JP6163898B2 - 計算装置、計算方法、および計算プログラム - Google Patents
計算装置、計算方法、および計算プログラム Download PDFInfo
- Publication number
- JP6163898B2 JP6163898B2 JP2013122786A JP2013122786A JP6163898B2 JP 6163898 B2 JP6163898 B2 JP 6163898B2 JP 2013122786 A JP2013122786 A JP 2013122786A JP 2013122786 A JP2013122786 A JP 2013122786A JP 6163898 B2 JP6163898 B2 JP 6163898B2
- Authority
- JP
- Japan
- Prior art keywords
- calculation
- instruction
- code
- performance value
- specific code
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images




















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/40—Transformation of program code
- G06F8/52—Binary to binary
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
- G06F11/3457—Performance evaluation by simulation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0888—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches using selective caching, e.g. bypass
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/10—Address translation
- G06F12/1027—Address translation using associative or pseudo-associative address translation means, e.g. translation look-aside buffer [TLB]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/40—Transformation of program code
- G06F8/41—Compilation
- G06F8/44—Encoding
- G06F8/443—Optimisation
- G06F8/4441—Reducing the execution time required by the program code
- G06F8/4442—Reducing the number of cache misses; Data prefetching
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
Description
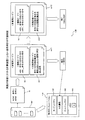
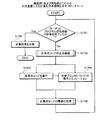
図2は、実施の形態にかかる計算装置のハードウェア構成例を示すブロック図である。計算装置100は、ホストCPU201と、ROM(Read Only Memory)202と、RAM203と、ディスクドライブ204と、ディスク205と、を有する。計算装置100は、I/F(Interface)206と、入力装置207と、出力装置208と、を有する。また、各部はバス200によってそれぞれ接続される。
メモリアドレス空間には、データキャッシュメモリを使用可能な領域と、データキャッシュメモリを使用不可能な領域と、がある。例えば、デバイスがマップされている領域などは、データキャッシュメモリを使用不可能な領域である。そのため、データキャッシュメモリを使用不可能な領域へのアクセス命令の性能値は、一定となる。そこで、実施例1では、アクセス命令を含むブロックの動作のシミュレーションにおいてアクセス命令のアクセス先がキャッシュメモリ使用不可の場合、キャッシュメモリの不使用を前提とした該ブロックの性能値を計算する計算用コードを生成する。これにより、該ブロックが再度対象となった際の計算量を低減させることができる。
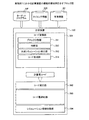
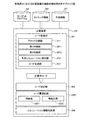
図3は、実施例1にかかる計算装置の機能的構成例を示すブロック図である。計算装置100は、コード変換部301と、コード実行部302と、コード最適化部303と、シミュレーション情報収集部304と、を有する。
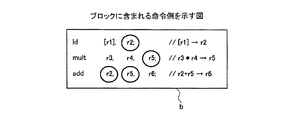
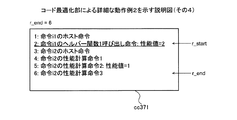
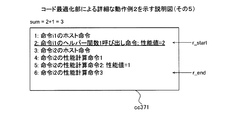
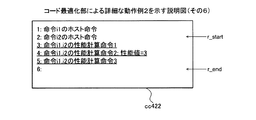
実施例2では、ブロックb内のアクセス命令がキャッシュメモリを使用可能である場合、キャッシュメモリの動作によって性能値を記憶領域の属性によらずに補正してブロックbの性能値を計算する計算用コードを生成する。これにより、ブロックbがあらたに計算対象となった場合に、記憶領域の属性を判断しないため、性能値の計算量の低減を図ることができる。実施例2では、実施例1で説明した機能や構成と同一の機能や構成についての詳細な説明を省略する。また、実施例2では、実施例1と同様にデータキャッシュメモリ1001を例に挙げるが、命令キャッシュメモリであってもよい。
「ld [r1],r2 :[r1]→r2;
mult r3,r4,r5 :r3*r4→r5;
add r2,r5,r6 :r2+r5→r6」
「ld [r1],r2 :[r1]→r2;
ld [r3],r4 :[r3]→r4;
mult r5,r6,r7 :r5*r6→r7;
add r2,r4,r2 :r2+r4→r2;
add r2,r7,r2 :r2+r7→r2」
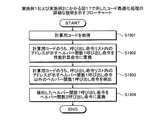
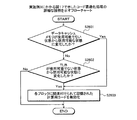
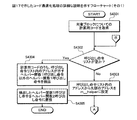
図17は、実施例1および実施例2にかかる計算装置による計算処理手順例を示すフローチャートである。計算装置100は、ターゲットプログラムpgrの性能値の計算を終了したか否かを判断する(ステップS1701)。終了していない場合(ステップS1701:No)、計算装置100は、計算用コードの生成処理を行う(ステップS1702)。
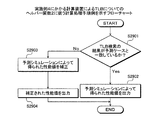
ターゲットCPU101の初期化中においてキャッシュメモリは使用可能でない状態になる。そのため、ターゲットCPU101の初期化が完了すれば、キャッシュメモリは使用可能な状態になる。そこで、実施例3では、キャッシュメモリが使用可能でない状態から使用可能な状態に変化するまでの間、キャッシュメモリを使用しない場合のアクセス命令の性能値によって対象ブロックbの性能値を計算する計算用コードを実行する。これにより、キャッシュメモリを使用可能でない状態の期間における対象ブロックbの性能値の計算量の減少を図ることができ、ターゲットプログラムpgrの性能値の計算を高速化させることができる。
図22は、実施例3にかかる計算装置の機能的構成例を示すブロック図である。計算装置100は、コード変換部301と、コード実行部302と、コード最適化部2201と、シミュレーション情報収集部304と、を有する。
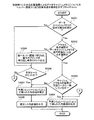
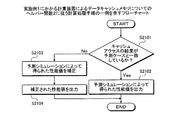
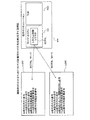
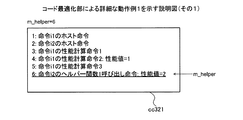
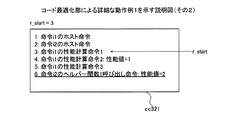
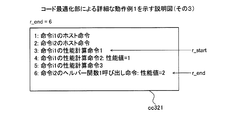
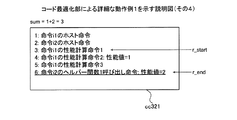
図23は、実施例3にかかるデータキャッシュメモリについての計算用コードの生成例1を示す説明図である。コンパイル済みでないと判断された場合、第2判断部2212は、動作のシミュレーションsimにおける対象ブロックb内のアクセス命令の実行時にデータキャッシュメモリ1001が使用可能な状態であるか否かを判断する。なお、ここでは、動作シミュレーションsimにおいて対象ブロックbを実行していない。そのため、第2判断部2212は、現在の動作シミュレーションsimにおける状態に基づいて動作シミュレーションsimにおいて対象ブロックb内のアクセス命令の実行時にデータキャッシュメモリ1001が使用可能な状態であるか否かを判断する。
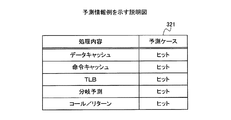
図24は、実施例3にかかるTLBについての計算用コードの生成例2を示す説明図である。TLB2401の場合もデータキャッシュメモリ1001の場合と同様に、各部の処理が行われる。そのため、第2判断部2212は、TLB2401が使用可能な状態であるか否かを判断する。具体的には、第2判断部2212は、システム制御レジスタSCTRLのMビットの値を検出する。第2判断部2212は、システム制御レジスタSCTRLのMビットの値が0である場合、TLB2401が使用可能な状態でないと判断する。第2判断部2212は、システム制御レジスタSCTRLのMビットの値が1である場合、TLB2401が使用可能な状態であると判断する。
実施例3では、実施例1および実施例2にかかる計算装置による計算処理手順例と同一の計算処理手順例については説明せずに、異なる計算処理手順について詳細に説明する。
ターゲットCPU101がARMプロセッサの場合、ターゲットCPU101は第1モードと、第1モードよりもターゲットCPU101の動作の制限が小さい第2モードと、の2つの動作モードを有する。第1モードは、ユーザモードと称し、第2モードは、特権モードである。特権モードとユーザモードとの2つの動作モードを有する。ユーザモード以外の動作モードはすべて特権モードと呼ばれる。特権モードは、ユーザモードよりプロセッサの動作の制限が少ない動作モードである。そのため、特権モードではカーネルなどが記憶されたシステム領域にアクセスすることができる。特権モード時のシステム領域へのアクセスは、TLB2401にヒットするように予め設計される。例えば、TLB2401では、システム領域を1個のページテーブルエントリで管理する。そして、TLB2401は、システム領域用の特別なフラグを用いてTLB2401から当該ページテーブルエントリが消去されないように予め設計される。これにより、当該アクセスがTLB2401にヒットするように実現できる。そのため、特権モード時のアクセス命令をターゲットCPU101が実行した場合、システム領域へのアクセスが行われるため、当該アクセス命令についてのTLB2401の動作は“ヒット”となる。
実施例4では、実施例1および実施例2にかかる計算装置100による計算処理手順例と同一の計算処理手順例については説明せずに、異なる計算処理手順について詳細に説明する。
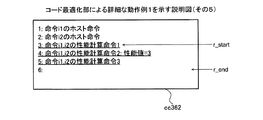
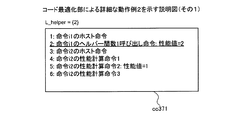
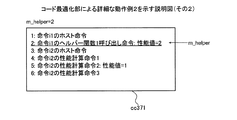
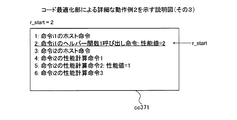
実施例5では、実施例1または4においてヘルパー関数1呼び出し命令を性能計算用命令に置き換える際に、連続する性能計算用命令を集約して1つの性能計算命令とする。これにより、対象ブロックbがあらたに計算対象となった場合の計算量の低減を図ることができる。また、実施例5では、実施例1〜実施例4のいずれかで説明した機能や構成と同一の機能や構成についての詳細な説明を省略する。
性能計算命令1:性能値をレジスタにロード
性能計算命令2:レジスタに性能値を加算
性能計算命令3:レジスタの値を性能値にストア
push pre_delay:3番目の引数をスタックに入れる
push rep_delay:2番目の引数をスタックに入れる
push addr :1番目の引数をスタックに入れる
call cache_ld:ヘルパー関数1cache_ldを呼び出す
の4つの命令を有する。算出部3104は、当該4つの命令のうち、pre_delayなどを参照して、データキャッシュメモリ1001を使用しない場合の性能値を計算することにより、ヘルパー関数1呼び出し命令の性能値を取得する。
実施例5では、実施例1および実施例2にかかる計算装置100による計算処理手順例と同一の計算処理手順例については説明せずに、異なる計算処理手順について詳細に説明する。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断する判断部と、
前記キャッシュメモリを使用可能なことを示す属性でないと前記判断部が判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成する生成部と、
前記特定コードがあらたに性能値の計算対象となった場合、生成した前記計算用コードを実行する実行部と、
を有することを特徴とする計算装置。
前記特定コード内の前記アクセス命令と異なる命令の各々について、前記命令の性能値を前記特定コードの性能値に加算させる第1計算命令と、前記アクセス命令について、前記属性に基づく前記アクセス命令の性能値を前記特定コードの性能値に加算させる第2計算命令と、を有する第2計算用コードを取得し、
取得した前記第2計算用コードのうち、前記キャッシュメモリを使用可能なことを示す属性でないと判断した前記アクセス命令についての第2計算命令を、前記キャッシュメモリを使用しない場合における前記アクセス命令の性能を前記特定コードの性能値に加算させる第3計算命令に置換する、
ことにより、前記第1計算用コードを生成することを特徴とする付記1に記載の計算装置。
前記特定コード内の前記アクセス命令と異なる命令の各々について、前記命令の性能値を前記特定コードの性能値に加算させる第1計算命令と、前記アクセス命令について、前記属性に基づく前記アクセス命令の性能値を前記特定コードの性能値に加算させる第2計算命令と、を有する第2計算用コードを取得し、
取得した前記第2計算用コードの中から、前記キャッシュメモリを使用可能なことを示す属性であると判断した前記アクセス命令についての第2計算命令を、前記キャッシュメモリを使用する場合における前記アクセス命令の性能値を前記特定コードの性能値に加算させる第3計算命令に置換する、
ことにより、前記第1計算用コードを生成することを特徴とする付記2に記載の計算装置。
前記特定コード内の前記アクセス命令と異なる命令の各々について、前記命令の性能値を前記特定コードの性能値に加算させる第1計算命令と、前記アクセス命令の各々について、前記属性に基づく前記アクセス命令の性能値を前記特定コードの性能値に加算させる第2計算命令と、を有する第2計算用コードを取得し、
取得した前記第2計算用コードの中から、前記キャッシュメモリを使用可能なことを示す属性でないと判断した前記アクセス命令についての第2計算命令を検出し、
検出した前記第2計算命令から、前記キャッシュメモリを使用可能なことを示す属性であると判断した前記アクセス命令についての第2計算命令までの間にある前記第1計算命令を前記第2計算用コードの中から検出し、
検出した前記第1計算命令が前記特定コードの性能値に加算させる前記命令の性能値と、前記キャッシュメモリを使用可能なことを示す属性でないと判断した前記アクセス命令の実行時に前記キャッシュメモリを使用しない場合における前記アクセス命令の性能値と、の合計値を算出し、
前記第2計算用コードのうち、検出した前記第1計算命令と検出した前記第2計算命令とを、前記合計値を前記特定コードの性能値に加算させる第3計算命令に置換する、
ことにより、前記第1計算用コードを生成することを特徴とする付記1または2に記載の計算装置。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断する判断部と、
前記キャッシュメモリを使用可能なことを示す属性であると前記判断部が判断した場合、前記キャッシュメモリを使用する場合における前記特定コード内の各命令の性能値によって、前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成する生成部と、
前記特定コードがあらたに性能値の計算対象となった場合、生成した前記計算用コードを実行する実行部と、
を有することを特徴とする計算装置。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断する第1判断部と、
使用可能な状態でないと前記第1判断部が判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記キャッシュメモリの状態によらずに計算する計算用コードを生成する生成部と、
前記生成部が生成した前記計算用コードを実行する第1実行部と、
前記特定コードがあらたに性能値の計算対象となった場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断する第2判断部と、
使用可能な状態でないと前記第2判断部が判断した場合、前記計算用コードを実行する第2実行部と、
を有することを特徴とする計算装置。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)が使用可能な状態か否かを判断する第1判断部と、
使用可能であると前記第1判断部が判断した場合、前記TLBを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記TLBの状態によらずに計算する計算用コードを生成する生成部と、
前記生成部が生成した前記計算用コードを実行する第1実行部と、
前記特定コードがあらたに性能値の計算対象となった場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記TLBが使用可能な状態であるか否かを判断する第2判断部と、
使用可能な状態でないと前記第2判断部が判断した場合、前記計算用コードを実行する第2実行部と、
を有することを特徴とする計算装置。
前記特定コードが性能値の計算対象となった場合、前記プログラムを前記プロセッサが実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記動作モードが前記第2モードであるか否かを判断する判断部と、
前記第2モードであると前記判断部が判断した場合、前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)に前記記憶領域を示す論理アドレスと前記記憶領域を示す物理アドレスとの変換情報が格納されている場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記動作モードによらずに計算する計算用コードを生成する生成部と、
前記特定コードがあらたに性能値の計算対象となった場合、前記生成部が生成した前記計算用コードを実行する実行部と、
を有することを特徴とする計算装置。
前記特定コード内の前記アクセス命令と異なる命令の各々について、前記命令の性能値を前記特定コードの性能値に加算させる第1計算命令と、前記アクセス命令について、前記TLBに前記変換情報が格納されているか否かに基づく前記アクセス命令の性能値を前記特定コードの性能値に加算させる第2計算命令と、を有する第2計算用コードを取得し、
取得した前記第2計算用コードのうち、前記第2モードであると判断した前記アクセス命令についての第2計算命令を、前記TLBが変換情報に格納されている場合における前記アクセス命令の性能を前記特定コードの性能値に加算させる第3計算命令に置換する、
ことにより、前記第1計算用コードを生成することを特徴とする付記11に記載の計算装置。
前記特定コード内の前記アクセス命令と異なる命令の各々について、前記命令の性能値を前記特定コードの性能値に加算させる第1計算命令と、前記アクセス命令の各々について、前記TLBに前記変換情報が格納されているか否かに基づく前記アクセス命令の性能値を前記特定コードの性能値に加算させる第2計算命令と、を有する第2計算用コードを取得し、
取得した前記第2計算用コードの中から、前記第2モードであると判断した前記アクセス命令についての第2計算命令を検出し、
検出した前記第2計算命令から、前記第2モードでないと判断した前記アクセス命令についての第2計算命令までの間にある前記第1計算命令を前記第2計算用コードの中から検出し、
検出した前記第1計算命令が前記特定コードの性能値に加算させる前記命令の性能値と、前記第2モードであると判断した前記アクセス命令の実行時に前記TLBに変換情報が格納されている場合における前記アクセス命令の性能値と、の合計値を算出し、
前記第2計算用コードのうち、検出した前記第1計算命令と検出した前記第2計算命令とを、前記合計値を前記特定コードの性能値に加算させる第3計算命令に置換する、
ことにより、前記第1計算用コードを生成することを特徴とする付記11に記載の計算装置。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断し、
前記キャッシュメモリを使用可能なことを示す属性でないと判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成し、
前記特定コードがあらたに性能値の計算対象となった場合、生成した前記計算用コードを実行する、
処理を実行することを特徴とする計算方法。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断し、
前記キャッシュメモリを使用可能なことを示す属性であると判断した場合、前記キャッシュメモリを使用する場合における前記特定コード内の各命令の性能値によって、前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成し、
前記特定コードがあらたに性能値の計算対象となった場合、生成した前記計算用コードを実行する、
処理を実行することを特徴とする計算方法。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断し、
使用可能な状態でないと判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記キャッシュメモリの状態によらずに計算する計算用コードを生成し、
生成した前記計算用コードを実行し、
前記特定コードがあらたに性能値の計算対象となった場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断し、
使用可能な状態でないと判断した場合、前記計算用コードを実行する、
処理を実行することを特徴とする計算方法。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)が使用可能な状態か否かを判断し、
使用可能であると判断した場合、前記TLBを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記TLBの状態によらずに計算する計算用コードを生成し、
生成した前記計算用コードを実行し、
前記特定コードがあらたに性能値の計算対象となった場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記TLBが使用可能な状態であるか否かを判断し、
使用可能な状態でないと判断した場合、前記計算用コードを実行する、
処理を実行することを特徴とする計算方法。
前記特定コードが性能値の計算対象となった場合、前記プログラムを前記プロセッサが実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記動作モードが前記第2モードであるか否かを判断し、
前記第2モードであると判断した場合、前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)に前記記憶領域を示す論理アドレスと前記記憶領域を示す物理アドレスとの変換情報が格納されている場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記動作モードによらずに計算する計算用コードを生成し、
前記特定コードがあらたに性能値の計算対象となった場合、生成した前記計算用コードを実行する、
処理を実行することを特徴とする計算方法。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断し、
前記キャッシュメモリを使用可能なことを示す属性でないと判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成し、
前記特定コードがあらたに性能値の計算対象となった場合、生成した前記計算用コードを実行する、
処理を実行させることを特徴とする計算プログラム。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断し、
前記キャッシュメモリを使用可能なことを示す属性であると判断した場合、前記キャッシュメモリを使用する場合における前記特定コード内の各命令の性能値によって、前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成し、
前記特定コードがあらたに性能値の計算対象となった場合、生成した前記計算用コードを実行する、
処理を実行させることを特徴とする計算プログラム。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断し、
使用可能な状態でないと判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記キャッシュメモリの状態によらずに計算する計算用コードを生成し、
生成した前記計算用コードを実行し、
前記特定コードがあらたに性能値の計算対象となった場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断し、
使用可能な状態でないと判断した場合、前記計算用コードを実行する、
処理を実行させることを特徴とする計算プログラム。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)が使用可能な状態か否かを判断し、
使用可能であると判断した場合、前記TLBを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記TLBの状態によらずに計算する計算用コードを生成し、
生成した前記計算用コードを実行し、
前記特定コードがあらたに性能値の計算対象となった場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記TLBが使用可能な状態であるか否かを判断し、
使用可能な状態でないと判断した場合、前記計算用コードを実行する、
処理を実行させることを特徴とする計算プログラム。
前記特定コードが性能値の計算対象となった場合、前記プログラムを前記プロセッサが実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記動作モードが前記第2モードであるか否かを判断し、
前記第2モードであると判断した場合、前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)に前記記憶領域を示す論理アドレスと前記記憶領域を示す物理アドレスとの変換情報が格納されている場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記動作モードによらずに計算する計算用コードを生成し、
前記特定コードがあらたに性能値の計算対象となった場合、生成した前記計算用コードを実行する、
処理を実行させることを特徴とする計算プログラム。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断し、
前記キャッシュメモリを使用可能なことを示す属性でないと判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成し、
前記特定コードがあらたに性能値の計算対象となった場合、生成した前記計算用コードを実行する、
処理を実行させる計算プログラムを記録したことを特徴とする記録媒体。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断し、
前記キャッシュメモリを使用可能なことを示す属性であると判断した場合、前記キャッシュメモリを使用する場合における前記特定コード内の各命令の性能値によって、前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成し、
前記特定コードがあらたに性能値の計算対象となった場合、生成した前記計算用コードを実行する、
処理を実行させる計算プログラムを記録したことを特徴とする記録媒体。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断し、
使用可能な状態でないと判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記キャッシュメモリの状態によらずに計算する計算用コードを生成し、
生成した前記計算用コードを実行し、
前記特定コードがあらたに性能値の計算対象となった場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断し、
使用可能な状態でないと判断した場合、前記計算用コードを実行する、
処理を実行させる計算プログラムを記録したことを特徴とする記録媒体。
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)が使用可能な状態か否かを判断し、
使用可能であると判断した場合、前記TLBを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記TLBの状態によらずに計算する計算用コードを生成し、
生成した前記計算用コードを実行し、
前記特定コードがあらたに性能値の計算対象となった場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記TLBが使用可能な状態であるか否かを判断し、
使用可能な状態でないと判断した場合、前記計算用コードを実行する、
処理を実行させる計算プログラムを記録したことを特徴とする記録媒体。
前記特定コードが性能値の計算対象となった場合、前記プログラムを前記プロセッサが実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記動作モードが前記第2モードであるか否かを判断し、
前記第2モードであると判断した場合、前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)に前記記憶領域を示す論理アドレスと前記記憶領域を示す物理アドレスとの変換情報が格納されている場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記動作モードによらずに計算する計算用コードを生成し、
前記特定コードがあらたに性能値の計算対象となった場合、生成した前記計算用コードを実行する、
処理を実行させる計算プログラムを記録したことを特徴とする記録媒体。
101 ターゲットCPU
102 キャッシュメモリ
103 メモリ
201 ホストCPU
301 コード変換部
302 コード実行部
303 コード最適化部
304 シミュレーション情報収集部
311 ブロック分割部
312,2221 判断部
313 予測シミュレーション実行部
314 コード生成部
901 実行部
902,2211 第1判断部
903,2212 第2判断部
904 出力部
905 補正部
1001 データキャッシュメモリ
2222 無効化部
2401 TLB
3101 取得部
3102 第1検出部
3103 第2検出部
3104 算出部
3105 置換部
bt,b ブロック
sim 動作のシミュレーション
cc11,cc12,cc101,cc112,cc123,cc232,cc233,cc242,cc243,cc2701,cc301,cc302−1,cc302−2 計算用コード
pgr ターゲットプログラム
Claims (19)
- プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算する計算装置であって、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断する判断部と、
前記キャッシュメモリを使用可能なことを示す属性でないと前記判断部が判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成する生成部と、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合、生成した前記計算用コードを実行する実行部と、
を有することを特徴とする計算装置。 - 前記生成部は、前記キャッシュメモリを使用可能なことを示す属性であると判断した場合、前記キャッシュメモリを使用する場合における前記特定コード内の各命令の性能値によって、前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成することを特徴とする請求項1に記載の計算装置。
- 前記計算用コード(以下、「第1計算用コード」と称する。)を生成する前記生成部は、
前記特定コード内の前記アクセス命令と異なる命令の各々について、前記命令の性能値を前記特定コードの性能値に加算させる第1計算命令と、前記アクセス命令の各々について、前記属性に基づく前記アクセス命令の性能値を前記特定コードの性能値に加算させる第2計算命令と、を有する第2計算用コードを取得し、
取得した前記第2計算用コードの中から、前記キャッシュメモリを使用可能なことを示す属性でないと判断した前記アクセス命令についての第2計算命令を検出し、
検出した前記第2計算命令から、前記キャッシュメモリを使用可能なことを示す属性であると判断した前記アクセス命令についての第2計算命令までの間にある前記第1計算命令を前記第2計算用コードの中から検出し、
検出した前記第1計算命令が前記特定コードの性能値に加算させる前記命令の性能値と、前記キャッシュメモリを使用可能なことを示す属性でないと判断した前記アクセス命令の実行時に前記キャッシュメモリを使用しない場合における前記アクセス命令の性能値と、の合計値を算出し、
前記第2計算用コードのうち、検出した前記第1計算命令と検出した前記第2計算命令とを、前記合計値を前記特定コードの性能値に加算させる第3計算命令に置換する、
ことにより、前記第1計算用コードを生成することを特徴とする請求項1または2に記載の計算装置。 - プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算する計算装置であって、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断する判断部と、
前記キャッシュメモリを使用可能なことを示す属性であると前記判断部が判断した場合、前記キャッシュメモリを使用する場合における前記特定コード内の各命令の性能値によって、前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成する生成部と、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合、生成した前記計算用コードを実行する実行部と、
を有することを特徴とする計算装置。 - プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算する計算装置であって、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断する第1判断部と、
使用可能な状態でないと前記第1判断部が判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記キャッシュメモリの状態によらずに計算する計算用コードを生成する生成部と、
前記生成部が生成した前記計算用コードを実行する第1実行部と、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断する第2判断部と、
使用可能な状態でないと前記第2判断部が判断した場合、前記計算用コードを実行する第2実行部と、
を有することを特徴とする計算装置。 - プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算する計算装置であって、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)が使用可能な状態か否かを判断する第1判断部と、
使用可能でないと前記第1判断部が判断した場合、前記TLBを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記TLBの状態によらずに計算する計算用コードを生成する生成部と、
前記生成部が生成した前記計算用コードを実行する第1実行部と、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記TLBが使用可能な状態であるか否かを判断する第2判断部と、
使用可能な状態でないと前記第2判断部が判断した場合、前記計算用コードを実行する第2実行部と、
を有することを特徴とする計算装置。 - 第1モードと、前記第1モードよりも動作の制限が少ない第2モードと、の動作モードを有するプロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算する計算装置であって、
前記特定コードが性能値の計算対象となった場合、前記プログラムを前記プロセッサが実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記動作モードが前記第2モードであるか否かを判断する判断部と、
前記第2モードであると前記判断部が判断した場合、前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)に前記記憶領域を示す論理アドレスと前記記憶領域を示す物理アドレスとの変換情報が格納されている場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記動作モードによらずに計算する計算用コードを生成する生成部と、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合、前記生成部が生成した前記計算用コードを実行する実行部と、
を有することを特徴とする計算装置。 - 前記生成部は、前記判断部が前記第2モードでないと判断した場合、前記TLBを使用する場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記動作モードによらずに計算する計算用コードを生成することを特徴とする請求項7に記載の計算装置。
- 前記計算用コード(以下、「第1計算用コード」と称する。)を生成する前記生成部は、
前記特定コード内の前記アクセス命令と異なる命令の各々について、前記命令の性能値を前記特定コードの性能値に加算させる第1計算命令と、前記アクセス命令の各々について、前記TLBに前記変換情報が格納されているか否かに基づく前記アクセス命令の性能値を前記特定コードの性能値に加算させる第2計算命令と、を有する第2計算用コードを取得し、
取得した前記第2計算用コードの中から、前記第2モードであると判断した前記アクセス命令についての第2計算命令を検出し、
検出した前記第2計算命令から、前記第2モードでないと判断した前記アクセス命令についての第2計算命令までの間にある前記第1計算命令を前記第2計算用コードの中から検出し、
検出した前記第1計算命令が前記特定コードの性能値に加算させる前記命令の性能値と、前記第2モードであると判断した前記アクセス命令の実行時に前記TLBに変換情報が格納されている場合における前記アクセス命令の性能値と、の合計値を算出し、
前記第2計算用コードのうち、検出した前記第1計算命令と検出した前記第2計算命令とを、前記合計値を前記特定コードの性能値に加算させる第3計算命令に置換する、
ことにより、前記第1計算用コードを生成することを特徴とする請求項7に記載の計算装置。 - プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算するコンピュータが、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断し、
前記キャッシュメモリを使用可能なことを示す属性でないと判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成し、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合、生成した前記計算用コードを実行する、
処理を実行することを特徴とする計算方法。 - プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算するコンピュータが、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断し、
前記キャッシュメモリを使用可能なことを示す属性であると判断した場合、前記キャッシュメモリを使用する場合における前記特定コード内の各命令の性能値によって、前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成し、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合、生成した前記計算用コードを実行する、
処理を実行することを特徴とする計算方法。 - プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算するコンピュータが、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断し、
使用可能な状態でないと判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記キャッシュメモリの状態によらずに計算する計算用コードを生成し、
生成した前記計算用コードを実行し、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断し、
使用可能な状態でないと判断した場合、前記計算用コードを実行する、
ことを特徴とする計算方法。 - プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算するコンピュータが、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)が使用可能な状態か否かを判断し、
使用可能であると判断した場合、前記TLBを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記TLBの状態によらずに計算する計算用コードを生成し、
生成した前記計算用コードを実行し、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記TLBが使用可能な状態であるか否かを判断し、
使用可能な状態でないと判断した場合、前記計算用コードを実行する、
処理を実行することを特徴とする計算方法。 - 第1モードと、前記第1モードよりも動作の制限が少ない第2モードと、の動作モードを有するプロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算するコンピュータが、
前記特定コードが性能値の計算対象となった場合、前記プログラムを前記プロセッサが実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記動作モードが前記第2モードであるか否かを判断し、
前記第2モードであると判断した場合、前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)に前記記憶領域を示す論理アドレスと前記記憶領域を示す物理アドレスとの変換情報が格納されている場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記動作モードによらずに計算する計算用コードを生成し、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合、生成した前記計算用コードを実行する、
処理を実行することを特徴とする計算方法。 - プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算するコンピュータに、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断し、
前記キャッシュメモリを使用可能なことを示す属性でないと判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成し、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合、生成した前記計算用コードを実行する、
処理を実行させることを特徴とする計算プログラム。 - プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算するコンピュータに、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記記憶領域の属性が、前記アクセス命令の指示に対して前記プロセッサがキャッシュメモリを使用可能なことを示す属性であるか否かを判断し、
前記キャッシュメモリを使用可能なことを示す属性であると判断した場合、前記キャッシュメモリを使用する場合における前記特定コード内の各命令の性能値によって、前記特定コードの性能値を前記属性によらずに計算する計算用コードを生成し、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合、生成した前記計算用コードを実行する、
処理を実行させることを特徴とする計算プログラム。 - プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算するコンピュータに、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断し、
使用可能な状態でないと判断した場合、前記キャッシュメモリを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記キャッシュメモリの状態によらずに計算する計算用コードを生成し、
生成した前記計算用コードを実行し、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なキャッシュメモリが使用可能な状態であるか否かを、前記シミュレーションにおける前記アクセス命令の実行前に判断し、
使用可能な状態でないと判断した場合、前記計算用コードを実行する、
ことを特徴とする計算プログラム。 - プロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算するコンピュータに、
前記特定コードが性能値の計算対象となった場合、前記プロセッサが前記プログラムを実行する動作のシミュレーションにおける前記アクセス命令の実行時に前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)が使用可能な状態か否かを判断し、
使用可能であると判断した場合、前記TLBを使用しない場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記TLBの状態によらずに計算する計算用コードを生成し、
生成した前記計算用コードを実行し、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合に、前記シミュレーションにおける前記アクセス命令の実行時に前記TLBが使用可能な状態であるか否かを判断し、
使用可能な状態でないと判断した場合、前記計算用コードを実行する、
処理を実行させることを特徴とする計算プログラム。 - 第1モードと、前記第1モードよりも動作の制限が少ない第2モードと、の動作モードを有するプロセッサが複数回実行する特定コードであって、前記プロセッサに記憶領域へのアクセスを指示するアクセス命令を有する特定コードを有するプログラムを前記プロセッサが実行した場合の前記プログラムの性能値を計算するコンピュータに、
前記特定コードが性能値の計算対象となった場合、前記プログラムを前記プロセッサが実行する動作のシミュレーションにおける前記アクセス命令の実行時の前記動作モードが前記第2モードであるか否かを判断し、
前記第2モードであると判断した場合、前記プロセッサがアクセス可能なTLB(Translation Lookaside Buffer)に前記記憶領域を示す論理アドレスと前記記憶領域を示す物理アドレスとの変換情報が格納されている場合における前記特定コード内の各命令の性能値によって、前記プロセッサが前記特定コードを実行した場合の前記特定コードの性能値を前記動作モードによらずに計算する計算用コードを生成し、
前記特定コードが、性能値の計算対象となり、かつ以前に性能値の計算対象となったことがある場合、生成した前記計算用コードを実行する、
処理を実行させることを特徴とする計算プログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013122786A JP6163898B2 (ja) | 2013-06-11 | 2013-06-11 | 計算装置、計算方法、および計算プログラム |
| US14/289,772 US9465595B2 (en) | 2013-06-11 | 2014-05-29 | Computing apparatus, computing method, and computing program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013122786A JP6163898B2 (ja) | 2013-06-11 | 2013-06-11 | 計算装置、計算方法、および計算プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014241031A JP2014241031A (ja) | 2014-12-25 |
| JP6163898B2 true JP6163898B2 (ja) | 2017-07-19 |
Family
ID=52006495
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013122786A Expired - Fee Related JP6163898B2 (ja) | 2013-06-11 | 2013-06-11 | 計算装置、計算方法、および計算プログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US9465595B2 (ja) |
| JP (1) | JP6163898B2 (ja) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| TW201512894A (zh) * | 2013-09-24 | 2015-04-01 | hong-jian Zhou | 資料存取系統及其資料與指令傳輸裝置 |
| US9977730B2 (en) * | 2015-05-08 | 2018-05-22 | Dell Products, Lp | System and method for optimizing system memory and input/output operations memory |
| WO2016189642A1 (ja) * | 2015-05-26 | 2016-12-01 | 三菱電機株式会社 | シミュレーション装置及びシミュレーション方法及びシミュレーションプログラム |
| JP6234640B2 (ja) * | 2015-05-28 | 2017-11-22 | 三菱電機株式会社 | シミュレーション装置及びシミュレーション方法及びシミュレーションプログラム |
| JP6740607B2 (ja) | 2015-12-18 | 2020-08-19 | 富士通株式会社 | シミュレーションプログラム、情報処理装置、シミュレーション方法 |
| JP6827798B2 (ja) * | 2016-12-21 | 2021-02-10 | キヤノン株式会社 | 画像形成装置、画像形成装置の制御方法、プログラム。 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4888688A (en) * | 1987-09-18 | 1989-12-19 | Motorola, Inc. | Dynamic disable mechanism for a memory management unit |
| US5845310A (en) * | 1993-12-15 | 1998-12-01 | Hewlett-Packard Co. | System and methods for performing cache latency diagnostics in scalable parallel processing architectures including calculating CPU idle time and counting number of cache misses |
| US5764962A (en) * | 1996-07-31 | 1998-06-09 | Hewlett-Packard Company | Emulation of asynchronous signals using a branch mechanism |
| JP3798476B2 (ja) * | 1996-08-30 | 2006-07-19 | 株式会社東芝 | コンピュータシステムおよびそのシステムにおけるキャッシュメモリのパワーダウン制御方法 |
| EP1012722B1 (en) * | 1997-05-14 | 2002-08-07 | Compuware Corporation | Accurate profile and timing information for multitasking systems |
| US6442652B1 (en) * | 1999-09-07 | 2002-08-27 | Motorola, Inc. | Load based cache control for satellite based CPUs |
| JP2001249829A (ja) | 2000-03-06 | 2001-09-14 | Hitachi Ltd | システムシミュレータ |
| US7007270B2 (en) * | 2001-03-05 | 2006-02-28 | Cadence Design Systems, Inc. | Statistically based estimate of embedded software execution time |
| JP2004240783A (ja) * | 2003-02-07 | 2004-08-26 | Oki Data Corp | シミュレータ |
| US20040193395A1 (en) * | 2003-03-26 | 2004-09-30 | Dominic Paulraj | Program analyzer for a cycle accurate simulator |
| US7546598B2 (en) * | 2003-09-03 | 2009-06-09 | Sap Aktiengesellschaft | Measuring software system performance using benchmarks |
| JP4342392B2 (ja) * | 2004-07-06 | 2009-10-14 | Okiセミコンダクタ株式会社 | ソフトウェア検証モデル生成方法 |
| US8601234B2 (en) * | 2007-11-07 | 2013-12-03 | Qualcomm Incorporated | Configurable translation lookaside buffer |
| JP5961971B2 (ja) * | 2011-10-12 | 2016-08-03 | 富士通株式会社 | シミュレーション装置,方法,およびプログラム |
-
2013
- 2013-06-11 JP JP2013122786A patent/JP6163898B2/ja not_active Expired - Fee Related
-
2014
- 2014-05-29 US US14/289,772 patent/US9465595B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| US9465595B2 (en) | 2016-10-11 |
| JP2014241031A (ja) | 2014-12-25 |
| US20140365735A1 (en) | 2014-12-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6163898B2 (ja) | 計算装置、計算方法、および計算プログラム | |
| Huynh et al. | Scope-aware data cache analysis for WCET estimation | |
| Gong et al. | Jitprof: Pinpointing jit-unfriendly javascript code | |
| US6006033A (en) | Method and system for reordering the instructions of a computer program to optimize its execution | |
| JP5961971B2 (ja) | シミュレーション装置,方法,およびプログラム | |
| US7093081B2 (en) | Method and apparatus for identifying false cache line sharing | |
| US20080215863A1 (en) | Method and Apparatus for Autonomically Initiating Measurement of Secondary Metrics Based on Hardware Counter Values for Primary Metrics | |
| US20080189687A1 (en) | Method and Apparatus for Maintaining Performance Monitoring Structures in a Page Table for Use in Monitoring Performance of a Computer Program | |
| US20070240141A1 (en) | Performing dynamic information flow tracking | |
| JPWO2012049728A1 (ja) | シミュレーション装置,方法,およびプログラム | |
| US20100070708A1 (en) | Arithmetic processing apparatus and method | |
| JP6064765B2 (ja) | シミュレーション装置、シミュレーション方法、およびシミュレーションプログラム | |
| US20130047050A1 (en) | Correction apparatus, correction method, and computer product | |
| Huber et al. | WCET driven design space exploration of an object cache | |
| JP6287650B2 (ja) | シミュレーション方法、シミュレーションプログラム | |
| Arafa et al. | Ppt-gpu: Performance prediction toolkit for gpus identifying the impact of caches | |
| Whitham et al. | The scratchpad memory management unit for microblaze: Implementation, testing, and case study | |
| Ballabriga et al. | An improved approach for set-associative instruction cache partial analysis | |
| US10671780B2 (en) | Information processing device that executes simulation and a simulation method | |
| Abel | Measurement-based inference of the cache hierarchy | |
| US8621179B2 (en) | Method and system for partial evaluation of virtual address translations in a simulator | |
| US10713167B2 (en) | Information processing apparatus and method including simulating access to cache memory and generating profile information | |
| JP3186867B2 (ja) | キャッシュメモリ構成判別方法および計算機システム | |
| Lehtonen et al. | Code Positioning in LLVM | |
| Qin et al. | A technique to exploit memory locality for fast instruction set simulation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160310 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20161227 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170110 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170313 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170523 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170605 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6163898 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |