JP4718012B2 - メモリキャンセルメッセージを用いたシステムメモリ帯域幅の節約およびキャッシュコヒーレンシ維持 - Google Patents
メモリキャンセルメッセージを用いたシステムメモリ帯域幅の節約およびキャッシュコヒーレンシ維持 Download PDFInfo
- Publication number
- JP4718012B2 JP4718012B2 JP2000590062A JP2000590062A JP4718012B2 JP 4718012 B2 JP4718012 B2 JP 4718012B2 JP 2000590062 A JP2000590062 A JP 2000590062A JP 2000590062 A JP2000590062 A JP 2000590062A JP 4718012 B2 JP4718012 B2 JP 4718012B2
- Authority
- JP
- Japan
- Prior art keywords
- processing node
- response
- node
- read
- memory
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/0815—Cache consistency protocols
- G06F12/0817—Cache consistency protocols using directory methods
- G06F12/0828—Cache consistency protocols using directory methods with concurrent directory accessing, i.e. handling multiple concurrent coherency transactions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/0813—Multiuser, multiprocessor or multiprocessing cache systems with a network or matrix configuration
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/0815—Cache consistency protocols
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
- G06F13/16—Handling requests for interconnection or transfer for access to memory bus
- G06F13/1605—Handling requests for interconnection or transfer for access to memory bus based on arbitration
- G06F13/1652—Handling requests for interconnection or transfer for access to memory bus based on arbitration in a multiprocessor architecture
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/25—Using a specific main memory architecture
- G06F2212/254—Distributed memory
- G06F2212/2542—Non-uniform memory access [NUMA] architecture
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/62—Details of cache specific to multiprocessor cache arrangements
- G06F2212/621—Coherency control relating to peripheral accessing, e.g. from DMA or I/O device
Description
【発明の背景】
1.技術分野
この発明は広くはコンピュータシステムに関し、より特定的には、マルチプロセッシング演算環境を達成するためのメッセージ通信方式に関する。
【0002】
2.関連技術分野の背景
一般的には、パーソナルコンピュータ(PC)およびその他の種類のコンピュータシステムは、メモリにアクセスするために共用バスシステムを中心に設計されてきた。1つ以上のプロセッサおよび1つ以上の入力/出力(I/O)装置が、共用バスを介してメモリに結合される。I/O装置はI/Oブリッジを介して共用バスに結合される場合もあり、該I/Oブリッジは共用バスとI/O装置との間の情報の転送を管理する。プロセッサは典型的には、直接またはキャッシュ階層構造を介して、共用バスに結合される。
【0003】
残念ながら、共用バスシステムはいくつかの欠点を有する。たとえば、共用バスには多数の装置が装着されることから、バスは典型的には比較的低い周波数で動作される。さらに、共用システムを介したシステムメモリ読出および書込サイクルは、プロセッサ内のキャッシュが関連するか、または2つ以上のプロセッサが関連する情報転送よりも、かなり長い時間を必要とする。共用バスシステムの他の欠点は、より多くの装置に対するスケーラビリティの欠如である。上述のように、帯域幅が固定される(そして、もし付加的な装置の追加によってバスの動作可能周波数が減じられると、減少し得る)。バスに(直接的にまたは間接的に)装着された装置の帯域幅要件が、一旦バスの利用可能な帯域幅を超えると、装置はバスへのアクセスを試みたときにしばしばストールし得る。限られたシステムメモリ帯域幅を節約する機構を提供しない限り、全体的な性能は減じられるであろう。
【0004】
ノンキャッシュシステムメモリに対しアドレス指定された書込または読出動作は、2つのプロセッサの間の、またはプロセッサとその内部キャッシュとの間の同様の動作よりも、より多くのプロセッサクロックサイクルをとる。バス帯域幅への制限は、システムメモリへの読出または書込のための長いアクセス時間とあいまって、コンピュータシステム性能に悪影響を及ぼす。
【0005】
上述の問題のうち1つまたはいくつかには、分散メモリシステムを用いて対処し得る。分散メモリシステムを用いるコンピュータシステムは、複数のノードを含む。2つ以上のノードがメモリに接続され、それらのノードは何らかの好適な相互接続を用いて相互接続される。たとえば、ノードの各々は専用ラインを用いて他のノードに互いに接続されることができる。これに代えて、ノードの各々は固定された数の他のノードに接続され、トランザクションは、第1のノードから1つ以上の中間ノードを介して、第1のノードに直接接続されていない第2のノードに経路制御されてもよい。メモリアドレス空間は、各々のノードのメモリにわたって割当てられる。
【0006】
ノードはさらに、1つ以上のプロセッサを含み得る。プロセッサは典型的には、メモリから読出したデータのキャッシュブロックをストアするキャッシュを含む。さらに、ノードはプロセッサの外部の1つ以上のキャッシュを含み得る。プロセッサおよび/またはノードは、他のノードからアクセスされるキャッシュブロックをストアし得るために、ノード内のコヒーレンシを維持するための機構が望まれる。
【0007】
EP−A−0 379 771は、デジタルコンピュータのためのメモリ制御システムを開示するが、ここでは、要求されたデータの変更された状態のものが別の関連のCPUキャッシュ内に利用可能である場合に、関連するメインメモリを備えたシステム制御ユニット(SCU)の読出が、関連の中央演算ユニット(CPU)に応答して自動的に打切られる。
C.A.プリート(C. A. Prete)による「密結合マルチプロセッサシステムのためのRTSキャッシュメモリ設計(RTS Cache Memory Design for a Tightly Coupled Multiprocessor System)」IEEE Micro. US, IEEE Inc. New York Vol.11 No.2、1991年4月11日、pp.16−19、40−52、は、縮小状態遷移(Reduced State Transitions)として知られる、マルチプロセッサシステムにおけるキャッシュメモリのためのコヒーレンスプロトコルを開示する。読出または書込動作の際にキャッシュミスが起こると、キャッシュはまずキャッシュコピーを置換え、次いで要求された動作を実行する。置換えの段階は、ヴィクティムキャッシュブロックを選択するステップと、ヴィクティムコピーに関連するメモリブロックを更新するステップと、読出ブロックトランザクションにより、要求されたメモリブロックを読出すステップと、からなる。
上に概略を述べた問題は、ここに説明するコンピュータシステムによってほとんどが解決される。コンピュータシステムは多数の処理ノードを含むことができ、そのうち2つ以上は分散メモリシステムを形成し得る別々のメモリに結合し得る。処理ノードはキャッシュを含むことができ、コンピュータシステムは、キャッシュと分散メモリシステムとの間のコヒーレンシを維持し得る。
【0008】
この発明の第1の局面によると、コンピュータシステムが提供され、該コンピュータシステムは読出トランザクションによりアドレス指定されたデータの変更されたコピーを保持していることに応答して、該読出トランザクションに対応するメモリキャンセル応答を送信するよう構成される第1の処理ノードを含み、該第1の処理ノードは、(i)第2の処理ノードからプローブを受取り、(ii)該読出トランザクションによってアドレス指定されたデータの変更されたコピーを検出し、(iii)該変更されたコピーの検出に応答して該メモリキャンセル応答を送信するよう構成される、処理ノードであり、該コンピュータシステムはさらに該第2の処理ノードを含み、該第2の処理ノードはトランザクションのターゲットノードを含み、かつシステムメモリの少なくとも一部に結合され、該システムメモリの少なくとも一部は、読出トランザクションによってアドレス指定されたデータに対応する記憶位置を含み、該第2の処理ノードは該第1の処理ノードから該メモリキャンセル応答を受け取るよう結合され、該第2の処理ノードは、該メモリキャンセル応答に応答して、該記憶位置への読出サイクルのさらなる処理を打ち切るよう構成される。
一実施例においては、処理ノードは複数のデュアル単方向リンクを介して相互接続される。単方向リンク対の各々は、処理ノードのうちの2つを接続するコヒーレントなリンク構造を形成する。単方向リンク対の一方のリンクは、第1の処理ノードから信号を、その単方向リンク対を介して接続された第2の処理ノードに送る。単方向リンク対の他方のリンクは、信号の逆のフローを運ぶ。すなわち、信号を第2の処理ノードから第1の処理ノードへ送る。こうして、単方向リンクの各々は、パケット化情報転送のために設計されたポイントツーポイント相互接続を形成する。2つの処理ノード間の通信は、システム内の1つ以上の残りのノードを介して経路制御されることもある。
【0009】
処理ノードの各々は、メモリバスを介してそれぞれのシステムメモリに結合されることができる。メモリバスは双方向であってもよい。処理ノードの各々は、少なくとも1つのプロセッサコアを含み、かつ選択によりそれぞれのシステムメモリと通信するためのメモリコントローラを含み得る。1つ以上のI/Oブリッジを介したさまざまなI/O装置との接続性を可能にするため、1つ以上の処理ノードに他のインターフェイスロジックを含んでもよい。
【0010】
一実施例においては、1つ以上のI/Oブリッジを、1組の非コヒーレントなデュアル単方向リンクを介してそれぞれの処理ノードに結合し得る。これらのI/Oブリッジは、この非コヒーレントなデュアル単方向リンクの組を介してそれらのホストプロセッサと通信するが、これは2つの直接リンクされたプロセッサがコヒーレントなデュアル単方向リンクを介して互いと通信するのとほぼ同じ方法である。
【0011】
プログラム実行の間のある時点で、キャッシュ内にメモリデータのダーティコピーを持つ処理ノードは、その変更されたデータを含むキャッシュブロックを捨てることができる。一実施例においては、その処理ノード(ソースノードとも呼ばれる)はヴィクティムブロックコマンドをキャッシュされたダーティなデータと併せて第2の処理ノードに送信するが、該第2の処理ノードはすなわち、キャッシュされたデータのための対応するメモリ位置を有するシステムメモリの一部に結合されたものである。この第2の処理ノード(ターゲットノードとも呼ばれる)は、応答してターゲット終了メッセージを送信処理ノードに送り、メモリ書込サイクルを開始して受取ったデータを関連のノンキャッシュメモリに転送し、対応するメモリ位置の内容を更新する。もし送信処理ノードが、ヴィクティムブロックコマンドを送った時間と、ターゲット終了メッセージを受取った時間との間で無効化プローブに出会えば、送信ノードはターゲットノード、すなわち第2の処理ノードにメモリキャンセル応答を送り、メモリ書込サイクルのさらなる処理を打切る。これはシステムメモリ帯域幅を節約するという効果をもたらし、ノンキャッシュメモリに書込まれるべきデータが失効している場合、時間がかかるメモリ書込動作を回避し得る。
【0012】
メモリキャンセル応答は、ヴィクティムブロック書込動作の間のキャッシュコヒーレンシを維持し得るが、特に、ヴィクティムブロックの宛先であるメモリ位置の内容を読出すための第3の処理ノード(ヴィクティムブロックを送ったソースノード以外のもの)からの読出コマンドの後に、ヴィクティムブロックがターゲットノード(すなわち、第2の処理ノード)に到着する状況において、コヒーレンシを維持し得る。読出コマンドは、そのメモリ位置から読出したデータを変更するという第3の処理ノードの意図を明らかにし得る。したがって、ターゲットノードは応答して、ソースノードを含むシステム内の処理ノードの各々に無効化プローブを伝送し得る。後から到着したヴィクティムブロックは、最新のデータを含み得ず、かつターゲットノードメモリ内の対応するメモリ位置にコミットする必要がないために、ソースノードがターゲット終了応答を受取ったときに、ソースノードはターゲットノードにメモリキャンセル応答を送る。さらに、ターゲット終了応答は無効化プローブの介入の後で受取られるために、ソースノードからのメモリキャンセル応答はこうして処理ノードの間のキャッシュコヒーレンシを維持する助けをする。
【0013】
一実施例においては、第1の処理ノードが第2の処理ノードに読出コマンドを送って、第2の処理ノードに関連する指定されたメモリ位置からデータを読出すと、第2の処理ノードは、応答してシステム内のすべての残りの処理ノードにプローブコマンドを送信する。指定されたメモリ位置のキャッシュされたコピーを有する処理ノードの各々は、そのキャッシュされたデータに関連するキャッシュタグを更新してデータの現在のステータスを反映させる。プローブコマンドを受取った処理ノードの各々は次いで、処理ノードがデータのキャッシュされたコピーを有するかどうかを示すプローブ応答を送る。処理ノードが指定されたメモリ位置のキャッシュされたコピーを有する場合には、その処理ノードからのプローブ応答はキャッシュされたデータの状態、すなわち変更、共用などをさらに含む。
【0014】
プローブコマンドを受取ると、すべての残りのノードは、指定されたメモリ位置のキャッシュされたコピーがもしあれば、上述のようにそのステータスをチェックする。ソースノードとターゲットノード以外の処理ノードが、指定されたメモリ位置のキャッシュされたコピーで、かつ変更された状態のものを見出した場合には、その処理ノードは応答してターゲットノード、すなわち第2の処理ノードにメモリキャンセル応答を送る。このメモリキャンセル応答は、第2の処理ノードにさらなる読出コマンドの処理を打切らせ、かつまだ読出応答を送っていなければ、読出応答の送信を中止させる。それでも他のすべての残りの処理ノードは、それらのプローブ応答を第1の処理ノードに送る。変更されたキャッシュされたデータを有する処理ノードは、その変更されたデータをそれ自体の読出応答を介して第1の処理ノードに送る。プローブ応答と読出応答とを含むメッセージ通信方式はこうして、システムメモリ読出動作の間にキャッシュコヒーレンシを維持する。
【0015】
メモリキャンセル応答はさらに、第2の処理ノードがそれ以前に読出応答を第1の処理ノードに送ったかどうかにかかわらず、第2の処理ノードがターゲット終了応答を第1の処理ノードに送信するようにさせる。第1の処理ノードは、すべての応答、すなわちプローブ応答、ターゲット終了応答、および変更されたキャッシュされたデータを有する処理ノードからの読出応答を待ち、その後で第2の処理ノードにソース終了応答を送ることにより、データ読出サイクルを完了させる。この実施例においては、メモリキャンセル応答は、要求されたデータの変更されたコピーが異なった処理ノードにおいてキャッシュされたときに時間のかかるメモリ読出動作を打切らせることにより、システムメモリ帯域幅を節約し得る。処理ノードとシステムメモリとの間の比較的低速のシステムメモリバスが関与する同様のデータ伝送よりも、高速デュアル単方向リンクを介した2つの処理ノード間のデータ伝送が実質的に速いことが観察されたとき、こうしてデータ転送レイテンシの減少が達成される。
【0016】
以下の図面と併せて、以下の好ましい実施例の詳細な説明を考察することにより、この発明はよりよく理解されるであろう。
【0017】
【発明の実施の形態】
図1は、マルチプロセッシングコンピュータシステム10の一実施例を示す。図1の実施例においては、コンピュータシステム10はいくつかの処理ノード12A、12B、12C、および12Dを含む。処理ノードの各々は、処理ノード12A−12Dにそれぞれ含まれるメモリコントローラ16A−16Dを介して、それぞれのメモリ14A−14Dに結合される。さらに、処理ノード12A−12Dは、インターフェイスロジックとしても知られる、1つ以上のインターフェイスポート18を含んで処理ノード12A−12Dの間で通信し、かつ処理ノードと対応するI/Oブリッジとの間でも通信する。たとえば、処理ノード12Aは、処理ノード12Bと通信するためのインターフェイスロジック18Aと、処理ノード12Cと通信するためのインターフェイスロジック18Bと、さらに別の処理ノード(図示せず)と通信するための第3のインターフェイスロジック18Cを含む。同様に、処理ノード12Bはインターフェイスロジック18D、18E、および18Fを含み、処理ノード12Cはインターフェイスロジック18G、18H、および18Iを含み、処理ノード12Dはインターフェイスロジック18J、18K、および18Lを含む。処理ノード12Dは、インターフェイスロジック18Lを介して結合されてI/Oブリッジ20と通信する。他の処理ノードは同様の様式で他のI/Oブリッジと通信し得る。I/Oブリッジ20はI/Oバス22に結合される。
【0018】
処理ノード12A−12Dを相互接続するインターフェイス構造は、1組のデュアル単方向リンクを含む。デュアル単方向リンクの各々は、パケットベースの1対の単方向リンクとして実現化されて、コンピュータシステム10内のどの2つの処理ノード間でも高速パケット化情報転送を達成する。単方向リンクの各々は、パイプライン化され分割されたトランザクションによる相互接続として見ることができる。単方向リンク24の各々は、1組のコヒーレントな単方向ラインを含む。こうして、単方向リンク対の各々は、第1の複数のバイナリパケットを担持する1つの送信バスと、第2の複数のバイナリパケットを担持する1つの受信バスとを含む、と見ることができる。バイナリパケットの内容は第1に、要求される動作の種類と、動作を開始する処理ノードとに依存する。デュアル単方向リンク構造の一例は、リンク24Aおよびリンク24Bである。単方向ライン24Aを用いてパケットを処理ノード12Aから処理ノード12Bに送信し、ライン24Bを用いてパケットを処理ノード12Bから処理ノード12Aに送信する。ライン24C−24Hの他の組を用いて、図1に示すようにそれらの対応する処理ノードの間のパケットを送信する。
【0019】
同様のデュアル単方向リンク構造を用いて、処理ノードとその対応のI/O装置、またはグラフィック装置、もしくは処理ノード12Dに関して示すI/Oブリッジとの間の相互接続を行ない得る。デュアル単方向リンクは、処理ノード間の通信のためにキャッシュコヒーレント様式で動作するか、または処理ノードと外部I/O、またはグラフィック装置、もしくはI/Oブリッジとの間の通信のために、非コヒーレント様式で動作し得る。一方の処理ノードから他方へ送信されるべきパケットは、1つ以上の残りのノードを通過し得ることに留意されたい。たとえば、処理ノード12Aによって処理ノード12Dに送信されるパケットは、図1の構成内の処理ノード12Bまたは処理ノード12Cのいずれをも通過し得る。好適な経路制御アルゴリズムのいずれを用いることもできる。コンピュータシステム10の他の実施例は、図1に示すものよりもより多くの、またはより少ない処理ノードを含み得る。
【0020】
処理ノード12A−12Dは、メモリコントローラおよびインターフェイスロジックに加えて、1つ以上のプロセッサコア、内部キャッシュメモリ、バスブリッジ、グラフィックスロジック、バスコントローラ、周辺装置コントローラなどの他の回路素子を含み得る。概略的には、処理ノードは少なくとも1つのプロセッサを含み、選択により、メモリおよび所望の他のロジックと通信するためのメモリコントローラを含む。さらに、処理ノード内の回路素子の各々は、処理ノードによって行なわれる機能に依拠して1つ以上のインターフェイスポートに結合されることができる。たとえばある回路素子は、I/Oブリッジを処理ノードに接続するインターフェイスロジックのみを結合し、他の回路素子は2つの処理ノードを接続するインターフェイスロジックのみを結合し得る。他の組合せは、所望のように容易に実現し得る。
【0021】
メモリ14A−14Dは、いずれかの好適なメモリ装置を含み得る。たとえば、メモリ14A−14Dは、1つ以上のRAMBUS DRAM(RDRAM)、シンクロナスDRAM(SDRAM)、スタティックRAMなどを含み得る。コンピュータシステム10のメモリアドレス空間は、メモリ14A−14Dの間で分割される。処理ノード12A−12Dの各々はメモリマップを含むことができ、該メモリマップを用いて、どのアドレスがどのメモリにマッピングされているかを判断し、よって、ある特定のアドレスに対するメモリ要求がどの処理ノード12A−12Dに経路制御されるべきかを判断する。一実施例においては、コンピュータシステム10内のアドレスに対するコヒーレンシ点は、アドレスに対応するバイトをストアしているメモリに結合された、メモリコントローラ16A−16Dである。言い換えると、メモリコントローラ16A−16Dは、対応するメモリ14A−14Dへのメモリアクセスの各々を、キャッシュコヒーレントな様式で起こることを確実にすることを担当している。メモリコントローラ16A−16Dは、メモリ14A−14Dにインターフェイスするための制御回路を含み得る。さらに、メモリコントローラ16A−16Dは、メモリ要求を待ち行列として管理するための、要求キューを含み得る。
【0022】
一般的には、インターフェイスロジック18A−18Lは、1つの単方向リンクからのパケットを受取り、かつ別の単方向リンクに送信されるべきパケットをバッファするための、さまざまなバッファを含み得る。コンピュータシステム10は、パケットを転送するための好適なフロー制御であればいずれでも用い得る。たとえば一実施例においては、送信インターフェイスロジック18の各々は、送信インターフェイスロジックが接続されたリンクの他端の受信インターフェイスロジック内に、いくつかの各種のバッファのカウントをストアする。インターフェイスロジックは、受信インターフェイスロジックがパケットをストアするフリーのバッファを有さない限り、パケットを送信しない。パケットを次に経路制御することにより受信バッファが解放されると、受信インターフェイスロジックは送信インターフェイスロジックにメッセージを送り、バッファが解放されたことを示す。そのような機構は、「クーポンに基づく」システムと呼べる。
【0023】
次に図2は、処理ノード12Aおよび12Bのブロック図を示し、処理ノード12Aおよび12Bを接続するデュアル単方向リンク構造のより詳細な一実施例を例示する。図2の実施例においては、ライン24A(単方向リンク24A)は、クロックライン24AAと、制御ライン24ABと、コマンド/アドレス/データバス24ACとを含む。同様に、ライン24B(単方向リンク24B)は、クロックライン24BAと、制御ライン24BBと、コマンド/アドレス/データバス24BCとを含む。
【0024】
クロックラインは、対応する制御ラインおよびコマンド/アドレス/データバスに対するサンプルポイントを示すクロック信号を送信する。特定の一実施例においては、データ/制御ビットはクロック信号のエッジの各々(すなわち立上がりエッジおよび立下がりエッジ)で送信される。したがって、クロックサイクルごとに、ラインごとに2つのデータビットを送信し得る。ラインごとに1ビットを送信するために使用される時間は、ここでは「ビット時間」と呼ぶ。上述の実施例は、クロックサイクルごとに2つのビット時間を含む。パケットは2つ以上のビット時間で伝送し得る。コマンド/アドレス/データバスの幅に依拠して、多数のクロックラインを用い得る。たとえば32ビットコマンド/アドレス/データバスに対しては2つのクロックラインを用い得る(コマンド/アドレス/データバスの半分では一方のクロックラインが参照され、残りの半分のコマンド/アドレス/データバスと制御ラインとでは他方のクロックラインが参照される)。
【0025】
制御ラインは、コマンド/アドレス/データバスに送信されたデータが、ビット時間の制御パケットか、またはビット時間のデータパケットであるかを示す。制御ラインはアサートされて制御パケットを示し、デアサートされてデータパケットを示す。ある制御パケットは、後にデータパケットが続くことを示す。データパケットは、対応する制御パケットのすぐ後に続き得る。一実施例においては、他の制御パケットがデータパケットの送信に割込むおそれがある。そのような割込は、データパケットの送信の間に制御ラインをいくつかのビット時間アサートし、かつ制御ラインがアサートされている間にビット時間の制御パケットを送信することにより行なわれる可能性がある。データパケットに割込む制御パケットは、データパケットが後に続くことを示さないおそれがある。
【0026】
コマンド/アドレス/データバスは、データ、コマンド、応答、およびアドレスビットを送信するための1組のラインを含む。一実施例においては、コマンド/アドレス/データバスは、8、16、または32のラインを含み得る。処理ノードまたはI/Oブリッジの各々は、設計選択にしたがってサポートされる数のラインのうちのいずれかを用い得る。他の実施例は、所望の他のサイズのコマンド/アドレス/データバスをサポートし得る。
【0027】
一実施例によると、コマンド/アドレス/データバスラインおよびクロックラインは、反転データを担持し得る(すなわち、論理1はライン上の低電圧として表わされ、論理0が高電圧として表わされる)。これに代えて、これらのラインは非反転データを担持してもよい(論理1はライン上の高電圧として表わされ、論理0は低電圧として表わされる)。好適な正および負論理の組合せもまた実現化し得る。
【0028】
図3から図7は、コンピュータシステム10の一実施例に従った、キャッシュコヒーレントな通信(すなわち処理ノード間の通信)に用いられる例示的なパケットを示す。図3から図6は制御パケットを示し、図7はデータパケットを示す。他の実施例は異なったパケット定義を用い得る。制御パケットおよびデータパケットは集合的にバイナリパケットとも呼ぶ。パケットの各々は、「ビット時間」の見出しの下に列挙される一連のビット時間で示される。パケットのビット時間は、リストされたビット時間順序に従って送信される。図3から図7は、8ビットコマンド/アドレス/データバス実現化のためのパケットを示す。したがって、(7から0まで番号が付与された)8ビットの制御情報またはデータ情報は、ビット時間の各々の間に8ビットコマンド/アドレス/データバス上を送信される。図中、いずれの値も付与されていないビットは、所与のパケットのために予約されているか、またはパケット特定情報を伝送するために用いられるかのいずれかであり得る。
【0029】
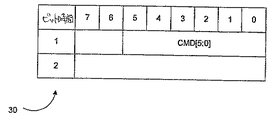
図3は情報パケット(infoパケット)30を示す。情報パケット30は、8ビットリンク上の2つのビット時間を含む。この実施例においては、コマンド符号化はビット時間1の間に送信され、かつコマンドフィールドCMD[5:0]で示す、6ビットを含む。例示的なコマンドフィールド符号化を図8に示す。図4、図5、図6に示す他方の制御パケットの各々は、ビット時間1の間に同じビット位置においてコマンド符号化を含む。メッセージがメモリアドレスを含まないときに、情報パケット30を用いてこのメッセージを処理ノード間で送信し得る。
【0030】
図4はアドレスパケット(addressパケット)32を示す。アドレスパケット32は、8ビットリンク上の8つのビット時間を含む。コマンド符号化は、DestNodeフィールドで示す宛先ノード番号の一部と併せて、ビット時間1の間に送信される。宛先ノード番号の残りとソースノード番号(SrcNode)とは、ビット時間2の間に送信される。ノード番号はコンピュータシステム10内の処理ノード12A−12Dのうちの1つを明確に識別し、かつ用いられてパケットをコンピュータシステム10を介して経路制御する。さらに、パケットのソースは、ビット時間2および3の間に送信されるソースタグ(SrcTag)を割当て得る。ソースタグは、ソースノードによって開始される特定のトランザクションに対応するパケットを識別する(すなわち、特定のトランザクションに対応するパケットの各々は、同一のソースタグを含む)。こうして、たとえばSrcTagフィールドが7ビット長さであれば、対応するソースノードはシステム内で進行する間に最大128(27)の異なったトランザクションを有し得る。システム内の他のノードからの応答は、応答内のSrcTagフィールドを介して対応のトランザクションと関連付けられる。ビット時間4から8までを用いて、アドレスフィールドAddr[39:0]で示すトランザクションによって影響されたメモリアドレスを送信する。アドレスパケット32を用いて、トランザクション、たとえば読出または書込トランザクションを開始し得る。
【0031】
図5は、応答パケット(responseパケット)34を示す。応答パケット34は、コマンド符号化、宛先ノード番号、ソースノード番号、およびアドレスパケット32と同様のソースタグを含む。SrcNode(ソースノード)フィールドは好ましくは、応答パケットの生成を促すトランザクションを発信したノードを識別する。一方、DestNode(宛先ノード)フィールドは、応答パケットの最終的なレシーバである処理ノードを、すなわちソースノードまたはターゲットノード(後に説明)を識別する。さまざまな種類の応答パケットが付加的な情報を含み得る。たとえば、図11Aを参照して後に説明する読出応答パケットは、以下のデータパケットで提供される読出データの量を示し得る。後に図12を参照して説明するプローブ応答は、要求されたキャッシュブロックに対してヒットが検出されたかどうかを示し得る。一般的に、応答パケット34は、トランザクションを行なう間にアドレスの送信を必要としないコマンドに対して用いられる。さらに、応答パケット34を用いて肯定応答パケットを送信してトランザクションを終了させることができる。
【0032】
図6は、コマンドパケット(commandパケット)36の例を示す。上述のように、単方向リンクの各々はパイプライン化され、分割されたトランザクション相互接続であって、トランザクションはソースノードによってタグ付けされ、応答は任意の所与の時間にも、パケットの経路制御に依存して順不同でソースノードに戻ることができる。ソースノードは、コマンドパケットを送信してトランザクションを開始する。ソースノードはアドレスマッピングテーブルを含み、ターゲットノード番号(TgtNodeフィールド)をコマンドパケットに入れて、コマンドパケット36の宛先である処理ノードを識別する。コマンドパケット36は、CMDフィールド、SrcNodeフィールド、SrcTagフィールド、およびAddrフィールドを有するが、これらはアドレスパケット32(図4)を参照に説明され示されたものと同様である。
【0033】
コマンドパケット36の1つの際立った特徴は、Countフィールドの存在である。キャッシュ不可能な読出または書込動作においては、データのサイズはキャッシュブロックのサイズよりも小さくあり得る。こうして、たとえば、キャッシュ不可能な読出動作は、システムメモリまたはI/O装置からのちょうど1バイトまたは1クワッドワード(64ビット長さ)だけのデータを必要とし得る。この種類のサイズ指定された読出または書込動作は、Countフィールドの助けによって容易となる。この例においては、Countフィールドは3ビット長さで示す。したがって、所与のサイズ指定されたデータ(バイト、クワッドワードなど)は、最高8回まで送信されることができる。たとえば、8ビットリンクにおいては、Countフィールドの値が0(バイナリ000)である場合、コマンドパケット36は1つのビット時間でのちょうど1バイトだけのデータの転送を示す。一方、Countフィールドの値が7(バイナリ111)である場合、クワッドワード、すなわち8バイトが、合計で8ビット時間の間に伝送されることができる。CMDフィールドは、いつキャッシュブロックが伝送されたのかを識別し得る。この場合、Countフィールドは固定値を有し、キャッシュブロックが64バイトサイズである場合7であるが、これは8クワッドワードがキャッシュブロックを読出または書込するために伝送されなければならないためである。8ビットワイドの単方向リンクの場合においては、64のビット時間にわたる8つの完全なデータパケット(図7)の伝送を必要とし得る。好ましくは、データパケット(図7を参照して後に説明)は、書込コマンドパケットまたは読出応答パケット(後に説明)の直後に続き、データバイトはアドレスの昇順で転送されることができる。単一のバイトまたはクワッドワードのデータ転送は、自然に整地されたそれぞれ8または64バイト境界をまたがらない。
【0034】
図7は、データパケット(dataパケット)38を示す。データパケット38は、図7の実施例において、8ビットリンク上の8つのビット時間を含む。データパケット38は、64バイトのキャッシュブロックを含み得るが、この場合キャッシュブロック転送を完了させるために(8ビットリンク上の)64のビット時間がかかるであろう。他の実施例では、キャッシュブロックのサイズを所望により別に定義し得る。さらに、コマンドパケット36(図6)を参照して上に説明したように、キャッシュ不可能な読出および書込に対するキャッシュブロックサイズよりも小さなサイズでデータを送信し得る。キャッシュブロックサイズより小さなデータを送信するためのデータパケットは、より少ないビット時間しか必要としない。
【0035】
図3から図7は、8ビットリンクのためのパケットを示す。16および32ビットリンクのためのパケットは、図3から図7に示す連続的なビット時間を連結することにより形成し得る。たとえば、16ビットリンク上のパケットのビット時間1は、8ビットリンク上のビット時間1および2の間に送信される情報を含み得る。同様に、32ビットリンク上のパケットのビット時間1は、8ビットリンク上のビット時間1から4までの間に送信される情報を含み得る。以下の式(1)および式(2)は、8ビットリンクに対するビット時間における、16ビットリンクのビット時間1および32ビットリンクのビット時間1の構成を示す。
【0036】
【数1】

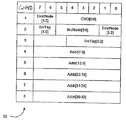
図8は、コンピュータシステム10内のデュアル単方向リンク構造の1つの例示的な実施例に対して用いられるコマンドを示すテーブル40を示す。テーブル40は、コマンドの各々に割当てられたコマンド符号化(CMDフィールド)を示すコマンド符号化列、コマンドの名前を示すコマンド列、およびどのコマンドパケット30−38(図3から図7)がそのコマンドに対して用いられるかを示すパケットタイプ列を含む。図8におけるコマンドのいくつかに対する簡単な機能の説明を以下に示す。
【0038】
読出トランザクションは、Rd(Sized),RdBlk,RdBlkSまたはRdBlkModのコマンドのうち、1つを用いて開始される。サイズ指定された読出コマンドであるRd(Sized)は、キャッシュ不可能な読出のために、またはサイズの合ったキャッシュブロック以外のデータの読出のために用いられる。読出されるべきデータ量は、Rd(Sized)コマンドパケット内に符号化される。キャッシュブロックの読出には、以下の場合以外にRdBlkコマンドを用いることができる。すなわち、(i)キャッシュブロックの書込可能なコピーを所望する場合。この場合はRdBlkModコマンドを用い得る。または(ii)キャッシュブロックのコピーを所望するが、ブロックを変更する意図があるとは分らない場合。RdBlkSコマンドを用いて、ある種のコヒーレントな方式(たとえばディレクトリに基づくコヒーレントな方式)をより効率化できる。RdBlkSコマンドに応答して、ターゲットノードはキャッシュブロックをソースノードに共用状態で返し得る。一般的に、適切な読出コマンドはソースノードから送信されて、ソースノードから要求されたキャッシュブロックに対応するメモリを有するターゲットノードへの読出トランザクションを開始する。
【0039】
ソースノードにストアされた書込不可能または読出専用状態のキャッシュブロックへの書込許可を得るために、ソースノードはChangeToDirtyパケットを送信し得る。ChangeToDirtyコマンドによって開始されるトランザクションは、ターゲットノードがデータを返さないという点を除いて、読出と同様に動作し得る。もしソースノードがキャッシュブロック全体を更新する意図があるのであれば、ValidateBlkコマンドを用いて、ソースノードにストアされていないキャッシュブロックへの書込許可を得ることができる。そのようなトランザクションに対してはソースノードへデータは転送されないが、それ以外では読出トランザクションと同様に動作する。好ましくは、ValidateBlkおよびChangeToDirtyコマンドは、メモリのみに向けられ、かつコヒーレントなノードによってのみ生成されることができる。
【0040】
InterruptBroadcast、InterruptTarget、およびIntrResponseパケットを用いて、それぞれ割込をブロードキャストし、特定のターゲットノードに割込を送り、かつ割込に応答し得る。CleanVicBlkコマンドを用いて、(たとえば、ディレクトリに基づくコヒーレントな方式のために)クリーンな状態のキャッシュブロック(ヴィクティムブロック)がノードから捨てられたことを伝えることができる。TgtStartコマンドはターゲットによって用いられて、(たとえば、後のトランザクションの順序付けのために)トランザクションが開始したことを示す。エラーコマンドを用いて、エラー表示を送信する。
【0041】
図9、図13および図14に、コンピュータシステム10内の処理ノードが指定されたメモリ位置の読出を試みるときのパケットのフローのいくつかの例を示す。指定されたシステムメモリ位置または対応のシステムメモリ位置は、例示のためにのみ、ターゲット処理ノード72に関連のシステムメモリ421内にあると想定する。システムメモリ421は、ターゲット処理ノード72の一部であるか、またはここに示すようにターゲットノード72の外部にあってもよい。さらに、メモリ読出トランザクションの間に、指定されたメモリ位置のコピーが既にターゲットノード72の内部または外部キャッシュメモリに存在する可能性がある。いずれにしても、ソースノード70が関連の指定されたメモリ位置を読出すために読出コマンドをターゲットノード72に送信するときはいつでも、パケットのフローは同じままである。いずれの処理ノード12A−12D(図1)もソースノードまたはターゲットノードとして機能し得ることに留意されたい。ソースノードでもターゲットノードでもないノードは残りのノードと呼ばれるが、ここではノード74および76である。図9、図13、図14において、理解を助けるためにのみ、同じ番号を用いてソースノード、ターゲットノードおよび残りのノードを識別する。これは図9におけるソースノード70が図13における同じソースノードであることを表示しない。
【0042】
上述のように、図1におけるいずれの処理ノードも、特定のトランザクションに依拠してソースノード、ターゲットノードまたは残りのノードとして機能し得る。図9、図13および図14の構成は例示のためにのみ示し、これらは処理ノード12A−12Dの間の同様の実際の接続を示すものではない。すなわち、残りのノード、たとえばノード76、またはターゲットノード72は、ソースノード70に直接接続されないかもしれない。したがって、付加的なパケット経路制御が生じ得る。さらに、図9、図13および図14の構成は、図1における回路トポロジーを参照して説明される。2つ以上の処理ノードの間の他の相互接続が企図可能であり、これらのさまざまな相互接続で図9、図13、および図14のパケット転送方式を容易に実現化し得ることが理解される。矢印は、従属性と、矢印によって結合されるそれぞれのノードの間で送信されるべきパケットとを示す。一般的に外部に向かう矢印は、対応の入来する従属関係のすべてが発生するまで、生じない。これを図9、図13、および図14に示す動作を参照して以下に詳述する。
【0043】
図9を参照して、読出トランザクションの間のパケット42のフローを示すが、該読出トランザクションは上述のようにRd(Sized)またはブロック読出(RdBlk、RdBlkS、RdBlkMod)である。ソースノード70内のプロセッサ(図示せず)は、適切な読出コマンドをターゲットノード72内のメモリコントローラ(図示せず)に送る。典型的なコマンドパケットは、図6を参照して既に説明した。ソースプロセッサから読出コマンドを受取ると、応答してターゲットメモリコントローラは、以下の2つの動作を行なう。(1)RdResponse(読出応答)パケットをメモリ421から要求されたデータと併せてソースノード70に送る。(2)コンピュータシステム10内のすべての処理ノードにProbe/Srcコマンドをブロードキャストする。一般的には、Probe/Srcコマンド(より簡単には、プローブコマンド)は、キャッシュブロックがノード内に含まれているかどうか判断するためのそのノードへの要求であり、かつもしキャッシュブロックがそのノードにストアされていれば、そのノードが取るべき動作を表示する。一実施例においては、パケットが1つ以上の宛先に対してブロードキャストされると、パケットを最初に受信する受信ノードのルータは、そのノードでパケットを終了させ、隣接する処理ノードにそのパケットのコピーを再生成し送信し得る。
【0044】
上述のこれら2つの動作の正確な実行の順序は、ターゲットノード72内のさまざまな内部バッファにおける未完了の動作のステータスに依拠し得る。好ましくは、コンピュータシステム10内の処理ノードの各々は、コマンドパケット、さまざまなコマンドパケットに関連のデータパケット(たとえば、メモリ書込コマンド)、プローブ、応答パケット(たとえば、ProbeResp、SrcDone、TgtDone、MemCancel)、および読出応答(RdResponseパケットおよびその関連のデータパケットの両方を含む)をストアするためのいくつものバッファを含む。データバッファの各々は、たとえば64バイトサイズのキャッシュブロックのための記憶装置を含み得る。これに代えて、設計要件に基づいて他の便利な記憶容量のいずれをも実現化し得る。
【0045】
上述のバッファを用いた2つの処理ノード間のバイナリパケットのフローは、上述の「クーポンに基づく」システムを実現化することにより、制御し得る。この実現化においては、送信ノードは、受信ノードの各種のバッファに対するカウンタを含み得る。システムリセットの際に送信ノードはそのカウンタをクリアすることができ、リセット信号がデアサートされたときには、受信ノードは情報パケットを(CMDフィールドがNopコマンドを識別する、図3に示すものと同様のフォーマットによって)送信ノードに送り、それが各種の利用可能なバッファをいくつ有するかを示す。送信ノードがパケットを受信ノードに送ると、これは関連のカウンタをデクリメントし、特定のカウンタが値0に到達すると、送信ノードプロセッサは関連のバッファへのパケットの送信を停止する。レシーバがバッファを解放すると、これは別の情報パケットをトランスミッタに送り、トランスミッタは関連のカウンタをインクリメントする。トランスミッタは、レシーバがコマンドバッファおよびデータバッファの両方を利用可能にしない限り、メモリ書込動作を開始し得ない。
【0046】
再び図9に戻ると、ターゲットノード72内のメモリコントローラは、Probe/Srcコマンドをシステム内の他のノードに送信して、これらのノード内のキャッシュブロックの状態を変化させることと、キャッシュブロックの更新されたコピーを有するノードに、キャッシュブロックをソースノードに送らせることとにより、コヒーレンシを維持する。方式は、プローブコマンド内で受信ノードを識別する表示を用いてプローブ応答を受信する。ここで、Probe/Srcコマンド(プローブコマンド)は、残りのノード74、76のそれぞれに、ProbeResp(プローブ応答)をソースノードに送信させる。プローブ応答は、動作が起こったことを示し、かつもしキャッシュブロックがノードによって変更されていればデータの送信を含み得る。もしプローブされたノードが読出データの更新されたコピー(すなわちダーティデータ)を有していれば、図13に関して後に説明するように、ノードはRdResponse(読出応答)パケットとダーティデータとを送信する。Probe/Srcコマンドは、(ターゲットノード72を含む)所与の処理ノード内のキャッシュコントローラによって受取られ、ProbeRespおよびRdResponseは、そのキャッシュコントローラによって生成されることができる。一般的には、関連のキャッシュを有する処理ノード内のキャッシュコントローラは、Probe/Srcコマンドに応答してプローブ応答パケットを生成し得る。一実施例においては、処理ノードがキャッシュを有さないとき、その処理ノードはプローブ応答パケットを生成し得ない。
【0047】
一旦(残りのノード74および76からの)プローブ応答と、(ターゲットノード72からの)要求されたデータを備えたRdResponseとがソースノードにおいて受取られると、ソースノードプロセッサはSrcDone(ソース終了)応答パケットをトランザクション終了の肯定応答としてターゲットノードメモリコントローラ(図示せず)に送信する。読出動作の各々の間の処理ノード間のコヒーレンシを維持するために、ソースノードは(残りのノードからの)すべてのプローブ応答をも受取るまで、ターゲットノード72からRdResponseを介して受取ったデータを使用し得ない。ターゲットノードがSrcDone応答を受取ったとき、これは(ソースノード70から受取った)読出コマンドをそのコマンドバッファキューから取除き、次いでこれは同様に指定されたメモリアドレスに対してコマンドへの応答を開始し得る。
【0048】
送られたコマンドに依拠してプローブ応答を異なった受信ノードへ経路制御する柔軟性を与えることにより、コヒーレンシの維持を比較的効率的な態様で行ない得る(たとえば、処理ノード間で最も少ない数のパケット送信を用いる)一方で、さらにコヒーレンシが維持されることを確実にする。たとえば、トランザクションのターゲットまたはソースがトランザクションに対応するプローブ応答を受取るべきであることを示すプローブコマンドをも含み得る。プローブコマンドは、トランザクションのソースを読出トランザクションに対する受信ノードとして特定し得る(それによりダーティデータをストアしていたノードからソースノードへダーティデータが引き渡される)。一方で、(トランザクションのターゲットノードのメモリ内でデータが更新される)書込トランザクションに対しては、プローブコマンドはトランザクションのターゲットを受信ノードとして特定し得る。こうして、ターゲットは書込データをいつメモリにコミットするか判断し、かつ書込データとマージされるべきダーティデータのいずれかを受取り得る。
【0049】
図10から図12は、プローブコマンド、読出応答およびプローブ応答パケットのそれぞれの一実施例を示す。図10Aのプローブコマンドパケット44は、図6に示す一般的なコマンドパケットとはやや異なる。CMDフィールドは、受信ノードにその応答をソースノード70へ送信することを要求するProbe/Srcコマンドとして、プローブを識別する。上述のように特定の他のトランザクションにおいてはターゲットノード72はプローブコマンドに対する応答の受信側であり得るが、CMDフィールドはまたこれらの場合でもそのように示すであろう。さらに、関連する経路制御に依拠して、ソースノード70またはターゲットノード72のいずれか、またはこれらの両方が、システム内の他の残りのノードよりも前かまたは同時にProbe/Srcコマンドを受取る可能性もある。プローブコマンドのSrcNodeおよびTgtNodeフィールドは、ソースノードとターゲットノードとをそれぞれ識別し、ソースノードキャッシュコントローラがプローブコマンドに応答することを防ぐであろう。SrcTagフィールドは、図4を参照に先に説明したものと同様に機能する。DM(データ移動)ビットは、このプローブコマンドに応答してデータ移動が要求されているかどうかを示す。たとえば、DMビットがクリアされていれば、それはいずれのデータ移動もないことを示す。一方で、もしDMビットがセットされていれば、プローブコマンドが残りのノード74または76のうちの1つの中の、内部(外部)キャッシュ内のダーティブロックまたは共用/ダーティブロックをヒットした場合に、データ移動が要求される。
【0050】
上述のように、ソースノードからの読出コマンドは、サイズ指定された読出コマンド[Rd(sized)]またはブロック読出コマンド[RdBlk、RdBlkS、またはRdPlkMmd]であり得る。どちらの種類の読出コマンドも好ましくはデータ移動を要求し、よってDMビットはターゲットノードのメモリコントローラによってセットされてデータ移動要求を示し得る。異なった実施例においては、DMビットはクリアされている場合に、データ移動を示し、DMビットはセットされている場合に、いずれのデータ移動もないことを示す。
【0051】
NextStateフィールド46(図10B)は、Probeビットがあった場合、すなわち、1つ以上の残りのノードが、プローブコマンドAddrフィールドによって識別される指定されたメモリ位置のキャッシュコピーを有する場合に、起こるべきステートトランザクションを示す2ビットフィールドである。図10BにNextStateフィールド46に対する1つの例示的な符号化を示す。ブロック読出コマンドの間では、NextStateフィールドは1であり、よってメモリデータのキャッシュコピーを有する残りのノードは、Probe/Srcコマンドを受信するとそのコピーを共用としてマークする。一方で、サイズ指定された読出コマンドの間では、NextStateフィールドは0であり、よって、いずれの残りのノードも、メモリ421からのデータのキャッシュコピーを有する場合であっても、対応のキャッシュタグを変える必要はない。特定の他のターゲットメモリトランザクション(たとえば特定の書込動作)においても、対応する残りのノード内のキャッシュされたデータを、値2でNextStateフィールド46によって示されるように、無効としてマークすることが望ましいであろう。
【0052】
こうしてプローブコマンドは、このNextStateフィールドを介してメモリ読出動作の間のシステム処理ノード間のキャッシュコヒーレンシを維持し得る。ターゲットノードキャッシュコントローラは、ターゲットノードメモリコントローラによるProbe/Srcコマンドブロードキャストの受信の際、およびターゲットノード(内部または外部)キャッシュメモリ内の要求されたデータの発見の際に、プローブ応答パケットを読出応答パケットと併せて送信し得る。後に説明するように、ソースノードは、RdResponseおよびProbeRespパケットによって供給される情報によって要求されたデータに関連のキャッシュタグを更新する。このようにしてソースノードは、(対応するキャッシュタグを介して)これが要求されたデータの排他的または共用コピーを有するかどうか表示し得る。ターゲットノードキャッシュコントローラからのプローブ応答パケットは、たとえばターゲットノードだけが要求されたデータのコピーをそのキャッシュ内に有し、他のいずれの残りのノードも要求されたデータのキャッシュコピーを有さない状況において、助けになり得る。しかしながら、ターゲットノードは、ターゲットノードがソースによって要求されたデータをそのキャッシュ内に有するときに、そのキャッシュ状態を自動的に更新するよう構成されてもよく、したがってこれはターゲットノードキャッシュからデータをソースへ送る。
【0053】
図11Aを参照すると、RdResponseパケット48に対する例示的な符号化を示す。ターゲットノード72内のメモリコントローラ(図示せず)は、サイズ指定された読出コマンドまたはブロック読出コマンドのいずれであっても、読出コマンドの各々に応答してRdResponseをソースノード70に送るよう構成されることができる。これに代えて上述のように、ターゲットノードキャッシュコントローラ(図示せず)は、要求されたデータがターゲットノード内にキャッシュされている場合に、適切な読出応答パケットを送るよう構成されてもよい。典型的には、RdResponseパケット48の後には要求されたデータを含むデータパケット38(図7)が続く。サイズ指定された読出動作に対するデータパケットは、最も低いアドレスのデータが最初に返され、残りのアドレスのデータが昇順に返されるよう構成されてもよい。しかしながら、キャッシュブロック読出に対するデータパケットは、要求されたクワッドワード(64ビット)が最初に返され、残りのキャッシュブロックはインタリーブラッピングを用いて返されるよう構成されてもよい。
【0054】
RdResponseパケット48内のCountフィールドは、読出トランザクションを開始する読出コマンド内のCountフィールド(たとえば図6を参照)と同一である。Typeフィールドは元の読出要求のサイズを符号化し、かつCountフィールドと併せて、データパケットのサイズの合計を表示する。Typeフィールドはバイナリ値0または1のいずれかをとり得る。一実施例においては、Typeフィールドは0であるとき、バイトサイズのデータが転送されるべきであることを示し得る。Typeフィールドが1であるとき、クワッドワード(64ビット)のデータが転送されるべきであることを示し得る。一方、Countフィールドは、Typeフィールドによって示されるそのサイズのデータが、リンクをわたって何回転送されるべきであるかを示し得る。こうして、CountフィールドとTypeフィールドとは組合わされて、転送されるべきデータの合計のサイズを判断し得る。たとえば、8ビット単方向リンクをわたるサイズ指定された読出動作の間、ダブルワードの転送のためにはTypeフィールドは0であって、Countフィールドは3でなければならない[バイナリでは011]。
【0055】
RdResponseパケット48内のRespNodeフィールドは、読出応答パケットが向けられるべきノードを識別する。SrcNodeフィールドは、トランザクションを開始したノード、すなわちソースノード70を識別する。読出動作の間、RespNodeおよびSrcNodeフィールドは、同一のノード、すなわちソースノード70を識別するであろう。図13を参照して後に説明するように、キャッシュ内に(ターゲットメモリ421内の)アドレス指定されたメモリ位置のダーティコピーを有する残りのノードのうちの1つによって、RdResponseが生成されるであろう。データ移動を要求するプローブに応答してノードによって読出応答48が生成されたことを示すために、プローブビットがセットされることができる。クリアされたProbeビットは、メモリコントローラ(図示せず)、またはターゲットノード72のキャッシュコントローラ(図示せず)のいずれからRdResponse48が来たのかを示し得る。
【0056】
Tgtビットは、CMD[5:0]フィールド内のビット位置[0]のビットである。一実施例においては、Tgtビットはセットされている場合に、RdResponse48がターゲットノード72内のメモリコントローラ(図示せず)に(たとえば、ある書込トランザクションの間に)宛先決めされていることを示し得る。一方で、Tgtビットはクリアされている場合に、RdResponse48がソースノード70に宛先決めされていることを示し得る。こうしてTgtビットは、どのようにデータフローがノード内で内部的に管理されているかを識別する。ある実施例においては、Tgtビットを省いてもよい。
【0057】
図11B内のテーブル50は、Probeビット、Tgtビット、Typeフィールド、およびCountフィールド間の関係の1つの例を示す。ここで示すように、RdResponse48がターゲットノード72のキャッシュコントローラ(図示せず)またはメモリコントローラ(図示せず)から来ている場合はいつでも、Probeビットはクリアされている。一実施例においては、ターゲットノード72は、(たとえばサイズ指定された読出動作の間)キャッシュブロックサイズよりも小さなデータを供給し得る。TypeフィールドとCountフィールドとは共にソースノード70に転送されるべきデータのサイズを特定し得る。後に説明するように、残りのノード(ノード74またはノード76)のうちの1つがソースノード70にRdResponseパケットを送るとき、転送されることのできるサイズのデータはキャッシュブロックのみである。この状況において(キャッシュブロックサイズが64バイトであると想定すると)64バイトのデータ転送を達成するためには、Countフィールドは7(バイナリ111)であり、Typeフィールドは1でなくてはならない。
【0058】
図12を参照して、ProbeRespパケット52の例を示す。一般的に、関連のキャッシュメモリを有する処理ノード(1つ以上の残りのノードまたはターゲットノード72)は、MissまたはHitNotDirtyを示してProbeRespパケットをソースノード70に向けることにより、Probe/Srcコマンドに応答する。しかしながら、もし応答するノードが要求されたデータの変更されたキャッシュされたコピーを有すれば、これは代わりに、後に説明するようにRdResponseを送信する。CMDフィールド、RespNodeフィールド、SrcNodeフィールド、およびSrcTagフィールドについては、既に1つ以上の制御パケットを参照して先に説明した。一実施例においては、ヒットビットがセットされていると、応答するノードがアドレス指定されたメモリ位置の変更されていないキャッシュされたコピーを有することを(ソース処理ノード72に)示す。別の実施例においては、クリアされたヒットビットが同様の表示を示し得る。こうして、ソースノード70は、ターゲットノード72から受取ったデータのブロックを(そのキャッシュ内に)どのようにマークするかについての必要な情報を得る。たとえば、もし残りのノード74または76のうちの1つが変更されていない(すなわちクリーンである)アドレス指定されたメモリ位置のコピーを有すれば、ソースノード70はターゲットメモリコントローラ(図示せず)から受取ったデータブロックをクリーン/共用であるとマークするであろう。一方で、もしこれがサイズ指定された読出動作であれば、ソースノード70は、読出したデータがキャッシュブロックよりもサイズが小さいために、受取ったデータに関連するそのキャッシュタグを変える必要はない。これは残りのノードを参照した先の説明(図10B)と極めて似ている。
【0059】
図13に、残りのノードの1つ(ここではノード76)がそのキャッシュ内にターゲットメモリ位置の変更されたコピー(すなわちダーティコピー)を有する場合のパケットのフローの例、すなわち配置54を示す。上述のように、ターゲットノードメモリコントローラ(図示せず)は、ソースノード70から読出コマンドを受取ると、Probe/SrcCommand(プローブコマンド)とRdResponseとを送る。ここで、ターゲットノード72は関連のキャッシュメモリを有すると想定し、よって、ターゲットノードキャッシュコントローラ(図示せず)は上述のようにソースノード70にプローブ応答を送る。ターゲットノード72もまた要求されたデータのキャッシュされたコピーを有する場合には、ターゲットノードキャッシュコントローラ(図示せず)は上述のように、要求されたデータと併せて読出応答パケットをも送る。関連のキャッシュがない場合には、ターゲットノード72はプローブ応答パケットを送り得ない。
【0060】
プローブコマンドパケットおよび読出応答パケットの一実施例は、それぞれ図10Aおよび図11Aに関して先に説明した。しかしながら、図13の実施例においては、応答ノード76はプローブコマンドに応答して、そのキャッシュコントローラを介して2つのパケットを送るよう構成される。すなわち、RdRespパケットをソースノード70内のプロセッサに送り、MemCancel応答をターゲットノードメモリコントローラ(図示せず)に送る。残りのノード76からの読出応答の後に、プローブコマンドパケット内のDM(データ移動)ビット(図10A)から要求されて、変更されたキャッシュブロックを含むデータパケットが続く。図11Aを参照して先に説明したように、非ターゲットノードからのRdResponseは、そのProbeビットをセットにしてデータブロックのソースがターゲットノード72ではないことを示し得る。応答ノード76からのこのRdResponseパケットを介して、ソースノード70は受取ったデータのキャッシュブロックの状態を(その内部キャッシュ内に)変更/共有としてマークするための表示を得る。
【0061】
残りのノード76からのRdResponseパケットは、読出コマンドがサイズ指定された読出トランザクションを識別した場合でも、対応するキャッシュブロックの全体を(変更された状態で)含む。異なった実施例においては、応答非ターゲットノード(ここではノード76)は、要求されたデータのみを直接ソースノードに送るよう構成されてもよい。この実施例においては、ソースノードに転送されるべきデータのサイズは、プローブコマンドの一部として符号化してもよい。さらなる別の実施例においては、応答ノード76は要求されたデータのみをターゲットノード72内のメモリコントローラ(図示せず)に送ってもよく、その後で、ターゲットノードメモリコントローラはデータをソースノード70に返す。
【0062】
応答ノード76からのMemCancel(メモリキャンセル)応答は、ターゲット処理ノード72のメモリコントローラにソースノード70からの読出コマンドのさらなる処理を打ち切らせる。言い換えると、MemCancel応答は、ターゲットノードメモリコントローラからのRdResponseパケット(および要求されたデータ)の送信をキャンセルし、かつターゲットノードメモリコントローラによる先行のメモリ読出サイクルさえもキャンセルする効果を有するが、該メモリ読出サイクルとは、もしターゲットノード読出応答バッファからのRdResponseパケットの解放の前、またはメモリ読出サイクルの完了の前に、ターゲットノードメモリコントローラがMemCancel応答をそれぞれ受取っていればソース70からの読出コマンドに応答して開始されているであろうものである。こうしてMemCancel応答は、2つの主要な目的を達成する。(1)システムメモリ(たとえば、メモリ421)が失効したデータを有する場合、比較的長いメモリアクセスを可能な限りなくすことにより、システムメモリバス帯域幅を節約する。これはまたコヒーレントなリンク上の不必要なデータ転送をも減じる。(2)処理ノード間で最新のキャッシュデータの転送を可能にすることにより、マルチプロセッシングコンピュータシステムにおいてさまざまな処理ノード間のキャッシュコヒーレンシを維持する。
【0063】
図1の回路構成に含まれる経路制御のために、応答ノード76からのMemCancel応答パケットのターゲットノード72への到達は、ターゲットノードメモリコントローラの読出応答パケットの送信または比較的長いメモリ読出サイクルを打ち切らせるのに間に合わないおそれがあることに留意されたい。そのような状況においては、ターゲット処理ノード72は、読出応答送信またはシステムメモリ読出サイクルに遅すぎる場合には、遅れて到着したMemCancel応答を単に無視し得る。トランザクションが打ち切られる正確な時点は、回路構成、実現化された経路制御、オペレーティングソフトウェア、さまざまな処理ノードを構成するハードウェアなどに依存し得る。ソースノードが、ターゲットノードメモリコントローラからRdResponseを受取るとき、これはこのRdResponse(およびその関連のデータパケット)を単に無視し、代わりに、残りのノード76からRdResponseパケットと併せて供給されたキャッシュブロックからの要求されたデータを受取る。
【0064】
MemCancel応答を受取ると、ターゲットノードメモリコントローラは、TgtDone(ターゲット終了)応答をソース処理ノード70に送信する。TgtDone応答は、それ以前にターゲットノードがRdResponseパケット(および要求されたデータ)をソースノード70に送ったかどうかにかかわらず、送信される。もしターゲットノードメモリコントローラがそれ以前にRdResponseパケットを送っていなければ、これはRdResponseパケット(および要求されたデータ)の送信をキャンセルし、代わりに、TgtDone応答をソースノード70に送る。TgtDone応答は、ソースノード70にキャッシュブロックフィルのソースを伝える機能を果たす。TgtDone応答の存在は、ターゲットノードメモリ421またはターゲットノード内部キャッシュ(図示せず)が要求されたデータの失効した状態のものを有することを、ソースノードに示し、よってソースノード70は残りのノードのうちの1つ(たとえばノード74または76)からのキャッシュブロックの変更されたコピーを待たねばならない。
【0065】
ソースノードプロセッサは、TgtDone応答の受取の前に、応答ノード76からのRdResponseパケットと併せて送信される変更されたキャッシュブロックを用い得る。しかしながら、ソースノード70は、SrcDone応答を送る前にそのソースタグ(図6の読出コマンドパケット内のSrcTagフィールド)を再使用し得ないが、これは読出コマンドパケットによって開始されたトランザクション、すなわち読出動作は、読出トランザクションの開始によって生成されたすべての応答をソースノード70が受取るまで、完了しないおそれがあるためである。したがってソースノード70は、(送信されていれば)ターゲットノード72からのRdResponse、ターゲットノードからのTgtDone応答、および他の残りのノードからの他の応答のいずれか(図14を参照して後に説明)を受取るまで待機し、その後でターゲットノードメモリコントローラへのSrcDone応答を送信する。図9を参照した説明と同様に、図13におけるSrcDone応答は、ソースノードによって開始されたメモリ読出トランザクションの完了の信号を、ターゲットノードに送る。ターゲットノード72がRdResponseとTgtDone応答とを送信すると、ソースノードはこれら両方の応答を待ってから、SrcDone応答を介した読出トランザクションの完了に対して肯定応答しなければならないであろう。SrcDone応答はこうして、メモリ読出トランザクションの間のキャッシュブロックのフィル−プローブ順序の維持を助けるが、これは要求されたデータのソースがターゲットノードメモリコントローラであるか、ターゲットノード内部(または外部)キャッシュであるか、または要求されたデータを含むキャッシュブロックのダーティコピーを有する残りのノードのうちの1つであるかにかかわらない。
【0066】
図14を参照すると、ソースノード70によって開始されるメモリ読出トランザクションに関するパケットフロー構成56を示す。この実施例は1つ以上の残りのノード、すなわちノード74および76を示し、残りのノードのうちの1つである76はそのキャッシュ内に要求されたデータを含むメモリブロックのダーティ(変更された)コピーを有すると想定する。図14に示すさまざまなコマンドおよび応答パケットは、図9から図13を参照して先に説明したものと同様である。ソースプロセッサは、ノード76からRdResponseと併せて受取ったデータを、システム内の他の残りのノードのすべて(ここではノード74のみ)からのプローブ応答をも受取るまで、使用し得ない。図13を参照して説明したように、ソースノードは開始されたトランザクション、すなわちメモリ読出動作がSrcDone応答の送信によって完全に確立されるまで、SrcTagを再使用し得ない。応答ノード76からのRdResponse、すべての残りの処理ノードからのプローブ応答、ターゲットノード72からのTgtDone応答、および(既に送信されていれば)ターゲットノードからのRdResponseが、ソースノード70によって受取られたときにSrcDone応答が送信される。(図9、図13、図14、図15Aおよび図15Bの)SrcDoneおよびTgtDone応答は、こうして用いられてコマンドと応答との間のエンドツーエンド肯定応答を提供する。
【0067】
図15Aは、ダーティヴィクティムブロック書込動作の間のパケット58の例示的なフローを示す。ダーティヴィクティムブロックとは一般的には、ヴィクティムブロック書込動作を発信する処理ノード、すなわちソースノード70内にあるキャッシュ(図示せず)から排除された、変更されたキャッシュブロックであって、好適なキャッシュブロック置き換えアルゴリズムのいずれかに従って置き換えられる。置き換えのためにダーティヴィクティムブロックが選択されると、ここではターゲットノード72に関連するメモリ421である、対応のシステムメモリ内にVicBlkコマンドを用いてライトバックされる。メモリライトバック動作は、VicBlkパケットを用いて開始され、その後に変更されたヴィクティムキャッシュブロックを含むデータパケットが続く。VicBlkコマンドに対してはプローブは必要ではない。したがって、ターゲットメモリコントローラが受取ったヴィクティムブロックデータをメモリ421にコミットするよう準備されると、ターゲットメモリコントローラはTgtDoneパケットをソースノードプロセッサに送る。ソースノードプロセッサは、SrcDoneパケットで応答してデータがコミットされるべきことを表示するか、またはMemCancelパケットで応答してデータがVicBlkコマンドの送信とTgtDoneパケットの受信との間で(たとえば、介入するプローブに応答して)無効化されたことを表示する。
【0068】
ソースノード70は、ヴィクティムブロックがシステムメモリ421内の適切なメモリ位置に書込まれるためにターゲットノードメモリコントローラ(図示せず)によって受取られるまで、該ヴィクティムブロックを所有することに留意されたい。ターゲットノード72は、受取ったヴィクティムブロックをそのコマンドデータバッファ内に配置し、ソースノードプロセッサ(図示せず)にTgtDone応答を送り返して、ヴィクティムブロックの受取を表示し得る。ソースノード70は、TgtDone応答を受取るまで、ヴィクティムブロック内に含まれるデータを含む他のトランザクションを処理し続ける。
【0069】
図15Bを参照すると、TgtDone応答の前のソースノード70による無効化プローブの受取を示す、パケット59の詳細なフローを示す。上述のように、制御またはデータパケットのターゲットノードへの引渡しは、システム10内に含まれる経路制御に依存する。図15Bに示すように、ソースノード70からのVicBlkコマンドおよびヴィクティムブロックデータパケット(図15Bにおいてデータ−1と示す)は、残りのノード74のうちの1つを含む経路を通過し得る。システム10内のパケット伝搬にかかわる時間は、一般的には経路内に介在する処理ノードの数と、介入するノードが受取ったコマンドおよびデータパケットを経路上の他の処理ノードに、またはこの場合のようにターゲットノード72に、伝送するためにかかる時間とに依存する。
【0070】
図15Bは、ソースノード70がVicBlkコマンドとヴィクティムブロック(データ−1)とを送信した後であって、このVicBlkコマンドがターゲットノードメモリコントローラ(図示せず)によって受取られる前に、残りの処理ノードのうちの1つ(ここではノード76)がRdBlkModコマンドをターゲットノード72に送る1つの例を示す。ノード76からのRdBlkModコマンドは、ソースノード70からのヴィクティムブロックに対する宛先である、メモリ421内の同一のメモリ位置を特定し得る。先に簡単に説明したように、キャッシュブロックの書込可能なコピーが所望である場合にはRdBlkModコマンドを用い得る。RdBlkModコマンドは、読出コマンドの1種であることから、RdBlkModコマンド実行の間に図9から図14を参照して示し説明したさまざまな信号フローパターンが生じ得る。
【0071】
RdBlkModコマンドに応答して、図9を参照して説明したように、ターゲットノード72はプローブコマンドパケット(図10A)をソースノード70と他の残りのノード74とに送信し得る。ソースノード70は、要求されたデータすなわちヴィクティムブロックと併せて読出応答パケット(図11A)を送ることにより、プローブコマンド(無効化プローブとしても知られる)に応答するが、これは(i)ソースノードは指定されたメモリ位置の変更されたコピー(すなわちヴィクティムブロック)を有し、かつ(ii)ソースノードは、先行して送信したヴィクティムブロックのターゲットノードによる受取と受認とを表示する、ターゲットノード72からのターゲット終了応答をまだ受取っていないためである。ソースノード70はまた、図13を参照して先に説明したように、メモリキャンセル応答(図15Bには図示せず)をターゲットノード72に送ってもよい。他の残りのノード74から読出コマンドのソースノード76へのプローブ応答は、より明確にするため図15Bには示さない。
【0072】
処理ノード76はまた、ソースノード70からの受取ったヴィクティムブロックを変更し、かつ変更されたデータ(データ−2)をターゲットノード72に送信して、データ−2をシステムメモリ421内の対応するメモリ位置にコミットさせることができる。図15に示す状況においては、VicBlkコマンドおよびもとのヴィクティムブロック(データ−1)は、ターゲットノードが変更されたヴィクティムブロック(データ−2)を受取った後で、ターゲットノードに到着する。もとのヴィクティムブロック(データ−1)を受取ると、ターゲットノードメモリコントローラ(図示せず)は、ターゲット終了応答をソースノード70に送信して、ヴィクティムブロックデータパケット(データ−1)の受認を表示する。ターゲットノード72はデータ送信事象の履歴を追跡し得ないために、ターゲットノード72が、変更されたヴィクティムブロック(データ−2)を含むメモリ位置に、(より早く送信されたが)遅れて到着した、失効したヴィクティムブロック(データ−1)を上書きすることを防ぐことが望ましい。この場合ソースノード70は、ソースノードがターゲットノード72からターゲット終了応答を受取ったときに、SrcDone応答の代わりにMemCancel応答をターゲットノードメモリコントローラに送信する。ソースノード70からのMemCancel応答はこうして、ターゲットノード72が失効したデータ(データ−1)を共通のメモリ位置に上書きすることを防ぐ。
【0073】
一般的に、ソースノード70は、ソースノードが無効化プローブをTgtDoneメッセージを受取る前であって、VicBlkコマンドおよびヴィクティムブロックデータパケットを送信した後であればいつでも、ターゲットノードからのTgtDoneメッセージに応答してメモリキャンセルメッセージ(MemCancel)を送る。メモリキャンセル応答はこうして、たとえば、ソースノード70以外の処理ノード(ここではノード76)が、図15Bに示されるように、ソースノード70によって先立って送られたヴィクティムブロック(データ−1)内に含まれるデータを変更する意図を表示する場合の、システム内のさまざまな処理ノード間のキャッシュコヒーレンシを維持する。メモリキャンセル応答はまた、システムメモリ421にコミットされるべきデータがもはや有効でない場合に、ターゲットノードメモリコントローラが長いメモリ書込動作を開始することを防ぐことにより、システムメモリ帯域幅を節約し得る。
【0074】
これに代えてソースノードプロセッサは、TgtDone応答が無効化プローブに先立って受取られた場合、図15Bに点線の矢印によって示すように、SrcDoneパケットをターゲットノードメモリコントローラに送ってもよい。言い換えると、ソースノードは、ヴィクティムブロックがまだ有効であれば、TgtDoneメッセージを受取った後にSrcDone応答をターゲットノードに送ってもよい。図15Bに示す状況においては、ソースノードは、プローブコマンドがターゲット終了応答の後に到着したときに、読出応答パケットの代わりにプローブ応答パケット(図12)を送ってもよいが、これはソースノードがソース終了メッセージを送ることによりヴィクティムブロックをターゲットノードに解放すると、もはやヴィクティムブロックを有し得ないためである。SrcDone応答は、ソースノードプロセッサによって開始されたダーティヴィクティムブロック(データ−1)書込動作の終了信号を送る。メモリキャンセル応答は必要ではないが、これはたとえば、変更されたヴィクティムブロック(データ−2)を含む同じメモリ位置への後の書込動作が、先行の(よって失効した)ヴィクティムブロック(データ−1)を正確に上書きするためである。処理ノード間のキャッシュコヒーレンシはこうして適切に維持される。
【0075】
ヴィクティムブロックコマンド(VicBlk)はシステムメモリに対してのみ向けられ、かつコヒーレントな処理ノード(すなわち図1における処理ノード12A−12Dのうちの1つ)によってのみ生成されることができ、たとえばI/Oブリッジ20によっては生成されないことに留意されたい。SrcDoneおよびTgtDone応答とは、上述のようにコマンドと応答とのエンドツーエンド肯定応答を提供するために用いられる。
【0076】
最後に、図16Aはメモリ書込動作に含まれるトランザクション(サイズ指定された読出またはブロック読出動作)に対する例示的なフローチャート60を示す。さらに、図16Bはダーティヴィクティムブロック書込動作に関連するトランザクションに対する例示的なフローチャート62を示す。図16Aおよび図16Bのフローチャート内のさまざまなブロックに関連の詳細のすべては、図9から図15Bを参照に先に説明した。(コマンドパケットと応答パケットとを含む)さまざまな制御パケットとデータパケットとが、図3から図8および図10から図12において例示的な実施例を用いて示された。システムは同様の目的のために他の制御およびデータパケットを実現化し得るが、異なったフォーマットおよび符号化を使用する。図1のシステム構成におけるコマンドおよび応答パケットを含むこのメッセージ通信方式は、他のシステム構成においても実現化し得る。
【0077】
先の説明は、マルチプロセッシングコンピュータシステム環境におけるキャッシュコヒーレントなデータ転送通信方式を開示する。データ転送通信方式は、ターゲット処理ノードにより遅いシステムメモリバスでの比較的長いメモリ読出または書込動作を打切らせることにより、システムメモリ帯域幅を節約し得る。コマンドと応答とのエンドツーエンド肯定応答は、マルチプロセッシングシステムを通してキャッシュコヒーレンシを維持し得る。
【0078】
この発明はさまざまな変形および代替形に対処するものであるが、その特定の実施例は本明細書と図面中に例示の目的でのみ示された。しかしながら、図面と詳細な説明とはこの発明の範囲を開示された特定の形に限定するものではなく、反対に、すべてのそのような変形、等価物および代替物を、前掲の特許請求の範囲に規定されるこの発明の精神および範囲に入れるものであることを理解されたい。
【0079】
【産業的用途】
この発明は一般的にコンピュータシステムに適する。
【図面の簡単な説明】
【図1】 コンピュータシステムの一実施例のブロック図である。
【図2】 図1からの、1対の処理ノードの間の相互接続の一実施例の詳細な図である。
【図3】 情報パケットの一実施例のブロック図である。
【図4】 アドレスパケットの一実施例のブロック図である。
【図5】 応答パケットの一実施例のブロック図である。
【図6】 コマンドパケットの一実施例のブロック図である。
【図7】 データパケットの一実施例のブロック図である。
【図8】 図1のコンピュータシステムにおいて用い得る例示的なパケットタイプを示すテーブルである。
【図9】 メモリ読出動作に対応するパケットのフローの例を示す図である。
【図10A】 プローブコマンドパケットの一実施例のブロック図である。
【図10B】 図10AのプローブコマンドパケットにおけるNextStateフィールドに対する符号化の一実施例のブロック図である。
【図11A】 読出応答パケットの一実施例のブロック図である。
【図11B】 一実施例において図11Aの読出応答パケットのProbe、TgtおよびTypeフィールドの間の関係を示す図である。
【図12】 プローブ応答パケットの一実施例のブロック図である。
【図13】 メモリキャンセル応答にかかわる、パケットのフローの例を示す図である。
【図14】 プローブコマンドとメモリキャンセル応答とを組合せるメッセージ通信方式を示すパケットのフローの例を示す図である。
【図15A】 ヴィクティムブロック書込動作の間のパケットのフローの例を一般的に示す図である。
【図15B】 ヴィクティムブロック書込動作の間の無効化プローブとメモリキャンセル応答とを示すパケットのフローを詳細に示す図である。
【図16A】 メモリ読出動作に含まれるトランザクションに対する例示的なフローチャートの図である。
【図16B】 ヴィクティムブロック書込動作に含まれるトランザクションに対する例示的なフローチャートの図である。
Claims (10)
- マルチプロセッシングコンピュータシステムであって、
相互接続構造を介して相互接続される複数の処理ノードを含み、前記複数の処理ノードは、
指定されたメモリ位置からデータを読出す第1の読出動作を開始するよう構成される第1の処理ノードと、
第2の処理ノードとを含み、前記第2の処理ノードは、前記第1の読出動作に応答して、前記第2の処理ノードに連結されたメモリ内の前記指定されたメモリ位置からデータを読出す第2の読出動作を開始するよう構成され、前記第2の処理ノードは、さらに、前記第1の読出動作に応答してプローブを発行するように構成され、前記マルチプロセッシングコンピュータシステムはさらに、
第3の処理ノードを含み、前記第3の処理ノードは、前記第2の処理ノードからのプローブを受取るように、かつ、前記プローブに応答して、前記指定されたメモリ位置に対応し、前記第3の処理ノード内に記憶された、変更されたデータを検出するように連結され、前記第3の処理ノードは、前記指定されたメモリ位置の変更されたコピーを前記第3の処理ノード内に検出すると、前記第2の処理ノードにメモリキャンセル応答を送信するよう構成され、前記メモリキャンセル応答は、前記第2の処理ノードに前記第2の読出動作のさらなる処理を打切らせ、
前記第2の処理ノードは、前記第2の読出動作の間に読出された前記データを、前記第1の処理ノードに第1の読出応答を送信することにより転送するよう構成され、前記メモリキャンセル応答は、前記第2の処理ノードが前記メモリキャンセル応答を前記第1の読出応答の送信前に受信した場合に、前記第2の処理ノードに前記第1の読出応答の送信をキャンセルさせ、
前記第3の処理ノードは前記メモリキャンセル応答と並行に第2の読出応答を送信するよう構成され、前記第2の読出応答は前記第1の処理ノードに送信される、マルチプロセッシングコンピュータシステム。 - 前記第2の処理ノードは、前記指定されたメモリ位置が前記第3の処理ノード内にキャッシュされているか否かに拘らず、プローブコマンドを送信するよう構成される、請求項1に記載のマルチプロセッシングコンピュータシステム。
- 前記第2の読出動作の間に読出された前記データのサイズは、前記第1の読出動作のタイプに依存する、請求項1に記載のマルチプロセッシングコンピュータシステム。
- 前記第2の読出応答は、前記第3の処理ノード内にキャッシュされた前記指定されたメモリ位置の前記変更されたコピーを含むデータパケットを含み、
前記第2の処理ノードは、前記第3の処理ノードから前記メモリキャンセル応答を受信すると、前記第1の処理ノードにtarget done応答を送信するよう構成され、前記target done応答は、前記第1の読出応答が送信されるか否かに拘らず送信される、請求項1に記載のマルチプロセッシングコンピュータシステム。 - 前記第1の処理ノードは、前記target done応答および前記第2の読出応答を受信すると、前記第2の処理ノードにsource doneメッセージを送信するよう構成される、請求項4に記載のマルチプロセッシングコンピュータシステム。
- 相互接続構造を介して相互接続される複数の処理ノードを含むマルチプロセッシングコンピュータシステムにおいて、前記複数の処理ノードは第1の処理ノードと、第2の処理ノードと、第3の処理ノードとを含み、前記第2の処理ノードに関連のメモリ内のメモリ位置の内容を選択的に読出すための方法であって、
前記第1の処理ノードによる前記メモリ位置の前記内容を読出す第1の読出動作を開始するステップと、
前記第1の読出動作に応答して、前記第2の処理ノードによる第2の読出動作をさらに開始するステップとを含み、前記第2の処理ノードは、前記第2の読出動作の間に前記第2の処理ノードに連結されたメモリ内の前記メモリ位置の前記内容を読出し、前記第2の処理ノードは、さらに、前記第1の読出動作に応答してプローブを発行し、前記第2の読出動作は前記第2の処理ノードから前記第1の処理ノードへの第1の読出応答を含み、前記第1の読出応答は前記メモリ位置の前記内容に対する第1のデータパケットを含み、方法はさらに、
前記第3の処理ノードが、前記第2の処理ノードからのプローブを受取り、前記プローブに応答して、前記メモリ位置に対応し、前記第3の処理ノード内に記憶された、変更されたデータを検出し、前記第3の処理ノードが、前記第3の処理ノード内に前記メモリ位置の変更されたコピーを検出すると、第2の処理ノードにメモリキャンセル応答を送信するステップと、 前記メモリキャンセル応答が、前記第2の処理ノードに前記第2の読出動作のさらなる処理を打切らせるステップと、
前記メモリキャンセル応答が、前記第2の処理ノードが前記メモリキャンセル応答を前記第1の読出応答の送信前に受信した場合に、前記第2の処理ノードに前記第1の読出応答の送信をキャンセルさせるステップと、
前記第3の処理ノードが前記メモリキャンセル応答と並行に第2の読出応答を送信するステップとを含み、前記第2の読出応答は前記第1の処理ノードに送信される、方法。 - 前記第1のデータパケットのサイズは、前記第1の読出動作のタイプに依存する、請求項6に記載の方法。
- 前記第2の読出応答は、前記第3の処理ノード内にキャッシュされた前記メモリ位置の前記変更されたコピーを含む第2のデータパケットを含む、請求項6に記載の方法。
- 前記第2の処理ノードが、前記第3の処理ノードから前記メモリキャンセル応答を受信すると、前記第1の処理ノードにtarget done応答を送信するステップをさらに含み、前記target done応答は、前記第1の読出応答が送信されるか否かに拘らず送信される、請求項8に記載の方法。
- 前記第1の処理ノードが、前記target done応答および前記第2の読出応答を受信すると、前記第2の処理ノードにsource doneメッセージを送信するステップをさらに含む、請求項9に記載の方法。
Applications Claiming Priority (9)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/217,212 | 1998-12-21 | ||
| US09/217,699 | 1998-12-21 | ||
| US09/217,699 US6370621B1 (en) | 1998-12-21 | 1998-12-21 | Memory cancel response optionally cancelling memory controller's providing of data in response to a read operation |
| US09/217,649 US6275905B1 (en) | 1998-12-21 | 1998-12-21 | Messaging scheme to maintain cache coherency and conserve system memory bandwidth during a memory read operation in a multiprocessing computer system |
| US09/217,649 | 1998-12-21 | ||
| US09/217,212 US6490661B1 (en) | 1998-12-21 | 1998-12-21 | Maintaining cache coherency during a memory read operation in a multiprocessing computer system |
| US09/370,970 US6393529B1 (en) | 1998-12-21 | 1999-08-10 | Conversation of distributed memory bandwidth in multiprocessor system with cache coherency by transmitting cancel subsequent to victim write |
| US09/370,970 | 1999-08-10 | ||
| PCT/US1999/019856 WO2000038070A1 (en) | 1998-12-21 | 1999-08-26 | Conservation of system memory bandwidth and cache coherency maintenance using memory cancel messages |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2002533813A JP2002533813A (ja) | 2002-10-08 |
| JP2002533813A5 JP2002533813A5 (ja) | 2006-09-07 |
| JP4718012B2 true JP4718012B2 (ja) | 2011-07-06 |
Family
ID=27499064
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2000590062A Expired - Lifetime JP4718012B2 (ja) | 1998-12-21 | 1999-08-26 | メモリキャンセルメッセージを用いたシステムメモリ帯域幅の節約およびキャッシュコヒーレンシ維持 |
Country Status (4)
| Country | Link |
|---|---|
| EP (2) | EP2320322A3 (ja) |
| JP (1) | JP4718012B2 (ja) |
| KR (1) | KR100615660B1 (ja) |
| WO (1) | WO2000038070A1 (ja) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6631401B1 (en) * | 1998-12-21 | 2003-10-07 | Advanced Micro Devices, Inc. | Flexible probe/probe response routing for maintaining coherency |
| US6799217B2 (en) * | 2001-06-04 | 2004-09-28 | Fujitsu Limited | Shared memory multiprocessor expansion port for multi-node systems |
| US8185602B2 (en) | 2002-11-05 | 2012-05-22 | Newisys, Inc. | Transaction processing using multiple protocol engines in systems having multiple multi-processor clusters |
| US7822929B2 (en) * | 2004-04-27 | 2010-10-26 | Intel Corporation | Two-hop cache coherency protocol |
| JP4572169B2 (ja) * | 2006-01-26 | 2010-10-27 | エヌイーシーコンピュータテクノ株式会社 | マルチプロセッサシステム及びその動作方法 |
| JP5505516B2 (ja) * | 2010-12-06 | 2014-05-28 | 富士通株式会社 | 情報処理システムおよび情報送信方法 |
| US11159636B2 (en) * | 2017-02-08 | 2021-10-26 | Arm Limited | Forwarding responses to snoop requests |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000076130A (ja) * | 1998-03-23 | 2000-03-14 | Internatl Business Mach Corp <Ibm> | リモ―ト資源管理システム |
| JP2000132531A (ja) * | 1998-10-23 | 2000-05-12 | Pfu Ltd | マルチプロセッサ |
| JP2002533812A (ja) * | 1998-12-21 | 2002-10-08 | アドバンスト・マイクロ・ディバイシズ・インコーポレイテッド | コヒーレンシ維持のための柔軟なプローブ/プローブ応答経路制御 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH02205963A (ja) * | 1989-01-27 | 1990-08-15 | Digital Equip Corp <Dec> | 読取中断処理 |
| EP0412353A3 (en) * | 1989-08-11 | 1992-05-27 | Hitachi, Ltd. | Multiprocessor cache system having three states for generating invalidating signals upon write accesses |
| FR2680026B1 (fr) * | 1991-07-30 | 1996-12-20 | Commissariat Energie Atomique | Architecture de systeme en tableau de processeurs a structure parallele. |
| US5590307A (en) * | 1993-01-05 | 1996-12-31 | Sgs-Thomson Microelectronics, Inc. | Dual-port data cache memory |
| US5659710A (en) * | 1995-11-29 | 1997-08-19 | International Business Machines Corporation | Cache coherency method and system employing serially encoded snoop responses |
| US5887138A (en) * | 1996-07-01 | 1999-03-23 | Sun Microsystems, Inc. | Multiprocessing computer system employing local and global address spaces and COMA and NUMA access modes |
-
1999
- 1999-08-26 EP EP10183401A patent/EP2320322A3/en not_active Withdrawn
- 1999-08-26 EP EP99944008A patent/EP1141838A1/en not_active Withdrawn
- 1999-08-26 KR KR1020017007742A patent/KR100615660B1/ko not_active IP Right Cessation
- 1999-08-26 JP JP2000590062A patent/JP4718012B2/ja not_active Expired - Lifetime
- 1999-08-26 WO PCT/US1999/019856 patent/WO2000038070A1/en active IP Right Grant
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000076130A (ja) * | 1998-03-23 | 2000-03-14 | Internatl Business Mach Corp <Ibm> | リモ―ト資源管理システム |
| JP2000132531A (ja) * | 1998-10-23 | 2000-05-12 | Pfu Ltd | マルチプロセッサ |
| JP2002533812A (ja) * | 1998-12-21 | 2002-10-08 | アドバンスト・マイクロ・ディバイシズ・インコーポレイテッド | コヒーレンシ維持のための柔軟なプローブ/プローブ応答経路制御 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2000038070A1 (en) | 2000-06-29 |
| JP2002533813A (ja) | 2002-10-08 |
| EP2320322A2 (en) | 2011-05-11 |
| KR100615660B1 (ko) | 2006-08-25 |
| KR20010082376A (ko) | 2001-08-29 |
| EP1141838A1 (en) | 2001-10-10 |
| EP2320322A3 (en) | 2011-08-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US6490661B1 (en) | Maintaining cache coherency during a memory read operation in a multiprocessing computer system | |
| US6275905B1 (en) | Messaging scheme to maintain cache coherency and conserve system memory bandwidth during a memory read operation in a multiprocessing computer system | |
| US6370621B1 (en) | Memory cancel response optionally cancelling memory controller's providing of data in response to a read operation | |
| JP4712974B2 (ja) | コヒーレンシ維持のための柔軟なプローブ/プローブ応答経路制御 | |
| US6948035B2 (en) | Data pend mechanism | |
| US6973543B1 (en) | Partial directory cache for reducing probe traffic in multiprocessor systems | |
| US7032078B2 (en) | Shared memory multiprocessing system employing mixed broadcast snooping and directory based coherency protocols | |
| EP0817073B1 (en) | A multiprocessing system configured to perform efficient write operations | |
| EP0817070B1 (en) | Multiprocessing system employing a coherency protocol including a reply count | |
| KR101497002B1 (ko) | 스누프 필터링 메커니즘 | |
| US7600080B1 (en) | Avoiding deadlocks in a multiprocessor system | |
| KR100324975B1 (ko) | 잠재적인 제3 노드 트랜잭션을 버퍼에 기록하여 통신 대기시간을 감소시키는 비균일 메모리 액세스(numa) 데이터 프로세싱 시스템 | |
| US20010013089A1 (en) | Cache coherence unit for interconnecting multiprocessor nodes having pipelined snoopy protocol | |
| US10592459B2 (en) | Method and system for ordering I/O access in a multi-node environment | |
| JP2002304328A (ja) | マルチプロセッサシステム用コヒーレンスコントローラ、およびそのようなコントローラを内蔵するモジュールおよびマルチモジュールアーキテクチャマルチプロセッサシステム | |
| US9372800B2 (en) | Inter-chip interconnect protocol for a multi-chip system | |
| US6393529B1 (en) | Conversation of distributed memory bandwidth in multiprocessor system with cache coherency by transmitting cancel subsequent to victim write | |
| US7222220B2 (en) | Multiprocessing system employing address switches to control mixed broadcast snooping and directory based coherency protocols transparent to active devices | |
| US7114043B2 (en) | Ambiguous virtual channels | |
| US20030105828A1 (en) | Systems using Mix of packet, coherent, and noncoherent traffic to optimize transmission between systems | |
| JP4718012B2 (ja) | メモリキャンセルメッセージを用いたシステムメモリ帯域幅の節約およびキャッシュコヒーレンシ維持 | |
| US6714994B1 (en) | Host bridge translating non-coherent packets from non-coherent link to coherent packets on conherent link and vice versa | |
| US20040044821A1 (en) | Compute node to mesh interface for highly scalable parallel processing system and method of exchanging data | |
| US6757793B1 (en) | Reducing probe traffic in multiprocessor systems using a victim record table |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20060712 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20060712 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20091216 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100112 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100406 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20101109 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110127 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110315 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110331 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4718012 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140408 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| EXPY | Cancellation because of completion of term |