JP2005500622A - データ転送ルーティングメカニズムを用いるコンピュータシステムパーティショニング - Google Patents
データ転送ルーティングメカニズムを用いるコンピュータシステムパーティショニング Download PDFInfo
- Publication number
- JP2005500622A JP2005500622A JP2003521964A JP2003521964A JP2005500622A JP 2005500622 A JP2005500622 A JP 2005500622A JP 2003521964 A JP2003521964 A JP 2003521964A JP 2003521964 A JP2003521964 A JP 2003521964A JP 2005500622 A JP2005500622 A JP 2005500622A
- Authority
- JP
- Japan
- Prior art keywords
- computer system
- processors
- resources
- processor
- partitioning
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000638 solvent extraction Methods 0.000 title claims abstract description 82
- 230000007246 mechanism Effects 0.000 title claims description 13
- 238000012546 transfer Methods 0.000 title description 5
- 238000005192 partition Methods 0.000 claims abstract description 57
- 230000005540 biological transmission Effects 0.000 claims abstract description 24
- 238000000034 method Methods 0.000 claims description 41
- 230000004044 response Effects 0.000 claims description 11
- 230000008859 change Effects 0.000 claims description 5
- 230000001427 coherent effect Effects 0.000 claims description 4
- 238000004590 computer program Methods 0.000 claims 1
- 238000004891 communication Methods 0.000 description 20
- 238000012360 testing method Methods 0.000 description 10
- 238000010586 diagram Methods 0.000 description 9
- 230000000694 effects Effects 0.000 description 5
- 230000003068 static effect Effects 0.000 description 5
- 238000012544 monitoring process Methods 0.000 description 3
- 238000013459 approach Methods 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 230000009471 action Effects 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000000059 patterning Methods 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Multi Processors (AREA)
Abstract
【解決手段】それぞれのパーティションは、前記複数のリソースのサブセットを備える。前記少なくとも1つのパーティショニングプロセッサは、以前に特定されたパーティショニングスキーマにしたがって前記複数のプロセッサのうちの少なくとも1つと前記複数のプロセッサのうちの少なくとも1つの他のものとの間の少なくとも1つのリンクをイネーブルすることによって前記リソースをコンフィギャするよう動作可能である。そのようにイネーブルされたリンク(群)は、前記ポイント・ツー・ポイント伝送インフラストラクチャの部分に対応する。
Description
【0001】
本発明は、大きくはコンピュータシステムにおけるリソースのパーティショニングに関する。より具体的には本発明は、そのようなリソースを従来に可能であったよりもより正確にパーティショニングする技術を提供する。
【背景技術】
【0002】
リソースを分散化コンピューティングシステムにおいて、または単一のコンピュータシステムの中央電子装置群(CEC)内においてパーティショニングする基本的なアイディアは、新しいものではない。しかし従来のパーティショニング技術にはシステムリソースを比較的粗いレベルで、例えば物理的に別個のマシン、プロセッサのグループなどにアロケートすることだけが可能なものもあったが、他のものは、例えばシステムの初期化においてだけマルチプロセッサグループ中のプロセッサ群のサブセットを永久にあるパーティションに割り当てるなど、柔軟性のない状態で動作する。
【0003】
従来のパーティショニング技術のいくつかの欠点は図1を参照して理解されるだろう。図1は、ハブ106および108を介して相互接続された2つの4プロセッサグループ(すなわちクワッド)102および104を持つ従来の8プロセッサシステム100を示す。従来のクワッド中のプロセッサ110のそれぞれは、ブロードキャストバス112に接続され、このバスはプロセッサのいずれをも他のプロセッサからアイソレートしない、つまり任意のプロセッサによる特定のリソース(例えばI/O114またはメモリ116)へのアクセス要求はいずれも他のプロセッサの全てによって受け取られる。よってこのようなシステムおいて起こる唯一のポイント・ツー・ポイント通信は、2つのクワッド間を接続するハブ間に行われるので、このようなシステムのパーティショニングはハブ間でだけしか行われない、つまり1つのパーティションに1クワッド、他のもう1つのパーティションにもう1つのクワッドという形になる。
【0004】
マルチプロセッサシステムの設計の比較的新しいアプローチは、プロセッサ間のブロードキャスト通信をポイント・ツー・ポイントデータ転送メカニズムに置き換える。このポイント・ツー・ポイントデータ転送おいては、プロセッサはネットワークノードと同様に分散化コンピューティングシステム内、例えばワイドエリアネットワーク内で通信を行う。すなわちプロセッサは複数の通信リンクを介して相互接続され、リクエストは、それぞれのプロセッサに関連付けられたルーティングテーブルにしたがってリンクにわたってプロセッサ間を転送される。この意図するところは、単位時間当たりにマルチプロセッサプラットフォーム内を伝送される情報量を増やすことにある。このアプローチの例は、カリフォルニア州サニーベールのアドバンスト・マイクロ・デバイス社(AMD)によって最近アナウンスされたハイパートランスポート(HT)アーキテクチャであり、例えば、カリフォルニア州、アナハイムにおける2001年3月26〜28日のWinHEC 2001において発表されたHyperTransportTM Technology: A High-Bandwidth, Low-Complexity Bus Architectureと題された論文に記載され、その全体が全ての目的のためにここで参照によって援用される。AMDアーキテクチャの動作は図2の簡略化されたブロック図を参照して簡単に説明される。
【0005】
システム200がブートアップするたびに、プロセッサ202a〜202dのそれぞれに関連付けられたルーティングテーブルは初期化されなければならない。残りのプロセッサ群がまだ動作しておらず、HTインフラストラクチャを用いてそれぞれのプロセッサ内のルーティングテーブルを構築する「ディスカバリ」アルゴリズムを実行するあいだに、プライマリプロセッサ202a、すなわちBIOS204と通信するプロセッサはスタートアップする。このアルゴリズムは「貪欲な」アルゴリズムであり、利用可能、つまり「到達可能な」システムリソースの全てをキャプチャし、単一の分割されないシステムをキャプチャされたリソースから構築しようと試みる。プライマリプロセッサ202aは、それに応答する全てのシステムリソース、すなわち全ての隣接装置を識別することによってこのプロセスを開始する。それからそれぞれのこのようなリソース(例えばメモリバンク206aおよびプロセッサ202bおよび202c)について、プライマリプロセッサ202aは、そのリソース(例えばメモリバンク206bおよび206c)に応答する(すなわち「所有されている」)全てのリソースを要求する。この情報を用いて、プライマリプロセッサはルーティングテーブルを構築する。残念ながらこのようなシステムによって生成されたルーティングテーブルは、リソース故障、負荷の不均衡、またはシステムリソースの再アロケーションが望ましい任意の状況変化にかかわらず、システム動作中は変化しない。
【発明の開示】
【発明が解決しようとする課題】
【0006】
上記を鑑みて、コンピュータシステムリソースがより柔軟に正確にパーティショニングされる技術を提供することが望ましい。
【課題を解決するための手段】
【0007】
本発明によれば、単一プラットフォーム、マルチプロセッサシステムにおけるプロセッサ間の分散化されたポイント・ツー・ポイント通信によって代表される革新が利用されることによって、コンピュータシステムリソースのパーティショニングにおいて従来可能であったよりもより高いレベルの柔軟性および正確さを提供する。すなわち分散化されたポイント・ツー・ポイント通信インフラストラクチャが採用されることで、以前に特定されたスキーマにしたがってルーティングテーブルを生成することを通してシステムリソースを正確にアロケートすることが可能となる。本発明のさまざまな実施形態によれば、このようなパーティショニングは、システムリソースの任意の所望のアロケーションを達成するために、静的に、例えばシステムのスタートアップ時に、あるいは動的に、例えばある種のイベントに応答してなされえる。
【0008】
すなわち本発明は、複数のプロセッサを含む複数のリソース、前記複数のプロセッサを相互接続する分散化されたポイント・ツー・ポイント伝送インフラストラクチャ、および前記複数のリソースを少なくとも1つのパーティションにコンフィギャする少なくとも1つのパーティショニングプロセッサを有するコンピュータシステムを提供する。それぞれのパーティションは、前記複数のリソースのサブセットを備える。前記少なくとも1つのパーティショニングプロセッサは、以前に特定されたパーティショニングスキーマにしたがって前記複数のプロセッサのうちの少なくとも1つと前記複数のプロセッサのうちの少なくとも1つの他のものとの間の少なくとも1つのリンクをイネーブルすることによって前記リソースをコンフィギャするよう動作可能である。そのようにイネーブルされたリンク(群)は、前記ポイント・ツー・ポイント伝送インフラストラクチャの部分に対応する。本発明の具体的な実施形態によれば、前記リンクを前記イネーブルすることは、前記以前に特定されたパーティショニングスキーマにしたがって前記プロセッサに関連付けられた複数のルーティングテーブルのうちの少なくとも1つに書き込むことによって実現される。
【0009】
このようなコンピュータシステムをパーティショニングする方法も記載される。具体的な実施形態によれば、前記複数のリソースは、少なくとも1つのパーティションにコンフィギャされる。それぞれのパーティションは、前記複数のリソースのサブセットを備える。前記リソースの前記コンフィギャすることは、以前に特定されたパーティショニングスキーマにしたがって前記複数のプロセッサのうちの少なくとも1つと前記複数のプロセッサのうちの少なくとも1つの他のものとの間の少なくとも1つのリンクをイネーブルすることによって実現される。このようにイネーブルされた少なくとも1つのリンクは、前記ポイント・ツー・ポイント伝送インフラストラクチャの部分に対応する。本発明の具体的な実施形態によれば、前記少なくとも1つのリンクを前記イネーブルすることは、前記以前に特定されたパーティショニングスキーマにしたがって前記プロセッサに関連付けられた複数のルーティングテーブルのうちの少なくとも1つに書き込むことによって実現される。
本発明の性質および優位性のさらなる理解は、明細書および図面の残りの部分を参照して達成されよう。
【発明を実施するための最良の形態】
【0010】
本発明の具体的な実施形態が、例えばAMDのハイパートランスポートマルチプロセッサアーキテクチャのような特定のポイント・ツー・ポイント通信インフラストラクチャを参照してこれから説明される。しかし本発明の範囲は、説明された特定の実施形態やAMDアーキテクチャに限定されないことが理解されよう。すなわち、そのプロセッサおよび/またはさまざまな他のシステムリソース内でポイント・ツー・ポイント通信を行う任意のマルチプロセッサアーキテクチャが本発明の具体的な実施形態を実現するのに適する。
【0011】
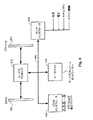
図3は、本発明の具体的な実施形態に基づいて設計されたサーバ300の簡略化されたブロック図を示す。サーバ300は、実質的に同一のプロセッサ302a〜302d、基本I/Oシステム(BIOS)304、メモリバンク306a〜306dを備えるメモリサブシステム、プロセッサ302a〜302dおよびI/Oスイッチ310を相互接続するためのポイント・ツー・ポイント通信リンク308a〜308e、およびリンク314a〜314eによって図3で示されるJTAGインタフェースを介してプロセッサ302a〜302dおよびI/Oスイッチ310と通信するサービスプロセッサ312を含む。I/Oスイッチ310はシステムの残りをI/Oアダプタ316および320に接続する。
【0012】
具体的な実施形態によれば、本発明のサービスプロセッサは、上述の「貪欲な」アルゴリズムの使用と対照的に、以前に特定されたパーティショニングスキーマによってシステムリソースをパーティショニングするインテリジェンスを有する。これは、システムプロセッサに関連付けられたルーティングテーブルをサービスプロセッサによって直接に操作することを通して達成され、これはポイント・ツー・ポイント通信インフラストラクチャによって可能になる。ルーティングテーブルは、システムリソースを制御および分離するのに用いられ、システムリソース間の接続関係がこの中で定義される。
【0013】
具体的な実施形態によれば、サービスプロセッサは、それ自身のオペレーティングシステムアプリケーションのセット(システムの残りと関連付けられたオペレーティングシステム(群)とは別個である)およびそれ自身のI/Oを持つ自律プロセッサである。このプロセッサは、残りのプロセッサ、メモリ、およびI/Oが機能していないときでも動作する。このプロセッサは、全てのシステムリソースが所望のように動作していることを確実にする外部管理インテリジェンスとして動作する。
【0014】
しかし以前に特定されたパーティショニングスキーマは、分離されたサービスプロセッサによってインプリメントされなければならないわけではないことに注意されたい。すなわち例えば、システムプロセッサのうちの1つがこの目的のために用いられてもよい。このような実施形態によれば、例えばシステムBIOSがシステムのプライマリプロセッサを用いてスキーマを有効にするよう変更されえる。
【0015】
さらに本発明のさまざまな実施形態によれば、パーティションは、さまざまなシステムリソースの組み合わせを表しえる。すなわち例えば、「キャパシティオンデマンド」のシナリオにおいては、パーティションは単一のプロセッサによって表されえ、この場合そのパーティションからプロセッサを取り除くことによって残りの要素はOSを走らせることができなくなる(よってユーザはこのパーティションについてはチャージされない)。パーティションはまたプロセッサおよびいくつかの関連するメモリまたはI/Oによって表される。大きくは、コンピュータシステム中で利用可能なリソースの任意の機能サブセットがパーティションとして考えられえる。
【0016】
より大きくは、図3に示される特定のアーキテクチャは単に例示的であり、本発明の実施形態は、異なる構成およびリソースの相互接続、および示されたシステムリソースのそれぞれについてのさまざまな代替物を有すると意図されることが理解されよう。しかし図示の目的のため、サーバ300の具体的な詳細が想定される。例えば図3に示されるリソースのほとんどは単一の電子的アセンブリ上に常駐すると想定される。さらにメモリバンク306a〜306dは、デュアルインラインメモリモジュール(DIMM)として物理的には提供されるダブルデータレート(DDR)メモリを備えてもよい。I/Oアダプタ316は例えば、永久記憶装置へのアクセスを提供するウルトラダイレクトメモリアクセス(UDMA)コントローラまたはスモールコンピュータシステムインタフェース(SCSI)コントローラでありえる。I/Oアダプタ320は、例えばローカルエリアネットワーク(LAN)またはインターネットのようなネットワークとの通信を提供するよう構成されるイーサネットカードでありえる。
【0017】
具体的な実施形態によれば図3に示されるように、I/Oアダプタ316および320の両方は対称的なI/Oアクセスを提供する。すなわちそれぞれがI/Oの対等なセットへのアクセスを提供する。理解されるようにこのような構成は、複数のパーティションが同じタイプのI/Oにアクセスするパーティショニングスキームを促進する。しかし実施形態によってはI/Oなしのパーティションが作られることも想定される。例えば、1つ以上のプロセッサおよび関連付けられたメモリリソース、すなわちメモリ複合体(memory complex)を含むパーティションは、そのメモリ複合体をテストする目的で作られえる。
【0018】
ある実施形態によれば、サービスプロセッサ312は集積されたチップセット機能を持つPPCコントローラであるモトローラMPC855Tである。
【0019】
サービスプロセッサ312は、サーバ300のリソースをパーティショニングすることに主に責任を負う。図3に示される実施形態によれば、サービスプロセッサ312は、プロセッサ302a〜302dおよびI/Oスイッチ310の利用をアロケートするが、例えばメモリバンクまたはさまざまなI/Oデバイスのような他のリソースを直接管理するようプログラムされてもよい。サービスプロセッサ312の構成は、通信リンク322を介してサーバプロセッサ312が接続される管理/サーバコンソール(不図示)を介して有効にされえる。
【0020】
図4は、ある実現例によるサービスプロセッサ312のための相互接続の高レベルブロック図である。本発明のパーティショニングエンジンは、図3〜5に示されるようなサービスプロセッサ312とは非常に異なって見えうることに注意することが重要である。すなわちポイント・ツー・ポイント通信インフラストラクチャを用いてルーティングテーブルをインテリジェントに再構成できる任意のメカニズムは本発明の範囲内である。例えば他のありえるメカニズムとしては、パーティショニングを行うために1つ以上のプロセッサ302を用いることも含まれる。
【0021】
しかしこの実施形態においては、サービスプロセッサ312は、DRAM記憶ブロック402およびフラッシュメモリ404に直接接続される。DRAM402は、フラッシュ404内に記憶されたプログラムのサービスプロセッサによる実行を促進する。サービスプロセッサ312はまたPCIバス406を介してセンサインタフェース408、イーサネットカード410、およびJTAGインタフェース412に接続される。センサインタフェース408は例えば、温度、電源電圧、またはセキュリティロックの表示を行うモニタリング回路(不図示)からの入力を含みえる。センサインタフェース408はまた、例えばシステムのファンを起動する制御信号のようなさまざまな出力を含みえる。イーサネットカード410は、サービスプロセッサ312と、例えばネットワークアドミニストレータがサーバをモニタおよびコンフィギャするサービスコンソールとの間のインタフェースを提供する。
【0022】
具体的な実施形態によれば、インタフェース412は、テストアクセスポートおよびバウンダリスキャンアーキテクチャの要件を記載するジョイントテストアクショングループ(JTAG)標準として知られるIEEE標準1149.1を完全にサポートする。テストアクセスポート(TAP)は、テストデータイン(TDI)ピン、テストデータアウト(TDO)ピン、テストクロック(TCK)ピン、テストモードセレクト(TMS)ピン、およびオプションとしてTAPコントローラをテストロジックリセットの状態に設定するテストリセット(TRST)ピンを含むいくつかのピンを備える。TAPコントローラは、集積回路上のバウンダリスキャンを制御する16ステートの有限ステートマシンである。詳細が後述されるように、JTAGインタフェース412は、サービスプロセッサ312およびプロセッサ302a〜302dの間の通信を促進し、それによりコンピュータシステムのリソースの静的および動的パーティショニングの両方を可能にする。具体的な実施形態によれば、この通信は簡単なアウトバウンドマルチプレクサを用いて促進される。
【0023】
再び図3を参照し本発明の具体的な実施形態によれば、プロセッサ302a〜302dはHTインフラストラクチャとして知られここでもそのように呼ぶポイント・ツー・ポイントデータ転送メカニズムを採用するAMD K8プロセッサを備えてもよい。すなわちプロセッサは複数のポイント・ツー・ポイント通信リンク(すなわち308a〜308e)を介して相互接続され、リクエストはそれぞれのプロセッサに関連付けられたルーティングテーブルにしたがってプロセッサ間でリンクを通して転送される。HTインフラストラクチャは、例えば、コンピュータシステム中の周辺機器相互接続(PCI)デバイス、アクセラレーテッドグラフィックポート(AGP)デバイス、ダイナミックランダムアクセスメモリ(DRAM)デバイス、および他の専用高バンド幅バスのようなさまざまなコンピュータリソースの相互接続を可能にする。
【0024】
HTには2つの形態がある。ノンコヒーレントな1つの形態、つまりncHTは、I/Oリンクのために開発され、図3に示される(308cおよび308d)。ここで説明されるコヒーレントHT、つまりcHTメカニズムは、遠くのメモリ、すなわちリモートクラスタにおけるプロセッサに接続されたメモリ同様、ローカルなメモリ、すなわちそのクラスタ内のプロセッサに接続されたメモリにプロセッサアレイがアクセスできる非均一なメモリアクセスマトリクスのためにAMDによって開発されてきた。
【0025】
本発明のさまざまな実施形態によれば、プロセッサ302a〜302dは実質的に同一である。図5は、そのようなプロセッサ302の簡略化されたブロック図であり、プロセッサ302は、複数のHTポート504a〜504cを持つHTインタフェース502およびそれらに関連付けられたルーティングテーブル506a〜506cを含む。それぞれのHTポートは、コンピュータシステムにおいて16ビットのHTリンク、例えば図3のリンク308a〜308eを介して、他のリソース、例えばプロセッサまたはI/Oデバイスとの通信を可能にする。
【0026】
図5に示されるcHTインフラストラクチャは、ポイント・ツー・ポイントの分散化されたルーティングメカニズムとして一般化されえ、このメカニズムは、任意のさまざまなトポロジ、例えばリング、メッシュなどによってシステムプロセッサを相互接続する複数のセグメント(例えばゴーズ・イン・ゴーズ・アウト(GIGO)バス)を備える。これらセグメントのそれぞれのエンドポイントのそれぞれは、ユニークなノードIDを持つ接続されたプロセッサ、およびそれが「所有する」複数の関連付けられたリソースに関連付けられ、例えばそれに接続されるメモリがどれだけであるか、それに接続されるI/Oは何であるかなどが関連付けられる。
【0027】
分散化されたルーティングメカニズム中のノードのそれぞれに関連付けられたルーティングテーブル群は、コンピュータシステムリソース間の相互接続の現在の状態を全体として表す。ある与えられたノード(例えばプロセッサ)によって所有されたリソースのそれぞれ(例えば特定のメモリ範囲またはI/Oデバイス)は、そのノードに関連付けられたルーティングテーブル(群)においてアドレスとして表現される。リクエストがノードに到達するとき、リクエストされたアドレスは、適切なノードおよびリンクを特定するノードのルーティングテーブル中の2レベルエントリと比較され、このルーティングテーブルは例えば、もしこのアドレスが要るならノードxに行け、もしノードxに行きたいならリンクyを用いろ、などが特定される。
【0028】
ルーティングテーブルに関連付けられたものとしては、これらテーブルが初期化または変更されるときに用いられるコントロールがある。これらコントロールは、システムが正しく動作することを続けながらもルーティングテーブル中の値を、原子性を保証しながら(atomically)変更する手段を提供する。
【0029】
図5に示されるように、プロセッサ302は、関連するルーティングテーブル中の情報にしたがってポイント・ツー・ポイント通信を3つの他のプロセッサと行うことができる。具体的な実施形態によれば、ルーティングテーブル506a〜506cは、2レベルのテーブルを備え、第1レベルはシステムリソース(例えばメモリバンク)のユニークなアドレスを対応するHTノード(例えばプロセッサのうちの1つ)に関連付け、第2レベルはそれぞれのHTノードを、現在のノードから当該ノードに到達するために利用されるべきリンク(例えば308a〜308e)に関連付ける。
【0030】
プロセッサ302はまた、JTAGハンドシェークレジスタ群508のセットを持ち、これらはとりわけサービスプロセッサおよびプロセッサ302の間の通信を促進する。すなわちサービスプロセッサは、ルーティングテーブル506a〜506cに結果として格納されるように、ルーティングテーブルエントリをハンドシェークレジスタ508に書き込む。図5に示されるプロセッサアーキテクチャは本発明の具体的な実施形態を説明する目的の例示的なものに過ぎないことを理解されたい。本発明の他の実施形態を実現するためには、例えばより少ないまたはより多い数のポートおよび/またはルーティングテーブルが用いられてもよい。
【0031】
具体的な実施形態によれば図3のサーバ300は、ここで説明される技術を用いて単一の4プロセッサシステムとして、または2つ以上の機能的に別個のパーティション群として動作するようコンフィギャされえる。結果としてできあがるシステムコンフィギュレーションのアプリオリの知識なしで動作するHTインフラストラクチャのデザイナによって想定される「貪欲な(greedy)」アルゴリズムとは対照的に、サービスプロセッサ312は、先に具体的に述べられたパターニングスキーマによって全てのまたはいくつかのプロセッサ302a〜302d(およびI/Oスイッチ310)に関連付けられたルーティングテーブルを生成および/またはダイナミックに変更することによってサーバ300のコンフィギュレーションを促進する。これは、ルーティングテーブルエントリを適切なプロセッサのJTAGハンドシェークレジスタ508(およびI/Oスイッチ310に関連付けられた同様のテーブル)に書き込むサービスプロセッサ312によって達成される。後で説明されるように、このシステムコンフィギュレーション/パーティショニングは、静的に、例えばサーバブートアップ時に、または動的に、例えばサーバ300の動作中に行われえる。
【0032】
本発明は、本発明にしたがって設計されたコンピュータシステム、例えばサーバが動的に再コンフィギャされる(例えば再パーティショニングされる)実施形態をも包含する。すなわち再コンフィギュレーションは、システムをリブートすることなく、またはサービスプロセッサの再イニシャライズ動作を行うことなく達成され、例えばシステムリソースの故障のようなあるランタイムイベントに応答して起こる。
【0033】
大きくは、本発明によるシステムリソースの動的パーティショニングは、さまざまな種類のランタイムイベントに応答して起こりえることを理解されたい。動的パーティショニングを起動しえるイベントまたはトリガの具体的な例には、現在存在するパーティションに関連付けられたリソース(例えばプロセッサ)の故障、所定期間(例えば特定のシステムリソースのメンテナンス期間)の満了、負荷分布を変える特定のアプリケーションまたはアプリケーション群の組み合わせを走らせること、およびパーティションを再コンフィギャする旨のユーザの命令が含まれる。
【0034】
このようなユーザの命令は、例えば、さまざまな条件についての負荷評価に関する実験、特定のアプリケーションのサポートのためのリソースの再アロケーション、一日の期間にわたっての既知の負荷変動を扱うためのリソースの再アロケーション、またはユーザまたはユーザのグループとの合意に基づくシステムリソースの再アロケーションでありえる。後者のシナリオにおいてシステムユーザたちは、彼等の使用のために彼等にアロケートされたリソースにしたがって、すなわちキャパシティオンデマンドで、しかし従来可能であったよりも粒状性のより細かいリソースレベルでチャージされえる。これは、複数のプロセッサを相互接続する分散化されたポイント・ツー・ポイント伝送インフラストラクチャ、例えばHTインフラストラクチャを採用することは、例えば単一のプロセッサ、メモリバンク、またはI/Oバスのアロケーションを可能にするからである。
【0035】
本発明の技術による静的および動的の両方のシステムコンフィギュレーション/パーティショニングが達成される特定の実施形態がこれから説明される。ここで用いられるように、静的なパーティショニングという語は、そのコンピュータシステムに関連付けられた1つ以上のオペレーティングシステムをシャットダウンして、パーティショニングを行い、1つ以上のオペレーティングシステムを再起動することを指す。対照的に、動的パーティショニングは、パーティショニングを行うために1つ以上の現在走っているオペレーティングシステムについて処理をすることを指す。
【0036】
例えば本発明のさまざまな実施形態によれば、サービスプロセッサは現在存在するパーティションからリソースを除去するためのリクエストを出すことができ、このリクエストに応答して、影響を受けるオペレーティングシステム(群)はシャットダウンすることなくリソース除去を扱えるかどうかを決定する。もし可能であれば、サービスプロセッサはここに記載されたように適切なルーティングテーブルを再コンフィギャすることが許される。もしそうでなければ、いかなるパーティショニングも静的になされなければならない。
【0037】
もし一方で、利用可能なリソースを現在存在するパーティションに追加するリクエストであれば、サービスプロセッサは、影響を受けるオペレーティングシステム(群)に対してリソースを追加する要求を出す。影響されるオペレーティングシステム(群)は、それから動作を止めることなくリソースを追加することが可能でありえる。
【0038】
今度は図6を参照する。電源がシステム(602)に与えられると、サービスプロセッサは、以前に特定されたコンフィギュレーションにしたがって、システムプロセッサに関連付けられたルーティングテーブルを生成する(604)ことによって、システムプロセッサのそれぞれを初期化する。すなわち静的パーティショニングが実行される。初期のシステムコンフィギュレーションは、例えばサービスプロセッサが接続されるフラッシュメモリに記憶されるか、またはシステムをオンラインにするシステムアドミニストレータによって特定されえる。システムコンフィギュレーションは、幅広いオペレーション上の目的を達成するために1つ以上の機能的に別個のパーティションに対応しえる。いったんルーティングテーブルが生成されると、システムオペレーションが開始し、ここでシステムリソースは1つ以上の機能的に別個のパーティションにアロケートされる(606)。
【0039】
サービスプロセッサはそれから、システムの再パーティショニングを必要とするランタイムイベントの発生がないかをチェックするため進行中のサーバアクティビティを監視し続ける(608)。上述のように本発明は、このような幅広いランタイムイベントが動的パーティショニングをトリガするのに適すると想定する。しかし説明の目的のために、システムリソースの故障がこの例示的な実施形態においては用いられる。よって608においてサービスプロセッサは、このような故障に関するシステムエラーメッセージを探す。もしこのようなエラーメッセージが検出されると(610)、メッセージはエラーの重大性を決定するために分析される(612)。もしエラーが破局的であるなら(614)、すなわちシステムが信頼性をもって動作しえないなら、リモートファシリティに知らせが行き(616)、システムはシャットダウンされる(618)。
【0040】
もし一方で、エラーが破局的でないなら(614)、故障した要素は分離され(620)、故障した要素(群)が結果として生じる機能パーティション群のいずれからも除去される新しいシステムコンフィギュレーションが導かれる(622)。実施形態によっては、この新しいシステムコンフィギュレーションの導出は、現在のシステムコンフィギュレーション、例えばサービスプロセッサに関連付けられたフラッシュメモリに記憶されたコンフィギュレーション、および故障情報を参照して行われる。サービスプロセッサはそれから、適切なシステムリソースを静止状態にし(624)、システムノード、例えばプロセッサに関連付けられたルーティングテーブルおよびコントロールに適切な変更を施す(626)ことによって新しいパーティショニングスキームを有効にする。
【0041】
本発明の具体的な実施形態によれば、サービスプロセッサは、任意の故障したプロセッサを自動的に静止状態にさせ、それによってそれを利用可能なプロセッサプールから除去するようコンフィギャされる。対応するコマンドはサービスプロセッサからオペレーティングシステムへとアドバンストコンフィギュレーション・パワーインタフェース(ACPI)2.0プロトコルを用いて送られえる。故障したプロセッサにアサインされたスレッドはすでに完了しており(もし可能であれば)、いったんオペレーティングシステムが静止状態になると、アクノリッジがサービスプロセッサに送られ、サービスプロセッサはこんどは故障したプロセッサをそのパーティションから取り除く。サービスプロセッサは、プロセッサ群のうちの他の1つを故障したプロセッサパーティションにアサインしてもよく、縮小された状態にパーティションを維持してもよく、あるいはパーティションごとなくしてもよい。
【0042】
故障した要素(群)が分離され、再パーティショニングが定義された後、新しく形成されたパーティションを適切に初期化するためにシステムをリスタートすることが必要かどうかについて判断がなされる(628)。もし必要であれば、システムリスタートが開始される(630)。もし必要でなければ、システム全体のリブートを必要とすることなく、ある特定のシステム要素が初期化を必要とするかどうかについて判断がなされる(632)。もし必要であれば、電源オンリセット信号が特定された要素(群)に送られる(634)。そうでなければサーバは、それから通常動作を続けることが許される。あるいはシステムリソースの故障によってしばしばシステムのリスタートが必要となると仮定するなら、そのような故障に応答してシステムが再パーティショニングされた後にはシステムリスタートが自動的に起こるような実施形態も想定される。
【0043】
前述のことを参照し本発明の技術は、サービスプロセッサではなくシステムプロセッサ群のうちの1つによってシステム初期化が導かれるようなシステムにおいて、中央処理装置(CPU)の電源オン時の故障を扱うためにも採用されえることが理解されよう。具体的な実施形態によれば本発明のサービスプロセッサは、そのルーティングテーブルをコンフィギャするために「アウトオブバンド」でシステムプロセッサと通信を行うので、コンピュータシステムは、プライマリシステムプロセッサが調子が悪くなり、セカンダリシステムプロセッサ(群)との初期化チェーン、すなわち「インバンド」通信を完了できないパーティションの故障に対してよりロバストに作られえる。このような場合、故障したプロセッサを除外し、新しいプライマリシステムプロセッサを指定し、中断した初期化を完了させるために、サービスプロセッサはプライマリプロセッサが故障したことを検出し、それからセカンダリシステムプロセッサ(群)のルーティングテーブルおよびコントロールがサービスプロセッサによって直接に変更されえる。
【0044】
前述のように本発明は、コンピュータシステムのリソースの動的な再パーティショニングが起動されえるさまざまなメカニズムを想定する。あるそのようなメカニズムである、システムアドミニストレータによって入力されたランタイムパーティショニングリクエストが図7のフローチャートを参照してここで説明される。図示される実施形態は、例えばシステム管理コンソールからのパーティショニングリクエストを探して、進行中のサーバアクティビティを監視することから始まる(702)。もしそのようなリクエストが受け取られると(704)、サービスプロセッサは、リクエストが有効かどうかを判断する(706)。本発明のさまざまな実施形態によれば、パーティショニングリクエストの有効性は、任意の判断基準にしたがって決定されえる。例えばリクエストによって示されるパーティションは、有効なパーティションのための最低リソースリストを照らしてチェックされえる。もしリクエストが有効でないと判断されると(706)、リクエストは無効であり拒絶されることを示すレスポンスがコンソールに送られる(708)。さまざまな実施形態によれば、レスポンスは、リクエストがなぜ無効かを示す、例えばリクエストがブートイメージを含まないパーティションを作ろうとしたことを示す付加的な情報を示してもよい。
【0045】
もし一方で、パーティショニングリクエストが有効であると判断されるなら(706)、サービスプロセッサは、新しいパーティションを有効にするために、適切なシステムリソース(例えばプロセッサ、メモリ、I/O)を静止状態にし(710)、静止状態にされたシステムリソースに関連付けられたルーティングテーブルに適切な変更を行う(712)ことによって要求されたパーティショニングスキームを実現する。
【0046】
システムパーティショニングが再定義された後で、新しく形成されたパーティションの適切な初期化のためにシステム全体をリスタートすることが必要かどうかについての判断がなされる(714)。もしそうならシステムがリスタートされる(716)。もし必要でないなら、特定のシステム要素(群)が初期化を必要とするかどうかについてのさらなる判断がなされる(718)。もし必要なら、それから電源オンリセット信号がそのような要素(群)に送られる(720)。再パーティショニングが完了した後で、進行中のサーバアクティビティのモニタリングが再開される(702)。よって本発明は、ランタイム中にサーバ(または任意のコンピュータシステム)を再パーティショニングすることを可能にする。
【0047】
より一般には上述のように、このような再パーティショニングは、幅広い種類のランタイムイベントによって、幅広い目的のために起こりえる。例えばシステムアドミニストレータからのリクエストに応答する代わりに、システムリソースの再パーティショニングは、走らされている特定の組み合わせのアプリケーション群に応答して起こりえる。すなわちシステムは、あるレベルのリソースをそれぞれ必要とするアプリケーション群の第1の組み合わせを走らせるように最初はパーティショニングされえる。システムリソースの異なるアロケーションを要求する第2の組み合わせのアプリケーション群が走らされるとき、リソース群の新しいアロケーションを有効にするためのシステムの自動再パーティショニングが起こりえる。
【0048】
本発明は特に具体的な実施形態について示され説明されてきたが、当業者には開示された実施形態の形態および詳細への変更が本発明の範囲から逸脱することなくなされえることが理解されよう。例えば本発明は、説明された実施形態から任意の数のプロセッサを持つ実現例へと一般化されえる。
【0049】
さらに本発明の技術は、ここに説明された静的および動的パーティショニングを実行するためには必ずしも別個のサービスプロセッサを必要としない。すなわちシステムプロセッサのうちの1つが、これらの機能をシステムスタートアップ時において、またはランタイムイベントに応答して実行するように構成されえる。マルチプロセッサが協働してパーティショニングを実行するように構成される実施形態も想定される。これらの種類の動作を命令するプログラムは例えばシステムBIOSメモリに記憶されえる。
【0050】
さらにシステム初期化において、およびシステム動作中においての両方で本発明の技術が採用される特定の実施形態がここでは説明されるが、本発明は、本発明によって可能になる技術がこれらのうちの一方か他方かにおいてだけ採用される実施形態も包含することが理解されよう。すなわち本発明がシステムを初期化するのにだけ用いられる実施形態も想定される。逆に、動的パーティショニングだけが実行される実施形態も想定される。
【0051】
ここで使用される「リソース」という語は、単一のプロセッサの物理的な実現例よりももっと多くを包含するよう想定される。すなわち本発明のさまざまな実施形態によれば、リソースは、コンピューティングシステムの主要な要素群のうちの任意のものとして考えられえる。そのような要素群にはいくつかを挙げれば、1つ以上のプロセッサ、メモリのバンク(典型的には物理的なメモリ、例えばDIMMのバンク)、I/Oバス(例えばPCIまたはISAバス)、およびバス上の要素(例えばSCSIカード、通信カード、ファイバーチャネルカード)のような物理的要素群が含まれる。しかしシステムリソースは、プロセッサに関連付けられた論理部品のような論理要素(例えばDMAエンジンまたはルーティング割り込みのための割り込みメカニズム)でありえることに注意されたい。
【0052】
また本発明は、パーティショニングスキームを実現するためにルーティングテーブルが操作される実施形態に限定されるべきではないことに注意されたい。すなわち本発明は、システムプロセッサ間のリンク群をイネーブルしたり、ディセーブルしたりすることによってパーティショニングが実現されるコンピュータシステムおよびパーティショニング方法を包含すると考えられえ、分散化されたポイント・ツー・ポイント伝送インフラストラクチャの部分を表すこれらリンク群は相互接続される。例えば、これらリンク群をイネーブルしたりディセーブルしたりする代替の方法は、スイッチを開いたり、閉じたりすることでありえる。
【0053】
最後に、本発明のさまざまな効果、局面、および目的がここにさまざまな実施形態を参照して説明されてきたが、本発明の範囲はこのような効果、局面、および目的を参照して限定されるべきではないことが理解されよう。むしろ本発明の範囲は添付の特許請求の範囲を参照して決定されるべきである。
【図面の簡単な説明】
【0054】
【図1】従来のマルチプロセッサシステムのブロック図である。
【図2】ポイント・ツー・ポイントデータ転送インフラストラクチャを持つマルチプロセッサシステムのブロック図である。
【図3】本発明の具体的な実施形態によって設計され動作するマルチプロセッサシステムの一部のブロック図である。
【図4】図3のマルチプロセッサシステムのパーティショニングを制御する例示的なメカニズムのブロック図である。
【図5】本発明とともに用いるプロセッサのブロック図である。
【図6】本発明の具体的な実施形態を示すフローチャートである。
【図7】本発明の他の具体的な実施形態を示すフローチャートである。
Claims (41)
- 複数のプロセッサを含む複数のリソース、
前記複数のプロセッサを相互接続する分散化されたポイント・ツー・ポイント伝送インフラストラクチャ、および
前記複数のリソースを少なくとも1つのパーティションにコンフィギャする少なくとも1つのパーティショニングプロセッサであって、それぞれのパーティションは、前記複数のリソースのサブセットを備え、前記少なくとも1つのパーティショニングプロセッサは、以前に特定されたパーティショニングスキーマにしたがって前記プロセッサに関連付けられた複数のルーティングテーブルのうちの少なくとも1つに書き込むことによって前記リソースをコンフィギャするよう動作可能であり、それぞれのルーティングテーブルは関連付けられたプロセッサおよび前記複数のプロセッサのうちの他のプロセッサの間のリンクを表し、前記リンクは前記ポイント・ツー・ポイント伝送インフラストラクチャの部分に対応する、少なくとも1つのパーティショニングプロセッサ
を備えるコンピュータシステム。 - 請求項1に記載のコンピュータシステムであって、前記複数のリソースは、メモリデバイス、メモリ範囲、I/Oバス、I/Oバスに接続されたI/Oデバイス、およびルーティング割り込みのための割り込みメカニズムのうちの少なくとも1つを含むコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記複数のリソースは、I/Oスイッチを含み、関連付けられた前記ルーティングテーブルのうちの1つを持つ前記I/Oスイッチは、前記I/Oスイッチ、前記プロセッサのうちの少なくとも1つ、および少なくとも1つのI/Oリソースの間のリンクを表すコンピュータシステム。
- 請求項3に記載のコンピュータシステムであって、前記少なくとも1つのI/Oリソースは少なくとも1つのイーサネットデバイスおよびSCSIデバイスを備えるコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、それぞれのルーティングテーブルはエントリ群のテーブルを備え、前記エントリ群の選択されたもののうちのそれぞれは、前記リソースのうちの1つのアドレスを、前記プロセッサのうちの1つおよび前記プロセッサのうちの前記1つと接続するリンクに関連付けるコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記分散化されたポイント・ツー・ポイント伝送インフラストラクチャはコヒーレントハイパートランスポート(cHT)インフラストラクチャを備えるコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記分散化されたポイント・ツー・ポイント伝送インフラストラクチャは、前記プロセッサをリングトポロジを用いて相互接続するコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記分散化されたポイント・ツー・ポイント伝送インフラストラクチャは、前記プロセッサをメッシュトポロジを用いて相互接続するコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記分散化されたポイント・ツー・ポイント伝送インフラストラクチャは、前記プロセッサのそれぞれを前記プロセッサの他のそれぞれに直接に接続するコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記少なくとも1つのパーティショニングプロセッサは、前記分散化ポイント・ツー・ポイント伝送インフラストラクチャによって相互接続された前記複数のプロセッサのうちの少なくとも1つを備えるコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記少なくとも1つのパーティショニングプロセッサは、前記分散化されたポイント・ツー・ポイント伝送インフラストラクチャによって相互接続された前記複数のプロセッサから分離されているコンピュータシステム。
- 請求項11に記載のコンピュータシステムであって、前記コンピュータシステムの初期化を促進するブートメモリをさらに備え、前記ブートメモリは、前記複数のプロセッサのうちの少なくとも1つの、前記少なくとも1つのパーティショニングプロセッサとしての動作を促進する、その中に記憶されたコンピュータプログラムインストラクションを有するコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記以前に特定されたパーティショニングスキーマは、前記コンピュータシステムの動作中に起こるイベントに応答して生成されるコンピュータシステム。
- 請求項13に記載のコンピュータシステムであって、前記イベントは、前記コンピュータシステムの初期化、前記リソースのうちの少なくとも1つの故障、前記リソースのうちの少なくとも1つと関連付けられた動作負荷の変化、時間の経過、特定のソフトウェアの使用、および利用可能な電源リソースの変化のうちの1つを含むコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記少なくとも1つのパーティショニングプロセッサをユーザインタフェースに接続する少なくとも1つのパーティショニングプロセッサリンクをさらに備え、前記以前に特定されたパーティショニングスキーマは、前記コンピュータシステムのユーザによって前記ユーザインタフェースおよび前記少なくとも1つのパーティショニングプロセッサリンクを介して特定されるコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記少なくとも1つのパーティショニングプロセッサは、前記コンピュータシステムの初期化のときに前記ルーティングテーブルを生成するよう動作可能であるコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記少なくとも1つのパーティショニングプロセッサは、前記コンピュータシステムの動作中に前記ルーティングテーブル群のうちの前記少なくとも1つのルーティングテーブルを改変するよう動作可能であるコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記少なくとも1つのパーティションは、複数のパーティション群を備えるコンピュータシステム。
- 請求項18に記載のコンピュータシステムであって、前記複数のパーティションのうちの少なくとも1つは、前記複数のリソースの機能的サブセットを備えるコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記少なくとも1つのパーティションは、前記複数のリソースのうちの全ての動作中のものを含む単一のパーティションを備えるコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記少なくとも1つのパーティショニングプロセッサは、1つのパーティショニングプロセッサを備えるコンピュータシステム。
- 請求項1に記載のコンピュータシステムであって、前記少なくとも1つのパーティショニングプロセッサは、1つより多いパーティショニングプロセッサを備えるコンピュータシステム。
- 複数のプロセッサおよび前記複数のプロセッサを相互接続する分散化されたポイント・ツー・ポイント伝送インフラストラクチャを含む複数のリソースを有するコンピュータシステムにおいて用いられるコンピュータによって実現される方法であって、前記方法は、
前記複数のリソースを少なくとも1つのパーティションにコンフィギャすることを含みえ、それぞれのパーティションは、前記複数のリソースのサブセットを備え、前記リソースの前記コンフィギャすることは、以前に特定されたパーティショニングスキーマにしたがって前記プロセッサに関連付けられた複数のルーティングテーブルのうちの少なくとも1つに書き込むことによって実現され、それぞれのルーティングテーブルは関連付けられたプロセッサおよび前記複数のプロセッサのうちの他のプロセッサの間のリンクを表し、前記リンクは前記ポイント・ツー・ポイント伝送インフラストラクチャの部分に対応する方法。 - 請求項23に記載の方法であって、前記複数のリソースは、I/Oスイッチを含み、関連付けられた前記ルーティングテーブルのうちの1つを持つ前記I/Oスイッチは、前記I/Oスイッチ、前記プロセッサのうちの少なくとも1つ、および少なくとも1つのI/Oリソースの間のリンクを表す方法。
- 請求項24に記載の方法であって、前記分散化されたポイント・ツー・ポイント伝送インフラストラクチャは非コヒーレントハイパートランスポート(ncHT)インフラストラクチャを備える方法。
- 請求項23に記載の方法であって、前記複数のリソースをコンフィギャすることは、前記分散化ポイント・ツー・ポイント伝送インフラストラクチャによって相互接続された前記複数のプロセッサのうちの少なくとも1つを備える少なくとも1つのパーティショニングプロセッサを用いて達成される方法。
- 請求項23に記載の方法であって、前記複数のリソースをコンフィギャすることは、前記分散化されたポイント・ツー・ポイント伝送インフラストラクチャによって相互接続された前記複数のプロセッサから分離されている少なくとも1つのパーティショニングプロセッサを用いて達成される方法。
- 請求項23に記載の方法であって、前記コンピュータシステムの動作中に起こるイベントに応答して前記以前に特定されたパーティショニングスキーマを生成することをさらに含む方法。
- 請求項28に記載の方法であって、前記イベントは、前記コンピュータシステムの初期化、前記リソースのうちの少なくとも1つの故障、前記リソースのうちの少なくとも1つと関連付けられた動作負荷の変化、時間の経過、特定のソフトウェアの使用、および利用可能な電源リソースの変化のうちの1つを含む方法。
- 請求項23に記載の方法であって、前記コンピュータシステムのユーザによって特定された前記以前に特定されたパーティショニングスキーマを受け取ることをさらに含む方法。
- 請求項23に記載の方法であって、前記複数のルーティングテーブルのうちの前記少なくとも1つに書き込むことは、前記コンピュータシステムの初期化のときに前記複数のルーティングテーブルを生成することを含む方法。
- 請求項23に記載の方法であって、前記複数のルーティングテーブルのうちの前記少なくとも1つに書き込むことは、前記コンピュータシステムの動作中に前記ルーティングテーブル群のうちの前記少なくとも1つのルーティングテーブルを改変することを含む方法。
- 請求項1に記載の方法であって、前記少なくとも1つのパーティションは、複数のパーティション群を備える方法。
- 請求項33に記載の方法であって、前記複数のパーティションのうちの少なくとも1つは、前記複数のリソースの機能的サブセットを備える方法。
- 請求項23に記載の方法であって、前記少なくとも1つのパーティションは、前記複数のリソースのうちの全ての動作中のものを含む単一のパーティションを備える方法。
- 複数のプロセッサを含む複数のリソース、
前記複数のプロセッサを相互接続する分散化されたポイント・ツー・ポイント伝送インフラストラクチャ、および
前記複数のリソースを少なくとも1つのパーティションにコンフィギャする少なくとも1つのパーティショニングプロセッサであって、それぞれのパーティションは、前記複数のリソースのサブセットを備え、前記少なくとも1つのパーティショニングプロセッサは、以前に特定されたパーティショニングスキーマにしたがって前記複数のプロセッサのうちの少なくとも1つと前記複数のプロセッサのうちの少なくとも1つの他のものとの間の少なくとも1つのリンクをイネーブルすることによって前記リソースをコンフィギャするよう動作可能であり、前記少なくとも1つのリンクは前記ポイント・ツー・ポイント伝送インフラストラクチャの部分に対応する、少なくとも1つのパーティショニングプロセッサ
を備えるコンピュータシステム。 - 請求項36に記載のコンピュータシステムであって、前記少なくとも1つのリンクをイネーブルすることは、前記以前に特定されたパーティショニングスキーマにしたがって前記プロセッサに関連付けられた複数のルーティングテーブルのうちの少なくとも1つに書き込むことを含むコンピュータシステム。
- 請求項36に記載のコンピュータシステムであって、前記少なくとも1つのリンクをイネーブルすることは、前記以前に特定されたパーティショニングスキーマにしたがって前記少なくとも1つのリンクに関連付けられた少なくとも1つのスイッチを閉じることを含むコンピュータシステム。
- 複数のプロセッサおよび前記複数のプロセッサを相互接続する分散化されたポイント・ツー・ポイント伝送インフラストラクチャを含む複数のリソースを有するコンピュータシステムにおいて用いられるコンピュータによって実現される方法であって、前記方法は、
前記複数のリソースを少なくとも1つのパーティションにコンフィギャすることを含みえ、それぞれのパーティションは、前記複数のリソースのサブセットを備え、前記リソースの前記コンフィギャすることは、以前に特定されたパーティショニングスキーマにしたがって前記複数のプロセッサのうちの少なくとも1つと前記複数のプロセッサのうちの少なくとも1つの他のものとの間の少なくとも1つのリンクをイネーブルすることによって実現され、それぞれのルーティングテーブルは関連付けられたプロセッサおよび前記複数のプロセッサのうちの他のプロセッサの間のリンクを表し、前記リンクは前記ポイント・ツー・ポイント伝送インフラストラクチャの部分に対応する方法。 - 請求項39に記載の方法であって、前記少なくとも1つのリンクをイネーブルすることは、前記以前に特定されたパーティショニングスキーマにしたがって前記プロセッサに関連付けられた複数のルーティングテーブルのうちの少なくとも1つに書き込むことを含む方法。
- 請求項39に記載の方法であって、前記少なくとも1つのリンクをイネーブルすることは、前記以前に特定されたパーティショニングスキーマにしたがって前記少なくとも1つのリンクに関連付けられた少なくとも1つのスイッチを閉じることを含む方法。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/932,456 US7921188B2 (en) | 2001-08-16 | 2001-08-16 | Computer system partitioning using data transfer routing mechanism |
| PCT/US2002/025530 WO2003017126A1 (en) | 2001-08-16 | 2002-08-09 | Computer system partitioning using data transfer routing mechanism |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005500622A true JP2005500622A (ja) | 2005-01-06 |
| JP2005500622A5 JP2005500622A5 (ja) | 2006-01-05 |
Family
ID=25462354
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003521964A Pending JP2005500622A (ja) | 2001-08-16 | 2002-08-09 | データ転送ルーティングメカニズムを用いるコンピュータシステムパーティショニング |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US7921188B2 (ja) |
| EP (1) | EP1442385A4 (ja) |
| JP (1) | JP2005500622A (ja) |
| AU (1) | AU2002324671B2 (ja) |
| CA (1) | CA2457666A1 (ja) |
| WO (1) | WO2003017126A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012173927A (ja) * | 2011-02-21 | 2012-09-10 | Nec Corp | 電子装置、集積装置、情報処理システム、および、処理方法 |
| US9032118B2 (en) | 2011-05-23 | 2015-05-12 | Fujitsu Limited | Administration device, information processing device, and data transfer method |
| JP2016009499A (ja) * | 2014-06-26 | 2016-01-18 | ブル エスエーエス | 相互接続を管理する方法およびシステム |
Families Citing this family (36)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7206879B2 (en) * | 2001-11-20 | 2007-04-17 | Broadcom Corporation | Systems using mix of packet, coherent, and noncoherent traffic to optimize transmission between systems |
| US7609718B2 (en) * | 2002-05-15 | 2009-10-27 | Broadcom Corporation | Packet data service over hyper transport link(s) |
| JP4181839B2 (ja) * | 2002-09-30 | 2008-11-19 | キヤノン株式会社 | システムコントローラ |
| US7085862B2 (en) * | 2003-03-13 | 2006-08-01 | International Business Machines Corporation | Apparatus and method for controlling resource transfers in a logically partitioned computer system by placing a resource in a power on reset state when transferring the resource to a logical partition |
| US8805981B2 (en) * | 2003-03-25 | 2014-08-12 | Advanced Micro Devices, Inc. | Computing system fabric and routing configuration and description |
| US7171568B2 (en) * | 2003-06-13 | 2007-01-30 | International Business Machines Corporation | Remote power control in a multi-node, partitioned data processing system |
| US7222262B2 (en) * | 2003-08-05 | 2007-05-22 | Newisys, Inc. | Methods and devices for injecting commands in systems having multiple multi-processor clusters |
| US7415551B2 (en) * | 2003-08-18 | 2008-08-19 | Dell Products L.P. | Multi-host virtual bridge input-output resource switch |
| US20050137897A1 (en) * | 2003-12-23 | 2005-06-23 | Hoffman Philip M. | Method and system for performance redistribution in partitioned computer systems |
| US7757033B1 (en) | 2004-02-13 | 2010-07-13 | Habanero Holdings, Inc. | Data exchanges among SMP physical partitions and I/O interfaces enterprise servers |
| US7664110B1 (en) | 2004-02-07 | 2010-02-16 | Habanero Holdings, Inc. | Input/output controller for coupling the processor-memory complex to the fabric in fabric-backplane interprise servers |
| US7860097B1 (en) | 2004-02-13 | 2010-12-28 | Habanero Holdings, Inc. | Fabric-backplane enterprise servers with VNICs and VLANs |
| US7953903B1 (en) | 2004-02-13 | 2011-05-31 | Habanero Holdings, Inc. | Real time detection of changed resources for provisioning and management of fabric-backplane enterprise servers |
| US7843906B1 (en) | 2004-02-13 | 2010-11-30 | Habanero Holdings, Inc. | Storage gateway initiator for fabric-backplane enterprise servers |
| US7633955B1 (en) | 2004-02-13 | 2009-12-15 | Habanero Holdings, Inc. | SCSI transport for fabric-backplane enterprise servers |
| US7873693B1 (en) | 2004-02-13 | 2011-01-18 | Habanero Holdings, Inc. | Multi-chassis fabric-backplane enterprise servers |
| US8145785B1 (en) | 2004-02-13 | 2012-03-27 | Habanero Holdings, Inc. | Unused resource recognition in real time for provisioning and management of fabric-backplane enterprise servers |
| US7685281B1 (en) | 2004-02-13 | 2010-03-23 | Habanero Holdings, Inc. | Programmatic instantiation, provisioning and management of fabric-backplane enterprise servers |
| US7843907B1 (en) | 2004-02-13 | 2010-11-30 | Habanero Holdings, Inc. | Storage gateway target for fabric-backplane enterprise servers |
| US7990994B1 (en) | 2004-02-13 | 2011-08-02 | Habanero Holdings, Inc. | Storage gateway provisioning and configuring |
| US7561571B1 (en) | 2004-02-13 | 2009-07-14 | Habanero Holdings, Inc. | Fabric address and sub-address resolution in fabric-backplane enterprise servers |
| US8868790B2 (en) | 2004-02-13 | 2014-10-21 | Oracle International Corporation | Processor-memory module performance acceleration in fabric-backplane enterprise servers |
| US7860961B1 (en) | 2004-02-13 | 2010-12-28 | Habanero Holdings, Inc. | Real time notice of new resources for provisioning and management of fabric-backplane enterprise servers |
| US7136952B2 (en) * | 2004-04-28 | 2006-11-14 | International Business Machines Corporation | Method for programming firmware hubs using service processors |
| US7106600B2 (en) * | 2004-04-29 | 2006-09-12 | Newisys, Inc. | Interposer device |
| US8713295B2 (en) | 2004-07-12 | 2014-04-29 | Oracle International Corporation | Fabric-backplane enterprise servers with pluggable I/O sub-system |
| US7734741B2 (en) * | 2004-12-13 | 2010-06-08 | Intel Corporation | Method, system, and apparatus for dynamic reconfiguration of resources |
| US7738484B2 (en) * | 2004-12-13 | 2010-06-15 | Intel Corporation | Method, system, and apparatus for system level initialization |
| US20070150699A1 (en) * | 2005-12-28 | 2007-06-28 | Schoinas Ioannis T | Firm partitioning in a system with a point-to-point interconnect |
| US7673113B2 (en) * | 2006-12-29 | 2010-03-02 | Intel Corporation | Method for dynamic load balancing on partitioned systems |
| JP5079342B2 (ja) | 2007-01-22 | 2012-11-21 | ルネサスエレクトロニクス株式会社 | マルチプロセッサ装置 |
| WO2008097597A2 (en) * | 2007-02-07 | 2008-08-14 | General Dynamics Advanced Information Systems, Inc. | Method and apparatus for a federated control plane in an orthogonal system |
| US8645965B2 (en) * | 2007-12-31 | 2014-02-04 | Intel Corporation | Supporting metered clients with manycore through time-limited partitioning |
| US20090254705A1 (en) * | 2008-04-07 | 2009-10-08 | International Business Machines Corporation | Bus attached compressed random access memory |
| JP4888742B2 (ja) | 2009-02-25 | 2012-02-29 | ソニー株式会社 | 情報処理装置および方法、並びにプログラム |
| CA2820081A1 (en) | 2010-12-16 | 2012-06-21 | Et International, Inc. | Distributed computing architecture |
Family Cites Families (29)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07111713B2 (ja) | 1988-02-24 | 1995-11-29 | 富士通株式会社 | 構成変更制御方式 |
| US5241652A (en) * | 1989-06-08 | 1993-08-31 | Digital Equipment Corporation | System for performing rule partitioning in a rete network |
| US5321813A (en) * | 1991-05-01 | 1994-06-14 | Teradata Corporation | Reconfigurable, fault tolerant, multistage interconnect network and protocol |
| US5561768A (en) | 1992-03-17 | 1996-10-01 | Thinking Machines Corporation | System and method for partitioning a massively parallel computer system |
| WO1994003860A1 (en) | 1992-08-07 | 1994-02-17 | Thinking Machines Corporation | Massively parallel computer including auxiliary vector processor |
| DE69331182T2 (de) * | 1992-12-18 | 2002-09-12 | Alcatel, Paris | ATM-Vermittlungsstelle und ATM-Vermittlungselement mit Leitweglenkungslogik |
| WO1995020197A1 (en) * | 1994-01-25 | 1995-07-27 | Advantage Logic, Inc. | Apparatus and method for partitioning resources for interconnections |
| JPH07271698A (ja) | 1994-03-28 | 1995-10-20 | Olympus Optical Co Ltd | 計算機ネットワークシステム |
| US5453978A (en) | 1994-04-04 | 1995-09-26 | International Business Machines Corporation | Technique for accomplishing deadlock free routing through a multi-stage cross-point packet switch |
| US5721819A (en) * | 1995-05-05 | 1998-02-24 | Silicon Graphics Corporation | Programmable, distributed network routing |
| US5959995A (en) | 1996-02-22 | 1999-09-28 | Fujitsu, Ltd. | Asynchronous packet switching |
| US5822531A (en) | 1996-07-22 | 1998-10-13 | International Business Machines Corporation | Method and system for dynamically reconfiguring a cluster of computer systems |
| US5802043A (en) * | 1996-11-21 | 1998-09-01 | Northern Telecom Limited | Transport architecture and network elements |
| CN1128553C (zh) | 1997-01-13 | 2003-11-19 | 阿尔卡特美国股份有限公司 | 动态控制路由选择 |
| US6003075A (en) | 1997-07-07 | 1999-12-14 | International Business Machines Corporation | Enqueuing a configuration change in a network cluster and restore a prior configuration in a back up storage in reverse sequence ordered |
| US6021442A (en) * | 1997-07-17 | 2000-02-01 | International Business Machines Corporation | Method and apparatus for partitioning an interconnection medium in a partitioned multiprocessor computer system |
| US6260068B1 (en) * | 1998-06-10 | 2001-07-10 | Compaq Computer Corporation | Method and apparatus for migrating resources in a multi-processor computer system |
| US5970232A (en) | 1997-11-17 | 1999-10-19 | Cray Research, Inc. | Router table lookup mechanism |
| JP2000155697A (ja) | 1998-11-18 | 2000-06-06 | Fujitsu Denso Ltd | ネットワーク上の装置の追加・削除方法及びネットワーク上の装置へのイベント送信方法 |
| US6490661B1 (en) | 1998-12-21 | 2002-12-03 | Advanced Micro Devices, Inc. | Maintaining cache coherency during a memory read operation in a multiprocessing computer system |
| US6167492A (en) | 1998-12-23 | 2000-12-26 | Advanced Micro Devices, Inc. | Circuit and method for maintaining order of memory access requests initiated by devices coupled to a multiprocessor system |
| JP3374910B2 (ja) | 1999-07-16 | 2003-02-10 | 日本電気株式会社 | マルチプロセッサシステム |
| US6553439B1 (en) | 1999-08-30 | 2003-04-22 | Intel Corporation | Remote configuration access for integrated circuit devices |
| WO2001084338A2 (en) | 2000-05-02 | 2001-11-08 | Sun Microsystems, Inc. | Cluster configuration repository |
| US20010037435A1 (en) | 2000-05-31 | 2001-11-01 | Van Doren Stephen R. | Distributed address mapping and routing table mechanism that supports flexible configuration and partitioning in a modular switch-based, shared-memory multiprocessor computer system |
| US6836750B2 (en) | 2001-04-23 | 2004-12-28 | Hewlett-Packard Development Company, L.P. | Systems and methods for providing an automated diagnostic audit for cluster computer systems |
| US7197536B2 (en) | 2001-04-30 | 2007-03-27 | International Business Machines Corporation | Primitive communication mechanism for adjacent nodes in a clustered computer system |
| US6961761B2 (en) * | 2001-05-17 | 2005-11-01 | Fujitsu Limited | System and method for partitioning a computer system into domains |
| US7043569B1 (en) | 2001-09-07 | 2006-05-09 | Chou Norman C | Method and system for configuring an interconnect device |
-
2001
- 2001-08-16 US US09/932,456 patent/US7921188B2/en not_active Expired - Fee Related
-
2002
- 2002-08-09 CA CA002457666A patent/CA2457666A1/en not_active Abandoned
- 2002-08-09 AU AU2002324671A patent/AU2002324671B2/en not_active Ceased
- 2002-08-09 WO PCT/US2002/025530 patent/WO2003017126A1/en active Application Filing
- 2002-08-09 EP EP02759329A patent/EP1442385A4/en not_active Ceased
- 2002-08-09 JP JP2003521964A patent/JP2005500622A/ja active Pending
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012173927A (ja) * | 2011-02-21 | 2012-09-10 | Nec Corp | 電子装置、集積装置、情報処理システム、および、処理方法 |
| US9032118B2 (en) | 2011-05-23 | 2015-05-12 | Fujitsu Limited | Administration device, information processing device, and data transfer method |
| JP5754504B2 (ja) * | 2011-05-23 | 2015-07-29 | 富士通株式会社 | 管理装置、情報処理装置、情報処理システム及びデータ転送方法 |
| JP2016009499A (ja) * | 2014-06-26 | 2016-01-18 | ブル エスエーエス | 相互接続を管理する方法およびシステム |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2003017126A1 (en) | 2003-02-27 |
| CA2457666A1 (en) | 2003-02-27 |
| AU2002324671B2 (en) | 2008-09-25 |
| EP1442385A1 (en) | 2004-08-04 |
| US7921188B2 (en) | 2011-04-05 |
| US20030037224A1 (en) | 2003-02-20 |
| EP1442385A4 (en) | 2006-01-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7921188B2 (en) | Computer system partitioning using data transfer routing mechanism | |
| AU2002324671A1 (en) | Computer system partitioning using data transfer routing mechanism | |
| US9798556B2 (en) | Method, system, and apparatus for dynamic reconfiguration of resources | |
| CN105204965B (zh) | 用于多节点环境中的动态节点修复的方法和装置 | |
| US8359415B2 (en) | Multi-root I/O virtualization using separate management facilities of multiple logical partitions | |
| US7398380B1 (en) | Dynamic hardware partitioning of symmetric multiprocessing systems | |
| JP5828348B2 (ja) | 試験サーバ、情報処理システム、試験プログラムおよび試験方法 | |
| US9842037B2 (en) | Method and apparatus for verifying configuration | |
| JP2004326808A (ja) | Smpにおけるサーバノードの非介入動的ホットプラグおよびホット除去 | |
| KR20040102074A (ko) | 데이터 관리 방법, 데이터 처리 시스템 및 컴퓨터 프로그램 | |
| US20030093510A1 (en) | Method and apparatus for enumeration of a multi-node computer system | |
| US20140067771A2 (en) | Management of a Scalable Computer System | |
| US7103639B2 (en) | Method and apparatus for processing unit synchronization for scalable parallel processing | |
| US10552168B2 (en) | Dynamic microsystem reconfiguration with collaborative verification | |
| US9092205B2 (en) | Non-interrupting performance tuning using runtime reset | |
| Baitinger et al. | System control structure of the IBM eServer z900 | |
| US20240303343A1 (en) | Partitioning of processor sockets | |
| JP5970846B2 (ja) | 計算機システム及び計算機システムの制御方法 | |
| US20240095020A1 (en) | Systems and methods for use of a firmware update proxy | |
| CN118779158A (zh) | 控制器选择性连接到单端口输入/输出设备 | |
| CN109992562A (zh) | 一种基于Zynq的存储服务器 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20050805 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20050805 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20071002 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20071226 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20080108 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080402 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20080909 |