JP4448784B2 - 並列計算機の同期方法及びプログラム - Google Patents
並列計算機の同期方法及びプログラム Download PDFInfo
- Publication number
- JP4448784B2 JP4448784B2 JP2005072633A JP2005072633A JP4448784B2 JP 4448784 B2 JP4448784 B2 JP 4448784B2 JP 2005072633 A JP2005072633 A JP 2005072633A JP 2005072633 A JP2005072633 A JP 2005072633A JP 4448784 B2 JP4448784 B2 JP 4448784B2
- Authority
- JP
- Japan
- Prior art keywords
- synchronization
- thread
- threads
- group
- barrier synchronization
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images























Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/52—Program synchronisation; Mutual exclusion, e.g. by means of semaphores
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/52—Program synchronisation; Mutual exclusion, e.g. by means of semaphores
- G06F9/522—Barrier synchronisation
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Multi Processors (AREA)
- Memory System Of A Hierarchy Structure (AREA)
Description
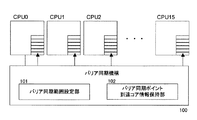
図1において、並列計算機は複数のプロセッサモジュール(プロセッサ)P0〜P7からなるマルチプロセッサを有し、各プロセッサモジュールP0〜P7は、ひとつのモジュールに複数のプロセッサコア(図中cpu0〜15)を実装しており、ひとつのプロセッサモジュールP0には、2つのプロセッサコアが実装されている。例えば、プロセッサモジュールP0は、プロセッサコアcpu0とcpu1を備え、2つのCPUが並列して動作可能となっている。
ハードウェアバリア同期機構100は、図3で示すように、各プロセッサコアcpu0〜15に接続されており、バリア同期処理を行うcpu0〜15の範囲またはグループを設定するバリア同期範囲設定部101と、プロセッサコアcpu0〜15毎にバリア同期ポイント(バリア同期の位置情報)に到達したプロセッサコアの情報を保持する同期ポイント到達情報保持部102を備えている。
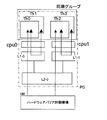
次に、図2は各プロセッサコアcpu0〜15で実行される処理の一例を示し、各cpu0〜15にそれぞれ2つのスレッドTh0〜31を割り当てて、合計32のスレッドを並列的に実行する例を示す。すなわち、ひとつのプロセッサモジュールには4つのスレッドが割り当てられ、モジュール上の2つのプロセッサコアにはそれぞれ2つのスレッドが均等に割り当てられる。
図4は、上記図2に示した同期グループGrの詳細を示す。
図6は、プロセッサモジュールP0、P1の同期グループで実行されるプログラム(ロードモジュール)の概要を示す。
図7、図8は、上記図6に示したプログラム(ロードモジュール)PGのうち初期設定処理PG1の詳細を示すフローチャートで、図9、図10は上記図6に示したプログラムPGの演算処理PG2のうちバリア同期処理の詳細を示すフローチャートである。
ただし、COREは一つのプロセッサモジュールが有するプロセッサコアの数を示し、本実施形態の例では、CORE=2である。なお、汎用性を持たせる場合には、このS7でひとつのプロセッサモジュールが有するプロセッサコアの数Nを入力するようにしてもよい。
例えば、図4の例では、使用プロセッサモジュール数K=4/2=2であるからバリア同期グループGrは階層数F=3となり、1次キャッシュL1で同一プロセッサコアのスレッドの同期を取る第1の同期グループと、2次キャッシュL2で同一プロセッサモジュールの親スレッド同士のバリア同期を取る第2のバリアループと、ハードウェアバリア同期機構100によりプロセッサモジュールP0、P1の親スレッド同士の同期を取る第3の同期グループの3階層となる。
上記図7、図8の初期設定によりスレッドを割り当てられたプロセッサモジュールで行われる演算処理のうち、バリア同期処理について図9、図10のフローチャートを参照しながら説明する。図9は最下位階層(第1階層)で行われる処理で、図10は上位階層(第2階層)で行われる処理を示し、各処理は所定の周期で実行される。なお、最上位階層となる第3階層はハードウェアバリア同期機構100を用いるため、フローチャートは省略した。
図15〜図20は、第2の実施形態を示し、前記第1実施形態に示したハードウェアバリア同期機構100を用いずに、ソフトウェアのみでバリア同期を行う例を示す。
図22、図23は、第3の実施形態を示し、前記第1実施形態に示したバリア同期処理を専用のスレッドで行うようにし、他のスレッドを並列演算処理専用としたもので、その他の構成は前記第1実施形態と同様である。
図24、図25は、第4の実施形態を示し、前記第1実施形態に示したバリア同期処理にデッドロックなどの障害を検知する機能を加えたもので、その他の構成は前記第1実施形態と同様である。
図26は、第5の実施形態を示し、前記第1実施形態の図6に示したプログラム(ロードモジュール)PGのうち演算処理PG2をロードモジュールとして生成する手順を示す。
cpu0〜15 プロセッサコア
L1−0〜15 1次キャッシュ
L2−0〜7 2次キャッシュ
L3 3次キャッシュ
MM 主記憶
Th0〜Th15 スレッド
100 ハードウェアバリア同期機構
Claims (11)
- それぞれが複数のプロセッサコアを有する複数のプロセッサと、前記複数のプロセッサコアがアクセスする主記憶とを有し、前記プロセッサコアと前記主記憶との間に前記複数のプロセッサコアで実行される複数のスレッド間または前記複数のプロセッサコア間あるいは前記複数のプロセッサ間で共有可能な共有記憶域を階層的に備えた計算機システムにおいて、前記複数のスレッドを並列的に実行するためのバリア同期を行う同期方法であって、
前記プロセッサコアのそれぞれに複数のスレッドを割り当てて実行させる処理と、
前記複数のスレッドを階層構造のグループに設定する処理と、
前記グループ毎にバリア同期を取る処理と、
を含み、
前記複数のスレッドを階層構造のグループに設定する処理は、
前記共有記憶域の階層毎にバリア同期を行うグループを設定し、
前記グループ毎にバリア同期を取る処理は、
前記グループ内でバリア同期を取る処理と、
前記グループ間でバリア同期を取る処理と、
を含むことを特徴とする並列計算機の同期方法。 - 前記グループ毎にバリア同期を取る処理は、
前記スレッドが予め設定したバリア同期ポイントに達したときに、当該スレッドが属するグループの共有記憶域に同期情報を書き込む処理と、
当該スレッドが属するグループの共有記憶域に格納された他のスレッドの同期情報を読み込む処理と、
当該スレッドの同期情報と他のスレッドの同期情報が一致したときに当該グループのバリア同期が完了したことを判定する処理と、
を含むことを特徴とする請求項1に記載の並列計算機の同期方法。 - 前記グループ毎にバリア同期を取る処理は、
前記プロセッサコア側の共有記憶域を用いるグループを下位グループとし、主記憶側の共有記憶域を用いるグループを上位グループとして、下位グループのバリア同期が完了した後に、順次上位グループのバリア同期をとることを特徴とする請求項1に記載の並列計算機の同期方法。 - 前記グループ毎にバリア同期を取る処理は、
前記プロセッサコア側の共有記憶域を用いるグループを下位グループとし、主記憶側の共有記憶域を用いるグループを上位グループとして、最上位のグループのバリア同期をハードウェアバリア同期機構により行うことを特徴とする請求項1に記載の並列計算機の同期方法。 - 前記複数のスレッドを階層構造のグループに設定する処理は、
前記グループの階層毎に異なる共有記憶域を用いることを特徴する請求項1に記載の並列計算機の同期方法。 - 前記複数のスレッドを割り当てて実行させる処理は、
前記プロセッサコアのうち使用するプロセッサコアの数を設定する処理と、
前記使用するプロセッサコアで実行させるスレッドの数を設定する処理と、
前記プロセッサコアの数とスレッドの数に基づいて使用するプロセッサコアにそれぞれスレッドを割り当てる処理と、
を含むことを特徴とする請求項1に記載の並列計算機の同期方法。 - 前記複数のスレッドを割り当てて実行させる処理は、
前記使用するプロセッサコアに割り当てたスレッドに、固有の識別子を付与する処理と、
前記識別子の大小関係に応じて、同一グループ内のスレッドのひとつを親スレッドとし、他のスレッドを子スレッドとして設定する処理と、
をさらに含み、
前記グループ毎にバリア同期を取る処理は、
前記グループ間でバリア同期を行う際に、前記親スレッド同士でバリア同期を行うことを特徴とする請求項6に記載の並列計算機の同期方法。 - 前記複数のスレッドを割り当てて実行させる処理は、
前記使用するプロセッサコアに前記スレッドのバリア同期を行う同期スレッドを割り当てる処理を含み、
前記グループ毎にバリア同期を取る処理は、
前記グループ間でバリア同期を行う際に、前記同期スレッド同士でバリア同期を行うことを特徴とする請求項6に記載の並列計算機の同期方法。 - 前記グループ毎にバリア同期を取る処理は、
前記スレッドが予め設定したバリア同期ポイントに達したときに、当該スレッドが属するグループの共有記憶域に同期情報を書き込む処理と、
当該スレッドが属するグループの共有記憶域に格納された他のスレッドの同期情報を読み込む処理と、
当該スレッドの同期情報と他のスレッドの同期情報が所定時間を超えて一致しない場合には、前記他のスレッドに障害が発生したと判定する処理と、
前記障害の発生時には、前記他のスレッドの同期情報を異なるグループの共有記憶域に書き込む処理と、
を含むことを特徴とする請求項1に記載の並列計算機の同期方法。 - 複数のプロセッサコアを有するプロセッサを複数備えた並列計算機で、複数のプロセッサで複数のスレッドを並列的に実行してバリア同期を行うプログラムであって、
前記プロセッサコアのそれぞれに複数のスレッドを割り当てて実行させる手順と、
前記複数のスレッドを階層構造のグループに設定する手順と、
前記グループ毎にバリア同期を取る手順と、を含み、
前記複数のスレッドを階層構造のグループに設定する手順は、
前記プロセッサコアから主記憶との間に配置されて、前記スレッド間または前記複数のプロセッサコア間あるいは前記複数のプロセッサ間で共有可能な共有記憶域の階層を設定する手順と、
前記共有記憶域の階層毎にバリア同期を行うグループを設定する手順と、を含み、
前記グループ毎にバリア同期を取る手順は、
前記グループ内でバリア同期を取る手順と、
前記グループ間でバリア同期を取る手順と、
を並列計算機に機能させることを特徴とするプログラム。 - 前記プロセッサコアのそれぞれに複数のスレッドを割り当てて実行させる手順は、
予め設定された並列計算機で使用するプロセッサコアの数と予め設定したスレッドの数に基づいて使用するプロセッサコアにそれぞれスレッドを割り当てる手順と、
を含み、
前記複数のスレッドを階層構造のグループに設定する手順は、
予め設定された並列計算機の共有記憶域の階層毎にバリア同期を行うグループを設定する手順と、
を含むことを特徴とする請求項10に記載のプログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005072633A JP4448784B2 (ja) | 2005-03-15 | 2005-03-15 | 並列計算機の同期方法及びプログラム |
| US11/312,345 US7908604B2 (en) | 2005-03-15 | 2005-12-21 | Synchronization method and program for a parallel computer |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005072633A JP4448784B2 (ja) | 2005-03-15 | 2005-03-15 | 並列計算機の同期方法及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2006259821A JP2006259821A (ja) | 2006-09-28 |
| JP4448784B2 true JP4448784B2 (ja) | 2010-04-14 |
Family
ID=37011844
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005072633A Expired - Fee Related JP4448784B2 (ja) | 2005-03-15 | 2005-03-15 | 並列計算機の同期方法及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US7908604B2 (ja) |
| JP (1) | JP4448784B2 (ja) |
Families Citing this family (74)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080005357A1 (en) * | 2006-06-30 | 2008-01-03 | Microsoft Corporation | Synchronizing dataflow computations, particularly in multi-processor setting |
| GB0613289D0 (en) * | 2006-07-04 | 2006-08-16 | Imagination Tech Ltd | Synchronisation of execution threads on a multi-threaded processor |
| US8056087B2 (en) * | 2006-09-25 | 2011-11-08 | International Business Machines Corporation | Effective use of a hardware barrier synchronization register for protocol synchronization |
| WO2008136045A1 (ja) * | 2007-04-19 | 2008-11-13 | Fujitsu Limited | 共有メモリ型スカラ並列計算機向け、実対称行列の三重対角化の並列処理方法 |
| WO2008136047A1 (ja) * | 2007-04-19 | 2008-11-13 | Fujitsu Limited | Smpノードからなるメモリ分散型並列計算機システム向けlu分解の並列処理方法 |
| JP2008287562A (ja) * | 2007-05-18 | 2008-11-27 | Sony Corp | 処理装置及びデバイス制御ユニット |
| WO2008155806A1 (ja) | 2007-06-20 | 2008-12-24 | Fujitsu Limited | バリア同期方法、装置、及びマルチコアプロセッサ |
| US8473948B1 (en) * | 2007-08-08 | 2013-06-25 | Nvidia Corporation | Method for synchronizing independent cooperative thread arrays running on a graphics processing unit |
| US8370845B1 (en) | 2007-08-08 | 2013-02-05 | Nvidia Corporation | Method for synchronizing independent cooperative thread arrays running on a graphics processing unit |
| WO2009028231A1 (ja) * | 2007-08-24 | 2009-03-05 | Nec Corporation | 通信方法 |
| US8930680B2 (en) | 2007-12-21 | 2015-01-06 | International Business Machines Corporation | Sync-ID for multiple concurrent sync dependencies in an out-of-order store queue |
| US9170962B2 (en) * | 2007-12-21 | 2015-10-27 | International Business Machines Corporation | Dynamic designation of retirement order in out-of-order store queue |
| KR101400286B1 (ko) * | 2008-01-22 | 2014-05-26 | 삼성전자주식회사 | 다중 프로세서 시스템에서 작업을 이동시키는 방법 및 장치 |
| JP2009176116A (ja) | 2008-01-25 | 2009-08-06 | Univ Waseda | マルチプロセッサシステムおよびマルチプロセッサシステムの同期方法 |
| WO2009118731A2 (en) | 2008-03-27 | 2009-10-01 | Rocketick Technologies Ltd | Design simulation using parallel processors |
| EP2297647A4 (en) * | 2008-07-10 | 2012-12-12 | Rocketick Technologies Ltd | EFFICIENT PARALLEL CALCULATION OF DEPENDENCE PROBLEMS |
| US9032377B2 (en) | 2008-07-10 | 2015-05-12 | Rocketick Technologies Ltd. | Efficient parallel computation of dependency problems |
| US8412889B2 (en) * | 2008-10-16 | 2013-04-02 | Microsoft Corporation | Low-level conditional synchronization support |
| TWI381315B (zh) * | 2008-10-24 | 2013-01-01 | Nat Univ Chung Cheng | Synchronization elements for multi-core embedded systems |
| US20100115236A1 (en) * | 2008-10-31 | 2010-05-06 | Cray Inc. | Hierarchical shared semaphore registers |
| JP4576452B2 (ja) * | 2008-11-06 | 2010-11-10 | イーソル株式会社 | オペレーティングシステムおよび情報処理装置 |
| JP5304194B2 (ja) | 2008-11-19 | 2013-10-02 | 富士通株式会社 | バリア同期装置、バリア同期システム及びバリア同期装置の制御方法 |
| FR2939922B1 (fr) * | 2008-12-16 | 2011-03-04 | Bull Sas | Gestionnaire physique de barriere de synchronisation entre processus multiples |
| WO2010109761A1 (ja) * | 2009-03-25 | 2010-09-30 | 日本電気株式会社 | 並列処理システム、並列処理方法、ネットワークスイッチ装置、及び並列処理プログラムの記録媒体 |
| US8352633B2 (en) * | 2009-06-22 | 2013-01-08 | Citrix Systems, Inc. | Systems and methods of state migration in a multi-core system |
| US9354944B2 (en) * | 2009-07-27 | 2016-05-31 | Advanced Micro Devices, Inc. | Mapping processing logic having data-parallel threads across processors |
| JP5447807B2 (ja) * | 2009-08-07 | 2014-03-19 | 株式会社日立製作所 | バリア同期方法及び計算機 |
| US8832712B2 (en) * | 2009-09-09 | 2014-09-09 | Ati Technologies Ulc | System and method for synchronizing threads using shared memory having different buffer portions for local and remote cores in a multi-processor system |
| FR2950714B1 (fr) * | 2009-09-25 | 2011-11-18 | Bull Sas | Systeme et procede de gestion de l'execution entrelacee de fils d'instructions |
| US9164969B1 (en) * | 2009-09-29 | 2015-10-20 | Cadence Design Systems, Inc. | Method and system for implementing a stream reader for EDA tools |
| CN103168291A (zh) * | 2010-10-20 | 2013-06-19 | 富士通株式会社 | 信息处理系统、存储装置、信息处理装置以及信息处理系统的控制方法 |
| US8949835B2 (en) * | 2010-11-30 | 2015-02-03 | Red Hat, Inc. | Yielding input/output scheduler to increase overall system throughput |
| WO2012124078A1 (ja) * | 2011-03-16 | 2012-09-20 | 富士通株式会社 | 同期方法、マルチコアプロセッサシステム、および同期システム |
| JPWO2012127534A1 (ja) * | 2011-03-23 | 2014-07-24 | 富士通株式会社 | バリア同期方法、バリア同期装置及び演算処理装置 |
| US9128748B2 (en) | 2011-04-12 | 2015-09-08 | Rocketick Technologies Ltd. | Parallel simulation using multiple co-simulators |
| EP2711839A4 (en) * | 2011-05-19 | 2014-12-03 | Nec Corp | PARALLEL PROCESSING DEVICE, PARALLEL PROCESSING METHOD, OPTIMIZATION DEVICE, OPTIMIZATION METHOD AND COMPUTER PROGRAM |
| US8621473B2 (en) | 2011-08-01 | 2013-12-31 | Honeywell International Inc. | Constrained rate monotonic analysis and scheduling |
| US8875146B2 (en) | 2011-08-01 | 2014-10-28 | Honeywell International Inc. | Systems and methods for bounding processing times on multiple processing units |
| DE102011084569B4 (de) * | 2011-10-14 | 2019-02-21 | Continental Automotive Gmbh | Verfahren zum Betreiben eines informationstechnischen Systems und informationstechnisches System |
| US8607247B2 (en) * | 2011-11-03 | 2013-12-10 | Advanced Micro Devices, Inc. | Method and system for workitem synchronization |
| US9092272B2 (en) * | 2011-12-08 | 2015-07-28 | International Business Machines Corporation | Preparing parallel tasks to use a synchronization register |
| US9207977B2 (en) | 2012-02-06 | 2015-12-08 | Honeywell International Inc. | Systems and methods for task grouping on multi-processors |
| US9513975B2 (en) * | 2012-05-02 | 2016-12-06 | Nvidia Corporation | Technique for computational nested parallelism |
| JP5974703B2 (ja) | 2012-07-20 | 2016-08-23 | 富士通株式会社 | 情報処理装置およびバリア同期方法 |
| US9612868B2 (en) | 2012-10-31 | 2017-04-04 | Honeywell International Inc. | Systems and methods generating inter-group and intra-group execution schedules for instruction entity allocation and scheduling on multi-processors |
| US8839216B2 (en) | 2012-11-07 | 2014-09-16 | International Business Machines Corporation | Compiler optimization based on collectivity analysis |
| JP5994601B2 (ja) * | 2012-11-27 | 2016-09-21 | 富士通株式会社 | 並列計算機、並列計算機の制御プログラム及び並列計算機の制御方法 |
| JP6221498B2 (ja) * | 2013-08-15 | 2017-11-01 | 富士通株式会社 | 情報処理システム及び情報処理システムの制御方法 |
| WO2015027403A1 (en) * | 2013-08-28 | 2015-03-05 | Hewlett-Packard Development Company, L.P. | Testing multi-threaded applications |
| JP6176166B2 (ja) * | 2014-03-25 | 2017-08-09 | 株式会社デンソー | データ処理装置 |
| JP6330569B2 (ja) * | 2014-08-14 | 2018-05-30 | 富士通株式会社 | 演算処理装置および演算処理装置の制御方法 |
| JP6442947B2 (ja) * | 2014-09-19 | 2018-12-26 | 日本電気株式会社 | 情報処理装置、情報処理方法及びそのプログラム |
| CN105745912B (zh) * | 2014-10-21 | 2018-05-18 | 株式会社东京机械制作所 | 图像处理装置 |
| US9760410B2 (en) * | 2014-12-12 | 2017-09-12 | Intel Corporation | Technologies for fast synchronization barriers for many-core processing |
| US10101786B2 (en) | 2014-12-22 | 2018-10-16 | Intel Corporation | Holistic global performance and power management |
| US9477533B2 (en) | 2014-12-26 | 2016-10-25 | Intel Corporation | Progress meters in parallel computing |
| JP2015127982A (ja) * | 2015-04-06 | 2015-07-09 | 学校法人早稲田大学 | マルチプロセッサシステム |
| US10402234B2 (en) * | 2016-04-15 | 2019-09-03 | Nec Corporation | Fine-grain synchronization in data-parallel jobs |
| US10402235B2 (en) * | 2016-04-15 | 2019-09-03 | Nec Corporation | Fine-grain synchronization in data-parallel jobs for distributed machine learning |
| US11353868B2 (en) | 2017-04-24 | 2022-06-07 | Intel Corporation | Barriers and synchronization for machine learning at autonomous machines |
| GB2575294B8 (en) * | 2018-07-04 | 2022-07-20 | Graphcore Ltd | Host Proxy On Gateway |
| JP7338354B2 (ja) * | 2019-09-20 | 2023-09-05 | 富士通株式会社 | 情報処理装置,情報処理システム及び通信管理プログラム |
| US11409579B2 (en) * | 2020-02-24 | 2022-08-09 | Intel Corporation | Multiple independent synchonization named barrier within a thread group |
| JP7476638B2 (ja) * | 2020-04-15 | 2024-05-01 | 株式会社デンソー | マルチプロセッサシステム |
| US20210382717A1 (en) * | 2020-06-03 | 2021-12-09 | Intel Corporation | Hierarchical thread scheduling |
| US11977895B2 (en) | 2020-06-03 | 2024-05-07 | Intel Corporation | Hierarchical thread scheduling based on multiple barriers |
| CN112306646B (zh) * | 2020-06-29 | 2024-11-22 | 北京京东拓先科技有限公司 | 用于处理事务的方法、装置、设备及可读存储介质 |
| GB202010806D0 (en) * | 2020-07-14 | 2020-08-26 | Graphcore Ltd | Extended sync network |
| US11720360B2 (en) * | 2020-09-11 | 2023-08-08 | Apple Inc. | DSB operation with excluded region |
| GB202110148D0 (en) * | 2021-07-14 | 2021-08-25 | Graphcore Ltd | Synchronisation for a multi-tile processing unit |
| CN114237878B (zh) * | 2021-12-06 | 2025-10-31 | 海光信息技术股份有限公司 | 指令控制方法、电路、装置及相关设备 |
| EP4206995A1 (en) | 2021-12-30 | 2023-07-05 | Rebellions Inc. | Neural processing device and method for synchronization thereof |
| US20230289242A1 (en) * | 2022-03-10 | 2023-09-14 | Nvidia Corporation | Hardware accelerated synchronization with asynchronous transaction support |
| KR102623397B1 (ko) * | 2023-04-07 | 2024-01-10 | 메티스엑스 주식회사 | 매니코어 시스템 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05151174A (ja) | 1991-11-28 | 1993-06-18 | Fujitsu Ltd | マルチプロセツサの同期方式 |
| JPH11312148A (ja) | 1998-04-28 | 1999-11-09 | Hitachi Ltd | バリア同期方法及び装置 |
| US6862027B2 (en) * | 2003-06-30 | 2005-03-01 | Microsoft Corp. | System and method for parallel execution of data generation tasks |
| US7512950B1 (en) * | 2003-08-14 | 2009-03-31 | Sun Microsystems, Inc. | Barrier synchronization object for multi-threaded applications |
-
2005
- 2005-03-15 JP JP2005072633A patent/JP4448784B2/ja not_active Expired - Fee Related
- 2005-12-21 US US11/312,345 patent/US7908604B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| US20060212868A1 (en) | 2006-09-21 |
| US7908604B2 (en) | 2011-03-15 |
| JP2006259821A (ja) | 2006-09-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4448784B2 (ja) | 並列計算機の同期方法及びプログラム | |
| KR100578437B1 (ko) | 다수의 스레드의 병행 실행을 지원하는 컴퓨터 시스템에서의 인터럽트 처리 메커니즘 | |
| CN101833475B (zh) | 用于执行指令原子块的方法和装置 | |
| US8640140B2 (en) | Adaptive queuing methodology for system task management | |
| US8739163B2 (en) | Critical path deterministic execution of multithreaded applications in a transactional memory system | |
| TWI537831B (zh) | 多核心處理器、用於執行處理程序切換之方法、用於保全一記憶體區塊之方法、用於致能使用一多核心裝置之異動處理之設備、以及用於執行記憶體異動處理之方法 | |
| US20110119452A1 (en) | Hybrid Transactional Memory System (HybridTM) and Method | |
| CN101563674A (zh) | 对来自多处理器系统上的多线程程序的存储器访问进行管理的方法和系统 | |
| CN114930292B (zh) | 协作式工作窃取调度器 | |
| US9378069B2 (en) | Lock spin wait operation for multi-threaded applications in a multi-core computing environment | |
| CN103140828A (zh) | 基于硬件限制利用可调事务尺寸来动态优化代码的装置、方法和系统 | |
| US10922137B2 (en) | Dynamic thread mapping | |
| CN107729267B (zh) | 资源的分散分配以及用于支持由多个引擎执行指令序列的互连结构 | |
| EP3588313B1 (en) | Non-volatile memory aware caching policies | |
| US11656967B2 (en) | Method and apparatus for supporting persistence and computing device | |
| Ceze et al. | Colorama: Architectural support for data-centric synchronization | |
| JP6135392B2 (ja) | キャッシュメモリ制御プログラム,キャッシュメモリを内蔵するプロセッサ及びキャッシュメモリ制御方法 | |
| Orosa et al. | Flexsig: Implementing flexible hardware signatures | |
| Duan et al. | Asymmetric memory fences: Optimizing both performance and implementability | |
| Duan et al. | BulkCompactor: Optimized deterministic execution via conflict-aware commit of atomic blocks | |
| He et al. | NUMA-Aware Contention Scheduling on Multicore Systems | |
| JP5847313B2 (ja) | 情報処理装置 | |
| Reif et al. | Migration-Based Synchronization | |
| Zhu et al. | SymS: a symmetrical scheduler to improve multi‐threaded program performance on NUMA systems | |
| CN117331669A (zh) | 基于锁语义实现应用透明的动态处理器缓存分区调度方法和系统 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080225 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20090911 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090929 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20091130 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20100105 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100125 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130129 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |