WO2024029020A1 - データ分析装置、データ分析方法及びデータ分析プログラム - Google Patents
データ分析装置、データ分析方法及びデータ分析プログラム Download PDFInfo
- Publication number
- WO2024029020A1 WO2024029020A1 PCT/JP2022/029892 JP2022029892W WO2024029020A1 WO 2024029020 A1 WO2024029020 A1 WO 2024029020A1 JP 2022029892 W JP2022029892 W JP 2022029892W WO 2024029020 A1 WO2024029020 A1 WO 2024029020A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data analysis
- calculation unit
- parameter
- gram matrix
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/16—Matrix or vector computation, e.g. matrix-matrix or matrix-vector multiplication, matrix factorization
Definitions
- the present invention relates to a data analysis device, a data analysis method, and a data analysis program.
- feature selection in data mining is a group of methods for selecting important features from data, and is one of the basic techniques.
- data features may have a group structure.
- weather data for each region can be regarded as data in which each region corresponds to a group, and each group includes characteristics such as "temperature,” “humidity,” “weather,” and “wind direction.”
- Group Lasso is a typical method for selecting feature groups.
- Group Lasso is a method based on linear regression and can handle feature groups by imposing group constraints on the coefficients of the linear regression model.
- Group Lasso there is a correspondence between data features and linear regression coefficients, and the coefficients are also grouped in correspondence with feature groups. At this time, an optimization problem for estimating the coefficients can be found by a solver, but if all the grouped coefficients are zero, the feature group corresponding to that group will not contribute to prediction and can be considered as an unimportant feature group. In this way, Group Lasso finds important and unimportant feature groups.
- Group Lasso has the theoretical drawback that the magnitude of the estimated coefficient is biased, and the consistency of the selected feature group may not be guaranteed.
- Group SCAD In order to overcome this drawback, a method called Group SCAD was proposed.
- the theoretical disadvantage of Group Lasso is that the regularization term (penalty term) for the coefficient is a convex function, so Group SCAD uses a non-convex function as the regularization term to overcome shortcomings.
- Group SCAD also selects important feature groups by solving an optimization problem.
- the present invention has been made in view of the above, and aims to provide a data analysis device, a data analysis method, and a data analysis program that can execute Group SCAD on large-scale data at high speed. .
- a data analysis device of the present invention selects important feature groups from data whose feature values have a group structure, and calculates a Gram matrix of data.
- a Gram matrix calculation unit a Gram matrix norm calculation unit that calculates the norm for each row of the Gram matrix calculated by the Gram matrix calculation unit, a snapshot acquisition unit that acquires parameters during optimization, and a snapshot acquisition unit.
- the present invention is characterized in that it includes a parameter addition calculation unit that adds the obtained parameter to the optimization problem, and an addition number count calculation unit that counts the number of parameter additions added by the parameter addition calculation unit.
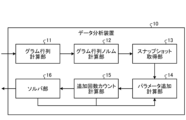
- FIG. 1 is a block diagram showing an example of the configuration of a data analysis device according to an embodiment.
- FIG. 2 is a block diagram showing an example of the configuration of the parameter addition calculation section according to the embodiment.
- FIG. 3 is a diagram showing an algorithm used by the data analysis device shown in FIG. 1.
- FIG. 4 is a diagram showing an algorithm used by the data analysis device shown in FIG. 1.
- FIG. 5 is a flowchart showing a data analysis processing procedure according to the embodiment.
- FIG. 6 is a diagram illustrating an example of a computer that executes a data analysis program.
- n be the number of data, and each data is expressed by a p-dimensional feature amount. Thereby, data can be expressed as a matrix of X ⁇ R ⁇ n ⁇ p ⁇ .
- the response can be expressed as a vector y ⁇ R ⁇ n in the number of data dimensions. Since linear regression performs prediction by calculating the inner product of data and a coefficient vector, this coefficient vector is expressed as ⁇ R ⁇ p ⁇ .
- Group SCAD extracts groups of important features by solving the optimization problem shown in the following equations (1) and (2).
- Equations (1) and (2) X ⁇ (g) ⁇ R ⁇ n ⁇ pg ⁇ is a submatrix of matrix X, and pg is the size of the feature amount of the g-th group. Similarly, ⁇ g ⁇ is the coefficient of the gth group. G represents the number of all groups. ⁇ and ⁇ are hyperparameters and are subject to manual tuning.
- a in FIG. 3 is a set of indexes of the group ⁇ 1,...,G ⁇ .
- the function S(., .) in equation (3) is calculated for the argument as shown in equation (5).
- z ⁇ _ ⁇ (g) is the upper bound of z ⁇ (g)
- z_ ⁇ _ ⁇ (g) is the lower bound of z ⁇ (g).
- ⁇ z ⁇ (g) and ⁇ (l) are values (snapshots) corresponding to z ⁇ (g) and ⁇ (l), respectively. These values are updated at regular intervals during the block coordinate descent iteration.
- the i-th element of ⁇ K ⁇ (g)[l] ⁇ R ⁇ (pg) is the i-th row of K(g,l) ⁇ R ⁇ pg ⁇ pl ⁇ , where it is a submatrix of K. It is calculated as the L2 norm of
- the data analysis device 10 according to the present embodiment is a linear regression model learning device that uses Group SCAD to extract groups of important features from large-scale data.
- FIG. 1 is a block diagram showing an example of the configuration of a data analysis device 10 according to an embodiment.
- the data analysis device 10 includes a Gram matrix calculation section 11, a Gram matrix norm calculation section 12, a snapshot acquisition section 13, a parameter addition calculation section 14, and an addition count calculation section 15. , has a solver section 16.
- a predetermined program is loaded into a computer or the like including, for example, ROM (Read Only Memory), RAM (Random Access Memory), CPU (Central Processing Unit), etc., and the CPU executes the predetermined program. This is achieved by
- the Gram matrix norm calculation unit 12 calculates the norm for each row of the Gram matrix calculated by the Gram matrix calculation unit 11. For example, the Gram matrix norm calculation unit 12 calculates the L2 norm
- the snapshot acquisition unit 13 acquires the parameters being optimized. For example, the snapshot acquisition unit 13 acquires snapshots ⁇ z ⁇ (g) and ⁇ (l) of equations (9) and (10). This acquisition is performed at regular intervals during the execution of the block coordinate descent solver, and may be acquired in the form shown in FIG. 4, for example.
- the parameter addition calculation unit 14 adds the parameters acquired by the snapshot acquisition unit 13 to the optimization problem. For example, the parameter addition calculation unit 14 uses equations (6), (7), and (8) to determine the importance of any ⁇ (l): high, medium, low, or other parameters. This is the part to judge. The parameter addition calculation unit 14 first extracts parameters with high importance, adds them to the optimization target, and moves on to the next part. The parameter addition calculation unit 14 thereafter executes this process in a loop in order of importance.
- the parameter addition calculation section 14 includes a count determination section 141 , a first parameter (importance: high) calculation section 142 , a second parameter (importance: medium) calculation section 143 , and a third parameter (importance: low) calculation section 144 , a fourth parameter (importance: other) calculation unit 145.
- the parameter addition calculation unit 14 adds parameters to the optimization problem in descending order of importance among the parameters distributed according to the number of parameter additions counted by the addition count calculation unit 15.
- the count determination unit 141 branches the process depending on the number of times the parameter is added.
- the first parameter calculation unit 142 calculates parameters with high importance.
- the second parameter calculation unit 143 calculates parameters with medium importance.
- the third parameter calculation unit 144 calculates parameters with low importance.
- the fourth parameter calculation unit 145 calculates other parameters. For example, the fourth parameter calculation unit 145 calculates parameters that cannot be classified by importance.
- the addition count calculation unit 15 counts the number of parameter additions added by the parameter addition calculation unit 14. For example, the addition count calculation unit 15 increments the count by one when a parameter is added to the optimization target by the parameter addition calculation unit 14.
- the variable step in the algorithm diagram corresponds to this count.
- the addition count calculation section 15 allocates the importance of the parameters extracted by the parameter addition calculation section 14 according to this count number. Specifically, the addition number count calculation unit 15 determines the importance level: high if it is 0, the importance level is medium if it is 1, the importance level is low if it is 2, and the other parameters if it is 3. Assign importance.
- the solver unit 16 performs optimization on the parameters added by the parameter addition calculation unit 14. For example, the solver unit 16 optimizes the optimization target parameter added by the parameter addition calculation unit 14 and the parameters added so far. At this time, it is also necessary to obtain snapshots used in equations (9) and (10) during optimization, so in the embodiment, for example, block coordinate descent, etc. that can obtain snapshots as shown in Fig. Conceivable. The solver unit 16 also determines whether optimization has been performed for all parameters.
- the data analysis device 10 ends the process when the count reaches 3 and all parameters have been optimized by the solver unit 16.
- FIG. 5 is a flowchart showing the processing procedure of the data analysis method according to the embodiment.
- the Gram matrix calculation unit 11 calculates a Gram matrix of data (step S11).
- the Gram matrix norm calculation unit 12 calculates the norm for each row of the Gram matrix of the given data (step S12).
- the snapshot acquisition unit 13 acquires the parameters being optimized (step S13).
- the parameter addition calculation unit 14 adds the parameters acquired by the snapshot acquisition unit 13 to the optimization problem (step S14). Then, the addition count calculation unit 15 counts the number of parameter additions added by the parameter addition calculation unit 14 (step S15).
- the solver unit 16 performs optimization on the parameters added by the parameter addition calculation unit 14 (step S16).
- the solver unit 16 determines whether all parameters have been optimized (step S17).
- step S17 "NO" the solver unit 16 determines that all parameters have not been optimized.
- step S17 determines that all parameters have been optimized.
- the data analysis device 10 is a linear regression model learning device that uses Group SCAD to extract groups of important features from large-scale data.
- the data analysis device 10 does not optimize all parameters from the beginning as in the conventional Group SCAD, but sequentially optimizes parameters starting from the most important, thereby solving optimization problems efficiently and at high speed. It can be expected that this will become a reality. This is because the data analysis device 10 can optimize highly important parameters in a manner that greatly contributes to prediction and greatly improves the value of the objective function. Furthermore, since the data analysis device 10 is a device that ultimately optimizes all parameters, there is almost no deterioration in accuracy. Therefore, according to this embodiment, Group SCAD can be executed accurately and at high speed.
- Each component of the data analysis device 10 shown in FIG. 1 is functionally conceptual, and does not necessarily need to be physically configured as shown.
- the specific form of distributing and integrating the functions of the data analysis device 10 is not limited to what is shown in the diagram, and all or part of it can be divided into functional or physical units in arbitrary units depending on various loads and usage conditions. It can be configured in a distributed or integrated manner.
- each process performed in the data analysis device 10 may be implemented in whole or in part by a CPU and a program that is analyzed and executed by the CPU. Furthermore, each process performed in the data analysis device 10 may be implemented as hardware using wired logic.
- FIG. 6 is a diagram showing an example of a computer that implements the data analysis device 10 by executing a program.
- Computer 1000 includes, for example, a memory 1010 and a CPU 1020.
- the computer 1000 also includes a hard disk drive interface 1030, a disk drive interface 1040, a serial port interface 1050, a video adapter 1060, and a network interface 1070. These parts are connected by a bus 1080.
- the memory 1010 includes a ROM 1011 and a RAM 1012.
- the ROM 1011 stores, for example, a boot program such as BIOS (Basic Input Output System).
- Hard disk drive interface 1030 is connected to hard disk drive 1090.
- Disk drive interface 1040 is connected to disk drive 1100.
- Serial port interface 1050 is connected to, for example, mouse 1110 and keyboard 1120.
- Video adapter 1060 is connected to display 1130, for example.
- the hard disk drive 1090 stores, for example, an OS 1091, an application program 1092, a program module 1093, and program data 1094. That is, a program that defines each process of the data analysis device 10 is implemented as a program module 1093 in which code executable by the computer 1000 is written.
- Program module 1093 is stored in hard disk drive 1090, for example.
- a program module 1093 for executing processing similar to the functional configuration of the data analysis device 10 is stored in the hard disk drive 1090.
- the hard disk drive 1090 may be replaced by an SSD (Solid State Drive).
- the setting data used in the processing of the embodiment described above is stored as program data 1094 in, for example, the memory 1010 or the hard disk drive 1090. Then, the CPU 1020 reads out the program module 1093 and program data 1094 stored in the memory 1010 and the hard disk drive 1090 to the RAM 1012 as necessary and executes them.
- program module 1093 and the program data 1094 are not limited to being stored in the hard disk drive 1090, but may be stored in a removable storage medium, for example, and read by the CPU 1020 via the disk drive 1100 or the like.
- the program module 1093 and the program data 1094 may be stored in another computer connected via a network (LAN (Local Area Network), WAN (Wide Area Network), etc.). The program module 1093 and program data 1094 may then be read by the CPU 1020 from another computer via the network interface 1070.
- LAN Local Area Network
- WAN Wide Area Network
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Computational Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Theoretical Computer Science (AREA)
- Computing Systems (AREA)
- Algebra (AREA)
- Databases & Information Systems (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Complex Calculations (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/029892 WO2024029020A1 (ja) | 2022-08-04 | 2022-08-04 | データ分析装置、データ分析方法及びデータ分析プログラム |
| JP2024538603A JP7750420B2 (ja) | 2022-08-04 | 2022-08-04 | データ分析装置、データ分析方法及びデータ分析プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/029892 WO2024029020A1 (ja) | 2022-08-04 | 2022-08-04 | データ分析装置、データ分析方法及びデータ分析プログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024029020A1 true WO2024029020A1 (ja) | 2024-02-08 |
Family
ID=89848699
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/029892 Ceased WO2024029020A1 (ja) | 2022-08-04 | 2022-08-04 | データ分析装置、データ分析方法及びデータ分析プログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7750420B2 (https=) |
| WO (1) | WO2024029020A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20230142452A1 (en) * | 2020-04-27 | 2023-05-11 | Nippon Telegraph And Telephone Corporation | Data processing method, data processing device, and data processing program |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015007826A (ja) * | 2013-06-24 | 2015-01-15 | 日本電信電話株式会社 | 信号処理装置、方法、及びプログラム |
| JP2020173674A (ja) * | 2019-04-11 | 2020-10-22 | 日本電信電話株式会社 | データ分析装置、データ分析方法及びデータ分析プログラム |
| WO2021229648A1 (ja) * | 2020-05-11 | 2021-11-18 | 日本電気株式会社 | 数式モデル生成システム、数式モデル生成方法および数式モデル生成プログラム |
-
2022
- 2022-08-04 JP JP2024538603A patent/JP7750420B2/ja active Active
- 2022-08-04 WO PCT/JP2022/029892 patent/WO2024029020A1/ja not_active Ceased
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015007826A (ja) * | 2013-06-24 | 2015-01-15 | 日本電信電話株式会社 | 信号処理装置、方法、及びプログラム |
| JP2020173674A (ja) * | 2019-04-11 | 2020-10-22 | 日本電信電話株式会社 | データ分析装置、データ分析方法及びデータ分析プログラム |
| WO2021229648A1 (ja) * | 2020-05-11 | 2021-11-18 | 日本電気株式会社 | 数式モデル生成システム、数式モデル生成方法および数式モデル生成プログラム |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20230142452A1 (en) * | 2020-04-27 | 2023-05-11 | Nippon Telegraph And Telephone Corporation | Data processing method, data processing device, and data processing program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7750420B2 (ja) | 2025-10-07 |
| JPWO2024029020A1 (https=) | 2024-02-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| TWI444844B (zh) | 模擬參數校正技術 | |
| US20200034745A1 (en) | Time series analysis and forecasting using a distributed tournament selection process | |
| Peltola et al. | Hierarchical Bayesian Survival Analysis and Projective Covariate Selection in Cardiovascular Event Risk Prediction. | |
| CN111523685B (zh) | 基于主动学习的降低性能建模开销的方法 | |
| CN118378900B (zh) | 一种基于机器学习模型的煤矿风险智能监测方法和计算机设备 | |
| US20230401361A1 (en) | Generating and analyzing material structures based on neural networks | |
| Fan et al. | Latuner: An llm-enhanced database tuning system based on adaptive surrogate model | |
| JP7750420B2 (ja) | データ分析装置、データ分析方法及びデータ分析プログラム | |
| JP7172816B2 (ja) | データ分析装置、データ分析方法及びデータ分析プログラム | |
| JP6577515B2 (ja) | 分析装置、分析方法及び分析プログラム | |
| JP6662754B2 (ja) | L1グラフ計算装置、l1グラフ計算方法及びl1グラフ計算プログラム | |
| Grohmann et al. | Baloo: Measuring and modeling the performance configurations of distributed dbms | |
| JP2005148901A (ja) | ジョブスケジューリングシステム | |
| Nguyen et al. | An efficient joint model for high dimensional longitudinal and survival data via generic association features | |
| JP7439923B2 (ja) | 学習方法、学習装置及びプログラム | |
| JP6659618B2 (ja) | 分析装置、分析方法及び分析プログラム | |
| Ahmad et al. | A prediction framework for fast sparse triangular solves | |
| JP2012221254A (ja) | 並列処理最適化装置及びシミュレーションプログラム | |
| KR20260026927A (ko) | 반도체 수율 예측 모델 해석 방법 및 그 시스템 | |
| Urbanek et al. | Using analytical programming and UCP method for effort estimation | |
| JP7456273B2 (ja) | データ解析システム、データ解析方法及びデータ解析プログラム | |
| JP7085521B2 (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| US20250181987A1 (en) | Trial production condition proposal system and trial production condition proposal method | |
| Akbari et al. | Regression Estimation for Length-Biased Data: A Review and Comparative Study | |
| JP6190333B2 (ja) | クラスタリング装置、クラスタリング方法およびクラスタリングプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22954009 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024538603 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22954009 Country of ref document: EP Kind code of ref document: A1 |