CN100440138C - 使用推测、基于掩码、由打包数据选择写入数据元素的方法、系统和处理器 - Google Patents
使用推测、基于掩码、由打包数据选择写入数据元素的方法、系统和处理器 Download PDFInfo
- Publication number
- CN100440138C CN100440138C CNB008159319A CN00815931A CN100440138C CN 100440138 C CN100440138 C CN 100440138C CN B008159319 A CNB008159319 A CN B008159319A CN 00815931 A CN00815931 A CN 00815931A CN 100440138 C CN100440138 C CN 100440138C
- Authority
- CN
- China
- Prior art keywords
- data
- instruction
- data element
- packing
- operand
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
- 238000000034 method Methods 0.000 claims abstract description 54
- 238000003860 storage Methods 0.000 claims abstract description 21
- 230000004044 response Effects 0.000 claims abstract description 11
- 238000012856 packing Methods 0.000 claims description 104
- 238000012545 processing Methods 0.000 claims description 31
- 238000012360 testing method Methods 0.000 claims description 13
- 230000008569 process Effects 0.000 claims description 11
- 239000000872 buffer Substances 0.000 claims description 9
- 238000006073 displacement reaction Methods 0.000 claims description 7
- 230000005055 memory storage Effects 0.000 claims 2
- 238000013519 translation Methods 0.000 claims 1
- 238000005516 engineering process Methods 0.000 description 5
- 230000014509 gene expression Effects 0.000 description 5
- 238000010586 diagram Methods 0.000 description 2
- 238000007667 floating Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 241001269238 Data Species 0.000 description 1
- 101000912503 Homo sapiens Tyrosine-protein kinase Fgr Proteins 0.000 description 1
- 102100026150 Tyrosine-protein kinase Fgr Human genes 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000005611 electricity Effects 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 238000006049 ring expansion reaction Methods 0.000 description 1
- 238000007493 shaping process Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30018—Bit or string instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
- G06F9/30038—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations using a mask
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30072—Arrangements for executing specific machine instructions to perform conditional operations, e.g. using predicates or guards
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30094—Condition code generation, e.g. Carry, Zero flag
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Executing Machine-Instructions (AREA)
- Advance Control (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
使用推测、基于掩码、由打包数据选择性地写数据元素的方法和装置。在本发明的一个实施例中,对于打包数据操作数的每一个数据元素,在并行处理单元中进行以下处理:由标明该数据元素是否被选中写入到对应的存储位置的对应的打包数据掩码元素的一个或多个位确定用于数据元素的推测值,并根据推测值将数据元素写入到对应的存储位置。
Description
发明背景
发明领域
本发明涉及计算机系统领域。更具体地,本发明涉及使用推测、基于掩码、由打包数据的数据元素的选择写入。
背景技术
计算机技术以不断增长的速度不停地发展。过去,计算机仅仅是主要用于文字处理和电子表格应用的商业工具。现在,随着多媒体应用的发展,计算机就像电视和家庭立体声系统一样成为普通的家用电器。确实,计算机系统和其它消费电器之间的界限变得模糊了,例如,在适当配置的计算机系统上进行的多媒体应用具有电视、收音机、视频播放设备等的功能。因此,计算机系统的市场普及通常由其价格和其执行这种多媒体应用的速度决定。
本领域的技术人员应理解,多媒体和通信应用需要处理由少量数据代表的大量数据,以提供我们所期望的音频和视频的逼真再现。例如,再现3D图像,必须类似地处理各个数据项(例如,8位数据)的相对较大的集合。
这些应用所要求的一个共同操作是从数据项集合中选择数据项以写入到存储器中。根据掩码确定给定的数据项是否要写入存储器中。移动所选择数据字节的方法使用测试、分支和写入指令系列。根据该方法,测试与每个数据项相对应的一个或多个掩码位,并用分支确定或者写或者不写字节到存储器中。然而,由于分支推测错误,该方法造成性能损失。
为了避免该分支推测错误损失,采用单指令多数据(SIMD)处理器结构支持SIMD“字节掩码写”指令将打包的数据从一个存储位置写到另一个存储位置(参看美国专利申请序列号09/052,802;filed3/31/98)。图1示出了在SIMD结构中用于实现SIMD字节掩码写指令的专用并行电路的方框图。图1示出了掩码的SIMD字节四字移动指令(MASKMOVQ),该指令将表示整形的多达64位数据由标记为MM1并由第一操作数表示为SRC1 100的第一SIMD寄存器移动到由位于第二SIMD寄存器中使用字节打包数据掩码的、标记为MM2并由第二操作数表示为SRC2 102的寄存器隐含指定的位于106的存储器中。通过存储在寄存器MM2 102的字节108和112,寄存器MM1 100的字节110和114为写允许。
如图1所示,SIMD字节掩码写指令要求在处理器中有专用电路来并行处理打包数据项中的每一个字节。虽然该专用电路的并行特性实现了较好的处理器吞吐特性,但该专用电路需要宝贵的管芯面积并且只能被图像和类似类型的处理所利用。
发明简介
下面说明使用推测、基于掩码、由打包数据选择写入数据元的方法和装置。在本发明的一个实施例中,对于打包数据操作数的每一个数据元素,在并行处理单元中进行以下处理:由标明该数据元素是否被选中写入到对应的存储位置的对应的打包数据掩码元素的一个或多个位确定用于数据元素的推测值,并根据推测值将数据元素写入到对应的存储位置。
附图简介
由随后对本发明的详细说明,本发明的特性和优点将变得明显。其中:
图1是在SIMD结构中用于实现SIMD字节掩码写指令的专用并行电路的方框图。
图2是根据本发明的一个实施例的计算机系统的方框图。
图3是根据本发明的一个实施例的流程图。
图4是根据本发明的一个实施例的计算机系统的经过选择的部分的方框图。
本发明的详细说明
在随后的说明中,为了说明的目的,将说明大量细节以更彻底的了解本发明。但是,对本领域的技术人员,为了实现本发明,显然这些特定的细节并不需要。在另一些例子中,众所周知的电结构和电路以方框图的形式示出,以免混淆本发明。
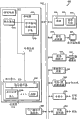
图2是根据本发明的一个实施例的计算机系统200的方框图。计算机系统200包括处理器210、存储设备220和总线215。处理器210通过总线215与存储设备220相连。此外,许多用户输入/输出设备240(例如,键盘、鼠标)也连接到总线215。处理器210表示各种结构类型的中央处理单元,例如CISC、RISC、VLIW或混合结构。此外,处理器210可由一个或多个芯片实现。总线215表示一个或多个总线(例如,AGP、PCI、ISA、X-BUS、VESA等)和桥。虽然本实施例以单处理器计算机系统进行说明,本发明也可在多处理器计算机系统中实现。
在其它设备中,一个或多个网络控制器255、TV广播信号接收机260、传真/调制解调器245、视频捕捉卡235和音频卡250可选择性地连接到总线215上。网络控制器255表示一个或多个网络连接(例如,以太网连接)。存储设备220和在网络上传播并由网络控制器255接收的介质表示一个或多个机器可读介质。因此,机器可读介质包括用可被机器(例如,计算机)读取的形式存储和发送的信息的任何机构。例如,机器可读介质包括只读存储器(ROM);随机访问存储器(RAM);磁盘存储介质;光学存储介质;快闪存储设备;电、光、声或其它形式的传播信号(例如,载波、红外线信号、数字信号等)等。
TV广播信号接收机260表示TV广播信号接收设备,传真/调制解调器245代表用于发送和/或接受代表数据的模拟信号的传真和/或调制解调器。图像捕捉卡235代表一个或多个数字化图像(即,扫描仪、摄像机等)的设备。音频卡250代表一个或多个输入和/或输出声音(例如,麦克风、扬声器、磁存储设备、光存储设备等)的设备。图像控制卡230也连接到总线215。图像控制卡230代表一个或多个产生图像的设备(例如,图形卡)。
图2还示出了存于存储设备220中的数据224和程序代码222。数据224代表以一种或多种形式存储的数据(例如,打包数据形式)。程序代码222代表实现本发明的任何和/或所有技术所必需的代码。特别是,程序代码222包含使处理器210采用推测和并行数据处理,根据掩码,进行由打包数据的高效的选择性的写数据元素的指令。当然,存储设备220包含对理解本发明不是必需的其它软件(为示出)。
图2还示出处理器210中包括译码器216、寄存器组214、执行单元212、内部总线211和推测电路213。当然,处理器210中包含对理解本发明不是必需的其它电路。译码器216、寄存器214、执行单元212和推测电路213由内部总线211连接在一起。译码器216用于将处理器210收到的指令译码为控制信号和/或微代码入口点。对应于这些控制信号和/或微代码入口点,执行单元212进行适当的操作。译码器216可采用各种不同的机构来实现(例如,查表、硬件实现、PLA等)。
所示的译码器216包括支持指令的译码电路218,以使处理器210根据掩码,进行由打包数据选择性的写数据元素。此外,在一个实施例中,处理器210为超标量流水线处理器,能够在每个时钟周期中完成一个或多个指令(忽略任何数据相关和流水线冻结)。除这些指令以外,处理器210能够执行新指令和/或与已有通用处理器中的指令类似或相同的指令。例如,在一个实施例中,处理器210支持与现有处理器所用的英特架构的指令集兼容的指令集,例如,由CA,Santa Clara的英特公司制造的 III处理器。
III处理器。
执行单元212包含多个并行处理单元219A-219N,可并行处理多个指令(例如,并行处理单元)。在本发明的一个实施例中,执行单元212还包含组合缓冲器270,以存储数据,直到64位写可以进行。该组合缓冲器270允许总线215用于其它目的而缓冲器存储要保存的数据,以最大限度地利用总线215。但是,应当理解,即使组合缓冲器270和总线215的宽度不是64位,也在本发明的范围内,并由此造成处理器单元的相应的某些细节的差别。
寄存器214代表处理器210上用于存储信息的存储区域,包括控制/状态信息、整数、浮点数、打包数据(整型和/或浮点型)和推测数据。应当理解,本发明的特征是对用于操作打包数据的指令的说明,以及如何使用这些指令。根据本发明的这些特征,用于存储推测数据的存储区域不是关键性的。在这里用到的术语“数据处理系统”是指任何用于处理数据的机器,包括参考图2说明的计算机系统。
在本发明的一个实施例中,推测电路213为可用于处理器216支持的指令集的任何指令的常规推测电路。推测允许所有指令的条件执行。因此,该技术允许它们自己消除分支,并由此消除推测失误造成的性能损失。参考1998年1月26日Peter Song在《微处理器报告》上发表的Demystifying the EPIC and IA-64和1991年12月18日BrianCase在《微处理器报告》上发表的ARM Architecture Offers High CodeDensity。虽然一个实施例说明了常规推测电路的使用,但是备选实施例仅支持对某些指令(例如,条件转移型指令)的推测。此外,虽然一个实施例说明了用于允许哪一个数据元素被写入的掩码的尺寸与数据元素的尺寸相同,但备选实施例中的掩码也可以有不同的尺寸(包括每个掩码只包含一位)。
图3为根据本发明的一个实施例的流程图。在块305中确定初始值,即为将被选中写入的打包的数据操作数的当前选中的数据元素确定可能的存储位置。由块305,步骤进入块310。
在块310中,确定当前选中的数据元素的推测值。在本发明的一个实施例中,使用测试位指令(“tbit”)确定推测值。根据该实施例,用tbit指令测试对应于将被选中写入的打包的数据操作数的当前选中的数据元素的打包掩码数据元素的位。该推测值可存储在各种存储介质中(例如,专用的推测寄存器、通用寄存器等)。
在图3的块320中,根据块310确定的推测值作决定。依照块320,如果推测值为真,处理流程开始进入块330。否则,处理流程开始进入块350。
在块330,打包数据操作数的当前选中数据元素被存储(对于图2,当前选中数据元素在组合缓冲器中存储)。在块330之后,处理流程加入块350。
在图3的块350中,根据当前选中的数据元素是否是要处理的打包数据操作数的最后的数据元素作出另一个决定。如果当前选定的数据元素是要处理的最后的数据元素,则处理流程结束。否则,处理流程由块350进入块360。
在图3的块360中,与存储位置相关的值递增。对于本发明的一个实施例,该值位于通用寄存器中。但是,与存储位置相关的值可位于任何存储介质中。然后,在图3的块370中,打包数据操作数移位一个数据元素的宽度(例如,假设打包数据操作数的最高位数据元素是当前选中的数据项,左移打包数据操作数而使次高位数据元素成为最高位数据元素,并由此成为当前选中的数据元素)。处理流程随后由块370返回到块310,并重复该过程,直到处理完最后的数据元素。
虽然所说明的一个实施例中采用移位来选择打包数据操作数的当前选中的数据元素,备选实施例可以采用其它技术(例如,指针、允许用于标识的支持指令(参考下面的tbit指令)等)。此外,虽然图3可理解为顺序处理的举例说明,但应该理解,可以按不同的顺序执行这些操作(例如,编译调度、旋环展开、硬件乱序执行等),可以并行执行各种操作,和/或在流传中引入各种其它操作。
如下是对本发明的一个实施例从概念上的理解:
R2=地址寄存器
R3=64位数据寄存器
R4=对应掩码元素(x0,x1,...,x7)的掩码寄存器
代码序列由存储在R3中的打包数据操作数选择性的写字节尺寸的数据元素:
| 指令组 | ||||
| 1) | p1,p2=tbit r4,x0 | |||
| 2) | <p1>store1 r2=r3 | r2=r2+1 | shiftr r3=r3<<8 | p1,p2=tbit r4,x1 |
| 3) | <p1>store1 r2=r3 | r2=r2+1 | shiftr r3=r3<<8 | p1,p2=tbit r4,x2 |
| 4) | <p1>store1 r2=r3 | r2=r2+1 | shiftr r3=r3<<8 | p1,p2=tbit r4,x3 |
| 5) | <p1>store1 r2=r3 | r2=r2+1 | shiftr r3=r3<<8 | p1,p2=tbit r4,x4 |
| 6) | <p1>store1 r2=r3 | r2=r2+1 | shiftr r3=r3<<8 | p1,p2=tbit r4,x5 |
| 7) | <p1>store1 r2=r3 | r2=r2+1 | shiftr r3=r3<<8 | p1,p2=tbit r4,x6 |
| 8) | <p1>store1 r2=r3 | r2=r2+1 | shiftr r3=r3<<8 | p1,p2=tbit r4,x7 |
| 9) | <p1>store1 r2=r3 |
寄存器R2包含与存储位置有关的值。寄存器R3包含64位打包数据,在该例中,分为八个数据元素。寄存器R4包含打包的掩码操作数,八个数据掩码元素x0-x7对应于R3中的八个数据元素。
在第一组指令中,代码序列采用tb it指令确定推测值。在该实施例中,tbit测试打包的掩码元素x0的最高位。如果该位为1,则推测值p1置为真,否则推测值p1置为假。备选实施例中如果位值为0时,可设推测值p1为真,相反地,如果位值为1时,设推测值p1为假。应当理解,tbit指令可测试对应的打包的掩码元素的任何位。
在该例中,在第二组指令中,存储的前一个推测值用于条件存储一个字节到与R4中的值有关的存储位置。仍在第二组指令期间,R2递增,R3向右移动八位,推测值p1以与第一组指令相同的方式重新设置,除了打包的掩码元素使用x1而不是x0。多路并行处理单元允许在同一个时钟周期中对在第二组指令中的所有四个指令并行处理。除了每组指令使用不同的打包的掩码元素以外,第三到第七组指令以与第二组指令相同的方式继续进行。第九组指令使用推测值条件存储最后的字节到与R4中的值有关的存储位置。在该例中,序列花费九个时钟周期。但是,时钟周期的数量可随着处理器的执行和/或打包数据操作数的数据元素的数量变化。
因此,本发明不要求使用专用的SIMD字节掩码写电路。而且,采用推测可以避免条件分支以及由于分支预测错误所造成的性能损失。多路并行处理单元可以提高处理器的吞吐量(例如,本发明的一个实施例具有所要求的并行处理单元的数量以并行处理上述每组指令)。该并行性和推测使本发明与实现字节掩码写的专用SIMD电路的性能相当。此外,与那些应用领域非常窄的专用字节掩码写指令电路(例如,图形处理)相比,在表1中的指令及支持这些指令的电路可用于多种目的。
在处理系统的各种级别均可实现本发明。例如,根据处理器结构,上述代码序列可以手工编码并提供给处理器、由编译器编译单个指令产生、由处理器中响应接收的单个指令的译码器产生等。
图4示出了根据本发明的一个实施例的计算机系统的选出的部分。该计算机系统的选出部分包括处理器410、存储设备420和总线415。图4中的处理器410含有对于理解本发明并不是必需的附加电路。
处理器410被设计用于执行两个不同的指令集(例如,64位指令集和32位指令集)。在这里术语“宏指令”表示处理器由外部接收的指令。在一个特别的实施例中,译码器416用于将第一个指令集410译码为控制信号和/或微代码入口点。在这种情况下,当处理器410由外部接收到第一个指令集410的指令是宏指令。此外,微代码转换器417用于将第二指令集420的指令(例如,I A 32英特结构指令)转换为第一个指令集410的指令,然后这些指令由译码器416处理。换句话说,至少某些第二指令集420的宏指令转换为由第一个指令集410的指令组成的第一级微代码。在这种情况下,由处理器410的内部产生的第一个指令集410的指令为微指令。在一个实施例中,转换采用微代码ROM实现。例如,在一个实施例中,单个SIMD字节掩码写宏指令提供给微代码转换器417,在那里被转换为第一个指令集410(这里作为微指令)的适当的指令,用于使用推测、基于掩码、由打包数据选择写数据元素。此外,用于选择写数据元素的与第一个指令集410相同的指令直接由译码器416作为宏指令接收。
本发明参考具体的示例性实施例进行了说明。但是,对于本领域的技术人员来说显然可以进行各种修改和变形同时不脱离本发明精神和范围。因此说明书和附图为示例性的而不是限定性的。
Claims (61)
1.一种计算机实现方法,包括:
选择打包数据操作数中的一个数据元素作为当前选中的数据元素,其中所述打包数据操作数中的每个数据元素具有相应的掩码数据元素,指示是否选中进行写入;
存储用于所述当前选中的数据元素的指示当前选中的存储位置的值;
由所述对应掩码元素的一个或多个位确定用于当前选中数据元素的推测值;
通过在并行处理单元中进行以下处理,选择性地写入所述打包数据操作数中当前选中的数据元素,
根据所述推测值将所述当前选中的数据元素写入到所述当前选中的存储位置,
增加用于指示所述当前选中的存储位置的所述值,
选择所述打包数据操作数的另一个数据元素作为所述当前选中的数据元素,并由所述对应掩码元素的一个或多个位确定那个数据元素的推测值;
重复所述选择性写入,直到所述打包数据操作数的最后的数据元素成为当前选中的数据元素;以及
根据所述推测值将所述当前选中的数据元素写入所述当前选中的存储位置。
2.根据权利要求1的方法,其中所述选择一个数据元素包括选择打包数据操作数的左面最高位的数据元素。
3.根据权利要求1的方法,其中所述选择另一个数据元素包括移位所述打包数据操作数一个数据元素。
4.根据权利要求1的方法,其中所述推测值存储在寄存器中。
5.根据权利要求1的方法,其中所述推测值通过使用测试位指令确定。
6.根据权利要求1的方法,其中响应于已经被译码为一个或多个微指令的单个宏指令执行各动作。
7.根据权利要求6的方法,其中所述宏指令为第一指令集的一部分,与包括所述微指令的第二指令集相区别和不同,其中所述第二指令集的指令可直接由所述处理器接收。
8.根据权利要求7的方法,其中所述第二指令集的指令译码为控制信号和/或微代码入口点。
9.一种计算机系统,包括:
在其上存有至少一组一个或多个指令的存储设备;以及连接到所述存储设备的处理器,所述处理器具有推测电路和并行处理单元,所述处理器使得所述推测电路响应于所述该组一个或多个指令、从对应打包数据掩码元素的一个或多个位中确定对于打包数据操作数的每个数据元素的预测值,其中每个打包数据掩码元素指示其对应的打包数据操作数的数据元素是否被选中用于写入到对应的存储位置,所述处理器还响应于所述该组一个或多个指令,在所述对应的存储位置中只存储由选中用于写入的预测值所指示的所述打包数据操作数的所述数据元素。
10.根据权利要求9的计算机系统,其中所述一个或多个指令的集包括由处理器译码为至少一个或多个导致所述处理器选择性地写每个数据元素的微指令的单个宏指令。
11.根据权利要求9的计算机系统,其中所述处理器包括组合缓冲器,以在写到所述对应的存储位置之前接收一个或多个根据所述推测选中的数据元素。
12.根据权利要求9的计算机系统,所述推测电路确定用于处理器支持的指令集的每条指令的推测值。
13.根据权利要求9的计算机系统,其中所述处理器包括用于译码第一指令集的宏指令的第一译码器,和用于将第二指令集的宏指令译码为由所述第一指令集的指令组成的微指令的第二译码器。
14.根据权利要求13的计算机系统,其中一个或多个指令的所述集由所述第一指令集的多个指令组成。
15.一种用于将打包的数据操作数的每个数据元素选择性地写入对应的存储位置的计算机实现方法,包括:
由标明所述元素是否被选中写入到所述对应存储位置的对应打包数据掩码元素的一个或多个位,确定对于所述打包数据操作数的当前选中的数据的推测值;
根据所述推测值将当前选中的数据元素存储到所述对应的存储位置;
确定当前选中的数据元素是否是所述打包数据操作数的最后数据元素;以及
如果当前选中的数据元素不是所述打包数据操作数的最后数据元素,则将所述打包数据操作数移位一个数据元素,以选择所述打包数据操作数的另一个数据元素作为当前选中的数据元素,并重复上述过程。
16.根据权利要求15的方法,其中通过使用测试位指令来确定所述推测值。
17.根据权利要求15的方法,其中响应于已经被译码为至少一个或多个微指令的单个宏指令执行各动作。
18.根据权利要求17的方法,其中所述宏指令为第一指令集的一部分,与包括所述微指令的第二指令集相区别和不同,其中所述第二指令集的指令可直接由所述处理器接收。
19.根据权利要求15的方法,还包括:
接收单个宏指令;
将所述单个宏指令译码为引起剩余操作执行的微指令序列。
20.一种用于将打包的数据操作数的每个数据元素选择性地写入对应的存储位置的计算机实现方法,包括:
对于所述打包数据操作数的每一个数据元素,在并行处理单元中进行以下处理:
由标明所述元素是否被选中写入到所述对应存储位置的对应打包数据掩码元素的一个或多个位确定用于所述数据元素的推测值,其中通过使用测试位指令来确定所述推测值;并
根据所述推测值将选中的数据元素存储到所述对应的存储位置。
21.根据权利要求20的方法,其中响应于已经被译码为至少一个或多个微指令的单个宏指令执行各动作。
22.根据权利要求21的方法,其中所述宏指令为第一指令集的一部分,与包括所述微指令的第二指令集相区别和不同,其中所述第二指令集的指令可直接由所述处理器接收。
23.根据权利要求20的方法,还包括:
接收单个宏指令;
将所述单个宏指令译码为微指令序列,其中所述微指令导致所述并行处理单元操作每个数据元素。
24.一种用于将打包的数据操作数的每个数据元素选择性地写入对应的存储位置的计算机实现方法,包括:
对于所述打包数据操作数的每一个数据元素,在并行处理单元中进行以下处理,其中如下处理响应于已经被译码为至少一个或多个微指令的单个宏指令而被执行,
由标明所述元素是否被选中写入到所述对应存储位置的对应打包数据掩码元素的一个或多个位确定用于所述数据元素的推测值;以及
根据所述推测值将选中的数据元素存储到所述对应的存储位置。
25.根据权利要求24的方法,其中所述宏指令为第一指令集的一部分,与包括所述微指令的第二指令集相区别和不同,其中所述第二指令集的指令可直接由所述处理器接收。
26.根据权利要求24的方法,还包括:
接收单个宏指令;
将所述单个宏指令译码为微指令序列,其中所述微指令导致所述并行处理单元操作每个数据元素。
27.一种用于将打包的数据操作数的每个数据元素选择性地写入对应的存储位置的计算机实现方法,包括:
接收单个宏指令;
将所述单个宏指令译码为微指令序列,其中所述微指令导致所述并行处理单元操作每个数据元素;
对于所述打包数据操作数的每一个数据元素,在所述并行处理单元中进行以下处理,
由标明所述元素是否被选中写入到所述对应存储位置的对应打包数据掩码元素的一个或多个位确定用于所述数据元素的推测值;以及
根据所述推测值将选中的数据元素存储到所述对应的存储位置。
28.根据权利要求27的方法,其中响应于已经被译码为至少一个或多个微指令的单个宏指令执行各动作,所述宏指令为第一指令集的一部分,与包括所述微指令的第二指令集相区别和不同,其中所述第二指令集的指令可直接由所述处理器接收。
29.一种用于将打包的数据操作数的每个数据元素选择性地写入对应的存储位置的计算机实现方法,包括:
响应于多条指令,对所述打包数据操作数的每个数据元素执行如下操作,
由标明所述元素是否被选中写入到所述对应存储位置的对应打包数据掩码元素的一个或多个位确定用于所述数据元素的推测值,其中通过使用测试位指令来确定所述推测值;并
根据所述推测值将选中的数据元素存储到所述对应的存储位置。
30.根据权利要求29的方法,其中还对所述打包数据操作数的每个数据元素执行如下操作:
将所述打包数据操作数移位一个数据元素。
31.根据权利要求29的方法,其中响应于已经生成所述多个指令的单个宏指令而执行各动作。
32.根据权利要求31的方法,其中所述宏指令为第一指令集的一部分,与包括所述多个指令的第二指令集相区别和不同,其中所述第二指令集的指令可直接由所述处理器接收。
33.根据权利要求29的方法,其中所述多个指令是微指令。
34.根据权利要求29的方法,其中所述多个指令是宏指令。
35.根据权利要求29的方法,还包括:
将单个指令翻译为所述多个指令。
36.一种处理器,包括:
用于对一个或多个指令的集进行译码以便将打包的数据操作数的每个打包数据元素选择性地写入对应的存储位置的译码器;
与所述译码器相连的推测电路,所述推测电路用于根据标明打包数据元素是否被选中写入到所述对应存储位置的打包数据掩码元素的一个或多个位,确定用于每个所述打包数据元素的推测值;
与所述译码器相连的执行单元,包括,
多个并行处理单元,所述多个并行处理单元用于导致根据所述推测值选择性地将所述打包数据元素写入到所述对应的位置;
组合缓冲器,所述组合缓冲器用于在写入所述对应存储位置之前,存储所述选中的数据元素。
37.根据权利要求36的处理器,其中一个或多个指令的集包括不止一个宏指令。
38.根据权利要求36的处理器,其中一个或多个指令的集包括单个宏指令。
39.根据权利要求36的处理器,其中一个或多个指令的集包括不止一个微指令。
40.一种方法,包括:
仿真识别打包数据操作数和打包掩码操作数的字节掩码写指令,其中所述仿真包括执行下列操作:
由所述打包掩码操作数的对应打包数据掩码元素的一个或多个位,确定对于所述打包数据操作数的每个数据元素的推测值,每个所述推测值标明其对应的数据元素是否被选中写入到对应存储位置;以及
仅存储被选中用于写入的那些所述数据元素,如在其对应存储位置中的其推测值所指示的。
41.根据权利要求40的方法,其中所述字节掩码写指令是x86指令。
42.根据权利要求40的方法,其中所述推测值是使用测试位指令确定的。
43.根据权利要求40的方法,其中对所述打包数据操作数的每个数据元素执行下列操作:
将所述打包数据操作数移位一个数据元素。
44.一种方法,包括:
仿真识别存储在第一寄存器中的打包数据操作数以及存储在第二寄存器中的打包掩码操作数的指令,其中所述仿真包括对所述打包数据操作数的每个数据元素执行下列操作:
由所述打包掩码操作数的对应打包数据掩码元素确定对于所述数据元素的推测值,其中所述对应的打包数据掩码元素和所述数据元素的大小相同,所述推测值指示所述数据元素是否被选中用于写入到具有由存储在第三寄存器中的值确定的存储器地址的对应存储位置中;
根据所述推测值在所述对应存储位置上存储所述数据元素;以及
将所述打包数据操作数移位一个数据元素;以及
增加所述值。
45.根据权利要求44的方法,其中所述指令是x86指令。
46.根据权利要求44的方法,其中所述指令是字节掩码写指令。
47.根据权利要求44的方法,其中所述推测值是使用测试位指令确定的。
48.根据权利要求44的方法,其中所述打包数据操作数是64位,所述数据元素是8位。
49.根据权利要求44的方法,其中所述打包掩码操作数是64位,所述打包数据掩码元素是8位。
50.一种方法,包括:
将第一指令集的字节掩码写指令转换为第二指令集的多个指令,其中所述多个指令是由处理器可接收的宏指令;
在所述处理器上执行所述多个指令,其中所述执行包括对打包数据操作数的每个数据元素执行下列操作,
由打包掩码操作数的对应打包数据掩码元素的一个或多个位确定对于所述数据元素的推测值,所述推测值指示所述数据元素是否被选中用于写入到应存储位置中;以及
根据所述推测值在所述对应存储位置中存储所选中的数据元素。
51.根据权利要求50的方法,其中所述字节掩码写指令是x86指令。
52.根据权利要求50的方法,其中所述推测值是使用测试位指令确定的。
53.一种处理器,包括:
第一指令集的译码器,以接收仿真第二指令集的字节掩码写指令的指令,该字节掩码写指令识别打包数据操作数和打包掩码操作数;
连接到所述译码器的推测电路,以根据所述打包掩码操作数的对应打包数据掩码元素的一个或多个位确定对于所述打包数据操作数的每个数据元素的推测值,所述推测值指示所述数据元素是否被选中用于写入到应存储位置中,其中所述数据元素和所述打包数据掩码元素的大小相同;
连接到所述译码器的执行单元,以执行所述第一指令集的指令,所述执行单元包括,
一组一个或多个处理单元,以根据所述推测值,使所述数据元素被有选择地写入所述对应存储位置中。
54.根据权利要求53的处理器,包括:
组合缓冲器,用于在被写入到所述对应存储位置之前存储所述选中的数据元素。
55.根据权利要求53的处理器,还包括:
连接到所述译码器的寄存器组,所述推测电路和所述执行单元,包括,
第一寄存器,以存储所述打包掩码操作数,
第二寄存器,以存储所述打包数据操作,以及
第三寄存器,以存储确定所述对应存储位置的值。
56.根据权利要求53的处理器,其中第二指令集包括x86指令。
57.根据权利要求53的处理器,其中第一指令集包括64位指令。
58.一种计算机系统,包括:
处理器,具有推测电路,并行处理单元,和第一指令集的译码器;以及
连接到所述处理器的存储装置,所述存储装置在其上具有存储的字节掩码写指令,所述字节掩码写指令属于第二指令集并指定打包数据操作数和打包掩码操作数,其中所述字节掩码写指令将被转换为所述第一指令集一个或多个指令,当由所述处理器执行这些指令时,使所述处理器通过下列操作有选择地将所述打包数据操作数的每个数据元素写入对应存储位置:
使所述推测电路由所述打包掩码操作数的对应打包数据掩码元素的一个或多个位,确定对于所述打包数据操作数的每个数据元素的推测值,所述推测值标明所述数据元素是否被选中写入到所述对应存储位置中;以及
在所述对应存储位置中仅存储那些如其推测值所指示的被选中用于写入的所述数据元素。
59.根据权利要求58的计算机系统,其中第二指令集是x86指令集。
60.根据权利要求58的计算机系统,其中第一指令集是64位指令集。
61.根据权利要求58的计算机系统,其中第一指令集是IA64指令集。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/399,612 US6484255B1 (en) | 1999-09-20 | 1999-09-20 | Selective writing of data elements from packed data based upon a mask using predication |
| US09/399,612 | 1999-09-20 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1391668A CN1391668A (zh) | 2003-01-15 |
| CN100440138C true CN100440138C (zh) | 2008-12-03 |
Family
ID=23580223
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB008159319A Expired - Lifetime CN100440138C (zh) | 1999-09-20 | 2000-08-29 | 使用推测、基于掩码、由打包数据选择写入数据元素的方法、系统和处理器 |
Country Status (8)
| Country | Link |
|---|---|
| US (2) | US6484255B1 (zh) |
| JP (1) | JP4921665B2 (zh) |
| CN (1) | CN100440138C (zh) |
| AU (1) | AU6945400A (zh) |
| DE (1) | DE10085391T1 (zh) |
| GB (1) | GB2371135B (zh) |
| HK (1) | HK1044202B (zh) |
| WO (1) | WO2001022216A1 (zh) |
Families Citing this family (39)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6484255B1 (en) | 1999-09-20 | 2002-11-19 | Intel Corporation | Selective writing of data elements from packed data based upon a mask using predication |
| JP3964593B2 (ja) * | 2000-02-24 | 2007-08-22 | 富士通株式会社 | 半導体記憶装置 |
| US7155601B2 (en) * | 2001-02-14 | 2006-12-26 | Intel Corporation | Multi-element operand sub-portion shuffle instruction execution |
| US7861071B2 (en) * | 2001-06-11 | 2010-12-28 | Broadcom Corporation | Conditional branch instruction capable of testing a plurality of indicators in a predicate register |
| US7818356B2 (en) | 2001-10-29 | 2010-10-19 | Intel Corporation | Bitstream buffer manipulation with a SIMD merge instruction |
| US7631025B2 (en) * | 2001-10-29 | 2009-12-08 | Intel Corporation | Method and apparatus for rearranging data between multiple registers |
| US7624138B2 (en) | 2001-10-29 | 2009-11-24 | Intel Corporation | Method and apparatus for efficient integer transform |
| US7725521B2 (en) * | 2001-10-29 | 2010-05-25 | Intel Corporation | Method and apparatus for computing matrix transformations |
| US7739319B2 (en) * | 2001-10-29 | 2010-06-15 | Intel Corporation | Method and apparatus for parallel table lookup using SIMD instructions |
| US7685212B2 (en) * | 2001-10-29 | 2010-03-23 | Intel Corporation | Fast full search motion estimation with SIMD merge instruction |
| US20040054877A1 (en) | 2001-10-29 | 2004-03-18 | Macy William W. | Method and apparatus for shuffling data |
| JP3773195B2 (ja) * | 2002-10-25 | 2006-05-10 | インターナショナル・ビジネス・マシーンズ・コーポレーション | メモリモジュール、情報処理装置、メモリモジュールに関する初期設定方法、並びにプログラム |
| US7275149B1 (en) * | 2003-03-25 | 2007-09-25 | Verisilicon Holdings (Cayman Islands) Co. Ltd. | System and method for evaluating and efficiently executing conditional instructions |
| US7478377B2 (en) * | 2004-06-07 | 2009-01-13 | International Business Machines Corporation | SIMD code generation in the presence of optimized misaligned data reorganization |
| US7475392B2 (en) * | 2004-06-07 | 2009-01-06 | International Business Machines Corporation | SIMD code generation for loops with mixed data lengths |
| US7395531B2 (en) * | 2004-06-07 | 2008-07-01 | International Business Machines Corporation | Framework for efficient code generation using loop peeling for SIMD loop code with multiple misaligned statements |
| US7386842B2 (en) * | 2004-06-07 | 2008-06-10 | International Business Machines Corporation | Efficient data reorganization to satisfy data alignment constraints |
| US8549501B2 (en) | 2004-06-07 | 2013-10-01 | International Business Machines Corporation | Framework for generating mixed-mode operations in loop-level simdization |
| US7367026B2 (en) * | 2004-06-07 | 2008-04-29 | International Business Machines Corporation | Framework for integrated intra- and inter-loop aggregation of contiguous memory accesses for SIMD vectorization |
| US7480787B1 (en) * | 2006-01-27 | 2009-01-20 | Sun Microsystems, Inc. | Method and structure for pipelining of SIMD conditional moves |
| US8156310B2 (en) * | 2006-09-11 | 2012-04-10 | International Business Machines Corporation | Method and apparatus for data stream alignment support |
| US20080071851A1 (en) * | 2006-09-20 | 2008-03-20 | Ronen Zohar | Instruction and logic for performing a dot-product operation |
| US20080077772A1 (en) * | 2006-09-22 | 2008-03-27 | Ronen Zohar | Method and apparatus for performing select operations |
| US9069547B2 (en) | 2006-09-22 | 2015-06-30 | Intel Corporation | Instruction and logic for processing text strings |
| US8006114B2 (en) * | 2007-03-09 | 2011-08-23 | Analog Devices, Inc. | Software programmable timing architecture |
| US9529592B2 (en) | 2007-12-27 | 2016-12-27 | Intel Corporation | Vector mask memory access instructions to perform individual and sequential memory access operations if an exception occurs during a full width memory access operation |
| US8078836B2 (en) | 2007-12-30 | 2011-12-13 | Intel Corporation | Vector shuffle instructions operating on multiple lanes each having a plurality of data elements using a common set of per-lane control bits |
| JP5930558B2 (ja) * | 2011-09-26 | 2016-06-08 | インテル・コーポレーション | ストライド機能及びマスク機能を有するベクトルロード及びベクトルストアを提供する命令及びロジック |
| US10203954B2 (en) * | 2011-11-25 | 2019-02-12 | Intel Corporation | Instruction and logic to provide conversions between a mask register and a general purpose register or memory |
| WO2013095642A1 (en) * | 2011-12-23 | 2013-06-27 | Intel Corporation | Systems, apparatuses, and methods for setting an output mask in a destination writemask register from a source write mask register using an input writemask and immediate |
| CN107025093B (zh) * | 2011-12-23 | 2019-07-09 | 英特尔公司 | 用于指令处理的装置、用于处理指令的方法和机器可读介质 |
| US9354877B2 (en) * | 2011-12-23 | 2016-05-31 | Intel Corporation | Systems, apparatuses, and methods for performing mask bit compression |
| WO2013095599A1 (en) * | 2011-12-23 | 2013-06-27 | Intel Corporation | Systems, apparatuses, and methods for performing a double blocked sum of absolute differences |
| WO2013095607A1 (en) * | 2011-12-23 | 2013-06-27 | Intel Corporation | Instruction execution unit that broadcasts data values at different levels of granularity |
| US9864602B2 (en) | 2011-12-30 | 2018-01-09 | Intel Corporation | Packed rotate processors, methods, systems, and instructions |
| US9304771B2 (en) * | 2013-02-13 | 2016-04-05 | International Business Machines Corporation | Indirect instruction predication |
| US9990202B2 (en) | 2013-06-28 | 2018-06-05 | Intel Corporation | Packed data element predication processors, methods, systems, and instructions |
| US9612840B2 (en) * | 2014-03-28 | 2017-04-04 | Intel Corporation | Method and apparatus for implementing a dynamic out-of-order processor pipeline |
| US10133570B2 (en) * | 2014-09-19 | 2018-11-20 | Intel Corporation | Processors, methods, systems, and instructions to select and consolidate active data elements in a register under mask into a least significant portion of result, and to indicate a number of data elements consolidated |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4747066A (en) * | 1983-01-22 | 1988-05-24 | Tokyo Shibaura Denki Kabushiki Kaisha | Arithmetic unit |
Family Cites Families (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4141005A (en) * | 1976-11-11 | 1979-02-20 | International Business Machines Corporation | Data format converting apparatus for use in a digital data processor |
| US4217638A (en) * | 1977-05-19 | 1980-08-12 | Tokyo Shibaura Electric Co., Ltd. | Data-processing apparatus and method |
| JPS6059469A (ja) * | 1983-09-09 | 1985-04-05 | Nec Corp | ベクトル処理装置 |
| JPS6089274A (ja) * | 1983-10-20 | 1985-05-20 | Nec Corp | ベクトルマスク制御システム |
| US5249266A (en) * | 1985-10-22 | 1993-09-28 | Texas Instruments Incorporated | Data processing apparatus with self-emulation capability |
| JPH0812660B2 (ja) * | 1989-02-02 | 1996-02-07 | 日本電気株式会社 | ベクトルデータ処理装置 |
| US5423010A (en) * | 1992-01-24 | 1995-06-06 | C-Cube Microsystems | Structure and method for packing and unpacking a stream of N-bit data to and from a stream of N-bit data words |
| JPH05250254A (ja) * | 1992-03-04 | 1993-09-28 | Nec Corp | 記憶回路 |
| US5467413A (en) * | 1993-05-20 | 1995-11-14 | Radius Inc. | Method and apparatus for vector quantization for real-time playback on low cost personal computers |
| US5630075A (en) * | 1993-12-30 | 1997-05-13 | Intel Corporation | Write combining buffer for sequentially addressed partial line operations originating from a single instruction |
| US5751982A (en) * | 1995-03-31 | 1998-05-12 | Apple Computer, Inc. | Software emulation system with dynamic translation of emulated instructions for increased processing speed |
| US5680332A (en) | 1995-10-30 | 1997-10-21 | Motorola, Inc. | Measurement of digital circuit simulation test coverage utilizing BDDs and state bins |
| JP2806346B2 (ja) * | 1996-01-22 | 1998-09-30 | 日本電気株式会社 | 演算処理装置 |
| US5784607A (en) * | 1996-03-29 | 1998-07-21 | Integrated Device Technology, Inc. | Apparatus and method for exception handling during micro code string instructions |
| US5996066A (en) * | 1996-10-10 | 1999-11-30 | Sun Microsystems, Inc. | Partitioned multiply and add/subtract instruction for CPU with integrated graphics functions |
| US5991531A (en) * | 1997-02-24 | 1999-11-23 | Samsung Electronics Co., Ltd. | Scalable width vector processor architecture for efficient emulation |
| JPH1153189A (ja) * | 1997-07-31 | 1999-02-26 | Toshiba Corp | 演算装置、演算方法及びコンピュータ読み取り可能な記録媒体 |
| US6052769A (en) * | 1998-03-31 | 2000-04-18 | Intel Corporation | Method and apparatus for moving select non-contiguous bytes of packed data in a single instruction |
| US6173393B1 (en) * | 1998-03-31 | 2001-01-09 | Intel Corporation | System for writing select non-contiguous bytes of data with single instruction having operand identifying byte mask corresponding to respective blocks of packed data |
| US6067617A (en) | 1998-04-07 | 2000-05-23 | International Business Machines Corporation | Specialized millicode instructions for packed decimal division |
| US6098087A (en) * | 1998-04-23 | 2000-08-01 | Infineon Technologies North America Corp. | Method and apparatus for performing shift operations on packed data |
| EP0967544B1 (en) | 1998-06-25 | 2006-04-19 | Texas Instruments Incorporated | Digital signal processor for data having a large bit-length |
| US20020002666A1 (en) * | 1998-10-12 | 2002-01-03 | Carole Dulong | Conditional operand selection using mask operations |
| US6484255B1 (en) * | 1999-09-20 | 2002-11-19 | Intel Corporation | Selective writing of data elements from packed data based upon a mask using predication |
| US7480787B1 (en) * | 2006-01-27 | 2009-01-20 | Sun Microsystems, Inc. | Method and structure for pipelining of SIMD conditional moves |
| US9529592B2 (en) * | 2007-12-27 | 2016-12-27 | Intel Corporation | Vector mask memory access instructions to perform individual and sequential memory access operations if an exception occurs during a full width memory access operation |
-
1999
- 1999-09-20 US US09/399,612 patent/US6484255B1/en not_active Expired - Lifetime
-
2000
- 2000-08-29 CN CNB008159319A patent/CN100440138C/zh not_active Expired - Lifetime
- 2000-08-29 JP JP2001525517A patent/JP4921665B2/ja not_active Expired - Lifetime
- 2000-08-29 WO PCT/US2000/023721 patent/WO2001022216A1/en active Application Filing
- 2000-08-29 AU AU69454/00A patent/AU6945400A/en not_active Abandoned
- 2000-08-29 GB GB0208629A patent/GB2371135B/en not_active Expired - Lifetime
- 2000-08-29 DE DE10085391T patent/DE10085391T1/de not_active Ceased
-
2002
- 2002-07-27 HK HK02105537.7A patent/HK1044202B/zh not_active IP Right Cessation
- 2002-10-23 US US10/279,553 patent/US20030046520A1/en not_active Abandoned
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4747066A (en) * | 1983-01-22 | 1988-05-24 | Tokyo Shibaura Denki Kabushiki Kaisha | Arithmetic unit |
Also Published As
| Publication number | Publication date |
|---|---|
| GB0208629D0 (en) | 2002-05-22 |
| JP2003510682A (ja) | 2003-03-18 |
| JP4921665B2 (ja) | 2012-04-25 |
| GB2371135A (en) | 2002-07-17 |
| HK1044202A1 (en) | 2002-10-11 |
| AU6945400A (en) | 2001-04-24 |
| US20030046520A1 (en) | 2003-03-06 |
| GB2371135B (en) | 2004-03-31 |
| WO2001022216A1 (en) | 2001-03-29 |
| HK1044202B (zh) | 2004-12-03 |
| DE10085391T1 (de) | 2002-12-12 |
| CN1391668A (zh) | 2003-01-15 |
| US6484255B1 (en) | 2002-11-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN100440138C (zh) | 使用推测、基于掩码、由打包数据选择写入数据元素的方法、系统和处理器 | |
| EP3629153B1 (en) | Systems and methods for performing matrix compress and decompress instructions | |
| CN101620525B (zh) | 混洗数据的方法和装置 | |
| CN100541422C (zh) | 用于执行具有取整和移位的组合型高位乘法的方法和装置 | |
| US7127593B2 (en) | Conditional execution with multiple destination stores | |
| CN111656367A (zh) | 神经网络加速器的系统和体系结构 | |
| CN102207849B (zh) | 用于执行逻辑比较操作的方法和装置 | |
| US20140129802A1 (en) | Methods, apparatus, and instructions for processing vector data | |
| CN117407058A (zh) | 用于执行用于复数的融合乘-加指令的系统和方法 | |
| CN107957976B (zh) | 一种计算方法及相关产品 | |
| US5561808A (en) | Asymmetric vector multiprocessor composed of a vector unit and a plurality of scalar units each having a different architecture | |
| US20090172349A1 (en) | Methods, apparatus, and instructions for converting vector data | |
| CN108121688B (zh) | 一种计算方法及相关产品 | |
| CN105612509A (zh) | 用于提供向量子字节解压缩功能性的方法、设备、指令和逻辑 | |
| EP1528481A2 (en) | Processor executing simd instructions | |
| TW201337732A (zh) | 用以執行將遮罩暫存器轉換為向量暫存器的系統、裝置及方法 | |
| CN104011658A (zh) | 用于提供向量线性内插功能的指令和逻辑 | |
| CN101980148A (zh) | 用于执行选择操作的方法和装置 | |
| US8707013B2 (en) | On-demand predicate registers | |
| US5265258A (en) | Partial-sized priority encoder circuit having look-ahead capability | |
| CN107957977B (zh) | 一种计算方法及相关产品 | |
| CN109328334B (zh) | 用于累积式求和的系统、装置和方法 | |
| TW201732571A (zh) | 用於獲得偶數和奇數資料元素的系統、裝置及方法 | |
| CN109328333B (zh) | 用于累积式乘积的系统、装置和方法 | |
| CN112230995B (zh) | 一种指令的生成方法、装置以及电子设备 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| CX01 | Expiry of patent term |
Granted publication date: 20081203 |
|
| CX01 | Expiry of patent term |