JP6224077B2 - 改変された核酸を用いてポリペプチドを発現させるための方法 - Google Patents
改変された核酸を用いてポリペプチドを発現させるための方法 Download PDFInfo
- Publication number
- JP6224077B2 JP6224077B2 JP2015506201A JP2015506201A JP6224077B2 JP 6224077 B2 JP6224077 B2 JP 6224077B2 JP 2015506201 A JP2015506201 A JP 2015506201A JP 2015506201 A JP2015506201 A JP 2015506201A JP 6224077 B2 JP6224077 B2 JP 6224077B2
- Authority
- JP
- Japan
- Prior art keywords
- amino acid
- codon
- codons
- motif
- seq
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/67—General methods for enhancing the expression
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/10—Immunoglobulins specific features characterized by their source of isolation or production
- C07K2317/14—Specific host cells or culture conditions, e.g. components, pH or temperature
Landscapes
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Microbiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Medicinal Chemistry (AREA)
- Immunology (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Peptides Or Proteins (AREA)
Description
Cannarozzi, G.らは、翻訳のダイナミクス(dynamics)におけるコドンの順序の役割を報告している(Cell 141 (2010) 355-367) (非特許文献1)。コドンバイアスの原因および結果は、Plotkin, J.B. and Kudla, G. (Nat. Rev. Gen. 12 (2011) 32-42) (非特許文献2)によって報告されている。Weygand-Durasevic, I.およびIbba, M.は、コドン使用の新しい役割を報告している(Science 329 (2010) 1473-1474) (非特許文献3)。タンパク質のコード配列内の重複コードは、Itzkovitz, S., et al. (Gen. Res. 20 (2010) 1582-1589) (非特許文献4)によって報告されている。
ポリペプチドの各アミノ酸残基は、1つまたは複数の(少なくとも1つの)コドンによってコードされており、同じアミノ酸残基をコードする(異なる)コドンは1つのグループにまとめられており、グループ中の各コドンは、グループ内での固有の使用頻度に基づいて定められ、1つのグループ中の全コドンの固有の使用頻度の合計は100%であり、
ポリペプチドをコードする核酸中の各コドンの総使用頻度は、そのグループ内でのその固有の使用頻度とほぼ同じである、方法である。
アラニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 01、02、03、04、および05より選択され、かつ/または
アルギニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 06およびSEQ ID NO: 07より選択され、かつ/または
アスパラギンのためのアミノ酸コドンモチーフは、SEQ ID NO: 08、09、10、11、および12より選択され、かつ/または
アスパラギン酸のためのアミノ酸コドンモチーフは、SEQ ID NO: 13およびSEQ ID NO: 14より選択され、かつ/または
システインのためのアミノ酸コドンモチーフは、SEQ ID NO: 15、16、および17より選択され、かつ/または
グルタミンのためのアミノ酸コドンモチーフは、SEQ ID NO: 18、19、20、および21より選択され、かつ/または
グルタミン酸のためのアミノ酸コドンモチーフは、SEQ ID NO: 22、23、および24より選択され、かつ/または
グリシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 25およびSEQ ID NO: 26より選択され、かつ/または
ヒスチジンのためのアミノ酸コドンモチーフは、SEQ ID NO: 27およびSEQ ID NO: 28より選択され、かつ/または
イソロイシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 29およびSEQ ID NO: 30より選択され、かつ/または
ロイシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 31、32、および33より選択され、かつ/または
リジンのためのアミノ酸コドンモチーフは、SEQ ID NO: 34、35、36、および37より選択され、かつ/または
フェニルアラニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 38、39、および40より選択され、かつ/または
プロリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 41、42、43、44、45、および46より選択され、かつ/または
セリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 47およびSEQ ID NO: 48より選択され、かつ/または
トレオニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 49、50、および51より選択され、かつ/または
チロシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 52およびSEQ ID NO: 53より選択され、かつ/または
バリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 54、55、および56より選択される。
アラニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 03であり、
アルギニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 07であり、
アスパラギンのためのアミノ酸コドンモチーフは、SEQ ID NO: 10であり、
アスパラギン酸のためのアミノ酸コドンモチーフは、SEQ ID NO: 13であり、
システインのためのアミノ酸コドンモチーフは、SEQ ID NO: 17であり、
グルタミンのためのアミノ酸コドンモチーフは、SEQ ID NO: 20であり、
グルタミン酸のためのアミノ酸コドンモチーフは、SEQ ID NO: 23であり、
グリシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 26であり、
ヒスチジンのためのアミノ酸コドンモチーフは、SEQ ID NO: 28であり、
イソロイシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 30であり、
ロイシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 33であり、
リジンのためのアミノ酸コドンモチーフは、SEQ ID NO: 36であり、
フェニルアラニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 39であり、
プロリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 43であり、
セリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 48であり、
トレオニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 51であり、
チロシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 53であり、かつ
バリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 56である。
アラニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 64、65、66、67、および68より選択され、かつ/または
アルギニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 69およびSEQ ID NO: 70より選択され、かつ/または
アスパラギンのためのアミノ酸コドンモチーフは、SEQ ID NO: 71およびSEQ ID NO: 72より選択され、かつ/または
アスパラギン酸のためのアミノ酸コドンモチーフは、SEQ ID NO: 73およびSEQ ID NO: 74より選択され、かつ/または
システインのためのアミノ酸コドンモチーフは、SEQ ID NO: 75およびSEQ ID NO: 76より選択され、かつ/または
グルタミンのためのアミノ酸コドンモチーフは、SEQ ID NO: 77、78、79、および80より選択され、かつ/または
グルタミン酸のためのアミノ酸コドンモチーフは、SEQ ID NO: 81およびSEQ ID NO: 82より選択され、かつ/または
グリシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 83およびSEQ ID NO: 84より選択され、かつ/または
ヒスチジンのためのアミノ酸コドンモチーフは、SEQ ID NO: 85およびSEQ ID NO: 86より選択され、かつ/または
イソロイシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 87およびSEQ ID NO: 88より選択され、かつ/または
ロイシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 89、90、および91より選択され、かつ/または
リジンのためのアミノ酸コドンモチーフは、SEQ ID NO: 92およびSEQ ID NO: 93より選択され、かつ/または
フェニルアラニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 94およびSEQ ID NO: 95より選択され、かつ/または
プロリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 96およびSEQ ID NO: 97より選択され、かつ/または
セリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 98、99、および100より選択され、かつ/または
トレオニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 101、102、および103より選択され、かつ/または
チロシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 104およびSEQ ID NO: 105より選択され、かつ/または
バリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 106、107、および108より選択される。
アラニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 68であり、
アルギニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 69であり、
アスパラギンのためのアミノ酸コドンモチーフは、SEQ ID NO: 72であり、
アスパラギン酸のためのアミノ酸コドンモチーフは、SEQ ID NO: 74であり、
システインのためのアミノ酸コドンモチーフは、SEQ ID NO: 76であり、
グルタミンのためのアミノ酸コドンモチーフは、SEQ ID NO: 79であり、
グルタミン酸のためのアミノ酸コドンモチーフは、SEQ ID NO: 82であり、
グリシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 84であり、
ヒスチジンのためのアミノ酸コドンモチーフは、SEQ ID NO: 86であり、
イソロイシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 88であり、
ロイシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 90であり、
リジンのためのアミノ酸コドンモチーフは、SEQ ID NO: 93であり、
フェニルアラニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 95であり、
プロリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 97であり、
セリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 99であり、
トレオニンのためのアミノ酸コドンモチーフは、SEQ ID NO: 103であり、
チロシンのためのアミノ酸コドンモチーフは、SEQ ID NO: 105であり、かつ
バリンのためのアミノ酸コドンモチーフは、SEQ ID NO: 108である。
その際、同じアミノ酸残基をコードする異なるコドンは1つのグループにまとめられており、グループ中の各コドンは、グループ内での固有の使用頻度に基づいて定められ、1つのグループ中の全コドンの固有の使用頻度の合計は100%であり、
ポリペプチドをコードする核酸中のあるコドンの使用頻度は、そのグループ内でのその固有の使用頻度とほぼ同じである。
-ポリペプチドをコードする核酸を提供する段階を含み、
その際、ポリペプチドの各アミノ酸残基は少なくとも1つのコドンによってコードされており、同じアミノ酸残基をコードする異なるコドンは1つのグループにまとめられており、グループ中の各コドンは、グループ内での固有の使用頻度に基づいて定められ、1つのグループ中の全コドンの固有の使用頻度の合計は100%であり、
ポリペプチドをコードする核酸中のあるコドンの使用頻度は、そのグループ内でのその固有の使用頻度とほぼ同じである、
方法である。
[本発明1001]
原核細胞中でポリペプチドを組換えによって作製するための方法であって、該ポリペプチドをコードする核酸を含む原核細胞を培養する段階、および該原核細胞または培養培地から該ポリペプチドを回収する段階を含み、
該ポリペプチドのアミノ酸残基のそれぞれは、少なくとも1つのコドンによってコードされており、同じアミノ酸残基をコードするコドンは1つのグループにまとめられており、かつグループ中のコドンのそれぞれは、該グループ内での固有の使用頻度に基づいて定められ、1つのグループ中の全コドンの固有の使用頻度の合計は100%であり、
ポリペプチドをコードする該核酸中の各コドンの総使用頻度は、そのグループ内でのその固有の使用頻度とほぼ同じである、
方法。
[本発明1002]
前記グループが、細胞ゲノム内での総使用頻度が5%より多いコドンのみを含むことを特徴とする、本発明1001の方法。
[本発明1003]
前記グループが、細胞ゲノム内での総使用頻度が8%またはそれ以上であるコドンのみを含むことを特徴とする、本発明1001の方法。
[本発明1004]
前記グループが、細胞ゲノム内での総使用頻度が10%またはそれ以上であるコドンのみを含むことを特徴とする、本発明1001の方法。
[本発明1005]
ポリペプチドのN末端から開始して、該ポリペプチド中に順次的に出現する特定のアミノ酸のそれぞれについて、コード核酸の対応する位置において、該特定のアミノ酸のための各々のアミノ酸コドンモチーフ中の対応する順次的位置に存在するものと同じコドンが使用されていることを特徴とする、本発明1001〜1004のいずれかの方法。
[本発明1006]
i)アミノ酸コドンモチーフの最終コドンの使用後、ポリペプチドにおいて特定のアミノ酸が次に出現する際、各々のアミノ酸コドンモチーフの最初の位置にあるコドンが、対応するコード核酸において再び使用され、
ii)該ポリペプチド中に順次的に出現する、さらなるこの特定のアミノ酸のそれぞれについて、該コード核酸の対応する位置において、該特定のアミノ酸のための各々のアミノ酸コドンモチーフ中の対応する位置に存在するコドンが使用される
ことを特徴とする、本発明1005の方法。
[本発明1007]
アミノ酸コドンモチーフ中のコドンが、固有の使用頻度が低くなる順に並べられ、固有の使用頻度が最も低いコドンまたは固有の使用頻度が二番目に低いコドンの後には、固有の使用頻度が最も高いコドンが使用されることを特徴とする、本発明1005〜1006のいずれかの方法。
[本発明1008]
アミノ酸コドンモチーフ中のコドンが、固有の使用頻度が低くなる順に並べられ、固有の使用頻度が最も低いコドンの後には、固有の使用頻度が最も高いコドンが使用されることを特徴とする、本発明1007の方法。
[本発明1009]
細胞が大腸菌(E. coli)であることを特徴とする、本発明1001〜1008のいずれかの方法。
[本発明1010]
アラニンのためのアミノ酸コドンモチーフが、SEQ ID NO: 01、02、03、04、および05より選択され、かつ/または
アルギニンのためのアミノ酸コドンモチーフが、SEQ ID NO: 06およびSEQ ID NO: 07より選択され、かつ/または
アスパラギンのためのアミノ酸コドンモチーフが、SEQ ID NO: 08、09、10、11、および12より選択され、かつ/または
アスパラギン酸のためのアミノ酸コドンモチーフが、SEQ ID NO: 13およびSEQ ID NO: 14より選択され、かつ/または
システインのためのアミノ酸コドンモチーフが、SEQ ID NO: 15、16、および17より選択され、かつ/または
グルタミンのためのアミノ酸コドンモチーフが、SEQ ID NO: 18、19、20、および21より選択され、かつ/または
グルタミン酸のためのアミノ酸コドンモチーフが、SEQ ID NO: 22、23、および24より選択され、かつ/または
グリシンのためのアミノ酸コドンモチーフが、SEQ ID NO: 25およびSEQ ID NO: 26より選択され、かつ/または
ヒスチジンのためのアミノ酸コドンモチーフが、SEQ ID NO: 27およびSEQ ID NO: 28より選択され、かつ/または
イソロイシンのためのアミノ酸コドンモチーフが、SEQ ID NO: 29およびSEQ ID NO: 30より選択され、かつ/または
ロイシンのためのアミノ酸コドンモチーフが、SEQ ID NO: 31、32、および33より選択され、かつ/または
リジンのためのアミノ酸コドンモチーフが、SEQ ID NO: 34、35、36、および37より選択され、かつ/または
フェニルアラニンのためのアミノ酸コドンモチーフが、SEQ ID NO: 38、39、および40より選択され、かつ/または
プロリンのためのアミノ酸コドンモチーフが、SEQ ID NO: 41、42、43、44、45、および46より選択され、かつ/または
セリンのためのアミノ酸コドンモチーフが、SEQ ID NO: 47およびSEQ ID NO: 48より選択され、かつ/または
トレオニンのためのアミノ酸コドンモチーフが、SEQ ID NO: 49、50、および51より選択され、かつ/または
チロシンのためのアミノ酸コドンモチーフが、SEQ ID NO: 52およびSEQ ID NO: 53より選択され、かつ/または
バリンのためのアミノ酸コドンモチーフが、SEQ ID NO: 54、55、および56より選択される
ことを特徴とする、本発明1009の方法。
[本発明1011]
ポリペプチドが、抗体、もしくは抗体断片、または抗体融合ポリペプチドであることを特徴とする、本発明1001〜1010のいずれかの方法。
定義
本出願内で使用される「アミノ酸」という用語は、核酸によって直接または前駆体の形態でコードされ得るカルボキシα-アミノ酸の群を意味する。個々のアミノ酸は、3個のヌクレオチドからなる核酸、いわゆるコドンまたは塩基トリプレットによってコードされている。各アミノ酸は、少なくとも1つのコドンによってコードされている。同じアミノ酸が異なるコドンによってコードされていることは、「遺伝コードの縮退(degeneration)」として公知である。本出願内で使用される「アミノ酸」という用語は、天然のカルボキシα-アミノ酸を意味し、アラニン(3文字記号:ala、1文字記号:A)、アルギニン(arg、R)、アスパラギン(asn、N)、アスパラギン酸(asp、D)、システイン(cys、C)、グルタミン(gln、Q)、グルタミン酸(glu、E)、グリシン(gly、G)、ヒスチジン(his、H)、イソロイシン(ile、I)、ロイシン(leu、L)、リジン(lys、K)、メチオニン(met、M)、フェニルアラニン(phe、F)、プロリン(pro、P)、セリン(ser、S)、トレオニン(thr、T)、トリプトファン(trp、W)、チロシン(tyr、Y)、およびバリン(val、V)を含んでいる。
(コードされるアミノ酸|コドン|使用頻度[%])
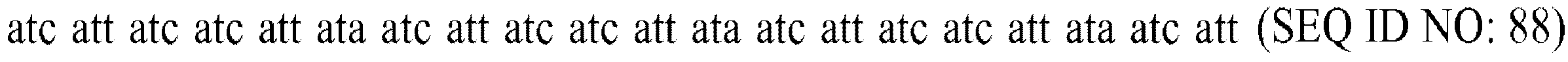
(コードされるアミノ酸|コドン|使用頻度[%])
(コードされるアミノ酸|コドン|使用頻度[%])
(コードされるアミノ酸|コドン|使用頻度[%])
抗体は、例えば、US4,816,567において説明されているようにして、組換え法および組換え組成物を用いて作製することができる。1つの態様において、本明細書において報告される抗体をコードする単離された核酸が提供される。このような核酸は、抗体のVLを含むアミノ酸配列および/または抗体のVHを含むアミノ酸配列(例えば、抗体の軽鎖および/または重鎖)をコードし得る。1つの態様において、このような核酸を含む1つまたは複数のベクター(例えば発現ベクター)が提供される。1つの態様において、このような核酸を含む細胞が提供される。1つの態様において、細胞は、(1)抗体のVLを含むアミノ酸配列および抗体のVHを含むアミノ酸配列をコードする核酸を含むベクター、または(2)抗体のVLを含むアミノ酸配列をコードする核酸を含む第1のベクターおよび抗体のVHを含むアミノ酸配列をコードする核酸を含む第2のベクターを含む(例えば、それらで形質転換されている)。1つの態様において、細胞は、真核生物性、例えばチャイニーズハムスター卵巣(CHO)細胞またはリンパ系細胞(例えば、Y0細胞、NS0細胞、Sp2/0細胞)である。1つの態様において、抗体を作製する方法が提供され、この方法は、抗体の発現に適した条件下で、本明細書において提供される抗体をコードする核酸を含む細胞を培養する段階、および任意で、細胞(または培地)から抗体を回収する段階を含む。
コドン使用表(例えば、前記の表を参照されたい)は、例えば、http://www.kazusa.or.jp/codon/において入手可能な「コドン使用データベース」から容易に入手可能であり、これらの表はいくつかの方法で改変され得る(adapted)(Nakamura, Y., et al., Nucl. Acids Res. 28 (2000) 292)。
細胞においてポリペプチドを発現させるためには、ポリペプチドをコードする核酸(各アミノ酸はコドングループによってコードされており、その際、コドングループ中の各コドンは、細胞ゲノムにおける総使用頻度に対応しているグループ中での固有の使用頻度に基づいて定められ、ポリペプチドをコードする(全)核酸におけるコドンの使用頻度は、グループ内での使用頻度とほぼ同じである)の使用が有益であることが判明している。
ポリペプチドをコードする核酸を含む細胞を培養する段階、および細胞または培養培地からポリペプチドを回収する段階を含み、
ポリペプチドの各アミノ酸残基は、少なくとも1つのコドンによってコードされており、同じアミノ酸残基をコードする異なるコドンが1つのグループにまとめられており、グループ中の各コドンは、グループ内での固有の使用頻度に基づいて定められ、1つのグループ中の全コドンの固有の使用頻度の合計は100%であり、
ポリペプチドをコードする核酸中のコドンの使用頻度は、そのグループ内でのその固有の使用頻度とほぼ同じである、
方法である。
280nmにおける光学濃度(OD)を測定し、アミノ酸配列に基づいて算出したモル吸光係数を用いることによって、タンパク質濃度を決定した。
Sambrook, J., et al., Molecular Cloning: A Laboratory Manual; Cold Spring Harbor Laboratory Press, Cold Spring Harbor, New York (1989)において説明されているように、標準的方法を用いてDNAを操作した。分子生物学的試薬は、製造業者の取扱い説明書に従って使用した。
試験ポリペプチド発現プラスミドの作製および説明
融合試験ポリペプチドを組換え手段によって調製した。発現される融合試験ポリペプチドのアミノ酸配列は、5'から3'の方向に、キャリアペプチドをコードするSEQ ID NO: 61の核酸、試験ポリペプチドをコードするSEQ ID NO: 62またはSEQ ID NO: 63の核酸、およびヘキサヒスチジン精製タグ(ポリHisタグ)をコードするSEQ ID NO: 59の核酸を含む核酸によってコードした。
プラスミド4980(4980-pBRori-URA3-LACI-SAC)は、大腸菌においてコアストレプトアビジンを発現させるための発現プラスミドである。これは、プラスミド1966(1966-pBRori-URA3-LACI-Tリピート;EP-B1422237において報告されている)に由来する3142bp長のEcoRI/CelIIベクター断片と、コアストレプトアビジンをコードする435bp長のEcoRI/CelII断片とのライゲーションによって作製した。
-大腸菌における複製のためのベクターpBR322に由来する複製起点(Sutcliffe, G., et al., Quant. Biol. 43 (1979) 77-90によると塩基対位置2517〜3160に対応する)、
-大腸菌のpyrF変異株(ウラシル栄養要求性)の補完によるプラスミド選択を可能にする、オロチジン5'-リン酸デカルボキシラーゼをコードするサッカロミセス・セレビシエのURA3遺伝子(Rose, M., et al., Gene 29 (1984) 113-124)、
-以下を含む、コアストレプトアビジン発現カセット
-T5ハイブリッドプロモーター(Bujard, H., et al., Methods. Enzymol. 155 (1987) 416-433およびStueber, D., et al., Immunol. Methods IV (1990) 121-152に記載の T5-PN25/03/04ハイブリッドプロモーター)(Stueber, D., et al.(前記を参照されたい)に記載の合成リボソーム結合部位を含む)、
-コアストレプトアビジン遺伝子、
-バクテリオファージに由来する2つの転写ターミネーター、すなわちλ-T0ターミネーター(Schwarz, E., et al., Nature 272 (1978) 410-414)およびfdターミネーター(Beck E. and Zink, B. Gene 1-3 (1981) 35-58)、
-大腸菌に由来するlacI抑制遺伝子(Farabaugh, P.J., Nature 274 (1978) 765-769)。
大腸菌における試験ポリペプチドの発現
融合試験ポリペプチドを発現させるために、大腸菌の栄養要求性(PyrF)の補完により抗生物質を用いずにプラスミドを選択することを可能にする大腸菌宿主/ベクター系を使用した(EP0972838およびUS6,291,245)。
先の段階で得られた発現プラスミド(それぞれ11020および11021)を用いて、大腸菌K12株CSPZ-2(leuB、proC、trpE、thi-1、ΔpyrF)を形質転換した。形質転換されたCSPZ-2細胞を、最初に37℃にて寒天プレート上で、続いて、0.5%カザミノ酸(Difco)を含むM9最少培地中で振盪培養して、550nmにおける光学濃度(OD550)が0.6〜0.9になるまで増殖させ、続いて、IPTG(最終濃度1〜5mmol/l)を用いて誘導した。
試験ポリペプチドの発現解析
発現された融合試験ポリペプチドを、SDS PAGE後に定量的なウェスタンブロット解析によって可視化した。したがって、大腸菌溶解物をドデシル硫酸ナトリウム(SDS)ポリアクリルアミドゲル電気泳動(SDS-PAGE)によって処理し、分離されたポリペプチドをゲルから膜に移し、続いて、免疫学的方法によって検出し定量した。
発現解析のために、約24時間の時間経過に渡って、大腸菌細胞培養物試料を振盪培養物から抜き取った。組換えタンパク質発現を誘導する前に、試料を1つ抜き取った。それ以降の試料は、割り当てられた(dedicated)時点、例えば、誘導後4時間目、6時間目、および21時間目に採取した。
LDS試料用緩衝液、4倍濃縮物(4×):グリセロール4g、TRIS塩基0.682g、TRIS塩酸塩0.666g、LDS(lithium dodecyl sulfate)0.8g、EDTA(ethylene diamin tetra acid)0.006g、1重量%(w/w)のServa Blue G250水溶液0.75ml、1重量%(w/w)のフェノールレッド溶液0.75ml、水を加えて総体積10mlにする。
転写緩衝液:39mMグリシン、48mM TRIS塩酸塩、0.04重量%(w/w)SDS、および20体積%メタノール(v/v)。
電気泳動転写(electro-transfer)の後、50mM Tris-HCl、pH7.5、150mM NaCl(TBS、tris buffered saline)中で膜を洗浄し、TBS、1%(w/v)ウェスタンブロッキング試薬(Roche、カタログ番号11921673001)中、4℃で一晩、非特異的結合部位をブロックした。
Claims (5)
- 大腸菌(E. coli)細胞中でポリペプチドを組換えによって作製するための方法であって、該ポリペプチドをコードする核酸を含む大腸菌(E. coli)細胞を培養する段階、および該大腸菌(E. coli)細胞または培養培地から該ポリペプチドを回収する段階を含み、
該ポリペプチドのアミノ酸残基のそれぞれは、少なくとも1つのコドンによってコードされており、同じアミノ酸残基をコードするコドンは1つのグループにまとめられており、かつグループ中のコドンのそれぞれは、該グループ内での固有の使用頻度に基づいて定められ、1つのグループ中の全コドンの固有の使用頻度の合計は100%であり、
ポリペプチドをコードする該核酸中の各コドンの総使用頻度は、そのグループ内でのその固有の使用頻度と同じであり、
ポリペプチドのN末端から開始して、該ポリペプチド中に順次的に出現する特定のアミノ酸のそれぞれについて、コード核酸の対応する位置において、該特定のアミノ酸のための各々のアミノ酸コドンモチーフ中の対応する順次的位置に存在するものと同じコドンが使用されていることを特徴とし、
アラニンのためのアミノ酸コドンモチーフが、SEQ ID NO: 01、02、03、04、および05より選択され、かつ/または
アルギニンのためのアミノ酸コドンモチーフが、SEQ ID NO: 06、および07より選択され、かつ/または
アスパラギンのためのアミノ酸コドンモチーフが、SEQ ID NO: 08、09、10、11、および12より選択され、かつ/または
アスパラギン酸のためのアミノ酸コドンモチーフが、SEQ ID NO: 13、および14より選択され、かつ/または
システインのためのアミノ酸コドンモチーフが、SEQ ID NO: 15、16、および17より選択され、かつ/または
グルタミンのためのアミノ酸コドンモチーフが、SEQ ID NO: 18、19、20、および21より選択され、かつ/または
グルタミン酸のためのアミノ酸コドンモチーフが、SEQ ID NO: 22、23、および24より選択され、かつ/または
グリシンのためのアミノ酸コドンモチーフが、SEQ ID NO: 25、および26より選択され、かつ/または
ヒスチジンのためのアミノ酸コドンモチーフが、SEQ ID NO: 27、および28より選択され、かつ/または
イソロイシンのためのアミノ酸コドンモチーフが、SEQ ID NO: 29、および30より選択され、かつ/または
ロイシンのためのアミノ酸コドンモチーフが、SEQ ID NO: 31、32、および33より選択され、かつ/または
リジンのためのアミノ酸コドンモチーフが、SEQ ID NO: 34、35、36、および37より選択され、かつ/または
フェニルアラニンのためのアミノ酸コドンモチーフが、SEQ ID NO: 38、39、および40より選択され、かつ/または
プロリンのためのアミノ酸コドンモチーフが、SEQ ID NO: 41、42、43、44、45、および46より選択され、かつ/または
セリンのためのアミノ酸コドンモチーフが、SEQ ID NO: 47、および48より選択され、かつ/または
トレオニンのためのアミノ酸コドンモチーフが、SEQ ID NO: 49、50、および51より選択され、かつ/または
チロシンのためのアミノ酸コドンモチーフが、SEQ ID NO: 52、および53より選択され、かつ/または
バリンのためのアミノ酸コドンモチーフが、SEQ ID NO: 54、55、および56より選択されることを特徴とする、方法。 - i)アミノ酸コドンモチーフの最終コドンの使用後、ポリペプチドにおいて特定のアミノ酸が次に出現する際、各々のアミノ酸コドンモチーフの最初の位置にあるコドンが、対応するコード核酸において再び使用され、
ii)該ポリペプチド中に順次的に出現する、さらなるこの特定のアミノ酸のそれぞれについて、該コード核酸の対応する位置において、該特定のアミノ酸のための各々のアミノ酸コドンモチーフ中の対応する位置に存在するコドンが使用される
ことを特徴とする、請求項1記載の方法。 - アミノ酸コドンモチーフ中のコドンが、固有の使用頻度が低くなる順に並べられ、固有の使用頻度が最も低いコドンまたは固有の使用頻度が二番目に低いコドンの後には、固有の使用頻度が最も高いコドンが使用されることを特徴とする、請求項1または2記載の方法。
- アミノ酸コドンモチーフ中のコドンが、固有の使用頻度が低くなる順に並べられ、固有の使用頻度が最も低いコドンの後には、固有の使用頻度が最も高いコドンが使用されることを特徴とする、請求項3記載の方法。
- ポリペプチドが、抗体、もしくは抗体断片、または抗体融合ポリペプチドであることを特徴とする、請求項1〜4のいずれか一項記載の方法。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP12164430 | 2012-04-17 | ||
| EP12164430.6 | 2012-04-17 | ||
| PCT/EP2013/057808 WO2013156443A1 (en) | 2012-04-17 | 2013-04-15 | Method for the expression of polypeptides using modified nucleic acids |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017193965A Division JP2018038408A (ja) | 2012-04-17 | 2017-10-04 | 改変された核酸を用いてポリペプチドを発現させるための方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2015514406A JP2015514406A (ja) | 2015-05-21 |
| JP6224077B2 true JP6224077B2 (ja) | 2017-11-01 |
Family
ID=48184161
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015506201A Active JP6224077B2 (ja) | 2012-04-17 | 2013-04-15 | 改変された核酸を用いてポリペプチドを発現させるための方法 |
| JP2017193965A Pending JP2018038408A (ja) | 2012-04-17 | 2017-10-04 | 改変された核酸を用いてポリペプチドを発現させるための方法 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017193965A Pending JP2018038408A (ja) | 2012-04-17 | 2017-10-04 | 改変された核酸を用いてポリペプチドを発現させるための方法 |
Country Status (11)
| Country | Link |
|---|---|
| US (2) | US20150246961A1 (ja) |
| EP (2) | EP2839011B1 (ja) |
| JP (2) | JP6224077B2 (ja) |
| KR (1) | KR102064025B1 (ja) |
| CN (2) | CN104245937B (ja) |
| BR (1) | BR112014025693B1 (ja) |
| CA (1) | CA2865676C (ja) |
| ES (1) | ES2599386T3 (ja) |
| MX (1) | MX349596B (ja) |
| RU (1) | RU2014144881A (ja) |
| WO (1) | WO2013156443A1 (ja) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| BR112014025693B1 (pt) * | 2012-04-17 | 2021-12-07 | F. Hoffmann-La Roche Ag | Método de produção recombinante de um polipeptídeo em uma célula bacteriana |
| WO2015017256A1 (en) | 2013-07-29 | 2015-02-05 | Danisco Us Inc. | Variant enzymes |
| US11345907B2 (en) * | 2018-05-29 | 2022-05-31 | Firmenich Sa | Method for producing albicanol compounds |
| GB201813528D0 (en) | 2018-08-20 | 2018-10-03 | Ucl Business Plc | Factor IX encoding nucleotides |
| CA3109579A1 (en) * | 2018-08-20 | 2020-02-27 | Ucl Business Ltd | Factor ix encoding nucleotides |
| BR112021025806A2 (pt) | 2019-06-28 | 2022-02-08 | Hoffmann La Roche | Métodos para produzir um anticorpo da subclasse igg1 humana cultivando uma célula cho e uso da remoção de sítios de splice de doador não pareados em uma parte de uma sequência de ácido nucleico de humano ou hamster |
| CN114774391B (zh) * | 2022-03-09 | 2023-03-14 | 华南农业大学 | 一种抗大肠杆菌的噬菌体内溶素及其应用 |
| CN114507682A (zh) * | 2022-03-16 | 2022-05-17 | 华南农业大学 | 编码重组NlpC/P60内肽酶蛋白的基因及其应用 |
Family Cites Families (32)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US5010182A (en) | 1987-07-28 | 1991-04-23 | Chiron Corporation | DNA constructs containing a Kluyveromyces alpha factor leader sequence for directing secretion of heterologous polypeptides |
| AU4005289A (en) | 1988-08-25 | 1990-03-01 | Smithkline Beecham Corporation | Recombinant saccharomyces |
| US5082767A (en) | 1989-02-27 | 1992-01-21 | Hatfield G Wesley | Codon pair utilization |
| US5959177A (en) | 1989-10-27 | 1999-09-28 | The Scripps Research Institute | Transgenic plants expressing assembled secretory antibodies |
| KR100249937B1 (ko) | 1991-04-25 | 2000-04-01 | 나가야마 오사무 | 인간 인터루킨-6 수용체에 대한 재구성 인간 항체 |
| WO1993006217A1 (en) | 1991-09-19 | 1993-04-01 | Genentech, Inc. | EXPRESSION IN E. COLI OF ANTIBODY FRAGMENTS HAVING AT LEAST A CYSTEINE PRESENT AS A FREE THIOL, USE FOR THE PRODUCTION OF BIFUNCTIONAL F(ab')2 ANTIBODIES |
| US5795737A (en) | 1994-09-19 | 1998-08-18 | The General Hospital Corporation | High level expression of proteins |
| US5789199A (en) | 1994-11-03 | 1998-08-04 | Genentech, Inc. | Process for bacterial production of polypeptides |
| US5840523A (en) | 1995-03-01 | 1998-11-24 | Genetech, Inc. | Methods and compositions for secretion of heterologous polypeptides |
| US6040498A (en) | 1998-08-11 | 2000-03-21 | North Caroline State University | Genetically engineered duckweed |
| EP0972838B1 (en) | 1998-07-15 | 2004-09-15 | Roche Diagnostics GmbH | Escherichia coli host/vector system based on antibiotic-free selection by complementation of an auxotrophy |
| US6291245B1 (en) | 1998-07-15 | 2001-09-18 | Roche Diagnostics Gmbh | Host-vector system |
| US7125978B1 (en) | 1999-10-04 | 2006-10-24 | Medicago Inc. | Promoter for regulating expression of foreign genes |
| NZ517906A (en) | 1999-10-04 | 2003-01-31 | Medicago Inc | Cloning of genomic sequences encoding nitrite reductase (NiR) for use in regulated expression of foreign genes in host plants |
| EP1156112B1 (en) | 2000-05-18 | 2006-03-01 | Geneart GmbH | Synthetic gagpol genes and their uses |
| GB0014288D0 (en) * | 2000-06-10 | 2000-08-02 | Smithkline Beecham Biolog | Vaccine |
| DE10037111A1 (de) * | 2000-07-27 | 2002-02-07 | Boehringer Ingelheim Int | Herstellung eines rekombinanten Proteins in einer prokaryontischen Wirtszelle |
| JP2004535166A (ja) * | 2001-03-22 | 2004-11-25 | デンドレオン・サンディエゴ・リミテッド・ライアビリティ・カンパニー | セリンプロテアーゼcvsp14をコードする核酸分子、コードされるポリペプチドおよびそれに基づく方法 |
| AU2003206684A1 (en) | 2002-02-20 | 2003-09-09 | Novozymes A/S | Plant polypeptide production |
| CA2480504A1 (en) | 2002-04-01 | 2003-10-16 | Evelina Angov | Method of designing synthetic nucleic acid sequences for optimal protein expression in a host cell |
| WO2003093296A2 (en) * | 2002-05-03 | 2003-11-13 | Sequenom, Inc. | Kinase anchor protein muteins, peptides thereof, and related methods |
| CA2443365C (en) | 2002-11-19 | 2010-01-12 | F. Hoffmann-La Roche Ag | Methods for the recombinant production of antifusogenic peptides |
| GB0308988D0 (en) * | 2003-04-17 | 2003-05-28 | Univ Singapore | Molecule |
| JP4228072B2 (ja) * | 2003-06-04 | 2009-02-25 | 独立行政法人農業・食品産業技術総合研究機構 | アビジンをコードする人工合成遺伝子 |
| US20060024670A1 (en) | 2004-05-18 | 2006-02-02 | Luke Catherine J | Influenza virus vaccine composition and methods of use |
| AU2007254993A1 (en) | 2006-05-30 | 2007-12-13 | Dow Global Technologies Llc | Codon optimization method |
| US7884262B2 (en) | 2006-06-06 | 2011-02-08 | Monsanto Technology Llc | Modified DMO enzyme and methods of its use |
| CN101627053A (zh) * | 2006-06-12 | 2010-01-13 | 西福根有限公司 | 泛细胞表面受体特异的治疗剂 |
| KR20090031897A (ko) | 2006-06-12 | 2009-03-30 | 리셉터 바이오로직스 인크 | 전-세포 표면 수용체-특이적 치료제 |
| EP2035561A1 (en) | 2006-06-29 | 2009-03-18 | DSMIP Assets B.V. | A method for achieving improved polypeptide expression |
| BR112014025693B1 (pt) | 2012-04-17 | 2021-12-07 | F. Hoffmann-La Roche Ag | Método de produção recombinante de um polipeptídeo em uma célula bacteriana |
-
2013
- 2013-04-15 BR BR112014025693-4A patent/BR112014025693B1/pt active IP Right Grant
- 2013-04-15 MX MX2014011805A patent/MX349596B/es active IP Right Grant
- 2013-04-15 EP EP13718536.9A patent/EP2839011B1/en active Active
- 2013-04-15 KR KR1020147028712A patent/KR102064025B1/ko active Active
- 2013-04-15 CN CN201380020266.6A patent/CN104245937B/zh active Active
- 2013-04-15 CN CN202111149491.2A patent/CN114107352A/zh active Pending
- 2013-04-15 WO PCT/EP2013/057808 patent/WO2013156443A1/en not_active Ceased
- 2013-04-15 EP EP16188552.0A patent/EP3138917B2/en active Active
- 2013-04-15 JP JP2015506201A patent/JP6224077B2/ja active Active
- 2013-04-15 RU RU2014144881A patent/RU2014144881A/ru not_active Application Discontinuation
- 2013-04-15 CA CA2865676A patent/CA2865676C/en active Active
- 2013-04-15 ES ES13718536.9T patent/ES2599386T3/es active Active
-
2014
- 2014-10-17 US US14/517,516 patent/US20150246961A1/en not_active Abandoned
-
2017
- 2017-10-04 JP JP2017193965A patent/JP2018038408A/ja active Pending
- 2017-12-06 US US15/833,012 patent/US12577293B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| EP3138917A1 (en) | 2017-03-08 |
| CA2865676C (en) | 2020-03-10 |
| JP2015514406A (ja) | 2015-05-21 |
| CA2865676A1 (en) | 2013-10-24 |
| US20150246961A1 (en) | 2015-09-03 |
| CN114107352A (zh) | 2022-03-01 |
| US20180100006A1 (en) | 2018-04-12 |
| EP2839011B1 (en) | 2016-09-14 |
| KR20140146105A (ko) | 2014-12-24 |
| HK1205186A1 (en) | 2015-12-11 |
| ES2599386T3 (es) | 2017-02-01 |
| MX2014011805A (es) | 2014-12-08 |
| EP3138917B1 (en) | 2019-08-21 |
| BR112014025693B1 (pt) | 2021-12-07 |
| BR112014025693A2 (en) | 2018-08-07 |
| KR102064025B1 (ko) | 2020-01-08 |
| EP3138917B2 (en) | 2024-10-23 |
| EP2839011A1 (en) | 2015-02-25 |
| RU2014144881A (ru) | 2016-06-10 |
| US12577293B2 (en) | 2026-03-17 |
| CN104245937B (zh) | 2021-09-21 |
| CN104245937A (zh) | 2014-12-24 |
| WO2013156443A1 (en) | 2013-10-24 |
| MX349596B (es) | 2017-08-04 |
| JP2018038408A (ja) | 2018-03-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6224077B2 (ja) | 改変された核酸を用いてポリペプチドを発現させるための方法 | |
| TWI605123B (zh) | Cho表現系統 | |
| US20100297697A1 (en) | Methods for increasing protein titers | |
| CN102498212B (zh) | Cho/cert细胞系 | |
| WO2022214065A1 (zh) | Rna修饰嵌合蛋白及其应用 | |
| KR102376287B1 (ko) | 다중특이적 항체 경쇄 잘못짝짓기의 검출 방법 | |
| EP3159411B1 (en) | Vector comprising gene fragment for enhancement of recombinant protein expression and use thereof | |
| JP7826509B2 (ja) | 選択マーカーとしての新規グルタミン合成酵素変異体 | |
| JP2026508076A (ja) | Il-18バリアントポリペプチド | |
| HK40062759A (en) | Method for the expression of polypeptides using modified nucleic acids | |
| HK1205186B (zh) | 使用修饰的核酸表达多肽的方法 | |
| JP7835713B2 (ja) | 抗体の製造方法 | |
| US20040209323A1 (en) | Protein expression by codon harmonization and translational attenuation | |
| JP4958905B2 (ja) | ペプチド鎖発現を増大させるための物質および方法 | |
| RU2162102C1 (ru) | Рекомбинантная плазмида, кодирующая гибридный белок с проинсулином человека (варианты) |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20150318 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160119 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20161109 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20161222 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20161222 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170417 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170524 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170911 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20171004 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6224077 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |