WO2023048290A1 - ポリペプチドの作製方法、タグ、発現ベクター、ポリペプチドの評価方法、核酸ディスプレイライブラリの作製方法及びスクリーニング方法 - Google Patents
ポリペプチドの作製方法、タグ、発現ベクター、ポリペプチドの評価方法、核酸ディスプレイライブラリの作製方法及びスクリーニング方法 Download PDFInfo
- Publication number
- WO2023048290A1 WO2023048290A1 PCT/JP2022/035787 JP2022035787W WO2023048290A1 WO 2023048290 A1 WO2023048290 A1 WO 2023048290A1 JP 2022035787 W JP2022035787 W JP 2022035787W WO 2023048290 A1 WO2023048290 A1 WO 2023048290A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- xaa
- polypeptide
- seq
- tag
- lys
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P21/00—Preparation of peptides or proteins
- C12P21/02—Preparation of peptides or proteins having a known sequence of two or more amino acids, e.g. glutathione
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/67—General methods for enhancing the expression
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K5/00—Peptides containing up to four amino acids in a fully defined sequence; Derivatives thereof
- C07K5/04—Peptides containing up to four amino acids in a fully defined sequence; Derivatives thereof containing only normal peptide links
- C07K5/10—Tetrapeptides
- C07K5/1002—Tetrapeptides with the first amino acid being neutral
- C07K5/1005—Tetrapeptides with the first amino acid being neutral and aliphatic
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K7/00—Peptides having 5 to 20 amino acids in a fully defined sequence; Derivatives thereof
- C07K7/04—Linear peptides containing only normal peptide links
- C07K7/06—Linear peptides containing only normal peptide links having 5 to 11 amino acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K7/00—Peptides having 5 to 20 amino acids in a fully defined sequence; Derivatives thereof
- C07K7/50—Cyclic peptides containing at least one abnormal peptide link
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1037—Screening libraries presented on the surface of microorganisms, e.g. phage display, E. coli display
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1065—Preparation or screening of tagged libraries, e.g. tagged microorganisms by STM-mutagenesis, tagged polynucleotides, gene tags
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B40/00—Libraries per se, e.g. arrays, mixtures
- C40B40/02—Libraries contained in or displayed by microorganisms, e.g. bacteria or animal cells; Libraries contained in or displayed by vectors, e.g. plasmids; Libraries containing only microorganisms or vectors
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B40/00—Libraries per se, e.g. arrays, mixtures
- C40B40/04—Libraries containing only organic compounds
- C40B40/06—Libraries containing nucleotides or polynucleotides, or derivatives thereof
- C40B40/08—Libraries containing RNA or DNA which encodes proteins, e.g. gene libraries
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B40/00—Libraries per se, e.g. arrays, mixtures
- C40B40/04—Libraries containing only organic compounds
- C40B40/10—Libraries containing peptides or polypeptides, or derivatives thereof
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/40—Fusion polypeptide containing a tag for immunodetection, or an epitope for immunisation
Definitions
- the present disclosure relates to methods for producing polypeptides, tags, expression vectors, methods for evaluating polypeptides, methods for producing nucleic acid display libraries, and screening methods.
- Tags are used for detection, isolation, immobilization, and the like of target proteins.
- Embodiments according to the present disclosure provide a method for producing a polypeptide with high productivity, a tag and an expression vector that increase the expression level of the polypeptide, an efficient method for evaluating the polypeptide, and a high expression level and a high expression level. To provide a method for preparing a nucleic acid display library with less bias and a highly reliable screening method.
- a method for producing a polypeptide comprising expressing the polypeptide as a tagged polypeptide, a nucleotide sequence encoding a tag consisting of the amino acid sequence of SEQ ID NO: 1, located immediately after the initiation codon; a base sequence encoding a polypeptide arranged in-frame downstream of a base sequence encoding a tag; expressing the tagged polypeptide from a nucleic acid having Methods of making polypeptides.
- ⁇ 3> The method for producing the polypeptide according to ⁇ 1>, wherein the tag is a tag consisting of the amino acid sequence of SEQ ID NO:3.
- ⁇ 4> The method for producing the polypeptide according to any one of ⁇ 1> to ⁇ 3>, wherein the tagged polypeptide is expressed from a nucleic acid using a cell-free peptide synthesis system or Escherichia coli.
- ⁇ 5> The method for producing a polypeptide according to any one of ⁇ 1> to ⁇ 4>, wherein the polypeptide contains an unnatural amino acid.
- ⁇ 6> A tag consisting of the amino acid sequence of SEQ ID NO:1.
- ⁇ 7> A tag consisting of the amino acid sequence of SEQ ID NO:2.
- ⁇ 8> A tag consisting of the amino acid sequence of SEQ ID NO:3.
- an expression vector having a sequence ⁇ 12> The expression vector of ⁇ 11>, wherein the tag consists of the amino acid sequence of SEQ ID NO:2.
- a polypeptide comprising: producing a polypeptide by the method for producing a polypeptide according to any one of ⁇ 1> to ⁇ 5>; and evaluating the binding of the polypeptide to a target substance. Peptide evaluation method.
- ⁇ 16> A nucleotide sequence encoding a tag consisting of the amino acid sequence of SEQ ID NO: 1 immediately after the initiation codon, and a base encoding a polypeptide located in-frame downstream of the nucleotide sequence encoding the tag. and expressing a tagged polypeptide from a nucleic acid having a sequence to generate a nucleic acid-polypeptide conjugate.
- the tag is a tag consisting of the amino acid sequence of SEQ ID NO:2.
- ⁇ 18> The method for producing a nucleic acid display library according to ⁇ 16>, wherein the tag consists of the amino acid sequence of SEQ ID NO:3.
- Producing a nucleic acid-polypeptide conjugate comprises producing an mRNA-polypeptide conjugate, and reverse-transcribes the mRNA of the mRNA-polypeptide conjugate to produce a cDNA-polypeptide conjugate.
- the method for producing a nucleic acid display library according to any one of ⁇ 16> to ⁇ 18>, including ⁇ 20> The method for preparing a nucleic acid display library according to any one of ⁇ 16> to ⁇ 19>, wherein the nucleic acid and the polypeptide are linked by a puromycin linker in the nucleic acid-polypeptide conjugate.
- ⁇ 21> The method for preparing a nucleic acid display library according to any one of ⁇ 16> to ⁇ 20>, wherein the polypeptide contains an unnatural amino acid.
- the polypeptide comprises an amino acid having a first functional group and an amino acid having a second functional group covalently bonded to the first functional group, and the amino acid having the first functional group and the second A polypeptide in which 2 to 28 amino acids intervene between an amino acid having a functional group, ⁇ 16> to ⁇ 21>, further comprising cyclizing the polypeptide of the nucleic acid-polypeptide conjugate by covalent bonding between the first functional group and the second functional group.
- ⁇ 23> Preparing a nucleic acid display library by the method for preparing a nucleic acid display library according to any one of ⁇ 16> to ⁇ 22>;
- a screening method comprising: selecting a nucleic acid-polypeptide conjugate having a desired activity from a nucleic acid display library; and identifying the nucleotide sequence of the nucleic acid of the selected nucleic acid-polypeptide conjugate.
- a method for producing a polypeptide with high productivity, a tag and an expression vector that increase the expression level of the polypeptide, an efficient method for evaluating the polypeptide, and a high expression level and Provided are a method for constructing a nucleic acid display library with less bias in expression level and a highly reliable screening method.
- FIG. 3 is a graph showing the amount of biosynthesis of fusion proteins for tags of SEQ ID NOs: 7 to 26, in which the tags are arranged in order of the amount of biosynthesis of fusion proteins.
- FIG. 4 is a graph showing the amount of fusion protein biosynthesis for the tags of SEQ ID NOs: 27, 28, 31, 37, 48 and 52.
- FIG. 10 is a graph showing the binding performance of integrin-binding peptides tagged with SEQ ID NO:27.
- FIG. FIG. 4 shows the structures of compounds introduced in SEQ ID NOS: 133-136.
- a numerical range indicated using “to” indicates a range including the numerical values before and after "to” as the minimum and maximum values, respectively.
- the upper limit or lower limit of one numerical range may be replaced with the upper or lower limit of another numerical range described step by step.
- the upper or lower limits of the numerical ranges may be replaced with the values shown in the examples.
- each component may contain multiple types of applicable substances.
- the amount of each component in the composition in this disclosure if there are multiple types of substances corresponding to each component in the composition, unless otherwise specified, multiple types of substances present in the composition means the total amount of
- a polypeptide refers to a molecule in which amino acids are linked by peptide bonds. There is no limit to the number of amino acid residues in a polypeptide, and polypeptide is a term that includes proteins.
- the polypeptide in the present disclosure preferably has 6 or more amino acid residues.
- Polypeptides include polypeptides with post-translational modifications of amino acids. Post-translational modifications of amino acids include phosphorylation, methylation, acetylation, and the like.
- nucleic acid refers to a molecule that carries information for synthesizing a polypeptide.
- Nucleic acids include all nucleic acids (e.g., DNA, RNA, analogues thereof, natural products, and artificial products), and all nucleic acids linked to low-molecular-weight compounds, groups, molecules other than nucleic acids, structures, etc. It is a term that includes A nucleic acid may be a single-stranded nucleic acid or a double-stranded nucleic acid.
- the present disclosure provides methods for producing highly productive polypeptides.
- a method of making a polypeptide according to the present disclosure includes expressing the polypeptide as a tagged polypeptide.
- the present disclosure provides tags and expression vectors that increase the expression level of polypeptides for highly productive methods of producing polypeptides.
- the tags provided by embodiments of the present disclosure are collectively referred to as VKKX tags.
- the method for producing a polypeptide according to the present disclosure comprises a nucleotide sequence encoding a VKKX tag immediately after the initiation codon and a base encoding a polypeptide located in-frame downstream of the nucleotide sequence encoding the VKKX tag. and expressing the tagged polypeptide from a nucleic acid having the sequence.
- the nucleotide sequence encoding the VKKX tag and the nucleotide sequence encoding the polypeptide are arranged in-frame in one nucleic acid molecule. That is, the VKKX tag and the polypeptide are placed in an open reading frame starting from the initiation codon immediately preceding the nucleotide sequence encoding the VKKX tag.
- the nucleotide sequence encoding the VKKX tag and the nucleotide sequence encoding the polypeptide may be directly linked or linked via another nucleotide sequence.
- the method for producing a polypeptide according to the present disclosure is a highly productive method for producing a polypeptide.
- the VKKX tag is a tag consisting of the amino acid sequence of SEQ ID NO:1.
- the VKKX tag is preferably a tag consisting of the amino acid sequence of SEQ ID NO:2, more preferably a tag consisting of the amino acid sequence of SEQ ID NO:3, and even more preferably a tag consisting of the amino acid sequence of SEQ ID NO:4.
- SEQ ID NO: 1 Val-Lys-Lys-(Xaa)n.
- (Xaa)n is a sequence of arbitrary n amino acids, n is an integer of 1 to 8, and (Xaa)n may be composed of one or more amino acids.
- amino acids constituting (Xaa)n are n selected from the group consisting of Ile, Lys, Arg, His, Ser, Thr, Asp, Cys, Asn, Tyr, Gln, Trp and Phe. Amino acids are preferred, and n amino acids selected from the group consisting of Ile, Lys, Arg, His, Ser, Thr and Asp are more preferred.
- n is preferably an integer of 1-7, more preferably an integer of 2-7.
- SEQ ID NO: 2 Val-Lys-Lys-Xaa-(Xaa)m.
- the 4th Xaa from the N-terminus is Ile, Lys, Arg, His, Ser and Thr and is one amino acid selected from the group consisting of, (Xaa) m is a string of m arbitrary amino acids, m is 0 It is an integer of ⁇ 7, and (Xaa)m may be composed of one or more amino acids.
- the fourth Xaa from the N-terminus is preferably one amino acid selected from the group consisting of Ile, Lys and Thr, more preferably Thr.
- the amino acids constituting (Xaa)m are m selected from the group consisting of Ile, Lys, Arg, His, Ser, Thr, Asp, Cys, Asn, Tyr, Gln, Trp and Phe. Amino acids are preferred, and m amino acids selected from the group consisting of Ile, Lys, Arg, His, Ser, Thr and Asp are more preferred.
- m is preferably an integer of 0-6, more preferably an integer of 1-6.
- SEQ ID NO: 3 Val-Lys-Lys-Xaa-(Xaa)k.
- Xaa at the 4th position from the N-terminus is one amino acid selected from the group consisting of Ile, Lys and Thr
- (Xaa)k is a string of k amino acids selected from the group consisting of Lys, Thr and Asp.
- k is an integer of 0 to 6
- (Xaa)k may be composed of one or more amino acids.
- Thr is preferred as the 4th Xaa from the N-terminus.
- k is preferably an integer of 1-6.
- SEQ ID NO: 4 Val-Lys-Lys-Thr-Lys-Thr-(Xaa)j.
- (Xaa)j is a string of j amino acids selected from the group consisting of Lys, Thr and Asp, j is an integer of 0 to 4, and (Xaa)j may consist of one or two amino acids. It can be more than that.
- VKKX tags include tags consisting of any one of the amino acid sequences of SEQ ID NOS: 7-52.
- the base sequence encoding the VKKX tag can be designed according to the codon table of the biosynthetic system (eg, cell-free peptide synthesis system, E. coli) used to express the tagged polypeptide.
- the biosynthetic system eg, cell-free peptide synthesis system, E. coli
- amino acids include natural amino acids, unnatural amino acids, modified amino acids and derivatives thereof.
- natural amino acids refer to amino acids that constitute general proteins, such as alanine (Ala, A), arginine (Arg, R), asparagine (Asn, N), aspartic acid (Asp, D), cysteine ( Cys, C), glutamine (Gln, Q), glutamic acid (Glu, E), glycine (Gly, G), histidine (His, H), isoleucine (Ile, I), leucine (Leu, L), lysine (Lys , K), methionine (Met, M), phenylalanine (Phe, F), proline (Pro, P), serine (Ser, S), threonine (Thr, T), tryptophan (Trp, W), tyrosine (Tyr, Y) and valine (Val, V).
- Natural amino acids may be natural or man-made.
- unnatural amino acids refer to amino acids other than the 20 types of amino acids described above, including both natural and
- unnatural amino acids include amino acids having a chloroacetyl group (eg, chloroacetylated amino acids such as chloroacetyl lysine, chloroacetyldiaminobutyric acid).
- unnatural amino acids include N-methylamino acids (eg, N-methylalanine, N-methylphenylalanine).
- a labeling compound is a substance detectable by biochemical, chemical, immunochemical or electromagnetic detection methods. Labeling compounds include dye compounds, fluorescent substances, chemiluminescent substances, bioluminescent substances, enzyme substrates, coenzymes, antigenic substances, substances that bind to specific proteins, and magnetic substances. Labeled amino acids are classified by function, and include, for example, fluorescence-labeled amino acids, radioactive isotope-labeled amino acids, photoresponsive amino acids, photoswitch amino acids, fluorescent probe amino acids, and the like.
- the amino acid and the labeling compound may be directly bound, or the amino acid and the labeling compound may be bound via a spacer.
- Spacers include polyolefins such as polyethylene and polypropylene; polyethers such as polyoxyethylene, polyethylene glycol and polyvinyl alcohol; polystyrene, polyvinyl chloride, polyester, polyamide, polyimide, polyurethane and polycarbonate.
- Derivatives of natural amino acids, unnatural amino acids or modified amino acids include, for example, hydroxy acids, mercapto acids and carboxylic acids.
- polypeptides examples include polypeptides containing non-natural amino acids. Specific examples include polypeptides containing N-methylamino acids (eg, N-methylalanine, N-methylphenylalanine). The number of amino acid residues in a polypeptide containing unnatural amino acids is, for example, 3-20.
- polypeptides examples include cyclic polypeptides containing non-natural amino acids. Specific examples include amino acids with a thiol group (e.g., cysteine), amino acids with a chloroacetyl group (e.g., chloroacetyldiaminobutyric acid, chloroacetylated lysine), and N-methylamino acids (e.g., N-methylalanine, N -methylphenylalanine) in one molecule.
- This polypeptide is cyclized by reaction of the thiol group and the chloroacetyl group to form a cyclic polypeptide.
- the number of amino acid residues in the cyclic polypeptide containing unnatural amino acids is, for example, 3-20.
- the VKKX tag and the polypeptide may be directly linked or linked via another amino acid sequence.
- Other amino acid sequences include protease recognition sequences (e.g., sortase recognition sequence, HRV3C recognition sequence, TEV protease recognition sequence), spacer sequences (e.g., at least one amino acid selected from the group consisting of glycine and serine), VKKX tag.
- Other tags eg, His tag, HA tag, FLAG tag, Myc tag, HiBiT tag
- a protease recognition sequence allows separation of the VKKX tag and the polypeptide. Spacer sequences increase the flexibility of tagged polypeptides.
- Other tags facilitate purification or detection of tagged polypeptides.
- tags may be on the C-terminal side of the polypeptide rather than between the VKKX tag and the polypeptide.
- an amino acid sequence having no specific function may be interposed between the VKKX tag and the polypeptide, or may be added to the C-terminal side of the polypeptide.
- the expression vector according to the present disclosure comprises a base sequence encoding a VKKX tag immediately after the initiation codon, a base sequence encoding a polypeptide positioned in-frame downstream of the base sequence encoding the VKKX tag, have
- the VKKX tag is a tag consisting of the amino acid sequence of SEQ ID NO:1.
- the VKKX tag is preferably a tag consisting of the amino acid sequence of SEQ ID NO:2, more preferably a tag consisting of the amino acid sequence of SEQ ID NO:3, and even more preferably a tag consisting of the amino acid sequence of SEQ ID NO:4.
- An expression vector according to the present disclosure may have a base sequence necessary for synthesizing a polypeptide by a biosynthetic system.
- Nucleotide sequences necessary for polypeptide synthesis include not only the initiation codon, the VKKX tag-encoding nucleotide sequence and the polypeptide-encoding nucleotide sequence, but also, for example, a promoter sequence and/or a ribosome binding sequence. good too.
- the expression vector may also have a nucleotide sequence encoding the other amino acid sequence. Promoter sequences, ribosome binding sequences, initiation codons, etc.
- the expression vector according to the present disclosure is a DNA fragment containing a promoter sequence, a ribosome binding sequence, an initiation codon, a nucleotide sequence encoding a VKKX tag, a nucleotide sequence encoding a polypeptide, etc., and is ligated by a method such as overlap extension PCR. can be made by
- Vectors used to construct the expression vector according to the present disclosure include plasmid DNA, cosmid DNA, phage DNA, animal virus vectors, insect virus vectors, and the like. Expression vectors may be linear or circular.
- An embodiment of the method for producing a polypeptide according to the present disclosure is realized by culturing a transformant containing an expression vector and recovering the tagged polypeptide or polypeptide from the culture.
- a transformant may be produced by transforming a host with an expression vector according to the present disclosure. Any of Escherichia coli, yeast, fungal cells, insect cells, animal cells, and plant cells can be used as hosts for the production of transformants.
- a cell-free peptide synthesis system is a reaction system for polypeptide synthesis that (1) translates nucleic acids or (2) transcribes and translates nucleic acids without using cells. is.
- a cell-free peptide synthesis system consists of a template nucleic acid, ribosomes, factors and enzymes for transcription and/or translation, enzymes necessary for constructing the system, various substrates, energy sources, buffers and salts.
- Factors and enzymes for transcription and/or translation include substances derived from prokaryotic cells such as E. coli; substances derived from eukaryotic cells such as wheat germ, animal cells and insect cells.
- the template nucleic acid in the cell-free peptide synthesis system may be DNA or RNA.
- a template nucleic acid may be a single-stranded nucleic acid or a double-stranded nucleic acid.
- a template nucleic acid may be a linear nucleic acid or a circular nucleic acid.
- the template nucleic acid may be a nucleic acid in which a nucleotide sequence required for polypeptide synthesis is incorporated into a vector (plasmid vector, cosmid vector, etc.).
- a template nucleic acid has a base sequence necessary for synthesizing a polypeptide by a cell-free peptide synthesis system.
- Nucleotide sequences necessary for polypeptide synthesis include not only coding regions but also promoter sequences and ribosome binding sequences, for example.
- the nucleotide sequence of the template nucleic acid may or may not contain a stop codon.
- a stop codon means a codon with no matching tRNA. If the base sequence of the template nucleic acid does not contain a stop codon, an mRNA-ribosome-polypeptide conjugate can be formed.
- a cell-free peptide synthesis system for translating a nucleic acid includes a ribosome, a translation initiation factor, a translation elongation factor, a translation termination factor, an aminoacyl-tRNA synthetase, and a tRNA that is aminoacylated by an aminoacyl-tRNA synthetase.
- a nucleic acid e.g., RNA
- a cell-free peptide synthesis system that transcribes and translates nucleic acids (e.g., DNA) comprises, in addition to the constituents of (1), RNA polymerase (e.g., T7 RNA polymerase) and nucleoside triphosphate, which is a substrate for RNA polymerase. Contains acid.
- RNA polymerase e.g., T7 RNA polymerase
- nucleoside triphosphate which is a substrate for RNA polymerase.
- the mRNA-ribosome-polypeptide conjugate can be formed by removing the translation terminator from the constituent substances.
- Enzymes other than factors and enzymes for transcription and/or translation include, for example, enzymes for regeneration of energy such as creatine kinase, myokinase, nucleoside diphosphate kinase (NDPK); inorganic pyrophosphatase Enzymes for decomposition of inorganic pyrophosphate generated in transcription and/or translation such as;
- Various substrates include natural and/or unnatural amino acids, nucleotide triphosphates as energy sources, creatine phosphate, formyl folic acid, and the like.
- Nucleotide triphosphates include ATP, GTP, CTP and UTP, ATP and GTP are used in (1), and ATP, GTP, CTP and UTP are used in (2).
- a potassium phosphate buffer (pH 7.3) is usually used.
- Commonly used salts include potassium glutamate, ammonium chloride, magnesium acetate, calcium chloride, putrescine, spermidine, dithiothreitol (DTT) and the like.
- any known cell-free peptide synthesis system can be employed for the method for producing the polypeptide according to the present disclosure.
- Examples of commercially available cell-free peptide synthesis systems include PUREfrex (Gene Frontier, “PUREfrex” is a registered trademark), PURExpress In Vitro Protein Synthesis Kit (New England BioLabs), Human Cell-Free Protein Expression System (Takara Bio), Rapid Translation System (Roche), Expressway Cell-Free Expression System (Invitrogen) and the like.
- the method of producing a polypeptide according to the present disclosure further comprises purifying the tagged polypeptide, concentrating the tagged polypeptide, cleaving the VKKX tag of the tagged polypeptide, and modifying the polypeptide of interest. etc. may be included.
- a method for evaluating a polypeptide according to the present disclosure includes producing a polypeptide by a method for producing a polypeptide according to the present disclosure, and evaluating binding of the polypeptide to a target substance.
- the polypeptide may be a tagged polypeptide with a VKKX tag, or a polypeptide excluding the VKKX tag from the tagged polypeptide.
- the surface plasmon resonance method is known as a method for evaluating the binding ability of a polypeptide to a target substance. Recently, a method of obtaining a polypeptide using a cell-free peptide synthesis system and evaluating the binding ability by ELISA has been reported. (Journal of Synthetic Organic Chemistry, Japan, 2017, Vol. 75, No. 11, 1171-1178). However, in the cell-free peptide synthesis system, the expression level may be biased depending on the amino acid sequence of the polypeptide, making it difficult to evaluate the binding of polypeptides with low expression levels.
- the method for evaluating a polypeptide according to the present disclosure it is possible to obtain a large amount of expression of a polypeptide and to obtain a less biased expression level among a plurality of types of polypeptides.
- the binding ability and the like of peptides can be evaluated.
- Target substance is a term that includes all chemical substances that exhibit physiological activity, including compounds, groups, molecules, proteins, nucleic acids, lipids, carbohydrates, and complexes thereof.
- Target substances include, for example, metal ions, lipid molecular assemblies, peptides, receptors, transcription factors, enzymes, coenzymes, regulatory factors, antibodies, antigens, DNA, RNA, membrane vesicles, extracellular vesicles, organelles , cells, fragments thereof, complexes thereof, modification groups thereof.
- An example of an embodiment of the method for evaluating a polypeptide according to the present disclosure includes contacting and incubating a polypeptide and a target substance (eg, target protein).
- a target substance eg, target protein
- the polypeptide and target substance are brought into contact with each other in a buffer solution and incubated while adjusting the pH and temperature of the buffer solution and the contact time.
- the target substance may be immobilized on a solid phase carrier, and the immobilized target substance may be brought into contact with the polypeptide.
- the polypeptide may be immobilized on a solid phase carrier, and the immobilized polypeptide may be brought into contact with the target substance.
- the solid-phase carrier is not limited as long as it can immobilize the target substance or polypeptide, and includes microtiter plates, substrates, beads, magnetic beads, nitrocellulose membranes, nylon membranes, PVDF membranes and the like. Target substances or polypeptides are immobilized on these solid phase carriers by known techniques.
- the polypeptide bound to the target substance eg, target protein
- the polypeptide bound to the target substance is quantified.
- Any known protein quantification technique can be used to quantify the polypeptide. For example, it is quantified by gel electrophoresis, absorption photometry, fluorescence method, ELISA (Enzyme-Linked ImmunoSorbent Assay), chromatography, surface plasmon resonance method and the like.
- the polypeptide to be evaluated includes tags other than the VKKX tag (e.g., His tag, HA tag, FLAG tag, Myc tag, HiBiT tag).
- the polypeptide bound to the target substance is quantified by adding and expressing the tag and utilizing other functions of the tag (for example, luminescence).
- a nucleic acid display library refers to a set of nucleic acid-polypeptide conjugates as a constituent unit, and a plurality of nucleic acid-polypeptide conjugates. There is no limit to the number of clones and copies of the nucleic acid-polypeptide conjugates that make up the nucleic acid display library.
- nucleic acid-polypeptide conjugates examples include mRNA-polypeptide conjugates and cDNA-polypeptide conjugates.
- a cDNA-polypeptide conjugate is the reverse transcription product of an mRNA-polypeptide conjugate.
- nucleic acid-polypeptide conjugate the nucleic acid and polypeptide are linked, for example, via a puromycin linker or ribosome.
- the polypeptide of the nucleic acid-polypeptide conjugate is not limited in its three-dimensional structure, amino acid sequence, number of amino acid residues, type of amino acid, and base sequence encoding the polypeptide.
- Amino acids include natural amino acids, unnatural amino acids, modified amino acids and derivatives thereof.
- the polypeptide of the nucleic acid-polypeptide conjugate is expressed as a tagged polypeptide to which a VKKX tag is added.
- a method for producing a nucleic acid display library includes expressing tagged polypeptides from nucleic acids to produce nucleic acid-polypeptide conjugates.
- the nucleic acid has a VKKX tag-encoding base sequence immediately following the start codon and a polypeptide-encoding base sequence downstream of the VKKX tag-encoding base sequence in-frame.
- the VKKX tag is a tag consisting of the amino acid sequence of SEQ ID NO:1.
- the VKKX tag is preferably a tag consisting of the amino acid sequence of SEQ ID NO:2, more preferably a tag consisting of the amino acid sequence of SEQ ID NO:3, and even more preferably a tag consisting of the amino acid sequence of SEQ ID NO:4.
- the method for producing a nucleic acid display library provides a nucleic acid display library with high expression levels and low bias in expression levels by arranging a base sequence encoding a VKKX tag immediately after the start codon of a template nucleic acid. can be made.
- An example of an embodiment of a method for producing a nucleic acid display library according to the present disclosure comprises producing mRNA-polypeptide conjugates, and reverse transcribing the mRNA of the mRNA-polypeptide conjugates to produce cDNA-polypeptide conjugates. Including. According to this embodiment, since the nucleic acid of the nucleic acid-polypeptide conjugate is DNA, a chemically more stable nucleic acid display library can be obtained.
- An embodiment of the method for producing a nucleic acid display library according to the present disclosure is performed by a cell-free peptide synthesis system.
- the cell-free peptide synthesis system may be either (1) a system for translating nucleic acid or (2) a system for transcribing and translating nucleic acid.
- the details of the cell-free peptide synthesis system are as described above. Any known cell-free peptide synthesis system and any known nucleic acid display library preparation technique can be employed in the method for preparing a nucleic acid display library according to the present disclosure.
- the nucleic acid to be translated (usually mRNA) and the translation product may be ligated via a puromycin linker, ligation via a ribosome, or the like.
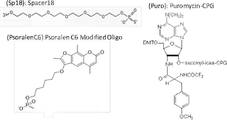
- the ligation between the nucleic acid to be translated and the translation product is preferably ligation via a puromycin linker from the viewpoints of facilitating the formation of an appropriate higher-order structure of the translation product and facilitating evaluation of the function of the translation product. Therefore, the nucleic acid to be translated in the cell-free peptide synthesis system is preferably a nucleic acid with a puromycin linker added to its 3' end.
- a linker for adding puromycin to a nucleic acid As a linker for adding puromycin to a nucleic acid, a 2'-O-methylated nucleic acid linker or a nucleic acid linker having an ultraviolet crosslinkable compound at the 5' end is preferable from the viewpoint of suppressing dissociation of the nucleic acid and puromycin. .
- the template nucleic acid in the cell-free peptide synthesis system may be DNA or RNA.
- a template nucleic acid is, for example, a population of double-stranded DNA fragments produced by performing overlap extension PCR using random primer sets containing random sequences.
- the random sequence is, for example, the triplet repeating sequence [NNK]m, where m is a positive integer, N is independently A, T, G or C, and K is independently T or G. Peptides of any length can be generated by setting the number of repeats of the triplet [NNK] to any number.
- the random sequence is preferably a trimer oligonucleotide in which one type of codon is assigned to one type of amino acid, from the viewpoint of suppressing the appearance of stop codons.
- the template nucleic acid may contain a base sequence encoding an amino acid sequence other than the VKKX tag and the target polypeptide.
- Other amino acid sequences include protease recognition sequences, spacer sequences, tags other than VKKX tags.
- the nucleotide sequence encoding the other amino acid sequence is in-frame between the nucleotide sequence encoding the VKKX tag and the nucleotide sequence encoding the polypeptide of interest, or downstream of the nucleotide sequence encoding the polypeptide of interest. is placed in
- the 3' end of the template nucleic acid has a base sequence encoding a spacer.
- a spacer is, for example, at least one amino acid selected from glycine and serine.
- Non-natural amino acids include non-natural amino acids; natural amino acids or modified amino acids of non-natural amino acids; derivatives of natural amino acids, non-natural amino acids or modified amino acids; The details of these amino acids are as described above.
- polypeptide to be expressed is an amino acid having a first functional group and an amino acid having a second functional group covalently bonded to the first functional group. and wherein 2 to 28 amino acids intervene between the amino acid having the first functional group and the amino acid having the second functional group.
- the polypeptide to be expressed may be a polypeptide with 6 to 16 amino acids intervening between the amino acid with the first functional group and the amino acid with the second functional group.
- the polypeptide can be cyclized by reaction of the first functional group and the second functional group, resulting in a cyclic polypeptide.
- the total number of amino acid residues in this cyclic polypeptide is, for example, 4-32.
- the method for producing a nucleic acid display library according to the present disclosure is such that the polypeptide of the nucleic acid-polypeptide conjugate is covalently bonded to the first functional group and the second functional group. Including cyclizing. Cyclization may occur at mRNA-polypeptide conjugates or at cDNA-polypeptide conjugates.
- the first functional group and the second functional group may be the same type of functional group or different types of functional groups as long as they are covalently bonded.
- Combinations of the first functional group and the second functional group include, for example, a thiol group and a chloroacetyl group, a thiol group and a thiol group, and a carboxy group in the side chain and an amino group in the side chain.
- Amino acids having a thiol group include, for example, cysteine.
- Amino acids having a chloroacetyl group include, for example, chloroacetyldiaminobutyric acid and chloroacetylated lysine.
- Amino acids having a carboxy group in the side chain include, for example, aspartic acid and glutamic acid.
- Amino acids having an amino group in the side chain include, for example, lysine, asparagine, and glutamine.
- the screening method according to the present disclosure comprises preparing a nucleic acid display library by the method for preparing a nucleic acid display library according to the present disclosure, selecting a nucleic acid-polypeptide conjugate having a desired activity from the nucleic acid display library, - identifying the base sequence of the nucleic acid of the polypeptide conjugate.
- Target activity is, for example, binding to a target substance.
- a target substance is a term that includes all chemical substances that exhibit physiological activity, and includes compounds, groups, molecules, proteins, nucleic acids, lipids, carbohydrates, complexes thereof, and the like.
- Target substances include, for example, metal ions, lipid molecular assemblies, peptides, receptors, transcription factors, enzymes, coenzymes, regulatory factors, antibodies, antigens, DNA, RNA, membrane vesicles, extracellular vesicles, organelles , cells, fragments thereof, complexes thereof, modification groups thereof.
- An example of an embodiment of the screening method according to the present disclosure includes contacting and incubating a nucleic acid display library and a target substance.
- the nucleic acid display library and the target substance are brought into contact with each other in a buffer solution, and incubated while adjusting the pH and temperature of the buffer solution and the contact time.
- the target substance may be immobilized on a solid-phase carrier, and the nucleic acid display library may be brought into contact with the immobilized target substance.
- the solid phase carrier is not limited as long as it can immobilize the target substance, and includes microtiter plates, substrates, beads, magnetic beads, nitrocellulose membranes, nylon membranes, PVDF membranes and the like. Target substances are immobilized on these solid phase carriers by known techniques.
- nucleic acid-polypeptide conjugate bound to the target substance is extracted, and the nucleic acid base sequence of the extracted nucleic acid-polypeptide conjugate is identified. Nucleotide sequence identification can be performed using a nucleic acid amplification system and a sequencer.
- a nucleic acid amplification system refers to a system that uses a nucleic acid as a template to amplify nucleic acid.
- the nucleic acid amplification reaction of the nucleic acid amplification system is polymerase chain reaction (PCR), ligase chain reaction (LCR), TMA (transcription mediated amplification), NASBA (nucleic acid sequence-based amplification), etc. It's okay.
- sequencer is a term that includes first-generation sequencers (capillary sequencers), second-generation sequencers (next-generation sequencers), third-generation sequencers, fourth-generation sequencers, and sequencers to be developed in the future.
- the sequencer may be a capillary sequencer, a next-generation sequencer, or any other sequencer.
- a next-generation sequencer is preferable from the viewpoints of speed of analysis, a large number of samples that can be processed at one time, and the like.
- a next generation sequencer refers to a sequencer classified as opposed to a capillary sequencer (called a first generation sequencer) using the Sanger method.
- next-generation sequencers are sequencers based on the principle of determining base sequences by capturing fluorescence or luminescence associated with complementary strand synthesis by DNA polymerase or complementary strand binding by DNA ligase.
- Specific examples include MiSeq (Illumina Inc., MiSeq is a registered trademark), HiSeq2000 (Illumina Inc., HiSeq is a registered trademark), Roche454 (Roche Inc.), and the like.
- the screening method according to the present disclosure is a highly reliable screening method because the population is a nucleic acid display library with high expression levels and little bias in expression levels.
- tags and the like according to the present disclosure will be more specifically described below with specific examples. Materials, processing procedures, and the like shown in the following specific examples can be changed as appropriate without departing from the gist of the present disclosure. The scope of tags and the like according to the present disclosure should not be construed to be limited by the specific examples shown below.
- Example 1 Examination of the amino acid sequence of the tag> In a cell-free peptide synthesis system derived from Escherichia coli, the effect of the VKKX tag on the amount of biosynthetic polypeptide was investigated. An integrin-binding peptide containing cysteine and chloroacetylated lysine was selected as a biosynthesized polypeptide. This polypeptide spontaneously forms a thioether bond between the thiol group of cysteine and the chloroacetyl group of chloroacetylated lysine, resulting in a cyclic polypeptide.
- a fusion protein was designed in which an integrin-binding peptide, a Myc tag and a HiBiT tag were linked in this order. Gly-Gly-Ser was inserted as a spacer between the integrin-binding peptide and the Myc tag and between the Myc tag and the HiBiT tag, respectively.
- the amino acid sequence of this fusion protein is SEQ ID NO:5, and the nucleotide sequence encoding this fusion protein is SEQ ID NO:6.
- the integrin-binding peptide is from the N-terminal to the 12th amino acid (ie, alanine), and the 11th amino acid from the N-terminal is chloroacetylated lysine.
- the 31st to 33rd triplet TAGs from the 5' end of the base sequence of SEQ ID NO: 6 are assigned to codons for chloroacetylated lysine.
- the end of the base sequence of SEQ ID NO: 6 is a termination codon TAA.
- SEQ ID NO: 5 ACIPRGDSFAXAGGSEQKLISEEDLGGSVSGWRLFKKIS (X is chloroacetylated lysine) SEQ.
- sequences of SEQ ID NOS: 7-52 were designed as VKKX tags, and the sequences of SEQ ID NOS: 53-98 were designed as base sequences encoding them.
- Tables 1-1 and 1-2 show the amino acid sequences and base sequences of VKKX tags.
- the sequences of SEQ ID NOS: 53-98 are embodiments of the nucleotide sequences encoding SEQ ID NOS: 7-52, respectively, and the nucleotide sequences encoding the sequences of SEQ ID NOS: 7-52 are limited to the sequences of SEQ ID NOS: 53-98. not a thing
- a nucleotide sequence was designed that encodes a tagged fusion protein in which methionine, a VKKX tag (any of SEQ ID NOS: 7-52), and a fusion protein (SEQ ID NO: 5) are linked in this order.
- the nucleotide sequence encoding the VKKX tag (any of SEQ ID NOS: 53 to 98) is arranged immediately after the initiation codon ATG, and the nucleotide sequence encoding the fusion protein is immediately after the nucleotide sequence encoding the VKKX tag. (sequence number 6) is arranged.
- a base sequence was designed in which a base sequence (SEQ ID NO: 6) encoding a fusion protein was placed immediately after the initiation codon ATG.
- a template DNA for expressing the fusion protein As a template DNA for expressing the fusion protein, a template DNA was prepared by connecting the T7 promoter sequence, the Shine-Dalgarno sequence, and the nucleotide sequence encoding the tagged fusion protein from the 5' end. Template DNA was prepared by two-step PCR.
- the DNA of SEQ ID NO: 99 (GAAATTAATACGACTCACTATAGGGAGACCACAACGGTTTCCCTCTAGAATAATTTTGTTTAACTTTAAGAAGGAGATATACCA) and the ligation DNA for each VKKX tag were mixed to 1 nmol/L each, and KOD-Plus-Ver. 2 (TOYOBO, KOD-211), four steps of 94°C/2 minutes, 98°C/10 seconds, 43°C/30 seconds, and 68°C/15 seconds were performed to ligate the two DNAs.
- An example embodiment of the ligating DNA for each VKKX tag is DNA having the base sequence of SEQ ID NO:100.
- the DNA having the base sequence of SEQ ID NO: 100 is the ligating DNA for the VKKX tag (VKKTKT) of SEQ ID NO: 27.
- SEQ ID NO: 100 CGCGCGGGATGCACGC [TGTTTTTGTTTTTAAC]CATTGGTATATCTCCTT
- the nucleotide sequence in [ ] is a complementary sequence to the nucleotide sequence of SEQ ID NO: 73 (GTTAAAAAAACAAAAAACA, nucleotide sequence encoding SEQ ID NO: 27).
- the nucleotide sequence in [ ] in the ligating DNA for each VKKX tag is a complementary sequence to any one of SEQ ID NOS:53-98.
- the DNA fragment prepared in the first stage and the DNA of SEQ ID NO: 103 were mixed to 20 pg/ ⁇ L and 0.2 nmol/L, respectively, and KOD-Plus-Ver. 2, 4 steps of 94° C./2 minutes, 98° C./10 seconds, 62° C./30 seconds, and 68° C./15 seconds were performed to ligate the two DNAs.
- template DNA is DNA having the base sequence of SEQ ID NO:106.
- the template DNA having the base sequence of SEQ ID NO: 106 is the template DNA of the tagged fusion protein to which the tag of SEQ ID NO: 27 is added.
- the nucleotide sequence of SEQ ID NO: 106 the nucleotide sequence of SEQ ID NO: 73 (nucleotide sequence encoding SEQ ID NO: 27) is arranged immediately after the initiation codon ATG, and the nucleotide sequence of SEQ ID NO: 6 (fusion protein A base sequence encoding a) is arranged.
- SEQ ID NO: 106 The base sequence in [ ] in SEQ ID NO: 106 is the sequence of SEQ ID NO: 73.
- the nucleotide sequence in [ ] is any of the sequences of SEQ ID NOS:53-98.
- a tRNA was prepared whose anticodon was CUA and which matched the UAG codon of the mRNA.
- This tRNA was aminoacylated with an N-chloroacetylated lysine pdCpA (phospho 2'deoxyribocytidylylriboadenosine) ester.
- This aminoacyl-tRNA is called aminoacyl-tRNA (1).
- Cell-free biosynthesis of polypeptides was carried out in a translation solution containing template DNA, PUREfrex2.0 (Gene Frontier, PF201-0.25-5) and aminoacyl-tRNA (1).
- the amount of biosynthesized polypeptide was measured by ELISA. 50 ng of Recombinant Human Integrin ⁇ V ⁇ 3 (R&D systems, 3050-AV-050) was immobilized in each well of a 96-well plate, and after blocking with Blocker Casein in PBS (Thermo, 37528), a can containing 5 mmol/L MgCl 2 was added. A cell-free biosynthesis solution diluted with Get Signal Immunoreaction Enhancer Solution I (TOYOBO, NKB-101) was added and allowed to react at room temperature for 3 hours.
- R&D systems Recombinant Human Integrin ⁇ V ⁇ 3
- PBS Thermo, 37528
- FIG. 1 is a graph showing the amount of fusion protein biosynthesis for tags of SEQ ID NOs: 7 to 26, in which the tags are arranged in order of the amount of fusion protein biosynthesis.
- the VKKI, VKKT, VKKR, VKKH, VKKS and VKKK tags increased the biosynthesis of the fusion protein by 4.4- to 6.2-fold. That is, as a tag consisting of 4 amino acids, a tag in which I (Ile), T (Thr), R (Arg), H (His), S (Ser) or K (Lys) is placed immediately after VKK is dominant. be.
- a tag consisting of VKKKT (SEQ ID NO: 27) increased the amount of fusion protein biosynthesis by 4.9 times.
- FIG. 2 is a graph showing biosynthesis of fusion proteins for the tags of SEQ ID NOS: 27, 28, 31, 37, 48 and 52. That is, the superiority of the tag in which 0 to 4 residues of T (Thr), K (Lys) and D (Asp) were arranged following VKKKT (that is, the total length of the tag was 10 amino acids or less) was shown.
- Example 2 Examination of the base sequence encoding the tag> Regarding the effect of the tag of SEQ ID NO: 27 (hereinafter referred to as VKKTKT tag) on increasing the amount of polypeptide biosynthesis, the influence of the GC content of the nucleotide sequence encoding the tag was investigated.
- VKKTKT tag the SKIK tag, which is known to have an effect of increasing the biosynthetic amount of polypeptide, was selected (SEQ ID NO: 107.
- the SKIK tag is disclosed in International Publication No. 2016/204198).
- the biosynthesized polypeptide is, as in Example 1, a fusion protein containing an integrin-binding peptide.
- Table 3 shows the amino acid sequences and nucleotide sequences of the tags.
- a base sequence encoding a tagged fusion protein in which methionine, a tag (SEQ ID NO: 107 or SEQ ID NO: 27) and a fusion protein (SEQ ID NO: 5) are linked in this order was designed.
- a nucleotide sequence encoding a tag (any of SEQ ID NOs: 108 to 112 and 73) is arranged immediately after the initiation codon ATG, and a nucleotide sequence encoding the fusion protein is immediately followed by the nucleotide sequence encoding the tag. (sequence number 6) is arranged.
- a template DNA was prepared by two-step PCR in the same manner as in Example 1.
- the DNA of SEQ ID NO: 99 and the DNA for ligation designed for each tag (embodiment example is SEQ ID NO: 100) were mixed to 1 nmol/L each, and KOD-Plus-Ver. 2 (TOYOBO, KOD-211), four steps of 94°C/2 minutes, 98°C/10 seconds, 43°C/30 seconds, and 68°C/15 seconds were performed to ligate the two DNAs.
- KOD-Plus-Ver. 2 TOYOBO, KOD-211
- the fusion protein was expressed by a cell-free peptide synthesis system and quantified by ELISA. The measurement was performed twice, and the average amount of the fusion protein was calculated.
- Table 4 shows the relative values of the amounts of each fusion protein, with the amount of the fusion protein of the control example as the standard value of 1.
- the reference value 1 control example has a form in which the nucleotide sequence (SEQ ID NO: 6) encoding the fusion protein is placed immediately after the initiation codon ATG.
- the expression level of the fusion protein was increased by the SKIK tag, and the rate of increase was 1.5 to 4.2 times.
- the degree of increase in the expression level was found to be affected by the GC content of the nucleotide sequence encoding the SKIK tag.
- the expression level of the fusion protein was increased by the VKKTKT tag, and the rate of increase was 3.8 to 4.9 times.
- the degree of increase in the expression level was hardly affected by the GC content of the nucleotide sequence encoding the VKKTKT tag. That is, the VKKTKT tag increased the expression level of the fusion protein regardless of the encoding base sequence.
- Example 3 Examination of translation conditions> Regarding the effect of increasing the amount of biosynthesis of polypeptides by the VKKX tags of SEQ ID NOs: 27 to 52, it was investigated whether the effect could be exhibited even if the incubation time for biosynthesis was shortened.
- the SKIK tag of SEQ ID NO: 107 was selected as a comparison control.
- the biosynthesized polypeptide is, as in Example 1, a fusion protein containing an integrin-binding peptide.
- the VKKX tag increased the expression level of the fusion protein, and the rate of increase was 7.2 to 36 times.
- the SKIK tag also increased the expression level of the fusion protein, but the rate of increase was 1.3 times. That is, the VKKX tag showed an effect of increasing the expression level even with a shorter biosynthetic reaction time.
- the biosynthetic polypeptide is a fusion protein containing a partial sequence of dihydrofolate reductase (DHFR) and a luminescent (HiBiT) tag.
- a fusion protein was designed in which a partial sequence of DHFR and a HiBiT tag were linked in this order. Gly-Gly-Ser was inserted as a spacer between the partial sequence of DHFR and the HiBiT tag.
- the amino acid sequences of these fusion proteins are SEQ ID NOS: 113 and 114, respectively, a fusion protein (80 amino acids long) of amino acids from the N-terminus of DHFR to the 66th amino acid and a HiBiT tag, and a fusion protein from the N-terminus of DHFR to the 86th amino acid. and a HiBiT tag fusion protein (100 amino acids long). Nucleotide sequences encoding these fusion proteins are SEQ ID NOs: 115 and 116.
- SEQ ID NO: 113 VGSLNCIVAVSQNMGIGKNGDLPWPPLRNEFRYFQRMTTTSSVEGKQNLVIMGKKTWFSIPEKNRPGGSVSGWRLFKKIS
- SEQ ID NO: 114 VGSLNCIVAVSQNMGIGKNGDLPWPPLRNEFRYFQRMTTTSSVEGKQNLVIMGKKTWFSIPEKNRPLKGRINLVLSRELKEPPQGAGGSVSGWRLFKKIS ⁇ 115:GTTGGATCCTTGAACTGCATCGTAGCTGTGAGCCAAAACATGGGAATTGGGAAGAACGGCGATTTACCCTGGCCACCGTTGCGGAATGAATTCCGCTATTTTCAGCGTATGACCACCACAAGTTCGGTGGAAGGGAAACAGAATCTGGTGATCATGGGCAAGAAAACGTGGTTTAGCATTCCGGAGAAGAATCGTCCTGGTGGCTCTGTAAGTGGATGGCGATTATTCAAGAAGATTAGC ⁇ 116:GTTGGATCC
- a base sequence encoding a tagged fusion protein in which methionine, a VKKTKT tag (SEQ ID NO: 27) or a SKIK tag (SEQ ID NO: 107), and a fusion protein (either SEQ ID NO: 113 or 114) are linked in this order was designed.
- the nucleotide sequence encoding the VKKTKT tag or SKIK tag (SEQ ID NO: 73 or 110) is arranged immediately after the initiation codon ATG, and each fusion protein is immediately followed by the nucleotide sequence encoding the VKKTKT tag or SKIK tag.
- the coding sequence (either SEQ ID NO: 115 or 116) is arranged.
- nucleotide sequence was designed in which the nucleotide sequence encoding each fusion protein (either SEQ ID NO: 115 or 116) is placed immediately after the initiation codon ATG. .
- a template DNA for expressing the fusion protein As a template DNA for expressing the fusion protein, a template DNA was prepared by connecting the T7 promoter sequence, the Shine-Dalgarno sequence, and the nucleotide sequence encoding the tagged fusion protein from the 5' end. Template DNAs containing the sequences of SEQ ID NOs: 115 and 116 were prepared by three-step PCR.
- the DNA encoding DHRF shown in SEQ ID NO: 117, the forward primer for VKKTKT tag addition of SEQ ID NO: 118 or the forward primer for SKIK tag addition of SEQ ID NO: 119, and the reverse primer of SEQ ID NO: 120 and were added at 0.3 ⁇ mol/L, respectively, and KOD-Plus-Ver. 3 steps of 98°C/10 seconds, 61°C/30 seconds, and 68°C/15 seconds were performed for 35 cycles in the presence of 2 to generate a DNA fragment having the full-length base sequence encoding DHFR tagged with a VKKKTKT tag or SKIK tag. made.
- the DNA fragment prepared in the 1st step and the DNA of SEQ ID NO: 99 were mixed to 1 nmol/L each, and KOD-Plus-Ver. 2 (TOYOBO, KOD-211), four steps of 94°C/2 minutes, 98°C/10 seconds, 43°C/30 seconds, and 68°C/15 seconds were performed to ligate the two DNAs.
- the DNA fragment prepared in the 2nd step and the DNA of SEQ ID NO: 123 or 124 were mixed to 1 nmol/L each, and KOD-Plus-Ver. 2 (TOYOBO, KOD-211), four steps of 94°C/2 minutes, 98°C/10 seconds, 43°C/30 seconds, and 68°C/15 seconds were performed to ligate the two DNAs.
- SEQ ID NO: 123 GGATTAGTTATTCATTAGCTAATCTTCTTGAATAATCGCCATCCACTTACAGAGCCACCAGGACGATTCTTCTCCGGAAT
- SEQ ID NO: 124 GGATTAGTTATTCATTAGCTAATCTTCTTGAATAATCGCCATCCACTTACAGAGCCACCTGCACCTTGTGGAGGCTCTTTT
- a control example of reference value 1 is a form in which a base sequence (SEQ ID NO: 115 or 116) encoding a fusion protein is placed immediately after the initiation codon ATG.
- the VKKTKT tag exhibits a translation-promoting effect even for fusion proteins with a length of 80 to 100 amino acids, and the promoting effect is 1.2-fold to 1.2-fold. was seven times. This effect was superior to that of the SKIK tag.
- Example 5 Evaluation of binding ability of tagged peptide> Since the polypeptide can be obtained in high yield by adding the tag sequence according to the present disclosure, it is believed that the Emax value and EC50 value, which are important indicators of binding ability, can be accurately measured by evaluating the binding of high-concentration polypeptides. be done. That is, it is considered that the method for biosynthesizing a polypeptide utilizing the tag sequence according to the present disclosure and the produced polypeptide can be utilized for evaluation of binding performance. Therefore, it was investigated whether binding evaluation can be performed using the VKKTKT-tagged polypeptide of SEQ ID NO:27.
- the integrin-binding peptide was biosynthesized in high yield.
- the integrin-binding ability of the obtained peptides was measured by ELISA evaluation of the amount of peptide binding to integrin at each peptide concentration.
- the details of the template DNA preparation method, the cell-free peptide biosynthesis method, and the ELISA work are the same as in Example 1.
- Peptide concentration was measured by using Can Get Signal Immunoreaction Enhancer Solution I (TOYOBO) containing 5 mmol/L MgCl 2 to dilute the peptide 5000-fold with a Nano Glo HiBiT Lytic Detection System (Promega) and a chemically synthesized peptide for a standard curve with a known concentration. (SEQ ID NO: 125) and measured according to the standard protocol of the Nano Glo HiBiT Lytic Detection System. SEQ ID NO: 125: EQKLISEEDLGGSVSGWRLFKKIS
- the binding ability (Kd value) of the integrin-binding peptide was measured by the SPR method.
- An integrin-binding peptide (SEQ ID NO: 126) was chemically synthesized and immobilized on a CM5 chip (Cytiva, BR100530) by an amine coupling method.
- Biacore T-100 (Cytiva)
- the ability of the immobilized integrin-binding peptide to bind to recombinant human integrin ⁇ V ⁇ 3 was measured.
- the measurement buffer used was HBS-N buffer (Cytiva, BR100670) with MgCl2 added to a final concentration of 5 mmol/L, and integrin was added at concentrations of 10, 30, 100, and 300 nmol/L for 10 minutes. .
- the CM5 chip was regenerated and used by repeating the addition of 500 mmol/L EDTA for 10 minutes twice.
- Example 6 Integrin-binding peptide screening from VKKX tag-containing nucleic acid display library> It was investigated that a polypeptide that binds to a target substance can be obtained from a VKKX tag-containing nucleic acid display library. Specifically, using integrin as a target substance, it was examined whether or not the extracted polypeptide group contained a polypeptide having a known binding motif (amino acid sequence RGD).
- VKKX tag-containing nucleic acid display libraries Sequences of SEQ ID NOs: 127-128 were used as a VKKX tag-containing nucleic acid display library.
- VKKX tag-containing nucleic acid display libraries translation starts from the 86th to 88th initiation codon (ATG) from the 5' end, 89th to 106th bases (GTTAAGAAAACAAAAAACA) are VKKX tags, and 107th to 142nd bases (NNNTGT (NNN) 8 TAGNNN (NNN is a trimer oligonucleotide, where N is each independently A, T, G or C)) is a random sequence, and the 143rd and subsequent bases are the puromycin linker junction and termination codon is.
- the polypeptide encoded by this random sequence has a cysteine thiol group and a chloroacetyl group of chloroacetylated lysine, as in Example 1. It spontaneously forms a thioether bond and becomes a cyclic polypeptide.
- trimer oligonucleotides represented by NNN are assigned one type of codon for one type of amino acid. Trimer oligos corresponding to 18 types of codons shown in Table 7 Equal mixture of nucleotides.
- a VKKX tag-containing nucleic acid display library of SEQ ID NOS: 127-128 was created by performing overlap extension PCR. Specifically, for the library of SEQ ID NOS: 127 to 128, three types of DNA, DNA of SEQ ID NO: 129, DNA of SEQ ID NO: 130, and DNA of any of SEQ ID NOS: 131 to 132 listed in Table 8, were prepared.
- SEQ ID NO: 129 GAAATTAATACGACTCACTATAGGGGAGACCACAACGGTTTCCCTCTAGAATAATTTTGTTTAACTTTTAAGAAGGAGATACATATATGGTTAAAAAAAACAAAAAAAC
- SEQ ID NO: 130 AAGAAGGAGATATACATATGGTTAAAAAAAACAAAAAACANNNTGT (NNN) 8 TAGNNNGGCGGTTCTGGCGGTAGC (NNN is a trimer oligonucleotide, where each N independently represents A, T, G or C)
- SEQ ID NO: 132 ATACTCAAGCTTATTTATTATCCCCGCCTCCCGCCCCCCGTCCGCTACCGCCAGAACCACCACC
- Recombinant Human Integrin ⁇ V ⁇ 3 (R&D Systems, 3050-AV-050) was used as the target substance (integrin), and immobilized on magnetic beads (NHS Mag Sepharose, Cytiva, 28951380) according to the protocol specified by the manufacturer (Cytiva). Integrin concentration at time: 1 ⁇ g/ ⁇ L).
- the sequencer After repeating the process of contacting and incubating the VKKX tag-containing nucleic acid display library with the target substance (magnetic bead-immobilized integrin) for a total of 4 rounds, the sequencer is used to identify the nucleic acid base sequence of the nucleic acid-polypeptide conjugate. bottom.
- VKKX tag-containing nucleic acid display library SEQ ID NOS: 127-128
- T7 RNA polymerase T7 RNA polymerase
- This DNA fragment was purified and diluted to 10 ⁇ M.
- the library transcript (5 ⁇ M final concentration), the puromycin linker (final concentration 10 ⁇ M ) in the combinations shown in Table 8, reacted at 95° C. for 5 minutes, and the mixture containing the puromycin linker with the UV-crosslinking compound (PsoralenC6) was irradiated with 10 J UV (365 nm) on ice. This produced a conjugate of the library transcript and the puromycin linker.
- SEQ ID NOS: 133-136 only show the sequences of the main body (that is, the portion that does not contain the linker and CC).
- a complex of library transcript and puromycin linker was translated in a translation solution containing PUREfrex2.0 (Gene Frontier, PF201-0.25-5) and aminoacyl-tRNA (same as in Example 1). 10 ⁇ L of the complex, 4.5 ⁇ L of PUREfrex 2.0 Solution I, 0.75 ⁇ L of Solution II, 0.75 ⁇ L of Solution III, and 3 ⁇ L of aminoacyl-tRNA (1) were mixed and allowed to react at 37° C. for 30 minutes to prepare an mRNA-polypeptide conjugate. .
- SEQ ID NO: 137 GCTACCGCCAGAACCACC
- cDNA-mRNA-polypeptide conjugate 25 ⁇ L of cDNA-mRNA-polypeptide conjugate was mixed with DNA of SEQ ID NO: 138 (final concentration 0.5 ⁇ M) and DNA of SEQ ID NO: 139 (final concentration 0.5 ⁇ M) (reaction volume 50 ⁇ L ), in the presence of Platinumtm SuperFi II DNA Polymerase (Thermo, 12361010), after 98°C/30 seconds, 3 steps of 98°C/10 seconds, 60°C/10 seconds, and 72°C/10 seconds were repeated for 6 to 15 cycles, Finally, an amplification product was obtained by performing treatment at 72°C/5 minutes. Amplification products were purified and diluted to 20 nM.
- SEQ ID NO: 138 GGAGATATACATATGGTTAAGAAAACAAAAAAAC
- SEQ ID NO: 139 CTGCTACCGCCAGAACCACC
- the first-step PCR amplification product (final concentration 10 nM), the DNA of SEQ ID NO: 129 (final concentration 0.5 ⁇ M), the DNA of any of SEQ ID NOs: 131 to 132 listed in Table 8 ( final concentration 0.5 ⁇ M), in the presence of Platinum SuperFi II DNA Polymerase (Thermo, 12361010), 98° C./30 seconds, 98° C./10 seconds, 60° C./10 seconds, 72° C./10 seconds.
- the steps were repeated for 6 cycles and finally treated at 72°C for 5 minutes to obtain DNA with the same sequence as the original VKKX tag-containing nucleic acid display library except for random sequences.
- the generated VKKX tag-containing nucleic acid display library was purified, diluted to 2 ng/ ⁇ L, and used in subsequent rounds.
- the base sequence of the 1st step PCR product of the 4th round was identified using MiSeq (manufactured by Illumina) and Miseq Reagent kit v2 (300 cycles) (Illumina, MS-102-2022) according to Illumina's standard protocol.
- Table 8 shows the proportion of polypeptides having a known integrin-binding motif (amino acid sequence RGD) within the identified polypeptide group. This result indicates that a polypeptide that binds to a target substance can be obtained from a VKKX tag-containing nucleic acid display library.
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- General Health & Medical Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Medicinal Chemistry (AREA)
- Microbiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Crystallography & Structural Chemistry (AREA)
- Bioinformatics & Computational Biology (AREA)
- Virology (AREA)
- Gastroenterology & Hepatology (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Peptides Or Proteins (AREA)
Priority Applications (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP22873041.2A EP4410982A4 (en) | 2021-09-27 | 2022-09-26 | METHOD FOR PRODUCING POLYPEPTIDE, LABEL, EXPRESSION VECTOR, METHOD FOR EVALUATING POLYPEPTIDE, METHOD FOR PRODUCING NUCLEIC ACID INDICATOR LIBRARY AND SCREENING METHOD |
| JP2023549777A JPWO2023048290A1 (https=) | 2021-09-27 | 2022-09-26 | |
| CN202280057601.9A CN117858950A (zh) | 2021-09-27 | 2022-09-26 | 多肽的制作方法、标签、表达载体、多肽的评价方法、核酸展示文库的制作方法及筛选方法 |
| KR1020247007512A KR20240042497A (ko) | 2021-09-27 | 2022-09-26 | 폴리펩타이드의 제작 방법, 태그, 발현 벡터, 폴리펩타이드의 평가 방법, 핵산 디스플레이 라이브러리의 제작 방법 및 스크리닝 방법 |
| CA3231403A CA3231403A1 (en) | 2021-09-27 | 2022-09-26 | Production method of polypeptide, tag, expression vector, evaluation method of polypeptide, production method of nucleic acid display library, and screening method |
| AU2022349179A AU2022349179A1 (en) | 2021-09-27 | 2022-09-26 | Method for producing polypeptide, tag, expression vector, method for evaluating polypeptide, method for producing nucleic acid display library, and screening method |
| US18/597,128 US20240247253A1 (en) | 2021-09-27 | 2024-03-06 | Production method of polypeptide, tag, expression vector, evaluation method of polypeptide, production method of nucleic acid display library, and screening method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021-157186 | 2021-09-27 | ||
| JP2021157186 | 2021-09-27 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/597,128 Continuation US20240247253A1 (en) | 2021-09-27 | 2024-03-06 | Production method of polypeptide, tag, expression vector, evaluation method of polypeptide, production method of nucleic acid display library, and screening method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023048290A1 true WO2023048290A1 (ja) | 2023-03-30 |
Family
ID=85720824
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/035787 Ceased WO2023048290A1 (ja) | 2021-09-27 | 2022-09-26 | ポリペプチドの作製方法、タグ、発現ベクター、ポリペプチドの評価方法、核酸ディスプレイライブラリの作製方法及びスクリーニング方法 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US20240247253A1 (https=) |
| EP (1) | EP4410982A4 (https=) |
| JP (1) | JPWO2023048290A1 (https=) |
| KR (1) | KR20240042497A (https=) |
| CN (1) | CN117858950A (https=) |
| AU (1) | AU2022349179A1 (https=) |
| CA (1) | CA3231403A1 (https=) |
| WO (1) | WO2023048290A1 (https=) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024209857A1 (ja) * | 2023-04-03 | 2024-10-10 | 富士フイルム株式会社 | 核酸ディスプレイライブラリの作製方法、スクリーニング方法、及びポリペプチドの作製方法 |
| WO2024214800A1 (ja) | 2023-04-11 | 2024-10-17 | 富士フイルム株式会社 | 生理活性評価用のポリペプチド溶液を調製する方法、及びポリペプチドの生理活性を評価する方法 |
| WO2025258399A1 (ja) * | 2024-06-10 | 2025-12-18 | 富士フイルム株式会社 | 環状ペプチドのライブラリ、スクリーニング方法、及びペプチドの作製方法 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8734812B1 (en) * | 1999-10-29 | 2014-05-27 | Novartis Ag | Neisserial antigenic peptides |
| WO2015030014A1 (ja) * | 2013-08-26 | 2015-03-05 | 国立大学法人東京大学 | 大環状ペプチド、その製造方法、及び大環状ペプチドライブラリを用いるスクリーニング方法 |
| WO2016204198A1 (ja) | 2015-06-16 | 2016-12-22 | 国立大学法人名古屋大学 | タンパク質の発現方法 |
| JP2021157186A (ja) | 2014-09-26 | 2021-10-07 | 株式会社半導体エネルギー研究所 | 発光装置 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2003089454A2 (en) * | 2002-04-19 | 2003-10-30 | California Institute Of Technology | Unnatural amino acid containing display libraries |
| WO2008143679A2 (en) * | 2006-06-01 | 2008-11-27 | Verenium Corporation | Nucleic acids and proteins and methods for making and using them |
| WO2010094288A1 (en) * | 2009-02-20 | 2010-08-26 | Aarhus Universitet | Expressivity tag and use thereof |
| EP2797617B1 (en) * | 2011-12-27 | 2020-01-22 | Sorbonne Université | Anti-tumor adjuvant therapy |
| WO2016156538A1 (en) * | 2015-03-31 | 2016-10-06 | Universite Pierre Et Marie Curie (Paris 6) | Peptides that inhibit binding between set and caspase-9 |
-
2022
- 2022-09-26 JP JP2023549777A patent/JPWO2023048290A1/ja active Pending
- 2022-09-26 AU AU2022349179A patent/AU2022349179A1/en active Pending
- 2022-09-26 WO PCT/JP2022/035787 patent/WO2023048290A1/ja not_active Ceased
- 2022-09-26 CA CA3231403A patent/CA3231403A1/en active Pending
- 2022-09-26 CN CN202280057601.9A patent/CN117858950A/zh active Pending
- 2022-09-26 EP EP22873041.2A patent/EP4410982A4/en active Pending
- 2022-09-26 KR KR1020247007512A patent/KR20240042497A/ko active Pending
-
2024
- 2024-03-06 US US18/597,128 patent/US20240247253A1/en active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8734812B1 (en) * | 1999-10-29 | 2014-05-27 | Novartis Ag | Neisserial antigenic peptides |
| WO2015030014A1 (ja) * | 2013-08-26 | 2015-03-05 | 国立大学法人東京大学 | 大環状ペプチド、その製造方法、及び大環状ペプチドライブラリを用いるスクリーニング方法 |
| JP2021157186A (ja) | 2014-09-26 | 2021-10-07 | 株式会社半導体エネルギー研究所 | 発光装置 |
| WO2016204198A1 (ja) | 2015-06-16 | 2016-12-22 | 国立大学法人名古屋大学 | タンパク質の発現方法 |
Non-Patent Citations (5)
| Title |
|---|
| GULYAEVA N., ZASLAVSKY A., CHAIT A., ZASLAVSKY B.: "Relative hydrophobicity of di- to hexapeptides as measured by aqueous two-phase partitioning : Hydrophobicity of di- to hexapeptides", JOURNAL OF PEPTIDE RESEARCH, BLACKWELL PUBLISHING LTD., OXFORD; GB, vol. 61, no. 3, 1 March 2003 (2003-03-01), OXFORD; GB , pages 129 - 139, XP093054250, ISSN: 1397-002X, DOI: 10.1034/j.1399-3011.2003.00040.x * |
| JOURNAL OF SYNTHETIC ORGANIC CHEMISTRY, JAPAN, vol. 75, no. 11, 2017, pages 1171 - 1178 |
| PROTEIN EXPRESSION AND PURIFICATION, vol. 70, 2010, pages 224 - 230 |
| SCIENCE, vol. 342, 2013, pages 475 - 479 |
| See also references of EP4410982A4 |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024209857A1 (ja) * | 2023-04-03 | 2024-10-10 | 富士フイルム株式会社 | 核酸ディスプレイライブラリの作製方法、スクリーニング方法、及びポリペプチドの作製方法 |
| WO2024214800A1 (ja) | 2023-04-11 | 2024-10-17 | 富士フイルム株式会社 | 生理活性評価用のポリペプチド溶液を調製する方法、及びポリペプチドの生理活性を評価する方法 |
| EP4678650A1 (en) | 2023-04-11 | 2026-01-14 | FUJIFILM Corporation | Method for preparing polypeptide solution for evaluating physiological activity, and method for evaluating physiological activity of polypeptide |
| WO2025258399A1 (ja) * | 2024-06-10 | 2025-12-18 | 富士フイルム株式会社 | 環状ペプチドのライブラリ、スクリーニング方法、及びペプチドの作製方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4410982A4 (en) | 2025-01-15 |
| KR20240042497A (ko) | 2024-04-02 |
| JPWO2023048290A1 (https=) | 2023-03-30 |
| US20240247253A1 (en) | 2024-07-25 |
| EP4410982A1 (en) | 2024-08-07 |
| AU2022349179A1 (en) | 2024-03-07 |
| CA3231403A1 (en) | 2023-03-30 |
| CN117858950A (zh) | 2024-04-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11970694B2 (en) | Rapid display method in translational synthesis of peptide | |
| WO2023048290A1 (ja) | ポリペプチドの作製方法、タグ、発現ベクター、ポリペプチドの評価方法、核酸ディスプレイライブラリの作製方法及びスクリーニング方法 | |
| US10195578B2 (en) | Peptide library production method, peptide library, and screening method | |
| US20180171321A1 (en) | Platform for a non-natural amino acid incorporation into proteins | |
| JP6440055B2 (ja) | ペプチドライブラリの製造方法、ペプチドライブラリ、及びスクリーニング方法 | |
| JPWO2014119600A1 (ja) | FlexibleDisplay法 | |
| CN116670284A (zh) | 筛选能够与多个靶分子一起形成复合体的候选分子的方法 | |
| TW201410709A (zh) | 肽庫及其利用 | |
| EP2593478B1 (en) | Rnf8-fha domain-modified protein and method of producing the same | |
| US20240229015A1 (en) | tRNA, AMINOACYL tRNA, REAGENT FOR POLYPEPTIDE SYNTHESIS, INTRODUCTION METHOD OF UNNATURAL AMINO ACID, PRODUCTION METHOD OF POLYPEPTIDE, PRODUCTION METHOD OF NUCLEIC ACID DISPLAY LIBRARY, NUCLEIC ACID-POLYPEPTIDE CONJUGATE, AND SCREENING METHOD | |
| WO2009107682A1 (ja) | ヒト型Fcレセプターをコードするポリヌクレオチド、およびそれを利用したヒト型Fcレセプターの製造方法 | |
| JP6332965B2 (ja) | アゾリン化合物及びアゾール化合物のライブラリー、並びにその製造方法 | |
| WO2022158554A1 (ja) | 二量体化した環状ペプチドをスクリーニングする方法 | |
| EP4063377A1 (en) | Modification of trna t-stem for enhancing n-methyl amino acid incorporation | |
| WO2025258399A1 (ja) | 環状ペプチドのライブラリ、スクリーニング方法、及びペプチドの作製方法 | |
| WO2015115661A1 (ja) | アゾール誘導体骨格を有するペプチドの製造方法 | |
| JP7777904B2 (ja) | リンカー | |
| CN112876536A (zh) | 一种多肽标签及其在体外蛋白合成中的应用 | |
| WO2024214800A1 (ja) | 生理活性評価用のポリペプチド溶液を調製する方法、及びポリペプチドの生理活性を評価する方法 | |
| JP5709098B2 (ja) | タンパク質の可逆的デュアルラベリング法 | |
| WO2026089003A1 (ja) | 標的物質とペプチドとの結合体を形成させる方法 | |
| WO2024209857A1 (ja) | 核酸ディスプレイライブラリの作製方法、スクリーニング方法、及びポリペプチドの作製方法 | |
| CN121464349A (zh) | 空间邻近试验 | |
| WO2006095474A1 (ja) | 非天然アミノ酸及び/又はヒドロキシ酸含有化合物の製造方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22873041 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023549777 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022349179 Country of ref document: AU Ref document number: AU2022349179 Country of ref document: AU |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280057601.9 Country of ref document: CN |
|
| ENP | Entry into the national phase |
Ref document number: 2022349179 Country of ref document: AU Date of ref document: 20220926 Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 3231403 Country of ref document: CA |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 11202401831V Country of ref document: SG |
|
| ENP | Entry into the national phase |
Ref document number: 2022873041 Country of ref document: EP Effective date: 20240429 |