CN112567050A - 检测方法 - Google Patents
检测方法 Download PDFInfo
- Publication number
- CN112567050A CN112567050A CN201980051265.5A CN201980051265A CN112567050A CN 112567050 A CN112567050 A CN 112567050A CN 201980051265 A CN201980051265 A CN 201980051265A CN 112567050 A CN112567050 A CN 112567050A
- Authority
- CN
- China
- Prior art keywords
- fecal
- subject
- rna
- sample
- biomarkers
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000001514 detection method Methods 0.000 title description 22
- 239000000090 biomarker Substances 0.000 claims abstract description 288
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims abstract description 228
- 230000002550 fecal effect Effects 0.000 claims abstract description 217
- 238000000034 method Methods 0.000 claims abstract description 201
- 230000014509 gene expression Effects 0.000 claims abstract description 166
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 166
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 158
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 158
- 208000003200 Adenoma Diseases 0.000 claims abstract description 58
- 239000000523 sample Substances 0.000 claims description 197
- 206010009944 Colon cancer Diseases 0.000 claims description 131
- 108090000623 proteins and genes Proteins 0.000 claims description 99
- 238000012360 testing method Methods 0.000 claims description 72
- 206010028980 Neoplasm Diseases 0.000 claims description 67
- 238000012163 sequencing technique Methods 0.000 claims description 44
- 238000002052 colonoscopy Methods 0.000 claims description 43
- 238000003752 polymerase chain reaction Methods 0.000 claims description 36
- 239000012472 biological sample Substances 0.000 claims description 34
- 238000011282 treatment Methods 0.000 claims description 34
- 108091093088 Amplicon Proteins 0.000 claims description 33
- 108700028369 Alleles Proteins 0.000 claims description 31
- -1 semna Proteins 0.000 claims description 28
- 206010001233 Adenoma benign Diseases 0.000 claims description 22
- 230000000984 immunochemical effect Effects 0.000 claims description 20
- 238000002493 microarray Methods 0.000 claims description 20
- 238000002405 diagnostic procedure Methods 0.000 claims description 17
- 238000007637 random forest analysis Methods 0.000 claims description 17
- 102100031181 Glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 claims description 16
- 238000002512 chemotherapy Methods 0.000 claims description 16
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 claims description 16
- 238000009169 immunotherapy Methods 0.000 claims description 16
- 238000001356 surgical procedure Methods 0.000 claims description 16
- 239000002299 complementary DNA Substances 0.000 claims description 15
- 230000035772 mutation Effects 0.000 claims description 14
- 108020004999 messenger RNA Proteins 0.000 claims description 12
- 238000001959 radiotherapy Methods 0.000 claims description 12
- 101150112388 cms1 gene Proteins 0.000 claims description 11
- 108020004566 Transfer RNA Proteins 0.000 claims description 10
- 208000032818 Microsatellite Instability Diseases 0.000 claims description 9
- 102100025725 Mothers against decapentaplegic homolog 4 Human genes 0.000 claims description 9
- 101710143112 Mothers against decapentaplegic homolog 4 Proteins 0.000 claims description 9
- 108020004417 Untranslated RNA Proteins 0.000 claims description 9
- 102000039634 Untranslated RNA Human genes 0.000 claims description 9
- 102100028914 Catenin beta-1 Human genes 0.000 claims description 8
- 101000916173 Homo sapiens Catenin beta-1 Proteins 0.000 claims description 8
- 238000002626 targeted therapy Methods 0.000 claims description 8
- 102100025981 Aminoacylase-1 Human genes 0.000 claims description 7
- 101000720039 Homo sapiens Aminoacylase-1 Proteins 0.000 claims description 7
- 101000601274 Homo sapiens Period circadian protein homolog 3 Proteins 0.000 claims description 7
- 101000610604 Homo sapiens Tumor necrosis factor receptor superfamily member 10B Proteins 0.000 claims description 7
- 102100037630 Period circadian protein homolog 3 Human genes 0.000 claims description 7
- 108020003224 Small Nucleolar RNA Proteins 0.000 claims description 7
- 102000042773 Small Nucleolar RNA Human genes 0.000 claims description 7
- 102100040112 Tumor necrosis factor receptor superfamily member 10B Human genes 0.000 claims description 7
- 102100032249 Dystonin Human genes 0.000 claims description 6
- 102100033902 Endothelin-1 Human genes 0.000 claims description 6
- 101000925493 Homo sapiens Endothelin-1 Proteins 0.000 claims description 6
- 101000881650 Homo sapiens Prolyl hydroxylase EGLN2 Proteins 0.000 claims description 6
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 claims description 6
- 102100037248 Prolyl hydroxylase EGLN2 Human genes 0.000 claims description 6
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 claims description 6
- 238000003757 reverse transcription PCR Methods 0.000 claims description 6
- 101150060184 ACHE gene Proteins 0.000 claims description 5
- 102100033639 Acetylcholinesterase Human genes 0.000 claims description 5
- 101001016186 Homo sapiens Dystonin Proteins 0.000 claims description 5
- 238000011529 RT qPCR Methods 0.000 claims description 5
- 101000832669 Rattus norvegicus Probable alcohol sulfotransferase Proteins 0.000 claims description 5
- 230000036952 cancer formation Effects 0.000 claims description 5
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 claims description 5
- 229960001756 oxaliplatin Drugs 0.000 claims description 5
- 238000003762 quantitative reverse transcription PCR Methods 0.000 claims description 5
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 claims description 4
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 claims description 4
- 208000005623 Carcinogenesis Diseases 0.000 claims description 4
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 claims description 4
- 229960004117 capecitabine Drugs 0.000 claims description 4
- 231100000504 carcinogenesis Toxicity 0.000 claims description 4
- 229960002949 fluorouracil Drugs 0.000 claims description 4
- 230000009826 neoplastic cell growth Effects 0.000 claims description 4
- 230000037430 deletion Effects 0.000 claims description 3
- 238000012217 deletion Methods 0.000 claims description 3
- 238000011304 droplet digital PCR Methods 0.000 claims description 3
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 claims description 3
- 229960004768 irinotecan Drugs 0.000 claims description 3
- 108020004485 Nonsense Codon Proteins 0.000 claims description 2
- 229960000397 bevacizumab Drugs 0.000 claims description 2
- 229960005395 cetuximab Drugs 0.000 claims description 2
- 231100000221 frame shift mutation induction Toxicity 0.000 claims description 2
- 230000037433 frameshift Effects 0.000 claims description 2
- 238000003780 insertion Methods 0.000 claims description 2
- 230000037431 insertion Effects 0.000 claims description 2
- 230000037434 nonsense mutation Effects 0.000 claims description 2
- 229960001972 panitumumab Drugs 0.000 claims description 2
- 230000037432 silent mutation Effects 0.000 claims description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 claims 34
- 241001537210 Perna Species 0.000 claims 2
- 208000031448 Genomic Instability Diseases 0.000 claims 1
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 claims 1
- 108091008036 Immune checkpoint proteins Proteins 0.000 claims 1
- 102000037982 Immune checkpoint proteins Human genes 0.000 claims 1
- 108091008026 Inhibitory immune checkpoint proteins Proteins 0.000 claims 1
- 102000037984 Inhibitory immune checkpoint proteins Human genes 0.000 claims 1
- KVUAALJSMIVURS-ZEDZUCNESA-L calcium folinate Chemical compound [Ca+2].C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC([O-])=O)C([O-])=O)C=C1 KVUAALJSMIVURS-ZEDZUCNESA-L 0.000 claims 1
- 235000008207 calcium folinate Nutrition 0.000 claims 1
- 239000011687 calcium folinate Substances 0.000 claims 1
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 claims 1
- JTEGQNOMFQHVDC-NKWVEPMBSA-N lamivudine Chemical compound O=C1N=C(N)C=CN1[C@H]1O[C@@H](CO)SC1 JTEGQNOMFQHVDC-NKWVEPMBSA-N 0.000 claims 1
- 229960001627 lamivudine Drugs 0.000 claims 1
- 239000000463 material Substances 0.000 abstract description 12
- 208000029742 colonic neoplasm Diseases 0.000 abstract description 2
- 239000002773 nucleotide Substances 0.000 description 70
- 125000003729 nucleotide group Chemical group 0.000 description 70
- 239000000243 solution Substances 0.000 description 45
- 201000010099 disease Diseases 0.000 description 43
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 43
- 238000004458 analytical method Methods 0.000 description 37
- 102000053602 DNA Human genes 0.000 description 33
- 108020004414 DNA Proteins 0.000 description 33
- 208000037062 Polyps Diseases 0.000 description 32
- 239000013615 primer Substances 0.000 description 32
- 239000011324 bead Substances 0.000 description 29
- 239000003153 chemical reaction reagent Substances 0.000 description 29
- 210000004027 cell Anatomy 0.000 description 26
- 239000000872 buffer Substances 0.000 description 25
- 238000012549 training Methods 0.000 description 24
- 208000018522 Gastrointestinal disease Diseases 0.000 description 22
- 238000000605 extraction Methods 0.000 description 22
- 201000011510 cancer Diseases 0.000 description 20
- 208000010643 digestive system disease Diseases 0.000 description 19
- 239000000203 mixture Substances 0.000 description 17
- 208000018685 gastrointestinal system disease Diseases 0.000 description 16
- 238000001962 electrophoresis Methods 0.000 description 15
- 238000003860 storage Methods 0.000 description 15
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 14
- 230000003321 amplification Effects 0.000 description 14
- 238000004891 communication Methods 0.000 description 14
- 238000003500 gene array Methods 0.000 description 14
- 238000003199 nucleic acid amplification method Methods 0.000 description 14
- 108091034117 Oligonucleotide Proteins 0.000 description 13
- 210000003527 eukaryotic cell Anatomy 0.000 description 13
- 239000012634 fragment Substances 0.000 description 13
- 108091028043 Nucleic acid sequence Proteins 0.000 description 12
- 150000001413 amino acids Chemical group 0.000 description 12
- 238000001574 biopsy Methods 0.000 description 12
- 239000007787 solid Substances 0.000 description 12
- 210000001072 colon Anatomy 0.000 description 10
- 230000000875 corresponding effect Effects 0.000 description 10
- 210000003608 fece Anatomy 0.000 description 10
- 238000009396 hybridization Methods 0.000 description 10
- 230000003902 lesion Effects 0.000 description 10
- 229920001184 polypeptide Polymers 0.000 description 10
- 238000002360 preparation method Methods 0.000 description 10
- 108090000765 processed proteins & peptides Proteins 0.000 description 10
- 102000004196 processed proteins & peptides Human genes 0.000 description 10
- 208000009956 adenocarcinoma Diseases 0.000 description 9
- 230000001580 bacterial effect Effects 0.000 description 9
- 102000040430 polynucleotide Human genes 0.000 description 9
- 108091033319 polynucleotide Proteins 0.000 description 9
- 239000002157 polynucleotide Substances 0.000 description 9
- 230000000087 stabilizing effect Effects 0.000 description 9
- 239000000758 substrate Substances 0.000 description 9
- 238000004422 calculation algorithm Methods 0.000 description 8
- 238000005119 centrifugation Methods 0.000 description 8
- 239000003795 chemical substances by application Substances 0.000 description 8
- 230000000295 complement effect Effects 0.000 description 8
- 238000011161 development Methods 0.000 description 8
- 230000018109 developmental process Effects 0.000 description 8
- 230000037361 pathway Effects 0.000 description 8
- 230000009467 reduction Effects 0.000 description 8
- 238000012216 screening Methods 0.000 description 8
- 230000000391 smoking effect Effects 0.000 description 8
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 7
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 7
- 241000894006 Bacteria Species 0.000 description 7
- 230000015572 biosynthetic process Effects 0.000 description 7
- 238000003745 diagnosis Methods 0.000 description 7
- 239000012139 lysis buffer Substances 0.000 description 7
- 239000013610 patient sample Substances 0.000 description 7
- 238000011002 quantification Methods 0.000 description 7
- 239000003161 ribonuclease inhibitor Substances 0.000 description 7
- 230000035945 sensitivity Effects 0.000 description 7
- 239000000377 silicon dioxide Substances 0.000 description 7
- 208000024891 symptom Diseases 0.000 description 7
- 238000003786 synthesis reaction Methods 0.000 description 7
- 208000004804 Adenomatous Polyps Diseases 0.000 description 6
- 241000282994 Cervidae Species 0.000 description 6
- 241000206602 Eukaryota Species 0.000 description 6
- 239000003855 balanced salt solution Substances 0.000 description 6
- 238000009534 blood test Methods 0.000 description 6
- 239000007853 buffer solution Substances 0.000 description 6
- 150000001875 compounds Chemical class 0.000 description 6
- 238000002790 cross-validation Methods 0.000 description 6
- 238000001914 filtration Methods 0.000 description 6
- 230000002209 hydrophobic effect Effects 0.000 description 6
- 238000011534 incubation Methods 0.000 description 6
- 239000008188 pellet Substances 0.000 description 6
- 239000000047 product Substances 0.000 description 6
- 230000002829 reductive effect Effects 0.000 description 6
- 238000011895 specific detection Methods 0.000 description 6
- 230000004083 survival effect Effects 0.000 description 6
- 102100030708 GTPase KRas Human genes 0.000 description 5
- 206010051066 Gastrointestinal stromal tumour Diseases 0.000 description 5
- 101000584612 Homo sapiens GTPase KRas Proteins 0.000 description 5
- 208000022559 Inflammatory bowel disease Diseases 0.000 description 5
- 241000124008 Mammalia Species 0.000 description 5
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 5
- 210000004369 blood Anatomy 0.000 description 5
- 239000008280 blood Substances 0.000 description 5
- 238000004590 computer program Methods 0.000 description 5
- 238000003066 decision tree Methods 0.000 description 5
- 238000011156 evaluation Methods 0.000 description 5
- 201000011243 gastrointestinal stromal tumor Diseases 0.000 description 5
- 230000036541 health Effects 0.000 description 5
- 208000028774 intestinal disease Diseases 0.000 description 5
- 208000002551 irritable bowel syndrome Diseases 0.000 description 5
- 150000002632 lipids Chemical class 0.000 description 5
- 210000001165 lymph node Anatomy 0.000 description 5
- 238000010606 normalization Methods 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 102000004169 proteins and genes Human genes 0.000 description 5
- 229920002477 rna polymer Polymers 0.000 description 5
- 238000000926 separation method Methods 0.000 description 5
- 241000894007 species Species 0.000 description 5
- 230000006641 stabilisation Effects 0.000 description 5
- 238000011105 stabilization Methods 0.000 description 5
- 239000004094 surface-active agent Substances 0.000 description 5
- 239000000107 tumor biomarker Substances 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- 102100025805 Cadherin-1 Human genes 0.000 description 4
- 108091007854 Cdh1/Fizzy-related Proteins 0.000 description 4
- 208000015943 Coeliac disease Diseases 0.000 description 4
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 4
- 102000004190 Enzymes Human genes 0.000 description 4
- 108090000790 Enzymes Proteins 0.000 description 4
- 108700039887 Essential Genes Proteins 0.000 description 4
- 241000282326 Felis catus Species 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- 238000003559 RNA-seq method Methods 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 230000003247 decreasing effect Effects 0.000 description 4
- 238000002474 experimental method Methods 0.000 description 4
- 230000002068 genetic effect Effects 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 230000000968 intestinal effect Effects 0.000 description 4
- 239000006166 lysate Substances 0.000 description 4
- 239000003550 marker Substances 0.000 description 4
- 238000012544 monitoring process Methods 0.000 description 4
- 239000002987 primer (paints) Substances 0.000 description 4
- 238000012545 processing Methods 0.000 description 4
- 239000002096 quantum dot Substances 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 238000012552 review Methods 0.000 description 4
- 238000013517 stratification Methods 0.000 description 4
- 238000002560 therapeutic procedure Methods 0.000 description 4
- 239000013598 vector Substances 0.000 description 4
- VVIAGPKUTFNRDU-UHFFFAOYSA-N 6S-folinic acid Natural products C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-UHFFFAOYSA-N 0.000 description 3
- 241000282979 Alces alces Species 0.000 description 3
- 241000282836 Camelus dromedarius Species 0.000 description 3
- 241000283707 Capra Species 0.000 description 3
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 3
- 108010022366 Carcinoembryonic Antigen Proteins 0.000 description 3
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 description 3
- 241000700199 Cavia porcellus Species 0.000 description 3
- 241000700112 Chinchilla Species 0.000 description 3
- 206010009900 Colitis ulcerative Diseases 0.000 description 3
- 241000699800 Cricetinae Species 0.000 description 3
- 208000011231 Crohn disease Diseases 0.000 description 3
- 102100028843 DNA mismatch repair protein Mlh1 Human genes 0.000 description 3
- 239000003155 DNA primer Substances 0.000 description 3
- 102000016911 Deoxyribonucleases Human genes 0.000 description 3
- 108010053770 Deoxyribonucleases Proteins 0.000 description 3
- 206010012735 Diarrhoea Diseases 0.000 description 3
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 3
- 241000283073 Equus caballus Species 0.000 description 3
- 102100039788 GTPase NRas Human genes 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- 239000012981 Hank's balanced salt solution Substances 0.000 description 3
- 101000744505 Homo sapiens GTPase NRas Proteins 0.000 description 3
- 101001052490 Homo sapiens Mitogen-activated protein kinase 3 Proteins 0.000 description 3
- 101000605639 Homo sapiens Phosphatidylinositol 4,5-bisphosphate 3-kinase catalytic subunit alpha isoform Proteins 0.000 description 3
- 101000984753 Homo sapiens Serine/threonine-protein kinase B-raf Proteins 0.000 description 3
- 208000018142 Leiomyosarcoma Diseases 0.000 description 3
- 102100024192 Mitogen-activated protein kinase 3 Human genes 0.000 description 3
- 241000699666 Mus <mouse, genus> Species 0.000 description 3
- 108010026664 MutL Protein Homolog 1 Proteins 0.000 description 3
- 241000283973 Oryctolagus cuniculus Species 0.000 description 3
- 108010011536 PTEN Phosphohydrolase Proteins 0.000 description 3
- 102000014160 PTEN Phosphohydrolase Human genes 0.000 description 3
- 241001494479 Pecora Species 0.000 description 3
- 102100038332 Phosphatidylinositol 4,5-bisphosphate 3-kinase catalytic subunit alpha isoform Human genes 0.000 description 3
- 229920001213 Polysorbate 20 Polymers 0.000 description 3
- 241000700159 Rattus Species 0.000 description 3
- 241000282806 Rhinoceros Species 0.000 description 3
- 241000282849 Ruminantia Species 0.000 description 3
- 102100027103 Serine/threonine-protein kinase B-raf Human genes 0.000 description 3
- 241000282898 Sus scrofa Species 0.000 description 3
- 201000006704 Ulcerative Colitis Diseases 0.000 description 3
- 239000002246 antineoplastic agent Substances 0.000 description 3
- 238000003556 assay Methods 0.000 description 3
- 238000002869 basic local alignment search tool Methods 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 235000011089 carbon dioxide Nutrition 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 238000012321 colectomy Methods 0.000 description 3
- 230000008878 coupling Effects 0.000 description 3
- 238000010168 coupling process Methods 0.000 description 3
- 238000005859 coupling reaction Methods 0.000 description 3
- 229940127089 cytotoxic agent Drugs 0.000 description 3
- 239000003814 drug Substances 0.000 description 3
- 238000001839 endoscopy Methods 0.000 description 3
- VVIAGPKUTFNRDU-ABLWVSNPSA-N folinic acid Chemical compound C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-ABLWVSNPSA-N 0.000 description 3
- 235000008191 folinic acid Nutrition 0.000 description 3
- 239000011672 folinic acid Substances 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 230000002496 gastric effect Effects 0.000 description 3
- 210000001035 gastrointestinal tract Anatomy 0.000 description 3
- 238000011065 in-situ storage Methods 0.000 description 3
- 238000002955 isolation Methods 0.000 description 3
- 229960001691 leucovorin Drugs 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 238000010801 machine learning Methods 0.000 description 3
- 238000004519 manufacturing process Methods 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 201000001441 melanoma Diseases 0.000 description 3
- 108091070501 miRNA Proteins 0.000 description 3
- 238000010208 microarray analysis Methods 0.000 description 3
- 238000007481 next generation sequencing Methods 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 210000000056 organ Anatomy 0.000 description 3
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 3
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 3
- 238000000513 principal component analysis Methods 0.000 description 3
- 230000005855 radiation Effects 0.000 description 3
- 210000000664 rectum Anatomy 0.000 description 3
- 230000002441 reversible effect Effects 0.000 description 3
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 3
- 206010041823 squamous cell carcinoma Diseases 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 208000011580 syndromic disease Diseases 0.000 description 3
- 230000002194 synthesizing effect Effects 0.000 description 3
- 230000008685 targeting Effects 0.000 description 3
- 210000001519 tissue Anatomy 0.000 description 3
- 238000010200 validation analysis Methods 0.000 description 3
- QRXMUCSWCMTJGU-UHFFFAOYSA-L (5-bromo-4-chloro-1h-indol-3-yl) phosphate Chemical compound C1=C(Br)C(Cl)=C2C(OP([O-])(=O)[O-])=CNC2=C1 QRXMUCSWCMTJGU-UHFFFAOYSA-L 0.000 description 2
- 108020004463 18S ribosomal RNA Proteins 0.000 description 2
- VGIRNWJSIRVFRT-UHFFFAOYSA-N 2',7'-difluorofluorescein Chemical compound OC(=O)C1=CC=CC=C1C1=C2C=C(F)C(=O)C=C2OC2=CC(O)=C(F)C=C21 VGIRNWJSIRVFRT-UHFFFAOYSA-N 0.000 description 2
- 108020005096 28S Ribosomal RNA Proteins 0.000 description 2
- LHYQAEFVHIZFLR-UHFFFAOYSA-L 4-(4-diazonio-3-methoxyphenyl)-2-methoxybenzenediazonium;dichloride Chemical compound [Cl-].[Cl-].C1=C([N+]#N)C(OC)=CC(C=2C=C(OC)C([N+]#N)=CC=2)=C1 LHYQAEFVHIZFLR-UHFFFAOYSA-L 0.000 description 2
- 102100034540 Adenomatous polyposis coli protein Human genes 0.000 description 2
- WHVNXSBKJGAXKU-UHFFFAOYSA-N Alexa Fluor 532 Chemical compound [H+].[H+].CC1(C)C(C)NC(C(=C2OC3=C(C=4C(C(C(C)N=4)(C)C)=CC3=3)S([O-])(=O)=O)S([O-])(=O)=O)=C1C=C2C=3C(C=C1)=CC=C1C(=O)ON1C(=O)CCC1=O WHVNXSBKJGAXKU-UHFFFAOYSA-N 0.000 description 2
- ZAINTDRBUHCDPZ-UHFFFAOYSA-M Alexa Fluor 546 Chemical compound [H+].[Na+].CC1CC(C)(C)NC(C(=C2OC3=C(C4=NC(C)(C)CC(C)C4=CC3=3)S([O-])(=O)=O)S([O-])(=O)=O)=C1C=C2C=3C(C(=C(Cl)C=1Cl)C(O)=O)=C(Cl)C=1SCC(=O)NCCCCCC(=O)ON1C(=O)CCC1=O ZAINTDRBUHCDPZ-UHFFFAOYSA-M 0.000 description 2
- IGAZHQIYONOHQN-UHFFFAOYSA-N Alexa Fluor 555 Chemical compound C=12C=CC(=N)C(S(O)(=O)=O)=C2OC2=C(S(O)(=O)=O)C(N)=CC=C2C=1C1=CC=C(C(O)=O)C=C1C(O)=O IGAZHQIYONOHQN-UHFFFAOYSA-N 0.000 description 2
- 108700020463 BRCA1 Proteins 0.000 description 2
- 102000036365 BRCA1 Human genes 0.000 description 2
- 101150072950 BRCA1 gene Proteins 0.000 description 2
- 102100024504 Bone morphogenetic protein 3 Human genes 0.000 description 2
- 229940045513 CTLA4 antagonist Drugs 0.000 description 2
- 208000037051 Chromosomal Instability Diseases 0.000 description 2
- 108010009392 Cyclin-Dependent Kinase Inhibitor p16 Proteins 0.000 description 2
- 238000001712 DNA sequencing Methods 0.000 description 2
- 206010059866 Drug resistance Diseases 0.000 description 2
- 206010058314 Dysplasia Diseases 0.000 description 2
- 102100031780 Endonuclease Human genes 0.000 description 2
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 2
- 101000924577 Homo sapiens Adenomatous polyposis coli protein Proteins 0.000 description 2
- 101000762375 Homo sapiens Bone morphogenetic protein 3 Proteins 0.000 description 2
- 101000995332 Homo sapiens Protein NDRG4 Proteins 0.000 description 2
- 101000808011 Homo sapiens Vascular endothelial growth factor A Proteins 0.000 description 2
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 2
- 239000002138 L01XE21 - Regorafenib Substances 0.000 description 2
- 206010025323 Lymphomas Diseases 0.000 description 2
- 241000282341 Mustela putorius furo Species 0.000 description 2
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 2
- 206010051606 Necrotising colitis Diseases 0.000 description 2
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 2
- 102100034432 Protein NDRG4 Human genes 0.000 description 2
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 2
- 108091081021 Sense strand Proteins 0.000 description 2
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 2
- 102000040945 Transcription factor Human genes 0.000 description 2
- 108091023040 Transcription factor Proteins 0.000 description 2
- 239000013504 Triton X-100 Substances 0.000 description 2
- 229920004890 Triton X-100 Polymers 0.000 description 2
- 108010078814 Tumor Suppressor Protein p53 Proteins 0.000 description 2
- 102000015098 Tumor Suppressor Protein p53 Human genes 0.000 description 2
- 102100033254 Tumor suppressor ARF Human genes 0.000 description 2
- 241000282458 Ursus sp. Species 0.000 description 2
- 102100039037 Vascular endothelial growth factor A Human genes 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 239000002671 adjuvant Substances 0.000 description 2
- 229960002833 aflibercept Drugs 0.000 description 2
- 108010081667 aflibercept Proteins 0.000 description 2
- 238000013019 agitation Methods 0.000 description 2
- WLDHEUZGFKACJH-UHFFFAOYSA-K amaranth Chemical compound [Na+].[Na+].[Na+].C12=CC=C(S([O-])(=O)=O)C=C2C=C(S([O-])(=O)=O)C(O)=C1N=NC1=CC=C(S([O-])(=O)=O)C2=CC=CC=C12 WLDHEUZGFKACJH-UHFFFAOYSA-K 0.000 description 2
- 150000001412 amines Chemical class 0.000 description 2
- 230000000692 anti-sense effect Effects 0.000 description 2
- 238000003491 array Methods 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 230000003196 chaotropic effect Effects 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 201000002758 colorectal adenoma Diseases 0.000 description 2
- 208000022136 colorectal lymphoma Diseases 0.000 description 2
- 238000005094 computer simulation Methods 0.000 description 2
- 230000002596 correlated effect Effects 0.000 description 2
- ZYGHJZDHTFUPRJ-UHFFFAOYSA-N coumarin Chemical compound C1=CC=C2OC(=O)C=CC2=C1 ZYGHJZDHTFUPRJ-UHFFFAOYSA-N 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 238000001085 differential centrifugation Methods 0.000 description 2
- 238000007847 digital PCR Methods 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- 229960004679 doxorubicin Drugs 0.000 description 2
- 230000037437 driver mutation Effects 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 2
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 2
- 238000013213 extrapolation Methods 0.000 description 2
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 2
- 238000005194 fractionation Methods 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 230000003862 health status Effects 0.000 description 2
- 238000012165 high-throughput sequencing Methods 0.000 description 2
- 230000005746 immune checkpoint blockade Effects 0.000 description 2
- 238000007689 inspection Methods 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 238000002595 magnetic resonance imaging Methods 0.000 description 2
- 238000007726 management method Methods 0.000 description 2
- 238000007620 mathematical function Methods 0.000 description 2
- 230000002503 metabolic effect Effects 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- 210000003097 mucus Anatomy 0.000 description 2
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 2
- 208000004995 necrotizing enterocolitis Diseases 0.000 description 2
- 239000002853 nucleic acid probe Substances 0.000 description 2
- 239000003960 organic solvent Substances 0.000 description 2
- VYNDHICBIRRPFP-UHFFFAOYSA-N pacific blue Chemical compound FC1=C(O)C(F)=C2OC(=O)C(C(=O)O)=CC2=C1 VYNDHICBIRRPFP-UHFFFAOYSA-N 0.000 description 2
- 244000045947 parasite Species 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 229960002621 pembrolizumab Drugs 0.000 description 2
- 201000006195 perinatal necrotizing enterocolitis Diseases 0.000 description 2
- XEBWQGVWTUSTLN-UHFFFAOYSA-M phenylmercury acetate Chemical compound CC(=O)O[Hg]C1=CC=CC=C1 XEBWQGVWTUSTLN-UHFFFAOYSA-M 0.000 description 2
- 210000002706 plastid Anatomy 0.000 description 2
- 238000011176 pooling Methods 0.000 description 2
- 238000004445 quantitative analysis Methods 0.000 description 2
- 229960004836 regorafenib Drugs 0.000 description 2
- FNHKPVJBJVTLMP-UHFFFAOYSA-N regorafenib Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=C(F)C(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 FNHKPVJBJVTLMP-UHFFFAOYSA-N 0.000 description 2
- 238000002271 resection Methods 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 108020004418 ribosomal RNA Proteins 0.000 description 2
- 238000007480 sanger sequencing Methods 0.000 description 2
- 230000011218 segmentation Effects 0.000 description 2
- 238000003196 serial analysis of gene expression Methods 0.000 description 2
- 238000002579 sigmoidoscopy Methods 0.000 description 2
- 230000000392 somatic effect Effects 0.000 description 2
- 238000003756 stirring Methods 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 238000012706 support-vector machine Methods 0.000 description 2
- 239000000725 suspension Substances 0.000 description 2
- MPLHNVLQVRSVEE-UHFFFAOYSA-N texas red Chemical compound [O-]S(=O)(=O)C1=CC(S(Cl)(=O)=O)=CC=C1C(C1=CC=2CCCN3CCCC(C=23)=C1O1)=C2C1=C(CCC1)C3=[N+]1CCCC3=C2 MPLHNVLQVRSVEE-UHFFFAOYSA-N 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 201000007423 tubular adenocarcinoma Diseases 0.000 description 2
- 238000002604 ultrasonography Methods 0.000 description 2
- 201000007553 villous adenocarcinoma Diseases 0.000 description 2
- 230000000007 visual effect Effects 0.000 description 2
- WDCYWAQPCXBPJA-UHFFFAOYSA-N 1,3-dinitrobenzene Chemical compound [O-][N+](=O)C1=CC=CC([N+]([O-])=O)=C1 WDCYWAQPCXBPJA-UHFFFAOYSA-N 0.000 description 1
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- CVOFKRWYWCSDMA-UHFFFAOYSA-N 2-chloro-n-(2,6-diethylphenyl)-n-(methoxymethyl)acetamide;2,6-dinitro-n,n-dipropyl-4-(trifluoromethyl)aniline Chemical compound CCC1=CC=CC(CC)=C1N(COC)C(=O)CCl.CCCN(CCC)C1=C([N+]([O-])=O)C=C(C(F)(F)F)C=C1[N+]([O-])=O CVOFKRWYWCSDMA-UHFFFAOYSA-N 0.000 description 1
- HSTOKWSFWGCZMH-UHFFFAOYSA-N 3,3'-diaminobenzidine Chemical compound C1=C(N)C(N)=CC=C1C1=CC=C(N)C(N)=C1 HSTOKWSFWGCZMH-UHFFFAOYSA-N 0.000 description 1
- BZTDTCNHAFUJOG-UHFFFAOYSA-N 6-carboxyfluorescein Chemical compound C12=CC=C(O)C=C2OC2=CC(O)=CC=C2C11OC(=O)C2=CC=C(C(=O)O)C=C21 BZTDTCNHAFUJOG-UHFFFAOYSA-N 0.000 description 1
- 102100023990 60S ribosomal protein L17 Human genes 0.000 description 1
- 102100033350 ATP-dependent translocase ABCB1 Human genes 0.000 description 1
- 206010000060 Abdominal distension Diseases 0.000 description 1
- 206010069754 Acquired gene mutation Diseases 0.000 description 1
- 102100035886 Adenine DNA glycosylase Human genes 0.000 description 1
- 239000012103 Alexa Fluor 488 Substances 0.000 description 1
- 239000012109 Alexa Fluor 568 Substances 0.000 description 1
- 239000012110 Alexa Fluor 594 Substances 0.000 description 1
- 239000012114 Alexa Fluor 647 Substances 0.000 description 1
- 239000012115 Alexa Fluor 660 Substances 0.000 description 1
- 239000012116 Alexa Fluor 680 Substances 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 108010074708 B7-H1 Antigen Proteins 0.000 description 1
- 102000008096 B7-H1 Antigen Human genes 0.000 description 1
- 244000063299 Bacillus subtilis Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 101000840545 Bacillus thuringiensis L-isoleucine-4-hydroxylase Proteins 0.000 description 1
- 206010004593 Bile duct cancer Diseases 0.000 description 1
- 239000002028 Biomass Substances 0.000 description 1
- LGRNGKUSEZTBMB-UHFFFAOYSA-M C3-indocyanine Chemical compound [I-].CC1(C)C2=CC=CC=C2N(CC)C1=CC=CC1=[N+](CC)C2=CC=CC=C2C1(C)C LGRNGKUSEZTBMB-UHFFFAOYSA-M 0.000 description 1
- 102100024119 CDK5 and ABL1 enzyme substrate 1 Human genes 0.000 description 1
- 102100021975 CREB-binding protein Human genes 0.000 description 1
- 102000008203 CTLA-4 Antigen Human genes 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 102100035356 Cadherin-related family member 5 Human genes 0.000 description 1
- 201000009030 Carcinoma Diseases 0.000 description 1
- 208000009458 Carcinoma in Situ Diseases 0.000 description 1
- 108090000994 Catalytic RNA Proteins 0.000 description 1
- 102000053642 Catalytic RNA Human genes 0.000 description 1
- 102100025064 Cellular tumor antigen p53 Human genes 0.000 description 1
- 102100033473 Cingulin Human genes 0.000 description 1
- 206010048832 Colon adenoma Diseases 0.000 description 1
- 206010010774 Constipation Diseases 0.000 description 1
- 108091029523 CpG island Proteins 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- 102100034157 DNA mismatch repair protein Msh2 Human genes 0.000 description 1
- 102100021147 DNA mismatch repair protein Msh6 Human genes 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 102100035619 DNA-(apurinic or apyrimidinic site) lyase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- SHIBSTMRCDJXLN-UHFFFAOYSA-N Digoxigenin Natural products C1CC(C2C(C3(C)CCC(O)CC3CC2)CC2O)(O)C2(C)C1C1=CC(=O)OC1 SHIBSTMRCDJXLN-UHFFFAOYSA-N 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 241000792859 Enema Species 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 201000006107 Familial adenomatous polyposis Diseases 0.000 description 1
- 208000000321 Gardner Syndrome Diseases 0.000 description 1
- 208000007882 Gastritis Diseases 0.000 description 1
- 208000005577 Gastroenteritis Diseases 0.000 description 1
- 208000012671 Gastrointestinal haemorrhages Diseases 0.000 description 1
- 206010017993 Gastrointestinal neoplasms Diseases 0.000 description 1
- 206010018691 Granuloma Diseases 0.000 description 1
- 208000002927 Hamartoma Diseases 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101001000351 Homo sapiens Adenine DNA glycosylase Proteins 0.000 description 1
- 101000809450 Homo sapiens Amphiregulin Proteins 0.000 description 1
- 101000910461 Homo sapiens CDK5 and ABL1 enzyme substrate 1 Proteins 0.000 description 1
- 101000896987 Homo sapiens CREB-binding protein Proteins 0.000 description 1
- 101000737803 Homo sapiens Cadherin-related family member 5 Proteins 0.000 description 1
- 101000944124 Homo sapiens Cingulin Proteins 0.000 description 1
- 101001134036 Homo sapiens DNA mismatch repair protein Msh2 Proteins 0.000 description 1
- 101000968658 Homo sapiens DNA mismatch repair protein Msh6 Proteins 0.000 description 1
- 101001137256 Homo sapiens DNA-(apurinic or apyrimidinic site) lyase Proteins 0.000 description 1
- 101001037256 Homo sapiens Indoleamine 2,3-dioxygenase 1 Proteins 0.000 description 1
- 101000584499 Homo sapiens Polycomb protein SUZ12 Proteins 0.000 description 1
- 101000652359 Homo sapiens Spermatogenesis-associated protein 2 Proteins 0.000 description 1
- 101000767597 Homo sapiens Vascular endothelial zinc finger 1 Proteins 0.000 description 1
- 206010020843 Hyperthermia Diseases 0.000 description 1
- 102100040061 Indoleamine 2,3-dioxygenase 1 Human genes 0.000 description 1
- 208000005016 Intestinal Neoplasms Diseases 0.000 description 1
- 208000032177 Intestinal Polyps Diseases 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 206010069755 K-ras gene mutation Diseases 0.000 description 1
- 102000017578 LAG3 Human genes 0.000 description 1
- 101150030213 Lag3 gene Proteins 0.000 description 1
- 102000043136 MAP kinase family Human genes 0.000 description 1
- 108091054455 MAP kinase family Proteins 0.000 description 1
- 229910015837 MSH2 Inorganic materials 0.000 description 1
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 1
- 108010047230 Member 1 Subfamily B ATP Binding Cassette Transporter Proteins 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 241000736262 Microbiota Species 0.000 description 1
- 102000008071 Mismatch Repair Endonuclease PMS2 Human genes 0.000 description 1
- 108010074346 Mismatch Repair Endonuclease PMS2 Proteins 0.000 description 1
- 208000007101 Muscle Cramp Diseases 0.000 description 1
- 102100038895 Myc proto-oncogene protein Human genes 0.000 description 1
- 206010061309 Neoplasm progression Diseases 0.000 description 1
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 1
- 208000008589 Obesity Diseases 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 208000025174 PANDAS Diseases 0.000 description 1
- 229910019142 PO4 Chemical group 0.000 description 1
- 208000021155 Paediatric autoimmune neuropsychiatric disorders associated with streptococcal infection Diseases 0.000 description 1
- 208000002193 Pain Diseases 0.000 description 1
- 240000000220 Panda oleosa Species 0.000 description 1
- 235000016496 Panda oleosa Nutrition 0.000 description 1
- 108091093037 Peptide nucleic acid Proteins 0.000 description 1
- 108010004729 Phycoerythrin Proteins 0.000 description 1
- ZYFVNVRFVHJEIU-UHFFFAOYSA-N PicoGreen Chemical compound CN(C)CCCN(CCCN(C)C)C1=CC(=CC2=[N+](C3=CC=CC=C3S2)C)C2=CC=CC=C2N1C1=CC=CC=C1 ZYFVNVRFVHJEIU-UHFFFAOYSA-N 0.000 description 1
- 102100037596 Platelet-derived growth factor subunit A Human genes 0.000 description 1
- 102100030702 Polycomb protein SUZ12 Human genes 0.000 description 1
- 101150104557 Ppargc1a gene Proteins 0.000 description 1
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 1
- 238000002123 RNA extraction Methods 0.000 description 1
- 229940076189 RNA modulator Drugs 0.000 description 1
- 230000004570 RNA-binding Effects 0.000 description 1
- 208000015634 Rectal Neoplasms Diseases 0.000 description 1
- 206010038063 Rectal haemorrhage Diseases 0.000 description 1
- 101710141795 Ribonuclease inhibitor Proteins 0.000 description 1
- 229940122208 Ribonuclease inhibitor Drugs 0.000 description 1
- 102100037968 Ribonuclease inhibitor Human genes 0.000 description 1
- 102000006382 Ribonucleases Human genes 0.000 description 1
- 108010083644 Ribonucleases Proteins 0.000 description 1
- 101001037255 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Indoleamine 2,3-dioxygenase Proteins 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- 102100030254 Spermatogenesis-associated protein 2 Human genes 0.000 description 1
- 208000005718 Stomach Neoplasms Diseases 0.000 description 1
- 208000007107 Stomach Ulcer Diseases 0.000 description 1
- 238000000692 Student's t-test Methods 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-L Sulfate Chemical group [O-]S([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 1
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 1
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 1
- 102100028983 Vascular endothelial zinc finger 1 Human genes 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 206010000059 abdominal discomfort Diseases 0.000 description 1
- 230000003187 abdominal effect Effects 0.000 description 1
- 206010000269 abscess Diseases 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 238000011360 adjunctive therapy Methods 0.000 description 1
- 238000011467 adoptive cell therapy Methods 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 238000000540 analysis of variance Methods 0.000 description 1
- 238000013103 analytical ultracentrifugation Methods 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 239000004037 angiogenesis inhibitor Substances 0.000 description 1
- 238000002583 angiography Methods 0.000 description 1
- 238000011394 anticancer treatment Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 239000012062 aqueous buffer Substances 0.000 description 1
- 229940000489 arsenate Drugs 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- GUBGYTABKSRVRQ-QUYVBRFLSA-N beta-maltose Chemical compound OC[C@H]1O[C@H](O[C@H]2[C@H](O)[C@@H](O)[C@H](O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@@H]1O GUBGYTABKSRVRQ-QUYVBRFLSA-N 0.000 description 1
- 208000026900 bile duct neoplasm Diseases 0.000 description 1
- 238000007622 bioinformatic analysis Methods 0.000 description 1
- 238000003766 bioinformatics method Methods 0.000 description 1
- 230000031018 biological processes and functions Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 208000024330 bloating Diseases 0.000 description 1
- 239000010836 blood and blood product Substances 0.000 description 1
- 210000000601 blood cell Anatomy 0.000 description 1
- 238000004820 blood count Methods 0.000 description 1
- 229940125691 blood product Drugs 0.000 description 1
- 229940022399 cancer vaccine Drugs 0.000 description 1
- 238000009566 cancer vaccine Methods 0.000 description 1
- 150000007942 carboxylates Chemical class 0.000 description 1
- 150000001732 carboxylic acid derivatives Chemical class 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 108091092328 cellular RNA Proteins 0.000 description 1
- 230000007960 cellular response to stress Effects 0.000 description 1
- 238000012412 chemical coupling Methods 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 238000011976 chest X-ray Methods 0.000 description 1
- YTRQFSDWAXHJCC-UHFFFAOYSA-N chloroform;phenol Chemical compound ClC(Cl)Cl.OC1=CC=CC=C1 YTRQFSDWAXHJCC-UHFFFAOYSA-N 0.000 description 1
- YDQXYRCYDMRJGD-UHFFFAOYSA-N chloroform;phenol;thiocyanic acid Chemical compound SC#N.ClC(Cl)Cl.OC1=CC=CC=C1 YDQXYRCYDMRJGD-UHFFFAOYSA-N 0.000 description 1
- 208000006990 cholangiocarcinoma Diseases 0.000 description 1
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- 208000029664 classic familial adenomatous polyposis Diseases 0.000 description 1
- 229940126523 co-drug Drugs 0.000 description 1
- 206010009887 colitis Diseases 0.000 description 1
- 230000000112 colonic effect Effects 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 238000002591 computed tomography Methods 0.000 description 1
- 210000002808 connective tissue Anatomy 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 239000002826 coolant Substances 0.000 description 1
- 229960000956 coumarin Drugs 0.000 description 1
- 235000001671 coumarin Nutrition 0.000 description 1
- 238000013500 data storage Methods 0.000 description 1
- 238000013136 deep learning model Methods 0.000 description 1
- 230000013872 defecation Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- KXGVEGMKQFWNSR-LLQZFEROSA-N deoxycholic acid Chemical compound C([C@H]1CC2)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC(O)=O)C)[C@@]2(C)[C@@H](O)C1 KXGVEGMKQFWNSR-LLQZFEROSA-N 0.000 description 1
- 229960003964 deoxycholic acid Drugs 0.000 description 1
- 238000000151 deposition Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 235000005911 diet Nutrition 0.000 description 1
- 230000037213 diet Effects 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- QONQRTHLHBTMGP-UHFFFAOYSA-N digitoxigenin Natural products CC12CCC(C3(CCC(O)CC3CC3)C)C3C11OC1CC2C1=CC(=O)OC1 QONQRTHLHBTMGP-UHFFFAOYSA-N 0.000 description 1
- SHIBSTMRCDJXLN-KCZCNTNESA-N digoxigenin Chemical compound C1([C@@H]2[C@@]3([C@@](CC2)(O)[C@H]2[C@@H]([C@@]4(C)CC[C@H](O)C[C@H]4CC2)C[C@H]3O)C)=CC(=O)OC1 SHIBSTMRCDJXLN-KCZCNTNESA-N 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- BFMYDTVEBKDAKJ-UHFFFAOYSA-L disodium;(2',7'-dibromo-3',6'-dioxido-3-oxospiro[2-benzofuran-1,9'-xanthene]-4'-yl)mercury;hydrate Chemical compound O.[Na+].[Na+].O1C(=O)C2=CC=CC=C2C21C1=CC(Br)=C([O-])C([Hg])=C1OC1=C2C=C(Br)C([O-])=C1 BFMYDTVEBKDAKJ-UHFFFAOYSA-L 0.000 description 1
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 1
- 230000035622 drinking Effects 0.000 description 1
- 229940121647 egfr inhibitor Drugs 0.000 description 1
- 230000005518 electrochemistry Effects 0.000 description 1
- 239000007920 enema Substances 0.000 description 1
- 229940095399 enema Drugs 0.000 description 1
- 210000004188 enterochromaffin-like cell Anatomy 0.000 description 1
- 210000003158 enteroendocrine cell Anatomy 0.000 description 1
- 230000009483 enzymatic pathway Effects 0.000 description 1
- 210000000981 epithelium Anatomy 0.000 description 1
- 239000006167 equilibration buffer Substances 0.000 description 1
- 230000029142 excretion Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 238000011347 external beam therapy Methods 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 238000011354 first-line chemotherapy Methods 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- 238000007672 fourth generation sequencing Methods 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 206010017758 gastric cancer Diseases 0.000 description 1
- 201000005917 gastric ulcer Diseases 0.000 description 1
- 210000003736 gastrointestinal content Anatomy 0.000 description 1
- 201000004528 gastrointestinal lymphoma Diseases 0.000 description 1
- 244000000050 gastrointestinal parasite Species 0.000 description 1
- 238000012252 genetic analysis Methods 0.000 description 1
- 230000002710 gonadal effect Effects 0.000 description 1
- 230000007773 growth pattern Effects 0.000 description 1
- ZJYYHGLJYGJLLN-UHFFFAOYSA-N guanidinium thiocyanate Chemical compound SC#N.NC(N)=N ZJYYHGLJYGJLLN-UHFFFAOYSA-N 0.000 description 1
- LNEPOXFFQSENCJ-UHFFFAOYSA-N haloperidol Chemical compound C1CC(O)(C=2C=CC(Cl)=CC=2)CCN1CCCC(=O)C1=CC=C(F)C=C1 LNEPOXFFQSENCJ-UHFFFAOYSA-N 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 208000035861 hematochezia Diseases 0.000 description 1
- 238000007417 hierarchical cluster analysis Methods 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 206010020718 hyperplasia Diseases 0.000 description 1
- 230000002390 hyperplastic effect Effects 0.000 description 1
- 230000036031 hyperthermia Effects 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 239000002955 immunomodulating agent Substances 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 201000004933 in situ carcinoma Diseases 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 230000008595 infiltration Effects 0.000 description 1
- 238000001764 infiltration Methods 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 210000004495 interstitial cells of cajal Anatomy 0.000 description 1
- 201000002313 intestinal cancer Diseases 0.000 description 1
- 210000004347 intestinal mucosa Anatomy 0.000 description 1
- 230000009545 invasion Effects 0.000 description 1
- 239000002563 ionic surfactant Substances 0.000 description 1
- 238000013532 laser treatment Methods 0.000 description 1
- 230000002045 lasting effect Effects 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- 238000012417 linear regression Methods 0.000 description 1
- 210000005229 liver cell Anatomy 0.000 description 1
- 230000003908 liver function Effects 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- DLBFLQKQABVKGT-UHFFFAOYSA-L lucifer yellow dye Chemical compound [Li+].[Li+].[O-]S(=O)(=O)C1=CC(C(N(C(=O)NN)C2=O)=O)=C3C2=CC(S([O-])(=O)=O)=CC3=C1N DLBFLQKQABVKGT-UHFFFAOYSA-L 0.000 description 1
- 238000004020 luminiscence type Methods 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 208000025036 lymphosarcoma Diseases 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 239000006249 magnetic particle Substances 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 210000002752 melanocyte Anatomy 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 210000004379 membrane Anatomy 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 201000008806 mesenchymal cell neoplasm Diseases 0.000 description 1
- 208000030159 metabolic disease Diseases 0.000 description 1
- 239000002207 metabolite Substances 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 230000001394 metastastic effect Effects 0.000 description 1
- 206010061289 metastatic neoplasm Diseases 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- 239000002679 microRNA Substances 0.000 description 1
- 238000012775 microarray technology Methods 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 230000033607 mismatch repair Effects 0.000 description 1
- 208000022499 mismatch repair cancer syndrome Diseases 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 201000010879 mucinous adenocarcinoma Diseases 0.000 description 1
- 210000004412 neuroendocrine cell Anatomy 0.000 description 1
- 229960003301 nivolumab Drugs 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 235000020824 obesity Nutrition 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 244000309459 oncolytic virus Species 0.000 description 1
- 230000003204 osmotic effect Effects 0.000 description 1
- 239000005022 packaging material Substances 0.000 description 1
- 238000012753 partial hepatectomy Methods 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 210000005259 peripheral blood Anatomy 0.000 description 1
- 239000011886 peripheral blood Substances 0.000 description 1
- 210000004303 peritoneum Anatomy 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical group [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Chemical group 0.000 description 1
- 239000002953 phosphate buffered saline Substances 0.000 description 1
- 150000008300 phosphoramidites Chemical class 0.000 description 1
- 238000002428 photodynamic therapy Methods 0.000 description 1
- 238000000206 photolithography Methods 0.000 description 1
- 239000000049 pigment Substances 0.000 description 1
- 108010017843 platelet-derived growth factor A Proteins 0.000 description 1
- 239000002798 polar solvent Substances 0.000 description 1
- 208000022131 polyp of large intestine Diseases 0.000 description 1
- 208000015768 polyposis Diseases 0.000 description 1
- 238000010837 poor prognosis Methods 0.000 description 1
- 239000002244 precipitate Substances 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
- 239000000092 prognostic biomarker Substances 0.000 description 1
- 230000002062 proliferating effect Effects 0.000 description 1
- 230000001012 protector Effects 0.000 description 1
- 238000001273 protein sequence alignment Methods 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 238000012175 pyrosequencing Methods 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 239000012857 radioactive material Substances 0.000 description 1
- 229960002633 ramucirumab Drugs 0.000 description 1
- 102000027426 receptor tyrosine kinases Human genes 0.000 description 1
- 108091008598 receptor tyrosine kinases Proteins 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 208000013718 rectal benign neoplasm Diseases 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 210000003705 ribosome Anatomy 0.000 description 1
- 108091092562 ribozyme Proteins 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000005204 segregation Methods 0.000 description 1
- 238000011896 sensitive detection Methods 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 210000002460 smooth muscle Anatomy 0.000 description 1
- 238000010532 solid phase synthesis reaction Methods 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 230000037439 somatic mutation Effects 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 238000009987 spinning Methods 0.000 description 1
- 238000011476 stem cell transplantation Methods 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 201000011549 stomach cancer Diseases 0.000 description 1
- BDHFUVZGWQCTTF-UHFFFAOYSA-M sulfonate Chemical group [O-]S(=O)=O BDHFUVZGWQCTTF-UHFFFAOYSA-M 0.000 description 1
- 238000011521 systemic chemotherapy Methods 0.000 description 1
- 238000012353 t test Methods 0.000 description 1
- ABZLKHKQJHEPAX-UHFFFAOYSA-N tetramethylrhodamine Chemical compound C=12C=CC(N(C)C)=CC2=[O+]C2=CC(N(C)C)=CC=C2C=1C1=CC=CC=C1C([O-])=O ABZLKHKQJHEPAX-UHFFFAOYSA-N 0.000 description 1
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 1
- 230000001225 therapeutic effect Effects 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 229960002952 tipiracil Drugs 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 239000003656 tris buffered saline Substances 0.000 description 1
- 208000022271 tubular adenoma Diseases 0.000 description 1
- 239000000439 tumor marker Substances 0.000 description 1
- 230000005751 tumor progression Effects 0.000 description 1
- 238000000870 ultraviolet spectroscopy Methods 0.000 description 1
- 208000009540 villous adenoma Diseases 0.000 description 1
- 238000003260 vortexing Methods 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 230000004580 weight loss Effects 0.000 description 1
- 238000007482 whole exome sequencing Methods 0.000 description 1
- 238000012070 whole genome sequencing analysis Methods 0.000 description 1
- 239000002023 wood Substances 0.000 description 1
Images

















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57407—Specifically defined cancers
- G01N33/57419—Specifically defined cancers of colon
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/106—Pharmacogenomics, i.e. genetic variability in individual responses to drugs and drug metabolism
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/118—Prognosis of disease development
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/158—Expression markers
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Engineering & Computer Science (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Pathology (AREA)
- Organic Chemistry (AREA)
- Analytical Chemistry (AREA)
- Molecular Biology (AREA)
- Microbiology (AREA)
- Hematology (AREA)
- Urology & Nephrology (AREA)
- Biotechnology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Physics & Mathematics (AREA)
- Biomedical Technology (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Oncology (AREA)
- Hospice & Palliative Care (AREA)
- Genetics & Genomics (AREA)
- Cell Biology (AREA)
- Biophysics (AREA)
- General Physics & Mathematics (AREA)
- Medicinal Chemistry (AREA)
- Food Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
Abstract
本文提供了用于检测结直肠肿瘤和结肠癌的材料和方法,其基于受试者(例如患者)的粪便样品中存在的真核核酸中的粪便来源的真核RNA生物标志物的表达水平。所述方法可用于检测高危腺瘤和结直肠肿瘤分子亚型。
Description
技术领域
本发明涉及从粪便样品提取真核核酸和使用所述核酸诊断和治疗肠疾病。
背景技术
胃肠病症,例如胃肠癌,和其它消化疾病,如溃疡性结肠炎、肠易激综合征和克罗恩病(Crohn's disease),是普遍存在的。在美国,胃肠病症估计每年影响6000万至7000万人。对于一些病症,早期筛查和诊断已经使得患者的死亡率降低和生活品质提高。然而,标准诊断方法,如结肠镜检查,是侵入性的,耗时的,并且与较高的成本相关。存在对在人类和动物中诊断胃肠病症的非侵入性方法的持续性需要。
发明内容
本文提供了在受试者中检测结直肠癌形成的方法,所述方法包括测量从受试者的粪便样品中提取的真核核酸中的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22,23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平,所述生物标志物选自表1或表2或表1和表2的组合所列出的生物标志物;将粪便样品中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平与对照中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平进行比较,其中粪便样品中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平相对于对照中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平的差异表明受试者患有结直肠癌。还提供了一种检测受试者结直肠癌形成的方法,所述方法包括:测量从受试者粪便样品中提取的真核核酸中的一种或多种变异生物标志物基因的变异等位基因频率,所述变异生物标志物基因选自表3中列出的生物标志物基因;将粪便样品中测得的一种或多种变异生物标志物基因的变异等位基因频率与对照中测得的一种或多种变异生物标志物基因的变异等位基因频率进行比较,其中一种或多种变异生物标志物基因的变异等位基因频率相对于对照中一种或多种变异生物标志物基因的变异等位基因频率的差异表明受试者具有或处于结直肠癌的风险。还提供了一种检测受试者结直肠癌分子亚型的方法,所述方法包括:测量从受试者粪便样品中提取的真核核酸中两种或多种生物标志物基因的表达水平,所述生物标志物基因选自表4中列出的任何结直肠肿瘤分子亚型生物标志物基因;将生物样品中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平与对照中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平进行比较,其中生物样品中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平相对于对照中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平的差异表明结直肠癌的分子亚型。
附图说明
本发明的这些和其它特征和优势将在本发明的优选实施例的以下详细描述中更充分公开或显而易见,所述详细描述将与附图一起考虑,其中同样数字表示同样部分,并且其中:
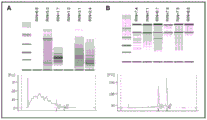
图1A是电泳文件运行。电泳分析用于根据文献中描述的方法检查提取的RNA的品质。
图1B是电泳文件运行。电泳分析用于根据本文中描述的方法检查提取的RNA的品质。
图2A是电泳文件运行。电泳分析用于检查立即提取而不在稳定缓冲液中孵育的样品的seRNA的品质。
图2B是电泳文件运行。电泳分析用于检查提取前在稳定缓冲液中孵育并在室温下储存24小时的样品的seRNA的品质。
图2C是电泳文件运行。电泳分析用于检查提取前在稳定缓冲液中孵育并在室温下储存48小时的样品的seRNA的品质。
图3A描述了SVM内部验证期间获得的各种患者群体的ROC分析。
图3B描绘了在独立测试集上使用的SVM预测的灵敏度。
图4A是列出了274个用于结直肠癌亚型联合分类器的结直肠肿瘤分子亚型生物标志物基因的表。
图4B是列出了25个用于鉴定结直肠癌亚型CMS1的示例性结直肠肿瘤分子亚型生物标志物基因的表。
图5是总结了使用结直肠癌亚型联和分类器按结直肠癌CMS(共有分子亚型)对患者进行的分层的热图。
图6绘出了当比较由Affymetrix Human Transcriptome Array 2.0和IlluminaTargeted RNA Custom Panel测量的398个基因的转录本表达时,4对生物复制子的相关性。
图7是绘出了13例结直肠癌、腺瘤和无肿瘤发现的患者的分层聚类的主成分分析图。
图8绘出了从诊断为腺瘤和结直肠癌的人类受试者粪便样本中鉴定的六种推定的体细胞变体。
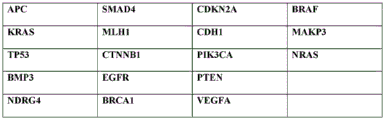
图9是列出与癌症、结直肠肿瘤和/或胃肠健康相关的生物标志物的表格,其中可以识别假定的体细胞变体。
图10是总结了与前瞻性培训集,前瞻性支持测试集,回顾性支持测试集和整个研究队列相关的患者人口统计数据和处理指标的表。
图11A是使用测试集的引导程序的合格特征选择的流程图。
图11B是所选合格特征的图。
图12是结肠镜检查、良性息肉、低风险腺瘤、中风险腺瘤、高风险腺瘤和结直肠癌无发现患者的原始GAPDH值图。
图13是显示基于内部交叉验证(n=154名患者)的高危腺瘤检测模型性能的图。
图14是按基尼系数重要性排列的特征表。
图15A是显示基于不具有粪便免疫化学试验(FIT)特征的独立支持试验组(n=110名患者)的HRAs检测模型性能的图。
图15B是显示基于具有粪便免疫化学试验(FIT)特征的独立支持试验组(n=110名患者)的HRAs检测模型性能的图。
图16A是显示在不具有粪便免疫化学试验(FIT)特征的情况下,按疾病严重程度分类的模型预测的图。
图16B是显示在具有粪便免疫化学试验(FIT)特征的情况下,按疾病严重程度分类的模型预测的图。
图17A是显示不具有粪便免疫化学测试(FIT)特征的增量下采样分析的结果的图。
图17B是显示具有粪便免疫化学测试(FIT)特征的增量下采样分析的结果的图。
图18是显示支持测试集中所有样本的模型性能的图表,包括11个额外的结直肠癌(CRC)样本。
图19是显示支持测试集中所有样本的模型性能的图表,包括11个额外的结直肠癌(CRC)样本,外推至广义筛查人群。
具体实施方式
对优选实施例的此部分记载希望结合附图来阅读,附图被视为本发明的整个书面记载的一部分。图未必按比例绘制,并且为了清楚和简明起见,本发明的某些特征可能在比例上放大地示出或以某种程度上示意性形式示出。在说明书中,相对术语如“水平”、“垂直”、“向上”、“向下”、“顶部”和“底部”以及其衍生物(例如,“水平地”、“朝下”、“朝上”等)应被解释为指代所描述的方向或如所讨论的图中所示。这些相对术语是为了便于描述,并且通常并不意图要求特定的方向。包括“朝内”对“朝外”、“纵向”对“横向”等的术语适当时应当相对于彼此或相对于伸长轴或旋转轴或旋转中心来解释。关于附接、偶联等的术语(如“连接”和“互连”)是指其中结构彼此间直接地或经由插入结构间接地固定或附接的关系,以及可移动或刚性附接或关系两者,除非以其它方式明确地描述。术语“可操作地连接”是此类附接、偶联或连接,其使得相关结构凭借所述关系按预期操作。当仅说明单个机器时,术语“机器”还应被视为包括机器的任何集合,所述机器个别地或共同地执行一组(或多组)指令以执行本文中论述的方法中的任一个或多个。在权利要求书中,装置加功能条款(如果使用的话)旨在涵盖由用于执行所述功能的书面描述或图式所描述、建议或显而易见的结构,不仅包括结构等效物而且包括等效结构。
本发明部分基于本发明人开发的一种将粪便样品(例如从哺乳动物获得的粪便样品)中的真核细胞与细菌细胞分离的方法。在结肠内,每克肠内容物约有1x1013个细菌细胞。这种结肠微生物群可以包括300-1000个物种。粪便或大便样品是一种复杂的大分子混合物,不仅包括从胃肠道肠腔中脱落的真核细胞,而且包括微生物,包括细菌和任何胃肠寄生虫,难以消化的未被吸收的食物残渣、肠细胞分泌物、和排泄物如粘液和色素。正常粪便由约75%的水和25%的固体物质组成。细菌占粪便总干质量的约60%。高细菌负荷可导致用于检测来自粪便样品的真核生物标志物的信噪比不利。此外,真核信号可能会大幅衰减。此类真核核酸的提取和处理可能会促进或加速衰减,这会严重限制进一步分析。
所述提取方法允许从粪便样品中分离高质量的真核RNA。所述方法在国际申请WO2018/081580中有所记载,其全部内容通过引用的方式并入本文。我们可以将提到的粪便来源的真核RNA(seRNA)特指为在粪便产生过程中保存的,并且其随后通过国际申请WO2018/081580中公开的方法从粪便样品中被提取出来的真核RNA。
因此,发明人开发了用于非侵入性评估人类结直肠癌和结直肠肿瘤的转录组的材料和方法。本文公开的材料和方法提供了对人类粪便样品中真核核酸的有效和灵敏的检测。发明人已经发现,他们可以基于来自受试者粪便样品中存在的真核核酸中粪便来源的真核RNA生物标志物的表达水平和变体来检测结直肠肿瘤。所述检测方法可以以对检测结直肠癌或结直肠肿瘤的各种形式和亚型有用的方式来配置。
更具体地,本文公开的材料和方法可用于基于来自受试者粪便样品中存在的真核核酸中粪便来源的真核RNA生物标志物的表达水平来检测高危腺瘤(HRAs)。本文公开了一种用于预测或鉴定结直肠肿瘤(特别是高危腺瘤)的基于模型的方法。在一些实施方案中,所述模型可以基于表1和表2中列出的两种或多种粪便来源的真核RNA生物标志物在来自受试者的粪便样品中存在的真核核酸中的表达水平。在一些实施方案中,所述模型可以基于两种或多种粪便来源的真核RNA生物标志物的表达水平,例如,选自表1或表2或表1和表2的组合中列出的粪便来源的真核RNA生物标志物的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种。在一些实施方案中,所述模型可以基于两种或多种粪便来源的真核RNA生物标志物的表达水平,例如表1中列出的粪便来源的真核RNA生物标志物的2、3、4、5、6、7、8、9、10或11种。所述模型还可以包括人口统计学特征,例如,受试者的年龄和吸烟状况。在一些实施方案中,所述模型还可以包括对来自受试者的粪便样本进行的粪便免疫化学测试(FIT)的结果。在一些实施方案中,本文公开的材料和方法可用于鉴别中等风险腺瘤(MRA)、低风险腺瘤(LRA)、或良性息肉。
还提供了用于检测结直肠癌的材料和方法,其基于来自受试者的粪便样品中真核核酸中的变体生物标志物的检测。在一些实施方案中,所述变体生物标志物物可以与结直肠癌肿瘤发生相关。所述变体可以是表3中列出的任何生物标志物的变体。变体可以是结直肠癌驱动基因(例如,TP53、KRAS、PIK3CA、BRAF、APC、BMP3、NDRG4、SMAD4、MLH1、CTNNB1、EGFR、BRCA1、CDKN2A、CDH1、PTEN、VEGFA、MAPK3或NRAS)的变体。
发明人已经发现,他们可以有效地检测粪便来源的真核RNA中与结直肠癌亚型联和(CRCSC)定义的共有分子亚型(CMS)相关的基因表达特征。更具体地,本文公开的材料和方法可用于从粪便样品中分离seRNA,其可指示结直肠癌特定亚型(例如CMS1,由CRCSC定义)的存在。在被诊断患有结直肠癌的个体中,大约14%具有CMS1分类。CMS1肿瘤的特征是微卫星不稳定性(MSI-H)增加、高突变和免疫浸润。这些特征与肿瘤一致,其中免疫系统在检测和勘测肿瘤部位中发挥积极作用。患有这种肿瘤的患者可以受益于靶向免疫疗法,例如免疫检查点阻断疗法。例如,KeyturdaTM(pembrolizumab)和OpdivoTM(nivolumab)均已获得FDA批准,用于治疗患有不可切除或转移性MSI-H实体瘤且不能从一线化疗中获益的成人和儿童患者。
因此,本文提供了用于确定患有结直肠癌的人类受试者是否具有与CMS1相关的基因表达特征的材料和方法。在疾病监测的背景下,所述方法可以无创和选择性地识别该患者群体,并使用seRNA提供治疗指导。使用粪便样本而不是血液或活组织检查样本,可以有效且无创地实施这些方法。所述方法可用于为患有结直肠癌或处于结直肠癌风险的受试者开发临床方案和治疗方法。在一些实施方案中,所述两种或多种生物标志物可以包括图4或表4中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、30、35、40、45、50、60、70、80、90、100、120、140、160、180或更多种标志物的组合。在一些实施方案中,所述标志物可以包含在与结直肠癌相关的差异表达转录本簇和/或共同途径中。示例性的途径包括微卫星不稳定性(MSI)、染色体不稳定性(CIN)和CpG岛甲基化表型(CIMP)。在一些实施方案中,所述途径可以是细胞成分途径、细胞对应激的反应、应激、和RNA结合途径。
在疾病监测的背景下,所述方法可以无创和选择性地识别患者群体并提供治疗指导。使用粪便样本而不是血液或活组织检查样本,可以有效且无创地实施这些方法。所述方法可用于为患有结直肠肿瘤或结直肠癌或处于结直肠肿瘤或结直肠癌风险的受试者开发临床方案和治疗方法。
本文公开的方法和材料包括从粪便样品分离真核核酸的方法。可以评估此类真核核酸的特定生物标志物的水平,其可以指示真核生物(例如哺乳动物)中的胃肠病症或疾病,例如结直肠肿瘤或结直肠癌。所述哺乳动物可以是人类或非人类动物,例如人类、狗、猫、非人类灵长类动物、反刍动物、熊科动物、马科动物、猪、绵羊、山羊、骆驼、水牛、鹿、麋鹿、驼鹿、鼬科动物、兔、豚鼠、仓鼠、大鼠、小鼠、厚皮动物、犀牛或灰鼠。
本发明人已经发现,他们可以有效地将真核生物粪便样品中的真核细胞与细菌细胞分离。本发明人还已经发现,他们可以检测从此类真核细胞分离的RNA中的真核生物标志物。此类生物标志物可以用于检测胃肠病症,例如结肠直肠癌、脂泻病、克罗恩病、溃疡性结肠炎、胃炎、肠胃炎、胃癌、胃溃疡、坏死性小肠结肠炎、胃肠间质瘤、胃肠淋巴瘤、胃肠瘤形成、淋巴肉瘤、腺瘤、增生性改变、腺癌、炎性肠病、肠易激综合征、胰腺瘤形成、肝瘤形成、胆管癌、结肠炎。本文提供了用于确定受试者(例如人类、狗或猫)是否处于胃肠疾病(例如结直肠肿瘤,例如高危腺瘤,或结直肠癌)风险的材料和方法。还提供了用于诊断疾病的材料和方法以及鉴定受试者的健康状态的方法。
本文公开的方法和组合物通常并且不同地用于检测、诊断、分类和治疗胃肠疾病,例如结直肠肿瘤或结直肠癌。检测方法可以包括测量来自患有胃肠病症或疑似患有胃肠病症的受试者(例如患者)的样品中的一种、两种或更多种生物标志物在粪便样品中的表达水平,以及比较所述测量的表达水平与对照中的一种、两种或更多种生物标志物的所测量表达水平。受试者样品中的一种、两种或更多种生物标志物的所测量表达水平相对于对照中的一种、两种或更多种生物标志物的所测量表达水平的差异是受试者患有胃肠病症的指示。在一些实施例中,受试者样品中的一种、两种或更多种生物标志物的所测量表达水平相对于对照中的一种、两种或更多种生物标志物的所测量表达水平的差异是受试者(例如患者)处于胃肠病症风险的指示。
在一些实施方案中,检测方法可以包括测量来自受试者的粪便样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的表达水平,所述受试者为例如患有胃肠疾病(例如结直肠肿瘤)或怀疑患有胃肠疾病(例如结直肠肿瘤)的患者,并将测量的表达水平与对照中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的测量的表达水平进行比较。受试者样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的测量表达水平相对于对照中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的测量表达水平的差异是所述受试者患有胃肠疾病(例如结直肠肿瘤)的指征。在一些实施方案中,受试者样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的测量表达水平相对于对照中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的测量表达水平的差异是受试者(例如患者)处于胃肠疾病(例如结直肠肿瘤)风险中的指征。在一些实施方案中,受试者样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物物的测量表达水平相对于对照中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的测量表达水平的差异是受试者(例如患者)处于特定类型的结直肠肿瘤(例如腺瘤,更具体地说,高风险腺瘤)风险的指征。在任一前述实施方案中,所述粪便来源的真核RNA生物标志物物可以选自表1或表2或表1和表2的组合中列出的粪便来源的真核RNA生物标志物物。检测方法还可以包括对特定生物标志物变体的分析。
在另一个实施方案中,检测疾病的方法可以包括测量相对表达水平比例,例如受试者的粪便样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的相对比率,并将这些粪便来源的真核RNA生物标志物的所述相对比例与对照中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的相对表达水平比例进行比较。受试者样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物物相对于对照中测量的相对表达水平比例的差异表明所述受试者患有胃肠疾病,例如结直肠癌。在一些实施方案中,受试者样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的测量的表达水平比例相对于对照中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的测量的表达水平比例的差异是所述受试者处于胃肠疾病(例如结直肠肿瘤)风险的指征。在一些实施方案中,受试者样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的测量的表达水平比例相对于对照中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的测量的表达水平比例的差异是所述受试者处于特定类型结直肠肿瘤(例如腺瘤,更具体地说,高风险腺瘤)风险的指征。在任一前述实施方案中,所述粪便来源的真核RNA生物标志物物可以选自表1或表2或表1和表2的组合中列出的粪便来源的真核RNA生物标志物物。检测方法还可以包括对特定生物标志物变体的分析。
所述方法可以包括通过确定2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物相对于对照中相同的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的水平是否是不同的,从而来确定在从受试者粪便样品中分离的真核RNA中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的表达水平。示例性粪便来源的真核RNA生物标志物列于表1和表2中。示例性粪便来源的真核RNA生物标志物可以包括ACY1、TNFRSF10B、DST、EGLN2、PER3、CTNNB1、ACHE、SMAD4、EDN1、ERBB2、GAPDH、ABCB1、MAPK3、VEZF1、KRAS、PTEN、CREBBP、SUZ12、CDHR5、CABLES1 AREG、SPATA2、PPARGC1A、DBP、CDH1、PDGFA、OGG1、CGN、和TCF7L2。
表1:粪便来源的真核RNA生物标志物
| 生物标志物 | 示例性Genbank条目 |
| ACY1 | NM_000666.3 |
| TNFRSF10B | NM_003842.5 |
| DST | XM_011514826.3 |
| EGLN2 | NM_080732.4 |
| PER3 | XM_024450585.1 |
| CTNNB1 | NM_001904.4 |
| ACHE | KJ425573.1 |
| SMAD4 | NM_005359.5 |
| EDN1 | NM_001955.5 |
| ERBB2 | XM_024450643.1 |
| GAPDH | NM_002046.7 |
表2:粪便来源的真核RNA生物标志物


在一些实施方案中,所述粪便来源的真核RNA生物标志物还可以包括表1和表2中列出的粪便来源的真核RNA生物标志物的子集。表1或表2或表1和表2的组合中列出的一些或所有粪便来源的真核RNA生物标志物可以形成一个组。例如,表1中的一些或所有粪便来源的真核RNA生物标志物可以形成一个组(组A)。例如,组A可以包括一些或所有粪便来源的真核RNA生物标志物ACY1、TNFRSF10B、DST、EGLN2、PER3、CTNNB1、ACHE、SMAD4、EDN1、ERBB2、GAPDH。所述组合物可以包括基因阵列和探针组,其被配置用于本文公开的标志物组的特异性检测。所述组合物还可以包括试剂盒,所述试剂盒包含基因阵列和探针组,其被配置用于本文公开的标志物组的特异性检测。所述方法可以包括鉴定粪便来源的真核RNA生物标志物的核酸序列中变体的存在,例如表1和表2中列出的粪便来源的真核RNA生物标志物。
还提供了检测真核核酸(例如,seRNA)中生物标志物的核酸序列中的变体的方法。变体可以是任何导致肿瘤存活、肿瘤进展或肿瘤转移的突变。我们可以称这种突变为“驱动突变”或“进行突变”。这种突变可以包括沉默突变、错义突变、插入、缺失、移码突变或无义突变。任何特定变体的表达也可以被描述为“变体等位基因频率”(VAF)。这种变体可以包括图8或图9中列出的任何生物标志物的变体。变体可以是结直肠癌驱动基因(例如,TP53、KRAS、PIK3CA、BRAF、APC、BMP3、NDRG4、SMAD4、MLH1、CTNNB1、EGFR、BRCA1、CDKN2A、CDH1、PTEN、VEGFA、MAKP3或NRAS)的变体。表3列出了示例性粪便来源的真核RNA变体生物标志物。
表3:粪便来源的真核RNA生物标志物和变体


所述方法可以包括鉴定生物标志物的核酸序列中变体的存在,例如表3中列出的生物标志物。表3中列出的一些或所有结直肠肿瘤生物标志物基因可以形成一个组(组B)。在一些实施方案中,表3中列出的结直肠肿瘤生物标志物基因也可以包括结直肠肿瘤亚型生物标志物的子集。所述组合物可以包括基因阵列和探针组,其被配置用于本文公开的标志物组的特异性检测。所述组合物还可以包括试剂盒,所述试剂盒包含基因阵列和探针组,其被配置用于本文公开的标志物组的特异性检测。
在另一个实施方案中,检测疾病的方法可以包括测量受试者粪便样品中表3中列出的任何生物标志物基因的一种、两种或多种变体的相对变体等位基因频率(例如相对比率),并将这些生物标志物的相对变体等位基因频率与对照中一种、两种或多种生物标志物的变体等位基因频率进行比较。受试者样本中测量的一种、两种或多种生物标志物的变体等位基因频率相对于对照中测量的变体等位基因频率的差异表明受试者患有胃肠疾病。在一些实施方案中,受试者样品中的一种、两种或多种生物标志物的变体等位基因频率相对于对照中的一种、两种或多种生物标志物测量的变体等位基因频率的差异是受试者处于胃肠疾病风险的指示。
还提供了检测结直肠肿瘤分子亚型生物标志物的方法。基于特定标志物的表达,结直肠癌可分为四种不同的分子亚型。四种共有分子亚型(CMS1-4)是基于274个基因的表达(基于它们独特的HUGO基因名称标识符)预测的,如图4A所示。CRCSC描述的随机森林分类器使用274个基因的表达作为特征来准确地识别分子亚型分类。四种CMS亚型包括CMS1-4。CMS1与高突变和微卫星不稳定性有关。CMS1肿瘤通常具有免疫浸润。CMS1肿瘤在诊断时往往具有较高的组织病理学级别,并且与较差的生存率相关。CMS2也被称为“典型”亚型,是以显著的WNT和MYC信号激活、拷贝数改变增加为特征的上皮肿瘤,并往往与长期存活有关。CMS3是上皮肿瘤,其特征是明显的代谢失调、KRAS突变、受体酪氨酸激酶和MAPK途径。CMS4肿瘤是以转化生长因子-β激活、间质侵袭和血管生成为特征的间充质肿瘤。CMS4肿瘤往往在晚期(第III和第IV阶段)诊断,与较差的总生存率和较差的无复发生存率相关。图4B和表4记载了25个基因(基于它们独特的HUGO基因名称标识符),它们对CMS1的预测特别有影响。
表4CMS1结直肠癌亚型粪便来源的真核RNA生物标志物


所述方法可以包括通过确定来自受试者的粪便样品中的两种或多种结直肠肿瘤亚型生物标志物基因的水平相对于对照中相同的两种或多种结直肠肿瘤亚型生物标志物基因的水平是否不同,来确定从受试者的粪便样品中分离的人RNA中的两种或多种结直肠肿瘤亚型生物标志物基因的表达水平。示例性结直肠肿瘤亚型生物标志物基因如表4所示。表4中列出的一些或所有结直肠肿瘤生物标志物基因可以形成一个组(组C)。在一些实施方案中,表4中列出的结直肠肿瘤生物标志物基因也可以包括结直肠肿瘤亚型生物标志物的子集。所述组合物可以包括基因阵列和探针组,其被配置用于本文公开的标志物组的特异性检测。所述组合物还可以包括试剂盒,所述试剂盒包含基因阵列和探针组,其被配置用于本文公开的标志物组的特异性检测。
在另一个实施方案中,检测疾病的方法可以包括测量受试者的粪便样品中的一种、两种或多种两种或多种结直肠肿瘤亚型生物标志物的相对表达水平比例(例如相对比率),和比较这些生物标志物的相对比例与对照中的一种、两种或更多种生物标志物的相对表达水平比例。受试者样品中测量的一种、两种或多种生物标记物相对表达水平比例相对于对照的差异可以指示结直肠癌的分子亚型。在一些实施方案中,受试者样品中的一种、两种或更多种生物标志物的所测量表达水平比例相对于对照中的一种、两种或更多种生物标志物的所测量表达水平比例的差异是所述受试者可能发展成结直肠癌特定亚型的指示。
可以使用检测CMS1肿瘤(也称为MSI-H肿瘤)的替代方法。POLE、MLH1、MSH2、MSH6和PMS2中与DNA错配修复缺陷相关的基因组变体已被用作免疫检查点阻断疗法临床试验中的预测性生物标志物。关注免疫抑制分子(包括PD-1、PD-L1、CTLA-4、LAG-3和IDO)表达的基因表达谱,可进一步用于预测MSI-H肿瘤微环境的免疫原性增加,并进一步预测患者从检查点免疫治疗中受益的资格。
本文提供了粪便来源的真核RNA生物标志物和粪便来源的真核RNA生物标志物组,用于结直肠肿瘤或特定亚型癌前病变或结直肠癌的诊断。生物标志物通常是可以客观地测量和定量并用于评估生物过程(例如结肠直肠赘瘤发展、进展、缓解或复发)的特征。生物标志物可以采取多种形式,包括核酸、多肽、代谢物或物理或生理参数。
一般来说,来自真核细胞的生物标志物可以包括:a)脱氧核糖核酸(DNA)序列,b)核糖核酸(RNA)序列,c)预测的氨基酸序列,其构成蛋白质骨架,d)核糖核酸生物标志物的表达水平,e)氨基酸序列的预测表达水平,或f)上述的任意组合。在一些实施方案中,生物标志物可以是更大序列的片段,例如,更长的RNA序列、更长的DNA序列或更长的多肽序列的片段。在一些实施方案中,生物标志物,例如GAPDH、ACTB或其它,可以用于其它生物标志物的标准化。在其它实施方案中,例如总RNA计数、总RNA输入或其它的特征,可以用作生物标志物或用于其它生物标志物的标准化。
粪便来源的真核生物RNA生物标志物可以使用扩增子进行定量。扩增子可以包含零个、一个、两个或多个独特的序列。同一粪便来源的真核生物RNA生物标志物的扩增子在序列同一性百分比上可能有所不同。扩增子可以设计成针对不同的基因座。目标基因座可以包括:a)相同基因的相同转录本上地理上相似的基因座,b)相同基因的相同转录本上地理上独特的基因座,c)相同基因的不同转录本上地理上独特的基因座,或d)不同基因的不同转录本上地理上独特的基因座。在一些实施方案中,设计用于靶向不同基因座的扩增子可以反映特定RNA的结构特征,例如,可能在粪便中被保护或优先降解的序列或二级结构。在一些实施方案中,设计成靶向不同基因座的扩增子可以反映特定的疾病参数,例如,在特异性选择性剪接转录本增加或减少的疾病中。
生物样品可以是含有细胞或其它细胞物质的样品,可以从中获得核酸或其它分析物。生物样品可以是对照或实验样品。生物样品可以是粪便样品。生物样品可以在厕所、地面、垃圾箱或收集装置中排便后立即获得。在一些实施方案中,生物样品可以在诸如灌肠、粪便拭子或内窥镜检查的过程之后或过程中获得。生物样品可以立即进行测试。或者,生物样品可以在测试之前储存在缓冲液中,所述缓冲液例如水性缓冲液、基于甘油的缓冲液、基于极性溶剂的缓冲液、渗透平衡缓冲液或足以保存生物样品的其它缓冲液。另外或替代地,生物样品可以被收集并且在测试之前储存,例如,在4℃下冷藏,或者,例如,在0℃、-20℃、-80℃、-140℃或更低温度下冷冻。生物样品可以在测试之前储存1个月、2个月、4个月、6个月、1年、2年或更久。
所述生物样品可以来自真核生物,例如哺乳动物。所述哺乳动物可以是人类或非人类动物,例如,人类、狗、猫、非人类灵长类动物、反刍动物、熊、马、猪、羊、山羊、骆驼、水牛、鹿、麋鹿、驼鹿、鼬鼠、兔子、豚鼠、仓鼠、大鼠、小鼠、厚皮动物、犀牛或栗鼠。因此,粪便样品可以从人或非人动物中获得,例如,人、狗、猫、非人灵长类动物、反刍动物、熊、马、猪、羊、山羊、骆驼、水牛、鹿、麋鹿、驼鹿、驼鹿、兔、豚鼠、仓鼠、大鼠、小鼠、厚皮动物、犀牛或栗鼠。
本文提供用于从富含真核核酸的生物样品(例如粪便样品)分离核酸的有用方法。所述方法可包括用缓冲液破坏粪便样品。可以对样品进行涡旋、摇晃、搅拌、旋转或其它足以分散固体和粪便细菌的搅动方法。进行搅动和离心步骤的温度可以改变,例如,从约4℃到约20℃,从约4℃到约1℃,从约4℃到约10℃,从约4℃到约6℃。破坏后可以对样品进行一轮或多轮离心。在一些实施方案中,破坏步骤和离心步骤可以重复一次、两次、三次或更多次。可商购的试剂,例如 试剂可以用于粪便破坏、洗涤和细胞裂解。裂解缓冲液也可以用于裂解真核细胞。裂解物可以在任何温度、以任何持续时间、以任何次数进一步离心。离心后,上清液可以用作输入到自动化RNA分离机器(例如
试剂可以用于粪便破坏、洗涤和细胞裂解。裂解缓冲液也可以用于裂解真核细胞。裂解物可以在任何温度、以任何持续时间、以任何次数进一步离心。离心后,上清液可以用作输入到自动化RNA分离机器(例如 仪器)中。在一些实施方案中,可以用DNA酶处理提取的核酸以降解溶液中的DNA。可以使用RNA纯化的其它方法;例如,在机械或酶细胞破碎后,可以进行固相方法,例如柱色谱或用有机溶剂提取,例如苯酚-氯仿或硫氰酸盐-苯酚-氯仿提取。在一些实施方案中,核酸可以被提取到功能化的珠上。在一些实施例中,功能化珠粒可以进一步包含磁芯(“磁珠”)。在一些实施例中,功能化珠粒可以包括用带电荷部分功能化的表面。带电荷部分可以选自:胺、羧酸、羧酸盐、季胺、硫酸盐、磺酸盐或磷酸盐。
仪器)中。在一些实施方案中,可以用DNA酶处理提取的核酸以降解溶液中的DNA。可以使用RNA纯化的其它方法;例如,在机械或酶细胞破碎后,可以进行固相方法,例如柱色谱或用有机溶剂提取,例如苯酚-氯仿或硫氰酸盐-苯酚-氯仿提取。在一些实施方案中,核酸可以被提取到功能化的珠上。在一些实施例中,功能化珠粒可以进一步包含磁芯(“磁珠”)。在一些实施例中,功能化珠粒可以包括用带电荷部分功能化的表面。带电荷部分可以选自:胺、羧酸、羧酸盐、季胺、硫酸盐、磺酸盐或磷酸盐。
为了提取核酸,可以在一种或多种缓冲液、表面活性剂和核糖核酸酶抑制剂的存在下破坏粪便样品以形成悬浮液。缓冲液可以是生物相容的缓冲液,例如,汉克斯(Hanks)平衡盐溶液,阿氏(Alsever's)溶液,厄尔氏(Earle's)平衡盐溶液,盖伊氏(Gey's)平衡盐溶液,磷酸盐缓冲盐水,帕克氏(Puck's)平衡盐溶液,林格氏(Ringer's)平衡盐溶液,西姆氏(Simm's)平衡盐溶液,TRIS-缓冲盐水或台氏(Tyrode's)平衡盐溶液。表面活性剂可以是离子或非离子表面活性剂,例如Tween-20或Triton-X-100。核糖核酸酶抑制剂可以是基于溶剂的,基于蛋白质的或其它类型的防止RNA破坏的方法,包括例如Protector RNaseInhibitor(Roche)、 (Promega)、SUPERase-InTM(Thermo Fisher Scientific)、RNAseOUTTM(Thermo Fisher Scientific)、抗RNA酶、重组RNA酶抑制剂或克隆的RNA酶抑制剂。可以以各种方式破坏粪便样品,例如通过涡旋、摇晃、搅拌、旋转或足以分散固体和粪便细菌的其它搅动方法。在一些实施例中,可以使用以下:经涂覆的珠粒;磁珠或搅拌工具,例如玻璃棒,金属棒,木棒或木制刀片来破坏粪便样品。
(Promega)、SUPERase-InTM(Thermo Fisher Scientific)、RNAseOUTTM(Thermo Fisher Scientific)、抗RNA酶、重组RNA酶抑制剂或克隆的RNA酶抑制剂。可以以各种方式破坏粪便样品,例如通过涡旋、摇晃、搅拌、旋转或足以分散固体和粪便细菌的其它搅动方法。在一些实施例中,可以使用以下:经涂覆的珠粒;磁珠或搅拌工具,例如玻璃棒,金属棒,木棒或木制刀片来破坏粪便样品。
然后可以将悬浮液分离成液体部分和固体部分。分离可以例如通过离心、过滤、特异性结合真核细胞的靶向探针、,抗体、基于柱的过滤、基于珠粒的过滤或色谱色谱方法来进行。液体部分富含细菌核酸并且可以丢弃。在存在或不存在表面活性剂和存在或不存在核糖核酸酶的情况下,可以将固体部分再悬浮于缓冲液中。分离步骤可以重复一次、两次、三次、四次、五次、六次、七次、八次或更多次。
进行破碎和分离步骤的温度可以变化,例如,从约4℃到约20℃,从约4℃到约15℃,从约4℃到约10℃,从约4℃到约6℃。
从分离步骤获得的所得小粒可以悬浮在裂解缓冲液(例如包含离液剂和任选的表面活性剂的缓冲液)中以形成裂解物。在一些实施例中,离液剂可以是硫氰酸胍并且表面活性剂可以是Triton-X-100。在一些实施例中,裂解缓冲液可以包括或不包括Tris-HCl、乙二胺四乙酸(EDTA),十二烷基硫酸钠(SDS)、Nonidet P-40、脱氧胆酸钠或二硫苏糖醇。
裂解物可以分级分离成富含真核核酸的部分。分级分离可以例如通过离心、过滤、特异性结合真核核酸的靶向探针、抗体、基于柱的过滤、基于珠粒的过滤或色谱方法来进行。在一些实施例中,通过离心分级分离可以导致形成底层(丸粒),其包含细胞碎片,包含真核核酸的亲水中间层和包含脂质和膜级分的疏水顶层。可以收集中间层。在一些实施例中,中间层和顶层可以一起收集。中间层可以通过窄孔口收集。窄孔口可以是移液器吸头或装有针头的注射器。移液器吸头可以是例如1μL、5μL、10μL、20μL或100μL移液器吸头。针可以是例如18号针或15号针。
可以对包含真核核酸的收集层进行进一步提取。进一步提取的方法可以变化。示例性方法包括基于磁性颗粒的方法、基于柱的方法、基于过滤器的方法、基于珠粒的方法或基于有机溶剂的方法。示例性的方法可以包括可商购试剂,例如 试剂(生物梅里埃(bioMerieux))。
试剂(生物梅里埃(bioMerieux))。
可以分析提取的核酸用于与胃肠病症或胃肠细胞相关的真核生物标志物。生物标志物可以提供关于个体(即受试者)健康状态的信息。来自真核细胞的这些生物标志物可以包括:a)脱氧核糖核酸(DNA)序列;b)核糖核酸(RNA)序列;c)预测的氨基酸序列,其包含蛋白质的主链;d)RNA生物标志物的表达水平或者表达水平比例;e)氨基酸序列的预测表达水平或预测表达水平比例;或f)上述的任何组合。从真核细胞中分离生物标志物可以考虑实验样品与对照之间的比较。从真核细胞中分离这些生物标志物可以提供检测实验样品中肠道疾病的方法。比较可以包括评估:a)DNA序列的变异;b)RNA序列的变异;c)预测的氨基酸序列的变异;d)RNA生物标志物的表达水平的变异或表达水平比例的变异;e)氨基酸序列的预测表达水平的变异或预测表达水平比例的变异;或f)构成上述任何组合的变异。当测量的实验样品的生物标志物与测量的对照中的生物标志物不同时,可以测定变异。
所述方法可以包括获得实验样品和对照,例如粪便样品。粪便样品含有脱落的真核细胞,可以评估其生物标志物。在一些实施例中,真核细胞可以是肠细胞、淋巴细胞、肠嗜铬样细胞、肠内分泌细胞、神经内分泌细胞、胰腺细胞、肝细胞、胃细胞或其它细胞。所述方法提供了一种方式,借此方式可以评估粪便样品中的真核细胞的真核生物标志物。生物标志物可以包括DNA序列、RNA序列、预测的氨基酸序列、RNA生物标志物的表达水平或表达水平的比例、氨基酸序列的预测的表达水平或预测表达水平比例或上述的任何组合。在具体的实施方案中,所述生物标志物是粪便来源的真核RNA生物标志物。在一些实施方案中,所述评估步骤包含任何类型的微阵列测序、聚合酶链反应(PCR)、核酸测序、扩增子测序、分子条形码或探针捕获。
所述方法和组合物还可用于为患有胃肠疾病(例如结直肠肿瘤或结肠直肠癌)的个体选择临床方案。通过这种方法,临床方案可以包括施用进一步诊断程序,例如结肠镜检查。在一些实施方案中,所述临床方案可以包括治疗方法。
可以使用各种方法评估粪便来源的真核RNA生物标志物的水平。表达水平可以在核酸水平(例如RNA水平)或在多肽水平测定。RNA表达可以包涵seRNA、总RNA、mRNA、tRNA、rRNA、ncRNA、smRNA、miRNA和snoRNA的表达。可以通过测量对应于相关RNA的cDNA水平直接或间接测量在RNA水平上的表达。或者或另外,还可以分析由RNA编码的多肽、编码相关转录因子的基因的RNA调节剂和转录因子多肽的水平。在mRNA水平测定基因表达的方法包括例如微阵列分析、基因表达的系列分析(SAGE)、RT-PCR、印迹、基于数字条形码定量分析的杂交、多重RT-PCR、微滴数字PCR(ddPCR)、数字PCR(dPCR)、NanoDrop分光光度计、RT-qPCR、qPCR、UV光谱、扩增子测序、RNA测序、下一代测序、利用分支链DNA信号扩增的基于裂解物的杂交分析(例如QuantiGene 2.0SingleΡlex)和分支链DNA分析方法。数字条形码定量分析可以包括珠粒阵列(BeadArray)(Illumina)、xMAP系统(Luminex)、nCounter(Nanostring)、HTG EdgeSe(High Throughput Genomics)、BioMark(Fluidigm)或Wafergen微阵列。分析可以包括DASL(Illumina)、RNA-Seq(Illumina)、TruSeq(Illumina)、SureSelect(Agilent)、Bioanalyzer(Agilent)、TaqMan(ThermoFisher)、GeneReader(Qiagen)、或QIAseq(Qiagen)。
我们可以互换地使用术语“核酸”和“多核苷酸”来指代RNA和DNA,包括cDNA、基因组DNA、合成DNA和含有核酸类似物的DNA(或RNA),其中任何一种都可以编码本发明的多肽并且其全部都被本发明涵盖。多核苷酸基本上可以具有任何三维结构。核酸可以是双链或单链的(即有义链或反义链)。多核苷酸的非限制性实例包括基因、基因片段、外显子、内含子、信使RNA(mRNA)和其部分、转移RNA、微RNA、核糖体RNA、siRNA、微RNA、核糖酶、cDNA、重组多核苷酸、分支链多核苷酸、质体、载体、任何序列的经分离DNA、任何序列的经分离RNA、核酸探针和引子以及核酸类似物。在本发明的上下文中,核酸可以编码生物标志物的片段,例如来自表1和表2中所列的任何生物标志物,其变体或表3或其变体或表4或其变体的粪便来源的真核RNA生物标志物。
“经分离的”核酸可以是例如DNA分子或其片段,条件是通常紧密侧接基因组中的DNA分子的核酸序列中的至少一个已移除或不存在。因此,经分离的核酸包括但不限于作为单独分子、独立于其它序列存在的DNA分子(例如化学合成核酸,或通过聚合酶链反应(PCR)或限制性内切酶处理产生的cDNA或基因组DNA片段)。经分离的核酸还指并入载体、自主复制质体、病毒或原核生物或真核生物的基因组DNA中的DNA分子。另外,经分离的核酸可以包括经工程改造的核酸,如为杂交或融合核酸的一部分的DNA分子。存在于例如cDNA库或基因组库内的多个(例如几十个或数百个到数百万个)其它核酸或含有基因组DNA限制性消化物的凝胶片中的核酸并非经分离的核酸。
经分离的核酸分子可以以各种方式产生。举例来说,聚合酶链反应(PCR)技术可用于获得含有本文所述核苷酸序列(包括编码本文所述多肽的核苷酸序列)的经分离的核酸。PCR可用于扩增来自DNA以及RNA的特定序列,包括来自总基因组DNA或总细胞RNA的序列。通常,使用来自关注或远端区域的末端的序列信息设计寡核苷酸引物,其序列与待扩增的模板的相反链相同或类似。还可以使用各种PCR策略,通过其可以将位点特异性核苷酸序列修饰引入模板核酸中。
经分离的核酸也可以化学合成,作为单个核酸分子(例如在3'至5'方向使用自动化DNA合成使用亚磷酰胺技术)或作为一系列寡核苷酸。举例来说,可合成一对或多对含有所需序列的长寡核苷酸(例如>50-100个核苷酸),每对含有互补性短片段(例如约15个核苷酸)从而在寡核苷酸对退火时形成双链体。DNA聚合酶用于扩展寡核苷酸,每个寡核苷酸对产生单个双链核酸分子,其接着可连接到载体中。
可以将两种核酸或其编码的多肽描述为彼此具有一定程度的同一性。例如,选自表1或表2或表1和表2的组合或表3或表4中的粪便来源的真核RNA生物标志物及其生物活性变体可被描述为表现出一定程度的同一性。比对可以通过在蛋白质信息研究(PIR)网站(http://pir.georgetown.edu)中定位短序列,然后用NCBI网站(http://www.ncbi.nlm.nih.gov/blast)上的“近乎相同的短序列”基本局部比对搜索工具(BLAST)算法进行分析来进行。
如本文所用,术语“序列同一性百分比”是指任何给定查询序列和目标序列之间的同一性程度。例如,表1或表2或表1和表2的组合或表3或表4中列出的粪便来源的真核RNA生物标志物序列可以是查询序列,表1或表2或表1和表2的组合或表3或表4中列出的粪便来源的真核RNA生物标志物序列的片段可以是目标序列。类似地,表1或表2或表1和表2的组合或表3或表4中列出的粪便来源的真核RNA生物标志物序列的片段可以是查询序列,并且其生物活性变体可以是目标序列。
为了测定序列同一性,可以使用计算机程序(例如ClustalW(1.83版,默认参数)、HISAT、HISTAT 2或SAMTools)将查询核酸或氨基酸序列分别与一个或多个目标核酸或氨基酸序列比对,其允许核酸或蛋白质序列比对在其整个长度中进行(全局比对)。
本文所述的核酸和多肽可称为“外源的”。术语“外源的”表示核酸或多肽是重组核酸构建体的一部分或由重组核酸构建体编码,或不在其天然环境中。举例来说,外源核酸可以是来自被引入到另一物种中的一种物种的序列,即异源核酸。通常,通过重组核酸构建体将此类外源核酸引入到其它物种中。外源核酸还可以是生物体原生并且被重新引入所述生物体的细胞中的序列。往往可通过连接到外源核酸的非天然序列(例如侧接重组核酸构建体中的原生序列的非原生调节序列)的存在来区分包括原生序列的外源核酸与原生序列。另外,稳定转型的外源核酸通常在除发现原生序列的位置以外的位置整合。
本发明的核酸可以包括具有表1或表2或表1和表2的组合或表3或表4中列出的任何一种粪便来源的真核RNA生物标志物的核苷酸序列的核酸,或与表1或表2或表1和表2的组合或表3或表4中列出的任何一种粪便来源的真核RNA生物标志物的核酸序列具有至少约70%、至少约75%、至少约80%、至少约85%、至少约90%、至少约95%、至少约99%的同一性。
核酸,例如对靶核酸具有特异性的寡核苷酸(例如探针或引物)将在合适的条件下与靶核酸杂交。我们可以将杂交称为寡核苷酸单链在限定的杂交条件下通过碱基配对与互补链退火的过程。其是两个互补多核苷酸之间的特异性(即非随机的)相互作用。杂交和杂交强度(即核酸之间缔合的强度)受如核酸之间的互补程度,所涉及的条件的严格度和所形成的杂交体的解链温度(Tm)等因素的影响。杂交产物可以是在溶液中或在固体支撑物上与标靶形成的双螺旋体或三螺旋体。
在一些实施方案中,核酸可以包括适用于分析和定量表1或表2或表1和表2的组合或表3或表4中列出的粪便来源的真核RNA生物标志物的短核酸序列。此类经分离的核酸可以是寡核苷酸引物。一般来说,寡核苷酸引物是与靶核苷酸序列(例如,表1或表2或表1和表2的组合或表3或表4中列出的任何粪便来源的真核RNA生物标志物的核苷酸序列)互补的寡核苷酸,其可以充当通过在DNA或RNA聚合酶存在下向引物的3'末端添加核苷酸来合成DNA的起点。引物的3'核苷酸通常应与相应核苷酸位置处的靶序列相同以进行最佳延伸和/或扩增。引物可以采取多种形式,包括例如肽核酸引物,锁核酸引物,解锁核酸引物和/或硫代磷酸酯修饰的引物。在一些实施例中,正向引物可以是与dsDNA的反义链互补的引物,且反向引物可以是与dsDNA的有义链互补的引物。我们也可以称为引物对。在一些实施例中,5'靶引物对可以是包括至少一个正向引物和至少一个反向引物的引物对,其扩增靶核苷酸序列的5'区域。在一些实施例中,3'靶引物对可以是包括至少一个正向引物和至少一个反向引物的引物对,其扩增靶核苷酸序列的3'区域。在一些实施例中,引物可以包括可检测标记,如下文所论述。在一些实施例中,可检测标记可以是可定量标记。
本文提供的寡核苷酸引物可用于扩增表1和表2或表3或表4中列出的任何粪便来源的真核RNA生物标志物。在一些实施方案中,寡核苷酸引物可以与本文公开的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物互补,例如表1和表2或表3或表4中列出的粪便来源的真核RNA生物标志物。引物长度可以根据探针的特定核酸序列的核苷酸碱基序列和组成以及使用探针的具体方法而改变。一般来说,有用的引物长度可以是约8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30个核苷酸碱基。有用的引物长度范围可以是8个核苷酸碱基到约60个核苷酸碱基;约12个核苷酸碱基到约50个核苷酸碱基;约12个核苷酸碱基到约45个核苷酸碱基;约12个核苷酸碱基到约40个核苷酸碱基;约12个核苷酸碱基到约35个核苷酸碱基;约15个核苷酸碱基到约40个核苷酸碱基;约15个核苷酸碱基到约35个核苷酸碱基;约18个核苷酸碱基到约50个核苷酸碱基;约18个核苷酸碱基到约40个核苷酸碱基;约18个核苷酸碱基到约35个核苷酸碱基;约18个核苷酸碱基到约30个核苷酸碱基;;约20个核苷酸碱基到约30个核苷酸碱基;约20个核苷酸碱基到约25个核苷酸碱基。
还提供了探针,即分离的核酸片段,其选择性结合并互补于表1和表2或表3或表4中列出的任何粪便来源的真核RNA生物标志物。探针可以是核苷酸碱基或主链中的寡核苷酸或多核苷酸,DNA或RNA,单链或双链以及天然的或经修饰的。探针可以通过各种方法产生,包括化学或酶促合成。
探针长度可以根据探针的特定核酸序列的核苷酸碱基序列和组成以及使用探针的具体方法而改变。一般来说,有用的探针长度可以是大约8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、35、40、50、55、60、65、70、75、80、85、90、100、110、120、140、150、175或200个核苷酸碱基。一般来说,有用的探针长度范围是长度为约8到约200个核苷酸碱基;约12到约175个核苷酸碱基;约15到约150个核苷酸碱基;约15到约100个核苷酸碱基,约15到约75个核苷酸碱基;约15到约60个核苷酸碱基;约20到约100个核苷酸碱基;约20到约75个核苷酸碱基;约20到约60个核苷酸碱基;约20到约50个核苷酸碱基。在一些实施方案中,探针组可以包括针对表1或表2或表1和表2的组合或表3或表4中列出的粪便来源的真核RNA生物标志物中的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种的探针。
本文公开的引物和探针可以被可检测地标记。标记可以是可检测的或导致可检测响应的分子部分或化合物,其可以直接或间接连接至核酸。直接标记可以使用键或相互作用来连接标记和探针,其包括共价键、非共价相互作用(氢键,疏水和离子相互作用)或螯合物或配位络合物。间接标记可以使用直接或间接标记的桥接部分或连接子(例如抗体、寡聚物或其它化合物),其可以扩增信号。标记包括任何可检测部分,例如放射性核素;配体,如生物素或抗生物素蛋白;酶;酶底物;反应性基团;发色团(可检测的染料,颗粒或珠粒);荧光团或发光化合物(生物发光、磷光或化学发光标记)。标记可以在均相分析中检测,其中混合物中的结合标记探针与未结合标记探针相比展现可检测的变化,例如稳定性或差异性降解,而不需要结合形式与未结合形式的物理分离。
合适的可检测标记可包括本身可检测的分子(例如荧光部分、电化学标记、金属螯合物等)以及可通过产生可检测反应产物(例如酶,如辣根过氧化物酶、碱性磷酸酶等)或通过本身可检测的特异性结合分子(例如生物素、洋地黄毒苷、麦芽糖、寡聚组氨酸、2,4-二硝基苯、苯基砷酸盐、ssDNA、dsDNA等)可间接检测的分子。如上文所论述,一个或多个配体基元和/或配体与可检测标记的偶联可以是直接的或间接的。检测可以是原位,活体内,活体外在组织切片上或在溶液中等。
在一些实施例中,方法包括使用碱性磷酸酶缀合的多核苷酸探针。当使用碱性磷酸酶(AP)-缀合的多核苷酸探针时,在依序添加适当的底物(例如固蓝或固红底物)后,AP分解底物以形成沉淀物,其允许原位检测特异性靶RNA分子。碱性磷酸酶可与许多底物一起使用,例如固蓝、固红或5-溴-4-氯-3-吲哚基-磷酸盐(BCIP)。
在一些实施例中,荧光团-缀合物探针可以是荧光染料缀合的标记探针,或利用除碱性磷酸酶之外的其它酶促途径用于产色检测途径,例如使用辣根过氧化物酶缀合的探针与如3,3’-二氨基联苯胺(DAB)的底物。
缀合标记探针中使用的荧光染料通常可分为多个家族,例如荧光素和其衍生物;罗丹明和其衍生物;花青和其衍生物;香豆素和其衍生物;Cascade BlueTM和其衍生物;萤黄(Lucifer Yellow)和其衍生物;BODIPY和其衍生物等等。示例性荧光团包括吲哚羰花青(C3)、吲哚二羰花青(C5)、Cy3、Cy3.5、Cy5、Cy5.5、Cy7、德克萨斯红(Texas Red)、太平洋蓝(Pacific Blue)、俄勒冈绿(Oregon Green)488、 Alexa Fluor 488、Alexa Fluor 532、Alexa Fluor 546、Alexa Fluor-555、Alexa Fluor 568、Alexa Fluor594、Alexa Fluor 647、Alexa Fluor 660、Alexa Fluor 680、JOE、丽丝胺(Lissamine)、罗丹明绿、BODIPY、异硫氰酸荧光素(FITC)、羧基荧光素(FAM)、藻红蛋白、罗丹明、二氯罗丹明(dRhodamineTM)、羧基四甲基罗丹明(TAMRATM)、羧基-X-罗丹明(ROXTM)、LIZTM、VICTM、NEDTM、PETTM、SYBR、PicoGreen、RiboGreen等等。近红外染料明确地在术语荧光团和荧光报道基团的预期含义内。
Alexa Fluor 488、Alexa Fluor 532、Alexa Fluor 546、Alexa Fluor-555、Alexa Fluor 568、Alexa Fluor594、Alexa Fluor 647、Alexa Fluor 660、Alexa Fluor 680、JOE、丽丝胺(Lissamine)、罗丹明绿、BODIPY、异硫氰酸荧光素(FITC)、羧基荧光素(FAM)、藻红蛋白、罗丹明、二氯罗丹明(dRhodamineTM)、羧基四甲基罗丹明(TAMRATM)、羧基-X-罗丹明(ROXTM)、LIZTM、VICTM、NEDTM、PETTM、SYBR、PicoGreen、RiboGreen等等。近红外染料明确地在术语荧光团和荧光报道基团的预期含义内。
在一些实施例中,可以在基因阵列上分析真核生物标志物的水平。可以在定制的基因阵列上进行微阵列分析。或者或另外,可以根据制造商的说明书和方案使用可商购的系统进行微阵列分析。示例性商购系统包括昂飞 技术(ThermoFisher,Walthum,MA)、安捷伦微阵列技术、
技术(ThermoFisher,Walthum,MA)、安捷伦微阵列技术、 分析系统(
分析系统( Technologies,Seattle,WA)和珠粒阵列微阵列技术(Illumina,San Diego,CA)。从粪便样品中提取的核酸可以与基因阵列上的探针杂交。探针-靶杂交可以通过化学发光来检测,以确定特定序列的相对丰度。特定序列的相对丰度可以跨基因阵列或在基因阵列内标准化。
Technologies,Seattle,WA)和珠粒阵列微阵列技术(Illumina,San Diego,CA)。从粪便样品中提取的核酸可以与基因阵列上的探针杂交。探针-靶杂交可以通过化学发光来检测,以确定特定序列的相对丰度。特定序列的相对丰度可以跨基因阵列或在基因阵列内标准化。
在一些实施例中,探针和探针组可以配置为基因阵列。基因阵列(也称为微阵列或基因芯片)是有序的核酸阵列,其允许平行分析复杂的生物样品。通常,基因阵列包括附接于固体底物(例如微芯片、玻璃载片或珠粒)的探针。附接通常涉及产生底物与探针之间的共价键的化学偶联。阵列中探针的数量可以改变,但每个探针固定在阵列或微芯片上的特定可寻址位置。在一些实施例中,探针的长度可以是约18个核苷酸碱基、约20个核苷酸碱基、约25个核苷酸碱基、约30个核苷酸碱基、约35个核苷酸碱基或约40个核苷酸碱基。在一些实施方案中,探针组包括针对表1或表2或表1和表2的组合或表3或表4中列出的粪便来源的真核RNA生物标志物中的至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种的探针。探针组可并入到包含5,000、10,000、20,000、50,000、100,000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1,000,000、2,000,000、3,000,000、4,000,000、5,000,000、6,000,000、7,000,000、8,000,000个更多个不同探针的高密度阵列中。
基因阵列合成的方法可以改变。示例性方法包括合成探针,然后通过“点样”、原位合成(在微电极阵列上使用例如光刻或电化学)沉积到阵列表面上。
在一些实施方案中,探针和探针组可以被配置为试剂,即允许复杂生物样品的平行分析的核酸池。试剂可以是例如一组扩增探针、文库制剂、扩增子板或捕获板。通常,试剂包括悬浮在溶液中的靶向探针。在一些实施方案中,探针被设计成靶向特定区域。可以以允许捕获特定核酸的方式配置探针。探针也可以被配置成允许特定核酸的扩增。试剂中探针的数量可以变化,但每个探针都是根据特定的序列设计的。在一些实施方案中,探针长度可以是约10个核苷酸碱基、约15个核苷酸碱基、约20个核苷酸碱基、约25个核苷酸碱基、约30个核苷酸碱基、约35个核苷酸碱基或约40个核苷酸碱基。在一些实施方案中,探针组包括针对表1或表2或表1和表2的组合或表3或表4中列出的粪便来源的真核RNA生物标志物中的至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种的探针。探针组可并入到包含5,000、10,000、20,000、50,000、100,000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1,000,000、2,000,000、3,000,000、4,000,000、5,000,000、6,000,000、7,000,000、8,000,000个更多个不同探针的高密度试剂中。
试剂合成的方法各不相同。示例性方法包括合成核酸探针,然后悬浮在稳定溶液中。探针试剂可以包含一个独特的区域作为分子标识。所述试剂可用于PCR、rtPCR、ddPCR、dPCR、下一代测序、扩增子测序、RNA测序和其它方法。
还可以通过DNA测序分析真核生物标志物的水平。DNA测序可以通过测序方法执行,例如靶向测序、全基因组测序、扩增子测序、或外显子组测序。测序方法可包括:Sanger测序或高通量测序。高通量测序可涉及合成测序、焦磷酸测序、连接测序、实时测序、纳米孔测序或Sanger测序。在一些实施例中,经分离RNA可用于生成对应的cDNA并且可对cDNA测序。
本文所述的测序方法可以以多重形式进行,使得同时操作多种不同的靶核酸。在一些实施例中,可以在共同的反应容器中或在特定底物的表面上处理不同的靶核酸,使得能够方便地递送测序试剂,移除未反应的试剂并以多重方式检测并入事件。在涉及表面结合靶核酸的一些实施例中,靶核酸可以是阵列形式。在阵列形式中,靶核酸通常可以以空间可区分的方式与表面偶联。举例来说,靶核酸可以通过直接共价附接、附接于珠粒或其它颗粒或与附接于表面的聚合酶或其它分子缔合来结合。阵列可以包括每个位点(也称为特征部)处的靶核酸的单拷贝或者具有相同序列的多拷贝可以存在于每个位点或特征部处。通过扩增方法产生多拷贝,例如桥式扩增、扩增子扩增、PCR或乳液PCR。
在一些实施例中,标准化步骤可用于控制核酸回收和样品之间的变异。在一些实施例中,可以将限定量的外源对照核酸添加(“掺入”)至提取的真核核酸。外源对照核酸可以是具有对应于一个或多个真核或非真核序列的序列的核酸,例如,PhiX。或者或另外,外源对照核酸可具有对应于在另一物种中发现的序列的序列,例如细菌序列,如枯草芽孢杆菌(Bacilis subtilis)序列。在一些实施例中,方法可以包括测定一种或多种管家基因的水平。在一些实施例中,方法可以包括将生物标志物的表达水平归一化至管家基因的水平。
所述方法包括确定实验样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30个或更多种粪便来源的真核RNA生物标志物测量的表达水平是否不同于对照中相同的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30个或更多种粪便来源的真核RNA生物标志物测量的表达水平。在另一个实施方案中,所述方法包括确定实验样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30个或更多种粪便来源的真核RNA生物标志物的表达水平的比例是否不同于对照中相同的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30个或更多种粪便来源的真核RNA生物标志物测量的表达水平的比例。表达水平或表达水平的比例的差异可以是增加或减少。
本文公开的组合物通常和不同地用于结直肠肿瘤的检测、诊断和治疗。检测方法可以包括测量粪便样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种选自表1或表2或表1和表2的组合或表3或表4中列出的生物标志物的粪便来源的真核RNA生物标志物的表达水平,以及将样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种选自表1或表2或表1和表2的组合或表3或表4中列出的生物标志物的粪便来源的真核RNA生物标志物的测量表达水平和对照中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种选自表1或表2或表1和表2的组合或表3或表4中列出的生物标志物的粪便来源的真核RNA生物标志物的测量表达水平进行比较。患者样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种选自表1或表2或表1和表2的组合或表3或表4中列出的生物标志物的粪便来源的真核RNA生物标志物的测量表达水平相对于对照中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种选自表1或表2或表1和表2的组合或表3或表4中列出的生物标志物的粪便来源的真核RNA生物标志物的测量表达水平的差异表明所述患者患有结直肠肿瘤,或更具体地说,高危腺瘤。在一些实施方案中,患者样品中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种选自表1或表2或表1和表2的组合或表3或表4中列出的生物标志物的粪便来源的真核RNA生物标志物的测量表达水平相对于对照中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种选自表1或表2或表1和表2的组合或表3或表4中列出的生物标志物的粪便来源的真核RNA生物标志物的测量表达水平的差异表明所述患者处于患结直肠肿瘤的风险,或更具体地说,有患高危腺瘤的风险。这些方法可以进一步包括识别受试者的步骤(例如,患者,更具体地说,人类患者),其患有结直肠肿瘤(例如结直肠癌或癌前病变)或者其处于发展为结直肠肿瘤的风险。
患者样品中1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17或18种表3中列出的生物标志物的粪便来源的真核RNA变体生物标志物的变体等位基因频率相对于对照中1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17或18种表3中列出的生物标志物的粪便来源的真核RNA变体生物标志物的变体等位基因频率的差异表明所述患者患有结直肠肿瘤。在一些实施方案中,患者样品中1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17或18种表3中列出的生物标志物的粪便来源的真核RNA变体生物标志物的变体等位基因频率相对于对照中1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17或18种表3中列出的生物标志物的粪便来源的真核RNA变体生物标志物的变体等位基因频率的差异表明所述患者处于患结直肠肿瘤的风险。这些方法可以进一步包括识别受试者的步骤(例如,患者,更具体地说,人类患者),,其患有结直肠肿瘤(例如结直肠癌或癌前病变)或者其处于发展为结直肠肿瘤的风险。
患者样品中1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种图4中列出的结直肠肿瘤分子亚型生物标志物基因的粪便来源的真核RNA生物标志物的测量表达水平相对于对照中1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种图4中列出的结直肠肿瘤分子亚型生物标志物基因的粪便来源的真核RNA生物标志物的测量表达水平的差异表明所述患者患有结直肠癌的分子亚型,例如CMS1。在一些实施方案中,患者样品中1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种图4中列出的结直肠肿瘤分子亚型生物标志物基因的粪便来源的真核RNA生物标志物的测量表达水平相对于对照中1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种图4中列出的结直肠肿瘤分子亚型生物标志物基因的粪便来源的真核RNA生物标志物的测量表达水平的差异表明所述患者处于结直肠癌分子亚型(例如CMS1)的风险。这些方法可以进一步包括识别患有结直肠肿瘤(例如结直肠癌或癌前病变)或者处于发展为结直肠肿瘤的风险的受试者的步骤(例如,患者,更具体地说,人类患者)。
结直肠肿瘤可以包括任何形式的结直肠癌。结直肠肿瘤也可包括息肉,例如癌前病变。结直肠癌通常始于结肠或直肠腔内膜的生长,称为息肉。大肠息肉一般分为两类:腺瘤性息肉和良性息肉。腺瘤性息肉也可称为腺瘤。良性息肉也可称为增生性息肉、错构瘤性息肉或炎性息肉。患有腺瘤性息肉或多发性腺瘤性息肉的患者可分为高危腺瘤、中危腺瘤或低危腺瘤。高危腺瘤包括任何大小的原位癌或高级别发育不良的腺瘤,任何大小的绒毛生长模式大于或等于25%的腺瘤,任何大小大于或等于1.0cm的腺瘤,或任何大小大于或等于1.0cm的锯齿状病变。中等风险腺瘤包括1或2个5.0mm至1.0cm大小的非高风险腺瘤,或大于或等于3个小于1.0cm大小的非高风险腺瘤。低风险腺瘤包括1或2个大小小于或等于5.0mm的非高风险腺瘤。腺瘤性息肉会导致结直肠癌。结直肠癌最常见的形式是腺癌,起源于结肠和/或直肠内的肠腺细胞。腺癌可包括管状腺癌,管状腺癌是有蒂茎上的腺癌。腺癌也包括绒毛状腺癌,这是一种平躺在结肠表面的腺癌。其它结直肠癌通过其来源组织来区分。这些包括胃肠道间质瘤(GIST),它起源于Cajal间质细胞;源于血液细胞的原发性结肠直肠淋巴瘤;平滑肌肉瘤,其是由结缔组织或平滑肌产生的肉瘤;黑色素瘤,其源于黑色素细胞:鳞状细胞癌,其源于分层鳞状上皮组织并局限于直肠;和粘液癌,其是通常与不良预后相关的上皮癌。
结直肠肿瘤或结直肠癌的症状可包括但不限于排便习惯的变化,包括腹泻或便秘或粪便稠度变化持续超过四周;直肠出血或便血;持续性腹部不适,如痉挛,胀气或疼痛;感觉肠道不能完全排空;虚弱或疲劳以及无法解释的体重减轻。疑似患有结直肠肿瘤或结直肠癌的患者可接受外周血试验,包括全血细胞计数(CBC);粪便隐血试验(FOBT);肝功能分析;粪便免疫化学试验(FIT)和/或某些肿瘤标志物的其它分析,例如癌胚抗原(CEA)和CA19-9。结直肠肿瘤或结直肠癌往往基于结肠镜检查诊断。在结肠镜检查期间,将所识别的任何息肉移除、活组织检查并分析以确定息肉是否含有结肠直肠癌细胞或经受癌前变化的细胞。当通过内窥镜检视时,上文所列的每种特定癌症可能看起来不同。绒毛腺瘤黑色素瘤和鳞状细胞癌通常是扁平的或无蒂的,而管状腺瘤、淋巴瘤、平滑肌肉瘤和GIST肿瘤通常是有蒂的。然而,胃肠病医生在结肠镜检查期间可能会遗漏扁平和无蒂腺瘤。可以基于特定基因的基因变化或微卫星不稳定性对活组织检查样品进行进一步分析。
其它诊断方法可包括乙状结肠镜检查;成像试验,例如算机断层摄影(CT或CAT)扫描;超声,例如腹部、直肠内或手术中超声;或磁共振成像(MRI)扫描,例如直肠内MRI。可以进行其它试验(例如血管造影和胸部X射线)以确定结肠直肠癌是否已经转移。
已经研发了各种用于分期结肠直肠癌的方法。最常用的系统——TNM系统基于三个因素:1)原发肿瘤(T)生长到肠壁和附近区域的距离;2)肿瘤是否已扩散到附近区域淋巴结(N);3)癌症是否已转移至其它器官(M)。其它分期方法包括Dukes分期和Astler-Coller分级。
TNM系统提供结肠直肠癌的四阶段分级。在阶段1(T1)结肠直肠癌中,肿瘤已经生长到结肠壁的层中,但是没有扩散到结肠壁外或扩散到淋巴结中。如果癌症是管状腺瘤息肉的一部分,则进行简单的切除并且患者可以继续接受针对未来癌症发展的常规试验。如果癌症是高级别或扁平/无蒂息肉的一部分,则可能需要更多手术并且将截取更大的余量;这可能包括切除一部分结肠的部分结肠切除术。在阶段2(T2)结肠直肠癌中,肿瘤已经生长到结肠壁中并可能生长到附近组织中但尚未扩散到附近的淋巴结。通常进行肿瘤的手术移除和部分结肠切除术。可以施用辅助疗法,例如用如5-氟尿嘧啶、甲酰四氢叶酸或卡培他滨(capecitabine)的药剂化疗。此类肿瘤不大可能复发,但通常需要增加对患者的筛查。在阶段3(T3)结肠直肠癌中,肿瘤已扩散到附近的淋巴结但未扩散到身体的其它部位。将需要手术移除结肠部分和所有受感染的淋巴结。通常建议用如5-氟尿嘧啶、甲酰四氢叶酸、奥沙利铂(oxaliplatin)或卡培他滨与奥沙利铂组合的药剂化疗。根据患者的年龄和肿瘤的侵袭性,还可使用放疗。在阶段4(T4)结肠直肠癌中,肿瘤通过血液从结肠扩散到远处器官。结肠直肠癌最常转移至肝、肺和/或腹膜。手术不大可能治愈这些癌症,并且通常需要化疗和/或放疗来提高存活率。
本文公开的方法通常用于结直肠癌的诊断和治疗。生物样品(例如来自受试者的粪便样品)中2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物(例如选自表1或表2或表1和表2的组合或表3或表4中的粪便来源的真核RNA生物标志物)的表达水平被测量。受试者可以是具有一种或多种上述指示患者处于结肠直肠癌的风险的症状的患者。受试者也可以是没有症状但是基于与结肠直肠肿瘤较高风险相关的年龄(例如50岁以上);家族病史;肥胖;饮食;饮酒;吸烟;结肠直肠息肉的先前诊断;种族和种族背景;炎性肠病以及遗传综合征,如家族性腺瘤性息肉病、加德纳(Gardner)综合征、林奇(Lynch)综合征、透克(Turcot)综合征、普-杰二氏(Peutz-Jeghers)综合征和MUTYH相关息肉病而可能处于结肠直肠癌的风险的患者。本文公开的方法还可用于监测先前已被诊断和治疗结肠直肠肿瘤或结直肠癌的患者以监测缓解和检测病变复发。
在一些实施例中,通过病理学评估确定受试者(即人类或非人类动物患者)的疾病状态。举例来说,在一种类型的疾病(例如结肠直肠癌)中,疾病的程度被分级为阶段1(T1)、阶段2(T2)、阶段3(T3)和阶段4(T4)。结肠直肠癌可以是管状腺癌、绒毛腺癌、胃肠间质瘤、原发性结肠直肠淋巴瘤、平滑肌肉瘤、黑色素瘤、鳞状细胞癌或粘液癌。在另一类型的疾病中(如炎性肠病),通过疾病沿肠道的位置和组织学特征如肉芽肿、白细胞浸润和/或隐窝脓肿确定疾病状态。用于确定疾病状态的其它方法,如医师确定、生理症状、粪便隐血试验、粪便免疫化学试验、乙状结肠镜检查、FIT-DNA、CT结肠成像或结肠镜检查也可以与本文公开的方法结合使用。
还提供了确定受试者是否处于肠道疾病风险的方法。肠道疾病可包括肠癌、结肠直肠癌、指示癌前变化的腺瘤性息肉、肠易激综合征、坏死性小肠结肠炎、溃疡性结肠炎、克罗恩病、乳糜泻或其它肠道疾病。确定受试者是否处于肠道疾病风险的方法可以是通过使用本发明来检测以下来确定:a)脱氧核糖核酸(DNA)序列;b)核糖核酸(RNA)序列;c)预测的氨基酸序列,其包含蛋白质的主链;d)核糖核酸生物标志物的表达水平;e)预测氨基酸中序列的变异或f)上述任何组合,其中对照和实验样品之间的差异可以指示受试者处于患肠病的风险。
所述方法和组合物还可用于为患有肠道疾病的受试者选择临床方案。通过这种方法,临床方案可以包括施用进一步诊断程序。在一些实施例中,临床方案可以包括治疗方法。
例如,用于确定诊断、状态或对治疗的反应的算法可以确定特定临床病况。本文所提供的方法中使用的算法可以是并入多个参数的数学函数,其可不受限制地定量使用医疗设备、临床评估分数或生物样品的生物/化学/物理试验。每个数学函数可以是确定为与所选临床病况相关的参数水平(例如测量水平)的权重调整表达。由于技术涉及加权和评估多个标志物组,具有合理计算能力的计算机可用于分析数据。
因此,诊断方法可包括从处于结直肠肿瘤风险或怀疑患有结直肠肿瘤的患者获取粪便样本;测定2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的表达,所述粪便来源的真核RNA生物标志物选自表1或表2或表1和表2的组合或表3或表4中列出的粪便来源的真核RNA生物标志物,以及通过机器学习算法提供测试值,所述机器学习算法结合了多个具有预定系数的粪便来源的真核RNA生物标志物。示例性的机器学习算法包括支持向量机、梯度增强、自适应增强、随机森林、朴素贝叶斯、决策树和k近邻,或其它。多个结直肠肿瘤生物标志物的表达相对于对照(例如健康个体群体)的显著变化表明患者患有结直肠肿瘤的可能性增加。在一些实施方案中,在样本中测量的表达水平用于导出或计算概率或置信度得分。该值可以从表达水平导出。可选地,或者另外,所述值可以从表达水平与其它因素(例如,患者的病史、种族、性别、年龄、吸烟状况、以前的基因组结果、以前的组织病理学结果和遗传背景)的组合中导出。可选地,或另外地,所述值可以从表达水平与粪便免疫化学试验(FIT)的组合中导出。在一些实施方案中,所述方法可以进一步包括将测试值传送给患者的步骤。该方法可以包括例如所述标志物的视觉呈现、所述标志物的数字输出或其它通信方法。
在一些实施方案中,可以使用基于模型的方法来生成一个或多个患者的预测。例如,在一些实施方案中,随机森林模型可以被配置成预测一个或多个组中的疾病不存在、疾病存在和/或疾病严重程度,例如结直肠癌、HRA、MRA、LRA、良性息肉或无发现。在一些实施方案中,可以应用验证数据集和/或测试数据集来测试或细化模型。一旦生成,所述模型用于基于所提供的输入,例如多个扩增子,预测一个或多个特定患者的疾病不存在、疾病存在和/或疾病严重程度。尽管本文讨论了特定的实施方案,但是应当理解,任何合适的模型可以包括任何数量的决策树、节点、输入层、输出层、隐藏层或其它变化的参数。在一些实施方案中,可能会产生使用更多和/或更少数量的决策树、更多和/或更少数量的合格特征等的随机森林模型。
在一些实施方案中,可以使用配置用于疾病检测的系统来生成、测试和/或执行一个或多个模型。在一些实施方案中,所述系统包括具有一个或多个处理器的计算机系统。每个处理器连接到通信基础设施(例如,通信总线、交叉杆或网络)。所述处理器可以被实现为中央处理单元、嵌入式处理器或微控制器、专用集成电路(ASIC)和/或被配置为执行计算机可执行指令以执行一个或多个步骤的任何其它电路。处理器类似于上面讨论的处理器,并且类似的描述在此不再重复。计算机系统可以包括显示接口,该显示接口将来自通信基础设施(或来自帧缓冲器)的图形、文本和其它数据转发给用户,以便在显示单元上显示。
计算机系统还可以包括主存储器,例如随机存取存储器(RAM),以及辅助存储器。主存储器和/或辅助存储器包括动态随机存取存储器(DRAM)。辅助存储器可以包括例如硬盘驱动器(HDD)和/或可移动存储驱动器,其可以代表固态存储器、光盘驱动器、闪存驱动器、磁带驱动器等。可移动存储驱动器读取和/或写入可移动存储单元。可移动存储单元可以是光盘、磁盘、软盘、磁带等。可移动存储单元可以包括计算机可读存储介质,其具有有形地存储在其中(或包含在其上)的数据和/或计算机可执行软件指令,例如,用于使处理器执行各种操作和/或一个或多个步骤。
在替代实施方案中,辅助存储器可以包括允许计算机程序或其它指令加载到计算机系统中的其它设备。辅助存储器可以包括可移动存储单元和相应的可移动存储接口,其可以类似于具有其自己的可移动存储单元的可移动存储驱动器。这种可移动存储单元的例子包括但不限于通用串行总线(USB)或闪存驱动器,其允许软件和数据从可移动存储单元传输到计算机系统。
计算机系统还可以包括通信接口(例如,网络接口)。通信接口允许指令和数据在计算机系统和一个或多个附加系统之间传输。通信接口还提供与其它外部设备的通信。通信接口的例子可以包括调制解调器、以太网接口、无线网络接口(例如,射频、IEEE 802.11接口、蓝牙接口等)、个人计算机存储卡国际协会(PCMCIA)插槽和卡等。经由通信接口传输的指令和数据可以是信号的形式,其可以是能够被通信接口接收的电子、电磁、光等。这些信号可以经由通信路径(例如,信道)提供给通信接口,所述通信路径可以使用电线、电缆、光纤、电话线、蜂窝链路、射频(RF)链路和其它通信信道来实现。
本文描述的方法和系统可以至少部分地以计算机实现的过程和用于实践这些过程的装置的形式来实施。所公开的方法也可以至少部分地以用计算机可执行程序代码编码的有形的、非暂时性的机器可读存储介质的形式来实现。所述介质可以包括例如,RAMs、ROMs、CD-ROMs、DVD-ROMs、BD-ROMs、硬盘驱动器、闪存或任何其它非暂时性机器可读存储介质,其中,当计算机程序代码被加载到计算机中并由计算机执行时,计算机变成用于实践所述方法的装置。所述方法也可以至少部分地以计算机的形式实施,计算机程序代码被加载和/或执行到该计算机中,使得该计算机成为用于实践这些方法的专用计算机。当在通用处理器上实现时,计算机程序代码段配置处理器来创建用于实现本文所公开的方法的特定连接、电路和算法。
可以(例如经适当地编程)使用和实施标准计算设备和系统以执行本文所描述的方法,例如执行测定本文所述值所需的计算。计算设备包括各种形式的数字计算机,如笔记本电脑、台式机、移动设备、工作站、个人数字助理、服务器、刀片式服务器、大型机和其它适当的计算机。在一些实施例中,计算设备是移动设备,如个人数字助理、蜂窝式电话、智能电话、平板电脑或其它类似的计算设备。
在一些实施例中,计算机可用于将信息传达给例如医疗保健专业人员。可以通过使信息电子化(例如以安全的方式)将信息传达给专业人员。举例来说,可以将信息放在计算机数据库上,使得医疗保健专业人员可以访问所述信息。另外,可以将信息传达给专业人员代理的医院,诊所或研究机构。通过开放网络(例如互联网或电子邮件)传输的信息可以被加密。患者的基因表达数据和分析可以通过加密存储在云中。具有篡改保护的256位AES方法可用于磁盘加密;SSL协议优选地可以确保数据传输中的保护,并且密钥管理技术SHA2-HMAC可以允许对数据进行认证访问。也可以使用其它安全数据存储装置。
上述分析的结果,例如,从表达水平与其它因素(例如,患者的病史、种族、性别、年龄、吸烟状况、以前的基因组结果、以前的组织病理学结果、遗传背景或粪便免疫化学测试(FIT))的组合中得出的概率或置信分数可以作为主治临床医生随访和治疗的基础。如果2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物(例如选自表1或表2或表1和表2的组合或表3或表4中的粪便来源的真核RNA生物标志物)的表达水平与对照中相同的粪便来源的真核RNA生物标志物的表达水平没有显著差异,则临床医生可以确定患者目前不处于结直肠肿瘤的风险。可以鼓励这类患者在未来返回重新筛查。2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物(例如选自表1或表2或表1和表2的组合或表3或表4中的粪便来源的真核RNA生物标志物)的表达水平与对照中相同的粪便来源的真核RNA生物标志物的表达水平没有显著差异的程度,可用于确定所需随访前的持续时间。在一些实施方案中,临床医生可以建议患者在1个月、2个月、3个月、6个月、1年、2年、3年、5年或10年后返回进行随访。本文公开的方法可用于监测结直肠肿瘤标志物水平随时间的任何变化。受试者可以在初始筛查和/或诊断后的任何时间长度内接受监测。例如,受试者可被监测至少2、4、6、8、10、12、14、16、18、20、25、30、35、40、45、50、55或60个月或更长时间,或至少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20或更多年。
本文公开的方法和组合物可用于为处于结直肠肿瘤或结直肠癌风险或者患有结直肠肿瘤或结直肠癌的受试者选择临床方案。临床方案可包括实施进一步的诊断程序,例如粪便潜血试验、粪便免疫化学试验或结肠镜检查,以去除癌症、息肉或癌前病变。在一些实施方案中,所述临床方案可以包括治疗方法。在一些实施方案中,所述方法包括为患有结直肠肿瘤或结直肠癌的受试者选择治疗方法。如果2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种的选自表1或表2或表1和表2的组合或表3或表4的粪便来源的真核RNA生物标志物的表达水平明显不同于对照中相同的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的表达水平,则患者可能患有结直肠肿瘤或结直肠癌。在这些情况下,可建议进一步筛查,例如,使用本文公开的方法以及粪便潜血试验、粪便免疫化学试验和/或结肠镜检查增加筛查频率。如果选自表1或表2或表1和表2的组合或表3或表4中的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的表达水平与对照中相同的选自表1或表2或表1和表2的组合或表3或表4中的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物的表达水平显著不同,则患者可能具有特定类型的结直肠肿瘤,例如高危腺瘤。在一些实施方案中,可以推荐治疗,包括例如切除息肉的结肠镜检查、化疗、免疫疗法或手术(例如肠切除术)。因此,所述方法可用于确定2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物(例如2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种选自表1或表2或表1和表2的组合或表3或表4或其变体的粪便来源的真核RNA生物标志物)的表达水平,然后确定治疗过程。只要出现临床有益结果,受试者(即患者)即被有效治疗。例如,这可能意味着疾病症状的完全解决、疾病症状严重性的降低或疾病进展的减缓。这些方法可以进一步包括以下步骤:a)识别受试者(例如,患者,更具体地说,人类患者),其患有结直肠肿瘤或结直肠癌,和b)向受试者提供抗癌治疗,例如治疗剂,例如免疫治疗剂、外科手术或放射疗法。向受试者提供的导致疾病症状完全缓解、疾病症状严重性降低或疾病进展减缓的治疗剂的量被认为是治疗有效量。本方法还可以包括监测步骤,以帮助优化给药和调度以及预测结果。监测还可用于检测耐药性的出现,快速区分有反应的患者和无反应的患者,或评估癌症的复发。如果有耐药或无反应的迹象,临床医生可以在肿瘤形成额外的逃逸机制之前选择替代或辅助药物。
本文公开的方法还可以与用于诊断和治疗结肠直肠癌的常规方法组合使用。因此,诊断方法可以与结肠直肠癌的标准诊断方法一起使用。举例来说,所述方法可以与粪便隐血试验、粪便免疫化学试验或结肠镜检查组合使用。所述方法还可以与其它结肠直肠癌标志物一起使用,例如KRAS、NRAS、BRAF、CEA、CA 19-9、p53、MSL、DCC、MSI和MMR。
本文公开的诊断方法还可以与结肠直肠癌治疗组合使用。结肠直肠癌治疗方法一般分为几类:手术、化疗、放射疗法、靶向疗法和免疫疗法。手术可以包括结肠切除术,结肠造口术连同部分肝切除或直肠切除术。化疗可以是全身化疗或局部化疗,其中化疗剂直接放置在受感染器官附近。示例性化疗剂可包括5-氟尿嘧啶、奥沙利铂或其衍生物、伊立替康(irinotecan)或其衍生物、甲酰四氢叶酸或卡培他滨、丝裂霉素C、顺铂和多柔比星(doxorubicin)。放疗可以是外部放疗(使用机器将放射线引向癌症),或者内部放疗,其中放射性物质直接放置在结肠直肠癌中或附近。靶向药剂可包括抗血管生成剂(如贝伐单抗(bevacizumab))或EGFR抑制剂单克隆抗体(西妥昔单抗(cetuximab)、帕尼单抗(panitumumab))、雷莫芦单抗(ramuciramab)(抗VEGFR2),阿柏西普(aflibercept)、瑞格非尼(regorafenib)、三氟尿苷-提普来昔(tripfluridine-tipiracil)或其组合。靶向药剂也可以与标准化疗剂组合。免疫疗法可包括施用特异性抗体,例如抗PD-1抗体、抗PD-L-1抗体和时间-CTLA-4抗体、抗-CD 27抗体;癌症疫苗、过继细胞疗法、溶瘤病毒疗法、辅助免疫疗法和基于细胞因子的疗法。示例性免疫疗法可以包括Keytruda、Opdiva和iplimumab。其它治疗方法包括干细胞移植、热疗、光动力疗法、血液制品捐赠和输血或激光治疗。
我们可以使用术语“增加的(increased)”、“增加(increase)”或“上调的(up-regulated)”来通常意指生物标志物水平的统计学上显著量的增加。在一些实施例中,与对照相比,增加可以是至少10%的增加,例如至少约20%、或至少约30%、或至少约40%、或至少约50%、或至少约60%、或至少约70%、或至少约80%、或至少约90%、或至多且包括100%增加的增加,或与对照相比在10%与100%之间的任何增加、或至少约0.5倍、或至少约1.0倍、或至少约1.2倍、或至少约1.5倍、或至少约2倍、或最少约3倍、或至少约4倍、或至少约5倍或至少约10倍、或与对照相比在1.0倍与10倍或更大增加之间的任何增加。
我们可以使用术语“减少(decrease)”、“减少的(decreased)”、“减小(reduced)”、“减小(reduction)”或“下调的(down-regulated)”来指真核生物标志物水平的统计学上显著量的降低。在一些实施例中,与对照相比,减少可以是至少10%的减少,例如至少约20%、或至少约30%、或至少约40%、或至少约50%、或至少约60%、或至少约70%、或至少约80%、或至少约90%、或至多且包括100%减少(即与对照相比不存在)的减少,或与对照相比在10%与100%之间的任何减少、或至少约0.5倍、或至少约1.0倍、或至少约1.2倍、或至少约1.5倍、或至少约2倍、或最少约3倍、或至少约4倍、或至少约5倍或至少约10倍、或与对照相比在1.0倍与10倍或更大减少之间的任何减少。
真核生物标志物的增加或真核生物标志物的减少的统计显著性可以表示为p值。根据特定的真核生物标志物,p值或q值可小于0.05、小于0.01、小于0.005、小于0.002、小于0.001或小于0.0005。q值可以是p值的导数。在一些实施方案中,q值可以是针对错误发现率调整的p值。
对照可以是从患者或一组患者获得的生物样品。在一些实施例中,对照可以是参考值。可以从已被诊断为健康的个体或个体群体获得对照。健康个体可包括例如在上一年内的粪便寄生虫试验、粪便细菌试验、结肠镜检查或内窥镜检查中检测为阴性的个体。可以从已被诊断为患病的个体或个体群体获得对照。患病个体可包括例如在上一年内的粪便寄生虫试验、粪便细菌试验、结肠镜检查或内窥镜检查中检测为阳性的个体。对照可以从先前已被诊断患有疾病但目前处于缓解、没有活跃的疾病,或目前未患所述疾病的个体或个体群体中获得。可以在一个、两个或更多个时间点从个体获得对照。举例来说,对照可以是在较早时间点从受试者获得的生物样品。对照可以是特定生物标志物的标准参考值。可以基于评估具有相似年龄、性别(sex)、性别(gender)、体型、品种,种族背景或一般健康状况的个体来推导标准参考值。在一些实施方案中,对照可以是从算法导出的一个或多个值。
实验样品可以是从受试者获得的生物样品。可以从具有已知或未知健康状态的受试者获得实验样品。在一些实施例中,可以例如通过分析实验样品、活组织检查、身体检查、实验室研究、目视检查或遗传分析来确定受试者的健康状况。可以通过实验样品确定的受试者的健康状况可以是患病的、处于疾病风险的或健康的。
制品
还提供了用于检测和定量生物样品(例如粪便样品)中选定的粪便来源的真核RNA生物标记的试剂盒。因此,包装产品(例如,含有一种或多种本文所述组合物并且以浓缩或即用浓度包装用于储存、运输或销售的无菌容器)和试剂盒也在本发明的范围内。产品可以包括含有一种或多种本发明组合物的容器(例如,小瓶、广口瓶、瓶、袋、微量板、微芯片或珠粒)。另外,制品可以进一步包括例如包装材料、使用说明书、注射器、递送装置、缓冲剂或其它控制试剂。
所述试剂盒可以包括能够检测生物样品中对应于2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物(例如选自表1或表2或表1和表2的组合或表3或表4的粪便来源的真核RNA生物标志物)的RNA的化合物或试剂;和标准品;和任选的一种或多种进行检测、定量或扩增所需的试剂。在一些实施方案中,所述试剂盒可以包括能够检测生物样品中对应于2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物(例如选自表1或表2或表1和表2的组合或表3或表4的粪便来源的真核RNA生物标志物)的RNA的化合物或试剂;和一个标准品;和任选的一种或多种进行检测、定量或扩增所需的试剂。所述化合物、试剂和/或试剂可以包装在合适的容器中。所述试剂盒可以进一步包括使用试剂盒检测和定量核酸的说明。所述试剂盒还可包含一个对照或一系列对照,可对其进行分析并与所含的测试样品进行比较。所述试剂盒的每种成分都可以封装在一个单独的容器中,所有不同的容器都可以封装在一个单独的包装中,并附有解释使用所述试剂盒进行的测定的结果的说明。在一些实施方案中,所述试剂盒可以包括对一种或多种对照标志物特异的引物或寡核苷酸探针。在一些实施方案中,所述试剂盒包括对2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多种粪便来源的真核RNA生物标志物(例如选自表1或表2或表1和表2的组合或表3或表4的粪便来源的真核RNA生物标志物)进行定量的特异性试剂。
在一些实施方案中,所述试剂盒可以包括特异性用于从患者(例如,人类患者)的粪便样品将真核细胞与细菌细胞和其它粪便组分分离和提取粪便来源的真核RNA的试剂。因此,试剂盒可以包括缓冲液、乳液珠粒、二氧化硅珠粒、稳定试剂和各种用于离心的过滤器和容器。试剂盒还可以包括用于粪便处理,以最小化样品的污染并确保粪便样品中粪便来源的真核RNA的稳定性的说明。试剂盒还可以包括确保样品保存的物品,例如,稳定缓冲液、冷却剂或加热包。在一些实施例中,试剂盒可以包括粪便收集装置。
产品还可以包括图例(例如,印刷标签或插入物或描述产品使用的其它介质(例如,音频或录像带或计算机可读介质))。图例可以与容器相关联(例如,附着到容器)并且可以描述可以使用试剂的方式。试剂可以是即用的(例如,存在于适当单位中),并且可以包括一种或多种另外的佐剂、载体或其它稀释剂。或者,试剂可以以浓缩形式连同稀释剂和对稀释的说明提供。
实施例
实施例1:人类粪便样品采集
人类粪便收集:要求患者排便到套在马桶座上的桶中,并将所得样品储存在冷冻柜中,直到所述样品被运送到哈尔科夫国立医科大学(Kharkiv National MedicalUniversity)(乌克兰哈尔科夫(Kharkiv,Ukraine))。将粪便等分到50mL锥形管中并储存在-80℃。将样品在干冰上从哈尔科夫国立医科大学装运到Capital Biosciences(马里兰州盖瑟斯堡(Gaithersburg,MD)),并立即转移到-80℃冷冻柜。将样品在干冰上从那里装运到BioGenerator Labs(密苏里州圣路易斯(Saint Louis,MO)),所述样品在那里储存在-80℃冷冻柜中直到进行提取。
人类样品类型:从195例结肠直肠癌(I-IV期)患者、126例癌前腺瘤患者、125名良性息肉患者和125名结肠镜检查阴性的患者,产生总计454个样品。健康个体是没有结肠直肠癌、炎性肠病、脂泻病、肠易激综合征、最近20天内腹泻或任何其它胃肠疾病史的患者。良性息肉患者在接受结肠镜检查前提供粪便样本,在结肠镜检查中,医生通过随后的活检和组织学评估检测出被认为是良性的息肉。患病的个体是被诊断患有结肠直肠癌或癌前腺瘤的患者。结肠直肠癌患者在过去一个月内通过结肠镜检查和随后的活组织检查被诊断为I期-IV期结肠直肠癌,并且尚未接受任何活组织检查后治疗,所述治疗可以包括化疗、放射和/或手术。癌前腺瘤患者在进行结肠镜检查之前提供粪便样品,其中医生通过随后的活组织检查和组织学评估检测到被认为是癌前的息肉。基于性别和年龄段(50-60岁、60-70岁、70-80岁和80-90岁),健康和良性息肉个体与腺瘤和癌症患者匹配。本采集使用的患者都获得Capital Biosciences的同意。舒尔曼内部审查委员会(Schulman Internal ReviewBoard)为本采集提供了道德监督。
实施例2:人类核酸提取
总核酸提取:将每个粪便样品放到50mL锥形管中。添加约1,000-25,000mg粪便到每个管。添加另外的20-40mL溶液到每个管。这种溶液含有汉克斯平衡盐溶液(HBSS)(西格玛-奥德里奇)与0.05%Tween-20(西格玛-奥德里奇)和0.0002%RNA酶抑制剂(西格玛-奥德里奇)的混合物。将粪便悬浮到溶液中并且在约0-10℃下旋转0-10分钟。将溶液在4℃以1000rpm离心10分钟并且丢弃上清液。添加约4-10mL 裂解缓冲液(bioMerieux)到球粒并且将球粒再悬浮到溶液中。将溶液在20-25℃下以2500-3500rpm离心10-15分钟。在差速离心期间,溶液分成三层。底层包括固体细胞碎片,中间层是富含人类核酸的亲水层,顶层是疏水脂质层。将顶部的两个层转移到新的15毫升锥形管中,并将溶液在20-25℃下以2500rpm再次离心10分钟。这个离心步骤的结果是分成三层:底层是固体细胞碎片,中间层是富含人类核酸的亲水层,顶层是疏水脂质层。为了从溶液中筛选大的碎片,将20μL移液器吸头放到1mL移液器吸头上,并从15mL管中移取2mL亲水层并转移到
裂解缓冲液(bioMerieux)到球粒并且将球粒再悬浮到溶液中。将溶液在20-25℃下以2500-3500rpm离心10-15分钟。在差速离心期间,溶液分成三层。底层包括固体细胞碎片,中间层是富含人类核酸的亲水层,顶层是疏水脂质层。将顶部的两个层转移到新的15毫升锥形管中,并将溶液在20-25℃下以2500rpm再次离心10分钟。这个离心步骤的结果是分成三层:底层是固体细胞碎片,中间层是富含人类核酸的亲水层,顶层是疏水脂质层。为了从溶液中筛选大的碎片,将20μL移液器吸头放到1mL移液器吸头上,并从15mL管中移取2mL亲水层并转移到 一次性料筒(bioMerieux)。另外,添加60μL
一次性料筒(bioMerieux)。另外,添加60μL 磁性二氧化硅(bioMerieux)到料筒。使用移液器将珠粒混合到溶液中0.5-1分钟。根据制造商的说明,使用特异性A方案将与珠粒结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是70μL。将这个核酸溶液移取到1.5mL管中并放在冰上。然后使用相同技术向前一步骤中使用的相同
磁性二氧化硅(bioMerieux)到料筒。使用移液器将珠粒混合到溶液中0.5-1分钟。根据制造商的说明,使用特异性A方案将与珠粒结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是70μL。将这个核酸溶液移取到1.5mL管中并放在冰上。然后使用相同技术向前一步骤中使用的相同 一次性料筒(bioMerieux)再装载来自先前使用的15mL管中的相同溶液的另外的2mL亲水层以筛选出大的碎片。添加另外的20μL
一次性料筒(bioMerieux)再装载来自先前使用的15mL管中的相同溶液的另外的2mL亲水层以筛选出大的碎片。添加另外的20μL  磁性二氧化硅(bioMerieux)到料筒。使用移液器将珠粒混合到溶液中0.5-1分钟。如上文所描述,根据制造商的说明,使用特异性A方案将与珠粒结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是70μL。将这个核酸溶液移取到已经含有第一个70μL洗脱液的原始1.5mL管中,并将合并的溶液放在冰上。
磁性二氧化硅(bioMerieux)到料筒。使用移液器将珠粒混合到溶液中0.5-1分钟。如上文所描述,根据制造商的说明,使用特异性A方案将与珠粒结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是70μL。将这个核酸溶液移取到已经含有第一个70μL洗脱液的原始1.5mL管中,并将合并的溶液放在冰上。
DNA酶处理:将140μL溶液用Baseline-Zero-DNase(Epicentre)在35-40℃处理20-40分钟。将1-2mL等分的 裂解缓冲液添加到DNA酶处理的溶液中,并将样品转移到新的
裂解缓冲液添加到DNA酶处理的溶液中,并将样品转移到新的 一次性料筒中。将整个溶液与60μL
一次性料筒中。将整个溶液与60μL 磁性二氧化硅一起添加到新料筒中。根据制造商的说明,使用
磁性二氧化硅一起添加到新料筒中。根据制造商的说明,使用 通用方案将与珠粒结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是25μL。将这个核酸溶液移取到1.5mL管中并储存在0-6℃下。
通用方案将与珠粒结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是25μL。将这个核酸溶液移取到1.5mL管中并储存在0-6℃下。
实施例3:人类粪便样品中的人类核酸水平的测量
提取结果:使用安捷伦2100生物分析仪对上述提取的1-2uL各样品的总核酸和RNA完整性进行评估。对样品进行了定性和定量分析。电泳分析用于检查提取的RNA的质量。所述电泳文件是通过将每个样品的条带与由RNA阶梯中的大小标记代表的条带进行比较,并识别18S和28S核糖体RNA(rRNA)条带来读取的。所述rRNA条带是标准化阶梯上围绕2000个核苷酸标记的两条大而突出的带。定性而言,足够的条带和较暗的条带强度表明,大量完整的核酸可用于进一步分析,如微阵列测序、聚合酶链反应(PCR)、核酸测序、分子条形码或探针捕获。电泳图谱是每个电泳文件的图形表示,带有RNA完整性数量(RIN)、总RNA质量和总rRNA质量的量化。定量而言,RIN值越大,总RNA质量越大;总rRNA质量越大,样品用于进一步分析(如微阵列测序、聚合酶链反应(PCR)、核酸测序、分子条形码或探针捕获)的可能性就越高。
图1A是根据文献中描述的方法提取的六个样品的电泳文件和一个样品的电泳图谱。图1B是上面提取的六个样品的电泳文件和一个样品的电泳图谱。以上提取的样品导致更大的RIN和更多的真核质量。上面提取的seRNA的更高质量还表现在更多不同的核糖体RNA带(18S和28S)和较少的细菌噪音上,18S带以下的最小条带证明了这一点。
实施例4:在稳定缓冲液中孵育seRNA
选择11个样品用稳定缓冲液进行测试。这些样品被分成5克等份,形成三个队列:队列1(n=11)、队列2(n=11)和队列3(n=8)。使用上述方法立即提取队列1样本。(图2A)。队列2样品在稳定缓冲液中孵育,并在室温下储存24小时,然后使用上述方法提取(图2B)。队列3样品在稳定缓冲液中孵育,并在室温下储存48小时,然后使用上述方法提取(图2C)。
提取后,使用安捷伦生物分析仪对所有样品(n=30)进行定性分析。用从所有样品中分离的RNA检测到清晰和独特的完整核糖体18S和28S带。18S和28S的强度(可用于估计真核RNA的量)随着在稳定缓冲液中孵育而增加。此外,细菌噪音(由18S以下条带显示)随着在稳定缓冲液中孵育而降低。
来自安捷伦生物分析仪的数据还能够定量分析RNA完整性数(RIN)和真核生物质量。RIN对所有样本来说都足够了。随着在稳定缓冲液中孵育,每个队列的总RIN数增加,队列1、队列2和队列3的平均相对标准偏差分别为4.6、5.9和7.1。真核生物的质量在所有样品中都是足够的。真核生物的总质量随着在稳定缓冲液中孵育而增加,队列1、队列2和队列3的平均质量分别为11.1ng、39.7ng和78.4ng。
实施例5:RNA转录本的分析
使用Affymetrix GeneChipTM人类转录组阵列2.0(Santa Clara,CA)选择330个样本进行分析。用Ambio WT-pico试剂盒扩增约100ng不含DNA酶的粪便RNA,随后按照制造商的方案与昂飞GeneChipTM人类转录本组阵列2.0杂交。使用信号空间变换-稳健多阵列分析(Signal Space Transformation-Robust Multiarray Analysis,SST-RMA)与昂飞Expression ConsoleTM对所有样品进行标准化。
在Affymetrix微阵列中的70,523个转录本簇中,预先选择了对应于3,977个基因的5,149个转录本簇的子集来评估差异表达。这种初始选择降低了错误发现率,并过滤掉了在癌症发展和进展中没有已知功能的基因。
这330个个体被分成265个个体的训练组和65个个体的测试组。所述训练组用于识别差异表达基因并建立计算模型,而测试组用于确定计算模型的检测精度。使用标准LIMMA包来鉴定在癌前腺瘤或CRC和结肠镜检查中没有发现的患者之间差异表达的RNA转录本簇的子集。所有生物标志物都根据对数优势分数进行排序,排名最高的200个生物标志物(p<0.05)作为构建机器学习模型的特征。模型开发选择了带RBF核的支持向量机模型(-SVM)。所述核函数通过将特征扩展到未明确计算的较高维空间来计算个人之间的距离。SVM找到了分隔标签组的最大边距超平面。所述参数定义用于确定最大边距的个人分数的下限。使用来自训练组中所有265个个体的200个转录本的表达水平来训练SVM模型。SVM的内部验证获得了0.776的总ROC AUC。当评估CRC和腺瘤时,该模型分别获得0.829和0.788的ROC AUC(图3A)。
这种多目标RNA生物标志物算法也用于独立的测试组中的65个个体。所述模型正确识别了在结肠镜检查结果为阳性的所有个体中的79%(43人中的34人)、95%的癌前腺瘤患者和65%的癌症患者。CRC的模型敏感性与肿瘤大小直接相关,因此72%直径>4cm的肿瘤被准确检测到。腺瘤的模型敏感性与大小无关,对小(<5mm)和大(>1cm)病变的预测准确率均为100%(图3B)。
实施例6:使用seRNA表达特征的CRC分子分型
在Affymetrix微阵列中的70,523个转录本簇中,选择了对应于274个基因的转录本簇子集,以注释来自诊断为结直肠癌的个体的患者样本,该患者样本具有由结直肠癌亚型联和(CRCSC)定义的CRC共有分子亚型(CMS)(图4A)。所述CRCSC分类器基于每个基因的重要性进行组织,以提高分子亚型分类的准确性。使用与每个基因相关的转录本簇的中值发光,在基因水平上总结转录本簇的表达。基因表达数据在基因水平和整个队列中使用中值表达水平进行标准化。标准化数据被用作R包CMS分类器中定义的随机森林分类器的输入,以标记共有分子亚型。
CMS分类器的输出包括四个值,每个值是样本与CMS1-4关联的后验概率。CMS1包括具有增加的微卫星不稳定性(MSI-H)和与免疫浸润相关的特征的肿瘤。图4B提供了用于鉴定结直肠癌亚型CMS1的25个示例性结直肠癌分子亚型生物标志物基因。CMS2-4分别与典型、代谢或间充质基因表达信号相关。根据CMS分类器,117个个体中有14个(12%)被分类为CMS1,117个个体中有100个(85%)被分类为CMS2-4(典型、代谢和间充质),117个个体中有3个(3%)被分类为CMS1/CMS2混合(图5)。
实施例7:人类粪便样品采集、提取和测量
人类粪便收集:患者被要求将粪便放入一个放在马桶座上的桶中,由此产生的样本由递送者收集,并运送到华盛顿大学医学院(密苏里州圣路易斯)的消化疾病研究核心中心。将粪便分装到50mL锥形管中,并在-80℃下储存。从那里,样本在干冰上被运送到BioGenerator实验室(密苏里州圣路易斯),在那里它们被储存在-80℃的冰箱中,直到提取。用于采集的病人得到了华盛顿大学医学院的同意。华盛顿大学医学院内部审查委员会也为该采集提供了道德监督。
人类样本类型:从6名结直肠癌患者(I-IV期)、4名癌前腺瘤患者和14名结肠镜检查结果为阴性的患者中获得粪便样本,得到24份总样本。这些样本来自哈尔科夫国立医科大学和华盛顿大学医学院的人类粪便标本。样本标签以与之前人类样本类型中概述的标准一致的方式识别和匹配。
总核酸提取:以与之前概述的总核酸提取方法(包括DNAse处理)一致的方式从样品中提取seRNA,并以与提取结果中概述的方法一致的方式分析seRNA的质量。
实施例8:RNA转录本的分析
文库制备:使用由398个定制扩增子组成的Illumina靶向RNA定制小组来产生seRNA文库。文库的制备依赖于以下步骤:使用ProtoScript II逆转录酶(Illumina)初步合成cDNA,将寡聚物池与目标seRNA杂交,使用Illumina试剂(AM1,ELM4,RSB,UB1)延伸寡聚物,以及通过聚合酶链反应(PCR)进行扩增。总质量输入范围为200-400ng,使用的PCR循环数范围为26-28x。文库扩增后,用Illumina试剂(RSB,AMPure,EtOh XP珠)清洗捕获的cDNA。使用安捷伦生物分析仪和Qubit Fluorometric Quantitation(Thermo Fisher)分析文库制剂的数量和质量。本分析中描述的所有样本都通过了初始质量检查,对于进行下一代测序合格。
测序:对单个样品使用独特的指数,以允许文库制备的汇集和所有样品在Illumina NextSeq系统上的同一流动池中的多路复用。所有24个样品在中间输出流动池(Illumina)中汇集在一个通道上。读长每端的前150个碱基对被测序(2x150),测序的读长被附加到输出的FASTQ文件。对FASTQ文件的质量检查表明,19个样品具有足够的总读长和足够的生物信息学分析质量。
比对:测序后,将定制引物序列从序列中剔除,经剔除的读长与最新的参考基因组(GRCh38)进行比对。转录表达通过计算位点间的平均覆盖率获得。转录表达由两个看家基因(GAPDH和ACTB)的平均覆盖率标准化。
实施例9:不同平台上的生物复制
在微阵列和测序中评估了四个样品。跨平台的398个转录本的线性回归显示中等的再现性(Pearson's r范围=0.48-0.63)。测序显示相对于微阵列的分辨率增加,低发光转录本的信号范围证明了这一点(图6)。
实施例10:使用seRNA的分层聚类分析
对所有13个独特样品的RNA测序数据进行无监督主成分分析(PCA)。在CRC患者、腺瘤患者和未发现肿瘤的患者中观察到聚类。来自癌症患者的样本显示了与其它患者群体最大的差异和分离,而来自未发现肿瘤的患者的样本显示了更窄的聚类(图7)。
实施例11:使用seRNA评估测序变体
变体识别和注释:整合基因组观察器用于识别与CRC肿瘤发生有关的变体。得到扩增子小组覆盖了398个捕获基因的基因组空间的大约3%。典型的驱动突变如图9所示。如图8所示,我们发现了几个潜在的驱动突变。这些突变包括高危腺瘤患者的APC中的错义突变(13%变体等位基因频率(VAF)),高危腺瘤患者的SMAD4中的错义突变(17%VAF),一期CRC患者的MAPK3调节区中的3’缺失(7%VAF),结肠镜检查无发现患者的PIK3CA中的错义突变(12%VAF),高危腺瘤患者的KRAS中的错义突变(3%VAF),以及高危腺瘤患者的CDH1中的错义突变(2%VAF)(图8)。
实施例12:人类粪便样品采集
人类粪便采集:粪便样本由华盛顿大学医学院(St.Louis,MO)消化疾病研究核心中心(DDRCC)获得。通过邮件向所有患者发送粪便样本采集工具包,并通过递送者将工具包返还给DDRCC。临床数据(例如,人口统计信息、结肠镜检查结果等)是由DDRCC采集的。在-80℃冷冻之前,使用市售的粪便免疫化学试验(FIT)(Polymedco,OC-Light S FIT)对每个样品进行粪便中的血液测试。本研究招募的每个患者都进行了结肠镜检查,阳性结果的患者进行了活检和随后的组织病理学检查,以确定肿瘤的分类。腺瘤的分类是基于组织病理学(良性与癌前病变)、息肉数量、息肉大小和分化分层的。癌症分类是根据美国癌症联合委员会(AJCC)7TNM系统分层的。如果患者在结肠镜检查中无发现,他或她被标记为健康。
人类样本类型:本研究共收集了275名个体的粪便样本。获得所有患者的测序数据、FIT、人口统计学信息(即性别、年龄、种族、吸烟状况和家族史)和结肠镜检查结果以及组织病理学信息(如果适用)。在这项研究中,11名患者患有CRC(I-IV期),26名患者患有高危腺瘤(HRAs),37名患者患有中危腺瘤(MRAs),61名患者患有低危腺瘤(LRAs),50名患者患有良性息肉,90名患者在结肠镜检查中无发现。患者类型、人口统计和处理信息总结在图10中。健康个体是在结肠镜检查中无发现的患者,并且没有结直肠癌、炎症性肠病、乳糜泻、肠易激综合征、过去20天内腹泻或任何其它胃肠疾病的病史。良性息肉患者在接受结肠镜检查前提供粪便样本,在结肠镜检查中,医生检测出通过随后的活检和组织学评估被认为是良性的息肉。患病个体是诊断为结直肠癌或癌前腺瘤的患者。结直肠癌患者在过去一个月内通过结肠镜检查和随后的活检被诊断为I-IV期结直肠癌,但尚未接受任何活检后治疗,包括化疗、放射和/或手术。癌前腺瘤患者(HRAs、MRAs和LRAs)在接受结肠镜检查前提供了粪便样本,在结肠镜检查中,医生检测出通过随后的活检和组织学评估被认为是癌前的息肉。腺瘤风险的分层是基于息肉的大小、息肉的数量、发育不良的程度和细胞形态。所述患者群体中的结直肠癌患者增多,但其余样本代表无症状筛查人群。用于采集的病人得到了华盛顿大学医学院的同意。华盛顿大学医学院内部审查委员会对该采集进行了道德监督。
分成训练和测试组:154个预期收集的粪便样本用作训练组,110个预期收集的粪便样本用作支持测试组。从CRC患者中回顾性收集的11份粪便样本也包括在支持测试组中。使用t检验(总体均值)或z检验(总体频率)评估训练组和支持测试组的分类、人口统计学和处理差异,如果p值小于0.05,则表明显著性。在训练组和支持测试组的特征之间有两个统计学上显著的差异。首先,回顾性收集样本(即,来自CRC患者的样本)不包括在训练组中。第二,相对于训练组,支持测试组具有不同的处理质量。具体而言,用于粪便来源的真核RNA提取的平均粪便输入量减少(12.9克对12.0克;p值=0.03),粪便来源的真核RNA平均浓度降低(168.6ng/uL对56.1ng/uL;p值<0.01),平均文库制备片段大小减少(200.6对碱基对192.2对碱基;p值<0.01)(图10)。
实施例13:自定义捕获板的开发
面板转录本:在Illumina DesignStudio中开发了一个由639个扩增子组成的定制捕获板,用于文库制备。定制的捕获探针与408个转录本相关联,这些转录本是使用先前进行的研究和文献选择的。
微阵列转录本:基于微阵列实验选择转录本。在本实验中,从粪便样本中提取总的seRNA,并使用Affymetrix人类转录组阵列2.0(Thermo Fisher Sciental,Waltham,MA)评估其表达。将177例CRC或癌前腺瘤患者(患病队列)的微阵列表达谱与88例结肠镜检查无发现的患者(健康队列)的表达谱进行比较。214个转录本被鉴定为差异表达(p<0.03),并被选择用于捕获板。
纳米串转录本:基于纳米串实验选择转录本。在本实验中,从粪便样本中提取总seRNA,并使用 PanCancer Pathways Panel(NanoString,Seattle,WA)和
PanCancer Pathways Panel(NanoString,Seattle,WA)和 PanCancer Progression Panel(NanoString,Seattle,WA)评估其表达。来源于59例CRC或癌前腺瘤患者(患病队列)的纳米串表达谱与26例结肠镜检查无发现的患者(健康队列)的表达谱进行了比较。123个转录本被鉴定为差异表达,并被选择用于捕获板。
PanCancer Progression Panel(NanoString,Seattle,WA)评估其表达。来源于59例CRC或癌前腺瘤患者(患病队列)的纳米串表达谱与26例结肠镜检查无发现的患者(健康队列)的表达谱进行了比较。123个转录本被鉴定为差异表达,并被选择用于捕获板。
其它转录本:评估文献中与CRC相关的其它转录本。这包括搜索GeneCards、ClinVar、癌症体细胞突变目录(COSMIC)、癌症变体的临床解释(CIViC)、结直肠癌亚型分类联合分类器和其它相关研究。使用这些文献为定制捕获板选择了71个转录本。
实施例14:人类核酸提取
总核酸提取:将每个粪便样品放到50mL锥形管中。添加约6,000-25,000mg粪便到每个管。添加另外的20-40mL溶液到每个管。该溶液在pH 7.5下包含10mM Trizma碱(Sigma-Aldrich,圣路易斯,密苏里州),1mM EDTA(Sigma Aldrich)与0.05%Tween-20(Sigma-Aldrich)和0.0002%RNase抑制剂(Sigma-Aldrich)的混合物。将溶液在4℃下以1000rpm离心10分钟,并弃去上清液。添加约4-10mL 裂解缓冲液(bioMérieux,Durham,NC)到沉淀中并且将沉淀再悬浮到溶液中。将所述溶液在20-25℃下以2500-3500rpm离心10-15分钟。在差速离心期间,所述溶液分成三层。底层包括固体细胞碎片,中间层是富含人类核酸的亲水层,顶层是疏水脂质层。将顶部的两个层转移到新的15mL锥形管中,并将溶液在20-25℃下以2500rpm再次离心15分钟。这个离心步骤的结果是分成三层:底层是固体细胞碎片,中间层是富含人类核酸的亲水层,顶层是疏水脂质层。为了从溶液中筛选大的碎片,将10μL移液器吸头放到1mL移液器吸头上,并从15mL管中移取2mL亲水层并转移到
裂解缓冲液(bioMérieux,Durham,NC)到沉淀中并且将沉淀再悬浮到溶液中。将所述溶液在20-25℃下以2500-3500rpm离心10-15分钟。在差速离心期间,所述溶液分成三层。底层包括固体细胞碎片,中间层是富含人类核酸的亲水层,顶层是疏水脂质层。将顶部的两个层转移到新的15mL锥形管中,并将溶液在20-25℃下以2500rpm再次离心15分钟。这个离心步骤的结果是分成三层:底层是固体细胞碎片,中间层是富含人类核酸的亲水层,顶层是疏水脂质层。为了从溶液中筛选大的碎片,将10μL移液器吸头放到1mL移液器吸头上,并从15mL管中移取2mL亲水层并转移到 一次性柱(bioMerieux)。另外,添加50μL
一次性柱(bioMerieux)。另外,添加50μL 磁性二氧化硅(bioMerieux)到所述柱。使用移液器将磁珠混合到溶液中0.5-1分钟。根据制造商的说明,使用特异性A方案将与磁珠结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是70μL。将这个核酸溶液移到1.5mL管中并放在冰上。然后使用相同技术向前一步骤中使用的相同
磁性二氧化硅(bioMerieux)到所述柱。使用移液器将磁珠混合到溶液中0.5-1分钟。根据制造商的说明,使用特异性A方案将与磁珠结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是70μL。将这个核酸溶液移到1.5mL管中并放在冰上。然后使用相同技术向前一步骤中使用的相同 一次性柱(bioMerieux)再装载来自先前使用的15mL管中的相同溶液的另外的2mL亲水层以筛选出大的碎片。添加另外的20μL
一次性柱(bioMerieux)再装载来自先前使用的15mL管中的相同溶液的另外的2mL亲水层以筛选出大的碎片。添加另外的20μL 磁性二氧化硅(bioMerieux)到所述柱。使用移液器将磁珠混合到溶液中0.5-1分钟。如上文所描述,根据制造商的说明,使用特异性A方案将与磁珠结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是70μL。将这个核酸溶液移取到已经含有第一个70μL洗脱液的原始1.5mL管中,并将合并的溶液放在冰上。
磁性二氧化硅(bioMerieux)到所述柱。使用移液器将磁珠混合到溶液中0.5-1分钟。如上文所描述,根据制造商的说明,使用特异性A方案将与磁珠结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是70μL。将这个核酸溶液移取到已经含有第一个70μL洗脱液的原始1.5mL管中,并将合并的溶液放在冰上。
DNA酶处理:将280μL溶液用Baseline-Zero-DNase(Epicentre)在35-40℃处理20-40分钟。将1-2mL等分的 裂解缓冲液添加到DNA酶处理的溶液中,并将样品转移到新的
裂解缓冲液添加到DNA酶处理的溶液中,并将样品转移到新的 一次性料筒中。将整个溶液与85μL
一次性料筒中。将整个溶液与85μL 磁性二氧化硅一起添加到新料筒中。根据制造商的说明,使用
磁性二氧化硅一起添加到新料筒中。根据制造商的说明,使用 通用方案将与珠粒结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是25μL。将这个核酸溶液移取到1.5mL管中并储存在-80℃下。
通用方案将与珠粒结合的核酸洗脱到缓冲溶液中。洗脱的核酸的体积是25μL。将这个核酸溶液移取到1.5mL管中并储存在-80℃下。
实施例15:人类粪便样品中的人类核酸水平的测量
提取结果:使用安捷伦2100生物分析仪对上述提取的1-2uL各样品的总核酸和RNA完整性进行评估。对样品进行了定性和定量分析。电泳分析用于检查提取的RNA的质量。所述电泳文件是通过将每个样品的条带与由RNA阶梯中的大小标记代表的条带进行比较,并识别18S和28S核糖体RNA(rRNA)条带来读取的。所述rRNA条带是标准化阶梯上围绕2000个核苷酸标记的两条大而突出的带。定性而言,足够的条带和较暗的条带强度表明,大量完整的核酸可用于进一步分析,如微阵列测序、聚合酶链反应(PCR)、核酸测序、分子条形码、扩增子测序或探针捕获。电泳图谱是每个电泳文件的图形表示,带有RNA完整性数量(RIN)、总RNA质量和总rRNA质量的量化。定量而言,RIN值越大,总RNA质量越大;总rRNA质量越大,样品用于进一步分析(如微阵列测序、聚合酶链反应(PCR)、核酸测序、分子条形码、扩增子测序或探针捕获)的可能性就越高。还使用Qubit 4.0荧光计评估样品的RNA浓度。RNA浓度是通过量化Qubit分析组件产生的荧光来确定的,所述Qubit分析组件选择性地结合洗脱液中存在的RNA。定量而言,RNA浓度越高,样品对进一步分析(如微阵列测序、聚合酶链反应(PCR)、核酸测序、分子条形码、扩增子测序或探针捕获)越有用。
实施例16:RNA转录本的分析
文库制备:使用由639个定制扩增子组成的Illumina靶向RNA定制小组来产生seRNA文库。文库的制备依赖于以下步骤:使用ProtoScript II逆转录酶(Illumina,SanDiego,CA)初步合成cDNA,将寡聚物池与目标seRNA杂交,使用Illumina试剂(AM1,ELM4,RSB,UB1)延伸寡聚物,以及通过聚合酶链反应(PCR)进行扩增。总质量输入范围为200-400ng,使用的PCR循环数范围为28x-30x。文库扩增后,用Illumina试剂(RSB,AMPure,EtOHXP珠)清洗捕获的cDNA。使用安捷伦2100生物分析仪和Qubit 4.0荧光计(Thermo Fisher)分析文库制剂的数量和质量。本分析中描述的所有样本都通过了初始质量检查,对于进行下游分析合格。
测序分析:对单个样品使用唯一的索引,以允许在Illumina NextSeq 550系统上汇集文库制备物并将样品多路复用到流动池中。使用PhiX插件进行质量控制。这275个样本汇集在8个单独的高输出流动池(Illumina)中。在一个读长的每一端多达150个碱基对被测序(2x150),测序的读长被附加到输出的FASTQ文件。对FASTQ文件的质量检查表明,所有275个样品具有足够的总读长(>100,000)和足够的生物信息学分析质量。
比对:测序后,将定制的引物序列从读长中剪裁并通过HISAT2.3.0与最新的参考基因组(GRCh38)进行比对。通过计算整个基因座的平均覆盖率获得转录本表达。对于每个转录本,将原始扩增子表达相对于内部看家基因GAPDH进行标准化,以使报告的表达等于每百万个映射的GAPDH读长的扩增子读长计数。
转录本选择:对训练组中的所有样本(n=154个样本)评估639个扩增子的标准化表达。在这639个扩增子中,48个扩增子没有在任何样品中表达,另外71个扩增子没有在所有样品的>95%中表达;从分析中消除了这些扩增子。对于剩余的扩增子,通过将训练组分成100个不同的9:1分段进行自举分析,由此评估每个分段的信息扩增子。如果两个对照组的绝对log2倍变化大于1,则扩增子被认为是信息丰富的(HRAs vs.LRAs,良性息肉,结肠镜检查无发现;MRAs vs.LRAs,良性息肉、结肠镜检查无发现),和对照组之间的方差分析的p值<0.05。转录本选择过程在图11A中进一步说明。在100个分段中的至少一个中总共有来自29个基因的40个扩增子被鉴定为信息丰富(图11B)。如果一个扩增子在至少33%的自举分段中被认为是信息丰富的,那么它被认为是差异表达的,对于作为模型开发的特征合格。有10个扩增子被鉴定为差异表达(在100个分段中的至少33个中有信息)(图11B)。原始GAPDH值被认为是每个样品中总真核RNA的量度。据观察,相对于健康患者,MRAs、HRAs、和CRC患者的原始GAPDH值升高(图12)。人口统计学特征(年龄、吸烟状况、既往家族史、种族和性别)也被考虑用于模型开发。最终,10个差异表达的转录本、原始GAPDH值和2个人口统计学标识(年龄和吸烟状况)对于作为模型开发的特征合格。
实施例17:随机森林模型开发
使用154名患者的训练组和所有13个符合条件的特征构建随机森林模型。从自举训练样本构建了5000棵决策树;每一个节点分段都用基尼系数进行了优化;每棵树都被建造直到它达到最大深度。虽然本文讨论了特定的实施方案,但是应当理解,可能会产生任何合适的模型,例如使用更多和/或更少数量的决策树、更多和/或更少数量的合格特征的随机森林模型等。此外,其它类型的模型,例如深度学习模型或支持向量模型可以与不同的参数一起使用。随机森林模型使用了合适的特征,如差异表达的转录本、原始GAPDH值、年龄和吸烟状况。虽然本文讨论了特定的实施方案,但是应当理解,可以生成任何合适的模型,例如使用所有信息特征和/或信息特征的选定子集的随机森林模型。
模型的输出被配置为提供0-1之间的预测,其中更大的数字反映了对肿瘤或阳性发现的信心增加。在一些实施方案中,使用粪便免疫化学测试(FIT)来改变肿瘤或阳性发现的可信度。例如,对于FIT阳性样本,预测得分将增加到1。三重内部交叉验证用于评估训练模型性能。三重内部交叉验证使用了3种不同的2:1分段,从而使用较大的分段构建模型,并在较小的分段上使用。使用模型预测创建接收器操作特性(ROC)曲线,并使用曲线(AUC)下面积测量模型性能。三分段的中位ROC曲线用于近似交叉验证性能。在包括和不包括FIT特征的情况下绘制ROC曲线。对于结合FIT特征绘制的ROC曲线,正FIT迫使模型预测等于1。在所提供的例子中,不具有FIT特征的内部交叉验证得出HRA相对于所有其它类别(MRA、LRA、良性息肉和结肠镜检查无发现)的ROC AUC为0.65。在所提供的例子中,具有FIT特征的内部交叉验证得出HRA相对于所有其它类别(MRA、LRA、良性息肉和结肠镜检查无发现)的ROCAUC为0.70(图13)。
支持测试组:使用训练组中的所有154个样本构建最终的随机森林模型。对于生成的模型,由基尼重要性测量的最有影响的特征是ACY1和TNFRSF10B(基尼重要性≥0.13),最不重要的特征是PER3(基尼重要性<0.05)。原始GAPDH值是构建随机森林模型的第四个最重要的特征(图14)。在支持测试组中对110个预期采集的粪便样本采用了此模型。绘制具有和不具有FIT特征的ROC曲线,并使用曲线(AUC)下面积来测量模型性能。该模型在不具有FIT特征的情况下获得了0.67的ROC AUC,在具有FIT特征的情况下获得了0.78的ROC AUC(图15)。
模型预测:支持测试组中的模型预测与疾病严重程度相关(图16)。模型输出与疾病严重程度的相关性是生物学的直接反映,而不是作为模型的一部分专门训练的。在前述实施方案中,特征选择和模型输入包括使用三个类别(HRAs、MRAs和所有其它类别),然而,疾病亚型(例如,HRA的子集)和疾病顺序(例如,HRA比MRA更严重)没有用作模型训练的特征。鉴于模型输出与疾病严重程度相关,这允许使用模型输出对特定亚型和疾病严重程度进行前瞻性识别。此外,改变模型参数以向模型提供疾病严重程度信息改善了阳性和阴性结果的分层。
下采样分析:为了了解模型训练的程度,选择训练组中154个样本的下采样分数,并使用支持测试组评估性能。下采样分数范围从30%到100%,增量为10%。对于每个下采样分数,使用自举来执行特征选择,使用合格的特征来训练随机森林模型,并且在支持测试组上使用该模型。支持测试组的ROC AUC用于评估模型性能。对每个下采样分数重复该过程10次,以减少二次采样中的选择偏差,并在包括和不包括FIT特征的情况下评估模型性能。下采样分析显示了用于训练的样本总数和支持测试组的性能之间的直接关系。当排除FIT特征时,HRA相对于所有其它类别的中位ROC AUC从0.55(训练数据的30%)增加到0.67(训练数据的100%)(图17A)。当包括FIT特征时,HRAs相对于所有其它类别的中位ROC AUC从0.72(训练数据的30%)增加到0.78(训练数据的100%)(图17B)。
最终准确性:继续上述实施方案,所述随机森林模型也用于从CRC患者回顾性采集的11个粪便样本。所述模型的输出提供了0-1之间的预测和等于1的正FIT强制模型预测。具有正粪便免疫化学测试(FIT+)或正模型预测(Model+)的样品被认为是阳性的,所有其它样品被认为是阴性的。绘制了一条ROC曲线,其中只有CRC样本被认为是阳性的,其它类别(HRA、MRA、LRA、良性息肉和结肠镜检查中无发现)被认为是阴性的。使用该补充的支持测试组中的所有121个样本,该模型获得了0.94的ROC AUC。绘制了一条单独的ROC曲线,其中CRC和HRA样本被视为阳性,所有其它类别(MRA、LRA、良性息肉和结肠镜检查无发现)被视为阴性。使用该补充的支持测试组中的所有121个样本,该模型获得了0.87的ROC AUC(图18)。选择ROC曲线上准确度最高的一点来计算灵敏度和特异性。在这一点上,该模型对CRC(n=11个样本)的敏感性为91%,对HRAs(n=11个样本)的敏感性为73%,特异性为89%(n=99个样本)(图18)。
筛选人群的外推法:为了获得最终模型性能的更好近似值,在补充的支持测试组上观察到的准确度曲线被外推到预期筛选人群中的相对频率。绘制上述ROC曲线以显示模型性能。当对前瞻性筛查人群中的癌症和HRA进行加权时,与所有其它类别相比,该模型对CRC和HRA样本的ROC AUC为0.80(图19)。将结果外推至预期筛查人群还可以计算肿瘤发现的混合敏感性、阴性预测值(NPV)和阳性预测值(PPV)。这种外推的准确性曲线显示了对CRC和HRA的混合敏感性为74%,阳性预测值为37%,阴性预测值为98%(图19)。
Claims (50)
1.一种检测受试者结直肠肿瘤的方法,所述方法包括:
a)测量从受试者的粪便样品中提取的真核核酸中的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平,所述真核RNA生物标志物选自表1或表2或表1和表2的组合中所列出的生物标志物;
b)将粪便样品中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平与对照中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平进行比较,其中粪便样品中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平相对于对照中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平的差异表明受试者患有结直肠肿瘤。
2.根据权利要求1所述的方法,其中,所述受试者是人。
3.根据权利要求1所述的方法,其中,所述结直肠肿瘤选自结直肠癌、高风险腺瘤、中风险腺瘤和低风险腺瘤。
4.根据权利要求1所述的方法,其中,所述粪便来源的真核RNA生物标志物选自ACY1、TNFRSF10B、DST、EGLN2、PER3、CTNNB1、ACHE、SMAD4、EDN1、ERBB2和GAPDH。
5.根据权利要求1所述的方法,其中,所述核酸包括RNA、总RNA、mRNA、seRNA、tRNA、rRNA、ncRNA、smRNA、或snoRNA,或RNA、总RNA、mRNA、seRNA、tRNA、rRNA、ncRNA、smRNA、或snoRNA的任意组合。
6.根据权利要求1所述的方法,其中,所述表达水平通过核酸测序、微阵列测序、分子条形码、扩增子测序、探针捕获、聚合酶链式反应(PCR)、ddPCR、dPCR、RT-PCR、或RT-qPCR来测量。
7.根据权利要求1所述的方法,进一步包括确定受试者的人口统计信息。
8.根据权利要求1所述的方法,进一步包括对所述受试者进行粪便免疫化学测试(FIT)。
9.一种为患有结直肠肿瘤或处于结直肠肿瘤风险的受试者选择临床方案的方法,所述方法包括:
a)测量来自受试者的粪便样品中存在的真核核酸中的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平,所述真核RNA生物标志物选自表1或表2或表1和表2的组合中所列出的生物标志物;
b)将粪便样品中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平与对照中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平进行比较,其中粪便样品中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平相对于对照中测得的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平的差异表明所述受试者患有结直肠肿瘤或处于结直肠肿瘤风险;
c)实施诊断程序或治疗或诊断程序和治疗的组合。
10.根据权利要求9所述的方法,其中,所述受试者是人。
11.根据权利要求9所述的方法,其中,所述结直肠肿瘤选自结直肠癌、高风险腺瘤、中风险腺瘤和低风险腺瘤。
12.根据权利要求9所述的方法,其中,所述粪便来源的真核RNA生物标志物选自ACY1、TNFRSF10B、DST、EGLN2、PER3、CTNNB1、ACHE、SMAD4、EDN1、ERBB2和GAPDH。
13.根据权利要求9所述的方法,其中,所述核酸包括RNA、总RNA、mRNA、seRNA、tRNA、rRNA、ncRNA、smRNA、或snoRNA,或RNA、总RNA、mRNA、seRNA、tRNA、rRNA、ncRNA、smRNA、或snoRNA的任意组合。
14.根据权利要求9所述的方法,其中,所述表达水平通过核酸测序、微阵列测序、分子条形码、扩增子测序、探针捕获、聚合酶链式反应(PCR)、ddPCR、dPCR、RT-PCR、或RT-qPCR来测量。
15.根据权利要求9所述的方法,其进一步包括确定受试者的人口统计信息。
16.根据权利要求9所述的方法,其进一步包括对所述受试者进行粪便免疫化学测试(FIT)。
17.根据权利要求9所述的方法,其中所述临床方案包括诊断程序或治疗。
18.根据权利要求9所述的方法,其中所述诊断程序包括结肠镜检查。
19.根据权利要求9所述的方法,其中所述治疗包括手术、化疗、放射疗法、靶向疗法或免疫疗法。
20.根据权利要求19所述的方法,其中所述化疗包括施用5-氟尿嘧啶、亚叶酸钙、卡培他滨、奥沙利铂、伊立替康或其组合。
21.根据权利要求19所述的方法,其中所述靶向疗法包括施用贝伐单抗(抗VEGF)、拉米夫定(抗VEGFR2)、阿夫利塞、雷科拉非尼、西妥昔单抗(抗EGFR)、帕尼妥珠单抗、曲氟啶-替吡拉西或其组合。
22.一种检测受试者结直肠肿瘤的方法,所述方法包括:
a)生成随机森林模型,所述随机森林模型被配置为基于预定的特征集来确定结直肠肿瘤的存在,所述特征包括选自表1或表2或表1和表2的组合中列出的生物标志物中的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平;
b)在受试者中测量选自表1或表2或表1和表2的组合中列出的生物标志物中的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物物的表达水平;和
c)在受试者中通过随机森林模型,基于选自表1或表2或表1和表2的组合中列出的生物标志物中的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物的表达水平,确定结直肠肿瘤的存在。
23.根据权利要求22所述的方法,其中所述预定的特征集包括人口统计信息。
24.根据权利要求22所述的方法,其包括通过随机森林模型应用阳性粪便免疫化学试验(FIT)强制模型。
25.根据权利要求22所述的方法,其中,所述2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物选自ACY1、TNFRSF10B、DST、EGLN2、PER3、CTNNB1、ACHE、SMAD4、EDN1、ERBB2和GAPDH。
26.一种治疗受试者结直肠肿瘤的方法,所述方法包括:
a)在来自受试者的粪便样品中确定来自患者的粪便样品中存在的真核核酸中表达升高水平的2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28或29种粪便来源的真核RNA生物标志物,所述真核RNA生物标志物选自表1或表2或表1和表2的组合中列出的生物标志物;和
b)对受试者施用结肠镜检查、手术、化疗、放射疗法、靶向疗法或免疫疗法。
27.一种检测受试者结直肠肿瘤的方法,所述方法包括:
a)测量从受试者粪便样品中提取的真核核酸中的一种或多种变异生物标志物基因的变异等位基因频率,所述变异生物标志物基因选自表3中列出的生物标志物基因;
b)将粪便样品中测得的一种或多种变异生物标志物基因的变异等位基因频率与对照中测得的一种或多种变异生物标志物基因的变异等位基因频率进行比较,其中一种或多种变异生物标志物基因的变异等位基因频率相对于对照中一种或多种变异生物标志物基因的变异等位基因频率的差异表明受试者患有结直肠癌或处于结直肠癌的风险。
28.一种确定受试者是否患有结直肠癌或处于结直肠癌风险的方法,所述方法包括:
a)在从受试者粪便样品中提取的真核核酸中,测量选自表3中所列生物标志物基因的一种或多种变异生物标志物基因的变体等位基因频率;
b)将粪便样品中测得的一种或多种变异生物标志物基因的变异等位基因频率与对照中测得的一种或多种变异生物标志物基因的变异等位基因频率进行比较,其中一种或多种变异生物标志物基因的变异等位基因频率相对于对照中一种或多种变异生物标志物基因的变异等位基因频率的差异表明受试者患有结直肠癌或处于结直肠癌的风险。
29.一种为患有结直肠癌或处于结直肠癌风险的受试者选择临床方案的方法,所述方法包括:
a)在来自受试者的生物样品中的真核核酸中,检测选自表3中列出的生物标志物基因的生物标志物基因的一个或多个变体等位基因,其中所述变体与结直肠癌肿瘤发生相关;
b)实施诊断程序或治疗或诊断程序和治疗的组合。
30.一种治疗受试者结直肠癌的方法,所述方法包括:
a)在来自受试者的粪便样品中的真核核酸中,检测选自表3中列出的生物标志物基因的生物标志物基因的一个或多个变体等位基因,其中所述变体与结直肠癌肿瘤发生相关;
b)对受试者施用结肠镜检查、手术、化疗、放射疗法、靶向疗法或免疫疗法。
31.根据权利要求27-30中任一项所述的方法,其中所述变体等位基因包括沉默突变、错义突变、插入、缺失、移码突变和/或无义突变。
32.根据权利要求27-31中任一项所述的方法,其中所述生物样品是粪便样品。
33.根据权利要求27-32中任一项所述的方法,其中所述粪便样品是人粪便样品。
34.根据权利要求27-33中任一项所述的方法,其中,所述核酸包括cDNA、RNA、总RNA、mRNA、seRNA、tRNA、rRNA、ncRNA、smRNA、或snoRNA,或cDNA、RNA、总RNA、mRNA、seRNA、tRNA、rRNA、ncRNA、smRNA、或snoRNA的任意组合。
35.根据权利要求27-34中任一项所述的方法,其中,所述表达水平通过核酸测序、微阵列测序、分子条形码、探针捕获、聚合酶链式反应(PCR)、ddPCR、RT-PCR、或RT-qPCR来测量。
36.根据权利要求27-35中任一项所述的方法,其中所述临床方案包括手术、化疗、放射治疗、免疫治疗和靶向治疗中的一种或多种。
37.一种检测受试者结直肠癌的分子亚型的方法,所述方法包括:
a)测量从受试者粪便样品中提取的真核核酸中两种或多种生物标志物基因的表达水平,所述生物标志物基因选自表4中列出的任何结直肠肿瘤分子亚型生物标志物基因;
b)将生物样品中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平与对照中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平进行比较,其中生物样品中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平相对于对照中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平的差异表明结直肠癌的分子亚型。
38.一种确定受试者是否患有结直肠癌分子亚型或处于结直肠癌分子亚型风险的方法,所述方法包括:
a)测量从受试者粪便样品中提取的真核核酸中两种或多种生物标志物基因的表达水平,所述生物标志物基因选自表4中列出的任何结直肠肿瘤分子亚型生物标志物基因;
b)将生物样品中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平与对照中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平进行比较,其中生物样品中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平相对于对照中所述两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平的差异表明所述受试者患有结直肠癌分子亚型或处于结直肠癌分子亚型的风险。
39.一种治疗患者结直肠癌的方法,所述方法包括:
a)测量来自患者粪便样品中的真核核酸中两种或多种生物标志物基因的表达水平,所述生物标志物基因选自表4中列出的与基因组不稳定性、微卫星不稳定性或免疫浸润相关的任何结直肠肿瘤分子亚型生物标志物基因;
b)将生物样品中两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平与对照中两种或多种结直肠肿瘤分子亚型生物标志物基因的测量表达水平进行比较,其中相对于对照中两种或多种基因的测量水平,与微卫星不稳定性或免疫浸润相关的结直肠肿瘤分子亚型生物标志物基因的水平有所调整表明患者是免疫治疗的候选对象;和
c)施用免疫疗法。
40.根据权利要求39所述的方法,其中所述免疫疗法是抑制性检查点分子或免疫检查点抑制剂。
41.一种为患有结直肠癌或处于结直肠癌风险的受试者选择临床方案的方法,所述方法包括:
a)测量来自受试者的生物样品中的真核核酸中两种或多种生物标志物基因的表达水平,所述生物标志物基因选自表4中列出的任何结直肠肿瘤分子亚型生物标志物基因;
b)将生物样品中两种或多种结直肠癌分子亚型生物标志物基因的测量表达水平与对照中两种或多种结直肠癌分子亚型生物标志物基因的测量表达水平进行比较,从而鉴定结直肠癌的分子亚型,
c)实施诊断程序或治疗或诊断程序和治疗的组合。
42.一种治疗结直肠肿瘤的方法,所述方法包括:
a)确定来自患者的粪便样品在来自受试者的粪便样品中存在的真核核酸中表达表4中列出的任何结直肠肿瘤分子亚型生物标志物基因的水平升高;和
b)对患者进行结肠镜检查、手术、化疗、放射治疗、靶向治疗或免疫治疗。
43.根据权利要求37-42中任一项所述的方法,其中所述结直肠肿瘤分子亚型选自CMS1、CMS2、CMS3和CMS4。
44.根据权利要求37-43中任一项所述的方法,其中所述生物样品是粪便样品。
45.根据权利要求37-44中任一项所述的方法,其中所述粪便样品是人粪便样品。
46.根据权利要求37-45中任一项所述的方法,其中,所述核酸包括cDNA、RNA、总RNA、mRNA、seRNA、tRNA、rRNA、ncRNA、smRNA、或snoRNA,或cDNA、RNA、总RNA、mRNA、seRNA、tRNA、rRNA、ncRNA、smRNA、或snoRNA的任意组合。
47.根据权利要求37-46中任一项所述的方法,其中,所述表达水平通过核酸测序、微阵列测序、分子条形码、探针捕获、聚合酶链式反应(PCR)、ddPCR、RT-PCR、或RT-qPCR来测量。
48.根据权利要求37-47中任一项所述的方法,其中所述临床方案包括手术、化疗、放射疗法、免疫疗法和靶向疗法中的一种或多种。
49.一种方法,包括:
a)确定来自患者的粪便样品相对于对照而言在来自受试者的粪便样品中存在的真核核酸中包含升高水平的两种或多种粪便来源的真核RNA生物标志物,所述真核RNA生物标志物选自表1或表2中列出的生物标志物或表1和表2或表3或表4的组合;
b)基于该确定,确定所述患者处于患结直肠癌的风险;和
c)对所述患者进行结肠镜检查。
50.根据权利要求1-49任一项所述的方法,进一步包含提供粪便样品的步骤。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862679621P | 2018-06-01 | 2018-06-01 | |
| US62/679,621 | 2018-06-01 | ||
| US201962797763P | 2019-01-28 | 2019-01-28 | |
| US62/797,763 | 2019-01-28 | ||
| PCT/US2019/035061 WO2019232483A1 (en) | 2018-06-01 | 2019-05-31 | Detection method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112567050A true CN112567050A (zh) | 2021-03-26 |
Family
ID=68698469
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201980051265.5A Pending CN112567050A (zh) | 2018-06-01 | 2019-05-31 | 检测方法 |
Country Status (8)
| Country | Link |
|---|---|
| US (3) | US20210214797A1 (zh) |
| EP (1) | EP3802885A4 (zh) |
| JP (1) | JP2021526375A (zh) |
| CN (1) | CN112567050A (zh) |
| AU (1) | AU2019276577A1 (zh) |
| CA (1) | CA3136405A1 (zh) |
| IL (1) | IL279125A (zh) |
| WO (1) | WO2019232483A1 (zh) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2017348369B2 (en) | 2016-10-27 | 2023-09-28 | Geneoscopy, Inc. | Detection method |
| KR102425034B1 (ko) * | 2021-12-14 | 2022-07-27 | 주식회사 에이아이더뉴트리진 | 표적 바이러스 검출을 위한 페이퍼 멤브레인 기반 현장용 rna 추출 플랫폼 |
| WO2024108271A1 (en) * | 2022-11-25 | 2024-05-30 | Denis King | Colorectal cancer risk assessment |
| WO2024159070A1 (en) * | 2023-01-26 | 2024-08-02 | Mayo Foundation For Medical Education And Research | Assessing and treating mammals having polyps |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101680025A (zh) * | 2007-01-09 | 2010-03-24 | 癌甲基化组科学公司 | 选定基因中的表观遗传变化和癌症 |
| CN103324846A (zh) * | 2013-06-13 | 2013-09-25 | 浙江加州国际纳米技术研究院绍兴分院 | 结直肠癌症治疗预后生物标记物的筛选方法 |
| CN107849107A (zh) * | 2015-08-05 | 2018-03-27 | 伊玛提克斯生物技术有限公司 | 用于前列腺癌和其他癌症免疫治疗的新型肽和肽组合物 |
Family Cites Families (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4033820B2 (ja) | 2003-07-29 | 2008-01-16 | 株式会社日立製作所 | 細胞回収方法 |
| JP2007175021A (ja) | 2005-12-28 | 2007-07-12 | Sysmex Corp | 大腸がんのリンパ節転移マーカー |
| EP1862803A1 (en) | 2006-06-02 | 2007-12-05 | Atlas Antibodies AB | Use of protein SATB2 as a marker for colorectal cancer |
| JP2009539404A (ja) | 2006-06-12 | 2009-11-19 | オンコメチローム サイエンシズ エス.エイ. | 大腸癌の早期検出および予後のためのメチル化マーカー |
| US20100196889A1 (en) * | 2006-11-13 | 2010-08-05 | Bankaitis-Davis Danute M | Gene Expression Profiling for Identification, Monitoring and Treatment of Colorectal Cancer |
| JPWO2008093530A1 (ja) | 2007-01-30 | 2010-05-20 | 国立大学法人浜松医科大学 | 大腸癌病期検出方法 |
| FR2919062B1 (fr) * | 2007-07-19 | 2009-10-02 | Biomerieux Sa | Procede de dosage de l'aminoacylase 1 pour le diagnostic in vitro du cancer colorectal. |
| WO2009042676A1 (en) | 2007-09-24 | 2009-04-02 | University Of South Florida | Method for early detection of cancers |
| JP5616786B2 (ja) | 2008-05-12 | 2014-10-29 | オリンパス株式会社 | 糞便処理容器 |
| CN102105583A (zh) | 2008-07-23 | 2011-06-22 | 奥林巴斯株式会社 | 从粪便试样中回收核酸的方法、核酸分析方法以及粪便试样处理装置 |
| US20100093552A1 (en) | 2008-10-09 | 2010-04-15 | Asit Panja | Use and identification of biomarkers for gastrointestinal diseases |
| US20100112713A1 (en) * | 2008-11-05 | 2010-05-06 | The Texas A&M University System | Methods For Detecting Colorectal Diseases And Disorders |
| WO2010134246A1 (ja) | 2009-05-20 | 2010-11-25 | オリンパス株式会社 | 核酸含有試料の調製方法 |
| JPWO2010134245A1 (ja) | 2009-05-20 | 2012-11-08 | オリンパス株式会社 | 哺乳細胞由来核酸の回収方法、核酸解析方法、及び採便用キット |
| WO2012087144A2 (en) * | 2010-12-23 | 2012-06-28 | Agendia N.V. | Methods and means for molecular classification of colorectal cancers |
| KR20140057354A (ko) * | 2011-08-31 | 2014-05-12 | 온코사이트 코포레이션 | 결장직장암의 치료 및 진단을 위한 방법 및 조성물 |
| CN105143876B (zh) | 2013-03-27 | 2018-04-20 | 豪夫迈·罗氏有限公司 | 生物标志物用于评估用β7整联蛋白拮抗剂治疗胃肠炎性病症的用途 |
| WO2015017537A2 (en) | 2013-07-30 | 2015-02-05 | H. Lee Moffitt Cancer Center And Research Institute, Inc. | Colorectal cancer recurrence gene expression signature |
| WO2016176446A2 (en) * | 2015-04-29 | 2016-11-03 | Geneoscopy, Llc | Colorectal cancer screening method and device |
| AU2017348369B2 (en) * | 2016-10-27 | 2023-09-28 | Geneoscopy, Inc. | Detection method |
-
2019
- 2019-05-31 US US15/734,170 patent/US20210214797A1/en not_active Abandoned
- 2019-05-31 WO PCT/US2019/035061 patent/WO2019232483A1/en unknown
- 2019-05-31 JP JP2020567097A patent/JP2021526375A/ja active Pending
- 2019-05-31 AU AU2019276577A patent/AU2019276577A1/en active Pending
- 2019-05-31 CA CA3136405A patent/CA3136405A1/en active Pending
- 2019-05-31 CN CN201980051265.5A patent/CN112567050A/zh active Pending
- 2019-05-31 EP EP19810799.7A patent/EP3802885A4/en active Pending
-
2020
- 2020-12-01 IL IL279125A patent/IL279125A/en unknown
-
2022
- 2022-01-19 US US17/578,523 patent/US11479824B2/en active Active
-
2023
- 2023-11-30 US US18/524,594 patent/US20240093312A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101680025A (zh) * | 2007-01-09 | 2010-03-24 | 癌甲基化组科学公司 | 选定基因中的表观遗传变化和癌症 |
| CN103324846A (zh) * | 2013-06-13 | 2013-09-25 | 浙江加州国际纳米技术研究院绍兴分院 | 结直肠癌症治疗预后生物标记物的筛选方法 |
| CN107849107A (zh) * | 2015-08-05 | 2018-03-27 | 伊玛提克斯生物技术有限公司 | 用于前列腺癌和其他癌症免疫治疗的新型肽和肽组合物 |
Non-Patent Citations (1)
| Title |
|---|
| ELIZABETH HERRING等: "A Stool Multitarget mRNA Assay for the Detection of Colorectal Neoplasms", 《COLORECTAL CANCER》, vol. 1765, 31 March 2018 (2018-03-31), pages 218 * |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2019276577A1 (en) | 2021-01-14 |
| US20220154291A1 (en) | 2022-05-19 |
| EP3802885A1 (en) | 2021-04-14 |
| CA3136405A1 (en) | 2019-12-05 |
| US20210214797A1 (en) | 2021-07-15 |
| EP3802885A4 (en) | 2022-03-02 |
| US20240093312A1 (en) | 2024-03-21 |
| IL279125A (en) | 2021-01-31 |
| US11479824B2 (en) | 2022-10-25 |
| JP2021526375A (ja) | 2021-10-07 |
| WO2019232483A1 (en) | 2019-12-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20210381062A1 (en) | Nasal epithelium gene expression signature and classifier for the prediction of lung cancer | |
| Berchuck et al. | Patterns of gene expression that characterize long-term survival in advanced stage serous ovarian cancers | |
| ES2611000T3 (es) | Método para usar la expresión génica para determinar el pronóstico de cáncer de próstata | |
| US11479824B2 (en) | Detection method for cancer using RNA biomarkers | |
| ES2821300T3 (es) | Predicción de pronóstico para el melanoma de cáncer | |
| US20220177976A1 (en) | Colorectal cancer screening method and device | |
| BRPI0706511A2 (pt) | marcadores de expressão genética para prognóstico de cáncer colorretal | |
| US20230203591A1 (en) | Detection method using eukaryotic cells | |
| JP2021526791A (ja) | セルフリー核酸の細胞起源を決定するための方法およびシステム | |
| WO2017223216A1 (en) | Compositions and methods for diagnosing lung cancers using gene expression profiles | |
| US20160222461A1 (en) | Methods and kits for diagnosing the prognosis of cancer patients | |
| AU2022289858A1 (en) | Cancer detection method, kit, and system | |
| US20130084241A1 (en) | DEVELOPMENT OF miRNA DIAGNOSTICS TOOLS IN BLADDER CANCER | |
| US20210079479A1 (en) | Compostions and methods for diagnosing lung cancers using gene expression profiles | |
| US20240209451A1 (en) | Cancer detection method, kit, and system | |
| WO2023125788A1 (en) | Biomarkers for colorectal cancer treatment | |
| Finlayson | The Application of Circulating Tumour DNA to the Management of Gastrointestinal Cancers. | |
| CN116479123A (zh) | m7G相关lncRNA作为生物标志物在肝癌预后或治疗反应预测中的应用及产品和系统 | |
| WO2013130869A1 (en) | Gene expression signatures in cancer |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| TA01 | Transfer of patent application right |
Effective date of registration: 20220110 Address after: Missouri, USA Applicant after: Gene replication Co.,Ltd. Address before: Missouri, USA Applicant before: GENEOSCOPY, LLC |
|
| TA01 | Transfer of patent application right |