JP6700712B2 - 畳み込み演算装置 - Google Patents
畳み込み演算装置 Download PDFInfo
- Publication number
- JP6700712B2 JP6700712B2 JP2015207499A JP2015207499A JP6700712B2 JP 6700712 B2 JP6700712 B2 JP 6700712B2 JP 2015207499 A JP2015207499 A JP 2015207499A JP 2015207499 A JP2015207499 A JP 2015207499A JP 6700712 B2 JP6700712 B2 JP 6700712B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- product
- sum
- signal
- filter
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/94—Hardware or software architectures specially adapted for image or video understanding
- G06V10/955—Hardware or software architectures specially adapted for image or video understanding using specific electronic processors
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/15—Correlation function computation including computation of convolution operations
- G06F17/153—Multidimensional correlation or convolution
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/44—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components
- G06V10/443—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components by matching or filtering
- G06V10/449—Biologically inspired filters, e.g. difference of Gaussians [DoG] or Gabor filters
- G06V10/451—Biologically inspired filters, e.g. difference of Gaussians [DoG] or Gabor filters with interaction between the filter responses, e.g. cortical complex cells
- G06V10/454—Integrating the filters into a hierarchical structure, e.g. convolutional neural networks [CNN]
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Multimedia (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Algebra (AREA)
- Databases & Information Systems (AREA)
- Biodiversity & Conservation Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Complex Calculations (AREA)
- Image Processing (AREA)
Description

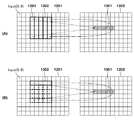
ここで、「input(x,y)」は座標(x,y)での参照画素値を示し、「output(x,y)」は、座標(x,y)でのFIRフィルタ演算結果を示す。また「weight(column,row)」は、座標(x+column,y+row)でのFIRフィルタ係数を示し、「columnSize」及び「rowSize」はカーネルのサイズを示し、図24の例ではいずれも「5」である。
それぞれ、第1及び第2の入力に入力されたデータを乗算する複数の第1の乗算手段と、
前記複数の第1の乗算手段に対応して設けられ、それぞれ対応する前記第1の乗算手段の乗算結果を累積する複数の第1の累積加算手段と、
前記複数の第1の乗算手段のそれぞれの前記第1の入力に第1のデータとして2次元フィルタカーネルの係数データを分解した水平方向の係数データを供給する第1のデータ供給手段と、
前記複数の第1の乗算手段の前記第2の入力に複数の第2のデータとして入力画像データの水平方向のデータを供給する第2のデータ供給手段と、を有する第一の積和演算手段と、
それぞれ、第1及び第2の入力に入力されたデータを乗算する複数の第2の乗算手段と、
前記複数の第2の乗算手段に対応して設けられ、それぞれ対応する前記第2の乗算手段の乗算結果を累積する複数の第2の累積加算手段と、
前記複数の第2の乗算手段のそれぞれの前記第1の入力に第3のデータとして2次元フィルタカーネルの係数データを分解した垂直方向の係数データを供給する第3のデータ供給手段と、
前記複数の第1の累積加算手段のそれぞれの出力から前記2次元フィルタカーネルの垂直方向の列単位で必要な参照データをリングバッファにロードして一括して保持し、当該ロードした参照データを動作クロックに応じてリング状にシフトして複数の第4のデータとして前記複数の第2の乗算手段の前記第2の入力に供給する第4のデータ供給手段と、を有する第二の積和演算手段と、
前記第一及び第二の積和演算手段による積和演算処理を並行して実行するように制御する制御手段と、を有し、
前記複数の第2の累積加算手段の出力として、前記入力画像データに対する前記2次元フィルタカーネルによる畳み込み演算の結果を得ることを特徴とする。
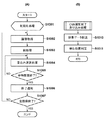
先ず、本発明の実施形態1を説明する。
尚、実際には、複数の水平方向及び垂直方向のフィルタカーネルの組み合わせを用い、式(3)に示すようにそれらのフィルタ演算結果の総和を取ることで近似精度を高める手法が取られることが多い。式(3)では、フィルタカーネルの組み合わせを添え字「pair」で示している。
これらの手法は、非特許文献1に詳しく記載されているため、これ以上の説明は省略する。
次に、本発明の実施形態2を説明する。実施形態2に係る演算装置は、水平方向フィルタのカーネルサイズと、垂直方向フィルタのカーネルサイズとが異なる点が実施形態1と相違しており、他の構成等は実施形態1と同様である。従って、実施形態2では、実施形態1と相違する部分についてのみ説明し、その他の部分に関しては実施形態1と同様として説明を省略する。実施形態2では、水平方向フィルタのカーネルサイズが「4」、垂直方向フィルタのカーネルサイズが「3」とする。
次に本発明の実施形態3について説明する。実施形態3に係る畳込み演算装置は、実施形態1の第一の積和演算回路200が第二の積和演算回路220の後段に直列に接続されている点が実施形態1と相違しており、他の構成等は実施形態1と同様である。従って、実施形態3では実施形態1と相違する部分についてのみ説明し、その他の部分に関しては実施形態1と同様として説明を省略する。
次に本発明の実施形態4について説明する。実施形態4に係るCNN処理部は、実施形態1における第二の積和演算回路220と同一の構成を有する第三の積和演算回路1900が、第二の積和演算回路220の後段に直列に接続されている点が実施形態1と相違している。他の構成等は実施形態1と同様である。従って、実施形態4では、前述の実施形態1と相違する部分についてのみ説明し、その他の部分に関しては実施形態1と同様として説明を省略する。
尚、実際には、複数の水平方向、垂直方向及び特徴面方向のフィルタカーネルの組み合わせを用い、式(5)に示すようにそれらのフィルタ演算結果の総和を取ることで近似精度を高める手法が取られることが多い。式(5)では、フィルタカーネルの組み合わせを添え字「pair」で示している。
これらの手法に関しては、非特許文献1で詳細が説明されているため、これ以上の説明は省略する。続いて、前記式(2)及び(3)を実行するための畳込み演算方法に関して説明する。
次に本発明の実施形態5について説明する。実施形態5に係る畳込み演算装置は、第二の積和演算回路220と同一の構成を有する第四の積和演算回路が、第三の積和演算回路1900の後段に直列に接続されている点が実施形態4と相違しており、他の構成等は実施形態4と同様である。従って、実施形態5では、実施形態4と相違する部分についてのみ説明し、その他の部分に関しては実施形態1と同様として説明を省略する。
尚、実際には、水平方向、垂直方向、特徴面方向及び時間方向のフィルタカーネルの組み合わせを用いて式(6)に示すようにそれらの乗算結果の総和を取ることで近似精度を高める手法が取られることが多い。式(7)では、フィルタカーネルの組み合わせを添え字「pair」で示している。
これらの手法に関しては、非特許文献1に詳細が述べられているため、これ以上の説明は省略する。
上述の実施形態1〜5に係るCNN処理部では、第一の積和演算回路200において、特許文献3と同様の演算を実行することが可能である。その場合は、例えば第二の積和演算回路220において実質的な演算を行わず、第一の積和演算回路200から入力されたデータをそのまま出力することで、同様の演算を実現することが可能である。また或いは第二の積和演算回路220をバイパスして、第一の積和演算回路200の出力を、直接、実施形態1に係るシフトレジスタ206に入力する構成を取っても良い。
上述の実施形態1〜5では、各実施形態に係るCNN処理部によってCNN演算処理を実行する例を示したが、実行可能な演算処理はこれに限るものでは無い。即ち、上記式(2)〜(7)で示されるような畳込み演算を実行するものであれば、例えば一般的なフィルタ演算を実行することも可能であり、本発明は実行対象となる演算処理を特定するものでは無い。
本発明は、上述の実施形態の1以上の機能を実現するプログラムを、ネットワーク又は記憶媒体を介してシステム又は装置に供給し、そのシステム又は装置のコンピュータにおける1つ以上のプロセッサーがプログラムを読出し実行する処理でも実現可能である。また、1以上の機能を実現する回路(例えば、ASIC)によっても実現可能である。
Claims (10)
- それぞれ、第1及び第2の入力に入力されたデータを乗算する複数の第1の乗算手段と、
前記複数の第1の乗算手段に対応して設けられ、それぞれ対応する前記第1の乗算手段の乗算結果を累積する複数の第1の累積加算手段と、
前記複数の第1の乗算手段のそれぞれの前記第1の入力に第1のデータとして2次元フィルタカーネルの係数データを分解した水平方向の係数データを供給する第1のデータ供給手段と、
前記複数の第1の乗算手段の前記第2の入力に複数の第2のデータとして入力画像データの水平方向のデータを供給する第2のデータ供給手段と、を有する第一の積和演算手段と、
それぞれ、第1及び第2の入力に入力されたデータを乗算する複数の第2の乗算手段と、
前記複数の第2の乗算手段に対応して設けられ、それぞれ対応する前記第2の乗算手段の乗算結果を累積する複数の第2の累積加算手段と、
前記複数の第2の乗算手段のそれぞれの前記第1の入力に第3のデータとして前記2次元フィルタカーネルの係数データを分解した垂直方向の係数データを供給する第3のデータ供給手段と、
前記複数の第1の累積加算手段のそれぞれの出力から前記2次元フィルタカーネルの垂直方向の列単位で必要な参照データをリングバッファにロードして一括して保持し、当該各ロードした参照データを動作クロックに応じてリング状にシフトして複数の第4のデータとして前記複数の第2の乗算手段の前記第2の入力に供給する第4のデータ供給手段と、を有する第二の積和演算手段と、
前記第一及び第二の積和演算手段による積和演算処理を並行して実行するように制御する制御手段と、を有し、
前記複数の第2の累積加算手段の出力として、前記入力画像データに対する前記2次元フィルタカーネルによる畳み込み演算の結果を得ることを特徴とする畳み込み演算装置。 - 前記複数の第1の乗算手段、前記複数の第1の累積加算手段、前記複数の第2の乗算手段、及び前記複数の第2の累積加算手段の個数は、前記2次元フィルタカーネルのサイズに対応していることを特徴とする請求項1に記載の畳み込み演算装置。
- 前記複数の第1の乗算手段と前記複数の第1の累積加算手段の個数は、前記複数の第2の乗算手段と前記複数の第2の累積加算手段の個数と等しいことを特徴とする請求項1又は2に記載の畳み込み演算装置。
- 前記2次元フィルタカーネルの水平方向のサイズと垂直方向のサイズが異なる場合、前記制御手段は、前記2次元フィルタカーネルの水平方向のサイズと垂直方向との差に応じたストールステージを、前記第一の積和演算手段の積和演算処理に挿入することを特徴とする請求項1に記載の畳み込み演算装置。
- 前記第二の積和演算手段の後段に、更に、当該第二の積和演算手段と同じ構成の第三の積和演算手段を直列に接続し、
前記第三の積和演算手段の、前記第二の積和演算手段の前記第4のデータ供給手段に相当するデータ供給手段は、前記第二の積和演算手段の前記複数の第2の累積加算手段のそれぞれの出力を入力して保持し、当該各出力を複数の第4のデータとして、前記第二の積和演算手段の前記複数の第2の乗算手段の相当する前記第三の積和演算手段の乗算手段の第2の入力に供給することを特徴とする請求項1乃至4のいずれか1項に記載の畳み込み演算装置。 - 前記第三の積和演算手段の後段に、更に、前記第三の積和演算手段と同じ構成の第四の積和演算手段を直列に接続し、
前記第四の積和演算手段の、前記第二の積和演算手段の前記第4のデータ供給手段に相当するデータ供給手段は、前記第三の積和演算手段の複数の累積加算手段のそれぞれの出力を入力して保持し、当該各出力を複数の第4のデータとして、前記第二の積和演算手段の前記複数の第2の乗算手段の相当する前記第四の積和演算手段の乗算手段の第2の入力に供給することを特徴とする請求項5に記載の畳み込み演算装置。 - 前記第二の積和演算手段の後段に前記第一の積和演算手段が接続され、前記第2のデータ供給手段は、前記複数の第2の累積加算手段のそれぞれの出力を前記複数の第2のデータとして前記複数の第1の乗算手段の前記第2の入力に供給することを特徴とする請求項1乃至4のいずれか1項に記載の畳み込み演算装置。
- 前記複数の第2の累積加算手段の出力に対して非線形変換を行う非線形変換手段を、更に有することを特徴とする請求項1乃至4のいずれか1項に記載の畳み込み演算装置。
- 前記第1の積和演算手段の前記第2のデータ供給手段は、あるタイミングで前記複数の第1の乗算手段のいずれかの第1の乗算手段の前記第2の入力に供給した前記第2のデータを、他のタイミングで、前記複数の第1の乗算手段のうちの他の第1の乗算手段の前記第2の入力に供給することを特徴とする請求項1乃至4のいずれか1項に記載の畳み込み演算装置。
- 前記第二の積和演算手段の前記第4のデータ供給手段は、あるタイミングで前記複数の第2の乗算手段のいずれかの第2の乗算手段の前記第2の入力に供給した前記第4のデータを、他のタイミングで、前記複数の第2の乗算手段の同じ第2の乗算手段の前記第2の入力に供給することを特徴とする請求項1乃至4のいずれか1項に記載の畳み込み演算装置。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015207499A JP6700712B2 (ja) | 2015-10-21 | 2015-10-21 | 畳み込み演算装置 |
| US15/331,044 US10210419B2 (en) | 2015-10-21 | 2016-10-21 | Convolution operation apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015207499A JP6700712B2 (ja) | 2015-10-21 | 2015-10-21 | 畳み込み演算装置 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2017079017A JP2017079017A (ja) | 2017-04-27 |
| JP2017079017A5 JP2017079017A5 (ja) | 2018-11-29 |
| JP6700712B2 true JP6700712B2 (ja) | 2020-05-27 |
Family
ID=58561708
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015207499A Active JP6700712B2 (ja) | 2015-10-21 | 2015-10-21 | 畳み込み演算装置 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US10210419B2 (ja) |
| JP (1) | JP6700712B2 (ja) |
Families Citing this family (45)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10963775B2 (en) * | 2016-09-23 | 2021-03-30 | Samsung Electronics Co., Ltd. | Neural network device and method of operating neural network device |
| US9940534B1 (en) * | 2016-10-10 | 2018-04-10 | Gyrfalcon Technology, Inc. | Digital integrated circuit for extracting features out of an input image based on cellular neural networks |
| US10360470B2 (en) | 2016-10-10 | 2019-07-23 | Gyrfalcon Technology Inc. | Implementation of MobileNet in a CNN based digital integrated circuit |
| US10043095B2 (en) * | 2016-10-10 | 2018-08-07 | Gyrfalcon Technology, Inc. | Data structure for CNN based digital integrated circuit for extracting features out of an input image |
| US10366302B2 (en) | 2016-10-10 | 2019-07-30 | Gyrfalcon Technology Inc. | Hierarchical category classification scheme using multiple sets of fully-connected networks with a CNN based integrated circuit as feature extractor |
| US10339445B2 (en) | 2016-10-10 | 2019-07-02 | Gyrfalcon Technology Inc. | Implementation of ResNet in a CNN based digital integrated circuit |
| US10402628B2 (en) | 2016-10-10 | 2019-09-03 | Gyrfalcon Technology Inc. | Image classification systems based on CNN based IC and light-weight classifier |
| US10366328B2 (en) | 2017-09-19 | 2019-07-30 | Gyrfalcon Technology Inc. | Approximating fully-connected layers with multiple arrays of 3x3 convolutional filter kernels in a CNN based integrated circuit |
| US10402527B2 (en) | 2017-01-04 | 2019-09-03 | Stmicroelectronics S.R.L. | Reconfigurable interconnect |
| JP6794854B2 (ja) * | 2017-02-02 | 2020-12-02 | 富士通株式会社 | 演算処理装置及び演算処理装置の制御方法 |
| US11468318B2 (en) * | 2017-03-17 | 2022-10-11 | Portland State University | Frame interpolation via adaptive convolution and adaptive separable convolution |
| JP7141401B2 (ja) * | 2017-08-24 | 2022-09-22 | ソニーセミコンダクタソリューションズ株式会社 | プロセッサおよび情報処理システム |
| JP2019040403A (ja) | 2017-08-25 | 2019-03-14 | ルネサスエレクトロニクス株式会社 | 半導体装置および画像認識システム |
| KR102356708B1 (ko) * | 2017-09-28 | 2022-01-27 | 삼성전자주식회사 | 컨볼루션 연산을 수행하는 연산 장치 및 연산 방법 |
| US20190102671A1 (en) * | 2017-09-29 | 2019-04-04 | Intel Corporation | Inner product convolutional neural network accelerator |
| JP2019074967A (ja) * | 2017-10-17 | 2019-05-16 | キヤノン株式会社 | フィルタ処理装置およびその制御方法 |
| US11386644B2 (en) * | 2017-10-17 | 2022-07-12 | Xilinx, Inc. | Image preprocessing for generalized image processing |
| KR102521889B1 (ko) * | 2017-11-06 | 2023-04-13 | 에이조 가부시키가이샤 | 화상처리장치, 화상처리방법 및 화상처리 프로그램을 기록한 기록 매체 |
| JP6839641B2 (ja) * | 2017-11-17 | 2021-03-10 | 株式会社東芝 | 演算処理装置 |
| US11265540B2 (en) * | 2018-02-23 | 2022-03-01 | Sk Telecom Co., Ltd. | Apparatus and method for applying artificial neural network to image encoding or decoding |
| US11537838B2 (en) * | 2018-05-04 | 2022-12-27 | Apple Inc. | Scalable neural network processing engine |
| JP7169768B2 (ja) * | 2018-05-08 | 2022-11-11 | キヤノン株式会社 | 画像処理装置、画像処理方法 |
| US10546044B2 (en) * | 2018-05-15 | 2020-01-28 | Apple Inc. | Low precision convolution operations |
| JP2020004247A (ja) * | 2018-06-29 | 2020-01-09 | ソニー株式会社 | 情報処理装置、情報処理方法およびプログラム |
| US10417342B1 (en) | 2018-07-03 | 2019-09-17 | Gyrfalcon Technology Inc. | Deep learning device for local processing classical chinese poetry and verse |
| US10311149B1 (en) | 2018-08-08 | 2019-06-04 | Gyrfalcon Technology Inc. | Natural language translation device |
| JP7129857B2 (ja) | 2018-09-07 | 2022-09-02 | ルネサスエレクトロニクス株式会社 | 積和演算装置、積和演算方法、及びシステム |
| CN109146065B (zh) * | 2018-09-30 | 2021-06-08 | 中国人民解放军战略支援部队信息工程大学 | 二维数据的卷积运算方法及装置 |
| JP7165018B2 (ja) * | 2018-10-03 | 2022-11-02 | キヤノン株式会社 | 情報処理装置、情報処理方法 |
| US10387772B1 (en) | 2018-10-22 | 2019-08-20 | Gyrfalcon Technology Inc. | Ensemble learning based image classification systems |
| JP7345262B2 (ja) | 2019-03-11 | 2023-09-15 | キヤノン株式会社 | データ圧縮装置、データ処理装置、データ圧縮方法、プログラム、及び学習済みモデル |
| JP7271244B2 (ja) * | 2019-03-15 | 2023-05-11 | 本田技研工業株式会社 | Cnn処理装置、cnn処理方法、およびプログラム |
| JP7204545B2 (ja) | 2019-03-15 | 2023-01-16 | 本田技研工業株式会社 | 音響信号処理装置、音響信号処理方法、およびプログラム |
| WO2020194594A1 (ja) | 2019-03-27 | 2020-10-01 | Tdk株式会社 | ニューラルネットワーク演算処理装置及びニューラルネットワーク演算処理方法 |
| JP7435602B2 (ja) | 2019-05-10 | 2024-02-21 | ソニーグループ株式会社 | 演算装置および演算システム |
| JP7402623B2 (ja) * | 2019-06-17 | 2023-12-21 | キヤノン株式会社 | フィルタ処理装置及びその制御方法 |
| JP7299770B2 (ja) * | 2019-07-01 | 2023-06-28 | キヤノン株式会社 | 演算処理装置及び演算処理方法 |
| CN110717588B (zh) * | 2019-10-15 | 2022-05-03 | 阿波罗智能技术(北京)有限公司 | 用于卷积运算的装置和方法 |
| US11475283B2 (en) * | 2019-10-24 | 2022-10-18 | Apple Inc. | Multi dimensional convolution in neural network processor |
| US11593609B2 (en) | 2020-02-18 | 2023-02-28 | Stmicroelectronics S.R.L. | Vector quantization decoding hardware unit for real-time dynamic decompression for parameters of neural networks |
| US11507831B2 (en) | 2020-02-24 | 2022-11-22 | Stmicroelectronics International N.V. | Pooling unit for deep learning acceleration |
| US11531873B2 (en) | 2020-06-23 | 2022-12-20 | Stmicroelectronics S.R.L. | Convolution acceleration with embedded vector decompression |
| JP2022022876A (ja) | 2020-07-09 | 2022-02-07 | キヤノン株式会社 | 畳み込みニューラルネットワーク処理装置 |
| KR20220010362A (ko) * | 2020-07-17 | 2022-01-25 | 삼성전자주식회사 | 뉴럴 네트워크 장치 및 그의 동작 방법 |
| WO2023095666A1 (ja) * | 2021-11-29 | 2023-06-01 | ソニーセミコンダクタソリューションズ株式会社 | 信号処理装置および信号処理方法、並びに固体撮像素子 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4328426A (en) * | 1980-08-04 | 1982-05-04 | Xerox Corporation | Filter for image pixels |
| US4694407A (en) * | 1985-06-11 | 1987-09-15 | Rca Corporation | Fractal generation, as for video graphic displays |
| JP2857292B2 (ja) * | 1991-12-18 | 1999-02-17 | ゼロックス コーポレイション | 2次元デジタルフィルタを実現するための装置 |
| JP3524250B2 (ja) * | 1995-11-27 | 2004-05-10 | キヤノン株式会社 | デジタル画像処理プロセッサ |
| JPH1021405A (ja) | 1996-07-04 | 1998-01-23 | Kiyoushiya:Kk | 回路パターンの外観検査方法および装置 |
| US6125212A (en) * | 1998-04-29 | 2000-09-26 | Hewlett-Packard Company | Explicit DST-based filter operating in the DCT domain |
| US6185336B1 (en) * | 1998-09-23 | 2001-02-06 | Xerox Corporation | Method and system for classifying a halftone pixel based on noise injected halftone frequency estimation |
| JP4891197B2 (ja) | 2007-11-01 | 2012-03-07 | キヤノン株式会社 | 画像処理装置および画像処理方法 |
| JP5376920B2 (ja) * | 2008-12-04 | 2013-12-25 | キヤノン株式会社 | コンボリューション演算回路、階層的コンボリューション演算回路及び物体認識装置 |
| US10078620B2 (en) | 2011-05-27 | 2018-09-18 | New York University | Runtime reconfigurable dataflow processor with multi-port memory access module |
| JP5906071B2 (ja) | 2011-12-01 | 2016-04-20 | キヤノン株式会社 | 情報処理方法、情報処理装置、および記憶媒体 |
| JP6195342B2 (ja) | 2013-03-27 | 2017-09-13 | キヤノン株式会社 | 情報処理装置およびメモリアクセス制御方法 |
| JP6442152B2 (ja) | 2014-04-03 | 2018-12-19 | キヤノン株式会社 | 画像処理装置、画像処理方法 |
| JP6395481B2 (ja) | 2014-07-11 | 2018-09-26 | キヤノン株式会社 | 画像認識装置、方法及びプログラム |
-
2015
- 2015-10-21 JP JP2015207499A patent/JP6700712B2/ja active Active
-
2016
- 2016-10-21 US US15/331,044 patent/US10210419B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2017079017A (ja) | 2017-04-27 |
| US20170116495A1 (en) | 2017-04-27 |
| US10210419B2 (en) | 2019-02-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6700712B2 (ja) | 畳み込み演算装置 | |
| JP5376920B2 (ja) | コンボリューション演算回路、階層的コンボリューション演算回路及び物体認識装置 | |
| US11068776B2 (en) | Convolutional neural network based data processing apparatus, method for controlling the same, and storage medium storing program | |
| EP3557485B1 (en) | Method for accelerating operations and accelerator apparatus | |
| US11467969B2 (en) | Accelerator comprising input and output controllers for feeding back intermediate data between processing elements via cache module | |
| JP6821002B2 (ja) | 処理装置と処理方法 | |
| JP2022064892A (ja) | 加速数学エンジン | |
| US4635292A (en) | Image processor | |
| EP3093757B1 (en) | Multi-dimensional sliding window operation for a vector processor | |
| Müller et al. | An improved cellular nonlinear network architecture for binary and grayscale image processing | |
| JP6532334B2 (ja) | 並列演算装置、画像処理装置及び並列演算方法 | |
| JP2018032190A (ja) | 演算回路、その制御方法及びプログラム | |
| JP2006154992A (ja) | ニューロプロセッサ | |
| JP2015185152A (ja) | Simdプロセッサ | |
| Müller et al. | NEROvideo: A general-purpose CNN-UM video processing system | |
| Schmidt et al. | A smart camera processing pipeline for image applications utilizing marching pixels | |
| Csordás et al. | Application of bit-serial arithmetic units for FPGA implementation of convolutional neural networks | |
| JP7321213B2 (ja) | 情報処理装置、情報処理方法 | |
| Ganesh et al. | Low power and single multiplier design for 2D convolutions | |
| JP2806436B2 (ja) | 演算回路 | |
| Hernandez et al. | A combined VLSI architecture for nonlinear image processing filters | |
| CN113778376A (zh) | 改进的用于执行乘法/累加运算的设备 | |
| Chandra et al. | Hardware Implementation of Pixel Comparison and Error Detection in Image | |
| JP2020086680A (ja) | 演算装置 | |
| Wong et al. | A new scalable systolic array processor architecture for simultaneous discrete convolution of k different (nxn) filter coefficient planes with a single image plane |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20181016 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20181016 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20190708 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20190830 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20191029 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20200327 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20200501 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 6700712 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |