JP6089884B2 - 情報処理システム,情報処理装置,情報処理装置の制御プログラム,及び情報処理システムの制御方法 - Google Patents
情報処理システム,情報処理装置,情報処理装置の制御プログラム,及び情報処理システムの制御方法 Download PDFInfo
- Publication number
- JP6089884B2 JP6089884B2 JP2013071904A JP2013071904A JP6089884B2 JP 6089884 B2 JP6089884 B2 JP 6089884B2 JP 2013071904 A JP2013071904 A JP 2013071904A JP 2013071904 A JP2013071904 A JP 2013071904A JP 6089884 B2 JP6089884 B2 JP 6089884B2
- Authority
- JP
- Japan
- Prior art keywords
- node
- state
- information processing
- information
- party
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images























Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L43/00—Arrangements for monitoring or testing data switching networks
- H04L43/10—Active monitoring, e.g. heartbeat, ping or trace-route
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operation
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1415—Saving, restoring, recovering or retrying at system level
- G06F11/142—Reconfiguring to eliminate the error
- G06F11/1425—Reconfiguring to eliminate the error by reconfiguration of node membership
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/2053—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where persistent mass storage functionality or persistent mass storage control functionality is redundant
- G06F11/2094—Redundant storage or storage space
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L43/00—Arrangements for monitoring or testing data switching networks
- H04L43/08—Monitoring or testing based on specific metrics, e.g. QoS, energy consumption or environmental parameters
- H04L43/0805—Monitoring or testing based on specific metrics, e.g. QoS, energy consumption or environmental parameters by checking availability
- H04L43/0817—Monitoring or testing based on specific metrics, e.g. QoS, energy consumption or environmental parameters by checking availability by checking functioning
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Signal Processing (AREA)
- Computer Networks & Wireless Communication (AREA)
- Quality & Reliability (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Cardiology (AREA)
- General Health & Medical Sciences (AREA)
- Environmental & Geological Engineering (AREA)
- Debugging And Monitoring (AREA)
- Hardware Redundancy (AREA)
Description
分散ストレージシステムにおいて、例えば、複数のノードのいずれかのノードに故障が発生した場合、分散ストレージシステムを使用するクライアントは、故障したノードへアクセスをすることができなくなる。
しかし、分散ストレージシステムでは、ノード又はノード間のリンクの故障により、複数のノードが分断され、分断された一方のノードと他方のノードとが、ノードの故障について異なる判断をすることがある。この状態をスプリットブレイン(Split Brain)状態という。スプリットブレイン状態の一例としては、一方のノードと他方のノードとの間でリンクの故障が発生することにより互いにアクセスができなくなる状態が発生するが、双方のノードは、互いにアクセスができなくなった相手のノードが故障したと判断する場合が挙げられる。
分散ストレージシステムにおいて、スプリットブレイン状態に陥ることを防止する手法としては、以下に例示する手法が知られている。
(1)複数のノードの各々が、複数のノードのうちの所定のノード(コントロールノード)へ自ノードの構成情報及び生存報告を通知する。コントロールノードは、複数のノードの各々から得た情報を集約して複数のノードを監視し、監視結果から故障したノードを検出すると、リカバリを行ない、管理者等へノードの故障を通知する。
(2)複数のノードの各々が、互いに生存報告のやり取りを行ない(情報交換フェーズ)、どのノードが監視及び故障ノードの検出を行なうかを、他のノードとの間で合意を取ることで選定する。合意を得たノード(決定ノード)は、複数のノードの各々の状態を監視し、監視結果から故障したノードを検出すると、リカバリを行ない、管理者等へノードの故障を通知する。
(3)複数のノードの各々が、所定のノードへ生存報告を行なう。故障ノードは所定のノードにより即座に検出はされず、管理者等が、所定のノードを参照し手動で故障ノードの検出及びリカバリ等の対応を行なう。
さらに、関連する他の技術として、ネットワーク監視装置が、複数ノードをグループ単位に分割し、分割したグループの1つのノードから論理回線状態を取得して、論理回線の監視を行なう技術が知られている(例えば、特許文献3参照)。
上記(2)の手法では、複数のノード間で合意を形成するために複雑な手順が行なわれるため、上記(1)の手法と比較して、合意を形成するまでの時間が余計にかかる場合がある。また上記(3)の手法では、管理者等による人為的な判断が行なわれるため、ノードの故障が発生してからノードの故障が検出され、リカバリ処理が行なわれるまでに、上記(1)及び(2)の手法と比較して時間がかかる場合がある。つまり、上記(2)及び(3)の手法では、障害が発生したノードに対するリカバリ処理等の開始が遅くなり、クライアントが分散ストレージシステムの利用を制限される時間が長くなるという課題がある。
このように、複数のストレージ装置をそなえるストレージシステムにおいて、複数のストレージ装置の各々の状態を判断する上述した技術では、ストレージシステムの可用性が低下するという課題がある。
1つの側面では、本発明は、複数の情報処理装置をそなえる情報処理システムにおいて、可用性の低下を抑止することを目的とする。
〔1〕第1実施形態
〔1−1〕ストレージシステムの構成
以下、図1及び図2を参照して、第1実施形態の一例としてのストレージシステム1の構成について説明する。
図1に示すように、第1実施形態に係るストレージシステム(情報処理システム)1は、複数(例えば5つ)のノード10−1〜10−5及び複数(例えば3つ)のスイッチ20−1〜20−3をそなえる。
ストレージシステム1は、複数のノード10及びスイッチ20により、SAN(Storage Area Network)を形成し、相互に接続される複数のノード10間で通信を行なう。また、ストレージシステム1は、図示しないクライアントに接続され、クライアントに対してノード10が有する記憶領域(リソース)を提供する。
なお、複数のノード10の各々が、分散データではなく他のノード10とは異なるデータを保持してもよい。
ノード10は、図2に示すように、CPU(Central Processing Unit)10a、メモリ10b、記憶部10c、ネットワークインタフェース10d、入出力部10e、記録媒体10f、及び読取部10gをそなえる。なお、ノード10−1〜10−5は、互いに同様のハードウェアをそなえることができるため、以下、任意のノード10がそなえるハードウェアについて説明する。
記憶部10cは、例えばHDD(Hard Disk Drive)等の磁気ディスク装置、SSD(Solid State Drive)等の半導体ドライブ装置、又はフラッシュメモリ等の不揮発性メモリ等の、種々のデータやプログラム等を格納する1以上のハードウェアである。記憶部10cが有する記憶領域は、クライアントにより用いられる。
記録媒体10fは、フラッシュメモリやROM等の記憶装置であり、種々のデータやプログラムを記録する。読取部10gは、光ディスクやUSB(Universal Serial Bus)メモリ等のコンピュータ読取可能な記録媒体10hに記録されたデータやプログラムを読み出す装置である。
スイッチ(接続装置)20は、複数のノード10間又は他のスイッチ20間に接続され、スイッチ20に接続されたノード10間でやり取りされるコマンド又はデータ等の情報を中継する。スイッチ20としては、例えばL2(Layer 2)スイッチ、FCスイッチ等のハードウェアスイッチが挙げられる。
〔1−2〕ノードの説明
第1実施形態の一例としてのストレージシステム1は、上述のように、相互に接続される複数のノード10を有し、複数のノード10間で通信を行なう。
(a)複数のノード10のうちの自ノード10以外の他ノード10の各々から、他ノード10により判定された複数のノード10の各々の状態に関するノード状態情報T1(図4参照)を受信する。
(c)判定した複数のノード10の各々の状態に関するノード状態情報T1を、他ノード10の各々へ送信する。
なお、ノード10の状態とは、ノード10が正常に動作しているか否かを示す種別であり、詳細は後述する。
次に、図3〜図10を参照して、第1実施形態の一例としてのノード10の構成について説明する。
図3は、第1実施形態の一例としてのノード10の機能構成例を示す図である。図4は、ノード10が送受信するノード状態情報T1を例示する図であり、図5は、ノード10(特にノード10−1)が管理するノード状態管理情報T2を例示する図である。
ノード状態保持部11は、図5に示すノード状態管理情報T2を保持する記憶領域であり、例えば上述したメモリ10bにより実現される。
〔1−3−2〕受信処理部
受信処理部12は、上記(a)の処理を行なう。具体的には、受信処理部12は、複数のノード10のうちの自ノード10以外の他ノード10の各々から、図4に例示するノード状態情報T1を受信し、ノード状態保持部11が保持するノード状態管理情報T2(図5参照)を更新する。
一例として、ノードID“1”には、状態“Alive”、IPアドレス“192.168.0.1”、ポート番号“12345”が対応付けられる。
また、ノード10のアドレスとして、IPアドレスを例に挙げたが、これに限定されるものではない。アドレスは、IP以外のプロトコルにおいてノード10を特定可能な種々のアドレスが用いられてもよい。
図5に示すように、ノード状態管理情報T2は、図4に示すノード状態情報T1と同様に、ノード10の識別情報の一例としてのノードID、ノード10ごとの状態、ノード10のアドレスの一例としてのIPアドレス、及びノード10のポート番号を含む。また、ノード状態管理情報T2はさらに、他のノード10から受信したノード状態情報T1に含まれるノード10ごとの状態(図5中、“by 2”〜“by 5”と表記)、及び他のノード10ごとの最終更新情報を含む。図5に示すノード状態管理情報T2は、ノード10−1〜10−5に対応するノードID“1”〜“5”の状態を含む。
なお、最終更新情報は、最後にハートビートを受信したのがいつであるかを示す情報であり、図5に示す例では、最終更新情報として、現在時刻と最後に受信を行なった時刻(最終受信時刻)との差を示しているが、これに限定されるものではない。例えば、ノード10は、最終更新情報に最終受信時刻そのものを設定することで、最終更新情報を更新してもよい。また、ノード10は、ノード10ごとに、時間の経過に応じて値が変化(例えば増加)するタイマを実行し、ノード状態管理情報T2の最終更新情報では、対応するタイマ値を参照してもよい。最終更新情報にタイマ値が用いられる場合、ノード10は、最終更新情報の更新の際に、タイマのカウント値をリセットすることで、最終更新情報を更新することができる。
図6は、第1実施形態の一例としての新規ノード10が送信する情報を例示する図であり、図7は、新規ノード10が受信する情報を例示する図である。
ノード10(後述する送信処理部14)は、起動後、つまりストレージシステム1に追加されると、自ノード10のIPアドレス及びポート番号を含む情報を全てのノード10へ通知する。具体的には、ストレージシステム1に追加されたノード(新規ノード)10は、図6に例示する送信情報T3を、ストレージシステム1内の全てのノード10へブロードキャスト等により通知する。
一例として、ノードID“6”には、新規ノード10が判定した状態“Alive”、IPアドレス“192.168.0.6”、ポート番号“12345”が対応付けられる。
新規ノード10(受信処理部12)は、受信したノード状態情報T1′に含まれる他ノード10のIPアドレス及びポート番号、並びに送信元のノードIDの情報からノード状態管理情報T2を作成又は更新する。これにより、新規ノード10は、ノード状態情報T1′をハートビートとして定期的に送信する送信処理部14のサービスを開始することができる。
ノード状態決定部(判定部)13は、上記(b)の処理を行なう。具体的には、ノード状態決定部13は、ノード状態管理情報T2を参照してノード10ごとの状態を判定し、ノード状態管理情報T2に設定する。より具体的に、ノード状態決定部13は、受信処理部12が受信したノード状態情報T1が示す複数のノード10の各々の状態と、他ノード10の各々からのノード状態情報T1の受信状況とに基づいて、複数のノード10の各々の状態を判定する。
図8は、第1実施形態の一例としてのノード10が他ノード10の状態を判定するときの状態遷移の一例を示す図であり、図9は、複数のノード10によるノード状態情報T1の送受信処理の一例を説明する図である。図10は、ノード10が自ノード10の状態を判定するときの状態遷移の一例を示す図である。
〔1−3−3−1〕ノード状態決定部が他ノードについて判定する各状態の説明
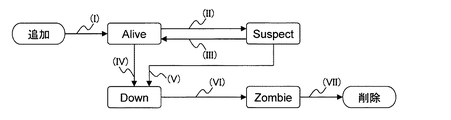
はじめに、ノード10(ノード状態決定部13)が他ノード10について判定する各状態について説明する。図8に示すように、ノード10が他ノード10について判定する状態には、Alive、Suspect、Down、及びZombieが含まれる。
なお、他ノード10がストレージシステム1に追加された場合、ノード状態決定部13は、追加された他ノード10に関する最初の判定において、追加された他ノード10の状態を初期状態であるAliveと判定する(図8の矢印(I)参照)。
以下、第1所定時間は1秒であり、第2所定時間は20秒であり、第1所定数はノード10の数の過半数であるものとして説明する。
Suspect(第1状態)は、ノード10が故障(停止)している疑いのある状態(停止の可能性)を示す。ノード状態決定部13は、ノード状態管理情報T2を参照して、最終更新情報が第2所定時間よりも前である他ノード10の状態、つまり第2所定時間内にノード状態情報T1を受信しなかった他ノード10の状態を、Suspectと判定する。すなわち、ノード状態決定部13は、ハートビートの不達時間が閾値(第2所定時間)を超えた他ノード10の状態を、Suspectと判定する。
また、ノード状態決定部13は、Suspectの状態と判定した他ノード10の状態が自ノード10又は他ノード10によりDownと判定される前に、当該他ノード10からノード状態情報T1を受信する場合がある。この場合、ノード状態決定部13は、当該他ノード10の状態をSuspectからAliveに遷移させる(図8の矢印(III)参照)。
例えば、ノード状態決定部13がAlive又はSuspectの状態と判定した他ノード10の状態について、過半数以上のノード10でSuspectと判定される場合、又は他ノード10のうちのいずれかがDownと判定される場合がある。この場合、ノード状態決定部13は、Alive又はSuspectの状態と判定した当該他ノード10の状態を、Downと判定する(図8の矢印(IV)又は(V)参照)。
つまり、自ノード10−1は、ノード10−4から20秒よりも長くノード状態情報T1を受け取っていないため、ノード10−4の状態をSuspectと判定する。また、他ノード10−3及び10−5も、ノード10−4から20秒よりも長くノード状態情報T1を受け取っておらず、他ノード10−3及び10−5によるノード10−4の状態の判定結果もSuspectとなる。この場合、ノード状態決定部13は、ノード10−4の状態が過半数のノード10によりSuspectと判定されたため、ノード10−4の状態をDownに遷移させる。
Zombie(第3状態)は、ノード10が後述するリカバリ処理部15によりリカバリ処理が行なわれている状態(リカバリ処理中)を示す。Zombieは、ノード10に故障等の障害が発生した後、障害が発生したノード10のノード情報が削除されるまでの暫定状態である。クライアント及びリカバリ処理に係わるノード10以外のノード10は、Zombieの状態のノード10へのアクセスが制限される。
ここで、第2所定数としては、第1所定数以上の数、好ましくは、全てのノード10の数とすることができる。以下、第2所定数は全てのノード10の数であるものとして説明する。
ノード状態決定部13は、全てのノード10からDownと判定されたノード10をZombieとすることで、全てのノード10の共通認識によって、障害が発生したノード10をリカバリすべきノード10であると確実に決定することができる。
以上のように、ノード状態決定部13は、受信処理部12が受信したノード状態情報T1が示す複数のノード10の各々の状態、つまり図5のノード状態管理情報T2における“他ノードからの情報”に基づいて、複数のノード10の各々の状態を判定する。
〔1−3−3−2〕ノード状態決定部が自ノードについて判定する各状態の説明
次に、ノード10(ノード状態決定部13)が自ノード10について判定する各状態について説明する。図10に示すように、ノード10が自ノード10について判定する状態には、Alive、Isolate、及びDownが含まれる。
自ノード10が起動したとき、ノード状態決定部13は、自ノード10に関する最初の判定において、自ノード10の状態をAliveと判定する(図10の矢印(i)参照)。
ノード状態決定部13は、ノード状態管理情報T2を参照して、第2所定時間内に第3所定数以上の他ノード10からノード状態情報T1を受信しなかった場合、自ノード10の状態を、AliveからIsolateに遷移させる。すなわち、ノード状態決定部13は、ハートビートの不達時間が閾値(第2所定時間)を超えた他ノード10の数が第3所定数以上である場合、自ノード10の状態をIsolateと判定するのである。
以下、第3所定数はノード10の数の過半数であるものとして説明する。
例えば、ノード状態決定部13は、ハートビートの不達時間が閾値を超えたノード10の数が過半数に達した場合に、自ノード10の状態をIsolateに遷移させる(図10の矢印(ii)参照)。
ところで、ノード10は、自ノード10の状態がIsolateに遷移した場合、ストレージシステム1から切り離されているため、自ノード10の状態がIsolateであることを他のノードへノード状態情報T1により伝えることができない。また、ノード10は、他ノード10の状態がIsolateになった場合にも、当該他ノード10はストレージシステム1から切り離されているため、他ノード10の状態がIsolateになったことをノード状態情報T1により検知することができない。
ノード状態決定部13は、自ノード10に例えば復旧不可能な障害が発生した場合、自ノード10の状態を、Downと判定する(図10の矢印(iv)参照)。
なお、ノード10は、自ノード10の状態をIsolate又はDownと判定した場合、他ノード10で判定される自ノード10の状態は、Suspect、Down、Zombieの順で遷移する。
ノード状態決定部13は、上述のように、自ノード10及び他ノード10の状態を判定し、ノード状態管理情報T2を更新する。
ノード状態決定部13は、以上のようにして、ノード状態管理情報T2に基づき複数のノード10の各々の状態を判定することができる。つまり、ノード状態決定部13は、受信処理部12が受信したノード状態情報T1が示す複数のノード10の各々の状態と、ノード状態決定部13が含まれる自ノード10の状態に関するノード状態情報T1に関する自己状態情報とに基づいて、上記判定を行なう。
また、ノード10は、ノード状態決定部13により自ノード10の状態がDown又はIsolateと判定された場合、ノード状態保持部11が保持するノード状態管理情報T2を、記録媒体10f等の不揮発性メモリに保存してもよい。これにより、リカバリ処理後、作業者等は、ノード10の停止要因が復旧不可能又は困難な障害(Down)によるものか、ストレージシステム1から切り離されたこと(Isolate)によるものかを判断でき、障害復旧を迅速に行なうことができる。
送信処理部14は、上記(c)の処理を行なう。具体的には、送信処理部14は、第1所定時間ごとに、ノード状態決定部13が判定した複数のノード10の各々の状態に関するノード状態情報T1を、他ノード10の各々へ送信する。
より具体的に、送信処理部14は、ノード状態管理情報T2を参照して、IPアドレス及びポート番号を取得し、他ノード10へ送信するノード状態情報T1の宛先ノードを判定する。また、送信処理部14は、ノード状態管理情報T2を参照して、自ノード10が判定した各ノード10についてのノードID、状態、IPアドレス、及びポート番号の情報からノード状態情報T1を生成する。そして、送信処理部14は、生成したノード状態情報T1を、ハートビートとして他ノード10の各々へ送信する。
また、送信処理部14は、ノード状態情報T1の送信に加え、上述のように、自ノード10の起動後、送信情報T3(図6参照)をストレージシステム1内の全てのノード10へブロードキャスト等により通知する。
リカバリ処理部15は、他ノード10に対してリカバリ処理を実行する。具体的には、リカバリ処理部15は、ノード状態決定部13がZombieと判定したノード10に対して、リカバリ処理を実行する。
なお、リカバリ処理は、全てのノード10により行なわれなくても、ノード状態管理情報T2においてZombieと判定されたノード10に関係するノード10により行なわれればよい。
停止処理部16は、自ノード10に所定の障害が発生し、ノード状態決定部13が自ノード10の状態をDownと判定した場合、又は、ノード状態決定部13が自ノード10の状態をIsolateと判定した場合、自ノード10を停止させる処理を行なう。
なお、停止処理部16による停止処理は、リカバリ処理部15によるリカバリ処理が完了した後、具体的にはリカバリ処理において故障ノード10内のデータが削除された後に行なわれることが好ましい。
以上のように、第1実施形態の一例としてのストレージシステム1によれば、複数のノード10により、メッシュ状に、ノード10間でハートビートが行なわれる。ハートビートには、各ノード10で判定された複数のノード10の各々の状態が含まれ、複数のノード10間でノード10の各々の状態が共有される。
さらに、各ノード10は、ノード10の状態をハートビート等の簡素な手法により共有するため、従来の手法と比較して、高速に、且つ容易に、自ノード10及び他ノード10の状態を判定することができる。
〔1−4〕動作例
次に、図11〜図13を参照して、上述の如く構成された第1実施形態の一例としてのノード10による動作例を説明する。図11は、第1実施形態の一例としての新規ノード10による起動後の動作例を説明するフローチャートである。図12は、ノード10による他ノード10の状態を判定する動作例を説明するフローチャートであり、図13は、ノード10による自ノード10の状態を判定する動作例を説明するフローチャートである。
はじめに、図11を参照して、新規ノード10による起動後の動作例を説明する。
図11に示すように、ノード(新規ノード)10が起動し(ステップS1)、ストレージシステム1内のネットワークに接続されると、新規ノード10のノード状態決定部13により、自ノード10の状態がAliveと判定される(ステップS2)。
送信情報T3を受信した他ノード10の各々は、新規ノード10のノード情報をノード状態管理情報T2に追加し、宛先に新規ノード10を含めてハートビート(ノード状態情報T1)を送信する。
〔1−4−2〕ノードによる他ノードの状態を判定する動作例
次に、図12を参照して、ノード10による他ノード10の状態を判定する動作例を説明する。
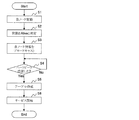
図12に示すように、ノード状態決定部13により、ノード状態管理情報T2内の“状態”が参照され、判定対象のノード10について直前に判定した状態がどの状態であるかが判定される(ステップS11,S16,S19)。
また、判定対象のノード10について直前に判定した状態がSuspectである場合(ステップS11のNoルートからステップS16のYesルート)、処理がステップS17に移行する。ステップS17では、ノード状態決定部13により、判定対象のノード10から新たなハートビートが受信されたか否か、つまりハートビートの不達時間が閾値未満となったか否かが判定される。このとき、ノード状態決定部13は、ノード状態管理情報T2の“最終更新情報”の時間が第2所定時間未満であるか否かを判定する。
〔1−4−3〕ノードによる自ノードの状態を判定する動作例
次に、図13を参照して、ノード10による自ノード10の状態を判定する動作例を説明する。
なお、図13に示すステップS31〜S34の処理は、ノード10の各々において、ノード状態決定部13により自ノード10の状態が判定される際に行なわれる処理である。従って、ステップS31〜S34の処理は、各ノード10のノード状態決定部13により、定期的(第1所定時間ごと)に実行される。
所定の障害の発生が検出されると(ステップS31のYesルート)、ノード状態決定部13により、自ノード10の状態がDownと判定され(ステップS32)、処理が終了する。このとき、ノード状態決定部13は、自ノード10について、ノード状態管理情報T2内の“状態”にDownを設定する。
以上のように、ノード10により、自ノード10の状態の判定処理が行なわれる。
このように、第1実施形態の一例としてのストレージシステム1によれば、複数のノード10の各々において、受信処理部12は、他ノード10の各々から、ノード状態情報T1を受信する。また、ノード状態決定部13は、受信処理部12が他ノード10の各々から受信したノード状態情報T1に基づいて、複数のノード10の各々の状態を判定する。さらに、送信処理部14は、ノード状態決定部13が判定した結果に基づき送信用ノード状態情報T1を、他ノード10の各々へ送信する。
また、ノード状態決定部13は、受信処理部12が受信したノード状態情報T1が示す複数のノード10の各々の状態と、他ノード10の各々からのノード状態情報T1の受信状況とに基づいて、複数のノード10の各々の状態を判定する。また、送信処理部14は、第1所定時間ごとに、送信用ノード状態情報T1を、他ノード10の各々へ送信する。
さらに、ノード状態決定部13は、第2所定時間内にノード状態情報T1を受信しなかった他ノード10の状態を、Suspectと判定する。また、ノード状態決定部13は、第1所定数以上の複数のノード10でSuspectであると判定されたノード10の状態、又は、他ノード10の少なくとも1つからDownであると判定されたノード10の状態を、Downと判定する。
また、ノード状態決定部13は、第2所定数以上の複数のノード10でDownであると判定されたノード10を、Zombieと判定する。また、リカバリ処理部15は、ノード状態決定部13がZombieと判定したノード10に対して、リカバリ処理を実行する。
〔2〕第2実施形態
〔2−1〕ノードの説明
次に、第2実施形態の一例としてのノード10Aについて説明する。
上述のように、第1実施形態に係るストレージシステム1は、全ノード10対全ノード10の完全なメッシュ状態でハートビートの通信を行なう。
一方、第2実施形態に係るストレージシステム1は、ノード10Aをある程度(例えば数〜数十台程度)のまとまり(以下、パーティという)に分割し、パーティ内のノード10A間では完全メッシュのハートビートの通信を行なう。一方、パーティ間では、各パーティの代表のノード10A(代表ノード10A)同士による完全メッシュのハートビートの通信を行なう。
次に、図14〜図23を参照して、第2実施形態の一例としてのノード10Aの構成について説明する。
図14は、第2実施形態の一例としてのノード10Aの機能構成例を示す図である。
第2実施形態に係るノード10Aは、第1実施形態に係るノード10と比べて、パーティ情報保持部101、パーティ間受信処理部102、パーティ間ノード状態決定部103、パーティ間送信処理部104、及びパーティ管理部105をさらにそなえる。
さらに、第2実施形態に係るノード10Aは、第1実施形態に係るノード10がそなえるノード状態決定部13及び送信処理部14とは一部の機能が異なるノード状態決定部13A及び送信処理部14Aをそなえる。
〔2−2−1〕パーティ情報保持部及びノード状態保持部
パーティ情報保持部101は、図15に示すパーティ管理情報T4を保持する記憶領域であり、例えば上述したメモリ10bにより実現される。
上述のように、第2実施形態の一例としてのストレージシステム1は、複数のノード10Aを数〜数十台程度の複数のパーティに分割する。
パーティ管理情報T4は、複数のパーティとパーティに属するノード10Aとを対応付けて管理する情報である。なお、ノード10Aは、図15に示すようにパーティ管理情報T4をテーブルとして生成し、送受信することができる。
一例として、パーティID“A”には、ノードID“1〜10”、バージョン番号“1”が対応付けられる。
また、ノード10の識別情報として、ノードIDを例に挙げたが、これに限定されるものではなく、第1実施形態において既述のように、ノード10Aを特定できるユニークな情報であればよい。
バージョン番号は、ノード10Aにおいて、自ノード10Aが持つパーティ管理情報T4が最新の情報であるか否かを判断するために用いられる。例えば、後述するパーティ管理部105により、パーティが分割又は統合される場合がある。この場合、分割又は統合が行なわれたパーティに属するノードIDも変化するため、各ノード10Aは、バージョン番号を参照して、最新のパーティ管理情報T4を識別するのである。
〔2−2−2〕パーティ間受信処理部及び受信処理部
次に、図16〜図19を参照して、パーティ間受信処理部102及び受信処理部12について説明する。
図16に例示するように、代表ノード(代表ストレージ装置,代表情報処理装置)10Aは、複数のパーティのうちの自パーティ以外の他のパーティの各々における他の代表ノード10Aとの間で、代表ノード状態情報T5を送受信する。また、代表ノード10Aは、自パーティのパーティメンバであるメンバノード10Aへ代表ノード状態情報T5を送信し、メンバノード10Aは、自パーティの代表ノード10Aへノード状態情報T6を送信する。
代表ノード10A及びメンバノード10Aは、特に言及しない限り互いに同様の機能をそなえることができるため、以下の説明において、任意のノード10Aがそなえる機能について説明する。
代表ノード状態情報(代表状態情報)T5は、送信元の代表ノード10Aにより判定された複数のパーティの代表ノード10Aの各々の状態に関する情報である。例えば、代表ノード10Aが送信する代表ノード状態情報T5には、代表ノード10Aが判定した自パーティ内のメンバノード10Aの状態と、他のパーティの代表ノード10Aから取得した他のパーティに属する全てのノード10Aの状態が含まれる。なお、代表ノード10Aは、図17に示すように代表ノード状態情報T5をテーブルとして生成し、送受信することができる。
つまり、パーティ内の代表ノード10A及びメンバノード10Aは、互いにパーティ内のノード10Aの状態の判定結果をハートビートで通知し合い、代表ノード10Aは、自パーティ内での判定結果を全パーティの代表ノード10Aへ伝達する。
ノード状態情報(状態情報)T6は、送信元のノード10Aで判定された自パーティにおける他ノード(メンバノード)10Aの各々の状態を含む情報である。例えば、図18に示す例では、図16に示すメンバノード10A−2は、自パーティに属するノード10A−1及び10A−3へ送信するノード状態情報T6に、自パーティ内で判定した各ノード10A−1〜10A−3の状態を含める。なお、ノード10Aは、図18に示すようにノード状態情報T6をテーブルとして生成し、送受信することができる。
以下、代表ノード状態情報T5及びノード状態情報T6を、単にノード状態情報T5及びT6と表記する場合がある。
ノード状態管理情報T7は、自ノード10A及び全パーティの全ノード10Aで判定された複数のノード10Aの各々の状態を管理する情報である。なお、ノード10Aは、図19に示すようにノード状態管理情報T7をテーブルとして生成し、管理することができる。
図19に示すように、ノード状態管理情報T7は、図5に示すノード状態管理情報T2と同様に、ノード10AのノードID、ノード10Aごとの状態、ノード10AのアドレスのIPアドレス、及びノード10Aのポート番号を含む。また、ノード状態管理情報T7はさらに、他のノード10Aから受信したノード状態情報T5又はT6に含まれるノード10Aごとの状態、及び他のノード10Aごとの最終更新情報を含む。例えば、他のノード10Aから受信したノード状態情報T5又はT6に含まれるノード10Aごとの状態には、“by 2”、“by 3”、“by 11”〜“by 13”、及び“by 21”〜“by 23”が含まれる。
一例として、ノードID“1”には、自ノード10Aが判定した状態“Alive”、他ノード10A−2、10A−3、10A−11、及び10A−21がそれぞれ判定した状態“Alive”、最終更新情報“1 sec ago”が対応付けられる。また、ノードID“1”にはさらに、IPアドレス“192.168.0.1”、ポート番号“12345”が対応付けられる。
パーティ間受信処理部102及び受信処理部12Aは、受信処理部12と同様に、ノード状態情報T5又はT6を受信した都度、又は第1所定時間ごとに、ノード状態管理情報T7を更新する。
また、パーティ間受信処理部102は、上述した代表ノード状態情報T5の受信に加え、図15に示すパーティ管理情報T4を受信することができる。
一例として、代表ノード10Aは、パーティに属するノード10Aの中で、最も小さいノードIDを持つノード10Aとすることができる。このように、各ノード10Aが保持する情報から判断可能な所定のルールを予め定めておくことで、各ノード10Aは、代表ノード10Aを容易に選出することができる。
パーティ間ノード状態決定部(グループ間判定部)103は、パーティ間受信処理部102が他の代表ノード10Aの各々から受信した代表ノード状態情報T5に基づいて、複数の代表ノード10Aの各々の状態を判定する。
なお、パーティ間ノード状態決定部103による、代表ノード10A間でのノード10Aの各々の状態の判定手法は、第1実施形態に係るノード状態決定部13によるノード10間でのノード10の各々の状態の判定と同様である。
なお、代表ノード10Aは、他のパーティの代表ノード10Aの状態が全ての代表ノード10AからDownであると判定された場合、パーティ管理情報T4及びノード状態管理情報T7から、当該他のパーティにおいて次に代表ノード10Aとなるべきノード10Aを判断する。この判断は、上述のように、代表ノード10Aを選出する所定のルールに基づいて行なわれる。
なお、ノード状態決定部13Aによる、自パーティ内のノード10A間でのノード10Aの各々の状態の判定手法は、第1実施形態に係るノード状態決定部13によるノード10間でのノード10の各々の状態の判定と同様である。
なお、ノード状態決定部13Aは、自パーティの代表ノード10Aの状態をDownと判定した場合、自パーティ内で生存している(Alive状態の)ノード10A間で、上述した代表ノード10Aを選出する所定のルールを適用する。
ここで、パーティ間ノード状態決定部103及びノード状態決定部13Aによる、ノード状態管理情報T7の参照箇所及び更新箇所について説明する。なお、この説明では、パーティ間ノード状態決定部103及びノード状態決定部13Aは、ノード10A−1にそなえられるものとする。
例えば、パーティ間ノード状態決定部103は、他の代表ノード10Aの最終更新情報を参照し、ハートビート(代表ノード状態情報T5)の到達の有無に応じてAlive又はSuspectの判定を行なう。また、パーティ間ノード状態決定部103は、他の代表ノード10Aについて、ノード状態管理情報T7における破線で丸く囲われた領域を参照し、Suspect、Down、又はZombieの判定を多数決等により行なう。
ノード状態決定部13Aは、他ノード10Aの最終更新情報を参照し、ハートビート(ノード状態情報T5又はT6)の到達の有無に応じてAlive又はSuspectの判定を行なう。また、ノード状態決定部13Aは、他ノード10Aについて、ノード状態管理情報T7における実線で角丸の四角で囲われた領域を参照し、Suspect、Down、又はZombieの判定を多数決等により行なう。
また、パーティ間ノード状態決定部103及びノード状態決定部13Aは、上述のように、ノード10Aの状態を判定すると、ノード状態管理情報T7を更新する。
具体的には、パーティ間ノード状態決定部103及びノード状態決定部13Aは、自ノード10A及び他ノード10Aの各々について判定した状態を、図19に例示するノード状態管理情報T7における“状態”の列に設定する。
〔2−2−4〕パーティ間送信処理部及び送信処理部
パーティ間送信処理部(グループ間送信処理部)104は、第1所定時間ごとに、パーティ間ノード状態決定部103が判定した複数の代表ノード10Aの各々の状態に関する代表ノード状態情報T5を、他の代表ノード10Aの各々へ送信する。
また、パーティ間送信処理部104は、代表ノード状態情報T5の送信に加え、後述するパーティ管理部105によりパーティ管理情報T4が更新された場合には、パーティ管理情報T4(図14参照)をストレージシステム1内の全てのノード10Aへ通知する。なお、この通知は、ブロードキャスト等により行なわれてもよい。
送信処理部14Aは、送信用ノード状態情報T6を、自パーティにおける他ノード10Aの各々へ送信する。
また、送信処理部14Aは、ノード状態管理情報T7を参照して、自ノード10Aが判定した各ノード10AについてのノードID、状態、IPアドレス、及びポート番号の情報からノード状態情報T6を生成する。そして、送信処理部14Aは、生成したノード状態情報T6を、ハートビートとして自パーティ内の他ノード10Aの各々へ送信する。
なお、パーティ間受信処理部102が受信する代表ノード状態情報T5及びパーティ間送信処理部104が送信する代表ノード状態情報T5は、同様のデータ構造である。また、受信処理部12Aが受信するノード状態情報T6及び送信処理部14Aが送信するノード状態情報T6は、同様のデータ構造である。以下、便宜上、パーティ間送信処理部104が送信する代表ノード状態情報T5を送信用代表ノード状態情報(送信用代表状態情報)T5といい、送信処理部14Aが送信するノード状態情報T6を送信用ノード状態情報(送信用状態情報)T6という場合がある。
次に、図20〜図23を参照して、パーティ管理部105について説明する。
図20は、第2実施形態の一例としてのストレージシステム1にノード10Aが追加される例を示す図であり、図21は、図20に示すストレージシステム1におけるパーティの分割処理の一例を説明する図である。図22は、図21に示すストレージシステム1におけるノード10Aの削除処理及びパーティの統合処理の一例を説明する図である。図23は、第2実施形態の一例としてのストレージシステム1におけるパーティの分割処理の具体例を説明する図である。
パーティ管理部(管理部)105は、自ノード10Aが属するパーティに関する管理を行なう。
具体的には、パーティ管理部105は、自パーティにおけるノード10Aの追加又は削除により、自パーティに属するノード10Aの数が所定の上限又は所定の下限を超えた場合、自パーティの分割又は統合を行なう。
また、逆に、パーティ管理部105は、パーティを構成するノード数が下限(第5所定値)を下回った場合、パーティを統合する。パーティを統合する理由は、少数のノード10Aを含むパーティが多数あると、代表ノード10A間のハートビートの通信による代表ノード10Aの処理負荷及びネットワーク負荷が高まるためである。また、パーティ管理情報T4が肥大化し、パーティの管理に係る処理負荷が増大することも理由の一つである。
パーティ管理部105によるパーティの分割又は統合に伴うパーティ管理情報T4の変更は、各パーティに所属する代表ノード10Aが、自パーティのエントリについて行なうことができる。代表ノード10Aがそなえるパーティ管理部105は、パーティ管理情報T4を変更すると、パーティ間送信処理部104を介して、ハートビートに載せて全ノード10Aへ伝達する。
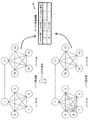
図20の紙面左上に示すように、ストレージシステム1が、パーティA及びBをそなえる場合を例に挙げて説明する。なお、パーティAは、ノードID“1”、“3”、“5”、“7”、及び“9”の5つのノード10Aを有し、パーティBは、ノードID“11”、“13”、“15”、“17”、及び“19”の5つのノード10Aをそなえるものとする。また、図20の紙面右側に示すように、パーティ管理情報T4には、パーティID“A”にノードID“1〜10”が、パーティID“B”にノードID“11〜20”が、それぞれ対応付けられているものとする。
以上の例において、パーティAにノードID“8”のノード10Aが追加される場合を想定する(図20の紙面左下及び図21の紙面左上参照)。この場合、パーティAには、6つのノードが含まれる。なお、ノードID“8”は、パーティAに対応付けられたノードIDの範囲内であるため、パーティ管理情報T4に変更はない。
図21の紙面左下に示すように、代表ノード10A−1のパーティ管理部105は、パーティ管理情報T4及びノード状態管理情報T7を参照して、パーティAをノード数が2分の1になるように分割する。例えば、パーティ管理部105は、パーティAに属するノードIDのうち、ノードIDが小さい順に3つのノード10AをパーティAに残し、それ以外の3つのノードをパーティCとして分割する。つまり、パーティ管理部105は、パーティAを、ノードID“1”、“3”、及び“5”をそなえる新たなパーティAと、ノードID“7”〜“9”をそなえるパーティCとに分割する。
代表ノード10A−1のパーティ管理部105は、パーティAを分割すると、パーティ管理情報T4のパーティID“A”のエントリにおいて、ノードIDを“1〜5”に設定し、バージョン番号を“2”に変更する。また、代表ノード10A−1のパーティ管理部105は、パーティ管理情報T4にパーティID“C”のエントリを追加し、ノードID“6〜10”、バージョン番号“1”を対応付ける。
なお、ノード10A−1は、新たなパーティAにおいて、引き続き代表ノード10Aとしてパーティ管理情報T4のパーティID“A”のエントリの管理を行なう。一方、パーティCでは、ノードID“7”〜“9”のノード10Aで、代表ノード10Aを選出する所定のルールが適用され、例えばノードID“7”のノード10A(以下、代表ノード10A−7という)が、代表ノード10Aになる。代表ノード10A−7は、代表ノード10A−1、10A−11とともに、代表ノード10A間でのハートビートの通信を行なうとともに、パーティCのエントリを管理する。
次いで、図22の紙面左上に示すように、パーティA内のノードID“3”及び“5”のノード10Aが障害等の発生により停止した場合を想定する。
代表ノード10A−1がそなえるパーティ管理部105は、自パーティAに属するノード10Aの数が、ノード10Aの停止に伴い下限である2つを超える(下回る)ため、パーティAを他のパーティと統合する。
なお、ノード10A−1は、新たなパーティAにおいて、引き続き代表ノード10Aとしてパーティ管理情報T4のパーティID“A”のエントリの管理を行なう。一方、パーティCの代表ノード10A−7は、新たなパーティAにおいて代表ノード10Aを選出する所定のルールの敗者であるので、メンバノード10A−7に降格する。
なお、代表ノード10Aのパーティ管理部105は、所定時間ごとに、自パーティのノード10Aの数が上限に達したか否か、及び下限を下回ったか否かを判定することができる。
さらに、代表ノード10Aのパーティ管理部105は、自パーティ内のノード10Aに障害等が発生し、当該ノード10Aのリカバリ処理が完了したことを契機に、自パーティのノード10Aの数が下限を下回ったか否かを判定してもよい。
そこで、パーティ管理部105は、以下で説明するように、パーティの分割及び統合に係るノード10Aの選定を、例えばノード10Aが接続されるスイッチ20に基づいて行なうことが好ましい。なお、以下の説明は、管理者等による、ストレージシステム1の運用開始前のパーティの初期設定の際や、運用中においてパーティの構成が複雑化したことによるパーティの再設定の際にも、同様に考慮されることが好ましい。
このように、パーティ管理部105は、自パーティにおけるノード10A及びスイッチ20の物理的な接続関係に関する情報に基づいて、パーティから分割するノード10Aを決定することができる。
ここまで、図23を参照してパーティ管理部105によるパーティの分割処理について説明したが、パーティ管理部105によるパーティの統合処理についても同様である。
〔2−3〕動作例
次に、図24〜図26を参照して、上述の如く構成された第2実施形態の一例としてのノード10Aによる動作例を説明する。図24は、第2実施形態の一例としての代表ノード10Aによる他の代表ノード10Aの状態を判定する動作例を説明するフローチャートである。図25は、ノード10Aによるパーティ内の他ノード10Aが停止した場合の動作例を説明するフローチャートである。図26は、ノード10Aによるパーティの分割処理及び統合処理の動作例を説明するフローチャートである。
はじめに、図24を参照して、代表ノード10Aによる他の代表ノード10Aの状態を判定する動作例を説明する。
なお、図24に示すステップS41〜S55の処理は、代表ノード10Aの各々において、パーティ間ノード状態決定部103により他の一の代表ノード10Aの状態が判定される際に行なわれる処理である。従って、ステップS41〜S55の処理は、各代表ノード10Aのパーティ間ノード状態決定部103により、他の代表ノード10Aの各々について、定期的(第1所定時間ごと)に実行される。
判定対象の代表ノード10Aについて直前に判定した状態がAliveである場合(ステップS41のYesルート)、処理がステップS42に移行する。ステップS42では、パーティ間ノード状態決定部103により、判定対象の代表ノード10Aからのハートビートの不達時間が閾値を超えたか否かが判定される。
また、判定対象の代表ノード10Aについて直前に判定した状態がSuspectである場合(ステップS41のNoルートからステップS46のYesルート)、処理がステップS47に移行する。ステップS47では、パーティ間ノード状態決定部103により、判定対象の代表ノード10Aから新たなハートビートが受信されたか否かが判定される。
〔2−3−2〕ノードによるパーティ内の他ノードが停止した場合の動作例
次に、図25を参照して、ノード10Aによるパーティ内の他ノード10Aが停止した場合の動作例を説明する。
自パーティの代表ノード10Aが停止していない場合(ステップS61のNoルート)、処理が終了する。ノード状態決定部13Aは、次の判定対象のメンバノード10Aがある場合、次の判定対象のメンバノード10Aに係る状態の判定処理に移行する。
ノード10Aにより、ステップS62において自ノード10Aが代表ノード10Aになると判定された場合(ステップS62のYesルート)、他のパーティの代表ノード10Aの各々との間のハートビートの通信が開始され(ステップS63)、処理が終了する。
以上のように、ノード10Aによるパーティ内の他ノード10Aが停止した場合の処理が終了する。
〔2−3−3〕ノードによるパーティの分割処理及び統合処理の動作例
次に、図26を参照して、ノード10Aによるパーティの分割処理及び統合処理の動作例を説明する。
ノード10Aの数が上限を上回った場合(ステップS71のYesルート)、代表ノード10Aのパーティ管理部105により、パーティが2つに分割され、パーティ管理情報T4が更新される(ステップS72)。なお、パーティ管理部105は、上述のように、自パーティをノード数が2分の1になるように分割し、余りが出る場合、余りのノード10Aを分割に係る2つのパーティのいずれかに割り振る。また、パーティ管理部105は、自パーティのノード10Aを分割後のいずれのパーティに割り当てるかを、ノードID、ノード10A及びスイッチ20の接続関係に基づき決定する。
ノード10Aの数が下限未満である場合(ステップS73のYesルート)、代表ノード10Aのパーティ管理部105により、自パーティと他のパーティとの統合が行なわれる。具体的には、代表ノード10Aのパーティ管理部105は、自パーティと統合する他のパーティを、ノードID、ノード10A及びスイッチ20の接続関係、又は他のパーティの代表ノード10Aまでのホップ数等に基づき決定する。
一方、統合後に自ノード10Aが代表ノード10Aになると判定された場合(ステップS74のYesルート)、代表ノード10Aのパーティ管理部105により、自パーティと他のパーティとが統合される。具体的には、代表ノード10Aのパーティ管理部105により、パーティ管理情報T4の自パーティのエントリのノードIDに、統合する他のパーティのノードIDがマージされて、パーティ管理情報T4が更新される(ステップS76)。そして、パーティ管理部105による処理が終了する。
また、ステップS73の処理は、自パーティ内のノード10Aに障害等が発生し、当該ノード10Aのリカバリ処理が完了したことを契機に開始されてもよい。
さらに、ステップS71及びS72の処理と、ステップS73〜S76の処理とは、互いに独立して実行されてもよいし、処理順序が変更されてもよい。
上述のように、第2実施形態の一例としてのノード10Aによれば、第1実施形態に係るノード10と同様の効果を奏することができる。
また、第2実施形態の一例としてのノード10Aによれば、複数のノード10Aが複数のパーティに分割される。そして、各パーティの代表ノード10Aの各々において、パーティ間受信処理部102は、他のパーティの各々における他の代表ノード10Aから、代表ノード状態情報T5を受信する。また、パーティ間ノード状態決定部103は、代表ノード状態情報T5に基づいて、複数の代表ノード10Aの各々の状態を判定する。さらに、パーティ間送信処理部104は、パーティ間ノード状態決定部103が判定した複数の代表ノード10Aの各々の状態に関する送信用代表ノード状態情報T5を、他の代表ノード10Aの各々へ送信する。
従って、ストレージシステム1においてノード10Aの数が増大した場合でも、ノード間でやり取りされる情報の直接の送信先を絞ることができるため、ハートビートの送受信のコストの増大を抑えることができる。
また、各代表ノード10Aにおいて、パーティ管理部105は、自パーティにおけるノード10Aの数が第4所定値を超えた場合、自パーティから、複数のノード10Aを分割して新たなパーティを作成する。
さらに、パーティ管理部105は、自パーティにおけるノード10A及びスイッチ20の接続関係に関する情報に基づいて、自パーティから分割する複数のノード10Aを決定する。
また、パーティ管理部105は、自パーティにおけるノード10Aの数が第5所定値未満の場合、自パーティと他のパーティのうちのいずれかのパーティとを統合する。
これにより、多数の代表ノード10A間のハートビートの通信による代表ノード10Aの処理負荷及びネットワーク負荷に起因した、ストレージシステム1の性能低下を抑止することができる。
以上、本発明の好ましい実施形態について詳述したが、本発明は、係る特定の実施形態に限定されるものではなく、本発明の趣旨を逸脱しない範囲内において、種々の変形、変更して実施することができる。
例えば、第1及び第2実施形態に係るストレージシステム1がそなえるノード10及び10A、並びにスイッチ20の構成及び台数は、上述したものに限定されず、任意の構成及び台数とすることができる。
また、第1実施形態に係るノード10及び第2実施形態に係るノード10Aの各種機能の全部もしくは一部は、コンピュータ(CPU,情報処理装置,各種端末を含む)が所定のプログラムを実行することによって実現されてもよい。
以上の第1及び第2実施形態に関し、更に以下の付記を開示する。
(付記1)
相互に接続される複数の情報処理装置を有し、前記複数の情報処理装置間で通信を行なう情報処理システムにおいて、
前記複数の情報処理装置の各々が、
前記複数の情報処理装置のうちの自情報処理装置以外の他の情報処理装置の各々から、前記他の情報処理装置により判定された前記複数の情報処理装置の各々の状態に関する状態情報を受信する受信処理部と、
前記受信処理部が前記他の情報処理装置の各々から受信した前記状態情報に基づいて、前記複数の情報処理装置の各々の状態を判定する判定部と、
前記判定部が判定した前記複数の情報処理装置の各々の状態に関する送信用状態情報を、前記他の情報処理装置の各々へ送信する送信処理部と、を有することを特徴とする、情報処理システム。
前記判定部は、
前記受信処理部が受信した前記状態情報が示す前記複数の情報処理装置の各々の状態と、前記他の情報処理装置の各々からの前記状態情報の受信状況とに基づいて、前記複数の情報処理装置の各々の状態を判定し、
前記送信処理部は、
第1所定時間ごとに、前記送信用状態情報を、前記他の情報処理装置の各々へ送信することを特徴とする、付記1記載の情報処理システム。
前記判定部は、
前記受信処理部が受信した前記状態情報が示す前記複数の情報処理装置の各々の状態と、前記判定部が含まれる自情報処理装置の状態に関する状態情報に関する自己状態情報とに基づいて、前記複数の情報処理装置の各々の状態を判定することを特徴とする、付記1記載の情報処理システム。
前記判定部は、
前記第1所定時間以上の時間である第2所定時間内に前記状態情報を受信しなかった他の情報処理装置の状態を、停止の可能性を示す第1状態と判定し、
前記受信処理部が受信した前記状態情報に基づいて、第1所定数以上の前記複数の情報処理装置で前記第1状態であると判定された情報処理装置の状態、又は、前記他の情報処理装置の少なくとも1つから停止を示す第2状態であると判定された情報処理装置の状態を、前記第2状態と判定することを特徴とする、付記2記載の情報処理システム。
前記判定部は、
前記受信処理部が受信した前記状態情報に基づいて、前記第1所定数以上の数である第2所定数以上の前記複数の情報処理装置で前記第2状態であると判定された情報処理装置を、リカバリ処理中を示す第3状態と判定し、
前記複数の情報処理装置のうちの1以上の情報処理装置はさらに、
前記判定部が前記第3状態と判定した情報処理装置に対して、リカバリ処理を実行するリカバリ処理部を有することを特徴とする、付記4記載の情報処理システム。
前記判定部は、
前記自情報処理装置に所定の障害が発生した場合、前記自情報処理装置の状態を前記第2状態と判定し、
前記第2所定時間内に第3所定数以上の前記他の情報処理装置から前記状態情報を受信しなかった場合、前記自情報処理装置の状態を、前記他の情報処理装置から切り離されたことを示す第4状態と判定し、
前記複数の情報処理装置の各々はさらに、
前記自情報処理装置に所定の障害が発生し、前記判定部が前記自情報処理装置の状態を前記第2状態と判定した場合、又は、前記判定部が前記自情報処理装置の状態を前期第4状態と判定した場合、前記自情報処理装置を停止させる処理を行なう停止処理部を有することを特徴とする、付記4又は付記5記載の情報処理システム。
前記複数の情報処理装置が複数のグループに分割され、
前記複数のグループの各々における代表情報処理装置はさらに、
前記複数のグループのうちの自グループ以外の他のグループの各々における他の代表情報処理装置から、前記他の代表情報処理装置により判定された前記複数のグループの代表情報処理装置の各々の状態に関する代表状態情報を受信するグループ間受信処理部と、
前記グループ間受信処理部が前記他の代表情報処理装置の各々から受信した前記代表状態情報に基づいて、前記複数の代表情報処理装置の各々の状態を判定するグループ間判定部と、
前記グループ間判定部が判定した前記複数の代表情報処理装置の各々の状態に関する送信用代表状態情報を、前記他の代表情報処理装置の各々へ送信するグループ間送信処理部と、を有し、
前記複数の情報処理装置の各々において、
前記送信処理部は、
前記送信用状態情報を、前記自グループにおける他の情報処理装置の各々へ送信し、
前記判定部は、
前記受信処理部が前記自グループにおける他の情報処理装置の各々から受信した前記状態情報に基づいて、前記自グループにおける情報処理装置の各々の状態を判定することを特徴とする、付記1〜6のいずれか1項記載の情報処理システム。
前記複数のグループの各々における代表情報処理装置はさらに、
前記自グループにおける情報処理装置の数が第4所定値を超えた場合、前記自グループから、複数の情報処理装置を分割して新たなグループを作成する管理部を有することを特徴とする、付記7記載の情報処理システム。
前記情報処理システムはさらに、
前記複数の情報処理装置間に介設され、前記複数の情報処理装置間で送受信される情報を中継する接続装置を有し、
前記管理部は、
前記自グループにおける情報処理装置及び前記接続装置の接続関係に関する情報に基づいて、前記自グループから分割する複数の情報処理装置を決定することを特徴とする、付記8記載の情報処理システム。
前記管理部は、
前記自グループにおける情報処理装置の数が第5所定値未満の場合、前記自グループと前記他のグループのうちのいずれかのグループとを統合することを特徴とする、付記8又は付記9記載の情報処理システム。
相互に接続される複数の情報処理装置の各々において、
前記複数の情報処理装置のうちの自情報処理装置以外の他の情報処理装置の各々から、前記他の情報処理装置により判定された前記複数の情報処理装置の各々の状態に関する状態情報を受信する受信処理部と、
前記受信処理部が前記他の情報処理装置の各々から受信した前記状態情報に基づいて、前記複数の情報処理装置の各々の状態を判定する判定部と、
前記判定部が判定した前記複数の情報処理装置の各々の状態に関する送信用状態情報を、前記他の情報処理装置の各々へ送信する送信処理部と、を有することを特徴とする、情報処理装置。
相互に接続される複数の情報処理装置の各々を制御する情報処理装置の制御プログラムにおいて、
前記情報処理装置に、
前記複数の情報処理装置のうちの自情報処理装置以外の他の情報処理装置の各々から、前記他の情報処理装置により判定された前記複数の情報処理装置の各々の状態に関する状態情報を受信させ、
前記他の情報処理装置の各々から受信した前記状態情報に基づいて、前記複数の情報処理装置の各々の状態を判定させ、
判定した前記複数の情報処理装置の各々の状態に関する送信用状態情報を、前記他の情報処理装置の各々へ送信させることを特徴とする、情報処理装置の制御プログラム。
前記情報処理装置に判定させる処理は、
受信した前記状態情報が示す前記複数の情報処理装置の各々の状態と、前記他の情報処理装置の各々からの前記状態情報の受信状況とに基づいて行なわれ、
前記情報処理装置に送信させる処理は、
第1所定時間ごとに行なわれることを特徴とする、付記12記載の情報処理装置の制御プログラム。
前記情報処理装置に判定させる処理は、
受信した前記状態情報が示す前記複数の情報処理装置の各々の状態と、自情報処理装置の状態に関する状態情報に関する自己状態情報とに基づいて、前記複数の情報処理装置の各々の状態を判定させることを特徴とする、付記12記載の情報処理装置の制御プログラム。
前記情報処理装置に、
前記第1所定時間以上の時間である第2所定時間内に前記状態情報を受信しなかった他の情報処理装置の状態を、停止の可能性を示す第1状態と判定させ、
受信した前記状態情報に基づいて、第1所定数以上の前記複数の情報処理装置で前記第1状態であると判定された情報処理装置の状態、又は、前記他の情報処理装置の少なくとも1つから停止を示す第2状態であると判定された情報処理装置の状態を、前記第2状態と判定させることを特徴とする、付記13記載の情報処理装置の制御プログラム。
前記情報処理装置に、
受信した前記状態情報に基づいて、前記第1所定数以上の数である第2所定数以上の前記複数の情報処理装置で前記第2状態であると判定された情報処理装置を、リカバリ処理中を示す第3状態と判定させ、
前記第3状態と判定した情報処理装置に対して、リカバリ処理を実行させることを特徴とする、付記15記載の情報処理装置の制御プログラム。
前記複数の情報処理装置が複数のグループに分割された前記情報処理システムにおける前記情報処理装置に、
前記複数のグループのうちの自グループ以外の他のグループの各々における他の代表情報処理装置から、前記他の代表情報処理装置により判定された前記複数のグループの代表情報処理装置の各々の状態に関する代表状態情報を受信させ、
前記他の代表情報処理装置の各々から受信した前記代表状態情報に基づいて、前記複数の代表情報処理装置の各々の状態を判定させ、
判定した前記複数の代表情報処理装置の各々の状態に関する送信用代表状態情報を、前記他の代表情報処理装置の各々へ送信させ、
前記情報処理装置に前記送信用状態情報を送信させる処理は、
前記送信用状態情報を、前記自グループにおける他の情報処理装置の各々へ送信させ、
前記情報処理装置に前記複数の情報処理装置の各々の状態を判定させる処理は、
前記自グループにおける他の情報処理装置の各々から受信した前記状態情報に基づいて、前記自グループにおける情報処理装置の各々の状態を判定させることを特徴とする、付記12〜16のいずれか1項記載の情報処理装置の制御プログラム。
前記情報処理装置に、
前記自グループにおける情報処理装置の数が第4所定値を超えた場合、前記自グループから、複数の情報処理装置を分割して新たなグループを作成させることを特徴とする、付記17記載の情報処理装置の制御プログラム。
前記自グループにおける情報処理装置と、前記複数の情報処理装置間に介設され前記複数の情報処理装置間で送受信される情報を中継する接続装置との接続関係に関する情報に基づいて、前記自グループから分割する複数の情報処理装置を決定させることを特徴とする、付記18記載の情報処理装置の制御プログラム。
前記情報処理装置に、
前記自グループにおける情報処理装置の数が第5所定値未満の場合、前記自グループと前記他のグループのうちのいずれかのグループとを統合させることを特徴とする、付記18又は付記19記載の情報処理装置の制御プログラム。
相互に接続される複数の情報処理装置を有し、前記複数の情報処理装置間で通信を行なう情報処理システムの制御方法において、
前記複数の情報処理装置の各々が、
前記複数の情報処理装置のうちの自情報処理装置以外の他の情報処理装置の各々から、前記他の情報処理装置により判定された前記複数の情報処理装置の各々の状態に関する状態情報を受信し、
前記他の情報処理装置の各々から受信した前記状態情報に基づいて、前記複数の情報処理装置の各々の状態を判定し、
判定した前記複数の情報処理装置の各々の状態に関する送信用状態情報を、前記他の情報処理装置の各々へ送信することを特徴とする、情報処理システムの制御方法。
相互に接続される複数の情報処理装置の各々において、
プロセッサを有し、
前記プロセッサが、
前記複数の情報処理装置のうちの自情報処理装置以外の他の情報処理装置の各々から、前記他の情報処理装置により判定された前記複数の情報処理装置の各々の状態に関する状態情報を受信し、
前記他の情報処理装置の各々から受信した前記状態情報に基づいて、前記複数の情報処理装置の各々の状態を判定し、
判定した前記複数の情報処理装置の各々の状態に関する送信用状態情報を、前記他の情報処理装置の各々へ送信することを特徴とする、情報処理装置。
10,10−1〜10−5,10A,10A−1〜10A−6,10A−11〜10A−13,10A−21〜10A−23 ノード(ストレージ装置,情報処理装置)
10a CPU(プロセッサ)
10b メモリ
10c 記憶部
10d ネットワークインタフェース
10e 入出力部
10f,10h 記録媒体
10g 読取部
11,11A ノード状態保持部
12,12A 受信処理部
13,13A ノード状態決定部(判定部)
14,14A 送信処理部
15 リカバリ処理部
16 停止処理部
101 パーティ情報保持部
102 パーティ間受信処理部(グループ間受信処理部)
103 パーティ間ノード状態決定部(グループ間判定部)
104 パーティ間送信処理部(グループ間送信処理部)
105 パーティ管理部(管理部)
20,20−1〜20−3 スイッチ(接続装置)
Claims (9)
- 相互に接続される複数の情報処理装置を有し、前記複数の情報処理装置間で通信を行なう情報処理システムにおいて、
前記複数の情報処理装置の各々が、
前記複数の情報処理装置のうちの自情報処理装置以外の他の情報処理装置の各々から、前記他の情報処理装置により判定された前記複数の情報処理装置の各々の状態に関する状態情報を受信する受信処理部と、
前記受信処理部が前記他の情報処理装置の各々から受信した前記状態情報に基づいて、前記複数の情報処理装置の各々の状態を判定する判定部と、
前記判定部が判定した前記複数の情報処理装置の各々の状態に関する送信用状態情報を、前記他の情報処理装置の各々へ送信する送信処理部と、を有し、
前記判定部は、
前記受信処理部が受信した前記状態情報が示す前記複数の情報処理装置の各々の状態と、前記他の情報処理装置の各々からの前記状態情報の受信状況とに基づいて、前記複数の情報処理装置の各々の状態を判定し、
前記送信処理部は、
第1所定時間ごとに、前記送信用状態情報を、前記他の情報処理装置の各々へ送信し、
前記判定部は、
前記第1所定時間以上の時間である第2所定時間内に前記状態情報を受信しなかった他の情報処理装置の状態を、停止の可能性を示す第1状態と判定し、
前記受信処理部が受信した前記状態情報に基づいて、第1所定数以上の前記複数の情報処理装置で前記第1状態であると判定された情報処理装置の状態、又は、前記他の情報処理装置の少なくとも1つから停止を示す第2状態であると判定された情報処理装置の状態を、前記第2状態と判定することを特徴とする、情報処理システム。 - 前記判定部は、
前記受信処理部が受信した前記状態情報が示す前記複数の情報処理装置の各々の状態と、前記判定部が含まれる自情報処理装置の状態に関する状態情報に関する自己状態情報とに基づいて、前記複数の情報処理装置の各々の状態を判定することを特徴とする、請求項1記載の情報処理システム。 - 前記判定部は、
前記受信処理部が受信した前記状態情報に基づいて、前記第1所定数以上の数である第2所定数以上の前記複数の情報処理装置で前記第2状態であると判定された情報処理装置を、リカバリ処理中を示す第3状態と判定し、
前記複数の情報処理装置のうちの1以上の情報処理装置はさらに、
前記判定部が前記第3状態と判定した情報処理装置に対して、リカバリ処理を実行するリカバリ処理部を有することを特徴とする、請求項1又は請求項2記載の情報処理システム。 - 前記複数の情報処理装置が複数のグループに分割され、
前記複数のグループの各々における代表情報処理装置はさらに、
前記複数のグループのうちの自グループ以外の他のグループの各々における他の代表情報処理装置から、前記他の代表情報処理装置により判定された前記複数のグループの代表情報処理装置の各々の状態に関する代表状態情報を受信するグループ間受信処理部と、
前記グループ間受信処理部が前記他の代表情報処理装置の各々から受信した前記代表状態情報に基づいて、前記複数の代表情報処理装置の各々の状態を判定するグループ間判定部と、
前記グループ間判定部が判定した前記複数の代表情報処理装置の各々の状態に関する送信用代表状態情報を、前記他の代表情報処理装置の各々へ送信するグループ間送信処理部と、を有し、
前記複数の情報処理装置の各々において、
前記送信処理部は、
前記送信用状態情報を、前記自グループにおける他の情報処理装置の各々へ送信し、
前記判定部は、
前記受信処理部が前記自グループにおける他の情報処理装置の各々から受信した前記状態情報に基づいて、前記自グループにおける情報処理装置の各々の状態を判定することを特徴とする、請求項1〜3のいずれか1項記載の情報処理システム。 - 前記複数のグループの各々における代表情報処理装置はさらに、
前記自グループにおける情報処理装置の数が第4所定値を超えた場合、前記自グループから、複数の情報処理装置を分割して新たなグループを作成する管理部を有することを特徴とする、請求項4記載の情報処理システム。 - 前記管理部は、
前記自グループにおける情報処理装置の数が第5所定値未満の場合、前記自グループと前記他のグループのうちのいずれかのグループとを統合することを特徴とする、請求項5記載の情報処理システム。 - 相互に接続される複数の情報処理装置の各々において、
前記複数の情報処理装置のうちの自情報処理装置以外の他の情報処理装置の各々から、前記他の情報処理装置により判定された前記複数の情報処理装置の各々の状態に関する状態情報を受信する受信処理部と、
前記受信処理部が前記他の情報処理装置の各々から受信した前記状態情報に基づいて、前記複数の情報処理装置の各々の状態を判定する判定部と、
前記判定部が判定した前記複数の情報処理装置の各々の状態に関する送信用状態情報を、前記他の情報処理装置の各々へ送信する送信処理部と、を有し、
前記判定部は、
前記受信処理部が受信した前記状態情報が示す前記複数の情報処理装置の各々の状態と、前記他の情報処理装置の各々からの前記状態情報の受信状況とに基づいて、前記複数の情報処理装置の各々の状態を判定し、
前記送信処理部は、
第1所定時間ごとに、前記送信用状態情報を、前記他の情報処理装置の各々へ送信し、
前記判定部は、
前記第1所定時間以上の時間である第2所定時間内に前記状態情報を受信しなかった他の情報処理装置の状態を、停止の可能性を示す第1状態と判定し、
前記受信処理部が受信した前記状態情報に基づいて、第1所定数以上の前記複数の情報処理装置で前記第1状態であると判定された情報処理装置の状態、又は、前記他の情報処理装置の少なくとも1つから停止を示す第2状態であると判定された情報処理装置の状態を、前記第2状態と判定することを特徴とする、情報処理装置。 - 相互に接続される複数の情報処理装置の各々を制御する情報処理装置に、
前記複数の情報処理装置のうちの自情報処理装置以外の他の情報処理装置の各々から、前記他の情報処理装置により判定された前記複数の情報処理装置の各々の状態に関する状態情報を受信し、
前記他の情報処理装置の各々から受信した前記状態情報に基づいて、前記複数の情報処理装置の各々の状態を判定し、
判定した前記複数の情報処理装置の各々の状態に関する送信用状態情報を、前記他の情報処理装置の各々へ送信する、処理を実行させ、
前記判定において、
受信した前記状態情報が示す前記複数の情報処理装置の各々の状態と、前記他の情報処理装置の各々からの前記状態情報の受信状況とに基づいて、前記複数の情報処理装置の各々の状態を判定し、
前記送信において、
第1所定時間ごとに、前記送信用状態情報を、前記他の情報処理装置の各々へ送信し、
前記判定において、
前記第1所定時間以上の時間である第2所定時間内に前記状態情報を受信しなかった他の情報処理装置の状態を、停止の可能性を示す第1状態と判定し、
受信した前記状態情報に基づいて、第1所定数以上の前記複数の情報処理装置で前記第1状態であると判定された情報処理装置の状態、又は、前記他の情報処理装置の少なくとも1つから停止を示す第2状態であると判定された情報処理装置の状態を、前記第2状態と判定することを特徴とする、情報処理装置の制御プログラム。 - 相互に接続される複数の情報処理装置を有し、前記複数の情報処理装置間で通信を行なう情報処理システムの制御方法において、
前記複数の情報処理装置の各々が、
前記複数の情報処理装置のうちの自情報処理装置以外の他の情報処理装置の各々から、前記他の情報処理装置により判定された前記複数の情報処理装置の各々の状態に関する状態情報を受信し、
前記他の情報処理装置の各々から受信した前記状態情報に基づいて、前記複数の情報処理装置の各々の状態を判定し、
判定した前記複数の情報処理装置の各々の状態に関する送信用状態情報を、前記他の情報処理装置の各々へ送信し、
前記判定において、
受信した前記状態情報が示す前記複数の情報処理装置の各々の状態と、前記他の情報処理装置の各々からの前記状態情報の受信状況とに基づいて、前記複数の情報処理装置の各々の状態を判定し、
前記送信において、
第1所定時間ごとに、前記送信用状態情報を、前記他の情報処理装置の各々へ送信し、
前記判定において、
前記第1所定時間以上の時間である第2所定時間内に前記状態情報を受信しなかった他の情報処理装置の状態を、停止の可能性を示す第1状態と判定し、
受信した前記状態情報に基づいて、第1所定数以上の前記複数の情報処理装置で前記第1状態であると判定された情報処理装置の状態、又は、前記他の情報処理装置の少なくとも1つから停止を示す第2状態であると判定された情報処理装置の状態を、前記第2状態と判定することを特徴とする、情報処理システムの制御方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013071904A JP6089884B2 (ja) | 2013-03-29 | 2013-03-29 | 情報処理システム,情報処理装置,情報処理装置の制御プログラム,及び情報処理システムの制御方法 |
| US14/197,266 US10298478B2 (en) | 2013-03-29 | 2014-03-05 | Information processing system, computer-readable recording medium having stored therein control program for information processing device, and control method of information processing system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013071904A JP6089884B2 (ja) | 2013-03-29 | 2013-03-29 | 情報処理システム,情報処理装置,情報処理装置の制御プログラム,及び情報処理システムの制御方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014197266A JP2014197266A (ja) | 2014-10-16 |
| JP6089884B2 true JP6089884B2 (ja) | 2017-03-08 |
Family
ID=51621964
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013071904A Active JP6089884B2 (ja) | 2013-03-29 | 2013-03-29 | 情報処理システム,情報処理装置,情報処理装置の制御プログラム,及び情報処理システムの制御方法 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US10298478B2 (ja) |
| JP (1) | JP6089884B2 (ja) |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105991325B (zh) * | 2015-02-10 | 2019-06-21 | 华为技术有限公司 | 处理至少一个分布式集群中的故障的方法、设备和系统 |
| WO2016135919A1 (ja) * | 2015-02-26 | 2016-09-01 | 株式会社日立製作所 | ストレージ装置 |
| JP6451467B2 (ja) * | 2015-04-07 | 2019-01-16 | 三菱電機株式会社 | 統合監視制御装置および統合監視制御システム |
| CN107748702B (zh) * | 2015-06-04 | 2021-05-04 | 华为技术有限公司 | 一种数据恢复方法和装置 |
| JP6588567B2 (ja) * | 2015-11-26 | 2019-10-09 | 日本電信電話株式会社 | 通信システム及び故障箇所特定方法 |
| EP3506099A4 (en) * | 2016-08-25 | 2019-09-04 | Fujitsu Limited | MAINTENANCE MANAGEMENT PROGRAM, MAINTENANCE MANAGEMENT METHOD, AND MAINTENANCE MANAGEMENT DEVICE |
| CN106878109A (zh) * | 2017-03-13 | 2017-06-20 | 网宿科技股份有限公司 | 服务器检测方法及服务器系统 |
| US11402243B1 (en) * | 2017-10-24 | 2022-08-02 | University Of South Florida | Distributed process state and input estimation for heterogeneous active/passive sensor networks |
| WO2019178714A1 (zh) * | 2018-03-19 | 2019-09-26 | 华为技术有限公司 | 一种故障检测的方法、装置及系统 |
| US11108640B2 (en) * | 2018-12-20 | 2021-08-31 | Advantest Corporation | Controlling devices in a decentralized storage environment |
| US11082505B2 (en) * | 2019-07-29 | 2021-08-03 | Cisco Technology, Inc. | Dynamic discovery of available storage servers |
| CN111510345B (zh) * | 2020-04-03 | 2022-04-26 | 网宿科技股份有限公司 | 一种边缘节点异常检测的方法及装置 |
| CN112202746B (zh) * | 2020-09-24 | 2023-04-21 | 北京百度网讯科技有限公司 | Rpc成员信息获取方法、装置、电子设备和存储介质 |
| CN114866422A (zh) * | 2022-05-12 | 2022-08-05 | 上海阵方科技有限公司 | 安全data sharing的安全多方计算系统和方法 |
| CN115550144B (zh) * | 2022-11-30 | 2023-03-24 | 季华实验室 | 分布式故障节点预测方法、装置、电子设备及存储介质 |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS57201945A (en) * | 1981-06-03 | 1982-12-10 | Omron Tateisi Electronics Co | Fault diagnosing method for multiple cpu system |
| JP2002132535A (ja) * | 2000-10-25 | 2002-05-10 | Chubu Electric Power Co Inc | 分散型計算機システムにおける計算機診断方式 |
| JP2002312199A (ja) * | 2001-04-13 | 2002-10-25 | Mitsubishi Electric Corp | 異常検知電子機器及び異常検知方法及び異常検知電子機器システム及び異常検知プログラム及び異常検知プログラムを記録したコンピュータ読み取り可能な記録媒体 |
| JP5158074B2 (ja) | 2007-03-20 | 2013-03-06 | 富士通株式会社 | ストレージ管理プログラム、ストレージ管理方法、ストレージ管理装置およびストレージシステム |
| EP2202921B1 (en) * | 2007-11-22 | 2013-03-27 | China Mobile Communications Corporation | A data storage method, a management server, a storage equipment and system |
| JP5176231B2 (ja) * | 2008-03-10 | 2013-04-03 | 株式会社日立製作所 | 計算機システム、計算機制御方法及び計算機制御プログラム |
| JP5458644B2 (ja) | 2009-04-22 | 2014-04-02 | 富士通株式会社 | 大規模ネットワーク監視方法 |
| JP2011055231A (ja) | 2009-09-01 | 2011-03-17 | Mitsubishi Electric Corp | ネットワーク管理システムおよびネットワーク管理方法 |
| US9130850B2 (en) * | 2012-07-20 | 2015-09-08 | Hitachi, Ltd. | Monitoring system and monitoring program with detection probability judgment for condition event |
| WO2014068705A1 (ja) * | 2012-10-31 | 2014-05-08 | 株式会社日立製作所 | 監視システム及び監視プログラム |
-
2013
- 2013-03-29 JP JP2013071904A patent/JP6089884B2/ja active Active
-
2014
- 2014-03-05 US US14/197,266 patent/US10298478B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US10298478B2 (en) | 2019-05-21 |
| US20140297845A1 (en) | 2014-10-02 |
| JP2014197266A (ja) | 2014-10-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6089884B2 (ja) | 情報処理システム,情報処理装置,情報処理装置の制御プログラム,及び情報処理システムの制御方法 | |
| US10489254B2 (en) | Storage cluster failure detection | |
| JP6586465B2 (ja) | ストレージ・クラスタ要素のモニタリングのための方法、装置、記憶媒体及びコンピュータ・プログラム | |
| US7921325B2 (en) | Node management device and method | |
| US8615676B2 (en) | Providing first field data capture in a virtual input/output server (VIOS) cluster environment with cluster-aware vioses | |
| JP5723990B2 (ja) | ファブリックに対する情報を集めるためにエージェントの等価サブセットを定める方法、およびそのシステム。 | |
| JP6215481B2 (ja) | クラウド環境におけるitインフラ管理のための方法とその装置 | |
| JP2011128917A (ja) | データ割当制御プログラム、データ割当制御方法、およびデータ割当制御装置 | |
| CN102394914A (zh) | 集群脑裂处理方法和装置 | |
| JP6212934B2 (ja) | ストレージシステム、情報処理装置の制御プログラム、およびストレージシステムの制御方法 | |
| JP6028641B2 (ja) | 情報処理システム、情報処理装置の制御プログラム及び情報処理システムの制御方法 | |
| US8234447B2 (en) | Storage control device for storage system provided with storage device coupled to switch network | |
| US20090164565A1 (en) | Redundant systems management frameworks for network environments | |
| JP2013542476A5 (ja) | ||
| JP5617304B2 (ja) | スイッチング装置、情報処理装置および障害通知制御プログラム | |
| CN108509296B (zh) | 一种处理设备故障的方法和系统 | |
| JP5884606B2 (ja) | ストレージ管理方法、システム、およびプログラム | |
| CN110661599B (zh) | 一种主、备节点间的ha实现方法、装置及存储介质 | |
| JP2019508975A (ja) | ハイパースケール環境における近隣監視 | |
| WO2015037103A1 (ja) | サーバシステム、計算機システム、サーバシステムの管理方法、及びコンピュータ読み取り可能な記憶媒体 | |
| WO2023275983A1 (ja) | 仮想化システム障害分離装置及び仮想化システム障害分離方法 | |
| JP6111791B2 (ja) | ネットワーク管理システム、ネットワーク管理装置、サーバ、ネットワーク管理方法、及びプログラム | |
| JP6984437B2 (ja) | 処理の引継ぎ方法、クラスタ構築プログラム及びクラスタ構築装置 | |
| JP6558012B2 (ja) | ストレージ管理装置、ストレージシステム、ストレージ管理方法及びプログラム | |
| JP2016131286A (ja) | 検証支援プログラム、検証支援装置、及び検証支援方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20151204 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160831 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20161004 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20161125 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170110 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170123 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6089884 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |