JP2010033249A - プログラム分析方法及びプログラム作成方法 - Google Patents
プログラム分析方法及びプログラム作成方法 Download PDFInfo
- Publication number
- JP2010033249A JP2010033249A JP2008193652A JP2008193652A JP2010033249A JP 2010033249 A JP2010033249 A JP 2010033249A JP 2008193652 A JP2008193652 A JP 2008193652A JP 2008193652 A JP2008193652 A JP 2008193652A JP 2010033249 A JP2010033249 A JP 2010033249A
- Authority
- JP
- Japan
- Prior art keywords
- program
- common
- source
- common element
- quasi
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images












Landscapes
- Stored Programmes (AREA)
Abstract
【解決手段】単語/記号/数字の単位抽出部2により複数のソースプログラム1からプログラム文を抽出し、共通要素抽出部3により、各ソースプログラム内で一つしかないプログラム文で、かつ全てのソースプログラム1に共通なプログラム文を共通要素として抽出し、共通要素間プログラム文抽出部4により、各ソースプログラム内で連続する共通要素間にあるプログラム文を抽出し、準共通要素抽出部5により、それらのプログラム文を比較して、一致するプログラム文を準共通要素として抽出し、非共通要素抽出部6により、共通要素及び準共通要素を除くプログラム文を非共通要素として抽出して、流用可能な単位のプログラム文を保存するようにした。
【選択図】図1
Description
また、流用元のプログラムが開発されたのは事業創設期であり、構造化プログラミングがされていないことが多い。
構造化プログラミングされているソースプログラムの共通部分を類型化する方法については、特許文献1が提案されている。
また、あるプログラムに動作不良が発生した場合、納入実績のあるプログラムのうちで改修対象となる対象を選定するにも、ソースプログラムを人間系で確認する必要があるため、ヒューマンエラーが入り込み易いという問題があった。
特許文献1は、構造化プログラミングされているソースプログラムの共通部分を類型化するものであり、構造化プログラミングされていないソースプログラムについてのものではなかった。
プログラム文のうち、各ソースプログラム内で一つしかないプログラム文であり、かつ複数のソースプログラムのすべてに存在するプログラム文を共通要素として抽出する第二のステップ、
各ソースプログラムの共通要素で区切られた同じ範囲において、複数のソースプログラムに存在するプログラム文を準共通要素として抽出する第三のステップ、
共通要素と準共通要素のどちらでもないプログラム文を非共通要素として抽出する第四のステップ、
抽出した共通要素、準共通要素および非共通要素のいずれかである各要素を記憶装置に保存するステップを含み、
共通要素は各ソースプログラムにおける順番がすべてのソースプログラムで同じであり、
準共通要素の各ソースプログラムにおける順番は、準共通要素を有するすべてのソースプログラムで同じであり、
各要素には、抽出された元のソースプログラムと、そのソースプログラムの中での位置を示す分類コードが付与されているものである。
プログラム文のうち、各ソースプログラム内で一つしかないプログラム文であり、かつ複数のソースプログラムのすべてに存在するプログラム文を共通要素として抽出する第二のステップ、
各ソースプログラムの共通要素で区切られた同じ範囲において、複数のソースプログラムに存在するプログラム文を準共通要素として抽出する第三のステップ、
共通要素と準共通要素のどちらでもないプログラム文を非共通要素として抽出する第四のステップ、
抽出した共通要素、準共通要素および非共通要素のいずれかである各要素を記憶装置に保存するステップを含み、
共通要素は各ソースプログラムにおける順番がすべてのソースプログラムで同じであり、
準共通要素の各ソースプログラムにおける順番は、準共通要素を有するすべてのソースプログラムで同じであり、
各要素には、抽出された元のソースプログラムと、そのソースプログラムの中での位置を示す分類コードが付与されているので、構造化プログラミングされていないプログラムでも、再利用可能な部品単位に分割することができる。
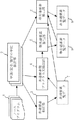
図1は、この発明の実施の形態1によるプログラム分析方法を示す概念図である。
図1において、プログラム分析方法は、5つの抽出部と3つの一覧データを有している。
3つの一覧データは、以下に示すプログラム文の3分類のそれぞれに対応するものである。
共通要素:1つのソースプログラム内で唯一無二のプログラム文であり、すべてのソースプログラムに存在しているもの。プログラムにより順番が入れ替わっているものは、共通要素とはしない。
準共通要素:複数のソースプログラムに存在する文であって、共通要素でないもの。ただし、共通要素により区切られた同じ範囲にあるものに限る。複数の連続するプログラム文が準共通要素に該当する場合は、まとめて1個の準共通要素とする。なお、他の準共通要素との前後関係も考慮するが、それについては後で説明する。
非共通要素:共通要素でも準共通要素でもないもの。
単語/記号/数字の単位抽出部2は、ソースプログラム1が入力され、単語/記号/数字の単位で区切ったプログラムの断片を抽出して、1個のプログラム文が1行に対応するように表形式で保存する。(図2のステップS01参照)。共通要素抽出部3は、1つのプログラム内で唯一無二のプログラム文で、すべてのソースプログラムに存在しているものを共通要素として抽出し、発見された順番に共通要素一覧データ7に保存する。(図2のステップS02、ステップS03参照)。
非共通要素抽出部6は、共通要素一覧データ7および準共通要素一覧データ8に登録されている各要素を、単語/記号/数字の単位で区切った表形式のデータから削除し、残ったプログラム文を、発見された順番に非共通要素一覧データ9に登録する。(図2のステップS05参照)。
なお、共通要素、準共通要素、非共通要素をまとめてプログラム要素ということもある。
図3(a)はフローチャートであり、図3(b)はステップS12の処理内容を示す図である。
図7は、この発明の実施の形態1によるプログラム分析方法において準共通要素を抽出する処理での共通要素で区切られた範囲を説明する例を示す図である。
図8は、この発明の実施の形態1によるプログラム分析方法において準共通要素を抽出する処理を説明する例を示す図である。
図9は、この発明の実施の形態1によるプログラム分析方法において非共通要素を抽出する処理を説明するフローチャートである。
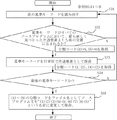
プログラム分析方法を実現するプログラムによる制御動作は、図2のフローチャートのとおりである。
図2で、ステップS01(第一のステップ)は、ソースプログラム1から、単語/記号/数字の単位で区切った表形式により抽出する。次に、ステップS02にて、1つのプログラム内で1つしかないプログラム文を抽出し、次いで、ステップS03では、ステップS02で抽出したプログラム文がすべてのプログラム文に共通して存在しているプログラム文であれば、共通要素として、発見された順番に共通要素一覧データ7に保存する。(ステップS02、S03は、第二のステップを構成する。)
次に、ステップS04(第三のステップ)で、ソースプログラム内に存在する共通要素で区切られた範囲を前から順に処理して、その範囲に存在するプログラム文を各ソースプログラムから抜粋する。そして、異なるソースプログラムの同じ共通要素の間に存在していたプログラム文同士を比較し、少なくとも二つのプログラムで共通なプログラム文を、共通であるプログラム数ができるだけ多くなるようにして切り出し、順番に準共通要素一覧データ8に登録する。加えて、最初に一致する行と共通要素との相対行/列を記録する。
ここで、登録とは、プログラム文がもつ分類コード(1)〜(9)を使い、ファイル名“(1)(2)(3)(4)(5)(6)(7)(8)(9)”としてTXTファイルで保存することをいう。なお、分類コード(1)〜(9)については後述する。
なお、共通要素一覧データ7、準共通要素一覧データ8、非共通要素一覧データ9に保存されたプログラム文は、分類コードを付けて保存する。
(1):分析対象の複数のソースプログラムのすべてに含まれる共通要素か、2つ以上のソースプログラムに含まれる準共通要素か、1つだけ発見された非共通要素かという分類記号(共通要素:1、準共通要素:2、非共通要素:3)
(2):共通要素、準共通要素、非共通要素としてそれぞれ見つかった順番
(3):分析対象である複数のプログラムに含まれる要素であれば、要素を含んでいるプログラム数
(4): そのプログラム文よりも前にある共通要素の中で最も近くに存在する共通要素の番号。共通要素の場合は、自分の番号が入る。
(5):(4)に記録した共通要素との相対行数。共通要素の場合は、0になる。
(6):プログラム文の構成要素数。表形式における列の数。
(7):プログラムが作成された日付
(8):解析元プログラム番号
(9):解析元プログラム内の要素の行数
「解析プログラムがソースプログラム内を解析している際に3番目に見つかった準共通要素で、5つのソースプログラムの中で2つのソースプログラムに含まれている準共通要素は、3列であり、ソースプログラムBにおいて10行目に存在し、最も近い共通要素は3行目にある2番目の共通要素であり、この共通要素からの相対行数は7行である。ソースプログラムB(番号2)は2007/08/03に作成されている。」
という場合、上記「」内の文章を分類コードが決まる毎に区切って説明すると、以下の通りである。
3番目に見つかった・・・・・・(2)は3
準共通要素で、・・・・・・・・(1)は2
5つのソースプログラムの中で2つのソースプログラムに含まれている・・・(3)は2
準共通要素は3列であり、・・・・・・・・・・・・・・・・・・(6)は3
ソースプログラムBにおいて10行目に存在し、・・・・・・・・(9)は10
最も近い共通要素は3列目にある2番目の共通要素であり、・・・(4)は2
この共通要素からの相対行数は7行である。・・・・・・・・・・(5)は7
ソースプログラムB(番号2)は ・・・・・・・・・・・・・・(8)は2
2007/08/03に作成されている。・・・・・・・・(7)は2007/08/03
以上をまとめると、
(1)2 (2)3 (3)2 (4)2 (5)7 (6)3
(7)20070803 (8)2 (9)10
となる。
図3(a)で、まず、ステップS11で、比較対象となる複数のソースプログラムにプログラム番号(1〜N)を付ける。これにより、分類コード(7)(8)が取得される。次いで、ステップS12で、次のプログラム番号のソースプログラムを空白・カンマ・括弧で区切り、単語/記号/数字の単位で表形式のフォーマットに読み込む。これにより、図3(b)のように読み込まれる。
次いで、ステップS13で、プログラム行間の改行、プログラム文内の構成要素間のスペースを削除する。ステップS14で、要素の行列を取得する。これにより、分類コード(9)(6)が取得される。次いで、ステップS15で、未確定な分類コードは♯とし、(1)〜(9)の分類コードをファイル名としてソースプログラム文を“♯♯♯♯♯♯(6)(7)(8)(9)”という名前で保存する。
先ず、ステップS21で、プログラム番号N番の表形式のファイルを読み込む。ステップS22で、次の行に含まれている単語/記号/数字(プログラム文)を読み込む。次いで、ステップS23で、プログラム番号N番の表形式のファイルの全行を順に処理して、S22で読み込んだ行と同一の行が、1行以上あるかどうかを判定し、NOであれば、ステップS24で、読み込まれた単語/記号/数字を基準キーワードとして登録する。YESであれば、ステップS22に戻る。ステップS24に次いで、ステップS25で、プログラム番号N番の最後の行かどうかを判定し、YESであれば、終了し、NOであれば、ステップS22に戻る。
まず、ステップS31で、次の基準キーワードを読み出す。ステップS32で、基準キーワードがすべてのソースプログラムにおいて、最も新しく見つかった共通要素よりも後の位置に含まれるかどうかを判定し、(これにより、分類コード(3)=N、(5)=0を取得する。)、NOであれば、ステップS31に戻り、YESであれば、ステップS33で、基準キーワードを行単位で共通要素として採番する。これにより、分類コード(1)(2)及び(4)=(2)を取得する。
次いで、ステップS34で、最後の基準キーワードかどうかを判定し、NOであれば、ステップS31に戻り、YESであれば、ステップS35で、(1)〜(9)の分類コードをファイル名としてソースプログラム文を“(1)(2)(3)(4)(5)(6)(7)(8)(9)”という名前に変更して保存する。
まず、図6に示すフローチャートにおけるステップS41で、共通要素で区切られた範囲の先頭を処理対象とする。具体的には、ソースプログラムの先頭から1個目の共通要素までの範囲を処理対象とする。図7が処理対象の範囲の例である。
ステップS42では、各ソースプログラムについて処理対象の範囲を取り出す。ステップS43では、すべての2個のソースプログラムの組み合わせについて、同じプログラム文が存在するかどうか検索し、同じプログラム文を1行単位で準共通要素の候補として抽出する。ステップS44では、連続した行が準共通要素の候補として抽出されている場合に、それらをまとめられるかどうかチェックし、まとめられる場合はまとめる。ステップS45では、準共通要素のデータを作成する。ステップS46では、未処理の範囲があるかチェックする。未処理の範囲があれば、ステップS47で次の範囲を処理対象として、ステップS42に戻る。未処理の範囲がなければ、処理を終了する。
対象プログラム文が基準プログラム文と異なれば、次のプログラム文を対象プログラム文とし、対象プログラムにおいて最後のプログラム文を処理しても基準プログラム文と同じプログラム文が無い場合は、基準プログラム文を次のプログラム文に移動させる。こうして、すべての基準プログラム文に対して対象プログラム文とのチェックが終了すれば、2個のソースプログラムの間でのチェックを終了する。
準準共通要素の候補でないか、準準共通要素の候補であっても基準候補を有するソースプログラムの集合が同じでない場合は、基準候補をそのまま準共通要素にし、次の準共通要素の候補を基準候補にする。こうして、すべての準準共通要素の候補を処理して、図8(c)に示すように、”BBB”と”CCC”が1個の準共通要素になる。なお、例えば、プログラム4の2行目の”MMM”が仮に”BBB”というプログラム文であれば、”BBB”はプログラム1、プログラム2およびプログラム4に共通な準共通要素として抽出され、”CCC”がプログラム1とプログラム2に共通な準共通要素として抽出されたままである。
共通要素に関して交差が発生する場合には、前に説明した処理方法では、先に発見したものを共通要素とし、交差するものは共通要素として抽出しない。共通要素と準共通要素のどちらかまたは両方の合計が大きくなる方を選択するようにしてもよいし、交差が発生するものは、どちらも共通要素としないようにしてもよい。
まず、ステップS61で、B=B+1を演算する。ステップS62で、C=C+1を演算する。
次いで、ステップS63で、“♯♯♯♯♯♯(6)(7)(8)(9)”という分類コードを持つ非共通要素の行番号(9)と、(8)が同じ数字の分類コードを持つ(1)=1でC番目の共通要素の行番号(9)との相対行(5)を取得し、最も小さな正数の相対行を持つ“♯♯♯♯♯♯(6)(7)(8)(9)”というファイル名を探す。
ステップS64で、発見されたファイルの行番号(9)は、C+1番目の共通要素の行番号(9)より小さいかどうかを判定し、NOであれば、ステップS62に戻り、YESであれば、ステップS65で、非共通要素である(1)=3、(3)=1とし、見つかった順番Bから(2)=B、関連する共通要素がCであることから、(4)=Cとして“(1)(2)(3)(4)(5)(6)(7)(8)(9)”という分類コードをつけて保存する。次いで、ステップS66で、“♯♯♯♯♯♯(6)(7)(8)(9)”が存在するかどうかを判定し、NOであれば、ステップS61に戻り、YESであれば、終了する。
実施の形態1では、プログラム文を分析して類似度を3つの要素に分類してデータを保存する方法について述べたが、実施の形態2は、分類コードを使って、図10に示すように、表示順序を採番していき、分類コードの共通要素と準共通要素と非共通要素のコードを読み取って、列毎に分けて表示するようにした。これにより、一つのプログラムの構成を一目で分かるように表示することができる。
図11は、この発明の実施の形態2によるプログラム分析方法の単一プログラムのプログラム要素の状態の画面例を示す図である。
図11において、横軸の分類コード(1)の共通要素11、準共通要素12、非共通要素13について、それぞれ縦軸で見つかった順番にプログラム文を示している。
ステップS70で、共通要素(n)に対して表示順を採番する。次いで、ステップS71で、共通要素(n)を分類コードに持っている要素の中で相対行の小さい順に上段から各要素に対して表示順を採番する。ステップS72で、n=n+1を演算する。ステップS73で、n>共通要素の最大数かどうかを判定し、NOであれば、ステップS70に戻り、YESであれば、終了する。
”分断したプログラム文の内で最も近くに存在している共通要素の分類コード”と“最も近くに存在している共通要素との相対距離にあたる行と文字数”から共通要素および非共通要素の表示行を決定する。
表示する要素は、図10に示すように、同プログラムの各要素に対して次の規則に従って採番する。
動作例を以下にあげる。
共通要素の1番を採番したのち、2番目の共通要素との間にある準共通要素および非共通要素を採番していく。1番目の共通要素を分類コードに持つ準共通要素および非共通要素について、1番目の共通要素との相対行の小さいものから順番に下段の行に表示する。
次に、2番の共通要素を採番し、その共通要素に属する準共通要素および非共通要素を2番目の共通要素との相対行の小さいものから順番に下段の行に表示する・・・といったサイクルで、順次、表示順序を決めて、図11のように表示する。
実施の形態2では、ソースプログラムの構成を一目で識別出来るような方法について述べたが、それぞれの要素が分析対象である複数のソースプログラム内にどの程度含まれていたかを確認することが出来ない。そこで、実施の形態3では、複数のソースプログラムの中で存在していたすべての要素について、ソースプログラム内での有無を表形式で表示するようにした。
図12において、分類コードをもとに、プログラム名と作成日付を横軸、複数のソースプログラムの中で存在していたすべての要素(同一行のものは1つの要素として扱う)を縦軸にして、プログラム内での有無を表形式で表示している
実施の形態3では、複数のプログラムで使用されている状態が一目で確認出来るようにしたが、実施の形態4は、この実施の形態3のような表示形式を使用して、縦軸に記載されているプログラム要素を複数選択し、選択されたプログラム要素を保存されている一覧データから読み込んで、選択された順に組み合せてプログラムを構築するようにしたものである。
図13において、図12の画面例にチェック欄を設け、プログラム要素を選択できるようにした。
図14は、この発明の実施の形態4によるプログラム分析方法のプログラム再構築の処理を示すフローチャートである。
まず、ステップS81で、分類コードのリストのn番目(ただし、初回はn=1)のデータを読み込む。次いで、ステップS82で、プログラム生成用の表のn行目にデータを書き込む。ステップS83で、n=n+1を演算する。次いで、ステップS84で、nが分類コードのリストの最大数を超えているかどうかを判定し、超えていると、終了し、超えていなければ、ステップS81に戻る。
また、リスト形式で編集することで容易にプログラム再構築を行える効果がある。
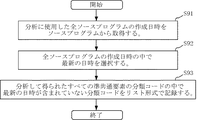
実施の形態5は、分類コードにおいて、分析対象である複数のソースプログラムに含まれる要素で2つ以上のプログラムに含まれているが、その要素が作られた日付より後のソースプログラム内に含まれていない要素である場合には、該当のソースプログラムとその要素を検出するプログラムである。
非共通要素については、分類コードに含まれる日付データを取得し、その日付データがもっとも新しいソースプログラムの作成日付のものをリストアップする。
すなわち、ステップS91で、分析に使用したすべてのソースプログラムの作成日時をソースプログラムからそれぞれ取得する。次いで、ステップS92で、すべてのソースプログラムの作成日時の中で最新の日時を選定する。次いで、ステップS93で、分析して得られたすべての準共通要素の分類コードの中で、最新の日時が含まれていない分類コードをリスト形式で記録する。
最新の日付でない準共通要素と最新の日付の非共通要素を抽出する場合で説明したが、日付としては最新でなくてもよく、いずれかのソースプログラムの作成日付でもよい。抽出する対象も指定した日付のもの、指定した日付よりも新しいもの、指定し日付の前後の所定期間のものなど、所定の時間関係にあるソースプログラムに含まれる準共通要素と非共通要素のどちらかまたは両方をリスト形式で表示するようにしてもよい。
2 単語/記号/数字の単位抽出部
3 共通要素抽出部
4 共通要素間プログラム文抽出部
5 準共通要素抽出部
6 非共通要素抽出部
7 共通要素一覧データ
8 準共通要素一覧データ
9 非共通要素一覧データ
11 共通要素
12 準共通要素
13 非共通要素
Claims (7)
- 複数のソースプログラムからソースプログラムごとにプログラムの構成要素であるプログラム文を抽出する第一のステップ、
上記プログラム文のうち、各ソースプログラム内で一つしかないプログラム文であり、かつ複数のソースプログラムのすべてに存在する上記プログラム文を共通要素として抽出する第二のステップ、
各ソースプログラムの上記共通要素で区切られた同じ範囲において、複数のソースプログラムに存在するプログラム文を準共通要素として抽出する第三のステップ、
上記共通要素と上記準共通要素のどちらでもない上記プログラム文を非共通要素として抽出する第四のステップ、
抽出した上記共通要素、上記準共通要素および上記非共通要素のいずれかである各要素を記憶装置に保存するステップを含み、
上記共通要素は各ソースプログラムにおける順番がすべてのソースプログラムで同じであり、
上記準共通要素の各ソースプログラムにおける順番は、上記準共通要素を有するすべてのソースプログラムで同じであり、
上記各要素には、抽出された元のソースプログラムと、そのソースプログラムの中での位置を示す分類コードが付与されていることを特徴とするプログラム分析方法。 - 一つのソースプログラムに存在する上記プログラム文を、記述された順番に、上記共通要素、上記準共通要素および上記非共通要素をそれぞれ別の列にして表示することを特徴とする請求項1に記載のプログラム分析方法。
- 複数のソースプログラムから抽出された上記各要素を、各ソースプログラムでの有無が分かるように表形式で表示することを特徴とする請求項1に記載のプログラム分析方法。
- 複数のソースプログラムの中のいずれかのソースプログラムの作成日付と所定の時間関係にあるいずれかのソースプログラムに含まれる上記準共通要素をリスト形式で表示することを特徴とする請求項1ないし請求項3のいずれかに記載のプログラム分析方法。
- 複数のソースプログラムの中のいずれかのソースプログラムの作成日付と所定の時間関係にあるいずれかのソースプログラムに含まれる上記非共通要素をリスト形式で表示することを特徴とする請求項1ないし請求項3のいずれかに記載のプログラム分析方法。
- 請求項1に記載のプログラム分析方法により複数のソースプログラムから抽出された上記各要素から所要のものを選択してソースプログラムを作成することを特徴とするプログラム作成方法。
- 複数のソースプログラムから抽出された上記各要素を、各ソースプログラムでの有無が分かるように表形式で表示した画面を用いて、プログラム作成に使用するものを選択することを特徴とする請求項6に記載のプログラム作成方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008193652A JP5020184B2 (ja) | 2008-07-28 | 2008-07-28 | プログラム分析方法及びプログラム作成方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008193652A JP5020184B2 (ja) | 2008-07-28 | 2008-07-28 | プログラム分析方法及びプログラム作成方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010033249A true JP2010033249A (ja) | 2010-02-12 |
| JP5020184B2 JP5020184B2 (ja) | 2012-09-05 |
Family
ID=41737664
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008193652A Expired - Fee Related JP5020184B2 (ja) | 2008-07-28 | 2008-07-28 | プログラム分析方法及びプログラム作成方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5020184B2 (ja) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0588863A (ja) * | 1991-09-27 | 1993-04-09 | Kyoraku Co Ltd | プログラム開発支援システム |
| JPH10149301A (ja) * | 1996-11-19 | 1998-06-02 | Hitachi Ltd | スクリプト作成装置 |
| JP2007115155A (ja) * | 2005-10-24 | 2007-05-10 | Hitachi Software Eng Co Ltd | プログラム構造管理装置及びプログラム構造管理プログラム |
-
2008
- 2008-07-28 JP JP2008193652A patent/JP5020184B2/ja not_active Expired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0588863A (ja) * | 1991-09-27 | 1993-04-09 | Kyoraku Co Ltd | プログラム開発支援システム |
| JPH10149301A (ja) * | 1996-11-19 | 1998-06-02 | Hitachi Ltd | スクリプト作成装置 |
| JP2007115155A (ja) * | 2005-10-24 | 2007-05-10 | Hitachi Software Eng Co Ltd | プログラム構造管理装置及びプログラム構造管理プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5020184B2 (ja) | 2012-09-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6542612B2 (ja) | テストシナリオ生成支援装置およびテストシナリオ生成支援方法 | |
| JP5665128B2 (ja) | 静的解析支援装置、静的解析支援方法、及びプログラム | |
| JP2009265810A (ja) | 状態遷移テスト支援装置、状態遷移テスト支援プログラム、および状態遷移テスト支援方法 | |
| JP5898584B2 (ja) | 六面体メッシュ生成装置 | |
| JP3828379B2 (ja) | テスト仕様生成支援装置、方法、プログラム及び記録媒体 | |
| CN104797993B (zh) | 系统构建辅助装置 | |
| JP2013246644A (ja) | ソフトウェアオブジェクト修正支援装置、ソフトウェアオブジェクト修正支援方法、および、プログラム | |
| JP5282522B2 (ja) | 情報管理装置、情報管理方法、及び情報管理プログラム | |
| JP2009048598A (ja) | 文書情報表示システム | |
| JP5020184B2 (ja) | プログラム分析方法及びプログラム作成方法 | |
| JP2015036876A (ja) | 画面自動生成装置、画面自動生成プログラムおよび画面自動生成方法 | |
| JP6245571B2 (ja) | データ構造、データ生成装置、その方法及びプログラム | |
| JP6737063B2 (ja) | ソフトウェア資産管理装置、ソフトウェア資産管理方法、および、ソフトウェア資産管理プログラム | |
| JP5504212B2 (ja) | テストケース自動生成システム、テストケース自動生成方法、およびテストケース自動生成プログラム | |
| JP4958848B2 (ja) | 原価積上計算装置及び原価積上計算方法 | |
| KR20090005684A (ko) | 도형상표 검색제공시스템 및 방법, 도형상표 데이터베이스,도형상표 데이터베이스 생성방법 및 생성시스템,클라이언트 측의 도형상표 검색 시스템 및 방법,클라이언트 도형상표 검색 프로그램이 내장된 저장매체 | |
| JP5535270B2 (ja) | 文書成分分析装置およびプログラム | |
| JP2007026389A (ja) | データ入力装置 | |
| JP6322291B2 (ja) | 文書処理装置および項目抽出方法 | |
| JP2010244439A (ja) | チェックリスト生成装置、チェックリスト生成方法及びチェックリスト生成プログラム | |
| JP2006099452A (ja) | Si対象ファイルおよびsi関連ファイル管理システム | |
| JP6741045B2 (ja) | データ入力装置、データ入力方法及びプログラム | |
| JP5581894B2 (ja) | データ処理プログラム自動生成システム | |
| JP2019016201A (ja) | プログラム比較方法、プログラム比較装置およびプログラム比較プログラム | |
| JP6699433B2 (ja) | データ管理プログラム、装置、及び方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20091208 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110119 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20120208 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120221 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120329 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120515 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120612 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 5020184 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150622 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |