JP5031416B2 - 検索方法および検索装置 - Google Patents
検索方法および検索装置 Download PDFInfo
- Publication number
- JP5031416B2 JP5031416B2 JP2007072634A JP2007072634A JP5031416B2 JP 5031416 B2 JP5031416 B2 JP 5031416B2 JP 2007072634 A JP2007072634 A JP 2007072634A JP 2007072634 A JP2007072634 A JP 2007072634A JP 5031416 B2 JP5031416 B2 JP 5031416B2
- Authority
- JP
- Japan
- Prior art keywords
- knowledge
- content
- search
- character string
- attribute
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images























Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
一方、知識や情報が「ヒト」「モノ」「カネ」と同様に組織活動における重要な基盤であるとの認識から、オフィス内に存在する文書やコンテンツ、あるいは個別に発信するメールといった電子的コミュニケーション手段などから得られる知識を資産と捉え、これを効率的に蓄積し、ユーザの目的に合わせて迅速かつ的確に知識を持つ人の情報を提供する(以下、Know‐Who検索と呼ぶ)ための手法が考えられている。
ユーザが作成した文書やユーザ間の会話からユーザの知識を抽出する方法としては、例えば、下記特許文献1に開示されている技術(以下、従来技術1という。)が知られている。
従来技術1では、あるユーザが作成した複数の文書に重複する文書特徴を見つけ出すことで、当該ユーザの仕事特徴を抽出し、抽出された仕事特徴によってユーザの知識を表現する。さらに前記文書特徴の抽出処理において、一般的な文書の文書特徴量を前もって保持しておき、見つけ出された文書特徴との差をとることによって文書特徴を抽出することもできる。
従来技術2では、複数のユーザが送受信を行ったメッセージ情報の各々に対して複数のユーザが行った操作、すなわち「作成」、「閲覧」、「返信」、「転送」、「削除」などの履歴と、メッセージ情報の内容を解析することで得るメッセージ情報間の内容の類似度とに基づいて、各メッセージ間における関係の強さを抽出する。
そして抽出された関係の強さにより、より多くのメッセージと強い関係を持つメッセージを、より価値のある知識を含むものとして特定する。さらに、任意の語によるメッセージ検索機能を備え、所望の知識に関連する語を検索条件に指定してメッセージ検索を行えば、指定した語を含むメッセージとそれに強い関係を持つ別のメッセージの両方を検索結果に得ることができ、得られるメッセージへの操作履歴を持つユーザを、所望の知識にかかわりを持つユーザとして特定できる。
例えば、あるシステムXを構築する組織Aの担当者が発注元の組織Bの担当者にシステム設計内容について説明した上で関連文書を郵送した旨のメールを送信し、組織Aの担当者が記述したメール内容を全文引用した上で、組織Bの担当者から郵便物が届いた旨のメールが届いたとする。この場合、組織Aの担当者はシステムXの知識を保有しているものと考えられるが、組織Bの担当者が現時点でシステムXの知識を保有しているとは考えにくい。しかし、従来技術2の方式では、組織Bの担当者も同等程度の知識を保有しているものとして提示されることになる。
従来技術1では、ユーザが所属する特定のグループ、すなわちユーザが職務上所属する特定の組織や事業所などの中において、相対的に特徴付けられるような文書特徴、並びに仕事特徴を抽出するためには、前記特定のグループにおいて一般的な文書の文書特徴量を前もって抽出し保持しておく必要があった。
従来技術2では、発信した各々のメッセージに対し、内容の関連度を抽出する仕組みは存在するが、メッセージの関係をまたがって、発信した人を中心としてメッセージの内容の解析をするような仕組みは存在しない。そのため、従来技術2では、ある内容に関連したトピックを追跡することはできるが、特定の知識を保有する人を検索するためには、実際にはシステムより提示された関連するメールなどの一覧およびその内容を全て確認し、本当に知識のある人は誰なのかを人手で探し出す作業が必要となった。
本発明は、前記従来技術の問題点を解決するためになされたものであり、本発明の目的は、メールやWeb上のコンテンツに対し、それらの利用傾向から個人の知識情報を算出し、検索に利用することができる高速かつ高精度なKnow−Who検索を実現することにある。
本発明の前記ならびにその他の目的と新規な特徴は、本明細書の記述及び添付図面によって明らかにする。
上記課題を解決するため、本発明では、(1)メールやWeb上のコンテンツ中に含まれる特徴文字列を抽出する部分文字列抽出ステップと、(2)抽出した特徴文字列をもとにメールやWeb上のコンテンツの作成者が含まれる成員の集合における特徴文字列の出現頻度情報を比較することにより作成した個人の知識属性を抽出する知識属性抽出ステップと、(3)抽出した知識属性の集合をもとに作成者のプロファイルデータを形成するプロファイル作成ステップと、(4)プロファイルデータを用いてKnow−Who検索者が指定した知識を持つ人物の有識度を算出する有識度算出ステップと、(5)算出された有識度を用いて検索結果を表示する検索結果表示ステップを有する。
特に、本発明においては、上記従来技術1における課題は前記(2)のステップにおいて、作成者の業務における特徴文字列の出現頻度を、作成者を含む成員の集合における特徴文字列の出現頻度と比較するステップを有することにより解決が可能となる。また、従来技術2における課題は前記(2)から(4)のステップにおいて、作成した個人の知識属性情報として各特徴文字列とその出現傾向を分析および蓄積するステップを有することにより解決が可能である。
本発明によれば、メールやWeb上のコンテンツに対し、それらの利用傾向から個人の知識情報を算出し、検索に利用することができる高速かつ高精度なKnow−Who検索を実現することが可能となる。
なお、実施例を説明するための全図において、同一機能を有するものは同一符号を付け、その繰り返しの説明は省略する。
[実施例1]
はじめに、本発明の実施例1におけるシステムの全体構成について説明する。
図1は、本実施例におけるシステムの全体構成を示す図である。本実施例は、知識情報登録サブシステム10、知識情報検索サーバ11、メールサーバ12、Webサーバ13、コンテンツ受信サーバ14、知識情報検索クライアント20、メールクライアント21、Webクライアント22、コンテンツ配信クライアント23およびネットワーク180から構成される。
知識情報登録サブシステム10は、ネットワーク180上に流通するコンテンツを捕捉し、捕捉されたコンテンツを解析し、検索時に必要となるプロファイルデータを作成する。このプロファイルデータは、ネットワーク180を介して知識情報検索サーバ11に転送され、後に知識情報検索サーバ11が検索処理を行なう際に用いられる。
知識情報検索サーバ11は、知識情報検索クライアント20からの検索コマンドを受け取り、知識情報登録サブシステム10が作成したプロファイルデータを用いて検索コマンドの指定する条件に適合する知識情報の検索を行ない、検索結果データを要求元の知識情報検索クライアント20に送り返す。
知識情報検索クライアント20は、ユーザが対話的に検索条件を指定する為の画面をディスプレイ150上に表示し、この画面上でユーザが指定した検索条件を、知識情報検索サーバ11にとって解釈可能なコマンドの形に変換し、この検索コマンドをネットワーク180を介して知識情報検索サーバ11に送信する。前述した通り、知識情報検索サーバ11が検索コマンドに対応する処理を行い、検索結果データを送り返してくると、知識情報検索クライアント20は受け取った検索結果データを画面に表示してユーザに提示する。なお、図1では1台のコンピュータを知識情報検索クライアント20として使用する構成例を示したが、知識情報検索クライアントを2台以上とする構成をとることもできる。
メールクライアント21は、電子メールの作成や送受信、受信したメールの保存・管理を行うソフトウェアを搭載したコンピュータである。メールクライアントについてはすでに公知であるため、ここでは言及しない。なお、図1では1台のコンピュータをメールクライアント21として使用する構成例を示したが、メールクライアント21を2台以上とする構成をとることもできる。
Webサーバ13は、WWWシステムにおける情報送信を行うコンピュータである。Webサーバについてはすでに公知であるため、ここでは言及しない。なお、図1では1台のコンピュータをWebサーバ13として使用する構成例を示したが、Webサーバを2台以上とする構成をとることもできる。
Webクライアント22は、WebブラウザなどWWWシステム上の情報を表示するためのクライアントソフトウェアを搭載したコンピュータである。Webクライアントについてはすでに公知であるため、ここでは言及しない。なお、図1では1台のコンピュータをWebクライアント22として使用する構成例を示したが、Webクライアントを2台以上とする構成をとることもできる。
コンテンツ配信クライアント23は、コンテンツを配信するためのコンピュータである。コンテンツ配信クライアントについてはすでに公知であるため、ここでは言及しない。なお、図1では1台のコンピュータをコンテンツ配信クライアント23として使用する構成例を示したが、コンテンツ配信クライアントを2台以上とする構成をとることもできる。
また、図1では、知識情報登録サブシステム10、メールサーバ12、Webサーバ13およびコンテンツ受信サーバ14を別個のコンピュータを使用する構成としたが、これらのシステムを組み合せて同一のコンピュータ上で実行する構成をとることもできる。また、図1では、知識情報検索クライアント20、メールクライアント21、Webクライアント22、コンテンツ配信クライアント23を別個のコンピュータを使用するものとしたが、これらのシステムを組み合せて同一のコンピュータ上で実行する構成をとることもできる。
以上が、本実施例におけるシステムの全体構成についての説明である。
知識情報登録サブシステム10は、ディスプレイ150、キーボードやマウスなどの入力装置160、主メモリ100、磁気ディスク装置200、通信制御装置170、システムバスおよび中央演算装置など一般的なコンピュータの構成をとる。
ディスプレイ150は、本サブシステムにおける処理の実行状況を表示するために使用する。入力装置160は、知識情報登録処理の実行などを指示するコマンドを入力するために使用する。主メモリ100は、本サブシステムによる処理を行うための各種プログラムおよび一時的なデータを保持するために使用する。磁気ディスク装置200は、本サブシステムが作成するインデックスファイル、知識属性テーブル、プロファイルテーブルを格納するために使用する。通信制御装置170は、ネットワーク180を介して知識情報検索サーバ11と通信し、知識情報登録あるいは知識情報検索に関するリクエストおよびデータの送受信を行うために使用する。
主メモリ100中には、システム制御プログラム1001、知識情報登録制御プログラム1002、特徴文字列抽出プログラム1003、知識属性算出プログラム1004、プロファイル作成プログラム1005が格納されると共にワークエリアが確保される。これらのプログラムは、フロッピーディスクや光磁気ディスクなどの可搬型媒体に格納され、ここから読み出し、磁気ディスク装置200へインストールする。本サブシステム起動時に、システム制御プログラム1001が起動し、これらのプログラムを磁気ディスク装置200から読み出し、主メモリ100へ格納する。
磁気ディスク装置200中には、インデックスファイル格納領域2001、知識属性テーブル格納領域2002、プロファイルテーブル格納領域2003および各種プログラム格納領域が確保される。
知識情報登録制御プログラム1002は、特徴文字列抽出プログラム1003、知識属性算出プログラム1004、プロファイル作成プログラム1005の起動および実行制御を行うと共に、これらのプログラムによって生成されたプロファイルテーブル格納領域2003に格納されているプロファイルテーブルをネットワーク180を介して前記知識情報検索サーバ11に転送する。
特徴文字列抽出プログラム1003は、メールクライアント21などから配信されたネットワーク180上に流通するコンテンツの内容から特徴的な部分文字列(以下、特徴文字列)を抽出し、コンテンツに付随する各種属性データと抽出した特徴文字列を元にインデックスデータを生成する。生成したインデックスデータをインデックスファイル格納領域2001に格納されているインデックステーブルに登録し、インデックステーブルを更新する。
知識属性算出プログラム1004は、前記特徴文字列抽出プログラム1003にて更新されたインデックステーブルを元に、特徴文字列に対して各々重み付けを行ない、知識属性テーブル格納領域2002に格納されている知識属性テーブルに登録し、知識属性テーブルを更新する。
プロファイル作成プログラム1005は、前記知識属性算出プログラム1004にて更新された知識属性テーブル格納領域2002に格納されている知識属性テーブルを元に、ユーザ毎の知識属性値を算出する。算出した知識属性値をプロファイルテーブル格納領域2003に格納されているプロファイルテーブルに登録し、プロファイルテーブルを更新する。
なお、本実施例ではネットワーク180上に流通するコンテンツを知識情報の登録対象とする構成としたが、フロッピーディスク、光磁気ディスク、追記型光ディスクなど可搬型媒体からコンテンツを読み込む構成を取ることもできる。さらに、メールサーバ12、Webサーバ13、コンテンツ受信サーバ14にすでに存在するコンテンツをネットワーク180を介して読み込む構成を取ることもできる。以上が、本実施例における知識情報登録サブシステムのシステム構成に関する説明である。
入力装置160からの登録指示コマンド等により、知識情報登録制御プログラム1002が起動されると、本プログラムはまずネットワーク180を観測し、ネットワーク上に流通するコンテンツを捕捉する。コンテンツを捕捉すると、すべてのコンテンツに対し、以下に示すステップA2からステップA6までの処理を繰り返し実行する(ステップA1)。
ステップA2では、捕捉したコンテンツに対してコンテンツ識別子を割り当て、ワークエリアへ格納する。なお、コンテンツ識別子はコンテンツデータベース中で特定のコンテンツを一意に識別する番号である。
ステップA3では、ワークエリアに格納されたコンテンツを入力とし、特徴文字列抽出プログラム1003を実行する。特徴文字列抽出プログラム1003は、コンテンツから特徴文字列とその特徴文字列の出現頻度を抽出する。特徴文字列の抽出方法は、形態素解析の手法やテキスト中に含まれる単語ベクトルの類似度に基づいたベクトル空間モデル、あるいは、前述の特許文献3で公開されている技術を用いても構わない。
次に、ステップA4では、ステップA3にて抽出された特徴文字列とその出現頻度、コンテンツ識別子、作成者、作成日付などのコンテンツの属性を元にインデックスデータを作成する。さらに、作成したインデックスデータをインデックスファイル格納領域2001に格納されているインデックステーブル20010に登録し、インデックステーブル20010を更新する。このステップA2からステップA4が図2におけるプロセス10030に相当する。
ステップA6では、ステップA5において更新された知識属性テーブル20020を入力としてプロファイル作成プログラム1005を実行する。プロファイル作成プログラム1005では、ユーザ毎の知識属性テーブルの重み値と全コンテンツにおける知識属性テーブル20020を比較することにより、ユーザ毎の特徴文字列とその知識属性の値を算出し、プロファイル更新データを生成する。生成したプロファイル更新データをプロファイルテーブル格納領域2003に登録し、プロファイルテーブルを更新する。なお、本ステップにおけるプロファイル作成プログラム1005の詳細な説明は後述する。このステップA6が図2におけるプロセス10050に相当する。
すべての登録対象コンテンツに対し、上記ステップA2からステップA6までに示す一連の処理が終了すると、知識情報登録制御プログラム1002は、ステップA7を実行して終了する。ステップA7では、プロファイルテーブル格納領域2003に格納されたすべてのプロファイルテーブルを、ネットワーク180を介して知識情報検索サーバ11に転送する。以上が、本実施例における知識情報登録処理の動作手順の概要である。
まずは、ステップA5の詳細について説明する。図3は、ステップA5の詳細、すなわち本実施例における知識属性算出プログラム1004の処理手順を示す図である。
知識属性算出プログラム1004は、インデックステーブルを入力として起動されると、まず、ステップ1051において、インデックステーブルから現時点での特徴文字列の出現情報および出現頻度を読み出す。
ステップ1052では、読み出したインデックステーブル中に存在するすべての特徴文字列の出現情報とその出現頻度を知識属性更新データとして生成する。生成した知識属性更新データと知識属性テーブル格納領域2002に格納されている全成員を母集団としたコンテンツ集合における知識属性テーブルを照合し、知識属性更新データと知識属性テーブルに差異がみられる場合には知識属性テーブルを更新する。
ステップ1053では、全成員を母集団としたコンテンツ集合に対応する各特徴文字列の重み値を再計算する。重み値の算出方法は、各特徴文字列の出現頻度に対し全成員を母集団とした場合におけるコンテンツの登録数で割った1コンテンツあたりの特徴文字列出現頻度平均値を用いてもよいし、前述の特許文献3に公開されている方式を用いてもよい。この重み値の算出方法については、すでに公知であるため、詳細については言及しない。
ステップ1054では、前記ステップ1053にて算出した各特徴文字列の重み値を元に、全成員を母集団としたコンテンツ集合における知識属性テーブルの重み値を更新する。
ステップ1056では、更新すべきユーザに対し、読み出したインデックステーブル中に存在する該ユーザの特徴文字列の出現情報とその出現頻度を知識属性更新データとして生成する。生成した知識属性更新データと知識属性テーブル格納領域2002に格納されている該ユーザを対象としたコンテンツ集合における知識属性テーブルを照合し、知識属性更新データと知識属性テーブルに差異がみられる場合には知識属性テーブルを更新する。
ステップ1057では、更新すべきユーザを対象としたコンテンツ集合に対応する各特徴文字列の重み値を再計算する。重み値の算出方法は、ステップ1053にて採用した方式と同じものを採用する。
ステップ1058では、前記ステップ1057にて算出した各特徴文字列の重み値を元に、更新すべきユーザを対象としたコンテンツ集合における知識属性テーブルの重み値を更新する。ステップ1058が終了すると、ステップ1055に戻り、処理を継続する。
以上、知識属性算出プログラム1004、すなわち、知識情報検索手段におけるステップA5の詳細についての説明である。
プロファイル作成プログラム1005は、知識属性テーブルを入力として起動されると、まず、ステップ1061において、知識属性テーブルから各ユーザの特徴文字列の出現情報およびその重み値を読み出す。
ステップ1062では、読み出した各ユーザの知識属性テーブルに対し、プロファイルテーブルを更新すべきかどうかを判定する。もし、更新すべきユーザであるならば、以下に示すステップ1063からステップ1065までの処理を実行する。もし、更新すべきユーザではない、あるいは、更新すべきすべてのユーザについて以下に示すステップ1063からステップ1065までの処理が終了した場合は、プロファイル作成プログラム1005を終了する。
ステップ1063では、該ユーザの知識属性テーブルに存在する各特徴文字列の重み値に対し、全成員を母集団としたコンテンツ集合における知識属性テーブルにおける当該特徴文字列の重み値との差分を算出する。この差分の値が該ユーザにおける当該特徴文字列の傾向を示す値となる。算出した各特徴文字列における傾向値をワークエリアに格納する。
ステップ1064では、まず、全成員を母集団としたコンテンツ集合に対するユーザが作成したコンテンツ集合の占有率を算出する。算出した占有率とワークエリアに格納されている各特徴文字列における傾向値を乗算することにより、ユーザの当該特徴文字列における知識属性を示す値を算出する。算出した各特徴文字列における知識属性値をワークエリアに格納する。
ステップ1065では、ワークエリアに格納されている各特徴文字列とその知識属性値を読み出し、プロファイルテーブル格納領域2003に格納されている該ユーザのプロファイルテーブルを更新する。ステップ1065が終了すると、ステップ1062に戻り、処理を継続する。
以上、プロファイル作成プログラム1005、すなわち、知識情報検索手段におけるステップA6の詳細についての説明である。
以上が、本発明の実施例における知識情報登録サブシステム10についての説明である。
まず、本発明の実施例における知識情報検索サーバ11のシステム構成について説明する。知識情報検索サーバ11は、ディスプレイ150、キーボードやマウスなどの入力装置160、主メモリ100、磁気ディスク装置200、通信制御装置170、システムバスおよび中央演算装置など一般的なコンピュータの構成をとる。
ディスプレイ150は、本検索サーバの稼動状況を表示するために使用する。入力装置160は、本検索サーバの起動・停止などを指示するコマンドを入力するために使用する。主メモリ100は、本検索サーバによる処理を行うための各種プログラムおよび一時的なデータを保持するために使用する。磁気ディスク装置200は、本検索サーバが使用するインデックスファイルなどを格納するために使用する。通信制御装置170は、ネットワーク180を介して前記知識情報登録サブシステム10および知識情報検索クライアント20と通信し、知識情報登録あるいは知識情報検索に関するリクエストおよびデータの送受信を行うために使用する。
主メモリ100中には、システム制御プログラム1001、知識情報検索制御プログラム1010、検索条件式解析プログラム1011、有識度算出プログラム1012、検索結果取得プログラム1013が格納されると共にワークエリアが確保される。これらのプログラムは、フロッピーディスクや光磁気ディスクなどの可搬型媒体に格納され、ここから読み出し、磁気ディスク装置200へインストールする。本検索サーバ起動時に、システム制御プログラム1001が起動し、これらのプログラムを磁気ディスク装置200から読み出し、主メモリ100へ格納する。
磁気ディスク装置200中には、プロファイルテーブル格納領域2003および各種プログラム格納領域が確保される。
知識情報検索制御プログラム1010は、検索条件式解析プログラム1011、有識度算出プログラム1012、検索結果取得プログラム1013の起動および実行制御を行うと共に、ネットワーク180を介して、知識情報登録サブシステム10および知識情報検索クライアント20との間で知識情報登録または知識情報検索に関するリクエストおよびデータの送受信を行う。
検索条件式解析プログラム1011は、知識情報検索クライアント20から受信した検索リクエスト中に含まれる検索条件式を解析し、有識度算出プログラム1012によって直接検索可能な条件指定に翻訳する。
有識度算出プログラム1012は、検索条件式解析プログラム1011によって翻訳された条件指定に従って、プロファイルテーブル格納領域2003に格納されているプロファイルテーブルを検索し、得られた検索結果データをワークエリアに格納する。
検索結果取得プログラム1013は、有識度算出プログラム1012によって取得された検索結果データを有識度の降順にソートし、この情報を要求元の検索クライアントに転送する。
以上が、本実施例における知識情報検索サーバ11のシステム構成に関する説明である。
入力装置160からのサーバ起動コマンド等により、知識情報検索制御プログラム1010が起動されると、本プログラムは、サーバとして、知識情報登録サブシステム10および知識情報検索クライアント20からリクエストを受信してはその処理を行なうループ(ステップB1)に入る。このループは入力装置160からサーバの停止を指示するコマンドが入力されるまで継続する。
ステップB1のループは、知識情報登録サブシステム10および知識情報検索クライアント20から知識情報登録あるいは知識情報検索に関するリクエストを受信する処理(ステップB2)と、受信したリクエストの種別を判定し、該種別に対応する処理に分岐する処理(ステップB3)を繰り返す。
ステップB3では、受信したリクエストの種別を判定し、該リクエストが知識情報登録サブシステムから送信されたデータベース更新リクエストであった場合、ステップB4の処理に分岐する。また、前記リクエストが知識情報検索クライアント20から送信された検索リクエスト(特定の検索条件を満たす知識情報群の検索を求めるリクエスト)であった場合、ステップB5、ステップB6、ステップB7、ステップB8からなる処理に分岐する。また、前記リクエストが知識情報検索クライアント20から送信された検索結果問合せリクエスト(特定の検索処理の結果を問合せるリクエスト)であった場合、ステップB9の処理に分岐する。分岐先の処理が終了した後は、再びステップB1に戻ってループを継続する。
ステップB5では、検索条件式解析プログラム1011を実行し、検索リクエスト中で指定された検索条件を解析し、該検索条件を有識度算出プログラム1012にて直接処理可能な条件指定に変換する。このステップB5が図5におけるプロセス10110に相当する。
次に、ステップB6では、ステップB5にて生成された条件指定を入力として、有識度算出プログラム1012を実行し、プロファイルテーブルに対し、該検索条件を満たす有識者を検索する。なお、有識者の有識度はプロファイルテーブル上の条件指定に対応する知識属性値を参照することで有識度を算出する。このステップB6が図5におけるプロセス10120に相当する。
次に、ステップB7では、検索結果取得プログラム1013を実行し、有識度算出プログラム1012にて算出された有識度の降順に有識者をソートし、この有識者リストと共に各有識者に対応した有識度といった情報をまとめた検索結果データをワークエリアに格納する。このステップB7が図5におけるプロセス10130に相当する。
次に、ステップB8では、検索結果データ集合を要求元の検索クライアントに返送する。
ステップB9では、問合せの内容に応じて前記ステップB7にて求めた検索結果データの一部もしくは全体をワークエリアから抽出し、要求元の検索クライアントに返送する。
以上が本実施例における知識情報検索処理の動作手順であり、本実施例における知識情報検索サーバ11の説明である。
ディスプレイ150は、ユーザが対話的に検索条件を入力するための画面や検索結果などを表示するために使用する。入力装置160は、検索条件の入力や検索処理の実行などを指示するコマンドを入力するために使用する。主メモリ100は、本検索クライアントによる処理を行うための各種プログラムおよび一時的なデータを保持するために使用する。磁気ディスク装置200は、検索結果として得られたデータおよびその他のデータやプログラムなどを格納するために使用する。通信制御装置170は、ネットワーク180を介して前記知識情報検索サーバ11と通信し、知識情報検索に関するリクエストおよびデータの送受信を行うために使用する。
主メモリ100中には、システム制御プログラム1001、知識情報検索入出力制御プログラム1020、検索条件入力プログラム1021、検索結果表示プログラム1022が格納されると共にワークエリアが確保される。これらのプログラムは、フロッピーディスクや光磁気ディスクなどの可搬型媒体に格納され、ここから読み出し、磁気ディスク装置200へインストールする。本検索クライアント起動時に、システム制御プログラム1001が起動し、これらのプログラムを磁気ディスク装置200から読み出し、主メモリ100へ格納する。
システム制御プログラム1001は、周辺機器との間のデータの入出力など、コンピュータ上で本検索クライアントを構成する各種プログラムを実行するための基本機能を提供する。
知識情報検索入出力制御プログラム1020は、検索条件入力プログラム1021、検索結果表示プログラム1022の起動および実行制御を行うと共に、ネットワーク180を介して、知識情報検索サーバ11との間で知識情報検索に関するリクエストおよびデータの送受信を行う。
検索条件入力プログラム1021は、ユーザと対話しつつ検索条件の入力および解釈を行なう。
検索結果表示プログラム1022は、知識情報検索サーバ11から受け取った検索結果の表示を行なう。
なお、本検索クライアントにプリンタを接続し、検索結果を印刷するようなシステム構成をとることもできる。
以上が、本実施例における知識情報検索クライアントのシステム構成に関する説明である。
入力装置160からのクライアント起動コマンド等により、知識情報検索入出力制御プログラム1020が起動されると、本プログラムはユーザから検索を指示するコマンドを受け取ってはその処理を行なうループに入る(ステップC1)。このループは、入力装置160からクライアントの停止を指示するコマンドが入力されるまで継続する。
ステップC1のループは、以下に示すステップC2からステップC8までの処理を繰り返す。
ステップC2では、ユーザが対話的に検索条件を入力するための画面を表示する。
ステップC3では、検索条件入力プログラム1021を実行し、ユーザとの対話により検索条件を入力し、知識情報検索サーバ11が解釈可能な検索リクエストに変換する。
ステップC4では、ネットワーク180を介し、変換した検索リクエストを知識情報検索サーバ11に送信する。このステップC2からステップC4までの処理が図5におけるプロセス10210に相当する。
ステップC5では、前記検索リクエストの返送として検索結果データ集合が返されるのを待ち、検索結果データ集合を受信する。
ステップC6では、受信した検索結果データ集合を入力として検索結果表示プログラム1022を起動し、ユーザと対話しつつ検索結果データの問合せおよび画面表示を行なう。このステップC5とステップC6が図5におけるプロセス10220に相当する。
以上、本実施例における知識情報検索クライアントの動作手順の概要である。
検索結果表示プログラム1022は、知識情報検索入出力制御プログラム1020から起動されると、直ちにステップD1のループに入る。該ループは、ユーザから検索結果表示の終了を指示するコマンドを入力されるまで、以下に示すステップD2からステップD9までに示す処理を繰り返し実行する。
ステップD1のループ内では、まずステップD2において、検索結果の表示とユーザからの指示入力のために用いる画面をディスプレイ150に表示する。
次に、ステップD3において、前記画面上でユーザが指定した指示内容を読み込む。
次に、ステップD4において、前記ユーザの指示内容の種別を判定し、その種別に対応した分岐を行なう。すなわち、該指示が検出有識者数の表示を求めるものであった場合は、以下に示すステップD5およびステップD6の処理に分岐し、該指示が有識者リスト表示を求めるものであった場合には、以下に示すステップD7およびステップD8の処理に分岐する。各分岐先の処理が終了するとステップD1に戻り、前記ループを継続する。
ステップD5では、検出有識者数を問合せるための検出有識者数問合せリクエストを作成し、該リクエストを知識情報検索サーバ11に送信する。
次に、ステップD6では、前記リクエストに対応して知識情報検索サーバ11から転送されてきた有識者数を受信し、該数値をディスプレイ150に表示する。
ステップD7では、検出有識者のリストを問合せるための有識者問合せリクエストを作成し、該リクエストを知識情報検索サーバ11に送信する。
次に、ステップD8では、前記リクエストに対応して知識情報検索サーバ11から転送されてきた有識者の集合を受信し、該集合に含まれる有識者リストを検索結果データ格納領域2020に格納し、ディスプレイ150に有識者のリストを表示する。
以上が、検索結果表示プログラム1022の詳細についての説明であり、本実施例における知識情報検索クライアント20の説明である。
まずは、知識情報登録における処理手順について、知識情報登録サブシステム10の処理手順に基づき、具体例を用いて説明する。
図6における400は、知識情報登録に用いるコンテンツの一例を示したものである。このコンテンツはユーザ「鈴木」がメールクライアント21において作成したメールの一部である。このメールはユーザ「斉藤」が作成したメールに対して返信する形にて作成されている。
このメールをユーザ「鈴木」がメールクライアント21からメールサーバ12へ向けて送信した場合、知識情報登録サブシステム10は、このコンテンツを捕捉することで、知識情報登録の処理手順が実行される(ステップA1)。
図7における500は、知識情報登録サブシステム10の処理手順におけるステップA2からステップA4によって生成されたインデックステーブルの一例である。今回のインデックステーブルからは、コンテンツのコンテンツ識別子が「msg2742」と割り当てられ、その作成者が「鈴木」、元作成者(ソース)が「斉藤」、作成日付が「2006/3/3」となっていることがわかる。また、特徴文字列としてApache(4)、HTTP(6)、Web(23)などが抽出されている。なお、カッコ内の数字は特徴文字列の出現回数を示している。
図7における500に示すようなインデックステーブルが作成されると、知識情報登録サブシステム10はステップA5、すなわち本実施例における知識属性算出プログラム1004を実行することにより、知識属性テーブルを更新する。このステップA5で更新する知識属性テーブルには、全成員を母集団としたコンテンツ集合に対する知識属性テーブルと各ユーザのコンテンツ集合に対する知識属性テーブルがある。
例えば、図7における500のインデックステーブル上で更新された部分におけるApacheという特徴文字列の出現回数の総計が10回であったとすると、図8における510の知識属性テーブルのApacheという特徴文字列の出現頻度を15010と更新する。また、図7における500のインデックステーブル上で更新された部分には、UBLという特徴文字列の出現回数の総計が12回であり、図8における510の知識属性テーブルにはUBLという特徴文字列が存在しなかった場合、新たにUBLという特徴文字列を追加し、その出現頻度を12と設定する。なお、ここでは、インデックステーブルは更新された部分のみ反映する方式としたが、インデックステーブルに含まれるすべての情報に対して知識属性テーブルにおける出現頻度の更新を行なう方式をとっても構わない。インデックステーブル上に存在するすべての特徴文字列とその出現頻度について知識属性テーブル20020の更新処理が終了すると、更新した出現頻度を元に重み値の算出を行なう(ステップ1053)。
まず、図8における510の知識属性テーブル20020では、このテーブルを構成するコンテンツの登録件数が100、000件存在したとする。図8における510では、Apacheという特徴文字列は15、000という出現頻度となっていることから、このApacheという特徴文字列の重み値は、15、000/100、000=0.15という値を算出することになる。この重み値を知識属性テーブルの重み値として設定する(ステップ1054)。同様の計算と設定を図8における510に存在するすべての特徴文字列に対して実行することで重み値の更新を行なう。
前記全成員を母集団としたコンテンツ集合に対する知識属性テーブルの更新が終了すると、ユーザ固有のコンテンツ集合に対する知識属性テーブルも更新することになる。
まず、図7における500のインデックステーブルに存在するユーザ「鈴木」が作成者として含まれる情報を抽出し、抽出された情報に含まれている特徴文字列とその出現頻度を算出する(ステップ1056)。
例えば、ユーザ「鈴木」が作成したコンテンツの特徴文字列としてApacheがあり、インデックステーブル上で更新された部分における出現回数の総計が7回だったとすると、図9における520のApacheという特徴文字列の出現頻度を17回に更新する。また、ユーザ「鈴木」に対するインデックステーブル上で更新された部分には、UBLという特徴文字列の出現回数の総計が6回存在し、図9における520の知識属性テーブルにはUBLという特徴文字列が存在しなかった場合、新たにUBLという特徴文字列を追加し、その出現頻度を6と設定する。
なお、ここでは、インデックステーブルは更新された部分のみ反映する方式としたが、インデックステーブルに含まれるすべての情報に対して知識属性テーブルにおける出現頻度の更新を行なう方式をとっても構わない。
インデックステーブル上に存在するすべての特徴文字列とその出現頻度について知識属性テーブルの更新処理が終了すると、更新した出現頻度を元に重み値の算出を行なう(ステップ1057)。この重み値の算出は、ステップ1053にて採用した算出方法と同様の方式をとる。例えば、図9における520の知識属性テーブルを構成するコンテンツの登録件数が100件であった場合、図9における520に存在する特徴文字列Apacheの重み値は、10/100=0.1という値になる。
図8における510および図9における520に示すような知識属性テーブルが作成されると、知識情報登録サブシステムはステップA6、すなわち本実施例におけるプロファイル作成プログラム1005を実行することにより、各ユーザのプロファイルテーブルを更新する。図10における530はあるユーザのプロファイルテーブルの一例である。なお、プロファイルテーブルはユーザ毎に作成される。ここでは、図10における530は、前記図9における520にて例示したユーザ「鈴木」のプロファイルテーブルを示すものとして説明を行なう。
まず、図9における520に格納されている特徴文字列とその重み値からユーザの知識傾向を示す値(知識傾向値)を算出する(ステップ1063)。知識傾向を示す値は、ユーザの知識属性テーブル(図9における520)に存在する各特徴文字列の重み値に対し、全成員を母集団としたコンテンツ集合における知識属性テーブル(図8における510)における当該特徴文字列の重み値との差分により算出する。例えば、ユーザ「鈴木」の知識属性テーブルでは、Apacheという特徴文字列に対して重み値0.1が設定されており、全成員を母集団としたコンテンツ集合における知識属性テーブルでは、Apacheの重み値は0.15である。したがって、ユーザ「鈴木」における特徴文字列Apacheの知識傾向値は0.1−0.15=−0.05と算出される。
次に、ステップ1063にて算出されたユーザの知識傾向値と占有率を乗算することにより、知識属性値が算出される。なお、占有率は0以上1以下の数値となるために各特徴文字列における知識属性値の差異が小さく算出されてしまうことを考慮し、特定の定数を乗算してもよい。ここでは、ユーザ「鈴木」の特徴文字列Apacheの知識傾向値が−0.05、ユーザ「鈴木」の占有率が0.001であるため、−0.05×0.001×10、000=−0.5という知識属性値が算出できる(なお、乗算した10、000は定数である)。この知識属性値をユーザ「鈴木」のプロファイルテーブルに設定する。同様の計算と設定を図9における520の知識属性テーブルに存在するすべての特徴文字列に対して実行することで重み値の更新を行なう。
図10の530は、ユーザ「鈴木」に対する前記の処理を行なった結果の一例となる。図10の530を俯瞰すると、ユーザ「鈴木」は例えば「Apache」というキーワードに対しては全成員の知識平均と比較して0.5ポイント不足しており、「XBRL」というキーワードについては、全成員の知識平均よりも11.7ポイント満足している。このことから、ユーザ「鈴木」は「XBRL」、「SOA」、「ESB」といった情報に詳しく、「Apache」に関する情報はそれほど詳しくないことがわかる。
以上の処理をすべてのユーザに対して実行し、生成したプロファイルテーブルをデータベース更新リクエストとして知識情報検索サーバ11に転送する(ステップA7)。
以上が、本発明の第一の実施例における知識情報登録の具体的な処理例である。
まず、知識情報検索クライアント20で、ユーザが対話的に検索条件を入力するための画面を表示する(ステップC1)。
表示された画面を用いてユーザは検索条件を入力し、検索情報クライアントは検索条件入力プログラム1021により、ユーザが入力した検索条件を知識情報検索サーバ11が解釈可能な検索リクエストに変換する(ステップC2)。ここでは、あるユーザが「XBRL」と「SOA」と「ESB」の知識がある人を検索したいと入力したとする。
図11の600は検索条件入力プログラム1021を用いてこの検索条件から生成された検索リクエストの一例である。この検索リクエストでは、DB1というデータベース内で「XBRL」、「SOA」、「ESB」のすべての特徴文字列を含むユーザを検索することになる。また、「XBRL」、「SOA」、「ESB」のいずれかの特徴文字列を含むユーザを検索したい場合には、上記特徴文字列と論理和(OR)で結合すればよい。この検索リクエストを知識情報検索サーバ11に送信する。
知識情報検索サーバ11においてこの検索リクエストを受信すると、知識情報検索サーバ11の処理手順におけるステップB5により、検索リクエスト中で指定された検索条件を解析し、有識度算出プログラム1012にて直接処理可能な条件指定に変換する。もし、受信した検索リクエストがそのまま有識度算出プログラム1012にて直接処理可能な条件指定となっている場合はこのステップは省略する。ここでは、図11における600の検索リクエストがそのまま有識度算出プログラム1012にて処理できるものとして説明する。
知識情報検索クライアントでは、検索結果データ集合を受信し、検索結果表示プログラム1022を実行することで検索結果を表示する。
以上説明したように、本実施例を適用することにより、ネットワーク上に流通するコンテンツに含まれるユーザの知識情報を蓄積することが可能となる。また、その知識情報を蓄積するために人手が必要になることもない。さらに、蓄積したユーザの知識情報には、全成員に対してどの程度知識があるのか、あるいは、どの程度影響力を保持しているのかを示す知識属性値が設定されており、その知識属性値を利用することにより、所望の知識を保有する有識者を高速かつ高精度に検索することが可能となる。つまり、高速かつ高精度なKnow−Who検索システムを実現することができる。
コンテンツを検索するためのクライアント(以下コンテンツ検索クライアント)で検索条件を元とした検索リクエストを作成する。コンテンツ検索クライアントは、作成した検索リクエストをコンテンツの検索を行なうためのサーバ(以下、コンテンツ検索サーバ)に送信する。コンテンツ検索サーバは検索リクエストを受信すると、コンテンツの検索処理を行なうと共に、知識情報検索サーバ11に対して検索リクエストを送信する。なお、コンテンツの検索処理については公知であるため、詳細は言及しない。
知識情報検索サーバ11は、検索リクエストを受信し、知識検索処理を実行する。実行後、検索結果データ集合をコンテンツ検索サーバに送信する。
コンテンツ検索サーバでは、検索結果データ集合を受信し、各コンテンツの作成者に対して、知識属性の値を信頼度として表示することで、各コンテンツの作成者の知識レベルの情報をユーザに提示できるようになる。なお、図12における700はコンテンツ検索クライアントにおける検索結果表示画面の一例である。このように、コンテンツの内容がユーザの所望するものであるかどうかを表示するだけでなく、そのコンテンツを作成した人の知識レベルを表示することにより、そのコンテンツがどの程度信頼できるものなのかを確認することができる。
次に、本発明の実施例2の検索方法と検索装置について、図面を用いて説明する。本実施例のシステム構成は、前述の実施例1と同一であるが、知識情報登録サブシステム10の処理において、知識属性算出方法とKnow−Who検索に用いるプロファイルテーブルの作成結果が異なっている。その結果、Know−Who検索による検索結果が前述の実施例1とは異なっている。
以下、本実施例における知識情報登録サブシステム10の詳細について説明する。本実施例のシステム構成は、図1に示す実施例1と同様である。ただし、主メモリ中に存在する知識属性算出プログラム1004およびプロファイル作成プログラム1005が異なる。また、磁気ディスク装置200中に存在する知識属性テーブル格納領域2002に格納されている知識属性テーブル20020の構成が異なる。
本実施例における知識属性算出プログラム1004は、前述の実施例1で説明した処理に加えて、次の処理を行う。
特徴文字列抽出プログラム1003にて、更新されたインデックステーブルの「作成者」と「ソース」の項目を元に、各コンテンツの作成者と元作成者を示すデータを抽出する。作成者の、知識属性テーブル格納領域2002に格納されている知識属性テーブルの「重み値」の項目を参照して元作成者の有用度を算出する。算出された有用度を元作成者の知識属性テーブルの「有用度」の項目に登録し、知識属性テーブルを更新する。
本実施例におけるプロファイル作成プログラム1005は、前述の実施例1で説明した処理に加えて、知識属性値を示す値を算出する過程において、知識属性テーブルの「重み値」の値に加えて、「有用度」の値を用いる。算出された知識属性値を示す値を、プロファイルテーブル格納領域2003に格納されているプロファイルテーブルに登録し、プロファイルテーブルを更新する。
ステップA5では、ステップA4(図2におけるプロセス10030)で更新されたインデックステーブルを入力として知識属性算出プログラム1004を実行する。
本実施例における知識属性算出プログラム1004は、前述の実施例1で説明した処理に加えて、インデックステーブルから元作成者を読み出し、元作成者の知識属性テーブルの有用度を更新する。なお、本ステップにおける知識属性算出プログラム1004の詳細な説明は後述する。このステップA5が図2におけるプロセス10040に相当する。
ステップA6では、ステップA5において更新された知識属性テーブルを入力としてプロファイル作成プログラム1005を実行する。本実施例におけるプロファイル作成プログラムでは、前述の実施例1で説明した処理に加えて、ユーザ毎の知識属性テーブルの有用度を元に、知識属性に反映する値を算出し、プロファイル更新データを生成する。
生成したプロファイル更新データをプロファイルテーブル格納領域2003のプロファイルテーブル20030に登録し、プロファイルテーブルを更新する。なお、本ステップにおけるプロファイル作成プログラム1005の詳細な説明は後述する。このステップA6が図2におけるプロセス10050に相当する。
以上、本実施例における知識情報登録処理の動作手順の概要である。
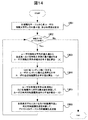
まずは、ステップA5の有用度算出ステップの詳細について説明する。図13は、ステップA5の詳細、すなわち本実施例における知識属性算出プログラム1004の処理手順を示す図である。ステップ1051から1058までは、前述の実施例1と同一であるため言及せず、ステップ1071からステップ1073、すなわち、有用度算出ステップの詳細について説明する。
知識属性算出プログラム1004は、インデックステーブルを入力として起動されると、全体およびユーザごとの知識属性テーブルを必要に応じて更新する。前述の実施例1ではステップ1055で、この処理が終了と判定された場合、知識属性算出プログラム1004を終了するが、本実施例では以下で説明する有用度の算出、および更新を行う。
まず、ステップ1071において、作成したコンテンツが引用、転記、転送などの手段により再利用されており、有用度を更新すべきユーザが存在するかを判定する。もし、該ユーザが存在する場合には、該ユーザに対し、以下に示すステップ1072からステップ1073までの処理を実行する。もし、該ユーザが存在しない、あるいは、処理すべき全てのユーザについて以下に示すステップ1072からステップ1073までの処理が終了した場合には、知識属性算出プログラム1004を終了する。
ステップ1072では、更新すべきユーザ、すなわち、再利用されたコンテンツの作成者(元作成者)に対して、再利用者の知識属性テーブルの重み値をもとに、有用度更新データを生成する。
ステップ1073では、ステップ1072で算出した有用度更新データをもとに、元作成者の知識属性テーブルの有用度を更新する。ステップ1073が終了すると、ステップ1071に戻り、処理を継続する。
以上が本実施例における知識属性算出プログラム1004、すなわち、前記知識情報登録手段におけるステップA5の詳細についての説明である。
ステップ1063からステップ1064までの重み値に関する処理については前述の実施例1と同一であるため、ここでは言及しない。また、本実施例では重み値から算出(ステップ1063からステップ1064)した知識属性値を自己知識属性値、有用度から算出した知識属性値を再利用知識属性値と呼ぶ。
以下では、有用度に関する処理について詳細を説明する。
プロファイル作成プログラム1005は、知識属性テーブルを入力として起動されると、まず、ステップ1061において、知識属性テーブルから各ユーザの特徴文字列の出現情報、重み値、及び有用度を読み出す。
ステップ1062では、読み出した各ユーザの知識属性テーブルに対し、プロファイルテーブルを更新すべきかどうかを判定する。もし、更新すべきユーザであるならば、以下に示すステップ1063からステップ1066までの処理を実行する。もし、更新すべきユーザではない、あるいは、更新すべきすべてのユーザについて以下に示すステップ1063からステップ1066までの処理が終了した場合は、プロファイル作成プログラム1005を終了する。
ステップ1065では、該ユーザの各特徴文字列に対する有用度と自己知識属性値に対する再利用知識属性値の重み値を乗算することで再利用知識属性値を算出する。算出した再利用知識属性値をワークエリアに格納する。
ステップ1066では、ワークエリアに格納されている各特徴文字列の自己知識属性値と再利用知識属性値を読み出し、両者を加算した値をプロファイルテーブル格納領域2003に格納されている該ユーザのプロファイルテーブルの知識属性として登録する。すべての特徴文字列についてプロファイルテーブルの更新が行なわれステップ1066が終了すると、ステップ1062に戻り、処理を継続する。
以上、プロファイル作成プログラム1005、すなわち、前記知識情報登録手段におけるステップA6の詳細についての説明である。
以上が本実施例におけるプロファイル作成プログラム1005、すなわち、知識情報登録処理手段におけるステップA6の詳細についての説明である。
以上、本実施例における知識情報登録サブシステム10についての説明である。
本実施例における知識情報登録の処理について、インデックステーブルの作成から知識属性テーブルの重み値の更新までは前述の実施例1と同様の処理手順である。そのため、ここでは、本実施例で追加された知識属性テーブルの有用度の更新処理、及び有用度を用いたプロファイルテーブルの更新に関する処理手順について、具体例を用いて説明する。
図7における500は、インデックステーブルの一例である。以下では、コンテンツ識別子が「msg2742」のコンテンツを用いて説明する。該コンテンツでは、その作成者が「鈴木」、元作成者(ソース)が「斉藤」となっている。この例では、作成者「鈴木」の知識属性テーブルの重み値から、元作成者「斉藤」の有用度を算出する。
本実施例における知識属性テーブルでは、前述の実施例1の知識属性テーブルに有用度の列を追加している。図15における540は、該コンテンツの作成者「鈴木」の知識属性テーブルである。
作成者「鈴木」の知識属性テーブルから、「鈴木」は特徴文字列「Apache」の重み値が0.35、「HTTP」の重み値が0.8、及び「Web」の重み値が1.2と分かる。こられの各特徴文字列の重み値から、元作成者「斉藤」の知識属性テーブルの有用度の値に加算する値(有用度更新データ)を算出する。
コンテンツ識別子が「msg2742」のコンテンツに含まれる特徴文字列「Apache」を例に説明する。元作成者「斉藤」の知識属性テーブルの特徴文字列「Apache」の重み値は0.55であり、元作成者「斉藤」はApacheの有識者と考えられる。そのため、作成者「鈴木」はコンテンツ識別子「msg2742」のコンテンツの作成にあたり、元作成者「斉藤」のコンテンツからApacheの情報を再利用したと判断する。
次に、「Apache」に関する有用度更新データを算出する。作成者「鈴木」の知識属性テーブルの特徴文字列「Apache」の重み値は、0.35である。また、ここでは、ユーザ「鈴木」のコンテンツ登録件数が100件、全成員を母集団としたコンテンツの登録件数が100、000件であるとする。この場合、占有率は100/100、000=0.001であるため、特徴文字列「Apache」の有用度更新データは、0.35×0.001=0.00035となる。算出された有用度更新データはワークエリアに格納される。
これらの処理は、作成者「鈴木」が再利用した全ての特徴文字列に対して行なわれる。また、ここでは元作成者「斉藤」の再利用者は作成者「鈴木」のみとして説明したが、他にも再利用者が存在する場合、同様の処理を繰り返すものとする。
図16における550は、この有用度算出処理を行った後の、元作成者「斉藤」の知識属性テーブルである。作成者「鈴木」の重み値を加算したため、特徴文字列「Apache」の有用度が0.00035となっている。
図15における540、および図16における550に示すような知識属性テーブルが作成されると、知識情報登録サブシステムはステップA6、すなわち、本実施例におけるプロファイル作成プログラム1005を実行することにより、各ユーザのプロファイルテーブルを更新する。
図17における560は、あるユーザのプロファイルテーブルの一例である。なお、プロファイルテーブルはユーザ毎に作成される。ここでは、図17における560は、図16における550にて例示したユーザ「斉藤」のプロファイルテーブルを示すものとして説明を行う。
再利用知識属性値は、図16における550に格納されている各特徴文字列の有用度と自己知識属性に対する重み値、及び定数を乗算することにより算出する。この自己知識属性に対する重み値は、自己知識属性に対する再利用知識属性の重み付けのために用いている。定数には自己知識属性値の算出で用いた定数と同様の値を用いる。
例えば、ユーザ「斉藤」の知識属性テーブルでは、特徴文字列「Apache」に対して有用度0.00035が設定されている。ここで、自己知識属性に対する重み値を0.01とした場合、0.00035×0.01×10、000=0.035と算出される。(なお、乗算した10、000は定数である)。
ワークエリアから(1)自己知識属性値を読み出して、(2)再利用知識属性値と加算することで、本実施例における知識属性値が算出される。例えば、ユーザ「斉藤」の再利用知識属性値は0.035であるため、(1)自己知識属性値と(2)再利用知識属性値を加算した最終的な知識属性値は8.0+0.035=8.035と算出される。
この知識属性値を、図17に示すように、ユーザ「斉藤」のプロファイルテーブルに設定する。同様の計算と設定を図16における550の知識属性テーブルに存在する、すべての特徴文字列に対して実行することで知識属性値の更新を行う。
以上の処理をすべてのユーザに対して実行し、生成したプロファイルテーブルをデータベース更新リクエストとして知識情報検索サーバ11に転送する(ステップA7)。
以下、本発明の実施例3について、図面を用いて説明する。本実施例のシステム構成は、前述の実施例1および実施例2と同様である。ただし、知識情報登録サブシステム10と、知識情報検索サーバ11の磁気ディスク内に時間空間管理テーブル格納領域2004が存在する点が異なっている。
また、知識情報登録サブシステム10の処理における知識属性算出方法と、知識情報検索サーバ11の処理における有識者検索方法が異なる。その結果、Know−Who検索における検索結果が、前述の実施例1および実施例2とは異なっている。
以下、本実施例における知識情報登録サブシステム10の詳細について説明する。
本実施例における全体のシステム構成を図18に示す。図1に示す前述の実施例1および実施例2の構成とは、磁気ディスク装置200中に存在する時間空間管理テーブル格納領域2004に格納されている時間空間管理テーブル20040が存在する点が異なる。また、主メモリ100中に存在する知識属性算出プログラム1004が異なる。
本実施例における知識属性算出プログラム1004は、前述の実施例1で説明した処理に加えて、特徴文字列抽出プログラム1003にて更新されたインデックステーブル20010から、「場所」と「日付」を読み出し、時間空間管理テーブル格納領域2004に格納されている時間空間管理テーブル20040を更新する処理を行う。
以上、本実施例における知識情報登録処理の動作手順の概要である。以下では、前記ステップA5における詳細について図20を用いて説明する。
ステップA5では、ステップA4(図19におけるプロセス10030)で更新されたインデックステーブルを入力として知識属性算出プログラム1004を実行する。本実施例における知識属性算出プログラム1004は、前述の実施例1で説明した処理に加えて、インデックステーブルから「作成者」、「場所」、及び「日付」を読み出し、時間空間管理テーブル格納領域2004に格納されている時間空間管理テーブル20040を更新する(時間空間属性抽出ステップ)。
このステップA5が、図19におけるプロセス10040に相当する。ステップ1052からステップ1054、ステップ1056からステップ1058までは前述の実施例1と同一であるため言及しない。
ステップ1055では、更新すべきユーザが存在するかどうかを判定する。もし、更新すべきユーザが存在する場合には、そのユーザに対し、以下に示すステップ1056からステップ1058までの処理を実行する。もし、更新すべきユーザが存在しない、あるいは、更新すべきすべてのユーザについて以下に示すステップ1056からステップ1058までの処理が終了した場合は、ステップ1081へ進み処理を継続する。
ステップ1081では、更新すべき特徴文字列が存在するかどうかを判定する。もし、更新すべき特徴文字列が存在する場合には、その特徴文字列に対し、以下に示すステップ1082の処理を実行する。もし、更新すべき特徴文字列が存在しない、あるいは、更新すべきすべての特徴文字列について以下に示すステップ1082の処理が終了した場合は、知識属性算出プログラム1004を終了する。
以上が本実施例における知識属性算出プログラム1004、すなわち、前記知識情報登録手段におけるステップA5の詳細についての説明である。
以上、本実施例における知識情報登録サブシステム10についての説明である。
本実施例におけるシステム構成を図18に示す。図1に示す前述の実施例1および実施例2の構成とは磁気ディスク装置200中に存在する時間空間管理テーブル格納領域2004に格納されている時間空間管理テーブル20040が存在する点が異なる。また、主メモリ100中に存在する有識度算出プログラム1012が異なる。
本実施例における有識度算出プログラム1012は、前述の実施例1で説明した処理に加えて、時間空間管理テーブル格納領域2004に格納されている時間空間管理テーブル20040から「作成者」、「日付」(時間属性)、及び「場所」(空間属性)を読み出し、コンテンツの作成日付にもとづく作成者の有識度(時間有識度)、コンテンツの公開場所にもとづく作成者の有識度(空間有識度)を算出して検索結果に反映する処理を行う。
次に、本実施例における知識情報検索処理の手順について図21を用いて説明する。本実施例における処理手順においては、図5に示す前述の実施例1の場合とステップB6(図21におけるプロセス10120)が異なる。
以上、本実施例における知識情報検索処理の動作手順の概要である。以下では、前述のステップB6における動作手順について図21を用いて説明する。
ステップB6では、ステップB5(図21におけるプロセス10110)にて生成された条件指定を入力として、有識度算出プログラム1012を実行する。
本実施例における有識度算出プログラム1012は、前述の実施例1で説明した処理に加えて、時間空間管理テーブルに対して、該検索条件を満たすコンテンツを検索する。本実施例における有識者の有識度は、前述の実施例1で説明したプロファイルテーブル上の条件指定に対応する知識属性値を参照して算出した有識度((A)知識属性有識度)と、時間空間管理テーブル上の条件指定に対応するコンテンツの時間空間属性にもとづいて算出した(B)時間有識度、(C)空間有識度の3種類の有識度を乗算((A)×(B)×(C))することで算出する。このステップB6が図21におけるプロセス10120に相当する。
本実施例では、ステップ1164からステップ1166の時間空間属性算出ステップが追加されている。また、ステップ1167における有識度の算出に関する処理内容が異なる。以下では各ステップの詳細について説明する。
まず、ステップ1161において、検索条件式解析プログラム1011の実行結果としてワークエリアに格納されている、有識度算出プログラム1012にて直接処理可能な条件指定を読み出す。検索条件式解析プログラム1011については、前述の実施例1と同様であるので、ここでは言及しない。
ステップ1162では、プロファイルテーブルから、検索条件を満たすユーザ(有識者)を抽出する。
ステップ1163では、ステップ1162で抽出された各有識者に対して、プロファイルテーブルの知識属性値から有識度(知識属性有識度)を算出する。知識属性有識度は、検索条件を満たす各特徴文字列の知識属性値の総和によって算出する。
ステップ1164では、時間空間管理テーブルから、検索条件を満たすデータを抽出する。
ステップ1165では、ステップ1164で抽出されたデータから、ステップ1162で抽出された各有識者が作成したコンテンツの時間属性を読み出し、各有識者の有識度(時間有識度)を算出する。時間有識度は、有識者の持つ知識の鮮度を表す。そのため、知識属性有識度に乗算することで、時間の経過に伴い有識度を低下させる係数として用いる。
時間有識度は、次の2ステップで算出する。
(1)各コンテンツに対して、作成から一定時間が経過するごとに加算する値の逆数を算出して、コンテンツ鮮度を算出。
(2)各有識者に対して、作成したコンテンツのコンテンツ鮮度の総和を算出して、この総和を各有識者が作成したコンテンツの総数で除算。
空間有識度は、コンテンツの公開場所・公開手段により有識者の持つ知識を重み付ける。そのため、知識属性有識度に乗算することで、公開場所・公開手段に応じて有識度を上下させる係数として用いる。
空間有識度は、次の2ステップで算出する。
(1)コンテンツの公開場所・公開手段ごとに重み値(空間有識度用重み値)を設定。
(2)各有識者に対して、作成した各コンテンツの空間有識度用重み値の総和を算出して、この総和を各有識者が作成したコンテンツの総数で除算。
ステップ1167では、有識者の有識度を示す値を算出してワークエリアに格納する。有識度は知識属性有識度、時間有識度、及び空間有識度の乗算によって算出する。
以上が本実施例における有識度算出プログラム1012、すなわち、前記知識情報検索手段におけるステップ116の詳細についての説明である。
以上が本実施例における知識情報検索処理の動作手順と、知識情報検索サーバ11の説明である。
まず、知識情報登録サブシステム10の処理手順に基づき、具体例を用いて説明する。
本実施例における知識情報登録の処理について、インデックステーブルの作成から知識属性テーブルの更新までは前述の実施例1と同様の処理手順である。そのため、ここでは、本実施例で追加された時間空間管理テーブルの更新に関する処理手順について、具体例を用いて説明する。
図7における500に示すようなインデックステーブルが作成されると、知識情報登録サブシステムはステップA5、すなわち本実施例における知識属性算出プログラム1004を実行することにより、知識属性テーブルと時間空間管理テーブルを更新する。
図23における570は、時間空間管理テーブルの一例である。既存の時間空間管理テーブルにインデックステーブルの作成者、公開場所、及び作成日付などのコンテンツ属性を特徴文字列(時間空間管理テーブル上ではキーワードとよぶ)ごとに追加することで更新する。もし、キーワードが時間空間管理テーブルに存在しない場合には、該キーワードとそのコンテンツ属性を新規に追加する。
例として、図7における500のインデックステーブルのコンテンツ識別子が「msg2742」のコンテンツにおける特徴文字列「Apache」をキーワードとした場合について説明する。
図23における570の時間空間管理テーブルのキーワード「Apache」のデータに、コンテンツ識別子が「msg2742」のコンテンツのコンテンツ属性として「作成者」に「鈴木」、「場所」に「メールサーバ1」、「日付」に「2006/3/3」を登録して更新する。
また、図7における500のインデックステーブル上で更新された部分に、UBLという特徴文字列があり、図23における570の時間空間管理テーブルにはUBLがキーワードとして存在しなかった場合、新たにUBLをキーワードとして追加し、コンテンツ識別子が「doc5637」のコンテンツのコンテンツ属性として「作成者」に「山田」、「場所」に「Webサーバ2」、「日付」に「2006/2/3」を登録して更新する。
同様の処理を図7における500の更新されたインデックスデータに存在するすべての特徴文字列(キーワード)に対して実行することで時間空間管理テーブルの更新を行う。
以降の本実施例における知識情報登録の具体的な処理は前述の実施例1と同様である。以上が、本発明の実施例3における知識情報登録の具体的な処理例である。
知識情報検索サーバ11の処理手順におけるステップB6において有識度算出プログラム1012によって、有識者の有識度の算出処理を行う。
本実施例における有識度算出プログラム1012では、有識度の算出にプロファイルテーブルの情報に加えて時間空間管理テーブルの情報を用いる。
例えば、図24における800のような検索条件が入力されると、プロファイルテーブルより、すべての特徴文字列を含むユーザを検索し、例えば、「鈴木」、「佐藤」、「田中」といったユーザを抽出してワークエリアに格納する。
一方、時間空間管理テーブルより「Apache」、「SOA」、「ESB」の各特徴文字列に該当するキーワードを検索し、該当するデータを抽出してワークエリアに格納する。これらの抽出した情報をもとに有識度を算出する。
ここでは、ユーザ「鈴木」が有識者としてプロファイルテーブルから抽出された場合を例として、キーワード「Apache」に関して有識度算出プログラムの具体的な処理について説明する。
時間空間管理テーブルから抽出したキーワード「Apache」のデータのコンテンツ属性情報には作成者「鈴木」、場所「メールサーバ1」、日付「2006/3/3」が存在する。該コンテンツ属性をもとに作成者「鈴木」の時間有識度、空間有識度を算出する。
次に、場所属性をもとに空間有識度を算出する。空間有識度は、予めコンテンツの公開場所ごとに重み付けを行っておき、その値(空間有識度用重み値)を用いて算出する。
例えば、空間有識度用重み値として、「Webサーバ1」を1、「メールサーバ1」を0.5と設定した場合、該コンテンツ属性では、キーワード「Apache」、作成者「鈴木」のコンテンツが「メールサーバ1」で公開されているため、「メールサーバ1」の0.5が、そのコンテンツの公開場所にもとづく重み値となる。
この算出処理を各有識者が作成した、該キーワードをもつ全てのコンテンツに対して行い総和を得る。この総和を各有識者が作成した、該キーワードをもつコンテンツの総数で除算する。例えば、「鈴木」が「メールサーバ1」と「Webサーバ1」で、それぞれ1つのコンテンツを公開していた場合、(0.5+1)÷2=0.75が空間有識度の値となる。
以降の本実施例における知識情報検索の具体的な処理は前述の実施例1と同様である。以上が本実施例1における知識情報検索の具体的な処理例である
以上説明したように、Know−Who検索を行う場合においては、ユーザは、本実施例の方式にて作成されたプロファイルデータを検索する仕組みを利用するだけで、所望の知識を保有する人物を検索することが可能となり、その結果表示においては所望の知識の有識度という数値で表現されるため、どの人物がより所望の知識を保有しているかを知ることが可能となる。
また、本実施例を適用することにより、通常の文書検索においても、作成した人物の当該知識の有識度を参照することにより、どの程度信頼できる文書であるかを表示することが可能となり、文書の信頼性を図る指標として利用することができる。
以上、本発明者によってなされた発明を、前記実施例に基づき具体的に説明したが、本発明は、前記実施例に限定されるものではなく、その要旨を逸脱しない範囲において種々変更可能であることは勿論である。
11 知識情報検索サーバ
12 メールサーバ
13 Webサーバ
14 コンテンツ受信サーバ
20 知識情報検索クライアント
21 メールクライアント
22 Webクライアント
23 コンテンツ配信クライアント
100 主メモリ
150 ディスプレイ
160 入力装置
170 通信制御装置
180 ネットワーク
200 磁気ディスク装置
1001 システム制御プログラム
1002 知識情報登録制御プログラム
1003 特徴文字列抽出プログラム
1004 知識属性算出プログラム
1005 プロファイル作成プログラム
1010 知識情報検索制御プログラム
1011 検索条件式解析プログラム
1012 有識度算出プログラム
1013 検索結果取得プログラム
1020 知識情報検索入出力制御プログラム
1021 検索条件入力プログラム
1022 検索結果表示プログラム
2001 インデックスファイル格納領域
2002 知識属性テーブル格納領域
2003 プロファイルテーブル格納領域
2004 時間空間管理テーブル格納領域
2020 検索結果データ格納領域
Claims (8)
- メールやWeb上のコンテンツに対し、各コンテンツのコンテンツ作成者の中から、検索者が指定した内容を知識として保有するコンテンツ作成者を検索する検索方法であって、
前記メールやWeb上のコンテンツ中に含まれる少なくとも1個以上の部分文字列を抽出する部分文字列抽出ステップと、
前記コンテンツ作成者が作成したコンテンツの集合における該当部分文字列の出現頻度情報と前記コンテンツ作成者を含む特定された成員の集合によって作成されたコンテンツの集合における該当部分文字列の出現頻度情報とに基づき、各コンテンツ作成者の知識属性を抽出する知識属性抽出ステップと、
前記知識属性抽出ステップにて抽出されたコンテンツ作成者の知識属性の集合を元にコンテンツ作成者のプロファイルテーブルを形成するプロファイル作成ステップと、
前記プロファイル作成ステップにて抽出された各コンテンツ作成者のプロファイルテーブルを用いて検索者が指定した知識をもつ可能性を算出する有識度算出ステップと、
前記有識度算出ステップにて算出された各コンテンツ作成者の有識度を用いて、前記検索者が指定した内容を知識として保有するコンテンツ作成者を検索する検索ステップとを有し、
前記知識属性抽出ステップは、前記コンテンツ作成者が作成したコンテンツの集合における該当部分文字列の重み値を求めるサブステップ1と、
前記コンテンツ作成者を含む特定された成員の集合によって作成されたコンテンツの集合における該当部分文字列の重み値を求めるサブステップ2とを有し、
前記プロファイル作成ステップは、前記サブステップ1で求めた前記コンテンツ作成者が作成したコンテンツの集合における該当部分文字列の重み値と、前記サブステップ2で求めた前記コンテンツ作成者を含む特定された成員の集合によって作成されたコンテンツの集合における該当部分文字列の重み値との差分を求め、前記コンテンツ作成者の知識傾向値を求めるサブステップ3と、
前記コンテンツ作成者を含む特定された成員の集合によって作成されたコンテンツの集合に対して、前記コンテンツ作成者が作成したコンテンツの集合が占める割合である占有率を求めるサブステップ4と、
前記サブステップ3で求めた知識傾向値と前記サブステップ4で求めた占有率とを乗算し、前記コンテンツ作成者の知識属性値を求めるサブステップ5とを有することを特徴とする検索方法。 - 前記知識属性抽出ステップは、各コンテンツ作成者が作成したコンテンツがどの程度他のコンテンツ作成者によって引用、転記、転送などの手段で再利用されたかという再利用度と再利用したコンテンツ作成者自身の前記有識度を元に当該コンテンツがどの程度有用であったかを算出する有用度算出ステップを有することを特徴とする請求項1に記載の検索方法。
- 前記知識属性抽出ステップは、コンテンツがどの程度時間が経過した情報であり、どういった手段で提供された情報であるかを抽出する時間空間属性抽出ステップを有し、
前記有識度算出ステップは、前記時間空間属性抽出ステップにて抽出されたコンテンツの経過時間情報や空間情報を用いて検索者が求める知識に対してどの程度時間空間的に有用なのかを算出する時間空間属性算出ステップを有することを特徴とする請求項1に記載の検索方法。 - 前記有識度算出ステップにて作成した各コンテンツ作成者の有識度情報、あるいは予め作成した各コンテンツ作成者の有識度情報を参照することにより、コンテンツの信頼度を表示するステップを有することを特徴とする請求項1ないし請求項3のいずれか1項に記載の検索方法。
- メールやWeb上のコンテンツに対し、各コンテンツのコンテンツ作成者の中から、検索者が指定した内容を知識として保有するコンテンツ作成者を検索する検索装置であって、
前記メールやWeb上のコンテンツ中に含まれる少なくとも1個以上の部分文字列を抽出する部分文字列抽出手段と、
前記コンテンツ作成者が作成したコンテンツの集合における該当部分文字列の出現頻度情報と前記コンテンツ作成者を含む特定された成員の集合によって作成されたコンテンツの集合における該当部分文字列の出現頻度情報とに基づき、各コンテンツ作成者の知識属性を抽出する知識属性抽出手段と、
前記知識属性抽出手段にて抽出されたコンテンツ作成者の知識属性の集合を元にコンテンツ作成者のプロファイルテーブルを形成するプロファイル作成手段と、
前記プロファイル作成手段にて抽出された各コンテンツ作成者のプロファイルテーブルを用いて検索者が指定した知識をもつ可能性を算出する有識度算出手段と、
前記有識度算出ステップにて算出された各コンテンツ作成者の有識度を用いて、前記検索者が指定した内容を知識として保有するコンテンツ作成者を検索する検索手段とを有し、
前記知識属性抽出手段は、前記コンテンツ作成者が作成したコンテンツの集合における該当部分文字列の重み値を求める手段1と、
前記コンテンツ作成者を含む特定された成員の集合によって作成されたコンテンツの集合における該当部分文字列の重み値を求める手段2とを有し、
前記プロファイル作成手段は、前記手段1で求めた前記コンテンツ作成者が作成したコンテンツの集合における該当部分文字列の重み値と、前記手段2で求めた前記コンテンツ作成者を含む特定された成員の集合によって作成されたコンテンツの集合における該当部分文字列の重み値との差分を求め、前記コンテンツ作成者の知識傾向値を求める手段3と、
前記コンテンツ作成者を含む特定された成員の集合によって作成されたコンテンツの集合に対して、前記コンテンツ作成者が作成したコンテンツの集合が占める割合である占有率を求める手段4と、
前記手段3で求めた知識傾向値と前記手段4で求めた占有率とを乗算し、前記コンテンツ作成者の知識属性値を求める手段5とを有することを特徴とする検索装置。 - 前記知識属性抽出手段は、各コンテンツ作成者が作成したコンテンツがどの程度他のコンテンツ作成者によって引用、転記、転送などの手段で再利用されたかという再利用度と再利用したコンテンツ作成者自身の前記有識度を元に当該コンテンツがどの程度有用であったかを算出する有用度算出手段を有することを特徴とする請求項5に記載の検索装置。
- 前記知識属性抽出手段は、コンテンツがどの程度時間が経過した情報であり、どういった手段で提供された情報であるかを抽出する時間空間属性抽出手段を有し、
前記有識度算出手段は、前記時間空間属性抽出手段にて抽出されたコンテンツの経過時間情報や空間情報を用いて検索者が求める知識に対してどの程度時間空間的に有用なのかを算出する時間空間属性算出手段を有することを特徴とする請求項5に記載の検索装置。 - 前記有識度算出手段で作成した各コンテンツ作成者の有識度情報、あるいは予め作成した各コンテンツ作成者の有識度情報を参照することにより、コンテンツの信頼度を表示する表示手段を有することを特徴とする請求項5ないし請求項7のいずれか1項に記載の検索装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007072634A JP5031416B2 (ja) | 2007-03-20 | 2007-03-20 | 検索方法および検索装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007072634A JP5031416B2 (ja) | 2007-03-20 | 2007-03-20 | 検索方法および検索装置 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2008234290A JP2008234290A (ja) | 2008-10-02 |
| JP2008234290A5 JP2008234290A5 (ja) | 2010-04-15 |
| JP5031416B2 true JP5031416B2 (ja) | 2012-09-19 |
Family
ID=39906988
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007072634A Active JP5031416B2 (ja) | 2007-03-20 | 2007-03-20 | 検索方法および検索装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5031416B2 (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010211733A (ja) * | 2009-03-12 | 2010-09-24 | Nec Corp | 検索装置および検索方法 |
| JP5499566B2 (ja) * | 2009-08-26 | 2014-05-21 | 日本電気株式会社 | 動画再生装置、動画再生方法及びプログラム |
| JP6586816B2 (ja) * | 2015-08-14 | 2019-10-09 | 富士ゼロックス株式会社 | 検索装置及びプログラム |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1166081A (ja) * | 1997-08-12 | 1999-03-09 | N T T Data:Kk | プロファイル取得システム、情報提供システム、プロファイル取得方法及び媒体 |
| JP3704933B2 (ja) * | 1997-12-18 | 2005-10-12 | 富士ゼロックス株式会社 | 個人プロファイル管理装置及び方法 |
| JP2000259529A (ja) * | 1999-03-09 | 2000-09-22 | Fuji Xerox Co Ltd | 個人プロファイル管理装置及び記憶媒体 |
| JP2001075993A (ja) * | 1999-09-07 | 2001-03-23 | Fuji Xerox Co Ltd | 人物推薦装置および記録媒体 |
| JP4135330B2 (ja) * | 2001-04-06 | 2008-08-20 | 富士ゼロックス株式会社 | 人物紹介システム |
| JP2005092370A (ja) * | 2003-09-12 | 2005-04-07 | Fuji Xerox Co Ltd | 情報管理装置 |
| JP2007012100A (ja) * | 2006-10-23 | 2007-01-18 | Hitachi Ltd | 人物情報に基づく検索方法および検索装置、あるいは情報提供システム |
-
2007
- 2007-03-20 JP JP2007072634A patent/JP5031416B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2008234290A (ja) | 2008-10-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10565234B1 (en) | Ticket classification systems and methods | |
| US8706748B2 (en) | Methods for enhancing digital search query techniques based on task-oriented user activity | |
| US8117198B2 (en) | Methods for generating search engine index enhanced with task-related metadata | |
| CN101655857B (zh) | 基于关联规则挖掘技术挖掘建设法规领域数据的方法 | |
| US8126888B2 (en) | Methods for enhancing digital search results based on task-oriented user activity | |
| US8990241B2 (en) | System and method for recommending queries related to trending topics based on a received query | |
| US7836460B2 (en) | Service broker realizing structuring of portlet services | |
| CN101194256B (zh) | 具有表意文字和音标字符的语言的自动输入完成的方法和系统 | |
| CN107729336A (zh) | 数据处理方法、设备及系统 | |
| JP4700462B2 (ja) | データベース利用システム | |
| US9971828B2 (en) | Document tagging and retrieval using per-subject dictionaries including subject-determining-power scores for entries | |
| JP2009271911A (ja) | 情報のシンボルによるリンクとインテリジェントな分類を行う方法及びシステム | |
| US9552415B2 (en) | Category classification processing device and method | |
| CN112269816B (zh) | 一种政务预约事项相关性检索方法 | |
| JP5237353B2 (ja) | 検索装置、検索システム、検索方法、検索プログラム、及び検索プログラムを記憶するコンピュータ読取可能な記録媒体 | |
| US8244704B2 (en) | Recording medium recording object contents search support program, object contents search support method, and object contents search support apparatus | |
| JP2002358315A (ja) | 文書検索システムおよびサーバ | |
| US20100031178A1 (en) | Computer system, information collection support device, and method for supporting information collection | |
| JP5266975B2 (ja) | 個人検索システム、情報処理装置、個人検索方法、プログラムおよび記録媒体 | |
| JP5031416B2 (ja) | 検索方法および検索装置 | |
| US20220156285A1 (en) | Data Tagging And Synchronisation System | |
| Chan et al. | Web Services Recommendation Based on User's Behavior | |
| KR101078907B1 (ko) | 문서 평가 시스템 | |
| JP2009093554A (ja) | 検索支援方法、検索支援システム、アプリケーションサーバ、及び検索支援プログラム | |
| JP3526198B2 (ja) | データベース類似検索方法及び装置及び類似検索プログラムを格納した記憶媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100301 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20100301 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20120322 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120327 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120521 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A712 Effective date: 20120521 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120626 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120627 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5031416 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150706 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |