서열에서의 임의의 일부에 상보적일 수 있다. "기능적 RNA"는 안티센스 RNA, 리보자임 RNA, 또는 번역되지는 않을 수 있지만 세포내 과정에 소정의 영향을 주는 기타 RNA를 지칭한다. 용어 "상보체" 및 "역 상보체"는 mRNA 전사체와 관련하여 본원에서 구별없이 사용되며, 메세지의 안티센스 RNA를 한정함을 의미한다.
용어 "작동가능하게 연결된"은, 단일 핵산 단편상에서 한 핵산 서열의 기능이 다른 핵산 서열에 의해 조절되도록 핵산 서열들이 연결된 것을 지칭한다. 예를 들어, 프로모터는 코딩 서열의 발현을 조절할 수 있는 경우에 그 코딩 서열과 작동가능하게 연결된 것이다 (즉, 코딩 서열이 프로모터의 전사 제어하에 있음). 코딩 서열은 조절 서열에 센스 또는 안티센스 배향으로 작동가능하게 연결될 수 있다. 또다른 예에서, 본 발명의 상보적 RNA 영역은 표적 mRNA에 5'로, 또는 표적 mRNA에 3'로, 또는 표적 mRNA 내에 직접 또는 간접적으로 작동가능하게 연결될 수도 있고, 또는 제1 상보적 영역이 표적 mRNA에 5'이고 그의 상보체가 mRNA에 3'이다.
본원에서 사용되는 표준 재조합 DNA 및 분자 클로닝 기술은 당업계에 널리 공지되어 있으며, 문헌 [Sambrook, J., Fritsch, E.F. and Maniatis, T. Molecular Cloning: A Laboratory Manual; Cold Spring Harbor Laboratory: Cold Spring Harbor, NY (1989)]에 보다 상세하게 기재되어 있다. 형질전환 방법은 당업자에게 널리 공지되어 있고, 하기에 기재되어 있다.
"PCR" 또는 "폴리머라제 연쇄 반응"은 특정 DNA 절편을 다량으로 합성하는 기술로서, 일련의 반복적 주기 (미국 코넥티커트주 노르워크 소재의 퍼킨 엘머 세투스 인스트루먼츠(Perkin Elmer Cetus Instruments))로 구성된다. 전형적으로는, 이중-가닥 DNA를 열 변성시키고, 표적 절편의 3' 경계부에 상보적인 2종의 프라이머를 저온에서 어닐링시킨 후에 중간 온도에서 신장시킨다. 이러한 3개의 연속적인 단계로 이루어진 한 세트를 "주기"라고 지칭한다.
용어 "재조합"은 예를 들어 화학적 합성 또는 유전자 조작 기술에 의한 단리된 핵산 절편들의 조작 등을 통해 2종의 상이한 분리된 서열 절편들을 인공 조합하는 것을 지칭한다.
용어 "플라스미드", "벡터" 및 "카세트"는 세포의 중추 대사의 일부가 아닌 유전자를 흔히 운반하고, 통상적으로 고리형 이중-가닥 DNA 단편 형태인 염색체외 요소를 지칭한다. 이러한 요소는 자율 복제 서열, 게놈 통합 서열, 파지 또는 뉴클레오티드 서열, 임의의 공급원으로부터 유래된 선형 또는 고리형의 단일-가닥 또는 이중-가닥 DNA 또는 RNA일 수 있는데, 수많은 뉴클레오티드 서열들이 연결 또는 재조합되어, 선별된 유전자 생성물에 대한 프로모터 단편 및 DNA 서열을 적절한 3' 비-번역 서열과 함께 세포 내로 도입할 수 있는 독특한 구축물이다. "형질전환 카세트"는 외래 유전자를 함유하고, 이러한 외래 유전자 이외에도 특정 숙주 세포의 형질전환을 용이하게 하는 요소를 갖는 특정 벡터를 지칭한다. "발현 카세트"는 외래 유전자를 함유하고, 이러한 외래 유전자 이외에도 외래 숙주 내에서 상기 유전자의 발현이 증대되도록 하는 요소를 갖는 특정 벡터 (즉, 핵산 서열 또는 단편이 이동될 수 있는 별개의 핵산 단편)를 지칭한다.
용어 "재조합 구축물", "발현 구축물", "키메라 구축물", "구축물", 및 "재조합 DNA 구축물"은 본원에서 구별없이 사용된다. 재조합 구축물은 핵산 단편들, 예를 들어 자연계에서는 함께 존재하지 않는 조절 서열 및 코딩 서열의 인공 조합을 포함한다. 예를 들어, 키메라 구축물은 상이한 공급원으로부터 유래되는 조절 서열과 코딩 서열을 포함할 수도 있고, 또는 동일한 공급원으로부터 유래되지만 자연계에 존재하는 것과는 상이한 방식으로 배열된 조절 서열과 코딩 서열을 포함할 수도 있다. 이러한 구축물은 그 자체로 이용될 수도 있고, 또는 벡터와 함께 이용될 수도 있다. 벡터가 사용되는 경우, 벡터의 선택은 당업자에게 널리 공지된 바와 같이 숙주 세포를 형질전환하는데 사용될 방법에 따라 달라진다. 예를 들어, 플라스미드 벡터가 사용될 수 있다. 당업자는 본 발명의 임의의 단리된 핵산 단편을 포함하는 숙주 세포를 성공적으로 형질전환시켜 선별하고 증식시키기 위해서 벡터에 존재해야 하는 유전자 요소를 잘 알고 있다. 당업자는 또한 여러 독립적인 형질전환 사건들이 상이한 수준 및 패턴의 발현을 일으킬 것을 알고 있을 것이므로 ([Jones et al., EMBO J., 4:2411-2418 (1985)], [De Almeida et al., Mol. Gen. Genetics, 218:78-86 (1989)]), 원하는 발현 수준 및 패턴을 디스플레이하는 세포주를 수득하기 위해서는 여러 사건들을 스크리닝하는 것이 바람직하다. 이러한 스크리닝은 특히 DNA의 써던 분석, mRNA 발현의 노던 분석, 단백질 발현의 면역블럿팅 분석 또는 표현형 분석으로 수행될 수 있다.
본원에서 사용된 바와 같이, 용어 "발현"은 기능적 최종-생성물 (예컨대, mRNA 또는 단백질 [전구체 또는 성숙])의 생성을 지칭한다.
용어 "도입된"은 핵산 (예컨대, 발현 구축물) 또는 단백질을 세포에 제공하는 것을 의미한다. "도입된"은 핵산이 세포의 게놈 내로 혼입될 수 있는, 진핵 또는 원핵 세포로의 핵산 혼입에 대한 지칭을 포함하고, 핵산 또는 단백질을 세포에 일시적으로 제공하는 것에 대한 지칭을 포함한다. "도입된"은 안정적 또는 일시적 형질전환 방법 뿐만이 아니라 생식 교배(sexual crossing)에 대한 지칭까지도 포함한다. 따라서, 핵산 단편 (예컨대, 재조합 DNA 구축물/발현 구축물)을 세포 내로 삽입하는 것과 관련한 "도입된"은 "형질감염" 또는 "형질전환" 또는 "형질도입"을 의미하며, 핵산 단편이 세포의 게놈 (예컨대, 염색체, 플라스미드, 색소체 또는 미토콘드리아 DNA) 내로 혼입되어 자율 레플리콘(replicon)으로 전환되거나 일시적으로 발현 (예컨대, 형질감염된 mRNA)될 수 있는, 진핵 또는 원핵 세포로의 핵산 단편 혼입에 대한 지칭을 포함한다.
"성숙" 단백질은 번역후 프로세싱된 폴리펩티드 (즉, 1차 번역 생성물에 존재하는 임의의 프리-펩티드(pre-peptide) 또는 프로-펩티드(pro-peptide)가 제거된 폴리펩티드)를 지칭한다. "전구체" 단백질은 mRNA 번역의 1차 생성물 (즉, 프리-펩티드 및 프로-펩티드는 여전히 존재함)을 지칭한다. 프리-펩티드 및 프로-펩티드는 세포내 국소화 신호일 수 있지만 이에 제한되지 않는다.
"안정적인 형질전환"은 핵 및 세포소기관의 게놈을 비롯한 숙주 유기체의 게놈에 핵산 단편을 전달하여 유전적으로 안정적인 유전형질이 생성된 것을 지칭한다. 반대로, "일시적 형질전환"은 숙주 유기체의 핵 또는 DNA-함유 세포소기관으로 핵산 단편을 전달하여 통합 또는 안정적인 유전형질 없이 유전자가 발현되는 것을 지칭한다. 형질전환된 핵산 단편을 함유하는 숙주 유기체는 "트랜스제닉" 유기체라고 지칭된다.
본원에서 사용된 바와 같이, "트랜스제닉"은 게놈 내에 이종 폴리뉴클레오티드를 포함하는 식물 또는 세포를 지칭한다. 상기 이종 폴리뉴클레오티드가 게놈 내에 안정적으로 통합되어 상기 폴리뉴클레오티드가 다음 세대로 전달되는 것이 바람직하다. 이종 폴리뉴클레오티드는 게놈에 단독으로 통합될 수도 있고 발현 구축물의 일부로 통합될 수도 있다. 본원에서 사용된 트랜스제닉은 임의의 세포, 세포주, 칼루스(callus), 조직, 식물 일부 또는 식물을 포함하며, 이의 유전형은 처음부터 그렇게 변경된 트랜스제닉 핵산 뿐만이 아니라 처음의 트랜스제닉 핵산으로부터 생식 교배 또는 무성 증식으로 인해 생성된 핵산까지 포함하는 이종 핵산의 존재로 인해 변경되어 있다. 본원에서 사용된 바와 같이, 용어 "트랜스제닉"은 통상적인 식물 교배 방법 또는 천연 사건, 예컨대 무작위 교차-수정, 비-재조합 바이러스 감염, 비-재조합 박테리아 형질전환, 비-재조합 전좌, 또는 자발적 돌연변이에 의한 게놈 (염색체 또는 염색체외)의 변경은 포함하지 않는다.
"안티센스 억제"는 표적 단백질의 발현을 저해할 수 있는 안티센스 RNA 전사체의 생성을 지칭한다. "동시 저해(co-suppression)"는 동일하거나 실질적으로 유사한 외래 또는 내인성 유전자의 발현을 저해할 수 있는 센스 RNA 전사체의 생성을 지칭한다 (미국 특허 제5,231,020호). 식물에서의 동시 저해 구축물은 센스 배향으로 내인성 mRNA에 상동성을 갖는 핵산 서열의 과다발현에 초점을 맞추어 이미 디자인된 바 있으며, 이로 인해 과다발현된 서열에 상동성을 갖는 모든 RNA의 감소가 야기되었다 ([Vaucheret et al., Plant J., 16:651-659 (1998)], [Gura, Nature, 404:804-808 (2000)]). 이러한 현상의 전반적인 효율은 낮으며, RNA 감소 정도는 매우 가변적이다. 보다 최근의 연구는 mRNA 코딩 서열의 전부 또는 일부를 상보적 배향으로 혼입하여 발현된 RNA에 대한 잠재적인 "스템-루프" 구조가 생성되는 "헤어핀" 구조의 사용을 기재하고 있다 (PCT 공개 제WO 99/53050호, PCT 공개 제WO 02/00904호). 이것은 회수된 트랜스제닉 식물에서의 동시 저해 빈도를 증가시킨다. 또다른 연구는 근위 mRNA 코딩 서열의 저해 또는 "침묵(silencing)"을 지시하는 식물 바이러스 서열의 사용을 기재한다 (PCT 공개 제WO 98/36083호). 유전적 증거가 이러한 복잡한 상황을 풀어나가기 시작했지만 [Elmayan et al., Plant Cell, 10:1747-1757 (1998)], 이들 동시 저해 현상은 기계적으로 해명되지 못했다.
용어 "유질"은 자신의 에너지원을 지질 형태로 저장하는 경향이 있는 유기체를 지칭한다 [Weete, In: Fungal Lipid Biochemistry, 2nd Ed., Plenum, 1980]. 유질인 것으로 확인된 식물 부류는 통상적으로 "유량종자(oilseed)" 식물이라 지칭된다. 유량종자 식물의 예로는 대두 (글리신(Glycine) 및 소야(Soja) 종), 아마 (리눔(Linum) 종), 평지씨 (브라씨카(Brassica) 종), 옥수수, 목화, 잇꽃 (카르타무스(Carthamus) 종) 및 해바라기 (헬리안투스(Helianthus) 종) 등이 있으나 이에 제한되지 않는다.
일반적으로, 유질 미생물의 세포내 오일 또는 TAG 함량은 S자형 곡선에 따르는데, 여기서 지질의 농도는 이것이 후기 대수 성장기 또는 초기 정지 성장기에서 최대에 도달할 때까지 증가하였다가 후기 정지기 및 사멸기 동안에 점차적으로 감소한다 [Yongmanitchai and Ward, Appl. Environ. Microbiol., 57:419-25 (1991)].
용어 "유질 효모"는 오일을 만들 수 있는 효모로 분류되는 이러한 미생물을 지칭한다. 유질 미생물이 자신의 건조 세포 중량의 약 25% 초과분을 오일로서 축적하는 것은 드문 일이 아니다. 유질 효모의 예에는 야로위아, 칸디다(Candida), 로도토룰라(Rhodotorula), 로도스포리듐(Rhodosporidium), 크립토콕쿠스(Cryptococcus), 트리코스포론(Trichosporon) 및 리포마이세스(Lipomyces) 속 등이 있지만 이에 제한되지 않는다.
용어 "유글레노피세애(Euglenophyceae)"는 담수, 해수, 토양 및 기생 환경의 생물에 존재하는, 무색이거나 광합성을 하는 단세포 편모충 ("녹색편모충")의 군을 지칭한다. 상기 부류는 고립 단세포(solitary unicell)임을 특징으로 하고, 대부분은 자유롭게 헤엄쳐다니며 저장고로 알려진 전방 함입부에서 나온 2개의 편모 (이 중 하나는 없을 수도 있음)를 갖는다. 광합성 녹색편모충은 1개 내지 많은 수의 엽록체를 함유하며, 이것은 미세한 디스크로부터 확장된 플레이트 또는 리본까지 다양하다. 무색의 녹색편모충은 영양소 동화에 대한 삼투영양성(osmotrophy) 또는 식영양성(phagotrophy)에 의존한다. 약 1000개 종이 발견되어 약 40개 속 및 6개 목으로 분류된 바 있다. 유글레노피세애의 예로는 하기 속 등이 있으나 이에 제한되지 않는다: 유트레프티엘라, 유글레나 및 테트루에트레프티아.
용어 "식물"은 온전한 식물, 식물 기관, 식물 조직, 종자, 식물 세포, 종자 및 그의 자손을 지칭한다. 식물 세포로는 종자로부터의 세포, 현탁 배양물, 배아, 분열조직 영역, 칼루스 조직, 잎, 뿌리, 새순, 배우체, 포자체, 화분 및 소포자 등이 있으나 이에 제한되지 않는다.
"자손"은 식물의 임의의 후속 세대를 포함한다.
개요: 지방산 및
트리아실글리세롤의
미생물 생합성
일반적으로, 유질 미생물 중에서의 지질 축적은 성장 배지 중에 존재하는 전체 탄소:질소 비율에 대한 반응으로 촉발된다. 이 과정은 유질 미생물 중에서 유리 팔미테이트 (16:0)가 드 노보 합성되도록 하며, PCT 공개 제WO 2004/101757호에 상세하게 기재되어 있다. 팔미테이트는 일롱가제 및 데새투라제의 작용을 통해 형성되는 더 긴 쇄의 포화 및 불포화 지방산 유도체의 전구체이다 (도 1).
TAG (지방산의 주요 저장 단위)는, 1) 아실트랜스퍼라제의 작용에 의해 아실-CoA 1개 분자가 글리세롤-3-포스페이트로 에스테르화되어 리소포스파티드산을 생성하고, 2) 아실트랜스퍼라제의 작용에 의해 2번째 분자의 아실-CoA가 에스테르화되어 1,2-디아실글리세롤 포스페이트 (통상, 포스파티드산으로 표시함)가 생성되고, 3) 포스파티드산 포스파타제에 의해 포스페이트가 제거되어 1,2-디아실글리세롤 (DAG)이 생성되며, 4) 아실트랜스퍼라제의 작용에 의해 3번째 지방산이 부가되어 TAG가 형성되는 것을 포함하는 일련의 반응들로 형성된다. 포화 및 불포화 지방산 및 단쇄 및 장쇄 지방산을 비롯한 광범위한 스펙트럼의 지방산이 TAG로 혼입될 수 있다.
오메가 지방산의 생합성
올레산이 장쇄 ω-3/ω-6 지방산으로 전환되는 대사 과정은 탄소 원자의 부가를 통한 탄소 쇄의 신장 및 이중 결합의 부가를 통한 상기 분자의 탈포화를 포함한다. 여기에는 소포체 막에 존재하는 일련의 특별한 탈포화 및 신장 효소가 필요하다. 그러나, 도 1에 나타나 있고 하기 기재된 바와 같이, 특정 ω-3/ω-6 지방산을 생성하기 위한 여러가지 별법의 경로가 흔히 존재한다.
구체적으로, 모든 경로에는 올레산이 Δ12 데새투라제에 의해 첫번째 ω-6 지방산인 LA로 초기 전환될 것이 요구된다. 이어서, "Δ9 일롱가제/Δ8 데새투라제 경로"를 이용하여, 장쇄 ω-6 지방산이 다음과 같이 형성된다: (1) LA가 Δ9 일롱가제에 의해 EDA로 전환되고, (2) EDA가 Δ8 데새투라제에 의해 DGLA로 전환되며, (3) DGLA가 Δ5 데새투라제에 의해 ARA로 전환된다. 별법으로, "Δ9 일롱가제/Δ8 데새투라제 경로"는 다음과 같이 장쇄 ω-3 지방산의 형성에 이용될 수 있다: (1) LA가 Δ15 데새투라제에 의해 첫번째 ω-3 지방산인 ALA로 전환되고, (2) ALA가 Δ9 일롱가제에 의해 ETrA로 전환되고, (3) ETrA가 Δ8 데새투라제에 의해 ETA로 전환되고, (4) ETA가 Δ5 데새투라제에 의해 EPA로 전환되고, (5) EPA가 C20 /22 일롱가제에 의해 DPA로 전환되며, (6) DPA가 Δ4 데새투라제에 의해 DHA로 전환된다. 임의로, ω-6 지방산은 ω-3 지방산으로 전환될 수 있으며, 예를 들어 Δ17 데새투라제 활성에 의해 DGLA 및 ARA 각각으로부터 ETA 및 EPA가 생성된다.
ω-3/ω-6 지방산의 생합성을 위한 별법의 경로는 Δ6 데새투라제 및 C18 /20 일롱가제를 이용한다 (즉, "Δ6 데새투라제/Δ6 일롱가제 경로"). 더욱 구체적으로, LA 및 ALA는 Δ6 데새투라제에 의해 각각 GLA 및 STA로 전환될 수 있고, 이후에 C18 /20 일롱가제는 GLA를 DGLA로 전환시키고/시키거나 STA를 ETA로 전환시킨다.
ω-3/ω-6 지방산을 생성하기 위해서 특정 숙주 유기체로 도입될 필요가 있는 특별한 기능성은 숙주 세포 (및 그의 천연 PUFA 프로파일 및/또는 데새투라제/일롱가제 프로파일), 기질의 이용가능성, 및 원하는 최종 생성물(들)에 따라 달라질 것이라고 여겨진다. 예를 들어, 일부 실시양태에서는 Δ6 데새투라제/Δ6 일롱가제 경로의 발현이 아니라 Δ9 일롱가제/Δ8 데새투라제 경로의 발현이 바람직할 수 있는데, 이는 Δ9 일롱가제/Δ8 데새투라제 경로에 의해 생성된 PUFA에는 GLA가 없기 때문이다.
당업자는 ω-3/ω-6 지방산 생합성을 위해 원하는 각 효소를 코딩하는 여러가지 후보 유전자를 확인할 수 있다. 유용한 데새투라제 및 일롱가제 서열은 임의의 공급원으로부터 유래될 수 있고, 예를 들어 천연 공급원 (박테리아, 조류, 진균, 식물, 동물 등)으로부터 단리될 수 있고, 또는 반-합성 경로를 통해 생성되거나 드 노보 합성될 수도 있다. 숙주로 도입되는 데새투라제 및 일롱가제 유전자의 특정 공급원은 중요하지 않지만, 데새투라제 또는 일롱가제 활성을 갖는 특정 폴리펩티드의 선택에 대한 고려사항에는 1) 해당 폴리펩티드의 기질 특이성, 2) 폴리펩티드 또는 그의 성분이 속도-제한 효소인지의 여부, 3) 데새투라제 또는 일롱가제가 원하는 PUFA의 합성에 필수적인지의 여부, 및/또는 4) 해당 폴리펩티드에 필요한 보조인자가 포함된다. 발현된 폴리펩티드는 숙주 세포 중 그의 위치의 생화학적 환경에 적합한 파라미터를 갖는 것이 바람직하다 (추가의 상세한 사항에 대하여는 PCT 공개 제WO 2004/101757호 참조).
추가의 실시양태에서, 각각의 특정 데새투라제 및/또는 일롱가제의 전환 효율을 고려하는 것도 유용하다. 더욱 구체적으로, 각각의 효소가 기질을 생성물로 전환시키는데 있어서 100% 효율로 기능하는 경우는 거의 없기 때문에, 숙주 세포 중의 미정제 오일의 최종 지질 프로파일은 전형적으로 원하는 ω-3/ω-6 지방산으로 이루어진 각종 PUFA 뿐만이 아니라 각종 상류 중간 매개 PUFA의 혼합물일 것이다. 따라서, 원하는 지방산의 생합성을 최적화할 때, 최종적으로 원하는 생성물의 지질 프로파일에 비추어 각 효소의 전환 효율 역시 가변적이라는 점을 고려해야 한다.
이러한 고려사항 각각을 염두에 두고, 적절한 데새투라제 및 일롱가제 활성을 갖는 후보 유전자 (예컨대, Δ6 데새투라제, C18 /20 일롱가제, Δ5 데새투라제, Δ17 데새투라제, Δ15 데새투라제, Δ9 데새투라제, Δ12 데새투라제, C14 /16 일롱가제, C16 /18 일롱가제, Δ9 일롱가제, Δ8 데새투라제, Δ4 데새투라제 및 C20 /22 일롱가제)가 공개적으로 입수가능한 문헌 (예컨대, 진뱅크), 특허 문헌, 및 PUFA 생산력을 갖는 유기체의 실험 분석에 따라 확인될 수 있다. 이들 유전자는 특정 숙주 유기체의 PUFA 합성을 가능하게 하거나 증대시키기 위해서 해당 유기체로 도입하기에 적합할 것이다.
신규한
Δ9
일롱가제의
서열 확인
본 발명에서, Δ9 일롱가제를 코딩하는 뉴클레오티드 서열은 유글레나 그라실리스 (본원에서는 "EgD9e"라고 지칭함) 및 유트레프티엘라 종 CCMP389 (본원에서는 "E389D9e"라고 지칭함)로부터 단리되었다.
클러스탈 브이 분석을 이용하여 EgD9e 뉴클레오티드 염기 및 추정된 아미노산 서열을 공개 데이타베이스와 비교함으로써, 가장 유사한 공지 서열 (즉, IgD9e)이 본원에서 보고한 EgD9e의 아미노산 서열과 258개 아미노산 길이에 걸쳐 약 31.8% 동일하다는 것이 밝혀졌다.
클러스탈 브이 분석을 이용하여 E389D9e 뉴클레오티드 염기 및 추정된 아미노산 서열을 공개 데이타베이스와 비교함으로써, 가장 유사한 공지 서열 (즉, IgD9e)이 본원에서 보고한 E389D9e의 아미노산 서열과 263개 아미노산 길이에 걸쳐 약 33.1% 동일하다는 것이 밝혀졌다.
참고로, 클러스탈 브이 분석을 이용하여 본원에서 서열 2 및 서열 5로 기재한 신규한 EgD9e 및 E389D9e 단백질 서열을 비교해 보니, 이것들은 65.1% 동일성을 공유하였다.
본 발명의 내용에서, 바람직한 아미노산 단편은 본원에서의 EgD9e 및 E389D9e 서열과 약 70% 내지 85% 이상 동일하며, 약 85% 내지 90% 이상 동일한 서열이 특히 적합하고, 약 90% 내지 95% 이상 동일한 서열이 가장 바람직하다. 본 발명의 ORF에 상응하는 핵산 서열을 코딩하는 바람직한 EgD9e 및 E389D9e는 활성 단백질을 코딩하고 본원에서 보고한 EgD9e 및 E389D9e 각각의 핵산 서열과 약 70% 내지 85% 이상 동일한 것들이며, 85% 내지 90% 이상 동일한 서열이 특히 적합하고, 약 90% 내지 95% 이상 동일한 서열이 가장 바람직하다.
별법의 실시양태에서, 본 발명의 EgD9e 및 E389D9e 서열은 특정 숙주 유기체에서의 발현을 위해 코돈-최적화될 수 있다. 당업계에 널리 공지된 바와 같이, 이것은 대체 숙주 내에서의 상기 효소 발현을 추가로 최적화하는데 유용한 수단일 수 있는데, 이는 숙주에 의해 선호되는 코돈의 사용이 해당 폴리펩티드를 코딩하는 외래 유전자의 발현을 실질적으로 증대시킬 수 있기 때문이다. 일반적으로, 숙주에 의해 선호되는 코돈은, 단백질에서의 코돈 사용을 시험하고 (바람직하게는 가장 다량으로 발현되는 것) 어떤 코돈이 가장 높은 빈도로 사용되는지를 결정하여 특정 관심 숙주 종에서 결정될 수 있다. 이어서, 예를 들어 일롱가제 활성을 갖는 관심 폴리펩티드에 대한 코딩 서열은 숙주 종에서 선호되는 코돈을 사용하여 온전하게 합성될 수도 있고 일부 합성될 수도 있다. DNA 전체 (또는 일부) 역시 임의의 불안정화 서열 또는 전사된 mRNA에 존재하는 2차 구조 영역이 제거되도록 합성될 수 있다. DNA 전체 (또는 일부)는 또한 염기 조성이 원하는 숙주 세포에서 보다 바람직한 것으로 변경되도록 합성될 수 있다.
본 발명의 한 바람직한 실시양태에서, EgD9e 및 E389D9e는 야로위아 리폴리티카 중에서의 발현을 위해 코돈-최적화되었다. 이것은 우선 야로위아 리폴리티카의 코돈 사용 프로파일 (PCT 공개 제WO 04/101757호 참조)을 결정하고, 선호되는 상기 코돈을 확인하여 가능하였다. 야로위아 리폴리티카 중 유전자 발현의 추가의 최적화는 'ATG' 개시 코돈 주위의 컨센서스(consensus) 서열을 결정하여 달성되었다.
EgD9e의 최적화는 777 bp 코딩 영역 중 117 bp (15.1%)를 변형시켰고, 106개 코돈을 최적화하였다. 코돈-최적화 유전자 ("EgD9eS", 서열 3)에서의 변형 중 그 어느 것도 코딩되는 단백질의 아미노산 서열 (서열 2)을 변화시키지 않았다. 실시예 8에 기재한 바와 같이, 코돈-최적화 유전자는 야로위아 리폴리티카에서 발현된 경우에 LA를 EDA로 신장시키는데 있어서 야생형 EgD9e 유전자보다 약 16.2% 더 효율적이었다.
유사하게, E389D9e의 최적화는 792 bp 코딩 영역 중 128 bp (16.2%)를 변형시켰고, 113개 코돈을 최적화하였다. 코돈-최적화 유전자 ("E389D9eS", 서열 6)에서의 변형 중 그 어느 것도 코딩되는 단백질의 아미노산 서열 (서열 5)을 변화시키지 않았다. 실시예 24에 기재한 바와 같이, 코돈-최적화 유전자는 야로위아 리폴리티카에서 발현된 경우에 LA를 EDA로 신장시키는데 있어서 야생형 유전자와 유사한 효율을 가졌다.
따라서, 본 발명은
(a) 클러스탈 브이 정렬 방법을 기초로 하여 서열 2 (EgD9e) 또는 서열 5 (E389D9e)에 기재된 바와 같은 아미노산 서열과 비교할 때 70% 이상의 아미노산 동일성을 가지며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열,
(b) BLASTN 정렬 방법을 기초로 하여 서열 1 (EgD9e), 서열 3 (EgD9eS), 서열 4 (E389D9e) 또는 서열 6 (E389D9eS)에 기재된 바와 같은 뉴클레오티드 서열과 비교할 때 70% 이상의 뉴클레오티드 서열 동일성을 가지며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열,
(c) 0.1× SSC, 0.1% SDS 중 65℃에서의 혼성화 및 2× SSC, 0.1% SDS를 사용한 세척 및 이후 0.1× SSC, 0.1% SDS를 사용한 세척의 엄격한 혼성화 조건하에서 서열 1 (EgD9e), 서열 3 (EgD9eS), 서열 4 (E389D9e) 또는 서열 6 (E389D9eS)에 기재된 바와 같은 뉴클레오티드 서열과 혼성화하며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열, 또는
(d) 상기 (a), (b) 또는 (c)의 뉴클레오티드 서열과 동일한 수의 뉴클레오티드로 이루어지며 100% 상보적인, 상기 (a), (b) 또는 (c)의 뉴클레오티드 서열의 상보체
로 구성된 군에서 선택된, Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 단리된 폴리뉴클레오티드 서열에 관한 것이다.
당업자는 야생형 EgD9e 및/또는 E389D9e 서열을 기초로 하여 대체 숙주 (즉, 야로위아 리폴리티카 이외의 숙주)에서의 최적의 발현에 적합한 각종 다른 코돈-최적화 Δ9 일롱가제 단백질을 생성하기 위해서 본원에서의 교시를 사용할 수 있다. 이러한 대체 숙주 유기체로는 식물 또는 식물의 일부 등을 들 수 있으나 이에 제한되지 않는다. 따라서, 본 발명은 야생형 EgD9e로부터 유래 (즉, 서열 2에 의해 코딩됨)되거나 야생형 E389D9e로부터 유래 (즉, 서열 5에 의해 코딩됨)된 임의의 코돈-최적화 Δ9 일롱가제 단백질에 관한 것이다. 이것으로는 야로위아 리폴리티카 중에서의 발현을 위해 코돈-최적화된, 서열 3에 기재한 뉴클레오티드 서열 (합성 Δ9 일롱가제 단백질 (즉, EgD9eS)을 코딩함) 및 서열 6에 기재한 뉴클레오티드 서열 (합성 Δ9 일롱가제 단백질 (즉, E389D9eS)을 코딩함) 등이 있으나 이에 제한되지 않는다.
또다른 측면에서, 본 발명은 서열 8 (즉, "IgD9e", 이소크리시스 갈바나로부터의 Δ9 일롱가제 (NCBI 관리 번호: AAL37626 (GI 17226123))을 제외한 Δ9 일롱가제를 코딩하는 핵산 서열을 포함하는 단리된 핵산 단편에 관한 것이고, 여기서 상기 Δ9 일롱가제를 포함하는 아미노산 서열은

(여기서, X는 임의의 아미노산일 수 있음)
로 구성된 군에서 선택된 아미노산 서열 모티프 중 하나 이상을 함유한다.
밑줄로 표시한 아미노산은 Δ9 일롱가제에 독특한 것일 수 있다. 도 2는 클러스탈 브이 정렬 (디폴트 파라미터 포함)을 이용하여 본 발명의 Δ9 일롱가제와 이소크리시스 갈바나로부터의 Δ9 일롱가제를 비교한 것을 보여준다. 구체적으로, 서열 2 (EgD9e), 서열 5 (E389D9e) 및 서열 8 (IgD9e)을 비교하였다. 본 발명의 모티프를 포함하는 영역에는 박스로 표시하였다.
상동체의
동정 및 단리
본 발명의 임의의 일롱가제 서열 (즉, EgD9e, EgD9eS, E389D9e, E389D9eS) 또는 그의 일부를 이용하여, 서열 분석 소프트웨어를 사용하여 동일하거나 상이한 박테리아, 조류, 진균, 녹색편모충 또는 식물 종에서의 Δ9 일롱가제 상동체에 대하여 조사할 수 있다. 일반적으로, 이러한 컴퓨터 소프트웨어는 상동성 정도를 다양한 치환, 결실 및 다른 변형에 할당하면서 유사한 서열을 매치시킨다.
별법으로, 본 발명의 임의의 일롱가제 서열 또는 그의 일부는 Δ9 일롱가제 상동체의 동정을 위한 혼성화 시약으로 사용될 수도 있다. 핵산 혼성화 시험의 기본 성분은 프로브, 관심 유전자 또는 유전자 단편을 함유할 것으로 추측되는 샘플, 및 구체적인 혼성화 방법을 포함한다. 전형적으로, 본 발명의 프로브는 검출될 핵산 서열에 상보적인 단일-가닥 핵산 서열이다. 프로브는 검출될 핵산 서열에 "혼성화가능"하다. 프로브 길이는 5개 염기 내지 수만개 염기에 이르기까지 다양할 수 있지만, 전형적으로는 약 15개 염기 내지 약 30개 염기의 프로브 길이가 적합하다. 검출될 핵산 서열에는 프로브 분자 중 오직 일부만 상보적일 필요가 있다. 추가로, 프로브와 표적 서열 사이의 상보성이 완벽할 필요는 없다. 혼성화는 불완전하게 상보적인 분자들 사이에서 일어나서, 혼성화된 영역의 염기 중 특정 일부가 적당한 상보적 염기와 쌍을 이루지 않게 된다.
혼성화 방법은 널리 규명되어 있다. 전형적으로, 프로브 및 샘플은 핵산 혼성화를 허용하는 조건하에 혼합되어야 한다. 이것은 무기 또는 유기 염의 존재하에 적당한 농도 및 온도 조건하에서 프로브 및 샘플을 접촉시키는 것을 수반한다. 프로브 및 샘플 핵산은 이러한 프로브와 샘플 핵산 사이에서 임의의 가능한 혼성화가 일어날 수 있을 만큼 충분히 오랜 시간 동안 접촉되어 있어야 한다. 혼합물 중 프로브 또는 표적의 농도가, 혼성화가 일어나는데 필요한 시간을 결정할 것이다. 프로브 또는 표적의 농도가 높을 수록, 필요한 혼성화 인큐베이션 시간이 더 짧다. 임의로는 카오트로프제(chaotropic agent) (예컨대, 구아니디늄 클로라이드, 구아니디늄 티오시아네이트, 나트륨 티오시아네이트, 리튬 테트라클로로아세테이트, 나트륨 퍼클로레이트, 루비듐 테트라클로로아세테이트, 칼륨 요오다이드, 세슘 트리플루오로아세테이트)가 추가될 수 있다. 원한다면, 상기 혼성화 혼합물에 포름아미드를 전형적으로는 30% 내지 50% (v/v)로 첨가할 수 있다.
각종 혼성화 용액을 사용할 수 있다. 전형적으로, 이것들은 극성 유기 용매를 약 20 부피% 내지 60 부피%, 바람직하게는 30 부피%로 포함한다. 통상의 혼성화 용액은 약 30% 내지 50% v/v 포름아미드, 약 0.15 M 내지 1 M 염화나트륨, 약 0.05 M 내지 0.1 M 완충제 (예를 들어, 시트르산나트륨, Tris-HCl, PIPES 또는 HEPES (pH 범위 약 6 내지 9)), 약 0.05% 내지 0.2% 디터전트(detergent) (예를 들어, 나트륨 도데실술페이트), 또는 0.5 mM 내지 20 mM EDTA, 피콜(FICOLL) (파마시아 인크(Pharmacia Inc.)) (약 300 내지 500 kdal), 폴리비닐피롤리돈 (약 250 내지 500 kdal), 및 혈청 알부민을 사용한다. 또한, 전형적인 혼성화 용액에는 약 0.1 mg/mL 내지 5 mg/mL의 표지되지 않은 운반체 핵산, 단편화된 핵 DNA (예를 들어, 송아지 흉선 또는 연어 정자 DNA, 또는 효모 RNA), 및 임의로는 약 0.5% 내지 2% wt/vol의 글리신이 포함될 것이다. 예를 들어 다양한 극성 수용성 또는 수팽윤성 작용제 (예를 들어, 폴리에틸에틸렌 글리콜), 음이온성 중합체 (예를 들어, 폴리아크릴레이트 또는 폴리메틸아크릴레이트) 및 음이온성 당류 중합체 (예를 들어, 덱스트란 술페이트)를 포함하는 부피 배제제(volume exclusion agent)와 같은 기타 첨가제도 포함될 수 있다.
핵산 혼성화는 각종 검정 포맷에 적용될 수 있다. 가장 적합한 것 중 하나가 샌드위치 검정 포맷이다. 샌드위치 검정은 특히 비-변성 조건하에서의 혼성화에 적용될 수 있다. 샌드위치형 검정의 주성분은 고체 지지체이다. 이러한 고체 지지체에는, 표지되지 않고 서열의 한 부분에 상보적인 고정화 핵산 프로브가 흡착되어 있거나 이와 공유적으로 커플링되어 있다.
추가의 실시양태에서, 본원에 기재한 임의의 Δ9 일롱가제 핵산 단편 (또는 본원에서 동정된 임의의 상동체)은 동일하거나 상이한 박테리아, 조류, 진균, 녹색편모충 또는 식물 종으로부터의 상동성 단백질을 코딩하는 유전자를 단리하는데 사용될 수 있다. 서열-의존적 프로토콜을 이용하여 상동성 유전자를 단리하는 방법은 당업계에 널리 공지되어 있다. 서열-의존적 프로토콜의 예로는 1) 핵산 혼성화 방법, 2) 핵산 증폭 기술의 다양한 사용으로 예시되는 바와 같은 DNA 및 RNA 증폭 방법 (예를 들어, 폴리머라제 연쇄 반응 (PCR) [Mullis et al., 미국 특허 제4,683,202호], 리가제 연쇄 반응 (LCR) [Tabor, S. et al., Proc. Acad. Sci. USA, 82:1074 (1985)] 또는 가닥 치환 증폭 (SDA) [Walker, et al., Proc. Natl. Acad. Sci. USA, 89:392 (1992)], 및 3) 라이브러리 구축 및 상보성에 의한 스크리닝 방법 등이 있으나 이에 제한되지 않는다
예를 들어, 본원에 기재한 Δ9 일롱가제와 유사한 단백질 또는 폴리펩티드를 코딩하는 유전자는, 당업자에게 널리 공지된 방법을 이용하여 본 발명의 핵산 단편의 전부 또는 일부를 예를 들어 임의의 원하는 효모 또는 진균 (이 경우, EDA 및/또는 ETrA를 생성하는 유기체가 바람직함)으로부터의 라이브러리를 스크리닝하기 위한 DNA 혼성화 프로브로서 사용함으로써 직접 단리할 수 있다. 본 발명의 핵산 서열에 기초한 특이적 올리고뉴클레오티드 프로브를 당업계에 공지된 방법으로 디자인하고 합성할 수 있다 [Maniatis, 상기 문헌]. 더우기, 전체 서열을 직접 사용하여, 당업자에게 공지된 방법 (예를 들어, 무작위 프라이머 DNA 표지화, 닉(nick) 번역 또는 말단-표지화 기술)에 의해 DNA 프로브를 합성하거나, 또는 이용가능한 시험관내 전사 시스템을 사용하여 RNA 프로브를 합성할 수 있다. 또한, 특이적 프라이머를 디자인하고 사용하여 본 발명의 서열의 일부 (또는 전장)를 증폭시킬 수 있다. 이로써 생성된 증폭 생성물을 증폭 반응 동안에 직접 표지시킬 수도 있고, 또는 증폭 반응 후에 표지시킬 수도 있으며, 이것을 적절한 엄격도 조건하에 프로브로서 사용하여 전장의 DNA 단편을 단리할 수 있다.
전형적으로, PCR형 증폭 기술에서는 프라이머가 상이한 서열을 갖고 서로에게 상보적이지 않다. 원하는 시험 조건에 따라, 프라이머의 서열은 표적 핵산의 효율적이면서도 신뢰할 만한 복제를 제공하도록 디자인해야 한다. PCR 프라이머 디자인 방법은 통상적이고 당업계에 널리 공지되어 있다 ([Thein and Wallace, "The use of oligonucleotide as specific hybridization probes in the Diagnosis of Genetic Disorders", in Human Genetic Diseases: A Practical Approach, K. E. Davis Ed., (1986) pp 33-50, IRL: Herndon, VA] 및 [Rychlik, W., In Methods in Molecular Biology, White, B. A. Ed., (1993) Vol. 15, pp 31-39, PCR Protocols: Current Methods and Applications. Humania: Totowa, NJ]).
일반적으로, 본 발명의 서열의 2개의 짧은 절편이 PCR 프로토콜에 사용되어 DNA 또는 RNA로부터의 상동성 유전자를 코딩하는 보다 긴 핵산 단편을 증폭시킬 수 있다. 또한, PCR은 클로닝된 핵산 단편들의 라이브러리에 대해 수행될 수 있고, 이때 한 프라이머의 서열은 본 발명의 핵산 단편에서 유래된 것이고, 나머지 다른 프라이머의 서열은 진핵 유전자를 코딩하는 mRNA 전구체의 3' 말단에서의 폴리아데닐산 구역이 존재하는 이점을 갖는다.
별법으로, 제2 프라이머 서열은 클로닝 벡터로부터 유래된 서열을 기초로 할 수 있다. 예를 들어, 전사체 중 한 지점과 3' 또는 5' 말단 사이 영역의 카피를 증폭시키는 PCR을 이용하여 cDNA를 생성하는 RACE 프로토콜 [Frohman et al., PNAS USA, 85:8998 (1988)]에 따를 수 있다. 3' 및 5' 방향으로 배향된 프라이머가 본 발명의 서열로부터 디자인될 수 있다. 시판되는 3' RACE 또는 5' RACE 시스템 (미국 메릴랜드주 가이터스버그 소재의 깁코(Gibco)/BRL)을 사용하여, 특이적 3' 또는 5' cDNA 단편을 단리할 수 있다 ([Ohara et al., PNAS USA, 86:5673 (1989)], [Loh et al., Science, 243:217 (1989)]).
다른 실시양태에서, 본원에 기재한 임의의 Δ9 일롱가제 핵산 단편 (또는 그의 동정된 임의의 상동체)을 이용하여 신규하고 개선된 지방산 일롱가제를 생성할 수 있다. 당업계에 널리 공지된 바와 같이, 시험관내 돌연변이유발 및 선별, 화학적 돌연변이유발, "유전자 셔플링(gene shuffling)" 방법 또는 다른 수단을 이용하여 천연 일롱가제 유전자의 돌연변이 (여기서, 이러한 돌연변이는 결실, 삽입 및 점 돌연변이, 또는 이들의 조합을 포함할 수 있음)를 달성할 수 있다. 이것으로, 숙주 세포에서의 기능에 더욱 바람직한 물리적 및 역학적 파라미터를 갖는 생체내 지방산 일롱가제 활성, 예를 들어 보다 긴 반감기 또는 원하는 PUFA의 보다 높은 생산률을 보유하는 폴리펩티드가 생성될 수 있다. 또는, 원한다면, 통상의 돌연변이유발, 이로써 생성된 돌연변이체 폴리펩티드의 발현 및 이들의 활성 결정을 통해 효소 활성에 중요한 관심 폴리펩티드 영역을 결정할 수 있다. 이러한 기술에 대한 개요는 PCT 공개 제WO 2004/101757호에 기재되어 있다. EgD9e, EgD9eS, E389D9e 및 E389D9eS로부터 유래된 이러한 모든 돌연변이체 단백질 및 이들을 코딩하는 뉴클레오티드 서열은 본 발명의 범위에 속한다.
별법으로, 개선된 지방산은 본원에 기재한 임의의 Δ9 일롱가제 핵산 단편의 기능적 도메인이 별법의 일롱가제 유전자 내의 기능적 도메인과 교환되어 신규한 단백질이 생성되는 도메인 스와핑(swapping)으로 합성될 수 있다.
각종 ω-3 및/또는 ω-6 지방산의 생성 방법
본원에 기재한 Δ9 일롱가제 (즉, EgD9e, EgD9eS, E389D9e, E389D9eS 또는 다른 돌연변이체 효소, 코돈-최적화 효소 또는 그의 상동체)를 코딩하는 키메라 유전자를 적절한 프로모터의 제어하에 도입하면 형질전환된 숙주 유기체에서 EDA 및/또는 ETrA 각각의 생성이 증가될 것으로 예상된다. 이와 같이, 본 발명은 지방산 기질 (즉, LA 및/또는 ALA)을 본원에 기재한 일롱가제 효소 (예컨대, EgD9e, EgD9eS, E389D9e, E389D9eS)와 접촉시켜서, 상기 기질이 원하는 지방산 생성물 (즉, EDA 및/또는 ETrA)로 전환되도록 하는 것을 포함하는, PUFA의 직접적인 생성 방법을 포함한다.
더욱 구체적으로, 본 발명의 목적은
a) (1) 클러스탈 브이 정렬 방법을 기초로 하여 서열 2 (EgD9e) 또는 서열 5 (E389D9e)에 기재된 바와 같은 아미노산 서열과 비교할 때 70% 이상의 아미노산 동일성을 가지며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열, 및
(2) 0.1× SSC, 0.1% SDS 중 65℃에서의 혼성화 및 2× SSC, 0.1% SDS를 사용한 세척 및 이후 0.1× SSC, 0.1% SDS를 사용한 세척의 엄격한 혼성화 조건하에서 서열 1 (EgD9e), 서열 3 (EgD9eS), 서열 4 (E389D9e) 또는 서열 6 (E389D9eS)에 기재된 바와 같은 뉴클레오티드 서열과 혼성화하며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열
로 구성된 군에서 선택된, Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 단리된 폴리뉴클레오티드 서열, 및
(ii) LA의 공급원
을 포함하는 숙주 세포 (예컨대, 유질 효모, 대두)에서의 EDA 생성 방법을 제공하는 것이고, 상기 숙주 세포는 Δ9 일롱가제가 발현되고 LA가 EDA로 전환되는 조건하에서 성장시키며, 상기 EDA는 임의로 회수된다.
본 발명의 별법의 실시양태에서, Δ9 일롱가제는 ALA를 ETrA로 전환시키는데 사용될 수 있다. 따라서, 본 발명은 ETrA의 생성 방법을 제공하고, 여기서의 숙주 세포는
a) (1) 클러스탈 브이 정렬 방법을 기초로 하여 서열 2 (EgD9e) 또는 서열 5 (E389D9e)에 기재된 바와 같은 아미노산 서열과 비교할 때 70% 이상의 아미노산 동일성을 가지며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열, 및
(2) 0.1× SSC, 0.1% SDS 중 65℃에서의 혼성화 및 2× SSC, 0.1% SDS를 사용한 세척 및 이후 0.1× SSC, 0.1% SDS를 사용한 세척의 엄격한 혼성화 조건하에서 서열 1 (EgD9e), 서열 3 (EgD9eS), 서열 4 (E389D9e) 또는 서열 6 (E389D9eS)에 기재된 바와 같은 뉴클레오티드 서열과 혼성화하며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열
로 구성된 군에서 선택된, Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 단리된 폴리뉴클레오티드 서열, 및
b) ALA의 공급원
을 포함하고, 상기 숙주 세포는 Δ9 일롱가제가 발현되고 ALA가 ETrA로 전환되는 조건하에서 성장시키며, 상기 ETrA는 임의로 회수된다.
별법으로, 본원에 기재한 각각의 Δ9 일롱가제 유전자 및 그의 상응하는 효소 생성물은 예를 들어 DGLA, ETA, ARA, EPA, DPA 및/또는 DHA를 비롯한 각종 ω-6 및 ω-3 PUFA의 생성에 간접적으로 이용될 수 있다 (도 1, PCT 공개 제WO 2004/101757호 참조). 지방산 기질이 원하는 지방산 생성물로 간접적으로 전환되는 ω-3/ω-6 PUFA의 간접적인 생성은 중간체 단계(들) 또는 경로 중간체(들)을 통해 일어난다. 따라서, 본원에 기재한 Δ9 일롱가제 (예컨대, EgD9e, EgD9eS, E389D9e, E389D9eS 또는 다른 돌연변이체 효소, 코돈-최적화 효소 또는 그의 상동체)는 PUFA 생합성 경로의 효소 (예컨대, Δ6 데새투라제, C18 /20 일롱가제, Δ17 데새투라제, Δ15 데새투라제, Δ9 데새투라제, Δ12 데새투라제, C14 /16 일롱가제, C16 /18 일롱가제, Δ5 데새투라제, Δ8 데새투라제, Δ4 데새투라제, C20 /22 일롱가제)를 코딩하는 추가의 유전자와 함께 발현되어 보다 긴 쇄의 ω-3/ω-6 지방산 (예컨대, ARA, EPA, DPA 및 DHA)의 생성 수준을 증가시킬 수 있다고 여겨진다.
바람직한 실시양태에서, 본 발명의 Δ9 일롱가제는 Δ8 데새투라제 (예컨대, 서열 61에 기재한 바와 같은 Δ8 데새투라제 [EgD8] 또는 서열 69에 기재한 바와 같은 코돈-최적화 Δ8 데새투라제 [EgD8S])와 함께 최소로 발현될 것이다. 그러나, 특정 발현 카세트에 포함되는 특정 유전자는 숙주 세포 (및 그의 PUFA 프로파일 및/또는 데새투라제/일롱가제 프로파일), 기질의 이용가능성 및 원하는 최종 생성물(들)에 따라 달라질 것이다.
별법의 실시양태에서, 숙주 유기체의 천연 Δ9 일롱가제를 본원에 기재한 완전 서열, 완전 서열의 상보체, 상기 서열의 상당 부분, 그로부터 유래된 코돈-최적화 일롱가제 및 그와 실질적으로 상동성인 서열을 기초로 하여 파괴하는 것이 유용할 수 있다.
식물 발현 시스템, 카세트 및 벡터, 및 형질전환
한 실시양태에서, 본 발명은 식물에서의 발현에 적합한 1종 이상의 조절 서열에 작동가능하게 연결된 본 발명의 임의의 한 Δ9 일롱가제 폴리뉴클레오티드를 포함하는 재조합 구축물에 관한 것이다.
프로모터는 식물의 세포내 기구가 해당 프로모터의 인접 코딩 서열 하류 (3')로부터 RNA를 생산하도록 지시하는 DNA 서열이다. 프로모터 영역은 유전자의 RNA 전사체가 생성되는 속도, 발생 단계 및 세포 유형에 영향을 준다. RNA 전사체는 프로세싱되어 RNA 서열을 코딩 폴리펩티드의 아미노산 서열로 번역하기 위한 주형으로 작용하는 mRNA를 생성한다. 5' 비-번역 리더 서열은 mRNA의 개시 및 번역에 소정의 역할을 할 수 있는 단백질 코딩 영역의 mRNA 상류 영역이다. 3' 전사 종결/폴리아데닐화 신호는 식물 세포에서 RNA 전사가 종결되고 폴리아데닐레이트 뉴클레오티드가 RNA의 3' 말단에 부가되도록 기능하는 단백질 코딩 영역의 비-번역 영역 하류이다.
Δ9 일롱가제 코딩 서열의 발현을 구동하도록 선택된 프로모터의 기원(origin)은, 그것이 정확한 시기에 원하는 숙주 조직에서 원하는 핵산 단편에 대한 번역가능한 mRNA를 발현함으로써 본 발명을 수행하기에 충분한 전사 활성을 지니는 한은 중요하지 않다. 이종 또는 비-이종 (즉, 내인성) 프로모터를 사용하여 본 발명을 실시할 수 있다. 예를 들어, 적합한 프로모터로는 β-콘글리시닌 프로모터의 α-프라임 서브유닛, 쿠니츠(Kunitz) 트립신 억제제 3 프로모터, 안넥신 프로모터, Gly1 프로모터, 베타-콘글리시닌 프로모터의 베타-서브유닛, P34/Gly Bd m 30K 프로모터, 알부민 프로모터, Leg A1 프로모터 및 Leg A2 프로모터 등이 있으나 이에 제한되지 않는다.
안넥신 또는 P34 프로모터는 PCT 공개 제WO 2004/071178호 (2004년 8월 26일자로 공개됨)에 기재되어 있다. 안넥신 프로모터의 활성 수준은 많은 공지된 강력한 프로모터, 예를 들어 (1) CaMV 35S 프로모터 ([Atanassova et al., Plant Mol. Biol., 37:275-285 (1998)], [Battraw and Hall, Plant Mol. Biol., 15:527-538 (1990)], [Holtorf et al., Plant Mol. Biol., 29:637-646 (1995)], [Jefferson et al., EMBO J., 6:3901-3907 (1987)], [Wilmink et al., Plant Mol. Biol., 28:949-955 (1995)]), (2) 아라비돕시스 올레오신 프로모터 ([Plant et al., Plant Mol. Biol., 25:193-205 (1994)], [Li, Texas A&M University Ph.D. dissertation, pp. 107-128 (1997)]), (3) 아라비돕시스 유비퀴틴 신장 단백질 프로모터 [Callis et al., J. Biol. Chem., 265(21):12486-93 (1990)], (4) 토마토 유비퀴틴 유전자 프로모터 [Rollfinke et al., Gene, 211(2):267-76 (1998)], (5) 대두 열 충격 단백질 프로모터 [Schoffl et al., Mol. Gen. Genet., 217(2-3):246-53 (1989)], 및 (6) 옥수수 H3 히스톤 유전자 프로모터 [Atanassova et al., Plant Mol. Biol., 37(2):275-85 (1989)]와 유사하다.
안넥신 프로모터의 또다른 유용한 특징은 발생 중인 종자 중에서의 그의 발현 프로파일이다. 안넥신 프로모터는 초기 단계의 발생 중인 종자에서 가장 활성이고 (수분 후 10일 전에), 후기 단계에서는 주로 휴면 상태이다. 안넥신 프로모터의 발현 프로파일은 발생 후기 단계에 흔히 최고의 활성을 나타내는 많은 종자-특이적 프로모터, 예를 들어 종자 저장 단백질 프로모터의 발현 프로파일과 상이하다 ([Chen et al., Dev. Genet., 10:112-122 (1989)], [Ellerstrom et al., Plant Mol. Biol., 32:1019-1027 (1996)], [Keddie et al., Plant Mol. Biol., 24:327-340 (1994)], [Plant et al., (상기 문헌)], [Li, (상기 문헌)]). 안넥신 프로모터는 보다 통상적인 발현 프로파일을 갖지만, 다른 공지된 종자 특이적 프로모터와는 여전히 구별된다. 따라서, 초기 발생 단계의 배아에서 유전자의 과다발현 또는 저해를 원하는 경우에 안넥신 프로모터는 매우 흥미로운 후보이다. 예를 들어, 초기 배아 발생을 조절하는 유전자 또는 종자 성숙 전의 대사에 관여하는 유전자의 과다발현이 바람직할 수 있다.
특정 Δ9 일롱가제 코딩 서열의 발현에 적합한 적절한 프로모터의 동정 후, 상기 프로모터는 당업자에게 널리 공지된 통상적인 수단을 이용하여 센스 배향으로 작동가능하게 연결된다.
본원에서 이용된 표준 재조합 DNA 및 분자 클로닝 기술은 당업계에 널리 공지되어 있고, 문헌 ([Sambrook, J. et al., In Molecular Cloning: A Laboratory Manual; 2nd ed.; Cold Spring Harbor Laboratory Press: Cold Spring Harbor, New York, 1989 (이하 "Sambrook et al., 1989")] 또는 [Ausubel, F. M., Brent, R., Kingston, R. E., Moore, D. D., Seidman, J. G., Smith, J. A. and Struhl, K., Eds.; In Current Protocols in Molecular Biology; John Wiley and Sons: New York, 1990 (이하 "Ausubel et al., 1990")])에 보다 상세하게 기재되어 있다.
일단 재조합 구축물이 생성되면, 이후에는 당업자에게 널리 공지된 방법 (예컨대, 형질감염, 형질전환 및 전기천공)에 의해 이것을 선택된 식물 세포로 도입할 수 있다. 유량종자 식물 세포가 바람직한 식물 세포이다. 이어서, 형질전환된 식물 세포를 배양하고, 장쇄 PUFA의 발현을 허용하는 적합한 조건하에 재생시킨 후에 임의로 회수 및 정제한다.
본 발명의 재조합 구축물은 식물 세포로 도입될 수도 있고, 또는 별법으로는 각 구축물이 별개의 식물 세포로 도입될 수도 있다.
식물 세포 중에서의 발현은 상기한 바와 같이 일시적 또는 안정적인 방식으로 달성될 수 있다.
원하는 장쇄 PUFA는 종자에서 발현될 수 있다. 또한, 본 발명의 범위 내에는 이러한 형질전환된 식물로부터 수득된 종자 또는 식물의 일부도 속한다.
식물의 일부는 뿌리, 줄기, 새순, 잎, 화분, 종자, 종양 조직 및 다양한 형태의 세포 및 배양물 (예컨대, 단일 세포, 원형질체, 배아 및 칼루스 조직)을 포함하지만 이에 제한되지 않는 분화 조직 및 미분화 조직을 포함한다. 식물 조직은 식물에 존재할 수도 있고, 또는 식물 기관, 조직 또는 세포 배양물에 존재할 수도 있다.
용어 "식물 기관"은 식물 조직 또는 식물의 형태적 및 기능적 별개의 부분을 구성하는 조직 군을 지칭한다. 용어 "게놈"은 1) 유기체의 각 세포 또는 바이러스 또는 세포소기관에 존재하는 유전자 물질 (유전자 및 비-코딩 서열)의 전체 상보체, 및/또는 2) 한쪽 부모로부터의 (반수체) 단위로 유전된 완전 세트의 염색체를 지칭한다.
따라서, 본 발명은 또한 세포를 본 발명의 재조합 구축물로 형질전환시키는 단계, 및 상기 재조합 구축물로 형질전환된 세포를 선별하는 단계를 포함하는, 세포의 형질전환 방법에 관한 것이기도 하다.
또한, 식물 세포를 본 발명의 Δ9 일롱가제 폴리뉴클레오티드로 형질전환시키는 단계, 및 상기 형질전환된 식물 세포로부터 식물을 재생시키는 단계를 포함하는, 형질전환된 식물의 생성 방법에도 관심이 있다.
쌍떡잎식물 (주로 아그로박테리움 투메파시엔스(Agrobacterium tumefaciens)를 사용함)을 형질전환하고 트랜스제닉 식물을 수득하는 방법은 특히 목화 (미국 특허 제5,004,83호, 미국 특허 제5,159,135호), 대두 (미국 특허 제5,569,834호, 미국 특허 제5,416,011호), 브라씨카 (미국 특허 제5,463,174호), 땅콩 ([Cheng et al., Plant Cell Rep., 15:653-657 (1996)], [McKently et al., Plant Cell Rep., 14:699-703 (1995)]), 파파야 [Ling, K. et al., Bio/technology, 9:752-758 (1991)] 및 완두 [Grant et al., Plant Cell Rep., 15:254-258 (1995)]에 대해 간행된 바 있다. 식물 형질전환에 통상적으로 사용되는 다른 방법을 검토하기 위해서는 문헌 [Newell, C.A. (Mol. Biotechnol., 16:53-65 (2000)]을 참조한다. 이러한 형질전환 방법 중 하나는 아그로박테리움 리조게네스(Agrobacterium rhizogenes) [Tepfler, M. and Casse-Delbart, F., Microbiol. Sci., 4:24-28 (1987)]를 이용한다. DNA의 직접 전달을 이용한 대두의 형질전환은 PEG 융합법 (PCT 공개 제WO 92/17598호), 전기천공법 ([Chowrira, G.M. et al., Mol. Biotechnol., 3:17-23 (1995)], [Christou, P. et al., Proc. Natl. Acad. Sci. USA, 84:3962-3966 (1987)]), 미세주입법 또는 입자 충격법(particle bombardment) ([McCabe, D.E. et al., Bio/Technology, 6:923 (1988)], [Christou et al., Plant Physiol., 87:671-674 (1988)])을 이용한 방법이 간행된 바 있다.
식물 조직으로부터 식물을 재생시키는 방법은 다양하다. 특정 재생 방법은 출발 식물 조직 및 재생시킬 특정 식물 종에 따라 달라질 것이다. 단일 식물 원형질체 형질전환체 또는 각종 형질전환된 외식편으로부터의 식물의 재생, 발생 및 배양은 당업계에 널리 공지되어 있다 [Weissbach and Weissbach, In: Methods for Plant Molecular Biology, (Eds.), Academic: San Diego, CA (1988)]. 전형적으로, 이러한 재생 및 성장 과정은 형질전환된 세포의 선별 단계, 및 뿌리를 내린 묘목 단계를 거치는 통상적인 배아 발생 단계를 통해 상기 개개의 세포를 배양하는 단계를 포함한다. 트랜스제닉 배아 및 종자는 유사하게 재생된다. 이후, 이로써 생성된 뿌리를 내린 트랜스제닉 새순을 토양과 같은 적절한 식물 성장 매질에 심는다. 바람직하게는, 재생된 식물이 자가-수분되어 동형 트랜스제닉 식물을 제공한다. 또는, 재생된 식물에서 얻은 화분을 작물재배학적으로 중요한 식물류의 종자에서 성장한 식물과 교배시킨다. 반대로, 이들 중요한 식물류에서 얻은 화분을 사용하여 재생된 식물을 수분시킨다. 원하는 폴리펩티드를 함유하는 본 발명의 트랜스제닉 식물은 당업자에게 널리 공지된 방법으로 배양된다.
상기 논의한 절차에 추가하여, 전문인은 거대분자 (예컨대, DNA 분자, 플라스미드 등)의 구축, 조작 및 단리, 재조합 DNA 단편 및 재조합 발현 구축물의 생성, 및 클론의 스크리닝 및 단리를 위한 구체적인 조건 및 절차를 기재한 표준 참고 자료를 알고 있을 것이다. 예를 들어 문헌 ([Sambrook et al., Molecular Cloning: A Laboratory Manual, Cold Spring Harbor: NY (1989)], [Maliga et al., Methods in Plant Molecular Biology, Cold Spring Harbor: NY (1995)], [Birren et al., Genome Analysis: Detecting Genes, Vol.1, Cold Spring Harbor: NY (1998)], [Birren et al., Genome Analysis: Analyzing DNA, Vol.2, Cold Spring Harbor: NY (1998)], [Plant Molecular Biology: A Laboratory Manual, eds. Clark, Springer: NY (1997)])을 참조한다.
유량종자 식물의 예로는 대두, 브라씨카 종, 해바라기, 옥수수, 목화, 아마 및 잇꽃 등이 있으나 이에 제한되지 않는다.
20개 이상의 탄소 원자 및 5개 이상의 탄소-탄소 이중 결합을 갖는 PUFA의 예로는 ω-3 지방산, 예컨대 EPA, DPA 및 DHA 등이 있으나 이에 제한되지 않는다. 이러한 식물로부터 수득한 종자 뿐만이 아니라 이러한 종자로부터 수득한 오일 역시 본 발명의 범위에 속한다.
따라서, 한 실시양태에서, 본 발명은
a) Δ9 일롱가제 폴리펩티드를 코딩하며 1종 이상의 조절 서열에 작동가능하게 연결된 단리된 폴리뉴클레오티드를 포함하는 제1 재조합 DNA 구축물, 및
b) Δ4 데새투라제, Δ5 데새투라제, Δ6 데새투라제, Δ8 데새투라제, Δ9 데새투라제, Δ12 데새투라제, Δ15 데새투라제, Δ17 데새투라제, C14 /16 일롱가제, C16/18 일롱가제, C18 /20 일롱가제 및 C20 /22 일롱가제로 구성된 군에서 선택된 폴리펩티드를 코딩하며 1종 이상의 조절 서열에 작동가능하게 연결된 단리된 폴리뉴클레오티드를 포함하는 1종 이상의 추가의 재조합 DNA 구축물
을 포함하는 유량종자 식물에 관한 것이다.
이러한 추가의 데새투라제는 예를 들어 미국 특허 제6,075,183호, 동 제5,968,809호, 동 제6,136,574호, 동 제5,972,664호, 동 제6,051,754호, 동 제6,410,288호 및 PCT 공개 제WO 98/46763호, 동 제WO 98/46764호, 동 제WO 00/12720호 및 동 제WO 00/40705호에서 논의되어 있다.
부분적으로는, 사용되는 카세트의 조합 선택이 형질전환될 유량종자 식물 세포의 PUFA 프로파일 및/또는 데새투라제/일롱가제 프로파일 및 발현될 장쇄 PUFA(들)에 따라 달라진다.
또다른 측면에서, 본 발명은
(a) 식물 세포를 본 발명의 재조합 구축물로 형질전환시키는 단계, 및
(b) 장쇄 PUFA를 생성하는 형질전환된 세포를 선별하는 단계
를 포함하는, 식물 세포에서의 장쇄 PUFA 생성 방법에 관한 것이다.
또다른 측면에서, 본 발명은
(a) 대두 세포를,
(i) 1종 이상의 조절 서열에 작동가능하게 연결된 Δ9 일롱가제 폴리펩티드를 코딩하는 단리된 폴리뉴클레오티드, 및
(ii) Δ4 데새투라제, Δ5 데새투라제, Δ6 데새투라제, Δ8 데새투라제, Δ9 데새투라제, Δ12 데새투라제, Δ15 데새투라제, Δ17 데새투라제, C14 /16 일롱가제, C16 /18 일롱가제, C18 /20 일롱가제 및 C20 /22 일롱가제로 구성된 군에서 선택된 폴리펩티드를 코딩하며 1종 이상의 조절 서열에 작동가능하게 연결된 단리된 폴리뉴클레오티드를 포함하는 1종 이상의 추가의 재조합 DNA 구축물
을 포함하는 제1 재조합 DNA 구축물로 형질전환시키는 단계,
(b) 상기 단계 (a)의 형질전환된 세포로부터 대두 식물을 재생시키는 단계, 및
(c) 상기 단계 (b)의 식물로부터 수득되고, 형질전환되지 않은 대두 식물로부터 수득되는 종자에서의 PUFA 수준과 비교할 때 PUFA 수준이 변경된 종자를 선별하는 단계
를 포함하는, 대두 세포에서의 1종 이상의 PUFA 생성 방법에 관한 것이다.
특히 바람직한 실시양태에서, 1종 이상의 추가의 재조합 DNA 구축물은 Δ8 데새투라제 활성, 예를 들어 유글레나 그라실리스로부터 단리되고/되거나 유래된 서열 61 및 서열 69 기재의 Δ8 데새투라제 활성을 갖는 폴리펩티드를 코딩한다.
미생물 발현 시스템, 카세트 및 벡터, 및 형질전환
본원에 기재한 Δ9 일롱가제 유전자 및 유전자 생성물 (즉, EgD9e, EgD9eS, E389D9e, E389D9eS, 또는 다른 돌연변이체 효소, 코돈-최적화 효소 또는 그의 상동체)은 이종 미생물 숙주 세포, 특히 유질 효모 (예컨대, 야로위아 리폴리티카)의 세포에서도 생성될 수 있다. 재조합 미생물 숙주에서의 발현은 각종 PUFA 경로 중간체를 생성하거나, 새로운 생성물의 합성을 위해서 지금까지는 해당 숙주를 이용하여 가능하지 않았던, 숙주에 이미 존재하는 PUFA 경로를 조정하는데 유용할 수 있다.
미생물 발현 시스템 및 외래 단백질의 높은 수준 발현을 지시하는 조절 서열을 함유하는 발현 벡터는 당업자에게 널리 공지되어 있다. 이 중 임의의 것이 본 발명의 서열의 유전자 생성물 중 임의의 것의 생성을 위한 키메라 유전자를 구축하는데 사용될 수 있다. 이 경우, 이들 키메라 유전자는 형질전환을 통해 적절한 미생물에 도입되어 그의 코딩 효소의 높은 수준 발현을 제공할 수 있다.
적합한 미생물 숙주 세포의 형질전환에 유용한 벡터 또는 DNA 카세트는 당업계에 널리 공지되어 있다. 구축물에 존재하는 특정 서열의 선택은 원하는 발현 생성물 (상기 문헌), 숙주 세포의 특성, 및 형질전환된 세포 vs. 비-형질전환된 세포를 분리하는 제시된 수단에 따라 달라진다. 그러나, 상기 벡터 또는 카세트는 전형적으로 관련 유전자(들), 선별가능한 마커, 및 자율 복제 또는 염색체 통합을 허용하는 서열의 전사 및 번역을 지시하는 서열을 함유한다. 적합한 벡터는 전사 개시를 제어하는 유전자의 5' 영역 (예컨대, 프로모터) 및 전사 종결을 제어하는 DNA 단편의 3' 영역 (즉, 종결자)를 포함한다. 2가지 제어 영역 모두가 형질전환된 미생물 숙주 세포의 유전자에서 유래된 것이 가장 바람직하지만, 이러한 제어 영역이 생산 숙주로 선택된 특정 종에 천연인 유전자로부터 유래된 것일 필요는 없다는 것이 이해될 것이다.
원하는 미생물 숙주 세포에서 본 발명의 Δ9 일롱가제 ORF의 발현을 구동하는데 유용한 개시 제어 영역 또는 프로모터는 많으며, 당업자에게 공지되어 있다. 사실, 선택된 숙주 세포에서 이들 유전자의 발현을 지시할 수 있는 임의의 프로모터가 본 발명에 적합하다. 미생물 숙주 세포에서의 발현은 일시적 방식 또는 안정적인 방식으로 달성될 수 있다. 일시적 발현은 관심 유전자에 작동가능하게 연결된 조절가능한 프로모터의 활성을 유도하여 달성될 수 있다. 안정적인 발현은 관심 유전자에 작동가능하게 연결된 구성적 프로모터를 사용하여 달성될 수 있다. 예를 들어, 숙주 세포가 효모인 경우, 효모 세포에서 기능적이며 특히 해당 숙주 종에서 유래된 전사 및 번역 영역이 제공된다 (예를 들어, 야로위아 리폴리티카에서 사용하기에 바람직한 전사 개시 조절 영역에 대하여는, PCT 공개 제WO 2004/101757호 [미국 공개 2005-0136519-A1] 및 PCT 공개 제WO 2006/052870호 [미국 공개 2006-0115881-A1] 참조). 구성적 전사 또는 유도된 전사를 원하는지, 관심 ORF의 발현에 있어서 해당 프로모터의 효율, 구축의 용이성 등에 따라 수많은 조절 서열 중 임의의 하나가 사용될 수 있다.
번역 개시 코돈 'ATG' 주위의 뉴클레오티드 서열은 효모 세포에서의 발현에 영향을 주는 것으로 밝혀졌다. 원하는 폴리펩티드가 효모에서의 발현이 불량하다면, 최적의 유전자 발현이 달성되도록 하는 효율적인 효모 번역 개시 서열이 포함되도록 외인성 유전자의 뉴클레오티드 서열을 변형시킬 수 있다. 효모에서의 발현을 위해, 이것은 비효율적으로 발현된 유전자를 내인성 효모 유전자, 바람직하게는 고도로 발현되는 유전자에 프레임에 맞게(in-frame) 융합시켜서 상기 유전자를 부위-지정 돌연변이유발시켜 수행될 수 있다. 별법으로, 숙주에서의 컨센서스 번역 개시 서열을 결정하고 이 서열을 관심 숙주에서 최적으로 발현되도록 이종 유전자로 조작해 넣을 수 있다.
종결 영역은 개시 영역이 수득된 유전자 또는 다른 유전자의 3' 영역에서 유래될 수 있다. 많은 수의 종결 영역이 공지되어 있으며, 다양한 숙주에서 만족스럽게 기능한다 (이것들이 유래한 것과는 동일한 속과 종에서 이용할 경우와 상이한 속과 종에서 이용할 경우 둘다). 종결 영역은 통상적으로 임의의 특정 특성이 아니라 편의성의 측면에서 선택된다. 바람직하게는, 미생물 숙주가 효모 세포인 경우, 종결 영역은 효모 유전자 (특히 사카로마이세스, 쉬조사카로마이세스, 칸디다, 야로위아 또는 클루베로마이세스(Kluyveromyces))로부터 유래된다. γ-인터페론 및 α-2 인터페론을 코딩하는 포유동물 유전자의 3'-영역도 효모에서 기능하는 것으로 알려져 있다. 종결 제어 영역 역시 바람직한 숙주에 천연인 각종 유전자로부터 유래될 수 있다. 임의로, 종결 부위는 필요하지 않을 수도 있지만, 이것이 포함되는 것이 가장 바람직하다. 제한하려는 것은 아니지만, 본원에서의 개시내용에 유용한 종결 영역으로는 야로위아 리폴리티카 세포외 프로테아제 (XPR, 진뱅크 관리 번호: M17741)의 3' 영역의 약 100 bp, 아실-coA 옥시다제 (Aco3, 진뱅크 관리 번호: AJ001301 및 CAA04661; Pox3, 뱅크 관리 번호: XP_503244) 종결자, Pex20 (진뱅크 관리 번호: AF054613) 종결자, Pex16 (진뱅크 관리 번호: U75433) 종결자, Lip1 (진뱅크 관리 번호: Z50020) 종결자, Lip2 (진뱅크 관리 번호: AJ012632) 종결자, 및 3-옥소아실-coA 티올라제 (OCT, 진뱅크 관리 번호: X69988) 종결자 등이 있다.
당업자가 알고 있는 바와 같이, 유전자를 클로닝 벡터에 단지 삽입하는 것으로는 그것이 필요한 수준만큼 성공적으로 발현될 것이라고 보장하지 못한다. 높은 발현율에 대한 필요에 따라, 전사, 번역, 단백질 안정성, 산소 제한 및 미생물 숙주 세포로부터의 분비 측면을 제어하는 수많은 여러가지 유전자 요소를 조작하여 많은 특수 발현 벡터가 생성되었다. 더욱 구체적으로, 유전자 발현을 제어하도록 조작된 일부 분자적 특성은 1) 관련 전사 프로모터 및 종결자 서열의 특성, 2) 클로닝된 유전자의 카피 수, 상기 유전자가 플라스미드에 보유된 것인지 또는 숙주 세포의 게놈에 통합된 것인지의 여부, 3) 합성된 외래 단백질의 최종적인 세포내 위치, 4) 숙주 유기체에서 단백질의 번역 및 올바른 폴딩의 효율, 5) 숙주 세포 중 클로닝된 유전자의 mRNA 및 단백질의 내재적 안정성, 및 6) 숙주 세포에서 선호되는 코돈 사용 빈도와 근접한, 클로닝된 유전자에서의 코돈 사용을 포함한다. 이러한 각 유형의 변형은 본원에 기재한 Δ9 일롱가제의 발현을 추가로 최적화하는 수단으로서 본 발명에 포함된다.
적절한 미생물 숙주 세포 (예컨대, 유질 효모)에서의 발현에 적합한 폴리펩티드를 코딩하는 DNA가 일단 수득되면 (예컨대, 프로모터, ORF 및 종결자를 포함하는 키메라 유전자), 이것을 숙주 세포에서 자율 복제할 수 있는 플라스미드 벡터 내에 위치시키거나 또는 숙주 세포의 게놈 내로 직접 통합시킨다. 발현 카세트의 통합은 숙주 게놈 내에서 무작위로 일어날 수도 있고, 또는 숙주 유전자좌 내에서의 재조합을 표적화하기에 충분할 만큼 숙주 게놈과 상동성인 영역을 함유하는 구축물을 사용함으로써 표적화할 수도 있다. 구축물이 내인성 유전자좌를 표적화하는 경우에는, 전사 및 번역 조절 영역의 전부 또는 일부가 내인성 유전자좌에 의해 제공될 수 있다.
본 발명에서, 야로위아 리폴리티카에서의 유전자 발현에 바람직한 방법은 선형 DNA를 숙주 게놈으로 통합시키는 것이고, 유전자의 높은 수준 발현을 원하는 경우에는 게놈 내 여러 위치로 통합시키는 것이 특히 유용할 수 있다. 이러한 목적을 위해서, 게놈 내에서 다중 카피로 존재하는 서열을 동정하는 것이 바람직하다.
문헌 [Schmid-Berger et al., J. Bact., 176(9):2477-2482 (1994)]은 야로위아 리폴리티카에서 제1 레트로트랜스포손-유사 요소를 발견하였다. 이 레트로트랜스포손은 제타 영역이라 불리는 장쇄 말단 반복부 (LTR, 각각이 대략 700 bp 길이임)가 존재하는 것을 특징으로 한다. Ylt1 및 solo 제타 요소는 게놈 내에서 산재된 방식으로 각각 게놈 1개 당 35개 카피 이상 및 게놈 1개 당 50개 내지 60개 카피로 존재하였다. 이들 2가지 요소 모두가 상동성 재조합 부위로 기능하는 것으로 결정되었다. 추가로, 문헌 [Juretzek et al., Yeast, 18:97-113 (2001)]의 연구는, 플라스미드를 효모 게놈의 반복 영역으로 표적화 (양 말단에 LTR 제타 영역을 갖는 선형 DNA를 사용함)하면 유전자 발현이 낮은 카피의 플라스미드 형질전환체를 이용하여 얻은 발현에 비하여 크게 증가될 수 있음을 입증하였다. 따라서, 제타-지시된 통합은 플라스미드 DNA가 야로위아 리폴리티카로 다수 통합되도록 하여 높은 수준의 유전자 발현을 허용하는 수단으로서 이상적일 수 있다. 그러나 불행히도, 야로위아 리폴리티카의 모든 균주가 제타 영역을 보유하는 것은 아니다 (예컨대, ATCC 관리 번호: #20362로 표시된 균주). 균주에 이러한 영역이 없는 경우에는 발현 카세트를 포함하는 플라스미드 DNA를 별법의 유전자좌에 통합시켜서 발현 카세트에 대하여 원하는 카피 수에 도달하게 하는 것도 가능하다. 예를 들어, 바람직한 별법의 유전자좌로는 Ura3 유전자좌 (진뱅크 관리 번호: AJ306421), Leu2 유전자 유전자좌 (진뱅크 관리 번호: AF260230), Lys5 유전자 (진뱅크 관리 번호: M34929), Aco2 유전자 유전자좌 (진뱅크 관리 번호: AJ001300), Pox3 유전자 유전자좌 (Pox3:진뱅크 관리 번호: XP_503244, 또는 Aco3, 진뱅크 관리 번호: AJ001301), Δ12 데새투라제 유전자 유전자좌 (PCT 공개 제WO 2004/104167호), Lip1 유전자 유전자좌 (진뱅크 관리 번호: Z50020) 및/또는 Lip2 유전자 유전자좌 (진뱅크 관리 번호: AJ012632) 등이 있다.
유리하게는, Ura3 유전자를 5-플루오로오로트산 (5-플루오로우라실-6-카르복실산 일수화물, "5-FOA") 선별 (하기함)과 병행하여 반복적으로 사용하여 유전자 변형체가 야로위아 게놈으로 편한 방식으로 쉽게 통합되도록 할 수 있다.
2종 이상의 유전자를 별개의 복제 벡터로부터 발현시키는 경우에는, 각 벡터가 상이한 선별 수단을 갖는 것이 바람직하며, 안정적인 발현을 유지하고 구축물들 사이에서의 요소의 재배열을 방지하기 위해 다른 구축물(들)과의 상동성은 결여되어야 한다. 조절 영역, 선별 수단 및 도입된 구축물(들)의 증식 방법의 현명한 선택은, 도입된 모든 유전자가 원하는 생성물의 합성을 제공하는데 필요한 수준으로 발현되도록 실험적으로 결정할 수 있다.
관심 유전자를 포함하는 구축물은 임의의 표준 기술에 의해 미생물 숙주 세포로 도입될 수 있다. 이러한 기술로는 형질전환 (예컨대, 아세트산리튬 형질전환 [Methods in Enzymology, 194:186-187 (1991)]), 원형질체 융합, 볼리스트 충격(bolistic impact), 전기천공, 미세주입, 또는 관심 유전자를 숙주 세포 내로 도입하는 임의의 다른 방법 등이 있다. 유질 효모 (즉, 야로위아 리폴리티카)에 적용가능한 보다 구체적인 교시로는 미국 특허 제4,880,741호 및 미국 특허 제5,071,764호, 및 [Chen, D. C. et al., Appl. Microbiol. Biotechnol., 48(2):232-235 (1997)] 등이 있다.
편의상, DNA 서열을 취하는 임의의 방법 (예를 들어 발현 카세트)으로 조작하였던 숙주 세포는 본원에서 "형질전환체" 또는 "재조합체"라고 지칭할 것이다. 형질전환된 숙주는 발현 구축물의 1개 이상의 카피를 가질 것이며, 유전자가 게놈내로 통합되는지, 증폭되는지 아니면 다중 카피 수를 갖는 염색체외 요소 상에 존재하는지의 여부에 따라서 2개 이상의 카피를 가질 수 있다.
PCT 공개 제WO 2004/101757호 [미국 공개 2005-0136519-A1] 및 PCT 공개 제WO 2006/052870호 [미국 공개 2006-0115881-A1]에 기재된 바와 같이, 형질전환된 숙주 세포는 다양한 선별 기술로 확인할 수 있다. 본원에서 사용하기에 바람직한 선별 방법은 카나마이신, 하이그로마이신 및 아미노 글리코시드 G418에 대한 내성 뿐만이 아니라 우라실, 루이신, 리신, 트립토판 또는 히스티딘이 결여된 배지 상에서 성장할 수 있는 능력이다. 별법의 실시양태에서, 5-FOA는 효모 Ura- 돌연변이체의 선별에 사용된다. 상기 화합물은 오로티딘 5'-모노포스페이트 데카르복실라제 (OMP 데카르복실라제)를 코딩하는 기능적 URA3 유전자를 보유하는 효모 세포에는 독성이며, 따라서, 5-FOA는 이러한 독성을 기초로 하여 Ura- 돌연변이체 효모 균주를 선별하고 동정하는데 특히 유용하다 [Bartel, P.L. and Fields, S., Yeast 2-Hybrid System, Oxford University: New York, v. 7, pp 109-147, 1997]. 더욱 구체적으로, 천연 Ura3 유전자를 우선 넉아웃(knockout)시켜서 Ura- 표현형을 갖는 균주를 생성할 수 있으며, 이때의 선별은 5-FOA 내성을 기초로 한다. 이후, 다중 키메라 유전자의 클러스터 및 새로운 Ura3 유전자를 야로위아 게놈의 상이한 유전자좌로 통합시켜서 Ura+ 표현형을 갖는 새로운 균주를 생성할 수 있다. 도입된 Ura3 유전자가 넉아웃되는 경우, 이후의 통합은 새로운 Ura3- 균주 (다시, 5-FOA 선별을 이용하여 동정함)를 생성한다. 따라서, Ura3 유전자 (5-FOA 선별 이용)는 여러회의 형질전환에서 선별 마커로 사용될 수 있다.
형질전환 후, 본 발명의 Δ9 일롱가제 (및 임의로는 숙주 세포 내에서 동시 발현되는 다른 PUFA 효소)에 적합한 기질은 천연적 또는 트랜스제닉으로 숙주에 의해 생성될 수도 있고, 또는 이들이 외적으로 제공될 수도 있다.
본 발명의 유전자 및 핵산 단편의 발현을 위한 미생물 숙주 세포는, 광범위한 범위의 온도 및 pH 값에 걸쳐, 단순 또는 복합 탄수화물, 지방산, 유기 산, 오일 및 알콜, 및/또는 탄화수소를 비롯한 각종 공급원료상에서 성장하는 숙주를 포함할 수 있다. 본 발명에 기재된 유전자가 유질 효모 (및 특히 야로위아 리폴리티카)에서의 발현을 위해 단리되긴 하였지만, 전사, 번역 및 단백질 생합성 기구는 고도로 보존되는 것이기 때문에, 임의의 박테리아, 효모, 조류 및/또는 진균이 본 발명의 핵산 단편을 발현하는데 적합한 미생물 숙주라고 여겨진다.
그러나, 바람직한 미생물 숙주는 유질 효모이다. 이들 유기체는 천연적으로 오일을 합성하고 축적할 수 있는데, 이때의 오일은 세포 건조 중량의 약 25% 초과, 더욱 바람직하게는 세포 건조 중량의 약 30% 초과, 가장 바람직하게는 세포 건조 중량의 약 40% 초과를 차지할 수 있다. 전형적으로 유질 효모로 확인된 속으로는 야로위아, 칸디다, 로도토룰라, 로도스포리듐, 크립토콕쿠스, 트리코스포론 및 리포마이세스 등이 있으나 이에 제한되지 않는다. 더욱 구체적으로, 오일을 합성하는 효모의 예로는 로도스포리듐 토룰로이데스(Rhodosporidium toruloides), 리포마이세스 스타르케이이(Lipomyces starkeyii), 엘. 리포페루스(L. lipoferus), 칸디다 레브카우피(Candida revkaufi), 씨. 풀케리마(C. pulcherrima), 씨. 트로피칼리스(C. tropicalis), 씨. 우틸리스(C. utilis), 트리코스포론 풀란스(Trichosporon pullans), 티. 쿠타네움(T. cutaneum), 로도토룰라 글루티누스(Rhodotorula glutinus), 알. 그라미니스(R. graminis), 및 야로위아 리폴리티카 (이전에는 칸디다 리폴리티카(Candida lipolytica)로서 분류되었음) 등이 있다.
가장 바람직한 것은 유질 효모 야로위아 리폴리티카이며, 추가의 실시양태에서 가장 바람직한 것은 ATCC #20362, ATCC #8862, ATCC #18944, ATCC #76982 및/또는 LGAM S(7)1로서 표시된 야로위아 리폴리티카 균주이다 [Papanikolaou S., and Aggelis G., Bioresour. Technol., 82(1):43-9 (2002)].
역사적으로, 다양한 균주의 야로위아 리폴리티카가 이소시트레이트 리아제, 리파제, 폴리히드록시알카노에이트, 시트르산, 에리트리톨, 2-옥소글루타르산, γ-데카락톤, γ-도데카락톤, 및 피루브산의 제조 및 생성에 사용되어 왔다. 야로위아 리폴리티카에서 ARA, EPA 및 DHA 생성을 조작하는데 적용가능한 구체적인 교시는 미국 특허 출원 제11/264784호 (PCT 공개 제WO 2006/055322호), 동 제11/265761호 (PCT 공개 제WO 2006/052870호) 및 동 제11/264737호 (PCT 공개 제WO 2006/052871호)에서 각각 제공된다.
다른 바람직한 미생물 숙주는 유질 박테리아, 조류 및 다른 진균을 포함하고, 이러한 광범위한 군의 미생물 숙주 중에서 특별한 관심이 있는 것은 ω-3/ω-6 지방산을 합성하는 미생물 (또는 그러한 목적을 위해서 유전자 조작될 수 있는 미생물 [예를 들어, 사카로마이세스 세레비지애와 같은 다른 효모])이다. 따라서, 예를 들어, 유도가능하거나 조절되는 프로모터의 제어하에 본 발명의 임의의 Δ9 일롱가제 유전자를 사용하여 모르티에렐라 알피나(Mortierella alpina) (ARA의 생성을 위해 상업적으로 사용됨)를 형질전환시키면, 증가된 양의 EDA를 합성할 수 있는 형질전환 유기체가 생성될 수 있고, Δ8 데새투라제 유전자가 동시 발현된다면 이것이 증가된 양의 DGLA로 전환될 수 있다. 모르티에렐라 알피나의 형질전환 방법은 문헌 [Mackenzie et al., Appl. Environ. Microbiol., 66:4655 (2000)]에 기재되어 있다. 유사하게, 트라우스토키트리알레스(Thraustochytriales) 미생물의 형질전환 방법은 미국 특허 제7,001,772호에 개시되어 있다.
상기한 교시내용을 기초로 하여, 본 발명은 한 실시양태에서
a) (i) Δ9 일롱가제 폴리펩티드를 코딩하며 1종 이상의 조절 서열에 작동가능하게 연결된 단리된 폴리뉴클레오티드를 포함하는 제1 재조합 DNA 구축물, 및
(ii) LA 또는 ALA 각각으로 구성된 일롱가제 기질의 공급원
을 포함하는 유질 효모를 제공하는 단계,
b) 적합한 발효가능한 탄소원의 존재하에 상기 단계 (a)의 효모를 성장시켜서, Δ9 일롱가제 폴리펩티드를 코딩하는 유전자를 발현시키고 LA를 EDA로 전환시키거나 ALA를 ETrA로 전환시키는 단계, 및
c) 임의로, 상기 단계 (b)의 EDA 또는 ETrA 각각을 회수하는 단계
를 포함하는, EDA 또는 ETrA 각각의 생성 방법에 관한 것이다.
기질 영양보급이 필요할 수 있다.
일부 바람직한 실시양태에서, Δ9 일롱가제를 코딩하는 유전자의 뉴클레오티드 서열은 서열 1 및 서열 4로 구성된 군에서 선택된다. 별법의 바람직한 실시양태에서, Δ9 일롱가제 폴리펩티드를 코딩하는 유전자의 뉴클레오티드 서열은 서열 3 (여기서, 106개 이상의 코돈이 서열 1에 비해 야로위아 중에서의 발현을 위해 최적화되어 있음)에 기재되어 있다. 또한, 다른 바람직한 실시양태에서, Δ9 일롱가제 폴리펩티드를 코딩하는 유전자의 뉴클레오티드 서열은 서열 6 (여기서, 113개 이상의 코돈이 서열 4에 비해 야로위아 중에서의 발현을 위해 최적화되어 있음)에 기재되어 있다.
물론, 유질 효모에서 천연적으로 생성된 PUFA는 18:2 지방산 (즉, LA) 및 덜 통상적으로는 18:3 지방산 (즉, ALA)으로 한정되기 때문에, 본 발명의 더욱 바람직한 실시양태에서는 상기 유질 효모가 본원에 기재한 Δ9 일롱가제에 추가하여 장쇄 PUFA 생합성에 필요한 다중 효소를 발현 (이로써, 예를 들어 ARA, EPA, DPA 및 DHA의 생성이 가능해 짐)하도록 유전자 조작될 것이다.
구체적으로, 본 발명은 한 실시양태에서
a) Δ9 일롱가제 폴리펩티드를 코딩하며 1종 이상의 조절 서열에 작동가능하게 연결된 단리된 폴리뉴클레오티드를 포함하는 제1 재조합 DNA 구축물, 및
b) Δ4 데새투라제, Δ5 데새투라제, Δ6 데새투라제, Δ9 데새투라제, Δ12 데새투라제, Δ15 데새투라제, Δ17 데새투라제, Δ8 데새투라제, C14 /16 일롱가제, C16/18 일롱가제, C18 /20 일롱가제 및 C20 /22 일롱가제로 구성된 군에서 선택된 폴리펩티드를 코딩하며 1종 이상의 조절 서열에 작동가능하게 연결된 단리된 폴리뉴클레오티드를 포함하는 1종 이상의 추가의 재조합 DNA 구축물
을 포함하는 유질 효모에 관한 것이다.
특히 바람직한 실시양태에서, 1종 이상의 추가의 재조합 DNA 구축물은 Δ8 데새투라제 활성을 갖는 폴리펩티드, 예를 들어 유글레나 그라실리스로부터 단리되고/되거나 유래된 서열 61 및 서열 69 기재의 Δ8 데새투라제를 코딩한다.
미생물 중 ω-3 및/또는 ω-6 지방산 생합성의 대사 조작
생화학적 경로의 조작 방법은 당업자에게 널리 공지되어 있고, 유질 효모, 특히 야로위아 리폴리티카에서 ω-3 및/또는 ω-6 지방산 생합성을 최대화하는 수많은 조작이 가능할 것으로 예상된다. 여기에는 PUFA 생합성 경로 내에서 직접 대사를 조작할 필요가 있을 수도 있고, 또는 여러가지 다른 대사 경로의 조작이 추가로 조합될 필요가 있을 수도 있다.
PUFA 생합성 경로 내에서 조작하는 경우, ω-6 및/또는 ω-3 지방산의 생성이 증가될 수 있도록 LA의 생성을 증가시키는 것이 바람직할 수 있다. 이것은, Δ9 데새투라제 및/또는 Δ12 데새투라제를 코딩하는 유전자의 도입 및/또는 증폭에 의해 달성될 수 있다. ω-6 불포화 지방산의 생성을 최대화하기 위해서는 ALA가 실질적으로 없는 숙주 미생물에서 생성하는 것이 유리하다는 것은 당업자에게 널리 공지되어 있고, 따라서 숙주는 LA가 ALA로 전환되는 것을 허용하는 Δ15 또는 ω-3 유형 데새투라제 활성을 없애거나 억제함으로써 선별되거나 수득되는 것이 바람직하다. 내인성 데새투라제 활성은 예를 들어 (1) Δ15 데새투라제 전사 생성물에 안티센스 서열의 전사를 위한 카세트를 제공하거나, (2) 표적 유전자 전체 또는 일부의 삽입, 치환 및/또는 결실을 통해 Δ15 데새투라제 유전자를 파괴하거나, 또는 (3) Δ15 데새투라제 활성이 천연적으로 낮거나 없는 [또는 그러하도록 돌연변이된) 숙주 세포를 사용함으로써 감소시키거나 없앨 수 있다. 원치않는 데새투라제 경로의 억제는 예를 들어 미국 특허 제4,778,630호에 기재된 것과 같은 특정 데새투라제 억제제를 사용하여 달성될 수도 있다.
별법으로, ω-3 지방산의 생성을 최대화 (및 ω-6 지방산의 합성을 최소화)하는 것이 바람직할 수 있다. 이러한 예에서는, 올레산이 LA로 전환되도록 하는 Δ12 데새투라제 활성이 제거되거나 억제된 숙주 미생물을 이용할 수 있고, 이후에는 적절한 발현 카세트를 ALA의 ω-3 지방산 유도체 (예컨대, STA, ETrA, ETA, EPA, DPA, DHA)로 전환시키기에 적절한 기질 (예컨대, ALA)과 함께 숙주에 도입한다.
별법의 실시양태에서, 에너지 또는 탄소에 대하여 ω-3 및/또는 ω-6 지방산 생합성 경로와 경쟁하는 생화학적 경로 또는 특정 PUFA 최종 생성물의 생성을 저해하는 천연 PUFA 생합성 경로 효소는 유전자 파괴에 의해 제거될 수도 있고, 또는 다른 수단 (예컨대, 안티센스 mRNA)을 이용하여 하향조절될 수도 있다.
ARA, EPA 또는 DHA를 증가시키는 수단 (및 그의 관련 기술)으로서 PUFA 생합성 경로 내의 조작에 관한 상세한 논의는 PCT 공개 제WO 2006/055322호 [미국 특허 공개 제2006-0094092-A1호], PCT 공개 제WO 2006/052870호 [미국 특허 공개 제2006-0115881-A1호] 및 PCT 공개 제WO 2006/052871호 [미국 특허 공개 제2006-0110806-A1호] 각각에 TAG 생합성 경로 및 TAG 분해 경로에서의 바람직한 조작 (및 그의 관련 기술)으로 기재되어 있다.
본 발명의 내용에서, 상기한 전략 중 임의의 것을 이용하여 지방산 생합성 경로의 발현을 조정하는 것이 유용할 수 있다. 예를 들어, 본 발명은 Δ9 일롱가제/Δ8 데새투라제 생합성 경로에서의 핵심 효소를 코딩하는 유전자가 ω-3 및/또는 ω-6 지방산의 생성을 위해서 유질 효모에 도입되는 방법을 제공한다. 천연적으로 ω-3 및/또는 ω-6 지방산 생합성 경로를 보유하지 않고 이들 유전자의 발현을 조화시키지 않는 유질 효모에서 숙주 유기체의 대사 조작을 위한 각종 수단을 이용하여 바람직한 PUFA 생성물의 생성을 최대화하기 위해서 본 발명의 Δ9 일롱가제 유전자를 발현시키는 것이 특히 유용할 것이다.
PUFA
생성을 위한 미생물 발효 공정
형질전환된 미생물 숙주 세포는, 키메라 데새투라제 및 일롱가제 유전자의 발현을 최적화하고 원하는 PUFA를 가장 많이 가장 경제적인 수율로 생성시키는 조건하에 성장시킨다. 일반적으로, 최적화시킬 수 있는 배지 조건에는 탄소원의 유형 및 양, 질소원의 유형 및 양, 탄소:질소의 비율, 산소 수준, 성장 온도, pH, 생물집단(biomass) 생산기의 길이, 오일 축적기의 길이 및 세포 수확 시간 및 방법이 포함된다. 관심 미생물, 예컨대 유질 효모 (예컨대, 야로위아 리폴리티카)를 복합 배지 (예를 들어, 효모 추출물-펩톤-덱스트로스 브로쓰(broth) (YPD)), 또는 성장에 필요한 성분이 결여되어 있어서 원하는 발현 카세트가 선별되도록 하는 규정된 최소 배지 (예를 들어 미국 미시건주 디트로이트 소재의 디프코 래버러토리즈(DIFCO Laboratories))에서 성장시킨다.
본 발명에서의 발효 배지는 적합한 탄소원을 함유해야 한다. 적합한 탄소원으로는 단당류 (예를 들어 글루코스, 프럭토스), 이당류 (예를 들어 락토스, 수크로스), 올리고당류, 다당류 (예를 들어 전분, 셀룰로스 또는 이들의 혼합물), 당 알콜 (예를 들어 글리세롤), 또는 재생가능한 공급원료로부터의 혼합물 (예를 들어 유장 투과물, 옥수수 침유, 사탕무 당밀, 보리 맥아) 등을 들 수 있으나 이에 제한되지 않는다. 추가로, 탄소원에는 알칸, 지방산, 지방산의 에스테르, 모노글리세리드, 디글리세리드, 트리글리세리드, 인지질, 및 식물성 오일 (예를 들어 대두유) 및 동물 지방을 비롯한 각종 시판 지방산 공급물이 포함될 수 있다. 탄소원에는 핵심적인 생화학적 중간체로의 대사 전환이 입증된 바 있는 1-탄소원 (예를 들어, 이산화탄소, 메탄올, 포름알데히드, 포르메이트 및 탄소-함유 아민)이 포함될 수 있다. 따라서, 본 발명에서 사용되는 탄소원은 광범위하게 다양한 탄소-함유 공급원을 포함할 수 있고 숙주 유기체의 선택에 의해서만 제한될 것으로 여겨진다. 바람직한 탄소원은 당, 글리세롤, 및/또는 지방산이다. 가장 바람직한 것은 글루코스 및/또는 10개 내지 22개 탄소를 함유하는 지방산이다.
질소는 무기 공급원 (예를 들어 (NH4)2SO4) 또는 유기 공급원 (예를 들어 우레아 또는 글루타메이트)으로부터 제공될 수 있다. 적절한 탄소원과 질소원 이외에도, 발효 배지는 적합한 광물질, 염, 보조인자, 완충제, 비타민, 및 유질 숙주의 성장과 PUFA 생성에 필요한 효소 경로의 촉진에 적합한 것으로 당업자에게 공지된 기타 성분도 함유해야 한다. 지질과 PUFA의 합성을 촉진시키는 몇가지 금속 이온 (예를 들어 Mn+2, Co+2, Zn+2, Mg+2)에 특히 주목해야 한다 [Nakahara, T. et al., Ind. Appl. Single Cell Oils, D. J. Kyle and R. Colin, eds. pp 61-97 (1992)].
본 발명에서 바람직한 성장 배지는 상업적으로 제조된 통상의 배지, 예를 들어 효모 질소 기재 (미국 미시건주 디트로이트 소재의 디프코 래보러토리즈)이다. 기타 규정된 성장 배지 또는 합성 성장 배지를 사용할 수도 있고, 형질전환체 숙주 세포의 성장에 적절한 배지는 미생물학 또는 발효 과학 분야의 전문가에게 공지되어 있을 것이다. 전형적으로, 발효에 적합한 pH 범위는 약 pH 4.0 내지 pH 8.0이며, pH 5.5 내지 pH 7.5가 초기 성장 조건의 범위로서 바람직하다. 발효는 호기성 또는 혐기성 조건하에 수행할 수 있으며, 미호기성(microaerobic) 조건이 바람직하다.
전형적으로, 높은 수준의 PUFA가 유질 효모 세포에 축적되기 위해서는 2-단계 공정이 필요한데, 이는 대사 상태가 성장과 지방의 합성/저장 사이에서 "균형을 맞춰"야만 하기 때문이다. 따라서, 가장 바람직하게는, 유질 효모 (예컨대, 야로위아 리폴리티카)에서 PUFA를 생성시키기 위해 2-단계 발효 공정이 필요하다. 이러한 접근법은 다양한 적합한 발효 공정 디자인 (즉, 회분식, 유가식(fed-batch) 및 연속식) 및 성장 동안의 고려사항 등에 대하여 PCT 공개 제WO 2004/101757호에 기재되어 있다.
PUFA
오일의 정제 및 가공
PUFA는 숙주 미생물 및 식물에서 유리 지방산으로 존재할 수도 있고, 또는 아실글리세롤, 인지질, 술포지질 또는 당지질과 같은 에스테르화 형태로 존재할 수도 있으며, 당업계에 널리 공지된 각종 수단을 통해 숙주 세포로부터 추출할 수 있다. 효모 지질에 대한 추출 기술, 품질 분석 및 허용 기준에 관한 검토 중 하나가 문헌 [Z Jacobs, Critical Reviews in Biotechnology, 12(5/6):463-491 (1992)]이다. 하류 가공에 관한 간단한 검토는 또한 문헌 [A Singh and O Ward, Adv. Appl. Microbiol., 45:271-312 (1997)]에서도 찾을 수 있다.
일반적으로, PUFA를 정제하기 위한 수단으로는 유기 용매를 사용한 추출, 초음파 처리, 초임계 유체 추출 (예를 들어, 이산화탄소를 사용함), 비누화 및 물리적 수단, 예를 들어 압착, 또는 이들의 조합 등을 들 수 있다. 보다 상세한 사항에 대하여는 PCT 공개 제WO 2004/101757호의 교시내용을 참조한다.
종자 오일의 단리 방법은 당업계에 널리 공지되어 있다 ([Young et al., Processing of Fats and Oils, In The Lipid Handbook, Gunstone et al., eds., Chapter 5, pp 253-257], [Chapman & Hall: London (1994)]). 예를 들어, 대두유는 오일-함유 종자로부터의 식용 오일 생성물을 추출 및 정제하는 것을 수반하는 일련의 단계들을 이용하여 생성된다. 대두유 및 대두 부산물은 하기 표 5에 나타낸 일반화된 단계를 이용하여 생성된다:
| 가공 단계 | 가공 | 제거된 불순물 및/또는 수득된 부산물 |
| #1 | 대두 종자 | |
| #2 | 오일 추출 | 가루 |
| #3 | 탈고무화(degumming) | 레시틴 |
| #4 | 알칼리 또는 물리적 정련(refining) | 고무, 유리 지방산, 안료 |
| #5 | 물 세척 | 비누 |
| #6 | 표백 | 착색제, 비누, 금속 |
| #7 | (수소화) | |
| #8 | (윈터리제이션 (winterization)) | 스테아린 |
| #9 | 탈취 | 유리 지방산, 토코페롤, 스테롤, 휘발물질 |
| #10 | 오일 생성물 |
더욱 구체적으로, 대두 종자를 세정, 조질화, 탈피 및 박편화시켜서 오일 추출 효율을 증가시킨다. 오일 추출은 통상적으로 용매 (예컨대, 헥산) 추출을 통해 달성되지만, 물리적 압력 및/또는 용매 추출의 조합으로 달성될 수도 있다. 이로써 생성된 오일을 조 오일이라고 부른다. 조 오일은, 인지질 및 수화되지 않은 트리글리세리드 분획 (대두유)으로부터의 분리를 용이하게 하는 기타 극성 및 중성 지질 복합체를 수화시켜서 탈고무화될 수 있다. 이로써 생성된 레시틴 고무는 다양한 식품 및 산업품에서 유화제 및 이형제 (즉, 항-고착제)로 사용되는 상업적으로 중요한 레시틴 생성물이 제조되도록 추가로 가공될 수 있다. 탈고무화된 오일은 불순물 (주로 유리 지방산, 안료 및 잔류 고무)을 제거하기 위해 추가로 정련될 수 있다. 정련은 유리 지방산과 반응하여 비누를 형성하고 조 오일 중의 포스파티드 및 단백질을 수화시키는 부식제를 첨가하여 달성된다. 물은 정련 동안 형성된 미량의 비누를 세척해 내는데 사용된다. 비누화물(soapstock) 부산물은 동물 사료에 직접 사용될 수도 있고, 또는 산성화시켜 유리 지방산을 회수할 수도 있다. 착색제는 대부분의 클로로필 및 카르테노이드 화합물을 제거하는 표백토를 사용한 흡착을 통해 제거된다. 정련된 오일은 수소화될 수 있으며, 이로써 다양한 용융 특성 및 텍스쳐(texture)를 갖는 지방이 생성된다. 윈터리제이션 (분획화)은 조심스럽게 제어되는 냉각 조건하에서의 결정화를 통해서 수소화 오일로부터 스테아린을 제거하는데 이용될 수 있다. 탈취 (주로 진공하의 증기 증류를 통해 수행함)는 마지막 단계이며, 오일에 냄새 또는 향을 부과하는 화합물을 제거하기 위해 디자인된 것이다. 다른 가치있는 부산물, 예컨대 토코페롤 및 스테롤은 탈취 공정 동안에 제거될 수 있다. 이러한 부산물을 함유하는 탈취된 증류물질은 천연 비타민 E 및 다른 고가의 제약 생성물 생성을 위해 판매될 수 있다. 정련, 표백 (수소화, 분획화) 및 탈취된 오일 및 지방은 포장되어 바로 판매될 수도 있고, 또는 더 특수한 생성물로 추가 가공될 수도 있다. 대두 종자 가공, 대두유 생성 및 부산물 이용에 관한 보다 상세한 언급은 문헌 [Erickson, Practical Handbook of Soybean Processing and Utilization, The American Oil Chemists' Society and United Soybean Board (1995)]에서 찾을 수 있다. 대두유는 오일, 예컨대 코코넛, 팜, 팜 커넬 및 코코아 버터와 비교할 때 포화 지방산 함량이 비교적 낮아서 실온에서 액체이다.
정련되고/되거나 정제된 PUFA를 함유하는 식물 및 미생물 오일은 수소화될 수 있으며, 이로써 다양한 용융 특성 및 텍스쳐를 갖는 지방이 생성된다. 많은 가공 지방 (스프레드, 제과용 지방, 하드 버터, 마가린, 베이킹 쇼트닝 등)은 실온에서의 고화도 정도가 다양할 것이 요구되며, 공급원 오일의 물리적 성질을 변경시켜야만 생성될 수 있다. 이것은 가장 통상적으로는 촉매적 수소화를 통해 달성된다.
수소화는 니켈과 같은 촉매의 보조하에 수소가 불포화 지방산 이중 결합에 첨가되는 화학 반응이다. 예를 들어, 올레산 고함량 대두유는 불포화 올레산, LA 및 리놀렌산 지방산을 함유하며, 이들 각각은 수소화될 수 있다. 수소화는 2가지 주요 효과를 갖는다. 첫째, 불포화 지방산 함량의 감소로 인해 오일의 산화적 안정성이 증가된다. 둘째, 지방산 변형이 용융점을 증가시켜서 실온에서 반-액체 또는 고체인 지방이 되기 때문에 오일의 물리적 성질이 변화된다.
수소화 반응에 영향을 미치고 따라서 최종 생성물의 조성을 변경시키는 변수는 많이 있다. 압력, 온도, 촉매 유형 및 농도, 교반 및 반응기 디자인 등을 비롯한 작업 조건은 제어될 수 있는 보다 중요한 파라미터이다. 덜 불포화된 지방산보다 더 불포화된 지방산을 수소화하는데에는 선택적인 수소화 조건이 이용될 수 있다. 매우 적은 정도 또는 약간의 수소화는 액체 오일의 안정성을 증가시키는데 흔히 이용된다. 추가의 수소화는 액체 오일을 물리적으로 고체인 지방으로 전환시킨다. 수소화 정도는 특정 최종 생성물을 위해 디자인된 원하는 성능 및 용융 특징에 따라 달라진다. 수소화로 달성될 수 있는 수많은 오일 및 지방 생성물에는 액체 쇼트닝 (베이킹 생성물의 제조에 사용됨. 고체 지방 및 쇼트닝은 상업적으로 튀기고 볶는 작업에 사용됨), 및 마가린 제조를 위한 베이스 스톡(base stock)이 포함된다. 수소화 및 수소화 생성물에 관한 보다 상세한 설명은 문헌 [Patterson, H. B. W., Hydrogenation of Fats and Oils: Theory and Practice. The American Oil Chemists' Society (1994)]에서 찾을 수 있다.
수소화 오일은 수소화 과정으로 인한 트랜스-지방산 이성질체의 존재로 인해 약간 논쟁거리가 되어 왔다. 트랜스-이성질체의 다량 섭취는 혈액 혈장 중 저밀도:고밀도 지단백질의 비율 증가 및 관상 심장 질환의 위험도 증가 등을 비롯하여 건강에 대한 해로운 영향과 관련이 있다.
식품에 사용하기 위한
PUFA
-함유 오일
시장은 현재 ω-3 및/또는 ω-6 지방산 (특히 ARA, EPA 및 DHA)을 혼입한 매우 다양한 식품 및 사료 제품을 선호하고 있다. PUFA를 포함하는 본 발명의 식물/종자 오일, 변경된 종자 및 미생물 오일은 식품 및 사료 제품에서 이들 제제의 건강상의 이점을 부여하는 기능을 한다고 여겨진다. 다른 식물성 오일과 비교할 때, 본 발명의 오일은 물리적 관점에서 볼 때 식품에 사용된 다른 오일과 유사하게 기능할 것으로 여겨진다 (예를 들어 대두유와 같은 부분적 수소화 오일은 베이킹하고 튀기기 위한 소프트 스프레드, 마가린 및 쇼트닝의 성분으로 널리 사용됨).
본원에 기재한 ω-3 및/또는 ω-6 지방산을 함유하는 식물/종자 오일, 변경된 종자 및 미생물 오일은 식품 유사물, 육류 제품, 시리얼 제품, 스낵 식품, 베이킹 식품 및 유제품을 포함하지만 이에 제한되지 않는 다양한 식품 및 사료 제품에 사용하기에 적합할 것이다. 추가로, 본 발명의 식물/종자 오일, 변경된 종자 및 미생물 오일은 의료용 영양제, 식이 보조제, 유아용 조제식 뿐만이 아니라 제약 생성물 등을 비롯한 의료용 식품에 건강상의 이점을 부여하기 위한 제제에 사용될 수 있다. 식품 가공 및 식품 제조 업계의 당업자는 소정량과 소정의 조성을 갖는 식물 및 미생물 오일이 식품 또는 사료 제품에 첨가될 수 있는 방법을 이해할 것이다. 이러한 양을 본원에서는 "유효량"이라 지칭할 것이고, 이것은 해당 생성물이 보충하도록 의도된 음식물인 식품 또는 사료 제품, 또는 해당 의료용 식품 또는 의료용 영양제가 보완하거나 처치되도록 의도된 의학적 상태에 따라 달라질 것이다.
식품 유사물은 당업자에게 널리 공지된 공정을 이용하여 제조될 수 있다. 육류 유사물, 치즈 유사물, 유류 유사물(milk analog) 등을 언급할 수 있다. 대두로 제조된 육류 유사물은 콩 단백질 또는 두부 및 다양한 종류의 육류를 모방하기 위해 한데 혼합된 기타 성분들을 함유한다. 이들 육류 대안물은 냉동 식품, 통조림 식품 또는 건조 식품으로 판매된다. 통상적으로, 이들은 이것들이 대체할 식품과 동일한 방식으로 사용될 수 있다. 대두로 제조된 육류 대안물은 단백질, 철 및 B 비타민의 우수한 공급원이다. 육류 유사물의 예로는 햄 유사물, 소시지 유사물, 베이컨 유사물 등이 있으나 이에 제한되지 않는다.
식품 유사물은 그의 기능적 특징과 조성적 특징에 따라 모방물(imitiation) 또는 대용물로 분류될 수 있다. 예를 들어, 모방 치즈(imitation cheese)는 그것이 대체하도록 디자인된 치즈와 닮기만 하면 된다. 그러나, 그 생성물이 대체한 치즈와 영양상 동등하고 그 치즈에 대한 최소의 조성 요건을 대신하여 충족시키기만 한다면, 그러한 생성물은 일반적으로 대용 치즈라 불릴 수 있다. 따라서, 대용 치즈는 흔히 모방 치즈보다 단백질 수준이 더 높을 것이고 비타민 및 광물질이 강화되어 있을 것이다.
유류 유사물 또는 비-유제품으로는 모방유(imitation milk) 및 비-유제품의 냉동 디저트 (예컨대, 대두 및/또는 콩 단백질 생성물로부터 제조된 것) 등이 있으나 이에 제한되지 않는다.
육류 제품은 매우 다양한 생성물을 포함한다. 미국에서는, "육류"가 소, 돼지 및 양에서 얻은 "살코기"를 포함한다. 살코기에 추가하여, 닭, 칠면조, 거위, 뿔닭, 오리 등을 비롯한 가금류 품목 및 어류와 조개류도 있다. 조미되고 가공된 육류 제품은 광범위하게 분류된다: 날 것, 보존처리되고 튀긴 것, 및 보존처리되고 요리된 것. 소시지 및 핫도그는 가공 육류 제품의 예이다. 따라서, 본원에서 사용된 바와 같이, 용어 "육류 제품"은 가공 육류 제품을 포함하지만 이에 제한되지 않는다.
시리얼 식품은 시리얼 곡물을 가공하여 유래된 식품이다. 시리얼 곡물은 식용 곡물 (종자)을 생산하는 목초류(grass family)에 속하는 임의의 식물을 포함한다. 가장 대중적인 곡물은 보리, 옥수수, 기장, 귀리, 키누아(quinoa), 쌀, 호밀, 사탕수수, 라이밀, 밀 및 야생미이다. 시리얼 식품의 예로는 전곡(whole grain), 분쇄 곡물, 그릿, 밀가루, 겨, 배아(germ), 아침식사용 시리얼, 압출 식품, 파스타 등이 있으나 이에 제한되지 않는다.
베이킹 제품은 상기 언급한 임의의 시리얼 식품을 포함하며, 베이킹된 것이거나 베이킹과 유사한 방식으로 가공된 것, 즉 열을 가하여 건조 또는 경화시킨 것이다. 베이킹 제품의 예로는 빵, 케이크, 도넛, 바아(bar), 파스타, 빵가루, 베이킹 스낵, 미니-비스킷, 미니-크래커, 미니-쿠키, 및 미니-프레첼 등이 있으나 이에 제한되지 않는다. 상기 언급한 바와 같이, 본 발명의 오일이 성분으로 사용될 수 있다.
스낵 식품은 상기하거나 하기한 임의의 식품을 포함한다.
튀긴 식품은 상기하거나 하기한 임의의 튀긴 식품을 포함한다.
건강 식품은 건강상의 이익을 부여하는 임의의 식품이다. 많은 유량종자-유래의 식품이 건강 식품으로 간주될 수 있다.
음료는 액체 또는 건조 분말 형태일 수 있다.
예를 들어, 과일 주스 (신선한 것, 냉동된 것, 캔에 들어 있거나 농축된 것), 향미료가 첨가되거나 첨가되지 않은 유류 드링크 등과 같은 비-탄산 드링크가 언급될 수 있다. 성인 및 유아용 영양 조제식은 당업계에 널리 공지되어 있으며 시판되고 있다 (예컨대, 시밀락(Similac)®, 엔슈어(Ensure)®, 제비티(Jevity)®, 및 알리멘툼(Alimentum)®, 애보트 래버러토리즈(Abbott Laboratories), 로스 프로덕츠 디비전(Ross Products Division)).
유아용 조제식은 유아 및 어린이에게 공급되는 액체 또는 재구성된 분말이다. 본원에서, "유아용 조제식"은 젖먹이 유아에서 인간 모유를 대체할 수 있는 소장 영양 생성물로 정의되며, 전형적으로 수용액 중 원하는 비율(%)의 탄수화물 및 단백질과 혼합된 원하는 비율(%)의 지방으로 이루어진다 (예를 들어 미국 특허 제4,670,285호 참조). 전 세계적인 조성 연구 및 전문가 그룹에 의해 규명된 수준을 기초로 할 때, 평균적인 인간 모유는 전형적으로 전체 지방산을 약 0.20% 내지 0.40%로 함유하며 (지방 칼로리의 약 50%로 추정됨), DHA:ARA의 비율은 일반적으로 약 1:1 내지 1:2의 범위이다 (예컨대, 엔파밀 리필™(Enfamil LIPIL™) [미드 존슨 앤드 컴파니(Mead Johnson & Company)] 및 시밀락 어드밴스™(Similac Advance™) [애보트 래버러토리즈, 로스 프로덕츠 디비젼]의 제제 참조). 유아용 조제식은 흔히 유아를 위한 유일한 영양 공급원이기 때문에, 유아용 조제식은 유아의 음식에서 특별한 역할을 하며, 유아에게는 모유수유가 여전히 최상의 영양공급책이지만 유아용 조제식은 아기가 생존만 하게 하는 것이 아니라 성장하도록 하는데도 충분한 차선책이다.
유제품은 유류로부터 유래된 생성물이다. 유류 유사물 또는 비-유제품은 유류 이외의 공급원, 예를 들어 앞서 논의한 두유에서 유래된다. 이러한 생성물로는 전유(全乳), 탈지유, 발효유 제품, 예컨대 요구르트 또는 산미유(酸味乳), 크림, 버터, 연유, 탈수유(dehydrated milk), 커피 화이트너, 커피 크리머, 아이스크림, 치즈 등이 있으나 이에 제한되지 않는다.
본 발명의 PUFA-함유 오일이 포함될 수 있는 추가의 식품으로는, 예를 들어 츄잉검, 제과류 및 프로스팅류(frostings), 젤라틴류 및 푸딩류, 경질 및 연질의 캔디, 잼 및 젤리, 과립화된 백설탕, 당 대용물, 달콤한 소스, 토핑류 및 시럽류, 및 건조 배합된 분말 혼합물 등이 있다.
건강 식품 및 의약품에 사용하기 위한
PUFA
-함유 오일
건강 식품은 건강상의 이익을 부여하는 임의의 식품이며, 기능성 식품, 의료용 식품, 의료용 영양제, 유아용 조제식 및 식이 보조제 등이 있다. 추가로, 본 발명의 식물/종자 오일, 변경된 종자 및 미생물 오일은 표준 제약 조성물에 사용될 수 있다. 예를 들어, 본 발명의 오일은 상기 언급한 임의의 식품에 쉽게 혼입되어 예를 들어 기능적 또는 의료용 식품을 생성할 수 있다. PUFA를 포함하는 보다 농축된 제제로는 인간 또는 인간 이외의 동물에서 식이 보조제로 사용될 수 있는 캡슐, 분말, 정제, 소프트겔, 겔캡, 액상 농축물 및 에멀젼 등이 있다.
동물 사료에 사용하기 위한
PUFA
-함유 오일
본원에서, 동물 사료는 일반적으로 인간 이외의 동물을 위한 사료로 사용되거나 그러한 사료에 혼합하기 위한 생성물로 정의된다. 본 발명의 식물/종자 오일, 변경된 종자 및 미생물 오일은 다양한 동물 사료 중의 성분으로서 사용될 수 있다.
보다 구체적으로, 본 발명의 오일은 애완동물 사료, 반추 동물 및 가금류 사료, 및 수산양식 사료 등을 포함하지만 이에 제한되지 않는 제품에 사용될 수 있다고 예측된다. 애완동물 사료는 애완동물 (예컨대, 개, 고양이, 새, 파충류, 설치류)에게 공급되도록 의도된 제품이고, 이러한 제품으로는 상기한 시리얼 및 건강 식품 뿐만이 아니라 육류 및 육류 부산물, 콩 단백질 생성물, 목초 및 건초 제품 (예컨대, 자주개자리, 큰조아재비, 귀리 또는 브롬 그래스, 야채) 등이 있다. 반추 동물 및 가금류 사료는 예를 들어 칠면조, 닭, 소 및 돼지에게 공급되도록 의도된 제품이다. 상기한 애완동물 사료와 마찬가지로, 이들 제품은 앞서 언급한 시리얼 및 건강 식품, 콩 단백질 생성물, 육류 및 육류 부산물, 및 목초 및 건초 제품을 포함할 수 있다. 수산양식 사료 (또는 "양식사료")는 담수 또는 해수 중에서 수상 유기체, 동물 및/또는 식물을 증식, 배양 또는 사육하는 양식에 사용되는 제품이다.
본 발명은 하기 실시예에서 추가로 설명되는데, 달리 언급하지 않는 한은 여기서의 부 및 백분율(%)은 중량부 및 중량%이고, 온도는 섭씨 온도이다. 이들 실시예가 본 발명의 바람직한 실시양태를 나타내는 것이긴 하지만 이는 오직 예시하는 것에 불과하다는 점을 이해해야 한다. 상기 논의 및 이들 실시예로부터, 당업자는 본 발명의 본질적 특성을 본 발명의 사상과 범위에서 벗어나지 않고 파악할 수 있을 것이고, 본 발명에 각종 변화와 변형을 가하여 여러 용도 및 조건에 적합하게 할 수 있다. 따라서, 본원에 나타내고 기재한 것에 추가하여 본 발명의 다양한 변형은 전술한 기재로부터 당업자에게 명백할 것이다. 이러한 변형 역시 청구의 범위에 포함되는 것으로 한다.
일반적인 방법
실시예에서 사용된 표준 재조합 DNA 및 분자 클로닝 기술은 당업계에 공지되어 있으며 하기 문헌에 기재되어 있다:

미생물 배양물의 유지 및 성장에 적합한 재료 및 방법은 당업계에 공지되어 있다. 하기하는 실시예에서 이용하기에 적합한 기술은 문헌 [Manual of Methods for General Bacteriology (Phillipp Gerhardt, R. G. E. Murray, Ralph N. Costilow, Eugene W. Nester, Willis A. Wood, Noel R. Krieg and G. Briggs Phillips, Eds), American Society for Microbiology: Washington, D.C. (1994)] 또는 [Thomas D. Brock in Biotechnology: A Textbook of Industrial Microbiology, 2nd ed., Sinauer Associates: Sunderland, MA (1989)]에 기재된 내용 등에서 찾을 수 있다. 달리 명시하지 않는 한은, 미생물 세포의 성장 및 유지에 이용되는 모든 시약, 제한 효소 및 재료는 알드리치 케미칼스(Aldrich Chemicals) (미국 위스콘신주 밀워키 소재), 디프코 래보러토리즈 (미국 미시건주 디트로이트 소재), 깁코/BRL (미국 메릴랜드주 가이터스버그 소재) 또는 시그마 케미칼 컴퍼니(Sigma Chemical Company) (미국 미주리주 세인트 루이스 소재)에서 구하였다. 전형적으로, 이. 콜라이(E. coli) 균주는 루리아 베르타니(Luria Bertani) (LB) 플레이트에서 37℃하에 성장시켰다.
일반적인 분자 클로닝은 표준 방법 [Sambrook et al., 상기 문헌]에 따라 수 행하였다. 벡터와 삽입물-특이적 프라이머의 조합물을 이용하여, 염료 종결자 기술 (미국 특허 제5,366,860호, 유럽 제272,007호)로 ABI 자동화 서열분석기에서 DNA 서열을 생성시켰다. 서열 교정(editing)은 시켄처(Sequencher) (미국 미시건주 앤 아버 소재의 진 코즈 코포레이션(Gene Codes Corporation)에서 수행하였다. 모든 서열은 양 방향으로 2배 이상의 적용 범위를 나타낸다. 유전자 서열의 비교는 디엔에이스타 소프트웨어 (미국 위스콘신주 매디슨 소재의 디엔에이스타, 인크.)를 사용하여 달성하였다.
사용된 약어의 의미는 하기와 같다: "sec"는 초(들)을 의미하고, "min"은 분(들)을 의미하고, "h"는 시간(들)을 의미하고, "d"는 일(들)을 의미하며, "㎕"는 마이크로리터(들)을 의미하고, "mL"는 밀리리터(들)을 의미하고, "L"는 리터(들)을 의미하고, "μM"은 마이크로몰 농도를 의미하며, "mM"은 밀리몰 농도를 의미하고, "M"은 몰 농도를 의미하며, "mmol"은 밀리몰(들)을 의미하고, "㎛ole"은 마이크로몰(들)을 의미하고, "g"은 그램(들)을 의미하고, "㎍"은 마이크로그램(들)을 의미하고, "ng"은 나노그램(들)을 의미하고, "U"는 유닛(들)을 의미하며, "bp"는 염기 쌍(들)을 의미하고, "kB"는 킬로염기(들)를 의미한다.
야로위아
리폴리티카의
형질전환 및 배양
ATCC 관리 번호 #20362, #76982 및 #90812의 야로위아 리폴리티카 균주는 아메리칸 타입 컬쳐 콜렉션 (미국 메릴랜드주 록크빌 소재)으로부터 구입하였다. 야로위아 리폴리티카 균주를 전형적으로 28℃하에 YPD 한천 (1% 효모 추출물, 2% 박토펩톤, 2% 글루코스, 2% 한천)에서 성장시켰다.
달리 언급되지 않는다면, 야로위아 리폴리티카의 형질전환은 문헌 [Chen, D. C. et al., Appl. Microbiol. Biotechnol., 48(2):232-235 (1997)]의 방법에 따라 수행하였다. 간략하게 설명하면, 야로위아를 YPD 플레이트에 스트리킹(streaking)하고 30℃에서 대략 18시간 동안 성장시켰다. 여러번의 많은 백금이량(loopful)의 세포를 플레이트에서 긁어내어 50% PEG (평균 MW 3350) 2.25 mL, 2 M 아세트산리튬 (pH 6.0) 0.125 mL, 2 M DTT 0.125 mL, 및 전단 연어 정자 DNA 50 ㎍을 함유하는 형질전환 완충제 1 mL 중에 재현탁하였다. 이어서, 선형화된 플라스미드 DNA 대략 500 ng을 재현탁된 세포 100 ㎕ 중에서 인큐베이션하고, 39℃에서 1시간 동안 15분 간격으로 볼텍스 혼합하며 유지시켰다. 세포를 선별 배지 플레이트에 플레이팅하고, 30℃에서 2일 내지 3일 동안 유지시켰다.
형질전환체를 선별하기 위해, 일반적으로 최소 배지 ("MM")를 사용하였고, MM의 조성은 다음과 같았다: 황산암모늄 또는 아미노산을 함유하지 않는 0.17% 효모 질소 기재 (미국 미시건주 디트로이트 소재의 디프코 래보러토리즈), 2% 글루코스, 0.1% 프롤린 (pH 6.1). 우라실 보충물을 적절히 가하여 최종 농도가 0.01%가 되도록 하였다 (이로써, 20 g/L 한천으로 제조된 "MMU" 선별 배지 생성).
별법으로, 형질전환체를 황산암모늄 또는 아미노산을 함유하지 않는 0.17% 효모 질소 기재 (미국 미시건주 디트로이트 소재의 디프코 래보러토리즈), 2% 글루코스, 0.1% 프롤린, 75 mg/L 우라실, 75 mg/L 유리딘, 900 mg/L FOA (미국 캘리포니아 오렌지 소재의 지모 리써치 코포레이션(Zymo Research Corp.)) 및 20 g/L 한천을 포함하는 5-플루오로오로트산 ("FOA", 또한 5-플루오로우라실-6-카르복실산 일수화물) 선별 배지에서 선별하였다.
야로위아
리폴리티카의
지방산 분석
지방산 분석을 위해, 세포를 원심분리로 수집하고 지질을 문헌 [Bligh, E. G. & Dyer, W. J. (Can. J. Biochem. Physiol., 37:911-917 (1959)]에 기재된 바와 같이 추출하였다. 상기 지질 추출물을 나트륨 메톡시드로 에스테르교환반응시켜서 지방산 메틸 에스테르를 제조하고 [Roughan, G., and Nishida I., Arch Biochem Biophys., 276(1):38-46 (1990)], 이후에는 30 m×0.25 mm (i.d.) HP-INNOWAX (휴렛-팩커드(Hewlett-Packard)) 컬럼이 장착된 휴렛-팩커드 6890 GC를 이용하여 분석하였다. 오븐 온도는 1분 당 3.5℃의 속도로 170℃ (25분 동안 유지)에서 185℃로 상승시켰다.
직접적인 염기 에스테르교환반응을 위해, 야로위아 배양물 (3 mL)을 수확하여 증류수 중에서 1회 세척하였고, 스피드-백(Speed-Vac)에서 진공하에 5분 내지 10분 동안 건조시켰다. 나트륨 메톡시드 (1%, 100 ㎕)를 샘플에 가한 후에 샘플을 볼텍싱시키고 20분 동안 요동시켰다. 1 M NaCl 3 방울과 헥산 400 ㎕를 가한 후에 샘플을 볼텍싱 및 회전시켰다. 상부 층을 들어내고, 상기 언급된 바와 같이 GC로 분석하였다.
실시예
1: 유글레나
그라실리스
성장 조건, 지질 프로파일 및
mRNA
단리
본 실시예는 유글레나 그라실리스의 성장, 배양물의 지질 분석 및 mRNA 단리에 관하여 기재한다.
성장 및 지질 분석
유글레나 그라실리스를 미시간 주립대학교 (미국 미시건주 이스트 랜싱 소재)의 리차드 트리에머(Richard Triemer) 박사 실험실에서 얻었다. 활력적으로 성장하고 있는 배양물 10 mL로부터의 분취액 1 mL를 500 mL 유리병 중의 유글레나 그라실리스 (Eg) 배지 250 mL에 옮겼다. Eg 배지는 물 970 mL 중에 아세트산나트륨 1 g, 소 추출물 (카탈로그 번호: U126-01, 미국 미시건주 디트로이트 소재의 디프코 래버러토리즈) 1 g, 박토(Bacto)® 트립톤 (카탈로그 번호: 0123-17-3, 디프코 래버러토리즈) 2 g 및 박토® 효모 추출물 (카탈로그 번호: 0127-17-9, 디프코 래버러토리즈) 2 g을 배합하여 제조하였다. 필터 멸균 후에, 토양수 상등액 (카탈로그 번호: 15-3790, 미국 노쓰 캐롤라이나주 벌링톤 소재의 캐롤라이나 바이올로지컬 서플라이 컴파니(Carolina Biological Supply Company)) 30 mL를 무균 첨가하여 최종 Eg 배지를 제조하였다. 유글레나 그라실리스 배양물을 23℃에서 교반 없이 2주 동안 광 주기 16시간, 암 주기 8시간으로 성장시켰다.
2주 후에, 배양물 10 mL을 지질 분석을 위해 들어내고, 1,800×g에서 5분 동안 원심분리하였다. 펠렛을 물로 1회 세척하고, 재-원심분리하였다. 생성된 펠렛을 5분 동안 진공하에 건조시키고, 트리메틸술포늄 히드록시드 (TMSH) 100 ㎕ 중에 재현탁하여 실온에서 15분 동안 진탕시키며 인큐베이션하였다. 이후, 헥산 0.5 mL를 첨가하고, 바이알을 실온에서 15분 동안 진탕시키며 인큐베이션하였다. 지방산 메틸 에스테르 (헥산층으로부터 5 ㎕ 주입됨)를 분리하고, 오메가왁스(Omegawax) 320 융합 실리카 모세관 컬럼 (카탈로그 번호: 24152, 수펠코 인크.(Supelco Inc.))가 장착된 휴렛-팩커드 6890 기체 크로마토그래피로 정량하였다. 오븐 온도는, 220℃에서 2.7분 동안 유지하고, 20℃/분으로 240℃까지 증가시켰다가 추가의 2.3분 동안 유지하도록 프로그래밍하였다. 운반 기체를 왓트만(Whatman) 수소 발생기로 제공하였다. 체류 시간을 시판되는 표준의 메틸 에스테르 (카탈로그 번호: U-99-A, 누-체크 프렙, 인크.(Nu-Chek Prep, Inc.))와 비교하고, 생성된 크로마토그램을 도 3에 나타냈다.
유글레나
그라실리스로부터의
mRNA
제조
나머지 2주 동안의 배양물 (240 mL)을 1,800×g에서 10분 동안 원심분리하여 펠렛화하고, 물로 1회 세척하고, 재-원심분리하였다. RNA STAT-60™ 시약 (미국 텍사스주 프랜즈우드 소재의 델-테스트, 인크.(TEL-TEST, Inc.))을 제조업체가 제공한 프로토콜에 따라 (물 0.5 mL에 RNA를 용해하고, 시약 5 mL를 사용) 사용하여, 상기 생성된 펠렛으로부터 전체 RNA를 추출하였다. 이러한 방법으로, 전체 RNA (2 mg/mL) 1 mg을 펠렛으로부터 수득하였다. mRNA 정제 키트 (미국 뉴저지주 피스카타웨이 소재의 아머샴 바이오사이언시스(Amersham Biosciences))를 제조업체가 제공한 프로토콜에 따라 사용하여 전체 RNA 1 mg으로부터 mRNA를 단리하였다. 이런 방식으로, mRNA 85 ㎍을 수득하였다.
실시예
2: 유글레나
그라실리스
cDNA
합성, 라이브러리 구축 및 서열분석
클론마이너(Cloneminer)™ cDNA 라이브러리 구축 키트 (카탈로그 번호: 18249-029, 미국 캘리포니아주 칼스배드 소재의 인비트로젠 코포레이션(Invitrogen Corporation))를 제조업체가 제공한 프로토콜 (버전 B, 25-0608)에 따라 사용하여 cDNA 라이브러리를 생성하였다. 비-방사성표지 방법을 이용하여, 바이오틴(Biotin)-attB2-올리고(dT) 프라이머를 사용하여 mRNA 3.2 ㎍ (실시예 1)으로부터 cDNA를 합성하였다. 제1 가닥과 제2 가닥의 합성 후, attB1 어댑터(adapter)를 첨가하여 라이게이션시키고, cDNA를 컬럼 크로마토그래피로 크기별 분획화하였다. 분획 7 및 분획 8의 DNA (크기 범위는 약 800 bp 내지 1500 bp)를 농축시키고, pDONR™ 222로 재조합시켜서 이것으로 이. 콜라이 일렉트로맥스(Electromax)™ DH10B™ T1 파지-내성 세포 (인비트로젠 코포레이션)를 형질전환시켰다. 상기 유글레나 그라실리스 라이브러리를 "eeg1c"라고 명명하였다.
서열분석을 위해, 384웰 동결 배지 플레이트에서 성장/동결시킨 보관된 글리세롤 배양물로부터 클론을 우선 회수하고, LB + 75 ㎍/mL 카나마이신을 함유하는 384웰 미량역가 플레이트 (복제 플레이트)에서 멸균 384 핀(pin) 복제기 (미국 매사추세츠주 보스톤 소재의 제네틱스(Genetix))로 복제하였다. 이어서, 템플리피(Templiphi) DNA 서열분석 주형 증폭 키트 방법 (아머샴 바이오사이언시스)을 제조업체의 프로토콜에 따라 사용하여 플라스미드를 단리하였다. 간략하게 설명하면, 상기 템플리피 방법은 박테리오파지 φ29 DNA 폴리머라제를 사용하여 등온 롤링 써클(rolling circle) 증폭 ([Dean et al., Genome Res., 11:1095-1099 (2001)], [Nelson et al., Biotechniques, 32:S44-S47 (2002])으로 고리형 단일-가닥 또는 이중-가닥 DNA를 증폭시킨다. 20시간 동안 37℃에서 성장시킨 후에, 복제 플레이트로부터의 세포를 희석 완충제 5 ㎕에 가하고 95℃에서 3분 동안 변성시켜서 세포를 부분적으로 용해시키고 변성된 주형을 유리시킨다. 이어서, 템플리피 사전혼합물 (5 ㎕)을 각 샘플에 가하고, 이로써 생성된 반응 혼합물을 30℃에서 16시간 동안 인큐베이션하였다가 65℃에서 10분 동안 인큐베이션하여, φ29 DNA 폴리머라제 활성을 불활성화시켰다. 증폭된 샘플을 증류수에 1:3으로 희석시킨 후에 피코그린(PicoGreen)® dsDNA 정량화 시약 (몰레큘라 프로브스(Molecular Probes))을 이용한 DNA 정량화를 실시하였다.
이어서, 증폭된 생성물을 95℃에서 10분 동안 변성시키고, M13F 범용 프라이머 (서열 18), 및 ABI BigDye 버전 3.1 프리즘 시퀀싱 키트(Prism Sequencing Kit)를 이용하여 384웰 플레이트에서 말단-서열분석을 실시하였다. 서열분석 반응을 위해서, 주형 100 ng 내지 200 ng 및 6.4 pmol의 프라이머를 사용하였고, 하기하는 반응 조건을 25회 반복하였다: 96℃에서 10초, 50℃에서 5초, 및 60℃에서 4분. 에탄올-기재의 세정 후에, 주기 서열분석 반응 생성물을 용해시켜 퍼킨-엘머(Perkin-Elmer) ABI 3730×l 자동화 서열분석기에서 검출하였다.
실시예
3: 유글레나
그라실리스
cDNA
라이브러리
eeg1c
으로부터, Δ9
일롱가제
효소
상동체의
동정
장쇄 다중불포화 지방산 신장 효소 상동체 (즉, LC-PUFA ELO 상동체 또는 Δ9 일롱가제)를 코딩하는 cDNA 클론은, BLAST (Basic Local Alignment Search Tool, [Altschul et al., J. Mol. Biol., 215:403-410 (1993)]) "nr" 데이타베이스 (모든 비-중복성 진뱅크 CDS 번역부, 3차원 구조 브룩하벤 프로테인 데이타 뱅크(Brookhaven Protein Data Bank), 최신 주요 SWISS-PROT 단백질 서열 데이타베이 스, EMBL 및 DDBJ 데이타베이스로부터 유래된 서열을 포함함)에 함유된 서열과의 유사성에 대하여 BLAST 검색을 수행하여 동정하였다. 실시예 2에서 수득한 cDNA 서열을 미국립 생물공학 정보 센터(National Center for Biotechnology Information, NCBI)가 제공하는 BLASTN 알고리즘을 사용하여 "nr" 데이타베이스 내에 함유된 공개적으로 입수가능한 모든 DNA 서열과의 유사성에 대하여 분석하였다. DNA 서열을 모든 리딩 프레임에서 번역시켰고, NCBI가 제공하는 BLASTX 알고리즘 [Gish and States, Nat. Genet., 3:266-272 (1993)]을 사용하여 "nr" 데이타베이스 내에 함유된 공개적으로 입수가능한 모든 단백질 서열과의 유사성에 대하여 비교하였다. 편의상, 검색한 데이타베이스 내에 함유된 서열에 대한 cDNA 서열의 매치가 단지 우연히 관찰되는 P-값 (확률)을 BLAST로 계산하여 본원에서는 "pLog" 값으로 보고하였고, 이것은 보고된 P-값의 음의 로그값을 나타낸다. 따라서, pLog 값이 높을 수록, cDNA 서열 및 BLAST "hit"가 상동성 단백질을 나타낼 가능성은 높아진다.
클론 eeg1c.pk001.n5.f의 뉴클레오티드 서열을 이용한 BLASTX 검색은 cDNA에 의해 코딩되는 단백질과 IgD9e (즉, 본원에서 서열 8로 기재한 이소크리시스 갈바나의 장쇄 PUFA 신장 효소. NCBI 관리 번호: AAL37626 (GI 17226123), 유전자좌 AAL37626, CDS AF390174. [Qi et al., FEBS Lett. 510(3):159-165 (2002)])와의 유사성을 밝혀냈다. 클론 eeg1c.pk001.n5.f cDNA 삽입물 일부의 서열을 서열 10 (cDNA 삽입물의 5' 말단)에 나타내었다.
상기한 바와 같이 하여 eeg1c.pk001.n5.1 cDNA 삽입물의 3' 말단에서 추가의 서열을 수득하였지만, 여기서는 폴리(A) 테일(tail)-프라이밍된 WobbleT 올리고뉴클레오티드를 사용하였다. 간략하게 설명하면, WobbleT 프라이머는 21-mer 폴리(T)A, 폴리(T)C, 및 폴리(T)G의 등몰 혼합물로서, cDNA 클론의 3' 말단을 서열분석하는데 사용된다. 3' 말단 서열을 서열 11에 나타내었다.
시켄처™ (버전 4.2, 미국 미시건주 앤 아버 소재의 진 코즈 코포레이션)을 사용하여 5' 서열과 3' 서열 둘다를 정렬하고, 이로써 생성된 cDNA 서열을 서열 12에 나타내었다. eeg1c.pk001.n5.f cDNA 코딩 서열의 서열 및 상응하는 추정 아미노산 서열은 서열 1 및 서열 2에 각각 나타내었다. 상기 보고한 상동체를 기초로, eeg1c.pk001.n5.1 cDNA 삽입물의 유글레나 그라실리스 유전자 생성물이 Δ9 일롱가제를 코딩할 것이라고 가정하였고, 이에 따라 "EgD9e"로 지칭하였다.
서열 2에 기재한 아미노산 서열 (즉, EgD9e)을 BLASTP로 평가하여 IgD9e (서열 8)에 대한 pLog 값이 38.70 (E 값 2e-39)으로 산출되었다. 조툰 하인(Jotun Hein) 방법을 이용할 때, EgD9e는 IgD9e와 39.4% 동일하다. 조툰 하인 방법 [Hein, J. J., Meth. Enz., 183:626-645 (1990)]으로 수행한 서열 동일성(%) 계산은 LASERGENE 바이오인포매틱스 컴퓨팅 수트 (미국 위스콘신주 매디슨 소재의 디엔에이스타, 인크.)의 메그얼라인™ v6.1 프로그램으로 수행하였고, 쌍별 정렬을 위한 디폴트 파라미터 (KTUPLE = 2)를 사용하였다. 클러스탈 브이 방법을 이용할 때, EgD9e (서열 2)는 IgD9e (서열 8)와 31.8% 동일하였다 (도 4). 클러스탈 브이 방법 ([Higgins, D.G. and Sharp, P.M., Comput. Appl. Biosci., 5:151-153 (1989)], [Higgins et al., Comput. Appl. Biosci., 8:189-191 (1992)])으로 수행 한 서열 동일성(%) 계산은 LASERGENE 바이오인포매틱스 컴퓨팅 수트의 메그얼라인™ v6.1 프로그램으로 수행하였고, 쌍별 정렬을 위한 디폴트 파라미터 (KTUPLE = 1, GAP PENALTY = 3, WINDOW = 5, DIAGONALS SAVED = 5 및 GAP LENGTH PENALTY = 10)를 사용하였다.
BLAST 스코어 및 확률은 본 발명의 핵산 단편 (서열 12)이 전체 유글레나 그라실리스 Δ9 일롱가제를 코딩함을 나타내었다.
실시예
4:
사카로마이세스
세레비지애
중 유글레나
그라실리스
Δ9
일롱가제
(
EgD9e
)의 기능적 분석
본 실시예는 사카로마이세스 세레비지애 중 EgD9e의 기능적 분석을 기재한다. 이를 위해서는, (1) 효모 발현 벡터 pY-75로 EgD9e을 클로닝하여 pY119를 생성하고, (2) 기질 공급 후, pY-75 및 pY119를 포함하는 형질전환 유기체 내에서의 지질 프로파일을 비교하며, (3) 기질 공급 없이 pY-75 및 pY119를 포함하는 형질전환 유기체 내에서의 지질 프로파일을 비교하는 것이 필요하다.
플라스미드
pY
-75 (대조군), 및
EgD9e
를 포함하는 플라스미드
pY119
의 구축
효모 에피솜 플라스미드 (YEp)-형 벡터 pRS425 [Christianson et al., Gene, 110:119-122 (1992)]는 사카로마이세스 세레비지애 2μ 내인성 플라스미드로부터의 서열, LEU2 선별가능한 마커 및 다기능적 파지미드 pBluescript II SK(+)의 주쇄에 기초한 서열을 함유한다. 사카로마이세스 세레비지애의 강력한 구성적 글리세르알데히드-3-포스페이트 데히드로게나제 (GPD) 프로모터를 pRS425의 SacII와 SpeI 부위 사이에 문헌 [Jia et al., Physiol. Genomics, 3:83-92 (2000)]에 기재된 것과 동일한 방식으로 클로닝하여 pGPD-425를 생산하였다. NotI 부위를 pGPD-425의 BamHI 부위 내에 도입하여 BamHI 부위에 의해 플랭킹(flanking)된 NotI 부위가 생성되었고, 이 플라스미드를 pY-75라고 칭하였다.
VentR® DNA 폴리머라제 (카탈로그 번호: M0254S, 미국 매사추세츠주 베벌리 소재의 뉴 잉글랜드 바이오랩스 인크.(New England Biolabs Inc.))를 제조업체의 프로토콜에 따라 사용하여, EgD9e를 올리고뉴클레오티드 프라이머 oEugEL1-1 (서열 19) 및 oEugEL1-2 (서열 20)을 사용하여 eeg1c.pk001.n5.f로부터 증폭시켰다. 이로써 생성된 DNA 단편을 제로 블런트(Zero Blunt)® PCR 클로닝 키트 (인비트로젠 코포레이션)를 제조업체의 프로토콜에 따라 사용하여 pCR-블런트(Blunt)® 클로닝 벡터에 클로닝하여 pKR906을 생성하였다. NotI 소화로 pKR906으로부터 EgD9e를 유리시키고, pY-75의 NotI 부위로 클로닝하여 pY119 (서열 21, 도 5)를 생성하였다. EgD9e는 도 5에서 "eug el1"로 표시하였다.
기질 공급에 의한,
EgD9e
일롱가제
활성의 기능적 분석
표준 아세트산리튬 형질전환 절차에 따라 플라스미드 pY119 및 pY-75로 카로마이세스 세레비지애 INVSC1 (인비트로젠 코포레이션)을 형질전환시켰다. 형질전환체는 CSM-leu (미국 캘리포니아주 칼스배드 소재의 큐바이오젠(Qbiogene))를 보충한 DOBA 배지 상에서 선별하였다. 각 플레이트로부터의 형질전환체를 CSM-leu (큐바이오젠) 및 0.2% 테르지톨로 보충한 DOB 배지 2 mL에 접종하였다. 세포를 1일 동안 30℃에서 성장시킨 후에, 0.1 mL를 LA [18:2(9,12)], ALA [18:3(9,12,15)], GLA [18:3(6,9,12)], STA [18:4(6,9,12,15)], ARA [20:4(5,8,11,14)] 또는 EPA [20:5(5,8,11,14,17)]를 0.175 mM로 보충한 동일한 배지 3 mL로 옮겼다. 이들을 16시간 동안 30℃에서 250 rpm으로 인큐베이션한 후에 원심분리로 펠렛을 수득하였다. 세포를 물로 1회 세척하고 원심분리로 펠렛화하여 공기 건조시켰다. 펠렛을 1% 나트륨 메톡시드 500 ㎕로 30분 동안 50℃에서 에스테르교환반응 [Roughan, G., and Nishida I., Arch Biochem Biophys., 276(1):38-46 (1990)]을 실시하고, 이후에는 1 M 염화나트륨 500 ㎕ 및 헵탄 100 ㎕를 첨가하였다. 철저한 혼합 및 원심분리 후에, 실시예 1에 기재한 바와 같이 GC로 지방산 메틸 에스테르 (FAME)를 분석하였다.
pY75 (벡터 대조군) 또는 pY119 (3개의 독립적 형질전환체. pY119-5, pY119-6 및 pY119-8이라 지칭됨)를 함유하는 영양공급 세포에 대한 결과를 도 6에 나타내었다. 지방산은 16:0 (팔미테이트), 16:1(9) (팔미톨레산), 18:0, 18:1(9) (올레산), LA, GLA, ALA, STA, EDA, DGLA, ARA, ETrA, ETA, EPA, 22:2(13,16) (도코사디엔산), 22:4(7,10,13,16) (아드렌산), DPA 및 24:1 (네르본산)으로 표시하였다. 공급된 각 지방산 ("FA")에 대하여 신장 효율 ("% Elo")을 계산하였다: [% FA생성물/(% FA생성물 + % FA기질)×100].
도 6의 데이타는 클로닝된 EgD9e가 LA 및 ALA를 각각 EDA 및 ETrA로 효율적으로 신장된시켰음을 입증하였다.
기질 공급이 없는 상태에서,
EgD9e
일롱가제
활성의 기능적 분석
추가로, 지방산이 공급되지 않은 세포의 FAME를 약간 상이한 온도 프로파일을 사용하여 GC 분석하여, 팔미톨레산 [PA-16:1(9)]의 신장 생성물인 올레산 [OA-18:1(9)] 및 박센산 [VA-18:1(11)]을 분리하였다. 지방산 메틸 에스테르 (헥산층으로부터 3 ㎕ 주입됨)를 분리하고, 오메가왁스 320 융합 실리카 모세관 컬럼 (수펠코 인크., 카탈로그 번호: 24152)가 장착된 휴렛-팩커드 6890 기체 크로마토그래피로 정량하였다. 오븐 온도는, 220℃에서 2.7분 동안 유지하고, 20℃/분으로 240℃까지 증가시켰다가 추가의 2.3분 동안 유지하도록 프로그래밍하였다. 결과는 하기 표 6에 나타냈다:

상기 나타낸 결과를 기초로 할 때, EgD9e는 LA 및 ALA를 각각 EDA 및 ETrA로 신장시킬 수 있는 Δ9 일롱가제로서의 주요 역할 이외에도 C16 /18 일롱가제 및 C18 /20 일롱가제 둘다로서도 작용할 수 있다.
실시예
5:
야로위아
리폴리티카
중에서의 발현을 위해 코돈-최적화된 합성 Δ9 일롱가제 유전자 (
IgD9eS
,
이소크리시스
갈바나에서
유래됨
)를 포함하는
야로위아
리
폴리티카
발현 벡터
pY115
의 구축
본 실시예는 키메라 FBAINm::IgD9eS::Pex20 유전자를 포함하는 야로위아 리폴리티카 발현 벡터 pY115의 구축에 대하여 기재하며, 여기서의 IgD9eS는 이소크리시스 갈바나에서 유래되고 야로위아 리폴리티카 중에서의 발현을 위해 코돈-최적화된 합성 Δ9 일롱가제이다. 하기하는 실시예 6 및 실시예 7에 기재한 바와 같이, 플라스미드 pY115는 IgD9eS의 Δ9 일롱가제 활성이 EgD9e의 Δ9 일롱가제 활성과 간접적으로 비교될 수 있게 하였다.
플라스미드 pY115 (서열 45, 도 8)의 구축에는 (1) pDMW263의 구축, (2) IgD9eS의 합성 및 플라스미드 pDMW237의 생성, 및 (3) 플라스미드 pDMW263 및 pDMW237로부터의 단편의 라이게이션이 필요하다.
pDMW263
의 구축
플라스미드 pY5-30 (도 7A. 이전에는 PCT 공개 제WO 05/003310호에 기재되었음 [상기 문헌의 내용은 본원에 참고로 포함됨])은 이. 콜라이 및 야로위아 리폴리티카 둘다에서 복제될 수 있는 셔틀 플라스미드이다. 플라스미드 pY5-30은 야로위아 자율 복제 서열 (ARS18), ColE1 플라스미드 복제 기점, 이. 콜라이에서의 선별을 위한 암피실린-내성 유전자 (AmpR), 야로위아에서의 선별을 위한 야로위아 LEU2 유전자, 및 키메라 TEF::GUS::XPR 유전자를 함유한다.
플라스미드 pDMW263 (서열 22, 도 7B)은 당업자에게 널리 공지된 기술로 pY5-30에서 TEF 프로모터를 야로위아 리폴리티카 FBAINm 프로모터 (PCT 공개 제WO 05/049805호)로 대체하여 생성하였다. 간략하게 설명하면, 상기 프로모터는 fba1 유전자에 의해 코딩되는 프럭토스-비스포스페이트 알돌라제 효소 (E.C. 4.1.2.13)의 'ATG' 번역 개시 코돈 앞쪽에 위치하고 발현에 필요한 5' 상류 비-번역 영역 및 인트론을 갖는 5' 코딩 영역의 일부에 위치한 변형된 프로모터를 지칭하고, FBAINm은 ATG 번역 개시 코돈과 FBAIN 프로모터의 인트론 사이에 52 bp 결실부를 가지며 (이로써, N-말단의 22개 아미노산만을 포함함) 인트론 뒤에 새로운 번역 컨센서스 모티프를 갖는다. 하기 표 7은 pDMW263의 성분을 요약한다:
| 서열 22 내의 RE 부위 및 뉴클레오티드 | 단편 및 키메라 유전자 성분의 기재 |
| 4992-4296 | ARS18 서열 (진뱅크 관리 번호: A17608) |
| SalI/SacII (8505-2014) | ·FBAINm: FBAINm 프로모터 (PCT 공개 제WO 2005/049805호. 도 7B에서 "Fba1+인트론"으로 표시됨) ·GUS: β-글루쿠로니다제를 코딩하는 이. 콜라이 유전자 [Jefferson, R.A. Nature. 14:342:837-838 (1989)] ·XPR: 야로위아 Xpr 유전자 (진뱅크 관리 번호: M17741) 3' 영역의 약 100 bp 을 포함하는 FBAINm::GUS::XPR |
| 6303-8505 | 야로위아 Leu2 유전자 (진뱅크 관리 번호: AF260230) |
IgD9eS
의
시험관내
합성
PCT 공개 제WO 2004/101753호 (US-2004-0253621-A1) 및 PCT 공개 제WO 2006/052870호 (US-2006-0115881-A1) (이들 문헌 각각은 본원에 그 전문이 참고로 포함됨)에 기재된 것과 유사한 방식으로, 이소크리시스 갈바나 Δ9 일롱가제 유전자 (IgD9e. 서열 7 및 서열 8)의 코돈 사용을 야로위아 리폴리티카 중에서의 발현을 위해 최적화시켰다. 구체적으로, IgD9e (서열 7)의 코딩 서열을 기초로 하여 야로위아 코돈 사용 패턴, ATG 번역 개시 코돈 주위의 컨센서스 서열, 및 RNA 안정성에 관한 일반적 규칙 [Guhaniyogi, G. and J. Brewer, Gene, 265(1-2):11-23 (2001)]에 따라 코돈-최적화 Δ9 일롱가제 유전자 ("IgD9eS"이라 지칭함. 서열 9)를 디자인하였다. 번역 개시 부위의 변형에 추가하여, 792 bp 코딩 영역 중 127 bp (16.0%)를 변형시켰고, 122개 코돈을 최적화하였다. 코돈-최적화 유전자에서의 변형 중 그 어느 것도 코딩되는 단백질의 아미노산 서열을 변화시키지 않았다 (서열 8).
더욱 구체적으로, 8쌍의 올리고뉴클레오티드를 디자인하여 IgD9eS의 전체 길이를 신장시켰다 (예컨대, 서열 23 내지 서열 38에 상응하는 IL3-1A, IL3-1B, IL3-2A, IL3-2B, IL3-3A, IL3-3B, IL3-4A, IL3-4B, IL3-5A, IL3-5B, IL3-6A, IL3-6B, IL3-7A, IL3-7B, IL3-8A 및 IL3-8B). 센스 (A) 및 안티센스 (B) 올리고뉴클레오티드의 각 쌍은 각 5'-말단에서의 4 bp 오버행(overhang) 이외에는 상보적이었다. 추가로, 이후의 서브클로닝을 위해서 프라이머 IL3-1F, IL3-4R, IL3-5F 및 IL3-8R (서열 39 내지 서열 42)에는 또한 NcoI, PstI, PstI 및 NotI 제한 부위를 각각 도입하였다.
각각의 올리고뉴클레오티드 (100 ng)는 37℃에서 1시간 동안 50 mM Tris-HCl (pH 7.5), 10 mM MgCl2, 10 mM DTT, 0.5 mM 스페르미딘, 0.5 mM ATP 및 10 U의 T4 폴리뉴클레오티드 키나제를 함유하는 부피 20 ㎕에서 인산화하였다. 센스 및 안티센스 올리고뉴클레오티드의 각 쌍을 혼합하고, 하기 파라미터를 이용하는 열주기장치(thermocycler)에서 어닐링시켰다: 95℃ (2분), 85℃ (2분), 65℃ (15분), 37℃ (15분), 24℃ (15분) 및 4℃ (15분). 따라서, IL3-1A (서열 23)를 IL3-1B (서열 24)에 어닐링시켜 이중-가닥 생성물 "IL3-1AB"를 생산하였다. 유사하게, IL3-2A (서열 25)를 IL3-2B (서열 26)에 어닐링시켜 이중-가닥 생성물 "IL3-2AB" 등을 생산하였다.
이어서, 어닐링된 이중-가닥 올리고뉴클레오티드의 2개의 개별적 풀(pool)을 하기에 나타내는 바와 같이 함께 라이게이션하였다: 풀 1 (IL3-1AB, IL3-2AB, IL3-3AB 및 IL3-4AB 포함) 및 풀 2 (IL3-5AB, IL3-6AB, IL3-7AB 및 IL3-8AB 포함). 어닐링된 올리고뉴클레오티드의 각 풀을 10 U의 T4 DNA 리가제를 함유하는 부피 20 ㎕에서 혼합하고, 라이게이션 반응물을 16℃에서 밤새 인큐베이션하였다.
이어서, 각 라이게이션 반응의 생성물을 주형으로서 사용하여 디자인된 DNA 단편을 PCR로 증폭시켰다. 구체적으로, 라이게이션된 "풀 1" 혼합물 (예컨대, IL3-1AB, IL3-2AB, IL3-3AB 및 IL3-4AB)을 주형으로 사용하고, 올리고뉴클레오티드 IL3-1F 및 IL3-4R (서열 39 및 서열 40)을 프라이머로 사용하여, IgD9eS의 제1 부분을 PCR로 증폭시켰다. 417 bp PCR 단편을 pGEM-T 이지(easy) 벡터 (프로메가(Promega)) 내로 서브클로닝하여 pT9(1-4) (서열 43)을 생성시켰다.
라이게이션된 "풀 2" 혼합물 (예컨대, IL3-5AB, IL3-6AB, IL3-7AB 및 IL3-8AB)을 주형으로 사용하고, 올리고뉴클레오티드 IL3-5F 및 IL3-8R (서열 41 및 서열 42)을 프라이머로서 사용하여, IgD9eS의 제2 부분을 PCR로 유사하게 증폭시키고, pGEM-T-이지(Easy) 벡터 내로 클로닝시켜 pT9(5-8) (서열 44)을 생성시켰다.
이. 콜라이를 pT9(1-4) (서열 43) 및 pT9(5-8) (서열 44)로 따로 형질전환시키고, 암피실린-내성 형질전환체로부터 플라스미드 DNA를 단리하였다. 플라스미드 DNA를 정제하고, 적절한 제한 엔도뉴클레아제로 소화시켜 pT9(1-4)의 417 bp NcoI/PstI 단편 및 pT9(5-8)의 377 bp PstI/NotI 단편을 유리시켰다. 이어서, 이들 2개의 단편을 합하고, NcoI/NotI 소화 pZUF17 (서열 121, 도 7C)와 함께 정해진 방향으로 라이게이션시켜 pDMW237 (서열 46)을 생성시켰다. 따라서, 합성 방식으로 생성된 IgD9eS 유전자는 발현 벡터 pDMW237 내에서 FBAIN 프로모터 및 야로위아 Pex20 종결자에 의해 플랭킹되었다.
야로위아
리폴리티카
발현 벡터
pY115
의 최종 구축
pDMW263의 NcoI/SalI DNA 단편 (야로위아 리폴리티카 FBAINm 프로모터를 함유함)을 pDMW237의 NcoI/SalI DNA 단편 (IgD9eS를 함유함)에 클로닝하여, 키메라 FBAINm::IgD9eS::Pex20 유전자를 포함하는 pY115 (서열 45, 도 8)를 생성하였다. 도 8에서, FBAINm은 "Fba1+인트론"으로 표시하고, IgD9eS는 "아이. 갈바나 synth D9 일롱가제"로 표시하였다.
실시예
6:
야로위아
리폴리티카
발현 벡터
pBY2
(
EgD9e
를 포함함) 및
pBY1
-
FAE
(
IgD9eS
를 포함함)의 구축
본 실시예는 야로위아 리폴리티카 발현 벡터 pBY2 (키메라 FBAINm::EgD9e::Pex20 유전자를 포함함) 및 pBY1-FAE (키메라 FBAINm::IgD9eS::Pex20 유전자를 포함함)의 합성을 기재한다. 실시예 7 (하기함)에 기재한 바와 같이 야로위아 리폴리티카에서 발현될 때의 IgD9eS의 델타-9 일롱가제 활성을 EgD9e의 경우와 비교하였다.
야로위아
리폴리티카
발현 벡터
pBY2
의 구축
플라스미드 pY115 (서열 45, 실시예 5)를 NcoI/NotI으로 소화시키고, 이로써 생성된 DNA 말단을 클레나우로 충전하였다. 충전시켜 평활(blunt) 말단을 형성한 후, 상기 DNA 단편을 송아지 장 알칼리성 포스파타제로 처리하고 아가로스 겔 전기영동을 이용하여 분리하였다. 야로위아 리폴리티카 FBAINm 프로모터를 함유하는 6989 bp 단편을 아가로스 겔에서 잘라내어 QIAquick® 겔 추출 키트 (미국 캘리포니아주 발렌시아 소재의 퀴아젠 인크.(Qiagen Inc.))를 제조업체의 프로토콜에 따라 사용하여 정제하였다. 정제된 6989 bp 단편을 게이트웨이 벡터 컨버젼 시스템(Gateway Vector Conversion System) (카탈로그 번호: 11823-029, 인비트로젠 코포레이션)을 제조업체의 프로토콜에 따라 사용하여 카세트 rfA와 라이게이션시켜서, 야로위아 리폴리티카 게이트웨이® 데스티네이션 벡터 pBY1 (서열 47, 도 9A)을 형성하였다.
QIAprep® 스핀 미니프렙 키트(Spin Miniprep Kit) (미국 캘리포니아주 발렌시아 소재의 퀴아젠 인크.)를 제조업체의 프로토콜에 따라 사용하여, 유글레나 그라실리스 클론 eeg1c.pk001.n5.f (실시예 2 및 실시예 3)로부터 플라스미드를 정제하였다. 게이트웨이® LR 클로나제(Clonase)™ II 효소 혼합물 (카탈로그 번호: 11791-020, 인비트로젠 코포레이션)을 제조업체의 프로토콜에 따라 사용하여, eeg1c.pk001.n5.f로부터의 cDNA를 pBY1로 전달하여 pBY2 (서열 48, 도 9B)를 형성하였다. 서열분석이 WobbleT 프라이머를 사용하여 수행되었기 때문에, eeg1c.pk001.n5.f 3' 말단의 전장 서열 (즉, 폴리A 테일을 함유함)은 알려지지 않았다. 제한 소화 및 아가로스 겔 분석을 기초로 할 때, 폴리A 테일은 길이가 100 bp 미만이라고 여겨진다.
야로위아
리폴리티카
발현 벡터
pBY1
-
FAE
의 구축
AccuPrime™ Taq 폴리머라제 하이 피델러티(High Fidelity) (카탈로그 번호: 12346-086, 인비트로젠 코포레이션)를 제조업체의 프로토콜에 따라 사용하여, 올리고뉴클레오티드 프라이머 ig-s (서열 49) 및 ig-as (서열 50)를 사용하여 IgD9eS를 pY115 (서열 45, 실시예 5)로부터 증폭시켰다. pENTR™ 다이렉셔날(Directional) TOPO® 클로닝 키트 (인비트로젠 코포레이션)를 제조업체의 프로토콜에 따라 사용하여, 상기 생성된 DNA 단편을 pENTR™/D-TOPO®로 클로닝하여 pENTR-FAE를 생성하였다. 상기한 바와 같이 QIAprep® 스핀 미니프렙 키트 (미국 캘리포니아주 발렌시아 소재의 퀴아젠 인크.)를 제조업체의 프로토콜에 따라 사용하여, 플라스미드 pENTR-FAE를 정제하였다. 게이트웨이® LR 클로나제™ II 효소 혼합물 (카탈로그 번호: 11791-020, 인비트로젠 코포레이션)을 제조업체의 프로토콜에 따라 사용하여, IgD9eS에 대한 CDS를 pBY1로 전달하여 pBY1-FAE (서열 51, 도 9C)를 형성하였다.
에쉐리히아
콜라이(
Escherichia coli
)로의
벡터 형질전환
pBY2 및 pBY1-FAE의 생성 후에, 각 벡터로 이. 콜라이 DH10B™ (인비트로젠 코포레이션) 세포를 형질전환시켰다. 형질전환체 세포를 성장시키고, QIAprep® 스핀 미니프렙 키트 (미국 캘리포니아주 발렌시아 소재의 퀴아젠 인크.)를 사용하여 pBY2 및 pBY1-FAE를 단리하였다.
실시예
7:
야로위아
리폴리티카
균주
Y2224
중
EgD9e
의 기능적 분석
본 실시예는 야로위아 리폴리티카 균주 Y2224 중 EgD9e의 기능적 분석을 기재한다. 여기에는 (1) 균주 Y2224 (즉, 야생형 야로위아 균주 ATCC #20362의 Ura3 유전자 자율 돌연변이로부터의 FOA 내성 돌연변이체)의 구축, 및 (2) pBY2 (EgD9e를 발현함) 또는 pBY1-FAE (IgD9eS를 발현함)를 포함하는 야로위아 리폴리티카 균주 Y2224의 형질전환 유기체 내 지질 프로파일의 비교가 필요하다.
야로위아
리폴리티카
균주
Y2224
의 생성
균주 Y2224를 하기하는 방식으로 단리하였다: YPD 한천 플레이트로부터의 야로위아 리폴리티카 ATCC #20362 세포를 250 mg/L 5-FOA (지모 리써치)를 함유하는 최소 배지 플레이트 (75 mg/L씩의 우라실 및 유리딘, 6.7 g/L YNB (아미노산은 없고 암모니아 술페이트는 함유함), 20 g/L 글루코스)에 스트리킹하였다. 플레이트를 28℃에서 인큐베이션하고, 이로써 생성된 콜로니 중 4개를 200 mg/mL 5-FOA를 함유하는 최소 배지 플레이트, 및 우라실 및 유리딘이 없는 최소 배지 플레이트로 따로 패치(patch)하여 우라실 Ura3 영양요구성을 확인하였다. 이후, 야로위아 리폴리티카 균주 Y2224를 28℃하에 YPD 한천에서 성장시켰다.
pBY1
-
FAE
및
pBY2
를 포함하는
야로위아
리폴리티카
형질전환체의 기능적 분석
'일반적인 방법'에 기재한 바와 같이, pBY1-FAE (키메라 FBAINm::IgD9eS::Pex20 유전자를 포함함) 및 pBY2 (키메라 FBAINm::EgD9e::Pex20 유전자를 포함함)로 야로위아 리폴리티카 균주 Y2224를 형질전환시켰다. 상기 세포를 우라실이 없는 최소 배지 플레이트에 플레이팅하고, 30℃에서 2일 내지 3일 동안 유지시켰다.
이어서, 형질전환체의 단일 콜로니를 우라실이 없는 최소 배지 3 mL 중에서 30℃하에 OD600 약 1.0까지 성장시켰다. 대조군으로서, Y2224는 우라실이 보충된 최소 배지에서 유사한 방식으로 성장시켰다. 이어서, 세포를 물로 세척하여 원심분리로 수거하고, 지질을 상기한 바와 같이 에스테르교환반응시켰다. pBY1-FAE 또는 pBY2를 함유하거나 발현 벡터를 함유하지 않는 세포로부터의 FAME를 실시예 4에 기재한 방법 (즉, pY119를 함유하는 사카로마이세스 세레비지애(S. cerevisiae) 세포에 대하여 기재한 방법)을 이용하여 GC 분석하였다. 각각의 3개 복제물의 평균에 대한 결과를 하기 표 8에 나타내었다. 지방산은 16:0 (팔미테이트), 16:1(9) (팔미톨레산), 17:1(9), 18:0, 18:1(9) (올레산), LA 및 EDA로 표시하였다. 신장 효율 ("% Elo LA")은 실시예 4에 기재한 바와 같이 하여 계산하였다.

표 8에 나타난 바와 같이, 상기 결과는 EgD9e가 LA를 EDA로 전환시키는데 있어서 IgD9eS보다 더 높은 기질 전환 효율로 기능한다는 것을 입증하였다.
실시예
8:
야로위아
리폴리티카
중에서의 발현을 위해 코돈-최적화된 합성 Δ9 일롱가제 유전자 (
EgD9eS
, 유글레나
그라실리스에서
유래됨
)를 포함하는
야로위아
리
폴리티카
발현 벡터
pZuFmEgD9ES
의 구축 및 기능적 분석
본 실시예는 키메라 FBAINm::EgD9ES::Pex20 유전자를 포함하는 야로위아 리폴리티카 벡터 pZuFmEgD9ES의 발현을 기재하며, 여기서의 EgD9eS는 유글레나 그라실리스에서 유래되고 야로위아 중에서의 발현을 위해 코돈-최적화된 합성 Δ9 일롱가제이다. 따라서, 본 분석에는 (1) EgD9eS의 합성, (2) pZuFmEgD9ES의 구축 및 야로위아 리폴리티카 균주 Y2224로의 형질전환, 및 (3) pZuFmEgD9ES (EgD9eS를 발현함)를 포함하는 야로위아 리폴리티카 균주 Y2224의 형질전환 유기체 내 지질 프로파일의 분석이 필요하다.
EgD9eS
의 합성
실시예 5 및 PCT 공개 제WO 2004/101753호에 기재된 것과 유사한 방식으로, 유글레나 그라실리스의 Δ9 일롱가제 유전자 (EgD9e, 서열 1 및 서열 2)의 코돈 사용을 야로위아 리폴리티카 중에서의 발현을 위해 최적화시켰다. 구체적으로, EgD9e (즉, 클론 eeg1c.pk001.n5.f에서 유래함)의 코딩 서열을 기초로 하여 야로위아 코돈 사용 패턴 (PCT 공개 제WO 2004/101753호), 'ATG' 번역 개시 코돈 주위의 컨센서스 서열, 및 RNA 안정성에 관한 일반적 규칙 [Guhaniyogi, G. and J. Brewer, Gene, 265(1-2):11-23 (2001)]에 따라 코돈-최적화 Δ9 일롱가제 유전자 ("EgD9eS"이라 지칭함. 서열 3)를 디자인하였다. 번역 개시 부위의 변형에 추가하여, 777 bp 코딩 영역 중 117 bp (15.1%)를 변형시켰고, 106개 코돈을 최적화하였다. 도 10은 EgD9e 및 EgD9eS의 뉴클레오티드 서열 비교를 보여준다. 코돈-최적화 유전자에서의 변형 중 그 어느 것도 코딩되는 단백질의 아미노산 서열 (서열 2)을 변화시키지 않았다. EgD9eS로 지칭된 유전자는 젠스크립트 코포레이션(GenScript Corporation) (미국 뉴저지주 피스카타웨이 소재)이 합성하였고, pUC57 (진뱅크 관리 번호: Y14837)로 클로닝하여 pEgD9S를 생성하였다.
구축물
pZuFmEgD9E
(
EgD9E
를 포함함) 및
pZuFmEgD9ES
(
EgD9ES
를 포함함)의 생성
pZUF17 (도 7C, 서열 121)의 NcoI/NotI 단편을 EgD9eS를 포함하는 pEgD9S의 NcoI/NotI 단편으로 대체하여, 키메라 FBAINm::EgD9ES::Pex20 유전자를 포함하는 플라스미드 pZuFmEgD9ES (서열 53)를 구축하였다. 상기 라이게이션의 생성물은 자율 복제되는 발현 벡터 pZuFmEgD9ES이었고, 이에 따라 하기 성분을 함유하였다:
| 서열 53 내의 RE 부위 및 뉴클레오티드 | 단편 및 키메라 유전자 성분의 기재 |
| SwaI/BsiWI (6067-318) | ·FBAINm: 야로위아 리폴리티카 FBAINm 프로모터 (PCT 공개 제WO 2005/049805호) ·EgD9eS: 유글레나 그라실리스에서 유래된 코돈-최적화 Δ9 일롱가제 (서열 3, 본원에서 EgD9eS로 기재함) ·Pex20: 야로위아 Pex20 유전자의 Pex20 종결자 서열 (진뱅크 관리 번호: AF054613) 을 포함하는 FBAINm::EgD9eS::Pex20 |
| 1354-474 | ColE1 플라스미드 복제 기점 |
| 2284-1424 | 이. 콜라이에서의 선별을 위한 암피실린-내성 유전자 (AmpR) |
| 3183-4487 | 야로위아 자율 복제 서열 (ARS18, 진뱅크 관리 번호: A17608) |
| 6020-4533 | 야로위아 Ura 3 유전자 (진뱅크 관리 번호: AJ306421) |
키메라 FBAINm::EgD9E::Pex20 유전자를 포함하는 플라스미드 pZuFmEgD9E (서열 52)를 pZUF17 플라스미드 주쇄를 사용하여 유사한 방식으로 합성하였다.
pZuFmEgD9E
및
pZuFmEgD9ES
를 포함하는
야로위아
리폴리티카
형질전환체의 기능적 분석
'일반적인 방법'에 기재한 바와 같이, 플라스미드 pZuFmEgD9E 및 pZuFmEgD9ES (각각, 키메라 FBAINm::EgD9e::Pex20 유전자 및 FBAINm::EgD9eS::Pex20 유전자를 포함함)로 균주 Y2224 (야생형 야로위아 균주 ATCC #20362의 Ura3 유전자 자율 돌연변이로부터의 FOA 내성 돌연변이체, 실시예 7)를 형질전환시켰다. 형질전환체를 MM 플레이트에서 선별하였다. 30℃에서 2일 동안 성장시킨 후에 MM 플레이트에서 성장한 3개의 형질전환체를 골라내어 신선한 MM 플레이트에 재-스트리킹하였다. 일단 성장하면, 이들 균주를 액체 MM 3 mL로 30℃하에 개별적으로 접종하고, 250 rpm/분으로 2일 동안 진탕시켰다. 세포를 원심분리로 수거하여 지질을 추출하고, 에스테르교환반응으로 지방산 메틸 에스테르를 제조한 후에 휴렛-팩커드 6890 GC로 분석하였다.
GC 분석은 pZuFmEgD9E를 갖는 모든 7개의 형질전환체에서 생성된 전체 지질 중에 EDA (C20:2)가 약 3.2%로 존재함을 보여주었는데, 이들 7개의 균주에서 LA (C18:2)로부터 EDA로의 평균 전환 효율은 약 18.3% (실시예 4에 기재한 바와 같이 계산한 평균값)인 것으로 결정되었다.
반대로, GC 분석은 pZuFmEgD9ES를 갖는 모든 7개의 형질전환체에서 생성된 전체 지질 중에 EDA (C20:2)가 약 3.6%로 존재함을 보여주었는데, 이들 7개의 균주에서 LA (C18:2)로부터 EDA로의 평균 전환 효율은 약 20.1% (평균값)인 것으로 결정되었다. 따라서, 상기 실험 데이타는 야로위아 리폴리티카 중에서의 발현을 위해 코돈-최적화된 합성 유글레나 그라실리스 Δ9 일롱가제 (즉, EgD9eS. 서열 3)가 LA를 EDA로 신장시키는데 있어서 야생형 EgD9e 유전자 (즉, 서열 1)보다 약 16.2% 더 효율적임을 입증하였다.
실시예
9: 유글레나
그라실리스
Δ9
일롱가제
(
EgD9e
)의 발현을 위한,
야로위아
리
폴리티카
발현 벡터
pY120
의 구축
본 실시예는 EgD9e의 발현을 위한 야로위아 리폴리티카 벡터 pY120의 구축을 기재한다. 구체적으로, pKR906 (EgD9e를 포함함. 실시예 4)로부터의 NcoI/NotI DNA 단편을 pY115 (도 8, 실시예 5, 야로위아 리폴리티카 FBAINm 프로모터를 포함함)로부터의 NcoI/NotI DNA 단편에 클로닝하여 pY120 (서열 54, 도 11A)을 생성하였다. 상기 도면에서, EgD9e는 "eug el1"로 표시하였다.
실시예
10: 유글레나
그라실리스
Δ9
일롱가제
(
EgD9e
)의 발현을 위한 대두 발현 벡터
pKR912
의 구축
본 실시예는 EgD9e의 발현을 위한 대두 벡터 pKR912의 구축을 기재한다.
PCT 공개 제WO 02/008269호 (상기 문헌의 내용은 본원에 참고로 포함됨)에 이미 기재되어 있는 pKS12의 유도체인 출발 플라스미드 pKR72 (ATCC 관리 번호: PTA-6019, 서열 55)는 T7 프로모터 및 전사 종결자에 의해 플랭킹되어 있는 하이그로마이신 B 포스포트랜스퍼라제 유전자 (HPT) (T7prom/HPT/T7term 카세트) [Gritz, L. and Davies, J., Gene, 25:179-188 (1983)], 및 박테리아 (예컨대, 이. 콜라이)에서의 선별 및 복제를 위한 박테리아 복제 기점 (ori)을 함유한다. 추가로, pKR72는 또한 대두와 같은 식물에서의 선별을 위한, 35S 프로모터 [Odell et al., Nature, 313:810-812 (1985)] 및 NOS 3' 전사 종결자에 의해 플랭킹되어 있는 HPT 유전자 (35S/HPT/NOS3' 카세트) [Depicker et al., J. Mol. Appl. Genet., 1:561-570 (1982)]를 함유한다. pKR72는 또한 β-콘글리시닌의 α' 서브유닛에 대한 프로모터 ("BCON Pro", [Beachy et al., EMBO J., 4:3047-3053 (1985)]) 및 파세올린 유전자의 3' 전사 종결 영역 [Doyle et al., J. Biol. Chem., 261:9228-9238 (1986)]에 의해 플랭킹되어 있는 NotI 제한 부위를 함유하여, NotI 부위로 클로닝된 유전자가 대두 종자에서 강력한 조직-특이적 발현을 나타내도록 한다.
pKR906 (실시예 4)을 NotI 소화시켜 EgD9e를 유리시키고, pKR72의 NotI 부위로 클로닝하여 pKR912 (서열 56)를 생성하였다. pKR912의 모식도는 도 11B에 나타내었고, 여기서 EgD9e는 "eug el1"로 표시하였다.
실시예
11: 유글레나
그라실리스
Δ9
일롱가제
(
EgD9e
)의 발현을 위한 대두 중간체
클로닝
벡터
pKR911
의 구축
본 실시예는 EgD9e의 발현을 위한 대두 벡터 pKR91의 구축에 대해 기재한다.
PCT 공개 제WO 02/00905호 (상기 문헌의 내용은 본원에 참고로 포함됨)에 이미 기재되어 있는 벡터 pKS102 (서열 57)는 T7prom/HPT/T7term 카세트 (실시예 10에 기재되어 있음), 및 박테리아 (예컨대, 이. 콜라이)에서의 선별 및 복제를 위한 박테리아 복제 기점 (ori)을 함유한다.
T7prom/HPT/T7term 카세트 및 박테리아 ori를 함유하는 플라스미드 pKS102 (서열 57)의 AscI 단편을 βcon/NotI/Phas 카세트를 함유하는 플라스미드 pKR72 (실시예 10에 기재되어 있음)의 AscI 단편과 합하여, PCT 공개 제WO 04/071467호 (상기 문헌의 내용은 본원에 참고로 포함됨)에 이미 기재되어 있는 벡터 pKR197 (서열 58)을 구축하였다.
pKR906 (실시예 4)을 NotI 소화시켜 EgD9e를 유리시키고, pKR197의 NotI 부위로 클로닝하여 중간체 클로닝 벡터 pKR911 (서열 59)를 생성하였다. pKR911의 모식도는 도 12A에 나타내었고, 여기서 EgD9e는 "eug el1"로 표시하였다.
실시예
12: 유글레나
그라실리스
Δ8
데새투라제
(
EgD8
)의
cDNA
합성 및
PCR
본 실시예는 미국 특허 출원 제11/166003호 및 동 제11/166993호 (PCT 공개 제WO 06/012325호 및 동 제WO 06/012326호 [상기 문헌의 내용은 본원에 참고로 포함됨]에 상응함)에 개시된 바와 같이 유글레나 그라실리스로부터의 Δ8 데새투라제 ("EgD8"이라 지칭함) 단리에 관해 기재한다. 상기 유전자의 단리는, EgD9e 및 EgD8이 동시발현될 수 있게 하여 Δ9 일롱가제/Δ8 데새투라제 경로가 발현되도록 하고, LA 및/또는 ALA로부터 DGLA 및/또는 ETA가 축적될 수 있도록 하는데 바람직하다.
cDNA 합성용 수퍼스크립트™ 초이스 (Superscript™ Choice) 시스템 (미국 캘리포니아주 칼스배드 소재의 인비트로젠™ 라이프 테크놀로지즈(Invitrogen™ Life Technologies))을 제조업체의 프로토콜에 따라 제공된 올리고(dT) 프라이머와 함께 사용하여, mRNA 765 ng (실시예 1)으로부터 유글레나 그라실리스 cDNA를 합성하였다. 합성된 cDNA를 물 20 ㎕에 용해하였다.
하기 조건을 이용하여, 유글레나 그라실리스 Δ8 데새투라제를 cDNA로부터 증폭시켰다. 구체적으로, cDNA (1 ㎕)를 50 pmol의 Eg5-1 (서열 62), 50 pmol의 Eg3-3 (서열 63), PCR 뉴클레오티드 혼합물 (10 mM, 미국 위스콘신주 매디슨 소재의 프로메가) 1 ㎕, 10× PCR 완충제 (인비트로젠 코포레이션) 5 ㎕, MgCl2 (50 mM, 인비트로젠 코포레이션) 1.5 ㎕, Taq 폴리머라제 (인비트로젠 코포레이션) 0.5 ㎕, 및 50 ㎕가 될 때까지의 물과 합하였다. 반응 조건은 94℃에서 3분, 이후 94℃에서 45초, 55℃에서 45초, 및 72℃에서 1분의 35회 주기를 수행하였다. PCR을 72℃에서 7분 동안 종결한 후에 4℃에서 유지시켰다. PCR 반응물 5 ㎕을 아가로스 겔 전기영동으로 분석하였고, 1.3 kB 정도의 분자량을 갖는 DNA 밴드가 관찰되었다. 나머지 45 ㎕의 생성물은 아가로스 겔 전기영동으로 분리하였고, 지모클린(Zymoclean)™ 겔 DNA 리커버리(Recovery) 키트 (미국 캘리포니아 오렌지 소재의 지모 리써치)를 제조업체의 프로토콜에 따라 사용하여 DNA 밴드를 정제하였다. 이로써 생성된 DNA를 pGEM®-T 이지 벡터 (프로메가)에 제조업체의 프로토콜에 따라 클로닝하였다. T7 (서열 64), M13-28Rev (서열 65), Eg3-2 (서열 66) 및 Eg5-2 (서열 67)를 사용하여 여러개의 클론을 서열분석하였다.
이로써, 유글레나 그라실리스 Δ8 데새투라제 (즉, Eg5)에 대한 DNA 서열 (서열 60)이 수득되었다. Eg5를 번역시켜, 서열 61에 기재한 단백질 서열을 수득하였다. 본원에서의 목적상, "Eg5"는 본 명세서의 이하 기재 전반에서 "EgD8"이라고 지칭된다.
본원에서 상술지는 않았지만, 상기 실시예 5에 기재한 방법을 이용하여 야로위아 리폴리티카 중에서의 발현을 위해 코돈-최적화된 합성 버전의 EgD8도 생성하였다 (미국 특허 출원 제11/166003호 및 동 제11/166993호 (PCT 공개 제WO 06/012325호 및 동 제WO 06/012326호에 상응함)에 개시된 바와 같음). 상기 유전자를 EgD8S로 지칭하며, 본원에서는 서열 68 및 서열 69로 기재한다.
실시예
13:
EgD9e
및
EgD8
의 동시발현을 위한 대두 발현 벡터
pKR913
의 구축
본 실시예는 EgD9e 및 EgD8의 동시발현을 위한 대두 벡터 pKR913의 구축에 관해 기재한다.
PCT 공개 제WO 02/00904호 (상기 문헌의 내용은 본원에 참고로 포함됨)에 이미 기재되어 있는 벡터 pKS121 (서열 70)은 쿠니츠 대두 트립신 억제제 (KTi) 프로모터 [Jofuku et al., Plant Cell, 1:1079-1093 (1989)] 및 KTi 3' 종결 영역에 의해 플랭킹되어 있는 NotI 부위를 함유하며, 이것의 단리는 미국 특허 제6,372,965호에 기재되어 있다 (KTi/NotI/KTi3' 카세트).
PCT 공개 제WO 05/047479호 (상기 문헌의 내용은 본원에 참고로 포함됨)에 이미 기재되어 있는 벡터 pKR457 (서열 71)은 KTi/NotI/KTi3' 카세트의 상류 및 하류 제한 부위가 수많은 서브클로닝 단계를 거치면서 변경되어 있는 pKS121의 유도체이다. 벡터 pKR457은 또한 KTi 종결자의 하류에 전사 종결을 길게 하고 강화시키는, PCT 공개 제WO 04/071467호 (상기 문헌의 내용은 본원에 참고로 포함됨)에 이미 기재되어 있는 콩 알부민 전사 종결자 (GM-ALB TERM)를 함유한다. pKR457에서, KTi/NotI/KTi3' 카세트 중 KTi 프로모터의 상류 BamHI 부위를 제거하고, BsiWI, SalI, SbfI 및 HindIII 부위를 함유하는 새로운 서열 (서열 72)을 BsiWI 부위가 KTi 프로모터의 5' 말단에 가장 가깝게 하여 부가하였다.
추가로, pKS121로부터의 KTi/NotI/KTi3' 카세트 중 KTi 종결자의 하류 SalI 부위를 제거하고, XbaI (KTi 종결자의 3' 말단에 가장 가까움), BamHI 부위, 콩 알부민 전사 종결자 서열, BsiWI 부위 및 또다른 BamHI 부위를 함유하는 새로운 서열 (서열 73)을 부가하였다. 알부민 전사 종결자는 상기 종결자의 3' 말단에 BsiWI 부위를 도입하도록 디자인된 프라이머 oSalb-12 (서열 74) 및 상기 종결자의 5' 말단에 BamHI 부위를 도입하도록 디자인된 프라이머 oSalb-13 (서열 75)을 이용하여 콩 게놈 DNA로부터 이미 증폭시켜 두었다.
실시예 12에 기재된 pGEM®-T 이지 벡터를 NotI 소화시켜 EgD8 (서열 60)을 유리시키고, pKR457의 NotI 부위로 클로닝하여 pKR680 (서열 76)을 생성하였다. 이어서, 플라스미드 pKR680을 BsiWI으로 소화시키고, EgD8을 함유하는 단편을 pKR911 (서열 59, 실시예 11)의 BsiWI 부위로 클로닝하여 pKR913 (서열 77)을 생성하였다. pKR913의 모식도는 도 12B에 나타내었다. 여기서, EgD9e는 "eug el1"로 표시하였고, EgD8은 eug d8-sq5로 표시하였다.
실시예
14:
EgD9e
및
EgD8
의 동시발현을 위한 대두 발현 벡터의 구축
본 실시예는 EgD9e 및 EgD8의 동시발현을 위한 대두 벡터의 구축에 관해 기재한다. 구체적으로, 플라스미드 pKR680 (서열 76, 실시예 13)을 BsiWI으로 소화시키고, EgD8 (서열 60)을 함유하는 단편을 pKR912 (서열 56, 실시예 10)의 BsiWI 부위로 클로닝하였다. 이러한 방법으로, EgD8을 강력한 종자-특이적 프로모터하에서 EgD9e와 동시발현시켰다.
실시예
15:
EgD9e
와
EgD8
및
모르티에렐라
알피나
Δ5
데새투라제
(
Mad5
)의 동시발현을 위한 벡터의 구축
본 실시예는 EgD9e 및 EgD8 및 다른 PUFA 유전자 (즉, Δ5 데새투라제)의 동시발현을 위한 대두 벡터의 구축에 관해 기재한다.
EgD8 (서열 60), EgD9e (서열 1) 및 모르티에렐라 알피나 Δ5 데새투라제 (서열 78; "Mad5")를 함유하는 대두 발현 벡터는 미국 특허 제6,075,183호 및 PCT 공개 제WO 04/071467호 및 동 제WO 05/0479479호 (상기 문헌의 내용은 본원에 참고로 포함됨)에 기재되어 있고, 모두가 강력한 종자-특이적 프로모터의 제어하에 있으며, 이것을 하기하는 방법으로 구축하였다.
수많은 서브클로닝 단계를 거쳐서, DNA 서열 (서열 80)을 벡터 pKR287 (PCT 공개 제WO 04/071467호에 기재되어 있음. 상기 문헌의 내용은 본원에 참고로 포함됨)의 SmaI 부위에 효과적으로 부가하여 pKR767 (서열 81)을 생성하였다. 이러한 방법으로, SbfI 제한 부위를 Gy1/Mad5/legA2 카세트의 leg1A 전사 종결자의 3' 말단에 부가하였고, 이것은 PCT 공개 제WO 04/071467호 및 동 제WO 05/0479479호에 기재되어 있다.
pKR767을 SbfI 소화시켜 Gy1/Mad5/legA2 카세트를 유리시키고, 이로써 생성된 단편을 실시예 14에 기재한 벡터의 SbfI 부위로 클로닝하여, 모든 3개의 유전자 (즉, EgD9e, EgD8 및 Mad5)를 강력한 종자-특이적 프로모터의 제어하에 동시 발현하는 새로운 벡터를 생성하였다.
실시예
16:
EgD9e
,
EgD8
및
Mad5
를 포함하는 대두 발현 벡터와
사프롤레그니아
디클리나(
Saprolegnia
diclina
) Δ17
데새투라제
(
SdD17
)의 동시 발현
본 실시예는 실시예 15에 기재한 대두 발현 벡터 (EgD9e, EgD8 및 Mad5를 발현함)와 여러개의 상이한 종자-특이적 프로모터/장쇄 PUFA-생합성 유전자 조합물을 발현하는 (예컨대, Δ17 데새투라제를 발현함) 다른 벡터의 동시-형질전환 수단에 관해 기재한다. 온전한 플라스미드, 또는 적절한 유전자 조합물을 함유하는 상기 플라스미드로부터의 정제된 AscI 단편을 사용하였다 (플라스미드의 임의의 단편의 임의의 조합일 수 있음).
예를 들어, 실시예 15에 기재한 벡터는 안넥신 프로모터의 제어하에 있는 사프롤레그니아 디클리나 Δ17 데새투라제 (SdD17)를 함유하고 식물에서의 선별을 위한 하이그로마이신 내성 유전자를 갖는 pKR328 (서열 82. PCT 공개 제WO 04/071467호에 기재되어 있음)과 함께 동시-형질전환될 수 있다.
유사하게, 실시예 15에 기재한 벡터는 pKR886 또는 pKR886r (각각, 도 13A 및 도 13B)과 동시-형질전환될 수 있는데, 이들 2개의 벡터는 pKR328과 유사하지만 식물에서의 선별을 위한 SAMS/ALS/ALS3' 카세트 (PCT 공개 제WO 04/071467호에 기재되어 있음)를 갖는다. 구체적으로, 벡터 pKR886 (서열 83) 및 pKR886r (서열 84)은 pKR271 (서열 85, PCT 공개 제WO 04/071467호에 기재되어 있음)로부터의 Ann/Sdd17/BD30 카세트를 함유하는 PstI 단편을 pKR226 (서열 86, PCT 공개 제WO 04/071467호에 기재되어 있음)의 SbfI 부위로 클로닝하여 제조된 것이다.
실시예
17:
EgD9e
,
EgD8
및
Mad5
를 포함하는 대두 발현 벡터와
SdD17
및 아라비돕
시스
Fad3
의 동시 발현
본 실시예는 실시예 15에 기재한 대두 발현 벡터 (EgD9e, EgD8 및 Mad5를 발현함)와 여러개의 상이한 종자-특이적 프로모터/장쇄 PUFA-생합성 유전자 조합물을 발현하는 (예컨대, Δ17 데새투라제 및 Fad3을 발현함) 다른 벡터의 동시-형질전환 수단에 관해 기재한다.
실시예 15에 기재한 벡터는 pKR275 (서열 87, PCT 공개 제WO 04/071467호에 기재되어 있으며, ATCC 관리 번호는 PTA-4989임) 또는 pKR329 (서열 88, PCT 공개 제WO 04/07146호에 기재되어 있음)와 함께 대두로 동시-형질전환될 수 있었다. 플라스미드 pKR275 및 pKR329는 각각 ALS 또는 하이그로마이신 선별을 가지며, Ann/Sdd17/BD30 카세트에 추가하여 KTi/Fad3/KTi3' 유전자 카세트 (PCT 공개 제WO 04/071467호에 기재되어 있음)를 함유한다. 이러한 방법으로, 아라비돕시스 Fad3 유전자를 강력한 종자-특이적 프로모터하에서 사프롤레그니아 디클리나 Δ17 데새투라제 (SdD17)와 동시 발현시킬 수 있었다.
실시예
18:
EgD9e
,
EgD8
및
Mad5
를 포함하는 대두 발현 벡터와
SdD17
및
푸사리움
모닐리포르메(
Fusarium
moniliforme
) Δ15
데새투라제
(
FmD15
)의 동시 발현
본 실시예는 실시예 15에 기재한 대두 발현 벡터 (EgD9e, EgD8 및 Mad5를 발현함)와 여러개의 상이한 종자-특이적 프로모터/장쇄 PUFA-생합성 유전자 조합물을 발현하는 (예컨대, Δ17 데새투라제 및 Δ15 데새투라제를 발현함) 다른 벡터의 동시-형질전환 수단에 관해 기재한다.
실시예 15에 기재한 벡터는 하이그로마이신 선별을 가지며 KTi 프로모터의 제어하의 푸사리움 모닐리포르메 Δ15 데새투라제 (FmD15)를 함유하는 pKR585 (서열 89, PCT 공개 제WO 05/0479479호에 기재되어 있으며 ATCC 관리 번호는 PTA-6019임)와 함께 대두로 동시-형질전환될 수 있었다.
실시예 15에 기재한 벡터는 또한 ALS 선별을 가지며 Ann/Sdd17/BD30 카세트에 추가하여 KTi 프로모터의 제어하의 푸사리움 모닐리포르메 Δ15 데새투라제를 함유하는 pKR669와 함께 대두로 동시-형질전환될 수도 있었다. 플라스미드 pKR669를 하기하는 방법으로 생성하였다. 플라스미드 pKR578 (서열 90, PCT 공개 제WO 05/0479479호에 기재되어 있으며 ATCC 관리 번호는 PTA-6280임)를 BsiWI 소화시켜 KTi 프로모터:FmD15:KTi 종결자 카세트를 유리시키고, 선별을 위한 ALS 유전자, T7prom/HPT/T7term 카세트 및 박테리아 ori 영역을 함유하는 플라스미드 pKR226 (서열 86, PCT 공개 제WO 04/071467호에 기재되어 있음)의 BsiWI 부위로 클로닝하여 pKR667 (서열 91)을 생성하였다. 플라스미드 pKR271 (서열 85, PCT 공개 제WO 04/071467호에 기재되어 있음)을 PstI으로 소화시키고, 사프롤레그니아 디클리나 Δ17 데새투라제를 함유하는 단편을 pKR667의 SbfI 부위로 클로닝하여 pKR669를 생성하였다. 이러한 방법으로, 푸사리움 모닐리포르메 Δ15 데새투라제를 강력한 종자-특이적 프로모터하에서 사프롤레그니아 디클리나 Δ17 데새투라제와 동시 발현시킬 수 있었다. pKR669의 모식도는 도 14A에 나타내었다.
실시예 15에 기재한 벡터는 또한 ALS 선별을 가지며 Ann/Sdd17/BD30 카세트에 추가하여 콩 알부민 프로모터 (PCT 공개 제WO 04/071467호에 기재되어 있음)의 제어하의 푸사리움 모닐리포르메 Δ15 데새투라제 (FmD15)를 함유하는 pKR873 (서열 92)와 함께 대두로 동시-형질전환될 수도 있었다. 구체적으로, 플라스미드 pKR873을 하기하는 방법으로 생성하였다. SA/NotI/SA3' 카세트를 PCR을 이용하여 플라스미드 pKR132 (서열 93, PCT 공개 제WO 04/071467호에 기재되어 있음)로부터 증폭시켰다. 프라이머 oSAlb-9 (서열 94)는 상기 프로모터의 5' 말단에 XbaI 및 BsiWI 부위를 도입하도록 디자인되었고, 프라이머 oSAlb-2 (서열 95)는 상기 종결자의 3' 말단에 BsiWI 및 XbaI 부위를 도입하도록 디자인되었다. 이후, 이로써 생성된 PCR 단편을 pCR-Script AMP SK(+) (미국 캘리포니아주 샌 디에고 소재의 스트라타진 컴파니(Stratagene Company))로 클로닝하여 pKR160 (서열 96)을 생성하였다. 이어서, 플라스미드 pKR160을 BsiWI으로 소화시키고, SA/NotI/SA3' 카세트를 pKR124 (서열 97, PCT 공개 제WO 05/0479479호에 기재되어 있음)의 BsiWI 부위로 라이게이션하여 pKR163 (서열 98)을 생성하였다. 푸사리움 모닐리포르메 Δ15 데새투라제를 함유하는 pY34 (서열 99, PCT 공개 제WO 05/0479479호에 기재되어 있음)로부터의 NotI 단편을 pKR163 (서열 98)의 NotI 부위로 클로닝하여 pKR863 (서열 100)을 생성하였다. 플라스미드 pKR863을 BsiWI 소화시켜 SA/FmD15/SA3' 카세트를 유리시키고, 선별을 위한 ALS 유전자, T7prom/HPT/T7term 카세트 및 박테리아 ori 영역을 함유하는 플라스미드 pKR226 (서열 86, PCT 공개 제WO 04/071467호에 기재되어 있음)의 BsiWI 부위로 클로닝하여 pKR869 (서열 101)를 생성하였다. 플라스미드 pKR271 (서열 85, PCT 공개 제WO 04/071467호에 기재되어 있음)을 PstI으로 소화시키고, 사프롤레그니아 디클리나 Δ17 데새투라제를 함유하는 단편을 pKR869 (서열 101)의 SbfI 부위로 클로닝하여 pKR873 (서열 92)을 생성하였다. 이러한 방법으로, 푸사리움 모닐리포르메 Δ15 데새투라제를 강력한 종자-특이적 프로모터하에서 사프롤레그니아 디클리나 Δ17 데새투라제와 동시 발현시킬 수 있었다. pKR873의 모식도는 도 14B에 나타내었다.
실시예
19:
EgD9e
,
EgD8
및
Mad5
를 포함하는 대두 발현 벡터와
SdD17
및 모르티에
렐라
알피나
일롱가제
(
MaELO
)의 동시 발현
본 실시예는 실시예 15에 기재한 대두 발현 벡터 (EgD9e, EgD8 및 Mad5를 발현함)와 여러개의 상이한 종자-특이적 프로모터/장쇄 PUFA-생합성 유전자 조합물을 발현하는 (예컨대, Δ17 데새투라제 및 일롱가제를 발현함) 다른 벡터의 동시-형질전환 수단에 관해 기재한다.
실시예 15에 기재한 벡터는 또한 ALS 선별을 가지며 Ann/Sdd17/BD30 카세트에 추가하여 콩 알부민 프로모터 (PCT 공개 제WO 04/071467호에 기재되어 있음)의 제어하의 모르티에렐라 알피나 일롱가제 (PCT 공개 제WO 04/071467호 및 동 제WO 00/12720호에 기재되어 있음)를 함유하는 벡터와 함께 대두로 동시-형질전환될 수도 있었다. 상기 플라스미드는 상기한 것과 유사한 방법으로 생성될 수 있다. 예를 들어, 모르티에렐라 알피나 일롱가제 ("Maelo")를 함유하는 pKR270 (서열 102, PCT 공개 제WO 04/071467호에 기재되어 있음)의 NotI 단편을 pKR163 (서열 98)의 NotI 부위에 클로닝하여 SA/Maelo/SA3' 카세트를 갖는 벡터를 생성할 수 있다. 상기 플라스미드를 BsiWI 소화시켜 SA/Maelo/SA3' 카세트를 유리시키고, 선별을 위한 ALS 유전자, T7prom/HPT/T7term 카세트 및 박테리아 ori 영역을 함유하는 플라스미드 pKR226 (서열 86, PCT 공개 제WO 04/071467호에 기재되어 있음)의 BsiWI 부위로 클로닝하여 새로운 플라스미드를 생성할 수 있다. 이어서, 플라스미드 pKR271 (서열 85, PCT 공개 제WO 04/071467호에 기재되어 있음)을 PstI으로 소화시킬 수 있었고, 사프롤레그니아 디클리나 Δ17 데새투라제를 함유하는 단편을 SA/Maelo/SA3' 카세트를 함유하는 상기 새로운 플라스미드의 SbfI 부위에 클로닝할 수 있었다. 이러한 방법으로, 모르티에렐라 알피나 일롱가제를 강력한 종자-특이적 프로모터하에서 사프롤레그니아 디클리나 Δ17 데새투라제와 동시 발현시킬 수 있었다.
실시예
20:
EgD9e
,
EgD8
및
Mad5
를 포함하는 대두 발현 벡터와
C
20
/22
일롱가제
및 Δ4
데새투라제의
동시 발현
본 실시예는 실시예 15에 기재한 대두 발현 벡터 (EgD9e, EgD8 및 Mad5를 발현함)와 여러개의 상이한 종자-특이적 프로모터/장쇄 PUFA-생합성 유전자 조합물을 발현하는 (예컨대, C20 /22 일롱가제 및 Δ4 데새투라제를 발현함) 다른 벡터의 동시-형질전환 수단에 관해 기재한다.
C20 /22 일롱가제 (또한 Δ5 일롱가제 및/또는 EPA 일롱가제로 지칭되기도 함) 및/또는 Δ4 데새투라제 역시 본원에 기재한 것과 유사한 대두 발현 벡터에서 동시 발현될 수 있다. 예를 들어, 쉬조키트리움 아그레가툼(Schizochytrium aggregatum)으로부터의 Δ4 데새투라제 (PCT 공개 제WO 02/090493호에 기재되어 있음) 또는 파블로바로부터의 Δ5 일롱가제 (PCT 공개 제WO 04/071467호에 기재되어 있음)는 PCT 공개 제WO 04/071467호에 기재되어 있는 것과 같은 적합한 대두 발현 벡터로 클로닝될 수 있다. Δ4 데새투라제 또는 Δ5 일롱가제의 5' 및 3' 말단에 NotI 부위를 도입하도록 디자인된 PCR 프라이머를 사용하여 유전자를 증폭시킬 수 있다. 이어서, 이로써 생성된 PCR 생성물을 NotI으로 소화시킬 수 있고, 강력한 종자-특이적 프로모터와 전사 종결자에 의해 플랭킹된 NotI 부위를 함유하는 적합한 대두 발현 벡터로 클로닝할 수 있다. 본원에 기재되거나 PCT 공개 제WO 04/071467호 또는 PCT 공개 제WO 05/047479호 등을 포함하지만 이에 제한되지 않는 문헌에 기재된 것과 같은 다른 벡터로의 추가의 서브클로닝은 대두 중 Δ4 데새투라제 및/또는 Δ5 일롱가제의 발현 및 동시발현에 적합한 벡터를 생성해야만 한다.
실시예
21:
유트레프티엘라
종
CCMP389
게놈
DNA
,
RNA
및
cDNA
의 제조
본 실시예는 CCMP (The Provasoli-Guillard National Center for Culture of Marine Phytoplankton) (미국 메인주 웨스트 부트베이 하버 조새의 비지로우 래버러토리 포 오션 사이언시스(Bigelow Laboratory for Ocean Sciences))로부터 구입한 유트레프티엘라 종 CCMP389로부터의 게놈 DNA, RNA 및 cDNA의 제조에 관해 기재한다.
유트레프티엘라
종
CCMP389
로부터의
RNA
및 게놈
DNA
의 제조
트리졸 시약 (미국 캘리포니아주 칼스배드 소재의 인비트로젠)을 제조업체의 프로토콜에 따라 사용하여, 배양물 1 L로부터 전체 RNA 및 게놈 DNA를 단리하였다. 구체적으로, 세포 펠렛을 0.5 mm 유리 비드 0.5 mL과 혼합한 트리졸 시약 0.75 mL 중에 재현탁하고, 최고치로 설정한 바이오스펙(Biospec) 미니 비드비터 (미국 오클라호마주 바르틀레스빌 소재)에서 3분 동안 균질화시켰다. 상기 혼합물을 에펜도르프(Eppendorf) 원심분리로 30초 동안 14,000 rpm에서 원심분리하여 부스러기(debris) 및 유리 비드를 제거하였다. 상등액을 24:1 클로로포름:이소아밀 알콜 (인비트로젠) 150 ㎕로 추출하였다. RNA 단리에는 위쪽의 수성 상을 사용하였고, DNA 단리에는 아래쪽의 유기 상을 사용하였다.
RNA 단리를 위해서, 수성 상을 이소프로필 알콜 0.375 mL와 혼합하고 실온에서 5분 동안 인큐베이션시켰다. 침전된 RNA를 8,000 rpm으로 4℃에서 5분 동안의 원심분리로 수거하였다. 펠렛을 80% 에탄올 0.7 mL로 1회 세척하고 공기 건조시켰다. 이러한 방법으로, 전체 RNA 360 ㎍을 수득하였다.
게놈 DNA 단리를 위해서, 아래쪽의 유기 상을 에탄올 75 ㎕와 혼합하고 실온에서 5분 동안 인큐베이션시켰다. 이어서, 상기 샘플을 5,000 rpm으로 2분 동안 에펜도르프 원심분리로 원심분리하였다. 펠렛을 0.1 M 시트르산나트륨:10% 에탄올 0.75 mL로 2회 세척하였다. 매번 마다 샘플을 세척 용액 중에 15분 동안 실온에서 인큐베이션시킨 후에 5,000 rpm으로 5분 동안 4℃에서 원심분리하였다. 펠렛을 공기 건조시켜 8 mM NaOH 300 ㎕ 중에 재용해하였다. 1 M HEPES를 사용하여 샘플의 pH를 7.5로 조정하였다. 이어서, 퀴아젠 PCR 정제 키트 (미국 캘리포니아주 발렌시아 소재)를 제조업체의 프로토콜에 기재된 대로 정확하게 사용하여 게놈 DNA를 추가로 정제하였다. 이로써, 게놈 DNA 40 ㎍이 단리되었다.
유트레프티엘라
종
CCMP389
로부터의
cDNA
제조
비디 바이오사이언스 클론테크(BD Bioscience Clontech) (미국 캘리포니아주 팔로 알토 소재)의 크리에이터(Creator)™ 스마트™ cDNA 라이브러리 구축 키트를 사용하여 이중-가닥 cDNA를 생성하였다. 구체적으로, 제1 가닥 cDNA 합성을 위해서 전체 RNA 샘플 (1.2 ㎍) 1 ㎕를 스마트™ IV 올리고뉴클레오티드 (서열 103) 1 ㎕, CDSIII/3' PCR 프라이머 (서열 104) 1 ㎕ 및 물 2 ㎕와 개별적으로 혼합하였다. 상기 혼합물을 75℃로 5분 동안 가열하고 빙상에서 5분 동안 냉각시켰다. 상기 샘플에 5× 제1 가닥 완충제 2 ㎕, 20 mM DTT 1 ㎕, dNTP 혼합물 (10 mM씩의 dATP, dCTP, dGTP 및 dTTP) 1 ㎕ 및 파워스크립트(PowerScript) 역전사효소 1 ㎕를 첨가하였다. 상기 샘플을 42℃에서 1시간 동안 인큐베이션하였다.
상기 제1 가닥 cDNA 합성 혼합물을 증폭을 위한 주형으로 사용하였다. 구체적으로, 상기 반응 혼합물은 상기 제1 가닥 cDNA 샘플 2 ㎕, 물 80 ㎕, 10× 어드밴티지(Advantage) 2 PCR 완충제 10 ㎕, 50× dNTP 혼합물 (10 mM씩의 dATP, dCTP, dGTP 및 dTTP) 2 ㎕, 5'-PCR 프라이머 (서열 105) 2 ㎕, CDSIII/3'-PCR 프라이머 (서열 104) 2 ㎕ 및 50× 어드밴티지 2 폴리머라제 혼합물 2 ㎕를 함유하였다. 하기 조건을 이용하여 PCR 증폭을 수행하였다: 95℃에서 1분, 이후 95℃에서 10초 및 68℃에서 6분의 20회 주기. 퀴아젠 PCR 정제 키트를 제조업체의 프로토콜에 따라 정확하게 사용하여 증폭 생성물을 정제하였다. 정제된 생성물을 물 50 ㎕로 용출시켰다.
실시예
22:
유트레프티엘라
종
CCMP389
로부터 전장 Δ9
일롱가제의
단리
본 실시예는 유글레나 그라실리스 Δ9 일롱가제 서열 (EgD9e, 실시예 3) 및 아이. 갈바나 Δ9 일롱가제 서열 (IgD9e)의 보존된 영역에서 유래된 프라이머를 사용하여 유트레프티엘라 종 CCMP389의 Δ9 일롱가제를 코딩하는 부분적 cDNA 단편을 동정하는 것에 관해 기재한다. 이어서, 상기 부분적 cDNA 단편의 서열을 기초로 하여, 상기 유전자의 5' 및 3' 말단을 단리하였다. 이것은, 유트레프티엘라 종 CCMP389 Δ9 일롱가제 번역 개시 'ATG' 코돈의 상류 51개 염기 및 Δ9 일롱가제 종결 코돈 뒤쪽의 662 bp를 신장시키는 콘티그 (서열 17)의 조립을 가능하게 하였다.
유레프티엘라
종
CCMP389
의 부분적 Δ9
일롱가제를
코딩하는
cDNA
단편의 동정
유트레프티엘라 종 CCMP389를 Δ9 일롱가제의 존재에 대하여 분석하였다. 유트레프티엘라 종 CCMP389 Δ9 일롱가제를 단리하는데 적합한 동의성 프라이머의 디자인은, EgD9e (서열 2)와 IgD9e (서열 8)의 정렬을 디엔에이스타 소프트웨어 메그얼라인™ 프로그램의 클러스탈 더블유(Clustal W) (느리고, 정확하며, 곤네트(Gonnet) 옵션. [Thompson et al., Nucleic Acids Res., 22:4673-4680 (1994)]) 방법을 사용하여 생성했을 때 상기 2종의 일롱가제 둘다에 공통적으로 보존된 아미노산 서열의 여러 스트레치에 대한 확인을 기초로 하였다 (도 4로 나타낸 EgD9e 및 IgD9e의 클러스탈 브이 정렬을 대신한 클러스탈 더블유 정렬은 본원에 나타내지 않음).
이러한 정렬을 기초로 하여, 하기 세트의 동의성 올리고뉴클레오티드를 디자인하여, 하기 표 10에 나타낸 바와 같은 유트레프티엘라 종 CCMP389 Δ9 일롱가제 유전자 코딩 영역의 일부를 증폭시켰다:

[주: 서열 106 및 서열에 사용된 핵산 동의성 코드는 다음과 같다: R = A/G, Y = C/T, D = G/A/T; 및 N = A/C/T/G]
상기 반응 혼합물은 1:20으로 희석된 cDNA 1 ㎕, 전방향 및 역방향 프라이머 (20 μM) 5 ㎕씩, 물 14 ㎕ 및 다까라(TaKaRa) ExTaq 2× 사전혼합물 (미국 캘리포니아주 마운틴 뷰 소재의 다까라 바이오(TaKaRa Bio)) 25 ㎕를 함유하였다. 하기 파라미터를 사용하여 PCR 증폭을 수행하였다: 94℃에서 1분, 이후 94℃에서 20초, 55℃에서 20초 및 72℃에서 1분의 35회 주기 및 이후 72℃에서 5분 동안의 최종 신장 주기.
PCR 생성물의 아가로스 겔 분석은 약 200 bp 단편이 수득되었음을 보여주었다. 상기 단편을 퀴아젠 PCR 정제 키트로 정제하여 pCR2.1-TOPO (인비트로젠)로 클로닝하고 서열분석하였다. 생성된 서열 (서열 13)은 번역될 경우에 BLAST 프로그램 분석 (Basic Local Alignment Search Tool, [Altschul, S. F., et al., J. Mol. Biol., 215:403-410 (1993)], 실시예 3)을 기초로 할 때 이소크리시스 갈바나 유래의 공지된 Δ9 일롱가제 (IgD9e, 서열 8)와의 상동성을 보유하였다.
유트레프티엘라
종
CCMP389
Δ9
일롱가제
5'-말단 서열의 단리
유트레프티엘라 종 CCMP389 (실시예 21)의 이중-가닥 cDNA를 2회의 별도의 PCR 증폭에서 주형으로 사용하였다. 제1회의 PCR 증폭에서, 올리고뉴클레오티드 프라이머는 유전자 특이적 올리고뉴클레오티드 (즉, 389Elo-5-1 [서열 110]) 및 비디-클론테크 크리에이터™ 스마트™ cDNA 라이브러리 키트의 일반적인 올리고뉴클레오티드 5'-PCR 프라이머 (서열 105)로 이루어졌다. PCR 증폭을 1:10으로 희석된 유트레프티엘라 종 CCMP389 cDNA (주형) 1 ㎕, 각 프라이머 (20 μM) 1 ㎕씩, 물 22 ㎕ 및 다까라 ExTaq 2× 사전혼합물 25 ㎕를 포함하는 총 부피 50 ㎕로 수행하였다. 증폭을 94℃에서 90초 동안 수행한 후에 94℃에서 30초, 55℃에서 30초, 및 72℃에서 1분의 30회 주기를 수행하고, 이후에는 72℃에서 7분 동안의 최종 신장 주기를 수행하였다.
제2회의 PCR 증폭은 상기 제1회 PCR 반응의 희석된 생성물 (1:50) 1 ㎕를 주형으로 사용하였다. 프라이머는 유전자 특이적 올리고뉴클레오티드 (즉, 389Elo-5-2 (서열 111)) 및 올리고뉴클레오티드 DNR CDS 5'-2 (서열 112)로 이루어졌다. 증폭은 상기한 바와 같이 수행하였다.
제2회 PCR 반응의 생성물을 1% (w/v) 아가로스에서 전기영동시켰고, 크기 범위 200 bp 내지 800 bp에 걸쳐 있는 넓은 밴드로 나타났다. 퀴아젠 겔 정제 키트를 제조업체의 프로토콜에 따라 사용하여 400 bp 내지 600 bp 사이의 생성물을 단리하고, pCR2.1-TOPO (인비트로젠)에 클로닝하여 이. 콜라이를 형질전환시켰다. 형질전환체를 암피실린 (100 ㎍/mL)-함유 LB 한천에서 선별하였다.
추정적인 Δ9 일롱가제 cDNA의 5' 영역을 포함하는 1개의 형질전환체로부터의 플라스미드 DNA의 서열 분석은 406 bp의 단편 (즉, 5'-cDNA 단편 1, 서열 14)을 밝혀냈다. 상기 단편을 유전자의 'ATG' 번역 개시 코돈 근처로 연장시켰지만, 출발 코돈이나 처음 20개 내지 30개 아미노산 그 어느 것도 서열 14에는 포함시키지 않았다.
이어서, 5'-cDNA 단편 1의 서열 (서열 14)을 기초로 하여 추가의 올리고뉴클레오티드 (즉, 389Elo-5-4 (서열 113))를 디자인하여, 상기 유전자의 완전 5' 말단이 PCR로 수득되도록 하였다. 반응 혼합물 및 증폭 조건은 상기한 제2회의 PCR에 대한 것과 동일하였지만, 여기서는 프라이머 389Elo-5-2를 389Elo-5-4로 대체하였다. 아가로스 겔 전기영동으로 분석했을 때, PCR 생성물은 다시 200 bp 내지 800 bp의 넓은 밴드로 나타났고, 200 bp 내지 500 bp 크기의 단편을 상기한 바와 같이 단리하여 클로닝하고 형질전환시켰다.
추정적인 Δ9 일롱가제 cDNA의 5' 영역을 포함하는 1개의 형질전환체로부터의 플라스미드 DNA의 서열 분석은 197 bp의 단편 (5'-cDNA 단편 2, 서열 15)을 밝혀냈다. 이것은 cDNA의 5'-말단 및 상류 비-번역 영역의 51 bp를 포함하였다.
유트레프티엘라
종
CCMP389
Δ9
일롱가제
3'-말단의 단리
추정적인 Δ9 델타 일롱가제의 3' 말단도 cDNA를 주형으로 사용한 PCR 증폭으로 단리하였다. 상기 방법은 5' 말단의 단리에 대하여 상기한 것과 같았으나, 제1회와 제2회의 PCR 증폭 둘다에 사용한 프라이머는 하기 표 11에 나타낸 바와 같고, 20 μM이 아니라 10 μM이었다. 추가로, 72℃에서의 최종 신장 주기를 7분이 아니라 5분으로 감소시켰다.
| 3' cDNA 단리에 사용된 올리고뉴클레오티드 프라이머 | ||
| PCR 증폭 | 유전자 특이적 올리고뉴클레오티드 | 일반적인 올리고뉴클레오티드 |
| 제1회 | 389Elo-3-1 (서열 114) | CDSIII/3' PCR 프라이머 (서열 104) |
| 제2회 | 389Elo-3-2 (서열 115) | CDSIII/3' PCR 프라이머 (서열 104) |
* CDSIII/3' PCR 프라이머는 클론테크의 크리에이터™ 스마트™ cDNA 라이브러리 구축 키트에서 제공되었음.
제2회 PCR 증폭으로 약 1 kB의 DNA 단편이 생성되었고, 이것을 퀴아젠 PCR 정제 키트로 정제하여 pCR2.1-TOPO로 클로닝하고 형질전환 및 서열분석을 실시하였다. 여러개 클론의 서열 분석은 약 1 kB의 DNA 단편이 폴리A 테일을 포함하는 추정적인 Δ9 일롱가제 cDNA의 3'-영역을 함유함을 보여주었다. 3'-영역의 920 bp 조립된 콘티그 서열은 서열 16으로 나타내었다.
유트레프티엘라
종
CCMP389
전장 Δ9
일롱가제
서열의 조립
처음의 부분적 cDNA 단편 (서열 13), 2개의 5' cDNA 단편 (서열 14 및 서열 15) 및 3'-cDNA 단편 (서열 16)의 조립으로, 유트레프티엘라 종 CCMP389 Δ9 일롱가제의 완전 서열 및 5' 비-번역 영역 51 bp 및 3' 비-번역 영역 662 bp가 생성되었다 (서열 17, 1504 bp). 코딩 영역은 792 bp 길이였고, 263개 아미노산 (서열 5)의 단백질을 코딩하였다. 서열 4는 유트레프티엘라 종 CCMP389 Δ9 일롱가제 (본원에서 E389D9e라고 지칭됨)의 코딩 서열의 뉴클레오티드 서열이다.
유트레프티엘라
종
CCMP389
(
E389D9e
)의 Δ9
일롱가제
서열과 공지의 Δ 9 일롱가
제의
비교
서열 5 (즉, E389D9e)의 동일성은, BLAST "nr" 데이타베이스에 함유된 서열 (실시예 3)과의 유사성에 대하여 BLAST 검색을 수행하여 결정하였다. 서열 5가 최고의 유사성을 나타내는 서열을 요약한 BLAST 비교 결과를 동일성(%),유사성(%), 및 기대값으로 보고하였다. "동일성(%)"은 2종의 단백질 사이에서 동일한 아미노산의 백분율(%)로 정의된다. "유사성(%)"은 2종의 단백질 사이에서 동일하거나 보존된 아미노산의 백분율(%)로 정의된다. "기대값"은 해당 크기의 데이타베이스 검색시에 절대적으로 우연히 예상되는 매치 수를 주어진 스코어로 명시하며 매치의 통계적 유의성을 추정한다.
따라서, 본원에서 서열 5로 기재한 아미노산 단편은 이소크리시스 갈바나의 Δ9 일롱가제 (서열 8)인 IgD9e에 대해 38% 동일성 및 56% 유사성을 공유하며, 기대값은 2E-43이다. 유사하게, E389D9e는 클러스탈 브이 방법을 사용할 때 IgD9e에 33.1% 동일하였고, E389D9e는 클러스탈 브이 방법을 사용할 때 EgD9e에 65.1% 동일하였다 (도 2). 클러스탈 브이 방법 ([Higgins, D.G. and Sharp, P.M., Comput. Appl. Biosci., 5:151-153 (1989)], [Higgins et al., Comput. Appl. Biosci., 8:189-191 (1992)])으로 수행한 서열 동일성(%) 계산은 LASERGENE 바이오인포매틱스 컴퓨팅 수트의 메그얼라인™ v6.1 프로그램으로 수행하였고, 쌍별 정렬을 위한 디폴트 파라미터 (KTUPLE = 1, GAP PENALTY = 3, WINDOW = 5, DIAGONALS SAVED = 5 및 GAP LENGTH PENALTY = 10)를 사용하였다.
실시예
23:
야로위아
리폴리티카
균주
Y2224
중
야로위아
리폴리티카
발현 벡터 pFBAIN-389Elo (
유트레프티엘라
종
CCMP389
Δ9
일롱가제
(
E389D9e
)를 포함함)의 구축 및 기능적 분석
본 실시예는 야로위아 리폴리티카 발현 벡터 pFBAIN-389Elo (키메라 FBAINm::E389D9e::Pex20 유전자를 포함함)의 합성에 관해 기재한다. 이후, E389D9e의 델타-9 일롱가제 활성은 야로위아 리폴리티카 균주 Y2224에서 발현되었을 때 결정하였다.
야로위아
리폴리티카
발현 벡터
pFBAIN
-389
Elo
의 구축
올리고뉴클레오티드 389Elo-F 및 389Elo-R1 (각각 서열 116 및 서열 117)을 E389D9e (서열 4)의 전장 cDNA를 증폭시키기 위한 프라이머로 사용하였다. 유트레프티엘라 종 CCMP389 cDNA (실시예 21)를 주형으로 사용한 PCR 반응은, 20 μM 전방향 및 역방향 프라이머 1 ㎕씩, cDNA 1 ㎕, 5× PCR 완충제 10 ㎕, dNTP 혼합물 (10 μM씩) 1 ㎕, 물 35 ㎕ 및 퓨젼(Phusion) 폴리머라제 (미국 매사추세츠주 이프스위치 소재의 뉴 잉글랜드 바이오랩스, 인크.) 1 ㎕를 포함하는 총 부피 50 ㎕로 개별적으로 수행하였다. 증폭을 98℃에서 1분 동안 수행한 후에 98℃에서 10초, 55℃에서 10초, 및 72℃에서 30초의 30회 주기를 수행하였고, 이후에는 72℃에서 5분 동안의 최종 신장 주기를 수행하였다. PCR 생성물을 NcoI 및 EarI으로 소화시켜 Δ9 일롱가제 cDNA의 5' 영역을 함유하는 약 210 bp 단편을 생성하였다. 또한, 이것을 EarI 및 NotI으로 소화시켜 상기 cDNA의 3' 영역을 함유하는 약 600 bp 단편을 생성하였다. NcoI/EarI 및 EarI/NotI으로 소화시킨 단편들을 1% (w/v) 아가로스 중에서의 겔 전기영동으로 정제하였다.
NcoI/EarI 및 EarI/NotI Δ9 일롱가제 소화 단편을 NcoI/NotI 소화된 pFBAIN-MOD-1 (서열 118)와 정해진 방향으로 라이게이션시켜셔, E389D9e 유전자가 야로위아 리폴리티카 FBAINm 프로모터 및 PEX20-3' 종결자 영역의 제어를 받도록 하였다. 구체적으로, 상기 라이게이션 반응물은 2× 라이게이션 완충제 10 ㎕, T4 DNA 리가제 (프로메가) 1 ㎕, 약 210 bp 및 약 600 bp의 단편 4 ㎕씩 (각각 약 300 ng씩), 및 pFBAIN-MOD-1 (약 150 ng) 1 ㎕를 함유하였다. 상기 반응 혼합물을 실온에서 2시간 동안 인큐베이션하고, 이것을 이용하여 이. 콜라이 Top10 감응성 세포 (인비트로젠)를 형질전환시켰다. 퀴아젠 미니프렙 키트를 사용하여, 형질전환체로부터 플라스미드 DNA를 회수하였다. 제한 맵핑을 통해 올바른 클론을 확인하고, 최종 구축물을 "pFBAIN-389Elo"라고 지칭하였다.
따라서, pFBAIN-389Elo (도 15A, 서열 119)는 이에 따라 하기 성분을 함유하였다:
| 서열 119 내의 RE 부위 및 뉴클레오티드 | 단편 및 키메라 유전자 성분의 기재 |
| BglII-BsiWI (6040-301) | ·FBAINm: 야로위아 리폴리티카 FBAINm 프로모터 (PCT 공개 제WO 2005/049805호) ·E389D9e: 유트레프티엘라 종 CCMP389 Δ9 일롱가제 (본원에서 서열 4로 기재함) ·Pex20: 야로위아 Pex20 유전자의 Pex20 종결자 서열 (진뱅크 관리 번호: AF054613) 을 포함하는 FBAINm::E389D9e::Pex20 |
| PacI-BglII (4533-6040) | 야로위아 Ura 3 유전자 (진뱅크 관리 번호: AJ306421) |
| (3123-4487) | 야로위아 자율 복제 서열 (ARS18, 진뱅크 관리 번호: A17608) |
| (2464-2864) | f1 기점 |
| (1424-2284) | 이. 콜라이에서의 선별을 위한 암피실린-내성 유전자 (AmpR) |
| (474-1354) | ColE1 플라스미드 복제 기점 |
pFBAIN
-389
Elo
를 포함하는
야로위아
리폴리티카
형질전환체의 기능적 분석
'일반적인 방법'에 기재한 바와 같이, pFBAIN-389Elo (E389D9e를 포함함)의 다섯 (5)개 개개의 클론 및 대조군 플라스미드 pFBAIN-MOD-1로 야로위아 리폴리티카 균주 Y2224 (실시예 7)를 형질전환시켰다. 세포를 우라실이 없는 MM 플레이트에 플레이팅하고, 30℃에서 2일 내지 3일 동안 유지시켰다. 이어서, 각 플레이트에서 세포를 긁어 내어 지질을 추출하고, 에스테르교환반응으로 지방산 메틸 에스테르를 제조한 후에 휴렛-팩커드 6890 GC로 분석하였다.
GC 분석은 pFBAIN-389Elo를 포함하는 모든 5개의 형질전환체에서는 EDA가 생성되었지만, 대조군 균주에서는 EDA가 생성되지 않았음을 보여주었다 (표 13). 지방산은 18:2 (LA) 및 20:2 (EDA)로 표시하였고, 각각의 조성은 전체 지방산의 비율(%)로 표시하였다. 전환 효율은 ([생성물]/[기질 + 생성물])×100의 식에 따라 계산하였고, 여기서의 '생성물'은 그것이 유래된 경로 중의 중간 생성물 및 모든 생성물을 포함한다.

상기 나타낸 결과는 본원에서 서열 4 및 서열 5로 기재한, 유트레프티엘라 종 CCMP389로부터 유래된 클로닝된 cDNA가 LA를 EDA로 효율적으로 탈포화시키며, 따라서 Δ9 일롱가제로 기능한다는 것을 확인시켜 주었다.
실시예
24:
야로위아
리폴리티카
중에서의 발현을 위해 코돈-최적화된 합성 Δ9 일
롱가제
유전자 (
유트레프티엘라
종
CCMP389
에서 유래함) (
E389D9eS
)를 포함하는
야
로위아
리폴리티카
발현 벡터
pZUFE389S
의 구축 및 기능적 분석
본 실시예는 키메라 FBAIN::E389D9eS::Pex20 유전자를 포함하는 야로위아 리폴리티카 벡터 pZUFE389S의 기능적 발현에 관해 기재하며, 여기서의 E389D9eS는 유트레프티엘라 종 CCMP389에서 유래되고 야로위아 중에서의 발현을 위해 코돈-최적화된 합성 Δ9 일롱가제이다. 따라서, 본 분석에는 (1) E389D9eS의 합성, (2) pZUFE389S의 구축 및 야로위아 리폴리티카 균주 Y2224로의 형질전환, 및 (3) pZUFE389S (E389D9eS를 발현함)를 포함하는 야로위아 리폴리티카 균주 Y2224의 형질전환 유기체 내 지질 프로파일의 분석이 필요하다.
E389D9eS
의 합성
실시예 5, 실시예 8 및 PCT 공개 제WO 2004/101753호에 기재된 것과 유사한 방식으로, 유트레프티엘라 종 CCMP389의 Δ9 일롱가제 유전자 (E389D9e, 서열 4 및 서열 5)의 코돈 사용을 야로위아 리폴리티카 중에서의 발현을 위해 최적화시켰다. 구체적으로, E389D9e (서열 4)의 코딩 서열을 기초로 하여 야로위아 코돈 사용 패턴 (PCT 공개 제WO 2004/101753호), 'ATG' 번역 개시 코돈 주위의 컨센서스 서열, 및 RNA 안정성에 관한 일반적 규칙 [Guhaniyogi, G. and J. Brewer, Gene, 265(1-2):11-23 (2001)]에 따라 코돈-최적화 Δ9 일롱가제 유전자 ("E389D9eS"라 지칭함. 서열 6)를 디자인하였다. 번역 개시 부위의 변형에 추가하여, 792 bp 코딩 영역 (정지 코돈을 포함함) 중 128 bp (16.2%)를 변형시켰고, 113개 코돈을 최적화하였다. GC 함량은 야생형 유전자 (즉, E389D9e) 내에서는 45.7%이었던 것이 합성 유전자 (즉, E389D9eS) 내에서는 50.1%로 증가되었다. NcoI 부위 및 NotI 부위를 각각 E389D9eS의 번역 개시 코돈 주위 및 정지 코돈 뒤에 혼입하였다. 도 16은 E389D9e 및 E389D9eS의 뉴클레오티드 서열 비교를 보여준다. 코돈-최적화 유전자에서의 변형 중 그 어느 것도 코딩되는 단백질의 아미노산 서열 (서열 5)을 변화시키지 않았다.
E389D9eS로 지칭된 유전자 (서열 6)는 젠스크립트 코포레이션 (미국 뉴저지주 피스카타웨이 소재)이 합성하였고, pUC57 (진뱅크 관리 번호: Y14837)로 클로닝하여 pE389S (서열 120)를 생성하였다.
E389D9eS
를 포함하는 구축물
pZUFE389S
의 생성
pZUF17 (도 7C, 서열 121)의 NcoI/NotI 단편을 E389D9eS를 포함하는 pE389S (서열 120)의 NcoI/NotI 단편으로 대체하여, 플라스미드 pZUFE389S (도 15B, 서열 122)를 구축하였다. 상기 라이게이션의 생성물은 pZUFE389S이었고, 이에 따라 하기 성분을 함유하였다:
| 서열 122 내의 RE 부위 및 뉴클레오티드 | 단편 및 키메라 유전자 성분의 기재 |
| EcoRI/BsiWI (6857-1112) | ·FBAIN: 야로위아 리폴리티카 FBAIN 프로모터 (PCT 공개 제WO 2005/049805호) ·E389D9eS: 유트레프티엘라 종 CCMP389에서 유래된 코돈-최적화 Δ9 일롱가제 (서열 6) ·Pex20: 야로위아 Pex20 유전자의 Pex20 종결자 서열 (진뱅크 관리 번호: AF054613) 을 포함하는 FBAIN::E389D9eS::Pex20 |
| 2148-1268 | ColE1 플라스미드 복제 기점 |
| 3078-2218 | 이. 콜라이에서의 선별을 위한 암피실린-내성 유전자 (AmpR) |
| 3977-5281 | 야로위아 자율 복제 서열 (ARS18, 진뱅크 관리 번호: A17608) |
| 6835-5324 | 야로위아 Ura 3 유전자 (진뱅크 관리 번호: AJ306421) |
pZUFE389S
를 포함하는
야로위아
리폴리티카
형질전환체의 기능적 분석
'일반적인 방법'에 기재한 바와 같이, 플라스미드 pZUFE389S로 균주 Y2224 (야생형 야로위아 균주 ATCC #20362의 Ura3 유전자 자율 돌연변이로부터의 FOA 내성 돌연변이체, 실시예 7)를 형질전환시켰다. 형질전환체를 MM 플레이트에서 선별하였다. 30℃에서 2일 동안 성장시킨 후에 형질전환체를 골라내어 신선한 MM 플레이트에 재-스트리킹하였다. 일단 성장하면, 이들 균주를 액체 MM 3 mL로 30℃하에 개별적으로 접종하고, 250 rpm/분으로 2일 동안 진탕시켰다. 세포를 원심분리로 수거하여 지질을 추출하고, 에스테르교환반응으로 지방산 메틸 에스테르를 제조한 후에 휴렛-팩커드 6890 GC로 분석하였다.
GC 분석은 모든 12개의 형질전환체에서 생성된 전체 지질 중에 C20:2 (EDA)가 약 2.2%로 존재함을 보여주었는데, 이들 12개의 균주에서 C18:2로부터 C20:2로의 전환 효율은 약 12% (실시예 23에 기재한 바와 같이 계산한 평균값)인 것으로 결정되었다.
실시예
25: 유글레나
그라실리스
(
EgD9e
또는
EgD9eS
) 및/또는
유트레프티엘라
종 CCMP389 (
E389D9e
또는
E389D9eS
) Δ9
일롱가제의
발현을 위한 별법의 대두 발현 벡터의 구축
당업자는 상기한 실시예가 예시를 위한 것이지 제한되는 것이 아님을 이해할 것이다. 예를 들어, 상기 실시예 10, 실시예 11 및 실시예 13 내지 실시예 15에서 EgD9e의 발현을 위해 생성된 임의의 대두 발현 벡터는 본원에 기재한 방법과 유사하지만 이에 제한되는 것은 아닌 방법을 이용하여 EgD9eS, E389D9e 및/또는 E389D9eS의 발현 (또는 동시발현)이 대신 가능하도록 쉽게 변형될 수 있다. Δ9 일롱가제의 5' 및 3' 말단에 NotI 부위를 도입하도록 디자인된 PCR 프라이머를 사용하여 유전자를 증폭시킬 수 있다. 이어서, 이로써 생성된 PCR 생성물을 NotI으로 소화시킬 수 있고, 강력한 종자-특이적 프로모터와 전사 종결자에 의해 플랭킹된 NotI 부위를 함유하는 적합한 대두 발현 벡터에 클로닝시킬 수 있다. 본원에 기재되거나 PCT 공개 제WO 2004/071467호 또는 동 제WO 2005/047479호 (그러나, 이들 문헌에 제한되지는 않음)에 기재된 것과 같은 다른 벡터로의 추가의 서브클로닝은 대두 중 Δ9 일롱가제의 발현에 적합한 벡터를 생성할 것이다.
추가로, 본원에 기재한 유전자, 프로모터, 종결자 및 유전자 카세트에 추가하여, 당업자라면 EgD9e, EgD9eS, E389D9e 및/또는 E389D9eS의 발현을 위한 다른 프로모터/유전자/종결자 카세트 조합물이 본원에 기재한 것과 유사하지만 그에 제한되지는 않는 방법으로 합성될 수 있다는 것을 이해할 수 있다. 유사하게, 본 발명의 임의의 Δ9 일롱가제와의 동시발현을 위한 다른 PUFA 유전자 (예컨대 하기 표 17에 기재한 것)를 발현시키는 것이 바람직할 수 있다.
예를 들어, PCT 공개 제WO 2004/071467호 및 동 제WO 2004/071178호는 대두에서의 배아-특이적 발현에 사용하기 위한 수많은 프로모터 및 전사 종결자 서열의 단리에 관해 기재한다. 추가로, PCT 공개 제WO 2004/071467호, 동 제WO 2005/047479호 및 동 제WO 2006/012325호는 개개의 프로모터, 유전자 및 전사 종결자를 독특한 조합으로 한데 라이게이션시켜서 다중 프로모터/유전자/종결자 카세트 조합물을 합성하는 것에 관해 기재한다. 일반적으로, 적합한 프로모터 (예컨대 하기 표 15에 기재한 것을 포함하지만 이에 제한되지는 않음)와 전사 종결자 (예컨대 하기 표 16에 기재한 것을 포함하지만 이에 제한되지는 않음)에 의해 플랭킹된 NotI 부위를 사용하여 원하는 유전자를 클로닝한다. NotI 부위는, 하기 표 17에 기재한 것을 포함하지만 이에 제한되지는 않는 것과 같은 관심 유전자에, 상기 유전자의 5' 및 3' 말단에 NotI 부위를 도입하도록 디자인된 올리고뉴클레오티드를 사용한 PCR 증폭을 이용하여 부가될 수 있다. 이어서, 이로써 생성된 PCR 생성물을 NotI으로 소화시켜서 적합한 프로모터/NotI/종결자 카세트로 클로닝한다.
추가로, PCT 공개 제WO 2004/071467호, 동 제WO 2005/047479호 및 동 제WO 2006/012325호는 개개의 유전자 카세트를 독특한 조합으로 (적합한 선별가능한 마커 카세트와 함께) 추가로 연결시켜서 원하는 표현형의 발현을 달성하는 것에 관해 기재한다. 이것은 주로 여러가지 제한 효소 부위를 이용하여 수행되지만, 당업자라면 원하는 프로모터/유전자/전사 종결자 조합을 달성하기 위해 수많은 기술이 이용될 수 있음을 이해할 수 있다. 이와 같이 하여 임의의 조합의 배아-특이적 프로모터/유전자/전사 종결자 카세트가 달성될 수 있다. 당업자는 또한 이러한 카세트가 개개의 DNA 단편 또는 여러 단편에 위치할 수 있어서 유전자들의 동시 발현이 여러 DNA 단편들의 동시-형질전환 결과인 것을 이해할 수 있다.
| 종자-특이적 프로모터 | ||
| 프로모터 | 유기체 | 프로모터 참조문헌 |
| 베타-콘글리시닌 α'-서브유닛 | 대두 | [Beachy et al., EMBO J., 4:3047-3053 (1985)] |
| 쿠니츠 트립신 억제제 | 대두 | [Jofuku et al., Plant Cell, 1:1079-1093 (1989)] |
| 안넥신 | 대두 | WO 2004/071467 |
| 글리시닌 Gy1 | 대두 | WO 2004/071467 |
| 알부민 2S | 대두 | 미국 특허 제6,177,613호 |
| 레구민 A1 | 완두 | [Rerie et al., Mol. Gen. Genet., 225:148-157 (1991)] |
| β-콘글리시닌 β-서브유닛 | 대두 | WO 2004/071467 |
| BD30 (또한 P34라고도 불림) | 대두 | WO 2004/071467 |
| 레구민 A2 | 완두 | [Rerie et al., Mol. Gen. Genet., 225:148-157 (1991)] |
| 전사 종결자 | ||
| 전사 종결자 | 유기체 | 참조문헌 |
| 파세올린 3' | 강낭콩 | WO 2004/071467 |
| 쿠니츠 트립신 억제제 3' | 대두 | WO 2004/071467 |
| BD30 (또한 P34라고도 불림) 3' | 대두 | WO 2004/071467 |
| 레구민 A2 3' | 완두 | WO 2004/071467 |
| 알부민 2S 3' | 대두 | WO 2004/071467 |
| PUFA 생합성 경로 유전자 | ||
| 유전자 | 유기체 | 참조문헌 |
| Δ6 데새투라제 | 사프롤레그니아 디클리나 | WO 2002/081668 |
| Δ6 데새투라제 | 모르티에렐라 알피나 | 미국 특허 제5,968,809호 |
| 일롱가제 | 모르티에렐라 알피나 | WO 2000/12720, 미국 특허 제6,403,349호 |
| Δ5 데새투라제 | 모르티에렐라 알피나 | 미국 특허 제6,075,183호 |
| Δ5 데새투라제 | 사프롤레그니아 디클리나 | WO 2002/081668 |
| Δ15 데새투라제 | 푸사리움 모닐리포르메 | WO 2005/047479 |
| Δ17 데새투라제 | 사프롤레그니아 디클리나 | WO 2002/081668 |
| 일롱가제 | 트라우스토키트리움 아우레움 | WO 2002/08401, 미국 특허 제6,677,145호 |
| 일롱가제 | 파블로바 종 | [Pereira et al., Biochem. J., 384:357-366 (2004)] |
| Δ4 데새투라제 | 쉬조키트리움 아그레가툼 | WO 2002/090493 |
| Δ9 일롱가제 | 이소크리시스 갈바나 | WO 2002/077213 |
| Δ8 데새투라제 | 유글레나 그라실리스 | WO 2000/34439, 미국 특허 제6,825,017호, WO 2004/057001, WO 2006/012325 |
| Δ8 데새투라제 | 아칸트아메바 카스텔라니이 | [Sayanova et al., FEBS Lett., 580:1946-1952 (2006)] |
| Δ8 데새투라제 | 파블로바 살리나 | WO 2005/103253 |
| Δ8 데새투라제 | 파블로바 루테리 | 미국 가출원 제60/795810호 |
| Δ8 데새투라제 | 테트루에트레프티아 폼퀘텐시스 CCMP1491 | 미국 가출원 제60/853563호 |
| Δ8 데새투라제 | 유트레프티엘라 종 CCMP389 | 미국 가출원 제60/853563호 |
| Δ8 데새투라제 | 유트레프티엘라 짐나스티카 CCMP1594 | 미국 가출원 제60/853563호 |
실시예
26: 체세포 대두 배아 배양물의 형질전환
배양 조건:
대두 배아 현탁 배양물 (cv. Jack)은 150 rpm하의 26℃ 회전 진탕기상의 액체 배지 SB196 (하기 제조 방법 참조) 35 mL 중에서 60 내지 85 μE/m2/s의 빛의 강도로 16시간:8시간 낮/밤 광주기의 백색(cool white) 형광등을 이용하여 유지시킬 수 있다. 7일 내지 2주 마다 대략 35 mg의 조직을 신선한 액체 SB196 35 mL에 접종하여 배양물을 계대 배양하였다 (바람직한 계대 배양 간격은 7일마다임).
대두 배아 현탁 배양물을 입자 건 충격법(particle gun bombardment)을 이용하여 앞서 기재한 플라스미드 및 DNA 단편으로 형질전환시킬 수 있다 ([Klein et al., Nature (London), 327:70-73 (1987)], 미국 특허 제4,945,050호). 듀폰(DuPont) 바이올리스틱(Biolistic)™ PDS1000/HE 기기 (헬륨 장비)를 모든 형질전환에 사용하였다.
대두 배아 현탁 배양의 개시:
대두 배양을 매달 2회씩 개시하면서 각 개시일 사이에는 5일 내지 7일의 간격을 두었다. 입수가능한 대두 식물을 심은 후 45일 내지 55일이 지난 후에 상기 식물의 미성숙 종자가 들어 있는 꼬투리를 골라 껍질을 벗기고 멸균된 마젠타 상자에 넣었다. 대두 종자를 15분 동안 1 방울의 아이보리 비누를 함유하는 5% 클로락스(Clorox) 용액 (즉, 오토클레이브된 증류수 95 mL + 클로락스 5 mL 및 1 방울의 비누를 잘 혼합함) 중에서 진탕시켜서 이 종자를 멸균시켰다. 이들 종자를 멸균 증류수 1-리터 병 2개로 헹구고, 4 mm 미만의 것들을 개개의 현미경 슬라이드에 두었다. 종자의 끝 약간을 잘라내어 떡잎을 종자 껍질 밖으로 당겨 냈다. 떡잎을 SB1 배지를 함유하는 플레이트로 옮겼다 (플레이트 1개 당 25개 내지 30개의 떡잎). 플레이트를 섬유 테이프로 싸서 8주 동안 저장하였다. 이 시간이 지난 후에, 2차 배아를 잘라내어 SB196 액체 배지에 7일 동안 두었다.
충격법을 위한 DNA 의 제조:
관심 유전자 및 선별가능한 마커 유전자를 함유하는 무손상 플라스미드 또는 DNA 플라스미드 단편을 충격법에 사용할 수 있다. pKR274 (ATCC 관리 번호: PTA-4988), pKR685 (ATCC 관리 번호: PTA-6047) 또는 pKR681 (ATCC 관리 번호: PTA-6046)과 같은 플라스미드 및/또는 다른 발현 플라스미드의 단편은 소화된 플라스미드의 겔 단리로 수득할 수 있다. 각 경우에, 플라스미드 DNA 100 ㎍을 하기하는 특정 효소 혼합물 0.5 mL 중에서 사용할 수 있다. 플라스미드는 NEBuffer 4 (20 mM Tris-아세테이트, 10 mM 아세트산마그네슘, 50 mM 아세트산칼륨, 1 mM 디티오트레이톨, pH 7.9), 100 ㎍/mL BSA, 및 5 mM 베타-메르캅토에탄올 중 37℃에서 1.5시간 동안 AscI (100 유닛)으로 소화시킬 수 있다. 이로써 생성된 DNA 단편은 1% SeaPlaque® GTG 아가로스 (바이오휘태커 모레큘라 어플리케이션즈(BioWhitaker Molecular Applications))에서의 겔 전기영동으로 분리할 수 있었고, PUFA 생합성 유전자를 함유하는 DNA 단편은 아가로스 겔에서 잘라낼 수 있다. GELase® 소화 효소를 제조업체의 프로토콜에 따라 사용하여, 아가로스에서 DNA를 정제할 수 있다. 별법으로, 온전한 플라스미드, 또는 온전한 플라스미드와 단편의 조합물을 사용할 수 있다.
금 입자 3 mg (금 3 mg)을 함유하는 멸균 증류수 50 ㎕ 분취액을 1 ㎍/㎕ DNA 용액 (무손상 플라스미드 또는 DNA 단편 (상기한 바와 같이 제조함)) 5 ㎕, 2.5 M CaCl2 50 ㎕ 및 0.1 M 스페르미딘 20 ㎕에 첨가할 수 있다. 상기 혼합물을 볼텍스 진탕기의 레벨 3에서 3분 동안 진탕시키고, 벤치(bench) 마이크로원심분리로 10초 동안 회전시켰다. 100% 에탄올 400 ㎕로 세척한 후, 펠렛을 100% 에탄올 40 ㎕ 중에서의 초음파 처리로 현탁시켰다. DNA 현탁액 5 ㎕를 바이올리스틱 PDS1000/HE 기기 디스크의 플라잉 디스크(flying disk) 각각에 분배하였다. 각각의 5 ㎕ 분취액은 충격기 (예컨대, 디스크) 당 대략 0.375 mg의 금을 함유하였다.
조직 제조 및 DNA 를 사용한 충격:
7일 동안의 배아 현탁 배양물 대략 150 mg 내지 200 mg을 비어있는 멸균 60×15 mm 페트리 접시에 놓고, 상기 접시를 플라스틱 메쉬로 덮었다. 1100 PSI로 설정한 막 파열 압력을 이용하여 플레이트 1개 당 1샷 또는 2샷으로 조직에 충격을 가하고, 챔버를 27 인치 내지 28 인치 수은의 진공으로 배기시켰다. 조직을 보유/정지 스크린에서 대략 3.5 인치 떨어뜨려 두었다.
형질전환된 배아의 선별:
형질전환된 배아는 하이그로마이신 (즉, 하이그로마이신 B 포스포트랜스퍼라제 (HPT) 유전자를 선별가능한 마커로 사용하는 경우) 또는 클로르술푸론 (즉, 아세토락테이트 신타제 (ALS) 유전자를 선별가능한 마커로 사용하는 경우)를 사용하여 선별하였다.
하이그로마이신 ( HPT ) 선별:
충격 후, 상기 조직을 신선한 SB196 배지에 넣어 상기한 바와 같이 배양하였다. 충격 후 6일이 지난 후에는 SB196을 30 mg/L 하이그로마이신 선별제를 함유하는 신선한 SB196으로 교체하였다. 선별 배지는 매주 교체해 주었다. 선별 후 4주 내지 6주가 지난 후에는, 형질전환되지 않은 괴사성 배아 클러스터로부터 성장하는 녹색의 형질전환된 조직을 관찰할 수 있었다. 단리된 녹색 조직을 꺼내어 다중 웰 플레이트로 접종하여, 새롭게 클론성 증식하는 형질전환된 배아 현탁 배양물을 생성하였다.
클로르술푸론 ( ALS ) 선별:
충격 후, 상기 조직을 신선한 SB196 배지를 함유하는 2개의 플라스크에 나눠 넣어 상기한 바와 같이 배양하였다. 충격 후 6일 내지 7일이 지난 후에는 SB196을 100 ng/mL 클로르술푸론 선별제를 함유하는 신선한 SB196으로 교체하였다. 선별 배지는 매주 교체해 주었다. 선별 후 4주 내지 6주가 지난 후에는, 형질전환되지 않은 괴사성 배아 클러스터로부터 성장하는 녹색의 형질전환된 조직을 관찰할 수 있었다. 단리된 녹색 조직을 꺼내어 SB196을 함유하는 다중 웰 플레이트로 접종하여, 새롭게 클론성 증식하는 형질전환된 배아 현탁 배양물을 생성하였다.
대두 체세포 배아의 식물로의 재생:
배아 현탁 배양물로부터 온전한 식물을 수득하기 위해서는, 조직을 재생시킬 필요가 있다.
배아 성숙:
생성된 형질전환체로부터의 형질전환된 배아 클러스터를 26℃에서 SB196 중에 상기한 바와 같은 다중웰 플레이트에서 90 내지 120 μE/m2s의 빛의 강도로 16시간:8시간 광주기의 백색 형광등 (필립스 백색 에코노와트(Phillips cool white Econowatt) F40/CW/RS/EW) 및 아그로(Agro) (필립스 F40 아그로) 전구 (40 와트)를 이용하여 4주 내지 6주 (모델 시스템의 경우에는 1주 내지 3주) 동안 배양하였다. 이 시간이 지난 후에, 배아 클러스터를 꺼내어 고체 한천 배지 SB166에 1주 내지 2주 (모델 시스템의 경우에는 1주) 동안 두었다가 3주 내지 4주 동안 SB103 배지로 계대 배양하여 성숙 배아가 되도록 하였다. 플레이트에서 SB103 중에서 성숙시킨 후, 상기 클러스터에서 개개의 배아를 꺼내어 건조시키고, 상기한 바와 같이 이들의 지방산 조성에 있어서의 변경에 대하여 스크리닝하였다. 원한다면, 하기하는 몇가지 사건에서 식물을 얻었다.
별법으로, 일부의 모델 시스템 실험에서는 변형된 절차를 이용하여 대두 조직분화 및 성숙 액체 배지 (SHaM 액체 배지, [Schmidt et al., Cell Biology and Morphogenesis 24:393 (2005)]) 중에서 배아를 성숙시켰다. 간략하게 설명하면, 상기한 바와 같이 SB196 중에서 4주 동안 선별한 후에, 배아 클러스터를 꺼내어 250 mL 에를렌메이어(Erlenmeyer) 플라스크 중 SB228 (SHaM 액체 배지) 35 mL로 옮겼다. 조직은 130 rpm하의 26℃ 회전 진탕기상의 SHaM 액체 배지 중에서 60 내지 85 μE/m2/s의 빛의 강도로 16시간:8시간 낮/밤 광주기의 백색 형광등을 이용하여 배아가 성숙 됨에 따라 2주 내지 3주 동안 유지시켰다. SHaM 액체 배지 중에서 2주 내지 3주 동안 성장한 배아는 크기 및 지방산 함량이 SB166/SB103에서 5주 내지 8주 동안 배양한 배아와 동등하였다.
SHaM 액체 배지 중에서의 성숙 후에, 클러스터로부터 개개의 배아를 꺼내어 건조시키고, 상기한 바와 같이 이들의 지방산 조성에 있어서의 변경에 대하여 스크리닝하였다. 원한다면, 하기하는 몇가지 사건에서 식물을 얻었다.
배아 건조 및 발아:
성숙된 개개의 배아를 비어 있는 작은 페트리 접시 (35×10 mm)에 대략 4일 내지 7일 동안 두어 건조시킬 수 있었다. 상기 플레이트를 섬유 테이프로 밀봉하였다 (작은 습윤 챔버 생성). 건조시킨 배아를 SB71-4 배지에 심을 수 있고, 여기서 이것들을 상기한 것과 동일한 배양 조건하에 발아되도록 하였다. 발아된 묘목을 발아 배지에서 꺼내어 물로 철저하게 헹군후에 24셀 팩 트레이 중의 레디-어쓰(Redi-Earth)로 심고 투명한 플라스틱 돔으로 덮었다. 2주 후에는 상기 돔을 치우고, 추가의 1주 동안 식물이 튼튼해지게 하였다. 묘목이 튼튼해 보이면, 이것들을 10 인치 포트의 레디-어쓰에 포트 1개 당 최대 3개의 묘목으로 심었다. 10주 내지 16주 후에는 성숙 종자를 수확하여 잘라내고 상기한 바와 같이 지방산에 대해 분석할 수 있었다.
배지 제조 방법
:
SB
196-
FN
라이트(
Lite
) 액체 증식 배지 (1 L 당)
MS FeEDTA - 100× 스톡 1 10 mL
MS 술페이트 - 100× 스톡 2 10 mL
FN 라이트 할라이드 - 100× 스톡 3 10 mL
FN 라이트 P, B, Mo - 100× 스톡 4 10 mL
B5 비타민 (1 mL/L) 1.0 mL
2,4-D (최종 농도: 10 mg/L) 1.0 mL
KNO3 2.83 g
(NH4)2SO4 0.463 g
아스파라진 1.0 g
수크로스 (1%) 10 g
pH 5.8
FN
라이트
스톡
용액
스톡 번호 1000 mL 500 mL
1-
MS
Fe
EDTA
100×
스톡
Na2 EDTA* 3.724 g 1.862 g
FeSO4 - 7H2O 2.784 g 1.392 g
*먼저 첨가하여 어두운 병에서 교반하며 용해시킴.
2-
MS
술페이트
100×
스톡
MgSO4 - 7H2O 37.0 g 18.5 g
MnSO4 - H2O 1.69 g 0.845 g
ZnSO4 - 7H2O 0.86 g 0.43 g
CuSO4 - 5H2O 0.0025 g 0.00125 g
3-
FN
라이트
할라이드
100×
스톡
CaCl2 - 2H2O 30.0 g 15.0 g
KI 0.083 g 0.0715 g
CoCl2 - 6H2O 0.0025 g 0.00125 g
4-
FN
라이트 P, B,
Mo
100×
스톡
KH2PO4 18.5 g 9.25 g
H3BO3 0.62 g 0.31 g
Na2MoO4 - 2H2O 0.025 g 0.0125 g
SB1 고체 배지 (1 L 당) : MS 염 (깁코/BRL - 카탈로그 번호: 11117-066) 1 패키지, 1000× 스톡 B5 비타민 1 mL, 수크로스 31.5 g, 2,4-D (최종 농도: 20 mg/L) 2 mL, pH 5.7, TC 한천 8 g
SB 166 고체 배지 (1 L 당) : MS 염 (깁코/BRL - 카탈로그 번호: 11117-066) 1 패키지, 1000× 스톡 B5 비타민 1 mL, 말토스 60 g, MgCl2 6수화물 750 mg, 활성 목탄 5 g, pH 5.7, 겔라이트 2 g
SB 103 고체 배지 (1 L 당) : MS 염 (깁코/BRL - 카탈로그 번호: 11117-066) 1 패키지, 1000× 스톡 B5 비타민 1 mL, 말토스 60 g, MgCl2 6수화물 750 mg, pH 5.7, 겔라이트 2 g
SB 71-4 고체 배지 (1 L 당) : 수크로스를 함유하는 감보르그(Gamborg's) B5 염 (깁코/BRL - 카탈로그 번호: 21153-036) 1병, pH 5.7, TC 한천 5 g
2,4-D 스톡 : 피토테크(Phytotech) 카탈로그 번호: D 295로부터 미리 제조하여 얻음 - 농도: 1 mg/mL
B5 비타민 스톡 (100 mL 당) : myo-이노시톨 10 g, 니코틴산 100 mg, 피리독신 HCl 100 mg, 티아민 1 g. 분취액은 -20℃에 저장. 상기 용액이 충분히 신속하게 용해되지 않는 경우에는 핫 교반 플레이트를 사용하여 낮은 수준의 열을 가함
클로르술푸론 스톡 : 0.01 N 수산화암모늄 중 1 mg/mL
체세포 배아를 유도하기 위해서, 표면 멸균된 미성숙 대두 종자 품종 A2872로부터 3 mm 내지 5 mm 길이로 절단한 떡잎을 26℃하에 적절한 한천 배지상에서 밝은 곳 또는 어두운 곳에서 6주 내지 10주 동안 배양할 수 있었다. 이어서, 2차 배아를 생성한 체세포 배아를 잘라 내어 적합한 액체 배지에 넣었다. 초기 구형상 단계의 배아로 증식된 체세포 배아 클러스터를 반복적으로 선별한 후, 상기 현탁액을 하기와 같이 유지시켰다.
대두 배아 현탁 배양물은 150 rpm하의 26℃ 회전 진탕기상의 액체 배지 35 mL 중에서 16시간:8시간 낮/밤 스케쥴의 형광등을 이용하여 유지시킬 수 있었다. 2주 마다 대략 35 mg의 조직을 액체 배지 35 mL에 접종하여 배양물을 계대 배양하였다.
이어서, 대두 배아 현탁 배양물을 입자 건 충격법 ([Klein et al., Nature (London), 327:70-73], 미국 특허 제4,945,050호)으로 형질전환시킬 수 있었다. 듀폰 바이올리스틱™ PDS1000/HE 기기 (헬륨 장비)를 이러한 형질전환에 사용할 수 있었다.
대두 형질전환을 용이하게 하는데 사용될 수 있는 선별가능한 마커 유전자는 콜리플라워 모자이크 바이러스의 35S 프로모터 [Odell et al., Nature, 313:810-812 (1985)], 플라스미드 pJR225의 하이그로마이신 B 포스포트랜스퍼라제 유전자 (이. 콜라이에서 유래. [Gritz et al., Gene, 25:179-188 (1983)]) 및 아그로박테리움 투메파시엔스 Ti 플라스미드의 T-DNA 유래의 노팔린 신타제 유전자 3' 영역으로 구성된 재조합 DNA 구축물이다. 파세올린 5' 영역, 본 발명의 폴리펩티드를 코딩하는 단편 및 파세올린 3' 영역을 포함하는 종자 발현 카세트를 제한 단편으로 단리할 수 있었다. 이어서, 상기 단편을 마커 유전자를 보유하는 벡터의 독특한 제한 부위에 삽입할 수 있었다.
60 mg/mL의 1 ㎛ 금 입자 현탁액 50 ㎕에 DNA (1 ㎍/㎕) 5 ㎕, 스페르미딘 (0.1 M) 20 ㎕, 및 CaCl2 (2.5 M) 50 ㎕를 (순서대로) 첨가하였다. 이어서, 상기 입자 제제를 3분 동안 교반하고 마이크로원심분리로 10초 동안 회전시키고, 상등액을 제거하였다. 이어서, DNA-코팅된 입자를 70% 에탄올 400 ㎕ 중에서 1회 세척하고, 무수 에탄올 40 ㎕ 중에 재현탁시켰다. DNA/입자 현탁액은 1초씩 3회 초음파처리할 수 있다. 이어서, DNA-코팅된 금 입자 5 ㎕를 각각의 마그코 캐리어 디스크에 로딩하였다.
2주간의 현탁 배양물 대략 300 mg 내지 400 mg을 비어 있는 60×15 mm 페트리 접시에 넣고, 피펫을 사용하여 잔류 액체를 조직으로부터 제거하였다. 각 형질전환 실험마다, 대략 5개 내지 10개 플레이트의 조직에 통상적으로 충격을 가하였다. 막 파열 압력은 1100 psi로 설정하였고, 챔버는 28 인치 수은의 진공으로 배기시켰다. 조직을 남아있는 스크린에서 대략 3.5 인치 떨어뜨려 두고 3회 충격을 가하였다. 충격 후, 상기 조직을 절반으로 나누어 다시 액체에 넣고 상기한 바와 같이 배양할 수 있다.
충격 후 5일 내지 7일이 지난 후에는 액체 배지를 신선한 배지로 교체할 수 있고, 충격 후 11일 내지 12일이 지난 후에는 50 mg/mL 하이그로마이신을 함유하는 신선한 배지로 교체할 수 있다. 이러한 선별 배지는 매주 교체할 수 있다. 충격후 7주 내지 8주가 지난 후에는, 형질전환되지 않은 괴사성 배아 클러스터로부터 성장하는 녹색의 형질전환된 조직을 관찰할 수 있었다. 단리된 녹색 조직을 꺼내어 개개의 플라스크에 접종하여, 새롭게 클론성 증식하는 형질전환된 배아 현탁 배양물을 생성하였다. 각각의 새로운 것을 독립적인 형질전환 사건으로 처리할 수 있다. 이어서, 이들 현탁액을 계대 배양하고 미성숙 배아의 클러스터로 유지하거나 개개의 체세포 배아의 성숙 및 발아에 의해 온전한 식물로 재생시킬 수 있다.
SEQUENCE LISTING
<110> E.I. duPont de Nemours and Company, Inc.
<120> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY ACIDS
<130> CL3600 PCT
<150> US 60/739989
<151> 2005-11-23
<160> 129
<170> PatentIn version 3.3
<210> 1
<211> 777
<212> DNA
<213> Euglena gracilis
<400> 1
atggaggtgg tgaatgaaat agtctcaatt gggcaggaag ttttacccaa agttgattat 60
gcccaactct ggagtgatgc cagtcactgt gaggtgcttt acttgtccat cgcatttgtc 120
atcttgaagt tcactcttgg cccccttggt ccaaaaggtc agtctcgtat gaagtttgtt 180
ttcaccaatt acaaccttct catgtccatt tattcgttgg gatcattcct ctcaatggca 240
tatgccatgt acaccatcgg tgttatgtct gacaactgcg agaaggcttt tgacaacaac 300
gtcttcagga tcaccacgca gttgttctat ttgagcaagt tcctggagta tattgactcc 360
ttctatttgc cactgatggg caagcctctg acctggttgc aattcttcca tcatttgggg 420
gcaccgatgg atatgtggct gttctataat taccgaaatg aagctgtttg gatttttgtg 480
ctgttgaatg gtttcatcca ctggatcatg tacggttatt attggaccag attgatcaag 540
ctgaagttcc ccatgccaaa atccctgatt acatcaatgc agatcattca attcaatgtt 600
ggtttctaca ttgtctggaa gtacaggaac attccctgtt atcgccaaga tgggatgagg 660
atgtttggct ggttcttcaa ttacttttat gttggcacag tcttgtgttt gttcttgaat 720
ttctatgtgc aaacgtatat cgtcaggaag cacaagggag ccaaaaagat tcagtga 777
<210> 2
<211> 258
<212> PRT
<213> Euglena gracilis
<220>
<221> MISC_FEATURE
<222> (1)..(258)
<223> delta-9 elongase (EgD9e)
<400> 2
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 3
<211> 777
<212> DNA
<213> Artificial Sequence
<220>
<223> EgD9eS: synthetic delta-9 elongase derived from Euglena gracilis
and codon-optimized for expression in Yarrowia lipolytica
<400> 3
atggaggtcg tgaacgaaat cgtctccatt ggccaggagg ttcttcccaa ggtcgactat 60
gctcagctct ggtctgatgc ctcgcactgc gaggtgctgt acctctccat cgccttcgtc 120
atcctgaagt tcacccttgg tcctctcgga cccaagggtc agtctcgaat gaagtttgtg 180
ttcaccaact acaacctgct catgtccatc tactcgctgg gctccttcct ctctatggcc 240
tacgccatgt acaccattgg tgtcatgtcc gacaactgcg agaaggcttt cgacaacaat 300
gtcttccgaa tcaccactca gctgttctac ctcagcaagt tcctcgagta cattgactcc 360
ttctatctgc ccctcatggg caagcctctg acctggttgc agttctttca ccatctcgga 420
gctcctatgg acatgtggct gttctacaac taccgaaacg aagccgtttg gatctttgtg 480
ctgctcaacg gcttcattca ctggatcatg tacggctact attggacccg actgatcaag 540
ctcaagttcc ctatgcccaa gtccctgatt acttctatgc agatcattca gttcaacgtt 600
ggcttctaca tcgtctggaa gtaccggaac attccctgct accgacaaga tggaatgaga 660
atgtttggct ggtttttcaa ctacttctac gttggtactg tcctgtgtct gttcctcaac 720
ttctacgtgc agacctacat cgtccgaaag cacaagggag ccaaaaagat tcagtga 777
<210> 4
<211> 792
<212> DNA
<213> Eutreptiella sp. CCMP389
<400> 4
atggctgcgg tgatagaggt cgccaacgag tttgtagcca tcacggcaga aacgctcccc 60
aaagttgact atcaacgact atggcgagac atttacagtt gtgagctact gtatttctcc 120
attgccttcg tgatcttgaa gtttacgttg ggcgagttga gcgacagcgg aaaaaagatt 180
ttgagagtgt tgttcaagtg gtacaatctc ttcatgtccg tgttctcctt ggtgtctttc 240
ctttgcatgg gctatgccat ttataccgtg ggcctatact ctaacgaatg cgacagggct 300
ttcgacaact cgttgttccg ctttgcaaca aaggtgttct actacagtaa gtttttggag 360
tacatcgact ctttttatct tccgctcatg gccaagccgc tgtctttcct gcaattcttc 420
catcacttgg gagcccccat ggacatgtgg ctctttgtcc aatattctgg ggaatctatt 480
tggatctttg tgtttttgaa tgggttcatt cactttgtta tgtacgggta ctactggact 540
cggctgatga agttcaattt cccaatgccc aagcagttga ttaccgcgat gcagatcacg 600
cagttcaacg ttggtttcta cctcgtgtgg tggtacaaag atattccctg ctaccgaaag 660
gatcccatgc gaatgttggc ctggatcttc aattactggt atgttgggac tgtcttgctg 720
ctgttcatta atttcttcgt caaatcctat gtgttcccaa agccgaagac tgcagataaa 780
aaggtccaat ag 792
<210> 5
<211> 263
<212> PRT
<213> Eutreptiella sp. CCMP389
<220>
<221> MISC_FEATURE
<222> (1)..(263)
<223> delta-9 elongase (E389D9e)
<400> 5
Met Ala Ala Val Ile Glu Val Ala Asn Glu Phe Val Ala Ile Thr Ala
1 5 10 15
Glu Thr Leu Pro Lys Val Asp Tyr Gln Arg Leu Trp Arg Asp Ile Tyr
20 25 30
Ser Cys Glu Leu Leu Tyr Phe Ser Ile Ala Phe Val Ile Leu Lys Phe
35 40 45
Thr Leu Gly Glu Leu Ser Asp Ser Gly Lys Lys Ile Leu Arg Val Leu
50 55 60
Phe Lys Trp Tyr Asn Leu Phe Met Ser Val Phe Ser Leu Val Ser Phe
65 70 75 80
Leu Cys Met Gly Tyr Ala Ile Tyr Thr Val Gly Leu Tyr Ser Asn Glu
85 90 95
Cys Asp Arg Ala Phe Asp Asn Ser Leu Phe Arg Phe Ala Thr Lys Val
100 105 110
Phe Tyr Tyr Ser Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro
115 120 125
Leu Met Ala Lys Pro Leu Ser Phe Leu Gln Phe Phe His His Leu Gly
130 135 140
Ala Pro Met Asp Met Trp Leu Phe Val Gln Tyr Ser Gly Glu Ser Ile
145 150 155 160
Trp Ile Phe Val Phe Leu Asn Gly Phe Ile His Phe Val Met Tyr Gly
165 170 175
Tyr Tyr Trp Thr Arg Leu Met Lys Phe Asn Phe Pro Met Pro Lys Gln
180 185 190
Leu Ile Thr Ala Met Gln Ile Thr Gln Phe Asn Val Gly Phe Tyr Leu
195 200 205
Val Trp Trp Tyr Lys Asp Ile Pro Cys Tyr Arg Lys Asp Pro Met Arg
210 215 220
Met Leu Ala Trp Ile Phe Asn Tyr Trp Tyr Val Gly Thr Val Leu Leu
225 230 235 240
Leu Phe Ile Asn Phe Phe Val Lys Ser Tyr Val Phe Pro Lys Pro Lys
245 250 255
Thr Ala Asp Lys Lys Val Gln
260
<210> 6
<211> 792
<212> DNA
<213> Artificial Sequence
<220>
<223> E389D9eS: synthetic delta-9 elongase derived from Eutreptiella
sp. CCMP389 and codon-optimized for expression in Yarrowia
lipolytica
<400> 6
atggctgccg tcatcgaggt ggccaacgag ttcgtcgcta tcactgccga gacccttccc 60
aaggtggact atcagcgact ctggcgagac atctactcct gcgagctcct gtacttctcc 120
attgctttcg tcatcctcaa gtttaccctt ggcgagctct cggattctgg caaaaagatt 180
ctgcgagtgc tgttcaagtg gtacaacctc ttcatgtccg tcttttcgct ggtgtccttc 240
ctctgtatgg gttacgccat ctacaccgtt ggactgtact ccaacgaatg cgacagagct 300
ttcgacaaca gcttgttccg atttgccacc aaggtcttct actattccaa gtttctggag 360
tacatcgact ctttctacct tcccctcatg gccaagcctc tgtcctttct gcagttcttt 420
catcacttgg gagctcctat ggacatgtgg ctcttcgtgc agtactctgg cgaatccatt 480
tggatctttg tgttcctgaa cggattcatt cactttgtca tgtacggcta ctattggaca 540
cggctgatga agttcaactt tcccatgccc aagcagctca ttaccgcaat gcagatcacc 600
cagttcaacg ttggcttcta cctcgtgtgg tggtacaagg acattccctg ttaccgaaag 660
gatcccatgc gaatgctggc ctggatcttc aactactggt acgtcggtac cgttcttctg 720
ctcttcatca acttctttgt caagtcctac gtgtttccca agcctaagac tgccgacaaa 780
aaggtccagt ag 792
<210> 7
<211> 1064
<212> DNA
<213> Isochrysis galbana (GenBank Accession No. AF390174)
<220>
<221> CDS
<222> (2)..(793)
<223> delta-9 elongase (IgD9e)
<400> 7
g atg gcc ctc gca aac gac gcg gga gag cgc atc tgg gcg gct gtg acc 49
Met Ala Leu Ala Asn Asp Ala Gly Glu Arg Ile Trp Ala Ala Val Thr
1 5 10 15
gac ccg gaa atc ctc att ggc acc ttc tcg tac ttg cta ctc aaa ccg 97
Asp Pro Glu Ile Leu Ile Gly Thr Phe Ser Tyr Leu Leu Leu Lys Pro
20 25 30
ctg ctc cgc aat tcc ggg ctg gtg gat gag aag aag ggc gca tac agg 145
Leu Leu Arg Asn Ser Gly Leu Val Asp Glu Lys Lys Gly Ala Tyr Arg
35 40 45
acg tcc atg atc tgg tac aac gtt ctg ctg gcg ctc ttc tct gcg ctg 193
Thr Ser Met Ile Trp Tyr Asn Val Leu Leu Ala Leu Phe Ser Ala Leu
50 55 60
agc ttc tac gtg acg gcg acc gcc ctc ggc tgg gac tat ggt acg ggc 241
Ser Phe Tyr Val Thr Ala Thr Ala Leu Gly Trp Asp Tyr Gly Thr Gly
65 70 75 80
gcg tgg ctg cgc agg caa acc ggc gac aca ccg cag ccg ctc ttc cag 289
Ala Trp Leu Arg Arg Gln Thr Gly Asp Thr Pro Gln Pro Leu Phe Gln
85 90 95
tgc ccg tcc ccg gtt tgg gac tcg aag ctc ttc aca tgg acc gcc aag 337
Cys Pro Ser Pro Val Trp Asp Ser Lys Leu Phe Thr Trp Thr Ala Lys
100 105 110
gca ttc tat tac tcc aag tac gtg gag tac ctc gac acg gcc tgg ctg 385
Ala Phe Tyr Tyr Ser Lys Tyr Val Glu Tyr Leu Asp Thr Ala Trp Leu
115 120 125
gtg ctc aag ggc aag agg gtc tcc ttt ctc cag gcc ttc cac cac ttt 433
Val Leu Lys Gly Lys Arg Val Ser Phe Leu Gln Ala Phe His His Phe
130 135 140
ggc gcg ccg tgg gat gtg tac ctc ggc att cgg ctg cac aac gag ggc 481
Gly Ala Pro Trp Asp Val Tyr Leu Gly Ile Arg Leu His Asn Glu Gly
145 150 155 160
gta tgg atc ttc atg ttt ttc aac tcg ttc att cac acc atc atg tac 529
Val Trp Ile Phe Met Phe Phe Asn Ser Phe Ile His Thr Ile Met Tyr
165 170 175
acc tac tac ggc ctc acc gcc gcc ggg tat aag ttc aag gcc aag ccg 577
Thr Tyr Tyr Gly Leu Thr Ala Ala Gly Tyr Lys Phe Lys Ala Lys Pro
180 185 190
ctc atc acc gcg atg cag atc tgc cag ttc gtg ggc ggc ttc ctg ttg 625
Leu Ile Thr Ala Met Gln Ile Cys Gln Phe Val Gly Gly Phe Leu Leu
195 200 205
gtc tgg gac tac atc aac gtc ccc tgc ttc aac tcg gac aaa ggg aag 673
Val Trp Asp Tyr Ile Asn Val Pro Cys Phe Asn Ser Asp Lys Gly Lys
210 215 220
ttg ttc agc tgg gct ttc aac tat gca tac gtc ggc tcg gtc ttc ttg 721
Leu Phe Ser Trp Ala Phe Asn Tyr Ala Tyr Val Gly Ser Val Phe Leu
225 230 235 240
ctc ttc tgc cac ttt ttc tac cag gac aac ttg gca acg aag aaa tcg 769
Leu Phe Cys His Phe Phe Tyr Gln Asp Asn Leu Ala Thr Lys Lys Ser
245 250 255
gcc aag gcg ggc aag cag ctc tag gcctcgagcc ggctcgcggg ttcaaggagg 823
Ala Lys Ala Gly Lys Gln Leu
260
gcgacacggg ggtgggacgt ttgcatggag atggattgtg gatgtcctta cgccttactc 883
atcaatgtcc tcccatctct cccctctaga ccttctacta gccatctaga agggcagctc 943
agagacggat accgttcccc ctccccttcc ttttcgtctt tgctttgcca ttgtttgttt 1003
gtctctattt tttaaactat tgacgctaac gcgttacgct cgcaaaaaaa aaaaaaaaaa 1063
a 1064
<210> 8
<211> 263
<212> PRT
<213> Isochrysis galbana (GenBank Accession No. AF390174)
<400> 8
Met Ala Leu Ala Asn Asp Ala Gly Glu Arg Ile Trp Ala Ala Val Thr
1 5 10 15
Asp Pro Glu Ile Leu Ile Gly Thr Phe Ser Tyr Leu Leu Leu Lys Pro
20 25 30
Leu Leu Arg Asn Ser Gly Leu Val Asp Glu Lys Lys Gly Ala Tyr Arg
35 40 45
Thr Ser Met Ile Trp Tyr Asn Val Leu Leu Ala Leu Phe Ser Ala Leu
50 55 60
Ser Phe Tyr Val Thr Ala Thr Ala Leu Gly Trp Asp Tyr Gly Thr Gly
65 70 75 80
Ala Trp Leu Arg Arg Gln Thr Gly Asp Thr Pro Gln Pro Leu Phe Gln
85 90 95
Cys Pro Ser Pro Val Trp Asp Ser Lys Leu Phe Thr Trp Thr Ala Lys
100 105 110
Ala Phe Tyr Tyr Ser Lys Tyr Val Glu Tyr Leu Asp Thr Ala Trp Leu
115 120 125
Val Leu Lys Gly Lys Arg Val Ser Phe Leu Gln Ala Phe His His Phe
130 135 140
Gly Ala Pro Trp Asp Val Tyr Leu Gly Ile Arg Leu His Asn Glu Gly
145 150 155 160
Val Trp Ile Phe Met Phe Phe Asn Ser Phe Ile His Thr Ile Met Tyr
165 170 175
Thr Tyr Tyr Gly Leu Thr Ala Ala Gly Tyr Lys Phe Lys Ala Lys Pro
180 185 190
Leu Ile Thr Ala Met Gln Ile Cys Gln Phe Val Gly Gly Phe Leu Leu
195 200 205
Val Trp Asp Tyr Ile Asn Val Pro Cys Phe Asn Ser Asp Lys Gly Lys
210 215 220
Leu Phe Ser Trp Ala Phe Asn Tyr Ala Tyr Val Gly Ser Val Phe Leu
225 230 235 240
Leu Phe Cys His Phe Phe Tyr Gln Asp Asn Leu Ala Thr Lys Lys Ser
245 250 255
Ala Lys Ala Gly Lys Gln Leu
260
<210> 9
<211> 792
<212> DNA
<213> Artificial Sequence
<220>
<223> IgD9eS: synthetic delta-9 elongase derived from Isochrysis
galbana and codon-optimized for expression in Yarrowia lipolytica
<400> 9
atggctctgg ccaacgacgc tggcgagcga atctgggctg ccgtcaccga tcccgaaatc 60
ctcattggca ccttctccta cctgctcctg aagcctctcc tgcgaaactc tggtctcgtg 120
gacgagaaga aaggagccta ccgaacctcc atgatctggt acaacgtcct cctggctctc 180
ttctctgccc tgtccttcta cgtgactgcc accgctctcg gctgggacta cggtactgga 240
gcctggctgc gaagacagac cggtgatact ccccagcctc tctttcagtg tccctctcct 300
gtctgggact ccaagctgtt cacctggact gccaaggcct tctactattc taagtacgtg 360
gagtacctcg acaccgcttg gctggtcctc aagggcaagc gagtgtcctt tctgcaggcc 420
ttccatcact ttggagctcc ctgggacgtc tacctcggca ttcgactgca caacgagggt 480
gtgtggatct tcatgttctt taactcgttc attcacacca tcatgtacac ctactatgga 540
ctgactgccg ctggctacaa gttcaaggcc aagcctctga tcactgccat gcagatttgc 600
cagttcgtcg gtggctttct cctggtctgg gactacatca acgttccctg cttcaactct 660
gacaagggca agctgttctc ctgggctttc aactacgcct acgtcggatc tgtctttctc 720
ctgttctgtc acttctttta ccaggacaac ctggccacca agaaatccgc taaggctggt 780
aagcagcttt ag 792
<210> 10
<211> 757
<212> DNA
<213> Euglena gracilis
<220>
<221> misc_feature
<222> (677)..(677)
<223> n is a, c, g, or t
<400> 10
ttttttttcg aacacttaat ggaggtggtg aatgaaatag tctcaattgg gcaggaagtt 60
ttacccaaag ttgattatgc ccaactctgg agtgatgcca gtcactgtga ggtgctttac 120
ttgtccatcg catttgtcat cttgaagttc actcttggcc cccttggtcc aaaaggtcag 180
tctcgtatga agtttgtttt caccaattac aaccttctca tgtccattta ttcgttggga 240
tcattcctct caatggcata tgccatgtac accatcggtg ttatgtctga caactgcgag 300
aaggcttttg acaacaacgt cttcaggatc accacgcagt tgttctattt gagcaagttc 360
ctggagtata ttgactcctt ctatttgcca ctgatgggca agcctctgac ctggttgcaa 420
ttcttccatc atttgggggc accgatggat atgtggctgt tctataatta ccgaaatgaa 480
gctgtttgga tttttgtgct gttgaatggt ttcatccact ggatcatgta cggttattat 540
tggaccagat tgatcaagct gaagttcccc atgccaaaat ccctgattac atcaatgcag 600
atcattcaat tcaatgttgg tttctacatt gtctggaagt acaggaacat tccctgttat 660
cgccaagatg ggatgangat gtttggctgg ttcttcaatt acttttatgt tggcacagtc 720
ttgtgtttgt tcttgaattt ctatgtgcaa acgtata 757
<210> 11
<211> 774
<212> DNA
<213> Euglena gracilis
<220>
<221> misc_feature
<222> (34)..(34)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (69)..(69)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (82)..(82)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (112)..(112)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (218)..(220)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (707)..(709)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (711)..(711)
<223> n is a, c, g, or t
<400> 11
tcaggatcac cacgcagttg ttctatttga gcangttcct ggagtatatt gactccttct 60
atttgccant gatgggcaag cntctgacct ggttgcaatt cttccatcat tngggggcac 120
cgatggatat gtggctgttc tataattacc gaaatgaagc tgtttggatt tttgtgctgt 180
tgaatggttt catccactgg atcatgtacg gttattannn gaccagattg atcaagctga 240
agttccccat gccaaaatcc ctgattacat caatgcagat cattcaattc aatgttggtt 300
tctacattgt ctggaagtac aggaacattc cctgttatcg ccaagatggg atgaggatgt 360
ttggctggtt cttcaattac ttttatgttg gcacagtctt gtgtttgttc ttgaatttct 420
atgtgcaaac gtatatcgtc aggaagcaca agggagccaa aaagattcag tgatatttcc 480
tcctctgcgg tggcctcttt tgacctcccc ttgacaccta taatgtggag gtgtcgggct 540
ctctccgtct caccagcact tgactctgca ggtgctcact tttatttttt acccatcttt 600
gcttgttgac cattcacctc tcccacttcc acatagtcca ttctaactgt tgcagactgc 660
ggtccatttt ttccagagct cccaatgacc atacgcgaca ccttgtnnnc ncccagccca 720
ttgtgcacaa ttcatagtgg catcgttttg ccttgatacg tgtgcatcca gcgg 774
<210> 12
<211> 1201
<212> DNA
<213> Euglena gracilis
<220>
<221> misc_feature
<222> (1134)..(1136)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1138)..(1138)
<223> n is a, c, g, or t
<400> 12
gacatggcaa ctatgatttt attttgactg atagtgacct gttcgttgca acaaattgat 60
gagcaatgct tttttataat gccaactttg tacaaaaaag ttggattttt tttcgaacac 120
ttaatggagg tggtgaatga aatagtctca attgggcagg aagttttacc caaagttgat 180
tatgcccaac tctggagtga tgccagtcac tgtgaggtgc tttacttgtc catcgcattt 240
gtcatcttga agttcactct tggccccctt ggtccaaaag gtcagtctcg tatgaagttt 300
gttttcacca attacaacct tctcatgtcc atttattcgt tgggatcatt cctctcaatg 360
gcatatgcca tgtacaccat cggtgttatg tctgacaact gcgagaaggc ttttgacaac 420
aacgtcttca ggatcaccac gcagttgttc tatttgagca agttcctgga gtatattgac 480
tccttctatt tgccactgat gggcaagcct ctgacctggt tgcaattctt ccatcatttg 540
ggggcaccga tggatatgtg gctgttctat aattaccgaa atgaagctgt ttggattttt 600
gtgctgttga atggtttcat ccactggatc atgtacggtt attattggac cagattgatc 660
aagctgaagt tccccatgcc aaaatccctg attacatcaa tgcagatcat tcaattcaat 720
gttggtttct acattgtctg gaagtacagg aacattccct gttatcgcca agatgggatg 780
aggatgtttg gctggttctt caattacttt tatgttggca cagtcttgtg tttgttcttg 840
aatttctatg tgcaaacgta tatcgtcagg aagcacaagg gagccaaaaa gattcagtga 900
tatttcctcc tctgcggtgg cctcttttga cctccccttg acacctataa tgtggaggtg 960
tcgggctctc tccgtctcac cagcacttga ctctgcaggt gctcactttt attttttacc 1020
catctttgct tgttgaccat tcacctctcc cacttccaca tagtccattc taactgttgc 1080
agactgcggt ccattttttc cagagctccc aatgaccata cgcgacacct tgtnnncncc 1140
cagcccattg tgcacaattc atagtggcat cgttttgcct tgatacgtgt gcatccagcg 1200
g 1201
<210> 13
<211> 200
<212> DNA
<213> Eutreptiella sp. CCMP389
<400> 13
ttacagttct tccaccactt gggagccccc atggacatgt ggctctttgt ccaatattct 60
ggggaatcta tttggatctt tgtgtttttg aatgggttca ttcactttgt tatgtacggg 120
tactactgga ctcggctgat gaagttcaat ttcccaatgc ccaagcagtt gattaccgcg 180
atgcagatca tccaattcaa 200
<210> 14
<211> 406
<212> DNA
<213> Eutreptiella sp. CCMP389
<400> 14
atggcgagac atttacagtt gtgagctact gtatttctcc attgccttcg tgatcttgaa 60
gtttacgttg ggcgagttga gcgacagcgg aaaaaagatt ttgagagtgt tgttcaagtg 120
gtacaatctc ttcatgtccg tgttctcctt ggtgtctttc ctttgcatgg gctatgccat 180
ttataccgtg ggcctatact ctaacgaatg cgacagggct ttcgacaact cgttgttccg 240
ctttgcaaca aaggtgttct actacagtaa gtttttggag tacatcgact ctttttatct 300
tccgctcatg gccaagccgc tgtctttcct gcaattcttc catcacttgg gagcccccat 360
ggacatgtgg ctctttgtcc aatattctgg ggaatctatt tggatc 406
<210> 15
<211> 197
<212> DNA
<213> Eutreptiella sp. CCMP389
<400> 15
tccatttcgc ccgtcaagcc agagtggcca ttacggctgg tcggacacaa catggctgcg 60
gtgatagagg tcgccaacga gtttgtagcc atcacggcag aaacgctccc caaagttgac 120
tatcaacgac tatggcgaga catttacagt tgtgagctac tgtatttctc cattgccttc 180
gtgatcttga agtttac 197
<210> 16
<211> 920
<212> DNA
<213> Eutreptiella sp. CCMP389
<400> 16
ctggactcgg ctgatgaagt tcaatttccc aatgcccaag cagttgatta ccgcgatgca 60
gatcacgcag ttcaacgttg gtttctacct cgtgtggtgg tacaaagata ttccctgcta 120
ccgaaaggat cccatgcgaa tgttggcctg gatcttcaat tactggtatg ttgggactgt 180
cttgctgctg ttcattaatt tcttcgtcaa atcctatgtg ttcccaaagc cgaagactgc 240
agataaaaag gtccaatagc tgcacacaca caattatgca gctccccacc actttctccc 300
caaaacagcc agccagcccc cttcccatga aacaagaacc taccccctcc ctgctcctct 360
ttttttaatc tcttattcca ccatacactt gatgacaaca gttgccgtgc agtggagcta 420
tgtggtgcat gctgcaatgc actggggcat catattaaga ttattgttat tagtggtgcc 480
cttgcttctc tgctttgtgc ccctggtacc agggtgcacc catgatgcag tacacaagtt 540
gttcaatgtg tgcactgtgg tattctctga attccttgag gagccattta gtttaaccaa 600
gcatgactcg gctggattgg ctcgaggtca ttgcggaagc aaaagttttg cgaggcagct 660
gccgaaggtg ctgctaagtt cggcttcaaa ctggcctttg cacacccagg tacccaggga 720
ttccaagtct catggctggc atattttagg tttcatgcat ccgcagtggc gtttatgcaa 780
ggcacagacg tttatattta tggatatgcg agtgaaggtt ggcttgccag cattggcatc 840
gcctgcctgc atactgagtt ttgttgtaaa agtacaaact cagtatcaac aatacaattt 900
ttktttgaaa aaaaaaaaaa 920
<210> 17
<211> 1504
<212> DNA
<213> Eutreptiella sp. CCMP389
<220>
<221> misc_feature
<222> (1487)..(1487)
<223> n is a, c, g, or t
<400> 17
tccatttcgc ccgtcaagcc agagtggcca ttacggctgg tcggacacaa catggctgcg 60
gtgatagagg tcgccaacga gtttgtagcc atcacggcag aaacgctccc caaagttgac 120
tatcaacgac tatggcgaga catttacagt tgtgagctac tgtatttctc cattgccttc 180
gtgatcttga agtttacgtt gggcgagttg agcgacagcg gaaaaaagat tttgagagtg 240
ttgttcaagt ggtacaatct cttcatgtcc gtgttctcct tggtgtcttt cctttgcatg 300
ggctatgcca tttataccgt gggcctatac tctaacgaat gcgacagggc tttcgacaac 360
tcgttgttcc gctttgcaac aaaggtgttc tactacagta agtttttgga gtacatcgac 420
tctttttatc ttccgctcat ggccaagccg ctgtctttcc tgcaattctt ccatcacttg 480
ggagccccca tggacatgtg gctctttgtc caatattctg gggaatctat ttggatcttt 540
gtgtttttga atgggttcat tcactttgtt atgtacgggt actactggac tcggctgatg 600
aagttcaatt tcccaatgcc caagcagttg attaccgcga tgcagatcac gcagttcaac 660
gttggtttct acctcgtgtg gtggtacaaa gatattccct gctaccgaaa ggatcccatg 720
cgaatgttgg cctggatctt caattactgg tatgttggga ctgtcttgct gctgttcatt 780
aatttcttcg tcaaatccta tgtgttccca aagccgaaga ctgcagataa aaaggtccaa 840
tagctgcaca cacacaatta tgcagctccc caccactttc tccccaaaac agccagccag 900
cccccttccc atgaaacaag aacctacccc ctccctgctc ctcttttttt aatctcttat 960
tccaccatac acttgatgac aacagttgcc gtgcagtgga gctatgtggt gcatgctgca 1020
atgcactggg gcatcatatt aagattattg ttattagtgg tgcccttgct tctctgcttt 1080
gtgcccctgg taccagggtg cacccatgat gcagtacaca agttgttcaa tgtgtgcact 1140
gtggtattct ctgaattcct tgaggagcca tttagtttaa ccaagcatga ctcggctgga 1200
ttggctcgag gtcattgcgg aagcaaaagt tttgcgaggc agctgccgaa ggtgctgcta 1260
agttcggctt caaactggcc tttgcacacc caggtaccca gggattccaa gtctcatggc 1320
tggcatattt taggtttcat gcatccgcag tggcgtttat gcaaggcaca gacgtttata 1380
tttatggata tgcgagtgaa ggttggcttg ccagcattgg catcgcctgc ctgcatactg 1440
agttttgttg taaaagtaca aactcagtat caacaataca atttttnttt gaaaaaaaaa 1500
aaaa 1504
<210> 18
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> M13F universal primer
<400> 18
tgtaaaacga cggccagt 18
<210> 19
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer oEugEL1-1
<400> 19
agcggccgca ccatggaggt ggtgaatgaa 30
<210> 20
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer oEugEL1-2
<400> 20
tgcggccgct cactgaatct ttttggctcc 30
<210> 21
<211> 8306
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pY119
<400> 21
ggccgcaggg cggatccccc gggctgcagg aattcgatat caagcttatc gataccgtcg 60
acctcgaggg ggggcccggt acccaattcg ccctatagtg agtcgtatta cgcgcgctca 120
ctggccgtcg ttttacaacg tcgtgactgg gaaaaccctg gcgttaccca acttaatcgc 180
cttgcagcac atcccccttt cgccagctgg cgtaatagcg aagaggcccg caccgatcgc 240
ccttcccaac agttgcgcag cctgaatggc gaatggcgcg acgcgccctg tagcggcgca 300
ttaagcgcgg cgggtgtggt ggttacgcgc agcgtgaccg ctacacttgc cagcgcccta 360
gcgcccgctc ctttcgcttt cttcccttcc tttctcgcca cgttcgccgg ctttccccgt 420
caagctctaa atcgggggct ccctttaggg ttccgattta gtgctttacg gcacctcgac 480
cccaaaaaac ttgattaggg tgatggttca cgtagtgggc catcgccctg atagacggtt 540
tttcgccctt tgacgttgga gtccacgttc tttaatagtg gactcttgtt ccaaactgga 600
acaacactca accctatctc ggtctattct tttgatttat aagggatttt gccgatttcg 660
gcctattggt taaaaaatga gctgatttaa caaaaattta acgcgaattt taacaaaata 720
ttaacgttta caatttcctg atgcggtatt ttctccttac gcatctgtgc ggtatttcac 780
accgcatatc gacggtcgag gagaacttct agtatatcca catacctaat attattgcct 840
tattaaaaat ggaatcccaa caattacatc aaaatccaca ttctcttcaa aatcaattgt 900
cctgtacttc cttgttcatg tgtgttcaaa aacgttatat ttataggata attatactct 960
atttctcaac aagtaattgg ttgtttggcc gagcggtcta aggcgcctga ttcaagaaat 1020
atcttgaccg cagttaactg tgggaatact caggtatcgt aagatgcaag agttcgaatc 1080
tcttagcaac cattattttt ttcctcaaca taacgagaac acacaggggc gctatcgcac 1140
agaatcaaat tcgatgactg gaaatttttt gttaatttca gaggtcgcct gacgcatata 1200
cctttttcaa ctgaaaaatt gggagaaaaa ggaaaggtga gaggccggaa ccggcttttc 1260
atatagaata gagaagcgtt catgactaaa tgcttgcatc acaatacttg aagttgacaa 1320
tattatttaa ggacctattg ttttttccaa taggtggtta gcaatcgtct tactttctaa 1380
cttttcttac cttttacatt tcagcaatat atatatatat ttcaaggata taccattcta 1440
atgtctgccc ctatgtctgc ccctaagaag atcgtcgttt tgccaggtga ccacgttggt 1500
caagaaatca cagccgaagc cattaaggtt cttaaagcta tttctgatgt tcgttccaat 1560
gtcaagttcg atttcgaaaa tcatttaatt ggtggtgctg ctatcgatgc tacaggtgtc 1620
ccacttccag atgaggcgct ggaagcctcc aagaaggttg atgccgtttt gttaggtgct 1680
gtggctggtc ctaaatgggg taccggtagt gttagacctg aacaaggttt actaaaaatc 1740
cgtaaagaac ttcaattgta cgccaactta agaccatgta actttgcatc cgactctctt 1800
ttagacttat ctccaatcaa gccacaattt gctaaaggta ctgacttcgt tgttgtcaga 1860
gaattagtgg gaggtattta ctttggtaag agaaaggaag acgatggtga tggtgtcgct 1920
tgggatagtg aacaatacac cgttccagaa gtgcaaagaa tcacaagaat ggccgctttc 1980
atggccctac aacatgagcc accattgcct atttggtcct tggataaagc taatcttttg 2040
gcctcttcaa gattatggag aaaaactgtg gaggaaacca tcaagaacga attccctaca 2100
ttgaaggttc aacatcaatt gattgattct gccgccatga tcctagttaa gaacccaacc 2160
cacctaaatg gtattataat caccagcaac atgtttggtg atatcatctc cgatgaagcc 2220
tccgttatcc caggttcctt gggtttgttg ccatctgcgt ccttggcctc tttgccagac 2280
aagaacaccg catttggttt gtacgaacca tgccacggtt ctgctccaga tttgccaaag 2340
aataaggttg accctatcgc cactatcttg tctgctgcaa tgatgttgaa attgtcattg 2400
aacttgcctg aagaaggtaa ggccattgaa gatgcagtta aaaaggtttt ggatgcaggt 2460
atcagaactg gtgatttagg tggttccaac agtaccaccg aagtcggtga tgctgtcgcc 2520
gaagaagtta agaaaatcct tgcttaaaaa gattctcttt ttttatgata tttgtacata 2580
aactttataa atgaaattca taatagaaac gacacgaaat tacaaaatgg aatatgttca 2640
tagggtagac gaaactatat acgcaatcta catacattta tcaagaagga gaaaaaggag 2700
gatagtaaag gaatacaggt aagcaaattg atactaatgg ctcaacgtga taaggaaaaa 2760
gaattgcact ttaacattaa tattgacaag gaggagggca ccacacaaaa agttaggtgt 2820
aacagaaaat catgaaacta cgattcctaa tttgatattg gaggattttc tctaaaaaaa 2880
aaaaaataca acaaataaaa aacactcaat gacctgacca tttgatggag tttaagtcaa 2940
taccttcttg aagcatttcc cataatggtg aaagttccct caagaatttt actctgtcag 3000
aaacggcctt acgacgtagt cgatatggtg cactctcagt acaatctgct ctgatgccgc 3060
atagttaagc cagccccgac acccgccaac acccgctgac gcgccctgac gggcttgtct 3120
gctcccggca tccgcttaca gacaagctgt gaccgtctcc gggagctgca tgtgtcagag 3180
gttttcaccg tcatcaccga aacgcgcgag acgaaagggc ctcgtgatac gcctattttt 3240
ataggttaat gtcatgataa taatggtttc ttagtatgat ccaatatcaa aggaaatgat 3300
agcattgaag gatgagacta atccaattga ggagtggcag catatagaac agctaaaggg 3360
tagtgctgaa ggaagcatac gataccccgc atggaatggg ataatatcac aggaggtact 3420
agactacctt tcatcctaca taaatagacg catataagta cgcatttaag cataaacacg 3480
cactatgccg ttcttctcat gtatatatat atacaggcaa cacgcagata taggtgcgac 3540
gtgaacagtg agctgtatgt gcgcagctcg cgttgcattt tcggaagcgc tcgttttcgg 3600
aaacgctttg aagttcctat tccgaagttc ctattctcta gaaagtatag gaacttcaga 3660
gcgcttttga aaaccaaaag cgctctgaag acgcactttc aaaaaaccaa aaacgcaccg 3720
gactgtaacg agctactaaa atattgcgaa taccgcttcc acaaacattg ctcaaaagta 3780
tctctttgct atatatctct gtgctatatc cctatataac ctacccatcc acctttcgct 3840
ccttgaactt gcatctaaac tcgacctcta cattttttat gtttatctct agtattactc 3900
tttagacaaa aaaattgtag taagaactat tcatagagtg aatcgaaaac aatacgaaaa 3960
tgtaaacatt tcctatacgt agtatataga gacaaaatag aagaaaccgt tcataatttt 4020
ctgaccaatg aagaatcatc aacgctatca ctttctgttc acaaagtatg cgcaatccac 4080
atcggtatag aatataatcg gggatgcctt tatcttgaaa aaatgcaccc gcagcttcgc 4140
tagtaatcag taaacgcggg aagtggagtc aggctttttt tatggaagag aaaatagaca 4200
ccaaagtagc cttcttctaa ccttaacgga cctacagtgc aaaaagttat caagagactg 4260
cattatagag cgcacaaagg agaaaaaaag taatctaaga tgctttgtta gaaaaatagc 4320
gctctcggga tgcatttttg tagaacaaaa aagaagtata gattctttgt tggtaaaata 4380
gcgctctcgc gttgcatttc tgttctgtaa aaatgcagct cagattcttt gtttgaaaaa 4440
ttagcgctct cgcgttgcat ttttgtttta caaaaatgaa gcacagattc ttcgttggta 4500
aaatagcgct ttcgcgttgc atttctgttc tgtaaaaatg cagctcagat tctttgtttg 4560
aaaaattagc gctctcgcgt tgcatttttg ttctacaaaa tgaagcacag atgcttcgtt 4620
caggtggcac ttttcgggga aatgtgcgcg gaacccctat ttgtttattt ttctaaatac 4680
attcaaatat gtatccgctc atgagacaat aaccctgata aatgcttcaa taatattgaa 4740
aaaggaagag tatgagtatt caacatttcc gtgtcgccct tattcccttt tttgcggcat 4800
tttgccttcc tgtttttgct cacccagaaa cgctggtgaa agtaaaagat gctgaagatc 4860
agttgggtgc acgagtgggt tacatcgaac tggatctcaa cagcggtaag atccttgaga 4920
gttttcgccc cgaagaacgt tttccaatga tgagcacttt taaagttctg ctatgtggcg 4980
cggtattatc ccgtattgac gccgggcaag agcaactcgg tcgccgcata cactattctc 5040
agaatgactt ggttgagtac tcaccagtca cagaaaagca tcttacggat ggcatgacag 5100
taagagaatt atgcagtgct gccataacca tgagtgataa cactgcggcc aacttacttc 5160
tgacaacgat cggaggaccg aaggagctaa ccgctttttt gcacaacatg ggggatcatg 5220
taactcgcct tgatcgttgg gaaccggagc tgaatgaagc cataccaaac gacgagcgtg 5280
acaccacgat gcctgtagca atggcaacaa cgttgcgcaa actattaact ggcgaactac 5340
ttactctagc ttcccggcaa caattaatag actggatgga ggcggataaa gttgcaggac 5400
cacttctgcg ctcggccctt ccggctggct ggtttattgc tgataaatct ggagccggtg 5460
agcgtgggtc tcgcggtatc attgcagcac tggggccaga tggtaagccc tcccgtatcg 5520
tagttatcta cacgacgggg agtcaggcaa ctatggatga acgaaataga cagatcgctg 5580
agataggtgc ctcactgatt aagcattggt aactgtcaga ccaagtttac tcatatatac 5640
tttagattga tttaaaactt catttttaat ttaaaaggat ctaggtgaag atcctttttg 5700
ataatctcat gaccaaaatc ccttaacgtg agttttcgtt ccactgagcg tcagaccccg 5760
tagaaaagat caaaggatct tcttgagatc ctttttttct gcgcgtaatc tgctgcttgc 5820
aaacaaaaaa accaccgcta ccagcggtgg tttgtttgcc ggatcaagag ctaccaactc 5880
tttttccgaa ggtaactggc ttcagcagag cgcagatacc aaatactgtc cttctagtgt 5940
agccgtagtt aggccaccac ttcaagaact ctgtagcacc gcctacatac ctcgctctgc 6000
taatcctgtt accagtggct gctgccagtg gcgataagtc gtgtcttacc gggttggact 6060
caagacgata gttaccggat aaggcgcagc ggtcgggctg aacggggggt tcgtgcacac 6120
agcccagctt ggagcgaacg acctacaccg aactgagata cctacagcgt gagctatgag 6180
aaagcgccac gcttcccgaa gggagaaagg cggacaggta tccggtaagc ggcagggtcg 6240
gaacaggaga gcgcacgagg gagcttccag ggggaaacgc ctggtatctt tatagtcctg 6300
tcgggtttcg ccacctctga cttgagcgtc gatttttgtg atgctcgtca ggggggcgga 6360
gcctatggaa aaacgccagc aacgcggcct ttttacggtt cctggccttt tgctggcctt 6420
ttgctcacat gttctttcct gcgttatccc ctgattctgt ggataaccgt attaccgcct 6480
ttgagtgagc tgataccgct cgccgcagcc gaacgaccga gcgcagcgag tcagtgagcg 6540
aggaagcgga agagcgccca atacgcaaac cgcctctccc cgcgcgttgg ccgattcatt 6600
aatgcagctg gcacgacagg tttcccgact ggaaagcggg cagtgagcgc aacgcaatta 6660
atgtgagtta cctcactcat taggcacccc aggctttaca ctttatgctt ccggctccta 6720
tgttgtgtgg aattgtgagc ggataacaat ttcacacagg aaacagctat gaccatgatt 6780
acgccaagcg cgcaattaac cctcactaaa gggaacaaaa gctggagctc caccgcggga 6840
tttcgaaact aagttcttgg tgttttaaaa ctaaaaaaaa gactaactat aaaagtagaa 6900
tttaagaagt ttaagaaata gatttacaga attacaatca atacctaccg tctttatata 6960
cttattagtc aagtagggga ataatttcag ggaactggtt tcaacctttt ttttcagctt 7020
tttccaaatc agagagagca gaaggtaata gaaggtgtaa gaaaatgaga tagatacatg 7080
cgtgggtcaa ttgccttgtg tcatcattta ctccaggcag gttgcatcac tccattgagg 7140
ttgtgcccgt tttttgcctg tttgtgcccc tgttctctgt agttgcgcta agagaatgga 7200
cctatgaact gatggttggt gaagaaaaca atattttggt gctgggattc tttttttttc 7260
tggatgccag cttaaaaagc gggctccatt atatttagtg gatgccagga ataaactgtt 7320
cacccagaca cctacgatgt tatatattct gtgtaacccg ccccctattt tgggcatgta 7380
cgggttacag cagaattaaa aggctaattt tttgactaaa taaagttagg aaaatcacta 7440
ctattaatta tttacgtatt ctttgaaatg gcagtattga taatgataaa ctcgaaatca 7500
ctagtggatc cgcccagcgg ccgcaccatg gaggtggtga atgaaatagt ctcaattggg 7560
caggaagttt tacccaaagt tgattatgcc caactctgga gtgatgccag tcactgtgag 7620
gtgctttact tgtccatcgc atttgtcatc ttgaagttca ctcttggccc ccttggtcca 7680
aaaggtcagt ctcgtatgaa gtttgttttc accaattaca accttctcat gtccatttat 7740
tcgttgggat cattcctctc aatggcatat gccatgtaca ccatcggtgt tatgtctgac 7800
aactgcgaga aggcttttga caacaacgtc ttcaggatca ccacgcagtt gttctatttg 7860
agcaagttcc tggagtatat tgactccttc tatttgccac tgatgggcaa gcctctgacc 7920
tggttgcaat tcttccatca tttgggggca ccgatggata tgtggctgtt ctataattac 7980
cgaaatgaag ctgtttggat ttttgtgctg ttgaatggtt tcatccactg gatcatgtac 8040
ggttattatt ggaccagatt gatcaagctg aagttcccca tgccaaaatc cctgattaca 8100
tcaatgcaga tcattcaatt caatgttggt ttctacattg tctggaagta caggaacatt 8160
ccctgttatc gccaagatgg gatgaggatg tttggctggt tcttcaatta cttttatgtt 8220
ggcacagtct tgtgtttgtt cttgaatttc tatgtgcaaa cgtatatcgt caggaagcac 8280
aagggagcca aaaagattca gtgagc 8306
<210> 22
<211> 9472
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pDMW263
<400> 22
catggcatgg atggtacgtc ctgtagaaac cccaacccgt gaaatcaaaa aactcgacgg 60
cctgtgggca ttcagtctgg atcgcgaaaa ctgtggaatt gatcagcgtt ggtgggaaag 120
cgcgttacaa gaaagccggg caattgctgt gccaggcagt tttaacgatc agttcgccga 180
tgcagatatt cgtaattatg cgggcaacgt ctggtatcag cgcgaagtct ttataccgaa 240
aggttgggca ggccagcgta tcgtgctgcg tttcgatgcg gtcactcatt acggcaaagt 300
gtgggtcaat aatcaggaag tgatggagca tcagggcggc tatacgccat ttgaagccga 360
tgtcacgccg tatgttattg ccgggaaaag tgtacgtatc accgtttgtg tgaacaacga 420
actgaactgg cagactatcc cgccgggaat ggtgattacc gacgaaaacg gcaagaaaaa 480
gcagtcttac ttccatgatt tctttaacta tgccgggatc catcgcagcg taatgctcta 540
caccacgccg aacacctggg tggacgatat caccgtggtg acgcatgtcg cgcaagactg 600
taaccacgcg tctgttgact ggcaggtggt ggccaatggt gatgtcagcg ttgaactgcg 660
tgatgcggat caacaggtgg ttgcaactgg acaaggcact agcgggactt tgcaagtggt 720
gaatccgcac ctctggcaac cgggtgaagg ttatctctat gaactgtgcg tcacagccaa 780
aagccagaca gagtgtgata tctacccgct tcgcgtcggc atccggtcag tggcagtgaa 840
gggcgaacag ttcctgatta accacaaacc gttctacttt actggctttg gtcgtcatga 900
agatgcggac ttacgtggca aaggattcga taacgtgctg atggtgcacg accacgcatt 960
aatggactgg attggggcca actcctaccg tacctcgcat tacccttacg ctgaagagat 1020
gctcgactgg gcagatgaac atggcatcgt ggtgattgat gaaactgctg ctgtcggctt 1080
taacctctct ttaggcattg gtttcgaagc gggcaacaag ccgaaagaac tgtacagcga 1140
agaggcagtc aacggggaaa ctcagcaagc gcacttacag gcgattaaag agctgatagc 1200
gcgtgacaaa aaccacccaa gcgtggtgat gtggagtatt gccaacgaac cggatacccg 1260
tccgcaagtg cacgggaata tttcgccact ggcggaagca acgcgtaaac tcgacccgac 1320
gcgtccgatc acctgcgtca atgtaatgtt ctgcgacgct cacaccgata ccatcagcga 1380
tctctttgat gtgctgtgcc tgaaccgtta ttacggatgg tatgtccaaa gcggcgattt 1440
ggaaacggca gagaaggtac tggaaaaaga acttctggcc tggcaggaga aactgcatca 1500
gccgattatc atcaccgaat acggcgtgga tacgttagcc gggctgcact caatgtacac 1560
cgacatgtgg agtgaagagt atcagtgtgc atggctggat atgtatcacc gcgtctttga 1620
tcgcgtcagc gccgtcgtcg gtgaacaggt atggaatttc gccgattttg cgacctcgca 1680
aggcatattg cgcgttggcg gtaacaagaa agggatcttc actcgcgacc gcaaaccgaa 1740
gtcggcggct tttctgctgc aaaaacgctg gactggcatg aacttcggtg aaaaaccgca 1800
gcagggaggc aaacaatgat taattaacta gagcggccgc caccgcggcc cgagattccg 1860
gcctcttcgg ccgccaagcg acccgggtgg acgtctagag gtacctagca attaacagat 1920
agtttgccgg tgataattct cttaacctcc cacactcctt tgacataacg atttatgtaa 1980
cgaaactgaa atttgaccag atattgtgtc cgcggtggag ctccagcttt tgttcccttt 2040
agtgagggtt aatttcgagc ttggcgtaat catggtcata gctgtttcct gtgtgaaatt 2100
gttatccgct cacaattcca cacaacatac gagccggaag cataaagtgt aaagcctggg 2160
gtgcctaatg agtgagctaa ctcacattaa ttgcgttgcg ctcactgccc gctttccagt 2220
cgggaaacct gtcgtgccag ctgcattaat gaatcggcca acgcgcgggg agaggcggtt 2280
tgcgtattgg gcgctcttcc gcttcctcgc tcactgactc gctgcgctcg gtcgttcggc 2340
tgcggcgagc ggtatcagct cactcaaagg cggtaatacg gttatccaca gaatcagggg 2400
ataacgcagg aaagaacatg tgagcaaaag gccagcaaaa ggccaggaac cgtaaaaagg 2460
ccgcgttgct ggcgtttttc cataggctcc gcccccctga cgagcatcac aaaaatcgac 2520
gctcaagtca gaggtggcga aacccgacag gactataaag ataccaggcg tttccccctg 2580
gaagctccct cgtgcgctct cctgttccga ccctgccgct taccggatac ctgtccgcct 2640
ttctcccttc gggaagcgtg gcgctttctc atagctcacg ctgtaggtat ctcagttcgg 2700
tgtaggtcgt tcgctccaag ctgggctgtg tgcacgaacc ccccgttcag cccgaccgct 2760
gcgccttatc cggtaactat cgtcttgagt ccaacccggt aagacacgac ttatcgccac 2820
tggcagcagc cactggtaac aggattagca gagcgaggta tgtaggcggt gctacagagt 2880
tcttgaagtg gtggcctaac tacggctaca ctagaaggac agtatttggt atctgcgctc 2940
tgctgaagcc agttaccttc ggaaaaagag ttggtagctc ttgatccggc aaacaaacca 3000
ccgctggtag cggtggtttt tttgtttgca agcagcagat tacgcgcaga aaaaaaggat 3060
ctcaagaaga tcctttgatc ttttctacgg ggtctgacgc tcagtggaac gaaaactcac 3120
gttaagggat tttggtcatg agattatcaa aaaggatctt cacctagatc cttttaaatt 3180
aaaaatgaag ttttaaatca atctaaagta tatatgagta aacttggtct gacagttacc 3240
aatgcttaat cagtgaggca cctatctcag cgatctgtct atttcgttca tccatagttg 3300
cctgactccc cgtcgtgtag ataactacga tacgggaggg cttaccatct ggccccagtg 3360
ctgcaatgat accgcgagac ccacgctcac cggctccaga tttatcagca ataaaccagc 3420
cagccggaag ggccgagcgc agaagtggtc ctgcaacttt atccgcctcc atccagtcta 3480
ttaattgttg ccgggaagct agagtaagta gttcgccagt taatagtttg cgcaacgttg 3540
ttgccattgc tacaggcatc gtggtgtcac gctcgtcgtt tggtatggct tcattcagct 3600
ccggttccca acgatcaagg cgagttacat gatcccccat gttgtgcaaa aaagcggtta 3660
gctccttcgg tcctccgatc gttgtcagaa gtaagttggc cgcagtgtta tcactcatgg 3720
ttatggcagc actgcataat tctcttactg tcatgccatc cgtaagatgc ttttctgtga 3780
ctggtgagta ctcaaccaag tcattctgag aatagtgtat gcggcgaccg agttgctctt 3840
gcccggcgtc aatacgggat aataccgcgc cacatagcag aactttaaaa gtgctcatca 3900
ttggaaaacg ttcttcgggg cgaaaactct caaggatctt accgctgttg agatccagtt 3960
cgatgtaacc cactcgtgca cccaactgat cttcagcatc ttttactttc accagcgttt 4020
ctgggtgagc aaaaacagga aggcaaaatg ccgcaaaaaa gggaataagg gcgacacgga 4080
aatgttgaat actcatactc ttcctttttc aatattattg aagcatttat cagggttatt 4140
gtctcatgag cggatacata tttgaatgta tttagaaaaa taaacaaata ggggttccgc 4200
gcacatttcc ccgaaaagtg ccacctgacg cgccctgtag cggcgcatta agcgcggcgg 4260
gtgtggtggt tacgcgcagc gtgaccgcta cacttgccag cgccctagcg cccgctcctt 4320
tcgctttctt cccttccttt ctcgccacgt tcgccggctt tccccgtcaa gctctaaatc 4380
gggggctccc tttagggttc cgatttagtg ctttacggca cctcgacccc aaaaaacttg 4440
attagggtga tggttcacgt agtgggccat cgccctgata gacggttttt cgccctttga 4500
cgttggagtc cacgttcttt aatagtggac tcttgttcca aactggaaca acactcaacc 4560
ctatctcggt ctattctttt gatttataag ggattttgcc gatttcggcc tattggttaa 4620
aaaatgagct gatttaacaa aaatttaacg cgaattttaa caaaatatta acgcttacaa 4680
tttccattcg ccattcaggc tgcgcaactg ttgggaaggg cgatcggtgc gggcctcttc 4740
gctattacgc cagctggcga aagggggatg tgctgcaagg cgattaagtt gggtaacgcc 4800
agggttttcc cagtcacgac gttgtaaaac gacggccagt gaattgtaat acgactcact 4860
atagggcgaa ttgggtaccg ggccccccct cgaggtcgat ggtgtcgata agcttgatat 4920
cgaattcatg tcacacaaac cgatcttcgc ctcaaggaaa cctaattcta catccgagag 4980
actgccgaga tccagtctac actgattaat tttcgggcca ataatttaaa aaaatcgtgt 5040
tatataatat tatatgtatt atatatatac atcatgatga tactgacagt catgtcccat 5100
tgctaaatag acagactcca tctgccgcct ccaactgatg ttctcaatat ttaaggggtc 5160
atctcgcatt gtttaataat aaacagactc catctaccgc ctccaaatga tgttctcaaa 5220
atatattgta tgaacttatt tttattactt agtattatta gacaacttac ttgctttatg 5280
aaaaacactt cctatttagg aaacaattta taatggcagt tcgttcattt aacaatttat 5340
gtagaataaa tgttataaat gcgtatggga aatcttaaat atggatagca taaatgatat 5400
ctgcattgcc taattcgaaa tcaacagcaa cgaaaaaaat cccttgtaca acataaatag 5460
tcatcgagaa atatcaacta tcaaagaaca gctattcaca cgttactatt gagattatta 5520
ttggacgaga atcacacact caactgtctt tctctcttct agaaatacag gtacaagtat 5580
gtactattct cattgttcat acttctagtc atttcatccc acatattcct tggatttctc 5640
tccaatgaat gacattctat cttgcaaatt caacaattat aataagatat accaaagtag 5700
cggtatagtg gcaatcaaaa agcttctctg gtgtgcttct cgtatttatt tttattctaa 5760
tgatccatta aaggtatata tttatttctt gttatataat ccttttgttt attacatggg 5820
ctggatacat aaaggtattt tgatttaatt ttttgcttaa attcaatccc ccctcgttca 5880
gtgtcaactg taatggtagg aaattaccat acttttgaag aagcaaaaaa aatgaaagaa 5940
aaaaaaaatc gtatttccag gttagacgtt ccgcagaatc tagaatgcgg tatgcggtac 6000
attgttcttc gaacgtaaaa gttgcgctcc ctgagatatt gtacattttt gcttttacaa 6060
gtacaagtac atcgtacaac tatgtactac tgttgatgca tccacaacag tttgttttgt 6120
ttttttttgt tttttttttt tctaatgatt cattaccgct atgtatacct acttgtactt 6180
gtagtaagcc gggttattgg cgttcaatta atcatagact tatgaatctg cacggtgtgc 6240
gctgcgagtt acttttagct tatgcatgct acttgggtgt aatattggga tctgttcgga 6300
aatcaacgga tgctcaaccg atttcgacag taataatttg aatcgaatcg gagcctaaaa 6360
tgaacccgag tatatctcat aaaattctcg gtgagaggtc tgtgactgtc agtacaaggt 6420
gccttcatta tgccctcaac cttaccatac ctcactgaat gtagtgtacc tctaaaaatg 6480
aaatacagtg ccaaaagcca aggcactgag ctcgtctaac ggacttgata tacaaccaat 6540
taaaacaaat gaaaagaaat acagttcttt gtatcatttg taacaattac cctgtacaaa 6600
ctaaggtatt gaaatcccac aatattccca aagtccaccc ctttccaaat tgtcatgcct 6660
acaactcata taccaagcac taacctacca aacaccacta aaaccccaca aaatatatct 6720
taccgaatat acagtaacaa gctaccacca cactcgttgg gtgcagtcgc cagcttaaag 6780
atatctatcc acatcagcca caactccctt cctttaataa accgactaca cccttggcta 6840
ttgaggttat gagtgaatat actgtagaca agacactttc aagaagactg tttccaaaac 6900
gtaccactgt cctccactac aaacacaccc aatctgcttc ttctagtcaa ggttgctaca 6960
ccggtaaatt ataaatcatc atttcattag cagggcaggg ccctttttat agagtcttat 7020
acactagcgg accctgccgg tagaccaacc cgcaggcgcg tcagtttgct ccttccatca 7080
atgcgtcgta gaaacgactt actccttctt gagcagctcc ttgaccttgt tggcaacaag 7140
tctccgacct cggaggtgga ggaagagcct ccgatatcgg cggtagtgat accagcctcg 7200
acggactcct tgacggcagc ctcaacagcg tcaccggcgg gcttcatgtt aagagagaac 7260
ttgagcatca tggcggcaga cagaatggtg gcaatggggt tgaccttctg cttgccgaga 7320
tcgggggcag atccgtgaca gggctcgtac agaccgaacg cctcgttggt gtcgggcaga 7380
gaagccagag aggcggaggg cagcagaccc agagaaccgg ggatgacgga ggcctcgtcg 7440
gagatgatat cgccaaacat gttggtggtg atgatgatac cattcatctt ggagggctgc 7500
ttgatgagga tcatggcggc cgagtcgatc agctggtggt tgagctcgag ctgggggaat 7560
tcgtccttga ggactcgagt gacagtcttt cgccaaagtc gagaggaggc cagcacgttg 7620
gccttgtcaa gagaccacac gggaagaggg gggttgtgct gaagggccag gaaggcggcc 7680
attcgggcaa ttcgctcaac ctcaggaacg gagtaggtct cggtgtcgga agcgacgcca 7740
gatccgtcat cctcctttcg ctctccaaag tagatacctc cgacgagctc tcggacaatg 7800
atgaagtcgg tgccctcaac gtttcggatg ggggagagat cggcgagctt gggcgacagc 7860
agctggcagg gtcgcaggtt ggcgtacagg ttcaggtcct ttcgcagctt gaggagaccc 7920
tgctcgggtc gcacgtcggt tcgtccgtcg ggagtggtcc atacggtgtt ggcagcgcct 7980
ccgacagcac cgagcataat agagtcagcc tttcggcaga tgtcgagagt agcgtcggtg 8040
atgggctcgc cctccttctc aatggcagct cctccaatga gtcggtcctc aaacacaaac 8100
tcggtgccgg aggcctcagc aacagacttg agcaccttga cggcctcggc aatcacctcg 8160
gggccacaga agtcgccgcc gagaagaaca atcttcttgg agtcagtctt ggtcttctta 8220
gtttcgggtt ccattgtgga tgtgtgtggt tgtatgtgtg atgtggtgtg tggagtgaaa 8280
atctgtggct ggcaaacgct cttgtatata tacgcacttt tgcccgtgct atgtggaaga 8340
ctaaacctcc gaagattgtg actcaggtag tgcggtatcg gctagggacc caaaccttgt 8400
cgatgccgat agcgctatcg aacgtacccc agccggccgg gagtatgtcg gaggggacat 8460
acgagatcgt caagggtttg tggccaactg gtaaataaat gatgtcgacg tttaaacagt 8520
gtacgcagat ctactataga ggaacattta aattgccccg gagaagacgg ccaggccgcc 8580
tagatgacaa attcaacaac tcacagctga ctttctgcca ttgccactag gggggggcct 8640
ttttatatgg ccaagccaag ctctccacgt cggttgggct gcacccaaca ataaatgggt 8700
agggttgcac caacaaaggg atgggatggg gggtagaaga tacgaggata acggggctca 8760
atggcacaaa taagaacgaa tactgccatt aagactcgtg atccagcgac tgacaccatt 8820
gcatcatcta agggcctcaa aactacctcg gaactgctgc gctgatctgg acaccacaga 8880
ggttccgagc actttaggtt gcaccaaatg tcccaccagg tgcaggcaga aaacgctgga 8940
acagcgtgta cagtttgtct taacaaaaag tgagggcgct gaggtcgagc agggtggtgt 9000
gacttgttat agcctttaga gctgcgaaag cgcgtatgga tttggctcat caggccagat 9060
tgagggtctg tggacacatg tcatgttagt gtacttcaat cgccccctgg atatagcccc 9120
gacaataggc cgtggcctca tttttttgcc ttccgcacat ttccattgct cgatacccac 9180
accttgcttc tcctgcactt gccaacctta atactggttt acattgacca acatcttaca 9240
agcggggggc ttgtctaggg tatatataaa cagtggctct cccaatcggt tgccagtctc 9300
ttttttcctt tctttcccca cagattcgaa atctaaacta cacatcacag aattccgagc 9360
cgtgagtatc cacgacaaga tcagtgtcga gacgacgcgt tttgtgtaat gacacaatcc 9420
gaaagtcgct agcaacacac actctctaca caaactaacc cagctctggt ac 9472
<210> 23
<211> 101
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-1A
<400> 23
gccaacgacg ctggcgagcg aatctgggct gccgtcaccg atcccgaaat cctcattggc 60
accttctcct acctgctcct gaagcctctc ctgcgaaact c 101
<210> 24
<211> 101
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-1B
<400> 24
accagagttt cgcaggagag gcttcaggag caggtaggag aaggtgccaa tgaggatttc 60
gggatcggtg acggcagccc agattcgctc gccagcgtcg t 101
<210> 25
<211> 100
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-2A
<400> 25
tggtctcgtg gacgagaaga aaggagccta ccgaacctcc atgatctggt acaacgtcct 60
cctggctctc ttctctgccc tgtccttcta cgtgactgcc 100
<210> 26
<211> 100
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-2B
<400> 26
cggtggcagt cacgtagaag gacagggcag agaagagagc caggaggacg ttgtaccaga 60
tcatggaggt tcggtaggct cctttcttct cgtccacgag 100
<210> 27
<211> 100
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-3A
<400> 27
accgctctcg gctgggacta cggtactgga gcctggctgc gaagacagac cggtgatact 60
ccccagcctc tctttcagtg tccctctcct gtctgggact 100
<210> 28
<211> 100
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-3B
<400> 28
ttggagtccc agacaggaga gggacactga aagagaggct ggggagtatc accggtctgt 60
cttcgcagcc aggctccagt accgtagtcc cagccgagag 100
<210> 29
<211> 100
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-4A
<400> 29
ccaagctgtt cacctggact gccaaggcct tctactattc taagtacgtg gagtacctcg 60
acaccgcttg gctggtcctc aagggcaagc gagtgtcctt 100
<210> 30
<211> 100
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-4B
<400> 30
cagaaaggac actcgcttgc ccttgaggac cagccaagcg gtgtcgaggt actccacgta 60
cttagaatag tagaaggcct tggcagtcca ggtgaacagc 100
<210> 31
<211> 89
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-5A
<400> 31
ttccatcact ttggagctcc ctgggacgtc tacctcggca ttcgactgca caacgagggt 60
gtgtggatct tcatgttctt taactcgtt 89
<210> 32
<211> 89
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-5B
<400> 32
aatgaacgag ttaaagaaca tgaagatcca cacaccctcg ttgtgcagtc gaatgccgag 60
gtagacgtcc cagggagctc caaagtgat 89
<210> 33
<211> 91
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-6A
<400> 33
cattcacacc atcatgtaca cctactatgg actgactgcc gctggctaca agttcaaggc 60
caagcctctg atcactgcca tgcagatttg c 91
<210> 34
<211> 91
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-6B
<400> 34
actggcaaat ctgcatggca gtgatcagag gcttggcctt gaacttgtag ccagcggcag 60
tcagtccata gtaggtgtac atgatggtgt g 91
<210> 35
<211> 94
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-7A
<400> 35
cagttcgtcg gtggctttct cctggtctgg gactacatca acgttccctg cttcaactct 60
gacaagggca agctgttctc ctgggctttc aact 94
<210> 36
<211> 94
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-7B
<400> 36
gcgtagttga aagcccagga gaacagcttg cccttgtcag agttgaagca gggaacgttg 60
atgtagtccc agaccaggag aaagccaccg acga 94
<210> 37
<211> 91
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-8A
<400> 37
acgcctacgt cggatctgtc tttctcctgt tctgtcactt cttttaccag gacaacctgg 60
ccaccaagaa atccgctaag gctggtaagc a 91
<210> 38
<211> 91
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-8B
<400> 38
aagctgctta ccagccttag cggatttctt ggtggccagg ttgtcctggt aaaagaagtg 60
acagaacagg agaaagacag atccgacgta g 91
<210> 39
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-1F
<400> 39
tttccatggc tctggccaac gacgctggcg agcgaatctg g 41
<210> 40
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-4R
<400> 40
tttctgcaga aaggacactc gcttgccctt gaggac 36
<210> 41
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-5F
<400> 41
tttctgcagg ccttccatca ctttggagct ccctgggacg t 41
<210> 42
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer IL3-8R
<400> 42
tttgcggccg ctaaagctgc ttaccagcct tagcggattt ct 42
<210> 43
<211> 417
<212> DNA
<213> Artificial Sequence
<220>
<223> 417 bp NcoI/PstI fragment pT9(1-4)
<400> 43
catggctctg gccaacgacg ctggcgagcg aatctgggct gccgtcaccg atcccgaaat 60
cctcattggc accttctcct acctgctcct gaagcctctc ctgcgaaact ctggtctcgt 120
ggacgagaag aaaggagcct accgaacctc catgatctgg tacaacgtcc tcctggctct 180
cttctctgcc ctgtccttct acgtgactgc caccgctctc ggctgggact acggtactgg 240
agcctggctg cgaagacaga ccggtgatac tccccagcct ctctttcagt gtccctctcc 300
tgtctgggac tccaagctgt tcacctggac tgccaaggcc ttctactatt ctaagtacgt 360
ggagtacctc gacaccgctt ggctggtcct caagggcaag cgagtgtcct ttctgca 417
<210> 44
<211> 377
<212> DNA
<213> Artificial Sequence
<220>
<223> 377 bp PstI/Not1 fragment pT9(5-8)
<400> 44
ggccttccat cactttggag ctccctggga cgtctacctc ggcattcgac tgcacaacga 60
gggtgtgtgg atcttcatgt tctttaactc gttcattcac accatcatgt acacctacta 120
tggactgact gccgctggct acaagttcaa ggccaagcct ctgatcactg ccatgcagat 180
ttgccagttc gtcggtggct ttctcctggt ctgggactac atcaacgttc cctgcttcaa 240
ctctgacaag ggcaagctgt tctcctgggc tttcaactac gcctacgtcg gatctgtctt 300
tctcctgttc tgtcacttct tttaccagga caacctggcc accaagaaat ccgctaaggc 360
tggtaagcag ctttagc 377
<210> 45
<211> 7783
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pY115
<400> 45
catggctctg gccaacgacg ctggcgagcg aatctgggct gccgtcaccg atcccgaaat 60
cctcattggc accttctcct acctgctcct gaagcctctc ctgcgaaact ctggtctcgt 120
ggacgagaag aaaggagcct accgaacctc catgatctgg tacaacgtcc tcctggctct 180
cttctctgcc ctgtccttct acgtgactgc caccgctctc ggctgggact acggtactgg 240
agcctggctg cgaagacaga ccggtgatac tccccagcct ctctttcagt gtccctctcc 300
tgtctgggac tccaagctgt tcacctggac tgccaaggcc ttctactatt ctaagtacgt 360
ggagtacctc gacaccgctt ggctggtcct caagggcaag cgagtgtcct ttctgcaggc 420
cttccatcac tttggagctc cctgggacgt ctacctcggc attcgactgc acaacgaggg 480
tgtgtggatc ttcatgttct ttaactcgtt cattcacacc atcatgtaca cctactatgg 540
actgactgcc gctggctaca agttcaaggc caagcctctg atcactgcca tgcagatttg 600
ccagttcgtc ggtggctttc tcctggtctg ggactacatc aacgttccct gcttcaactc 660
tgacaagggc aagctgttct cctgggcttt caactacgcc tacgtcggat ctgtctttct 720
cctgttctgt cacttctttt accaggacaa cctggccacc aagaaatccg ctaaggctgg 780
taagcagctt tagcggccgc aagtgtggat ggggaagtga gtgcccggtt ctgtgtgcac 840
aattggcaat ccaagatgga tggattcaac acagggatat agcgagctac gtggtggtgc 900
gaggatatag caacggatat ttatgtttga cacttgagaa tgtacgatac aagcactgtc 960
caagtacaat actaaacata ctgtacatac tcatactcgt acccgggcaa cggtttcact 1020
tgagtgcagt ggctagtgct cttactcgta cagtgtgcaa tactgcgtat catagtcttt 1080
gatgtatatc gtattcattc atgttagttg cgtacgagcc ggaagcataa agtgtaaagc 1140
ctggggtgcc taatgagtga gctaactcac attaattgcg ttgcgctcac tgcccgcttt 1200
ccagtcggga aacctgtcgt gccagctgca ttaatgaatc ggccaacgcg cggggagagg 1260
cggtttgcgt attgggcgct cttccgcttc ctcgctcact gactcgctgc gctcggtcgt 1320
tcggctgcgg cgagcggtat cagctcactc aaaggcggta atacggttat ccacagaatc 1380
aggggataac gcaggaaaga acatgtgagc aaaaggccag caaaaggcca ggaaccgtaa 1440
aaaggccgcg ttgctggcgt ttttccatag gctccgcccc cctgacgagc atcacaaaaa 1500
tcgacgctca agtcagaggt ggcgaaaccc gacaggacta taaagatacc aggcgtttcc 1560
ccctggaagc tccctcgtgc gctctcctgt tccgaccctg ccgcttaccg gatacctgtc 1620
cgcctttctc ccttcgggaa gcgtggcgct ttctcatagc tcacgctgta ggtatctcag 1680
ttcggtgtag gtcgttcgct ccaagctggg ctgtgtgcac gaaccccccg ttcagcccga 1740
ccgctgcgcc ttatccggta actatcgtct tgagtccaac ccggtaagac acgacttatc 1800
gccactggca gcagccactg gtaacaggat tagcagagcg aggtatgtag gcggtgctac 1860
agagttcttg aagtggtggc ctaactacgg ctacactaga aggacagtat ttggtatctg 1920
cgctctgctg aagccagtta ccttcggaaa aagagttggt agctcttgat ccggcaaaca 1980
aaccaccgct ggtagcggtg gtttttttgt ttgcaagcag cagattacgc gcagaaaaaa 2040
aggatctcaa gaagatcctt tgatcttttc tacggggtct gacgctcagt ggaacgaaaa 2100
ctcacgttaa gggattttgg tcatgagatt atcaaaaagg atcttcacct agatcctttt 2160
aaattaaaaa tgaagtttta aatcaatcta aagtatatat gagtaaactt ggtctgacag 2220
ttaccaatgc ttaatcagtg aggcacctat ctcagcgatc tgtctatttc gttcatccat 2280
agttgcctga ctccccgtcg tgtagataac tacgatacgg gagggcttac catctggccc 2340
cagtgctgca atgataccgc gagacccacg ctcaccggct ccagatttat cagcaataaa 2400
ccagccagcc ggaagggccg agcgcagaag tggtcctgca actttatccg cctccatcca 2460
gtctattaat tgttgccggg aagctagagt aagtagttcg ccagttaata gtttgcgcaa 2520
cgttgttgcc attgctacag gcatcgtggt gtcacgctcg tcgtttggta tggcttcatt 2580
cagctccggt tcccaacgat caaggcgagt tacatgatcc cccatgttgt gcaaaaaagc 2640
ggttagctcc ttcggtcctc cgatcgttgt cagaagtaag ttggccgcag tgttatcact 2700
catggttatg gcagcactgc ataattctct tactgtcatg ccatccgtaa gatgcttttc 2760
tgtgactggt gagtactcaa ccaagtcatt ctgagaatag tgtatgcggc gaccgagttg 2820
ctcttgcccg gcgtcaatac gggataatac cgcgccacat agcagaactt taaaagtgct 2880
catcattgga aaacgttctt cggggcgaaa actctcaagg atcttaccgc tgttgagatc 2940
cagttcgatg taacccactc gtgcacccaa ctgatcttca gcatctttta ctttcaccag 3000
cgtttctggg tgagcaaaaa caggaaggca aaatgccgca aaaaagggaa taagggcgac 3060
acggaaatgt tgaatactca tactcttcct ttttcaatat tattgaagca tttatcaggg 3120
ttattgtctc atgagcggat acatatttga atgtatttag aaaaataaac aaataggggt 3180
tccgcgcaca tttccccgaa aagtgccacc tgacgcgccc tgtagcggcg cattaagcgc 3240
ggcgggtgtg gtggttacgc gcagcgtgac cgctacactt gccagcgccc tagcgcccgc 3300
tcctttcgct ttcttccctt cctttctcgc cacgttcgcc ggctttcccc gtcaagctct 3360
aaatcggggg ctccctttag ggttccgatt tagtgcttta cggcacctcg accccaaaaa 3420
acttgattag ggtgatggtt cacgtagtgg gccatcgccc tgatagacgg tttttcgccc 3480
tttgacgttg gagtccacgt tctttaatag tggactcttg ttccaaactg gaacaacact 3540
caaccctatc tcggtctatt cttttgattt ataagggatt ttgccgattt cggcctattg 3600
gttaaaaaat gagctgattt aacaaaaatt taacgcgaat tttaacaaaa tattaacgct 3660
tacaatttcc attcgccatt caggctgcgc aactgttggg aagggcgatc ggtgcgggcc 3720
tcttcgctat tacgccagct ggcgaaaggg ggatgtgctg caaggcgatt aagttgggta 3780
acgccagggt tttcccagtc acgacgttgt aaaacgacgg ccagtgaatt gtaatacgac 3840
tcactatagg gcgaattggg taccgggccc cccctcgagg tcgatggtgt cgataagctt 3900
gatatcgaat tcatgtcaca caaaccgatc ttcgcctcaa ggaaacctaa ttctacatcc 3960
gagagactgc cgagatccag tctacactga ttaattttcg ggccaataat ttaaaaaaat 4020
cgtgttatat aatattatat gtattatata tatacatcat gatgatactg acagtcatgt 4080
cccattgcta aatagacaga ctccatctgc cgcctccaac tgatgttctc aatatttaag 4140
gggtcatctc gcattgttta ataataaaca gactccatct accgcctcca aatgatgttc 4200
tcaaaatata ttgtatgaac ttatttttat tacttagtat tattagacaa cttacttgct 4260
ttatgaaaaa cacttcctat ttaggaaaca atttataatg gcagttcgtt catttaacaa 4320
tttatgtaga ataaatgtta taaatgcgta tgggaaatct taaatatgga tagcataaat 4380
gatatctgca ttgcctaatt cgaaatcaac agcaacgaaa aaaatccctt gtacaacata 4440
aatagtcatc gagaaatatc aactatcaaa gaacagctat tcacacgtta ctattgagat 4500
tattattgga cgagaatcac acactcaact gtctttctct cttctagaaa tacaggtaca 4560
agtatgtact attctcattg ttcatacttc tagtcatttc atcccacata ttccttggat 4620
ttctctccaa tgaatgacat tctatcttgc aaattcaaca attataataa gatataccaa 4680
agtagcggta tagtggcaat caaaaagctt ctctggtgtg cttctcgtat ttatttttat 4740
tctaatgatc cattaaaggt atatatttat ttcttgttat ataatccttt tgtttattac 4800
atgggctgga tacataaagg tattttgatt taattttttg cttaaattca atcccccctc 4860
gttcagtgtc aactgtaatg gtaggaaatt accatacttt tgaagaagca aaaaaaatga 4920
aagaaaaaaa aaatcgtatt tccaggttag acgttccgca gaatctagaa tgcggtatgc 4980
ggtacattgt tcttcgaacg taaaagttgc gctccctgag atattgtaca tttttgcttt 5040
tacaagtaca agtacatcgt acaactatgt actactgttg atgcatccac aacagtttgt 5100
tttgtttttt tttgtttttt ttttttctaa tgattcatta ccgctatgta tacctacttg 5160
tacttgtagt aagccgggtt attggcgttc aattaatcat agacttatga atctgcacgg 5220
tgtgcgctgc gagttacttt tagcttatgc atgctacttg ggtgtaatat tgggatctgt 5280
tcggaaatca acggatgctc aatcgatttc gacagtaatt aattaagtca tacacaagtc 5340
agctttcttc gagcctcata taagtataag tagttcaacg tattagcact gtacccagca 5400
tctccgtatc gagaaacaca acaacatgcc ccattggaca gatcatgcgg atacacaggt 5460
tgtgcagtat catacatact cgatcagaca ggtcgtctga ccatcataca agctgaacaa 5520
gcgctccata cttgcacgct ctctatatac acagttaaat tacatatcca tagtctaacc 5580
tctaacagtt aatcttctgg taagcctccc agccagcctt ctggtatcgc ttggcctcct 5640
caataggatc tcggttctgg ccgtacagac ctcggccgac aattatgata tccgttccgg 5700
tagacatgac atcctcaaca gttcggtact gctgtccgag agcgtctccc ttgtcgtcaa 5760
gacccacccc gggggtcaga ataagccagt cctcagagtc gcccttaggt cggttctggg 5820
caatgaagcc aaccacaaac tcggggtcgg atcgggcaag ctcaatggtc tgcttggagt 5880
actcgccagt ggccagagag cccttgcaag acagctcggc cagcatgagc agacctctgg 5940
ccagcttctc gttgggagag gggactagga actccttgta ctgggagttc tcgtagtcag 6000
agacgtcctc cttcttctgt tcagagacag tttcctcggc accagctcgc aggccagcaa 6060
tgattccggt tccgggtaca ccgtgggcgt tggtgatatc ggaccactcg gcgattcggt 6120
gacaccggta ctggtgcttg acagtgttgc caatatctgc gaactttctg tcctcgaaca 6180
ggaagaaacc gtgcttaaga gcaagttcct tgagggggag cacagtgccg gcgtaggtga 6240
agtcgtcaat gatgtcgata tgggttttga tcatgcacac ataaggtccg accttatcgg 6300
caagctcaat gagctccttg gtggtggtaa catccagaga agcacacagg ttggttttct 6360
tggctgccac gagcttgagc actcgagcgg caaaggcgga cttgtggacg ttagctcgag 6420
cttcgtagga gggcattttg gtggtgaaga ggagactgaa ataaatttag tctgcagaac 6480
tttttatcgg aaccttatct ggggcagtga agtatatgtt atggtaatag ttacgagtta 6540
gttgaactta tagatagact ggactatacg gctatcggtc caaattagaa agaacgtcaa 6600
tggctctctg ggcgtcgcct ttgccgacaa aaatgtgatc atgatgaaag ccagcaatga 6660
cgttgcagct gatattgttg tcggccaacc gcgccgaaaa cgcagctgtc agacccacag 6720
cctccaacga agaatgtatc gtcaaagtga tccaagcaca ctcatagttg gagtcgtact 6780
ccaaaggcgg caatgacgag tcagacagat actcgtcgac gtttaaacag tgtacgcaga 6840
tctactatag aggaacattt aaattgcccc ggagaagacg gccaggccgc ctagatgaca 6900
aattcaacaa ctcacagctg actttctgcc attgccacta ggggggggcc tttttatatg 6960
gccaagccaa gctctccacg tcggttgggc tgcacccaac aataaatggg tagggttgca 7020
ccaacaaagg gatgggatgg ggggtagaag atacgaggat aacggggctc aatggcacaa 7080
ataagaacga atactgccat taagactcgt gatccagcga ctgacaccat tgcatcatct 7140
aagggcctca aaactacctc ggaactgctg cgctgatctg gacaccacag aggttccgag 7200
cactttaggt tgcaccaaat gtcccaccag gtgcaggcag aaaacgctgg aacagcgtgt 7260
acagtttgtc ttaacaaaaa gtgagggcgc tgaggtcgag cagggtggtg tgacttgtta 7320
tagcctttag agctgcgaaa gcgcgtatgg atttggctca tcaggccaga ttgagggtct 7380
gtggacacat gtcatgttag tgtacttcaa tcgccccctg gatatagccc cgacaatagg 7440
ccgtggcctc atttttttgc cttccgcaca tttccattgc tcgataccca caccttgctt 7500
ctcctgcact tgccaacctt aatactggtt tacattgacc aacatcttac aagcgggggg 7560
cttgtctagg gtatatataa acagtggctc tcccaatcgg ttgccagtct cttttttcct 7620
ttctttcccc acagattcga aatctaaact acacatcaca gaattccgag ccgtgagtat 7680
ccacgacaag atcagtgtcg agacgacgcg ttttgtgtaa tgacacaatc cgaaagtcgc 7740
tagcaacaca cactctctac acaaactaac ccagctctgg tac 7783
<210> 46
<211> 7879
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pDMW237
<400> 46
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgactcag gcgacgacgg aattcctgca gcccatctgc 6060
agaattcagg agagaccggg ttggcggcgt atttgtgtcc caaaaaacag ccccaattgc 6120
cccggagaag acggccaggc cgcctagatg acaaattcaa caactcacag ctgactttct 6180
gccattgcca ctaggggggg gcctttttat atggccaagc caagctctcc acgtcggttg 6240
ggctgcaccc aacaataaat gggtagggtt gcaccaacaa agggatggga tggggggtag 6300
aagatacgag gataacgggg ctcaatggca caaataagaa cgaatactgc cattaagact 6360
cgtgatccag cgactgacac cattgcatca tctaagggcc tcaaaactac ctcggaactg 6420
ctgcgctgat ctggacacca cagaggttcc gagcacttta ggttgcacca aatgtcccac 6480
caggtgcagg cagaaaacgc tggaacagcg tgtacagttt gtcttaacaa aaagtgaggg 6540
cgctgaggtc gagcagggtg gtgtgacttg ttatagcctt tagagctgcg aaagcgcgta 6600
tggatttggc tcatcaggcc agattgaggg tctgtggaca catgtcatgt tagtgtactt 6660
caatcgcccc ctggatatag ccccgacaat aggccgtggc ctcatttttt tgccttccgc 6720
acatttccat tgctcggtac ccacaccttg cttctcctgc acttgccaac cttaatactg 6780
gtttacattg accaacatct tacaagcggg gggcttgtct agggtatata taaacagtgg 6840
ctctcccaat cggttgccag tctctttttt cctttctttc cccacagatt cgaaatctaa 6900
actacacatc acacaatgcc tgttactgac gtccttaagc gaaagtccgg tgtcatcgtc 6960
ggcgacgatg tccgagccgt gagtatccac gacaagatca gtgtcgagac gacgcgtttt 7020
gtgtaatgac acaatccgaa agtcgctagc aacacacact ctctacacaa actaacccag 7080
ctctccatgg ctctggccaa cgacgctggc gagcgaatct gggctgccgt caccgatccc 7140
gaaatcctca ttggcacctt ctcctacctg ctcctgaagc ctctcctgcg aaactctggt 7200
ctcgtggacg agaagaaagg agcctaccga acctccatga tctggtacaa cgtcctcctg 7260
gctctcttct ctgccctgtc cttctacgtg actgccaccg ctctcggctg ggactacggt 7320
actggagcct ggctgcgaag acagaccggt gatactcccc agcctctctt tcagtgtccc 7380
tctcctgtct gggactccaa gctgttcacc tggactgcca aggccttcta ctattctaag 7440
tacgtggagt acctcgacac cgcttggctg gtcctcaagg gcaagcgagt gtcctttctg 7500
caggccttcc atcactttgg agctccctgg gacgtctacc tcggcattcg actgcacaac 7560
gagggtgtgt ggatcttcat gttctttaac tcgttcattc acaccatcat gtacacctac 7620
tatggactga ctgccgctgg ctacaagttc aaggccaagc ctctgatcac tgccatgcag 7680
atttgccagt tcgtcggtgg ctttctcctg gtctgggact acatcaacgt tccctgcttc 7740
aactctgaca agggcaagct gttctcctgg gctttcaact acgcctacgt cggatctgtc 7800
tttctcctgt tctgtcactt cttttaccag gacaacctgg ccaccaagaa atccgctaag 7860
gctggtaagc agctttagc 7879
<210> 47
<211> 8704
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pBY1
<400> 47
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atgatcacaa gtttgtacaa aaaagctgaa 7020
cgagaaacgt aaaatgatat aaatatcaat atattaaatt agattttgca taaaaaacag 7080
actacataat actgtaaaac acaacatatc cagtcatatt ggcggccgca ttaggcaccc 7140
caggctttac actttatgct tccggctcgt ataatgtgtg gattttgagt taggatccgt 7200
cgagattttc aggagctaag gaagctaaaa tggagaaaaa aatcactgga tataccaccg 7260
ttgatatatc ccaatggcat cgtaaagaac attttgaggc atttcagtca gttgctcaat 7320
gtacctataa ccagaccgtt cagctggata ttacggcctt tttaaagacc gtaaagaaaa 7380
ataagcacaa gttttatccg gcctttattc acattcttgc ccgcctgatg aatgctcatc 7440
cggaattccg tatggcaatg aaagacggtg agctggtgat atgggatagt gttcaccctt 7500
gttacaccgt tttccatgag caaactgaaa cgttttcatc gctctggagt gaataccacg 7560
acgatttccg gcagtttcta cacatatatt cgcaagatgt ggcgtgttac ggtgaaaacc 7620
tggcctattt ccctaaaggg tttattgaga atatgttttt cgtctcagcc aatccctggg 7680
tgagtttcac cagttttgat ttaaacgtgg ccaatatgga caacttcttc gcccccgttt 7740
tcaccatggg caaatattat acgcaaggcg acaaggtgct gatgccgctg gcgattcagg 7800
ttcatcatgc cgtttgtgat ggcttccatg tcggcagaat gcttaatgaa ttacaacagt 7860
actgcgatga gtggcagggc ggggcgtaaa cgcgtggatc cggcttacta aaagccagat 7920
aacagtatgc gtatttgcgc gctgattttt gcggtataag aatatatact gatatgtata 7980
cccgaagtat gtcaaaaaga ggtatgctat gaagcagcgt attacagtga cagttgacag 8040
cgacagctat cagttgctca aggcatatat gatgtcaata tctccggtct ggtaagcaca 8100
accatgcaga atgaagcccg tcgtctgcgt gccgaacgct ggaaagcgga aaatcaggaa 8160
gggatggctg aggtcgcccg gtttattgaa atgaacggct cttttgctga cgagaacagg 8220
ggctggtgaa atgcagttta aggtttacac ctataaaaga gagagccgtt atcgtctgtt 8280
tgtggatgta cagagtgata ttattgacac gcccgggcga cggatggtga tccccctggc 8340
cagtgcacgt ctgctgtcag ataaagtctc ccgtgaactt tacccggtgg tgcatatcgg 8400
ggatgaaagc tggcgcatga tgaccaccga tatggccagt gtgccggtct ccgttatcgg 8460
ggaagaagtg gctgatctca gccaccgcga aaatgacatc aaaaacgcca ttaacctgat 8520
gttctgggga atataaatgt caggctccct tatacacagc cagtctgcag gtcgaccata 8580
gtgactggat atgttgtgtt ttacagcatt atgtagtctg ttttttatgc aaaatctaat 8640
ttaatatatt gatatttata tcattttacg tttctcgttc agctttcttg tacaaagtgg 8700
tgat 8704
<210> 48
<211> 8145
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pBY2
<220>
<221> misc_feature
<222> (8028)..(8031)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (8063)..(8065)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (8067)..(8069)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (8071)..(8073)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (8075)..(8075)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (8126)..(8135)
<223> n is a, c, g, or t
<400> 48
cttgtacaaa gtggtgatgg ccgcaagtgt ggatggggaa gtgagtgccc ggttctgtgt 60
gcacaattgg caatccaaga tggatggatt caacacaggg atatagcgag ctacgtggtg 120
gtgcgaggat atagcaacgg atatttatgt ttgacacttg agaatgtacg atacaagcac 180
tgtccaagta caatactaaa catactgtac atactcatac tcgtacccgg gcaacggttt 240
cacttgagtg cagtggctag tgctcttact cgtacagtgt gcaatactgc gtatcatagt 300
ctttgatgta tatcgtattc attcatgtta gttgcgtacg agccggaagc ataaagtgta 360
aagcctgggg tgcctaatga gtgagctaac tcacattaat tgcgttgcgc tcactgcccg 420
ctttccagtc gggaaacctg tcgtgccagc tgcattaatg aatcggccaa cgcgcgggga 480
gaggcggttt gcgtattggg cgctcttccg cttcctcgct cactgactcg ctgcgctcgg 540
tcgttcggct gcggcgagcg gtatcagctc actcaaaggc ggtaatacgg ttatccacag 600
aatcagggga taacgcagga aagaacatgt gagcaaaagg ccagcaaaag gccaggaacc 660
gtaaaaaggc cgcgttgctg gcgtttttcc ataggctccg cccccctgac gagcatcaca 720
aaaatcgacg ctcaagtcag aggtggcgaa acccgacagg actataaaga taccaggcgt 780
ttccccctgg aagctccctc gtgcgctctc ctgttccgac cctgccgctt accggatacc 840
tgtccgcctt tctcccttcg ggaagcgtgg cgctttctca tagctcacgc tgtaggtatc 900
tcagttcggt gtaggtcgtt cgctccaagc tgggctgtgt gcacgaaccc cccgttcagc 960
ccgaccgctg cgccttatcc ggtaactatc gtcttgagtc caacccggta agacacgact 1020
tatcgccact ggcagcagcc actggtaaca ggattagcag agcgaggtat gtaggcggtg 1080
ctacagagtt cttgaagtgg tggcctaact acggctacac tagaaggaca gtatttggta 1140
tctgcgctct gctgaagcca gttaccttcg gaaaaagagt tggtagctct tgatccggca 1200
aacaaaccac cgctggtagc ggtggttttt ttgtttgcaa gcagcagatt acgcgcagaa 1260
aaaaaggatc tcaagaagat cctttgatct tttctacggg gtctgacgct cagtggaacg 1320
aaaactcacg ttaagggatt ttggtcatga gattatcaaa aaggatcttc acctagatcc 1380
ttttaaatta aaaatgaagt tttaaatcaa tctaaagtat atatgagtaa acttggtctg 1440
acagttacca atgcttaatc agtgaggcac ctatctcagc gatctgtcta tttcgttcat 1500
ccatagttgc ctgactcccc gtcgtgtaga taactacgat acgggagggc ttaccatctg 1560
gccccagtgc tgcaatgata ccgcgagacc cacgctcacc ggctccagat ttatcagcaa 1620
taaaccagcc agccggaagg gccgagcgca gaagtggtcc tgcaacttta tccgcctcca 1680
tccagtctat taattgttgc cgggaagcta gagtaagtag ttcgccagtt aatagtttgc 1740
gcaacgttgt tgccattgct acaggcatcg tggtgtcacg ctcgtcgttt ggtatggctt 1800
cattcagctc cggttcccaa cgatcaaggc gagttacatg atcccccatg ttgtgcaaaa 1860
aagcggttag ctccttcggt cctccgatcg ttgtcagaag taagttggcc gcagtgttat 1920
cactcatggt tatggcagca ctgcataatt ctcttactgt catgccatcc gtaagatgct 1980
tttctgtgac tggtgagtac tcaaccaagt cattctgaga atagtgtatg cggcgaccga 2040
gttgctcttg cccggcgtca atacgggata ataccgcgcc acatagcaga actttaaaag 2100
tgctcatcat tggaaaacgt tcttcggggc gaaaactctc aaggatctta ccgctgttga 2160
gatccagttc gatgtaaccc actcgtgcac ccaactgatc ttcagcatct tttactttca 2220
ccagcgtttc tgggtgagca aaaacaggaa ggcaaaatgc cgcaaaaaag ggaataaggg 2280
cgacacggaa atgttgaata ctcatactct tcctttttca atattattga agcatttatc 2340
agggttattg tctcatgagc ggatacatat ttgaatgtat ttagaaaaat aaacaaatag 2400
gggttccgcg cacatttccc cgaaaagtgc cacctgacgc gccctgtagc ggcgcattaa 2460
gcgcggcggg tgtggtggtt acgcgcagcg tgaccgctac acttgccagc gccctagcgc 2520
ccgctccttt cgctttcttc ccttcctttc tcgccacgtt cgccggcttt ccccgtcaag 2580
ctctaaatcg ggggctccct ttagggttcc gatttagtgc tttacggcac ctcgacccca 2640
aaaaacttga ttagggtgat ggttcacgta gtgggccatc gccctgatag acggtttttc 2700
gccctttgac gttggagtcc acgttcttta atagtggact cttgttccaa actggaacaa 2760
cactcaaccc tatctcggtc tattcttttg atttataagg gattttgccg atttcggcct 2820
attggttaaa aaatgagctg atttaacaaa aatttaacgc gaattttaac aaaatattaa 2880
cgcttacaat ttccattcgc cattcaggct gcgcaactgt tgggaagggc gatcggtgcg 2940
ggcctcttcg ctattacgcc agctggcgaa agggggatgt gctgcaaggc gattaagttg 3000
ggtaacgcca gggttttccc agtcacgacg ttgtaaaacg acggccagtg aattgtaata 3060
cgactcacta tagggcgaat tgggtaccgg gccccccctc gaggtcgatg gtgtcgataa 3120
gcttgatatc gaattcatgt cacacaaacc gatcttcgcc tcaaggaaac ctaattctac 3180
atccgagaga ctgccgagat ccagtctaca ctgattaatt ttcgggccaa taatttaaaa 3240
aaatcgtgtt atataatatt atatgtatta tatatataca tcatgatgat actgacagtc 3300
atgtcccatt gctaaataga cagactccat ctgccgcctc caactgatgt tctcaatatt 3360
taaggggtca tctcgcattg tttaataata aacagactcc atctaccgcc tccaaatgat 3420
gttctcaaaa tatattgtat gaacttattt ttattactta gtattattag acaacttact 3480
tgctttatga aaaacacttc ctatttagga aacaatttat aatggcagtt cgttcattta 3540
acaatttatg tagaataaat gttataaatg cgtatgggaa atcttaaata tggatagcat 3600
aaatgatatc tgcattgcct aattcgaaat caacagcaac gaaaaaaatc ccttgtacaa 3660
cataaatagt catcgagaaa tatcaactat caaagaacag ctattcacac gttactattg 3720
agattattat tggacgagaa tcacacactc aactgtcttt ctctcttcta gaaatacagg 3780
tacaagtatg tactattctc attgttcata cttctagtca tttcatccca catattcctt 3840
ggatttctct ccaatgaatg acattctatc ttgcaaattc aacaattata ataagatata 3900
ccaaagtagc ggtatagtgg caatcaaaaa gcttctctgg tgtgcttctc gtatttattt 3960
ttattctaat gatccattaa aggtatatat ttatttcttg ttatataatc cttttgttta 4020
ttacatgggc tggatacata aaggtatttt gatttaattt tttgcttaaa ttcaatcccc 4080
cctcgttcag tgtcaactgt aatggtagga aattaccata cttttgaaga agcaaaaaaa 4140
atgaaagaaa aaaaaaatcg tatttccagg ttagacgttc cgcagaatct agaatgcggt 4200
atgcggtaca ttgttcttcg aacgtaaaag ttgcgctccc tgagatattg tacatttttg 4260
cttttacaag tacaagtaca tcgtacaact atgtactact gttgatgcat ccacaacagt 4320
ttgttttgtt tttttttgtt tttttttttt ctaatgattc attaccgcta tgtataccta 4380
cttgtacttg tagtaagccg ggttattggc gttcaattaa tcatagactt atgaatctgc 4440
acggtgtgcg ctgcgagtta cttttagctt atgcatgcta cttgggtgta atattgggat 4500
ctgttcggaa atcaacggat gctcaatcga tttcgacagt aattaattaa gtcatacaca 4560
agtcagcttt cttcgagcct catataagta taagtagttc aacgtattag cactgtaccc 4620
agcatctccg tatcgagaaa cacaacaaca tgccccattg gacagatcat gcggatacac 4680
aggttgtgca gtatcataca tactcgatca gacaggtcgt ctgaccatca tacaagctga 4740
acaagcgctc catacttgca cgctctctat atacacagtt aaattacata tccatagtct 4800
aacctctaac agttaatctt ctggtaagcc tcccagccag ccttctggta tcgcttggcc 4860
tcctcaatag gatctcggtt ctggccgtac agacctcggc cgacaattat gatatccgtt 4920
ccggtagaca tgacatcctc aacagttcgg tactgctgtc cgagagcgtc tcccttgtcg 4980
tcaagaccca ccccgggggt cagaataagc cagtcctcag agtcgccctt aggtcggttc 5040
tgggcaatga agccaaccac aaactcgggg tcggatcggg caagctcaat ggtctgcttg 5100
gagtactcgc cagtggccag agagcccttg caagacagct cggccagcat gagcagacct 5160
ctggccagct tctcgttggg agaggggact aggaactcct tgtactggga gttctcgtag 5220
tcagagacgt cctccttctt ctgttcagag acagtttcct cggcaccagc tcgcaggcca 5280
gcaatgattc cggttccggg tacaccgtgg gcgttggtga tatcggacca ctcggcgatt 5340
cggtgacacc ggtactggtg cttgacagtg ttgccaatat ctgcgaactt tctgtcctcg 5400
aacaggaaga aaccgtgctt aagagcaagt tccttgaggg ggagcacagt gccggcgtag 5460
gtgaagtcgt caatgatgtc gatatgggtt ttgatcatgc acacataagg tccgacctta 5520
tcggcaagct caatgagctc cttggtggtg gtaacatcca gagaagcaca caggttggtt 5580
ttcttggctg ccacgagctt gagcactcga gcggcaaagg cggacttgtg gacgttagct 5640
cgagcttcgt aggagggcat tttggtggtg aagaggagac tgaaataaat ttagtctgca 5700
gaacttttta tcggaacctt atctggggca gtgaagtata tgttatggta atagttacga 5760
gttagttgaa cttatagata gactggacta tacggctatc ggtccaaatt agaaagaacg 5820
tcaatggctc tctgggcgtc gcctttgccg acaaaaatgt gatcatgatg aaagccagca 5880
atgacgttgc agctgatatt gttgtcggcc aaccgcgccg aaaacgcagc tgtcagaccc 5940
acagcctcca acgaagaatg tatcgtcaaa gtgatccaag cacactcata gttggagtcg 6000
tactccaaag gcggcaatga cgagtcagac agatactcgt cgacgtttaa acagtgtacg 6060
cagatctact atagaggaac atttaaattg ccccggagaa gacggccagg ccgcctagat 6120
gacaaattca acaactcaca gctgactttc tgccattgcc actagggggg ggccttttta 6180
tatggccaag ccaagctctc cacgtcggtt gggctgcacc caacaataaa tgggtagggt 6240
tgcaccaaca aagggatggg atggggggta gaagatacga ggataacggg gctcaatggc 6300
acaaataaga acgaatactg ccattaagac tcgtgatcca gcgactgaca ccattgcatc 6360
atctaagggc ctcaaaacta cctcggaact gctgcgctga tctggacacc acagaggttc 6420
cgagcacttt aggttgcacc aaatgtccca ccaggtgcag gcagaaaacg ctggaacagc 6480
gtgtacagtt tgtcttaaca aaaagtgagg gcgctgaggt cgagcagggt ggtgtgactt 6540
gttatagcct ttagagctgc gaaagcgcgt atggatttgg ctcatcaggc cagattgagg 6600
gtctgtggac acatgtcatg ttagtgtact tcaatcgccc cctggatata gccccgacaa 6660
taggccgtgg cctcattttt ttgccttccg cacatttcca ttgctcgata cccacacctt 6720
gcttctcctg cacttgccaa ccttaatact ggtttacatt gaccaacatc ttacaagcgg 6780
ggggcttgtc tagggtatat ataaacagtg gctctcccaa tcggttgcca gtctcttttt 6840
tcctttcttt ccccacagat tcgaaatcta aactacacat cacagaattc cgagccgtga 6900
gtatccacga caagatcagt gtcgagacga cgcgttttgt gtaatgacac aatccgaaag 6960
tcgctagcaa cacacactct ctacacaaac taacccagct ctggtaccat gatcacaagt 7020
ttgtacaaaa aagttggatt ttttttcgaa cacttaatgg aggtggtgaa tgaaatagtc 7080
tcaattgggc aggaagtttt acccaaagtt gattatgccc aactctggag tgatgccagt 7140
cactgtgagg tgctttactt gtccatcgca tttgtcatct tgaagttcac tcttggcccc 7200
cttggtccaa aaggtcagtc tcgtatgaag tttgttttca ccaattacaa ccttctcatg 7260
tccatttatt cgttgggatc attcctctca atggcatatg ccatgtacac catcggtgtt 7320
atgtctgaca actgcgagaa ggcttttgac aacaacgtct tcaggatcac cacgcagttg 7380
ttctatttga gcaagttcct ggagtatatt gactccttct atttgccact gatgggcaag 7440
cctctgacct ggttgcaatt cttccatcat ttgggggcac cgatggatat gtggctgttc 7500
tataattacc gaaatgaagc tgtttggatt tttgtgctgt tgaatggttt catccactgg 7560
atcatgtacg gttattattg gaccagattg atcaagctga agttccccat gccaaaatcc 7620
ctgattacat caatgcagat cattcaattc aatgttggtt tctacattgt ctggaagtac 7680
aggaacattc cctgttatcg ccaagatggg atgaggatgt ttggctggtt cttcaattac 7740
ttttatgttg gcacagtctt gtgtttgttc ttgaatttct atgtgcaaac gtatatcgtc 7800
aggaagcaca agggagccaa aaagattcag tgatatttcc tcctctgcgg tggcctcttt 7860
tgacctcccc ttgacaccta taatgtggag gtgtcgggct ctctccgtct caccagcact 7920
tgactctgca ggtgctcact tttatttttt acccatcttt gcttgttgac cattcacctc 7980
tcccacttcc acatagtcca ttctaactgt tgcagactgc ggtccatnnn ntccagagct 8040
cccaatgacc atacgcgaca ccnnntnnna nnncngccca ttgtgcacaa ttcatagtgg 8100
catcgttttg ccttgatacg tgtgcnnnnn nnnnnaccca acttt 8145
<210> 49
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer ig-s
<400> 49
caccatggct ctggccaacg acgctggcga g 31
<210> 50
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer ig-as
<400> 50
ctaaagctgc ttaccagcct tagcgg 26
<210> 51
<211> 7877
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pBY1-FAE
<400> 51
cttgtacaaa gtggtgatgg ccgcaagtgt ggatggggaa gtgagtgccc ggttctgtgt 60
gcacaattgg caatccaaga tggatggatt caacacaggg atatagcgag ctacgtggtg 120
gtgcgaggat atagcaacgg atatttatgt ttgacacttg agaatgtacg atacaagcac 180
tgtccaagta caatactaaa catactgtac atactcatac tcgtacccgg gcaacggttt 240
cacttgagtg cagtggctag tgctcttact cgtacagtgt gcaatactgc gtatcatagt 300
ctttgatgta tatcgtattc attcatgtta gttgcgtacg agccggaagc ataaagtgta 360
aagcctgggg tgcctaatga gtgagctaac tcacattaat tgcgttgcgc tcactgcccg 420
ctttccagtc gggaaacctg tcgtgccagc tgcattaatg aatcggccaa cgcgcgggga 480
gaggcggttt gcgtattggg cgctcttccg cttcctcgct cactgactcg ctgcgctcgg 540
tcgttcggct gcggcgagcg gtatcagctc actcaaaggc ggtaatacgg ttatccacag 600
aatcagggga taacgcagga aagaacatgt gagcaaaagg ccagcaaaag gccaggaacc 660
gtaaaaaggc cgcgttgctg gcgtttttcc ataggctccg cccccctgac gagcatcaca 720
aaaatcgacg ctcaagtcag aggtggcgaa acccgacagg actataaaga taccaggcgt 780
ttccccctgg aagctccctc gtgcgctctc ctgttccgac cctgccgctt accggatacc 840
tgtccgcctt tctcccttcg ggaagcgtgg cgctttctca tagctcacgc tgtaggtatc 900
tcagttcggt gtaggtcgtt cgctccaagc tgggctgtgt gcacgaaccc cccgttcagc 960
ccgaccgctg cgccttatcc ggtaactatc gtcttgagtc caacccggta agacacgact 1020
tatcgccact ggcagcagcc actggtaaca ggattagcag agcgaggtat gtaggcggtg 1080
ctacagagtt cttgaagtgg tggcctaact acggctacac tagaaggaca gtatttggta 1140
tctgcgctct gctgaagcca gttaccttcg gaaaaagagt tggtagctct tgatccggca 1200
aacaaaccac cgctggtagc ggtggttttt ttgtttgcaa gcagcagatt acgcgcagaa 1260
aaaaaggatc tcaagaagat cctttgatct tttctacggg gtctgacgct cagtggaacg 1320
aaaactcacg ttaagggatt ttggtcatga gattatcaaa aaggatcttc acctagatcc 1380
ttttaaatta aaaatgaagt tttaaatcaa tctaaagtat atatgagtaa acttggtctg 1440
acagttacca atgcttaatc agtgaggcac ctatctcagc gatctgtcta tttcgttcat 1500
ccatagttgc ctgactcccc gtcgtgtaga taactacgat acgggagggc ttaccatctg 1560
gccccagtgc tgcaatgata ccgcgagacc cacgctcacc ggctccagat ttatcagcaa 1620
taaaccagcc agccggaagg gccgagcgca gaagtggtcc tgcaacttta tccgcctcca 1680
tccagtctat taattgttgc cgggaagcta gagtaagtag ttcgccagtt aatagtttgc 1740
gcaacgttgt tgccattgct acaggcatcg tggtgtcacg ctcgtcgttt ggtatggctt 1800
cattcagctc cggttcccaa cgatcaaggc gagttacatg atcccccatg ttgtgcaaaa 1860
aagcggttag ctccttcggt cctccgatcg ttgtcagaag taagttggcc gcagtgttat 1920
cactcatggt tatggcagca ctgcataatt ctcttactgt catgccatcc gtaagatgct 1980
tttctgtgac tggtgagtac tcaaccaagt cattctgaga atagtgtatg cggcgaccga 2040
gttgctcttg cccggcgtca atacgggata ataccgcgcc acatagcaga actttaaaag 2100
tgctcatcat tggaaaacgt tcttcggggc gaaaactctc aaggatctta ccgctgttga 2160
gatccagttc gatgtaaccc actcgtgcac ccaactgatc ttcagcatct tttactttca 2220
ccagcgtttc tgggtgagca aaaacaggaa ggcaaaatgc cgcaaaaaag ggaataaggg 2280
cgacacggaa atgttgaata ctcatactct tcctttttca atattattga agcatttatc 2340
agggttattg tctcatgagc ggatacatat ttgaatgtat ttagaaaaat aaacaaatag 2400
gggttccgcg cacatttccc cgaaaagtgc cacctgacgc gccctgtagc ggcgcattaa 2460
gcgcggcggg tgtggtggtt acgcgcagcg tgaccgctac acttgccagc gccctagcgc 2520
ccgctccttt cgctttcttc ccttcctttc tcgccacgtt cgccggcttt ccccgtcaag 2580
ctctaaatcg ggggctccct ttagggttcc gatttagtgc tttacggcac ctcgacccca 2640
aaaaacttga ttagggtgat ggttcacgta gtgggccatc gccctgatag acggtttttc 2700
gccctttgac gttggagtcc acgttcttta atagtggact cttgttccaa actggaacaa 2760
cactcaaccc tatctcggtc tattcttttg atttataagg gattttgccg atttcggcct 2820
attggttaaa aaatgagctg atttaacaaa aatttaacgc gaattttaac aaaatattaa 2880
cgcttacaat ttccattcgc cattcaggct gcgcaactgt tgggaagggc gatcggtgcg 2940
ggcctcttcg ctattacgcc agctggcgaa agggggatgt gctgcaaggc gattaagttg 3000
ggtaacgcca gggttttccc agtcacgacg ttgtaaaacg acggccagtg aattgtaata 3060
cgactcacta tagggcgaat tgggtaccgg gccccccctc gaggtcgatg gtgtcgataa 3120
gcttgatatc gaattcatgt cacacaaacc gatcttcgcc tcaaggaaac ctaattctac 3180
atccgagaga ctgccgagat ccagtctaca ctgattaatt ttcgggccaa taatttaaaa 3240
aaatcgtgtt atataatatt atatgtatta tatatataca tcatgatgat actgacagtc 3300
atgtcccatt gctaaataga cagactccat ctgccgcctc caactgatgt tctcaatatt 3360
taaggggtca tctcgcattg tttaataata aacagactcc atctaccgcc tccaaatgat 3420
gttctcaaaa tatattgtat gaacttattt ttattactta gtattattag acaacttact 3480
tgctttatga aaaacacttc ctatttagga aacaatttat aatggcagtt cgttcattta 3540
acaatttatg tagaataaat gttataaatg cgtatgggaa atcttaaata tggatagcat 3600
aaatgatatc tgcattgcct aattcgaaat caacagcaac gaaaaaaatc ccttgtacaa 3660
cataaatagt catcgagaaa tatcaactat caaagaacag ctattcacac gttactattg 3720
agattattat tggacgagaa tcacacactc aactgtcttt ctctcttcta gaaatacagg 3780
tacaagtatg tactattctc attgttcata cttctagtca tttcatccca catattcctt 3840
ggatttctct ccaatgaatg acattctatc ttgcaaattc aacaattata ataagatata 3900
ccaaagtagc ggtatagtgg caatcaaaaa gcttctctgg tgtgcttctc gtatttattt 3960
ttattctaat gatccattaa aggtatatat ttatttcttg ttatataatc cttttgttta 4020
ttacatgggc tggatacata aaggtatttt gatttaattt tttgcttaaa ttcaatcccc 4080
cctcgttcag tgtcaactgt aatggtagga aattaccata cttttgaaga agcaaaaaaa 4140
atgaaagaaa aaaaaaatcg tatttccagg ttagacgttc cgcagaatct agaatgcggt 4200
atgcggtaca ttgttcttcg aacgtaaaag ttgcgctccc tgagatattg tacatttttg 4260
cttttacaag tacaagtaca tcgtacaact atgtactact gttgatgcat ccacaacagt 4320
ttgttttgtt tttttttgtt tttttttttt ctaatgattc attaccgcta tgtataccta 4380
cttgtacttg tagtaagccg ggttattggc gttcaattaa tcatagactt atgaatctgc 4440
acggtgtgcg ctgcgagtta cttttagctt atgcatgcta cttgggtgta atattgggat 4500
ctgttcggaa atcaacggat gctcaatcga tttcgacagt aattaattaa gtcatacaca 4560
agtcagcttt cttcgagcct catataagta taagtagttc aacgtattag cactgtaccc 4620
agcatctccg tatcgagaaa cacaacaaca tgccccattg gacagatcat gcggatacac 4680
aggttgtgca gtatcataca tactcgatca gacaggtcgt ctgaccatca tacaagctga 4740
acaagcgctc catacttgca cgctctctat atacacagtt aaattacata tccatagtct 4800
aacctctaac agttaatctt ctggtaagcc tcccagccag ccttctggta tcgcttggcc 4860
tcctcaatag gatctcggtt ctggccgtac agacctcggc cgacaattat gatatccgtt 4920
ccggtagaca tgacatcctc aacagttcgg tactgctgtc cgagagcgtc tcccttgtcg 4980
tcaagaccca ccccgggggt cagaataagc cagtcctcag agtcgccctt aggtcggttc 5040
tgggcaatga agccaaccac aaactcgggg tcggatcggg caagctcaat ggtctgcttg 5100
gagtactcgc cagtggccag agagcccttg caagacagct cggccagcat gagcagacct 5160
ctggccagct tctcgttggg agaggggact aggaactcct tgtactggga gttctcgtag 5220
tcagagacgt cctccttctt ctgttcagag acagtttcct cggcaccagc tcgcaggcca 5280
gcaatgattc cggttccggg tacaccgtgg gcgttggtga tatcggacca ctcggcgatt 5340
cggtgacacc ggtactggtg cttgacagtg ttgccaatat ctgcgaactt tctgtcctcg 5400
aacaggaaga aaccgtgctt aagagcaagt tccttgaggg ggagcacagt gccggcgtag 5460
gtgaagtcgt caatgatgtc gatatgggtt ttgatcatgc acacataagg tccgacctta 5520
tcggcaagct caatgagctc cttggtggtg gtaacatcca gagaagcaca caggttggtt 5580
ttcttggctg ccacgagctt gagcactcga gcggcaaagg cggacttgtg gacgttagct 5640
cgagcttcgt aggagggcat tttggtggtg aagaggagac tgaaataaat ttagtctgca 5700
gaacttttta tcggaacctt atctggggca gtgaagtata tgttatggta atagttacga 5760
gttagttgaa cttatagata gactggacta tacggctatc ggtccaaatt agaaagaacg 5820
tcaatggctc tctgggcgtc gcctttgccg acaaaaatgt gatcatgatg aaagccagca 5880
atgacgttgc agctgatatt gttgtcggcc aaccgcgccg aaaacgcagc tgtcagaccc 5940
acagcctcca acgaagaatg tatcgtcaaa gtgatccaag cacactcata gttggagtcg 6000
tactccaaag gcggcaatga cgagtcagac agatactcgt cgacgtttaa acagtgtacg 6060
cagatctact atagaggaac atttaaattg ccccggagaa gacggccagg ccgcctagat 6120
gacaaattca acaactcaca gctgactttc tgccattgcc actagggggg ggccttttta 6180
tatggccaag ccaagctctc cacgtcggtt gggctgcacc caacaataaa tgggtagggt 6240
tgcaccaaca aagggatggg atggggggta gaagatacga ggataacggg gctcaatggc 6300
acaaataaga acgaatactg ccattaagac tcgtgatcca gcgactgaca ccattgcatc 6360
atctaagggc ctcaaaacta cctcggaact gctgcgctga tctggacacc acagaggttc 6420
cgagcacttt aggttgcacc aaatgtccca ccaggtgcag gcagaaaacg ctggaacagc 6480
gtgtacagtt tgtcttaaca aaaagtgagg gcgctgaggt cgagcagggt ggtgtgactt 6540
gttatagcct ttagagctgc gaaagcgcgt atggatttgg ctcatcaggc cagattgagg 6600
gtctgtggac acatgtcatg ttagtgtact tcaatcgccc cctggatata gccccgacaa 6660
taggccgtgg cctcattttt ttgccttccg cacatttcca ttgctcgata cccacacctt 6720
gcttctcctg cacttgccaa ccttaatact ggtttacatt gaccaacatc ttacaagcgg 6780
ggggcttgtc tagggtatat ataaacagtg gctctcccaa tcggttgcca gtctcttttt 6840
tcctttcttt ccccacagat tcgaaatcta aactacacat cacagaattc cgagccgtga 6900
gtatccacga caagatcagt gtcgagacga cgcgttttgt gtaatgacac aatccgaaag 6960
tcgctagcaa cacacactct ctacacaaac taacccagct ctggtaccat gatcacaagt 7020
ttgtacaaaa aagcaggctc cgcggccgcc cccttcacca tggctctggc caacgacgct 7080
ggcgagcgaa tctgggctgc cgtcaccgat cccgaaatcc tcattggcac cttctcctac 7140
ctgctcctga agcctctcct gcgaaactct ggtctcgtgg acgagaagaa aggagcctac 7200
cgaacctcca tgatctggta caacgtcctc ctggctctct tctctgccct gtccttctac 7260
gtgactgcca ccgctctcgg ctgggactac ggtactggag cctggctgcg aagacagacc 7320
ggtgatactc cccagcctct ctttcagtgt ccctctcctg tctgggactc caagctgttc 7380
acctggactg ccaaggcctt ctactattct aagtacgtgg agtacctcga caccgcttgg 7440
ctggtcctca agggcaagcg agtgtccttt ctgcaggcct tccatcactt tggagctccc 7500
tgggacgtct acctcggcat tcgactgcac aacgagggtg tgtggatctt catgttcttt 7560
aactcgttca ttcacaccat catgtacacc tactatggac tgactgccgc tggctacaag 7620
ttcaaggcca agcctctgat cactgccatg cagatttgcc agttcgtcgg tggctttctc 7680
ctggtctggg actacatcaa cgttccctgc ttcaactctg acaagggcaa gctgttctcc 7740
tgggctttca actacgccta cgtcggatct gtctttctcc tgttctgtca cttcttttac 7800
caggacaacc tggccaccaa gaaatccgct aaggctggta agcagcttta gaagggtggg 7860
cgcgccgacc cagcttt 7877
<210> 52
<211> 7771
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZUFmEgD9e
<400> 52
catggaggtg gtgaatgaaa tagtctcaat tgggcaggaa gttttaccca accagttgat 60
tatgcccaac tctggagtga tgccagtcac tgtgaggtgc tttacttgtc catcgcattt 120
gtcatcttga agttcactct tggccccctt ggtccaaaag gtcagtctcg tatgaagttt 180
gttttcacca attacaacct tctcatgtcc atttattcgt tgggatcatt cctctcaatg 240
gcatatgcca tgtacaccat cggtgttatg tctgacaact gcgagaaggc ttttgacaac 300
aacgtcttca ggatcaccac gcagttgttc tatttgagca agttcctgga gtatattgac 360
tccttctatt tgccactgat gggcaagcct ctgacctggt tgcaattctt ccatcatttg 420
ggggcaccga tggatatgtg gctgttctat aattaccgaa atgaagctgt ttggattttt 480
gtgctgttga atggtttcat ccactggatc atgtacggtt attattggac cagattgatc 540
aagctgaagt tccccatgcc aaaatccctg attacatcaa tgcagatcat tcaattcaat 600
gttggtttct acattgtctg gaagtacagg aacattccct gttatcgcca agatgggatg 660
aggatgtttg gctggttctt caattacttt tatgttggca cagtcttgtg tttgttcttg 720
aatttctatg tgcaaacgta tatcgtcagg aagcacaagg gagccaaaaa gattcagtga 780
gcggccgcaa gtgtggatgg ggaagtgagt gcccggttct gtgtgcacaa ttggcaatcc 840
aagatggatg gattcaacac agggatatag cgagctacgt ggtggtgcga ggatatagca 900
acggatattt atgtttgaca cttgagaatg tacgatacaa gcactgtcca agtacaatac 960
taaacatact gtacatactc atactcgtac ccgggcaacg gtttcacttg agtgcagtgg 1020
ctagtgctct tactcgtaca gtgtgcaata ctgcgtatca tagtctttga tgtatatcgt 1080
attcattcat gttagttgcg tacgagccgg aagcataaag tgtaaagcct ggggtgccta 1140
atgagtgagc taactcacat taattgcgtt gcgctcactg cccgctttcc agtcgggaaa 1200
cctgtcgtgc cagctgcatt aatgaatcgg ccaacgcgcg gggagaggcg gtttgcgtat 1260
tgggcgctct tccgcttcct cgctcactga ctcgctgcgc tcggtcgttc ggctgcggcg 1320
agcggtatca gctcactcaa aggcggtaat acggttatcc acagaatcag gggataacgc 1380
aggaaagaac atgtgagcaa aaggccagca aaaggccagg aaccgtaaaa aggccgcgtt 1440
gctggcgttt ttccataggc tccgcccccc tgacgagcat cacaaaaatc gacgctcaag 1500
tcagaggtgg cgaaacccga caggactata aagataccag gcgtttcccc ctggaagctc 1560
cctcgtgcgc tctcctgttc cgaccctgcc gcttaccgga tacctgtccg cctttctccc 1620
ttcgggaagc gtggcgcttt ctcatagctc acgctgtagg tatctcagtt cggtgtaggt 1680
cgttcgctcc aagctgggct gtgtgcacga accccccgtt cagcccgacc gctgcgcctt 1740
atccggtaac tatcgtcttg agtccaaccc ggtaagacac gacttatcgc cactggcagc 1800
agccactggt aacaggatta gcagagcgag gtatgtaggc ggtgctacag agttcttgaa 1860
gtggtggcct aactacggct acactagaag gacagtattt ggtatctgcg ctctgctgaa 1920
gccagttacc ttcggaaaaa gagttggtag ctcttgatcc ggcaaacaaa ccaccgctgg 1980
tagcggtggt ttttttgttt gcaagcagca gattacgcgc agaaaaaaag gatctcaaga 2040
agatcctttg atcttttcta cggggtctga cgctcagtgg aacgaaaact cacgttaagg 2100
gattttggtc atgagattat caaaaaggat cttcacctag atccttttaa attaaaaatg 2160
aagttttaaa tcaatctaaa gtatatatga gtaaacttgg tctgacagtt accaatgctt 2220
aatcagtgag gcacctatct cagcgatctg tctatttcgt tcatccatag ttgcctgact 2280
ccccgtcgtg tagataacta cgatacggga gggcttacca tctggcccca gtgctgcaat 2340
gataccgcga gacccacgct caccggctcc agatttatca gcaataaacc agccagccgg 2400
aagggccgag cgcagaagtg gtcctgcaac tttatccgcc tccatccagt ctattaattg 2460
ttgccgggaa gctagagtaa gtagttcgcc agttaatagt ttgcgcaacg ttgttgccat 2520
tgctacaggc atcgtggtgt cacgctcgtc gtttggtatg gcttcattca gctccggttc 2580
ccaacgatca aggcgagtta catgatcccc catgttgtgc aaaaaagcgg ttagctcctt 2640
cggtcctccg atcgttgtca gaagtaagtt ggccgcagtg ttatcactca tggttatggc 2700
agcactgcat aattctctta ctgtcatgcc atccgtaaga tgcttttctg tgactggtga 2760
gtactcaacc aagtcattct gagaatagtg tatgcggcga ccgagttgct cttgcccggc 2820
gtcaatacgg gataataccg cgccacatag cagaacttta aaagtgctca tcattggaaa 2880
acgttcttcg gggcgaaaac tctcaaggat cttaccgctg ttgagatcca gttcgatgta 2940
acccactcgt gcacccaact gatcttcagc atcttttact ttcaccagcg tttctgggtg 3000
agcaaaaaca ggaaggcaaa atgccgcaaa aaagggaata agggcgacac ggaaatgttg 3060
aatactcata ctcttccttt ttcaatatta ttgaagcatt tatcagggtt attgtctcat 3120
gagcggatac atatttgaat gtatttagaa aaataaacaa ataggggttc cgcgcacatt 3180
tccccgaaaa gtgccacctg acgcgccctg tagcggcgca ttaagcgcgg cgggtgtggt 3240
ggttacgcgc agcgtgaccg ctacacttgc cagcgcccta gcgcccgctc ctttcgcttt 3300
cttcccttcc tttctcgcca cgttcgccgg ctttccccgt caagctctaa atcgggggct 3360
ccctttaggg ttccgattta gtgctttacg gcacctcgac cccaaaaaac ttgattaggg 3420
tgatggttca cgtagtgggc catcgccctg atagacggtt tttcgccctt tgacgttgga 3480
gtccacgttc tttaatagtg gactcttgtt ccaaactgga acaacactca accctatctc 3540
ggtctattct tttgatttat aagggatttt gccgatttcg gcctattggt taaaaaatga 3600
gctgatttaa caaaaattta acgcgaattt taacaaaata ttaacgctta caatttccat 3660
tcgccattca ggctgcgcaa ctgttgggaa gggcgatcgg tgcgggcctc ttcgctatta 3720
cgccagctgg cgaaaggggg atgtgctgca aggcgattaa gttgggtaac gccagggttt 3780
tcccagtcac gacgttgtaa aacgacggcc agtgaattgt aatacgactc actatagggc 3840
gaattgggta ccgggccccc cctcgaggtc gatggtgtcg ataagcttga tatcgaattc 3900
atgtcacaca aaccgatctt cgcctcaagg aaacctaatt ctacatccga gagactgccg 3960
agatccagtc tacactgatt aattttcggg ccaataattt aaaaaaatcg tgttatataa 4020
tattatatgt attatatata tacatcatga tgatactgac agtcatgtcc cattgctaaa 4080
tagacagact ccatctgccg cctccaactg atgttctcaa tatttaaggg gtcatctcgc 4140
attgtttaat aataaacaga ctccatctac cgcctccaaa tgatgttctc aaaatatatt 4200
gtatgaactt atttttatta cttagtatta ttagacaact tacttgcttt atgaaaaaca 4260
cttcctattt aggaaacaat ttataatggc agttcgttca tttaacaatt tatgtagaat 4320
aaatgttata aatgcgtatg ggaaatctta aatatggata gcataaatga tatctgcatt 4380
gcctaattcg aaatcaacag caacgaaaaa aatcccttgt acaacataaa tagtcatcga 4440
gaaatatcaa ctatcaaaga acagctattc acacgttact attgagatta ttattggacg 4500
agaatcacac actcaactgt ctttctctct tctagaaata caggtacaag tatgtactat 4560
tctcattgtt catacttcta gtcatttcat cccacatatt ccttggattt ctctccaatg 4620
aatgacattc tatcttgcaa attcaacaat tataataaga tataccaaag tagcggtata 4680
gtggcaatca aaaagcttct ctggtgtgct tctcgtattt atttttattc taatgatcca 4740
ttaaaggtat atatttattt cttgttatat aatccttttg tttattacat gggctggata 4800
cataaaggta ttttgattta attttttgct taaattcaat cccccctcgt tcagtgtcaa 4860
ctgtaatggt aggaaattac catacttttg aagaagcaaa aaaaatgaaa gaaaaaaaaa 4920
atcgtatttc caggttagac gttccgcaga atctagaatg cggtatgcgg tacattgttc 4980
ttcgaacgta aaagttgcgc tccctgagat attgtacatt tttgctttta caagtacaag 5040
tacatcgtac aactatgtac tactgttgat gcatccacaa cagtttgttt tgtttttttt 5100
tgtttttttt ttttctaatg attcattacc gctatgtata cctacttgta cttgtagtaa 5160
gccgggttat tggcgttcaa ttaatcatag acttatgaat ctgcacggtg tgcgctgcga 5220
gttactttta gcttatgcat gctacttggg tgtaatattg ggatctgttc ggaaatcaac 5280
ggatgctcaa tcgatttcga cagtaattaa ttaagtcata cacaagtcag ctttcttcga 5340
gcctcatata agtataagta gttcaacgta ttagcactgt acccagcatc tccgtatcga 5400
gaaacacaac aacatgcccc attggacaga tcatgcggat acacaggttg tgcagtatca 5460
tacatactcg atcagacagg tcgtctgacc atcatacaag ctgaacaagc gctccatact 5520
tgcacgctct ctatatacac agttaaatta catatccata gtctaacctc taacagttaa 5580
tcttctggta agcctcccag ccagccttct ggtatcgctt ggcctcctca ataggatctc 5640
ggttctggcc gtacagacct cggccgacaa ttatgatatc cgttccggta gacatgacat 5700
cctcaacagt tcggtactgc tgtccgagag cgtctccctt gtcgtcaaga cccaccccgg 5760
gggtcagaat aagccagtcc tcagagtcgc ccttaggtcg gttctgggca atgaagccaa 5820
ccacaaactc ggggtcggat cgggcaagct caatggtctg cttggagtac tcgccagtgg 5880
ccagagagcc cttgcaagac agctcggcca gcatgagcag acctctggcc agcttctcgt 5940
tgggagaggg gactaggaac tccttgtact gggagttctc gtagtcagag acgtcctcct 6000
tcttctgttc agagacagtt tcctcggcac cagctcgcag gccagcaatg attccggttc 6060
cgggtacacc gtgggcgttg gtgatatcgg accactcggc gattcggtga caccggtact 6120
ggtgcttgac agtgttgcca atatctgcga actttctgtc ctcgaacagg aagaaaccgt 6180
gcttaagagc aagttccttg agggggagca cagtgccggc gtaggtgaag tcgtcaatga 6240
tgtcgatatg ggttttgatc atgcacacat aaggtccgac cttatcggca agctcaatga 6300
gctccttggt ggtggtaaca tccagagaag cacacaggtt ggttttcttg gctgccacga 6360
gcttgagcac tcgagcggca aaggcggact tgtggacgtt agctcgagct tcgtaggagg 6420
gcattttggt ggtgaagagg agactgaaat aaatttagtc tgcagaactt tttatcggaa 6480
ccttatctgg ggcagtgaag tatatgttat ggtaatagtt acgagttagt tgaacttata 6540
gatagactgg actatacggc tatcggtcca aattagaaag aacgtcaatg gctctctggg 6600
cgtcgccttt gccgacaaaa atgtgatcat gatgaaagcc agcaatgacg ttgcagctga 6660
tattgttgtc ggccaaccgc gccgaaaacg cagctgtcag acccacagcc tccaacgaag 6720
aatgtatcgt caaagtgatc caagcacact catagttgga gtcgtactcc aaaggcggca 6780
atgacgagtc agacagatac tcgtcgacgt ttaaacagtg tacgcagatc tactatagag 6840
gaacatttaa attgccccgg agaagacggc caggccgcct agatgacaaa ttcaacaact 6900
cacagctgac tttctgccat tgccactagg ggggggcctt tttatatggc caagccaagc 6960
tctccacgtc ggttgggctg cacccaacaa taaatgggta gggttgcacc aacaaaggga 7020
tgggatgggg ggtagaagat acgaggataa cggggctcaa tggcacaaat aagaacgaat 7080
actgccatta agactcgtga tccagcgact gacaccattg catcatctaa gggcctcaaa 7140
actacctcgg aactgctgcg ctgatctgga caccacagag gttccgagca ctttaggttg 7200
caccaaatgt cccaccaggt gcaggcagaa aacgctggaa cagcgtgtac agtttgtctt 7260
aacaaaaagt gagggcgctg aggtcgagca gggtggtgtg acttgttata gcctttagag 7320
ctgcgaaagc gcgtatggat ttggctcatc aggccagatt gagggtctgt ggacacatgt 7380
catgttagtg tacttcaatc gccccctgga tatagccccg acaataggcc gtggcctcat 7440
ttttttgcct tccgcacatt tccattgctc gatacccaca ccttgcttct cctgcacttg 7500
ccaaccttaa tactggttta cattgaccaa catcttacaa gcggggggct tgtctagggt 7560
atatataaac agtggctctc ccaatcggtt gccagtctct tttttccttt ctttccccac 7620
agattcgaaa tctaaactac acatcacaga attccgagcc gtgagtatcc acgacaagat 7680
cagtgtcgag acgacgcgtt ttgtgtaatg acacaatccg aaagtcgcta gcaacacaca 7740
ctctctacac aaactaaccc agctctggta c 7771
<210> 53
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZUFmEgD9eS
<400> 53
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acctctccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
acctggttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgatcaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 54
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pY120
<400> 54
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtgg tgaatgaaat agtctcaatt 7020
gggcaggaag ttttacccaa agttgattat gcccaactct ggagtgatgc cagtcactgt 7080
gaggtgcttt acttgtccat cgcatttgtc atcttgaagt tcactcttgg cccccttggt 7140
ccaaaaggtc agtctcgtat gaagtttgtt ttcaccaatt acaaccttct catgtccatt 7200
tattcgttgg gatcattcct ctcaatggca tatgccatgt acaccatcgg tgttatgtct 7260
gacaactgcg agaaggcttt tgacaacaac gtcttcagga tcaccacgca gttgttctat 7320
ttgagcaagt tcctggagta tattgactcc ttctatttgc cactgatggg caagcctctg 7380
acctggttgc aattcttcca tcatttgggg gcaccgatgg atatgtggct gttctataat 7440
taccgaaatg aagctgtttg gatttttgtg ctgttgaatg gtttcatcca ctggatcatg 7500
tacggttatt attggaccag attgatcaag ctgaagttcc ccatgccaaa atccctgatt 7560
acatcaatgc agatcattca attcaatgtt ggtttctaca ttgtctggaa gtacaggaac 7620
attccctgtt atcgccaaga tgggatgagg atgtttggct ggttcttcaa ttacttttat 7680
gttggcacag tcttgtgttt gttcttgaat ttctatgtgc aaacgtatat cgtcaggaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 55
<211> 7085
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR72
<400> 55
gtacggatcc gtcgacggcg cgcccgatca tccggatata gttcctcctt tcagcaaaaa 60
acccctcaag acccgtttag aggccccaag gggttatgct agttattgct cagcggtggc 120
agcagccaac tcagcttcct ttcgggcttt gttagcagcc ggatcgatcc aagctgtacc 180
tcactattcc tttgccctcg gacgagtgct ggggcgtcgg tttccactat cggcgagtac 240
ttctacacag ccatcggtcc agacggccgc gcttctgcgg gcgatttgtg tacgcccgac 300
agtcccggct ccggatcgga cgattgcgtc gcatcgaccc tgcgcccaag ctgcatcatc 360
gaaattgccg tcaaccaagc tctgatagag ttggtcaaga ccaatgcgga gcatatacgc 420
ccggagccgc ggcgatcctg caagctccgg atgcctccgc tcgaagtagc gcgtctgctg 480
ctccatacaa gccaaccacg gcctccagaa gaagatgttg gcgacctcgt attgggaatc 540
cccgaacatc gcctcgctcc agtcaatgac cgctgttatg cggccattgt ccgtcaggac 600
attgttggag ccgaaatccg cgtgcacgag gtgccggact tcggggcagt cctcggccca 660
aagcatcagc tcatcgagag cctgcgcgac ggacgcactg acggtgtcgt ccatcacagt 720
ttgccagtga tacacatggg gatcagcaat cgcgcatatg aaatcacgcc atgtagtgta 780
ttgaccgatt ccttgcggtc cgaatgggcc gaacccgctc gtctggctaa gatcggccgc 840
agcgatcgca tccatagcct ccgcgaccgg ctgcagaaca gcgggcagtt cggtttcagg 900
caggtcttgc aacgtgacac cctgtgcacg gcgggagatg caataggtca ggctctcgct 960
gaattcccca atgtcaagca cttccggaat cgggagcgcg gccgatgcaa agtgccgata 1020
aacataacga tctttgtaga aaccatcggc gcagctattt acccgcagga catatccacg 1080
ccctcctaca tcgaagctga aagcacgaga ttcttcgccc tccgagagct gcatcaggtc 1140
ggagacgctg tcgaactttt cgatcagaaa cttctcgaca gacgtcgcgg tgagttcagg 1200
cttttccatg ggtatatctc cttcttaaag ttaaacaaaa ttatttctag agggaaaccg 1260
ttgtggtctc cctatagtga gtcgtattaa tttcgcggga tcgagatcga tccaattcca 1320
atcccacaaa aatctgagct taacagcaca gttgctcctc tcagagcaga atcgggtatt 1380
caacaccctc atatcaacta ctacgttgtg tataacggtc cacatgccgg tatatacgat 1440
gactggggtt gtacaaaggc ggcaacaaac ggcgttcccg gagttgcaca caagaaattt 1500
gccactatta cagaggcaag agcagcagct gacgcgtaca caacaagtca gcaaacagac 1560
aggttgaact tcatccccaa aggagaagct caactcaagc ccaagagctt tgctaaggcc 1620
ctaacaagcc caccaaagca aaaagcccac tggctcacgc taggaaccaa aaggcccagc 1680
agtgatccag ccccaaaaga gatctccttt gccccggaga ttacaatgga cgatttcctc 1740
tatctttacg atctaggaag gaagttcgaa ggtgaaggtg acgacactat gttcaccact 1800
gataatgaga aggttagcct cttcaatttc agaaagaatg ctgacccaca gatggttaga 1860
gaggcctacg cagcaggtct catcaagacg atctacccga gtaacaatct ccaggagatc 1920
aaataccttc ccaagaaggt taaagatgca gtcaaaagat tcaggactaa ttgcatcaag 1980
aacacagaga aagacatatt tctcaagatc agaagtacta ttccagtatg gacgattcaa 2040
ggcttgcttc ataaaccaag gcaagtaata gagattggag tctctaaaaa ggtagttcct 2100
actgaatcta aggccatgca tggagtctaa gattcaaatc gaggatctaa cagaactcgc 2160
cgtgaagact ggcgaacagt tcatacagag tcttttacga ctcaatgaca agaagaaaat 2220
cttcgtcaac atggtggagc acgacactct ggtctactcc aaaaatgtca aagatacagt 2280
ctcagaagac caaagggcta ttgagacttt tcaacaaagg ataatttcgg gaaacctcct 2340
cggattccat tgcccagcta tctgtcactt catcgaaagg acagtagaaa aggaaggtgg 2400
ctcctacaaa tgccatcatt gcgataaagg aaaggctatc attcaagatg cctctgccga 2460
cagtggtccc aaagatggac ccccacccac gaggagcatc gtggaaaaag aagacgttcc 2520
aaccacgtct tcaaagcaag tggattgatg tgacatctcc actgacgtaa gggatgacgc 2580
acaatcccac tatccttcgc aagacccttc ctctatataa ggaagttcat ttcatttgga 2640
gaggacacgc tcgagctcat ttctctatta cttcagccat aacaaaagaa ctcttttctc 2700
ttcttattaa accatgaaaa agcctgaact caccgcgacg tctgtcgaga agtttctgat 2760
cgaaaagttc gacagcgtct ccgacctgat gcagctctcg gagggcgaag aatctcgtgc 2820
tttcagcttc gatgtaggag ggcgtggata tgtcctgcgg gtaaatagct gcgccgatgg 2880
tttctacaaa gatcgttatg tttatcggca ctttgcatcg gccgcgctcc cgattccgga 2940
agtgcttgac attggggaat tcagcgagag cctgacctat tgcatctccc gccgtgcaca 3000
gggtgtcacg ttgcaagacc tgcctgaaac cgaactgccc gctgttctgc agccggtcgc 3060
ggaggccatg gatgcgatcg ctgcggccga tcttagccag acgagcgggt tcggcccatt 3120
cggaccgcaa ggaatcggtc aatacactac atggcgtgat ttcatatgcg cgattgctga 3180
tccccatgtg tatcactggc aaactgtgat ggacgacacc gtcagtgcgt ccgtcgcgca 3240
ggctctcgat gagctgatgc tttgggccga ggactgcccc gaagtccggc acctcgtgca 3300
cgcggatttc ggctccaaca atgtcctgac ggacaatggc cgcataacag cggtcattga 3360
ctggagcgag gcgatgttcg gggattccca atacgaggtc gccaacatct tcttctggag 3420
gccgtggttg gcttgtatgg agcagcagac gcgctacttc gagcggaggc atccggagct 3480
tgcaggatcg ccgcggctcc gggcgtatat gctccgcatt ggtcttgacc aactctatca 3540
gagcttggtt gacggcaatt tcgatgatgc agcttgggcg cagggtcgat gcgacgcaat 3600
cgtccgatcc ggagccggga ctgtcgggcg tacacaaatc gcccgcagaa gcgcggccgt 3660
ctggaccgat ggctgtgtag aagtactcgc cgatagtgga aaccgacgcc ccagcactcg 3720
tccgagggca aaggaatagt gaggtaccta aagaaggagt gcgtcgaagc agatcgttca 3780
aacatttggc aataaagttt cttaagattg aatcctgttg ccggtcttgc gatgattatc 3840
atataatttc tgttgaatta cgttaagcat gtaataatta acatgtaatg catgacgtta 3900
tttatgagat gggtttttat gattagagtc ccgcaattat acatttaata cgcgatagaa 3960
aacaaaatat agcgcgcaaa ctaggataaa ttatcgcgcg cggtgtcatc tatgttacta 4020
gatcgatgtc gaatcgatca acctgcatta atgaatcggc caacgcgcgg ggagaggcgg 4080
tttgcgtatt gggcgctctt ccgcttcctc gctcactgac tcgctgcgct cggtcgttcg 4140
gctgcggcga gcggtatcag ctcactcaaa ggcggtaata cggttatcca cagaatcagg 4200
ggataacgca ggaaagaaca tgtgagcaaa aggccagcaa aaggccagga accgtaaaaa 4260
ggccgcgttg ctggcgtttt tccataggct ccgcccccct gacgagcatc acaaaaatcg 4320
acgctcaagt cagaggtggc gaaacccgac aggactataa agataccagg cgtttccccc 4380
tggaagctcc ctcgtgcgct ctcctgttcc gaccctgccg cttaccggat acctgtccgc 4440
ctttctccct tcgggaagcg tggcgctttc tcaatgctca cgctgtaggt atctcagttc 4500
ggtgtaggtc gttcgctcca agctgggctg tgtgcacgaa ccccccgttc agcccgaccg 4560
ctgcgcctta tccggtaact atcgtcttga gtccaacccg gtaagacacg acttatcgcc 4620
actggcagca gccactggta acaggattag cagagcgagg tatgtaggcg gtgctacaga 4680
gttcttgaag tggtggccta actacggcta cactagaagg acagtatttg gtatctgcgc 4740
tctgctgaag ccagttacct tcggaaaaag agttggtagc tcttgatccg gcaaacaaac 4800
caccgctggt agcggtggtt tttttgtttg caagcagcag attacgcgca gaaaaaaagg 4860
atctcaagaa gatcctttga tcttttctac ggggtctgac gctcagtgga acgaaaactc 4920
acgttaaggg attttggtca tgacattaac ctataaaaat aggcgtatca cgaggccctt 4980
tcgtctcgcg cgtttcggtg atgacggtga aaacctctga cacatgcagc tcccggagac 5040
ggtcacagct tgtctgtaag cggatgccgg gagcagacaa gcccgtcagg gcgcgtcagc 5100
gggtgttggc gggtgtcggg gctggcttaa ctatgcggca tcagagcaga ttgtactgag 5160
agtgcaccat atggacatat tgtcgttaga acgcggctac aattaataca taaccttatg 5220
tatcatacac atacgattta ggtgacacta tagaacggcg cgccaagctt gttgaaacat 5280
ccctgaagtg tctcatttta ttttatttat tctttgctga taaaaaaata aaataaaaga 5340
agctaagcac acggtcaacc attgctctac tgctaaaagg gttatgtgta gtgttttact 5400
gcataaatta tgcagcaaac aagacaactc aaattaaaaa atttcctttg cttgtttttt 5460
tgttgtctct gacttgactt tcttgtggaa gttggttgta taaggattgg gacaccattg 5520
tccttcttaa tttaatttta ttctttgctg ataaaaaaaa aaatttcata tagtgttaaa 5580
taataatttg ttaaataacc aaaaagtcaa atatgtttac tctcgtttaa ataattgaga 5640
ttcgtccagc aaggctaaac gattgtatag atttatgaca atatttactt ttttatagat 5700
aaatgttata ttataataaa tttatataca tatattatat gttatttatt attattttaa 5760
atccttcaat attttatcaa accaactcat aatttttttt ttatctgtaa gaagcaataa 5820
aattaaatag acccacttta aggatgatcc aacctttata cagagtaaga gagttcaaat 5880
agtacccttt catatacata tcaactaaaa tattagaaat atcatggatc aaaccttata 5940
aagacattaa ataagtggat aagtataata tataaatggg tagtatataa tatataaatg 6000
gatacaaact tctctcttta taattgttat gtctccttaa catcctaata taatacataa 6060
gtgggtaata tataatatat aaatggagac aaacttcttc cattataatt gttatgtctt 6120
cttaacactt atgtctcgtt cacaatgcta aggttagaat tgtttagaaa gtcttatagt 6180
acacatttgt ttttgtacta tttgaagcat tccataagcc gtcacgattc agatgattta 6240
taataataag aggaaattta tcatagaaca ataaggtgca tagatagagt gttaatatat 6300
cataacatcc tttgtttatt catagaagaa gtgagatgga gctcagttat tatactgtta 6360
catggtcgga tacaatattc catgctctcc atgagctctt acacctacat gcattttagt 6420
tcatacttgc ggccgcagta tatcttaaat tctttaatac ggtgtactag gatattgaac 6480
tggttcttga tgatgaaaac ctgggccgag attgcagcta tttatagtca taggtcttgt 6540
taacatgcat ggacatttgg ccacggggtg gcatgcagtt tgacgggtgt tgaaataaac 6600
aaaaatgagg tggcggaaga gaatacgagt ttgaggttgg gttagaaaca acaaatgtga 6660
gggctcatga tgggttgagt tggtgaatgt tttgggctgc tcgattgaca cctttgtgag 6720
tacgtgttgt tgtgcatggc ttttggggtc cagttttttt ttcttgacgc ggcgatcctg 6780
atcagctagt ggataagtga tgtccactgt gtgtgattgc gtttttgttt gaattttatg 6840
aacttagaca ttgctatgca aaggatactc tcattgtgtt ttgtcttctt ttgttccttg 6900
gctttttctt atgatccaag agactagtca gtgttgtggc attcgagact accaagatta 6960
attatgatgg gggaaggata agtaactgat tagtacggac tgttaccaaa ttaattaata 7020
agcggcaaat gaagggcatg gatcaaaagc ttggatctcc tgcaggatct ggccggccgg 7080
atctc 7085
<210> 56
<211> 7873
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR912
<400> 56
ggccgcaagt atgaactaaa atgcatgtag gtgtaagagc tcatggagag catggaatat 60
tgtatccgac catgtaacag tataataact gagctccatc tcacttcttc tatgaataaa 120
caaaggatgt tatgatatat taacactcta tctatgcacc ttattgttct atgataaatt 180
tcctcttatt attataaatc atctgaatcg tgacggctta tggaatgctt caaatagtac 240
aaaaacaaat gtgtactata agactttcta aacaattcta accttagcat tgtgaacgag 300
acataagtgt taagaagaca taacaattat aatggaagaa gtttgtctcc atttatatat 360
tatatattac ccacttatgt attatattag gatgttaagg agacataaca attataaaga 420
gagaagtttg tatccattta tatattatat actacccatt tatatattat acttatccac 480
ttatttaatg tctttataag gtttgatcca tgatatttct aatattttag ttgatatgta 540
tatgaaaggg tactatttga actctcttac tctgtataaa ggttggatca tccttaaagt 600
gggtctattt aattttattg cttcttacag ataaaaaaaa aattatgagt tggtttgata 660
aaatattgaa ggatttaaaa taataataaa taacatataa tatatgtata taaatttatt 720
ataatataac atttatctat aaaaaagtaa atattgtcat aaatctatac aatcgtttag 780
ccttgctgga cgaatctcaa ttatttaaac gagagtaaac atatttgact ttttggttat 840
ttaacaaatt attatttaac actatatgaa attttttttt ttatcagcaa agaataaaat 900
taaattaaga aggacaatgg tgtcccaatc cttatacaac caacttccac aagaaagtca 960
agtcagagac aacaaaaaaa caagcaaagg aaatttttta atttgagttg tcttgtttgc 1020
tgcataattt atgcagtaaa acactacaca taaccctttt agcagtagag caatggttga 1080
ccgtgtgctt agcttctttt attttatttt tttatcagca aagaataaat aaaataaaat 1140
gagacacttc agggatgttt caacaagctt ggcgcgccgt tctatagtgt cacctaaatc 1200
gtatgtgtat gatacataag gttatgtatt aattgtagcc gcgttctaac gacaatatgt 1260
ccatatggtg cactctcagt acaatctgct ctgatgccgc atagttaagc cagccccgac 1320
acccgccaac acccgctgac gcgccctgac gggcttgtct gctcccggca tccgcttaca 1380
gacaagctgt gaccgtctcc gggagctgca tgtgtcagag gttttcaccg tcatcaccga 1440
aacgcgcgag acgaaagggc ctcgtgatac gcctattttt ataggttaat gtcatgacca 1500
aaatccctta acgtgagttt tcgttccact gagcgtcaga ccccgtagaa aagatcaaag 1560
gatcttcttg agatcctttt tttctgcgcg taatctgctg cttgcaaaca aaaaaaccac 1620
cgctaccagc ggtggtttgt ttgccggatc aagagctacc aactcttttt ccgaaggtaa 1680
ctggcttcag cagagcgcag ataccaaata ctgtccttct agtgtagccg tagttaggcc 1740
accacttcaa gaactctgta gcaccgccta catacctcgc tctgctaatc ctgttaccag 1800
tggctgctgc cagtggcgat aagtcgtgtc ttaccgggtt ggactcaaga cgatagttac 1860
cggataaggc gcagcggtcg ggctgaacgg ggggttcgtg cacacagccc agcttggagc 1920
gaacgaccta caccgaactg agatacctac agcgtgagca ttgagaaagc gccacgcttc 1980
ccgaagggag aaaggcggac aggtatccgg taagcggcag ggtcggaaca ggagagcgca 2040
cgagggagct tccaggggga aacgcctggt atctttatag tcctgtcggg tttcgccacc 2100
tctgacttga gcgtcgattt ttgtgatgct cgtcaggggg gcggagccta tggaaaaacg 2160
ccagcaacgc ggccttttta cggttcctgg ccttttgctg gccttttgct cacatgttct 2220
ttcctgcgtt atcccctgat tctgtggata accgtattac cgcctttgag tgagctgata 2280
ccgctcgccg cagccgaacg accgagcgca gcgagtcagt gagcgaggaa gcggaagagc 2340
gcccaatacg caaaccgcct ctccccgcgc gttggccgat tcattaatgc aggttgatcg 2400
attcgacatc gatctagtaa catagatgac accgcgcgcg ataatttatc ctagtttgcg 2460
cgctatattt tgttttctat cgcgtattaa atgtataatt gcgggactct aatcataaaa 2520
acccatctca taaataacgt catgcattac atgttaatta ttacatgctt aacgtaattc 2580
aacagaaatt atatgataat catcgcaaga ccggcaacag gattcaatct taagaaactt 2640
tattgccaaa tgtttgaacg atctgcttcg acgcactcct tctttaggta cctcactatt 2700
cctttgccct cggacgagtg ctggggcgtc ggtttccact atcggcgagt acttctacac 2760
agccatcggt ccagacggcc gcgcttctgc gggcgatttg tgtacgcccg acagtcccgg 2820
ctccggatcg gacgattgcg tcgcatcgac cctgcgccca agctgcatca tcgaaattgc 2880
cgtcaaccaa gctctgatag agttggtcaa gaccaatgcg gagcatatac gcccggagcc 2940
gcggcgatcc tgcaagctcc ggatgcctcc gctcgaagta gcgcgtctgc tgctccatac 3000
aagccaacca cggcctccag aagaagatgt tggcgacctc gtattgggaa tccccgaaca 3060
tcgcctcgct ccagtcaatg accgctgtta tgcggccatt gtccgtcagg acattgttgg 3120
agccgaaatc cgcgtgcacg aggtgccgga cttcggggca gtcctcggcc caaagcatca 3180
gctcatcgag agcctgcgcg acggacgcac tgacggtgtc gtccatcaca gtttgccagt 3240
gatacacatg gggatcagca atcgcgcata tgaaatcacg ccatgtagtg tattgaccga 3300
ttccttgcgg tccgaatggg ccgaacccgc tcgtctggct aagatcggcc gcagcgatcg 3360
catccatggc ctccgcgacc ggctgcagaa cagcgggcag ttcggtttca ggcaggtctt 3420
gcaacgtgac accctgtgca cggcgggaga tgcaataggt caggctctcg ctgaattccc 3480
caatgtcaag cacttccgga atcgggagcg cggccgatgc aaagtgccga taaacataac 3540
gatctttgta gaaaccatcg gcgcagctat ttacccgcag gacatatcca cgccctccta 3600
catcgaagct gaaagcacga gattcttcgc cctccgagag ctgcatcagg tcggagacgc 3660
tgtcgaactt ttcgatcaga aacttctcga cagacgtcgc ggtgagttca ggctttttca 3720
tggtttaata agaagagaaa agagttcttt tgttatggct gaagtaatag agaaatgagc 3780
tcgagcgtgt cctctccaaa tgaaatgaac ttccttatat agaggaaggg tcttgcgaag 3840
gatagtggga ttgtgcgtca tcccttacgt cagtggagat gtcacatcaa tccacttgct 3900
ttgaagacgt ggttggaacg tcttcttttt ccacgatgct cctcgtgggt gggggtccat 3960
ctttgggacc actgtcggca gaggcatctt gaatgatagc ctttccttta tcgcaatgat 4020
ggcatttgta ggagccacct tccttttcta ctgtcctttc gatgaagtga cagatagctg 4080
ggcaatggaa tccgaggagg tttcccgaaa ttatcctttg ttgaaaagtc tcaatagccc 4140
tttggtcttc tgagactgta tctttgacat ttttggagta gaccagagtg tcgtgctcca 4200
ccatgttgac gaagattttc ttcttgtcat tgagtcgtaa aagactctgt atgaactgtt 4260
cgccagtctt cacggcgagt tctgttagat cctcgatttg aatcttagac tccatgcatg 4320
gccttagatt cagtaggaac taccttttta gagactccaa tctctattac ttgccttggt 4380
ttatgaagca agccttgaat cgtccatact ggaatagtac ttctgatctt gagaaatatg 4440
tctttctctg tgttcttgat gcaattagtc ctgaatcttt tgactgcatc tttaaccttc 4500
ttgggaaggt atttgatctc ctggagattg ttactcgggt agatcgtctt gatgagacct 4560
gctgcgtagg cctctctaac catctgtggg tcagcattct ttctgaaatt gaagaggcta 4620
accttctcat tatcagtggt gaacatagtg tcgtcacctt caccttcgaa cttccttcct 4680
agatcgtaaa gatagaggaa atcgtccatt gtaatctccg gggcaaagga gatctctttt 4740
ggggctggat cactgctggg ccttttggtt cctagcgtga gccagtgggc tttttgcttt 4800
ggtgggcttg ttagggcctt agcaaagctc ttgggcttga gttgagcttc tcctttgggg 4860
atgaagttca acctgtctgt ttgctgactt gttgtgtacg cgtcagctgc tgctcttgcc 4920
tctgtaatag tggcaaattt cttgtgtgca actccgggaa cgccgtttgt tgccgccttt 4980
gtacaacccc agtcatcgta tataccggca tgtggaccgt tatacacaac gtagtagttg 5040
atatgagggt gttgaatacc cgattctgct ctgagaggag caactgtgct gttaagctca 5100
gatttttgtg ggattggaat tggatcgatc tcgatcccgc gaaattaata cgactcacta 5160
tagggagacc acaacggttt ccctctagaa ataattttgt ttaactttaa gaaggagata 5220
tacccatgga aaagcctgaa ctcaccgcga cgtctgtcga gaagtttctg atcgaaaagt 5280
tcgacagcgt ctccgacctg atgcagctct cggagggcga agaatctcgt gctttcagct 5340
tcgatgtagg agggcgtgga tatgtcctgc gggtaaatag ctgcgccgat ggtttctaca 5400
aagatcgtta tgtttatcgg cactttgcat cggccgcgct cccgattccg gaagtgcttg 5460
acattgggga attcagcgag agcctgacct attgcatctc ccgccgtgca cagggtgtca 5520
cgttgcaaga cctgcctgaa accgaactgc ccgctgttct gcagccggtc gcggaggcta 5580
tggatgcgat cgctgcggcc gatcttagcc agacgagcgg gttcggccca ttcggaccgc 5640
aaggaatcgg tcaatacact acatggcgtg atttcatatg cgcgattgct gatccccatg 5700
tgtatcactg gcaaactgtg atggacgaca ccgtcagtgc gtccgtcgcg caggctctcg 5760
atgagctgat gctttgggcc gaggactgcc ccgaagtccg gcacctcgtg cacgcggatt 5820
tcggctccaa caatgtcctg acggacaatg gccgcataac agcggtcatt gactggagcg 5880
aggcgatgtt cggggattcc caatacgagg tcgccaacat cttcttctgg aggccgtggt 5940
tggcttgtat ggagcagcag acgcgctact tcgagcggag gcatccggag cttgcaggat 6000
cgccgcggct ccgggcgtat atgctccgca ttggtcttga ccaactctat cagagcttgg 6060
ttgacggcaa tttcgatgat gcagcttggg cgcagggtcg atgcgacgca atcgtccgat 6120
ccggagccgg gactgtcggg cgtacacaaa tcgcccgcag aagcgcggcc gtctggaccg 6180
atggctgtgt agaagtactc gccgatagtg gaaaccgacg ccccagcact cgtccgaggg 6240
caaaggaata gtgaggtaca gcttggatcg atccggctgc taacaaagcc cgaaaggaag 6300
ctgagttggc tgctgccacc gctgagcaat aactagcata accccttggg gcctctaaac 6360
gggtcttgag gggttttttg ctgaaaggag gaactatatc cggatgatcg ggcgcgccgt 6420
cgacggatcc gtacgagatc cggccggcca gatcctgcag gagatccaag cttttgatcc 6480
atgcccttca tttgccgctt attaattaat ttggtaacag tccgtactaa tcagttactt 6540
atccttcccc catcataatt aatcttggta gtctcgaatg ccacaacact gactagtctc 6600
ttggatcata agaaaaagcc aaggaacaaa agaagacaaa acacaatgag agtatccttt 6660
gcatagcaat gtctaagttc ataaaattca aacaaaaacg caatcacaca cagtggacat 6720
cacttatcca ctagctgatc aggatcgccg cgtcaagaaa aaaaaactgg accccaaaag 6780
ccatgcacaa caacacgtac tcacaaaggt gtcaatcgag cagcccaaaa cattcaccaa 6840
ctcaacccat catgagccct cacatttgtt gtttctaacc caacctcaaa ctcgtattct 6900
cttccgccac ctcatttttg tttatttcaa cacccgtcaa actgcatgcc accccgtggc 6960
caaatgtcca tgcatgttaa caagacctat gactataaat agctgcaatc tcggcccagg 7020
ttttcatcat caagaaccag ttcaatatcc tagtacaccg tattaaagaa tttaagatat 7080
actgcggccg caccatggag gtggtgaatg aaatagtctc aattgggcag gaagttttac 7140
ccaaagttga ttatgcccaa ctctggagtg atgccagtca ctgtgaggtg ctttacttgt 7200
ccatcgcatt tgtcatcttg aagttcactc ttggccccct tggtccaaaa ggtcagtctc 7260
gtatgaagtt tgttttcacc aattacaacc ttctcatgtc catttattcg ttgggatcat 7320
tcctctcaat ggcatatgcc atgtacacca tcggtgttat gtctgacaac tgcgagaagg 7380
cttttgacaa caacgtcttc aggatcacca cgcagttgtt ctatttgagc aagttcctgg 7440
agtatattga ctccttctat ttgccactga tgggcaagcc tctgacctgg ttgcaattct 7500
tccatcattt gggggcaccg atggatatgt ggctgttcta taattaccga aatgaagctg 7560
tttggatttt tgtgctgttg aatggtttca tccactggat catgtacggt tattattgga 7620
ccagattgat caagctgaag ttccccatgc caaaatccct gattacatca atgcagatca 7680
ttcaattcaa tgttggtttc tacattgtct ggaagtacag gaacattccc tgttatcgcc 7740
aagatgggat gaggatgttt ggctggttct tcaattactt ttatgttggc acagtcttgt 7800
gtttgttctt gaatttctat gtgcaaacgt atatcgtcag gaagcacaag ggagccaaaa 7860
agattcagtg agc 7873
<210> 57
<211> 2540
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKS102
<400> 57
cgatcatccg gatatagttc ctcctttcag caaaaaaccc ctcaagaccc gtttagaggc 60
cccaaggggt tatgctagtt attgctcagc ggtggcagca gccaactcag cttcctttcg 120
ggctttgtta gcagccggat cgatccaagc tgtacctcac tattcctttg ccctcggacg 180
agtgctgggg cgtcggtttc cactatcggc gagtacttct acacagccat cggtccagac 240
ggccgcgctt ctgcgggcga tttgtgtacg cccgacagtc ccggctccgg atcggacgat 300
tgcgtcgcat cgaccctgcg cccaagctgc atcatcgaaa ttgccgtcaa ccaagctctg 360
atagagttgg tcaagaccaa tgcggagcat atacgcccgg agccgcggcg atcctgcaag 420
ctccggatgc ctccgctcga agtagcgcgt ctgctgctcc atacaagcca accacggcct 480
ccagaagaag atgttggcga cctcgtattg ggaatccccg aacatcgcct cgctccagtc 540
aatgaccgct gttatgcggc cattgtccgt caggacattg ttggagccga aatccgcgtg 600
cacgaggtgc cggacttcgg ggcagtcctc ggcccaaagc atcagctcat cgagagcctg 660
cgcgacggac gcactgacgg tgtcgtccat cacagtttgc cagtgataca catggggatc 720
agcaatcgcg catatgaaat cacgccatgt agtgtattga ccgattcctt gcggtccgaa 780
tgggccgaac ccgctcgtct ggctaagatc ggccgcagcg atcgcatcca tagcctccgc 840
gaccggctgc agaacagcgg gcagttcggt ttcaggcagg tcttgcaacg tgacaccctg 900
tgcacggcgg gagatgcaat aggtcaggct ctcgctgaat tccccaatgt caagcacttc 960
cggaatcggg agcgcggccg atgcaaagtg ccgataaaca taacgatctt tgtagaaacc 1020
atcggcgcag ctatttaccc gcaggacata tccacgccct cctacatcga agctgaaagc 1080
acgagattct tcgccctccg agagctgcat caggtcggag acgctgtcga acttttcgat 1140
cagaaacttc tcgacagacg tcgcggtgag ttcaggcttt tccatgggta tatctccttc 1200
ttaaagttaa acaaaattat ttctagaggg aaaccgttgt ggtctcccta tagtgagtcg 1260
tattaatttc gcgggatcga gatctgatca acctgcatta atgaatcggc caacgcgcgg 1320
ggagaggcgg tttgcgtatt gggcgctctt ccgcttcctc gctcactgac tcgctgcgct 1380
cggtcgttcg gctgcggcga gcggtatcag ctcactcaaa ggcggtaata cggttatcca 1440
cagaatcagg ggataacgca ggaaagaaca tgtgagcaaa aggccagcaa aaggccagga 1500
accgtaaaaa ggccgcgttg ctggcgtttt tccataggct ccgcccccct gacgagcatc 1560
acaaaaatcg acgctcaagt cagaggtggc gaaacccgac aggactataa agataccagg 1620
cgtttccccc tggaagctcc ctcgtgcgct ctcctgttcc gaccctgccg cttaccggat 1680
acctgtccgc ctttctccct tcgggaagcg tggcgctttc tcaatgctca cgctgtaggt 1740
atctcagttc ggtgtaggtc gttcgctcca agctgggctg tgtgcacgaa ccccccgttc 1800
agcccgaccg ctgcgcctta tccggtaact atcgtcttga gtccaacccg gtaagacacg 1860
acttatcgcc actggcagca gccactggta acaggattag cagagcgagg tatgtaggcg 1920
gtgctacaga gttcttgaag tggtggccta actacggcta cactagaagg acagtatttg 1980
gtatctgcgc tctgctgaag ccagttacct tcggaaaaag agttggtagc tcttgatccg 2040
gcaaacaaac caccgctggt agcggtggtt tttttgtttg caagcagcag attacgcgca 2100
gaaaaaaagg atctcaagaa gatcctttga tcttttctac ggggtctgac gctcagtgga 2160
acgaaaactc acgttaaggg attttggtca tgacattaac ctataaaaat aggcgtatca 2220
cgaggccctt tcgtctcgcg cgtttcggtg atgacggtga aaacctctga cacatgcagc 2280
tcccggagac ggtcacagct tgtctgtaag cggatgccgg gagcagacaa gcccgtcagg 2340
gcgcgtcagc gggtgttggc gggtgtcggg gctggcttaa ctatgcggca tcagagcaga 2400
ttgtactgag agtgcaccat atggacatat tgtcgttaga acgcggctac aattaataca 2460
taaccttatg tatcatacac atacgattta ggtgacacta tagaacggcg cgccaagctt 2520
ggatccgtcg acggcgcgcc 2540
<210> 58
<211> 4359
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR197
<400> 58
cgcgcccgat catccggata tagttcctcc tttcagcaaa aaacccctca agacccgttt 60
agaggcccca aggggttatg ctagttattg ctcagcggtg gcagcagcca actcagcttc 120
ctttcgggct ttgttagcag ccggatcgat ccaagctgta cctcactatt cctttgccct 180
cggacgagtg ctggggcgtc ggtttccact atcggcgagt acttctacac agccatcggt 240
ccagacggcc gcgcttctgc gggcgatttg tgtacgcccg acagtcccgg ctccggatcg 300
gacgattgcg tcgcatcgac cctgcgccca agctgcatca tcgaaattgc cgtcaaccaa 360
gctctgatag agttggtcaa gaccaatgcg gagcatatac gcccggagcc gcggcgatcc 420
tgcaagctcc ggatgcctcc gctcgaagta gcgcgtctgc tgctccatac aagccaacca 480
cggcctccag aagaagatgt tggcgacctc gtattgggaa tccccgaaca tcgcctcgct 540
ccagtcaatg accgctgtta tgcggccatt gtccgtcagg acattgttgg agccgaaatc 600
cgcgtgcacg aggtgccgga cttcggggca gtcctcggcc caaagcatca gctcatcgag 660
agcctgcgcg acggacgcac tgacggtgtc gtccatcaca gtttgccagt gatacacatg 720
gggatcagca atcgcgcata tgaaatcacg ccatgtagtg tattgaccga ttccttgcgg 780
tccgaatggg ccgaacccgc tcgtctggct aagatcggcc gcagcgatcg catccatagc 840
ctccgcgacc ggctgcagaa cagcgggcag ttcggtttca ggcaggtctt gcaacgtgac 900
accctgtgca cggcgggaga tgcaataggt caggctctcg ctgaattccc caatgtcaag 960
cacttccgga atcgggagcg cggccgatgc aaagtgccga taaacataac gatctttgta 1020
gaaaccatcg gcgcagctat ttacccgcag gacatatcca cgccctccta catcgaagct 1080
gaaagcacga gattcttcgc cctccgagag ctgcatcagg tcggagacgc tgtcgaactt 1140
ttcgatcaga aacttctcga cagacgtcgc ggtgagttca ggcttttcca tgggtatatc 1200
tccttcttaa agttaaacaa aattatttct agagggaaac cgttgtggtc tccctatagt 1260
gagtcgtatt aatttcgcgg gatcgagatc tgatcaacct gcattaatga atcggccaac 1320
gcgcggggag aggcggtttg cgtattgggc gctcttccgc ttcctcgctc actgactcgc 1380
tgcgctcggt cgttcggctg cggcgagcgg tatcagctca ctcaaaggcg gtaatacggt 1440
tatccacaga atcaggggat aacgcaggaa agaacatgtg agcaaaaggc cagcaaaagg 1500
ccaggaaccg taaaaaggcc gcgttgctgg cgtttttcca taggctccgc ccccctgacg 1560
agcatcacaa aaatcgacgc tcaagtcaga ggtggcgaaa cccgacagga ctataaagat 1620
accaggcgtt tccccctgga agctccctcg tgcgctctcc tgttccgacc ctgccgctta 1680
ccggatacct gtccgccttt ctcccttcgg gaagcgtggc gctttctcaa tgctcacgct 1740
gtaggtatct cagttcggtg taggtcgttc gctccaagct gggctgtgtg cacgaacccc 1800
ccgttcagcc cgaccgctgc gccttatccg gtaactatcg tcttgagtcc aacccggtaa 1860
gacacgactt atcgccactg gcagcagcca ctggtaacag gattagcaga gcgaggtatg 1920
taggcggtgc tacagagttc ttgaagtggt ggcctaacta cggctacact agaaggacag 1980
tatttggtat ctgcgctctg ctgaagccag ttaccttcgg aaaaagagtt ggtagctctt 2040
gatccggcaa acaaaccacc gctggtagcg gtggtttttt tgtttgcaag cagcagatta 2100
cgcgcagaaa aaaaggatct caagaagatc ctttgatctt ttctacgggg tctgacgctc 2160
agtggaacga aaactcacgt taagggattt tggtcatgac attaacctat aaaaataggc 2220
gtatcacgag gccctttcgt ctcgcgcgtt tcggtgatga cggtgaaaac ctctgacaca 2280
tgcagctccc ggagacggtc acagcttgtc tgtaagcgga tgccgggagc agacaagccc 2340
gtcagggcgc gtcagcgggt gttggcgggt gtcggggctg gcttaactat gcggcatcag 2400
agcagattgt actgagagtg caccatatgg acatattgtc gttagaacgc ggctacaatt 2460
aatacataac cttatgtatc atacacatac gatttaggtg acactataga acggcgcgcc 2520
aagcttgttg aaacatccct gaagtgtctc attttatttt atttattctt tgctgataaa 2580
aaaataaaat aaaagaagct aagcacacgg tcaaccattg ctctactgct aaaagggtta 2640
tgtgtagtgt tttactgcat aaattatgca gcaaacaaga caactcaaat taaaaaattt 2700
cctttgcttg tttttttgtt gtctctgact tgactttctt gtggaagttg gttgtataag 2760
gattgggaca ccattgtcct tcttaattta attttattct ttgctgataa aaaaaaaaat 2820
ttcatatagt gttaaataat aatttgttaa ataaccaaaa agtcaaatat gtttactctc 2880
gtttaaataa ttgagattcg tccagcaagg ctaaacgatt gtatagattt atgacaatat 2940
ttactttttt atagataaat gttatattat aataaattta tatacatata ttatatgtta 3000
tttattatta ttttaaatcc ttcaatattt tatcaaacca actcataatt ttttttttat 3060
ctgtaagaag caataaaatt aaatagaccc actttaagga tgatccaacc tttatacaga 3120
gtaagagagt tcaaatagta ccctttcata tacatatcaa ctaaaatatt agaaatatca 3180
tggatcaaac cttataaaga cattaaataa gtggataagt ataatatata aatgggtagt 3240
atataatata taaatggata caaacttctc tctttataat tgttatgtct ccttaacatc 3300
ctaatataat acataagtgg gtaatatata atatataaat ggagacaaac ttcttccatt 3360
ataattgtta tgtcttctta acacttatgt ctcgttcaca atgctaaggt tagaattgtt 3420
tagaaagtct tatagtacac atttgttttt gtactatttg aagcattcca taagccgtca 3480
cgattcagat gatttataat aataagagga aatttatcat agaacaataa ggtgcataga 3540
tagagtgtta atatatcata acatcctttg tttattcata gaagaagtga gatggagctc 3600
agttattata ctgttacatg gtcggataca atattccatg ctctccatga gctcttacac 3660
ctacatgcat tttagttcat acttgcggcc gcagtatatc ttaaattctt taatacggtg 3720
tactaggata ttgaactggt tcttgatgat gaaaacctgg gccgagattg cagctattta 3780
tagtcatagg tcttgttaac atgcatggac atttggccac ggggtggcat gcagtttgac 3840
gggtgttgaa ataaacaaaa atgaggtggc ggaagagaat acgagtttga ggttgggtta 3900
gaaacaacaa atgtgagggc tcatgatggg ttgagttggt gaatgttttg ggctgctcga 3960
ttgacacctt tgtgagtacg tgttgttgtg catggctttt ggggtccagt ttttttttct 4020
tgacgcggcg atcctgatca gctagtggat aagtgatgtc cactgtgtgt gattgcgttt 4080
ttgtttgaat tttatgaact tagacattgc tatgcaaagg atactctcat tgtgttttgt 4140
cttcttttgt tccttggctt tttcttatga tccaagagac tagtcagtgt tgtggcattc 4200
gagactacca agattaatta tgatggggga aggataagta actgattagt acggactgtt 4260
accaaattaa ttaataagcg gcaaatgaag ggcatggatc aaaagcttgg atctcctgca 4320
ggatctggcc ggccggatct cgtacggatc cgtcgacgg 4359
<210> 59
<211> 5147
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR911
<400> 59
ggccgcaagt atgaactaaa atgcatgtag gtgtaagagc tcatggagag catggaatat 60
tgtatccgac catgtaacag tataataact gagctccatc tcacttcttc tatgaataaa 120
caaaggatgt tatgatatat taacactcta tctatgcacc ttattgttct atgataaatt 180
tcctcttatt attataaatc atctgaatcg tgacggctta tggaatgctt caaatagtac 240
aaaaacaaat gtgtactata agactttcta aacaattcta accttagcat tgtgaacgag 300
acataagtgt taagaagaca taacaattat aatggaagaa gtttgtctcc atttatatat 360
tatatattac ccacttatgt attatattag gatgttaagg agacataaca attataaaga 420
gagaagtttg tatccattta tatattatat actacccatt tatatattat acttatccac 480
ttatttaatg tctttataag gtttgatcca tgatatttct aatattttag ttgatatgta 540
tatgaaaggg tactatttga actctcttac tctgtataaa ggttggatca tccttaaagt 600
gggtctattt aattttattg cttcttacag ataaaaaaaa aattatgagt tggtttgata 660
aaatattgaa ggatttaaaa taataataaa taacatataa tatatgtata taaatttatt 720
ataatataac atttatctat aaaaaagtaa atattgtcat aaatctatac aatcgtttag 780
ccttgctgga cgaatctcaa ttatttaaac gagagtaaac atatttgact ttttggttat 840
ttaacaaatt attatttaac actatatgaa attttttttt ttatcagcaa agaataaaat 900
taaattaaga aggacaatgg tgtcccaatc cttatacaac caacttccac aagaaagtca 960
agtcagagac aacaaaaaaa caagcaaagg aaatttttta atttgagttg tcttgtttgc 1020
tgcataattt atgcagtaaa acactacaca taaccctttt agcagtagag caatggttga 1080
ccgtgtgctt agcttctttt attttatttt tttatcagca aagaataaat aaaataaaat 1140
gagacacttc agggatgttt caacaagctt ggcgcgccgt tctatagtgt cacctaaatc 1200
gtatgtgtat gatacataag gttatgtatt aattgtagcc gcgttctaac gacaatatgt 1260
ccatatggtg cactctcagt acaatctgct ctgatgccgc atagttaagc cagccccgac 1320
acccgccaac acccgctgac gcgccctgac gggcttgtct gctcccggca tccgcttaca 1380
gacaagctgt gaccgtctcc gggagctgca tgtgtcagag gttttcaccg tcatcaccga 1440
aacgcgcgag acgaaagggc ctcgtgatac gcctattttt ataggttaat gtcatgacca 1500
aaatccctta acgtgagttt tcgttccact gagcgtcaga ccccgtagaa aagatcaaag 1560
gatcttcttg agatcctttt tttctgcgcg taatctgctg cttgcaaaca aaaaaaccac 1620
cgctaccagc ggtggtttgt ttgccggatc aagagctacc aactcttttt ccgaaggtaa 1680
ctggcttcag cagagcgcag ataccaaata ctgtccttct agtgtagccg tagttaggcc 1740
accacttcaa gaactctgta gcaccgccta catacctcgc tctgctaatc ctgttaccag 1800
tggctgctgc cagtggcgat aagtcgtgtc ttaccgggtt ggactcaaga cgatagttac 1860
cggataaggc gcagcggtcg ggctgaacgg ggggttcgtg cacacagccc agcttggagc 1920
gaacgaccta caccgaactg agatacctac agcgtgagca ttgagaaagc gccacgcttc 1980
ccgaagggag aaaggcggac aggtatccgg taagcggcag ggtcggaaca ggagagcgca 2040
cgagggagct tccaggggga aacgcctggt atctttatag tcctgtcggg tttcgccacc 2100
tctgacttga gcgtcgattt ttgtgatgct cgtcaggggg gcggagccta tggaaaaacg 2160
ccagcaacgc ggccttttta cggttcctgg ccttttgctg gccttttgct cacatgttct 2220
ttcctgcgtt atcccctgat tctgtggata accgtattac cgcctttgag tgagctgata 2280
ccgctcgccg cagccgaacg accgagcgca gcgagtcagt gagcgaggaa gcggaagagc 2340
gcccaatacg caaaccgcct ctccccgcgc gttggccgat tcattaatgc aggttgatca 2400
gatctcgatc ccgcgaaatt aatacgactc actataggga gaccacaacg gtttccctct 2460
agaaataatt ttgtttaact ttaagaagga gatataccca tggaaaagcc tgaactcacc 2520
gcgacgtctg tcgagaagtt tctgatcgaa aagttcgaca gcgtctccga cctgatgcag 2580
ctctcggagg gcgaagaatc tcgtgctttc agcttcgatg taggagggcg tggatatgtc 2640
ctgcgggtaa atagctgcgc cgatggtttc tacaaagatc gttatgttta tcggcacttt 2700
gcatcggccg cgctcccgat tccggaagtg cttgacattg gggaattcag cgagagcctg 2760
acctattgca tctcccgccg tgcacagggt gtcacgttgc aagacctgcc tgaaaccgaa 2820
ctgcccgctg ttctgcagcc ggtcgcggag gctatggatg cgatcgctgc ggccgatctt 2880
agccagacga gcgggttcgg cccattcgga ccgcaaggaa tcggtcaata cactacatgg 2940
cgtgatttca tatgcgcgat tgctgatccc catgtgtatc actggcaaac tgtgatggac 3000
gacaccgtca gtgcgtccgt cgcgcaggct ctcgatgagc tgatgctttg ggccgaggac 3060
tgccccgaag tccggcacct cgtgcacgcg gatttcggct ccaacaatgt cctgacggac 3120
aatggccgca taacagcggt cattgactgg agcgaggcga tgttcgggga ttcccaatac 3180
gaggtcgcca acatcttctt ctggaggccg tggttggctt gtatggagca gcagacgcgc 3240
tacttcgagc ggaggcatcc ggagcttgca ggatcgccgc ggctccgggc gtatatgctc 3300
cgcattggtc ttgaccaact ctatcagagc ttggttgacg gcaatttcga tgatgcagct 3360
tgggcgcagg gtcgatgcga cgcaatcgtc cgatccggag ccgggactgt cgggcgtaca 3420
caaatcgccc gcagaagcgc ggccgtctgg accgatggct gtgtagaagt actcgccgat 3480
agtggaaacc gacgccccag cactcgtccg agggcaaagg aatagtgagg tacagcttgg 3540
atcgatccgg ctgctaacaa agcccgaaag gaagctgagt tggctgctgc caccgctgag 3600
caataactag cataacccct tggggcctct aaacgggtct tgaggggttt tttgctgaaa 3660
ggaggaacta tatccggatg atcgggcgcg ccgtcgacgg atccgtacga gatccggccg 3720
gccagatcct gcaggagatc caagcttttg atccatgccc ttcatttgcc gcttattaat 3780
taatttggta acagtccgta ctaatcagtt acttatcctt cccccatcat aattaatctt 3840
ggtagtctcg aatgccacaa cactgactag tctcttggat cataagaaaa agccaaggaa 3900
caaaagaaga caaaacacaa tgagagtatc ctttgcatag caatgtctaa gttcataaaa 3960
ttcaaacaaa aacgcaatca cacacagtgg acatcactta tccactagct gatcaggatc 4020
gccgcgtcaa gaaaaaaaaa ctggacccca aaagccatgc acaacaacac gtactcacaa 4080
aggtgtcaat cgagcagccc aaaacattca ccaactcaac ccatcatgag ccctcacatt 4140
tgttgtttct aacccaacct caaactcgta ttctcttccg ccacctcatt tttgtttatt 4200
tcaacacccg tcaaactgca tgccaccccg tggccaaatg tccatgcatg ttaacaagac 4260
ctatgactat aaatagctgc aatctcggcc caggttttca tcatcaagaa ccagttcaat 4320
atcctagtac accgtattaa agaatttaag atatactgcg gccgcaccat ggaggtggtg 4380
aatgaaatag tctcaattgg gcaggaagtt ttacccaaag ttgattatgc ccaactctgg 4440
agtgatgcca gtcactgtga ggtgctttac ttgtccatcg catttgtcat cttgaagttc 4500
actcttggcc cccttggtcc aaaaggtcag tctcgtatga agtttgtttt caccaattac 4560
aaccttctca tgtccattta ttcgttggga tcattcctct caatggcata tgccatgtac 4620
accatcggtg ttatgtctga caactgcgag aaggcttttg acaacaacgt cttcaggatc 4680
accacgcagt tgttctattt gagcaagttc ctggagtata ttgactcctt ctatttgcca 4740
ctgatgggca agcctctgac ctggttgcaa ttcttccatc atttgggggc accgatggat 4800
atgtggctgt tctataatta ccgaaatgaa gctgtttgga tttttgtgct gttgaatggt 4860
ttcatccact ggatcatgta cggttattat tggaccagat tgatcaagct gaagttcccc 4920
atgccaaaat ccctgattac atcaatgcag atcattcaat tcaatgttgg tttctacatt 4980
gtctggaagt acaggaacat tccctgttat cgccaagatg ggatgaggat gtttggctgg 5040
ttcttcaatt acttttatgt tggcacagtc ttgtgtttgt tcttgaattt ctatgtgcaa 5100
acgtatatcg tcaggaagca caagggagcc aaaaagattc agtgagc 5147
<210> 60
<211> 1266
<212> DNA
<213> Euglena gracilis
<400> 60
atgaagtcaa agcgccaagc gcttcccctt acaattgatg gaacaacata tgatgtgtct 60
gcctgggtca atttccaccc tggtggtgcg gaaattatag agaattacca aggaagggat 120
gccactgatg ccttcatggt tatgcactct caagaagcct tcgacaagct caagcgcatg 180
cccaaaatca atcccagttc tgagttgcca ccccaggctg cagtgaatga agctcaagag 240
gatttccgga agctccgaga agagttgatc gcaactggca tgtttgatgc ctcccccctc 300
tggtactcat acaaaatcag caccacactg ggccttggag tgctgggtta tttcctgatg 360
gttcagtatc agatgtattt cattggggca gtgttgcttg ggatgcacta tcaacagatg 420
ggctggcttt ctcatgacat ttgccaccac cagactttca agaaccggaa ctggaacaac 480
ctcgtgggac tggtatttgg caatggtctg caaggttttt ccgtgacatg gtggaaggac 540
agacacaatg cacatcattc ggcaaccaat gttcaagggc acgaccctga tattgacaac 600
ctccccctct tagcctggtc tgaggatgac gtcacacggg cgtcaccgat ttcccgcaag 660
ctcattcagt tccagcagta ctatttcttg gtcatctgta tcttgttgcg gttcatttgg 720
tgtttccaga gcgtgttgac cgtgcgcagt ttgaaggaca gagataacca attctatcgc 780
tctcagtata agaaggaggc cattggcctc gccctgcact ggaccttgaa gaccctgttc 840
cacttattct ttatgcccag catcctcaca tcgctgttgg tgtttttcgt ttcggagctg 900
gttggcggct tcggcattgc gatcgtggtg ttcatgaacc actacccact ggagaagatc 960
ggggactcag tctgggatgg ccatggattc tcggttggcc agatccatga gaccatgaac 1020
attcggcgag ggattatcac agattggttt ttcggaggct tgaattacca gattgagcac 1080
catttgtggc cgaccctccc tcgccacaac ctgacagcgg ttagctacca ggtggaacag 1140
ctgtgccaga agcacaacct gccgtatcgg aacccgctgc cccatgaagg gttggtcatc 1200
ctgctgcgct atctggcggt gttcgcccgg atggcggaga agcaacccgc ggggaaggct 1260
ctataa 1266
<210> 61
<211> 421
<212> PRT
<213> Euglena gracilis
<220>
<221> MISC_FEATURE
<223> delta-8 desaturase ("Eg5" or "EgD8")
<300>
<302> DELTA-8 DESATURASE AND ITS USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> WO 2006/012325 and WO 2006/012326
<311> 2005-06-24
<312> 2006-02-02
<313> (1)..(421)
<300>
<302> DELTA-8 DESATURASE AND ITS USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> US_2005-0287652-A1
<311> 2005-06-24
<312> 2005-12-29
<313> (1)..(421)
<400> 61
Met Lys Ser Lys Arg Gln Ala Leu Pro Leu Thr Ile Asp Gly Thr Thr
1 5 10 15
Tyr Asp Val Ser Ala Trp Val Asn Phe His Pro Gly Gly Ala Glu Ile
20 25 30
Ile Glu Asn Tyr Gln Gly Arg Asp Ala Thr Asp Ala Phe Met Val Met
35 40 45
His Ser Gln Glu Ala Phe Asp Lys Leu Lys Arg Met Pro Lys Ile Asn
50 55 60
Pro Ser Ser Glu Leu Pro Pro Gln Ala Ala Val Asn Glu Ala Gln Glu
65 70 75 80
Asp Phe Arg Lys Leu Arg Glu Glu Leu Ile Ala Thr Gly Met Phe Asp
85 90 95
Ala Ser Pro Leu Trp Tyr Ser Tyr Lys Ile Ser Thr Thr Leu Gly Leu
100 105 110
Gly Val Leu Gly Tyr Phe Leu Met Val Gln Tyr Gln Met Tyr Phe Ile
115 120 125
Gly Ala Val Leu Leu Gly Met His Tyr Gln Gln Met Gly Trp Leu Ser
130 135 140
His Asp Ile Cys His His Gln Thr Phe Lys Asn Arg Asn Trp Asn Asn
145 150 155 160
Leu Val Gly Leu Val Phe Gly Asn Gly Leu Gln Gly Phe Ser Val Thr
165 170 175
Trp Trp Lys Asp Arg His Asn Ala His His Ser Ala Thr Asn Val Gln
180 185 190
Gly His Asp Pro Asp Ile Asp Asn Leu Pro Leu Leu Ala Trp Ser Glu
195 200 205
Asp Asp Val Thr Arg Ala Ser Pro Ile Ser Arg Lys Leu Ile Gln Phe
210 215 220
Gln Gln Tyr Tyr Phe Leu Val Ile Cys Ile Leu Leu Arg Phe Ile Trp
225 230 235 240
Cys Phe Gln Ser Val Leu Thr Val Arg Ser Leu Lys Asp Arg Asp Asn
245 250 255
Gln Phe Tyr Arg Ser Gln Tyr Lys Lys Glu Ala Ile Gly Leu Ala Leu
260 265 270
His Trp Thr Leu Lys Thr Leu Phe His Leu Phe Phe Met Pro Ser Ile
275 280 285
Leu Thr Ser Leu Leu Val Phe Phe Val Ser Glu Leu Val Gly Gly Phe
290 295 300
Gly Ile Ala Ile Val Val Phe Met Asn His Tyr Pro Leu Glu Lys Ile
305 310 315 320
Gly Asp Ser Val Trp Asp Gly His Gly Phe Ser Val Gly Gln Ile His
325 330 335
Glu Thr Met Asn Ile Arg Arg Gly Ile Ile Thr Asp Trp Phe Phe Gly
340 345 350
Gly Leu Asn Tyr Gln Ile Glu His His Leu Trp Pro Thr Leu Pro Arg
355 360 365
His Asn Leu Thr Ala Val Ser Tyr Gln Val Glu Gln Leu Cys Gln Lys
370 375 380
His Asn Leu Pro Tyr Arg Asn Pro Leu Pro His Glu Gly Leu Val Ile
385 390 395 400
Leu Leu Arg Tyr Leu Ala Val Phe Ala Arg Met Ala Glu Lys Gln Pro
405 410 415
Ala Gly Lys Ala Leu
420
<210> 62
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg5-1
<400> 62
gaaatgaagt caaagcgcc 19
<210> 63
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg3-3
<400> 63
ccttatagag ccttccccg 19
<210> 64
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> T7 primer
<400> 64
ggaaacagct atgaccatg 19
<210> 65
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer M13-28Rev
<400> 65
gtaatacgac tcactatagg gc 22
<210> 66
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg3-2
<400> 66
aatgttcatg gtctcatgg 19
<210> 67
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg5-2
<400> 67
ttggcaatgg tctgcaagg 19
<210> 68
<211> 1272
<212> DNA
<213> Euglena gracilis
<220>
<221> misc_feature
<222> (2)..(1270)
<223> synthetic delta-8 desaturase CDS, codon-optimized for expression
in Yarrowia lipolytica ("D8SF" or "EgD8S")
<300>
<302> DELTA-8 DESATURASE AND ITS USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> WO 2006/012325 and WO 2006/012326
<311> 2005-06-24
<312> 2006-02-02
<313> (1)..(1272)
<300>
<302> DELTA-8 DESATURASE AND ITS USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> US-2005-0287652-A1
<311> 2005-06-24
<312> 2005-12-29
<313> (1)..(1272)
<400> 68
catggtgaag tccaagcgac aggctctgcc cctcaccatc gacggaacta cctacgacgt 60
ctccgcttgg gtgaacttcc accctggtgg agctgaaatc attgagaact accagggacg 120
agatgctact gacgccttca tggttatgca ctctcaggaa gccttcgaca agctcaagcg 180
aatgcccaag atcaacccct cctccgagct gcctccccag gctgccgtca acgaagctca 240
ggaggatttc cgaaagctcc gagaagagct gatcgccact ggcatgtttg acgcctctcc 300
cctctggtac tcgtacaaga tctccaccac cctgggtctt ggcgtgcttg gatacttcct 360
gatggtccag taccagatgt acttcattgg tgctgtgctg ctcggtatgc actaccagca 420
aatgggatgg ctgtctcatg acatctgcca ccaccagacc ttcaagaacc gaaactggaa 480
taacctcgtg ggtctggtct ttggcaacgg actccagggc ttctccgtga cctggtggaa 540
ggacagacac aacgcccatc attctgctac caacgttcag ggtcacgatc ccgacattga 600
taacctgcct ctgctcgcct ggtccgagga cgatgtcact cgagcttctc ccatctcccg 660
aaagctcatt cagttccaac agtactattt cctggtcatc tgtattctcc tgcgattcat 720
ctggtgtttc cagtctgtgc tgaccgttcg atccctcaag gaccgagaca accagttcta 780
ccgatctcag tacaagaaag aggccattgg actcgctctg cactggactc tcaagaccct 840
gttccacctc ttctttatgc cctccatcct gacctcgctc ctggtgttct ttgtttccga 900
gctcgtcggt ggcttcggaa ttgccatcgt ggtcttcatg aaccactacc ctctggagaa 960
gatcggtgat tccgtctggg acggacatgg cttctctgtg ggtcagatcc atgagaccat 1020
gaacattcga cgaggcatca ttactgactg gttctttgga ggcctgaact accagatcga 1080
gcaccatctc tggcccaccc tgcctcgaca caacctcact gccgtttcct accaggtgga 1140
acagctgtgc cagaagcaca acctccccta ccgaaaccct ctgccccatg aaggtctcgt 1200
catcctgctc cgatacctgg ccgtgttcgc tcgaatggcc gagaagcagc ccgctggcaa 1260
ggctctctaa gc 1272
<210> 69
<211> 422
<212> PRT
<213> Euglena gracilis
<220>
<221> MISC_FEATURE
<223> synthetic delta-8 desaturase codon-optimized for expression in
Yarrowia lipolytica ("D8SF" or "EgD8S")
<300>
<302> DELTA-8 DESATURASE AND ITS USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> WO 2006/012325 and WO 2006/012326
<311> 2005-06-24
<312> 2006-02-02
<313> (1)..(422)
<300>
<302> DELTA-8 DESATURASE AND ITS USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> US-2005-0287652-A1
<311> 2005-06-24
<312> 2005-12-29
<313> (1)..(422)
<400> 69
Met Val Lys Ser Lys Arg Gln Ala Leu Pro Leu Thr Ile Asp Gly Thr
1 5 10 15
Thr Tyr Asp Val Ser Ala Trp Val Asn Phe His Pro Gly Gly Ala Glu
20 25 30
Ile Ile Glu Asn Tyr Gln Gly Arg Asp Ala Thr Asp Ala Phe Met Val
35 40 45
Met His Ser Gln Glu Ala Phe Asp Lys Leu Lys Arg Met Pro Lys Ile
50 55 60
Asn Pro Ser Ser Glu Leu Pro Pro Gln Ala Ala Val Asn Glu Ala Gln
65 70 75 80
Glu Asp Phe Arg Lys Leu Arg Glu Glu Leu Ile Ala Thr Gly Met Phe
85 90 95
Asp Ala Ser Pro Leu Trp Tyr Ser Tyr Lys Ile Ser Thr Thr Leu Gly
100 105 110
Leu Gly Val Leu Gly Tyr Phe Leu Met Val Gln Tyr Gln Met Tyr Phe
115 120 125
Ile Gly Ala Val Leu Leu Gly Met His Tyr Gln Gln Met Gly Trp Leu
130 135 140
Ser His Asp Ile Cys His His Gln Thr Phe Lys Asn Arg Asn Trp Asn
145 150 155 160
Asn Leu Val Gly Leu Val Phe Gly Asn Gly Leu Gln Gly Phe Ser Val
165 170 175
Thr Trp Trp Lys Asp Arg His Asn Ala His His Ser Ala Thr Asn Val
180 185 190
Gln Gly His Asp Pro Asp Ile Asp Asn Leu Pro Leu Leu Ala Trp Ser
195 200 205
Glu Asp Asp Val Thr Arg Ala Ser Pro Ile Ser Arg Lys Leu Ile Gln
210 215 220
Phe Gln Gln Tyr Tyr Phe Leu Val Ile Cys Ile Leu Leu Arg Phe Ile
225 230 235 240
Trp Cys Phe Gln Ser Val Leu Thr Val Arg Ser Leu Lys Asp Arg Asp
245 250 255
Asn Gln Phe Tyr Arg Ser Gln Tyr Lys Lys Glu Ala Ile Gly Leu Ala
260 265 270
Leu His Trp Thr Leu Lys Thr Leu Phe His Leu Phe Phe Met Pro Ser
275 280 285
Ile Leu Thr Ser Leu Leu Val Phe Phe Val Ser Glu Leu Val Gly Gly
290 295 300
Phe Gly Ile Ala Ile Val Val Phe Met Asn His Tyr Pro Leu Glu Lys
305 310 315 320
Ile Gly Asp Ser Val Trp Asp Gly His Gly Phe Ser Val Gly Gln Ile
325 330 335
His Glu Thr Met Asn Ile Arg Arg Gly Ile Ile Thr Asp Trp Phe Phe
340 345 350
Gly Gly Leu Asn Tyr Gln Ile Glu His His Leu Trp Pro Thr Leu Pro
355 360 365
Arg His Asn Leu Thr Ala Val Ser Tyr Gln Val Glu Gln Leu Cys Gln
370 375 380
Lys His Asn Leu Pro Tyr Arg Asn Pro Leu Pro His Glu Gly Leu Val
385 390 395 400
Ile Leu Leu Arg Tyr Leu Ala Val Phe Ala Arg Met Ala Glu Lys Gln
405 410 415
Pro Ala Gly Lys Ala Leu
420
<210> 70
<211> 4826
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKS121
<220>
<221> misc_feature
<222> (3711)..(3711)
<223> n is a, c, g, or t
<400> 70
tcgacggcgc gcccgatcat ccggatatag ttcctccttt cagcaaaaaa cccctcaaga 60
cccgtttaga ggccccaagg ggttatgcta gttattgctc agcggtggca gcagccaact 120
cagcttcctt tcgggctttg ttagcagccg gatcgatcca agctgtacct cactattcct 180
ttgccctcgg acgagtgctg gggcgtcggt ttccactatc ggcgagtact tctacacagc 240
catcggtcca gacggccgcg cttctgcggg cgatttgtgt acgcccgaca gtcccggctc 300
cggatcggac gattgcgtcg catcgaccct gcgcccaagc tgcatcatcg aaattgccgt 360
caaccaagct ctgatagagt tggtcaagac caatgcggag catatacgcc cggagccgcg 420
gcgatcctgc aagctccgga tgcctccgct cgaagtagcg cgtctgctgc tccatacaag 480
ccaaccacgg cctccagaag aagatgttgg cgacctcgta ttgggaatcc ccgaacatcg 540
cctcgctcca gtcaatgacc gctgttatgc ggccattgtc cgtcaggaca ttgttggagc 600
cgaaatccgc gtgcacgagg tgccggactt cggggcagtc ctcggcccaa agcatcagct 660
catcgagagc ctgcgcgacg gacgcactga cggtgtcgtc catcacagtt tgccagtgat 720
acacatgggg atcagcaatc gcgcatatga aatcacgcca tgtagtgtat tgaccgattc 780
cttgcggtcc gaatgggccg aacccgctcg tctggctaag atcggccgca gcgatcgcat 840
ccatagcctc cgcgaccggc tgcagaacag cgggcagttc ggtttcaggc aggtcttgca 900
acgtgacacc ctgtgcacgg cgggagatgc aataggtcag gctctcgctg aattccccaa 960
tgtcaagcac ttccggaatc gggagcgcgg ccgatgcaaa gtgccgataa acataacgat 1020
ctttgtagaa accatcggcg cagctattta cccgcaggac atatccacgc cctcctacat 1080
cgaagctgaa agcacgagat tcttcgccct ccgagagctg catcaggtcg gagacgctgt 1140
cgaacttttc gatcagaaac ttctcgacag acgtcgcggt gagttcaggc ttttccatgg 1200
gtatatctcc ttcttaaagt taaacaaaat tatttctaga gggaaaccgt tgtggtctcc 1260
ctatagtgag tcgtattaat ttcgcgggat cgagatctga tcaacctgca ttaatgaatc 1320
ggccaacgcg cggggagagg cggtttgcgt attgggcgct cttccgcttc ctcgctcact 1380
gactcgctgc gctcggtcgt tcggctgcgg cgagcggtat cagctcactc aaaggcggta 1440
atacggttat ccacagaatc aggggataac gcaggaaaga acatgtgagc aaaaggccag 1500
caaaaggcca ggaaccgtaa aaaggccgcg ttgctggcgt ttttccatag gctccgcccc 1560
cctgacgagc atcacaaaaa tcgacgctca agtcagaggt ggcgaaaccc gacaggacta 1620
taaagatacc aggcgtttcc ccctggaagc tccctcgtgc gctctcctgt tccgaccctg 1680
ccgcttaccg gatacctgtc cgcctttctc ccttcgggaa gcgtggcgct ttctcaatgc 1740
tcacgctgta ggtatctcag ttcggtgtag gtcgttcgct ccaagctggg ctgtgtgcac 1800
gaaccccccg ttcagcccga ccgctgcgcc ttatccggta actatcgtct tgagtccaac 1860
ccggtaagac acgacttatc gccactggca gcagccactg gtaacaggat tagcagagcg 1920
aggtatgtag gcggtgctac agagttcttg aagtggtggc ctaactacgg ctacactaga 1980
aggacagtat ttggtatctg cgctctgctg aagccagtta ccttcggaaa aagagttggt 2040
agctcttgat ccggcaaaca aaccaccgct ggtagcggtg gtttttttgt ttgcaagcag 2100
cagattacgc gcagaaaaaa aggatctcaa gaagatcctt tgatcttttc tacggggtct 2160
gacgctcagt ggaacgaaaa ctcacgttaa gggattttgg tcatgacatt aacctataaa 2220
aataggcgta tcacgaggcc ctttcgtctc gcgcgtttcg gtgatgacgg tgaaaacctc 2280
tgacacatgc agctcccgga gacggtcaca gcttgtctgt aagcggatgc cgggagcaga 2340
caagcccgtc agggcgcgtc agcgggtgtt ggcgggtgtc ggggctggct taactatgcg 2400
gcatcagagc agattgtact gagagtgcac catatggaca tattgtcgtt agaacgcggc 2460
tacaattaat acataacctt atgtatcata cacatacgat ttaggtgaca ctatagaacg 2520
gcgcgccaag cttggatcct cgaagagaag ggttaataac acatttttta acatttttaa 2580
cacaaatttt agttatttaa aaatttatta aaaaatttaa aataagaaga ggaactcttt 2640
aaataaatct aacttacaaa atttatgatt tttaataagt tttcaccaat aaaaaatgtc 2700
ataaaaatat gttaaaaagt atattatcaa tattctcttt atgataaata aaaagaaaaa 2760
aaaaataaaa gttaagtgaa aatgagattg aagtgacttt aggtgtgtat aaatatatca 2820
accccgccaa caatttattt aatccaaata tattgaagta tattattcca tagcctttat 2880
ttatttatat atttattata taaaagcttt atttgttcta ggttgttcat gaaatatttt 2940
tttggtttta tctccgttgt aagaaaatca tgtgctttgt gtcgccactc actattgcag 3000
ctttttcatg cattggtcag attgacggtt gattgtattt ttgtttttta tggttttgtg 3060
ttatgactta agtcttcatc tctttatctc ttcatcaggt ttgatggtta cctaatatgg 3120
tccatgggta catgcatggt taaattaggt ggccaacttt gttgtgaacg atagaatttt 3180
ttttatatta agtaaactat ttttatatta tgaaataata ataaaaaaaa tattttatca 3240
ttattaacaa aatcatatta gttaatttgt taactctata ataaaagaaa tactgtaaca 3300
ttcacattac atggtaacat ctttccaccc tttcatttgt tttttgtttg atgacttttt 3360
ttcttgttta aatttatttc ccttctttta aatttggaat acattatcat catatataaa 3420
ctaaaatact aaaaacagga ttacacaaat gataaataat aacacaaata tttataaatc 3480
tagctgcaat atatttaaac tagctatatc gatattgtaa aataaaacta gctgcattga 3540
tactgataaa aaaatatcat gtgctttctg gactgatgat gcagtatact tttgacattg 3600
cctttatttt atttttcaga aaagctttct tagttctggg ttcttcatta tttgtttccc 3660
atctccattg tgaattgaat catttgcttc gtgtcacaaa tacaatttag ntaggtacat 3720
gcattggtca gattcacggt ttattatgtc atgacttaag ttcatggtag tacattacct 3780
gccacgcatg cattatattg gttagatttg ataggcaaat ttggttgtca acaatataaa 3840
tataaataat gtttttatat tacgaaataa cagtgatcaa aacaaacagt tttatcttta 3900
ttaacaagat tttgtttttg tttgatgacg ttttttaatg tttacgcttt cccccttctt 3960
ttgaatttag aacactttat catcataaaa tcaaatacta aaaaaattac atatttcata 4020
aataataaca caaatatttt taaaaaatct gaaataataa tgaacaatat tacatattat 4080
cacgaaaatt cattaataaa aatattatat aaataaaatg taatagtagt tatatgtagg 4140
aaaaaagtac tgcacgcata atatatacaa aaagattaaa atgaactatt ataaataata 4200
acactaaatt aatggtgaat catatcaaaa taatgaaaaa gtaaataaaa tttgtaatta 4260
acttctatat gtattacaca cacaaataat aaataatagt aaaaaaaatt atgataaata 4320
tttaccatct cataagatat ttaaaataat gataaaaata tagattattt tttatgcaac 4380
tagctagcca aaaagagaac acgggtatat ataaaaagag tacctttaaa ttctactgta 4440
cttcctttat tcctgacgtt tttatatcaa gtggacatac gtgaagattt taattatcag 4500
tctaaatatt tcattagcac ttaatacttt tctgttttat tcctatccta taagtagtcc 4560
cgattctccc aacattgctt attcacacaa ctaactaaga aagtcttcca tagcccccca 4620
agcggccgcg acacaagtgt gagagtacta aataaatgct ttggttgtac gaaatcatta 4680
cactaaataa aataatcaaa gcttatatat gccttccgct aaggccgaat gcaaagaaat 4740
tggttctttc tcgttatctt ttgccacttt tactagtacg tattaattac tacttaatca 4800
tctttgttta cggctcatta tatccg 4826
<210> 71
<211> 5252
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR457
<220>
<221> misc_feature
<222> (3872)..(3872)
<223> n is a, c, g, or t
<400> 71
gtacgtgggc ggatcccccg ggctgcagga attcactggc cgtcgtttta caacgtcgtg 60
actgggaaaa ccctggcgtt acccaactta atcgccttgc agcacatccc cctttcgcca 120
gctggcgtaa tagcgaagag gcccgcaccg atcgcccttc ccaacagttg cgcagcctga 180
atggcgaatg gcgcctgatg cggtattttc tccttacgca tctgtgcggt atttcacacc 240
gcatatggtg cactctcagt acaatctgct ctgatgccgc atagttaagc cagccccgac 300
acccgccaac acccgctgac gcgccctgac gggcttgtct gctcccggca tccgcttaca 360
gacaagctgt gaccgtctcc gggagctgca tgtgtcagag gttttcaccg tcatcaccga 420
aacgcgcgag acgaaagggc ctcgtgatac gcctattttt ataggttaat gtcatgataa 480
taatggtttc ttagacgtca ggtggcactt ttcggggaaa tgtgcgcgga acccctattt 540
gtttattttt ctaaatacat tcaaatatgt atccgctcat gagacaataa ccctgataaa 600
tgcttcaata atattgaaaa aggaagagta tgagtattca acatttccgt gtcgccctta 660
ttcccttttt tgcggcattt tgccttcctg tttttgctca cccagaaacg ctggtgaaag 720
taaaagatgc tgaagatcag ttgggtgcac gagtgggtta catcgaactg gatctcaaca 780
gcggtaagat ccttgagagt tttcgccccg aagaacgttt tccaatgatg agcactttta 840
aagttctgct atgtggcgcg gtattatccc gtattgacgc cgggcaagag caactcggtc 900
gccgcataca ctattctcag aatgacttgg ttgagtactc accagtcaca gaaaagcatc 960
ttacggatgg catgacagta agagaattat gcagtgctgc cataaccatg agtgataaca 1020
ctgcggccaa cttacttctg acaacgatcg gaggaccgaa ggagctaacc gcttttttgc 1080
acaacatggg ggatcatgta actcgccttg atcgttggga accggagctg aatgaagcca 1140
taccaaacga cgagcgtgac accacgatgc ctgtagcaat ggcaacaacg ttgcgcaaac 1200
tattaactgg cgaactactt actctagctt cccggcaaca attaatagac tggatggagg 1260
cggataaagt tgcaggacca cttctgcgct cggcccttcc ggctggctgg tttattgctg 1320
ataaatctgg agccggtgag cgtgggtctc gcggtatcat tgcagcactg gggccagatg 1380
gtaagccctc ccgtatcgta gttatctaca cgacggggag tcaggcaact atggatgaac 1440
gaaatagaca gatcgctgag ataggtgcct cactgattaa gcattggtaa ctgtcagacc 1500
aagtttactc atatatactt tagattgatt taaaacttca tttttaattt aaaaggatct 1560
aggtgaagat cctttttgat aatctcatga ccaaaatccc ttaacgtgag ttttcgttcc 1620
actgagcgtc agaccccgta gaaaagatca aaggatcttc ttgagatcct ttttttctgc 1680
gcgtaatctg ctgcttgcaa acaaaaaaac caccgctacc agcggtggtt tgtttgccgg 1740
atcaagagct accaactctt tttccgaagg taactggctt cagcagagcg cagataccaa 1800
atactgtcct tctagtgtag ccgtagttag gccaccactt caagaactct gtagcaccgc 1860
ctacatacct cgctctgcta atcctgttac cagtggctgc tgccagtggc gataagtcgt 1920
gtcttaccgg gttggactca agacgatagt taccggataa ggcgcagcgg tcgggctgaa 1980
cggggggttc gtgcacacag cccagcttgg agcgaacgac ctacaccgaa ctgagatacc 2040
tacagcgtga gctatgagaa agcgccacgc ttcccgaagg gagaaaggcg gacaggtatc 2100
cggtaagcgg cagggtcgga acaggagagc gcacgaggga gcttccaggg ggaaacgcct 2160
ggtatcttta tagtcctgtc gggtttcgcc acctctgact tgagcgtcga tttttgtgat 2220
gctcgtcagg ggggcggagc ctatggaaaa acgccagcaa cgcggccttt ttacggttcc 2280
tggccttttg ctggcctttt gctcacatgt tctttcctgc gttatcccct gattctgtgg 2340
ataaccgtat taccgccttt gagtgagctg ataccgctcg ccgcagccga acgaccgagc 2400
gcagcgagtc agtgagcgag gaagcggaag agcgcccaat acgcaaaccg cctctccccg 2460
cgcgttggcc gattcattaa tgcagctggc acgacaggtt tcccgactgg aaagcgggca 2520
gtgagcgcaa cgcaattaat gtgagttagc tcactcatta ggcaccccag gctttacact 2580
ttatgcttcc ggctcgtatg ttgtgtggaa ttgtgagcgg ataacaattt cacacaggaa 2640
acagctatga ccatgattac gccaagcttg catgcctgca ggtcgactcg acgtacgtcc 2700
tcgaagagaa gggttaataa cacatttttt aacattttta acacaaattt tagttattta 2760
aaaatttatt aaaaaattta aaataagaag aggaactctt taaataaatc taacttacaa 2820
aatttatgat ttttaataag ttttcaccaa taaaaaatgt cataaaaata tgttaaaaag 2880
tatattatca atattctctt tatgataaat aaaaagaaaa aaaaaataaa agttaagtga 2940
aaatgagatt gaagtgactt taggtgtgta taaatatatc aaccccgcca acaatttatt 3000
taatccaaat atattgaagt atattattcc atagccttta tttatttata tatttattat 3060
ataaaagctt tatttgttct aggttgttca tgaaatattt ttttggtttt atctccgttg 3120
taagaaaatc atgtgctttg tgtcgccact cactattgca gctttttcat gcattggtca 3180
gattgacggt tgattgtatt tttgtttttt atggttttgt gttatgactt aagtcttcat 3240
ctctttatct cttcatcagg tttgatggtt acctaatatg gtccatgggt acatgcatgg 3300
ttaaattagg tggccaactt tgttgtgaac gatagaattt tttttatatt aagtaaacta 3360
tttttatatt atgaaataat aataaaaaaa atattttatc attattaaca aaatcatatt 3420
agttaatttg ttaactctat aataaaagaa atactgtaac attcacatta catggtaaca 3480
tctttccacc ctttcatttg ttttttgttt gatgactttt tttcttgttt aaatttattt 3540
cccttctttt aaatttggaa tacattatca tcatatataa actaaaatac taaaaacagg 3600
attacacaaa tgataaataa taacacaaat atttataaat ctagctgcaa tatatttaaa 3660
ctagctatat cgatattgta aaataaaact agctgcattg atactgataa aaaaatatca 3720
tgtgctttct ggactgatga tgcagtatac ttttgacatt gcctttattt tatttttcag 3780
aaaagctttc ttagttctgg gttcttcatt atttgtttcc catctccatt gtgaattgaa 3840
tcatttgctt cgtgtcacaa atacaattta gntaggtaca tgcattggtc agattcacgg 3900
tttattatgt catgacttaa gttcatggta gtacattacc tgccacgcat gcattatatt 3960
ggttagattt gataggcaaa tttggttgtc aacaatataa atataaataa tgtttttata 4020
ttacgaaata acagtgatca aaacaaacag ttttatcttt attaacaaga ttttgttttt 4080
gtttgatgac gttttttaat gtttacgctt tcccccttct tttgaattta gaacacttta 4140
tcatcataaa atcaaatact aaaaaaatta catatttcat aaataataac acaaatattt 4200
ttaaaaaatc tgaaataata atgaacaata ttacatatta tcacgaaaat tcattaataa 4260
aaatattata taaataaaat gtaatagtag ttatatgtag gaaaaaagta ctgcacgcat 4320
aatatataca aaaagattaa aatgaactat tataaataat aacactaaat taatggtgaa 4380
tcatatcaaa ataatgaaaa agtaaataaa atttgtaatt aacttctata tgtattacac 4440
acacaaataa taaataatag taaaaaaaat tatgataaat atttaccatc tcataagata 4500
tttaaaataa tgataaaaat atagattatt ttttatgcaa ctagctagcc aaaaagagaa 4560
cacgggtata tataaaaaga gtacctttaa attctactgt acttccttta ttcctgacgt 4620
ttttatatca agtggacata cgtgaagatt ttaattatca gtctaaatat ttcattagca 4680
cttaatactt ttctgtttta ttcctatcct ataagtagtc ccgattctcc caacattgct 4740
tattcacaca actaactaag aaagtcttcc atagcccccc aagcggccgc gacacaagtg 4800
tgagagtact aaataaatgc tttggttgta cgaaatcatt acactaaata aaataatcaa 4860
agcttatata tgccttccgc taaggccgaa tgcaaagaaa ttggttcttt ctcgttatct 4920
tttgccactt ttactagtac gtattaatta ctacttaatc atctttgttt acggctcatt 4980
atatccggtc tagaggatcc aaggccgcga agttaaaagc aatgttgtca cttgtcgtac 5040
taacacatga tgtgatagtt tatgctagct agctataaca taagctgtct ctgagtgtgt 5100
tgtatattaa taaagatcat cactggtgaa tggtgatcgt gtacgtaccc tacttagtag 5160
gcaatggaag cacttagagt gtgctttgtg catggccttg cctctgtttt gagacttttg 5220
taatgttttc gagtttaaat ctttgccttt gc 5252
<210> 72
<211> 37
<212> DNA
<213> Artificial Sequence
<220>
<223> KTi cassette 5' end MCS for pKR457
<400> 72
aagcttgcat gcctgcaggt cgactcgacg tacgtcc 37
<210> 73
<211> 282
<212> DNA
<213> Artificial Sequence
<220>
<223> KTi cassette 3' end MCS for pKR457 including the soy albumin
transcription 3' terminator
<400> 73
ggtctagagg atccaaggcc gcgaagttaa aagcaatgtt gtcacttgtc gtactaacac 60
atgatgtgat agtttatgct agctagctat aacataagct gtctctgagt gtgttgtata 120
ttaataaaga tcatcactgg tgaatggtga tcgtgtacgt accctactta gtaggcaatg 180
gaagcactta gagtgtgctt tgtgcatggc cttgcctctg ttttgagact tttgtaatgt 240
tttcgagttt aaatctttgc ctttgcgtac gtgggcggat cc 282
<210> 74
<211> 32
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer oSalb-12
<400> 74
tttggatcct ctagacgtac gcaaaggcaa ag 32
<210> 75
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer oSalb-13
<400> 75
aaaggatcca aggccgcgaa gttaaaagca atgttg 36
<210> 76
<211> 6559
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR680
<220>
<221> misc_feature
<222> (4340)..(4340)
<223> n is a, c, g, or t
<400> 76
ggccgcgaca caagtgtgag agtactaaat aaatgctttg gttgtacgaa atcattacac 60
taaataaaat aatcaaagct tatatatgcc ttccgctaag gccgaatgca aagaaattgg 120
ttctttctcg ttatcttttg ccacttttac tagtacgtat taattactac ttaatcatct 180
ttgtttacgg ctcattatat ccggtctaga ggatccaagg ccgcgaagtt aaaagcaatg 240
ttgtcacttg tcgtactaac acatgatgtg atagtttatg ctagctagct ataacataag 300
ctgtctctga gtgtgttgta tattaataaa gatcatcact ggtgaatggt gatcgtgtac 360
gtaccctact tagtaggcaa tggaagcact tagagtgtgc tttgtgcatg gccttgcctc 420
tgttttgaga cttttgtaat gttttcgagt ttaaatcttt gcctttgcgt acgtgggcgg 480
atcccccggg ctgcaggaat tcactggccg tcgttttaca acgtcgtgac tgggaaaacc 540
ctggcgttac ccaacttaat cgccttgcag cacatccccc tttcgccagc tggcgtaata 600
gcgaagaggc ccgcaccgat cgcccttccc aacagttgcg cagcctgaat ggcgaatggc 660
gcctgatgcg gtattttctc cttacgcatc tgtgcggtat ttcacaccgc atatggtgca 720
ctctcagtac aatctgctct gatgccgcat agttaagcca gccccgacac ccgccaacac 780
ccgctgacgc gccctgacgg gcttgtctgc tcccggcatc cgcttacaga caagctgtga 840
ccgtctccgg gagctgcatg tgtcagaggt tttcaccgtc atcaccgaaa cgcgcgagac 900
gaaagggcct cgtgatacgc ctatttttat aggttaatgt catgataata atggtttctt 960
agacgtcagg tggcactttt cggggaaatg tgcgcggaac ccctatttgt ttatttttct 1020
aaatacattc aaatatgtat ccgctcatga gacaataacc ctgataaatg cttcaataat 1080
attgaaaaag gaagagtatg agtattcaac atttccgtgt cgcccttatt cccttttttg 1140
cggcattttg ccttcctgtt tttgctcacc cagaaacgct ggtgaaagta aaagatgctg 1200
aagatcagtt gggtgcacga gtgggttaca tcgaactgga tctcaacagc ggtaagatcc 1260
ttgagagttt tcgccccgaa gaacgttttc caatgatgag cacttttaaa gttctgctat 1320
gtggcgcggt attatcccgt attgacgccg ggcaagagca actcggtcgc cgcatacact 1380
attctcagaa tgacttggtt gagtactcac cagtcacaga aaagcatctt acggatggca 1440
tgacagtaag agaattatgc agtgctgcca taaccatgag tgataacact gcggccaact 1500
tacttctgac aacgatcgga ggaccgaagg agctaaccgc ttttttgcac aacatggggg 1560
atcatgtaac tcgccttgat cgttgggaac cggagctgaa tgaagccata ccaaacgacg 1620
agcgtgacac cacgatgcct gtagcaatgg caacaacgtt gcgcaaacta ttaactggcg 1680
aactacttac tctagcttcc cggcaacaat taatagactg gatggaggcg gataaagttg 1740
caggaccact tctgcgctcg gcccttccgg ctggctggtt tattgctgat aaatctggag 1800
ccggtgagcg tgggtctcgc ggtatcattg cagcactggg gccagatggt aagccctccc 1860
gtatcgtagt tatctacacg acggggagtc aggcaactat ggatgaacga aatagacaga 1920
tcgctgagat aggtgcctca ctgattaagc attggtaact gtcagaccaa gtttactcat 1980
atatacttta gattgattta aaacttcatt tttaatttaa aaggatctag gtgaagatcc 2040
tttttgataa tctcatgacc aaaatccctt aacgtgagtt ttcgttccac tgagcgtcag 2100
accccgtaga aaagatcaaa ggatcttctt gagatccttt ttttctgcgc gtaatctgct 2160
gcttgcaaac aaaaaaacca ccgctaccag cggtggtttg tttgccggat caagagctac 2220
caactctttt tccgaaggta actggcttca gcagagcgca gataccaaat actgtccttc 2280
tagtgtagcc gtagttaggc caccacttca agaactctgt agcaccgcct acatacctcg 2340
ctctgctaat cctgttacca gtggctgctg ccagtggcga taagtcgtgt cttaccgggt 2400
tggactcaag acgatagtta ccggataagg cgcagcggtc gggctgaacg gggggttcgt 2460
gcacacagcc cagcttggag cgaacgacct acaccgaact gagataccta cagcgtgagc 2520
tatgagaaag cgccacgctt cccgaaggga gaaaggcgga caggtatccg gtaagcggca 2580
gggtcggaac aggagagcgc acgagggagc ttccaggggg aaacgcctgg tatctttata 2640
gtcctgtcgg gtttcgccac ctctgacttg agcgtcgatt tttgtgatgc tcgtcagggg 2700
ggcggagcct atggaaaaac gccagcaacg cggccttttt acggttcctg gccttttgct 2760
ggccttttgc tcacatgttc tttcctgcgt tatcccctga ttctgtggat aaccgtatta 2820
ccgcctttga gtgagctgat accgctcgcc gcagccgaac gaccgagcgc agcgagtcag 2880
tgagcgagga agcggaagag cgcccaatac gcaaaccgcc tctccccgcg cgttggccga 2940
ttcattaatg cagctggcac gacaggtttc ccgactggaa agcgggcagt gagcgcaacg 3000
caattaatgt gagttagctc actcattagg caccccaggc tttacacttt atgcttccgg 3060
ctcgtatgtt gtgtggaatt gtgagcggat aacaatttca cacaggaaac agctatgacc 3120
atgattacgc caagcttgca tgcctgcagg tcgactcgac gtacgtcctc gaagagaagg 3180
gttaataaca cattttttaa catttttaac acaaatttta gttatttaaa aatttattaa 3240
aaaatttaaa ataagaagag gaactcttta aataaatcta acttacaaaa tttatgattt 3300
ttaataagtt ttcaccaata aaaaatgtca taaaaatatg ttaaaaagta tattatcaat 3360
attctcttta tgataaataa aaagaaaaaa aaaataaaag ttaagtgaaa atgagattga 3420
agtgacttta ggtgtgtata aatatatcaa ccccgccaac aatttattta atccaaatat 3480
attgaagtat attattccat agcctttatt tatttatata tttattatat aaaagcttta 3540
tttgttctag gttgttcatg aaatattttt ttggttttat ctccgttgta agaaaatcat 3600
gtgctttgtg tcgccactca ctattgcagc tttttcatgc attggtcaga ttgacggttg 3660
attgtatttt tgttttttat ggttttgtgt tatgacttaa gtcttcatct ctttatctct 3720
tcatcaggtt tgatggttac ctaatatggt ccatgggtac atgcatggtt aaattaggtg 3780
gccaactttg ttgtgaacga tagaattttt tttatattaa gtaaactatt tttatattat 3840
gaaataataa taaaaaaaat attttatcat tattaacaaa atcatattag ttaatttgtt 3900
aactctataa taaaagaaat actgtaacat tcacattaca tggtaacatc tttccaccct 3960
ttcatttgtt ttttgtttga tgactttttt tcttgtttaa atttatttcc cttcttttaa 4020
atttggaata cattatcatc atatataaac taaaatacta aaaacaggat tacacaaatg 4080
ataaataata acacaaatat ttataaatct agctgcaata tatttaaact agctatatcg 4140
atattgtaaa ataaaactag ctgcattgat actgataaaa aaatatcatg tgctttctgg 4200
actgatgatg cagtatactt ttgacattgc ctttatttta tttttcagaa aagctttctt 4260
agttctgggt tcttcattat ttgtttccca tctccattgt gaattgaatc atttgcttcg 4320
tgtcacaaat acaatttagn taggtacatg cattggtcag attcacggtt tattatgtca 4380
tgacttaagt tcatggtagt acattacctg ccacgcatgc attatattgg ttagatttga 4440
taggcaaatt tggttgtcaa caatataaat ataaataatg tttttatatt acgaaataac 4500
agtgatcaaa acaaacagtt ttatctttat taacaagatt ttgtttttgt ttgatgacgt 4560
tttttaatgt ttacgctttc ccccttcttt tgaatttaga acactttatc atcataaaat 4620
caaatactaa aaaaattaca tatttcataa ataataacac aaatattttt aaaaaatctg 4680
aaataataat gaacaatatt acatattatc acgaaaattc attaataaaa atattatata 4740
aataaaatgt aatagtagtt atatgtagga aaaaagtact gcacgcataa tatatacaaa 4800
aagattaaaa tgaactatta taaataataa cactaaatta atggtgaatc atatcaaaat 4860
aatgaaaaag taaataaaat ttgtaattaa cttctatatg tattacacac acaaataata 4920
aataatagta aaaaaaatta tgataaatat ttaccatctc ataagatatt taaaataatg 4980
ataaaaatat agattatttt ttatgcaact agctagccaa aaagagaaca cgggtatata 5040
taaaaagagt acctttaaat tctactgtac ttcctttatt cctgacgttt ttatatcaag 5100
tggacatacg tgaagatttt aattatcagt ctaaatattt cattagcact taatactttt 5160
ctgttttatt cctatcctat aagtagtccc gattctccca acattgctta ttcacacaac 5220
taactaagaa agtcttccat agccccccaa gcggccgcgg gaattcgatt gaaatgaagt 5280
caaagcgcca agcgcttccc cttacaattg atggaacaac atatgatgtg tctgcctggg 5340
tcaatttcca ccctggtggt gcggaaatta tagagaatta ccaaggaagg gatgccactg 5400
atgccttcat ggttatgcac tctcaagaag ccttcgacaa gctcaagcgc atgcccaaaa 5460
tcaatcccag ttctgagttg ccaccccagg ctgcagtgaa tgaagctcaa gaggatttcc 5520
ggaagctccg agaagagttg atcgcaactg gcatgtttga tgcctccccc ctctggtact 5580
catacaaaat cagcaccaca ctgggccttg gagtgctggg ttatttcctg atggttcagt 5640
atcagatgta tttcattggg gcagtgttgc ttgggatgca ctatcaacag atgggctggc 5700
tttctcatga catttgccac caccagactt tcaagaaccg gaactggaac aacctcgtgg 5760
gactggtatt tggcaatggt ctgcaaggtt tttccgtgac atggtggaag gacagacaca 5820
atgcacatca ttcggcaacc aatgttcaag ggcacgaccc tgatattgac aacctccccc 5880
tcttagcctg gtctgaggat gacgtcacac gggcgtcacc gatttcccgc aagctcattc 5940
agttccagca gtactatttc ttggtcatct gtatcttgtt gcggttcatt tggtgtttcc 6000
agagcgtgtt gaccgtgcgc agtttgaagg acagagataa ccaattctat cgctctcagt 6060
ataagaagga ggccattggc ctcgccctgc actggacctt gaagaccctg ttccacttat 6120
tctttatgcc cagcatcctc acatcgctgt tggtgttttt cgtttcggag ctggttggcg 6180
gcttcggcat tgcgatcgtg gtgttcatga accactaccc actggagaag atcggggact 6240
cagtctggga tggccatgga ttctcggttg gccagatcca tgagaccatg aacattcggc 6300
gagggattat cacagattgg tttttcggag gcttgaatta ccagattgag caccatttgt 6360
ggccgaccct ccctcgccac aacctgacag cggttagcta ccaggtggaa cagctgtgcc 6420
agaagcacaa cctgccgtat cggaacccgc tgccccatga agggttggtc atcctgctgc 6480
gctatctggc ggtgttcgcc cggatggcgg agaagcaacc cgcggggaag gctctataag 6540
gaatcactag tgaattcgc 6559
<210> 77
<211> 9014
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR913
<220>
<221> misc_feature
<222> (7839)..(7839)
<223> n is a, c, g, or t
<400> 77
gtacgagatc cggccggcca gatcctgcag gagatccaag cttttgatcc atgcccttca 60
tttgccgctt attaattaat ttggtaacag tccgtactaa tcagttactt atccttcccc 120
catcataatt aatcttggta gtctcgaatg ccacaacact gactagtctc ttggatcata 180
agaaaaagcc aaggaacaaa agaagacaaa acacaatgag agtatccttt gcatagcaat 240
gtctaagttc ataaaattca aacaaaaacg caatcacaca cagtggacat cacttatcca 300
ctagctgatc aggatcgccg cgtcaagaaa aaaaaactgg accccaaaag ccatgcacaa 360
caacacgtac tcacaaaggt gtcaatcgag cagcccaaaa cattcaccaa ctcaacccat 420
catgagccct cacatttgtt gtttctaacc caacctcaaa ctcgtattct cttccgccac 480
ctcatttttg tttatttcaa cacccgtcaa actgcatgcc accccgtggc caaatgtcca 540
tgcatgttaa caagacctat gactataaat agctgcaatc tcggcccagg ttttcatcat 600
caagaaccag ttcaatatcc tagtacaccg tattaaagaa tttaagatat actgcggccg 660
caccatggag gtggtgaatg aaatagtctc aattgggcag gaagttttac ccaaagttga 720
ttatgcccaa ctctggagtg atgccagtca ctgtgaggtg ctttacttgt ccatcgcatt 780
tgtcatcttg aagttcactc ttggccccct tggtccaaaa ggtcagtctc gtatgaagtt 840
tgttttcacc aattacaacc ttctcatgtc catttattcg ttgggatcat tcctctcaat 900
ggcatatgcc atgtacacca tcggtgttat gtctgacaac tgcgagaagg cttttgacaa 960
caacgtcttc aggatcacca cgcagttgtt ctatttgagc aagttcctgg agtatattga 1020
ctccttctat ttgccactga tgggcaagcc tctgacctgg ttgcaattct tccatcattt 1080
gggggcaccg atggatatgt ggctgttcta taattaccga aatgaagctg tttggatttt 1140
tgtgctgttg aatggtttca tccactggat catgtacggt tattattgga ccagattgat 1200
caagctgaag ttccccatgc caaaatccct gattacatca atgcagatca ttcaattcaa 1260
tgttggtttc tacattgtct ggaagtacag gaacattccc tgttatcgcc aagatgggat 1320
gaggatgttt ggctggttct tcaattactt ttatgttggc acagtcttgt gtttgttctt 1380
gaatttctat gtgcaaacgt atatcgtcag gaagcacaag ggagccaaaa agattcagtg 1440
agcggccgca agtatgaact aaaatgcatg taggtgtaag agctcatgga gagcatggaa 1500
tattgtatcc gaccatgtaa cagtataata actgagctcc atctcacttc ttctatgaat 1560
aaacaaagga tgttatgata tattaacact ctatctatgc accttattgt tctatgataa 1620
atttcctctt attattataa atcatctgaa tcgtgacggc ttatggaatg cttcaaatag 1680
tacaaaaaca aatgtgtact ataagacttt ctaaacaatt ctaaccttag cattgtgaac 1740
gagacataag tgttaagaag acataacaat tataatggaa gaagtttgtc tccatttata 1800
tattatatat tacccactta tgtattatat taggatgtta aggagacata acaattataa 1860
agagagaagt ttgtatccat ttatatatta tatactaccc atttatatat tatacttatc 1920
cacttattta atgtctttat aaggtttgat ccatgatatt tctaatattt tagttgatat 1980
gtatatgaaa gggtactatt tgaactctct tactctgtat aaaggttgga tcatccttaa 2040
agtgggtcta tttaatttta ttgcttctta cagataaaaa aaaaattatg agttggtttg 2100
ataaaatatt gaaggattta aaataataat aaataacata taatatatgt atataaattt 2160
attataatat aacatttatc tataaaaaag taaatattgt cataaatcta tacaatcgtt 2220
tagccttgct ggacgaatct caattattta aacgagagta aacatatttg actttttggt 2280
tatttaacaa attattattt aacactatat gaaatttttt tttttatcag caaagaataa 2340
aattaaatta agaaggacaa tggtgtccca atccttatac aaccaacttc cacaagaaag 2400
tcaagtcaga gacaacaaaa aaacaagcaa aggaaatttt ttaatttgag ttgtcttgtt 2460
tgctgcataa tttatgcagt aaaacactac acataaccct tttagcagta gagcaatggt 2520
tgaccgtgtg cttagcttct tttattttat ttttttatca gcaaagaata aataaaataa 2580
aatgagacac ttcagggatg tttcaacaag cttggcgcgc cgttctatag tgtcacctaa 2640
atcgtatgtg tatgatacat aaggttatgt attaattgta gccgcgttct aacgacaata 2700
tgtccatatg gtgcactctc agtacaatct gctctgatgc cgcatagtta agccagcccc 2760
gacacccgcc aacacccgct gacgcgccct gacgggcttg tctgctcccg gcatccgctt 2820
acagacaagc tgtgaccgtc tccgggagct gcatgtgtca gaggttttca ccgtcatcac 2880
cgaaacgcgc gagacgaaag ggcctcgtga tacgcctatt tttataggtt aatgtcatga 2940
ccaaaatccc ttaacgtgag ttttcgttcc actgagcgtc agaccccgta gaaaagatca 3000
aaggatcttc ttgagatcct ttttttctgc gcgtaatctg ctgcttgcaa acaaaaaaac 3060
caccgctacc agcggtggtt tgtttgccgg atcaagagct accaactctt tttccgaagg 3120
taactggctt cagcagagcg cagataccaa atactgtcct tctagtgtag ccgtagttag 3180
gccaccactt caagaactct gtagcaccgc ctacatacct cgctctgcta atcctgttac 3240
cagtggctgc tgccagtggc gataagtcgt gtcttaccgg gttggactca agacgatagt 3300
taccggataa ggcgcagcgg tcgggctgaa cggggggttc gtgcacacag cccagcttgg 3360
agcgaacgac ctacaccgaa ctgagatacc tacagcgtga gcattgagaa agcgccacgc 3420
ttcccgaagg gagaaaggcg gacaggtatc cggtaagcgg cagggtcgga acaggagagc 3480
gcacgaggga gcttccaggg ggaaacgcct ggtatcttta tagtcctgtc gggtttcgcc 3540
acctctgact tgagcgtcga tttttgtgat gctcgtcagg ggggcggagc ctatggaaaa 3600
acgccagcaa cgcggccttt ttacggttcc tggccttttg ctggcctttt gctcacatgt 3660
tctttcctgc gttatcccct gattctgtgg ataaccgtat taccgccttt gagtgagctg 3720
ataccgctcg ccgcagccga acgaccgagc gcagcgagtc agtgagcgag gaagcggaag 3780
agcgcccaat acgcaaaccg cctctccccg cgcgttggcc gattcattaa tgcaggttga 3840
tcagatctcg atcccgcgaa attaatacga ctcactatag ggagaccaca acggtttccc 3900
tctagaaata attttgttta actttaagaa ggagatatac ccatggaaaa gcctgaactc 3960
accgcgacgt ctgtcgagaa gtttctgatc gaaaagttcg acagcgtctc cgacctgatg 4020
cagctctcgg agggcgaaga atctcgtgct ttcagcttcg atgtaggagg gcgtggatat 4080
gtcctgcggg taaatagctg cgccgatggt ttctacaaag atcgttatgt ttatcggcac 4140
tttgcatcgg ccgcgctccc gattccggaa gtgcttgaca ttggggaatt cagcgagagc 4200
ctgacctatt gcatctcccg ccgtgcacag ggtgtcacgt tgcaagacct gcctgaaacc 4260
gaactgcccg ctgttctgca gccggtcgcg gaggctatgg atgcgatcgc tgcggccgat 4320
cttagccaga cgagcgggtt cggcccattc ggaccgcaag gaatcggtca atacactaca 4380
tggcgtgatt tcatatgcgc gattgctgat ccccatgtgt atcactggca aactgtgatg 4440
gacgacaccg tcagtgcgtc cgtcgcgcag gctctcgatg agctgatgct ttgggccgag 4500
gactgccccg aagtccggca cctcgtgcac gcggatttcg gctccaacaa tgtcctgacg 4560
gacaatggcc gcataacagc ggtcattgac tggagcgagg cgatgttcgg ggattcccaa 4620
tacgaggtcg ccaacatctt cttctggagg ccgtggttgg cttgtatgga gcagcagacg 4680
cgctacttcg agcggaggca tccggagctt gcaggatcgc cgcggctccg ggcgtatatg 4740
ctccgcattg gtcttgacca actctatcag agcttggttg acggcaattt cgatgatgca 4800
gcttgggcgc agggtcgatg cgacgcaatc gtccgatccg gagccgggac tgtcgggcgt 4860
acacaaatcg cccgcagaag cgcggccgtc tggaccgatg gctgtgtaga agtactcgcc 4920
gatagtggaa accgacgccc cagcactcgt ccgagggcaa aggaatagtg aggtacagct 4980
tggatcgatc cggctgctaa caaagcccga aaggaagctg agttggctgc tgccaccgct 5040
gagcaataac tagcataacc ccttggggcc tctaaacggg tcttgagggg ttttttgctg 5100
aaaggaggaa ctatatccgg atgatcgggc gcgccgtcga cggatccgta cgcaaaggca 5160
aagatttaaa ctcgaaaaca ttacaaaagt ctcaaaacag aggcaaggcc atgcacaaag 5220
cacactctaa gtgcttccat tgcctactaa gtagggtacg tacacgatca ccattcacca 5280
gtgatgatct ttattaatat acaacacact cagagacagc ttatgttata gctagctagc 5340
ataaactatc acatcatgtg ttagtacgac aagtgacaac attgctttta acttcgcggc 5400
cttggatcct ctagaccgga tataatgagc cgtaaacaaa gatgattaag tagtaattaa 5460
tacgtactag taaaagtggc aaaagataac gagaaagaac caatttcttt gcattcggcc 5520
ttagcggaag gcatatataa gctttgatta ttttatttag tgtaatgatt tcgtacaacc 5580
aaagcattta tttagtactc tcacacttgt gtcgcggccg cgaattcact agtgattcct 5640
tatagagcct tccccgcggg ttgcttctcc gccatccggg cgaacaccgc cagatagcgc 5700
agcaggatga ccaacccttc atggggcagc gggttccgat acggcaggtt gtgcttctgg 5760
cacagctgtt ccacctggta gctaaccgct gtcaggttgt ggcgagggag ggtcggccac 5820
aaatggtgct caatctggta attcaagcct ccgaaaaacc aatctgtgat aatccctcgc 5880
cgaatgttca tggtctcatg gatctggcca accgagaatc catggccatc ccagactgag 5940
tccccgatct tctccagtgg gtagtggttc atgaacacca cgatcgcaat gccgaagccg 6000
ccaaccagct ccgaaacgaa aaacaccaac agcgatgtga ggatgctggg cataaagaat 6060
aagtggaaca gggtcttcaa ggtccagtgc agggcgaggc caatggcctc cttcttatac 6120
tgagagcgat agaattggtt atctctgtcc ttcaaactgc gcacggtcaa cacgctctgg 6180
aaacaccaaa tgaaccgcaa caagatacag atgaccaaga aatagtactg ctggaactga 6240
atgagcttgc gggaaatcgg tgacgcccgt gtgacgtcat cctcagacca ggctaagagg 6300
gggaggttgt caatatcagg gtcgtgccct tgaacattgg ttgccgaatg atgtgcattg 6360
tgtctgtcct tccaccatgt cacggaaaaa ccttgcagac cattgccaaa taccagtccc 6420
acgaggttgt tccagttccg gttcttgaaa gtctggtggt ggcaaatgtc atgagaaagc 6480
cagcccatct gttgatagtg catcccaagc aacactgccc caatgaaata catctgatac 6540
tgaaccatca ggaaataacc cagcactcca aggcccagtg tggtgctgat tttgtatgag 6600
taccagaggg gggaggcatc aaacatgcca gttgcgatca actcttctcg gagcttccgg 6660
aaatcctctt gagcttcatt cactgcagcc tggggtggca actcagaact gggattgatt 6720
ttgggcatgc gcttgagctt gtcgaaggct tcttgagagt gcataaccat gaaggcatca 6780
gtggcatccc ttccttggta attctctata atttccgcac caccagggtg gaaattgacc 6840
caggcagaca catcatatgt tgttccatca attgtaaggg gaagcgcttg gcgctttgac 6900
ttcatttcaa tcgaattccc gcggccgctt ggggggctat ggaagacttt cttagttagt 6960
tgtgtgaata agcaatgttg ggagaatcgg gactacttat aggataggaa taaaacagaa 7020
aagtattaag tgctaatgaa atatttagac tgataattaa aatcttcacg tatgtccact 7080
tgatataaaa acgtcaggaa taaaggaagt acagtagaat ttaaaggtac tctttttata 7140
tatacccgtg ttctcttttt ggctagctag ttgcataaaa aataatctat atttttatca 7200
ttattttaaa tatcttatga gatggtaaat atttatcata atttttttta ctattattta 7260
ttatttgtgt gtgtaataca tatagaagtt aattacaaat tttatttact ttttcattat 7320
tttgatatga ttcaccatta atttagtgtt attatttata atagttcatt ttaatctttt 7380
tgtatatatt atgcgtgcag tacttttttc ctacatataa ctactattac attttattta 7440
tataatattt ttattaatga attttcgtga taatatgtaa tattgttcat tattatttca 7500
gattttttaa aaatatttgt gttattattt atgaaatatg taattttttt agtatttgat 7560
tttatgatga taaagtgttc taaattcaaa agaaggggga aagcgtaaac attaaaaaac 7620
gtcatcaaac aaaaacaaaa tcttgttaat aaagataaaa ctgtttgttt tgatcactgt 7680
tatttcgtaa tataaaaaca ttatttatat ttatattgtt gacaaccaaa tttgcctatc 7740
aaatctaacc aatataatgc atgcgtggca ggtaatgtac taccatgaac ttaagtcatg 7800
acataataaa ccgtgaatct gaccaatgca tgtacctanc taaattgtat ttgtgacacg 7860
aagcaaatga ttcaattcac aatggagatg ggaaacaaat aatgaagaac ccagaactaa 7920
gaaagctttt ctgaaaaata aaataaaggc aatgtcaaaa gtatactgca tcatcagtcc 7980
agaaagcaca tgatattttt ttatcagtat caatgcagct agttttattt tacaatatcg 8040
atatagctag tttaaatata ttgcagctag atttataaat atttgtgtta ttatttatca 8100
tttgtgtaat cctgttttta gtattttagt ttatatatga tgataatgta ttccaaattt 8160
aaaagaaggg aaataaattt aaacaagaaa aaaagtcatc aaacaaaaaa caaatgaaag 8220
ggtggaaaga tgttaccatg taatgtgaat gttacagtat ttcttttatt atagagttaa 8280
caaattaact aatatgattt tgttaataat gataaaatat tttttttatt attatttcat 8340
aatataaaaa tagtttactt aatataaaaa aaattctatc gttcacaaca aagttggcca 8400
cctaatttaa ccatgcatgt acccatggac catattaggt aaccatcaaa cctgatgaag 8460
agataaagag atgaagactt aagtcataac acaaaaccat aaaaaacaaa aatacaatca 8520
accgtcaatc tgaccaatgc atgaaaaagc tgcaatagtg agtggcgaca caaagcacat 8580
gattttctta caacggagat aaaaccaaaa aaatatttca tgaacaacct agaacaaata 8640
aagcttttat ataataaata tataaataaa taaaggctat ggaataatat acttcaatat 8700
atttggatta aataaattgt tggcggggtt gatatattta tacacaccta aagtcacttc 8760
aatctcattt tcacttaact tttatttttt ttttcttttt atttatcata aagagaatat 8820
tgataatata ctttttaaca tatttttatg acatttttta ttggtgaaaa cttattaaaa 8880
atcataaatt ttgtaagtta gatttattta aagagttcct cttcttattt taaatttttt 8940
aataaatttt taaataacta aaatttgtgt taaaaatgtt aaaaaatgtg ttattaaccc 9000
ttctcttcga ggac 9014
<210> 78
<211> 1482
<212> DNA
<213> Mortierella alpina
<220>
<221> CDS
<222> (59)..(1399)
<223> delta-5 desaturase
<400> 78
gcttcctcca gttcatcctc catttcgcca cctgcattct ttacgaccgt taagcaag 58
atg gga acg gac caa gga aaa acc ttc acc tgg gaa gag ctg gcg gcc 106
Met Gly Thr Asp Gln Gly Lys Thr Phe Thr Trp Glu Glu Leu Ala Ala
1 5 10 15
cat aac acc aag gac gac cta ctc ttg gcc atc cgc ggc agg gtg tac 154
His Asn Thr Lys Asp Asp Leu Leu Leu Ala Ile Arg Gly Arg Val Tyr
20 25 30
gat gtc aca aag ttc ttg agc cgc cat cct ggt gga gtg gac act ctc 202
Asp Val Thr Lys Phe Leu Ser Arg His Pro Gly Gly Val Asp Thr Leu
35 40 45
ctg ctc gga gct ggc cga gat gtt act ccg gtc ttt gag atg tat cac 250
Leu Leu Gly Ala Gly Arg Asp Val Thr Pro Val Phe Glu Met Tyr His
50 55 60
gcg ttt ggg gct gca gat gcc att atg aag aag tac tat gtc ggt aca 298
Ala Phe Gly Ala Ala Asp Ala Ile Met Lys Lys Tyr Tyr Val Gly Thr
65 70 75 80
ctg gtc tcg aat gag ctg ccc atc ttc ccg gag cca acg gtg ttc cac 346
Leu Val Ser Asn Glu Leu Pro Ile Phe Pro Glu Pro Thr Val Phe His
85 90 95
aaa acc atc aag acg aga gtc gag ggc tac ttt acg gat cgg aac att 394
Lys Thr Ile Lys Thr Arg Val Glu Gly Tyr Phe Thr Asp Arg Asn Ile
100 105 110
gat ccc aag aat aga cca gag atc tgg gga cga tac gct ctt atc ttt 442
Asp Pro Lys Asn Arg Pro Glu Ile Trp Gly Arg Tyr Ala Leu Ile Phe
115 120 125
gga tcc ttg atc gct tcc tac tac gcg cag ctc ttt gtg cct ttc gtt 490
Gly Ser Leu Ile Ala Ser Tyr Tyr Ala Gln Leu Phe Val Pro Phe Val
130 135 140
gtc gaa cgc aca tgg ctt cag gtg gtg ttt gca atc atc atg gga ttt 538
Val Glu Arg Thr Trp Leu Gln Val Val Phe Ala Ile Ile Met Gly Phe
145 150 155 160
gcg tgc gca caa gtc gga ctc aac cct ctt cat gat gcg tct cac ttt 586
Ala Cys Ala Gln Val Gly Leu Asn Pro Leu His Asp Ala Ser His Phe
165 170 175
tca gtg acc cac aac ccc act gtc tgg aag att ctg gga gcc acg cac 634
Ser Val Thr His Asn Pro Thr Val Trp Lys Ile Leu Gly Ala Thr His
180 185 190
gac ttt ttc aac gga gca tcg tac ctg gtg tgg atg tac caa cat atg 682
Asp Phe Phe Asn Gly Ala Ser Tyr Leu Val Trp Met Tyr Gln His Met
195 200 205
ctc ggc cat cac ccc tac acc aac att gct gga gca gat ccc gac gtg 730
Leu Gly His His Pro Tyr Thr Asn Ile Ala Gly Ala Asp Pro Asp Val
210 215 220
tcg acg tct gag ccc gat gtt cgt cgt atc aag ccc aac caa aag tgg 778
Ser Thr Ser Glu Pro Asp Val Arg Arg Ile Lys Pro Asn Gln Lys Trp
225 230 235 240
ttt gtc aac cac atc aac cag cac atg ttt gtt cct ttc ctg tac gga 826
Phe Val Asn His Ile Asn Gln His Met Phe Val Pro Phe Leu Tyr Gly
245 250 255
ctg ctg gcg ttc aag gtg cgc att cag gac atc aac att ttg tac ttt 874
Leu Leu Ala Phe Lys Val Arg Ile Gln Asp Ile Asn Ile Leu Tyr Phe
260 265 270
gtc aag acc aat gac gct att cgt gtc aat ccc atc tcg aca tgg cac 922
Val Lys Thr Asn Asp Ala Ile Arg Val Asn Pro Ile Ser Thr Trp His
275 280 285
act gtg atg ttc tgg ggc ggc aag gct ttc ttt gtc tgg tat cgc ctg 970
Thr Val Met Phe Trp Gly Gly Lys Ala Phe Phe Val Trp Tyr Arg Leu
290 295 300
att gtt ccc ctg cag tat ctg ccc ctg ggc aag gtg ctg ctc ttg ttc 1018
Ile Val Pro Leu Gln Tyr Leu Pro Leu Gly Lys Val Leu Leu Leu Phe
305 310 315 320
acg gtc gcg gac atg gtg tcg tct tac tgg ctg gcg ctg acc ttc cag 1066
Thr Val Ala Asp Met Val Ser Ser Tyr Trp Leu Ala Leu Thr Phe Gln
325 330 335
gcg aac cac gtt gtt gag gaa gtt cag tgg ccg ttg cct gac gag aac 1114
Ala Asn His Val Val Glu Glu Val Gln Trp Pro Leu Pro Asp Glu Asn
340 345 350
ggg atc atc caa aag gac tgg gca gct atg cag gtc gag act acg cag 1162
Gly Ile Ile Gln Lys Asp Trp Ala Ala Met Gln Val Glu Thr Thr Gln
355 360 365
gat tac gca cac gat tcg cac ctc tgg acc agc atc act ggc agc ttg 1210
Asp Tyr Ala His Asp Ser His Leu Trp Thr Ser Ile Thr Gly Ser Leu
370 375 380
aac tac cag gct gtg cac cat ctg ttc ccc aac gtg tcg cag cac cat 1258
Asn Tyr Gln Ala Val His His Leu Phe Pro Asn Val Ser Gln His His
385 390 395 400
tat ccc gat att ctg gcc atc atc aag aac acc tgc agc gag tac aag 1306
Tyr Pro Asp Ile Leu Ala Ile Ile Lys Asn Thr Cys Ser Glu Tyr Lys
405 410 415
gtt cca tac ctt gtc aag gat acg ttt tgg caa gca ttt gct tca cat 1354
Val Pro Tyr Leu Val Lys Asp Thr Phe Trp Gln Ala Phe Ala Ser His
420 425 430
ttg gag cac ttg cgt gtt ctt gga ctc cgt ccc aag gaa gag tag 1399
Leu Glu His Leu Arg Val Leu Gly Leu Arg Pro Lys Glu Glu
435 440 445
aagaaaaaaa gcgccgaatg aagtattgcc ccctttttct ccaagaatgg caaaaggaga 1459
tcaagtggac attctctatg aag 1482
<210> 79
<211> 446
<212> PRT
<213> Mortierella alpina
<400> 79
Met Gly Thr Asp Gln Gly Lys Thr Phe Thr Trp Glu Glu Leu Ala Ala
1 5 10 15
His Asn Thr Lys Asp Asp Leu Leu Leu Ala Ile Arg Gly Arg Val Tyr
20 25 30
Asp Val Thr Lys Phe Leu Ser Arg His Pro Gly Gly Val Asp Thr Leu
35 40 45
Leu Leu Gly Ala Gly Arg Asp Val Thr Pro Val Phe Glu Met Tyr His
50 55 60
Ala Phe Gly Ala Ala Asp Ala Ile Met Lys Lys Tyr Tyr Val Gly Thr
65 70 75 80
Leu Val Ser Asn Glu Leu Pro Ile Phe Pro Glu Pro Thr Val Phe His
85 90 95
Lys Thr Ile Lys Thr Arg Val Glu Gly Tyr Phe Thr Asp Arg Asn Ile
100 105 110
Asp Pro Lys Asn Arg Pro Glu Ile Trp Gly Arg Tyr Ala Leu Ile Phe
115 120 125
Gly Ser Leu Ile Ala Ser Tyr Tyr Ala Gln Leu Phe Val Pro Phe Val
130 135 140
Val Glu Arg Thr Trp Leu Gln Val Val Phe Ala Ile Ile Met Gly Phe
145 150 155 160
Ala Cys Ala Gln Val Gly Leu Asn Pro Leu His Asp Ala Ser His Phe
165 170 175
Ser Val Thr His Asn Pro Thr Val Trp Lys Ile Leu Gly Ala Thr His
180 185 190
Asp Phe Phe Asn Gly Ala Ser Tyr Leu Val Trp Met Tyr Gln His Met
195 200 205
Leu Gly His His Pro Tyr Thr Asn Ile Ala Gly Ala Asp Pro Asp Val
210 215 220
Ser Thr Ser Glu Pro Asp Val Arg Arg Ile Lys Pro Asn Gln Lys Trp
225 230 235 240
Phe Val Asn His Ile Asn Gln His Met Phe Val Pro Phe Leu Tyr Gly
245 250 255
Leu Leu Ala Phe Lys Val Arg Ile Gln Asp Ile Asn Ile Leu Tyr Phe
260 265 270
Val Lys Thr Asn Asp Ala Ile Arg Val Asn Pro Ile Ser Thr Trp His
275 280 285
Thr Val Met Phe Trp Gly Gly Lys Ala Phe Phe Val Trp Tyr Arg Leu
290 295 300
Ile Val Pro Leu Gln Tyr Leu Pro Leu Gly Lys Val Leu Leu Leu Phe
305 310 315 320
Thr Val Ala Asp Met Val Ser Ser Tyr Trp Leu Ala Leu Thr Phe Gln
325 330 335
Ala Asn His Val Val Glu Glu Val Gln Trp Pro Leu Pro Asp Glu Asn
340 345 350
Gly Ile Ile Gln Lys Asp Trp Ala Ala Met Gln Val Glu Thr Thr Gln
355 360 365
Asp Tyr Ala His Asp Ser His Leu Trp Thr Ser Ile Thr Gly Ser Leu
370 375 380
Asn Tyr Gln Ala Val His His Leu Phe Pro Asn Val Ser Gln His His
385 390 395 400
Tyr Pro Asp Ile Leu Ala Ile Ile Lys Asn Thr Cys Ser Glu Tyr Lys
405 410 415
Val Pro Tyr Leu Val Lys Asp Thr Phe Trp Gln Ala Phe Ala Ser His
420 425 430
Leu Glu His Leu Arg Val Leu Gly Leu Arg Pro Lys Glu Glu
435 440 445
<210> 80
<211> 69
<212> DNA
<213> Artificial Sequence
<220>
<223> Restriction enzyme sites added to pKR287 to produce pKR767
<400> 80
ccatggtcaa tcaatgagac gccaacttct taatctattg agacctgcag gtctagaagg 60
gcggatccc 69
<210> 81
<211> 5561
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR767
<400> 81
catggtcaat caatgagacg ccaacttctt aatctattga gacctgcagg tctagaaggg 60
cggatccccg ggtaccgagc tcgaattcac tggccgtcgt tttacaacgt cgtgactggg 120
aaaaccctgg cgttacccaa cttaatcgcc ttgcagcaca tccccctttc gccagctggc 180
gtaatagcga agaggcccgc accgatcgcc cttcccaaca gttgcgcagc ctgaatggcg 240
aatggcgcct gatgcggtat tttctcctta cgcatctgtg cggtatttca caccgcatat 300
ggtgcactct cagtacaatc tgctctgatg ccgcatagtt aagccagccc cgacacccgc 360
caacacccgc tgacgcgccc tgacgggctt gtctgctccc ggcatccgct tacagacaag 420
ctgtgaccgt ctccgggagc tgcatgtgtc agaggttttc accgtcatca ccgaaacgcg 480
cgagacgaaa gggcctcgtg atacgcctat ttttataggt taatgtcatg ataataatgg 540
tttcttagac gtcaggtggc acttttcggg gaaatgtgcg cggaacccct atttgtttat 600
ttttctaaat acattcaaat atgtatccgc tcatgagaca ataaccctga taaatgcttc 660
aataatattg aaaaaggaag agtatgagta ttcaacattt ccgtgtcgcc cttattccct 720
tttttgcggc attttgcctt cctgtttttg ctcacccaga aacgctggtg aaagtaaaag 780
atgctgaaga tcagttgggt gcacgagtgg gttacatcga actggatctc aacagcggta 840
agatccttga gagttttcgc cccgaagaac gttttccaat gatgagcact tttaaagttc 900
tgctatgtgg cgcggtatta tcccgtattg acgccgggca agagcaactc ggtcgccgca 960
tacactattc tcagaatgac ttggttgagt actcaccagt cacagaaaag catcttacgg 1020
atggcatgac agtaagagaa ttatgcagtg ctgccataac catgagtgat aacactgcgg 1080
ccaacttact tctgacaacg atcggaggac cgaaggagct aaccgctttt ttgcacaaca 1140
tgggggatca tgtaactcgc cttgatcgtt gggaaccgga gctgaatgaa gccataccaa 1200
acgacgagcg tgacaccacg atgcctgtag caatggcaac aacgttgcgc aaactattaa 1260
ctggcgaact acttactcta gcttcccggc aacaattaat agactggatg gaggcggata 1320
aagttgcagg accacttctg cgctcggccc ttccggctgg ctggtttatt gctgataaat 1380
ctggagccgg tgagcgtggg tctcgcggta tcattgcagc actggggcca gatggtaagc 1440
cctcccgtat cgtagttatc tacacgacgg ggagtcaggc aactatggat gaacgaaata 1500
gacagatcgc tgagataggt gcctcactga ttaagcattg gtaactgtca gaccaagttt 1560
actcatatat actttagatt gatttaaaac ttcattttta atttaaaagg atctaggtga 1620
agatcctttt tgataatctc atgaccaaaa tcccttaacg tgagttttcg ttccactgag 1680
cgtcagaccc cgtagaaaag atcaaaggat cttcttgaga tccttttttt ctgcgcgtaa 1740
tctgctgctt gcaaacaaaa aaaccaccgc taccagcggt ggtttgtttg ccggatcaag 1800
agctaccaac tctttttccg aaggtaactg gcttcagcag agcgcagata ccaaatactg 1860
tccttctagt gtagccgtag ttaggccacc acttcaagaa ctctgtagca ccgcctacat 1920
acctcgctct gctaatcctg ttaccagtgg ctgctgccag tggcgataag tcgtgtctta 1980
ccgggttgga ctcaagacga tagttaccgg ataaggcgca gcggtcgggc tgaacggggg 2040
gttcgtgcac acagcccagc ttggagcgaa cgacctacac cgaactgaga tacctacagc 2100
gtgagctatg agaaagcgcc acgcttcccg aagggagaaa ggcggacagg tatccggtaa 2160
gcggcagggt cggaacagga gagcgcacga gggagcttcc agggggaaac gcctggtatc 2220
tttatagtcc tgtcgggttt cgccacctct gacttgagcg tcgatttttg tgatgctcgt 2280
caggggggcg gagcctatgg aaaaacgcca gcaacgcggc ctttttacgg ttcctggcct 2340
tttgctggcc ttttgctcac atgttctttc ctgcgttatc ccctgattct gtggataacc 2400
gtattaccgc ctttgagtga gctgataccg ctcgccgcag ccgaacgacc gagcgcagcg 2460
agtcagtgag cgaggaagcg gaagagcgcc caatacgcaa accgcctctc cccgcgcgtt 2520
ggccgattca ttaatgcagc tggcacgaca ggtttcccga ctggaaagcg ggcagtgagc 2580
gcaacgcaat taatgtgagt tagctcactc attaggcacc ccaggcttta cactttatgc 2640
ttccggctcg tatgttgtgt ggaattgtga gcggataaca atttcacaca ggaaacagct 2700
atgaccatga ttacgccaag cttgcatgcc tgcaggctag cctaagtacg tactcaaaat 2760
gccaacaaat aaaaaaaaag ttgctttaat aatgccaaaa caaattaata aaacacttac 2820
aacaccggat tttttttaat taaaatgtgc catttaggat aaatagttaa tatttttaat 2880
aattatttaa aaagccgtat ctactaaaat gatttttatt tggttgaaaa tattaatatg 2940
tttaaatcaa cacaatctat caaaattaaa ctaaaaaaaa aataagtgta cgtggttaac 3000
attagtacag taatataaga ggaaaatgag aaattaagaa attgaaagcg agtctaattt 3060
ttaaattatg aacctgcata tataaaagga aagaaagaat ccaggaagaa aagaaatgaa 3120
accatgcatg gtcccctcgt catcacgagt ttctgccatt tgcaatagaa acactgaaac 3180
acctttctct ttgtcactta attgagatgc cgaagccacc tcacaccatg aacttcatga 3240
ggtgtagcac ccaaggcttc catagccatg catactgaag aatgtctcaa gctcagcacc 3300
ctacttctgt gacgtgtccc tcattcacct tcctctcttc cctataaata accacgcctc 3360
aggttctccg cttcacaact caaacattct ctccattggt ccttaaacac tcatcagtca 3420
tcaccgcggc cgcatgggaa cggaccaagg aaaaaccttc acctgggaag agctggcggc 3480
ccataacacc aaggacgacc tactcttggc catccgcggc agggtgtacg atgtcacaaa 3540
gttcttgagc cgccatcctg gtggagtgga cactctcctg ctcggagctg gccgagatgt 3600
tactccggtc tttgagatgt atcacgcgtt tggggctgca gatgccatta tgaagaagta 3660
ctatgtcggt acactggtct cgaatgagct gcccatcttc ccggagccaa cggtgttcca 3720
caaaaccatc aagacgagag tcgagggcta ctttacggat cggaacattg atcccaagaa 3780
tagaccagag atctggggac gatacgctct tatctttgga tccttgatcg cttcctacta 3840
cgcgcagctc tttgtgcctt tcgttgtcga acgcacatgg cttcaggtgg tgtttgcaat 3900
catcatggga tttgcgtgcg cacaagtcgg actcaaccct cttcatgatg cgtctcactt 3960
ttcagtgacc cacaacccca ctgtctggaa gattctggga gccacgcacg actttttcaa 4020
cggagcatcg tacctggtgt ggatgtacca acatatgctc ggccatcacc cctacaccaa 4080
cattgctgga gcagatcccg acgtgtcgac gtctgagccc gatgttcgtc gtatcaagcc 4140
caaccaaaag tggtttgtca accacatcaa ccagcacatg tttgttcctt tcctgtacgg 4200
actgctggcg ttcaaggtgc gcattcagga catcaacatt ttgtactttg tcaagaccaa 4260
tgacgctatt cgtgtcaatc ccatctcgac atggcacact gtgatgttct ggggcggcaa 4320
ggctttcttt gtctggtatc gcctgattgt tcccctgcag tatctgcccc tgggcaaggt 4380
gctgctcttg ttcacggtcg cggacatggt gtcgtcttac tggctggcgc tgaccttcca 4440
ggcgaaccac gttgttgagg aagttcagtg gccgttgcct gacgagaacg ggatcatcca 4500
aaaggactgg gcagctatgc aggtcgagac tacgcaggat tacgcacacg attcgcacct 4560
ctggaccagc atcactggca gcttgaacta ccaggctgtg caccatctgt tccccaacgt 4620
gtcgcagcac cattatcccg atattctggc catcatcaag aacacctgca gcgagtacaa 4680
ggttccatac cttgtcaagg atacgttttg gcaagcattt gcttcacatt tggagcactt 4740
gcgtgttctt ggactccgtc ccaaggaaga gtaggcggcc gcatttcgca ccaaatcaat 4800
gaaagtaata atgaaaagtc tgaataagaa tacttaggct tagatgcctt tgttacttgt 4860
gtaaaataac ttgagtcatg tacctttggc ggaaacagaa taaataaaag gtgaaattcc 4920
aatgctctat gtataagtta gtaatactta atgtgttcta cggttgtttc aatatcatca 4980
aactctaatt gaaactttag aaccacaaat ctcaatcttt tcttaatgaa atgaaaaatc 5040
ttaattgtac catgtttatg ttaaacacct tacaattggt tggagaggag gaccaaccga 5100
tgggacaaca ttgggagaaa gagattcaat ggagatttgg ataggagaac aacattcttt 5160
ttcacttcaa tacaagatga gtgcaacact aaggatatgt atgagacttt cagaagctac 5220
gacaacatag atgagtgagg tggtgattcc tagcaagaaa gacattagag gaagccaaaa 5280
tcgaacaagg aagacatcaa gggcaagaga caggaccatc catctcagga aaaggagctt 5340
tgggatagtc cgagaagttg tacaagaaat tttttggagg gtgagtgatg cattgctggt 5400
gactttaact caatcaaaat tgagaaagaa agaaaaggga gggggctcac atgtgaatag 5460
aagggaaacg ggagaatttt acagttttga tctaatgggc atcccagcta gtggtaacat 5520
attcaccatg tttaaccttc acgtacgtct agaggatccc c 5561
<210> 82
<211> 8671
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR328
<400> 82
ggatctggcc ggccggatct cgtacggatc cgtcgacggc gcgcccgatc atccggatat 60
agttcctcct ttcagcaaaa aacccctcaa gacccgttta gaggccccaa ggggttatgc 120
tagttattgc tcagcggtgg cagcagccaa ctcagcttcc tttcgggctt tgttagcagc 180
cggatcgatc caagctgtac ctcactattc ctttgccctc ggacgagtgc tggggcgtcg 240
gtttccacta tcggcgagta cttctacaca gccatcggtc cagacggccg cgcttctgcg 300
ggcgatttgt gtacgcccga cagtcccggc tccggatcgg acgattgcgt cgcatcgacc 360
ctgcgcccaa gctgcatcat cgaaattgcc gtcaaccaag ctctgataga gttggtcaag 420
accaatgcgg agcatatacg cccggagccg cggcgatcct gcaagctccg gatgcctccg 480
ctcgaagtag cgcgtctgct gctccataca agccaaccac ggcctccaga agaagatgtt 540
ggcgacctcg tattgggaat ccccgaacat cgcctcgctc cagtcaatga ccgctgttat 600
gcggccattg tccgtcagga cattgttgga gccgaaatcc gcgtgcacga ggtgccggac 660
ttcggggcag tcctcggccc aaagcatcag ctcatcgaga gcctgcgcga cggacgcact 720
gacggtgtcg tccatcacag tttgccagtg atacacatgg ggatcagcaa tcgcgcatat 780
gaaatcacgc catgtagtgt attgaccgat tccttgcggt ccgaatgggc cgaacccgct 840
cgtctggcta agatcggccg cagcgatcgc atccatagcc tccgcgaccg gctgcagaac 900
agcgggcagt tcggtttcag gcaggtcttg caacgtgaca ccctgtgcac ggcgggagat 960
gcaataggtc aggctctcgc tgaattcccc aatgtcaagc acttccggaa tcgggagcgc 1020
ggccgatgca aagtgccgat aaacataacg atctttgtag aaaccatcgg cgcagctatt 1080
tacccgcagg acatatccac gccctcctac atcgaagctg aaagcacgag attcttcgcc 1140
ctccgagagc tgcatcaggt cggagacgct gtcgaacttt tcgatcagaa acttctcgac 1200
agacgtcgcg gtgagttcag gcttttccat gggtatatct ccttcttaaa gttaaacaaa 1260
attatttcta gagggaaacc gttgtggtct ccctatagtg agtcgtatta atttcgcggg 1320
atcgagatcg atccaattcc aatcccacaa aaatctgagc ttaacagcac agttgctcct 1380
ctcagagcag aatcgggtat tcaacaccct catatcaact actacgttgt gtataacggt 1440
ccacatgccg gtatatacga tgactggggt tgtacaaagg cggcaacaaa cggcgttccc 1500
ggagttgcac acaagaaatt tgccactatt acagaggcaa gagcagcagc tgacgcgtac 1560
acaacaagtc agcaaacaga caggttgaac ttcatcccca aaggagaagc tcaactcaag 1620
cccaagagct ttgctaaggc cctaacaagc ccaccaaagc aaaaagccca ctggctcacg 1680
ctaggaacca aaaggcccag cagtgatcca gccccaaaag agatctcctt tgccccggag 1740
attacaatgg acgatttcct ctatctttac gatctaggaa ggaagttcga aggtgaaggt 1800
gacgacacta tgttcaccac tgataatgag aaggttagcc tcttcaattt cagaaagaat 1860
gctgacccac agatggttag agaggcctac gcagcaggtc tcatcaagac gatctacccg 1920
agtaacaatc tccaggagat caaatacctt cccaagaagg ttaaagatgc agtcaaaaga 1980
ttcaggacta attgcatcaa gaacacagag aaagacatat ttctcaagat cagaagtact 2040
attccagtat ggacgattca aggcttgctt cataaaccaa ggcaagtaat agagattgga 2100
gtctctaaaa aggtagttcc tactgaatct aaggccatgc atggagtcta agattcaaat 2160
cgaggatcta acagaactcg ccgtgaagac tggcgaacag ttcatacaga gtcttttacg 2220
actcaatgac aagaagaaaa tcttcgtcaa catggtggag cacgacactc tggtctactc 2280
caaaaatgtc aaagatacag tctcagaaga ccaaagggct attgagactt ttcaacaaag 2340
gataatttcg ggaaacctcc tcggattcca ttgcccagct atctgtcact tcatcgaaag 2400
gacagtagaa aaggaaggtg gctcctacaa atgccatcat tgcgataaag gaaaggctat 2460
cattcaagat gcctctgccg acagtggtcc caaagatgga cccccaccca cgaggagcat 2520
cgtggaaaaa gaagacgttc caaccacgtc ttcaaagcaa gtggattgat gtgacatctc 2580
cactgacgta agggatgacg cacaatccca ctatccttcg caagaccctt cctctatata 2640
aggaagttca tttcatttgg agaggacacg ctcgagctca tttctctatt acttcagcca 2700
taacaaaaga actcttttct cttcttatta aaccatgaaa aagcctgaac tcaccgcgac 2760
gtctgtcgag aagtttctga tcgaaaagtt cgacagcgtc tccgacctga tgcagctctc 2820
ggagggcgaa gaatctcgtg ctttcagctt cgatgtagga gggcgtggat atgtcctgcg 2880
ggtaaatagc tgcgccgatg gtttctacaa agatcgttat gtttatcggc actttgcatc 2940
ggccgcgctc ccgattccgg aagtgcttga cattggggaa ttcagcgaga gcctgaccta 3000
ttgcatctcc cgccgtgcac agggtgtcac gttgcaagac ctgcctgaaa ccgaactgcc 3060
cgctgttctg cagccggtcg cggaggccat ggatgcgatc gctgcggccg atcttagcca 3120
gacgagcggg ttcggcccat tcggaccgca aggaatcggt caatacacta catggcgtga 3180
tttcatatgc gcgattgctg atccccatgt gtatcactgg caaactgtga tggacgacac 3240
cgtcagtgcg tccgtcgcgc aggctctcga tgagctgatg ctttgggccg aggactgccc 3300
cgaagtccgg cacctcgtgc acgcggattt cggctccaac aatgtcctga cggacaatgg 3360
ccgcataaca gcggtcattg actggagcga ggcgatgttc ggggattccc aatacgaggt 3420
cgccaacatc ttcttctgga ggccgtggtt ggcttgtatg gagcagcaga cgcgctactt 3480
cgagcggagg catccggagc ttgcaggatc gccgcggctc cgggcgtata tgctccgcat 3540
tggtcttgac caactctatc agagcttggt tgacggcaat ttcgatgatg cagcttgggc 3600
gcagggtcga tgcgacgcaa tcgtccgatc cggagccggg actgtcgggc gtacacaaat 3660
cgcccgcaga agcgcggccg tctggaccga tggctgtgta gaagtactcg ccgatagtgg 3720
aaaccgacgc cccagcactc gtccgagggc aaaggaatag tgaggtacct aaagaaggag 3780
tgcgtcgaag cagatcgttc aaacatttgg caataaagtt tcttaagatt gaatcctgtt 3840
gccggtcttg cgatgattat catataattt ctgttgaatt acgttaagca tgtaataatt 3900
aacatgtaat gcatgacgtt atttatgaga tgggttttta tgattagagt cccgcaatta 3960
tacatttaat acgcgataga aaacaaaata tagcgcgcaa actaggataa attatcgcgc 4020
gcggtgtcat ctatgttact agatcgatgt cgaatcgatc aacctgcatt aatgaatcgg 4080
ccaacgcgcg gggagaggcg gtttgcgtat tgggcgctct tccgcttcct cgctcactga 4140
ctcgctgcgc tcggtcgttc ggctgcggcg agcggtatca gctcactcaa aggcggtaat 4200
acggttatcc acagaatcag gggataacgc aggaaagaac atgtgagcaa aaggccagca 4260
aaaggccagg aaccgtaaaa aggccgcgtt gctggcgttt ttccataggc tccgcccccc 4320
tgacgagcat cacaaaaatc gacgctcaag tcagaggtgg cgaaacccga caggactata 4380
aagataccag gcgtttcccc ctggaagctc cctcgtgcgc tctcctgttc cgaccctgcc 4440
gcttaccgga tacctgtccg cctttctccc ttcgggaagc gtggcgcttt ctcaatgctc 4500
acgctgtagg tatctcagtt cggtgtaggt cgttcgctcc aagctgggct gtgtgcacga 4560
accccccgtt cagcccgacc gctgcgcctt atccggtaac tatcgtcttg agtccaaccc 4620
ggtaagacac gacttatcgc cactggcagc agccactggt aacaggatta gcagagcgag 4680
gtatgtaggc ggtgctacag agttcttgaa gtggtggcct aactacggct acactagaag 4740
gacagtattt ggtatctgcg ctctgctgaa gccagttacc ttcggaaaaa gagttggtag 4800
ctcttgatcc ggcaaacaaa ccaccgctgg tagcggtggt ttttttgttt gcaagcagca 4860
gattacgcgc agaaaaaaag gatctcaaga agatcctttg atcttttcta cggggtctga 4920
cgctcagtgg aacgaaaact cacgttaagg gattttggtc atgacattaa cctataaaaa 4980
taggcgtatc acgaggccct ttcgtctcgc gcgtttcggt gatgacggtg aaaacctctg 5040
acacatgcag ctcccggaga cggtcacagc ttgtctgtaa gcggatgccg ggagcagaca 5100
agcccgtcag ggcgcgtcag cgggtgttgg cgggtgtcgg ggctggctta actatgcggc 5160
atcagagcag attgtactga gagtgcacca tatggacata ttgtcgttag aacgcggcta 5220
caattaatac ataaccttat gtatcataca catacgattt aggtgacact atagaacggc 5280
gcgccaagct tggatctcct gcagcccggg ggatccgccc acgtacggta ccatctgcta 5340
atattttaaa tcacatgcaa gagaggaggc atggttccat tttctacctt cacattattt 5400
gagaaaaacg aacttgttct gtgttttatt tttgcccttc acattagtac aacgtggaag 5460
actcatggtt acacagaatc atacataagt acaatgcttg tccctaagaa aacaagcact 5520
cgttgtattg aacctttacg gctcatgcgg ccgcgaattc actagtgatt gaattcgcgg 5580
ccgcttagtc cgacttggcc ttggcggccg cggccgactc tttgagcgtg aagatctgcg 5640
ccgtctcggg cacagcgccg tagttgacaa agaggtgcgc ggtcttgaag aaggccgtga 5700
tgatgggctc gtcgttcctg cgcacgaggt gcgggtacgc ggccgcaaag tgcttggtgg 5760
cttcgttgag cttgtagtgc ggaatgatcg ggaacaagtg gtggacctgg tgcgtgccaa 5820
tgtggtggct caggttgtcc acgaacgcgc cgtacgagcg gtcgacgctc gagaggttgc 5880
ccttgacgta cgtccactcc gagtcgccgt accacggcgt cgcttcgtcg ttgtggtgca 5940
agaaggtcgt aatgacgagg aacgaagcaa agacaaagag cggcgcatag tagtagaggc 6000
ccatgacggc aaagccgagc gagtatgtga ggtacgcgta cgcggcgaag aaggcggccc 6060
agacgccgag cgacacgatg acggccgacg cgcggcgaag gaggagcggg tcccacgggt 6120
caaagtggct catcgtgcgc ggggcatacc cgaccttcaa gtagacaaac cacgcaccgc 6180
cgagcgtgta gacccattgg cgcacgtcct ggaggtcctt gaccgaccgg tgcgggtaaa 6240
agatctcgtc cttatcaatg ttgcccgtgt tcttgtggtg gtggcggtgc gtcacgcgcc 6300
agctctcgaa cggcgtcaaa atcgcagagt gcatgatgca gccgatgata aagttgacgc 6360
tgtggtagcg cgagaaggcc gagtggccgc agtcgtggcc gaccgtgaag aagccccaga 6420
agatgacgcc ctgcacgtag atgtaggtgg cgcaaacgag cgcgtggagc agaacgttat 6480
cggcaatgaa cggcgtcgag cgcgccgcgt agagcagcgc cgccgaggcc gacgcgttga 6540
agatcgcgcg ggccgtgtag tagagcgaga ggccgaggtt cgactcaaag cacgcgttcg 6600
ggatcgagtg cttgagctcc gtgagcgtcg ggaactcgac cttcgtctta tcctcagtca 6660
tgcggccgct gaagtattgc ttcttagtta acctttcctt tctctctcag ctatgtgaat 6720
tcattttgct ttcgtcacaa tttatatagt gaaattggat ctttggagtt aacgccttca 6780
caggattatc gtgttagaac aatgcttttt catgttctaa ttagtagtac attacaaatg 6840
tgcactctat tcaataagca tcttttggca cgttaataaa tcatgtgaaa aaaaaatact 6900
actatttcaa agaaagtgtt gtaaaaagaa acggaaagag agctggcttc agttgttgag 6960
acttgtttgc tagtaaaaat ggtgtgaaga gtgattcatg gtgaggtggt ttttcgtccc 7020
tttctgtttg catgaaaaac aaatggcaag agatgacgta ggattccttc ccttaacgat 7080
tatctgtttt taatttcaaa tatacatata ggaatttatg aattactaag gttgtaaaat 7140
atgctggtca tttatttatg gctaaaatat ttttttttct cgtaaatata aaaatattta 7200
aaatttattt ttatcatatt ttttatcctt ataaaattat gtgtacaacc tatataaaaa 7260
aatatcatat ttaatattga ttatatgttt aatcaatata aaaaatcatt atcatatatt 7320
tagatttatt cgaatataca tctaaacaaa aaataacata ttttaatttt atgaagaaaa 7380
aaaaatattt tatcctttat ttatttaaga ttaattaata gttatgtatt gtggaaagac 7440
ttttacacat gcaatagata tactgaatca attagatgcc aatgctgagt tggaaatcac 7500
ttgaggaggg gaggagactt gccaatgctt ttcagtttca tttaaatgat ttagtggagg 7560
agatagagta gtgataaagg catgccccaa ttttggagtg tatatatgag tggaaataag 7620
agagggatag agagaaaaaa taaagagagt aaaaataatt aatgtgaaat gatatgataa 7680
aaaaataaag aaagagataa agagaaaaat gaaatgagag atagatgaaa tagagagtag 7740
atacatgttt gtttaggttt tttttaggaa ataacacatt tttttctcat cacttattac 7800
tcactgtcaa tttcctctct ttcaatcata atgatatgat ttgtttaaca aaaatgtgaa 7860
aaaacatata aagtaaaata tttttataaa ttgataaata aaaatttaca aaatttattt 7920
cttattaaat tgaatagaaa atgaaagaaa agaaaagaaa aagtatatat aaaatgatat 7980
agctttaaaa agaataaatt tttcatatca gtcttttttt aataatttag aaatatttaa 8040
gtatatagca aaaatataat gtactttaca tatgcataaa taataatttg aaaatagaac 8100
taatagaata gagaaaaaag taatataata attaactata tgaaaattta gaagggacaa 8160
tatttttaat taagaatata aacaatattt cttttcatgt aatgagggac ggatgtacgg 8220
ggccagtgtt ggagtcaaag ccaaaatagt cacggggaaa ttaatgcact gcatgactat 8280
tcgaaaaaat tcactagcct tacttagatg ttagattaat agctaggggg tgcagataat 8340
tttgaaaggc atgaaaaaca ttaatttgta cattgcaagc ttttgatgac aagctttgca 8400
attgttcaca ctaccttatg ccatttataa atagagtgat tggcatatga aggaaatcat 8460
gagagtcgaa gcgaaaaaca aagcttgaga gtgtaggaaa aatacagttt ttttggtaaa 8520
aatacagtat ttgaatagga gcgaaaaata tcctttcaaa atgatccttt tctttttttt 8580
tttttttctt gttgttcttg gtcagttatt caaaggaaaa gggattgaaa taaaaacttg 8640
catgtgggat cgtacgtcga gtcgacctgc a 8671
<210> 83
<211> 9892
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR886
<400> 83
ggtcgactcg acgtacgtct agaggatccg tcgacggcgc gcccgatcat ccggatatag 60
ttcctccttt cagcaaaaaa cccctcaaga cccgtttaga ggccccaagg ggttatgcta 120
gttattgctc agcggtggca gcagccaact cagcttcctt tcgggctttg ttagcagccg 180
gatcgatcca agctgtacct cactattcct ttgccctcgg acgagtgctg gggcgtcggt 240
ttccactatc ggcgagtact tctacacagc catcggtcca gacggccgcg cttctgcggg 300
cgatttgtgt acgcccgaca gtcccggctc cggatcggac gattgcgtcg catcgaccct 360
gcgcccaagc tgcatcatcg aaattgccgt caaccaagct ctgatagagt tggtcaagac 420
caatgcggag catatacgcc cggagccgcg gcgatcctgc aagctccgga tgcctccgct 480
cgaagtagcg cgtctgctgc tccatacaag ccaaccacgg cctccagaag aagatgttgg 540
cgacctcgta ttgggaatcc ccgaacatcg cctcgctcca gtcaatgacc gctgttatgc 600
ggccattgtc cgtcaggaca ttgttggagc cgaaatccgc gtgcacgagg tgccggactt 660
cggggcagtc ctcggcccaa agcatcagct catcgagagc ctgcgcgacg gacgcactga 720
cggtgtcgtc catcacagtt tgccagtgat acacatgggg atcagcaatc gcgcatatga 780
aatcacgcca tgtagtgtat tgaccgattc cttgcggtcc gaatgggccg aacccgctcg 840
tctggctaag atcggccgca gcgatcgcat ccatagcctc cgcgaccggc tgcagaacag 900
cgggcagttc ggtttcaggc aggtcttgca acgtgacacc ctgtgcacgg cgggagatgc 960
aataggtcag gctctcgctg aattccccaa tgtcaagcac ttccggaatc gggagcgcgg 1020
ccgatgcaaa gtgccgataa acataacgat ctttgtagaa accatcggcg cagctattta 1080
cccgcaggac atatccacgc cctcctacat cgaagctgaa agcacgagat tcttcgccct 1140
ccgagagctg catcaggtcg gagacgctgt cgaacttttc gatcagaaac ttctcgacag 1200
acgtcgcggt gagttcaggc ttttccatgg gtatatctcc ttcttaaagt taaacaaaat 1260
tatttctaga gggaaaccgt tgtggtctcc ctatagtgag tcgtattaat ttcgcgggat 1320
cgagatctga tcaacctgca ttaatgaatc ggccaacgcg cggggagagg cggtttgcgt 1380
attgggcgct cttccgcttc ctcgctcact gactcgctgc gctcggtcgt tcggctgcgg 1440
cgagcggtat cagctcactc aaaggcggta atacggttat ccacagaatc aggggataac 1500
gcaggaaaga acatgtgagc aaaaggccag caaaaggcca ggaaccgtaa aaaggccgcg 1560
ttgctggcgt ttttccatag gctccgcccc cctgacgagc atcacaaaaa tcgacgctca 1620
agtcagaggt ggcgaaaccc gacaggacta taaagatacc aggcgtttcc ccctggaagc 1680
tccctcgtgc gctctcctgt tccgaccctg ccgcttaccg gatacctgtc cgcctttctc 1740
ccttcgggaa gcgtggcgct ttctcaatgc tcacgctgta ggtatctcag ttcggtgtag 1800
gtcgttcgct ccaagctggg ctgtgtgcac gaaccccccg ttcagcccga ccgctgcgcc 1860
ttatccggta actatcgtct tgagtccaac ccggtaagac acgacttatc gccactggca 1920
gcagccactg gtaacaggat tagcagagcg aggtatgtag gcggtgctac agagttcttg 1980
aagtggtggc ctaactacgg ctacactaga aggacagtat ttggtatctg cgctctgctg 2040
aagccagtta ccttcggaaa aagagttggt agctcttgat ccggcaaaca aaccaccgct 2100
ggtagcggtg gtttttttgt ttgcaagcag cagattacgc gcagaaaaaa aggatctcaa 2160
gaagatcctt tgatcttttc tacggggtct gacgctcagt ggaacgaaaa ctcacgttaa 2220
gggattttgg tcatgacatt aacctataaa aataggcgta tcacgaggcc ctttcgtctc 2280
gcgcgtttcg gtgatgacgg tgaaaacctc tgacacatgc agctcccgga gacggtcaca 2340
gcttgtctgt aagcggatgc cgggagcaga caagcccgtc agggcgcgtc agcgggtgtt 2400
ggcgggtgtc ggggctggct taactatgcg gcatcagagc agattgtact gagagtgcac 2460
catatggaca tattgtcgtt agaacgcggc tacaattaat acataacctt atgtatcata 2520
cacatacgat ttaggtgaca ctatagaacg gcgcgccaag ctgggtctag aactagaaac 2580
gtgatgccac ttgttattga agtcgattac agcatctatt ctgttttact atttataact 2640
ttgccatttc tgacttttga aaactatctc tggatttcgg tatcgctttg tgaagatcga 2700
gcaaaagaga cgttttgtgg acgcaatggt ccaaatccgt tctacatgaa caaattggtc 2760
acaatttcca ctaaaagtaa ataaatggca agttaaaaaa ggaatatgca ttttactgat 2820
tgcctaggtg agctccaaga gaagttgaat ctacacgtct accaaccgct aaaaaaagaa 2880
aaacattgat atgtaacctg attccattag cttttgactt cttcaacaga ttctctactt 2940
agatttctaa cagaaatatt attactagca catcattttc agtctcacta cagcaaaaaa 3000
tccaacggca caatacagac aacaggagat atcagactac agagatagat agatgctact 3060
gcatgtagta agttaaataa aaggaaaata aaatgtcttg ctaccaaaac tactacagac 3120
tatgatgctc accacaggcc aaatcctgca actaggacag cattatctta tatatattgt 3180
acaaaacaag catcaaggaa catttggtct aggcaatcag tacctcgttc taccatcacc 3240
ctcagttatc acatccttga aggatccatt actgggaatc atcggcaaca catgctcctg 3300
atggggcaca atgacatcaa gaaggtaggg gccaggggtg tccaacattc tctgaattgc 3360
cgctctaagc tcttccttct tcgtcactcg cgctgccggt atcccacaag catcagcaaa 3420
cttgagcatg tttgggaata tctcgctctc gctagacgga tctccaagat aggtgtgagc 3480
tctattggac ttgtagaacc tatcctccaa ctgaaccacc atacccaaat gctgattgtt 3540
caacaacaat atcttaactg ggagattctc cactcttata gtggccaact cctgaacatt 3600
catgatgaaa ctaccatccc catcaatgtc aaccacaaca gccccagggt tagcaacagc 3660
agcaccaata gccgcaggca atccaaaacc catggctcca agaccccctg aggtcaacca 3720
ctgcctcggt ctcttgtact tgtaaaactg cgcagcccac atttgatgct gcccaacccc 3780
agtactaaca atagcatctc cattagtcaa ctcatcaaga acctcgatag catgctgcgg 3840
agaaatcgcg tcctggaatg tcttgtaacc caatggaaac ttgtgtttct gcacattaat 3900
ctcttctctc caacctccaa gatcaaactt accctccact cctttctcct ccaaaatcat 3960
attaattccc ttcaaggcca acttcaaatc cgcgcaaacc gacacgtgcg cctgcttgtt 4020
cttcccaatc tcggcagaat caatatcaat gtgaacaatc ttagccctac tagcaaaagc 4080
ctcaagcttc ccagtaacac ggtcatcaaa ccttacccca aaggcaagca acaaatcact 4140
attgtcaaca gcatagttag cataaacagt accatgcata cccagcatct gaagggaata 4200
ttcatcacca ataggaaaag ttccaagacc cattaaagtg ctagcaacgg gaataccagt 4260
gagttcaaca aagcgcctca attcagcact ggaattcaaa ctgccaccgc cgacgtagag 4320
aacgggcttt tgggcctcca tgatgagtct gacaatgtgt tccaattggg cctcggcggg 4380
gggcctgggc agcctggcga ggtaaccggg gaggttaacg ggctcgtccc aattaggcac 4440
ggcgagttgc tgctgaacgt ctttgggaat gtcgatgagg accggaccgg ggcggccgga 4500
ggtggcgacg aagaaagcct cggcgacgac gcgggggatg tcgtcgacgt cgaggatgag 4560
gtagttgtgc ttcgtgatgg atctgctcac ctccacgatc ggggtttctt ggaaggcgtc 4620
ggtgccgatc atccggcggg cgacctggcc ggtgatggcg acgactggga cgctgtccat 4680
taaagcgtcg gcgaggccgc tcacgaggtt ggtggcgccg gggccggagg tggcaatgca 4740
gacgccgggg aggccggagg aacgcgcgta gccttcggcg gcgaagacgc cgccctgctc 4800
gtggcgcggg agcacgttgc ggatggcggc ggagcgcgtg agcgcctggt ggatctccat 4860
cgacgcaccg ccggggtacg cgaacaccgt cgtcacgccc tgcctctcca gcgcctccac 4920
aaggatgtcc gcgcccttgc gaggttcgcc ggaggcgaac cgtgacacga agggctccgt 4980
ggtcggcgct tccttggtga agggcgccgc cgtggggggt ttggagatgg aacatttgat 5040
tttgagagcg tggttgggtt tggtgagggt ttgatgagag agagggaggg tggatctagt 5100
aatgcgtttg gggaaggtgg ggtgtgaaga ggaagaagag aatcgggtgg ttctggaagc 5160
ggtggccgcc attgtgttgt gtggcatggt tatacttcaa aaactgcaca acaagcctag 5220
agttagtacc taaacagtaa atttacaaca gagagcaaag acacatgcaa aaatttcagc 5280
cataaaaaaa gttataatag aatttaaagc aaaagtttca ttttttaaac atatatacaa 5340
acaaactgga tttgaaggaa gggattaatt cccctgctca aagtttgaat tcctattgtg 5400
acctatactc gaataaaatt gaagcctaag gaatgtatga gaaacaagaa aacaaaacaa 5460
aactacagac aaacaagtac aattacaaaa ttcgctaaaa ttctgtaatc accaaacccc 5520
atctcagtca gcacaaggcc caaggtttat tttgaaataa aaaaaaagtg attttatttc 5580
tcataagcta aaagaaagaa aggcaattat gaaatgattt cgactagatc tgaaagtcca 5640
acgcgtattc cgcagatatt aaagaaagag tagagtttca catggatcct agatggaccc 5700
agttgaggaa aaagcaaggc aaagcaaacc agaagtgcaa gatccgaaat tgaaccacgg 5760
aatctaggat ttggtagagg gagaagaaaa gtaccttgag aggtagaaga gaagagaaga 5820
gcagagagat atatgaacga gtgtgtcttg gtctcaactc tgaagcgata cgagtttaga 5880
ggggagcatt gagttccaat ttatagggaa accgggtggc aggggtgagt taatgacgga 5940
aaagccccta agtaacgaga ttggattgtg ggttagattc aaccgtttgc atccgcggct 6000
tagattgggg aagtcagagt gaatctcaac cgttgactga gttgaaaatt gaatgtagca 6060
accaattgag ccaaccccag cctttgccct ttgattttga tttgtttgtt gcatactttt 6120
tatttgtctt ctggttctga ctctctttct ctcgtttcaa tgccaggttg cctactccca 6180
caccactcac aagaagattc tactgttagt attaaatatt ttttaatgta ttaaatgatg 6240
aatgcttttg taaacagaac aagactatgt ctaataagtg tcttgcaaca ttttttaaga 6300
aattaaaaaa aatatattta ttatcaaaat caaatgtatg aaaaatcatg aataatataa 6360
ttttatacat ttttttaaaa aatcttttaa tttcttaatt aatatcttaa aaataatgat 6420
taatatttaa cccaaaataa ttagtatgat tggtaaggaa gatatccatg ttatgtttgg 6480
atgtgagttt gatctagagc aaagcttact agagtcgacc tgcaggtcga ctcgacgtac 6540
gatcccacat gcaagttttt atttcaatcc cttttccttt gaataactga ccaagaacaa 6600
caagaaaaaa aaaaaaaaag aaaaggatca ttttgaaagg atatttttcg ctcctattca 6660
aatactgtat ttttaccaaa aaaactgtat ttttcctaca ctctcaagct ttgtttttcg 6720
cttcgactct catgatttcc ttcatatgcc aatcactcta tttataaatg gcataaggta 6780
gtgtgaacaa ttgcaaagct tgtcatcaaa agcttgcaat gtacaaatta atgtttttca 6840
tgcctttcaa aattatctgc accccctagc tattaatcta acatctaagt aaggctagtg 6900
aattttttcg aatagtcatg cagtgcatta atttccccgt gactattttg gctttgactc 6960
caacactggc cccgtacatc cgtccctcat tacatgaaaa gaaatattgt ttatattctt 7020
aattaaaaat attgtccctt ctaaattttc atatagttaa ttattatatt acttttttct 7080
ctattctatt agttctattt tcaaattatt atttatgcat atgtaaagta cattatattt 7140
ttgctatata cttaaatatt tctaaattat taaaaaaaga ctgatatgaa aaatttattc 7200
tttttaaagc tatatcattt tatatatact ttttcttttc ttttctttca ttttctattc 7260
aatttaataa gaaataaatt ttgtaaattt ttatttatca atttataaaa atattttact 7320
ttatatgttt tttcacattt ttgttaaaca aatcatatca ttatgattga aagagaggaa 7380
attgacagtg agtaataagt gatgagaaaa aaatgtgtta tttcctaaaa aaaacctaaa 7440
caaacatgta tctactctct atttcatcta tctctcattt catttttctc tttatctctt 7500
tctttatttt tttatcatat catttcacat taattatttt tactctcttt attttttctc 7560
tctatccctc tcttatttcc actcatatat acactccaaa attggggcat gcctttatca 7620
ctactctatc tcctccacta aatcatttaa atgaaactga aaagcattgg caagtctcct 7680
cccctcctca agtgatttcc aactcagcat tggcatctaa ttgattcagt atatctattg 7740
catgtgtaaa agtctttcca caatacataa ctattaatta atcttaaata aataaaggat 7800
aaaatatttt tttttcttca taaaattaaa atatgttatt ttttgtttag atgtatattc 7860
gaataaatct aaatatatga taatgatttt ttatattgat taaacatata atcaatatta 7920
aatatgatat ttttttatat aggttgtaca cataatttta taaggataaa aaatatgata 7980
aaaataaatt ttaaatattt ttatatttac gagaaaaaaa aatattttag ccataaataa 8040
atgaccagca tattttacaa ccttagtaat tcataaattc ctatatgtat atttgaaatt 8100
aaaaacagat aatcgttaag ggaaggaatc ctacgtcatc tcttgccatt tgtttttcat 8160
gcaaacagaa agggacgaaa aaccacctca ccatgaatca ctcttcacac catttttact 8220
agcaaacaag tctcaacaac tgaagccagc tctctttccg tttcttttta caacactttc 8280
tttgaaatag tagtattttt ttttcacatg atttattaac gtgccaaaag atgcttattg 8340
aatagagtgc acatttgtaa tgtactacta attagaacat gaaaaagcat tgttctaaca 8400
cgataatcct gtgaaggcgt taactccaaa gatccaattt cactatataa attgtgacga 8460
aagcaaaatg aattcacata gctgagagag aaaggaaagg ttaactaaga agcaatactt 8520
cagcggccgc atgactgagg ataagacgaa ggtcgagttc ccgacgctca cggagctcaa 8580
gcactcgatc ccgaacgcgt gctttgagtc gaacctcggc ctctcgctct actacacggc 8640
ccgcgcgatc ttcaacgcgt cggcctcggc ggcgctgctc tacgcggcgc gctcgacgcc 8700
gttcattgcc gataacgttc tgctccacgc gctcgtttgc gccacctaca tctacgtgca 8760
gggcgtcatc ttctggggct tcttcacggt cggccacgac tgcggccact cggccttctc 8820
gcgctaccac agcgtcaact ttatcatcgg ctgcatcatg cactctgcga ttttgacgcc 8880
gttcgagagc tggcgcgtga cgcaccgcca ccaccacaag aacacgggca acattgataa 8940
ggacgagatc ttttacccgc accggtcggt caaggacctc caggacgtgc gccaatgggt 9000
ctacacgctc ggcggtgcgt ggtttgtcta cttgaaggtc gggtatgccc cgcgcacgat 9060
gagccacttt gacccgtggg acccgctcct ccttcgccgc gcgtcggccg tcatcgtgtc 9120
gctcggcgtc tgggccgcct tcttcgccgc gtacgcgtac ctcacatact cgctcggctt 9180
tgccgtcatg ggcctctact actatgcgcc gctctttgtc tttgcttcgt tcctcgtcat 9240
tacgaccttc ttgcaccaca acgacgaagc gacgccgtgg tacggcgact cggagtggac 9300
gtacgtcaag ggcaacctct cgagcgtcga ccgctcgtac ggcgcgttcg tggacaacct 9360
gagccaccac attggcacgc accaggtcca ccacttgttc ccgatcattc cgcactacaa 9420
gctcaacgaa gccaccaagc actttgcggc cgcgtacccg cacctcgtgc gcaggaacga 9480
cgagcccatc atcacggcct tcttcaagac cgcgcacctc tttgtcaact acggcgctgt 9540
gcccgagacg gcgcagatct tcacgctcaa agagtcggcc gcggccgcca aggccaagtc 9600
ggactaagcg gccgcgaatt caatcactag tgaattcgcg gccgcatgag ccgtaaaggt 9660
tcaatacaac gagtgcttgt tttcttaggg acaagcattg tacttatgta tgattctgtg 9720
taaccatgag tcttccacgt tgtactaatg tgaagggcaa aaataaaaca cagaacaagt 9780
tcgtttttct caaataatgt gaaggtagaa aatggaacca tgcctcctct cttgcatgtg 9840
atttaaaata ttagcagatg gtaccgtacg tgggcggatc ccccgggctg ca 9892
<210> 84
<211> 9892
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR886r
<400> 84
ggtcgactcg acgtacgtct agaggatccg tcgacggcgc gcccgatcat ccggatatag 60
ttcctccttt cagcaaaaaa cccctcaaga cccgtttaga ggccccaagg ggttatgcta 120
gttattgctc agcggtggca gcagccaact cagcttcctt tcgggctttg ttagcagccg 180
gatcgatcca agctgtacct cactattcct ttgccctcgg acgagtgctg gggcgtcggt 240
ttccactatc ggcgagtact tctacacagc catcggtcca gacggccgcg cttctgcggg 300
cgatttgtgt acgcccgaca gtcccggctc cggatcggac gattgcgtcg catcgaccct 360
gcgcccaagc tgcatcatcg aaattgccgt caaccaagct ctgatagagt tggtcaagac 420
caatgcggag catatacgcc cggagccgcg gcgatcctgc aagctccgga tgcctccgct 480
cgaagtagcg cgtctgctgc tccatacaag ccaaccacgg cctccagaag aagatgttgg 540
cgacctcgta ttgggaatcc ccgaacatcg cctcgctcca gtcaatgacc gctgttatgc 600
ggccattgtc cgtcaggaca ttgttggagc cgaaatccgc gtgcacgagg tgccggactt 660
cggggcagtc ctcggcccaa agcatcagct catcgagagc ctgcgcgacg gacgcactga 720
cggtgtcgtc catcacagtt tgccagtgat acacatgggg atcagcaatc gcgcatatga 780
aatcacgcca tgtagtgtat tgaccgattc cttgcggtcc gaatgggccg aacccgctcg 840
tctggctaag atcggccgca gcgatcgcat ccatagcctc cgcgaccggc tgcagaacag 900
cgggcagttc ggtttcaggc aggtcttgca acgtgacacc ctgtgcacgg cgggagatgc 960
aataggtcag gctctcgctg aattccccaa tgtcaagcac ttccggaatc gggagcgcgg 1020
ccgatgcaaa gtgccgataa acataacgat ctttgtagaa accatcggcg cagctattta 1080
cccgcaggac atatccacgc cctcctacat cgaagctgaa agcacgagat tcttcgccct 1140
ccgagagctg catcaggtcg gagacgctgt cgaacttttc gatcagaaac ttctcgacag 1200
acgtcgcggt gagttcaggc ttttccatgg gtatatctcc ttcttaaagt taaacaaaat 1260
tatttctaga gggaaaccgt tgtggtctcc ctatagtgag tcgtattaat ttcgcgggat 1320
cgagatctga tcaacctgca ttaatgaatc ggccaacgcg cggggagagg cggtttgcgt 1380
attgggcgct cttccgcttc ctcgctcact gactcgctgc gctcggtcgt tcggctgcgg 1440
cgagcggtat cagctcactc aaaggcggta atacggttat ccacagaatc aggggataac 1500
gcaggaaaga acatgtgagc aaaaggccag caaaaggcca ggaaccgtaa aaaggccgcg 1560
ttgctggcgt ttttccatag gctccgcccc cctgacgagc atcacaaaaa tcgacgctca 1620
agtcagaggt ggcgaaaccc gacaggacta taaagatacc aggcgtttcc ccctggaagc 1680
tccctcgtgc gctctcctgt tccgaccctg ccgcttaccg gatacctgtc cgcctttctc 1740
ccttcgggaa gcgtggcgct ttctcaatgc tcacgctgta ggtatctcag ttcggtgtag 1800
gtcgttcgct ccaagctggg ctgtgtgcac gaaccccccg ttcagcccga ccgctgcgcc 1860
ttatccggta actatcgtct tgagtccaac ccggtaagac acgacttatc gccactggca 1920
gcagccactg gtaacaggat tagcagagcg aggtatgtag gcggtgctac agagttcttg 1980
aagtggtggc ctaactacgg ctacactaga aggacagtat ttggtatctg cgctctgctg 2040
aagccagtta ccttcggaaa aagagttggt agctcttgat ccggcaaaca aaccaccgct 2100
ggtagcggtg gtttttttgt ttgcaagcag cagattacgc gcagaaaaaa aggatctcaa 2160
gaagatcctt tgatcttttc tacggggtct gacgctcagt ggaacgaaaa ctcacgttaa 2220
gggattttgg tcatgacatt aacctataaa aataggcgta tcacgaggcc ctttcgtctc 2280
gcgcgtttcg gtgatgacgg tgaaaacctc tgacacatgc agctcccgga gacggtcaca 2340
gcttgtctgt aagcggatgc cgggagcaga caagcccgtc agggcgcgtc agcgggtgtt 2400
ggcgggtgtc ggggctggct taactatgcg gcatcagagc agattgtact gagagtgcac 2460
catatggaca tattgtcgtt agaacgcggc tacaattaat acataacctt atgtatcata 2520
cacatacgat ttaggtgaca ctatagaacg gcgcgccaag ctgggtctag aactagaaac 2580
gtgatgccac ttgttattga agtcgattac agcatctatt ctgttttact atttataact 2640
ttgccatttc tgacttttga aaactatctc tggatttcgg tatcgctttg tgaagatcga 2700
gcaaaagaga cgttttgtgg acgcaatggt ccaaatccgt tctacatgaa caaattggtc 2760
acaatttcca ctaaaagtaa ataaatggca agttaaaaaa ggaatatgca ttttactgat 2820
tgcctaggtg agctccaaga gaagttgaat ctacacgtct accaaccgct aaaaaaagaa 2880
aaacattgat atgtaacctg attccattag cttttgactt cttcaacaga ttctctactt 2940
agatttctaa cagaaatatt attactagca catcattttc agtctcacta cagcaaaaaa 3000
tccaacggca caatacagac aacaggagat atcagactac agagatagat agatgctact 3060
gcatgtagta agttaaataa aaggaaaata aaatgtcttg ctaccaaaac tactacagac 3120
tatgatgctc accacaggcc aaatcctgca actaggacag cattatctta tatatattgt 3180
acaaaacaag catcaaggaa catttggtct aggcaatcag tacctcgttc taccatcacc 3240
ctcagttatc acatccttga aggatccatt actgggaatc atcggcaaca catgctcctg 3300
atggggcaca atgacatcaa gaaggtaggg gccaggggtg tccaacattc tctgaattgc 3360
cgctctaagc tcttccttct tcgtcactcg cgctgccggt atcccacaag catcagcaaa 3420
cttgagcatg tttgggaata tctcgctctc gctagacgga tctccaagat aggtgtgagc 3480
tctattggac ttgtagaacc tatcctccaa ctgaaccacc atacccaaat gctgattgtt 3540
caacaacaat atcttaactg ggagattctc cactcttata gtggccaact cctgaacatt 3600
catgatgaaa ctaccatccc catcaatgtc aaccacaaca gccccagggt tagcaacagc 3660
agcaccaata gccgcaggca atccaaaacc catggctcca agaccccctg aggtcaacca 3720
ctgcctcggt ctcttgtact tgtaaaactg cgcagcccac atttgatgct gcccaacccc 3780
agtactaaca atagcatctc cattagtcaa ctcatcaaga acctcgatag catgctgcgg 3840
agaaatcgcg tcctggaatg tcttgtaacc caatggaaac ttgtgtttct gcacattaat 3900
ctcttctctc caacctccaa gatcaaactt accctccact cctttctcct ccaaaatcat 3960
attaattccc ttcaaggcca acttcaaatc cgcgcaaacc gacacgtgcg cctgcttgtt 4020
cttcccaatc tcggcagaat caatatcaat gtgaacaatc ttagccctac tagcaaaagc 4080
ctcaagcttc ccagtaacac ggtcatcaaa ccttacccca aaggcaagca acaaatcact 4140
attgtcaaca gcatagttag cataaacagt accatgcata cccagcatct gaagggaata 4200
ttcatcacca ataggaaaag ttccaagacc cattaaagtg ctagcaacgg gaataccagt 4260
gagttcaaca aagcgcctca attcagcact ggaattcaaa ctgccaccgc cgacgtagag 4320
aacgggcttt tgggcctcca tgatgagtct gacaatgtgt tccaattggg cctcggcggg 4380
gggcctgggc agcctggcga ggtaaccggg gaggttaacg ggctcgtccc aattaggcac 4440
ggcgagttgc tgctgaacgt ctttgggaat gtcgatgagg accggaccgg ggcggccgga 4500
ggtggcgacg aagaaagcct cggcgacgac gcgggggatg tcgtcgacgt cgaggatgag 4560
gtagttgtgc ttcgtgatgg atctgctcac ctccacgatc ggggtttctt ggaaggcgtc 4620
ggtgccgatc atccggcggg cgacctggcc ggtgatggcg acgactggga cgctgtccat 4680
taaagcgtcg gcgaggccgc tcacgaggtt ggtggcgccg gggccggagg tggcaatgca 4740
gacgccgggg aggccggagg aacgcgcgta gccttcggcg gcgaagacgc cgccctgctc 4800
gtggcgcggg agcacgttgc ggatggcggc ggagcgcgtg agcgcctggt ggatctccat 4860
cgacgcaccg ccggggtacg cgaacaccgt cgtcacgccc tgcctctcca gcgcctccac 4920
aaggatgtcc gcgcccttgc gaggttcgcc ggaggcgaac cgtgacacga agggctccgt 4980
ggtcggcgct tccttggtga agggcgccgc cgtggggggt ttggagatgg aacatttgat 5040
tttgagagcg tggttgggtt tggtgagggt ttgatgagag agagggaggg tggatctagt 5100
aatgcgtttg gggaaggtgg ggtgtgaaga ggaagaagag aatcgggtgg ttctggaagc 5160
ggtggccgcc attgtgttgt gtggcatggt tatacttcaa aaactgcaca acaagcctag 5220
agttagtacc taaacagtaa atttacaaca gagagcaaag acacatgcaa aaatttcagc 5280
cataaaaaaa gttataatag aatttaaagc aaaagtttca ttttttaaac atatatacaa 5340
acaaactgga tttgaaggaa gggattaatt cccctgctca aagtttgaat tcctattgtg 5400
acctatactc gaataaaatt gaagcctaag gaatgtatga gaaacaagaa aacaaaacaa 5460
aactacagac aaacaagtac aattacaaaa ttcgctaaaa ttctgtaatc accaaacccc 5520
atctcagtca gcacaaggcc caaggtttat tttgaaataa aaaaaaagtg attttatttc 5580
tcataagcta aaagaaagaa aggcaattat gaaatgattt cgactagatc tgaaagtcca 5640
acgcgtattc cgcagatatt aaagaaagag tagagtttca catggatcct agatggaccc 5700
agttgaggaa aaagcaaggc aaagcaaacc agaagtgcaa gatccgaaat tgaaccacgg 5760
aatctaggat ttggtagagg gagaagaaaa gtaccttgag aggtagaaga gaagagaaga 5820
gcagagagat atatgaacga gtgtgtcttg gtctcaactc tgaagcgata cgagtttaga 5880
ggggagcatt gagttccaat ttatagggaa accgggtggc aggggtgagt taatgacgga 5940
aaagccccta agtaacgaga ttggattgtg ggttagattc aaccgtttgc atccgcggct 6000
tagattgggg aagtcagagt gaatctcaac cgttgactga gttgaaaatt gaatgtagca 6060
accaattgag ccaaccccag cctttgccct ttgattttga tttgtttgtt gcatactttt 6120
tatttgtctt ctggttctga ctctctttct ctcgtttcaa tgccaggttg cctactccca 6180
caccactcac aagaagattc tactgttagt attaaatatt ttttaatgta ttaaatgatg 6240
aatgcttttg taaacagaac aagactatgt ctaataagtg tcttgcaaca ttttttaaga 6300
aattaaaaaa aatatattta ttatcaaaat caaatgtatg aaaaatcatg aataatataa 6360
ttttatacat ttttttaaaa aatcttttaa tttcttaatt aatatcttaa aaataatgat 6420
taatatttaa cccaaaataa ttagtatgat tggtaaggaa gatatccatg ttatgtttgg 6480
atgtgagttt gatctagagc aaagcttact agagtcgacc tgcagcccgg gggatccgcc 6540
cacgtacggt accatctgct aatattttaa atcacatgca agagaggagg catggttcca 6600
ttttctacct tcacattatt tgagaaaaac gaacttgttc tgtgttttat ttttgccctt 6660
cacattagta caacgtggaa gactcatggt tacacagaat catacataag tacaatgctt 6720
gtccctaaga aaacaagcac tcgttgtatt gaacctttac ggctcatgcg gccgcgaatt 6780
cactagtgat tgaattcgcg gccgcttagt ccgacttggc cttggcggcc gcggccgact 6840
ctttgagcgt gaagatctgc gccgtctcgg gcacagcgcc gtagttgaca aagaggtgcg 6900
cggtcttgaa gaaggccgtg atgatgggct cgtcgttcct gcgcacgagg tgcgggtacg 6960
cggccgcaaa gtgcttggtg gcttcgttga gcttgtagtg cggaatgatc gggaacaagt 7020
ggtggacctg gtgcgtgcca atgtggtggc tcaggttgtc cacgaacgcg ccgtacgagc 7080
ggtcgacgct cgagaggttg cccttgacgt acgtccactc cgagtcgccg taccacggcg 7140
tcgcttcgtc gttgtggtgc aagaaggtcg taatgacgag gaacgaagca aagacaaaga 7200
gcggcgcata gtagtagagg cccatgacgg caaagccgag cgagtatgtg aggtacgcgt 7260
acgcggcgaa gaaggcggcc cagacgccga gcgacacgat gacggccgac gcgcggcgaa 7320
ggaggagcgg gtcccacggg tcaaagtggc tcatcgtgcg cggggcatac ccgaccttca 7380
agtagacaaa ccacgcaccg ccgagcgtgt agacccattg gcgcacgtcc tggaggtcct 7440
tgaccgaccg gtgcgggtaa aagatctcgt ccttatcaat gttgcccgtg ttcttgtggt 7500
ggtggcggtg cgtcacgcgc cagctctcga acggcgtcaa aatcgcagag tgcatgatgc 7560
agccgatgat aaagttgacg ctgtggtagc gcgagaaggc cgagtggccg cagtcgtggc 7620
cgaccgtgaa gaagccccag aagatgacgc cctgcacgta gatgtaggtg gcgcaaacga 7680
gcgcgtggag cagaacgtta tcggcaatga acggcgtcga gcgcgccgcg tagagcagcg 7740
ccgccgaggc cgacgcgttg aagatcgcgc gggccgtgta gtagagcgag aggccgaggt 7800
tcgactcaaa gcacgcgttc gggatcgagt gcttgagctc cgtgagcgtc gggaactcga 7860
ccttcgtctt atcctcagtc atgcggccgc tgaagtattg cttcttagtt aacctttcct 7920
ttctctctca gctatgtgaa ttcattttgc tttcgtcaca atttatatag tgaaattgga 7980
tctttggagt taacgccttc acaggattat cgtgttagaa caatgctttt tcatgttcta 8040
attagtagta cattacaaat gtgcactcta ttcaataagc atcttttggc acgttaataa 8100
atcatgtgaa aaaaaaatac tactatttca aagaaagtgt tgtaaaaaga aacggaaaga 8160
gagctggctt cagttgttga gacttgtttg ctagtaaaaa tggtgtgaag agtgattcat 8220
ggtgaggtgg tttttcgtcc ctttctgttt gcatgaaaaa caaatggcaa gagatgacgt 8280
aggattcctt cccttaacga ttatctgttt ttaatttcaa atatacatat aggaatttat 8340
gaattactaa ggttgtaaaa tatgctggtc atttatttat ggctaaaata tttttttttc 8400
tcgtaaatat aaaaatattt aaaatttatt tttatcatat tttttatcct tataaaatta 8460
tgtgtacaac ctatataaaa aaatatcata tttaatattg attatatgtt taatcaatat 8520
aaaaaatcat tatcatatat ttagatttat tcgaatatac atctaaacaa aaaataacat 8580
attttaattt tatgaagaaa aaaaaatatt ttatccttta tttatttaag attaattaat 8640
agttatgtat tgtggaaaga cttttacaca tgcaatagat atactgaatc aattagatgc 8700
caatgctgag ttggaaatca cttgaggagg ggaggagact tgccaatgct tttcagtttc 8760
atttaaatga tttagtggag gagatagagt agtgataaag gcatgcccca attttggagt 8820
gtatatatga gtggaaataa gagagggata gagagaaaaa ataaagagag taaaaataat 8880
taatgtgaaa tgatatgata aaaaaataaa gaaagagata aagagaaaaa tgaaatgaga 8940
gatagatgaa atagagagta gatacatgtt tgtttaggtt ttttttagga aataacacat 9000
ttttttctca tcacttatta ctcactgtca atttcctctc tttcaatcat aatgatatga 9060
tttgtttaac aaaaatgtga aaaaacatat aaagtaaaat atttttataa attgataaat 9120
aaaaatttac aaaatttatt tcttattaaa ttgaatagaa aatgaaagaa aagaaaagaa 9180
aaagtatata taaaatgata tagctttaaa aagaataaat ttttcatatc agtctttttt 9240
taataattta gaaatattta agtatatagc aaaaatataa tgtactttac atatgcataa 9300
ataataattt gaaaatagaa ctaatagaat agagaaaaaa gtaatataat aattaactat 9360
atgaaaattt agaagggaca atatttttaa ttaagaatat aaacaatatt tcttttcatg 9420
taatgaggga cggatgtacg gggccagtgt tggagtcaaa gccaaaatag tcacggggaa 9480
attaatgcac tgcatgacta ttcgaaaaaa ttcactagcc ttacttagat gttagattaa 9540
tagctagggg gtgcagataa ttttgaaagg catgaaaaac attaatttgt acattgcaag 9600
cttttgatga caagctttgc aattgttcac actaccttat gccatttata aatagagtga 9660
ttggcatatg aaggaaatca tgagagtcga agcgaaaaac aaagcttgag agtgtaggaa 9720
aaatacagtt tttttggtaa aaatacagta tttgaatagg agcgaaaaat atcctttcaa 9780
aatgatcctt ttcttttttt ttttttttct tgttgttctt ggtcagttat tcaaaggaaa 9840
agggattgaa ataaaaactt gcatgtggga tcgtacgtcg agtcgacctg ca 9892
<210> 85
<211> 6021
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR271
<400> 85
ggccgcgaat tcaatcacta gtgaattcgc ggccgcatga gccgtaaagg ttcaatacaa 60
cgagtgcttg ttttcttagg gacaagcatt gtacttatgt atgattctgt gtaaccatga 120
gtcttccacg ttgtactaat gtgaagggca aaaataaaac acagaacaag ttcgtttttc 180
tcaaataatg tgaaggtaga aaatggaacc atgcctcctc tcttgcatgt gatttaaaat 240
attagcagat ggtaccgtac gtgggcggat cccccgggct gcaggaattc actggccgtc 300
gttttacaac gtcgtgactg ggaaaaccct ggcgttaccc aacttaatcg ccttgcagca 360
catccccctt tcgccagctg gcgtaatagc gaagaggccc gcaccgatcg cccttcccaa 420
cagttgcgca gcctgaatgg cgaatggcgc ctgatgcggt attttctcct tacgcatctg 480
tgcggtattt cacaccgcat atggtgcact ctcagtacaa tctgctctga tgccgcatag 540
ttaagccagc cccgacaccc gccaacaccc gctgacgcgc cctgacgggc ttgtctgctc 600
ccggcatccg cttacagaca agctgtgacc gtctccggga gctgcatgtg tcagaggttt 660
tcaccgtcat caccgaaacg cgcgagacga aagggcctcg tgatacgcct atttttatag 720
gttaatgtca tgataataat ggtttcttag acgtcaggtg gcacttttcg gggaaatgtg 780
cgcggaaccc ctatttgttt atttttctaa atacattcaa atatgtatcc gctcatgaga 840
caataaccct gataaatgct tcaataatat tgaaaaagga agagtatgag tattcaacat 900
ttccgtgtcg cccttattcc cttttttgcg gcattttgcc ttcctgtttt tgctcaccca 960
gaaacgctgg tgaaagtaaa agatgctgaa gatcagttgg gtgcacgagt gggttacatc 1020
gaactggatc tcaacagcgg taagatcctt gagagttttc gccccgaaga acgttttcca 1080
atgatgagca cttttaaagt tctgctatgt ggcgcggtat tatcccgtat tgacgccggg 1140
caagagcaac tcggtcgccg catacactat tctcagaatg acttggttga gtactcacca 1200
gtcacagaaa agcatcttac ggatggcatg acagtaagag aattatgcag tgctgccata 1260
accatgagtg ataacactgc ggccaactta cttctgacaa cgatcggagg accgaaggag 1320
ctaaccgctt ttttgcacaa catgggggat catgtaactc gccttgatcg ttgggaaccg 1380
gagctgaatg aagccatacc aaacgacgag cgtgacacca cgatgcctgt agcaatggca 1440
acaacgttgc gcaaactatt aactggcgaa ctacttactc tagcttcccg gcaacaatta 1500
atagactgga tggaggcgga taaagttgca ggaccacttc tgcgctcggc ccttccggct 1560
ggctggttta ttgctgataa atctggagcc ggtgagcgtg ggtctcgcgg tatcattgca 1620
gcactggggc cagatggtaa gccctcccgt atcgtagtta tctacacgac ggggagtcag 1680
gcaactatgg atgaacgaaa tagacagatc gctgagatag gtgcctcact gattaagcat 1740
tggtaactgt cagaccaagt ttactcatat atactttaga ttgatttaaa acttcatttt 1800
taatttaaaa ggatctaggt gaagatcctt tttgataatc tcatgaccaa aatcccttaa 1860
cgtgagtttt cgttccactg agcgtcagac cccgtagaaa agatcaaagg atcttcttga 1920
gatccttttt ttctgcgcgt aatctgctgc ttgcaaacaa aaaaaccacc gctaccagcg 1980
gtggtttgtt tgccggatca agagctacca actctttttc cgaaggtaac tggcttcagc 2040
agagcgcaga taccaaatac tgtccttcta gtgtagccgt agttaggcca ccacttcaag 2100
aactctgtag caccgcctac atacctcgct ctgctaatcc tgttaccagt ggctgctgcc 2160
agtggcgata agtcgtgtct taccgggttg gactcaagac gatagttacc ggataaggcg 2220
cagcggtcgg gctgaacggg gggttcgtgc acacagccca gcttggagcg aacgacctac 2280
accgaactga gatacctaca gcgtgagcta tgagaaagcg ccacgcttcc cgaagggaga 2340
aaggcggaca ggtatccggt aagcggcagg gtcggaacag gagagcgcac gagggagctt 2400
ccagggggaa acgcctggta tctttatagt cctgtcgggt ttcgccacct ctgacttgag 2460
cgtcgatttt tgtgatgctc gtcagggggg cggagcctat ggaaaaacgc cagcaacgcg 2520
gcctttttac ggttcctggc cttttgctgg ccttttgctc acatgttctt tcctgcgtta 2580
tcccctgatt ctgtggataa ccgtattacc gcctttgagt gagctgatac cgctcgccgc 2640
agccgaacga ccgagcgcag cgagtcagtg agcgaggaag cggaagagcg cccaatacgc 2700
aaaccgcctc tccccgcgcg ttggccgatt cattaatgca gctggcacga caggtttccc 2760
gactggaaag cgggcagtga gcgcaacgca attaatgtga gttagctcac tcattaggca 2820
ccccaggctt tacactttat gcttccggct cgtatgttgt gtggaattgt gagcggataa 2880
caatttcaca caggaaacag ctatgaccat gattacgcca agcttgcatg cctgcaggtc 2940
gactcgacgt acgatcccac atgcaagttt ttatttcaat cccttttcct ttgaataact 3000
gaccaagaac aacaagaaaa aaaaaaaaaa agaaaaggat cattttgaaa ggatattttt 3060
cgctcctatt caaatactgt atttttacca aaaaaactgt atttttccta cactctcaag 3120
ctttgttttt cgcttcgact ctcatgattt ccttcatatg ccaatcactc tatttataaa 3180
tggcataagg tagtgtgaac aattgcaaag cttgtcatca aaagcttgca atgtacaaat 3240
taatgttttt catgcctttc aaaattatct gcacccccta gctattaatc taacatctaa 3300
gtaaggctag tgaatttttt cgaatagtca tgcagtgcat taatttcccc gtgactattt 3360
tggctttgac tccaacactg gccccgtaca tccgtccctc attacatgaa aagaaatatt 3420
gtttatattc ttaattaaaa atattgtccc ttctaaattt tcatatagtt aattattata 3480
ttactttttt ctctattcta ttagttctat tttcaaatta ttatttatgc atatgtaaag 3540
tacattatat ttttgctata tacttaaata tttctaaatt attaaaaaaa gactgatatg 3600
aaaaatttat tctttttaaa gctatatcat tttatatata ctttttcttt tcttttcttt 3660
cattttctat tcaatttaat aagaaataaa ttttgtaaat ttttatttat caatttataa 3720
aaatatttta ctttatatgt tttttcacat ttttgttaaa caaatcatat cattatgatt 3780
gaaagagagg aaattgacag tgagtaataa gtgatgagaa aaaaatgtgt tatttcctaa 3840
aaaaaaccta aacaaacatg tatctactct ctatttcatc tatctctcat ttcatttttc 3900
tctttatctc tttctttatt tttttatcat atcatttcac attaattatt tttactctct 3960
ttattttttc tctctatccc tctcttattt ccactcatat atacactcca aaattggggc 4020
atgcctttat cactactcta tctcctccac taaatcattt aaatgaaact gaaaagcatt 4080
ggcaagtctc ctcccctcct caagtgattt ccaactcagc attggcatct aattgattca 4140
gtatatctat tgcatgtgta aaagtctttc cacaatacat aactattaat taatcttaaa 4200
taaataaagg ataaaatatt tttttttctt cataaaatta aaatatgtta ttttttgttt 4260
agatgtatat tcgaataaat ctaaatatat gataatgatt ttttatattg attaaacata 4320
taatcaatat taaatatgat atttttttat ataggttgta cacataattt tataaggata 4380
aaaaatatga taaaaataaa ttttaaatat ttttatattt acgagaaaaa aaaatatttt 4440
agccataaat aaatgaccag catattttac aaccttagta attcataaat tcctatatgt 4500
atatttgaaa ttaaaaacag ataatcgtta agggaaggaa tcctacgtca tctcttgcca 4560
tttgtttttc atgcaaacag aaagggacga aaaaccacct caccatgaat cactcttcac 4620
accattttta ctagcaaaca agtctcaaca actgaagcca gctctctttc cgtttctttt 4680
tacaacactt tctttgaaat agtagtattt ttttttcaca tgatttatta acgtgccaaa 4740
agatgcttat tgaatagagt gcacatttgt aatgtactac taattagaac atgaaaaagc 4800
attgttctaa cacgataatc ctgtgaaggc gttaactcca aagatccaat ttcactatat 4860
aaattgtgac gaaagcaaaa tgaattcaca tagctgagag agaaaggaaa ggttaactaa 4920
gaagcaatac ttcagcggcc gcatgactga ggataagacg aaggtcgagt tcccgacgct 4980
cacggagctc aagcactcga tcccgaacgc gtgctttgag tcgaacctcg gcctctcgct 5040
ctactacacg gcccgcgcga tcttcaacgc gtcggcctcg gcggcgctgc tctacgcggc 5100
gcgctcgacg ccgttcattg ccgataacgt tctgctccac gcgctcgttt gcgccaccta 5160
catctacgtg cagggcgtca tcttctgggg cttcttcacg gtcggccacg actgcggcca 5220
ctcggccttc tcgcgctacc acagcgtcaa ctttatcatc ggctgcatca tgcactctgc 5280
gattttgacg ccgttcgaga gctggcgcgt gacgcaccgc caccaccaca agaacacggg 5340
caacattgat aaggacgaga tcttttaccc gcaccggtcg gtcaaggacc tccaggacgt 5400
gcgccaatgg gtctacacgc tcggcggtgc gtggtttgtc tacttgaagg tcgggtatgc 5460
cccgcgcacg atgagccact ttgacccgtg ggacccgctc ctccttcgcc gcgcgtcggc 5520
cgtcatcgtg tcgctcggcg tctgggccgc cttcttcgcc gcgtacgcgt acctcacata 5580
ctcgctcggc tttgccgtca tgggcctcta ctactatgcg ccgctctttg tctttgcttc 5640
gttcctcgtc attacgacct tcttgcacca caacgacgaa gcgacgccgt ggtacggcga 5700
ctcggagtgg acgtacgtca agggcaacct ctcgagcgtc gaccgctcgt acggcgcgtt 5760
cgtggacaac ctgagccacc acattggcac gcaccaggtc caccacttgt tcccgatcat 5820
tccgcactac aagctcaacg aagccaccaa gcactttgcg gccgcgtacc cgcacctcgt 5880
gcgcaggaac gacgagccca tcatcacggc cttcttcaag accgcgcacc tctttgtcaa 5940
ctacggcgct gtgcccgaga cggcgcagat cttcacgctc aaagagtcgg ccgcggccgc 6000
caaggccaag tcggactaag c 6021
<210> 86
<211> 6524
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR226
<400> 86
gtacgtctag aggatccgtc gacggcgcgc ccgatcatcc ggatatagtt cctcctttca 60
gcaaaaaacc cctcaagacc cgtttagagg ccccaagggg ttatgctagt tattgctcag 120
cggtggcagc agccaactca gcttcctttc gggctttgtt agcagccgga tcgatccaag 180
ctgtacctca ctattccttt gccctcggac gagtgctggg gcgtcggttt ccactatcgg 240
cgagtacttc tacacagcca tcggtccaga cggccgcgct tctgcgggcg atttgtgtac 300
gcccgacagt cccggctccg gatcggacga ttgcgtcgca tcgaccctgc gcccaagctg 360
catcatcgaa attgccgtca accaagctct gatagagttg gtcaagacca atgcggagca 420
tatacgcccg gagccgcggc gatcctgcaa gctccggatg cctccgctcg aagtagcgcg 480
tctgctgctc catacaagcc aaccacggcc tccagaagaa gatgttggcg acctcgtatt 540
gggaatcccc gaacatcgcc tcgctccagt caatgaccgc tgttatgcgg ccattgtccg 600
tcaggacatt gttggagccg aaatccgcgt gcacgaggtg ccggacttcg gggcagtcct 660
cggcccaaag catcagctca tcgagagcct gcgcgacgga cgcactgacg gtgtcgtcca 720
tcacagtttg ccagtgatac acatggggat cagcaatcgc gcatatgaaa tcacgccatg 780
tagtgtattg accgattcct tgcggtccga atgggccgaa cccgctcgtc tggctaagat 840
cggccgcagc gatcgcatcc atagcctccg cgaccggctg cagaacagcg ggcagttcgg 900
tttcaggcag gtcttgcaac gtgacaccct gtgcacggcg ggagatgcaa taggtcaggc 960
tctcgctgaa ttccccaatg tcaagcactt ccggaatcgg gagcgcggcc gatgcaaagt 1020
gccgataaac ataacgatct ttgtagaaac catcggcgca gctatttacc cgcaggacat 1080
atccacgccc tcctacatcg aagctgaaag cacgagattc ttcgccctcc gagagctgca 1140
tcaggtcgga gacgctgtcg aacttttcga tcagaaactt ctcgacagac gtcgcggtga 1200
gttcaggctt ttccatgggt atatctcctt cttaaagtta aacaaaatta tttctagagg 1260
gaaaccgttg tggtctccct atagtgagtc gtattaattt cgcgggatcg agatctgatc 1320
aacctgcatt aatgaatcgg ccaacgcgcg gggagaggcg gtttgcgtat tgggcgctct 1380
tccgcttcct cgctcactga ctcgctgcgc tcggtcgttc ggctgcggcg agcggtatca 1440
gctcactcaa aggcggtaat acggttatcc acagaatcag gggataacgc aggaaagaac 1500
atgtgagcaa aaggccagca aaaggccagg aaccgtaaaa aggccgcgtt gctggcgttt 1560
ttccataggc tccgcccccc tgacgagcat cacaaaaatc gacgctcaag tcagaggtgg 1620
cgaaacccga caggactata aagataccag gcgtttcccc ctggaagctc cctcgtgcgc 1680
tctcctgttc cgaccctgcc gcttaccgga tacctgtccg cctttctccc ttcgggaagc 1740
gtggcgcttt ctcaatgctc acgctgtagg tatctcagtt cggtgtaggt cgttcgctcc 1800
aagctgggct gtgtgcacga accccccgtt cagcccgacc gctgcgcctt atccggtaac 1860
tatcgtcttg agtccaaccc ggtaagacac gacttatcgc cactggcagc agccactggt 1920
aacaggatta gcagagcgag gtatgtaggc ggtgctacag agttcttgaa gtggtggcct 1980
aactacggct acactagaag gacagtattt ggtatctgcg ctctgctgaa gccagttacc 2040
ttcggaaaaa gagttggtag ctcttgatcc ggcaaacaaa ccaccgctgg tagcggtggt 2100
ttttttgttt gcaagcagca gattacgcgc agaaaaaaag gatctcaaga agatcctttg 2160
atcttttcta cggggtctga cgctcagtgg aacgaaaact cacgttaagg gattttggtc 2220
atgacattaa cctataaaaa taggcgtatc acgaggccct ttcgtctcgc gcgtttcggt 2280
gatgacggtg aaaacctctg acacatgcag ctcccggaga cggtcacagc ttgtctgtaa 2340
gcggatgccg ggagcagaca agcccgtcag ggcgcgtcag cgggtgttgg cgggtgtcgg 2400
ggctggctta actatgcggc atcagagcag attgtactga gagtgcacca tatggacata 2460
ttgtcgttag aacgcggcta caattaatac ataaccttat gtatcataca catacgattt 2520
aggtgacact atagaacggc gcgccaagct gggtctagaa ctagaaacgt gatgccactt 2580
gttattgaag tcgattacag catctattct gttttactat ttataacttt gccatttctg 2640
acttttgaaa actatctctg gatttcggta tcgctttgtg aagatcgagc aaaagagacg 2700
ttttgtggac gcaatggtcc aaatccgttc tacatgaaca aattggtcac aatttccact 2760
aaaagtaaat aaatggcaag ttaaaaaagg aatatgcatt ttactgattg cctaggtgag 2820
ctccaagaga agttgaatct acacgtctac caaccgctaa aaaaagaaaa acattgatat 2880
gtaacctgat tccattagct tttgacttct tcaacagatt ctctacttag atttctaaca 2940
gaaatattat tactagcaca tcattttcag tctcactaca gcaaaaaatc caacggcaca 3000
atacagacaa caggagatat cagactacag agatagatag atgctactgc atgtagtaag 3060
ttaaataaaa ggaaaataaa atgtcttgct accaaaacta ctacagacta tgatgctcac 3120
cacaggccaa atcctgcaac taggacagca ttatcttata tatattgtac aaaacaagca 3180
tcaaggaaca tttggtctag gcaatcagta cctcgttcta ccatcaccct cagttatcac 3240
atccttgaag gatccattac tgggaatcat cggcaacaca tgctcctgat ggggcacaat 3300
gacatcaaga aggtaggggc caggggtgtc caacattctc tgaattgccg ctctaagctc 3360
ttccttcttc gtcactcgcg ctgccggtat cccacaagca tcagcaaact tgagcatgtt 3420
tgggaatatc tcgctctcgc tagacggatc tccaagatag gtgtgagctc tattggactt 3480
gtagaaccta tcctccaact gaaccaccat acccaaatgc tgattgttca acaacaatat 3540
cttaactggg agattctcca ctcttatagt ggccaactcc tgaacattca tgatgaaact 3600
accatcccca tcaatgtcaa ccacaacagc cccagggtta gcaacagcag caccaatagc 3660
cgcaggcaat ccaaaaccca tggctccaag accccctgag gtcaaccact gcctcggtct 3720
cttgtacttg taaaactgcg cagcccacat ttgatgctgc ccaaccccag tactaacaat 3780
agcatctcca ttagtcaact catcaagaac ctcgatagca tgctgcggag aaatcgcgtc 3840
ctggaatgtc ttgtaaccca atggaaactt gtgtttctgc acattaatct cttctctcca 3900
acctccaaga tcaaacttac cctccactcc tttctcctcc aaaatcatat taattccctt 3960
caaggccaac ttcaaatccg cgcaaaccga cacgtgcgcc tgcttgttct tcccaatctc 4020
ggcagaatca atatcaatgt gaacaatctt agccctacta gcaaaagcct caagcttccc 4080
agtaacacgg tcatcaaacc ttaccccaaa ggcaagcaac aaatcactat tgtcaacagc 4140
atagttagca taaacagtac catgcatacc cagcatctga agggaatatt catcaccaat 4200
aggaaaagtt ccaagaccca ttaaagtgct agcaacggga ataccagtga gttcaacaaa 4260
gcgcctcaat tcagcactgg aattcaaact gccaccgccg acgtagagaa cgggcttttg 4320
ggcctccatg atgagtctga caatgtgttc caattgggcc tcggcggggg gcctgggcag 4380
cctggcgagg taaccgggga ggttaacggg ctcgtcccaa ttaggcacgg cgagttgctg 4440
ctgaacgtct ttgggaatgt cgatgaggac cggaccgggg cggccggagg tggcgacgaa 4500
gaaagcctcg gcgacgacgc gggggatgtc gtcgacgtcg aggatgaggt agttgtgctt 4560
cgtgatggat ctgctcacct ccacgatcgg ggtttcttgg aaggcgtcgg tgccgatcat 4620
ccggcgggcg acctggccgg tgatggcgac gactgggacg ctgtccatta aagcgtcggc 4680
gaggccgctc acgaggttgg tggcgccggg gccggaggtg gcaatgcaga cgccggggag 4740
gccggaggaa cgcgcgtagc cttcggcggc gaagacgccg ccctgctcgt ggcgcgggag 4800
cacgttgcgg atggcggcgg agcgcgtgag cgcctggtgg atctccatcg acgcaccgcc 4860
ggggtacgcg aacaccgtcg tcacgccctg cctctccagc gcctccacaa ggatgtccgc 4920
gcccttgcga ggttcgccgg aggcgaaccg tgacacgaag ggctccgtgg tcggcgcttc 4980
cttggtgaag ggcgccgccg tggggggttt ggagatggaa catttgattt tgagagcgtg 5040
gttgggtttg gtgagggttt gatgagagag agggagggtg gatctagtaa tgcgtttggg 5100
gaaggtgggg tgtgaagagg aagaagagaa tcgggtggtt ctggaagcgg tggccgccat 5160
tgtgttgtgt ggcatggtta tacttcaaaa actgcacaac aagcctagag ttagtaccta 5220
aacagtaaat ttacaacaga gagcaaagac acatgcaaaa atttcagcca taaaaaaagt 5280
tataatagaa tttaaagcaa aagtttcatt ttttaaacat atatacaaac aaactggatt 5340
tgaaggaagg gattaattcc cctgctcaaa gtttgaattc ctattgtgac ctatactcga 5400
ataaaattga agcctaagga atgtatgaga aacaagaaaa caaaacaaaa ctacagacaa 5460
acaagtacaa ttacaaaatt cgctaaaatt ctgtaatcac caaaccccat ctcagtcagc 5520
acaaggccca aggtttattt tgaaataaaa aaaaagtgat tttatttctc ataagctaaa 5580
agaaagaaag gcaattatga aatgatttcg actagatctg aaagtccaac gcgtattccg 5640
cagatattaa agaaagagta gagtttcaca tggatcctag atggacccag ttgaggaaaa 5700
agcaaggcaa agcaaaccag aagtgcaaga tccgaaattg aaccacggaa tctaggattt 5760
ggtagaggga gaagaaaagt accttgagag gtagaagaga agagaagagc agagagatat 5820
atgaacgagt gtgtcttggt ctcaactctg aagcgatacg agtttagagg ggagcattga 5880
gttccaattt atagggaaac cgggtggcag gggtgagtta atgacggaaa agcccctaag 5940
taacgagatt ggattgtggg ttagattcaa ccgtttgcat ccgcggctta gattggggaa 6000
gtcagagtga atctcaaccg ttgactgagt tgaaaattga atgtagcaac caattgagcc 6060
aaccccagcc tttgcccttt gattttgatt tgtttgttgc atacttttta tttgtcttct 6120
ggttctgact ctctttctct cgtttcaatg ccaggttgcc tactcccaca ccactcacaa 6180
gaagattcta ctgttagtat taaatatttt ttaatgtatt aaatgatgaa tgcttttgta 6240
aacagaacaa gactatgtct aataagtgtc ttgcaacatt ttttaagaaa ttaaaaaaaa 6300
tatatttatt atcaaaatca aatgtatgaa aaatcatgaa taatataatt ttatacattt 6360
ttttaaaaaa tcttttaatt tcttaattaa tatcttaaaa ataatgatta atatttaacc 6420
caaaataatt agtatgattg gtaaggaaga tatccatgtt atgtttggat gtgagtttga 6480
tctagagcaa agcttactag agtcgacctg caggtcgact cgac 6524
<210> 87
<211> 13514
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR275
<220>
<221> misc_feature
<222> (1192)..(1192)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (2675)..(2675)
<223> n is a, c, g, or t
<400> 87
ggtcgactcg acgtacgtcc tcgaagagaa gggttaataa cacatttttt aacattttta 60
acacaaattt tagttattta aaaatttatt aaaaaattta aaataagaag aggaactctt 120
taaataaatc taacttacaa aatttatgat ttttaataag ttttcaccaa taaaaaatgt 180
cataaaaata tgttaaaaag tatattatca atattctctt tatgataaat aaaaagaaaa 240
aaaaaataaa agttaagtga aaatgagatt gaagtgactt taggtgtgta taaatatatc 300
aaccccgcca acaatttatt taatccaaat atattgaagt atattattcc atagccttta 360
tttatttata tatttattat ataaaagctt tatttgttct aggttgttca tgaaatattt 420
ttttggtttt atctccgttg taagaaaatc atgtgctttg tgtcgccact cactattgca 480
gctttttcat gcattggtca gattgacggt tgattgtatt tttgtttttt atggttttgt 540
gttatgactt aagtcttcat ctctttatct cttcatcagg tttgatggtt acctaatatg 600
gtccatgggt acatgcatgg ttaaattagg tggccaactt tgttgtgaac gatagaattt 660
tttttatatt aagtaaacta tttttatatt atgaaataat aataaaaaaa atattttatc 720
attattaaca aaatcatatt agttaatttg ttaactctat aataaaagaa atactgtaac 780
attcacatta catggtaaca tctttccacc ctttcatttg ttttttgttt gatgactttt 840
tttcttgttt aaatttattt cccttctttt aaatttggaa tacattatca tcatatataa 900
actaaaatac taaaaacagg attacacaaa tgataaataa taacacaaat atttataaat 960
ctagctgcaa tatatttaaa ctagctatat cgatattgta aaataaaact agctgcattg 1020
atactgataa aaaaatatca tgtgctttct ggactgatga tgcagtatac ttttgacatt 1080
gcctttattt tatttttcag aaaagctttc ttagttctgg gttcttcatt atttgtttcc 1140
catctccatt gtgaattgaa tcatttgctt cgtgtcacaa atacaattta gntaggtaca 1200
tgcattggtc agattcacgg tttattatgt catgacttaa gttcatggta gtacattacc 1260
tgccacgcat gcattatatt ggttagattt gataggcaaa tttggttgtc aacaatataa 1320
atataaataa tgtttttata ttacgaaata acagtgatca aaacaaacag ttttatcttt 1380
attaacaaga ttttgttttt gtttgatgac gttttttaat gtttacgctt tcccccttct 1440
tttgaattta gaacacttta tcatcataaa atcaaatact aaaaaaatta catatttcat 1500
aaataataac acaaatattt ttaaaaaatc tgaaataata atgaacaata ttacatatta 1560
tcacgaaaat tcattaataa aaatattata taaataaaat gtaatagtag ttatatgtag 1620
gaaaaaagta ctgcacgcat aatatataca aaaagattaa aatgaactat tataaataat 1680
aacactaaat taatggtgaa tcatatcaaa ataatgaaaa agtaaataaa atttgtaatt 1740
aacttctata tgtattacac acacaaataa taaataatag taaaaaaaat tatgataaat 1800
atttaccatc tcataagata tttaaaataa tgataaaaat atagattatt ttttatgcaa 1860
ctagctagcc aaaaagagaa cacgggtata tataaaaaga gtacctttaa attctactgt 1920
acttccttta ttcctgacgt ttttatatca agtggacata cgtgaagatt ttaattatca 1980
gtctaaatat ttcattagca cttaatactt ttctgtttta ttcctatcct ataagtagtc 2040
ccgattctcc caacattgct tattcacaca actaactaag aaagtcttcc atagcccccc 2100
aagcggccgc ctctctctct ctctcttctc tctttctctc cccctctctc cggcgatggt 2160
tgttgctatg gaccaacgca ccaatgtgaa cggagatccc ggcgccggag accggaagaa 2220
agaagaaagg tttgatccga gtgcacaacc accgttcaag atcggagata taagggcggc 2280
gattcctaag cactgttggg ttaagagtcc tttgagatca atgagttacg tcgtcagaga 2340
cattatcgcc gtcgcggctt tggccatcgc tgccgtgtat gttgatagct ggttcctttg 2400
gcctctttat tgggccgccc aaggaacact tttctgggcc atctttgttc tcggccacga 2460
ctgtggacat gggagtttct cagacattcc tctactgaat agtgtggttg gtcacattct 2520
tcattctttc atcctcgttc cttaccatgg ttggagaata agccaccgga cacaccacca 2580
gaaccatggc catgttgaaa acgacgagtc atgggttccg ttaccagaaa gggtgtacaa 2640
gaaattgccc cacagtactc ggatgctcag atacnctgtc cctctcccca tgctcgcata 2700
tcctctctat ttgtgctaca gaagtcctgg aaaagaagga tcacatttta acccatacag 2760
tagtttattt gctccaagcg agagaaagct tattgcaact tcaactactt gttggtccat 2820
aatgttcgtc agtcttatcg ctctatcttt cgtcttcggt ccactcgcgg ttcttaaagt 2880
ctacggtgta ccgtacatta tctttgtgat gtggttggat gctgtcacgt atttgcatca 2940
tcatggtcac gatgagaagt tgccttggta tagaggcaag gaatggagtt atctacgtgg 3000
aggattaaca acaattgata gagattacgg aatctttaac aacattcatc acgacattgg 3060
aactcacgtg atccatcatc tcttcccaca aatccctcac tatcacttgg tcgacgccac 3120
gaaagcagct aaacatgtgt tgggaagata ctacagagaa ccaaagacgt caggagcaat 3180
accgatccac ttggtggaga gtttggtcgc aagtattaag aaagatcatt acgtcagcga 3240
cactggtgat attgtcttct acgagacaga tccagatctc tacgtttacg cttctgacaa 3300
atctaaaatc aattaatctc catttgttta gctctattag gaataaacca gcccactttt 3360
aaaattttta tttcttgttg tttttaagtt aaaagtgtac tcgtgaaact cttttttttt 3420
tctttttttt tattaatgta tttacattac aaggcgtaaa gcggccgcga cacaagtgtg 3480
agagtactaa ataaatgctt tggttgtacg aaatcattac actaaataaa ataatcaaag 3540
cttatatatg ccttccgcta aggccgaatg caaagaaatt ggttctttct cgttatcttt 3600
tgccactttt actagtacgt attaattact acttaatcat ctttgtttac ggctcattat 3660
atccgtacgt ctagaggatc cgtcgacggc gcgcccgatc atccggatat agttcctcct 3720
ttcagcaaaa aacccctcaa gacccgttta gaggccccaa ggggttatgc tagttattgc 3780
tcagcggtgg cagcagccaa ctcagcttcc tttcgggctt tgttagcagc cggatcgatc 3840
caagctgtac ctcactattc ctttgccctc ggacgagtgc tggggcgtcg gtttccacta 3900
tcggcgagta cttctacaca gccatcggtc cagacggccg cgcttctgcg ggcgatttgt 3960
gtacgcccga cagtcccggc tccggatcgg acgattgcgt cgcatcgacc ctgcgcccaa 4020
gctgcatcat cgaaattgcc gtcaaccaag ctctgataga gttggtcaag accaatgcgg 4080
agcatatacg cccggagccg cggcgatcct gcaagctccg gatgcctccg ctcgaagtag 4140
cgcgtctgct gctccataca agccaaccac ggcctccaga agaagatgtt ggcgacctcg 4200
tattgggaat ccccgaacat cgcctcgctc cagtcaatga ccgctgttat gcggccattg 4260
tccgtcagga cattgttgga gccgaaatcc gcgtgcacga ggtgccggac ttcggggcag 4320
tcctcggccc aaagcatcag ctcatcgaga gcctgcgcga cggacgcact gacggtgtcg 4380
tccatcacag tttgccagtg atacacatgg ggatcagcaa tcgcgcatat gaaatcacgc 4440
catgtagtgt attgaccgat tccttgcggt ccgaatgggc cgaacccgct cgtctggcta 4500
agatcggccg cagcgatcgc atccatagcc tccgcgaccg gctgcagaac agcgggcagt 4560
tcggtttcag gcaggtcttg caacgtgaca ccctgtgcac ggcgggagat gcaataggtc 4620
aggctctcgc tgaattcccc aatgtcaagc acttccggaa tcgggagcgc ggccgatgca 4680
aagtgccgat aaacataacg atctttgtag aaaccatcgg cgcagctatt tacccgcagg 4740
acatatccac gccctcctac atcgaagctg aaagcacgag attcttcgcc ctccgagagc 4800
tgcatcaggt cggagacgct gtcgaacttt tcgatcagaa acttctcgac agacgtcgcg 4860
gtgagttcag gcttttccat gggtatatct ccttcttaaa gttaaacaaa attatttcta 4920
gagggaaacc gttgtggtct ccctatagtg agtcgtatta atttcgcggg atcgagatct 4980
gatcaacctg cattaatgaa tcggccaacg cgcggggaga ggcggtttgc gtattgggcg 5040
ctcttccgct tcctcgctca ctgactcgct gcgctcggtc gttcggctgc ggcgagcggt 5100
atcagctcac tcaaaggcgg taatacggtt atccacagaa tcaggggata acgcaggaaa 5160
gaacatgtga gcaaaaggcc agcaaaaggc caggaaccgt aaaaaggccg cgttgctggc 5220
gtttttccat aggctccgcc cccctgacga gcatcacaaa aatcgacgct caagtcagag 5280
gtggcgaaac ccgacaggac tataaagata ccaggcgttt ccccctggaa gctccctcgt 5340
gcgctctcct gttccgaccc tgccgcttac cggatacctg tccgcctttc tcccttcggg 5400
aagcgtggcg ctttctcaat gctcacgctg taggtatctc agttcggtgt aggtcgttcg 5460
ctccaagctg ggctgtgtgc acgaaccccc cgttcagccc gaccgctgcg ccttatccgg 5520
taactatcgt cttgagtcca acccggtaag acacgactta tcgccactgg cagcagccac 5580
tggtaacagg attagcagag cgaggtatgt aggcggtgct acagagttct tgaagtggtg 5640
gcctaactac ggctacacta gaaggacagt atttggtatc tgcgctctgc tgaagccagt 5700
taccttcgga aaaagagttg gtagctcttg atccggcaaa caaaccaccg ctggtagcgg 5760
tggttttttt gtttgcaagc agcagattac gcgcagaaaa aaaggatctc aagaagatcc 5820
tttgatcttt tctacggggt ctgacgctca gtggaacgaa aactcacgtt aagggatttt 5880
ggtcatgaca ttaacctata aaaataggcg tatcacgagg ccctttcgtc tcgcgcgttt 5940
cggtgatgac ggtgaaaacc tctgacacat gcagctcccg gagacggtca cagcttgtct 6000
gtaagcggat gccgggagca gacaagcccg tcagggcgcg tcagcgggtg ttggcgggtg 6060
tcggggctgg cttaactatg cggcatcaga gcagattgta ctgagagtgc accatatgga 6120
catattgtcg ttagaacgcg gctacaatta atacataacc ttatgtatca tacacatacg 6180
atttaggtga cactatagaa cggcgcgcca agctgggtct agaactagaa acgtgatgcc 6240
acttgttatt gaagtcgatt acagcatcta ttctgtttta ctatttataa ctttgccatt 6300
tctgactttt gaaaactatc tctggatttc ggtatcgctt tgtgaagatc gagcaaaaga 6360
gacgttttgt ggacgcaatg gtccaaatcc gttctacatg aacaaattgg tcacaatttc 6420
cactaaaagt aaataaatgg caagttaaaa aaggaatatg cattttactg attgcctagg 6480
tgagctccaa gagaagttga atctacacgt ctaccaaccg ctaaaaaaag aaaaacattg 6540
atatgtaacc tgattccatt agcttttgac ttcttcaaca gattctctac ttagatttct 6600
aacagaaata ttattactag cacatcattt tcagtctcac tacagcaaaa aatccaacgg 6660
cacaatacag acaacaggag atatcagact acagagatag atagatgcta ctgcatgtag 6720
taagttaaat aaaaggaaaa taaaatgtct tgctaccaaa actactacag actatgatgc 6780
tcaccacagg ccaaatcctg caactaggac agcattatct tatatatatt gtacaaaaca 6840
agcatcaagg aacatttggt ctaggcaatc agtacctcgt tctaccatca ccctcagtta 6900
tcacatcctt gaaggatcca ttactgggaa tcatcggcaa cacatgctcc tgatggggca 6960
caatgacatc aagaaggtag gggccagggg tgtccaacat tctctgaatt gccgctctaa 7020
gctcttcctt cttcgtcact cgcgctgccg gtatcccaca agcatcagca aacttgagca 7080
tgtttgggaa tatctcgctc tcgctagacg gatctccaag ataggtgtga gctctattgg 7140
acttgtagaa cctatcctcc aactgaacca ccatacccaa atgctgattg ttcaacaaca 7200
atatcttaac tgggagattc tccactctta tagtggccaa ctcctgaaca ttcatgatga 7260
aactaccatc cccatcaatg tcaaccacaa cagccccagg gttagcaaca gcagcaccaa 7320
tagccgcagg caatccaaaa cccatggctc caagaccccc tgaggtcaac cactgcctcg 7380
gtctcttgta cttgtaaaac tgcgcagccc acatttgatg ctgcccaacc ccagtactaa 7440
caatagcatc tccattagtc aactcatcaa gaacctcgat agcatgctgc ggagaaatcg 7500
cgtcctggaa tgtcttgtaa cccaatggaa acttgtgttt ctgcacatta atctcttctc 7560
tccaacctcc aagatcaaac ttaccctcca ctcctttctc ctccaaaatc atattaattc 7620
ccttcaaggc caacttcaaa tccgcgcaaa ccgacacgtg cgcctgcttg ttcttcccaa 7680
tctcggcaga atcaatatca atgtgaacaa tcttagccct actagcaaaa gcctcaagct 7740
tcccagtaac acggtcatca aaccttaccc caaaggcaag caacaaatca ctattgtcaa 7800
cagcatagtt agcataaaca gtaccatgca tacccagcat ctgaagggaa tattcatcac 7860
caataggaaa agttccaaga cccattaaag tgctagcaac gggaatacca gtgagttcaa 7920
caaagcgcct caattcagca ctggaattca aactgccacc gccgacgtag agaacgggct 7980
tttgggcctc catgatgagt ctgacaatgt gttccaattg ggcctcggcg gggggcctgg 8040
gcagcctggc gaggtaaccg gggaggttaa cgggctcgtc ccaattaggc acggcgagtt 8100
gctgctgaac gtctttggga atgtcgatga ggaccggacc ggggcggccg gaggtggcga 8160
cgaagaaagc ctcggcgacg acgcggggga tgtcgtcgac gtcgaggatg aggtagttgt 8220
gcttcgtgat ggatctgctc acctccacga tcggggtttc ttggaaggcg tcggtgccga 8280
tcatccggcg ggcgacctgg ccggtgatgg cgacgactgg gacgctgtcc attaaagcgt 8340
cggcgaggcc gctcacgagg ttggtggcgc cggggccgga ggtggcaatg cagacgccgg 8400
ggaggccgga ggaacgcgcg tagccttcgg cggcgaagac gccgccctgc tcgtggcgcg 8460
ggagcacgtt gcggatggcg gcggagcgcg tgagcgcctg gtggatctcc atcgacgcac 8520
cgccggggta cgcgaacacc gtcgtcacgc cctgcctctc cagcgcctcc acaaggatgt 8580
ccgcgccctt gcgaggttcg ccggaggcga accgtgacac gaagggctcc gtggtcggcg 8640
cttccttggt gaagggcgcc gccgtggggg gtttggagat ggaacatttg attttgagag 8700
cgtggttggg tttggtgagg gtttgatgag agagagggag ggtggatcta gtaatgcgtt 8760
tggggaaggt ggggtgtgaa gaggaagaag agaatcgggt ggttctggaa gcggtggccg 8820
ccattgtgtt gtgtggcatg gttatacttc aaaaactgca caacaagcct agagttagta 8880
cctaaacagt aaatttacaa cagagagcaa agacacatgc aaaaatttca gccataaaaa 8940
aagttataat agaatttaaa gcaaaagttt cattttttaa acatatatac aaacaaactg 9000
gatttgaagg aagggattaa ttcccctgct caaagtttga attcctattg tgacctatac 9060
tcgaataaaa ttgaagccta aggaatgtat gagaaacaag aaaacaaaac aaaactacag 9120
acaaacaagt acaattacaa aattcgctaa aattctgtaa tcaccaaacc ccatctcagt 9180
cagcacaagg cccaaggttt attttgaaat aaaaaaaaag tgattttatt tctcataagc 9240
taaaagaaag aaaggcaatt atgaaatgat ttcgactaga tctgaaagtc caacgcgtat 9300
tccgcagata ttaaagaaag agtagagttt cacatggatc ctagatggac ccagttgagg 9360
aaaaagcaag gcaaagcaaa ccagaagtgc aagatccgaa attgaaccac ggaatctagg 9420
atttggtaga gggagaagaa aagtaccttg agaggtagaa gagaagagaa gagcagagag 9480
atatatgaac gagtgtgtct tggtctcaac tctgaagcga tacgagttta gaggggagca 9540
ttgagttcca atttataggg aaaccgggtg gcaggggtga gttaatgacg gaaaagcccc 9600
taagtaacga gattggattg tgggttagat tcaaccgttt gcatccgcgg cttagattgg 9660
ggaagtcaga gtgaatctca accgttgact gagttgaaaa ttgaatgtag caaccaattg 9720
agccaacccc agcctttgcc ctttgatttt gatttgtttg ttgcatactt tttatttgtc 9780
ttctggttct gactctcttt ctctcgtttc aatgccaggt tgcctactcc cacaccactc 9840
acaagaagat tctactgtta gtattaaata ttttttaatg tattaaatga tgaatgcttt 9900
tgtaaacaga acaagactat gtctaataag tgtcttgcaa cattttttaa gaaattaaaa 9960
aaaatatatt tattatcaaa atcaaatgta tgaaaaatca tgaataatat aattttatac 10020
atttttttaa aaaatctttt aatttcttaa ttaatatctt aaaaataatg attaatattt 10080
aacccaaaat aattagtatg attggtaagg aagatatcca tgttatgttt ggatgtgagt 10140
ttgatctaga gcaaagctta ctagagtcga cctgcaggtc gactcgacgt acgatcccac 10200
atgcaagttt ttatttcaat cccttttcct ttgaataact gaccaagaac aacaagaaaa 10260
aaaaaaaaaa agaaaaggat cattttgaaa ggatattttt cgctcctatt caaatactgt 10320
atttttacca aaaaaactgt atttttccta cactctcaag ctttgttttt cgcttcgact 10380
ctcatgattt ccttcatatg ccaatcactc tatttataaa tggcataagg tagtgtgaac 10440
aattgcaaag cttgtcatca aaagcttgca atgtacaaat taatgttttt catgcctttc 10500
aaaattatct gcacccccta gctattaatc taacatctaa gtaaggctag tgaatttttt 10560
cgaatagtca tgcagtgcat taatttcccc gtgactattt tggctttgac tccaacactg 10620
gccccgtaca tccgtccctc attacatgaa aagaaatatt gtttatattc ttaattaaaa 10680
atattgtccc ttctaaattt tcatatagtt aattattata ttactttttt ctctattcta 10740
ttagttctat tttcaaatta ttatttatgc atatgtaaag tacattatat ttttgctata 10800
tacttaaata tttctaaatt attaaaaaaa gactgatatg aaaaatttat tctttttaaa 10860
gctatatcat tttatatata ctttttcttt tcttttcttt cattttctat tcaatttaat 10920
aagaaataaa ttttgtaaat ttttatttat caatttataa aaatatttta ctttatatgt 10980
tttttcacat ttttgttaaa caaatcatat cattatgatt gaaagagagg aaattgacag 11040
tgagtaataa gtgatgagaa aaaaatgtgt tatttcctaa aaaaaaccta aacaaacatg 11100
tatctactct ctatttcatc tatctctcat ttcatttttc tctttatctc tttctttatt 11160
tttttatcat atcatttcac attaattatt tttactctct ttattttttc tctctatccc 11220
tctcttattt ccactcatat atacactcca aaattggggc atgcctttat cactactcta 11280
tctcctccac taaatcattt aaatgaaact gaaaagcatt ggcaagtctc ctcccctcct 11340
caagtgattt ccaactcagc attggcatct aattgattca gtatatctat tgcatgtgta 11400
aaagtctttc cacaatacat aactattaat taatcttaaa taaataaagg ataaaatatt 11460
tttttttctt cataaaatta aaatatgtta ttttttgttt agatgtatat tcgaataaat 11520
ctaaatatat gataatgatt ttttatattg attaaacata taatcaatat taaatatgat 11580
atttttttat ataggttgta cacataattt tataaggata aaaaatatga taaaaataaa 11640
ttttaaatat ttttatattt acgagaaaaa aaaatatttt agccataaat aaatgaccag 11700
catattttac aaccttagta attcataaat tcctatatgt atatttgaaa ttaaaaacag 11760
ataatcgtta agggaaggaa tcctacgtca tctcttgcca tttgtttttc atgcaaacag 11820
aaagggacga aaaaccacct caccatgaat cactcttcac accattttta ctagcaaaca 11880
agtctcaaca actgaagcca gctctctttc cgtttctttt tacaacactt tctttgaaat 11940
agtagtattt ttttttcaca tgatttatta acgtgccaaa agatgcttat tgaatagagt 12000
gcacatttgt aatgtactac taattagaac atgaaaaagc attgttctaa cacgataatc 12060
ctgtgaaggc gttaactcca aagatccaat ttcactatat aaattgtgac gaaagcaaaa 12120
tgaattcaca tagctgagag agaaaggaaa ggttaactaa gaagcaatac ttcagcggcc 12180
gcatgactga ggataagacg aaggtcgagt tcccgacgct cacggagctc aagcactcga 12240
tcccgaacgc gtgctttgag tcgaacctcg gcctctcgct ctactacacg gcccgcgcga 12300
tcttcaacgc gtcggcctcg gcggcgctgc tctacgcggc gcgctcgacg ccgttcattg 12360
ccgataacgt tctgctccac gcgctcgttt gcgccaccta catctacgtg cagggcgtca 12420
tcttctgggg cttcttcacg gtcggccacg actgcggcca ctcggccttc tcgcgctacc 12480
acagcgtcaa ctttatcatc ggctgcatca tgcactctgc gattttgacg ccgttcgaga 12540
gctggcgcgt gacgcaccgc caccaccaca agaacacggg caacattgat aaggacgaga 12600
tcttttaccc gcaccggtcg gtcaaggacc tccaggacgt gcgccaatgg gtctacacgc 12660
tcggcggtgc gtggtttgtc tacttgaagg tcgggtatgc cccgcgcacg atgagccact 12720
ttgacccgtg ggacccgctc ctccttcgcc gcgcgtcggc cgtcatcgtg tcgctcggcg 12780
tctgggccgc cttcttcgcc gcgtacgcgt acctcacata ctcgctcggc tttgccgtca 12840
tgggcctcta ctactatgcg ccgctctttg tctttgcttc gttcctcgtc attacgacct 12900
tcttgcacca caacgacgaa gcgacgccgt ggtacggcga ctcggagtgg acgtacgtca 12960
agggcaacct ctcgagcgtc gaccgctcgt acggcgcgtt cgtggacaac ctgagccacc 13020
acattggcac gcaccaggtc caccacttgt tcccgatcat tccgcactac aagctcaacg 13080
aagccaccaa gcactttgcg gccgcgtacc cgcacctcgt gcgcaggaac gacgagccca 13140
tcatcacggc cttcttcaag accgcgcacc tctttgtcaa ctacggcgct gtgcccgaga 13200
cggcgcagat cttcacgctc aaagagtcgg ccgcggccgc caaggccaag tcggactaag 13260
cggccgcatg agccgtaaag gttcaataca acgagtgctt gttttcttag ggacaagcat 13320
tgtacttatg tatgattctg tgtaaccatg agtcttccac gttgtactaa tgtgaagggc 13380
aaaaataaaa cacagaacaa gttcgttttt ctcaaataat gtgaaggtag aaaatggaac 13440
catgcctcct ctcttgcatg tgatttaaaa tattagcaga tggtaccgta cgtgggcgga 13500
tcccccgggc tgca 13514
<210> 88
<211> 12323
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR329
<220>
<221> misc_feature
<222> (1201)..(1201)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (2684)..(2684)
<223> n is a, c, g, or t
<400> 88
ggatctggcc ggccggatct cgtacgtcct cgaagagaag ggttaataac acatttttta 60
acatttttaa cacaaatttt agttatttaa aaatttatta aaaaatttaa aataagaaga 120
ggaactcttt aaataaatct aacttacaaa atttatgatt tttaataagt tttcaccaat 180
aaaaaatgtc ataaaaatat gttaaaaagt atattatcaa tattctcttt atgataaata 240
aaaagaaaaa aaaaataaaa gttaagtgaa aatgagattg aagtgacttt aggtgtgtat 300
aaatatatca accccgccaa caatttattt aatccaaata tattgaagta tattattcca 360
tagcctttat ttatttatat atttattata taaaagcttt atttgttcta ggttgttcat 420
gaaatatttt tttggtttta tctccgttgt aagaaaatca tgtgctttgt gtcgccactc 480
actattgcag ctttttcatg cattggtcag attgacggtt gattgtattt ttgtttttta 540
tggttttgtg ttatgactta agtcttcatc tctttatctc ttcatcaggt ttgatggtta 600
cctaatatgg tccatgggta catgcatggt taaattaggt ggccaacttt gttgtgaacg 660
atagaatttt ttttatatta agtaaactat ttttatatta tgaaataata ataaaaaaaa 720
tattttatca ttattaacaa aatcatatta gttaatttgt taactctata ataaaagaaa 780
tactgtaaca ttcacattac atggtaacat ctttccaccc tttcatttgt tttttgtttg 840
atgacttttt ttcttgttta aatttatttc ccttctttta aatttggaat acattatcat 900
catatataaa ctaaaatact aaaaacagga ttacacaaat gataaataat aacacaaata 960
tttataaatc tagctgcaat atatttaaac tagctatatc gatattgtaa aataaaacta 1020
gctgcattga tactgataaa aaaatatcat gtgctttctg gactgatgat gcagtatact 1080
tttgacattg cctttatttt atttttcaga aaagctttct tagttctggg ttcttcatta 1140
tttgtttccc atctccattg tgaattgaat catttgcttc gtgtcacaaa tacaatttag 1200
ntaggtacat gcattggtca gattcacggt ttattatgtc atgacttaag ttcatggtag 1260
tacattacct gccacgcatg cattatattg gttagatttg ataggcaaat ttggttgtca 1320
acaatataaa tataaataat gtttttatat tacgaaataa cagtgatcaa aacaaacagt 1380
tttatcttta ttaacaagat tttgtttttg tttgatgacg ttttttaatg tttacgcttt 1440
cccccttctt ttgaatttag aacactttat catcataaaa tcaaatacta aaaaaattac 1500
atatttcata aataataaca caaatatttt taaaaaatct gaaataataa tgaacaatat 1560
tacatattat cacgaaaatt cattaataaa aatattatat aaataaaatg taatagtagt 1620
tatatgtagg aaaaaagtac tgcacgcata atatatacaa aaagattaaa atgaactatt 1680
ataaataata acactaaatt aatggtgaat catatcaaaa taatgaaaaa gtaaataaaa 1740
tttgtaatta acttctatat gtattacaca cacaaataat aaataatagt aaaaaaaatt 1800
atgataaata tttaccatct cataagatat ttaaaataat gataaaaata tagattattt 1860
tttatgcaac tagctagcca aaaagagaac acgggtatat ataaaaagag tacctttaaa 1920
ttctactgta cttcctttat tcctgacgtt tttatatcaa gtggacatac gtgaagattt 1980
taattatcag tctaaatatt tcattagcac ttaatacttt tctgttttat tcctatccta 2040
taagtagtcc cgattctccc aacattgctt attcacacaa ctaactaaga aagtcttcca 2100
tagcccccca agcggccgcc tctctctctc tctcttctct ctttctctcc ccctctctcc 2160
ggcgatggtt gttgctatgg accaacgcac caatgtgaac ggagatcccg gcgccggaga 2220
ccggaagaaa gaagaaaggt ttgatccgag tgcacaacca ccgttcaaga tcggagatat 2280
aagggcggcg attcctaagc actgttgggt taagagtcct ttgagatcaa tgagttacgt 2340
cgtcagagac attatcgccg tcgcggcttt ggccatcgct gccgtgtatg ttgatagctg 2400
gttcctttgg cctctttatt gggccgccca aggaacactt ttctgggcca tctttgttct 2460
cggccacgac tgtggacatg ggagtttctc agacattcct ctactgaata gtgtggttgg 2520
tcacattctt cattctttca tcctcgttcc ttaccatggt tggagaataa gccaccggac 2580
acaccaccag aaccatggcc atgttgaaaa cgacgagtca tgggttccgt taccagaaag 2640
ggtgtacaag aaattgcccc acagtactcg gatgctcaga tacnctgtcc ctctccccat 2700
gctcgcatat cctctctatt tgtgctacag aagtcctgga aaagaaggat cacattttaa 2760
cccatacagt agtttatttg ctccaagcga gagaaagctt attgcaactt caactacttg 2820
ttggtccata atgttcgtca gtcttatcgc tctatctttc gtcttcggtc cactcgcggt 2880
tcttaaagtc tacggtgtac cgtacattat ctttgtgatg tggttggatg ctgtcacgta 2940
tttgcatcat catggtcacg atgagaagtt gccttggtat agaggcaagg aatggagtta 3000
tctacgtgga ggattaacaa caattgatag agattacgga atctttaaca acattcatca 3060
cgacattgga actcacgtga tccatcatct cttcccacaa atccctcact atcacttggt 3120
cgacgccacg aaagcagcta aacatgtgtt gggaagatac tacagagaac caaagacgtc 3180
aggagcaata ccgatccact tggtggagag tttggtcgca agtattaaga aagatcatta 3240
cgtcagcgac actggtgata ttgtcttcta cgagacagat ccagatctct acgtttacgc 3300
ttctgacaaa tctaaaatca attaatctcc atttgtttag ctctattagg aataaaccag 3360
cccactttta aaatttttat ttcttgttgt ttttaagtta aaagtgtact cgtgaaactc 3420
tttttttttt cttttttttt attaatgtat ttacattaca aggcgtaaag cggccgcgac 3480
acaagtgtga gagtactaaa taaatgcttt ggttgtacga aatcattaca ctaaataaaa 3540
taatcaaagc ttatatatgc cttccgctaa ggccgaatgc aaagaaattg gttctttctc 3600
gttatctttt gccactttta ctagtacgta ttaattacta cttaatcatc tttgtttacg 3660
gctcattata tccgtacgga tccgtcgacg gcgcgcccga tcatccggat atagttcctc 3720
ctttcagcaa aaaacccctc aagacccgtt tagaggcccc aaggggttat gctagttatt 3780
gctcagcggt ggcagcagcc aactcagctt cctttcgggc tttgttagca gccggatcga 3840
tccaagctgt acctcactat tcctttgccc tcggacgagt gctggggcgt cggtttccac 3900
tatcggcgag tacttctaca cagccatcgg tccagacggc cgcgcttctg cgggcgattt 3960
gtgtacgccc gacagtcccg gctccggatc ggacgattgc gtcgcatcga ccctgcgccc 4020
aagctgcatc atcgaaattg ccgtcaacca agctctgata gagttggtca agaccaatgc 4080
ggagcatata cgcccggagc cgcggcgatc ctgcaagctc cggatgcctc cgctcgaagt 4140
agcgcgtctg ctgctccata caagccaacc acggcctcca gaagaagatg ttggcgacct 4200
cgtattggga atccccgaac atcgcctcgc tccagtcaat gaccgctgtt atgcggccat 4260
tgtccgtcag gacattgttg gagccgaaat ccgcgtgcac gaggtgccgg acttcggggc 4320
agtcctcggc ccaaagcatc agctcatcga gagcctgcgc gacggacgca ctgacggtgt 4380
cgtccatcac agtttgccag tgatacacat ggggatcagc aatcgcgcat atgaaatcac 4440
gccatgtagt gtattgaccg attccttgcg gtccgaatgg gccgaacccg ctcgtctggc 4500
taagatcggc cgcagcgatc gcatccatag cctccgcgac cggctgcaga acagcgggca 4560
gttcggtttc aggcaggtct tgcaacgtga caccctgtgc acggcgggag atgcaatagg 4620
tcaggctctc gctgaattcc ccaatgtcaa gcacttccgg aatcgggagc gcggccgatg 4680
caaagtgccg ataaacataa cgatctttgt agaaaccatc ggcgcagcta tttacccgca 4740
ggacatatcc acgccctcct acatcgaagc tgaaagcacg agattcttcg ccctccgaga 4800
gctgcatcag gtcggagacg ctgtcgaact tttcgatcag aaacttctcg acagacgtcg 4860
cggtgagttc aggcttttcc atgggtatat ctccttctta aagttaaaca aaattatttc 4920
tagagggaaa ccgttgtggt ctccctatag tgagtcgtat taatttcgcg ggatcgagat 4980
cgatccaatt ccaatcccac aaaaatctga gcttaacagc acagttgctc ctctcagagc 5040
agaatcgggt attcaacacc ctcatatcaa ctactacgtt gtgtataacg gtccacatgc 5100
cggtatatac gatgactggg gttgtacaaa ggcggcaaca aacggcgttc ccggagttgc 5160
acacaagaaa tttgccacta ttacagaggc aagagcagca gctgacgcgt acacaacaag 5220
tcagcaaaca gacaggttga acttcatccc caaaggagaa gctcaactca agcccaagag 5280
ctttgctaag gccctaacaa gcccaccaaa gcaaaaagcc cactggctca cgctaggaac 5340
caaaaggccc agcagtgatc cagccccaaa agagatctcc tttgccccgg agattacaat 5400
ggacgatttc ctctatcttt acgatctagg aaggaagttc gaaggtgaag gtgacgacac 5460
tatgttcacc actgataatg agaaggttag cctcttcaat ttcagaaaga atgctgaccc 5520
acagatggtt agagaggcct acgcagcagg tctcatcaag acgatctacc cgagtaacaa 5580
tctccaggag atcaaatacc ttcccaagaa ggttaaagat gcagtcaaaa gattcaggac 5640
taattgcatc aagaacacag agaaagacat atttctcaag atcagaagta ctattccagt 5700
atggacgatt caaggcttgc ttcataaacc aaggcaagta atagagattg gagtctctaa 5760
aaaggtagtt cctactgaat ctaaggccat gcatggagtc taagattcaa atcgaggatc 5820
taacagaact cgccgtgaag actggcgaac agttcataca gagtctttta cgactcaatg 5880
acaagaagaa aatcttcgtc aacatggtgg agcacgacac tctggtctac tccaaaaatg 5940
tcaaagatac agtctcagaa gaccaaaggg ctattgagac ttttcaacaa aggataattt 6000
cgggaaacct cctcggattc cattgcccag ctatctgtca cttcatcgaa aggacagtag 6060
aaaaggaagg tggctcctac aaatgccatc attgcgataa aggaaaggct atcattcaag 6120
atgcctctgc cgacagtggt cccaaagatg gacccccacc cacgaggagc atcgtggaaa 6180
aagaagacgt tccaaccacg tcttcaaagc aagtggattg atgtgacatc tccactgacg 6240
taagggatga cgcacaatcc cactatcctt cgcaagaccc ttcctctata taaggaagtt 6300
catttcattt ggagaggaca cgctcgagct catttctcta ttacttcagc cataacaaaa 6360
gaactctttt ctcttcttat taaaccatga aaaagcctga actcaccgcg acgtctgtcg 6420
agaagtttct gatcgaaaag ttcgacagcg tctccgacct gatgcagctc tcggagggcg 6480
aagaatctcg tgctttcagc ttcgatgtag gagggcgtgg atatgtcctg cgggtaaata 6540
gctgcgccga tggtttctac aaagatcgtt atgtttatcg gcactttgca tcggccgcgc 6600
tcccgattcc ggaagtgctt gacattgggg aattcagcga gagcctgacc tattgcatct 6660
cccgccgtgc acagggtgtc acgttgcaag acctgcctga aaccgaactg cccgctgttc 6720
tgcagccggt cgcggaggcc atggatgcga tcgctgcggc cgatcttagc cagacgagcg 6780
ggttcggccc attcggaccg caaggaatcg gtcaatacac tacatggcgt gatttcatat 6840
gcgcgattgc tgatccccat gtgtatcact ggcaaactgt gatggacgac accgtcagtg 6900
cgtccgtcgc gcaggctctc gatgagctga tgctttgggc cgaggactgc cccgaagtcc 6960
ggcacctcgt gcacgcggat ttcggctcca acaatgtcct gacggacaat ggccgcataa 7020
cagcggtcat tgactggagc gaggcgatgt tcggggattc ccaatacgag gtcgccaaca 7080
tcttcttctg gaggccgtgg ttggcttgta tggagcagca gacgcgctac ttcgagcgga 7140
ggcatccgga gcttgcagga tcgccgcggc tccgggcgta tatgctccgc attggtcttg 7200
accaactcta tcagagcttg gttgacggca atttcgatga tgcagcttgg gcgcagggtc 7260
gatgcgacgc aatcgtccga tccggagccg ggactgtcgg gcgtacacaa atcgcccgca 7320
gaagcgcggc cgtctggacc gatggctgtg tagaagtact cgccgatagt ggaaaccgac 7380
gccccagcac tcgtccgagg gcaaaggaat agtgaggtac ctaaagaagg agtgcgtcga 7440
agcagatcgt tcaaacattt ggcaataaag tttcttaaga ttgaatcctg ttgccggtct 7500
tgcgatgatt atcatataat ttctgttgaa ttacgttaag catgtaataa ttaacatgta 7560
atgcatgacg ttatttatga gatgggtttt tatgattaga gtcccgcaat tatacattta 7620
atacgcgata gaaaacaaaa tatagcgcgc aaactaggat aaattatcgc gcgcggtgtc 7680
atctatgtta ctagatcgat gtcgaatcga tcaacctgca ttaatgaatc ggccaacgcg 7740
cggggagagg cggtttgcgt attgggcgct cttccgcttc ctcgctcact gactcgctgc 7800
gctcggtcgt tcggctgcgg cgagcggtat cagctcactc aaaggcggta atacggttat 7860
ccacagaatc aggggataac gcaggaaaga acatgtgagc aaaaggccag caaaaggcca 7920
ggaaccgtaa aaaggccgcg ttgctggcgt ttttccatag gctccgcccc cctgacgagc 7980
atcacaaaaa tcgacgctca agtcagaggt ggcgaaaccc gacaggacta taaagatacc 8040
aggcgtttcc ccctggaagc tccctcgtgc gctctcctgt tccgaccctg ccgcttaccg 8100
gatacctgtc cgcctttctc ccttcgggaa gcgtggcgct ttctcaatgc tcacgctgta 8160
ggtatctcag ttcggtgtag gtcgttcgct ccaagctggg ctgtgtgcac gaaccccccg 8220
ttcagcccga ccgctgcgcc ttatccggta actatcgtct tgagtccaac ccggtaagac 8280
acgacttatc gccactggca gcagccactg gtaacaggat tagcagagcg aggtatgtag 8340
gcggtgctac agagttcttg aagtggtggc ctaactacgg ctacactaga aggacagtat 8400
ttggtatctg cgctctgctg aagccagtta ccttcggaaa aagagttggt agctcttgat 8460
ccggcaaaca aaccaccgct ggtagcggtg gtttttttgt ttgcaagcag cagattacgc 8520
gcagaaaaaa aggatctcaa gaagatcctt tgatcttttc tacggggtct gacgctcagt 8580
ggaacgaaaa ctcacgttaa gggattttgg tcatgacatt aacctataaa aataggcgta 8640
tcacgaggcc ctttcgtctc gcgcgtttcg gtgatgacgg tgaaaacctc tgacacatgc 8700
agctcccgga gacggtcaca gcttgtctgt aagcggatgc cgggagcaga caagcccgtc 8760
agggcgcgtc agcgggtgtt ggcgggtgtc ggggctggct taactatgcg gcatcagagc 8820
agattgtact gagagtgcac catatggaca tattgtcgtt agaacgcggc tacaattaat 8880
acataacctt atgtatcata cacatacgat ttaggtgaca ctatagaacg gcgcgccaag 8940
cttggatctc ctgcagcccg ggggatccgc ccacgtacgg taccatctgc taatatttta 9000
aatcacatgc aagagaggag gcatggttcc attttctacc ttcacattat ttgagaaaaa 9060
cgaacttgtt ctgtgtttta tttttgccct tcacattagt acaacgtgga agactcatgg 9120
ttacacagaa tcatacataa gtacaatgct tgtccctaag aaaacaagca ctcgttgtat 9180
tgaaccttta cggctcatgc ggccgcgaat tcactagtga ttgaattcgc ggccgcttag 9240
tccgacttgg ccttggcggc cgcggccgac tctttgagcg tgaagatctg cgccgtctcg 9300
ggcacagcgc cgtagttgac aaagaggtgc gcggtcttga agaaggccgt gatgatgggc 9360
tcgtcgttcc tgcgcacgag gtgcgggtac gcggccgcaa agtgcttggt ggcttcgttg 9420
agcttgtagt gcggaatgat cgggaacaag tggtggacct ggtgcgtgcc aatgtggtgg 9480
ctcaggttgt ccacgaacgc gccgtacgag cggtcgacgc tcgagaggtt gcccttgacg 9540
tacgtccact ccgagtcgcc gtaccacggc gtcgcttcgt cgttgtggtg caagaaggtc 9600
gtaatgacga ggaacgaagc aaagacaaag agcggcgcat agtagtagag gcccatgacg 9660
gcaaagccga gcgagtatgt gaggtacgcg tacgcggcga agaaggcggc ccagacgccg 9720
agcgacacga tgacggccga cgcgcggcga aggaggagcg ggtcccacgg gtcaaagtgg 9780
ctcatcgtgc gcggggcata cccgaccttc aagtagacaa accacgcacc gccgagcgtg 9840
tagacccatt ggcgcacgtc ctggaggtcc ttgaccgacc ggtgcgggta aaagatctcg 9900
tccttatcaa tgttgcccgt gttcttgtgg tggtggcggt gcgtcacgcg ccagctctcg 9960
aacggcgtca aaatcgcaga gtgcatgatg cagccgatga taaagttgac gctgtggtag 10020
cgcgagaagg ccgagtggcc gcagtcgtgg ccgaccgtga agaagcccca gaagatgacg 10080
ccctgcacgt agatgtaggt ggcgcaaacg agcgcgtgga gcagaacgtt atcggcaatg 10140
aacggcgtcg agcgcgccgc gtagagcagc gccgccgagg ccgacgcgtt gaagatcgcg 10200
cgggccgtgt agtagagcga gaggccgagg ttcgactcaa agcacgcgtt cgggatcgag 10260
tgcttgagct ccgtgagcgt cgggaactcg accttcgtct tatcctcagt catgcggccg 10320
ctgaagtatt gcttcttagt taacctttcc tttctctctc agctatgtga attcattttg 10380
ctttcgtcac aatttatata gtgaaattgg atctttggag ttaacgcctt cacaggatta 10440
tcgtgttaga acaatgcttt ttcatgttct aattagtagt acattacaaa tgtgcactct 10500
attcaataag catcttttgg cacgttaata aatcatgtga aaaaaaaata ctactatttc 10560
aaagaaagtg ttgtaaaaag aaacggaaag agagctggct tcagttgttg agacttgttt 10620
gctagtaaaa atggtgtgaa gagtgattca tggtgaggtg gtttttcgtc cctttctgtt 10680
tgcatgaaaa acaaatggca agagatgacg taggattcct tcccttaacg attatctgtt 10740
tttaatttca aatatacata taggaattta tgaattacta aggttgtaaa atatgctggt 10800
catttattta tggctaaaat attttttttt ctcgtaaata taaaaatatt taaaatttat 10860
ttttatcata ttttttatcc ttataaaatt atgtgtacaa cctatataaa aaaatatcat 10920
atttaatatt gattatatgt ttaatcaata taaaaaatca ttatcatata tttagattta 10980
ttcgaatata catctaaaca aaaaataaca tattttaatt ttatgaagaa aaaaaaatat 11040
tttatccttt atttatttaa gattaattaa tagttatgta ttgtggaaag acttttacac 11100
atgcaataga tatactgaat caattagatg ccaatgctga gttggaaatc acttgaggag 11160
gggaggagac ttgccaatgc ttttcagttt catttaaatg atttagtgga ggagatagag 11220
tagtgataaa ggcatgcccc aattttggag tgtatatatg agtggaaata agagagggat 11280
agagagaaaa aataaagaga gtaaaaataa ttaatgtgaa atgatatgat aaaaaaataa 11340
agaaagagat aaagagaaaa atgaaatgag agatagatga aatagagagt agatacatgt 11400
ttgtttaggt tttttttagg aaataacaca tttttttctc atcacttatt actcactgtc 11460
aatttcctct ctttcaatca taatgatatg atttgtttaa caaaaatgtg aaaaaacata 11520
taaagtaaaa tatttttata aattgataaa taaaaattta caaaatttat ttcttattaa 11580
attgaataga aaatgaaaga aaagaaaaga aaaagtatat ataaaatgat atagctttaa 11640
aaagaataaa tttttcatat cagtcttttt ttaataattt agaaatattt aagtatatag 11700
caaaaatata atgtacttta catatgcata aataataatt tgaaaataga actaatagaa 11760
tagagaaaaa agtaatataa taattaacta tatgaaaatt tagaagggac aatattttta 11820
attaagaata taaacaatat ttcttttcat gtaatgaggg acggatgtac ggggccagtg 11880
ttggagtcaa agccaaaata gtcacgggga aattaatgca ctgcatgact attcgaaaaa 11940
attcactagc cttacttaga tgttagatta atagctaggg ggtgcagata attttgaaag 12000
gcatgaaaaa cattaatttg tacattgcaa gcttttgatg acaagctttg caattgttca 12060
cactacctta tgccatttat aaatagagtg attggcatat gaaggaaatc atgagagtcg 12120
aagcgaaaaa caaagcttga gagtgtagga aaaatacagt ttttttggta aaaatacagt 12180
atttgaatag gagcgaaaaa tatcctttca aaatgatcct tttctttttt tttttttttc 12240
ttgttgttct tggtcagtta ttcaaaggaa aagggattga aataaaaact tgcatgtggg 12300
atcgtacgtc gagtcgacct gca 12323
<210> 89
<211> 12456
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR585
<220>
<221> misc_feature
<222> (1201)..(1201)
<223> n is a, c, g, or t
<400> 89
ggatctggcc ggccggatct cgtacgtcct cgaagagaag ggttaataac acatttttta 60
acatttttaa cacaaatttt agttatttaa aaatttatta aaaaatttaa aataagaaga 120
ggaactcttt aaataaatct aacttacaaa atttatgatt tttaataagt tttcaccaat 180
aaaaaatgtc ataaaaatat gttaaaaagt atattatcaa tattctcttt atgataaata 240
aaaagaaaaa aaaaataaaa gttaagtgaa aatgagattg aagtgacttt aggtgtgtat 300
aaatatatca accccgccaa caatttattt aatccaaata tattgaagta tattattcca 360
tagcctttat ttatttatat atttattata taaaagcttt atttgttcta ggttgttcat 420
gaaatatttt tttggtttta tctccgttgt aagaaaatca tgtgctttgt gtcgccactc 480
actattgcag ctttttcatg cattggtcag attgacggtt gattgtattt ttgtttttta 540
tggttttgtg ttatgactta agtcttcatc tctttatctc ttcatcaggt ttgatggtta 600
cctaatatgg tccatgggta catgcatggt taaattaggt ggccaacttt gttgtgaacg 660
atagaatttt ttttatatta agtaaactat ttttatatta tgaaataata ataaaaaaaa 720
tattttatca ttattaacaa aatcatatta gttaatttgt taactctata ataaaagaaa 780
tactgtaaca ttcacattac atggtaacat ctttccaccc tttcatttgt tttttgtttg 840
atgacttttt ttcttgttta aatttatttc ccttctttta aatttggaat acattatcat 900
catatataaa ctaaaatact aaaaacagga ttacacaaat gataaataat aacacaaata 960
tttataaatc tagctgcaat atatttaaac tagctatatc gatattgtaa aataaaacta 1020
gctgcattga tactgataaa aaaatatcat gtgctttctg gactgatgat gcagtatact 1080
tttgacattg cctttatttt atttttcaga aaagctttct tagttctggg ttcttcatta 1140
tttgtttccc atctccattg tgaattgaat catttgcttc gtgtcacaaa tacaatttag 1200
ntaggtacat gcattggtca gattcacggt ttattatgtc atgacttaag ttcatggtag 1260
tacattacct gccacgcatg cattatattg gttagatttg ataggcaaat ttggttgtca 1320
acaatataaa tataaataat gtttttatat tacgaaataa cagtgatcaa aacaaacagt 1380
tttatcttta ttaacaagat tttgtttttg tttgatgacg ttttttaatg tttacgcttt 1440
cccccttctt ttgaatttag aacactttat catcataaaa tcaaatacta aaaaaattac 1500
atatttcata aataataaca caaatatttt taaaaaatct gaaataataa tgaacaatat 1560
tacatattat cacgaaaatt cattaataaa aatattatat aaataaaatg taatagtagt 1620
tatatgtagg aaaaaagtac tgcacgcata atatatacaa aaagattaaa atgaactatt 1680
ataaataata acactaaatt aatggtgaat catatcaaaa taatgaaaaa gtaaataaaa 1740
tttgtaatta acttctatat gtattacaca cacaaataat aaataatagt aaaaaaaatt 1800
atgataaata tttaccatct cataagatat ttaaaataat gataaaaata tagattattt 1860
tttatgcaac tagctagcca aaaagagaac acgggtatat ataaaaagag tacctttaaa 1920
ttctactgta cttcctttat tcctgacgtt tttatatcaa gtggacatac gtgaagattt 1980
taattatcag tctaaatatt tcattagcac ttaatacttt tctgttttat tcctatccta 2040
taagtagtcc cgattctccc aacattgctt attcacacaa ctaactaaga aagtcttcca 2100
tagcccccca agcggccgca caatggcgac tcgacagcga actgccacca ctgttgtggt 2160
cgaggacctt cccaaggtca ctcttgaggc caagtctgaa cctgtgttcc ccgatatcaa 2220
gaccatcaag gatgccattc ccgcgcactg cttccagccc tcgctcgtca cctcattcta 2280
ctacgtcttc cgcgattttg ccatggtctc tgccctcgtc tgggctgctc tcacctacat 2340
ccccagcatc cccgaccaga ccctccgcgt cgcagcttgg atggtctacg gcttcgtcca 2400
gggtctgttc tgcaccggtg tctggattct cggccatgag tgcggccacg gtgctttctc 2460
tctccacgga aaggtcaaca atgtgaccgg ctggttcctc cactcgttcc tcctcgtccc 2520
ctacttcagc tggaagtact ctcaccaccg ccaccaccgc ttcaccggcc acatggatct 2580
cgacatggct ttcgtcccca agactgagcc caagccctcc aagtcgctca tgattgctgg 2640
cattgacgtc gccgagcttg ttgaggacac ccccgctgct cagatggtca agctcatctt 2700
ccaccagctt ttcggatggc aggcgtacct cttcttcaac gctagctctg gcaagggcag 2760
caagcagtgg gagcccaaga ctggcctctc caagtggttc cgagtcagtc acttcgagcc 2820
taccagcgct gtcttccgcc ccaacgaggc catcttcatc ctcatctccg atatcggtct 2880
tgctctaatg ggaactgctc tgtactttgc ttccaagcaa gttggtgttt cgaccattct 2940
cttcctctac cttgttccct acctgtgggt tcaccactgg ctcgttgcca ttacctacct 3000
ccaccaccac cacaccgagc tccctcacta caccgctgag ggctggacct acgtcaaggg 3060
agctctcgcc actgtcgacc gtgagtttgg cttcatcgga aagcacctct tccacggtat 3120
cattgagaag cacgttgttc accatctctt ccctaagatc cccttctaca aggctgacga 3180
ggccaccgag gccatcaagc ccgtcattgg cgaccactac tgccacgacg accgaagctt 3240
cctgggccag ctgtggacca tcttcggcac gctcaagtac gtcgagcacg accctgcccg 3300
acccggtgcc atgcgatgga acaaggacta ggctaggcgg ccgcgacaca agtgtgagag 3360
tactaaataa atgctttggt tgtacgaaat cattacacta aataaaataa tcaaagctta 3420
tatatgcctt ccgctaaggc cgaatgcaaa gaaattggtt ctttctcgtt atcttttgcc 3480
acttttacta gtacgtatta attactactt aatcatcttt gtttacggct cattatatcc 3540
ggtctagagg atccaaggcc gcgaagttaa aagcaatgtt gtcacttgtc gtactaacac 3600
atgatgtgat agtttatgct agctagctat aacataagct gtctctgagt gtgttgtata 3660
ttaataaaga tcatcactgg tgaatggtga tcgtgtacgt accctactta gtaggcaatg 3720
gaagcactta gagtgtgctt tgtgcatggc cttgcctctg ttttgagact tttgtaatgt 3780
tttcgagttt aaatctttgc ctttgcgtac ggatccgtcg acggcgcgcc cgatcatccg 3840
gatatagttc ctcctttcag caaaaaaccc ctcaagaccc gtttagaggc cccaaggggt 3900
tatgctagtt attgctcagc ggtggcagca gccaactcag cttcctttcg ggctttgtta 3960
gcagccggat cgatccaagc tgtacctcac tattcctttg ccctcggacg agtgctgggg 4020
cgtcggtttc cactatcggc gagtacttct acacagccat cggtccagac ggccgcgctt 4080
ctgcgggcga tttgtgtacg cccgacagtc ccggctccgg atcggacgat tgcgtcgcat 4140
cgaccctgcg cccaagctgc atcatcgaaa ttgccgtcaa ccaagctctg atagagttgg 4200
tcaagaccaa tgcggagcat atacgcccgg agccgcggcg atcctgcaag ctccggatgc 4260
ctccgctcga agtagcgcgt ctgctgctcc atacaagcca accacggcct ccagaagaag 4320
atgttggcga cctcgtattg ggaatccccg aacatcgcct cgctccagtc aatgaccgct 4380
gttatgcggc cattgtccgt caggacattg ttggagccga aatccgcgtg cacgaggtgc 4440
cggacttcgg ggcagtcctc ggcccaaagc atcagctcat cgagagcctg cgcgacggac 4500
gcactgacgg tgtcgtccat cacagtttgc cagtgataca catggggatc agcaatcgcg 4560
catatgaaat cacgccatgt agtgtattga ccgattcctt gcggtccgaa tgggccgaac 4620
ccgctcgtct ggctaagatc ggccgcagcg atcgcatcca tagcctccgc gaccggctgc 4680
agaacagcgg gcagttcggt ttcaggcagg tcttgcaacg tgacaccctg tgcacggcgg 4740
gagatgcaat aggtcaggct ctcgctgaat tccccaatgt caagcacttc cggaatcggg 4800
agcgcggccg atgcaaagtg ccgataaaca taacgatctt tgtagaaacc atcggcgcag 4860
ctatttaccc gcaggacata tccacgccct cctacatcga agctgaaagc acgagattct 4920
tcgccctccg agagctgcat caggtcggag acgctgtcga acttttcgat cagaaacttc 4980
tcgacagacg tcgcggtgag ttcaggcttt tccatgggta tatctccttc ttaaagttaa 5040
acaaaattat ttctagaggg aaaccgttgt ggtctcccta tagtgagtcg tattaatttc 5100
gcgggatcga gatcgatcca attccaatcc cacaaaaatc tgagcttaac agcacagttg 5160
ctcctctcag agcagaatcg ggtattcaac accctcatat caactactac gttgtgtata 5220
acggtccaca tgccggtata tacgatgact ggggttgtac aaaggcggca acaaacggcg 5280
ttcccggagt tgcacacaag aaatttgcca ctattacaga ggcaagagca gcagctgacg 5340
cgtacacaac aagtcagcaa acagacaggt tgaacttcat ccccaaagga gaagctcaac 5400
tcaagcccaa gagctttgct aaggccctaa caagcccacc aaagcaaaaa gcccactggc 5460
tcacgctagg aaccaaaagg cccagcagtg atccagcccc aaaagagatc tcctttgccc 5520
cggagattac aatggacgat ttcctctatc tttacgatct aggaaggaag ttcgaaggtg 5580
aaggtgacga cactatgttc accactgata atgagaaggt tagcctcttc aatttcagaa 5640
agaatgctga cccacagatg gttagagagg cctacgcagc aggtctcatc aagacgatct 5700
acccgagtaa caatctccag gagatcaaat accttcccaa gaaggttaaa gatgcagtca 5760
aaagattcag gactaattgc atcaagaaca cagagaaaga catatttctc aagatcagaa 5820
gtactattcc agtatggacg attcaaggct tgcttcataa accaaggcaa gtaatagaga 5880
ttggagtctc taaaaaggta gttcctactg aatctaaggc catgcatgga gtctaagatt 5940
caaatcgagg atctaacaga actcgccgtg aagactggcg aacagttcat acagagtctt 6000
ttacgactca atgacaagaa gaaaatcttc gtcaacatgg tggagcacga cactctggtc 6060
tactccaaaa atgtcaaaga tacagtctca gaagaccaaa gggctattga gacttttcaa 6120
caaaggataa tttcgggaaa cctcctcgga ttccattgcc cagctatctg tcacttcatc 6180
gaaaggacag tagaaaagga aggtggctcc tacaaatgcc atcattgcga taaaggaaag 6240
gctatcattc aagatgcctc tgccgacagt ggtcccaaag atggaccccc acccacgagg 6300
agcatcgtgg aaaaagaaga cgttccaacc acgtcttcaa agcaagtgga ttgatgtgac 6360
atctccactg acgtaaggga tgacgcacaa tcccactatc cttcgcaaga cccttcctct 6420
atataaggaa gttcatttca tttggagagg acacgctcga gctcatttct ctattacttc 6480
agccataaca aaagaactct tttctcttct tattaaacca tgaaaaagcc tgaactcacc 6540
gcgacgtctg tcgagaagtt tctgatcgaa aagttcgaca gcgtctccga cctgatgcag 6600
ctctcggagg gcgaagaatc tcgtgctttc agcttcgatg taggagggcg tggatatgtc 6660
ctgcgggtaa atagctgcgc cgatggtttc tacaaagatc gttatgttta tcggcacttt 6720
gcatcggccg cgctcccgat tccggaagtg cttgacattg gggaattcag cgagagcctg 6780
acctattgca tctcccgccg tgcacagggt gtcacgttgc aagacctgcc tgaaaccgaa 6840
ctgcccgctg ttctgcagcc ggtcgcggag gccatggatg cgatcgctgc ggccgatctt 6900
agccagacga gcgggttcgg cccattcgga ccgcaaggaa tcggtcaata cactacatgg 6960
cgtgatttca tatgcgcgat tgctgatccc catgtgtatc actggcaaac tgtgatggac 7020
gacaccgtca gtgcgtccgt cgcgcaggct ctcgatgagc tgatgctttg ggccgaggac 7080
tgccccgaag tccggcacct cgtgcacgcg gatttcggct ccaacaatgt cctgacggac 7140
aatggccgca taacagcggt cattgactgg agcgaggcga tgttcgggga ttcccaatac 7200
gaggtcgcca acatcttctt ctggaggccg tggttggctt gtatggagca gcagacgcgc 7260
tacttcgagc ggaggcatcc ggagcttgca ggatcgccgc ggctccgggc gtatatgctc 7320
cgcattggtc ttgaccaact ctatcagagc ttggttgacg gcaatttcga tgatgcagct 7380
tgggcgcagg gtcgatgcga cgcaatcgtc cgatccggag ccgggactgt cgggcgtaca 7440
caaatcgccc gcagaagcgc ggccgtctgg accgatggct gtgtagaagt actcgccgat 7500
agtggaaacc gacgccccag cactcgtccg agggcaaagg aatagtgagg tacctaaaga 7560
aggagtgcgt cgaagcagat cgttcaaaca tttggcaata aagtttctta agattgaatc 7620
ctgttgccgg tcttgcgatg attatcatat aatttctgtt gaattacgtt aagcatgtaa 7680
taattaacat gtaatgcatg acgttattta tgagatgggt ttttatgatt agagtcccgc 7740
aattatacat ttaatacgcg atagaaaaca aaatatagcg cgcaaactag gataaattat 7800
cgcgcgcggt gtcatctatg ttactagatc gatgtcgaat cgatcaacct gcattaatga 7860
atcggccaac gcgcggggag aggcggtttg cgtattgggc gctcttccgc ttcctcgctc 7920
actgactcgc tgcgctcggt cgttcggctg cggcgagcgg tatcagctca ctcaaaggcg 7980
gtaatacggt tatccacaga atcaggggat aacgcaggaa agaacatgtg agcaaaaggc 8040
cagcaaaagg ccaggaaccg taaaaaggcc gcgttgctgg cgtttttcca taggctccgc 8100
ccccctgacg agcatcacaa aaatcgacgc tcaagtcaga ggtggcgaaa cccgacagga 8160
ctataaagat accaggcgtt tccccctgga agctccctcg tgcgctctcc tgttccgacc 8220
ctgccgctta ccggatacct gtccgccttt ctcccttcgg gaagcgtggc gctttctcaa 8280
tgctcacgct gtaggtatct cagttcggtg taggtcgttc gctccaagct gggctgtgtg 8340
cacgaacccc ccgttcagcc cgaccgctgc gccttatccg gtaactatcg tcttgagtcc 8400
aacccggtaa gacacgactt atcgccactg gcagcagcca ctggtaacag gattagcaga 8460
gcgaggtatg taggcggtgc tacagagttc ttgaagtggt ggcctaacta cggctacact 8520
agaaggacag tatttggtat ctgcgctctg ctgaagccag ttaccttcgg aaaaagagtt 8580
ggtagctctt gatccggcaa acaaaccacc gctggtagcg gtggtttttt tgtttgcaag 8640
cagcagatta cgcgcagaaa aaaaggatct caagaagatc ctttgatctt ttctacgggg 8700
tctgacgctc agtggaacga aaactcacgt taagggattt tggtcatgac attaacctat 8760
aaaaataggc gtatcacgag gccctttcgt ctcgcgcgtt tcggtgatga cggtgaaaac 8820
ctctgacaca tgcagctccc ggagacggtc acagcttgtc tgtaagcgga tgccgggagc 8880
agacaagccc gtcagggcgc gtcagcgggt gttggcgggt gtcggggctg gcttaactat 8940
gcggcatcag agcagattgt actgagagtg caccatatgg acatattgtc gttagaacgc 9000
ggctacaatt aatacataac cttatgtatc atacacatac gatttaggtg acactataga 9060
acggcgcgcc aagcttggat ctcctgcagc ccgggggatc cgcccacgta cggtaccatc 9120
tgctaatatt ttaaatcaca tgcaagagag gaggcatggt tccattttct accttcacat 9180
tatttgagaa aaacgaactt gttctgtgtt ttatttttgc ccttcacatt agtacaacgt 9240
ggaagactca tggttacaca gaatcataca taagtacaat gcttgtccct aagaaaacaa 9300
gcactcgttg tattgaacct ttacggctca tgcggccgcg aattcactag tgattgaatt 9360
cgcggccgct tagtccgact tggccttggc ggccgcggcc gactctttga gcgtgaagat 9420
ctgcgccgtc tcgggcacag cgccgtagtt gacaaagagg tgcgcggtct tgaagaaggc 9480
cgtgatgatg ggctcgtcgt tcctgcgcac gaggtgcggg tacgcggccg caaagtgctt 9540
ggtggcttcg ttgagcttgt agtgcggaat gatcgggaac aagtggtgga cctggtgcgt 9600
gccaatgtgg tggctcaggt tgtccacgaa cgcgccgtac gagcggtcga cgctcgagag 9660
gttgcccttg acgtacgtcc actccgagtc gccgtaccac ggcgtcgctt cgtcgttgtg 9720
gtgcaagaag gtcgtaatga cgaggaacga agcaaagaca aagagcggcg catagtagta 9780
gaggcccatg acggcaaagc cgagcgagta tgtgaggtac gcgtacgcgg cgaagaaggc 9840
ggcccagacg ccgagcgaca cgatgacggc cgacgcgcgg cgaaggagga gcgggtccca 9900
cgggtcaaag tggctcatcg tgcgcggggc atacccgacc ttcaagtaga caaaccacgc 9960
accgccgagc gtgtagaccc attggcgcac gtcctggagg tccttgaccg accggtgcgg 10020
gtaaaagatc tcgtccttat caatgttgcc cgtgttcttg tggtggtggc ggtgcgtcac 10080
gcgccagctc tcgaacggcg tcaaaatcgc agagtgcatg atgcagccga tgataaagtt 10140
gacgctgtgg tagcgcgaga aggccgagtg gccgcagtcg tggccgaccg tgaagaagcc 10200
ccagaagatg acgccctgca cgtagatgta ggtggcgcaa acgagcgcgt ggagcagaac 10260
gttatcggca atgaacggcg tcgagcgcgc cgcgtagagc agcgccgccg aggccgacgc 10320
gttgaagatc gcgcgggccg tgtagtagag cgagaggccg aggttcgact caaagcacgc 10380
gttcgggatc gagtgcttga gctccgtgag cgtcgggaac tcgaccttcg tcttatcctc 10440
agtcatgcgg ccgctgaagt attgcttctt agttaacctt tcctttctct ctcagctatg 10500
tgaattcatt ttgctttcgt cacaatttat atagtgaaat tggatctttg gagttaacgc 10560
cttcacagga ttatcgtgtt agaacaatgc tttttcatgt tctaattagt agtacattac 10620
aaatgtgcac tctattcaat aagcatcttt tggcacgtta ataaatcatg tgaaaaaaaa 10680
atactactat ttcaaagaaa gtgttgtaaa aagaaacgga aagagagctg gcttcagttg 10740
ttgagacttg tttgctagta aaaatggtgt gaagagtgat tcatggtgag gtggtttttc 10800
gtccctttct gtttgcatga aaaacaaatg gcaagagatg acgtaggatt ccttccctta 10860
acgattatct gtttttaatt tcaaatatac atataggaat ttatgaatta ctaaggttgt 10920
aaaatatgct ggtcatttat ttatggctaa aatatttttt tttctcgtaa atataaaaat 10980
atttaaaatt tatttttatc atatttttta tccttataaa attatgtgta caacctatat 11040
aaaaaaatat catatttaat attgattata tgtttaatca atataaaaaa tcattatcat 11100
atatttagat ttattcgaat atacatctaa acaaaaaata acatatttta attttatgaa 11160
gaaaaaaaaa tattttatcc tttatttatt taagattaat taatagttat gtattgtgga 11220
aagactttta cacatgcaat agatatactg aatcaattag atgccaatgc tgagttggaa 11280
atcacttgag gaggggagga gacttgccaa tgcttttcag tttcatttaa atgatttagt 11340
ggaggagata gagtagtgat aaaggcatgc cccaattttg gagtgtatat atgagtggaa 11400
ataagagagg gatagagaga aaaaataaag agagtaaaaa taattaatgt gaaatgatat 11460
gataaaaaaa taaagaaaga gataaagaga aaaatgaaat gagagataga tgaaatagag 11520
agtagataca tgtttgttta ggtttttttt aggaaataac acattttttt ctcatcactt 11580
attactcact gtcaatttcc tctctttcaa tcataatgat atgatttgtt taacaaaaat 11640
gtgaaaaaac atataaagta aaatattttt ataaattgat aaataaaaat ttacaaaatt 11700
tatttcttat taaattgaat agaaaatgaa agaaaagaaa agaaaaagta tatataaaat 11760
gatatagctt taaaaagaat aaatttttca tatcagtctt tttttaataa tttagaaata 11820
tttaagtata tagcaaaaat ataatgtact ttacatatgc ataaataata atttgaaaat 11880
agaactaata gaatagagaa aaaagtaata taataattaa ctatatgaaa atttagaagg 11940
gacaatattt ttaattaaga atataaacaa tatttctttt catgtaatga gggacggatg 12000
tacggggcca gtgttggagt caaagccaaa atagtcacgg ggaaattaat gcactgcatg 12060
actattcgaa aaaattcact agccttactt agatgttaga ttaatagcta gggggtgcag 12120
ataattttga aaggcatgaa aaacattaat ttgtacattg caagcttttg atgacaagct 12180
ttgcaattgt tcacactacc ttatgccatt tataaataga gtgattggca tatgaaggaa 12240
atcatgagag tcgaagcgaa aaacaaagct tgagagtgta ggaaaaatac agtttttttg 12300
gtaaaaatac agtatttgaa taggagcgaa aaatatcctt tcaaaatgat ccttttcttt 12360
tttttttttt ttcttgttgt tcttggtcag ttattcaaag gaaaagggat tgaaataaaa 12420
acttgcatgt gggatcgtac gtcgagtcga cctgca 12456
<210> 90
<211> 9088
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR578
<220>
<221> misc_feature
<222> (6951)..(6951)
<223> n is a, c, g, or t
<400> 90
ggccgcgaca caagtgtgag agtactaaat aaatgctttg gttgtacgaa atcattacac 60
taaataaaat aatcaaagct tatatatgcc ttccgctaag gccgaatgca aagaaattgg 120
ttctttctcg ttatcttttg ccacttttac tagtacgtat taattactac ttaatcatct 180
ttgtttacgg ctcattatat ccggtctaga ggatccaagg ccgcgaagtt aaaagcaatg 240
ttgtcacttg tcgtactaac acatgatgtg atagtttatg ctagctagct ataacataag 300
ctgtctctga gtgtgttgta tattaataaa gatcatcact ggtgaatggt gatcgtgtac 360
gtaccctact tagtaggcaa tggaagcact tagagtgtgc tttgtgcatg gccttgcctc 420
tgttttgaga cttttgtaat gttttcgagt ttaaatcttt gcctttgcgt acggatccgt 480
cgacggcgcg cccgatcatc cggatatagt tcctcctttc agcaaaaaac ccctcaagac 540
ccgtttagag gccccaaggg gttatgctag ttattgctca gcggtggcag cagccaactc 600
agcttccttt cgggctttgt tagcagccgg atcgatccaa gctgtacctc actattcctt 660
tgccctcgga cgagtgctgg ggcgtcggtt tccactatcg gcgagtactt ctacacagcc 720
atcggtccag acggccgcgc ttctgcgggc gatttgtgta cgcccgacag tcccggctcc 780
ggatcggacg attgcgtcgc atcgaccctg cgcccaagct gcatcatcga aattgccgtc 840
aaccaagctc tgatagagtt ggtcaagacc aatgcggagc atatacgccc ggagccgcgg 900
cgatcctgca agctccggat gcctccgctc gaagtagcgc gtctgctgct ccatacaagc 960
caaccacggc ctccagaaga agatgttggc gacctcgtat tgggaatccc cgaacatcgc 1020
ctcgctccag tcaatgaccg ctgttatgcg gccattgtcc gtcaggacat tgttggagcc 1080
gaaatccgcg tgcacgaggt gccggacttc ggggcagtcc tcggcccaaa gcatcagctc 1140
atcgagagcc tgcgcgacgg acgcactgac ggtgtcgtcc atcacagttt gccagtgata 1200
cacatgggga tcagcaatcg cgcatatgaa atcacgccat gtagtgtatt gaccgattcc 1260
ttgcggtccg aatgggccga acccgctcgt ctggctaaga tcggccgcag cgatcgcatc 1320
catagcctcc gcgaccggct gcagaacagc gggcagttcg gtttcaggca ggtcttgcaa 1380
cgtgacaccc tgtgcacggc gggagatgca ataggtcagg ctctcgctga attccccaat 1440
gtcaagcact tccggaatcg ggagcgcggc cgatgcaaag tgccgataaa cataacgatc 1500
tttgtagaaa ccatcggcgc agctatttac ccgcaggaca tatccacgcc ctcctacatc 1560
gaagctgaaa gcacgagatt cttcgccctc cgagagctgc atcaggtcgg agacgctgtc 1620
gaacttttcg atcagaaact tctcgacaga cgtcgcggtg agttcaggct tttccatggg 1680
tatatctcct tcttaaagtt aaacaaaatt atttctagag ggaaaccgtt gtggtctccc 1740
tatagtgagt cgtattaatt tcgcgggatc gagatcgatc caattccaat cccacaaaaa 1800
tctgagctta acagcacagt tgctcctctc agagcagaat cgggtattca acaccctcat 1860
atcaactact acgttgtgta taacggtcca catgccggta tatacgatga ctggggttgt 1920
acaaaggcgg caacaaacgg cgttcccgga gttgcacaca agaaatttgc cactattaca 1980
gaggcaagag cagcagctga cgcgtacaca acaagtcagc aaacagacag gttgaacttc 2040
atccccaaag gagaagctca actcaagccc aagagctttg ctaaggccct aacaagccca 2100
ccaaagcaaa aagcccactg gctcacgcta ggaaccaaaa ggcccagcag tgatccagcc 2160
ccaaaagaga tctcctttgc cccggagatt acaatggacg atttcctcta tctttacgat 2220
ctaggaagga agttcgaagg tgaaggtgac gacactatgt tcaccactga taatgagaag 2280
gttagcctct tcaatttcag aaagaatgct gacccacaga tggttagaga ggcctacgca 2340
gcaggtctca tcaagacgat ctacccgagt aacaatctcc aggagatcaa ataccttccc 2400
aagaaggtta aagatgcagt caaaagattc aggactaatt gcatcaagaa cacagagaaa 2460
gacatatttc tcaagatcag aagtactatt ccagtatgga cgattcaagg cttgcttcat 2520
aaaccaaggc aagtaataga gattggagtc tctaaaaagg tagttcctac tgaatctaag 2580
gccatgcatg gagtctaaga ttcaaatcga ggatctaaca gaactcgccg tgaagactgg 2640
cgaacagttc atacagagtc ttttacgact caatgacaag aagaaaatct tcgtcaacat 2700
ggtggagcac gacactctgg tctactccaa aaatgtcaaa gatacagtct cagaagacca 2760
aagggctatt gagacttttc aacaaaggat aatttcggga aacctcctcg gattccattg 2820
cccagctatc tgtcacttca tcgaaaggac agtagaaaag gaaggtggct cctacaaatg 2880
ccatcattgc gataaaggaa aggctatcat tcaagatgcc tctgccgaca gtggtcccaa 2940
agatggaccc ccacccacga ggagcatcgt ggaaaaagaa gacgttccaa ccacgtcttc 3000
aaagcaagtg gattgatgtg acatctccac tgacgtaagg gatgacgcac aatcccacta 3060
tccttcgcaa gacccttcct ctatataagg aagttcattt catttggaga ggacacgctc 3120
gagctcattt ctctattact tcagccataa caaaagaact cttttctctt cttattaaac 3180
catgaaaaag cctgaactca ccgcgacgtc tgtcgagaag tttctgatcg aaaagttcga 3240
cagcgtctcc gacctgatgc agctctcgga gggcgaagaa tctcgtgctt tcagcttcga 3300
tgtaggaggg cgtggatatg tcctgcgggt aaatagctgc gccgatggtt tctacaaaga 3360
tcgttatgtt tatcggcact ttgcatcggc cgcgctcccg attccggaag tgcttgacat 3420
tggggaattc agcgagagcc tgacctattg catctcccgc cgtgcacagg gtgtcacgtt 3480
gcaagacctg cctgaaaccg aactgcccgc tgttctgcag ccggtcgcgg aggccatgga 3540
tgcgatcgct gcggccgatc ttagccagac gagcgggttc ggcccattcg gaccgcaagg 3600
aatcggtcaa tacactacat ggcgtgattt catatgcgcg attgctgatc cccatgtgta 3660
tcactggcaa actgtgatgg acgacaccgt cagtgcgtcc gtcgcgcagg ctctcgatga 3720
gctgatgctt tgggccgagg actgccccga agtccggcac ctcgtgcacg cggatttcgg 3780
ctccaacaat gtcctgacgg acaatggccg cataacagcg gtcattgact ggagcgaggc 3840
gatgttcggg gattcccaat acgaggtcgc caacatcttc ttctggaggc cgtggttggc 3900
ttgtatggag cagcagacgc gctacttcga gcggaggcat ccggagcttg caggatcgcc 3960
gcggctccgg gcgtatatgc tccgcattgg tcttgaccaa ctctatcaga gcttggttga 4020
cggcaatttc gatgatgcag cttgggcgca gggtcgatgc gacgcaatcg tccgatccgg 4080
agccgggact gtcgggcgta cacaaatcgc ccgcagaagc gcggccgtct ggaccgatgg 4140
ctgtgtagaa gtactcgccg atagtggaaa ccgacgcccc agcactcgtc cgagggcaaa 4200
ggaatagtga ggtacctaaa gaaggagtgc gtcgaagcag atcgttcaaa catttggcaa 4260
taaagtttct taagattgaa tcctgttgcc ggtcttgcga tgattatcat ataatttctg 4320
ttgaattacg ttaagcatgt aataattaac atgtaatgca tgacgttatt tatgagatgg 4380
gtttttatga ttagagtccc gcaattatac atttaatacg cgatagaaaa caaaatatag 4440
cgcgcaaact aggataaatt atcgcgcgcg gtgtcatcta tgttactaga tcgatgtcga 4500
atcgatcaac ctgcattaat gaatcggcca acgcgcgggg agaggcggtt tgcgtattgg 4560
gcgctcttcc gcttcctcgc tcactgactc gctgcgctcg gtcgttcggc tgcggcgagc 4620
ggtatcagct cactcaaagg cggtaatacg gttatccaca gaatcagggg ataacgcagg 4680
aaagaacatg tgagcaaaag gccagcaaaa ggccaggaac cgtaaaaagg ccgcgttgct 4740
ggcgtttttc cataggctcc gcccccctga cgagcatcac aaaaatcgac gctcaagtca 4800
gaggtggcga aacccgacag gactataaag ataccaggcg tttccccctg gaagctccct 4860
cgtgcgctct cctgttccga ccctgccgct taccggatac ctgtccgcct ttctcccttc 4920
gggaagcgtg gcgctttctc aatgctcacg ctgtaggtat ctcagttcgg tgtaggtcgt 4980
tcgctccaag ctgggctgtg tgcacgaacc ccccgttcag cccgaccgct gcgccttatc 5040
cggtaactat cgtcttgagt ccaacccggt aagacacgac ttatcgccac tggcagcagc 5100
cactggtaac aggattagca gagcgaggta tgtaggcggt gctacagagt tcttgaagtg 5160
gtggcctaac tacggctaca ctagaaggac agtatttggt atctgcgctc tgctgaagcc 5220
agttaccttc ggaaaaagag ttggtagctc ttgatccggc aaacaaacca ccgctggtag 5280
cggtggtttt tttgtttgca agcagcagat tacgcgcaga aaaaaaggat ctcaagaaga 5340
tcctttgatc ttttctacgg ggtctgacgc tcagtggaac gaaaactcac gttaagggat 5400
tttggtcatg acattaacct ataaaaatag gcgtatcacg aggccctttc gtctcgcgcg 5460
tttcggtgat gacggtgaaa acctctgaca catgcagctc ccggagacgg tcacagcttg 5520
tctgtaagcg gatgccggga gcagacaagc ccgtcagggc gcgtcagcgg gtgttggcgg 5580
gtgtcggggc tggcttaact atgcggcatc agagcagatt gtactgagag tgcaccatat 5640
ggacatattg tcgttagaac gcggctacaa ttaatacata accttatgta tcatacacat 5700
acgatttagg tgacactata gaacggcgcg ccaagcttgg atctcctgca ggatctggcc 5760
ggccggatct cgtacgtcct cgaagagaag ggttaataac acatttttta acatttttaa 5820
cacaaatttt agttatttaa aaatttatta aaaaatttaa aataagaaga ggaactcttt 5880
aaataaatct aacttacaaa atttatgatt tttaataagt tttcaccaat aaaaaatgtc 5940
ataaaaatat gttaaaaagt atattatcaa tattctcttt atgataaata aaaagaaaaa 6000
aaaaataaaa gttaagtgaa aatgagattg aagtgacttt aggtgtgtat aaatatatca 6060
accccgccaa caatttattt aatccaaata tattgaagta tattattcca tagcctttat 6120
ttatttatat atttattata taaaagcttt atttgttcta ggttgttcat gaaatatttt 6180
tttggtttta tctccgttgt aagaaaatca tgtgctttgt gtcgccactc actattgcag 6240
ctttttcatg cattggtcag attgacggtt gattgtattt ttgtttttta tggttttgtg 6300
ttatgactta agtcttcatc tctttatctc ttcatcaggt ttgatggtta cctaatatgg 6360
tccatgggta catgcatggt taaattaggt ggccaacttt gttgtgaacg atagaatttt 6420
ttttatatta agtaaactat ttttatatta tgaaataata ataaaaaaaa tattttatca 6480
ttattaacaa aatcatatta gttaatttgt taactctata ataaaagaaa tactgtaaca 6540
ttcacattac atggtaacat ctttccaccc tttcatttgt tttttgtttg atgacttttt 6600
ttcttgttta aatttatttc ccttctttta aatttggaat acattatcat catatataaa 6660
ctaaaatact aaaaacagga ttacacaaat gataaataat aacacaaata tttataaatc 6720
tagctgcaat atatttaaac tagctatatc gatattgtaa aataaaacta gctgcattga 6780
tactgataaa aaaatatcat gtgctttctg gactgatgat gcagtatact tttgacattg 6840
cctttatttt atttttcaga aaagctttct tagttctggg ttcttcatta tttgtttccc 6900
atctccattg tgaattgaat catttgcttc gtgtcacaaa tacaatttag ntaggtacat 6960
gcattggtca gattcacggt ttattatgtc atgacttaag ttcatggtag tacattacct 7020
gccacgcatg cattatattg gttagatttg ataggcaaat ttggttgtca acaatataaa 7080
tataaataat gtttttatat tacgaaataa cagtgatcaa aacaaacagt tttatcttta 7140
ttaacaagat tttgtttttg tttgatgacg ttttttaatg tttacgcttt cccccttctt 7200
ttgaatttag aacactttat catcataaaa tcaaatacta aaaaaattac atatttcata 7260
aataataaca caaatatttt taaaaaatct gaaataataa tgaacaatat tacatattat 7320
cacgaaaatt cattaataaa aatattatat aaataaaatg taatagtagt tatatgtagg 7380
aaaaaagtac tgcacgcata atatatacaa aaagattaaa atgaactatt ataaataata 7440
acactaaatt aatggtgaat catatcaaaa taatgaaaaa gtaaataaaa tttgtaatta 7500
acttctatat gtattacaca cacaaataat aaataatagt aaaaaaaatt atgataaata 7560
tttaccatct cataagatat ttaaaataat gataaaaata tagattattt tttatgcaac 7620
tagctagcca aaaagagaac acgggtatat ataaaaagag tacctttaaa ttctactgta 7680
cttcctttat tcctgacgtt tttatatcaa gtggacatac gtgaagattt taattatcag 7740
tctaaatatt tcattagcac ttaatacttt tctgttttat tcctatccta taagtagtcc 7800
cgattctccc aacattgctt attcacacaa ctaactaaga aagtcttcca tagcccccca 7860
agcggccgca caatggcgac tcgacagcga actgccacca ctgttgtggt cgaggacctt 7920
cccaaggtca ctcttgaggc caagtctgaa cctgtgttcc ccgatatcaa gaccatcaag 7980
gatgccattc ccgcgcactg cttccagccc tcgctcgtca cctcattcta ctacgtcttc 8040
cgcgattttg ccatggtctc tgccctcgtc tgggctgctc tcacctacat ccccagcatc 8100
cccgaccaga ccctccgcgt cgcagcttgg atggtctacg gcttcgtcca gggtctgttc 8160
tgcaccggtg tctggattct cggccatgag tgcggccacg gtgctttctc tctccacgga 8220
aaggtcaaca atgtgaccgg ctggttcctc cactcgttcc tcctcgtccc ctacttcagc 8280
tggaagtact ctcaccaccg ccaccaccgc ttcaccggcc acatggatct cgacatggct 8340
ttcgtcccca agactgagcc caagccctcc aagtcgctca tgattgctgg cattgacgtc 8400
gccgagcttg ttgaggacac ccccgctgct cagatggtca agctcatctt ccaccagctt 8460
ttcggatggc aggcgtacct cttcttcaac gctagctctg gcaagggcag caagcagtgg 8520
gagcccaaga ctggcctctc caagtggttc cgagtcagtc acttcgagcc taccagcgct 8580
gtcttccgcc ccaacgaggc catcttcatc ctcatctccg atatcggtct tgctctaatg 8640
ggaactgctc tgtactttgc ttccaagcaa gttggtgttt cgaccattct cttcctctac 8700
cttgttccct acctgtgggt tcaccactgg ctcgttgcca ttacctacct ccaccaccac 8760
cacaccgagc tccctcacta caccgctgag ggctggacct acgtcaaggg agctctcgcc 8820
actgtcgacc gtgagtttgg cttcatcgga aagcacctct tccacggtat cattgagaag 8880
cacgttgttc accatctctt ccctaagatc cccttctaca aggctgacga ggccaccgag 8940
gccatcaagc ccgtcattgg cgaccactac tgccacgacg accgaagctt cctgggccag 9000
ctgtggacca tcttcggcac gctcaagtac gtcgagcacg accctgcccg acccggtgcc 9060
atgcgatgga acaaggacta ggctaggc 9088
<210> 91
<211> 10309
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR667
<220>
<221> misc_feature
<222> (7704)..(7704)
<223> n is a, c, g, or t
<400> 91
gtacgtctag aggatccgtc gacggcgcgc ccgatcatcc ggatatagtt cctcctttca 60
gcaaaaaacc cctcaagacc cgtttagagg ccccaagggg ttatgctagt tattgctcag 120
cggtggcagc agccaactca gcttcctttc gggctttgtt agcagccgga tcgatccaag 180
ctgtacctca ctattccttt gccctcggac gagtgctggg gcgtcggttt ccactatcgg 240
cgagtacttc tacacagcca tcggtccaga cggccgcgct tctgcgggcg atttgtgtac 300
gcccgacagt cccggctccg gatcggacga ttgcgtcgca tcgaccctgc gcccaagctg 360
catcatcgaa attgccgtca accaagctct gatagagttg gtcaagacca atgcggagca 420
tatacgcccg gagccgcggc gatcctgcaa gctccggatg cctccgctcg aagtagcgcg 480
tctgctgctc catacaagcc aaccacggcc tccagaagaa gatgttggcg acctcgtatt 540
gggaatcccc gaacatcgcc tcgctccagt caatgaccgc tgttatgcgg ccattgtccg 600
tcaggacatt gttggagccg aaatccgcgt gcacgaggtg ccggacttcg gggcagtcct 660
cggcccaaag catcagctca tcgagagcct gcgcgacgga cgcactgacg gtgtcgtcca 720
tcacagtttg ccagtgatac acatggggat cagcaatcgc gcatatgaaa tcacgccatg 780
tagtgtattg accgattcct tgcggtccga atgggccgaa cccgctcgtc tggctaagat 840
cggccgcagc gatcgcatcc atagcctccg cgaccggctg cagaacagcg ggcagttcgg 900
tttcaggcag gtcttgcaac gtgacaccct gtgcacggcg ggagatgcaa taggtcaggc 960
tctcgctgaa ttccccaatg tcaagcactt ccggaatcgg gagcgcggcc gatgcaaagt 1020
gccgataaac ataacgatct ttgtagaaac catcggcgca gctatttacc cgcaggacat 1080
atccacgccc tcctacatcg aagctgaaag cacgagattc ttcgccctcc gagagctgca 1140
tcaggtcgga gacgctgtcg aacttttcga tcagaaactt ctcgacagac gtcgcggtga 1200
gttcaggctt ttccatgggt atatctcctt cttaaagtta aacaaaatta tttctagagg 1260
gaaaccgttg tggtctccct atagtgagtc gtattaattt cgcgggatcg agatctgatc 1320
aacctgcatt aatgaatcgg ccaacgcgcg gggagaggcg gtttgcgtat tgggcgctct 1380
tccgcttcct cgctcactga ctcgctgcgc tcggtcgttc ggctgcggcg agcggtatca 1440
gctcactcaa aggcggtaat acggttatcc acagaatcag gggataacgc aggaaagaac 1500
atgtgagcaa aaggccagca aaaggccagg aaccgtaaaa aggccgcgtt gctggcgttt 1560
ttccataggc tccgcccccc tgacgagcat cacaaaaatc gacgctcaag tcagaggtgg 1620
cgaaacccga caggactata aagataccag gcgtttcccc ctggaagctc cctcgtgcgc 1680
tctcctgttc cgaccctgcc gcttaccgga tacctgtccg cctttctccc ttcgggaagc 1740
gtggcgcttt ctcaatgctc acgctgtagg tatctcagtt cggtgtaggt cgttcgctcc 1800
aagctgggct gtgtgcacga accccccgtt cagcccgacc gctgcgcctt atccggtaac 1860
tatcgtcttg agtccaaccc ggtaagacac gacttatcgc cactggcagc agccactggt 1920
aacaggatta gcagagcgag gtatgtaggc ggtgctacag agttcttgaa gtggtggcct 1980
aactacggct acactagaag gacagtattt ggtatctgcg ctctgctgaa gccagttacc 2040
ttcggaaaaa gagttggtag ctcttgatcc ggcaaacaaa ccaccgctgg tagcggtggt 2100
ttttttgttt gcaagcagca gattacgcgc agaaaaaaag gatctcaaga agatcctttg 2160
atcttttcta cggggtctga cgctcagtgg aacgaaaact cacgttaagg gattttggtc 2220
atgacattaa cctataaaaa taggcgtatc acgaggccct ttcgtctcgc gcgtttcggt 2280
gatgacggtg aaaacctctg acacatgcag ctcccggaga cggtcacagc ttgtctgtaa 2340
gcggatgccg ggagcagaca agcccgtcag ggcgcgtcag cgggtgttgg cgggtgtcgg 2400
ggctggctta actatgcggc atcagagcag attgtactga gagtgcacca tatggacata 2460
ttgtcgttag aacgcggcta caattaatac ataaccttat gtatcataca catacgattt 2520
aggtgacact atagaacggc gcgccaagct gggtctagaa ctagaaacgt gatgccactt 2580
gttattgaag tcgattacag catctattct gttttactat ttataacttt gccatttctg 2640
acttttgaaa actatctctg gatttcggta tcgctttgtg aagatcgagc aaaagagacg 2700
ttttgtggac gcaatggtcc aaatccgttc tacatgaaca aattggtcac aatttccact 2760
aaaagtaaat aaatggcaag ttaaaaaagg aatatgcatt ttactgattg cctaggtgag 2820
ctccaagaga agttgaatct acacgtctac caaccgctaa aaaaagaaaa acattgatat 2880
gtaacctgat tccattagct tttgacttct tcaacagatt ctctacttag atttctaaca 2940
gaaatattat tactagcaca tcattttcag tctcactaca gcaaaaaatc caacggcaca 3000
atacagacaa caggagatat cagactacag agatagatag atgctactgc atgtagtaag 3060
ttaaataaaa ggaaaataaa atgtcttgct accaaaacta ctacagacta tgatgctcac 3120
cacaggccaa atcctgcaac taggacagca ttatcttata tatattgtac aaaacaagca 3180
tcaaggaaca tttggtctag gcaatcagta cctcgttcta ccatcaccct cagttatcac 3240
atccttgaag gatccattac tgggaatcat cggcaacaca tgctcctgat ggggcacaat 3300
gacatcaaga aggtaggggc caggggtgtc caacattctc tgaattgccg ctctaagctc 3360
ttccttcttc gtcactcgcg ctgccggtat cccacaagca tcagcaaact tgagcatgtt 3420
tgggaatatc tcgctctcgc tagacggatc tccaagatag gtgtgagctc tattggactt 3480
gtagaaccta tcctccaact gaaccaccat acccaaatgc tgattgttca acaacaatat 3540
cttaactggg agattctcca ctcttatagt ggccaactcc tgaacattca tgatgaaact 3600
accatcccca tcaatgtcaa ccacaacagc cccagggtta gcaacagcag caccaatagc 3660
cgcaggcaat ccaaaaccca tggctccaag accccctgag gtcaaccact gcctcggtct 3720
cttgtacttg taaaactgcg cagcccacat ttgatgctgc ccaaccccag tactaacaat 3780
agcatctcca ttagtcaact catcaagaac ctcgatagca tgctgcggag aaatcgcgtc 3840
ctggaatgtc ttgtaaccca atggaaactt gtgtttctgc acattaatct cttctctcca 3900
acctccaaga tcaaacttac cctccactcc tttctcctcc aaaatcatat taattccctt 3960
caaggccaac ttcaaatccg cgcaaaccga cacgtgcgcc tgcttgttct tcccaatctc 4020
ggcagaatca atatcaatgt gaacaatctt agccctacta gcaaaagcct caagcttccc 4080
agtaacacgg tcatcaaacc ttaccccaaa ggcaagcaac aaatcactat tgtcaacagc 4140
atagttagca taaacagtac catgcatacc cagcatctga agggaatatt catcaccaat 4200
aggaaaagtt ccaagaccca ttaaagtgct agcaacggga ataccagtga gttcaacaaa 4260
gcgcctcaat tcagcactgg aattcaaact gccaccgccg acgtagagaa cgggcttttg 4320
ggcctccatg atgagtctga caatgtgttc caattgggcc tcggcggggg gcctgggcag 4380
cctggcgagg taaccgggga ggttaacggg ctcgtcccaa ttaggcacgg cgagttgctg 4440
ctgaacgtct ttgggaatgt cgatgaggac cggaccgggg cggccggagg tggcgacgaa 4500
gaaagcctcg gcgacgacgc gggggatgtc gtcgacgtcg aggatgaggt agttgtgctt 4560
cgtgatggat ctgctcacct ccacgatcgg ggtttcttgg aaggcgtcgg tgccgatcat 4620
ccggcgggcg acctggccgg tgatggcgac gactgggacg ctgtccatta aagcgtcggc 4680
gaggccgctc acgaggttgg tggcgccggg gccggaggtg gcaatgcaga cgccggggag 4740
gccggaggaa cgcgcgtagc cttcggcggc gaagacgccg ccctgctcgt ggcgcgggag 4800
cacgttgcgg atggcggcgg agcgcgtgag cgcctggtgg atctccatcg acgcaccgcc 4860
ggggtacgcg aacaccgtcg tcacgccctg cctctccagc gcctccacaa ggatgtccgc 4920
gcccttgcga ggttcgccgg aggcgaaccg tgacacgaag ggctccgtgg tcggcgcttc 4980
cttggtgaag ggcgccgccg tggggggttt ggagatggaa catttgattt tgagagcgtg 5040
gttgggtttg gtgagggttt gatgagagag agggagggtg gatctagtaa tgcgtttggg 5100
gaaggtgggg tgtgaagagg aagaagagaa tcgggtggtt ctggaagcgg tggccgccat 5160
tgtgttgtgt ggcatggtta tacttcaaaa actgcacaac aagcctagag ttagtaccta 5220
aacagtaaat ttacaacaga gagcaaagac acatgcaaaa atttcagcca taaaaaaagt 5280
tataatagaa tttaaagcaa aagtttcatt ttttaaacat atatacaaac aaactggatt 5340
tgaaggaagg gattaattcc cctgctcaaa gtttgaattc ctattgtgac ctatactcga 5400
ataaaattga agcctaagga atgtatgaga aacaagaaaa caaaacaaaa ctacagacaa 5460
acaagtacaa ttacaaaatt cgctaaaatt ctgtaatcac caaaccccat ctcagtcagc 5520
acaaggccca aggtttattt tgaaataaaa aaaaagtgat tttatttctc ataagctaaa 5580
agaaagaaag gcaattatga aatgatttcg actagatctg aaagtccaac gcgtattccg 5640
cagatattaa agaaagagta gagtttcaca tggatcctag atggacccag ttgaggaaaa 5700
agcaaggcaa agcaaaccag aagtgcaaga tccgaaattg aaccacggaa tctaggattt 5760
ggtagaggga gaagaaaagt accttgagag gtagaagaga agagaagagc agagagatat 5820
atgaacgagt gtgtcttggt ctcaactctg aagcgatacg agtttagagg ggagcattga 5880
gttccaattt atagggaaac cgggtggcag gggtgagtta atgacggaaa agcccctaag 5940
taacgagatt ggattgtggg ttagattcaa ccgtttgcat ccgcggctta gattggggaa 6000
gtcagagtga atctcaaccg ttgactgagt tgaaaattga atgtagcaac caattgagcc 6060
aaccccagcc tttgcccttt gattttgatt tgtttgttgc atacttttta tttgtcttct 6120
ggttctgact ctctttctct cgtttcaatg ccaggttgcc tactcccaca ccactcacaa 6180
gaagattcta ctgttagtat taaatatttt ttaatgtatt aaatgatgaa tgcttttgta 6240
aacagaacaa gactatgtct aataagtgtc ttgcaacatt ttttaagaaa ttaaaaaaaa 6300
tatatttatt atcaaaatca aatgtatgaa aaatcatgaa taatataatt ttatacattt 6360
ttttaaaaaa tcttttaatt tcttaattaa tatcttaaaa ataatgatta atatttaacc 6420
caaaataatt agtatgattg gtaaggaaga tatccatgtt atgtttggat gtgagtttga 6480
tctagagcaa agcttactag agtcgacctg caggtcgact cgacgtacgt cctcgaagag 6540
aagggttaat aacacatttt ttaacatttt taacacaaat tttagttatt taaaaattta 6600
ttaaaaaatt taaaataaga agaggaactc tttaaataaa tctaacttac aaaatttatg 6660
atttttaata agttttcacc aataaaaaat gtcataaaaa tatgttaaaa agtatattat 6720
caatattctc tttatgataa ataaaaagaa aaaaaaaata aaagttaagt gaaaatgaga 6780
ttgaagtgac tttaggtgtg tataaatata tcaaccccgc caacaattta tttaatccaa 6840
atatattgaa gtatattatt ccatagcctt tatttattta tatatttatt atataaaagc 6900
tttatttgtt ctaggttgtt catgaaatat ttttttggtt ttatctccgt tgtaagaaaa 6960
tcatgtgctt tgtgtcgcca ctcactattg cagctttttc atgcattggt cagattgacg 7020
gttgattgta tttttgtttt ttatggtttt gtgttatgac ttaagtcttc atctctttat 7080
ctcttcatca ggtttgatgg ttacctaata tggtccatgg gtacatgcat ggttaaatta 7140
ggtggccaac tttgttgtga acgatagaat tttttttata ttaagtaaac tatttttata 7200
ttatgaaata ataataaaaa aaatatttta tcattattaa caaaatcata ttagttaatt 7260
tgttaactct ataataaaag aaatactgta acattcacat tacatggtaa catctttcca 7320
ccctttcatt tgttttttgt ttgatgactt tttttcttgt ttaaatttat ttcccttctt 7380
ttaaatttgg aatacattat catcatatat aaactaaaat actaaaaaca ggattacaca 7440
aatgataaat aataacacaa atatttataa atctagctgc aatatattta aactagctat 7500
atcgatattg taaaataaaa ctagctgcat tgatactgat aaaaaaatat catgtgcttt 7560
ctggactgat gatgcagtat acttttgaca ttgcctttat tttatttttc agaaaagctt 7620
tcttagttct gggttcttca ttatttgttt cccatctcca ttgtgaattg aatcatttgc 7680
ttcgtgtcac aaatacaatt tagntaggta catgcattgg tcagattcac ggtttattat 7740
gtcatgactt aagttcatgg tagtacatta cctgccacgc atgcattata ttggttagat 7800
ttgataggca aatttggttg tcaacaatat aaatataaat aatgttttta tattacgaaa 7860
taacagtgat caaaacaaac agttttatct ttattaacaa gattttgttt ttgtttgatg 7920
acgtttttta atgtttacgc tttccccctt cttttgaatt tagaacactt tatcatcata 7980
aaatcaaata ctaaaaaaat tacatatttc ataaataata acacaaatat ttttaaaaaa 8040
tctgaaataa taatgaacaa tattacatat tatcacgaaa attcattaat aaaaatatta 8100
tataaataaa atgtaatagt agttatatgt aggaaaaaag tactgcacgc ataatatata 8160
caaaaagatt aaaatgaact attataaata ataacactaa attaatggtg aatcatatca 8220
aaataatgaa aaagtaaata aaatttgtaa ttaacttcta tatgtattac acacacaaat 8280
aataaataat agtaaaaaaa attatgataa atatttacca tctcataaga tatttaaaat 8340
aatgataaaa atatagatta ttttttatgc aactagctag ccaaaaagag aacacgggta 8400
tatataaaaa gagtaccttt aaattctact gtacttcctt tattcctgac gtttttatat 8460
caagtggaca tacgtgaaga ttttaattat cagtctaaat atttcattag cacttaatac 8520
ttttctgttt tattcctatc ctataagtag tcccgattct cccaacattg cttattcaca 8580
caactaacta agaaagtctt ccatagcccc ccaagcggcc gcacaatggc gactcgacag 8640
cgaactgcca ccactgttgt ggtcgaggac cttcccaagg tcactcttga ggccaagtct 8700
gaacctgtgt tccccgatat caagaccatc aaggatgcca ttcccgcgca ctgcttccag 8760
ccctcgctcg tcacctcatt ctactacgtc ttccgcgatt ttgccatggt ctctgccctc 8820
gtctgggctg ctctcaccta catccccagc atccccgacc agaccctccg cgtcgcagct 8880
tggatggtct acggcttcgt ccagggtctg ttctgcaccg gtgtctggat tctcggccat 8940
gagtgcggcc acggtgcttt ctctctccac ggaaaggtca acaatgtgac cggctggttc 9000
ctccactcgt tcctcctcgt cccctacttc agctggaagt actctcacca ccgccaccac 9060
cgcttcaccg gccacatgga tctcgacatg gctttcgtcc ccaagactga gcccaagccc 9120
tccaagtcgc tcatgattgc tggcattgac gtcgccgagc ttgttgagga cacccccgct 9180
gctcagatgg tcaagctcat cttccaccag cttttcggat ggcaggcgta cctcttcttc 9240
aacgctagct ctggcaaggg cagcaagcag tgggagccca agactggcct ctccaagtgg 9300
ttccgagtca gtcacttcga gcctaccagc gctgtcttcc gccccaacga ggccatcttc 9360
atcctcatct ccgatatcgg tcttgctcta atgggaactg ctctgtactt tgcttccaag 9420
caagttggtg tttcgaccat tctcttcctc taccttgttc cctacctgtg ggttcaccac 9480
tggctcgttg ccattaccta cctccaccac caccacaccg agctccctca ctacaccgct 9540
gagggctgga cctacgtcaa gggagctctc gccactgtcg accgtgagtt tggcttcatc 9600
ggaaagcacc tcttccacgg tatcattgag aagcacgttg ttcaccatct cttccctaag 9660
atccccttct acaaggctga cgaggccacc gaggccatca agcccgtcat tggcgaccac 9720
tactgccacg acgaccgaag cttcctgggc cagctgtgga ccatcttcgg cacgctcaag 9780
tacgtcgagc acgaccctgc ccgacccggt gccatgcgat ggaacaagga ctaggctagg 9840
cggccgcgac acaagtgtga gagtactaaa taaatgcttt ggttgtacga aatcattaca 9900
ctaaataaaa taatcaaagc ttatatatgc cttccgctaa ggccgaatgc aaagaaattg 9960
gttctttctc gttatctttt gccactttta ctagtacgta ttaattacta cttaatcatc 10020
tttgtttacg gctcattata tccggtctag aggatccaag gccgcgaagt taaaagcaat 10080
gttgtcactt gtcgtactaa cacatgatgt gatagtttat gctagctagc tataacataa 10140
gctgtctctg agtgtgttgt atattaataa agatcatcac tggtgaatgg tgatcgtgta 10200
cgtaccctac ttagtaggca atggaagcac ttagagtgtg ctttgtgcat ggccttgcct 10260
ctgttttgag acttttgtaa tgttttcgag tttaaatctt tgcctttgc 10309
<210> 92
<211> 12403
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR873
<400> 92
ggtcgactcg acgtacgaaa ccaactgcgt ttggggctcc agattaaacg acgccgtttc 60
gttcctttcg cttcacggct taacgatgtc gtttctgtct gtgcccaaaa aataaaggca 120
tttgttattt gcaccagata tttactaagt gcaccctagt ttgacaagta ggcgataatt 180
acaaatagat gcggtgcaaa taataaattt tgaaggaaat aattacaaaa gaacagaact 240
tatatttact ttattttaaa aaactaaaat gaaagaacaa aaaaagtaaa aaatacaaaa 300
aatgtgcttt aaccactttc attatttgtt acagaaagta tgattctact caaattgatc 360
tgttgtatct ggtgctgcct tgtcacactg gcgatttcaa tcccctaaag atatggtgca 420
aactgcgaag tgatcaatat ctgctcggtt aatttagatt aattaataat attcaacgtg 480
atgtaccaaa aaaagacaat tttttgctcc attgacaaat taaacctcat caaggtaatt 540
tccaaaccta taagcaaaaa aatttcacat taattggccc gcaatcctat tagtcttatt 600
atactagagt aggaaaaaaa acaattacac aacttgtctt attattctct atgctaatga 660
atatttttcc cttttgttag aaatcagtgt ttcctaattt attgagtatt aattccactc 720
accgcatata tttaccgttg aataagaaaa ttttacacat aattcttttt aagataaata 780
atttttttat actagatctt atatgattac gtgaagccaa gtgggttata ctaatgatat 840
ataatgtttg atagtaatca gtttataaac caaatgcatg gaaatgttac gtggaagcac 900
gtaaattaac aagcattgaa gcaaatgcag ccaccgcacc aaaaccaccc cacttcactt 960
ccacgtacca tattccatgc aactacaaca ccctaaaact tcaataaatg cccccacctt 1020
cacttcactt cacccatcaa tagcaagcgg ccgcacaatg gcgactcgac agcgaactgc 1080
caccactgtt gtggtcgagg accttcccaa ggtcactctt gaggccaagt ctgaacctgt 1140
gttccccgat atcaagacca tcaaggatgc cattcccgcg cactgcttcc agccctcgct 1200
cgtcacctca ttctactacg tcttccgcga ttttgccatg gtctctgccc tcgtctgggc 1260
tgctctcacc tacatcccca gcatccccga ccagaccctc cgcgtcgcag cttggatggt 1320
ctacggcttc gtccagggtc tgttctgcac cggtgtctgg attctcggcc atgagtgcgg 1380
ccacggtgct ttctctctcc acggaaaggt caacaatgtg accggctggt tcctccactc 1440
gttcctcctc gtcccctact tcagctggaa gtactctcac caccgccacc accgcttcac 1500
cggccacatg gatctcgaca tggctttcgt ccccaagact gagcccaagc cctccaagtc 1560
gctcatgatt gctggcattg acgtcgccga gcttgttgag gacacccccg ctgctcagat 1620
ggtcaagctc atcttccacc agcttttcgg atggcaggcg tacctcttct tcaacgctag 1680
ctctggcaag ggcagcaagc agtgggagcc caagactggc ctctccaagt ggttccgagt 1740
cagtcacttc gagcctacca gcgctgtctt ccgccccaac gaggccatct tcatcctcat 1800
ctccgatatc ggtcttgctc taatgggaac tgctctgtac tttgcttcca agcaagttgg 1860
tgtttcgacc attctcttcc tctaccttgt tccctacctg tgggttcacc actggctcgt 1920
tgccattacc tacctccacc accaccacac cgagctccct cactacaccg ctgagggctg 1980
gacctacgtc aagggagctc tcgccactgt cgaccgtgag tttggcttca tcggaaagca 2040
cctcttccac ggtatcattg agaagcacgt tgttcaccat ctcttcccta agatcccctt 2100
ctacaaggct gacgaggcca ccgaggccat caagcccgtc attggcgacc actactgcca 2160
cgacgaccga agcttcctgg gccagctgtg gaccatcttc ggcacgctca agtacgtcga 2220
gcacgaccct gcccgacccg gtgccatgcg atggaacaag gactaggcta ggcggccgcg 2280
aagttaaaag caatgttgtc acttgtcgta ctaacacatg atgtgatagt ttatgctagc 2340
tagctataac ataagctgtc tctgagtgtg ttgtatatta ataaagatca tcactggtga 2400
atggtgatcg tgtacgtacc ctacttagta ggcaatggaa gcacttagag tgtgctttgt 2460
gcatggcctt gcctctgttt tgagactttt gtaatgtttt cgagtttaaa tctttgcctt 2520
tgcgtacgtc tagaggatcc gtcgacggcg cgcccgatca tccggatata gttcctcctt 2580
tcagcaaaaa acccctcaag acccgtttag aggccccaag gggttatgct agttattgct 2640
cagcggtggc agcagccaac tcagcttcct ttcgggcttt gttagcagcc ggatcgatcc 2700
aagctgtacc tcactattcc tttgccctcg gacgagtgct ggggcgtcgg tttccactat 2760
cggcgagtac ttctacacag ccatcggtcc agacggccgc gcttctgcgg gcgatttgtg 2820
tacgcccgac agtcccggct ccggatcgga cgattgcgtc gcatcgaccc tgcgcccaag 2880
ctgcatcatc gaaattgccg tcaaccaagc tctgatagag ttggtcaaga ccaatgcgga 2940
gcatatacgc ccggagccgc ggcgatcctg caagctccgg atgcctccgc tcgaagtagc 3000
gcgtctgctg ctccatacaa gccaaccacg gcctccagaa gaagatgttg gcgacctcgt 3060
attgggaatc cccgaacatc gcctcgctcc agtcaatgac cgctgttatg cggccattgt 3120
ccgtcaggac attgttggag ccgaaatccg cgtgcacgag gtgccggact tcggggcagt 3180
cctcggccca aagcatcagc tcatcgagag cctgcgcgac ggacgcactg acggtgtcgt 3240
ccatcacagt ttgccagtga tacacatggg gatcagcaat cgcgcatatg aaatcacgcc 3300
atgtagtgta ttgaccgatt ccttgcggtc cgaatgggcc gaacccgctc gtctggctaa 3360
gatcggccgc agcgatcgca tccatagcct ccgcgaccgg ctgcagaaca gcgggcagtt 3420
cggtttcagg caggtcttgc aacgtgacac cctgtgcacg gcgggagatg caataggtca 3480
ggctctcgct gaattcccca atgtcaagca cttccggaat cgggagcgcg gccgatgcaa 3540
agtgccgata aacataacga tctttgtaga aaccatcggc gcagctattt acccgcagga 3600
catatccacg ccctcctaca tcgaagctga aagcacgaga ttcttcgccc tccgagagct 3660
gcatcaggtc ggagacgctg tcgaactttt cgatcagaaa cttctcgaca gacgtcgcgg 3720
tgagttcagg cttttccatg ggtatatctc cttcttaaag ttaaacaaaa ttatttctag 3780
agggaaaccg ttgtggtctc cctatagtga gtcgtattaa tttcgcggga tcgagatctg 3840
atcaacctgc attaatgaat cggccaacgc gcggggagag gcggtttgcg tattgggcgc 3900
tcttccgctt cctcgctcac tgactcgctg cgctcggtcg ttcggctgcg gcgagcggta 3960
tcagctcact caaaggcggt aatacggtta tccacagaat caggggataa cgcaggaaag 4020
aacatgtgag caaaaggcca gcaaaaggcc aggaaccgta aaaaggccgc gttgctggcg 4080
tttttccata ggctccgccc ccctgacgag catcacaaaa atcgacgctc aagtcagagg 4140
tggcgaaacc cgacaggact ataaagatac caggcgtttc cccctggaag ctccctcgtg 4200
cgctctcctg ttccgaccct gccgcttacc ggatacctgt ccgcctttct cccttcggga 4260
agcgtggcgc tttctcaatg ctcacgctgt aggtatctca gttcggtgta ggtcgttcgc 4320
tccaagctgg gctgtgtgca cgaacccccc gttcagcccg accgctgcgc cttatccggt 4380
aactatcgtc ttgagtccaa cccggtaaga cacgacttat cgccactggc agcagccact 4440
ggtaacagga ttagcagagc gaggtatgta ggcggtgcta cagagttctt gaagtggtgg 4500
cctaactacg gctacactag aaggacagta tttggtatct gcgctctgct gaagccagtt 4560
accttcggaa aaagagttgg tagctcttga tccggcaaac aaaccaccgc tggtagcggt 4620
ggtttttttg tttgcaagca gcagattacg cgcagaaaaa aaggatctca agaagatcct 4680
ttgatctttt ctacggggtc tgacgctcag tggaacgaaa actcacgtta agggattttg 4740
gtcatgacat taacctataa aaataggcgt atcacgaggc cctttcgtct cgcgcgtttc 4800
ggtgatgacg gtgaaaacct ctgacacatg cagctcccgg agacggtcac agcttgtctg 4860
taagcggatg ccgggagcag acaagcccgt cagggcgcgt cagcgggtgt tggcgggtgt 4920
cggggctggc ttaactatgc ggcatcagag cagattgtac tgagagtgca ccatatggac 4980
atattgtcgt tagaacgcgg ctacaattaa tacataacct tatgtatcat acacatacga 5040
tttaggtgac actatagaac ggcgcgccaa gctgggtcta gaactagaaa cgtgatgcca 5100
cttgttattg aagtcgatta cagcatctat tctgttttac tatttataac tttgccattt 5160
ctgacttttg aaaactatct ctggatttcg gtatcgcttt gtgaagatcg agcaaaagag 5220
acgttttgtg gacgcaatgg tccaaatccg ttctacatga acaaattggt cacaatttcc 5280
actaaaagta aataaatggc aagttaaaaa aggaatatgc attttactga ttgcctaggt 5340
gagctccaag agaagttgaa tctacacgtc taccaaccgc taaaaaaaga aaaacattga 5400
tatgtaacct gattccatta gcttttgact tcttcaacag attctctact tagatttcta 5460
acagaaatat tattactagc acatcatttt cagtctcact acagcaaaaa atccaacggc 5520
acaatacaga caacaggaga tatcagacta cagagataga tagatgctac tgcatgtagt 5580
aagttaaata aaaggaaaat aaaatgtctt gctaccaaaa ctactacaga ctatgatgct 5640
caccacaggc caaatcctgc aactaggaca gcattatctt atatatattg tacaaaacaa 5700
gcatcaagga acatttggtc taggcaatca gtacctcgtt ctaccatcac cctcagttat 5760
cacatccttg aaggatccat tactgggaat catcggcaac acatgctcct gatggggcac 5820
aatgacatca agaaggtagg ggccaggggt gtccaacatt ctctgaattg ccgctctaag 5880
ctcttccttc ttcgtcactc gcgctgccgg tatcccacaa gcatcagcaa acttgagcat 5940
gtttgggaat atctcgctct cgctagacgg atctccaaga taggtgtgag ctctattgga 6000
cttgtagaac ctatcctcca actgaaccac catacccaaa tgctgattgt tcaacaacaa 6060
tatcttaact gggagattct ccactcttat agtggccaac tcctgaacat tcatgatgaa 6120
actaccatcc ccatcaatgt caaccacaac agccccaggg ttagcaacag cagcaccaat 6180
agccgcaggc aatccaaaac ccatggctcc aagaccccct gaggtcaacc actgcctcgg 6240
tctcttgtac ttgtaaaact gcgcagccca catttgatgc tgcccaaccc cagtactaac 6300
aatagcatct ccattagtca actcatcaag aacctcgata gcatgctgcg gagaaatcgc 6360
gtcctggaat gtcttgtaac ccaatggaaa cttgtgtttc tgcacattaa tctcttctct 6420
ccaacctcca agatcaaact taccctccac tcctttctcc tccaaaatca tattaattcc 6480
cttcaaggcc aacttcaaat ccgcgcaaac cgacacgtgc gcctgcttgt tcttcccaat 6540
ctcggcagaa tcaatatcaa tgtgaacaat cttagcccta ctagcaaaag cctcaagctt 6600
cccagtaaca cggtcatcaa accttacccc aaaggcaagc aacaaatcac tattgtcaac 6660
agcatagtta gcataaacag taccatgcat acccagcatc tgaagggaat attcatcacc 6720
aataggaaaa gttccaagac ccattaaagt gctagcaacg ggaataccag tgagttcaac 6780
aaagcgcctc aattcagcac tggaattcaa actgccaccg ccgacgtaga gaacgggctt 6840
ttgggcctcc atgatgagtc tgacaatgtg ttccaattgg gcctcggcgg ggggcctggg 6900
cagcctggcg aggtaaccgg ggaggttaac gggctcgtcc caattaggca cggcgagttg 6960
ctgctgaacg tctttgggaa tgtcgatgag gaccggaccg gggcggccgg aggtggcgac 7020
gaagaaagcc tcggcgacga cgcgggggat gtcgtcgacg tcgaggatga ggtagttgtg 7080
cttcgtgatg gatctgctca cctccacgat cggggtttct tggaaggcgt cggtgccgat 7140
catccggcgg gcgacctggc cggtgatggc gacgactggg acgctgtcca ttaaagcgtc 7200
ggcgaggccg ctcacgaggt tggtggcgcc ggggccggag gtggcaatgc agacgccggg 7260
gaggccggag gaacgcgcgt agccttcggc ggcgaagacg ccgccctgct cgtggcgcgg 7320
gagcacgttg cggatggcgg cggagcgcgt gagcgcctgg tggatctcca tcgacgcacc 7380
gccggggtac gcgaacaccg tcgtcacgcc ctgcctctcc agcgcctcca caaggatgtc 7440
cgcgcccttg cgaggttcgc cggaggcgaa ccgtgacacg aagggctccg tggtcggcgc 7500
ttccttggtg aagggcgccg ccgtgggggg tttggagatg gaacatttga ttttgagagc 7560
gtggttgggt ttggtgaggg tttgatgaga gagagggagg gtggatctag taatgcgttt 7620
ggggaaggtg gggtgtgaag aggaagaaga gaatcgggtg gttctggaag cggtggccgc 7680
cattgtgttg tgtggcatgg ttatacttca aaaactgcac aacaagccta gagttagtac 7740
ctaaacagta aatttacaac agagagcaaa gacacatgca aaaatttcag ccataaaaaa 7800
agttataata gaatttaaag caaaagtttc attttttaaa catatataca aacaaactgg 7860
atttgaagga agggattaat tcccctgctc aaagtttgaa ttcctattgt gacctatact 7920
cgaataaaat tgaagcctaa ggaatgtatg agaaacaaga aaacaaaaca aaactacaga 7980
caaacaagta caattacaaa attcgctaaa attctgtaat caccaaaccc catctcagtc 8040
agcacaaggc ccaaggttta ttttgaaata aaaaaaaagt gattttattt ctcataagct 8100
aaaagaaaga aaggcaatta tgaaatgatt tcgactagat ctgaaagtcc aacgcgtatt 8160
ccgcagatat taaagaaaga gtagagtttc acatggatcc tagatggacc cagttgagga 8220
aaaagcaagg caaagcaaac cagaagtgca agatccgaaa ttgaaccacg gaatctagga 8280
tttggtagag ggagaagaaa agtaccttga gaggtagaag agaagagaag agcagagaga 8340
tatatgaacg agtgtgtctt ggtctcaact ctgaagcgat acgagtttag aggggagcat 8400
tgagttccaa tttataggga aaccgggtgg caggggtgag ttaatgacgg aaaagcccct 8460
aagtaacgag attggattgt gggttagatt caaccgtttg catccgcggc ttagattggg 8520
gaagtcagag tgaatctcaa ccgttgactg agttgaaaat tgaatgtagc aaccaattga 8580
gccaacccca gcctttgccc tttgattttg atttgtttgt tgcatacttt ttatttgtct 8640
tctggttctg actctctttc tctcgtttca atgccaggtt gcctactccc acaccactca 8700
caagaagatt ctactgttag tattaaatat tttttaatgt attaaatgat gaatgctttt 8760
gtaaacagaa caagactatg tctaataagt gtcttgcaac attttttaag aaattaaaaa 8820
aaatatattt attatcaaaa tcaaatgtat gaaaaatcat gaataatata attttataca 8880
tttttttaaa aaatctttta atttcttaat taatatctta aaaataatga ttaatattta 8940
acccaaaata attagtatga ttggtaagga agatatccat gttatgtttg gatgtgagtt 9000
tgatctagag caaagcttac tagagtcgac ctgcagcccg ggggatccgc ccacgtacgg 9060
taccatctgc taatatttta aatcacatgc aagagaggag gcatggttcc attttctacc 9120
ttcacattat ttgagaaaaa cgaacttgtt ctgtgtttta tttttgccct tcacattagt 9180
acaacgtgga agactcatgg ttacacagaa tcatacataa gtacaatgct tgtccctaag 9240
aaaacaagca ctcgttgtat tgaaccttta cggctcatgc ggccgcgaat tcactagtga 9300
ttgaattcgc ggccgcttag tccgacttgg ccttggcggc cgcggccgac tctttgagcg 9360
tgaagatctg cgccgtctcg ggcacagcgc cgtagttgac aaagaggtgc gcggtcttga 9420
agaaggccgt gatgatgggc tcgtcgttcc tgcgcacgag gtgcgggtac gcggccgcaa 9480
agtgcttggt ggcttcgttg agcttgtagt gcggaatgat cgggaacaag tggtggacct 9540
ggtgcgtgcc aatgtggtgg ctcaggttgt ccacgaacgc gccgtacgag cggtcgacgc 9600
tcgagaggtt gcccttgacg tacgtccact ccgagtcgcc gtaccacggc gtcgcttcgt 9660
cgttgtggtg caagaaggtc gtaatgacga ggaacgaagc aaagacaaag agcggcgcat 9720
agtagtagag gcccatgacg gcaaagccga gcgagtatgt gaggtacgcg tacgcggcga 9780
agaaggcggc ccagacgccg agcgacacga tgacggccga cgcgcggcga aggaggagcg 9840
ggtcccacgg gtcaaagtgg ctcatcgtgc gcggggcata cccgaccttc aagtagacaa 9900
accacgcacc gccgagcgtg tagacccatt ggcgcacgtc ctggaggtcc ttgaccgacc 9960
ggtgcgggta aaagatctcg tccttatcaa tgttgcccgt gttcttgtgg tggtggcggt 10020
gcgtcacgcg ccagctctcg aacggcgtca aaatcgcaga gtgcatgatg cagccgatga 10080
taaagttgac gctgtggtag cgcgagaagg ccgagtggcc gcagtcgtgg ccgaccgtga 10140
agaagcccca gaagatgacg ccctgcacgt agatgtaggt ggcgcaaacg agcgcgtgga 10200
gcagaacgtt atcggcaatg aacggcgtcg agcgcgccgc gtagagcagc gccgccgagg 10260
ccgacgcgtt gaagatcgcg cgggccgtgt agtagagcga gaggccgagg ttcgactcaa 10320
agcacgcgtt cgggatcgag tgcttgagct ccgtgagcgt cgggaactcg accttcgtct 10380
tatcctcagt catgcggccg ctgaagtatt gcttcttagt taacctttcc tttctctctc 10440
agctatgtga attcattttg ctttcgtcac aatttatata gtgaaattgg atctttggag 10500
ttaacgcctt cacaggatta tcgtgttaga acaatgcttt ttcatgttct aattagtagt 10560
acattacaaa tgtgcactct attcaataag catcttttgg cacgttaata aatcatgtga 10620
aaaaaaaata ctactatttc aaagaaagtg ttgtaaaaag aaacggaaag agagctggct 10680
tcagttgttg agacttgttt gctagtaaaa atggtgtgaa gagtgattca tggtgaggtg 10740
gtttttcgtc cctttctgtt tgcatgaaaa acaaatggca agagatgacg taggattcct 10800
tcccttaacg attatctgtt tttaatttca aatatacata taggaattta tgaattacta 10860
aggttgtaaa atatgctggt catttattta tggctaaaat attttttttt ctcgtaaata 10920
taaaaatatt taaaatttat ttttatcata ttttttatcc ttataaaatt atgtgtacaa 10980
cctatataaa aaaatatcat atttaatatt gattatatgt ttaatcaata taaaaaatca 11040
ttatcatata tttagattta ttcgaatata catctaaaca aaaaataaca tattttaatt 11100
ttatgaagaa aaaaaaatat tttatccttt atttatttaa gattaattaa tagttatgta 11160
ttgtggaaag acttttacac atgcaataga tatactgaat caattagatg ccaatgctga 11220
gttggaaatc acttgaggag gggaggagac ttgccaatgc ttttcagttt catttaaatg 11280
atttagtgga ggagatagag tagtgataaa ggcatgcccc aattttggag tgtatatatg 11340
agtggaaata agagagggat agagagaaaa aataaagaga gtaaaaataa ttaatgtgaa 11400
atgatatgat aaaaaaataa agaaagagat aaagagaaaa atgaaatgag agatagatga 11460
aatagagagt agatacatgt ttgtttaggt tttttttagg aaataacaca tttttttctc 11520
atcacttatt actcactgtc aatttcctct ctttcaatca taatgatatg atttgtttaa 11580
caaaaatgtg aaaaaacata taaagtaaaa tatttttata aattgataaa taaaaattta 11640
caaaatttat ttcttattaa attgaataga aaatgaaaga aaagaaaaga aaaagtatat 11700
ataaaatgat atagctttaa aaagaataaa tttttcatat cagtcttttt ttaataattt 11760
agaaatattt aagtatatag caaaaatata atgtacttta catatgcata aataataatt 11820
tgaaaataga actaatagaa tagagaaaaa agtaatataa taattaacta tatgaaaatt 11880
tagaagggac aatattttta attaagaata taaacaatat ttcttttcat gtaatgaggg 11940
acggatgtac ggggccagtg ttggagtcaa agccaaaata gtcacgggga aattaatgca 12000
ctgcatgact attcgaaaaa attcactagc cttacttaga tgttagatta atagctaggg 12060
ggtgcagata attttgaaag gcatgaaaaa cattaatttg tacattgcaa gcttttgatg 12120
acaagctttg caattgttca cactacctta tgccatttat aaatagagtg attggcatat 12180
gaaggaaatc atgagagtcg aagcgaaaaa caaagcttga gagtgtagga aaaatacagt 12240
ttttttggta aaaatacagt atttgaatag gagcgaaaaa tatcctttca aaatgatcct 12300
tttctttttt tttttttttc ttgttgttct tggtcagtta ttcaaaggaa aagggattga 12360
aataaaaact tgcatgtggg atcgtacgtc gagtcgacct gca 12403
<210> 93
<211> 3983
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR132
<400> 93
ctagagtcga cctgcaggca tgcaagcttg gcgtaatcat ggtcatagct gtttcctgtg 60
tgaaattgtt atccgctcac aattccacac aacatacgag ccggaagcat aaagtgtaaa 120
gcctggggtg cctaatgagt gagctaactc acattaattg cgttgcgctc actgcccgct 180
ttccagtcgg gaaacctgtc gtgccagctg cattaatgaa tcggccaacg cgcggggaga 240
ggcggtttgc gtattgggcg ctcttccgct tcctcgctca ctgactcgct gcgctcggtc 300
gttcggctgc ggcgagcggt atcagctcac tcaaaggcgg taatacggtt atccacagaa 360
tcaggggata acgcaggaaa gaacatgtga gcaaaaggcc agcaaaaggc caggaaccgt 420
aaaaaggccg cgttgctggc gtttttccat aggctccgcc cccctgacga gcatcacaaa 480
aatcgacgct caagtcagag gtggcgaaac ccgacaggac tataaagata ccaggcgttt 540
ccccctggaa gctccctcgt gcgctctcct gttccgaccc tgccgcttac cggatacctg 600
tccgcctttc tcccttcggg aagcgtggcg ctttctcata gctcacgctg taggtatctc 660
agttcggtgt aggtcgttcg ctccaagctg ggctgtgtgc acgaaccccc cgttcagccc 720
gaccgctgcg ccttatccgg taactatcgt cttgagtcca acccggtaag acacgactta 780
tcgccactgg cagcagccac tggtaacagg attagcagag cgaggtatgt aggcggtgct 840
acagagttct tgaagtggtg gcctaactac ggctacacta gaaggacagt atttggtatc 900
tgcgctctgc tgaagccagt taccttcgga aaaagagttg gtagctcttg atccggcaaa 960
caaaccaccg ctggtagcgg tggttttttt gtttgcaagc agcagattac gcgcagaaaa 1020
aaaggatctc aagaagatcc tttgatcttt tctacggggt ctgacgctca gtggaacgaa 1080
aactcacgtt aagggatttt ggtcatgaga ttatcaaaaa ggatcttcac ctagatcctt 1140
ttaaattaaa aatgaagttt taaatcaatc taaagtatat atgagtaaac ttggtctgac 1200
agttaccaat gcttaatcag tgaggcacct atctcagcga tctgtctatt tcgttcatcc 1260
atagttgcct gactccccgt cgtgtagata actacgatac gggagggctt accatctggc 1320
cccagtgctg caatgatacc gcgagaccca cgctcaccgg ctccagattt atcagcaata 1380
aaccagccag ccggaagggc cgagcgcaga agtggtcctg caactttatc cgcctccatc 1440
cagtctatta attgttgccg ggaagctaga gtaagtagtt cgccagttaa tagtttgcgc 1500
aacgttgttg ccattgctac aggcatcgtg gtgtcacgct cgtcgtttgg tatggcttca 1560
ttcagctccg gttcccaacg atcaaggcga gttacatgat cccccatgtt gtgcaaaaaa 1620
gcggttagct ccttcggtcc tccgatcgtt gtcagaagta agttggccgc agtgttatca 1680
ctcatggtta tggcagcact gcataattct cttactgtca tgccatccgt aagatgcttt 1740
tctgtgactg gtgagtactc aaccaagtca ttctgagaat agtgtatgcg gcgaccgagt 1800
tgctcttgcc cggcgtcaat acgggataat accgcgccac atagcagaac tttaaaagtg 1860
ctcatcattg gaaaacgttc ttcggggcga aaactctcaa ggatcttacc gctgttgaga 1920
tccagttcga tgtaacccac tcgtgcaccc aactgatctt cagcatcttt tactttcacc 1980
agcgtttctg ggtgagcaaa aacaggaagg caaaatgccg caaaaaaggg aataagggcg 2040
acacggaaat gttgaatact catactcttc ctttttcaat attattgaag catttatcag 2100
ggttattgtc tcatgagcgg atacatattt gaatgtattt agaaaaataa acaaataggg 2160
gttccgcgca catttccccg aaaagtgcca cctgacgtct aagaaaccat tattatcatg 2220
acattaacct ataaaaatag gcgtatcacg aggccctttc gtctcgcgcg tttcggtgat 2280
gacggtgaaa acctctgaca catgcagctc ccggagacgg tcacagcttg tctgtaagcg 2340
gatgccggga gcagacaagc ccgtcagggc gcgtcagcgg gtgttggcgg gtgtcggggc 2400
tggcttaact atgcggcatc agagcagatt gtactgagag tgcaccatat gcggtgtgaa 2460
ataccgcaca gatgcgtaag gagaaaatac cgcatcaggc gccattcgcc attcaggctg 2520
cgcaactgtt gggaagggcg atcggtgcgg gcctcttcgc tattacgcca gctggcgaaa 2580
gggggatgtg ctgcaaggcg attaagttgg gtaacgccag ggttttccca gtcacgacgt 2640
tgtaaaacga cggccagtga attcgagctc ggtacccggg gatcctctag acctgcaggc 2700
caactgcgtt tggggctcca gattaaacga cgccgtttcg ttcctttcgc ttcacggctt 2760
aacgatgtcg tttctgtctg tgcccaaaaa ataaaggcat ttgttatttg caccagatat 2820
ttactaagtg caccctagtt tgacaagtag gcgataatta caaatagatg cggtgcaaat 2880
aataaatttt gaaggaaata attacaaaag aacagaactt atatttactt tattttaaaa 2940
aactaaaatg aaagaacaaa aaaagtaaaa aatacaaaaa atgtgcttta accactttca 3000
ttatttgtta cagaaagtat gattctactc aaattgatct gttgtatctg gtgctgcctt 3060
gtcacactgg cgatttcaat cccctaaaga tatggtgcaa actgcgaagt gatcaatatc 3120
tgctcggtta atttagatta attaataata ttcaacgtga tgtaccaaaa aaagacaatt 3180
ttttgctcca ttgacaaatt aaacctcatc aaggtaattt ccaaacctat aagcaaaaaa 3240
atttcacatt aattggcccg caatcctatt agtcttatta tactagagta ggaaaaaaaa 3300
caattacaca acttgtctta ttattctcta tgctaatgaa tatttttccc ttttgttaga 3360
aatcagtgtt tcctaattta ttgagtatta attccactca ccgcatatat ttaccgttga 3420
ataagaaaat tttacacata attcttttta agataaataa tttttttata ctagatctta 3480
tatgattacg tgaagccaag tgggttatac taatgatata taatgtttga tagtaatcag 3540
tttataaacc aaatgcatgg aaatgttacg tggaagcacg taaattaaca agcattgaag 3600
caaatgcagc caccgcacca aaaccacccc acttcacttc cacgtaccat attccatgca 3660
actacaacac cctaaaactt caataaatgc ccccaccttc acttcacttc acccatcaat 3720
agcaagcggc cgcgaagtta aaagcaatgt tgtcacttgt cgtactaaca catgatgtga 3780
tagtttatgc tagctagcta taacataagc tgtctctgag tgtgttgtat attaataaag 3840
atcatcactg gtgaatggtg atcgtgtacg taccctactt agtaggcaat ggaagcactt 3900
agagtgtgct ttgtgcatgg ccttgcctct gttttgagac ttttgtaatg ttttcgagtt 3960
taaatctttg cctttgcgta cgt 3983
<210> 94
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer oSAlb-9
<400> 94
ttctagacgt acgaaaccaa ctgcgtttgg ggc 33
<210> 95
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer oSAlb-2
<400> 95
aatctagacg tacgcaaagg caaagattta aactc 35
<210> 96
<211> 4268
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR160
<400> 96
aatctagacg tacgcaaagg caaagattta aactcgaaaa cattacaaaa gtctcaaaac 60
agaggcaagg ccatgcacaa agcacactct aagtgcttcc attgcctact aagtagggta 120
cgtacacgat caccattcac cagtgatgat ctttattaat atacaacaca ctcagagaca 180
gcttatgtta tagctagcta gcataaacta tcacatcatg tgttagtacg acaagtgaca 240
acattgcttt taacttcgcg gccgcttgct attgatgggt gaagtgaagt gaaggtgggg 300
gcatttattg aagttttagg gtgttgtagt tgcatggaat atggtacgtg gaagtgaagt 360
ggggtggttt tggtgcggtg gctgcatttg cttcaatgct tgttaattta cgtgcttcca 420
cgtaacattt ccatgcattt ggtttataaa ctgattacta tcaaacatta tatatcatta 480
gtataaccca cttggcttca cgtaatcata taagatctag tataaaaaaa ttatttatct 540
taaaaagaat tatgtgtaaa attttcttat tcaacggtaa atatatgcgg tgagtggaat 600
taatactcaa taaattagga aacactgatt tctaacaaaa gggaaaaata ttcattagca 660
tagagaataa taagacaagt tgtgtaattg ttttttttcc tactctagta taataagact 720
aataggattg cgggccaatt aatgtgaaat ttttttgctt ataggtttgg aaattacctt 780
gatgaggttt aatttgtcaa tggagcaaaa aattgtcttt ttttggtaca tcacgttgaa 840
tattattaat taatctaaat taaccgagca gatattgatc acttcgcagt ttgcaccata 900
tctttagggg attgaaatcg ccagtgtgac aaggcagcac cagatacaac agatcaattt 960
gagtagaatc atactttctg taacaaataa tgaaagtggt taaagcacat tttttgtatt 1020
ttttactttt tttgttcttt cattttagtt ttttaaaata aagtaaatat aagttctgtt 1080
cttttgtaat tatttccttc aaaatttatt atttgcaccg catctatttg taattatcgc 1140
ctacttgtca aactagggtg cacttagtaa atatctggtg caaataacaa atgcctttat 1200
tttttgggca cagacagaaa cgacatcgtt aagccgtgaa gcgaaaggaa cgaaacggcg 1260
tcgtttaatc tggagcccca aacgcagttg gtttcgtacg tctagaaggg ctagagcggc 1320
cgccaccgcg gtggagctcc agcttttgtt ccctttagtg agggttaatt gcgcgcttgg 1380
cgtaatcatg gtcatagctg tttcctgtgt gaaattgtta tccgctcaca attccacaca 1440
acatacgagc cggaagcata aagtgtaaag cctggggtgc ctaatgagtg agctaactca 1500
cattaattgc gttgcgctca ctgcccgctt tccagtcggg aaacctgtcg tgccagctgc 1560
attaatgaat cggccaacgc gcggggagag gcggtttgcg tattgggcgc tcttccgctt 1620
cctcgctcac tgactcgctg cgctcggtcg ttcggctgcg gcgagcggta tcagctcact 1680
caaaggcggt aatacggtta tccacagaat caggggataa cgcaggaaag aacatgtgag 1740
caaaaggcca gcaaaaggcc aggaaccgta aaaaggccgc gttgctggcg tttttccata 1800
ggctccgccc ccctgacgag catcacaaaa atcgacgctc aagtcagagg tggcgaaacc 1860
cgacaggact ataaagatac caggcgtttc cccctggaag ctccctcgtg cgctctcctg 1920
ttccgaccct gccgcttacc ggatacctgt ccgcctttct cccttcggga agcgtggcgc 1980
tttctcatag ctcacgctgt aggtatctca gttcggtgta ggtcgttcgc tccaagctgg 2040
gctgtgtgca cgaacccccc gttcagcccg accgctgcgc cttatccggt aactatcgtc 2100
ttgagtccaa cccggtaaga cacgacttat cgccactggc agcagccact ggtaacagga 2160
ttagcagagc gaggtatgta ggcggtgcta cagagttctt gaagtggtgg cctaactacg 2220
gctacactag aaggacagta tttggtatct gcgctctgct gaagccagtt accttcggaa 2280
aaagagttgg tagctcttga tccggcaaac aaaccaccgc tggtagcggt ggtttttttg 2340
tttgcaagca gcagattacg cgcagaaaaa aaggatctca agaagatcct ttgatctttt 2400
ctacggggtc tgacgctcag tggaacgaaa actcacgtta agggattttg gtcatgagat 2460
tatcaaaaag gatcttcacc tagatccttt taaattaaaa atgaagtttt aaatcaatct 2520
aaagtatata tgagtaaact tggtctgaca gttaccaatg cttaatcagt gaggcaccta 2580
tctcagcgat ctgtctattt cgttcatcca tagttgcctg actccccgtc gtgtagataa 2640
ctacgatacg ggagggctta ccatctggcc ccagtgctgc aatgataccg cgagacccac 2700
gctcaccggc tccagattta tcagcaataa accagccagc cggaagggcc gagcgcagaa 2760
gtggtcctgc aactttatcc gcctccatcc agtctattaa ttgttgccgg gaagctagag 2820
taagtagttc gccagttaat agtttgcgca acgttgttgc cattgctaca ggcatcgtgg 2880
tgtcacgctc gtcgtttggt atggcttcat tcagctccgg ttcccaacga tcaaggcgag 2940
ttacatgatc ccccatgttg tgcaaaaaag cggttagctc cttcggtcct ccgatcgttg 3000
tcagaagtaa gttggccgca gtgttatcac tcatggttat ggcagcactg cataattctc 3060
ttactgtcat gccatccgta agatgctttt ctgtgactgg tgagtactca accaagtcat 3120
tctgagaata gtgtatgcgg cgaccgagtt gctcttgccc ggcgtcaata cgggataata 3180
ccgcgccaca tagcagaact ttaaaagtgc tcatcattgg aaaacgttct tcggggcgaa 3240
aactctcaag gatcttaccg ctgttgagat ccagttcgat gtaacccact cgtgcaccca 3300
actgatcttc agcatctttt actttcacca gcgtttctgg gtgagcaaaa acaggaaggc 3360
aaaatgccgc aaaaaaggga ataagggcga cacggaaatg ttgaatactc atactcttcc 3420
tttttcaata ttattgaagc atttatcagg gttattgtct catgagcgga tacatatttg 3480
aatgtattta gaaaaataaa caaatagggg ttccgcgcac atttccccga aaagtgccac 3540
ctaaattgta agcgttaata ttttgttaaa attcgcgtta aatttttgtt aaatcagctc 3600
attttttaac caataggccg aaatcggcaa aatcccttat aaatcaaaag aatagaccga 3660
gatagggttg agtgttgttc cagtttggaa caagagtcca ctattaaaga acgtggactc 3720
caacgtcaaa gggcgaaaaa ccgtctatca gggcgatggc ccactacgtg aaccatcacc 3780
ctaatcaagt tttttggggt cgaggtgccg taaagcacta aatcggaacc ctaaagggag 3840
cccccgattt agagcttgac ggggaaagcc ggcgaacgtg gcgagaaagg aagggaagaa 3900
agcgaaagga gcgggcgcta gggcgctggc aagtgtagcg gtcacgctgc gcgtaaccac 3960
cacacccgcc gcgcttaatg cgccgctaca gggcgcgtcc cattcgccat tcaggctgcg 4020
caactgttgg gaagggcgat cggtgcgggc ctcttcgcta ttacgccagc tggcgaaagg 4080
gggatgtgct gcaaggcgat taagttgggt aacgccaggg ttttcccagt cacgacgttg 4140
taaaacgacg gccagtgagc gcgcgtaata cgactcacta tagggcgaat tgggtaccgg 4200
gccccccctc gaggtcgacg gtatcgataa gcttgatatc gaattcctgc agcccggggg 4260
atccgccc 4268
<210> 97
<211> 4990
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR124
<220>
<221> misc_feature
<222> (1186)..(1186)
<223> n is a, c, g, or t
<400> 97
ctagacgtac gtcctcgaag agaagggtta ataacacatt ttttaacatt tttaacacaa 60
attttagtta tttaaaaatt tattaaaaaa tttaaaataa gaagaggaac tctttaaata 120
aatctaactt acaaaattta tgatttttaa taagttttca ccaataaaaa atgtcataaa 180
aatatgttaa aaagtatatt atcaatattc tctttatgat aaataaaaag aaaaaaaaaa 240
taaaagttaa gtgaaaatga gattgaagtg actttaggtg tgtataaata tatcaacccc 300
gccaacaatt tatttaatcc aaatatattg aagtatatta ttccatagcc tttatttatt 360
tatatattta ttatataaaa gctttatttg ttctaggttg ttcatgaaat atttttttgg 420
ttttatctcc gttgtaagaa aatcatgtgc tttgtgtcgc cactcactat tgcagctttt 480
tcatgcattg gtcagattga cggttgattg tatttttgtt ttttatggtt ttgtgttatg 540
acttaagtct tcatctcttt atctcttcat caggtttgat ggttacctaa tatggtccat 600
gggtacatgc atggttaaat taggtggcca actttgttgt gaacgataga atttttttta 660
tattaagtaa actattttta tattatgaaa taataataaa aaaaatattt tatcattatt 720
aacaaaatca tattagttaa tttgttaact ctataataaa agaaatactg taacattcac 780
attacatggt aacatctttc caccctttca tttgtttttt gtttgatgac tttttttctt 840
gtttaaattt atttcccttc ttttaaattt ggaatacatt atcatcatat ataaactaaa 900
atactaaaaa caggattaca caaatgataa ataataacac aaatatttat aaatctagct 960
gcaatatatt taaactagct atatcgatat tgtaaaataa aactagctgc attgatactg 1020
ataaaaaaat atcatgtgct ttctggactg atgatgcagt atacttttga cattgccttt 1080
attttatttt tcagaaaagc tttcttagtt ctgggttctt cattatttgt ttcccatctc 1140
cattgtgaat tgaatcattt gcttcgtgtc acaaatacaa tttagntagg tacatgcatt 1200
ggtcagattc acggtttatt atgtcatgac ttaagttcat ggtagtacat tacctgccac 1260
gcatgcatta tattggttag atttgatagg caaatttggt tgtcaacaat ataaatataa 1320
ataatgtttt tatattacga aataacagtg atcaaaacaa acagttttat ctttattaac 1380
aagattttgt ttttgtttga tgacgttttt taatgtttac gctttccccc ttcttttgaa 1440
tttagaacac tttatcatca taaaatcaaa tactaaaaaa attacatatt tcataaataa 1500
taacacaaat atttttaaaa aatctgaaat aataatgaac aatattacat attatcacga 1560
aaattcatta ataaaaatat tatataaata aaatgtaata gtagttatat gtaggaaaaa 1620
agtactgcac gcataatata tacaaaaaga ttaaaatgaa ctattataaa taataacact 1680
aaattaatgg tgaatcatat caaaataatg aaaaagtaaa taaaatttgt aattaacttc 1740
tatatgtatt acacacacaa ataataaata atagtaaaaa aaattatgat aaatatttac 1800
catctcataa gatatttaaa ataatgataa aaatatagat tattttttat gcaactagct 1860
agccaaaaag agaacacggg tatatataaa aagagtacct ttaaattcta ctgtacttcc 1920
tttattcctg acgtttttat atcaagtgga catacgtgaa gattttaatt atcagtctaa 1980
atatttcatt agcacttaat acttttctgt tttattccta tcctataagt agtcccgatt 2040
ctcccaacat tgcttattca cacaactaac taagaaagtc ttccatagcc ccccaagcgg 2100
ccgcgacaca agtgtgagag tactaaataa atgctttggt tgtacgaaat cattacacta 2160
aataaaataa tcaaagctta tatatgcctt ccgctaaggc cgaatgcaaa gaaattggtt 2220
ctttctcgtt atcttttgcc acttttacta gtacgtatta attactactt aatcatcttt 2280
gtttacggct cattatatcc gtacgtcgag tcgacctgca ggcatgcaag cttggcgtaa 2340
tcatggtcat agctgtttcc tgtgtgaaat tgttatccgc tcacaattcc acacaacata 2400
cgagccggaa gcataaagtg taaagcctgg ggtgcctaat gagtgagcta actcacatta 2460
attgcgttgc gctcactgcc cgctttccag tcgggaaacc tgtcgtgcca gctgcattaa 2520
tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg ggcgctcttc cgcttcctcg 2580
ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag cggtatcagc tcactcaaag 2640
gcggtaatac ggttatccac agaatcaggg gataacgcag gaaagaacat gtgagcaaaa 2700
ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc tggcgttttt ccataggctc 2760
cgcccccctg acgagcatca caaaaatcga cgctcaagtc agaggtggcg aaacccgaca 2820
ggactataaa gataccaggc gtttccccct ggaagctccc tcgtgcgctc tcctgttccg 2880
accctgccgc ttaccggata cctgtccgcc tttctccctt cgggaagcgt ggcgctttct 2940
catagctcac gctgtaggta tctcagttcg gtgtaggtcg ttcgctccaa gctgggctgt 3000
gtgcacgaac cccccgttca gcccgaccgc tgcgccttat ccggtaacta tcgtcttgag 3060
tccaacccgg taagacacga cttatcgcca ctggcagcag ccactggtaa caggattagc 3120
agagcgaggt atgtaggcgg tgctacagag ttcttgaagt ggtggcctaa ctacggctac 3180
actagaagga cagtatttgg tatctgcgct ctgctgaagc cagttacctt cggaaaaaga 3240
gttggtagct cttgatccgg caaacaaacc accgctggta gcggtggttt ttttgtttgc 3300
aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag atcctttgat cttttctacg 3360
gggtctgacg ctcagtggaa cgaaaactca cgttaaggga ttttggtcat gagattatca 3420
aaaaggatct tcacctagat ccttttaaat taaaaatgaa gttttaaatc aatctaaagt 3480
atatatgagt aaacttggtc tgacagttac caatgcttaa tcagtgaggc acctatctca 3540
gcgatctgtc tatttcgttc atccatagtt gcctgactcc ccgtcgtgta gataactacg 3600
atacgggagg gcttaccatc tggccccagt gctgcaatga taccgcgaga cccacgctca 3660
ccggctccag atttatcagc aataaaccag ccagccggaa gggccgagcg cagaagtggt 3720
cctgcaactt tatccgcctc catccagtct attaattgtt gccgggaagc tagagtaagt 3780
agttcgccag ttaatagttt gcgcaacgtt gttgccattg ctacaggcat cgtggtgtca 3840
cgctcgtcgt ttggtatggc ttcattcagc tccggttccc aacgatcaag gcgagttaca 3900
tgatccccca tgttgtgcaa aaaagcggtt agctccttcg gtcctccgat cgttgtcaga 3960
agtaagttgg ccgcagtgtt atcactcatg gttatggcag cactgcataa ttctcttact 4020
gtcatgccat ccgtaagatg cttttctgtg actggtgagt actcaaccaa gtcattctga 4080
gaatagtgta tgcggcgacc gagttgctct tgcccggcgt caatacggga taataccgcg 4140
ccacatagca gaactttaaa agtgctcatc attggaaaac gttcttcggg gcgaaaactc 4200
tcaaggatct taccgctgtt gagatccagt tcgatgtaac ccactcgtgc acccaactga 4260
tcttcagcat cttttacttt caccagcgtt tctgggtgag caaaaacagg aaggcaaaat 4320
gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa tactcatact cttccttttt 4380
caatattatt gaagcattta tcagggttat tgtctcatga gcggatacat atttgaatgt 4440
atttagaaaa ataaacaaat aggggttccg cgcacatttc cccgaaaagt gccacctgac 4500
gtctaagaaa ccattattat catgacatta acctataaaa ataggcgtat cacgaggccc 4560
tttcgtctcg cgcgtttcgg tgatgacggt gaaaacctct gacacatgca gctcccggag 4620
acggtcacag cttgtctgta agcggatgcc gggagcagac aagcccgtca gggcgcgtca 4680
gcgggtgttg gcgggtgtcg gggctggctt aactatgcgg catcagagca gattgtactg 4740
agagtgcacc atatgcggtg tgaaataccg cacagatgcg taaggagaaa ataccgcatc 4800
aggcgccatt cgccattcag gctgcgcaac tgttgggaag ggcgatcggt gcgggcctct 4860
tcgctattac gccagctggc gaaaggggga tgtgctgcaa ggcgattaag ttgggtaacg 4920
ccagggtttt cccagtcacg acgttgtaaa acgacggcca gtgaattcga gctcggtacc 4980
cggggatcct 4990
<210> 98
<211> 3982
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR163
<400> 98
gtacgaaacc aactgcgttt ggggctccag attaaacgac gccgtttcgt tcctttcgct 60
tcacggctta acgatgtcgt ttctgtctgt gcccaaaaaa taaaggcatt tgttatttgc 120
accagatatt tactaagtgc accctagttt gacaagtagg cgataattac aaatagatgc 180
ggtgcaaata ataaattttg aaggaaataa ttacaaaaga acagaactta tatttacttt 240
attttaaaaa actaaaatga aagaacaaaa aaagtaaaaa atacaaaaaa tgtgctttaa 300
ccactttcat tatttgttac agaaagtatg attctactca aattgatctg ttgtatctgg 360
tgctgccttg tcacactggc gatttcaatc ccctaaagat atggtgcaaa ctgcgaagtg 420
atcaatatct gctcggttaa tttagattaa ttaataatat tcaacgtgat gtaccaaaaa 480
aagacaattt tttgctccat tgacaaatta aacctcatca aggtaatttc caaacctata 540
agcaaaaaaa tttcacatta attggcccgc aatcctatta gtcttattat actagagtag 600
gaaaaaaaac aattacacaa cttgtcttat tattctctat gctaatgaat atttttccct 660
tttgttagaa atcagtgttt cctaatttat tgagtattaa ttccactcac cgcatatatt 720
taccgttgaa taagaaaatt ttacacataa ttctttttaa gataaataat ttttttatac 780
tagatcttat atgattacgt gaagccaagt gggttatact aatgatatat aatgtttgat 840
agtaatcagt ttataaacca aatgcatgga aatgttacgt ggaagcacgt aaattaacaa 900
gcattgaagc aaatgcagcc accgcaccaa aaccacccca cttcacttcc acgtaccata 960
ttccatgcaa ctacaacacc ctaaaacttc aataaatgcc cccaccttca cttcacttca 1020
cccatcaata gcaagcggcc gcgaagttaa aagcaatgtt gtcacttgtc gtactaacac 1080
atgatgtgat agtttatgct agctagctat aacataagct gtctctgagt gtgttgtata 1140
ttaataaaga tcatcactgg tgaatggtga tcgtgtacgt accctactta gtaggcaatg 1200
gaagcactta gagtgtgctt tgtgcatggc cttgcctctg ttttgagact tttgtaatgt 1260
tttcgagttt aaatctttgc ctttgcgtac gtcgagtcga cctgcaggca tgcaagcttg 1320
gcgtaatcat ggtcatagct gtttcctgtg tgaaattgtt atccgctcac aattccacac 1380
aacatacgag ccggaagcat aaagtgtaaa gcctggggtg cctaatgagt gagctaactc 1440
acattaattg cgttgcgctc actgcccgct ttccagtcgg gaaacctgtc gtgccagctg 1500
cattaatgaa tcggccaacg cgcggggaga ggcggtttgc gtattgggcg ctcttccgct 1560
tcctcgctca ctgactcgct gcgctcggtc gttcggctgc ggcgagcggt atcagctcac 1620
tcaaaggcgg taatacggtt atccacagaa tcaggggata acgcaggaaa gaacatgtga 1680
gcaaaaggcc agcaaaaggc caggaaccgt aaaaaggccg cgttgctggc gtttttccat 1740
aggctccgcc cccctgacga gcatcacaaa aatcgacgct caagtcagag gtggcgaaac 1800
ccgacaggac tataaagata ccaggcgttt ccccctggaa gctccctcgt gcgctctcct 1860
gttccgaccc tgccgcttac cggatacctg tccgcctttc tcccttcggg aagcgtggcg 1920
ctttctcata gctcacgctg taggtatctc agttcggtgt aggtcgttcg ctccaagctg 1980
ggctgtgtgc acgaaccccc cgttcagccc gaccgctgcg ccttatccgg taactatcgt 2040
cttgagtcca acccggtaag acacgactta tcgccactgg cagcagccac tggtaacagg 2100
attagcagag cgaggtatgt aggcggtgct acagagttct tgaagtggtg gcctaactac 2160
ggctacacta gaaggacagt atttggtatc tgcgctctgc tgaagccagt taccttcgga 2220
aaaagagttg gtagctcttg atccggcaaa caaaccaccg ctggtagcgg tggttttttt 2280
gtttgcaagc agcagattac gcgcagaaaa aaaggatctc aagaagatcc tttgatcttt 2340
tctacggggt ctgacgctca gtggaacgaa aactcacgtt aagggatttt ggtcatgaga 2400
ttatcaaaaa ggatcttcac ctagatcctt ttaaattaaa aatgaagttt taaatcaatc 2460
taaagtatat atgagtaaac ttggtctgac agttaccaat gcttaatcag tgaggcacct 2520
atctcagcga tctgtctatt tcgttcatcc atagttgcct gactccccgt cgtgtagata 2580
actacgatac gggagggctt accatctggc cccagtgctg caatgatacc gcgagaccca 2640
cgctcaccgg ctccagattt atcagcaata aaccagccag ccggaagggc cgagcgcaga 2700
agtggtcctg caactttatc cgcctccatc cagtctatta attgttgccg ggaagctaga 2760
gtaagtagtt cgccagttaa tagtttgcgc aacgttgttg ccattgctac aggcatcgtg 2820
gtgtcacgct cgtcgtttgg tatggcttca ttcagctccg gttcccaacg atcaaggcga 2880
gttacatgat cccccatgtt gtgcaaaaaa gcggttagct ccttcggtcc tccgatcgtt 2940
gtcagaagta agttggccgc agtgttatca ctcatggtta tggcagcact gcataattct 3000
cttactgtca tgccatccgt aagatgcttt tctgtgactg gtgagtactc aaccaagtca 3060
ttctgagaat agtgtatgcg gcgaccgagt tgctcttgcc cggcgtcaat acgggataat 3120
accgcgccac atagcagaac tttaaaagtg ctcatcattg gaaaacgttc ttcggggcga 3180
aaactctcaa ggatcttacc gctgttgaga tccagttcga tgtaacccac tcgtgcaccc 3240
aactgatctt cagcatcttt tactttcacc agcgtttctg ggtgagcaaa aacaggaagg 3300
caaaatgccg caaaaaaggg aataagggcg acacggaaat gttgaatact catactcttc 3360
ctttttcaat attattgaag catttatcag ggttattgtc tcatgagcgg atacatattt 3420
gaatgtattt agaaaaataa acaaataggg gttccgcgca catttccccg aaaagtgcca 3480
cctgacgtct aagaaaccat tattatcatg acattaacct ataaaaatag gcgtatcacg 3540
aggccctttc gtctcgcgcg tttcggtgat gacggtgaaa acctctgaca catgcagctc 3600
ccggagacgg tcacagcttg tctgtaagcg gatgccggga gcagacaagc ccgtcagggc 3660
gcgtcagcgg gtgttggcgg gtgtcggggc tggcttaact atgcggcatc agagcagatt 3720
gtactgagag tgcaccatat gcggtgtgaa ataccgcaca gatgcgtaag gagaaaatac 3780
cgcatcaggc gccattcgcc attcaggctg cgcaactgtt gggaagggcg atcggtgcgg 3840
gcctcttcgc tattacgcca gctggcgaaa gggggatgtg ctgcaaggcg attaagttgg 3900
gtaacgccag ggttttccca gtcacgacgt tgtaaaacga cggccagtga attcgagctc 3960
ggtacccggg gatcctctag ac 3982
<210> 99
<211> 8878
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pY34
<400> 99
ggccgcacag gccgcacaat ggcgactcga cagcgaactg ccaccactgt tgtggtcgag 60
gaccttccca aggtcactct tgaggccaag tctgaacctg tgttccccga tatcaagacc 120
atcaaggatg ccattcccgc gcactgcttc cagccctcgc tcgtcacctc attctactac 180
gtcttccgcg attttgccat ggtctctgcc ctcgtctggg ctgctctcac ctacatcccc 240
agcatccccg accagaccct ccgcgtcgca gcttggatgg tctacggctt cgtccagggt 300
ctgttctgca ccggtgtctg gattctcggc catgagtgcg gccacggtgc tttctctctc 360
cacggaaagg tcaacaatgt gaccggctgg ttcctccact cgttcctcct cgtcccctac 420
ttcagctgga agtactctca ccaccgccac caccgcttca ccggccacat ggatctcgac 480
atggctttcg tccccaagac tgagcccaag ccctccaagt cgctcatgat tgctggcatt 540
gacgtcgccg agcttgttga ggacaccccc gctgctcaga tggtcaagct catcttccac 600
cagcttttcg gatggcaggc gtacctcttc ttcaacgcta gctctggcaa gggcagcaag 660
cagtgggagc ccaagactgg cctctccaag tggttccgag tcagtcactt cgagcctacc 720
agcgctgtct tccgccccaa cgaggccatc ttcatcctca tctccgatat cggtcttgct 780
ctaatgggaa ctgctctgta ctttgcttcc aagcaagttg gtgtttcgac cattctcttc 840
ctctaccttg ttccctacct gtgggttcac cactggctcg ttgccattac ctacctccac 900
caccaccaca ccgagctccc tcactacacc gctgagggct ggacctacgt caagggagct 960
ctcgccactg tcgaccgtga gtttggcttc atcggaaagc acctcttcca cggtatcatt 1020
gagaagcacg ttgttcacca tctcttccct aagatcccct tctacaaggc tgacgaggcc 1080
accgaggcca tcaagcccgt cattggcgac cactactgcc acgacgaccg aagcttcctg 1140
ggccagctgt ggaccatctt cggcacgctc aagtacgtcg agcacgaccc tgcccgaccc 1200
ggtgccatgc gatggaacaa ggactaggct aggcggccgc caccgcggcc cgagattccg 1260
gcctcttcgg ccgccaagcg acccgggtgg acgtctagag gtacctagca attaacagat 1320
agtttgccgg tgataattct cttaacctcc cacactcctt tgacataacg atttatgtaa 1380
cgaaactgaa atttgaccag atattgtgtc cgcggtggag ctccagcttt tgttcccttt 1440
agtgagggtt aatttcgagc ttggcgtaat catggtcata gctgtttcct gtgtgaaatt 1500
gttatccgct cacaattcca cacaacgtac gagccggaag cataaagtgt aaagcctggg 1560
gtgcctaatg agtgagctaa ctcacattaa ttgcgttgcg ctcactgccc gctttccagt 1620
cgggaaacct gtcgtgccag ctgcattaat gaatcggcca acgcgcgggg agaggcggtt 1680
tgcgtattgg gcgctcttcc gcttcctcgc tcactgactc gctgcgctcg gtcgttcggc 1740
tgcggcgagc ggtatcagct cactcaaagg cggtaatacg gttatccaca gaatcagggg 1800
ataacgcagg aaagaacatg tgagcaaaag gccagcaaaa ggccaggaac cgtaaaaagg 1860
ccgcgttgct ggcgtttttc cataggctcc gcccccctga cgagcatcac aaaaatcgac 1920
gctcaagtca gaggtggcga aacccgacag gactataaag ataccaggcg tttccccctg 1980
gaagctccct cgtgcgctct cctgttccga ccctgccgct taccggatac ctgtccgcct 2040
ttctcccttc gggaagcgtg gcgctttctc atagctcacg ctgtaggtat ctcagttcgg 2100
tgtaggtcgt tcgctccaag ctgggctgtg tgcacgaacc ccccgttcag cccgaccgct 2160
gcgccttatc cggtaactat cgtcttgagt ccaacccggt aagacacgac ttatcgccac 2220
tggcagcagc cactggtaac aggattagca gagcgaggta tgtaggcggt gctacagagt 2280
tcttgaagtg gtggcctaac tacggctaca ctagaaggac agtatttggt atctgcgctc 2340
tgctgaagcc agttaccttc ggaaaaagag ttggtagctc ttgatccggc aaacaaacca 2400
ccgctggtag cggtggtttt tttgtttgca agcagcagat tacgcgcaga aaaaaaggat 2460
ctcaagaaga tcctttgatc ttttctacgg ggtctgacgc tcagtggaac gaaaactcac 2520
gttaagggat tttggtcatg agattatcaa aaaggatctt cacctagatc cttttaaatt 2580
aaaaatgaag ttttaaatca atctaaagta tatatgagta aacttggtct gacagttacc 2640
aatgcttaat cagtgaggca cctatctcag cgatctgtct atttcgttca tccatagttg 2700
cctgactccc cgtcgtgtag ataactacga tacgggaggg cttaccatct ggccccagtg 2760
ctgcaatgat accgcgagac ccacgctcac cggctccaga tttatcagca ataaaccagc 2820
cagccggaag ggccgagcgc agaagtggtc ctgcaacttt atccgcctcc atccagtcta 2880
ttaattgttg ccgggaagct agagtaagta gttcgccagt taatagtttg cgcaacgttg 2940
ttgccattgc tacaggcatc gtggtgtcac gctcgtcgtt tggtatggct tcattcagct 3000
ccggttccca acgatcaagg cgagttacat gatcccccat gttgtgcaaa aaagcggtta 3060
gctccttcgg tcctccgatc gttgtcagaa gtaagttggc cgcagtgtta tcactcatgg 3120
ttatggcagc actgcataat tctcttactg tcatgccatc cgtaagatgc ttttctgtga 3180
ctggtgagta ctcaaccaag tcattctgag aatagtgtat gcggcgaccg agttgctctt 3240
gcccggcgtc aatacgggat aataccgcgc cacatagcag aactttaaaa gtgctcatca 3300
ttggaaaacg ttcttcgggg cgaaaactct caaggatctt accgctgttg agatccagtt 3360
cgatgtaacc cactcgtgca cccaactgat cttcagcatc ttttactttc accagcgttt 3420
ctgggtgagc aaaaacagga aggcaaaatg ccgcaaaaaa gggaataagg gcgacacgga 3480
aatgttgaat actcatactc ttcctttttc aatattattg aagcatttat cagggttatt 3540
gtctcatgag cggatacata tttgaatgta tttagaaaaa taaacaaata ggggttccgc 3600
gcacatttcc ccgaaaagtg ccacctgacg cgccctgtag cggcgcatta agcgcggcgg 3660
gtgtggtggt tacgcgcagc gtgaccgcta cacttgccag cgccctagcg cccgctcctt 3720
tcgctttctt cccttccttt ctcgccacgt tcgccggctt tccccgtcaa gctctaaatc 3780
gggggctccc tttagggttc cgatttagtg ctttacggca cctcgacccc aaaaaacttg 3840
attagggtga tggttcacgt agtgggccat cgccctgata gacggttttt cgccctttga 3900
cgttggagtc cacgttcttt aatagtggac tcttgttcca aactggaaca acactcaacc 3960
ctatctcggt ctattctttt gatttataag ggattttgcc gatttcggcc tattggttaa 4020
aaaatgagct gatttaacaa aaatttaacg cgaattttaa caaaatatta acgcttacaa 4080
tttccattcg ccattcaggc tgcgcaactg ttgggaaggg cgatcggtgc gggcctcttc 4140
gctattacgc cagctggcga aagggggatg tgctgcaagg cgattaagtt gggtaacgcc 4200
agggttttcc cagtcacgac gttgtaaaac gacggccagt gaattgtaat acgactcact 4260
atagggcgaa ttgggtaccg ggccccccct cgaggtcgat ggtgtcgata agcttgatat 4320
cgaattcatg tcacacaaac cgatcttcgc ctcaaggaaa cctaattcta catccgagag 4380
actgccgaga tccagtctac actgattaat tttcgggcca ataatttaaa aaaatcgtgt 4440
tatataatat tatatgtatt atatatatac atcatgatga tactgacagt catgtcccat 4500
tgctaaatag acagactcca tctgccgcct ccaactgatg ttctcaatat ttaaggggtc 4560
atctcgcatt gtttaataat aaacagactc catctaccgc ctccaaatga tgttctcaaa 4620
atatattgta tgaacttatt tttattactt agtattatta gacaacttac ttgctttatg 4680
aaaaacactt cctatttagg aaacaattta taatggcagt tcgttcattt aacaatttat 4740
gtagaataaa tgttataaat gcgtatggga aatcttaaat atggatagca taaatgatat 4800
ctgcattgcc taattcgaaa tcaacagcaa cgaaaaaaat cccttgtaca acataaatag 4860
tcatcgagaa atatcaacta tcaaagaaca gctattcaca cgttactatt gagattatta 4920
ttggacgaga atcacacact caactgtctt tctctcttct agaaatacag gtacaagtat 4980
gtactattct cattgttcat acttctagtc atttcatccc acatattcct tggatttctc 5040
tccaatgaat gacattctat cttgcaaatt caacaattat aataagatat accaaagtag 5100
cggtatagtg gcaatcaaaa agcttctctg gtgtgcttct cgtatttatt tttattctaa 5160
tgatccatta aaggtatata tttatttctt gttatataat ccttttgttt attacatggg 5220
ctggatacat aaaggtattt tgatttaatt ttttgcttaa attcaatccc ccctcgttca 5280
gtgtcaactg taatggtagg aaattaccat acttttgaag aagcaaaaaa aatgaaagaa 5340
aaaaaaaatc gtatttccag gttagacgtt ccgcagaatc tagaatgcgg tatgcggtac 5400
attgttcttc gaacgtaaaa gttgcgctcc ctgagatatt gtacattttt gcttttacaa 5460
gtacaagtac atcgtacaac tatgtactac tgttgatgca tccacaacag tttgttttgt 5520
ttttttttgt tttttttttt tctaatgatt cattaccgct atgtatacct acttgtactt 5580
gtagtaagcc gggttattgg cgttcaatta atcatagact tatgaatctg cacggtgtgc 5640
gctgcgagtt acttttagct tatgcatgct acttgggtgt aatattggga tctgttcgga 5700
aatcaacgga tgctcaaccg atttcgacag taataatttg aatcgaatcg gagcctaaaa 5760
tgaacccgag tatatctcat aaaattctcg gtgagaggtc tgtgactgtc agtacaaggt 5820
gccttcatta tgccctcaac cttaccatac ctcactgaat gtagtgtacc tctaaaaatg 5880
aaatacagtg ccaaaagcca aggcactgag ctcgtctaac ggacttgata tacaaccaat 5940
taaaacaaat gaaaagaaat acagttcttt gtatcatttg taacaattac cctgtacaaa 6000
ctaaggtatt gaaatcccac aatattccca aagtccaccc ctttccaaat tgtcatgcct 6060
acaactcata taccaagcac taacctacca aacaccacta aaaccccaca aaatatatct 6120
taccgaatat acagtaacaa gctaccacca cactcgttgg gtgcagtcgc cagcttaaag 6180
atatctatcc acatcagcca caactccctt cctttaataa accgactaca cccttggcta 6240
ttgaggttat gagtgaatat actgtagaca agacactttc aagaagactg tttccaaaac 6300
gtaccactgt cctccactac aaacacaccc aatctgcttc ttctagtcaa ggttgctaca 6360
ccggtaaatt ataaatcatc atttcattag cagggcaggg ccctttttat agagtcttat 6420
acactagcgg accctgccgg tagaccaacc cgcaggcgcg tcagtttgct ccttccatca 6480
atgcgtcgta gaaacgactt actccttctt gagcagctcc ttgaccttgt tggcaacaag 6540
tctccgacct cggaggtgga ggaagagcct ccgatatcgg cggtagtgat accagcctcg 6600
acggactcct tgacggcagc ctcaacagcg tcaccggcgg gcttcatgtt aagagagaac 6660
ttgagcatca tggcggcaga cagaatggtg gcaatggggt tgaccttctg cttgccgaga 6720
tcgggggcag atccgtgaca gggctcgtac agaccgaacg cctcgttggt gtcgggcaga 6780
gaagccagag aggcggaggg cagcagaccc agagaaccgg ggatgacgga ggcctcgtcg 6840
gagatgatat cgccaaacat gttggtggtg atgatgatac cattcatctt ggagggctgc 6900
ttgatgagga tcatggcggc cgagtcgatc agctggtggt tgagctcgag ctgggggaat 6960
tcgtccttga ggactcgagt gacagtcttt cgccaaagtc gagaggaggc cagcacgttg 7020
gccttgtcaa gagaccacac gggaagaggg gggttgtgct gaagggccag gaaggcggcc 7080
attcgggcaa ttcgctcaac ctcaggaacg gagtaggtct cggtgtcgga agcgacgcca 7140
gatccgtcat cctcctttcg ctctccaaag tagatacctc cgacgagctc tcggacaatg 7200
atgaagtcgg tgccctcaac gtttcggatg ggggagagat cggcgagctt gggcgacagc 7260
agctggcagg gtcgcaggtt ggcgtacagg ttcaggtcct ttcgcagctt gaggagaccc 7320
tgctcgggtc gcacgtcggt tcgtccgtcg ggagtggtcc atacggtgtt ggcagcgcct 7380
ccgacagcac cgagcataat agagtcagcc tttcggcaga tgtcgagagt agcgtcggtg 7440
atgggctcgc cctccttctc aatggcagct cctccaatga gtcggtcctc aaacacaaac 7500
tcggtgccgg aggcctcagc aacagacttg agcaccttga cggcctcggc aatcacctcg 7560
gggccacaga agtcgccgcc gagaagaaca atcttcttgg agtcagtctt ggtcttctta 7620
gtttcgggtt ccattgtgga tgtgtgtggt tgtatgtgtg atgtggtgtg tggagtgaaa 7680
atctgtggct ggcaaacgct cttgtatata tacgcacttt tgcccgtgct atgtggaaga 7740
ctaaacctcc gaagattgtg actcaggtag tgcggtatcg gctagggacc caaaccttgt 7800
cgatgccgat agcgctatcg aacgtacccc agccggccgg gagtatgtcg gaggggacat 7860
acgagatcgt caagggtttg tggccaactg gtatttaaat gatgtcgacg cagtaggatg 7920
tcctgcacgg gtctttttgt ggggtgtgga gaaaggggtg cttggagatg gaagccggta 7980
gaaccgggct gcttgtgctt ggagatggaa gccggtagaa ccgggctgct tggggggatt 8040
tggggccgct gggctccaaa gaggggtagg catttcgttg gggttacgta attgcggcat 8100
ttgggtcctg cgcgcatgtc ccattggtca gaattagtcc ggataggaga cttatcagcc 8160
aatcacagcg ccggatccac ctgtaggttg ggttgggtgg gagcacccct ccacagagta 8220
gagtcaaaca gcagcagcaa catgatagtt gggggtgtgc gtgttaaagg aaaaaaaaga 8280
agcttgggtt atattcccgc tctatttaga ggttgcggga tagacgccga cggagggcaa 8340
tggcgccatg gaaccttgcg gatatcgata cgccgcggcg gactgcgtcc gaaccagctc 8400
cagcagcgtt ttttccgggc cattgagccg actgcgaccc cgccaacgtg tcttggccca 8460
cgcactcatg tcatgttggt gttgggaggc cactttttaa gtagcacaag gcacctagct 8520
cgcagcaagg tgtccgaacc aaagaagcgg ctgcagtggt gcaaacgggg cggaaacggc 8580
gggaaaaagc cacgggggca cgaattgagg cacgccctcg aatttgagac gagtcacggc 8640
cccattcgcc cgcgcaatgg ctcgccaacg cccggtcttt tgcaccacat caggttaccc 8700
caagccaaac ctttgtgtta aaaagcttaa catattatac cgaacgtagg tttgggcggg 8760
cttgctccgt ctgtccaagg caacatttat ataagggtct gcatcgccgg ctcaattgaa 8820
tcttttttct tcttctcttc tctatattca ttcttgaatt aaacacacat caatccgc 8878
<210> 100
<211> 5207
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR863
<400> 100
ggccgcgaag ttaaaagcaa tgttgtcact tgtcgtacta acacatgatg tgatagttta 60
tgctagctag ctataacata agctgtctct gagtgtgttg tatattaata aagatcatca 120
ctggtgaatg gtgatcgtgt acgtacccta cttagtaggc aatggaagca cttagagtgt 180
gctttgtgca tggccttgcc tctgttttga gacttttgta atgttttcga gtttaaatct 240
ttgcctttgc gtacgtcgag tcgacctgca ggcatgcaag cttggcgtaa tcatggtcat 300
agctgtttcc tgtgtgaaat tgttatccgc tcacaattcc acacaacata cgagccggaa 360
gcataaagtg taaagcctgg ggtgcctaat gagtgagcta actcacatta attgcgttgc 420
gctcactgcc cgctttccag tcgggaaacc tgtcgtgcca gctgcattaa tgaatcggcc 480
aacgcgcggg gagaggcggt ttgcgtattg ggcgctcttc cgcttcctcg ctcactgact 540
cgctgcgctc ggtcgttcgg ctgcggcgag cggtatcagc tcactcaaag gcggtaatac 600
ggttatccac agaatcaggg gataacgcag gaaagaacat gtgagcaaaa ggccagcaaa 660
aggccaggaa ccgtaaaaag gccgcgttgc tggcgttttt ccataggctc cgcccccctg 720
acgagcatca caaaaatcga cgctcaagtc agaggtggcg aaacccgaca ggactataaa 780
gataccaggc gtttccccct ggaagctccc tcgtgcgctc tcctgttccg accctgccgc 840
ttaccggata cctgtccgcc tttctccctt cgggaagcgt ggcgctttct catagctcac 900
gctgtaggta tctcagttcg gtgtaggtcg ttcgctccaa gctgggctgt gtgcacgaac 960
cccccgttca gcccgaccgc tgcgccttat ccggtaacta tcgtcttgag tccaacccgg 1020
taagacacga cttatcgcca ctggcagcag ccactggtaa caggattagc agagcgaggt 1080
atgtaggcgg tgctacagag ttcttgaagt ggtggcctaa ctacggctac actagaagga 1140
cagtatttgg tatctgcgct ctgctgaagc cagttacctt cggaaaaaga gttggtagct 1200
cttgatccgg caaacaaacc accgctggta gcggtggttt ttttgtttgc aagcagcaga 1260
ttacgcgcag aaaaaaagga tctcaagaag atcctttgat cttttctacg gggtctgacg 1320
ctcagtggaa cgaaaactca cgttaaggga ttttggtcat gagattatca aaaaggatct 1380
tcacctagat ccttttaaat taaaaatgaa gttttaaatc aatctaaagt atatatgagt 1440
aaacttggtc tgacagttac caatgcttaa tcagtgaggc acctatctca gcgatctgtc 1500
tatttcgttc atccatagtt gcctgactcc ccgtcgtgta gataactacg atacgggagg 1560
gcttaccatc tggccccagt gctgcaatga taccgcgaga cccacgctca ccggctccag 1620
atttatcagc aataaaccag ccagccggaa gggccgagcg cagaagtggt cctgcaactt 1680
tatccgcctc catccagtct attaattgtt gccgggaagc tagagtaagt agttcgccag 1740
ttaatagttt gcgcaacgtt gttgccattg ctacaggcat cgtggtgtca cgctcgtcgt 1800
ttggtatggc ttcattcagc tccggttccc aacgatcaag gcgagttaca tgatccccca 1860
tgttgtgcaa aaaagcggtt agctccttcg gtcctccgat cgttgtcaga agtaagttgg 1920
ccgcagtgtt atcactcatg gttatggcag cactgcataa ttctcttact gtcatgccat 1980
ccgtaagatg cttttctgtg actggtgagt actcaaccaa gtcattctga gaatagtgta 2040
tgcggcgacc gagttgctct tgcccggcgt caatacggga taataccgcg ccacatagca 2100
gaactttaaa agtgctcatc attggaaaac gttcttcggg gcgaaaactc tcaaggatct 2160
taccgctgtt gagatccagt tcgatgtaac ccactcgtgc acccaactga tcttcagcat 2220
cttttacttt caccagcgtt tctgggtgag caaaaacagg aaggcaaaat gccgcaaaaa 2280
agggaataag ggcgacacgg aaatgttgaa tactcatact cttccttttt caatattatt 2340
gaagcattta tcagggttat tgtctcatga gcggatacat atttgaatgt atttagaaaa 2400
ataaacaaat aggggttccg cgcacatttc cccgaaaagt gccacctgac gtctaagaaa 2460
ccattattat catgacatta acctataaaa ataggcgtat cacgaggccc tttcgtctcg 2520
cgcgtttcgg tgatgacggt gaaaacctct gacacatgca gctcccggag acggtcacag 2580
cttgtctgta agcggatgcc gggagcagac aagcccgtca gggcgcgtca gcgggtgttg 2640
gcgggtgtcg gggctggctt aactatgcgg catcagagca gattgtactg agagtgcacc 2700
atatgcggtg tgaaataccg cacagatgcg taaggagaaa ataccgcatc aggcgccatt 2760
cgccattcag gctgcgcaac tgttgggaag ggcgatcggt gcgggcctct tcgctattac 2820
gccagctggc gaaaggggga tgtgctgcaa ggcgattaag ttgggtaacg ccagggtttt 2880
cccagtcacg acgttgtaaa acgacggcca gtgaattcga gctcggtacc cggggatcct 2940
ctagacgtac gaaaccaact gcgtttgggg ctccagatta aacgacgccg tttcgttcct 3000
ttcgcttcac ggcttaacga tgtcgtttct gtctgtgccc aaaaaataaa ggcatttgtt 3060
atttgcacca gatatttact aagtgcaccc tagtttgaca agtaggcgat aattacaaat 3120
agatgcggtg caaataataa attttgaagg aaataattac aaaagaacag aacttatatt 3180
tactttattt taaaaaacta aaatgaaaga acaaaaaaag taaaaaatac aaaaaatgtg 3240
ctttaaccac tttcattatt tgttacagaa agtatgattc tactcaaatt gatctgttgt 3300
atctggtgct gccttgtcac actggcgatt tcaatcccct aaagatatgg tgcaaactgc 3360
gaagtgatca atatctgctc ggttaattta gattaattaa taatattcaa cgtgatgtac 3420
caaaaaaaga caattttttg ctccattgac aaattaaacc tcatcaaggt aatttccaaa 3480
cctataagca aaaaaatttc acattaattg gcccgcaatc ctattagtct tattatacta 3540
gagtaggaaa aaaaacaatt acacaacttg tcttattatt ctctatgcta atgaatattt 3600
ttcccttttg ttagaaatca gtgtttccta atttattgag tattaattcc actcaccgca 3660
tatatttacc gttgaataag aaaattttac acataattct ttttaagata aataattttt 3720
ttatactaga tcttatatga ttacgtgaag ccaagtgggt tatactaatg atatataatg 3780
tttgatagta atcagtttat aaaccaaatg catggaaatg ttacgtggaa gcacgtaaat 3840
taacaagcat tgaagcaaat gcagccaccg caccaaaacc accccacttc acttccacgt 3900
accatattcc atgcaactac aacaccctaa aacttcaata aatgccccca ccttcacttc 3960
acttcaccca tcaatagcaa gcggccgcac aatggcgact cgacagcgaa ctgccaccac 4020
tgttgtggtc gaggaccttc ccaaggtcac tcttgaggcc aagtctgaac ctgtgttccc 4080
cgatatcaag accatcaagg atgccattcc cgcgcactgc ttccagccct cgctcgtcac 4140
ctcattctac tacgtcttcc gcgattttgc catggtctct gccctcgtct gggctgctct 4200
cacctacatc cccagcatcc ccgaccagac cctccgcgtc gcagcttgga tggtctacgg 4260
cttcgtccag ggtctgttct gcaccggtgt ctggattctc ggccatgagt gcggccacgg 4320
tgctttctct ctccacggaa aggtcaacaa tgtgaccggc tggttcctcc actcgttcct 4380
cctcgtcccc tacttcagct ggaagtactc tcaccaccgc caccaccgct tcaccggcca 4440
catggatctc gacatggctt tcgtccccaa gactgagccc aagccctcca agtcgctcat 4500
gattgctggc attgacgtcg ccgagcttgt tgaggacacc cccgctgctc agatggtcaa 4560
gctcatcttc caccagcttt tcggatggca ggcgtacctc ttcttcaacg ctagctctgg 4620
caagggcagc aagcagtggg agcccaagac tggcctctcc aagtggttcc gagtcagtca 4680
cttcgagcct accagcgctg tcttccgccc caacgaggcc atcttcatcc tcatctccga 4740
tatcggtctt gctctaatgg gaactgctct gtactttgct tccaagcaag ttggtgtttc 4800
gaccattctc ttcctctacc ttgttcccta cctgtgggtt caccactggc tcgttgccat 4860
tacctacctc caccaccacc acaccgagct ccctcactac accgctgagg gctggaccta 4920
cgtcaaggga gctctcgcca ctgtcgaccg tgagtttggc ttcatcggaa agcacctctt 4980
ccacggtatc attgagaagc acgttgttca ccatctcttc cctaagatcc ccttctacaa 5040
ggctgacgag gccaccgagg ccatcaagcc cgtcattggc gaccactact gccacgacga 5100
ccgaagcttc ctgggccagc tgtggaccat cttcggcacg ctcaagtacg tcgagcacga 5160
ccctgcccga cccggtgcca tgcgatggaa caaggactag gctaggc 5207
<210> 101
<211> 9035
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR869
<400> 101
gtacgtctag aggatccgtc gacggcgcgc ccgatcatcc ggatatagtt cctcctttca 60
gcaaaaaacc cctcaagacc cgtttagagg ccccaagggg ttatgctagt tattgctcag 120
cggtggcagc agccaactca gcttcctttc gggctttgtt agcagccgga tcgatccaag 180
ctgtacctca ctattccttt gccctcggac gagtgctggg gcgtcggttt ccactatcgg 240
cgagtacttc tacacagcca tcggtccaga cggccgcgct tctgcgggcg atttgtgtac 300
gcccgacagt cccggctccg gatcggacga ttgcgtcgca tcgaccctgc gcccaagctg 360
catcatcgaa attgccgtca accaagctct gatagagttg gtcaagacca atgcggagca 420
tatacgcccg gagccgcggc gatcctgcaa gctccggatg cctccgctcg aagtagcgcg 480
tctgctgctc catacaagcc aaccacggcc tccagaagaa gatgttggcg acctcgtatt 540
gggaatcccc gaacatcgcc tcgctccagt caatgaccgc tgttatgcgg ccattgtccg 600
tcaggacatt gttggagccg aaatccgcgt gcacgaggtg ccggacttcg gggcagtcct 660
cggcccaaag catcagctca tcgagagcct gcgcgacgga cgcactgacg gtgtcgtcca 720
tcacagtttg ccagtgatac acatggggat cagcaatcgc gcatatgaaa tcacgccatg 780
tagtgtattg accgattcct tgcggtccga atgggccgaa cccgctcgtc tggctaagat 840
cggccgcagc gatcgcatcc atagcctccg cgaccggctg cagaacagcg ggcagttcgg 900
tttcaggcag gtcttgcaac gtgacaccct gtgcacggcg ggagatgcaa taggtcaggc 960
tctcgctgaa ttccccaatg tcaagcactt ccggaatcgg gagcgcggcc gatgcaaagt 1020
gccgataaac ataacgatct ttgtagaaac catcggcgca gctatttacc cgcaggacat 1080
atccacgccc tcctacatcg aagctgaaag cacgagattc ttcgccctcc gagagctgca 1140
tcaggtcgga gacgctgtcg aacttttcga tcagaaactt ctcgacagac gtcgcggtga 1200
gttcaggctt ttccatgggt atatctcctt cttaaagtta aacaaaatta tttctagagg 1260
gaaaccgttg tggtctccct atagtgagtc gtattaattt cgcgggatcg agatctgatc 1320
aacctgcatt aatgaatcgg ccaacgcgcg gggagaggcg gtttgcgtat tgggcgctct 1380
tccgcttcct cgctcactga ctcgctgcgc tcggtcgttc ggctgcggcg agcggtatca 1440
gctcactcaa aggcggtaat acggttatcc acagaatcag gggataacgc aggaaagaac 1500
atgtgagcaa aaggccagca aaaggccagg aaccgtaaaa aggccgcgtt gctggcgttt 1560
ttccataggc tccgcccccc tgacgagcat cacaaaaatc gacgctcaag tcagaggtgg 1620
cgaaacccga caggactata aagataccag gcgtttcccc ctggaagctc cctcgtgcgc 1680
tctcctgttc cgaccctgcc gcttaccgga tacctgtccg cctttctccc ttcgggaagc 1740
gtggcgcttt ctcaatgctc acgctgtagg tatctcagtt cggtgtaggt cgttcgctcc 1800
aagctgggct gtgtgcacga accccccgtt cagcccgacc gctgcgcctt atccggtaac 1860
tatcgtcttg agtccaaccc ggtaagacac gacttatcgc cactggcagc agccactggt 1920
aacaggatta gcagagcgag gtatgtaggc ggtgctacag agttcttgaa gtggtggcct 1980
aactacggct acactagaag gacagtattt ggtatctgcg ctctgctgaa gccagttacc 2040
ttcggaaaaa gagttggtag ctcttgatcc ggcaaacaaa ccaccgctgg tagcggtggt 2100
ttttttgttt gcaagcagca gattacgcgc agaaaaaaag gatctcaaga agatcctttg 2160
atcttttcta cggggtctga cgctcagtgg aacgaaaact cacgttaagg gattttggtc 2220
atgacattaa cctataaaaa taggcgtatc acgaggccct ttcgtctcgc gcgtttcggt 2280
gatgacggtg aaaacctctg acacatgcag ctcccggaga cggtcacagc ttgtctgtaa 2340
gcggatgccg ggagcagaca agcccgtcag ggcgcgtcag cgggtgttgg cgggtgtcgg 2400
ggctggctta actatgcggc atcagagcag attgtactga gagtgcacca tatggacata 2460
ttgtcgttag aacgcggcta caattaatac ataaccttat gtatcataca catacgattt 2520
aggtgacact atagaacggc gcgccaagct gggtctagaa ctagaaacgt gatgccactt 2580
gttattgaag tcgattacag catctattct gttttactat ttataacttt gccatttctg 2640
acttttgaaa actatctctg gatttcggta tcgctttgtg aagatcgagc aaaagagacg 2700
ttttgtggac gcaatggtcc aaatccgttc tacatgaaca aattggtcac aatttccact 2760
aaaagtaaat aaatggcaag ttaaaaaagg aatatgcatt ttactgattg cctaggtgag 2820
ctccaagaga agttgaatct acacgtctac caaccgctaa aaaaagaaaa acattgatat 2880
gtaacctgat tccattagct tttgacttct tcaacagatt ctctacttag atttctaaca 2940
gaaatattat tactagcaca tcattttcag tctcactaca gcaaaaaatc caacggcaca 3000
atacagacaa caggagatat cagactacag agatagatag atgctactgc atgtagtaag 3060
ttaaataaaa ggaaaataaa atgtcttgct accaaaacta ctacagacta tgatgctcac 3120
cacaggccaa atcctgcaac taggacagca ttatcttata tatattgtac aaaacaagca 3180
tcaaggaaca tttggtctag gcaatcagta cctcgttcta ccatcaccct cagttatcac 3240
atccttgaag gatccattac tgggaatcat cggcaacaca tgctcctgat ggggcacaat 3300
gacatcaaga aggtaggggc caggggtgtc caacattctc tgaattgccg ctctaagctc 3360
ttccttcttc gtcactcgcg ctgccggtat cccacaagca tcagcaaact tgagcatgtt 3420
tgggaatatc tcgctctcgc tagacggatc tccaagatag gtgtgagctc tattggactt 3480
gtagaaccta tcctccaact gaaccaccat acccaaatgc tgattgttca acaacaatat 3540
cttaactggg agattctcca ctcttatagt ggccaactcc tgaacattca tgatgaaact 3600
accatcccca tcaatgtcaa ccacaacagc cccagggtta gcaacagcag caccaatagc 3660
cgcaggcaat ccaaaaccca tggctccaag accccctgag gtcaaccact gcctcggtct 3720
cttgtacttg taaaactgcg cagcccacat ttgatgctgc ccaaccccag tactaacaat 3780
agcatctcca ttagtcaact catcaagaac ctcgatagca tgctgcggag aaatcgcgtc 3840
ctggaatgtc ttgtaaccca atggaaactt gtgtttctgc acattaatct cttctctcca 3900
acctccaaga tcaaacttac cctccactcc tttctcctcc aaaatcatat taattccctt 3960
caaggccaac ttcaaatccg cgcaaaccga cacgtgcgcc tgcttgttct tcccaatctc 4020
ggcagaatca atatcaatgt gaacaatctt agccctacta gcaaaagcct caagcttccc 4080
agtaacacgg tcatcaaacc ttaccccaaa ggcaagcaac aaatcactat tgtcaacagc 4140
atagttagca taaacagtac catgcatacc cagcatctga agggaatatt catcaccaat 4200
aggaaaagtt ccaagaccca ttaaagtgct agcaacggga ataccagtga gttcaacaaa 4260
gcgcctcaat tcagcactgg aattcaaact gccaccgccg acgtagagaa cgggcttttg 4320
ggcctccatg atgagtctga caatgtgttc caattgggcc tcggcggggg gcctgggcag 4380
cctggcgagg taaccgggga ggttaacggg ctcgtcccaa ttaggcacgg cgagttgctg 4440
ctgaacgtct ttgggaatgt cgatgaggac cggaccgggg cggccggagg tggcgacgaa 4500
gaaagcctcg gcgacgacgc gggggatgtc gtcgacgtcg aggatgaggt agttgtgctt 4560
cgtgatggat ctgctcacct ccacgatcgg ggtttcttgg aaggcgtcgg tgccgatcat 4620
ccggcgggcg acctggccgg tgatggcgac gactgggacg ctgtccatta aagcgtcggc 4680
gaggccgctc acgaggttgg tggcgccggg gccggaggtg gcaatgcaga cgccggggag 4740
gccggaggaa cgcgcgtagc cttcggcggc gaagacgccg ccctgctcgt ggcgcgggag 4800
cacgttgcgg atggcggcgg agcgcgtgag cgcctggtgg atctccatcg acgcaccgcc 4860
ggggtacgcg aacaccgtcg tcacgccctg cctctccagc gcctccacaa ggatgtccgc 4920
gcccttgcga ggttcgccgg aggcgaaccg tgacacgaag ggctccgtgg tcggcgcttc 4980
cttggtgaag ggcgccgccg tggggggttt ggagatggaa catttgattt tgagagcgtg 5040
gttgggtttg gtgagggttt gatgagagag agggagggtg gatctagtaa tgcgtttggg 5100
gaaggtgggg tgtgaagagg aagaagagaa tcgggtggtt ctggaagcgg tggccgccat 5160
tgtgttgtgt ggcatggtta tacttcaaaa actgcacaac aagcctagag ttagtaccta 5220
aacagtaaat ttacaacaga gagcaaagac acatgcaaaa atttcagcca taaaaaaagt 5280
tataatagaa tttaaagcaa aagtttcatt ttttaaacat atatacaaac aaactggatt 5340
tgaaggaagg gattaattcc cctgctcaaa gtttgaattc ctattgtgac ctatactcga 5400
ataaaattga agcctaagga atgtatgaga aacaagaaaa caaaacaaaa ctacagacaa 5460
acaagtacaa ttacaaaatt cgctaaaatt ctgtaatcac caaaccccat ctcagtcagc 5520
acaaggccca aggtttattt tgaaataaaa aaaaagtgat tttatttctc ataagctaaa 5580
agaaagaaag gcaattatga aatgatttcg actagatctg aaagtccaac gcgtattccg 5640
cagatattaa agaaagagta gagtttcaca tggatcctag atggacccag ttgaggaaaa 5700
agcaaggcaa agcaaaccag aagtgcaaga tccgaaattg aaccacggaa tctaggattt 5760
ggtagaggga gaagaaaagt accttgagag gtagaagaga agagaagagc agagagatat 5820
atgaacgagt gtgtcttggt ctcaactctg aagcgatacg agtttagagg ggagcattga 5880
gttccaattt atagggaaac cgggtggcag gggtgagtta atgacggaaa agcccctaag 5940
taacgagatt ggattgtggg ttagattcaa ccgtttgcat ccgcggctta gattggggaa 6000
gtcagagtga atctcaaccg ttgactgagt tgaaaattga atgtagcaac caattgagcc 6060
aaccccagcc tttgcccttt gattttgatt tgtttgttgc atacttttta tttgtcttct 6120
ggttctgact ctctttctct cgtttcaatg ccaggttgcc tactcccaca ccactcacaa 6180
gaagattcta ctgttagtat taaatatttt ttaatgtatt aaatgatgaa tgcttttgta 6240
aacagaacaa gactatgtct aataagtgtc ttgcaacatt ttttaagaaa ttaaaaaaaa 6300
tatatttatt atcaaaatca aatgtatgaa aaatcatgaa taatataatt ttatacattt 6360
ttttaaaaaa tcttttaatt tcttaattaa tatcttaaaa ataatgatta atatttaacc 6420
caaaataatt agtatgattg gtaaggaaga tatccatgtt atgtttggat gtgagtttga 6480
tctagagcaa agcttactag agtcgacctg caggtcgact cgacgtacga aaccaactgc 6540
gtttggggct ccagattaaa cgacgccgtt tcgttccttt cgcttcacgg cttaacgatg 6600
tcgtttctgt ctgtgcccaa aaaataaagg catttgttat ttgcaccaga tatttactaa 6660
gtgcacccta gtttgacaag taggcgataa ttacaaatag atgcggtgca aataataaat 6720
tttgaaggaa ataattacaa aagaacagaa cttatattta ctttatttta aaaaactaaa 6780
atgaaagaac aaaaaaagta aaaaatacaa aaaatgtgct ttaaccactt tcattatttg 6840
ttacagaaag tatgattcta ctcaaattga tctgttgtat ctggtgctgc cttgtcacac 6900
tggcgatttc aatcccctaa agatatggtg caaactgcga agtgatcaat atctgctcgg 6960
ttaatttaga ttaattaata atattcaacg tgatgtacca aaaaaagaca attttttgct 7020
ccattgacaa attaaacctc atcaaggtaa tttccaaacc tataagcaaa aaaatttcac 7080
attaattggc ccgcaatcct attagtctta ttatactaga gtaggaaaaa aaacaattac 7140
acaacttgtc ttattattct ctatgctaat gaatattttt cccttttgtt agaaatcagt 7200
gtttcctaat ttattgagta ttaattccac tcaccgcata tatttaccgt tgaataagaa 7260
aattttacac ataattcttt ttaagataaa taattttttt atactagatc ttatatgatt 7320
acgtgaagcc aagtgggtta tactaatgat atataatgtt tgatagtaat cagtttataa 7380
accaaatgca tggaaatgtt acgtggaagc acgtaaatta acaagcattg aagcaaatgc 7440
agccaccgca ccaaaaccac cccacttcac ttccacgtac catattccat gcaactacaa 7500
caccctaaaa cttcaataaa tgcccccacc ttcacttcac ttcacccatc aatagcaagc 7560
ggccgcacaa tggcgactcg acagcgaact gccaccactg ttgtggtcga ggaccttccc 7620
aaggtcactc ttgaggccaa gtctgaacct gtgttccccg atatcaagac catcaaggat 7680
gccattcccg cgcactgctt ccagccctcg ctcgtcacct cattctacta cgtcttccgc 7740
gattttgcca tggtctctgc cctcgtctgg gctgctctca cctacatccc cagcatcccc 7800
gaccagaccc tccgcgtcgc agcttggatg gtctacggct tcgtccaggg tctgttctgc 7860
accggtgtct ggattctcgg ccatgagtgc ggccacggtg ctttctctct ccacggaaag 7920
gtcaacaatg tgaccggctg gttcctccac tcgttcctcc tcgtccccta cttcagctgg 7980
aagtactctc accaccgcca ccaccgcttc accggccaca tggatctcga catggctttc 8040
gtccccaaga ctgagcccaa gccctccaag tcgctcatga ttgctggcat tgacgtcgcc 8100
gagcttgttg aggacacccc cgctgctcag atggtcaagc tcatcttcca ccagcttttc 8160
ggatggcagg cgtacctctt cttcaacgct agctctggca agggcagcaa gcagtgggag 8220
cccaagactg gcctctccaa gtggttccga gtcagtcact tcgagcctac cagcgctgtc 8280
ttccgcccca acgaggccat cttcatcctc atctccgata tcggtcttgc tctaatggga 8340
actgctctgt actttgcttc caagcaagtt ggtgtttcga ccattctctt cctctacctt 8400
gttccctacc tgtgggttca ccactggctc gttgccatta cctacctcca ccaccaccac 8460
accgagctcc ctcactacac cgctgagggc tggacctacg tcaagggagc tctcgccact 8520
gtcgaccgtg agtttggctt catcggaaag cacctcttcc acggtatcat tgagaagcac 8580
gttgttcacc atctcttccc taagatcccc ttctacaagg ctgacgaggc caccgaggcc 8640
atcaagcccg tcattggcga ccactactgc cacgacgacc gaagcttcct gggccagctg 8700
tggaccatct tcggcacgct caagtacgtc gagcacgacc ctgcccgacc cggtgccatg 8760
cgatggaaca aggactaggc taggcggccg cgaagttaaa agcaatgttg tcacttgtcg 8820
tactaacaca tgatgtgata gtttatgcta gctagctata acataagctg tctctgagtg 8880
tgttgtatat taataaagat catcactggt gaatggtgat cgtgtacgta ccctacttag 8940
taggcaatgg aagcacttag agtgtgcttt gtgcatggcc ttgcctctgt tttgagactt 9000
ttgtaatgtt ttcgagttta aatctttgcc tttgc 9035
<210> 102
<211> 5108
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pKR270
<400> 102
ggccgcattt cgcaccaaat caatgaaagt aataatgaaa agtctgaata agaatactta 60
ggcttagatg cctttgttac ttgtgtaaaa taacttgagt catgtacctt tggcggaaac 120
agaataaata aaaggtgaaa ttccaatgct ctatgtataa gttagtaata cttaatgtgt 180
tctacggttg tttcaatatc atcaaactct aattgaaact ttagaaccac aaatctcaat 240
cttttcttaa tgaaatgaaa aatcttaatt gtaccatgtt tatgttaaac accttacaat 300
tggttggaga ggaggaccaa ccgatgggac aacattggga gaaagagatt caatggagat 360
ttggatagga gaacaacatt ctttttcact tcaatacaag atgagtgcaa cactaaggat 420
atgtatgaga ctttcagaag ctacgacaac atagatgagt gaggtggtga ttcctagcaa 480
gaaagacatt agaggaagcc aaaatcgaac aaggaagaca tcaagggcaa gagacaggac 540
catccatctc aggaaaagga gctttgggat agtccgagaa gttgtacaag aaattttttg 600
gagggtgagt gatgcattgc tggtgacttt aactcaatca aaattgagaa agaaagaaaa 660
gggagggggc tcacatgtga atagaaggga aacgggagaa ttttacagtt ttgatctaat 720
gggcatccca gctagtggta acatattcac catgtttaac cttcacgtac gtctagagga 780
tccccgggta ccgagctcga attcactggc cgtcgtttta caacgtcgtg actgggaaaa 840
ccctggcgtt acccaactta atcgccttgc agcacatccc cctttcgcca gctggcgtaa 900
tagcgaagag gcccgcaccg atcgcccttc ccaacagttg cgcagcctga atggcgaatg 960
gcgcctgatg cggtattttc tccttacgca tctgtgcggt atttcacacc gcatatggtg 1020
cactctcagt acaatctgct ctgatgccgc atagttaagc cagccccgac acccgccaac 1080
acccgctgac gcgccctgac gggcttgtct gctcccggca tccgcttaca gacaagctgt 1140
gaccgtctcc gggagctgca tgtgtcagag gttttcaccg tcatcaccga aacgcgcgag 1200
acgaaagggc ctcgtgatac gcctattttt ataggttaat gtcatgataa taatggtttc 1260
ttagacgtca ggtggcactt ttcggggaaa tgtgcgcgga acccctattt gtttattttt 1320
ctaaatacat tcaaatatgt atccgctcat gagacaataa ccctgataaa tgcttcaata 1380
atattgaaaa aggaagagta tgagtattca acatttccgt gtcgccctta ttcccttttt 1440
tgcggcattt tgccttcctg tttttgctca cccagaaacg ctggtgaaag taaaagatgc 1500
tgaagatcag ttgggtgcac gagtgggtta catcgaactg gatctcaaca gcggtaagat 1560
ccttgagagt tttcgccccg aagaacgttt tccaatgatg agcactttta aagttctgct 1620
atgtggcgcg gtattatccc gtattgacgc cgggcaagag caactcggtc gccgcataca 1680
ctattctcag aatgacttgg ttgagtactc accagtcaca gaaaagcatc ttacggatgg 1740
catgacagta agagaattat gcagtgctgc cataaccatg agtgataaca ctgcggccaa 1800
cttacttctg acaacgatcg gaggaccgaa ggagctaacc gcttttttgc acaacatggg 1860
ggatcatgta actcgccttg atcgttggga accggagctg aatgaagcca taccaaacga 1920
cgagcgtgac accacgatgc ctgtagcaat ggcaacaacg ttgcgcaaac tattaactgg 1980
cgaactactt actctagctt cccggcaaca attaatagac tggatggagg cggataaagt 2040
tgcaggacca cttctgcgct cggcccttcc ggctggctgg tttattgctg ataaatctgg 2100
agccggtgag cgtgggtctc gcggtatcat tgcagcactg gggccagatg gtaagccctc 2160
ccgtatcgta gttatctaca cgacggggag tcaggcaact atggatgaac gaaatagaca 2220
gatcgctgag ataggtgcct cactgattaa gcattggtaa ctgtcagacc aagtttactc 2280
atatatactt tagattgatt taaaacttca tttttaattt aaaaggatct aggtgaagat 2340
cctttttgat aatctcatga ccaaaatccc ttaacgtgag ttttcgttcc actgagcgtc 2400
agaccccgta gaaaagatca aaggatcttc ttgagatcct ttttttctgc gcgtaatctg 2460
ctgcttgcaa acaaaaaaac caccgctacc agcggtggtt tgtttgccgg atcaagagct 2520
accaactctt tttccgaagg taactggctt cagcagagcg cagataccaa atactgtcct 2580
tctagtgtag ccgtagttag gccaccactt caagaactct gtagcaccgc ctacatacct 2640
cgctctgcta atcctgttac cagtggctgc tgccagtggc gataagtcgt gtcttaccgg 2700
gttggactca agacgatagt taccggataa ggcgcagcgg tcgggctgaa cggggggttc 2760
gtgcacacag cccagcttgg agcgaacgac ctacaccgaa ctgagatacc tacagcgtga 2820
gctatgagaa agcgccacgc ttcccgaagg gagaaaggcg gacaggtatc cggtaagcgg 2880
cagggtcgga acaggagagc gcacgaggga gcttccaggg ggaaacgcct ggtatcttta 2940
tagtcctgtc gggtttcgcc acctctgact tgagcgtcga tttttgtgat gctcgtcagg 3000
ggggcggagc ctatggaaaa acgccagcaa cgcggccttt ttacggttcc tggccttttg 3060
ctggcctttt gctcacatgt tctttcctgc gttatcccct gattctgtgg ataaccgtat 3120
taccgccttt gagtgagctg ataccgctcg ccgcagccga acgaccgagc gcagcgagtc 3180
agtgagcgag gaagcggaag agcgcccaat acgcaaaccg cctctccccg cgcgttggcc 3240
gattcattaa tgcagctggc acgacaggtt tcccgactgg aaagcgggca gtgagcgcaa 3300
cgcaattaat gtgagttagc tcactcatta ggcaccccag gctttacact ttatgcttcc 3360
ggctcgtatg ttgtgtggaa ttgtgagcgg ataacaattt cacacaggaa acagctatga 3420
ccatgattac gccaagcttg catgcctgca ggctagccta agtacgtact caaaatgcca 3480
acaaataaaa aaaaagttgc tttaataatg ccaaaacaaa ttaataaaac acttacaaca 3540
ccggattttt tttaattaaa atgtgccatt taggataaat agttaatatt tttaataatt 3600
atttaaaaag ccgtatctac taaaatgatt tttatttggt tgaaaatatt aatatgttta 3660
aatcaacaca atctatcaaa attaaactaa aaaaaaaata agtgtacgtg gttaacatta 3720
gtacagtaat ataagaggaa aatgagaaat taagaaattg aaagcgagtc taatttttaa 3780
attatgaacc tgcatatata aaaggaaaga aagaatccag gaagaaaaga aatgaaacca 3840
tgcatggtcc cctcgtcatc acgagtttct gccatttgca atagaaacac tgaaacacct 3900
ttctctttgt cacttaattg agatgccgaa gccacctcac accatgaact tcatgaggtg 3960
tagcacccaa ggcttccata gccatgcata ctgaagaatg tctcaagctc agcaccctac 4020
ttctgtgacg tgtccctcat tcaccttcct ctcttcccta taaataacca cgcctcaggt 4080
tctccgcttc acaactcaaa cattctctcc attggtcctt aaacactcat cagtcatcac 4140
cgcggccgca tggagtcgat tgcgccattc ctcccatcaa agatgccgca agatctgttt 4200
atggaccttg ccaccgctat cggtgtccgg gccgcgccct atgtcgatcc tctcgaggcc 4260
gcgctggtgg cccaggccga gaagtacatc cccacgattg tccatcacac gcgtgggttc 4320
ctggtcgcgg tggagtcgcc tttggcccgt gagctgccgt tgatgaaccc gttccacgtg 4380
ctgttgatcg tgctcgctta tttggtcacg gtctttgtgg gcatgcagat catgaagaac 4440
tttgagcggt tcgaggtcaa gacgttttcg ctcctgcaca acttttgtct ggtctcgatc 4500
agcgcctaca tgtgcggtgg gatcctgtac gaggcttatc aggccaacta tggactgttt 4560
gagaacgctg ctgatcatac cttcaagggt cttcctatgg ccaagatgat ctggctcttc 4620
tacttctcca agatcatgga gtttgtcgac accatgatca tggtcctcaa gaagaacaac 4680
cgccagatct ccttcttgca cgtttaccac cacagctcca tcttcaccat ctggtggttg 4740
gtcacctttg ttgcacccaa cggtgaagcc tacttctctg ctgcgttgaa ctcgttcatc 4800
catgtgatca tgtacggcta ctacttcttg tcggccttgg gcttcaagca ggtgtcgttc 4860
atcaagttct acatcacgcg ctcgcagatg acacagttct gcatgatgtc ggtccagtct 4920
tcctgggaca tgtacgccat gaaggtcctt ggccgccccg gatacccctt cttcatcacg 4980
gctctgcttt ggttctacat gtggaccatg ctcggtctct tctacaactt ttacagaaag 5040
aacgccaagt tggccaagca ggccaaggcc gacgctgcca aggagaaggc aaggaagttg 5100
cagtaagc 5108
<210> 103
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> Smart(TM) IV oligonucleotide
<400> 103
aagcagtggt atcaacgcag agtggccatt acggccggg 39
<210> 104
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> CDSIII/3'PCR primer
<220>
<221> misc_feature
<222> (28)..(57)
<223> thymidine (dT); see BD Biosciences Clontech's SMART cDNA
technology
<220>
<221> misc_feature
<222> (59)..(59)
<223> n is a, c, g, or t
<400> 104
attctagagg ccgaggcggc cgacatgttt tttttttttt tttttttttt tttttttvn 59
<210> 105
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> 5'-PCR primer
<400> 105
aagcagtggt atcaacgcag agt 23
<210> 106
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer EuEF3
<220>
<221> misc_feature
<222> (3)..(3)
<223> n is a, c, g, or t
<400> 106
ytncarttyt tycaycaytt 20
<210> 107
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Primer EuEF3 (translation)
<400> 107
Leu Gln Phe Phe His His Leu
1 5
<210> 108
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer EuER3
<400> 108
ttraaytgda tdatytgcat 20
<210> 109
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Primer EuER3 (translation)
<400> 109
Met Gln Ile Ile Gln Phe Asn
1 5
<210> 110
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer 389Elo-5-1
<400> 110
gaatgaaccc attcaaaaac ac 22
<210> 111
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer 389Elo-5-2
<400> 111
gatccaaata gattccccag aa 22
<210> 112
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer DNR CDS 5'-2
<400> 112
caacgcagag tggccattac gg 22
<210> 113
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer 389Elo-5-4
<400> 113
gtaaacttca agatcacgaa g 21
<210> 114
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer 389Elo-3-1
<400> 114
gttcattcac tttgttatgt ac 22
<210> 115
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer 389Elo-3-2
<400> 115
ctggactcgg ctgatgaagt tc 22
<210> 116
<211> 29
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer 389ELO-F
<400> 116
aagatcccat ggctgcggtg atagaggtc 29
<210> 117
<211> 37
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer 389ELO-R1
<400> 117
aagatcgcgg ccgcctattg gaccttttta tctgcag 37
<210> 118
<211> 7222
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pFBAIN-MOD1
<400> 118
catggatcca ggcctgttaa cggccattac ggcctgcagg atccgaaaaa acctcccaca 60
cctccccctg aacctgaaac ataaaatgaa tgcaattgtt gttgttaact tgtttattgc 120
agcttataat ggttacaaat aaagcaatag catcacaaat ttcacaaata aagcattttt 180
ttcactgcat tctagttgtg gtttgtccaa actcatcaat gtatcttatc atgtctgcgg 240
ccgcaagtgt ggatggggaa gtgagtgccc ggttctgtgt gcacaattgg caatccaaga 300
tggatggatt caacacaggg atatagcgag ctacgtggtg gtgcgaggat atagcaacgg 360
atatttatgt ttgacacttg agaatgtacg atacaagcac tgtccaagta caatactaaa 420
catactgtac atactcatac tcgtacccgg gcaacggttt cacttgagtg cagtggctag 480
tgctcttact cgtacagtgt gcaatactgc gtatcatagt ctttgatgta tatcgtattc 540
attcatgtta gttgcgtacg agccggaagc ataaagtgta aagcctgggg tgcctaatga 600
gtgagctaac tcacattaat tgcgttgcgc tcactgcccg ctttccagtc gggaaacctg 660
tcgtgccagc tgcattaatg aatcggccaa cgcgcgggga gaggcggttt gcgtattggg 720
cgctcttccg cttcctcgct cactgactcg ctgcgctcgg tcgttcggct gcggcgagcg 780
gtatcagctc actcaaaggc ggtaatacgg ttatccacag aatcagggga taacgcagga 840
aagaacatgt gagcaaaagg ccagcaaaag gccaggaacc gtaaaaaggc cgcgttgctg 900
gcgtttttcc ataggctccg cccccctgac gagcatcaca aaaatcgacg ctcaagtcag 960
aggtggcgaa acccgacagg actataaaga taccaggcgt ttccccctgg aagctccctc 1020
gtgcgctctc ctgttccgac cctgccgctt accggatacc tgtccgcctt tctcccttcg 1080
ggaagcgtgg cgctttctca tagctcacgc tgtaggtatc tcagttcggt gtaggtcgtt 1140
cgctccaagc tgggctgtgt gcacgaaccc cccgttcagc ccgaccgctg cgccttatcc 1200
ggtaactatc gtcttgagtc caacccggta agacacgact tatcgccact ggcagcagcc 1260
actggtaaca ggattagcag agcgaggtat gtaggcggtg ctacagagtt cttgaagtgg 1320
tggcctaact acggctacac tagaaggaca gtatttggta tctgcgctct gctgaagcca 1380
gttaccttcg gaaaaagagt tggtagctct tgatccggca aacaaaccac cgctggtagc 1440
ggtggttttt ttgtttgcaa gcagcagatt acgcgcagaa aaaaaggatc tcaagaagat 1500
cctttgatct tttctacggg gtctgacgct cagtggaacg aaaactcacg ttaagggatt 1560
ttggtcatga gattatcaaa aaggatcttc acctagatcc ttttaaatta aaaatgaagt 1620
tttaaatcaa tctaaagtat atatgagtaa acttggtctg acagttacca atgcttaatc 1680
agtgaggcac ctatctcagc gatctgtcta tttcgttcat ccatagttgc ctgactcccc 1740
gtcgtgtaga taactacgat acgggagggc ttaccatctg gccccagtgc tgcaatgata 1800
ccgcgagacc cacgctcacc ggctccagat ttatcagcaa taaaccagcc agccggaagg 1860
gccgagcgca gaagtggtcc tgcaacttta tccgcctcca tccagtctat taattgttgc 1920
cgggaagcta gagtaagtag ttcgccagtt aatagtttgc gcaacgttgt tgccattgct 1980
acaggcatcg tggtgtcacg ctcgtcgttt ggtatggctt cattcagctc cggttcccaa 2040
cgatcaaggc gagttacatg atcccccatg ttgtgcaaaa aagcggttag ctccttcggt 2100
cctccgatcg ttgtcagaag taagttggcc gcagtgttat cactcatggt tatggcagca 2160
ctgcataatt ctcttactgt catgccatcc gtaagatgct tttctgtgac tggtgagtac 2220
tcaaccaagt cattctgaga atagtgtatg cggcgaccga gttgctcttg cccggcgtca 2280
atacgggata ataccgcgcc acatagcaga actttaaaag tgctcatcat tggaaaacgt 2340
tcttcggggc gaaaactctc aaggatctta ccgctgttga gatccagttc gatgtaaccc 2400
actcgtgcac ccaactgatc ttcagcatct tttactttca ccagcgtttc tgggtgagca 2460
aaaacaggaa ggcaaaatgc cgcaaaaaag ggaataaggg cgacacggaa atgttgaata 2520
ctcatactct tcctttttca atattattga agcatttatc agggttattg tctcatgagc 2580
ggatacatat ttgaatgtat ttagaaaaat aaacaaatag gggttccgcg cacatttccc 2640
cgaaaagtgc cacctgacgc gccctgtagc ggcgcattaa gcgcggcggg tgtggtggtt 2700
acgcgcagcg tgaccgctac acttgccagc gccctagcgc ccgctccttt cgctttcttc 2760
ccttcctttc tcgccacgtt cgccggcttt ccccgtcaag ctctaaatcg ggggctccct 2820
ttagggttcc gatttagtgc tttacggcac ctcgacccca aaaaacttga ttagggtgat 2880
ggttcacgta gtgggccatc gccctgatag acggtttttc gccctttgac gttggagtcc 2940
acgttcttta atagtggact cttgttccaa actggaacaa cactcaaccc tatctcggtc 3000
tattcttttg atttataagg gattttgccg atttcggcct attggttaaa aaatgagctg 3060
atttaacaaa aatttaacgc gaattttaac aaaatattaa cgcttacaat ttccattcgc 3120
cattcaggct gcgcaactgt tgggaagggc gatcggtgcg ggcctcttcg ctattacgcc 3180
agctggcgaa agggggatgt gctgcaaggc gattaagttg ggtaacgcca gggttttccc 3240
agtcacgacg ttgtaaaacg acggccagtg aattgtaata cgactcacta tagggcgaat 3300
tgggtaccgg gccccccctc gaggtcgatg gtgtcgataa gcttgatatc gaattcatgt 3360
cacacaaacc gatcttcgcc tcaaggaaac ctaattctac atccgagaga ctgccgagat 3420
ccagtctaca ctgattaatt ttcgggccaa taatttaaaa aaatcgtgtt atataatatt 3480
atatgtatta tatatataca tcatgatgat actgacagtc atgtcccatt gctaaataga 3540
cagactccat ctgccgcctc caactgatgt tctcaatatt taaggggtca tctcgcattg 3600
tttaataata aacagactcc atctaccgcc tccaaatgat gttctcaaaa tatattgtat 3660
gaacttattt ttattactta gtattattag acaacttact tgctttatga aaaacacttc 3720
ctatttagga aacaatttat aatggcagtt cgttcattta acaatttatg tagaataaat 3780
gttataaatg cgtatgggaa atcttaaata tggatagcat aaatgatatc tgcattgcct 3840
aattcgaaat caacagcaac gaaaaaaatc ccttgtacaa cataaatagt catcgagaaa 3900
tatcaactat caaagaacag ctattcacac gttactattg agattattat tggacgagaa 3960
tcacacactc aactgtcttt ctctcttcta gaaatacagg tacaagtatg tactattctc 4020
attgttcata cttctagtca tttcatccca catattcctt ggatttctct ccaatgaatg 4080
acattctatc ttgcaaattc aacaattata ataagatata ccaaagtagc ggtatagtgg 4140
caatcaaaaa gcttctctgg tgtgcttctc gtatttattt ttattctaat gatccattaa 4200
aggtatatat ttatttcttg ttatataatc cttttgttta ttacatgggc tggatacata 4260
aaggtatttt gatttaattt tttgcttaaa ttcaatcccc cctcgttcag tgtcaactgt 4320
aatggtagga aattaccata cttttgaaga agcaaaaaaa atgaaagaaa aaaaaaatcg 4380
tatttccagg ttagacgttc cgcagaatct agaatgcggt atgcggtaca ttgttcttcg 4440
aacgtaaaag ttgcgctccc tgagatattg tacatttttg cttttacaag tacaagtaca 4500
tcgtacaact atgtactact gttgatgcat ccacaacagt ttgttttgtt tttttttgtt 4560
tttttttttt ctaatgattc attaccgcta tgtataccta cttgtacttg tagtaagccg 4620
ggttattggc gttcaattaa tcatagactt atgaatctgc acggtgtgcg ctgcgagtta 4680
cttttagctt atgcatgcta cttgggtgta atattgggat ctgttcggaa atcaacggat 4740
gctcaatcga tttcgacagt aattaattaa gtcatacaca agtcagcttt cttcgagcct 4800
catataagta taagtagttc aacgtattag cactgtaccc agcatctccg tatcgagaaa 4860
cacaacaaca tgccccattg gacagatcat gcggatacac aggttgtgca gtatcataca 4920
tactcgatca gacaggtcgt ctgaccatca tacaagctga acaagcgctc catacttgca 4980
cgctctctat atacacagtt aaattacata tccatagtct aacctctaac agttaatctt 5040
ctggtaagcc tcccagccag ccttctggta tcgcttggcc tcctcaatag gatctcggtt 5100
ctggccgtac agacctcggc cgacaattat gatatccgtt ccggtagaca tgacatcctc 5160
aacagttcgg tactgctgtc cgagagcgtc tcccttgtcg tcaagaccca ccccgggggt 5220
cagaataagc cagtcctcag agtcgccctt aggtcggttc tgggcaatga agccaaccac 5280
aaactcgggg tcggatcggg caagctcaat ggtctgcttg gagtactcgc cagtggccag 5340
agagcccttg caagacagct cggccagcat gagcagacct ctggccagct tctcgttggg 5400
agaggggact aggaactcct tgtactggga gttctcgtag tcagagacgt cctccttctt 5460
ctgttcagag acagtttcct cggcaccagc tcgcaggcca gcaatgattc cggttccggg 5520
tacaccgtgg gcgttggtga tatcggacca ctcggcgatt cggtgacacc ggtactggtg 5580
cttgacagtg ttgccaatat ctgcgaactt tctgtcctcg aacaggaaga aaccgtgctt 5640
aagagcaagt tccttgaggg ggagcacagt gccggcgtag gtgaagtcgt caatgatgtc 5700
gatatgggtt ttgatcatgc acacataagg tccgacctta tcggcaagct caatgagctc 5760
cttggtggtg gtaacatcca gagaagcaca caggttggtt ttcttggctg ccacgagctt 5820
gagcactcga gcggcaaagg cggacttgtg gacgttagct cgagcttcgt aggagggcat 5880
tttggtggtg aagaggagac tgaaataaat ttagtctgca gaacttttta tcggaacctt 5940
atctggggca gtgaagtata tgttatggta atagttacga gttagttgaa cttatagata 6000
gactggacta tacggctatc ggtccaaatt agaaagaacg tcaatggctc tctgggcgtc 6060
gcctttgccg acaaaaatgt gatcatgatg aaagccagca atgacgttgc agctgatatt 6120
gttgtcggcc aaccgcgccg aaaacgcagc tgtcagaccc acagcctcca acgaagaatg 6180
tatcgtcaaa gtgatccaag cacactcata gttggagtcg tactccaaag gcggcaatga 6240
cgagtcagac agatactcgt cgaaaacagt gtacgcagat ctactataga ggaacattta 6300
aattgccccg gagaagacgg ccaggccgcc tagatgacaa attcaacaac tcacagctga 6360
ctttctgcca ttgccactag gggggggcct ttttatatgg ccaagccaag ctctccacgt 6420
cggttgggct gcacccaaca ataaatgggt agggttgcac caacaaaggg atgggatggg 6480
gggtagaaga tacgaggata acggggctca atggcacaaa taagaacgaa tactgccatt 6540
aagactcgtg atccagcgac tgacaccatt gcatcatcta agggcctcaa aactacctcg 6600
gaactgctgc gctgatctgg acaccacaga ggttccgagc actttaggtt gcaccaaatg 6660
tcccaccagg tgcaggcaga aaacgctgga acagcgtgta cagtttgtct taacaaaaag 6720
tgagggcgct gaggtcgagc agggtggtgt gacttgttat agcctttaga gctgcgaaag 6780
cgcgtatgga tttggctcat caggccagat tgagggtctg tggacacatg tcatgttagt 6840
gtacttcaat cgccccctgg atatagcccc gacaataggc cgtggcctca tttttttgcc 6900
ttccgcacat ttccattgct cggtacccac accttgcttc tcctgcactt gccaacctta 6960
atactggttt acattgacca acatcttaca agcggggggc ttgtctaggg tatatataaa 7020
cagtggctct cccaatcggt tgccagtctc ttttttcctt tctttcccca cagattcgaa 7080
atctaaacta cacatcacag aattccgagc cgtgagtatc cacgacaaga tcagtgtcga 7140
gacgacgcgt tttgtgtaat gacacaatcc gaaagtcgct agcaacacac actctctaca 7200
caaactaacc cagctctggt ac 7222
<210> 119
<211> 7779
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pFBAIN-389Elo
<400> 119
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgaaaaca gtgtacgcag atctactata gaggaacatt 6060
taaattgccc cggagaagac ggccaggccg cctagatgac aaattcaaca actcacagct 6120
gactttctgc cattgccact aggggggggc ctttttatat ggccaagcca agctctccac 6180
gtcggttggg ctgcacccaa caataaatgg gtagggttgc accaacaaag ggatgggatg 6240
gggggtagaa gatacgagga taacggggct caatggcaca aataagaacg aatactgcca 6300
ttaagactcg tgatccagcg actgacacca ttgcatcatc taagggcctc aaaactacct 6360
cggaactgct gcgctgatct ggacaccaca gaggttccga gcactttagg ttgcaccaaa 6420
tgtcccacca ggtgcaggca gaaaacgctg gaacagcgtg tacagtttgt cttaacaaaa 6480
agtgagggcg ctgaggtcga gcagggtggt gtgacttgtt atagccttta gagctgcgaa 6540
agcgcgtatg gatttggctc atcaggccag attgagggtc tgtggacaca tgtcatgtta 6600
gtgtacttca atcgccccct ggatatagcc ccgacaatag gccgtggcct catttttttg 6660
ccttccgcac atttccattg ctcggtaccc acaccttgct tctcctgcac ttgccaacct 6720
taatactggt ttacattgac caacatctta caagcggggg gcttgtctag ggtatatata 6780
aacagtggct ctcccaatcg gttgccagtc tcttttttcc tttctttccc cacagattcg 6840
aaatctaaac tacacatcac agaattccga gccgtgagta tccacgacaa gatcagtgtc 6900
gagacgacgc gttttgtgta atgacacaat ccgaaagtcg ctagcaacac acactctcta 6960
cacaaactaa cccagctctg gtaccatggc tgcggtgata gaggtcgcca acgagtttgt 7020
agccatcacg gcagaaacgc tccccaaagt tgactatcaa cgactatggc gagacattta 7080
cagttgtgag ctactgtatt tctccattgc cttcgtgatc ttgaagttta cgttgggcga 7140
gttgagcgac agcggaaaaa agattttgag agtgttgttc aagtggtaca atctcttcat 7200
gtccgtgttc tccttggtgt ctttcctttg catgggctat gccatttata ccgtgggcct 7260
atactctaac gaatgcgaca gggctttcga caactcgttg ttccgctttg caacaaaggt 7320
gttctactac agtaagtttt tggagtacat cgactctttt tatcttccgc tcatggccaa 7380
gccgctgtct ttcctgcaat tcttccatca cttgggagcc cccatggaca tgtggctctt 7440
tgtccaatat tctggggaat ctatttggat ctttgtgttt ttgaatgggt tcattcactt 7500
tgttatgtac gggtactact ggactcggct gatgaagttc aatttcccaa tgcccaagca 7560
gttgattacc gcgatgcaga tcacgcagtt caacgttggt ttctacctcg tgtggtggta 7620
caaagatatt ccctgctacc gaaaggatcc catgcgaatg ttggcctgga tcttcaatta 7680
ctggtatgtt gggactgtct tgctgctgtt cattaatttc ttcgtcaaat cctatgtgtt 7740
cccaaagccg aagactgcag ataaaaaggt ccaataggc 7779
<210> 120
<211> 3511
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pE389S
<400> 120
tcgcgcgttt cggtgatgac ggtgaaaacc tctgacacat gcagctcccg gagacggtca 60
cagcttgtct gtaagcggat gccgggagca gacaagcccg tcagggcgcg tcagcgggtg 120
ttggcgggtg tcggggctgg cttaactatg cggcatcaga gcagattgta ctgagagtgc 180
accatatgcg gtgtgaaata ccgcacagat gcgtaaggag aaaataccgc atcaggcgcc 240
attcgccatt caggctgcgc aactgttggg aagggcgatc ggtgcgggcc tcttcgctat 300
tacgccagct ggcgaaaggg ggatgtgctg caaggcgatt aagttgggta acgccagggt 360
tttcccagtc acgacgttgt aaaacgacgg ccagtgaatt cgagctcggt acctcgcgaa 420
tgcatctaga tccatggctg ccgtcatcga ggtggccaac gagttcgtcg ctatcactgc 480
cgagaccctt cccaaggtgg actatcagcg actctggcga gacatctact cctgcgagct 540
cctgtacttc tccattgctt tcgtcatcct caagtttacc cttggcgagc tctcggattc 600
tggcaaaaag attctgcgag tgctgttcaa gtggtacaac ctcttcatgt ccgtcttttc 660
gctggtgtcc ttcctctgta tgggttacgc catctacacc gttggactgt actccaacga 720
atgcgacaga gctttcgaca acagcttgtt ccgatttgcc accaaggtct tctactattc 780
caagtttctg gagtacatcg actctttcta ccttcccctc atggccaagc ctctgtcctt 840
tctgcagttc tttcatcact tgggagctcc tatggacatg tggctcttcg tgcagtactc 900
tggcgaatcc atttggatct ttgtgttcct gaacggattc attcactttg tcatgtacgg 960
ctactattgg acacggctga tgaagttcaa ctttcccatg cccaagcagc tcattaccgc 1020
aatgcagatc acccagttca acgttggctt ctacctcgtg tggtggtaca aggacattcc 1080
ctgttaccga aaggatccca tgcgaatgct ggcctggatc ttcaactact ggtacgtcgg 1140
taccgttctt ctgctcttca tcaacttctt tgtcaagtcc tacgtgtttc ccaagcctaa 1200
gactgccgac aaaaaggtcc agtagcggcc gcatcggatc ccgggcccgt cgactgcaga 1260
ggcctgcatg caagcttggc gtaatcatgg tcatagctgt ttcctgtgtg aaattgttat 1320
ccgctcacaa ttccacacaa catacgagcc ggaagcataa agtgtaaagc ctggggtgcc 1380
taatgagtga gctaactcac attaattgcg ttgcgctcac tgcccgcttt ccagtcggga 1440
aacctgtcgt gccagctgca ttaatgaatc ggccaacgcg cggggagagg cggtttgcgt 1500
attgggcgct cttccgcttc ctcgctcact gactcgctgc gctcggtcgt tcggctgcgg 1560
cgagcggtat cagctcactc aaaggcggta atacggttat ccacagaatc aggggataac 1620
gcaggaaaga acatgtgagc aaaaggccag caaaaggcca ggaaccgtaa aaaggccgcg 1680
ttgctggcgt ttttccatag gctccgcccc cctgacgagc atcacaaaaa tcgacgctca 1740
agtcagaggt ggcgaaaccc gacaggacta taaagatacc aggcgtttcc ccctggaagc 1800
tccctcgtgc gctctcctgt tccgaccctg ccgcttaccg gatacctgtc cgcctttctc 1860
ccttcgggaa gcgtggcgct ttctcatagc tcacgctgta ggtatctcag ttcggtgtag 1920
gtcgttcgct ccaagctggg ctgtgtgcac gaaccccccg ttcagcccga ccgctgcgcc 1980
ttatccggta actatcgtct tgagtccaac ccggtaagac acgacttatc gccactggca 2040
gcagccactg gtaacaggat tagcagagcg aggtatgtag gcggtgctac agagttcttg 2100
aagtggtggc ctaactacgg ctacactaga agaacagtat ttggtatctg cgctctgctg 2160
aagccagtta ccttcggaaa aagagttggt agctcttgat ccggcaaaca aaccaccgct 2220
ggtagcggtg gtttttttgt ttgcaagcag cagattacgc gcagaaaaaa aggatctcaa 2280
gaagatcctt tgatcttttc tacggggtct gacgctcagt ggaacgaaaa ctcacgttaa 2340
gggattttgg tcatgagatt atcaaaaagg atcttcacct agatcctttt aaattaaaaa 2400
tgaagtttta aatcaatcta aagtatatat gagtaaactt ggtctgacag ttaccaatgc 2460
ttaatcagtg aggcacctat ctcagcgatc tgtctatttc gttcatccat agttgcctga 2520
ctccccgtcg tgtagataac tacgatacgg gagggcttac catctggccc cagtgctgca 2580
atgataccgc gagacccacg ctcaccggct ccagatttat cagcaataaa ccagccagcc 2640
ggaagggccg agcgcagaag tggtcctgca actttatccg cctccatcca gtctattaat 2700
tgttgccggg aagctagagt aagtagttcg ccagttaata gtttgcgcaa cgttgttgcc 2760
attgctacag gcatcgtggt gtcacgctcg tcgtttggta tggcttcatt cagctccggt 2820
tcccaacgat caaggcgagt tacatgatcc cccatgttgt gcaaaaaagc ggttagctcc 2880
ttcggtcctc cgatcgttgt cagaagtaag ttggccgcag tgttatcact catggttatg 2940
gcagcactgc ataattctct tactgtcatg ccatccgtaa gatgcttttc tgtgactggt 3000
gagtactcaa ccaagtcatt ctgagaatag tgtatgcggc gaccgagttg ctcttgcccg 3060
gcgtcaatac gggataatac cgcgccacat agcagaactt taaaagtgct catcattgga 3120
aaacgttctt cggggcgaaa actctcaagg atcttaccgc tgttgagatc cagttcgatg 3180
taacccactc gtgcacccaa ctgatcttca gcatctttta ctttcaccag cgtttctggg 3240
tgagcaaaaa caggaaggca aaatgccgca aaaaagggaa taagggcgac acggaaatgt 3300
tgaatactca tactcttcct ttttcaatat tattgaagca tttatcaggg ttattgtctc 3360
atgagcggat acatatttga atgtatttag aaaaataaac aaataggggt tccgcgcaca 3420
tttccccgaa aagtgccacc tgacgtctaa gaaaccatta ttatcatgac attaacctat 3480
aaaaataggc gtatcacgag gccctttcgt c 3511
<210> 121
<211> 8165
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZUF17
<400> 121
gtacgagccg gaagcataaa gtgtaaagcc tggggtgcct aatgagtgag ctaactcaca 60
ttaattgcgt tgcgctcact gcccgctttc cagtcgggaa acctgtcgtg ccagctgcat 120
taatgaatcg gccaacgcgc ggggagaggc ggtttgcgta ttgggcgctc ttccgcttcc 180
tcgctcactg actcgctgcg ctcggtcgtt cggctgcggc gagcggtatc agctcactca 240
aaggcggtaa tacggttatc cacagaatca ggggataacg caggaaagaa catgtgagca 300
aaaggccagc aaaaggccag gaaccgtaaa aaggccgcgt tgctggcgtt tttccatagg 360
ctccgccccc ctgacgagca tcacaaaaat cgacgctcaa gtcagaggtg gcgaaacccg 420
acaggactat aaagatacca ggcgtttccc cctggaagct ccctcgtgcg ctctcctgtt 480
ccgaccctgc cgcttaccgg atacctgtcc gcctttctcc cttcgggaag cgtggcgctt 540
tctcatagct cacgctgtag gtatctcagt tcggtgtagg tcgttcgctc caagctgggc 600
tgtgtgcacg aaccccccgt tcagcccgac cgctgcgcct tatccggtaa ctatcgtctt 660
gagtccaacc cggtaagaca cgacttatcg ccactggcag cagccactgg taacaggatt 720
agcagagcga ggtatgtagg cggtgctaca gagttcttga agtggtggcc taactacggc 780
tacactagaa ggacagtatt tggtatctgc gctctgctga agccagttac cttcggaaaa 840
agagttggta gctcttgatc cggcaaacaa accaccgctg gtagcggtgg tttttttgtt 900
tgcaagcagc agattacgcg cagaaaaaaa ggatctcaag aagatccttt gatcttttct 960
acggggtctg acgctcagtg gaacgaaaac tcacgttaag ggattttggt catgagatta 1020
tcaaaaagga tcttcaccta gatcctttta aattaaaaat gaagttttaa atcaatctaa 1080
agtatatatg agtaaacttg gtctgacagt taccaatgct taatcagtga ggcacctatc 1140
tcagcgatct gtctatttcg ttcatccata gttgcctgac tccccgtcgt gtagataact 1200
acgatacggg agggcttacc atctggcccc agtgctgcaa tgataccgcg agacccacgc 1260
tcaccggctc cagatttatc agcaataaac cagccagccg gaagggccga gcgcagaagt 1320
ggtcctgcaa ctttatccgc ctccatccag tctattaatt gttgccggga agctagagta 1380
agtagttcgc cagttaatag tttgcgcaac gttgttgcca ttgctacagg catcgtggtg 1440
tcacgctcgt cgtttggtat ggcttcattc agctccggtt cccaacgatc aaggcgagtt 1500
acatgatccc ccatgttgtg caaaaaagcg gttagctcct tcggtcctcc gatcgttgtc 1560
agaagtaagt tggccgcagt gttatcactc atggttatgg cagcactgca taattctctt 1620
actgtcatgc catccgtaag atgcttttct gtgactggtg agtactcaac caagtcattc 1680
tgagaatagt gtatgcggcg accgagttgc tcttgcccgg cgtcaatacg ggataatacc 1740
gcgccacata gcagaacttt aaaagtgctc atcattggaa aacgttcttc ggggcgaaaa 1800
ctctcaagga tcttaccgct gttgagatcc agttcgatgt aacccactcg tgcacccaac 1860
tgatcttcag catcttttac tttcaccagc gtttctgggt gagcaaaaac aggaaggcaa 1920
aatgccgcaa aaaagggaat aagggcgaca cggaaatgtt gaatactcat actcttcctt 1980
tttcaatatt attgaagcat ttatcagggt tattgtctca tgagcggata catatttgaa 2040
tgtatttaga aaaataaaca aataggggtt ccgcgcacat ttccccgaaa agtgccacct 2100
gacgcgccct gtagcggcgc attaagcgcg gcgggtgtgg tggttacgcg cagcgtgacc 2160
gctacacttg ccagcgccct agcgcccgct cctttcgctt tcttcccttc ctttctcgcc 2220
acgttcgccg gctttccccg tcaagctcta aatcgggggc tccctttagg gttccgattt 2280
agtgctttac ggcacctcga ccccaaaaaa cttgattagg gtgatggttc acgtagtggg 2340
ccatcgccct gatagacggt ttttcgccct ttgacgttgg agtccacgtt ctttaatagt 2400
ggactcttgt tccaaactgg aacaacactc aaccctatct cggtctattc ttttgattta 2460
taagggattt tgccgatttc ggcctattgg ttaaaaaatg agctgattta acaaaaattt 2520
aacgcgaatt ttaacaaaat attaacgctt acaatttcca ttcgccattc aggctgcgca 2580
actgttggga agggcgatcg gtgcgggcct cttcgctatt acgccagctg gcgaaagggg 2640
gatgtgctgc aaggcgatta agttgggtaa cgccagggtt ttcccagtca cgacgttgta 2700
aaacgacggc cagtgaattg taatacgact cactataggg cgaattgggt accgggcccc 2760
ccctcgaggt cgatggtgtc gataagcttg atatcgaatt catgtcacac aaaccgatct 2820
tcgcctcaag gaaacctaat tctacatccg agagactgcc gagatccagt ctacactgat 2880
taattttcgg gccaataatt taaaaaaatc gtgttatata atattatatg tattatatat 2940
atacatcatg atgatactga cagtcatgtc ccattgctaa atagacagac tccatctgcc 3000
gcctccaact gatgttctca atatttaagg ggtcatctcg cattgtttaa taataaacag 3060
actccatcta ccgcctccaa atgatgttct caaaatatat tgtatgaact tatttttatt 3120
acttagtatt attagacaac ttacttgctt tatgaaaaac acttcctatt taggaaacaa 3180
tttataatgg cagttcgttc atttaacaat ttatgtagaa taaatgttat aaatgcgtat 3240
gggaaatctt aaatatggat agcataaatg atatctgcat tgcctaattc gaaatcaaca 3300
gcaacgaaaa aaatcccttg tacaacataa atagtcatcg agaaatatca actatcaaag 3360
aacagctatt cacacgttac tattgagatt attattggac gagaatcaca cactcaactg 3420
tctttctctc ttctagaaat acaggtacaa gtatgtacta ttctcattgt tcatacttct 3480
agtcatttca tcccacatat tccttggatt tctctccaat gaatgacatt ctatcttgca 3540
aattcaacaa ttataataag atataccaaa gtagcggtat agtggcaatc aaaaagcttc 3600
tctggtgtgc ttctcgtatt tatttttatt ctaatgatcc attaaaggta tatatttatt 3660
tcttgttata taatcctttt gtttattaca tgggctggat acataaaggt attttgattt 3720
aattttttgc ttaaattcaa tcccccctcg ttcagtgtca actgtaatgg taggaaatta 3780
ccatactttt gaagaagcaa aaaaaatgaa agaaaaaaaa aatcgtattt ccaggttaga 3840
cgttccgcag aatctagaat gcggtatgcg gtacattgtt cttcgaacgt aaaagttgcg 3900
ctccctgaga tattgtacat ttttgctttt acaagtacaa gtacatcgta caactatgta 3960
ctactgttga tgcatccaca acagtttgtt ttgttttttt ttgttttttt tttttctaat 4020
gattcattac cgctatgtat acctacttgt acttgtagta agccgggtta ttggcgttca 4080
attaatcata gacttatgaa tctgcacggt gtgcgctgcg agttactttt agcttatgca 4140
tgctacttgg gtgtaatatt gggatctgtt cggaaatcaa cggatgctca atcgatttcg 4200
acagtaatta attaagtcat acacaagtca gctttcttcg agcctcatat aagtataagt 4260
agttcaacgt attagcactg tacccagcat ctccgtatcg agaaacacaa caacatgccc 4320
cattggacag atcatgcgga tacacaggtt gtgcagtatc atacatactc gatcagacag 4380
gtcgtctgac catcatacaa gctgaacaag cgctccatac ttgcacgctc tctatataca 4440
cagttaaatt acatatccat agtctaacct ctaacagtta atcttctggt aagcctccca 4500
gccagccttc tggtatcgct tggcctcctc aataggatct cggttctggc cgtacagacc 4560
tcggccgaca attatgatat ccgttccggt agacatgaca tcctcaacag ttcggtactg 4620
ctgtccgaga gcgtctccct tgtcgtcaag acccaccccg ggggtcagaa taagccagtc 4680
ctcagagtcg cccttaggtc ggttctgggc aatgaagcca accacaaact cggggtcgga 4740
tcgggcaagc tcaatggtct gcttggagta ctcgccagtg gccagagagc ccttgcaaga 4800
cagctcggcc agcatgagca gacctctggc cagcttctcg ttgggagagg ggactaggaa 4860
ctccttgtac tgggagttct cgtagtcaga gacgtcctcc ttcttctgtt cagagacagt 4920
ttcctcggca ccagctcgca ggccagcaat gattccggtt ccgggtacac cgtgggcgtt 4980
ggtgatatcg gaccactcgg cgattcggtg acaccggtac tggtgcttga cagtgttgcc 5040
aatatctgcg aactttctgt cctcgaacag gaagaaaccg tgcttaagag caagttcctt 5100
gagggggagc acagtgccgg cgtaggtgaa gtcgtcaatg atgtcgatat gggttttgat 5160
catgcacaca taaggtccga ccttatcggc aagctcaatg agctccttgg tggtggtaac 5220
atccagagaa gcacacaggt tggttttctt ggctgccacg agcttgagca ctcgagcggc 5280
aaaggcggac ttgtggacgt tagctcgagc ttcgtaggag ggcattttgg tggtgaagag 5340
gagactgaaa taaatttagt ctgcagaact ttttatcgga accttatctg gggcagtgaa 5400
gtatatgtta tggtaatagt tacgagttag ttgaacttat agatagactg gactatacgg 5460
ctatcggtcc aaattagaaa gaacgtcaat ggctctctgg gcgtcgcctt tgccgacaaa 5520
aatgtgatca tgatgaaagc cagcaatgac gttgcagctg atattgttgt cggccaaccg 5580
cgccgaaaac gcagctgtca gacccacagc ctccaacgaa gaatgtatcg tcaaagtgat 5640
ccaagcacac tcatagttgg agtcgtactc caaaggcggc aatgacgagt cagacagata 5700
ctcgtcgact caggcgacga cggaattcct gcagcccatc tgcagaattc aggagagacc 5760
gggttggcgg cgtatttgtg tcccaaaaaa cagccccaat tgccccggag aagacggcca 5820
ggccgcctag atgacaaatt caacaactca cagctgactt tctgccattg ccactagggg 5880
ggggcctttt tatatggcca agccaagctc tccacgtcgg ttgggctgca cccaacaata 5940
aatgggtagg gttgcaccaa caaagggatg ggatgggggg tagaagatac gaggataacg 6000
gggctcaatg gcacaaataa gaacgaatac tgccattaag actcgtgatc cagcgactga 6060
caccattgca tcatctaagg gcctcaaaac tacctcggaa ctgctgcgct gatctggaca 6120
ccacagaggt tccgagcact ttaggttgca ccaaatgtcc caccaggtgc aggcagaaaa 6180
cgctggaaca gcgtgtacag tttgtcttaa caaaaagtga gggcgctgag gtcgagcagg 6240
gtggtgtgac ttgttatagc ctttagagct gcgaaagcgc gtatggattt ggctcatcag 6300
gccagattga gggtctgtgg acacatgtca tgttagtgta cttcaatcgc cccctggata 6360
tagccccgac aataggccgt ggcctcattt ttttgccttc cgcacatttc cattgctcgg 6420
tacccacacc ttgcttctcc tgcacttgcc aaccttaata ctggtttaca ttgaccaaca 6480
tcttacaagc ggggggcttg tctagggtat atataaacag tggctctccc aatcggttgc 6540
cagtctcttt tttcctttct ttccccacag attcgaaatc taaactacac atcacacaat 6600
gcctgttact gacgtcctta agcgaaagtc cggtgtcatc gtcggcgacg atgtccgagc 6660
cgtgagtatc cacgacaaga tcagtgtcga gacgacgcgt tttgtgtaat gacacaatcc 6720
gaaagtcgct agcaacacac actctctaca caaactaacc cagctctcca tggctgagga 6780
taagaccaag gtcgagttcc ctaccctgac tgagctgaag cactctatcc ctaacgcttg 6840
ctttgagtcc aacctcggac tctcgctcta ctacactgcc cgagcgatct tcaacgcatc 6900
tgcctctgct gctctgctct acgctgcccg atctactccc ttcattgccg ataacgttct 6960
gctccacgct ctggtttgcg ccacctacat ctacgtgcag ggtgtcatct tctggggttt 7020
ctttaccgtc ggtcacgact gtggtcactc tgccttctcc cgataccact ccgtcaactt 7080
catcattggc tgcatcatgc actctgccat tctgactccc ttcgagtcct ggcgagtgac 7140
ccaccgacac catcacaaga acactggcaa cattgataag gacgagatct tctaccctca 7200
tcggtccgtc aaggacctcc aggacgtgcg acaatgggtc tacaccctcg gaggtgcttg 7260
gtttgtctac ctgaaggtcg gatatgctcc tcgaaccatg tcccactttg acccctggga 7320
ccctctcctg cttcgacgag cctccgctgt catcgtgtcc ctcggagtct gggctgcctt 7380
cttcgctgcc tacgcctacc tcacatactc gctcggcttt gccgtcatgg gcctctacta 7440
ctatgctcct ctctttgtct ttgcttcgtt cctcgtcatt actaccttct tgcatcacaa 7500
cgacgaagct actccctggt acggtgactc ggagtggacc tacgtcaagg gcaacctgag 7560
ctccgtcgac cgatcgtacg gagctttcgt ggacaacctg tctcaccaca ttggcaccca 7620
ccaggtccat cacttgttcc ctatcattcc ccactacaag ctcaacgaag ccaccaagca 7680
ctttgctgcc gcttaccctc acctcgtgag acgtaacgac gagcccatca ttactgcctt 7740
cttcaagacc gctcacctct ttgtcaacta cggagctgtg cccgagactg ctcagatttt 7800
caccctcaaa gagtctgccg ctgcagccaa ggccaagagc gactaagcgg ccgcaagtgt 7860
ggatggggaa gtgagtgccc ggttctgtgt gcacaattgg caatccaaga tggatggatt 7920
caacacaggg atatagcgag ctacgtggtg gtgcgaggat atagcaacgg atatttatgt 7980
ttgacacttg agaatgtacg atacaagcac tgtccaagta caatactaaa catactgtac 8040
atactcatac tcgtacccgg gcaacggttt cacttgagtg cagtggctag tgctcttact 8100
cgtacagtgt gcaatactgc gtatcatagt ctttgatgta tatcgtattc attcatgtta 8160
gttgc 8165
<210> 122
<211> 7879
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZUFE389S
<400> 122
catggctgcc gtcatcgagg tggccaacga gttcgtcgct atcactgccg agacccttcc 60
caaggtggac tatcagcgac tctggcgaga catctactcc tgcgagctcc tgtacttctc 120
cattgctttc gtcatcctca agtttaccct tggcgagctc tcggattctg gcaaaaagat 180
tctgcgagtg ctgttcaagt ggtacaacct cttcatgtcc gtcttttcgc tggtgtcctt 240
cctctgtatg ggttacgcca tctacaccgt tggactgtac tccaacgaat gcgacagagc 300
tttcgacaac agcttgttcc gatttgccac caaggtcttc tactattcca agtttctgga 360
gtacatcgac tctttctacc ttcccctcat ggccaagcct ctgtcctttc tgcagttctt 420
tcatcacttg ggagctccta tggacatgtg gctcttcgtg cagtactctg gcgaatccat 480
ttggatcttt gtgttcctga acggattcat tcactttgtc atgtacggct actattggac 540
acggctgatg aagttcaact ttcccatgcc caagcagctc attaccgcaa tgcagatcac 600
ccagttcaac gttggcttct acctcgtgtg gtggtacaag gacattccct gttaccgaaa 660
ggatcccatg cgaatgctgg cctggatctt caactactgg tacgtcggta ccgttcttct 720
gctcttcatc aacttctttg tcaagtccta cgtgtttccc aagcctaaga ctgccgacaa 780
aaaggtccag tagcggccgc aagtgtggat ggggaagtga gtgcccggtt ctgtgtgcac 840
aattggcaat ccaagatgga tggattcaac acagggatat agcgagctac gtggtggtgc 900
gaggatatag caacggatat ttatgtttga cacttgagaa tgtacgatac aagcactgtc 960
caagtacaat actaaacata ctgtacatac tcatactcgt acccgggcaa cggtttcact 1020
tgagtgcagt ggctagtgct cttactcgta cagtgtgcaa tactgcgtat catagtcttt 1080
gatgtatatc gtattcattc atgttagttg cgtacgagcc ggaagcataa agtgtaaagc 1140
ctggggtgcc taatgagtga gctaactcac attaattgcg ttgcgctcac tgcccgcttt 1200
ccagtcggga aacctgtcgt gccagctgca ttaatgaatc ggccaacgcg cggggagagg 1260
cggtttgcgt attgggcgct cttccgcttc ctcgctcact gactcgctgc gctcggtcgt 1320
tcggctgcgg cgagcggtat cagctcactc aaaggcggta atacggttat ccacagaatc 1380
aggggataac gcaggaaaga acatgtgagc aaaaggccag caaaaggcca ggaaccgtaa 1440
aaaggccgcg ttgctggcgt ttttccatag gctccgcccc cctgacgagc atcacaaaaa 1500
tcgacgctca agtcagaggt ggcgaaaccc gacaggacta taaagatacc aggcgtttcc 1560
ccctggaagc tccctcgtgc gctctcctgt tccgaccctg ccgcttaccg gatacctgtc 1620
cgcctttctc ccttcgggaa gcgtggcgct ttctcatagc tcacgctgta ggtatctcag 1680
ttcggtgtag gtcgttcgct ccaagctggg ctgtgtgcac gaaccccccg ttcagcccga 1740
ccgctgcgcc ttatccggta actatcgtct tgagtccaac ccggtaagac acgacttatc 1800
gccactggca gcagccactg gtaacaggat tagcagagcg aggtatgtag gcggtgctac 1860
agagttcttg aagtggtggc ctaactacgg ctacactaga aggacagtat ttggtatctg 1920
cgctctgctg aagccagtta ccttcggaaa aagagttggt agctcttgat ccggcaaaca 1980
aaccaccgct ggtagcggtg gtttttttgt ttgcaagcag cagattacgc gcagaaaaaa 2040
aggatctcaa gaagatcctt tgatcttttc tacggggtct gacgctcagt ggaacgaaaa 2100
ctcacgttaa gggattttgg tcatgagatt atcaaaaagg atcttcacct agatcctttt 2160
aaattaaaaa tgaagtttta aatcaatcta aagtatatat gagtaaactt ggtctgacag 2220
ttaccaatgc ttaatcagtg aggcacctat ctcagcgatc tgtctatttc gttcatccat 2280
agttgcctga ctccccgtcg tgtagataac tacgatacgg gagggcttac catctggccc 2340
cagtgctgca atgataccgc gagacccacg ctcaccggct ccagatttat cagcaataaa 2400
ccagccagcc ggaagggccg agcgcagaag tggtcctgca actttatccg cctccatcca 2460
gtctattaat tgttgccggg aagctagagt aagtagttcg ccagttaata gtttgcgcaa 2520
cgttgttgcc attgctacag gcatcgtggt gtcacgctcg tcgtttggta tggcttcatt 2580
cagctccggt tcccaacgat caaggcgagt tacatgatcc cccatgttgt gcaaaaaagc 2640
ggttagctcc ttcggtcctc cgatcgttgt cagaagtaag ttggccgcag tgttatcact 2700
catggttatg gcagcactgc ataattctct tactgtcatg ccatccgtaa gatgcttttc 2760
tgtgactggt gagtactcaa ccaagtcatt ctgagaatag tgtatgcggc gaccgagttg 2820
ctcttgcccg gcgtcaatac gggataatac cgcgccacat agcagaactt taaaagtgct 2880
catcattgga aaacgttctt cggggcgaaa actctcaagg atcttaccgc tgttgagatc 2940
cagttcgatg taacccactc gtgcacccaa ctgatcttca gcatctttta ctttcaccag 3000
cgtttctggg tgagcaaaaa caggaaggca aaatgccgca aaaaagggaa taagggcgac 3060
acggaaatgt tgaatactca tactcttcct ttttcaatat tattgaagca tttatcaggg 3120
ttattgtctc atgagcggat acatatttga atgtatttag aaaaataaac aaataggggt 3180
tccgcgcaca tttccccgaa aagtgccacc tgacgcgccc tgtagcggcg cattaagcgc 3240
ggcgggtgtg gtggttacgc gcagcgtgac cgctacactt gccagcgccc tagcgcccgc 3300
tcctttcgct ttcttccctt cctttctcgc cacgttcgcc ggctttcccc gtcaagctct 3360
aaatcggggg ctccctttag ggttccgatt tagtgcttta cggcacctcg accccaaaaa 3420
acttgattag ggtgatggtt cacgtagtgg gccatcgccc tgatagacgg tttttcgccc 3480
tttgacgttg gagtccacgt tctttaatag tggactcttg ttccaaactg gaacaacact 3540
caaccctatc tcggtctatt cttttgattt ataagggatt ttgccgattt cggcctattg 3600
gttaaaaaat gagctgattt aacaaaaatt taacgcgaat tttaacaaaa tattaacgct 3660
tacaatttcc attcgccatt caggctgcgc aactgttggg aagggcgatc ggtgcgggcc 3720
tcttcgctat tacgccagct ggcgaaaggg ggatgtgctg caaggcgatt aagttgggta 3780
acgccagggt tttcccagtc acgacgttgt aaaacgacgg ccagtgaatt gtaatacgac 3840
tcactatagg gcgaattggg taccgggccc cccctcgagg tcgatggtgt cgataagctt 3900
gatatcgaat tcatgtcaca caaaccgatc ttcgcctcaa ggaaacctaa ttctacatcc 3960
gagagactgc cgagatccag tctacactga ttaattttcg ggccaataat ttaaaaaaat 4020
cgtgttatat aatattatat gtattatata tatacatcat gatgatactg acagtcatgt 4080
cccattgcta aatagacaga ctccatctgc cgcctccaac tgatgttctc aatatttaag 4140
gggtcatctc gcattgttta ataataaaca gactccatct accgcctcca aatgatgttc 4200
tcaaaatata ttgtatgaac ttatttttat tacttagtat tattagacaa cttacttgct 4260
ttatgaaaaa cacttcctat ttaggaaaca atttataatg gcagttcgtt catttaacaa 4320
tttatgtaga ataaatgtta taaatgcgta tgggaaatct taaatatgga tagcataaat 4380
gatatctgca ttgcctaatt cgaaatcaac agcaacgaaa aaaatccctt gtacaacata 4440
aatagtcatc gagaaatatc aactatcaaa gaacagctat tcacacgtta ctattgagat 4500
tattattgga cgagaatcac acactcaact gtctttctct cttctagaaa tacaggtaca 4560
agtatgtact attctcattg ttcatacttc tagtcatttc atcccacata ttccttggat 4620
ttctctccaa tgaatgacat tctatcttgc aaattcaaca attataataa gatataccaa 4680
agtagcggta tagtggcaat caaaaagctt ctctggtgtg cttctcgtat ttatttttat 4740
tctaatgatc cattaaaggt atatatttat ttcttgttat ataatccttt tgtttattac 4800
atgggctgga tacataaagg tattttgatt taattttttg cttaaattca atcccccctc 4860
gttcagtgtc aactgtaatg gtaggaaatt accatacttt tgaagaagca aaaaaaatga 4920
aagaaaaaaa aaatcgtatt tccaggttag acgttccgca gaatctagaa tgcggtatgc 4980
ggtacattgt tcttcgaacg taaaagttgc gctccctgag atattgtaca tttttgcttt 5040
tacaagtaca agtacatcgt acaactatgt actactgttg atgcatccac aacagtttgt 5100
tttgtttttt tttgtttttt ttttttctaa tgattcatta ccgctatgta tacctacttg 5160
tacttgtagt aagccgggtt attggcgttc aattaatcat agacttatga atctgcacgg 5220
tgtgcgctgc gagttacttt tagcttatgc atgctacttg ggtgtaatat tgggatctgt 5280
tcggaaatca acggatgctc aatcgatttc gacagtaatt aattaagtca tacacaagtc 5340
agctttcttc gagcctcata taagtataag tagttcaacg tattagcact gtacccagca 5400
tctccgtatc gagaaacaca acaacatgcc ccattggaca gatcatgcgg atacacaggt 5460
tgtgcagtat catacatact cgatcagaca ggtcgtctga ccatcataca agctgaacaa 5520
gcgctccata cttgcacgct ctctatatac acagttaaat tacatatcca tagtctaacc 5580
tctaacagtt aatcttctgg taagcctccc agccagcctt ctggtatcgc ttggcctcct 5640
caataggatc tcggttctgg ccgtacagac ctcggccgac aattatgata tccgttccgg 5700
tagacatgac atcctcaaca gttcggtact gctgtccgag agcgtctccc ttgtcgtcaa 5760
gacccacccc gggggtcaga ataagccagt cctcagagtc gcccttaggt cggttctggg 5820
caatgaagcc aaccacaaac tcggggtcgg atcgggcaag ctcaatggtc tgcttggagt 5880
actcgccagt ggccagagag cccttgcaag acagctcggc cagcatgagc agacctctgg 5940
ccagcttctc gttgggagag gggactagga actccttgta ctgggagttc tcgtagtcag 6000
agacgtcctc cttcttctgt tcagagacag tttcctcggc accagctcgc aggccagcaa 6060
tgattccggt tccgggtaca ccgtgggcgt tggtgatatc ggaccactcg gcgattcggt 6120
gacaccggta ctggtgcttg acagtgttgc caatatctgc gaactttctg tcctcgaaca 6180
ggaagaaacc gtgcttaaga gcaagttcct tgagggggag cacagtgccg gcgtaggtga 6240
agtcgtcaat gatgtcgata tgggttttga tcatgcacac ataaggtccg accttatcgg 6300
caagctcaat gagctccttg gtggtggtaa catccagaga agcacacagg ttggttttct 6360
tggctgccac gagcttgagc actcgagcgg caaaggcgga cttgtggacg ttagctcgag 6420
cttcgtagga gggcattttg gtggtgaaga ggagactgaa ataaatttag tctgcagaac 6480
tttttatcgg aaccttatct ggggcagtga agtatatgtt atggtaatag ttacgagtta 6540
gttgaactta tagatagact ggactatacg gctatcggtc caaattagaa agaacgtcaa 6600
tggctctctg ggcgtcgcct ttgccgacaa aaatgtgatc atgatgaaag ccagcaatga 6660
cgttgcagct gatattgttg tcggccaacc gcgccgaaaa cgcagctgtc agacccacag 6720
cctccaacga agaatgtatc gtcaaagtga tccaagcaca ctcatagttg gagtcgtact 6780
ccaaaggcgg caatgacgag tcagacagat actcgtcgac tcaggcgacg acggaattcc 6840
tgcagcccat ctgcagaatt caggagagac cgggttggcg gcgtatttgt gtcccaaaaa 6900
acagccccaa ttgccccgga gaagacggcc aggccgccta gatgacaaat tcaacaactc 6960
acagctgact ttctgccatt gccactaggg gggggccttt ttatatggcc aagccaagct 7020
ctccacgtcg gttgggctgc acccaacaat aaatgggtag ggttgcacca acaaagggat 7080
gggatggggg gtagaagata cgaggataac ggggctcaat ggcacaaata agaacgaata 7140
ctgccattaa gactcgtgat ccagcgactg acaccattgc atcatctaag ggcctcaaaa 7200
ctacctcgga actgctgcgc tgatctggac accacagagg ttccgagcac tttaggttgc 7260
accaaatgtc ccaccaggtg caggcagaaa acgctggaac agcgtgtaca gtttgtctta 7320
acaaaaagtg agggcgctga ggtcgagcag ggtggtgtga cttgttatag cctttagagc 7380
tgcgaaagcg cgtatggatt tggctcatca ggccagattg agggtctgtg gacacatgtc 7440
atgttagtgt acttcaatcg ccccctggat atagccccga caataggccg tggcctcatt 7500
tttttgcctt ccgcacattt ccattgctcg gtacccacac cttgcttctc ctgcacttgc 7560
caaccttaat actggtttac attgaccaac atcttacaag cggggggctt gtctagggta 7620
tatataaaca gtggctctcc caatcggttg ccagtctctt ttttcctttc tttccccaca 7680
gattcgaaat ctaaactaca catcacacaa tgcctgttac tgacgtcctt aagcgaaagt 7740
ccggtgtcat cgtcggcgac gatgtccgag ccgtgagtat ccacgacaag atcagtgtcg 7800
agacgacgcg ttttgtgtaa tgacacaatc cgaaagtcgc tagcaacaca cactctctac 7860
acaaactaac ccagctctc 7879
<210> 123
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> X = L or F
<220>
<221> misc_feature
<222> (5)..(8)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (10)..(11)
<223> Xaa can be any naturally occurring amino acid
<400> 123
Tyr Asn Xaa Xaa Xaa Xaa Xaa Xaa Ser Xaa Xaa Ser Phe
1 5 10
<210> 124
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (6)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> MISC_FEATURE
<222> (8)..(8)
<223> X = E or D
<220>
<221> misc_feature
<222> (10)..(10)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> MISC_FEATURE
<222> (12)..(12)
<223> X = T or S
<220>
<221> misc_feature
<222> (13)..(14)
<223> Xaa can be any naturally occurring amino acid
<400> 124
Phe Tyr Xaa Ser Lys Xaa Xaa Xaa Tyr Xaa Asp Xaa Xaa Xaa Leu
1 5 10 15
<210> 125
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> MISC_FEATURE
<222> (2)..(2)
<223> X = Q or H
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (7)..(7)
<223> Xaa can be any naturally occurring amino acid
<400> 125
Leu Xaa Xaa Phe His His Xaa Gly Ala
1 5
<210> 126
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (6)..(12)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> MISC_FEATURE
<222> (13)..(13)
<223> X = K or R or N
<400> 126
Met Tyr Xaa Tyr Tyr Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Phe
1 5 10
<210> 127
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> X = I or L or M
<220>
<221> misc_feature
<222> (6)..(7)
<223> Xaa can be any naturally occurring amino acid
<400> 127
Lys Xaa Leu Xaa Thr Xaa Xaa Gln
1 5
<210> 128
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (6)..(6)
<223> Xaa can be any naturally occurring amino acid
<400> 128
Trp Xaa Phe Asn Tyr Xaa Tyr
1 5
<210> 129
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (6)..(7)
<223> Xaa can be any naturally occurring amino acid
<400> 129
Tyr Xaa Gly Xaa Val Xaa Xaa Leu Phe
1 5
Claims (21)
- (a) 클러스탈 브이(Clustal V) 정렬 방법을 기초로 하여 서열 2 또는 서열 5에 기재된 바와 같은 아미노산 서열과 비교할 때 70% 이상의 아미노산 동일성을 가지며 Δ9 일롱가제(elongase) 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열,(b) BLASTN 정렬 방법을 기초로 하여 서열 1, 서열 3, 서열 4 또는 서열 6에 기재된 바와 같은 뉴클레오티드 서열과 비교할 때 70% 이상의 서열 동일성을 가지며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열,(c) 0.1× SSC, 0.1% SDS 중 65℃에서의 혼성화 및 2× SSC, 0.1% SDS를 사용한 세척 및 이후 0.1× SSC, 0.1% SDS를 사용한 세척의 엄격한 혼성화 조건하에서 서열 1, 서열 3, 서열 4 또는 서열 6에 기재된 바와 같은 뉴클레오티드 서열과 혼성화하며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열, 또는(d) 상기 (a), (b) 또는 (c)의 뉴클레오티드 서열과 동일한 수의 뉴클레오티드로 이루어지며 100% 상보적인, 상기 (a), (b) 또는 (c)의 뉴클레오티드 서열의 상보체로 구성된 군에서 선택된 단리된 폴리뉴클레오티드.
- 제1항에 있어서, 뉴클레오티드 서열이 서열 1, 서열 3, 서열 4 또는 서열 6을 포함하는 것인 폴리뉴클레오티드.
- 제2항에 있어서, 서열 1, 서열 3, 서열 4 또는 서열 6으로 구성된 군에서 선택된 폴리뉴클레오티드.
- 아미노산 서열이(a) 서열 2 또는 서열 5에 기재된 바와 같은 아미노산 서열, 및(b) 1개 이상의 보존적 아미노산 치환으로 인해 상기 (a)에서의 아미노산 서열과 상이한 아미노산 서열로 구성된 군에서 선택된 것인 Δ9 일롱가제 폴리펩티드.
- 제1항의 단리된 핵산 서열을 포함하는 단리된 형질전환된 숙주 세포.
- 제5항에 있어서, 조류(algae), 박테리아, 효모, 난균 및 진균으로 구성된 군에서 선택된 형질전환된 숙주 세포.
- 제6항에 있어서, 트라우스토키트리움(Thraustochytrium) 종, 쉬조키트리움(Schizochytrium) 종 및 모르티에렐라(Mortierella) 종으로 구성된 군에서 선택된 진균인 형질전환된 숙주 세포.
- 제6항에 있어서, 효모가 유질(oleaginous) 효모인 형질전환된 숙주 세포.
- 제8항에 있어서, 유질 효모가 야로위아(Yarrowia), 칸디다(Candida), 로도토룰라(Rhodotorula), 로도스포리듐(Rhodosporidium), 크립토콕쿠스(Cryptococcus), 트리코스포론(Trichosporon) 및 리포마이세스(Lipomyces)로 구성된 군에서 선택된 것인 형질전환된 숙주 세포.
- 제9항에 있어서, 효모가 야로위아 종인 형질전환된 숙주 세포.
- 제10항에 있어서, 야로위아 종이 야로위아 리폴리티카(Yarrowia lipolytica) ATCC #20362, 야로위아 리폴리티카 ATCC #8862, 야로위아 리폴리티카 ATCC #18944, 야로위아 리폴리티카 ATCC #76982 및 야로위아 리폴리티카 LGAM S(7)1로 구성된 군에서 선택된 것인 형질전환된 숙주 세포.
- a) i) (1) 클러스탈 브이 정렬 방법을 기초로 하여 서열 2 또는 서열 5에 기재된 바와 같은 아미노산 서열과 비교할 때 70% 이상의 아미노산 동일성을 가지며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열, 및(2) 0.1× SSC, 0.1% SDS 중 65℃에서의 혼성화 및 2× SSC, 0.1% SDS를 사용한 세척 및 이후 0.1× SSC, 0.1% SDS를 사용한 세척의 엄격한 혼성화 조건하에서 서열 1, 서열 3, 서열 4 또는 서열 6에 기재된 바와 같은 뉴클레오티드 서열과 혼성화하며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열로 구성된 군에서 선택된, Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 단리된 폴리뉴클레오티드 서열, 및(ii) 리놀레산의 공급원을 포함하는 단리된 형질전환된 효모 숙주 세포를 제공하는 단계,b) Δ9 일롱가제 폴리펩티드를 코딩하는 핵산 서열이 발현되고 리놀레산이 에이코사디엔산으로 전환되는 조건하에서 상기 단계 (a)의 효모 숙주 세포를 성장시키는 단계, 및c) 임의로, 상기 단계 (b)의 에이코사디엔산을 회수하는 단계를 포함하는, 에이코사디엔산의 생성 방법.
- a) i) (1) 클러스탈 브이 정렬 방법을 기초로 하여 서열 2 또는 서열 5에 기재된 바와 같은 아미노산 서열과 비교할 때 70% 이상의 아미노산 동일성을 가지며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열, 및(2) 0.1× SSC, 0.1% SDS 중 65℃에서의 혼성화 및 2× SSC, 0.1% SDS를 사용한 세척 및 이후 0.1× SSC, 0.1% SDS를 사용한 세척의 엄격한 혼성화 조건하에서 서열 1, 서열 3, 서열 4 또는 서열 6에 기재된 바와 같은 뉴클레오티드 서열과 혼성화하며 Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 뉴클레오티드 서열을 포함하는 단리된 핵산 서열로 구성된 군에서 선택된, Δ9 일롱가제 활성을 갖는 폴리펩티드를 코딩하는 단리된 폴리뉴클레오티드 서열, 및(ii) α-리놀렌산의 공급원을 포함하는 단리된 형질전환된 효모 숙주 세포를 제공하는 단계,b) Δ9 일롱가제 폴리펩티드를 코딩하는 핵산 서열이 발현되고 α-리놀렌산이 에이코사트리엔산으로 전환되는 조건하에서 상기 단계 (a)의 숙주 세포를 성장시키는 단계, 및c) 임의로, 상기 단계 (b)의 에이코사트리엔산을 회수하는 단계를 포함하는, 에이코사트리엔산의 생성 방법.
- 제12항 또는 제13항에 있어서, Δ9 일롱가제 폴리펩티드를 코딩하는 단리된 폴리뉴클레오티드 서열이 서열 2 또는 서열 5에 기재된 바와 같은 아미노산 서열을 포함하는 폴리펩티드를 코딩하는 것인 방법.
- 제14항에 있어서, Δ9 일롱가제 폴리펩티드를 코딩하는 단리된 폴리뉴클레오티드 서열이a) 113개 이상의 코돈이 야로위아 중에서의 발현을 위해 코돈-최적화된 서열 5, 및b) 106개 이상의 코돈이 야로위아 중에서의 발현을 위해 코돈-최적화된 서열 2로 구성된 군에서 선택된 것인 방법.
- 제6항의 숙주 세포에 의해 생성된 미생물 오일.
- 제16항의 유효량의 미생물 오일을 포함하는 식품.
- 제17항에 있어서, 식품 유사물, 육류 제품, 시리얼 제품, 베이킹 식품, 스낵 식품 및 유제품으로 구성된 군에서 선택된 식품.
- 제16항의 유효량의 미생물 오일을 포함하는 의료용 식품, 식이 보조제, 유아용 조제식(infant formula) 및 의약품으로 구성된 군에서 선택된 제품.
- 제16항의 유효량의 미생물 오일을 포함하는 동물 사료.
- 제20항에 있어서, 애완동물 사료, 반추 동물 사료, 가금류 사료, 및 수산양식 사료로 구성된 군에서 선택된 동물 사료.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US73998905P | 2005-11-23 | 2005-11-23 | |
| US60/739,989 | 2005-11-23 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20080071190A true KR20080071190A (ko) | 2008-08-01 |
Family
ID=37836626
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020087015062A KR20080071190A (ko) | 2005-11-23 | 2006-11-16 | 델타-9 일롱가제, 및 다중불포화 지방산 생성에 있어서의이들의 용도 |
Country Status (11)
| Country | Link |
|---|---|
| US (6) | US7645604B2 (ko) |
| EP (2) | EP1951866B1 (ko) |
| JP (1) | JP5123861B2 (ko) |
| KR (1) | KR20080071190A (ko) |
| CN (1) | CN101365788B (ko) |
| AU (2) | AU2006318738B2 (ko) |
| BR (1) | BRPI0620552A2 (ko) |
| CA (2) | CA2624661C (ko) |
| DK (1) | DK1951866T3 (ko) |
| NO (1) | NO20082466L (ko) |
| WO (2) | WO2007061742A1 (ko) |
Families Citing this family (60)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DK1756280T3 (en) | 2004-04-22 | 2015-02-02 | Commw Scient Ind Res Org | SYNTHESIS OF CHAIN, polyunsaturated fatty acids BY RECOMBINANT CELLS |
| EP2357243B1 (en) | 2004-04-22 | 2018-12-12 | Commonwealth Scientific and Industrial Research Organisation | Synthesis of long-chain polyunsaturated fatty acids by recombinant cells |
| GB0603160D0 (en) * | 2006-02-16 | 2006-03-29 | Rothamsted Res Ltd | Nucleic acid |
| EP2059588A4 (en) | 2006-08-29 | 2010-07-28 | Commw Scient Ind Res Org | FATTY ACID SYNTHESIS |
| EP2390338B1 (en) * | 2006-10-23 | 2013-08-21 | E. I. du Pont de Nemours and Company | Delta-8 desaturases and their use in making polyunsaturated fatty acids |
| US8916361B2 (en) * | 2006-11-17 | 2014-12-23 | Abbott Laboratories | Elongase gene and uses thereof |
| US20080125487A1 (en) * | 2006-11-17 | 2008-05-29 | Tapas Das | Elongase gene and uses thereof |
| US7709239B2 (en) * | 2006-12-07 | 2010-05-04 | E.I. Du Pont De Nemours And Company | Mutant Δ8 desaturase genes engineered by targeted mutagenesis and their use in making polyunsaturated fatty acids |
| US8389808B2 (en) | 2007-02-12 | 2013-03-05 | E.I. Du Pont De Nemours And Company | Production of arachidonic acid in oilseed plants |
| MX2009010574A (es) | 2007-04-03 | 2009-10-22 | Du Pont | Multienzimas y su uso en la fabricacion de acidos grasos poliinsaturados. |
| US7790156B2 (en) | 2007-04-10 | 2010-09-07 | E. I. Du Pont De Nemours And Company | Δ-8 desaturases and their use in making polyunsaturated fatty acids |
| US8119860B2 (en) * | 2007-04-16 | 2012-02-21 | E. I. Du Pont De Nemours And Company | Delta-9 elongases and their use in making polyunsaturated fatty acids |
| CA2695112A1 (en) | 2007-07-31 | 2009-02-05 | Basf Plant Science Gmbh | Elongases and processes for the production of polyunsaturated fatty acids in transgenic organisms |
| DK2198005T3 (da) * | 2007-10-03 | 2014-07-21 | Du Pont | Peroxisom-biogenesefaktorprotein(PEX)-brud til ændring af indholdet af flerumættede fedtsyrer og det totale lipidindhold i olieholdige eukaryote organismer |
| WO2009046231A1 (en) * | 2007-10-03 | 2009-04-09 | E. I. Du Pont De Nemours And Company | Optimized strains of yarrowia lipolytica for high eicosapentaenoic acid production |
| US8168858B2 (en) | 2008-06-20 | 2012-05-01 | E. I. Du Pont De Nemours And Company | Delta-9 fatty acid elongase genes and their use in making polyunsaturated fatty acids |
| CN113957105B (zh) | 2008-11-18 | 2024-11-01 | 联邦科学技术研究组织 | 产生ω-3脂肪酸的酶和方法 |
| US9175318B2 (en) | 2008-12-18 | 2015-11-03 | E. I. Dupont De Nemours And Company | Reducing byproduction of malonates by yeast in a fermentation process |
| AU2010232639B2 (en) | 2009-04-01 | 2016-02-04 | Corteva Agriscience Llc | Use of a seed specific promoter to drive ODP1 expression in cruciferous oilseed plants to increase oil content while maintaining normal germination |
| WO2010118362A1 (en) * | 2009-04-09 | 2010-10-14 | The Regents Of The University Of Colorado, A Body Corporate | Methods and compositions for inducing physiological hypertrophy |
| DK2443248T3 (en) | 2009-06-16 | 2018-03-12 | Du Pont | IMPROVEMENT OF LONG-CHAIN POLYUM Saturated OMEGA-3 AND OMEGA-6 FATTY ACID BIOS SYNTHESIS BY EXPRESSION OF ACYL-CoA LYSOPHOSPHOLIPID ACYL TRANSFERASES |
| CN102803289B (zh) | 2009-06-16 | 2015-07-22 | 纳幕尔杜邦公司 | 用于高水平生产二十碳五烯酸的改善的优化的解脂耶氏酵母菌株 |
| AU2010260234B2 (en) | 2009-06-16 | 2015-02-26 | E. I. Du Pont De Nemours And Company | High eicosapentaenoic acid oils from improved optimized strains of Yarrowia lipolytica |
| WO2011008510A2 (en) | 2009-06-30 | 2011-01-20 | E. I. Du Pont De Nemours And Company | Plant seeds with altered storage compound levels, related constructs and methods involving genes encoding cytosolic pyrophosphatase |
| US8188335B2 (en) * | 2009-07-17 | 2012-05-29 | Abbott Laboratories | Δ9-elongase for production of polyunsaturated fatty acid-enriched oils |
| AR078829A1 (es) | 2009-10-30 | 2011-12-07 | Du Pont | Plantas y semillas con niveles alterados de compuesto de almacenamiento, construcciones relacionadas y metodos relacionados con genes que codifican proteinas similares a las aldolasas bacterianas de la clase ii del acido 2,4- dihidroxi-hept-2-eno-1,7-dioico |
| IN2012DN05162A (ko) | 2009-12-24 | 2015-10-23 | Du Pont | |
| WO2011087981A2 (en) | 2010-01-15 | 2011-07-21 | E. I. Du Pont De Nemours And Company | Clinical benefits of eicosapentaenoic acid in humans |
| WO2011109618A2 (en) | 2010-03-03 | 2011-09-09 | E. I. Du Pont De Nemours And Company | Plant seeds with altered storage compound levels, related constructs and methods involving genes encoding oxidoreductase motif polypeptides |
| EP2561050A1 (en) | 2010-04-22 | 2013-02-27 | E.I. Du Pont De Nemours And Company | Method for obtaining polyunsaturated fatty acid-containing compositions from microbial biomass |
| AU2011271497A1 (en) | 2010-07-01 | 2013-01-10 | E. I. Du Pont De Nemours And Company | Plant seeds with altered storage compound levels, related constructs and methods involving genes encoding PAE and PAE-like polypeptides |
| EP2603094A1 (en) | 2010-08-11 | 2013-06-19 | E.I. Du Pont De Nemours And Company | A sustainable aquaculture feeding strategy |
| CA2805882A1 (en) | 2010-08-11 | 2012-02-16 | E. I. Dupont De Nemours And Company | Improved aquaculture meat products |
| US20120040076A1 (en) | 2010-08-11 | 2012-02-16 | E. I. Du Pont De Nemours And Company | Aquaculture feed compositions |
| JP5963749B2 (ja) * | 2010-08-26 | 2016-08-03 | イー・アイ・デュポン・ドウ・ヌムール・アンド・カンパニーE.I.Du Pont De Nemours And Company | 変異δ9エロンガーゼおよび多価不飽和脂肪酸の製造におけるそれらの使用 |
| US8703473B2 (en) | 2010-08-26 | 2014-04-22 | E I Du Pont De Nemours And Company | Recombinant microbial host cells for high eicosapentaenoic acid production |
| WO2012027698A1 (en) | 2010-08-26 | 2012-03-01 | E.I. Du Pont De Nemours And Company | Mutant hpgg motif and hdash motif delta-5 desaturases and their use in making polyunsaturated fatty acids |
| JP2014503216A (ja) | 2010-12-30 | 2014-02-13 | イー・アイ・デュポン・ドウ・ヌムール・アンド・カンパニー | スクロース利用のための、ヤロウィア・リポリティカ(Yarrowialipolytica)におけるサッカロミセス・セレビシア(Saccharomycescerevisiae)SUC2遺伝子の使用 |
| US20130040340A1 (en) | 2011-02-07 | 2013-02-14 | E. I. Du Pont De Nemours And Company | Production of alcohol esters in situ using alcohols and fatty acids produced by microorganisms |
| CA2825039C (en) | 2011-02-11 | 2020-04-28 | E.I. Du Pont De Nemours And Company | Method for obtaining a lipid-containing composition from microbial biomass |
| WO2012135773A1 (en) | 2011-03-31 | 2012-10-04 | E. I. Du Pont De Nemours And Company | Yarrowia diacylglycerol acyltransferase promoter regions for gene expression in yeast |
| EP2694665A1 (en) | 2011-04-01 | 2014-02-12 | E. I. Du Pont de Nemours and Company | Yarrowia esterase/lipase promoter regions for gene expression in yeast |
| US20120247066A1 (en) | 2011-04-01 | 2012-10-04 | Ice House America, Llc | Ice bagging apparatus and methods |
| EP2694657A1 (en) | 2011-04-05 | 2014-02-12 | E. I. Du Pont de Nemours and Company | Yarrowia n-alkane-hydroxylating cytochrome p450 promoter regions for gene expression in yeast |
| WO2012138612A1 (en) | 2011-04-07 | 2012-10-11 | E. I. Du Pont De Nemours And Company | Yarrowia peroxisomal 2,4-dienoyl-coa reductase promoter regions for gene expression in yeast |
| WO2013096562A1 (en) | 2011-12-22 | 2013-06-27 | E. I. Du Pont De Nemours And Company | Use of the soybean sucrose synthase promoter to increase plant seed lipid content |
| US20150089689A1 (en) | 2012-01-23 | 2015-03-26 | E I Du Pont Nemours And Company | Down-regulation of gene expression using artificial micrornas for silencing fatty acid biosynthetic genes |
| UA127917C2 (uk) | 2012-06-15 | 2024-02-14 | Коммонвелт Сайнтіфік Енд Індастріел Рісерч Організейшн | Рекомбінантна клітина brassica napus, яка містить довголанцюгові поліненасичені жирні кислоти, трансгенна рослина та насіння brassica napus, спосіб отримання екстрагованого ліпіду рослин, харчового продукту та етилового ефіру поліненасичених жирних кислот |
| JP2016502851A (ja) | 2012-12-21 | 2016-02-01 | イー・アイ・デュポン・ドウ・ヌムール・アンド・カンパニーE.I.Du Pont De Nemours And Company | 微生物細胞中における脂質生成を改変するためのsou2ソルビトール利用タンパク質をコードするポリヌクレオチドの下方制御 |
| EP3030647A4 (en) * | 2013-06-12 | 2017-05-03 | Solarvest Bioenergy Inc. | Methods of producing algal cell cultures and biomass, lipid compounds and compositions, and related products |
| US20160272997A1 (en) | 2013-10-25 | 2016-09-22 | Pioneer Hi-Bred International, Inc. | Stem canker tolerant soybeans and methods of use |
| US9725399B2 (en) | 2013-12-18 | 2017-08-08 | Commonwealth Scientific And Industrial Research Organisation | Lipid comprising long chain polyunsaturated fatty acids |
| KR102527795B1 (ko) | 2014-06-27 | 2023-05-02 | 커먼웰쓰 사이언티픽 앤 인더스트리알 리서치 오거니제이션 | 도코사펜타에노산을 포함하는 지질 |
| FR3028527A1 (fr) * | 2014-11-13 | 2016-05-20 | Pivert | Identification de facteurs de transcription de yarrowia lipolytica |
| ES2608968B1 (es) * | 2015-09-08 | 2018-03-01 | Neol Biosolutions, S.A. | Producción de aceites microbianos con alto contenido en ácidos grasos de cadena muy larga |
| EP3377653A4 (en) | 2015-11-19 | 2019-04-17 | Peking University | METHODS FOR OBTAINING AND CORRECTING BIOLOGICAL SEQUENCE INFORMATION |
| CN106874709B (zh) * | 2015-12-12 | 2019-03-01 | 北京大学 | 测序结果中序列数据错误的检测和校正方法 |
| US11096344B2 (en) | 2016-02-05 | 2021-08-24 | Pioneer Hi-Bred International, Inc. | Genetic loci associated with brown stem rot resistance in soybean and methods of use |
| FR3053052B1 (fr) * | 2016-06-28 | 2021-02-12 | Fermentalg | Microalgue modifiee pour une production enrichie en tag |
| US10513718B2 (en) * | 2017-06-06 | 2019-12-24 | City University Of Hong Kong | Method of producing polyunsaturated fatty acid |
Family Cites Families (43)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US2454404A (en) | 1942-10-03 | 1948-11-23 | American Cyanamid Co | Preparation of piperazine |
| US2454504A (en) | 1946-01-29 | 1948-11-23 | Franz F Ehrenhaft | Nonintermittent cinematographic projector |
| US4670285A (en) | 1982-08-06 | 1987-06-02 | The University Of Toronto Innovations Foundation | Infant formula |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US5107065A (en) | 1986-03-28 | 1992-04-21 | Calgene, Inc. | Anti-sense regulation of gene expression in plant cells |
| US5188958A (en) | 1986-05-29 | 1993-02-23 | Calgene, Inc. | Transformation and foreign gene expression in brassica species |
| US5004863B2 (en) | 1986-12-03 | 2000-10-17 | Agracetus | Genetic engineering of cotton plants and lines |
| US5416011A (en) | 1988-07-22 | 1995-05-16 | Monsanto Company | Method for soybean transformation and regeneration |
| WO1992017598A1 (en) | 1991-03-29 | 1992-10-15 | The Board Of Trustees Of The University Of Illinois | Production fo transgenic soybean plants |
| US6372965B1 (en) | 1992-11-17 | 2002-04-16 | E.I. Du Pont De Nemours And Company | Genes for microsomal delta-12 fatty acid desaturases and hydroxylases from plants |
| US5968809A (en) | 1997-04-11 | 1999-10-19 | Abbot Laboratories | Methods and compositions for synthesis of long chain poly-unsaturated fatty acids |
| US6075183A (en) * | 1997-04-11 | 2000-06-13 | Abbott Laboratories | Methods and compositions for synthesis of long chain poly-unsaturated fatty acids in plants |
| US5972664A (en) | 1997-04-11 | 1999-10-26 | Abbott Laboratories | Methods and compositions for synthesis of long chain poly-unsaturated fatty acids |
| US6051754A (en) | 1997-04-11 | 2000-04-18 | Abbott Laboratories | Methods and compositions for synthesis of long chain poly-unsaturated fatty acids in plants |
| WO1998046764A1 (en) | 1997-04-11 | 1998-10-22 | Calgene Llc | Methods and compositions for synthesis of long chain polyunsaturated fatty acids in plants |
| US6432684B1 (en) | 1997-04-11 | 2002-08-13 | Abbott Laboratories | Human desaturase gene and uses thereof |
| JP2002510205A (ja) | 1997-06-04 | 2002-04-02 | カルジーン エルエルシー | ポリケチド様合成遺伝子を植物内で発現させることによる多不飽和脂肪酸の製造 |
| WO1999064614A2 (en) | 1998-06-12 | 1999-12-16 | Calgene Llc | Polyunsaturated fatty acids in plants |
| US6677145B2 (en) * | 1998-09-02 | 2004-01-13 | Abbott Laboratories | Elongase genes and uses thereof |
| US6403349B1 (en) | 1998-09-02 | 2002-06-11 | Abbott Laboratories | Elongase gene and uses thereof |
| CA2791961A1 (en) | 1998-12-07 | 2000-06-15 | Washington State University Research Foundation | Desaturases and methods of using them for synthesis of polyunsaturated fatty acids |
| US6825017B1 (en) * | 1998-12-07 | 2004-11-30 | Washington State University Research Foundation | Desaturases and methods of using them for synthesis of polyunsaturated fatty acids |
| KR20020073580A (ko) * | 2000-02-09 | 2002-09-27 | 바스프 악티엔게젤샤프트 | 신규 연장효소 유전자 및 다가불포화 지방산의 제조 방법 |
| DE60144517D1 (de) | 2000-06-23 | 2011-06-09 | Pioneer Hi Bred Int | Rekombinante konstrukte und ihre verwendung bei der reduzierung der genexpression |
| AU2001270244A1 (en) | 2000-06-28 | 2002-01-08 | Monsanto Technology Llc | Plant regulatory sequences for selective control of gene expression |
| CA2410663C (en) | 2000-07-21 | 2011-12-13 | E.I. Du Pont De Nemours And Company | A cytochrome p450 enzyme associated with the synthesis of .delta. 12-epoxy groups in fatty acids of plants |
| US7087432B2 (en) | 2000-09-28 | 2006-08-08 | Bioriginal Food & Science Corp. | Fad4, Fad5, Fad5-2 and Fad6, novel fatty acid desaturase family members and uses thereof |
| GB0107510D0 (en) * | 2001-03-26 | 2001-05-16 | Univ Bristol | New elongase gene and a process for the production of -9-polyunsaturated fatty acids |
| TWI377253B (en) | 2001-04-16 | 2012-11-21 | Martek Biosciences Corp | Product and process for transformation of thraustochytriales microorganisms |
| BR0317304A (pt) * | 2002-12-19 | 2005-11-08 | Univ Bristol | Processo para a produção de compostos, sequência de ácido nucleico isolada, sequência de aminoácidos, construção gênica, vetor, e, organismo |
| US7129089B2 (en) | 2003-02-12 | 2006-10-31 | E. I. Du Pont De Nemours And Company | Annexin and P34 promoters and use in expression of transgenic genes in plants |
| US20040172682A1 (en) | 2003-02-12 | 2004-09-02 | Kinney Anthony J. | Production of very long chain polyunsaturated fatty acids in oilseed plants |
| AU2004227075B8 (en) | 2003-04-08 | 2009-07-16 | Basf Plant Science Gmbh | Delta-4 Desaturases from Euglena gracilis, expressing plants, and oils containing PUFA |
| US7125672B2 (en) * | 2003-05-07 | 2006-10-24 | E. I. Du Pont De Nemours And Company | Codon-optimized genes for the production of polyunsaturated fatty acids in oleaginous yeasts |
| US7238482B2 (en) | 2003-05-07 | 2007-07-03 | E. I. Du Pont De Nemours And Company | Production of polyunsaturated fatty acids in oleaginous yeasts |
| US7259255B2 (en) | 2003-06-25 | 2007-08-21 | E. I. Du Pont De Nemours And Company | Glyceraldehyde-3-phosphate dehydrogenase and phosphoglycerate mutase promoters for gene expression in oleaginous yeast |
| MX353906B (es) | 2003-08-01 | 2018-02-02 | Basf Plant Science Gmbh | Metodo para la produccion de acidos grasos poli-insaturados en organismos transgenicos. |
| US6953287B2 (en) | 2003-11-06 | 2005-10-11 | 3M Innovative Properties Company | Anchor for fiber optic cable |
| AU2004290052B2 (en) | 2003-11-12 | 2008-12-04 | Corteva Agriscience Llc | Delta-15 desaturases suitable for altering levels of polyunsaturated fatty acids in oleaginous plants and yeast |
| EP1723220B1 (de) | 2004-02-27 | 2013-04-10 | BASF Plant Science GmbH | Verfahren zur herstellung mehrfach ungesättigter fettsäuren in transgenen pflanzen |
| EP2357243B1 (en) | 2004-04-22 | 2018-12-12 | Commonwealth Scientific and Industrial Research Organisation | Synthesis of long-chain polyunsaturated fatty acids by recombinant cells |
| US7256033B2 (en) | 2004-06-25 | 2007-08-14 | E. I. Du Pont De Nemours And Company | Delta-8 desaturase and its use in making polyunsaturated fatty acids |
| US7550286B2 (en) | 2004-11-04 | 2009-06-23 | E. I. Du Pont De Nemours And Company | Docosahexaenoic acid producing strains of Yarrowia lipolytica |
-
2006
- 2006-11-16 DK DK06837764.7T patent/DK1951866T3/da active
- 2006-11-16 CA CA2624661A patent/CA2624661C/en not_active Expired - Fee Related
- 2006-11-16 US US11/601,564 patent/US7645604B2/en active Active
- 2006-11-16 WO PCT/US2006/044480 patent/WO2007061742A1/en active Application Filing
- 2006-11-16 AU AU2006318738A patent/AU2006318738B2/en not_active Ceased
- 2006-11-16 EP EP06837764.7A patent/EP1951866B1/en not_active Not-in-force
- 2006-11-16 KR KR1020087015062A patent/KR20080071190A/ko not_active Application Discontinuation
- 2006-11-16 EP EP06837908A patent/EP1957641A2/en not_active Withdrawn
- 2006-11-16 BR BRPI0620552-6A patent/BRPI0620552A2/pt not_active IP Right Cessation
- 2006-11-16 US US11/992,899 patent/US8049062B2/en not_active Expired - Fee Related
- 2006-11-16 AU AU2006316610A patent/AU2006316610B2/en not_active Ceased
- 2006-11-16 CA CA2625855A patent/CA2625855C/en active Active
- 2006-11-16 US US11/601,563 patent/US20070118929A1/en not_active Abandoned
- 2006-11-16 WO PCT/US2006/044676 patent/WO2007061845A2/en active Application Filing
- 2006-11-16 CN CN200680051550XA patent/CN101365788B/zh not_active Expired - Fee Related
- 2006-11-16 JP JP2008542346A patent/JP5123861B2/ja not_active Expired - Fee Related
-
2008
- 2008-06-02 NO NO20082466A patent/NO20082466L/no not_active Application Discontinuation
-
2009
- 2009-11-17 US US12/619,706 patent/US8048653B2/en active Active
-
2010
- 2010-03-17 US US12/725,482 patent/US8420892B2/en active Active
-
2013
- 2013-03-15 US US13/834,813 patent/US9150874B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| EP1951866B1 (en) | 2014-07-30 |
| CN101365788A (zh) | 2009-02-11 |
| WO2007061845A3 (en) | 2007-08-02 |
| AU2006316610A1 (en) | 2007-05-31 |
| US20090119795A1 (en) | 2009-05-07 |
| WO2007061845A2 (en) | 2007-05-31 |
| US8048653B2 (en) | 2011-11-01 |
| DK1951866T3 (da) | 2014-10-27 |
| AU2006318738A1 (en) | 2007-05-31 |
| CN101365788B (zh) | 2012-11-14 |
| US20070118929A1 (en) | 2007-05-24 |
| US7645604B2 (en) | 2010-01-12 |
| US20100175148A1 (en) | 2010-07-08 |
| AU2006318738B2 (en) | 2011-12-22 |
| EP1957641A2 (en) | 2008-08-20 |
| CA2624661A1 (en) | 2007-05-31 |
| AU2006316610B2 (en) | 2012-06-14 |
| US20100075387A1 (en) | 2010-03-25 |
| US9150874B2 (en) | 2015-10-06 |
| CA2625855C (en) | 2016-04-19 |
| CA2624661C (en) | 2015-06-30 |
| WO2007061742A1 (en) | 2007-05-31 |
| JP5123861B2 (ja) | 2013-01-23 |
| US8420892B2 (en) | 2013-04-16 |
| NO20082466L (no) | 2008-08-20 |
| EP1951866A1 (en) | 2008-08-06 |
| CA2625855A1 (en) | 2007-05-31 |
| BRPI0620552A2 (pt) | 2011-11-22 |
| US20130254931A1 (en) | 2013-09-26 |
| US8049062B2 (en) | 2011-11-01 |
| US20070117190A1 (en) | 2007-05-24 |
| JP2009517019A (ja) | 2009-04-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101365788B (zh) | Δ-9延伸酶及其在制备多不饱和脂肪酸中的用途 | |
| CN101939434B (zh) | 用于在大豆中提高种子贮藏油脂的生成和改变脂肪酸谱的来自解脂耶氏酵母的dgat基因 | |
| DK2087105T3 (da) | Delta 17-desaturase og anvendelse heraf ved fremstilling af flerumættede fedtsyrer | |
| DK2140006T3 (en) | DELTA-5 desaturases AND USE THEREOF FOR THE PRODUCTION OF polyunsaturated fatty acids | |
| KR102700050B1 (ko) | 조작된 내수송/외수송을 가진 미생물 숙주에서 모유 올리고당류의 생산 | |
| DK2087106T3 (en) | MUTATING DELTA8 DESATURATION GENES CONSTRUCTED BY TARGETED MUTAGENES AND USE THEREOF IN THE MANUFACTURE OF MULTI-Saturated FAT ACIDS | |
| KR20070085669A (ko) | 고농도의 아라키돈산을 생성하는 야로위아 리폴리티카 균주 | |
| CA2683497C (en) | .delta.8 desaturases and their use in making polyunsaturated fatty acids | |
| AU2023226754A1 (en) | Compositions and methods for modifying genomes | |
| CN101646766B (zh) | △17去饱和酶及其用于制备多不饱和脂肪酸的用途 | |
| KR20210149060A (ko) | Tn7-유사 트랜스포존을 사용한 rna-유도된 dna 통합 | |
| BRPI0806354A2 (pt) | plantas oleaginosas transgências, sementes, óleos, produtos alimentìcios ou análogos a alimento, produtos alimentìcios medicinais ou análogos alimentìcios medicinais, produtos farmacêuticos, bebidas fórmulas para bebês, suplementos nutricionais, rações para animais domésticos, alimentos para aquacultura, rações animais, produtos de sementes inteiras, produtos de óleos misturados, produtos, subprodutos e subprodutos parcialmente processados | |
| DK2324119T3 (en) | Mutant DELTA5 Desaturases AND USE THEREOF FOR THE PRODUCTION OF polyunsaturated fatty acids | |
| DK2443248T3 (en) | IMPROVEMENT OF LONG-CHAIN POLYUM Saturated OMEGA-3 AND OMEGA-6 FATTY ACID BIOS SYNTHESIS BY EXPRESSION OF ACYL-CoA LYSOPHOSPHOLIPID ACYL TRANSFERASES | |
| KR20140092759A (ko) | 숙주 세포 및 아이소부탄올의 제조 방법 | |
| KR20140113997A (ko) | 부탄올 생성을 위한 유전자 스위치 | |
| BRPI0711020A2 (pt) | polinucleotìdeo isolado, construto de dna recombinente, célula, método para transformar uma célula, método para produzir uma planta trasfornanda, sementes transgênicas, método para a produção de ácidos graxos poliinsaturados de cadeia longa em uma célula vegetal, óleos ou subporudots, método para produzir pelo menos um ácido graxo poliinsaturado em uma célula vegetal de uma semente oleaginosa, plantas de semente oleoginosa, sementes transgênicas, produto alimentìcios, progênies de plantas e molécula de ácido nucléico isolada | |
| DK2324120T3 (en) | Manipulating SNF1 protein kinase OF REVISION OF OIL CONTENT IN OLEAGINOUS ORGANISMS | |
| KR20140099224A (ko) | 케토-아이소발레레이트 데카르복실라제 효소 및 이의 이용 방법 | |
| KR20220012327A (ko) | 피토칸나비노이드 및 피토칸나비노이드 전구체의 생산을 위한 방법 및 세포 | |
| KR20130032897A (ko) | 알코올 발효 시의 알코올 에스테르의 생성 및 원위치에서의 생성물 제거 | |
| KR20140015136A (ko) | 3-히드록시프로피온산 및 다른 생성물의 제조 방법 | |
| KR20120099509A (ko) | 재조합 숙주 세포에서 육탄당 키나아제의 발현 | |
| KR20120136349A (ko) | 고가의 화학적 생성물의 미생물 생산, 및 관련 조성물, 방법 및 시스템 | |
| CN108779480A (zh) | 生产鞘氨醇碱和鞘脂类的方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |