CN116323945A - 驱动环状rna翻译的遗传元件和使用方法 - Google Patents
驱动环状rna翻译的遗传元件和使用方法 Download PDFInfo
- Publication number
- CN116323945A CN116323945A CN202180052292.1A CN202180052292A CN116323945A CN 116323945 A CN116323945 A CN 116323945A CN 202180052292 A CN202180052292 A CN 202180052292A CN 116323945 A CN116323945 A CN 116323945A
- Authority
- CN
- China
- Prior art keywords
- ires
- sequence
- protein
- nucleic acid
- circular rna
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images









































































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/67—General methods for enhancing the expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
- C12N2310/531—Stem-loop; Hairpin
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2840/00—Vectors comprising a special translation-regulating system
- C12N2840/20—Vectors comprising a special translation-regulating system translation of more than one cistron
- C12N2840/203—Vectors comprising a special translation-regulating system translation of more than one cistron having an IRES
Abstract
本文提供的是重组环状RNA(circRNA)分子,其包含可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES)。IRES包括至少一个RNA二级结构元件;以及与18S核糖体RNA(rRNA)互补的序列区域。还提供的是使用重组circRNA分子在细胞中产生蛋白质的方法。
Description
相关申请的交叉引用
本申请要求于2021年5月10日提交的美国临时申请号63/186,507、以及于2020年6月25日提交的美国临时申请号63/043,964的优先权,所述美国临时申请的内容通过引用以其整体并入本文。
序列表
以电子方式随同提交的文本文件的内容通过引用以其整体并入本文:序列表的计算机可读格式副本(文件名:CRCB_003_02WO_SeqList_ST25.txt,创建日期:2021年6月24日,文件大小:约12.8兆字节)。
技术领域
本发明涉及包含内部核糖体进入位点(IRES)的重组环状RNA(circRNA)分子以及其使用方法,所述内部核糖体进入位点含有RNA二级结构元件以及与18S rRNA互补的核酸序列区域。
关于联邦资助研究的声明
本发明在由美国国立卫生研究院(National Institutes of Health)授予的合同CA209919下由政府支持完成。政府在本发明中享有某些权利。
背景技术
在过去十年中,来自深度测序和计算分析的结果已提示了,环状RNA(circRNA)是哺乳动物细胞中的一大类RNA,其在各种生物过程中起重要作用。已发现circRNA表达的破坏与人疾病相关,所述疾病例如阿尔茨海默病、糖尿病和癌症。此外,circRNA的特殊稳定性和细胞特异性表达模式已导致使用circRNA作为疾病如癌症的生物标记物、以及作为某些治疗的功效的指示剂。虽然大多数研究证实了circRNA充当非编码RNA,例如关于miRNA的海绵、mRNA剪接机制的调节剂、RNA结合蛋白(RBP)的隔离、RBP相互作用的调节剂和免疫应答的激活剂,但新出现的证据提示一些circRNA编码肽和/或蛋白质,并且从而通过这些编码的多肽发挥功能。已知由circRNA翻译的蛋白质调控细胞增殖、分化、迁移和肌生成。circRNA编码的蛋白质的失调已与某些癌症中的肿瘤发生相关。相应地,circRNA编码的蛋白质可能是生物学有关的circRNA类别与癌症以及可能的其它疾病之间的重要联系。因此,理解circRNA翻译的机制可能有助于利用circRNA生物学及其编码的蛋白质的治疗方法和/或形式的开发。
因为circRNA由剪接体介导的前体mRNA的头尾连接而生成,所以它不含通常已知为帽依赖性翻译所需的5'帽。因此,circRNA翻译利用替代机制来起始帽不依赖性翻译,例如使用由核糖体识别的内部核糖体进入位点(IRES)序列。在合成生成的circRNA上引入IRES足以起始编码的circRNA蛋白的翻译,从而提示了包含IRES序列的内源性circRNA在它们输出到细胞质时可能具有翻译潜力。
鉴于本领域的快速进展但仍处于初期的状态,仍然需要鉴定和表征除了IRES的存在之外的遗传元件,其可以促进、起始、指导或调控circRNA翻译。特别地,需要鉴定新型IRES序列,其可以可操作地促进由circRNA编码的蛋白质的表达。
发明内容
本公开内容提供了编码一种或多种环状RNA(circRNA)分子的多核苷酸(例如,DNA序列);其中所述环状RNA分子包含有效负荷序列区域(例如,蛋白质编码或非编码序列区域)、以及可操作地连接到有效负荷序列区域的内部核糖体进入位点(IRES)序列区域。在一些实施方案中,IRES包含:具有RNA二级结构元件的至少一个序列区域;以及与18S核糖体RNA(rRNA)互补的序列区域。在一些实施方案中,IRES具有小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度。本公开内容的一些实施方案包括其中RNA二级结构序列区域或元件由在IRES的约位置40至约位置60处的核苷酸形成的那些实施方案,其中在IRES的5'端处的第一个核苷酸被视为位置1。
本公开内容还提供了编码环状RNA分子的多核苷酸(例如,DNA序列);其中所述环状RNA分子包含蛋白质编码核酸序列和内部核糖体进入位点(IRES),其中所述IRES由以下编码:SEQ ID NO:1-228或SEQ ID NO:229-17201中的任何一个核酸序列、或者在至少50%的核酸序列长度上与其具有至少90%或至少95%同一性或同源性的核酸序列。
本公开内容还提供了重组环状RNA分子,其包含蛋白质编码核酸序列区域、以及可操作地连接到蛋白质编码核酸序列区域的内部核糖体进入位点(IRES)序列区域,其中所述IRES包含:具有二级结构元件的至少一个序列区域;以及与18S核糖体RNA(rRNA)互补的序列区域;其中所述IRES具有小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度。在一些实施方案中,蛋白质编码核酸序列区域以非天然构型可操作地连接到IRES。
本公开内容还提供了重组环状RNA分子,其包含蛋白质编码核酸序列区域、以及可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES)序列区域;其中所述IRES由以下编码:SEQ ID NO:1-228或SEQ ID NO:229-17201中列出的任何一个核酸序列、或者与其具有至少90%或至少95%同源性或同一性的核酸序列。在一些实施方案中,蛋白质编码核酸序列区域以非天然构型可操作地连接到IRES。
还提供的是使用上述重组环状RNA分子或编码其的多核苷酸(例如,DNA分子)在细胞中产生蛋白质的方法。
还提供的是包含上述重组环状RNA分子或编码其的DNA分子的载体。
还提供的是包含上述重组环状RNA分子或编码其的DNA分子的宿主细胞。
还提供的是组合物,其包含(i)编码环状RNA的DNA序列、以及(ii)非编码环状RNA或编码其的DNA序列。
还提供的是用于将非编码环状RNA递送至细胞的方法,该方法包括使细胞与包含以下的组合物接触:编码环状RNA的DNA序列、以及(ii)非编码环状RNA或编码其的DNA序列,从而将非编码环状RNA递送至细胞。
本公开内容进一步提供了包含核酸序列区域的寡核苷酸,所述核酸序列区域与环状RNA分子上存在的内部核糖体进入位点(IRES)序列区域杂交,并且在杂交后抑制环状RNA分子的编码序列区域的翻译。还提供的是使用上述寡核苷酸抑制环状RNA分子的蛋白质编码核酸序列区域(例如有效负荷)翻译的方法。
这些及其它实施方案将在下文以及附图中更详细地解释。
附图说明
专利或申请文件含有至少一张彩色绘图。带有彩色附图的本专利或专利申请公开的副本将在请求和支付必要费用后由专利局提供。
图1A-1D显示了RNA序列的高通量鉴定,所述RNA序列可以促进circRNA上的帽不依赖性翻译活性。图1A提供了用于鉴定circRNA IRES的高通量拆分-eGFP circRNA报道分子筛选测定的示意性概述。含有55,000种寡核苷酸的合成寡核苷酸文库被克隆到拆分-eGFPcircRNA报道分子内。由于全长eGFP仅在反向剪接成circRNA时才重构,eGFP荧光信号只能来自通过circRNA上的插入寡核苷酸驱动的帽不依赖性翻译活性。eGFP(+)细胞通过其eGFP荧光强度用FACS分选成七个表达框。关于每个框内的每种合成寡核苷酸的读数数目通过下一代DNA测序进行确定。根据来自两个独立生物重复的跨越七个表达框的读数数目分布,通过平均加权框数目来定量关于每种合成寡核苷酸的最终eGFP表达。图1B中显示的是40,855种捕获的合成寡核苷酸的eGFP表达分布。eGFP(+)寡核苷酸被定义为eGFP表达高于背景eGFP阈值(无寡核苷酸插入的eGFP circRNA报道分子的eGFP表达)的寡核苷酸。饼图表示eGFP(+)寡核苷酸中的不同寡核苷酸类别的组成。图1C中显示的是在筛选测定中源自报道的IRES、病毒5'UTR或人5'UTR序列的寡核苷酸中捕获的eGFP(+)寡核苷酸百分比的定量。图1D中显示的是环状和线性RNA特异性IRES的鉴定。在利用相同的合成寡核苷酸文库,对环状RNA(本文所述的)或线性RNA(Weingarten-Gabbay等人,2016))筛选系统执行的筛选测定中,对于每种捕获的寡核苷酸显示了标准化的eGFP表达(log10)。通过比较分别仅在环状或线性RNA筛选系统中检测到的寡核苷酸的IRES活性,鉴定了环状IRES(绿色圆圈)或线性IRES(蓝色圆圈)。红色虚线表示标准化的eGFP表达阈值。
图2A-2E显示了含有eGFP(+)寡核苷酸的circRNA具有更高的帽不依赖性翻译活性。图2A显示了用于捕获翻译的circRNA的circRNA多核糖体概况分析方法的示意性概述。图2B显示了用含有合成寡核苷酸文库的拆分-eGFP circRNA报道分子转染的细胞的(多)核糖体分级,随后为环己酰亚胺(CHX)处理。根据Abs254模式,将级分7至12(蓝色阴影)确定为(多)核糖体级分。图2C中显示的分别是eGFP表达低于第20个百分位数的捕获的eGFP(-)寡核苷酸或eGFP表达高于第80个百分位数的eGFP(+)寡核苷酸中的(多)核糖体富集的寡核苷酸百分比的定量。图2D提供了在基因上绘制的来自Ribo-seq和QTI-seq的测序读数,其显示了包含aTIS(顶部)、nTIS(中间)和dTIS(底部)的eGFP(+)寡核苷酸,伴随重叠的注释的circRNA(棕色区段)。图2E显示了不含TIS(TIS(-))(左)或包含多于一个TIS(TIS(+))(右)的eGFP(-)或eGFP(+)寡核苷酸百分比的定量,以及eGFP(+)/TIS(+)寡核苷酸中的aTIS、nTIS或dTIS寡核苷酸的百分比。
图3A-3J显示了IRES上的18S rRNA互补序列促进了circRNA帽不依赖性翻译活性。图3A中提供的是用于映射人18S rRNA上的活性区域的合成寡核苷酸的滑动窗口设计的示意图。图3B显示了与跨越人18SrRNA的相应位置重叠的合成寡核苷酸的平均eGFP表达的定量。虚线指示了背景eGFP表达。18S rRNA上鉴定的活性区域为绿色阴影。图3C提供了人18SrRNA的二级结构的图示,其显示了18S rRNA上鉴定的活性区域和报道的RNA接触区域。鉴定的活性区域1至6为绿色阴影。方框概述了18S rRNA上已报道与mRNA(红色)或IRES RNA(橙色)接触的区域。图3D显示了在Tukey箱形图上绘制的由eGFP(+)或eGFP(-)寡核苷酸所包含的18S rRNA活性7聚体或者随机7聚体数目的定量(异常值未显示)。通过非配对双样品t检验,Ns:不显著;****:p值<0.001。图3E中显示的是通过FACS(MFIeGFP/mRuby)确定的,关于具有更高或更低18S rRNA互补性的寡核苷酸的IRES活性的定量。通过非配对双样品t检验(n=4-6个独立重复),相对于野生型(WT)寡核苷酸,*:p值<0.05。误差条:SEM。图3F提供了用于系统扫描诱变的合成寡核苷酸的设计示意图。图3G显示了在HCV IRES上的相应位置处含有随机取代突变的每种寡核苷酸的eGFP表达。黑点表示在IRES上的每个突变的起始位置。所鉴定的必需元件为蓝色阴影。红线表示已报道的HCV IRES上的功能结构域。关于每种寡核苷酸的eGFP表达针对HCV IRES上的所有寡核苷酸的平均eGFP表达进行标准化。在图3H中,提供了通过扫描诱变鉴定的具有局部和总体敏感性的circRNA IRES的实例。IRES上鉴定的必需元件为蓝色阴影。在图3I中,在跨越IRES的每个突变位置处显示了具有总体敏感性的所有circRNA IRES寡核苷酸的平均eGFP表达。包含调控元件的区域为不同的10种颜色的阴影(蓝色:5-15nt和135-165nt;红色:40-60nt)。图3J中显示的是在IRES上的15核苷酸(nt)滑动窗口中的局部MFE的定量。包含调控元件的区域为不同颜色的阴影(蓝色:5-15nt和135-165nt;红色:40-60nt)。
图4A-4K显示了在IRES上的40-60核苷酸(nt)位置处的不同SuRE可以促进循环IRES活性。图4A–4H显示了由M2-seq确定的突变的IRES(SEQ ID NO:33925-33932)的二级结构。箭头指示了通过M2-net鉴定的高置信度二级结构;相应的位置在RNA结构小组上用相同的颜色进行标记。红色箭头指示了在环状IRES上的40-60nt位置处的SuRE。CircIRES-dis:具有被序列取代破坏的SuRE的环状IRES。CircIRES-relocate:其中SuRE重新定位到90-110nt区域的环状IRES。CircIRES-single和circIRES-comp:分别具有单一互补突变和补偿性双重互补突变的环状IRES。circIRES-BoxB:其中SuRE被BoxB茎环取代的环状IRES。linearIRES-add:其中40-60nt区域被环状IRES上的40-60nt位置处的SuRE取代的线性IRES。图4I中显示的是通过FACS(MFIeGFP/mRuby)确定的,关于每种突变的IRES的IRES活性的定量。每种置换的IRES的活性针对线性IRES进行标准化。通过非配对双样品t检验(n=4-6个独立重复),相对于线性IRES,Ns:不显著;**:p值<0.01,****:p值<0.001。误差条:SEM。图4J中显示的是包含18S rRNA互补性或SuRE元件的eGFP(+)寡核苷酸(左)和内源性翻译的circRNA(右)百分比的定量。图4K提供了以下两种关键调控元件的图示:互补的18S rRNA序列以及在IRES上的40-60nt位置处的SuRE,其促进了circRNA帽不依赖性翻译。
图5A-5E显示了IRES元件促进内源性circRNA的翻译起始。图5A显示了通过共转染靶向IRES上的特异性区域的反义LNA,来破坏寡核苷酸-拆分-eGFP-circRNA报道分子的IRES上的关键调控元件的示意图。LNA-18S:靶向IRES上的18S rRNA互补序列的LNA;LNA-SuRE:靶向IRES上的40-60nt位置处的SuRE的LNA;LNA-Rnd:靶向IRES上的LNA-18S或LNA-SuRE下游的随机位置的LNA。图5B中显示的是细胞的标准化的eGFP荧光信号强度的定量,所述细胞用相应的LNA和携带相应IRES的寡核苷酸-拆分-eGFP-circRNA报道分子进行共转染。数字表示寡核苷酸的索引编号。通过非配对双样品t检验(n=3-5个独立重复),相对于模拟转染,Ns:不显著;*:p值<0.05;**:p值<0.01,***:p值<0.005。误差条:SEM。在图5C中提供的是翻译起始内源性circRNA水平的QTI-qRT-PCR定量的示意图。图5D显示了在通过相应的LNA转染破坏IRES后,含有相应IRES的人内源性circRNA的翻译起始RNA水平的定量。circRNA水平针对GAPDH mRNA进行标准化。通过非配对双样品t检验(n=4-6个独立重复),相对于模拟转染,Ns:不显著;*:p值<0.05;**:p值<0.01,***:p值<0.005。误差条:SEM。图5E中显示的是蛋白质印迹的图像,其显示了在通过相应LNA的转染的IRES破坏后,由内源性circRNA产生的蛋白质水平。
图6A-6L证实了推定的内源性circRNA编码的蛋白质的鉴定。图6A显示了IRES映射的人内源性circRNA百分比的定量,所述人内源性circRNA包含一个或多个eGFP(+)寡核苷酸序列(IRES(+)circRNA)或不含eGFP(+)寡核苷酸序列(IRES(-)circRNA)。图6B显示了IRES(+)circRNA中的亲本基因分布的定量。饼图的每个部分表示不同的基因。图6C显示了来自CSCD的潜在癌症相关IRES(+)circRNA百分比的定量。图6D中提供的是显示通过每种个别IRES(+)circRNA(在n=20处加帽)包含的IRES数目分布的直方图。图6E是显示关于每种个别eGFP(+)寡核苷酸(在n=20处加帽)的映射circRNA的数目分布的直方图。图6F显示了来自GO术语分析的前12个代表的生物过程,其富含IRES(+)circRNA的亲本基因。图6G中提供的是生成推定的内源性circORF列表的示意图。图6H显示了来自Pfam分析的前15个代表的保守基序,其富含预测的circRNA编码的多肽。图6I显示了推定的circORF的肽组学验证的示意图。图6J中提供的是显示在每种MS捕获的circORF的肽组学数据集中检测到的独特胰蛋白酶多肽数目的热图。图6K中显示的是由circORF_575捕获的代表性胰蛋白酶BSJ多肽(SEQ ID NO:33933)的MS1和MS2谱。图6L显示了来自circORF_19的掺入重同位素标记的多肽(右上(SEQ ID NO:33934))和样品胰蛋白酶多肽(右下(SEQ ID NO:33934))的代表性MS2谱和排名前三的PRM-MS过渡离子谱。[V]:重同位素标记的缬氨酸(13C5,15N;+6Da)。
图7A-7L显示了circRNA编码的circFGFR1p在应激条件下压制细胞增殖。图7A提供的是FGFR1和circFGFR1转录物的CDS的示意图。图7B中显示的是连接RT-PCR引物(黑色箭头)的设计和检测circFGFR1(SEQ ID NO:33935)的反向剪接连接点(back-splicingjunction)(黄色框)的桑格测序结果的示意图。图7C提供了FGFR1和circFGFR1p上的保守基序的示意图。Ab(两者):可以检测FGFR1和circFGFR1p两者的抗体。Ab-circFGFR1p:定制的circFGFR1p抗体。蓝线指示了关于每种抗体的抗原肽的定位。图7D显示了使用针对circFGFR1p的独特区域(以粗体)(circFGFR1p(SEQ ID NO:33902);circFGFR1p片段(SEQID NO:33936))的定制抗体,通过IP-LC-MS.MS(下划线)捕获的多肽的示意图,所述多肽匹配circFGFR1p独特区域(红色)以及与FGFR1重叠的区域(黑色)。在考马斯蓝染色的SDS-PAGE凝胶上的提取区域(~30-45kDa)以红色框标出。图7E中显示的是circFGFR1p的掺入重同位素标记的多肽(顶部(SEQ ID NO:33937))和BJ胰蛋白酶多肽(底部(SEQ ID NO:33937))的代表性MS2谱和排名前三的PRM-MS过渡离子谱。[L]:重同位素标记的亮氨酸(13C6,15N;+7Da)。图7F提供的是HEK-293T细胞中的FGFR1(红色)、circFGFR1p(绿色)和DAPI(蓝色)的图像,所述细胞用表达HA-FGFR1和FLAG-circFGFR1p的质粒进行共转染,而无渗透化。比例尺:10微米。图7G中显示的是显示了circFGFR1p和FGFR1蛋白质水平(Ab-两者)的蛋白质印迹,以及通过用siRNA或LNA转染的细胞的qRT-PCR对FGFR1和circFGFR1 RNA水平的定量。siCtrl:非靶向siRNA;siCircFGFR1:circFGFR1特异性siRNA;circFGFR1-LNA:靶向circFGFR1 IRES上的18S rRNA互补序列的反义LNA寡核苷酸。P-FGFR1:磷酸化的FGFR1。通过非配对双样品t检验(n=3个独立重复),相对于siCtrl,Ns:不显著;**p值<0.01。误差条:SEM。(图7H)显示的是伴随FGF1添加,从第1天到第4天,具有circFGFR1 RNA(siCircFGFR1)或circFGFR1p(circFGFR1-LNA)的敲减的细胞中的细胞增殖的定量。通过非配对双样品t检验(n=3-5个独立重复),相对于siCtrl,*p值<0.05;**p值<0.01;***p值<0.005。误差条:SEM。图7I中提供的是显示了具有FGFR1、circFGFR1p或FGFR1+circFGFR1p过表达的细胞的蛋白质印迹图像(左图),及伴随FGF1添加,从第1天到第4天的其相应的细胞增殖(右图)。通过非配对双样品t检验(n=4-6个独立重复),相对于模拟转染,Ns:不显著;*p值<0.05,**p值<0.01,****p值<0.001。误差条:SEM。图7J提供了蛋白质印迹的图像,其显示了伴随或不伴随热休克的FGFR1蛋白和circFGFR1p水平。图7K显示了在正常(WT)和热休克(HS)条件下,相对于FGFR1(所有同种型),circFGFR1p蛋白质水平的蛋白质印迹的定量。误差条:来自三个独立印迹的SEM。通过非配对双样品t检验(n=3个独立印迹),相对于WT,*p值<0.05。图7L中显示的是蛋白质印迹的定量,其显示了在热休克条件下,FGFR1和circFGFR1p的蛋白质水平的变化。蛋白质水平针对每种条件的GAPDH蛋白质装载对照进行标准化。误差条:来自三个独立印迹的SEM。通过单样品t检验(n=3个独立印迹),相对于1,Ns:不显著;*p值<0.05。
图8A-8C显示了寡核苷酸-拆分-eGFP-circRNA报道构建体并不生成来自反式剪接的eGFP信号。图8A显示了伴随或不伴随RNA酶R处理,使用针对报道分子转录物上的mRuby、3'eGFP和eGFP反向剪接连接点区域的探针,IRES-拆分-eGFP circRNA报道分子转染和mRuby(+)/eGFP(+)分选的细胞的RNA印迹的图像。图8B中显示的是相对于RNA酶R(-)样品,在IRES-拆分-eGFP circRNA报道分子转染和mRuby(+)/eGFP(+)分选的细胞总RNA中,eGFPcircRNA或mRuby线性转录物的RNA水平的定量。RNA水平针对每个样品中的GAPDH mRNA水平进行标准化。误差条:SEM。通过非配对双样品t检验(n=3个独立重复),相对于RNA酶R(-)样品,Ns:不显著;****:p值<0.001。误差条:SEM。图8C示出了在用相应的报道构建体转染后,eGFP(+)细胞的流式细胞术分析。根据具有模拟转染的细胞,对eGFP(+)细胞进行门控。
图9A-9F显示了IRES序列的高通量鉴定,所述IRES序列可以促进circRNA上的帽不依赖性翻译活性。图9A提供了对于来自筛选测定的两个独立生物学重复的每种捕获的寡核苷酸,eGFP表达的再现性测量。仅将在两个重复中均回收的寡核苷酸包括在分析中。R代表皮尔逊相关系数。图9B中提供的是定量报道构建体的线性和环状转录物的表达水平的引物设计的示意图。跨越circRNA的反向剪接连接点的背靠背环状引物(divergent circularprimer)应该仅检测到环状转录物。图9C显示了通过转染寡核苷酸-拆分-eGFP报道质粒的七个随机挑选的克隆的qRT-PCR进行的环化效率的定量。通过将环状转录物的表达水平针对线性转录物的表达水平进行标准化,来计算环化效率。数字指示了寡核苷酸的索引。No-IRES:无IRES插入的报道质粒。通过非配对双样品t检验(n=3个独立重复),相对于空circRNA,Ns:不显著。误差条:SEM。图9D示出了跨越用IRES-拆分-eGFP circRNA报道分子转染的细胞的所有7个框,读数分数的分布,所述报道分子携带no-IRES(背景eGFP表达),或者显示高(寡核苷酸#25674)、中等(寡核苷酸#26338)或无(寡核苷酸#26961)帽不依赖性翻译活性的寡核苷酸。黑线表示分布的多项式趋势线。图9E提供了蛋白质印迹的图像,其显示了来自含有no-IRES或相应IRES的拆分-eGFP circRNA报道分子的eGFP、Cre和CD4的表达水平。数字指示了寡核苷酸的索引。图9F中提供的是蛋白质印迹的图像,其显示了帽依赖性翻译的线性RNA(CMV启动子驱动的)和帽不依赖性翻译的circRNA(IRES驱动的;寡核苷酸#8788)的eGFP表达水平。
图10A-10C显示了高通量IRES筛选测定可以捕获来自病毒和人5'UTR的IRES。这些图显示了在报道的IRES(即线性IRES)(图10A)、病毒5'UTR(图10B)和人5’UTR(图10C)中,在筛选测定中捕获的具有前10的eGFP表达的IRES实例。
图11A-11D显示了在捕获的线性和环状IRES中的IRES组成。图11A提供了通过将来自研究(环状RNA系统)的结果与来自Weingarten-Gabbay等人,Science 351,aad4939(2016)中所述的研究(线性RNA系统)的结果进行比较,表示环状和线性特异性IRES的数目的文氏图。图11B-11C中显示的是环状IRES(图11B)、线性IRES(图11C)、以及在线性和环状RNA系统两者中均显示帽不依赖性翻译活性的IRES(两者)(图11D)中捕获的病毒和人IRES的组成。
图12A-12E显示了含有eGFP(+)寡核苷酸序列的circRNA更活跃地被翻译。图12A显示了细胞的40S和(多)核糖体的级分,所述细胞用含有合成寡核苷酸文库的拆分-eGFP报道分子进行转染,并且用嘌呤霉素(PMY;左图)或环己酰亚胺(CHX;右图)进行处理,随后为蔗糖梯度分级。图12B显示了以时间过程方式,使用RNA酶R处理(20U RNA酶R/20μg RNA),相对于IRES-拆分-eGFP circRNA报道分子转染和mRuby(+)/eGFP(+)分选的细胞总RNA的mRuby线性转录物水平,eGFP circRNA水平的比率的定量。误差条:SEM。图12C中显示的是使用PMY或CHX处理,40S和(多)核糖体级分中捕获的寡核苷酸的总读数数目的分数的定量。图12D提供了在RNA酶R处理之前和之后,所捕获的eGFP(-)和eGFP(+)寡核苷酸的数目。图12E显示了使用RNA酶R处理的总捕获寡核苷酸和多(核糖体)级分中捕获的寡核苷酸的标准化的读数数目。
图13A-13D显示了eGFP(+)寡核苷酸更频繁地与人基因组上的翻译起始位点(TIS)重叠。图13A中显示的是人基因组上的eGFP(+)或eGFP(-)寡核苷酸中的TIS读数数目的定量。****表示通过非配对双样品t检验的p值<0.001。误差条:SEM。图13B中显示的是寡核苷酸上绘制的每种TIS(+)寡核苷酸上的TIS映射位置。TIS位置通过寡核苷酸上的映射位置进行分选。图13C显示了在所有eGFP(+)寡核苷酸中,在寡核苷酸上的每个位置上的活性7聚体数目的百分比。图13D显示了在eGFP(+)和eGFP(-)寡核苷酸上的RRACH基序数目的累积频率分布。Ns:通过Kolmogorov-Smirnov累积分布检验不显著。
图14A-14G显示了线性和环状IRES序列之间的特征比较。图14A中显示的是环状IRES和线性IRES的GC含量(左)和MFE(右)的定量,其绘制为Tukey箱形图(异常值未显示)。****表示通过非配对双样品t检验的p值<0.001。图14B显示了在环状和线性IRES上的规范翻译起始密码子(ATG)数目的累积频率分布。Ns:通过Kolmogorov-Smirnov累积分布检验不显著。图14C中显示的是在环状和线性IRES上的m6A基序(RRACH,SEQ ID NO:3394)数目的累积频率分布。Ns:通过Kolmogorov-Smirnov累积分布检验不显著。图14D中显示的是在环状和线性IRES上的Kozak序列(ACCATGG,SEQ ID NO:33945)数目的定量。Ns:通过非配对双样品t检验不显著。误差条:SEM。图14E显示了环状RNA报道分子(左)和线性RNA报道分子(右)中分别的寡核苷酸的IRES活性的定量。通过将由寡核苷酸驱动的eGFP中等荧光强度(MFIeGFP)针对由mRuby中等荧光强度(MFImRuby)确定的报道构建体的线性RNA表达水平进行标准化,使用FACS来确定IRES活性。该值进一步针对寡核苷酸-6472进行标准化。通过非配对双样品t检验(n=4-6个独立重复),相对于寡核苷酸-6472,Ns:不显著,*:p值<0.05,***:p值<0.005,****:p值<0.001。误差条:SEM。图14F-14G显示了通过M2-seq确定的示例性环状IRES(SEQ ID NO:33938-33940)和线性IRES(SEQ ID NO:33941-33943)(各三个IRES)的二级结构。箭头指示了通过M2-net鉴定的高置信度二级结构;相应的位置在RNA结构小组上用相同的颜色进行标记。红色箭头指示了在环状IRES上的40-60nt位置处的SuRE。
图15A-15B显示了IRES元件促进内源性circRNA的翻译起始。图15A显示了相对于细胞的mRuby线性转录物水平,eGFP circRNA水平的定量,所述细胞用相应LNA和携带相应IRES的寡核苷酸-拆分-eGFP-circRNA报道分子进行共转染。通过非配对双样品t检验(n=4-6个独立重复),相对于模拟转染,Ns:不显著;*:p值<0.05。误差条:SEM。图15B中显示的是在通过相应的LNA转染破坏IRES后,包含相应IRES的人内源性circRNA水平的定量。circRNA水平针对GAPDH mRNA进行标准化。通过非配对双样品t检验(n=4-6个独立重复),相对于模拟转染,Ns:不显著。误差条:SEM。
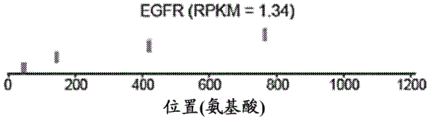
图16A-16L显示了推定的内源性circRNA编码的多肽的鉴定。图16A显示了不含寡核苷酸序列、不含eGFP(+)寡核苷酸序列、或者包含一种或多种eGFP(+)寡核苷酸序列的所有内源性人circRNA百分比的定量。图16B中提供的是直方图,其显示了通过由159种转录物生成的circRNA中的每种个别IRES(+)circRNA(在n=20处加帽)所包含的IRES数目的分布,针对所述转录物跨越整个转录物平铺设计寡核苷酸。图16C中提供的是直方图,其显示了对于由159种转录物生成的circRNA中的每种个别eGFP(+)寡核苷酸(在n=20处加帽)所映射的circRNA数目的分布,针对所述转录物跨越整个转录物平铺设计寡核苷酸。图16D中显示的是每种circRNA(在nt=2000处加帽)上从反向剪接连接点到映射的IRES的距离分布。计算从反向剪接连接点到IRES的第一个映射核苷酸的距离。GC匹配的寡核苷酸:其长度和GC含量与映射的IRES相同的circRNA上的RNA序列。通过获取circRNA上从反向剪接连接点到所有GC匹配的寡核苷酸的平均距离,来确定每种IRES映射的circRNA上GC匹配的寡核苷酸的距离。图16E示出了其ORF与circRNA上的IRES区域重叠的circRNA编码多肽的百分比的定量。图16F中显示的是在IRES重叠ORF中,在circRNA上具有无限递归ORF的circRNA编码多肽的百分比的定量。图16G显示了蛋白质印迹的图像,其显示了用含有框内IRES(寡核苷酸-2007)的拆分-eGFP circRNA报道分子转染的细胞的无限递归eGFP翻译。图16H提供了显示预测的circRNA编码的多肽的大小分布的直方图。图16I中显示的是使用映射的IRES ORF分析方法或传统ORF分析方法,具有匹配sORF的circORF百分比的定量。图16J中显示的是通过肽组学鉴定的circRNA百分比的定量,所述circRNA含有与反向剪接连接点独特重叠的至少一个RFP片段。图16K中显示的是在人iPSC中具有不同表达水平的每种蛋白质上MS-20鉴定的多肽的覆盖率百分比。如Chen等人(2020)中所述,获得并映射了MS概况分析数据。图16L显示了在人iPSC中低表达的EGFR蛋白上MS鉴定的多肽的覆盖率。红色框代表在蛋白质上MS鉴定的多肽的映射位置。
图17A-17I显示了circRNA编码的circFGFR1p在应激条件下压制细胞生长。图17A显示了从FGFR1和circFGFR1的基因组区域上的ENCODE获得的H3K4me3水平,其显示了在circFGFR1 IRES附近没有启动子特征的富集。图17B提供的是HEK-293T细胞中的FGFR1(红色)、circFGFR1p(绿色)和DAPI(蓝色)的图像,所述细胞用表达FGFR1和FLAG-circFGFR1p的质粒进行共转染,伴随渗透化。比例尺:10微米。图17C中显示的是肿瘤样品和正常相邻样品中的circFGFR1表达水平的定量,其绘制为Tukey箱形图(未显示异常值)。数据无需过滤从TCGA分析中进行提取(Nair等人,Oncotarget 7,80967,(2016))。ERBC:雌激素受体阳性乳腺癌;TNBC:三阴性乳腺癌。图17D中显示的是未转化的细胞系和癌细胞系中的circFGFR1表达水平的定量,其绘制为Tukey箱形图。数据从CSCD数据库(Xia等人,2018)中提取。图17E显示了伴随或不伴随热休克,circFGFR1 IRES活性的定量。通过非配对双样品t检验(n=3个独立重复),相对于正常条件(WT),Ns:不显著。误差条:SEM。图17F中显示的是通过分别使用线性和环状RNA特异性引物,将circFGFR1RNA水平针对线性FGFR1 RNA水平进行标准化,使用qRT-PCR,在正常或热休克(HS)条件下,circFGFR1 RNA的相对环化效率的定量。通过非配对双样品t检验(n=3个独立重复),相对于正常条件,Ns:不显著。图17G中显示的是伴随或不伴随热休克,通过qRT-PCR的circFGFR1 RNA水平的定量(针对GAPDH mRNA水平进行标准化)。通过非配对双样品t检验(n=3个独立重复),相对于正常条件,Ns:不显著。图17H中提供的是示意图,其显示了在正常条件下,在FGF添加后,FGFR1经历二聚化和自磷酸化,激活下游细胞信号传导途径且促进细胞增殖。图17I中提供的是示意图,其显示了在应激条件下,FGFR1 RNA的翻译是下调的,导致低FGFR1蛋白质水平,其中circFGFR1 IRES的帽不依赖性翻译活性保持稳态。在FGF添加后,circFGFR1p与FGFR1二聚化。然而,由于circFGFR1p缺乏自磷酸化结构域,circFGFR1p-FGFR1二聚体不能激活下游细胞信号传导途径,导致细胞增殖的压制。
图18A-18B显示了在本文所述的筛选中鉴定和/或测试的各种IRES的平均自由能(MFE)。图18A显示了关于以DNA形式的所有病毒IRES阳性寡核苷酸以及以DNA形式的所有人IRES阳性寡核苷酸的MFE。图18B中提供的是直方图,其显示了通过来自基于DNA的IRES筛选的代表性病毒IRES驱动的eGFP表达水平。
图19A和19B提供了作为IRES的部分的二级结构元件的固定位置的示意图,其中所述二级结构元件跨越距IRES序列的+1起始位点大约40-60bp的核苷酸位置。18S互补序列可以位于二级结构元件的5'(图19A)或3'(图19B)。在这些图中,二级结构元件是发夹;然而,二级结构元件可以具有如本文所述的一种或多种替代结构。
具体实施方案
本公开内容至少部分基于高通量报道分子测定的开发,所述高通量报道分子测定可以系统地筛选且定量可以促进circRNA翻译的RNA序列的IRES活性。该测定可以鉴定circRNA IRES的一级结构和二级结构中的元件,其对于促进circRNA翻译是重要的。该测定还使得能够鉴定潜在的内源性蛋白质编码circRNA,进一步扩展目前理解的蛋白质组。例如,本公开内容证实了circRNA编码的蛋白质circFGFR1p的鉴定,所述蛋白质通过显性失活机制充当FGFR1的负调控因子,以在应激条件下压制细胞生长。本文描述的实施方案提供了识别且操纵circRNA翻译的资源,并且揭示了内源性circRNA蛋白质组的新范围,这提供了circRNA相关疾病的见解以及靶向circRNA编码的蛋白质的新治疗方法的开发。
本公开内容进一步基于以下发现:circFGFR1p是一种内源性circRNA编码的蛋白质,其是FGFR1信号传导的负调控因子,并且在应激条件下压制细胞生长。虽然细胞在应激条件下降低总体翻译,但许多IRES可以在应激条件下驱动更高的帽不依赖性翻译活性,包括circZNF-609的IRES。本文描述的实施方案突出显示了细胞如何利用不同的翻译机制来响应应激条件的重要调控机制,并且示出了circRNA如何可以在此类条件下用于维持蛋白质翻译。虽然细胞占优势地利用帽依赖性线性mRNA翻译来产生蛋白质,但它们可以通过在应激条件下上调circRNA IRES的帽不依赖性翻译活性,将RNA翻译来源转向circRNA。人癌症中circFGFR1的消耗可能发生,以下调circFGFR1p并增加通过FGF信号传导的增殖信号传导。circRNA编码的蛋白质可以用于表达多结构域蛋白质的个别亚基或“模块”,允许细胞能够独立地控制其翻译。本公开内容提供了circRNA翻译如何通过不同于线性mRNA翻译的机制进行调控,以及细胞如何利用circRNA编码的蛋白质来响应动态环境的新模型。本公开内容还提供了包含蛋白质编码核酸序列以及可操作地连接到蛋白质编码核酸序列的IRES的重组环状RNA,其可以用于在细胞中表达一种或多种目的蛋白质。
定义
为了促进本技术的理解,下文定义了多个术语和短语。在整个详细描述中阐述了另外的定义。
在描述本发明的上下文中(尤其是在下述权利要求的上下文中),术语“一个”和“一种”和“该/所述”和“至少一个/种”以及类似的指示物的使用,应解释为覆盖单数和复数两者,除非本文另有说明或与上下文明显矛盾。术语“至少一个”随后为一个或多个项目的列表(例如,“A和B中的至少一个”)的使用,应解释为意指选自所列项目的一个项目(A或B)、或者两个或更多个所列项目的任何组合(A和B),除非本文另有说明或与上下文明显矛盾。除非本文另有说明,否则本文中数值范围的叙述仅仅预期充当个别地提及落入该范围内的每个分开值的速记方法,并且每个分开的值被并入说明书内,如同它在本文中个别地叙述一样。除非本文另有说明或以其他方式与上下文明显矛盾,否则本文所述的所有方法都可以以任何次序执行。本文提供的任何和所有实例或示例性语言(如,“例如”)的使用仅仅预期更好地阐明本发明,并且不对本发明的范围构成限制,除非另有声明。说明书中的任何语言都不应该解释为指示任何未请求保护的要素对于本发明的实践是必需的。
术语“核酸序列”、“多核苷酸”和“寡核苷酸”在本文中可互换使用,并且分别指嘧啶和/或嘌呤碱基例如胞嘧啶、胸腺嘧啶和尿嘧啶以及腺嘌呤和鸟嘌呤的聚合物或寡聚物(参见Albert L.Lehninger,Principles of Biochemistry,在793-800处(WorthPub.1982))。该术语涵盖任何脱氧核糖核苷酸、核糖核苷酸或肽核酸组分,及其任何化学变体,例如这些碱基的甲基化、羟甲基化或糖基化形式。聚合物或寡聚物在组成中可以是异质的或均质的,可以从天然存在的来源中分离,或者可以是人工或合成产生的。另外,核酸可以是DNA或RNA或其混合物,并且可以以单链或双链形式,包括同源双链体、异源双链体和杂合状态永久或过渡性存在。核酸或核酸序列可以包含其它种类的核酸结构,例如DNA/RNA螺旋、肽核酸(PNA)、吗啉代核酸(参见例如,Braasch和Corey,Biochemistry,41(14):4503-4510(2002)和美国专利5,034,506)、锁核酸(LNA;参见Wahlestedt等人,Proc.Natl.Acad.Sci.U.S.A.,97:5633-5638(2000))、环己烯基核酸(参见Wang,J.Am.Chem.Soc.,122:8595-8602(2000))和/或核酶。术语“核酸”和“核酸序列”还可以涵盖包含非天然核苷酸、修饰的核苷酸和/或可以显示出与天然核苷酸相同功能的非核苷酸构件块(例如,“核苷酸类似物”)的链。术语“DNA序列”在本文中用于指包含一系列DNA碱基的核酸。
术语“多肽”和“蛋白质”在本文中可互换使用,并且指包含至少两个或更多个邻接氨基酸、化学或生物化学修饰或衍生的氨基酸的氨基酸聚合形式,以及具有修饰的肽主链的多肽。如本文使用的,术语“肽”指一类短多肽。术语肽可以指具有至多约100个氨基酸的长度的氨基酸(天然或非天然存在的)聚合物。例如,肽可以具有约1至约10、约10至约25、约25至约50、约50至约75、约75至约100个氨基酸的长度。在一些实施方案中,肽的长度是5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49或50个氨基酸。
本文使用的关于核苷酸、核酸、核苷和氨基酸的命名法与国际纯粹与应用化学联合会(International Union of Pure and Applied Chemistry)(IUPAC)标准(参见例如,bioinformatics.org/sms/iupac.html)一致。
当提及核酸序列或蛋白质序列时,术语“同一性”用于表示两个序列之间的相似性。可以使用本领域已知的标准技术来确定序列相似性或同一性,所述技术包括但不限于Smith&Waterman,Adv.Appl.Math.2,482(1981)的局部序列同一性算法,通过Needleman&Wunsch,J Mol.Biol.48,443(1970)的序列同一性比对算法,通过Pearson&Lipman,Proc.Natl.Acad.Sci.USA 85,2444(1988)的相似性搜索方法,通过这些算法的计算机化实现(Wisconsin Genetics Software Package,Genetics Computer Group,575ScienceDrive,Madison,WI中的GAP、BESTFIT、FASTA和TFASTA),通过Devereux等人,Nucl.AcidRes.12,387-395(1984)描述的Best Fit序列程序或通过检查。另一种算法是Altschul等人,J Mol.Biol.215,403-410,(1990),以及Karlin等人,Proc.Natl.Acad.Sci.USA 90,5873-5787(1993)中描述的BLAST算法。特别有用的BLAST程序是WU-BLAST-2程序,其得自Altschul等人,Methods in Enzymology,266,460-480(1996);blast.wustl/edu/blast/README.html。WU-BLAST-2使用几个搜索参数,其任选地设定为默认值。参数是动态值,并且通过程序本身根据特定序列的组成和针对其搜索目的序列的特定数据库的组成来建立;然而,值可以进行调整以增加灵敏度。进一步地,另外有用的算法是缺口BLAST,如通过Altschul等人,(1997)Nucleic Acids Res.25,3389-3402报道的。除非另有说明,否则使用可在互联网址处获得的算法在本文中确定百分比同一性:blast.ncbi.nlm.nih.gov/Blast.cgi。
术语“内部核糖体进入位点”、“内部核糖体进入序列”、“IRES”和“IRES序列区域”在本文中可互换使用,并且指病毒或人细胞RNA(例如,信使RNA(mRNA)和/或circRNA)的顺式元件,其绕过了规范真核帽依赖性翻译起始的步骤。由绝大多数真核mRNA使用的规范帽依赖性机制需要在mRNA的5'端处的m7G帽、起始Met-tRNAmet、十几种起始因子蛋白、定向扫描和GTP水解,以将有翻译能力的核糖体放置在起始密码子处。IRES通常由长且高度结构化的5'-UTR构成,该5'-UTR介导翻译起始复合物结合并催化功能性核糖体的形成。
当提及核酸序列时,术语“编码序列”、“编码序列区域”、“编码区”和“CDS”在本文中可互换使用,以指DNA或RNA序列的一部分,例如,其被翻译成或可能被翻译成蛋白质。术语“读码框”、“开放读码框”和“ORF”在本文中可互换使用,以指始于起始密码子(例如,ATG),并且在一些实施方案中以终止密码子(例如,TAA、TAG或TGA)结束的核苷酸序列。开放读码框可能含有内含子和外显子,并且因此,所有CDS都是ORF,但并非所有ORF都是CDS。
术语“互补的”和“互补性”指两个核酸序列或核酸单体之间的关系,所述两个核酸序列或核酸单体具有通过传统的沃森-克里克碱基配对或其它非传统类型的配对彼此形成氢键的能力。两个核酸序列之间的互补性程度可以通过核酸序列中可以与第二核酸序列形成氢键(例如,沃森-克里克碱基配对)的核苷酸的百分比来指示(例如,约50%、约60%、约70%、约80%、约90%和100%互补的)。如果核酸序列的所有邻接核苷酸与第二核酸序列中相同数目的邻接核苷酸氢键合,则两个核酸序列是“完全互补的”。如果两个核酸序列之间的互补性程度在至少8个核苷酸(例如,至少9、至少10、至少11、至少12、至少13、至少14、至少15、至少16、至少17、至少18、至少19、至少20、至少21、至少22、至少23、至少24、至少25、至少30、至少35、至少40、至少45、至少50个或更多个核苷酸)的区域上是至少60%(例如,至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少97%、至少98%、至少99%或100%),或者如果两个核酸序列在至少中等严格性条件下或在一些实施方案中在高严格性条件下杂交,则两个核酸序列是“基本上互补的”。示例性的中等严格性条件包括在37℃下,在包含20%甲酰胺、5×SSC(150mM NaCl、15mM柠檬酸三钠)、50mM磷酸钠(pH7.6)、5×Denhardt氏溶液、10%硫酸葡聚糖和20mg/ml变性的剪切的鲑鱼精DNA的溶液中的过夜温育,随后为在约37-50℃下在1×SSC中洗涤过滤器,或基本上相似的条件,例如,Sambrook,J.,Molecular Cloning:ALaboratory Manual,Cold Spring HarborLaboratory Press;第4版(2012年6月15日)中所述的中等严格性条件。高严格性条件是这样的条件,其使用例如(1)低离子强度和高温用于洗涤,例如在50℃下的0.015M氯化钠/0.0015M柠檬酸钠/0.1%十二烷基硫酸钠(SDS),(2)在42℃下在杂交过程中采用变性剂,例如甲酰胺,例如具有0.1%牛血清白蛋白(BSA)的50%(v/v)甲酰胺/0.1% Ficoll/0.1%聚乙烯吡咯烷酮(PVP)/具有750mM氯化钠和75mM柠檬酸钠的以pH 6.5的50mM磷酸钠缓冲液,或(3)在42℃下采用50%甲酰胺、5×SSC(0.75M NaCl、0.075M柠檬酸钠)、50mM磷酸钠(pH6.8)、0.1%焦磷酸钠、5×Denhardt氏溶液、超声处理的鲑鱼精DNA(50μg/ml)、0.1% SDS和10%硫酸葡聚糖,伴随(i)在42℃下在0.2×SSC中、(ii)在55℃下在50%甲酰胺中、以及(iii)在55℃下在0.1×SSC(任选地与EDTA组合)中的洗涤。杂交反应的严格性的另外细节和解释在例如Sambrook,同上;以及Ausubel等人,编辑,Short Protocols in MolecularBiology,第5版,John Wiley&Sons,Inc.,Hoboken,N.J.(2002)中提供。当提及核酸序列时,术语“杂交”或“杂交的”是在具有互补性的序列之间和/或之中形成的结合。
如本文使用的,提及核酸序列(例如,RNA、DNA等)的术语“二级结构”或“二级结构元件”或“二级结构序列区域”指任何非线性构象的核苷酸或核糖核苷酸单元。此类非线性构象可以包括在单个核酸聚合物内或在两个聚合物之间的碱基配对相互作用。单链RNA通常形成错综复杂的碱基配对相互作用,这是由于其源于核糖中的额外羟基形成氢键的能力增加。二级结构或二级结构元件的实例包括但不限于例如茎环、发夹结构、凸起、内部环、多环、卷曲、无规卷曲、螺旋、部分螺旋和假结。在一些实施方案中,术语“二级结构”可以指SuRE元件。术语“SuRE”代表茎环结构化RNA元件(SuRE)。
如本文使用的,术语“自由能”指通过使解折叠的多核苷酸(例如,RNA或DNA等)分子折叠而释放的能量,或者相反,必须添加以便使折叠的多核苷酸(例如RNA或DNA等)解折叠的能量的量。多核苷酸(例如DNA、RNA等)的“最小自由能(MFE)”描述了当对于其各种二级结构进行评价时,对于多核苷酸观察到的自由能的最低值。RNA分子的MFE可以用于预测RNA或DNA二级结构,并且受RNA或RNA核苷酸的数目、组成和排列的影响。结构具有的负自由能越多,其形成的可能性就越大,因为通过结构的形成释放更多贮存的能量。
术语“解链温度(Tm)”指在其下约50%的双链核酸结构(例如,DNA/DNA、DNA/RNA或RNA/RNA双链体)变性且解离为单链结构的温度。
如本文使用的,术语“重组”意指特定核酸(DNA或RNA)是克隆、限制性、聚合酶链反应(PCR)和/或连接步骤的各种组合的产物,所述组合导致具有可与天然系统中发现的内源性核酸区分的结构编码或非编码序列的构建体。编码多肽的DNA序列可以从cDNA片段或一系列合成寡核苷酸进行组装,以提供合成核酸,其能够从细胞或无细胞转录和翻译系统中包含的重组转录单元表达。包含相关序列的基因组DNA也可以用于形成重组基因或转录单元。非翻译DNA的序列可能存在于开放读码框的5'或3',其中此类序列并不干扰编码区的操纵或表达,并且可以通过各种机制作用于调节所需产物的产生。可替代地,编码未翻译的RNA的DNA序列也可以被视为重组的。因此,术语“重组”核酸还指以下核酸,其并非天然存在,例如,通过经由人为干预将两个否则分开的序列区段人工组合进行制备。这种人工组合经常通过化学合成手段,或通过例如经由遗传改造技术进行的分离的核酸区段的人工操纵来完成。通常这样做是为了将密码子替换为编码相同氨基酸、保守氨基酸或非保守氨基酸的密码子。可替代地,可以执行人工组合,以将具有所需功能的核酸区段连接在一起,以生成所需的功能组合。这种人工组合经常通过化学合成手段,或通过例如经由遗传改造技术进行的分离的核酸区段的人工操纵来完成。当重组多核苷酸编码多肽时,所编码多肽的序列可以是天然存在的(“野生型”)或可以是天然存在的序列的变体(例如,突变体)。因此,术语“重组”多肽不一定指其序列并非天然存在的多肽。相反,“重组”多肽由重组DNA序列编码,但多肽的序列可以是天然存在的(“野生型”)或非天然存在的(例如,变体、突变体等)。因此,“重组”多肽是人为干预的结果,但可以包含天然存在的氨基酸序列。
如本文使用的,术语“可操作地连接的(operably linked)”和“可操作地连接的(operatively linked)”指元件的排列,所述元件经配置,以便以下述方式执行、发挥功能或结构化,所述方式使得适合于预期目的。例如,当存在适当的酶时,可操作地连接到编码序列的给定启动子能够实现编码序列的表达。表达意欲包括编码环状RNA的重组核酸、或者来自DNA或RNA模板的mRNA中的任何一种或多种的转录,并且可以进一步包括来自包含IRES序列(例如,非天然IRES)的重组环状RNA的蛋白质的翻译。因此,例如,在启动子序列和编码序列之间可以存在间插的未翻译但转录的序列,并且启动子序列仍可以被视为与编码序列“可操作地连接的”。
如本文使用的,术语“非病毒样颗粒”可以指并非病毒或病毒样颗粒的任何基于蛋白质的颗粒。例如,在一些实施方案中,非病毒样颗粒是允许封装的蛋白质纳米凝胶或蛋白质球体。
如本文提及脂质纳米颗粒使用的,术语“装饰的(decorated)”指与一种或多种靶向剂(例如,小分子、肽、多肽、碳水化合物等)偶联的脂质纳米颗粒。靶向剂结合一种或多种肽、多肽、碳水化合物、细胞等,并且允许脂质纳米颗粒特异性地靶向那里。
环状RNA
环状RNA(circRNA)是头尾相连的单链RNA,并且最初在致病性基因组如丁型肝炎病毒(HDV)和植物类病毒中发现(Kos等人,Nature,323:558-560(1986);Sanger等人,PNASUSA,73:3852-3856(1976))。circRNA已被公认为真核细胞中普遍存在的一类非编码RNA(Salzman等人,PLoS One,7:e30733,(2012);Memczak等人,Nature,495:333-338(2013);Hansen等人,Nature,495:384-388,(2013))。由于其非凡的稳定性,通常通过反向剪接生成的circRNA已被假定在细胞间信息传递或记忆中发挥功能(Jeck,W.R.&Sharpless,N.E.,Nat Biotech,32:453-461,(2014))。
尽管内源性circRNA的功能尚不清楚,但它们的大量数目和病毒circRNA基因组的存在需要circRNA免疫系统,如通过经由NF90/NF110调控的病毒抗性的人circRNA调节和经由PKR调控的自身免疫的最近发现所证明的。环状RNA可以充当有力的佐剂来诱导特异性T和B细胞应答。另外,circRNA可以诱导先天性和适应性免疫应答两者,并且具有抑制肿瘤建立和生长的能力。
本发明人先前已显示了,内含子特性决定了circRNA免疫。参见例如,Chen,YG等人,Mol.Cell(2019)76(1):96-109.e9;Chen,YG等人,Mol.Cell(2017)67(2):228-238.e5。因为内含子不是最终circRNA产物的部分,所以已假设内含子可以指导一种或多种共价化学标记在circRNA上的沉积。在超过100种已知的RNA化学修饰中,m6A是线性mRNA和长链非编码RNA上最丰富的修饰,存在于哺乳动物多聚A加尾的转录物中的所有腺苷的0.2%至0.6%上(Roundtree等人,Cell,169:1187-1200(2017))。最近已在哺乳动物circRNA上检测到m6A(Zhou等人,Cell Reports,20:2262-2276(2017))。基于编程其反向剪接的内含子,人内源性circRNA似乎在出生时通过一种或多种共价m6A修饰进行标记。
本公开内容提供了重组环状RNA分子和编码其的DNA序列,所述重组环状RNA分子包含蛋白质编码核酸序列、以及可操作地连接到蛋白质编码核酸序列的非天然内部核糖体进入位点(IRES)。重组circRNA分子可以根据几种方法进行生成或改造。例如,重组circRNA分子可以通过线性RNA的反向剪接而生成。例如,在一些实施方案中,通过下游5'剪接位点(剪接供体)至上游3'剪接位点(剪接受体)的反向剪接,来产生重组环状RNA。剪接供体和/或剪接受体可以例如在人内含子或其一部分中找到,人内含子或其一部分通常用于在内源基因座处的circRNA产生,如图1A中所示。在一些实施方案中,通过使细胞与DNA质粒接触来产生重组环状RNA,其中所述DNA质粒编码线性RNA,并且所述线性RNA进行反向剪接,以产生重组环状RNA。在一些实施方案中,DNA质粒包含来自哺乳动物ZKSCAN1基因的内含子。
可以通过任何非哺乳动物剪接方法生成环状RNA。例如,含有各种类型的内含子的线性RNA可以进行环化,所述内含子包括自剪接I型内含子、自剪接II型内含子、剪接体内含子和tRNA内含子。特别地,I型和II型内含子具有的优点在于,它们可以容易地用于在体外以及在体内生产环状RNA,这是因为由于其自催化核酶活性,它们经历自剪接的能力。
可替代地,环状RNA可以通过RNA的5'和3'端的化学或酶促连接,在体外从线性RNA产生。可以例如使用用于激活核苷酸磷酸单酯基以允许磷酸二酯键形成的溴化氰(BrCN)或乙基-3-(3'-二甲基氨基丙基)碳二亚胺(EDC)来执行化学连接(Sokolova,FEBS Lett,232:153-155(1988);Dolinnaya等人,Nucleic Acids Res.,19:3067-3072(1991);Fedorova,Nucleosides Nucleotides Nucleic Acids,15:1137-1147(1996))。可替代地,酶促连接可以用于使RNA环化。可以使用的示例性连接酶包括T4 DNA连接酶(T4 Dnl)、T4 RNA连接酶1(T4 Rnl 1)和T4 RNA连接酶2(T4 Rnl2)。
在其它实施方案中,夹板连接可以用于生成环状RNA。夹板连接涉及使用与线性RNA的两端杂交的寡核苷酸夹板,以将线性RNA的端部聚集在一起用于连接。可以是脱氧核糖寡核苷酸或核糖寡核苷酸的夹板的杂交,使RNA端部的5'-磷酸酯和3'-OH定向用于连接。如上所述,可以使用化学或酶促技术执行后续连接。例如,可以用T4 DNA连接酶(需要DNA夹板)、T4 RNA连接酶1(需要RNA夹板)或T4 RNA连接酶2(DNA或RNA夹板)执行酶促连接。如果杂交的夹板-RNA复合物的结构干扰酶促活性,则化学连接例如使用BrCN或EDC的化学连接在一些情况下比酶促连接更有效(参见例如,Dolinnaya等人Nucleic Acids Res,21(23):5403-5407(1993);Petkovic等人,Nucleic Acids Res,43(4):2454-2465(2015))。
虽然环状RNA一般比其线性对应物更稳定,主要是由于不存在外切核酸酶介导的降解所必需的自由端部,但可以对本文所述的重组circRNA进行另外的修饰,以进一步改善稳定性。另外其它种类的修饰可以改善环化效率、circRNA的纯化和/或来自circRNA的蛋白质表达。例如,重组circRNA可以被改造为包括“同源臂”(即,在前体RNA的5'和3'端处放置的长度9-19个核苷酸,目的是使5'和3'剪接位点彼此接近)、间隔区序列和/或硫代磷酸酯(PS)帽(Wesselhoeft等人,Nat.Commun.,9:2629(2018))。重组circRNA还可以被改造为包括2'-O-甲基-、-氟-或-O-甲氧基乙基缀合物,硫代磷酸酯主链或2',4'-环状2'-O-乙基修饰,以增加其稳定性(Holdt等人,Front Physiol.,9:1262(2018);Krützfeldt等人,Nature,438(7068):685-9(2005);以及Crooke等人,Cell Metab.,27(4):714-739(2018))。重组circRNA分子还可以包含减少circRNA分子在宿主中的先天免疫原性的一种或多种修饰,例如至少一种N6-甲基腺苷(m6A)。
在一些实施方案中,重组环状RNA分子由包含至少两个内含子和至少一个外显子的核酸编码。在一些实施方案中,编码环状RNA分子的DNA序列包含编码至少两个内含子和至少一个外显子的序列。如本文使用的,术语“外显子”指存在于基因中的核酸序列,其在转录过程中切除内含子后以成熟形式的RNA分子表示。外显子可以翻译成蛋白质(例如,在信使RNA(mRNA)的情况下)。如本文使用的,术语“内含子”指存在于给定基因中的核酸序列,其在最终RNA产物成熟过程中通过RNA剪接去除。内含子一般在外显子之间发现。在转录过程中,内含子从前体信使RNA(mRNA前体)中去除,并且外显子经由RNA剪接进行连接。在一些实施方案中,重组环状RNA分子包含包括一个或多个外显子和一个或多个内含子的核酸序列。
相应地,可以通过内源或外源内含子的剪接来生成环状RNA,如WO 2017/222911中所述。如本文使用的,术语“内源内含子”意指对于其中产生circRNA的宿主细胞天然的内含子序列。例如,当circRNA在人细胞中表达时,人内含子是内源内含子。“外源内含子”意指对于其中生成circRNA的宿主细胞异源的内含子。例如,当circRNA在人细胞中表达时,细菌内含子将是外源内含子。来自广泛各种生物和病毒的众多内含子序列是已知的,并且包括衍生自编码蛋白质、核糖体RNA(rRNA)或转移RNA(tRNA)的基因的序列。代表性内含子序列可在各种数据库中获得,所述数据库包括I型内含子序列和结构数据库(rna.whu.edu.cn/gissd/)、细菌II型内含子数据库(webapps2.ucalgary.ca/~groupii/index.html)、移动II型内含子数据库(fp.ucalgary.ca/group2introns)、酵母内含子数据库(emblS16heidelberg.de/ExternalInfo/seraphin/yidb.html)、Ares Lab酵母内含子数据库(compbio.soe.ucsc.edu/yeast_introns.html)、U12内含子数据库(genome.crg.es/cgibin/u12db/u12db.cgi)和外显子-内含子数据库(bpg.utoledo.edu/~afedorov/lab/eid.html)。
在一些实施方案中,编码重组环状RNA分子的DNA分子包含自剪接I型内含子的核酸编码。I型内含子是一类独特的RNA自剪接内含子,其催化其自身从广泛范围的生物中的mRNA、tRNA和rRNA前体中的切除。存在于真核细胞核中的所有已知的I型内含子都中断定位于核糖体DNA基因座中的功能性核糖体RNA基因。核I型内含子在真核微生物中普遍存在,并且原生质体粘菌(粘菌)含有丰富的自剪接内含子。包括在环状RNA分子中的自剪接I型内含子可以得自或衍生自任何生物,例如细菌、细菌噬菌体和真核病毒。自剪接I型内含子也可能在某些细胞器例如线粒体和叶绿体中发现,并且此类自剪接内含子可以掺入环状RNA分子内。
在一些实施方案中,重组环状RNA分子由DNA分子生成,所述DNA分子包含噬菌体T4胸苷酸合酶(td)基因的自剪接I型内含子。噬菌体T4胸苷酸合酶(td)基因的I型内含子充分表征为当外显子线性剪接在一起时环化(Chandry和Belfort,Genes Dev.,1:1028-1037(1987);Ford和Ares,Proc.Natl.Acad.Sci.USA,91:3117–3121(1994);以及Perriman和Ares,RNA,4:1047-1054(1998))。当侧接任何外显子序列的td内含子次序被置换(即,5'一半置于3'位置处,且反之亦然)时,外显子经由两个自催化酯交换反应进行环化(Ford和Ares,同上;Puttaraju和Been,Nucleic Acids Symp.Ser.,33:49-51(1995))。
在一些实施方案中,重组环状RNA分子由包含ZKSCAN1内含子的DNA分子编码。ZKSCAN1内含子在例如Yao,Z.等人,Mol.Oncol.(2017)11(4):422-437中进行描述。在一些实施方案中,重组环状RNA分子由包含miniZKSCAN1内含子的DNA分子编码。
重组环状RNA分子可以具有任何长度或大小。例如,重组环状RNA分子可以包含约200个核苷酸至约10,000个核苷酸(例如,约300、约400、约500、约600、约700、约800、约900、约1,000、约2,000、约3,000、约4,000、约5,000、约6,000、约7,000、约8,000或约9,000个核苷酸,或由前述值中的任何两个限定的范围)。在一些实施方案中,重组环状RNA分子包含约500至约6,000个核苷酸(约550、约650、约750、约850、约950、约1,100、约1,200、约1,300、约1,400、约1,500、约1,600、约1,700、约1,800、约1,900、约2,100、约2,200、约2,300、约2,400、约2,500、约2,600、约2,700、约2,800、约2,900、约3,100、约3,300、约3,500、约3,700、约3,800、约3,900、约4,100、约4,300、约4,500、约4,700、约4,900、约5,100、约5,300、约5,500、约5,700或约5,900个核苷酸,或由前述值中的任何两个限定的范围)。在一个实施方案中,重组环状RNA分子包含约1,500个核苷酸。
在一些实施方案中,重组环状RNA分子包含蛋白质编码核酸序列区域、以及可操作地连接到蛋白质编码核酸序列区域的内部核糖体进入位点(IRES)序列区域,其中所述IRES包含:具有二级结构元件的至少一个序列区域;以及与18S核糖体RNA(rRNA)互补的序列区域;其中所述IRES具有小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度。在一些实施方案中,IRES序列以非天然构型连接到蛋白质编码核酸序列区域。
本公开内容还提供了重组环状RNA分子,其包含蛋白质编码核酸序列区域、以及可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES)序列区域;其中所述IRES由以下编码:SEQ ID NO:1-228或SEQ ID NO:229-17201中列出的任何一个核酸序列、或者与其具有至少90%或至少95%同一性或同源性的核酸序列。在一些实施方案中,IRES序列以非天然构型连接到蛋白质编码核酸序列区域。
circRNA内部核糖体进入位点
本文描述的重组环状RNA包含内部核糖体进入位点(IRES),其以非天然构型可操作地连接到circRNA的蛋白质编码序列。IRES的包括允许来自环状RNA的一个或多个开放读码框的翻译。IRES元件吸引真核核糖体翻译起始复合物并促进翻译起始。应了解,在真核生物中存在通过其起始翻译的两种已知机制。第一种是由绝大多数真核mRNA使用的规范帽依赖性机制,其需要在mRNA的5'端处的m7G帽、起始Met-tRNAmet、十几种起始因子蛋白、定向扫描和GTP水解,以将有翻译能力的核糖体放置在起始密码子处。第二种机制是由一些mRNA以及许多感染真核生物的病毒使用的帽不依赖性起始。这种机制绕过了对于帽以及经常的许多蛋白质因子的需要,使用顺式作用IRES RNA元件来募集核糖体并起始蛋白质合成。按照其序列、提议的二级结构和关于蛋白质因子的功能要求,在病毒IRES RNA中存在很大的多样性,但都驱动依赖于IRES中的特异性RNA序列和可能的特异性RNA结构的翻译起始模式。
相应地,本文提供的是各种IRES序列,当存在于circRNA中时,所述IRES序列可以驱动蛋白质的翻译。在一些实施方案中,circRNA的IRES可以可操作地连接到蛋白质编码核酸序列。在一些实施方案中,circRNA的IRES以非天然构型可操作地连接到蛋白质编码核酸序列。在一些实施方案中,IRES是人IRES。在一些实施方案中,IRES是病毒IRES。
如本文使用的,术语“非天然构型”指在IRES和蛋白质编码核酸之间的键合,其不存在于天然存在的circRNA分子中。例如,病毒IRES可能可操作连接到环状RNA中的蛋白质编码核酸序列,或者在天然存在的circRNA分子中并未发现的IRES可能可操作连接到circRNA中的蛋白质编码核酸序列。在一些实施方案中,在天然存在的circRNA分子中发现的可操作连接到某种蛋白质编码核酸的IRES,可操作连接到不同的蛋白质编码核酸(即,在任何天然存在的circRNA中,IRES并未与其可操作连接的核酸)。在一些实施方案中,在天然存在的线性mRNA中发现的IRES可操作地连接到环状RNA中的蛋白质编码序列。
许多线性IRES序列是已知的,并且可以包括在如本文所述的重组环状RNA分子中。例如,线性IRES序列可以衍生自广泛各种病毒,例如微小核糖核酸病毒(例如,脑心肌炎病毒(EMCV)UTR)的前导序列(Jang等人,J.Virol.,63:1651-1660(1989))、脊髓灰质炎前导序列、甲型肝炎病毒前导区、丙型肝炎病毒IRES、人鼻病毒2型IRES(Dobrikova等人,Proc.Natl.Acad.Sci.,100(25):15125-15130(2003))、来自口蹄疫病毒的IRES元件(Ramesh等人,Nucl.Acid Res.,24:2697-2700(1996))和贾第虫病毒IRES(Garlapati等人,J.Biol.Chem.,279(5):3389-3397(2004))。各种非病毒IRES序列也可以包括在环状RNA分子中,包括但不限于来自酵母的IRES序列、人血管紧张素II 1型受体IRES(Martin等人,Mol.Cell Endocrinol.,212:51-61(2003))、成纤维细胞生长因子IRES(例如,FGF-1IRES和FGF-2IRES,Martineau等人,Mol.Cell.Biol.,24(17):7622-7635(2004))、血管内皮生长因子IRES(Baranick等人,Proc.Natl.Acad.Sci.U.S.A.,105(12):4733-4738(2008);Stein等人,Mol.Cell.Biol.,18(6):3112-3119(1998);Bert等人,RNA,12(6):1074-1083(2006))、以及胰岛素样生长因子2IRES(Pedersen等人,Biochem.J.,363(Pt 1):37-44(2002))。
IRES序列和编码IRES元件的载体从各种来源商购可得,所述来源例如Clontech(Mountain View,CA)、Invivogen(San Diego,CA)、Addgene(Cambridge,MA)和GeneCopoeia(Rockville,MD),以及IRESite:实验验证的IRES结构数据库(iresite.org)。值得注意的是,这些数据库集中于mRNA(即线性RNA)中的IRES序列的活性,而不是集中于circRNA IRES活性概况。
在一些实施方案中,IRES包含至少一个RNA二级结构元件。分子内RNA碱基配对经常是RNA二级结构的基础,并且在一些情况下是整体大分子折叠的关键决定因素。与辅因子和RNA结合蛋白(RBP)结合,二级结构元件可以形成更高阶的三级结构,并且从而赋予RNA催化、调控和支架功能。因此,IRES可以包含赋予此类结构或功能决定因素的任何RNA二级结构元件。在一些实施方案中,RNA二级结构可以由在IRES的相对于其5'端的约位置40至约位置60处的核苷酸形成。最常见的RNA二级结构是螺旋、环、凸起和连接,其中茎环或发夹环是RNA二级结构中最常见的元件。当RNA链在自身上向后折叠以形成称为茎的双螺旋束时,形成茎环,其中非配对核苷酸形成称为环的单链区域。凸起和内环通过经由非配对核苷酸分开一条链(凸起)或两条链(内环)上的双螺旋束而形成。四环是一种四碱基对的发夹RNA结构。核糖体RNA中存在三个常见的四环家族:UNCG、GNRA和CUUG(N是四种核苷酸之一,且R是嘌呤)。当来自发夹环的核苷酸与发夹外的单链区域配对以形成螺旋区段时,形成假结。RNA二级结构在例如Vandivier等人,Annu Rev Plant Biol.,67:463-488(2016);以及Tinoco和Bustamante,同上)中进一步描述。在一些实施方案中,重组circRNA分子的IRES包含至少一个茎环结构。至少一个RNA二级结构元件可以定位于IRES的任何位置处,只要从IRES有效地起始翻译。在一些实施方案中,茎环的茎部分可以包含3-7个碱基对、4、5、6、7、8、9、10、11或12个或更多个碱基对。茎环的环部分可以包含3-12个核苷酸,包括4、5、6、7、8、9、10、11、12个或更多个核苷酸。茎环结构也可能在茎的任一侧上具有一个或多个凸起(错配)。在一些实施方案中,RNA二级结构元件由在IRES的约位置40至约位置60处的核苷酸形成,其中在IRES的5'端处的第一个核酸被视为位置1。在一些实施方案中,与18S rRNA互补的序列定位于至少一个RNA二级结构元件的5'(即,在IRES的约位置1至约位置40的范围内,参见图19A)。在一些实施方案中,与18S rRNA互补的序列定位于至少一个RNA二级结构元件的3’(即,在IRES的约位置61至端部的范围内,参见图19B)。SEQ ID NO:17202-28976中提供了编码示例性二级结构形成RNA序列的序列,所述二级结构形成RNA序列可以包括在本文所述的IRES中。
在一些实施方案中,IRES的至少一个RNA二级结构元件是茎环。在一些实施方案中,至少一个RNA二级结构元件由SEQ ID NO:17202-28976中的任何一个核酸序列编码。在一些实施方案中,至少一个RNA二级结构元件由核酸序列编码,所述核酸序列相对于SEQ IDNO:17202-28976中的任何一个具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的序列同一性。在一些实施方案中,至少一个RNA二级结构元件由核酸序列编码,所述核酸序列相对于SEQ IDNO:17202-28976中的任何一个具有至少1、至少2、至少3、至少4、至少5、至少6、至少7、至少8、至少9、至少10个或更多个核苷酸取代。
RNA二级结构通常可以由实验热力学数据加上化学映射、核磁共振(NMR)光谱和/或序列比较进行预测。在一些实施方案中,RNA二级结构由机器学习/深度学习算法(例如CNN)进行预测(参见Zhao,Q.等人,“Review of Machine-Learning Methods for RNASecondary Structure Prediction”,2020年9月1日(可在万维网上获得:arxiv.org/abs/2009.08868)。用于RNA二级结构预测和分析的各种算法和软件包是本领域已知的,并且可以用于本公开内容的上下文中(参见例如,Hofacker I.L.(2014)Energy-Directed RNAStructure Prediction.载于:Gorodkin J.,Ruzzo W.(编辑)RNA Sequence,Structure,and Function:Computational and Bioinformatic Methods.Methods in MolecularBiology(Methods and Protocols),第1097卷.Humana Press,Totowa,NJ;Mathews等人,同上;Mathews等人“RNA secondary structure prediction,”Current Protocols inNucleic Acid Chemistry,第11章(2007):第11.2单元.doi:10.1002/0471142700.nc1102s28;Lorenz等人,Methods,103:86-98(2016);Mathews等人,ColdSpring Harb Perspect Biol.,2(12):a003665(2010))。
在一些实施方案中,重组circRNA的IRES可以包含与18S核糖体RNA(rRNA)互补的核酸序列。真核核糖体,也称为“80S”核糖体,具有两个不相等的亚基,根据其沉降系数指定为小亚基(40S)(也称为“SSU”)和大亚基(60S)(也称为“LSU”)。这两个亚基均含有排列在由核糖体RNA(rRNA)构成的支架上的数十个核糖体蛋白。在真核生物中,真核80S核糖体含有大于5500个核苷酸的rRNA:小亚基中的18S rRNA,以及大亚基中的5S、5.8S和25S rRNA。小亚基监测tRNA反密码子和mRNA之间的互补性,而大亚基催化肽键形成。核糖体通常含有约60%的rRNA和约40%的蛋白质。尽管rRNA序列的一级结构可以跨越生物不同,但这些序列内的碱基配对通常形成茎环构型。
在一些实施方案中,重组circRNA的IRES可以包含与任何真核18SrRNA序列互补的任何核酸序列。在一些实施方案中,与18S rRNA互补的核酸序列由表1中所示的任何一个核酸序列编码。在一些实施方案中,与18S rRNA互补的核酸序列由特定核酸序列编码,所述特定核酸序列与表1中所示的序列具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的同一性或同源性。在一些实施方案中,与18S rRNA互补的核酸序列由特定核酸序列编码,所述特定核酸序列相对于表1中所示的核酸序列具有至少1、至少2、至少3、至少4、至少5、至少6、至少7、至少8、至少9、至少10个或更多个核苷酸取代。
表1:编码与18S RNA互补的RNA序列的说明性DNA序列

关于RNA二级结构预测的最常用标准是最小自由能(MFE),因为根据热力学,MFE结构不仅是最稳定的,而且是热力学平衡中最可能的结构。RNA或DNA分子的MFE受RNA/DNA序列中的核苷酸的三个性质影响:数目、组成和排列。例如,较长的序列平均起来是更稳定的,因为它们可以形成更多的堆叠和氢键相互作用,富含鸟嘌呤-胞嘧啶(GC)的RNA通常比富含腺嘌呤-尿嘧啶(AU)的序列更稳定,并且核苷酸次序影响折叠结构的稳定性,因为它决定了环和双螺旋构象的数目和延伸。已发现了,给定其核苷酸数目和组成,与其它非编码RNA不同,mRNA和微小RNA前体具有比预计的更大的负MFE。因此,自由能也可以用作用于鉴定功能性RNA的标准。
重组circRNA分子的IRES可以包含小于约-15kJ/mol(例如,小于约-16kJ/mol、小于约-17kJ/mol、小于约-18.5kJ/mol、小于约-19kJ/mol、小于约-18.9kJ/mol、小于约-20kJ/mol、小于约-30kJ/mol)的最小自由能(MFE)。在一些实施方案中,MFE大于约-90kJ/mol(例如,大于约-85kJ/mol、大于约-80kJ/mol、大于约-70kJ/mol、大于约-60kJ/mol、大于约-50kJ/mol、大于约-40kJ/mol)。在一些实施方案中,IRES具有约-18.9kJ/mol或更小的最小自由能(MFE)。在一些实施方案中,IRES具有在约-15.9kJ/mol至约-79.9kJ/mol范围内的MFE。在一些实施方案中,IRES可以包含在约-12.55kJ/mol至约-100.15kJ/mol范围内的MFE。在一些实施方案中,IRES是病毒IRES,并且具有在约-15.9kJ/mol至约-79.9kJ/mol范围内的MFE。在一些实施方案中,IRES是人IRES,并且具有在约-12.55kJ/mol至约-100.15kJ/mol范围内的MFE。
在一些实施方案中,IRES的至少一个二级结构元件可以包含小于约-0.4kJ/mol、小于约-0.5kJ/mol、小于约-0.6kJ/mol、小于约-0.7kJ/mol、小于约-0.8kJ/mol、小于约-0.9kJ/mol或小于约-1.0kJ/mol的最小自由能(MFE)。在一些实施方案中,IRES的至少一个二级结构元件可以包含小于约-0.7kJ/mol的MFE。
在一些实施方案中,包含在本文所述的circRNA的IRES的约位置40至约位置60处的核苷酸的RNA序列可以包含小于约-0.4kJ/mol、小于约-0.5kJ/mol、小于约-0.6kJ/mol、小于约-0.7kJ/mol、小于约-0.8kJ/mol、小于约-0.9kJ/mol或小于约-1.0kJ/mol的最小自由能(MFE)。在一些实施方案中,包含在IRES的约位置40至约位置60处的核苷酸的RNA序列可以包含小于约-0.7kJ/mol的MFE。
如上文讨论的,可以使用各种计算方法和算法来确定特定RNA(例如,由DNA序列产生的RNA)的最小自由能。用于通过MFE算法预测二级RNA或DNA结构的最常用的软件程序,利用所谓的最近邻能量模型。该模型使用基于经验热力学参数的自由能规则(Mathews等人,JMol Biol,288:911-940(1999);以及Mathews等人,Proc Natl Acad Sci USA,101:7287-7292(2004)),并且通过添加由于相邻碱基对和环区域所致的局部自由能相互作用的独立贡献,来计算RNA或DNA结构的整体稳定性。在具有同质核苷酸排列和组成的序列中,局部自由能贡献的加性和独立性质提示了在计算的MFE与序列长度之间的线性关系(Trotta,E.,PLoS One,9(11):e113380(2014))。用于确定MFE的算法在例如Hajiaghayi等人,BMCBioinformatics,13:22(2012);Mathews,D.H.,Bioinformatics,第21卷,第10期:2246-2253(2005);以及Doshi等人,BMC Bioinformatics,5:105(2004)doi 10.1186/1471-2105-5-105)中进一步描述。
本领域普通技术人员将了解,特定circRNA分子的解链温度(Tm)也可以指示稳定性。实际上,具有高Tm的RNA序列一般含有热稳定的功能上重要的RNA结构(参见例如,Nucleic Acids Res.,45(10):6109-6118(2017))。因此,在一些实施方案中,重组circRNA分子的IRES具有至少35.0℃的解链温度。在一些实施方案中,重组circRNA分子的IRES具有至少35.0℃但不超过约85℃的解链温度。在一些实施方案中,在一些实施方案中,RNA二级结构具有至少35℃、至少36℃、至少37℃、至少38℃、至少39℃、至少40℃、至少41℃、至少42℃、至少43℃、至少44℃、至少45℃、至少46℃、至少47℃、至少48℃、至少49℃或更高的解链温度。在一些实施方案中,解链温度不超过约85℃、不超过约75℃、不超过约70℃、不超过约65℃、不超过约60℃、不超过约55℃、不超过约50℃或更低。
可以使用本文描述和本领域已知的热力学分析和算法,来确定特定核酸分子的解链温度(参见例如,Kibbe W.A.,Nucleic Acids Res.,35(网页服务器期号):W43-W46(2007).doi:10.1093/nar/gkm234;以及Dumousseau等人,BMC Bioinformatics,13:101(2012).doi.org/10.1186/1471-2105-13-101)。
在一些实施方案中,IRES包含至少一个RNA二级结构元件;以及与18S核糖体RNA(rRNA)互补的核酸序列;其中所述IRES具有-18.9kJ/mol或更低的最小自由能(MFE)和至少35.0℃的解链温度。在一些实施方案中,IRES的RNA二级结构元件具有小于-18.9kJ/mol的最小自由能(MFE),并且由在IRES的约位置40至约位置60处的核苷酸形成,其中在IRES的5'端处的第一个核酸被视为位置1。在一些实施方案中,RNA二级结构元件具有至少35.0℃的解链温度,并且由在IRES的约位置40至约位置60处的核苷酸形成,其中在IRES的5'端处的第一个核酸被视为位置1。
因为circRNA分子经常通过下游5'剪接位点(剪接供体)至上游3'剪接位点(剪接受体)的反向剪接由线性RNA生成,所以重组环状RNA分子可以进一步包含反向剪接连接点。在一些实施方案中,IRES可以定位于反向剪接连接点的约100至约200个核苷酸内。另外,已观察到,含有较高G-C含量的RNA区域具有比含有较低G-C含量的RNA链更稳定的二级结构。因此,在一些实施方案中,重组circRNA分子的IRES可以进一步包含最低水平的G-C碱基对。例如,重组circRNA分子的非天然IRES可以包含至少25%(例如,至少30%、至少35%、至少40%、至少45%或更多),但不超过约75%(例如,约70%、约65%、约60%、约55%、约50%或更少)的G-C含量。在一些实施方案中,IRES具有至少25%的G-C含量。
给定核酸序列的G-C含量可以使用本领域已知的任何方法进行测量,所述方法例如化学映射方法(参见例如,Cheng等人,PNAS,114(37):9876-9881(2017);以及Tian,S.和Das,R.,Quarterly Reviews of Biophysics,49:e7 doi:10.1017/S0033583516000020(2016))。
编码IRES用于本公开内容的circRNA分子中的示例性序列在SEQ ID NO:1-228或SEQ ID NO:229-17201中示出。因此,本公开内容进一步提供了重组环状RNA分子,其包含蛋白质编码核酸序列、以及以非天然构型可操作地连接到蛋白质编码核酸序列的IRES;其中所述IRES由SEQ ID NO:1-228或SEQ ID NO:229-17201中列出的任何一个核酸序列编码。
在一些实施方案中,IRES由SEQ ID NO:1-228中任何一个中所示的任何一个核酸序列编码。在一些实施方案中,IRES由核酸序列编码,所述核酸序列与SEQ ID NO:1-228中的任何一个核酸序列具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98或至少99%的同一性。在一些实施方案中,IRES由核酸序列编码,所述核酸序列相对于SEQ ID NO:1-228中的任何一个序列具有至少1、至少2、至少3、至少4、至少5、至少6、至少7、至少8、至少9、至少10个或更多个核苷酸取代。
在一些实施方案中,IRES由SEQ ID NO:229-17201中任何一个中所示的任何一个核酸序列编码。在一些实施方案中,IRES由核酸序列编码,所述核酸序列与SEQ ID NO:229-17201中的任何一个核酸序列具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98或至少99%的同一性或同源性。在一些实施方案中,IRES由核酸序列编码,所述核酸序列相对于SEQ ID NO:229-17201中任何一个中的任何一个序列具有至少1、至少2、至少3、至少4、至少5、至少6、至少7、至少8、至少9、至少10个或更多个核苷酸取代。
在一些实施方案中,IRES由表示为索引876(SEQ ID NO:531)、6063(SEQ ID NO:2270)、7005(SEQ ID NO:2602)、8228(SEQ ID NO:3042)或8778(SEQ ID NO:3244)的核酸序列编码。在一些实施方案中,IRES由SEQ ID NO:33948的核酸序列编码。
在一些实施方案中,IRES由表2中所示的任何一个核酸序列编码。在一些实施方案中,IRES由核酸序列编码,所述核酸序列与表2的一个或多个核酸序列具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98或至少99%的同一性或同源性。在一些实施方案中,IRES由核酸序列编码,所述核酸序列相对于表2中的任何一个序列具有至少1、至少2、至少3、至少4、至少5、至少6、至少7、至少8、至少9、至少10个或更多个核苷酸取代。
表2:编码IRES序列的说明性序列








IRES可以具有任何长度或大小。例如,IRES的长度可以为约100个核苷酸至约600个核苷酸(例如,长度约200、约225、约250、约275、约300、约325、约350、约375、约400、约425、约450、约475、约500、约525、约550或约575个核苷酸,或由前述值中的任何两个限定的范围)。在一些实施方案中,IRES的长度可以为约200个核苷酸至约800个核苷酸(长度约200、约210、约220、约240、约260、约280、约320、约340、约360、约380、约420、约440、约460、约480、约500、约520、约540、约560、约580、约600、约620、约640、约660、约680、约700、约720、约740、约760、约780或约800个核苷酸,或由前述值中的任何两个限定的范围)。在一些实施方案中,IRES的长度可以为约200至约400、约400至约600、约600至约700、或约600至约800个核苷酸。在一些实施方案中,IRES的长度为约210个核苷酸。在一些实施方案中,IRES的长度可以为约100至约3000个核苷酸。
在一些实施方案中,环状RNA分子包含IRES序列,所述IRES序列由通过SEQ ID NO:1-228或SEQ ID NO:229-17201中任何一个的DNA序列编码的序列组成。在一些实施方案中,环状RNA分子包含由SEQ ID NO:1-228或SEQ ID NO:229-17201中任何一个的DNA序列编码的IRES序列,其中所述IRES序列另外包含至多1000个另外的核苷酸。在一些实施方案中,IRES序列由SEQ ID NO:1-228或SEQ ID NO:229-17201中任何一个的序列编码,并且另外包含定位于该序列的5'端处的至多1000个另外的核苷酸。在一些实施方案中,IRES序列由SEQID NO:1-228或SEQ ID NO:229-17201中任何一个的序列编码,并且另外包含定位于该序列的3'端处的至多1000个另外的核苷酸。在一些实施方案中,IRES序列由SEQ ID NO:1-228或SEQ ID NO:229-17201中任何一个的序列编码,并且另外包含定位于该序列的5'端处的至多1000个另外的核苷酸以及定位于该序列的5'端处的至多1000个另外的核苷酸。
在一些实施方案中,环状RNA分子包含内部核糖体进入位点(IRES)序列区域,其中所述IRES序列区域包含由SEQ ID NO:1-228或SEQ ID NO:229-17201中任何一个的DNA序列编码的序列,并且其中由SEQ ID NO:1-228或SEQ ID NO:229-17201中任何一个的DNA序列编码的序列具有小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度。
在一些实施方案中,环状RNA分子包含内部核糖体进入位点(IRES)序列区域,其中所述IRES序列区域包含由SEQ ID NO:1-228或SEQ ID NO:229-17201中任何一个的DNA序列编码的序列,并且其中所述IRES序列区域具有在其整体长度上小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度。
在一些实施方案中,环状RNA分子包含内部核糖体进入位点(IRES)序列区域,其中所述IRES序列区域包含由SEQ ID NO:1-228或SEQ ID NO:229-17201中任何一个的DNA序列编码的序列,并且另外包含定位于5'端处的至多1000个另外的核苷酸以及定位于5'端处的至多1000个另外的核苷酸,并且其中所述IRES序列区域具有在其整体长度上小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度。
在一些实施方案中,重组环状RNA分子包含以非天然构型可操作地连接到IRES的蛋白质编码核酸序列。任何目的蛋白质或多肽(例如,肽、多肽、蛋白质片段、蛋白质复合物、融合蛋白、重组蛋白、磷蛋白、糖蛋白或脂蛋白)都可以由蛋白质编码核酸序列编码。在一些实施方案中,蛋白质编码核酸序列编码治疗性蛋白质。合适的治疗性蛋白质的实例包括细胞因子、毒素、肿瘤抑制蛋白、生长因子、激素、受体、有丝分裂原、免疫球蛋白、神经肽、神经递质和酶。可替代地,蛋白质编码核酸序列可以编码病原体(例如,细菌、病毒、真菌、原生生物或寄生虫)的抗原,并且circRNA可以用作疫苗或疫苗的一种组分。治疗性蛋白质及其实例在例如Dimitrov,D.S.,Methods Mol Biol.,899:1-26(2012);以及Lagassé等人,F1000Research,6:113(2017)中进一步描述。
理想地,IRES关于蛋白质编码核酸序列“在框内”,即IRES位于circRNA分子中关于所编码的蛋白质的正确读码框中。发现与一个或多个编码序列在框内的IRES元件的实例在SEQ ID NO:28984-32953中示出。然而,在一些实施方案中,IRES可能关于蛋白质编码核酸序列“在框外”,使得IRES的位置破坏了蛋白质编码核酸序列的ORF。在其它实施方案中,IRES可以与蛋白质编码核酸序列的一个或多个ORF重叠。另外,虽然在一些实施方案中蛋白质编码核酸序列包含至少一个终止密码子,但在其它实施方案中蛋白质编码核酸序列可能缺乏终止密码子。本发明人已发现了,包含具有框内非天然IRES且缺乏终止密码子的蛋白质编码核酸序列的circRNA分子可以起始递归(即,无限循环)翻译机制。此类递归翻译可能产生串联的蛋白质多聚体(例如,>200kDa)。这种特殊的circRNA设计允许产生单个ORF大小的至多10倍的重复ORF单元。不受任何特定理论的束缚,使用本文描述的circRNA用于递归基因编码可以代表用于基因的新型“数据压缩”算法,解决了与许多当前基因治疗应用相关的基因大小限制。
在一些实施方案中,IRES包含(i)至少一个RNA二级结构元件、以及(ii)与18SrRNA互补的序列。在一些实施方案中,IRES包含(i)至少一个RNA二级结构元件、以及(ii)与18S rRNA互补的序列,其中所述IRES的RNA二级结构由在IRES的约位置40至约位置60处的核苷酸形成,其中在IRES的5'端处的第一个核酸被视为位置1。至少一个RNA二级结构以及与18S RNA互补的序列的相对定位可以变化。例如,在一些实施方案中,IRES包含(i)至少一个RNA二级结构元件、以及(ii)与18S rRNA互补的序列,并且其中所述至少一个RNA二级结构定位于与18S rRNA互补的序列的5'(参见图4K)。在一些实施方案中,IRES包含(i)至少一个RNA二级结构元件、以及(ii)与18S rRNA互补的序列,并且其中所述至少一个RNA二级结构元件定位于与18S rRNA互补的序列的3'(参见图19B)。
DNA分子、载体和细胞
在一些实施方案中,本公开内容提供了DNA分子,其包含编码本文公开的任何一种重组circRNA分子的核酸序列。相应地,本文描述的是可以用于编码环状RNA的DNA序列。在一些实施方案中,DNA序列编码包含IRES的环状RNA。在一些实施方案中,DNA序列编码包含蛋白质编码核酸的环状RNA。在一些实施方案中,DNA序列编码环状RNA分子;其中所述环状RNA分子包含蛋白质编码核酸序列、以及以非天然构型可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES)。在一些实施方案中,DNA序列编码蛋白质编码核酸序列,其中所述蛋白质是治疗性蛋白质。
在一些实施方案中,本文公开的DNA序列可以包含至少一个非编码功能序列。例如,非编码功能序列可以是微小RNA(miRNA)海绵。微小RNA海绵可以包含与目的miRNA互补的结合位点。在一些实施方案中,海绵的结合位点对于miRNA种子区域是特异性的,这允许其阻断相关miRNA的整个家族。在一些实施方案中,miRNA海绵选自下表3中所示的任何一种miRNA海绵。
表3:miRNA海绵


在一些实施方案中,非编码序列可以是RNA结合蛋白位点。因此,RNA结合蛋白和结合位点在本领域技术人员已知的众多数据库中列出,所述数据库包括RBPDB(rbpdb.ccbr.utoronto.ca)。在一些实施方案中,RNA结合蛋白包含一个或多个RNA结合结构域,其选自RNA结合结构域(RBD,也称为RNP结构域和RNA识别基序,RRM)、K同源性(KH)结构域(I型和II型),RGG(Arg-Gly-Gly)盒,Sm结构域;DEAD/DEAH盒(SEQ ID NO:34036和34037)、锌指(ZnF,主要是C-x8-X-x5-X-x3-H(SEQ ID NO:34038))、双链RNA结合结构域(dsRBD)、冷休克结构域;Pumilio/FBF(PUF或Pum-HD)结构域、以及Piwi/Argonaute/Zwille(PAZ)结构域。
在一些实施方案中,DNA序列包含适体。适体是短的单链DNA分子,其可以选择性地结合特异性靶。靶可以是例如蛋白质、肽、碳水化合物、小分子、毒素或活细胞。一些适体可以结合DNA、RNA、自身适体或其它非自身适体。适体由于其形成螺旋和单链环的倾向而呈现各种形状。示例性DNA和RNA适体在适体数据库(scicrunch.org/resources/Any/record/nlx_144509-1/SCR_001781/resolver?q=*&l=)中列出。
在一些实施方案中,DNA序列编码包含约200个核苷酸至约10,000个核苷酸的环状RNA分子。
在一些实施方案中,DNA序列编码环状RNA分子,其包含在IRES和蛋白质编码核酸序列的起始密码子之间的间隔区。间隔区可以具有任何长度。例如,在一些实施方案中,间隔区的长度选择为优化蛋白质编码核酸序列的翻译。
在一些实施方案中,DNA序列编码包含IRES的环状RNA分子,所述IRES被配置为促进滚环翻译。在一些实施方案中,DNA序列编码包含蛋白质编码核酸序列的环状RNA,所述蛋白质编码核酸序列缺乏终止密码子。在一些实施方案中,DNA序列编码环状RNA分子,其包含(i)配置为促进滚环翻译的IRES、以及(ii)缺乏终止密码子的蛋白质编码核酸序列。
本文描述的DNA序列可以包含在一种或多种载体中。例如,在一些实施方案中,病毒载体包含编码环状RNA的DNA序列。病毒载体可以是例如腺伴随病毒(AAV)载体、腺病毒载体、逆转录病毒载体、慢病毒载体、牛痘病毒或疱疹病毒载体。
在一些实施方案中,病毒载体是AAV。如本文使用的,术语“腺伴随病毒”(AAV)包括但不限于AAV1、AAV2、AAV3(包括3A和3B型)、AAV4、AAV5、AAV6、AAV7、AAV8、AAV9、AAV10、AAV11、AAV12、禽类AAV、牛AAV、犬AAV、马AAV、绵羊AAV以及目前已知或以后发现的任何其它AAV。在一些实施方案中,AAV载体可以是下述中的一种或多种的修饰形式(即,包含相对于其的一种或多种氨基酸修饰的形式):AAV1、AAV2、AAV3(包括3A和3B型)、AAV4、AAV5、AAV6、AAV7、AAV8、AAV9、AAV10、AAV11、AAV12、禽类AAV、牛AAV、犬AAV、马AAV或绵羊AAV。各种AAV血清型及其变体在例如BERNARD N.FIELDS等人,VIROLOGY,第2卷,第69章(第4版,Lippincott-Raven Publishers)中进行描述。已鉴定了许多相对新的AAV血清型和进化枝(参见例如,Gao等人(2004)J Virology 78:6381-6388;Moris等人(2004)Virology 33-:375-383)。AAV的各种血清型的基因组序列,以及天然末端重复(TR)、Rep蛋白和衣壳亚基的序列是本领域已知的。此类序列可以在文献或公共数据库例如 Database中找到。参见例如,GenBank登录号NC_044927、NC_002077、NC_001401、NC_001729、NC_001863、NC_001829、NC_001862、NC_000883、NC_001701、NC_001510、NC_006152、NC_006261、AF063497、U89790、AF043303、AF028705、AF028704、J02275、JO 1901、J02275、X01457、AF288061、AH009962、AY028226、AY028223、NC_001358、NC_001540、AF513851、AF513852、AY530579;其公开内容通过引用并入本文用于教导细小病毒和AAV核酸序列和氨基酸序列。还参见例如,Srivistava等人(1983)J Virology 45:555;Chiorini等人(1998)J.Virology71:6823;Chiorini等人(1999)J Virology 73:1309;Bantel-Schaal等人(1999)J.Virology 73:939;Xiao等人(1999)J.Virology 73:3994;Muramatsu等人(1996)Virology 221:208;Shade等人(1986)J Virol.58:921;Gao等人(2002)Proc.Nat.Acad.Sci.USA 99:1 1854;Moris等人(2004)Virology 33-:375-383;国际专利公开WO 00/28061,WO 99/61601,WO 98/11244;以及美国专利号6,156,303;其公开内容通过引用并入本文。
Database中找到。参见例如,GenBank登录号NC_044927、NC_002077、NC_001401、NC_001729、NC_001863、NC_001829、NC_001862、NC_000883、NC_001701、NC_001510、NC_006152、NC_006261、AF063497、U89790、AF043303、AF028705、AF028704、J02275、JO 1901、J02275、X01457、AF288061、AH009962、AY028226、AY028223、NC_001358、NC_001540、AF513851、AF513852、AY530579;其公开内容通过引用并入本文用于教导细小病毒和AAV核酸序列和氨基酸序列。还参见例如,Srivistava等人(1983)J Virology 45:555;Chiorini等人(1998)J.Virology71:6823;Chiorini等人(1999)J Virology 73:1309;Bantel-Schaal等人(1999)J.Virology 73:939;Xiao等人(1999)J.Virology 73:3994;Muramatsu等人(1996)Virology 221:208;Shade等人(1986)J Virol.58:921;Gao等人(2002)Proc.Nat.Acad.Sci.USA 99:1 1854;Moris等人(2004)Virology 33-:375-383;国际专利公开WO 00/28061,WO 99/61601,WO 98/11244;以及美国专利号6,156,303;其公开内容通过引用并入本文。
在一些实施方案中,本文描述的DNA序列包含在AAV2载体或其变体中。在一些实施方案中,本文描述的DNA序列包含在AAV4载体或其变体中。在一些实施方案中,本文描述的DNA序列包含在AAV8载体或其变体中。在一些实施方案中,本文描述的DNA序列包含在AAV9载体或其变体中。
在一些实施方案中,本文描述的DNA序列包含在病毒样颗粒(VLP)中。病毒样颗粒是非常类似病毒的分子,但是非传染性的,因为它们含有很少的病毒遗传材料或不含病毒遗传材料。它们可以是天然存在的,或通过病毒结构蛋白的个别表达而合成的,所述病毒结构蛋白然后可以自组装成病毒样结构(virus-lie structure)。来自不同病毒的结构衣壳蛋白的组合可以用于产生VLP。例如,VLP可以衍生自AAV、逆转录病毒、黄病毒科(Flaviviridae)、副粘病毒科(paramyoxoviridae)或细菌噬菌体。VLP可以在多重细胞培养系统中产生,所述细胞培养系统包括细菌、哺乳动物细胞系、昆虫细胞系、酵母和植物细胞。
在一些实施方案中,本文描述的DNA序列包含在非病毒载体中。非病毒载体可以是例如包含DNA序列的质粒。在一些实施方案中,非病毒载体是闭合端DNA(closed-endedDNA)。闭合端DNA是具有共价闭合端的非病毒、无衣壳的DNA载体(参见例如,WO2019/169233)。在一些实施方案中,微型内含子质粒载体包含本文描述的DNA序列。微型内含子质粒是表达系统,其含有细菌复制起点和选择标记物,维持如在小环中的转基因表达盒的5'和3'端的并列(参见例如,Lu,J.等人,Mol Ther(2013)21(5)954-963)。
在一些实施方案中,本文描述的DNA序列包含在脂质纳米颗粒中。脂质纳米颗粒(或LNP)是亚微米大小的脂质乳状液,并且可以提供下述优点中的一个或多个:(i)控制和/或靶向药物释放,(ii)高稳定性,(iii)所使用的脂质的生物降解性,(iv)避免有机溶剂,(v)易于扩大和灭菌,(vi)比基于聚合物/表面活性剂的载剂更便宜,(vii)更易于验证和获得监管批准。在一些实施方案中,脂质纳米颗粒的直径范围为约10至约1000nm。
在一些实施方案中,DNA序列编码环状RNA分子,其中所述环状RNA分子包含蛋白质编码核酸序列、以及以非天然构型可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES),其中所述IRES包含:至少一个RNA二级结构;以及与18S核糖体RNA(rRNA)互补的序列。
在一些实施方案中,DNA序列编码环状RNA分子,其中所述环状RNA分子包含蛋白质编码核酸序列、以及以非天然构型可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES),其中所述IRES包含:至少一个RNA二级结构元件;以及与18S核糖体RNA(rRNA)互补的序列;其中所述IRES具有小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度;并且其中所述RNA二级结构元件由在IRES的约位置40至约位置60处的核苷酸形成,其中在IRES的5'端处的第一个核酸被视为位置1。
在一些实施方案中,DNA序列包含编码环状RNA分子的核酸序列;其中所述环状RNA分子包含蛋白质编码核酸序列、以及以非天然构型可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES);其中所述IRES由SEQ ID NO:1-228或SEQ ID NO:229-17201中列出的任何一个核酸序列、或者与其具有至少90%或至少95%同一性的核酸序列编码。
本文还提供的是包含本文所述的重组circRNA分子、DNA分子或载体的细胞。可以接触并稳定维持重组circRNA分子、编码重组circRNA分子的DNA分子、或包含重组circRNA分子的载体的任何原核或真核细胞都可以用于本公开内容的上下文中。原核细胞的实例包括但不限于来自芽孢杆菌属(Bacillus)(例如枯草芽孢杆菌(Bacillus subtilis)和短芽孢杆菌(Bacillus brevis))、埃希氏菌属(Escherichia)(例如大肠杆菌(E.coli))、假单胞菌属(Pseudomonas)、链霉菌属(Streptomyces)、沙门氏菌属(Salmonella)和欧文氏菌属(Erwinia)的细胞。在一些实施方案中,宿主细胞是真核细胞。合适的真核细胞是本领域已知的,并且包括例如酵母细胞、昆虫细胞和哺乳动物细胞。酵母细胞的实例包括来自汉逊酵母属(Hansenula)、克鲁维酵母属(Kluyveromyces)、毕赤酵母属(Pichia)、鼻孢子菌属(Rhinosporidium)、酵母属(Saccharomyces)和裂殖酵母属(Schizosaccharomyces)的那些细胞。合适的昆虫细胞包括Sf-9和HIS细胞(Invitrogen,Carlsbad,Calif.),并且在例如Kitts等人,Biotechniques,14:810-817(1993);Lucklow,Curr.Opin.Biotechnol.,4:564-572(1993);以及Lucklow等人,J.Virol.,67:4566-4579(1993)中进行描述。
在一些实施方案中,细胞是哺乳动物细胞。许多哺乳动物细胞是本领域已知的,其中许多可从美国典型培养物保藏中心(ATCC,Manassas,Va.)获得。哺乳动物细胞的实例包括但不限于HeLa细胞、HepG2细胞、中国仓鼠卵巢细胞(CHO)(例如,ATCC编号CCL61)、CHODHFR-细胞(Urlaub等人,Proc.Natl.Acad.Sci.USA,97:4216-4220(1980))、人胚肾(HEK)293或293T细胞(例如,ATCC编号CRL1573)和3T3细胞(例如,ATCC编号CCL92)。其它哺乳动物细胞系是猴COS-1(例如,ATCC编号CRL1650)和COS-7细胞系(例如,ATCC编号CRL1651),以及CV-1细胞系(例如,ATCC编号CCL70)。进一步的示例性哺乳动物宿主细胞包括灵长类动物细胞系和啮齿类动物细胞系,包括转化细胞系。正常二倍体细胞、衍生自原代组织的体外培养的细胞株以及原代外植体也是合适的。其它哺乳动物细胞系包括但不限于小鼠神经母细胞瘤N2A细胞、HeLa、小鼠L-929细胞和BHK或HaK仓鼠细胞系,所有这些都可从美国典型培养物保藏中心(ATCC;Manassas,VA)获得。用于选择哺乳动物细胞的方法,以及用于转化、培养、扩增、筛选和纯化此类细胞的方法是本领域众所周知的(参见例如,Ausubel等人,同上)。在一些实施方案中,哺乳动物细胞是人细胞。
生产蛋白质的方法
本公开内容进一步提供了在细胞中产生蛋白质的方法,其包括在由此蛋白质编码核酸序列被翻译并在细胞中产生蛋白质的条件下,使细胞与上述重组环状RNA分子、包含编码重组circRNA分子的核酸序列的上述DNA分子、或包含重组circRNA分子的载体接触。
在一些实施方案中,在细胞中产生蛋白质的方法包括在由此蛋白质编码核酸序列被翻译并在细胞中产生蛋白质的条件下,使细胞与本文描述的DNA序列或包含DNA序列的载体接触。还提供的是通过所公开的方法产生的蛋白质。
在一些实施方案中,蛋白质的产生是组织特异性的。例如,可以在下述组织中的一种或多种中选择性地产生蛋白质:肌肉、肝、肾、脑、肺、皮肤、胰腺、血液或心脏。
在一些实施方案中,蛋白质在细胞中递归地表达。
在一些实施方案中,环状RNA在细胞中的半衰期为约1至约7天。例如,环状RNA的半衰期可以是约1天、约2天、约3天、约4天、约5天、约6天、约7天或更多天。
在一些实施方案中,与使用编码线性RNA的病毒载体或作为线性RNA,将蛋白质编码核酸序列提供给细胞时相比,在细胞中产生蛋白质的持续时间长至少约10%、至少约20%或至少约30%。
在一些实施方案中,与使用病毒载体或作为线性RNA,将蛋白质编码核酸序列提供给细胞时相比,在细胞中产生蛋白质的水平高至少约10%、至少约20%或至少约30%。
在一些实施方案中,使用本文所述的IRES序列由环状RNA表达蛋白质可以允许甚至在应激条件下在细胞中由环状RNA持续表达蛋白质。响应一种或多种应激条件,由线性RNA生产蛋白质经常是压制的。相应地,在一些实施方案中,circRNA可以用作在应激条件过程中由线性RNA生产蛋白质的替代方案。在一些实施方案中,在细胞中由环状RNA表达的蛋白质在一种或多种应激条件下表达。在一些实施方案中,当细胞暴露于一种或多种应激条件时,细胞中来自环状RNA的蛋白质表达并未被大量破坏。例如,细胞暴露于一种或多种应激条件可能使来自环状RNA的蛋白质表达改变小于15%、小于10%、小于5%、小于3%、小于1%或小于0.5%。在一些实施方案中,由环状RNA表达的蛋白质在一种或多种应激条件下的表达水平与在一种或多种应激条件的不存在下在相同细胞中表达的水平基本上相同。在一些实施方案中,相对于在一种或多种应激条件的不存在下的表达水平,在细胞中来自环状RNA的蛋白质的表达水平为至少约70%、至少约75%、至少约80%、至少约85%、至少约90%、至少约95%或至少约99%。可能引起细胞应激的条件的非限制性列表包括温度变化(包括暴露于极端温度和/或热休克)、暴露于毒素(包括病毒或细菌毒素、重金属等)、暴露于电磁辐射、机械损伤、病毒感染等。
在一些实施方案中,本文描述的circRNA(包括其组分,例如IRES序列)促进来自circRNA的帽不依赖性翻译活性。通过帽不依赖性机制的规范翻译在一些人疾病中可能是减少的。相应地,使用circRNA表达蛋白质可能特别有助于治疗此类疾病。在一些实施方案中,在其中帽依赖性翻译在细胞中是减少或关闭的条件下,本文所述的circRNA的使用促进来自circRNA的帽不依赖性翻译活性。
如上文讨论的,当IRES与蛋白质编码核酸序列在框内并且蛋白质编码序列缺乏终止密码子时,蛋白质编码核酸序列的翻译可能以无限循环(即,递归地)发生。因此,在一些实施方案中,在细胞中产生蛋白质的方法产生串联蛋白质。
可以使本文描述的任何原核或真核宿主细胞与重组circRNA分子或包含circRNA分子的载体接触。宿主细胞可以是哺乳动物细胞,例如人细胞。在一些实施方案中,细胞是在体内的。在一些实施方案中,细胞是在体外的。在一些实施方案中,细胞是离体的。在一些实施方案中,细胞在哺乳动物例如人中。
在一些实施方案中,无论选择的细胞类型如何,5'帽依赖性翻译在细胞中是受损的(例如,降低的、减少的、抑制的或完全消除的)。在一些实施方案中,在细胞中不存在大量5'帽依赖性翻译。
重组环状RNA分子、编码其的DNA分子或包含其的载体可以通过任何方法引入细胞内,所述方法包括例如通过转染、转化或转导。术语“转染”、“转化”和“转导”在本文中可互换使用,并且指通过使用物理或化学方法将一种或多种外源多核苷酸引入宿主细胞内。许多转染技术是本领域已知的,并且包括例如磷酸钙DNA共沉淀(参见例如,Murray E.J.(编辑),Methods in Molecular Biology,第7卷,Gene Transfer and ExpressionProtocols,Humana Press(1991));DEAE-葡聚糖;电穿孔;阳离子脂质体介导的转染;钨粒促进的微粒轰击(Johnston,Nature,346:776-777(1990));磷酸锶DNA共沉淀(Brash等人,Mol.Cell.Biol.,7:2031-2034(1987);以及基于磁性纳米颗粒的基因递送(Dobson,J.,Gene Ther,13(4):283-7(2006))。
裸露RNA、编码环状RNA分子的DNA分子、或者包含环状RNA或编码环状RNA的DNA的载体可以以组合物的形式施用于细胞。在一些实施方案中,组合物包含药学上可接受的载剂。载剂的选择将部分由特定的环状RNA分子、DNA序列或载体,以及环状RNA分子、DNA序列或载体引入其内的细胞(或多种细胞)类型决定。相应地,各种组合物制剂是可能的。例如,组合物可以含有防腐剂,例如对羟基苯甲酸甲酯、对羟基苯甲酸丙酯、苯甲酸钠和苯扎氯铵。可以任选地使用两种或更多种防腐剂的混合物。另外,缓冲剂可以用于组合物中。合适的缓冲剂包括例如柠檬酸、柠檬酸钠、磷酸、磷酸钾以及各种其它酸和盐。可以任选地使用两种或更多种缓冲剂的混合物。用于制备用于药物用途的组合物的方法是本领域技术人员已知的,并且在例如Remington:The Science and Practice of Pharmacy,LippincottWilliams&Wilkins;第21版(2005年5月1日)中更详细地描述。
在一些实施方案中,含有重组环状RNA分子、DNA序列或载体的组合物可以配制为包合络合物,例如环糊精包合络合物,或脂质体。脂质体可以用于靶向宿主细胞或增加环状RNA分子的半衰期。用于制备脂质体递送系统的方法在例如Szoka等人,Ann.Rev.Biophys.Bioeng.,9:467(1980),以及美国专利4,235,871;4,501,728;4,837,028;和5,019,369中进行描述。重组circRNA分子也可以配制为纳米颗粒。
宿主细胞可以在体内或体外与重组circRNA分子、DNA序列、或载体、或含有前述任一种的组合物接触。术语“在体内”指在以其正常、完整状态的活生物内进行的方法,而“体外”方法使用已从其通常的生物背景中分离的生物的组分进行。当方法在体内进行时,在一些实施方案中,蛋白质的产生是组织特异性的。“组织特异性”意指蛋白质仅在生物内的组织类型子集中产生,或者相对于跨越所有组织类型的基线表达,在组织类型子集中以更高水平产生。蛋白质可以在任何组织类型中产生,所述组织类型例如肌肉、肝、肾、脑、肺、皮肤、胰腺、血液或心脏的组织。
抑制circRNA翻译
本公开内容还提供了包含核酸序列的寡核苷酸分子,所述核酸序列与环状RNA分子上存在的内部核糖体进入位点(IRES)杂交,并且抑制环状RNA分子的翻译。在一些实施方案中,环状RNA分子是天然存在的环状RNA分子。在一些实施方案中,环状RNA分子是重组环状RNA分子,例如本文所述的重组circRNA分子。在一些实施方案中,重组circRNA分子可以包含蛋白质编码核酸序列、以及(任选地,以非天然构型)可操作地连接到蛋白质编码核酸序列的IRES,其中所述IRES包含至少一个二级RNA结构;以及与18S核糖体RNA(rRNA)互补的序列;并且其中所述IRES具有小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度,如本文所述的。在一些实施方案中,重组circRNA分子可以包含蛋白质编码核酸序列、以及(任选地,以非天然构型)可操作地连接到蛋白质编码核酸序列的IRES;其中所述IRES由SEQ ID NO:1-228或SEQ ID NO:229-17201中列出的任何一个核酸序列、或者与其具有至少90%或至少95%同一性的核酸序列编码。
与重组circRNA分子上的IRES杂交的寡核苷酸可以具有任何类型和大小。在一些实施方案中,寡核苷酸可以是长度约8至约80个核苷酸,例如长度约15至约30个核苷酸。在一些实施方案中,寡核苷酸的长度可以为约20、约22或约24个核苷酸。在一些实施方案中,寡核苷酸可以是反义寡核苷酸(也被称为“ASO”)。如本文使用的,术语“反义寡核苷酸”指短的、合成的、单链寡脱氧核苷酸或寡脱氧核糖核苷酸,其与靶RNA序列互补并且可以通过几种不同的机制减少、恢复或改变蛋白质表达(Rinaldi,C.,Wood,M.,Nat Rev Neurol,14:9-21(2018);Crooke,S.T.,Nucleic Acid Ther.,27:70-77(2017);以及Chan等人,Clin.Exp.Pharmacol.Physiol.33:533-540(2006))。在一些实施方案中,反义寡核苷酸可以是锁核酸寡核苷酸(LNA)。术语“锁核酸(LNA)”指含有一个或多个核苷酸构件块的寡核苷酸,其中额外的亚甲基桥将核糖部分固定为C3'-内(β-D-LNA)或C2'-内(α-L-LNA)构象(Grünweller A,Hartmann RK,BioDrugs,21(4):235-243(2007))。在一些实施方案中,寡核苷酸是小干扰RNA(siRNA)、小发夹RNA(shRNA)、CRISPR(sgRNA)或微小RNA(miRNA)。
寡核苷酸可以包含一种或多种修饰,其增强寡核苷酸与circRNA分子的IRES的杂交和/或circRNA分子翻译的抑制。修饰可以在寡核苷酸的5'或3'端处。合适的修饰包括但不限于修饰的核苷间键合、修饰的糖或修饰的核碱基。在一些实施方案中,寡核苷酸可以与荧光团(例如,Cy3、FAM、Alexa 488等)或另一种分子(例如,生物素、碱性磷酸酶、抗体、核酸适体、肽等)缀合。在一些实施方案中,寡核苷酸可以用肽或蛋白质,例如使用点击化学进行标记。应了解,RNA和DNA的天然存在的核苷间键合是3'至5'磷酸二酯键合。已知具有一个或多个修饰的,即非天然存在的核苷间键合的寡核苷酸显示出期望性质,例如细胞摄取增强、对于靶核酸的亲和力增强和在核酸酶的存在下的稳定性增加。修饰的核苷间键合包括例如保留磷原子的核苷间键合以及不具有磷原子的核苷间键合。代表性的含磷核苷间键合包括但不限于磷酸二酯、磷酸三酯、甲基膦酸酯、氨基磷酸酯和硫代磷酸酯。制备含磷键合和不含磷键合的方法是众所周知的。
在一些实施方案中,寡核苷酸分子可以包含修饰的主链。具有修饰的主链的寡核苷酸包括在主链中保留磷原子的寡核苷酸和在主链中不具有磷原子的寡核苷酸。在其核苷间主链中不具有磷原子的修饰的寡核苷酸可以被称为“寡核苷”。修饰的寡核苷酸主链的实例包括但不限于具有正常3'-5'键合的硫代磷酸酯、手性硫代磷酸酯、二硫代磷酸酯、磷酸三酯、氨烷基磷酸三酯、甲基和其它烷基膦酸酯(包括3'-亚烷基膦酸酯、5'-亚烷基膦酸酯和手性膦酸酯)、次膦酸酯、氨基磷酸酯(包括3'-氨基氨基磷酸酯和氨基烷基氨基磷酸酯)、硫羰氨基磷酸酯、硫羰烷基膦酸酯、硫羰烷基磷酸三酯、硒代磷酸酯和硼代磷酸酯,这些的2'-5'连接的类似物,以及具有反转极性的那些,其中一个或多个核苷酸间键合是3'至3'、5'至5'或2'至2'键合。
寡核苷酸分子可以进一步包含具有修饰的糖部分的一个或多个核苷酸。糖修饰可以赋予寡核苷酸核酸酶稳定性、结合亲和力或一些其它有益的生物学性质。核苷的呋喃糖基糖环可以以多种方式进行修饰,包括但不限于特别是在2'位置处添加取代基;两个非孪生环原子的桥接以形成双环核酸(BNA);以及用原子或基团如—S—、—N(R)—或—C(R1)(R2)取代在4'-位置处的环氧。修饰的糖包括但不限于:取代的糖,尤其是具有2’-F、2’-OCH2(2’-OMe)或2’-O(CH2)2-OCH3(2’-O-甲氧基乙基或2'-MOE)取代基的2’-取代的糖;以及具有4’-(CH2)n-O-2’桥的双环修饰的糖(BNA),其中n=1或n=2。用于制备修饰的糖的方法是本领域技术人员众所周知的。
在一些实施方案中,寡核苷酸可以在其5'和/或其3'端处进行化学修饰。换言之,一个或多个部分可以以化学方式(例如,共价)连接到寡核苷酸分子的5’和/或3’端。此类修饰包括例如蛋白质或糖部分与寡核苷酸分子的5'和/或3'端的化学键合。增强寡核苷酸对于靶核酸的亲和力和/或增加寡核苷酸稳定性的其它修饰是本领域已知的(参见例如,美国专利申请公开US 2019/0323013),并且可以用于本公开内容的上下文中。
本公开内容还提供了抑制环状RNA分子上存在的蛋白质编码核酸序列翻译的方法,所述方法包括使环状RNA分子与上述寡核苷酸分子接触,由此寡核苷酸分子与环状RNA分子的IRES上存在的RNA二级结构和/或同18S rRNA互补的核酸序列杂交,并且抑制环状RNA分子的翻译。
在一些实施方案中,寡核苷酸可以与IRES上存在的RNA二级结构元件或同18SrRNA互补的核酸序列杂交。在其它实施方案中,寡核苷酸可以与RNA二级结构元件以及同18S rRNA互补的核酸序列两者杂交。例如,第一寡核苷酸可以与RNA二级结构元件杂交,并且第二寡核苷酸可以与同18S rRNA互补的核酸序列杂交。可替代地,单一寡核苷酸可以与IRES上存在的RNA二级结构元件以及同18S rRNA互补的核酸序列两者杂交。本文描述了适当的杂交严格性条件。
还提供的是组合物,其包含(i)本文公开的DNA序列,以及(ii)非编码环状RNA、或编码其的DNA序列。DNA序列可以编码circRNA。在一些实施方案中,非编码环状RNA可以包含关于RNA结合蛋白、适体或miRNA海绵的一个或多个结合位点。在一些实施方案中,非编码环状RNA可以具有一种或多种功能,例如使miRNA海绵化(sponging)、调控mRNA剪接机制、隔离RNA结合蛋白(RBP)、调控RBP相互作用或激活免疫应答。
还提供的是将非编码环状RNA递送至细胞的方法,该方法包括使细胞与组合物接触,从而将非编码环状RNA递送至细胞,所述组合物包含(i)本文公开的DNA序列,以及(ii)非编码环状RNA、或编码其的DNA序列。
下述实施例进一步说明了本发明,但当然不应解释为以任何方式限制其范围。
实施例
下述实施例描述了高通量筛选的开发,以系统地鉴定且定量可以指导circRNA翻译的RNA序列。超过17,000个circRNA内部核糖体进入位点(IRES)得到鉴定且验证,并且显示了IRES上的18S rRNA互补性和结构化RNA元件对于促进circRNA帽不依赖性翻译是重要的。使用IRES的基因组和肽组学分析,鉴定了近1,000种推定的内源性蛋白质编码circRNA,连同由这些circRNA编码的数百个翻译单元。还表征了circFGFR1p,一种由circFGFR1编码的蛋白质。该蛋白质充当FGFR1的负调控因子,以压制在应激条件下的细胞生长。
实施例1
该实施例描述了促进帽不依赖性circRNA翻译的RNA序列的系统鉴定。经由帽不依赖性机制的规范翻译在众多人疾病中可能是减少的。相应地,使用circRNA表达蛋白质可能特别有助于治疗此类疾病。
为了系统地鉴定可以促进circRNA上的帽不依赖性翻译的RNA序列,开发了寡核苷酸-拆分-eGFP-circRNA报道分子构建体,其允许以高通量方式筛选且定量在circRNA上的合成寡核苷酸插入物(下文“寡核苷酸”)的帽不依赖性翻译活性(图1A)。具体地,该构建体含有双顺反子mRuby报道分子,随后为侧翼为人ZKSCAN1内含子的置换的拆分-eGFP报道分子,其中在转录过程中,该构建体的前体mRNA将经历剪接体介导的反向剪接,并且在环状RNA上重构全长eGFP。因为全长eGFP仅在反向剪接后重构,所以eGFP荧光信号只能通过帽不依赖性翻译来自circRNA。然后将合成寡核苷酸文库克隆到构建体内,以驱动eGFP报道分子的表达(图1A)。该文库含有来自IRESite数据库(包括人和非人IRES;参见 等人,Nucleic acids research 38,D131-D136(2009))中报道的IRES的序列、病毒和人基因的天然5'非翻译区(5’UTR)、以及来自病毒和人转录物的天然和合成序列的55,000种寡核苷酸(图1A)。文库设计在Weingarten-Gabbay等人,Science 351,aad4939(2016)中进行详述。对于病毒和人转录物,选择了已报道在帽依赖性翻译被压制时仍与多核糖体结合的基因、以及具有在其翻译起始位点方面不同的替代同种型的基因(图1A)。
等人,Nucleic acids research 38,D131-D136(2009))中报道的IRES的序列、病毒和人基因的天然5'非翻译区(5’UTR)、以及来自病毒和人转录物的天然和合成序列的55,000种寡核苷酸(图1A)。文库设计在Weingarten-Gabbay等人,Science 351,aad4939(2016)中进行详述。对于病毒和人转录物,选择了已报道在帽依赖性翻译被压制时仍与多核糖体结合的基因、以及具有在其翻译起始位点方面不同的替代同种型的基因(图1A)。
关于双顺反子IRES筛选的两个众所周知的关注分别是激活下游开放读码框(ORF)的转录或通读的隐性启动子或剪接位点。本文使用的设计避免了这两个关注,因为仅拆分-eGFP的5'片段的异位转录不能产生荧光信号。RNA印迹、定量逆转录聚合酶链反应(qRT-PCR)、RNA酶R处理和报道基因实验确认了,所检测到的eGFP信号并非来自eGFP circRNA的反式剪接或切口(图8A-8C)。报道分子产生~3000核苷酸(nt)的初级线性转录物和~900nt的eGFP circRNA;RNA酶R核酸外切酶处理可以有效地去除线性转录物,而不是circRNA(图8A)。mRuby基因允许通过常规线性mRNA的翻译对于转导效率进行标准化。在转染到人胚肾(HEK)293T细胞内之后,转染的细胞按eGFP/mRuby荧光的比率分选到七个框内,并且通过深度测序对每个池中的寡核苷酸序列频率进行解卷积(图1A)。使用该系统,以高通量方式对于文库中的每种寡核苷酸定量在circRNA上的帽不依赖性翻译活性是可能的。
55,000种寡核苷酸中的40,855种从文库中进行捕获(~74.3%)。为了定量每种寡核苷酸的eGFP表达水平,计算了跨越框的读数的平均加权等级分布。每个框的权重是该框中的读数数目占其在所有七个框中总读数的分数。等级是从具有最低eGFP强度的框(框#1)到具有最高eGFP强度的框(框#7)的框编号。(图1B)。发现了翻译活性的定量在两个独立的生物重复之间是高度可重复的(皮尔逊相关系数R=0.70)(图9A)。进一步确认了,结果并未被由于不同寡核苷酸插入物所致的circRNA反向剪接效率的变化而混淆(图9B和9C)。该筛选测定根据其eGFP表达水平揭示了三组寡核苷酸-并未显示eGFP表达的一组(~2,500)寡核苷酸(eGFP表达(框)=0.0),以及显示eGFP表达的双峰分布的两组寡核苷酸(eGFP表达(框)分别=0.8-2.2和2.4-7.0)。为了确定具有帽不依赖性翻译活性的寡核苷酸(eGFP(+)寡核苷酸),将用no-IRES插入的报道质粒(空eGFP circRNA)转染的细胞的eGFP强度的加权等级分布计算为背景eGFP表达。定义为eGFP(+)寡核苷酸的寡核苷酸是eGFP表达高于背景eGFP表达的寡核苷酸(eGFP表达(框)=3.466387)(图1B)。背景eGFP表达基于跨越框的读数分布而不是简单的截止值进行计算,其为避免可能的假阳性事件的更保守方法,因为空的circRNA eGFP报道分子可能具有弱翻译活性(图9D)。使用这种方法,从筛选测定中鉴定了17,201种eGFP(+)寡核苷酸(图1B,SEQ ID NO:1-17201)。进一步地,验证了筛选结果并非eGFP报道分子特异性的,因为所鉴定的eGFP(+)寡核苷酸能够起始具有不同编码序列(CDS)的报道分子的circRNA翻译(图9E)。尽管可重复地检测到circRNA翻译,但与由帽依赖性翻译驱动的线性RNA翻译相比,对于由eGFP(+)寡核苷酸驱动的circRNA观察到基本上更弱的帽不依赖性翻译活性(图9F)。
因为先前的研究已在线性双顺反子eGFP报道分子筛选测定上利用了相同的合成寡核苷酸文库,以鉴定在线性RNA上帽不依赖性翻译活性超过作为阈值的no-IRES插入的报道质粒的寡核苷酸(Weingarten-Gabbay等人,2016),所以分别比较线性RNA和环状RNA上的每种寡核苷酸序列的帽不依赖性翻译活性是可能的。对于每种寡核苷酸,计算了来自circRNA相对于来自线性RNA模板的标准化的eGFP表达。发现了在circRNA和线性RNA报道分子筛选两者中捕获的寡核苷酸(n=13,645)中,大量寡核苷酸在线性和环状RNA筛选系统两者中均显示了帽不依赖性翻译活性(n=7,424)(图1D、图11A)。然而,在环状RNA相对于线性RNA的总体IRES活性之间存在很少的相关性(皮尔森R=0.014;斯皮尔曼R=0.010)(图1D)。有趣的是,还捕获了一些寡核苷酸,其在线性或环状筛选系统中特异性地显示了IRES活性(分别为线性IRES和环状IRES)(图1D)。为了限定线性和环状IRES,采取了更保守的方法,其中线性IRES代表仅在线性RNA筛选系统中显示帽不依赖性翻译活性的寡核苷酸;而环状IRES代表仅在环状RNA筛选系统中显示帽不依赖性翻译活性的寡核苷酸。使用这种方法,鉴定了4,582种环状IRES和1,639种线性IRES(图1D、图11A)。
此外,当分别在环状IRES、线性IRES以及在线性和环状RNA两者中显示翻译活性的IRES中检查人和病毒IRES的分布时,在IRES中并未发现显著差异(图11B-11D)。结果提示了,环状IRES上的circRNA特异性IRES反式作用因子(ITAF)的募集或活性可能取决于circRNA特异性生物发生,例如circRNA反向剪接或circRNA核输出,以区分circRNA与线性RNA。总之,这些结果证实了,利用circRNA报道构建体的高通量筛选测定能够系统地鉴定具有IRES活性的RNA序列,其可以促进circRNA上的帽不依赖性翻译。
实施例2
该实施例证实了,包含eGFP+寡核苷酸序列的合成circRNA被活跃地翻译。
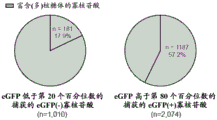
为了验证实施例1的筛选结果,使用多核糖体概况分析来检查含有所鉴定的eGFP(+)寡核苷酸序列的circRNA是否被活跃地翻译并且在核糖体上接合。首先,HEK-293T细胞用含有合成寡核苷酸文库的寡核苷酸-拆分-eGFP-circRNA报道构建体进行转染,用环己酰亚胺(CHX)处理转染的细胞,并且用蔗糖梯度分级来分离(多)核糖体相关RNA(图2A、2B、图12A)。进一步地,用RNA酶R处理级分,以获得(多)核糖体相关circRNA的高富集,并且执行高通量测序,以鉴定每个级分中由circRNA包含的IRES序列。RNA酶R处理在允许RNA酶R有效消化含有潜在G-四链体的线性RNA的条件下执行,并且RNA酶R消化持续时间进行优化,以获得相对于线性RNA>100倍的circRNA富集(图12B)。与CHX处理相比,用嘌呤霉素(PMY)处理转染的细胞导致翻译的circRNA从多(核糖体)相关级分转变为40S级分(图12C),提示了CHX处理能够捕获翻译的circRNA。为了避免结果被弱翻译的circRNA混淆(数据未显示),计算了eGFP(+)寡核苷酸中eGFP表达高于第80个百分位数的(多)核糖体富集寡核苷酸的比率,并且与eGFP表达低于第20个百分位数的eGFP(-)寡核苷酸进行比较。结果证实了,与eGFP(-)寡核苷酸(17.9%)相比,eGFP(+)寡核苷酸在(多)核糖体级分(57.2%)中更富集(图2C)。确认了(多)核糖体相关eGFP(+)寡核苷酸的较高富集并非由寡核苷酸的捕获效率或表达水平引起(图12D和12E)。结果提示了,含有eGFP(+)寡核苷酸序列的circRNA被更活跃地翻译。然而,由于多核糖体概况分析对于捕获弱翻译的circRNA具有较低的灵敏度(数据未显示),因此利用定量翻译起始测序(QTI-seq)数据用于另外的验证。接下来,检查了来自QTI-seq的公开数据,所述QTI-seq是修改的核糖体概况分析(Ribo-seq)技术,其绘制在全基因组范围内的翻译起始位点(TIS)(Gao等人,Nat Methods 12,147-153,2015)。首先,检查eGFP(+)寡核苷酸序列是否与人转录物上的那些鉴定的TIS重叠。结果证实了,在衍生自具有Ribo-seq覆盖的人基因组的寡核苷酸中,大多数eGFP(+)寡核苷酸(~76%)与通过QTI-seq鉴定的人转录物上鉴定的TIS重叠(TIS(+)寡核苷酸),而仅30%的eGFP(-)寡核苷酸是TIS(+)(图2D和2E、图13A),提示了eGFP(+)寡核苷酸比eGFP(-)寡核苷酸更有可能在那些TIS处起始翻译。有趣的是,通过检查人基因组上的eGFP(+)/TIS(+)寡核苷酸,鉴定了三种类型的eGFP(+)/TIS(+)寡核苷酸:(1)含有在线性转录物上已注释的翻译起始位点的寡核苷酸(注释的TIS;aTIS),(2)含有在线性转录物上并未注释的翻译起始位点的寡核苷酸(未注释的TIS;nTIS),所述翻译起始位点可以定位于转录物的5’UTR、CDS或3’UTR区域处,以及(3)含有aTIS和nTIS信号两者的寡核苷酸(双重TIS;dTIS)(图2D和2E)。这些不同类型的TIS(+)寡核苷酸可能提示了寡核苷酸利用不同的机制用于起始翻译。虽然aTIS寡核苷酸(~30%)可能利用与线性转录物相同的注释的翻译起始位点用于帽不依赖性翻译,但相比之下nTIS(~41%)代表了用于帽不依赖性翻译的不同于线性转录物的新型翻译起始位点,该帽不依赖性翻译已在起始替代翻译产物的合成时观察到。对于dTIS寡核苷酸,它们可能利用一些未表征的调控机制来协调aTIS和nTIS之间的双重活性,这需要进一步的调查。重要的是,虽然寡核苷酸文库富含定位于注释的起始密码子上游处的寡核苷酸,但并未观察到朝向aTIS寡核苷酸比率的偏向,提示了结果并未被寡核苷酸文库的设计所混淆。有趣的是,发现了eGFP(+)/TIS(+)寡核苷酸定位于编码注释的circRNA的基因组区域内(图2D),这提示了这些circRNA可能利用寡核苷酸上的TIS用于起始内源性circRNA翻译。然而,当翻译起始位点的位置被映射到每种寡核苷酸上时,在寡核苷酸上没有观察到翻译起始热点(图13B),提示了翻译起始不受寡核苷酸上的位置的影响。总之,上文结果提供了以下的强烈证据:本文所述的筛选测定能够鉴定能够促进circRNA上的帽不依赖性翻译活性的寡核苷酸序列。
实施例3
该实施例描述了促进circRNA翻译的18S rRNA互补序列的鉴定。
已证实了IRES和18S核糖体RNA(18S rRNA)之间的沃森-克里克碱基配对促进线性mRNA的帽不依赖性翻译。因此,评估了筛选是否可以鉴定人18S rRNA上可以与circRNAIRES相互作用并促进帽不依赖性翻译的区域。合成寡核苷酸文库设计为含有具有与人18SrRNA互补的序列的171种寡核苷酸,伴随在重构整个1869-nt全长18S rRNA序列的每个连续的寡核苷酸之间的10-nt滑动窗口(图3A,SEQ ID NO:28977-28983)。对于18S rRNA上的每个位置,计算了含有相应互补序列的所有寡核苷酸的平均eGFP表达。使用这种滑动窗口方法,对于跨越人18S rRNA序列的每个10-nt窗口确定了circRNA IRES活性(图3A)。鉴定了18S rRNA上的六个“活性区域”,其中这些活性区域内的互补序列显示了高于背景eGFP表达的平均eGFP表达(图3B)。有趣的是,活性区域2、4、5和6包含螺旋,已报道所述螺旋与真核核糖体起始复合物中的mRNA接触并与翻译的RNA相互作用(Pisarev等人,EMBO J 27,1609-1621(2008))(图3C)。此外,活性区域4以及活性区域2和6包含这样的序列,其已表征为通过沃森-克里克碱基配对分别促进IGF1R和HCV IRES的帽不依赖性翻译(图3C)。活性区域3定位于18S rRNA的扩展区段之一(ES6S)中,所述扩展区段之一已牵涉真核起始因子3(eIF3)的募集。eIF3直接结合线性mRNA的5’UTR N6-甲基腺苷(m6A),并且起始帽不依赖性翻译,提示了18S rRNA上的活性区域3可能对于eIF3-m6A介导的帽不依赖性翻译至关重要。活性区域1定位于18S rRNA上的另一个扩展区段(ES3S)中,所述扩展区段与活性区域3相互作用并形成三级结构,这提示了活性区域1也可能涉及eIF3-m6A介导的帽不依赖性翻译。这些结果提示了,所鉴定的18S rRNA上的活性区域确实在促进帽不依赖性翻译中发挥作用。
由于衍生自活性区域4的7聚体已显示在关于线性RNA的报道IRES中富集,所有7聚体都从与18S rRNA的活性区域互补的序列中提取(活性7聚体),并且比较了分别由eGFP(+)和eGFP(-)寡核苷酸包含的活性7聚体的数目。发现了eGFP(+)寡核苷酸具有比eGFP(-)寡核苷酸更高的活性7聚体富集(图3D)。相反之下,当比较在eGFP(+)和eGFP(-)寡核苷酸之间不与活性7聚体重叠的随机7聚体的匹配数目时,并未发现显著差异(图3D),提示了此处观察到的eGFP(+)寡核苷酸中的活性7聚体的更高富集对于18S rRNA互补序列是特异性的。然而,并未观察到定位于circRNA IRES上的活性7聚体的热点位置(图13C)。为了进一步验证结果,IRES的18S rRNA互补性通过用随机7聚体取代18S rRNA互补序列或将侧翼18S rRNA互补序列加入IRES进行扰乱,并且测量其circRNA翻译活性(图3E)。对于IRES上的较低18SrRNA互补性,观察到缩减的IRES活性,并且相反地,对于对IRES添加的较高的18S rRNA互补性,编程更强的IRES活性(图3E)。这些结果提示了,含有与18S rRNA上的活性区域互补的RNA序列的circRNA IRES是可以促进circRNA上的帽不依赖性翻译的调控元件之一。
实施例4
该实施例描述了使用系统扫描诱变来鉴定circRNA IRES上的必需元件。
采用扫描诱变来限定circRNA IRES上的必需元件。该分析中包括的是设计用于扫描合成寡核苷酸文库中的99种报道的IRES和734种天然5’UTR的诱变的寡核苷酸。寡核苷酸被设计为跨越整个IRES或5’UTR平铺的14-nt随机取代突变的非重叠滑动窗口(图3F)。使用筛选结果,跨越每种寡核苷酸序列确定每个14-nt窗口上的取代突变对IRES活性的作用是可能的(图3F)。必需元件(图3G;以蓝色突出显示)被确定为从其中存在IRES活性的急剧下降的突变起始位置(图3G;黑点)到其中IRES活性恢复或高于平均eGFP表达水平的突变的下一个起始位置的区域。通过将定量结果与充分表征的IRES——丙型肝炎病毒(HCV)IRES进行比较,观察到HCV IRES上的已知功能结构域(图3G;红线)与突变位置共定位,所述突变位置具有急剧减少的IRES活性。在这些突变位置处的IRES活性的特异性减少提示了突变破坏IRES的必需元件,消除了其帽不依赖性翻译活性。结果证实了该测定确实可以捕获HCVIRES上所有报道的必需元件,以及一种可能的尚未表征的新型必需元件(图3G)。
还利用相同的扫描诱变测定,以通过扫描诱变进一步鉴定所鉴定的circRNA IRES上的必需元件。合成寡核苷酸文库含有携带跨越circRNA IRES平铺的14-nt随机取代突变的滑动窗口的寡核苷酸。使用扫描诱变,捕获了两类circRNA IRES-具有局部敏感性的circRNA IRES,其显示了仅当特定位置突变时circRNA IRES活性的减少(图3H;顶部),以及具有总体敏感性的circRNA IRES,其中在大多数位置中的突变可以导致IRES活性的减少(图3H;底部)。局部和总体敏感性IRES分别定义为IRES活性是受单一突变的影响还是受多重突变的影响。与局部敏感性IRES相比,总体敏感性IRES具有更加结构化的序列(即显著较低的最小自由能(MFE)值);这提示了总体敏感性IRES的整体二级结构对于其IRES活性至关重要,因为无论突变的位置如何,所述更加结构化的序列更有可能受突变的影响。另一方面,局部敏感性IRES具有更不结构化的序列且对突变更具抗性;这提示了局部敏感性IRES的IRES活性可能受作为必需元件的短序列的调控。
通过叠加具有总体敏感性的所有捕获的circRNA IRES的eGFP表达水平,在IRES上鉴定了三个区域(5-15nt、40-60nt和135-165nt),其中当突变命中这些区域时,IRES活性显著降低(图3I),提示了这些区域可能包含用于促进circRNA IRES的帽不依赖性翻译的关键元件。为了进一步表征由这些区域所包含的元件是否是结构依赖性的,以15nt非重叠窗口沿着具有总体敏感性的circRNA IRES计算了局部MFE。发现circRNA IRES上的40-60nt区域的局部MFE显示了显著较低的局部MFE(图3I和3J;红色阴影),提示了该区域可能包含可以驱动circRNA翻译的局部结构元件。相比之下,5-15nt和135-165nt区域的局部MFE与IRES上的其它区域并无不同(图3I和3J;蓝色阴影),这提示了定位于这两个区域处的调控元件并不涉及局部二级结构。
总的来说,该数据指示了,使用扫描诱变,该测定能够确定具有局部或总体敏感性的circRNA IRES,并且以高通量方式系统地鉴定对于IRES活性所需的必需circRNA IRES元件。
实施例5
该实施例证实了,在circRNA IRES上的不同位置处的茎环结构促进了帽不依赖性的翻译。
虽然已报道许多天然和合成的IRES能够促进circRNA上的帽不依赖性翻译,但大多数IRES在线性RNA报道系统中进行表征,并且尚未报道线性相对于环状RNA上的IRES的差异IRES活性。通过将来自本文描述的circRNA报道系统的筛选结果与使用相同合成寡核苷酸文库在线性RNA报道系统上完成的先前筛选研究进行比较,鉴定了两组不同的寡核苷酸,其特异性地包含线性或环状RNA上的IRES活性(分别为线性IRES和环状IRES)。为了表征可以区分线性和环状IRES的这些寡核苷酸上的特征,分析了寡核苷酸的一级序列,并且发现了环状IRES含有比线性IRES更高的GC含量和更低的MFE(图14A)。另一方面,规范翻译起始密码子(AUG)、Kozak共有序列(ACCAUGG,SEQ ID NO:34039)和m6A基序(RRACH,SEQ ID NO:33944)的数目并未显示在线性和环状IRES之间的差异(图14B-14D)。由于具有低MFE的RNA经常指示了RNA具有稳定的二级结构,因此环状IRES的低MFE提示了一些结构元件可能在促进circRNA上的帽不依赖性翻译活性中发挥作用。
然后用M2-seq表征线性和环状IRES的二级结构,所述M2-seq是系统突变概况分析和化学结构探测的测定,其以非常低的假阳性率捕获RNA二级结构。选择了四种环状IRES和线性IRES,其分别在circRNA或线性RNA上特异性地显示了IRES活性(图14E),并且其二级结构用M2-seq进行确定。选择这些寡核苷酸是因为它们分别在环状RNA系统(环状IRES:6742、9128、19420和18377)或线性RNA系统(线性IRES:6885、6103、5471和6527)中包含强IRES活性,并且在线性双顺反子构建体上不显示通读翻译、核糖体重新起始和隐藏的启动子活性的任何活性,以确保在此处在线性双顺反子构建体上检测到的eGFP信号来自寡核苷酸的帽不依赖性翻译。M2-seq结果揭示了,虽然线性IRES包含结构化元件,但环状IRES一般而言比线性IRES更加结构化(图4A和4B、图14F和14G)。在检查的所有四种环状IRES中,全部含有在IRES上的不同位置(距IRES的+1位置(第一个核苷酸)40-60nt位置)处的茎环结构化RNA元件(SuRE),而检查的所有线性IRES在此位置处并不含有此类结构(图4A和4B、图14F和14G)。与先前的系统扫描突变概况分析一致,所述分析也提示了IRES上的这个不同位置含有促进circRNA翻译所需的结构元件(图3I和3J),提议了在IRES上的这个不同位置处的SuRE可以促进环状IRES上的帽不依赖性翻译活性。
为了验证这个假设,通过用从线性IRES(寡核苷酸索引:6885)上的相同位置提取的序列取代其来破坏在环状IRES(寡核苷酸索引:6742)上的40-60nt位置处的SuRE,在此位置处形成不同的二级结构(图4C)。有趣的是,破坏在环状IRES上的这个位置处的SuRE导致其IRES活性的减少(图4I)。此外,为了测试SuRE元件是否是位置敏感性的,通过交换IRES上的这两个区域的序列,将SuRE元件从40-60nt位置重新定位到90-110nt位置。观察到IRES的翻译活性降低(图4D和4I)。为了进一步验证SuRE是结构依赖性而不是序列依赖性的,执行了SuRE元件的补偿性诱变。具体地,在SuRE元件的茎区域上的七个碱基对各自进行突变,以破坏其双链体结构。观察到IRES的较低翻译活性(图4E和4I)。此外,IRES的翻译活性可以通过补偿性双重互补突变来拯救,以恢复茎区域上的七个碱基对中的每一个(图4F和4I)。有趣的是,当SuRE被具有相似RNA结构的MS2或BoxB取代时,观察到与野生型IRES相同的IRES活性(图4G和4I),提示了受SuRE调控的IRES活性确实是结构依赖性而不是序列依赖性的。最后,通过将SuRE从环状IRES移植到线性IRES上的40-60nt位置,将线性IRES转换成环状IRES(图4H和4I)。上文结果提示了在IRES上的40-60nt SuRE确实可以促进circRNA翻译。
总之,上文结果连同18S rRNA概况分析提示了,circRNA IRES上的两个关键调控元件:IRES上的18S rRNA互补性和40-60nt SuRE,可以促进circRNA上的帽不依赖性翻译。与该模型一致,在通过筛选捕获的17,201种eGFP(+)寡核苷酸中,其中12,091种(~70%)包含高18S rRNA互补性(18S rRNA互补性(+))或40-60nt SuRE(SuRE(+))(图4J),这提示了这两个调控元件可以促进外源报道分子circRNA的翻译。为了进一步验证这两个调控元件是否也可以促进内源性circRNA翻译,检查了HEK-293细胞中捕获的多核糖体相关circRNA(翻译circRNA)(Ragan等人,2019),并且发现了165种内源性翻译circRNA中的123种(~75%)是18SrRNA互补性(+)或40-60nt SuRE(+)circRNA(图4J),指示了这两个调控元件是内源性翻译的circRNA中的共同特征。这些结果提示了,18SrRNA互补性和40-60nt SuRE可以促进外源性报道分子circRNA和内源性circRNA两者的翻译。然而,并未观察到18S互补序列对SuRE的5'或3'的优先定位(图13C);这提示了IRES上的SuRE可能导致RNA解旋的暂停,增加IRES上的18S互补序列与核糖体上的18S 25rRNA相互作用的机会,并且促进circRNA上的帽不依赖性翻译(图4K)。
实施例6
该实施例证实了IRES元件促进内源性circRNA的翻译起始。
为了检查IRES上鉴定的关键调控元件,例如18S rRNA互补序列以及在40-60nt位置处的SuRE,是否可以促进人内源性circRNA的翻译,利用锁核酸(LNA)来破坏IRES上的这些关键元件,因为LNA已用于特异性地破坏HCV IRES上的功能区域并抑制HCV IRES活性。对于所鉴定的IRES,设计了靶向以下的反义LNA:(i)IRES上的18S rRNA互补序列,以阻断18SrRNA与IRES的结合(LNA-18S),(ii)在40-60nt位置处的SuRE,以破坏IRES上的SuRE(LNA-SuRE),以及(iii)在IRES上的LNA-18S或LNA-SuRE下游的随机位置(LNA-Rnd)(图5A)。然后将LNA分别与含有相应IRES的寡核苷酸-拆分-eGFP-circRNA报道构建体共转染,并且通过其标准化的荧光信号强度测量eGFP报道分子的翻译活性。发现了共转染LNA-18S或LNA-SuRE确实可以破坏所有IRES的帽不依赖性翻译活性(10个LNA中的10个),而大部分LNA-Rnd共转染并不影响IRES的翻译活性(5个LNA中的4个)(图5B)。还确认了结果并未被circRNA表达水平的变化所混淆,因为共转染LNA一般并不改变circRNA表达水平(图15A)。结果提示了,用LNA破坏IRES上的关键元件可以影响外源报道分子circRNA的帽不依赖性翻译活性。
为了进一步检查IRES上鉴定的关键调控元件是否也可以促进人内源性circRNA的翻译,细胞用相应的反义LNA进行转染并且通过QTI方法定量翻译circRNA。具体地,为了分离翻译RNA,LNA转染的细胞用lactimidomycin(LTM)进行处理,随后为嘌呤霉素(PMY)处理,用蔗糖垫使核糖体相关RNA沉降,并且纯化翻译RNA(图5C)。然后使用跨越circRNA的反向剪接连接点的背靠背引物,通过qRT-PCR定量含有LNA靶向IRES的翻译内源性circRNA的水平。发现通过LNA-18S或LNA-SuRE破坏内源性circRNA的IRES上的关键调控元件一般而言可以导致circRNA的翻译活性降低(10个LNA中的8个),而所有LNA-Rnd都不影响内源性circRNA的翻译活性(5个LNA中的5个)(图5D)。还确认了LNA转染并未改变内源性circRNA的表达水平(图15B)。由于QTI方法特异性地捕获处于翻译的起始阶段的RNA,因此提示了在LNA转染后观察到的内源性circRNA翻译的降低来自翻译起始的降低。通过经由蛋白质印迹定量由内源性circRNA产生的蛋白质水平,进一步验证了结果。蛋白质印迹结果与QTI-qRT-PCR结果中观察到的相匹配-破坏内源性circRNA的IRES上的关键调控元件一般减少由circRNA产生的蛋白质水平(4个LNA中的3个)(图5E)。上文结果提示了,在IRES上鉴定的关键元件,例如18S rRNA互补序列以及在40-60nt位置处的SuRE,对于促进内源性circRNA的翻译起始是重要的。
实施例7
该实施例描述了可能的内源性蛋白质编码circRNA的鉴定。在circRNA上引入合成IRES足以起始帽不依赖性翻译,提示了包含活性环状IRES的内源性circRNA可能具有以帽不依赖性翻译产生蛋白质的潜力。因此,为了确定潜在的circRNA蛋白质组,将筛选中捕获的eGFP(+)寡核苷酸序列导入人circRNA数据库(circBase)Glazar等人,RNA 20,1666-1670(2014))内,以鉴定包含活性IRES的内源性circRNA。通过仅考虑已通过两种不同的circRNA预测算法注释的circRNA,并且在该分析中仅包括具有高映射评分的circRNA,数据针对假阳性进行门控。结果提示了,高比例的内源性circRNA潜在地是蛋白质编码的:在含有来自用于筛选测定的合成文库的寡核苷酸序列的2,052种内源性circRNA中,979种circRNA(~48%)含有一个或多个eGFP(+)寡核苷酸序列(IRES(+)circRNA)(图6A、图16A、表6)。这些circRNA由各种亲本基因生成,所述亲本基因显示了跨越基因组相当均匀的分布(基尼指数=0.38)(图6B)。为了进一步确定这些IRES(+)circRNA是否与癌症进展相关,检查了癌症特异性circRNA数据库(CSCD)(Xia等人,Nucleic Acids Res 46,D925-D929(2018)),其含有通过分析228个癌症和正常细胞系进行的RNA-seq数据的潜在癌症相关circRNA的集合。有趣的是,发现了979种IRES(+)circRNA中的294种(~30%)分别在非转化的细胞系(n=141个细胞系)或癌细胞系(跨越19种癌症类型的n=87个细胞系)中特异性表达(图6C),指示了其与癌症进展的潜在相关。
发现了大多数IRES(+)circRNA仅含有一个IRES(图6D),并且大多数eGFP(+)寡核苷酸仅映射到一个circRNA(图6E),提示了这些IRES(+)circRNA以及由其编码的蛋白质之间的特异性一对一关系。部分地基于文库设计预计了这一结果。另外,对于针对其设计了跨越整个转录物平铺的寡核苷酸的159种转录物,观察到每circRNA一个IRES的优势(图16B和16C)。因此,circRNA IRES难以(如果不可能)通过跨越circRNA的比较序列分析来发现,但可以通过无偏功能筛选来发现。结果还提示了,circRNA IRES活性可能需要长RNA序列,其更有可能每个转录物出现一次,而不是每个转录物出现多次的极短序列或重复序列。此外,发现了映射的eGFP(+)寡核苷酸在circRNA上的位置最频繁地在circRNA的反向剪接连接点处附近(在距连接点100-200nt内),而GC匹配的寡核苷酸(具有与映射的eGFP(+)寡核苷酸相同的GC含量、在IRES映射的circRNA上的174nt寡核苷酸)的平均位置显示跨越距circRNA上的反向剪接连接点广泛范围的距离的随机分布(距连接点100至2000nt)(图16D)。这一结果提示了IRES对circRNA的帽不依赖性翻译活性是反向剪接依赖性的-IRES元件或其下游开放读码框(ORF)仅在反向剪接后进行组装。这要求IRES定位于连接点附近,以促进其帽不依赖性翻译活性。最后,这些circRNA的亲本基因的基因本体论(GO)分析提示了它们富含应激应答和翻译调控(图6F)。最重要的是,这些结果证实了,使用鉴定的eGFP(+)寡核苷酸序列,确定具有潜在帽不依赖性翻译活性的内源性circRNA是可能的,所述内源性circRNA可能编码新的蛋白质同种型。
实施例8
该实施例描述了潜在的内源性circRNA编码的多肽的鉴定。
为了确定由RNA编码的蛋白质的多肽序列,限定了RNA上的蛋白质编码序列。这通常通过ORF分析来实现。然而,由于缺乏翻译在circRNA上哪里起始的信息,circRNA上的ORF分析经常返回大量结果。本文呈现的数据可以映射eGFP(+)寡核苷酸序列在circRNA上的位置,这允许确定circRNA上翻译起始位点可能定位于其中的区域。因此,为了确定由内源性circRNA编码的蛋白质的潜在多肽序列,将eGFP(+)寡核苷酸序列映射到circBase中的每种个别高置信度circRNA的序列(如上所述预门控高置信度circRNA),以确定IRES在每种circRNA上的位置(图6G)。然后通过从映射的IRES位置的立即下游翻译起始密码子(AUG)执行ORF分析,生成由每种circRNA编码的蛋白质的预测的多肽序列(图6G)。因为已报道许多IRES能够从非规范起始密码子起始翻译,所以还对具有来自映射的IRES位置的非规范起始密码子的前三个框(+1到+3)执行了ORF分析(图6G)。使用这种方法,生成了由人内源性circRNA(circORF)编码的预测的多肽序列列表。为了保守起见,还检查了由线性RNA编码的微肽,并且在最终列表中排除了任何重叠的circORF(n=5种重叠的circORF)。最终列表含有958种由内源性circRNA编码的潜在circORF(图6G,SEQ ID NO:32954,-33911,表7A和7B)。
通过分析在circRNA上的circORF序列以及映射的IRES位置,发现了一些circRNA含有与ORF的翻译区重叠的IRES序列(n=457;~48%)(图16E)。在一些内源性circRNA编码的蛋白质中已观察到IRES重叠的ORF,这提示了在circRNA翻译的起始和延伸之间可能存在一些调控机制。有趣的是,在具有IRES重叠ORF的这些circRNA中,其中一些含有不含终止密码子的框内ORF(n=82;~18%),形成递归ORF,其可能是扩大circRNA编码蛋白质的表达水平的机制(图16F)。进一步证实了框内IRES确实可以在eGFP circRNA报道分子上产生递归ORF(图16G)。
接下来,通过在预测的多肽序列上搜索保守基序来表征这些潜在circORF的一般功能。Pfam分析揭示了大量的circORF含有保守的基序。顶部的基序是DNA结合基序、翻译延伸因子结合基序、蛋白激酶结构域和蛋白质二聚化结构域(图6H),提示了circORF可能在调控各种生物学功能(包括信号转导、转录和翻译)中发挥作用。大多数这些潜在的circORF的大小很小(<100个氨基酸)(图16H),这提示了其中大多数可能是由其亲本线性转录物生成的蛋白质的截短形式。
为了进一步验证潜在的circORF,检查了短的开放读码框(sORF)数据库(Olexiouk等人,Nucleic acids research 46,D497-D502(2017)),其含有来自通过多重核糖体概况分析研究聚集的所鉴定的sORF的多肽序列(<100个氨基酸),以检查这些sORF的多肽序列是否可以与circORF相匹配。sORF首先被映射到当前的蛋白质组数据库(UniProt),并且与注释的线性转录物的ORF完全匹配的那些sORF被排除。然后将剩余的sORF映射到潜在的circORF。鉴定了317种预测的circORF,其可以被sORF相匹配(~33%)(图16I),提示了映射的IRES ORF分析方法可以有效地鉴定内源性circORF。另一方面,采用所有可能的翻译起始位置的在相同circRNA上的传统ORF分析,给出了大量的预测多肽(n=426,439),其中这些多肽中的仅极小部分被sORF研究捕获(n=9,970;~2%)(图16I)。因此,circRNA IRES的了解导致预测circRNA衍生的sORF的~15倍改善。总之,结果提示了,与传统的ORF分析相比,映射的IRES ORF分析能够更有效地鉴定内源性circORF。
随后,对串联质谱法(MS/MS)数据集执行肽组学分析,以验证circORF的内源表达。具体地,将预测的circORF列表附加到当前蛋白质组数据库(UniProt;线性蛋白质组),并且生成组合的蛋白质组数据库(circORF+线性蛋白质组)。然后从广泛范围的细胞系(包括K562、H358、U2OS)、亚细胞区室SubCellBarCode(SCBC)数据库、以及来自GTEx集合的32种正常人组织中获取原始MS/MS数据,并且针对组合的蛋白质组数据库执行肽谱匹配(PSM)(图6I)。为了区分circORF与线性蛋白质组,如果circORF被还可匹配线性蛋白质组的胰蛋白酶多肽相匹配,则排除circORF(图6I)。捕获了含有MS匹配的独特胰蛋白酶多肽的118种circORF(图6J),其中包含MS匹配的胰蛋白酶多肽的22种circORF跨越circRNA反向剪接连接点(BSJ)(图6K)。除转化的细胞系外,还捕获了正常人组织的肽组学中的circORF(Jiang等人,2020),提示了这些circORF在正常人细胞中表达。此外,执行了平行反应监测-MS(PRM-MS),以提供K562和U2OS中的circORF表达的高分辨率验证。具体地,设计并合成了从K562和U2OS MS/MS肽组学鉴定的circORF独特区域的重同位素标记的参考多肽,将标记的参考多肽掺入到胰蛋白酶多肽样品内,并且根据标记的参考多肽执行前体和过渡离子检测(图6L,SEQ ID NO:32954-33911,以及表7A和7B)。PRM-MS进一步验证了8种靶向circORF中的6种的存在(图6L,SEQ ID NO:32954-33911,以及表7A和7B)。MS/MS和PRM-MS肽组学提供了证实circORF确实是内源性表达的强烈证据。作为一种补充方法,在人iPSC中检查了核糖体足迹(RFP)数据(Chen等人,Science(2020)367(6482):1140-1146),并且发现了7种MS/MS检测到的circORF含有与circRNA反向剪接连接点唯一重叠的至少一个RFP片段(图16J)。总之,这些结果提示了使用circRNA IRES筛选测定构建推定的circORF列表是可能的,所述circRNA IRES筛选测定可以通过基因组和肽组学分析进行验证。
为了进一步检查circORF是否涉及抗原呈递,分析了人白细胞抗原I(HLA1)相关肽组学(Bassani-Sternberg等人,2015)。鉴定了两种HLA1相关的circORF(图6J)。计算机芯片上(In silico)的HLA1结合预测物NetMHC4.1分析(Reynisson等人,2020)提示了这两种circORF确实是针对HLA1肽组学中使用的细胞系中表达的HLA1变体的HLA1强结合剂(关于成纤维细胞中的circORF_674的HLA-A03:01;关于JY中的circORF_917的HLA-C07:02)(表7A和7B)。结果指示了circORF的新功能作用:一些circORF可能进入HLA-I呈递途径并促成抗原储库。
值得注意的是,通过基于MS的肽组学的circORF检测受到以下的限制:(i)一般而言捕获起因于低circRNA表达水平的低丰度circORF的能力不足,(ii)circRNA编码的多肽的潜在不稳定性,(iii)检测一般较短的circORF的固有困难,(iv)可用的肽组学数据集的细胞系/类型的数目,以及(v)circORF独特多肽的狭窄参考空间,因为排除了由circORF和线性蛋白质组共享的所有区域。鉴于circORF肽组学的局限性,circORF的鉴定被解释为阳性验证;MS蛋白质组学数据中的检测的不存在并不排除circRNA候选物的翻译潜力。与上述局限性一致,当相同的局限性应用于由已知mRNA编码的蛋白质时,匹配表达水平和检查的细胞系、以及下取样参考空间,发现了在与平均circRNA RPKM相同的RPKM的情况下,当前的肽组学数据只能回收由mRNA编码的蛋白质的~5%多肽(图16K和16L)。此外,circORF的预计发现率估计为约~4%,因为仅搜索了circORF独特区域。有可能用肽组学验证~12.3%(958种中的118种)circORF(这远高于circORF的预期发现率)这一事实,进一步突出显示了本文公开的方法可以有效地鉴定候选内源性circORF,并且支持类似于中等表达的mRNA,circRNA广泛编码多肽的观点。
实施例9
该实施例证实了,circFGFR1p通过显性失活调控压制在应激条件下的细胞增殖。
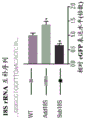
为了评估扩展的circRNA蛋白质组的潜在功能,选择了潜在的蛋白质编码circRNA的实例,hsa_circ_0084007,并且进一步检查了其编码蛋白质的功能。circRNA由人成纤维细胞生长因子受体1(FGFR1)转录物的外显子2和外显子7的反向剪接生成;因此,名称circFGFR1和circFGFR1p分别用于指该circRNA及其编码的蛋白质。在临床癌症患者样品中已观察到circFGFR1的下调,这可能提示了其在调控重要生物过程中的作用。CircFGFR1包含在筛选测定中显示强eGFP表达的IRES(前2%),定位于FGFR1的5’UTR区域中,随后立即是注释的AUG翻译起始密码子(图7A)。使用立即下游AUG的ORF分析揭示了,反向剪接在circFGFR1的IRES内生成了重新的终止密码子,导致与IRES部分重叠的ORF(circORF_949)(图7A)。为了更好地表征受circFGFR1调控的表型和功能,利用未转化的人细胞系BJ成纤维细胞用于后续分析。该细胞系具有二倍体基因组,用于更好的表型分析和高FGFR1表达。首先,使用侧接circFGFR1上的外显子2和外显子7的反向剪接连接点的背靠背引物,通过逆转录酶PCR(RT-PCR)和桑格测序检查是否可以在BJ细胞中检测到circFGFR1表达(图7B)。结果证实了,可以成功地检测到BJ细胞中的circFGFR1表达。
预测的蛋白质序列的分析指示了,circFGFR1p编码截短形式的FGFR1,其具有完整的细胞外成纤维细胞生长因子1(FGF1)配体结合位点、二聚化结构域的部分(IgI、IgII和IgIII的部分N'末端),但缺乏细胞内FGFR1酪氨酸激酶结构域(图7C)。由于circFGFR1反向剪接,CircFGFR1p也包含独特的区域,其中该区域的多肽序列不存在于线性蛋白质组(UniProt)数据库中(图7C)。使用针对circFGFR1p和FGFR1的共同区域的抗体(Ab-两者)的蛋白质印迹显示了在circFGFR1p(~38kDa)和FGFR1(70-90kDa)的相应大小处的信号(图7K)。ENCODE数据证实了在circFGFR1p IRES附近不存在启动子的染色质特征(H3K4me3)(图17A),提示了该蛋白质并非由于定位于FGFR1的外显子2中的隐藏启动子,由截短的线性转录物生成。与上文观察一致,所鉴定的circFGFR1 IRES(寡核苷酸索引:8228)并未展示来自线性RNA IRES报道分子筛选的启动子活性(评分=0)(Weingarten-Gabbay等人,2016)。
为了验证内源性circFGFR1p表达,生成了针对circFGFR1p的独特区域的定制抗体。通过使用定制抗体的免疫沉淀(IP)来分离circFGFR1p,并且使蛋白质(在聚丙烯酰胺凝胶上选择~30-45kDa的大小,以将circFGFR1p与FGFR1分开)经受液相层析伴串联质谱法(LC-MS/MS)(图7D)。虽然在IgG对照样品中并未检测到circFGFR1p多肽,但在IP-LC-MS/MS样品中检测到circFGFR1p的独特区域的胰蛋白酶多肽以及与线性FGFR1重叠的胰蛋白酶多肽是可能的(图7D)。结果提示了circFGFR1p确实得到表达并且可以被circFGFR1p抗体捕获。为了进一步以高分辨率确认circFGFR1p表达,使用circFGFR1p独特区域的合成重同位素标记的参考多肽执行PRM-MS。分别从BJ细胞中鉴定标记的参考多肽和取样胰蛋白酶多肽的相应前体和过渡离子是可能的(图7E)。总的来说,IP-MS和PRM-MS提供了证实内源性circFGFR1p表达的强烈证据。
在与FGF结合后,全长FGFR1使激酶结构域二聚化并且自磷酸化,这进一步触发了下游信号传导途径并促进细胞增殖。通过在HEK-293T细胞中共表达加上HA标签的FGFR1和加上FLAG标签的circFGFR1p,并且共染色HA-和FLAG-标签以分别标记FGFR1和circFGFR1p,确认了circFGFR1p类似于FGFR1定位于细胞膜处的补丁结构域(patchy domain)和核内体中(图7F和图17B)。CircFGFR1含有FGFR1二聚化/配体结合结构域,但缺乏激酶结构域,提示了circFGFR1p可能充当压制细胞增殖的FGFR1的显性失活调控因子。此外,与来自分析来自癌症基因组图谱(The Cancer Genome Atlas)(TCGA)的RNA测序数据的研究的正常相邻样品相比,在不同亚型的乳腺癌的肿瘤样品中发现了较低的circFGFR1表达水平(图17C)。另外,在CSCD数据库(Xia等人,2018)上的非转化的细胞系(141个非转化的细胞系样品中,n=5个独特的非转化的细胞类型)中特异性地检测到circFGFR1表达,但在癌细胞系中并未检测到(在87个癌细胞系样品中,n=87个癌细胞系)(图17D)。这些研究提示了,减少的circFGFR1表达水平可能通过上调细胞增殖与癌症进展相关。因此,circFGFR1p似乎通过压制细胞增殖的显性失活机制充当FGFR1的负调控因子。
为了测试这个假设,首先用靶向circFGFR1的反向剪接连接点的siRNA特异性敲减circFGFR1(图7G)。发现circFGFR1的敲减确实可以促进FGF添加后的细胞增殖(图7H),提示了circFGFR1负调控FGFR1促进细胞增殖的功能。为了确认所观察到的细胞增殖表型起因于circFGFR1p蛋白而不是circFGFR1 RNA的下调,在通过破坏circFGFR1p IRES的帽不依赖性翻译特异性下调circFGFR1p蛋白后,进一步检查细胞增殖表型。由于翻译起始通常是翻译的限速步骤,因此利用了靶向circFGFR1 IRES上的18S rRNA互补序列的反义LNA(IRES-8228的LNA-18S),其被发现有效地阻断circFGFR1p翻译起始(图5B和5D),以特异性敲减circFGFR1p而不改变circFGFR1或FGFR1 RNA的水平(图7G)。LNA介导的circFGFR1 IRES抑制导致circFGFR1p的较低表达水平和磷酸化FGFR1的较高水平(图7G),提示了敲减circFGFR1p而不是circFGFR1RNA,确实可以导致FGFR1磷酸化的增加,导致更高水平的活性FGFR1(磷酸化FGFR1)。这也与敲减circFGFR1p导致更高的细胞增殖率的观察(图7H)一致。有趣的是,circFGFR1p的耗尽也导致更高水平的总FGFR1蛋白(图7G)。结果提示了,circFGFR1p不仅充当FGFR1信号转导的显性失活,而且circFGF1p还以某种方式抑制全长FGFR1累积,可能是通过增加FGFR1周转或降解。当FGFR1的显性失活变体在体内表达时,也已观察到类似的FGFR1降解表型。相反,通过编码具有FLAG表位标签的circFGFR1p,检查细胞中的circFGFR1过表达是否可以压制细胞增殖。然后,将其克隆到由CMV启动子驱动的线性mRNA表达质粒内,以有效地过表达circFGFR1p,并且将circFGFR1p表达质粒转染到BJ细胞内(图7I)。结果证实了,circFGFR1p过表达(circFGFR1pOE)确实可以压制细胞增殖(图7I)。另外,当FGFR1和circFGFR1p在细胞中共过表达时(FGFR1OE+circFGFR1pOE),细胞增殖悬浮液的表型得到部分拯救(图7I),这进一步提示了circFGFR1p对于FGFR1的拮抗功能。这些结果提示了,circRNA编码的circFGFR1p可以通过经由显性失活机制与FGFR1相互作用来压制细胞生长。
与FGFR1相比,circFGFR1p的表达水平相对较低(图7J和7K),这指示了circFGFR1p在正常条件下可能不是强调节剂。然而,已报道了许多IRES在应激条件下具有稳态的帽不依赖性翻译活性,包括一些内源性蛋白质编码circRNA的IRES,例如circZNF-609。因此,进一步检查了circFGFR1 IRES在应激条件下例如在热休克下的帽不依赖性翻译活性。首先,用通过circFGFR1 IRES驱动的寡核苷酸-拆分-eGFP-circRNA报道构建体转染细胞,并且伴随或不伴随热休克定量circFGFR1 IRES活性。结果证实了,15FGFR1 IRES的帽不依赖性翻译活性在热休克期间保持稳态(图17E)。然后,在热休克条件下检查了FGFR1和circFGFR1p蛋白水平。观察到FGFR1蛋白水平在热休克后下调(图7J和7L),这很可能是由于通过在热休克期间许多真核起始因子的磷酸化状态变化以及经由Hsc70的eIF4G隔离引起的帽依赖性翻译的总体减少所致。另一方面,受帽不依赖性翻译调控的circFGFR1p水平在热休克后保持稳态(图7J、7L以及图17F和17G)。结果提示了,在热休克期间,虽然总体FGFR1帽依赖性翻译减少并非由circFGFR1p水平直接引起,但减少的FGFR1水平和稳定的circFGFR1p水平增强了circFGFR1p的显性失活效应,并进一步降低了细胞生长速率。此外,已显示FGFR1在被细胞粘附分子诱导时形成同源多聚体。FGFR1寡聚化的性质可能进一步增强了circFGFR1p的显性失活效应,因为一个circFGFR1p可以加入并“毒害”多个FGFR1分子的信号传导能力或导致多个FGFR1分子的降解。这些现象可以解释低表达的circFGFR1p如何可以在热休克或其它形式的细胞应激条件下有效地调控高度表达的FGFR1且压制细胞增殖(图17H和17I)。
有趣的是,虽然circFGFR1 IRES(寡核苷酸索引:8228)在circRNA上展示强烈的帽不依赖性翻译活性(前2%),但相同的IRES在线性RNA上显示了非常弱的帽不依赖性翻译活性(后10%)(Weingarten-Gabbay等人,2016)。这个观察提示了,circFGFR1 IRES的帽不依赖性翻译活性优先在circFGFR1而不是线性FGFR1转录物上激活。circFGFR1 IRES的这种circRNA-5偏向IRES活性也可以解释在热休克条件下,circFGFR1 IRES可以如何选择性地产生稳态量的circFGFR1p,而不增加由circFGFR1IRES对线性FGFR1转录物的帽不依赖性活性产生的FGFR1蛋白同种型的水平,允许circFGFR1p更有效地调控FGFR1功能。总之,上文呈现的发现证实了,使用所公开的方法,发现并非新型的circRNA编码的蛋白质circFGFR1p,其在应激条件下通过显性失活机制负调控FGFR1并压制细胞增殖。本研究还揭示了circRNA及其编码的蛋白质的重要调控机制。
本文描述了本发明的各个实施方案,包括本发明人已知的用于实施本发明的最佳模式。在阅读上述说明书后,这些实施方案的变化对于本领域普通技术人员可以变得显而易见。本发明人期望技术人员适当地采用此类变化,并且本发明人预期以不同于本文具体描述的方式来实践本发明。相应地,本发明包括如由适用法律允许的,与其附着的权利要求中叙述的主题的所有修改和等价物。此外,除非本文另有说明或以其它方式与上下文明显矛盾,否则本发明涵盖以其所有可能变化的上述要素的任何组合。
通过引用并入
本文引用的所有参考文献,包括出版物、专利申请和专利,都在此通过引用并入,其程度如同每个参考文献个别地且具体地指示通过引用并入,并且以其整体在本文中阐述一样。
编号的实施方案
尽管所附权利要求,下述编号的实施方案也构成本公开内容的部分。
1.一种编码环状RNA分子的多核苷酸序列;其中所述环状RNA分子包含蛋白质编码核酸序列区域、以及可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES)序列区域,其中所述IRES序列区域包含:具有RNA二级结构元件的至少一个序列区域;以及与18S核糖体RNA(rRNA)互补的序列区域;其中所述IRES序列区域具有小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度;并且其中所述RNA二级结构元件由在IRES的约位置40至约位置60处的核苷酸形成,其中在所述IRES的5’端处的第一个核酸被视为位置1。
2.实施方案1的多核苷酸序列,其中所述蛋白质编码核酸序列区域以非天然构型可操作地连接到IRES序列区域。
3.实施方案1或2的多核苷酸序列,其中所述多核苷酸序列是DNA序列。
4.实施方案1-3中任何一个的多核苷酸序列,其中与18S rRNA互补的序列是SEQID NO:28977-28983中的任何一个。
5.实施方案1-4中任何一个的多核苷酸序列,其中所述至少一个RNA二级结构元件定位于与18S rRNA互补的序列区域的5'。
6.实施方案1-4中任何一个的多核苷酸序列,其中所述至少一个RNA二级结构元件定位于与18S rRNA互补的序列区域的3'。
7.实施方案1-6中任何一个的多核苷酸序列,其中所述至少一个RNA二级结构元件是茎环。
8.实施方案1-7中任何一个的多核苷酸序列,其中所述至少一个RNA二级结构元件包含表2中列出的任何一个核酸序列。
9.实施方案1-8中任何一个的多核苷酸序列,其中所述IRES序列区域的长度为约100至约1000个核苷酸。
10.实施方案1-8中任何一个的多核苷酸序列,其中所述IRES序列区域的长度为约200至约800个核苷酸。
11.实施方案1-8中任何一个的多核苷酸序列,其中所述IRES序列的长度为150-200个核苷酸、160-180个核苷酸、或200-210个核苷酸。
12.实施方案1-11中任何一个的多核苷酸序列,其包含至少一个非编码功能序列。
13.实施方案12的多核苷酸序列,其中所述非编码功能序列包含一个或多个(a)微小RNA结合位点或(b)RNA结合蛋白结合位点。
14.实施方案1-11中任何一个的多核苷酸序列,其中所述DNA序列包含适体。
15.一种重组环状RNA分子,其由实施方案1-14中任何一个的多核苷酸序列编码。
16.一种编码环状RNA分子的DNA序列;其中所述环状RNA分子包含蛋白质编码核酸序列区域、以及可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES)序列区域;其中所述IRES序列区域包含SEQ ID NO:1-228或SEQ ID NO:229-17201中列出的任何一个核酸序列、或者与其具有至少90%或至少95%同一性或同源性的核酸序列。
17.实施方案16的DNA序列,其中所述蛋白质编码核酸序列以非天然构型可操作地连接到IRES序列区域。
18.实施方案16-17中任何一个的DNA序列,其中所述IRES序列区域具有至少25%的G-C含量。
19.实施方案16-18中任何一个的DNA序列,其中所述IRES序列区域包含SEQ IDNO:1-228中的任何一个核酸序列。
20.实施方案16-18中任何一个的DNA序列,其中所述IRES序列区域包含SEQ IDNO:229-17201中的任何一个核酸序列。
21.实施方案16-20中任何一个的DNA序列,其中所述IRES序列区域包含SEQ IDNO:531、2270、2602、3042、3244和33948中任何一个的核酸序列。
22.实施方案16-21中任何一个的DNA序列,其中所述IRES序列区域包含人IRES。
23.实施方案16-22中任何一个的DNA序列,其中所述蛋白质编码核酸序列区域编码治疗性肽或蛋白质。
24.实施方案16-23中任何一个的DNA序列,其中所述环状RNA分子包含约200个核苷酸至约10,000个核苷酸。
25.实施方案13-24中任何一个的DNA序列,其中所述环状RNA分子包含在IRES序列区域和蛋白质编码核酸序列区域的起始密码子之间的间隔区。
26.实施方案25的DNA序列,其中所述间隔区的长度经选择以相对于不具有间隔区或具有与所选间隔区不同的间隔区的环状RNA的翻译,增加蛋白质编码核酸序列区域的翻译。
27.实施方案16-26中任何一个的DNA序列,其中所述IRES序列区域被配置为促进滚环翻译。
28.实施方案16-26中任何一个的DNA序列,其中所述蛋白质编码核酸序列区域缺乏终止密码子。
29.实施方案16-26中任何一个的DNA序列,其中(i)所述IRES序列区域被配置为促进滚环翻译,并且(ii)所述蛋白质编码核酸序列区域缺乏终止密码子。
30.一种重组环状RNA分子,其由实施方案16-29中任何一个的DNA序列编码。
31.一种病毒载体,其包含实施方案1-14中任何一个的多核苷酸或实施方案16-29中任何一个的DNA序列。
32.实施方案31的病毒载体,其选自腺伴随病毒(AAV)载体、腺病毒载体、逆转录病毒载体、慢病毒载体、牛痘病毒和疱疹病毒载体。
33.实施方案31或32的病毒载体,其中所述病毒载体是AAV。
34.实施方案33的病毒载体,其中所述AAV血清型选自AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV8、AAV9、AAVrh10或其具有基本上相同的向性的任何变体。
35.一种病毒样颗粒,其包含实施方案1-14中任何一个的多核苷酸或实施方案16-29中任何一个的DNA序列。
36.一种非病毒样颗粒,其包含实施方案1-14中任何一个的多核苷酸或实施方案16-29中任何一个的DNA序列。
37.一种闭合端DNA序列,其包含实施方案1-14中任何一个的多核苷酸或实施方案16-29中任何一个的DNA序列。
38.一种质粒,其包含实施方案1-14中任何一个的多核苷酸或实施方案16-29中任何一个的DNA序列。
39.一种微型内含子质粒载体,其包含实施方案1-14中任何一个的多核苷酸或实施方案16-29中任何一个的DNA序列。
40.一种组合物,其包含实施方案1-14中任何一个的多核苷酸、实施方案16-29中任何一个的DNA序列、或者实施方案15或30的重组环状RNA分子。
41.实施方案40的组合物,其中所述脂质纳米颗粒是装饰的。
42.一种宿主细胞,其包含实施方案1-14中任何一个的多核苷酸、实施方案16-29中任何一个的DNA序列、或者实施方案15或30的重组环状RNA分子。
43.一种在细胞中产生蛋白质的方法,所述方法包括在由此环状RNA的蛋白质编码核酸序列被翻译并在细胞中产生蛋白质的条件下,使所述细胞与以下接触:(a)实施方案1-14中任何一个的多核苷酸,(b)实施方案16-29中任何一个的DNA序列,(c)实施方案15或30中任何一个的环状RNA分子,(d)实施方案31-34中任何一个的病毒载体,(e)实施方案35的病毒样颗粒,(f)实施方案36的非病毒样颗粒,(g)实施方案37的闭合端DNA序列,(h)实施方案38的质粒,(i)实施方案39的微型内含子质粒载体,或(j)实施方案40-41中任何一个的组合物。
44.实施方案43的方法,其中所述细胞中的5'帽依赖性翻译受损或不存在。
45.实施方案43或44的方法,其中所述细胞是在体内的。
46.实施方案45的方法,其中所述细胞是哺乳动物细胞。
47.实施方案46的方法,其中所述哺乳动物细胞衍生自人。
48.实施方案45-46中任何一个的方法,其中所述蛋白质的产生是组织特异性的。
49.实施方案48的方法,其中所述组织特异性定位于选自肌肉、肝、肾、脑、肺、皮肤、胰腺、血液和心脏的组织。
50.实施方案43或44的方法,其中所述细胞是在体外的。
51.实施方案43-48中任何一个的方法,其中所述蛋白质在细胞中递归表达。
52.实施方案43-51中任何一个的方法,其中所述环状RNA在细胞中的半衰期为约1至约7天。
53.实施方案43-55中任何一个的方法,其中与蛋白质编码核酸序列以线性形式RNA提供给细胞或作为线性RNA编码用于转录时相比,在细胞中产生所述蛋白质的持续时间长至少约10%、至少约20%或至少约30%。
54.一种蛋白质,其通过实施方案43-53中任何一个的方法产生。
55.一种重组环状RNA分子,其包含蛋白质编码核酸序列、以及可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES),其中所述IRES包含:至少一个RNA二级结构;以及与18S核糖体RNA(rRNA)互补的序列;其中所述IRES具有小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度。
56.实施方案55的重组环状RNA分子,其中所述蛋白质编码核酸序列以非天然构型可操作地连接到IRES。
57.实施方案55或56的重组环状RNA分子,其中与18S rRNA互补的序列由SEQ IDNO:28977-28983中的任何一个编码。
58.实施方案55-57中任何一个的重组环状RNA分子,其中所述至少一个RNA二级结构定位于与18S rRNA互补的序列的5'。
59.实施方案55-57中任何一个的重组环状RNA分子,其中所述至少一个RNA二级结构定位于与18S rRNA互补的序列的3'。
60.实施方案55-59中任何一个的重组环状RNA分子,其中所述至少一个RNA二级结构是茎环。
61.实施方案55-59中任何一个的重组环状RNA分子,其中所述至少一个RNA二级结构包含由表2中列出的任何一个DNA序列编码的序列。
62.实施方案55-61中任何一个的重组环状RNA,其中所述IRES的长度为约100至约1000个核苷酸。
63.实施方案55-61中任何一个的重组环状RNA,其中所述IRES的长度为约200至约200个核苷酸。
64.实施方案55-61中任何一个的重组环状RNA,其中所述IRES序列的长度为150-200个核苷酸、160-180个核苷酸、或200-210个核苷酸。
65.实施方案62-64中任何一个的重组环状RNA,其中所述RNA二级结构由在所述IRES的相对于其5'端的约位置40至约位置60处的核苷酸形成。
66.实施方案55-65中任何一个的重组环状RNA,其包含至少一个非编码功能序列。
67.实施方案66的重组环状RNA,其中所述非编码功能序列包含一个或多个(a)微小RNA结合位点或(b)RNA结合蛋白结合位点。
68.实施方案55-65中任何一个的重组环状RNA,其中所述环状RNA包含适体。
69.一种重组环状RNA分子,其包含蛋白质编码核酸序列、以及可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES);其中所述IRES由SEQ ID NO:1-228或SEQID NO:229-17201中列出的任何一个DNA序列、或者与其具有至少90%或至少95%同一性或同源性的DNA序列编码。
70.实施方案69的重组环状RNA分子,其中所述蛋白质编码核酸序列以非天然构型可操作地连接到IRES。
71.实施方案55-70中任何一个的重组环状RNA,其中所述重组环状RNA包含反向剪接连接点,并且其中所述IRES定位于反向剪接连接点的约100至约200个核苷酸内。
72.实施方案55-71中任何一个的重组环状RNA分子,其中所述IRES具有至少25%的G-C含量。
73.实施方案55-72中任何一个的重组环状RNA分子,其中所述IRES由SEQ ID NO:1-228中的任何DNA序列编码。
74.实施方案55-72中任何一个的重组环状RNA分子,其中所述IRES由SEQ ID NO:229-17201中的任何一个DNA序列编码。
75.实施方案74的重组环状RNA分子,其中所述IRES由SEQ ID NO:531、2270、2602、3042、3244、33948中所示的任何一个DNA序列编码。
76.实施方案55-75中任何一个的重组环状RNA分子,其中所述IRES是人IRES。
77.实施方案55-76中任何一个的重组环状RNA分子,其中所述蛋白质编码核酸序列编码治疗性肽或蛋白质。
78.实施方案55-77中任何一个的重组环状RNA分子,其中所述环状RNA包含约200个核苷酸至约10,000个核苷酸。
79.实施方案55-78中任何一个的重组环状RNA分子,其中所述环状RNA分子包含在IRES序列区域和蛋白质编码核酸序列区域的起始密码子之间的间隔区。
80.实施方案79的重组环状RNA分子,其中所述间隔区的长度经选择以相对于不具有间隔区或具有与所选间隔区不同的间隔区的环状RNA的翻译,增加蛋白质编码核酸序列区域的翻译。
81.实施方案55-78中任何一个的重组环状RNA分子,其中所述IRES序列区域被配置为促进滚环翻译。
82.实施方案55-78中任何一个的重组环状RNA分子,其中所述蛋白质编码核酸序列区域缺乏终止密码子。
83.实施方案55-78中任何一个的重组环状RNA分子,其中(i)所述IRES序列区域被配置为促进滚环翻译,并且(ii)所述蛋白质编码核酸序列区域缺乏终止密码子。
84.一种组合物,其包含实施方案55-83中任何一个的重组环状RNA分子。
85.一种宿主细胞,其包含实施方案55-83中任何一个的重组环状RNA分子或实施方案84的组合物。
86.一种在细胞中产生蛋白质的方法,所述方法包括在由此蛋白质编码核酸序列被翻译并在细胞中产生蛋白质的条件下,使所述细胞与实施方案55-83中任何一个的重组环状RNA分子或实施方案84的组合物接触。
87.实施方案86的方法,其中所述细胞中的5'帽依赖性翻译受损或不存在。
88.实施方案86或87的方法,其中所述细胞是在体内的。
89.实施方案86或87的方法,其中所述细胞是哺乳动物细胞。
90.实施方案89的方法,其中所述哺乳动物细胞衍生自人。
91.实施方案55-90中任何一个的方法,其中所述蛋白质的产生是组织特异性的。
92.实施方案91的方法,其中所述组织特异性定位于选自肌肉、肝、肾、脑、肺、皮肤、胰腺、血液和心脏的组织。
93.实施方案86或87的方法,其中所述细胞是在体外的。
94.实施方案86-93中任何一个的方法,其中所述蛋白质在细胞中递归表达。
95.实施方案86-94中任何一个的方法,其中所述环状RNA在细胞中的半衰期为约1至约7天。
96.实施方案86-94中任何一个的方法,其中与蛋白质编码核酸序列以线性形式RNA提供给细胞或作为线性RNA编码用于转录时相比,在细胞中产生所述蛋白质的持续时间长至少约10%、至少约20%或至少约30%。
97.一种蛋白质,其通过实施方案86-96中任何一个的方法产生。
98.一种寡核苷酸分子,其包含与环状RNA分子上存在的内部核糖体进入位点(IRES)杂交并抑制环状RNA分子翻译的核酸序列。
99.实施方案98的寡核苷酸分子,其中所述环状RNA是重组环状RNA。
100.实施方案98的寡核苷酸分子,其中所述重组环状RNA是实施方案55-83中任何一个的重组环状RNA。
101.实施方案98的寡核苷酸分子,其中所述环状RNA是天然存在的环状RNA。
102.实施方案98-101中任何一个的寡核苷酸分子,其中所述寡核苷酸是反义寡核苷酸。
103.实施方案102的寡核苷酸,其中所述反义寡核苷酸是锁核酸寡核苷酸(LNA)。
104.实施方案98-103中任何一个的寡核苷酸,其中所述寡核苷酸在其5'和/或其3'端处进行化学修饰。
105.一种抑制环状RNA分子上存在的蛋白质编码核酸序列翻译的方法,所述方法包括使环状RNA分子与实施方案98-104中任何一个的寡核苷酸分子接触,由此所述寡核苷酸分子与环状RNA分子的IRES上存在的RNA二级结构和/或同18S rRNA互补的核酸序列杂交,并且抑制环状RNA分子的翻译。
106.实施方案105的方法,其中所述寡核苷酸与RNA二级结构或同18S rRNA互补的核酸序列杂交。
107.实施方案105的方法,其中所述寡核苷酸与RNA二级结构以及同18S rRNA互补的核酸序列杂交。
108.实施方案105的方法,其中第一寡核苷酸与RNA二级结构杂交,并且第二寡核苷酸与同18S rRNA互补的核酸序列杂交。





















































































































































































































































Claims (108)
1.一种编码环状RNA分子的多核苷酸序列;
其中所述环状RNA分子包含蛋白质编码核酸序列区域、以及可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES)序列区域,其中所述IRES序列区域包含:
具有RNA二级结构元件的至少一个序列区域;以及
与18S核糖体RNA(rRNA)互补的序列区域;
其中所述IRES序列区域具有小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度;并且
其中所述RNA二级结构元件由在IRES的约位置40至约位置60处的核苷酸形成,其中在所述IRES的5’端处的第一个核酸被视为位置1。
2.权利要求1的多核苷酸序列,其中所述蛋白质编码核酸序列区域以非天然构型可操作地连接到IRES序列区域。
3.权利要求1或2的多核苷酸序列,其中所述多核苷酸序列是DNA序列。
4.权利要求1-3中任一项的多核苷酸序列,其中与18S rRNA互补的序列是SEQ ID NO:28977-28983中的任何一个。
5.权利要求1-4中任一项的多核苷酸序列,其中所述至少一个RNA二级结构元件定位于与18S rRNA互补的序列区域的5'。
6.权利要求1-4中任一项的多核苷酸序列,其中所述至少一个RNA二级结构元件定位于与18S rRNA互补的序列区域的3'。
7.权利要求1-6中任一项的多核苷酸序列,其中所述至少一个RNA二级结构元件是茎环。
8.权利要求1-7中任一项的多核苷酸序列,其中所述至少一个RNA二级结构元件包含表2中列出的任何一个核酸序列。
9.权利要求1-8中任一项的多核苷酸序列,其中所述IRES序列区域的长度为约100至约1000个核苷酸。
10.权利要求1-8中任一项的多核苷酸序列,其中所述IRES序列区域的长度为约200至约800个核苷酸。
11.权利要求1-8中任一项的多核苷酸序列,其中所述IRES序列的长度为150-200个核苷酸、160-180个核苷酸、或200-210个核苷酸。
12.权利要求1-11中任一项的多核苷酸序列,其包含至少一个非编码功能序列。
13.权利要求12的多核苷酸序列,其中所述非编码功能序列包含一个或多个(a)微小RNA结合位点或(b)RNA结合蛋白结合位点。
14.权利要求1-11中任一项的多核苷酸序列,其中所述DNA序列包含适体。
15.一种重组环状RNA分子,其由权利要求1-14中任一项的多核苷酸序列编码。
16.一种编码环状RNA分子的DNA序列;
其中所述环状RNA分子包含蛋白质编码核酸序列区域、以及可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES)序列区域;
其中所述IRES序列区域包含SEQ ID NO:1-228或SEQ ID NO:229-17201中列出的任何一个核酸序列、或者与其具有至少90%或至少95%同一性或同源性的核酸序列。
17.权利要求16的DNA序列,其中所述蛋白质编码核酸序列以非天然构型可操作地连接到IRES序列区域。
18.权利要求16-17中任一项的DNA序列,其中所述IRES序列区域具有至少25%的G-C含量。
19.权利要求16-18中任一项的DNA序列,其中所述IRES序列区域包含SEQ ID NO:1-228中的任何一个核酸序列。
20.权利要求16-18中任一项的DNA序列,其中所述IRES序列区域包含SEQ ID NO:229-17201中的任何一个核酸序列。
21.权利要求16-20中任一项的DNA序列,其中所述IRES序列区域包含SEQ ID NO:531、2270、2602、3042、3244和33948中任何一个的核酸序列。
22.权利要求16-21中任一项的DNA序列,其中所述IRES序列区域包含人IRES。
23.权利要求16-22中任一项的DNA序列,其中所述蛋白质编码核酸序列区域编码治疗性肽或蛋白质。
24.权利要求16-23中任一项的DNA序列,其中所述环状RNA分子包含约200个核苷酸至约10,000个核苷酸。
25.权利要求13-24中任一项的DNA序列,其中所述环状RNA分子包含在IRES序列区域和蛋白质编码核酸序列区域的起始密码子之间的间隔区。
26.权利要求25的DNA序列,其中所述间隔区的长度经选择以相对于不具有间隔区或具有与所选间隔区不同的间隔区的环状RNA的翻译,增加蛋白质编码核酸序列区域的翻译。
27.权利要求16-26中任一项的DNA序列,其中所述IRES序列区域被配置为促进滚环翻译。
28.权利要求16-26中任一项的DNA序列,其中所述蛋白质编码核酸序列区域缺乏终止密码子。
29.权利要求16-26中任一项的DNA序列,其中(i)所述IRES序列区域被配置为促进滚环翻译,并且(ii)所述蛋白质编码核酸序列区域缺乏终止密码子。
30.一种重组环状RNA分子,其由权利要求16-29中任一项的DNA序列编码。
31.一种病毒载体,其包含权利要求1-14中任一项的多核苷酸或权利要求16-29中任一项的DNA序列。
32.权利要求31的病毒载体,其选自腺伴随病毒(AAV)载体、腺病毒载体、逆转录病毒载体、慢病毒载体、牛痘病毒和疱疹病毒载体。
33.权利要求31或32的病毒载体,其中所述病毒载体是AAV。
34.权利要求33的病毒载体,其中所述AAV血清型选自AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV8、AAV9、AAVrh10或其具有基本上相同的向性的任何变体。
35.一种病毒样颗粒,其包含权利要求1-14中任一项的多核苷酸或权利要求16-29中任一项的DNA序列。
36.一种非病毒样颗粒,其包含权利要求1-14中任一项的多核苷酸或权利要求16-29中任一项的DNA序列。
37.一种闭合端DNA序列,其包含权利要求1-14中任一项的多核苷酸或权利要求16-29中任一项的DNA序列。
38.一种质粒,其包含权利要求1-14中任一项的多核苷酸或权利要求16-29中任一项的DNA序列。
39.一种微型内含子质粒载体,其包含权利要求1-14中任一项的多核苷酸或权利要求16-29中任一项的DNA序列。
40.一种组合物,其包含权利要求1-14中任一项的多核苷酸、权利要求16-29中任一项的DNA序列、或者权利要求15或30的重组环状RNA分子。
41.权利要求40的组合物,其中所述脂质纳米颗粒是装饰的。
42.一种宿主细胞,其包含权利要求1-14中任一项的多核苷酸、权利要求16-29中任一项的DNA序列、或者权利要求15或30的重组环状RNA分子。
43.一种在细胞中产生蛋白质的方法,所述方法包括在由此环状RNA的蛋白质编码核酸序列被翻译并在细胞中产生蛋白质的条件下,使所述细胞与以下接触:(a)权利要求1-14中任一项的多核苷酸,(b)权利要求16-29中任一项的DNA序列,(c)权利要求15或30中任一项的环状RNA分子,(d)权利要求31-34中任一项的病毒载体,(e)权利要求35的病毒样颗粒,(f)权利要求36的非病毒样颗粒,(g)权利要求37的闭合端DNA序列,(h)权利要求38的质粒,(i)权利要求39的微型内含子质粒载体,或(j)权利要求40-41中任一项的组合物。
44.权利要求43的方法,其中所述细胞中的5'帽依赖性翻译受损或不存在。
45.权利要求43或44的方法,其中所述细胞是在体内的。
46.权利要求45的方法,其中所述细胞是哺乳动物细胞。
47.权利要求46的方法,其中所述哺乳动物细胞衍生自人。
48.权利要求45-46中任一项的方法,其中所述蛋白质的产生是组织特异性的。
49.权利要求48的方法,其中所述组织特异性定位于选自肌肉、肝、肾、脑、肺、皮肤、胰腺、血液和心脏的组织。
50.权利要求43或44的方法,其中所述细胞是在体外的。
51.权利要求43-48中任一项的方法,其中所述蛋白质在细胞中递归表达。
52.权利要求43-51中任一项的方法,其中所述环状RNA在细胞中的半衰期为约1至约7天。
53.权利要求43-55中任一项的方法,其中与蛋白质编码核酸序列以线性形式RNA提供给细胞或作为线性RNA编码用于转录时相比,在细胞中产生所述蛋白质的持续时间长至少约10%、至少约20%或至少约30%。
54.一种蛋白质,其通过权利要求43-53中任一项的方法产生。
55.一种重组环状RNA分子,其包含蛋白质编码核酸序列、以及可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES),其中所述IRES包含:
至少一个RNA二级结构;以及
与18S核糖体RNA(rRNA)互补的序列;
其中所述IRES具有小于-18.9kJ/mol的最小自由能(MFE)和至少35.0℃的解链温度。
56.权利要求55的重组环状RNA分子,其中所述蛋白质编码核酸序列以非天然构型可操作地连接到IRES。
57.权利要求55或56的重组环状RNA分子,其中与18S rRNA互补的序列由SEQ ID NO:28977-28983中的任何一个编码。
58.权利要求55-57中任一项的重组环状RNA分子,其中所述至少一个RNA二级结构定位于与18S rRNA互补的序列的5'。
59.权利要求55-57中任一项的重组环状RNA分子,其中所述至少一个RNA二级结构定位于与18S rRNA互补的序列的3'。
60.权利要求55-59中任一项的重组环状RNA分子,其中所述至少一个RNA二级结构是茎环。
61.权利要求55-59中任一项的重组环状RNA分子,其中所述至少一个RNA二级结构包含由表2中列出的任何一个DNA序列编码的序列。
62.权利要求55-61中任一项的重组环状RNA,其中所述IRES的长度为约100至约1000个核苷酸。
63.权利要求55-61中任一项的重组环状RNA,其中所述IRES的长度为约200至约200个核苷酸。
64.权利要求55-61中任一项的重组环状RNA,其中所述IRES序列的长度为150-200个核苷酸、160-180个核苷酸、或200-210个核苷酸。
65.权利要求62-64中任一项的重组环状RNA,其中所述RNA二级结构由在所述IRES的相对于其5'端的约位置40至约位置60处的核苷酸形成。
66.权利要求55-65中任一项的重组环状RNA,其包含至少一个非编码功能序列。
67.权利要求66的重组环状RNA,其中所述非编码功能序列包含一个或多个(a)微小RNA结合位点或(b)RNA结合蛋白结合位点。
68.权利要求55-65中任一项的重组环状RNA,其中所述环状RNA包含适体。
69.一种重组环状RNA分子,其包含蛋白质编码核酸序列、以及可操作地连接到蛋白质编码核酸序列的内部核糖体进入位点(IRES);
其中所述IRES由SEQ ID NO:1-228或SEQ ID NO:229-17201中列出的任何一个DNA序列、或者与其具有至少90%或至少95%同一性或同源性的DNA序列编码。
70.权利要求69的重组环状RNA分子,其中所述蛋白质编码核酸序列以非天然构型可操作地连接到IRES。
71.权利要求55-70中任一项的重组环状RNA,其中所述重组环状RNA包含反向剪接连接点,并且其中所述IRES定位于反向剪接连接点的约100至约200个核苷酸内。
72.权利要求55-71中任一项的重组环状RNA分子,其中所述IRES具有至少25%的G-C含量。
73.权利要求55-72中任一项的重组环状RNA分子,其中所述IRES由SEQ ID NO:1-228中的任何DNA序列编码。
74.权利要求55-72中任一项的重组环状RNA分子,其中所述IRES由SEQ ID NO:229-17201中的任何一个DNA序列编码。
75.权利要求74的重组环状RNA分子,其中所述IRES由SEQ IDNO:531、2270、2602、3042、3244、33948中所示的任何一个DNA序列编码。
76.权利要求55-75中任一项的重组环状RNA分子,其中所述IRES是人IRES。
77.权利要求55-76中任一项的重组环状RNA分子,其中所述蛋白质编码核酸序列编码治疗性肽或蛋白质。
78.权利要求55-77中任一项的重组环状RNA分子,其中所述环状RNA包含约200个核苷酸至约10,000个核苷酸。
79.权利要求55-78中任一项的重组环状RNA分子,其中所述环状RNA分子包含在IRES序列区域和蛋白质编码核酸序列区域的起始密码子之间的间隔区。
80.权利要求79的重组环状RNA分子,其中所述间隔区的长度经选择以相对于不具有间隔区或具有与所选间隔区不同的间隔区的环状RNA的翻译,增加蛋白质编码核酸序列区域的翻译。
81.权利要求55-78中任一项的重组环状RNA分子,其中所述IRES序列区域被配置为促进滚环翻译。
82.权利要求55-78中任一项的重组环状RNA分子,其中所述蛋白质编码核酸序列区域缺乏终止密码子。
83.权利要求55-78中任一项的重组环状RNA分子,其中(i)所述IRES序列区域被配置为促进滚环翻译,并且(ii)所述蛋白质编码核酸序列区域缺乏终止密码子。
84.一种组合物,其包含权利要求55-83中任一项的重组环状RNA分子。
85.一种宿主细胞,其包含权利要求55-83中任一项的重组环状RNA分子或权利要求84的组合物。
86.一种在细胞中产生蛋白质的方法,所述方法包括在由此蛋白质编码核酸序列被翻译并在细胞中产生蛋白质的条件下,使所述细胞与权利要求55-83中任一项的重组环状RNA分子或权利要求84的组合物接触。
87.权利要求86的方法,其中所述细胞中的5'帽依赖性翻译受损或不存在。
88.权利要求86或87的方法,其中所述细胞是在体内的。
89.权利要求86或87的方法,其中所述细胞是哺乳动物细胞。
90.权利要求89的方法,其中所述哺乳动物细胞衍生自人。
91.权利要求55-90中任一项的方法,其中所述蛋白质的产生是组织特异性的。
92.权利要求91的方法,其中所述组织特异性定位于选自肌肉、肝、肾、脑、肺、皮肤、胰腺、血液和心脏的组织。
93.权利要求86或87的方法,其中所述细胞是在体外的。
94.权利要求86-93中任一项的方法,其中所述蛋白质在细胞中递归表达。
95.权利要求86-94中任一项的方法,其中所述环状RNA在细胞中的半衰期为约1至约7天。
96.权利要求86-94中任一项的方法,其中与蛋白质编码核酸序列以线性形式RNA提供给细胞或作为线性RNA编码用于转录时相比,在细胞中产生所述蛋白质的持续时间长至少约10%、至少约20%或至少约30%。
97.一种蛋白质,其通过权利要求86-96中任一项的方法产生。
98.一种寡核苷酸分子,其包含与环状RNA分子上存在的内部核糖体进入位点(IRES)杂交并抑制环状RNA分子翻译的核酸序列。
99.权利要求98的寡核苷酸分子,其中所述环状RNA是重组环状RNA。
100.权利要求98的寡核苷酸分子,其中所述重组环状RNA是权利要求55-83中任一项的重组环状RNA。
101.权利要求98的寡核苷酸分子,其中所述环状RNA是天然存在的环状RNA。
102.权利要求98-101中任一项的寡核苷酸分子,其中所述寡核苷酸是反义寡核苷酸。
103.权利要求102的寡核苷酸,其中所述反义寡核苷酸是锁核酸寡核苷酸(LNA)。
104.权利要求98-103中任一项的寡核苷酸,其中所述寡核苷酸在其5'和/或其3'端处进行化学修饰。
105.一种抑制环状RNA分子上存在的蛋白质编码核酸序列翻译的方法,所述方法包括使环状RNA分子与权利要求98-104中任一项的寡核苷酸分子接触,由此所述寡核苷酸分子与环状RNA分子的IRES上存在的RNA二级结构和/或同18S rRNA互补的核酸序列杂交,并且抑制环状RNA分子的翻译。
106.权利要求105的方法,其中所述寡核苷酸与RNA二级结构或同18S rRNA互补的核酸序列杂交。
107.权利要求105的方法,其中所述寡核苷酸与RNA二级结构以及同18S rRNA互补的核酸序列杂交。
108.权利要求105的方法,其中第一寡核苷酸与RNA二级结构杂交,并且第二寡核苷酸与同18S rRNA互补的核酸序列杂交。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063043964P | 2020-06-25 | 2020-06-25 | |
| US63/043964 | 2020-06-25 | ||
| US202163186507P | 2021-05-10 | 2021-05-10 | |
| US63/186507 | 2021-05-10 | ||
| PCT/US2021/039127 WO2021263124A2 (en) | 2020-06-25 | 2021-06-25 | Genetic elements driving circular rna translation and methods of use |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116323945A true CN116323945A (zh) | 2023-06-23 |
Family
ID=79281918
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202180052292.1A Pending CN116323945A (zh) | 2020-06-25 | 2021-06-25 | 驱动环状rna翻译的遗传元件和使用方法 |
Country Status (8)
| Country | Link |
|---|---|
| US (3) | US11560567B2 (zh) |
| EP (1) | EP4171631A2 (zh) |
| JP (1) | JP2023532663A (zh) |
| KR (1) | KR20230028375A (zh) |
| CN (1) | CN116323945A (zh) |
| AU (1) | AU2021297340A1 (zh) |
| CA (1) | CA3180224A1 (zh) |
| WO (1) | WO2021263124A2 (zh) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA3207655A1 (en) * | 2021-02-09 | 2022-08-18 | Guizhi ZHU | Mini circular rna therapeutics and vaccines and methods of use thereof |
| WO2023097003A2 (en) | 2021-11-24 | 2023-06-01 | Flagship Pioneering Innovations Vi, Llc | Immunogenic compositions and their uses |
| WO2023096990A1 (en) | 2021-11-24 | 2023-06-01 | Flagship Pioneering Innovation Vi, Llc | Coronavirus immunogen compositions and their uses |
| WO2023096963A1 (en) | 2021-11-24 | 2023-06-01 | Flagship Pioneering Innovations Vi, Llc | Varicella-zoster virus immunogen compositions and their uses |
| AR128002A1 (es) | 2021-12-17 | 2024-03-20 | Flagship Pioneering Innovations Vi Llc | Métodos de enriquecimiento de rna circular en condiciones desnaturalizantes |
| TW202340461A (zh) | 2021-12-22 | 2023-10-16 | 美商旗艦先鋒創新有限責任公司 | 用於純化多核糖核苷酸之組成物和方法 |
| WO2023122789A1 (en) | 2021-12-23 | 2023-06-29 | Flagship Pioneering Innovations Vi, Llc | Circular polyribonucleotides encoding antifusogenic polypeptides |
| WO2023161159A1 (en) * | 2022-02-24 | 2023-08-31 | Probiogen Ag | Circular rna-delivery mediated by virus like particles |
| WO2023178294A2 (en) * | 2022-03-17 | 2023-09-21 | The Board Of Trustees Of The Leland Stanford Junior University | Compositions and methods for improved protein translation from recombinant circular rnas |
| WO2023231959A2 (en) | 2022-05-30 | 2023-12-07 | Shanghai Circode Biomed Co., Ltd | Synthetic circular rna compositions and methods of use thereof |
| WO2023250528A1 (en) * | 2022-06-24 | 2023-12-28 | The Broad Institute, Inc. | Compositions and methods for preparing capped circular rna molecules |
| WO2024010028A1 (ja) * | 2022-07-06 | 2024-01-11 | 国立大学法人京都大学 | 環状rna分子及びこれを用いた翻訳制御方法、翻訳活性化システム、並びに医薬組成物 |
| CN115394376B (zh) * | 2022-09-28 | 2023-04-18 | 奥明(杭州)生物医药有限公司 | 一种预测环状rna ires的方法 |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5766903A (en) * | 1995-08-23 | 1998-06-16 | University Technology Corporation | Circular RNA and uses thereof |
| DE10162480A1 (de) | 2001-12-19 | 2003-08-07 | Ingmar Hoerr | Die Applikation von mRNA für den Einsatz als Therapeutikum gegen Tumorerkrankungen |
| WO2010084371A1 (en) | 2009-01-26 | 2010-07-29 | Mitoprod | Novel circular interfering rna molecules |
| US8790879B2 (en) * | 2010-01-22 | 2014-07-29 | Gen-Probe Incorporated | Probes for detecting the presence of Trichomonas vaginalis in a sample |
| US20150299702A1 (en) | 2012-11-30 | 2015-10-22 | Aarhus Universitet | Circular rna for inhibition of microrna |
| WO2014186334A1 (en) | 2013-05-15 | 2014-11-20 | Robert Kruse | Intracellular translation of circular rna |
| AU2015289656A1 (en) | 2014-07-16 | 2017-02-16 | Modernatx, Inc. | Circular polynucleotides |
| US20180312545A1 (en) * | 2015-11-09 | 2018-11-01 | Curevac Ag | Optimized nucleic acid molecules |
| WO2017222911A1 (en) | 2016-06-20 | 2017-12-28 | The Board Of Trustees Of The Leland Stanford Junior University | Circular rnas and their use in immunomodulation |
| JP2021531022A (ja) * | 2018-07-24 | 2021-11-18 | フラッグシップ パイオニアリング イノベーションズ シックス,エルエルシー | 環状ポリリボヌクレオチドを含む組成物及びその使用 |
| CN114258430A (zh) | 2019-04-22 | 2022-03-29 | T细胞受体治疗公司 | 使用融合蛋白进行tcr重编程的组合物和方法 |
-
2021
- 2021-06-25 CN CN202180052292.1A patent/CN116323945A/zh active Pending
- 2021-06-25 WO PCT/US2021/039127 patent/WO2021263124A2/en unknown
- 2021-06-25 JP JP2022580043A patent/JP2023532663A/ja active Pending
- 2021-06-25 CA CA3180224A patent/CA3180224A1/en active Pending
- 2021-06-25 AU AU2021297340A patent/AU2021297340A1/en active Pending
- 2021-06-25 EP EP21829176.3A patent/EP4171631A2/en active Pending
- 2021-06-25 KR KR1020237001270A patent/KR20230028375A/ko unknown
-
2022
- 2022-03-16 US US17/696,606 patent/US11560567B2/en active Active
- 2022-10-03 US US17/937,617 patent/US11685924B2/en active Active
-
2023
- 2023-06-23 US US18/340,582 patent/US20230407317A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| AU2021297340A1 (en) | 2023-01-19 |
| US11685924B2 (en) | 2023-06-27 |
| KR20230028375A (ko) | 2023-02-28 |
| US20230407317A1 (en) | 2023-12-21 |
| US11560567B2 (en) | 2023-01-24 |
| CA3180224A1 (en) | 2021-12-30 |
| EP4171631A2 (en) | 2023-05-03 |
| US20220251578A1 (en) | 2022-08-11 |
| US20230125935A1 (en) | 2023-04-27 |
| WO2021263124A2 (en) | 2021-12-30 |
| WO2021263124A3 (en) | 2022-02-03 |
| JP2023532663A (ja) | 2023-07-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11560567B2 (en) | Genetic elements driving circular RNA translation and methods of use | |
| Liu et al. | Circular RNAs: Characterization, cellular roles, and applications | |
| Novikova et al. | Sizing up long non-coding RNAs: do lncRNAs have secondary and tertiary structure? | |
| Chen et al. | Translational control by DHX36 binding to 5′ UTR G-quadruplex is essential for muscle stem-cell regenerative functions | |
| Pereira‐Castro et al. | On the function and relevance of alternative 3′‐UTRs in gene expression regulation | |
| Mroczek et al. | U6 RNA biogenesis and disease association | |
| CN106661580A (zh) | 用于治疗庞帕病的反义寡核苷酸 | |
| US20170240900A1 (en) | Ras exon 2 skipping for cancer treatment | |
| WO2022090733A1 (en) | Functional nucleic acid molecules incorporating protein binding domains | |
| US20160319277A1 (en) | METHODS OF IMPROVED PROTEIN PRODUCTION USING MIRNAs AND SIRNAs | |
| EP3669193B1 (en) | Enhanced rna interactome capture (eric) | |
| Yu et al. | The rat mitochondrial Ori L encodes a novel small RNA resembling an ancestral tRNA | |
| CN107532216A (zh) | 寡核苷酸的同步检测及其相关的试剂盒和用途 | |
| US20220073903A1 (en) | Methods of purifying ribonucleic acid species | |
| Chen et al. | mRNA translation control by Dhx36 binding to 5’UTR G-quadruplex structures is essential for skeletal muscle stem cell regenerative functions | |
| Liu et al. | NAP-seq reveals multiple classes of structured noncoding RNAs with regulatory functions | |
| Simko | RNA Secondary Structure Recognition by Paraspeckle Protein Nono | |
| WO2023178294A9 (en) | Compositions and methods for improved protein translation from recombinant circular rnas | |
| WO2011138787A1 (en) | Identification of mrna-specific micrornas | |
| KR20240003761A (ko) | mRNA 번역 증가용 조절 엘리먼트를 스크리닝하는 방법,상기 방법에 따른 신규 조절 엘리먼트, 및 이의 용도 | |
| CN117561333A (zh) | 用于改善来自重组环状rna的蛋白翻译的组合物和方法 | |
| Pashler | The Role of Exoribonucleases in Human Cells using Osteosarcoma as a Model | |
| KR20240024171A (ko) | 재조합 원형 rna로부터 개선된 단백질 번역을 위한 조성물 및 방법 | |
| Xiao et al. | Research progress in digging and validation of miRNA target genes using experimental methods | |
| WO2022171899A1 (en) | A virus-encoded microrna for use in the diagnosis, prognosis and treatment of sars-cov-2 infection and associated disease |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |