JP4703142B2 - ヘッドマウント型多感覚応用音声入力システム(headmountedmulti−sensoryaudioinputsystem) - Google Patents
ヘッドマウント型多感覚応用音声入力システム(headmountedmulti−sensoryaudioinputsystem) Download PDFInfo
- Publication number
- JP4703142B2 JP4703142B2 JP2004220690A JP2004220690A JP4703142B2 JP 4703142 B2 JP4703142 B2 JP 4703142B2 JP 2004220690 A JP2004220690 A JP 2004220690A JP 2004220690 A JP2004220690 A JP 2004220690A JP 4703142 B2 JP4703142 B2 JP 4703142B2
- Authority
- JP
- Japan
- Prior art keywords
- speech
- signal
- user
- microphone
- voice
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images








Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/14—Throat mountings for microphones
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/20—Speech recognition techniques specially adapted for robustness in adverse environments, e.g. in noise, of stress induced speech
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/24—Speech recognition using non-acoustical features
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2460/00—Details of hearing devices, i.e. of ear- or headphones covered by H04R1/10 or H04R5/033 but not provided for in any of their subgroups, or of hearing aids covered by H04R25/00 but not provided for in any of its subgroups
- H04R2460/13—Hearing devices using bone conduction transducers
Description
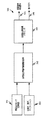
404 マイクロフォン
406 A/D
407 フレームコントラクタ
408 特徴抽出器
412 デコーダ
420 信頼度モジュール
422 出力モジュール
426 訓練用テキスト
424 トレーナー
418 音響モデル
414 辞書
416 言語モデル
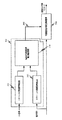
301 発話音声センサ
303 従来の(音声)マイクロフォン
302 多感覚応用信号捕捉構成回路
304 多感覚応用信号プロセッサ
Claims (13)
- 感知された音声入力に基づいてマイクロフォン信号を出力する音声マイクロフォンと、
発話行為により生成された音声以外の入力に基づいてセンサ信号を出力する発話音声センサと、
前記マイクロフォン信号と前記センサ信号の第1の特徴の分散レベルとに基づいて、ユーザが話し中である確率を示す発話音声検出信号を出力する発話音声検出コンポーネントであって、前記センサ信号の前記第1の特徴は、ユーザが話し中の場合の第1の分散レベルとユーザが話し中でない場合の第2の分散レベルを有し、前記発話音声検出コンポーネントは、所定の時間にわたり前記第1の分散レベルと前記第2の分散レベルのうちの予め定められた一方である前記第1の特徴の基線分散レベルと比較して、前記センサ信号の前記第1の特徴の前記分散レベルに基づいて前記発話音声検出信号を出力し、前記発話音声検出コンポーネントは、前記発話音声検出信号に、前記マイクロフォン信号を乗ずることにより、結合信号を計算することを更に備える発話音声検出コンポーネントと、
前記発話音声検出信号が前記ユーザが話し中であることを示す確率が高い場合に発話音声が認識される可能性が増加し、前記発話音声検出信号が前記ユーザが話し中であることを示す確率が低い場合に発話音声が認識される可能性が減少した前記結合信号に基づいて、前記マイクロフォン信号内の発話音声を示す認識出力を提供するために発話音声を認識する発話音声認識器とを備える
ことを特徴とする発話音声検出システム。 - 前記基線分散レベルは、所定の時間にわたる前記第1の特徴の分散レベルを平均することによって計算されることを特徴とする請求項1に記載の発話音声検出システム。
- 前記基線分散レベルは、前記発話音声検出システムが動作中に断続的に再計算されることを特徴とする請求項1に記載の発話音声検出システム。
- 前記基線分散レベルは、分解時間窓にわたる前記第1の特徴の前記分散レベルを表すために周期的に再計算されることを特徴とする請求項3に記載の発話音声検出システム。
- 前記発話音声検出コンポーネントは、前記基線分散レベルと、前記センサ信号の前記第1の特徴の前記分散レベルとの比較結果に基づいて前記発話音声検出信号を出力し、前記比較は周期的に行われることを特徴とする請求項3に記載の発話音声検出システム。
- 前記比較は、前記基線分散レベルの再計算の頻度よりも高い頻度で行われることを特徴とする請求項5に記載の発話音声検出システム。
- 前記音声マイクロフォンと前記発話音声センサは、ヘッドフォンに搭載されていることを特徴とする請求項1に記載の発話音声検出システム。
- 発話音声検出システムを備えた発話音声認識システムであって、
前記発話音声検出システムは、
感知された音声入力に基づいてマイクロフォン信号を出力する音声マイクロフォンと、
発話行為によって生成された音声以外の入力に基づいてセンサ信号を出力する発話音声センサと、
前記マイクロフォン信号と前記センサ信号とに基づいてユーザが話し中である確率を示す発話音声検出信号を出力する発話音声検出コンポーネントであって、発話音声検出信号を前記マイクロフォン信号に乗ずることにより結合信号を生成する発話音声検出コンポーネントと、
前記発話音声検出信号が前記ユーザが話し中であることを示す確率が高い場合に発話音声が認識される可能性が増加し、前記発話音声検出信号が前記ユーザが話し中であることを示す確率が低い場合に発話音声が認識される可能性が減少した前記結合信号に基づいて前記感知された音声入力内の発話音声を示す認識出力を提供するために発話音声を認識する発話音声認識エンジンと
を備えることを特徴とする発話音声認識システム。 - 前記音声マイクロフォンと前記発話音声センサは、ヘッドフォンに搭載されていることを特徴とする請求項8に記載の発話音声認識システム。
- 音声マイクロフォンを用いて音声入力を表す第1の信号を生成すること、
顔の動きセンサによって感知されるユーザの顔の動きを表す第2の信号を生成すること、
前記第1の信号と前記第2の信号に基づいて前記ユーザが話し中である確率を示す発話音声検出信号である第3の信号を生成すること、
前記ユーザが話し中である可能性を前記第1の信号に乗ずることにより第4の信号を生成すること、
前記第4の信号と前記発話音声検出信号に基づき発話音声を認識すること
を含み、
前記発話音声を認識することは、
前記発話音声検出信号が前記ユーザが話し中であることを示す確率が高い場合に発話音声が認識される可能性が増加すること、
前記発話音声検出信号が前記ユーザが話し中であることを示す確率が低い場合に発話音声が認識される可能性が減少すること
を含むことを特徴とする発話音声認識方法。 - 前記第2の信号を生成することは、前記ユーザの顎および首のうちの一方の振動を感知することを含むことを特徴とする請求項10に記載の方法。
- 前記第2の信号を生成することは、前記ユーザの口の動きを示す画像を感知することを含むことを特徴とする請求項10に記載の方法。
- 前記ユーザが話し中であるかどうかを検出した結果に基づいて発話音声検出信号を提供することを更に含むことを特徴とする請求項10に記載の方法。
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/629,278 | 2003-07-29 | ||
| US10/629,278 US7383181B2 (en) | 2003-07-29 | 2003-07-29 | Multi-sensory speech detection system |
| US10/636,176 US20050033571A1 (en) | 2003-08-07 | 2003-08-07 | Head mounted multi-sensory audio input system |
| US10/636,176 | 2003-08-07 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2005049876A JP2005049876A (ja) | 2005-02-24 |
| JP2005049876A5 JP2005049876A5 (ja) | 2007-09-13 |
| JP4703142B2 true JP4703142B2 (ja) | 2011-06-15 |
Family
ID=33544784
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004220690A Expired - Fee Related JP4703142B2 (ja) | 2003-07-29 | 2004-07-28 | ヘッドマウント型多感覚応用音声入力システム(headmountedmulti−sensoryaudioinputsystem) |
Country Status (14)
| Country | Link |
|---|---|
| EP (1) | EP1503368B1 (ja) |
| JP (1) | JP4703142B2 (ja) |
| KR (1) | KR101098601B1 (ja) |
| CN (1) | CN100573664C (ja) |
| AT (1) | ATE471554T1 (ja) |
| AU (1) | AU2004203357B2 (ja) |
| BR (1) | BRPI0403027A (ja) |
| CA (1) | CA2473195C (ja) |
| DE (1) | DE602004027687D1 (ja) |
| HK (1) | HK1073010A1 (ja) |
| MX (1) | MXPA04007313A (ja) |
| MY (1) | MY138807A (ja) |
| RU (1) | RU2363994C2 (ja) |
| TW (1) | TWI383377B (ja) |
Families Citing this family (36)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4667082B2 (ja) * | 2005-03-09 | 2011-04-06 | キヤノン株式会社 | 音声認識方法 |
| JP2009512232A (ja) * | 2005-06-13 | 2009-03-19 | テクニオン リサーチ アンド デヴェロップメント リミテッド | 遮蔽通信変換器 |
| JP2007171637A (ja) * | 2005-12-22 | 2007-07-05 | Toshiba Tec Corp | 音声処理装置 |
| JP2007267331A (ja) * | 2006-03-30 | 2007-10-11 | Railway Technical Res Inst | 発話音声収集用コンビネーション・マイクロフォンシステム |
| CN100583006C (zh) * | 2006-12-13 | 2010-01-20 | 鸿富锦精密工业(深圳)有限公司 | 具有摇动响应机制的音乐播放装置 |
| JP2010010869A (ja) * | 2008-06-25 | 2010-01-14 | Audio Technica Corp | マイクロホン装置 |
| JP5499633B2 (ja) * | 2009-10-28 | 2014-05-21 | ソニー株式会社 | 再生装置、ヘッドホン及び再生方法 |
| US8626498B2 (en) * | 2010-02-24 | 2014-01-07 | Qualcomm Incorporated | Voice activity detection based on plural voice activity detectors |
| US9025782B2 (en) | 2010-07-26 | 2015-05-05 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for multi-microphone location-selective processing |
| FR2976111B1 (fr) * | 2011-06-01 | 2013-07-05 | Parrot | Equipement audio comprenant des moyens de debruitage d'un signal de parole par filtrage a delai fractionnaire, notamment pour un systeme de telephonie "mains libres" |
| FR2982451A1 (fr) * | 2011-11-03 | 2013-05-10 | Joel Pedre | Speak world 3 ou traducteur verbal integre et amplifie a emetteur infrarouge et a micro intra auriculaire |
| WO2014032738A1 (en) | 2012-09-03 | 2014-03-06 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for providing an informed multichannel speech presence probability estimation |
| GB2513559B8 (en) * | 2013-04-22 | 2016-06-29 | Ge Aviat Systems Ltd | Unknown speaker identification system |
| CN104123930A (zh) * | 2013-04-27 | 2014-10-29 | 华为技术有限公司 | 喉音识别方法及装置 |
| KR102282366B1 (ko) | 2013-06-03 | 2021-07-27 | 삼성전자주식회사 | 음성 향상 방법 및 그 장치 |
| CN103309642A (zh) * | 2013-06-09 | 2013-09-18 | 张家港市鸿嘉数字科技有限公司 | 一种识别声音操作平板电脑的方法 |
| US9311298B2 (en) | 2013-06-21 | 2016-04-12 | Microsoft Technology Licensing, Llc | Building conversational understanding systems using a toolset |
| US9589565B2 (en) | 2013-06-21 | 2017-03-07 | Microsoft Technology Licensing, Llc | Environmentally aware dialog policies and response generation |
| US9564128B2 (en) | 2013-12-09 | 2017-02-07 | Qualcomm Incorporated | Controlling a speech recognition process of a computing device |
| US9674599B2 (en) * | 2014-03-07 | 2017-06-06 | Wearhaus, Inc. | Headphones for receiving and transmitting audio signals |
| FR3019423B1 (fr) * | 2014-03-25 | 2017-07-21 | Elno | Circuit electronique pour bandeau osteophonique |
| US9529794B2 (en) | 2014-03-27 | 2016-12-27 | Microsoft Technology Licensing, Llc | Flexible schema for language model customization |
| US9706294B2 (en) * | 2015-03-18 | 2017-07-11 | Infineon Technologies Ag | System and method for an acoustic transducer and environmental sensor package |
| US20160284363A1 (en) * | 2015-03-24 | 2016-09-29 | Intel Corporation | Voice activity detection technologies, systems and methods employing the same |
| CN104766610A (zh) * | 2015-04-07 | 2015-07-08 | 马业成 | 基于振动的声音识别系统和识别方法 |
| JP6500625B2 (ja) * | 2015-06-16 | 2019-04-17 | カシオ計算機株式会社 | 検知装置、検知システム、検知方法及びプログラム |
| EP3185244B1 (en) * | 2015-12-22 | 2019-02-20 | Nxp B.V. | Voice activation system |
| CN107734416B (zh) * | 2017-10-11 | 2024-01-09 | 深圳市三诺数字科技有限公司 | 一种激光面纹识别降噪装置、耳机及方法 |
| CN108735219B (zh) * | 2018-05-09 | 2021-08-31 | 深圳市宇恒互动科技开发有限公司 | 一种声音识别控制方法及装置 |
| CN108766468B (zh) * | 2018-06-12 | 2021-11-02 | 歌尔科技有限公司 | 一种智能语音检测方法、无线耳机、tws耳机及终端 |
| CN109410957B (zh) * | 2018-11-30 | 2023-05-23 | 福建实达电脑设备有限公司 | 基于计算机视觉辅助的正面人机交互语音识别方法及系统 |
| RU2719659C1 (ru) * | 2019-01-10 | 2020-04-21 | Общество с ограниченной ответственностью "Центр речевых технологий" (ООО "ЦРТ") | Устройство для регистрации и управления вводом речевой информации |
| JP7331523B2 (ja) * | 2019-07-24 | 2023-08-23 | 富士通株式会社 | 検出プログラム、検出方法、検出装置 |
| JP7378770B2 (ja) * | 2019-08-27 | 2023-11-14 | 国立大学法人静岡大学 | 評価装置、評価方法、及び評価プログラム |
| EP4131256A1 (en) * | 2021-08-06 | 2023-02-08 | STMicroelectronics S.r.l. | Voice recognition system and method using accelerometers for sensing bone conduction |
| CN113810819B (zh) * | 2021-09-23 | 2022-06-28 | 中国科学院软件研究所 | 一种基于耳腔振动的静默语音采集处理方法及设备 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04184495A (ja) * | 1990-11-20 | 1992-07-01 | Seiko Epson Corp | 音声認識装置 |
| JP2002358089A (ja) * | 2001-06-01 | 2002-12-13 | Denso Corp | 音声処理装置及び音声処理方法 |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3383466A (en) * | 1964-05-28 | 1968-05-14 | Navy Usa | Nonacoustic measures in automatic speech recognition |
| TW219993B (en) * | 1992-05-21 | 1994-02-01 | Ind Tech Res Inst | Speech recognition system |
| US5625697A (en) * | 1995-05-08 | 1997-04-29 | Lucent Technologies Inc. | Microphone selection process for use in a multiple microphone voice actuated switching system |
| US5647834A (en) * | 1995-06-30 | 1997-07-15 | Ron; Samuel | Speech-based biofeedback method and system |
| US6006175A (en) * | 1996-02-06 | 1999-12-21 | The Regents Of The University Of California | Methods and apparatus for non-acoustic speech characterization and recognition |
| TW404103B (en) * | 1998-06-02 | 2000-09-01 | Inventec Corp | Telephone answering system which is capable of transmitting image and audio data |
| JP3893763B2 (ja) * | 1998-08-17 | 2007-03-14 | 富士ゼロックス株式会社 | 音声検出装置 |
| US6594629B1 (en) | 1999-08-06 | 2003-07-15 | International Business Machines Corporation | Methods and apparatus for audio-visual speech detection and recognition |
| JP2001292489A (ja) * | 2000-04-10 | 2001-10-19 | Kubota Corp | 骨伝導マイク付きヘッドホン |
| WO2002077972A1 (en) | 2001-03-27 | 2002-10-03 | Rast Associates, Llc | Head-worn, trimodal device to increase transcription accuracy in a voice recognition system and to process unvocalized speech |
| US6671379B2 (en) * | 2001-03-30 | 2003-12-30 | Think-A-Move, Ltd. | Ear microphone apparatus and method |
| TW541824B (en) * | 2001-05-29 | 2003-07-11 | Inventec Multimedia & Telecom | Multi-channel voice conferencing equipment and method there for |
| US6707921B2 (en) * | 2001-11-26 | 2004-03-16 | Hewlett-Packard Development Company, Lp. | Use of mouth position and mouth movement to filter noise from speech in a hearing aid |
| US20050141730A1 (en) * | 2001-12-21 | 2005-06-30 | Rti Tech Pte Ltd. | Vibration-based talk-through method and apparatus |
| US7219062B2 (en) * | 2002-01-30 | 2007-05-15 | Koninklijke Philips Electronics N.V. | Speech activity detection using acoustic and facial characteristics in an automatic speech recognition system |
-
2004
- 2004-07-07 CA CA2473195A patent/CA2473195C/en not_active Expired - Fee Related
- 2004-07-09 MY MYPI20042739A patent/MY138807A/en unknown
- 2004-07-09 EP EP04016226A patent/EP1503368B1/en not_active Not-in-force
- 2004-07-09 AT AT04016226T patent/ATE471554T1/de not_active IP Right Cessation
- 2004-07-09 DE DE602004027687T patent/DE602004027687D1/de active Active
- 2004-07-20 TW TW093121624A patent/TWI383377B/zh not_active IP Right Cessation
- 2004-07-22 AU AU2004203357A patent/AU2004203357B2/en not_active Ceased
- 2004-07-27 BR BR0403027-3A patent/BRPI0403027A/pt not_active IP Right Cessation
- 2004-07-28 JP JP2004220690A patent/JP4703142B2/ja not_active Expired - Fee Related
- 2004-07-28 RU RU2004123352/09A patent/RU2363994C2/ru not_active IP Right Cessation
- 2004-07-28 KR KR1020040059346A patent/KR101098601B1/ko not_active IP Right Cessation
- 2004-07-28 MX MXPA04007313A patent/MXPA04007313A/es active IP Right Grant
- 2004-07-29 CN CNB2004100557384A patent/CN100573664C/zh not_active Expired - Fee Related
-
2005
- 2005-05-24 HK HK05104345.9A patent/HK1073010A1/xx not_active IP Right Cessation
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04184495A (ja) * | 1990-11-20 | 1992-07-01 | Seiko Epson Corp | 音声認識装置 |
| JP2002358089A (ja) * | 2001-06-01 | 2002-12-13 | Denso Corp | 音声処理装置及び音声処理方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN100573664C (zh) | 2009-12-23 |
| CA2473195A1 (en) | 2005-01-29 |
| CA2473195C (en) | 2014-02-04 |
| KR20050013969A (ko) | 2005-02-05 |
| BRPI0403027A (pt) | 2005-05-31 |
| EP1503368A1 (en) | 2005-02-02 |
| JP2005049876A (ja) | 2005-02-24 |
| MXPA04007313A (es) | 2005-07-26 |
| DE602004027687D1 (de) | 2010-07-29 |
| CN1591568A (zh) | 2005-03-09 |
| EP1503368B1 (en) | 2010-06-16 |
| MY138807A (en) | 2009-07-31 |
| AU2004203357B2 (en) | 2010-01-28 |
| ATE471554T1 (de) | 2010-07-15 |
| RU2363994C2 (ru) | 2009-08-10 |
| AU2004203357A1 (en) | 2005-02-17 |
| TW200519834A (en) | 2005-06-16 |
| KR101098601B1 (ko) | 2011-12-23 |
| RU2004123352A (ru) | 2006-01-27 |
| TWI383377B (zh) | 2013-01-21 |
| HK1073010A1 (en) | 2005-09-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4703142B2 (ja) | ヘッドマウント型多感覚応用音声入力システム(headmountedmulti−sensoryaudioinputsystem) | |
| US7383181B2 (en) | Multi-sensory speech detection system | |
| US20050033571A1 (en) | Head mounted multi-sensory audio input system | |
| US10586534B1 (en) | Voice-controlled device control using acoustic echo cancellation statistics | |
| Zhang et al. | Multi-sensory microphones for robust speech detection, enhancement and recognition | |
| US9293133B2 (en) | Improving voice communication over a network | |
| US10721661B2 (en) | Wireless device connection handover | |
| WO2017134935A1 (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| US10728941B2 (en) | Bidirectional sending and receiving of wireless data | |
| JP2005049876A5 (ja) | ||
| CN111432303B (zh) | 单耳耳机、智能电子设备、方法和计算机可读介质 | |
| US20230045237A1 (en) | Wearable apparatus for active substitution | |
| CN110097875B (zh) | 基于麦克风信号的语音交互唤醒电子设备、方法和介质 | |
| US20120284022A1 (en) | Noise reduction system using a sensor based speech detector | |
| CN110428806B (zh) | 基于麦克风信号的语音交互唤醒电子设备、方法和介质 | |
| JP2009178783A (ja) | コミュニケーションロボット及びその制御方法 | |
| CN116324969A (zh) | 具有定位反馈的听力增强和可穿戴系统 | |
| US11064281B1 (en) | Sending and receiving wireless data | |
| JP3838159B2 (ja) | 音声認識対話装置およびプログラム | |
| WO2019207912A1 (ja) | 情報処理装置及び情報処理方法 | |
| JP7172041B2 (ja) | 音伝達装置及びプログラム | |
| WO2019187543A1 (ja) | 情報処理装置および情報処理方法 | |
| JP4189744B2 (ja) | 無音声通信システム | |
| JP2022181437A (ja) | 音声処理システム及び音声処理方法 | |
| JP2009162931A (ja) | 音声認識装置、音声認識方法および音声認識プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070730 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070730 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100326 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100625 |
|
| RD13 | Notification of appointment of power of sub attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7433 Effective date: 20100809 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20100809 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100910 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20101210 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110107 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20110207 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20110210 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110308 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees | ||
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |