WO2020235061A1 - 動作規則決定装置、動作規則決定方法および記録媒体 - Google Patents
動作規則決定装置、動作規則決定方法および記録媒体 Download PDFInfo
- Publication number
- WO2020235061A1 WO2020235061A1 PCT/JP2019/020324 JP2019020324W WO2020235061A1 WO 2020235061 A1 WO2020235061 A1 WO 2020235061A1 JP 2019020324 W JP2019020324 W JP 2019020324W WO 2020235061 A1 WO2020235061 A1 WO 2020235061A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- degree
- state
- risk
- operation rule
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images













Classifications
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B15/00—Systems controlled by a computer
- G05B15/02—Systems controlled by a computer electric
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B13/00—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion
- G05B13/02—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion electric
- G05B13/0265—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion electric the criterion being a learning criterion
-
- G—PHYSICS
- G08—SIGNALLING
- G08B—SIGNALLING SYSTEMS, e.g. PERSONAL CALLING SYSTEMS; ORDER TELEGRAPHS; ALARM SYSTEMS
- G08B31/00—Predictive alarm systems characterised by extrapolation or other computation using updated historic data
-
- G—PHYSICS
- G08—SIGNALLING
- G08G—TRAFFIC CONTROL SYSTEMS
- G08G1/00—Traffic control systems for road vehicles
- G08G1/16—Anti-collision systems
Definitions
- the present invention relates to an operation rule determination device, an operation rule determination method, and a recording medium.
- Patent Document 1 describes an online risk learning system that learns and recognizes risks contained in the external environment of moving objects such as automobiles.
- This online risk learning system adaptively learns the risk of the state by using the training information created by using the information indicating the state of the external environment and the risk information related to the risk of the state. Recognize the degree of danger contained in the external environment.
- Patent Document 1 does not disclose a method of determining an action in consideration of risk in reinforcement learning.
- An example of an object of the present invention is to provide an operation rule determining device, an operation rule determining method, and a recording medium capable of solving the above problems.
- the operation rule determining device uses the degree information associated with the state of the controlled object and the degree of desirability of the state for a series of operations with respect to the controlled object.
- the environment execution unit that obtains the state after each operation and the degree associated with that state, and the cumulative degree obtained by accumulating the obtained degree for the series of operations are calculated, and the cumulative degree satisfies the condition. It also includes a risk-considered history generator that reduces the degree associated with a series of post-operation states in the degree information.
- the operation rule determining method is a series of operations with respect to the controlled object by the computer using the degree information in which the state of the controlled object and the degree of desirability of the state are associated with each other.
- the process of obtaining the state after each operation and the degree associated with the state, and the computer calculates the cumulative degree obtained by accumulating the obtained degree for the series of operations, and the cumulative degree is a condition. If satisfied, it includes a step of reducing the degree associated with a series of post-operation states in the degree information.
- the recording medium uses a computer to perform a series of operations with respect to the controlled object by using the degree information associated with the state of the controlled object and the degree of desirability of the state. , The process of obtaining the state after each operation and the degree associated with the state, and the cumulative degree obtained by accumulating the obtained degree for the series of operations are calculated, and when the accumulated degree satisfies the condition.
- a recording medium on which a program for executing a step of reducing the degree associated with a series of post-operation states in the degree information is recorded.
- a planner who determines an operation according to a state can determine an operation in consideration of risk.
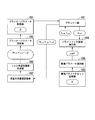
- FIG. 1 is a schematic block diagram showing an example of a functional configuration of the operation rule determining device according to the first embodiment.
- the operation rule determining device 100 includes a communication unit 110, a storage unit 180, and a control unit 190.
- the storage unit 180 includes a planner parameter storage unit 181, an interaction history storage unit 182, and an environment parameter set storage unit 183.
- the control unit 190 includes a planner unit 191, a planner parameter setting unit 192, a risk-considered history generation unit 193, a parametric environment execution unit 194, and an environment parameter selection unit 195.
- the operation rule determination device 100 determines the operation (control, action) rule of the controlled object by reinforcement learning.
- the operation rule determining device 100 may control the control target according to the determined rule.
- Reinforcement learning is a reward that expresses the operation rules that determine the operation of the controlled object in a certain environment, the operation of the controlled object, the observed state of the environment and the controlled object, and the degree of desirability of the controlled object state. It is machine learning that learns based on.
- the degree of desirability of the state of the controlled object referred to here is a degree indicating how desirable the state is.
- the degree of desirability of the state to be controlled is given to the operation rule determining device 100 by, for example, degree information representing the degree.
- the degree information is information in which the state of the controlled object is associated with the degree of desirability of the state.
- the degree of desirability will be referred to as "reward”.
- the control target of the operation rule determining device 100 is not limited to a specific one.
- the control target may be, for example, a moving body such as an automobile, an airplane, or a ship, a processing factory, or a manufacturing process.
- the control target of the operation rule determination device 100 can perform reinforcement learning of the operation of the control target, and can make the control target perform an operation determined based on the reinforcement learning.
- the surrounding environment to be controlled is also simply referred to as an environment.
- the environment here is the environment in reinforcement learning.
- the environment can affect the controlled object, for example, the environment can affect the operation of the controlled object.
- the environment may change depending on the operation of the controlled object. For example, moving a controlled object from one place to another changes the environment.
- Information that can be obtained from the environment or the controlled object is called a state.
- the state here is the state in reinforcement learning. Examples of the state include, but are not limited to, the measured value by the sensor and the position of the controlled object.
- the operation rule referred to here is a rule for determining the operation of the controlled object according to the state.
- the operation obtained by applying the state to the operation rule is also called an operation plan or simply a plan.
- the process of requesting an operation is called planning.
- the subject who performs planning is called a planner.
- the operation rule determining device 100 stores the operation rule including the parameter in advance, and determines the operation rule by determining the value of this parameter. Therefore, the operation rule determining device 100 may control the control target according to the determined parameter value.
- the parameters included in the operation rule are called planner parameters.
- the operation rule determining device 100 calculates information about the environment by simulation. This simulation is also called an environment simulation or simply a simulation.
- the model used by the operation rule determining device 100 for the simulation includes parameters other than the state. This parameter is called an environment parameter.
- the value of the environmental parameter can affect the controlled object.
- Examples of environmental parameters include, but are not limited to, the coefficient of static friction, the coefficient of dynamic friction, and the temperature of a place where a temperature sensor is not provided.
- the static friction coefficient and the dynamic friction coefficient are information that can be acquired, for example, by actually moving the controlled object on the floor.
- the set of values that an environmental parameter can take is called an environmental parameter set.
- Environmental parameter sets are given stochastically, such as given by probability distribution.
- the environment parameter set indicates the values that the environment parameters can take and the probabilities that the environment parameters can take those values.
- the environment parameter is not limited to one type of parameter, and may be a plurality of types of parameters.
- the environment parameter set is given to the operation rule determination device 100 in advance, for example, set by the user of the operation rule determination device 100.
- the operation rule determining device 100 samples the value of the environment parameter indicated by the environment parameter set according to the probability indicated by the environment parameter set, sets the sampled value in the environment parameter of the simulation model, and controls according to the set environment parameter. Simulate the operation.
- the operation rule determining device 100 acquires, for example, the state of the controlled object after the operation by the simulation.
- the operation rule determining device 100 specifies the state after the operation of the controlled object, and determines the reward according to the specified state by using the degree information.
- the operation rule determining device 100 calculates the reward obtained by the operation based on the determined reward.
- the operation rule determining device 100 uses the degree information to obtain the degree associated with the state.
- the operation is not limited to the operation at one timing, and may be each operation at a plurality of timings.
- the process of determining the reward according to the state is not only the process of determining based on the given degree information in which the state and the reward in the state are associated, but also the operation rule determination as described later.
- the process may be determined based on the reward determined by the device 100.
- the method of calculating the reward obtained by the action is not only the method of calculating the total value of the reward at each timing, but also the method of multiplying the reward by a weight that becomes smaller toward the future timing and summing the obtained values. There may be.
- the method of calculating the reward may be given to the operation rule determining device 100 in advance, for example, given by the user of the operation rule determining device 100.
- the method of calculating the reward may be given to the operation rule determining device 100 in the form of a mathematical formula, but the method is not limited thereto.
- the operation rule determining device 100 applies the state and the operation to the reward calculation method to calculate the reward.
- the operation rule determining device 100 generates the interaction history information.
- the interaction history information is historical information in which an operation determined according to a state based on an operation rule, a state calculated according to the operation in a simulation, and a reward calculated according to the operation and the state are combined. ..
- one turn represents a process of determining the operation of the controlled object at one timing and the state of the controlled object after the operation.
- the repetition of the turn from the initial state until the predetermined end condition is satisfied is called one episode. That is, it can be said that the episode represents a series of actions for the controlled object.
- the operation rule determining device 100 generates risk-considered history information based on the interaction history information.
- the risk-considered history information is information obtained by reflecting the risk shown in the interaction history information in the reward.
- the operation rule determining device 100 may perform reinforcement learning by using a penalty instead of the reward.
- the reward may be represented by a positive value, for example, when the controlled state is in the desired state (or is approaching the desired state).
- the penalty may be expressed by a negative value when the state to be controlled is not a desired state (or is away from the desired state).
- the reward and the penalty can be expressed using positive and negative values, respectively.
- the reward and the penalty may be collectively referred to as "reward".
- the communication unit 110 communicates with another device.
- the communication unit 110 receives information indicating a state from a sensor or the like in the actual operation of the operation rule determining device 100.
- the actual operation of the operation rule determining device 100 is to calculate the operation of the controlled object based on the operation rule obtained by the reinforcement learning after the completion of the reinforcement learning.
- the operation rule determining device 100 may directly control the operation of the controlled object.
- the operation rule determining device 100 may propose the calculated operation to the person in charge of control.
- the operation rule determining device 100 may instruct the control device controlling the plant to operate the controlled object.
- the storage unit 180 stores various information.
- the storage unit 180 is configured by using the storage device included in the operation rule determining device 100.
- the planner parameter storage unit 181 stores the planner parameters.
- the interaction history storage unit 182 stores the interaction history information.
- the environment parameter set storage unit 183 stores the environment parameter set.
- the control unit 190 controls each unit of the operation rule determining device 100 to execute various processes.
- the function of the control unit 190 is executed by the CPU (Central Processing Unit) included in the operation rule determining device 100 reading a program from the storage unit 180 and executing the program.
- the planner unit 191 performs planning. That is, the planner unit 191 determines the operation by applying the state to the operation rule for determining the operation of the controlled object according to the state.
- the risk-considered history generation unit 193 generates risk-considered interaction history information based on the interaction history information.
- the planner parameter setting unit 192 determines the value of the planner parameter based on the risk-considered history information.
- the parametric environment execution unit 194 executes the simulation described above.
- the environment parameter selection unit 195 samples the value of the environment parameter from the environment parameter set according to the probability shown in the environment parameter set.
- the parametric environment execution unit 194 corresponds to the example of the environment execution unit.
- FIG. 2 is a diagram showing an example of data flow in the operation rule determining device 100.
- the environment parameter set storage unit 183 stores the environment parameter set P.
- the environment parameter set P shows the probability distribution of the values that the environment parameter p can take. That is, the environment parameter set P indicates a value that the environment parameter p can take and a probability that the environment parameter p can take that value.
- the environment parameter set P is stored in advance by the environment parameter set storage unit 183, for example, by being given by the user of the operation rule determination device 100.
- the environment parameter selection unit 195 samples the value of the environment parameter p from the environment parameter set P according to the probability shown in the environment parameter set P.
- the environment parameter selection unit 195 outputs the obtained value to the parametric environment execution unit 194.
- the parametric environment execution unit 194 simulates the environment.
- the parametric environment execution unit 194 applies the value of the environment parameter p sampled by the environment parameter selection unit 195 to the simulation model, and simulates the operation of the controlled object and the like.
- Environmental parameter selection unit 195 in the simulation, the state s t, m for operation a t, m planners unit 191 outputs, these operations a t, m and state s t, compensation based on the m r t, and m Is calculated.
- m is an identifier representing one episode.
- t is an identifier representing one timing.
- "t, m" is an identifier representing the t-th timing of the m-th episode.
- the planner unit 191 determines the operation according to the state based on the operation rule. In the first turn of an episode, the planner unit 191 determines the action according to the initial state.
- the initial state referred to here is the initial value of the state.
- the user of the operation rule determining device 100 may give an initial state. Alternatively, the planner unit 191 may automatically set the initial state. From the second turn onward in one episode, the planner unit 191 determines the behavior according to the state calculated by the parametric environment execution unit 194 in the simulation of the previous turn.
- Planner unit 191 operates a t in one turn, m and state s t, m and reward r t, interaction history information summarized 1 episode fraction combines with m, to produce each episode.
- the planner unit 191 stores the interaction history information for each episode in the interaction history storage unit 182. That is, the planner unit 191 associates a series of operations with respect to the controlled object with the state after each operation and the state by using the degree information in which the state of the controlled object and the degree of desirability of the state are associated with each other. Find the degree to which it was done.
- the planner unit 191 generates interaction history information in which the obtained state and the degree related to the obtained state are combined, and stores the generated interaction history information in the interaction history storage unit 182.
- the risk-considered history generation unit 193 generates risk-considered history information according to the interaction history information. Specifically, the risk-considered history generation unit 193 reads the interaction history information from the interaction history storage unit 182, and reflects the risk in the read interaction history information. The risk-considered history generation unit 193 reads, for example, the degree of desirability of the state in one episode from the interaction history storage unit 182, and calculates the cumulative degree representing the accumulated degree of the read degree. When the cumulative degree satisfies the condition, the risk-considered history generation unit 193 reduces the degree associated with the state after a series of operations in the degree information.
- the risk-considered history generation unit 193 reduces the degree of desirability (reward) of the state in the interaction history information representing after a series of operations when the cumulative degree satisfies the condition. By such processing, the risk-considered history generation unit 193 reflects the risk in the read interaction history information.
- the condition referred to here may be indicated by, for example, the value of the reward (degree of desirability of the state) being equal to or less than a predetermined threshold value, but is not limited thereto.
- the risk-considered history generation unit 193 may reflect the risk in the interaction history information by, for example, subtracting an amount (risk portion) according to the cumulative degree from the reward of the episode including the risk. However, it is not limited to this.
- the risk-considered history generation unit 193 may perform a process of subtracting an amount (risk portion) according to the cumulative degree of the episode from the degree representing the final state of the episode in the degree information.
- the risk-considered history generation unit 193 outputs the generated risk-considered history information to the planner parameter setting unit 192.
- the planner parameter setting unit 192 determines the value of the planner parameter ⁇ based on the risk-considered history information.
- the planner parameter setting unit 192 determines the value of the planner parameter ⁇ so as to maximize the reward, such as maximizing the total reward (for example, the sum of the rewards in all turns of all episodes).
- the planner parameter setting unit 192 may update the planner parameter ⁇ so that the cumulative degree increases, for example.
- FIG. 3 is a flowchart showing an example of a processing procedure in which the operation rule determining device 100 determines a plan.
- the environment parameter selection unit 195 stochastically samples the environment parameters from the environment parameter set stored in the environment parameter set storage unit 183 (step S11).
- the environment parameter selection unit 195 transmits the sampled environment parameters to the parametric environment execution unit 194.
- the planner unit 191 and the parametric environment execution unit 194 interact with each other, and the history of the interaction is stored in the interaction history storage unit 182 (step S12). Specifically, the planner unit 191 determines the operation to be controlled, and the parametric environment execution unit 194 calculates the state for the operation in the environment according to the environment parameters. The parametric environment execution unit 194 may calculate the state of the controlled object after the operation by, for example, simulating the operation of the controlled object according to the parameter value. In addition, the parametric environment execution unit 194 calculates the reward based on the obtained state.
- the planner unit 191 determines the operation of the controlled object according to the state calculated by the parametric environment execution unit 194. In this way, the planner unit 191 and the parametric environment execution unit 194 repeat the determination of the operation, the calculation of the state, and the calculation of the reward until a predetermined end condition is satisfied.
- the planner unit 191 stores the history of the combination of the action, the state, and the reward in the interaction history storage unit 182 as the interaction history information.
- the risk-considered history generation unit 193 reads the risk from the interaction history information stored in the interaction history storage unit 182, and reflects the risk in the interaction history information (step S13). Then, the operation rule determining device 100 determines whether or not the predetermined end condition is satisfied (step S14).
- the termination condition here is not limited to a specific one as long as it can be determined whether or not the reinforcement learning is terminated by adopting the obtained plan. For example, as the termination condition here, whether the parameters are converged, the reflection of the risk in the plan satisfies a predetermined condition, or the execution of the interaction between the planner unit 191 and the parametric environment execution unit 194 is predetermined.
- step S14 NO
- step S14: YES the operation rule determining device 100 ends the process of FIG.
- the parametric environment execution unit 194 uses the degree information in which the state of the controlled object and the degree of desirability of the state are associated with each other to perform a series of operations with respect to the controlled object, and the state after each operation. And the degree associated with that state.
- the risk-considered history generation unit 193 calculates the cumulative degree obtained by accumulating the obtained degree for the series of operations, and when the cumulative degree satisfies the condition, associates the obtained degree with the state after the series of operations in the degree information. Decrease the above degree.
- the operation rule considering the risk can be obtained by determining the operation rule using the risk-considered interaction history information in which the risk is reflected. As a result, the planner who determines the operation according to the state can determine the operation in consideration of the risk.
- the planner parameter setting unit 192 updates the parameter value indicating the operation of the controlled object so that the cumulative degree increases. This makes it possible to obtain operating rules that take risks into consideration. As a result, in the operation rule determining device 100, as described above, the planner who determines the operation according to the state can determine the operation in consideration of the risk.
- the risk-considered history generation unit 193 calculates the above cumulative degree for each of a plurality of series of operations, obtains the calculated cumulative degree frequency, and determines the condition (reward) using the obtained frequency.
- the planner parameter setting unit 192 can obtain an operation rule in consideration of the risk by setting the value of the planner parameter based on the condition determined by the risk consideration type history generation unit 193.
- the planner unit 191 controls the control target according to the parameter value set by the planner parameter setting unit 192. As a result, the planner unit 191 can control the controlled object in consideration of the risk.
- the planner parameter setting unit 192 simulates the operation of the controlled object based on the parameter value.
- the parametric environment execution unit 194 can calculate the control result in consideration of the risk to the controlled object.
- the risk-considered history generation unit 193 reduces the amount according to the cumulative degree from the degree in the degree information. As a result, the risk-considered history generation unit 193 can generate interaction history information that reflects the risk.
- the planner parameter setting unit 192 sets the value of the planner parameter using the interaction history information reflecting the risk, so that the operation rule considering the risk can be obtained.
- the risk-considered history generation unit 193 has a risk detected from the interaction history information which is the history information of the combination of the operation of the controlled object, the state observed for the controlled object or the environment, and the reward according to the environment. Is reflected in the interaction history information to generate risk-considered interaction history information.
- the planner parameter setting unit 192 determines the value of the planner parameter, which is a parameter of the operation rule for determining the operation to be performed by the controlled object according to the state, based on the risk-considered interaction history information.
- the planner unit 191 determines the operation of the controlled object by using the operation rule in which the value of the planner parameter determined by the planner parameter setting unit 192 is set.
- the planner unit 191 may control the operation of the controlled object according to the value of the planner parameter.
- the operation rule determining device 100 by setting the parameter value of the operation rule using the risk-considered interaction history information in which the risk is reflected, the operation rule considering the risk can be obtained. As a result, the planner who determines the operation according to the state can determine the operation in consideration of the risk.
- the environment parameter selection unit 195 sets the value of the environment parameter, which is a parameter included in the simulation model of the environment, from the value that the environment parameter can take and the environment parameter set indicating the probability distribution of the value, based on the probability distribution. select.
- the parametric environment execution unit 194 simulates the environment using a simulation model in which the values of the environment parameters selected by the environment parameter selection unit 195 are set, and calculates information indicating the state. According to the operation rule determining device 100, the risk in an environment in which the behavior differs depending on the value of the environment parameter can be reflected in the operation rule.
- the risk-considered history generation unit 193 when the risk-considered history generation unit 193 satisfies the condition that the reward value indicated by the interaction history information is smaller than a predetermined value, the risk is reduced by reducing the reward value indicated by the interaction history information. Generate consideration-type interaction history information. In this way, the risk-considered history generation unit 193 can learn the operation rule based on the reward by reflecting the risk indicated by the value of the reward being smaller than the predetermined value in the reward. Further, the risk-considered history generation unit 193 may obtain a cumulative frequency for a plurality of episodes and determine a predetermined value using the obtained frequency. The risk-considered history generation unit 193 may determine a predetermined value at the quantile of the frequency distribution (for example, about 1%, about 5%, about 10%).
- the information represented by the two-dimensional coordinates is used as the position information of Hopper as the state. Further, as the operation, the numerical value of the torque for controlling the operation of Hopper is used.
- the parametric environment execution unit 194 will simulate the operation of Hopper using a physics simulator. The coefficient of friction of the ground in the simulation is used as the environmental parameter. Rewards shall be given according to Hopper's forward progress.
- the coefficient of friction between Hopper and the ground is also simply referred to as the coefficient of friction.
- Prob indicates the probability that the environment parameter will take the value shown in parentheses. Therefore, the environmental parameter selection unit 195 acquires the information that "the coefficient of friction is 2.0 with a probability of 0.9 and 0.1 with a probability of 0.1". The environmental parameter selection unit 195 selects the environmental parameter value according to the probability shown in the obtained environmental parameter set.
- step S12 of FIG. 3 the planner unit 191 and the parametric environment execution unit 194 interact with each other to accumulate the interaction history information in the interaction history storage unit 182.
- the interaction history information here is the history of the combination of the position information of the Hopper in the two-dimensional coordinates, the numerical value of the torque for operating the Hopper, and the reward.
- the maximum number of turns is set to three, and the planner unit 191 and the parametric environment execution unit 194 reach the maximum number of turns or the Hopper falls for each episode. The interaction shall be repeated until.
- FIG. 4 is a diagram showing an example of the first turn of the first episode. Therefore, FIG. 4 shows the initial state in the first episode.
- the Hopper 801 and the target position 802 are shown.
- the target position 802 is arranged at the position of the progress target of the Hopper 801.
- the target position 802 is fixed. Therefore, the target position 802 is located at the same position in any turn of any episode.
- FIG. 5 is a diagram showing an example of the second turn of the first episode. In the example of FIG. 5, the Hopper 801 is closer to the target position 802 than in the case of the first turn shown in FIG.
- FIG. 6 is a diagram showing an example of the third turn of the first episode.
- the Hopper 801 is closer to the target position 802 than in the case of the second turn shown in FIG.
- the interaction between the planner unit 191 and the parametric environment execution unit 194 ends.
- the planner unit 191 interacts with the position information of the Hopper 801 in the two-dimensional coordinates from the first turn to the third turn in the first episode, the numerical value of the torque for operating the Hopper 801 and the history of the combination of the reward. It is stored in the interaction history storage unit 182 as history information.
- FIG. 7 is a diagram showing an example of the first turn of the second episode. Therefore, FIG. 7 shows the initial state in the second episode.
- FIG. 8 is a diagram showing an example of the second turn of the second episode.
- Hopper 801 has fallen. Therefore, the interaction between the planner unit 191 and the parametric environment execution unit 194 ends. Then, the planner unit 191 displays the position information of the Hopper 801 in the two-dimensional coordinates from the first turn to the second turn in the second episode, the numerical value of the torque for controlling the operation of the Hopper 801 and the history of the combination of the reward. It is stored in the interaction history storage unit 182 as the interaction history information.
- FIG. 9 is a diagram showing an example of interaction history information.
- the interaction history information is shown in tabular form, with one row showing the interaction information in one turn.
- m indicates an episode identification number.
- t indicates the identification number of the turn.
- the motions at and m indicate the numerical values of the torques that control the motion of the Hopper 801 in the t-turn of the m-th episode.
- State s t, m is in the t-turn of the m episode, indicating the coordinates (position information) of Hopper801.
- the reward rt and m indicate the reward in the t-turn of the m-th episode.
- the reward is 0 because of the initial state in the episode.
- the reward is given according to the progress of Hopper 801 toward the target position 802.
- Hopper801 fell, so a reward of -10 is given.
- the risk-considered history generation unit 193 generates risk-considered interaction history information by reflecting the risk in the interaction history information.
- FIG. 10 is a diagram showing an example of risk-considered interaction history information.
- the states st and m of the interaction history information of FIG. 9 are replaced with the risk-considered state information s't and m , and the rewards rt and m are risks.
- the risk-considered interaction history information replaced by the considered-type reward r't , m is generated.
- the risk-considered history generation unit 193 generates risk-considered state information s't, m based on the equation (1).
- T m indicates the number of turns in the m-th episode.
- the storage unit 180 may store the threshold value v separately from the risk-considered state information s't, m .
- the risk-considered history generation unit 193 generates risk-considered rewards r't , m based on the equation (2).
- ⁇ is a coefficient that determines how important the penalty is.
- the process of penalizing the final state in the m-episode that is, the process of subtracting the reward in the final state from the given reward
- the process of penalizing the final state in the m-episode that is, the process of subtracting the reward in the final state from the given reward
- it can also be said that it represents.
- an operation is selected so that the state to be controlled reaches the final state even when the possibility (or frequency) of the final state occurring is low. It has the effect of reducing the possibility of That is, in the present embodiment, the risk can be said to be the case where the cumulative reward for the m-th episode is smaller than v.
- the threshold value v can be introduced by the equation (2) to extract the risk from the interaction history information. Specifically, an episode in which the cumulative reward is less than the threshold value v can be regarded as a risk.
- the risk-considered history generation unit 193 gives a penalty to the reward in order to make it difficult for the planner parameter setting unit 192 to select the behavior of such an episode when determining the value of the planner parameter.
- the risk-considered history generation unit 193 gives a penalty to the reward according to how much the cumulative reward falls below the threshold value v.
- the planner parameter setting unit 192 updates the value of the planner parameter based on the risk-considered interaction history information.
- a method for the planner parameter setting unit 192 to update the value of the planner parameter based on the risk-considered interaction history information a known method for generating an operation rule based on the reward can be used.
- the planner parameter setting unit 192 may update the value of the planner parameter by the policy gradient method using the equation (3).
- M indicates the number of episodes.
- T m indicates the number of turns in the m-th episode.
- ⁇ is a coefficient for adjusting the magnitude of updating the planner parameter ⁇ .
- s't, m , ⁇ ) indicates the probability that the operation at , m is selected under the states s't, m and the planner parameter ⁇ .
- s 't, m, ⁇ ) is, Logpai by ⁇ (a t, m
- the planner parameter setting unit 192 updates the value of the planner parameter ⁇ in the direction of the inclination indicated by ⁇ ⁇ log ⁇ (at , m
- the planner parameter setting unit 192 uses the planner parameter in the direction opposite to the direction of inclination indicated by ⁇ ⁇ log ⁇ (at , m
- the planner parameter setting unit 192 updates the value of the planner parameter ⁇ so as to maximize the cumulative value of the risk-considered reward r'by using the equation (3).
- the risk-considered history generation unit 193 subtracts the penalty from the reward of the episode including the risk, so that the probability that the action of the episode including the risk is selected is reduced.
- the operation rule determining device 100 is used for controlling the plant.
- the operation rule determining device 100 is applicable not only to the plant but also to various control targets to which reinforcement learning can be applied.
- the parametric environment execution unit 194 is configured to include a simulator of the plant to be controlled. The environment in the example of the third embodiment is provided by this simulator.
- the simulator model provided by the parametric environment execution unit 194 includes the outside air temperature around the plant as an environmental parameter.
- the possible outside air temperature around the plant is used as the environmental parameter set.
- the environmental parameter selection unit 195 for example, samples the outside air temperature from the truncated normal distribution.
- the interaction history information is generated by the combination of the planner unit 191 and the parametric environment execution unit 194, and stored in the interaction history storage unit 182.
- the planner unit 191 determines the operation according to the state.
- the parametric environment execution unit 194 sets the outside air temperature selected from the environment parameter set by the environment parameter selection unit 195 as the parameters of the simulator, and executes the simulation of the plant according to the set parameters.
- the parametric environment execution unit 194 calculates the state of the controlled object after the operation by simulation.
- the planner unit 191 calculates the reward based on the state and the operation.
- the parametric environment execution unit 194 calculates the simulation value of the value of the sensor installed in the plant such as the pressure sensor and the flow rate sensor as the state. Further, the planner unit 191 calculates a control command value for the plant as an operation, such as an opening command value of a predetermined flow rate control valve. The planner unit 191 may calculate the control command value for the plant by the PID (Proportional Integral Differential) control value, but the present invention is not limited to this. In addition, the planner unit 191 calculates the reward according to the amount of deliverables calculated by the plant simulation by the parametric environment execution unit 194, such as the amount of ethylene or the amount of gasoline.
- PID Proportional Integral Differential
- FIG. 11 is a diagram showing a data flow in the operation rule determining device 100 according to the third embodiment.
- 28 ° C. and 10 ° C. are shown as the values of the environmental parameters selected by the environmental parameter selection unit 195
- the parametric environment execution unit 194 is configured to include the plant simulator. It differs from the case of FIG. 2 in that it is clearly shown.
- FIG. 11 is similar to FIG.
- the operation rule determining device 100 can calculate the control command value in consideration of the risk of the outside air temperature by determining the operation rule in consideration of the risk in the setting of the possible outside air temperature.
- the operation rule determining device 100 considers the risk caused by the uncertainty of the outside air temperature in the plant control plan. Can be presented to the plant operator.
- the operation rule determining device 100 may determine the operation rule in addition to or instead of the outside air temperature, using a possible equipment failure as an environmental parameter. As a result, the operation rule determining device 100 can present the plant operator with plant control so that the disadvantage in the event of equipment failure is relatively small. Alternatively, the operation rule determining device 100 may determine the operation rule with a possible natural disaster as an environmental parameter. As a result, the operation rule determining device 100 can present the plant operator with plant control so that the disadvantage in the event of a natural disaster is relatively small.
- FIG. 12 is a diagram showing an example of the configuration of the operation rule determining device according to the fourth embodiment.
- the operation rule determination device 500 includes an environment execution unit 501 and a risk-considered history generation unit 502.
- the environment execution unit 501 uses the degree information associated with the state of the controlled object and the degree of desirability of the state to obtain the state after each operation and the state after each operation for a series of operations with respect to the controlled object. Find the degree associated with that state.
- the risk-considered history generation unit 502 calculates the cumulative degree obtained by accumulating the obtained degree for the series of operations, and when the cumulative degree satisfies the condition, associates the obtained degree with the state after the series of operations in the degree information. Decrease the above degree.
- the operation rule considering the risk can be obtained by determining the operation rule using the risk-considered interaction history information reflecting the risk.
- the planner who determines the operation according to the state can determine the operation in consideration of the risk.
- FIG. 13 is a diagram showing an example of a processing procedure in the operation rule determining method according to the fifth embodiment.
- the operation rule determination method shown in FIG. 13 includes the steps S51 to S52.
- step S51 the computer associates a series of operations with respect to the controlled object with the state after each operation and the state by using the degree information in which the state of the controlled object and the degree of desirability of the state are associated with each other. Find the degree to which it was done.
- step S52 the computer calculates the cumulative degree obtained by accumulating the obtained degree for a series of operations, and when the cumulative degree satisfies the condition, the degree associated with the state after the series of operations in the degree information is calculated. Decrease.
- step S53 the operation to be performed by the control target is determined by using the operation rule in which the value of the planner parameter determined by the parameter setting unit is set.
- an operation rule considering the risk can be obtained by determining the operation rule using the risk-considered interaction history information reflecting the risk.
- the planner who determines the operation according to the state can determine the operation in consideration of the risk.
- FIG. 14 is a schematic block diagram showing the configuration of a computer according to at least one embodiment.
- the computer 700 includes a CPU 710, a main storage device 720, an auxiliary storage device 730, and an interface 740. Any one or more of the above-mentioned operation rule determination device 100 and the operation rule determination device 500 may be mounted on the computer 700. In that case, the operation of each of the above-mentioned processing units is stored in the auxiliary storage device 730 in the form of a program.
- the CPU 710 reads the program from the auxiliary storage device 730, expands it to the main storage device 720, and executes the above processing according to the program.
- the CPU 710 secures a storage area corresponding to each of the above-mentioned storage units in the main storage device 720 according to the program. Communication between each device and other devices is executed by having the interface 740 have a communication function and performing communication according to the control of the CPU 710.
- the operations of the control unit 190 and each unit thereof are stored in the auxiliary storage device 730 in the form of a program.
- the CPU 710 reads the program from the auxiliary storage device 730, expands it to the main storage device 720, and executes the above processing according to the program. Further, the CPU 710 secures a storage area corresponding to the storage unit 180 in the main storage device 720 according to the program.
- the communication performed by the communication unit 110 is executed by the interface 740 having a communication function and performing communication according to the control of the CPU 710.
- the operations of the environment execution unit 501 and the risk-considered history generation unit 502 are stored in the auxiliary storage device 730 in the form of a program.
- the CPU 710 reads the program from the auxiliary storage device 730, expands it to the main storage device 720, and executes the above processing according to the program.
- a program for realizing all or a part of the functions of the operation rule determining device 100 or the operation rule determining device 500 is recorded on a computer-readable recording medium, and the program recorded on the recording medium is recorded on the computer. You may process each part by loading it into the system and executing it.
- the term "computer system” as used herein includes hardware such as an OS (operating system) and peripheral devices.
- "Computer readable recording medium” includes flexible disks, magneto-optical disks, portable media such as ROM (Read Only Memory) and CD-ROM (Compact Disc Read Only Memory), hard disks built into computer systems, and the like.
- the above-mentioned program may be a program for realizing a part of the above-mentioned functions, and may be a program for realizing the above-mentioned functions in combination with a program already recorded in the computer system.
- the embodiment of the present invention may be applied to an operation rule determining device, an operation rule determining method, and a recording medium.
- Operation rule determination device 110 Communication unit 180 Storage unit 181 Planner parameter storage unit 182 Interaction history storage unit 183 Environmental parameter set storage unit 190 Control unit 191 Planner unit 192 Planner parameter setting unit 193, 502 Risk consideration type history generation unit 194 Parametric environment execution unit 195 Environment parameter selection unit 501 Environment execution unit
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Automation & Control Theory (AREA)
- Artificial Intelligence (AREA)
- Emergency Management (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Business, Economics & Management (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Alarm Systems (AREA)
- Traffic Control Systems (AREA)
- Feedback Control In General (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/020324 WO2020235061A1 (ja) | 2019-05-22 | 2019-05-22 | 動作規則決定装置、動作規則決定方法および記録媒体 |
| US17/611,694 US12093001B2 (en) | 2019-05-22 | 2019-05-22 | Operation rule determination device, method, and recording medium using frequency of a cumulative reward calculated for series of operations |
| JP2021519989A JP7173317B2 (ja) | 2019-05-22 | 2019-05-22 | 動作規則決定装置、動作規則決定方法およびプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/020324 WO2020235061A1 (ja) | 2019-05-22 | 2019-05-22 | 動作規則決定装置、動作規則決定方法および記録媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020235061A1 true WO2020235061A1 (ja) | 2020-11-26 |
Family
ID=73458170
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/020324 Ceased WO2020235061A1 (ja) | 2019-05-22 | 2019-05-22 | 動作規則決定装置、動作規則決定方法および記録媒体 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US12093001B2 (https=) |
| JP (1) | JP7173317B2 (https=) |
| WO (1) | WO2020235061A1 (https=) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11645498B2 (en) * | 2019-09-25 | 2023-05-09 | International Business Machines Corporation | Semi-supervised reinforcement learning |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011014038A (ja) * | 2009-07-03 | 2011-01-20 | Fuji Heavy Ind Ltd | オンラインリスク認識システム |
| JP2013225192A (ja) * | 2012-04-20 | 2013-10-31 | Nippon Telegr & Teleph Corp <Ntt> | 報酬関数推定装置、報酬関数推定方法、およびプログラム |
| WO2018181020A1 (ja) * | 2017-03-29 | 2018-10-04 | 三菱重工業株式会社 | 予兆検知システム及び予兆検知方法 |
| JP2018165693A (ja) * | 2017-03-28 | 2018-10-25 | パナソニックIpマネジメント株式会社 | 運転支援方法およびそれを利用した運転支援装置、自動運転制御装置、車両、プログラム、提示システム |
| JP2019020885A (ja) * | 2017-07-13 | 2019-02-07 | 横河電機株式会社 | プラント制御支援装置、プラント制御支援方法、プラント制御支援プログラム及び記録媒体 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5750657B2 (ja) * | 2011-03-30 | 2015-07-22 | 株式会社国際電気通信基礎技術研究所 | 強化学習装置、制御装置、および強化学習方法 |
| CN106101379B (zh) * | 2016-05-26 | 2019-08-06 | Oppo广东移动通信有限公司 | 一种移动终端的防沉迷方法、装置及移动终端 |
| JP6453922B2 (ja) * | 2017-02-06 | 2019-01-16 | ファナック株式会社 | ワークの取り出し動作を改善するワーク取り出し装置およびワーク取り出し方法 |
| KR20180096113A (ko) * | 2017-02-20 | 2018-08-29 | 엘지전자 주식회사 | 설비 기기 제어 시스템 |
| JP6895334B2 (ja) * | 2017-07-11 | 2021-06-30 | 株式会社東芝 | 運用ルール抽出装置、運用ルール抽出システムおよび運用ルール抽出方法 |
| JP7379833B2 (ja) * | 2019-03-04 | 2023-11-15 | 富士通株式会社 | 強化学習方法、強化学習プログラム、および強化学習システム |
-
2019
- 2019-05-22 US US17/611,694 patent/US12093001B2/en active Active
- 2019-05-22 WO PCT/JP2019/020324 patent/WO2020235061A1/ja not_active Ceased
- 2019-05-22 JP JP2021519989A patent/JP7173317B2/ja active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011014038A (ja) * | 2009-07-03 | 2011-01-20 | Fuji Heavy Ind Ltd | オンラインリスク認識システム |
| JP2013225192A (ja) * | 2012-04-20 | 2013-10-31 | Nippon Telegr & Teleph Corp <Ntt> | 報酬関数推定装置、報酬関数推定方法、およびプログラム |
| JP2018165693A (ja) * | 2017-03-28 | 2018-10-25 | パナソニックIpマネジメント株式会社 | 運転支援方法およびそれを利用した運転支援装置、自動運転制御装置、車両、プログラム、提示システム |
| WO2018181020A1 (ja) * | 2017-03-29 | 2018-10-04 | 三菱重工業株式会社 | 予兆検知システム及び予兆検知方法 |
| JP2019020885A (ja) * | 2017-07-13 | 2019-02-07 | 横河電機株式会社 | プラント制御支援装置、プラント制御支援方法、プラント制御支援プログラム及び記録媒体 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2020235061A1 (https=) | 2020-11-26 |
| US20220197230A1 (en) | 2022-06-23 |
| JP7173317B2 (ja) | 2022-11-16 |
| US12093001B2 (en) | 2024-09-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11627165B2 (en) | Multi-agent reinforcement learning with matchmaking policies | |
| CN113168566B (zh) | 通过使用熵约束来控制机器人 | |
| KR102857413B1 (ko) | 리스크 척도를 나타내는 파라미터에 기반하여 훈련된 모델을 사용하여, 주어진 상황에 대한 디바이스의 행동을 결정하는 방법 및 시스템 | |
| US8326780B2 (en) | Smoothed sarsa: reinforcement learning for robot delivery tasks | |
| CN112388628B (zh) | 用于训练高斯过程回归模型的设备和方法 | |
| US12162150B2 (en) | Learning method, learning apparatus, and learning system | |
| CN113671942B (zh) | 用于控制机器人的设备和方法 | |
| WO2020065001A1 (en) | Learning motor primitives and training a machine learning system using a linear-feedback-stabilized policy | |
| CN110546653A (zh) | 使用神经网络的用于强化学习的动作选择 | |
| CN118493364B (zh) | 一种绳驱柔性臂的末端位置控制方法 | |
| JP7180696B2 (ja) | 制御装置、制御方法およびプログラム | |
| JP7468619B2 (ja) | 学習装置、学習方法、及び、記録媒体 | |
| JP7336856B2 (ja) | 情報処理装置、方法及びプログラム | |
| US20240198518A1 (en) | Device and method for controlling a robot | |
| WO2020235061A1 (ja) | 動作規則決定装置、動作規則決定方法および記録媒体 | |
| JP7626239B2 (ja) | 学習装置、学習方法、制御システムおよびプログラム | |
| US11514268B2 (en) | Method for the safe training of a dynamic model | |
| JP2023175199A (ja) | 学習装置、制御装置、ロボットシステム、学習方法、およびプログラム | |
| EP3995377A1 (en) | Latency mitigation system and method | |
| US20240330702A1 (en) | Learning device, learning method, and storage medium | |
| JP7574940B2 (ja) | 動作規則決定装置、動作規則決定方法およびプログラム | |
| KR20230079804A (ko) | 상태 전이를 선형화하는 강화 학습에 기반한 전자 장치 및 그 방법 | |
| JP7754309B2 (ja) | 学習装置、学習方法およびプログラム | |
| JP7611763B2 (ja) | シミュレーション装置及びシミュレーション方法 | |
| Schmidt-Rohr et al. | Bridging the Gap of Abstraction for Probabilistic Decision Making on a Multi-Modal Service Robot. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19929993 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021519989 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19929993 Country of ref document: EP Kind code of ref document: A1 |