JP2018514187A - 発現レベルおよび配列変種情報を用いて疾患の発症または再発のリスクを評価するための方法 - Google Patents
発現レベルおよび配列変種情報を用いて疾患の発症または再発のリスクを評価するための方法 Download PDFInfo
- Publication number
- JP2018514187A JP2018514187A JP2017546066A JP2017546066A JP2018514187A JP 2018514187 A JP2018514187 A JP 2018514187A JP 2017546066 A JP2017546066 A JP 2017546066A JP 2017546066 A JP2017546066 A JP 2017546066A JP 2018514187 A JP2018514187 A JP 2018514187A
- Authority
- JP
- Japan
- Prior art keywords
- risk
- genes
- disease
- sample
- nucleic acid
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 title claims abstract description 197
- 201000010099 disease Diseases 0.000 title claims abstract description 175
- 238000000034 method Methods 0.000 title claims abstract description 160
- 230000014509 gene expression Effects 0.000 title claims description 88
- 108090000623 proteins and genes Proteins 0.000 claims description 341
- 239000000523 sample Substances 0.000 claims description 220
- 206010028980 Neoplasm Diseases 0.000 claims description 94
- 201000011510 cancer Diseases 0.000 claims description 82
- 150000007523 nucleic acids Chemical class 0.000 claims description 78
- 230000035772 mutation Effects 0.000 claims description 56
- 102000039446 nucleic acids Human genes 0.000 claims description 46
- 108020004707 nucleic acids Proteins 0.000 claims description 46
- 238000004422 calculation algorithm Methods 0.000 claims description 43
- 238000012163 sequencing technique Methods 0.000 claims description 41
- 230000004927 fusion Effects 0.000 claims description 32
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 31
- 102100033601 Collagen alpha-1(I) chain Human genes 0.000 claims description 27
- 108010029483 alpha 1 Chain Collagen Type I Proteins 0.000 claims description 27
- 230000015654 memory Effects 0.000 claims description 21
- 238000003745 diagnosis Methods 0.000 claims description 20
- 238000004458 analytical method Methods 0.000 claims description 19
- 101001067522 Homo sapiens Inactive polypeptide N-acetylgalactosaminyltransferase-like protein 5 Proteins 0.000 claims description 15
- 101001134126 Homo sapiens Nuclear pore membrane glycoprotein 210-like Proteins 0.000 claims description 15
- 101000829538 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 15 Proteins 0.000 claims description 15
- 101000888117 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 18 Proteins 0.000 claims description 15
- 101000742002 Homo sapiens Prickle-like protein 1 Proteins 0.000 claims description 15
- 101000848718 Homo sapiens Rap guanine nucleotide exchange factor 5 Proteins 0.000 claims description 15
- 101000650694 Homo sapiens Roundabout homolog 1 Proteins 0.000 claims description 15
- 101000618138 Homo sapiens Sperm-associated antigen 4 protein Proteins 0.000 claims description 15
- 101000662963 Homo sapiens Transmembrane protein 92 Proteins 0.000 claims description 15
- 101000776449 Homo sapiens Uncharacterized protein C6orf136 Proteins 0.000 claims description 15
- 102100034218 Nuclear pore membrane glycoprotein 210-like Human genes 0.000 claims description 15
- 102100023229 Polypeptide N-acetylgalactosaminyltransferase 15 Human genes 0.000 claims description 15
- 102100038630 Prickle-like protein 1 Human genes 0.000 claims description 15
- 102100034590 Rap guanine nucleotide exchange factor 5 Human genes 0.000 claims description 15
- 102100027702 Roundabout homolog 1 Human genes 0.000 claims description 15
- 102100021907 Sperm-associated antigen 4 protein Human genes 0.000 claims description 15
- 102100037640 Transmembrane protein 92 Human genes 0.000 claims description 15
- 102100031218 Uncharacterized protein C6orf136 Human genes 0.000 claims description 15
- 210000001685 thyroid gland Anatomy 0.000 claims description 15
- 102100032025 ETS homologous factor Human genes 0.000 claims description 14
- 101000921245 Homo sapiens ETS homologous factor Proteins 0.000 claims description 14
- 101001065609 Homo sapiens Lumican Proteins 0.000 claims description 14
- 102100032114 Lumican Human genes 0.000 claims description 14
- 230000003321 amplification Effects 0.000 claims description 14
- 238000003199 nucleic acid amplification method Methods 0.000 claims description 14
- 238000001356 surgical procedure Methods 0.000 claims description 14
- 101000633605 Homo sapiens Thrombospondin-2 Proteins 0.000 claims description 13
- 102100029529 Thrombospondin-2 Human genes 0.000 claims description 13
- 239000003550 marker Substances 0.000 claims description 13
- 238000012360 testing method Methods 0.000 claims description 12
- 101001069684 Homo sapiens Psoriasis susceptibility 1 candidate gene 1 protein Proteins 0.000 claims description 10
- 102100033833 Psoriasis susceptibility 1 candidate gene 1 protein Human genes 0.000 claims description 10
- -1 AC019117.2P Proteins 0.000 claims description 9
- 101000680015 Homo sapiens Thioredoxin-related transmembrane protein 1 Proteins 0.000 claims description 9
- 102100022169 Thioredoxin-related transmembrane protein 1 Human genes 0.000 claims description 9
- 238000009396 hybridization Methods 0.000 claims description 9
- 102100028228 COUP transcription factor 1 Human genes 0.000 claims description 8
- 101150016325 EPHA3 gene Proteins 0.000 claims description 8
- 102100030324 Ephrin type-A receptor 3 Human genes 0.000 claims description 8
- 101000860854 Homo sapiens COUP transcription factor 1 Proteins 0.000 claims description 8
- 101000581984 Homo sapiens Neural cell adhesion molecule 2 Proteins 0.000 claims description 8
- 101000700626 Homo sapiens Protein sprouty homolog 3 Proteins 0.000 claims description 8
- 102100030467 Neural cell adhesion molecule 2 Human genes 0.000 claims description 8
- 102100029292 Protein sprouty homolog 3 Human genes 0.000 claims description 8
- 101710186714 2-acylglycerol O-acyltransferase 1 Proteins 0.000 claims description 7
- 102100037039 Acyl-coenzyme A diphosphatase FITM2 Human genes 0.000 claims description 7
- 102100022622 Alpha-1,3-mannosyl-glycoprotein 2-beta-N-acetylglucosaminyltransferase Human genes 0.000 claims description 7
- 102100024505 Bone morphogenetic protein 4 Human genes 0.000 claims description 7
- 102100031611 Collagen alpha-1(III) chain Human genes 0.000 claims description 7
- 102100024338 Collagen alpha-3(VI) chain Human genes 0.000 claims description 7
- 102100028202 Cytochrome c oxidase subunit 6C Human genes 0.000 claims description 7
- 102100024469 Dephospho-CoA kinase domain-containing protein Human genes 0.000 claims description 7
- 102100036242 HLA class II histocompatibility antigen, DQ alpha 2 chain Human genes 0.000 claims description 7
- 108010086786 HLA-DQA1 antigen Proteins 0.000 claims description 7
- 108010067802 HLA-DR alpha-Chains Proteins 0.000 claims description 7
- 102100031180 Hereditary hemochromatosis protein Human genes 0.000 claims description 7
- 101000878263 Homo sapiens Acyl-coenzyme A diphosphatase FITM2 Proteins 0.000 claims description 7
- 101000762379 Homo sapiens Bone morphogenetic protein 4 Proteins 0.000 claims description 7
- 101000993285 Homo sapiens Collagen alpha-1(III) chain Proteins 0.000 claims description 7
- 101000909506 Homo sapiens Collagen alpha-3(VI) chain Proteins 0.000 claims description 7
- 101000861049 Homo sapiens Cytochrome c oxidase subunit 6C Proteins 0.000 claims description 7
- 101000832260 Homo sapiens Dephospho-CoA kinase domain-containing protein Proteins 0.000 claims description 7
- 101000993059 Homo sapiens Hereditary hemochromatosis protein Proteins 0.000 claims description 7
- 101000730000 Homo sapiens Late secretory pathway protein AVL9 homolog Proteins 0.000 claims description 7
- 101001036258 Homo sapiens Little elongation complex subunit 2 Proteins 0.000 claims description 7
- 101000976899 Homo sapiens Mitogen-activated protein kinase 15 Proteins 0.000 claims description 7
- 101001098523 Homo sapiens PAX-interacting protein 1 Proteins 0.000 claims description 7
- 101001073216 Homo sapiens Period circadian protein homolog 2 Proteins 0.000 claims description 7
- 101000866971 Homo sapiens Putative HLA class I histocompatibility antigen, alpha chain H Proteins 0.000 claims description 7
- 101000606535 Homo sapiens Receptor-type tyrosine-protein phosphatase epsilon Proteins 0.000 claims description 7
- 101000854800 Homo sapiens V-set and immunoglobulin domain-containing protein 10-like Proteins 0.000 claims description 7
- 102100032642 Late secretory pathway protein AVL9 homolog Human genes 0.000 claims description 7
- 102100039420 Little elongation complex subunit 2 Human genes 0.000 claims description 7
- 102100023483 Mitogen-activated protein kinase 15 Human genes 0.000 claims description 7
- 102100037141 PAX-interacting protein 1 Human genes 0.000 claims description 7
- 102100035787 Period circadian protein homolog 2 Human genes 0.000 claims description 7
- 102100039665 Receptor-type tyrosine-protein phosphatase epsilon Human genes 0.000 claims description 7
- 108091006555 SLC30A5 Proteins 0.000 claims description 7
- 108091006984 SLC41A3 Proteins 0.000 claims description 7
- 102100037254 Solute carrier family 41 member 3 Human genes 0.000 claims description 7
- 102100020801 V-set and immunoglobulin domain-containing protein 10-like Human genes 0.000 claims description 7
- 102100026644 Zinc transporter 5 Human genes 0.000 claims description 7
- 238000000540 analysis of variance Methods 0.000 claims description 7
- 230000002068 genetic effect Effects 0.000 claims description 7
- 238000003752 polymerase chain reaction Methods 0.000 claims description 7
- 102100036241 HLA class II histocompatibility antigen, DQ beta 1 chain Human genes 0.000 claims description 6
- 108010065026 HLA-DQB1 antigen Proteins 0.000 claims description 6
- 101000704156 Homo sapiens Sarcalumenin Proteins 0.000 claims description 6
- 101000830598 Homo sapiens Tumor necrosis factor ligand superfamily member 12 Proteins 0.000 claims description 6
- 102100031881 Sarcalumenin Human genes 0.000 claims description 6
- 101000984202 Streptomyces rimosus Lipase Proteins 0.000 claims description 6
- 102100024584 Tumor necrosis factor ligand superfamily member 12 Human genes 0.000 claims description 6
- 108700039887 Essential Genes Proteins 0.000 claims description 5
- 238000006243 chemical reaction Methods 0.000 claims description 5
- 238000009826 distribution Methods 0.000 claims description 5
- 238000002493 microarray Methods 0.000 claims description 5
- 238000003757 reverse transcription PCR Methods 0.000 claims description 5
- 238000006467 substitution reaction Methods 0.000 claims description 5
- 102100040084 A-kinase anchor protein 9 Human genes 0.000 claims description 4
- 102100040176 Archaemetzincin-1 Human genes 0.000 claims description 4
- 102100033890 Arylsulfatase G Human genes 0.000 claims description 4
- 102100021534 Calcium/calmodulin-dependent protein kinase kinase 2 Human genes 0.000 claims description 4
- 102100036568 Cell cycle and apoptosis regulator protein 2 Human genes 0.000 claims description 4
- 102100032348 Coiled-coil domain-containing protein 93 Human genes 0.000 claims description 4
- 102100025177 Dimethylglycine dehydrogenase, mitochondrial Human genes 0.000 claims description 4
- 102100028555 Disheveled-associated activator of morphogenesis 1 Human genes 0.000 claims description 4
- 102100034568 E3 ubiquitin-protein ligase PDZRN3 Human genes 0.000 claims description 4
- 102100028640 HLA class II histocompatibility antigen, DR beta 5 chain Human genes 0.000 claims description 4
- 108010016996 HLA-DRB5 Chains Proteins 0.000 claims description 4
- 101000890598 Homo sapiens A-kinase anchor protein 9 Proteins 0.000 claims description 4
- 101000889842 Homo sapiens Archaemetzincin-1 Proteins 0.000 claims description 4
- 101000925538 Homo sapiens Arylsulfatase G Proteins 0.000 claims description 4
- 101000971617 Homo sapiens Calcium/calmodulin-dependent protein kinase kinase 2 Proteins 0.000 claims description 4
- 101000715194 Homo sapiens Cell cycle and apoptosis regulator protein 2 Proteins 0.000 claims description 4
- 101000797736 Homo sapiens Coiled-coil domain-containing protein 93 Proteins 0.000 claims description 4
- 101001005618 Homo sapiens Dimethylglycine dehydrogenase, mitochondrial Proteins 0.000 claims description 4
- 101000915413 Homo sapiens Disheveled-associated activator of morphogenesis 1 Proteins 0.000 claims description 4
- 101001131834 Homo sapiens E3 ubiquitin-protein ligase PDZRN3 Proteins 0.000 claims description 4
- 101000598002 Homo sapiens Interferon regulatory factor 1 Proteins 0.000 claims description 4
- 101000613960 Homo sapiens Lysine-specific histone demethylase 1B Proteins 0.000 claims description 4
- 101000967135 Homo sapiens N6-adenosine-methyltransferase catalytic subunit Proteins 0.000 claims description 4
- 101000969961 Homo sapiens Neurexin-3 Proteins 0.000 claims description 4
- 101000969963 Homo sapiens Neurexin-3-beta Proteins 0.000 claims description 4
- 101000614405 Homo sapiens P2X purinoceptor 1 Proteins 0.000 claims description 4
- 101000582936 Homo sapiens Pleckstrin Proteins 0.000 claims description 4
- 101001000998 Homo sapiens Protein phosphatase 1 regulatory subunit 12C Proteins 0.000 claims description 4
- 101000659053 Homo sapiens Synaptopodin-2 Proteins 0.000 claims description 4
- 101000868045 Homo sapiens Uncharacterized protein C1orf87 Proteins 0.000 claims description 4
- 101000976580 Homo sapiens Zinc finger protein 133 Proteins 0.000 claims description 4
- 102100036981 Interferon regulatory factor 1 Human genes 0.000 claims description 4
- 102100040596 Lysine-specific histone demethylase 1B Human genes 0.000 claims description 4
- 102100040619 N6-adenosine-methyltransferase catalytic subunit Human genes 0.000 claims description 4
- 102100021310 Neurexin-3 Human genes 0.000 claims description 4
- 102100040444 P2X purinoceptor 1 Human genes 0.000 claims description 4
- 102100030264 Pleckstrin Human genes 0.000 claims description 4
- 102100035620 Protein phosphatase 1 regulatory subunit 12C Human genes 0.000 claims description 4
- 238000000692 Student's t-test Methods 0.000 claims description 4
- 102100035603 Synaptopodin-2 Human genes 0.000 claims description 4
- 102100032994 Uncharacterized protein C1orf87 Human genes 0.000 claims description 4
- 102100023575 Zinc finger protein 133 Human genes 0.000 claims description 4
- 238000012217 deletion Methods 0.000 claims description 4
- 230000037430 deletion Effects 0.000 claims description 4
- 230000008569 process Effects 0.000 claims description 4
- 102100030401 Biglycan Human genes 0.000 claims description 3
- 101001126865 Homo sapiens Biglycan Proteins 0.000 claims description 3
- 206010027476 Metastases Diseases 0.000 claims description 3
- 239000000090 biomarker Substances 0.000 claims description 3
- 238000003780 insertion Methods 0.000 claims description 3
- 230000037431 insertion Effects 0.000 claims description 3
- 230000009401 metastasis Effects 0.000 claims description 3
- 238000012353 t test Methods 0.000 claims description 3
- 230000005945 translocation Effects 0.000 claims description 3
- 238000000585 Mann–Whitney U test Methods 0.000 claims description 2
- 108010051862 Methylmalonyl-CoA mutase Proteins 0.000 claims 1
- 102100030979 Methylmalonyl-CoA mutase, mitochondrial Human genes 0.000 claims 1
- 101100364280 Oryza sativa subsp. japonica RSS3 gene Proteins 0.000 claims 1
- 101100478972 Oryza sativa subsp. japonica SUS3 gene Proteins 0.000 claims 1
- 238000013517 stratification Methods 0.000 abstract description 12
- 229920002477 rna polymer Polymers 0.000 description 74
- 201000002510 thyroid cancer Diseases 0.000 description 52
- 208000024770 Thyroid neoplasm Diseases 0.000 description 51
- 210000001519 tissue Anatomy 0.000 description 50
- 210000004027 cell Anatomy 0.000 description 45
- 230000003211 malignant effect Effects 0.000 description 27
- 208000035475 disorder Diseases 0.000 description 22
- 208000011580 syndromic disease Diseases 0.000 description 20
- 206010033701 Papillary thyroid cancer Diseases 0.000 description 19
- 208000030045 thyroid gland papillary carcinoma Diseases 0.000 description 19
- 108020004414 DNA Proteins 0.000 description 18
- 102000053602 DNA Human genes 0.000 description 18
- 238000003860 storage Methods 0.000 description 18
- 230000035945 sensitivity Effects 0.000 description 14
- 230000003325 follicular Effects 0.000 description 12
- 230000036438 mutation frequency Effects 0.000 description 12
- 230000002380 cytological effect Effects 0.000 description 11
- 208000009956 adenocarcinoma Diseases 0.000 description 10
- 239000002773 nucleotide Substances 0.000 description 10
- 125000003729 nucleotide group Chemical group 0.000 description 10
- 102000040430 polynucleotide Human genes 0.000 description 10
- 108091033319 polynucleotide Proteins 0.000 description 10
- 239000002157 polynucleotide Substances 0.000 description 10
- 238000012706 support-vector machine Methods 0.000 description 10
- 208000003200 Adenoma Diseases 0.000 description 9
- 238000012549 training Methods 0.000 description 9
- 206010006187 Breast cancer Diseases 0.000 description 8
- 208000026310 Breast neoplasm Diseases 0.000 description 8
- 208000009018 Medullary thyroid cancer Diseases 0.000 description 8
- 208000023356 medullary thyroid gland carcinoma Diseases 0.000 description 8
- 201000004462 Leydig Cell Tumor Diseases 0.000 description 7
- 238000001574 biopsy Methods 0.000 description 7
- 230000000694 effects Effects 0.000 description 7
- 230000001225 therapeutic effect Effects 0.000 description 7
- 102100040505 HLA class II histocompatibility antigen, DR alpha chain Human genes 0.000 description 6
- 208000026350 Inborn Genetic disease Diseases 0.000 description 6
- 238000003559 RNA-seq method Methods 0.000 description 6
- 238000004891 communication Methods 0.000 description 6
- 201000004260 follicular adenoma Diseases 0.000 description 6
- 208000030878 follicular thyroid adenoma Diseases 0.000 description 6
- 208000016361 genetic disease Diseases 0.000 description 6
- 238000002360 preparation method Methods 0.000 description 6
- 102000004169 proteins and genes Human genes 0.000 description 6
- 208000008839 Kidney Neoplasms Diseases 0.000 description 5
- 206010025323 Lymphomas Diseases 0.000 description 5
- 241001465754 Metazoa Species 0.000 description 5
- 206010038389 Renal cancer Diseases 0.000 description 5
- 239000000427 antigen Substances 0.000 description 5
- 108091007433 antigens Proteins 0.000 description 5
- 102000036639 antigens Human genes 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 238000003556 assay Methods 0.000 description 5
- 239000003153 chemical reaction reagent Substances 0.000 description 5
- 238000002790 cross-validation Methods 0.000 description 5
- 238000001514 detection method Methods 0.000 description 5
- 238000011161 development Methods 0.000 description 5
- 230000018109 developmental process Effects 0.000 description 5
- 229940079593 drug Drugs 0.000 description 5
- 239000003814 drug Substances 0.000 description 5
- 230000003463 hyperproliferative effect Effects 0.000 description 5
- 201000010982 kidney cancer Diseases 0.000 description 5
- 201000001441 melanoma Diseases 0.000 description 5
- 238000007481 next generation sequencing Methods 0.000 description 5
- 206010041823 squamous cell carcinoma Diseases 0.000 description 5
- 238000010972 statistical evaluation Methods 0.000 description 5
- 206010001233 Adenoma benign Diseases 0.000 description 4
- 108700028369 Alleles Proteins 0.000 description 4
- 208000001446 Anaplastic Thyroid Carcinoma Diseases 0.000 description 4
- 206010002240 Anaplastic thyroid cancer Diseases 0.000 description 4
- 208000003950 B-cell lymphoma Diseases 0.000 description 4
- 201000009030 Carcinoma Diseases 0.000 description 4
- HEDRZPFGACZZDS-UHFFFAOYSA-N Chloroform Chemical compound ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 4
- 206010013801 Duchenne Muscular Dystrophy Diseases 0.000 description 4
- 206010058314 Dysplasia Diseases 0.000 description 4
- 102100037412 Germinal-center associated nuclear protein Human genes 0.000 description 4
- 101710194542 Germinal-center associated nuclear protein Proteins 0.000 description 4
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 4
- 201000003793 Myelodysplastic syndrome Diseases 0.000 description 4
- 201000000582 Retinoblastoma Diseases 0.000 description 4
- 208000024799 Thyroid disease Diseases 0.000 description 4
- 208000007502 anemia Diseases 0.000 description 4
- 230000027455 binding Effects 0.000 description 4
- 210000003169 central nervous system Anatomy 0.000 description 4
- 208000017333 follicular variant thyroid gland papillary carcinoma Diseases 0.000 description 4
- 206010020718 hyperplasia Diseases 0.000 description 4
- 230000003287 optical effect Effects 0.000 description 4
- 210000002990 parathyroid gland Anatomy 0.000 description 4
- 230000037361 pathway Effects 0.000 description 4
- 210000001428 peripheral nervous system Anatomy 0.000 description 4
- 230000003234 polygenic effect Effects 0.000 description 4
- 238000007637 random forest analysis Methods 0.000 description 4
- 230000002441 reversible effect Effects 0.000 description 4
- 238000012216 screening Methods 0.000 description 4
- 210000003491 skin Anatomy 0.000 description 4
- 208000002320 spinal muscular atrophy Diseases 0.000 description 4
- 238000010186 staining Methods 0.000 description 4
- 208000019179 thyroid gland undifferentiated (anaplastic) carcinoma Diseases 0.000 description 4
- 210000003932 urinary bladder Anatomy 0.000 description 4
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 3
- 108091093088 Amplicon Proteins 0.000 description 3
- 206010003591 Ataxia Diseases 0.000 description 3
- 208000023275 Autoimmune disease Diseases 0.000 description 3
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 3
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 3
- 102100030981 Beta-alanine-activating enzyme Human genes 0.000 description 3
- 206010005003 Bladder cancer Diseases 0.000 description 3
- 206010008342 Cervix carcinoma Diseases 0.000 description 3
- 206010009944 Colon cancer Diseases 0.000 description 3
- 206010010356 Congenital anomaly Diseases 0.000 description 3
- 206010011878 Deafness Diseases 0.000 description 3
- 206010061818 Disease progression Diseases 0.000 description 3
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 3
- 208000024412 Friedreich ataxia Diseases 0.000 description 3
- 102100040196 GRB10-interacting GYF protein 2 Human genes 0.000 description 3
- 208000015872 Gaucher disease Diseases 0.000 description 3
- 108010007707 Hepatitis A Virus Cellular Receptor 2 Proteins 0.000 description 3
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 3
- 208000028782 Hereditary disease Diseases 0.000 description 3
- 101000773364 Homo sapiens Beta-alanine-activating enzyme Proteins 0.000 description 3
- 101001037074 Homo sapiens GRB10-interacting GYF protein 2 Proteins 0.000 description 3
- 101000919980 Homo sapiens Protoheme IX farnesyltransferase, mitochondrial Proteins 0.000 description 3
- 101000704168 Homo sapiens Soluble scavenger receptor cysteine-rich domain-containing protein SSC5D Proteins 0.000 description 3
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 3
- 208000024556 Mendelian disease Diseases 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 108020005196 Mitochondrial DNA Proteins 0.000 description 3
- 208000003019 Neurofibromatosis 1 Diseases 0.000 description 3
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 3
- 206010031096 Oropharyngeal cancer Diseases 0.000 description 3
- 206010057444 Oropharyngeal neoplasm Diseases 0.000 description 3
- 206010033128 Ovarian cancer Diseases 0.000 description 3
- 206010035226 Plasma cell myeloma Diseases 0.000 description 3
- 241000097929 Porphyria Species 0.000 description 3
- 208000010642 Porphyrias Diseases 0.000 description 3
- 206010060862 Prostate cancer Diseases 0.000 description 3
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 3
- 102100030729 Protoheme IX farnesyltransferase, mitochondrial Human genes 0.000 description 3
- 102100031878 Soluble scavenger receptor cysteine-rich domain-containing protein SSC5D Human genes 0.000 description 3
- 208000000728 Thymus Neoplasms Diseases 0.000 description 3
- 208000009453 Thyroid Nodule Diseases 0.000 description 3
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 3
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 3
- 230000005540 biological transmission Effects 0.000 description 3
- 208000035269 cancer or benign tumor Diseases 0.000 description 3
- 208000002458 carcinoid tumor Diseases 0.000 description 3
- 201000010881 cervical cancer Diseases 0.000 description 3
- 208000037516 chromosome inversion disease Diseases 0.000 description 3
- 230000000295 complement effect Effects 0.000 description 3
- 238000013500 data storage Methods 0.000 description 3
- 230000007812 deficiency Effects 0.000 description 3
- 230000005750 disease progression Effects 0.000 description 3
- 238000010195 expression analysis Methods 0.000 description 3
- 238000000605 extraction Methods 0.000 description 3
- 239000012634 fragment Substances 0.000 description 3
- 231100000888 hearing loss Toxicity 0.000 description 3
- 230000010370 hearing loss Effects 0.000 description 3
- 208000016354 hearing loss disease Diseases 0.000 description 3
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 3
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 3
- 238000011532 immunohistochemical staining Methods 0.000 description 3
- 239000003112 inhibitor Substances 0.000 description 3
- 238000007477 logistic regression Methods 0.000 description 3
- 201000005202 lung cancer Diseases 0.000 description 3
- 208000020816 lung neoplasm Diseases 0.000 description 3
- 238000010801 machine learning Methods 0.000 description 3
- 238000007726 management method Methods 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012544 monitoring process Methods 0.000 description 3
- 201000006958 oropharynx cancer Diseases 0.000 description 3
- 238000012545 processing Methods 0.000 description 3
- 230000019491 signal transduction Effects 0.000 description 3
- 208000030901 thyroid gland follicular carcinoma Diseases 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 206010044412 transitional cell carcinoma Diseases 0.000 description 3
- 201000005112 urinary bladder cancer Diseases 0.000 description 3
- 208000010543 22q11.2 deletion syndrome Diseases 0.000 description 2
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 2
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 2
- 206010003571 Astrocytoma Diseases 0.000 description 2
- 102100022548 Beta-hexosaminidase subunit alpha Human genes 0.000 description 2
- 206010005949 Bone cancer Diseases 0.000 description 2
- 208000018084 Bone neoplasm Diseases 0.000 description 2
- 206010007275 Carcinoid tumour Diseases 0.000 description 2
- 201000006867 Charcot-Marie-Tooth disease type 4 Diseases 0.000 description 2
- 206010008723 Chondrodystrophy Diseases 0.000 description 2
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 2
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 2
- 201000003883 Cystic fibrosis Diseases 0.000 description 2
- 208000000398 DiGeorge Syndrome Diseases 0.000 description 2
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- 206010016935 Follicular thyroid cancer Diseases 0.000 description 2
- 208000030836 Hashimoto thyroiditis Diseases 0.000 description 2
- 208000009292 Hemophilia A Diseases 0.000 description 2
- 241000711549 Hepacivirus C Species 0.000 description 2
- 206010019629 Hepatic adenoma Diseases 0.000 description 2
- 208000008051 Hereditary Nonpolyposis Colorectal Neoplasms Diseases 0.000 description 2
- 208000017095 Hereditary nonpolyposis colon cancer Diseases 0.000 description 2
- 208000017604 Hodgkin disease Diseases 0.000 description 2
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 2
- 101000847952 Homo sapiens Trypsin-3 Proteins 0.000 description 2
- 241000701806 Human papillomavirus Species 0.000 description 2
- 208000023105 Huntington disease Diseases 0.000 description 2
- 208000025500 Hutchinson-Gilford progeria syndrome Diseases 0.000 description 2
- 206010021042 Hypopharyngeal cancer Diseases 0.000 description 2
- 206010056305 Hypopharyngeal neoplasm Diseases 0.000 description 2
- 208000007766 Kaposi sarcoma Diseases 0.000 description 2
- 206010023825 Laryngeal cancer Diseases 0.000 description 2
- 208000002404 Liver Cell Adenoma Diseases 0.000 description 2
- 208000007433 Lymphatic Metastasis Diseases 0.000 description 2
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 2
- 201000005027 Lynch syndrome Diseases 0.000 description 2
- 208000001826 Marfan syndrome Diseases 0.000 description 2
- 208000008948 Menkes Kinky Hair Syndrome Diseases 0.000 description 2
- 208000012583 Menkes disease Diseases 0.000 description 2
- 208000003452 Multiple Hereditary Exostoses Diseases 0.000 description 2
- 208000034578 Multiple myelomas Diseases 0.000 description 2
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 2
- 208000014767 Myeloproliferative disease Diseases 0.000 description 2
- 208000001894 Nasopharyngeal Neoplasms Diseases 0.000 description 2
- 206010061306 Nasopharyngeal cancer Diseases 0.000 description 2
- 208000034176 Neoplasms, Germ Cell and Embryonal Diseases 0.000 description 2
- 208000024834 Neurofibromatosis type 1 Diseases 0.000 description 2
- 208000014060 Niemann-Pick disease Diseases 0.000 description 2
- 208000035544 Nonketotic hyperglycinaemia Diseases 0.000 description 2
- 206010061535 Ovarian neoplasm Diseases 0.000 description 2
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 2
- 201000009928 Patau syndrome Diseases 0.000 description 2
- 201000011252 Phenylketonuria Diseases 0.000 description 2
- 206010036182 Porphyria acute Diseases 0.000 description 2
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 2
- 208000007932 Progeria Diseases 0.000 description 2
- 208000006289 Rett Syndrome Diseases 0.000 description 2
- 208000000453 Skin Neoplasms Diseases 0.000 description 2
- 208000027077 Stickler syndrome Diseases 0.000 description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 description 2
- 208000022292 Tay-Sachs disease Diseases 0.000 description 2
- 208000024313 Testicular Neoplasms Diseases 0.000 description 2
- 206010057644 Testis cancer Diseases 0.000 description 2
- 206010044686 Trisomy 13 Diseases 0.000 description 2
- 208000006284 Trisomy 13 Syndrome Diseases 0.000 description 2
- 102100034396 Trypsin-3 Human genes 0.000 description 2
- 208000002495 Uterine Neoplasms Diseases 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 210000001766 X chromosome Anatomy 0.000 description 2
- 208000008919 achondroplasia Diseases 0.000 description 2
- 150000001413 amino acids Chemical class 0.000 description 2
- 201000008279 amyotrophic lateral sclerosis type 4 Diseases 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 210000000988 bone and bone Anatomy 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 206010012601 diabetes mellitus Diseases 0.000 description 2
- 208000010932 epithelial neoplasm Diseases 0.000 description 2
- 230000001815 facial effect Effects 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 206010017758 gastric cancer Diseases 0.000 description 2
- 201000011205 glycine encephalopathy Diseases 0.000 description 2
- 201000009277 hairy cell leukemia Diseases 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 201000002735 hepatocellular adenoma Diseases 0.000 description 2
- 201000006866 hypopharynx cancer Diseases 0.000 description 2
- 238000003364 immunohistochemistry Methods 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 210000003734 kidney Anatomy 0.000 description 2
- 206010023841 laryngeal neoplasm Diseases 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 201000007270 liver cancer Diseases 0.000 description 2
- 230000036210 malignancy Effects 0.000 description 2
- 208000006178 malignant mesothelioma Diseases 0.000 description 2
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 2
- 206010027191 meningioma Diseases 0.000 description 2
- 230000001394 metastastic effect Effects 0.000 description 2
- 206010061289 metastatic neoplasm Diseases 0.000 description 2
- 208000005135 methemoglobinemia Diseases 0.000 description 2
- 208000028260 mitochondrial inheritance Diseases 0.000 description 2
- 230000023202 mitochondrion inheritance Effects 0.000 description 2
- 201000006938 muscular dystrophy Diseases 0.000 description 2
- 208000007538 neurilemmoma Diseases 0.000 description 2
- 230000004770 neurodegeneration Effects 0.000 description 2
- 208000002761 neurofibromatosis 2 Diseases 0.000 description 2
- 208000029974 neurofibrosarcoma Diseases 0.000 description 2
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 210000001672 ovary Anatomy 0.000 description 2
- 201000002528 pancreatic cancer Diseases 0.000 description 2
- 208000008443 pancreatic carcinoma Diseases 0.000 description 2
- 210000000277 pancreatic duct Anatomy 0.000 description 2
- 230000007170 pathology Effects 0.000 description 2
- 238000000513 principal component analysis Methods 0.000 description 2
- 239000013074 reference sample Substances 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 238000012502 risk assessment Methods 0.000 description 2
- 206010039667 schwannoma Diseases 0.000 description 2
- 208000007056 sickle cell anemia Diseases 0.000 description 2
- 201000000849 skin cancer Diseases 0.000 description 2
- 238000007619 statistical method Methods 0.000 description 2
- 201000011549 stomach cancer Diseases 0.000 description 2
- 201000003120 testicular cancer Diseases 0.000 description 2
- 210000004881 tumor cell Anatomy 0.000 description 2
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 2
- 206010046766 uterine cancer Diseases 0.000 description 2
- 210000001215 vagina Anatomy 0.000 description 2
- 230000009790 vascular invasion Effects 0.000 description 2
- 208000026120 1p36 deletion syndrome Diseases 0.000 description 1
- 206010000021 21-hydroxylase deficiency Diseases 0.000 description 1
- VZCCTDLWCKUBGD-UHFFFAOYSA-N 8-[[4-(dimethylamino)phenyl]diazenyl]-10-phenylphenazin-10-ium-2-amine;chloride Chemical compound [Cl-].C1=CC(N(C)C)=CC=C1N=NC1=CC=C(N=C2C(C=C(N)C=C2)=[N+]2C=3C=CC=CC=3)C2=C1 VZCCTDLWCKUBGD-UHFFFAOYSA-N 0.000 description 1
- 101150070510 AOX3 gene Proteins 0.000 description 1
- 102100024643 ATP-binding cassette sub-family D member 1 Human genes 0.000 description 1
- 201000007994 Aceruloplasminemia Diseases 0.000 description 1
- 201000010028 Acrocephalosyndactylia Diseases 0.000 description 1
- 241000251468 Actinopterygii Species 0.000 description 1
- 208000005452 Acute intermittent porphyria Diseases 0.000 description 1
- 108700037034 Adenylosuccinate lyase deficiency Proteins 0.000 description 1
- 208000006468 Adrenal Cortex Neoplasms Diseases 0.000 description 1
- 201000011452 Adrenoleukodystrophy Diseases 0.000 description 1
- 208000016683 Adult T-cell leukemia/lymphoma Diseases 0.000 description 1
- 208000011403 Alexander disease Diseases 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 201000004384 Alopecia Diseases 0.000 description 1
- 208000024827 Alzheimer disease Diseases 0.000 description 1
- 206010061424 Anal cancer Diseases 0.000 description 1
- 208000009575 Angelman syndrome Diseases 0.000 description 1
- 208000007860 Anus Neoplasms Diseases 0.000 description 1
- 208000032467 Aplastic anaemia Diseases 0.000 description 1
- 206010003805 Autism Diseases 0.000 description 1
- 208000020706 Autistic disease Diseases 0.000 description 1
- 206010061666 Autonomic neuropathy Diseases 0.000 description 1
- 108050001427 Avidin/streptavidin Proteins 0.000 description 1
- 208000005440 Basal Cell Neoplasms Diseases 0.000 description 1
- 206010004146 Basal cell carcinoma Diseases 0.000 description 1
- 201000007791 Beare-Stevenson cutis gyrata syndrome Diseases 0.000 description 1
- 206010004593 Bile duct cancer Diseases 0.000 description 1
- 201000004569 Blindness Diseases 0.000 description 1
- 208000005692 Bloom Syndrome Diseases 0.000 description 1
- 208000020084 Bone disease Diseases 0.000 description 1
- 208000003174 Brain Neoplasms Diseases 0.000 description 1
- 208000014644 Brain disease Diseases 0.000 description 1
- 206010048409 Brain malformation Diseases 0.000 description 1
- 206010068597 Bulbospinal muscular atrophy congenital Diseases 0.000 description 1
- 102100022361 CAAX prenyl protease 1 homolog Human genes 0.000 description 1
- 102000055006 Calcitonin Human genes 0.000 description 1
- 108060001064 Calcitonin Proteins 0.000 description 1
- 208000022526 Canavan disease Diseases 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 101800001318 Capsid protein VP4 Proteins 0.000 description 1
- 206010007279 Carcinoid tumour of the gastrointestinal tract Diseases 0.000 description 1
- 208000005024 Castleman disease Diseases 0.000 description 1
- 108010067225 Cell Adhesion Molecules Proteins 0.000 description 1
- 102000016289 Cell Adhesion Molecules Human genes 0.000 description 1
- 206010008025 Cerebellar ataxia Diseases 0.000 description 1
- 208000010693 Charcot-Marie-Tooth Disease Diseases 0.000 description 1
- 201000006892 Charcot-Marie-Tooth disease type 1 Diseases 0.000 description 1
- 208000035758 Charcot-Marie-Tooth disease type 2S Diseases 0.000 description 1
- 206010008805 Chromosomal abnormalities Diseases 0.000 description 1
- 208000031404 Chromosome Aberrations Diseases 0.000 description 1
- 208000016718 Chromosome Inversion Diseases 0.000 description 1
- 206010009269 Cleft palate Diseases 0.000 description 1
- 102100026735 Coagulation factor VIII Human genes 0.000 description 1
- 208000015943 Coeliac disease Diseases 0.000 description 1
- 102100029136 Collagen alpha-1(II) chain Human genes 0.000 description 1
- 208000002330 Congenital Heart Defects Diseases 0.000 description 1
- 206010053138 Congenital aplastic anaemia Diseases 0.000 description 1
- 208000034958 Congenital erythropoietic porphyria Diseases 0.000 description 1
- 206010010510 Congenital hypothyroidism Diseases 0.000 description 1
- 206010010543 Congenital methaemoglobinaemia Diseases 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 102000012437 Copper-Transporting ATPases Human genes 0.000 description 1
- 208000012609 Cowden disease Diseases 0.000 description 1
- 201000002847 Cowden syndrome Diseases 0.000 description 1
- 208000011231 Crohn disease Diseases 0.000 description 1
- 206010011469 Crying Diseases 0.000 description 1
- 208000037461 Cutis gyrata-acanthosis nigricans-craniosynostosis syndrome Diseases 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 206010011891 Deafness neurosensory Diseases 0.000 description 1
- 208000024940 Dent disease Diseases 0.000 description 1
- 206010048768 Dermatosis Diseases 0.000 description 1
- 208000013558 Developmental Bone disease Diseases 0.000 description 1
- 208000012239 Developmental disease Diseases 0.000 description 1
- 206010061819 Disease recurrence Diseases 0.000 description 1
- 201000010374 Down Syndrome Diseases 0.000 description 1
- 208000011345 Duchenne and Becker muscular dystrophy Diseases 0.000 description 1
- 241001317099 Dystaxia Species 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 101150029707 ERBB2 gene Proteins 0.000 description 1
- 208000005189 Embolism Diseases 0.000 description 1
- 208000032274 Encephalopathy Diseases 0.000 description 1
- 206010014733 Endometrial cancer Diseases 0.000 description 1
- 206010014759 Endometrial neoplasm Diseases 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 206010014967 Ependymoma Diseases 0.000 description 1
- 208000007209 Erythropoietic Porphyria Diseases 0.000 description 1
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 1
- 208000006168 Ewing Sarcoma Diseases 0.000 description 1
- 208000012468 Ewing sarcoma/peripheral primitive neuroectodermal tumor Diseases 0.000 description 1
- 201000003727 FG syndrome Diseases 0.000 description 1
- 208000024720 Fabry Disease Diseases 0.000 description 1
- 201000003542 Factor VIII deficiency Diseases 0.000 description 1
- 208000005050 Familial Hypophosphatemic Rickets Diseases 0.000 description 1
- 206010016207 Familial Mediterranean fever Diseases 0.000 description 1
- 208000004248 Familial Primary Pulmonary Hypertension Diseases 0.000 description 1
- 108700000224 Familial apoceruloplasmin deficiency Proteins 0.000 description 1
- 201000004939 Fanconi anemia Diseases 0.000 description 1
- 208000007659 Fibroadenoma Diseases 0.000 description 1
- 208000001914 Fragile X syndrome Diseases 0.000 description 1
- 102000034286 G proteins Human genes 0.000 description 1
- 108091006027 G proteins Proteins 0.000 description 1
- 208000025499 G6PD deficiency Diseases 0.000 description 1
- 208000027472 Galactosemias Diseases 0.000 description 1
- 108010001517 Galectin 3 Proteins 0.000 description 1
- 102100039558 Galectin-3 Human genes 0.000 description 1
- 208000022072 Gallbladder Neoplasms Diseases 0.000 description 1
- 206010051066 Gastrointestinal stromal tumour Diseases 0.000 description 1
- 201000004311 Gilles de la Tourette syndrome Diseases 0.000 description 1
- 208000032612 Glial tumor Diseases 0.000 description 1
- 206010018338 Glioma Diseases 0.000 description 1
- 208000010055 Globoid Cell Leukodystrophy Diseases 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- 102100033495 Glycine dehydrogenase (decarboxylating), mitochondrial Human genes 0.000 description 1
- 206010018498 Goitre Diseases 0.000 description 1
- 101000691214 Haloarcula marismortui (strain ATCC 43049 / DSM 3752 / JCM 8966 / VKM B-1809) 50S ribosomal protein L44e Proteins 0.000 description 1
- 208000018565 Hemochromatosis Diseases 0.000 description 1
- 201000000361 Hemochromatosis type 2 Diseases 0.000 description 1
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 1
- 108091005904 Hemoglobin subunit beta Proteins 0.000 description 1
- 208000031220 Hemophilia Diseases 0.000 description 1
- 241000700721 Hepatitis B virus Species 0.000 description 1
- 208000002972 Hepatolenticular Degeneration Diseases 0.000 description 1
- 208000000627 Hereditary Coproporphyria Diseases 0.000 description 1
- 208000032087 Hereditary Leber Optic Atrophy Diseases 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000824531 Homo sapiens CAAX prenyl protease 1 homolog Proteins 0.000 description 1
- 101000911390 Homo sapiens Coagulation factor VIII Proteins 0.000 description 1
- 101000771163 Homo sapiens Collagen alpha-1(II) chain Proteins 0.000 description 1
- 101000579425 Homo sapiens Proto-oncogene tyrosine-protein kinase receptor Ret Proteins 0.000 description 1
- 101001067100 Homo sapiens Uroporphyrinogen-III synthase Proteins 0.000 description 1
- 206010020365 Homocystinuria Diseases 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 208000001021 Hyperlipoproteinemia Type I Diseases 0.000 description 1
- 206010020772 Hypertension Diseases 0.000 description 1
- 206010020864 Hypertrichosis Diseases 0.000 description 1
- 206010053574 Immunoblastic lymphoma Diseases 0.000 description 1
- 208000005726 Inflammatory Breast Neoplasms Diseases 0.000 description 1
- 208000022559 Inflammatory bowel disease Diseases 0.000 description 1
- 206010021980 Inflammatory carcinoma of the breast Diseases 0.000 description 1
- 108010036012 Iodide peroxidase Proteins 0.000 description 1
- 208000009289 Jackson-Weiss syndrome Diseases 0.000 description 1
- 238000006029 Jeger synthesis reaction Methods 0.000 description 1
- 201000008645 Joubert syndrome Diseases 0.000 description 1
- 208000027747 Kennedy disease Diseases 0.000 description 1
- 102100032700 Keratin, type I cytoskeletal 20 Human genes 0.000 description 1
- 108010066370 Keratin-20 Proteins 0.000 description 1
- 208000028226 Krabbe disease Diseases 0.000 description 1
- 208000031671 Large B-Cell Diffuse Lymphoma Diseases 0.000 description 1
- 201000000639 Leber hereditary optic neuropathy Diseases 0.000 description 1
- 241000270322 Lepidosauria Species 0.000 description 1
- 208000009625 Lesch-Nyhan syndrome Diseases 0.000 description 1
- 241000020990 Macrodes Species 0.000 description 1
- 208000004059 Male Breast Neoplasms Diseases 0.000 description 1
- 208000007466 Male Infertility Diseases 0.000 description 1
- 208000006644 Malignant Fibrous Histiocytoma Diseases 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 208000000172 Medulloblastoma Diseases 0.000 description 1
- 108010049137 Member 1 Subfamily D ATP Binding Cassette Transporter Proteins 0.000 description 1
- 206010027193 Meningioma malignant Diseases 0.000 description 1
- 208000036626 Mental retardation Diseases 0.000 description 1
- 206010054949 Metaplasia Diseases 0.000 description 1
- 208000037431 Micro syndrome Diseases 0.000 description 1
- 208000037699 Monosomy 18p Diseases 0.000 description 1
- 208000003445 Mouth Neoplasms Diseases 0.000 description 1
- 208000016285 Movement disease Diseases 0.000 description 1
- 208000003090 Mowat-Wilson syndrome Diseases 0.000 description 1
- 208000002678 Mucopolysaccharidoses Diseases 0.000 description 1
- 208000007326 Muenke Syndrome Diseases 0.000 description 1
- 208000008770 Multiple Hamartoma Syndrome Diseases 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 1
- 201000007224 Myeloproliferative neoplasm Diseases 0.000 description 1
- 206010068871 Myotonic dystrophy Diseases 0.000 description 1
- 208000031790 Neonatal hemochromatosis Diseases 0.000 description 1
- 206010029260 Neuroblastoma Diseases 0.000 description 1
- 201000004404 Neurofibroma Diseases 0.000 description 1
- 208000009905 Neurofibromatoses Diseases 0.000 description 1
- 108010085839 Neurofibromin 2 Proteins 0.000 description 1
- 102000007517 Neurofibromin 2 Human genes 0.000 description 1
- 238000010826 Nissl staining Methods 0.000 description 1
- 206010029748 Noonan syndrome Diseases 0.000 description 1
- 208000010505 Nose Neoplasms Diseases 0.000 description 1
- 208000008589 Obesity Diseases 0.000 description 1
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 206010031243 Osteogenesis imperfecta Diseases 0.000 description 1
- 108010021592 Pantothenate kinase Proteins 0.000 description 1
- 102100024122 Pantothenate kinase 1 Human genes 0.000 description 1
- 208000000821 Parathyroid Neoplasms Diseases 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 208000004843 Pendred Syndrome Diseases 0.000 description 1
- 208000002471 Penile Neoplasms Diseases 0.000 description 1
- 206010034299 Penile cancer Diseases 0.000 description 1
- 201000004014 Pfeiffer syndrome Diseases 0.000 description 1
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 1
- 208000012641 Pigmentation disease Diseases 0.000 description 1
- 208000007913 Pituitary Neoplasms Diseases 0.000 description 1
- 201000010769 Prader-Willi syndrome Diseases 0.000 description 1
- 208000004777 Primary Hyperoxaluria Diseases 0.000 description 1
- 208000024777 Prion disease Diseases 0.000 description 1
- 206010036790 Productive cough Diseases 0.000 description 1
- 201000005660 Protein C Deficiency Diseases 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 206010051292 Protein S Deficiency Diseases 0.000 description 1
- 102100028680 Protein patched homolog 1 Human genes 0.000 description 1
- 101710161390 Protein patched homolog 1 Proteins 0.000 description 1
- 102100028286 Proto-oncogene tyrosine-protein kinase receptor Ret Human genes 0.000 description 1
- 208000035955 Proximal myotonic myopathy Diseases 0.000 description 1
- 206010064911 Pulmonary arterial hypertension Diseases 0.000 description 1
- 239000013614 RNA sample Substances 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 230000010799 Receptor Interactions Effects 0.000 description 1
- 208000015634 Rectal Neoplasms Diseases 0.000 description 1
- 208000017442 Retinal disease Diseases 0.000 description 1
- 102100027609 Rho-related GTP-binding protein RhoD Human genes 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 208000004337 Salivary Gland Neoplasms Diseases 0.000 description 1
- 206010061934 Salivary gland cancer Diseases 0.000 description 1
- 208000021811 Sandhoff disease Diseases 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 208000009966 Sensorineural Hearing Loss Diseases 0.000 description 1
- 208000003274 Sertoli cell tumor Diseases 0.000 description 1
- 208000020221 Short stature Diseases 0.000 description 1
- BQCADISMDOOEFD-UHFFFAOYSA-N Silver Chemical compound [Ag] BQCADISMDOOEFD-UHFFFAOYSA-N 0.000 description 1
- 206010072610 Skeletal dysplasia Diseases 0.000 description 1
- 206010040829 Skin discolouration Diseases 0.000 description 1
- 206010041067 Small cell lung cancer Diseases 0.000 description 1
- 208000032383 Soft tissue cancer Diseases 0.000 description 1
- 206010041415 Spastic paralysis Diseases 0.000 description 1
- 208000010112 Spinocerebellar Degenerations Diseases 0.000 description 1
- 208000037140 Steinert myotonic dystrophy Diseases 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 208000012827 T-B+ severe combined immunodeficiency due to gamma chain deficiency Diseases 0.000 description 1
- 206010043189 Telangiectasia Diseases 0.000 description 1
- 206010069116 Tetrahydrobiopterin deficiency Diseases 0.000 description 1
- 108010034949 Thyroglobulin Proteins 0.000 description 1
- 102000009843 Thyroglobulin Human genes 0.000 description 1
- 102100027188 Thyroid peroxidase Human genes 0.000 description 1
- 206010044041 Tooth hypoplasia Diseases 0.000 description 1
- 208000035317 Total hypoxanthine-guanine phosphoribosyl transferase deficiency Diseases 0.000 description 1
- 208000000323 Tourette Syndrome Diseases 0.000 description 1
- 208000016620 Tourette disease Diseases 0.000 description 1
- 206010066901 Treatment failure Diseases 0.000 description 1
- 206010044688 Trisomy 21 Diseases 0.000 description 1
- 206010073104 Tubular breast carcinoma Diseases 0.000 description 1
- 208000026928 Turner syndrome Diseases 0.000 description 1
- 102100037256 Ubiquitin-conjugating enzyme E2 C Human genes 0.000 description 1
- 101710193031 Ubiquitin-conjugating enzyme E2 C Proteins 0.000 description 1
- 208000015778 Undifferentiated pleomorphic sarcoma Diseases 0.000 description 1
- 102100034397 Uroporphyrinogen-III synthase Human genes 0.000 description 1
- 208000014769 Usher Syndromes Diseases 0.000 description 1
- 108091008605 VEGF receptors Proteins 0.000 description 1
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 description 1
- 206010047741 Vulval cancer Diseases 0.000 description 1
- 208000004354 Vulvar Neoplasms Diseases 0.000 description 1
- 208000026724 Waardenburg syndrome Diseases 0.000 description 1
- 208000033559 Waldenström macroglobulinemia Diseases 0.000 description 1
- 201000002916 Warburg micro syndrome Diseases 0.000 description 1
- 201000000021 Weissenbacher-Zweymuller syndrome Diseases 0.000 description 1
- 208000018839 Wilson disease Diseases 0.000 description 1
- 208000006254 Wolf-Hirschhorn Syndrome Diseases 0.000 description 1
- 208000006269 X-Linked Bulbo-Spinal Atrophy Diseases 0.000 description 1
- 208000023940 X-Linked Combined Immunodeficiency disease Diseases 0.000 description 1
- 208000031878 X-linked hypophosphatemia Diseases 0.000 description 1
- 208000035724 X-linked hypophosphatemic rickets Diseases 0.000 description 1
- 201000007146 X-linked severe combined immunodeficiency Diseases 0.000 description 1
- 201000006083 Xeroderma Pigmentosum Diseases 0.000 description 1
- 210000002593 Y chromosome Anatomy 0.000 description 1
- 108700029634 Y-Linked Genes Proteins 0.000 description 1
- 208000028258 Y-linked inheritance Diseases 0.000 description 1
- 210000000683 abdominal cavity Anatomy 0.000 description 1
- 230000003187 abdominal effect Effects 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 208000000391 adenylosuccinate lyase deficiency Diseases 0.000 description 1
- 201000002454 adrenal cortex cancer Diseases 0.000 description 1
- 201000006966 adult T-cell leukemia Diseases 0.000 description 1
- 208000006682 alpha 1-Antitrypsin Deficiency Diseases 0.000 description 1
- 206010002026 amyotrophic lateral sclerosis Diseases 0.000 description 1
- 201000008266 amyotrophic lateral sclerosis type 2 Diseases 0.000 description 1
- 239000003098 androgen Substances 0.000 description 1
- 206010068168 androgenetic alopecia Diseases 0.000 description 1
- 201000002996 androgenic alopecia Diseases 0.000 description 1
- 201000011165 anus cancer Diseases 0.000 description 1
- 101150059062 apln gene Proteins 0.000 description 1
- 230000001174 ascending effect Effects 0.000 description 1
- 208000006673 asthma Diseases 0.000 description 1
- 230000002567 autonomic effect Effects 0.000 description 1
- 208000036351 autosomal dominant otospondylomegaepiphyseal dysplasia Diseases 0.000 description 1
- 208000036201 autosomal recessive hearing loss Diseases 0.000 description 1
- 201000006796 autosomal recessive nonsyndromic deafness Diseases 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 208000005980 beta thalassemia Diseases 0.000 description 1
- 230000002146 bilateral effect Effects 0.000 description 1
- 208000026900 bile duct neoplasm Diseases 0.000 description 1
- 239000012472 biological sample Substances 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 101150048834 braF gene Proteins 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 201000003149 breast fibroadenoma Diseases 0.000 description 1
- BBBFJLBPOGFECG-VJVYQDLKSA-N calcitonin Chemical compound N([C@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(N)=O)C(C)C)C(=O)[C@@H]1CSSC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1 BBBFJLBPOGFECG-VJVYQDLKSA-N 0.000 description 1
- 229960004015 calcitonin Drugs 0.000 description 1
- 208000012056 cerebral malformation Diseases 0.000 description 1
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 1
- 210000003679 cervix uteri Anatomy 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 201000002797 childhood leukemia Diseases 0.000 description 1
- 208000006990 cholangiocarcinoma Diseases 0.000 description 1
- 208000004664 chromosome 18p deletion syndrome Diseases 0.000 description 1
- 201000004723 chromosome 1p36 deletion syndrome Diseases 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 210000004081 cilia Anatomy 0.000 description 1
- 238000007635 classification algorithm Methods 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 208000029742 colonic neoplasm Diseases 0.000 description 1
- 208000030251 communication disease Diseases 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 208000003611 congenital autoimmune diabetes mellitus Diseases 0.000 description 1
- 208000028831 congenital heart disease Diseases 0.000 description 1
- 208000018631 connective tissue disease Diseases 0.000 description 1
- 230000008602 contraction Effects 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 208000030381 cutaneous melanoma Diseases 0.000 description 1
- 201000008230 cutaneous porphyria Diseases 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- 201000002268 dental enamel hypoplasia Diseases 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- JIONSDIFUGDYLD-UHFFFAOYSA-N diaminomethylideneazanium;phenol;thiocyanate Chemical compound [S-]C#N.NC([NH3+])=N.OC1=CC=CC=C1 JIONSDIFUGDYLD-UHFFFAOYSA-N 0.000 description 1
- 206010012818 diffuse large B-cell lymphoma Diseases 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- 208000013916 distal hereditary motor neuronopathy type 5 Diseases 0.000 description 1
- 210000004177 elastic tissue Anatomy 0.000 description 1
- 230000005221 enamel hypoplasia Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 229940088598 enzyme Drugs 0.000 description 1
- 238000001952 enzyme assay Methods 0.000 description 1
- YQGOJNYOYNNSMM-UHFFFAOYSA-N eosin Chemical compound [Na+].OC(=O)C1=CC=CC=C1C1=C2C=C(Br)C(=O)C(Br)=C2OC2=C(Br)C(O)=C(Br)C=C21 YQGOJNYOYNNSMM-UHFFFAOYSA-N 0.000 description 1
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 1
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 1
- 210000002745 epiphysis Anatomy 0.000 description 1
- 210000003237 epithelioid cell Anatomy 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 201000008220 erythropoietic protoporphyria Diseases 0.000 description 1
- 201000004101 esophageal cancer Diseases 0.000 description 1
- 210000003238 esophagus Anatomy 0.000 description 1
- 238000012869 ethanol precipitation Methods 0.000 description 1
- ZMMJGEGLRURXTF-UHFFFAOYSA-N ethidium bromide Chemical compound [Br-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CC)=C1C1=CC=CC=C1 ZMMJGEGLRURXTF-UHFFFAOYSA-N 0.000 description 1
- 229960005542 ethidium bromide Drugs 0.000 description 1
- 208000024519 eye neoplasm Diseases 0.000 description 1
- 108010091897 factor V Leiden Proteins 0.000 description 1
- 201000011110 familial lipoprotein lipase deficiency Diseases 0.000 description 1
- 210000003608 fece Anatomy 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- 210000001650 focal adhesion Anatomy 0.000 description 1
- 238000007672 fourth generation sequencing Methods 0.000 description 1
- 210000000232 gallbladder Anatomy 0.000 description 1
- 201000010175 gallbladder cancer Diseases 0.000 description 1
- 201000011243 gastrointestinal stromal tumor Diseases 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 208000005017 glioblastoma Diseases 0.000 description 1
- 208000008605 glucosephosphate dehydrogenase deficiency Diseases 0.000 description 1
- 230000002710 gonadal effect Effects 0.000 description 1
- 208000030316 grade III meningioma Diseases 0.000 description 1
- 230000009036 growth inhibition Effects 0.000 description 1
- 230000003862 health status Effects 0.000 description 1
- 210000002216 heart Anatomy 0.000 description 1
- 208000019622 heart disease Diseases 0.000 description 1
- 201000005787 hematologic cancer Diseases 0.000 description 1
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 1
- 201000000388 hemochromatosis type 4 Diseases 0.000 description 1
- 208000024977 hereditary methemoglobinemia Diseases 0.000 description 1
- 201000010928 hereditary multiple exostoses Diseases 0.000 description 1
- 208000013746 hereditary thrombophilia due to congenital protein C deficiency Diseases 0.000 description 1
- 210000004276 hyalin Anatomy 0.000 description 1
- 230000002390 hyperplastic effect Effects 0.000 description 1
- 208000003074 hypochondrogenesis Diseases 0.000 description 1
- 206010021198 ichthyosis Diseases 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 238000012151 immunohistochemical method Methods 0.000 description 1
- 238000007901 in situ hybridization Methods 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 238000011273 incision biopsy Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 238000012880 independent component analysis Methods 0.000 description 1
- 208000000509 infertility Diseases 0.000 description 1
- 230000036512 infertility Effects 0.000 description 1
- 231100000535 infertility Toxicity 0.000 description 1
- 201000004653 inflammatory breast carcinoma Diseases 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 201000002696 invasive tubular breast carcinoma Diseases 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 208000013094 juvenile primary lateral sclerosis Diseases 0.000 description 1
- 230000003780 keratinization Effects 0.000 description 1
- 201000003723 learning disability Diseases 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 208000036546 leukodystrophy Diseases 0.000 description 1
- 208000012987 lip and oral cavity carcinoma Diseases 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 208000014018 liver neoplasm Diseases 0.000 description 1
- 238000011068 loading method Methods 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 208000026807 lung carcinoid tumor Diseases 0.000 description 1
- 210000002751 lymph Anatomy 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 201000003175 male breast cancer Diseases 0.000 description 1
- 208000010907 male breast carcinoma Diseases 0.000 description 1
- 208000025854 malignant tumor of adrenal cortex Diseases 0.000 description 1
- 208000026045 malignant tumor of parathyroid gland Diseases 0.000 description 1
- 210000005075 mammary gland Anatomy 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 208000008585 mastocytosis Diseases 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 230000008774 maternal effect Effects 0.000 description 1
- 208000030159 metabolic disease Diseases 0.000 description 1
- 230000037353 metabolic pathway Effects 0.000 description 1
- 230000015689 metaplastic ossification Effects 0.000 description 1
- 201000003694 methylmalonic acidemia Diseases 0.000 description 1
- 208000004141 microcephaly Diseases 0.000 description 1
- 201000010225 mixed cell type cancer Diseases 0.000 description 1
- 208000029638 mixed neoplasm Diseases 0.000 description 1
- 230000003990 molecular pathway Effects 0.000 description 1
- 206010028093 mucopolysaccharidosis Diseases 0.000 description 1
- 201000006417 multiple sclerosis Diseases 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 230000009756 muscle regeneration Effects 0.000 description 1
- 201000000050 myeloid neoplasm Diseases 0.000 description 1
- 201000009340 myotonic dystrophy type 1 Diseases 0.000 description 1
- 201000008709 myotonic dystrophy type 2 Diseases 0.000 description 1
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 1
- 208000037830 nasal cancer Diseases 0.000 description 1
- 238000013188 needle biopsy Methods 0.000 description 1
- 210000005036 nerve Anatomy 0.000 description 1
- 208000015122 neurodegenerative disease Diseases 0.000 description 1
- 201000004931 neurofibromatosis Diseases 0.000 description 1
- 208000022032 neurofibromatosis type 2 Diseases 0.000 description 1
- 208000018360 neuromuscular disease Diseases 0.000 description 1
- 201000001119 neuropathy Diseases 0.000 description 1
- 230000007823 neuropathy Effects 0.000 description 1
- PGSADBUBUOPOJS-UHFFFAOYSA-N neutral red Chemical compound Cl.C1=C(C)C(N)=CC2=NC3=CC(N(C)C)=CC=C3N=C21 PGSADBUBUOPOJS-UHFFFAOYSA-N 0.000 description 1
- 208000004235 neutropenia Diseases 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 201000006790 nonsyndromic deafness Diseases 0.000 description 1
- 235000020824 obesity Nutrition 0.000 description 1
- 201000008106 ocular cancer Diseases 0.000 description 1
- 238000001543 one-way ANOVA Methods 0.000 description 1
- 239000013307 optical fiber Substances 0.000 description 1
- 210000003463 organelle Anatomy 0.000 description 1
- 201000008968 osteosarcoma Diseases 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 208000033808 peripheral neuropathy Diseases 0.000 description 1
- 230000008823 permeabilization Effects 0.000 description 1
- 230000019612 pigmentation Effects 0.000 description 1
- 208000010916 pituitary tumor Diseases 0.000 description 1
- 208000001061 polyostotic fibrous dysplasia Diseases 0.000 description 1
- 208000015768 polyposis Diseases 0.000 description 1
- 230000002980 postoperative effect Effects 0.000 description 1
- 230000003334 potential effect Effects 0.000 description 1
- 201000008312 primary pulmonary hypertension Diseases 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 108090000765 processed proteins & peptides Proteins 0.000 description 1
- 230000002062 proliferating effect Effects 0.000 description 1
- 201000004012 propionic acidemia Diseases 0.000 description 1
- 210000002307 prostate Anatomy 0.000 description 1
- 238000002731 protein assay Methods 0.000 description 1
- 238000007388 punch biopsy Methods 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- WQGWDDDVZFFDIG-UHFFFAOYSA-N pyrogallol Chemical group OC1=CC=CC(O)=C1O WQGWDDDVZFFDIG-UHFFFAOYSA-N 0.000 description 1
- 239000002096 quantum dot Substances 0.000 description 1
- 108700042226 ras Genes Proteins 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 206010038038 rectal cancer Diseases 0.000 description 1
- 201000001275 rectum cancer Diseases 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 208000037922 refractory disease Diseases 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
- 208000017443 reproductive system disease Diseases 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 201000009410 rhabdomyosarcoma Diseases 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 210000000582 semen Anatomy 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 231100000879 sensorineural hearing loss Toxicity 0.000 description 1
- 208000023573 sensorineural hearing loss disease Diseases 0.000 description 1
- 230000001953 sensory effect Effects 0.000 description 1
- 229910052709 silver Inorganic materials 0.000 description 1
- 239000004332 silver Substances 0.000 description 1
- 208000037968 sinus cancer Diseases 0.000 description 1
- 210000002027 skeletal muscle Anatomy 0.000 description 1
- 238000007390 skin biopsy Methods 0.000 description 1
- 201000008261 skin carcinoma Diseases 0.000 description 1
- 208000017520 skin disease Diseases 0.000 description 1
- 239000010454 slate Substances 0.000 description 1
- 208000000649 small cell carcinoma Diseases 0.000 description 1
- 208000000587 small cell lung carcinoma Diseases 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 210000002460 smooth muscle Anatomy 0.000 description 1
- 208000027765 speech disease Diseases 0.000 description 1
- 210000003802 sputum Anatomy 0.000 description 1
- 208000024794 sputum Diseases 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 238000011477 surgical intervention Methods 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 208000009056 telangiectasis Diseases 0.000 description 1
- 230000002381 testicular Effects 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- 208000008732 thymoma Diseases 0.000 description 1
- 229960002175 thyroglobulin Drugs 0.000 description 1
- 208000021510 thyroid gland disease Diseases 0.000 description 1
- 206010043778 thyroiditis Diseases 0.000 description 1
- 229950003937 tolonium Drugs 0.000 description 1
- HNONEKILPDHFOL-UHFFFAOYSA-M tolonium chloride Chemical compound [Cl-].C1=C(C)C(N)=CC2=[S+]C3=CC(N(C)C)=CC=C3N=C21 HNONEKILPDHFOL-UHFFFAOYSA-M 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 230000014616 translation Effects 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- UNXRWKVEANCORM-UHFFFAOYSA-N triphosphoric acid Chemical compound OP(O)(=O)OP(O)(=O)OP(O)(O)=O UNXRWKVEANCORM-UHFFFAOYSA-N 0.000 description 1
- 208000026485 trisomy X Diseases 0.000 description 1
- 210000002993 trophoblast Anatomy 0.000 description 1
- 230000005760 tumorsuppression Effects 0.000 description 1
- 238000007492 two-way ANOVA Methods 0.000 description 1
- 238000002604 ultrasonography Methods 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 208000037965 uterine sarcoma Diseases 0.000 description 1
- 206010046885 vaginal cancer Diseases 0.000 description 1
- 208000013139 vaginal neoplasm Diseases 0.000 description 1
- 230000002792 vascular Effects 0.000 description 1
- 208000024523 vestibulocochlear nerve neoplasm Diseases 0.000 description 1
- 108700026220 vif Genes Proteins 0.000 description 1
- 208000006542 von Hippel-Lindau disease Diseases 0.000 description 1
- 201000005102 vulva cancer Diseases 0.000 description 1
Images









































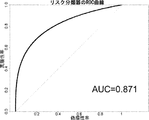





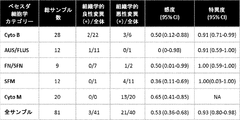




Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/20—Allele or variant detection, e.g. single nucleotide polymorphism [SNP] detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B25/00—ICT specially adapted for hybridisation; ICT specially adapted for gene or protein expression
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B25/00—ICT specially adapted for hybridisation; ICT specially adapted for gene or protein expression
- G16B25/10—Gene or protein expression profiling; Expression-ratio estimation or normalisation
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/10—Sequence alignment; Homology search
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H50/00—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics
- G16H50/30—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics for calculating health indices; for individual health risk assessment
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/118—Prognosis of disease development
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/156—Polymorphic or mutational markers
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/158—Expression markers
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A90/00—Technologies having an indirect contribution to adaptation to climate change
- Y02A90/10—Information and communication technologies [ICT] supporting adaptation to climate change, e.g. for weather forecasting or climate simulation
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biotechnology (AREA)
- Biophysics (AREA)
- Analytical Chemistry (AREA)
- Molecular Biology (AREA)
- Organic Chemistry (AREA)
- Pathology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Theoretical Computer Science (AREA)
- Immunology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Public Health (AREA)
- Oncology (AREA)
- Microbiology (AREA)
- Hospice & Palliative Care (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- Primary Health Care (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Biomedical Technology (AREA)
- Epidemiology (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
Abstract
Description
本願は、各々全体が参照により本明細書に組み入れられる2015年3月4日に出願された米国特許仮出願第62/128,463号、2015年3月4日に出願された米国特許仮出願第62/128,469号および2015年10月8日に出願された米国特許仮出願第62/238,893号からの優先権を主張する。
疾患治療、例えば甲状腺がん治療に対するリスク適応型アプローチは、疾患特異的に生存性を改善するのに加えて、疾患発症のリスクを最小限に抑制し得る。現在、初期の対象管理に対するこのリスク適応型アプローチは、大部分が、2009 米国甲状腺学会(American Thyroid Association)(ATA)病期体系を用いた高、中、または低疾患再発リスクのいずれかへの対象の手術後分類に基づいている。この解剖学的病期体系は、臨床的に有用であることが証明されているが、それは侵襲的な甲状腺摘出術の前に正確に評価されることができず、かつそれは疾患結果のいかなる分子的予測因子も含まない。
疾患の発症および/または再発のリスクを評価または層別化するための様々な方法が、本明細書において提供されている。診断前評価または診断評価、例えば微細針吸引(FNA)の間に取得された転写データは、疾患、例えば甲状腺がんの発症のリスクの手術前予測を改善し得、かつ対象の治療および処置のさらなる個別化を提供し得る。本開示の方法は、比較的非侵襲的な様式でかつ少ないサンプル量を用いて疾患の発症および/または再発のリスクに関する評価を提供し得る。
本明細書で言及されているすべての刊行物、特許、および特許出願は、各々個々の刊行物、特許、または特許出願が具体的かつ個別に参照により組み入れられることが示されているものとして、参照により本明細書に組み入れられる。参照により組み入れられる刊行物および特許または特許出願が本明細書に含まれる開示と相反する範囲では、本明細書があらゆるそのような相反するものに取って代わるかまたはそれよりも優先される。
本明細書において本発明の様々な態様が示され説明されているが、そのような態様は例として提供されるにすぎないことが当業者に明らかであろう。当業者は、本発明から逸脱することなく、多数のバリエーション、変更および置換を思い浮かべるであろう。本明細書に記載される本発明の態様に対する様々な代替物が用いられ得ることが理解されるべきである。
本開示は、対象における疾患の発症または再発のリスクを判定するために、いくつかの例では、疾患の新規遺伝子バイオマーカーを決定するために対象の組織サンプルを評価するための方法を提供する。そのような方法は、対象から取得された核酸サンプル中の第1の遺伝子セットの1つまたは複数の遺伝子の各々に対応する発現レベルを取得する工程を含み得る。いくつかの例において、発現レベルは、第1の遺伝子セットの1つまたは複数の遺伝子に選択的なプローブを用いるマイクロアレイを用いて取得される。核酸サンプルは、対象によってまたは別の個人によって、例えば医療専門家によって取得され得る。第1の遺伝子セットは、対象における疾患の発症のリスクに関連し得る。いくつかの例において、核酸サンプルは、FNA、手術(例えば、外科生検)または対象からサンプルを取得する他のアプローチによって取得される。核酸サンプルは、対象から取得された組織サンプル(例えば、甲状腺組織サンプル)、血液サンプル中または体液サンプル中に含まれ得る。1つの例において、核酸サンプルは、対象から取得されたFNAサンプルに含まれ得る。
対象から取得されるサンプルは、組織、細胞、細胞フラグメント、細胞オルガネラ、核酸、遺伝子、遺伝子フラグメント、発現産物、遺伝子発現産物、遺伝子発現産物フラグメント、またはそれらの任意の組み合わせを含み得る。サンプルは、不均質または均質であり得る。サンプルは、血液、尿、脳脊髄液、精液、唾液、痰、排泄物、リンパ液、組織、またはそれらの任意の組み合わせを含み得る。サンプルは、組織特異的サンプル、例えば甲状腺組織、皮膚、心臓、肺、腎臓、乳房、膵臓、肝臓、筋肉、平滑筋、膀胱、胆嚢、結腸、腸、脳、食道または前立腺から取得されるサンプルであり得る。
疾患の発症のリスクの評価を含む、本明細書に記載される方法は、サンプルの細胞学的分析を含み得る。細胞学的分析の例は、エオシン・アズール(EA)染色、ヘマトキシリン染色、CYTO-STAIN(商標)、パパニコロウ染色、エオシン、ニッスル染色、トルイジンブルー、銀染色、アゾカルミン染色、ニュートラルレッドまたはヤヌスグリーンを含むがこれらに限定されない任意の多くの方法および適切な試薬によって実施される細胞染色技術および/または顕微鏡試験を含む。2つ以上の染色が、他の染色と組み合わせて使用され得る。いくつかの例において、細胞は、全く染色されない。細胞は、染色手順の前にまたはその中で、例えばメタノール、エタノール、グルタルアルデヒドまたはホルムアルデヒドを用いて固定および/または透過処理され得る。いくつかの例において、細胞は、固定されない場合がある。染色手順はまた、例えば臭化エチジウム、ヘマトキシリン、ニッスル染色または任意の他の核酸染色を用いて、サンプルの核酸量を測定するために使用され得る。
疾患は、本明細書で開示される場合、甲状腺がんを含み得る。甲状腺がんは、甲状腺の任意の悪性腫瘍、例えば、甲状腺乳頭がん(PTC)、濾胞性甲状腺がん(FTC)、濾胞型甲状腺乳頭がん(FVPTC)、甲状腺髄様がん(MTC)、濾胞がん(FC)、ハースル細胞がん(HC)、および/または未分化甲状腺がん(ATC)を含むがこれらに限定されない甲状腺がんの任意のサブタイプを含み得る。いくつかの例において、甲状腺がんは、分化型であり得る。いくつかの例において、甲状腺がんは、未分化型であり得る。
疾患の発症のリスクは、サンプルを、下位リスク群に層別化し得る。下位群は、低疾患発症性リスクを有するサンプルおよび中〜高疾患発症性リスクを有するサンプルを含み得る。下位群は、低リスク、中リスクおよび高リスク群を含み得る。低リスクは、約1%、5%、10%、15%、20%、25%、30%、35%、40%、または約45%の疾患発症性リスクを有するサンプルを含み得る。低リスクは、約1%〜約25%の疾患発症性リスクを有するサンプルを含み得る。低リスクは、約1%〜約30%の疾患発症性リスクを有するサンプルを含み得る。低リスクは、約1%〜約40%の疾患発症性リスクを有するサンプルを含み得る。中〜高リスクは、約55%、60%、65%、70%、75%、80%、85%、90%、95%、または100%の疾患発症性リスクを有するサンプルを含み得る。中〜高リスクは、約50%〜約100%の疾患発症性リスクを有するサンプルを含み得る。中〜高リスクは、約55%〜約100%の疾患発症性リスクを有するサンプルを含み得る。中〜高リスクは、約60%〜約100%の疾患発症性リスクを有するサンプルを含み得る。
アレイハイブリダイゼーション、核酸配列決定、核酸増幅、または他の増幅反応を実施するのに適した試薬は、DNAポリメラーゼ、マーカー、例えばフォワードおよびリバースプライマー、デオキシヌクレオチド三リン酸(dNTP)および1つまたは複数の緩衝液を含むがこれらに限定されない。そのような試薬は、関心対象の所定配列、例えば第1の遺伝子セットおよび/または第2の遺伝子セットの1つまたは複数の遺伝子について選択されたプライマーを含み得る。
分類器の結果、例えば疾患発症のリスク、または本明細書において開示される方法からのデータ、例えば遺伝子発現レベルもしくは配列変種データは、分子プロファイリング事業、個人、医療専門家または保険事業の代表者または代理人によってアクセス用データベースに入力され得る。データのコンピュータまたはアルゴリズムによる分析は、自動的に提供され得る。結果は、コンピュータスクリーン上でのレポートとしてまたは紙面による記録として提示され得る。結果は、いくつかの例において、データベースまたはリモートサーバに自動的にアップロードされ得る。レポートは、以下の1つまたは複数のような情報を含み得るがこれらに限定されない:原サンプルの適性、示差的に発現される遺伝子の名前および/もしくは数、配列変種を含む遺伝子の名前および/もしくは数、配列変種のタイプ、示差的に発現される遺伝子の発現レベル、数的な分類器のスコア、対象の診断、診断に対する統計学的信頼性、疾患の発症のリスク、指示された治療法またはそれらの任意の組み合わせ。
疾患診断事業、分子プロファイリング事業、製薬事業、または患者の保健に関連する他の事業は、疾患の発症のリスクの判定を実施するためのキットを提供し得る。キットは、分類器、アルゴリズムを訓練するためのサンプルコホートおよび各特徴空間のための遺伝子リスト、例えば第1の遺伝子セットおよび第2の遺伝子セットを含み得る。いくつかの例において、キットは、分類器および各特徴空間のための遺伝子リストを含み得る。キットは、すべての疾患タイプのための汎用キットであり得る。キットは、特定の疾患、例えばがんのための特別キット、または疾患サブタイプ、例えば甲状腺がんに対する特別キットであり得る。キットは、キットには提供されないサンプルコホートを用いてすでに訓練されている分類器を提供し得る。キットは、分類器とともに使用するサンプルコホートまたは特徴空間のための遺伝子リストの定期的な更新を提供し得る。キットは、医療専門家によって報告され得もしくは表示され得もしくはダウンロードされ得る結果概要、および/またはデータベースに入力され得る結果概要を自動化するソフトウェアを提供し得る。結果概要は、患者に対する処置オプションの推奨および疾患の発症リスクを含む、本明細書の開示される結果のいずれかを含み得る。キットはまた、対象からサンプルを取得するためのユニットまたはデバイス(例えば、アスピレーターに接続された針を含むデバイス)を提供し得る。キットはまた、本明細書において開示される方法を実施するための説明書を提供し得、RNA配列決定および次世代(NextGen)配列決定のためのすべての必要な緩衝液および試薬を含み得る。キットはまた、結果を分析するための説明書を含み得る。そのような説明書は、使用者を結果分析のためのソフトウェア(例えば、訓練されたアルゴリズムを含むソフトウェア)およびデータベースに誘導することを含む。
本開示は、本開示の方法を実行するようプログラムされたコンピュータ制御システムを提供する。図9は、本明細書において提供される方法を実行するようプログラムされたまたはそれ以外の方法でそのように構成されたコンピュータシステム9001を示している。コンピュータシステム9001は、本開示の疾患発症のリスクを層別化する、例えば分類器を稼働させ、アルゴリズムを訓練し、層別化された発症リスクを報告する様々な局面を制御し得る。コンピュータシステム9001は、使用者の電子デバイスまたはその電子デバイスから遠隔に設置されたコンピュータシステムであり得る。電子デバイスは、携帯型電子デバイスであり得る。
甲状腺がんの初期管理に対する現在のリスク適応型アプローチは、2009 米国甲状腺学会病期体系(ATA)を用いた高〜中発症リスクまたは低発症リスクのいずれかへの対象の手術後分類に基づいている。この解剖学的病期体系は、臨床的に有用であり得るが、甲状腺摘出術前に正確に評価することができず、かつ対象の結果の分子予測因子を含み得ない。この研究は、悪性甲状腺結節の診断的微細針吸引(FNA)で取得された転写データを使用して、甲状腺手術前のリスク層別化を強化できるかどうかを判定する。
手術前リスク層別化が機械学習を使用することによって強化されるかどうかを判定するため、Gene Expression Classifier(GEC)を変異パネルに用いて不確定甲状腺結節を試験する。図10は、訓練ラベルの決定を示す流れ図である。組織学的に良性のサンプルと組織学的に悪性のサンプルの間を区別するためにAfirma GECバージョン1訓練ラベルを使用する。組織学的に悪性のサンプルをさらに、米国甲状腺学会(ATA)リスク訓練ラベルを用いて低発症リスクと中/高発症リスクの間を区別する。中/高リスクの特徴は、リンパ節転移、血管侵襲、甲状腺外拡張、またはそれらの任意の組み合わせを含む。リスク訓練用サンプルコホートが、図1に示されている。中/高発症リスクの組織学的特徴を有するサンプルの比率が、図2に示されている。10分割交差検証を行い、線形サポートベクターマシン(SVM)、ランダムフォレスト、GLMNetおよびアンサンブル分類器を含む異なる学習モデルで曲線下面積(AUC)を評価する。この実施例において、最良のモデルは、AUCが0.871(図11Aに示されている)、感度が86%(図11Bに示されている)、特異度が86%(図11Bに示されている)、陽性的中率(PPV)が91.3%、陰性的中率(NPV)が78.3%であるアンサンブル分類である。初期特徴空間は、50カウントおよび800個の変種を含む850個の初期特徴空間である。最良のパフォーマンスは、240個の組み合わされた特徴を使用している。各分割で分類器によって選択された変種の上位の特徴が、図12に示されている。10分割で分類器によって8〜10回選択されたカウントの上位の特徴が、図13に示されている。
微細針吸引(FNA)サンプル(n=81)は、回収され、手術後に専門家のパネルによって悪性(甲状腺乳頭がん(PTC)、多発性甲状腺乳頭がん(mPTC)、濾胞型甲状腺乳頭がん(FVPTC)、甲状腺乳頭がん高細胞型(PTC-TCV)、甲状腺髄様がん(MTC)、詳細不明高分化がん(well-differentiated carcinoma-not otherwise specified(WDC-NOS))、肝細胞がん(HCC)、濾胞がん(FC))または良性(良性家族性好中球減少症(BFN)、線維腺腫(FA)、肝細胞腺腫(HCA)、硝子化索状腺腫(HTA)、ライディッヒ細胞腫(LCT))と診断される。組織病理学的に真である手術組織サンプル(n=57)も分析する。組織病理を示さない臨床検査室改善修正法(CLIA)ラボからの連続する不確定FNAの系列(n=101)も分析する。サンプルを次世代配列決定(NGS)に供し、14個の遺伝子(図14)を、5つの異なる変異パネルにおいて漸増数の調査ゲノム部位および融合対により評価する。図14に示されるように、上の表は、5つの変異パネルの各々についてのゲノム部位の数および融合対の数を示している。変異パネル1は、9箇所のゲノム部位および3対の融合対から構成される。変異パネル2は、19箇所のゲノム部位および25対の融合対から構成される。変異パネル3は、208箇所のゲノム部位および25対の融合対から構成される。変異パネル4は、929箇所のゲノム部位および25対の融合対から構成される。変異パネル5は、3670箇所のゲノム部位および25対の融合対から構成される。図14の下の表は、変異パネルの1つまたは複数において標的とされた14個の遺伝子を示している。
Claims (52)
- 以下の工程を含む、対象における疾患の発症のリスクを判定するために該対象の組織サンプルを評価するための方法:
(a)該対象から取得した針吸引サンプルにおける核酸サンプル中の第1の遺伝子セットの1つまたは複数の遺伝子の各々に対応する発現レベルを取得する工程であって、該第1の遺伝子セットが該対象における該疾患の発症のリスクに関連する、工程;
(b)該核酸サンプル中の第2の遺伝子セットの1つまたは複数の遺伝子の各々に対応する核酸配列の存在を判定する工程であって、該第2の遺伝子セットが該対象における該疾患の発症のリスクに関連する、工程;
(c)対照と、(i)(a)において取得した発現レベルおよび(ii)(b)において取得した核酸配列を別々に比較して、該対照に対する該発現レベルおよび該核酸配列の比較を提供する工程であって、該対照中の参照配列に対する該核酸配列の比較により、該第2の遺伝子セットの所定の遺伝子に関する1つまたは複数の配列変種の存在が示される、工程;ならびに
(d)訓練されたアルゴリズムを用いてプログラムされたコンピュータプロセッサを使用して、(i)該比較を分析し、かつ(ii)該比較に基づき該疾患の発症のリスクを判定する工程。 - 前記疾患ががんである、請求項1に記載の方法。
- (a)の前に、前記対象から前記針吸引サンプルを取得する工程をさらに含む、請求項1に記載の方法。
- (a)の前に、前記針吸引サンプルにおける前記核酸サンプル由来の前記発現レベルを決定する工程をさらに含む、請求項1に記載の方法。
- (b)の前に、前記針吸引サンプルにおける前記核酸サンプル由来の前記核酸配列を決定する工程をさらに含む、請求項1に記載の方法。
- 前記核酸配列を前記参照配列と比較して、前記1つまたは複数の配列変種を同定する工程をさらに含む、請求項5に記載の方法。
- 前記参照配列が、前記対象由来のハウスキーピング遺伝子である、請求項6に記載の方法。
- 前記第1の遺伝子セット中または前記第2の遺伝子セット中の前記1つまたは複数の遺伝子が、複数の遺伝子を含む、請求項1に記載の方法。
- 前記針吸引サンプルが、細胞学的に不明瞭であるとまたは疑わしいと判明している、請求項1に記載の方法。
- 前記針吸引サンプルが、約1マイクロリットルまたはそれ未満の容積を有する、請求項1に記載の方法。
- 前記針吸引サンプルが、約9.0またはそれ未満のRNA Integrity Number(RIN)値を有する、請求項1に記載の方法。
- 前記針吸引サンプルが、約6.0またはそれ未満のRIN値を有する、請求項10に記載の方法。
- 前記疾患の発症のリスクが、前記対象における該疾患の再発のリスクを含む、請求項1に記載の方法。
- 前記がんの発症のリスクが、前記対象における転移のリスクを含む、請求項2に記載の方法。
- 前記訓練されたアルゴリズムが、前記疾患を有すると診断された少なくとも25体の対象由来の組織サンプルを用いて訓練される、請求項1に記載の方法。
- 前記訓練されたアルゴリズムが、前記疾患を有すると診断された少なくとも200体の対象由来の組織サンプルを用いて訓練される、請求項15に記載の方法。
- (d)が手術前に行われる、請求項1に記載の方法。
- 前記対象が陽性の疾患診断を受ける前に(d)が行われる、請求項1に記載の方法。
- (d)が、前記発症のリスクを低発症リスクまたは中〜高発症リスクに層別化する工程をさらに含み、該低発症リスクが、約50%〜約80%の発症率を有し、かつ該中〜高発症リスクが、約80%〜100%の発症率を有する、請求項1に記載の方法。
- 前記層別化する工程が、少なくとも80%の精度を有する、請求項19に記載の方法。
- 前記層別化する工程が、少なくとも80%の特異度を有する、請求項19に記載の方法。
- 1つもしくは複数のフィルター、1つもしくは複数のラッパー、1つもしくは複数の組み込みプロトコル、またはそれらの任意の組み合わせを前記比較に適用する工程をさらに含む、請求項1に記載の方法。
- 1つまたは複数の前記フィルターを前記比較に適用する工程をさらに含む、請求項22に記載の方法。
- 1つまたは複数の前記フィルターが、t検定、分散分析(ANOVA)分析、ベイズフレームワーク、ガンマ分布、ウィルコクソン順位和検定、二乗検定の級間・級内和、ランクプロダクト法(rank product method)、ランダム置換法、誤分類の閾値(TNoM)、二変数法、相関に基づく特徴選択(CFS)法、最小冗長性最大関連性(MRMR)法、マルコフブランケットフィルター法、非相関収縮重心法、またはそれらの任意の組み合わせを含む、請求項23に記載の方法。
- 前記1つまたは複数の配列変種が、点変異、融合遺伝子、置換、欠失、挿入、逆位、変換、転座、またはそれらの任意の組み合わせの1つまたは複数を含む、請求項23に記載の方法。
- 1つまたは複数の前記点変異が、約5個〜約4000個の点変異である、請求項25に記載の方法。
- 1つまたは複数の前記融合遺伝子が、少なくとも2つの融合遺伝子である、請求項25に記載の方法。
- 前記第1のセットまたは前記第2のセットの前記1つまたは複数の遺伝子が、約15個未満の遺伝子である、請求項1に記載の方法。
- 前記第1のセットまたは前記第2のセットの前記1つまたは複数の遺伝子が、約75個未満の遺伝子である、請求項1に記載の方法。
- 前記第1のセットまたは前記第2のセットの前記1つまたは複数の遺伝子が、約50個〜約400個の遺伝子である、請求項1に記載の方法。
- (b)における取得する工程が、前記核酸配列を取得するために前記FNAサンプルにおける核酸サンプルを配列決定する工程を含む、請求項1に記載の方法。
- 前記配列決定する工程が、前記第2の遺伝子セットの1つもしくは複数の前記遺伝子またはその変種を濃縮する工程を含む、請求項31に記載の方法。
- (a)が、前記第1の遺伝子セットの前記1つまたは複数の遺伝子に選択的なプローブを用いるマイクロアレイを使用する工程を含む、請求項1に記載の方法。
- 前記組織サンプルが甲状腺組織サンプルである、請求項1に記載の方法。
- 前記第1の遺伝子セットおよび前記第2の遺伝子セットが、COL1A1、THBS2、またはそれらの任意の組み合わせを含む、請求項34に記載の方法。
- 前記第2の遺伝子セットが、EPHA3、COL1A1、EHF、RAPGEF5、PRICKLE1、TMEM92、ROBO1、C6orf136、SPAG4、GALNT15、LUM、NCAM2、NUP210L、NR2F1、THBS2、PSORS1C1、またはそれらの任意の組み合わせを含む、請求項34に記載の方法。
- 前記第1の遺伝子セットが、COL1A1、TMEM92、C1orf87、SPAG4、EHF、COL3A1、GALNT15、NUP210L、PDZRN3、C6orf136、NA、NRXN3、COL6A3、RAPGEF5、PRICKLE1、LUM、ROBO1、BGN、AC019117.2、PRSS3P1、またはそれらの任意の組み合わせを含む、請求項34に記載の方法。
- 前記第2の遺伝子セットが、EPHA3、COL1A1、EHF、RAPGEF5、PRICKLE1、TMEM92、ROBO1、C6orf136、SPAG4、GALNT15、LUM、NCAM2、SYNPO2、NUP210L、AMZ1、NR2F1、THBS2、PSORS1C1、FTH1P24、またはそれらの任意の組み合わせを含む、請求項34に記載の方法。
- 前記第2の遺伝子セットが、AKAP9、SPRY3、SPRY3、CAMKK2、COL1A1、FITM2、COX6C、VSIG10L、CYC1、KDM1B、MAPK15、ARSG、PAXIP1、DAAM1、AVL9、DMGDH、HLA-DQA1、HLA-DQB1、HLA-DRA、HLA-DRB5、HLA-H、IRF1、MGAT1、P2RX1、PLEK、CCDC93、PPP1R12C、SLC41A3、METTL3、CCAR2、PTPRE、SRL、SLC30A5、BMP4、ZNF133、ICE2、DCAKD、TMX1、TNFSF12、PER2、MCM3AP、またはそれらの任意の組み合わせを含む、請求項34に記載の方法。
- 前記第1の遺伝子セットおよび前記第2の遺伝子セットが異なる、請求項1に記載の方法。
- 前記疾患の新規遺伝子バイオマーカーを同定する工程をさらに含む、請求項1に記載の方法。
- (a)における取得する工程が、前記1つまたは複数の遺伝子の各々に対応する前記発現レベルについてアッセイする工程を含む、請求項1に記載の方法。
- 前記アッセイする工程が、前記1つまたは複数の遺伝子の各々について選択されたマーカーを用いるアレイハイブリダイゼーション、核酸配列決定、または核酸増幅を含む、請求項42に記載の方法。
- 前記マーカーが、前記1つまたは複数の遺伝子の各々について選択されたプライマーである、請求項43に記載の方法。
- 前記アッセイする工程が逆転写ポリメラーゼ連鎖反応(PCR)を含む、請求項43に記載の方法。
- 前記判定する工程が、前記核酸サンプル中の前記第2の遺伝子セットの前記1つまたは複数の遺伝子の各々についてアッセイする工程を含む、請求項1に記載の方法。
- 前記アッセイする工程が、前記1つまたは複数の遺伝子の各々について選択されたマーカーを用いるアレイハイブリダイゼーション、核酸配列決定、または核酸増幅を含む、請求項46に記載の方法。
- 前記マーカーが、前記1つまたは複数の遺伝子の各々について選択されたプライマーである、請求項47に記載の方法。
- 前記アッセイする工程が逆転写ポリメラーゼ連鎖反応(PCR)を含む、請求項47に記載の方法。
- 前記針吸引サンプルが微細針吸引サンプルである、請求項1に記載の方法。
- 以下を備える、対象における疾患の発症のリスクを判定するために該対象の組織サンプルを評価するためのシステム:
(a)第1の遺伝子セットが該対象における該疾患の発症のリスクに関連する、該対象から取得した針吸引サンプルにおける核酸サンプル中の該第1の遺伝子セットの1つまたは複数の遺伝子の各々に対応する発現と、(b)第2の遺伝子セットが該対象における該疾患の発症のリスクに関連する、該核酸サンプル中の該第2の遺伝子セットの1つまたは複数の遺伝子の各々に対応する核酸配列の存在の表示とを保存する、1つまたは複数のコンピュータメモリ;ならびに
該1つまたは複数のコンピュータメモリに接続され、かつ、
(i)対照と、(1)該コンピュータメモリ中の発現レベルおよび(2)該核酸配列を別々に比較して、該対照に対する該発現レベルおよび該核酸配列の比較を提供し、該対照中の参照配列に対する該核酸配列の比較により、該第2の遺伝子セットの所定の遺伝子に関する1つまたは複数の配列変種の存在が示されるよう、かつ
(ii)訓練されたアルゴリズムを使用して、(1)該比較を分析し、かつ(2)該比較に基づき該疾患の発症のリスクを判定するよう
プログラムされた、コンピュータプロセッサ。 - 1つまたは複数のコンピュータプロセッサによって実行されると対象における疾患の発症のリスクを判定するために該対象の組織サンプルを評価するための方法を実施する機械実行可能なコードを備える非一時的コンピュータ読み取り可能媒体であって、該方法が以下の工程を含む、非一時的コンピュータ読み取り可能媒体:
(a)該対象から取得した針吸引サンプルにおける核酸サンプル中の第1の遺伝子セットの1つまたは複数の遺伝子の各々に対応する発現レベルを取得する工程であって、該第1の遺伝子セットが該対象における該疾患の発症のリスクに関連する、工程;
(b)該核酸サンプル中の第2の遺伝子セットの1つまたは複数の遺伝子の各々に対応する核酸配列の存在を判定する工程であって、該第2の遺伝子セットが該対象における該疾患の発症のリスクに関連する、工程;
(c)対照と、(i)(a)において取得した発現レベルおよび(ii)(b)において取得した核酸配列を別々に比較して、該対照に対する該発現レベルおよび該核酸配列の比較を提供する工程であって、該対照中の参照配列に対する該核酸配列の比較により、該第2の遺伝子セットの所定の遺伝子に関する1つまたは複数の配列変種の存在が示される、工程;ならびに
(d)訓練されたアルゴリズムを用いてプログラムされたコンピュータプロセッサを使用して、(i)該比較を分析し、かつ(ii)該比較に基づき該疾患の発症のリスクを判定する工程。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022002016A JP2022050571A (ja) | 2015-03-04 | 2022-01-11 | 発現レベルおよび配列変種情報を用いて疾患の発症または再発のリスクを評価するための方法 |
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562128463P | 2015-03-04 | 2015-03-04 | |
| US201562128469P | 2015-03-04 | 2015-03-04 | |
| US62/128,463 | 2015-03-04 | ||
| US62/128,469 | 2015-03-04 | ||
| US201562238893P | 2015-10-08 | 2015-10-08 | |
| US62/238,893 | 2015-10-08 | ||
| PCT/US2016/020583 WO2016141127A1 (en) | 2015-03-04 | 2016-03-03 | Methods for assessing the risk of disease occurrence or recurrence using expression level and sequence variant information |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022002016A Division JP2022050571A (ja) | 2015-03-04 | 2022-01-11 | 発現レベルおよび配列変種情報を用いて疾患の発症または再発のリスクを評価するための方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2018514187A true JP2018514187A (ja) | 2018-06-07 |
| JP2018514187A5 JP2018514187A5 (ja) | 2019-04-11 |
Family
ID=56849098
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017546066A Withdrawn JP2018514187A (ja) | 2015-03-04 | 2016-03-03 | 発現レベルおよび配列変種情報を用いて疾患の発症または再発のリスクを評価するための方法 |
| JP2022002016A Pending JP2022050571A (ja) | 2015-03-04 | 2022-01-11 | 発現レベルおよび配列変種情報を用いて疾患の発症または再発のリスクを評価するための方法 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022002016A Pending JP2022050571A (ja) | 2015-03-04 | 2022-01-11 | 発現レベルおよび配列変種情報を用いて疾患の発症または再発のリスクを評価するための方法 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US20180016642A1 (ja) |
| EP (1) | EP3265588A4 (ja) |
| JP (2) | JP2018514187A (ja) |
| CN (2) | CN107636171A (ja) |
| AU (1) | AU2016226253A1 (ja) |
| CA (1) | CA2978442A1 (ja) |
| WO (1) | WO2016141127A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021256525A1 (ja) * | 2020-06-18 | 2021-12-23 | 国立研究開発法人産業技術総合研究所 | 情報処理システム、情報処理方法、同定方法及びプログラム |
Families Citing this family (34)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2008058018A2 (en) | 2006-11-02 | 2008-05-15 | Mayo Foundation For Medical Education And Research | Predicting cancer outcome |
| AU2009253675A1 (en) | 2008-05-28 | 2009-12-03 | Genomedx Biosciences, Inc. | Systems and methods for expression-based discrimination of distinct clinical disease states in prostate cancer |
| US10407731B2 (en) | 2008-05-30 | 2019-09-10 | Mayo Foundation For Medical Education And Research | Biomarker panels for predicting prostate cancer outcomes |
| US10236078B2 (en) | 2008-11-17 | 2019-03-19 | Veracyte, Inc. | Methods for processing or analyzing a sample of thyroid tissue |
| US9495515B1 (en) | 2009-12-09 | 2016-11-15 | Veracyte, Inc. | Algorithms for disease diagnostics |
| US9074258B2 (en) | 2009-03-04 | 2015-07-07 | Genomedx Biosciences Inc. | Compositions and methods for classifying thyroid nodule disease |
| EP2430574A1 (en) | 2009-04-30 | 2012-03-21 | Patientslikeme, Inc. | Systems and methods for encouragement of data submission in online communities |
| EP2427575B1 (en) | 2009-05-07 | 2018-01-24 | Veracyte, Inc. | Methods for diagnosis of thyroid conditions |
| US10446272B2 (en) | 2009-12-09 | 2019-10-15 | Veracyte, Inc. | Methods and compositions for classification of samples |
| CA2858581A1 (en) | 2011-12-13 | 2013-06-20 | Genomedx Biosciences, Inc. | Cancer diagnostics using non-coding transcripts |
| DK3435084T3 (da) | 2012-08-16 | 2023-05-30 | Mayo Found Medical Education & Res | Prostatakræftprognose under anvendelse af biomarkører |
| US11976329B2 (en) | 2013-03-15 | 2024-05-07 | Veracyte, Inc. | Methods and systems for detecting usual interstitial pneumonia |
| CN107206043A (zh) | 2014-11-05 | 2017-09-26 | 维拉赛特股份有限公司 | 使用机器学习和高维转录数据在经支气管活检上诊断特发性肺纤维化的系统和方法 |
| US10395759B2 (en) | 2015-05-18 | 2019-08-27 | Regeneron Pharmaceuticals, Inc. | Methods and systems for copy number variant detection |
| NZ745249A (en) | 2016-02-12 | 2021-07-30 | Regeneron Pharma | Methods and systems for detection of abnormal karyotypes |
| CN110506127B (zh) | 2016-08-24 | 2024-01-12 | 维拉科特Sd公司 | 基因组标签预测前列腺癌患者对术后放射疗法应答性的用途 |
| US20190264264A1 (en) * | 2016-10-26 | 2019-08-29 | Integrated Nano-Technologies, Inc. | Systems and methods for analyzing rna transcripts |
| US11208697B2 (en) | 2017-01-20 | 2021-12-28 | Decipher Biosciences, Inc. | Molecular subtyping, prognosis, and treatment of bladder cancer |
| WO2018152093A1 (en) * | 2017-02-15 | 2018-08-23 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Method of diagnosing cancer using mitochondrial dna heterogeneity |
| US11873532B2 (en) | 2017-03-09 | 2024-01-16 | Decipher Biosciences, Inc. | Subtyping prostate cancer to predict response to hormone therapy |
| CA3062716A1 (en) | 2017-05-12 | 2018-11-15 | Decipher Biosciences, Inc. | Genetic signatures to predict prostate cancer metastasis and identify tumor agressiveness |
| US11217329B1 (en) | 2017-06-23 | 2022-01-04 | Veracyte, Inc. | Methods and systems for determining biological sample integrity |
| GB2581584A (en) * | 2017-07-27 | 2020-08-26 | Veracyte Inc | Genomic sequencing classifier |
| CN108416190A (zh) * | 2018-02-11 | 2018-08-17 | 广州市碳码科技有限责任公司 | 基于深度学习的肿瘤早期筛查方法、装置、设备及介质 |
| CN112585270B (zh) * | 2018-08-15 | 2023-12-05 | 中国科学院遗传与发育生物学研究所 | 评估或改善脑功能、学习能力或记忆力的组合物和方法 |
| CN112740239A (zh) * | 2018-10-08 | 2021-04-30 | 福瑞诺姆控股公司 | 转录因子分析 |
| US11894139B1 (en) * | 2018-12-03 | 2024-02-06 | Patientslikeme Llc | Disease spectrum classification |
| CA3164331A1 (en) * | 2020-01-09 | 2021-07-15 | Jason Su | Methods and systems for performing real-time radiology |
| CN112326965B (zh) * | 2020-10-22 | 2022-03-04 | 南京医科大学 | Daam1蛋白在制备肾透明细胞癌诊断及预后评估试剂盒中的应用 |
| CN114622007A (zh) * | 2020-12-10 | 2022-06-14 | 深圳先进技术研究院 | 一种Cox6c检测引物及其应用 |
| CN112715484B (zh) * | 2020-12-29 | 2022-04-22 | 四川省人民医院 | 构建视网膜色素变性疾病模型的方法、应用以及繁育方法 |
| US11367521B1 (en) | 2020-12-29 | 2022-06-21 | Kpn Innovations, Llc. | System and method for generating a mesodermal outline nourishment program |
| CN113504370B (zh) * | 2021-06-29 | 2024-02-09 | 广州金研生物医药研究院有限公司 | Mapk15蛋白在前列腺癌的恶性程度或预后程度预测中的应用 |
| WO2023201054A1 (en) * | 2022-04-15 | 2023-10-19 | Memorial Sloan-Kettering Cancer Center | Multi-modal machine learning to determine risk stratification |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002510975A (ja) * | 1997-07-01 | 2002-04-09 | アンスティテュ パストゥール ドゥ リール | アルツハイマー病の診断方法 |
| US20110312520A1 (en) * | 2010-05-11 | 2011-12-22 | Veracyte, Inc. | Methods and compositions for diagnosing conditions |
| JP2013212052A (ja) * | 2012-03-30 | 2013-10-17 | Yale Univ | Krasバリアントおよび腫瘍生物学 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2005008213A2 (en) * | 2003-07-10 | 2005-01-27 | Genomic Health, Inc. | Expression profile algorithm and test for cancer prognosis |
| GB0417740D0 (en) * | 2004-08-10 | 2004-09-08 | Uc3 | Methods and kit for the prognosis of breast cancer |
| US20130303826A1 (en) * | 2011-01-11 | 2013-11-14 | University Health Network | Prognostic signature for oral squamous cell carcinoma |
| US20130142728A1 (en) * | 2011-10-27 | 2013-06-06 | Asuragen, Inc. | Mirnas as diagnostic biomarkers to distinguish benign from malignant thyroid tumors |
-
2016
- 2016-03-03 WO PCT/US2016/020583 patent/WO2016141127A1/en active Application Filing
- 2016-03-03 CN CN201680026050.4A patent/CN107636171A/zh active Pending
- 2016-03-03 CN CN202210267696.9A patent/CN114634985A/zh active Pending
- 2016-03-03 CA CA2978442A patent/CA2978442A1/en active Pending
- 2016-03-03 JP JP2017546066A patent/JP2018514187A/ja not_active Withdrawn
- 2016-03-03 AU AU2016226253A patent/AU2016226253A1/en not_active Abandoned
- 2016-03-03 EP EP16759458.9A patent/EP3265588A4/en not_active Withdrawn
-
2017
- 2017-09-01 US US15/694,157 patent/US20180016642A1/en not_active Abandoned
-
2022
- 2022-01-11 JP JP2022002016A patent/JP2022050571A/ja active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002510975A (ja) * | 1997-07-01 | 2002-04-09 | アンスティテュ パストゥール ドゥ リール | アルツハイマー病の診断方法 |
| US20110312520A1 (en) * | 2010-05-11 | 2011-12-22 | Veracyte, Inc. | Methods and compositions for diagnosing conditions |
| JP2013212052A (ja) * | 2012-03-30 | 2013-10-17 | Yale Univ | Krasバリアントおよび腫瘍生物学 |
Non-Patent Citations (3)
| Title |
|---|
| ALI SZ., ET AL., "USE OF THE AFIRMA GENE EXPRESSION CLASSIFIER FOR PREOPERATIVE IDENTIFICATION OF BE, JPN6020014081, 11 February 2013 (2013-02-11), ISSN: 0004590159 * |
| NAT COMMUN., 2015 JAN 9, VOL. 6, ARTICLE NO. 5901 (PP. 1-11), JPN6020014086, ISSN: 0004590160 * |
| ONCOTARGET, 2015 OCT 9, VOL. 6, NO. 42, PP. 44971-44984, JPN6020014089, ISSN: 0004422022 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021256525A1 (ja) * | 2020-06-18 | 2021-12-23 | 国立研究開発法人産業技術総合研究所 | 情報処理システム、情報処理方法、同定方法及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114634985A (zh) | 2022-06-17 |
| EP3265588A4 (en) | 2018-10-10 |
| JP2022050571A (ja) | 2022-03-30 |
| US20180016642A1 (en) | 2018-01-18 |
| CN107636171A (zh) | 2018-01-26 |
| EP3265588A1 (en) | 2018-01-10 |
| CA2978442A1 (en) | 2016-09-09 |
| WO2016141127A1 (en) | 2016-09-09 |
| AU2016226253A1 (en) | 2017-09-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2022050571A (ja) | 発現レベルおよび配列変種情報を用いて疾患の発症または再発のリスクを評価するための方法 | |
| JP7022188B2 (ja) | 無細胞核酸の多重解像度分析のための方法 | |
| JP6684775B2 (ja) | 甲状腺状態の診断のための方法および組成物 | |
| US20180349548A1 (en) | Methods and compositions that utilize transcriptome sequencing data in machine learning-based classification | |
| US10731223B2 (en) | Algorithms for disease diagnostics | |
| JP6227095B2 (ja) | 遺伝的変異の非侵襲的評価のための方法およびプロセス | |
| JP6680680B2 (ja) | 染色体変化の非侵襲性評価のための方法およびプロセス | |
| ES2907069T3 (es) | Resolución de fracciones genómicas usando recuentos de polimorfismos | |
| JP2018196389A (ja) | 遺伝子の変動の非侵襲的評価のための方法および処理 | |
| KR20210023804A (ko) | 조직 특이적 메틸화 마커 | |
| US20230175058A1 (en) | Methods and systems for abnormality detection in the patterns of nucleic acids | |
| JP2023540257A (ja) | がんを分類するためのサンプルの検証 | |
| KR20240104202A (ko) | 순환 종양 핵산 분자의 다중모드 분석 | |
| JP2022527316A (ja) | ウィルスに関連した癌のリスクの層別化 | |
| CN115667544A (zh) | 鉴定染色体外dna特征的方法 | |
| WO2022120076A1 (en) | Clinical classifiers and genomic classifiers and uses thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20171004 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20190301 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20190301 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20200413 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200713 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20210106 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20210115 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210402 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20210908 |
|
| C60 | Trial request (containing other claim documents, opposition documents) |
Free format text: JAPANESE INTERMEDIATE CODE: C60 Effective date: 20220111 |
|
| C116 | Written invitation by the chief administrative judge to file amendments |
Free format text: JAPANESE INTERMEDIATE CODE: C116 Effective date: 20220120 |
|
| C22 | Notice of designation (change) of administrative judge |
Free format text: JAPANESE INTERMEDIATE CODE: C22 Effective date: 20220120 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220221 |
|
| C22 | Notice of designation (change) of administrative judge |
Free format text: JAPANESE INTERMEDIATE CODE: C22 Effective date: 20230111 |
|
| C22 | Notice of designation (change) of administrative judge |
Free format text: JAPANESE INTERMEDIATE CODE: C22 Effective date: 20230407 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20230912 |
|
| A761 | Written withdrawal of application |
Free format text: JAPANESE INTERMEDIATE CODE: A761 Effective date: 20231214 |