JP5456222B2 - Il−1関連ポリペプチド - Google Patents
Il−1関連ポリペプチド Download PDFInfo
- Publication number
- JP5456222B2 JP5456222B2 JP2000591188A JP2000591188A JP5456222B2 JP 5456222 B2 JP5456222 B2 JP 5456222B2 JP 2000591188 A JP2000591188 A JP 2000591188A JP 2000591188 A JP2000591188 A JP 2000591188A JP 5456222 B2 JP5456222 B2 JP 5456222B2
- Authority
- JP
- Japan
- Prior art keywords
- amino acid
- hil
- polypeptide
- seq
- sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
- 108090000765 processed proteins & peptides Proteins 0.000 title claims description 718
- 102000004196 processed proteins & peptides Human genes 0.000 title claims description 696
- 229920001184 polypeptide Polymers 0.000 title claims description 690
- 108010002352 Interleukin-1 Proteins 0.000 title claims description 60
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 544
- 108020004414 DNA Proteins 0.000 claims description 338
- 125000000539 amino acid group Chemical group 0.000 claims description 336
- 150000007523 nucleic acids Chemical group 0.000 claims description 160
- 102000053602 DNA Human genes 0.000 claims description 152
- 239000013598 vector Substances 0.000 claims description 147
- 239000002299 complementary DNA Substances 0.000 claims description 114
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 85
- 102000039446 nucleic acids Human genes 0.000 claims description 79
- 108020004707 nucleic acids Proteins 0.000 claims description 79
- 230000000295 complement effect Effects 0.000 claims description 76
- 108700026244 Open Reading Frames Proteins 0.000 claims description 74
- 239000002773 nucleotide Substances 0.000 claims description 74
- 125000003729 nucleotide group Chemical group 0.000 claims description 74
- 125000000729 N-terminal amino-acid group Chemical group 0.000 claims description 58
- 108091081021 Sense strand Proteins 0.000 claims description 48
- 230000014509 gene expression Effects 0.000 claims description 35
- 108060003951 Immunoglobulin Proteins 0.000 claims description 28
- 102000018358 immunoglobulin Human genes 0.000 claims description 28
- 238000004519 manufacturing process Methods 0.000 claims description 11
- 238000012258 culturing Methods 0.000 claims description 6
- 238000004113 cell culture Methods 0.000 claims description 5
- 108020004635 Complementary DNA Proteins 0.000 claims description 4
- 101100394073 Caenorhabditis elegans hil-1 gene Proteins 0.000 claims description 3
- 238000010804 cDNA synthesis Methods 0.000 claims description 3
- 244000005700 microbiome Species 0.000 claims description 3
- 230000003796 beauty Effects 0.000 claims 6
- 238000000034 method Methods 0.000 description 173
- 238000011282 treatment Methods 0.000 description 145
- 210000004027 cell Anatomy 0.000 description 127
- 235000001014 amino acid Nutrition 0.000 description 115
- 108090000623 proteins and genes Proteins 0.000 description 112
- 230000027455 binding Effects 0.000 description 99
- 229940024606 amino acid Drugs 0.000 description 90
- 150000001413 amino acids Chemical group 0.000 description 82
- 241000124008 Mammalia Species 0.000 description 78
- 102000004169 proteins and genes Human genes 0.000 description 72
- 235000018102 proteins Nutrition 0.000 description 71
- 108010017537 Interleukin-18 Receptors Proteins 0.000 description 65
- 102000004557 Interleukin-18 Receptors Human genes 0.000 description 65
- 102000019223 Interleukin-1 receptor Human genes 0.000 description 64
- 108050006617 Interleukin-1 receptor Proteins 0.000 description 64
- 230000004927 fusion Effects 0.000 description 62
- 102000000589 Interleukin-1 Human genes 0.000 description 52
- 239000002253 acid Substances 0.000 description 51
- 230000001404 mediated effect Effects 0.000 description 50
- 230000004071 biological effect Effects 0.000 description 47
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 42
- 101001076407 Homo sapiens Interleukin-1 receptor antagonist protein Proteins 0.000 description 34
- 241001465754 Metazoa Species 0.000 description 30
- 239000000523 sample Substances 0.000 description 29
- 201000010099 disease Diseases 0.000 description 28
- 230000000694 effects Effects 0.000 description 27
- 102000003810 Interleukin-18 Human genes 0.000 description 26
- 108090000171 Interleukin-18 Proteins 0.000 description 26
- 239000002609 medium Substances 0.000 description 26
- 238000009396 hybridization Methods 0.000 description 24
- 210000001519 tissue Anatomy 0.000 description 23
- 108010076504 Protein Sorting Signals Proteins 0.000 description 22
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 22
- 208000009329 Graft vs Host Disease Diseases 0.000 description 21
- 208000024908 graft versus host disease Diseases 0.000 description 21
- 238000006467 substitution reaction Methods 0.000 description 21
- 239000012634 fragment Substances 0.000 description 20
- 102000051628 Interleukin-1 receptor antagonist Human genes 0.000 description 18
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 18
- 208000006673 asthma Diseases 0.000 description 18
- 108020001507 fusion proteins Proteins 0.000 description 18
- 102000037865 fusion proteins Human genes 0.000 description 18
- 102000046824 human IL1RN Human genes 0.000 description 18
- 239000003407 interleukin 1 receptor blocking agent Substances 0.000 description 18
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 17
- 241000699666 Mus <mouse, genus> Species 0.000 description 17
- 239000000243 solution Substances 0.000 description 17
- 229940119178 Interleukin 1 receptor antagonist Drugs 0.000 description 16
- 238000003556 assay Methods 0.000 description 16
- 210000004408 hybridoma Anatomy 0.000 description 16
- 238000003752 polymerase chain reaction Methods 0.000 description 15
- 102000005962 receptors Human genes 0.000 description 15
- 238000012360 testing method Methods 0.000 description 15
- 108020003175 receptors Proteins 0.000 description 14
- 101710144554 Interleukin-1 receptor antagonist protein Proteins 0.000 description 13
- 210000004899 c-terminal region Anatomy 0.000 description 13
- 239000003446 ligand Substances 0.000 description 13
- 108091060211 Expressed sequence tag Proteins 0.000 description 12
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 12
- 102100026018 Interleukin-1 receptor antagonist protein Human genes 0.000 description 12
- 239000003623 enhancer Substances 0.000 description 12
- 108020004999 messenger RNA Proteins 0.000 description 12
- 230000014616 translation Effects 0.000 description 12
- 108020004705 Codon Proteins 0.000 description 11
- 208000022559 Inflammatory bowel disease Diseases 0.000 description 11
- 241000699670 Mus sp. Species 0.000 description 11
- 201000004681 Psoriasis Diseases 0.000 description 11
- 239000000556 agonist Substances 0.000 description 11
- 238000004458 analytical method Methods 0.000 description 11
- 210000004102 animal cell Anatomy 0.000 description 11
- 239000005557 antagonist Substances 0.000 description 11
- 239000003636 conditioned culture medium Substances 0.000 description 11
- 239000013604 expression vector Substances 0.000 description 11
- 238000011534 incubation Methods 0.000 description 11
- 230000003834 intracellular effect Effects 0.000 description 11
- 230000000302 ischemic effect Effects 0.000 description 11
- 239000013612 plasmid Substances 0.000 description 11
- 239000002243 precursor Substances 0.000 description 11
- 206010039073 rheumatoid arthritis Diseases 0.000 description 11
- 238000013519 translation Methods 0.000 description 11
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 10
- 201000009794 Idiopathic Pulmonary Fibrosis Diseases 0.000 description 10
- 208000027866 inflammatory disease Diseases 0.000 description 10
- 208000036971 interstitial lung disease 2 Diseases 0.000 description 10
- 210000004962 mammalian cell Anatomy 0.000 description 10
- 239000000203 mixture Substances 0.000 description 10
- 230000001575 pathological effect Effects 0.000 description 10
- 230000010410 reperfusion Effects 0.000 description 10
- 230000003248 secreting effect Effects 0.000 description 10
- 239000000126 substance Substances 0.000 description 10
- 206010001052 Acute respiratory distress syndrome Diseases 0.000 description 9
- 108091026890 Coding region Proteins 0.000 description 9
- 206010009900 Colitis ulcerative Diseases 0.000 description 9
- 241000588724 Escherichia coli Species 0.000 description 9
- 241000282412 Homo Species 0.000 description 9
- 206010063837 Reperfusion injury Diseases 0.000 description 9
- 208000013616 Respiratory Distress Syndrome Diseases 0.000 description 9
- 201000006704 Ulcerative Colitis Diseases 0.000 description 9
- 208000011341 adult acute respiratory distress syndrome Diseases 0.000 description 9
- 201000000028 adult respiratory distress syndrome Diseases 0.000 description 9
- 239000003153 chemical reaction reagent Substances 0.000 description 9
- 238000010367 cloning Methods 0.000 description 9
- 239000003814 drug Substances 0.000 description 9
- -1 his Chemical compound 0.000 description 9
- 238000001114 immunoprecipitation Methods 0.000 description 9
- 201000008482 osteoarthritis Diseases 0.000 description 9
- 238000000746 purification Methods 0.000 description 9
- 230000002829 reductive effect Effects 0.000 description 9
- 239000011780 sodium chloride Substances 0.000 description 9
- 102000004190 Enzymes Human genes 0.000 description 8
- 108090000790 Enzymes Proteins 0.000 description 8
- 229920002684 Sepharose Polymers 0.000 description 8
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 8
- 239000002671 adjuvant Substances 0.000 description 8
- 229940088598 enzyme Drugs 0.000 description 8
- 230000013595 glycosylation Effects 0.000 description 8
- 238000006206 glycosylation reaction Methods 0.000 description 8
- 238000003119 immunoblot Methods 0.000 description 8
- 238000000338 in vitro Methods 0.000 description 8
- 230000035772 mutation Effects 0.000 description 8
- 208000010125 myocardial infarction Diseases 0.000 description 8
- 208000031225 myocardial ischemia Diseases 0.000 description 8
- 230000001323 posttranslational effect Effects 0.000 description 8
- 238000012545 processing Methods 0.000 description 8
- 108091008146 restriction endonucleases Proteins 0.000 description 8
- 230000009261 transgenic effect Effects 0.000 description 8
- 241000894006 Bacteria Species 0.000 description 7
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 7
- 206010035226 Plasma cell myeloma Diseases 0.000 description 7
- 206010040047 Sepsis Diseases 0.000 description 7
- 241000700605 Viruses Species 0.000 description 7
- 230000015572 biosynthetic process Effects 0.000 description 7
- 206010008118 cerebral infarction Diseases 0.000 description 7
- 208000026106 cerebrovascular disease Diseases 0.000 description 7
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 7
- 238000004590 computer program Methods 0.000 description 7
- 229940124452 immunizing agent Drugs 0.000 description 7
- 230000002163 immunogen Effects 0.000 description 7
- 208000015181 infectious disease Diseases 0.000 description 7
- 239000003112 inhibitor Substances 0.000 description 7
- 238000002955 isolation Methods 0.000 description 7
- 230000004048 modification Effects 0.000 description 7
- 238000012986 modification Methods 0.000 description 7
- 201000000050 myeloid neoplasm Diseases 0.000 description 7
- 238000002360 preparation method Methods 0.000 description 7
- 239000013615 primer Substances 0.000 description 7
- 239000000047 product Substances 0.000 description 7
- 238000003259 recombinant expression Methods 0.000 description 7
- 238000012216 screening Methods 0.000 description 7
- 230000028327 secretion Effects 0.000 description 7
- 208000024891 symptom Diseases 0.000 description 7
- 238000013518 transcription Methods 0.000 description 7
- 230000035897 transcription Effects 0.000 description 7
- 238000001890 transfection Methods 0.000 description 7
- 108091034117 Oligonucleotide Proteins 0.000 description 6
- 101710120037 Toxin CcdB Proteins 0.000 description 6
- 239000000427 antigen Substances 0.000 description 6
- 150000001720 carbohydrates Chemical group 0.000 description 6
- 239000006143 cell culture medium Substances 0.000 description 6
- 230000008859 change Effects 0.000 description 6
- 238000003776 cleavage reaction Methods 0.000 description 6
- 239000000499 gel Substances 0.000 description 6
- 238000001415 gene therapy Methods 0.000 description 6
- 235000011187 glycerol Nutrition 0.000 description 6
- 239000001963 growth medium Substances 0.000 description 6
- 238000001727 in vivo Methods 0.000 description 6
- 238000003780 insertion Methods 0.000 description 6
- 230000037431 insertion Effects 0.000 description 6
- 239000002244 precipitate Substances 0.000 description 6
- 238000001556 precipitation Methods 0.000 description 6
- 230000007017 scission Effects 0.000 description 6
- 241000701447 unidentified baculovirus Species 0.000 description 6
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 5
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 5
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 5
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 5
- 108010052285 Membrane Proteins Proteins 0.000 description 5
- 239000002202 Polyethylene glycol Substances 0.000 description 5
- 241000700159 Rattus Species 0.000 description 5
- 108700019146 Transgenes Proteins 0.000 description 5
- 206010069351 acute lung injury Diseases 0.000 description 5
- 238000001042 affinity chromatography Methods 0.000 description 5
- 235000004279 alanine Nutrition 0.000 description 5
- 108091007433 antigens Proteins 0.000 description 5
- 102000036639 antigens Human genes 0.000 description 5
- 238000005119 centrifugation Methods 0.000 description 5
- 238000006243 chemical reaction Methods 0.000 description 5
- 239000003795 chemical substances by application Substances 0.000 description 5
- 238000012217 deletion Methods 0.000 description 5
- 230000037430 deletion Effects 0.000 description 5
- 238000004520 electroporation Methods 0.000 description 5
- 230000002255 enzymatic effect Effects 0.000 description 5
- 230000012010 growth Effects 0.000 description 5
- 239000003550 marker Substances 0.000 description 5
- 239000012528 membrane Substances 0.000 description 5
- 229920001223 polyethylene glycol Polymers 0.000 description 5
- 239000001509 sodium citrate Substances 0.000 description 5
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 5
- 238000010561 standard procedure Methods 0.000 description 5
- 230000001225 therapeutic effect Effects 0.000 description 5
- 230000009466 transformation Effects 0.000 description 5
- 238000005406 washing Methods 0.000 description 5
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 4
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 4
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 4
- 206010003445 Ascites Diseases 0.000 description 4
- 102000004127 Cytokines Human genes 0.000 description 4
- 108090000695 Cytokines Proteins 0.000 description 4
- 102100024746 Dihydrofolate reductase Human genes 0.000 description 4
- 241000238631 Hexapoda Species 0.000 description 4
- 108010091358 Hypoxanthine Phosphoribosyltransferase Proteins 0.000 description 4
- 206010061218 Inflammation Diseases 0.000 description 4
- 102100039880 Interleukin-1 receptor accessory protein Human genes 0.000 description 4
- 101710180389 Interleukin-1 receptor accessory protein Proteins 0.000 description 4
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 4
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 4
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 4
- 102000018697 Membrane Proteins Human genes 0.000 description 4
- 229910019142 PO4 Inorganic materials 0.000 description 4
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 4
- 241000283984 Rodentia Species 0.000 description 4
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 4
- 239000003242 anti bacterial agent Substances 0.000 description 4
- 239000001506 calcium phosphate Substances 0.000 description 4
- 229910000389 calcium phosphate Inorganic materials 0.000 description 4
- 235000011010 calcium phosphates Nutrition 0.000 description 4
- 230000002950 deficient Effects 0.000 description 4
- 229960000633 dextran sulfate Drugs 0.000 description 4
- 108020001096 dihydrofolate reductase Proteins 0.000 description 4
- 229940079593 drug Drugs 0.000 description 4
- 210000003527 eukaryotic cell Anatomy 0.000 description 4
- 125000005842 heteroatom Chemical group 0.000 description 4
- 229940098197 human immunoglobulin g Drugs 0.000 description 4
- 230000004054 inflammatory process Effects 0.000 description 4
- 210000003734 kidney Anatomy 0.000 description 4
- 239000002502 liposome Substances 0.000 description 4
- 239000012160 loading buffer Substances 0.000 description 4
- 210000004698 lymphocyte Anatomy 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- 229960004452 methionine Drugs 0.000 description 4
- 102000034288 naturally occurring fusion proteins Human genes 0.000 description 4
- 108091006048 naturally occurring fusion proteins Proteins 0.000 description 4
- 239000010452 phosphate Substances 0.000 description 4
- 238000010814 radioimmunoprecipitation assay Methods 0.000 description 4
- 238000010188 recombinant method Methods 0.000 description 4
- 230000010076 replication Effects 0.000 description 4
- 238000012552 review Methods 0.000 description 4
- 230000019491 signal transduction Effects 0.000 description 4
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 210000004989 spleen cell Anatomy 0.000 description 4
- 239000006228 supernatant Substances 0.000 description 4
- 238000003786 synthesis reaction Methods 0.000 description 4
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 4
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 3
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 3
- 208000035473 Communicable disease Diseases 0.000 description 3
- 229920002307 Dextran Polymers 0.000 description 3
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 3
- 238000002965 ELISA Methods 0.000 description 3
- 241000196324 Embryophyta Species 0.000 description 3
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 3
- 239000004471 Glycine Substances 0.000 description 3
- 102100029098 Hypoxanthine-guanine phosphoribosyltransferase Human genes 0.000 description 3
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 3
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 3
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 3
- 239000004472 Lysine Substances 0.000 description 3
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 3
- 208000006011 Stroke Diseases 0.000 description 3
- 210000001744 T-lymphocyte Anatomy 0.000 description 3
- IXKSXJFAGXLQOQ-XISFHERQSA-N WHWLQLKPGQPMY Chemical compound C([C@@H](C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CNC=N1 IXKSXJFAGXLQOQ-XISFHERQSA-N 0.000 description 3
- 230000004913 activation Effects 0.000 description 3
- 229940088710 antibiotic agent Drugs 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 3
- 210000000349 chromosome Anatomy 0.000 description 3
- 238000004440 column chromatography Methods 0.000 description 3
- 238000007796 conventional method Methods 0.000 description 3
- 229960002086 dextran Drugs 0.000 description 3
- 238000009826 distribution Methods 0.000 description 3
- 239000003937 drug carrier Substances 0.000 description 3
- 238000002474 experimental method Methods 0.000 description 3
- 230000001605 fetal effect Effects 0.000 description 3
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 3
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 3
- 230000001900 immune effect Effects 0.000 description 3
- 238000000099 in vitro assay Methods 0.000 description 3
- 230000028709 inflammatory response Effects 0.000 description 3
- 238000002347 injection Methods 0.000 description 3
- 239000007924 injection Substances 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 238000002372 labelling Methods 0.000 description 3
- 210000000265 leukocyte Anatomy 0.000 description 3
- 238000002703 mutagenesis Methods 0.000 description 3
- 231100000350 mutagenesis Toxicity 0.000 description 3
- 239000012071 phase Substances 0.000 description 3
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 3
- 238000000159 protein binding assay Methods 0.000 description 3
- 238000011002 quantification Methods 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 230000004044 response Effects 0.000 description 3
- 238000007423 screening assay Methods 0.000 description 3
- 238000002864 sequence alignment Methods 0.000 description 3
- 239000012679 serum free medium Substances 0.000 description 3
- 150000003384 small molecules Chemical class 0.000 description 3
- 229940124597 therapeutic agent Drugs 0.000 description 3
- 238000002560 therapeutic procedure Methods 0.000 description 3
- 241000701161 unidentified adenovirus Species 0.000 description 3
- 230000003612 virological effect Effects 0.000 description 3
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- GZCWLCBFPRFLKL-UHFFFAOYSA-N 1-prop-2-ynoxypropan-2-ol Chemical compound CC(O)COCC#C GZCWLCBFPRFLKL-UHFFFAOYSA-N 0.000 description 2
- OSJPPGNTCRNQQC-UWTATZPHSA-N 3-phospho-D-glyceric acid Chemical compound OC(=O)[C@H](O)COP(O)(O)=O OSJPPGNTCRNQQC-UWTATZPHSA-N 0.000 description 2
- 102000013563 Acid Phosphatase Human genes 0.000 description 2
- 108010051457 Acid Phosphatase Proteins 0.000 description 2
- 229920000936 Agarose Polymers 0.000 description 2
- 102100034044 All-trans-retinol dehydrogenase [NAD(+)] ADH1B Human genes 0.000 description 2
- 101710193111 All-trans-retinol dehydrogenase [NAD(+)] ADH4 Proteins 0.000 description 2
- 108020004491 Antisense DNA Proteins 0.000 description 2
- 108020005544 Antisense RNA Proteins 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- 208000002109 Argyria Diseases 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 241000972773 Aulopiformes Species 0.000 description 2
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 241000283707 Capra Species 0.000 description 2
- 108090000565 Capsid Proteins Proteins 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 241000699802 Cricetulus griseus Species 0.000 description 2
- 241000701022 Cytomegalovirus Species 0.000 description 2
- 230000004544 DNA amplification Effects 0.000 description 2
- 108010069941 DNA receptor Proteins 0.000 description 2
- 201000004624 Dermatitis Diseases 0.000 description 2
- 241000233866 Fungi Species 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- 108010070600 Glucose-6-phosphate isomerase Proteins 0.000 description 2
- 102100031181 Glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 2
- 108010031186 Glycoside Hydrolases Proteins 0.000 description 2
- 102000005744 Glycoside Hydrolases Human genes 0.000 description 2
- 101000878605 Homo sapiens Low affinity immunoglobulin epsilon Fc receptor Proteins 0.000 description 2
- 102000039996 IL-1 family Human genes 0.000 description 2
- 108091069196 IL-1 family Proteins 0.000 description 2
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 2
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 2
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 description 2
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 description 2
- 108090001007 Interleukin-8 Proteins 0.000 description 2
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 2
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 2
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- 102100038007 Low affinity immunoglobulin epsilon Fc receptor Human genes 0.000 description 2
- 102000003945 NF-kappa B Human genes 0.000 description 2
- 108010057466 NF-kappa B Proteins 0.000 description 2
- 238000000636 Northern blotting Methods 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- 108091000080 Phosphotransferase Proteins 0.000 description 2
- 206010035664 Pneumonia Diseases 0.000 description 2
- 241000235070 Saccharomyces Species 0.000 description 2
- 229920005654 Sephadex Polymers 0.000 description 2
- 239000012507 Sephadex™ Substances 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- 108091081024 Start codon Proteins 0.000 description 2
- 101150006914 TRP1 gene Proteins 0.000 description 2
- 239000004098 Tetracycline Substances 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- 206010067584 Type 1 diabetes mellitus Diseases 0.000 description 2
- 206010047115 Vasculitis Diseases 0.000 description 2
- 108020005202 Viral DNA Proteins 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- 230000001154 acute effect Effects 0.000 description 2
- 238000001261 affinity purification Methods 0.000 description 2
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 2
- 201000009961 allergic asthma Diseases 0.000 description 2
- 238000012870 ammonium sulfate precipitation Methods 0.000 description 2
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 2
- 229960000723 ampicillin Drugs 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 230000000890 antigenic effect Effects 0.000 description 2
- 239000003816 antisense DNA Substances 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 108010051210 beta-Fructofuranosidase Proteins 0.000 description 2
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 2
- 108091008324 binding proteins Proteins 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 229940098773 bovine serum albumin Drugs 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 210000003169 central nervous system Anatomy 0.000 description 2
- 239000013522 chelant Substances 0.000 description 2
- 230000009920 chelation Effects 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 230000002759 chromosomal effect Effects 0.000 description 2
- 230000001684 chronic effect Effects 0.000 description 2
- 230000000052 comparative effect Effects 0.000 description 2
- 239000003184 complementary RNA Substances 0.000 description 2
- 239000002131 composite material Substances 0.000 description 2
- 239000000356 contaminant Substances 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 238000004132 cross linking Methods 0.000 description 2
- 239000003431 cross linking reagent Substances 0.000 description 2
- 230000009260 cross reactivity Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 238000001212 derivatisation Methods 0.000 description 2
- 238000000502 dialysis Methods 0.000 description 2
- 208000035475 disorder Diseases 0.000 description 2
- 210000002308 embryonic cell Anatomy 0.000 description 2
- 210000001671 embryonic stem cell Anatomy 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 201000001155 extrinsic allergic alveolitis Diseases 0.000 description 2
- 238000000855 fermentation Methods 0.000 description 2
- 230000004151 fermentation Effects 0.000 description 2
- 239000012530 fluid Substances 0.000 description 2
- 238000009472 formulation Methods 0.000 description 2
- 238000001502 gel electrophoresis Methods 0.000 description 2
- 239000008103 glucose Substances 0.000 description 2
- 108010037896 heparin-binding hemagglutinin Proteins 0.000 description 2
- 208000006454 hepatitis Diseases 0.000 description 2
- 231100000283 hepatitis Toxicity 0.000 description 2
- 238000002744 homologous recombination Methods 0.000 description 2
- 230000006801 homologous recombination Effects 0.000 description 2
- 208000022098 hypersensitivity pneumonitis Diseases 0.000 description 2
- FDGQSTZJBFJUBT-UHFFFAOYSA-N hypoxanthine Chemical compound O=C1NC=NC2=C1NC=N2 FDGQSTZJBFJUBT-UHFFFAOYSA-N 0.000 description 2
- 230000003053 immunization Effects 0.000 description 2
- 238000002649 immunization Methods 0.000 description 2
- 230000016784 immunoglobulin production Effects 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 238000011532 immunohistochemical staining Methods 0.000 description 2
- 239000012133 immunoprecipitate Substances 0.000 description 2
- 230000008676 import Effects 0.000 description 2
- 238000007901 in situ hybridization Methods 0.000 description 2
- 230000001965 increasing effect Effects 0.000 description 2
- 230000002757 inflammatory effect Effects 0.000 description 2
- 230000000977 initiatory effect Effects 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 239000001573 invertase Substances 0.000 description 2
- 235000011073 invertase Nutrition 0.000 description 2
- 210000001161 mammalian embryo Anatomy 0.000 description 2
- 238000013507 mapping Methods 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 2
- 229930182817 methionine Natural products 0.000 description 2
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 2
- 238000000520 microinjection Methods 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 230000002107 myocardial effect Effects 0.000 description 2
- 230000007935 neutral effect Effects 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 235000015097 nutrients Nutrition 0.000 description 2
- 210000001672 ovary Anatomy 0.000 description 2
- 230000007310 pathophysiology Effects 0.000 description 2
- 239000008188 pellet Substances 0.000 description 2
- 238000010647 peptide synthesis reaction Methods 0.000 description 2
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 2
- 239000008194 pharmaceutical composition Substances 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- 230000026731 phosphorylation Effects 0.000 description 2
- 238000006366 phosphorylation reaction Methods 0.000 description 2
- 102000020233 phosphotransferase Human genes 0.000 description 2
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 2
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 2
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- 230000000770 proinflammatory effect Effects 0.000 description 2
- 238000001742 protein purification Methods 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 229940044551 receptor antagonist Drugs 0.000 description 2
- 239000002464 receptor antagonist Substances 0.000 description 2
- 210000002345 respiratory system Anatomy 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 235000019515 salmon Nutrition 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 230000035939 shock Effects 0.000 description 2
- FQENQNTWSFEDLI-UHFFFAOYSA-J sodium diphosphate Chemical compound [Na+].[Na+].[Na+].[Na+].[O-]P([O-])(=O)OP([O-])([O-])=O FQENQNTWSFEDLI-UHFFFAOYSA-J 0.000 description 2
- 239000001488 sodium phosphate Substances 0.000 description 2
- 229910000162 sodium phosphate Inorganic materials 0.000 description 2
- 229940048086 sodium pyrophosphate Drugs 0.000 description 2
- 239000007790 solid phase Substances 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 239000003381 stabilizer Substances 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 208000011580 syndromic disease Diseases 0.000 description 2
- 230000009885 systemic effect Effects 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 229960002180 tetracycline Drugs 0.000 description 2
- 229930101283 tetracycline Natural products 0.000 description 2
- 235000019364 tetracycline Nutrition 0.000 description 2
- 150000003522 tetracyclines Chemical class 0.000 description 2
- 235000019818 tetrasodium diphosphate Nutrition 0.000 description 2
- 239000001577 tetrasodium phosphonato phosphate Substances 0.000 description 2
- 125000000341 threoninyl group Chemical group [H]OC([H])(C([H])([H])[H])C([H])(N([H])[H])C(*)=O 0.000 description 2
- 229940104230 thymidine Drugs 0.000 description 2
- 239000003104 tissue culture media Substances 0.000 description 2
- 231100000607 toxicokinetics Toxicity 0.000 description 2
- 230000005030 transcription termination Effects 0.000 description 2
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 2
- 208000035408 type 1 diabetes mellitus 1 Diseases 0.000 description 2
- 239000011534 wash buffer Substances 0.000 description 2
- HDTRYLNUVZCQOY-UHFFFAOYSA-N α-D-glucopyranosyl-α-D-glucopyranoside Natural products OC1C(O)C(O)C(CO)OC1OC1C(O)C(O)C(O)C(CO)O1 HDTRYLNUVZCQOY-UHFFFAOYSA-N 0.000 description 1
- DIGQNXIGRZPYDK-WKSCXVIASA-N (2R)-6-amino-2-[[2-[[(2S)-2-[[2-[[(2R)-2-[[(2S)-2-[[(2R,3S)-2-[[2-[[(2S)-2-[[2-[[(2S)-2-[[(2S)-2-[[(2R)-2-[[(2S,3S)-2-[[(2R)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[2-[[(2S)-2-[[(2R)-2-[[2-[[2-[[2-[(2-amino-1-hydroxyethylidene)amino]-3-carboxy-1-hydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1,5-dihydroxy-5-iminopentylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]hexanoic acid Chemical compound C[C@@H]([C@@H](C(=N[C@@H](CS)C(=N[C@@H](C)C(=N[C@@H](CO)C(=NCC(=N[C@@H](CCC(=N)O)C(=NC(CS)C(=N[C@H]([C@H](C)O)C(=N[C@H](CS)C(=N[C@H](CO)C(=NCC(=N[C@H](CS)C(=NCC(=N[C@H](CCCCN)C(=O)O)O)O)O)O)O)O)O)O)O)O)O)O)O)N=C([C@H](CS)N=C([C@H](CO)N=C([C@H](CO)N=C([C@H](C)N=C(CN=C([C@H](CO)N=C([C@H](CS)N=C(CN=C(C(CS)N=C(C(CC(=O)O)N=C(CN)O)O)O)O)O)O)O)O)O)O)O)O DIGQNXIGRZPYDK-WKSCXVIASA-N 0.000 description 1
- NWUYHJFMYQTDRP-UHFFFAOYSA-N 1,2-bis(ethenyl)benzene;1-ethenyl-2-ethylbenzene;styrene Chemical compound C=CC1=CC=CC=C1.CCC1=CC=CC=C1C=C.C=CC1=CC=CC=C1C=C NWUYHJFMYQTDRP-UHFFFAOYSA-N 0.000 description 1
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 1
- 125000003287 1H-imidazol-4-ylmethyl group Chemical group [H]N1C([H])=NC(C([H])([H])[*])=C1[H] 0.000 description 1
- 150000003923 2,5-pyrrolediones Chemical class 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- BFSVOASYOCHEOV-UHFFFAOYSA-N 2-diethylaminoethanol Chemical compound CCN(CC)CCO BFSVOASYOCHEOV-UHFFFAOYSA-N 0.000 description 1
- BIGBDMFRWJRLGJ-UHFFFAOYSA-N 3-benzyl-1,5-didiazoniopenta-1,4-diene-2,4-diolate Chemical compound [N-]=[N+]=CC(=O)C(C(=O)C=[N+]=[N-])CC1=CC=CC=C1 BIGBDMFRWJRLGJ-UHFFFAOYSA-N 0.000 description 1
- QFVHZQCOUORWEI-UHFFFAOYSA-N 4-[(4-anilino-5-sulfonaphthalen-1-yl)diazenyl]-5-hydroxynaphthalene-2,7-disulfonic acid Chemical compound C=12C(O)=CC(S(O)(=O)=O)=CC2=CC(S(O)(=O)=O)=CC=1N=NC(C1=CC=CC(=C11)S(O)(=O)=O)=CC=C1NC1=CC=CC=C1 QFVHZQCOUORWEI-UHFFFAOYSA-N 0.000 description 1
- TVZGACDUOSZQKY-LBPRGKRZSA-N 4-aminofolic acid Chemical compound C1=NC2=NC(N)=NC(N)=C2N=C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 TVZGACDUOSZQKY-LBPRGKRZSA-N 0.000 description 1
- NLPWSMKACWGINL-UHFFFAOYSA-N 4-azido-2-hydroxybenzoic acid Chemical compound OC(=O)C1=CC=C(N=[N+]=[N-])C=C1O NLPWSMKACWGINL-UHFFFAOYSA-N 0.000 description 1
- 102000007469 Actins Human genes 0.000 description 1
- 108010085238 Actins Proteins 0.000 description 1
- 241000589155 Agrobacterium tumefaciens Species 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 101710187573 Alcohol dehydrogenase 2 Proteins 0.000 description 1
- 101710133776 Alcohol dehydrogenase class-3 Proteins 0.000 description 1
- 206010001889 Alveolitis Diseases 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 208000023275 Autoimmune disease Diseases 0.000 description 1
- 241000713842 Avian sarcoma virus Species 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 201000001178 Bacterial Pneumonia Diseases 0.000 description 1
- 208000009137 Behcet syndrome Diseases 0.000 description 1
- 101001011741 Bos taurus Insulin Proteins 0.000 description 1
- 101000766308 Bos taurus Serotransferrin Proteins 0.000 description 1
- 241000701822 Bovine papillomavirus Species 0.000 description 1
- 206010048962 Brain oedema Diseases 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 206010006458 Bronchitis chronic Diseases 0.000 description 1
- 125000001433 C-terminal amino-acid group Chemical group 0.000 description 1
- 102000001902 CC Chemokines Human genes 0.000 description 1
- 108010040471 CC Chemokines Proteins 0.000 description 1
- 108050006947 CXC Chemokine Proteins 0.000 description 1
- 102000019388 CXC chemokine Human genes 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- 241000222122 Candida albicans Species 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 201000009030 Carcinoma Diseases 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 102100023321 Ceruloplasmin Human genes 0.000 description 1
- 108091062157 Cis-regulatory element Proteins 0.000 description 1
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 1
- 102000029816 Collagenase Human genes 0.000 description 1
- 108060005980 Collagenase Proteins 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 238000011537 Coomassie blue staining Methods 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 208000011231 Crohn disease Diseases 0.000 description 1
- 239000004971 Cross linker Substances 0.000 description 1
- 102000008130 Cyclic AMP-Dependent Protein Kinases Human genes 0.000 description 1
- 108010049894 Cyclic AMP-Dependent Protein Kinases Proteins 0.000 description 1
- 102000004654 Cyclic GMP-Dependent Protein Kinases Human genes 0.000 description 1
- 108010003591 Cyclic GMP-Dependent Protein Kinases Proteins 0.000 description 1
- 102000005927 Cysteine Proteases Human genes 0.000 description 1
- 108010005843 Cysteine Proteases Proteins 0.000 description 1
- 201000003883 Cystic fibrosis Diseases 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- 108020001019 DNA Primers Proteins 0.000 description 1
- 239000003155 DNA primer Substances 0.000 description 1
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 1
- 101710088194 Dehydrogenase Proteins 0.000 description 1
- 102100037840 Dehydrogenase/reductase SDR family member 2, mitochondrial Human genes 0.000 description 1
- 206010012438 Dermatitis atopic Diseases 0.000 description 1
- 239000004375 Dextrin Substances 0.000 description 1
- 229920001353 Dextrin Polymers 0.000 description 1
- 108090000204 Dipeptidase 1 Proteins 0.000 description 1
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 1
- 102000015689 E-Selectin Human genes 0.000 description 1
- 108010024212 E-Selectin Proteins 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- 101710202200 Endolysin A Proteins 0.000 description 1
- 241000588921 Enterobacteriaceae Species 0.000 description 1
- 108010013369 Enteropeptidase Proteins 0.000 description 1
- 102100029727 Enteropeptidase Human genes 0.000 description 1
- 101710146739 Enterotoxin Proteins 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 101000867232 Escherichia coli Heat-stable enterotoxin II Proteins 0.000 description 1
- 241001646716 Escherichia coli K-12 Species 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 206010015866 Extravasation Diseases 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 229920001917 Ficoll Polymers 0.000 description 1
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- 102000006395 Globulins Human genes 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- 108010073178 Glucan 1,4-alpha-Glucosidase Proteins 0.000 description 1
- 102100022624 Glucoamylase Human genes 0.000 description 1
- 102000030595 Glucokinase Human genes 0.000 description 1
- 108010021582 Glucokinase Proteins 0.000 description 1
- 102100031132 Glucose-6-phosphate isomerase Human genes 0.000 description 1
- 102000005731 Glucose-6-phosphate isomerase Human genes 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- 244000068988 Glycine max Species 0.000 description 1
- 235000010469 Glycine max Nutrition 0.000 description 1
- 206010018691 Granuloma Diseases 0.000 description 1
- HVLSXIKZNLPZJJ-TXZCQADKSA-N HA peptide Chemical compound C([C@@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HVLSXIKZNLPZJJ-TXZCQADKSA-N 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 208000031886 HIV Infections Diseases 0.000 description 1
- 208000037357 HIV infectious disease Diseases 0.000 description 1
- 101100082540 Haemophilus influenzae (strain ATCC 51907 / DSM 11121 / KW20 / Rd) pcp gene Proteins 0.000 description 1
- 208000010496 Heart Arrest Diseases 0.000 description 1
- 206010019728 Hepatitis alcoholic Diseases 0.000 description 1
- 229920000209 Hexadimethrine bromide Polymers 0.000 description 1
- 102000005548 Hexokinase Human genes 0.000 description 1
- 108700040460 Hexokinases Proteins 0.000 description 1
- LYCVKHSJGDMDLM-LURJTMIESA-N His-Gly Chemical compound OC(=O)CNC(=O)[C@@H](N)CC1=CN=CN1 LYCVKHSJGDMDLM-LURJTMIESA-N 0.000 description 1
- 101000950669 Homo sapiens Mitogen-activated protein kinase 9 Proteins 0.000 description 1
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 1
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 241000701109 Human adenovirus 2 Species 0.000 description 1
- 206010020751 Hypersensitivity Diseases 0.000 description 1
- 206010021137 Hypovolaemia Diseases 0.000 description 1
- UGQMRVRMYYASKQ-UHFFFAOYSA-N Hypoxanthine nucleoside Natural products OC1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 UGQMRVRMYYASKQ-UHFFFAOYSA-N 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 1
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 1
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 1
- 102000012745 Immunoglobulin Subunits Human genes 0.000 description 1
- 108010079585 Immunoglobulin Subunits Proteins 0.000 description 1
- 208000026350 Inborn Genetic disease Diseases 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 102100039898 Interleukin-18 Human genes 0.000 description 1
- 108010028784 Interleukin-18 Receptor alpha Subunit Proteins 0.000 description 1
- 102100039340 Interleukin-18 receptor 1 Human genes 0.000 description 1
- 102100035010 Interleukin-18 receptor accessory protein Human genes 0.000 description 1
- 101710138729 Interleukin-18 receptor accessory protein Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 108010055717 JNK Mitogen-Activated Protein Kinases Proteins 0.000 description 1
- 241000235649 Kluyveromyces Species 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- LRQKBLKVPFOOQJ-YFKPBYRVSA-N L-norleucine Chemical compound CCCC[C@H]([NH3+])C([O-])=O LRQKBLKVPFOOQJ-YFKPBYRVSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 1
- 208000005777 Lupus Nephritis Diseases 0.000 description 1
- 239000006137 Luria-Bertani broth Substances 0.000 description 1
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 201000009906 Meningitis Diseases 0.000 description 1
- 102000003792 Metallothionein Human genes 0.000 description 1
- 108090000157 Metallothionein Proteins 0.000 description 1
- 102100037809 Mitogen-activated protein kinase 9 Human genes 0.000 description 1
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 1
- 101001010588 Mus musculus Interleukin-1 receptor antagonist protein Proteins 0.000 description 1
- 101710135898 Myc proto-oncogene protein Proteins 0.000 description 1
- 102100038895 Myc proto-oncogene protein Human genes 0.000 description 1
- 241001460678 Napo <wasp> Species 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 230000004989 O-glycosylation Effects 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 108010067372 Pancreatic elastase Proteins 0.000 description 1
- 102000016387 Pancreatic elastase Human genes 0.000 description 1
- 206010033645 Pancreatitis Diseases 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 108010087702 Penicillinase Proteins 0.000 description 1
- 206010034464 Periarthritis Diseases 0.000 description 1
- 241000287462 Phalacrocorax carbo Species 0.000 description 1
- 102000001105 Phosphofructokinases Human genes 0.000 description 1
- 108010069341 Phosphofructokinases Proteins 0.000 description 1
- 102000012288 Phosphopyruvate Hydratase Human genes 0.000 description 1
- 108010022181 Phosphopyruvate Hydratase Proteins 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 241001505332 Polyomavirus sp. Species 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- XBDQKXXYIPTUBI-UHFFFAOYSA-M Propionate Chemical compound CCC([O-])=O XBDQKXXYIPTUBI-UHFFFAOYSA-M 0.000 description 1
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 1
- 101710188053 Protein D Proteins 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 108010011939 Pyruvate Decarboxylase Proteins 0.000 description 1
- 102000013009 Pyruvate Kinase Human genes 0.000 description 1
- 108020005115 Pyruvate Kinase Proteins 0.000 description 1
- 108020005067 RNA Splice Sites Proteins 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 101710132893 Resolvase Proteins 0.000 description 1
- 206010038669 Respiratory arrest Diseases 0.000 description 1
- 206010039710 Scleroderma Diseases 0.000 description 1
- 208000034189 Sclerosis Diseases 0.000 description 1
- 206010040070 Septic Shock Diseases 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- 241000256251 Spodoptera frugiperda Species 0.000 description 1
- 241000269319 Squalius cephalus Species 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 230000024932 T cell mediated immunity Effects 0.000 description 1
- 108091036066 Three prime untranslated region Proteins 0.000 description 1
- 102000006601 Thymidine Kinase Human genes 0.000 description 1
- 108020004440 Thymidine kinase Proteins 0.000 description 1
- 108010034949 Thyroglobulin Proteins 0.000 description 1
- 102000009843 Thyroglobulin Human genes 0.000 description 1
- 101710150448 Transcriptional regulator Myc Proteins 0.000 description 1
- HDTRYLNUVZCQOY-WSWWMNSNSA-N Trehalose Natural products O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-WSWWMNSNSA-N 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- 229940122618 Trypsin inhibitor Drugs 0.000 description 1
- 101710162629 Trypsin inhibitor Proteins 0.000 description 1
- 102000004243 Tubulin Human genes 0.000 description 1
- 108090000704 Tubulin Proteins 0.000 description 1
- 108050002568 Tumor necrosis factor ligand superfamily member 6 Proteins 0.000 description 1
- 102100031988 Tumor necrosis factor ligand superfamily member 6 Human genes 0.000 description 1
- 108091034131 VA RNA Proteins 0.000 description 1
- 244000000188 Vaccinium ovalifolium Species 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Chemical compound CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- 206010052428 Wound Diseases 0.000 description 1
- 208000027418 Wounds and injury Diseases 0.000 description 1
- HMNZFMSWFCAGGW-XPWSMXQVSA-N [3-[hydroxy(2-hydroxyethoxy)phosphoryl]oxy-2-[(e)-octadec-9-enoyl]oxypropyl] (e)-octadec-9-enoate Chemical compound CCCCCCCC\C=C\CCCCCCCC(=O)OCC(COP(O)(=O)OCCO)OC(=O)CCCCCCC\C=C\CCCCCCCC HMNZFMSWFCAGGW-XPWSMXQVSA-N 0.000 description 1
- SNVQVLIHTDFQDH-UHFFFAOYSA-L [Li+].P(=O)(O)([O-])[O-].[Na+] Chemical compound [Li+].P(=O)(O)([O-])[O-].[Na+] SNVQVLIHTDFQDH-UHFFFAOYSA-L 0.000 description 1
- 208000002223 abdominal aortic aneurysm Diseases 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 206010000891 acute myocardial infarction Diseases 0.000 description 1
- 230000002730 additional effect Effects 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 238000012867 alanine scanning Methods 0.000 description 1
- 208000002353 alcoholic hepatitis Diseases 0.000 description 1
- HDTRYLNUVZCQOY-LIZSDCNHSA-N alpha,alpha-trehalose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-LIZSDCNHSA-N 0.000 description 1
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 1
- 108010026331 alpha-Fetoproteins Proteins 0.000 description 1
- 102000013529 alpha-Fetoproteins Human genes 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 230000009435 amidation Effects 0.000 description 1
- 238000007112 amidation reaction Methods 0.000 description 1
- 150000001412 amines Chemical group 0.000 description 1
- 229960003896 aminopterin Drugs 0.000 description 1
- 238000004873 anchoring Methods 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 230000003110 anti-inflammatory effect Effects 0.000 description 1
- 210000000628 antibody-producing cell Anatomy 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 235000006708 antioxidants Nutrition 0.000 description 1
- 239000000074 antisense oligonucleotide Substances 0.000 description 1
- 238000012230 antisense oligonucleotides Methods 0.000 description 1
- 208000007474 aortic aneurysm Diseases 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 229960005070 ascorbic acid Drugs 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 201000008937 atopic dermatitis Diseases 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 244000052616 bacterial pathogen Species 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 102000005936 beta-Galactosidase Human genes 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 102000006635 beta-lactamase Human genes 0.000 description 1
- GUBGYTABKSRVRQ-QUYVBRFLSA-N beta-maltose Chemical compound OC[C@H]1O[C@H](O[C@H]2[C@H](O)[C@@H](O)[C@H](O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@@H]1O GUBGYTABKSRVRQ-QUYVBRFLSA-N 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 238000004166 bioassay Methods 0.000 description 1
- 230000008512 biological response Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 230000006287 biotinylation Effects 0.000 description 1
- 238000007413 biotinylation Methods 0.000 description 1
- 210000002459 blastocyst Anatomy 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- IXIBAKNTJSCKJM-BUBXBXGNSA-N bovine insulin Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@H]1CSSC[C@H]2C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@H](C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=3C=CC(O)=CC=3)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=3C=CC(O)=CC=3)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=3C=CC(O)=CC=3)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=3NC=NC=3)NC(=O)[C@H](CO)NC(=O)CNC1=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O)=O)CSSC[C@@H](C(N2)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](NC(=O)CN)[C@@H](C)CC)C(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C=CC=CC=1)C(C)C)C1=CN=CN1 IXIBAKNTJSCKJM-BUBXBXGNSA-N 0.000 description 1
- 208000006752 brain edema Diseases 0.000 description 1
- 201000009267 bronchiectasis Diseases 0.000 description 1
- 206010006451 bronchitis Diseases 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 238000007675 cardiac surgery Methods 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 238000012219 cassette mutagenesis Methods 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 239000003729 cation exchange resin Substances 0.000 description 1
- 238000000423 cell based assay Methods 0.000 description 1
- 239000012930 cell culture fluid Substances 0.000 description 1
- 230000007910 cell fusion Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 210000002421 cell wall Anatomy 0.000 description 1
- 230000030570 cellular localization Effects 0.000 description 1
- 230000004637 cellular stress Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- 238000011098 chromatofocusing Methods 0.000 description 1
- 239000012539 chromatography resin Substances 0.000 description 1
- 208000023819 chronic asthma Diseases 0.000 description 1
- 208000007451 chronic bronchitis Diseases 0.000 description 1
- 208000019425 cirrhosis of liver Diseases 0.000 description 1
- 230000004186 co-expression Effects 0.000 description 1
- 238000012761 co-transfection Methods 0.000 description 1
- 229960002424 collagenase Drugs 0.000 description 1
- 238000012875 competitive assay Methods 0.000 description 1
- 230000009137 competitive binding Effects 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 230000002844 continuous effect Effects 0.000 description 1
- 210000004351 coronary vessel Anatomy 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 230000001461 cytolytic effect Effects 0.000 description 1
- 230000009615 deamination Effects 0.000 description 1
- 238000006481 deamination reaction Methods 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 230000022811 deglycosylation Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 201000001981 dermatomyositis Diseases 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 235000019425 dextrin Nutrition 0.000 description 1
- 206010062952 diffuse panbronchiolitis Diseases 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- XEYBRNLFEZDVAW-ARSRFYASSA-N dinoprostone Chemical compound CCCCC[C@H](O)\C=C\[C@H]1[C@H](O)CC(=O)[C@@H]1C\C=C/CCCC(O)=O XEYBRNLFEZDVAW-ARSRFYASSA-N 0.000 description 1
- 229960002986 dinoprostone Drugs 0.000 description 1
- 150000002016 disaccharides Chemical class 0.000 description 1
- 125000004119 disulfanediyl group Chemical group *SS* 0.000 description 1
- 125000002228 disulfide group Chemical group 0.000 description 1
- 238000009509 drug development Methods 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 150000002066 eicosanoids Chemical class 0.000 description 1
- 210000002257 embryonic structure Anatomy 0.000 description 1
- 230000012202 endocytosis Effects 0.000 description 1
- 231100000655 enterotoxin Toxicity 0.000 description 1
- 239000000147 enterotoxin Substances 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- 208000010932 epithelial neoplasm Diseases 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 238000012869 ethanol precipitation Methods 0.000 description 1
- 238000002270 exclusion chromatography Methods 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 230000036251 extravasation Effects 0.000 description 1
- 208000024711 extrinsic asthma Diseases 0.000 description 1
- 239000012091 fetal bovine serum Substances 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 238000005194 fractionation Methods 0.000 description 1
- 238000004108 freeze drying Methods 0.000 description 1
- 239000012737 fresh medium Substances 0.000 description 1
- 229930182830 galactose Natural products 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 208000016361 genetic disease Diseases 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- 108060003196 globin Proteins 0.000 description 1
- 102000018146 globin Human genes 0.000 description 1
- 125000000291 glutamic acid group Chemical group N[C@@H](CCC(O)=O)C(=O)* 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 1
- 102000006602 glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 1
- 230000002414 glycolytic effect Effects 0.000 description 1
- 229930182470 glycoside Natural products 0.000 description 1
- 150000002338 glycosides Chemical class 0.000 description 1
- 229940093915 gynecological organic acid Drugs 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 238000013537 high throughput screening Methods 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 208000033519 human immunodeficiency virus infectious disease Diseases 0.000 description 1
- 230000028996 humoral immune response Effects 0.000 description 1
- 229920001477 hydrophilic polymer Polymers 0.000 description 1
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 1
- 238000012872 hydroxylapatite chromatography Methods 0.000 description 1
- 230000033444 hydroxylation Effects 0.000 description 1
- 238000005805 hydroxylation reaction Methods 0.000 description 1
- 150000002463 imidates Chemical class 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 230000000984 immunochemical effect Effects 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 108010023260 immunoglobulin Fv Proteins 0.000 description 1
- 230000002134 immunopathologic effect Effects 0.000 description 1
- 230000002637 immunotoxin Effects 0.000 description 1
- 239000002596 immunotoxin Substances 0.000 description 1
- 231100000608 immunotoxin Toxicity 0.000 description 1
- 229940051026 immunotoxin Drugs 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 230000002458 infectious effect Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 208000030603 inherited susceptibility to asthma Diseases 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 208000014674 injury Diseases 0.000 description 1
- 150000002484 inorganic compounds Chemical class 0.000 description 1
- 229910010272 inorganic material Inorganic materials 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 239000000543 intermediate Substances 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 108010045069 keyhole-limpet hemocyanin Proteins 0.000 description 1
- 208000017169 kidney disease Diseases 0.000 description 1
- 238000011813 knockout mouse model Methods 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 150000002611 lead compounds Chemical class 0.000 description 1
- 125000001909 leucine group Chemical class [H]N(*)C(C(*)=O)C([H])([H])C(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 101150074251 lpp gene Proteins 0.000 description 1
- 210000005265 lung cell Anatomy 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 239000012931 lyophilized formulation Substances 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- DFTAZNAEBRBBKP-UHFFFAOYSA-N methyl 4-sulfanylbutanimidate Chemical compound COC(=N)CCCS DFTAZNAEBRBBKP-UHFFFAOYSA-N 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 229940035032 monophosphoryl lipid a Drugs 0.000 description 1
- 150000002772 monosaccharides Chemical class 0.000 description 1
- 208000037890 multiple organ injury Diseases 0.000 description 1
- 201000006417 multiple sclerosis Diseases 0.000 description 1
- 230000000869 mutational effect Effects 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 201000008383 nephritis Diseases 0.000 description 1
- 230000003472 neutralizing effect Effects 0.000 description 1
- 239000002547 new drug Substances 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- 230000005937 nuclear translocation Effects 0.000 description 1
- 238000010899 nucleation Methods 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 150000002894 organic compounds Chemical class 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 229950009506 penicillinase Drugs 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 210000005105 peripheral blood lymphocyte Anatomy 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- NMHMNPHRMNGLLB-UHFFFAOYSA-N phloretic acid Chemical compound OC(=O)CCC1=CC=C(O)C=C1 NMHMNPHRMNGLLB-UHFFFAOYSA-N 0.000 description 1
- 150000004713 phosphodiesters Chemical group 0.000 description 1
- 230000035790 physiological processes and functions Effects 0.000 description 1
- 210000002826 placenta Anatomy 0.000 description 1
- 210000002706 plastid Anatomy 0.000 description 1
- 229920001983 poloxamer Polymers 0.000 description 1
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 208000005987 polymyositis Diseases 0.000 description 1
- 108010055896 polyornithine Proteins 0.000 description 1
- 229920002714 polyornithine Polymers 0.000 description 1
- 229920001451 polypropylene glycol Polymers 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- QLNJFJADRCOGBJ-UHFFFAOYSA-N propionamide Chemical compound CCC(N)=O QLNJFJADRCOGBJ-UHFFFAOYSA-N 0.000 description 1
- XEYBRNLFEZDVAW-UHFFFAOYSA-N prostaglandin E2 Natural products CCCCCC(O)C=CC1C(O)CC(=O)C1CC=CCCCC(O)=O XEYBRNLFEZDVAW-UHFFFAOYSA-N 0.000 description 1
- 238000001243 protein synthesis Methods 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 238000003156 radioimmunoprecipitation Methods 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 239000000018 receptor agonist Substances 0.000 description 1
- 229940044601 receptor agonist Drugs 0.000 description 1
- 230000010837 receptor-mediated endocytosis Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 238000010242 retro-orbital bleeding Methods 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 230000036303 septic shock Effects 0.000 description 1
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 1
- 210000000717 sertoli cell Anatomy 0.000 description 1
- 230000036332 sexual response Effects 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 239000012064 sodium phosphate buffer Substances 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 238000009987 spinning Methods 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 230000035882 stress Effects 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 238000004114 suspension culture Methods 0.000 description 1
- 238000013268 sustained release Methods 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 208000001608 teratocarcinoma Diseases 0.000 description 1
- 229960002175 thyroglobulin Drugs 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- 108091008023 transcriptional regulators Proteins 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 230000008733 trauma Effects 0.000 description 1
- YNJBWRMUSHSURL-UHFFFAOYSA-N trichloroacetic acid Chemical compound OC(=O)C(Cl)(Cl)Cl YNJBWRMUSHSURL-UHFFFAOYSA-N 0.000 description 1
- HRXKRNGNAMMEHJ-UHFFFAOYSA-K trisodium citrate Chemical compound [Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O HRXKRNGNAMMEHJ-UHFFFAOYSA-K 0.000 description 1
- 229940038773 trisodium citrate Drugs 0.000 description 1
- 239000002753 trypsin inhibitor Substances 0.000 description 1
- 210000004881 tumor cell Anatomy 0.000 description 1
- 230000006433 tumor necrosis factor production Effects 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images













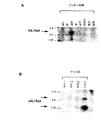









Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/54—Interleukins [IL]
- C07K14/545—IL-1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
Landscapes
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Gastroenterology & Hepatology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Zoology (AREA)
- Genetics & Genomics (AREA)
- Medicinal Chemistry (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Toxicology (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Description
本発明は一般にインターロイキン−1(IL-1)又はインターロイキン−1レセプターアンタゴニスト(IL-1Ra)と相同性を有する新規なDNAの同定と単離、及びここでインターロイキン−1様ポリペプチド(「IL-1lp」)と命名した新規なポリペプチドの組換え生産に関する。
インターロイキン−1は炎症反応の初期に重要な役割を果たす二つのタンパク質(IL-1αとIL-1β)を意味する(レビューのためには、Dinarello, Blood, 87: 2095-2147 (1996)とそこに含まれる参考文献を参照されたい)。そのタンパク質は双方とも、分泌時に切断されて生物活性な成熟カルボキシ末端17kDa断片を生じる細胞内前駆体タンパク質として生成される。IL-1βの場合、この切断には、不活性な前駆体から活性な断片を放出するのに必要とされるICEとして知られた細胞内システインプロテアーゼが関与する。IL-1αの前駆体は活性である。
これら二種のタンパク質は、殆ど全ての細胞型に見出される細胞表面レセプターへ結合し、ある範囲の反応を単独もしくは他の分泌因子と協力して引き起こすことにより作用する。これらは、増殖(例えば繊維芽細胞、T細胞)アポトーシス(例えばA375メラノーマ細胞)への効果、サイトカイン誘導(例えばTNF、IL-1、IL-8)、レセプター活性化(例えばEセレクチン)、エイコサノイド産生(例えばPGE2)及び分解系酵素の分泌(例えばコラゲナーゼ)に及んでいる。これらの効果を達成するために、IL-1はNF−KB及びAP−1のような転写制御因子を活性化させる。標的細胞に対するIL-1作用の活性の幾つかは、例えばストレス活性化MAPキナーゼJNK/SAPK及びp38のような細胞性ストレスも伴うキナーゼカスケードの活性化を介して媒介されると考えられる。
細胞内シグナル又は生物学的応答を伝達しないがIL-1レセプターに結合することによってIL-1αとIL-1βの自然のアンタゴニストとして作用するIL-1ファミリーの第3のメンバーが引き続いて発見された。該タンパク質はIL-1Ra(IL-1レセプターアンタゴニスト)又はIRAP(IL-1レセプターアンタゴニストタンパク質)と呼ばれている。IL-1Raの少なくとも3つの選択的スプライス型が存在する:一つは、分泌性IL-1Ra(「sIL-1Ra」)としても知られる分泌タンパク質をコードし(Eisenberg等, Nature, 343: 341-346 (1990)に記載されている)、他の二つは細胞内タンパク質をコードする。IL-1α、IL-1β及びIL-1Raは互いにおよそ25−30%の配列同一性を示し、内部の3重反復構造モチーフを持つ、βバレルに折り畳まれた12のβストランドからなる類似の三次元構造を共有している。
IL-1Ra、I型IL-1レセプター細胞外ドメインに由来する可溶型IL-1R、IL-1α又はIL-1βに対する抗体、及びこれらの遺伝子についてのトランスジェニックノックアウトマウスを使用した多くの研究が、IL-1が多くの病態生理学において役割を担っていることを示している(レビューのためには、Dinarello, Blood, 87: 2095-2147 (1996)を参照されたい)。例えば、IL-1Raは、敗血症ショック、関節リウマチ、移植片対宿主病(GVHD)、脳卒中、心臓性虚血、乾癬、炎症性腸疾患、及び喘息の動物モデルにおいて有効であると示されている。また、IL-1Raは関節リウマチとGVHDのための臨床実験において効能が実証されており、炎症性腸疾患、喘息及び乾癬に対する臨床実験においても同様である。
更に最近では、インターロイキン−18(IL-18)がIL-1ファミリーに入れられた(レビューのためには、Dinarello等, J. Leukocyte Biol., 63: 658-664 (1998)を参照されたい)。IL-18はIL-1α及びIL-1βのβプリーツバレル様型を共有している。また、IL-18はIL-1R関連タンパク質(IL-1Rrp)としてかつては知られていた(今はIL-18レセプター(IL-18R)として知られている)IL-1レセプターファミリーメンバーの天然のリガンドである。IL-18は、リンパ球とNK細胞上に構成型IL-18レセプターをトリガーし、活性化された細胞においてTNF産生を誘発することにより末梢血単核球(PBMCs)の混合集団において炎症性サイトカインカスケードを開始することが知られている。TNFは続いてCD14+細胞においてIL-1及びIL-8の産生を刺激する。TNF、IL-1、及びC−CとC−X−Cの双方のケモカインを誘発するその能力のため、またIL-18がFasリガンド並びに核因子κB(NF−κB)の核転移を誘発するので、IL-18は全身性及び局所性炎症に対する可能な貢献者として他の炎症誘発性サイトカインと同格である。
新規なポリペプチドをコードするインターロイキン−1と相同性を持つcDNAクローンのファミリー(DNA85066、DNA96786、DNA94618、DNA102043、DNA114876、DNA102044、DNA92929、DNA96787、及びDNA92505)が同定された。新規なポリペプチドとその変異体は本出願では集合的に「インターロイキン−1様ポリペプチド」又は「IL-1lp」と命名し、ここで更に定義される。従って、本発明の一側面は単離されたIL-1lpポリペプチドである。
他の実施態様では、本発明はIL-1lpポリペプチドをコードする単離された核酸分子を提供する。
他の実施態様では、本発明は、IL-1lpポリペプチドをコードする異種核酸配列を含んでなる宿主細胞を、IL-1lpポリペプチドが発現される条件下で培養し、宿主細胞からIL-1lpポリペプチドを回収することを含んでなるIL-1lpを生産する方法を提供する。
他の実施態様では、本発明は抗IL-1lp抗体を提供する。
他の実施態様では、本発明は、異種ポリペプチド又はアミノ酸配列に融合したIL-1lpポリペプチドを含んでなるキメラ分子を提供する。このようなキメラ分子の例は、エピトープタグ配列又は免疫グロブリンのFc領域に融合したIL-1lpポリペプチドを含む。
他の実施態様では、本発明はIL-1lpポリペプチドに特異的に結合する抗体を提供する。場合によっては、抗体はモノクローナル抗体である。
更に他の実施態様では、本発明は天然IL-1lpポリペプチドのアゴニストとアンタゴニストに関する。特定の実施態様では、アゴニスト又はアンタゴニストは抗IL-1lp抗体である。
更なる実施態様では、本発明は、天然のIL-1lpポリペプチドを候補分子に接触させ、上記ポリペプチドにより仲介される生物活性を監視することによって、天然のIL-1lpポリペプチドのアゴニスト又はアンタゴニストを同定する方法に関する。
また更なる実施態様では、本発明は、製薬的に許容可能な担体と組み合わせて、IL-1lpポリペプチド、又は上で定義したアゴニスト又はアンタゴニストを含有してなる組成物に関する。
I.定義:
「インターロイキン-1-様ポリペプチド」、「インターロイキン-1-様タンパク質」、「IL-11p」、「IL-11pポリペプチド」、及び「IL-11pタンパク質」という用語は、任意の天然配列IL-11pを包含し、及びさらにIL-11p変異体(ここでさらに定義される)を含む。IL-11pは例えばヒト組織型又はその他の供給源等様々な供給源から単離してもよく、組換え及び/又は合成の方法から用意してもよい。
「天然配列IL-11p」は天然配列hIL-1Ra1、hIL-1Ra1L、hIL-1Ra2、hIL-1Ra3,又はmIL-1Ra3,の様な同じアミノ酸配列を有するポリペプチド含む(ここでさらに定義される)。該天然配列IL-11pは天然由来のものから単離することができるし、組換え及び/又は合成の方法によっても生産されうる。「天然配列IL-11p」という用語は、特に自然に生じる切断又は分泌形態(例えば加工した、成熟した配列)及び自然に生じるIL-11pの対立遺伝子変異体を含む。
「自然に生じるアミノ酸配列」及び「天然アミノ酸配列」という用語は自然に存在するポリペプチドに見られる、つまり自然に発生するポリペプチド中に存在する任意のアミノ酸配列を意味する。
「非自然に生じるアミノ酸配列」及び「非天然アミノ酸配列」という用語は自然に存在するポリペプチドに見ることのない、つまり自然に発生するポリペプチド中には存在しない任意のアミノ酸配列を意味する。
「IL-11p変異体」はhIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、HIL-1Ra3,又はmIL-1Ra3の変異体を含む任意のポリペプチドと定義される(ここでさらに定義される)。
「天然配列hIL-Ra1」は:(1)図2(配列番号:5)のアミノ酸残基37又は約37から63又は約63のアミノ酸配列;(2)図2(配列番号:5)のアミノ酸残基37又は約37から203又は約203のアミノ酸配列;(3)図3(配列番号:7)のアミノ酸残基15又は約15から53又は約53のアミノ酸配列;(4)図3(配列番号:7)のアミノ酸残基15又は約15から193又は約193のアミノ酸配列;(5)(1)又は(2)又は(3)又は(4)のアミノ酸配列を含むポリペプチドの任意の自然に生じる切断又は分泌型又は任意の自然に生じる対立遺伝子変異体のアミノ酸配列よりなる群より選ばれる自然に生じるアミノ酸配列を含むポリペプチドを意味する。本発明の一実施形態では、天然配列hIL-1Ra1は図2(配列番号:5)のアミノ酸37又は約37から203又は約203、又は図3(配列番号:7)のアミノ酸15又は約15から193又は約193を含んでなる。
「hIL-1Ra1変異体」は任意のhIL-1Ra1 N−末端変異体又はhIL-1Ra1全配列変異体と定義される(ここでさらに定義される)。
「hIL-1Ra1全配列変異体」は天然配列hIL-1Ra1以外の任意のhIL-1Ra1を意味し、その変異体は、例えばIL-18R結合能力のような天然配列hIL-1Ra1の少なくとも1つの生物的活性を保持し、そしてその変異体は、(1)図2(配列番号:5)のアミノ酸残基37又は約37から203又は約203のアミノ酸配列;及び(2)図3(配列番号:7)のアミノ酸残基15又は約15から193又は約193のアミノ酸配列からなる群より選ばれたアミノ酸配列と少なくとも約80%のアミノ酸配列同一性、又は少なくとも約85%のアミノ酸配列同一性、又は少なくとも約90%のアミノ酸配同一性、又は少なくとも約95%のアミノ酸配列同一性を持つ。該hIL-1Ra1全配列変異は、例えば、図2(配列番号:5)のアミノ酸残基37又は約37から203又は約203の配列、又は図3(配列番号:7)のアミノ酸残基15又は約15から193又は約193の配列で、1又は複数のアミノ酸残基が内部に又はN−又はC−末端に加えられ、又は減らされているhIL-1Ra1ポリペプチドを含む。
「天然配列hIL-1Ra1L」は:(1)図15(配列番号:19)のアミノ酸残基26又は約26から44又は約44のアミノ酸配列;(2)図15(配列番号:19)のアミノ酸残基26又は約26から207又は約207のアミノ酸配列;及び(3)(1)又は(2)のアミノ酸配列を含むポリペプチドの任意の自然発生切断又は分泌型又は任意の自然発生対立遺伝子変異体のアミノ酸配列よりなる群より選ばれる自然に生じるアミノ酸配列を含むポリペプチドを意味する。本発明の一実施形態では、天然配列hIL-1Ra1Lは図15(配列番号:19)のアミノ酸26又は約26から207又は約207を含んでなる。
「hIL-1Ra1L変異体」は任意のhIL-1Ra1L N−末端変異体又はhIL-1Ra1L全配列変異体又はhIL-1Ra1L融合変異体と定義される(ここでさらに定義される)。
「hIL-1Ra1L N−末端変異体」は天然配列hIL-1Ra1L以外の任意のhIL-1Ra1Lを意味し、その変異体は、下に定義されるように、図15(配列番号:19)のアミノ酸残基26又は約26から44又は約44のアミノ酸配列と少なくとも約80%のアミノ酸配列同一性を有する活性hIL-1Ra1Lである。そのようなhIL-1Ra1L N−末端変異体は、例えば、図15(配列番号:19)のアミノ酸残基26又は約26から44又は約44の配列に、1又は複数のアミノ酸残基が内部に又はN−又はC−末端で加えられ、又は減らされているhIL-1Ra1Lポリペプチドを含む。通常は、あるhIL-1Ra1L N−末端変異体は、図15(配列番号:19)のアミノ酸残基26又は約26から44又は約44のアミノ酸配列と少なくとも約80%のアミノ酸配列同一性、又は少なくとも85%のアミノ酸配列同一性、又は少なくとも90%のアミノ酸配列同一性、又は少なくとも95%のアミノ酸配列同一性を有しうる。
「hIL-1Ra1L融合変異体」は天然配列hIL-1Ra1LがそのN−又はC−末端でヘテロアミノ酸又はアミノ酸配列を融合している構成を持つキメラhIL-1Ra1Lを意味する。一実施様態ではhIL-1Ra1L融合変異体ポリペプチドはそのN−末端又はC−末端でヘテロアミノ酸又はアミノ酸配列と融合した天然配列hIL-1Ra1Lから成り、そのヘテロアミノ酸又はアミノ酸配列は天然配列と異種であり、つまりその結果物キメラ配列は非天然に存在している。他の実施様態では、hIL-1Ra1L融合変異体は、図15(配列番号:19)のアミノ酸26又は約26から207又は約207のアミノ酸配列、又は図15(配列番号:19)のアミノ酸残基1又は約1から207又は約207のアミノ酸配列からなり、N−末端又はC−末端で非天然に発生する融合タンパク質を形成するヘテロアミノ酸又はアミノ酸配列と融合されている。そのようなhIL-1Ra1L融合変異体は、例えばヘテロ分泌リーダー配列が図15(配列番号:19)のアミノ酸残基26又は約26から207又は約207、又は図15(配列番号:19)のアミノ酸残基1又は約1から207又は約207の配列のN−末端に融合されるhIL-1Ra1Lポリペプチドを含む。
「天然配列hIL-1Ra1V」は:(1)図19(配列番号:25)のアミノ酸残基46又は約46から55又は約55のアミノ酸配列;(2)図19(配列番号:25)のアミノ酸残基46又は約46から218又は約218のアミノ酸配列;(3)図19(配列番号:25)のアミノ酸残基37又は約37から218又は約218のアミノ酸配列;(4)図19(配列番号:25)のアミノ酸残基12又は約12から218又は約218のアミノ酸配列;(5)(1)又は(2)又は(3)又は(4)のアミノ酸配列を含むポリペプチドの任意の自然に生じる切断又は分泌型又は任意の自然に生じる対立遺伝子変異体のアミノ酸配列よりなる群より選ばれる自然に生じるアミノ酸配列を含むポリペプチドを意味する。本発明の一実施形態では、天然配列hIL-1Ra1Vは図19(配列番号:25)のアミノ酸46又は約46から218又は約218、又は図19(配列番号:25)のアミノ酸37又は約37から218又は約218、又は図19(配列番号:25)のアミノ酸12又は約12から218又は約218、又は図19(配列番号:25)のアミノ酸1又は約1から218又は約218を含んでなる。
「hIL-Ra1V N−末端変異体」は天然配列hIL-1Ra1V以外の任意のhIL-1Ra1Vを意味し、その変異体は、下で定義されるように、図19(配列番号:25)のアミノ酸残基46又は約46から89又は約89のアミノ酸配列と少なくとも約80%のアミノ酸配列同一性を有する活性hIL-1Ra1Vである。該hIL-Ra1V N−末端変異体は、例えば、図19(配列番号:25)のアミノ酸残基46又は約46から89又は約89の配列に、1又は複数のアミノ酸残基が内部に又はN−又はC−末端で加えられ、又は減らされているhIL-1Ra1Vポリペプチドを含む。通常は、あるhIL-1Ra1V N−末端変異体は、図19(配列番号:25)のアミノ酸残基46又は約46から89又は約89の配列と少なくとも約80%のアミノ酸配列同一性、又は少なくとも85%のアミノ酸配列同一性、又は少なくとも90%のアミノ酸配列同一性、又は少なくとも95%のアミノ酸配列同一性を有しうる。
「hIL-1Ra1V全配列変異体」は天然配列hIL-1Ra1V以外の任意のhIL-1Ra1Vを意味し、その変異体は、例えばIL-18R結合能力のような天然配列hIL-1Ra1Vの少なくとも1つの生物的活性を保持し、そしてその変異体は、図19(配列番号:25)のアミノ酸残基46又は約46から218又は約218の配列と少なくとも約80%のアミノ酸配列同一性、又は少なくとも約85%のアミノ酸配列同一性、又は少なくとも約90%のアミノ酸配同一性、又は少なくとも約95%のアミノ酸配列同一性を持つ。
「天然配列hIL-1Ra1S」は:(1)図16(配列番号:21)のアミノ酸残基1又は約1から38又は約38のアミノ酸配列;(2)図16(配列番号:21)のアミノ酸残基26又は約26から167又は約167のアミノ酸配列;(3)図16(配列番号:21)のアミノ酸残基39又は約39から167又は約167のアミノ酸配列;(4)図16(配列番号:21)のアミノ酸残基47又は約47から167又は約167のアミノ酸配列;(5)(1)又は(2)又は(3)又は(4)のアミノ酸配列を含むポリペプチドの任意の自然に生じる切断又は分泌型又は任意の自然に生じる対立遺伝子変異体のアミノ酸配列よりなる群より選ばれる自然に生じるアミノ酸配列を含むポリペプチドを意味する。本発明の一実施形態では、天然配列hIL-1Ra1Sは図16(配列番号:21)のアミノ酸26又は約26から167又は約167、又は図16(配列番号:21)のアミノ酸1又は約1から167又は約167を含んでなる。他の実施様態では、天然配列hIL-1Ra1Sは図16(配列番号:21)のアミノ酸47又は約47から167又は約167、又は図16(配列番号:21)のアミノ酸39又は約39から167又は約167よりなる。
「天然配列hIL-1Ra2」は(1)図5(配列番号:10)のアミノ酸残基1又は約1から134又は約134のアミノ酸配列又は(2)(1)のポリペプチドの自然に生じる切断又は分泌型よりなるポリペプチドを意味する。本発明の一実施形態では、天然配列hIL-1Ra2は図5(配列番号:10)のアミノ酸27又は約27から134又は約134、又は図5(配列番号:10)のアミノ酸1又は約1から134又は約134からなる。
「hIL-1Ra2融合変異体」及び「hIL-1Ra2変異体」は天然配列hIL-1Ra2がそのN−末端又はC−末端でヘテロアミノ酸又はアミノ酸配列を融合している構成を持つキメラhIL-1Ra2を意味する。一実施様態ではhIL-1Ra2融合変異体ポリペプチドはそのN−末端又はC−末端でヘテロアミノ酸又はアミノ酸配列と融合した天然配列hIL-1Ra2から成り、そのヘテロアミノ酸又はアミノ酸配列は天然配列と異種であり、つまりその結果物キメラ配列は非天然に存在している。他の実施様態では、hIL-1Ra2変異体は、図5(配列番号:10)のアミノ酸27又は約27から134又は約134のアミノ酸配列、又は図5(配列番号:10)のアミノ酸残基1又は約1から134又は約134のアミノ酸配列からなり、N−末端又はC−末端で非天然で発生する融合タンパク質を形成するヘテロアミノ酸又はアミノ酸配列と融合されている。該hIL-1Ra2融合変異体は、例えば、ヘテロ分泌リーダー配列が図5(配列番号:10)のアミノ酸残基27又は約27から134又は約134、又は図5(配列番号:10)のアミノ酸残基1又は約1から134又は約134の配列のN−末端に融合されるhIL-1Ra2ポリペプチドを含む。
「天然配列hIL-1Ra3」は:(1)図7(配列番号:13)のアミノ酸残基95又は約95から134又は約134のアミノ酸配列;(2)図7(配列番号:13)のアミノ酸残基34又は約34から155又は約155のアミノ酸配列;及び(3)(1)又は(2)のアミノ酸配列を含むポリペプチドの任意の自然発生切断又は分泌型又は任意の自然発生対立遺伝子変異体のアミノ酸配列よりなる群より選ばれる自然に生じるアミノ酸配列を含むポリペプチドを意味する。本発明の一実施形態では、天然配列hIL-1Ra3は図7(配列番号:13)のアミノ酸2又は約2から155又は約155を含んでなる。
「hIL-1Ra3変異体」は任意のhIL-1Ra3 C−末端変異体又はhIL-1Ra3全配列変異体と定義される(ここでさらに定義される)。
「hIL-1Ra3 C−末端変異体」は天然配列hIL-1Ra3以外の任意のhIL-1Ra3を意味し、その変異体は、上で定義されたように、図7(配列番号:13)のアミノ酸残基95又は約95から134又は約134のアミノ酸配列と少なくとも約80%のアミノ酸配列同一性を有する活性hIL-1Ra3である。該hIL-1Ra3 C−末端変異体は、例えば、図7(配列番号:13)のアミノ酸残基95又は約95から134又は約134の配列又は図7(配列番号:13)のアミノ酸残基80又は約80から155又は約155の配列に、1又は複数のアミノ酸残基が内部に又はN−又はC−末端で加えられ、又は減らされているhIL-1Ra3ポリペプチドを含む。通常は、あるhIL-1Ra3 C−末端変異体は、図7(配列番号:13)のアミノ酸残基95又は約95から134又は約134のアミノ酸配列又は図7(配列番号:13)のアミノ酸残基80又は約80から155又は約155のアミノ酸配列と少なくとも約80%のアミノ酸配列同一性、又は少なくとも85%のアミノ酸配列同一性、又は少なくとも90%のアミノ酸配列同一性、又は少なくとも95%のアミノ酸配列同一性を有しうる。
「天然配列mIL-1Ra3」は:(1)図9(配列番号:16)のアミノ酸残基95又は約95から134又は約134のアミノ酸配列;(2)図9(配列番号:16)のアミノ酸残基34又は約34から155又は約155のアミノ酸配列;及び(3)(1)又は(2)のアミノ酸配列を含むポリペプチドの任意の自然発生切断又は分泌型又は任意の自然発生対立遺伝子変異体のアミノ酸配列よりなる群より選ばれる自然に生じるアミノ酸配列を含むポリペプチドを意味する。本発明の一実施形態では、天然配列mIL-1Ra3は図9(配列番号:16)のアミノ酸34又は約34から155又は約155を含んでなる。
「mIL-1Ra3変異体」は任意のmIL-1Ra3 C−末端変異体又はmIL-1Ra3全配列変異体と定義される(ここでさらに定義される)。
「mIL-1Ra3 C−末端変異体」は天然配列mIL-1Ra3以外の任意のmIL-1Ra3を意味し、その変異体は、上で定義されたように、図9(配列番号:16)のアミノ酸残基95又は約95から134又は約134のアミノ酸配列と少なくとも約80%のアミノ酸配列同一性を有する活性mIL-1Ra3である。該mIL-1Ra3 C−末端変異体は、例えば、図9(配列番号:16)のアミノ酸残基95又は約95から134又は約134の配列に、1又は複数のアミノ酸残基が内部に又はN−又はC−末端で加えられ、又は減らされているmIL-1Ra3ポリペプチドを含む。通常は、あるmIL-1Ra3 C−末端変異体は、図9(配列番号:16)のアミノ酸95から134のアミノ酸配列と少なくとも約80%のアミノ酸配列同一性、又は少なくとも85%のアミノ酸配列同一性、又は少なくとも90%のアミノ酸配列同一性、又は少なくとも95%のアミノ酸配列同一性を有しうる。
「天然配列hIL-11p」及び「天然配列は天然配列hIL-1Raa」は、天然配列hIL-1Ra1、hIL-1Ra2、又はhIL-1Ra3を含んでなる任意のポリペプチドと定義される。
「IL-11p変異体」はhIL-1Ra1、hIL-1Ra1L、hIL-1Ra2、又はHIL-1Ra3の変異体を含んでなる任意のポリペプチドと定義される。
「インターロイキン-1レセプター」、「インターロイキン-1レセプターポリペプチド」、「インターロイキン-1レセプタータンパク質」、「IL-1レセプター」、「IL-1R」、「IL-1ポリペプチド」、及び「IL-1Rタンパク質」、はたとえばヒトやマウスのような種におけるインターロイキン-1(IL-1)との結合及び/又はIL-1-誘発シグナル形質導入で機能する細胞表面タンパク質のファミリーと定義される。IL-1RはSims等、Proc. Natl. Acad. Sci. (USA), 86: 9846-8950(1989)で明らかにされているヒトT細胞-発現IL-1レセプターを含む。
「インターロイキン-18レセプター」、「インターロイキン-18レセプターポリペプチド」、「インターロイキン-18レセプタータンパク質」、「IL-18レセプター」、「IL-18R」、「IL-18ポリペプチド」、及び「IL-18Rタンパク質」、はたとえばヒトやマウスのような種におけるインターロイキン-18(IL-18)との結合及び/又はIL-18-誘発シグナル形質導入で機能する細胞表面タンパク質のファミリーと定義される。IL-18RはTorigoe等、J. Biol. Chem., 272: 25737-25742(1997)に記載されたIL-1レセプター関連タンパク質(IL-1Rrp)とBorn等、J. Biol. Chem., 273: 29445-29450(1998)に記載されたIL-18レセプターアクセサリータンパク-様分子(IL-18RAcPL)を含む。
「インターロイキン-1様ファミリー」及び「IL-1-様ファミリー」はIL-1R又はIL-18Rのリガンドに関するポリペプチドのファミリーを表すのに使用される。IL-1-様ファミリーはIL-1α(Bazan等、Nature, 379: 591 (1996)に記載)、IL-1β(Bazan等)、IL-18(インターフェロンγ誘発因子)(IGIF)(Bazan等)、例えばIL-1Ra(sIL-Ra)(Eisenberg等、Nature, 343: 341-346(1990)に記載)、及び細胞内IL-1Ra(icIL-1Ra)(Haskill等、Proc. Natl. Acad. Sci. (USA), 88: 3681-3685(1991)に記載)のようなIL-1レセプターアンタゴニストポリペプチド、及び本発明のIL-1lpポリペプチドのようなIL-レセプターアゴニスト及びアンタゴニスト及び関連ポリペプチドを含む。
分率X/Yの100倍
ここで、Xは配列アラインメントプログラムALIGN-2によってそのプログラムのA及びBのアラインメントにおいて等しく一致していると評価されたアミノ酸残基の数であり、YはBの全アミノ酸残基数である。アミノ酸配列Aの長さがアミノ酸配列Bの長さと異なる場合、AのBに対する%アミノ酸配列同一性は、BのAに対する%アミノ酸配列同一性とは異なることは理解されるであろう。%アミノ酸配列同一性の計算の例として、表2A−2Bは、「比較タンパク質」と命名したアミノ酸配列の「PRO」と命名したアミノ酸配列に対する%アミノ酸配列同一性の計算方法を示している。
特に断らない限り、ここで使用される全ての%アミノ酸配列同一性の値はALIGN-2コンピュータプログラムを用いて上記のようにして得られる。しかし、%アミノ酸配列同一性の値は、配列比較プログラムNCBI-BLAST2(Altschul等, Nucleic Acids Res. 25:3389-3402 (1997))を用いて決定してもよい。NCBI-BLAST2配列比較プログラムは、http://ww.ncbi.nlm.nih.govからダウンロードできる。NCBI-BLAST2は幾つかの検索パラメータを使用し、それら検索パラメータの全てはデフォルト値に設定され、例えば、unmask=可、鎖=全て、予測される発生=10、最小低複合長=15/5、マルチパスe-値=0.01、マルチパスの定数=25、最終ギャップアラインメントのドロップオフ=25、及びスコアリングマトリクス=BLOSUM62を含む。
アミノ酸配列比較にNCBI-BLAST2が用いれれる状況では、与えられたアミノ酸配列Aの、与えられたアミノ酸配列Bに対する、それとの、又はそれと対照した%アミノ酸配列同一性(与えられたアミノ酸配列Bに対する、それとの又はそれと対照して或る程度の%アミノ酸配列同一性を持つ又は含む与えられたアミノ酸配列Aと言うこともできる)は次のように計算される:
分率X/Yの100倍
ここで、Xは配列アラインメントプログラムNCBI-BLAST2によって該プログラムのA及びBのアラインメントにおいて等しく一致すると評価されたアミノ酸残基の数であり、YはBの全アミノ酸残基数である。アミノ酸配列Aの長さがアミノ酸配列Bの長さと異なる場合、AのBに対する%アミノ酸配列同一性は、BのAに対する%アミノ酸配列同一性とは異なることは理解されるであろう。
ここでの目的に対して、与えられた核酸配列Cの、与えられた核酸配列Dに対する、それとの又はそれと対照した%核酸配列同一性(与えられた核酸配列Dに対する、それとの又はそれと対照した或る程度の%核酸配列同一性を持つ又は含む与えられた核酸配列Cと言うこともできる)は次のように計算される:
分率W/Zの100倍
ここで、Wは配列アラインメントプログラムALIGN-2によって該プログラムのC及びDのアラインメントにおいて等しく一致すると評価されたヌクレオチドの数であり、ZはDの全ヌクレオチド数である。核酸配列Cの長さが核酸配列Dの長さと異なる場合、CのDに対する%核酸配列同一性は、DのCに対する%核酸配列同一性とは異なることは理解されるであろう。%核酸配列同一性の計算の例として、表2C−2Dは、「比較DNA」と命名した核酸配列の「PRO-DNA」と命名した核酸配列に対する%核酸配列同一性の計算方法を実証している。
核酸配列比較にNCBI-BLAST2が用いれれる状況では、与えられた核酸配列Cの、与えられた核酸配列Dに対する、それとの、又はそれと対照した%核酸配列同一性(与えられた核酸配列Dに対する、それとの、又はそれと対照した或る程度の%核酸配列同一性を持つ又は含む与えられた核酸配列Cと言うこともできる)は次のように計算される:
分率W/Zの100倍
ここで、Wは配列アラインメントプログラムNCBI-BLAST2によっってそのプログラムのC及びDのアラインメントにおいて等しく一致すると評価された核酸残基の数であり、ZはDの全核酸残基数である。核酸配列Cの長さが核酸配列Dの長さと異なる場合、CのDに対する%核酸配列同一性は、DのCに対する%核酸配列同一性とは異なることは理解されるであろう。
ここでの目的に対して、与えられたアミノ酸配列Aの、与えられたアミノ酸配列Bに対する、それとの、又はそれと対照した陽性の%値(与えられたアミノ酸配列Bに対する、それとの、又はそれと対照した或る程度の%アミノ酸配列同一性を持つ又は含む与えられたアミノ酸配列Aと言うこともできる)は次のように計算される:
分率X/Yの100倍
ここで、Xは配列アラインメントプログラムALIGN-2によりそのプログラムののA及びBのアラインメントにおいて陽性値と評価されたアミノ酸残基の数であり、YはBの全アミノ酸残基数である。アミノ酸配列Aの長さがアミノ酸配列Bの長さと等しくない場合、AのBに対する%陽性は、BのAに対する%陽性とは異なることが理解されるであろう。
IL-1lpポリペプチドをコードする「単離された」核酸は、同定され、IL-1lpをコードする核酸の天然源に通常付随している少なくとも1つの汚染核酸分子から分離された核酸分子である。単離されたIL-1lpコード化核酸分子は、天然に見出される形態あるいは設定以外のものである。ゆえに、単離された核酸分子は、天然の細胞中に存在するIL-1lpコード化核酸分子とは区別される。しかし、IL-1lpポリペプチドをコードする単離された核酸分子は、例えば、核酸分子が天然細胞のものとは異なった染色体位置にあるIL-1lpを通常発現する細胞に含まれるIL-1lpコード核酸分子を含む。
「コントロール配列」という表現は、特定の宿主生物において作用可能に関連したコード配列を発現するために必要なDNA配列を指す。例えば原核生物に好適なコントロール配列は、プロモーター、場合によってはオペレータ配列、及びリボソーム結合部位を含む。真核生物の細胞は、プロモーター、ポリアデニル化シグナル及びエンハンサーを利用することが知られている。
核酸は、他の核酸配列と機能的な関係にあるときに「作用可能に関連し」ている。例えば、プレ配列あるいは分泌リーダーのDNAは、ポリペプチドの分泌に参画するプレタンパク質として発現されているなら、そのポリペプチドのDNAに作用可能に関連している;プロモーター又はエンハンサーは、配列の転写に影響を及ぼすならば、コード配列に作用可能に関連している;又はリボソーム結合部位は、もしそれが翻訳を容易にするような位置にあるなら、コード配列と作用可能に関連している。一般的に、「作用可能に関連している」とは、関連したDNA配列が近接しており、分泌リーダーの場合には近接していて読みフェーズにあることを意味する。しかし、エンハンサーは必ずしも近接している必要はない。関連は簡便な制限部位でのライゲーションにより達成される。そのような部位が存在しない場合は、従来の手法に従って、合成オリゴヌクレオチドアダプターあるいはリンカーが使用される。
ハイブリッド形成反応の「緊縮性」は、当業者によって容易に決定され、一般的にプローブ長、洗浄温度、及び塩濃度に依存する経験的な計算である。一般に、プローブが長くなると適切なアニーリングのための温度が高くなり、プローブが短くなると温度は低くなる。ハイブリッド形成は、一般的に、相補的鎖がその融点に近いがそれより低い環境に存在する場合における変性DNAの再アニールする能力に依存する。プローブとハイブリッド形成可能な配列との間の所望の相同性の程度が高くなると、使用できる相対温度が高くなる。その結果、より高い相対温度は、反応条件をより緊縮性にするが、低い温度は緊縮性を低下させる。ハイブリッド形成反応の緊縮性の更なる詳細及び説明は、Ausubel等, Current Protocols in Molecular Biology, Wiley Interscience Publishers, (1995)を参照のこと。
ここで定義される「緊縮性条件」又は「高度の緊縮性条件」は、(1)洗浄のために低イオン強度及び高温度、例えば、50℃において0.015Mの塩化ナトリウム/0.0015Mのクエン酸ナトリウム/0.1%のドデシル硫酸ナトリウムを用いるもの;(2)ハイブリッド形成中にホルムアミド等の変性剤、例えば、42℃において50%(v/v)ホルムアミドと0.1%ウシ血清アルブミン/0.1%フィコール/0.1%のポリビニルピロリドン/50mMのpH6.5のリン酸ナトリウムバッファー、及び750mMの塩化ナトリウム、75mMクエン酸ナトリウムを用いるもの;又は(3)42℃における50%ホルムアミド、5xSSC(0.75MのNaCl、0.075Mのクエン酸ナトリウム)、50mMのリン酸ナトリウム(pH6.8)、0.1%のピロリン酸ナトリウム、5xデンハート液、超音波処理サケ精子DNA(50μg/ml)、0.1%SDS、及び10%のデキストラン硫酸と、42℃における0.2xSSC(塩化ナトリウム/クエン酸ナトリウム)中の洗浄及び55℃での50%ホルムアミド、次いで55℃におけるEDTAを含む0.1xSSCからなる高緊縮性洗浄を用いるものによって特定される。
「中程度の緊縮性条件」は、Sambrook等, Molecular Cloning: A Laboratory Manual, New York: Cold Spring Harbor Laboratory Press, 1989に記載されているように特定され、上記の緊縮性より低い洗浄溶液及びハイブリッド形成条件(例えば、温度、イオン強度及び%SDS)の使用を含む。中程度の緊縮性条件は、20%ホルムアミド、5xSSC(150mMのNaCl、15mMのクエン酸三ナトリウム)、50mMリン酸ナトリウム(pH7.6)、5xデンハート液、10%デキストラン硫酸、及び20mg/mLの変性剪断サケ精子DNAを含む溶液中の37℃での終夜インキュベーション、次いで1xSSC中37−50℃でのフィルターの洗浄といった条件である。当業者であれば、プローブ長などの因子に適合させる必要に応じて、どのようにして温度、イオン強度等を調節するかを認識するであろう。
ここで用いられる「イムノアドヘシン」なる用語は、異種タンパク質(「アドヘシン」)の結合特異性と免疫グロブリン定常ドメインとを結合した抗体様分子を指す。構造的には、イムノアドヘシンは、所望の結合特異性を持ち、抗体の抗原認識及び結合部位以外である(即ち「異種の」)アミノ酸配列と、免疫グロブリン定常ドメイン配列との融合物を含む。イムノアドヘシン分子のアドへシン部分は、典型的には少なくともレセプター又はリガンドの結合部位を含む隣接アミノ酸配列である。イムノアドヘシンの免疫グロブリン定常ドメイン配列は、IgG-1、IgG-2、IgG-3又はIgG-4サブタイプ、IgA(IgA-1及びIgA-2を含む)、IgE、IgD又はIgMなどの任意の免疫グロブリンから得ることができる。
ここで意図している「活性な」及び「活性」とは、天然又は天然に生じるIL-1lpの一又は複数の生物学的活性を保持するか、天然又は天然に生じるIL-1lpと免疫学的交差反応性を示すIL-1lpの形態を意味する。
ここで用いるところの「生物活性」又は「生物学的活性」とは、IL-1lpの免疫原生又は抗原性機能を除く、哺乳動物の生理機能又は病態生理においてIL-1lpによって示される任意のエフェクター機能を意味する。IL-1lpの免疫原生及び抗原性機能とはIL-1lpに特異的な体液性又は細胞性免疫応答を生じるIL-1lpの能力、及び哺乳動物において抗IL-1lp抗体、B細胞又はT細胞を特異的に認識しこれと相互作用をなす能力を意味する。
ここで用いるところの、IL-1lpとの「免疫学的交差反応性」とは、候補ポリペプチドがIL-1lpに対して産生されたポリクローナル又はモノクローナル抗体へのIL-1lpの結合を競合的に阻害することができることを意味する。
一実施態様では、IL-1lp活性は、任意のIL-1様ファミリーメンバーの一又は複数の生物学的活性を作動又は拮抗する能力、例えばIL-1媒介又はIL-18媒介炎症反応に拮抗するIL-1lp活性を含む。他の実施態様では、IL-1lp活性はIL-18レセプター及び/又はIL-1レセプターに結合する能力を含む。
「アンタゴニスト」なる用語は最も広い意味で用いられ、ここに開示した天然IL-1lpポリペプチドの生物学的活性を部分的もしくは完全に阻止、阻害、又は中和する任意の分子を指す。同様に「アゴニスト」なる用語は最も広い意味で用いられ、ここに開示した天然IL-1lpポリペプチドの生物学的活性を模倣する任意の分子を指す。好適なアゴニスト又はアンタゴニスト分子は特に、アゴニスト又はアンタゴニスト抗体又は抗体断片、天然IL-1lpポリペプチドの断片又はアミノ酸配列変異体、ペプチド、有機小分子などを含む。
「慢性」投与とは、急性様式とは異なり連続的な様式での薬剤を投与し、初期の治療効果(活性)を長時間に渡って維持することを意味する。「間欠」投与とは、中断無く連続的になされるのではなく、むしろ周期的になされる性質の治療である。
治療の対象のための「哺乳動物」は、ヒト、家庭及び農業用動物、動物園、スポーツ、又はペット動物、例えばイヌ、ネコ、ウシ、ウマ、ヒツジ、ブタ、ウサギなどを含む哺乳類に分類される任意の動物を意味する。好ましくは、哺乳動物はヒトである。
一又は複数の治療薬と「組み合わせた」投与とは、同時(同時期)及び任意の順序での連続した投与を含む。
「炎症性障害」及び「炎症性疾患」なる用語は、ここでは置き換え可能に使用され、炎症を生じる病理的状態を指す。このような障害の例には、乾癬とアトピー性皮膚炎のような炎症性皮膚病;炎症性強皮症と硬化症;炎症性腸疾患関連応答(クローン病と潰瘍性大腸炎など);外科組織再灌流損傷、心筋虚血症状を含む虚血性再灌流疾患、例えば心筋梗塞、心停止、心臓手術後の再灌流及び経皮経管冠動脈形成、脳卒中、及び腹部大動脈瘤;脳卒中に続いて起こる脳浮腫;頭蓋外傷;血液量減少性ショック;呼吸停止;成人呼吸窮迫症候群;急性肺障害;ベーチェット病;皮膚筋炎;多発性筋炎;多発性硬化症;皮膚炎;髄膜炎;脳炎;ブドウ膜炎;変形性関節症;自己免疫疾患、たとえば関節リウマチ、シェーゲン症候群、血管炎、及びインスリン依存性糖尿病(IDDM);白血球血管外遊出に関連する疾患;中枢神経系(CNS)炎症性障害;敗血症又は外傷に続いて起こる多発性臓器傷害症候群;アルコール性肝炎及び肝線維症を含む肝臓の炎症性疾患;肉芽腫症、肝炎、及び細菌性肺炎における病的炎症を含む感染に対する病的宿主反応;糸球体腎炎を含む抗原抗体複合体媒介性疾患;敗血症;多臓器肉芽腫性疾患;移植片対宿主疾患(GVHD)を含む組織/器官移植に対する免疫病理反応;肋膜炎、肺胞炎、血管炎、肺炎、慢性気管支炎、気管支拡張症、びまん性汎細気管支炎、過敏性肺臓炎、特発性肺線維症(IPF)、及び嚢胞性線維症を含む肺の炎症;ループス腎炎のような急性又は慢性の腎炎性症状を含む腎臓病における炎症;膵炎等々が含まれる。好適な適応症には、関節リウマチ、骨関節炎、敗血症、急性肺障害、成人呼吸窮迫症候群、特発性肺線維症、(外科組織再灌流損傷、脳卒中、心筋虚血症状及び急性心筋梗塞を含む)虚血性再灌流疾患、喘息、乾癬、移植片対宿主疾患(GVHD)、及び潰瘍性大腸炎のような炎症性腸疾患が含まれる。
ここで使用されるところの「喘息」、「喘息性障害」、「喘息疾患」、及び「気管支喘息」という用語は下気道の広範囲の狭窄がある肺の症状を意味する。「アトピー性喘息」及び「アレルギー喘息」は、例えば喘息の症状を調節するために吸入又は全身性ステロイドの頻繁な又は定常的な使用を必要とする症状のような中程度又は重症の慢性喘息を含む、下気道におけるIgEを介した超過敏反応の症状である喘息を意味する。好適な適応症はアレルギー喘息である。
本発明は、本出願でIL-1lpと称されるポリペプチドをコードする新規に同定され単離されたヌクレオチド配列を提供する。特に下記の実施例で更に詳細に開示するように、IL-1lpポリペプチドをコードするcDNAが同定され単離された。
NCBI-BLAST2配列アラインメントコンピュータプログラムを使用して、全長天然配列hIL-1Ra1(図3と配列番号:7に示す)がヒトIL-1レセプターアンタゴニストβ(hIL-1Raβ)及びTANGO−77タンパク質と幾らかのアミノ酸配列同一性を有し、全長天然配列hIL-1Ra1L(図15と配列番号:19に示す)がヒトIL-1レセプターアンタゴニストβ(hIL-1Raβ)及びTANGO−77タンパク質と幾らかのアミノ酸配列同一性を有し、全長天然配列hIL-1Ra1V(図19と配列番号:25に示す)がヒトIL-1レセプターアンタゴニストβ(hIL-1Raβ)及びTANGO−77タンパク質と幾らかのアミノ酸配列同一性を有し、全長天然配列hIL-1Ra1S(図16と配列番号:21に示す)がTANGO−77の対立遺伝子変異体であると思われ、ヒトIL-1レセプターアンタゴニストβ(hIL-1Raβ)と幾らかのアミノ酸配列同一性を有し、全長天然配列hIL-1Ra2(図5と配列番号:10に示す)がhIL-1Raβと幾らかのアミノ酸配列同一性を有し、全長天然配列hIL-1Ra3(図7と配列番号:13に示す)がヒト細胞内IL-1レセプターアンタゴニスト(hicIL-1Ra)と幾らかのアミノ酸配列同一性を有し、全長天然配列mIL-1Ra3(図9と配列番号:16に示す)がマウスIL-1レセプターアンタゴニスト(mIL-1Ra)と幾らかのアミノ酸配列同一性を有しhicIL-1Raと幾らかのアミノ酸配列同一性を有することが見出された。hIL-1Raβは1998年7月29日に公開されたEP0855404に記載されている。TANGO−77は1999年2月11日に公開されたWO99/06426に記載されている。hicIL-1Raは1995年4月20日に公開されたWO95/10298及びHaskill等, Proc. Natl. Acad. Sci. (USA), 88:3681-3685 (1991)に記載されている。mIL-1RaはZahedi等, J. Immunol., 146:4228-4233 (1991)、Matsushime等, Blood, 78:616-623 (1991)、Zahedi等, Cytokine, 6:1-9 (1994)、Eisenber等, Proc. Natl. Acad. Sci. (USA), 88:5232-5236 (1991)及びShuck等, Eur. J. Immunol., 21: 2775-2780 (1991)に記載されている。従って、本願に開示されたIL-1lpポリペプチドはインターロイキン−1様ファミリーの新規に同定されたメンバーであり、IL-1様ファミリーに典型的な炎症性又は抗炎症性活性、あるいは他の細胞性応答活性化もしくは阻害活性を保有していると現在考えられる。
IL-1lp変異体は、IL-1lpDNAに適当なヌクレオチド変化を導入することにより、及び/又は所望のIL-1lpポリペプチドを合成することにより調製できる。当業者であれば、グリコシル化部位の数又は位置の変化あるいは膜固着特性の変化などのアミノ酸変化がIL-1lpの翻訳後プロセスを変えうることは理解できるであろう。
天然全長配列IL-1lp又はここに記載したIL-1lpの種々のドメインにおける変異は、例えば、米国特許第5364934号に記載されている保存的及び非保存的変異についての技術と指針の任意のものを用いてなすことができる。変異は、天然配列IL-1lpと比較したときIL-1lpのアミノ酸配列の変化を生じるIL-1lpをコードする一又は複数のコドンの置換、欠失又は挿入でありうる。場合によっては、変異は少なくとも1つのアミノ酸の、IL-1lpの一又は複数のドメインの任意の他のアミノ酸による置換である。何れのアミノ酸残基が所望の活性に悪影響を与えることなく挿入、置換又は欠失されるかの指針は、IL-1lpの配列を相同的な既知のタンパク質分子の配列と比較し、相同性の高い領域内でなされるアミノ酸配列変化の数を最小にすることによって見出される。アミノ酸置換は、一のアミノ酸の、類似した構造及び/又は化学的性質を持つ他のアミノ酸での置換、例えばロイシンのセリンでの置換、すなわち保存的アミノ酸置換の結果とすることができる。挿入又は欠失は、場合によっては1から5のアミノ酸の範囲内とすることができる。許容される変異は、配列においてアミノ酸の挿入、欠失又は置換を系統的になし、得られた変異体について以下の実施例に記載されたインビトロアッセイで活性を試験することにより決定される。

(1)疎水性:ノルロイシン, met, ala, val, leu, ile;
(2)中性の親水性:cys, ser, thr;
(3)酸性:asp, glu;
(4)塩基性:asn, gln, his, lys, arg;
(5)鎖配向に影響する残基:gly, pro; 及び
(6)芳香族:trp, tyr, phe。
非保存的置換は、これらの分類の一つのメンバーを他の分類と交換することを必要とするであろう。また、そのように置換された残基は、保存的置換部位、より好ましくは残された(非保存)部位に導入されうる。
変異は、オリゴヌクレオチド媒介(部位特異的)突然変異誘発、アラニンスキャンニング、及びPCR突然変異誘発のようなこの分野で知られた方法を用いてなすことができる。部位特異的突然変異誘発(Carter等, Nucl. Acids Res., 13: 4331 (1986); Zoller等, Nucl. Acids Res., 10: 6487 (1987))、カセット突然変異誘発(Wells等, Gene, 34: 315 (1985))、制限的選択突然変異誘発[Wells等, Philos. Trans. R. Soc. London SerA, 317: 415 (1986)]もしくは他の方法をクローニングしたDNAに実施してIL-1lp変異体DNAを作成することもできる。
また、スキャンニングアミノ酸分析は、隣接配列に沿って一又は複数のアミノ酸を同定するのに用いることができる。好ましいスキャンニングアミノ酸は比較的小さく、中性のアミノ酸である。そのようなアミノ酸は、アラニン、グリシン、セリン、及びシステインを含む。アラニンは、ベータ炭素を越える側鎖を排除し変異体の主鎖構造を変化させにくいので、この群の中で典型的に好ましいスキャンニングアミノ酸である[Cuningham及びWells, Science, 244: 1081-1085 (1989)]。また、アラニンは最もありふれたアミノ酸であるため典型的に好ましい。更に、それは埋もれた位置と露出した位置の両方に見られることが多い[Creighton, The Proteins, (W.H. Freeman & Co., N.Y.); Chothia, J. Mol. Biol., 150: 1 (1976)]。アラニン置換が十分な量の変異体を生じない場合は、アイソテリック(isoteric)アミノ酸を用いることができる。
他の修飾は、グルタミニル及びアスパラギニル残基の各々対応するグルタミル及びアスパルチルへの脱アミノ化、プロリン及びリシンのヒドロキシル化、セリル又はトレオニル残基のヒドロキシル基のリン酸化、リシン、アルギニン、及びヒスチジン側鎖のα-アミノ基のメチル化[T.E. Creighton, Proteins: Structure and Molecular Properties, W.H. Freeman & Co., San Francisco, pp.79-86 (1983)]、N末端アミンのアセチル化、及び任意のC末端カルボキシル基のアミド化を含む。
IL-1lpポリペプチドへのグリコシル化部位の付加はアミノ酸配列の変更を伴ってもよい。この変更は、例えば、一又は複数のセリン又はスレオニン残基の天然配列IL-1lp(O-結合グリコシル化部位)への付加、又は置換によってなされてもよい。IL-1lpアミノ酸配列は、場合によっては、DNAレベルでの変化、特に、IL-1lpポリペプチドをコードするDNAを予め選択された塩基において変異させ、所望のアミノ酸に翻訳されるコドンを生成させることを通して変更されてもよい。
IL-1lpポリペプチド上に存在する炭水化物部分の除去は、化学的又は酵素的に、あるいはグルコシル化の標的となるアミノ酸残基をコードするコドンの変異的置換によってなすことができる。化学的脱グリコシル化技術は、この分野で知られており、例えば、Hakimuddin等, Arch. Biochem. Biophys., 259:52 (1987)により、及びEdge等, Anal. Biochem., 118: 131 (1981)により記載されている。ポリペプチド上の炭水化物部分の酵素的切断は、Thotakura等, Meth. Enzymol. 138:350 (1987)に記載されているように、種々のエンド及びエキソグリコシダーゼを用いることにより達成できる。
IL-1lpの共有結合的修飾の他の型は、IL-1lpポリぺプチドの、種々の非タンパク質様ポリマー、例えばポリエチレングリコール(PEG)、ポリプロピレングリコール、又はポリオキシアルキレンの一つへの、米国特許第4640835号;第4496689号;第4301144号;第4670417号;第4791192号又は第4179337号に記載された方法での結合を含む。
一実施態様では、このようなキメラ分子は、抗タグ抗体が選択的に結合できるエピトープを提供するタグポリペプチドとIL-1lpとの融合を含む。エピトープタグは、一般的にはIL-1lpのアミノ又はカルボキシル末端に位置する。IL-1lpのこのようなエピトープタグ形態の存在は、タグポリペプチドに対する抗体を用いて検出することができる。また、エピトープタグの提供は、抗タグ抗体又はエピトープタグに結合する他の型の親和性マトリクスを用いたアフィニティ精製によってIL-1lpを容易に精製できるようにする。様々なタグポリペプチドとそれら各々の抗体はこの分野で良く知られている。例としては、ポリ-ヒスチジン(poly-his)又はポリ-ヒスチジン−グリシン(poly-his-gly)タグ;flu HAタグポリペプチド及びその抗体12CA5[Field等, Mol. Cell. Biol., 8:2159-2165 (1988)];c-mycタグ及びそれに対する8F9、3C7、6E10、G4、B7及び9E10抗体[Evan等, Molecular and Cellular Biology, 5:3610-3616 (1985)];及び単純ヘルペスウイルス糖タンパク質D(gD)タグとその抗体[Paborsky等, Protein Engineering, 3(6):547-553 (1990)]を含む。他のタグポリペプチドは、フラッグペプチド[Hopp等, BioTechnology, 6:1204-1210 (1988)];KT3エピトープペプチド[Martin等, Science, 255:192-194 (1992)];αチューブリンエピトープペプチド[Skinner等, J. Biol. Chem., 266:15163-15166 (1991)];及びT7遺伝子10タンパク質ペプチドタグ[Lutz-Freyermuth等, Proc. Natl. Acad. Sci. USA, 87:6393-6397 (1990)]を含む。
別の実施態様では、キメラ分子はIL-1lpの免疫グロブリン又は免疫グロブリンの特定の領域との融合体を含んでもよい。キメラ分子の二価形態(「イムノアドヘシン」とも呼ばれる)については、そのような融合体はIgG分子のFc領域であり得る。Ig融合体は、好ましくはIg分子内の少なくとも1つの可変領域に換えてのIL-1lpポリペプチドの可溶型の置換を含む。特に好ましい実施態様では、免疫グロブリン融合体は、IgG1分子のヒンジ、CH2及びCH3、又はヒンジ、CH1、CH2及びCH3領域を含む。免疫グロブリン融合体の製造については、1995年6月27日発行の米国特許第5428130号を参照のこと。
他の側面では、本発明は、天然配列IL-1lpの少なくとも一の生物活性、例えば天然配列hIL-1Ra1、hIL-1Ra1L、又はhIL-1Ra1VのIL-18R結合活性を保持するIL-1lpポリペプチドをコードするDNAを含んでなり、DNAが、(a)(1)図15(配列番号:19)の1又は約1から207又は約207のアミノ酸残基を含んでなるIL-1lpポリペプチドをコードするDNA分子、及び(2)図19(配列番号:25)の1又は約1から218又は約218のアミノ酸残基を含んでなるIL-1lpポリペプチドをコードするDNA分子からなる群から選択されるDNA分子;又は(b)(a)のDNA分子の相補鎖に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有する単離された核酸を提供する。
他の側面では、本発明は、天然配列IL-1lpの少なくとも一の生物活性、例えば天然配列hIL-1Ra1のIL-18R結合活性、又は天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性を保持するIL-1lpポリペプチドをコードするDNAを含んでなり、DNAが、(a)図7(配列番号:13)の80又は約80から155又は約155のアミノ酸残基を含んでなるIL-1lpポリペプチドをコードするDNA分子、又は(b)(a)のDNA分子の相補鎖に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有する単離された核酸を提供する。
他の側面では、本発明は、天然配列IL-1lpの少なくとも一の生物活性、例えば天然配列hIL-1Ra1のIL-18R結合活性、又は天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性を保持するIL-1lpポリペプチドをコードするDNAを含んでなり、DNAが、(a)(1)図7(配列番号:13)の2又は約2から155又は約155のアミノ酸残基を含んでなるIL-1lpポリペプチドをコードするDNA分子、及び(2)図9(配列番号:16)の2又は約2から155又は約155のアミノ酸残基を含んでなるIL-1lpポリペプチドをコードするDNA分子からなる群から選択されるDNA分子、又は(b)(a)のDNA分子の相補鎖に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有する単離された核酸を提供する。
他の側面では、本発明は、(a)図7(配列番号:13)の80又は約80から155又は約155のアミノ酸残基を含んでなるIL-1lpポリペプチドをコードするDNA分子、又は(b)(a)のDNA分子の相補鎖に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有するDNAを含んでなる単離された核酸を提供する。
他の側面では、本発明は、(a)(1)図7(配列番号:13)の2又は約2から155又は約155のアミノ酸残基を含んでなるIL-1lpポリペプチドをコードするDNA分子、及び(2)図9(配列番号:16)の2又は約2から155又は約155のアミノ酸残基を含んでなるIL-1lpポリペプチドをコードするDNA分子からなる群から選択されるDNA分子、又は(b)(a)のDNA分子の相補鎖に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有するDNAを含んでなる単離された核酸を提供する。
他の側面では、本発明は、少なくとも90のヌクレオチド長であり、(1)図7(配列番号:12)のセンス鎖の238又は約238から465又は約465のヌクレオチド位置からなる核酸配列;(2)図9(配列番号:15)のセンス鎖の427又は約427から609又は約609のヌクレオチド位置からなる核酸配列;及び(3)図15(配列番号:18)のセンス鎖の115は約115ら135又は約135のヌクレオチド位置からなる核酸配列からなる群から選択される核酸配列の相補鎖にハイブリッド形成するDNAを含んでなる単離された核酸分子に関する。好ましくは、ハイブリッド形成は緊縮性ハイブリッド形成及び洗浄条件下で生じる。
他の側面では、本発明は、天然配列IL-1lpの少なくとも一の生物活性、例えば天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性、又は天然配列hIL-1Ra1、hIL-1Ra1L、又はhIL-1Ra1VのIL-18R結合活性を保持するIL-1lpポリペプチドをコードするDNAを含んでなり、DNAが、(1)図2(配列番号:4)のセンス鎖の118又は約118から231又は約231のヌクレオチド位置からなる核酸配列;(2)図7(配列番号:12)のセンス鎖の100又は約100から465又は約465のヌクレオチド位置からなる核酸配列;(3)図9(配列番号:15)のセンス鎖の244又は約244から609又は約609のヌクレオチド位置からなる核酸配列;及び(4)図19(配列番号:24)のセンス鎖の208又は約208から339又は約339のヌクレオチド位置からなる核酸配列からなる群から選択される核酸配列の相補鎖にハイブリッド形成する単離された核酸分子に関する。好ましくは、ハイブリッド形成は緊縮性ハイブリッド形成及び洗浄条件下で生じる。
他の側面では、本発明は、天然配列IL-1lpの少なくとも一の生物活性、例えば天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性を保持するIL-1lpポリペプチドをコードするDNAを含んでなり、DNAが、(1)図7(配列番号:12)のセンス鎖の4又は約4から465又は約465のヌクレオチド位置からなる核酸配列;及び(2)図9(配列番号:15)のセンス鎖の148又は約148から609又は約609のヌクレオチド位置からなる核酸配列からなる群から選択される核酸配列の相補鎖にハイブリッド形成する単離された核酸分子に関する。好ましくは、ハイブリッド形成は緊縮性ハイブリッド形成及び洗浄条件下で生じる。
更なる側面では、本発明は、天然配列IL-1lpの少なくとも一の生物活性、例えば天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性、又は天然配列hIL-1Ra1、hIL-1Ra1L、又はhIL-1Ra1VのIL-18R結合活性を保持するIL-1lpポリペプチドをコードするDNAを含んでなり、DNAが、(a)ATCC寄託番号203588(DNA85066−2534)、ATCC寄託番号203587(DNA96786−2534)、ATCC寄託番号203589(DNA96787−2534)、ATCC寄託番号203590(DNA92505−2534)、ATCC寄託番号203846(DNA102043−2534)、及びATCC寄託番号203973(DNA114876−2534)として寄託されたベクターからなる群から選択されるベクターのcDNA挿入断片の最長のオープンリーディングフレームによりコードされる全体アミノ酸配列をコードするDNA、又は(b)(a)のDNA分子の相補鎖に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有する単離された核酸を提供する。好適な実施態様では、核酸は、(a)ATCC寄託番号203588(DNA85066−2534)、ATCC寄託番号203587(DNA96786−2534)、ATCC寄託番号203586(DNA92929−2534)、ATCC寄託番号203589(DNA96787−2534)、及びATCC寄託番号203590(DNA92505−2534)として寄託されたベクターからなる群から選択されたベクターのcDNA挿入断片の最長のオープンリーディングフレームによりコードされる全体アミノ酸配列をコードするDNA、又は(a)のDNAの相補鎖を含んでなる。他の好適な実施態様では、核酸は、(a)ATCC寄託番号203846(DNA102043−2534)、ATCC寄託番号203855(DNA102044−2534)、及びATCC寄託番号203973(DNA114876−2534)として寄託されたベクターからなる群から選択されたベクターのcDNA挿入断片の最長のオープンリーディングフレームによりコードされる全体アミノ酸配列をコードするDNA、又は(a)のDNAの相補鎖を含んでなる。
またさらなる側面では、本発明は、(a)天然配列IL-1lpの少なくとも一の生物活性、例えばhIL-1Ra1のIL-18R結合活性、又は天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性を保持するIL-1lpポリペプチドで、そしてそれが(1)図7(配列番号:13)のアミノ酸残基95又は約95から134又は約134、及び(2)図9(配列番号:16)のアミノ酸残基95又は約95から134又は約134からなる群から選択されるアミノ酸配列に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有するIL-11pポリペプチドをコードするDNA、又は(b)(a)のDNAの相補鎖を含んでなる単離された核酸分子に関する。
またさらなる側面では、本発明は、(a)天然配列IL-1lpの少なくとも一の生物活性、例えばhIL-1Ra1のIL-18R結合活性、又は天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性を保持するIL-1lpポリペプチドで、そしてそれが(1)図7(配列番号:13)のアミノ酸残基2又は約2から155又は約155、及び(2)図9(配列番号:16)のアミノ酸残基2又は約2から155又は約155からなる群から選択されるアミノ酸配列に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有するIL-11pポリペプチドをコードするDNA、又は(b)(a)のDNAの相補鎖を含んでなる単離された核酸分子に関する。
またさらなる側面では、本発明は、(a)(1)図7(配列番号:13)のアミノ酸残基95又は約95から134又は約134、及び(2)図9(配列番号:16)のアミノ酸残基95又は約95から134又は約134からなる群から選択されるアミノ酸配列に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有するIL-11pポリペプチドをコードするDNA、又は(b)(a)のDNAの相補鎖を含んでなる単離された核酸分子に関する。
またさらなる側面では、本発明は、(a)図7(配列番号:13)のアミノ酸残基80又は約80から155又は約155のアミノ酸配列に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有するIL-11pポリペプチドをコードするDNA、又は(b)(a)のDNAの相補鎖を含んでなる単離された核酸分子に関する。
またさらなる側面では、本発明は、(a)天然配列IL-1lpの少なくとも一の生物活性、例えばhIL-1Ra1、hIL-1Ra1L、又は天然配列hIL-1Ra1VのIL-18R結合活性を保持するIL-1lpポリペプチドで、そしてそれが(1)図15(配列番号:19)のアミノ酸残基1又は約1から207又は約207、及び(2)図19(配列番号:25)のアミノ酸残基1又は約1から218又は約218からなる群から選択されるアミノ酸配列に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有するIL-11pポリペプチドをコードするDNA、又は(b)(a)のDNAの相補鎖を含んでなる単離された核酸分子に関する。
またさらなる側面では、本発明は、天然配列IL-1lpの少なくとも一の生物活性、例えば天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性、又は天然配列hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1S、又はhIL-1Ra1VのIL-18R結合活性を有するIL-1lpをコードするDNAを含んでなる単離された核酸分子に関し、そのDNAは緊縮条件下で(a)(1)図2(配列番号:5)のアミノ酸残基37又は約37から203又は約203の配列をを含んでなるIL-1lpポリペプチド、(2)図3(配列番号:7)のアミノ酸残基15又は約15から193又は約193の配列をを含んでなるIL-1lpポリペプチド、(3)図7(配列番号:13)のアミノ酸残基34又は約34から155又は約155の配列をを含んでなるIL-1lpポリペプチド、(4)図9(配列番号:16)のアミノ酸残基34又は約34から155又は約155の配列をを含んでなるIL-1lpポリペプチド、(5)図15(配列番号:19)のアミノ酸残基26又は約26から207又は約207の配列をを含んでなるIL-1lpポリペプチド、及び(6)図19(配列番号:25)のアミノ酸残基46又は約46から218又は約218の配列をを含んでなるIL-1lpポリペプチドからなる群から選択されるIL-1lpポリペプチドをコードするDNA分子、又は(b)(a)のDNA分子の相補鎖を用いて試験DNAをハイブリッド形成することによって、及び試験DNA分子が天然配列IL-1lpの少なくとも一の生物活性、例えば天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性、又は天然配列hIL-1Ra1、hIL-1Ra1L、又はhIL-1Ra1VのIL-18R結合活性を有するIL-1lpをコードする場合、及び試験DNA分子が(a)又は(b)のDNA分子と少なくとも約80%の配列同一性、又は少なくとも約85%の配列同一性、又は少なくとも90%の配列同一性、又は少なくとも約95%の配列同一性を有する場合には、試験DNA分子を単離することにより、生成される。
他の側面では、本発明は(a)(1)図15(配列番号:19)のアミノ酸残基26又は約26から44又は約44を含んでなる、例えばhIL-1Ra1Lポリペプチドのようなポリペプチド;(2)図15(配列番号:19)のアミノ酸残基1又は約1から44又は約44を含んでなる、例えばhIL-1Ra1Lポリペプチドのようなポリペプチド;(3)図15(配列番号:19)のアミノ酸残基26又は約26から78又は約78を含んでなる、例えばhIL-1Ra1Lポリペプチドのようなポリペプチド;(4)図15(配列番号:19)のアミノ酸残基1又は約1から78又は約78を含んでなる、例えばhIL-1Ra1Lポリペプチドのようなポリペプチド;(5)図16(配列番号:21)のアミノ酸残基1又は約1から38又は約38を含んでなる、例えばhIL-1Ra1Sポリペプチドのようなポリペプチド;(6)図19(配列番号:25)のアミノ酸残基37又は約37から55又は約55を含むhIL-1Ra1Vの天然アミノ酸配列を含んでなる、例えばhIL-1Ra2融合変異体ポリペプチドのようなポリペプチド;(7)図19(配列番号:25)のアミノ酸残基12又は約12から55又は約55を含んでなる、例えばhIL-1Ra1Vポリペプチドのようなポリペプチド;(8)図19(配列番号:25)のアミノ酸残基1又は約1から55又は約55を含んでなる、例えばhIL-1Ra1Vポリペプチドのようなポリペプチド;(9)図19(配列番号:25)のアミノ酸残基46又は約46から55又は約55を含んでなる、例えばhIL-1Ra1Vポリペプチドのようなポリペプチド;(10)図19(配列番号:25)のアミノ酸残基46又は約46から89又は約89を含んでなる、例えばhIL-1Ra1Vポリペプチドのようなポリペプチド;(11)図19(配列番号:25)のアミノ酸残基37又は約37から89又は約89を含んでなる、例えばhIL-1Ra1Vポリペプチドのようなポリペプチド;(12)図19(配列番号:25)のアミノ酸残基12又は約12から89又は約89を含んでなる、例えばhIL-1Ra1Vポリペプチドのようなポリペプチド;及び(13)図19(配列番号:25)のアミノ酸残基1又は約1から89又は約89を含んでなる、例えばhIL-1Ra1Vポリペプチドのようなポリペプチドからなる群より選択された、例えばIL-1lpポリペプチドのようなポリペプチドをコードするDNA;又は(b)(a)のDNAの相補鎖を構成する単離された核酸分子を提供する。
他の側面では、本発明は(1)図15(配列番号:19)のアミノ酸残基26又は約26から207又は約207のアミノ酸配列を含んでなる、例えばhIL-1Ra1LポリペプチドのようなポリペプチドをコードするDNA分子;(2)図16(配列番号:21)のアミノ酸残基26又は約26から167又は約167のアミノ酸配列を含んでなる、例えばhIL-1Ra1SポリペプチドのようなポリペプチドをコードするDNA分子;(3)図19(配列番号:25)のアミノ酸残基37又は約37から218又は約218のアミノ酸配列を含んでなる、例えばhIL-1Ra1VポリペプチドのようなポリペプチドをコードするDNA分子;(4)図19(配列番号:25)のアミノ酸残基46又は約46から218又は約218のアミノ酸配列を含んでなる、例えばhIL-1Ra1VポリペプチドのようなポリペプチドをコードするDNA分子;及び(5)(1)−(4)のDNA分子のいずれかの相補鎖からなる群より選択された単離されたDNA分子を提供する。
他の側面では、本発明は(1)図2(配列番号:5)のアミノ酸残基80又は約80から155又は約155のアミノ酸配列を含んでなる、例えばhIL-1Ra3ポリペプチドのようなポリペプチドをコードするDNA分子;及び(2)(1)のDNA分子の相補鎖からなる群より選択された単離されたDNA分子を提供する。
他の側面では、本発明は(1)図2(配列番号:5)のアミノ酸残基1又は約1から203又は約203のアミノ酸配列を含んでなる、例えばhIL-1Ra1ポリペプチドのようなポリペプチドをコードするDNA分子;(2)図3(配列番号:7)のアミノ酸残基1又は約1から193又は約193のアミノ酸配列を含んでなる、例えばhIL-1Ra1ポリペプチドのようなポリペプチドをコードするDNA分子;(3)図7(配列番号:13)のアミノ酸残基34又は約34から155又は約155のアミノ酸配列を含んでなる、例えばhIL-1Ra3ポリペプチドのようなポリペプチドをコードするDNA分子;(4)図9(配列番号:16)のアミノ酸残基34又は約34から155又は約155のアミノ酸配列を含んでなる、例えばhIL-1Ra3ポリペプチドのようなポリペプチドをコードするDNA分子;及び(5)(1)−(4)のDNA分子のいずれかの相補鎖からなる群より選択された単離されたDNA分子を提供する。
他の側面では、本発明は(1)図7(配列番号:13)のアミノ酸残基2又は約2から155又は約155のアミノ酸配列を含んでなる、例えばhIL-1Ra3ポリペプチドのようなポリペプチドをコードするDNA分子;(2)図9(配列番号:16)のアミノ酸残基2又は約2から155又は約155のアミノ酸配列を含んでなる、例えばhIL-1Ra3ポリペプチドのようなポリペプチドをコードするDNA分子;及び(3)(1)−(2)のDNA分子のいずれかの相補鎖からなる群より選択された単離されたDNA分子を提供する。
他の側面では本発明は、(a):(1)ATCC寄託番号203588として寄託されたベクターのcDNA挿入断片によってコードされる、例えば成熟hIL-1Ra1ポリペプチドのようなhIL-1Ra1ポリペプチドを含んでなるポリペプチド;(2)ATCC寄託番号203587として寄託されたベクターのcDNA挿入断片によってコードされる、例えば成熟hIL-1Ra1ポリペプチドのようなhIL-1Ra1ポリペプチドを含んでなるポリペプチド;(3)ATCC寄託番号203586として寄託されたベクターのcDNA挿入断片によってコードされる、例えば成熟hIL-1Ra2ポリペプチドのようなhIL-1Ra2ポリペプチドで、それがそのN−末端又はC−末端でヘテロアミノ酸又はアミノ酸配列と融合されたhIL-1Ra2ポリペプチドを含んでなるポリペプチド;(4)ATCC寄託番号203586として寄託されたベクターのcDNA挿入断片によってコードされる、例えば成熟hIL-1Ra2ポリペプチドのようなhIL-1Ra2ポリペプチドを含んでなるポリペプチド;(5)ATCC寄託番号203589として寄託されたベクターのcDNA挿入断片によってコードされる、例えば成熟hIL-1Ra3ポリペプチドのようなhIL-1Ra3ポリペプチドを含んでなるポリペプチド;(6)ATCC寄託番号203590として寄託されたベクターのcDNA挿入断片によってコードされる、例えば成熟hIL-1Ra3ポリペプチドのようなhIL-1Ra3ポリペプチドを含んでなるポリペプチドからなる群より選ばれるポリペプチドをコードするDNA分子;又は(b)(a)のDNA分子の相補鎖を構成する単離された核酸分子を提供する。
他の側面では、本発明は、(a)ATCC寄託番号203855として寄託されたベクターのcDNA挿入断片によってコードされる、例えば成熟hIL-1Ra1SポリペプチドのようなhIL-1Ra1Sポリペプチドを含んでなるポリペプチドをコードするDNA;又は(b)(a)のDNA分子の相補鎖を含んでなる単離された核酸分子を提供する。
他の側面では、本発明は、(a)ATCC寄託番号203588、203586、203589、293590、及び203973として寄託されたベクターよりなる群より選ばれるベクターのcDNA挿入断片の最長のオープンリーディングフレームによってコードされる全アミノ酸配列を含んでなるポリペプチドをコードするDNA;又は(b)(a)のDNA分子の相補鎖を含んでなる単離された核酸分子を提供する。
他の側面では、本発明は、(a)ATCC寄託番号203855として寄託されたベクターのcDNA挿入断片の最長のオープンリーディングフレームによりコードされる、該配列の38のN末端アミノ酸残基を除く全体アミノ酸配列、又は該配列の46のN末端アミノ酸残基を除く全体アミノ酸配列が、そのN−末端又はC−末端でヘテロアミノ酸又はアミノ酸配列と融合することにより形成された非天然に生じるキメラポリペプチドをコードするDNA;又は(b)(a)のDNAの相補鎖を構成する単離された核酸分子を提供する。
他の側面では、本発明は(a)ATCC寄託番号203846、203855及び203973として寄託されたベクターからなる群より選ばれたベクターのcDNA挿入断片の最長のオープンリーディングフレームによりコードされる全体アミノ酸配列を構成するポリペプチドをコードするDNA分子、又は(b)(a)のDNAの相補鎖を構成する単離された核酸分子を提供する。
他の側面では、本発明は(1)そのN−末端又はC−末端でヘテロアミノ酸又はアミノ酸配列と融合され、図19(配列番号:25)のアミノ酸残基37又は約37から218又は約218からなるhIL-1Ra1Vの天然アミノ酸配列からなる、例えばhIL-1Ra1V融合変異体ポリペプチドのようなポリペプチドをコードし、そのDNA分子が図19(配列番号:24)のセンス鎖で天然アミノ酸配列をコードするアミノ酸配列を構成する、DNA分子;(2)そのN−末端又はC−末端でヘテロアミノ酸又はアミノ酸配列と融合され、図19(配列番号:25)のアミノ酸残基46又は約46から218又は約218からなるhIL-1Ra1Vの天然アミノ酸配列からなる、例えばhIL-1Ra1V融合変異体ポリペプチドのようなポリペプチドをコードし、そのDNA分子が図19(配列番号:24)のセンス鎖で天然アミノ酸配列をコードするアミノ酸配列を構成する、DNA分子;(3)図19(配列番号:25)のアミノ酸残基37又は約37から218又は約218からなるhIL-1Ra1Vの天然アミノ酸配列からなる、例えばhIL-1Ra1Vポリペプチドのようなポリペプチドをコードし、そのDNA分子が図19(配列番号:24)のセンス鎖で天然アミノ酸配列をコードするアミノ酸配列を構成する、DNA分子;(4)図19(配列番号:25)のアミノ酸残基46又は約46から218又は約218からなるhIL-1Ra1Vの天然アミノ酸配列からなる、例えばhIL-1Ra1Vポリペプチドのようなポリペプチドをコードし、そのDNA分子が図19(配列番号:24)のセンス鎖で天然アミノ酸配列をコードするアミノ酸配列を構成する、DNA分子;及び(5)(1)−(4)のDNA分子のいずれかの相補鎖からなる群より選ばれる単離されたDNA分子を提供する。
他の側面では、本発明は(1)図3(配列番号:6)のセンス鎖のヌクレオチド位置103又は約103から681又は約681の核酸配列を構成するDNA分子;(2)図7(配列番号:12)のセンス鎖のヌクレオチド位置100又は約100から465又は約465の核酸配列を構成するDNA分子;(3);図9(配列番号:15)のセンス鎖のヌクレオチド位置244又は約244から609又は約609の核酸配列を構成するDNA分子(4)(1)−(3)のDNA分子のいずれかの相補鎖からなる群より選択される単離されたDNA分子を提供する。
他の側面では、本発明は(a)図2(配列番号:4)、図3(配列番号:6)、図5(配列番号:9)、図7(配列番号:12)、図9(配列番号:15)のセンス鎖の完全DNA配列、又は(b)(a)の相補配列を構成する単離されたDNA分子を提供する。
他の側面では、本発明は(a)図15(配列番号:18)、図16(配列番号:20)、図19(配列番号:24)のセンス鎖の完全DNA配列、又は(b)(a)の相補配列を構成する単離されたDNA分子を提供する。
図15(配列番号:19)のアミノ酸1又は約1から207又は約207のIL-1lp配列は、ある動物細胞では成熟配列(翻訳後のプロセッシングで取り除かれるプレ配列を持たない)ように振る舞うと考えられる。
図16(配列番号:21)のアミノ酸1又は約1から167又は約167のIL-1lp配列は、ある動物細胞では成熟配列(翻訳後のプロセッシングで取り除かれるプレ配列を持たない)ように振る舞うと考えられる。さらに他の動物細胞では翻訳後のプロセッシングにおいて図16(配列番号:21)のIL-1lp配列のアミノ酸位置1から約46の配列に含まれる1又は複数のシグナルペプチドが認識され、取り除かれると考えられている。
図19(配列番号:25)のアミノ酸1又は約1から218又は約218のIL-1lp配列は、ある動物細胞では成熟配列(翻訳後のプロセッシングで取り除かれるプレ配列を持たない)ように振る舞うと考えられる。またヌクレオチド位置106−108で生じる開始コドンで翻訳の開始の結果生じる図19(配列番号:25)のアミノ酸12又は約12型218又は約218のIL-1lpの配列はある動物細胞では成熟配列として振る舞うと考えられている。さらに他の動物細胞では翻訳後のプロセッシングにおいて図19(配列番号:25)のアミノ酸位置1から218のIL-1lpポリペプチドのアミノ酸位置1から45の配列に含まれるか、又は図19(配列番号:25)のアミノ酸位置12から218のIL-1lpポリペプチドのアミノ酸位置12から45の配列に含まれる1又は複数のシグナルペプチドが認識され、取り除かれると考えられている。
また更なる側面では本発明は(a)天然配列IL-1lpの少なくとも1の生物活性、例えば天然配列hIL-1Ra1のIL-18R結合活性、又は天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性を保持し、そのIL-1lpポリペプチドが:(1)図7(配列番号:13)のアミノ酸残基95又は約95から134又は約134、及び(2)図9(配列番号:16)のアミノ酸残基95又は約95から134又は約134からなる群より選択されるアミノ酸配列と少なくとも80%又は約80%ポジティブ、又は少なくとも85%又は約85%ポジティブ、又は少なくとも90%又は約90%ポジティブ、又は少なくとも95%又は約95%ポジティブを有するIL-1lpポリペプチドをコードするDNA、(b)(a)のDNAの相補鎖を構成する単離された核酸分子に関する。
また更なる側面では本発明は(a)天然配列IL-1lpの少なくとも1の生物活性、例えば天然配列hIL-1Ra1のIL-18R結合活性、又は天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性を保持し、そのIL-1lpポリペプチドが:(1)図7(配列番号:13)のアミノ酸残基2又は約2から155又は約155、及び(2)図9(配列番号:16)のアミノ酸残基2又は約2から155又は約155からなる群より選択されるアミノ酸配列と少なくとも80%又は約80%ポジティブ、又は少なくとも85%又は約85%ポジティブ、又は少なくとも90%又は約90%ポジティブ、又は少なくとも95%又は約95%ポジティブを有するIL-1lpポリペプチドをコードするDNA、(b)(a)のDNAの相補鎖を構成する単離された核酸分子に関する。
また更なる側面では本発明は(a)(1)図7(配列番号:13)のアミノ酸残基95又は約95から134又は約134、及び(2)図9(配列番号:16)のアミノ酸残基95又は約95から134又は約134からなる群より選択されるアミノ酸配列と少なくとも80%又は約80%ポジティブ、又は少なくとも85%又は約85%ポジティブ、又は少なくとも90%又は約90%ポジティブ、又は少なくとも95%又は約95%ポジティブを有するIL-1lpポリペプチドをコードするDNA、(b)(a)のDNAの相補鎖を構成する単離された核酸分子に関する。
また更なる側面では本発明は(a)(1)図7(配列番号:13)のアミノ酸残基2又は約2から155又は約155、及び(2)図9(配列番号:16)のアミノ酸残基2又は約2から155又は約155からなる群より選択されるアミノ酸配列と少なくとも80%又は約80%ポジティブ、又は少なくとも85%又は約85%ポジティブ、又は少なくとも90%又は約90%ポジティブ、又は少なくとも95%又は約95%ポジティブを有するIL-1lpポリペプチドをコードするDNA、(b)(a)のDNAの相補鎖を構成する単離された核酸分子に関する。
また更なる側面では本発明は(a)天然配列IL-1lpの少なくとも1の生物活性、例えば天然配列hIL-1Ra1、hIL-1Ra1L、又はhIL-1Ra1VのIL-18R結合活性を保持し、そのIL-1lpポリペプチドが:(1)図15(配列番号:19)のアミノ酸残基1又は約1から207又は約207、及び(2)図19(配列番号:25)のアミノ酸残基1又は約1から218又は約218からなる群より選択されるアミノ酸配列と少なくとも80%又は約80%ポジティブ、又は少なくとも85%又は約85%ポジティブ、又は少なくとも90%又は約90%ポジティブ、又は少なくとも95%又は約95%ポジティブを有するIL-1lpポリペプチドをコードするDNA、(b)(a)のDNAの相補鎖を構成する単離された核酸分子に関する。
また、例えばベクターを含んでなる宿主細胞も提供する。一例として、宿主細胞は、CHO細胞、大腸菌、又は酵母であり得る。さらにIL-1lpポリペプチドを生成する過程が提供され、IL-1lpの発現に適した条件下での宿主細胞の培養及び細胞培地からのIL-1lpの取り出しを構成する。
他の実施態様では、本発明は上で定義されたどの単離された核酸配列によってでもコードされる単離されたIL-1lpポリペプチドを提供する。
他の側面では、本発明は単離された天然配列IL-1lpポリペプチドを提供し、その一実施態様では、:(1)図2(配列番号:5)の残基37又は約37から203又は約203のアミノ酸配列、(2)図3(配列番号:7)の残基15又は約15から193又は約193のアミノ酸配列、(3)図7(配列番号:13)の残基34又は約34から155又は約155のアミノ酸配列、及び(4)図9(配列番号:16)の残基34又は約34から155又は約155のアミノ酸配列からなる群より選択されるアミノ酸配列を含んでなる。
他の側面では、本発明は単離された天然配列IL-1lpポリペプチドを提供し、その一実施態様では、:(1)図15(配列番号:19)の残基1又は約1から207又は約207のアミノ酸配列、(2)図15(配列番号:19)の残基26又は約26から207又は約207のアミノ酸配列、(3)図16(配列番号:21)の残基1又は約1から167又は約167のアミノ酸配列、及び(4)図16(配列番号:21)の残基26又は約26から167又は約167のアミノ酸配列(5)図19(配列番号:25)の残基1又は約1から218又は約218のアミノ酸配列、(6)図19(配列番号:25)の残基12又は約12から218又は約218のアミノ酸配列(7)図19(配列番号:25)の残基37又は約37から218又は約218のアミノ酸配列、及び(8)図19(配列番号:25)の残基46又は約46から218又は約218のアミノ酸配列、からなる群より選択されるアミノ酸配列を含んでなる。
他の側面では、本発明は天然配列IL-1lpの少なくとも1の生物活性、例えば天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性、または天然配列hIL-1Ra1、hIL-1Ra1L、又はhIL-1Ra1VのIL-18R結合活性を保持し、さらに図15(配列番号:19)のアミノ酸残基1又は約1から207又は約207の配列、又は図19(配列番号:25)のアミノ酸残基1又は約1から218又は約218の配列に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有するアミノ酸配列からなる、単離されたIL-1lpポリペプチドに関する。
他の側面では、本発明は(1)図2(配列番号:5)のアミノ酸残基37又は約37から63又は約63の配列に対して、少なくとも80%又は約80%、又は少なくとも85%又は約85%、又は少なくとも90%又は約90%、又は少なくとも95%又は約95%の配列同一性を有するアミノ酸配列からなる、例えばhIL-1Ra1ポリペプチドのようなポリぺプチド;(2)図3(配列番号:7)のアミノ酸残基15又は約15から53又は約53の配列に対して、少なくとも80%又は約80%、又は少なくとも85%又は約85%、又は少なくとも90%又は約90%、又は少なくとも95%又は約95%の配列同一性を有するアミノ酸配列からなる、例えばhIL-1Ra1ポリペプチドのようなポリぺプチド;(3)図5(配列番号:10)のアミノ酸残基1又は約1から134又は約134のアミノ酸配列からなる、例えばhIL-1Ra2ポリペプチドのようなポリぺプチド;(4)図5(配列番号:10)のアミノ酸残基10又は約10から134又は約134のアミノ酸配列からなるポリぺプチド;(5)図5(配列番号:10)のアミノ酸残基27又は約27から134又は約134のアミノ酸配列からなる、例えばhIL-1Ra2ポリペプチドのようなポリぺプチド;(6)そのN−末端又はC−末端でヘテロアミノ酸又はアミノ酸配列と融合された、図5(配列番号:10)のアミノ酸残基27又は約27から134又は約134からなるhIL-1Ra2の天然アミノ酸配列からなる、例えばhIL-1Ra2融合変異体ポリペプチドのようなポリペプチド;(7)図7(配列番号:13)のアミノ酸残基95又は約95から134又は約134の配列に対して、少なくとも80%又は約80%、又は少なくとも85%又は約85%、又は少なくとも90%又は約90%、又は少なくとも95%又は約95%の配列同一性を有するアミノ酸配列からなる、例えばhIL-1Ra3ポリペプチドのようなポリぺプチド;(8)図9(配列番号:16)のアミノ酸残基95又は約95から134又は約134の配列に対して、少なくとも80%又は約80%、又は少なくとも85%又は約85%、又は少なくとも90%又は約90%、又は少なくとも95%又は約95%の配列同一性を有するアミノ酸配列からなる、例えばmIL-1Ra3ポリペプチドのようなポリぺプチドからなる群より選択された単離されたIL-1lpを提供する。
他の側面では、本発明は図2(配列番号:5)のアミノ酸残基37又は約37から203又は約203の配列、図3(配列番号:7)のアミノ酸残基15又は約15から193又は約193の配列、図7(配列番号:13)のアミノ酸残基34又は約34から155又は約155の配列、図9(配列番号:16)のアミノ酸残基34又は約34から155又は約155の配列、図15(配列番号:19)のアミノ酸残基26又は約26から207又は約207の配列、又は図19(配列番号:25)のアミノ酸残基46又は約46から218又は約218の配列に対して、少なくとも80%又は約80%、又は少なくとも85%又は約85%、又は少なくとも90%又は約90%、又は少なくとも95%又は約95%の配列同一性を有するアミノ酸配列からなる単離されたIL-1lpポリペプチドに関する。
他の側面では、本発明は図7(配列番号:13)のアミノ酸残基80又は約80から155又は約155の配列に対して、少なくとも80%又は約80%、又は少なくとも85%又は約85%、又は少なくとも90%又は約90%、又は少なくとも95%又は約95%の配列同一性を有するアミノ酸配列からなる、例えばhIL-1Ra3ポリペプチドのような単離されたポリペプチドに関する。
更なる側面では、本発明は天然配列IL-1lpの少なくとも1の生物活性、例えば天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性、または天然配列hIL-1Ra1、hIL-1Ra1L、又はhIL-1Ra1VのIL-18R結合活性を保持し、さらにATCC寄託番号203588(DNA85066−2534)、ATCC寄託番号203587(DNA96786−2534)、ATCC寄託番号203589(DNA96787−2534)、ATCC寄託番号203590(DNA92505−2534)、ATCC寄託番号203846(DNA102043−2534)、又はATCC寄託番号203973(DNA114876−2534)として寄託されたベクターのcDNA挿入断片によってコードされる、例えば成熟IL-1lpポリペプチドのようなIL-1lpのアミノ酸配列に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有するアミノ酸配列からなる、単離されたIL-1lpポリペプチドに関する。好ましい実施態様では、IL-1lpポリペプチドは、ATCC寄託番号203588(DNA85066−2534)、ATCC寄託番号203587(DNA96786−2534)、ATCC寄託番号203586(DNA92929−2534)、ATCC寄託番号203589(DNA96787−2534)、ATCC寄託番号203590(DNA92505−2534)、ATCC寄託番号203846(DNA102043−2534)、ATCC寄託番号203973(DNA114876−2534)、又はATCC寄託番号203855(DNA102044−2534)として寄託されたベクターのcDNA挿入断片によってコードされる、例えば成熟IL-1lpポリペプチドのようなIL-1lpのアミノ酸配列を構成する。
更なる側面では、本発明はATCC寄託番号203588(DNA85066−2534)、ATCC寄託番号203587(DNA96786−2534)、ATCC寄託番号203589(DNA96787−2534)、ATCC寄託番号203590(DNA92505−2534)、ATCC寄託番号203846(DNA102043−2534)、及びATCC寄託番号203973(DNA114876−2534)として寄託されたベクターからなる群より選択されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列に対して少なくとも80又は約80%の配列同一性、少なくとも85又は約85%の配列同一性、少なくとも90又は約90%の配列同一性、又は少なくとも95又は約95%の配列同一性を有するアミノ酸配列からなる、単離されたIL-1lpポリペプチドに関する。
好ましい実施態様では、IL-1lpポリペプチドは:(1)ATCC寄託番号203588として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、(2)ATCC寄託番号203587として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、又は該配列の36のN−末端アミノ酸残基以外の全体アミノ酸配列、(3)ATCC寄託番号203589として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、又は該配列のN−末端アミノ酸残基以外の全体アミノ酸配列、(4)ATCC寄託番号203590として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、又は該配列のN−末端アミノ酸残基以外の全体アミノ酸配列、(5)ATCC寄託番号203846として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、又は該配列の34のN−末端アミノ酸残基以外の全体アミノ酸配列、及び(6)ATCC寄託番号203973として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、又は該配列の45のN−末端アミノ酸残基以外の全体アミノ酸配列からなる群より選択されたアミノ酸配列を構成する。
他の側面では、本発明は天然配列IL-1lpの少なくとも1の生物活性、例えば天然配列hIL-1Ra1、hIL-1Ra1L、又はhIL-1Ra1VのIL-18R結合活性を保持し、図15(配列番号:19)のアミノ酸残基1又は約1から207又は約207の配列、又は図19(配列番号:25)のアミノ酸残基1又は約1から218又は約218の配列に対して、少なくとも80%又は約80%ポジティブ、又は少なくとも85%又は約85%ポジティブ、又は少なくとも90%又は約90%ポジティブ、又は少なくとも95%又は約95%ポジティブを有するアミノ酸配列からなる単離されたIL-1lpポリペプチドに関する。
他の側面では、本発明は図2(配列番号:5)のアミノ酸残基37又は約37から203又は約203の配列、図3(配列番号:7)のアミノ酸残基15又は約15から193又は約193の配列、図7(配列番号:13)のアミノ酸残基34又は約34から155又は約155の配列、図9(配列番号:16)のアミノ酸残基34又は約34から155又は約155の配列、又は図19(配列番号:25)のアミノ酸残基46又は約46から218又は約218の配列に対して、少なくとも80%又は約80%ポジティブ、又は少なくとも85%又は約85%ポジティブ、又は少なくとも90%又は約90%ポジティブ、又は少なくとも95%又は約95%ポジティブを有するアミノ酸配列からなる単離されたIL-1lpに関する。
他の側面では、本発明は図15(配列番号:19)のアミノ酸残基1又は約1から207又は約207の配列、又は図19(配列番号:25)のアミノ酸残基1又は約1から218又は約218の配列に対して、少なくとも80%又は約80%ポジティブ、又は少なくとも85%又は約85%ポジティブ、又は少なくとも90%又は約90%ポジティブ、又は少なくとも95%又は約95%ポジティブを有するアミノ酸配列からなる単離されたIL-1lpに関する。
更なる側面では、本発明は天然配列IL-1lpの少なくとも1の生物活性、例えば天然配列hIL-1Ra3又はmIL-1Ra3のIL-1R結合活性、または天然配列hIL-1Ra1、hIL-1Ra1L、又はhIL-1Ra1VのIL-18R結合活性を保持し、ATCC寄託番号203588(DNA85066−2534)、ATCC寄託番号203587(DNA96786−2534)、ATCC寄託番号203589(DNA96787−2534)、ATCC寄託番号203590(DNA92505−2534)、ATCC寄託番号203846(DNA102043−2534)、及びATCC寄託番号203973(DNA114876−2534)として寄託されたベクターからなる群から選択されるベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる、全体アミノ酸配列に対して少なくとも80又は約80%ポジティブ、少なくとも85又は約85%ポジティブ、少なくとも90又は約90%ポジティブ、又は少なくとも95又は約95%ポジティブを有するアミノ酸配列からなる、単離されたIL-1lpポリペプチドに関する。
更なる側面では、本発明は、ATCC寄託番号203588(DNA85066−2534)、ATCC寄託番号203587(DNA96786−2534)、ATCC寄託番号203589(DNA96787−2534)、ATCC寄託番号203590(DNA92505−2534)、ATCC寄託番号203846(DNA102043−2534)、又はATCC寄託番号203973(DNA114876−2534)として寄託されたベクターのcDNA挿入断片によってコードされる、例えば成熟IL-1lpのようなILーlpのアミノ酸配列に対して少なくとも80又は約80%ポジティブ、少なくとも85又は約85%ポジティブ、少なくとも90又は約90%ポジティブ、又は少なくとも95又は約95%ポジティブを有するアミノ酸配列からなる、単離されたIL-1lpポリペプチドに関する。
他の側面では、本発明は(1)ATCC寄託番号203588として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、(2)ATCC寄託番号203587として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、又は該配列の36のN−末端アミノ酸残基を除く全体アミノ酸配列、(3)ATCC寄託番号203589として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、又は該配列のN−末端アミノ酸残基を除く全体アミノ酸配列、(4)ATCC寄託番号203590として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、又は該配列のN−末端アミノ酸残基を除く全体アミノ酸配列、(5)ATCC寄託番号203846として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、又は該配列のN−末端アミノ酸残基を除く全体アミノ酸配列、又は該配列の34のN−末端アミノ酸残基を除く全体アミノ酸配列、及び(6)ATCC寄託番号203973として寄託されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列、又は該配列のN−末端アミノ酸残基を除く全体アミノ酸配列、又は該配列の45のN−末端アミノ酸残基を除く全体アミノ酸配列からなる群より選択されるアミノ酸配列に対して少なくとも80又は約80%ポジティブ、少なくとも85又は約85%ポジティブ、少なくとも90又は約90%ポジティブ、又は少なくとも95又は約95%ポジティブを有するアミノ酸配列からなる、単離されたIL-1lpポリペプチドに関する。
他の側面では、本発明は、図7(配列番号:13)のアミノ酸残基80又は約80から155又は約155の配列に対して、少なくとも80%又は約80%、又は少なくとも85%又は約85%、又は少なくとも90%又は約90%、又は少なくとも95%又は約95%の%ポジティブ値を有するアミノ酸配列からなる、例えばhIL-1Ra3ポリペプチドのような単離されたポリペプチドを提供する。
また他の側面では、本発明は(1)図15(配列番号:19)のアミノ酸残基26又は約26から44又は約44;(2)図19(配列番号:25)のアミノ酸残基26又は約26から78又は約78;及び(3)図19(配列番号:25)のアミノ酸残基46又は約46から89又は約89からなる群から選択されたアミノ酸配列を構成する単離されたIL-1lpポリペプチド、又は該アミノ酸配列の少なくとも10近接アミノ酸の伸長と一致する該IL-1lpポリペプチドの断片に関し、そのIL-1lpポリペプチド又はその断片が抗−IL-1lp抗体との結合部位を提供するのに十分なものである。好ましくは、IL-1lp断片は、天然配列IL-1lpポリペプチドの少なくとも1の生物活性を有する。
更なる側面では、本発明は(1)図2(配列番号:5)のアミノ酸残基37又は約37から63又は約63を構成する、例えばhIL-1Ra1ポリペプチドのようなポリペプチド;(2)図3(配列番号:7)のアミノ酸残基15又は約15から53又は約53を構成する、例えばhIL-1Ra1ポリペプチドのようなポリペプチド;(3)図7(配列番号:13)のアミノ酸残基95又は約95から134又は約134を構成する、例えばhIL-1Ra3ポリペプチドのようなポリペプチド;及び(4)図9(配列番号:16)のアミノ酸残基95又は約95から134又は約134を構成する、例えばmIL-1Ra3ポリペプチドのようなポリペプチドからなる群から選択された単離されたIL-1lpポリペプチドを提供する。
更なる側面では、本発明は(1)図2(配列番号:5)のアミノ酸残基37又は約37から203又は約203を構成する、例えばhIL-1Ra1ポリペプチドのようなポリペプチド;(2)図3(配列番号:7)のアミノ酸残基15又は約15から193又は約193を構成する、例えばhIL-1Ra1ポリペプチドのようなポリペプチド;(3)図7(配列番号:13)のアミノ酸残基34又は約34から155又は約155を構成する、例えばhIL-1Ra3ポリペプチドのようなポリペプチド;及び(3)図9(配列番号:16)のアミノ酸残基34又は約34から155又は約155を構成する、例えばmIL-1Ra3ポリペプチドのようなポリペプチドからなる群から選択された単離されたIL-1lpポリペプチドを提供する。
更なる側面では、本発明は(1)図15(配列番号:19)のアミノ酸残基26又は約26から44又は約44を構成する、例えばhIL-1Ra1Lポリペプチドのようなポリペプチド;(2)図15(配列番号:19)のアミノ酸残基1又は約1から44又は約44を構成する、例えばhIL-1Ra1Lポリペプチドのようなポリペプチド;(3)図16(配列番号:21)のアミノ酸残基1又は約1から38又は約38を構成する、例えばhIL-1Ra1Sポリペプチドのようなポリペプチド;(4)図19(配列番号:25)のアミノ酸残基37又は約37から55又は約55を構成する、例えばhIL-1Ra1Vポリペプチドのようなポリペプチド;(5)図19(配列番号:25)のアミノ酸残基12又は約12から55又は約55を構成する、例えばhIL-1Ra1Vポリペプチドのようなポリペプチド;及び(6)図19(配列番号:25)のアミノ酸残基1又は約1から55又は約55を構成する、例えばhIL-1Ra1Vポリペプチドのようなポリペプチドからなる群から選択された単離されたポリペプチドを提供する。
更なる側面では、本発明は:(1)図19(配列番号:25)のアミノ酸残基37又は約37から218又は約218を含んでなる、例えばhIL-1Ra1Vポリペプチドのようなポリペプチド;及び(2)図19(配列番号:25)のアミノ酸残基46又は約46から218又は約218を含んでなる、例えばhIL-1Ra1Vポリペプチドのようなポリペプチドからなる群から選択された単離されたIL-1lpポリペプチドを提供する。
更なる側面では、本発明は:(1)そのN−末端又はC−末端でヘテロアミノ酸又はアミノ酸配列と融合した図5(配列番号:10)等のアミノ酸残基10から134のアミノ酸配列からなるポリペプチド;(2)図5(配列番号:10)のアミノ酸残基10から134のアミノ酸配列からなるポリペプチド;(3)そのN−末端又はC−末端でヘテロアミノ酸又はアミノ酸配列と融合した図7(配列番号:13)等のアミノ酸残基2から155からなるhIL-1Ra3の天然アミノ酸配列からなる、例えばhIL-1Ra3ポリペプチドのようなポリペプチド;(4)図7(配列番号:13)のアミノ酸残基2から155のアミノ酸配列からなる、例えばhIL-1Ra3ポリペプチドのようなポリペプチド;(5)そのN−末端又はC−末端でヘテロアミノ酸又はアミノ酸配列と融合した図9(配列番号:16)等のアミノ酸残基2から155からなるmIL-1Ra3の天然アミノ酸配列からなる、例えばmIL-1Ra3ポリペプチドのようなポリペプチド;(6)図9(配列番号:16)のアミノ酸残基2から155のアミノ酸配列からなる、例えばmIL-1Ra3ポリペプチドのようなポリペプチドからなる群から選択された単離されたIL-1lpポリペプチドを提供する。
また更なる側面では、本発明は、ATCC寄託番号203588、203587、203586、203589、及び203590として寄託されたベクターからなる群より選択されたベクターのcDNA挿入断片によってコードされる成熟ポリペプチドと同様である単離されたIL-1lpポリペプチドを提供する。
また更なる側面では、本発明は、ATCC寄託番号203846、203855及び203973として寄託されたベクターからなる群より選択されたベクターのcDNA挿入断片によってコードされる成熟ポリペプチドと同様である単離されたIL-1lpポリペプチドを提供する。
また更なる側面では、本発明は、ATCC寄託番号203588、203586、203589、及び203590として寄託されたベクターからなる群より選択されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列を含んでなる単離されたポリペプチドを提供する。
また更なる側面では、本発明は、ATCC寄託番号203846、203855及び203973として寄託されたベクターからなる群より選択されたベクターのcDNA挿入断片にある最長オープンリーディングフレームによってコードされる全体アミノ酸配列を含んでなる単離されたポリペプチドを提供する。
更なる側面では、本発明は(i)試験DNA分子を緊縮条件下で(a):(1)図15(配列番号:19)のアミノ酸残基26又は約26から207又は約207;(2)図19(配列番号:25)のアミノ酸残基1又は約1から218又は約218;(3)図19(配列番号:25)のアミノ酸残基12又は約12から218又は約218;(4)図19(配列番号:25)のアミノ酸残基37又は約37から218又は約218;及び(5)図19(配列番号:25)のアミノ酸残基46又は約46から218又は約218からなる群から選択されるアミノ酸配列をコードするDNA分子、又は(b)(a)のDNA分子の相補鎖とハイブリッド化し、そして試験DNA分子が、天然配列IL-1lpの少なくとも1の生物活性、例えば天然配列hIL-1Ra1、hIL-1Ra1L、又はhIL-1Ra1VのIL-18R結合活性を有するIL-1lpポリペプチドをコードする場合には、さらに試験DNA分子が(a)又は(b)のDNA分子に対して少なくとも80又は約80%配列同一性、少なくとも85又は約85%配列同一性、少なくとも90又は約90%配列同一性、又は少なくとも95又は約95%配列同一性を有する場合には、(ii)IL-1lpポリペプチドの発現に適した条件下で試験DNA分子を含んでなる宿主細胞を培養し、さらに(iii)細胞培地からIL-1lpポリペプチドを回収することによって、生成されるポリペプチドを提供する。
以下の説明は、主として、IL-1lp核酸を含むベクターで形質転換又は形質移入された細胞を培養することによりIL-1lpを生産する方法に関する。もちろん、当該分野においてよく知られている他の方法を用いてIL-1lpを調製することができると考えられる。例えば、IL-1lp配列、又はその一部は、固相技術を用いた直接ペプチド合成によって生産してもよい[例えば、Stewart等, Solid-Phase Peptide Synthesis, W.H. Freeman Co., San Francisco, CA (1969);Merrifield, J. Am. Chem. Soc., 85:2149-2154 (1963)参照]。手動技術又は自動によるインビトロタンパク質合成を行ってもよい。自動合成は、例えば、アプライド・バイオシステムズ・ペプチド合成機(Foster City, CA)を用いて、製造者の指示により実施してもよい。IL-1lpの種々の部分は、別々に化学的に合成され、化学的又は酵素的方法を用いて結合させて全長IL-1lpを生産してもよい。
1.IL-1lpをコードするDNAの単離
IL-1lpをコードするDNAは、IL-1lpmRNAを保有していてそれを検出可能なレベルで発現すると考えられる組織から調製されたcDNAライブラリから得ることができる。従って、ヒトIL-1lpDNAは、実施例に記載されるように、ヒトの組織から調製されたcDNAライブラリから簡便に得ることができる。またIL-1lp-コード化遺伝子は、ゲノムライブラリから又はオリゴヌクレオチド合成により得ることもできる。
ライブラリは、対象となる遺伝子あるいはその遺伝子によりコードされるタンパク質を同定するために設計されたプローブ(IL-1lpに対する抗体又は少なくとも約20−80塩基のオリゴヌクレオチド等)によってスクリーニングできる。選択されたプローブによるcDNA又はゲノムライブラリのスクリーニングは、例えばSambrook等, Molecular Cloning: A Laboratory Manual(New York: Cold Spring Harbor Laboratory Press, 1989)に記載されている標準的な手順を使用して実施することができる。IL-1lpポリペプチドをコードする遺伝子を単離する他の方法はPCR法を使用するものである[Sambrook等,上掲;Dieffenbach等, PCR Primer:A Laboratory Manual(Cold Spring Harbor Laboratory Press, 1995)]。
このようなライブラリースクリーニング法において同定された配列は、Genbank等の公共データベース又は個人の配列データベースに寄託され公衆に利用可能とされている周知の配列と比較及びアラインメントすることができる。分子の決定された領域内又は全長に渡っての(アミノ酸又はヌクレオチドレベルのいずれかでの)配列同一性は、この分野で知られた、そしてここに記載した方法を用いて決定することができる。
タンパク質コード配列を有する核酸は、初めてここで開示された推定アミノ酸配列を使用し、また必要ならば、cDNAに逆転写されなかったmRNAの生成中間体及び先駆物質を検出する上掲のSambrook等に記述されているような従来のプライマー伸展法を使用し、選択されたcDNA又はゲノムライブラリをスクリーニングすることにより得られる。
宿主細胞を、ここに記載したIL-1lp生産のための発現又はクローニングベクターで形質移入又は形質転換し、プロモーターを誘導し、形質転換体を選択し、又は所望の配列をコードする遺伝子を増幅するために適当に変性された常套的栄養培地で培養する。培養条件、例えば培地、温度、pH等々は、過度の実験をすることなく当業者が選ぶことができる。一般に、細胞培養の生産性を最大にするための原理、プロトコール、及び実用技術は、Mammalian Cell Biotechnology: a Practical Approach, M.Butler編 (IRL Press, 1991)及びSambrook等, 上掲に見出すことができる。
原核生物細胞形質移入及び真核生物細胞形質移入の方法、例えば、CaCl2、CaPO4、リポソーム媒介及びエレクトロポレーションは当業者に知られている。用いられる宿主細胞に応じて、その細胞に対して適した標準的な方法を用いて形質転換はなされる。前掲のSambrook等に記載された塩化カルシウムを用いるカルシウム処理又はエレクトロポレーションが、一般的に原核生物に対して用いられる。アグロバクテリウム・トゥメファシエンスによる感染が、Shaw等, Gene, 23:315 (1983)及び1989年6月29日公開のWO 89/05859に記載されているように、或る種の植物細胞の形質転換に用いられる。このような細胞壁のない哺乳動物の細胞に対しては、Graham及びvan der Eb, Virology, 52:456-457 (1978)のリン酸カルシウム沈降法が好ましい。哺乳動物細胞の宿主系形質転換の一般的な態様は米国特許第4,399,216号に記載されている。酵母菌中への形質転換は、典型的には、Van solingen等, J. Bact., 130:946 (1977)及びHsiao等, Proc. Natl. Acad. Sci. USA, 76:3829 (1979)の方法に従って実施される。しかしながら、DNAを細胞中に導入する他の方法、例えば、核マイクロインジェクション、エレクトロポレーション、無傷の細胞、又はポリカチオン、例えばポリブレン、ポリオルニチン等を用いる細菌プロトプラスト融合もまた用いることもできる。哺乳動物細胞を形質転換するための種々の技術については、Keown等, Methods in Enzymology, 185:527-537 (1990)及び Mansour等, Nature, 336:348-352 (1988)を参照のこと。
原核生物に加えて、糸状菌又は酵母菌のような真核微生物は、IL-1lpポリペプチドコード化ベクターのための適切なクローニング又は発現宿主である。サッカロミセス・セレヴィシアは、通常用いられる下等真核生物宿主微生物である。
グリコシル化IL-1lpの発現に適切な宿主細胞は、多細胞生物から誘導される。無脊椎動物細胞の例としては、ショウジョウバエS2及びスポドスペラSf9等の昆虫細胞並びに植物細胞が含まれる。有用な哺乳動物宿主株化細胞の例は、チャイニーズハムスター卵巣(CHO)及びCOS細胞を含む。より詳細な例は、SV40によって形質転換されたサル腎臓CV1株 (COS-7, ATCC CRL 1651);ヒト胚腎臓株(293又は懸濁培養での増殖のためにサブクローン化された293細胞、Graham等, J. Gen Virol., 36:59 (1977));チャイニーズハムスター卵巣細胞/-DHFR(CHO, Urlaub及びChasin, Proc. Natl. Acad. Sci. USA, 77:4216 (1980));マウスのセルトリ細胞(TM4, Mather, Biol. Reprod., 23:243-251 (1980))ヒト肺細胞 (W138, ATCC CCL 75); ヒト肝細胞 (Hep G2, HB 8065); 及びマウス乳房腫瘍細胞 (MMT 060562, ATCC CCL51)を含む。適切な宿主細胞の選択は、この分野の技術常識内にある。
IL-1lpをコードする核酸(例えば、cDNA又はゲノムDNA)は、クローニング(DNAの増幅)又は発現のために複製可能なベクター内に挿入される。様々なベクターが公的に入手可能である。ベクターは、例えば、プラスミド、コスミド、ウイルス粒子、又はファージの形態とすることができる。適切な核酸配列が、種々の手法によってベクターに挿入される。一般に、DNAはこの分野で周知の技術を用いて適当な制限エンドヌクレアーゼ部位に挿入される。ベクター成分としては、一般に、これらに制限されるものではないが、一又は複数のシグナル配列、複製開始点、一又は複数のマーカー遺伝子、エンハンサーエレメント、プロモーター、及び転写終結配列を含む。これらの成分の一又は複数を含む適当なベクターの作成には、当業者に知られた標準的なライゲーション技術を用いる。
IL-1lpは直接的に組換え手法によって生産されるだけではなく、シグナル配列あるいは成熟タンパク質あるいはポリペプチドのN-末端に特異的切断部位を有する他のポリペプチドである異種ポリペプチドとの融合ペプチドとしても生産される。一般に、シグナル配列はベクターの成分であるか、ベクターに挿入されるIL-1lp-コード化DNAの一部である。シグナル配列は、例えばアルカリホスファターゼ、ペニシリナーゼ、lppあるいは熱安定性エンテロトキシンIIリーダーの群から選択される原核生物シグナル配列であってよい。酵母の分泌に関しては、シグナル配列は、酵母インベルターゼリーダー、α因子リーダー(酵母菌属(Saccharomyces)及びクルイベロマイシス(Kluyveromyces)α因子リーダーを含み、後者は米国特許第5,010,182号に記載されている)、又は酸ホスフォターゼリーダー、白体(C.albicans)グルコアミラーゼリーダー(1990年4月4日発行のEP362179)、又は1990年11月15日に公開されたWO 90/13646に記載されているシグナルであり得る。哺乳動物細胞の発現においては、哺乳動物シグナル配列は、同一あるいは関連ある種の分泌ポリペプチド由来のシグナル配列並びにウイルス分泌リーダーのようなタンパク質の直接分泌に使用してもよい。
発現及びクローニングベクターは、典型的には、選択性マーカーとも称される選択遺伝子を含む。典型的な選択遺伝子は、(a)アンピシリン、ネオマイシン、メトトレキセートあるいはテトラサイクリンのような抗生物質あるいは他の毒素に耐性を与え、(b)栄養要求性欠陥を補い、又は(c)例えば桿菌のD-アラニンラセマーゼコード化遺伝子のような、複合培地から得られない重要な栄養素を供給するタンパク質をコードする。
哺乳動物細胞に適切な選べるマーカーの例は、DHFRあるいはチミジンキナーゼのように、IL-1lp-コード化核酸を取り込むことのできる細胞成分を同定することのできるものである。野生型DHFRを用いた場合の好適な宿主細胞は、Urlaub 等により, Proc. Natl. Acad. Sci. USA, 77:4216 (1980)に記載されているようにして調製され増殖されたDHFR活性に欠陥のあるCHO株化細胞である。酵母菌中での使用に好適な選択遺伝子は酵母プラスミドYRp7に存在するtrp1遺伝子である[Stinchcomb等, Nature, 282:39(1979);Kingsman等, Gene, 7:141(1979);Tschemper等, Gene, 10:157(1980)]。trp1遺伝子は、例えば、ATCC番号44076あるいはPEP4-1のようなトリプトファン内で成長する能力を欠く酵母菌の突然変異株に対する選択マーカーを提供する[Jones, Genetics, 85:12 (1977)]。
酵母宿主と共に用いて好適なプロモーター配列の例としては、3-ホスホグリセラートキナーゼ[Hitzeman 等, J. Biol. Chem., 255:2073 (1980)]又は他の糖分解酵素[Hess 等, J. Adv. Enzyme Reg., 7:149 (1968);Holland, Biochemistry, 17:4900(1987)]、例えばエノラーゼ、グリセルアルデヒド-3-リン酸デヒドロゲナーゼ、ヘキソキナーゼ、ピルビン酸デカルボキシラーゼ、ホスホフルクトキナーゼ、グルコース-6-リン酸イソメラーゼ、3-ホスホグリセレートムターゼ、ピルビン酸キナーゼ、トリオセリン酸イソメラーゼ、ホスホグルコースイソメラーゼ、及びグルコキナーゼが含まれる。
他の酵母プロモーターとしては、成長条件によって転写が制御される付加的効果を有する誘発的プロモーターであり、アルコールデヒドロゲナーゼ2、イソチトクロムC、酸ホスファターゼ、窒素代謝と関連する分解性酵素、メタロチオネイン、グリセルアルデヒド-3-リン酸デヒドロゲナーゼ、及びマルトース及びガラクトースの利用を支配する酵素のプロモーター領域がある。酵母菌での発現に好適に用いられるベクターとプロモータはEP 73,657に更に記載されている。
哺乳動物の宿主細胞におけるベクターからのIL-1lp転写は、例えば、ポリオーマウィルス、伝染性上皮腫ウィルス(1989年7月5日公開のUK 2,211,504)、アデノウィルス(例えばアデノウィルス2)、ウシ乳頭腫ウィルス、トリ肉腫ウィルス、サイトメガロウィルス、レトロウィルス、B型肝炎ウィルス及びサルウィルス40(SV40)のようなウィルスのゲノムから得られるプロモーター、異種哺乳動物プロモーター、例えばアクチンプロモーター又は免疫グロブリンプロモーター、及び熱衝撃プロモーターから得られるプロモーターによって、このようなプロモーターが宿主細胞系に適合し得る限り制御される。
また真核生物宿主細胞(酵母、真菌、昆虫、植物、動物、ヒト、又は他の多細胞生物由来の有核細胞)に用いられる発現ベクターは、転写の終結及びmRNAの安定化に必要な配列も含む。このような配列は、真核生物又はウィルスのDNA又はcDNAの通常は5’、時には3’の非翻訳領域から取得できる。これらの領域は、IL-1lpをコードするmRNAの非翻訳部分にポリアデニル化断片として転写されるヌクレオチドセグメントを含む。
組換え脊椎動物細胞培養でのIL-1lpの合成に適応化するのに適切な他の方法、ベクター及び宿主細胞は、Gething等, Nature, 293:620-625 (1981); Mantei等, Nature, 281:40-46 (1979); EP 117,060; 及びEP 117,058に記載されている。
遺伝子の増幅及び/又は発現は、ここで提供された配列に基づき、適切に標識されたプローブを用い、例えば、従来よりのサザンブロット法、mRNAの転写を定量化するノーザンブロット法[Thomas, Proc. Natl. Acad. Sci. USA,77:5201-5205 (1980)]、ドットブロット法(DNA分析)、又はインサイツハイブリッド形成法によって、直接的に試料中で測定することができる。あるいは、DNA二本鎖、RNA二本鎖及びDNA−RNAハイブリッド二本鎖又はDNA-タンパク二本鎖を含む、特異的二本鎖を認識することができる抗体を用いることもできる。次いで、抗体を標識し、アッセイを実施することができ、ここで二本鎖は表面に結合しており、その結果二本鎖の表面での形成の時点でその二本鎖に結合した抗体の存在を検出することができる。
あるいは、遺伝子の発現は、遺伝子産物の発現を直接的に定量する免疫学的な方法、例えば細胞又は組織切片の免疫組織化学的染色及び細胞培養又は体液のアッセイによって、測定することもできる。試料液の免疫組織化学的染色及び/又はアッセイに有用な抗体は、モノクローナルでもポリクローナルでもよく、任意の哺乳動物で調製することができる。簡便には、抗体は、天然配列IL-1lpポリペプチドに対して、又はここで提供されるDNA配列をベースとした合成ペプチドに対して、又はIL-1lpDNAに融合し特異的抗体エピトープをコードする外因性配列に対して調製され得る。
IL-1lpの形態は、培地又は宿主細胞の溶菌液から回収することができる。膜結合性であるならば、適切な洗浄液(例えばトリトン-X100)又は酵素的切断を用いて膜から引き離すことができる。IL-1lpの発現に用いられる細胞は、凍結融解サイクル、超音波処理、機械的破壊、又は細胞溶解剤などの種々の化学的又は物理的手段によって破壊することができる。IL-1lpを、組換え細胞タンパク又はポリペプチドから精製することが望ましい。適切な精製手順の例である次の手順により精製される:すなわち、イオン交換カラムでの分画;エタノール沈殿;逆相HPLC;シリカ又はカチオン交換樹脂、例えばDEAEによるクロマトグラフィー;クロマトフォーカシング;SDS-PAGE;硫酸アンモニウム沈殿;例えばセファデックスG-75を用いるゲル濾過;IgGのような汚染物を除くプロテインAセファロースカラム;及びIL-1lpポリペプチドのエピトープタグ形態を結合させる金属キレート化カラムである。この分野で知られ、例えば、Deutscher, Methodes in Enzymology, 182 (1990);Scopes, Protein Purification: Principles and Practice, Springer-Verlag, New York (1982)に記載された多くのタンパク質精製方法を用いることができる。選ばれる精製過程は、例えば、用いられる生産方法及び特に生産される特定のIL-1lpの性質に依存する。
特定のIL-1lp変異体ポリペプチドの生物活性又は活性は当該技術で既知の様々なin vitroアッセイを使用することで特徴づけることができる。例えば、hIL-1Ra3変異体ポリペプチド又はmIL-1RA3変異体ポリペプチドのIL-1R結合の能力は、ヒト免疫グロブリンGのFc領域と融合されたIL-1R細胞外ドメイン(ECD)(IL-1R ECD-Fc)(それは、例えば以下の実施例9及び10のように準備されうる)が放射性標識されたhIL-1Ra3変異体ポリペプチド又はmIL-1Ra3変異体ポリペプチドの入った溶液で、標識された複合体を形成するためにインキュベートされ、その後ヤギ抗−ヒトIgG Fcとの標識された複合体の免疫沈降、及び沈殿中の放射能の定量をする、放射性免疫沈降法アッセイを用いて検定されることができる。他の例では、hIL-1Ra3変異体ポリペプチド-FLAGタグ融合タンパク質コード化DNA及びIL-1R ECD-Fcコード化DNAは宿主細胞で共発現され、さらに細胞培養培地に分泌され、その後タンパク質Gセファロースを用いた培地の上澄みの免疫沈降、及び抗-FLAGモノクローナル抗体を用いた免疫ブロット法による結合hIL-1Ra3変異体ポリペプチド-FLAGタグ融合タンパク質の同定をし、原則として以下の実施例9に記載されている。
他の実施態様では、hIL-1Ra3変異体ポリペプチド又はmIL-1Ra3変異体ポリペプチドのIL-1とIL-1Rの結合抑制の能力は、結合蛋白競合測定法を用いて検定されうる。たとえば、放射性免疫沈降法アッセイが用いられ、それはIL-1R ECD-Fcが標識されていないhIL-1Ra3変異体ポリペプチド又は標識されていないmIL-1Ra3変異体ポリペプチドを有する又は有しない放射性標識されたIL-1の溶液中で標識された又は標識されていない複合体を形成するためにインキュベートされ、続いて抗-ヒト Fcを有する複合体の免疫沈降、及び沈殿物中の放射能の定量をする。もし、インキュベーション液中のhIL-1Ra3変異体ポリペプチド又はmIL-1Ra3変異体ポリペプチドの存在が免疫沈降の結果測定された放射能を減少させている場合には、当該hIL-1Ra3変異体ポリペプチド又はmIL-1Ra3変異体ポリペプチドはIL-1とIL-1Rとの結合を抑制剤とみなす。また他の実施様態では、IL-1R ECD-Fc及びhIL-1Ra3変異体-FLAGタグ融合タンパク質又はmIL-1Ra3変異体-FLAGタグ融合タンパク質は、個々の細胞培地中で組換え発現によって観察され(原則的に以下の実施例10に記載されているように)、IL-1及びIL-1R ECD-Fcは、hIL-1Ra3変異体-FLAGタグ融合タンパク質又はmIL-1Ra3変異体-FLAGタグ融合タンパク質と一緒に又は別々に混ぜられ、さらに溶液中でインキュベートされ、インキュベーション液はタンパク質Gセファロースで免疫沈降され、さらに結合したhIL-1Ra3変異体-FLAGタグ融合タンパク質又はmIL-1Ra3変異体-FLAGタグ融合タンパク質は、抗-FLAGモノクローナル抗体を用いて免疫ブロット法により同定される。インキュベーション液中のIL-1の存在が抗-FLAG免疫ブロット法により検出されたシグナルを減少させる場合には、当該hIL-1Ra3変異体ポリペプチド又はmIL-1Ra3変異体ポリペプチドはIL-1のIL-1R結合の抑制剤とみなす。
他の実施態様では、hIL-1Ra1変異体ポリペプチドのIL-18とIL-18Rの結合抑制の能力は、結合蛋白競合測定法を用いて検定されうる。たとえば、放射性免疫沈降法アッセイが用いられ、それはIL-18R ECD-Fcが標識されていないhIL-1Ra1変異体ポリペプチドを有する又は有しない放射性標識されたIL-18の溶液中で標識された又は標識されていない複合体を形成するためにインキュベートされ、続いて抗-ヒト Fcを有する複合体の免疫沈降、及び沈殿中の放射能の定量をする。もし、インキュベーション液中のhIL-1Ra1変異体ポリペプチドの存在が免疫沈降の結果測定された放射能を減少させている場合には、当該hIL-1Ra1変異体ポリペプチドはIL-18のIL-18Rとの結合の抑制剤とみなす。また他の実施様態では、IL-18R ECD-Fc及びhIL-1Ra1変異体-FLAGタグ融合タンパク質は、個々の細胞培地中で組換え発現によって観察され(原則的に以下の実施例10に記載されているように)、IL-18及びIL-18R ECD-Fcは、hIL-1Ra1変異体-FLAGタグ融合タンパク質と一緒に又は別々に混ぜられ、さらに溶液中でインキュベートされ、インキュベーション液はタンパク質Gセファロースで免疫沈降され、さらに結合したhIL-1Ra1変異体-FLAGタグ融合タンパク質は抗-FLAGモノクローナル抗体を用いて免疫ブロット法により同定される。インキュベーション液中のIL-18の存在が抗-FLAG免疫ブロット法により検出されたシグナルを減少させる場合には、当該hIL-1Ra1変異体ポリペプチドはIL-18のIL-18R結合の抑制剤とみなす。
IL-1lpをコードするヌクレオチド配列(又はそれらの相補配列)は、ハイブリッド形成プローブとしての使用を含む分子生物学の分野において、染色体及び遺伝子マッピングにおいて、及びアンチセンスRNA及びDNAの生成において種々の用途を有している。また、IL-1lp核酸も、ここに記載される組換え技術によるIL-1lpポリペプチドの調製に有用であろう。
図1(配列番号:1)、図2(配列番号:4)、図3(配列番号:6)、図5(配列番号:9)、図7(配列番号:12)図9(配列番号:15、図15(配列番号:18)、及び図16(配列番号:20)、及び図19(配列番号:24)の全長天然配列IL-1lp遺伝子又はその一部は、全長IL-1lp遺伝子の単離又は図1(配列番号:1)、図2(配列番号:4)、図3(配列番号:6)、図5(配列番号:9)、図7(配列番号:12)図9(配列番号:15)、図15(配列番号:18)、図16(配列番号:20)、又は図19(配列番号:24)に開示したIL-1lp配列に対して所望の配列同一性を持つ更に他の遺伝子(例えば、IL-1lpの天然発生変異体又は他の種からのIL-1lpをコードするもの)の単離のためのcDNAライブラリ用のハイブリッド形成プローブとして使用できる。場合によっては、プローブの長さは約20〜約50塩基である。ハイブリッド形成プローブは、図1(配列番号:1)、図2(配列番号:4)、図3(配列番号:6)、図5(配列番号:9)、図7(配列番号:12)図9(配列番号:15)、図15(配列番号:18)、図16(配列番号:20)、又は図19(配列番号:24)のヌクレオチド配列から、又は天然配列IL-1lpのプロモーター、エンハンサー成分及びイントロンを含むゲノム配列から誘導され得る。例えば、スクリーニング法は、IL-1lpポリペプチド遺伝子のコード化領域を周知のDNA配列を用いて単離して約40塩基の選択されたプローブを合成することを含む。ハイブリッド形成プローブは、32P又は35S等の放射性ヌクレオチド、又はアビディン/ビオチン結合系を介してプローブに結合したアルカリホスファターゼ等の酵素標識を含む種々の標識で標識されうる。本発明のIL-1lpポリペプチド遺伝子に相補的な配列を有する標識されたプローブは、ヒトcDNA、ゲノムDNA又はmRNAのライブラリーをスクリーニングし、そのライブラリーの何れのメンバーがプローブにハイブッド形成するかを決定するのに使用できる。ハイブリッド形成技術は、以下の実施例において更に詳細に記載する。
また、IL-1lpをコードするヌクレオチド配列は、そのIL-1lpをコードする遺伝子のマッピングのため、及び遺伝子疾患を持つ個体の遺伝子分析のためのハイブリッド形成プローブの作成にも用いることができる。ここに提供される核酸配列は、インサイツハイブリッド形成、既知の染色体マーカーに対する結合分析、及びライブラリーでのハイブリッド形成スクリーニング等の周知の技術を用いて、染色体及び染色体の特定領域にマッピングすることができる。
IL-1lpのコード配列が他のタンパク質に結合するタンパク質をコードする場合(例えば、IL-1lpがIL-1レセプター又はIL-18レセプターと結合する場合)、IL-1lpは、そのリガンドを同定するアッセイに用いることができる。このような方法により、レセプター/リガンド結合作用のインヒビターを同定することができる。このような結合性相互作用に含まれるタンパク質も、ペプチド又は小分子阻害剤又は結合性相互作用のアゴニストのスクリーニングに用いることができる。また、レセプターIL-1lpは関連するリガンドの単離にも使用できる。スクリーニングアッセイは、天然IL-1lp又はIL-1lpのレセプターの生物学的活性に似たリード化合物の発見のために設計される。このようなスクリーニングアッセイは、化学的ライブラリーの高スループットスクリーニングにも用いられ、小分子候補薬剤の同定に特に適したものとする。考慮される小分子は、合成有機又は無機化合物を含む。アッセイは、この分野で良く知られ特徴付けられているタンパク質−タンパク質結合アッセイ、生物学的スクリーニングアッセイ、免疫検定及び細胞ベースのアッセイを含む種々の型式で実施される。
あるいは、IL-1lpの非ヒト相同体は、動物の胚性細胞に導入されたIL-1lpをコードする変更ゲノムDNAと、IL-1lpをコードする内在性遺伝子との間の相同的組換えによって、IL-1lpをコードする欠陥又は変更遺伝子を有するIL-1lp「ノックアウト」動物を作成するために使用できる。例えば、IL-1lpをコードするcDNAは、確立された技術に従い、IL-1lpをコードするゲノムDNAのクローニングに使用できる。IL-1lpをコードするゲノムDNAの一部を欠失したり、組み込みを監視するために使用する選択可能なマーカーをコードする遺伝子等の他の遺伝子で置換することができる。典型的には、ベクターは無変化のフランキングDNA(5’と3’末端の両方)を数キロベース含む[例えば、相同的組換えベクターについてはThomas及びCapecchi, Cell, 51:503(1987)を参照のこと]。ベクターは胚性幹細胞に(例えばエレクトロポレーションによって)導入し、導入されたDNAが内在性DNAと相同的に組換えられた細胞が選択される[例えば、Li等, Cell, 69:915(1992)参照]。選択された細胞は次に動物(例えばマウス又はラット)の胚盤胞内に注入されて集合キメラを形成する[例えば、Bradley, Teratocarcinomas and Embryonic Stem Cells: A Practical Approach, E. J. Robertson, ed. (IRL, Oxford, 1987), pp. 113-152参照]。その後、キメラ性胚を適切な偽妊娠の雌性乳母に移植し、期間をおいて「ノックアウト」動物をつくり出す。胚細胞に相同的に組換えられたDNAを有する子孫は標準的な技術により同定され、それらを利用して動物の全細胞が相同的に組換えられたDNAを含む動物を繁殖させることができる。ノックアウト動物は、IL-1lpポリペプチドが不在であることによるある種の病理的状態及びその病理的状態の進行に対する防御能力によって特徴付けられる。
生存可能な細胞に核酸を導入するための種々の技術が存在する。これらの技術は、核酸が培養細胞にインビトロで、あるいは意図する宿主の細胞においてインビボで移入されるかに応じて変わる。核酸を哺乳動物細胞にインビトロで移入するのに適した方法は、リポソーム、エレクトロポレーション、マイクロインジェクション、細胞融合、DEAE-デキストラン、リン酸カルシウム沈殿法などを含む。現在好ましいインビボ遺伝子移入技術は、ウイルス(典型的にはレトロウイルス)ベクターでの形質移入及びウイルス被覆タンパク質-リポソーム媒介形質移入である(Dzau等, Trends, in Biotechnology 11, 205-210(1993))。幾つかの状況では、核酸供給源を、細胞表面膜タンパク質又は標的細胞に特異的な抗体、標的細胞上のレセプターに対するリガンド等の標的細胞を標的化する薬剤とともに提供するのが望ましい。リポソームを用いる場合、エンドサイトーシスを伴って細胞表面膜タンパク質に結合するタンパク質、例えば、特定の細胞型向性のカプシドタンパク質又はその断片、サイクルにおいて内部移行を受けるタンパク質に対する抗体、細胞内局在化を標的とし細胞内半減期を向上させるタンパク質が、標的化及び/又は取り込みの促進のために用いられる。レセプター媒介エンドサイトーシスの技術は、例えば、Wu等, J. Biol. Chem. 262, 4429-4432 (1987); 及びWagner等, Proc. Natl. Acad. Sci. USA 87, 3410-3414 (1990)によって記述されている。遺伝子作成及び遺伝子治療のプロトコールの概説については、Anderson等, Science 256, 808-813 (1992)を参照のこと。
ここで、本発明の製薬組成物は一般に、無菌のアクセスポートを具備する容器、例えば、皮下注射針で貫通可能なストッパーを持つ静脈内バッグ又はバイアル内に配される。
投与経路は周知の方法、例えば、静脈内、腹膜内、脳内、筋肉内、眼内、動脈内又は病巣内経路での注射又は注入、局所投与、又は徐放系による。
本発明の製薬組成物の用量及び望ましい薬物濃度は、意図する特定の用途に応じて変化する。適切な用量又は投与経路の決定は、通常の内科医の技量の範囲内である。動物実験は、ヒト治療のための有効量の決定についての信頼できるガイダンスを提供する。有効量の種間スケーリングは、Toxicokinetics and New Drug Development, Yacobi等, 編, Pergamon Press, New York 1989, pp. 42-96のMordenti, J. 及びChappell, W. 「The use of interspecies scaling in toxicokinetics」に記載された原理に従って実施できる。
IL-1lpの治療に用いられるのに「有効な量」は、たとえば治療の目的、投与の経路、患者の状態による。従って、療法士には、投与量を定め、最良の治療効果が得られるのに必要とされるような投与の経路を考えることが必要とされる。典型的に、臨床医は投与量が要求する効果が成されるように達成されるまで、IL-1lpを投与する。この治療のプロセスは従来のアッセイによって容易に監視される。
他の実施態様では、本発明は、IL-1-媒介疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、IL-1-媒介疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、IL-18-媒介疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列IL-1lpのようなIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、IL-18-媒介疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、IL-18-媒介疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、IL-18-媒介疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、炎症疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、炎症疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、炎症疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、喘息を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列IL-1lpのようなIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、喘息を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、喘息を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、喘息を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、リウマチ様関節炎を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、リウマチ様関節炎を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、リウマチ様関節炎を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、変形性関節症を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列IL-1lpのようなIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、変形性関節症を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、変形性関節症を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、変形性関節症を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、敗血症を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、敗血症を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、敗血症を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、急性リンパ性白血病を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列IL-1lpのようなIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、急性リンパ性白血病を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、急性リンパ性白血病を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、急性リンパ性白血病を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、成人呼吸窮迫症候群を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、成人呼吸窮迫症候群を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、成人呼吸窮迫症候群を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、特発性肺線維症を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列IL-1lpのようなIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、特発性肺線維症を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、特発性肺線維症を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、特発性肺線維症を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、虚血性再潅流疾患、たとえば外科的組織再潅流傷害を脳梗塞、心筋虚血、又は心筋梗塞を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、虚血性再潅流疾患、たとえば外科的組織再潅流傷害を脳梗塞、心筋虚血、又は心筋梗塞を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、虚血性再潅流疾患、たとえば外科的組織再潅流傷害を脳梗塞、心筋虚血、又は心筋梗塞を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、乾癬を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列IL-1lpのようなIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、乾癬を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、乾癬を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、乾癬を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、移植片対宿主疾患(GVHD)を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、移植片対宿主疾患(GVHD)を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、移植片対宿主疾患(GVHD)を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、潰瘍性大腸炎のような炎症性腸疾患を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列IL-1lpのようなIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、潰瘍性大腸炎のような炎症性腸疾患を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、hIL-1Ra1、hIL-1Ra1L、hIL-1Ra1V、hIL-1Ra1S、hIL-1Ra2、hIL-1Ra3、及びmIL-1Ra3からなる群より選択されるIL-1lpを有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、潰瘍性大腸炎のような炎症性腸疾患を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1lpのようなhIL-1lp、たとえば天然配列hIL-1Ra1、またはhIL-1Ra3を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、潰瘍性大腸炎のような炎症性腸疾患を治療するための、そのような治療を必要とする哺乳動物、たとえばヒトに、天然配列hIL-1Ra1LのようなhIL-1Ra1Lの有効量、または天然配列hIL-1Ra1VのようなhIL-1Ra1Vの有効量、または天然配列hIL-1Ra1SのようなhIL-1Ra1Sの有効量を投与することを含んでなる方法を提供する。
本発明は抗IL-1lp抗体を更に提供する。抗体の例としては、ポリクローナル、モノクローナル、ヒト化、二重特異性及びヘテロ抱合体抗体が含まれる。
1.ポリクローナル抗体
抗IL-1lp抗体はポリクローナル抗体を含む。ポリクローナル抗体の調製方法は当業者に知られている。哺乳動物においてポリクローナル抗体は、例えば免疫化剤、及び所望するのであればアジュバントを、一又は複数回注射することで発生させることができる。典型的には、免疫化剤及び/又はアジュバントを複数回皮下又は腹腔内注射により、哺乳動物に注射する。免疫化剤は、IL-1lpポリペプチド又はその融合タンパク質を含みうる。免疫化剤を免疫化された哺乳動物において免疫原性が知られているタンパク質に抱合させるのが有用である。このような免疫原タンパク質の例は、これらに限られないが、キーホールリンペットヘモシアニン、血清アルブミン、ウシサイログロブリン及び大豆トリプシンインヒビターが含まれる。使用され得るアジュバントの例には、フロイント完全アジュバント及びMPL-TDMアジュバント(モノホスホリル脂質A、合成トレハロースジコリノミコラート)が含まれる。免疫化プロトコールは、過度の実験なく当業者により選択されるであろう。
あるいは、抗IL-1lp抗体はモノクローナル抗体であってもよい。モノクローナル抗体は、Kohler及びMilstein, Nature, 256:495 (1975)に記載されているようなハイブリドーマ法を使用することで調製することができる。ハイブリドーマ法では、マウス、ハムスター又は他の適切な宿主動物を典型的には免疫化剤により免疫化することで、免疫化剤に特異的に結合する抗体を生成するかあるいは生成可能なリンパ球を誘発する。また、リンパ球をインビトロで免疫化することもできる。
免疫化剤は、典型的には対象とするIL-1lpポリペプチド又はその融合タンパク質を含む。一般にヒト由来の細胞が望まれる場合には末梢血リンパ球(「PBL」)が使用され、あるいは非ヒト哺乳動物源が望まれている場合は、脾臓細胞又はリンパ節細胞が使用される。次いで、ポリエチレングリコール等の適当な融合剤を用いてリンパ球を不死化株化細胞と融合させ、ハイブリドーマ細胞を形成する[Goding, Monoclonal Antibodies: Principles and Practice, Academic Press, (1986) pp. 59-103]。不死化株化細胞は、通常は、形質転換した哺乳動物細胞、特に齧歯動物、ウシ、及びヒト由来の骨髄腫細胞である。通常、ラット又はマウスの骨髄腫株化細胞が使用される。ハイブリドーマ細胞は、好ましくは、未融合の不死化細胞の生存又は成長を阻害する一又は複数の物質を含有する適切な培地で培養される。例えば、親細胞が、酵素のヒポキサンチングアニンホスホリボシルトランスフェラーゼ(HGPRT又はHPRT)を欠いていると、ハイブリドーマの培地は、典型的には、ヒポキサチン、アミノプチリン及びチミジンを含み(「HAT培地」)、この物質がHGPRT欠乏性細胞の増殖を阻止する。
好ましい不死化株化細胞は、効率的に融合し、選択された抗体生成細胞による安定した高レベルの抗体発現を支援し、HAT培地のような培地に対して感受性である。より好ましい不死化株化細胞はマウス骨髄腫株であり、これは例えばカリフォルニア州サンディエゴのSalk Institute Cell Distribution Centerやバージニア州マナッサスのアメリカン・タイプ・カルチャー・コレクションより入手可能である。ヒトモノクローナル抗体を生成するためのヒト骨髄腫及びマウス-ヒト異種骨髄腫株化細胞も開示されている[Kozbor, J. Immunol., 133:3001 (1984)、Brodeur等, Monoclonal Antibody Production Techniques and Applications, Marcel Dekker, Inc., New York, (1987) pp. 51-63]。
所望のハイブリドーマ細胞が同定された後、クローンを制限希釈工程によりサブクローニングし、標準的な方法で成長させることができる[Goding, 上掲]。この目的のための適当な培地には、例えば、ダルベッコの改変イーグル培地及びRPMI-1640倍地が含まれる。あるいは、ハイブリドーマ細胞は哺乳動物においてインビボで腹水として成長させることもできる。
サブクローンによって分泌されたモノクローナル抗体は、例えばプロテインA−セファロース法、ヒドロキシルアパタイトクロマトグラフィー法、ゲル電気泳動法、透析法又はアフィニティークロマトグラフィー等の従来の免疫グロブリン精製方法によって培養培地又は腹水液から単離又は精製される。
抗体は一価抗体であってもよい。一価抗体の調製方法は当該分野においてよく知られてる。例えば、一つの方法は免疫グロブリン軽鎖と修飾重鎖の組換え発現を含む。重鎖は一般的に、重鎖の架橋を防止するようにFc領域の任意の点で切断される。あるいは、関連するシステイン残基を他のアミノ酸残基で置換するか欠失させて架橋を防止する。
一価抗体の調製にはインビトロ法がまた適している。抗体の消化による、その断片、特にFab断片の生成は、当該分野において知られている慣用的技術を使用して達成できる。
本発明の抗IL-1lp抗体は、さらにヒト化抗体又はヒト抗体を含む。非ヒト(例えばマウス)抗体のヒト化形とは、キメラ免疫グロブリン、免疫グロブリン鎖あるいはその断片(例えばFv、Fab、Fab'、F(ab')2あるいは抗体の他の抗原結合サブ配列)であって、非ヒト免疫グロブリンに由来する最小配列を含むものである。ヒト化抗体はレシピエントの相補性決定領域(CDR)の残基が、マウス、ラット又はウサギのような所望の特異性、親和性及び能力を有する非ヒト種(ドナー抗体)のCDRの残基によって置換されたヒト免疫グロブリン(レシピエント抗体)を含む。幾つかの例では、ヒト免疫グロブリンのFvフレームワーク残基は、対応する非ヒト残基によって置換されている。また、ヒト化抗体は、レシピエント抗体にも、移入されたCDRもしくはフレームワーク配列にも見出されない残基を含んでいてもよい。一般に、ヒト化抗体は、全てあるいはほとんど全てのCDR領域が非ヒト免疫グロブリンのものに対応し、全てあるいはほとんど全てのFR領域がヒト免疫グロブリンコンセンサス配列のものである、少なくとも1つ、典型的には2つの可変ドメインの実質的に全てを含む。ヒト化抗体は、最適には免疫グロブリン定常領域(Fc)、典型的にはヒトの免疫グロブリンの定常領域の少なくとも一部を含んでなる[Jones等, Nature, 321:522-525 (1986); Riechmann等, Nature, 332:323-329 (1988); 及びPresta, Curr. Op Struct. Biol., 2:593-596 (1992)]。
非ヒト抗体をヒト化する方法はこの分野でよく知られている。一般的に、ヒト化抗体には非ヒト由来の一又は複数のアミノ酸残基が導入される。これら非ヒトアミノ酸残基は、しばしば、典型的には「移入」可変ドメインから得られる「移入」残基と称される。ヒト化は基本的に齧歯動物のCDR又はCDR配列でヒト抗体の該当する配列を置換することによりウィンター(winter)及び共同研究者[Jones等, Nature, 321:522-525 (1986);Riechmann等, Nature, 332:323-327 (1988);Verhoeyen等, Science, 239:1534-1536 (1988)]の方法に従って、齧歯類CDR又はCDR配列をヒト抗体の対応する配列に置換することにより実施される。よって、このような「ヒト化」抗体は、無傷のヒト可変ドメインより実質的に少ない分が非ヒト種由来の対応する配列で置換されたキメラ抗体(米国特許第4,816,567号)である。実際には、ヒト化抗体は典型的には幾つかのCDR残基及び場合によっては幾つかのFR残基が齧歯類抗体の類似する部位からの残基によって置換されたヒト抗体である。
二重特異性抗体は、少なくとも2つの異なる抗原に対して結合特異性を有するモノクローナル抗体、好ましくはヒトもしくはヒト化抗体である。本発明の場合において、結合特異性の一方はIL-1lpに対してであり、他方は任意の他の抗原、好ましくは細胞表面タンパク質又はレセプター又はレセプターサブユニットに対してである。
二重特異性抗体を作成する方法は当該技術分野において周知である。伝統的には、二重特異性抗体の組換え生産は、二つの重鎖が異なる特異性を持つ二つの免疫グロブリン重鎖/軽鎖対の同時発現に基づく[Milstein及びCuello, Nature, 305:537-539 (1983)]。免疫グロブリンの重鎖と軽鎖を無作為に取り揃えるため、これらハイブリドーマ(クアドローマ)は10種の異なる抗体分子の潜在的混合物を生成し、その内一種のみが正しい二重特異性構造を有する。正しい分子の精製は、アフィニティークロマトグラフィー工程によって通常達成される。同様の手順が1993年5月13日公開のWO93/08829、及びTraunecker等, EMBO J.,10:3655-3659 (1991)に開示されている。
所望の結合特異性(抗体-抗原結合部位)を有する抗体可変ドメインを免疫グロブリン定常ドメイン配列に融合できる。融合は、好ましくは少なくともヒンジ部、CH2及びCH3領域の一部を含む免疫グロブリン重鎖定常ドメインとのものである。少なくとも一つの融合には軽鎖結合に必要な部位を含む第一の重鎖定常領域(CH1)が存在することが望ましい。免疫グロブリン重鎖融合をコードするDNA、及び望むのであれば免疫グロブリン軽鎖を、別々の発現ベクターに挿入し、適当な宿主生物に同時形質移入する。二重特異性抗体を作成するための更なる詳細については、例えばSuresh等, Methods in Enzymology, 121:210(1986)を参照されたい。
ヘテロ抱合抗体もまた本発明の範囲に入る。ヘテロ抱合抗体は、2つの共有結合した抗体からなる。このような抗体は、例えば、免疫系細胞を不要な細胞に対してターゲティングさせるため[米国特許第4,676,980号]及びHIV感染の治療のために[WO 91/00360; WO 92/200373; EP 03089]提案されている。この抗体は、架橋剤に関連したものを含む合成タンパク化学における既知の方法を使用して、インビトロで調製することができると考えられる。例えば、ジスルフィド交換反応を使用するか又はチオエーテル結合を形成することにより、免疫毒素を作成することができる。この目的に対して好適な試薬の例には、イミノチオレート及びメチル-4-メルカプトブチリミデート、及び例えば米国特許第4,6767,980号に開示されているものが含まれる。
本発明の抗IL-1lp抗体は様々な有用性を有している。例えば、抗IL-1lp抗体は、IL-1lpの診断アッセイ、例えばその特定細胞、組織、又は血清での発現の検出に用いられる。競合的結合アッセイ、直接又は間接サンドウィッチアッセイ及び不均一又は均一相で行われる免疫沈降アッセイ[Zola, Monoclonal Antibodies: A Manual of Techniques, CRC Press, Inc. (1987) pp. 147-158]等のこの分野で知られた種々の診断アッセイ技術が使用される。診断アッセイで用いられる抗体は、検出可能な部位で標識される。検出可能な部位は、直接又は間接に、検出可能なシグナルを発生しなければならない。例えば、検出可能な部位は、3H、14C、32P、35S又は125I等の放射性同位体、フルオレセインイソチオシアネート、ローダミン又はルシフェリン等の蛍光又は化学発光化合物、あるいはアルカリホスファターゼ、ベータ-ガラクトシダーゼ又はセイヨウワサビペルオキシダーゼ等の酵素であってよい。抗体に検出可能な部位を抱合させるためにこの分野で知られた任意の方法が用いられ、それにはHunter等 Nature, 144:945 (1962);David等, Biochemistry, 13: 1014 (1974);Pain等, J. Immunol. Meth., 40:219 (1981) ;及びNygren, J. Histochem. and Cytochem., 30:407 (1982)に記載された方法が含まれる。
また、抗IL-1lp抗体は組換え細胞培養又は天然供給源からのIL-1lpのアフィニティー精製にも有用である。この方法においては、IL-1lpに対する抗体を、当該分野でよく知られている方法を使用して、セファデックス樹脂や濾紙のような適当な支持体に固定化する。次に、固定化された抗体を、精製するIL-1lpを含む試料と接触させた後、固定化された抗体に結合したIL-1lp以外の試料中の物質を実質的に全て除去する適当な溶媒で支持体を洗浄する。最後に、IL-1lpを抗体から脱離させる他の適当な溶媒で支持体を洗浄する。
基本的な計画としては、一投与当たりの非経口投与される抗体又は抗体断片の初回の薬剤的有効量は、0.3から20mg/kg/日、より好ましくは2から5mg/kg/日とされている抗体の標準的な初回範囲を有する、一日当たり約0.1から50mg/患者体重kgの範囲である。
一実施様態では、全身投与に用いる場合、初回薬剤的有効量は約2から5mg/kg/日である。
吸入による投与を用いた本発明の方法では、初回薬剤的有効量は約1マイクログラム(μg)/kg/日から100mg/kg/日の範囲である。
他の実施態様では、本発明は、hIL-1lp-媒介喘息疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1Ra1-媒介喘息疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1Ra1抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介リウマチ様関節炎疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介リウマチ様関節炎疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1Ra1-媒介リウマチ様関節炎疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1Ra1抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介変形性関節症疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介変形性関節症疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1Ra1-媒介変形性関節症疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1Ra1抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介感染性疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1Ra1-媒介感染性疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1Ra1抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介急性肺障害の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介急性肺障害の治療のための、そのような治療を必要とするヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1Ra1-媒介急性肺障害の治療のための、そのような治療を必要とするヒトに、抗-hIL-1Ra1抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介成人呼吸窮迫症候群の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介成人呼吸窮迫症候群の治療のための、そのような治療を必要とするヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1Ra1-媒介成人呼吸窮迫症候群の治療のための、そのような治療を必要とするヒトに、抗-hIL-1Ra1抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介特発性肺線維症の治療のための、そのような治療を必要とするヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1Ra1-媒介特発性肺線維症の治療のための、そのような治療を必要とするヒトに、抗-hIL-1Ra1抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介虚血性再潅流疾患、たとえば外科的組織再潅流傷害を脳梗塞、心筋虚血、又は心筋梗塞の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介虚血性再潅流疾患、たとえば外科的組織再潅流傷害を脳梗塞、心筋虚血、又は心筋梗塞の治療のための、そのような治療を必要とするヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1Ra1-媒介虚血性再潅流疾患、たとえば外科的組織再潅流傷害を脳梗塞、心筋虚血、又は心筋梗塞の治療のための、そのような治療を必要とするヒトに、抗-hIL-1Ra1抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介乾癬疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介乾癬疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1Ra1-媒介乾癬疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1Ra1抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介移植片対宿主疾患(GVHD)の治療のための、そのような治療を必要とするヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1Ra1-媒介移植片対宿主疾患(GVHD)の治療のための、そのような治療を必要とするヒトに、抗-hIL-1Ra1抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介潰瘍性大腸炎のような炎症性腸疾患の治療のための、そのような治療を必要とする哺乳動物、たとえばヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1lp-媒介潰瘍性大腸炎のような炎症性腸疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1lp抗体を有効量投与することを含んでなる方法を提供する。
他の実施態様では、本発明は、hIL-1Ra1-媒介潰瘍性大腸炎のような炎症性腸疾患の治療のための、そのような治療を必要とするヒトに、抗-hIL-1Ra1抗体を有効量投与することを含んでなる方法を提供する。
以下の実施例は例示するためにのみ提供されるものであって、本発明の範囲を決して限定することを意図するものではない。
本明細書で引用した全ての特許及び参考文献の全体を、出典明示によりここに取り込む。
実施例で言及されている全ての市販試薬は、特に示さない限りは製造者の使用説明に従い使用した。ATCC登録番号により以下の実施例及び明細書全体を通して特定されている細胞の供給源はアメリカン・タイプ・カルチャー・コレクション、マナッサス、VAである。
実施例1:hIL-1Ra1及びmIL-1Ra3をコードするDNAの単離
公的な発現配列タグ(EST)DNAデータベース(Genbank)を、ヒトインターロイキン-1レセプターアンタゴニスト(hIL-1Ra)配列(分泌ヒトインターロイキン-1レセプターアンタゴニスト(「sIL-1Ra」)配列としても知られる)で検索し、AI014548と命名されるヒトEST(図4、配列番号:8のヌクレオチド145−629に対応する)とW08205と命名されるマウスEST(図10,配列番号:17)を同定し、それは既知のタンパク質hIL-1Ra(sIL-1Ra)と相同性を示した。
ESTクローンAI014548及びW08205はResearch Genetics(ハンツビル、アラバマ州)から購入し、cDNA挿入断片を取得し、その全体を配列決定した。
DNA85066と命名される、クローンAI014548の完全ヌクレオチド配列は図1(配列番号:1)に示される。クローンDNA85066は、見かけのイントロン配列によって中断される単鎖オープンリーディングフレームを含む。イントロンはヌクレオチド位置181から186(スプライス供与部位)及びヌクレオチド位置430から432(スプライス受容位置)(図1;配列番号:1)でスプライス部位によって結合される。
事実上処理されたヌクレオチド配列(図3;配列番号:6)はDNA94618と命名され、クローンDNA85066から見かけのイントロン配列が取り除かれることにより導かれた。クローンDNA94618はヌクレオチド位置103−105に見かけの翻訳開始部位、及びヌクレオチド位置682−684に終止コドンを有する単鎖オープンリーディングフレームを含む(図3;配列番号:6)。予測されるポリペプチド前駆体(hIL-1Ra1)(図3;配列番号:7)は193アミノ酸長である。推定のシグナル配列はアミノ酸位置1から14まで達する。推定のcAMP-及びcGMP-依存プロテインキナーゼリン酸化部位はアミノ酸位置33−36に位置する。推定のN−ミリストイル化部位はアミノ酸位置50−55及びアミノ酸位置87−92に位置する。
全長配列(配列番号:7)の配列構造分析に基づいて、hIL-1Ra1はhIL-1Ra(sIL-1Ra)及びhIL-1Raβタンパク質と有意な配列同一性があることが示された。
クローンW08205の完全ヌクレオチド配列は、DNA92505と命名され、図9(配列番号:15)に示される。クローンDNA92505は、ヌクレオチド位置145−147に見かけの翻訳開始部位、及びヌクレオチド位置610−612に終止コドンを有する単鎖オープンリーディングフレームを含む(図9;配列番号15)。予測されるポリペプチド前駆体(mIL-1Ra3)(図9;配列番号:16)は155アミノ酸長である。推定のシグナル配列はアミノ酸位置1−33まで達する。推定のN−ミリストイル化部位はアミノ酸位置29−34、60−65、63−68、91−96及び106−111に位置する。インターロイキン-1-様配列はアミノ酸位置111−131に位置する。
クローンDNA92505(DNA92505−2534と命名される)はATCCに寄託され、ATCC寄託番号203590が付与された。図9(配列番号:16)に示される全長mIL-1Ra3タンパク質は約17,134ダルトンの推定分子量及び約4.8のpIを持つ。
全長配列(配列番号:16)の配列構造分析に基づいて、mIL-1Ra3はmIL-1Ra、hicIL-1Ra、hIL-1Ra(sIL-1Ra)及びhIL-1Raβタンパク質と有意な配列同一性があることが示された。
発現配列タグ(EST)DNAデータベース(LIFESEQ(商品名)、Incyte Pharmaceuticals、Palo Alto, CA)を、ヒトインターロイキン-1レセプターアンタゴニスト(hIL-1Ra)配列(分泌ヒトインターロイキン-1レセプターアンタゴニスト(「sIL-1Ra」)配列としても知られる)で検索し、1433156(図5、配列番号:11)と5120028(図8、配列番号:14)と命名されるESTを同定し、それは既知のタンパク質hIL-1Raと相同性を示した。
ESTクローン1433156及び5120028をPharmaceuticals(Palo Alto, CA)から購入し、cDNA挿入断片を取得し、その全体を配列決定した。
DNA92929と命名される、クローン1433156の完全ヌクレオチド配列は図5(配列番号:9)に示される。クローンDNA92929は、ヌクレオチド位置96−98に見かけの翻訳開始部位、及びヌクレオチド位置498−500に終止コドンを有する単鎖オープンリーディングフレームを含む(図5;配列番号:9)。予測されるポリペプチド前駆体(hIL-1Ra2)(図5;配列番号:10)は134アミノ酸長である。推定のシグナル配列はアミノ酸位置1−26まで達する。
クローンDNA92929(DNA92929−2534と命名される)はATCCに寄託され、ATCC寄託番号203586が付与された。図5(配列番号:10)に示される全長hIL-1Ra2タンパク質は約14,927ダルトンの推定分子量及び約4.8のpIを持つ。
クローン5120028の完全ヌクレオチド配列は、DNA96787と命名され、図7(配列番号:12)に示される。クローンDNA96787は、ヌクレオチド位置1−3に見かけの翻訳開始部位、及びヌクレオチド位置466−468に終止コドンを有する単鎖オープンリーディングフレームを含む(図7;配列番号12)。予測されるポリペプチド前駆体(hIL-1Ra3)(図7;配列番号:13)は155アミノ酸長である。推定のシグナル配列はアミノ酸位置1−33まで達する。推定のN−ミリストイル化部位はアミノ酸位置29−34、60−65、63−68、73−78、91−96及び106−111に位置する。インターロイキン-1-様配列はアミノ酸位置111−131に位置する。
hIL-1Ra3の予測される155アミノ酸ポリペプチドは特定の動物細胞では成熟配列(翻訳後プロセッシングで取り除かれたプレ配列を持たない)として振る舞うと考えられる。また、他の動物細胞はアミノ酸位置1から約33まで伸びる一又は複数のシグナルペプチドを認知し、取り除くと考えられる。以下の実施例14に示されるように、一過性に形質移入されたCHO宿主細胞は図7(配列番号:13)の配列で単にN−末端メチオニンが欠失したhIL-1Ra3の型を分泌する。
クローンDNA96787(DNA96787−2534と命名される)はATCCに寄託され、ATCC寄託番号203589が付与された。図7(配列番号:13)に示される全長hIL-1Ra3タンパク質は約19,961ダルトンの推定分子量及び約4.9のpIを持つ。
全長配列(配列番号:13)の配列構造分析に基づいて、hIL-1Ra3はhicIL-1Ra及びhIL-1Ra(sIL-1Ra)タンパク質と有意な配列同一性があることが示された。
ヒト組織におけるhIL-1Ra3 mRNAの発現及びマウス組織におけるmIL-1Ra3 mRNAの発現を、ノーザンブロット分析によって検査した。ヒト及びマウス多組織ノーザン(RNA)ブロット及びマウス胚ブロットはClontechから購入され、製造メーカーの指示による対応cDNAを用いてプローブした。
図.11に示すように、hIL-1Ra3 mRNA(2.7kb)はヒト胎盤にだけ検出され、mIL-1Ra3 mRNA転写物(1.4kb及び2.5kb)は17日目マウス胚にだけ検出された。
以下の方法は、IL-1lpをコードするヌクレオチド配列のハイブリッド形成プローブとしての使用を記載する。
全長IL-1lpのコード配列(図3,5,7,9,15,16及び19;配列番号:6,9,12,15,18,20,及び24)を含むDNAは、ヒト組織cDNAライブラリ又はヒト組織ゲノムライブラリにおける相同性DNA(IL-1lpの天然に生じる変異体をコードするものなど)のスクリーニングのためのプローブとして用いられる。
いずれかのライブラリDNAを含むフィルターのハイブリッド形成及び洗浄は、以下の高緊縮条件で実施した。放射標識IL-1lp誘導プローブのフィルターへのハイブリッド形成は、50%ホルムアミド、5xSSC、0.1%SDS、0.1%ピロリン酸ナトリウム、50mMリン酸ナトリウム、pH6.8、2xデンハート液、及び10%デキストラン硫酸の溶液中で、42℃において20時間行った。フィルターの洗浄は、0.1xSSC及び0.1%SDSの水溶液中、42℃で行った。
次いで、全長天然配列IL-1lpをコードするDNAと所望の配列同一性を有するDNAは、この分野で知られた標準的な方法を用いて同定できる。
この実施例は、大腸菌における組み換え発現による所望のIL-1lpの非グリコシル化形態の調製を例示する。
IL-1lpをコードするDNA配列は、選択されたPCRプライマーを用いて最初に増幅した。プライマーは、選択された発現ベクターの制限酵素部位に対応する制限酵素部位を持たなければならない。種々の発現ベクターを用いることができる。好適なベクターの例は、pBR322(大腸菌から誘導されたもの;Bolivar等, Gene, 2:95 (1977)を参照)であり、アンピシリン及びテトラサイクリン耐性についての遺伝子を含む。ベクターは、制限酵素で消化され、脱リン酸化される。PCR増幅した配列は、次いで、ベクターに結合させる。ベクターは、好ましくは抗生物質耐性遺伝子、trpプロモーター、polyhisリーダー(最初の6つのSTIIコドン、polyhis配列、及びエンテロキナーゼ切断部位を含む)、IL-1lpコード化領域、ラムダ転写終結区、及びargU遺伝子を含む。
ライゲーション混合物は、次いで、上掲のSambrook等に記載された方法を用いた選択した大腸菌株の形質転換に使用される。形質転換体は、それらのLBプレートで成長する能力により同定され、次いで抗生物質耐性クローンが選択される。プラスミドDNAが単離され、制限分析及びDNA配列分析で確認される。
選択されたクローンは、抗生物質を添加したLBブロスなどの液体培地で終夜成長させることができる。終夜培養は、続いて大規模培養の播種に用いられる。次に細胞を最適光学密度まで成長させ、その間に発現プロモーターが作動する。
更に数時間の培養の後、細胞を採集して遠心分離できる。遠心分離で得られた細胞ペレットは、この分野で知られた種々の試薬を用いて可溶化され、次いで可溶化IL-1lpタンパク質を金属キレート化カラムを用いてタンパク質を緊密に結合させる条件下で精製することができる。
この実施例は、哺乳動物細胞における組み換え発現による潜在的にグリコシル化した形態のIL-1lpの調製を例示する。
発現ベクターとしてベクターpRK5(1989年3月15日公開のEP 307,247参照)を用いた。場合によっては、IL-1lp DNAを選択した制限酵素を持つpRK5に結合させ、上掲のSambrook等に記載されたようなライゲーション方法を用いてIL-1lpDNAを挿入させる。得られたベクターは、pRK5−IL-1lpと呼ばれる。
一実施態様では、選択された宿主細胞は293細胞とすることができる。ヒト293細胞(ATCC CCL 1573)は、ウシ胎児血清及び場合によっては滋養成分及び/又は抗生物質を添加したDMEMなどの培地中で組織培養プレートにおいて成長させて集密化した。約10μgのpRK5−IL-1lpポリペプチドDNAを約1μgのVA RNA遺伝子コード化DNA[Thimmappaya等, Cell, 31:543 (1982))]と混合し、500μlの1mMトリス-HCl、0.1mMEDTA、0.227MCaCl2に溶解させた。この混合物に、滴状の、500μlの50mMHEPES(pH7.35)、280mMのNaCl、1.5mMのNaPO4を添加し、25℃で10分間析出物を形成させた。析出物を懸濁し、293細胞に加えて37℃で約4時間定着させた。培地を吸引し、2mlのPBS中20%グリセロールを30秒間添加した。293細胞は、次いで無血清培地で洗浄し、新鮮な培地を添加し、細胞を約5日間インキュベートした。
形質移入の約24時間後、培地を除去し、培地(のみ)又は200μCi/ml35S−システイン及び200μCi/ml35S−メチオニンを含む培地で置換した。12時間のインキュベーションの後、条件培地を回収し、スピンフィルターで濃縮し、15%SDSゲルに添加した。処理したゲルを乾燥させ、IL-1lpポリペプチドの存在を現す選択された時間にわたってフィルムにさらした。形質転換した細胞を含む培地に、更なるインキュベーションを施し(無血清培地で)、培地を選択されたバイオアッセイで試験した。
他の実施態様では、IL-1lpをCHO細胞で発現させることができる。pRK5−IL-1lpは、CaPO4又はDEAE−デキストランなどの公知の試薬を用いてCHO細胞に形質移入することができる。上記したように、細胞培地をインキュベートし、培地を培養培地(のみ)又は35S-メチオニン等の放射性標識を含む培地に置換することができる。IL-1lpポリペプチドの存在を同定した後、培地を無血清培地に置換してもよい。好ましくは、培地を約6日間インキュベートし、次いで条件培地を回収する。次いで、発現されたIL-1lpを含む培地を濃縮して、任意の選択した方法によって精製することができる。
また、エピトープタグIL-1lpは、宿主CHO細胞において発現させてもよい。IL-1lpはpRK5ベクターからサブクローニングしてもよい。サブクローン挿入物は、PCRを施してバキュロウイルス発現ベクター中のポリ-hisタグ等の選択されたエピトープタグを持つ枠に融合できる。ポリ-ヒスタグIL-1lp挿入物は、次いで、安定なクローンの選択のためのDHFR等の選択マーカーを含むSV40誘導ベクターにサブクローニングできる。最後に、CHO細胞をSV40誘導ベクターで(上記のように)形質移入した。発現を確認するために、上記のように標識化を行ってもよい。発現されたポリ-ヒスタグIL-1lpを含む培地は、次いで濃縮し、Ni2+−キレートアフィニティクロマトグラフィー等の選択された方法により精製できる。
以下の方法は、酵母菌中でのIL-1lpの組換え発現を記載する。
第1に、ADH2/GAPDHプロモーターからのIL-1lpの細胞内生産又は分泌のための酵母菌発現ベクターを作成する。IL-1lpをコードするDNA及びプロモーターを選択したプラスミドの適当な制限酵素部位に挿入してIL-1lpの細胞内発現を指示する。分泌のために、IL-1lpをコードするDNAを選択したプラスミドに、ADH2/GAPDHプロモーターをコードするDNA、天然IL-1lpシグナルペプチド又は他の哺乳動物シグナルペプチド、又は、例えば酵母菌α因子又はインベルターゼ分泌シグナル/リーダー配列、及び(必要ならば)IL-1lpの発現のためのリンカー配列とともにクローニングすることができる。
酵母菌株AB110等の酵母菌は、次いで上記の発現プラスミドで形質転換し、選択された発酵培地中で培養できる。形質転換した酵母菌上清は、10%トリクロロ酢酸での沈降及びSDS−PAGEによる分離で分析し、次いでクマシーブルー染色でゲルの染色をすることができる。
続いて組換えIL-1lpは、発酵培地から遠心分離により酵母菌細胞を除去し、次いで選択されたカートリッジフィルターを用いて培地を濃縮することによって単離及び精製できる。IL-1lpを含む濃縮物は、選択されたカラムクロマトグラフィー樹脂を用いてさらに精製してもよい。
以下の方法は、バキュロウイルス感染昆虫細胞中におけるIL-1lpの組換え発現を記載する。
IL-1lpコードする配列を、バキュロウイルス発現ベクターに含まれるエピトープタグの上流に融合させた。このようなエピトープタグは、ポリ-hisタグ及び免疫グロブリンタグ(IgGのFc領域など)を含む。pVL1393(Navogen)などの市販されているプラスミドから誘導されるプラスミドを含む種々のプラスミドを用いることができる。簡単には、IL-1lp又はIL-1lpコード配列の所定部分、例えば膜貫通タンパク質の細胞外ドメインをコードする配列又はタンパク質が細胞外である場合の成熟タンパク質をコードする配列などが、5’及び3’領域に相補的なプライマーでのPCRにより増幅される。5’プライマーは、隣接する(選択された)制限酵素部位を包含していてもよい。生産物は、次いで、選択された制限酵素で消化され、発現ベクターにサブクローニングされる。
組換えバキュロウイルスは、上記のプラスミド及びBaculoGold(商品名)ウイルスDNA(Pharmingen)を、Spodoptera frugiperda(「Sf9」)細胞(ATCC CRL 1711)中にリポフェクチン(GIBCO-BRLから市販)を用いて同時形質移入することにより作成される。28℃で4-5日インキュベートした後、放出されたウイルスを回収し、更なる増幅に用いた。ウイルス感染及びタンパク質発現は、O'Reilley等, Baculovirus expression vectors: A laboratory Manual, Oxford: Oxford University Press (1994)に記載されているように実施した。
次に、発現されたポリ-ヒスタグIL-1lpは、例えばNi2+−キレートアフィニティクロマトグラフィーにより次のように精製される。抽出は、Rupert等, Nature, 362:175-179 (1993)に記載されているように、ウイルス感染した組み換えSf9細胞から調製した。簡単には、Sf9細胞を洗浄し、超音波処理用バッファー(25mMのHepes、pH7.9;12.5mMのMgCl2;0.1mM EDTA;10%グリセロール;0.1%のNP−40;0.4MのKCl)中に再懸濁し、氷上で2回20秒間超音波処理した。超音波処理物を遠心分離で透明化し、上清を負荷バッファー(50mMリン酸塩、300mMのNaCl、10%グリセロール、pH7.8)で50倍希釈し、0.45μmフィルターで濾過した。Ni2+−NTAアガロースカラム(Qiagenから市販)を5mLの総容積で調製し、25mLの水で洗浄し、25mLの負荷バッファーで平衡させた。濾過した細胞抽出物は、毎分0.5mLでカラムに負荷した。カラムを、分画回収が始まる点であるA280のベースラインまで負荷バッファーで洗浄した。次に、カラムを、結合タンパク質を非特異的に溶離する二次洗浄バッファー(50mMリン酸塩;300mMのNaCl、10%グリセロール、pH6.0)で洗浄した。A280のベースラインに再度到達した後、カラムを二次洗浄バッファー中で0から500mMイミダゾール勾配で展開した。1mLの分画を回収し、SDS−PAGE及び銀染色又はアルカリホスファターゼ(Qiagen)に複合したNi2+−NTAでのウェスタンブロットで分析した。溶離したHis10−タグIL-1lpを含む画分をプールして負荷バッファーで透析した。
あるいは、IgGタグ(又はFcタグ)IL-1lpの精製は、例えば、プロテインA又はプロテインGカラムクロマトグラフィーを含む公知のクロマトグラフィー技術を用いて実施できる。
hIL-1Ra1の特徴付けを容易にするために、クローンDNA85066(図1;配列番号3)の不完全ORFを含むPCR断片が、ベクターによってコードされるNH2-末端プレプロトリプシン及びFLAGタグとのフレーム内融合としてpCMV1FLAG(IBI Kodak, Pan等,Science, 276: 111-113に記載)中に複製された。組換えpCMV1FLAGベクタークローン完全cDNA挿入断片(クローンDNA96786と命名された)が配列決定された(図2;配列番号:4)。hIL1R及びhIL18R(以前はhIL1Rrpとして知られていた)の細胞外ドメインをコードするcDNAがポリメラーゼ連鎖反応(PCR)によって取得され、ヒト免疫グロブリンGのFc部位を用いたフレーム内融合が許容される変異pCMV1FLAGベクター中に複製された。
ヒト胎児腎臓293細胞が高グルコースDMEM(ジェネンテック社)中に生育された。細胞はプレート(100mm)当たり3−4X106で蒔かれ、リン酸カルシウム沈殿の手段によってpCMV1FLAG-hIL-1Ra1及びpCMV1FLAG-IL1R-ECD-Fc又はpCMV1FLAG-IL18R-ECD-Fcを用いて共トランスフェクションされた。培地はトランスフェクション後12時間で取り替えられた。結果として生じた条件培地(それぞれ10ml)はさらに70−74時間のインキュベーションの後回収され、遠心分離によって不純物除去され、分量され、−70℃で保存された。1.5mlの条件培地からのレセプター-Fc及びリガンド混合物がタンパク質G-セファロースで免疫沈降され、50mM Hepes、pH7.0、150mM NaCl、1mM EDTA、1%NP-40、及びプロテアーゼ阻害物質カクテル(BMB)を含む緩衝液で3回洗浄され、10−20%SDS−PAGEゲル上で分離された。結合したリガンドは抗-FLAGモノクローナル抗体(BMB)を用いた免疫ブロット法によって同定された。
図13Aに示されるように、分泌FLAGhIL-1Ra1融合タンパク質はIL-18Rと結合し、IL-1R ECDとは結合しなかった。そしてそれはIL-18Rのアゴニスト又はアンタゴニストであり得るということを示唆される。
mIL-1Ra3をコードするcDNA(図9;配列番号15に示されるDNA92505)を、カルボキシ末端FLAGタグを有するpRK7中にクローニングした。得られた発現構築物を、リン酸カルシウム沈殿法によってヒト胎児腎臓293細胞中にトランスフェクションした。トランスフェクション後84−90時間で、分泌されたFLAGmIL-1Ra3融合タンパク質を含む条件培地を回収した。分泌されたIL-18R-Fc及びIL-1R-Fcタンパク質を含有する条件培地は、293細胞をpCMV1FLAG-IL1R-ECD-FcかpCMV1FLAG-IL18R-ECD-Fcの何れか(pCMV1FLAG-IL-1Ra1の同時トランスフェクションなし)を用いてトランスフェクションされた点以外は上記の実施例9に記載されているようにして調製した。
インビトロ結合アッセイでは、0.5mlの条件培地由来のIL-1R-Fc又はIL-18R-FcをプロテインG-アガロースに固定し、次いで1.2mlのFRAGmIL-1Ra3含有条件培地と混合した。レセプター-リガンド複合体を10−20%のSDS-PAGEゲルで洗浄し、分離し、結合リガンドを、抗FLAGモノクローナル抗体(Boehringer Mannheim)を用いた免疫ブロット法を用いて検出した。
図14に示されるように、FLAGmIL-1Ra3融合タンパク質はIL-1R ECDに結合したが、IL-18R ECDには結合しなかった。mIL-1Ra3のアミノ酸配列が既知のインターロイキン-1レセプターアンタゴニストタンパク質(IL-1Ra)のアミノ酸配列に関連しているので、mIL-3Ra3は新規なIL-1レセプターアンタゴニストであると考えられる。
図13Bに示されるように、FLAGhIL-1Ra3融合タンパク質はIL-1R ECD-Fcに結合したが、IL-18R-ECD-Fc又はDR6-Fcには結合しなかった。hIL-1Ra3のアミノ酸配列が既知のインターロイキン-1レセプターアンタゴニストタンパク質(IL-1Ra)のアミノ酸配列に関連しているので、hIL-3Ra3は新規なIL-1レセプターアンタゴニストであると考えられる。
この実施例は、IL-1lpに特異的に結合できるモノクローナル抗体の調製を例示する。
モノクローナル抗体の産生のための技術は当該分野で知られており、例えば、上掲のGodingに記載されている。用いられ得る免疫原には、精製IL-1lp、IL-1lpを含む融合タンパク質、細胞表面に組換えIL-1lpを発現する細胞が含まれれる。免疫原の選択は、当業者が過度の実験をすることなく、選択することができる。
Balb/c等のマウスを、完全フロイントアジュバントに乳化して皮下又は腹腔内に1−100マイクログラムの量で注入したIL-1lp免疫原で免疫化する。あるいは、免疫原をMPL−TDMアジュバント(Ribi Immunochemical Researh, Hamilton, MT)に乳化し、動物の後足蹠に注入する。免疫化したマウスを、次いで10から12日後に、選択したアジュバント中に乳化した付加的な免疫源で追加免疫する。その後、数週間の間に、マウスを更なる免疫化注射で追加免疫する。ELISAアッセイで試験して抗IL-1lp抗体を検出するために、後眼窩(retro-orbital)出血により血清試料をマウスから周期的に採取してもよい。
適当な抗体力価が検出された後、抗体に「ポジティブ(陽性)」な動物に、IL-1lpの最後の静脈内注射の注入をすることができる。3から4日後、マウスを屠殺し、脾臓細胞を取り出す。次いで脾臓細胞を(35%ポリエチレングリコールを用いて)、ATCCから番号CRL1597で入手可能なP3X63AgU.1等の選択されたマウス骨髄腫株化細胞に融合させる。融合によりハイブリドーマ細胞が生成され、次いで、HAT(ヒポキサンチン、アミノプテリン、及びチミジン)培地を含む96ウェル組織培養プレートに蒔き、非融合細胞、骨髄腫ハイブリッド、及び脾臓細胞ハイブリッドの増殖を阻害する。
ハイブリドーマ細胞は、IL-1lpに対する反応性についてELISAでスクリーニングされる。IL-1lpに対する所望のモノクローナル抗体を分泌する「ポジティブ(陽性)」ハイブリドーマ細胞の決定は、当業者の技量の範囲内である。
陽性ハイブリドーマ細胞を同系のBalb/cマウスに腹腔内注入し、抗IL-1lpモノクローナル抗体を含む腹水を生成させる。あるいは、ハイブリドーマ細胞を、組織培養フラスコ又はローラーボトル中で成長させることもできる。腹水中に生成されたモノクローナル抗体の精製は、硫酸アンモニウム沈降、それに続くゲル排除クロマトグラフィ−を用いて行うことができる。あるいは、抗体のプロテインA又はプロテインGへの結合性に基づくアフィニティクロマトグラフィーを用いることもできる。
hIL-1Ra1L、hIL-1Ra1V及びhIL-1Ra1SをコードするDNAの単離
hIL-1Ra1イントロン含有クローンDNA85066(図2)(配列番号:4)に関連した幾つかのイントロン含有cDNAクローンをヒト精巣cDNAライブラリーから単離し、完全に配列決定した。イントロン含有cDNA配列をGENESCANプログラム(http://CCR-081.mitedu/GENESCAN.html)を用いて全長オープンリーディングフレーム(ORF)を決定するために用いた。ORF-コード配列を用いて二種のDNAプライマー、ggc gga tcc aaa atg ggc tct gag gac tgg g(配列番号:29)(1Ra1016)及びgcg gaa ttc taa tcg ctg acc tca ctg ggg(配列番号:30)(1Ra1017)を設計した。1Ra1016及び1Ra1017プライマーを合成し、ポリメラーゼ連鎖反応(PCR)を使用してヒト胎児皮膚及びSK-lu-1細胞cDNAライブラリーからcDNAをクローニングするために使用した。幾つかのPCR産物を単離し配列決定した。PCR産物から二つの全長cDNAクローン(DNA102043及びDNA102044と命名)がhIL-1Ra1イソ型をコードしていることが分かった。
クローンDNA102043の全ヌクレオチド配列は図15(配列番号:18)に示される。クローンDNA102043は、ヌクレオチド位置4−6に見かけの翻訳開始部位を、ヌクレオチド位置625−627に停止コドンを持つ単一のオープンリーディングフレームを含む(図15;配列番号:18)。予想されるポリペプチド前駆体(hIL-1Ra1Lと命名)(図15;配列番号:19)は207アミノ酸長である。推定シグナル配列はアミノ酸位置1−34にわたる。
クローンDNA102043(DNA102043−2534と命名)はATCCに寄託され、ATCC寄託番号203846が付与された。図15(配列番号:19)に示された全長hIL-1Ra1Lタンパク質は約23000ダルトンの推定分子量と約6.08のpIを有している。
クローンDNA102044の全ヌクレオチド配列は図16(配列番号:20)に示される。クローンDNA102044は、ヌクレオチド位置4−6に見かけの翻訳開始部位を、ヌクレオチド位置505−507に停止コドンを持つ単一のオープンリーディングフレームを含む(図16;配列番号:20)。予想されるポリペプチド前駆体(hIL-1Ra1Sと命名)(図16;配列番号:21)は167アミノ酸長であり、ある種の動物細胞においては成熟配列(翻訳後プロセシングにおいて除かれるシグナル配列を持たないもの)として挙動すると考えられている。また、他の動物細胞は、アミノ酸位置1から約46にわたる配列に含まれる一又は複数のシグナルペプチドを認識し翻訳後プロセシングにおいて除去すると考えられている。
クローンDNA102044(DNA102044−2534と命名)はATCCに寄託され、ATCC寄託番号203855が付与された。図16(配列番号:21)に示された全長hIL-1Ra1Sタンパク質は約18478ダルトンの推定分子量と約5.5のpIを有している。
全長配列(配列番号:21)の配列アラインメント分析に基づき、hIL-1Ra1SはTANGO-77タンパク質の対立遺伝子変異体であると思われ、またhIL-1Raβと有意なアミノ酸配列同一性を示す。また、クローンDNA102044(図16)(配列番号:20)のDNA配列の一部はEST AI014548のDNA配列(図4)(配列番号:8)及びEST AI323258のDNA配列の相補配列(図17)(配列番号:23)と一致することが見出された。
クローンDNA114876(DNA114876−2534と命名)はATCCに寄託され、ATCC寄託番号203973が付与された。図19(配列番号:25)に示された全長hIL-1Ra1Vタンパク質は約24124の推定分子量と約6.1のpIを有している。
全長配列(配列番号:25)の配列アラインメント分析に基づき、hIL-1Ra1VはhIL-1Raβと有意なアミノ酸配列同一性を示す。hIL-1Ra1VはhIL-1Ra1Lの対立遺伝子変異体であると考えられる。
hIL-1Ra1SのIL-18レセプター及びIL-1レセプター結合
hIL-1Ra1Sの特徴付けを容易にするために、クローンDNA102044(図16;配列番号:21)のORFのアミノ酸残基39−167をコードするPCR断片を、ベクターによりコードされるNH2-末端プレプロトリプシンリーダー配列及びFLAGタグとのインフレーム融合体としてpCMV1FLAG(Pan等, Science, 276: 111-113に記載のIBI Kodak)中にクローニングしてプラスミドpCMV1FLAG-IL-1Ra1Sを生成した。プラスミドpCMV1FLAG-IL18R-ECD-Fcを上記の実施例9に記載されているようにして取得した。
ヒト胎児腎臓293細胞を高グルコースDMEM(ジェネンテク社)中で増殖させた。細胞をプレート(100mm)当たり3−4x106で蒔き、リン酸カルシウム沈降法によってpCMV1FLAG-hIL-1Ra1S及びpCMV1FLAG-IL18R-ECD-Fcで同時トランスフェクトした。トランスフェクション後12時間で培地を変えた。得られた培地(それぞれ10ml)を更に70−74時間のインキュベーション後に回収し、遠心分離によって清涼化し、等分し、−70℃で保存した。1.5mlの条件培地からのレセプター-Fcとリガンドの複合体をプロテインG-セファロースで免疫沈降させ、50mMのHepes、pH7.0と150mMのNaClと1mMのEDTAと1%のNP-40とプロテアーゼインヒビターカクテル(BMB)を含むバッファーで3回洗浄し、10−20%のSDS-PAGEゲルで分離した。結合したリガンドを抗FLAGモノクローナル抗体(RMB)を使用して免疫ブロット法により同定した。
免疫ブロットの結果は、分泌されたFLAGhIL-1Ra1S融合タンパク質がIL-18R ECDに結合したことを示している。これらのデータは、hIL-1Ra1SがIL-18Rのアゴニスト又はアンタゴニストでありうることを示している。
hIL-1Ra1V、hIL-1Ra1L及びhIL-1Ra3プロセシング
全長hIL-1Ra1V(図19(配列番号:25)に示したクローンDNA114876のORFのアミノ酸1−218)、全長hIL-1Ra1L(図15(配列番号:19)に示したクローンDNA102043のORFのアミノ酸1−207)、及び全長hIL-1Ra3(図7(配列番号:13)に示したクローンDNA96787のORFのアミノ酸1−155)をコードするcDNAをそれぞれカルボキシ末端FLAG-タグ配列と共にインフレーム融合体としてpRK7発現ベクター中にクローニングした。哺乳類細胞の一過性トランスフェクションのための調製において、CHO DP12細胞をトランスフェクションの前日に成長培地(PS20、5%FBS、1x GHT、1Xpen/strep、1XのL-グルタミン)中にプレート(100mmペトリ皿)当たり4x106細胞で蒔いた。トランスフェクションの日に細胞をPBSで洗浄し、10mlの無血清トランスフェクション培地(PS20、1X GHT)に供給した。DNA-脂質トランスフェクション混合物を、エッペンドルフ型チューブ中に(1)400μlのトランスフェクション培地(PS20,1X GHT);(2)12μgのDNA;(3)10μgのポリ-リシン;及び(4)50μlのドスパーリポソームトランスフェクション試薬(Boehringer Mannheim)を徐々に加えることによって調製した。DNA-脂質混合物を室温で15分間インキュベートし、細胞培養皿に滴下して加えた。細胞を37℃で一晩インキュベートした。トランスフェクション後の日に、細胞をPBSで洗浄し、10mlの無血清生産培地(PS24、10mg/Lインスリン、1X微量元素、1.4mg/L脂質EtOH)を供給し、32℃のインキュベーターに配した。5日後に、発現したタンパク質を含む培地を回収し、遠心分離により清澄化した。各発現タンパク質のペプチド配列の決定のために、発現タンパク質を含む5−10mlの条件培地を、アガロースビードと結合されたモノクローナル抗FLAG抗体(Boehringer Mannheim)と共にインキュベートした。免疫沈降したFLAGタグタンパク質を1%のNP-40バッファー(125mMのNaCl、1mMのEDTA及び50mMのトリス-HCl、pH7.4)で十分に洗浄した。免疫沈殿物をSDSポリアクリルアミドゲルにかけ、ゲル上に分離したポリペプチドをPVDF膜に移し、PVDF膜をクーマシーブルーで染色し、対応するタンパク質バンドを膜から切り取った。アミノ末端タンパク質配列を常法により取得した。
hIL-1Ra3及びmIL-1Ra3ポリペプチドの両方のプロセシングを受けたN末端配列はVLSGALCFRM(配列番号:32)であると決定された。条件培地から回収されたhIL-1Ra3及びmIL-1Ra3材料のおよそ100%がプロセシングを受けたN末端配列を示しており、CHO宿主細胞が、N末端メチオニンを欠き、図7(配列番号:13)のアミノ酸配列のアミノ酸残基2から155と図9(配列番号:16)のアミノ酸配列のアミノ酸残基2から155に対応するプロセシングを受けたN末端配列を示した。
次の材料をアメリカン・タイプ・カルチャー・コレクション, 10801 ユニバーシティ ブルバード,マナッサス,ヴァージニア20110-2209,米国(ATCC)に寄託した:
材料 ATCC寄託番号 寄託日
pSPORT1系プラスミド 203586 1999年1月12日
DNA92929-2534
pCMV-1Flag-pcmv5プラスミド 203587 1999年1月12日
DNA96786-2534
pT7T3D-Pacプラスミド 203588 1999年1月12日
DNA85066-2534
pINCY系プラスミド 203589 1999年1月12日
DNA96787-2534
pT7T3D-Pacプラスミド 203590 1999年1月12日
DNA92505-2534
pRK7系プラスミド 203846 1999年3月16日
DNA102043-2534
pRK7系プラスミド 203855 1999年3月16日
DNA102044-2534
pRK7系プラスミド 203973 1999年4月27日
DNA114876-2534
本出願の譲受人は、寄託した培養物が、適切な条件下で培養されていた場合に死亡もしくは損失又は破壊されたならば、材料は通知時に同一の他のものと即座に取り替えることに同意する。寄託物質の入手可能性は、特許法に従いあらゆる政府の権限下で認められた権利に違反して、本発明を実施するライセンスであるとみなされるものではない。
上記の文書による明細書は、当業者に本発明を実施できるようにするために十分であると考えられる。寄託した態様は、本発明のある側面の一つの説明として意図されており、機能的に等価なあらゆる作成物がこの発明の範囲内にあるため、寄託された作成物により、本発明の範囲が限定されるものではない。ここでの物質の寄託は、ここに含まれる文書による説明が、そのベストモードを含む、本発明の任意の側面の実施を可能にするために不十分であることを認めるものではないし、それが表す特定の例証に対して請求の範囲を制限するものと解釈されるものでもない。実際、ここに示し記載したものに加えて、本発明を様々に改変することは、前記の記載から当業者にとっては明らかなものであり、添付の請求の範囲内に入るものである。
【図1A】 天然配列hIL-1Ra1に関連したヌクレオチド配列(配列番号:1)と誘導したアミノ酸配列(配列番号:2−3)を示す。ヌクレオチド配列(配列番号:1)はヌクレオチド位置181から432にわたると考えられるイントロンを含み、ヌクレオチド位置181から186にスプライス供与部位を持ち、ヌクレオチド位置430から432にスプライス受容部位を持つ。アミノ酸配列(配列番号:2及び3)は、プロセシングを受けた(イントロンのない)コード配列を構成すると考えられるエキソン配列から導かれる。
【図1B】 図1Aの続きの図である。
【図2】 N末端が異種シグナルペプチド(アミノ酸位置1−15)、フラッグペプチドアフィニティハンドル(アミノ酸位置16−23)及びペプチドリンカー(アミノ酸位置24−36)に融合した天然配列hIL-1Ra1ポリペプチドのヌクレオチド配列(配列番号:4)と誘導したアミノ酸配列(配列番号:5)を示す。
【図3】 天然配列hIL-1Ra1ポリペプチドのヌクレオチド配列(配列番号:6)と誘導したアミノ酸配列(配列番号:7)を示す。ヌクレオチド配列(配列番号:6)及び誘導したアミノ酸配列(配列番号:7)は、それぞれ図1のヌクレオチド配列(配列番号:1)とアミノ酸配列(配列番号:2−3)のプロセシングを受けた(イントロンのない)型及び無傷のhIL-1Ra1ポリペプチドを表すと考えられる。コード配列の開始及び停止コドンはそれぞれヌクレオチド位置103−105及び682−684に位置している。推定上のシグナル配列はアミノ酸位置1から14にわたる。推定上のcAMP及びcGMP依存性プロテインキナーゼリン酸化部位はアミノ酸位置33−36に位置している。推定上のN−ミリストイル化部位はアミノ酸位置50−55及び87−92に位置している。
【図4】 EST AI014548に対応するヌクレオチド145−629のヌクレオチド配列(配列番号:8)を示す。
【図5A】 天然配列hIL-1Ra2ポリペプチドのヌクレオチド配列(配列番号:9)と誘導したアミノ酸配列(配列番号:10)を示す。コード配列の開始及び停止コドンはそれぞれヌクレオチド位置96−98及び498−500に位置している。推定上のシグナル配列はアミノ酸位置1−26にわたる。
【図5B】 図5Aの続きの図である。
【図6】 EST1433156のヌクレオチド配列(配列番号:11)を示す。
【図7】 天然配列hIL-1Ra3ポリペプチドのヌクレオチド配列(配列番号:12)と誘導したアミノ酸配列(配列番号:13)を示す。コード配列の開始及び停止コドンはそれぞれヌクレオチド位置1−3及び466−468に位置している。推定上のシグナル配列はアミノ酸位置1−33にわたる。推定上のN−ミリストイル化部位はアミノ酸位置29−34、30−35、60−65、63−68、73−78、91−96及び106−111に位置している。インターロイキン−1様配列はアミノ酸位置111−131に位置している。
【図8】 EST5120028のヌクレオチド配列(配列番号:14)を示す。
【図9A】 天然配列mIL-1Ra3ポリペプチドのヌクレオチド配列(配列番号:15)と誘導したアミノ酸配列(配列番号:16)を示す。コード配列の開始及び停止コドンはそれぞれヌクレオチド位置145−147及び610−612に位置している。推定上のシグナル配列はアミノ酸位置1−33にわたる。推定上のN−ミリストイル化部位はアミノ酸位置29−34、60−65、63−68、91−96及び106−111に位置している。インターロイキン−1様配列はアミノ酸位置111−131に位置している。
【図9B】 図9Aの続きの図である。
【図10】 EST W08205のヌクレオチド配列(配列番号:17)を示す。
【図11】 胎盤組織中でのhIL-1Ra3mRNAの発現と17日齢のマウス胚組織中でのmIL-1Ra3の発現を示すノーザンブロットのオートラジオグラフである。
【図12】 天然配列hIL-1Ra1L(配列番号:19)、hIL-1Ra1V(配列番号:25)、hIL-1Ra1S(配列番号:21)、天然配列hIL-1Ra2(配列番号:10)、hIL-1Ra3(配列番号:13)及びmIL-1Ra3(配列番号:16)ポリペプチドの、分泌性hIL-1Ra(「sIL-1Ra」及び「hIL-1Ra」とも称される)(配列番号:26)、hIL-1Raβ(配列番号:27)及びTANGO−77(配列番号:28)とのアミノ酸配列アラインメントである。
【図13A】 hIL-1Ra1のインターロイキン−18レセプター(IL-18R)結合活性を示すウェスタンブロットである。(およそ22kDのタンパク質バンドを示す)上部パネルでは、FLAGhIL-1Ra1及びFLAGIL-1R−ECD−Fcを含む条件培地(左側レーンに示す)とFLAGhIL-1Ra1及びFLAGIL-18R−ECD−Fcを含む条件培地(右側レーンに示す)がそれぞれプロテインG−セファロースで免疫沈降され、得られた沈殿物がゲル電気泳動法及び抗FLAGモノクローナル抗体でのウェスタンブロット法により分離された。(およそ22kDと85kDのタンパク質バンドを示す)中央及び底部パネルでは、上部パネルで使用されたFLAGhIL-1Ra1及びFLAGIL-1R−ECD−Fc条件培地からの第2のアリコート(左側レーンに示す)と上部パネルで使用されたFLAGhIL-1Ra1及びFLAGIL-18R−ECD−Fc条件培地からの第2のアリコート(右側レーンに示す)がそれぞれ抗FLAGモノクローナル抗体で免疫沈降され、得られた沈殿物がゲル電気泳動法及び抗FLAGモノクローナル抗体でのウェスタンブロット法により分離された。
【図13B】 hIL-1Ra3のIL-1R結合活性を示すウェスタンブロットである。(およそ20kDのタンパク質バンドを示す)上部パネルでは、hIL-1Ra3−FLAG及びFLAGDR6−Fcを含む条件培地(左側レーンに示す)、hIL-1Ra3−FLAG及びFLAGIL-1R−ECD−Fcを含む条件培地(中央レーンに示す)、及びhIL-1Ra3−FLAG及びFLAGIL-18R−ECD−Fcを含む条件培地(右側レーンに示す)がそれぞれプロテインG−セファロースで免疫沈降され、得られた沈殿物がゲル電気泳動法及び抗FLAGモノクローナル抗体でのウェスタンブロット法により分離された。(およそ20kDと85kDのタンパク質バンドを示す)中央及び底部パネルでは、上部パネルで使用されたhIL-1Ra3−FLAG及びFLAGDR6−Fc条件培地からの第2のアリコート(左側レーンに示す)、上部パネルで使用されたhIL-1Ra3−FLAG及びFLAGIL-1R−ECD−Fc条件培地からの第2のアリコート(中央レーンに示す)及び上部パネルで使用されたhIL-1Ra3−FLAG及びFLAGIL-18R−ECD−Fc条件培地からの第2のアリコート(右側レーンに示す)がそれぞれ抗FLAGモノクローナル抗体で免疫沈降され、得られた沈殿物がゲル電気泳動法及び抗FLAGモノクローナル抗体でのウェスタンブロット法により分離された。
【図14】 mIL-1Ra3のインターロイキン−1レセプター(IL-1R)結合活性を示すウェスタンブロットである。(およそ21kDのタンパク質バンドを示す)上部パネルと(およそ85kDのタンパク質バンドを示す)底部パネルでは、条件培地中のFLAGIL-1R−ECD−Fc(左側レーンに示す)と条件培地中のFLAGIL-18R−ECD−Fc(右側レーンに示す)がプロテインG−アガロースで固定され、得られた固相がFLAGmIL-1Ra3を含む条件培地に接触させられ、得られた結合複合体がゲル電気泳動法及び抗FLAGモノクローナル抗体でのウェスタンブロット法により分離された。
【図15】 天然配列hIL-1Ra1Lポリペプチドのヌクレオチド配列(配列番号:18)と誘導したアミノ酸配列(配列番号:19)を示す。コード配列の開始及び停止コドンはそれぞれヌクレオチド位置4−6及び625−627に位置している。推定上のシグナル配列はアミノ酸位置1から34にわたる。推定上のcAMP及びcGMP依存性プロテインキナーゼリン酸化部位はアミノ酸位置47−50に位置している。推定上のN−ミリストイル化部位はアミノ酸位置64−69及び101−106に位置している。
【図16】 天然配列hIL-1Ra1Sポリペプチドのヌクレオチド配列(配列番号:20)と誘導したアミノ酸配列(配列番号:21)を示す。コード配列の開始及び停止コドンはそれぞれヌクレオチド位置4−6及び505−507に位置している。推定上のシグナル配列はアミノ酸位置1から46にわたる。推定上のN−ミリストイル化部位はアミノ酸位置61−66に位置している。
【図17】 相補ヌクレオチド配列(配列番号:22)(上方のストランド)に沿った、EST AI343258(下方のストランド)の一本鎖ヌクレオチド配列(配列番号:23)を示す。
【図18】 天然配列hIL-1Ra1(配列番号:3)、hIL-1Ra1L(配列番号:19)、hIL-1Ra1V(配列番号:25)及びhIL-1Ra1S(配列番号:21)ポリペプチドのアミノ酸配列アラインメントである。
【図19】 天然配列hIL-1Ra1Vポリペプチドのヌクレオチド配列(配列番号:24)と誘導したアミノ酸配列(配列番号:25)を示す。コード配列の開始及び停止コドンはそれぞれヌクレオチド位置73−75及び727−729に位置している。別の開始コドンはヌクレオチド位置106−108に位置している。推定上のシグナル配列はアミノ酸位置1から48にわたる。
Claims (22)
- (1)図3(配列番号:7)の15から193のアミノ酸残基のアミノ酸配列を含んで
なるhIL-1Ra1ポリペプチドをコードするDNA分子;(2)図15(配列番号:
19)の26から207のアミノ酸残基のアミノ酸配列を含んでなるhIL-1Ra1L
ポリペプチドをコードするDNA分子;及び(3)(1)−(2)のDNA分子の何れか
の相補鎖からなる群から選択される単離されたDNA分子。
- (1)図3(配列番号:7)の15から193のアミノ酸残基のアミノ酸配列を含んで
なるhIL-1Ra1ポリペプチドをコードするDNA分子;及び(2)(1)のDNA
分子の相補鎖からなる群から選択される請求項1に記載の単離されたDNA分子。
- (1)図15(配列番号:19)の26から207のアミノ酸残基のアミノ酸配列を含
んでなるhIL-1Ra1LポリペプチドをコードするDNA分子;及び(2)(1)の
DNA分子の相補鎖からなる群から選択される請求項1に記載の単離されたDNA分子。
- (1)図15(配列番号:19)の1から207のアミノ酸残基のアミノ酸配列を含ん
でなるhIL-1Ra1LポリペプチドをコードするDNA分子;及び(2)(1)のD
NA分子の相補鎖からなる群から選択される請求項3に記載の単離されたDNA分子。
- (1)hIL-1Ra1ポリペプチドをコードし、図3(配列番号:6)のセンス鎖の
145から681のヌクレオチド位置の核酸配列を含んでなるDNA分子;(2)hIL
-1Ra1Lポリペプチドをコードし、図15(配列番号:18)のセンス鎖の79から
624のヌクレオチド位置の核酸配列を含んでなるDNA分子;及び(3)(1)−(2
)のDNA分子の何れかの相補鎖からなる群から選択される請求項1に記載の単離された
DNA分子。
- (1)hIL-1Ra1ポリペプチドをコードし、図3(配列番号:6)のセンス鎖の
145から681のヌクレオチド位置の核酸配列を含んでなるDNA分子;及び(2)(
1)のDNA分子の相補鎖からなる群から選択される請求項5に記載の単離されたDNA
分子。
- (1)hIL-1Ra1Lポリペプチドをコードし、図15(配列番号:18)のセン
ス鎖の79から624のヌクレオチド位置の核酸配列を含んでなるDNA分子;及び(2
)(1)のDNA分子の相補鎖からなる群から選択される請求項5に記載の単離されたD
NA分子。
- (1)hIL-1Ra1Lポリペプチドをコードし、図15(配列番号:18)のセン
ス鎖の4から624のヌクレオチド位置の核酸配列を含んでなるDNA分子;及び(2)
(1)のDNA分子の相補鎖からなる群から選択される請求項7に記載の単離されたDN
A分子。
- (1)図3(配列番号:6)のセンス鎖の103から681のヌクレオチド位置の核酸
配列を含んでなるDNA分子;及び(2)(1)のDNA分子の相補鎖からなる群から選
択される請求項6に記載の単離されたDNA分子。
- (a)図3(配列番号:6)のセンス鎖の完全DNA配列;又は(b)(a)の相補鎖
を含んでなる請求項6に記載の単離されたDNA分子。
- (a)(1)ATCC寄託番号203588として寄託された微生物に含まれるベクタ
ーのcDNA挿入物の最長のオープンリーディングフレームによりコードされる全体アミ
ノ酸配列を含んでなるポリペプチド;及び(2)ATCC寄託番号203846として寄
託された微生物に含まれるベクターのcDNA挿入物の最長のオープンリーディングフレ
ームによりコードされる全体アミノ酸配列、又は該配列の34のN末端アミノ酸残基を除
く全体アミノ酸配列を含んでなるポリペプチドからなる群から選択されるポリペプチドを
コードするDNA分子;又は(b)(a)のDNA分子の相補鎖を含んでなる単離された
核酸分子。
- 請求項1に記載のDNA分子を含んでなるベクター。
- ベクターを形質移入した宿主細胞に認識されるコントロール配列に作用可能に連結され
た請求項12に記載のベクター。
- 請求項12に記載のベクターを含んでなる宿主細胞。
- (1)請求項1に記載のDNA分子を含んでなる宿主細胞を、該DNA分子によりコー
ドされるIL-1lpポリペプチドの発現に適した条件下で培養し、及び(2)細胞培養
物から上記IL-1lpポリペプチドを回収する工程を含んでなるIL-1lpポリペプチ
ドを製造する方法。
- 請求項1に記載のDNA分子によりコードされる単離されたIL-1lpポリペプチド
。
- (1)図3(配列番号:7)の15から193のアミノ酸残基を含んでなるhIL-1
Ra1ポリペプチド;及び(2)図15(配列番号:19)の26から207のアミノ酸
残基を含んでなるhIL-1Ra1Lポリペプチドからなる群から選択される単離された
IL-1lpポリペプチド。
- 図15(配列番号:19)の1から207のアミノ酸残基を含んでなるhIL-1Ra
1Lポリペプチドである請求項17に記載の単離されたIL-1lpポリペプチド。
- 請求項11に記載の(a)のDNA分子によりコードされるポリペプチド。
- 異種アミノ酸配列にC末端又はN末端で融合したIL-1lpの天然アミノ酸配列を含
んでなる請求項17に記載のIL-1lpポリペプチド。
- 上記異種アミノ酸配列がエピトープタグ配列である請求項20に記載のIL-1lpポ
リペプチド。
- 上記異種アミノ酸配列が免疫グロブリンのFc領域である請求項20に記載のIL-1
lpポリペプチド。
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US11343098P | 1998-12-23 | 1998-12-23 | |
| US60/113,430 | 1998-12-23 | ||
| US11684399P | 1999-01-22 | 1999-01-22 | |
| US60/116,843 | 1999-01-22 | ||
| US12912299P | 1999-04-13 | 1999-04-13 | |
| US60/129,122 | 1999-04-13 | ||
| PCT/US1999/030720 WO2000039297A2 (en) | 1998-12-23 | 1999-12-22 | Il-1 related polypeptides |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011001700A Division JP2011155971A (ja) | 1998-12-23 | 2011-01-07 | Il−1関連ポリペプチド |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2002533122A JP2002533122A (ja) | 2002-10-08 |
| JP2002533122A5 JP2002533122A5 (ja) | 2007-06-21 |
| JP5456222B2 true JP5456222B2 (ja) | 2014-03-26 |
Family
ID=27381318
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2000591188A Expired - Lifetime JP5456222B2 (ja) | 1998-12-23 | 1999-12-22 | Il−1関連ポリペプチド |
| JP2011001700A Pending JP2011155971A (ja) | 1998-12-23 | 2011-01-07 | Il−1関連ポリペプチド |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011001700A Pending JP2011155971A (ja) | 1998-12-23 | 2011-01-07 | Il−1関連ポリペプチド |
Country Status (7)
| Country | Link |
|---|---|
| US (4) | US20070042466A1 (ja) |
| EP (3) | EP2319929A1 (ja) |
| JP (2) | JP5456222B2 (ja) |
| AU (1) | AU778759B2 (ja) |
| CA (1) | CA2354027A1 (ja) |
| IL (1) | IL143593A0 (ja) |
| WO (1) | WO2000039297A2 (ja) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2317918A1 (en) | 1998-01-09 | 1999-07-15 | Immunex Corporation | Il-1 delta dna and polypeptides |
| US6541623B1 (en) * | 1998-04-03 | 2003-04-01 | Hyseq, Inc. | Interleukin—1 receptor antagonist and uses thereof |
| US7033783B2 (en) | 1998-12-14 | 2006-04-25 | Immunex Corp. | Polynucleotide encoding IL-1 zeta polypeptide |
| CA2378954A1 (en) * | 1999-07-16 | 2001-01-25 | Interleukin Genetics, Inc. | The il-1l1 gene and polypeptide products |
| US7087726B2 (en) | 2001-02-22 | 2006-08-08 | Genentech, Inc. | Anti-interferon-α antibodies |
| WO2004028479A2 (en) * | 2002-09-25 | 2004-04-08 | Genentech, Inc. | Nouvelles compositions et methodes de traitement du psoriasis |
| US20100031378A1 (en) | 2008-08-04 | 2010-02-04 | Edwards Joel A | Novel gene disruptions, compositions and methods relating thereto |
| SG10202001668PA (en) | 2015-07-06 | 2020-04-29 | Immatics Biotechnologies Gmbh | Novel peptides and combination of peptides for use in immunotherapy against esophageal cancer and other cancers |
| PE20211295A1 (es) | 2018-12-21 | 2021-07-20 | 23Andme Inc | Anticuerpos anti il-36 y procedimientos de uso de estos |
Family Cites Families (51)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4179337A (en) | 1973-07-20 | 1979-12-18 | Davis Frank F | Non-immunogenic polypeptides |
| FR2413974A1 (fr) | 1978-01-06 | 1979-08-03 | David Bernard | Sechoir pour feuilles imprimees par serigraphie |
| JPS6023084B2 (ja) | 1979-07-11 | 1985-06-05 | 味の素株式会社 | 代用血液 |
| US4399216A (en) | 1980-02-25 | 1983-08-16 | The Trustees Of Columbia University | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| ZA811368B (en) | 1980-03-24 | 1982-04-28 | Genentech Inc | Bacterial polypedtide expression employing tryptophan promoter-operator |
| NZ201705A (en) | 1981-08-31 | 1986-03-14 | Genentech Inc | Recombinant dna method for production of hepatitis b surface antigen in yeast |
| US4640835A (en) | 1981-10-30 | 1987-02-03 | Nippon Chemiphar Company, Ltd. | Plasminogen activator derivatives |
| US4870009A (en) | 1982-11-22 | 1989-09-26 | The Salk Institute For Biological Studies | Method of obtaining gene product through the generation of transgenic animals |
| AU2353384A (en) | 1983-01-19 | 1984-07-26 | Genentech Inc. | Amplification in eukaryotic host cells |
| US4713339A (en) | 1983-01-19 | 1987-12-15 | Genentech, Inc. | Polycistronic expression vector construction |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US4496689A (en) | 1983-12-27 | 1985-01-29 | Miles Laboratories, Inc. | Covalently attached complex of alpha-1-proteinase inhibitor with a water soluble polymer |
| US4736866B1 (en) | 1984-06-22 | 1988-04-12 | Transgenic non-human mammals | |
| DE3675588D1 (de) | 1985-06-19 | 1990-12-20 | Ajinomoto Kk | Haemoglobin, das an ein poly(alkenylenoxid) gebunden ist. |
| US4676980A (en) | 1985-09-23 | 1987-06-30 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Target specific cross-linked heteroantibodies |
| AU597574B2 (en) | 1986-03-07 | 1990-06-07 | Massachusetts Institute Of Technology | Method for enhancing glycoprotein stability |
| US4791192A (en) | 1986-06-26 | 1988-12-13 | Takeda Chemical Industries, Ltd. | Chemically modified protein with polyethyleneglycol |
| US5010182A (en) | 1987-07-28 | 1991-04-23 | Chiron Corporation | DNA constructs containing a Kluyveromyces alpha factor leader sequence for directing secretion of heterologous polypeptides |
| IL87737A (en) | 1987-09-11 | 1993-08-18 | Genentech Inc | Method for culturing polypeptide factor dependent vertebrate recombinant cells |
| GB8724885D0 (en) | 1987-10-23 | 1987-11-25 | Binns M M | Fowlpox virus promotors |
| KR0154872B1 (ko) | 1987-12-21 | 1998-10-15 | 로버트 에이. 아미테이지 | 발아하는 식물종자의 아크로박테리움 매개된 형질전환 |
| AU4005289A (en) | 1988-08-25 | 1990-03-01 | Smithkline Beecham Corporation | Recombinant saccharomyces |
| GB8823869D0 (en) | 1988-10-12 | 1988-11-16 | Medical Res Council | Production of antibodies |
| US5225538A (en) | 1989-02-23 | 1993-07-06 | Genentech, Inc. | Lymphocyte homing receptor/immunoglobulin fusion proteins |
| FR2646437B1 (fr) | 1989-04-28 | 1991-08-30 | Transgene Sa | Nouvelles sequences d'adn, leur application en tant que sequence codant pour un peptide signal pour la secretion de proteines matures par des levures recombinantes, cassettes d'expression, levures transformees et procede de preparation de proteines correspondant |
| DE69029036T2 (de) | 1989-06-29 | 1997-05-22 | Medarex Inc | Bispezifische reagenzien für die aids-therapie |
| US5633425A (en) | 1990-08-29 | 1997-05-27 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5545806A (en) | 1990-08-29 | 1996-08-13 | Genpharm International, Inc. | Ransgenic non-human animals for producing heterologous antibodies |
| US5625126A (en) | 1990-08-29 | 1997-04-29 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| AU8507191A (en) | 1990-08-29 | 1992-03-30 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5661016A (en) | 1990-08-29 | 1997-08-26 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| US5206161A (en) | 1991-02-01 | 1993-04-27 | Genentech, Inc. | Human plasma carboxypeptidase B |
| CA2102511A1 (en) | 1991-05-14 | 1992-11-15 | Paul J. Higgins | Heteroconjugate antibodies for treatment of hiv infection |
| WO1993008829A1 (en) | 1991-11-04 | 1993-05-13 | The Regents Of The University Of California | Compositions that mediate killing of hiv-infected cells |
| AU8016094A (en) | 1993-10-12 | 1995-05-04 | Mary Lake Polan | Method of contraception |
| US5863769A (en) * | 1997-01-28 | 1999-01-26 | Smithkline Beecham Corporation | DNA encoding interleukin-1 receptor antagonist (IL-1raβ) |
| AU7103198A (en) * | 1997-04-21 | 1998-11-13 | Schering Corporation | Mammalian cytokines; related reagents and methods |
| ES2284214T3 (es) * | 1997-08-04 | 2007-11-01 | Millennium Pharmaceuticals, Inc. | Nuevas moleculas de la familia de las proteinas tango-77 y usos de las mismas. |
| CA2317918A1 (en) * | 1998-01-09 | 1999-07-15 | Immunex Corporation | Il-1 delta dna and polypeptides |
| US6294655B1 (en) | 1998-04-03 | 2001-09-25 | Hyseq, Inc. | Anti-interleukin-1 receptor antagonist antibodies and uses thereof |
| JP2002510492A (ja) * | 1998-04-03 | 2002-04-09 | ハイセック,インコーポレーテッド | インターロイキン−1レセプターアンタゴニストおよびその使用 |
| WO2000008045A2 (en) | 1998-08-07 | 2000-02-17 | Millennium Pharmaceuticals, Inc. | Novel molecules of the tango-93-related protein family and uses thereof |
| WO2000017363A2 (en) * | 1998-09-18 | 2000-03-30 | Schering Corporation | Interleukin-1 like molecule: interleukin-1-zeta; nucleic acids, polypeptides, antibodies, their uses |
| US6680380B1 (en) * | 1998-09-18 | 2004-01-20 | Schering Corporation | Nucleic acids encoding mammalian interleukin-1ζ, related reagents and methods |
| WO2000020595A1 (en) * | 1998-10-08 | 2000-04-13 | Zymogenetics, Inc. | Interleukin-1 homolog |
| ES2249040T3 (es) * | 1998-10-27 | 2006-03-16 | Zymogenetics, Inc. | Homologo de interleuquina-1 zil1a4. |
| CA2353483C (en) * | 1998-12-14 | 2009-01-27 | Immunex Corporation | Il-1 zeta, il-1 zeta splice variants and xrec2 dnas and polypeptides |
| US7033783B2 (en) * | 1998-12-14 | 2006-04-25 | Immunex Corp. | Polynucleotide encoding IL-1 zeta polypeptide |
| ES2314521T3 (es) * | 1999-03-23 | 2009-03-16 | Genentech, Inc. | Polipeptidos secretados y transmembrana y acidos nucleicos que los codifican. |
| WO2001040247A1 (en) | 1999-12-01 | 2001-06-07 | Smithkline Beecham Corporation | Interleukin-1 homologue, mat il-1h4 |
| CA2395417A1 (en) | 1999-12-10 | 2001-06-14 | Amgen Inc. | Interleukin-1 receptor antagonist-related molecules and uses thereof |
-
1999
- 1999-12-22 JP JP2000591188A patent/JP5456222B2/ja not_active Expired - Lifetime
- 1999-12-22 EP EP10183813A patent/EP2319929A1/en not_active Withdrawn
- 1999-12-22 CA CA002354027A patent/CA2354027A1/en not_active Abandoned
- 1999-12-22 WO PCT/US1999/030720 patent/WO2000039297A2/en active IP Right Grant
- 1999-12-22 EP EP10183614A patent/EP2330198A1/en not_active Withdrawn
- 1999-12-22 IL IL14359399A patent/IL143593A0/xx unknown
- 1999-12-22 AU AU25935/00A patent/AU778759B2/en not_active Ceased
- 1999-12-22 EP EP99968539A patent/EP1141299A2/en not_active Withdrawn
-
2006
- 2006-10-10 US US11/548,249 patent/US20070042466A1/en not_active Abandoned
-
2009
- 2009-06-30 US US12/495,633 patent/US8628777B2/en not_active Expired - Fee Related
- 2009-07-01 US US12/496,197 patent/US7951916B2/en not_active Expired - Fee Related
- 2009-07-01 US US12/496,363 patent/US20090269811A1/en not_active Abandoned
-
2011
- 2011-01-07 JP JP2011001700A patent/JP2011155971A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US20090269811A1 (en) | 2009-10-29 |
| US20070042466A1 (en) | 2007-02-22 |
| US20090270595A1 (en) | 2009-10-29 |
| CA2354027A1 (en) | 2000-07-06 |
| JP2011155971A (ja) | 2011-08-18 |
| US20090304701A1 (en) | 2009-12-10 |
| IL143593A0 (en) | 2002-04-21 |
| AU2593500A (en) | 2000-07-31 |
| JP2002533122A (ja) | 2002-10-08 |
| WO2000039297A3 (en) | 2001-02-22 |
| AU778759B2 (en) | 2004-12-16 |
| EP2319929A1 (en) | 2011-05-11 |
| EP2330198A1 (en) | 2011-06-08 |
| EP1141299A2 (en) | 2001-10-10 |
| US8628777B2 (en) | 2014-01-14 |
| WO2000039297A2 (en) | 2000-07-06 |
| US7951916B2 (en) | 2011-05-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3577586B2 (ja) | Il−17相同的ポリペプチドとその治療用途 | |
| US6299877B1 (en) | Type I interferons | |
| JP2011155971A (ja) | Il−1関連ポリペプチド | |
| JP4602954B2 (ja) | インターロイキン−22ポリペプチド及びそれに結合する抗体の使用 | |
| JP2010046065A (ja) | インターロイキン−8と相同なポリペプチドとその治療用途 | |
| JP2002533122A5 (ja) | ||
| JP4931310B2 (ja) | ヘルパーt細胞性疾患の治療のためのt細胞分化の調節 | |
| JP2009219492A (ja) | Gdnfrと配列類似性を有する新規ポリペプチド及びこれをコードする核酸 | |
| JP2005519590A (ja) | 免疫関連疾患の治療のための組成物及び方法 | |
| KR20010085816A (ko) | 면역 관련 질환 치료용 조성물 및 치료 방법 | |
| JP3886899B2 (ja) | インターロイキン−22ポリペプチド、それをコードする核酸並びに膵臓疾患の治療方法 | |
| JP2007537691A (ja) | 免疫不全の治療のための新規組成物と方法 | |
| JP4166254B2 (ja) | ボールカインポリペプチド及び核酸 | |
| US6967245B2 (en) | Ucp5 | |
| US7342102B2 (en) | Uncoupling protein 5 (UCP5) | |
| JP2005502317A (ja) | ボールカインポリペプチド及び核酸 | |
| US20040215007A1 (en) | Novel secreted proteins and their uses | |
| WO2000017353A1 (en) | Ucp4 | |
| JP2002533062A5 (ja) |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20061213 |
|
| A524 | Written submission of copy of amendment under article 19 pct |
Free format text: JAPANESE INTERMEDIATE CODE: A524 Effective date: 20070426 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20091110 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20100209 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20100217 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20100310 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20100317 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20100409 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20100416 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100510 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20100907 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110107 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20110118 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20121002 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20121009 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20121105 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20121108 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20121203 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20121206 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20131114 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20140108 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 Ref document number: 5456222 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| EXPY | Cancellation because of completion of term |