JP6867045B2 - 血漿dnaの単分子配列決定 - Google Patents
血漿dnaの単分子配列決定 Download PDFInfo
- Publication number
- JP6867045B2 JP6867045B2 JP2018506601A JP2018506601A JP6867045B2 JP 6867045 B2 JP6867045 B2 JP 6867045B2 JP 2018506601 A JP2018506601 A JP 2018506601A JP 2018506601 A JP2018506601 A JP 2018506601A JP 6867045 B2 JP6867045 B2 JP 6867045B2
- Authority
- JP
- Japan
- Prior art keywords
- cell
- free dna
- dna fragments
- concatemer
- sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
- C12Q1/6874—Methods for sequencing involving nucleic acid arrays, e.g. sequencing by hybridisation
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6806—Preparing nucleic acids for analysis, e.g. for polymerase chain reaction [PCR] assay
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/483—Physical analysis of biological material
- G01N33/487—Physical analysis of biological material of liquid biological material
- G01N33/48707—Physical analysis of biological material of liquid biological material by electrical means
- G01N33/48721—Investigating individual macromolecules, e.g. by translocation through nanopores
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/10—Sequence alignment; Homology search
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2521/00—Reaction characterised by the enzymatic activity
- C12Q2521/50—Other enzymatic activities
- C12Q2521/501—Ligase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2525/00—Reactions involving modified oligonucleotides, nucleic acids, or nucleotides
- C12Q2525/10—Modifications characterised by
- C12Q2525/151—Modifications characterised by repeat or repeated sequences, e.g. VNTR, microsatellite, concatemer
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2525/00—Reactions involving modified oligonucleotides, nucleic acids, or nucleotides
- C12Q2525/10—Modifications characterised by
- C12Q2525/191—Modifications characterised by incorporating an adaptor
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2525/00—Reactions involving modified oligonucleotides, nucleic acids, or nucleotides
- C12Q2525/10—Modifications characterised by
- C12Q2525/197—Modifications characterised by incorporating a spacer/coupling moiety
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2527/00—Reactions demanding special reaction conditions
- C12Q2527/146—Concentration of target or template
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2565/00—Nucleic acid analysis characterised by mode or means of detection
- C12Q2565/60—Detection means characterised by use of a special device
- C12Q2565/631—Detection means characterised by use of a special device being a biochannel or pore
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Organic Chemistry (AREA)
- Physics & Mathematics (AREA)
- Analytical Chemistry (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biotechnology (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Immunology (AREA)
- Genetics & Genomics (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Medical Informatics (AREA)
- Evolutionary Biology (AREA)
- Theoretical Computer Science (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Urology & Nephrology (AREA)
- Hematology (AREA)
- Nanotechnology (AREA)
- Food Science & Technology (AREA)
- Medicinal Chemistry (AREA)
- General Physics & Mathematics (AREA)
- Pathology (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
- Investigating Or Analyzing Materials By The Use Of Electric Means (AREA)
Description
本出願は、2015年8月12日に出願された、米国特許仮出願第62/204,396号の利益を主張するものであり、その内容は、全ての目的のために、参照により本明細書に組み込まれる。
実施形態は、比較的小さなDNA断片で試料を分析する場合の単分子配列決定技術の効率を改善する。例えば、試料中のDNA断片の濃度を有意に増加させることができ、それにより、より多くのDNA断片を配列決定装置(例えば、ナノポア)と相互作用させることができる。別の例として、DNA断片をコンカテマーに結合させて、より長い分子を読み取ることができ、それにより、1分子の配列を介して複数のDNA断片(すなわち、試料中にもともとあるDNA断片)を効率的に読み取ることができる。バイオインフォーマティック手法を用いて、同じコンカテマーの一部である異なるDNA試料を検出することができる。実施形態は、2つの技術を組み合わせることができる。
「組織」は、機能単位として一緒に群を成す細胞群に対応する。1つの組織内に2つ以上のタイプの細胞を見出すことができる。異なるタイプの組織は、異なるタイプの細胞(例えば、肝細胞、肺胞細胞または血液細胞)からなることができるが、異なる生物(母親または胎児)由来の組織または健常細胞対腫瘍細胞に対応してもよい。
実施形態は、約200塩基の比較的短い断片である生体試料(例えば、血漿または血清中)中の細胞を含まないDNA断片に適用される場合、単分子配列決定の効率を改善することができる。血漿DNA断片などの細胞を含まないDNA断片は、小さくまたは短く、典型的には生体試料に低濃度で存在するため、細胞を含まないDNA断片を配列決定するためのナノポアの使用は、正確な結果をもたらすとは考えられない。小さな細孔を通過する小さな断片は、断片がナノポア内にある間に断片を配列決定するのを困難にする。さらに、小さな断片では、予想される配列決定誤差を考慮すると、参照ゲノムへの整列がより困難になるかもしれない。ナノポア配列決定は、約10〜15%の配列決定誤差を有し得る。いくつかの実施形態において、効率は、配列決定されるべきより長い分子を生成するためのDNA断片のコンカテマー化によって改善され得る。他の実施形態では、効率は、試料中のDNA断片の濃度を増加させることによって改善することができる。
血漿または血清DNAは、ヒト対象の循環系に見出され、細胞死のプロセスの間に自然な代謝回転または病理学的プロセスの一部として放出される細胞を含まない核酸分子である。DNA分子は細胞分解プロセスの一部として循環中に放出されるので、短い断片(<200bp)の形で循環し、低濃度で存在する。健康な対象の血漿DNAの大部分は、血液細胞に由来することが知られている(6)。
ナノポア配列決定は、DNA塩基がナノポアの使用によって検出される単分子配列決定装置の一形態である。オックスフォードナノポアテクノロジーズは、タンパク質細孔、α-溶血素を使用している。このような細孔のマトリックスは、膜上に位置するように作製される(5)。タンパク質細孔に加えて、ナノポアは、ナノポアが、窒化ケイ素およびグラフェンなどのケイ素化合物を含む半導体材料で製造される固体状態のナノポアであり得る。各ポアは、電気回路に接続されてもよい。
本実施形態はまた、ナノポアを使用する技術以外の単分子配列決定技術を含み得る。例えば、Helicos単分子配列決定装置(SeqLL)を用いて、DNA分子をガラス表面上にハイブリダイズさせることができる。次いで、蛍光標識されたヌクレオチドを各DNA分子に添加し、画像を捕捉することができる。次いで、蛍光分子を切断して洗い流し、別の蛍光標識ヌクレオチドを添加して、このプロセスを繰り返すことができる。各ヌクレオチドは異なる蛍光標識を有することができ、DNAを配列決定することができる。
効率を高めるために、1つの選択肢は、配列決定チャンバまたはフローセルに適用される有限体積内の試料中の遺伝物質の量を増加させるために、血漿DNAプールを増幅することである。しかしながら、このようなプロトコルの採用は、元のDNA鋳型と複製されたDNA断片の全てを配列決定するため、単分子配列決定をもはや実行しないことを意味する。複製されたDNA断片のそのような使用は、元のDNA断片についての定量的情報、例えば染色体全体のような所与のゲノム領域における元のDNA断片のコピー数を得るときにエラーを引き起こす可能性がある。
いくつかの実施形態では、図1Bに示すように、DNA断片(例えば、血漿DNA断片)をコンカテマー化してもよい。コンカテマー化は、一連のDNA断片を互いに結合させることができる。例えば、DNA断片152およびDNA断片154は、試料中に存在し得る。DNA断片を互いに付着させるための最初の手順として、DNA断片152およびDNA断片154の末端を、末端にリン酸基を付加して調製して、DNA断片156およびDNA断片158を得ることができる。次いで、DNA断片を平滑末端ライゲーションでリガーゼ酵素によって一緒に連結して、長いDNA分子、例えばコンカテマー160を形成することができる。コンカテマー160は、DNA断片152と154の組み合わせである新しい分子と考えることができる。コンカテマー160は、DNA断片152および154に対応するサブシーケンスの組み合わせである配列を有する。
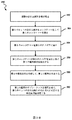
図3Aは、DNA断片をコンカテマー化し、本発明の実施形態による単分子配列決定を使用することによってDNA断片を配列決定する方法300の簡略ブロックフロー図を示す。
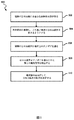
図3Bは、本発明の実施形態によるナノポア配列決定を使用してDNA断片を配列決定する方法350の簡略ブロックフロー図を示す。方法350において、配列決定装置はナノポアであり、これは基体上のナノポアのアレイに存在し得る。方法350の態様は、方法300を実施するときに実行することができる。
図4に示されるように、実施形態は、コンピュータシステムによって実行される方法400を含むことができる。図4は、本発明の実施形態によるコンカテマーの配列を分析する方法の簡略ブロックフロー図を示す。
別の実施形態は、フローセルの試料チャンバにロードされた血漿DNAライブラリの濃度を増加させることを含むことができる。血漿DNAの濃度を増加させることは、通常、ナノポア配列決定の効率を増加させるとは予想されない。ナノポアは、比較的高い配列決定誤差を有し、このような細胞を含まない試料中の低DNA濃度と同様に、血漿および他の細胞を含まない試料から分析するための小さいDNA断片を考慮すると、ナノポアは断片を効果的に配列決定することは期待されない。DNA断片の濃度の増加は、この問題に対処することは期待されない。しかしながら、抽出されたDNAまたは入力配列決定ライブラリを濃縮することにより、DNA分子がナノポアまたは他の単分子分析技術に到達する機会が増強される。抽出されたDNAを濃縮することは、配列決定技術に適合する体積を得るために必要なレベルを超えて濃縮することを含む。場合によっては、抽出されたDNAの濃度が10倍以上増加することがある。換言すれば、体積は元の10%未満に低減されてもよい。
実施例は、血漿DNAを濃縮してナノポア配列決定の効率を高めながら、正確な結果を提供できることを示している。高めた濃度を用いた配列決定について、Cheng S. H. et al., “Noninvasive prenatal testing by nanopore sequencing of maternal plasma DNA: feasibility assessment, ” Clin. Chem. 61: 10 (2015)にさらに記載されている。
血漿試料は、インフォームドコンセントおよび施設承認を得て募集された4グループの集団、すなわち、男性胎児をみごもる3回目の妊娠の妊婦、女性胎児をみごもる3回目の妊娠の妊婦、成人男性および非妊娠女性から得た。EDTA血漿試料を各グループ内にプールして、群当たり少なくとも20mLの血漿を提供した。プールした血漿試料を、QIAamp DSP DNA血液ミニキット(Qiagen、Germany)を用いて抽出した(2)。プールあたり1,050μLの溶出血漿DNAをSpeedvac濃縮装置(Thermo Fisher Scientific、Waltham、MA)により85μLまで濃縮した。各濃縮血漿DNAプールは、エンドリペアおよびAテーリングモジュール(New England Biolabs、Ipswich、MA)およびゲノムDNA配列決定キット(SQK-MAP-005、Oxford Nanopore Technologies、UK)を用いるDNAライブラリの調製のために完全に消費された。各ライブラリ(150μL)をMinION Flow Cell(v7.3)(Nanopore)に完全にロードし、配列決定した。出力データファイルは、METRICHORTM(商標)ソフトウェア(Nanopore)を用いてベースコールされた。LAST Genome-Scale Sequence Comparisonソフトウェア(Computational Biology Research Consortium、Japan)を用いて、2D読み取りを抽出し、参照ゲノムhg19に整列させた。
図8は、hg19で標識された、マッピング可能なヒトゲノムから予想される分布と比較した、染色体の読み取り分布を示す。染色体はx軸上に列挙されている。y軸上で、各染色体への読み取りの比例分布(ゲノム表現)は、その試料から配列決定され、頻度としておよびパーセンテージとして表された一意的に整列された読み取りの総数に対する各染色体に整列した読み取りの数をカウントすることにより、各試料について計算した。hg19でプロットされているのは、男性胎児をみごもる母胎血漿、女性胎児をみごもる母体血漿、男性血漿および非妊娠女性血漿の結果である。全ての4つの血漿DNAプールについての常染色体への読み取り分布は、マッピング可能なヒトゲノムについて予測されたものと同等であった。
循環する細胞を含まないDNAは、癌のリアルタイムモニタリングのための「液体生検」として使用することができる。細胞を含まないDNAは、基礎となる腫瘍において見出される遺伝的異常を示し、これは超並列配列決定技術によって検出することができる。癌患者の血漿DNAにおけるこれらの染色体異常はまた、ナノポア配列決定を用いて検出することができる。肝細胞癌(HCC)を有する2人の患者由来の血漿DNA試料を、ナノポア配列決定およびイルミナのプラットフォーム上の超並列配列決定の両方によって分析した。
手術前にHCCと診断された2人の患者から末梢血をそれぞれ20ミリリットル採取した。血漿を、1600×gで10分間遠心分離し、次いで16000×gで10分間遠心分離することにより単離した。QIAamp DSP DNA血液ミニキット(Qiagen)を用いて8mLの血漿からDNAを抽出した。血漿DNAの4分の3をナノポア配列決定に供し、残りのDNAはNextSeq 500(Illumina)によって配列決定した。
各染色体アーム(ゲノム表現、GR)に対する整列した読み取りの比例分布を各試料について計算した。換言すれば、染色体アーム、pまたはqアームに整列した高品質通過フィルターの読み取りの数は、試料から配列決定された高品質通過フィルター読み取りの割合として表された。次いで、正常個体の血漿DNA試料に対するGRの差を計算した。染色体アームのGRが対照群の平均より3標準偏差上である場合、その領域はコピー数増加を示すと考えられる。染色体アームのGRが対照群の平均よりも3標準偏差低い場合、その領域はコピー数の減少を示すと考えられる。
血漿DNA分子は典型的には短く(<200bp)、典型的には、長いDNA分子を配列決定するためにナノポア配列決定が使用され得る。短い血漿DNA分子の配列決定の効率は、コンカテマーと呼ばれる長い分子を構築するために個々の分子を連結または結合することによって改善することができる。
1.血漿DNAコンカテマーの生成
2人の異なる対象からの試料を試験した。妊娠していない女性被験者および男性胎児をみごもる女性被験者の両方から、末梢静脈血20ミリリットルを採取した。1600×gで10分間の遠心分離後に血漿を回収し、さらに16000×gで10分間遠心分離した。次いで、QIAamp DSP DNA血液ミニキット(Qiagen)を用いて8mLの血漿からDNAを抽出し、420μLの血漿DNA量を得た。抽出したDNAをSpeedVac濃縮装置(Thermo Scientific)で85μLに濃縮し、NEBNextエンドリペアモジュール(New England Biolabs、NEB)で末端修復した。末端修復されたDNAを、MinElute Reaction Cleanup Kit(Qiagen)を用いて精製し、20μLの緩衝液EBで溶出した。次に、20μLの血漿DNAをBlunt/TA Ligase Master Mix(NEB)を加えて25℃で4時間インキュベートすることにより連結し、インキュベーション後にMinElute Reaction Cleanupキットで精製した。
次いで濃縮DNAを、エンドリペアおよびAテーリングモジュール(NEB)およびゲノムDNA配列決定キット(SQK-MAP-005、Oxford Nanopore Technologies)によるナノポア配列決定ライブラリ調製に使用した。ライブラリをMinion Flow Cell(v7.3)(Nanopore)に完全にロードし、配列決定した。出力データファイルは、METRICHORTM(商標)ソフトウェア(Nanopore)を用いてベースコールされた。2D読み取りが抽出された。
整列は、LASTソフトウェアを用いて行った。それぞれの可能な開始位置についての最初の一致をみつけた。マッチは、参照ゲノム中の最大回数で起こる最小長のマッチに限定されたか、マッチは特定の所定の長さに制限された。これらの最初のマッチから、これらの最初のマッチよりも長い配列の付加的な整列が実施され、あるギャップスコアを有するものが、配列決定エラーの所望の許容差に基づいて保持された。複数の整列が同じエンドポイントを共有していた場合、最も高いスコアの整列が保持された。このようにして、ヒトゲノムに整列した断片が同定された。LASTで使用されるパラメータとルールは、精度と正確さの考慮事項によって変更される可能性がある。
連結した血漿DNAを、ライブラリが消費されるまで6時間MinIONで配列決定した。
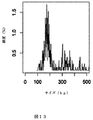
ベースコールは、2,234の2D読み取りをもたらし、読み取りの長さは86から8,672bpの範囲であった。図10は、非妊娠女性から配列決定されたコンカテマーのサイズの頻度分布曲線を示す。塩基対におけるコンカテマーのサイズは、x軸上にある。指定されたコンカテマーサイズが配列決定された試料中に存在する頻度(パーセンテージとして表される)は、y軸上にプロットされる。グラフの可読性を向上させるために、8,672bpの外れ値データポイントの外れ値データポイントは示されていない。配列決定された各試料について、約20〜50個の長いDNA分子が検出された。
妊娠した女性の男性胎児は、血液試料を採取したときに、38週の妊娠期間と4日間の妊娠期間を有していた。妊娠は正常とみなされた。血漿DNA断片をナノポア配列決定のための処理の前にコンカテマー化した。コンカテマーのサイズは100〜13,466bpであり、メジアンサイズは676bpであり、平均サイズは965bpであった。
実施形態1は、複数のDNA断片を受け取ることと、複数のDNA断片の第1のセットをコンカテマー化して第1のコンカテマーを得ることと、前記第1のコンカテマーが前記第1のナノポアを通ることと、前記第1のコンカテマーが前記第1のナノポアを通るときに第1の電気信号を検出することと、前記電気信号は前記第1のコンカテマーの前記第1の配列に対応することとを含む方法を含む。
図15は、本発明の実施形態による単分子配列決定を実施するためのシステム1500のブロック図を示す。生体試料は、抽出装置1504によって患者1502から得ることができる。生体試料は、本明細書に記載される任意の体液または任意の生体試料であり得る。抽出装置1504は、尿などの試料を採取するためのシリンジ、ランセット、スワブ、または容器またはバイアルを含み得る。抽出装置1504は、QIAamp DSP DNA血液ミニキット(Qiagen、Germany)を含むことができる(2)。生体試料は、細胞を含まないDNA断片を含んでいてもよく、これは調製装置1506に送られる。調製装置1506は、単分子配列決定により効率的な細胞を含まないDNA断片の形態を生成する装置を含むことができる。例えば、調製装置1506の出力は、コンカテマーまたは細胞を含まないDNA断片の濃縮試料であってもよい。
本明細書で言及されるコンピュータシステムのいずれも、任意の適切な数のサブシステムを利用することができる。コンピュータシステム10における、そのようなサブシステムの例を図16に示す。いくつかの実施形態では、コンピュータシステムは、単一のコンピュータ装置を含み、サブシステムは、コンピュータ装置の構成要素とすることができる。他の実施形態では、コンピュータシステムは、それぞれが内部構成要素を有するサブシステムである複数のコンピュータ装置を含むことができる。コンピュータシステムは、デスクトップおよびラップトップコンピュータ、タブレット、携帯電話および他のモバイルデバイスを含むことができる。
1. Dondorp W, de Wert G, Bombard Y, Bianchi DW, Bergmann C, Borry P, et al. Non-invasive prenatal testing for aneuploidy and beyond: Challenges of responsible innovation in prenatal screening. Eur J Hum Genet 2015.
2. Chiu RWK, Chan KCA, Gao Y, Lau VYM, Zheng W, Leung TY, et al. Noninvasive prenatal diagnosis of fetal chromosomal aneuploidy by massively parallel genomic sequencing of dna in maternal plasma. Proc Natl Acad Sci USA 2008; 105: 20458-63.
3. Jain M, Fiddes IT, Miga KH, Olsen HE, Paten B, Akeson M. Improved data analysis for the MinION nanopore sequencer. Nat Methods 2015; 12: 351-6.
4. Lo YMD, Chan KCA, Sun H, Chen EZ, Jiang P, Lun FMF, et al. Maternal plasma DNA sequencing reveals the genome-wide genetic and mutational profile of the fetus. Sci Transl Med 2010; 2: 61ra91-61ra91.
5. Bayley H. Nanopore sequencing: From imagination to reality. Clin Chem 2015; 61: 25-31.
6. Zheng YW, Chan KCA, Sun H, Jiang P, Su X, Chen EZ, et al. Nonhematopoietically derived DNA is shorter than hematopoietically derived DNA in plasma: A transplantation model. Clin Chem 2012; 58: 549-58.
7. Lun FMF, Chiu RWK, Sun K, Leung TY, Jiang P, Chan KCA, et al. Noninvasive prenatal methylomic analysis by genomewide bisulfite sequencing of maternal plasma DNA. Clin Chem 2013; 59: 1583-94.
8. Chan KCA, Jiang P, Zheng YW, Liao GJW, Sun H, Wong J, et al. Cancer genome scanning in plasma: Detection of tumor-associated copy number aberrations, single-nucleotide variants, and tumoral heterogeneity by massively parallel sequencing. Clin Chem 2013; 59: 211-24.
9. Chan KCA, Jiang P, Chan CWM, Sun K, Wong J, Hui EP, et al. Noninvasive detection of cancer-associated genome-wide hypomethylation and copy number aberrations by plasma DNA bisulfite sequencing. Proc Natl Acad Sci U S A 2013; 110: 18761-8.
10. Chan RWY, Wong J, Chan HLY, Mok TSK, Lo WYW, Lee V, et al. Aberrant concentrations of liver-derived plasma albumin mrna in liver pathologies. Clin Chem 2010; 56: 82-9.
11. Chan RWY, Jiang P, Peng X, Tam LS, Liao GJW, Li EK, et al. Plasma DNA aberrations in systemic lupus erythematosus revealed by genomic and methylomic sequencing. Proc Natl Acad Sci U S A 2014; 111: E5302-11.
12. Schreiber J, Wescoe ZL, Abu-Shumays R, Vivian JT, Baatar B, Karplus K, Akeson M. Error rates for nanopore discrimination among cytosine, methylcytosine, and hydroxymethylcytosine along individual DNA strands. Proc Natl Acad Sci U S A 2013; 110: 18910-5.
Claims (39)
- 対象から得られた生物試料を準備し、ここで、当該生物試料はセルフリーDNA断片を含む体液を含み、
当該生物試料から複数のセルフリーDNA断片を抽出し、
前記複数のセルフリーDNA断片の第1のセットをコンカテマー化して第1のコンカテマーを得、ここで、当該第1のセットのセルフリーDNA断片は、異なった配列を有し、対象のゲノムでの異なった位置由来であり、前記第1のコンカテマーの単分子配列決定を行って、第1の配列を得ること、ここで、当該第1の配列は、当該第1の配列内のサブシーケンスとして、複数のセルフリーDNA断片の第1のセットの異なった配列を含む、
を含む、方法。 - 前記単分子配列決定の実行の一部として、配列決定装置に前記第1のコンカテマーを提供し、
前記配列決定装置を用いて、前記第1のコンカテマーに対応する複数の信号、前記第1のコンカテマーの前記第1の配列に対応する複数の信号を検出すること、
をさらに含む、請求項1に記載の方法。 - 前記配列決定装置が第1のナノポアを含み、方法は、さらに、
前記第1のコンカテマーが前記第1のナノポアを通り、
前記第1のコンカテマーが前記第1のナノポアを通るときに第1の電気信号を検出すること、ここで、前記第1の電気信号は前記第1のコンカテマーの前記第1の配列に対応し、前記複数の信号は前記第1の電気信号を含む、
を含む、請求項2に記載の方法。 - 前記第1の配列を決定するために前記第1の電気信号を分析し、
参照ゲノムに対して前記第1の配列のサブシーケンスを整列させて、前記複数のセルフリーDNA断片の前記第1のセットそれぞれに対応する断片配列を同定すること、をコンピュータシステムにより実行することをさらに含む、請求項3に記載の方法。 - 前記第1のコンカテマーが前記第1のナノポアを通ることは、
前記第1のコンカテマーの第1の鎖が前記第1のナノポアを通ること、及び、
その後、前記第1のコンカテマーの第2の鎖が前記第1のナノポアを通ること、
を含む、請求項3に記載の方法。 - 前記第1の鎖および前記第2の鎖についての前記第1の電気信号をコンピュータシステムにより分析して、前記第1の配列を決定することをさらに含む、請求項5に記載の方法。
- 前記第1のナノポアは、基体上の複数のナノポアの1つである、請求項3に記載の方法。
- 前記複数のセルフリーDNA断片の第2のセットをコンカテマー化して第2のコンカテマーを得、
前記第2のコンカテマーが前記複数のナノポアの第2のナノポアを通り、
前記第2のコンカテマーが前記第2のナノポアを通るときに複数の第2の電気信号を検出すること、ここで、前記第2の電気信号は前記第2のコンカテマーの第2の配列に対応する、
をさらに含む、請求項7に記載の方法。 - 前記第1のコンカテマーに対して蛍光標識されたヌクレオチドをハイブリダイズし、蛍光シグナルを検出すること、ここで、前記蛍光シグナルはヌクレオチドに対応する、をさらに含む、請求項2に記載の方法。
- 参照ゲノムに対して前記第1の配列のサブシーケンスを整列させて、前記セルフリーDNA断片の前記第1のセットそれぞれに対応する断片配列を同定することを、コンピュータシステムにより実行することをさらに含む、請求項1に記載の方法。
- 前記サブシーケンスの整列に基づいて、前記複数のセルフリーDNA断片の前記第1のセットそれぞれのサイズを決定することをさらに含む、請求項10に記載の方法。
- 前記複数のセルフリーDNA断片の前記第1のセットをコンカテマー化することは、前記複数のセルフリーDNA断片の前記第1のセットおよび既知の配列を有する前記複数のセルフリーDNA断片の第2のセットをコンカテマー化することを含み、前記複数のセルフリーDNA断片の前記第2のセットは前記複数のセルフリーDNA断片の前記第1のセットの中に分散され、
前記第1の配列のサブシーケンスを整列させることは、前記既知の配列に対してサブシーケンスを整列させて、前記第1のコンカテマーにおける前記複数のセルフリーDNA断片の前記第2のセットの位置を同定することを含む、請求項10に記載の方法。 - 前記コンカテマー化は、前記複数のセルフリーDNA断片の前記第2のセットの1つのセルフリーDNA断片を、前記複数のセルフリーDNA断片の前記第1のセットの2つのセルフリーDNA断片間に配置する、請求項12に記載の方法。
- 前記第1のサブシーケンスの前に、前記複数のセルフリーDNA断片の前記第2のセットの既知の配列の1つを同定することに基づいて、前記複数のセルフリーDNA断片の前記第1のセットの第1のセルフリーDNA断片に対応する第1のサブシーケンスの開始塩基を、前記コンピュータシステムにより同定し、
前記第1のサブシーケンスの後に、前記複数のセルフリーDNA断片の前記第2のセットの既知の配列の1つを同定することに基づいて、前記複数のセルフリーDNA断片の前記第1のセットの前記第1のセルフリーDNA断片に対応する前記第1のサブシーケンスの終了塩基を、前記コンピュータシステムにより同定すること、
を前記コンピュータシステムにより実行することをさらに含む、請求項13に記載の方法。 - 前記複数のセルフリーDNA断片の前記第2のセットの各セルフリーDNA断片は7ヌクレオチド以下の既知の配列を有する、請求項12に記載の方法。
- 前記複数のセルフリーDNA断片の前記第2のセットそれぞれは、同じ既知の配列を有する、請求項12に記載の方法。
- 前記サブシーケンスの整列は、
前記参照ゲノムに前記第1の配列のスライドウィンドウを整列させることであって、各スライドウィンドウは前記参照ゲノムに整列されたサブシーケンスに対応する、整列させることと、
2つのスライドウィンドウが前記参照ゲノムの異なる領域に整列するとき同定して、前記複数のセルフリーDNA断片の前記第1のセットの2つのセルフリーDNA断片の配列間を区別すること、
とを含む、請求項10に記載の方法。 - 前記参照ゲノムの前記異なる領域に整列させる2つのスライドウィンドウに基づいて、前記複数のセルフリーDNA断片の前記第1のセットの第1のセルフリーDNA断片の終了および開始の第1のサブシーケンスを決定することを、前記コンピュータシステムにより実行することをさらに含む、請求項17に記載の方法。
- 前記参照ゲノムの前記異なる領域は、異なる染色体上の領域を含む、請求項17に記載の方法。
- 前記2つのスライドウィンドウ間の1つ以上のウィンドウが、前記参照ゲノムに整列していないものとして同定される、請求項17に記載の方法。
- 前記複数のセルフリーDNA断片の前記第1のセットの第1のセルフリーDNA断片のサイズを決定することをさらに含み、前記第1のセルフリーDNA断片の前記サイズを決定することは、
前記参照ゲノムの1つの領域に整列させる最も長いサブシーケンスの長さを決定することを含む、請求項20に記載の方法。 - 前記生体試料は、血漿または血清である、請求項1に記載の方法。
- 前記セルフリーDNA断片の前記第1セットが複数の染色体からランダムに分布されている、請求項1に記載の方法。
- 前記複数のセルフリーDNA断片の第2のセットをコンカテマー化して第2のコンカテマーを得、ここで、当該第2のセットのセルフリーDNA断片は、前記第1のコンカテマーとは異なるセルフリーDNA断片のコンビネーション又はパーミュテーションを含み、ここで、複数のセルフリーDNA断片の第2のセットをコンカテマー化することは、複数のセルフリーDNA断片の第1のセットをコンカテマー化することと並行して起こる、
前記第2のコンカテマーの単分子配列決定を行って、第2の配列を得ること、ここで、当該第2の配列は、当該第2の配列内のサブシーケンスとして、複数のセルフリーDNA断片の第2のセットの異なった配列を含む、
をさらに含む、請求項1に記載の方法。 - 前記第1のコンカテマーが、複数のセルフリーDNA断片の複製されたDNA断片を含まず、前記第2のコンカテマーが、複数のセルフリーDNA断片の複製されたDNA断片を含まない、請求項24に記載の方法。
- 前記第1のコンカテマーが、複数のセルフリーDNA断片の第1のセットのセルフリーDNA断片間に既知の配列を有するスペーサー断片を含まない、請求項1に記載の方法。
- 第1の配列内のサブシーケンスを用いて複数のセルフリーDNA断片のサイズ分布を決定することを更に含む、請求項1に記載の方法。
- 前記生物試料が、母親セルフリーDNA断片及び胎児セルフリーDNA断片を含む母親血漿であり、そこから、複数のセルフリーDNA断片の少なくとも第1のセットが得られる、請求項1に記載の方法。
- (1)第1のコンカテマーを生成するセルフリーDNA断片の第1のセットをコンカテマー化し、(2)第1のコンカテマーの単一分子配列決定を行って、第1の配列を得ることにより生成された第1のコンカテマーの第1の配列を準備し、ここで、
前記セルフリーDNA断片の第1のセットは、生物試料から抽出され、
前記生物試料は対象から得られ、
前記生物試料は、前記セルフリーDNA断片を含む体液を含み、
前記第1の配列のサブシーケンスを整列させて、前記セルフリーDNA断片の前記第1のセットの各セルフリーDNA断片に対応する断片配列を同定すること、
をコンピュータシステムにより実行することを含む、方法。 - 前記第1のコンカテマーは、前記DNA断片の前記第1のセットとDNA断片の第2のセットとをコンカテマー化することにより生成され、
前記第1の配列のサブシーケンスを整列させることは、前記DNA断片の前記第2のセットにサブシーケンスを整列させることを含む、請求項29に記載の方法。 - 前記セルフリーDNA断片の前記第2のセットの各セルフリーDNA断片は、7ヌクレオチド以下の既知の配列を含む、請求項30に記載の方法。
- 前記第1の配列のサブシーケンスを整列させることは、参照ゲノムに前記第1の配列のサブシーケンスを整列させることを含む、請求項29に記載の方法。
- 前記サブシーケンスの前記整列は、
前記参照ゲノムに前記第1の配列のウィンドウを整列させることと、
前記参照ゲノムの異なる領域に2つのウィンドウを整列させるときに同定することとを含む、請求項32に記載の方法。 - 前記2つのウィンドウ間の1つ以上のウィンドウが前記参照ゲノムに整列していないものとして同定される、請求項33に記載の方法。
- 請求項29〜34のいずれか1項に記載の操作を実行するために前記コンピュータシステムを制御するための複数のインストラクションを保存する、コンピュータ読み取り可能媒体。
- 請求項35のコンピュータ読み取り可能媒体と、
前記コンピュータ読み取り可能媒体に保存されるインストラクションを実行するための1つ以上のプロセッサと
を含む、システム。 - 請求項29〜34のいずれか1項を実行するための手段を含む、システム。
- 請求項29〜34のいずれか1項を実行するために構成される、システム。
- 請求項29〜34のいずれか1項に記載のステップをそれぞれ実行するモジュールを含む、システム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021060027A JP7506408B2 (ja) | 2015-08-12 | 2021-03-31 | 血漿dnaの単分子配列決定 |
| JP2024092950A JP7810455B2 (ja) | 2015-08-12 | 2024-06-07 | 血漿dnaの単分子配列決定 |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562204396P | 2015-08-12 | 2015-08-12 | |
| US62/204,396 | 2015-08-12 | ||
| PCT/CN2016/094802 WO2017025059A1 (en) | 2015-08-12 | 2016-08-12 | Single-molecule sequencing of plasma dna |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021060027A Division JP7506408B2 (ja) | 2015-08-12 | 2021-03-31 | 血漿dnaの単分子配列決定 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2018531583A JP2018531583A (ja) | 2018-11-01 |
| JP2018531583A5 JP2018531583A5 (ja) | 2019-09-05 |
| JP6867045B2 true JP6867045B2 (ja) | 2021-04-28 |
Family
ID=57983895
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018506601A Active JP6867045B2 (ja) | 2015-08-12 | 2016-08-12 | 血漿dnaの単分子配列決定 |
| JP2021060027A Active JP7506408B2 (ja) | 2015-08-12 | 2021-03-31 | 血漿dnaの単分子配列決定 |
| JP2024092950A Active JP7810455B2 (ja) | 2015-08-12 | 2024-06-07 | 血漿dnaの単分子配列決定 |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021060027A Active JP7506408B2 (ja) | 2015-08-12 | 2021-03-31 | 血漿dnaの単分子配列決定 |
| JP2024092950A Active JP7810455B2 (ja) | 2015-08-12 | 2024-06-07 | 血漿dnaの単分子配列決定 |
Country Status (12)
| Country | Link |
|---|---|
| US (2) | US11319586B2 (ja) |
| EP (1) | EP3334843A4 (ja) |
| JP (3) | JP6867045B2 (ja) |
| CN (2) | CN115433769A (ja) |
| AU (3) | AU2016305103C1 (ja) |
| CA (1) | CA2995422A1 (ja) |
| HK (1) | HK1248286A1 (ja) |
| IL (3) | IL285795B (ja) |
| MY (1) | MY188348A (ja) |
| SA (1) | SA518390907B1 (ja) |
| TW (2) | TWI728994B (ja) |
| WO (1) | WO2017025059A1 (ja) |
Families Citing this family (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111356772B (zh) | 2017-08-23 | 2023-10-03 | 豪夫迈·罗氏有限公司 | 酶筛选方法 |
| CA3074689A1 (en) * | 2017-09-07 | 2019-03-14 | Coopergenomics, Inc. | Systems and methods for non-invasive preimplantation genetic diagnosis |
| EP3700856A4 (en) | 2017-10-26 | 2021-12-15 | Ultima Genomics, Inc. | METHODS AND SYSTEMS FOR SEQUENCE CALL |
| EP3731959B1 (en) | 2017-12-29 | 2025-10-08 | Clear Labs, Inc. | Automated priming and library loading device |
| WO2019204720A1 (en) * | 2018-04-20 | 2019-10-24 | The Regents Of The University Of California | Nucleic acid sequencing methods and computer-readable media for practicing same |
| CN113795887A (zh) | 2019-03-10 | 2021-12-14 | 阿尔缇玛基因组学公司 | 用于序列判定的方法和系统 |
| CN114531916A (zh) | 2019-06-21 | 2022-05-24 | 酷博尔外科器械有限公司 | 确定精子提供者、卵母细胞提供者和对应受孕体之间的遗传关系的系统和方法 |
| US20220411863A1 (en) * | 2019-11-25 | 2022-12-29 | William Marsh Rice University | Linear dna assembly for nanopore sequencing |
| WO2022008641A1 (en) | 2020-07-08 | 2022-01-13 | Roche Sequencing Solutions, Inc. | Split-pool synthesis apparatus and methods of performing split-pool synthesis |
| US20240058753A1 (en) | 2020-10-15 | 2024-02-22 | Roche Sequencing Solutions, Inc. | Electrophoretic devices and methods for next-generation sequencing library preparation |
| CN114507708A (zh) * | 2020-11-16 | 2022-05-17 | 唐纳德·李 | 一种制备长分子测序dna的方法 |
| EP4308723B1 (en) | 2021-03-15 | 2025-04-23 | F. Hoffmann-La Roche AG | Targeted next-generation sequencing via anchored primer extension |
| EP4314330A1 (en) | 2021-03-26 | 2024-02-07 | F. Hoffmann-La Roche AG | Hybridization buffer formulations |
| WO2022207682A1 (en) | 2021-04-01 | 2022-10-06 | F. Hoffmann-La Roche Ag | Immune cell counting of sars-cov-2 patients based on immune repertoire sequencing |
| EP4323539A4 (en) * | 2021-04-12 | 2025-02-05 | The Chinese University of Hong Kong | ANALYSIS OF BASE MODIFICATION USING ELECTRICAL SIGNALS |
| WO2023023561A1 (en) * | 2021-08-17 | 2023-02-23 | Quantapore, Inc. | Multiplex binding assays with optical nanopore readout |
| IL312140A (en) * | 2021-10-18 | 2024-06-01 | Belgian Volition Srl | Use of nanopore sequencing for determining the origin of circulating dna |
| JP2025521678A (ja) | 2022-06-30 | 2025-07-10 | カパ バイオシステムズ,インコーポレイティド | 古細菌ヒストン様タンパク質を使用したタグメンテーション配列決定ライブラリーインサートサイズの制御 |
| CN114898802B (zh) * | 2022-07-14 | 2022-09-30 | 臻和(北京)生物科技有限公司 | 基于血浆游离dna甲基化测序数据的末端序列频率分布特征确定方法、评价方法及装置 |
| WO2024046992A1 (en) | 2022-09-02 | 2024-03-07 | F. Hoffmann-La Roche Ag | Improvements to next-generation target enrichment performance |
| EP4677328A1 (en) | 2023-04-13 | 2026-01-14 | Ventana Medical Systems, Inc. | Proliferation assay for fixed solid tumors |
| CN121605113A (zh) | 2023-06-14 | 2026-03-03 | 豪夫迈·罗氏有限公司 | 5-甲酰基胞嘧啶的加速标记及在核酸甲基化测序中的应用 |
| WO2025193604A1 (en) | 2024-03-11 | 2025-09-18 | Ventana Medical Systems, Inc. | Non-enzymatic dissociation of ffpe tissue and generation of single cells with intact cell surface markers |
| WO2025210056A1 (en) | 2024-04-03 | 2025-10-09 | Roche Sequencing Solutions, Inc. | In vitro amplification of dna methylation patterns |
| WO2025247632A1 (en) | 2024-05-27 | 2025-12-04 | European Molecular Biology Laboratory | Preparation of cell-free fragmented nucleic acids for genetic analysis sequencing |
Family Cites Families (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20020197618A1 (en) * | 2001-01-20 | 2002-12-26 | Sampson Jeffrey R. | Synthesis and amplification of unstructured nucleic acids for rapid sequencing |
| GB0504774D0 (en) * | 2005-03-08 | 2005-04-13 | Lingvitae As | Method |
| JP2008161056A (ja) | 2005-04-08 | 2008-07-17 | Hiroaki Mita | Dna配列解析装置、dna配列解析方法およびプログラム |
| KR20250002752A (ko) | 2007-07-23 | 2025-01-07 | 더 차이니즈 유니버시티 오브 홍콩 | 대규모 병렬 게놈 서열분석을 이용한 태아 염색체 이수성의 진단 방법 |
| EP2370598B1 (en) | 2008-12-11 | 2017-02-15 | Pacific Biosciences Of California, Inc. | Classification of nucleic acid templates |
| DE102008061772A1 (de) * | 2008-12-11 | 2010-06-17 | Febit Holding Gmbh | Verfahren zur Untersuchung von Nukleinsäure-Populationen |
| PT3241914T (pt) | 2009-11-05 | 2019-04-30 | Sequenom Inc | Análise genómica fetal a partir de uma amostra biológica materna |
| ES3026544T3 (en) | 2009-11-06 | 2025-06-11 | Univ Hong Kong Chinese | Size-based genomic analysis for prenatal diagnosis |
| US9121823B2 (en) * | 2010-02-19 | 2015-09-01 | The Trustees Of The University Of Pennsylvania | High-resolution analysis devices and related methods |
| KR20120045922A (ko) * | 2010-11-01 | 2012-05-09 | 엘지전자 주식회사 | 나노 포어를 포함하는 염기 서열 결정 장치 |
| CN114678128B (zh) | 2010-11-30 | 2026-01-09 | 香港中文大学 | 与癌症相关的遗传或分子畸变的检测 |
| BR112014001699A2 (pt) * | 2011-07-25 | 2017-06-13 | Oxford Nanopore Tech Ltd | método para sequenciar de um polinucleotídeo alvo de filamento duplo, kit, métodos para preparar um polinucleotídeo alvo de filamento duplo para sequenciamento e para sequenciar um polinucleotídeo alvo de filamento duplo, e, aparelho |
| EP2563937A1 (en) * | 2011-07-26 | 2013-03-06 | Verinata Health, Inc | Method for determining the presence or absence of different aneuploidies in a sample |
| US20130040827A1 (en) * | 2011-08-14 | 2013-02-14 | Stephen C. Macevicz | Method and compositions for detecting and sequencing nucleic acids |
| WO2013109970A1 (en) | 2012-01-20 | 2013-07-25 | Genia Technologies, Inc. | Nanopore based molecular detection and sequencing |
| GB2557509A (en) * | 2012-06-08 | 2018-06-20 | Pacific Biosciences California Inc | Modified base detection with nanopore sequencing |
| WO2013188841A1 (en) * | 2012-06-15 | 2013-12-19 | Genia Technologies, Inc. | Chip set-up and high-accuracy nucleic acid sequencing |
| US11261494B2 (en) * | 2012-06-21 | 2022-03-01 | The Chinese University Of Hong Kong | Method of measuring a fractional concentration of tumor DNA |
| GB201215449D0 (en) | 2012-08-30 | 2012-10-17 | Zoragen Biotechnologies Llp | Method of detecting chromosonal abnormalities |
| SMT202100256T1 (it) | 2012-09-20 | 2021-05-07 | Univ Hong Kong Chinese | Determinazione non invasiva di metiloma di tumore dal plasma |
| EP3080298B1 (en) * | 2013-12-11 | 2018-10-31 | AccuraGen Holdings Limited | Methods for detecting rare sequence variants |
| EP3218519B1 (en) * | 2014-11-11 | 2020-12-02 | BGI Shenzhen | Multi-pass sequencing |
| US10916945B2 (en) | 2016-05-10 | 2021-02-09 | Nec Corporation | Demand and supply adjustment system, control apparatus, control method, and program |
-
2016
- 2016-08-12 MY MYPI2018000139A patent/MY188348A/en unknown
- 2016-08-12 TW TW105125873A patent/TWI728994B/zh active
- 2016-08-12 CN CN202211147693.8A patent/CN115433769A/zh active Pending
- 2016-08-12 TW TW110115619A patent/TWI793586B/zh active
- 2016-08-12 CA CA2995422A patent/CA2995422A1/en active Pending
- 2016-08-12 CN CN201680046621.0A patent/CN107849607B/zh active Active
- 2016-08-12 JP JP2018506601A patent/JP6867045B2/ja active Active
- 2016-08-12 HK HK18108082.2A patent/HK1248286A1/zh unknown
- 2016-08-12 IL IL285795A patent/IL285795B/en unknown
- 2016-08-12 WO PCT/CN2016/094802 patent/WO2017025059A1/en not_active Ceased
- 2016-08-12 AU AU2016305103A patent/AU2016305103C1/en active Active
- 2016-08-12 EP EP16834683.1A patent/EP3334843A4/en active Pending
- 2016-08-12 US US15/235,630 patent/US11319586B2/en active Active
-
2018
- 2018-01-22 IL IL257074A patent/IL257074B/en unknown
- 2018-02-12 SA SA518390907A patent/SA518390907B1/ar unknown
-
2020
- 2020-03-26 AU AU2020202153A patent/AU2020202153B2/en active Active
-
2021
- 2021-03-31 JP JP2021060027A patent/JP7506408B2/ja active Active
-
2022
- 2022-03-18 US US17/698,574 patent/US20220205038A1/en active Pending
- 2022-06-22 IL IL294192A patent/IL294192B2/en unknown
-
2023
- 2023-04-27 AU AU2023202572A patent/AU2023202572B2/en active Active
-
2024
- 2024-06-07 JP JP2024092950A patent/JP7810455B2/ja active Active
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7810455B2 (ja) | 血漿dnaの単分子配列決定 | |
| JP6392904B2 (ja) | Dnaのサイズに基づく解析 | |
| JP6073461B2 (ja) | 標的大規模並列配列決定法を使用した対立遺伝子比分析による胎児トリソミーの非侵襲的出生前診断 | |
| TWI727938B (zh) | 血漿粒線體dna分析之應用 | |
| CN110023509A (zh) | 基因型分型测定中的非独特条形码 | |
| Chang et al. | Somatic diseases (cancer): amplification-based next-generation sequencing | |
| HK40083172A (en) | Single-molecule sequencing of plasma dna | |
| HK1245850B (en) | Single-molecule sequencing of plasma dna | |
| HK1245842B (zh) | 母体血浆中胎儿dna分数的基於大小的分析 | |
| HK1246361B (zh) | 母体血浆中胎儿dna分数的基於大小的分析 | |
| WO2013013066A2 (en) | Methods for assessing genomic instabilities in tumors |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20190725 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20190725 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20200417 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20200630 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200929 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20210302 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20210401 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6867045 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |