JP2019197319A - 情報処理装置、情報処理方法および情報処理プログラム - Google Patents
情報処理装置、情報処理方法および情報処理プログラム Download PDFInfo
- Publication number
- JP2019197319A JP2019197319A JP2018090015A JP2018090015A JP2019197319A JP 2019197319 A JP2019197319 A JP 2019197319A JP 2018090015 A JP2018090015 A JP 2018090015A JP 2018090015 A JP2018090015 A JP 2018090015A JP 2019197319 A JP2019197319 A JP 2019197319A
- Authority
- JP
- Japan
- Prior art keywords
- link
- flow
- value
- performance information
- information
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G06F9/5044—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals considering hardware capabilities
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/10—Program control for peripheral devices
- G06F13/12—Program control for peripheral devices using hardware independent of the central processor, e.g. channel or peripheral processor
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/3003—Monitoring arrangements specially adapted to the computing system or computing system component being monitored
- G06F11/3031—Monitoring arrangements specially adapted to the computing system or computing system component being monitored where the computing system component is a motherboard or an expansion card
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/3003—Monitoring arrangements specially adapted to the computing system or computing system component being monitored
- G06F11/3041—Monitoring arrangements specially adapted to the computing system or computing system component being monitored where the computing system component is an input/output interface
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
- G06F11/3409—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment for performance assessment
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
- G06F11/3409—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment for performance assessment
- G06F11/3419—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment for performance assessment by assessing time
- G06F11/3423—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment for performance assessment by assessing time where the assessed time is active or idle time
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5011—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resources being hardware resources other than CPUs, Servers and Terminals
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2209/00—Indexing scheme relating to G06F9/00
- G06F2209/50—Indexing scheme relating to G06F9/50
- G06F2209/501—Performance criteria
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2209/00—Indexing scheme relating to G06F9/00
- G06F2209/50—Indexing scheme relating to G06F9/50
- G06F2209/509—Offload
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Quality & Reliability (AREA)
- Computing Systems (AREA)
- Computer Hardware Design (AREA)
- Mathematical Physics (AREA)
- Debugging And Monitoring (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
Abstract
Description
110 通信部
111 表示部
112 操作部
113 HDD
114 バス
120 メモリ
130 CPU
131 OS/VM
140 FPGA
141 制御回路
142,143 Mux/demux
144 モニタ
145 フローテーブル
146 リンクテーブル
147 セレクタ
A1〜Am アプリケーション
IF1〜IFn インタフェース
L1〜Ln リンク
UL1〜ULm ユーザロジック
Claims (8)
- 複数のリンクを経由してCPUと接続されるオフロード回路において、
アプリケーションの処理を演算する論理回路と、
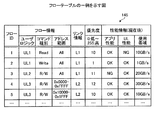
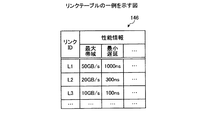
前記アプリケーションの処理に対応するフローごとの前記リンクの性能情報を示す値と、前記リンクごとの使用可能な性能情報の最大値とを収集する収集部と、
前記フローごとの前記リンクの性能情報を示す値に基づいて、要する性能情報を満たしていないフローを判定し、前記リンクごとの使用可能な性能情報の最大値と、前記リンクごとの現在使用されている性能情報の値とに基づいて、前記フローの振り分け先のリンクを選択して振り分ける選択部と、
を備えることを特徴とする情報処理装置。 - 前記収集部は、前記アプリケーションの処理に対応するフローごとの前記リンクの使用帯域を示す値と、前記リンクごとの使用可能な帯域の最大値とを収集し、
前記選択部は、前記フローごとの前記リンクの使用帯域を示す値に基づいて、要する帯域を満たしていないフローを判定し、前記リンクごとの使用可能な帯域の最大値と、前記リンクごとの現在使用されている帯域の値とに基づいて、前記フローの振り分け先のリンクを選択して振り分ける、
ことを特徴とする請求項1に記載の情報処理装置。 - 前記収集部は、前記アプリケーションの処理、または、前記論理回路の性能が性能要件を満たしていない場合、対応する前記フローの優先度を上げる、
ことを特徴とする請求項2に記載の情報処理装置。 - 前記選択部は、前記リンクごとの使用可能な帯域の最大値と、前記リンクごとの現在使用されている帯域の値とに基づいて、前記フローの振り分け先のリンクを選択し、選択した前記振り分け先のリンクに該フローを振り分けると、前記振り分け先のリンクの使用可能な帯域の最大値を超える場合、前記振り分け先のリンクを使用する最も優先度が低いフローを、振り分け元のリンクに振り分ける、
ことを特徴とする請求項2または3に記載の情報処理装置。 - 前記収集部は、所定時間ごとに、前記リンクの使用帯域を示す値と、前記リンクごとの使用可能な帯域の最大値とを収集し、
前記選択部は、前記所定時間ごとに、前記要する帯域を満たしていないフローを判定する、
ことを特徴とする請求項2〜4のいずれか1つに記載の情報処理装置。 - 前記収集部は、前記アプリケーションの処理に対応するフローごとの前記リンクのレイテンシを示す値と、前記リンクごとのレイテンシの最大値とを収集し、
前記選択部は、前記フローごとの前記リンクのレイテンシを示す値に基づいて、要するレイテンシを満たしていないフローを判定し、前記リンクごとのレイテンシの最大値と、前記リンクごとの現在のレイテンシの値とに基づいて、前記フローの振り分け先のリンクを選択して振り分ける、
ことを特徴とする請求項1に記載の情報処理装置。 - 複数のリンクを経由してCPUと接続され、アプリケーションの処理を演算する論理回路を備えるオフロード回路において、
前記アプリケーションの処理に対応するフローごとの前記リンクの性能情報を示す値と、前記リンクごとの使用可能な性能情報の最大値とを収集し、
前記フローごとの前記リンクの性能情報を示す値に基づいて、要する性能情報を満たしていないフローを判定し、前記リンクごとの使用可能な性能情報の最大値と、前記リンクごとの現在使用されている性能情報の値とに基づいて、前記フローの振り分け先のリンクを選択して振り分ける、
ことを特徴とする情報処理方法。 - 複数のリンクを経由してCPUと接続され、アプリケーションの処理を演算する論理回路を備えるオフロード回路において、
前記アプリケーションの処理に対応するフローごとの前記リンクの性能情報を示す値と、前記リンクごとの使用可能な性能情報の最大値とを収集し、
前記フローごとの前記リンクの性能情報を示す値に基づいて、要する性能情報を満たしていないフローを判定し、前記リンクごとの使用可能な性能情報の最大値と、前記リンクごとの現在使用されている性能情報の値とに基づいて、前記フローの振り分け先のリンクを選択して振り分ける、
処理をコンピュータに実行させることを特徴とする情報処理プログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018090015A JP7087649B2 (ja) | 2018-05-08 | 2018-05-08 | 情報処理装置、情報処理方法および情報処理プログラム |
| US16/366,528 US10810047B2 (en) | 2018-05-08 | 2019-03-27 | Information processing device, information processing method, and computer-readable recording medium storing program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018090015A JP7087649B2 (ja) | 2018-05-08 | 2018-05-08 | 情報処理装置、情報処理方法および情報処理プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2019197319A true JP2019197319A (ja) | 2019-11-14 |
| JP7087649B2 JP7087649B2 (ja) | 2022-06-21 |
Family
ID=68464683
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018090015A Active JP7087649B2 (ja) | 2018-05-08 | 2018-05-08 | 情報処理装置、情報処理方法および情報処理プログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US10810047B2 (ja) |
| JP (1) | JP7087649B2 (ja) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11182221B1 (en) | 2020-12-18 | 2021-11-23 | SambaNova Systems, Inc. | Inter-node buffer-based streaming for reconfigurable processor-as-a-service (RPaaS) |
| US11200096B1 (en) * | 2021-03-26 | 2021-12-14 | SambaNova Systems, Inc. | Resource allocation for reconfigurable processors |
| JP2023007160A (ja) * | 2021-07-01 | 2023-01-18 | 富士通株式会社 | 情報処理装置,制御方法および制御プログラム |
| CN114860431B (zh) * | 2022-04-22 | 2025-11-25 | 浪潮商用机器有限公司 | 一种内存访问方法、装置、设备及介质 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006331207A (ja) * | 2005-05-27 | 2006-12-07 | Sony Computer Entertainment Inc | 情報処理方法、情報処理装置、およびサーバ |
| JP2010171562A (ja) * | 2009-01-21 | 2010-08-05 | Fujitsu Ltd | 通信装置および通信制御方法 |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030135609A1 (en) * | 2002-01-16 | 2003-07-17 | Sun Microsystems, Inc. | Method, system, and program for determining a modification of a system resource configuration |
| US7415595B2 (en) | 2005-05-24 | 2008-08-19 | Coresonic Ab | Data processing without processor core intervention by chain of accelerators selectively coupled by programmable interconnect network and to memory |
| US7940661B2 (en) * | 2007-06-01 | 2011-05-10 | Cisco Technology, Inc. | Dynamic link aggregation |
| TWI408557B (zh) * | 2010-03-18 | 2013-09-11 | Faraday Tech Corp | 高速輸入輸出系統及其節能控制方法 |
| US8929220B2 (en) * | 2012-08-24 | 2015-01-06 | Advanced Micro Devices, Inc. | Processing system using virtual network interface controller addressing as flow control metadata |
| JP5660149B2 (ja) | 2013-03-04 | 2015-01-28 | 日本電気株式会社 | 情報処理装置、ジョブスケジューリング方法およびジョブスケジューリングプログラム |
| US10050884B1 (en) * | 2017-03-21 | 2018-08-14 | Citrix Systems, Inc. | Method to remap high priority connection with large congestion window to high latency link to achieve better performance |
-
2018
- 2018-05-08 JP JP2018090015A patent/JP7087649B2/ja active Active
-
2019
- 2019-03-27 US US16/366,528 patent/US10810047B2/en not_active Expired - Fee Related
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006331207A (ja) * | 2005-05-27 | 2006-12-07 | Sony Computer Entertainment Inc | 情報処理方法、情報処理装置、およびサーバ |
| JP2010171562A (ja) * | 2009-01-21 | 2010-08-05 | Fujitsu Ltd | 通信装置および通信制御方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7087649B2 (ja) | 2022-06-21 |
| US20190347136A1 (en) | 2019-11-14 |
| US10810047B2 (en) | 2020-10-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6961686B2 (ja) | トリガ動作を用いたgpuリモート通信 | |
| JP5871233B2 (ja) | 計算機及び帯域制御方法 | |
| JP5088366B2 (ja) | 仮想計算機制御プログラム、仮想計算機制御システムおよび仮想計算機移動方法 | |
| JP7087649B2 (ja) | 情報処理装置、情報処理方法および情報処理プログラム | |
| JP6231679B2 (ja) | 周辺コンポーネント相互接続エクスプレスドメインのためのリソース管理 | |
| JP6022650B2 (ja) | バーチャルマシンの間でサービスチェーンフローパケットを経路指定するための技術 | |
| US8972611B2 (en) | Multi-server consolidated input/output (IO) device | |
| US20170075838A1 (en) | Quality of service in interconnects with multi-stage arbitration | |
| CN109218355A (zh) | 负载均衡引擎,客户端,分布式计算系统以及负载均衡方法 | |
| JP2016119064A (ja) | エンドツーエンドデータセンタ性能制御 | |
| EP3224728B1 (en) | Providing shared cache memory allocation control in shared cache memory systems | |
| US10614542B2 (en) | High granularity level GPU resource allocation method and system | |
| US20180077649A1 (en) | Communications fabric with split paths for control and data packets | |
| EP2625619B1 (en) | Arbitrating stream transactions based on information related to the stream transaction(s) | |
| JP2011503731A (ja) | リンクに基づくシステムにおけるシステムルーティング情報の変更 | |
| JP2014186411A (ja) | 管理装置、情報処理システム、情報処理方法、及びプログラム | |
| JP5331549B2 (ja) | 分散処理システム及び分散処理方法 | |
| CN120492166A (zh) | 一种通道带宽的切换方法、硬盘背板、计算机设备及存储介质 | |
| JP6427083B2 (ja) | リソース割当管理装置、および、サービスチェイニングシステム | |
| TWI650979B (zh) | 負載平衡調整系統及其方法 | |
| US12056072B1 (en) | Low latency memory notification | |
| WO2024072935A1 (en) | Connection modification based on traffic pattern | |
| JP2007179200A (ja) | コンピュータシステムおよびストレージ仮想化装置 | |
| US10467156B1 (en) | System and method of improving efficiency in parallel data processing of a RAID array | |
| US8346988B2 (en) | Techniques for dynamically sharing a fabric to facilitate off-chip communication for multiple on-chip units |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20210210 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20211228 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20220104 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220228 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20220510 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20220523 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7087649 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |