WO2010068068A2 - 사용자의 의도에 기반한 정보 검색방법 및 정보 제공방법 - Google Patents
사용자의 의도에 기반한 정보 검색방법 및 정보 제공방법 Download PDFInfo
- Publication number
- WO2010068068A2 WO2010068068A2 PCT/KR2009/007443 KR2009007443W WO2010068068A2 WO 2010068068 A2 WO2010068068 A2 WO 2010068068A2 KR 2009007443 W KR2009007443 W KR 2009007443W WO 2010068068 A2 WO2010068068 A2 WO 2010068068A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- information
- search
- intention
- metadata
- editor
- Prior art date
Links
Images



















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/951—Indexing; Web crawling techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/211—Syntactic parsing, e.g. based on context-free grammar [CFG] or unification grammars
Definitions
- the present invention relates to a multifunctional information retrieval method and system for providing and searching information using words, phrases and sentences of a natural language as a search word, and providing more accurate information and searching based on a user's intention.
- convergence technology of wired / wireless broadcasting communication technology, integrated information web service technology, and development of user interface technology convenient for various user layers are representative ones.
- the specific contents of these technologies are to automatically interpret the provided or provided contents, the quality and meaning of the information with a computer, so that the information contents are presented and provided in a convenient and various manner according to the taste and intention of the information contents user.
- Market technology is expected.
- Korean Patent Publication No. 10-2006-0043333 (system and method for determining the intent of data and responding to data based on the intent) is a system for facilitating data handling, comprising: a component for receiving data;
- a component for receiving data For purposes of a system comprising a data manager for determining an intent of the data, reorganizing at least a subset of the data based on the intent, and automatically presenting the reorganized data to a user,
- a system for analyzing the data classifying the data into one or more sets having related features, and extracting features from at least one set of the data sets to form a subset of the data;
- the metadata of the data Uses at least one of data, attributes, content, context, keywords, history, heuristics, reasoning, rules, demarcation, time of day, day of the week, associated handling costs, associated handling gains, and sources.
- a system that is extracted based at least in part on one of syntactic, syntactic, linguistic, and linguistic properties, wherein the linguistic features include words that occur in sentences, double-word words that occur in sentences, and An object is to include at least one of the word trigrams generated in a sentence.
- Korean Patent Publication No. 2002-0028593 is a step in which a computer user enters member information and accesses a management server, and the computer user registers / transmits the information input screen displayed by the management server.
- the harmful word blocking module of the management server determining whether the harmful word is included in the information input by the computer user
- the management server is configured to determine whether the harmful word blocking module Characterized by the harmful word blocking method characterized in that the connection to the user, or the step of registering / transmitting the information, characterized in that the definition of the harmful word refers to slang, profanity, sexual insults or personal insults. If the message you send does not contain harmful words, please It consists of a processing module in progress.
- the patent is based on the presence of harmful words in the message on the chat.
- Korean Patent Publication No. 10-2006-0062300 (a multi-step text filtering method for blocking harmful sites) divides the text to be used as a material for blocking pornographic sites into at least one set by dividing it into at least one set and then database And collecting text from a web site being accessed and comparing the text with text in the set to perform at least one multi-step filtering to determine whether to block the web site being accessed.
- Multi-level text filtering method for blocking harmful sites is to block harmful sites according to the degree of lewdness in the text.
- Korean Patent Laid-Open Publication No. 10-2006-0087735 (system and method for providing improved spam message filtering) is a system for providing spam message filtering, wherein the wireless network receives a message for transmission from a sender terminal to a user terminal.
- the server, the use cases of the natural language sentences, and accessory information on these use cases are stored, and a large-scale language database (Corpus DB) which can be classified into categories according to each use purpose, and the corpus DB in the wireless network server.
- a lexical analyzer detecting a reception and extracting at least one noun type keyword from a sentence included in the received message, and selecting one of the extracted noun type keywords and setting the user to a spam message In sentences contained in each of the user categories in the Corpus DB.
- a corpus search unit for searching spam frequencies used and a general frequency used in sentences included in a category other than the user category, and when the at least one spam frequency and the general frequency are input, the selected noun-type keyword is entered.
- Probability calculation unit for calculating the probability that the included sentence is included in the user category, and control the lexical analysis unit and the corpus search unit to calculate the spam message inclusion probability for each noun type keyword from the probability calculation unit, and calculate And a filtering control unit for calculating whether or not the received message is a spam message by calculating statistical values of the probabilities, and transmitting the determination result to the wireless network server.
- Evaluate, analyze, and analyze messages for spam Ryu is a methodology.
- Korean Patent Publication No. 10-2008-0000416 (harmful message filtration system and filtering method thereof and a recording medium recording the same) has a database storing messages received from clients connected through a network, and a system for filtering harmful messages.
- the method may include: a message receiving means for receiving the message, a word extracting means for extracting a plurality of words from the received message, and determining whether the message is harmful by using the extracted plurality of words, and storing the message in the database; Means, wherein the evaluating means determines whether the message is harmful using the word evaluation value stored in the database, and classifies the message into a plurality of harmful message classifications.
- Korean Patent Registration No. 10-0484944 (morphological semantic automatic tagging device based on local syntactic relation and semantic air dictionary) is a basic syntax structure generation rule, dependency syntax rule, stemming semantic electronic dictionary, semantic framework and Short phrase recognition means for recognizing short sentences by means of lexical phrases, semantic frame and lexical phrases Means of restoring the auxiliary fire using auxiliary air dictionaries, lexical argument using lexical phrase air dictionaries Determining the meaning of nouns in noun phrases and compound nouns in a noun phrase using a noun phrase meaning determination means, and a noun phrase that consists of nouns / investigations / nouns and noun / noun air information Means for determining the meaning of a noun phrase, comprising a morpheme based on local syntax and meaning
- the correct syntax air information context information it means that devices using the syntax structure information from the linguistic point of view on auto-tagging devices presents a way to resolve the ambiguity meaning of the noun
- Korean Patent Registration No. 10-0757951 (a search method through stemming analysis of a web page) is a client of a computer, a notebook, a mobile phone, a PDA, and the like, and an analysis server for providing information to the client, wherein the client user taps
- the analysis server analyzes the context of the content displayed in the tab browser of the client through context morpheme analysis. Identifying a frequency, a sentence having a frequency above a reference value among the identified words, selecting a word as a keyword as an important word, outputting the selected important word as a title of each tab browser, and displaying each of the tab browsers.
- the present invention relates to a search method through morphological analysis of a web page comprising the step of outputting the contents of a web page.
- the patent is a methodology of a search system that calculates the number of sentences and words appearing in text by morphological processing. How to output it as a tab web browser title as a keyword.
- Korean Patent Registration No. 10-0691400 (a method for analyzing a morpheme using additional information and a morpheme analyzer for performing the method), in a morpheme analysis method, includes a morphological analysis target and a morphological analysis target from a search index data. Obtaining an associated additional information, generating a key based on the additional information, and performing a morphological analysis on the morphological analysis object using the key. Way.
- Korean Patent Publication No. 10-2007-0029389 (a method for providing an advertisement service using a core keyword, a system and a recording medium on which a program for implementing the same) is recorded is provided to a digital processing apparatus to provide a keyword advertisement service using a core keyword.
- a program of instructions that can be executed by a program is tangibly embodied and can be read by a digital processing device.
- the method includes extracting keywords by analyzing the morphemes of content texts, and key keywords through interfacing with an advertisement keyword DB server. Determining an advertisement, receiving an advertisement list matching the core keyword through interfacing with an advertisement DB server, and inserting at least one of advertisements included in the advertisement list into the content text. Recording media.
- Korean Patent Publication No. 10-2006-0011333 (Regional Information Providing System and Method through Message Analysis) is a database for storing advertisement information for each region and industry, message recognition means for analyzing stored short messages or text messages. Requesting the message recognition means and the voice recognition means to store the voice recognition means for analyzing the stored voice message, the location information collecting means for confirming the current location of the subscriber station, and the message related to the service subscriber.
- Confirming the message analysis result transmitted from the recognition means and the voice recognition means optionally request the current location information of the subscriber station to the location information collecting means, and desired according to the message analysis result to deliver the desired information to the subscriber terminal Services that provide industry and local information
- Message generation means for retrieving information from the database using the business type and area information transmitted from the service control means and the service control means, and including the search result in a short message and transmitting the result to the subscriber station. Local information provision system through.
- Korean Patent Publication No. 10-2007-0015752 (Advertising-induced messaging service system and method thereof) is an advertisement-induced messaging service system that detects an advertisement-inducing identifier by analyzing a message transmitted from a calling terminal, and then designates a predetermined advertisement message. After transmitting to the calling terminal, and the message server for transmitting the contents of the message to the receiving terminal.
- Korean Patent Registration No. 10-0775680 (Method and system for providing advertisement contents using a chat of a mobile communication terminal) is a method of exchanging messages with each other through a messenger between a mobile communication terminal and a server connected through a wireless communication network. Determining whether the mobile communication terminal connected to the server selects a virtual chat partner to be chatted with, and the server extracts a chat scenario of an advertisement content product according to user preference information of the mobile communication terminal. Transmitting a message according to a scenario rule to the mobile communication terminal, transmitting a response message to the message of the server in the mobile communication terminal, and analyzing the message of the mobile communication terminal received from the server.
- Advertising content information according to the intention and the above scenario rule Transmitting a message requesting the cloth permission to the mobile communication terminal; and transmitting the advertisement content information to the mobile communication terminal when the server transmits a message for recommending the advertisement content information from the mobile communication terminal.
- the transmitting of the message to the mobile terminal by the server may include: previously, analyzing the message of the mobile terminal by the server and adjusting a character state of the messenger according to the intention of the user. Advertising content providing method using a chat of the mobile communication terminal further comprising.
- Korean Patent Registration No. 10-0597435 (Hybrid-based Question Classification System and Method in Information Retrieval and Question Answer System) is a question title processing unit that recognizes the name of the work included in the input question, a morphological analysis of the question, and an individual name.
- Question language analysis unit that converts individual vocabularies into meaningful codes through recognition and lexical semantic tagging process, and rules that classify the correct type of answers required by the question using meaningful LSP form codes of the questions and predefined question classification rules.
- Korean Patent Registration No. 10-0361166 (Information Retrieval System and Method) includes a plurality of information classified by a field, a code is assigned to each classified field, and a plurality of information included in the corresponding field in association with a code of each field. If a user who wants to search the data is coded with a database representing words of information and a user who wants to search the data is connected through a network using a communication device, and inputs a word indicating the information to be searched or indicates a field to which the information belongs, A processing device for encoding the coded words and searching the database based on the coded words to find information corresponding to the coded words, wherein the information stored in the database is classified into a plurality of information areas and the information area.
- Each is assigned an information classification code and contains one or more details.
- the detailed information areas are coded in association with an information classification code of the corresponding information area, and words having the same or similar meanings among the words representing the information are stored with the same code.
- Information retrieval system method arranged in set order.
- Korean Patent Publication No. 10-2005-0092955 (Online Advertising System and Advertising Method) includes a first storage device for storing information to be advertised, a second storage device for storing original content, and original content from a second storage device. At least one server to take a and analyze the natural language processing technique, the information to be advertised corresponding to the analysis result from the first storage device and insert some of the advertisement information into the original content and by the at least one server And a third storage device storing the content in which the advertisement information is inserted.
- Korean Patent Registration No. 10-0669534 (document summary method and system using sentence abstraction and probability rule and sentence meaning analysis and expression method) includes a sentence input step of inputting and storing document contents to be summarized; A parsing step for parsing and storing the data stored in the step; A sentence main component extraction step of sequentially reading the syntax data in the step, extracting main components from each sentence, and storing the ontology data; The ontology data value in the step is compared with the cognitive upper category information, which is a predetermined classification criterion for the meaning of each of the selected main elements, and the data value identified as the abstract meaning for each of the selected main elements.
- Sentence abstracting step of storing A topic selection step of reading a stored value in the step and inputting it into a probability rule program operating unit to select a plurality of topics having probability between phrases, and storing identification values for the selected plurality of topics respectively;
- a summary sentence output step of judging whether there is an output control signal and, if so, outputting and displaying the data value stored in the step through the operation of the output means.
- Korean Patent Registration No. 10-0836878 (a subject or field allocating apparatus and method thereof in an information retrieval system) is connected to a user terminal, a web portal site, or a web site through the Internet to search for information and provide searched information.
- a subject or field assignment apparatus in a search system the information search server comprising: a search engine for performing an information search on a document based on a query word or an index word corresponding to a document; A database for storing and managing information retrieved from the search engine; A thesaurus matching unit for extracting an index word from the original text stored in the database and performing a thesaurus matching by the index word to assign a subject or a field to the original text;
- a subject in an information retrieval system comprising a; taxonomy processing unit for extracting a term from a definition sentence stored in the database and assigning a subject using the extracted term and assigning a subject using a taxonomy A field allocation device.
- the information retrieval system used by large information search portals such as Google and Yahoo is mainly based on the search key method of "word" unit, even though the "old" unit input is possible, Rather than the linguistic processing method, Ngram-based index keys are linked to logical operators (AND, OR, NOT) to present search results. Therefore, current technology has a limitation in improving reproducibility and accuracy of information retrieval. In particular, 'mobile information retrieval' technology is attracting attention as the next generation information retrieval field, and the new web retrieval technology is being proposed and discussed.
- the present invention has been made to solve the above problems, and an object of the present invention is to expand the search key by phrase unit and sentence unit in an information retrieval system using a word unit as a search word to view a user interface of the information retrieval system. Not only is it convenient, but also it is to provide a multifunctional integrated information retrieval method and system capable of integrated processing such as providing, searching, classifying, evaluating and monitoring information.
- the present invention is to provide a multifunctional integrated information retrieval method and system that grasps the intention of the information searcher or the information provider and provides an information result based on the identified intention.
- an information retrieval method using an analysis result for the search word, to determine the intention of the searcher; Providing the searcher with an editor suitable for the searcher's intention; And searching for content having metadata associated with metadata input through the input items of the editor.
- the information retrieval method may further include: separating the input search word into meaningful words; And parsing the separated search terms, wherein the searching of the searcher's intention is preferably to grasp the searcher's intention using the syntax analysis result in the parsing process.
- the syntactic analysis step it is preferable to output a syntax expression obtained by analyzing what grammatical and semantic relations the separated words have in the sentence as the syntax analysis result.
- syntax expression is preferably at least one of a logical expression, a formula-defense expression, and a syntax list item.
- the syntax parsing step in order to interpret what grammatical and semantic relations the separated words have in a sentence, refer to a syntax grammar rule dictionary, and the syntax syntax rule dictionary is a phrase structure grammar, case. It is preferable that at least one of grammar, dependency syntax, and lexical syntax be included.
- the separating step it is preferable to separate the search word by parts of speech.
- the separating step it is preferable to divide the search word by parts of speech by referring to the information on the parts of speech of each word in the morpheme dictionary.
- the method may further include extracting metadata about content suitable for the searcher's intention, and the providing of the editor may include: an editor in which the extracted metadata are input items; It is desirable to provide.
- the information retrieval method may further include determining a directory in which a search is to be performed by referring to the intention of the information provider, wherein the retrieving step includes searching the content in a directory identical or similar to the determined directory. desirable.
- the search word may be any one of a word unit, a phrase unit, and a sentence unit.
- the searching may include content having metadata identical to at least one of metadata input through the input items of the editor or at least one of metadata input through the input items of the editor. It is desirable to search for.
- the information retrieval method may further include adding an additional service to the search result in the search step.
- the additional service may be a content context awareness service, and the content context perception may include at least one of a guide service, a trading service, an advertisement service, an education service, a counseling service, a recommendation service, an auction service, and an administrative service. It is preferable to include one.
- At least one of the input items of the editor may be automatically input into real data generated using the search word.
- the information retrieval method may further include selecting and outputting highly matched contents by comparing the input metadata with metadata constituting the searched content.
- the search information providing method using the analysis result of the text included in the information, grasping the intention of the information provider providing the information; Providing a user with an editor suitable for the intention of the information provider; And storing content integrating metadata input through the input items of the editor.
- the search information providing method may further include: separating the text included in the input information into meaningful words; And parsing the separated words; wherein the determining of the intention of the information provider comprises using the result of parsing in the syntax parsing step, to grasp the intention of the information provider providing the information. desirable.
- the syntactic analysis step it is preferable to output a syntax expression obtained by analyzing what grammatical and semantic relations the separated words have in the sentence as the syntax analysis result.
- syntax expression is preferably at least one of a logical expression, a formula-defense expression, and a syntax list item.
- the syntax parsing step in order to interpret what grammatical and semantic relations the separated words have in a sentence, refer to a syntax grammar rule dictionary, and the syntax syntax rule dictionary is a phrase structure grammar, case. It is preferable that at least one of grammar, dependency syntax, and lexical syntax be included.
- the separating step it is preferable to separate the text by parts of speech.
- the separating step it is preferable to divide the text by parts of speech by referring to the information on the parts of speech of each word that is databased in the morpheme dictionary.
- the search information providing method may further include extracting metadata about content corresponding to the intention of the information provider, and the providing of the editor may include an editor in which the extracted metadata are input items. It is desirable to provide an editor suitable for the intention of the information provider.
- the method for providing information for searching further includes determining a directory in which the information is to be stored with reference to the intention of the information provider, wherein the content storing step preferably stores the content in the determined directory. Do.
- the search information providing method may further include collecting text included in contents classified for each directory, wherein the grasping step may use an analysis result of the collected text.
- a method for providing information for search includes: collecting text included in contents classified for each directory; Identifying the intention of the information provider who provided the information by using the analysis result of the collected text; Providing a user with an editor suitable for the intention of the information provider; And storing content integrating metadata input through the input items of the editor.
- the information retrieval method the step of receiving a search word; Receiving an intention of a searcher who inputs the search word; Providing the searcher with an editor suitable for the ultimate intention that integrates the search result of the search term and the searcher's intention; And searching for content having metadata associated with metadata input through the input items of the editor.
- the information retrieval method may further include: separating the input search word into meaningful words; And parsing the separated search terms.
- the editor providing step preferably uses a result of parsing in the parsing.
- search information providing method the step of receiving information; Receiving an intention of an information provider who inputs the information; Providing the information provider with an editor suitable for the ultimate intention that integrates the interpretation result of the information with the intention of the information provider; And storing content integrating metadata input through the input items of the editor.
- the search information providing method may further include: separating the input information into meaningful words; And parsing the separated words.
- the editor providing step preferably uses a result of parsing in the parsing step.
- the present invention by defining a different metadata for each content, and using an editor generated based on the metadata, by adopting a method for developing the information provision and search content in more detail, the existing search method It makes the search easier and more sophisticated.
- the present invention grasps the searcher's intention from the information input by the searcher, induces detailed metadata input based on the identified intention, and searches in a directory that matches the searcher's intention using the input metadata. It can be done.
- the information provider or searcher can enter the metadata more conveniently, and can also be provided with a guide on what kind of metadata should be input, thereby increasing the convenience of input. Will be.
- the corresponding information may be classified for each directory, and the corresponding metadata may be matched and stored.
- the intention of the searcher is grasped from the information input by the searcher, and the detailed metadata input is derived based on the intention of the searcher, but the metadata capable of generating the real data can be automatically inputted.
- the information provider and the information searcher can be directly input the intention, so that the intention of the information provider and the information searcher can be more accurately understood, and ultimately, accurate information provision and retrieval are possible.
- FIG. 1 is a diagram illustrating a search system according to an embodiment of the present invention
- 3 is a diagram illustrating a Korean morpheme dictionary
- FIG. 6 is a flowchart provided to explain a search method according to another embodiment of the present invention.
- FIG. 7 is a diagram provided in the description of a geographic guidance service stored in an additional service database and an example of an additional service generated by an additional service generator;
- FIG. 8 is a view provided to explain a method of providing an additional service of a different type from FIG. 7;
- FIG. 9 is a view illustrating an example of an information providing / search window provided with an information search window and an information providing window;
- FIG. 10 is a diagram illustrating a search system according to another embodiment of the present invention.
- FIG. 13 is a view provided to explain a search method according to another embodiment of the present invention.
- FIG. 14 to 16 are views provided for further explanation of the search method shown in FIG. 13;
- FIG. 17 is a diagram illustrating a search system according to another embodiment of the present invention.
- 20 is a diagram showing an example applied to the promotional offer for the candidate for the electronic vote.
- searcher intent grasp 106 information monitor
- search directory determiner 110 searcher
- metadata DB 120 information provider intention grasp
- Information Monitor 122 Information Parser
- stemming dictionary 126 information input device
- search result indicator 1001 information search box
- stemming dictionary 1024 directory content crawler
- Metadata DB 1714 Metadata Extractor for Search
- FIG. 1 is a diagram illustrating a search system according to an exemplary embodiment of the present invention.
- the blocks constituting the search system according to the present embodiment can be implemented in S / W as well as in H / W.
- some of the blocks constituting the search system may be implemented as S / W and others as H / W.
- the search system may classify and store information provided by an information provider for each directory according to the intention of the provider, determine the search intention of the information searcher, and perform a search for the information stored in the corresponding directory.
- a consensus / customized search service is provided.
- the metadata is data that can define in more detail and systematically the characteristics of the content to be provided / searched.
- the metadata for a book includes details about the book, such as the book name, author, publisher, year of publication, price, and subject.
- the metadata makes it possible to input and confirm through an editor having a predetermined frame.
- the format of a frame can be implemented in a table form or a sentence form.
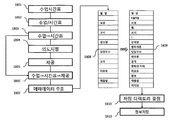
- FIG. 2 is a diagram illustrating metadata for contents. As shown in FIG. 2, it can be seen that essential metadata is defined for contents of all regions.
- the real estate sales 202 can confirm that the metadata, such as "sale”, “location”, “hope”, “feature”, “subway information” and “image information” is standardized.
- Metadata for the contents shown in FIG. 2 is stored in the metadata DB 119 shown in FIG. 1.
- the search system according to the present embodiment, as shown in Figure 1, the information search window 101, the search term input unit 102, search term stem processor 103, search term syntax interpreter 104, searcher intention grasp 105, information monitor 106, metadata extractor 107 for search, editor 108 for search, search directory determiner 109, searcher 110, metadata comparator 111, additional service database ( 112, supplementary service generator 113, search result generator 114, information storage 115, storage directory determiner 116, information providing editor 117, information providing metadata extractor 118, meta Data DB 119, information provider intent determiner 120, information monitor 121, information parser 122, syntax grammar rule dictionary 123, information stemmer 124, stemming dictionary 125, information An input unit 126, an information providing window 127, an information DB 128, and a search result indicator 129 are included.
- additional service database 112, supplementary service generator 113, search result generator 114, information storage 115, storage directory determiner 116, information providing editor 117, information providing metadata extractor 118,
- the information input unit 126 transfers the information input by the user to the information stemmer 124 through the information providing window 127.
- the part-of-speech information of each word is made into a database.
- extended information such as semantic information of each word, synonym information, and band foreign language is also made into a database.
- the part-of-speech information contained in the morpheme dictionary 125 is referred to to separate the text into parts of speech, and the semantic information is used to grasp the intention of the content creator or the searcher.
- synonym information is used to perform a wider range of extended searches, and band foreign languages are used to perform multilingual searches.
- the morpheme dictionary 125 Since the information contained in the morpheme dictionary 125 is illustrated in FIG. 3, the morpheme dictionary 125 will be described in detail later with reference to FIG. 3.
- the information stemmer 124 separates the text received from the information inputter 126 into units of meaningful words.
- the term 'sense of words' refers to a part-of-speech, and accordingly, the information morph processor 124 may be understood to separate the text into parts of speech.
- the information morpheme processor 124 may refer to the part-of-speech information on words that are databased in the morpheme dictionary 125 to separate text by parts of speech.
- the information syntax interpreter 122 parses the information input by the user based on the result of the morpheme processing of the information stemmer 124.
- the information syntax interpreter 122 refers to the grammar rules contained in the syntax grammar rule 123 in performing syntax analysis.
- the information provider intention determiner 120 uses the syntax analysis result output from the information syntax interpreter 122 to grasp the intention of the information provider.
- the information monitor 121 outputs the intention of the information provider identified by the information provider intention determiner 120 for the user to see. To this end, the information monitor 121 may use a graphical tool.
- the information providing metadata extractor 118 extracts metadata about content corresponding to the intention of the information provider identified by the information provider intention determiner 120 from the metadata DB 119.
- the information providing editor 117 generates an editor in which metadata extracted by the information providing metadata extractor 118 is an input item and provides the information to the information provider.
- Storage directory determiner 116 determines a directory on information DB 128 suitable for storing content.
- the storage directory determiner 116 may determine the directory by referring to the intention of the information provider identified by the information provider intention determiner 120.
- the information store 115 stores the content incorporating the metadata generated by the information providing editor 117 in the information DB 128. At this time, the content is stored in the directory determined by the storage directory determiner 116.
- the configurations described so far are used to generate and store information necessary for providing information.
- the information searcher requests a search by inputting a search word
- the configuration for enabling a more accurate search by identifying a search intention and inducing a more detailed search word input will be described in detail.
- the search word input by the user includes not only words but also phrases or sentences.
- the information search window 101 provides an input window through which a user can input a search word as a word, phrase, or sentence.
- the search term input unit 102 transmits the search term input by the user to the search term stem processor 103 through the information search window 101.
- the search term stem processor 103 divides the search term received from the search term inputter 102 into units of 'word meaning'.
- the term 'sense of words' refers to a part-of-speech, and accordingly, the search term morpheme processor 103 may be understood as separating the search terms by parts of speech in the same manner as the information morpheme processor 124.
- the search term morpheme processor 103 may refer to the part-of-speech information on words that are databased in the morpheme dictionary 125 to separate text by parts of speech.
- the search term phrase interpreter 104 parses the search word input by the searcher based on the result of the morpheme processing of the search term stem processor 103.
- the search term syntax interpreter 104 refers to the syntax grammar rule dictionary 123 in performing syntax analysis.
- the searcher intention determiner 105 may determine the searcher's intention by using the parse result output from the search term parser 104.
- the information monitor 106 outputs the searcher's intention grasped by the searcher intention determiner 105 for the user to see. To this end, the information monitor 106 may use graphical tools.
- the search metadata extractor 107 extracts metadata about the content corresponding to the searcher's intention grasped by the searcher intention determiner 105 from the metadata DB 119.
- the search editor 108 generates an editor in which metadata extracted by the search metadata extractor 107 is an input item and provides the searcher.
- Search directory determiner 109 determines a directory on information DB 128 suitable for searching content.
- the search directory determiner 109 may determine the directory with reference to the searcher's intention determined by the searcher intention determiner 105.
- the search directory determiner 109 may further determine directories similar to the determined directory. This is to allow a wider search.
- the searcher 110 searches the information DB 128 for contents having the same metadata as the metadata input by the search editor 108. At this time, the search is performed in the directory determined by the search directory determiner 109.
- the searcher 110 may of course perform an extended search that replaces the metadata input by the search editor 108 with the metadata of the agreement.
- the searcher 110 may search not only metadata having the same structure and words as the metadata, but also content having only the same metadata as the structure and the words. That is, the searcher 110 may perform a partial search or a related search as well as the same search.
- the metadata comparator 111 compares the metadata input through the search editor 108 with metadata constituting the content searched by the searcher 110, and selects and outputs only the content having high matching result. . As such, the comparison (matching degree of determination) is possible by comparing each of the metadata in the form of a table.
- the additional service database 112 stores site information or a related advertisement service suitable for a searcher's search intent.
- the additional service generator 113 generates an additional service related to the search key.
- the supplementary service generator 113 uses an supplementary service suitable for a searcher's search intention among the supplementary services stored in the supplementary service database 112.
- the additional service provided by the additional service database 112 and the additional service generator 113 may be implemented as a content context awareness service.
- the content context-sensitive service includes a guide service, a trading service, an advertising service, an education service, a counseling service, a recommendation service, an administrative service, and the like.
- the search result generator 114 adds the additional service generated by the additional service generator 113 to a degree of matching with the search result (contents) output from the metadata comparator 111.
- the search result indicator 129 outputs the search result to which the additional service generated by the search result generator 114 is added through the screen and provides the result to the user.
- the additional service generator 113 may not generate the additional service, or the search result generator 114 may not add the generated additional service even if the additional service generator 113 generates the additional service.
- FIG. 3 illustrates an example of a morpheme dictionary in Korean.
- the morpheme dictionary 125 includes 1) a word in a first column, 2) a part-of-speech information in a second column, and 3) a semantic information of a word in a third column.
- column 4 a set of synonyms, synonyms, and / or representatives, 5) band English in column 5, 6) band Japanese in column 6, and 7) band Chinese in column 7. , Each listed.
- the information morpheme processor 124 is used to morph text
- the search term morpheme 103 is used to morph the search term.
- morphological processing is to indicate what meaningful words the elements of a given sentence consist of. For example, when stemming "go to school”, it is morpheme processing to divide the word boundary as "school + goes to + goes to school.”
- the information to be used is the part-of-speech information stored in the morpheme dictionary 125 to examine the possible relations between each part-of-speech, and as a result of the processing, such as "school / noun + to / investigative + verb / verb / mother".
- linguistic statistics such as "word frequency” and "sentence number” can be obtained as secondary information of morphological processing, and semantic information, synonym information, and band foreign language can be simultaneously output.
- the classification presented above is only one example and is not fixed. Since the meaning of words changes from time to time, the classification of meanings is not fixed but can change according to the change of the times.
- the lexical dictionary by thesaurus classification may be referred.
- Nom 125-5 may know that part-of-speech information is a “noun”, semantic information is “despite”, and synonym information is “over”.
- Semantic information and synonym information may be used to expand and expand the search. For example, when “Rhee Syngman” is used as a search word, it is possible to further provide a search result related to "Rhee Syngman” as well as a search result related to "Korean President".
- carbon dioxide measures when used as a search term, the search results for "carbon dioxide measures” as well as “harmful substances”, “CO 2 measures” and “global warming measures” can be further provided. Do.
- the morpheme dictionary 125 contains semantic information and synonym information in addition to the part-of-speech information, rich information retrieval is possible.
- Syntactic analysis is the process of interpreting the structure of each meaningful word that constitutes a sentence.
- Syntactic analysis uses grammar theory to describe the natural language.
- Grammar theories describing natural languages include grammar, grammar, dependence, and lexical grammar.
- the input sentences that have completed the morpheme processing 401 shown in FIG. 4 are separated into meaningful word units, and the parts of speech information is added to each of the separated words (402).
- Part-of-speech information includes ⁇ nouns, pronouns, investigations, adjectives, adverbs, investigations... ⁇ There are about 10-12 parts of speech.
- each syntax expression expression may be output 404 according to a grammar theory. Accordingly, the expression 405 by the part-of-speech information, the expression 406 by the semantic information, and the expression 407 by the synonym / phrase can be output.
- FIG. 5 is a flowchart provided to explain a search method according to another embodiment of the present invention.
- the information inputter 126 transmits the information input by the user to the information stemmer 124 (501). .
- the information morpheme processor 124 refers to the morpheme dictionary 125 and separates "used car sales" by parts of speech and outputs it as "used car / dig / sell" (502).
- the part-of-speech information and semantic information are output together as a result of the morpheme processing.
- the part-of-speech information is a noun, a verb, a mother, and the meaning information is a used car, a sale, and respect.
- the information parser 122 performs syntax analysis on the result of the morpheme processing, and outputs the result (used car ⁇ sale) (503).
- the information provider intention determiner 120 uses the syntax analysis result output from the information parser 122 to identify the intention of the information provider as 'used car sale' (504).
- the information providing metadata extractor 118 extracts metadata about the content suitable for 'used car sales', which is the intention of the information provider, from the metadata DB 119 (505).
- the information providing editor 117 generates an editor in which the extracted metadata are input items and provides them to the information provider (506). The information provider then enters the metadata via the provided editor (507).
- the storage directory determiner 116 determines a directory on the information DB 128 suitable for storing the content, and adds a directory index key (used car, sold). This is to allow the content to be stored in the directory. Meanwhile, the storage directory determiner 116 may add a user ID in addition to the directory index key (used car, sale) (508).
- the information storage unit 115 stores the content integrating the metadata input by the information providing editor 117 in the information DB 128. At this time, the content is stored in the directory determined by the storage directory determiner 116.
- FIG. 6 is a view provided to explain a search method according to another embodiment of the present invention.
- the searcher's search intention is grasped, and detailed and accurate search is possible based on the identified searcher's intention.
- the search word input by the user includes not only words but also phrases or sentences.
- the query morpheme processor 103 separates the inputted search words by parts of speech (used used cars / companies). And the part-of-speech information and semantic information of (noun / used car, company / purchase, mother / grand) are added and output (602).
- search term syntax interpreter 104 performs syntax analysis based on the result of the morpheme processing, and outputs (used difference ⁇ purchase) as a result (603).
- the searcher intention determiner 105 determines the searcher's intention as 'used-to-buy' using the syntax analysis result (604).
- the search metadata extractor 107 extracts metadata about content suitable for the 'used car purchase', which is the intention of the searcher, from the metadata DB 119, and the search editor 108 searches the metadata extractor for search ( In step 605, an editor in which metadata extracted by 107 is an input item is generated and provided to a searcher.
- the searcher then enters metadata 606 via the provided editor.
- metadata 606 via the provided editor.
- Search directory determiner 109 determines a directory on information DB 128 suitable for searching for content, and searcher 110 retrieves content having the same metadata as the metadata input by search editor 108. The information is retrieved from the DB 128 (607). The search is performed in the directory determined by the search directory determiner 109.
- the search directory determiner 109 determines a directory by referring to the searcher's intention determined by the searcher intention determiner 105, and may further determine directories similar to the determined directory. This is to allow a wider search.
- the searcher 110 may perform a partial search or a related search.
- the metadata comparator 111 compares the metadata input through the search editor 108 with metadata constituting the content searched by the searcher 110 (608). In operation 609, the metadata comparator 111 selects and outputs only the contents having high matching result.
- the searcher's intention is identified from the information entered by the searcher, the detailed metadata input is derived based on the identified intention, and the input metadata is used to perform a search in a directory that matches the searcher's intention.
- the process has been described in detail.
- the metadata is input using a standardized or standardized editor. Accordingly, the information provider or the searcher may enter the metadata more conveniently, and may also be provided with a guide on what kind of metadata should be input, thereby increasing the convenience of the input.
- the metadata input method using such a standard editor can be applied to a device such as a mobile phone or an IPTV.
- conditional search is to perform a search with the search term "used cars of 1.2 million won or less".
- FIG. 7 is a diagram of a geographic guidance service stored in the supplementary service DB 112 and an example of an additional service generated by the supplementary service generator 113.
- the input sentence 701 is morphed by the search term stem processor 103, separated into " near / delicious /// pantry / restaurant / silver " (702), and " nearby / near " Noun / Current Location, Delicious / Adjective / Food Evaluation, Silver / Investigation / Formula, Italy / Noun / Country, Restaurant / Noun / Restaurant, Silver / Investigation / Presentation "(703) is output.
- the search term syntax interpreter 104 parses the morpheme processing result, and the searcher intention determiner 105 determines the searcher's intention through the syntax interpretation result. Specifically, the searcher intention determiner 105 recognizes the search request because the meaning information of the context-sensitive word 'silver' represents 'present', and the context-sensitive word “nearby”. Is understood to mean that the current location that can be identified by the GPS should be acquired, and the Italian restaurant is intended to require a search of a restaurant database.
- the supplementary service generator 113 detects the current position using the GPS (704), the searcher 110 performs a search for a delicious Italian restaurant (705), and the supplementary service generator 113 executes a map. In operation 706, a map displaying delicious Italian restaurants found on the map on which the current location is displayed is output (707).
- the illustrated additional service is to provide various additional information related to a specific word and a subject included in the text output as a search result.
- various kinds of information such as organization information 801, advertisement 802, person information 803, topic topic information 804, and company information 805 stored in the additional service database 112 may be utilized. Of course, it can be obtained from other databases connected through the network.
- FIG. 9 is a diagram illustrating an example of an information providing / search window provided with an information search window and an information providing window.
- the input window 901 is a window used to input a search word
- the information providing button 902 is a button used to provide / register information input in the input window 901.
- the information retrieval button 903 is a button used to command information retrieval for the search word entered in the input window 901.
- buttons 904 provided below are buttons used to set a search method and a search result providing method.
- the "exact search” button shown in FIG. 9 is a button used to set the search method to a perfect search
- the "ad allow” button is used to allow the display of advertisements related to the search results with the search results.
- the "Allow related service provision” button is a button used to allow additional information on words and phrases included in a search result.
- FIG. 10 is a diagram illustrating a search system according to another embodiment of the present invention.
- the blocks constituting the search system according to the present embodiment can be implemented in S / W as well as in H / W.
- some of the blocks constituting the search system may be implemented as S / W and others as H / W.
- the search system includes an information search window 1001, a search term inputter 1002, a search term stemmer 1003, a search term syntax interpreter 1004, and a searcher intention determiner ( 1005), information monitor 1006, metadata extractor 1007 for search, editor 1008 for search, searcher 1009, metadata comparator 1010, supplementary service database 1011, supplementary service generator 1012 , Search result generator 1013, information store 1014, information providing editor 1015, information providing metadata extractor 1016, metadata DB 1017, content provider intention finder 1018, information Monitor 1019, parser 1020, syntax grammar rule 1021, stemmer 1022, stemmer dictionary 1023, directory content crawler 1024, information DB 1025, search result indicator 1026 , A search directory determiner 1027 and a storage directory determiner 1028.
- the directory content crawler 1024 collects text included in content classified by directory.
- the text collected by directory content crawler 1024 is passed to stemmer 1022, which will be described later.
- contents are stored in a directory, such as job offer information 21, college entrance examination information 13, real estate 23, finance 24, automobile 25, movie theater 26, shopping 27, Traffic information 28, travel information 29, recommendation 30, etc. are assumed, but other directories may be applied.
- the morpheme dictionary 1023 may be implemented as the same as the morpheme dictionary 125 illustrated in FIG. 1.
- the morpheme processor 1022 refers to the morpheme dictionary 1023 and separates and outputs the text transmitted from the directory content crawler 1024 by parts of speech.
- the syntax interpreter 1020 performs syntax analysis on the text included in the content based on the stemming result of the stemmer 84. In performing the syntax analysis, the parser 1020 refers to the syntax grammar rule 1021.
- the content provider intention determiner 1018 uses the syntax analysis result output from the syntax interpreter 1020 to grasp the intention of the content creator.
- the information monitor 1019 outputs the intention of the content creator identified by the content provider intention determiner 1018 for the user to see. To this end, the information monitor 1019 may use graphical tools.
- the information-providing metadata extractor 1016 extracts metadata about the content corresponding to the intention of the content provider identified by the content provider intention determiner 1018 from the metadata DB 1017.
- the information providing editor 1015 generates an editor in which metadata extracted by the information providing metadata extractor 1016 is an input item and provides the information to the information provider.
- the storage directory determiner 1028 determines a directory on the information DB 1025 suitable for storing content.
- the storage directory determiner 1028 may determine the directory by referring to the intention of the content provider identified by the content provider intention determiner 1020.
- the information store 1014 stores the content integrating the metadata generated by the information providing editor 1015 in the information DB 1025. At this time, the content is stored in the directory determined by the storage directory determiner 1028.
- the components described so far are components used to collect content and store the collected contents based on the intention of the creator.
- the information searcher requests a search by inputting a search word
- the configurations for enabling a more accurate search by identifying a search intention and inducing a more detailed search word input will be described in detail.
- the search word input by the user includes not only words but also phrases or sentences.
- the information search window 1001 provides an input window through which a user can input a search word as a word, phrase, or sentence.
- the search term input unit 1002 transmits the search term input by the user to the search term stem processor 1003 through the information search window 1001.
- the search term morpheme processor 1003 refers to the morpheme dictionary 1023, and separates and outputs the search term received from the search term inputter 1002 for each part of speech.
- the search term syntax interpreter 1004 performs syntax analysis on the search term input by the searcher based on the result of the morpheme processing of the search term stem processor 1003.
- the search term parser 1004 refers to a syntax grammar rule 1021 in performing syntax analysis.
- the searcher intention determiner 1005 detects the searcher's intention by using the syntax interpretation result output from the search term syntax interpreter 1004.
- the information monitor 1006 outputs the searcher's intention grasped by the searcher intention determiner 1005 for the user to see. To this end, the information monitor 1006 may use graphical tools.
- the search metadata extractor 1007 extracts metadata about the content corresponding to the searcher's intention grasped by the searcher intention determiner 1005 from the metadata DB 1017.
- the search editor 1008 generates an editor in which metadata extracted by the search metadata extractor 1007 is an input item and provides the searcher.
- Search directory determiner 1027 determines a directory on information DB 1025 suitable for searching for content.
- the search directory determiner 1027 may determine the directory by referring to the searcher's intention determined by the searcher intention determiner 1005.
- the search directory determiner 1027 can further determine directories similar to the determined directory. This is to allow a wider search.
- the searcher 1009 searches the information DB 1025 for content having the same metadata as the metadata input by the search editor 1008. At this time, the search is performed in the directory determined by the search directory determiner 1027.
- the searcher 1009 may of course perform an extended search that replaces the metadata input by the search editor 1008 with metadata of a consent and searches.
- the searcher 1009 may search not only metadata having the same structure and words as the metadata, but also contents having only the same metadata as the structure and the words. That is, the searcher 1009 can perform a partial search or a related search as well as the same search.
- the metadata comparator 1010 compares the metadata input through the search editor 1008 with metadata constituting the content searched by the searcher 1010, and selects and outputs only the content having high matching result. do. As such, the comparison (matching degree of determination) is possible by comparing each of the metadata in the form of a table.
- the comparison is possible by comparing each of the metadata in the form of a table.
- the supplementary service database 1011 stores means for providing site information or related advertisement service suitable for a searcher's search intent.
- the additional service generator 1012 generates an additional service related to the search key. To this end, the supplementary service generator 1012 uses an supplementary service suitable for a searcher's search intention among the supplementary services stored in the supplementary service database 1011.
- the supplementary service provided by the supplementary service database 1011 and the supplementary service generator 1012 may be implemented as a content context awareness service.
- the content context-sensitive service includes a guide service, a trading service, an advertisement service, an education service, a counseling service, a recommendation service, and the like.
- the search result generator 1013 adds an additional service generated by the additional service generator 1012 to match the search result output from the metadata comparator 1010.
- the search result indicator 1026 outputs the search result to which the additional service generated by the search result generator 1013 is added through the screen and provides the result to the user.
- the additional service generator 1012 may not generate the additional service, or the search result generator 1013 may not add the generated additional service even if the additional service generator 1012 is generated.
- FIG. 11 is a view provided to explain a search method according to another embodiment of the present invention.
- the directory content crawler 1024 collects recommendation text posted in the recommendation directory 30 and delivers the recommendation text to the stemmer processor 1022.
- the morpheme processor 1022 then performs a morpheme processing with reference to the morpheme dictionary 1023.
- the result of the morpheme processing by the morpheme processor 1022 is as shown in Fig. 11B.
- the syntax interpreter 1020 performs syntax analysis on FIG. 11B.
- the result of syntax analysis by the syntax interpreter 1020 is as shown in FIG.
- the content provider intention determiner 1018 determines the intention of the provider based on FIG. 11C.
- the intention of the provider identified by the content provider intention determiner 1018 is as shown in FIG.
- the information providing metadata extractor 1016 extracts metadata about the content corresponding to the intention of the provider from the metadata DB 1017.
- the information providing editor 1015 generates an editor in which the extracted metadata are input items and provides them to the user.
- the content corresponding to "stone feast ⁇ place ⁇ recommendation" is "provide stone feast place”.
- the information providing editor 1015 summarizes the intention of the content provider identified by the content provider intention determiner 1018 as shown in FIG. 11E.
- the information providing editor 1015 automatically inputs corresponding metadata to each item of the editor shown in FIG. 12A, and the input result is as shown in FIG. 12B.
- the storage directory determiner 1028 determines a directory on the information DB 1025 suitable for storing content.
- the storage directory determiner 1028 may determine the directory by referring to the intention of the content provider identified by the information provider intention determiner 1018.
- the information store 1014 stores the content integrating the metadata generated by the information providing editor 1015 in the information DB 1025. At this time, the content is stored in the directory determined by the storage directory determiner 1028.
- the corresponding information is classified for each directory based on the intention of the content provider, and the corresponding metadata may be matched and stored.
- the searcher 13 is a view provided to explain a search method according to another embodiment of the present invention.
- the searcher's search intention is grasped, and detailed and accurate search is possible based on the identified searcher's intention.
- the search word input by the user includes not only words but also phrases or sentences.
- the query morpheme processor 1003 separates the input search word by parts of speech. (1302), (noun / present, noun / day, adjective / crush, noun / musical, noun / recommendation, verb / request) And semantic information are added and output (1303).
- the search term syntax interpreter 1004 performs syntax analysis based on the result of the morpheme processing, and outputs the result (from ⁇ Saturday, highlight ⁇ musical, ⁇ recommendation, ⁇ wind) as a result (1304).
- search term syntax interpreter 1004 performs context-sensitive processing on the former, which will be described in detail below.
- 14 are contextual words representing times, which may be contained in a morpheme dictionary 1023. As shown in FIG. 14, semantic information of each language is defined as “past”, “present”, “future”, and the like.
- FIG. 15 is a diagram illustrating that the current time is designated by the year, month, day, day of the week, hour, minute, and second, and managed by the system.
- Fig. 16 shows a method of calculating the language expression "this Saturday” quantitatively at the present time.
- it is the actual quantitative time in the language expression that represents the time, so when morphing "this Saturday", the day of the current time is obtained from the system calendar and "Wednesday” from the semantic information of "this / current, Saturday / Saturday.”
- the current system "Saturday” is three days after "Wed ⁇ Thu ⁇ Fri ⁇ Sat”, so if you add 3 days to the current date of November 6, 2008, you can generate the real data of November 9, 2008. .
- the searcher intention determiner 1005 grasps the searcher's intention as 'musical ⁇ recommend ⁇ request' using the syntax analysis result (1308).
- the search metadata extractor 1007 extracts metadata about content suitable for the 'musical recommendation request', which is the intention of the searcher, from the metadata DB 1017, and the search editor 1008 extracts the search metadata extractor.
- the searcher then enters the metadata through the provided editor (1312).
- Search directory determiner 1027 determines a directory on information DB 1025 suitable for searching content, and searcher 1009 retrieves content having the same metadata as the metadata input by search editor 1008. The information is retrieved from the DB 1025 (1313). The search is performed in the directory determined by the search directory determiner 1027.
- the search directory determiner 1027 determines a directory by referring to the searcher's intention determined by the searcher intention determiner 1005, and may further determine directories similar to the determined directory. This is to allow a wider search.
- the searcher 1009 may perform a partial search or a related search.
- the metadata comparator 1010 compares the metadata input through the search editor 1008 with metadata constituting the content searched by the searcher 1009 (1314). In operation 1315, the metadata comparator 1010 selects and outputs only the contents having a high match.
- the searcher's intention is identified from the information entered by the searcher, and the detailed metadata input is derived based on the identified intention, but the metadata capable of generating real data is automatically entered.
- the process of performing a search in a directory that matches the intention of the searcher has been described in detail.
- the intention of the information provider or the information searcher is automatically detected by analyzing the input language expression.
- a method of allowing the information provider or the information searcher to directly input the information provider and the information searcher is not automatically understood. This is to more accurately grasp the intention of the information provider and the information searcher.
- FIG. 17 is a diagram illustrating a search system according to an embodiment to which the above is applied.
- the blocks constituting the search system according to the present embodiment can be implemented in S / W as well as in H / W.
- some of the blocks constituting the search system may be implemented as S / W and others as H / W.
- the search system includes an information providing / search window 1701, a morpheme processor 1702, a morpheme dictionary 1703, a syntax interpreter 1704, and a syntax grammar rule dictionary 1705. ), Intent designator 1706, information monitor 1707, information providing metadata extractor 1708, information providing editor 1709, storage directory determiner 1710, information storage 1711, information DB ( 1712, metadata DB 1713, metadata extractor 1714 for search, editor 1715 for search, search directory determiner 1716, searcher 1917, metadata comparator 1718, search result generator 1917 ), A search result indicator 1720, an additional service database 1721, and an additional service generator 1722.
- the information providing / search window 1701 is a user interface used for inputting information to be registered by the information provider or for inputting a search word by the information searcher.
- the information providing / search window 1701 is provided with an input window 1701-1, an information providing button 1701-2, and an information searching button 1701-3.
- the input window 1701-1 is a window used to input information or a search word to be provided, and the information and the search word may be input as words, phrases, or sentences in the input window 1701-1.
- the information providing button 1701-2 is a button used to provide / register information input to the input window 1701-1, and the information search button 1701-3 is input to the input window 1701-1. This button is used to command information retrieval for the searched keyword.
- Information or search word input through the information providing / search window 1701 is transferred to the stemmer 1702.
- the morpheme dictionary 1703 may be implemented as the same as the morpheme dictionary 125 illustrated in FIG. 1.
- the morpheme processor 1702 refers to the morpheme dictionary 1023 and separately outputs information or a search word input through the information providing / search window 1701 by parts of speech.
- the syntax interpreter 1704 performs syntax analysis on information or a search word input by a user based on the stemming result of the stemmer 1702.
- the syntax parser 1704 refers to the grammar rules contained in the syntax grammar rule 1705 in performing syntax analysis.
- the intention designator 1706 provides a user interface means for directly designating the intention of the information provider or the intention of the information searcher, and outputs the ultimate intention by integrating the designated intention in the parse result.
- the information monitor 1707 outputs the ultimate intention output from the intention designator 1706 for the user to see. To this end, the information monitor 1707 may use graphical tools.
- the information-providing metadata extractor 1708 extracts metadata about the content corresponding to the ultimate intention of the information provider output from the intention designator 1706 from the metadata DB 1713.
- the information providing editor 1709 generates an editor in which metadata extracted by the information providing metadata extractor 1708 is an input item and provides the information to the information provider.
- the storage directory determiner 1710 determines a directory on the information DB 1712 suitable for storing content. In this case, the storage directory determiner 1710 may determine a directory by referring to the ultimate intention of the information provider identified by the intention designator 1706.
- the information storage unit 1711 stores in the information DB 1712 content in which the metadata generated by the information providing editor 1709 is integrated. At this time, the content is stored in the directory determined by the storage directory determiner 1710.
- the metadata extractor 1714 for searching extracts metadata about the content that matches the ultimate intention of the information searcher output from the intention designator 1706 from the metadata DB 1713.
- the search editor 1715 generates an editor in which metadata extracted by the search metadata extractor 1714 is an input item and provides the searcher.
- Search directory determiner 1716 determines a directory on information DB 1712 suitable for searching for content. In this case, the search directory determiner 1716 may determine the directory by referring to the ultimate intention of the searcher output from the intention designator 1706.
- the search directory determiner 1716 may further determine directories similar to the determined directory. This is to allow a wider search.
- the searcher 1917 searches the information DB 1712 for content having the same metadata as the metadata input by the search editor 1715. At this time, the search is performed in the directory determined by the search directory determiner 1716.
- the searcher 1917 may of course perform an extended search that replaces the metadata input by the search editor 1715 with metadata of the agreement.
- the searcher 1917 may search not only metadata having the same structure and words as the metadata, but also contents having only the same metadata as the structure and the words. That is, the searcher 1917 can perform a partial search or a related search as well as the same search.
- the metadata comparator 1718 compares the metadata input through the search editor 1715 with metadata constituting the content searched by the searcher 1917, and selects and outputs only the contents having high matching result. . As such, the comparison (matching degree of determination) is possible by comparing each of the metadata in the form of a table.
- the additional service database 1721 stores site information suitable for the searcher's search intention or means for providing related advertisement services.
- the additional service generator 1722 generates an additional service related to the search key. To this end, the supplementary service generator 1722 uses an supplementary service suitable for a searcher's search intention among the supplementary services stored in the supplementary service database 1721.
- the additional service provided by the additional service database 1721 and the additional service generator 1722 may be implemented as a content context awareness service.
- the content context-sensitive service includes a guide service, a trading service, an advertising service, an education service, a counseling service, a recommendation service, an administrative service, and the like.
- the search result generator 1725 adds the additional service generated by the additional service generator 1722 to match the search result (contents) output from the metadata comparator 1718.
- the search result indicator 1720 outputs the search result to which the additional service generated by the search result generator 1719 is added to the user through the screen.
- the additional service generator 1722 may not generate the additional service or even if the additional service generator 1722 does not add the generated additional service.
- the stemming dictionary 1703 is divided into parts of speech and output as a class / timetable, with reference to the morpheme dictionary 1703.
- the syntax interpreter 1704 performs syntax analysis on the result of the morpheme processing, and outputs the result (class ⁇ timetable) (1803).
- the intention designator 1706 is the ultimate intention "class ⁇ timetable which incorporates the intention specified in the parse result. ⁇ provide " (1806).
- the information providing metadata extractor 1708 then extracts 1807 metadata about the content suitable for "Teaching ⁇ Timetable ⁇ Providing", which is the ultimate intention of the information provider, from the metadata DB 1713.
- the information providing editor 1709 generates an editor in which the extracted metadata are input items and provides the information to the information provider (1808). The information provider then enters the metadata via the provided editor (1809).
- the storage directory determiner 1710 determines 1810 a directory on the information DB 1712 suitable for storing the content.
- the information storage unit 1711 stores the content in which the metadata inputted by the information providing editor 1709 is integrated in the information DB 1712. At this time, the content is stored in the directory determined by the storage directory determiner 1710.
- the information searcher enables detailed and accurate search based on the search word and the intention.
- the search word input by the user includes not only words but also phrases or sentences.
- the stemmer 1702 Refers to the morpheme dictionary 1703 and separates the "schedule table” by parts of speech and outputs it as “schedule / table” (1902).
- the syntax interpreter 1704 then parses the result of the morpheme processing and outputs the result (Schedule-> Table) (1903).
- the intention designator 1706 is the ultimate intention "schedule ⁇ table which incorporates the intention specified in the parse result. Output the search " (1906).
- the search metadata extractor 1714 extracts metadata about content suitable for the searcher's ultimate intention of 'schedule ⁇ table ⁇ search' from the metadata DB 1713, and the search editor 1715 searches.
- the application metadata extractor 1714 generates an editor in which the extracted metadata is an input item, and provides the editor to the searcher (1908).
- the searcher then enters metadata 1909 via the provided editor.
- the search directory determiner 1716 determines a directory on the information DB 1712 suitable for searching for content (1910), and the searcher 1917 uses the same metadata as the metadata input by the search editor 1715.
- the retrieved content is retrieved from the information DB 1712 (1911).
- the search is performed in the directory determined by the search directory determiner 1716.
- the search directory determiner 1716 determines a directory by referring to the searcher's intention determined by the intention designator 1706, and may further determine directories similar to the determined directory. This is to allow a wider search.
- the searcher 1917 may perform a partial search or a related search.
- the metadata comparator 1718 compares the metadata input through the search editor 1715 with metadata constituting the content searched by the searcher 1917 (1912).
- the metadata comparator 1718 selects and outputs only the contents having a high match as a result of the comparison (1913).
- a user inputs "providing candidates for promotion" to enter metadata in an editor provided by an information provider and an editor created after morphing, parsing, specifying intent, and extracting metadata. The results are shown in FIG. 20.
- the promotional material for the candidate can be distributed to the voters using a PC, a mobile phone, or the like. According to this, it is possible to cheaply and quickly provide a candidate promotional material by the paper poster currently in use.
- the embodiments described so far can be implemented in mobile information devices such as mobile phones as well as other information devices.
- the information providing button and the information searching button may correspond to / assign a specific button (key) of mobile information devices such as a mobile phone as well as other information devices.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Machine Translation (AREA)
Abstract
Description
Claims (30)
- 검색어에 대한 해석결과를 이용하여, 검색자의 의도를 파악하는 단계;상기 검색자의 의도에 맞는 편집기를 상기 검색자에게 제공하는 단계; 및상기 편집기의 입력 항목들을 통해 입력된 메타데이터들과 관련된 메타데이터를 가지는 컨텐츠를 검색하는 단계;를 포함하는 것을 특징으로 하는 정보 검색방법.
- 제 1항에 있어서,입력된 검색어를 의미 있는 단어들로 분리하는 단계; 및분리된 검색어들을 구문 해석하는 단계;를 더 포함하고,상기 검색자의 의도 파악단계는,상기 구문 해석단계에서의 구문 해석결과를 이용하여, 상기 검색자의 의도를 파악하는 것을 특징으로 하는 정보 검색방법.
- 제 2항에 있어서,상기 구문 해석단계는,상기 분리된 단어들이 문장 내에서 어떠한 문법적 관계 및 의미적 관계를 가지는지를 해석하여 얻어지는 구문 표현식을 상기 구문 해석결과로 출력하는 것을 특징으로 하는 정보 검색방법.
- 제 3항에 있어서,상기 구문 표현식은,논리식, 수식-피수식 및 구문목 리스트식 중 적어도 하나인 것을 특징으로 하는 정보 검색방법.
- 제 3항에 있어서,상기 구문 해석단계는,상기 분리된 단어들이 문장 내에서 어떠한 문법적 관계 및 의미적 관계를 가지는지를 해석하기 위해, 구문문법 규칙사전을 참조하며,상기 구문문법 규칙사전은,구구조문법, 격문법, 의존문법 및 어휘문법 중 적어도 하나가 수록되어 있는 것을 특징으로 하는 정보 검색방법.
- 제 2항에 있어서,상기 분리단계는,상기 검색어를 품사 별로 분리하는 것을 특징으로 하는 정보 검색방법.
- 제 6항에 있어서,상기 분리단계는,형태소 사전에 데이터 베이스화되어 있는 각 단어의 품사에 대한 정보를 참조하여, 상기 검색어를 품사 별로 분리하는 것을 특징으로 하는 정보 검색방법.
- 제 1항에 있어서,상기 검색자의 의도에 맞는 컨텐츠에 대한 메타데이터들을 추출하는 단계;를 더 포함하고,상기 편집기 제공단계는,추출된 메타데이터들이 입력 항목으로 되어 있는 편집기를, 상기 검색자의 의도에 맞는 편집기로 제공하는 것을 특징으로 하는 정보 검색방법.
- 제 1항에 있어서,상기 정보 제공자의 의도를 참조하여 검색을 수행할 디렉토리를 결정하는 단계;를 더 포함하고,상기 검색 단계는,결정된 디렉토리와 동일 또는 유사한 디렉토리에서 상기 컨텐츠를 검색하는 것을 특징으로 하는 정보 검색방법.
- 제 1항에 있어서,상기 검색어는,단어 단위, 구 단위 및 문장 단위 중 어느 하나인 것을 특징으로 하는 정보 검색방법.
- 제 1항에 있어서,상기 검색단계는,상기 편집기의 입력 항목들을 통해 입력된 메타데이터들 중 적어도 하나와 동일한 메타데이터 또는 상기 편집기의 입력 항목들을 통해 입력된 메타데이터들 중 적어도 하나와 동의의 메타데이터를 가지는 컨텐츠를 검색하는 것을 특징으로 하는 정보 검색방법.
- 제 1항에 있어서,상기 검색단계에서의 검색결과에 부가서비스를 부가하는 단계;를 더 포함하는 것을 특징으로 하는 정보 검색방법.
- 제 12항에 있어서,상기 부가서비스는, 컨텐츠 문맥 지각형(Context awareness) 서비스이고,상기 컨텐츠 문맥 지각형은,안내서비스, 매매서비스, 광고서비스, 교육서비스, 상담서비스, 추천서비스, 경매서비스 및 행정서비스 중 적어도 하나를 포함하는 것을 특징으로 하는 정보 검색방법.
- 제 1항에 있어서,상기 편집기의 입력 항목들 중 적어도 하나는, 상기 검색어를 이용하여 생성한 리얼데이터로 자동입력되는 것을 특징으로 하는 정보 검색방법.
- 제 1항에 있어서,상기 입력된 메타데이터들 및 검색된 컨텐츠를 구성하는 메타데이터들을 각각 비교하여 일치도가 높은 컨텐츠들을 선별하여 출력하는 단계;를 더 포함하는 것을 특징으로 하는 정보 검색방법.
- 정보에 포함된 텍스트에 대한 해석결과를 이용하여, 상기 정보를 제공한 정보 제공자의 의도를 파악하는 단계;상기 정보 제공자의 의도에 맞는 편집기를 사용자에게 제공하는 단계; 및상기 편집기의 입력 항목들을 통해 입력된 메타데이터들을 통합한 컨텐츠를 저장하는 단계;를 포함하는 것을 특징으로 하는 검색용 정보 제공방법.
- 제 16항에 있어서,입력된 정보에 포함된 상기 텍스트를 의미 있는 단어들로 분리하는 단계; 및분리된 단어들을 구문 해석하는 단계;를 더 포함하고,상기 정보 제공자의 의도 파악단계는,상기 구문 해석단계에서의 구문 해석결과를 이용하여, 상기 정보를 제공한 정보 제공자의 의도를 파악하는 것을 특징으로 하는 검색용 정보 제공방법.
- 제 17항에 있어서,상기 구문 해석단계는,상기 분리된 단어들이 문장 내에서 어떠한 문법적 관계 및 의미적 관계를 가지는지를 해석하여 얻어지는 구문 표현식을 상기 구문 해석결과로 출력하는 것을 특징으로 하는 검색용 정보 제공방법.
- 제 18항에 있어서,상기 구문 표현식은,논리식, 수식-피수식 및 구문목 리스트식 중 적어도 하나인 것을 특징으로 하는 검색용 정보 제공방법.
- 제 18항에 있어서,상기 구문 해석단계는,상기 분리된 단어들이 문장 내에서 어떠한 문법적 관계 및 의미적 관계를 가지는지를 해석하기 위해, 구문문법 규칙사전을 참조하며,상기 구문문법 규칙사전은,구구조문법, 격문법, 의존문법 및 어휘문법 중 적어도 하나가 수록되어 있는 것을 특징으로 하는 검색용 정보 제공방법.
- 제 17항에 있어서,상기 분리단계는,상기 텍스트를 품사 별로 분리하는 것을 특징으로 하는 검색용 정보 제공방법.
- 제 21항에 있어서,상기 분리단계는,형태소 사전에 데이터 베이스화되어 있는 각 단어의 품사에 대한 정보를 참조하여, 상기 텍스트를 품사 별로 분리하는 것을 특징으로 하는 검색용 정보 제공방법.
- 제 16항에 있어서,상기 정보 제공자의 의도에 맞는 컨텐츠에 대한 메타데이터들을 추출하는 단계;를 더 포함하고,상기 편집기 제공단계는,추출된 메타데이터들이 입력 항목으로 되어 있는 편집기를, 상기 정보 제공자의 의도에 맞는 편집기로 제공하는 것을 특징으로 하는 검색용 정보 제공방법.
- 제 16항에 있어서,상기 정보 제공자의 의도를 참조하여 상기 정보가 저장될 디렉토리를 결정하는 단계;를 더 포함하고,상기 컨텐츠 저장단계는,결정된 디렉토리에 상기 컨텐츠를 저장하는 것을 특징으로 하는 검색용 정보 제공방법.
- 제 16항에 있어서,디렉토리 별로 구분되어 있는 컨텐츠에 포함되어 있는 텍스트를 수집하는 단계;를 더 포함하고,상기 파악 단계는,수집된 텍스트에 대한 해석결과를 이용하는 것을 특징으로 하는 검색용 정보 제공방법.
- 디렉토리 별로 구분되어 있는 컨텐츠에 포함되어 있는 텍스트를 수집하는 단계;수집된 텍스트에 대한 해석결과를 이용하여, 상기 정보를 제공한 정보 제공자의 의도를 파악하는 단계;상기 정보 제공자의 의도에 맞는 편집기를 사용자에게 제공하는 단계; 및상기 편집기의 입력 항목들을 통해 입력된 메타데이터들을 통합한 컨텐츠를 저장하는 단계;를 포함하는 것을 특징으로 하는 검색용 정보 제공방법.
- 검색어를 입력받는 단계;상기 검색어를 입력한 검색자의 의도를 입력받는 단계;상기 검색어에 대한 해석결과와 상기 검색자의 의도를 통합한 궁극적인 의도에 맞는 편집기를 상기 검색자에게 제공하는 단계; 및상기 편집기의 입력 항목들을 통해 입력된 메타데이터들과 관련된 메타데이터를 가지는 컨텐츠를 검색하는 단계;를 포함하는 것을 특징으로 하는 정보 검색방법.
- 제 27항에 있어서,입력된 검색어를 의미 있는 단어들로 분리하는 단계; 및분리된 검색어들을 구문 해석하는 단계;를 더 포함하고,상기 편집기 제공단계는,상기 구문 해석단계에서의 구문 해석결과를 이용하는 것을 특징으로 하는 정보 검색방법.
- 정보를 입력받는 단계;상기 정보를 입력한 정보 제공자의 의도를 입력받는 단계;상기 정보에 대한 해석결과와 상기 정보 제공자의 의도를 통합한 궁극적인 의도에 맞는 편집기를 상기 정보 제공자에게 제공하는 단계; 및상기 편집기의 입력 항목들을 통해 입력된 메타데이터들을 통합한 컨텐츠를 저장하는 단계;를 포함하는 것을 특징으로 하는 검색용 정보 제공방법.
- 제 29항에 있어서,입력된 정보를 의미 있는 단어들로 분리하는 단계; 및분리된 단어들을 구문 해석하는 단계;를 더 포함하고,상기 편집기 제공 단계는,상기 구문 해석단계에서의 구문 해석결과를 이용하는 것을 특징으로 하는 검색용 정보 제공방법.
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/139,118 US9256679B2 (en) | 2008-12-11 | 2009-12-11 | Information search method and system, information provision method and system based on user's intention |
| CN200980150114.1A CN102246164B (zh) | 2008-12-11 | 2009-12-11 | 基于用户意图的信息搜索方法以及信息提供方法 |
| JP2011540611A JP5481615B2 (ja) | 2008-12-11 | 2009-12-11 | 使用者の意図に基づく情報検索方法及び情報提供方法 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020080125767A KR101042515B1 (ko) | 2008-12-11 | 2008-12-11 | 사용자의 의도에 기반한 정보 검색방법 및 정보 제공방법 |
| KR10-2008-0125767 | 2008-12-11 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2010068068A2 true WO2010068068A2 (ko) | 2010-06-17 |
| WO2010068068A3 WO2010068068A3 (ko) | 2010-09-16 |
Family
ID=42243243
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/KR2009/007443 WO2010068068A2 (ko) | 2008-12-11 | 2009-12-11 | 사용자의 의도에 기반한 정보 검색방법 및 정보 제공방법 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US9256679B2 (ko) |
| JP (1) | JP5481615B2 (ko) |
| KR (1) | KR101042515B1 (ko) |
| CN (1) | CN102246164B (ko) |
| WO (1) | WO2010068068A2 (ko) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101883341A (zh) * | 2010-06-29 | 2010-11-10 | 中国人民大学 | 一种基于短信终端的信息查询系统及查询方法 |
| WO2012145906A1 (en) | 2011-04-28 | 2012-11-01 | Microsoft Corporation | Alternative market search result toggle |
| CN103703488A (zh) * | 2011-07-19 | 2014-04-02 | Sk普兰尼特有限公司 | 智能信息提供系统和方法 |
| CN107027065A (zh) * | 2017-04-21 | 2017-08-08 | 海信集团有限公司 | 非标准频道名称的识别方法和装置 |
| KR20190113712A (ko) * | 2012-09-10 | 2019-10-08 | 구글 엘엘씨 | 환경 콘텍스트를 이용한 질문 답변 |
Families Citing this family (58)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101106772B1 (ko) * | 2009-05-14 | 2012-01-18 | 주식회사 솔트룩스 | 사용자 선호 지식 베이스 기반의 컨텐츠 추천 방법 및 시스템 |
| WO2011067888A1 (ja) * | 2009-12-03 | 2011-06-09 | 株式会社 日立ハイテクノロジーズ | 自動分析装置 |
| TWI480742B (zh) * | 2011-03-18 | 2015-04-11 | Ind Tech Res Inst | 基於動態語言模型之推薦方法與推薦系統 |
| CN103164449B (zh) * | 2011-12-15 | 2016-04-13 | 腾讯科技(深圳)有限公司 | 一种搜索结果的展现方法与装置 |
| KR101347123B1 (ko) * | 2012-04-17 | 2014-01-03 | 박석일 | 정보검색장치 및 정보검색방법, 컴퓨터 판독가능 기록매체 |
| US9747373B2 (en) | 2012-05-11 | 2017-08-29 | Zte Corporation | Inquiry method and system, inquiry search server and inquiry terminal |
| GB2503223A (en) * | 2012-06-19 | 2013-12-25 | Ibm | Redrafting text strings using a vocabulary |
| US9424233B2 (en) | 2012-07-20 | 2016-08-23 | Veveo, Inc. | Method of and system for inferring user intent in search input in a conversational interaction system |
| US9465833B2 (en) | 2012-07-31 | 2016-10-11 | Veveo, Inc. | Disambiguating user intent in conversational interaction system for large corpus information retrieval |
| CN102866989B (zh) * | 2012-08-30 | 2016-09-07 | 北京航空航天大学 | 基于词语依存关系的观点抽取方法 |
| CN102880723B (zh) * | 2012-10-22 | 2015-08-05 | 深圳市宜搜科技发展有限公司 | 一种识别用户检索意图的搜索方法和系统 |
| US9383216B2 (en) | 2012-10-31 | 2016-07-05 | International Business Machines Corporation | Providing online mapping with user selected preferences |
| WO2014157746A1 (ko) * | 2013-03-27 | 2014-10-02 | ㈜네오넷코리아 | 키워드 검색을 통해 사진 검색이 가능한 사진 공유 시스템 및 사진 공유 방법 |
| CN104077320B (zh) * | 2013-03-29 | 2019-12-17 | 北京百度网讯科技有限公司 | 一种用于生成待发布信息的方法和装置 |
| DK2994908T3 (da) | 2013-05-07 | 2019-09-23 | Veveo Inc | Grænseflade til inkrementel taleinput med realtidsfeedback |
| CN104142955A (zh) * | 2013-05-08 | 2014-11-12 | 中国移动通信集团浙江有限公司 | 一种推荐学习课程的方法和终端 |
| CN103400273A (zh) * | 2013-07-18 | 2013-11-20 | 苏州悦驾信息科技有限公司 | 本地化汽车o2o服务系统 |
| WO2015037814A1 (ko) * | 2013-09-16 | 2015-03-19 | 고려대학교 산학협력단 | 사용자 의도 추론에 기반한 휴대용 단말 장치 및 이를 이용한 컨텐츠 추천 방법 |
| KR20150062832A (ko) * | 2013-11-29 | 2015-06-08 | 현대엠엔소프트 주식회사 | 내비게이션의 검색 방법 및 그 장치 |
| US10778618B2 (en) * | 2014-01-09 | 2020-09-15 | Oath Inc. | Method and system for classifying man vs. machine generated e-mail |
| CN104462212B (zh) * | 2014-11-04 | 2017-12-22 | 百度在线网络技术(北京)有限公司 | 信息展示方法和装置 |
| KR102094934B1 (ko) * | 2014-11-19 | 2020-03-31 | 한국전자통신연구원 | 자연어 질의 응답 시스템 및 방법 |
| US9852136B2 (en) | 2014-12-23 | 2017-12-26 | Rovi Guides, Inc. | Systems and methods for determining whether a negation statement applies to a current or past query |
| US9854049B2 (en) | 2015-01-30 | 2017-12-26 | Rovi Guides, Inc. | Systems and methods for resolving ambiguous terms in social chatter based on a user profile |
| US20160224524A1 (en) * | 2015-02-03 | 2016-08-04 | Nuance Communications, Inc. | User generated short phrases for auto-filling, automatically collected during normal text use |
| US20160283845A1 (en) * | 2015-03-25 | 2016-09-29 | Google Inc. | Inferred user intention notifications |
| US20160285816A1 (en) * | 2015-03-25 | 2016-09-29 | Facebook, Inc. | Techniques for automated determination of form responses |
| KR101656741B1 (ko) * | 2015-04-23 | 2016-09-12 | 고려대학교 산학협력단 | 프레임 기반 의견스팸 판단장치, 프레임 기반 의견스팸 판단방법, 프레임 기반으로 의견스팸을 판단하기 위한 컴퓨터 프로그램 및 컴퓨터 판독가능 기록매체 |
| CN104899308A (zh) * | 2015-06-12 | 2015-09-09 | 北京奇虎科技有限公司 | 用于浏览器页面出错时的信息推荐方法及装置 |
| WO2017017738A1 (ja) * | 2015-07-24 | 2017-02-02 | 富士通株式会社 | 符号化プログラム、符号化装置、及び符号化方法 |
| CN105068661B (zh) * | 2015-09-07 | 2018-09-07 | 百度在线网络技术(北京)有限公司 | 基于人工智能的人机交互方法和系统 |
| CN105425978A (zh) * | 2015-10-26 | 2016-03-23 | 百度在线网络技术(北京)有限公司 | 输入数据的处理方法及装置 |
| US10613825B2 (en) * | 2015-11-30 | 2020-04-07 | Logmein, Inc. | Providing electronic text recommendations to a user based on what is discussed during a meeting |
| CN108885617B (zh) * | 2016-03-23 | 2022-05-31 | 株式会社野村综合研究所 | 语句解析系统以及程序 |
| CN106407181B (zh) * | 2016-09-07 | 2019-05-14 | 武汉众犇慧通科技有限公司 | 旅游目的地中的数据语义关联分析方法及系统 |
| US10650621B1 (en) | 2016-09-13 | 2020-05-12 | Iocurrents, Inc. | Interfacing with a vehicular controller area network |
| CN106599304B (zh) * | 2016-12-29 | 2020-03-24 | 中南大学 | 一种针对中小型网站的模块化用户检索意图建模方法 |
| US10009462B1 (en) * | 2017-03-28 | 2018-06-26 | International Business Machines Corporation | Call filtering to a user equipment |
| CN107832432A (zh) * | 2017-11-15 | 2018-03-23 | 北京百度网讯科技有限公司 | 一种搜索结果排序方法、装置、服务器和存储介质 |
| CN108228191B (zh) * | 2018-02-06 | 2022-01-25 | 威盛电子股份有限公司 | 语法编译系统以及语法编译方法 |
| TWI660341B (zh) * | 2018-04-02 | 2019-05-21 | 和碩聯合科技股份有限公司 | 一種搜尋方法以及一種應用該方法的電子裝置 |
| KR102072723B1 (ko) * | 2018-05-25 | 2020-02-03 | 에스케이텔레콤 주식회사 | 콘텐츠 추천어 제공 방법 및 그 콘텐츠 제공 장치 |
| EP3809282A4 (en) * | 2018-06-13 | 2021-07-28 | Sony Group Corporation | INFORMATION PROCESSING DEVICE AND INFORMATION PROCESSING METHOD |
| CN110347910A (zh) * | 2019-05-28 | 2019-10-18 | 成都美美臣科技有限公司 | 一个电子商务网站搜索结果过滤规则 |
| CN110413882B (zh) * | 2019-07-15 | 2023-10-31 | 创新先进技术有限公司 | 信息推送方法、装置及设备 |
| US12045572B2 (en) | 2020-03-10 | 2024-07-23 | MeetKai, Inc. | System and method for handling out of scope or out of domain user inquiries |
| WO2021183681A1 (en) | 2020-03-10 | 2021-09-16 | MeetKai, Inc. | Parallel hypothetical reasoning to power a multi-lingual, multi-turn, multi-domain virtual assistant |
| US11995561B2 (en) | 2020-03-17 | 2024-05-28 | MeetKai, Inc. | Universal client API for AI services |
| CN115699036A (zh) | 2020-03-17 | 2023-02-03 | 梅特凯股份有限公司 | 支持跨平台、边缘-云混合人工智能服务的智能层 |
| CN111475722B (zh) * | 2020-03-31 | 2023-04-18 | 百度在线网络技术(北京)有限公司 | 用于发送信息的方法和装置 |
| CN111625706B (zh) * | 2020-05-22 | 2023-05-30 | 北京百度网讯科技有限公司 | 信息检索方法、装置、设备及存储介质 |
| WO2021262605A1 (en) * | 2020-06-24 | 2021-12-30 | MeetKai, Inc. | A system and method for handling out of scope or out of domain user inquiries |
| WO2022076471A1 (en) | 2020-10-05 | 2022-04-14 | MeetKai, Inc. | System and method for automatically generating question and query pairs |
| TWI804763B (zh) * | 2020-10-22 | 2023-06-11 | 楊蕙如 | 適合於通訊或社群平台的交易方法及系統 |
| CN112883165B (zh) * | 2021-03-16 | 2022-12-02 | 山东亿云信息技术有限公司 | 一种基于语义理解的智能全文检索方法及系统 |
| KR102625347B1 (ko) | 2021-11-10 | 2024-01-15 | 동의대학교 산학협력단 | 동사와 형용사와 같은 품사를 이용한 음식 메뉴 명사 추출 방법과 이를 이용하여 음식 사전을 업데이트하는 방법 및 이를 위한 시스템 |
| US12074956B2 (en) | 2021-12-08 | 2024-08-27 | Samsung Electronics Co., Ltd. | Electronic device and method for operating thereof |
| CN114169966B (zh) * | 2021-12-08 | 2022-08-05 | 海南港航控股有限公司 | 一种用张量提取货物订单元数据的方法及系统 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20030006201A (ko) * | 2001-07-12 | 2003-01-23 | 서정연 | 홈페이지 자동 검색을 위한 통합형 자연어 질의-응답시스템 |
| KR100786342B1 (ko) * | 2007-01-30 | 2007-12-17 | (주) 프람트 | 사용자 동적 정보를 이용한 콘텐츠의 검색 방법 |
| KR20080052173A (ko) * | 2006-12-05 | 2008-06-11 | 한국전자통신연구원 | 자연어 분석을 통한 미디어 정보 검색 방법 |
Family Cites Families (36)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0962739A (ja) * | 1995-08-22 | 1997-03-07 | Hitachi Ltd | 相談窓口割り当て方法および装置 |
| KR100361166B1 (ko) | 1999-11-13 | 2002-11-18 | 김시환 | 정보 검색 시스템 및 그 방법 |
| US6766320B1 (en) * | 2000-08-24 | 2004-07-20 | Microsoft Corporation | Search engine with natural language-based robust parsing for user query and relevance feedback learning |
| KR20020028593A (ko) | 2000-10-11 | 2002-04-17 | 김중문 | 유해 단어 차단 방법 |
| KR100484944B1 (ko) | 2002-12-24 | 2005-04-25 | 한국전자통신연구원 | 국소 구문관계 및 의미 공기사전에 기반한 형태소 의미자동 태깅장치 |
| JP2004234421A (ja) * | 2003-01-31 | 2004-08-19 | Hitachi Kokusai Electric Inc | 情報検索方法およびそれを用いた情報検索システム |
| JP2004302660A (ja) * | 2003-03-28 | 2004-10-28 | Toshiba Corp | 質問応答システム、質問応答方法及びプログラム |
| US7660400B2 (en) * | 2003-12-19 | 2010-02-09 | At&T Intellectual Property Ii, L.P. | Method and apparatus for automatically building conversational systems |
| US7496500B2 (en) | 2004-03-01 | 2009-02-24 | Microsoft Corporation | Systems and methods that determine intent of data and respond to the data based on the intent |
| JP2005258496A (ja) * | 2004-03-09 | 2005-09-22 | Hitachi Ltd | 検索意図を表す文字列を利用した情報検索システム |
| KR20050092955A (ko) | 2004-03-17 | 2005-09-23 | (주)다음소프트 | 온라인 광고 시스템 및 광고 방법 |
| US7747601B2 (en) * | 2006-08-14 | 2010-06-29 | Inquira, Inc. | Method and apparatus for identifying and classifying query intent |
| KR100594500B1 (ko) | 2004-07-30 | 2006-06-30 | 에스케이 텔레콤주식회사 | 메시지 분석을 통한 지역정보 제공 시스템 및 그 방법 |
| US7565627B2 (en) * | 2004-09-30 | 2009-07-21 | Microsoft Corporation | Query graphs indicating related queries |
| KR100670789B1 (ko) | 2004-12-03 | 2007-01-17 | 한국전자통신연구원 | 유해 사이트 차단을 위한 다단계 텍스트 필터링 방법 |
| KR100597435B1 (ko) | 2004-12-07 | 2006-07-10 | 한국전자통신연구원 | 정보검색 및 질문응답시스템에서의 하이브리드 기반 질문분류 시스템 및 방법 |
| KR100669534B1 (ko) | 2004-12-09 | 2007-01-16 | 학교법인 울산공업학원 | 문장추상화와 개연규칙을 활용하는 문서요약 방법과 시스템, 그리고 문장 의미 분석 및 표현방법 |
| WO2006080149A1 (ja) * | 2005-01-25 | 2006-08-03 | Matsushita Electric Industrial Co., Ltd. | 音復元装置および音復元方法 |
| KR20060087735A (ko) | 2005-01-31 | 2006-08-03 | 삼성전자주식회사 | 개선된 스팸성 메시지 필터링을 제공하는 시스템 및 방법 |
| US20060212142A1 (en) * | 2005-03-16 | 2006-09-21 | Omid Madani | System and method for providing interactive feature selection for training a document classification system |
| JP2006285847A (ja) * | 2005-04-04 | 2006-10-19 | Konica Minolta Holdings Inc | 画像検索システム、およびプログラム |
| KR100726603B1 (ko) | 2005-08-01 | 2007-06-11 | 에스케이 텔레콤주식회사 | 광고 유발 메시징 서비스 시스템 및 그 방법 |
| KR20070029389A (ko) | 2005-09-09 | 2007-03-14 | 주식회사 엠퓨처 | 핵심 키워드를 이용한 광고 서비스 제공 방법, 시스템 및이를 구현하기 위한 프로그램이 기록된 기록매체 |
| KR100775680B1 (ko) | 2005-10-25 | 2007-11-09 | 에스케이 텔레콤주식회사 | 이동통신 단말기의 채팅을 이용한 광고 컨텐츠 제공 방법및 그 시스템 |
| JP4468294B2 (ja) * | 2005-12-08 | 2010-05-26 | 日本電信電話株式会社 | 体験情報評価装置及びプログラム及びコンピュータ読み取り可能な記録媒体 |
| KR100691400B1 (ko) | 2006-03-31 | 2007-03-12 | 엔에이치엔(주) | 부가 정보를 이용하여 형태소를 분석하는 방법 및 상기방법을 수행하는 형태소 분석기 |
| KR100857124B1 (ko) | 2006-06-27 | 2008-09-05 | 성균관대학교산학협력단 | 유해 메시지 여과 시스템과 그 여과 방법 및 이를 기록한기록매체 |
| US8255383B2 (en) * | 2006-07-14 | 2012-08-28 | Chacha Search, Inc | Method and system for qualifying keywords in query strings |
| KR100836878B1 (ko) | 2006-11-29 | 2008-06-11 | 한국과학기술정보연구원 | 정보 검색 시스템에서의 주제 또는 분야 할당 장치 및 그방법 |
| JP4722819B2 (ja) * | 2006-11-29 | 2011-07-13 | 日本電信電話株式会社 | 情報公開システムおよび情報公開方法 |
| KR100757951B1 (ko) | 2007-01-02 | 2007-09-11 | 김수현 | 웹페이지의 형태소 분석을 통한 검색 방법 |
| US20080172380A1 (en) * | 2007-01-17 | 2008-07-17 | Wojciech Czyz | Information retrieval based on information location in the information space. |
| US7805450B2 (en) * | 2007-03-28 | 2010-09-28 | Yahoo, Inc. | System for determining the geographic range of local intent in a search query |
| KR100892842B1 (ko) * | 2007-08-08 | 2009-04-10 | 엔에이치엔(주) | 사용자 중심 정보탐색 방법 및 시스템 |
| EP2223243A4 (en) * | 2007-11-21 | 2011-01-12 | Chacha Search Inc | METHOD AND SYSTEM FOR IMPROVING THE LOADING OF SEARCH PERSONS |
| US20090313117A1 (en) * | 2008-06-16 | 2009-12-17 | Yahoo! Inc. | Targeted advertising |
-
2008
- 2008-12-11 KR KR1020080125767A patent/KR101042515B1/ko active IP Right Grant
-
2009
- 2009-12-11 CN CN200980150114.1A patent/CN102246164B/zh active Active
- 2009-12-11 JP JP2011540611A patent/JP5481615B2/ja active Active
- 2009-12-11 US US13/139,118 patent/US9256679B2/en active Active
- 2009-12-11 WO PCT/KR2009/007443 patent/WO2010068068A2/ko active Application Filing
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20030006201A (ko) * | 2001-07-12 | 2003-01-23 | 서정연 | 홈페이지 자동 검색을 위한 통합형 자연어 질의-응답시스템 |
| KR20080052173A (ko) * | 2006-12-05 | 2008-06-11 | 한국전자통신연구원 | 자연어 분석을 통한 미디어 정보 검색 방법 |
| KR100786342B1 (ko) * | 2007-01-30 | 2007-12-17 | (주) 프람트 | 사용자 동적 정보를 이용한 콘텐츠의 검색 방법 |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101883341A (zh) * | 2010-06-29 | 2010-11-10 | 中国人民大学 | 一种基于短信终端的信息查询系统及查询方法 |
| WO2012145906A1 (en) | 2011-04-28 | 2012-11-01 | Microsoft Corporation | Alternative market search result toggle |
| EP2702509A4 (en) * | 2011-04-28 | 2015-05-20 | Microsoft Technology Licensing Llc | SEARCH RESULTS FOR ALTERNATIVE MARKETS |
| CN103703488A (zh) * | 2011-07-19 | 2014-04-02 | Sk普兰尼特有限公司 | 智能信息提供系统和方法 |
| CN103703488B (zh) * | 2011-07-19 | 2019-09-17 | Sk 普兰尼特有限公司 | 智能信息提供系统和方法 |
| KR20190113712A (ko) * | 2012-09-10 | 2019-10-08 | 구글 엘엘씨 | 환경 콘텍스트를 이용한 질문 답변 |
| KR102140177B1 (ko) | 2012-09-10 | 2020-08-03 | 구글 엘엘씨 | 환경 콘텍스트를 이용한 질문 답변 |
| CN107027065A (zh) * | 2017-04-21 | 2017-08-08 | 海信集团有限公司 | 非标准频道名称的识别方法和装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| US9256679B2 (en) | 2016-02-09 |
| JP2012511769A (ja) | 2012-05-24 |
| CN102246164B (zh) | 2017-09-08 |
| JP5481615B2 (ja) | 2014-04-23 |
| US20110246496A1 (en) | 2011-10-06 |
| KR101042515B1 (ko) | 2011-06-17 |
| CN102246164A (zh) | 2011-11-16 |
| KR20100067285A (ko) | 2010-06-21 |
| WO2010068068A3 (ko) | 2010-09-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2010068068A2 (ko) | 사용자의 의도에 기반한 정보 검색방법 및 정보 제공방법 | |
| WO2010036012A2 (ko) | 인터넷을 이용한 의견 검색 시스템, 의견 검색 및 광고 서비스 시스템과 그 방법 | |
| WO2020009297A1 (ko) | 도메인 추출기반의 언어 이해 성능 향상장치및 성능 향상방법 | |
| WO2012074338A2 (ko) | 자연어 및 수학식 처리 방법과 그를 위한 장치 | |
| WO2017176100A1 (en) | Method and device for translating object information and acquiring derivative information | |
| WO2019177182A1 (ko) | 속성 정보 분석을 통한 멀티미디어 컨텐츠 검색장치 및 검색방법 | |
| WO2020017849A1 (en) | Electronic device and method for providing artificial intelligence services based on pre-gathered conversations | |
| WO2010036013A2 (ko) | 웹 문서에서의 의견 추출 및 분석 장치 및 그 방법 | |
| WO2022065811A1 (en) | Multimodal translation method, apparatus, electronic device and computer-readable storage medium | |
| WO2017209564A1 (ko) | 앱 리스트 제공 방법 및 그 장치 | |
| WO2011007935A1 (ko) | 홈페이지 통합 서비스 제공 시스템 및 방법 | |
| WO2012091360A2 (ko) | 유저 맞춤형 컨텐츠 제공 방법 및 시스템 | |
| WO2013176365A1 (en) | Method and electronic device for easily searching for voice record | |
| WO2012134180A2 (ko) | 문장에 내재한 감정 분석을 위한 감정 분류 방법 및 컨텍스트 정보를 이용한 다중 문장으로부터의 감정 분류 방법 | |
| EP3403415A1 (en) | Method and device for accelerated playback, transmission and storage of media files | |
| WO2017146437A1 (en) | Electronic device and method for operating the same | |
| WO2014030962A1 (en) | Method of recommending friends, and server and terminal therefor | |
| WO2011137724A1 (zh) | 基于语义逻辑的类自然语言人机对话装置 | |
| WO2017142127A1 (ko) | 단어/숙어 시험 문제 출제 방법, 서버 및 컴퓨터 프로그램 | |
| WO2021137637A1 (en) | Server, client device, and operation methods thereof for training natural language understanding model | |
| WO2012130145A1 (zh) | 获取和搜索相关知识信息的方法及装置 | |
| WO2015129989A1 (ko) | 콘텐츠 및 음원 추천 장치 및 방법 | |
| WO2020197257A1 (ko) | 가시적 표현 요소를 이용한 번역 방법 및 그 장치 | |
| WO2011155736A2 (ko) | 모든 자연어 표현의 각각의 의미마다 별도의 용어를 동적으로 생성하는 방법 및 이를 기반으로 하는 사전 관리기,문서작성기, 용어 주석기, 검색 시스템 및 문서정보체계 구축장치 | |
| WO2014163283A1 (ko) | 메시지 서비스 방법, 이를 위한 장치, 시스템 및 프로그램을 기록한 기록 매체 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 200980150114.1 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 09832151 Country of ref document: EP Kind code of ref document: A2 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 13139118 Country of ref document: US Ref document number: 2011540611 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 4112/CHENP/2011 Country of ref document: IN |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 09832151 Country of ref document: EP Kind code of ref document: A2 |