WO2016136766A1 - 核酸配列増幅方法 - Google Patents
核酸配列増幅方法 Download PDFInfo
- Publication number
- WO2016136766A1 WO2016136766A1 PCT/JP2016/055314 JP2016055314W WO2016136766A1 WO 2016136766 A1 WO2016136766 A1 WO 2016136766A1 JP 2016055314 W JP2016055314 W JP 2016055314W WO 2016136766 A1 WO2016136766 A1 WO 2016136766A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sequence
- primer
- nucleic acid
- acid sequence
- additional nucleic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images













Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6806—Preparing nucleic acids for analysis, e.g. for polymerase chain reaction [PCR] assay
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6844—Nucleic acid amplification reactions
- C12Q1/6851—Quantitative amplification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6844—Nucleic acid amplification reactions
- C12Q1/686—Polymerase chain reaction [PCR]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
- C12Q1/6874—Methods for sequencing involving nucleic acid arrays, e.g. sequencing by hybridisation
Definitions
- the present invention relates to a nucleic acid sequence amplification method for preparing a sample for quantifying mRNA using a next-generation sequencer, in particular, a next-generation sequencer at a small number of cells, preferably at a single cell level.
- the present invention relates to a nucleic acid sequence amplification method that enables quantitative analysis of mRNA.
- Quantitative transcriptome analysis in single cells is an important tool for embryology, stem cell and cancer research.
- it is necessary to amplify cDNA produced by reverse transcription of mRNA in the single cell, and two methods are proposed as this amplification method.
- One is an amplification method by PCR, and the other is an amplification method by T7 RNA polymerase.
- PCR is used, the amplification efficiency is high, and it is a simple and highly stable method, so it is very useful for transcriptome analysis of a single cell.
- RNA-seq RNA sequencing
- Non-Patent Documents 6 to 10 In order to proceed with absolute quantification of transcripts, single molecule identification (UMI) in which a tag is attached to the 5 'side or 3' side of the first cDNA is performed (Non-Patent Documents 6 to 10). In addition, a method of analyzing by recognizing individual cells by a barcode sequence, a method of capturing a single cell by a microchannel, and the like have been proposed (Non-patent Documents 11 and 12).
- RNA-seq is often accompanied by PCR amplification as described above, but PCR does not have a 100% amplification rate, so the reproducibility of the copy number after amplification is particularly small when amplified from a small number of copies. bad.
- PCR does not have a 100% amplification rate, so the reproducibility of the copy number after amplification is particularly small when amplified from a small number of copies. bad.
- the analysis unit price per cell is high, so it is difficult to analyze many cells.
- the sample obtained by the conventional nucleic acid sequence amplification method is intended for the full length of cDNA, the longer the cDNA, the lower the quantitativeness of mRNA analysis using the next-generation sequencer.
- a method for amplifying a nucleic acid sequence for preparing a sample with higher quantitativeness at low cost is required.
- the following method is used to amplify cDNA using the poly-A sequence of mRNA, and after further fragmenting, a primer sequence is selectively added, so that only the 3 ′ end is added.
- a sample containing was successfully obtained.
- SC3-seq Single-cell-mRNA- 3'end-sequence
- the present invention relates to the following: [1] A method for preparing a nucleic acid population containing an amplification product retaining a relative relationship between gene expression levels in a biological sample,
- A A double-stranded DNA composed of an arbitrary additional nucleic acid sequence X, a poly T sequence, an mRNA sequence isolated from a biological sample, a poly A sequence and an optional additional nucleic acid sequence Y as a template, 5 'Includes a first primer, optionally containing an additional nucleic acid sequence X with an amine added, and optionally further comprising a poly T sequence downstream thereof; and an optional additional nucleic acid sequence Y, optionally comprising a poly Amplifying the double-stranded DNA using a second primer that may further comprise a T sequence;
- B a step of fragmenting the double-stranded DNA obtained by the step (a),
- C phosphorylating the 5 ′ end of the fragmented duplex DNA obtained by the step (b),
- D A method for
- a method comprising a step of amplifying the double-stranded DNA using a good fifth primer.
- the strand DNA is prepared by a method comprising the following steps: (I) a step of preparing primary strand cDNA by reverse transcription using mRNA isolated from a biological sample as a template and a sixth primer comprising said additional nucleic acid sequence Y and poly T sequence; (Ii) The primary strand cDNA obtained in the step (i) is subjected to a poly A tailing reaction, and a secondary primer is then used as a template using a seventh primer comprising the additional nucleic acid sequence X and the poly T sequence.
- a step of preparing a double-stranded DNA as a strand, and (iii) the double-stranded DNA obtained by the step (ii) contains the additional nucleic acid sequence X and optionally further contains a poly T sequence downstream thereof.
- Amplifying using a good eighth primer and a ninth primer which contains the additional nucleic acid sequence Y and optionally further may contain a poly T sequence downstream thereof.
- the step (c) further includes a step of selecting a fragmented double-stranded DNA having a size of 200 to 250 bases or 300 to 350 bases.
- the method according to claim 1. [6] The method according to any one of [1] to [5], wherein in step (a), amplification is performed by PCR of 2 to 8 cycles.
- step (f) The method according to any one of [1] to [6], wherein in step (f), the amplification is performed by PCR of 5 to 20 cycles.
- the step (iii) the amplification is performed by PCR of 5 to 30 cycles.
- a kit for preparing a cDNA population to be applied to the measurement of the amount of mRNA by a next-generation sequencer including: (A) a first primer that includes an optional additional nucleic acid sequence X with an amine added to the 5 ′ end and optionally further includes a poly-T sequence downstream thereof; (b) includes an optional additional nucleic acid sequence Y; A second primer that may further comprise a poly-T sequence downstream thereof (c) may comprise any additional nucleic acid sequence Z and said additional nucleic acid sequence Y in this order, optionally further comprising a poly-T sequence downstream thereof Third primer (d) Double-stranded DNA containing an arbitrary sequence V having thymine (T) as an overhang at the 3 ′ end (E) a fourth primer comprising the sequence V; (f) a fifth primer comprising the additional nucleic acid sequence Z and optionally further comprising the additional nucleic acid sequence Y downstream thereof [14] of (f) The kit according to [13], wherein the fifth primer further
- the present invention provides a reliable, quantitative, and extremely small amount of cDNA amplification technology that can be directly applied to oligonucleotide microarrays by a simple PCR method.
- the method of the present invention it is possible to synthesize and amplify a sufficient amount of template cDNA from a single cell for a microarray experiment in one day experiment.
- Comparison between the conventional method and the method of the present invention was performed using real-time PCR experiments using several gene products as probes, and it was confirmed that both systematic error (systematic error) and random error were remarkably improved. It was done.
- transcriptome analysis experiments conducted using the method of the present invention it was confirmed that quantitative analysis at the single cell level with much better reproducibility was possible than the conventional method. It was.
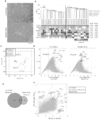
- FIG. 1A shows a conceptual diagram of SC3-seq.
- SC3-seq means that only the 3 'end side indicated by the broken line frame in the figure is to be analyzed.
- FIG. 1B shows a graph in which genes encoding 21,254 proteins annotated in the mouse mm10 database are arranged according to the length of the transcript (left figure).
- the right figure is a graph showing that when the total length of all transcripts is 60 Mbp, the total of 200 bp from the 3 'end of all transcripts is only 4 Mbp.
- FIG. 1C shows the SC3-seq scheme.
- the left figure shows the steps of cDNA synthesis and amplification, and the right figure shows the steps of library construction.
- FIG. 1A shows a conceptual diagram of SC3-seq.
- FIG. 1B shows a graph in which genes encoding 21,254 proteins annotated in the mouse mm10 database are arranged according to the length of the transcript (left figure).
- 1D is a graph plotting average SC3-seq tracks (read density (RPM, ⁇ 1,000 reads) against the position of reads from the annotated TTS (transcription termination site) at 100 ng of RNA extracted from mESC.
- the red line indicates the track of the lead mapped with the sense strand
- the blue line indicates the track of the lead mapped with the antisense strand
- Fig. IE shows SC3 of the Pou5f1 and Nanog loci.
- -seq indicates the position of the lead
- the red peak indicates the lead mapped with the sense strand
- the blue peak indicates the lead mapped with the antisense strand
- FIG. 1G shows the number of genes (black bars) or the number of mis-annotated genes due to the expanded definition of TTS.
- the number of genes more than twice the definition of TTS expanded to 10 Kb ( ⁇ 2, ⁇ in Fig. 1F) 205 genes presenting 3, x 4) were detected by comparison with published RNA-seq data for the correct number of genes or mis-annotated genes.
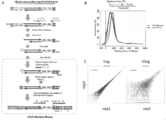
- Fig. 2A shows the amplified cDNA expressed by Q-PCR (CT value) for each SC3-seq [log 2 (RPM + 1)] (1 ng before SC3-seq library construction (middle)).
- FIG. 2B shows the amount of ERCC RNA and SC3-seq [SC 2 -seq [log 2 (RPM + 1)] in dilutions of total mESC RNA (MS01T01 and MS01T17, 100 ng and 10 pg, respectively). log 2 (RPM + 1)] is a graph showing the relationship between the level. SC3-seq data for ERCC spike-in RNA with more than 10 copies per 10 pg was used for the regression line.
- FIG. 1 shows the amount of ERCC RNA and SC3-seq [SC 2 -seq [log 2 (RPM + 1)] in dilutions of total mESC RNA (MS01T01 and MS01T17, 100 ng and 10 pg, respectively). log 2 (RPM + 1)] is a graph showing the relationship between the level. SC3-seq data for ERCC spike-in RNA with more than 10 copies per 10 pg was used for the regression line.
- 2C is a scatter plot showing a comparison between two independently amplified replicates from 100 ng, 10 ng, 1 ng, 100 pg and 10 pg of total mESC RNA.
- white and yellow regions indicate expression levels with a difference of 2 and 4 times, respectively.
- the number of copies per 10 pg total RNA detected by SC3-seq read of ERCC spike-in RNA in 100 ng RNA is indicated by a dotted line (vertical line) (from the right, 1,000 copies, 100 copies, 10 copies and 1 copy).
- 2D is a scatter plot showing a comparison between replicates from 10 ng, 1 ng, 100 pg, and 10 pg of total RNA of mESC and replicates from 100 ng of total RNA.
- white and yellow regions indicate expression levels with a difference of 2 and 4 times, respectively.
- the number of copies per 10 pg total RNA detected by SC3-seq read of ERCC spike-in RNA in 100 ng RNA is indicated by a dotted line (vertical line) (from the right, 1,000 copies, 100 copies, 10 copies and 1 copy).
- FIG. 2E shows a scatter plot comparing 100 ng average SC3-seq data (log 2 (RPM + 1)) of total RNA of mESC with average SC3-seq data of 10 pg total RNA.
- white and yellow regions indicate expression levels with a difference of 2 and 4 times, respectively.
- the number of copies per 10 pg total RNA detected by SC3-seq read of ERCC spike-in RNA in 100 ng RNA is indicated by a dotted line (vertical line) (from the right, 1,000 copies, 100 copies, 10 copies and 1 copy).
- FIG. 2F is a graph plotting standard deviation of gene expression level against gene expression level by SC3-seq in 8 10 pg RNA samples. Fig.
- FIG. 2G shows genes with minimum (min) and maximum (max) correlation coefficients (R 2 ) and differential expression of 2-fold and 4-fold (all gene expression and genes expressed over 20 copies per 10 pg) The relationship which compared the percentage of is shown.
- FIG. 2H is a graph showing the total number of mRNA molecules per 10 pg RNA calculated from the copy number of ERCC spike-in RNA in 100 ng, 10 ng, 1 ng, 100 pg and 10 pg mESC total RNA.
- FIG. 3A is a graph showing SC3-seq coverage from 10 pg total RNA as a function of expression level (log 2 (RPM + 1)) in 100 ng total RNA. The black line shows the average value of coverage in a single sample convolution.
- FIG. 3B is a graph showing the accuracy (Accuracy) of SC3-seq from 10 pg total RNA as a function of expression level (log 2 (RPM + 1)). The black line shows the average value of accuracy in a single sample.
- FIG. 3C shows 100 ng, 10 ng, 1 ng, 100 gene counts (log 2 (RPM + 1) ⁇ 4, ⁇ 2 times compared to the gene expression level determined by full-length reads) as the function of reads.
- FIG. 5 is a graph plotted for each SC3-seq from total RNA of pg and 10 pg mESC.
- Figure 3D shows 10 pg of mESC total RNA as a function of read, as a percentage ( ⁇ 2 fold compared to gene expression levels determined by full length reads) classified by the range of expression levels in 100 ng total RNA. Is a graph plotted for each SC3-seq.
- FIG. 1 shows 10 pg of mESC total RNA as a function of read, as a percentage ( ⁇ 2 fold compared to gene expression levels determined by full length reads) classified by the range of expression levels in 100 ng total RNA.
- 4A shows SC3-seq (100 ng (1 replication, MS01T01), 10 ng (1 replication, MS01T05) and 10 pg (1 replication, MS01T17)) diluted samples from total RNA and single Diluted sample from total RNA of HEK293 with 1 mESC (MS04T18) and single human ESC (MS04T66)), Smart-seq2 (1 ng (Smart-seq2_1ng, HEK_rep1) and 10 pg (Smart-seq2_10 pg, HEK_rep1) , And single mESC and single mouse embryonic fibroblasts (Smart-seq2_MEF, single replication)) and single cell RNA-seq (single human ESC (Yan_hESC_1) and full-length RNA- This is a graph plotting the expression level detected by seq (Ohta_mESC and Ohta_MEF) and the length of the transcript.The expression level by SC3-seq is expressed
- Fig. 4C is a graph showing the distribution of reads mapped at the 3 'end of transcripts by RNA-seq by cells
- Fig. 4C shows the mapping by length of transcripts by RNA-seq by three single cells.
- 4D shows all three single-cell RNA-seq methods (above) and short transcripts (less than 1 Kbp, 913 and 832 genes in mouse and human, respectively) ) (Below) detection limit (in mouse and human, gene expression levels higher than 6655th and 6217th, respectively (1/4 of all transcripts annotated for mouse and human), ⁇ log 2 RPM ⁇ 3.69 ⁇ 0.05 (SC3-seq), ⁇ log 2 FPKM ⁇ 2.21 ⁇ 1.28 (Yan et al.), And ⁇ log 2 FPKM ⁇ 2.92 ⁇ 0.27 (Picelli et al.), Compared to gene expression level by full length read And ⁇ 2 times) That.
- FIGS. 5A and B show Unsupervised hierarchical clustering (UHC) (FIG. 5A) and epiblasts, primitive endoderm (PE) with all expressed genes (log 2 (RPM + 1) ⁇ 4, 12,010 genes in all samples)
- FIG. 5B shows a heat map (FIG. 5B) of expression levels of marker genes for trophectoderm (TE).
- Annotated cell types epiblast, PE, polar TE and wall TE were defined by classification, location and marker gene expression.
- FIG. 5C shows the results of the principal component analysis (PCA) of the cells with all the expressed genes. Shown as an expanded view on PC1 and PC2 (top) or PC1 and PC3 (bottom).
- 5D is a graph plotting the difference in mean gene expression between epiblast (9 samples) and PE (9 samples) (left) and between mTE (9 samples) and pTE (10 samples) (right). is there.
- the difference in gene expression indicates a difference of 4 times or more in one cell type having an average log 2 (RPM + 1) ⁇ 4.
- the genes whose expression is elevated in PE (504 gene), epiblast (309 gene), pTE (231 gene) and mTE (391 gene) are shown in blue, green, yellow and red, respectively.
- FIG. 5E is a graph showing the expression of genes whose expression is increased in mTE (left figure) or pTE (right figure) among the four cell types. In the figure, the bar in the box indicates the average expression level.
- FIG. 1 is a graph plotting the difference in mean gene expression between epiblast (9 samples) and PE (9 samples) (left) and between mTE (9 samples) and pTE (10 samples) (right). is there.
- the difference in gene expression indicates a difference of 4 times
- FIG. 5F shows the results of Gene ontology (GO) analysis of genes whose expression is increased by mTE (upper panel) or pTE (lower panel).
- FIG. 5G is a graph showing the average gene expression level calculated based on the copy number of ERCC spike-in RNA in four cell types. In the figure, the bar in the box indicates the average expression level.
- FIG. 6A shows hiPSC colonies (585B1) cultured on SNL feeder cells (top figure) and phase contrast microscopic images of the same cells cultured on feeder-free conditions.
- FIG. 6B shows a heat map of UHC results and gene expression levels for all expressed genes (log 2 (RPM + 1) ⁇ 4, 12,406 genes in all samples).
- FIG. 6C shows the PCA results for all cells with all genes expressed.
- FIG. 6D shows hiPSC gene expression on feeder cells (left) and feeder-free conditions (right) with the maximum expression level in each group (MS04T72, MS04T67 and MS04T78 in FIG. 6C) with standard deviation (SD). The graph plotted against is shown. Genes with maximum gene expression levels of ⁇ 6 and SD of ⁇ 2 were defined as heterogeneously expressed genes (699 genes for hiPSC cultured on feeder cells, 61 genes for hiPSC in feeder-free conditions).
- FIG. 6E shows a Venn diagram representing the relationship of heterogeneously expressed genes in FIG. 6D.
- FIG. 6F shows a graph plotting SD values of gene expression levels in hiPSCs cultured on feeder cells and hiPSCs in feeder-free conditions.
- FIG. 7A shows a schematic diagram of the mechanism that allows library construction at the 3 'end with SC3-seq. 3 shows that after fragmentation, three fragments are generated: a fragment having a V3 tag at the 5 ′ end, a fragment having no tag, and a fragment having a V1 tag. All of these are polished and shown to be phosphorylated at the blunt end.
- the Int sequence is added only to the fragment having the 3 'end to which the V1 tag is added.
- FIG. 7B shows the results of Q-PCR of the amplification levels of ERCC spike-in RNA amplified from 100 ng, 10 ng, 1 ng, 100 pg, and 10 pg of ESC total RNA. The number of copies per 10 pg RNA and the corresponding ERCC code are shown.
- FIG. 7C shows the expression level (Q-PCR CT value) and SC3 ⁇ of the amplified cDNA (V1V3 cDNA from total RNA of 1 ng (middle, 4 samples) and 10 pg (right, 16 samples)).
- the graph which compared the expression level (CT value of Q-PCR) of a seq library is shown (it was set as MS01T05 and MS01T17 with respect to 1 ng and 10 pg of total RNA, respectively).
- the left figure shows a conceptual diagram of the comparison method.
- FIG. 8A shows the detection of reads at the Let7a-7d locus.
- FIG. 8B shows the detection of reads at the Mir290-295 locus.
- Non-coding D7Ertd143e represents the precursor of Mir290-295.
- the upper panel shows the mapping with the sense strand of SC3-seq
- the middle panel shows the mapping with the antisense strand of SC3-seq
- the lower panel shows the mapping with Ohta et al.
- FIG. 8C shows detection of reads at the Mir684-1 locus.
- a single miRNA is encoded in the intron of the gene encoding Dusp19.
- the upper panel shows the mapping with the sense strand of SC3-seq
- the middle panel shows the mapping with the antisense strand of SC3-seq
- the lower panel shows the mapping with Ohta et al.
- FIG. 8D shows detection of unclassified noncoding RNA (Gm19693) reads. Annotated with the reverse strand at the 3 'end of H2afz.
- the upper panel shows the mapping with the sense strand of SC3-seq
- the middle panel shows the mapping with the antisense strand of SC3-seq
- the lower panel shows the mapping with Ohta et al.
- Figure 9A shows mESC total RNA (100 ng: 2 replicates, 10 ng: 2 replicates, 1 ng: 4 replicates, 100 pg: 8 replicates, 10 pg: 16 replicates)
- the relationship between the amount of ERCC RNA after dilution and the calculated level of ERCC spike-in RNA by SC3-seq (log 2 (RPM + 1)) is shown.
- SC3-seq data for ERCC spike-in RNA with more than 10 copies per 10 pg was used for the regression line.
- FIG. 9B shows a heat map of the correlation coefficient (R 2 ) between all samples measured by SC3-seq from a dilution of total RNA of ESC and all samples amplified (the left figure is all The right figure shows the data with 20 or more copies of the expressed gene per 10 pg).
- FIG. 9C shows the maximum value (max) and the minimum value (min) of the pairwise correlation coefficient between the groups shown in FIG. 9B (the left figure shows the data for all the expressed genes, the right figure Shows data with 20 copies or more of the expressed gene per 10 pg).
- FIG. 10A shows a heat map of the correlation coefficient of diluted sample cans measured with diluted samples amplified with SC3-seq (left) and Smart-seq2 (right).
- FIG. 10B shows the maximum value (max) and the minimum value (min) of the pairwise correlation coefficient between the groups shown in FIG. 10A (the left figure is SC3-seq, the right figure is Smart-seq2). .
- 10C shows all RNA-seq transcripts (upper left), transcripts less than 1 Kbp (lower left), transcripts less than 750 bp (upper right) and transcripts less than 500 bp (upper right)
- the results of the detection limit analysis shown in the lower right figure are shown (in the mouse and human, respectively, the gene expression levels of the top 6555 and above and 6217 and above (1/4 of all transcripts annotated for mouse and human respectively) ) ⁇ Log 2 RPM ⁇ 3.69 ⁇ 0.05 (SC3-seq), ⁇ log 2 FPKM ⁇ 2.21 ⁇ 1.28 (Yan et al.) And ⁇ log 2 FPKM ⁇ 2.92 ⁇ 0.27 (Picelli et al.) ⁇ 2 times compared to gene expression level).
- FIG. 11A shows immunofluorescent staining analysis of the expression of marker genes (NANOG (epiblast), POU5F1 (epiblast and PE), GATA4 (PE) and CDX2 (TE)) in the preimplantation embryo on day E4.5. Results are shown. The scale bar is 100 ⁇ m.
- FIG. 11B shows marker genes (NANOG (epiblast), GATA4 (PE), CDX2 (TE) and Gapdh in single-cell amplified cDNA (67 cDNAs of quality confirmed) of E4.5 day pre-implantation embryo. The results of Q-PCR analysis of (housekeeping) expression are shown.
- FIG. 11A shows immunofluorescent staining analysis of the expression of marker genes (NANOG (epiblast), POU5F1 (epiblast and PE), GATA4 (PE) and CDX2 (TE)) in the preimplantation embryo on day E4.5. Results are shown.
- the scale bar is 100 ⁇ m.
- FIG. 11B shows marker genes (NA
- FIG. 11C shows a scatter plot comparing the ERCC spike-in RNA of the amplified sample measured by SC3-seq [log 2 (RPM + 1)] with the original copy number. The regression curve and correlation coefficient were calculated from the average of probes having a copy number of 10 or more.
- FIG. 11D shows the result of box plotting the distribution of gene expression levels in each cell.
- FIG. 11E shows a heat map of the correlation coefficient (R 2 ) between all germ cells.
- FIG. 11F shows the result of box plotting the expression level of a gene highly expressed in epiblast compared to PE (left) or a gene highly expressed in PE compared to epiblast (right). Show.
- FIG. 11C shows a scatter plot comparing the ERCC spike-in RNA of the amplified sample measured by SC3-seq [log 2 (RPM + 1)] with the original copy number. The regression curve and correlation coefficient were calculated from the average of probes having a copy number of 10 or more.
- FIG. 11D shows the
- FIG. 11G shows the results of GO analysis of a gene highly expressed in epiblast compared to PE (upper figure) or a gene highly expressed in PE compared to epiblast (lower figure).
- Fig. 12A shows the expression of cDNA (112 confirmed quality cDNAs) pluripotency genes (POU5F1, NANOG, SOX2) and GAPDH (housekeeping) amplified from hiPSCs (585A1 and 585B1) cultured on feeder cells or free of charge. The result of PCR analysis is shown.
- FIG. 12B shows a scatter plot comparing the ERCC spike-in RNA of the amplified sample measured by SC3-seq (log 2 (RPM + 1)) with the original copy number.
- FIG. 12C shows the result of box plotting the distribution of gene expression levels in each cell.
- FIG. 12D shows a heat map of the correlation coefficient (R 2 ) between all germ cells.
- FIG. 13A shows the results of expression gene analysis obtained from cynomolgus monkey embryos before and after implantation using SC3-seq. Heat expression levels of UHC and pluripotent cell markers, primitive endoderm markers, and differentiation markers associated with gastrulation in all expressed genes (log2 (RPM + 1) ⁇ 4, 18,353 genes in all samples) Shown by map.
- FIG. 13B and C show the PCA results for all expressed genes.
- FIG. 13D shows a heat map showing the expression level of a gene whose expression varies greatly in definitive cell development. The right shows the representative genes contained in each cluster and the results of Gene Ontology analysis.
- FIG. 14A shows a schematic diagram of library creation corresponding to illumina's next-generation sequencer (Miseq, Nextseq500, Hiseq2000 / 2500/3000/4000). The difference from the above-mentioned library for SOLiD5500xl is a part (red broken line) in which a DNA sequence designated by illumina is used for the tag.
- FIG. 14B is a graph plotting average SC3-seq tracks (read density (RPM, ⁇ 1,000 reads) against the position of reads from the annotated TTS (transcription termination site) in 1 ng of RNA extracted from mESC.
- Fig. 14C is a scatter plot showing a comparison between replicate products of two independently amplified replicates from 1 ng and 10 pg of mESC total RNA analyzed with Illumina Miseq.
- FIG. 15A shows an outline of the SC3-seq method for analyzing the above-described V1V3 by changing to a new DNA sequence called P1P2 and using illumina next-generation sequencers (Miseq, Nextseq500, Hiseq2000 / 2500/3000/4000). Show.
- FIGS. 15B and 15D show results obtained by analyzing cDNAs amplified from 1 ng and 10 pgRNA using V1V3 tag and P1P2 tag using illumina Miseq, respectively, and showing distribution of expression levels of all genes in box plots ( The number of genes detected as C) is shown as a bar graph (D).
- the present invention maintains the relative relationship of gene expression levels in biological samples
- a method for preparing a nucleic acid population containing the amplified product, and a nucleic acid population obtained by the method are provided.
- the “amplification product retaining the relative relationship of the gene expression level in the biological sample” means that the composition of the entire gene product group in the biological sample (quantity ratio between each gene product) is It means an amplification product (group) that is almost retained and has a level that can be applied to a standard protocol for quantifying mRNA using a next-generation sequencer.
- the “biological sample” refers to a biological species having poly A at the 3 ′ end of mRNA, for example, animals including mammals such as humans, mice, and cynomolgus monkeys, plants, fungi, and prokaryotic organisms. Means a cell.
- the present invention is expected to be applied to cells contained in embryos during development as biological samples and pluripotent stem cells having diversity.
- the number of cells as a biological sample is not particularly limited, but considering that the present invention can be amplified with good reproducibility while maintaining the relative relationship of gene expression levels in the biological sample, the number of cells. Can be applied to the cell level of 100 or less, several tens, one to several, and finally one.
- RNA sequencing also referred to as RNA-Seq
- RNA-Seq RNA sequencing
- RNA-Seq is the counting of mRNA having the sequence, that is, quantification, together with the sequencing of mRNA.
- next-generation sequencer those commercially available from illumina, Life Technologies, and Roche Diagnostic can be used.
- the method of the present invention includes the following steps.
- A any additional nucleic acid sequence X, poly T sequence, mRNA sequence isolated from a biological sample (actually a cDNA sequence corresponding to the mRNA sequence (hereinafter the same)), poly A sequence and any addition
- FIGS. 1C, 14A, and 15A The outline of the method of the present invention is shown in FIGS. 1C, 14A, and 15A. These drawings are only descriptions of examples of the method of the present invention, and those skilled in the art can implement the present invention with appropriate modifications. Hereinafter, each step of the method of the present invention will be described in detail with reference to FIGS. 1C and 15A.
- a double-stranded DNA composed of an arbitrary additional nucleic acid sequence X, poly T sequence, mRNA sequence isolated from a biological sample, poly A sequence and optional additional nucleic acid sequence Y used in this step is Can be prepared by a method comprising steps (i) to (iii) of (see WO2006 / 085616).
- the reverse transcription reaction time is preferably shortened to 5-10 minutes, more preferably about 5 minutes, so that the amplification efficiency in the subsequent PCR reaction does not depend on the length of the template cDNA.
- primary strand cDNA with equal length is synthesize
- the remaining primer may be degraded with exonuclease I or exonuclease T. Alternatively, it can be inactivated by modifying the 3 'side of the remaining primer with alkaline phosphatase or the like.
- the first primer used here and the second primer used in step (i) have different nucleic acid sequences from each other, but have a certain identity and do not contain a promoter sequence. .
- sixth and seventh primers will be described in more detail.
- seventh primer used in step (ii): additional nucleic acid sequence X and Y in additional nucleic acid sequence X and poly T sequence are different in arrangement.
- the additional nucleic acid sequences X and Y are further selected such that the Tm value of the common sequence in X and Y is lower than the Tm values in the sixth and seventh primers, respectively, and the value is as much as possible. Try to leave. By doing so, it is possible to prevent undesirable cross-annealing in which the sixth and seventh primers anneal to different sites during annealing in the subsequent PCR reaction.
- the Tm value of the consensus sequence is selected so as not to exceed the annealing temperature after annealing the sixth and seventh primers.
- the Tm value is the temperature at which half of the DNA molecules anneal with the complementary strand.
- the annealing temperature is set to a temperature that enables primer pairing, and is usually a temperature lower than the Tm value of the primer.
- the nucleic acid sequences of the sixth primer and the seventh primer have 77% or more, more preferably 78% or more, still more preferably 80 ⁇ 1%, and most preferably 79% identity.
- the upper limit of sequence identity is the upper limit% at which the Tm value of the common sequence of both primers does not exceed the annealing temperature.
- both the additional nucleic acid sequences X and Y have the identity of 55% or more, more preferably 57% or more, and further preferably 60 ⁇ 2%. It can also be defined as an array.
- the upper limit is the upper limit% at which the Tm value of the common sequence in the additional nucleic acid sequences X and Y does not exceed the annealing temperature in the PCR reaction.
- the added nucleic acid sequences X and Y in the sixth and seventh primers used preferably each have a palindromic sequence. Specifically, almost all restriction enzyme sites such as restriction enzyme sites such as AscI, BamHI, SalI, XhoI sites, and other EcoRI, EcoRIV, NruI, NotI have palindromic sequences. be able to.
- the nucleic acid molecule having the nucleic acid sequence shown in SEQ ID NO: 1 (atatctcgagggcgcgccggatcctttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttt
- the P2 (dT) 24 sequence (SEQ ID NO: 6: ctgccccgggttcctcattcttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttttt
- the sixth and seventh primers to be used are primers having a higher specificity or a higher Tm value than those used in normal PCR.
- the annealing temperature can be brought close to the Tm value of the primer, thereby suppressing non-specific annealing. Since the annealing temperature is typically 55 ° C, the Tm value used for normal PCR is 60 ° C. Therefore, the annealing temperature of the primer used in the present invention is 60 ° C. or higher and lower than 90 ° C., preferably about 70 ° C., and most preferably 67 ° C.
- step (Iii) PCR amplification
- an eighth primer containing the additional nucleic acid sequence X and a ninth primer containing the additional nucleic acid sequence Y Add and perform PCR amplification.
- the eighth primer the seventh primer further including a poly T sequence downstream of the additional nucleic acid sequence X
- the ninth primer further includes a poly T sequence downstream of the additional nucleic acid sequence Y.
- a sixth primer may be used (FIG. 1C).
- the P1 sequence (SEQ ID NO: 8: ccactacgcctccgctttcctctctatg) can be used as the eighth primer
- the P2 sequence (SEQ ID NO: 10: ctgccccgggttcctcattct) can be used as the ninth primer (FIG. 15A).
- the PCR cycle can be appropriately changed. For example, PCR of 5 to 30 cycles is exemplified.
- mRNA contained in 100 ng of total RNA when mRNA contained in 100 ng of total RNA is used as a template, 7 cycles are exemplified, and similarly, when mRNA contained in 10 ng of total RNA is used as a template, 11 cycles are exemplified, When mRNA contained in 1 ng of total RNA is used as a template, 14 cycles are exemplified, and when mRNA contained in 100 pg of total RNA is used as a template, 17 cycles are exemplified, and in 10 pg of total RNA, When the contained mRNA is used as a template, 20 cycles are exemplified.
- non-specific annealing can be suppressed by bringing the annealing temperature in PCR amplification close to the Tm value of the primer used.
- the annealing temperature is 60 ° C. or higher and lower than 90 ° C., preferably about 70 ° C., most Preferably it is 67 degreeC.
- step (iii) the primary strand cDNA derived from the same starting sample is divided into a plurality of, for example, 3-10, preferably about 4 tubes, each of which is subjected to a PCR reaction and finally mixed again. preferable. By doing so, random errors are averaged and can be significantly suppressed.
- step (iii) The double-stranded DNA amplified in step (iii) is amplified together using, for example, ERCC spike-in RNA commercially available from Life Technologies, as a template, and the amount is compared with the estimated copy number. Thus, it can be confirmed whether or not the above-described amplification by PCR has been performed normally.
- a first primer including the additional nucleic acid sequence X to which an amine is added at the 5 ′ end, and a first primer including the additional nucleic acid sequence Y are included.
- an amine can be added to the 5 ′ end of the additional nucleic acid sequence X in the double-stranded DNA.
- the first and second primers may optionally further comprise a poly T sequence downstream of the additional nucleic acid sequences X and Y, respectively.
- the first primer an amine added to the 5 ′ end of the seventh primer used in step (ii), and the sixth primer used in step (i) as the second primer Can be used respectively (FIG. 1C).
- the first primer is obtained by adding an amine to the 5 ′ end of the eighth primer.
- the ninth primer can also be used as the second primer, respectively (FIG. 15A).
- the amplification in this step (a) is not particularly limited as long as an amine can be added to the 5 ′ end of the additional nucleic acid sequence X in the double-stranded DNA.
- the amplification is performed by 2 to 8 cycles of PCR, Preferably, there are 4 cycles.
- the amine to be added is not particularly limited as long as phosphorylation at the 5 ′ end in step (c) can be suppressed, but an amino group is preferably added.
- the step of fragmenting the double-stranded DNA obtained in the step (a) is a step of fragmenting the double-stranded DNA obtained in the step (a).
- Examples of DNA fragmentation include a method of dividing using ultrasonic waves and a method of using DNA fragmenting enzymes. In the present invention, a method of dividing using ultrasonic waves is preferably used.
- the step (c) is the step of 5% of the fragmented duplex DNA obtained by the step (b).
- This is a step of phosphorylating the terminal, and the phosphorylation can be performed using a nucleic acid kinase known per se.
- the amine-added 5 ′ end cannot be phosphorylated.
- the cut ends may not be smoothed. Therefore, after blunting the ends using a DNA polymerase, this step It is desirable to perform (c).
- a step of selecting fragmented double-stranded DNA having an arbitrary base length may be performed.
- This base length is not particularly limited as long as mRNA can be recognized by sequencing, but preferably 200 to 250 base length in Life Technologies SOLiD5500xl, and in illumina Miseq / NextSeq500 / Hiseq2000 / 2500/3000/4000. The length is 350 to 500 bases.
- the step of selecting DNA may be performed using any means known in the art such as a DNA adsorption method, a gel filtration method, and a gel electrophoresis method.
- a DNA adsorption method a DNA adsorption method
- a gel filtration method a gel electrophoresis method.
- BeckmanAMPCoulter AMPureXP beads it can be done easily.
- step (D) Using the double-stranded DNA phosphorylated at the 5 ′ end obtained in the step (c) as a template, a third primer containing any additional nucleic acid sequence Z and the additional nucleic acid sequence Y in this order Step of preparing cDNA using and adding adenine (A) to its 3 ′ end In this step (d), the double-stranded DNA phosphorylated at the 5 ′ end obtained in step (c) was used as a template. Using a third primer that further includes an optional additional nucleic acid sequence Z on the 5 ′ side of the second primer that includes the additional nucleic acid sequence Y (and optionally further a poly T sequence), the 5 ′ end is phosphorylated.
- the additional nucleic acid sequence Z is added to the double-stranded DNA thus prepared.
- the additional nucleic acid sequence Z can be added to the additional nucleic acid sequence Y in the double-stranded DNA.
- an enzyme having TdT activity that adds adenine (A) to the 3 ′ end as a DNA polymerase adenine (A) is added to the 3 ′ end of each strand of the double-stranded DNA.
- This step (d) is composed of mRNA sequence isolated from a biological sample phosphorylated at the 5 ′ end, poly A sequence, optional additional nucleic acid sequence Y, and optional additional nucleic acid sequence Z. Heavy chain DNA can be obtained.
- the arbitrary additional nucleic acid sequence Z is a sequence depending on the next-generation sequencer to be used, and can be performed using a sequence recommended by the manufacturer of the sequencer. For example, when SOLID5500XL of Life technologies is used, an Int sequence represented by SEQ ID NO: 3 (ctgctgtacggccaaggcgt) can be used as an arbitrary additional nucleic acid sequence Z.
- the Rd2SP sequence represented by SEQ ID NO: 13 (gtgactggagttcagacgtgtgctcttccgatc) can be used as the additional nucleic acid sequence Z.
- (E) A step of ligating the double-stranded DNA obtained in the step (d) with a double-stranded DNA containing an arbitrary sequence V having a thymine (T) as an overhang at the 3 ′ end.
- a double-stranded DNA comprising an arbitrary sequence V having a thymine (T) as an overhang at the 3 ′ end of the double-stranded DNA obtained in d) Is a double-stranded DNA having only one base (T) on the 3 ′ end side and no complementary strand, and the overhanging portion is similarly one base (5 base) at the 5 ′ end of the double-stranded DNA to be ligated ( A) When having an overhang complementary strand, ligation at the protruding end is possible.
- the sequence V is a sequence that depends on the next-generation sequencer to be used, and can be performed using, for example, a sequence commercially available from Life technologies or illumina.
- P1-T SEQ ID NO: 11: ccactacgcctccgctttcctctctatgt
- Rd1SP-T SEQ ID NO: 12: tctttccctacacgacctcttccgatct
- the fourth primer and the fifth primer to be used are sequences depending on the next-generation sequencer to be used.
- the fifth primer only needs to contain at least the additional nucleic acid sequence Z, and may optionally further include the additional nucleic acid sequence Y downstream thereof.
- the fifth primer further includes a barcode sequence, and preferably further includes an adapter sequence having an arbitrary sequence.
- the fourth primer and the fifth primer can be performed using sequences commercially available from Life technologies or illumina.
- the amplification is carried out by using a double-stranded DNA that is not amplified by the fourth primer and the fifth primer (a fragmented double-stranded DNA containing the 3 ′ end of the mRNA sequence or an internal sequence). If it decreases, the number of cycles is not particularly limited. For example, PCR of 5 to 30 cycles is exemplified, and preferably 9 cycles.
- the nucleic acid population of the present invention obtained by the above steps is useful as a sample for sequencing and measuring the number of nucleic acids when applied to a next-generation sequencer.
- a library containing a part of mRNA can be constructed with certainty. Therefore, since the amplified mRNA is excellent in quantification, it is possible to detect a more accurate expression level of comprehensive mRNA as compared with conventional RNA-Seq.
- the present invention provides a kit for preparing a cDNA population to be applied to the measurement of the amount of mRNA by a next-generation sequencer.
- the kit of the present invention may be constituted by the following primers described above; (A) a first primer comprising an optional additional nucleic acid sequence X (and optionally further a poly T sequence) with an amine added to the 5 ′ end; (b) an optional additional nucleic acid sequence Y (and optionally further a poly T sequence).
- a second primer comprising (c) an optional additional nucleic acid sequence Z and said additional nucleic acid sequence Y (and optionally further a poly T sequence) in this order (d) thymine (T) at the 3 ′ end A double-stranded DNA comprising any sequence V having an overhang (E) a fourth primer comprising said sequence V, and (f) a fifth primer comprising said additional nucleic acid sequence Z (and optionally further said additional nucleic acid sequence Y).
- the kit is for preparing a double-stranded DNA composed of an arbitrary additional nucleic acid sequence X, a poly T sequence, an mRNA sequence isolated from a biological sample, a poly A sequence, and an optional additional nucleic acid sequence Y.
- primer sets (G) a sixth primer comprising the additional nucleic acid sequence Y and a poly T sequence; (H) a seventh primer comprising the additional nucleic acid sequence X and a poly T sequence; (I) an eighth primer comprising the additional nucleic acid sequence X, optionally further comprising a poly T sequence downstream thereof; and (j) comprising the additional nucleic acid sequence Y, optionally comprising a poly T sequence downstream thereof.
- a ninth primer that may further be included may be further included.
- the sixth primer and the ninth primer may be the same, and the seventh primer and the eighth primer may be the same.
- the second primer and the ninth primer may be the same.
- the kit may further include other reagents necessary for the PCR reaction (eg, DNA polymerase, dNTP mix, buffer solution, etc.), other reagents necessary for the ligation reaction, reverse transcription reaction, terminal phosphorylation reaction, and the like. .
- reagents necessary for the PCR reaction eg, DNA polymerase, dNTP mix, buffer solution, etc.
- other reagents necessary for the ligation reaction eg, reverse transcription reaction, terminal phosphorylation reaction, and the like.
- RNA-extracted mice were performed according to the ethical guidance of Kyoto University.
- BVSC R8 a mouse embryonic stem cell (mESC) strain, was cultured according to a conventional method (Hayashi, K. et al, Cell, 146, 519-532, 2011). Extraction of total RNA from the cell line was performed using the RNeasy mini kit. (Qiagen (74104)) according to the manufacturer's manual.
- the extracted RNA is diluted with double-distilled water (DDW) to concentrations of 250 ng / ⁇ l, 25 ng / ⁇ l, 2.5 ng / ⁇ l, 250 pg / ⁇ l and 25 pg / ⁇ l, and single-cell mRNA 3- It was used for the quantitative evaluation of prime end sequencing (hereinafter referred to as SC3-seq).
- DSW double-distilled water
- iPSC lines 585A1 and 585B1 which are human iPS cells (hiPSC)
- KSR Knockout Serum Replacement
- 1% vol / vol
- GlutaMax Life Technologies (35050-061)
- 0.1 mM nonessential amino acids Life Technologies (11140-050)
- 4 ng / ml recombinant human bFGF Wako Pure Chemical Industries (064-04541)
- conventional culture on SNL feeder cells in DMEM / F12 Life Technologies (11330-32)
- DMEM / F12 Life Technologies (11330-32)
- M3148 2-mercaptoethanol
- V1V3-cDNA synthesis and amplification from isolated single cell RNA can be performed using existing methods (Kurimoto, K. et al, Nucleic Acids Res, 34, e42, 2006 or Kurimoto, K. et al, Nature protocols, 2, 739-752, 2007).
- RNA spike-in developed by Qiagen RNase inhibitor (0.4 U / sample) (Qiagen (129916)), Porcine Liver RNase inhibitor (0.4 U / sample) (Takara Bio (2311A)) and External RNA Controls Consortium (ERCC) Use of RNA (ERCC spike-in RNA) (Life Technologies (4456740)) and the number of PCR cycles per total RNA (7 cycles for 100 ng total RNA, 11 cycles for 10 ng total RNA, 1 ng total 14 cycles for RNA, 17 cycles for 100 pg total RNA, and 20 cycles for 10 pg total RNA) are different from the conventional method.
- P1P2-cDNA synthesis and amplification differs from V1V3-cDNA synthesis and amplification in the use of SuperScript4 (Life Technologies (18090200)) and KOD FX NEO (Toyobo (KFX-201)).
- SuperScript4 Life Technologies (18090200)
- KOD FX NEO Toyobo (KFX-201)
- ERCC spike-in RNA ERCC-00074 (9030 copies), ERCC-00004 (4515 copies), ERCC-00113 (2257 copies), RCC-00136 (112.8 copies) ), ERCC-00042 (282.2 copies), ERCC-00095 (70.5 copies), RCC-00019 (17.6 copies) and ERCC-00154 (4.4 copies), and RCC for mouse preimplantation embryos and hiPSCs -00096 (1806 copies), ERCC-00171 (451.5 copies), ERCC-00111 (56.4 copies) were used, and the genes listed in Table 1 were used for the endogenous genes.
- Q-PCR Quantitative PCR
- the cDNA was 30 ⁇ l Internal adaptor extension buffer (1 ⁇ ExTaq Buffer, 0.23 mM each dNTP, 0.67 ⁇ M IntV1 (dT) 24 primer (HPLC-purified) , 0.033 U / ⁇ l ExTaqHS) was subjected to a thermal cycler with 95 ° C. for 3 min, 67 ° C. for 2 min and 72 ° C.
- the cDNA was subjected to Final amplification buffer (1 ⁇ ExTaq buffer, 0.2 mM each dNTP, 1 ⁇ M P1 primer, 1 ⁇ M BarT0XX_IntV1 primer (HPLC -purified) (XX represents an integer of 2 digits, specific primers are listed in Table 2), 0.025 U / ⁇ l ExTaqHS), 3 min incubation at 95 ° C, 30 sec at 95 ° C, 9 cycles of 1 min at 67 ° C. and 1 min at 72 ° C. were applied to a thermal cycler with a program of 3 min at 72 ° C.
- Final amplification buffer (1 ⁇ ExTaq buffer, 0.2 mM each dNTP, 1 ⁇ M P1 primer, 1 ⁇ M BarT0XX_IntV1 primer (HPLC -purified) (XX represents an integer of 2 digits, specific primers are listed in Table 2)
- the cDNA library was purified using 1.2 volumes of AMPureXP and dissolved in 20 ⁇ l TE buffer.
- the quality and capacity of the constructed library were evaluated by LabChip GX or Bioanalyzer 2100 using a Qubit dsDNA HS assay kit (Life Technologies (Q32851)) and SOLiD Library TaqMan Quantitation kit (Life Technologies (4449639)).
- Amplification of the library on the beads by emulsion PCR was performed on the E120 scale using the SOLiD TM EZ Bead TM System (Life Technologies (4449639)) according to the manufacturer's manual.
- the obtained bead library was loaded on a flowchip and measured with 50 bp and 5 bp barcode plus Exact Call Chemistry (ECC) of SOLiD 5500XL system.
- ECC Exact Call Chemistry
- the purified cDNAs were diluted with double-distilled water (DDW) to 130 ⁇ l and fragmented using Covaris S2 or E210 (Covaris).
- End-polish buffer (1 ⁇ NEBnext End Repair Reaction buffer (NEB (B6052S)), 0.01 U / ⁇ l T4 DNA polymerase (NEB (M0203)) and 0.033 U / ⁇ l T4 polynucleotide kinase (NEB (M0201))
- NEB (B6052S) NEBnext End Repair Reaction buffer
- NEB (M0203) 0.01 U / ⁇ l T4 DNA polymerase
- 0.033 U / ⁇ l T4 polynucleotide kinase (M0201))
- the cDNA was 30 ⁇ l Internal adapter extension buffer (1 ⁇ ExTaq Buffer, 0.23 mM each dNTP, 0.67 ⁇ M Rd2SP-P2 primer (HPLC-purified), 0.033 U / ⁇ l ExTaqHS) was subjected to a thermal cycler with programs of 95 ° C. for 3 min, 60 ° C. for 2 min and 72 ° C. for 2 min.
- reaction was stopped by cooling with ice, 20 ⁇ l of Rd1SP-adaptor ligation buffer (10 ⁇ l of 5 ⁇ NEBNext Quick Ligation Reaction Buffer (NEB (B6058S)), 0.6 ⁇ l of 10 ⁇ M of the Rd1SP adaptor and 1 ⁇ l of T4 ligase (mixture of NEB (M0202M)) was added, followed by incubation at 20 ° C. for 15 minutes and 72 ° C. for 20 minutes.
- NEB NEBNext Quick Ligation Reaction Buffer
- the cDNA was subjected to Final amplification buffer (1 ⁇ KOD FX NEO buffer, 0.4 mM each dNTP, 0.3125 ⁇ M S5XX primer (XX is double digit) Integers, specific primers listed in Table 3), 0.3125 ⁇ M N7XX primer (HPLC-purified) (XX represents a two-digit integer, specific primers listed in Table 3), 0.02 U / ⁇ l KOD FX NEO), followed by incubation at 95 ° C for 3 min, 95 cycles for 10 sec, 1 min at 60 ° C and 1 min at 68 ° C for 9 cycles, then thermal at 68 ° C for 3 min It was subjected to a cycler and amplified by PCR.
- Final amplification buffer (1 ⁇ KOD FX NEO buffer, 0.4 mM each dNTP, 0.3125 ⁇ M S5XX primer (XX is double digit) Integers, specific primers listed in Table 3), 0.3
- the cDNA library was purified using 0.9-fold amount of AMPureXP and dissolved in 20 ⁇ l TE buffer.
- the quality and capacity of the constructed library were evaluated by a Qubit dsDNA HS assay kit (Life Technologies (Q32851)), KAPA Library Quantification Kits (KAPA (KK4828)), and LabChip GX or Bioanalyzer 2100.
- the obtained Library DNA was analyzed using Miseq Reagent kit v3, 150 cycle (illumina (MS-102-3001)).
- mapping adapter to reference genome or poly-A sequence was trimmed by cutadapt-1.3 and all reads were searched. However, trimmed reads below 30 bp were excluded. Adapter and poly-A sequences were confirmed in approximately 1-20% and 5% of total reads, respectively. Untrimmed and trimmed reads over 30 bp were mapped by tophat-1.4.1 / bowtie1.0.1 with the “-no-coverage-search” option for mouse genome mm10 and ERCC spike-in RNA.
- cufflinks-2.2.0 When evaluating the expression level of several genes, the cufflinks option “-max-mle-iterations” with the default of 5,000 resulted in “FAILED”, so the cufflinks option “-max-mle” -iterations ”was set to 50,000.
- the transcription termination site (TTS) of the reference gene was extended to more than 10 kb downstream in order to correctly estimate the expression level of a gene having a transcript longer than the reference in the 3 ′ direction.
- TTS transcription termination site
- ERCC spike-in RNA reads are normalized to the number of reads per million-mapped (RPM) by the total reads mapped on the genome used for gene expression analysis. It was. The mapped leads were visualized using igv-2.3.34. Conversion of mapped reads to expression levels with HTSeq-0.6.0 was consistent with the results with cufflinks-2.2.0 using the options described above.
- the determination of the optimal definition at the 3 'end of the transcript was performed by correcting the reference gene annotation gff3 file.
- the definition of the 3 'end of the transcript was expanded to 10 kb in units of 1 kb and to 100 kb in units of 10 kb, the expression levels of all genes were calculated. Genes whose expression levels were increased to 10%, 20%, 30%, 40%, 50%, 80%, 100%, 200% and 300% were counted.
- Accuracy as total RNA [log 2 (RPM + 1 ) ⁇ 1] Percentage of genes in amplified samples from 10 pg, 100 ng of total RNAs [log 2 (RPM + 1 ) ⁇ 1] Defined based on the number of genes detected in the sample amplified from The expressed gene was defined as the gene detected with [log 2 (RPM + 1) ⁇ 1] in the sample prepared with SC3-seq from 100 ng RNA. Multi-sample analysis (8 samples) for coverage and accuracy was performed by calculating coverage and accuracy under a detection definition in which 1 to 8 or more of the 8 amplified samples present leads.
- Oneway_analysis of variance (ANOVA) and qvalue function were used to calculate p-value and false discovery ratio, respectively, in order to recognize gene groups (DEG) with different expression among multiple groups.
- Gene ontology (GO) analysis was performed using the DAVID web tool.
- Anti-mouse NANOG (rat monoclonal) (eBioscience (eBio14-5761)), anti-mouse POU5F1 (mouse monoclonal) (Santa Cruz (sc-5279)), anti-mouse GATA4 (goat polyclonal) (Santa Cruz) (sc-1237)), anti-mouse CDX2 (rabbit monoclonal, clone EPR2764Y) (Abcam (ab76541)) was used.
- Secondary antibodies include Alexa Fluor 488 anti-rat IgG (Life Technologies (A21208)), Alexa Fluor 555 anti-rabbit (Life Technologies (A31572)), Alexa Fluor 568 anti-mouse IgG (Life Technologies (A10037)) and Alexa Fluor 647 anti-goat IgG (Life Technologies (A21447)) (all donkey polyclonal) was used. Fluorescence images were obtained using a confocal microscope (Olympus (FV1000)).
- SC3-seq design and construction Single-cell cDNA amplification used a high-density oligonucleotide microarray-like method of concentrating the 3 'end (Kurimoto, K., et al., Nucleic Acids Res, 34, e42 , 2006 and Kurimoto, K., et al., Nature protocols, 2, 739-752, 2007).
- the method involves analysis of heterogeneous cell types such as mouse blastocysts, elucidation of transcriptome in the development of primordial germ cells (PGC), and elucidation of neuronal cell types in the development of cerebral cortex Useful for analysis.
- PPC primordial germ cells
- a method for amplifying and sequencing the 3 'end of cDNA synthesized from a single cell is called SC3-seq, and the method is shown in Fig. 1C.
- cDNA was amplified from single-cell level RNA by a conventional method (FIG. 1C).
- the first cDNA strand was synthesized using V1 (dT) 24 primer, and the mRNA annealed with excess V1 (dT) 24 primer was digested with Exonuclease I and RNaseH, respectively, and the poly (dA) tail was the first It was added to the 3 ′ end of the cDNA strand.
- the second cDNA strand was synthesized using V3 (dT) 24 primer, and the resulting cDNA was used with V1 (dT) 24 primer and V3 (dT) 24 primer to determine the number of PCR cycles depending on the initial amount. (20 cell cycles per single cell or 10 ⁇ g pg total RNA).
- V1 (dT) 24 primer was used for the construction of the library (FIGS. 1C and 7A).
- the amplified cDNA was tagged by NH2-V3 (dT) 24 primer by PCR, the primer dimer was removed by purification three times by AMPureXP, and the tagged cDNA was fragmented by ultrasound. In addition, end-polish and size selection with AMPure®XP.
- the resulting 200-250 bp cDNA was denatured and annealed with an IntV1 (dT) 24-primer with an internal adapter extension sequence to capture the 3 'end. Ligation and sequence expansion using P1 adapter and final amplification using BarT0XX-IntV1 primer with P1 primer, 96-length barcode and IntV1 (dT) 24 primer.
- the final amplification product was sequenced from the end of the P1 adapter, and the 3 'end side of the mRNA at the locus was mapped. Since SC3-seq provides sequence reads only on the 3 'end of mRNA, the number of reads is a percentage of the absolute mRNA expression level regardless of the total length, and simpler and more accurate gene expression level quantification Bring. Normalized by sequence reads per million mapped reads and accurately quantified.
- RNA 100 ng (equivalent to 10,000 cells) 2 replicates, 10 ng (equivalent to 1,000 cells) 2 replicates, 1 ng (equivalent to 100 cells) 4 replicates, 100 pg (equivalent to 10 cells) ) 8 replicates and 10 pg (single cell equivalent) 16)
- RNA was collected with externalikespike-in ⁇ ⁇ ⁇ ⁇ RNA control developed by External RNA Controls Consortium (ERCC) and amplified (100 ng , 10 ng, 1 ng, 100 pg and 10 pg total RNA were used as initial PCR cycles of 7, 11, 14, ⁇ 17 and 20 respectively, and these were sequenced by SC3-seq.
- ERCC External RNA Controls Consortium
- FIG. 1D shows the average sequence read distribution of one 100 ng RNA amplification product by SC3-seq ( ⁇ 40-50% mapping efficiency).
- the mapping read contained many 3 'ends (150 bp upstream from TTS) of all mapped RefSeq genes. There were a few reads mapped in the antisense strand of the exon. This means that the V1 (dT) 24 primer is part of the amplification product by misannealing at the 5 ′ end of the cDNA for amplification (FIG. 1C).
- the SC3-seq track around the Pou5f1 locus presented a single peak that coincided with the 3 ′ end of the sense strand of Pou5f1 with a small peak in the antisense strand of exon (FIG. 1E).
- the SC3-seq read peak was observed downstream from the 3 ′ end of the annotated RefSeq transcript. This presents a matching locus upstream of the 3 ′ end of the transcript (FIGS. 1D and 1E).
- an SC3-seq peak was observed 1 Kb downstream of the 3 ′ end of Nanog (FIG. 1E).
- the number of genes presenting an increase in mapped reads increases with an expanded TTS definition from annotated TTS, and 450 genes by extending the TTS definition to 10 Kb
- the number of mapped leads has increased. Since we found that an extension up to 10 Kb or more was incorrectly annotated, we defined a peak detected within 10 Kb downstream from the annotated TTS indicating the expression of the immediately upstream gene, and analyzed the SC3-seq data . The analysis of the published RNA-seq data confirmed the stability of the mESC comprehensive RNA amount by this definition.
- spike RNA which was less than 30 copies in 10 pg RNA, showed insufficient amplification, but the SC3-seq read of ERCC spike-in RNA in all amplified libraries obtained by dilution. [Log 2 (RPM + 1)] values correlated with the original copy number (FIG. 2B) (indicating ERCC spike-in RNA copy number per 10 pg total RNA at each dilution). This made it possible to estimate the number of gene copies per 10 pg of RNA from the number of SC3-seq reads.
- RNA samples amplified from 10 pg (equivalent to 1 cell) of RNA showed good correlation, with 77.6% and 86.1% plotted in the 2-fold and 4-fold difference lines, respectively (FIGS. 2C and 2G).
- SC-seq coverage of 10 pg RNA using 8 amplification data (number of genes detected in 10 pg RNA (log 2 (RPM + 1) ⁇ 1) / 100 ng RNA (number of genes detected with log 2 (RPM + 1) ⁇ 1) and accuracy (100 ng RNAs (log 2 (RPM + 1) ⁇ 1) detected with an additional 10 pg RNA) (number of genes detected by log 2 (RPM + 1) ⁇ 1) was evaluated.
- the expressed gene was defined as a gene detected with [log 2 (RPM + 1) ⁇ 1] in a sample prepared by SC3-seq from 100 ng RNA.
- the coverage of a single amplified sample was plotted (black line in FIG. 3A). From previous reports and the above data (Figure 2), coverage is dependent on expression level, but the majority of the expressed genes (cumulative percentage, 94.1%) expressed more than 10 copies per 10 pg RNA It has been detected (Fig. 3A).
- the accuracy of single amplified samples was also plotted, confirming that 99.7% (cumulative percentage) of the detected genes were expressed in expression level regions of 10 copies or more per 10 pg of RNA ( Figure 3B). .
- SC3-seq is a short transcript ( ⁇ 500 bp) and requires a 0.2-mega mapped read (the gene expression level is higher than the top 6,555 genes (transcripts annotated in mice). 1/4 of product, log 2 RPM ⁇ 3.69 ⁇ 0.05), other methods require short transcripts ( ⁇ 500 bp) and 1 Mb or more mapped reads (less than 500 bp, gene expression levels Are the top 6,555 and 6,217+ genes (1/4 of mouse and human annotated transcripts, respectively), log 2 FPKM ⁇ 2.21 ⁇ 0.05 (Yan et al.) Or 2.92 ⁇ 0.27 (Picelli et al .)) (Figure 4D). These results suggest that SC3-seq is a more quantitative and effective method for transcriptome analysis of single cells than the conventional method.
- pre-implantation mouse embryos consist of at least three cell types: epiblast, primordial endoderm (PE) and trophectoderm (TE) Consists of.
- the previous two cells form an inner cell mass (ICM).
- ICM inner cell mass
- TE is in direct contact with two cell types, ICM, to form embryonic ectoderm (ExE) and part of the extra-embryonic tissue of blastocyst and later early nutrients. It is classified into mTE (wall TE) that forms blast layer giant cells.
- mTE wall TE
- SC3-seq we investigated whether cell types in blastocysts could be distinguished.
- genes with high expression in PE include Sparc, Lama1, Lamb1, Col4a1, Gata4, Gata6, Pdgfra and Sox17, and GO terms include “lipid biosynthesis process”, “glycolipid metabolism process” and “Embryogenesis during birth or hatch” was seen (FIGS. 5D and 11G).
- genes with different expression between pTE and mTE were searched. 218 genes highly expressed in pTE including Hspd1, Ddah1, Gsto1, and Dnmt3b were found, and many GO terms related to cell cycle such as “cell cycle”, “M phase” and “end of mitosis” (FIGS. 5D and 5F). Genes that are highly expressed in pTE compared to mTE are the same as in pTE and are expressed in epiblasts and PE ( Figure 5E), and these genes are down especially in blastocyst mTE It was confirmed that it was controlled.
- Detection of human iPS cell heterogeneity SC3-seq was investigated to detect gene expression heterogeneity in a homogeneous cell population. Gene expression was measured in hiPSC (on-feeder hiPSC) cultured on feeder cells and hiPSC (feeder-free hiPSC) cultured in feeder-free conditions. For this purpose, two hiPSC strains (585A1 and 585B1) were cultured on SNL feeder cells and in feeder-free conditions (a total of 112 single-cell cDNAs were obtained) (FIGS.
- on-feeder hiPSC the maximum expression level was log 2 (RPM + 1) ⁇ 6 and 630 genes with SD ⁇ 2 were found, but in feeder-free hiPSC, 109 genes were found. That is, it was shown that the SD value of on-feeder hiPSC was higher in all gene expression regions than the SD value of feeder-free iPSC, consistent with the results of PCA analysis.
- the SD value of the gene expression level of feeder-free iPSC is plotted against that of on-feeder hiPSC, the SD value is high in feeder-free iPSC including PK1B, UNC5D, SCGB3A2, HERC1, RPS4Y1 and RBM14 / RBM4 75 genes, ZFP42, ANXA3, LEFTY1, PTCD1 and LDOC1, including both feeder-free hiPSC and on-feeder hiPSC, have high SD values (SD ⁇ 2), and FGF19, CAV1, NODAL, SGK1, CTGF, and SFRP1 596 genes showing higher SD values with on-feeder hiPSC were found (FIGS. 6B, 6E and 6F).
- Each cell was defined and classified based on UHC clusters, pluripotent cell markers, primitive endoderm markers, and differentiation marker gene expression patterns associated with gastrulation (post_paTE; post-implantation embryo-derived wall side nutrition Ectoderm, preL_TE; late-implantation ectoderm from preimplantation embryo, HYP; preimplantation-derived blastodermal sublayer, preE_TE; early-implantation ectoderm from preimplantation embryo, ICM; inner cell mass from preimplantation embryo, pre_EPI: pre-implantation embryo-derived epiblast, postE_EPI; post-implantation embryo-derived early epiblast, postL_EPI; post-implantation embryo-derived late epiblast, Gast1, 2a, 2b; post-implantation embryo-derived gastrulation cells, YE ; Post-implantation embryo-derived yolk endoderm, ExMchy; post-implantation embryo-derived extracorporeal stromal cells).
- post_paTE post-implantation embryo-derived wall side nutrition Ectoderm, preL_TE
- FIGS. 13B and 13C show the results of PCA using all the expressed genes
- FIG. 13D shows the expression levels of genes that greatly change in expression during definitive cell development in a heat map. From the above, it was confirmed that cells of the same group showed similar gene expression patterns, which reflects that SC3-seq has high quantitativeness and reproducibility. These findings also indicate that SC3-seq was able to distinguish different cell populations and their expression patterns in the development of cynomolgus monkey epiblasts.
- FIG. 1 shows a schematic diagram of library creation corresponding to illumina's next-generation sequencers (Miseq, Nextseq500, Hiseq2000 / 2500/3000/4000) by changing the P1-T sequence in Fig. 1C to the Rd1SP-T sequence. .
- the average SC3-seq track (read density (RPM, x1,000 reads)) was plotted against 1 ng of RNA extracted from mESCs versus the position of reads from the annotated TTS (transcription termination site) (FIG. 14B). From 1 ng and 10 pg of total RNA of mESC, two independently amplified replicates were analyzed using the Illumina Miseq (FIG.
- FIG. 15A shows that the V1 (dT) 24 sequence used for cDNA amplification was converted to P2 (dT) 24 sequence and the V3 (dT) 24 sequence was converted to P1 (dT) 24 sequence in the analysis using the above-mentioned illumina Miseq.
- Rd2SPV1 (dT) 24 sequence was changed to Rd2SP-P2 sequence (SEQ ID NO: 15: gtgactggagttcagacgtgtgctcttccgatcctgccccgggttcctcattct). From 1 ng and 10 pg of total RNA of mESC, using P1 (dT) 24 sequence and P2 (dT) 24 sequence (P1P2 tag), two independently amplified replication products were used with illumina Miseq (FIG. 15B).
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Health & Medical Sciences (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Engineering & Computer Science (AREA)
- Analytical Chemistry (AREA)
- Molecular Biology (AREA)
- Immunology (AREA)
- Microbiology (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017502400A JP6825768B2 (ja) | 2015-02-23 | 2016-02-23 | 核酸配列増幅方法 |
| US15/553,091 US11028426B2 (en) | 2015-02-23 | 2016-02-23 | Nucleic acid sequence amplification method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015-033432 | 2015-02-23 | ||
| JP2015033432 | 2015-02-23 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2016136766A1 true WO2016136766A1 (ja) | 2016-09-01 |
Family
ID=56788777
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2016/055314 Ceased WO2016136766A1 (ja) | 2015-02-23 | 2016-02-23 | 核酸配列増幅方法 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US11028426B2 (enExample) |
| JP (2) | JP6825768B2 (enExample) |
| WO (1) | WO2016136766A1 (enExample) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112094916B (zh) * | 2020-11-17 | 2021-02-19 | 苏州科贝生物技术有限公司 | 一种血浆游离dna肺癌基因联合检测试剂盒 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6271002B1 (en) * | 1999-10-04 | 2001-08-07 | Rosetta Inpharmatics, Inc. | RNA amplification method |
| EP1845160A4 (en) * | 2005-02-10 | 2009-07-01 | Riken | NUCLEOTIDE-amplification |
-
2016
- 2016-02-23 WO PCT/JP2016/055314 patent/WO2016136766A1/ja not_active Ceased
- 2016-02-23 US US15/553,091 patent/US11028426B2/en active Active
- 2016-02-23 JP JP2017502400A patent/JP6825768B2/ja active Active
-
2020
- 2020-07-08 JP JP2020117947A patent/JP2020202830A/ja active Pending
Non-Patent Citations (3)
| Title |
|---|
| BECK AH ET AL.: "3'-End Sequencing for Expression Quantification (3SEQ) from Archival Tumor Samples", PLOS ONE, vol. 5, no. 1, 2010, pages e8768, ISSN: 1932-6203 * |
| LIANG J ET AL.: "Single- cell sequencing technologies: current and future", J. GENET. GENOMICS, vol. 41, no. 10, 2014, pages 513 - 528, ISSN: 1673-8527 * |
| NAKAMURA T ET AL.: "SC3-seq: a method for highly parallel and quantitative measurement of single- cell gene expression", NUCLEIC ACIDS RES., vol. 43, no. 9, 2015, pages e60, ISSN: 1362-4962 * |
Also Published As
| Publication number | Publication date |
|---|---|
| US11028426B2 (en) | 2021-06-08 |
| JPWO2016136766A1 (ja) | 2017-11-30 |
| JP6825768B2 (ja) | 2021-02-03 |
| JP2020202830A (ja) | 2020-12-24 |
| US20180044714A1 (en) | 2018-02-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Berrens et al. | Locus-specific expression of transposable elements in single cells with CELLO-seq | |
| Liu et al. | Comprehensive characterization of distinct states of human naive pluripotency generated by reprogramming | |
| Nakamura et al. | SC3-seq: a method for highly parallel and quantitative measurement of single-cell gene expression | |
| Bagnoli et al. | Sensitive and powerful single-cell RNA sequencing using mcSCRB-seq | |
| Gafni et al. | Derivation of novel human ground state naive pluripotent stem cells | |
| Murase et al. | Long‐term expansion with germline potential of human primordial germ cell‐like cells in vitro | |
| Bleckwehl et al. | Enhancer-associated H3K4 methylation safeguards in vitro germline competence | |
| JP6626830B2 (ja) | Dna操作のための複数のトランスポザーゼアダプター | |
| AU2024219947A1 (en) | High-Throughput Single-Cell Sequencing With Reduced Amplification Bias | |
| Durruthy-Durruthy et al. | The primate-specific noncoding RNA HPAT5 regulates pluripotency during human preimplantation development and nuclear reprogramming | |
| Vassena et al. | Waves of early transcriptional activation and pluripotency program initiation during human preimplantation development | |
| Yang et al. | Follicular hyperandrogenism downregulates aromatase in luteinized granulosa cells in polycystic ovary syndrome women | |
| Guo et al. | Resolution of cell fate decisions revealed by single-cell gene expression analysis from zygote to blastocyst | |
| KR102451174B1 (ko) | 핵산의 다중 검출 | |
| Virant-Klun et al. | Gene expression profiling of human oocytes developed and matured in vivo or in vitro | |
| Allègre et al. | NANOG initiates epiblast fate through the coordination of pluripotency genes expression | |
| Oomen et al. | An atlas of transcription initiation reveals regulatory principles of gene and transposable element expression in early mammalian development | |
| US20240209435A1 (en) | Methods of identifying combinations of transcription factors | |
| CA3211616A1 (en) | Cell barcoding compositions and methods | |
| Bui et al. | Retrotransposon expression as a defining event of genome reprograming in fertilized and cloned bovine embryos | |
| Brinkhof et al. | Characterization of bovine embryos cultured under conditions appropriate for sustaining human naïve pluripotency | |
| US11441169B2 (en) | Methods of small-RNA transcriptome sequencing and applications thereof | |
| JP2020202830A (ja) | 核酸配列増幅方法 | |
| Hu et al. | Single‐cell RNA‐Seq reveals the earliest lineage specification and X chromosome dosage compensation in bovine preimplantation embryos | |
| Chialastri et al. | Integrated single-cell sequencing reveals principles of epigenetic regulation of human gastrulation and germ cell development in a 3D organoid model |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 16755510 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2017502400 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 15553091 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 16755510 Country of ref document: EP Kind code of ref document: A1 |