JP7513086B2 - 統合装置、データテーブル統合方法、プログラム - Google Patents
統合装置、データテーブル統合方法、プログラム Download PDFInfo
- Publication number
- JP7513086B2 JP7513086B2 JP2022522413A JP2022522413A JP7513086B2 JP 7513086 B2 JP7513086 B2 JP 7513086B2 JP 2022522413 A JP2022522413 A JP 2022522413A JP 2022522413 A JP2022522413 A JP 2022522413A JP 7513086 B2 JP7513086 B2 JP 7513086B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- row
- data table
- ascending
- elements
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2282—Tablespace storage structures; Management thereof
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/21—Design, administration or maintenance of databases
- G06F16/211—Schema design and management
- G06F16/213—Schema design and management with details for schema evolution support
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/06—Arrangements for sorting, selecting, merging, or comparing data on individual record carriers
- G06F7/08—Sorting, i.e. grouping record carriers in numerical or other ordered sequence according to the classification of at least some of the information they carry
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Document Processing Apparatus (AREA)
Description
図1は同実施形態による統合装置を備えた情報処理システムの構成を示す図である。
図1が示すように、情報処理システム100は、統合装置1と端末2とを通信ネットワークにより接続して構成されてよい。統合装置1は、あらかじめ自装置などで記憶する少なくとも2つのデータテーブルを、1つのデータテーブルへと統合した統合データテーブルを生成する。端末2は統合装置1を操作するユーザが利用する。統合装置1と端末2とはそれぞれコンピュータである。
図2で示すように、統合装置1は、CPU(Central Processing Unit)101、ROM(Read Only Memory)102、RAM(Random Access Memory)103、データベース104、通信モジュール105等の各ハードウェアを備えたコンピュータである。なお、端末2も、同様のハードウェアを備えたコンピュータである。
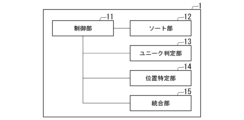
統合装置1は、統合データテーブル生成プログラムを実行する。これにより統合装置1は、制御部11、ソート部12、ユニーク判定部13、位置特定部14、統合部15の各機能を発揮する。
ソート部12は、少なくとも大小比較のできるデータ要素を一つの行の情報として含むデータテーブルの各行を、当該行に含まれるデータ要素に基づいてソートする。
図4で示す統合データテーブルの生成例では、購入履歴テーブル41と、購入者テーブル42の2つのデータテーブルを統合した統合データテーブル43を生成する例を示している。購入履歴テーブル41と、購入者テーブル42の2つのデータテーブルは、それぞれ大小比較のできるデータ要素として購入者IDを、各行のデータ要素として含んでいる。なお、購入履歴テーブル41は2つのデータテーブルのうちの第一データテーブル、購入者テーブル42を2つのデータテーブルのうちの第二データテーブルと見做すことができる。購入者テーブル42を2つのデータテーブルのうちの第一データテーブル、購入履歴テーブル41を2つのデータテーブルのうちの第二データテーブルと見做してもよい。
本実施形態による統合対象の2つのデータテーブルである、右テーブル51(第一データテーブル)と左テーブル52(第二データテーブル)とを図5に示す。右テーブル51と左テーブル52のそれぞれは、行IDとキーとを紐づけた行を複数行有している。本実施形態において、右テーブル51と、左テーブル52の2つのデータテーブルは、それぞれ大小比較のできるデータ要素となるキーを、各行のデータ要素として含んでいる。
図7は統合装置の処理概要を示す第一の図である。
ユーザは端末2を操作して統合装置1にアクセスする。そしてユーザは端末2を操作して、統合装置1に統合対象となる2つのデータテーブルの指定と、それらデータテーブルにおいて大小比較のできるデータ要素の指定と、統合開始の指示を与える。これにより、統合装置1は2つのデータテーブルの統合処理を開始する(ステップS101)。2つのデータテーブルは、図5で示した右テーブル51(第一データテーブル)と、左テーブル52(第二データテーブル)であるとする。なお2つのデータテーブルにおいて大小比較のできるデータ要素の種類は同じであるとする。図6においてはキーが大小比較のできるデータ要素である。2つのデータテーブルにおけるキーの情報は、同じ種類の情報である。
右テーブル61(第一データテーブル)と左テーブル62(第二データテーブル)とを図6に示す。右テーブル61と左テーブル62のそれぞれは、行IDとキーとを紐づけた行を複数行有している。図8で示すように右テーブル61と左テーブル62の何れのデータテーブルも、データテーブル内の各行の大小比較のできるデータ要素としてのキーがそれぞれユニークでない。例えば右テーブル61ではキー「1」となる行が2つ存在し、各行の大小比較のできるデータ要素としてのキーがそれぞれユニークでない。また左テーブル62ではキー「3」となる行が2つ存在し、各行の大小比較のできるデータ要素としてのキーがそれぞれユニークでない。このように、いずれのデータテーブルも各行の大小比較のできるデータ要素としてのキーがそれぞれユニークでない場合、以下のデータテーブルの統合処理が行われる。
すでにステップS102により昇順ソートが行われているとすると、図9(2)の右テーブル61で示すように、右テーブル61の各行のキーが、上から順に「1」、「1」「2」、「3」となるよう各行が昇順に並び替えられている。また図9(2)の左テーブル62で示すように、左テーブル62の各行のキーが、上から順に「1」、「3」、「3」、「5」となるよう各行が昇順に並び変えられている。
図11は最小構成による統合装置の処理フローを示す図である。
図10で示すように統合装置1は、ユニーク判定手段1001、位置特定手段1002、統合手段1003を少なくとも備える。
ユニーク判定手段1001は、少なくとも大小比較のできるデータ要素を一つの行の情報として含む2つのデータテーブルのうちの第一データテーブルのデータ要素それぞれがユニークであるかを判定する(ステップS301)。
位置特定手段1002は、第一データテーブルのデータ要素それぞれがユニークである場合には、第二データテーブルの各行のデータ要素と第一データテーブルの各行のデータ要素を用いた昇順ソート後の各行のデータ要素との大小比較を行って、昇順ソートに適合するように第二データテーブルの行を昇順ソート後の第一データテーブルの最下行に加えることのできる下限位置を特定する(ステップS302)。
統合手段1003は、第二データテーブルの行のデータ要素と、当該行のデータ要素を用いて特定した昇順ソート後の第一データテーブルにおける下限位置の昇順ソートにおける次の行のデータ要素とが一致する場合に、それらデータ要素を示す統合対象行を特定し、少なくともそれら第二データテーブルと第一データテーブルとの統合対象行を統合した統合データテーブルを生成する(ステップS303)。
2・・・端末
11・・・制御部
12・・・ソート部
13・・・ユニーク判定部
14・・・位置特定部
15・・・統合部
100・・・情報処理システム
Claims (6)
- 少なくとも大小比較のできるデータ要素を一つの行の情報として含む2つのデータテーブルのうちの第一データテーブルのデータ要素それぞれがユニークであるかを判定し、 前記2つのデータテーブルのうちの一方のデータテーブルを前記第一データテーブルとして定義して前記第一データテーブルのデータ要素それぞれがユニークであるかを判定した結果、当該第一データテーブルのデータ要素それぞれがユニークでない場合、前記2つのデータテーブルのうちの他方のデータテーブルを前記第一データテーブルとして新たに定義して前記第一データテーブルのデータ要素それぞれがユニークであるかを判定するユニーク判定手段と、
前記第一データテーブルのデータ要素それぞれがユニークである場合には、前記2つのデータテーブルのうちの第二データテーブルの各行のデータ要素と前記第一データテーブルの各行のデータ要素を用いた昇順ソート後の各行のデータ要素との大小比較を行って、前記昇順ソートに適合するように前記第二データテーブルの行を前記昇順ソート後の前記第一データテーブルの最下行に加えることのできる下限位置を特定する位置特定手段と、
前記第二データテーブルの行のデータ要素と、当該行のデータ要素を用いて特定した前記昇順ソート後の前記第一データテーブルにおける前記下限位置の前記昇順ソートにおける次の行のデータ要素とが一致する場合に、それらデータ要素を示す統合対象行を、前記第二データテーブルと前記第一データテーブルとにおいて特定し、少なくともそれら前記第二データテーブルと前記第一データテーブルとの前記統合対象行を統合した統合データテーブルを生成する統合手段と、
を備える統合装置。 - 前記統合手段は、前記第二データテーブルの行のデータ要素と、当該行のデータ要素を用いて特定した前記昇順ソート後の前記第一データテーブルにおける前記下限位置の前記昇順ソートにおける次の行のデータ要素とが一致しない場合には、当該第二データテーブルの行を、前記第一データテーブルにおける前記下限位置の前記昇順ソートにおける次の行と統合せずに、前記統合データテーブルにマージする
請求項1に記載の統合装置。 - 前記統合手段は、前記第二データテーブルの行のデータ要素と、当該行のデータ要素を用いて特定した前記昇順ソート後の前記第一データテーブルにおける前記下限位置の前記昇順ソートにおける次の行のデータ要素とが一致しない場合には、当該第一データテーブルにおける前記下限位置の前記昇順ソートにおける次の行を、前記第二データテーブルの行と統合せずに、前記統合データテーブルにマージする
請求項1または請求項2に記載の統合装置。 - 二分探索を用いて前記大小比較を行う請求項1から請求項3の何れか一項に記載の統合装置。
- 少なくとも大小比較のできるデータ要素を一つの行の情報として含む2つのデータテーブルのうちの第一データテーブルのデータ要素それぞれがユニークであるかを判定し、
前記2つのデータテーブルのうちの一方のデータテーブルを前記第一データテーブルとして定義して前記第一データテーブルのデータ要素それぞれがユニークであるかを判定した結果、当該第一データテーブルのデータ要素それぞれがユニークでない場合、前記2つのデータテーブルのうちの他方のデータテーブルを前記第一データテーブルとして新たに定義して前記第一データテーブルのデータ要素それぞれがユニークであるかを判定し、
前記第一データテーブルのデータ要素の配列において当該データ要素それぞれがユニークである場合には、前記2つのデータテーブルのうちの第二データテーブルの各行のデータ要素と前記第一データテーブルの各行のデータ要素を用いた昇順ソート後の各行のデータ要素との大小比較を行って、前記第二データテーブルの各行のデータ要素についての前記昇順ソート後の前記第一データテーブルの各行のデータ要素の配列における下限位置を特定し、
前記第二データテーブルの行のデータ要素と、当該行のデータ要素を用いて特定した前記下限位置であって前記昇順ソート後の前記第一データテーブルの配列における前記下限位置を持つ行のデータ要素とが一致する統合対象行を、前記第二データテーブルと前記第一データテーブルとにおいて特定し、少なくともそれら前記第二データテーブルと前記第一データテーブルとの前記統合対象行を統合した統合データテーブルを生成する
データテーブル統合方法。 - 統合装置のコンピュータを、
少なくとも大小比較のできるデータ要素を一つの行の情報として含む2つのデータテーブルのうちの第一データテーブルのデータ要素それぞれがユニークであるかを判定し、 前記2つのデータテーブルのうちの一方のデータテーブルを前記第一データテーブルとして定義して前記第一データテーブルのデータ要素それぞれがユニークであるかを判定した結果、当該第一データテーブルのデータ要素それぞれがユニークでない場合、前記2つのデータテーブルのうちの他方のデータテーブルを前記第一データテーブルとして新たに定義して前記第一データテーブルのデータ要素それぞれがユニークであるかを判定するユニーク判定手段、
前記第一データテーブルのデータ要素の配列において当該データ要素それぞれがユニークである場合には、前記2つのデータテーブルのうちの第二データテーブルの各行のデータ要素と前記第一データテーブルの各行のデータ要素を用いた昇順ソート後の各行のデータ要素との大小比較を行って、前記第二データテーブルの各行のデータ要素についての前記昇順ソート後の前記第一データテーブルの各行のデータ要素の配列における下限位置を特定する位置特定手段、
前記第二データテーブルの行のデータ要素と、当該行のデータ要素を用いて特定した前記下限位置であって前記昇順ソート後の前記第一データテーブルの配列における前記下限位置を持つ行のデータ要素とが一致する統合対象行を、前記第二データテーブルと前記第一データテーブルとにおいて特定し、少なくともそれら前記第二データテーブルと前記第一データテーブルとの前記統合対象行を統合した統合データテーブルを生成する統合手段、
として機能させるプログラム。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/019121 WO2021229724A1 (ja) | 2020-05-13 | 2020-05-13 | 統合装置、データテーブル統合方法、プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2021229724A1 JPWO2021229724A1 (ja) | 2021-11-18 |
| JP7513086B2 true JP7513086B2 (ja) | 2024-07-09 |
Family
ID=78525507
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022522413A Active JP7513086B2 (ja) | 2020-05-13 | 2020-05-13 | 統合装置、データテーブル統合方法、プログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US12086124B2 (ja) |
| JP (1) | JP7513086B2 (ja) |
| WO (1) | WO2021229724A1 (ja) |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH03288967A (ja) | 1990-04-06 | 1991-12-19 | Toshiba Corp | データベース処理システム |
| US5664172A (en) * | 1994-07-19 | 1997-09-02 | Oracle Corporation | Range-based query optimizer |
| JPH09325888A (ja) | 1996-06-04 | 1997-12-16 | Hitachi Ltd | データ処理装置 |
| JP5913722B1 (ja) * | 2015-11-26 | 2016-04-27 | 株式会社博報堂 | 情報処理システム及びプログラム |
| US11227002B2 (en) * | 2015-11-30 | 2022-01-18 | International Business Machines Corporation | Method and apparatus for identifying semantically related records |
| JP6744179B2 (ja) * | 2016-09-14 | 2020-08-19 | 株式会社エスペラントシステム | データ統合方法、データ統合装置、データ処理システム及びコンピュータプログラム |
| US11699032B2 (en) * | 2017-11-03 | 2023-07-11 | Microsoft Technology Licensing, Llc | Data set lookup with binary search integration and caching |
| US20210117828A1 (en) * | 2018-06-27 | 2021-04-22 | Sony Corporation | Information processing apparatus, information processing method, and program |
| EP3641275A1 (de) * | 2018-10-18 | 2020-04-22 | Siemens Aktiengesellschaft | Verfahren, vorrichtung und computerprogramm zur automatischen verarbeitung von datenbezeichnern |
| US11016978B2 (en) * | 2019-09-18 | 2021-05-25 | Bank Of America Corporation | Joiner for distributed databases |
| US11604797B2 (en) * | 2019-11-14 | 2023-03-14 | Microstrategy Incorporated | Inferring joins for data sets |
-
2020
- 2020-05-13 JP JP2022522413A patent/JP7513086B2/ja active Active
- 2020-05-13 US US17/924,139 patent/US12086124B2/en active Active
- 2020-05-13 WO PCT/JP2020/019121 patent/WO2021229724A1/ja not_active Ceased
Non-Patent Citations (1)
| Title |
|---|
| 的野 晃整 外,範囲マージ結合:読み飛し可能なB+木間結合アルゴリズム,第2回データ工学と情報マネジメントに関するフォーラム-DEIM 2010-論文集 [online],日本,電子情報通信学会データ工学研究専門委員会,2010年05月25日,pp. 1-8 |
Also Published As
| Publication number | Publication date |
|---|---|
| US12086124B2 (en) | 2024-09-10 |
| JPWO2021229724A1 (ja) | 2021-11-18 |
| US20230195711A1 (en) | 2023-06-22 |
| WO2021229724A1 (ja) | 2021-11-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2009163497A (ja) | 事務フロー生成装置およびその方法 | |
| JP7513086B2 (ja) | 統合装置、データテーブル統合方法、プログラム | |
| US6968314B1 (en) | Enhanced security features for an automated order fulfillment system | |
| JP3418876B2 (ja) | データ・ベース検索装置および方法 | |
| JPS63249267A (ja) | 電子ファイリング装置の管理方法 | |
| RU2309450C1 (ru) | Способ защиты частной информации пользователя в системе обработки информации | |
| US6643632B1 (en) | Data processing system and computer-readable recording medium recorded with a program for causing a computer to process data | |
| JPS59121436A (ja) | デ−タ群のソ−ト方法 | |
| JP3549251B2 (ja) | ソート処理装置及びソート処理方法 | |
| JPH1139344A (ja) | 2次元配列コードを用いた文字列検索方法 | |
| JP5292956B2 (ja) | テストデータ生成プログラム | |
| JP4507972B2 (ja) | データレコードの検索方法とそのためのプログラム | |
| JP2921045B2 (ja) | インデックス生成方式 | |
| JPH04264979A (ja) | 2分決定グラフの変数順決定方式 | |
| CN113779157A (zh) | 基于区块链技术的关系数据库写入方法及系统 | |
| JPH0934899A (ja) | 検索経路出力方法及び装置 | |
| JP2004302618A (ja) | キーワード頻度算出方法及びそれを実行するプログラム | |
| JP6354501B2 (ja) | 比較プログラム、比較方法および情報処理装置 | |
| JPH04138575A (ja) | 有限要素データ再作成装置 | |
| Roach et al. | A knowledge-rich approach to the rapid enumeration of Quasi-Magic Sudoku search spaces | |
| JP3111081B2 (ja) | データ検索装置 | |
| JP2001344007A (ja) | 部品表管理装置及び方法並びに部品表及び部品表管理プログラムを記録した記録媒体 | |
| JPH01270131A (ja) | パスワード入力方式 | |
| JPH01228022A (ja) | 二次元データ格納方式 | |
| JPS58137068A (ja) | デ−タ処理方式 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20221101 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240109 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240308 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240326 |
|
| RD01 | Notification of change of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7421 Effective date: 20240408 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240520 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240528 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240610 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7513086 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |