JP6212934B2 - ストレージシステム、情報処理装置の制御プログラム、およびストレージシステムの制御方法 - Google Patents
ストレージシステム、情報処理装置の制御プログラム、およびストレージシステムの制御方法 Download PDFInfo
- Publication number
- JP6212934B2 JP6212934B2 JP2013097648A JP2013097648A JP6212934B2 JP 6212934 B2 JP6212934 B2 JP 6212934B2 JP 2013097648 A JP2013097648 A JP 2013097648A JP 2013097648 A JP2013097648 A JP 2013097648A JP 6212934 B2 JP6212934 B2 JP 6212934B2
- Authority
- JP
- Japan
- Prior art keywords
- storage
- disk
- storage device
- raid
- group
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images
















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/08—Error detection or correction by redundancy in data representation, e.g. by using checking codes
- G06F11/10—Adding special bits or symbols to the coded information, e.g. parity check, casting out 9's or 11's
- G06F11/1076—Parity data used in redundant arrays of independent storages, e.g. in RAID systems
- G06F11/1092—Rebuilding, e.g. when physically replacing a failing disk
Description
[第1の実施形態]
まず、第1の実施形態のストレージシステムについて図1を用いて説明する。図1は、第1の実施形態のストレージシステムの構成の一例を示す図である。
次に、第2の実施形態のストレージシステムの構成について図2を用いて説明する。図2は、第2の実施形態のストレージシステムの構成の一例を示す図である。
次に、第2の実施形態のディスクエンクロージャの構成について図3を用いて説明する。図3は、第2の実施形態のディスクエンクロージャの構成の一例を示す図である。
サーバ12は、プロセッサ101によって装置全体が制御されている。プロセッサ101には、バス106を介してRAM(Random Access Memory)102と複数の周辺機器が接続されている。プロセッサ101は、マルチプロセッサであってもよい。プロセッサ101は、たとえばCPU(Central Processing Unit)、MPU(Micro Processing Unit)、DSP(Digital Signal Processor)、ASIC(Application Specific Integrated Circuit)、またはPLD(Programmable Logic Device)である。またプロセッサ101は、CPU、MPU、DSP、ASIC、PLDのうちの2以上の要素の組み合わせであってもよい。
不揮発性メモリ103は、サーバ12の電源遮断時においても記憶内容を保持する。不揮発性メモリ103は、たとえば、EEPROM(Electrically Erasable Programmable Read-Only Memory)やフラッシュメモリなどの半導体記憶装置や、HDDなどである。また、不揮発性メモリ103は、サーバ12の補助記憶装置として使用される。不揮発性メモリ103には、オペレーティングシステムのプログラムやファームウェア、アプリケーションプログラム、および各種データが格納される。
通信インタフェース105は、通信パス16,18を形成するネットワークと接続することで、通信パス16,18を介して、リソースマネージャ11やディスクエンクロージャ13との間でデータの送受信をおこなう。
RAID構成情報50は、サーバ12(たとえば、サーバ12a)が管理するRAIDグループの構成を示す情報である。サーバ12は、たとえば、不揮発性メモリ103にRAID構成情報50を保持する。RAID構成情報50は、RAIDグループID(Identification)、ブロックNo.、ステータス、ディスクエンクロージャID、ディスクIDを含む。
故障処理は、ストレージ資源の故障を検出してRAIDの再構成をおこなう処理である。故障処理は、サーバ12が定期的に実行する処理である。
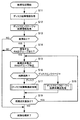
[ステップS16]制御部は、故障個所がディスク15かディスクエンクロージャ13かを判定する。制御部は、故障個所がディスク15の場合にステップS17にすすみ、故障個所がディスクエンクロージャ13の場合にステップS18にすすむ。
[ステップS23]制御部は、RAIDグループを構成するディスクが属さないディスクエンクロージャ13(DE)、すなわちRAID構成外DEに空きディスクがあるか否かを判定する。制御部は、リソースマネージャ11に照会することにより、RAID構成外DEに空きディスクがあるか否かを判定することができる。制御部は、空きディスクがある場合にステップS24にすすみ、空きディスクがない場合にステップS25にすすむ。
[ステップS25]制御部は、RAIDグループを構成するディスクが属する2以上のディスクエンクロージャ13(DE)、すなわちRAID構成DEに空きディスクがあるか否かを判定する。制御部は、リソースマネージャ11に照会することにより、2以上のRAID構成DEに空きディスクがあるか否かを判定することができる。制御部は、2以上のRAID構成DEに空きディスクがない場合にステップS26にすすみ、2以上のRAID構成DEに空きディスクがある場合にステップS27にすすむ。
[ステップS27]制御部は、2以上のRAID構成DEのうちの2つのRAID構成DEから1つずつディスク15の割当を受けて、代替ディスクを獲得する。
次に、第2の実施形態のディスクエンクロージャ故障再構成処理について図9を用いて説明する。図9は、第2の実施形態のディスクエンクロージャ故障再構成処理のフローチャートを示す図である。ディスクエンクロージャ故障再構成処理は、故障処理のステップS18でサーバ12が実行する処理である。
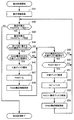
[ステップS33]制御部は、RAIDグループを構成するディスクが属する2以上のディスクエンクロージャ13(DE)、すなわちRAID構成DEに空きディスクがあるか否かを判定する。制御部は、リソースマネージャ11に照会することにより、2以上のRAID構成DEに空きディスクがあるか否かを判定することができる。制御部は、2以上のRAID構成DEに空きディスクがない場合にステップS34にすすみ、2以上のRAID構成DEに空きディスクがある場合にステップS35にすすむ。
[ステップS35]制御部は、2以上のRAID構成DEのうちの2つのRAID構成DEから1つずつディスク15の割当を受けて、代替ディスクを獲得する。
次に、第2の実施形態のRAID構成DEから代替ディスクを獲得する場合のRAID再構成について図10から図12を用いて説明する。まず、RAID構成DEの1つが故障して、代替ディスクを他のRAID構成DEから獲得しなければならない場合について図10を用いて説明する。図10は、第2の実施形態のサーバが構成するRAIDグループの一例を示す図である。
RAID構成情報51は、ブロックNo.「1」が2つと、ブロックNo.「2」,「3」,「4」が1つずつの合計5つのディスク15からRAIDグループID「#0001」のRAIDグループ30が構成されていることを示す。また、RAID構成情報51は、ステータス「RAID1」より、ブロックNo.「1」の2つのディスク15がRAID1を構成していることを示す。ステータス「RAID1」は、ディスク15が複製を有することを示す。すなわち、ステータス「RAID1」は、ディスク15が複製を有するか否かを判別可能な複製判別情報に相当する。
[ステップS44]制御部は、1つのディスクエンクロージャ13(同一DE)に属するRAIDグループを構成するディスク(RAID構成ディスク)の有無を判定する。制御部は、同一DEに属するRAID構成ディスクがある場合にステップS45にすすみ、同一DEに属するRAID構成ディスクがない場合にステップS49にすすむ。
[ステップS47]制御部は、同一DEに属するRAID構成ディスクについて代替ディスクとの間でRAID1化をおこなう。
[ステップS49]制御部は、復旧情報とRAID構成情報とにもとづいて、特定したRAIDグループに属さないディスクエンクロージャ13(RAID構成外DE)から代替ディスクを獲得可能か否かを判定する。制御部は、RAID構成外DEから代替ディスクを獲得できる場合にステップS50にすすみ、RAID構成外DEから代替ディスクを獲得できない場合にステップS42にすすむ。
[ステップS52]制御部は、RAID1を構成していたディスク15から代替ディスクにコピーバック処理をおこなう。
[ステップS54]制御部は、RAID構成情報を更新してステップS42にすすむ。
ここで、獲得ディスクへのコピーバックと、RAID1を構成していたディスク15の解放について図14を用いて説明する。図14は、第2の実施形態のサーバが構成するRAIDグループの一例を示す図である。
次に、第3の実施形態のディスクエンクロージャ故障再構成処理について図15、図16を用いて説明する。図15および図16は、第3の実施形態のディスクエンクロージャ故障再構成処理のフローチャートを示す図である。第3の実施形態のディスクエンクロージャ故障再構成処理は、RAID1を併用するRAIDグループを構成するディスクエンクロージャ13の故障に対応する。
[ステップS64]制御部は、故障ディスクに代えて代替ディスクでRAID1を復元する。
[ステップS66]制御部は、RAIDグループを構成するディスクが属さないディスクエンクロージャ13(RAID構成外DE)に空きディスクがあるか否かを判定する。制御部は、RAID構成外DEに空きディスクがある場合にステップS67にすすみ、RAID構成外DEに空きディスクがない場合にステップS68にすすむ。
[ステップS68]制御部は、2以上のRAID構成DEに空きディスクがあるか否かを判定する。制御部は、2以上のRAID構成DEに空きディスクがない場合にステップS69にすすみ、2以上のRAID構成DEに空きディスクがある場合にステップS70にすすむ。
[ステップS70]制御部は、2以上のRAID構成DEのうちの2つのRAID構成DEから1つずつディスク15の割当を受けて、代替ディスクを獲得する。
[ステップS74]制御部は、すべての故障ディスクについて代替ディスクを獲得したか否かを判定する。制御部は、すべての故障ディスクについて代替ディスクを獲得していない場合にステップS61にすすみ、すべての故障ディスクについて代替ディスクを獲得した場合にディスクエンクロージャ故障再構成処理を終了する。
RAIDグループ30dは、ディスクエンクロージャ13c,13dのいずれか一方が故障しても、サーバ12がRAIDグループ30に対してアクセス可能である。
RAID構成情報52は、ブロックNo.「1」,「2」が2つと、ブロックNo.「3」,「4」が1つずつの合計6つのディスク15からRAIDグループID「#0001」のRAIDグループ30が構成されていることを示す。また、RAID構成情報52は、ステータス「RAID1」より、ブロックNo.「1」の2つのディスク15がRAID1を構成し、ブロックNo.「2」の2つのディスク15がもう1つのRAID1を構成していることを示す。また、RAID構成情報52は、ブロックNo.「1」の1つのディスク15がディスクエンクロージャID「#C」、ディスクID「#2」であることを示す。また、RAID構成情報52は、ブロックNo.「1」のもう1つのディスク15がディスクエンクロージャID「#D」、ディスクID「#3」であることを示す。また、RAID構成情報52は、ブロックNo.「2」の1つのディスク15がディスクエンクロージャID「#C」、ディスクID「#3」であることを示す。また、RAID構成情報52は、ブロックNo.「2」のもう1つのディスク15がディスクエンクロージャID「#D」、ディスクID「#2」であることを示す。同様に、RAID構成情報52は、ブロックNo.「3」のディスク15がディスクエンクロージャID「#C」、ディスクID「#1」であることを示す。同様に、RAID構成情報52は、ブロックNo.「4」のディスク15がディスクエンクロージャID「#D」、ディスクID「#1」であることを示す。
2 管理装置
3 情報処理装置
3a 構成部
3b 検出部
3c 再構成部
3d 複製部
4,4a,4b,4c,4d ストレージユニット
5,5a,5b,5c,5d,5e,5f ストレージデバイス
6,7,8,16,17,18 通信パス
11 リソースマネージャ
12,12a,12b,12c サーバ
13,13a,13b,13c,13d ディスクエンクロージャ
14 スイッチ
15 ディスク
25 コントローラ
26 電源部
27 冷却部
101 プロセッサ
102 RAM
103 不揮発性メモリ
104 入出力インタフェース
105 通信インタフェース
106 バス
Claims (8)
- 複数のストレージデバイスを有する複数のストレージユニットと、前記ストレージデバイスを管理する管理装置と、前記管理装置から割当を受けて前記ストレージデバイスと接続可能な情報処理装置と、を備えるストレージシステムであって、
前記情報処理装置は、
それぞれ異なる前記ストレージユニットに属する前記ストレージデバイスの割当を受けて第1のグループを構成する第1の構成部と、
前記第1のグループを構成するストレージデバイスの障害を検出する検出部と、
障害を検出したストレージデバイスを代替するストレージデバイスを、前記第1のグループを構成するその余のストレージデバイスが属するストレージユニットから割当を受ける場合に、前記その余のストレージデバイスが属するストレージユニットのうちの第1のストレージユニットから第1のストレージデバイスの割当を受けて前記第1のグループの構成を前記その余のストレージデバイスと前記第1のストレージデバイスとが属する第2のグループに構成する第2の構成部と、
前記その余のストレージデバイスが属するストレージユニットのうちの第2のストレージユニットから第2のストレージデバイスの割当を受けて、前記第2のストレージデバイスに前記第1のストレージデバイスを複製する複製部と、
を備えることを特徴とするストレージシステム。 - 前記情報処理装置は、前記第2のグループを構成するストレージデバイスが属さないストレージユニットから第3のストレージデバイスの割当を受けて、前記第1のストレージデバイスまたは前記第2のストレージデバイスを前記第3のストレージデバイスに複製して前記第2のグループの構成を前記その余のストレージデバイスと前記第3のストレージデバイスとが属する第3のグループに構成する第3の構成部を備えることを特徴とする請求項1記載のストレージシステム。
- 前記情報処理装置は、前記第3のグループに構成した後、前記第1のストレージデバイスおよび前記第2のストレージデバイスの割当を解放することを特徴とする請求項2記載のストレージシステム。
- 前記情報処理装置は、前記第2のグループを構成するストレージデバイスを特定可能な管理情報を記憶する記憶部を有し、
前記管理情報は、前記ストレージデバイスが複製を有するか否かを判別可能な複製判別情報を含む、
ことを特徴とする請求項1記載のストレージシステム。 - 前記情報処理装置と前記ストレージユニットの接続と接続解除を切替可能なスイッチを備え、
前記管理装置は、前記スイッチの接続と接続解除の切替を制御して、前記情報処理装置に前記ストレージデバイスを割り当てる、
ことを特徴とする請求項1記載のストレージシステム。 - 前記管理装置は、前記ストレージユニットの障害を検出し、検出した前記ストレージユニットの障害を前記情報処理装置に通知することを特徴とする請求項1記載のストレージシステム。
- 複数のストレージデバイスを有する複数のストレージユニットを管理する管理装置と接続される情報処理装置の制御プログラムにおいて、
前記情報処理装置に、
それぞれ異なる前記ストレージユニットに属する前記ストレージデバイスの割当を受けて第1のグループを構成させ、
前記第1のグループを構成するストレージデバイスの障害を検出させ、
障害を検出したストレージデバイスを代替するストレージデバイスを、前記第1のグループを構成するその余のストレージデバイスが属するストレージユニットから割当を受ける場合に、前記その余のストレージデバイスが属するストレージユニットのうちの第1のストレージユニットから第1のストレージデバイスの割当を受けて前記第1のグループの構成を前記その余のストレージデバイスと前記第1のストレージデバイスとが属する第2のグループに構成させ、
前記その余のストレージデバイスが属するストレージユニットのうちの第2のストレージユニットから第2のストレージデバイスの割当を受けて、前記第2のストレージデバイスに前記第1のストレージデバイスを複製させる、
ことを特徴とする情報処理装置の制御プログラム。 - 複数のストレージデバイスを有する複数のストレージユニットと、前記ストレージデバイスを管理する管理装置と、前記管理装置から割当を受けて前記ストレージデバイスと接続可能な情報処理装置と、を備えるストレージシステムの制御方法において、
前記情報処理装置が、
それぞれ異なる前記ストレージユニットに属する前記ストレージデバイスの割当を受けて第1のグループを構成し、
前記第1のグループを構成するストレージデバイスの障害を検出し、
障害を検出したストレージデバイスを代替するストレージデバイスを、前記第1のグループを構成するその余のストレージデバイスが属するストレージユニットから割当を受ける場合に、前記その余のストレージデバイスが属するストレージユニットのうちの第1のストレージユニットから第1のストレージデバイスの割当を受けて前記第1のグループの構成を前記その余のストレージデバイスと前記第1のストレージデバイスとが属する第2のグループに構成し、
前記その余のストレージデバイスが属するストレージユニットのうちの第2のストレージユニットから第2のストレージデバイスの割当を受けて、前記第2のストレージデバイスに前記第1のストレージデバイスを複製する、
ことを特徴とするストレージシステムの制御方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013097648A JP6212934B2 (ja) | 2013-05-07 | 2013-05-07 | ストレージシステム、情報処理装置の制御プログラム、およびストレージシステムの制御方法 |
| US14/208,145 US9507664B2 (en) | 2013-05-07 | 2014-03-13 | Storage system including a plurality of storage units, a management device, and an information processing apparatus, and method for controlling the storage system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013097648A JP6212934B2 (ja) | 2013-05-07 | 2013-05-07 | ストレージシステム、情報処理装置の制御プログラム、およびストレージシステムの制御方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014219787A JP2014219787A (ja) | 2014-11-20 |
| JP6212934B2 true JP6212934B2 (ja) | 2017-10-18 |
Family
ID=51865736
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013097648A Active JP6212934B2 (ja) | 2013-05-07 | 2013-05-07 | ストレージシステム、情報処理装置の制御プログラム、およびストレージシステムの制御方法 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US9507664B2 (ja) |
| JP (1) | JP6212934B2 (ja) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105468484B (zh) * | 2014-09-30 | 2020-07-28 | 伊姆西Ip控股有限责任公司 | 用于在存储系统中确定故障位置的方法和装置 |
| JP2016157257A (ja) * | 2015-02-24 | 2016-09-01 | Necプラットフォームズ株式会社 | ディスクアレイ装置およびその制御方法 |
| JP6228347B2 (ja) * | 2015-02-25 | 2017-11-08 | 株式会社日立製作所 | ストレージ装置及び記憶デバイス |
| JP6472508B2 (ja) * | 2015-04-06 | 2019-02-20 | 株式会社日立製作所 | 管理計算機およびリソース管理方法 |
| US11288017B2 (en) | 2017-02-23 | 2022-03-29 | Smart IOPS, Inc. | Devices, systems, and methods for storing data using distributed control |
| US11354247B2 (en) | 2017-11-10 | 2022-06-07 | Smart IOPS, Inc. | Devices, systems, and methods for configuring a storage device with cache |
| US10394474B2 (en) * | 2017-11-10 | 2019-08-27 | Smart IOPS, Inc. | Devices, systems, and methods for reconfiguring storage devices with applications |
| CN110058963B (zh) * | 2018-01-18 | 2023-05-09 | 伊姆西Ip控股有限责任公司 | 用于管理存储系统的方法、设备和计算机程序产品 |
| US10531592B1 (en) * | 2018-07-19 | 2020-01-07 | Quanta Computer Inc. | Smart rack architecture for diskless computer system |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06230903A (ja) * | 1993-01-31 | 1994-08-19 | Hitachi Ltd | ディスクアレイ装置の障害回復方法、およびディスクアレイ装置 |
| JP2005100259A (ja) | 2003-09-26 | 2005-04-14 | Hitachi Ltd | ドライブの2重障害を防止するアレイ型ディスク装置、プログラム、及び方法 |
| JP4412989B2 (ja) * | 2003-12-15 | 2010-02-10 | 株式会社日立製作所 | 複数の記憶システムを有するデータ処理システム |
| JP4426939B2 (ja) * | 2004-03-11 | 2010-03-03 | 株式会社日立製作所 | ストレージ装置 |
| US7249277B2 (en) * | 2004-03-11 | 2007-07-24 | Hitachi, Ltd. | Disk array including plural exchangeable magnetic disk unit |
| JP4476683B2 (ja) * | 2004-04-28 | 2010-06-09 | 株式会社日立製作所 | データ処理システム |
| US9043639B2 (en) * | 2004-11-05 | 2015-05-26 | Drobo, Inc. | Dynamically expandable and contractible fault-tolerant storage system with virtual hot spare |
| JP2006227964A (ja) * | 2005-02-18 | 2006-08-31 | Fujitsu Ltd | ストレージシステム、処理方法及びプログラム |
| JP5052193B2 (ja) * | 2007-04-17 | 2012-10-17 | 株式会社日立製作所 | 記憶制御装置および記憶制御方法 |
| JP4500346B2 (ja) * | 2007-11-21 | 2010-07-14 | 富士通株式会社 | ストレージシステム |
| JP4952605B2 (ja) * | 2008-02-07 | 2012-06-13 | 日本電気株式会社 | ディスクアレイ装置、データ切り戻し方法およびデータ切り戻しプログラム |
| JP2009252114A (ja) * | 2008-04-09 | 2009-10-29 | Hitachi Ltd | ストレージシステム及びデータ退避方法 |
| JP5252574B2 (ja) * | 2009-04-21 | 2013-07-31 | Necシステムテクノロジー株式会社 | ディスクアレイ制御装置及び方法並びにプログラム |
| WO2012140692A1 (en) * | 2011-04-12 | 2012-10-18 | Hitachi, Ltd. | Storage apparatus and method of controlling the same |
| JP2014056445A (ja) * | 2012-09-12 | 2014-03-27 | Fujitsu Ltd | ストレージ装置、ストレージ制御プログラムおよびストレージ制御方法 |
| WO2014091600A1 (ja) * | 2012-12-13 | 2014-06-19 | 株式会社日立製作所 | ストレージ装置及びストレージ装置移行方法 |
-
2013
- 2013-05-07 JP JP2013097648A patent/JP6212934B2/ja active Active
-
2014
- 2014-03-13 US US14/208,145 patent/US9507664B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014219787A (ja) | 2014-11-20 |
| US20140337665A1 (en) | 2014-11-13 |
| US9507664B2 (en) | 2016-11-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6212934B2 (ja) | ストレージシステム、情報処理装置の制御プログラム、およびストレージシステムの制御方法 | |
| US8234467B2 (en) | Storage management device, storage system control device, storage medium storing storage management program, and storage system | |
| JP4606455B2 (ja) | ストレージ管理装置、ストレージ管理プログラムおよびストレージシステム | |
| JP5158074B2 (ja) | ストレージ管理プログラム、ストレージ管理方法、ストレージ管理装置およびストレージシステム | |
| CN109857334B (zh) | 存储系统及其控制方法 | |
| JP2010097385A (ja) | データ管理プログラム、ストレージ装置診断プログラム、およびマルチノードストレージシステム | |
| JP5412882B2 (ja) | 論理ボリューム構成情報提供プログラム、論理ボリューム構成情報提供方法、および論理ボリューム構成情報提供装置 | |
| JP6850771B2 (ja) | 情報処理システム、情報処理システムの管理方法及びプログラム | |
| WO2011057885A1 (en) | Method and apparatus for failover of redundant disk controllers | |
| JP5218284B2 (ja) | 仮想ディスク管理プログラム、ストレージ装置管理プログラム、マルチノードストレージシステム、および仮想ディスク管理方法 | |
| JP4979348B2 (ja) | ストレージ・アレイ内でネットワーク・アドレスを割り当てるための装置および方法 | |
| CN104994168A (zh) | 分布式存储方法及分布式存储系统 | |
| JP2007200299A (ja) | データ記憶システムに配置された記憶アレイを再構成するための装置及び方法 | |
| JP6540334B2 (ja) | システム、情報処理装置、および情報処理方法 | |
| JP4454299B2 (ja) | ディスクアレイ装置及びディスクアレイ装置の保守方法 | |
| JP2010049637A (ja) | 計算機システム、ストレージシステム及び構成管理方法 | |
| US7506201B2 (en) | System and method of repair management for RAID arrays | |
| US10719265B1 (en) | Centralized, quorum-aware handling of device reservation requests in a storage system | |
| CN116204137B (zh) | 基于dpu的分布式存储系统、控制方法、装置及设备 | |
| JP5169993B2 (ja) | データストレージシステム、データ領域管理方法 | |
| JP5348300B2 (ja) | データ管理プログラム、およびマルチノードストレージシステム | |
| US8578206B2 (en) | Disk controller and disk control method | |
| JP5773446B2 (ja) | 記憶装置、冗長性回復方法、およびプログラム | |
| JP3636163B2 (ja) | 疎結合システムにおけるリカバリ方式及び排他制御装置 | |
| JP2010009476A (ja) | コンピュータシステム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160226 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20161221 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170110 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170307 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170822 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170904 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6212934 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |