[本開示が示す実施形態の説明]
本開示が示す実施形態の概要を説明する。
(1)第1ユーザの頭部に装着される第1ヘッドマウントデバイスを有する第1ユーザ端末と、第2ユーザの頭部に装着される第2ヘッドマウントデバイスを有する第2ユーザ端末と、を備えた仮想空間配信システムにおいてコンピュータによって実行される情報処理方法であって、
前記情報処理方法は、
(a)前記第1ユーザに関連付けられた第1アバターと、前記第2ユーザに関連付けられた第2アバターとを含む仮想空間を規定する仮想空間データを生成するステップと、
(b)前記第2ヘッドマウントデバイスの動きと前記仮想空間データに基づいて、前記第2ヘッドマウントデバイスに表示される視野画像を更新するステップと、
(d)前記第1ユーザが前記第1ヘッドマウントデバイスを装着していないことを示す非装着情報を受信した場合に、前記第1ユーザが前記第1ヘッドマウントデバイスを装着していないことを前記第2ユーザ端末によって前記第2ユーザに提示するステップと、を含む、情報処理方法。
上記方法によれば、第1ユーザが第1ヘッドマウントデバイス(以下、第1HMD)を装着していないことを示す非装着情報が受信された場合に、第2ユーザ端末によって第1ユーザが第1HMDを装着していないことが第2ユーザに提示される。このように、第2ユーザは、仮想空間上において第1ユーザとコミュニケーションを行っているときに、第1ユーザが第1HMDを装着していないことを容易に把握することができる。従って、ユーザにリッチな仮想体験を提供することができる。
特に、第2ユーザは、第1ユーザが第1HMDを装着していないことを把握してなければ、リアクションを示さない第1ユーザに対して違和感を抱く場合がある。このように、第1ユーザが第1HMDを装着していないことを第2ユーザに把握させることで、第2ユーザがリアクションを示さない第1ユーザに対して違和感を抱くといった状況を回避することが可能となる。
(2)前記ステップ(d)は、
前記非装着情報を受信した場合に、前記第1ユーザが前記第1ヘッドマウントデバイスを装着していないことを前記第2ヘッドマウントデバイスに表示される視野画像上において可視化するステップを含む、項目(1)に記載の情報処理方法。
上記方法によれば、第1ユーザが第1ヘッドマウントデバイス(第1HMD)を装着していないことを示す非装着情報が受信された場合に、第1ユーザが第1HMDを装着していないことを示す情報が第2ヘッドマウントデバイス(第2HMD)に表示される視野画像上において可視化される。このように、第2ユーザは、仮想空間上において第1ユーザとコミュニケーションを行っているときに、第2HMDを通じて第1ユーザが第1HMDを装着していないことを示す情報を視認することで、第1ユーザが第1HMDを装着していないことを容易に把握することができる。
(3)(e)前記第1アバターの顔の表情を示す顔情報を受信した場合に、前記顔情報に基づいて、前記第1アバターの顔の表情を更新するステップをさらに含み、
前記ステップ(d)は、
前記非装着情報を受信した場合に、表情が第1の態様に設定された第1アバターを前記第2ヘッドマウントデバイスに表示される視野画像上において可視化するステップを含む、項目(1)又は(2)に記載の情報処理方法。
上記方法によれば、第1ユーザが第1ヘッドマウントデバイス(第1HMD)を装着していないことを示す非装着情報が受信された場合に、表情が第1の態様に設定された第1アバターが第2ヘッドマウントデバイス(第2HMD)に表示される視野画像上において可視化される。このように、第2ユーザは、仮想空間上において第1ユーザとコミュニケーションを行っているときに、第1アバターの顔の表情が所定の表情となっていることを視認することで、第1ユーザが第1HMDを装着していないことを容易に把握することができる。
特に、第1ユーザが第1HMDを装着していない場合には、第1アバターの顔の表情が全く更新されない。このため、第2ユーザは、第1ユーザが第1HMDを装着していないことを把握してなければ、第1ユーザに対して違和感を抱く場合がある。このように、第1ユーザが第1HMDを装着していないことを第2ユーザに把握させることで、第2ユーザがリアクションを示さない第1ユーザに対して違和感を抱くといった状況を回避することが可能となる。
(4)前記第1の態様は、デフォルト設定された前記第1アバターの顔の表情である、項目(3)に記載の情報処理方法。
上記方法によれば、第1ユーザが第1ヘッドマウントデバイス(第1HMD)を装着していないことを示す非装着情報が受信された場合に、第1アバターの顔の表情がデフォルト設定された第1アバターの顔の表情となる。このように、第2ユーザは、仮想空間上において第1ユーザとコミュニケーションを行っているときに、第1アバターの顔の表情がデフォルト設定された顔の表情になっていることを視認することで、第1ユーザが第1HMDを装着していないことを容易に把握することができる。
(5)前記第1の態様は、前記第1ユーザが前記第1ヘッドマウントデバイスを装着していないことを示す態様として予め選択された表情である、項目(3)に記載の情報処理方法。
上記方法によれば、第1ユーザが第1ヘッドマウントデバイス(第1HMD)を装着していないことを示す非装着情報が受信された場合に、第1アバターの顔の表情が第1ユーザが第1ヘッドマウントデバイスを装着していないことを示す態様として第1ユーザによって予め選択された表情(以下、選択表情という。)に設定される。このように、第2ユーザは、仮想空間上において第1ユーザとコミュニケーションを行っているときに、第1アバターの顔の表情が選択表情になっていることを視認することで、第1ユーザが第1HMDを装着していないことを容易に把握することができる。
(6)前記第1ユーザ端末は、前記第1ユーザが前記第1ヘッドマウントデバイスを装着しているかどうかを検出するように構成された装着センサをさらに備え、
前記第1ユーザが前記第1ヘッドマウントデバイスを装着していないことを前記装着センサが検出した場合に、前記第1ユーザ端末は、前記非装着情報を出力し、前記第2ユーザ端末は、出力された前記非装着情報を前記第1ユーザ端末から受信する、項目(1)から(5)のうちいずれか一項に記載の情報処理方法。
上記方法によれば、第1ユーザ端末の装着センサから送信された情報に応じて、第1ユーザが第1ヘッドマウントデバイス(第1HMD)を装着していないことが特定される。その後、第1ユーザが第1HMDを装着していないことを示す非装着情報が送信される。このように、第1ユーザ端末の装着センサから出力された情報に応じて、第1ユーザが第1HMDを装着していないことを自動的に特定することが可能となる。
(7)(f)前記第1ヘッドマウントデバイスが前記第1ユーザから取り外された後に再び装着されたことを示す装着情報を受信した場合、前記第1ユーザが前記第1ヘッドマウントデバイスを装着していることを前記第2ユーザ端末によって前記第2ユーザに提示するステップをさらに含む、項目(1)から(6)のうちいずれか一項に記載の情報処理方法。
上記方法によれば、第1ヘッドマウントデバイス(第1HMD)が第1ユーザから取り外された後に再び装着されたことを示す装着情報が受信された場合、第2ユーザ端末によって第1ユーザが第1HMDを装着していることが第2ユーザに提示される。このように、第2ユーザは、第1ユーザが第1HMDを再び装着したことを容易に把握することができる。従って、ユーザにリッチな仮想体験を提供することができる。
(8)項目(1)から(7)のうちいずれか一項に記載の情報処理方法をコンピュータに実行させるためのプログラム。
上記プログラムによれば、ユーザにリッチな仮想体験を提供することができる。
(9)第1ユーザの頭部に装着される第1ヘッドマウントデバイスを有する第1ユーザ端末と、第2ユーザの頭部に装着される第2ヘッドマウントデバイスを有する第2ユーザ端末と、を備え、項目(1)から(7)のうちいずれか一項に記載の情報処理方法を実行するように構成された、仮想空間配信システム。
上記仮想空間配信システムによれば、ユーザにリッチな仮想体験を提供することができる。
(10)プロセッサと、
コンピュータ可読命令を記憶するメモリと、を備えた装置であって、
前記コンピュータ可読命令が前記プロセッサにより実行されると、前記装置は項目(1)から(7)のうちいずれか一項に記載の情報処理方法を実行する、装置。
上記装置によれば、ユーザにリッチな仮想体験を提供することができる。
(11)ユーザに仮想体験を提供するためのコンピュータに、
前記ユーザの身体の一部の動きに応じて、仮想空間内で操作オブジェクトを動かすステップと、
前記ユーザとは異なる他のユーザの動きに基づいて前記仮想空間内での動作が制御可能な仮想オブジェクトに対して、前記操作オブジェクトによる第1アクションを実行するステップと、
前記第1アクションの実行に基づいて、前記他のユーザに対する第2アクションを実行するステップと、
を実行させるための、プログラム。
上記プログラムによれば、ユーザの仮想体験を向上させることができる。特に、操作オブジェクトを用いた直感的な操作により仮想空間を共有する複数のユーザ間でアクションを実行することで、仮想空間におけるコミュニケーションを、没入感を損なうことなく円滑に行うことができる。
(12)前記他のユーザにより前記仮想オブジェクトが制御されていない状態において前記第1アクションが実行された場合に、前記第2アクションを実行する、項目(11)に記載のプログラム。
上記プログラムによれば、制御されていない状態の仮想オブジェクトに対して第2アクションを実行することで、他のユーザを仮想空間へ誘引させることができる。
(13)前記第1アクションは、前記操作オブジェクトの反復運動の過程で前記仮想オブジェクトに接触する動作を含む、項目(11)または(12)に記載のプログラム。
(14)前記第1アクションは、一定値以上の加速度での前記反復運動の過程における前記仮想オブジェクトへの接触動作を含む、項目(13)に記載のプログラム。
(15)前記第1アクションは、前記仮想オブジェクトに関連付けられた相対座標を一定時間内に所定の回数以上通過する動作を含む、項目(13)または(14)に記載のプログラム。
これらのプログラムによれば、誤って操作オブジェクトが仮想オブジェクトに接触してしまった場合を勘案しないことで、操作オブジェクトの動作の誤検知を防止することができる。
(16)前記第2アクションは、前記他のユーザの前記仮想空間への参加を促す通知を含む、項目(11)から(15)のいずれかに記載のプログラム。
上記プログラムによれば、仮想空間を共有する他のユーザに対して、例えばマルチプレイが打診されていることを容易に認識させることができ、マルチプレイの利用を促進させることができる。
(17)前記第2アクションに対するリアクションが行われた場合に、前記仮想オブジェクトを第1状態から第2状態へと遷移させるステップと、
前記第2状態への遷移後に、一定時間内に前記他のユーザにより前記仮想オブジェクトが制御されている状態になった場合には、前記仮想オブジェクトを第3状態へと遷移させるステップと、
をさらに前記コンピュータに実行させるための、項目(16)に記載のプログラム。
上記プログラムによれば、他のユーザからリアクションがあったことや、他のユーザにより仮想オブジェクトが制御された状態となったことを、第1アクションを実行したユーザが容易に把握することができる。
(18)前記第2状態への遷移後に、一定時間内に前記他のユーザにより前記仮想オブジェクトが制御されている状態にならない場合には、前記仮想オブジェクトを前記第1状態へ戻すステップをさらに前記コンピュータに実行させるための、項目(17)に記載のプログラム。
上記プログラムによれば、第2アクションを実行したにも関わらず他のユーザにより仮想オブジェクトが制御されている状態にならないことを、第1アクションを実行したユーザが容易に把握することができる。
(19)前記仮想オブジェクトに対する前記第1アクションの動作の強度と前記第1アクションの種類との少なくとも一方に応じて、前記通知の内容が異なっている、項目(16)から(18)のいずれかに記載のプログラム。
上記方法によれば、他のユーザは、第1アクションを実行したユーザからのマルチプレイの要望度の高低を把握することができ、要望度の高さに応じて仮想空間へ参加するかどうかを決定することができる。
(20)前記仮想空間内での動作がコンピュータ制御可能な他の仮想オブジェクトに対し、前記操作オブジェクトにより前記第1アクションを実行するステップと、
前記第1アクションの実行に基づいて、前記仮想空間において提供されるゲームを第1シーンから第2シーンへと遷移させるステップと、
をさらに前記コンピュータに実行させるための、項目(11)から(19)のいずれかに記載のプログラム。
上記プログラムによれば、ユーザの仮想空間への没入感を損なわずにゲームを進行させることができる。
(21)ユーザに仮想体験を提供するための情報処理装置であって、
前記情報処理装置が備えるプロセッサの制御により、
前記ユーザの身体の一部の動きに応じて、仮想空間内で操作オブジェクトを動かすステップと、
前記ユーザとは異なる他のユーザの動きに基づいて前記仮想空間内での動作が制御可能な仮想オブジェクトに対して、前記操作オブジェクトによる第1アクションを実行するステップと、
前記第1アクションの実行に基づいて、前記他のユーザに対する第2アクションを実行するステップと、
が実行される、情報処理装置。
上記情報処理装置によれば、ユーザの仮想体験を向上させることができる。
(22)ユーザに仮想体験を提供するための情報処理システムであって、
前記情報処理システムが備える複数のプロセッサの制御により、
前記ユーザの身体の一部の動きに応じて、仮想空間内で操作オブジェクトを動かすステップと、
前記ユーザとは異なる他のユーザの動きに基づいて前記仮想空間内での動作が制御可能な仮想オブジェクトに対して、前記操作オブジェクトによる第1アクションを実行するステップと、
前記第1アクションの実行に基づいて、前記他のユーザに対する第2アクションを実行するステップと、
が実行される、情報処理システム。
上記情報処理システムによれば、ユーザの仮想体験を向上させることができる。
(23)ユーザに仮想体験を提供するためにコンピュータによって実行される情報処理方法であって、
前記ユーザの身体の一部の動きに応じて、仮想空間内で操作オブジェクトを動かすステップと、
前記ユーザとは異なる他のユーザの動きに基づいて前記仮想空間内での動作が制御可能な仮想オブジェクトに対して、前記操作オブジェクトによる第1アクションを実行するステップと、
前記第1アクションの実行に基づいて、前記他のユーザに対する第2アクションを実行するステップと、
を含む、情報処理方法。
上記情報処理方法によれば、ユーザの仮想体験を向上させることができる。
(24)ユーザに仮想体験を提供するためのコンピュータに、
仮想空間内で第1アクションを実行するステップと、
前記第1アクションの実行に基づいて、前記ユーザとは異なる他のユーザに対する第2アクションを実行するステップと、
前記第2アクションに対するリアクションに基づいて、前記仮想空間内で第3アクションを実行するステップと、
を実行させるための、プログラム。
上記プログラムによれば、ユーザの仮想体験を向上させることができる。特に、他のユーザに対して実行される第2アクションに対するリアクションに基づいて仮想空間内で第3アクションを実行することで、現実空間と仮想空間との境界がシームレスとなる新規な仮想体験を提供することができる。
(25)前記第1アクションは、前記他のユーザを特定するためのアクションであり、前記第3アクションは、前記仮想空間内において前記他のユーザに関連付けられた仮想オブジェクトが実行するアクションである、項目(24)に記載のプログラム。
上記プログラムによれば、仮想空間を共有する複数のユーザ間でアクションが実行されることで、仮想空間におけるコミュニケーションを円滑に行うことができる。
(26)前記ユーザの身体の一部の動きに応じて、前記仮想空間内で操作オブジェクトを動かすステップを、さらに前記コンピュータに実行させ、
前記第1アクションは前記操作オブジェクトを用いて実行される、項目(24)または(25)に記載のプログラム。
上記プログラムによれば、仮想空間を共有する複数のユーザ間で、操作オブジェクトを用いた直感的な操作によりアクションを実行することができ、ユーザの没入感を損なうことない。
(27)前記第2アクションは、前記他のユーザの前記仮想空間への参加を促す通知を含む、項目(24)から(26)のいずれかに記載のプログラム。
上記プログラムによれば、仮想空間を共有する他のユーザに対して、例えばマルチプレイが打診されていることを容易に認識させることができ、マルチプレイの利用を促進させることができる。
(28)前記第3アクションは、前記仮想空間内において前記他のユーザに関連付けられた仮想オブジェクトが実行するアクションを、第1状態から第2状態へと遷移させることを含む、項目(24)から(27)のいずれかに記載のプログラム。
上記方法によれば、他のユーザによるリアクションの有無を、第1アクションを実行したユーザが容易に把握することができる。
(29)ユーザに仮想体験を提供するための情報処理装置であって、
前記情報処理装置が備えるプロセッサの制御により、
仮想空間内で第1アクションを実行するステップと、
前記第1アクションの実行に基づいて、前記ユーザとは異なる他のユーザに対する第2アクションを実行するステップと、
前記第2アクションに対するリアクションに基づいて、前記仮想空間内で第3アクションを実行するステップと、
が実行される、情報処理装置。
上記情報処理装置によれば、ユーザの仮想体験を向上させることができる。
(30)ユーザに仮想体験を提供するための情報処理システムであって、
前記情報処理システムが備える複数のプロセッサの制御により、
仮想空間内で第1アクションを実行するステップと、
前記第1アクションの実行に基づいて、前記ユーザとは異なる他のユーザに対する第2アクションを実行するステップと、
前記第2アクションに対するリアクションに基づいて、前記仮想空間内で第3アクションを実行するステップと、
が実行される、情報処理システム。
上記情報処理システムによれば、ユーザの仮想体験を向上させることができる。
(31)ユーザに仮想体験を提供するためにコンピュータによって実行される情報処理方法であって、
仮想空間内で第1アクションを実行するステップと、
前記第1アクションの実行に基づいて、前記ユーザとは異なる他のユーザに対する第2アクションを実行するステップと、
前記第2アクションに対するリアクションに基づいて、前記仮想空間内で第3アクションを実行するステップと、
を含む、情報処理方法。
上記情報処理方法によれば、ユーザの仮想体験を向上させることができる。
[本開示が示す実施形態の詳細]
以下、本開示が示す実施形態について図面を参照しながら説明する。尚、本実施形態の説明において既に説明された要素と同一の参照番号を有する要素については、説明の便宜上、その説明は繰り返さない。
最初に、仮想空間配信システム100の構成の概略について図1を参照して説明する。図1は、仮想空間配信システム100(以下、単に配信システム100という。)の概略図である。図1に示すように、配信システム100は、ヘッドマウントデバイス(HMD)110(第1HMD)を装着したユーザA(第1ユーザ)によって操作されるユーザ端末1A(第1ユーザ端末)と、HMD110(第2HMD)を装着したユーザB(第2ユーザ)によって操作されるユーザ端末1B(第2ユーザ端末)と、サーバ2とを備える。ユーザ端末1A,1Bは、インターネット等の通信ネットワーク3を介してサーバ2に通信可能に接続されている。尚、本実施形態において、仮想空間とは、VR(Virtual Reality)空間を含むものである。また、以降では、説明の便宜上、各ユーザ端末1A,1Bを単にユーザ端末1と総称する場合がある。さらに、各ユーザA,Bを単にユーザUと総称する場合がある。また、本実施形態では、ユーザ端末1A,1Bは、同一の構成を備えているものとする。
次に、図2を参照してユーザ端末1の構成について説明する。図2は、ユーザ端末1を示す概略図である。図2に示すように、ユーザ端末1は、ユーザUの頭部に装着されたヘッドマウントデバイス(HMD)110と、ヘッドフォン116と、フェイスカメラ117と、マイク118と、位置センサ130と、外部コントローラ320と、制御装置120とを備える。
HMD110は、表示部112と、HMDセンサ114と、注視センサ140と、フェイスカメラ113と、装着センサ115とを備えている。表示部112は、HMD110を装着したユーザUの視界(視野)を完全に覆うように構成された非透過型の表示装置を備えている。これにより、ユーザUは、表示部112に表示された視野画像のみを見ることで仮想空間に没入することができる。尚、表示部112は、ユーザUの左目に画像を提供するように構成された左目用表示部と、ユーザUの右目に画像を提供するように構成された右目用表示部とから構成されてもよい。また、HMD110は、透過型の表示装置を備えてもよい。この場合、透過型の表示装置は、その透過率を調整することで、一時的に非透過型の表示装置として構成されてもよい。
HMDセンサ114は、HMD110の表示部112の近傍に搭載される。HMDセンサ114は、地磁気センサ、加速度センサ、傾きセンサ(角速度センサやジャイロセンサ等)のうちの少なくとも1つを含み、ユーザUの頭部に装着されたHMD110の各種動き(傾き等)を検出することができる。
注視センサ140は、ユーザUの視線を検出するアイトラッキング機能を有する。注視センサ140は、例えば、右目用注視センサと、左目用注視センサを備えてもよい。右目用注視センサは、ユーザUの右目に例えば赤外光を照射して、右目(特に、角膜や虹彩)から反射された反射光を検出することで、右目の眼球の回転角に関する情報を取得してもよい。一方、左目用注視センサは、ユーザUの左目に例えば赤外光を照射して、左目(特に、角膜や虹彩)から反射された反射光を検出することで、左目の眼球の回転角に関する情報を取得してもよい。
フェイスカメラ113は、HMD110がユーザUに装着された状態でユーザUの目(左目と右目)とまゆげ(左まゆげと右まゆげ)が表示された画像(特に、動画像)を取得するように構成されている。フェイスカメラ113は、ユーザUの目とまゆげを撮像可能なようにHMD110の内側の所定箇所に配置されている。フェイスカメラ113によって取得される動画像のフレームレートは、HMD110に表示される視野画像(後述する)のフレームレートよりも大きくてもよい。
装着センサ115は、ユーザUがHMD110を装着しているかどうかを示すためのイベント情報を生成するように構成されている。具体的には、ユーザUがHMD110を取り外したときに(HMD110の状態が装着状態から非装着状態に遷移したときに)、装着センサ115は、イベント情報を生成した上で、当該イベント情報を制御装置120に送信する。また、ユーザUがHMD110を装着したときに(HMD110の状態が非装着状態から装着状態に遷移したときに)、装着センサ115は、イベント情報を生成した上で、当該イベント情報を制御装置120に送信する。また、装着センサ115の構成は特に限定されない。例えば、ユーザUがHMD110を装着したときに、HMD110に設けられたバネの弾性力が変化すると仮定する。この場合、装着センサ115は、このバネの弾性力の変化に基づいて、イベント情報を生成してもよい。さらに、ユーザUがHMD110を装着したときに、HMD110に設けられた身体の一部(鼻部分)に接触する2つのパッド間を流れる電流が変化すると仮定する。この場合、装着センサ115は、この2つのパッド間を流れる電流の変化に基づいて、イベント情報を生成してもよい。
ヘッドフォン116(音声出力部)は、ユーザUの左耳と右耳にそれぞれ装着されている。ヘッドフォン116は、制御装置120から音声データ(電気信号)を受信し、当該受信した音声データに基づいて音声を出力するように構成されている。マイク118(音声入力部)は、ユーザUから発声された音声を収集し、当該収集された音声に基づいて音声データ(電気信号)を生成するように構成されている。さらに、マイク118は、音声データを制御装置120に送信するように構成されている。
フェイスカメラ117は、ユーザUの口及びその周辺が表示された画像(特に、動画像)を取得するように構成されている。フェイスカメラ117は、ユーザUの口及びその周辺を撮像可能なようにユーザUの口に対向する位置に配置されてもよい。また、フェイスカメラ117は、HMD110と連結されていてもよい。フェイスカメラ117によって取得される動画像のフレームレートは、HMD110に表示される視野画像のフレームレートよりも大きくてもよい。
位置センサ130は、例えば、ポジション・トラッキング・カメラにより構成され、HMD110と外部コントローラ320の位置を検出するように構成されている。位置センサ130は、制御装置120に無線又は有線により通信可能に接続されており、HMD110に設けられた図示しない複数の検知点の位置、傾き又は発光強度に関する情報を検出するように構成されている。さらに、位置センサ130は、外部コントローラ320に設けられた図示しない複数の検知点の位置、傾き及び/又は発光強度に関する情報を検出するように構成されている。検知点は、例えば、赤外線や可視光を放射する発光部である。また、位置センサ130は、赤外線センサや複数の光学カメラを含んでもよい。
外部コントローラ320は、ユーザUの身体の一部(頭部以外の部位であり、本実施形態においてはユーザUの手)の動きを検知することにより、仮想空間内に表示されるアバターの手の動作を制御するために使用される。外部コントローラ320は、ユーザUの右手によって操作される右手用外部コントローラ320R(以下、単にコントローラ320Rという。)と、ユーザUの左手によって操作される左手用外部コントローラ320L(以下、単にコントローラ320Lという。)と、を有する。コントローラ320Rは、ユーザUの右手の位置や右手の手指の動きを示す装置である。また、コントローラ320Rの動きに応じて仮想空間内に存在するアバターの右手が動く。コントローラ320Lは、ユーザUの左手の位置や左手の手指の動きを示す装置である。また、コントローラ320Lの動きに応じて仮想空間内に存在するアバターの左手が動く。
制御装置120は、HMD110を制御するように構成されたコンピュータである。制御装置120は、位置センサ130から取得された情報に基づいて、HMD110の位置情報を特定し、当該特定された位置情報に基づいて、仮想空間における仮想カメラの位置(アバターの位置)と、現実空間におけるHMD110を装着したユーザUの位置を正確に対応付けることができる。さらに、制御装置120は、位置センサ130及び/又は外部コントローラ320に内蔵されたセンサから取得された情報に基づいて、外部コントローラ320の動作を特定し、当該特定された外部コントローラ320の動作に基づいて、仮想空間内に表示されるアバターの手の動作と現実空間における外部コントローラ320の動作を正確に対応付けることができる。特に、制御装置120は、位置センサ130及び/又はコントローラ320Lに内蔵されたセンサから取得された情報に基づいて、コントローラ320Lの動作を特定し、当該特定されたコントローラ320Lの動作に基づいて、仮想空間内に表示されるアバターの左手の動作と現実空間におけるコントローラ320Lの動作(ユーザUの左手の動作)を正確に対応付けることができる。同様に、制御装置120は、位置センサ及び/コントローラ320Rに内蔵されたセンサから取得された情報に基づいて、コントローラ320Rの動作を特定し、当該特定されたコントローラ320Rの動作に基づいて、仮想空間内に表示されるアバターの右手の動作と現実空間におけるコントローラ320Rの動作(ユーザUの右手の動作)を正確に対応付けることができる。
また、制御部121は、フェイスカメラ113,117によって取得された動画像に基づいて、ユーザUの顔の表情(状態)とユーザUのアバターの顔の表情(状態)を対応付けることができる。ユーザUの顔の表情とアバターの顔の表情を互いに対応づける処理の詳細については後述する。
また、制御装置120は、注視センサ140(左目用注視センサと右目用注視センサ)から送信された情報に基づいて、ユーザUの右目の視線と左目の視線をそれぞれ特定し、当該右目の視線と当該左目の視線の交点である注視点を特定することができる。さらに、制御装置120は、特定された注視点に基づいて、ユーザUの両目の視線(ユーザUの視線)を特定することができる。ここで、ユーザUの視線は、ユーザUの両目の視線であって、ユーザUの右目と左目を結ぶ線分の中点と注視点を通る直線の方向に一致する。
次に、図3を参照して、HMD110の位置や傾きに関する情報を取得する方法について説明する。図3は、HMD110を装着したユーザUの頭部を示す図である。HMD110を装着したユーザUの頭部の動きに連動したHMD110の位置や傾きに関する情報は、位置センサ130及び/又はHMD110に搭載されたHMDセンサ114により検出可能である。図2に示すように、HMD110を装着したユーザUの頭部を中心として、3次元座標(uvw座標)が規定される。ユーザUが直立する垂直方向をv軸として規定し、v軸と直交しHMD110の中心を通る方向をw軸として規定し、v軸およびw軸と直交する方向をu軸として規定する。位置センサ130及び/又はHMDセンサ114は、各uvw軸回りの角度(すなわち、v軸を中心とする回転を示すヨー角、u軸を中心とした回転を示すピッチ角、w軸を中心とした回転を示すロール角で決定される傾き)を検出する。制御装置120は、検出された各uvw軸回りの角度変化に基づいて、仮想カメラの視軸を制御するための角度情報を決定する。
次に、図4を参照することで、制御装置120のハードウェア構成について説明する。図4は、制御装置120のハードウェア構成を示す図である。図4に示すように、制御装置120は、制御部121と、記憶部123と、I/O(入出力)インターフェース124と、通信インターフェース125と、バス126とを備える。制御部121と、記憶部123と、I/Oインターフェース124と、通信インターフェース125は、バス126を介して互いに通信可能に接続されている。
制御装置120は、HMD110とは別体に、パーソナルコンピュータ、スマートフォン、ファブレット、タブレット又はウェアラブルデバイスとして構成されてもよいし、HMD110に内蔵されていてもよい。また、制御装置120の一部の機能がHMD110に搭載されると共に、制御装置120の残りの機能がHMD110とは別体の他の装置に搭載されてもよい。
制御部121は、メモリとプロセッサを備えている。メモリは、例えば、各種プログラム等が格納されたROM(Read Only Memory)やプロセッサにより実行される各種プログラム等が格納される複数ワークエリアを有するRAM(Random Access Memory)等から構成される。プロセッサは、例えばCPU(Central Processing Unit)、MPU(Micro Processing Unit)及び/又はGPU(Graphics Processing Unit)であって、ROMに組み込まれた各種プログラムから指定されたプログラムをRAM上に展開し、RAMとの協働で各種処理を実行するように構成されている。
特に、プロセッサが制御プログラムをRAM上に展開し、RAMとの協働で制御プログラムを実行することで、制御部121は、制御装置120の各種動作を制御してもよい。制御部121は、視野画像データに基づいてHMD110の表示部112に視野画像を表示する。これにより、ユーザUは、仮想空間に没入することができる。
記憶部(ストレージ)123は、例えば、HDD(Hard Disk Drive)、SSD(Solid State Drive)、USBフラッシュメモリ等の記憶装置であって、プログラムや各種データを格納するように構成されている。記憶部123は、本実施形態に係る情報処理方法の少なくとも一部をコンピュータに実行させるための制御プログラムや、複数のユーザによる仮想空間の共有を実現するための制御プログラムを格納してもよい。また、記憶部123には、ユーザUの認証プログラムや各種画像やオブジェクト(例えば、アバター等)に関するデータが格納されてもよい。さらに、記憶部123には、各種データを管理するためのテーブルを含むデータベースが構築されてもよい。
I/Oインターフェース124は、HMD110と、位置センサ130と、外部コントローラ320と、ヘッドフォン116と、フェイスカメラ117と、マイク118とをそれぞれ制御装置120に通信可能に接続するように構成されており、例えば、USB(Universal Serial Bus)端子、DVI(Digital Visual Interface)端子、HDMI(登録商標)(High―Definition Multimedia Interface)端子等により構成されている。尚、制御装置120は、HMD110と、位置センサ130と、外部コントローラ320と、ヘッドフォン116と、フェイスカメラ117と、マイク118とのそれぞれと無線接続されていてもよい。
通信インターフェース125は、制御装置120をLAN(Local Area Network)、WAN(Wide Area Network)又はインターネット等の通信ネットワーク3に接続させるように構成されている。通信インターフェース125は、通信ネットワーク3を介してサーバ2等の外部装置と通信するための各種有線接続端子や、無線接続のための各種処理回路を含んでおり、通信ネットワーク3を介して通信するための通信規格に適合するように構成されている。
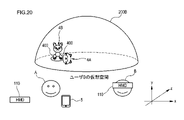
次に、図5から図8を参照することで視野画像をHMD110に表示するための処理について説明する。図5は、視野画像をHMD110に表示する処理を示すフローチャートである。図6は、仮想空間200の一例を示すxyz空間図である。図7の状態(a)は、図6に示す仮想空間200のyx平面図である。図7の状態(b)は、図6に示す仮想空間200のzx平面図である。図8は、HMD110に表示された視野画像Vの一例を示す図である。
図5に示すように、ステップS1において、制御部121(図4参照)は、仮想カメラ300と、各種オブジェクトとを含む仮想空間200を示す仮想空間データを生成する。図6に示すように、仮想空間200は、中心位置210を中心とした全天球として規定される(図6では、上半分の天球のみが図示されている)。また、仮想空間200では、中心位置210を原点とするxyz座標系が設定されている。仮想カメラ300は、HMD110に表示される視野画像V(図8参照)を特定するための視軸Lを規定している。仮想カメラ300の視野を定義するuvw座標系は、現実空間におけるユーザUの頭部を中心として規定されたuvw座標系に連動するように決定される。また、HMD110を装着したユーザUの現実空間における移動に連動して、制御部121は、仮想カメラ300を仮想空間200内で移動させてもよい。
次に、ステップS2において、制御部121は、仮想カメラ300の視野CV(図7参照)を特定する。具体的には、制御部121は、位置センサ130及び/又はHMDセンサ114から送信されたHMD110の状態を示すデータに基づいて、HMD110の位置や傾きに関する情報を取得する。次に、制御部121は、HMD110の位置や傾きに関する情報に基づいて、仮想空間200内における仮想カメラ300の位置や向きを特定する。次に、制御部121は、仮想カメラ300の位置や向きから仮想カメラ300の視軸Lを決定し、決定された視軸Lから仮想カメラ300の視野CVを特定する。ここで、仮想カメラ300の視野CVは、HMD110を装着したユーザUが視認可能な仮想空間200の一部の領域に相当する(換言すれば、HMD110に表示される仮想空間200の一部の領域に相当する)。また、視野CVは、図7の状態(a)に示すxy平面において、視軸Lを中心とした極角αの角度範囲として設定される第1領域CVaと、図7の状態(b)に示すxz平面において、視軸Lを中心とした方位角βの角度範囲として設定される第2領域CVbとを有する。尚、制御部121は、注視センサ140から送信されたユーザUの視線を示すデータに基づいてユーザUの視線を特定し、特定されたユーザUの視線とHMD110の位置や傾きに関する情報に基づいて、仮想カメラ300の向き(仮想カメラの視軸L)を決定してもよい。また、後述するように、制御部121は、HMD110の位置や傾きに関する情報に基づいて、ユーザUのアバターの顔の向きを決定してもよい。
このように、制御部121は、位置センサ130及び/又はHMDセンサ114からのデータに基づいて、仮想カメラ300の視野CVを特定することができる。ここで、HMD110を装着したユーザUが動くと、制御部121は、位置センサ130及び/又はHMDセンサ114から送信されたHMD110の動きを示すデータに基づいて、仮想カメラ300の視野CVを更新することができる。つまり、制御部121は、HMD110の動きに応じて、視野CVを更新することができる。同様に、ユーザUの視線が変化すると、制御部121は、注視センサ140から送信されたユーザUの視線を示すデータに基づいて、仮想カメラ300の視野CVを更新してもよい。つまり、制御部121は、ユーザUの視線の変化に応じて、視野CVを変化させてもよい。
次に、ステップS3において、制御部121は、HMD110の表示部112に表示される視野画像Vを示す視野画像データを生成する。具体的には、制御部121は、仮想空間200を規定する仮想空間データと、仮想カメラ300の視野CVとに基づいて、視野画像データを生成する。
次に、ステップS4において、制御部121は、視野画像データに基づいて、HMD110の表示部112に視野画像Vを表示する(図7参照)。このように、HMD110を装着しているユーザUの動きに応じて、仮想カメラ300の視野CVが変化し、HMD110の表示部112に表示される視野画像Vが変化するので、ユーザUは仮想空間200に没入することができる。
尚、仮想カメラ300は、左目用仮想カメラと右目用仮想カメラを含んでもよい。この場合、制御部121は、仮想空間データと左目用仮想カメラの視野に基づいて、左目用の視野画像を示す左目用視野画像データを生成する。さらに、制御部121は、仮想空間データと、右目用仮想カメラの視野に基づいて、右目用の視野画像を示す右目用視野画像データを生成する。その後、制御部121は、左目用視野画像データに基づいて、左目用表示部に左目用の視野画像を表示すると共に、右目用視野画像データに基づいて、右目用表示部に右目用の視野画像を表示する。このようにして、ユーザUは、左目用視野画像と右目用視野画像との間の視差により、視野画像を3次元的に視認することができる。尚、仮想カメラは、後述するように、ユーザによって操作されるアバターの目の位置に配置されてもよい。例えば、左目用仮想カメラは、アバターの左目に配置される一方で、右目用仮想カメラは、アバターの右目に配置されてもよい。
また、図5に示すステップS1~S4の処理は1フレーム(動画を構成する静止画像)毎に実行されてもよい。例えば、動画のフレームレートが90fpsである場合、ステップS1~S4の処理はΔT=1/90(秒)間隔で繰り返し実行されてもよい。このように、ステップS1~S4の処理が所定間隔ごとに繰り返し実行されるため、HMD110の動作に応じて仮想カメラ300の視野が更新されると共に、HMD110の表示部112に表示される視野画像Vが更新される。
次に、図1に示すサーバ2のハードウェア構成について図9を参照して説明する。図9は、サーバ2のハードウェア構成を示す図である。図9に示すように、サーバ2は、制御部23と、記憶部22と、通信インターフェース21と、バス24とを備える。制御部23と、記憶部22と、通信インターフェース21は、バス24を介して互いに通信可能に接続されている。制御部23は、メモリとプロセッサを備えており、メモリは、例えば、ROM及びRAM等から構成されると共に、プロセッサは、例えば、CPU、MPU及び/又はGPUにより構成される。
記憶部(ストレージ)22は、例えば、大容量のHDD等である。記憶部22は、本実施形態に係る情報処理方法の少なくとも一部をコンピュータに実行させるための制御プログラムや、複数のユーザによる仮想空間の共有を実現させるための制御プログラムを格納してもよい。また、記憶部22は、各ユーザを管理するためのユーザ管理情報や各種画像やオブジェクト(例えば、アバター等)に関するデータを格納してもよい。通信インターフェース21は、サーバ2を通信ネットワーク3に接続させるように構成されている。
次に、図1,10及び11を参照してユーザ端末1Aとユーザ端末1B間において各アバター4A,4Bの動きを同期させる処理の一例について説明する。図10の状態(a)は、ユーザAに提供される仮想空間200Aを示す図である。図10の状態(b)は、ユーザBに提供される仮想空間200Bを示す図である。図11は、ユーザ端末1Aとユーザ端末1B間において各アバター4A,4Bの動きを同期させる処理の一例を説明するためのシーケンス図である。本説明では、前提条件として、図10に示すように、ユーザ端末1A(ユーザA)に関連付けられたアバター4A(第1アバター)と、ユーザ端末1B(ユーザB)に関連付けられたアバター4B(第2アバター)が同一の仮想空間を共有しているものとする。つまり、通信ネットワーク3を介してユーザAとユーザBが一つの仮想空間を共有するものとする。
図10の状態(a)に示すように、ユーザAの仮想空間200Aは、アバター4Aと、アバター4Bとを含む。アバター4Aは、ユーザAによって操作されると共に、ユーザAの動作に連動する。アバター4Aは、ユーザ端末1Aのコントローラ320Lの動作(ユーザAの左手の動作)に連動する左手(アバター4Aの仮想身体の一部)と、ユーザ端末1Aのコントローラ320Rの動作(ユーザAの右手の動作)に連動する右手と、表情がユーザAの顔の表情に連動する顔を有する。アバター4Aの顔は、複数の顔パーツ(例えば、目、まゆげ、口等)を有する。アバター4Bは、ユーザBによって操作されると共に、ユーザBの動作に連動する。アバター4Bは、ユーザBの左手の動作を示すユーザ端末1Bのコントローラ320Lの動作に連動する左手と、ユーザBの右手の動作を示すユーザ端末1Bのコントローラ320Rの動作に連動する右手と、表情がユーザBの顔の表情と連動する顔を有する。アバター4Bの顔は、複数の顔パーツ(例えば、目、まゆげ、口等)を有する。
尚、ユーザAに提供される仮想空間200Aでは、アバター4Aが可視化されない場合も想定される。この場合、仮想空間200Aに配置されるアバター4Aは、少なくともユーザ端末1AのHMD110の動きに連動する仮想カメラ300を含む。
また、ユーザ端末1A,1BのHMD110の位置に応じてアバター4A,4Bの位置が特定されてもよい。同様に、ユーザ端末1A,1BのHMD110の傾きに応じてアバター4A,4Bの顔の向きが特定されてもよい。さらに、ユーザ端末1A,1Bの外部コントローラ320の動作に応じてアバター4A,4Bの手の動作が特定されてもよい。特に、ユーザ端末1A,1Bのコントローラ320Lの動作に応じてアバター4A,4Bの左手の動作が特定されると共に、ユーザ端末1A,1Bのコントローラ320Rの動作に応じてアバター4A,4Bの右手の動作が特定されてもよい。また、ユーザA,Bの顔の表情(状態)に応じてアバター4A,4Bの顔の表情が特定されてもよい。
また、アバター4A,4Bの各々の目には、仮想カメラ300(図6)が配置されてもよい。特に、アバター4A,4Bの左目には、左目用仮想カメラが配置されると共に、アバター4A,4Bの右目には、右目用仮想カメラが配置されてもよい。尚、以降の説明では、仮想カメラ300は、アバター4A,4Bの目に配置されているものとする。このため、アバター4Aの視野CVは、アバター4Aに配置された仮想カメラ300の視野CV(図7参照)と一致するものとする。同様に、アバター4Bの視野CVは、アバター4Bに配置された仮想カメラ300の視野CV(図7参照)と一致するものとする。
図10の状態(b)に示すように、ユーザBの仮想空間200Bは、アバター4Aと、アバター4Bとを含む。仮想空間200A内におけるアバター4A,4Bの位置は、仮想空間200B内におけるアバター4A,4Bの位置に対応してもよい。
尚、ユーザBに提供される仮想空間200Bでは、アバター4Bが可視化されない場合も想定される。この場合、仮想空間200Bに配置されるアバター4Bは、少なくともユーザ端末1BのHMD110の動きに連動する仮想カメラ300を含む。
次に、図11を参照すると、ステップS10において、ユーザ端末1Aの制御部121は、ユーザAの音声データを生成する。例えば、ユーザAがユーザ端末1Aのマイク118(音声入力部)に音声を入力したときに、マイク118は、入力された音声を示す音声データを生成する。その後、マイク118は生成された音声データをI/Oインターフェース124を介して制御部121に送信する。
次に、ステップS11において、ユーザ端末1Aの制御部121は、アバター4Aの制御情報を生成した上で、当該生成したアバター4Aの制御情報とユーザAの音声を示す音声データ(ユーザAの音声データ)をサーバ2に送信する。その後、サーバ2の制御部23は、ユーザ端末1Aからアバター4Aの制御情報とユーザAの音声データを受信する(ステップS12)。
ここで、アバター4Aの制御情報は、アバター4Aの動作を制御するために必要な情報である。アバター4Aの制御情報は、アバター4Aの位置に関する情報(位置情報)と、アバター4Aの顔の向きに関する情報(顔向き情報)と、アバター4Aの手(左手と右手)の状態に関する情報(手情報)と、アバター4Aの顔の表情に関する情報(顔情報)とを含んでもよい。
アバター4Aの顔情報は、複数の顔パーツの状態を示す情報を有する。複数の顔パーツの状態を示す情報は、アバター4Aの目の状態(白目の形状及び白目に対する黒目の位置等)を示す情報(目情報)と、アバター4Aのまゆげの情報(まゆげの位置及び形状等)を示す情報(まゆげ情報)と、アバター4Aの口の状態(口の位置及び形状等)を示す情報(口情報)を有する。
詳細には、アバター4Aの目情報は、アバター4Aの左目の状態を示す情報と、アバター4Aの右目の状態を示す情報を有する。アバター4Aのまゆげ情報は、アバター4Aの左まゆげの状態を示す情報と、アバター4Aの右まゆげの状態を示す情報を有する。
ユーザ端末1Aの制御部121は、HMD110に搭載されたフェイスカメラ113からユーザAの目(左目と右目)とまゆげ(左まゆげと右まゆげ)を示す画像を取得した上で、当該取得された画像と所定の画像処理アルゴリズムに基づいてユーザAの目(左目と右目)とまゆげ(左まゆげと右まゆげ)の状態を特定する。次に、制御部121は、特定されたユーザAの目とまゆげの状態に基づいて、アバター4Aの目(左目と右目)の状態を示す情報とアバター4Aのまゆげ(左まゆげと右まゆげ)の状態を示す情報をそれぞれ生成する。
同様に、ユーザ端末1Aの制御部121は、フェイスカメラ117からユーザAの口及びその周辺を示す画像を取得した上で、当該取得された画像と所定の画像処理アルゴリズムに基づいてユーザAの口の状態を特定する。次に、制御部121は、特定されたユーザAの口の状態に基づいて、アバター4Aの口の状態を示す情報を生成する。
このように、ユーザ端末1Aの制御部121は、ユーザAの目に対応するアバター4Aの目情報と、ユーザAのまゆげに対応するアバター4Aのまゆげ情報と、ユーザAの口に対応するアバター4Aの口情報を生成することが可能となる。
また、制御部121は、フェイスカメラ113によって撮像された画像と、フェイスカメラ117によって撮像された画像と、所定の画像処理アルゴリズムに基づいて、記憶部123又はメモリに記憶された複数の種類の顔の表情(例えば、笑顔、悲しい表情、無表情、怒りの表情、驚いた表情、困った表情等)の中からユーザAの顔の表情(例えば、笑顔)を特定してもよい。その後、制御部121は、特定されたユーザAの顔の表情に基づいて、アバター4Aの顔の表情(例えば、笑顔)を示す顔情報を生成することが可能となる。この場合、アバター4Aの複数の種類の顔の表情と、各々が当該複数の種類の顔の表情の一つに関連付けられた複数のアバター4Aの顔情報を含む表情データが記憶部123に保存されてもよい。
例えば、制御部121は、アバター4Aの顔の表情を笑顔として特定した場合、アバター4Aの顔の表情(笑顔)と表情データに基づいて、アバター4Aの笑顔を示す顔情報を取得する。ここで、アバター4Aの笑顔を示す顔情報は、アバター4Aの顔の表情が笑顔のときのアバター4Aの目情報、まゆげ情報及び口情報を含む。
次に、ステップS13において、ユーザ端末1Bの制御部121は、アバター4Bの制御情報を生成した上で、当該生成したアバター4Bの制御情報をサーバ2に送信する。その後、サーバ2の制御部23は、ユーザ端末1Bからアバター4Bの制御情報を受信する(ステップS14)。
ここで、アバター4Bの制御情報は、アバター4Bの動作を制御するために必要な情報である。アバター4Bの制御情報は、アバター4Bの位置に関する情報(位置情報)と、アバター4Bの顔の向きに関する情報(顔向き情報)と、アバター4Bの手(左手と右手)の状態に関する情報(手情報)と、アバター4Bの顔の表情に関する情報(顔情報)とを含んでもよい。
アバター4Bの顔情報は、複数の顔パーツの状態を示す情報を有する。複数の顔パーツの状態を示す情報は、アバター4Bの目の状態(白目の形状及び白目に対する黒目の位置等)を示す情報(目情報)と、アバター4Bのまゆげの情報(まゆげの位置及び形状等)を示す情報(まゆげ情報)と、アバター4Bの口の状態(口の位置及び形状等)を示す情報(口情報)を有する。アバター4Bの顔情報の取得方法は、アバター4Aの顔情報の取得方法と同様である。
次に、サーバ2は、アバター4Bの制御情報をユーザ端末1Aに送信する一方(ステップS15)、アバター4Aの制御情報とユーザAの音声データをユーザ端末1Bに送信する(ステップS19)。その後、ユーザ端末1Aの制御部121は、ステップS16においてアバター4Bの制御情報を受信した後に、アバター4A,4Bの制御情報に基づいて、アバター4A,4Bの状態を更新した上で、仮想空間200A(図10の状態(a)参照)を示す仮想空間データを更新する(ステップS17)。
詳細には、ユーザ端末1Aの制御部121は、アバター4A,4Bの位置情報に基づいて、アバター4A,4Bの位置を更新する。制御部121は、アバター4A,4Bの顔向き情報に基づいて、アバター4A,4Bの顔の向きを更新する。制御部121は、アバター4A,4Bの手情報に基づいて、アバター4A,4Bの手を更新する。制御部121は、アバター4A,4Bの顔情報に基づいて、アバター4A,4Bの顔の表情を更新する。このように、更新されたアバター4A,4Bを含む仮想空間200Aを示す仮想空間データが更新される。
その後、ユーザ端末1Aの制御部121は、HMD110の位置や傾きに応じてアバター4A(仮想カメラ300)の視野CVを特定した上で、更新された仮想空間データと、アバター4Aの視野CVとに基づいて、HMD110に表示される視野画像を更新する(ステップS18)。
一方、ユーザ端末1Bの制御部121は、ステップS20においてアバター4Aの制御情報とユーザAの音声データを受信した後に、アバター4A,4Bの制御情報に基づいて、アバター4A,4Bの状態を更新した上で、仮想空間200B(図10の状態(b)参照)を示す仮想空間データを更新する(ステップS21)。
詳細には、ユーザ端末1Bの制御部121は、アバター4A,4Bの位置情報に基づいて、アバター4A,4Bの位置を更新する。制御部121は、アバター4A,4Bの顔向き情報に基づいて、アバター4A,4Bの顔の向きを更新する。制御部121は、アバター4A,4Bの手情報に基づいて、アバター4A,4Bの手を更新する。制御部121は、アバター4A,4Bの顔情報に基づいて、アバター4A,4Bの顔の表情を更新する。このように、更新されたアバター4A,4Bを含む仮想空間を示す仮想空間データが更新される。
その後、ユーザ端末1Bの制御部121は、HMD110の位置や傾きに応じてアバター4B(仮想カメラ300)の視野CVを特定した上で、更新された仮想空間データと、アバター4Bの視野CVとに基づいて、HMD110に表示される視野画像を更新する(ステップS22)。
その後、ユーザ端末1Bの制御部121は、受信したユーザAの音声データと、アバター4Aの制御情報に含まれるアバター4Aの位置に関する情報と、アバター4Bの位置に関する情報と、所定の音声処理アルゴリズムに基づいてユーザAの音声データを加工する。その後、制御部121は、加工された音声データをヘッドフォン116(音声出力部)に送信した上で、ヘッドフォン116は、加工された音声データに基づいてユーザAの音声を出力する(ステップS23)。このように、仮想空間上においてユーザ間(アバター間)の音声チャット(VRチャット)を実現することができる。
本実施形態では、ユーザ端末1A,1Bがサーバ2にアバター4Aの制御情報とアバター4Bの制御情報をそれぞれ送信した後に、サーバ2がアバター4Aの制御情報をユーザ端末1Bに送信する一方、アバター4Bの制御情報をユーザ端末1Aに送信する。このように、ユーザ端末1Aとユーザ端末1B間において各アバター4A,4Bの動きを同期させることが可能となる。
次に、図12及び図14を主に参照することで、ユーザAのHMD110を取り外した場合における本実施形態に係る情報処理方法について説明する。図12は、ユーザAがHMD110を取り外した場合における本実施形態に係る情報処理方法を説明するためのフローチャートの一例である。図14は、本実施形態に係る情報処理方法を説明するためのユーザBに提供される仮想空間200Bの一例を示す図である。尚、図12に示すフローチャートでは、ユーザ端末1Aの制御部121がアバター4Aの制御情報をサーバ2に送信する処理やユーザ端末1Bの制御部121がアバター4Bの制御情報をサーバ2に送信する処理については説明の便宜上省略している。
本実施形態では、前提条件として、図14に示すように、アバター4Aと、アバター4Bが同一の仮想空間を共有しているものとする。つまり、通信ネットワーク3を介してユーザA,Bが一つの仮想空間を共有するものとする。
ユーザBの仮想空間200Bは、アバター4Aと、アバター4Bとを含む。ユーザ端末1Bの制御部121は、仮想空間200Bを示す仮想空間データを更新する。本説明では、説明の便宜上、アバター4Aに提供される仮想空間200Aの図示は省略する。
図12を参照すると、ステップS30において、ユーザ端末1Aの制御部121は、ユーザAがHMD110を取り外したかどうかを判定する。この点において、制御部121は、HMDセンサ114から送信されたHMD110の傾き情報又は装着センサ115から送信されたイベント情報に基づいて、ユーザAがHMD110を取り外したかどうかを判定してもよい。HMD114と装着センサ115は、HMD110を装着しているかどうかを検出するように構成されたセンサとして機能する。
図13の状態(a)を参照して、HMDセンサ114を用いてユーザAがHMD110を取り外したかどうかを判定する処理について説明する。図13の状態(a)は、HMDセンサ114を用いてユーザAがHMD110を取り外したかどうかを判定するための処理を説明するためのフローチャートの一例である。図13の状態(a)に示すように、制御部121は、HMDセンサ114からHMD110の傾き(ロール角、ヨー角、ピッチ角)を示す傾き情報を受信する(ステップS301)。次に、制御部121は、受信した傾き情報に基づいて、HMD110の傾きが所定の傾きよりも大きいかどうかを判定する(S302)。ここで、所定の傾きは、ユーザによって適宜設定されてもよい。ユーザAがHMD110を装着している間では、HMD110の傾きが所定の傾きよりも大きくなることがないものとする。つまり、ユーザAがHMD110を装着している間では、HMD110の傾きは所定の傾き以下となる一方で、ユーザAがHMD110を取り外すときは、HMD110が大きく傾くため、HMD110の傾きが所定の傾きを超えることがある。このような観点より、所定の傾きが設定される。
例えば、制御部121は、HMD110の傾きの一例として、HMD110のピッチ角θが所定の角度θthよりも大きいと判定した場合に(ステップS302でYES)、ユーザAがHMD110を取り外した(換言すれば、ユーザAがHMD110を装着していない)ことを特定した上で、ステップS31の処理を実行する。一方、制御部121は、HMD110のピッチ角θが所定の角度θth以下であると判定した場合に(ステップS302でNO)、ユーザAがHMD110を装着していることを特定した上で、HMDセンサ114からのHMD110の傾き情報を受信するまで待機する。
次に、図13の状態(b)を参照して、装着センサ115を用いてユーザAがHMD110を取り外したかどうかを判定する処理について説明する。図13の状態(b)は、装着センサ115を用いてユーザAがHMD110を取り外したかどうかを判定するための処理を説明するためのフローチャートの一例である。図13の状態(b)に示すように、制御部121は、装着センサ115からイベント情報を受信したかどうかを判定する(ステップS303)。ここで、装着センサ115から送信されたイベント情報は、ユーザ端末1AのHMD110の状態が装着状態と非装着状態との間で変化したことを示す情報である。例えば、ユーザAがHMD110を取り外したときに(HMD110の状態が装着状態から非装着状態に遷移したときに)、装着センサ115はイベント情報を出力する。また、ユーザAがHMD110を装着したときに(HMD110の状態が非装着状態から装着状態に遷移したときに)、装着センサ115はイベント情報を出力する。
制御部121は、装着センサ115からイベント情報を受信したと判定した場合に(ステップS303でYES)、ユーザAがHMD110を取り外した(換言すれば、ユーザAがHMD110を装着していない)ことを特定した上で、ステップS31の処理を実行する。一方、制御部121は、装着センサ115からイベント情報を受信していないと判定した場合に(ステップS303でNO)、ユーザAはHMD110を装着していることを特定した上で、イベント情報を装着センサ115から受信するまで待機する。
次に、図12に戻ると、制御部121は、ユーザAがHMD110を取り外した(換言すれば、ユーザAがHMD110を装着していない)と判定した場合に(ステップS30YES)、ユーザAがHMD110を装着していないことを示す情報(非装着情報)を生成する(ステップS31)。その後、制御部121は、通信ネットワーク3を介して非装着情報をサーバ2に送信する(ステップS32)。
次に、サーバ2は、非装着情報をユーザ端末1Aから受信した後に、通信ネットワーク3を介して非装着情報をユーザ端末1Bに送信する(ステップS33)。その後、ユーザ端末1Bの制御部121は、非装着情報をサーバ2から受信した後に、仮想空間200Bに配置されたアバター4Aの顔の表情をデフォルトの顔の表情(換言すれば、デフォルト設定された顔の表情)に設定する(ステップS34)。ここで、アバター4Aのデフォルトの顔の表情とは、アバター4Aの顔の表情の更新を開始する前の初期状態におけるアバター4Aの顔の表情をいう。デフォルトの顔の表情が笑顔の場合、図14に示すように、アバター4Aの顔の表情は笑顔に設定される。また、制御部121は、アバター4Bの制御情報に基づいて、アバター4Bの動作(アバター4Bの顔の表情を含む)を更新する。
尚、ステップS34において、制御部121は、ユーザAがHMD110を装着していないことを示す態様として、アバター4Aの顔の表情をユーザAによって予め選択された表情に設定してもよい。この場合、ユーザAによって選択されたアバター4Aの表情に関する情報がユーザ端末1Aからユーザ端末1Bに送信された上で、ユーザ端末1Bの記憶部123に予め保存されてもよい。
次に、制御部121は、図14に示すように、アバター4Aに関連付けられた吹き出しオブジェクト42Aを仮想空間200Bに生成する。吹き出しオブジェクト42Aには、ユーザAがHMD110を装着していないことを示す情報(例えば、「ユーザAは退席中です。」等)が表示される。
尚、制御部121は、吹き出しオブジェクト42Aの代わりに、テロップオブジェクト43Aを仮想空間200Bに生成してもよい(図15参照)。図15に示すように、テロップオブジェクト43Aには、ユーザAがHMD110を装着していないことを示す情報(例えば、「ユーザAは退席中です。」等)が表示される。テロップオブジェクト43Aは、アバター4Aの近くに配置されてもよいし、アバター4Bの視野CV内に常に配置されるように、アバター4Bの視野CVの動きに連動してもよい。さらに、ユーザAがHMD110を装着していないことを示す情報を示すテロップがHMD110に表示される視野画像上に重畳されてもよい。
その後、制御部121は、仮想空間200Bを示す仮想空間データを更新すると共に、ユーザ端末1BのHMD110の動きに応じてアバター4Bの視野CVを更新する。次に、制御部121は、更新された仮想空間データと更新されたアバター4Bの視野CVに基づいて視野画像データを更新した上で、更新された視野画像データに基づいて視野画像をHMD110に表示する(ステップS36)。
一方、ユーザ端末1Aの制御部121は、通信ネットワーク3を介して非装着情報をサーバ2に送信した後に、アクティブモードからスリープモードに移行する(ステップS37)。この場合、制御部121のモードがスリープモードである一方、センサ(装着センサ115又はHMDセンサ114)のモードはアクティブモードであることが好ましい。
本実施形態によれば、ユーザAがHMD110を装着していない場合に、ユーザ端末1BによってユーザAがHMD110を装着していないことがユーザBに提示される。特に、本実施形態によれば、ユーザAがHMD110を装着していない場合に、ユーザAがHMD110を装着していないことを示す情報がユーザ端末1BのHMD110に表示される視野画像上において可視化される。この点において、表情がデフォルトの表情に設定されたアバター4Aと吹き出しオブジェクト42Aがユーザ端末1BのHMD110に表示される視野画像上において可視化される。
このように、ユーザBは、仮想空間200B上においてユーザAとコミュニケーションを行っているときに、アバター4Aのデフォルトの表情(例えば、笑顔)及び吹き出しオブジェクト42Aに表示された情報を視認することで、ユーザAがHMD110を装着していないことを容易に把握することができる。従って、ユーザにリッチな仮想体験を提供することができる。
特に、ユーザBは、ユーザAがHMD110を装着していないことを把握してなければ、リアクションを示さないユーザAに対して違和感を抱く場合がある。このように、ユーザAがHMD100を装着していないことをユーザBに把握させることで、ユーザBがリアクションを示さないユーザAに対して違和感(例えば、不気味の谷現象)を抱くといった状況を回避することが可能となる。
また、本実施形態によれば、ユーザ端末1Aのセンサ(HMDセンサ114又は装着センサ115)から送信された情報(傾き情報又はイベント情報)に応じて、ユーザAがHMD110を装着していないことが特定される。その後、ユーザAがHMD110を装着していないことを示す非装着情報がサーバ2に送信される。このように、ユーザ端末1Aのセンサから出力された情報に応じて、ユーザAがHMD110を装着していないことを自動的に特定することが可能となる。
尚、本実施形態では、ユーザ端末1Aは、サーバ2を介して非装着情報をユーザ端末1Bに送信しているが、非装着情報に代わって、HMDセンサ114から送信された傾き情報をユーザ端末1Bに送信してもよい。この場合、ユーザ端末1Bの制御部121は、受信した傾き情報に基づいて、ユーザAがHMD110を装着していないことを特定した上で、ステップS34からS36に規定される処理を実行してもよい。
次に、図16及び図17を主に参照することで、HMD110を取り外したユーザAがHMD110を再び装着した場合における本実施形態に係る情報処理方法について説明する。図16は、ユーザAがHMD110を再び装着した場合における本実施形態に係る情報処理方法を説明するためのフローチャートの一例である。図17は、本実施形態に係る情報処理方法を説明するためのユーザBに提供される仮想空間200Bの一例を示す図である。
図16を参照すると、ステップS40において、ユーザ端末1Aの制御部121は、ユーザAが再びHMD110を装着したかどうかを判定する。この点において、制御部121は、HMDセンサ114から送信されたHMD110の傾き情報又は装着センサ115から送信されたイベント情報に基づいて、ユーザAがHMD110を再び装着したかどうかを判定してもよい。例えば、制御部121は、装着センサ115からイベント情報を受信したと判定した場合に、ユーザAがHMD110を装着したことを特定した上で、ステップS41の処理を実行する。一方、制御部121は、装着センサ115からイベント情報を受信していないと判定した場合に、ユーザAはHMD110を装着していないことを特定した上で、イベント情報を装着センサ115から受信するまで待機する。
ステップS40の判定結果がYESの場合、制御部121は、スリープモードからアクティブモードに移行する(ステップS41)。次に、アクティブモードに移行した制御部121は、アバター4Aの制御情報を生成すると共に、ユーザAがHMD110を装着したことを示す装着情報を生成する(ステップS42)。その後、制御部121は、通信ネットワーク3を介してアバター4Aの制御情報と装着情報をサーバ2に送信する(ステップS43)。
次に、サーバ2は、アバター4Aの制御情報と装着情報をユーザ端末1Aから受信した後に、通信ネットワーク3を介してアバター4Aの制御情報と装着情報をユーザ端末1Bに送信する(ステップS44)。その後、ユーザ端末1Bの制御部121は、アバター4Aの制御情報に基づいてアバター4Aの動作を更新する共に、アバター4Bの制御情報に基づいてアバター4Bの動作を更新する(ステップS45)。特に、制御部121は、アバター4Aの制御情報に含まれるアバター4Aの顔情報に基づいて、アバター4Aの顔の表情を更新すると共に、アバター4Bの制御情報に含まれるアバター4Bの顔情報に基づいて、アバター4Bの顔の表情を更新する。
次に、制御部121は、図17に示すように、アバター4Aに関連付けられた吹き出しオブジェクト44Aを仮想空間200Bに生成する(ステップS46)。吹き出しオブジェクト44Aには、ユーザAがHMD110を装着したことを示す情報(例えば、「ユーザAは席に戻りました。」等)が表示される。
その後、制御部121は、仮想空間200Bを示す仮想空間データを更新すると共に、ユーザ端末1BのHMD110の動きに応じてアバター4Bの視野CVを更新する。次に、制御部121は、更新された仮想空間データと更新されたアバター4Bの視野CVに基づいて視野画像データを更新した上で、更新された視野画像データに基づいて視野画像をHMD110に表示する(ステップS47)。
本実施形態によれば、ユーザAがHMD110を取り外した後に再び装着した場合、ユーザ端末1BによってユーザAがHMD110を装着していることがユーザBに提示される。このように、ユーザBは、更新されたアバター4Aの表情と吹き出しオブジェクト44Aを視認することで、ユーザAがHMD110を再び装着したことを容易に把握することができる。従って、ユーザにリッチな仮想体験を提供することができる。
尚、本実施形態の説明では、ユーザAがHMD110を装着したこと又は装着していないことを示す情報が視野画像上に可視化されているが、本実施形態はこれには限定されない。例えば、ユーザAがHMD110を装着していないことを示す音声案内(例えば、「ユーザAは退席しました。」等)やユーザAがHMD110を装着したことを示す音声案内(例えば、「ユーザAは席に戻りました。」等)がユーザ端末1Bのヘッドフォン116(音声出力部)から出力されてもよい。この場合、ユーザ端末1Aの制御部121は、サーバ2を介して非装着情報(又は装着情報)と共に音声案内データをユーザ端末1Bに送信する。
また、本実施形態の説明では、仮想空間200Bを示す仮想空間データがユーザ端末1B側で更新されていることを前提としているが、仮想空間データはサーバ2側で更新されてもよい。さらに、視野画像に対応する視野画像データがユーザ端末1B側で更新されていることを前提としているが、視野画像データはサーバ2側で更新されてもよい。この場合、ユーザ端末1Bは、サーバ2から送信された視野画像データに基づいて、HMD110に視野画像を表示する。
また、図12及び16に示す各ステップで規定される処理の順番はあくまでも一例であって、これらのステップの順番は適宜変更可能である。
(変形例1)
次に、図18から図25を参照して、ユーザAのHMD110を取り外した場合における本実施形態に係る情報処理方法の変形例1について説明する。図18は、変形例1に係る情報処理方法を説明するためのフローチャートの一例である。図19、20、22及び23は、変形例1に係る情報処理方法を説明するためのユーザBに提供される仮想空間200Bの一例を示す図である。図21は、変形例1に係る情報処理方法を説明するためのユーザAに関連付けられたユーザ端末5の表示例を示す図である。図24は、ユーザAが既読情報の受信から一定時間内にHMDを装着していない場合における変形例1に係る情報処理方法を説明するためのフローチャートの一例である。
図18を参照すると、ユーザ端末1Aの制御部121は、ユーザAがHMD110を取り外したかどうかを判定する(ステップS50)。HMDセンサ114を用いてユーザAがHMD110を取り外したかどうかを判定する処理については、上記の実施形態において説明した通りであるため、その詳細な説明は省略する。
ステップS50において、ユーザAがHMD110を取り外した(換言すれば、ユーザAがHMD110を装着していない)と判定した場合に(ステップS50のYES)、制御部121は、ユーザAがHMD110を装着していないことを示す情報(非装着情報)を生成する(ステップS51)。その後、制御部121は、通信ネットワーク3を介して非装着情報をサーバ2に送信する(ステップS52)。尚、ステップS51において、制御部121は、HMD110と外部コントローラ320との位置関係を示す位置関係情報を生成し、当該位置関係情報を非装着情報と共にサーバ2に送信してもよい。
次に、サーバ2は、非装着情報をユーザ端末1Aから受信した後に、通信ネットワーク3を介して非装着情報をユーザ端末1Bに送信する(ステップS53)。
一方、ユーザ端末1Aの制御部121は、通信ネットワーク3を介して非装着情報をサーバ2に送信した後に、アクティブモードからスリープモードに移行する(ステップS54)。この場合、制御部121のモードがスリープモードである一方、センサ(装着センサ115又はHMDセンサ114)のモードはアクティブモードであることが好ましい。
次に、ユーザ端末1Bの制御部121は、サーバ2から受信した非装着情報に基づいて、仮想空間200Bに配置されたアバター4Aの姿勢をデフォルトの姿勢(換言すれば、デフォルト設定された姿勢)に設定する(ステップS55)。変形例1では、仮想空間が、マルチプレイの相手を探す場であるルームである場合を想定して説明するが、これに限定されるものではない。ここで、アバター4Aのデフォルトの姿勢とは、アバター4Aの初期状態における姿勢をいう。デフォルトの姿勢が、横たわった状態である場合、図19に示すように、アバター4Aの姿勢は床に横たわった状態に設定される。
尚、ステップS55において、制御部121は、ユーザAがHMD110を装着していないことを示す態様として、アバター4Aの姿勢をユーザAによって予め選択された姿勢に設定してもよい。この場合、ユーザAによって選択されたアバター4Aの姿勢に関する情報がユーザ端末1Aからユーザ端末1Bに送信された上で、ユーザ端末1Bの記憶部123に予め保存されてもよい。
また、ユーザ1Bが、HMD110と外部コントローラ320との位置関係を示す位置関係情報を受信している場合には、ステップS55において、制御部121は、アバター4Aの姿勢を当該位置関係情報に基づいて設定してもよい。すなわち、ユーザAがHMD110を装着していない場合には、HMD110および外部コントローラ320が現実空間の床や机に置かれている場合が多い。この場合は、仮想空間200Bのアバター4Aは、HMD110と外部コントローラ320との位置関係情報に基づいて、床の上に潰れているような姿勢となるように設定され得る。
次に、ユーザ端末1Bの制御部121は、仮想空間200Bに配置されたアバター4Aの顔の表情をデフォルトの顔の表情(換言すれば、デフォルト設定された顔の表情)に設定する(ステップS56)。デフォルトの顔の表情が目を閉じた状態である場合、図19に示すように、アバター4Aの顔の表情は目を閉じた状態に設定される。
尚、ステップS56において、制御部121は、ユーザAがHMD110を装着していないことを示す態様として、アバター4Aの顔の表情をユーザAによって予め選択された表情に設定してもよい。この場合、ユーザAによって選択されたアバター4Aの表情に関する情報がユーザ端末1Aからユーザ端末1Bに送信された上で、ユーザ端末1Bの記憶部123に予め保存されてもよい。
次に、制御部121は、仮想空間200Bを示す仮想空間データを更新すると共に、ユーザ端末1BのHMD110の動きに応じてアバター4Bの視野CVを更新する。次に、制御部121は、更新された仮想空間データと更新されたアバター4Bの視野CVに基づいて視野画像データを更新した上で、更新された視野画像データに基づいて視野画像をHMD110に表示する(ステップS57)。
このように、仮想空間200Bにおいてアバター4Aの姿勢および顔の表示がデフォルト設定の状態(目を閉じて横たわった状態)で表示されていることで、ユーザBは、ユーザAがHMD110を装着しておらず、仮想空間200Bに提供されるコンテンツに参加していないことを容易に認識することができる。
次に、ユーザ端末1Bの制御部121は、ステップS56で視野画像を更新した後に、仮想空間200Bにおいて、ユーザBに関連付けられたアバター4BがユーザAに関連付けられたアバター4Aに対して特定アクション(第1アクションの一例)を実行したかどうかを判定する(ステップS58)。
アバター4Bがアバター4Aに対して実行する特定アクションは、例えば、アバター4Aとアバター4Bとの身体的干渉を伴う動作を含む。アバター4Aとアバター4Bとの身体的干渉は、他のオブジェクトとの衝突を検出するためのコライダ(コリジョンオブジェクト)を用いて検知される。図示は省略するが、コライダは、アバター4A,4Bの身体に関連付けられており、アバター4Aとアバター4Bとのコリジョン判定(当たり判定)に供される。例えば、コライダが設定されたアバター4Bの仮想手400がコライダが設定されたアバター4Aに接触することで、アバター4Bとアバター4Aとが接触したことが判定される。コライダは、アバター4A,4Bの身体の全体範囲に設定されてもよく、アバター4A,4Bの身体の特定箇所(例えば、手、足、頭、肩、腰など)に設定されてもよい。特に、仮想手400においては各指先にコライダが設定されており、当たり判定もそれぞれの指において独立に検知されることが好ましい。これにより、他のオブジェクトと指との当たり判定を正確に行うことができる。尚、コライダは、透明体として構成されており、視野画像V(図8)内に表示されるものではない。
尚、上記の例では、制御部121は、アバター4Bの動き(例えば、仮想手400の動き)に基づいてアバター4Aに対するアバター4Bの当たり判定を特定しているが、この例に限られない。例えば、制御部121は、ユーザBの動き(例えば、ユーザBの手の動き)に基づいてアバター4Aに対する当たり判定を特定してもよい。
身体的干渉を伴う動作を含む特定アクションとは、例えば、アバター4Bが仮想手400を用いてアバター4Aに触れる動作の他、アバター4Aの身体を掴んで揺さぶる動作や、アバター4Aを叩く(例えば、アバター4Aの顔や肩を平手打ちする)動作等を含み得る。特定アクションは、反復運動を含んだ動作、すなわち、仮想手400の反復運動の過程でアバター4Aに接触する動作としてもよい。このようにすれば、アバター4BがユーザBの誤操作により誤ってアバター4Aに触れてしまった場合であっても、特定アクションではないことを検知でき、仮想手400の動作の誤検知を防止することができる。
例えば、図20に示すように、アバター4Bが仮想手400によりアバター4Aの身体(例えば、胴体)を掴んだ状態で、仮想手400の反復運動がなされた場合には、制御部121は、特定アクションとして揺さぶり動作が実行されたと特定する。仮想手400によるアバター4Aの身体の掴み(選択)は、例えば、仮想手400のコライダとアバター4Aの身体のコライダとが接触された状態で、ユーザBが外部コントローラ320の図示せぬキーを操作(押下)することで実現できる。この揺さぶり動作は、一定値以上の加速度での仮想手400の反復運動の過程におけるアバター4Aへの接触動作を含んでもよい。例えば、図20に示す状態の場合、仮想手400でアバター4Aの身体を掴んだ状態で、仮想手400をz軸方向に往復移動させ、+z軸方向における加速度が一定値以上であり、かつ、-z軸方向における加速度が一定値以上である状態が連続して所定回数以上続く場合、揺さぶり動作としてもよい。但し、仮想手400を往復移動させる方向はz軸方向に限定されるものではなく、任意の方向でよい。また、揺さぶり動作は、仮想手400がアバター4Aに関連付けられた1以上の相対座標を一定時間内に所定の回数以上往復する動作を含んでもよい。例えば、図20に示す状態の場合、1以上の相対座標は、仮想手400で掴まれたアバター4Aの身体の箇所を基準に、+z軸方向の任意の位置に設けられた第1の相対座標、及び-z軸方向の任意の位置に設けられた第2の相対座標が挙げられる。この例では、仮想手400でアバター4Aの身体を掴んだ状態で、仮想手400をz軸方向に往復移動させ、第1の相対座標を一定時間内に所定の回数以上往復するとともに、第2の相対座標を一定時間内に所定の回数以上往復する場合、揺さぶり動作としてもよい。但し、仮想手400を往復移動させる方向はz軸方向に限定されるものではなく、任意の方向でよい。この場合、仮想手400に対する相対座標も、任意の方向に対して設ければよい。
尚、ユーザB自身が揺さぶりと認識して行った動作について、特定アクションが実行されたと判定することが好ましい。つまり、揺さぶる方向は、画一的ではなく、ユーザによって異なることが想定されるため、仮想手400の移動方向はいずれの方向であってもよく、特定の方向に限定する必要はない。ただし、特定アクションの動作を厳密に判定したり、アバター4Bの動作にリアリティを持たせたりする(例えば、仮想手400のアバター4Aに対するめり込み等を防止する)必要がある場合には、制御部121は、仮想手400の移動方向を加味して、特定の方向に反復運動がなされた場合に揺さぶり動作があったものと判定してもよい。
一方、アバター4Bが仮想手400によりアバター4Aの身体を掴んでいない状態で、仮想手400が一定加速度以上でアバター4Aへ接触(コライダ衝突)した場合には、制御部121は、特定アクションとして叩き動作が実行されたと特定する。仮想手400の動作の誤検知を防止するため、叩き動作は、特に仮想手400の一定加速度以上の反復運動がなされると共に当該反復運動の過程におけるアバター4Aへの複数回の接触動作(コライダ衝突)を含むことが好ましい(具体的には、往復ビンタ動作)。例えば、図19に示す状態の場合、仮想手400をy軸方向に往復移動させ、+y軸方向における加速度が一定値以上であり、かつ、-y軸方向における加速度が一定値以上である状態で、仮想手400のコライダとアバター4Aの顔のコライダとの接触が所定回数以上起こると、叩き動作としてもよい。但し、仮想手400を往復移動させる方向はy軸方向に限定されるものではなく、任意の方向でよい。この往復ビンタ動作は、例えば、アバター4Bの仮想手400がアバター4Aに関連付けられた相対座標を一定時間内に所定の回数以上往復するとともに、一定時間内にアバター4Aへの複数回の接触動作(当たり判定)があったことにより特定されてもよい。例えば、図19に示す状態の場合、1以上の相対座標は、アバター4Aの顔を基準に、+y軸方向の任意の位置に設けられた第1の相対座標、及び-y軸方向の任意の位置に設けられた第2の相対座標が挙げられる。この例では、仮想手400をy軸方向に往復移動させ、第1の相対座標を一定時間内に所定の回数以上往復するとともに、第2の相対座標を一定時間内に所定の回数以上往復する状態で、仮想手400のコライダとアバター4Aの顔のコライダとの接触が所定回数以上起こると、叩き動作としてもよい。但し、仮想手400を往復移動させる方向はy軸方向に限定されるものではなく、任意の方向でよい。この場合、仮想手400に対する相対座標も、任意の方向に対して設ければよい。ただし、制御部121は、仮想手400の移動方向を加味して、特定の方向に反復運動がなされた場合に叩き動作があったものと判定してもよい。
尚、アバター4Aは、アバター4Bの動きに追従して動作するように設定されてもよい。例えば、図20に示すように、アバター4Bがアバター4Aに対して揺さぶり動作を実行した場合には、制御部121は、アバター4Aが当該揺さぶり動作に追従して揺さぶられるようにアバター4Aの動きを設定し得る。ただし、アバター4Bがアバター4Aに対して揺さぶり動作や叩き動作を行った場合に、アバター4Aがその動きに追従しない、すなわち、動かないように設定してもよい。
次に、制御部121は、アバター4Bがアバター4Aに対して特定アクションを実行したと判定した場合に(ステップS58のYES)、ユーザBにより当該特定アクションが実行されたことを示す情報(アクション実行情報)を生成する(ステップS60)。その後、制御部121は、通信ネットワーク3を介してアクション実行情報をサーバ2に送信する(ステップS61)。
次に、サーバ2は、ユーザ端末1Bから受信したアクション実行情報に基づいて、ユーザAに仮想空間200で提供されるコンテンツへの参加を打診するための参加打診通知に関する情報(参加打診通知情報)を生成する(ステップS62)。参加打診通知とは、HMD110を取り外しているユーザAに、仮想空間200で提供されるコンテンツへ参加することを打診するための通知である。参加打診通知情報には、例えば、特定アクションを実行したアバター4Bの識別情報、特定アクションを受けたアバター4Aの識別情報に加えて、特定アクションの種類や特定アクションの動作の強度等が含まれてもよい。
次に、サーバ2は、生成された参加打診通知情報に基づき、ユーザAの個人情報を特定する(ステップS63)。例えば、ユーザAの個人情報(例えば、メールアドレスやSNS(Social Networking Service)アドレス等)がサーバ2の記憶部22に記憶された情報テーブルに予め登録され、アバター4Aの識別情報と関連付けられて管理されている。ステップS63において、サーバ2は、記憶部22に記憶された情報テーブルを参照して、参加打診通知情報に含まれるアバター4Aの識別情報に基づき、ユーザAの個人情報を取得する。但し、ユーザAの個人情報は、サーバ2とは異なるサーバで管理されていてもよい。サーバ2とは異なるサーバとしては、例えば、個人情報が登録されたユーザに対してゲームプログラムを配信可能なサーバ、即ち、ゲーム配信のプラットフォームの役割を担うサーバなどが挙げられるが、これに限定されるものではない。
次に、サーバ2は、ステップS63において取得した送信先(例えば、ユーザAのメールアドレス)へ、参加打診通知情報を送信する(ステップS64)。ユーザAへの参加打診通知情報の送信方法としては、例えば、電子メール、チャット、SNS等のコミュニケーションツールを用いることができる。
次に、ユーザ端末5は、参加打診通知情報をコミュニケーションツールにより受信し、参加打診通知情報の受信通知を表示部6に表示する(ステップS65)。ユーザ端末5は、ユーザAが所有する端末機器であり、例えば、スマートフォン、PDA(Personal Digital Assistant)、タブレットまたはファブレット型コンピュータ、ウェアラブルデバイス等の携帯可能な端末であってもよいし、パーソナルコンピュータ、ビデオゲーム機器等であってもよい。
次に、ユーザ端末5は、受信通知を見たユーザAによる入力操作に基づき、コミュニケーションツールを起動し、図21に示すように、メッセージM1を表示部6に表示する(ステップS66)。メッセージM1は、ユーザBがユーザAに対して仮想空間200への参加を打診していることを示す情報(例えば、「たった今、[コンテンツ名(例えば、仮想空間200に提供されるコンテンツの名前)]の中で[相手プレイヤ名(例えば、ユーザB)]からコミュニケーションを受けています。[コンテンツ]を起動させて、会いに行きましょう!」等)を含む。尚、ユーザ端末5がパーソナルコンピュータやビデオゲーム機器であり、これらの機器のディスプレイにも仮想空間200で提供されるコンテンツの映像が表示されている場合には、そのディスプレイ上に参加打診通知に関するメッセージを表示してもよい。また、メッセージM1は、ユーザ端末1AのHMD110の装着をユーザAに促すメッセージであってもよい。
次に、ユーザ端末5は、メッセージM1が表示部6に表示されたことに基づき、ユーザAがメッセージM1を読了したと判定し、メッセージM1が既読となったことを示す既読情報を生成する(ステップS67)。既読情報は、メッセージM1に対するユーザAのリアクションに基づいて生成されるものであり、例えば、メール返信や「いいね!」ポイントの付与等に基づいて生成されてもよい。その後、ユーザ端末5は、通信ネットワークを介して既読情報をサーバ2に送信する(ステップS68)。
次に、サーバ2は、既読情報をユーザ端末5から受信した後に、通信ネットワーク3を介して既読情報をユーザ端末1Bに送信する(ステップS69)。
次に、ユーザ端末1Bの制御部121は、サーバ2から受信した既読情報に基づいて、仮想空間200Bに配置されたアバター4Aの顔の表情を更新された顔の表情に設定する(ステップS70)。例えば、制御部121は、図22に示すように、目を閉じた状態(第1状態の一例)であったアバター4Aの表情を、目を開けた状態(第2状態の一例)に更新する。
尚、ステップS70において、制御部121は、サーバ2から受信した既読情報に基づいて、アバター4Aの姿勢を更新してもよい。例えば、横たわっていた状態のアバター4Aの姿勢を座っている状態に更新してもよい。
次に、制御部121は、仮想空間200Bを示す仮想空間データを更新すると共に、ユーザ端末1BのHMD110の動きに応じてアバター4Bの視野CVを更新する。次に、制御部121は、更新された仮想空間データと更新されたアバター4Bの視野CVに基づいて視野画像データを更新した上で、更新された視野画像データに基づいて視野画像をHMD110に表示する(ステップS71)。これにより、ユーザBは、アバター4Aが目を開けた状態となったことを視認することで、ユーザAが参加打診通知に対するリアクションを行ったことを容易に把握することができる。
一方、ステップS72において、サーバ2は、ユーザ端末1Bに加えて、ユーザ端末1Aに対しても既読情報を送信する。
次に、ユーザ端末1Aの制御部121は、既読情報の受信から一定時間内に、ユーザAがHMD110を装着したかどうかを判定する(ステップS73)。制御部121は、HMDセンサ114から送信されたHMD110の傾き情報又は装着センサ115から送信されたイベント情報に基づいて、ユーザAがHMD110を装着したかどうかを判定してもよい。ユーザAがHMD110を装着したかどうかの判定は、HMDセンサ114で取得されるHMD110の傾き(ロール角、ヨー角、ピッチ角)を示す傾き情報に基づいて、HMD110の傾きが所定の傾きよりも小さいかどうかで判定し得る。上述の通り、ユーザAがHMD110を装着している間では、HMD110の傾きは所定の傾き以下となるため、HMD110の傾きが所定の傾きよりも小さい場合には、ユーザAがHMD110を装着していることが特定される。
ステップS73においてユーザAがHMD110を装着したと判定された場合には(ステップS73のYES)、ユーザ端末1Aの制御部121は、スリープモードからアクティブモードに移行する(ステップS74)。次に、アクティブモードに移行した制御部121は、アバター4Aの制御情報を生成すると共に、ユーザAがHMD110を装着したことを示す装着情報を生成する(ステップS75)。その後、制御部121は、通信ネットワーク3を介してアバター4Aの制御情報と装着情報をサーバ2に送信する(ステップS76)。
次に、サーバ2は、アバター4Aの制御情報と装着情報をユーザ端末1Aから受信した後に、通信ネットワーク3を介してアバター4Aの制御情報と装着情報をユーザ端末1Bに送信する(ステップS77)。
次に、ユーザ端末1Bの制御部121は、アバター4Aの制御情報に基づいてアバター4Aの動作を更新する共に、アバター4Bの制御情報に基づいてアバター4Bの動作を更新する(ステップS78)。特に、制御部121は、アバター4Aの装着情報に基づいて、アバター4Aの姿勢を更新する。また制御部121は、アバター4Bの制御情報に含まれるアバター4Bの顔情報に基づいて、アバター4Bの顔の表情を更新してもよい。具体的には、制御部121は、例えば、図23に示すように、アバター4Aの姿勢を、起き上がった状態(第3状態の一例)に設定する。
尚、図17に示す実施形態と同様に、制御部121は、アバター4Aに関連付けられた吹き出しオブジェクトを仮想空間200Bに生成してもよい。吹き出しオブジェクトには、ユーザAがHMD110を装着したことを示す情報(例えば、「ユーザAは席に戻りました。」等)が表示される。
その後、制御部121は、仮想空間200Bを示す仮想空間データを更新すると共に、ユーザ端末1BのHMD110の動きに応じてアバター4Bの視野CVを更新する。次に、制御部121は、更新された仮想空間データと更新されたアバター4Bの視野CVに基づいて視野画像データを更新した上で、更新された視野画像データに基づいて視野画像をHMD110に表示する(ステップS79)。
一方、ステップS73において、既読情報の受信から一定時間内に、ユーザAがHMD110を装着していないと判定された場合には(ステップS73のNO)、図24の処理に進む。次に、図24に示すように、制御部121は、ユーザAがHMD110を装着していないことを示す非装着情報を生成する(ステップS80)。その後、制御部121は、通信ネットワーク3を介して非装着情報をサーバ2に送信する(ステップS81)。
次に、サーバ2は、非装着情報をユーザ端末1Aから受信した後に、通信ネットワーク3を介して非装着情報をユーザ端末1Bに送信する(ステップS82)。
次に、ユーザ端末1Bの制御部121は、サーバ2から受信した非装着情報に基づいて、仮想空間200Bに配置されたアバター4Aの顔の表情をデフォルトの表情に設定する(ステップS83)。例えば、デフォルトの顔の表情が目を閉じた状態である場合、図19に示すように、アバター4Aの顔の表情は目を閉じた状態に更新される。なお、ステップS83の処理は、ユーザ端末1Bの制御部121が、既読情報の受信から一定時間を計測し、一定時間内にアバター4Aの制御情報と装着情報を受信しなければ、アバター4Aの顔の表情をデフォルトの表情に設定するようにしてもよい。尚、図18のステップS70において既読情報に基づいてアバター4Aの目が開いた状態となっている場合には、本ステップS83においてアバター4Aの顔の表情は目を閉じた状態に戻される。一方、参加打診通知が既読になっていない場合(ステップS66のNOの場合)には、アバター4Aは目を閉じた状態が維持されているため、本ステップS83においてアバター4Aの顔の表情は変更されない。
その後、制御部121は、仮想空間200Bを示す仮想空間データを更新すると共に、ユーザ端末1BのHMD110の動きに応じてアバター4Bの視野CVを更新する。次に、制御部121は、更新された仮想空間データと更新されたアバター4Bの視野CVに基づいて視野画像データを更新した上で、更新された視野画像データに基づいて視野画像をHMD110に表示する(ステップS84)。
以上説明したように、変形例1に係る情報処理方法によれば、ユーザBの動きに応じて仮想空間200内で仮想手400を動かすステップと、ユーザAの動きに基づいて仮想空間200内での動作が制御可能なアバター4Aに対して、仮想手400による揺さぶり動作等のアクション(第1アクション)を実行するステップと、当該アクションの実行に基づいて、ユーザA(に関連付けられたユーザ端末5)に対して仮想空間200への参加を打診する参加打診通知の送信(第2アクション)を実行するステップと、を含む。この方法によれば、仮想手400を用いた直感的な操作により、仮想空間200を共有する複数のユーザA,B間で所定のアクションを実行することで、仮想空間200内でのコミュニケーションを、ユーザの没入感を損なうことなく円滑に行うことができる。このように、変形例1によれば、ユーザ間でのコミュニケーションのために、メニュー操作やキー操作を必要としないユーザ・インタフェース(いわゆる、ダイエジェティックUI)を提供することで、ユーザの仮想体験を向上させることができる。
特に、ユーザBからアバター4Aに対して実行された特定アクションに基づいてユーザAに関連付けられたユーザ端末5へ参加打診通知を送信することで、ユーザBから仮想空間200に提供されるコンテンツへの参加が打診されていることをユーザAが容易に認識することができる。これにより、仮想空間200において複数ユーザが同時にプレイする必要のあるコンテンツ(例えば、マルチプレイゲーム)の利用を促進させることができる。
また、変形例1に係る情報処理方法においては、ユーザAによりアバター4Aが制御されていない状態(すなわち、ユーザAがHMD110を装着していない状態)においてユーザBによるアバター4Aに対する特定アクションが実行された場合に、参加打診通知がユーザAに送信される。そのため、HMD110を装着していない状態のユーザAを仮想空間200で提供されるコンテンツへ誘引させることができ、コンテンツへの参加をさらに促進させることができる。特に、VRゲームでは、ルームに待機しているユーザ(アバター)が少ない場合、即ち、マルチプレイの相手の候補者が少ない場合、ユーザ(アバター)はとりあえずルームに入室するが、マルチプレイの候補者が現れるまでHMDを外して待機することが多いので、このような待機中のユーザをVRゲームのマルチプレイに効果的に誘引できる。
また、変形例1に係る情報処理方法は、参加打診通知に対してユーザAからリアクションが行われた場合(例えば、メッセージM1が既読になった場合)に、仮想空間200B内のアバター4Aを、目を閉じた状態(第1状態)から目を開けた状態(第2状態)へと遷移させるステップと、アバター4Aが目を開けた状態へ遷移した後に、一定時間内にユーザAによりアバター4Aが制御されている状態になった場合には、仮想空間200Bにおけるアバター4Aを起立した状態(第3状態)へと遷移させるステップと、をさらに含んでもよい。これにより、ユーザAからリアクションがあったことや、ユーザAがHMD110を装着してアバター4Aが制御されている状態となったことを、ユーザBが容易に把握することができる。
一方で、アバター4Aが目を開けた状態へ遷移した後に、一定時間内にユーザAによりアバター4Aが制御されている状態にならない場合には、仮想空間200Bにおけるアバター4Aを、目を閉じた状態へと戻してもよい。これにより、参加打診通知を送信したにも関わらずユーザAによりアバター4Aが制御されている状態にならない(すなわち、ユーザAがコンテンツに参加していない)ことを、ユーザBが容易に把握することができる。そのため、ユーザBは、アバター4Aを再び揺さぶって仮想空間への参加を再度打診したり、仮想空間200を共有するユーザA以外の他のユーザに関連付けられたアバターに対して仮想空間への参加を打診したりすることができる。
尚、ユーザAによりアバター4Aが制御されていない状態とは、ユーザAがHMD110を外している場合だけでなく、ユーザAが仮想空間200に提供されるコンテンツにそもそもログインしていない場合も含まれ得る。尚、ユーザAがコンテンツにログインしていない場合は、通常、アバター4Aは、ユーザBのユーザ端末1Bで提供される仮想空間200Bには存在しないが、ユーザBがユーザAをフレンド登録していれば、ユーザAが当該コンテンツにログインしていなくてもユーザAのアバター4Aは仮想空間200Bに存在させることができる。このフレンド登録の有無は、例えば、各ユーザの個人情報とともにサーバ2などに登録しておけばよい。この場合に、ユーザ端末1Bの制御部121は、ユーザAがコンテンツにログインしていないことに基づいて、仮想空間200Bに配置されたアバター4Aの姿勢および表情をデフォルト設定することができる(図18のステップS54)。このように、コンテンツにログインしていない状態のユーザAに関連付けられたアバター4Aを仮想空間200Bに存在させておき、アバター4Bからアバター4Aへの特定アクションの実行に基づいて、ユーザAへ参加打診通知を送信することで、ユーザAをコンテンツへログインさせるための動機づけを提供することができる。
また、アバター4Bによるアバター4Aに対する特定アクションの動作の強度に応じて、参加打診通知(メッセージM1)の内容が異なっていてもよい。例えば、仮想手400による動作の加速度に対して、複数のしきい値を段階的に設け、その加速度のしきい値に応じて、メッセージM1の内容を変更してもよい。例えば、メッセージM1に参加要望度に関する情報を含め、揺さぶり動作の強さに応じて、参加要望度に関する情報を変更してもよい。具体的には、揺さぶり動作が激しい場合には、メッセージM1としてユーザBからの参加要望度が高いことを示す内容(例えば、「参加要望度:☆☆☆(星3つ)」)を表示するようにしてもよい。尚、仮想手400がアバター4Aに関連付けられた相対座標を通過する回数について所定のしきい値を設け、その通過回数のしきい値に応じて、特定アクションの動作の強度を特定してもよい。
また、アバター4Aに対して複数のアバターが同時に(あるいは協働して)特定アクションを行った場合に、メッセージM1の内容を変更してもよい。この場合は、アバターAを複数のアバターにより同時に掴むことができるように、アバターAの身体の特定箇所ごとに専用のコライダを設けておくことが好ましい。これにより、複数のアバターによるアバター4Aの揺さぶり動作が可能となる。なお、このケースでは、アバター4Aに対して特定アクションを行うユーザ数が多いほど、参加要望度を高くすることが好ましい。
また、アバター4Aに対して実行される特定アクションの種類に応じて、メッセージM1の内容が異なっていてもよい。例えば、アバター4Bがアバター4Aを平手打ちした場合には、アバター4Bがアバター4Aを揺さぶった場合に比べて、メッセージM1に表示される参加要望度を高くしてもよい。
このように、アバター4Bによるアバター4Aに対する特定アクションの動作の強度や特定アクションの種類に応じて、参加打診通知の内容を異ならせることにより、ユーザAは、ユーザBからのコンテンツへの参加要望度の高低を把握することができる。そのため、ユーザAは、要望度の高さに応じてコンテンツへ参加するかどうかを決めることができる。
また、本実施形態においては、アバター4Bによるアバター4Aに対する特定アクションとして、身体的干渉を伴うアクションを例示しているが、この例に限られない。特定アクションは、ユーザAを特定するためのアクションであればよく、例えば、アバター4Bからアバター4Aに対して実行される特定アクションは、視線、声、レーザポインタ、顔の表情(笑顔、睨む等)、拍手などにより特定されてもよい。また、仮想空間200Bに表示されるアバター一覧(ユーザ一覧)からユーザBがコンテンツへの参加を打診したいアバター(ユーザ)を選択するようにしてもよい。すなわち、アバター4Bが実行する特定アクションは、アバター4Aに対する直接的なアクションでもよく、間接的なアクションでもよい。また、直接的なアクションと間接的なアクションとを組み合わせてもよい。
また、仮想空間200に提供されるコンテンツの内容に応じて、参加打診通知の送信タイミングを異ならせてもよい。例えば、マルチプレイの開始に必要なユーザの人数が3人以上である場合には、ユーザ端末1Bの制御部121は、ユーザBが、マルチプレイの開始に必要な人数の複数のアバターのうち最後のアバターに対して特定アクションを実行したと判定した場合に、ユーザ端末1Bの制御部121は、特定アクションを実行した複数のアバターにそれぞれ関連付けられた各ユーザに対して、まとめて参加打診通知を送信するようにしてもよい。尚、マルチプレイの開始に必要なユーザの人数が3人以上である場合であっても、ユーザ端末1Bの制御部121は、アバター4Bが各アバターに特定アクションを実行したタイミングで、各アバターに対して個別に参加打診通知を送信するようにしてもよい。
また、上記の実施形態においては、参加打診通知に対するユーザAのリアクション(例えば、参加打診通知に関するメッセージM1が既読となったこと)に基づいて、目を閉じていたアバター4Aの顔の表情を、目を開けた状態に更新しているが、この例に限られない。例えば、アバター4Bによるアバター4Aに対する特定アクションが実行されたことに基づいて、アバター4Aの目を開けた状態に更新してもよい。これにより、アバター4Aに対して特定アクションが適切に実行されたことを、ユーザBが容易に把握することができる。尚、ユーザAがHMD110を装着したことに基づいて、アバター4Aの目を開けた状態に更新してもよい。
また、変形例1に係る情報処理方法は、仮想空間200内でユーザBからユーザAに対して身体的干渉を伴う所定のアクション(第1アクションの一例)を実行するステップと、当該アクションの実行に基づいて、ユーザAに対する参加打診通知(第2アクションの一例)を実行するステップと、参加打診通知に対するユーザAのリアクション(例えば、参加打診通知に関するメッセージM1が既読となったこと)に基づいて、仮想空間200内でアバター4Aの姿勢および/または顔の表情の更新(第3アクションの一例)を実行するステップと、を含む。この方法によれば、ユーザAへ送信される参加打診通知に対するユーザAのリアクションに基づいて、ユーザAに関連付けられたアバター4Aの仮想空間200Bにおける姿勢や顔の表情を更新することで、仮想空間200内でのユーザA,B間でのコミュニケーションを円滑に行うことができる。このように、現実空間での参加打診通知に対するユーザAのリアクションを仮想空間200へ反映させることで、現実空間と仮想空間との境界を曖昧にするようなシームレスな仮想体験を提供することができる。
(変形例2)
次に、図25から図28を参照して、本実施形態に係る情報処理方法の変形例2について説明する。変形例2では、仮想空間200(200B)においてユーザBのみがプレイするゲーム(いわゆるシングルプレイゲーム)が提供される場合のゲーム開始時の情報処理方法を例示する。図25は、変形例2に係る情報処理方法を説明するためのフローチャートの一例である。図26から図28は、変形例2に係る情報処理方法を説明するためのユーザBに提供される仮想空間200Bの一例を示す図である。なお、図26に示すように、変形例2においては、仮想空間200Bは、アバター4Bとアバター4Cとを含んでいる。アバター4Cは、サーバ2により制御可能なアバター4C(いわゆる、Non Player Character(NPC))である。
図25を参照して、まず、ユーザ端末1Bの制御部121は、ユーザBによる操作に基づいて、ゲーム開始入力を受け付ける(ステップS100)。次に、制御部121は、通信ネットワーク3を介して、サーバ2へゲーム開始入力情報を送信する(ステップS101)。
次に、サーバ2は、制御部121から受信したゲーム開始入力情報に基づいて、記憶部22からオープニングムービーのデータを読み出す(ステップS102)。なお、オープニングムービーは、ゲーム開始時に導入されるシナリオシーン(第1シーンの一例)として仮想空間200Bで再生される映像である。次に、サーバ2は、通信ネットワーク3を介して、ユーザ端末1Bの制御部121へ、オープニングムービーのデータを送信する(ステップS103)。
次に、ユーザ端末1Bの制御部121は、サーバ2から受信したオープニングムービーのデータに基づき、仮想空間200Bにおいてオープニングムービーを再生する(ステップS104)。
オープニングムービーの再生中または再生後に、ユーザ端末1Bの制御部121は、アバター4Cの姿勢および顔の表情をデフォルトの姿勢および顔の表情に設定する(ステップS105)。デフォルトの姿勢が横たわった状態であり、デフォルトの顔の表情が目を閉じた状態であるとすると、図26に示すように、アバター4Cの姿勢は横たわった状態に設定され、アバター4Cの顔の表情は目を閉じた状態に設定される。
次に、制御部121は、仮想空間200Bを示す仮想空間データを更新すると共に、ユーザ端末1BのHMD110の動きに応じてアバター4Bの視野CVを更新する。次に、制御部121は、更新された仮想空間データと更新されたアバター4Bの視野CVに基づいて視野画像データを更新した上で、更新された視野画像データに基づいて視野画像をHMD110に表示する(ステップS106)。
次に、ステップS106での視野画像の更新の後で、制御部121は、ユーザBに関連付けられたアバター4Bが、サーバ2に関連付けられたアバター4Cに対して特定アクション(第1アクションの一例)を実行したか否かを判定する(ステップS107)。特定アクションの判定処理については変形例1と同様であるためその詳細な説明は省略する。尚、アバター4Bによるアバター4Cへの特定アクションの実行を促すため、制御部121は、ステップS104におけるオープニングムービーの再生後に、「アバター4Cを起こしてください。」といった内容のメッセージを仮想空間200Bへ表示してもよい。
次に、制御部121は、アバター4Bがアバター4Cに対して特定アクションを実行したと判定した場合に(ステップS107のYES)、ユーザBにより特定アクションが実行されたことを示すアクション実行情報を生成する(ステップS108)。その後、制御部121は、通信ネットワーク3を介してアクション実行情報をサーバ2に送信する(ステップS109)。
次に、サーバ2は、ユーザ端末1Bから受信したアクション実行情報に基づいて、シーン遷移情報を生成する(ステップS110)。シーン遷移情報とは、仮想空間200Bに提供されるゲームを、シナリオシーンからゲームシーン(第2シーンの一例)へと遷移させるための情報である。次に、サーバ2は、通信ネットワーク3を介して、シーン遷移情報をユーザ端末1Bの制御部121へ送信する(ステップS111)。
次に、ユーザ端末1Bの制御部121は、サーバ2から受信したシーン遷移情報に基づき、アバター4Cの姿勢と顔の表情の設定を更新する(ステップS112)。具体的には、例えば、図28に示すように、アバター4Cの姿勢は起き上がった状態に設定され、アバター4Cの顔の表情は目を開けた状態に設定される。
次に、制御部121は、アバター4Cに関連付けられた吹き出しオブジェクト45Aを仮想空間200Bに生成する(ステップS113)。吹き出しオブジェクト45Aには、アバター4Cがアバター4Bの仲間に加わったことを示す情報(例えば、「アバター4Cが仲間に加わりました。」等)が表示される。
その後、制御部121は、仮想空間200Bを示す仮想空間データを更新すると共に、ユーザ端末1BのHMD110の動きに応じてアバター4Bの視野CVを更新する。次に、制御部121は、更新された仮想空間データと更新されたアバター4Bの視野CVに基づいて視野画像データを更新した上で、更新された視野画像データに基づいて視野画像をHMD110に表示する(ステップS114)。
その後、シーン遷移情報に基づいて、制御部121は、ゲームシーンの表示を開始する(ステップS115)。
以上説明したように、変形例2に係る情報処理方法は、仮想空間200B内での動作がコンピュータ制御可能なアバター4Cに対し、仮想手400により揺さぶり動作等の特定アクションを実行するステップと、特定アクションの実行に基づいて仮想空間200Bにおいて提供されるゲームをシナリオシーン(第1シーン)からゲームシーン(第2シーン)へと遷移させるステップと、を含む。従来、ゲームシーンを開始するためにはシナリオシーンの再生後にゲームを進行させるためのユーザ・インタフェース(例えば、「Press Any Button」)が表示され、ユーザが外部コントローラ320の所定のボタンを押下することによりゲームシーンが開始されていた。これに対して、変形例2に係る方法によれば、アバター4Cに対するユーザBの特定アクションの実行に基づいてゲームシーンが開始されるため、ユーザBの仮想空間200Bへの没入感を損なわずにゲームを進行させることができる。なお、変形例2では、変形例2の処理がサーバ2とユーザ端末1Bとを有するシステムで実行される場合を例にとり説明したが、これに限定されず、ユーザ端末1B単独で実行されてもよい。
また、変形例2に係るゲームを進行させるための情報処理方法は、ゲームを開始する際の場面に限られず、ゲームの途中においてゲームを再開させる場面にも適用可能である。例えば、複数のアバター(例えば、アバター4Bとアバター4C)により編成されたパーティにより行われるゲームが仮想空間200Bに提供される場合において、ゲーム進行の中断後に、アバター4Bからアバター4Cへ特定アクションが実行されたと判定された場合に、ゲームを再開するようにしてもよい。具体的には、パーティが宿屋に宿泊したシーンにおいて、翌朝になってもアバター4Cが寝ている状態となっているとする。この状態で、アバター4Bがアバター4Cに対して揺さぶり動作や叩き動作等の特定アクションを実行することで、アバター4Cが目覚めゲームの進行が再開するようにしてもよい。このような方法によれば、ユーザBの仮想空間200Bへの没入感を損なわずにゲームの進行を再開させることができる。
また、図18、図24及び図25に示す各ステップで規定される処理の順番はあくまでも一例であって、これらのステップの順番は適宜変更可能である。
また、上記の実施形態や変形例の説明では、HMD110の装着の有無を、HMDセンサ114から送信されたHMD110の傾き情報又は装着センサ115から送信されたイベント情報で検知することを前提としているが、この例に限られない。例えば、ユーザ端末の制御部121は、位置センサ130及び/又はHMDセンサ114によりHMD110の動きを検知して、当該動きが所定の軌道を描いた場合に、ユーザがHMD110を装着したこと、あるいはHMD110を取り外したことを特定してもよい。また、制御部121は、位置センサ130及び/又はHMDセンサ114によりHMD110の動きの有無を検知して、例えば、HMD110の位置が一定時間の間に全く変化しない場合には、ユーザがHMD110を装着していないと特定してもよい。さらに、制御部121は、HMD110と外部コントローラ320との相対的位置関係を検知することで、HMD110の装着の有無を検知してもよい。例えば、制御部121は、HMD110と外部コントローラ320とが一定距離以上離れている場合には、ユーザがHMD110を装着していないと特定してもよい。
また、上記の実施形態や変形例の説明では、仮想空間200Bを示す仮想空間データがユーザ端末1B側で更新されていることを前提としているが、仮想空間データはサーバ2側で更新されてもよい。さらに、視野画像に対応する視野画像データがユーザ端末1B側で更新されていることを前提としているが、視野画像データはサーバ2側で更新されてもよい。この場合、ユーザ端末1Bは、サーバ2から送信された視野画像データに基づいて、HMD110に視野画像を表示する。
また、図12及び16に示す各ステップで規定される処理の順番はあくまでも一例であって、これらのステップの順番は適宜変更可能である。
また、本実施形態においては、HMD装置によってユーザが没入する仮想空間(VR空間)を例示して説明したが、HMD装置として、透過型のHMD装置を採用してもよい。この場合、透過型のHMD装置を介してユーザが視認する現実空間に仮想空間を構成する画像の一部を合成した視界画像を出力することにより、拡張現実(AR:Augumented Reality)空間または複合現実(MR:Mixed Reality)空間における仮想体験をユーザに提供してもよい。この場合、仮想手に代えて、ユーザの手の動きに基づいて、仮想空間内における対象オブジェクトへの作用を生じさせてもよい。具体的には、プロセッサは、現実空間におけるユーザの手の位置の座標情報を特定するとともに、仮想空間内における対象オブジェクトの位置を現実空間における座標情報との関係で定義してもよい。これにより、プロセッサは、現実空間におけるユーザの手と仮想空間2における対象オブジェクトとの位置関係を把握し、ユーザの手と対象オブジェクトとの間で上述したコリジョン制御等に対応する処理を実行可能となる。その結果、ユーザの手の動きに基づいて対象オブジェクトに作用を与えることが可能となる。
また、ユーザ端末1の制御部121によって実行される各種処理をソフトウェアによって実現するために、各種処理をコンピュータ(プロセッサ)に実行させるための制御プログラムが記憶部123又はメモリに予め組み込まれていてもよい。または、制御プログラムは、磁気ディスク(HDD、フロッピーディスク)、光ディスク(CD-ROM,DVD-ROM、Blu-ray(登録商標)ディスク等)、光磁気ディスク(MO等)、フラッシュメモリ(SDカード、USBメモリ、SSD等)等のコンピュータ読取可能な記憶媒体に格納されていてもよい。この場合、記憶媒体が制御装置120に接続されることで、当該記憶媒体に格納された制御プログラムが、記憶部123に組み込まれる。そして、記憶部123に組み込まれた制御プログラムがRAM上にロードされて、プロセッサがロードされた当該プログラムを実行することで、制御部121は各種処理を実行する。
また、制御プログラムは、通信ネットワーク3上のコンピュータから通信インターフェース125を介してダウンロードされてもよい。この場合も同様に、ダウンロードされた当該制御プログラムが記憶部123に組み込まれる。
以上、本開示の実施形態について説明をしたが、本発明の技術的範囲が本実施形態の説明によって限定的に解釈されるべきではない。本実施形態は一例であって、特許請求の範囲に記載された発明の範囲内において、様々な実施形態の変更が可能であることが当業者によって理解されるところである。本発明の技術的範囲は特許請求の範囲に記載された発明の範囲及びその均等の範囲に基づいて定められるべきである。