CN114286865A - 检测变体核酸的解链温度方法、试剂盒和报告寡核苷酸 - Google Patents
检测变体核酸的解链温度方法、试剂盒和报告寡核苷酸 Download PDFInfo
- Publication number
- CN114286865A CN114286865A CN202080035128.5A CN202080035128A CN114286865A CN 114286865 A CN114286865 A CN 114286865A CN 202080035128 A CN202080035128 A CN 202080035128A CN 114286865 A CN114286865 A CN 114286865A
- Authority
- CN
- China
- Prior art keywords
- sequence
- nucleotides
- nucleic acid
- reporter oligonucleotide
- nucleotide
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 108091034117 Oligonucleotide Proteins 0.000 title claims abstract description 292
- 150000007523 nucleic acids Chemical class 0.000 title claims abstract description 279
- 238000002844 melting Methods 0.000 title claims abstract description 189
- 230000008018 melting Effects 0.000 title claims abstract description 189
- 238000000034 method Methods 0.000 title claims abstract description 151
- 108020004707 nucleic acids Proteins 0.000 title claims description 120
- 102000039446 nucleic acids Human genes 0.000 title claims description 120
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 title abstract description 26
- 125000003729 nucleotide group Chemical group 0.000 claims abstract description 544
- 239000002773 nucleotide Substances 0.000 claims abstract description 498
- 108091028043 Nucleic acid sequence Proteins 0.000 claims abstract description 136
- 230000002209 hydrophobic effect Effects 0.000 claims abstract description 126
- 239000000523 sample Substances 0.000 claims abstract description 124
- 238000004458 analytical method Methods 0.000 claims abstract description 59
- 208000032818 Microsatellite Instability Diseases 0.000 claims abstract description 37
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims abstract description 28
- 239000003814 drug Substances 0.000 claims abstract description 22
- 229940079593 drug Drugs 0.000 claims abstract description 20
- 108091093088 Amplicon Proteins 0.000 claims description 109
- 108091092878 Microsatellite Proteins 0.000 claims description 81
- 239000000138 intercalating agent Substances 0.000 claims description 56
- 239000000178 monomer Substances 0.000 claims description 52
- 230000003252 repetitive effect Effects 0.000 claims description 49
- 206010028980 Neoplasm Diseases 0.000 claims description 48
- 238000007846 asymmetric PCR Methods 0.000 claims description 42
- 230000000295 complement effect Effects 0.000 claims description 37
- 238000009396 hybridization Methods 0.000 claims description 36
- 230000035772 mutation Effects 0.000 claims description 30
- 125000005647 linker group Chemical group 0.000 claims description 27
- 230000003321 amplification Effects 0.000 claims description 23
- 238000003199 nucleic acid amplification method Methods 0.000 claims description 23
- 238000003752 polymerase chain reaction Methods 0.000 claims description 21
- 201000011510 cancer Diseases 0.000 claims description 16
- 238000001514 detection method Methods 0.000 claims description 16
- 201000010099 disease Diseases 0.000 claims description 16
- 239000013074 reference sample Substances 0.000 claims description 15
- 229910052739 hydrogen Inorganic materials 0.000 claims description 14
- 238000011282 treatment Methods 0.000 claims description 14
- 239000001257 hydrogen Substances 0.000 claims description 13
- 208000008051 Hereditary Nonpolyposis Colorectal Neoplasms Diseases 0.000 claims description 11
- 208000017095 Hereditary nonpolyposis colon cancer Diseases 0.000 claims description 11
- 208000035475 disorder Diseases 0.000 claims description 11
- 201000005027 Lynch syndrome Diseases 0.000 claims description 5
- 230000002596 correlated effect Effects 0.000 claims description 2
- GNFTZDOKVXKIBK-UHFFFAOYSA-N 3-(2-methoxyethoxy)benzohydrazide Chemical compound COCCOC1=CC=CC(C(=O)NN)=C1 GNFTZDOKVXKIBK-UHFFFAOYSA-N 0.000 claims 1
- 238000003780 insertion Methods 0.000 abstract description 10
- 230000037431 insertion Effects 0.000 abstract description 10
- 238000010606 normalization Methods 0.000 description 65
- 108020004414 DNA Proteins 0.000 description 49
- 238000003556 assay Methods 0.000 description 36
- 210000001519 tissue Anatomy 0.000 description 29
- 238000011144 upstream manufacturing Methods 0.000 description 26
- 210000004027 cell Anatomy 0.000 description 15
- -1 bromo, fluoro, chloro, iodo, mercapto, thio Chemical group 0.000 description 14
- 238000001574 biopsy Methods 0.000 description 13
- 238000002474 experimental method Methods 0.000 description 13
- BBEAQIROQSPTKN-UHFFFAOYSA-N pyrene Chemical compound C1=CC=C2C=CC3=CC=CC4=CC=C1C2=C43 BBEAQIROQSPTKN-UHFFFAOYSA-N 0.000 description 10
- 230000008859 change Effects 0.000 description 8
- 210000004369 blood Anatomy 0.000 description 7
- 239000008280 blood Substances 0.000 description 7
- GVEPBJHOBDJJJI-UHFFFAOYSA-N fluoranthrene Natural products C1=CC(C2=CC=CC=C22)=C3C2=CC=CC3=C1 GVEPBJHOBDJJJI-UHFFFAOYSA-N 0.000 description 7
- 210000004602 germ cell Anatomy 0.000 description 7
- 150000003839 salts Chemical class 0.000 description 7
- MWPLVEDNUUSJAV-UHFFFAOYSA-N anthracene Chemical compound C1=CC=CC2=CC3=CC=CC=C3C=C21 MWPLVEDNUUSJAV-UHFFFAOYSA-N 0.000 description 6
- 238000006243 chemical reaction Methods 0.000 description 6
- 238000012217 deletion Methods 0.000 description 6
- 230000037430 deletion Effects 0.000 description 6
- YNPNZTXNASCQKK-UHFFFAOYSA-N phenanthrene Chemical compound C1=CC=C2C3=CC=CC=C3C=CC2=C1 YNPNZTXNASCQKK-UHFFFAOYSA-N 0.000 description 6
- RDOWQLZANAYVLL-UHFFFAOYSA-N phenanthridine Chemical compound C1=CC=C2C3=CC=CC=C3C=NC2=C1 RDOWQLZANAYVLL-UHFFFAOYSA-N 0.000 description 6
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 5
- 208000026350 Inborn Genetic disease Diseases 0.000 description 5
- 125000004429 atom Chemical group 0.000 description 5
- 239000000872 buffer Substances 0.000 description 5
- 208000016361 genetic disease Diseases 0.000 description 5
- DXBHBZVCASKNBY-UHFFFAOYSA-N 1,2-Benz(a)anthracene Chemical compound C1=CC=C2C3=CC4=CC=CC=C4C=C3C=CC2=C1 DXBHBZVCASKNBY-UHFFFAOYSA-N 0.000 description 4
- 102000014461 Ataxins Human genes 0.000 description 4
- 108010078286 Ataxins Proteins 0.000 description 4
- 208000005692 Bloom Syndrome Diseases 0.000 description 4
- 201000010717 Bruton-type agammaglobulinemia Diseases 0.000 description 4
- 206010008025 Cerebellar ataxia Diseases 0.000 description 4
- 208000023105 Huntington disease Diseases 0.000 description 4
- 201000009794 Idiopathic Pulmonary Fibrosis Diseases 0.000 description 4
- 208000009415 Spinocerebellar Ataxias Diseases 0.000 description 4
- DGEZNRSVGBDHLK-UHFFFAOYSA-N [1,10]phenanthroline Chemical compound C1=CN=C2C3=NC=CC=C3C=CC2=C1 DGEZNRSVGBDHLK-UHFFFAOYSA-N 0.000 description 4
- 150000004056 anthraquinones Chemical class 0.000 description 4
- 201000004562 autosomal dominant cerebellar ataxia Diseases 0.000 description 4
- 230000000875 corresponding effect Effects 0.000 description 4
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 4
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 4
- 208000036971 interstitial lung disease 2 Diseases 0.000 description 4
- 239000003550 marker Substances 0.000 description 4
- 230000033607 mismatch repair Effects 0.000 description 4
- 229910052698 phosphorus Inorganic materials 0.000 description 4
- GBROPGWFBFCKAG-UHFFFAOYSA-N picene Chemical compound C1=CC2=C3C=CC=CC3=CC=C2C2=C1C1=CC=CC=C1C=C2 GBROPGWFBFCKAG-UHFFFAOYSA-N 0.000 description 4
- 150000004032 porphyrins Chemical class 0.000 description 4
- 108090000623 proteins and genes Proteins 0.000 description 4
- ZCCUUQDIBDJBTK-UHFFFAOYSA-N psoralen Chemical compound C1=C2OC(=O)C=CC2=CC2=C1OC=C2 ZCCUUQDIBDJBTK-UHFFFAOYSA-N 0.000 description 4
- 238000003753 real-time PCR Methods 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 235000021286 stilbenes Nutrition 0.000 description 4
- 208000011580 syndromic disease Diseases 0.000 description 4
- VEPOHXYIFQMVHW-XOZOLZJESA-N 2,3-dihydroxybutanedioic acid (2S,3S)-3,4-dimethyl-2-phenylmorpholine Chemical compound OC(C(O)C(O)=O)C(O)=O.C[C@H]1[C@@H](OCCN1C)c1ccccc1 VEPOHXYIFQMVHW-XOZOLZJESA-N 0.000 description 3
- 206010069754 Acquired gene mutation Diseases 0.000 description 3
- 229930024421 Adenine Natural products 0.000 description 3
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 3
- 108700028369 Alleles Proteins 0.000 description 3
- 238000012408 PCR amplification Methods 0.000 description 3
- PCNDJXKNXGMECE-UHFFFAOYSA-N Phenazine Natural products C1=CC=CC2=NC3=CC=CC=C3N=C21 PCNDJXKNXGMECE-UHFFFAOYSA-N 0.000 description 3
- 108091028664 Ribonucleotide Proteins 0.000 description 3
- XBDYBAVJXHJMNQ-UHFFFAOYSA-N Tetrahydroanthracene Natural products C1=CC=C2C=C(CCCC3)C3=CC2=C1 XBDYBAVJXHJMNQ-UHFFFAOYSA-N 0.000 description 3
- 229960000643 adenine Drugs 0.000 description 3
- 125000003342 alkenyl group Chemical group 0.000 description 3
- 125000003545 alkoxy group Chemical group 0.000 description 3
- 125000000217 alkyl group Chemical group 0.000 description 3
- 125000004414 alkyl thio group Chemical group 0.000 description 3
- 125000000304 alkynyl group Chemical group 0.000 description 3
- 150000001408 amides Chemical class 0.000 description 3
- PYKYMHQGRFAEBM-UHFFFAOYSA-N anthraquinone Natural products CCC(=O)c1c(O)c2C(=O)C3C(C=CC=C3O)C(=O)c2cc1CC(=O)OC PYKYMHQGRFAEBM-UHFFFAOYSA-N 0.000 description 3
- 125000003118 aryl group Chemical group 0.000 description 3
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 3
- 125000004093 cyano group Chemical group *C#N 0.000 description 3
- 230000007547 defect Effects 0.000 description 3
- 239000005547 deoxyribonucleotide Substances 0.000 description 3
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 3
- 230000009977 dual effect Effects 0.000 description 3
- 125000001072 heteroaryl group Chemical group 0.000 description 3
- 125000000623 heterocyclic group Chemical group 0.000 description 3
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 3
- 230000002779 inactivation Effects 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 244000005700 microbiome Species 0.000 description 3
- 208000022499 mismatch repair cancer syndrome Diseases 0.000 description 3
- 239000000203 mixture Substances 0.000 description 3
- CTRLRINCMYICJO-UHFFFAOYSA-N phenyl azide Chemical compound [N-]=[N+]=NC1=CC=CC=C1 CTRLRINCMYICJO-UHFFFAOYSA-N 0.000 description 3
- 238000010791 quenching Methods 0.000 description 3
- 230000000171 quenching effect Effects 0.000 description 3
- 230000010076 replication Effects 0.000 description 3
- 230000004044 response Effects 0.000 description 3
- 239000002336 ribonucleotide Substances 0.000 description 3
- 125000002652 ribonucleotide group Chemical group 0.000 description 3
- 230000037439 somatic mutation Effects 0.000 description 3
- IFLREYGFSNHWGE-UHFFFAOYSA-N tetracene Chemical compound C1=CC=CC2=CC3=CC4=CC=CC=C4C=C3C=C21 IFLREYGFSNHWGE-UHFFFAOYSA-N 0.000 description 3
- 238000013518 transcription Methods 0.000 description 3
- 230000035897 transcription Effects 0.000 description 3
- YBYIRNPNPLQARY-UHFFFAOYSA-N 1H-indene Chemical compound C1=CC=C2CC=CC2=C1 YBYIRNPNPLQARY-UHFFFAOYSA-N 0.000 description 2
- XVEUJPQIDXXNFD-UHFFFAOYSA-N 1h-pyrido[2,3]thieno[2,4-d]pyrimidin-4-one Chemical compound C12=CC=CN=C2SC2=C1N=CNC2=O XVEUJPQIDXXNFD-UHFFFAOYSA-N 0.000 description 2
- PZMKGWRBZNOIPQ-UHFFFAOYSA-N 1h-thieno[3,2-d]pyrimidin-4-one Chemical compound OC1=NC=NC2=C1SC=C2 PZMKGWRBZNOIPQ-UHFFFAOYSA-N 0.000 description 2
- VXGRJERITKFWPL-UHFFFAOYSA-N 4',5'-Dihydropsoralen Natural products C1=C2OC(=O)C=CC2=CC2=C1OCC2 VXGRJERITKFWPL-UHFFFAOYSA-N 0.000 description 2
- 102100024378 AF4/FMR2 family member 2 Human genes 0.000 description 2
- GDALETGZDYOOGB-UHFFFAOYSA-N Acridone Natural products C1=C(O)C=C2N(C)C3=CC=CC=C3C(=O)C2=C1O GDALETGZDYOOGB-UHFFFAOYSA-N 0.000 description 2
- 206010003694 Atrophy Diseases 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- 206010006187 Breast cancer Diseases 0.000 description 2
- 208000026310 Breast neoplasm Diseases 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- 206010009944 Colon cancer Diseases 0.000 description 2
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 2
- 208000001914 Fragile X syndrome Diseases 0.000 description 2
- 208000031448 Genomic Instability Diseases 0.000 description 2
- 101000833172 Homo sapiens AF4/FMR2 family member 2 Proteins 0.000 description 2
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- 208000036626 Mental retardation Diseases 0.000 description 2
- 206010068871 Myotonic dystrophy Diseases 0.000 description 2
- UFWIBTONFRDIAS-UHFFFAOYSA-N Naphthalene Chemical compound C1=CC=CC2=CC=CC=C21 UFWIBTONFRDIAS-UHFFFAOYSA-N 0.000 description 2
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 2
- 206010060862 Prostate cancer Diseases 0.000 description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 2
- 108091081062 Repeated sequence (DNA) Proteins 0.000 description 2
- PJANXHGTPQOBST-VAWYXSNFSA-N Stilbene Natural products C=1C=CC=CC=1/C=C/C1=CC=CC=C1 PJANXHGTPQOBST-VAWYXSNFSA-N 0.000 description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- 208000002495 Uterine Neoplasms Diseases 0.000 description 2
- 208000016349 X-linked agammaglobulinemia Diseases 0.000 description 2
- FZEYVTFCMJSGMP-UHFFFAOYSA-N acridone Chemical compound C1=CC=C2C(=O)C3=CC=CC=C3NC2=C1 FZEYVTFCMJSGMP-UHFFFAOYSA-N 0.000 description 2
- 210000004102 animal cell Anatomy 0.000 description 2
- 230000037444 atrophy Effects 0.000 description 2
- CUFNKYGDVFVPHO-UHFFFAOYSA-N azulene Chemical compound C1=CC=CC2=CC=CC2=C1 CUFNKYGDVFVPHO-UHFFFAOYSA-N 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 239000012472 biological sample Substances 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 150000001924 cycloalkanes Chemical class 0.000 description 2
- 229940104302 cytosine Drugs 0.000 description 2
- 238000003745 diagnosis Methods 0.000 description 2
- 230000004069 differentiation Effects 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 210000003527 eukaryotic cell Anatomy 0.000 description 2
- NIHNNTQXNPWCJQ-UHFFFAOYSA-N fluorene Chemical compound C1=CC=C2CC3=CC=CC=C3C2=C1 NIHNNTQXNPWCJQ-UHFFFAOYSA-N 0.000 description 2
- 238000001506 fluorescence spectroscopy Methods 0.000 description 2
- 206010017758 gastric cancer Diseases 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 150000002467 indacenes Chemical class 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 238000012886 linear function Methods 0.000 description 2
- 201000005202 lung cancer Diseases 0.000 description 2
- 208000020816 lung neoplasm Diseases 0.000 description 2
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 108091070501 miRNA Proteins 0.000 description 2
- 239000002679 microRNA Substances 0.000 description 2
- 101150061338 mmr gene Proteins 0.000 description 2
- UHOVQNZJYSORNB-UHFFFAOYSA-N monobenzene Natural products C1=CC=CC=C1 UHOVQNZJYSORNB-UHFFFAOYSA-N 0.000 description 2
- 201000000585 muscular atrophy Diseases 0.000 description 2
- 239000003471 mutagenic agent Substances 0.000 description 2
- 230000000869 mutational effect Effects 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 229960003301 nivolumab Drugs 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 201000002528 pancreatic cancer Diseases 0.000 description 2
- 208000008443 pancreatic carcinoma Diseases 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000004393 prognosis Methods 0.000 description 2
- 210000001236 prokaryotic cell Anatomy 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- PJANXHGTPQOBST-UHFFFAOYSA-N stilbene Chemical compound C=1C=CC=CC=1C=CC1=CC=CC=C1 PJANXHGTPQOBST-UHFFFAOYSA-N 0.000 description 2
- 150000001629 stilbenes Chemical class 0.000 description 2
- 201000011549 stomach cancer Diseases 0.000 description 2
- 229910052717 sulfur Inorganic materials 0.000 description 2
- NQRYJNQNLNOLGT-UHFFFAOYSA-N tetrahydropyridine hydrochloride Natural products C1CCNCC1 NQRYJNQNLNOLGT-UHFFFAOYSA-N 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- 206010046766 uterine cancer Diseases 0.000 description 2
- NOIRDLRUNWIUMX-UHFFFAOYSA-N 2-amino-3,7-dihydropurin-6-one;6-amino-1h-pyrimidin-2-one Chemical compound NC=1C=CNC(=O)N=1.O=C1NC(N)=NC2=C1NC=N2 NOIRDLRUNWIUMX-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- 101001007348 Arachis hypogaea Galactose-binding lectin Proteins 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- FGUUSXIOTUKUDN-IBGZPJMESA-N C1(=CC=CC=C1)N1C2=C(NC([C@H](C1)NC=1OC(=NN=1)C1=CC=CC=C1)=O)C=CC=C2 Chemical compound C1(=CC=CC=C1)N1C2=C(NC([C@H](C1)NC=1OC(=NN=1)C1=CC=CC=C1)=O)C=CC=C2 FGUUSXIOTUKUDN-IBGZPJMESA-N 0.000 description 1
- 208000005623 Carcinogenesis Diseases 0.000 description 1
- 208000024172 Cardiovascular disease Diseases 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- BDAGIHXWWSANSR-UHFFFAOYSA-M Formate Chemical compound [O-]C=O BDAGIHXWWSANSR-UHFFFAOYSA-M 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 206010051922 Hereditary non-polyposis colorectal cancer syndrome Diseases 0.000 description 1
- 108091027305 Heteroduplex Proteins 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 description 1
- 241000204031 Mycoplasma Species 0.000 description 1
- 239000012807 PCR reagent Substances 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- 241000606701 Rickettsia Species 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 239000007984 Tris EDTA buffer Substances 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 125000004054 acenaphthylenyl group Chemical group C1(=CC2=CC=CC3=CC=CC1=C23)* 0.000 description 1
- HXGDTGSAIMULJN-UHFFFAOYSA-N acetnaphthylene Natural products C1=CC(C=C2)=C3C2=CC=CC3=C1 HXGDTGSAIMULJN-UHFFFAOYSA-N 0.000 description 1
- 238000007844 allele-specific PCR Methods 0.000 description 1
- 125000003368 amide group Chemical group 0.000 description 1
- 150000001454 anthracenes Chemical class 0.000 description 1
- KNNXFYIMEYKHBZ-UHFFFAOYSA-N as-indacene Chemical compound C1=CC2=CC=CC2=C2C=CC=C21 KNNXFYIMEYKHBZ-UHFFFAOYSA-N 0.000 description 1
- 230000037429 base substitution Effects 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 125000002529 biphenylenyl group Chemical group C1(=CC=CC=2C3=CC=CC=C3C12)* 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 238000007470 bone biopsy Methods 0.000 description 1
- 210000001185 bone marrow Anatomy 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 239000003560 cancer drug Substances 0.000 description 1
- 230000036952 cancer formation Effects 0.000 description 1
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 1
- 231100000504 carcinogenesis Toxicity 0.000 description 1
- 210000000845 cartilage Anatomy 0.000 description 1
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 210000005266 circulating tumour cell Anatomy 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 206010012601 diabetes mellitus Diseases 0.000 description 1
- 230000037213 diet Effects 0.000 description 1
- 235000005911 diet Nutrition 0.000 description 1
- 230000003292 diminished effect Effects 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- 239000000890 drug combination Substances 0.000 description 1
- 230000009982 effect on human Effects 0.000 description 1
- 210000004696 endometrium Anatomy 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 230000037433 frameshift Effects 0.000 description 1
- 230000009395 genetic defect Effects 0.000 description 1
- 238000003205 genotyping method Methods 0.000 description 1
- DDTGNKBZWQHIEH-UHFFFAOYSA-N heptalene Chemical compound C1=CC=CC=C2C=CC=CC=C21 DDTGNKBZWQHIEH-UHFFFAOYSA-N 0.000 description 1
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 238000011862 kidney biopsy Methods 0.000 description 1
- 238000012317 liver biopsy Methods 0.000 description 1
- 210000002751 lymph Anatomy 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 239000012139 lysis buffer Substances 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 208000030159 metabolic disease Diseases 0.000 description 1
- LSDPWZHWYPCBBB-UHFFFAOYSA-M methanethiolate Chemical compound [S-]C LSDPWZHWYPCBBB-UHFFFAOYSA-M 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- 244000000010 microbial pathogen Species 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 239000003068 molecular probe Substances 0.000 description 1
- 238000001964 muscle biopsy Methods 0.000 description 1
- 230000001613 neoplastic effect Effects 0.000 description 1
- 230000004770 neurodegeneration Effects 0.000 description 1
- 208000015122 neurodegenerative disease Diseases 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000003204 osmotic effect Effects 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 239000013610 patient sample Substances 0.000 description 1
- 229960002621 pembrolizumab Drugs 0.000 description 1
- GUVXZFRDPCKWEM-UHFFFAOYSA-N pentalene Chemical compound C1=CC2=CC=CC2=C1 GUVXZFRDPCKWEM-UHFFFAOYSA-N 0.000 description 1
- XDJOIMJURHQYDW-UHFFFAOYSA-N phenalene Chemical compound C1=CC(CC=C2)=C3C2=CC=CC3=C1 XDJOIMJURHQYDW-UHFFFAOYSA-N 0.000 description 1
- 150000002987 phenanthrenes Chemical class 0.000 description 1
- 150000005053 phenanthridines Chemical class 0.000 description 1
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-L phosphoramidate Chemical compound NP([O-])([O-])=O PTMHPRAIXMAOOB-UHFFFAOYSA-L 0.000 description 1
- 150000008300 phosphoramidites Chemical group 0.000 description 1
- 125000004437 phosphorous atom Chemical group 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 150000003039 picenes Chemical class 0.000 description 1
- 210000002381 plasma Anatomy 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 125000006239 protecting group Chemical group 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 150000003220 pyrenes Chemical class 0.000 description 1
- 238000011897 real-time detection Methods 0.000 description 1
- 210000001995 reticulocyte Anatomy 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- WEMQMWWWCBYPOV-UHFFFAOYSA-N s-indacene Chemical compound C=1C2=CC=CC2=CC2=CC=CC2=1 WEMQMWWWCBYPOV-UHFFFAOYSA-N 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- JRPHGDYSKGJTKZ-UHFFFAOYSA-K selenophosphate Chemical compound [O-]P([O-])([O-])=[Se] JRPHGDYSKGJTKZ-UHFFFAOYSA-K 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 238000007390 skin biopsy Methods 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 238000013517 stratification Methods 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 230000002381 testicular Effects 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 150000003518 tetracenes Chemical class 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 210000001541 thymus gland Anatomy 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- 210000004881 tumor cell Anatomy 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
Images


































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
- C12Q1/6816—Hybridisation assays characterised by the detection means
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
- C12Q1/6827—Hybridisation assays for detection of mutation or polymorphism
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
- C12Q1/6816—Hybridisation assays characterised by the detection means
- C12Q1/6818—Hybridisation assays characterised by the detection means involving interaction of two or more labels, e.g. resonant energy transfer
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2525/00—Reactions involving modified oligonucleotides, nucleic acids, or nucleotides
- C12Q2525/10—Modifications characterised by
- C12Q2525/117—Modifications characterised by incorporating modified base
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2525/00—Reactions involving modified oligonucleotides, nucleic acids, or nucleotides
- C12Q2525/10—Modifications characterised by
- C12Q2525/151—Modifications characterised by repeat or repeated sequences, e.g. VNTR, microsatellite, concatemer
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2527/00—Reactions demanding special reaction conditions
- C12Q2527/107—Temperature of melting, i.e. Tm
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2565/00—Nucleic acid analysis characterised by mode or means of detection
- C12Q2565/10—Detection mode being characterised by the assay principle
- C12Q2565/101—Interaction between at least two labels
- C12Q2565/1015—Interaction between at least two labels labels being on the same oligonucleotide
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/156—Polymorphic or mutational markers
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Analytical Chemistry (AREA)
- Genetics & Genomics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Immunology (AREA)
- Microbiology (AREA)
- Molecular Biology (AREA)
- Physics & Mathematics (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Pathology (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
本发明涉及用于检测包含目的核苷酸的靶核酸序列中变体序列的存在、特别是用于检测微卫星不稳定性的基于解链分析的方法。所述方法采用探针作为具有荧光团和猝灭剂的报告寡核苷酸,并且其中所述核苷酸序列包含具有疏水嵌入残基的核苷酸。还公开用于确定药物的功效以及用于预测个体中临床障碍的存在的方法,以及用于进行所述方法的报告寡核苷酸和试剂盒。
Description
技术领域
本发明涉及用于检测包含目的核苷酸的靶核酸序列中变体序列的存在、特别是检测种系和体细胞突变以及微卫星不稳定性的方法。还公开用于预测药物功效以及用于检测个体中临床障碍的存在的方法,以及用于进行所述方法的报告寡核苷酸和试剂盒。
背景技术
可遗传的(种系)或不可遗传的(体细胞)突变事件,如单一核苷酸取代、缺失、插入、易位和重复,对人体生物学发挥工具性影响。基因图谱的确定揭示关于对环境因素(如运动和饮食)的反应以及在疾病诊断、预后和适用的治疗方案中的信息。遗传评价通常用像DNA测序或等位基因特异性PCR的工具来进行。涉及分子探针的可变结合的方法适用于种系变异,但是在与像HRM的技术组合时也适用于低等位基因频率体细胞突变。
在许多生物体中观察到重复性核苷酸序列(如同向或反向重复序列)。作为例子,成百上千的微卫星基因座分布于整个人基因组中,并且因此,在统计学上以约每100,000个碱基对一次出现。微卫星基因座是基因组DNA中包括短串联重复序列的区域,在所述短串联重复序列中,最短的重复性单元的长度通常为一至五个核苷酸。因此,如果适用,一般将特定微卫星基因座的重复性单元称为单、二、三、四或五核苷酸重复基因座。给定的微卫星基因座通常包括呈串联排列的约10与40个之间的这些重复性单元。此外,大多数二倍体物种的正常基因组DNA的每个微卫星基因座(如来自哺乳动物物种的基因组DNA)在每个基因座处包括两个等位基因。所述两个等位基因的长度可以彼此相同或不同,并且可以在个体间变化。
微卫星不稳定性(MSI)或复制错误(RER)是在某些人肿瘤中出现的基因组不稳定性的例子,在所述肿瘤中肿瘤细胞准确复制其DNA的能力减小。MSI是人DNA错配修复(MMR)基因的潜在功能失活的常见标记。MMR基因的功能丧失被认为是由于双等位基因失活而发生,所述双等位基因失活是通过编码区突变、杂合性丢失(LOH)和/或启动子甲基化来进行。此外,已知MMR基因的种系突变是大多数遗传性非息肉病结肠癌(HNPCC)家族中的常染色体线性遗传缺陷。HNPCC个体中由肿瘤突变引发的其他突变导致特定MMR基因的双等位基因失活,从而引起肿瘤中微卫星DNA的准确复制的丧失。因此,MSI是潜在DNA错配修复缺陷的标记,并且也与编码DNA中增强的突变率相关。除了导致MSI以外,这种源自MMR缺陷的增变基因表型在同向重复序列处以相等频率引起编码区碱基取代和移码突变二者。MMR缺陷的生成和所得增变基因表型被认为是肿瘤发生中的早期事件。
MSI不仅与HNPCC家族中的种系缺陷有关,还在约15%至20%的散发性结直肠癌中发现了MSI,其中所述发现也反映了基因组不稳定性(也测量为肿瘤突变负荷)的总体增加。肿瘤中MSI缺陷的发现还与分期匹配肿瘤的更好预后相关。因此,在临床上相关的是,鉴定具有MSI的肿瘤不仅暗示种系MMR缺陷(HNPCC家族),而且用于预后分层。尽管临床(Bethesda指南(Rodriguez-Bigas等人,1997)和组织病理学特征可能引起如下怀疑:结直肠肿瘤是微卫星不稳定的并且可能在HNPCC家族中出现,但临床病理学特征通常不足以诊断MSI的存在。因此,可以利用分子测试来阐明临床上怀疑的肿瘤的MSI状态(Boland等人,1998)。
除了结直肠肿瘤外,MSI还与其他类型的癌症和其他遗传障碍相关。为了说明,这些癌症和遗传障碍尤其包括胰腺癌、胃癌、膀胱癌、前列腺癌、肺癌、子宫癌和乳腺癌。被认为与微卫星不稳定性有关的其他示例性遗传障碍包括例如亨廷顿病(HD)、齿状核-红核-苍白球-丘脑下部萎缩(DRPLA)、脊髓延髓和肌萎缩(SBMA)、强直性肌营养不良(DM)、脆性X综合征、FRAXE精神发育迟缓和脊髓小脑共济失调(SCA)、布鲁顿X连锁无丙种球蛋白血症(XLA)、布卢姆综合征(BS)、颅额鼻综合征(CFNS)和特发性肺纤维化(IPF)。
根据上文清楚,对变体核苷酸序列(例如重复性核苷酸序列,如微卫星)的分析尤其具有许多诊断和预后应用。因此需要灵敏的、客观的且可靠的测定。
发明内容
本发明如权利要求中所限定。本文所述的方法代表一种用于研究种系和体细胞突变以及微卫星不稳定性的快速、容易、无偏且灵敏的方法。
本文提供一种用于检测由两条链组成并且包含优选地含有重复序列的一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的方法,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述方法包括以下步骤:
a)提供第一样品,其包含怀疑含有所述变体序列的核酸;
b)提供第二样品,其包含含有所述参考序列的核酸,其中所述第二样品是参考样品;
c)提供报告寡核苷酸;
d)提供引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增包含所述NOI的所述靶核酸序列;
e)在所述第一样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含怀疑含有变体序列的核酸的第一扩增子;并且在所述第二样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含所述参考序列的第二扩增子,其中所述第二扩增子是参考扩增子;
f)进行所述第一扩增子的解链分析,如高分辨率解链(HRM)分析,从而获得特征为第一解链曲线的第一图谱,并且进行所述第二扩增子的解链分析,如HRM分析,从而获得特征为第二解链曲线的第二图谱,其中所述第二图谱是特征为参考解链曲线的参考图谱;其中每个扩增子包含第一链和第二链,其中所述解链分析涉及所述报告寡核苷酸与每个扩增子的一条链的杂交、对荧光团发射的信号的检测以及获得所述第一和所述第二解链曲线;
其中所述报告寡核苷酸是范围为10至50个核苷酸、优选地范围为15至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,
其中所述报告寡核苷酸包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,并且
其中所述报告寡核苷酸包含杂交序列H,
其中所述杂交序列与所述靶核酸序列中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸序列中第二链的序列的连续延伸段互补,
并且其中所述报告寡核苷酸的杂交序列包含重复性序列和在其5'端和/或在其3'端的至少一个辅助序列或由所述重复性序列和辅助序列组成,其中所述辅助序列不包含重复序列,并且能够在所述杂交序列与所述第一和所述第二扩增子杂交时与所述扩增子杂交;以及
g)将所述第一图谱与所述参考图谱进行比较,其中所述第一图谱与所述参考图谱之间的差异表明,所述第一样品含有变体序列。
本文提供一种用于检测由两条链组成并且包含一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的方法,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述方法包括以下步骤:
a)提供第一样品,其包含怀疑含有所述变体序列的核酸;
b)提供第二样品,其包含含有所述参考序列的核酸,其中所述第二样品是参考样品;
c)提供报告寡核苷酸;
d)提供引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增所述靶核酸序列;
e)在所述第一样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含怀疑含有变体序列的核酸的第一扩增子;并且在所述第二样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含所述参考序列的第二扩增子,其中所述第二扩增子是参考扩增子;
f)进行所述第一扩增子的高分辨率解链(HRM)分析,从而获得特征为第一解链曲线的第一HRM图谱,并且进行所述第二扩增子的HRM分析,从而获得特征为第二解链曲线的第二HRM图谱,其中所述第二HRM图谱是特征为参考解链曲线的参考图谱;其中每个扩增子包含第一链和第二链,其中所述HRM分析涉及所述报告寡核苷酸与每个扩增子的一条链的杂交、对荧光团发射的信号的检测以及获得所述第一和所述第二解链曲线;
其中所述报告寡核苷酸是范围为10至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,
其中所述报告寡核苷酸包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,并且
其中所述报告寡核苷酸包含杂交序列H,
其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分;并且
其中所述杂交序列与所述靶核酸序列中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸序列中第二链的序列的连续延伸段互补;以及
g)将所述第一HRM图谱与参考HRM图谱进行比较,其中所述第一HRM图谱与所述参考HRM图谱之间的差异表明,所述第一样品含有变体序列。
本文还提供一种用于检测由两条链组成并且包含优选地含有重复序列的一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的多部分试剂盒,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述多部分试剂盒包含:
a)报告寡核苷酸,其包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,
其中所述报告寡核苷酸是范围为10至50个核苷酸、优选地范围为15至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
并且
其中所述杂交序列与所述靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补;
并且其中所述报告寡核苷酸的杂交序列包含重复性序列和在其5'端和/或在其3'端的至少一个辅助序列或由所述重复性序列和辅助序列组成,其中所述辅助序列不包含重复序列,并且能够在所述杂交序列与所述第一和所述第二扩增子杂交时与所述扩增子杂交;以及
b)引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增所述靶核酸序列。
本文还提供一种用于检测由两条链组成并且包含一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的多部分试剂盒,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述多部分试剂盒包含:
a)报告寡核苷酸,其包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,
其中所述报告寡核苷酸是范围为10至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分;并且
其中所述杂交序列与包含所述参考序列的所述靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补;以及
b)引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增所述靶核酸。
本文还提供一种报告寡核苷酸,其可以与由两条链组成并且包含优选地含有重复序列的一个或多个目的核苷酸(NOI)的靶核酸的一条链杂交,所述报告寡核苷酸包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,其中所述报告寡核苷酸是范围为10至50个核苷酸、优选地范围为15至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
其中所述杂交序列与所述靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补,
并且其中所述报告寡核苷酸的杂交序列包含重复性序列和在其5'端和/或在其3'端的至少一个辅助序列或由所述重复性序列和辅助序列组成,其中所述辅助序列不包含重复序列,并且能够在所述杂交序列与所述第一和所述第二扩增子的第二链杂交时与所述链杂交。
本文还提供一种报告寡核苷酸,其包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,其中所述报告寡核苷酸是范围为10至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分;并且
其中所述杂交序列与所述靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补。
本文还提供用于预测治疗个体的临床病症的功效的方法,其可以包括以下步骤:
a.提供来自所述个体的样品;
b.进行如本文所述的用于检测变体序列的存在的方法,以确定所述样品是否包含所述变体序列
其中所述变体序列的存在指示所述药物是否在治疗所述个体的所述临床病症方面有效。
本文还提供用于预测或甚至诊断个体中与特定突变相关的任何临床病症的存在的方法,其包括以下步骤:
a)提供来自所述个体的样品;
b)通过进行如本文所述的用于检测变体序列的方法来检测与所述临床病症相关的突变在所述样品中的存在;
其中所述变体序列的存在指示所述个体患有所述临床病症。
附图说明
图1用于检测包含NOI的变体核酸序列的方法的原理。(A)提供靶核酸(黑色链)。第二链包含NOI(浅灰色)。第一链是互补的(黑色线)。箭头指示引物。第一引物与第二链杂交并且发生引物的扩增(虚线)。第二引物与第一链杂交并且发生引物的扩增(虚线)。为了便于概述,仅显示靶核酸的扩增的部分。与第一引物相比,在此处过量提供第二引物(不对称PCR)。因此,生成更多包含NOI序列(黑色虚线和灰色虚线)的DNA。(B)扩增的DNA由双链靶核酸与包含NOI的单链靶核酸的混合物组成。此处显示包含NOI的单链序列(浅灰色)。报告寡核苷酸(RO)与该链杂交。其在此处包含荧光团F'(圆形)和猝灭剂Q(正方形)。获得解链曲线(x轴:T是温度;y轴:F是荧光)。
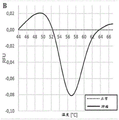
图2微卫星不稳定性并非必然导致解链温度的显著变化。使用不对称PCR的BAT25测定。X轴显示温度。(A)解链曲线,其中应用双线性归一化和强度阈值为0.1RFU的温度漂移。曲线之间的差异(测量为曲线之间幅度的最大差异)为约0.07RFU。(B)一阶负导数曲线,不应用温度漂移,正常组织的Tm为57.31℃并且肿瘤组织的Tm为57.41℃。
图3双线性归一化使解链曲线的斜率在实际解链期之前和之后更接近0。使用不对称PCR和报告寡核苷酸来分析微卫星NR22。X轴显示温度。用以下获得HRM曲线:(A)标准归一化,无温度漂移;(B)双线性归一化,无温度漂移。
图4双线性归一化使解链曲线的斜率在实际解链之前和之后更接近0。HRM曲线与图3的解链曲线的差异,其中将参考HRM曲线设为基线,从另一(此处为第一)解链曲线减去所述基线。X轴显示温度。(A)无双线性归一化,无温度漂移;(B)双线性归一化,无温度漂移。
图5在理论上,在来自微卫星稳定的人的正常组织样品与肿瘤组织样品之间,解链温度不应存在任何差异。然而,样品之间的量、盐浓度、杂质和其他变量的差异可以导致解链温度的小差异。然而,双线性归一化和温度漂移可以减小微卫星稳定的患者中正常组织与肿瘤组织之间的差异。使用不对称PCR和报告寡核苷酸的NR24测定。X轴显示温度。(A)HRM图谱,其中应用标准归一化。曲线之间的差异(测量为在差异图表上的归一化区域之间,在给定温度下的荧光的最大差异)为~0.04RFU。X轴显示温度。(B)HRM图谱,其中应用双线性归一化,但是不应用温度漂移阈值。曲线之间的差异为~0.02RFU。(C)HRM曲线,其中应用双线性归一化和强度阈值为0.1RFU的温度漂移。曲线之间的差异为~0.01RFU。
图6温度漂移可以中和由DNA缓冲液中的不同盐浓度引起的解链温度的变化。使用不对称PCR和报告寡核苷酸的NR24测定。X轴显示温度。(A)HRM曲线,其中应用双线性归一化,但是不应用温度漂移。曲线之间的差异(测量为在差异图表上的归一化区域之间,在给定温度下的荧光的最大差异)为~0.07RFU。(B)HRM曲线,其中应用双线性归一化和0.1RFU的温度漂移强度阈值。曲线之间的差异为~0.01RFU。
图7用于针对16个正常组织DNA样品,使用不对称PCR研究微卫星MONO27的测定。用以下获得HRM曲线:(A)双线性归一化,无温度漂移;(B)双线性归一化,和强度阈值为0.1RFU的温度漂移。X轴显示温度。应用温度漂移允许使用一个样品作为通用参考。
图8图7中HRM曲线的差异图。(A)双线性归一化,无温度漂移;(B)双线性归一化,和强度阈值为0.1RFU的温度漂移。X轴显示温度。
图9不对称PCR产生更多单链靶扩增子。使用对称和不对称PCR的NR22测定。X轴显示PCR循环次数,并且Y轴显示荧光。
图10不对称PCR产生更高信噪比和更陡峭的解链(即更窄的解链峰)。使用对称和不对称PCR的NR22测定。(A)解链曲线;(B):解链曲线,使用标准归一化进行归一化。X轴显示温度。
图11不对称PCR使得更易于区分MSS患者与MSI患者。显示使用NR22测定的数据。用不对称PCR(A)或用对称PCR(B)在应用标准归一化后获得HRM曲线。X轴显示温度。
图12不对称PCR使得更易于区分MSS患者与MSI患者。显示使用NR22测定的数据。来自图11中的HRM曲线的差异图。(A)不对称PCR;(B):对称PCR。X轴显示温度。
图13报告寡核苷酸中的单端突出端可以增加解链温度。显示基于NR22测定的数据,所述NR22测定使用利用报告寡核苷酸的不对称PCR,有两种不同的报告寡核苷酸。(A)HRM曲线。(B)所述HRM曲线的负一阶导数。X轴显示温度。
图14双重猝灭报告寡核苷酸增加信噪比。显示使用利用不对称PCR的BAT26测定的数据。HRM曲线(A)和负一阶导数曲线(B),其使用单一猝灭的(“非DQ探针”)和双重猝灭的(“DQ探针”)报告寡核苷酸。X轴显示温度。
图15报告寡核苷酸的杂交序列中另外的核苷酸重复序列使得可能检测更长的微卫星。显示使用利用不对称PCR的NR21测定的数据。X轴显示温度。
图16单点突变将解链温度改变几度。使用KIT外显子13测定进行实验。按不对称PCR进行PCR。X轴显示温度。虚线显示针对野生型靶核酸的结果,并且实线显示针对包含突变的靶核酸的结果。(A)归一化的HRM曲线;Y轴显示荧光。(B)解链峰(解链曲线的负一阶导数)。Y轴是-dF/dT。
图17强辅助序列帮助区分野生型与突变体。使用NR24测定进行实验。按不对称PCR进行PCR。X轴显示温度,并且y轴显示荧光。虚线显示针对野生型靶核酸的结果,并且实线显示针对包含突变的靶核酸的结果。(A)归一化的HRM曲线,其使用包含第一辅助序列的第一报告寡核苷酸。(B)归一化的HRM曲线,其使用包含第二辅助序列的第二报告寡核苷酸,所述第二辅助序列强于所述第一辅助序列。
图18强辅助序列帮助区分野生型与突变体。使用NR24测定进行实验。按不对称PCR进行PCR。X轴显示温度,并且y轴显示荧光。虚线显示针对野生型靶核酸的结果,并且实线显示针对包含突变的靶核酸的结果。(A)差异图,其使用包含第一辅助序列的第一报告寡核苷酸。(B)差异图,其使用包含第二辅助序列的第二报告寡核苷酸,所述第二辅助序列强于所述第一辅助序列。
具体实施方式
定义
扩增子“扩增子”是指通过复制或转录分子制备的另一分子。其中可以产生扩增子的示例性过程包括转录、克隆和/或聚合酶链反应(PCR)或另一种核酸扩增技术(例如,链置换PCR扩增(SDA)、双重PCR扩增等)。通常,扩增子是所选核酸(例如,模板或靶核酸)的拷贝或者与其互补。
双线性归一化 术语“双线性归一化”在本文中用于指代通过将不同曲线的荧光数据缩放至归一化曲线而应用于一条或多条曲线的数学转换。这允许在去除可以影响荧光信号的其他因素(如仪器中不同位置之间的不同信号强度、塑料的不同透明度以及引入荧光测量的变量的其他因素)的情况下比较不同曲线。双线性归一化迫使一条或多条曲线具有相同的值(在归一化区域的平均值处)以及在所选归一化区域中尽可能水平(平坦)的曲线路线。几种算法是本领域中已知的,可以将其应用至曲线,从而将一条或多条曲线转换为允许比较不同解链曲线的一条或多条曲线。归一化还减小孔之间的不同光学和机械差异的影响。
疏水核苷酸 如本文所用术语“疏水核苷酸”是指下文在章节“疏水核苷酸”中详细描述的疏水核苷酸。特定地,根据本发明的疏水核苷酸含有经由接头连接至核苷酸/核苷酸类似物/骨架单体单元的嵌入剂。
解链温度 如本文所用术语“解链温度”表示以摄氏度计的温度,在所述温度下,存在50%螺旋(杂交的)与线圈(未杂交的)形式。解链温度也可以称为(Tm)。核酸和核酸类似物的解链是指双链核酸分子中两条链的热分离。
微卫星 术语“微卫星”、“微卫星标记”或“微卫星基因座”是指基因组DNA中包括串联核苷酸重复序列的区域。这些重复序列或“重复性单元”的长度通常为约一个至约七个碱基对。微卫星基因座通常包括呈串联排列的约10至40之间的这些重复性单元。除了单核苷酸重复序列(其为一个核苷酸的重复序列)外,其他示例性重复性核苷酸序列包括二核苷酸重复序列(例如AT重复序列和GC重复序列)、三核苷酸重复序列(例如,CGG重复序列、CGC重复序列、TAT重复序列、ATT重复序列)、四核苷酸重复序列、五核苷酸重复序列和/或其互补重复序列。
核苷酸类似物 术语“核苷酸类似物”包括能够被掺入核酸骨架中并且能够进行特异性碱基配对的所有核苷酸类似物,基本上如天然存在的核苷酸。根据本发明的核苷酸类似物包括但不限于选自以下的核苷酸类似物:PNA、HNA、MNA、ANA、LNA、XNA、INA、CNA、CeNA、TNA、(2'-NH)-TNA、(3'-NH)-TNA、α-L-核-LNA、α-L-木-LNA、β-D-木-LNA、α-D-核-LNA、[3.2.1]-LNA、二环-DNA、6-氨基-二环-DNA、5-表-二环-DNA、α-二环-DNA、三环-DNA、二环[4.3.0]-DNA、二环[3.2.1]-DNA、二环[4.3.0]酰胺-DNA、β-D-吡喃核糖基-NA、α-L-吡喃木糖基-NA、2'-R1-RNA、2'-OR1-RNA(R1是取代基)、α-L-RNA、α-D-RNA和β-D-RNA。
目的核苷酸 如本文所用术语“一个或多个目的核苷酸”是指靶核酸序列内的一个或多个核苷酸,所述核苷酸可能存在于两个不同变体中。“一个或多个目的核苷酸”在本文中也可以称为“NOI”。因此,NOI可以由变体序列组成,或者其可以由参考序列组成,在本文中也称为“参考序列”。在一些实施方案中,所述参考序列可以是野生型序列。
核苷酸 如本文所用术语“核苷酸”是指天然存在的核苷酸,例如天然存在的核糖核苷酸或脱氧核糖核苷酸,或者核糖核苷酸或脱氧核糖核苷酸的天然存在的衍生物。天然存在的核苷酸包括包含四个核碱基腺嘌呤(A)、胸腺嘧啶(T)、鸟嘌呤(G)或胞嘧啶(C)之一的脱氧核糖核苷酸,以及包含四个核碱基腺嘌呤(A)、尿嘧啶(U)、鸟嘌呤(G)或胞嘧啶(C)之一的核糖核苷酸。
寡核苷酸 如本文所用术语“寡核苷酸”是指核苷酸和/或核苷酸类似物和/或疏水核苷酸的寡聚物。优选地,并且寡核苷酸是任选地包含一个或多个疏水核苷酸的核苷酸寡聚物。
参考靶序列 术语“参考靶序列”是指包含参考序列的靶核酸序列的延伸段。
标准归一化 术语“标准归一化”是指将不同曲线的荧光数据缩放至归一化曲线,并且允许在去除可以影响荧光信号的其他因素(如仪器中不同位置之间的不同信号强度、塑料的不同透明度以及引入荧光测量的变量的其他因素)的情况下比较不同曲线。
靶核酸序列 如本文所用术语“靶核酸序列”是指包含一个或多个目的核苷酸(NOI)的核酸序列。靶核酸序列可以使用引物组来扩增。
温度漂移 如本文所用术语“温度漂移”是指如下数学工具,将其应用至两个或更多个归一化的曲线,从而使这些曲线在温度方向上漂移,以在给定荧光极限(强度阈值)下具有完全相同的Tm。将这种转换算法应用至数据集减小例如不同样品中的不同盐浓度的影响。
变体序列 如本文所用术语“变体序列”是指靶核酸序列内与参考序列不同的一个或多个核苷酸。因此,靶核酸序列可以含有作为变体序列的NOI,或者靶核酸序列可以含有作为参考序列的NOI,或者NOI甚至可以是又另一个变体序列。变体序列可以例如是突变,如单一核苷酸突变,或者它可以是插入或缺失。变体序列和参考序列可以重叠,使得一者的序列包含另一者的全部序列。在此类情形中,变体序列和参考序列中构成序列的核苷酸数量可以不同。
用于检测靶核酸序列中变体序列的存在的方法
本发明涉及用于检测靶核酸序列中的变体序列的方法。因此,所述方法特别用于检测靶核酸序列中特定序列的存在,所述特定序列可能与两个或更多个不同序列同时存在。所述方法可以例如用于区分野生型序列与突变体序列,以及用于区分不同的多态性序列。所述方法特别用于通过检测长度与野生型或参考序列不同的变体序列的存在来检测源于微卫星不稳定性的变体序列。因此,所述方法可以有利地用于检测包含重复序列、特别是微卫星的靶核酸序列。
本文提供一种用于检测由两条链组成并且包含优选地含有重复序列的一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的方法,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述方法包括以下步骤:
a)提供第一样品,其包含怀疑含有所述变体序列的核酸;
b)提供第二样品,其包含含有所述参考序列的核酸,其中所述第二样品是参考样品;
c)提供报告寡核苷酸;
d)提供引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增包含所述NOI的所述靶核酸序列;
e)在所述第一样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含怀疑含有变体序列的核酸的第一扩增子;并且在所述第二样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含所述参考序列的第二扩增子,其中所述第二扩增子是参考扩增子;
f)进行所述第一扩增子的解链分析,如高分辨率解链(HRM)分析,从而获得特征为第一解链曲线的第一图谱,并且进行所述第二扩增子的解链分析,如HRM分析,从而获得特征为第二解链曲线的第二图谱,其中所述第二图谱是特征为参考解链曲线的参考图谱;其中每个扩增子包含第一链和第二链,其中所述解链分析涉及所述报告寡核苷酸与每个扩增子的一条链的杂交、对荧光团发射的信号的检测以及获得所述第一和所述第二解链曲线;
其中所述报告寡核苷酸是范围为10至50个核苷酸、优选地范围为15至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,
其中所述报告寡核苷酸包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,并且
其中所述报告寡核苷酸包含杂交序列H,
其中所述杂交序列与所述靶核酸序列中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸序列中第二链的序列的连续延伸段互补,
并且其中所述报告寡核苷酸的杂交序列包含重复性序列和在其5'端和/或在其3'端的至少一个辅助序列或由所述重复性序列和辅助序列组成,其中所述辅助序列不包含重复序列,并且能够在所述杂交序列与所述第一和所述第二扩增子杂交时与所述扩增子杂交;以及
g)将所述第一图谱与所述参考图谱进行比较,其中所述第一图谱与所述参考图谱之间的差异表明,所述第一样品含有变体序列。
因此,本文提供一种用于检测由两条链组成并且包含一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的方法,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述方法包括以下步骤:
a)提供第一样品,其包含怀疑含有所述变体序列的核酸;
b)提供第二样品,其包含含有所述参考序列的核酸,其中所述第二样品是参考样品;
c)提供报告寡核苷酸;
d)提供引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增所述靶核酸序列;
e)在所述第一样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含怀疑含有变体序列的核酸的第一扩增子;并且在所述第二样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含所述参考序列的第二扩增子,其中所述第二扩增子是参考扩增子;
f)进行所述第一扩增子的高分辨率解链(HRM)分析,从而获得特征为第一解链曲线的第一HRM图谱,并且进行所述第二扩增子的HRM分析,从而获得特征为第二解链曲线的第二HRM图谱,其中所述第二HRM图谱是特征为参考解链曲线的参考图谱;其中每个扩增子包含第一链和第二链,其中所述HRM分析涉及所述报告寡核苷酸与每个扩增子的一条链的杂交、对荧光团发射的信号的检测以及获得所述第一和所述第二解链曲线;
其中所述报告寡核苷酸是范围为10至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,
其中所述报告寡核苷酸包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,并且
其中所述报告寡核苷酸包含杂交序列H,
其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分;并且
其中所述杂交序列与所述靶核酸序列中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸序列中第二链的序列的连续延伸段互补;以及
g)将所述第一HRM图谱与参考HRM图谱进行比较,其中所述第一HRM图谱与所述参考HRM图谱之间的差异表明,所述第一样品含有变体序列。
因此,当存在两个或更多个不同的靶核酸序列时,所述方法用于区分至少两个不同的靶核酸序列,即包含变体序列的靶核酸序列与不含所述变体序列的靶核酸序列。后者也可以称为“参考序列”。任选地,所述方法还可以用于区分包含其他变体序列的靶核酸序列。所述方法的一般原理例示于图1中。简言之,第一与第二图谱之间的差异、特别是分析的解链图谱与参考解链图谱之间的差异表明,所测试的样品(第一样品)含有变体序列;应理解,在本公开文本通篇中,差异优选地是指显著差异。
在本发明将所述方法用于区分野生型序列与突变体序列的实施方案中,突变体序列可以是参考序列。然而,野生型序列经常将为参考序列。本发明的方法也可以用于区分野生型序列与几种不同的突变体序列,在所述情形中,所述野生型序列通常将为参考序列,并且所述几种不同的突变体序列将为变体序列。在所述方法的一些实施方案中,参考序列是微卫星序列。则变体序列可以是微卫星序列,其由多个串联重复序列组成,串联重复序列的数量与参考序列中串联重复序列的数量不同。例如,变体序列可能是微卫星不稳定性的结果-在这些情形中,变体序列可以是具有不同的串联重复序列数量的多种变体序列。相比之下,则参考序列将具有恒定数量的串联重复序列。
在一些实施方案中,变体序列可以是指示疾病状态的突变,或者它可以预示给定治疗的功效。
一个或多个目的核苷酸(NOI)、变体序列和参考序列
变体序列可以是任何序列,其与另一序列、特别是参考序列不同。通常,变体序列是突变体序列,例如与野生型序列不同的序列,例如由于存在用核苷酸替代另一核苷酸的突变,和/或由于与参考序列相比插入和/或缺失核苷酸。然而,变体序列也可以是与参考序列不同的多态性序列或任何其他序列。优选地,变体序列是微卫星的变体,其长度与微卫星的正常长度不同。本发明方法实际上对于检测微卫星不稳定性特别有用。它们可以用于检测短(小于15个核苷酸)微卫星以及较长微卫星(大于15个核苷酸)的不稳定性。在具有微卫星不稳定性的受试者中,较长微卫星通常将在较短微卫星之前发生突变,因此,可以有利地使用作为较长微卫星的靶核酸,其长度为15个或更多个核苷酸。
变体序列可以由至少一个(如1个、例如2个、如3个、例如4个、如5个、例如6个、如7个、例如8个、如9个、例如10个、如10至20个、例如20至50个、如超过50个)核苷酸组成。优选地,变体序列由10个或更多个核苷酸(如15个或更多个核苷酸)组成。因此,在一些实施方案中,变体序列由11、12、13、14、15、16、17、19、20个或更多个核苷酸(如25、30、35、40、45或50个或更多个核苷酸)组成。例如,变体序列由20、21、22、23、24、25、26、27、28、29或30个或更多个核苷酸组成。
在本发明的一些实施方案中,变体序列是单一核苷酸突变或单核苷酸多态性(SNP)。
变体序列可以是与参考靶序列相比,一个或多个核苷酸变为一个或多个其他核苷酸。此外,术语变体序列可以是在核酸内缺失或插入核苷酸,例如与参考靶序列相比缺失或插入核苷酸。
靶核酸序列可以包含多态性位点(详情见下文),并且因此参考靶序列可以包含一个多态性,而“变体序列”可以构成另一个多态性。
在一个实施方案中,参考靶序列是野生型序列,即最频繁的天然存在的序列,而与所述野生型序列相比,变体序列包含一个或多个突变、插入或缺失。因此,在一个实施方案中,根据本发明的变体序列可以是多态性,如单核苷酸多态性(SNP)。例如,多态性可以指示特定DNA图谱。特定DNA图谱的知识可以例如用于鉴定个体。例如,特定DNA图谱可以用于鉴定罪犯或潜在的罪犯,或者用于鉴定尸体或尸体的一部分。此外,特定DNA图谱可以用于确定个体之间的关系,例如亲子关系或更远的关系。关系也可以是不同物种之间或给定物种的不同群体之间的关系。
在一些实施方案中,参考序列是或包含具有给定数量的重复序列的微卫星。则变体序列可以是一个或几个变体序列,其重复序列的数量与在参考或野生型序列中观察到的数量不同。
在一个实施方案中,变体序列可以指示临床病症,或者突变可以指示临床病症的增加的风险。特定地,变体序列可以是微卫星,并且临床病症可能与微卫星不稳定性相关。
所述临床病症可以例如选自肿瘤疾病、神经系统变性疾病、心血管疾病和代谢障碍(包括糖尿病)。
此外,变体序列可以指示对预定药物治疗的特定反应。例如,变体序列的存在可以指示个体是否会对所述药物治疗有正面反应,或者个体是否可以抑或无法耐受特定药物治疗。例如,MSI的检测可以用于规定使用检查点抑制剂的决策过程中,所述检查点抑制剂如例如 (派姆单抗,Merck&Co.Inc.)或Opdivo(纳武单抗,Bristol-MyersSquibb)。
(派姆单抗,Merck&Co.Inc.)或Opdivo(纳武单抗,Bristol-MyersSquibb)。
变体序列可以定位于特定基因、基因区段、微卫星或任何其他DNA序列中。此外,变体序列可以定位于mRNA、miRNA或任何其他RNA序列中。本文所述的方法使得能够检测特定DNA,所述特定DNA可以具有真核、原核、古细菌或病毒来源。例如,本发明可以通过测定已知与特定微生物相关的特定序列来辅助对各种感染性疾病进行诊断和/或基因分型。
靶核酸序列
本发明方法用于检测由两条链组成并且包含一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在。尽管靶核酸序列由两条链组成并且通常是DNA,但是应理解,可以容易地调整本发明方法以通过扩增靶核酸序列的单链来检测靶核酸中变体序列的存在,例如如果所述扩增是RNA的扩增。因此,本发明方法也可以用于检测靶RNA中的变体序列,所述靶RNA源自例如由两条链组成的靶核酸序列的转录。
因此,靶核酸是怀疑包含变体序列的目的序列。换言之,其通常对应于特定基因座。
靶核酸序列可以由至少一个(如1个、例如2个、如3个、例如4个、如5个、例如6个、如7个、例如8个、如9个、例如10个、如10至20个、例如20至50个、如超过50个)核苷酸组成。优选地,靶核酸序列由15个或更多个核苷酸组成。因此,在一些实施方案中,靶核酸序列由11、12、13、14、15、16、17、19、20个或更多个核苷酸(如25、30、35、40、45或50个或更多个核苷酸)组成。例如,靶核酸序列由20、21、22、23、24、25、26、27、28、29或30个或更多个核苷酸组成。因为本发明方法对于检测微卫星(特别是长度为15个或更多个核苷酸的微卫星)的变体序列特别有用,在靶核酸序列是参考序列的情况下,其长度优选地为15个或更多个核苷酸。
在一些实施方案中,靶核酸是包含一定数量的串联重复序列的微卫星。对于参考序列,串联重复序列的数量是M,其中M是整数。对于参考序列,总长度为n个核苷酸。变体序列具有M'个串联重复序列并且总长度为n'个核苷酸。M和M'是不同的整数。n和n'是不同的整数。然而,一些变体序列可能具有M个串联重复序列并且总长度为n个核苷酸,然而,在此情形中,一些或大多数变体序列仍将具有与参考序列相比不同数量的重复序列和不同的总长度,这将使得本发明方法能够检测与参考序列不同的变体序列的存在。
在一些实施方案中,n和/或n'是1,如1个、例如2个、如3个、例如4个、如5个、例如6个、如7个、例如8个、如9个、例如10个、如10至20个、例如20至50个、如超过50个核苷酸。优选地,n和/或n'是15个或更多个核苷酸;在一些实施方案中,至少n是15个或更多个核苷酸。因此,在一些实施方案中,n和/或n'由11、12、13、14、15、16、17、18、19、20个或更多个核苷酸(如25、30、35、40、45或50个或更多个核苷酸)组成。例如,n和/或n'由20、21、22、23、24、25、26、27、28、29或30个或更多个核苷酸组成。优选地,至少n由15、16、17、18、19、20个或更多个核苷酸(如20、21、22、23、24、25、26、27、28、29或30个或更多个核苷酸,如25、30、35、40、45或50个或更多个核苷酸)组成。在一些实施方案中,n'是1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个或更多个核苷酸,如25、30、35、40、45或50个或更多个核苷酸。
本发明方法可以用于检测可以指示特定障碍的变体序列。例如,所述障碍与微卫星不稳定性相关。
通常有利地研究样品中几种不同变体序列的存在。因此,可以调整本发明方法,使得同时检测几种变体序列。有时,仅确定多个变体序列中的至少一个是否存在就已足够。
在一些实施方案中,靶核酸序列是包含BAT25、BAT26、NR21、NR22、NR24和MONO27(它们是包含单核苷酸重复序列的微卫星标记)中的一种或多种的多个靶核酸序列。所述方法允许检测如下变体序列,所述变体序列具有与这些靶核酸序列的参考序列不同数量的重复序列,并因此具有不同总长度。
人BAT25的参考或野生型序列如SEQ ID NO:1中所示。BAT25的单核苷酸重复序列对应于SEQ ID NO:1的位置147至171。参考序列因此具有M个单核苷酸重复序列,其中M=25。
人BAT26的参考或野生型序列如SEQ ID NO:2中所示。BAT26的单核苷酸重复序列对应于SEQ ID NO:2的位置222至248。参考序列因此具有M个单核苷酸重复序列,其中M=27。
人NR21的参考或野生型序列如SEQ ID NO:3中所示。NR21的单核苷酸重复序列对应于SEQ ID NO:3的位置189至209。参考序列因此具有M个单核苷酸重复序列,其中M=21。
人NR22的参考或野生型序列如SEQ ID NO:4中所示。NR22的单核苷酸重复序列对应于SEQ ID NO:4的位置152至172。参考序列因此具有M个单核苷酸重复序列,其中M=21。
人NR24的参考或野生型序列如SEQ ID NO:5中所示。NR24的单核苷酸重复序列对应于SEQ ID NO:5的位置165至187。参考序列因此具有M个单核苷酸重复序列,其中M=23。
人MONO27的参考或野生型序列如SEQ ID NO:6中所示。MONO27的单核苷酸重复序列对应于SEQ ID NO:6的位置300至327。参考序列因此具有M个单核苷酸重复序列,其中M=28。
在一些实施方案中,靶核酸序列是如SEQ ID NO:1中所示的BAT25,并且NOI对应于由SEQ ID NO:1的位置147至171限定的序列。在其他实施方案中,靶核酸序列是如SEQ IDNO:2中所示的BAT26,并且NOI对应于由SEQ ID NO:2的位置222至248限定的序列。在其他实施方案中,靶核酸序列是如SEQ ID NO:3中所示的NR21,并且NOI对应于由SEQ ID NO:3的位置189至209限定的序列。在其他实施方案中,靶核酸序列是如SEQ ID NO:4中所示的NR22,并且NOI对应于由SEQ ID NO:4的位置152至172限定的序列。在其他实施方案中,靶核酸序列是如SEQ ID NO:5中所示的NR24,并且NOI对应于由SEQ ID NO:5的位置165至187限定的序列。在其他实施方案中,靶核酸序列是如SEQ ID NO:6中所示的MONO27,并且NOI对应于由SEQ ID NO:6的位置300至327限定的序列。
在其他实施方案中,靶核酸序列是两个靶核酸序列。例如,所述两个靶核酸序列是BAT25和BAT26;BAT25和NR21;BAT25和NR22;BAT25和NR24;BAT25和MONO27;BAT26和NR21;BAT26和NR22;BAT26和NR24;BAT26和MONO27;NR21和NR22;NR21和NR24;NR21和MONO27;NR22和NR24;NR22和MONO27;NR24和MONO27,其中NOI如上文所定义。
在其他实施方案中,靶核酸序列是三个靶核酸序列。例如,所述三个靶核酸序列是BAT25、BAT26和NR21;BAT25、BAT26和NR22;BAT25、BAT26和NR24;BAT25、BAT26和MONO27;BAT25、NR21和NR22;BAT25、NR21和NR24;BAT25、NR21和MONO27;BAT25、NR22和NR24;BAT25、NR22和MONO27;BAT25、NR24和MONO27;BAT26、NR21和NR22;BAT26、NR21和NR24;BAT26、NR21和MONO27;BAT26、NR22和NR24;BAT26、NR22和MONO27;BAT26、NR24和MONO27;NR21、NR22和NR24;NR21、NR22和MONO27;NR21、NR24和MONO27;NR22、NR24和MONO27,其中NOI如上文所定义。
在其他实施方案中,靶核酸序列是四个靶核酸序列。例如,所述四个靶核酸序列是BAT25、BAT26、NR21和NR22;BAT25、BAT26、NR21和NR24;BAT25、BAT26、NR21和MONO27;BAT25、BAT26、NR22和NR24;BAT25、BAT26、NR22和MONO27;BAT26、NR21、NR22和NR24;BAT26、NR21、NR22和MONO27;BAT26、NR21、NR24和MONO27;NR21、NR22、NR24和MONO27,其中NOI如上文所定义。
在其他实施方案中,靶核酸序列是五个靶核酸序列。例如,所述五个靶核酸序列是BAT25、BAT26、NR21、NR22和NR24;BAT25、BAT26、NR21、NR22和MONO27;BAT25、BAT26、NR22、NR24和MONO27;BAT26、NR21、NR22、NR24和MONO27,其中NOI如上文所定义。
在其他实施方案中,靶核酸序列是六个靶核酸序列。例如,所述六个靶核酸序列是BAT25、BAT26、NR21、NR22、NR24和MONO27,其中NOI如上文所定义。
在优选实施方案中,靶核酸是五个靶核酸,优选地BAT25、BAT26、NR21、NR22和NR24;或BAT25、BAT26、NR22、NR24和MONO27,其中NOI如上文所定义。在其他优选实施方案中,靶核酸序列是六个靶核酸序列,优选地BAT25、BAT26、NR21、NR22、NR24和MONO27,其中NOI如上文所定义。
样品
在所述方法的第一步骤中,提供第一样品,其包含怀疑含有要检测的变体序列的核酸。在所述方法的第二步骤中,提供第二样品,其包含参考序列。因此,第二样品是参考样品,并且所述术语在本文中将可互换使用。
所述样品可以包含含有所述核酸的细胞。所述细胞可以例如是原核细胞或真核细胞,如植物细胞或哺乳动物细胞。
所述样品可以例如是合成制备的样品,其可能已经或可能尚未在体外进行进一步处理,然而最通常地,所述样品是从个体获得的样品。
在一些实施方案中,第一样品是从患有或怀疑患有特征为变体序列的存在的疾病或障碍的个体获得的样品,并且第二样品是从健康个体获得的样品。还可以使用包含例如来自怀疑患有疾病的一名个体的患病组织的细胞(即怀疑含有疾病所特有的变体序列的细胞)的第一样品,以及包含来自同一个体的健康组织的细胞(即不含变体序列的细胞)的第二样品。在一些实施方案中,本发明方法允许使用通用参考样品。
因此,通常,期望测试个体(如哺乳动物,例如人类)的DNA或RNA。在该情形中,样品是源自所述个体的样品。因此,样品可以例如包含选自DNA、mRNA、miRNA或任何其他RNA序列的核酸。样品可以源自体液样品,例如血液样品、活检、毛发、指甲等的样品或任何其他合适的样品。在本发明的其中个体患有癌症的实施方案中,样品可以是通过手术从个体取出的癌症肿瘤的样品,或者所述肿瘤的活检。然而,在本发明的其中个体患有癌症的实施方案中,样品也可以是血液样品,其通常可以含有CTC和cfDNA。
可以在检测变体序列的存在之前在体外处理样品。例如,可以使样品经历一个或多个纯化步骤,从而可以将核酸从样品完全或部分纯化。此外,样品可能已经经历逆转录。
样品可以包含核酸(RNA和DNA)与非核酸的复杂生物混合物,例如完整细胞或粗细胞提取物。
如果靶DNA是双链的或以其他方式具有可能干扰其检测的二级和/或三级结构,则可能需要在进行本发明的方法之前加热所述靶DNA。在一些情形中,也可能期望在进行扩增之前通过本领域中已知的任何方法从复杂生物样品提取核酸。
样品可以包含众多种真核和原核细胞,包括原生质体;或者可能具有靶脱氧核糖核酸的其他生物材料。所述方法因此适用于组织培养的动物细胞、动物细胞(例如,血液、血清、血浆、网织红细胞、淋巴细胞、尿、骨髓组织、脑脊液或者从血液或淋巴制备的任何产物)、或任何类型的组织活检(例如肌肉活检、肝脏活检、肾脏活检、膀胱活检、骨活检、软骨活检、皮肤活检、胰腺活检、肠道活检、胸腺活检、哺乳动物活检、子宫活检、睾丸活检、眼活检或脑活检,在裂解缓冲液中匀浆化)、对渗透冲击敏感的植物细胞或其他细胞,以及细菌、酵母、病毒、支原体、原生动物、立克次氏体、真菌的细胞和其他小型微生物细胞等。本发明的测定和分离程序用于例如检测非致病的或致病的目的微生物。通过检测生物样品中变体序列的存在,可以确立微生物的存在。
在一些实施方案中,至少第一样品是从患有或怀疑患有特征为如本文所详述的变体序列的存在(特别是变体微卫星序列的存在或突变体序列的存在)的疾病或障碍的个体获得。在一些实施方案中,所述疾病是癌症或遗传障碍,例如胰腺癌、胃癌、膀胱癌、前列腺癌、肺癌、子宫癌、乳腺癌、遗传性非息肉病结直肠癌。在一些实施方案中,所述疾病是遗传障碍,如林奇综合征、亨廷顿病(HD)、齿状核-红核-苍白球-丘脑下部萎缩(DRPLA)、脊髓延髓和肌萎缩(SBMA)、强直性肌营养不良(DM)、脆性X综合征、FRAXE精神发育迟缓和脊髓小脑共济失调(SCA)、布鲁顿X连锁无丙种球蛋白血症(XLA)、布卢姆综合征(BS)、颅额鼻综合征(CFNS)和特发性肺纤维化(IPF)。
扩增
本发明方法需要扩增来自第一样品和第二样品的包含NOI的所述靶核酸序列。这需要提供引物组。引物组由第一引物和第二引物组成,它们一起能够扩增包含NOI的所述靶核酸序列,如本领域中已知的。
当在所述靶核酸序列的存在下,并且与如本领域中以其他方式已知的试剂一起用于例如PCR(如实时PCR)中时,引物组能够启动靶核酸序列的扩增。此类试剂是技术人员熟知的,并且例如描述于以下文献中:Sambrook J等人2000.Molecular Cloning:ALaboratory Manual(第三版),Cold Spring Habor Laboratory Press。然后反应生成扩增子。当在第一样品的存在下进行扩增时,将所生成的扩增子称为第一扩增子。当在第二(或参考)样品的存在下进行扩增时,将所生成的扩增子称为第二扩增子或参考扩增子。
为了使引物组对靶核酸序列具有特异性,引物包含与所述靶核酸序列的延伸段相同的序列。特定地,第一和第二引物的3'端可以包含至少15个核苷酸的序列,所述序列除了最多一个错配外,与包含参考或变体序列的靶核酸序列的延伸段相同。
可以调整所述引物中与靶核酸序列的延伸段相同的序列的确切长度,以获得解链温度可用于PCR扩增的引物。引物的解链温度取决于多种因素,但是特别取决于GC含量和长度。因为引物应优选地与包含变体序列(或与所述变体序列互补的序列)的靶核酸序列的延伸段相同,对引物的特定序列存在限制。因此,可以通过调整引物的长度特定地调整解链温度。技术人员能够熟练地设计具有合适的解链温度的引物,并且用于该目的的有用软件是公众可获得的。
因此,引物的3'端可以包含至少15个核苷酸(例如至少20个核苷酸,如至少25个核苷酸,例如在15至50个核苷酸范围内,如在20至40个核苷酸范围内)的序列,所述序列除了最多一个错配外,与包含变体序列的靶核酸序列相同。
在本发明的一个实施方案中,第一和/或第二引物由至少15个核苷酸(例如至少20个核苷酸,如至少25个核苷酸,例如在15至50个核苷酸范围内,如在20至40个核苷酸范围内)的序列组成,所述序列除了最多一个错配外,与包含变体序列的靶核酸序列相同。
如上文所提及,引物的所述序列包含除了最多一个错配外,与包含变体序列的靶核酸序列相同(或互补)的序列或由其组成。在一些实施方案中,在第一和第二引物中的一者或二者中存在一个错配,因为这可能甚至会进一步改进测定的特异性。特定地,所述错配可以定位于来自引物3'端的位置2、3或4。
在一些实施方案中,可以有用地设计如下引物:其与靶核酸序列在对应于变体序列的区域外部杂交。例如,如果靶核酸序列是微卫星,并且变体序列与参考序列的不同之处在于核苷酸重复序列的数量,则引物优选地在由串联重复序列组成的区域的上游和下游杂交,因为所述扩增原本可能是非特异性的并且产生不同长度的多种扩增子。
引物可以包含至少一个如本文所述的疏水核苷酸。
扩增步骤可以是PCR,如实时PCR。在一些实施方案中,扩增(例如PCR或实时PCR)反应是不对称反应。不对称意味着,引导所述反应以扩增模板的一条链多于另一条链。其实通过提供不同量的引物对中的引物来进行。
第一引物与靶核酸序列中包含NOI序列的第一链杂交。第二引物与靶核酸序列中与NOI序列互补的第二链杂交。在下一步骤中,通过在报告探针的存在下分析扩增子的解链图谱来检测变体序列的存在,所述变体序列包含与NOI序列相同的序列,如下文所述。如实施例中所示,当扩增子中可以与报告寡核苷酸杂交的链存在的量大于扩增子中与报告寡核苷酸互补的链时,有助于对解链图谱的分析。因此,在优选实施方案中,扩增步骤是不对称的,其进行所用第二引物的量大于第一引物的量。这引导扩增以生成更多的扩增子中与报告寡核苷酸杂交的链。
解链分析(包括HRM分析)
解链分析、特别是HRM(高分辨率解链)分析是基于对所形成的异源双链化扩增子的解链特性的分析(特定地,来自双链至单链期的过渡图谱)。扩增子的解链图谱取决于其鸟嘌呤-胞嘧啶含量、长度、序列和杂合性。核苷酸序列的变化导致形成异源双链体,与野生型解链图谱相比,所述异源双链体改变解链曲线的形状。
一旦已经获得第一扩增子和第二扩增子(例如通过使用不对称扩增反应),所述方法包括进行解链分析(特别是HRM分析)以获得每个扩增子的解链图谱(例如HRM图谱)。获得第一扩增子的第一解链图谱(或第一HRM图谱),并且获得第二扩增子的第二解链图谱(或第二HRM图谱,也称为参考图谱(或参考HRM图谱))。然后如下文所详述来比较所述解链图谱(或HRM图谱)。
每个解链(例如HRM)图谱的特征为解链曲线。第一扩增子的第一解链(例如HRM)图谱的特征为第一解链曲线,并且第二扩增子的第二(或参考)解链(例如HRM)图谱的特征为第二(或参考)解链曲线。
每个扩增子的解链(例如HRM)分析涉及包含至少一种荧光团和一种猝灭剂的报告寡核苷酸与每个扩增子的一条链(具有与NOI序列相同的序列,例如第二链)的杂交。报告寡核苷酸更详细地描述于下文中。在杂交后,检测荧光团发射的信号以获得第一和第二解链曲线,如本领域中以其他方式已知的。所述方法可以进一步包括在进一步分析之前转换解链曲线的步骤。例如,可以将解链曲线转换为负一阶导数曲线,然后对其进行比较。
然后比较第一解链(例如HRM)图谱与第二解链(例如HRM)图谱。如果第一样品含有变体序列,则第一解链曲线(和任选地差异曲线,以及解链曲线的导数)将与对应于参考样品的第二解链曲线(和任选地其导数)不同。对第一与第二解链(例如HRM)图谱之间的差异的检测由此表明,第一样品含有变体序列。
解链(例如HRM)图谱之间的差异可以是解链曲线或差异曲线的形状差异,或者是解链曲线的导数的形状差异。例如,在一些实施方案中,第一解链曲线的形状与参考解链曲线不同。通常,解链曲线的导数是具有最大值的正常曲线(或钟形曲线)。第一解链曲线的斜率可能不如第二曲线的斜率“陡峭”,这引起第一解链曲线与第二解链曲线相比的形状变化。第一解链曲线的导数的斜率可能比第二曲线的导数的斜率“更陡峭”,例如,至少在其一个或多个拐点中,第一解链曲线的导数的斜率绝对值大于第二解链曲线的导数的斜率绝对值。为了确定解链(例如HRM)图谱之间的差异,分析可以包括获得差异曲线的步骤,其中将一个解链曲线设为参考并将其从另一解链曲线减去,优选地其中将参考样品的解链曲线设为参考并将其从变体样品的解链曲线减去。
两条曲线(或者差异曲线或导数)可能在每个温度T下彼此相隔距离DT。针对每个温度确定距离DT,并且如果最大距离maxDT的绝对值大于预定阈值,则所述最大距离的绝对值指示两条曲线之间的差异。
技术人员将了解如何确定阈值的合适的值。阈值是允许区分展示微卫星不稳定性的受试者与正常受试者的DT值。DT值是针对参考(或野生型)获得的解链图谱与针对一个或多个变体序列获得的解链图谱之间的差异,例如负差或正差。为了确定合适的阈值,建立多名受试者(通常100-500名患者)的解链图谱,对于所述受试者,已知他们是否具有微卫星不稳定性。使用这些解链图谱,将阈值确立为允许在野生型与变体序列之间进行所需或合适的区分的值。
由此计算分析的解链图谱之间的差异并与阈值进行比较;该差异因此可以是数值差异,可以将其与数值阈值进行比较。如果分析的解链图谱(例如HRM图谱)之间的该差异大于阈值,则将用于确定第一解链图谱的样品归类为包含变体序列。在靶核酸序列是微卫星时,由此将从其获得所述样品的受试者视为具有微卫星不稳定性。如果分析的解链图谱(例如HRM图谱)之间的差异低于阈值,则将所述样品归类为包含野生型序列。在靶核酸序列是微卫星时,由此将从其获得所述样品的受试者视为不具有微卫星不稳定性。
替代方案是确定曲线之间的面积。如果所述面积大于预定的阈值,则认为所述第一和所述第二解链曲线是不同的。这里也一样,技术人员将了解如何设定阈值的值。
表征两条解链曲线或其差异曲线或其导数之间的差异的其他方式对于技术人员将是清楚的。
第一与第二解链曲线之间或其差异曲线或者第一与第二解链曲线的导数之间的上述差异中的任一者指示第一与第二HRM图谱之间的差异,并且由此表明在第一样品中存在变体序列。
在一些实施方案中,将第一和第二解链曲线和/或其导数和/或差异曲线归一化。例如,靠近测量解链的最低温度或在所述最低温度下,如在距所述最低温度0.5至20℃内,将曲线归一化为第一值,并且靠近测量解链的最高温度或在所述最高温度下,如在距所述最高温度0.5至20℃内,将曲线归一化为第二值。例如,第一值是1并且第二值是0。
为了使曲线之间的差异更明显,解链分析(例如HRM分析)可以包括标准归一化的步骤,其对应于在初始和最终归一化区域中基于平均染料强度使曲线在y轴对齐。
也可以将双线性归一化应用至每条曲线(解链曲线、差异图表或导数)。将第一线性函数拟合至初始染料强度,并将其用作最终校正标尺的顶端。将第二线性函数拟合至最终染料强度,并将其用作校正标尺的底端。
解链分析(例如HRM分析)也可以或者可替代地包括将温度调整(温度漂移)在某一相对荧光单位(RFU)下应用至曲线(解链曲线或差异曲线)的步骤。此类步骤也可以降低假阳性的风险。在优选实施方案中,解链分析至少包括将温度调整以某一相对荧光单位应用至解链曲线的步骤。
因此,在一些实施方案中,比较第一图谱与参考图谱的步骤包括以下步骤或由以下步骤组成:
i)将所述第一和所述第二解链曲线在给定荧光强度下沿温度轴对齐,从而消除所述第一与所述第二解链曲线之间在所述荧光强度下的解链温度差异;
ii)确定在所述第一与所述第二解链曲线之间由荧光团发射的信号的差异;以及
iii)将在ii)中确定的所述差异与阈值进行比较,其中差异大于所述阈值表明,所述第一样品包含变体序列,并且差异小于所述阈值表明,所述第一样品包含所述参考序列。
所述阈值是如上文所解释来确定的。所述差异是数值差异,如上文所解释将其与数值阈值进行比较。因此在步骤iii)中,如果阈值是正阈值,则差异大于所述阈值表明,第一样品包含变体序列。如果阈值是负阈值,则差异小于所述阈值表明,第一样品包含变体序列。
在一些实施方案中,本文所公开的方法不包括确定变体序列的确切长度和/或序列的步骤。这是因为通常不需要确定变体序列的确切长度和/或序列才能确定其中发现所述变体序列的个体患有如本文所述的疾病或障碍。相反,通常确立存在差异就足够了,所述差异的确切性质并非总是有关。在优选实施方案中,本文所公开的方法不包括确定变体序列的确切长度和/或序列的步骤。这是因为对变体序列的检测可能足以选择样品用于进一步分析;通常不需要确定所述变体序列的确切长度和/或序列。
报告寡核苷酸
本发明方法需要报告寡核苷酸来进行HRM分析。报告寡核苷酸包含至少第一荧光团和至少第一猝灭剂。这些有助于解链分析,如HRM分析。优选地,报告寡核苷酸至少在其5'端或至少在其3'端或者在距5'端或3'端4个核苷酸内包含第一荧光团。报告寡核苷酸优选地至少在其5'端或至少在其3'端或者在距5'端或3'端4个核苷酸内包含第一猝灭剂。因此,荧光团和猝灭剂可以位于5'端或3'端或者在距5'端或3'端4个核苷酸内,但是不一定位于报告寡核苷酸的最后一个核苷酸处。优选地,如果第一荧光团位于5'端处或者在距5'端4个核苷酸内,则第一猝灭剂不位于5'端处或者在距5'端4个核苷酸内。相反,其位于3'端处或者在距3'端4个核苷酸内或者在报告物的内部区域中。相反,如果第一荧光团位于3'端处或者在距3'端4个核苷酸内,则第一猝灭剂不位于3'端处或者在距3'端4个核苷酸内。相反,其位于5'端处或者在距5'端4个核苷酸内或者在报告物的内部区域中。此处的术语内部区域是报告寡核苷酸中不包括每一端的5个末端核苷酸的区域。优选地,第一荧光团和第一猝灭剂不在彼此的附近。
有用的荧光团和猝灭剂是技术人员易于获得的,所述技术人员将不难选择有用的荧光团和猝灭剂来进行本发明方法。
报告寡核苷酸用于解链分析(或HRM分析)。因此,报告寡核苷酸的序列受到一些约束,这取决于其要杂交和检测的序列。报告寡核苷酸包含杂交序列H,所述杂交序列H例如与NOI相同,并且所述杂交序列H与NOI的互补链杂交。换言之,报告寡核苷酸与所述第一和所述第二扩增子中包含NOI的链杂交。在其中NOI包含重复序列的实施方案中,报告寡核苷酸因此也包含重复序列,即杂交序列H也包含重复序列,如下文进一步所详述。
除了与NOI相同的序列以外,报告寡核苷酸还可以在杂交序列中包含另外的核苷酸。例如,如下文实施例中所示,这在靶核酸是微卫星或者如果预期变体序列会包含插入的情形中可能特别相关。如果微卫星具有参考序列中的总长度为n个核苷酸的M个串联重复序列,报告寡核苷酸的杂交序列优选地具有M”个串联重复序列,其中M”≥M+1,优选地M”≥M+1或者M”≥M+2。如果串联重复序列是单核苷酸重复序列,则杂交序列的长度为n”个核苷酸,其中n”≥n+1,优选地n”≥n+1或者n”≥n+2。换言之,杂交序列可以包含至少一个或两个另外的核苷酸。这允许更灵敏地区分较长的变体序列与参考序列。
在一些实施方案中,特别是在NOI是微卫星的情况下,报告寡核苷酸的杂交序列优选地包含由与NOI的重复序列相同或互补的重复序列组成的序列,并且还可以有利地包含末端序列,本文中称为辅助序列,所述末端序列在杂交序列与所述第一和所述第二扩增子杂交时紧邻重复序列的上游或紧邻重复序列的下游与所述扩增子杂交。换言之,报告寡核苷酸的杂交序列优选地包含重复序列,并且另外包含1至10个核苷酸,如1、2、3、4、5、6、7、8、9或10个核苷酸,所述核苷酸紧邻重复性序列的上游或下游与NOI或其互补链杂交。在与所述第一和所述第二扩增子杂交时,辅助序列由此允许杂交序列与所述重复性序列杂交。辅助序列对其互补序列的亲和力通常将高于杂交序列对其互补序列的亲和力。换言之,辅助序列通常将比杂交序列将与其互补序列杂交更快地与其互补序列杂交。
辅助序列可以是3'末端的或5'末端的。优选地,报告寡核苷酸包含5'末端辅助序列,所述辅助序列在杂交序列与所述第一和所述第二扩增子杂交时紧邻重复序列的上游或紧邻重复序列的下游与所述扩增子杂交。辅助序列有助于区分解链图谱,如实施例13中所示。如果辅助序列在所述辅助序列与第一或第二扩增子杂交时导致杂交序列的高Tm增加,则将所述辅助序列称为强辅助序列。技术人员熟知,如果与包含更高比例的A/T的两个杂交的序列相比,序列包含更高比例的G/C,则两个序列之间的杂交更强;因此,所包含G/C比例高于A/T的辅助序列将比所包含G/C比例低于A/T的辅助序列更强。也已知,较长序列产生比较短序列更强的杂交,因此可以通过增加与第一和/或第二扩增子杂交的长度来调整辅助序列的强度。增加辅助序列的强度可以是促进区分变体序列与参考序列的良好方式。优选地,辅助序列不包含重复序列,即使在NOI包含重复序列的实施方案中。
在一些实施方案中,特别是在靶核酸序列是微卫星的情况下,与不含辅助序列的相同杂交序列的Tm相比,辅助序列将杂交序列的Tm增加至少5℃、如至少6℃、如至少7℃、如至少8℃、如至少9℃、如至少10℃、如至少11℃、如至少12℃、如至少13℃、如至少14℃、如至少15℃或更多。因此,包含辅助序列的杂交序列的Tm可以比不含辅助序列的杂交序列的Tm高5与25℃之间,例如高10与20℃之间,如高12.5与17.5℃之间。
报告寡核苷酸可以包含第二猝灭剂。优选地,第二猝灭剂位于非末端区域中,即位于报告寡核苷酸的内部区域中。换言之,第二猝灭剂不位于5'端处或3'端处或者距5'或3'端4个核苷酸内。在一些实施方案中,包括第二猝灭剂可以有助于区分变体序列与参考序列。
尽管可以使用可以使得能够进行解链分析(特别是HRM分析)的任何报告寡核苷酸,即具有上述特征的任何报告寡核苷酸,但是一些报告寡核苷酸是特别有利的。在报告寡核苷酸的特定位置包括疏水核苷酸特别令人感兴趣。正如从实施例中可以看到的,包含此类疏水核苷酸的报告寡核苷酸增加所述方法的灵敏度。
因此,在一些实施方案中,除了上述特征以外,报告寡核苷酸包含位于其5'端处或在距5'端10个核苷酸内的至少一个疏水核苷酸,和/或报告寡核苷酸包含位于其3'端处或在距3'端10个核苷酸内的至少一个疏水核苷酸。
疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
骨架单体单元X可以是下文在章节“骨架单体单元”中所述的任何骨架单体单元。
嵌入剂Q可以是下文在章节“嵌入剂”中所述的任何嵌入剂。
可用于本公开文本的情况下的疏水核苷酸详细描述于国际专利申请WO2017/045689中,具体的在第30l.2至l.25页的标题为“疏水核苷酸”的章节中。
在一些实施方案中,报告寡核苷酸具有以下一般结构
5'-(N)a-Z-(N)d-Z-(N)e-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如项目1中所定义的疏水核苷酸;并且
核苷酸或核苷酸类似物的总数量是至少10;并且
a和b单独地是在0至4范围内的整数;并且
d和e单独地是在1至19范围内的整数;并且
a+b+d+e是至少10;并且
(N)a-(N)d-(N)e-(N)b与参考序列相同。
在其他实施方案中,报告寡核苷酸具有以下一般结构
5'-(N)a-Z-(N)f-Z-(N)g-Z-(N)h-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如权利要求1中所定义的疏水核苷酸;并且
a和b单独地是在0至4范围内的整数;并且
f、g和h单独地是在1至18范围内的整数;并且
a+b+f+g+h是至少10且至多50;并且
(N)a-(N)f-(N)g-(N)h-(N)b与包含参考序列的靶核酸序列的延伸段相同;或者
具有以下一般结构
5'-(N)a-Z-(N)i-Z-(N)j-Z-(N)k-Z-(N)l-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如权利要求1中所定义的疏水核苷酸;并且
a和b单独地是在0至4范围内的整数;并且
i、j、k和l单独地是在1至17范围内的整数;并且
a+b+i+j+k+l是至少10且至多50;并且
(N)a-(N)i-(N)j-(N)k-(N)l-(N)b与包含参考序列的靶核酸序列的延伸段相同;或者
具有以下一般结构
5'-(N)a-Z-(N)m-Z-(N)n-Z-(N)o-Z-(N)p-Z-(N)q-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如权利要求1中所定义的疏水核苷酸;并且
a和b单独地是在0至4范围内的整数;并且
m、n、o、p和q单独地是在1至16范围内的整数;并且
a+b+m+n+o+p+q是至少10且至多50;并且
(N)a-(N)m-(N)n-(N)o-(N)p-Z-(N)q-(N)b与包含参考序列的靶核酸序列的延伸段相同。
在一些实施方案中,报告寡核苷酸用于检测微卫星。在此类实施方案中,杂交序列至少包含串联重复序列。优选地,杂交序列还包含辅助序列,所述辅助序列由紧接串联重复序列上游或下游的1与20个之间的核苷酸(如紧接串联重复序列上游或下游的1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个核苷酸)组成,优选地其中已经插入至少一个如本文所述的疏水核苷酸。辅助序列可以由至少一个(如1个、例如2个、如3个、例如4个、如5个、例如6个、如7个、例如8个、如9个、例如10个、如10至20个、例如20至50个、如超过50个)核苷酸组成。例如,辅助序列由15个或更多个核苷酸组成。因此,在一些实施方案中,辅助序列由5、6、7、8、9、10、11、12、13、14、15、16、17、19、20个或更多个核苷酸(如25、30、35、40、45或50个或更多个核苷酸)组成。例如,辅助序列由20、21、22、23、24、25、26、27、28、29或30个或更多个核苷酸组成。例如,辅助序列由7、8、9、10、11、12、13、14或15个或更多个核苷酸(例如9个核苷酸)组成。
在报告寡核苷酸要用于检测微卫星(如上文所述的BAT25、BAT26、NR21、NR22、NR24或MONO27)的实施方案中。
嵌入剂
在本发明方法的情况下,术语嵌入剂是指包含至少一个基本上平面共轭体系的任何分子部分,其能够与核酸的核碱基共堆积。优选地,嵌入剂基本上由至少一个基本上平面共轭体系组成,其能够与核酸的核碱基共堆积。
嵌入剂包含至少一个π(phi)电子体系,其根据本发明可以与包含π电子体系的其他分子相互作用。这些相互作用可以以正面或负面的方式为所述嵌入剂的疏水相互作用作贡献。Hunter和Sanders(1990)J.Am Chem.Soc.112:5525-5534已经提出多种不同的取向和条件,其中两个π电子体系可以与彼此积极地相互作用。
优选地,嵌入剂包含选自多芳香基(polyaromate)和杂多芳香基的化学基团,并且甚至更优选地,嵌入剂基本上由多芳香基或杂多芳香基组成。最优选地,嵌入剂选自多芳香基和杂多芳香基。
根据本发明的多芳香基或杂多芳香基可以由任何合适数量的环组成,所述数量如1、例如2、如3、例如4、如5、例如6、如7、例如8、如大于8。此外,多芳香基或杂多芳香基可以被选自以下的一者或多者取代:羟基、溴、氟、氯、碘、巯基、硫基、氰基、烷硫基、杂环、芳基、杂芳基、羧基、碳烷酰基、烷基、烯基、炔基、硝基、氨基、烷氧基、羰基和酰胺基。
因此,嵌入剂Q可以例如是选自以下的嵌入剂:菲咯啉、吩嗪、菲啶、蒽醌、芘、蒽、环烷烃、菲、苉、 并四苯、吖啶酮、苯并蒽、茋、草酰-吡啶并咔唑、叠氮基苯、卟啉、补骨脂素,以及被选自以下的一者或多者取代的任何上文提及的嵌入剂:羟基、溴、氟、氯、碘、巯基、硫基、氰基、烷硫基、杂环、芳基、杂芳基、羧基、碳烷酰基、烷基、烯基、炔基、硝基、氨基、烷氧基和/或酰胺基。
并四苯、吖啶酮、苯并蒽、茋、草酰-吡啶并咔唑、叠氮基苯、卟啉、补骨脂素,以及被选自以下的一者或多者取代的任何上文提及的嵌入剂:羟基、溴、氟、氯、碘、巯基、硫基、氰基、烷硫基、杂环、芳基、杂芳基、羧基、碳烷酰基、烷基、烯基、炔基、硝基、氨基、烷氧基和/或酰胺基。
优选地,嵌入剂选自菲咯啉、吩嗪、菲啶、蒽醌、芘、蒽、环烷烃、菲、苉、 并四苯、吖啶酮、苯并蒽、茋、草酰-吡啶并咔唑、叠氮基苯、卟啉和补骨脂素。
并四苯、吖啶酮、苯并蒽、茋、草酰-吡啶并咔唑、叠氮基苯、卟啉和补骨脂素。
在一个优选的实施方案中,嵌入剂选自菲咯啉、吩嗪、菲啶、蒽醌、芘、蒽、菲、 并四苯、苯并蒽、茋和卟啉。
并四苯、苯并蒽、茋和卟啉。
在另一优选的实施方案中,嵌入剂包含芘或吡啶并[3',2':4,5]噻吩并[3,2-d]嘧啶-4(1H)-酮或7,9-二甲基-吡啶并[3',2',4,5]噻吩并[3,2-d]嘧啶-4(3H)-酮。嵌入剂也可以由芘或吡啶并[3',2':4,5]噻吩并[3,2-d]嘧啶-4(1H)-酮或7,9-二甲基-吡啶并[3',2',4,5]噻吩并[3,2-d]嘧啶-4(3H)-酮组成。
疏水核苷酸可以包含其他嵌入剂,特别是在WO 2017/045689中第30l.26页至第40l.4页的标题为“嵌入剂”的章节中或者在国际专利申请WO 03/052132中第46,l.10页至第54,l.13页的章节“嵌入剂”中所述的嵌入剂。
骨架单体单元
X也可以是能够被掺入核酸或核酸类似物的骨架中的骨架单体单元。本文的核苷酸或核苷酸类似物的骨架单体单元是指核苷酸中参与掺入核酸或核酸类似物的骨架中的部分。骨架单体单元(X)优选地与接头(Y)共价连接,所述接头(Y)与嵌入剂共价连接。可以采用任何合适的骨架单体单元用于将嵌入剂掺入寡核苷酸类似物中。也可以采用连接所述骨架单体单元与所述嵌入剂的任何种类的接头。另外,骨架单体单元可以包含一个或多个离去基团、保护基团和/或反应基团,可以在包含所述骨架单体单元的寡核苷酸或寡核苷酸类似物的合成期间或合成后以任何方式去除或改变所述基团。
骨架单体单元可以是任何合适的骨架单体单元。在一个实施方案中,骨架单体单元可以例如选自以下的骨架单体单元:DNA、RNA、PNA、HNA、XNA、MNA、ANA、LNA、CNA、CeNA、TNA、(2'-NH)-TNA、(3'-NH)-TNA、α-L-核-LNA、α-L-木-LNA、β-D-木-LNA、α-D-核-LNA、[3.2.1]-LNA、二环-DNA、6-氨基-二环-DNA、5-表-二环-DNA、α-二环-DNA、三环-DNA、二环[4.3.0]-DNA、二环[3.2.1]-DNA、二环[4.3.0]酰胺-DNA、β-D-吡喃核糖基-NA、α-L-吡喃木糖基-NA、2'-R-RNA、α-L-RNA或α-D-RNA、β-D-RNA及其混合物和其杂合物,以及其磷原子修饰,例如但不限于硫代磷酸酯、甲基磷酸酯、氨基磷酸酯、二硫代磷酸酯、硒代磷酸酯、磷酸三酯和硼代磷酸酯(phosphoboranoate)。另外,含有非磷的化合物可以用于连接至核苷酸,所述化合物例如但不限于甲基亚氨基甲基、甲乙酸酯、硫代甲乙酸酯和包含酰胺的连接基团。
多种骨架单体单元描述于以下文献中:国际专利申请WO 2017/045689中第40l.5页至第56l.3页的标题为“骨架单体单元”的章节中,以及国际专利申请WO 03/052132中第24,l.27页至第43,l.14页的章节“骨架单体单元”中。这些文献还描述可用于本发明的核苷酸和核苷酸类似物的多种不同的骨架单体单元,以及如何经由附接在骨架单体单元的一个或两个位置的接头将所述骨架单体单元连接至核碱基。
接头
嵌入剂核苷酸的接头是连接嵌入剂与所述疏水核苷酸的骨架单体,优选地共价连接所述嵌入剂与骨架单体单元的部分。接头可以包含一个或多个原子或原子之间的一个或多个键。
根据上文给出的骨架和嵌入剂的定义,接头是连接骨架与嵌入剂的最短路径。如果嵌入剂与骨架直接连接,则接头是键。
接头通常由原子链或原子支链组成。链可以是饱和的以及不饱和的。接头也可以是具有或不具有共轭键的环结构。
有用的接头详细描述于国际专利申请WO 2017/045689中,特别是在第56l.5页至第59l.10页的标题为“接头”的章节中,以及在WO 03/052132中第54,l.15页至第58,l.7页的章节“接头”中。
多部分试剂盒
本文还提供一种用于检测由两条链组成并且包含优选地含有重复序列的一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的多部分试剂盒,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述多部分试剂盒包含:
a)报告寡核苷酸,其包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,
其中所述报告寡核苷酸是范围为10至50个核苷酸、优选地范围为15至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
并且
其中所述杂交序列与所述靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补;
并且其中所述报告寡核苷酸的杂交序列包含重复性序列和在其5'端和/或在其3'端的至少一个辅助序列或由所述重复性序列和辅助序列组成,其中所述辅助序列不包含重复序列,并且能够在所述杂交序列与所述第一和所述第二扩增子杂交时与所述扩增子杂交;以及
b)引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增所述靶核酸序列。
本文还提供一种多部分试剂盒,其包含:
a)报告寡核苷酸,其可以是下文在章节“报告寡核苷酸”中描述的任何报告寡核苷酸
b)引物组,其由第一引物和第二引物组成,其可以是上文在章节“扩增”中描述的任何引物组。
多部分试剂盒对于进行本发明方法特别有用。
因此,本文提供一种用于检测由两条链组成并且包含一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的多部分试剂盒,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述多部分试剂盒包含:
a)报告寡核苷酸,其包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,
其中所述报告寡核苷酸是范围为10至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分;并且
其中所述杂交序列与包含所述参考序列的所述靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补;以及
b)引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增所述靶核酸。
除了所述报告寡核苷酸和所述引物组以外,多部分试剂盒还可以包含另外的组分。例如,多部分试剂盒还可以包含PCR试剂。多部分试剂盒还可以包含检测探针,如允许实时检测PCR产物的生成的探针。
上述试剂盒特别可用于进行本文所述的方法,特别是用于检测优选地包含重复序列(例如微卫星)的靶核酸序列的变体序列。特定地,其中野生型或参考序列是15个或更多个核苷酸的微卫星,如上文所详述。
报告寡核苷酸
如上文所详述,本发明方法需要报告寡核苷酸来进行解链分析,例如进行HRM分析。在不受理论束缚的情况下,本发明者已经发现,包含疏水核苷酸的报告寡核苷酸特别可用于进行本发明方法,因为它们可以增加测定的灵敏度。因此,此类报告寡核苷酸也公开于本文中。
本文还提供一种报告寡核苷酸,其可以与由两条链组成并且包含优选地含有重复序列的一个或多个目的核苷酸(NOI)的靶核酸的一条链杂交,所述报告寡核苷酸包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,其中所述报告寡核苷酸是范围为10至50个核苷酸、优选地范围为15至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
其中所述杂交序列与所述靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补,
并且其中所述报告寡核苷酸的杂交序列包含重复性序列和在其5'端和/或在其3'端的至少一个辅助序列或由所述重复性序列和辅助序列组成,其中所述辅助序列不包含重复序列,并且能够在所述杂交序列与所述第一和所述第二扩增子的第二链杂交时与所述链杂交。
本文还提供一种报告寡核苷酸,其包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,其中所述报告寡核苷酸是范围为10至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分;并且
其中所述杂交序列与靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补。
报告寡核苷酸可以包含第二猝灭剂。优选地,第二猝灭剂位于非末端区域中,即位于报告寡核苷酸的内部区域中。换言之,第二猝灭剂不位于5'端处或3'端处或者距5'或3'端4个核苷酸内。
骨架单体单元X可以是上文在章节“骨架单体单元”中所述的任何骨架单体单元。
嵌入剂Q可以是上文在章节“嵌入剂”中所述的任何嵌入剂。
可用于本公开文本的情况下的疏水核苷酸详细描述于国际专利申请WO2017/045689中,具体的在第30l.2至l.25页的标题为“疏水核苷酸”的章节中。
在一些实施方案中,报告寡核苷酸具有以下一般结构
5'-(N)a-Z-(N)d-Z-(N)e-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如项目1中所定义的疏水核苷酸;并且
核苷酸或核苷酸类似物的总数量是至少10;并且
a和b单独地是在0至4范围内的整数;并且
d和e单独地是在1至19范围内的整数;并且
a+b+d+e是至少10;并且
(N)a-(N)d-(N)e-(N)b与参考序列相同。
在其他实施方案中,报告寡核苷酸具有以下一般结构
5'-(N)a-Z-(N)f-Z-(N)g-Z-(N)h-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如权利要求1中所定义的疏水核苷酸;并且
a和b单独地是在0至4范围内的整数;并且
f、g和h单独地是在1至18范围内的整数;并且
a+b+f+g+h是至少10且至多50;并且
(N)a-(N)f-(N)g-(N)h-(N)b与包含参考序列的靶核酸序列的延伸段相同;或者
具有以下一般结构
5'-(N)a-Z-(N)i-Z-(N)j-Z-(N)k-Z-(N)l-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如权利要求1中所定义的疏水核苷酸;并且
a和b单独地是在0至4范围内的整数;并且
i、j、k和l单独地是在1至17范围内的整数;并且
a+b+i+j+k+l是至少10且至多50;并且
(N)a-(N)i-(N)j-(N)k-(N)l-(N)b与包含参考序列的靶核酸序列的延伸段相同;或者
具有以下一般结构
5'-(N)a-Z-(N)m-Z-(N)n-Z-(N)o-Z-(N)p-Z-(N)q-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如权利要求1中所定义的疏水核苷酸;并且
a和b单独地是在0至4范围内的整数;并且
m、n、o、p和q单独地是在1至16范围内的整数;并且
a+b+m+n+o+p+q是至少10且至多50;并且
(N)a-(N)m-(N)n-(N)o-(N)p-Z-(N)q-(N)b与包含参考序列的靶核酸序列的延伸段相同。
报告寡核苷酸可以包含突出端,即其可以在其一个末端中包含不与靶核酸序列杂交的核苷酸。突出端可以是3'末端的或5'末端的。优选地,报告寡核苷酸包含5'-末端序列,所述5'-末端序列相对于所述第一和所述第二扩增子中可以与杂交序列杂交的链形成5'-突出端。
报告寡核苷酸包含至少第一荧光团和至少第一猝灭剂。这些有助于解链分析和/或HRM分析。优选地,报告寡核苷酸至少在其5'端或至少在其3'端或者在距5'端或3'端4个核苷酸内包含第一荧光团。报告寡核苷酸优选地至少在其5'端或至少在其3'端或者在距5'端或3'端4个核苷酸内包含第一猝灭剂。因此,荧光团和猝灭剂可以位于5'端或3'端或者在距5'端或3'端4个核苷酸内,但是不一定位于报告寡核苷酸的最后一个核苷酸处。优选地,如果第一荧光团位于5'端处或者在距5'端4个核苷酸内,则第一猝灭剂不位于5'端处或者在距5'端4个核苷酸内。相反,其位于3'端处或者在距3'端4个核苷酸内或者在报告物的内部区域中。相反,如果第一荧光团位于3'端处或者在距3'端4个核苷酸内,则第一猝灭剂不位于3'端处或者在距3'端4个核苷酸内。相反,其位于5'端处或者在距5'端4个核苷酸内或者在报告物的内部区域中。此处的术语内部区域是报告寡核苷酸中不包括每一端的5个末端核苷酸的区域。优选地,第一荧光团和第一猝灭剂不在彼此的附近。
有用的荧光团和猝灭剂是技术人员易于获得的,所述技术人员将不难选择有用的荧光团和猝灭剂来进行本发明方法。
报告寡核苷酸用于进行解链分析,例如HRM分析。因此,报告寡核苷酸的序列受到一些约束,这取决于其要杂交和检测的序列。报告寡核苷酸包含杂交序列H,所述杂交序列H例如与NOI相同,并且所述杂交序列H与NOI的互补链杂交。在其中NOI包含重复序列的实施方案中,报告寡核苷酸因此也包含重复序列,即杂交序列H也包含重复序列,如下文进一步所详述。
除了与NOI相同的序列以外,报告寡核苷酸还可以在杂交序列中包含另外的核苷酸。例如,如下文实施例中所示,这在靶核酸是微卫星的情形中可能特别相关。如果微卫星具有参考序列中的总长度为n个核苷酸的M个串联重复序列,报告寡核苷酸的杂交序列优选地具有M”个串联重复序列,其中M”≥M+1,优选地M”≥M+1或者M”≥M+2。如果串联重复序列是单核苷酸重复序列,则杂交序列的长度为n”个核苷酸,其中n”≥n+1,优选地n”≥n+1或者n”≥n+2。换言之,杂交序列可以包含至少一个或两个另外的核苷酸。这允许更灵敏地区分变体序列与参考序列,尤其在变体序列包含插入时。
在一些实施方案中,特别是在NOI是微卫星的情况下,报告寡核苷酸的杂交序列优选地包含由与NOI的重复序列相同或互补的重复序列组成的序列,并且还可以有利地包含末端序列,如一个或两个末端序列,本文中称为一个或多个辅助序列,所述末端序列在杂交序列与所述第一和所述第二扩增子的链杂交时紧邻重复序列的上游或紧邻重复序列的下游与所述扩增子的链杂交。换言之,报告寡核苷酸的杂交序列优选地包含重复序列,并且另外包含1至20个核苷酸,如1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个核苷酸,所述核苷酸紧邻重复性序列的上游或下游与NOI或其互补链杂交。
辅助序列可以是3'末端的或5'末端的。优选地,报告寡核苷酸包含5'末端辅助序列,所述辅助序列在杂交序列与所述第一和所述第二扩增子的链杂交时紧邻重复序列的上游或紧邻重复序列的下游与所述扩增子的链杂交。辅助序列有助于区分解链图谱,如实施例13中所示。如果辅助序列在与第一或第二扩增子杂交时具有高Tm,则将所述辅助序列称为强辅助序列。技术人员熟知,如果与包含更高比例的A/T的两个杂交的序列相比,序列包含更高比例的G/C,则两个序列之间的杂交更强;因此,所包含G/C比例高于A/T的辅助序列将比所包含G/C比例低于A/T的辅助序列更强。也已知,较长序列产生比较短序列更强的杂交,因此可以通过增加与第一和/或第二扩增子杂交的长度来调整辅助序列的强度。
在一些实施方案中,报告寡核苷酸可用于检测指示微卫星不稳定性的变体序列,即参考序列包含微卫星序列。在参考序列包含总长度为n个核苷酸的M个串联重复序列的微卫星序列时,报告寡核苷酸的杂交序列H的长度为n”,其中n”≥n+1,优选地n”≥n+1或n”≥n+2。
上文报告寡核苷酸可以包含第二猝灭剂。优选地,第二猝灭剂位于非末端区域中,即位于报告寡核苷酸的内部区域中。换言之,第二猝灭剂不位于5'端处或3'端处或者距5'或3'端4个核苷酸内。
有用的荧光团和猝灭剂是本领域中已知的并且是技术人员易于获得的,所述技术人员不难选择合适的荧光团和猝灭剂。
本文还提供包含疏水核苷酸的此类报告寡核苷酸在用于检测变体核酸的方法中的用途,特别是其在本文所述的方法中的用途。报告寡核苷酸还可以用于预测治疗临床病症的功效的方法中,以及用于预测临床病症的存在的方法中,具体如下文所述。
预测治疗临床病症的功效
本公开文本还涉及用于预测用预定药物治疗有需要的个体的临床病症的功效的方法,其中用所述药物治疗所述临床病症的功效与变体序列的存在相关。
因此,一些突变可以指示某种药物是否可以有效用于治疗个体。特定地,特定突变可以指示对预定药物治疗的特定反应。例如,突变可以指示个体是否会对所述药物治疗有正面反应,个体的疾病是否抵抗给定药物,或者个体是否无法耐受特定药物治疗。
用于预测治疗个体的临床病症的功效的方法可以包括以下步骤:
a.提供来自所述个体的样品;
b.进行如本文所述的用于检测变体序列的存在的方法,以确定所述样品是否包含所述变体序列
其中所述变体序列的存在指示所述药物是否在治疗所述个体的所述临床病症方面有效。
临床病症可以例如是癌症,或者本文所述的任何临床病症、疾病或障碍。已经鉴定出许多突变,所述突变指示给定癌症药物或药物组合是否在治疗特定癌症方面有效。
在一些实施方案中,变体序列是微卫星的变体,如上文所详述。
预测临床病症的存在
本发明方法也可用于预测或甚至诊断个体中与特定突变相关的任何临床病症的存在。
此类方法可以包括以下步骤:
a)提供来自所述个体的样品;
b)通过进行如本文所述的用于检测变体序列的方法来检测与所述临床病症相关的突变在所述样品中的存在;
其中所述变体序列的存在指示所述个体患有所述临床病症。
已知多种临床病症与特定突变相关,并且可以设计用于检测任何这种突变的报告寡核苷酸和引物组。本发明方法特别可用于在用于检测微卫星的变体序列时检测与微卫星不稳定性相关的病症,优选地其中相应野生型或参考序列的长度为至少15个核苷酸,如上文所详述。
在一个实施方案中,临床病症是癌症,如遗传性非息肉病结直肠癌。在另一个实施方案中,临床病症是林奇综合征。
所述方法可以进一步包括治疗所述临床病症的步骤。如果发现指示临床病症的存在的变体序列,则将个体归类为患有所述临床病症,并且所述方法可以进一步包括将治疗剂以有效量施用至所述个体的步骤。
实施例
实施例1:微卫星不稳定性并非必然导致解链温度的变化。
使用不对称PCR的BAT25测定,所述不对称PCR使用在包含单核苷酸重复序列的区域的上游和下游杂交的引物。所述测定用于检测BAT25微卫星中的变体序列。此实施例中使用的报告寡核苷酸携带在5'端的FAM荧光团和在3'端的BHQ-1猝灭剂以及内部猝灭剂。报告寡核苷酸与SEQ ID NO:1的位置142至171杂交,并且具有在其3'端的突出端和在其5'端的辅助序列,所述辅助序列在单核苷酸重复序列的上游杂交。另外,其包含在距5'端10个核苷酸内的疏水核苷酸和在距3'端10个核苷酸内的疏水核苷酸。测试来自微卫星不稳定患者的CRC或子宫内膜样品的1-2ng/μL正常组织DNA和肿瘤组织DNA。初始归一化区间是39-40℃,并且最终归一化区间是63-64℃。获得两条解链曲线(图2A),将其转换为负一阶导数曲线(图2B)。当应用双线性归一化并通过应用0.1RFU的温度漂移强度阈值(其高于0.05RFU阈值)来调整温度时,所述两条曲线不同(两条曲线的幅度之间的最大差异是~0.07RFU(绝对值),未显示)。0.07的差异高于针对此特定测定设置的0.05RFU阈值,并且因此,将样品归类为对于BAT25不稳定。负一阶导数曲线显示于图2B中。正如可以看到的,正常组织的Tm为57.31℃并且肿瘤组织的Tm为57.41℃。这个小差异通常不显著,并且可能是由于样品中的不同盐浓度或仪器差异所致。
从此实施例可以得出结论,从正常样品至突变的肿瘤样品,解链温度并非必然发生显著变化,但是解链曲线的形状改变,这在应用双线性归一化和温度漂移时甚至更易于可视化。由此可以使用HRM曲线之间的形状差异来区分正常样品与肿瘤样品,即使Tm差异极低。
实施例2:双线性归一化
使用不对称PCR的NR22测定,所述不对称PCR使用在包含单核苷酸重复序列的区域的上游和下游杂交的引物。所述测定用于检测NR22微卫星中的变体序列。此实施例中使用的报告寡核苷酸携带在5'端的FAM荧光团和在3'端的BHQ-1猝灭剂以及内部BHQ-1猝灭剂。报告寡核苷酸与SEQ ID NO:4的位置143至172杂交,并且具有在其3'端的突出端(2个核苷酸)和在其5'端的辅助序列(9个核苷酸;导致Tm增加14.2℃),所述辅助序列在单核苷酸重复序列的上游杂交。另外,其包含在距5'端10个核苷酸内的疏水核苷酸和在距3'端10个核苷酸内的疏水核苷酸。测试来自微卫星不稳定患者的1-2ng/μLFFPE纯化的正常和肿瘤组织DNA。获得两条解链曲线(图3)。图3A显示不应用双线性归一化或温度漂移的解链曲线。图3B显示在应用双线性归一化(无温度漂移)后的解链曲线。
图4显示参考样品(在任何给定温度下将荧光设为零;样品来自患者的健康细胞)与肿瘤样品之间随温度而变化的荧光差异DT。这也称为差异图、差异曲线或差异图表。将最大差异maxDT测量为差异曲线的最大幅度的绝对值。在应用标准归一化之后(图4A)或在应用双线性归一化(无温度漂移)后(图4B)显示的数据。
此实施例显示,双线性归一化可以补偿在不同样品解链之前和之后看到的荧光的不同降低,并且帮助区分正常(健康)样品与肿瘤样品的HRM图谱。
实施例3:双线性归一化和温度漂移可以减小解链曲线之间的差异
使用不对称PCR的NR24测定。所述测定用于检测NR24微卫星中的变体序列。此实施例中使用的报告寡核苷酸携带在5'端的FAM荧光团和在3'端的BHQ-1猝灭剂以及内部猝灭剂。报告寡核苷酸与SEQ ID NO:5的位置158至187杂交,并且具有在其3'端的突出端和在其5'端的辅助序列(导致Tm增加14.8℃),所述辅助序列在单核苷酸重复序列的上游杂交。另外,其包含在距5'端10个核苷酸内的疏水核苷酸和在距3'端10个核苷酸内的疏水核苷酸。测试来自同一微卫星稳定的患者的1-2ng/μL正常组织DNA和肿瘤组织DNA。应用标准归一化,初始区间为44-45℃(设为值1)并且最终区间为66-67℃(设为值0)。结果显示于图5中。
在不应用双线性归一化和温度漂移强度阈值时,曲线之间的差异为~0.04RFU(图5A)。在应用双线性归一化但不应用温度漂移强度阈值时,曲线之间的差异为~0.02RFU(图5B)。在应用双线性归一化和0.1RFU的温度漂移强度阈值时,曲线之间的差异为~0.01RFU(图5C)。
从此实施例可以得出结论,双线性归一化和温度漂移可以减小来自微卫星稳定的患者的健康和正常样品的解链曲线之间的差异。这会降低假阳性的风险。
实施例4:温度漂移强度阈值可以中和由DNA缓冲液中的不同盐浓度引起的解链温度的变化
使用不对称PCR的NR24测定。所述测定用于检测NR24微卫星中的变体序列。此实施例中使用的报告寡核苷酸携带在5'端的FAM荧光团和在3'端的BHQ-1猝灭剂以及内部BHQ-1猝灭剂。报告寡核苷酸与SEQ ID NO:5的位置158至187杂交,并且具有在其3'端的突出端(2个核苷酸)和在其5'端的辅助序列(导致Tm增加14.8℃),所述辅助序列在单核苷酸重复序列的上游杂交。另外,其包含在距5'端10个核苷酸内的疏水核苷酸和在距3'端10个核苷酸内的疏水核苷酸。将正常组织DNA分别在水和TE缓冲液中从40ng/μL稀释至2ng/μL。在区域44-45℃中进行初始归一化,并且在区域66-67℃中进行最终归一化。结果显示于图6中。
在应用双线性归一化但不应用温度漂移时,曲线之间的最大差异maxDT是~0.07RFU(图6A)。在应用双线性归一化和强度阈值为0.1RFU的温度漂移时,maxDT为~0.01RFU(图6B)。
从此实施例可以得出结论,在差异是由DNA缓冲液中的不同盐浓度引起时,应用温度漂移可以减小两个样品之间的差异。因此,在应用双线性归一化和温度漂移后,一个样品的等分样品可以得到相同的HRM图谱,即使所述等分样品是用不同的缓冲液获得的。这显著降低了假阳性识别的风险,因为所述测定对于所比较样品之间的盐和缓冲液浓度变化的脆弱性降低。
实施例5:温度漂移产生使用一种通用参考样品的可能性
使用不对称PCR的MONO27测定,所述不对称PCR使用在包含单核苷酸重复序列的区域的上游和下游杂交的引物。所述测定用于检测MON27微卫星中的变体序列。此实施例中使用的报告寡核苷酸携带在5'端的FAM荧光团和在3'端的BHQ-1猝灭剂以及内部BHQ-1猝灭剂。报告寡核苷酸与SEQ ID NO:6的位置300至333杂交,并且具有在其3'端的突出端和在其5'端的辅助序列(导致Tm增加10.8℃),所述辅助序列在单核苷酸重复序列的上游杂交。另外,其包含在距5'端10个核苷酸内的疏水核苷酸和在距3'端10个核苷酸内的疏水核苷酸。测试来自16名不同患者的1-2ng/μL FFPE纯化的正常组织DNA。初始归一化区间是44-45℃,并且最终归一化区间是66-67℃。
图7A显示HRM曲线,其中应用双线性归一化但不应用温度漂移。曲线之间的最大差异maxDT是~0.25RFU。图7B显示HRM曲线,其中应用双线性归一化和强度阈值为0.1RFU的温度漂移,maxDT降低至~0.06RFU。
图8A和图8B分别显示图7A和图7B中HRM曲线的差异图。
从此实验可以得出结论,应用温度漂移减小来自不同患者的健康样品之间的差异。这产生了对于每名患者使用一种通用参考样品来代替成对的正常样品和肿瘤样品的可能性。
实施例6:不对称PCR产生更多单链扩增子
使用不对称PCR的NR22测定,所述不对称PCR使用在包含单核苷酸重复序列的区域的上游和下游杂交的引物。所述测定用于检测NR22微卫星中的变体序列。此实施例中使用的报告寡核苷酸携带在5'端的FAM荧光团和在3'端的BHQ-1猝灭剂以及内部BHQ-1猝灭剂。报告寡核苷酸与SEQ ID NO:4的位置142至172杂交,并且具有在其3'端的突出端和在其5'端的辅助序列(导致Tm增加14.2℃),所述辅助序列在单核苷酸重复序列的上游杂交。另外,其包含在距5'端10个核苷酸内的疏水核苷酸和在距3'端10个核苷酸内的疏水核苷酸。
测试1-2ng/μL血液的纯化的正常组织DNA。在图上,看到实时PCR曲线。对称PCR曲线在循环45后停止增加RFU,并且对于不对称PCR,扩增在指数期后以线性扩增继续进行。
从此实验可以看到,不对称PCR产生更多单DNA链,所述单DNA链包含报告寡核苷酸的杂交序列可以结合的序列。
实施例7:不对称PCR产生更高的信噪比和更陡峭的解链曲线
如实施例6中所述进行测定。获得归一化的HRM曲线并显示于图10中。
从此实验可以得出结论,不对称PCR产生更高的信噪比并且产生“更陡峭的”解链图谱。
实施例8:不对称PCR使得更易于区分MSS患者与MSI患者
如实施例6中所述进行NR22测定。测试来自微卫星不稳定患者的1-2ng/μL FFPE纯化的正常和肿瘤组织DNA。
图11显示在应用标准归一化后用不对称PCR(图11A)或用对称PCR(图11B)获得的HRM曲线。相应差异曲线分别显示于图12A和图12B中。
从此实施例可以得出结论,对于微卫星不稳定患者,与对称PCR相比,用不对称PCR扩增产生正常和肿瘤组织曲线之间的更大差异。因此,不对称PCR使得更易于区分MSS患者与MSI患者。
实施例9:报告寡核苷酸中的单端突出端可以增加解链温度
使用不对称PCR的NR22测定,所述不对称PCR使用在包含单核苷酸重复序列的区域的上游和下游杂交的引物。所述测定用于检测NR22微卫星中的变体序列。
在此实验中使用两种不同的报告寡核苷酸。此实施例中使用的第一报告寡核苷酸携带在5'端的FAM荧光团和在3'端的BHQ-1猝灭剂。第一报告寡核苷酸与SEQ ID NO:4的位置148至177杂交。杂交序列还包含在5'端的长4个核苷酸的辅助序列(导致Tm增加7.5℃)和在3'端的长5个核苷酸的辅助序列(导致Tm增加3.6℃),所述辅助序列与NR22中紧邻重复序列上游和下游的区域互补。第二报告寡核苷酸携带在5'端的FAM荧光团和在3'端的BHQ-1猝灭剂以及内部猝灭剂。第二报告寡核苷酸与SEQ ID NO:4的位置143至172杂交,并且具有在其3'端的突出端和仅在其5'端的长9个核苷酸的辅助序列(导致Tm增加14.2℃),所述辅助序列在单核苷酸重复序列的上游杂交。另外,两种报告寡核苷酸都包含在距5'端10个核苷酸内的疏水核苷酸和在距3'端10个核苷酸内的疏水核苷酸。测试1-2ng/μL血液的纯化的正常组织DNA。
使用第一报告寡核苷酸的测定结果以虚线显示于图13中;使用第二报告寡核苷酸的结果以实线显示。解链曲线显示于图13A中并且导数曲线显示于图13B中。不应用双线性归一化和温度漂移。
看到第二报告寡核苷酸的解链温度高于第一报告寡核苷酸的解链温度。第二报告寡核苷酸的更低背景荧光可能是由于存在另外的内部猝灭剂所致。
从此实验可以看到,用一端中的一个较长辅助序列来代替每一端中的两个较小辅助序列可以增加探针的解链温度,并且在研究单核苷酸重复性微卫星时可以是一个优点。
实施例10:双重猝灭报告寡核苷酸增加信噪比
使用不对称PCR的BAT26测定,所述不对称PCR使用在包含单核苷酸重复序列的区域的上游和下游杂交的引物。所述测定用于检测BAT26微卫星中的变体序列。测试1-2ng/μL血液的纯化的正常组织DNA。A:HRM曲线,其中应用标准归一化。在此实施例中使用两种报告寡核苷酸,两种都携带在5'端的FAM荧光团和在3'端的BHQ-1猝灭剂。作为仅单一猝灭的报告寡核苷酸的例子,使用非DQ探针BAT26报告寡核苷酸FAM5'-CZCCTTTTTTTTTTTTTTTTTTTTTTTTTTTTAZC-3'BHQ-1(SEQ ID NO:7)。使用BAT26报告寡核苷酸FAM5'-CZCCTTTTTTTTTTXTTTTTTTTTTTTTTTTTTAZC-3'BHQ-1(SEQ ID NO:8)来说明双重猝灭的DQ报告寡核苷酸;X指示内部猝灭剂。
报告寡核苷酸与SEQ ID NO:2的位置220至251杂交,并且具有在其3'端的突出端和在其5'端(导致Tm增加5.2℃)和其3'端(导致Tm增加1.9℃)两端的辅助序列,所述辅助序列在单核苷酸重复序列的上游和下游杂交。另外,其包含在距5'端10个核苷酸内的疏水核苷酸和在距3'端10个核苷酸内的疏水核苷酸。
HRM曲线和负一阶导数曲线分别显示于图14A和图14B中。看到与双重猝灭的报告寡核苷酸(DQ探针)相比,单一猝灭的报告寡核苷酸(非DQ探针)的背景荧光更高。从此实验可以得出结论,与单一猝灭的报告寡核苷酸相比,DQ报告寡核苷酸减少荧光噪音并使解链更剧烈。双重猝灭的报告寡核苷酸的使用可以由此有助于区分正常样品与肿瘤样品。
实施例11:报告寡核苷酸的杂交序列中另外的核苷酸重复序列使得可以检测更长的微卫星
使用不对称PCR进行NR21测定。所述测定用于检测NR21微卫星中的变体序列。此实施例中使用的报告寡核苷酸携带在5'端的FAM荧光团和在3'端的BHQ-1猝灭剂以及内部猝灭剂。报告寡核苷酸与SEQ ID NO:2的位置189至214杂交,并且具有在其3'端的突出端和在其5'端的辅助序列(导致Tm增加15.2℃),所述辅助序列在单核苷酸重复序列的下游杂交。另外,报告寡核苷酸包含距5'端5个核苷酸内的2个疏水核苷酸和距3'端5个核苷酸内的一个疏水核苷酸。报告寡核苷酸的杂交序列包含22个T核苷酸重复序列;在大多数正常细胞中,NR21微卫星由21个重复序列组成。因此,与参考序列相比,报告寡核苷酸具有一个另外的T。
针对21、22或23个腺嘌呤重复序列的人工靶标测试报告寡核苷酸。
在应用双线性归一化但不应用温度漂移后的HRM曲线显示于图15中。从此实验可以得出结论,在报告寡核苷酸的杂交序列中添加一个额外的重复序列允许检测比参考的21个重复序列更长的微卫星。
实施例12:单点突变将解链温度改变几度
KIT外显子13测定用于检测KIT外显子13中的变体序列。按不对称PCR进行PCR。报告寡核苷酸携带在其5'端的FAM荧光团和在其3'端的BHQ1猝灭剂。检查1ng/ul来自野生型样品的FFPE纯化的组织DNA和来自患者样品的FFPE纯化的肿瘤组织。初始归一化区间为70-71℃并且最终归一化区间为80-81℃。结果显示于图16中。野生型组织得出79.1℃的Tm,并且肿瘤组织得出两个Tm:75.7℃和79.1℃。
从此实验可以得出结论,探针的解链温度被改变高达3.4℃,并且在单点突变的情形中,解链曲线的形状发生显著变化。由此可以区分健康样品与肿瘤样品。
实施例13:更强的单端辅助序列增加差异并有助于区分突变体与野生型
使用不对称PCR的NR24测定,所述不对称PCR使用在包含单核苷酸重复序列的区域的上游和下游杂交的引物。所述测定用于检测NR24微卫星中的变体序列。
在此实验中使用两种不同的报告寡核苷酸。第一报告寡核苷酸携带在5'端的FAM荧光团和在3'端的BHQ-1猝灭剂以及内部BHQ-1猝灭剂。第一报告寡核苷酸与SEQ ID NO:5的位置159至187杂交,并且具有在其3'端的突出端(2个核苷酸)和在其5'端的长5个核苷酸的辅助序列(导致Tm增加10.5℃),所述辅助序列在单核苷酸重复序列的上游杂交。另外,其包含距5'端10个核苷酸内的两个疏水核苷酸和距3'端10个核苷酸内的疏水核苷酸。第二报告物描述于实施例4中。测试来自微卫星不稳定患者的1-2ng/μL FFPE纯化的正常和肿瘤组织DNA。
在区域40.5-41.5℃中进行初始归一化,并且在区域66-67℃中进行最终归一化。应用双线性归一化和在0.05RFU的温度漂移。结果显示于图17和图18中;比较图17A和图18A(使用第一报告寡核苷酸的结果)与图17B和图18B(使用第二报告寡核苷酸的结果)。
第二辅助序列在杂交时导致Tm的增加(14.8℃,即高4.3℃)高于第一辅助序列,从而有助于区分两个解链图谱。
看到更强的辅助序列增加突变体的maxDT。具有弱辅助序列的第一报告寡核苷酸在正常组织与肿瘤组织之间产生~0.03RFU的maxDT。这低于针对NR24标记设置的阈值,并且突变体会因此被错误地归类为野生型(图18A)。具有更强辅助序列的第二报告寡核苷酸产生~0.17的maxDT,并且因此样品被正确地归类为突变体(图18B)。
从此实验可以得出结论,更强地辅助序列可以增加野生型与突变体之间的差异,这在研究单核苷酸重复性微卫星时可以是一个优点。
序列




参考文献
Boland et al.(1998)"A National Cancer Institute workshop onmicrosatellite instability for cancer detection and familial predisposition:development of international criteria for the determination of microsatelliteinstability in colorectal cancer,"Cancer Res 58:5248-5257
Rodriguez-Bigas et al.(1997)"A National Cancer Institute workshop onhereditary nonpolyposis colorectal cancer syndrome:meeting highlights andBethesda guidelines,"J Natl Cancer Inst 89:1758-1762
Hunter and Sanders(1990)J.Am Chem.Soc.112:5525-5534
WO 2017/045689
WO 03/052132
项目
1.一种用于检测由两条链组成并且包含一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的方法,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述方法包括以下步骤:
a)提供第一样品,其包含怀疑含有所述变体序列的核酸;
b)提供第二样品,其包含含有所述参考序列的核酸,其中所述第二样品是参考样品;
c)提供报告寡核苷酸;
d)提供引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增所述靶核酸序列;
e)在所述第一样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含怀疑含有变体序列的核酸的第一扩增子;并且在所述第二样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含所述参考序列的第二扩增子,其中所述第二扩增子是参考扩增子;
f)进行所述第一扩增子的高分辨率解链(HRM)分析,从而获得特征为第一解链曲线的第一HRM图谱,并且进行所述第二扩增子的HRM分析,从而获得特征为第二解链曲线的第二HRM图谱,其中所述第二HRM图谱是特征为参考解链曲线的参考图谱;其中每个扩增子包含第一链和第二链,其中所述HRM分析涉及所述报告寡核苷酸与每个扩增子的一条链的杂交、对荧光团发射的信号的检测以及获得所述第一和所述第二解链曲线;
其中所述报告寡核苷酸是范围为10至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,
其中所述报告寡核苷酸包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,并且
其中所述报告寡核苷酸包含杂交序列H,
其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分;并且
其中所述杂交序列与所述靶核酸序列中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸序列中第二链的序列的连续延伸段互补;以及
g)将所述第一HRM图谱与参考HRM图谱进行比较,其中所述第一HRM图谱与所述参考HRM图谱之间的差异表明,所述第一样品含有变体序列。
2.根据项目1所述的方法,其中所述NOI包含重复序列,并且其中所述报告寡核苷酸的杂交序列由重复性序列和在其5'端和/或在其3'端的辅助序列组成,其中所述辅助序列不包含重复序列,并且能够在所述杂交序列与所述第一和所述第二扩增子的第一链或第二链杂交时与所述链杂交,优选地其中所述报告寡核苷酸由重复性序列和在其5'端或其3'端的仅一个辅助序列组成。
3.根据项目2所述的方法,其中所述辅助序列包含1至20个核苷酸,如1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个核苷酸,或由所述核苷酸组成,优选地其中所述辅助序列包含如项目1中所定义的至少一个疏水寡核苷酸。
4.根据前述项目中任一项所述的方法,其中将如项目1中所定义的至少一个疏水核苷酸如1、2或3个疏水核苷酸插入距所述报告寡核苷酸的3'端1至10个核苷酸内,如距3'端1、2、3、4、5、6、7、8、9或10个核苷酸内。
5.根据前述项目中任一项所述的方法,其中将如项目1中所定义的至少一个疏水核苷酸如1、2或3个疏水核苷酸插入距所述报告寡核苷酸的5'端1至10个核苷酸内,如距5'端1、2、3、4、5、6、7、8、9或10个核苷酸内。
6.根据前述项目中任一项所述的方法,其中所述多个靶核酸序列由BAT25和BAT26组成,优选地所述多个靶核酸序列由如SEQ ID NO:1中所示的BAT25和如SEQ ID NO:2中所示的BAT26组成。
7.根据前述项目中任一项所述的方法,其中所述靶核酸序列是包含以下中的一种或多种的一个或多个核酸序列:BAT25、BAT26、NR21、NR22、NR24和MONO27,优选地如SEQ IDNO:1中所示的BAT25、如SEQ ID NO:2中所示的BAT26、如SEQ ID NO:3中所示的NR21、如SEQID NO:4中所示的NR22、如SEQ ID NO:5中所示的NR24和如SEQ ID NO:6中所示的MONO27。
8.根据前述项目中任一项所述的方法,其中所述靶核酸是由BAT25、BAT26、NR21、NR22和NR24组成的多个靶核酸序列,优选地所述多个靶核酸序列由如SEQ ID NO:1中所示的BAT25、如SEQ ID NO:2中所示的BAT26、如SEQ ID NO:3中所示的NR21、如SEQ ID NO:4中所示的NR22和如SEQ ID NO:5中所示的NR24组成。
9.根据前述项目中任一项所述的方法,其中所述靶核酸是由BAT25、BAT26、NR22、NR24和MONO27组成的多个靶核酸序列,优选地所述多个靶核酸序列由如SEQ ID NO:1中所示的BAT25、如SEQ ID NO:2中所示的BAT26、如SEQ ID NO:4中所示的NR22、如SEQ ID NO:5中所示的NR24和如SEQ ID NO:6中所示的MONO27组成。
10.根据前述项目中任一项所述的方法,其中所述靶核酸是由BAT25、BAT26、NR21、NR22、NR24和MONO27组成的多个靶核酸序列,优选地所述多个靶核酸序列由如SEQ ID NO:1中所示的BAT25、如SEQ ID NO:2中所示的BAT26、如SEQ ID NO:3中所示的NR21、如SEQ IDNO:4中所示的NR22、如SEQ ID NO:5中所示的NR24和如SEQ ID NO:6中所示的MONO27组成。
11.根据前述项目中任一项所述的方法,其中步骤e)中的扩增是通过聚合酶链反应(PCR)进行,优选地通过不对称PCR进行,其中所述第一和所述第二引物以不同量来提供,从而引导所述PCR以扩增每个扩增子的第二链多于每个扩增子的第一链。
12.根据前述项目中任一项所述的方法,其中所述第一样品已经从患有或怀疑患有疾病的个体分离,所述疾病例如癌症,优选地所述癌症是遗传性非息肉病结直肠癌。
13.根据前述项目中任一项所述的方法,其中所述NOI是微卫星。
14.根据前述项目中任一项所述的方法,其中所述参考序列包含总长度为n个核苷酸的M个串联重复序列的微卫星序列,并且其中所述变体序列具有总长度为n'个核苷酸的M'个串联重复序列,其中M和M'是不同的整数。
15.根据前述项目中任一项所述的方法,其中所述报告寡核苷酸的杂交序列H的长度为n”,其中n”≥n+1,优选地n”≥n+1或n”≥n+2。
16.根据前述项目中任一项所述的方法,其中所述报告寡核苷酸包含定位于所述报告寡核苷酸的非末端位置的第二猝灭剂。
17.根据前述项目中任一项所述的方法,其中所述第一样品是包含或怀疑包含具有所述疾病所特有的突变的细胞的组织的样品。
18.根据前述项目中任一项所述的方法,其中所述参考样品是从与所述第一样品相同的个体分离,任选地从未患病组织分离,或者其中所述参考样品是从健康个体分离。
19.根据前述项目中任一项所述的方法,其中步骤f)包括转换所述第一和所述第二HRM解链曲线以获得所述第一和所述第二解链曲线的负一阶导数的步骤,其中所述第一HRM图谱与所述参考HRM图谱之间的差异是所述第一解链曲线与第二解链曲线的所述负一阶导数之间的差异。
20.根据前述项目中任一项所述的方法,其中将所述第一解链曲线的荧光和所述第二解链曲线的荧光归一化,并且其中所述HRM图谱之间的差异是随温度而变化的所述第一解链曲线与第二解链曲线的荧光之间的差异。
21.根据前述项目中任一项所述的方法,其中将所述第一HRM图谱与所述参考HRM图谱之间的差异测量为所述第一HRM曲线与所述第二HRM曲线之间的上和下归一化区域的边界内相对荧光单位的绝对最大差异。
22.根据前述项目中任一项所述的方法,其中所述HRM分析包括所述第一和所述第二解链曲线的双线性归一化的步骤。
23.根据前述项目中任一项所述的方法,其中所述HRM分析包括将温度调整以某一相对荧光单位(RFU)应用至所述第一和所述第二解链曲线和/或应用至所述第一和所述第二解链曲线的负一阶导数的步骤。
24.根据前述项目中任一项所述的方法,其中所述第二引物包含至少15个核苷酸的序列,所述序列与所述靶核酸序列的连续序列互补。
25.根据前述项目中任一项所述的方法,其中与所述参考序列相比,所述变体序列包含一个或多个核苷酸的插入或由所述插入组成。
26.根据前述项目中任一项所述的方法,其中与所述参考序列相比,所述变体序列包含一个或多个核苷酸的缺失或由所述缺失组成。
27.根据前述项目中任一项所述的方法,其中所述报告寡核苷酸具有以下一般结构
5'-(N)a-Z-(N)d-Z-(N)e-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如项目1中所定义的疏水核苷酸;并且
核苷酸或核苷酸类似物的总数量是至少10;并且
a和b单独地是在0至4范围内的整数;并且
d和e单独地是在1至19范围内的整数;并且
a+b+d+e是至少10;并且
(N)a-(N)d-(N)e-(N)b与参考序列相同。
28.根据前述项目中任一项所述的方法,其中所述报告寡核苷酸具有以下一般结构:
5'-(N)a-Z-(N)f-Z-(N)g-Z-(N)h-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如项目1中所定义的疏水核苷酸;并且
a和b单独地是在0至4范围内的整数;并且
f、g和h单独地是在1至18范围内的整数;并且
a+b+f+g+h是至少10且至多50;并且
(N)a-(N)f-(N)g-(N)h-(N)b与包含参考序列的靶核酸序列的延伸段相同;或者
具有以下一般结构
5'-(N)a-Z-(N)i-Z-(N)j-Z-(N)k-Z-(N)l-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如项目1中所定义的疏水核苷酸;并且
a和b单独地是在0至4范围内的整数;并且
i、j、k和l单独地是在1至17范围内的整数;并且
a+b+i+j+k+l是至少10且至多50;并且
(N)a-(N)i-(N)j-(N)k-(N)l-(N)b与包含参考序列的靶核酸序列的延伸段相同;或者
具有以下一般结构
5'-(N)a-Z-(N)m-Z-(N)n-Z-(N)o-Z-(N)p-Z-(N)q-Z-(N)b-3'
其中
N是任何核苷酸或核苷酸类似物;并且
Z是如项目1中所定义的疏水核苷酸;并且
a和b单独地是在0至4范围内的整数;并且
m、n、o、p和q单独地是在1至16范围内的整数;并且
a+b+m+n+o+p+q是至少10且至多50;并且
(N)a-(N)m-(N)n-(N)o-(N)p-Z-(N)q-(N)b与包含参考序列的靶核酸序列的延伸段相同。
29.根据前述项目中任一项所述的方法,其中至少一种嵌入剂Q选自多芳香基和杂多芳香基,所述多芳香基和杂多芳香基任选地被选自以下的一者或多者取代:羟基、溴、氟、氯、碘、巯基、硫基、氰基、烷硫基、杂环、芳基、杂芳基、羧基、碳烷酰基、烷基、烯基、炔基、硝基、氨基、烷氧基和酰胺基。
30.根据前述项目中任一项所述的方法,其中所述嵌入剂选自苯、并环戊二烯、茚、萘、薁、不对称引达省(as-indacene)、对称引达省(s-indacene)、亚联苯基、苊、非那烯、庚搭烯、菲蒽烷(phenanthrane)、荧蒽、菲咯啉、吩嗪、菲啶、蒽醌、芘、蒽、环烷烃、菲、芴(flurene)、苉、 并四苯、吖啶酮、苯并蒽、茋、草酰-吡啶并咔唑、叠氮基苯、卟啉和补骨脂素及其衍生物。
并四苯、吖啶酮、苯并蒽、茋、草酰-吡啶并咔唑、叠氮基苯、卟啉和补骨脂素及其衍生物。
31.根据前述项目中任一项所述的方法,其中至少一个、例如所有骨架单体单元X是亚磷酰胺。
32.根据前述项目中任一项所述的方法,其中至少一个接头Y包含x个原子的链,所述原子选自C、O、S、N和P,任选地其中所述链被选自C、H、O、S、N和P的一者或多者取代。
33.根据前述项目中任一项所述的方法,其中所述靶核酸序列是多个靶核酸序列。
34.一种用于检测由两条链组成并且包含一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的多部分试剂盒,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述多部分试剂盒包含:
a)报告寡核苷酸,其包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,
其中所述报告寡核苷酸是范围为10至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分;并且
其中所述杂交序列与所述靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补;以及
b)引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增所述靶核酸。
35.根据项目34所述的试剂盒,其中所述报告寡核苷酸和所述第一引物和所述第二引物如前述项目中的任一项所定义。
36.一种报告寡核苷酸,其能够与靶核酸的一条链杂交,所述报告寡核苷酸包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,其中所述报告寡核苷酸是范围为10至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分;并且
其中所述杂交序列与所述靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补。
37.根据项目36所述的报告寡核苷酸,其中所述NOI包含重复序列,并且其中所述报告寡核苷酸的杂交序列由重复性序列和在其5'端和/或在其3'端的辅助序列组成,其中所述辅助序列不包含重复序列,并且能够在所述杂交序列与所述靶核酸的第二链杂交时与所述链杂交,优选地其中所述报告寡核苷酸由重复性序列和在其5'端或其3'端的仅一个辅助序列组成。
38.根据项目36至37中任一项所述的报告寡核苷酸,其中所述辅助序列包含1至20个核苷酸,如1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个核苷酸,或由所述核苷酸组成,优选地其中所述辅助序列包含如项目1中所定义的至少一个疏水寡核苷酸。
39.根据项目36至38中任一项所述的报告寡核苷酸,其中所述参考序列包含总长度为n个核苷酸的M个串联重复序列的微卫星序列,并且其中所述报告寡核苷酸的杂交序列H的长度为n”,其中n”≥n+1,优选地n”≥n+1或n”≥n+2。
40.根据项目36至39中任一项所述的报告寡核苷酸,其中所述报告寡核苷酸包含定位于所述报告寡核苷酸的非末端位置的第二猝灭剂。
41.一种预测用预定药物治疗有需要的个体的临床病症的功效的方法,其中用所述药物治疗所述临床病症的功效与变体序列的存在相关,所述方法包括以下步骤:
a.提供来自所述个体的样品;
b.进行根据项目1至33中任一项所述的方法以确定所述变体序列的存在;
其中所述变体序列的存在指示所述药物是否在治疗所述个体的所述临床病症方面有效。
42.一种预测有需要的个体中临床病症的存在的方法,其中所述临床病症与包含变体序列的靶核酸序列的存在相关,所述方法包括以下步骤:
a.提供来自所述个体的样品;
b.进行根据项目1至33中任一项所述的方法以确定变体序列的存在;
其中变体序列的存在指示所述个体患有所述临床病症。
43.根据项目41至42中任一项所述的方法,其中所述临床病症是癌症,优选地遗传性非息肉病结直肠癌。
44.根据项目41至43中任一项所述的方法,其还包括将治疗剂以有效量施用至所述个体的步骤。
序列表
<110> 潘塔贝斯公司
<120> 检测变体核酸的解链温度方法、试剂盒和报告寡核苷酸
<130> P5295PC00
<160> 8
<170> PatentIn version 3.5
<210> 1
<211> 301
<212> DNA
<213> 智人
<220>
<221> misc_feature
<222> (147)..(171)
<223> 单核苷酸重复序列
<400> 1
gccatcatgg aggatgacga gttggcccta gacttagaag acttgctgag cttttcttac 60
caggtggcaa agggcatggc tttcctcgcc tccaagaatg taagtgggag tgattctcta 120
aagagttttg tgttttgttt ttttgatttt tttttttttt tttttttttt tgagaacaga 180
gcattttaga gccatagtta aaatgcagaa tgtcattttg aagtgtggta accaaaagca 240
gaggaaattt agtttcttca tgttccaact gctgtctctt tggaattcct gttctaattt 300
a 301
<210> 2
<211> 401
<212> DNA
<213> 智人
<220>
<221> misc_feature
<222> (222)..(248)
<223> 单核苷酸重复序列
<400> 2
gttttttaaa atctttagaa ctggatccag tggtatagaa atcttcgatt tttaaattct 60
taattttagg ttgcagtttc atcactgtct gcggtaatca agtttttaga actcttatca 120
gatgattcca actttggaca gtttgaactg actacttttg acttcagcca gtatatgaaa 180
ttggatattg cagcagtcag agcccttaac ctttttcagg taaaaaaaaa aaaaaaaaaa 240
aaaaaaaagg gttaaaaatg ttgaatggtt aaaaaatgtt ttcattgaca tatactgaag 300
aagcttataa aggagctaaa atattttgaa atattattat acttggatta gataactagc 360
tttaaatggc tgtatttttc tctcccctcc tccactccac t 401
<210> 3
<211> 301
<212> DNA
<213> 智人
<220>
<221> misc_feature
<222> (188)..(209)
<223> 单核苷酸重复序列
<400> 3
ccctttctaa atgcgtattc gtgtaaatat attgggagag agctttgaat tagaacgtcc 60
ttttccgaaa taggaaccac tgctactctc taaaaaaggc aagcagataa aagagaacac 120
gaaaaatatt cctactccgc attcacactt tctggtcact cgcgtttaca aacaagaaaa 180
gtgttgctaa aaaaaaaaaa aaaaaaaaag gccaggggag acatacattt aaatataaaa 240
atagaactgt gccagcgact ccggctggaa ttctgctgaa agggatgtgt cttcagaaac 300
c 301
<210> 4
<211> 291
<212> DNA
<213> 智人
<220>
<221> misc_feature
<222> (151)..(172)
<223> 单核苷酸重复序列
<400> 4
tctccaaagt tgatctgatt gtaaatatta aactgacatc tttatgttgc aggtaaagga 60
cctggataat cgaggcttgt caaggacata aatgtcacgt ccagctctga tatgcttcgc 120
actgagcaca tcacatttag gacgttgaag attttttttt tttttttttt ttaatatgca 180
gtttgtaaga acaaaactgg atggcatcag aattgtctgg aagttttgtc ttgggcagta 240
tgggctgggc caaatgaaat gatttttata attctaaaca ggttaccaaa t 291
<210> 5
<211> 301
<212> DNA
<213> 智人
<400> 5
caaatgaccc cttcctgccc atcactgcct tcctcaagac ctaaaatagc tccctattta 60
gtgaaaaatt atctgaatat ttaaggtctg ccttaacgtg atccccattg ctgaatttta 120
cctcctgact ccaaaaactc ttctcttccc tgggcccagt cctatttttt tttttttttt 180
tttttttgtg agacagagtc tcactctgtc acccaggttg gaatgcaatg gcacaatctc 240
cgctcactgc aagctccgcc tcccgggttc acgccattct cctgcctcag cctcccgaat 300
a 301
<210> 6
<211> 601
<212> DNA
<213> 智人
<220>
<221> misc_feature
<222> (299)..(327)
<223> 单核苷酸重复序列
<400> 6
ttaaaaagca aaaaattggc tgggcacagt ggctcacacc tgtaattcca gcacttcagg 60
aggctgaggc aggaagattg cttgagccca gaaattcaat accagcctgg gcaagataat 120
gagaccccat ctctgcaaaa aatgaaaaat aaactagcca ggtgtggtgg catgcaccta 180
tgcccccagc cactcaagag gctgaggtgg gaggatcact tgagcccagg aggtcgaggc 240
tgcagtgagc tgtgattgca ctacactcca gcctgggtga cataatgaga ccctgtctca 300
aaaaaaaaaa aaaaaaaaaa aaaaaaactg gagccaggca cagtaggaca gtagtaattc 360
atgcctgtag tcctagctta catttcagta gaattgttta gggatattaa gtctgttgct 420
taaacttgta aaactttatt atatattgaa aaacatgcgt tgactaattt tatgagtatt 480
aattgtcttc ttttacagta actggacctc tgtcagaact gcaaattgca tatgttagca 540
gagaaacact gcaggtaaat caagtgctaa ttcaaaaata acatttttca ttaaactaag 600
g 601
<210> 7
<211> 35
<212> DNA
<213> 人工序列
<220>
<223> 示例性报告寡核苷酸
<220>
<221> misc_feature
<222> (2)..(2)
<223> n是疏水核苷酸
<220>
<221> misc_feature
<222> (34)..(34)
<223> n是疏水核苷酸
<400> 7
cncctttttt tttttttttt tttttttttt ttanc 35
<210> 8
<211> 35
<212> DNA
<213> 人工序列
<220>
<223> 示例性报告寡核苷酸
<220>
<221> misc_feature
<222> (2)..(2)
<223> z是疏水核苷酸
<220>
<221> misc_feature
<222> (15)..(15)
<223> 在残留物15和16之间插入内部淬灭剂
<220>
<221> misc_feature
<222> (24)..(24)
<223> z是疏水核苷酸
<220>
<221> misc_feature
<222> (34)..(34)
<223> n is a, c, g, or t
<400> 8
cncctttttt tttttttttt tttttttttt ttanc 35
Claims (26)
1.一种用于检测由两条链组成并且包含优选地含有重复序列的一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的方法,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述方法包括以下步骤:
a)提供第一样品,其包含怀疑含有所述变体序列的核酸;
b)提供第二样品,其包含含有所述参考序列的核酸,其中所述第二样品是参考样品;
c)提供报告寡核苷酸;
d)提供引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增包含所述NOI的所述靶核酸序列;
e)在所述第一样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含怀疑含有变体序列的核酸的第一扩增子;并且在所述第二样品、所述第一引物和所述第二引物的存在下扩增所述靶核酸序列,从而获得包含所述参考序列的第二扩增子,其中所述第二扩增子是参考扩增子;
f)进行所述第一扩增子的解链分析,如高分辨率解链(HRM)分析,从而获得特征为第一解链曲线的第一图谱,并且进行所述第二扩增子的解链分析,如HRM分析,从而获得特征为第二解链曲线的第二图谱,其中所述第二图谱是特征为参考解链曲线的参考图谱;其中每个扩增子包含第一链和第二链,其中所述解链分析涉及所述报告寡核苷酸与每个扩增子的一条链的杂交、对荧光团发射的信号的检测以及获得所述第一和所述第二解链曲线;
其中所述报告寡核苷酸是范围为10至50个核苷酸、优选地范围为15至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,其中所述报告寡核苷酸包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,并且其中所述报告寡核苷酸包含杂交序列H,
其中所述杂交序列与所述靶核酸序列中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸序列中第二链的序列的连续延伸段互补,
并且其中所述报告寡核苷酸的杂交序列包含重复性序列和在其5'端和/或在其3'端的至少一个辅助序列或由所述重复性序列和辅助序列组成,其中所述辅助序列不包含重复序列,并且能够在所述杂交序列与所述第一和所述第二扩增子杂交时与所述扩增子杂交;以及
g)将所述第一图谱与所述参考图谱进行比较,其中所述第一图谱与所述参考图谱之间的差异表明,所述第一样品含有变体序列。
2.根据权利要求1所述的方法,其中步骤g)包括以下步骤或由以下步骤组成:
i)将所述第一和所述第二解链曲线在给定荧光强度下沿温度轴对齐,从而消除所述第一与所述第二解链曲线之间的解链温度差异;
ii)确定在所述第一与所述第二解链曲线之间由所述荧光团发射的信号的差异,优选地其中所述差异是数值差异;以及
iii)将在ii)中确定的所述差异与阈值进行比较,其中差异大于所述阈值表明,所述第一样品包含变体序列,并且差异小于所述阈值表明,所述第一样品包含所述参考序列。
3.根据前述权利要求中任一项所述的方法,其中所述参考序列的长度为15个或更多个核苷酸,如16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个或更多个核苷酸。
4.根据前述权利要求中任一项所述的方法,其中所述报告寡核苷酸由重复性序列和在其5'端或其3'端的仅一个辅助序列组成,或者其中所述报告寡核苷酸由重复性序列和两个辅助序列组成,所述两个辅助序列例如在所述报告寡核苷酸的5'端和3'端两端的一个辅助序列。
5.根据前述权利要求中任一项所述的方法,其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
6.根据前述权利要求中任一项所述的方法,其中所述辅助序列包含1至20个核苷酸,如1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个核苷酸,或由所述核苷酸组成。
7.根据前述权利要求中任一项所述的方法,其中所述辅助序列包含如权利要求3中所定义的至少一个疏水寡核苷酸。
8.根据前述权利要求中任一项所述的方法,其中将如权利要求3中所定义的至少一个疏水核苷酸如1、2或3个疏水核苷酸插入距所述报告寡核苷酸的3'端1至10个核苷酸内,如距3'端1、2、3、4、5、6、7、8、9或10个核苷酸内。
9.根据前述权利要求中任一项所述的方法,其中将如权利要求3中所定义的至少一个疏水核苷酸如1、2或3个疏水核苷酸插入距所述报告寡核苷酸的5'端1至10个核苷酸内,如距5'端1、2、3、4、5、6、7、8、9或10个核苷酸内。
10.根据前述权利要求中任一项所述的方法,其中步骤e)中的扩增是通过聚合酶链反应(PCR)进行,优选地通过不对称PCR进行,其中所述第一和所述第二引物以不同量来提供,从而引导所述PCR以扩增每个扩增子的一条链多于每个扩增子的另一条链。
11.根据前述权利要求中任一项所述的方法,其中所述第一样品已经从患有或怀疑患有疾病或障碍的个体分离,所述疾病例如癌症,优选地所述癌症是遗传性非息肉病结直肠癌,所述障碍优选地是与微卫星不稳定性相关的障碍。
12.根据前述权利要求中任一项所述的方法,其中所述NOI是微卫星,如总长度为n个核苷酸的M个串联重复序列的微卫星序列,并且其中所述变体序列具有总长度为n'个核苷酸的M'个串联重复序列,其中M和M'是不同的整数。
13.根据权利要求12所述的方法,其中n是15或更大,如16、17、18、19、20、25、30、35、40、45、50或更大。
14.根据前述权利要求中任一项所述的方法,其中所述报告寡核苷酸的杂交序列H的长度为n”,其中n”≥n+1,优选地n”≥n+1或n”≥n+2。
15.根据权利要求14所述的方法,其中n”是16个或更多个,如17、18、19、20个或更多个核苷酸,如25、30、35、40、45、50或更大。
16.根据前述权利要求中任一项所述的方法,其中所述第一样品是包含或怀疑包含具有所述疾病或障碍所特有的突变的细胞的组织的样品。
17.一种用于检测由两条链组成并且包含优选地含有重复序列的一个或多个目的核苷酸(NOI)的靶核酸序列中变体序列的存在的多部分试剂盒,其中所述靶核酸序列由变体序列组成或由参考序列组成,所述多部分试剂盒包含:
a)报告寡核苷酸,其包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,
其中所述报告寡核苷酸是范围为10至50个核苷酸、优选地范围为15至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
并且
其中所述杂交序列与所述靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补;
并且其中所述报告寡核苷酸的杂交序列包含重复性序列和在其5'端和/或在其3'端的至少一个辅助序列或由所述重复性序列和辅助序列组成,其中所述辅助序列不包含重复序列,并且能够在所述杂交序列与所述第一和所述第二扩增子杂交时与所述扩增子杂交;以及
b)引物组,其由第一引物和第二引物组成,其中所述引物组一起能够扩增所述靶核酸序列。
18.根据权利要求17所述的试剂盒,优选地其中所述报告寡核苷酸、所述第一引物和所述第二引物如权利要求1至16中任一项所定义。
19.根据权利要求17至18中任一项所述的试剂盒,其中所述报告寡核苷酸由重复性序列和在其5'端或其3'端的仅一个辅助序列组成,或者其中所述报告寡核苷酸由重复性序列和两个辅助序列组成,所述两个辅助序列例如在所述报告寡核苷酸的5'端和3'端两端的一个辅助序列。
20.根据权利要求17至19中任一项所述的试剂盒,其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
21.一种报告寡核苷酸,其能够与由两条链组成并且包含优选地含有重复序列的一个或多个目的核苷酸(NOI)的靶核酸的一条链杂交,所述报告寡核苷酸包含优选地在其5'端或距5'端4个核苷酸内的第一荧光团以及优选地在其3'端或距3'端4个核苷酸内的第一猝灭剂,其中所述报告寡核苷酸是范围为10至50个核苷酸、优选地范围为15至50个核苷酸的序列,在其中已经插入范围为2至10个的疏水核苷酸,并且其中所述报告寡核苷酸包含杂交序列H,
其中所述杂交序列与所述靶核酸中第一链的序列的连续延伸段相同,并且其中所述杂交序列与所述靶核酸中第二链的序列的连续延伸段互补,并且其中所述报告寡核苷酸的杂交序列包含重复性序列和在其5'端和/或在其3'端的至少一个辅助序列或由所述重复性序列和辅助序列组成,其中所述辅助序列不包含重复序列,并且能够在所述杂交序列与所述第一和所述第二扩增子的第二链杂交时与所述链杂交。
22.根据权利要求21所述的报告寡核苷酸,其中所述报告寡核苷酸由重复性序列和在其5'端或其3'端的仅一个辅助序列组成,或者其中所述报告寡核苷酸由重复性序列和两个辅助序列组成,所述两个辅助序列例如在所述报告寡核苷酸的5'端和3'端两端的一个辅助序列。
23.根据权利要求21至22中任一项所述的报告寡核苷酸,其中
至少一个疏水核苷酸定位于所述报告寡核苷酸的5'端或距5'端10个核苷酸内;和/或
至少一个疏水核苷酸定位于所述报告寡核苷酸的3'端或距3'端10个核苷酸内;并且
其中所述疏水核苷酸具有以下结构
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
24.根据权利要求21至14中任一项所述的报告寡核苷酸,其中所述辅助序列包含1至20个核苷酸,如1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个核苷酸,或由所述核苷酸组成,优选地其中所述辅助序列包含如权利要求3中所定义的至少一个疏水寡核苷酸。
25.一种预测用预定药物治疗有需要的个体的临床病症的功效的方法,其中用所述药物治疗所述临床病症的功效与变体序列的存在相关,所述方法包括以下步骤:
a.提供来自所述个体的样品;
b.进行根据权利要求1至16中任一项所述的方法以确定所述变体序列的存在;
其中所述变体序列的存在指示所述药物是否在治疗所述个体的所述临床病症方面有效。
26.一种预测有需要的个体中临床病症的存在的方法,其中所述临床病症与包含变体序列的靶核酸序列的存在相关,所述方法包括以下步骤:
a.提供来自所述个体的样品;
b.进行根据权利要求1至16中任一项所述的方法以确定变体序列的存在;
其中变体序列的存在指示所述个体患有所述临床病症。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP19174084.4 | 2019-05-13 | ||
| EP19174084 | 2019-05-13 | ||
| PCT/EP2020/063269 WO2020229510A1 (en) | 2019-05-13 | 2020-05-13 | Melting temperature methods, kits and reporter oligo for detecting variant nucleic acids |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114286865A true CN114286865A (zh) | 2022-04-05 |
Family
ID=66529868
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202080035128.5A Pending CN114286865A (zh) | 2019-05-13 | 2020-05-13 | 检测变体核酸的解链温度方法、试剂盒和报告寡核苷酸 |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US20220205024A1 (zh) |
| EP (1) | EP3969614A1 (zh) |
| JP (1) | JP2022533088A (zh) |
| KR (1) | KR20220031544A (zh) |
| CN (1) | CN114286865A (zh) |
| AU (1) | AU2020275447A1 (zh) |
| CA (1) | CA3137670A1 (zh) |
| SG (1) | SG11202110814QA (zh) |
| WO (1) | WO2020229510A1 (zh) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114464246A (zh) * | 2022-01-19 | 2022-05-10 | 华中科技大学同济医学院附属协和医院 | 基于CovMutt框架检测与遗传性增加相关的突变的方法 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101448957A (zh) * | 2006-03-16 | 2009-06-03 | 潘塔贝斯公司 | 用于检测核酸、核酸的甲基化状态和突变体的包含信号对和疏水性核苷酸、无茎信标的寡核苷酸 |
| CN102459651A (zh) * | 2009-06-15 | 2012-05-16 | 悉尼大学 | 测定对免疫调节组合物治疗的应答的方法 |
| CN108350506A (zh) * | 2015-09-22 | 2018-07-31 | 比奥卡尔齐斯股份有限公司 | 改进的短同聚重复的检测 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2003052133A2 (en) | 2001-12-18 | 2003-06-26 | Human Genetic Signatures Pty Ltd | Oligonucleotide analogues comprising intercalator pseudonucleotides |
| JP2011135823A (ja) * | 2009-12-28 | 2011-07-14 | Nagoya Univ | オリゴヌクレオチドプローブ及びその利用 |
| US10988810B2 (en) | 2015-09-14 | 2021-04-27 | Pentabase Aps | Methods and materials for detection of mutations |
-
2020
- 2020-05-13 WO PCT/EP2020/063269 patent/WO2020229510A1/en unknown
- 2020-05-13 EP EP20724155.5A patent/EP3969614A1/en active Pending
- 2020-05-13 SG SG11202110814QA patent/SG11202110814QA/en unknown
- 2020-05-13 US US17/610,878 patent/US20220205024A1/en active Pending
- 2020-05-13 CA CA3137670A patent/CA3137670A1/en active Pending
- 2020-05-13 AU AU2020275447A patent/AU2020275447A1/en active Pending
- 2020-05-13 CN CN202080035128.5A patent/CN114286865A/zh active Pending
- 2020-05-13 JP JP2021567881A patent/JP2022533088A/ja active Pending
- 2020-05-13 KR KR1020217036168A patent/KR20220031544A/ko unknown
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101448957A (zh) * | 2006-03-16 | 2009-06-03 | 潘塔贝斯公司 | 用于检测核酸、核酸的甲基化状态和突变体的包含信号对和疏水性核苷酸、无茎信标的寡核苷酸 |
| CN102459651A (zh) * | 2009-06-15 | 2012-05-16 | 悉尼大学 | 测定对免疫调节组合物治疗的应答的方法 |
| CN108350506A (zh) * | 2015-09-22 | 2018-07-31 | 比奥卡尔齐斯股份有限公司 | 改进的短同聚重复的检测 |
Non-Patent Citations (1)
| Title |
|---|
| XIANG DONGSHAN等: "The G-BHQ synergistic effect: Improved double quenching molecular beacons based on guanine and Black Hole Quencher for sensitive simultaneous detection of two DNAs", TALANTA, ELSEVIER, AMSTERDAM, NL, vol. 174, 8 June 2017 (2017-06-08), pages 289 - 294, XP085138315, DOI: 10.1016/j.talanta.2017.06.020 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114464246A (zh) * | 2022-01-19 | 2022-05-10 | 华中科技大学同济医学院附属协和医院 | 基于CovMutt框架检测与遗传性增加相关的突变的方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CA3137670A1 (en) | 2020-11-19 |
| JP2022533088A (ja) | 2022-07-21 |
| WO2020229510A1 (en) | 2020-11-19 |
| KR20220031544A (ko) | 2022-03-11 |
| SG11202110814QA (en) | 2021-11-29 |
| US20220205024A1 (en) | 2022-06-30 |
| EP3969614A1 (en) | 2022-03-23 |
| AU2020275447A1 (en) | 2021-10-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101815789B (zh) | 靶序列的富集 | |
| CN110129436A (zh) | Dna甲基化的数字序列分析 | |
| EP2013561A2 (en) | Binary probes for fluorescent analysis of nucleic acids | |
| US8877910B2 (en) | Probe for detecting polymorphism in exon 12 of NPM1 gene and use thereof | |
| JP4743787B2 (ja) | Dna中のシトシンのメチル化法および検出法 | |
| KR20140010093A (ko) | 혼합 집단 중 표적 dna의 서열분석을 위한 키트 및 방법 | |
| EP3350347B1 (en) | Methods and materials for detection of mutations | |
| CN114286865A (zh) | 检测变体核酸的解链温度方法、试剂盒和报告寡核苷酸 | |
| JP2008182974A (ja) | 核酸プローブセットおよびその使用方法 | |
| EP2319922B1 (en) | Nucleic acid probe set and method of using the same | |
| US20220298557A1 (en) | Method for designing a probe combination | |
| US6821733B2 (en) | Methods and compositions for detecting differences between nucleic acids | |
| US20100311609A1 (en) | Methylation Profile of Neuroinflammatory Demyelinating Diseases | |
| RU2821911C2 (ru) | Способы детектирования вариантов нуклеиновых кислот | |
| KR20120124029A (ko) | 다형 검출용 프로브, 다형 검출 방법, 약효 판정 방법 및 다형 검출용 시약 키트 | |
| JP5687414B2 (ja) | 多型の識別方法 | |
| US20030129598A1 (en) | Methods for detection of differences in nucleic acids | |
| WO2009098998A1 (ja) | 核酸検出方法及び核酸検出用キット | |
| WO2024074669A1 (en) | Detection of molecular analytes based on tailored probe competition | |
| CN113897418A (zh) | 检测dna点突变的探针、试剂盒及应用 | |
| Gunn et al. | Biomarkers of early effect in the study of cancer risk | |
| CN116209775A (zh) | 甲基化状态的检测 | |
| CN114480632A (zh) | 人微卫星不稳定位点的检测方法及其应用 | |
| JP2012105645A (ja) | Egfrエクソン21l858r遺伝子多型検出用プライマー及びその用途 | |
| JP2010246445A (ja) | 一塩基反復多型解析方法及び一塩基多型解析方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |