JP7299770B2 - 演算処理装置及び演算処理方法 - Google Patents
演算処理装置及び演算処理方法 Download PDFInfo
- Publication number
- JP7299770B2 JP7299770B2 JP2019123135A JP2019123135A JP7299770B2 JP 7299770 B2 JP7299770 B2 JP 7299770B2 JP 2019123135 A JP2019123135 A JP 2019123135A JP 2019123135 A JP2019123135 A JP 2019123135A JP 7299770 B2 JP7299770 B2 JP 7299770B2
- Authority
- JP
- Japan
- Prior art keywords
- memory
- unit
- characteristic
- layer
- feature
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/20—Processor architectures; Processor configuration, e.g. pipelining
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/60—Memory management
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Molecular Biology (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Neurology (AREA)
- Image Analysis (AREA)
- Image Processing (AREA)
- Memory System (AREA)
Description

output(x,y) : 座標(x、y)での演算結果
weight(column,row) : output(x、y)の演算に使用する重み係数
columnSize、rowSize : コンボリューションカーネルサイズ
L : 前階層の特徴マップの数
CNNによる処理では、複数のコンボリューションカーネルを画素単位で走査しながら積和演算を繰り返し、最終的な積和結果を非線形変換することで特徴面を算出する。なお、特徴面903aを算出する場合は、前階層との結合数が1であるため、コンボリューションカーネルは1つである。ここで、9021b、9021c、9021dはそれぞれ特徴面903b、903c、903dを算出する際に使用されるコンボリューションカーネルである。
前記各階層における特徴面を、該階層の前の階層の特徴面を参照して算出する演算部と、
前記演算部によって算出され、参照される特徴面を保持する複数のメモリを有する特徴面保持部と、
前記演算処理を行うそれぞれの階層に関する情報であるネットワーク情報に基づいて、前記複数のメモリに前記演算部によって算出された特徴面を配置して書き込み、該複数のメモリから前記演算部によって参照される特徴面を読み出すメモリアクセス管理部と、
前記特徴面保持部がメモリ空間にアドレスマップされており、前記ネットワーク情報に基づいて該メモリ空間にアドレスマップされた特徴面の画素値のアドレスを算出し、該アドレスを用いて該特徴面保持部から画素値を読み出して処理するプロセッサと
を備えることを特徴とする。
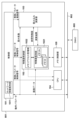
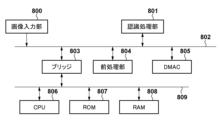
先ず、本実施形態に係る演算処理装置としての認識処理装置を利用した画像処理システムのハードウェア構成例について、図8のブロック図を用いて説明する。本実施形態に係る画像処理システムは、入力された画像データから特定の物体の領域を検出する機能を有する。
格納メモリがメモリ1のとき、アドレス=A1×4+0x2000
格納メモリがメモリ2のとき、アドレス=A1×4+0x4000
格納メモリがメモリ3のとき、アドレス=A1×4+0x6000
格納メモリがメモリ4のとき、アドレス=A1×4+0x8000
格納メモリがメモリ5のとき、アドレス=A1×4+0xa000
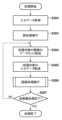
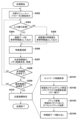
そしてステップS3104ではCPU104は、変換後のアドレスでメモリ制御部105にアクセス要求を出し、該アクセス要求に応じて読み出された特徴面の画素値を取得し、位置座標を特定する。
以下では第1の実施形態との差分について説明し、以下で特に触れない限りは第1の実施形態と同様であるものとする。本実施形態に係る認識処理部801の構成例について、図11のブロック図を用いて説明する。
メモリ制御部1051は、SRAMインターフェースは1つ(チップセレクトは1つ)であるという構成の元、アクセス要求アドレスをそのままSRAMのアドレス信号とする。SRAMインターフェースはメモリアクセス管理部1024に接続される。ステップS310にてA2へのSRAMアクセスがそのままメモリアクセス管理部1024に通知される。
本発明は、上述の実施形態の1以上の機能を実現するプログラムを、ネットワーク又は記憶媒体を介してシステム又は装置に供給し、そのシステム又は装置のコンピュータにおける1つ以上のプロセッサがプログラムを読出し実行する処理でも実現可能である。また、1以上の機能を実現する回路(例えば、ASIC)によっても実現可能である。
Claims (8)
- 階層型ニューラルネットワークに入力データを入力して該階層型ニューラルネットワークの各階層における演算処理を行う演算処理装置であって、
前記各階層における特徴面を、該階層の前の階層の特徴面を参照して算出する演算部と、
前記演算部によって算出され、参照される特徴面を保持する複数のメモリを有する特徴面保持部と、
前記演算処理を行うそれぞれの階層に関する情報であるネットワーク情報に基づいて、前記複数のメモリに前記演算部によって算出された特徴面を配置して書き込み、該複数のメモリから前記演算部によって参照される特徴面を読み出すメモリアクセス管理部と、
前記特徴面保持部がメモリ空間にアドレスマップされており、前記ネットワーク情報に基づいて該メモリ空間にアドレスマップされた特徴面の画素値のアドレスを算出し、該アドレスを用いて該特徴面保持部から画素値を読み出して処理するプロセッサと
を備えることを特徴とする演算処理装置。 - 前記ネットワーク情報は、階層ごとの特徴面の幅および高さ、特徴面の数、を含むことを特徴とする請求項1に記載の演算処理装置。
- 前記メモリは前記それぞれの階層のうち中間層または最終層の特徴面を格納し、前記プロセッサは中間層または最終層の特徴面を処理することを特徴とする請求項1に記載の演算処理装置。
- 前記プロセッサは前記ネットワーク情報と前記メモリアクセス管理部の情報に基づき前記アドレスを算出することを特徴とする請求項1に記載の演算処理装置。
- 前記メモリアクセス管理部は、前記特徴面保持部の特徴面を、階層を単位に複数のメモリにインターリーブさせて配置することを特徴とする請求項1に記載の演算処理装置。
- 前記メモリアクセス管理部は、前記特徴面保持部の特徴面を、ラインを単位に複数のメモリにインターリーブさせて配置することを特徴とする請求項1に記載の演算処理装置。
- 前記メモリアクセス管理部は、前記プロセッサのアクセス要求アドレスに基づき、前記メモリの格納先を算出し、データを読み出し、返すことを特徴とする請求項1に記載の演算処理装置。
- 階層型ニューラルネットワークに入力データを入力して該階層型ニューラルネットワークの各階層における演算処理を行う演算処理装置が行う演算処理方法であって、
前記演算処理装置は、
前記各階層における特徴面を、該階層の前の階層の特徴面を参照して算出する演算部と、
前記演算部によって算出され、参照される特徴面を保持する複数のメモリを有する特徴面保持部と、
前記メモリに対する読み書きを管理するメモリアクセス管理部と、
前記特徴面保持部へアクセスするプロセッサと
を備え、
前記メモリアクセス管理部は、前記演算処理を行うそれぞれの階層に関する情報であるネットワーク情報に基づいて、前記複数のメモリに前記演算部によって算出された特徴面を配置して書き込み、該複数のメモリから前記演算部によって参照される特徴面を読み出し、
前記特徴面保持部がメモリ空間にアドレスマップされており、前記プロセッサは、前記ネットワーク情報に基づいて該メモリ空間にアドレスマップされた特徴面の画素値のアドレスを算出し、該アドレスを用いて該特徴面保持部から画素値を読み出して処理することを特徴とする演算処理方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019123135A JP7299770B2 (ja) | 2019-07-01 | 2019-07-01 | 演算処理装置及び演算処理方法 |
| US16/916,507 US11704546B2 (en) | 2019-07-01 | 2020-06-30 | Operation processing apparatus that calculates addresses of feature planes in layers of a neutral network and operation processing method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019123135A JP7299770B2 (ja) | 2019-07-01 | 2019-07-01 | 演算処理装置及び演算処理方法 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2021009566A JP2021009566A (ja) | 2021-01-28 |
| JP2021009566A5 JP2021009566A5 (ja) | 2022-07-11 |
| JP7299770B2 true JP7299770B2 (ja) | 2023-06-28 |
Family
ID=74066056
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019123135A Active JP7299770B2 (ja) | 2019-07-01 | 2019-07-01 | 演算処理装置及び演算処理方法 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US11704546B2 (ja) |
| JP (1) | JP7299770B2 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6970827B2 (ja) * | 2018-06-25 | 2021-11-24 | オリンパス株式会社 | 演算処理装置 |
| JP7278150B2 (ja) * | 2019-05-23 | 2023-05-19 | キヤノン株式会社 | 画像処理装置、撮像装置、画像処理方法 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017168174A (ja) | 2016-03-18 | 2017-09-21 | 力晶科技股▲ふん▼有限公司 | 半導体記憶装置とそのアドレス制御方法 |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS6162187A (ja) | 1984-09-03 | 1986-03-31 | Fuji Xerox Co Ltd | 画像処理装置 |
| JP5368687B2 (ja) | 2007-09-26 | 2013-12-18 | キヤノン株式会社 | 演算処理装置および方法 |
| JP6700712B2 (ja) * | 2015-10-21 | 2020-05-27 | キヤノン株式会社 | 畳み込み演算装置 |
| US9665799B1 (en) | 2016-01-29 | 2017-05-30 | Fotonation Limited | Convolutional neural network |
| JP6964969B2 (ja) * | 2016-09-30 | 2021-11-10 | キヤノン株式会社 | 演算処理装置、演算処理方法及びプログラム |
| JP6945986B2 (ja) * | 2016-10-28 | 2021-10-06 | キヤノン株式会社 | 演算回路、その制御方法及びプログラム |
| WO2018103736A1 (en) * | 2016-12-09 | 2018-06-14 | Beijing Horizon Information Technology Co., Ltd. | Systems and methods for data management |
| JP6936592B2 (ja) * | 2017-03-03 | 2021-09-15 | キヤノン株式会社 | 演算処理装置およびその制御方法 |
| US10558386B2 (en) | 2017-09-22 | 2020-02-11 | Kabushiki Kaisha Toshiba | Operation device and operation system |
| JP2019207458A (ja) | 2018-05-28 | 2019-12-05 | ルネサスエレクトロニクス株式会社 | 半導体装置及びメモリアクセス設定方法 |
| US11443185B2 (en) * | 2018-10-11 | 2022-09-13 | Powerchip Semiconductor Manufacturing Corporation | Memory chip capable of performing artificial intelligence operation and method thereof |
-
2019
- 2019-07-01 JP JP2019123135A patent/JP7299770B2/ja active Active
-
2020
- 2020-06-30 US US16/916,507 patent/US11704546B2/en active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017168174A (ja) | 2016-03-18 | 2017-09-21 | 力晶科技股▲ふん▼有限公司 | 半導体記憶装置とそのアドレス制御方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20210004667A1 (en) | 2021-01-07 |
| JP2021009566A (ja) | 2021-01-28 |
| US11704546B2 (en) | 2023-07-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6945986B2 (ja) | 演算回路、その制御方法及びプログラム | |
| US11699067B2 (en) | Arithmetic processing apparatus and control method therefor | |
| US9135553B2 (en) | Convolution operation circuit and object recognition apparatus | |
| JP7299770B2 (ja) | 演算処理装置及び演算処理方法 | |
| JP6800656B2 (ja) | 演算回路、その制御方法及びプログラム | |
| CN110738308A (zh) | 一种神经网络加速器 | |
| JP7308674B2 (ja) | 演算処理装置及び演算処理方法 | |
| JP6532334B2 (ja) | 並列演算装置、画像処理装置及び並列演算方法 | |
| WO2022160704A1 (zh) | 一种图像处理方法、装置、计算机设备及存储介质 | |
| US11775809B2 (en) | Image processing apparatus, imaging apparatus, image processing method, non-transitory computer-readable storage medium | |
| JP7391553B2 (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| JP7410961B2 (ja) | 演算処理装置 | |
| US6809422B2 (en) | One-chip image processing apparatus | |
| JP4970378B2 (ja) | メモリコントローラおよび画像処理装置 | |
| JP7297468B2 (ja) | データ処理装置及びその方法 | |
| CN115242990A (zh) | 图像传感器模块和操作图像传感器模块的方法 | |
| US8503793B2 (en) | Correlation processing apparatus and medium readable by correlation processing apparatus | |
| US20230334820A1 (en) | Image processing apparatus, image processing method, and non-transitory computer-readable storage medium | |
| US11748862B2 (en) | Image processing apparatus including neural network processor and method of operation | |
| US20220392207A1 (en) | Information processing apparatus, information processing method, and non-transitory computer-readable storage medium | |
| JP4865021B2 (ja) | 画像処理装置および画像処理方法 | |
| US6489967B1 (en) | Image formation apparatus and image formation method | |
| JP6929734B2 (ja) | 判別演算装置、判別演算方法及びプログラム | |
| CN117422608A (zh) | 图像引导滤波方法及系统 | |
| JP6319420B2 (ja) | 情報処理装置、デジタルカメラおよびプロセッサ |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD01 | Notification of change of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7421 Effective date: 20210103 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210113 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220701 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220701 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20230519 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20230517 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20230616 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 7299770 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |