WO2022250050A1 - scpBNA又はAmNAを含むヘテロ核酸 - Google Patents
scpBNA又はAmNAを含むヘテロ核酸 Download PDFInfo
- Publication number
- WO2022250050A1 WO2022250050A1 PCT/JP2022/021251 JP2022021251W WO2022250050A1 WO 2022250050 A1 WO2022250050 A1 WO 2022250050A1 JP 2022021251 W JP2022021251 W JP 2022021251W WO 2022250050 A1 WO2022250050 A1 WO 2022250050A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- nucleic acid
- acid strand
- double
- stranded nucleic
- strand
- Prior art date
Links
- 239000002253 acid Substances 0.000 title description 3
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 495
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 495
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 494
- 239000002777 nucleoside Substances 0.000 claims abstract description 222
- 150000003833 nucleoside derivatives Chemical class 0.000 claims abstract description 110
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 71
- 230000000295 complement effect Effects 0.000 claims abstract description 50
- 230000000692 anti-sense effect Effects 0.000 claims abstract description 37
- 230000002829 reductive effect Effects 0.000 claims abstract description 14
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 claims abstract description 11
- 125000004435 hydrogen atom Chemical group [H]* 0.000 claims abstract description 8
- 125000003835 nucleoside group Chemical group 0.000 claims description 124
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical group C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 claims description 46
- 239000008194 pharmaceutical composition Substances 0.000 claims description 46
- 239000005549 deoxyribonucleoside Substances 0.000 claims description 30
- 235000012000 cholesterol Nutrition 0.000 claims description 24
- 239000002342 ribonucleoside Substances 0.000 claims description 18
- GVJHHUAWPYXKBD-UHFFFAOYSA-N d-alpha-tocopherol Natural products OC1=C(C)C(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-UHFFFAOYSA-N 0.000 claims description 17
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 claims description 16
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 claims description 15
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 claims description 15
- 229930003799 tocopherol Natural products 0.000 claims description 15
- 239000011732 tocopherol Substances 0.000 claims description 15
- 235000010384 tocopherol Nutrition 0.000 claims description 15
- 229960001295 tocopherol Drugs 0.000 claims description 15
- 102000004127 Cytokines Human genes 0.000 claims description 14
- 108090000695 Cytokines Proteins 0.000 claims description 14
- 102000019034 Chemokines Human genes 0.000 claims description 11
- 108010012236 Chemokines Proteins 0.000 claims description 11
- 206010018341 Gliosis Diseases 0.000 claims description 9
- 230000007387 gliosis Effects 0.000 claims description 9
- 206010061218 Inflammation Diseases 0.000 claims description 8
- 239000004480 active ingredient Substances 0.000 claims description 8
- 230000004054 inflammatory process Effects 0.000 claims description 8
- 239000003446 ligand Substances 0.000 claims description 8
- 230000002159 abnormal effect Effects 0.000 claims description 6
- 208000015114 central nervous system disease Diseases 0.000 claims description 6
- 230000006698 induction Effects 0.000 claims description 5
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 claims description 4
- 125000002640 tocopherol group Chemical group 0.000 claims description 2
- 125000000548 ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 claims 1
- 230000001988 toxicity Effects 0.000 abstract description 18
- 231100000419 toxicity Toxicity 0.000 abstract description 18
- 230000014509 gene expression Effects 0.000 description 69
- 108020004999 messenger RNA Proteins 0.000 description 63
- 108091034117 Oligonucleotide Proteins 0.000 description 44
- 235000000346 sugar Nutrition 0.000 description 43
- 239000003795 chemical substances by application Substances 0.000 description 37
- 230000000694 effects Effects 0.000 description 37
- 125000003729 nucleotide group Chemical group 0.000 description 35
- 108020004414 DNA Proteins 0.000 description 34
- 239000002773 nucleotide Substances 0.000 description 32
- 241000699670 Mus sp. Species 0.000 description 30
- 125000005647 linker group Chemical group 0.000 description 29
- 238000000034 method Methods 0.000 description 28
- 239000000074 antisense oligonucleotide Substances 0.000 description 27
- 238000012230 antisense oligonucleotides Methods 0.000 description 27
- -1 nucleic acid compound Chemical class 0.000 description 26
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 20
- 108091007767 MALAT1 Proteins 0.000 description 19
- 102100032543 Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase and dual-specificity protein phosphatase PTEN Human genes 0.000 description 17
- 210000002966 serum Anatomy 0.000 description 17
- 230000008685 targeting Effects 0.000 description 17
- GVJHHUAWPYXKBD-IEOSBIPESA-N α-tocopherol Chemical compound OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-IEOSBIPESA-N 0.000 description 17
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 16
- 108010011536 PTEN Phosphohydrolase Proteins 0.000 description 16
- 239000002552 dosage form Substances 0.000 description 15
- 210000004369 blood Anatomy 0.000 description 14
- 239000008280 blood Substances 0.000 description 14
- 125000004432 carbon atom Chemical group C* 0.000 description 13
- 238000001727 in vivo Methods 0.000 description 13
- 238000001990 intravenous administration Methods 0.000 description 13
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 12
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 12
- 238000005259 measurement Methods 0.000 description 12
- 230000007935 neutral effect Effects 0.000 description 12
- 206010019851 Hepatotoxicity Diseases 0.000 description 11
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 11
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 11
- 238000004458 analytical method Methods 0.000 description 11
- 230000037396 body weight Effects 0.000 description 11
- 238000002474 experimental method Methods 0.000 description 11
- 230000006870 function Effects 0.000 description 11
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 10
- 108010078068 alpha-tocopherol transfer protein Proteins 0.000 description 10
- 210000004027 cell Anatomy 0.000 description 10
- 150000001875 compounds Chemical class 0.000 description 10
- 231100000304 hepatotoxicity Toxicity 0.000 description 10
- 230000007686 hepatotoxicity Effects 0.000 description 10
- 230000004048 modification Effects 0.000 description 10
- 238000012986 modification Methods 0.000 description 10
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 10
- ZRALSGWEFCBTJO-UHFFFAOYSA-N Guanidine Chemical compound NC(N)=N ZRALSGWEFCBTJO-UHFFFAOYSA-N 0.000 description 9
- 108091093037 Peptide nucleic acid Proteins 0.000 description 9
- 239000002299 complementary DNA Substances 0.000 description 9
- 238000010195 expression analysis Methods 0.000 description 9
- 150000002632 lipids Chemical class 0.000 description 9
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 9
- 238000003757 reverse transcription PCR Methods 0.000 description 9
- 125000001424 substituent group Chemical group 0.000 description 9
- 201000010099 disease Diseases 0.000 description 8
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 8
- 210000003734 kidney Anatomy 0.000 description 8
- 210000004185 liver Anatomy 0.000 description 8
- 239000002679 microRNA Substances 0.000 description 8
- 230000036961 partial effect Effects 0.000 description 8
- 150000008163 sugars Chemical class 0.000 description 8
- 125000004169 (C1-C6) alkyl group Chemical group 0.000 description 7
- KYVBNYUBXIEUFW-UHFFFAOYSA-N 1,1,3,3-tetramethylguanidine Chemical compound CN(C)C(=N)N(C)C KYVBNYUBXIEUFW-UHFFFAOYSA-N 0.000 description 7
- 102000053171 Glial Fibrillary Acidic Human genes 0.000 description 7
- 101710193519 Glial fibrillary acidic protein Proteins 0.000 description 7
- 239000003814 drug Substances 0.000 description 7
- 229940079593 drug Drugs 0.000 description 7
- 210000005046 glial fibrillary acidic protein Anatomy 0.000 description 7
- 210000001320 hippocampus Anatomy 0.000 description 7
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 7
- 239000000203 mixture Substances 0.000 description 7
- 210000004165 myocardium Anatomy 0.000 description 7
- 102000004169 proteins and genes Human genes 0.000 description 7
- 238000006467 substitution reaction Methods 0.000 description 7
- 230000001629 suppression Effects 0.000 description 7
- 229930024421 Adenine Natural products 0.000 description 6
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 6
- 241000699666 Mus <mouse, genus> Species 0.000 description 6
- 229960000643 adenine Drugs 0.000 description 6
- 150000001408 amides Chemical class 0.000 description 6
- 125000002619 bicyclic group Chemical group 0.000 description 6
- 230000008859 change Effects 0.000 description 6
- 229940104302 cytosine Drugs 0.000 description 6
- 230000037440 gene silencing effect Effects 0.000 description 6
- 230000002757 inflammatory effect Effects 0.000 description 6
- 239000007924 injection Substances 0.000 description 6
- 238000002347 injection Methods 0.000 description 6
- 108091070501 miRNA Proteins 0.000 description 6
- 229910052698 phosphorus Inorganic materials 0.000 description 6
- 235000018102 proteins Nutrition 0.000 description 6
- 210000003314 quadriceps muscle Anatomy 0.000 description 6
- 230000009467 reduction Effects 0.000 description 6
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 description 5
- 108091027305 Heteroduplex Proteins 0.000 description 5
- 101150070547 MAPT gene Proteins 0.000 description 5
- 101710163270 Nuclease Proteins 0.000 description 5
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 5
- 125000000217 alkyl group Chemical group 0.000 description 5
- 230000015556 catabolic process Effects 0.000 description 5
- 125000002091 cationic group Chemical group 0.000 description 5
- 150000001841 cholesterols Chemical class 0.000 description 5
- 238000006731 degradation reaction Methods 0.000 description 5
- 238000010586 diagram Methods 0.000 description 5
- 238000009472 formulation Methods 0.000 description 5
- 108091033319 polynucleotide Proteins 0.000 description 5
- 102000040430 polynucleotide Human genes 0.000 description 5
- 239000002157 polynucleotide Substances 0.000 description 5
- 238000002360 preparation method Methods 0.000 description 5
- 102000004196 processed proteins & peptides Human genes 0.000 description 5
- 108090000765 processed proteins & peptides Proteins 0.000 description 5
- 238000000746 purification Methods 0.000 description 5
- 229940113082 thymine Drugs 0.000 description 5
- 210000001519 tissue Anatomy 0.000 description 5
- 238000013519 translation Methods 0.000 description 5
- 229940035893 uracil Drugs 0.000 description 5
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 4
- 102100032367 C-C motif chemokine 5 Human genes 0.000 description 4
- 102100025248 C-X-C motif chemokine 10 Human genes 0.000 description 4
- 101710098275 C-X-C motif chemokine 10 Proteins 0.000 description 4
- 108010055166 Chemokine CCL5 Proteins 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- 108010052185 Myotonin-Protein Kinase Proteins 0.000 description 4
- 206010029155 Nephropathy toxic Diseases 0.000 description 4
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- QYIXCDOBOSTCEI-UHFFFAOYSA-N alpha-cholestanol Natural products C1CC2CC(O)CCC2(C)C2C1C1CCC(C(C)CCCC(C)C)C1(C)CC2 QYIXCDOBOSTCEI-UHFFFAOYSA-N 0.000 description 4
- 210000004556 brain Anatomy 0.000 description 4
- 229910052799 carbon Inorganic materials 0.000 description 4
- 230000003247 decreasing effect Effects 0.000 description 4
- 150000002357 guanidines Chemical group 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 239000013642 negative control Substances 0.000 description 4
- 230000007694 nephrotoxicity Effects 0.000 description 4
- 231100000417 nephrotoxicity Toxicity 0.000 description 4
- 108091027963 non-coding RNA Proteins 0.000 description 4
- 102000042567 non-coding RNA Human genes 0.000 description 4
- 238000001668 nucleic acid synthesis Methods 0.000 description 4
- 210000000056 organ Anatomy 0.000 description 4
- 238000007911 parenteral administration Methods 0.000 description 4
- 150000004713 phosphodiesters Chemical class 0.000 description 4
- 239000011574 phosphorus Substances 0.000 description 4
- 125000006239 protecting group Chemical group 0.000 description 4
- 150000003839 salts Chemical class 0.000 description 4
- 239000000126 substance Substances 0.000 description 4
- 239000003826 tablet Substances 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 208000024827 Alzheimer disease Diseases 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 102100034343 Integrase Human genes 0.000 description 3
- 101710203526 Integrase Proteins 0.000 description 3
- 102000018658 Myotonin-Protein Kinase Human genes 0.000 description 3
- CHJJGSNFBQVOTG-UHFFFAOYSA-N N-methyl-guanidine Natural products CNC(N)=N CHJJGSNFBQVOTG-UHFFFAOYSA-N 0.000 description 3
- 208000012902 Nervous system disease Diseases 0.000 description 3
- 208000025966 Neurological disease Diseases 0.000 description 3
- 241000209094 Oryza Species 0.000 description 3
- 235000007164 Oryza sativa Nutrition 0.000 description 3
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 3
- 125000002947 alkylene group Chemical group 0.000 description 3
- 125000000129 anionic group Chemical group 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 101150006308 botA gene Proteins 0.000 description 3
- SWSQBOPZIKWTGO-UHFFFAOYSA-N dimethylaminoamidine Natural products CN(C)C(N)=N SWSQBOPZIKWTGO-UHFFFAOYSA-N 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 238000009396 hybridization Methods 0.000 description 3
- 229910052739 hydrogen Inorganic materials 0.000 description 3
- 239000001257 hydrogen Substances 0.000 description 3
- 230000002401 inhibitory effect Effects 0.000 description 3
- 238000000185 intracerebroventricular administration Methods 0.000 description 3
- 238000002372 labelling Methods 0.000 description 3
- 230000003908 liver function Effects 0.000 description 3
- 210000004072 lung Anatomy 0.000 description 3
- 238000004519 manufacturing process Methods 0.000 description 3
- 125000005699 methyleneoxy group Chemical group [H]C([H])([*:1])O[*:2] 0.000 description 3
- 125000004430 oxygen atom Chemical group O* 0.000 description 3
- 229920000642 polymer Polymers 0.000 description 3
- 230000001105 regulatory effect Effects 0.000 description 3
- 235000009566 rice Nutrition 0.000 description 3
- 239000002904 solvent Substances 0.000 description 3
- 238000007920 subcutaneous administration Methods 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- 210000003462 vein Anatomy 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- BQPPJGMMIYJVBR-UHFFFAOYSA-N (10S)-3c-Acetoxy-4.4.10r.13c.14t-pentamethyl-17c-((R)-1.5-dimethyl-hexen-(4)-yl)-(5tH)-Delta8-tetradecahydro-1H-cyclopenta[a]phenanthren Natural products CC12CCC(OC(C)=O)C(C)(C)C1CCC1=C2CCC2(C)C(C(CCC=C(C)C)C)CCC21C BQPPJGMMIYJVBR-UHFFFAOYSA-N 0.000 description 2
- IOWMKBFJCNLRTC-XWXSNNQWSA-N (24S)-24-hydroxycholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CC[C@H](O)C(C)C)[C@@]1(C)CC2 IOWMKBFJCNLRTC-XWXSNNQWSA-N 0.000 description 2
- CHGIKSSZNBCNDW-UHFFFAOYSA-N (3beta,5alpha)-4,4-Dimethylcholesta-8,24-dien-3-ol Natural products CC12CCC(O)C(C)(C)C1CCC1=C2CCC2(C)C(C(CCC=C(C)C)C)CCC21 CHGIKSSZNBCNDW-UHFFFAOYSA-N 0.000 description 2
- QYIXCDOBOSTCEI-QCYZZNICSA-N (5alpha)-cholestan-3beta-ol Chemical compound C([C@@H]1CC2)[C@@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@H](C)CCCC(C)C)[C@@]2(C)CC1 QYIXCDOBOSTCEI-QCYZZNICSA-N 0.000 description 2
- XYTLYKGXLMKYMV-UHFFFAOYSA-N 14alpha-methylzymosterol Natural products CC12CCC(O)CC1CCC1=C2CCC2(C)C(C(CCC=C(C)C)C)CCC21C XYTLYKGXLMKYMV-UHFFFAOYSA-N 0.000 description 2
- ASJSAQIRZKANQN-CRCLSJGQSA-N 2-deoxy-D-ribose Chemical compound OC[C@@H](O)[C@@H](O)CC=O ASJSAQIRZKANQN-CRCLSJGQSA-N 0.000 description 2
- IOWMKBFJCNLRTC-UHFFFAOYSA-N 24S-hydroxycholesterol Natural products C1C=C2CC(O)CCC2(C)C2C1C1CCC(C(C)CCC(O)C(C)C)C1(C)CC2 IOWMKBFJCNLRTC-UHFFFAOYSA-N 0.000 description 2
- OTXNTMVVOOBZCV-UHFFFAOYSA-N 2R-gamma-tocotrienol Natural products OC1=C(C)C(C)=C2OC(CCC=C(C)CCC=C(C)CCC=C(C)C)(C)CCC2=C1 OTXNTMVVOOBZCV-UHFFFAOYSA-N 0.000 description 2
- FPTJELQXIUUCEY-UHFFFAOYSA-N 3beta-Hydroxy-lanostan Natural products C1CC2C(C)(C)C(O)CCC2(C)C2C1C1(C)CCC(C(C)CCCC(C)C)C1(C)CC2 FPTJELQXIUUCEY-UHFFFAOYSA-N 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- 238000011740 C57BL/6 mouse Methods 0.000 description 2
- JMDJVWXCQJZDSH-UHFFFAOYSA-N COCCCP(=O)(O)O Chemical compound COCCCP(=O)(O)O JMDJVWXCQJZDSH-UHFFFAOYSA-N 0.000 description 2
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 2
- UCTLRSWJYQTBFZ-UHFFFAOYSA-N Dehydrocholesterol Natural products C1C(O)CCC2(C)C(CCC3(C(C(C)CCCC(C)C)CCC33)C)C3=CC=C21 UCTLRSWJYQTBFZ-UHFFFAOYSA-N 0.000 description 2
- 102100023688 Eotaxin Human genes 0.000 description 2
- IAYPIBMASNFSPL-UHFFFAOYSA-N Ethylene oxide Chemical group C1CO1 IAYPIBMASNFSPL-UHFFFAOYSA-N 0.000 description 2
- BKLIAINBCQPSOV-UHFFFAOYSA-N Gluanol Natural products CC(C)CC=CC(C)C1CCC2(C)C3=C(CCC12C)C4(C)CCC(O)C(C)(C)C4CC3 BKLIAINBCQPSOV-UHFFFAOYSA-N 0.000 description 2
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical group C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 2
- 108010065805 Interleukin-12 Proteins 0.000 description 2
- LOPKHWOTGJIQLC-UHFFFAOYSA-N Lanosterol Natural products CC(CCC=C(C)C)C1CCC2(C)C3=C(CCC12C)C4(C)CCC(C)(O)C(C)(C)C4CC3 LOPKHWOTGJIQLC-UHFFFAOYSA-N 0.000 description 2
- 206010067125 Liver injury Diseases 0.000 description 2
- 108700011259 MicroRNAs Proteins 0.000 description 2
- CAHGCLMLTWQZNJ-UHFFFAOYSA-N Nerifoliol Natural products CC12CCC(O)C(C)(C)C1CCC1=C2CCC2(C)C(C(CCC=C(C)C)C)CCC21C CAHGCLMLTWQZNJ-UHFFFAOYSA-N 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- 108091081021 Sense strand Proteins 0.000 description 2
- 238000000692 Student's t-test Methods 0.000 description 2
- 125000002252 acyl group Chemical group 0.000 description 2
- 239000000654 additive Substances 0.000 description 2
- 210000000577 adipose tissue Anatomy 0.000 description 2
- 239000000443 aerosol Substances 0.000 description 2
- 150000001298 alcohols Chemical class 0.000 description 2
- 125000003342 alkenyl group Chemical group 0.000 description 2
- 229940087168 alpha tocopherol Drugs 0.000 description 2
- RZFHLOLGZPDCHJ-DLQZEEBKSA-N alpha-Tocotrienol Natural products Oc1c(C)c(C)c2O[C@@](CC/C=C(/CC/C=C(\CC/C=C(\C)/C)/C)\C)(C)CCc2c1C RZFHLOLGZPDCHJ-DLQZEEBKSA-N 0.000 description 2
- 150000001412 amines Chemical class 0.000 description 2
- 125000003277 amino group Chemical group 0.000 description 2
- 125000002344 aminooxy group Chemical group [H]N([H])O[*] 0.000 description 2
- 238000000137 annealing Methods 0.000 description 2
- 230000003078 antioxidant effect Effects 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 125000003710 aryl alkyl group Chemical group 0.000 description 2
- 125000003118 aryl group Chemical group 0.000 description 2
- 230000004700 cellular uptake Effects 0.000 description 2
- 210000003169 central nervous system Anatomy 0.000 description 2
- 238000007385 chemical modification Methods 0.000 description 2
- UCTLRSWJYQTBFZ-DDPQNLDTSA-N cholesta-5,7-dien-3beta-ol Chemical compound C1[C@@H](O)CC[C@]2(C)[C@@H](CC[C@@]3([C@@H]([C@H](C)CCCC(C)C)CC[C@H]33)C)C3=CC=C21 UCTLRSWJYQTBFZ-DDPQNLDTSA-N 0.000 description 2
- VZWXIQHBIQLMPN-UHFFFAOYSA-N chromane Chemical compound C1=CC=C2CCCOC2=C1 VZWXIQHBIQLMPN-UHFFFAOYSA-N 0.000 description 2
- 239000011248 coating agent Substances 0.000 description 2
- 238000000576 coating method Methods 0.000 description 2
- QYIXCDOBOSTCEI-NWKZBHTNSA-N coprostanol Chemical compound C([C@H]1CC2)[C@@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@H](C)CCCC(C)C)[C@@]2(C)CC1 QYIXCDOBOSTCEI-NWKZBHTNSA-N 0.000 description 2
- 125000004122 cyclic group Chemical group 0.000 description 2
- 235000014113 dietary fatty acids Nutrition 0.000 description 2
- QBSJHOGDIUQWTH-UHFFFAOYSA-N dihydrolanosterol Natural products CC(C)CCCC(C)C1CCC2(C)C3=C(CCC12C)C4(C)CCC(C)(O)C(C)(C)C4CC3 QBSJHOGDIUQWTH-UHFFFAOYSA-N 0.000 description 2
- 239000003937 drug carrier Substances 0.000 description 2
- 239000003995 emulsifying agent Substances 0.000 description 2
- 239000003889 eye drop Substances 0.000 description 2
- 229940012356 eye drops Drugs 0.000 description 2
- 229930195729 fatty acid Natural products 0.000 description 2
- 239000000194 fatty acid Substances 0.000 description 2
- 239000000796 flavoring agent Substances 0.000 description 2
- 239000012530 fluid Substances 0.000 description 2
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 2
- 230000037406 food intake Effects 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- WIGCFUFOHFEKBI-UHFFFAOYSA-N gamma-tocopherol Natural products CC(C)CCCC(C)CCCC(C)CCCC1CCC2C(C)C(O)C(C)C(C)C2O1 WIGCFUFOHFEKBI-UHFFFAOYSA-N 0.000 description 2
- 125000005843 halogen group Chemical group 0.000 description 2
- 231100000234 hepatic damage Toxicity 0.000 description 2
- 125000000623 heterocyclic group Chemical group 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 238000007913 intrathecal administration Methods 0.000 description 2
- 238000007914 intraventricular administration Methods 0.000 description 2
- CAHGCLMLTWQZNJ-RGEKOYMOSA-N lanosterol Chemical compound C([C@]12C)C[C@@H](O)C(C)(C)[C@H]1CCC1=C2CC[C@]2(C)[C@H]([C@H](CCC=C(C)C)C)CC[C@@]21C CAHGCLMLTWQZNJ-RGEKOYMOSA-N 0.000 description 2
- 229940058690 lanosterol Drugs 0.000 description 2
- 210000005240 left ventricle Anatomy 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 239000012669 liquid formulation Substances 0.000 description 2
- 230000008818 liver damage Effects 0.000 description 2
- 239000006210 lotion Substances 0.000 description 2
- 230000004060 metabolic process Effects 0.000 description 2
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- 239000002674 ointment Substances 0.000 description 2
- 210000003463 organelle Anatomy 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- 239000010452 phosphate Substances 0.000 description 2
- 150000003904 phospholipids Chemical class 0.000 description 2
- 125000004437 phosphorous atom Chemical group 0.000 description 2
- 230000004962 physiological condition Effects 0.000 description 2
- 229920001184 polypeptide Polymers 0.000 description 2
- 239000000843 powder Substances 0.000 description 2
- 108010078070 scavenger receptors Proteins 0.000 description 2
- 102000014452 scavenger receptors Human genes 0.000 description 2
- 210000000813 small intestine Anatomy 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 241000894007 species Species 0.000 description 2
- 239000003381 stabilizer Substances 0.000 description 2
- 125000002328 sterol group Chemical group 0.000 description 2
- 125000000472 sulfonyl group Chemical group *S(*)(=O)=O 0.000 description 2
- 229910052717 sulfur Inorganic materials 0.000 description 2
- 239000000829 suppository Substances 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 239000000375 suspending agent Substances 0.000 description 2
- 238000012353 t test Methods 0.000 description 2
- 125000003396 thiol group Chemical group [H]S* 0.000 description 2
- 229960000984 tocofersolan Drugs 0.000 description 2
- 150000003611 tocopherol derivatives Chemical class 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- 238000005303 weighing Methods 0.000 description 2
- 235000004835 α-tocopherol Nutrition 0.000 description 2
- 239000002076 α-tocopherol Substances 0.000 description 2
- WGVKWNUPNGFDFJ-DQCZWYHMSA-N β-tocopherol Chemical compound OC1=CC(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C WGVKWNUPNGFDFJ-DQCZWYHMSA-N 0.000 description 2
- GZIFEOYASATJEH-VHFRWLAGSA-N δ-tocopherol Chemical compound OC1=CC(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1 GZIFEOYASATJEH-VHFRWLAGSA-N 0.000 description 2
- FGYKUFVNYVMTAM-UHFFFAOYSA-N (R)-2,5,8-trimethyl-2-(4,8,12-trimethyl-trideca-3t,7t,11-trienyl)-chroman-6-ol Natural products OC1=CC(C)=C2OC(CCC=C(C)CCC=C(C)CCC=C(C)C)(C)CCC2=C1C FGYKUFVNYVMTAM-UHFFFAOYSA-N 0.000 description 1
- VOXZDWNPVJITMN-ZBRFXRBCSA-N 17β-estradiol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 VOXZDWNPVJITMN-ZBRFXRBCSA-N 0.000 description 1
- PIINGYXNCHTJTF-UHFFFAOYSA-N 2-(2-azaniumylethylamino)acetate Chemical compound NCCNCC(O)=O PIINGYXNCHTJTF-UHFFFAOYSA-N 0.000 description 1
- CRYCZDRIXVHNQB-UHFFFAOYSA-N 2-amino-8-bromo-3,7-dihydropurin-6-one Chemical compound N1C(N)=NC(=O)C2=C1N=C(Br)N2 CRYCZDRIXVHNQB-UHFFFAOYSA-N 0.000 description 1
- 125000003903 2-propenyl group Chemical group [H]C([*])([H])C([H])=C([H])[H] 0.000 description 1
- ODADKLYLWWCHNB-UHFFFAOYSA-N 2R-delta-tocotrienol Natural products OC1=CC(C)=C2OC(CCC=C(C)CCC=C(C)CCC=C(C)C)(C)CCC2=C1 ODADKLYLWWCHNB-UHFFFAOYSA-N 0.000 description 1
- 108020005345 3' Untranslated Regions Proteins 0.000 description 1
- 108020003589 5' Untranslated Regions Proteins 0.000 description 1
- ZLAQATDNGLKIEV-UHFFFAOYSA-N 5-methyl-2-sulfanylidene-1h-pyrimidin-4-one Chemical compound CC1=CNC(=S)NC1=O ZLAQATDNGLKIEV-UHFFFAOYSA-N 0.000 description 1
- QZLYKIGBANMMBK-UGCZWRCOSA-N 5α-Androstane Chemical compound C([C@@H]1CC2)CCC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CCC[C@@]2(C)CC1 QZLYKIGBANMMBK-UGCZWRCOSA-N 0.000 description 1
- QFVKLKDEXOWFSL-UHFFFAOYSA-N 6-amino-5-bromo-1h-pyrimidin-2-one Chemical compound NC=1NC(=O)N=CC=1Br QFVKLKDEXOWFSL-UHFFFAOYSA-N 0.000 description 1
- UFVWJVAMULFOMC-UHFFFAOYSA-N 6-amino-5-iodo-1h-pyrimidin-2-one Chemical compound NC=1NC(=O)N=CC=1I UFVWJVAMULFOMC-UHFFFAOYSA-N 0.000 description 1
- CKOMXBHMKXXTNW-UHFFFAOYSA-N 6-methyladenine Chemical compound CNC1=NC=NC2=C1N=CN2 CKOMXBHMKXXTNW-UHFFFAOYSA-N 0.000 description 1
- FVXHPCVBOXMRJP-UHFFFAOYSA-N 8-bromo-7h-purin-6-amine Chemical compound NC1=NC=NC2=C1NC(Br)=N2 FVXHPCVBOXMRJP-UHFFFAOYSA-N 0.000 description 1
- 102000007469 Actins Human genes 0.000 description 1
- 108010085238 Actins Proteins 0.000 description 1
- 102100036475 Alanine aminotransferase 1 Human genes 0.000 description 1
- 108010082126 Alanine transaminase Proteins 0.000 description 1
- 206010002091 Anaesthesia Diseases 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- 108020005544 Antisense RNA Proteins 0.000 description 1
- 101710095342 Apolipoprotein B Proteins 0.000 description 1
- 102100040202 Apolipoprotein B-100 Human genes 0.000 description 1
- 102000018616 Apolipoproteins B Human genes 0.000 description 1
- 108010027006 Apolipoproteins B Proteins 0.000 description 1
- 108091023037 Aptamer Proteins 0.000 description 1
- 108010003415 Aspartate Aminotransferases Proteins 0.000 description 1
- 102000004625 Aspartate Aminotransferases Human genes 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 208000003174 Brain Neoplasms Diseases 0.000 description 1
- 101710155857 C-C motif chemokine 2 Proteins 0.000 description 1
- 102100021943 C-C motif chemokine 2 Human genes 0.000 description 1
- 102100036170 C-X-C motif chemokine 9 Human genes 0.000 description 1
- 101710085500 C-X-C motif chemokine 9 Proteins 0.000 description 1
- 125000004406 C3-C8 cycloalkylene group Chemical group 0.000 description 1
- 108700012434 CCL3 Proteins 0.000 description 1
- 206010007269 Carcinogenicity Diseases 0.000 description 1
- 206010048610 Cardiotoxicity Diseases 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 102000000013 Chemokine CCL3 Human genes 0.000 description 1
- 108010055165 Chemokine CCL4 Proteins 0.000 description 1
- 102000001326 Chemokine CCL4 Human genes 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 1
- 229930105110 Cyclosporin A Natural products 0.000 description 1
- 108010036949 Cyclosporine Proteins 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- AUNGANRZJHBGPY-UHFFFAOYSA-N D-Lyxoflavin Natural products OCC(O)C(O)C(O)CN1C=2C=C(C)C(C)=CC=2N=C2C1=NC(=O)NC2=O AUNGANRZJHBGPY-UHFFFAOYSA-N 0.000 description 1
- GZIFEOYASATJEH-UHFFFAOYSA-N D-delta tocopherol Natural products OC1=CC(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1 GZIFEOYASATJEH-UHFFFAOYSA-N 0.000 description 1
- ZZZCUOFIHGPKAK-UHFFFAOYSA-N D-erythro-ascorbic acid Natural products OCC1OC(=O)C(O)=C1O ZZZCUOFIHGPKAK-UHFFFAOYSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- 125000000824 D-ribofuranosyl group Chemical group [H]OC([H])([H])[C@@]1([H])OC([H])(*)[C@]([H])(O[H])[C@]1([H])O[H] 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 102000016911 Deoxyribonucleases Human genes 0.000 description 1
- 108010053770 Deoxyribonucleases Proteins 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 206010013710 Drug interaction Diseases 0.000 description 1
- 108010042407 Endonucleases Proteins 0.000 description 1
- 102000004533 Endonucleases Human genes 0.000 description 1
- 101710139422 Eotaxin Proteins 0.000 description 1
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 1
- 108060002716 Exonuclease Proteins 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 102100031181 Glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 1
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 1
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102000004457 Granulocyte-Macrophage Colony-Stimulating Factor Human genes 0.000 description 1
- 101000978392 Homo sapiens Eotaxin Proteins 0.000 description 1
- 101001051093 Homo sapiens Low-density lipoprotein receptor Proteins 0.000 description 1
- 101000901659 Homo sapiens Myotonin-protein kinase Proteins 0.000 description 1
- 101000896414 Homo sapiens Nuclear nucleic acid-binding protein C1D Proteins 0.000 description 1
- 101001043564 Homo sapiens Prolow-density lipoprotein receptor-related protein 1 Proteins 0.000 description 1
- 208000023105 Huntington disease Diseases 0.000 description 1
- 102100037850 Interferon gamma Human genes 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- 108090000174 Interleukin-10 Proteins 0.000 description 1
- 108010002350 Interleukin-2 Proteins 0.000 description 1
- 108010002386 Interleukin-3 Proteins 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 108010002616 Interleukin-5 Proteins 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- 108010002586 Interleukin-7 Proteins 0.000 description 1
- 108010002335 Interleukin-9 Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- PIWKPBJCKXDKJR-UHFFFAOYSA-N Isoflurane Chemical compound FC(F)OC(Cl)C(F)(F)F PIWKPBJCKXDKJR-UHFFFAOYSA-N 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 102100024640 Low-density lipoprotein receptor Human genes 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 108010046938 Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102000007651 Macrophage Colony-Stimulating Factor Human genes 0.000 description 1
- 108091027974 Mature messenger RNA Proteins 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- WXJXBKBJAKPJRN-UHFFFAOYSA-N Methanephosphonothioic acid Chemical compound CP(O)(O)=S WXJXBKBJAKPJRN-UHFFFAOYSA-N 0.000 description 1
- 101710151803 Mitochondrial intermediate peptidase 2 Proteins 0.000 description 1
- 101000891583 Mus musculus Microtubule-associated protein tau Proteins 0.000 description 1
- 101000901664 Mus musculus Myotonin-protein kinase Proteins 0.000 description 1
- SGSSKEDGVONRGC-UHFFFAOYSA-N N(2)-methylguanine Chemical compound O=C1NC(NC)=NC2=C1N=CN2 SGSSKEDGVONRGC-UHFFFAOYSA-N 0.000 description 1
- PJKKQFAEFWCNAQ-UHFFFAOYSA-N N(4)-methylcytosine Chemical compound CNC=1C=CNC(=O)N=1 PJKKQFAEFWCNAQ-UHFFFAOYSA-N 0.000 description 1
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 1
- 206010028851 Necrosis Diseases 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 101150073900 PTEN gene Proteins 0.000 description 1
- 208000018737 Parkinson disease Diseases 0.000 description 1
- 101710132081 Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase and dual-specificity protein phosphatase PTEN Proteins 0.000 description 1
- 206010034972 Photosensitivity reaction Diseases 0.000 description 1
- 229920001214 Polysorbate 60 Polymers 0.000 description 1
- 108010071690 Prealbumin Proteins 0.000 description 1
- 102100021923 Prolow-density lipoprotein receptor-related protein 1 Human genes 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 238000010357 RNA editing Methods 0.000 description 1
- 230000026279 RNA modification Effects 0.000 description 1
- 230000007022 RNA scission Effects 0.000 description 1
- 206010074268 Reproductive toxicity Diseases 0.000 description 1
- AUNGANRZJHBGPY-SCRDCRAPSA-N Riboflavin Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)CN1C=2C=C(C)C(C)=CC=2N=C2C1=NC(=O)NC2=O AUNGANRZJHBGPY-SCRDCRAPSA-N 0.000 description 1
- 102100025290 Ribonuclease H1 Human genes 0.000 description 1
- 108010083644 Ribonucleases Proteins 0.000 description 1
- 102000006382 Ribonucleases Human genes 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 206010039897 Sedation Diseases 0.000 description 1
- BLRPTPMANUNPDV-UHFFFAOYSA-N Silane Chemical compound [SiH4] BLRPTPMANUNPDV-UHFFFAOYSA-N 0.000 description 1
- 229930182558 Sterol Natural products 0.000 description 1
- 108091046869 Telomeric non-coding RNA Proteins 0.000 description 1
- 102000009190 Transthyretin Human genes 0.000 description 1
- 108020004417 Untranslated RNA Proteins 0.000 description 1
- 102000039634 Untranslated RNA Human genes 0.000 description 1
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 1
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 1
- 229930003451 Vitamin B1 Natural products 0.000 description 1
- 229930003471 Vitamin B2 Natural products 0.000 description 1
- 229930003268 Vitamin C Natural products 0.000 description 1
- 229930003427 Vitamin E Natural products 0.000 description 1
- 208000027418 Wounds and injury Diseases 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 230000007059 acute toxicity Effects 0.000 description 1
- 231100000403 acute toxicity Toxicity 0.000 description 1
- 230000009218 additive inhibitory effect Effects 0.000 description 1
- 208000009956 adenocarcinoma Diseases 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 210000004100 adrenal gland Anatomy 0.000 description 1
- 150000001345 alkine derivatives Chemical group 0.000 description 1
- 125000003545 alkoxy group Chemical group 0.000 description 1
- 125000005600 alkyl phosphonate group Chemical group 0.000 description 1
- 125000004414 alkyl thio group Chemical group 0.000 description 1
- 229940064063 alpha tocotrienol Drugs 0.000 description 1
- 125000003368 amide group Chemical group 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 206010002026 amyotrophic lateral sclerosis Diseases 0.000 description 1
- 230000037005 anaesthesia Effects 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 235000006708 antioxidants Nutrition 0.000 description 1
- 210000001130 astrocyte Anatomy 0.000 description 1
- 125000004429 atom Chemical group 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 239000012752 auxiliary agent Substances 0.000 description 1
- 239000002585 base Substances 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 229940066595 beta tocopherol Drugs 0.000 description 1
- FGYKUFVNYVMTAM-YMCDKREISA-N beta-Tocotrienol Natural products Oc1c(C)c2c(c(C)c1)O[C@@](CC/C=C(\CC/C=C(\CC/C=C(\C)/C)/C)/C)(C)CC2 FGYKUFVNYVMTAM-YMCDKREISA-N 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 230000001851 biosynthetic effect Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 238000004159 blood analysis Methods 0.000 description 1
- 230000008499 blood brain barrier function Effects 0.000 description 1
- 210000001218 blood-brain barrier Anatomy 0.000 description 1
- 210000000133 brain stem Anatomy 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- 239000006172 buffering agent Substances 0.000 description 1
- 239000004067 bulking agent Substances 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 150000004657 carbamic acid derivatives Chemical class 0.000 description 1
- 230000007670 carcinogenicity Effects 0.000 description 1
- 231100000260 carcinogenicity Toxicity 0.000 description 1
- 231100000259 cardiotoxicity Toxicity 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 210000001638 cerebellum Anatomy 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 230000007665 chronic toxicity Effects 0.000 description 1
- 231100000160 chronic toxicity Toxicity 0.000 description 1
- 229960001265 ciclosporin Drugs 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 125000005159 cyanoalkoxy group Chemical group 0.000 description 1
- 125000000753 cycloalkyl group Chemical group 0.000 description 1
- 125000002993 cycloalkylene group Chemical group 0.000 description 1
- 125000000113 cyclohexyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- 125000004956 cyclohexylene group Chemical group 0.000 description 1
- 229930182912 cyclosporin Natural products 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 235000010389 delta-tocopherol Nutrition 0.000 description 1
- BTNBMQIHCRIGOU-UHFFFAOYSA-N delta-tocotrienol Natural products CC(=CCCC(=CCCC(=CCCOC1(C)CCc2cc(O)cc(C)c2O1)C)C)C BTNBMQIHCRIGOU-UHFFFAOYSA-N 0.000 description 1
- 239000005547 deoxyribonucleotide Chemical group 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 210000000188 diaphragm Anatomy 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- 238000007922 dissolution test Methods 0.000 description 1
- 239000008298 dragée Substances 0.000 description 1
- 239000006196 drop Substances 0.000 description 1
- 210000005069 ears Anatomy 0.000 description 1
- 235000006694 eating habits Nutrition 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 239000002662 enteric coated tablet Substances 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- FGYKUFVNYVMTAM-MUUNZHRXSA-N epsilon-Tocopherol Natural products OC1=CC(C)=C2O[C@@](CCC=C(C)CCC=C(C)CCC=C(C)C)(C)CCC2=C1C FGYKUFVNYVMTAM-MUUNZHRXSA-N 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 229960005309 estradiol Drugs 0.000 description 1
- 229930182833 estradiol Natural products 0.000 description 1
- 102000013165 exonuclease Human genes 0.000 description 1
- 150000004665 fatty acids Chemical class 0.000 description 1
- 239000007941 film coated tablet Substances 0.000 description 1
- 235000019634 flavors Nutrition 0.000 description 1
- XRECTZIEBJDKEO-UHFFFAOYSA-N flucytosine Chemical compound NC1=NC(=O)NC=C1F XRECTZIEBJDKEO-UHFFFAOYSA-N 0.000 description 1
- 229960004413 flucytosine Drugs 0.000 description 1
- 108091006047 fluorescent proteins Proteins 0.000 description 1
- 102000034287 fluorescent proteins Human genes 0.000 description 1
- 229960000304 folic acid Drugs 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 235000013355 food flavoring agent Nutrition 0.000 description 1
- 235000003599 food sweetener Nutrition 0.000 description 1
- 239000003205 fragrance Substances 0.000 description 1
- 230000009454 functional inhibition Effects 0.000 description 1
- 150000002243 furanoses Chemical class 0.000 description 1
- 125000003843 furanosyl group Chemical group 0.000 description 1
- OTXNTMVVOOBZCV-YMCDKREISA-N gamma-Tocotrienol Natural products Oc1c(C)c(C)c2O[C@@](CC/C=C(\CC/C=C(\CC/C=C(\C)/C)/C)/C)(C)CCc2c1 OTXNTMVVOOBZCV-YMCDKREISA-N 0.000 description 1
- 235000010382 gamma-tocopherol Nutrition 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 231100000025 genetic toxicology Toxicity 0.000 description 1
- 230000001738 genotoxic effect Effects 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 1
- 239000008187 granular material Substances 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 210000002216 heart Anatomy 0.000 description 1
- 102000048595 human DMPK Human genes 0.000 description 1
- 125000004029 hydroxymethyl group Chemical group [H]OC([H])([H])* 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 208000014674 injury Diseases 0.000 description 1
- 239000000543 intermediate Substances 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 229960002725 isoflurane Drugs 0.000 description 1
- 239000000644 isotonic solution Substances 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 231100000053 low toxicity Toxicity 0.000 description 1
- 239000007937 lozenge Substances 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 208000030159 metabolic disease Diseases 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 239000002207 metabolite Substances 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 1
- 230000000116 mitigating effect Effects 0.000 description 1
- 125000004573 morpholin-4-yl group Chemical group N1(CCOCC1)* 0.000 description 1
- 201000006417 multiple sclerosis Diseases 0.000 description 1
- 230000017074 necrotic cell death Effects 0.000 description 1
- 210000001577 neostriatum Anatomy 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 231100001092 no hepatotoxicity Toxicity 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 230000001293 nucleolytic effect Effects 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- 239000003960 organic solvent Substances 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 229940021222 peritoneal dialysis isotonic solution Drugs 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-L phosphoramidate Chemical compound NP([O-])([O-])=O PTMHPRAIXMAOOB-UHFFFAOYSA-L 0.000 description 1
- 150000003014 phosphoric acid esters Chemical class 0.000 description 1
- 208000007578 phototoxic dermatitis Diseases 0.000 description 1
- 231100000018 phototoxicity Toxicity 0.000 description 1
- 239000002504 physiological saline solution Substances 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 230000001124 posttranscriptional effect Effects 0.000 description 1
- 244000144977 poultry Species 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 238000010791 quenching Methods 0.000 description 1
- 230000000171 quenching effect Effects 0.000 description 1
- 150000003254 radicals Chemical class 0.000 description 1
- 238000003753 real-time PCR Methods 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 231100000372 reproductive toxicity Toxicity 0.000 description 1
- 230000007696 reproductive toxicity Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 229960002477 riboflavin Drugs 0.000 description 1
- 108010052833 ribonuclease HI Proteins 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 125000006413 ring segment Chemical group 0.000 description 1
- 230000036280 sedation Effects 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 229910000077 silane Inorganic materials 0.000 description 1
- 125000003808 silyl group Chemical group [H][Si]([H])([H])[*] 0.000 description 1
- 239000007974 sodium acetate buffer Substances 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 229960002920 sorbitol Drugs 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 230000003637 steroidlike Effects 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 150000003432 sterols Chemical class 0.000 description 1
- 235000003702 sterols Nutrition 0.000 description 1
- 125000005156 substituted alkylene group Chemical group 0.000 description 1
- 239000007940 sugar coated tablet Substances 0.000 description 1
- 125000004434 sulfur atom Chemical group 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 125000001412 tetrahydropyranyl group Chemical group 0.000 description 1
- 229960003495 thiamine Drugs 0.000 description 1
- DPJRMOMPQZCRJU-UHFFFAOYSA-M thiamine hydrochloride Chemical compound Cl.[Cl-].CC1=C(CCO)SC=[N+]1CC1=CN=C(C)N=C1N DPJRMOMPQZCRJU-UHFFFAOYSA-M 0.000 description 1
- 239000002562 thickening agent Substances 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 150000003852 triazoles Chemical class 0.000 description 1
- 125000000876 trifluoromethoxy group Chemical group FC(F)(F)O* 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 239000008158 vegetable oil Substances 0.000 description 1
- 230000002861 ventricular Effects 0.000 description 1
- 229920002554 vinyl polymer Polymers 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 235000010374 vitamin B1 Nutrition 0.000 description 1
- 239000011691 vitamin B1 Substances 0.000 description 1
- 235000019164 vitamin B2 Nutrition 0.000 description 1
- 239000011716 vitamin B2 Substances 0.000 description 1
- 235000019154 vitamin C Nutrition 0.000 description 1
- 239000011718 vitamin C Substances 0.000 description 1
- 235000019165 vitamin E Nutrition 0.000 description 1
- 239000011709 vitamin E Substances 0.000 description 1
- 229940046009 vitamin E Drugs 0.000 description 1
- 150000003722 vitamin derivatives Chemical class 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- RZFHLOLGZPDCHJ-XZXLULOTSA-N α-Tocotrienol Chemical compound OC1=C(C)C(C)=C2O[C@@](CC/C=C(C)/CC/C=C(C)/CCC=C(C)C)(C)CCC2=C1C RZFHLOLGZPDCHJ-XZXLULOTSA-N 0.000 description 1
- 239000011730 α-tocotrienol Substances 0.000 description 1
- 235000019145 α-tocotrienol Nutrition 0.000 description 1
- 239000011590 β-tocopherol Substances 0.000 description 1
- 235000007680 β-tocopherol Nutrition 0.000 description 1
- 239000011723 β-tocotrienol Substances 0.000 description 1
- 235000019151 β-tocotrienol Nutrition 0.000 description 1
- FGYKUFVNYVMTAM-WAZJVIJMSA-N β-tocotrienol Chemical compound OC1=CC(C)=C2O[C@@](CC/C=C(C)/CC/C=C(C)/CCC=C(C)C)(C)CCC2=C1C FGYKUFVNYVMTAM-WAZJVIJMSA-N 0.000 description 1
- 239000002478 γ-tocopherol Substances 0.000 description 1
- QUEDXNHFTDJVIY-DQCZWYHMSA-N γ-tocopherol Chemical compound OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1 QUEDXNHFTDJVIY-DQCZWYHMSA-N 0.000 description 1
- 239000011722 γ-tocotrienol Substances 0.000 description 1
- 235000019150 γ-tocotrienol Nutrition 0.000 description 1
- OTXNTMVVOOBZCV-WAZJVIJMSA-N γ-tocotrienol Chemical compound OC1=C(C)C(C)=C2O[C@@](CC/C=C(C)/CC/C=C(C)/CCC=C(C)C)(C)CCC2=C1 OTXNTMVVOOBZCV-WAZJVIJMSA-N 0.000 description 1
- 239000002446 δ-tocopherol Substances 0.000 description 1
- 239000011729 δ-tocotrienol Substances 0.000 description 1
- 235000019144 δ-tocotrienol Nutrition 0.000 description 1
- ODADKLYLWWCHNB-LDYBVBFYSA-N δ-tocotrienol Chemical compound OC1=CC(C)=C2O[C@@](CC/C=C(C)/CC/C=C(C)/CCC=C(C)C)(C)CCC2=C1 ODADKLYLWWCHNB-LDYBVBFYSA-N 0.000 description 1
Images




















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/0012—Galenical forms characterised by the site of application
- A61K9/0019—Injectable compositions; Intramuscular, intravenous, arterial, subcutaneous administration; Compositions to be administered through the skin in an invasive manner
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/06—Immunosuppressants, e.g. drugs for graft rejection
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1138—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against receptors or cell surface proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/11—Antisense
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering N.A.
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/315—Phosphorothioates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/321—2'-O-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/323—Chemical structure of the sugar modified ring structure
- C12N2310/3231—Chemical structure of the sugar modified ring structure having an additional ring, e.g. LNA, ENA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/33—Chemical structure of the base
- C12N2310/334—Modified C
- C12N2310/3341—5-Methylcytosine
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/34—Spatial arrangement of the modifications
- C12N2310/341—Gapmers, i.e. of the type ===---===
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/34—Spatial arrangement of the modifications
- C12N2310/343—Spatial arrangement of the modifications having patterns, e.g. ==--==--==--
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
- C12N2310/3515—Lipophilic moiety, e.g. cholesterol
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2320/00—Applications; Uses
- C12N2320/30—Special therapeutic applications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2320/00—Applications; Uses
- C12N2320/50—Methods for regulating/modulating their activity
- C12N2320/53—Methods for regulating/modulating their activity reducing unwanted side-effects
Definitions
- the present invention relates to a double-stranded nucleic acid complex containing scpBNA or AmNA, a pharmaceutical composition containing the same, and the like.
- oligonucleotides In recent years, in the ongoing development of medicines called nucleic acid medicines, attention has been focused on oligonucleotides. is being actively developed.
- a partial sequence of mRNA or miRNA transcribed from the target gene is used as the target sense strand, and a complementary oligonucleotide (antisense oligonucleotide: in this specification, often referred to as "ASO (Antisense Oligonucleotide)").
- ASO Antisense Oligonucleotide
- Non-Patent Document 1 Non-Patent Documents 1 and 2.
- the double-stranded nucleic acid complex has a high antisense effect and is an epoch-making technology that crosses the blood-brain barrier and enables control of the central nervous system.
- treatment of neurological diseases such as Alzheimer's disease requires administration at high doses, and serious side effects such as liver damage may become a problem.
- the present inventors have conducted intensive research to solve the above problems, and found that 2'-O,4'-C-spirocyclopropylene crosslinked nucleic acid (scpBNA) or amide crosslinked nucleic acid (AmNA) is a double-stranded nucleic acid. introduced into the complex. As a result, they found that introduction of scpBNA or AmNA can dramatically reduce or eliminate the toxicity of double-stranded nucleic acid complexes. This toxicity-suppressing effect is a surprising effect that greatly exceeds conventional expectations. Furthermore, it was found that the introduction of scpBNA or AmNA did not impair the efficacy of the double-stranded nucleic acid complex.
- the present invention is based on the above findings, and provides the following.
- a double-stranded nucleic acid complex comprising a first nucleic acid strand and a second nucleic acid strand, wherein the first nucleic acid strand is capable of hybridizing to at least a portion of a target gene or transcript thereof; having an antisense effect on the target gene or its transcript, the second nucleic acid strand comprising a base sequence complementary to the first nucleic acid strand, and the first nucleic acid strand and/or the second nucleic acid
- the chain has the following formula (I) or formula (II): (Wherein, R represents a hydrogen atom or a methyl group.)
- the double-stranded nucleic acid complex comprising at least one crosslinked non-natural nucleoside represented by (2)
- the first nucleic acid strand is [1] a central region comprising at least 4 consecutive deoxyribonucleosides; [2] a 5' wing region containing a non-natural nucleoside located at the 5' end of the central region; and [3] a 3' wing region containing a non-natural nucleoside located at the 3' end of the central region.
- the double-stranded nucleic acid complex according to (2) comprising a wing region.
- said second nucleic acid strand comprises at least 4 contiguous ribonucleosides complementary to at least 4 contiguous deoxyribonucleosides in said central region of said first nucleic acid strand, (3) or (4) ).
- the region consisting of a base sequence complementary to the 5' wing region and/or the 3' wing region of the first nucleic acid strand is represented by the formula (I) or formula (II).
- the first nucleic acid strand and/or the second nucleic acid strand are 2'-O-methyl modified nucleosides, 2'-O-methoxyethyl modified nucleosides, and 2'-O-[2-(N-methyl
- a pharmaceutical composition comprising the double-stranded nucleic acid complex according to any one of (1) to (14) as an active ingredient.
- the pharmaceutical composition according to (15) or (16) which is administered intracerebroventricularly or intrathecally.
- a double-stranded nucleic acid complex with reduced toxicity is provided without impairing efficacy.
- FIG. 1 shows the structures of various crosslinked nucleic acids.
- FIG. 2 is a diagram showing the structures of various natural or non-natural nucleotides.
- 3 is a schematic diagram of the structure of the nucleic acid used in Example 1.
- FIG. 3A shows the structure of ASO (LNA) containing 3 LNA nucleosides at the 5′ and 3′ ends and 10 DNA nucleosides between them.
- FIG. 3B shows the structure of HDO (LNA) comprising ASO (LNA) as the first nucleic acid strand and RNA having a sequence complementary to the first nucleic acid strand as the second nucleic acid strand.
- LNA ASO
- LNA HDO
- FIG. 3C shows the structure of ASO (scpBNA) containing 3 scpBNA nucleosides at each of the 5' and 3' ends and 10 DNA nucleosides between them.
- FIG. 3D shows the structure of HDO (scpBNA) comprising ASO (scpBNA) as the first nucleic acid strand and RNA having a sequence complementary to the first nucleic acid strand as the second nucleic acid strand.
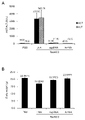
- FIG. 4 shows Mapt mRNA expression levels in the hippocampus of mice to which various nucleic acid agents were intracerebroventricularly administered. Error bars indicate standard error.
- FIG. 5 shows the expression levels of TNF ⁇ mRNA and GFAP mRNA in the hippocampus of mice to which various nucleic acid agents were intracerebroventricularly administered.
- FIG. 5A shows the expression level of TNF ⁇ mRNA.
- FIG. 5B shows the expression level of GFAP mRNA. Error bars indicate standard error.
- 6 is a schematic diagram of the structure of the nucleic acid used in Example 2.
- FIG. Figure 6A shows the structure of Toc-HDO (LNA).
- Figure 6B shows the structure of Toc-HDO (scpBNA).
- Figure 6C shows the structure of Toc-HDO (AmNA). Toc indicates tocopherol.
- FIG. 1 shows the expression levels of TNF ⁇ mRNA and GFAP mRNA in the hippocampus of mice to which various nucleic acid agents were intracerebroventricularly administered.
- FIG. 5A shows the expression level of TNF ⁇ mRNA.
- FIG. 5B shows the expression level
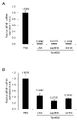
- FIG. 7 shows the expression level of malat1 mRNA in mice to which a single dose of the double-stranded nucleic acid complex agent was intravenously administered.
- FIG. 7A shows the expression level of malat1 mRNA in the liver.
- FIG. 7B shows the expression level of malat1 mRNA in kidney. Error bars indicate standard error.
- FIG. 8 shows the expression level of malat1 mRNA in mice to which a single dose of the double-stranded nucleic acid complex agent was intravenously administered.
- FIG. 8A shows the expression level of malat1 mRNA in quadriceps muscle.
- FIG. 8B shows the expression level of malat1 mRNA in myocardium. Error bars indicate standard error.
- FIG. 8A shows the expression level of malat1 mRNA in quadriceps muscle.
- FIG. 8B shows the expression level of malat1 mRNA in myocardium. Error bars indicate standard error.
- FIG. 8A shows the expression level of
- FIG. 9 shows the results of serum analysis and body weight measurement in mice to which a single dose of a double-stranded nucleic acid complex agent targeting malat1 was intravenously administered.
- FIG. 9A shows the measurement results of AST and ALT in serum.
- FIG. 9B shows the body weight measurement results. Error bars indicate standard error.
- 10 is a schematic diagram of the structure of the nucleic acids used in Examples 3 and 4.
- FIG. 10A shows the structure of Toc-HDO (LNA).
- Figure 10B shows the structure of Toc-HDO (scpBNA).
- Figure 10C shows the structure of Toc-HDO (AmNA). Toc indicates tocopherol.
- FIG. 10A shows the structure of Toc-HDO (LNA).
- Figure 10B shows the structure of Toc-HDO (scpBNA).
- Figure 10C shows the structure of Toc-HDO (AmNA).
- Toc indicates tocopherol.
- FIG. 10A shows the structure of Toc
- FIG. 11 shows the expression level of PTEN mRNA in mice to which the double-stranded nucleic acid complex agent was intravenously administered once.
- FIG. 11A shows the expression level of PTEN mRNA in the liver.
- FIG. 11B shows the expression level of PTEN mRNA in kidney. Error bars indicate standard error.
- FIG. 12 shows the expression levels of PTEN mRNA in mice to which a single dose of the double-stranded nucleic acid complex agent was intravenously administered.
- FIG. 12A shows the expression level of PTEN mRNA in quadriceps muscle.
- FIG. 12B shows the expression level of PTEN mRNA in myocardium. Error bars indicate standard error.
- FIG. 12 shows the expression levels of PTEN mRNA in mice to which the double-stranded nucleic acid complex agent was intravenously administered once.
- FIG. 11A shows the expression level of PTEN mRNA in the liver.
- FIG. 11B shows the expression level of PTEN mRNA in kidney
- FIG. 13 shows the results of serum analysis and body weight measurement in mice that received a single intravenous administration of a double-stranded nucleic acid complex agent targeting PTEN.
- FIG. 13A shows the results of measuring AST and ALT in serum.
- FIG. 13B shows changes in body weight before and after administration of the double-stranded nucleic acid complex agent. Error bars indicate standard error.
- FIG. 14 shows the expression level of SR-B1 mRNA in mice to which the double-stranded nucleic acid complex agent was intravenously administered once.
- FIG. 14A shows the expression level of SR-B1 mRNA in liver.
- FIG. 14B shows the expression level of SR-B1 mRNA in kidney. Error bars indicate standard error.
- FIG. 14A shows the expression level of SR-B1 mRNA in liver.
- FIG. 14B shows the expression level of SR-B1 mRNA in kidney. Error bars indicate standard error.
- FIG. 14A shows the expression level of
- FIG. 15 shows the expression level of SR-B1 mRNA in mice to which a double-stranded nucleic acid complex agent was intravenously administered once.
- FIG. 15A shows the expression level of SR-B1 mRNA in quadriceps muscle.
- FIG. 15B shows the expression level of SR-B1 mRNA in myocardium. Error bars indicate standard error.
- FIG. 16 shows the results of serum analysis and body weight measurement in mice that received a single intravenous administration of a double-stranded nucleic acid complex agent targeting SR-B1.
- FIG. 16A shows the measurement results of AST and ALT in serum.
- FIG. 16B shows changes in body weight before and after administration of the double-stranded nucleic acid complex agent. Error bars indicate standard error.
- FIG. 17 is a schematic diagram of the structure of the nucleic acid used in Example 5.
- FIG. Figure 17A shows the structure of Chol-HDO (LNA).
- Figure 17B shows the structure of Chol-HDO (scpBNA). Chol indicates cholesterol.
- FIG. 18 shows the expression level of SR-B1 mRNA in mice to which double-stranded nucleic acid complex agents were intravenously administered multiple times.
- Figure 18A shows SR-B1 mRNA in Cortex, Cerebellum, Striatum, Hippocampus, Brain stem, Cervical SC, and Lumbar SC.
- FIG. 19 shows the measurement results of serum AST and ALT in mice to which double-stranded nucleic acid complex agents were intravenously administered multiple times.
- LNA Chol-HDO
- FIG. 20 shows the measurement results of TNF ⁇ in the blood of mice to which the double-stranded nucleic acid complex agent was intravenously administered once.
- FIG. 20A shows results for Toc-HDO (PTEN) and Toc-HDO (Malat1).
- FIG. 20B shows the results for Toc-HDO (SR-B1).
- FIG. 21 shows the measurement results of IP-10 in the blood of mice to which a double-stranded nucleic acid complex agent was intravenously administered once.
- FIG. 21A shows results for Toc-HDO (PTEN) and Toc-HDO (Malat1).
- Figure 21B shows the results for Toc-HDO (SR-B1).
- FIG. 22 shows the measurement results of RANTES in the blood of mice to which a double-stranded nucleic acid complex agent was intravenously administered once.
- FIG. 22A shows results for Toc-HDO (PTEN) and Toc-HDO (Malat1).
- Figure 22B shows the results for Toc-HDO (SR-B1).
- Double-stranded nucleic acid complex 1-1 A first aspect of the present invention is a double-stranded nucleic acid complex.
- the double-stranded nucleic acid complex of the present invention comprises a first nucleic acid strand and a second nucleic acid strand, the first nucleic acid strand and/or the second nucleic acid strand comprising at least one scpBNA or AmNA.
- the double-stranded nucleic acid complex of the present invention has reduced toxicity such as hepatotoxicity, and reduced induction of inflammation or gliosis, or abnormal elevation of cytokines or chemokines.
- a "transcript" of a target gene refers to any RNA that is directly targeted by the nucleic acid complex of the present invention and synthesized by RNA polymerase. Specifically, mRNA transcribed from target genes (including mature mRNA, pre-mRNA, and mRNA that has not undergone base modification), non-coding RNA such as miRNA (non-coding RNA, ncRNA), long non-coding RNA RNA (lncRNA), which may include natural antisense RNA.
- target genes including mature mRNA, pre-mRNA, and mRNA that has not undergone base modification
- non-coding RNA such as miRNA (non-coding RNA, ncRNA), long non-coding RNA RNA (lncRNA), which may include natural antisense RNA.
- Target gene whose expression is regulated (eg, suppressed, altered, or modified) by the antisense effect is not particularly limited, but includes, for example, genes whose expression is increased in various diseases.
- Target gene transcripts include, for example, SR-B1 mRNA, which is the transcript of the SR-B1 gene, Malat1 non-coding RNA, which is the transcript of the Malat1 gene, and DMPK mRNA, which is the transcript of the DMPK gene.
- a “target transcript” is, for example, scavenger receptor B1 (often referred to herein as “SR-B1”), myotonic dystrophy protein kinase (often referred to herein as “DMPK”), transthyretin (often referred to herein as “TTR”), Apolipoprotein B (often referred to herein as “ApoB”), metastasis-associated lung It may also be the gene for adenocarcinoma transcript 1 (metastasis associated lung adenocarcinoma transcript 1; often referred to herein as "Malat1”), such as their non-coding RNA or mRNA.
- SR-B1 scavenger receptor B1
- DMPK myotonic dystrophy protein kinase
- TTR transthyretin
- Apolipoprotein B often referred to herein as "ApoB”
- metastasis-associated lung It may also be the gene for aden
- SEQ ID NO: 19 shows the base sequence of mouse Malat1 non-coding RNA
- SEQ ID NO: 20 shows the base sequence of human Malat1 non-coding RNA
- SEQ ID NO: 21 shows the base sequence of mouse SR-B1 mRNA
- SEQ ID NO: 22 shows the base sequence of human SR-B1 mRNA
- SEQ ID NO: 23 shows the nucleotide sequence of mouse DMPK mRNA
- SEQ ID NO: 24 shows the nucleotide sequence of human DMPK mRNA.
- the base sequence of mRNA is replaced with the base sequence of DNA.
- the base sequence information of these genes and transcripts can be obtained from known databases such as NCBI (National Center for Biotechnology Information) databases (eg, GenBank, Trace Archive, Sequence Read Archive, BioSample, BioProject).
- antisense oligonucleotides or “antisense nucleic acids” are capable of hybridizing (i.e., complementary a) refers to a single-stranded oligonucleotide containing a base sequence and capable of producing an antisense effect on a target transcript.
- the first nucleic acid strand functions as an ASO, and its target region is 3'UTR, 5'UTR, exon, intron, coding region, translation initiation region, translation termination region, or Any other nucleic acid region may be included.
- the target region of the target transcript is at least 8 bases long, e.g. It can be 16-22 bases long, or 16-20 bases long.
- Antisense effect refers to the effect of regulating the expression or editing of a target transcript (eg, RNA sense strand) by hybridizing the ASO to the target transcript.
- “Modulating the expression or editing of a target transcript” refers to the expression of a target gene or the expression level of a target transcript (herein, “target transcript expression level” is often referred to as “target transcript level”). expression), inhibition of translation, RNA editing, splicing function modification effects (eg, splicing switch, exon inclusion, exon skipping, etc.), or degradation of transcripts.
- RNA oligonucleotide when introduced into a cell as an ASO, the ASO forms a partial duplex by annealing with mRNA, the transcript of the target gene. This partial double strand serves as a cover to prevent translation by the ribosome, thereby inhibiting the expression of the target protein encoded by the target gene at the translational level (steric blocking).
- oligonucleotides containing DNA as ASO are introduced into cells, partial DNA-RNA heteroduplexes are formed. Recognition of this heteroduplex structure by RNase H results in degradation of target gene mRNA and inhibition of expression of the protein encoded by the target gene at the expression level.
- antisense effects can also be produced by targeting introns in pre-mRNAs.
- antisense effects can also be produced by targeting miRNAs.
- the functional inhibition of the miRNA can increase the expression of genes whose expression is normally controlled by the miRNA.
- modulating expression of the target transcript may be reduction in target transcript abundance.
- the antisense effect is measured, for example, by administering a test nucleic acid compound to a subject (eg, a mouse), and, for example, several days later (eg, 2 to 7 days later), the expression is regulated by the antisense effect provided by the test nucleic acid compound. It can be carried out by measuring the expression level of the target gene or the level (amount) of the target transcript (for example, the amount of mRNA or RNA such as microRNA, the amount of cDNA, the amount of protein, etc.).
- the measured target gene expression level or target transcript level is at least 10%, at least 20%, at least 25%, at least 30%, or at least 40% compared to a negative control (e.g., vehicle administration) If so, it indicates that the test nucleic acid compound is capable of producing an antisense effect (eg, reduction in target transcript abundance).
- a negative control e.g., vehicle administration
- the number, type and position of non-natural nucleotides in the nucleic acid chain can affect the antisense effect provided by the nucleic acid complex.
- the selection of modification may differ depending on the sequence of the target gene, etc., but a person skilled in the art should refer to the literature related to the antisense method (for example, WO 2007/143315, WO 2008/043753, and WO 2008/049085).
- the preferred embodiment can be determined by reference.
- the measured value thus obtained is not significantly lower than the measured value of the nucleic acid complex before modification (e.g., When the measured value obtained after modification is 70% or more, 80% or more, or 90% or more of the measured value of the nucleic acid complex before modification), the relevant modification can be evaluated.
- target gene translation product refers to any polypeptide or protein synthesized by translation of the target transcript or target gene transcript that is the direct target of the nucleic acid complex of the present invention. Say.
- nucleic acid or “nucleic acid molecule” as used herein may refer to a monomeric nucleotide or nucleoside, or may refer to an oligonucleotide composed of multiple monomers.
- nucleic acid strand or simply “strand” means an oligonucleotide or polynucleotide. Nucleic acid strands can be produced full length or partial strands by chemical synthetic methods, for example, using automated synthesizers, or by enzymatic processes using polymerases, ligases, or restriction reactions. A nucleic acid strand may comprise naturally occurring and/or non-naturally occurring nucleotides.
- Nucleoside generally refers to a molecule consisting of a combination of a base and a sugar.
- the sugar moiety of a nucleoside is usually, but not limited to, composed of pentofuranosyl sugars, specific examples of which include ribose and deoxyribose.
- the base portion (nucleobase) of a nucleoside is usually a heterocyclic base portion. Non-limiting examples include adenine, cytosine, guanine, thymine, or uracil, as well as other modified nucleobases (modified bases).
- Nucleotide refers to a molecule in which a phosphate group is covalently bonded to the sugar moiety of the nucleoside. Nucleotides containing a pentofuranosyl sugar typically have a phosphate group attached to the hydroxyl group at the 2', 3', or 5' position of the sugar.
- Oligonucleotide refers to a linear oligomer formed by covalently linking several to several tens of hydroxyl groups and phosphate groups of sugar moieties between adjacent nucleotides.
- polynucleotide refers to a linear polymer formed by linking several tens or more, preferably several hundred or more nucleotides by covalent bonds, which is larger than that of oligonucleotides.
- phosphate groups are commonly considered to form internucleoside linkages.
- Natural nucleoside refers to a nucleoside that exists in nature. Examples thereof include ribonucleosides composed of ribose and a base such as adenine, cytosine, guanine, or uracil, and deoxyribonucleosides composed of deoxyribose and a base such as adenine, cytosine, guanine, or thymine.
- ribonucleosides found in RNA and deoxyribonucleosides found in DNA are often referred to as "DNA nucleosides" and "RNA nucleosides", respectively.
- naturally occurring nucleotide refers to a naturally occurring nucleotide in which a phosphate group is covalently bonded to the sugar moiety of the natural nucleoside.
- ribonucleotides known as structural units of RNA, in which a phosphate group is bound to a ribonucleoside
- deoxyribonucleotides known as a structural unit of DNA, in which a phosphate group is bound to a deoxyribonucleoside.
- non-natural nucleotide refers to any nucleotide other than natural nucleotides, including modified nucleotides and nucleotide mimetics.
- modified nucleotide means a nucleotide having any one or more of modified sugar moieties, modified internucleoside linkages, and modified nucleobases.
- nucleotide mimetics include structures that are used to replace nucleosides and linkages at one or more positions of an oligomeric compound.
- Peptide Nucleic Acid is a nucleotide mimetic with a backbone of N-(2-aminoethyl)glycine instead of sugar linked by amide bonds.
- Nucleic acid strands comprising unnatural oligonucleotides, as used herein, are often characterized by, for example, enhanced cellular uptake, enhanced affinity for nucleic acid targets, increased stability in the presence of nucleases, or increased inhibitory activity. has the desired properties of Therefore, it is preferred over natural nucleotides.
- non-natural nucleoside refers to any nucleoside other than natural nucleosides. Examples include modified nucleosides and nucleoside mimetics. As used herein, “modified nucleoside” means a nucleoside having a modified sugar moiety and/or modified nucleobase.
- mimetics refers to functional groups that replace sugars, nucleobases, and/or internucleoside linkages. In general, mimetics are used in place of the sugar or sugar-internucleoside linkage combination so that the nucleobase is maintained for hybridization to a target of choice.
- nucleoside mimetic refers to substitution of a sugar at one or more positions of an oligomeric compound, substitution of a sugar and a base, or binding between monomer subunits constituting an oligomeric compound. Contains the structure used to replace.
- oligomeric compound is meant a polymer of linked monomeric subunits capable of hybridizing to at least a region of a nucleic acid molecule.
- Nucleoside mimetics include, for example, morpholino, cyclohexenyl, cyclohexyl, tetrahydropyranyl, bicyclic or tricyclic sugar mimetics, eg, nucleoside mimetics having non-furanose sugar units.
- Modified sugar refers to a sugar that has a substitution and/or any change from the natural sugar moiety (i.e., sugar moieties found in DNA (2'-H) or RNA (2'-OH));
- a “sugar modification” refers to a substitution and/or any change from a naturally occurring sugar moiety.
- Nucleic acid strands may optionally contain one or more modified nucleosides, including modified sugars.
- a “sugar modified nucleoside” refers to a nucleoside having a modified sugar moiety. Such sugar-modified nucleosides may confer enhanced nuclease stability, increased binding affinity, or some other beneficial biological property to nucleic acid chains.
- nucleosides include chemically modified ribofuranose ring moieties.
- chemically modified ribofuranose rings include, but are not limited to, addition of substituents (including 5' and 2' substituents), bridging of non-geminal ring atoms to form bicyclic nucleic acids (bridged nucleic acids, BNA ), S, N(R), or C(R1)(R2) of the ribosyl ring oxygen atom (R, R1 and R2 are each independently H, C1 - C12 alkyl, or a protecting group ), and combinations thereof.
- sugar modified nucleosides include, but are not limited to, 5'-vinyl, 5'-methyl (R or S), 5'-allyl (R or S), 4'-S, 2'-F ( 2'-fluoro group), 2'- OCH3 (2'-OMe group or 2'-O-methyl group), 2'-O-[2-(N-methylcarbamoyl)ethyl] (2'-O- MCE group), and nucleosides containing 2'-O-methoxyethyl (2'-O- MOE or 2-O( CH2 ) 2OCH3 ) substituents.
- a "2'-modified sugar” means a furanosyl sugar modified at the 2' position.
- a nucleoside containing a 2'-modified sugar is sometimes referred to as a "2'-sugar modified nucleoside".
- Bicyclic nucleoside refers to a modified nucleoside containing a bicyclic sugar moiety. Nucleic acids containing bicyclic sugar moieties are commonly referred to as bridged nucleic acid (BNA). Nucleosides containing a bicyclic sugar moiety are sometimes referred to as “bridged nucleosides,” “bridged non-natural nucleosides,” or “BNA nucleosides.” Some examples of crosslinked nucleic acids are shown in FIG.
- a bicyclic sugar may be a sugar in which the 2' and 4' carbon atoms are bridged by two or more atoms. Examples of bicyclic sugars are known to those of skill in the art.
- One subgroup of bicyclic sugar containing nucleic acids (BNA) or BNA nucleosides are 4'-( CH2 ) p -O-2', 4'-( CH2 ) p - CH2-2 ', 4 '-( CH2 ) p -S-2', 4'-( CH2 ) p -OCO-2', 4'-( CH2 ) n -N( R3 )-O-( CH2 ) m- 2' [wherein p, m and n represent an integer of 1 to 4, an integer of 0 to 2, and an integer of 1 to 3, respectively; and R 3 is a hydrogen atom, an alkyl group, an alkenyl group, a cyclo Represents an alkyl group, an aryl group,
- R 1 and R 2 are typically is a hydrogen atom, which may be the same or different, and is also a hydroxyl group-protecting group for nucleic acid synthesis, an alkyl group, an alkenyl group, a cycloalkyl group, an aryl group, an aralkyl group, an acyl a sulfonyl group, a silyl group, a phosphate group, a phosphate group protected by a protecting group for nucleic acid synthesis, or P(R 4 )R 5 [wherein R 4 and R 5 are a hydroxyl group, a hydroxyl group protected by a protecting group for nucleic acid synthesis, a mercapto group, a mercapto group protected by a protecting group for nucleic acid synthesis, an amino group, 1
- BNA nucleosides include methyleneoxy(4'- CH2 -O-2') BNA nucleosides (LNA nucleosides, also known as 2',4'-BNA nucleosides) (e.g., ⁇ -L-methyleneoxy(4'- CH2 -O-2')BNA nucleoside, ⁇ -D-methyleneoxy(4'-CH2 - O-2')BNA nucleoside), ethyleneoxy(4'-(CH 2 ) 2 -O-2')BNA nucleoside (ENA nucleosides), ⁇ -D-thio(4'- CH2 -S-2')BNA nucleosides, aminooxy(4'-CH2 - ON( R3 )-2')BNA nucleosides, Oxyamino (4'-CH2 - N( R3 )-O-2') BNA nucleosides (also known as 2',4'-BNA NC nucle
- amine BNA nucleosides also known as 2'-Amino-LNA nucleosides
- 2'-Amino-LNA nucleosides e.g., 3-(Bis(3-amino propyl)amino)propanoyl substituted nucleosides
- 2'-O,4'-C-spirocyclopropylene bridged nucleosides also known as scpBNA nucleosides
- other BNA nucleosides known to those skilled in the art.
- a "cationic nucleoside” refers to, at a certain pH (e.g., human physiological pH (about 7.4), pH of a delivery site (e.g., organelle, cell, tissue, organ, organism, etc.)) A modified nucleoside that exists as a cationic form as compared to a neutral form (such as the neutral form of a ribonucleoside).
- Cationic nucleosides may contain one or more cationic modifying groups at any position of the nucleoside.
- the cationic nucleosides are 2'-Amino-LNA nucleosides (e.g.
- Bicyclic nucleosides with a methyleneoxy (4'- CH2 -O-2') bridge are sometimes referred to as LNA nucleosides.
- modified internucleoside linkage refers to an internucleoside linkage that has a substitution or any change from a naturally occurring internucleoside linkage (ie, a phosphodiester linkage).
- Modified internucleoside linkages include internucleoside linkages containing a phosphorus atom and internucleoside linkages without a phosphorus atom.
- Representative phosphorus-containing internucleoside linkages include phosphodiester linkages, phosphorothioate linkages, phosphorodithioate linkages, phosphotriester linkages (methylphosphotriester and ethylphosphotriester linkages described in US Pat. No.
- alkyl Phosphonate linkages e.g., methylphosphonate linkages described in U.S. Pat. Nos. 5,264,423 and 5,286,717, methoxypropylphosphonate linkages described in WO 2015/168172
- alkylthiophosphonate linkages e.g., methylthiophosphonate linkages, boranophosphate linkages, cyclic guanidine moieties
- An internucleoside bond containing e.g., a substructure represented by the following formula (III):
- an internucleoside linkage comprising a guanidine moiety substituted with 1-4 C 1-6 alkyl groups e.g., a tetramethylguanidine (TMG) moiety
- TMG tetramethylguanidine
- a phosphorothioate linkage refers to an internucleoside linkage in which a sulfur atom replaces the non-bridging oxygen atom of a phosphodiester linkage.
- Methods for preparing phosphorus-containing and non-phosphorus-containing linkages are well known.
- Modified internucleoside linkages are preferably linkages that are more resistant to nucleases than naturally occurring internucleoside linkages.
- the internucleoside linkage When the internucleoside linkage has a chiral center, the internucleoside linkage may be chirally controlled. "Chirally controlled” is intended to exist in a single diastereomer about a chiral center, eg, a chiral bound phosphorus. Chirally controlled internucleoside linkages can be completely chirally pure or highly chiral pure, e.g. It may have a chiral purity of %de, 99.9% de, or higher.
- chiral purity refers to the proportion of one diastereomer in a mixture of diastereomers, expressed as diastereomeric excess (% de), (diastereomer of interest minus other diastereomer defined as (stereomers)/(total diastereomers) ⁇ 100 (%).
- internucleoside linkages may be phosphorothioate linkages chiral controlled to the Rp or Sp configuration, guanidine moieties substituted with 1-4 C 1-6 alkyl groups (e.g., tetramethylguanidine (TMG) moieties; e.g. Alexander A. Lomzov et al., Biochem Biophys Res Commun., 2019, 513(4), 807-811), including internucleoside linkages (e.g. substructures represented by formula (IV)), and /or an internucleoside linkage containing a cyclic guanidine moiety (eg, a substructure represented by formula (III)).
- TMG tetramethylguanidine
- nucleobase or “base” used herein is a base component (heterocyclic moiety) that constitutes a nucleic acid, and adenine, guanine, cytosine, thymine, and uracil are mainly known.
- nucleobase or “base” includes both modified and unmodified nucleobases (bases) unless otherwise specified.
- the purine base can be either modified or unmodified purine base.
- the pyrimidine base may be a modified or unmodified pyrimidine base.
- Modified nucleobase or “modified base” means any nucleobase other than adenine, cytosine, guanine, thymine, or uracil.
- Unmodified nucleobases or “unmodified bases” (natural nucleobases) include the purine bases adenine (A) and guanine (G), and the pyrimidine bases thymine (T), cytosine (C), and means uracil (U).
- modified nucleobases include 5-methylcytosine, 5-fluorocytosine, 5-bromocytosine, 5-iodocytosine or N4-methylcytosine; N6-methyladenine or 8-bromoadenine; 2-thio-thymine; Examples include, but are not limited to, N2-methylguanine or 8-bromoguanine.
- the modified nucleobase is preferably 5-methylcytosine.
- the term “complementary” means that the nucleobases can form so-called Watson-Crick base pairs (natural base pairs) or non-Watson-Crick base pairs (Hoogsteen bases) through hydrogen bonding. It means a relationship that can form an equality).
- the antisense oligonucleotide region in the first nucleic acid strand does not necessarily have to be completely complementary to at least part of the target transcript (for example, the transcript of the target gene). Complementarity of at least 70%, preferably at least 80%, even more preferably at least 90% (eg, 95%, 96%, 97%, 98%, or 99% or more) is acceptable.
- the antisense oligonucleotide region in the first nucleic acid strand is complementary in base sequence (typically when the base sequence is complementary to the base sequence of at least a portion of the target transcript), It can hybridize to a target transcript.
- the region of complementarity in the second nucleic acid strand need not necessarily be completely complementary to at least a portion of the first nucleic acid strand, but has a base sequence of at least 70%, preferably at least 80%, and even More preferably, at least 90% (eg, 95%, 96%, 97%, 98%, or 99% or more) complementarity is acceptable.
- the complementary regions in the second nucleic acid strand can anneal when they are complementary in base sequence to at least a portion of the first nucleic acid strand.
- Complementarity of base sequences can be determined by using the BLAST program or the like.
- a person skilled in the art can easily determine the conditions (temperature, salt concentration, etc.) under which two strands can anneal or hybridize, taking into consideration the degree of complementarity between the strands.
- a person skilled in the art can easily design an antisense nucleic acid complementary to the target transcript, for example, based on information on the base sequence of the target gene.
- Hybridization conditions may be various stringent conditions such as low stringent conditions and high stringent conditions.
- Low stringent conditions may be relatively low temperature and high salt conditions, eg, 30° C., 2 ⁇ SSC, 0.1% SDS.
- Highly stringent conditions may be relatively high temperature and low salt conditions, eg, 65° C., 0.1 ⁇ SSC, 0.1% SDS.
- Hybridization stringency can be adjusted by varying conditions such as temperature and salt concentration.
- 1 ⁇ SSC contains 150 mM sodium chloride and 15 mM sodium citrate.
- the term "subject” refers to a subject to which the double-stranded nucleic acid complex or pharmaceutical composition of the present invention is applied.
- Subjects include organs, tissues, and cells as well as individuals.
- any animal including humans can be applicable.
- various livestock, poultry, pets, experimental animals, and the like can be mentioned.
- a subject may be an individual in need of decreased expression of a target transcript or an individual in need of treatment or prevention of a disease.
- the double-stranded nucleic acid complex of the present invention comprises a first nucleic acid strand and a second nucleic acid strand. Specific configurations of each nucleic acid strand are shown below.
- the first nucleic acid strand can hybridize to at least a portion of the target gene or its transcript and has an antisense effect on the target gene or its transcript.
- the second nucleic acid strand comprises a base sequence complementary to the first nucleic acid strand, and the first nucleic acid strand and/or said second nucleic acid strand has the following formula (I) or formula (II): (Wherein, R represents a hydrogen atom or a methyl group.) contains at least one crosslinked non-natural nucleoside represented by
- the crosslinked non-natural nucleoside represented by formula (I) above is a 2'-O,4'-C-spirocyclopropylene crosslinked nucleic acid, and is mainly referred to as "scpBNA" in this specification.
- R may be either a hydrogen atom or a methyl group.
- R may be either a hydrogen atom or a methyl group.
- a methyl group can also be written as AmNA[N-Me].
- the number of crosslinked non-natural nucleosides represented by the above formula (I) or (II) contained in the first nucleic acid strand and/or the second nucleic acid strand constituting the double-stranded nucleic acid complex is at least one. Yes, for example, 2 or more, 3 or more, 4 or more, 5 or more, 6 or more, 7 or more, 8 or more, 9 or more, or 10 or more, 30 or less, 25 , 20 or less, 15 or less, 10 or less, 9 or less, 8 or less, 7 or less, 6 or less, 5 or less, 4 or less, 3 or less, or 2 or less good too.
- the number of crosslinked non-natural nucleosides represented by formula (I) or formula (II) may be 1-10, preferably 1-6. For example, it may be 1, 2, 3, 4, 5, or 6.
- the first nucleic acid strand and/or the second nucleic acid strand that constitutes the double-stranded nucleic acid complex of the present invention has the formula (I ), may include only those represented by formula (II), or may include both of formulas (I) and (II).
- crosslinked non-natural nucleosides represented by formulas (I) and (II) above may be contained only in the first nucleic acid strand, may be contained only in the second nucleic acid strand, or may be contained only in the second nucleic acid strand. It may be contained in both the nucleic acid strand and the second nucleic acid strand.
- the base lengths of the first nucleic acid strand and the second nucleic acid strand are not particularly limited, but are at least 8 bases long, at least 9 bases long, at least 10 bases long, at least 11 bases long, at least 12 bases long, at least 13 bases long, at least It may be 14 bases long, or at least 15 bases long.
- the base lengths of the first nucleic acid strand and the second nucleic acid strand are 35 base lengths or less, 30 base lengths or less, 25 base lengths or less, 24 base lengths or less, 23 base lengths or less, 22 base lengths or less, and 21 base lengths or less. , 20 bases or less, 19 bases or less, 18 bases or less, 17 bases or less, or 16 bases or less.
- the first nucleic acid strand and the second nucleic acid strand may have the same length or different lengths (eg, one may be 1 to 3 bases shorter or longer).
- the double-stranded structure formed by the first nucleic acid strand and the second nucleic acid strand may contain a bulge.
- the choice of length can be determined by the balance between the strength of the antisense effect and the specificity of the nucleic acid strand for its target, among other factors such as cost, synthetic yield, and the like.
- the first nucleic acid strand can contain at least 4, at least 5, at least 6, or at least 7 contiguous nucleosides that are recognized by RNase H when hybridized to the target transcript. Generally, any region containing consecutive nucleosides of 4 to 20 bases, 5 to 16 bases, or 6 to 12 bases may be used. As a nucleoside recognized by RNase H, for example, natural deoxyribonucleoside can be used. Suitable nucleosides containing modified deoxyribonucleosides and other bases are well known in the art. It is also known that nucleosides having a hydroxy group at the 2'-position, such as ribonucleosides, are unsuitable as the nucleosides.
- the suitability of nucleosides for use in this region containing "at least 4 contiguous nucleosides" can readily be determined.
- the first nucleic acid strand may comprise at least 4 contiguous deoxyribonucleosides.
- the nucleosides of the first nucleic acid strand comprise or consist of deoxyribonucleosides, e.g., 70% or more, 80% or more, 90% or more, or 95% or more of the nucleosides of the first nucleic acid strand are deoxyribonucleosides. be.
- the first nucleic acid strand may be a gapmer.
- the term "gapmer” basically refers to a central region (DNA gap region) and wing regions located directly at its 5' and 3' ends (5' wing region and 3' wing region, respectively). It refers to a single-stranded nucleic acid consisting of The length of the DNA gap region is 13 to 22 bases, 16 to 22 bases, or 16 to 20 bases, or 4 to 20 bases, 5 to 18 bases, 6 to 16 bases, or 7 to 14 bases. long, or 8-12 bases long.
- the central region in the gapmer contains at least 4 contiguous deoxyribonucleosides and the wing regions contain at least one non-natural nucleoside.
- non-natural nucleosides contained in the wing regions usually have higher binding strength to RNA than natural nucleosides and have high resistance to nucleolytic enzymes (nucleases and the like).
- the non-naturally occurring nucleosides making up the wing regions comprise or consist of bridging nucleosides
- said gapmers are specifically referred to as "BNA/DNA gapmers”.
- the number of bridging nucleosides contained in the 5' wing region and the 3' wing region is at least 1, and may be, for example, 2 or 3.
- the bridging nucleosides contained in the 5' wing region and the 3' wing region may be present continuously or non-contiguously within the 5' wing region and the 3' wing region.
- Bridging nucleosides can further include modified nucleobases (eg, 5-methylcytosine).
- modified nucleobases eg, 5-methylcytosine
- the bridging nucleosides are LNA nucleosides
- said gapmers are referred to as "LNA/DNA gapmers”.
- the non-natural nucleosides making up the 5' and 3' wing regions comprise or consist of peptide nucleic acids
- said gapmers are specifically referred to as "peptide nucleic acid gapmers”.
- the unnatural nucleosides making up the 5' and 3' wing regions comprise or consist of morpholino nucleic acids
- said gapmers are specifically referred to as "morpholino nucleic acid gapmers”.
- the base lengths of the 5' wing region and the 3' wing region may each independently be at least 2 bases long, for example, 2 to 10 bases long, 2 to 7 bases long, or 3 to 5 bases long.
- the 5′ wing region and/or the 3′ wing region may contain at least one non-natural nucleoside, and may further contain natural nucleosides.
- the 5' and 3' wing regions may be, for example, non-natural nucleosides linked by modified internucleoside linkages such as phosphorothioate linkages, eg 2'-O-methyl modified nucleosides.
- the first nucleic acid strand constituting the gapmer is, in order from the 5′ end, a bridging nucleoside of 2 to 7 bases or 3 to 5 bases (for example, 2 or 3 bases), 4 to 15 bases or 8 to 12 bases. It may be composed of ribonucleosides or deoxyribonucleosides having a base length (eg, 8 or 10 base lengths) and bridging nucleosides having a length of 2 to 7 bases or 3 to 5 bases (eg, 2 or 3 base lengths).
- a nucleic acid strand having a wing region only on either the 5'-end side or the 3'-end side is called a "hemigapmer" in the art. shall be included.
- the 5' wing region and/or 3' wing region of the first nucleic acid strand may contain a crosslinked non-natural nucleoside represented by formula (I) or formula (II) above.
- the number of bridged non-natural nucleosides represented by the above formula (I) or formula (II) contained in each region of the 5' wing region or 3' wing region may be at least 1, for example 2.
- the number may be greater than or equal to 3, or may be 5 or less, 4 or less, 3 or less, or 2 or less. For example, it may be 1, 2, 3, or 4.
- the 5' wing region and/or 3' wing region of the first nucleic acid strand may consist of a crosslinked non-natural nucleoside represented by formula (I) or formula (II) above. .
- the 5' wing region and/or 3' wing region of the first nucleic acid strand comprises a bridged non-natural nucleoside and an LNA nucleoside represented by formula (I) or (II) above.
- the first nucleic acid strand may be a mixmer.
- the term "mixmer” refers to a nucleic acid chain that contains alternating natural and unnatural nucleosides of periodic or random segment length and is free of four or more contiguous deoxyribonucleosides and ribonucleosides. .
- Mixmers in which the unnatural nucleoside is a bridged nucleoside and the natural nucleoside is a deoxyribonucleoside are particularly referred to as "BNA/DNA mixmers".
- the bridged nucleoside may be a bridged non-natural nucleoside represented by formula (I) or formula (II) above.
- Mixmers in which the non-natural nucleoside is a peptide nucleic acid and the natural nucleoside is a deoxyribonucleoside are particularly referred to as "peptide nucleic acid/DNA mixmers".
- Mixmers in which the unnatural nucleoside is a morpholinonucleic acid and the natural nucleoside is a deoxyribonucleoside are particularly referred to as "morpholinonucleic acid/DNA mixmers”.
- Mixmers are not limited to containing only two nucleosides.
- Mixmers can include any number of types of nucleosides, whether natural or modified nucleosides or nucleoside mimetics.
- bridging nucleoside e.g., LNA nucleoside or a bridging non-natural nucleoside represented by formula (I) or (II) above.
- Bridging nucleosides may further include modified nucleobases (eg, 5-methylcytosine).
- All nucleosides of the second nucleic acid strand may be composed of ribonucleosides and/or modified nucleosides.
- all nucleosides of the second nucleic acid strand may consist of ribonucleosides.
- All nucleosides of the second nucleic acid strand may be composed of deoxyribonucleosides and/or modified nucleosides, or may be free of ribonucleosides.
- the second nucleic acid strand comprises at least 4 contiguous ribonucleosides complementary to the at least 4 contiguous nucleosides (e.g., deoxyribonucleosides) in the central region of the first nucleic acid strand. good too. This is so that the second nucleic acid strand forms a partial DNA-RNA heteroduplex with the first nucleic acid strand and is recognized and cleaved by RNaseH. At least four consecutive ribonucleosides in the second nucleic acid strand are preferably linked by naturally occurring internucleoside linkages, ie phosphodiester linkages.
- the second nucleic acid strand may further comprise at least 2 consecutive deoxyribonucleosides in addition to the at least 4 consecutive ribonucleosides described above.
- the at least two contiguous deoxyribonucleosides are complementary to the first nucleic acid strand and may be included in a region complementary to the central region of the first nucleic acid strand.
- the at least two consecutive deoxyribonucleosides may be positioned on either the 5' side or the 3' side of the at least four consecutive ribonucleosides, and may be positioned on both the 5' and 3' sides.
- the at least two consecutive deoxyribonucleosides may be 2, 3, 4, 5, 6 or more consecutive deoxyribonucleosides.
- Modified nucleosides may include modified sugars and/or modified nucleobases.
- Modified sugars may be 2'-modified sugars (eg, sugars containing a 2'-O-methyl group).
- a modified nucleobase can also be 5-methylcytosine.
- the second nucleic acid strand is, in order from the 5' end, a modified nucleoside (e.g., a modified nucleoside containing a 2'-modified sugar) having a length of 2 to 7 bases or a length of 3 to 5 bases (for example, 2 or 3 bases), 4 to ribonucleosides or deoxyribonucleosides (optionally linked by modified internucleoside linkages) 15 bases long or 8-12 bases long (eg 8 or 10 bases long) and 2-7 bases long or 3-5 bases long ( (eg, 2 or 3 bases long) modified nucleosides (eg, modified nucleosides containing 2'-modified sugars).
- the first nucleic acid strand may be a gapmer.
- the second nucleic acid strand is represented by the above formula (I) or formula (II) in a region consisting of a base sequence complementary to the 5' wing region and/or 3' wing region of the first nucleic acid strand It may also contain non-natural nucleosides in cross-linked form.
- Number of bridged nucleosides other than the bridged non-natural nucleoside represented by the above formula (I) or (II), contained in the first nucleic acid strand and/or the second nucleic acid strand constituting the double-stranded nucleic acid complex is, but is not limited to, 0-50, 0-40, 0-30, 0-20, 0-15, 0-12, 0-10, 0-8, or 0- 6, preferably 0 to 5, for example 0, 1, 2, 3, 4 or 5.
- a non-natural nucleoside other than the crosslinked non-natural nucleoside represented by the above formula (I) or (II), contained in the first nucleic acid strand and/or the second nucleic acid strand constituting the double-stranded nucleic acid complex The number of is not limited, but is, for example, 0 to 30, 0 to 20, 0 to 15, 0 to 12, 0 to 10, 0 to 8, or 0 to 6, preferably 0 There may be ⁇ 5, such as 0, 1, 2, 3, 4, or 5.
- the first nucleic acid strand and/or the second nucleic acid strand constituting the double-stranded nucleic acid complex in addition to the crosslinked non-natural nucleoside represented by the above formula (I) or (II), It may contain at least one ribose 2'-modified nucleoside.
- the ribose 2' modified nucleosides are 2'-O-methyl modified nucleosides (2'-O-Me-modified nucleosides), 2'-O-methoxyethyl modified nucleosides (2'-O-MOE modified nucleosides), and at least one ribose 2'-modified nucleoside selected from the group consisting of 2'-O-[2-(N-methylcarbamoyl)ethyl] modified nucleosides (2'-O-MCE-modified nucleosides) good.
- the first nucleic acid strand and/or the second nucleic acid strand that constitutes the double-stranded nucleic acid complex contains at least one crosslinked non-natural nucleoside represented by formula (I) or formula (II) above. and at least one 2'-O-methyl modified nucleoside (2'-O-Me-modified nucleoside).
- the first nucleic acid strand and/or the second nucleic acid strand that constitutes the double-stranded nucleic acid complex contains at least one crosslinked non-natural nucleoside represented by formula (I) or formula (II) above. and at least one 2'-O-methoxyethyl modified nucleoside (2'-O-MOE modified nucleoside).
- the first nucleic acid strand and/or the second nucleic acid strand that constitutes the double-stranded nucleic acid complex contains at least one crosslinked non-natural nucleoside represented by formula (I) or formula (II) above. and at least one 2'-O-[2-(N-methylcarbamoyl)ethyl]-modified nucleoside (2'-O-MCE-modified nucleoside).
- the 5' wing region of the first nucleic acid strand comprises at least one bridged non-natural nucleoside represented by formula (I) or formula (II) above, and at least one
- the 3' wing region of the first nucleic acid strand may contain a ribose 2'-modified nucleoside, and the 3' wing region of the first nucleic acid strand comprises at least one bridged non-natural nucleoside represented by formula (I) or formula (II) above, and 5' may include at least one ribose 2'-modified nucleoside.
- the 5' wing region of the first nucleic acid strand comprises at least one bridged non-natural nucleoside represented by formula (I) or formula (II) above, and at least one
- the 3' wing region of the first nucleic acid strand may contain a ribose 2'-modified nucleoside, and the 3' wing region of the first nucleic acid strand comprises at least one bridged non-natural nucleoside represented by formula (I) or formula (II) above, and 5' may include at least one ribose 2'-modified nucleoside.
- the 5' wing region of the first nucleic acid strand comprises at least one bridged non-natural nucleoside represented by formula (I) or formula (II) above, and at least one
- the 3' wing region of the first nucleic acid strand may comprise a ribose 2'-modified nucleoside, and the 3' wing region of the first nucleic acid strand comprises at least one bridged non-natural nucleoside represented by formula (I) or formula (II) above, and 3' may include at least one ribose 2'-modified nucleoside.
- the 5' wing region of the first nucleic acid strand comprises at least one bridged non-natural nucleoside represented by formula (I) or formula (II) above, and at least one
- the 3' wing region of the first nucleic acid strand may comprise a ribose 2'-modified nucleoside, and the 3' wing region of the first nucleic acid strand comprises at least one bridged non-natural nucleoside represented by formula (I) or formula (II) above, and 3' may include at least one ribose 2'-modified nucleoside.
- the first nucleic acid strand and/or the second nucleic acid strand may contain nucleoside mimics or nucleotide mimics in whole or in part.
- Nucleotide mimetics may be peptide nucleic acids and/or morpholino nucleic acids.
- the internucleoside linkages in the first nucleic acid strand and the second nucleic acid strand may be naturally occurring internucleoside linkages and/or modified internucleoside linkages. At least 1, at least 2, or at least 3 internucleoside linkages from the end (5′ end, 3′ end, or both ends) of the first nucleic acid strand and/or the second nucleic acid strand are modified internucleoside linkages, but are not limited to A bond is preferred.
- two internucleoside bonds from the end of a nucleic acid chain mean the internucleoside bond closest to the end of the nucleic acid chain and the internucleoside bond adjacent thereto and located on the opposite side of the end. Modified internucleoside linkages in terminal regions of nucleic acid strands are preferred because they can reduce or inhibit unwanted degradation of the nucleic acid strand.
- all or part of the internucleoside linkages of the first nucleic acid strand and/or the second nucleic acid strand may be modified internucleoside linkages.
- the first nucleic acid strand and/or the second nucleic acid strand each has 1, 2, 3, 4, 5, 6, 7, 8, 9 modified internucleoside linkages. 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, It may contain 26, 27, 28, 29, 30, 35, 40, 45, 50 or more.
- the first nucleic acid strand and/or the second nucleic acid strand each have at least 5%, at least 10%, at least 20%, at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, at least 93%, at least 95%, at least 98%, or 100%.
- the modified internucleoside linkage may be a phosphorothioate linkage.
- the first nucleic acid strand and/or the second nucleic acid strand each have 1, 2, 3, 4, 5, 6, 7, 8 chirally controlled internucleoside linkages. 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, It may contain 25, 26, 27, 28, 29, 30, 35, 40, 45, 50 or more.
- the first nucleic acid strand and/or the second nucleic acid strand each have at least 5%, at least 10%, at least 20%, at least 30%, at least 40%, at least 50% chirally controlled internucleoside linkages. %, at least 60%, at least 70%, at least 80%, at least 90%, or more.
- the first nucleic acid strand and/or the second nucleic acid strand each have 1, 2, 3, 4 non-negatively charged internucleoside linkages (preferably neutral internucleoside linkages), 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 45, 50 or more.
- the first nucleic acid strand and/or the second nucleic acid strand each have at least 5%, at least 10%, at least 20%, at least 30%, at least 40%, at least 50% non-negatively charged internucleoside linkages. , at least 60%, at least 70%, at least 80%, at least 90%, or more.
- At least 1, at least 2, or at least 3 internucleoside linkages from the 5' end of the second nucleic acid strand may be modified internucleoside linkages. At least 1, at least 2, or at least 3 internucleoside linkages from the 3′ end of the second nucleic acid strand are replaced with modified internucleoside linkages, such as phosphorothioate linkages, 1-4 C 1-6 alkyl groups an internucleoside linkage (e.g., partial structure represented by formula (IV)) containing a guanidine moiety (e.g., TMG moiety) and/or an internucleoside linkage (e.g., a cyclic guanidine moiety) (e.g., represented by formula (III) may be a partial structure). Modified internucleoside linkages may be chirally controlled to the Rp or Sp configuration.
- At least one (eg, three) internucleoside linkage from the 3' end of the second nucleic acid strand may be a modified internucleoside linkage such as a highly RNase-resistant phosphorothioate linkage.
- the double-stranded nucleic acid complex has an improved gene suppressing activity, which is preferable.
- the modified internucleoside linkages of the first nucleic acid strand and/or the second nucleic acid strand are controlled at a pH (e.g., human physiological pH (about 7.4), a delivery site (e.g., an organelle, cell, tissue, organ).
- a pH e.g., human physiological pH (about 7.4)
- a delivery site e.g., an organelle, cell, tissue, organ.
- the modified internucleoside linkage is in an anionic form (e.g., -OP(O)(O - )-O- (anionic form of natural phosphate linkage), -OP(O) (S ⁇ )—O— (anionic form of phosphorothioate linkages, etc.)), including non-negatively charged (neutral or cationic, respectively) internucleoside linkages that exist as neutral or cationic forms.
- the modified internucleoside linkages of the first and/or second nucleic acid strand comprise neutral internucleoside linkages.
- the modified internucleoside linkages of the first and/or second nucleic acid strand comprise cationic internucleoside linkages.
- a non-negatively charged internucleoside linkage e.g., a neutral internucleoside linkage
- the non-negatively charged internucleoside linkage is, for example, a methylphosphonate linkage as described in U.S. Patent Nos.
- the non-negatively charged internucleoside linkage comprises a triazole or alkyne moiety.
- the non-negatively charged internucleoside linkage comprises a cyclic guanidine moiety and/or a guanidine moiety (preferably a TMG moiety) substituted with 1-4 C 1-6 alkyl groups.
- a modified internucleoside linkage comprising a cyclic guanidine moiety has a substructure represented by Formula (III).
- the guanidine moiety substituted with 1-4 C 1-6 alkyl groups has a substructure represented by Formula (IV).
- neutral internucleoside linkages comprising cyclic guanidine moieties and/or guanidine moieties substituted with 1-4 C 1-6 alkyl groups are chirally controlled.
- the disclosure relates to a composition
- a composition comprising an oligonucleotide comprising at least one neutral internucleoside linkage and at least one phosphorothioate internucleoside linkage.
- neutral internucleotide linkages have properties compared to equivalent nucleic acids that do not contain neutral internucleotide linkages. and/or improve activity, e.g., improve delivery, improve resistance to exonucleases and endonucleases, improve cellular uptake, improve endosomal escape, and/or improve nuclear uptake, etc. do.
- the second nucleic acid strand may be lipid-bound.
- Lipids include tocopherol, cholesterol, fatty acids, phospholipids and their analogs; folic acid, vitamin C, vitamin B1, vitamin B2; estradiol, androstane and their analogs; steroids and their analogs; LDLR, SRBI or LRP1 /2 ligands; FK-506, and cyclosporin; lipids described in PCT/JP2019/12077, PCT/JP2019/10392 and PCT/JP2020/035117, but are not limited thereto.
- tocopherol is a methylated derivative of tocorol, a fat-soluble vitamin (vitamin E) with a cyclic structure called chroman. Tocorol has a strong antioxidant action, and therefore, in vivo, as an antioxidant substance, it has the function of quenching free radicals generated by metabolism and protecting cells from injury.
- tocopherol Several different forms of tocopherol are known, consisting of ⁇ -tocopherol, ⁇ -tocopherol, ⁇ -tocopherol, and ⁇ -tocopherol, based on the position of the methyl group that binds to the chroman.
- a tocopherol herein can be any tocopherol.
- Analogues of tocopherol include various unsaturated analogues of tocopherol, such as ⁇ -tocotrienol, ⁇ -tocotrienol, ⁇ -tocotrienol and ⁇ -tocotrienol.
- the tocopherol is ⁇ -tocopherol.
- cholesterol is a type of sterol, also known as steroidal alcohol, and is particularly abundant in animals. Cholesterol plays an important role in metabolic processes in vivo, and in animal cells, it is also a major constituent of the cell membrane system together with phospholipids. Analogs of cholesterol also refer to various cholesterol metabolites and analogs, which are alcohols having a sterol backbone, including, but not limited to, cholestanol, lanosterol, cerebrosterol, dehydrocholesterol, and coprostanol. etc.
- analog refers to compounds having the same or similar basic skeleton and having similar structures and properties. Analogs include, for example, biosynthetic intermediates, metabolites, compounds with substituents, and the like. A person skilled in the art can determine whether a compound is an analog of another compound based on common general technical knowledge.
- Cholesterol analogs refer to various cholesterol metabolites and analogs, etc., which are alcohols with a sterol backbone, including, but not limited to, cholestanol, lanosterol, cerebrosterol, dehydrocholesterol, and coprostanol. include.
- the second nucleic acid strand may be conjugated with tocopherol or cholesterol or analogues thereof.
- the second nucleic acid strand bound to cholesterol or its analogue may have a group represented by general formula (V) below.
- R c represents an optionally substituted alkylene group having 4 to 18 carbon atoms, preferably 5 to 16 carbon atoms (wherein the substituent is a halogen atom or a hydroxy an alkyl group having 1 to 3 carbon atoms which may be substituted with a group such as a hydroxymethyl group, and non-adjacent carbon atoms of the alkylene group may be substituted with oxygen atoms).
- R c represents an optionally substituted alkylene group having 4 to 18 carbon atoms, preferably 5 to 16 carbon atoms (wherein the substituent is a halogen atom or a hydroxy an alkyl group having 1 to 3 carbon atoms which may be substituted with a group such as a hydroxymethyl group, and non-
- Rc is, but is not limited to, -( CH2 ) 3 -O-( CH2 ) 2 -O-( CH2 ) 2- O-( CH2 ) 2- O-( CH2 ) 2- , -( CH2 ) 3 -O-( CH2 ) 2- O-( CH2 ) 2- O-( CH2 ) 2- O- CH2 -CH( CH2OH )- or -( CH2 ) 6- may be
- the group represented by general formula (V) above can be bound to the 5' end or 3' end of the second nucleic acid strand via a phosphate ester bond.
- a lipid such as cholesterol or an analogue thereof may be bound to either the 5' end, the 3' end, or both ends of the second nucleic acid strand.
- the cholesterol or analogue lipid may also be attached to an internal nucleotide of the second nucleic acid strand.
- Cholesterol or analogs thereof attached to the 5' end of the second nucleic acid strand are particularly preferred, but are not limited thereto.
- the second nucleic acid strand contains multiple cholesterols or analogues thereof, they may be the same or different. For example, this applies to the case where the second nucleic acid strand has one cholesterol bound to the 5′ end and one other cholesterol analogue bound to the 3′ end. With respect to the binding position, the cholesterol or analogue thereof may be bound at multiple positions and/or at one position as a group on the second nucleic acid strand. Cholesterol or analogs thereof may be linked to the 5' end and the 3' end of the second nucleic acid strand, respectively.
- the binding between the second nucleic acid strand and the lipid may be direct binding or indirect binding mediated by another substance.
- the second nucleic acid strand and the lipid When the second nucleic acid strand and the lipid are directly bound, they may be bound to the second nucleic acid strand via, for example, covalent bonds, ionic bonds, hydrogen bonds, or the like.
- a covalent bond is preferred in view of the fact that a more stable bond can be obtained.
- the second nucleic acid strand is not bound to a ligand.
- ligand-free means that lipids such as tocopherol and cholesterol are not bound.
- the double-stranded nucleic acid complex of the invention is unliganded, ie neither the first nor the second nucleic acid strand is bound with a ligand.
- linker When the second nucleic acid strand and cholesterol or analogs thereof are indirectly bonded, they may be bonded via a linking group (herein often referred to as "linker").
- a linker can be either a cleavable linker or an uncleavable linker.
- “Cleavable linker” means a linker that can be cleaved under physiological conditions, for example, intracellularly or in an animal body (eg, human body). Cleavable linkers are selectively cleaved by endogenous enzymes such as nucleases. Cleavable linkers include, but are not limited to, amides, esters, phosphodiester esters or both, phosphate esters, carbamates, and disulfide bonds, as well as natural DNA linkers. As an example, cholesterol or an analogue thereof may be linked via a disulfide bond.
- Non-cleavable linker means a linker that is not cleaved under physiological conditions, such as within a cell or within an animal (eg, within a human body).
- Non-cleavable linkers include, but are not limited to, phosphorothioate linkages, and linkers composed of modified or unmodified deoxyribonucleosides or modified or unmodified ribonucleosides linked by phosphorothioate linkages.
- the linker is a nucleic acid such as DNA or an oligonucleotide
- the chain length is not particularly limited, but usually it may be 2 to 20 bases, 3 to 10 bases, or 4 to 6 bases.
- linker is a linker represented by formula (VI) below.
- L2 is a substituted or unsubstituted C1 - C12 alkylene group (e.g. propylene, hexylene, dodecylene), a substituted or unsubstituted C3 - C8 cycloalkylene group (e.g.
- L3 represents -NH- or a bond
- L4 is a substituted or unsubstituted C1 - C 12 alkylene groups (e.g., ethylene, pentylene, heptylene, anddecylene), substituted or unsubstituted C3-8 cycloalkylene groups (e.g., cyclohexylene), -( CH2 ) 2- [O- ( CH2 ) 2 ] m- , or
- the linker represented by formula (VI) is such that L 2 is an unsubstituted C 3 -C 6 alkylene group (eg, propylene, hexylene), —(CH 2 ) 2 —O—( CH2 ) 2- O-( CH2 ) 2- O-( CH2 ) 3- or -( CH2 ) 2- O-(CH2) 2- O-( CH2 ) 2- O- (CH 2 ) 2 -O-( CH2 ) 3- , L3 is -NH-, and L4 and L5 are a bond.
- C 3 -C 6 alkylene group eg, propylene, hexylene
- L3 is -NH-
- L4 and L5 are a bond.
- linker is a linker represented by general formula (VII) below. [wherein, n represents 0 or 1; ]
- the first nucleic acid strand and/or the second nucleic acid strand may further contain at least one functional moiety bound to the polynucleotides constituting the nucleic acid strand.
- a “functional portion” refers to a portion that imparts a desired function to a double-stranded nucleic acid complex and/or a nucleic acid strand to which the functional portion is bound. Desired functions include, for example, labeling functions, purification functions, and the like. Examples of moieties that provide a labeling function include compounds such as fluorescent proteins and luciferase.
- moieties that impart a purification function include compounds such as biotin, avidin, His-tag peptides, GST-tag peptides and FLAG-tag peptides.
- a functional moiety is added to the second nucleic acid strand.
- a molecule having an activity of delivering a double-stranded nucleic acid complex in certain embodiments to a target site is bound.
- moieties that provide targeted delivery functions include lipids, antibodies, aptamers, ligands for specific receptors, and the like.
- the first nucleic acid strand and/or the second nucleic acid strand (preferably the second nucleic acid strand) is associated with a functional moiety.
- the binding between the second nucleic acid strand and the functional moiety may be direct binding or indirect binding via another substance. It is preferable that the second nucleic acid strand and the functional moiety are directly bonded by, for example, a hydrogen bond, and a covalent bond is more preferable from the viewpoint of obtaining a more stable bond.
- the second nucleic acid strand may further comprise at least one overhang region located on one or both of the 5' and 3' ends of the complementary region.
- An example of this embodiment is described in WO2018/062510.
- the first nucleic acid strand and the second nucleic acid strand may be linked via a linker.
- the first nucleic acid strand and the second nucleic acid strand can be linked via a linker to form a single strand.
- the functional region has the same configuration as that of the double-stranded nucleic acid complex even in that case, such a single-stranded nucleic acid is also included in the present specification as an embodiment of the double-stranded nucleic acid complex of the present invention. do.
- a linker can be any polymer. Examples include polynucleotides, polypeptides, alkylenes, and the like.
- the linker can be composed of, for example, natural nucleotides such as DNA and RNA, or non-natural nucleotides such as peptide nucleic acids and morpholino nucleic acids.
- the linker may have a chain length of at least 1 base, such as 3-10 bases or 4-6 bases. A chain length of 4 bases is preferred.
- the position of the linker can be either on the 5' side or the 3' side of the first nucleic acid strand. , the 5′ end of the first nucleic acid strand and the 3′ end of the second nucleic acid strand are linked via the linker.
- Linkers may be either cleavable or non-cleavable.
- the antisense effect of the first nucleic acid strand on the target transcript can be measured by a method known in the art. For example, after introducing a double-stranded nucleic acid complex into a cell or the like, measurement may be performed using a known technique such as Northern blotting, quantitative PCR, or Western blotting. By measuring the expression level of the target gene or the level of the target transcript (for example, the amount of mRNA or RNA such as microRNA, the amount of cDNA, the amount of protein, etc.), the expression of the target gene is suppressed by the double-stranded nucleic acid complex.
- Criteria for the determination include, but are not limited to, the target gene expression level or target transcript measured by at least 5%, at least 10%, or at least 15% compared to the measured value of a negative control (e.g. vehicle administration). %, at least 20%, at least 25%, at least 30%, or at least 40%, it may be determined that the double-stranded nucleic acid complex of the present invention has an antisense effect.
- the double-stranded nucleic acid complex of the present invention is not limited to the above exemplary embodiments.
- the double-stranded nucleic acid complex of the present invention can be produced by a person skilled in the art by appropriately selecting a known method. Although not limited, it usually starts with designing and manufacturing each of the first nucleic acid strand and the second nucleic acid strand that constitute the double-stranded nucleic acid complex.
- the first nucleic acid strand is designed based on information on the nucleotide sequence of the target transcript (for example, the nucleotide sequence of the target gene), and the second nucleic acid strand is designed as its complementary strand.
- each nucleic acid chain may be synthesized using, for example, a commercially available automatic nucleic acid synthesizer from GE Healthcare, Thermo Fisher Scientific, Beckman Coulter, and the like. Thereafter, the obtained oligonucleotide can be purified using a reversed-phase column or the like.
- the first nucleic acid strand may be produced according to the above method.
- the functional moiety-bound second nucleic acid strand can be produced by performing the above-described synthesis and purification using a nucleic acid species to which a functional moiety has been bound in advance.
- a nucleic acid species with pre-bound cholesterol or an analog thereof may be used to produce a second nucleic acid strand by performing the synthesis and purification described above.
- cholesterol or an analogue thereof may be bound to the second nucleic acid strand produced by carrying out the synthesis and purification described above by a known method.
- the first and second nucleic acid strands are annealed to produce a double-stranded nucleic acid complex to which the desired functional moiety is bound.
- the nucleic acids are mixed in a suitable buffer solution, denatured at about 90° C.-98° C. for several minutes (eg, 5 minutes), and then the nucleic acids are annealed at about 30° C.-70° C. for about 1-8 hours. to produce one of the double-stranded nucleic acid complexes of the present invention.
- Methods for linking functional moieties to nucleic acids are well known in the art. Nucleic acid chains can also be obtained by ordering from various manufacturers (eg, Gene Design Co., Ltd.) specifying the nucleotide sequence, modification site and type.
- the toxicity of the double-stranded nucleic acid complex can be reduced or eliminated without impairing the efficacy of the double-stranded nucleic acid complex. That is, compared with conventional double-stranded nucleic acid complexes, hepatotoxicity and nephrotoxicity are reduced without impairing the antisense effect on the target gene, and inflammation or gliosis is induced, or cytokines or chemokines are abnormally increased. is reduced.
- a second aspect of the present invention is a pharmaceutical composition.
- the pharmaceutical composition of the present invention contains the double-stranded nucleic acid complex of the first aspect as an active ingredient.
- the pharmaceutical composition of the present invention has low hepatotoxicity and/or low nephrotoxicity. In addition, induction of inflammation or gliosis, or abnormal elevation of cytokines or chemokines is reduced.
- Each component that can be included in the pharmaceutical composition of the present invention is specifically described below.
- the pharmaceutical composition of the present invention includes at least the double-stranded nucleic acid complex according to the first aspect as an active ingredient.
- the pharmaceutical composition of the present invention may contain two or more types of double-stranded nucleic acid complexes.
- the amount (content) of the double-stranded nucleic acid complex contained in the pharmaceutical composition depends on the type of the double-stranded nucleic acid complex, the delivery site, the dosage form of the pharmaceutical composition, the dosage of the pharmaceutical composition, and the carrier described later. depends on the type of Therefore, it is sufficient to determine them as appropriate in consideration of each condition.
- a single dose of the pharmaceutical composition is adjusted to include an effective amount of the double-stranded nucleic acid complex.
- Effective amount means an amount necessary for the double-stranded nucleic acid complex to exhibit its function as an active ingredient, and an amount that imparts little or no harmful side effects to the living body to which it is applied. Say. This effective amount may vary depending on various conditions such as subject information, route of administration, and frequency of administration. Ultimately, it is determined by the judgment of a doctor, veterinarian, pharmacist, or the like.
- Subject information is various individual information of a living body to which the pharmaceutical composition is applied. For example, if the subject is a human, the information includes age, weight, sex, dietary habits, health condition, disease progression and severity, drug sensitivity, presence or absence of concomitant drugs, and the like.
- Carrier A pharmaceutical composition of the present invention can comprise a pharmaceutically acceptable carrier.
- “Pharmaceutically acceptable carrier” refers to additives commonly used in the field of formulation technology. For example, solvents, vegetable oils, bases, emulsifiers, suspending agents, surfactants, pH adjusters, stabilizers, flavorants, fragrances, excipients, vehicles, preservatives, binders, diluents, Tonicity agents, soothing agents, bulking agents, disintegrating agents, buffering agents, coating agents, lubricants, coloring agents, sweetening agents, thickening agents, flavoring agents, solubilizing agents, and other additives.
- the solvent may be, for example, water or other pharmaceutically acceptable aqueous solution, or a pharmaceutically acceptable organic solvent.
- Aqueous solutions include, for example, physiological saline, isotonic solutions containing glucose and other adjuvants, phosphate buffers, and sodium acetate buffers.
- auxiliary agents include D-sorbitol, D-mannose, D-mannitol, sodium chloride, low-concentration nonionic surfactants, polyoxyethylene sorbitan fatty acid esters, and the like.
- the carrier is used to avoid or suppress in vivo degradation of the double-stranded nucleic acid complex, which is an active ingredient, by enzymes, etc., facilitate formulation and administration methods, and maintain the dosage form and efficacy. and can be used as needed.
- the dosage form of the pharmaceutical composition of the present invention is such that the active ingredient, the double-stranded nucleic acid complex according to the first aspect, is delivered to the target site without being inactivated by degradation or the like, and is effective in vivo.
- the form can exhibit the pharmacological effect of the component (antisense effect on target gene expression).
- Specific dosage forms differ depending on the administration method and/or prescription conditions. Since administration methods can be broadly classified into parenteral administration and oral administration, dosage forms suitable for each administration method may be used.
- the preferred dosage form is a liquid formulation that can be administered directly to the target site or systemically administered via the circulatory system.
- liquid formulations include injections. Injections are appropriately combined with the aforementioned excipients, elixirs, emulsifiers, suspending agents, surfactants, stabilizers, pH adjusters, etc., and mixed in a unit dosage form generally accepted for pharmaceutical practice. It can be formulated by Other formulations include ointments, plasters, cataplasms, transdermal formulations, lotions, inhalants, aerosols, eye drops, and suppositories.
- preferred dosage forms may be solids or liquids, such as tablets, capsules, drops, lozenges, pills, granules, powders, powders, and liquids for internal use. , emulsions, syrups, pellets, sublingual agents, peptizers, buccal preparations, pastes, suspensions, elixirs, coatings, ointments, plasters, cataplasms, oral Skins, lotions, inhalants, aerosols, eye drops, injections, and suppositories.
- a solid formulation it is optionally made into a dosage form with a coating known in the art, such as a sugar-coated tablet, a gelatin-coated tablet, an enteric-coated tablet, a film-coated tablet, a double tablet, and a multilayer tablet. be able to.
- a coating known in the art, such as a sugar-coated tablet, a gelatin-coated tablet, an enteric-coated tablet, a film-coated tablet, a double tablet, and a multilayer tablet.
- each dosage form described above are not particularly limited as long as they are within the range of dosage forms known in the art for each dosage form.
- the method for producing the pharmaceutical composition of the present invention it may be formulated according to a conventional method in the technical field.
- the double-stranded nucleic acid complex of the present invention has excellent solubility in water, Japanese Pharmacopoeia Dissolution Test 2nd Fluid, or Japanese Pharmacopoeia Disintegration Test 2nd Fluid, drug half-life, brain penetration, metabolic stability, CYP inhibition) and low toxicity (e.g., acute toxicity, chronic toxicity, genotoxicity, reproductive toxicity, cardiotoxicity, drug interaction, carcinogenicity, phototoxicity) It is superior as a drug in terms of, etc.) and has excellent properties as a drug, such as less side effects (for example, suppression of sedation and avoidance of lamellar necrosis).
- Dosage Forms and Dosages There is no particular limitation herein on the preferred dosage form of the pharmaceutical composition.
- oral administration or parenteral administration may be used.
- Specific examples of parenteral administration include intramuscular administration, intravenous administration, intraarterial administration, intraperitoneal administration, subcutaneous administration (including continuous subcutaneous implanted administration), intradermal administration, tracheal/bronchial administration, rectal administration, and by blood transfusion.
- the dosage or ingestion is, for example, 0.00001 mg/kg/day to 10000 mg/kg/day, or 0.001 mg/kg/day of the included double-stranded nucleic acid complex. It should be between 100mg/kg/day.
- the pharmaceutical composition may be single-dose or multi-dose. In the case of multiple administrations, it can be administered daily or at appropriate time intervals (eg, at intervals of 1 day, 2 days, 3 days, 1 week, 2 weeks, 1 month), for example, 2 to 20 doses.
- a single dose of the above double-stranded nucleic acid complex is, for example, 0.001 mg/kg or more, 0.005 mg/kg or more, 0.01 mg/kg or more, 0.25 mg/kg or more, 0.5 mg/kg or more, 1.0 mg /kg or more, 2.0mg/kg or more, 2.5mg/kg or more, 3.0mg/kg or more, 4.0mg/kg or more, 5mg/kg or more, 10mg/kg or more, 20mg/kg or more, 30mg/kg or more, 40mg/kg or more kg or more, 50 mg/kg or more, 75 mg/kg or more, 100 mg/kg or more, 150 mg/kg or more, 200 mg/kg or more, 300 mg/kg or more, 400 mg/kg or more, or 500 mg/kg or more, such as , any amount within the range of 0.001 mg/kg to 500 mg/kg (e.g., 0.001 mg/kg, 0.01 mg/kg, 0.1 mg/kg, 1 mg
- the double-stranded nucleic acid complex of the present invention may be administered at a dose of 0.01 to 10 mg/kg (eg, about 6.25 mg/kg) twice a week for 4 times.
- the double-stranded nucleic acid complex is administered at a dose of 0.05 to 30 mg/kg (eg, about 25 mg/kg) at a frequency of 1 to 2 times a week, 2 to 4 times, for example, twice a week. good too.
- Employment of such a dosing regimen can reduce toxicity (eg, avoid platelet depletion) and reduce burden on the subject compared to single administration of higher doses.
- the pharmaceutical composition has an additive inhibitory effect in cells even after repeated administration.
- the pharmaceutical composition of this aspect is administered intracerebroventricularly or intrathecally.
- 0.01 mg or more, 0.1 mg or more, or 1 mg or more, for example, 2 mg or more, 3 mg or more, 4 mg or more, or 5 mg or more is administered to monkeys or humans.
- 1 mg to 20 mg may be administered, and in the case of mice, 1 ⁇ g or more may be administered.
- the pharmaceutical composition of this aspect is administered intravenously or subcutaneously.
- the diseases to which the pharmaceutical composition is applied are not limited, and can be diseases associated with increased expression of target genes, such as neurological diseases, central nervous system diseases, metabolic diseases, tumors, and infectious diseases. .
- pharmaceutical compositions of this aspect can be used to treat central nervous system disease in a subject.
- the central nervous system disease to which the pharmaceutical composition of this aspect is applied is not particularly limited, but examples thereof include brain tumor, Alzheimer's disease, Parkinson's disease, amyotrophic lateral sclerosis, multiple sclerosis, Huntington's disease, and the like. be done.
- the pharmaceutical composition of the present invention has low hepatotoxicity and/or low nephrotoxicity.
- the pharmaceutical composition of the present invention has a reduced induction of inflammation or gliosis, or an abnormal increase in cytokines or chemokines due to intracerebroventricular, intrathecal, intravenous, or subcutaneous administration.
- diseases can be treated or prevented by suppressing or inhibiting the expression of specific genes substantially without hepatotoxicity and/or nephrotoxicity.
- diseases can be treated or prevented while reducing abnormal increases in cytokines or chemokines without substantially inducing inflammation or gliosis.
- the treatment of neurological diseases requires the administration of high doses of nucleic acid agents, which poses a problem of serious side effects such as liver damage. It is possible to significantly reduce it.
- a method for treating and/or preventing a disease such as a central nervous system disease comprises administering the double-stranded nucleic acid complex or pharmaceutical composition described above to a subject.
- Example 1 Gene suppression effect and toxicity reduction effect by intracerebroventricular administration of HDO (scpBNA)> (Purpose)
- a heteroduplex oligonucleotide containing hereinafter referred to as "HDO(scpBNA)
- the first nucleic acid strand of HDO contains 5' and 3' wing regions composed of 3 scpBNA nucleosides at the 5' and 3' ends, respectively, with 10 DNA nucleosides between them.
- a scpBNA/DNA gapmer-type antisense nucleic acid containing The base sequence of the first nucleic acid strand is complementary to a portion of mouse microtubule-associated protein tau (Mapt) mRNA.
- the second nucleic acid strand of HDO is composed of RNA having a sequence complementary to the first nucleic acid strand. Neither the first nucleic acid strand nor the second nucleic acid of HDO(scpBNA) is bound to the ligand.
- the scpBNA used in the examples of this specification has the following formula (I): is a non-natural nucleoside represented by
- HDO(LNA) heteroduplex oligonucleotide
- ASO(LNA) LNA/DNA gapmer-type antisense nucleic acid
- Table 2 and FIG. 3B show the structures and base sequences of the first and second nucleic acid strands that constitute the HDO (LNA) used in this example. Neither the first nucleic acid strand nor the second nucleic acid strand of HDO (LNA) is bound to a ligand.
- the first and second nucleic acid strands are mixed in equimolar amounts, the solution is heated at 95°C for 5 minutes, then cooled to 37°C for 1
- a double-stranded nucleic acid complex was prepared by holding for a period of time, thereby annealing the nucleic acid strands. Annealed nucleic acids were stored at 4°C or on ice. All oligonucleotides were custom synthesized by Gene Design Co., Ltd. (Osaka, Japan).
- Quantitative RT-PCR was performed using the resulting cDNA as a template in order to evaluate the gene-suppressing effect and toxicity of various nucleic acid agents.
- Quantitative RT-PCR was performed by TaqMan (Roche Applied Science). Primers used in quantitative RT-PCR were products designed and manufactured by Thermo Fisher Scientific (formerly Life Technologies Corp) based on different gene numbers. there were.
- Amplification conditions were as follows: 95° C. for 15 seconds, 60° C. for 30 seconds, and 72° C. for 1 second (1 cycle) repeated for 40 cycles.
- TNF ⁇ tumor necrosis factor- ⁇
- GFAP glial fibrillary acidic protein
- FIG. 4 shows Mapt mRNA expression levels in the left hippocampus of mice to which various nucleic acid agents were administered into the left ventricle. Intraventricular administration of ASO (LNA), HDO (LNA), ASO (scpBNA), and HDO (scpBNA) did not show any significant difference in Mapt gene suppression effect.
- LNA ASO
- LNA HDO
- scpBNA ASO
- scpBNA HDO
- Figure 5 shows the expression levels of TNF ⁇ mRNA and GFAP mRNA in the left hippocampus of mice to which various nucleic acid agents were administered into the left ventricle.
- ASO (LNA) and HDO (LNA) significantly increased the expression levels of TNF ⁇ mRNA and GFAP mRNA compared to PBS administration.
- ASO (scpBNA) and HDO (scpBNA) did not significantly increase the expression levels of TNF ⁇ mRNA and GFAP mRNA compared to PBS administration, and induced inflammatory cytokine gliosis attenuated. .
- Example 2 Gene suppression effect and hepatotoxicity reduction effect by single intravenous administration of Toc-HDO (scpBNA) targeting mMalat1>
- scpBNA Toc-HDO
- mMalat1> Purpose
- a double-stranded nucleic acid complex consisting of a scpBNA/DNA gapmer-type antisense nucleic acid and a tocopherol-binding complementary strand, and a duplex consisting of an AmNA/DNA gapmer-type antisense nucleic acid and a tocopherol-binding complementary strand, targeting mMalat1 Regarding the stranded nucleic acid complex, the effect of suppressing target gene expression by single intravenous administration and the effect of reducing toxicity will be verified.
- Method 1 (1) Preparation of Nucleic Acid
- the target gene was metastasis-associated lung adenocarcinoma transcript 1 (mMalat1).
- Table 3 and FIG. 6 show the base sequences of the first and second nucleic acid strands that constitute the three types of double-stranded nucleic acid complexes used in this example.
- the first nucleic acid strand targets the mMalat1 gene and is composed of a 13-mer gapmer having a nucleotide sequence complementary to a part of the non-coding RNA of malat1, which is its transcription product.
- the first nucleic acid chain of Toc-HDO (LNA) includes a 5' wing region composed of three LNA nucleosides at the 5' end, a 3' wing region composed of two LNA nucleosides at the 3' end, and Eight between them consist of DNA nucleosides.
- Toc-HDO scpBNA
- Toc-HDO AmNA
- some of the LNA nucleosides in the 5' and 3' wing regions are replaced with scpBNA or AmNA nucleosides.
- the second nucleic acid strand has a complementary sequence to the first nucleic acid strand and is composed of a tocopherol-binding complementary strand RNA with tocopherol bound to its 5' end.
- the AmNA used in the examples of the present specification has the following formula (II): (In the formula, R represents a methyl group.) is a non-natural nucleoside represented by
- a double-stranded nucleic acid complex was prepared in the same manner as in Example 1 (1).
- a single dose of the double-stranded nucleic acid complex agent was injected intravenously into mice at 50 mg/kg through the tail vein.
- a single injection of PBS alone was also prepared as a negative control group. Mice were perfused with PBS after blood collection at 72 hours post-dose. Mice were then dissected and the liver, kidney, heart muscle, and quadriceps muscle were removed.
- the resulting amplified product was quantified by quantitative RT-PCR, the expression levels of malat1 mRNA and GAPDH mRNA (internal standard gene) were calculated, the relative expression level was obtained from the ratio of the two, and the average relative expression level was obtained. and standard errors were calculated. And the difference between each group was analyzed by t-test.
- Fig. 9A The results of serum analysis are shown in Fig. 9A.
- AST aspartate aminotransferase
- ALT alanine aminotransferase
- Toc-HDO(LNA)-administered group showed a decrease in body weight, while the Toc-HDO(scpBNA)-administered group and the Toc-HDO(AmNA)-administered group showed no significant change in body weight (Fig. 9B).
- Example 3 Gene suppression effect and hepatotoxicity reduction effect by single intravenous administration of Toc-HDO (scpBNA) targeting PTEN> (Purpose) A double-stranded nucleic acid complex consisting of a scpBNA/DNA gapmer-type antisense nucleic acid and a tocopherol-binding complementary strand, and a duplex consisting of an AmNA/DNA gapmer-type antisense nucleic acid and a tocopherol-binding complementary strand, targeting PTEN Regarding the stranded nucleic acid complex, the effect of suppressing target gene expression by single intravenous administration and the effect of reducing toxicity will be verified.
- the target gene was PTEN (Phosphatase and Tensin Homolog Deleted from Chromosome 10).
- Table 4 and FIG. 10 show the base sequences and chemical modifications of the first and second nucleic acid strands that constitute the three types of double-stranded nucleic acid complexes used in this example.
- the first nucleic acid strand targets the PTEN gene and is composed of a 14-mer gapmer having a base sequence complementary to part of the PTEN mRNA.
- the first nucleic acid strand of Toc-HDO includes a 5' wing region composed of two LNA nucleosides at the 5' end, a 3' wing region composed of two LNA nucleosides at the 3' end, and Consists of 10 DNA nucleosides between them.
- Toc-HDO scpBNA
- Toc-HDO Toc-HDO
- AmNA Toc-HDO
- all of the LNA nucleosides in the 5' and 3' wing regions are replaced with scpBNA or AmNA nucleosides.
- the second nucleic acid strand has a complementary sequence to the first nucleic acid strand and is composed of a tocopherol-binding complementary strand RNA with tocopherol bound to its 5' end.
- a double-stranded nucleic acid complex was prepared in the same manner as in Example 1 (1).
- Example 2 The in vivo experiment was performed in the same manner as in Example 2, except that the double-stranded nucleic acid complex agent was intravenously injected into mice at 35 mg/kg. Expression analysis and serum analysis were performed in the same manner as in Example 2.
- Example 4 Gene suppression effect and hepatotoxicity reduction effect by single intravenous administration of Toc-HDO (scpBNA) targeting SR-B1>
- scpBNA Toc-HDO
- SR-B1 A double-stranded nucleic acid complex consisting of a scpBNA/DNA gapmer-type antisense nucleic acid and a tocopherol-binding complementary strand, and an AmNA/DNA gapmer-type antisense nucleic acid and a tocopherol-binding complementary strand, targeting SR-B1
- the target gene was the scavenger receptor B1 (SR-B1) gene.
- Table 5 and FIG. 10 show the base sequences of the first and second nucleic acid strands that constitute the three types of double-stranded nucleic acid complexes used in this example.
- the first nucleic acid strand targets the SR-B1 gene and is composed of a 14-mer gapmer having a nucleotide sequence complementary to part of the SR-B1 mRNA.
- the first nucleic acid strand of Toc-HDO (LNA) includes a 5' wing region composed of two LNA nucleosides at the 5' end, a 3' wing region composed of two LNA nucleosides at the 3' end, and Ten among them consist of DNA nucleosides.
- Toc-HDO scpBNA
- Toc-HDO Toc-HDO
- AmNA Toc-HDO
- all of the LNA nucleosides in the 5' and 3' wing regions are replaced with scpBNA or AmNA nucleosides.
- the second nucleic acid strand has a complementary sequence to the first nucleic acid strand and is composed of a tocopherol-binding complementary strand RNA with tocopherol bound to its 5' end.
- a double-stranded nucleic acid complex was prepared in the same manner as in Example 1 (1).
- Toc-HDO(LNA)-administered group showed a decrease in body weight
- Toc-HDO(scpBNA)-administered group and the Toc-HDO(AmNA)-administered group showed no significant change in body weight (Fig. 16B).
- Example 5 Gene-suppressing effect and hepatotoxicity-reducing effect by multiple intravenous administrations of Chol-HDO (scpBNA)> (Purpose)
- scpBNA Chol-HDO
- a double-stranded nucleic acid complex consisting of a scpBNA/DNA gapmer-type antisense nucleic acid and a cholesterol-bound complementary strand targeting SR-B1 was examined for its effect of suppressing target gene expression by multiple intravenous administrations. Verify the mitigation effect.
- the first nucleic acid strand targets the SR-B1 gene and is composed of a 14-mer gapmer having a nucleotide sequence complementary to part of the SR-B1 mRNA.
- the first nucleic acid strand of Chol-HDO includes a 5' wing region composed of two LNA nucleosides at the 5' end, a 3' wing region composed of two LNA nucleosides at the 3' end, and Consists of 10 DNA nucleosides between them.
- scpBNA Chol-HDO
- all of the LNA nucleosides in the 5' and 3' wing regions are replaced with scpBNA nucleosides.
- the second nucleic acid strand has a complementary sequence to the first nucleic acid strand and is composed of a cholesterol-binding complementary strand RNA with cholesterol bound to its 5' end.
- a double-stranded nucleic acid complex was prepared in the same manner as in Example 1 (1).
- the resulting amplified product was quantified by quantitative RT-PCR, and based on the results, the expression levels of SR-B1 mRNA and Actin mRNA (internal standard gene) were calculated, and the relative expression level was obtained from the ratio of the two. rice field. Mean values and standard errors of relative expression levels were calculated. And the difference between each group was analyzed by t-test.
- Example 6 Effect of single intravenous administration of Toc-HDO (scpBNA) to reduce the expression of blood inflammatory cytokines/chemokines> (Purpose) To verify the expression of inflammatory cytokines/chemokines in the blood when a double-stranded nucleic acid complex consisting of an scpBNA/DNA gapmer-type antisense nucleic acid and a tocopherol-binding complementary strand is intravenously administered.
- scpBNA Toc-HDO
- Method 1 Preparation of nucleic acids
- Toc-HDO (LNA), Toc-HDO (scpBNA), and Toc-HDO (AmNA) targeting mMalat1 listed in Table 3 and PTEN listed in Table 4 were used.
- Targeting Toc-HDO (LNA), Toc-HDO (scpBNA), and Toc-HDO (AmNA) and Toc-HDO (LNA), Toc-HDO (scpBNA) targeting SR-B1 listed in Table 5 ), and Toc-HDO (AmNA).
- a double-stranded nucleic acid complex was prepared in the same manner as in Example 1 (1).
- the following protein groups G-CSF, GM-CSF, IFN- ⁇ , IL-1 ⁇ , IL-1 ⁇ , IL-2, IL-3, IL-4, IL-5 , IL-6, IL-7, IL-9, IL-10, IL-12 (p40), IL-12 (p70), IL-13, IL-15, IL-17, IP-10, KC, LIF , LIX, MCP-1, M-CSF, MIG, MIP-1 ⁇ , MIP-1 ⁇ , MIP-2, RANTES, TNF ⁇ , VEGF, and Eotaxin/CCL11.
- TNF ⁇ , IP-10, and RANTES which were elevated by Toc-HDO (LNA) administration, were measured as indices of inflammation.
- FIGS. 20 to 22 The results of measuring the amount of inflammatory cytokines in blood are shown in FIGS. 20 to 22.
- FIG. 20 to 22 compared with the Toc-HDO (LNA) administration group, the Toc-HDO (scpBNA) administration group and the Toc-HDO (AmNA) administration group showed TNF ⁇ (FIG. 20), IP-10 It was shown that the expression levels of both (Fig. 21) and RANTES (Fig. 22) were low. All publications, patents and patent applications cited herein are hereby incorporated by reference in their entirety.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Organic Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Public Health (AREA)
- Medicinal Chemistry (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- General Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Molecular Biology (AREA)
- Biotechnology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Rheumatology (AREA)
- Pain & Pain Management (AREA)
- Transplantation (AREA)
- Epidemiology (AREA)
- Dermatology (AREA)
- Neurology (AREA)
- Neurosurgery (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Saccharide Compounds (AREA)
Abstract
Description

で示される架橋型の非天然ヌクレオシドを少なくとも1個含む、前記二本鎖核酸複合体。
(2)前記第1核酸鎖がギャップマーである、(1)に記載の二本鎖核酸複合体。
(3)前記第1核酸鎖が、
[1]少なくとも4個の連続するデオキシリボヌクレオシドを含む中央領域、
[2]前記中央領域の5'末端側に配置された、非天然ヌクレオシドを含む5’ウイング領域、及び
[3]前記中央領域の3'末端側に配置された、非天然ヌクレオシドを含む3’ウイング領域を含む、(2)に記載の二本鎖核酸複合体。
(4)前記5’ウイング領域及び/又は前記3’ウイング領域が前記式(I)又は式(II)で示される架橋型の非天然ヌクレオシドを含む、(3)に記載の二本鎖核酸複合体。
(5)前記第2核酸鎖が、前記第1核酸鎖の前記中央領域における少なくとも4個の連続するデオキシリボヌクレオシドに相補的な、少なくとも4個の連続するリボヌクレオシドを含む、(3)又は(4)に記載の二本鎖核酸複合体。
(6)前記第2核酸鎖が、少なくとも2個の連続するデオキシリボヌクレオシドをさらに含む、(5)に記載の二本鎖核酸複合体。
(7)前記第2核酸鎖において、前記第1核酸鎖の5’ウイング領域及び/又は3’ウイング領域に相補的な塩基配列からなる領域に前記式(I)又は式(II)で示される架橋型の非天然ヌクレオシドを含む、(3)~(6)のいずれかに記載の二本鎖核酸複合体。
(8)前記第1核酸鎖がミックスマーである、(1)に記載の二本鎖核酸複合体。
(9)前記第1核酸鎖及び/又は前記第2核酸鎖が、2'-O-メチル修飾ヌクレオシド、2'-O-メトキシエチル修飾ヌクレオシド、及び2'-O-[2-(N-メチルカルバモイル)エチル]修飾ヌクレオシドからなる群から選択される少なくとも1個のリボース2'位修飾ヌクレオシドを含む、(1)~(8)のいずれかに記載の二本鎖核酸複合体。
(10)前記第1核酸鎖及び/又は前記第2核酸鎖のヌクレオシド間結合の全部又は一部が修飾ヌクレオシド間結合である、(1)~(9)のいずれかに記載の二本鎖核酸複合体。
(11)前記修飾ヌクレオシド間結合がホスホロチオエート結合である、(10)に記載の二本鎖核酸複合体。
(12)前記第2核酸鎖が、トコフェロール若しくはコレステロール又はそれらの類縁体と結合している、(1)~(11)のいずれかに記載の二本鎖核酸複合体。
(13)リガンドと結合していない、(1)~(11)のいずれかに記載の二本鎖核酸複合体。
(14)前記第1核酸鎖と前記第2核酸鎖とが切断性又は非切断性リンカーを介して結合している、(1)~(13)のいずれかに記載の二本鎖核酸複合体。
(15)(1)~(14)のいずれかに記載の二本鎖核酸複合体を有効成分として含む医薬組成物。
(16)被検体の中枢神経系疾患を治療するための、(15)に記載の医薬組成物。
(17)脳室内投与又は髄腔内投与される、(15)又は(16)に記載の医薬組成物。
(18)前記二本鎖核酸複合体が0.1mg~200mg投与される、(17)に記載の医薬組成物。
(19)静脈内投与又は皮下投与される、(15)又は(16)に記載の医薬組成物。
(20)前記二本鎖核酸複合体が0.1mg/kg~100mg/kg投与される、(19)に記載の医薬組成物。
(21)炎症若しくはグリオーシスの惹起、又はサイトカイン若しくはケモカインの異常上昇が低減されている、(15)~(20)のいずれかに記載の医薬組成物。
本明細書は本願の優先権の基礎となる日本国特許出願番号2021-087941号の開示内容を包含する。
1-1.概要
本発明の第1態様は二本鎖核酸複合体である。本発明の二本鎖核酸複合体は第1核酸鎖及び第2核酸鎖を含み、第1核酸鎖及び/又は第2核酸鎖はscpBNA又はAmNAを少なくとも1個含む。本発明の二本鎖核酸複合体は、肝毒性等の毒性が低減されており、炎症若しくはグリオーシスの惹起、又はサイトカイン若しくはケモカインの異常上昇が低減されている。
本明細書において、標的遺伝子の「転写産物」とは、本発明の核酸複合体の直接的な標的となり、かつRNAポリメラーゼによって合成される任意のRNAをいう。具体的には、標的遺伝子から転写されるmRNA(成熟mRNA、mRNA前駆体、塩基修飾を受けていないmRNA等を含む)、miRNA等のノンコーディングRNA(non-coding RNA、ncRNA)、ロングノンコーディングRNA(lncRNA)、ナチュラルアンチセンスRNAを含み得る。


本発明の二本鎖核酸複合体は、第1核酸鎖と第2核酸鎖とを含む。各核酸鎖の具体的な構成を以下に示す。

で示される架橋型の非天然ヌクレオシドを少なくとも1個含む。


L2は、置換された若しくは置換されていないC1~C12のアルキレン基(例、プロピレン、ヘキシレン、ドデシレン)、置換された若しくは置換されていないC3~C8シクロアルキレン基(例、シクロヘキシレン)、-(CH2)2-O-(CH2)2-O-(CH2)2-O-(CH2)3-、-(CH2)2-O-(CH2)2-O-(CH2)2-O-(CH2)2-O-(CH2)3-、又はCH(CH2-OH)-CH2-O-(CH2)2-O-(CH2)2-O-(CH2)2-O-(CH2)3-を表し、L3は、-NH-又は結合を表し、L4は、置換された若しくは置換されていないC1~C12のアルキレン基(例、エチレン、ペンチレン、へプチレン、アンデシレン)、置換された若しくは置換されていないC3~8のシクロアルキレン基(例、シクロヘキシレン)、-(CH2)2-[O-(CH2)2]m-、又は結合を表し、ここで、mは1~25の整数を表し、L5は、-NH-(C=O)-、-(C=O)-、又は結合を表す(ここで、該置換は、好ましくはハロゲン原子によりなされる)。

本発明の二本鎖核酸複合体は、当業者であれば、公知の方法を適切に選択することによって製造することができる。限定はしないが、通常は、まず二本鎖核酸複合体を構成する第1核酸鎖及び第2核酸鎖のそれぞれを設計し、製造するところから始まる。例えば、標的転写産物の塩基配列(例えば、標的遺伝子の塩基配列)情報に基づいて第1核酸鎖を設計し、その相補鎖として第2核酸鎖を設計する。続いて、設計した塩基配列情報に基づいて、それぞれの核酸鎖を、例えば、GE Healthcare社、Thermo Fisher Scientific社、Beckman Coulter社等の市販の自動核酸合成装置を使用して合成すればよい。その後は、得られたオリゴヌクレオチドに逆相カラム等を使用して精製することもできる。
本発明の二本鎖核酸複合体によれば、二本鎖核酸複合体の有効性が損なうことなく、二本鎖核酸複合体の毒性を軽減又は消失することができる。すなわち、従来の二本鎖核酸複合体と比較して、標的遺伝子に対するアンチセンス効果を損なうことなく、肝毒性や腎毒性が低減されており、炎症若しくはグリオーシスの惹起、又はサイトカイン若しくはケモカインの異常上昇が低減されている。
2-1.概要
本発明の第2態様は医薬組成物である。本発明の医薬組成物は、前記第1態様の二本鎖核酸複合体を有効成分として含む。本発明の医薬組成物は、低肝毒性及び/又は低腎毒性である。また、炎症若しくはグリオーシスの惹起、又はサイトカイン若しくはケモカインの異常上昇が低減されている。
以下、本発明の医薬組成物が包含し得る各成分について具体的に説明をする。
2-2-1.有効成分
本発明の医薬組成物は、有効成分として少なくとも第1態様に記載の二本鎖核酸複合体を包含する。本発明の医薬組成物は、二本鎖核酸複合体を二種以上含んでもよい。
医薬組成物に含まれる二本鎖核酸複合体の量(含有量)は、二本鎖核酸複合体の種類、送達部位、医薬組成物の剤形、医薬組成物の投与量、並びに後述する担体の種類によって異なる。したがって、それぞれの条件を勘案して適宜定めればよい。通常は、単回投与量の医薬組成物に有効量の二本鎖核酸複合体が包含されるように調整する。「有効量」とは、二本鎖核酸複合体が有効成分としての機能を発揮する上で必要な量であって、かつそれを適用する生体に対して有害な副作用をほとんど又は全く付与しない量をいう。この有効量は、被検体の情報、投与経路、及び投与回数等の様々な条件によって変化し得る。最終的には医師、獣医師又は薬剤師等の判断によって決定される。「被検体の情報」とは、医薬組成物を適用する生体の様々な個体情報である。例えば、被検体がヒトであれば、年齢、体重、性別、食生活、健康状態、疾患の進行度や重症度、薬剤感受性、併用薬物の有無等を含む。
本発明の医薬組成物は、薬学的に許容可能な担体を含むことができる。「薬学的に許容可能な担体」とは、製剤技術分野において通常使用する添加剤をいう。例えば、溶媒、植物性油、基剤、乳化剤、懸濁化剤、界面活性剤、pH調整剤、安定化剤、香味料、香料、賦形剤、ビヒクル、防腐剤、結合剤、希釈剤、等張化剤、鎮静剤、増量剤、崩壊剤、緩衝剤、コーティング剤、滑沢剤、着色剤、甘味剤、増粘剤、矯味剤、溶解助剤、及び他の添加剤が挙げられる。
本発明の医薬組成物の剤形は、有効成分である第1態様に記載の二本鎖核酸複合体を分解等により不活化させることなく、標的部位まで送達し、生体内でその有効成分の薬理効果(標的遺伝子の発現に対するアンチセンス効果)を発揮し得る形態であれば特に限定しない。
本明細書において、医薬組成物の好ましい投与形態には特定の限定はない。例えば、経口投与又は非経口投与であればよい。非経口投与の具体例として、筋肉内投与、静脈内投与、動脈内投与、腹腔内投与、皮下投与(埋め込み型持続皮下投与を含む)、皮内投与、気管/気管支投与、直腸投与、輸血による投与、脳室内投与、髄腔内投与、経鼻投与、及び筋肉内投与が挙げられる。
医薬組成物の適用対象となる疾患は、限定せず、神経疾患、中枢神経系疾患、代謝性疾患、腫瘍、感染症といった標的遺伝子の発現亢進に伴う疾患を対象とすることができる。 一実施形態において、本態様の医薬組成物は被検体の中枢神経系疾患を治療するために用いることができる。本態様の医薬組成物の適用対象となる中枢神経系疾患として、特に限定されないが、例えば、脳腫瘍、アルツハイマー病、パーキンソン病、筋萎縮性側索硬化症、多発性硬化症、ハンチントン病等が挙げられる。
本発明の医薬組成物は、低肝毒性及び/又は低腎毒性である。また、本発明の医薬組成物は、脳室内投与、髄腔内投与、静脈内投与、皮下投与等による炎症若しくはグリオーシスの惹起、又はサイトカイン若しくはケモカインの異常上昇が低減されている。
(目的)
scpBNA/DNAギャップマー型アンチセンス核酸(以下、「ASO(scpBNA)」と称する)からなる第1核酸鎖、及び第1核酸鎖に相補的な塩基配列を有するRNAで構成される第2核酸鎖を含むヘテロ二重鎖オリゴヌクレオチド(以下、「HDO(scpBNA)」と称する)について、脳室内投与による遺伝子抑制効果及び毒性軽減効果をin vivo実験により検証する。
(1)核酸の調製
本実施例で用いたHDO(scpBNA)を構成する第1核酸鎖及び第2核酸鎖の塩基配列と化学修飾を表1及び図3Dに示す。



7週齢雌のICRマウスを、2.5~4%イソフルレン麻酔下にて脳定位固定装置に固定した。その後、耳間に前後2~3cmで皮膚を切開し、ブレグマ(bregma)の1mm左方かつ0.2mm後方に1mm径ドリルで穿孔した。ハミルトン(Hamilton)シリンジ内に核酸剤を充填した。穿孔部より針を3mm程度刺入し、2~3μl/分の速度で、マウス1匹あたり24μmol/匹の用量の核酸剤を左側脳室内投与し(n=2)、ナイロン糸で皮膚縫合した。注射の7日後、PBSをマウスに灌流させ、その後マウスを解剖して左海馬を摘出した。
IsogenIキット(株式会社ジーンデザイン)を使用して、摘出した左海馬からRNAを抽出した。cDNAは、Transcriptor Universal cDNA Master, DNase (ロシュ・ダイアグノスティックス社(Roche Diagnostics))を使用してプロトコルに従って合成した。
図4は、各種核酸剤を左側脳室内に投与したマウスの左海馬におけるMapt mRNA発現量を示す。ASO(LNA)、HDO(LNA)、ASO(scpBNA)、及びHDO(scpBNA)の脳室内投与では、Mapt遺伝子抑制効果に有意な差は認められなかった。
(目的)
mMalat1を標的とする、scpBNA/DNAギャップマー型アンチセンス核酸とトコフェロール結合型相補鎖からなる二本鎖核酸複合体、及びAmNA/DNAギャップマー型アンチセンス核酸とトコフェロール結合型相補鎖からなる二本鎖核酸複合体について、単回静脈内投与による標的遺伝子発現抑制効果を検証すると共に、毒性軽減効果について検証する。
(1)核酸の調製
標的遺伝子は転移関連肺腺癌転写産物1(mMalat1)とした。本実施例で用いた3種類の二本鎖核酸複合体を構成する第1核酸鎖及び第2核酸鎖の塩基配列を表3及び図6に示す。


で示される非天然ヌクレオシドである。
二本鎖核酸複合体剤を投与するマウスは、体重20gの6~7週齢の雄のC57BL/6マウスを用いた。各条件についてn=4で実験を行った。
二本鎖核酸複合体剤を単回投与で、尾静脈を通じて50mg/kgでマウスに静脈内注射した。さらに、陰性対照群としてPBSのみを単回投与で注射したマウスも作製した。
投与後72時間の時点で採血後、PBSをマウスに灌流させた。その後マウスを解剖して肝臓、腎臓、心筋、及び大腿四頭筋を摘出した。
ハイスループット全自動核酸抽出装置MagNA Pure 96(ロシュ・ライフサイエンス社)を使用して、各組織からmRNAをプロトコルに従って抽出した。cDNAは、Transcriptor Universal cDNA Master(ロシュ・ライフサイエンス社)のプロトコルに従って合成した。定量RT-PCRは、TaqMan(ロシュ・ライフサイエンス社)により実施した。定量RT-PCRにおいて使用したプライマーは、様々な遺伝子数に基づいて、サーモ・フィッシャー・サイエンティフィック社(Thermo Fisher Scientific)によって設計及び製造された製品を用いた。PCR条件(温度及び時間)は、95℃で15秒、60℃で30秒、及び72℃で1秒を1サイクルとして、40サイクルの繰り返しとした。得られた増幅産物を定量RT-PCRによって定量し、malat1 mRNA及びGAPDH mRNA(内部標準遺伝子)の発現量を計算し、両者の比率から相対的発現レベルを得て、相対的発現レベルの平均値及び標準誤差を算出した。また各群の間の差をt-検定によって解析した。
採血して得られた血清は、株式会社エスアールエル八王子ラボへの委託により解析した。
発現解析の結果を図7~8に示す。Toc-HDO(scpBNA)及びToc-HDO(AmNA)は、肝臓(図7A)、腎臓(図7B)、大腿四頭筋(図8A)、及び心筋(図8B)のいずれにおいても、Toc-HDO(LNA)と同等な遺伝子抑制効果を示した。
(目的)
PTENを標的とする、scpBNA/DNAギャップマー型アンチセンス核酸とトコフェロール結合型相補鎖からなる二本鎖核酸複合体、及びAmNA/DNAギャップマー型アンチセンス核酸とトコフェロール結合型相補鎖からなる二本鎖核酸複合体について、単回静脈内投与による標的遺伝子発現抑制効果を検証すると共に、毒性軽減効果について検証する。
標的遺伝子はPTEN(Phosphatase and Tensin Homolog Deleted from Chromosome 10)とした。本実施例で用いた3種類の二本鎖核酸複合体を構成する第1核酸鎖及び第2核酸鎖の塩基配列と化学修飾を表4及び図10に示す。

発現解析の結果を図11~12に示す。Toc-HDO(scpBNA)及びToc-HDO(AmNA)は、肝臓(図11A)、腎臓(図11B)、大腿四頭筋(図12A)、及び心筋(図12B)において、Toc-HDO(LNA)と概ね同等以上の遺伝子抑制効果を示した。
(目的)
SR-B1を標的とする、scpBNA/DNAギャップマー型アンチセンス核酸とトコフェロール結合型相補鎖からなる二本鎖核酸複合体、及びAmNA/DNAギャップマー型アンチセンス核酸とトコフェロール結合型相補鎖からなる二本鎖核酸複合体について、単回静脈内投与による標的遺伝子発現抑制効果を検証すると共に、毒性軽減効果について検証する。
標的遺伝子はスカベンジャー受容体B1(scavenger receptor B1; SR-B1)遺伝子とした。本実施例で用いた3種類の二本鎖核酸複合体を構成する第1核酸鎖及び第2核酸鎖の塩基配列を表5及び図10に示す。

発現解析の結果を図14~15に示す。Toc-HDO(scpBNA)及びToc-HDO(AmNA)は、肝臓(図14A)、腎臓(図14B)、大腿四頭筋(図15A)、及び心筋(図15B)のいずれにおいても、Toc-HDO(LNA)と同等な遺伝子抑制効果を示した。
(目的)
SR-B1を標的とする、scpBNA/DNAギャップマー型アンチセンス核酸とコレステロール結合型相補鎖からなる二本鎖核酸複合体について、複数回静脈内投与による標的遺伝子発現抑制効果を検証すると共に、毒性軽減効果について検証する。
(1)核酸の調製
標的遺伝子はSR-B1遺伝子とした。本実施例で用いた2種類の二本鎖核酸複合体を構成する第1核酸鎖及び第2核酸鎖の塩基配列を表6及び図17に示す。

二本鎖核酸複合体剤を投与するマウスは、体重20gの6~7週齢の雄のC57BL/6マウスを用いた。各条件についてn=4で実験を行った。
二本鎖核酸複合体剤を複数回投与(週1回、計4回投与)で、尾静脈を通じて50mg/kgでマウスに静脈内注射した。さらに、陰性対照群としてPBSのみを単回投与で注射したマウスも作製した。
投与後72時間の時点で採血後、PBSをマウスに灌流させた。その後マウスを解剖して脳の各部位及び全身を摘出した。
ハイスループット全自動核酸抽出装置MagNA Pure 96(ロシュ・ライフサイエンス社)を使用して、各組織からmRNAをプロトコルに従って抽出した。cDNAは、Transcriptor Universal cDNA Master(ロシュ・ライフサイエンス社)のプロトコルに従って合成した。定量RT-PCRは、TaqMan(ロシュ・ライフサイエンス社)により実施した。定量RT-PCRにおいて使用したプライマーは、様々な遺伝子数に基づいて、サーモ・フィッシャー・サイエンティフィック社(Thermo Fisher Scientific)によって設計及び製造された製品を用いた。PCR条件(温度及び時間)は、95℃で15秒、60℃で30秒、及び72℃で1秒を1サイクルとして、40サイクルの繰り返しとした。得られた増幅産物を定量RT-PCRによって定量し、その結果に基づいて、SR-B1 mRNA及びActin mRNA(内部標準遺伝子)の発現量をそれぞれ計算し、両者の比率から相対的発現レベルを得た。相対的発現レベルの平均値及び標準誤差を算出した。また各群の間の差をt-検定によって解析した。
採血して得られた血清は、株式会社エスアールエル八王子ラボへの委託により解析した。
発現解析の結果を図18に示す。Chol-HDO(scpBNA)は、脳内(図18A)及び全身臓器(図18B)で強い遺伝子抑制効果を示した。
血清解析の結果を図19に示す。Chol-HDO(LNA)投与群では、初回投与後、3日後にAST/ALTが高度に上昇し、5~6日後に死亡した。これに対して、Chol-HDO(scpBNA)投与群では4回投与後も生存して、AST/ALTの上昇は軽度であった。
(目的)
scpBNA/DNAギャップマー型アンチセンス核酸とトコフェロール結合型相補鎖からなる二本鎖核酸複合体を静脈内投与した場合の血中炎症性サイトカイン/ケモカイン発現について検証する。
(1)核酸の調製
本実施例では、表3に記載のmMalat1を標的とするToc-HDO(LNA)、Toc-HDO(scpBNA)、及びToc-HDO(AmNA)、表4に記載のPTENを標的とするToc-HDO(LNA)、Toc-HDO(scpBNA)、及びToc-HDO(AmNA)、並びに表5に記載のSR-B1を標的とするToc-HDO(LNA)、Toc-HDO(scpBNA)、及びToc-HDO(AmNA)を用いた。二本鎖核酸複合体は、実施例1の(1)と同様の方法で調製した。
in vivo実験は、mMalat1を標的とするHDOの投与量を50mg/kgとし、PTENを標的とするHDOの投与量を35mg/kgとした点を除き、実施例2と同様に行った。すなわち、二本鎖核酸複合体剤を単回投与で、尾静脈を通じて静脈内投与した。
投与後72時間の時点で採血を行った。
採血して得られた血液の解析は、MILLIPLEX MAP Mouse Cytokine/Chemokine Magnetic Bead Panel - Immunology Multiplex(Millipore)を用いて、説明書に記載の方法に従って行った。核酸剤による毒性を評価するために、以下のタンパク質群:G-CSF、GM-CSF、IFN-γ、IL-1α、IL-1β、IL-2、IL-3、IL-4、IL-5、IL-6、IL-7、IL-9、IL-10、IL-12 (p40)、IL-12 (p70)、IL-13、IL-15、IL-17、IP-10、KC、LIF、LIX、MCP-1、M-CSF、MIG、MIP-1α、MIP-1β、MIP-2、RANTES、TNFα、VEGF、及びEotaxin/CCL11を対象としてタンパク質量を測定した。その結果、Toc-HDO(LNA)投与で上昇がみられた、TNFα、IP-10、及びRANTESを炎症の指標として測定した。
血中の炎症性サイトカイン量を測定した結果を図20~図22に示す。
図20~図22に示す通り、Toc-HDO(LNA)投与群と比較して、Toc-HDO(scpBNA)投与群及びToc-HDO(AmNA)投与群では、TNFα(図20)、IP-10(図21)、及びRANTES(図22)のいずれの発現量も低いことが示された。
本明細書で引用した全ての刊行物、特許及び特許出願はそのまま引用により本明細書に組み入れられるものとする。
Claims (21)
- 第1核酸鎖と第2核酸鎖とを含む二本鎖核酸複合体であって、
前記第1核酸鎖は、標的遺伝子又はその転写産物の少なくとも一部にハイブリダイズすることができ、前記標的遺伝子又はその転写産物に対してアンチセンス効果を有し、
前記第2核酸鎖は、前記第1核酸鎖に相補的な塩基配列を含み、
前記第1核酸鎖及び/又は前記第2核酸鎖は、以下の式(I)又は式(II):

で示される架橋型の非天然ヌクレオシドを少なくとも1個含む、前記二本鎖核酸複合体。 - 前記第1核酸鎖がギャップマーである、請求項1に記載の二本鎖核酸複合体。
- 前記第1核酸鎖が、
(1)少なくとも4個の連続するデオキシリボヌクレオシドを含む中央領域、
(2)前記中央領域の5'末端側に配置された、非天然ヌクレオシドを含む5’ウイング領域、及び
(3)前記中央領域の3'末端側に配置された、非天然ヌクレオシドを含む3’ウイング領域を含む、請求項2に記載の二本鎖核酸複合体。 - 前記5’ウイング領域及び/又は前記3’ウイング領域が前記式(I)又は式(II)で示される架橋型の非天然ヌクレオシドを含む、請求項3に記載の二本鎖核酸複合体。
- 前記第2核酸鎖が、前記第1核酸鎖の前記中央領域における少なくとも4個の連続するデオキシリボヌクレオシドに相補的な、少なくとも4個の連続するリボヌクレオシドを含む、請求項3又は4に記載の二本鎖核酸複合体。
- 前記第2核酸鎖が、少なくとも2個の連続するデオキシリボヌクレオシドをさらに含む、請求項5に記載の二本鎖核酸複合体。
- 前記第2核酸鎖において、前記第1核酸鎖の5’ウイング領域及び/又は3’ウイング領域に相補的な塩基配列からなる領域に前記式(I)又は式(II)で示される架橋型の非天然ヌクレオシドを含む、請求項3~6のいずれか一項に記載の二本鎖核酸複合体。
- 前記第1核酸鎖がミックスマーである、請求項1に記載の二本鎖核酸複合体。
- 前記第1核酸鎖及び/又は前記第2核酸鎖が、2'-O-メチル修飾ヌクレオシド、2'-O-メトキシエチル修飾ヌクレオシド、及び2'-O-[2-(N-メチルカルバモイル)エチル]修飾ヌクレオシドからなる群から選択される少なくとも1個のリボース2'位修飾ヌクレオシドを含む、請求項1~8のいずれか一項に記載の二本鎖核酸複合体。
- 前記第1核酸鎖及び/又は前記第2核酸鎖のヌクレオシド間結合の全部又は一部が修飾ヌクレオシド間結合である、請求項1~9のいずれか一項に記載の二本鎖核酸複合体。
- 前記修飾ヌクレオシド間結合がホスホロチオエート結合である、請求項10に記載の二本鎖核酸複合体。
- 前記第2核酸鎖が、トコフェロール若しくはコレステロール又はそれらの類縁体と結合している、請求項1~11のいずれか一項に記載の二本鎖核酸複合体。
- リガンドと結合していない、請求項1~11のいずれか一項に記載の二本鎖核酸複合体。
- 前記第1核酸鎖と前記第2核酸鎖とが切断性又は非切断性リンカーを介して結合している、請求項1~13のいずれか一項に記載の二本鎖核酸複合体。
- 請求項1~14のいずれか一項に記載の二本鎖核酸複合体を有効成分として含む医薬組成物。
- 被検体の中枢神経系疾患を治療するための、請求項15に記載の医薬組成物。
- 脳室内投与又は髄腔内投与される、請求項15又は16に記載の医薬組成物。
- 前記二本鎖核酸複合体が0.1mg~200mg投与される、請求項17に記載の医薬組成物。
- 静脈内投与又は皮下投与される、請求項15又は16に記載の医薬組成物。
- 前記二本鎖核酸複合体が0.1mg/kg~100mg/kg投与される、請求項19に記載の医薬組成物。
- 炎症若しくはグリオーシスの惹起、又はサイトカイン若しくはケモカインの異常上昇が低減されている、請求項15~20のいずれか一項に記載の医薬組成物。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US18/563,128 US20240240183A1 (en) | 2021-05-25 | 2022-05-24 | Heteronucleic acid containing scpBNA or AmNA |
| JP2023523485A JPWO2022250050A1 (ja) | 2021-05-25 | 2022-05-24 | |
| EP22811320.5A EP4349986A1 (en) | 2021-05-25 | 2022-05-24 | Heteronucleic acid containing scpbna or amna |
| CA3221584A CA3221584A1 (en) | 2021-05-25 | 2022-05-24 | Heteronucleic acid containing scpbna or amna |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021087941 | 2021-05-25 | ||
| JP2021-087941 | 2021-05-25 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022250050A1 true WO2022250050A1 (ja) | 2022-12-01 |
Family
ID=84228791
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/021251 WO2022250050A1 (ja) | 2021-05-25 | 2022-05-24 | scpBNA又はAmNAを含むヘテロ核酸 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20240240183A1 (ja) |
| EP (1) | EP4349986A1 (ja) |
| JP (1) | JPWO2022250050A1 (ja) |
| CA (1) | CA3221584A1 (ja) |
| WO (1) | WO2022250050A1 (ja) |
Citations (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5264423A (en) | 1987-03-25 | 1993-11-23 | The United States Of America As Represented By The Department Of Health And Human Services | Inhibitors for replication of retroviruses and for the expression of oncogene products |
| US5286717A (en) | 1987-03-25 | 1994-02-15 | The United States Of America As Represented By The Department Of Health And Human Services | Inhibitors for replication of retroviruses and for the expression of oncogene products |
| US5955599A (en) | 1995-06-01 | 1999-09-21 | Hybridon, Inc. | Process for making oligonucleotides containing o- and s- methylphosphotriester internucleoside linkages |
| WO2007143315A2 (en) | 2006-05-05 | 2007-12-13 | Isis Pharmaceutical, Inc. | Compounds and methods for modulating expression of pcsk9 |
| WO2008043753A2 (en) | 2006-10-09 | 2008-04-17 | Santaris Pharma A/S | Rna antagonist compounds for the modulation of pcsk9 |
| WO2008049085A1 (en) | 2006-10-18 | 2008-04-24 | Isis Pharmaceuticals, Inc. | Antisense compounds |
| WO2013089283A1 (en) | 2011-12-16 | 2013-06-20 | National University Corporation Tokyo Medical And Dental University | Chimeric double-stranded nucleic acid |
| WO2014192310A1 (en) | 2013-05-30 | 2014-12-04 | National University Corporation Tokyo Medical And Dental University | Double-stranded agents for delivering therapeutic oligonucleotides |
| WO2015168172A1 (en) | 2014-04-28 | 2015-11-05 | Isis Pharmaceuticals, Inc. | Linkage modified oligomeric compounds |
| WO2016081600A1 (en) | 2014-11-18 | 2016-05-26 | Zata Pharmaceuticals, Inc. | Phosphoramidite synthones for the synthesis of self-neutralizing oligonucleotide compounds |
| WO2018056442A1 (ja) * | 2016-09-23 | 2018-03-29 | 国立大学法人東京医科歯科大学 | 血液脳関門通過型ヘテロ2本鎖核酸 |
| WO2018062510A1 (ja) | 2016-09-29 | 2018-04-05 | 国立大学法人東京医科歯科大学 | オーバーハングを有する二本鎖核酸複合体 |
| WO2020209285A1 (ja) * | 2019-04-08 | 2020-10-15 | 国立大学法人東京医科歯科大学 | 筋疾患治療用医薬組成物 |
| JP2021087941A (ja) | 2019-11-21 | 2021-06-10 | 日本無機株式会社 | エアフィルタ |
-
2022
- 2022-05-24 CA CA3221584A patent/CA3221584A1/en active Pending
- 2022-05-24 EP EP22811320.5A patent/EP4349986A1/en active Pending
- 2022-05-24 WO PCT/JP2022/021251 patent/WO2022250050A1/ja active Application Filing
- 2022-05-24 US US18/563,128 patent/US20240240183A1/en active Pending
- 2022-05-24 JP JP2023523485A patent/JPWO2022250050A1/ja active Pending
Patent Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5264423A (en) | 1987-03-25 | 1993-11-23 | The United States Of America As Represented By The Department Of Health And Human Services | Inhibitors for replication of retroviruses and for the expression of oncogene products |
| US5286717A (en) | 1987-03-25 | 1994-02-15 | The United States Of America As Represented By The Department Of Health And Human Services | Inhibitors for replication of retroviruses and for the expression of oncogene products |
| US5955599A (en) | 1995-06-01 | 1999-09-21 | Hybridon, Inc. | Process for making oligonucleotides containing o- and s- methylphosphotriester internucleoside linkages |
| WO2007143315A2 (en) | 2006-05-05 | 2007-12-13 | Isis Pharmaceutical, Inc. | Compounds and methods for modulating expression of pcsk9 |
| WO2008043753A2 (en) | 2006-10-09 | 2008-04-17 | Santaris Pharma A/S | Rna antagonist compounds for the modulation of pcsk9 |
| WO2008049085A1 (en) | 2006-10-18 | 2008-04-24 | Isis Pharmaceuticals, Inc. | Antisense compounds |
| WO2013089283A1 (en) | 2011-12-16 | 2013-06-20 | National University Corporation Tokyo Medical And Dental University | Chimeric double-stranded nucleic acid |
| JP2015502134A (ja) * | 2011-12-16 | 2015-01-22 | 国立大学法人 東京医科歯科大学 | キメラ2重鎖核酸 |
| WO2014192310A1 (en) | 2013-05-30 | 2014-12-04 | National University Corporation Tokyo Medical And Dental University | Double-stranded agents for delivering therapeutic oligonucleotides |
| WO2015168172A1 (en) | 2014-04-28 | 2015-11-05 | Isis Pharmaceuticals, Inc. | Linkage modified oligomeric compounds |
| WO2016081600A1 (en) | 2014-11-18 | 2016-05-26 | Zata Pharmaceuticals, Inc. | Phosphoramidite synthones for the synthesis of self-neutralizing oligonucleotide compounds |
| WO2018056442A1 (ja) * | 2016-09-23 | 2018-03-29 | 国立大学法人東京医科歯科大学 | 血液脳関門通過型ヘテロ2本鎖核酸 |
| WO2018062510A1 (ja) | 2016-09-29 | 2018-04-05 | 国立大学法人東京医科歯科大学 | オーバーハングを有する二本鎖核酸複合体 |
| WO2020209285A1 (ja) * | 2019-04-08 | 2020-10-15 | 国立大学法人東京医科歯科大学 | 筋疾患治療用医薬組成物 |
| JP2021087941A (ja) | 2019-11-21 | 2021-06-10 | 日本無機株式会社 | エアフィルタ |
Non-Patent Citations (16)
| Title |
|---|
| ALEXANDER A. LOMZOV ET AL., BIOCHEM BIOPHYS RES COMMUN., vol. 513, no. 4, 2019, pages 807 - 811 |
| ANASTASIA KHVOROVA ET AL., NAT. BIOTECHNOL., vol. 35, no. 3, 2017, pages 238 - 248 |
| ASAMI Y ET AL.: "Drug delivery system of therapeutic oligonucleotides", DRUG DISCOVERIES & THERAPEUTICS, vol. 10, no. 5, 2016, pages 256 - 262, XP055634473, DOI: 10.5582/ddt.2016.01065 |
| ASAMI YUTARO, NAGATA TETSUYA, YOSHIOKA KOTARO, KUNIEDA TAIKI, YOSHIDA-TANAKA KIE, BENNETT C. FRANK, SETH PUNIT P., YOKOTA TAKANORI: "Efficient Gene Suppression by DNA/DNA Double-Stranded Oligonucleotide In Vivo", MOLECULAR THERAPY, ELSEVIER INC., US, vol. 29, no. 2, 1 February 2021 (2021-02-01), US , pages 838 - 847, XP055834158, ISSN: 1525-0016, DOI: 10.1016/j.ymthe.2020.10.017 * |
| MASAHIKO HORIBA, TAKAO YAMAGUCHI, SATOSHI OBIKA: "Synthesis of scpBNA- m C, -A, and -G Monomers and Evaluation of the Binding Affinities of scpBNA-Modified Oligonucleotides toward Complementary ssRNA and ssDNA", THE JOURNAL OF ORGANIC CHEMISTRY, AMERICAN CHEMICAL SOCIETY, vol. 81, no. 22, 18 November 2016 (2016-11-18), pages 11000 - 11008, XP055376695, ISSN: 0022-3263, DOI: 10.1021/acs.joc.6b02036 * |
| NAOKI IWAMOTO ET AL., ANGEW. CHEM. INT. ED. ENGL., vol. 48, no. 3, 2009, pages 496 - 9 |
| NAOKI IWAMOTO ET AL., NAT. BIOTECHNOL, vol. 35, no. 9, 2017, pages 845 - 851 |
| NATSUHISA OKA ET AL., J. AM. CHEM. SOC., vol. 125, 2003, pages 8307 - 8317 |
| NATSUHISA OKA ET AL., J. AM. CHEM. SOC., vol. 130, 2008, pages 16031 - 16037 |
| NISHIKAWA MAKIYA, YUKITAKE YOSHIOKA, MAKOTO NAGAOKA, KOSUKE KUSAMORI: "Development of Oligonucleotide Therapeutics: Tissue Distribution and Drug Delivery System", DDS. DRUG DELIVERY SYSTEM, vol. 36, no. 1, 25 January 2021 (2021-01-25), pages 40 - 50, XP093006747, DOI: 10.2745/dds.36.40 * |
| NISHINA K: "DNA/RNA heteroduplex oligonucleotide for highly efficient gene silencing", NATURE COMMUNICATION, vol. 6, 2015, pages 7969, XP055834307, DOI: 10.1038/ncomms8969 |
| OKIBA SATOSHI: "Building a platform for innovative non-toxic oligonucleotide therapeutics -Synthesis, screening, and evaluation of dual-modified artificial nucleic acids-", BASIC SCIENCE AND PLATFORM TECHNOLOGY PROGRAM FOR INNOVATIVE BIOLOGICAL MEDICINE; FY2015 GENERAL RESEARCH AND DEVELOPMENT REPORT, 1 January 2015 (2015-01-01), XP093006748 * |
| SETOGUCHI KIYOKO, CUI LIN, HACHISUKA NOBUTAKA, OBCHOEI SUMALEE, SHINKAI KENTARO, HYODO FUMINORI, KATO KIYOKO, WADA FUMITO, YAMAMOT: "Antisense Oligonucleotides Targeting Y-Box Binding Protein-1 Inhibit Tumor Angiogenesis by Downregulating Bcl-xL-VEGFR2/-Tie Axes", MOLECULAR THERAPY-NUCLEIC ACIDS, CELL PRESS, US, vol. 9, 1 December 2017 (2017-12-01), US , pages 170 - 181, XP055941192, ISSN: 2162-2531, DOI: 10.1016/j.omtn.2017.09.004 * |
| TAKAO INOUE, KIYOMI SASAKI, TOKUYUKI YOSHIDA: "Current status of development of oligonucleotide therapeutics", DRUG DELIVERY SYSTEM., NIHON D D S GAKKAI, JAPAN, vol. 34, no. 2, 25 March 2019 (2019-03-25), Japan , pages 86 - 98, XP009539425, ISSN: 0913-5006, DOI: 10.2745/dds.34.86 * |
| YOHEI NUKAGA ET AL., J. ORG. CHEM., vol. 77, 2012, pages 7913 - 7922 |
| YOHEI NUKAGA ET AL., J. ORG. CHEM., vol. 81, 2016, pages 2753 - 2762 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4349986A1 (en) | 2024-04-10 |
| CA3221584A1 (en) | 2022-12-01 |
| US20240240183A1 (en) | 2024-07-18 |
| JPWO2022250050A1 (ja) | 2022-12-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2020196662A1 (ja) | 二本鎖核酸複合体及びその使用 | |
| JP7554488B2 (ja) | 血液脳関門通過型ヘテロ2本鎖核酸 | |
| WO2020209285A1 (ja) | 筋疾患治療用医薬組成物 | |
| US11260134B2 (en) | Double-stranded nucleic acid complex having overhang | |
| JP7333079B2 (ja) | 毒性が軽減した核酸 | |
| WO2021054370A1 (ja) | 核酸複合体 | |
| WO2021187392A1 (ja) | モルホリノ核酸を含むヘテロ核酸 | |
| WO2021157730A1 (ja) | 核酸医薬とその使用 | |
| JP7394392B2 (ja) | 核酸複合体 | |
| WO2022250050A1 (ja) | scpBNA又はAmNAを含むヘテロ核酸 | |
| JP6934695B2 (ja) | 核酸医薬とその使用 | |
| WO2023042876A1 (ja) | 2'-修飾ヌクレオシドを含むヘテロ核酸 | |
| WO2023022229A1 (ja) | モルホリノ核酸を含む修飾ヘテロ核酸 | |
| WO2024071099A1 (ja) | 5'-シクロプロピレン修飾を含む核酸分子 | |
| WO2021070959A1 (ja) | 修飾ヘテロ核酸 | |
| WO2024005156A1 (ja) | 核酸医薬の毒性軽減剤 | |
| WO2023127848A1 (ja) | Ebv関連疾患を標的とする核酸医薬 | |
| WO2024071362A1 (ja) | 神経系送達促進剤 | |
| WO2020262555A1 (ja) | 核酸医薬副作用軽減剤、該核酸医薬副作用軽減剤を含む医薬組成物、並びに核酸医薬の副作用惹起性を軽減する方法 | |
| WO2024106545A1 (ja) | 髄腔内投与のためのヘテロ核酸 | |
| WO2023080225A1 (ja) | 脊髄小脳失調症治療用医薬組成物 | |
| CN117412773A (zh) | 配体结合核酸复合物 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22811320 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023523485 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18563128 Country of ref document: US |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 3221584 Country of ref document: CA |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022811320 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 2022811320 Country of ref document: EP Effective date: 20240102 |