WO2010016104A1 - マルチプロセッサシステム,マルチプロセッサシステム用管理装置およびマルチプロセッサシステム用管理プログラムを記録したコンピュータ読取可能な記録媒体 - Google Patents
マルチプロセッサシステム,マルチプロセッサシステム用管理装置およびマルチプロセッサシステム用管理プログラムを記録したコンピュータ読取可能な記録媒体 Download PDFInfo
- Publication number
- WO2010016104A1 WO2010016104A1 PCT/JP2008/063977 JP2008063977W WO2010016104A1 WO 2010016104 A1 WO2010016104 A1 WO 2010016104A1 JP 2008063977 W JP2008063977 W JP 2008063977W WO 2010016104 A1 WO2010016104 A1 WO 2010016104A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- resources
- data movement
- multiprocessor system
- partition
- distribution
- Prior art date
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5077—Logical partitioning of resources; Management or configuration of virtualized resources
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5066—Algorithms for mapping a plurality of inter-dependent sub-tasks onto a plurality of physical CPUs
Definitions
- the present invention relates to a multiprocessor that allocates and divides a plurality of resources such as a CPU (Central Processing Unit) and a memory into a plurality of partitions, and executes data processing for each partition using resources belonging to each partition
- the present invention relates to a technique suitable for use in a computer system such as a system.
- NUMA Non-Uniform Memory Access
- This NUMA architecture is characterized by non-uniform memory latencies, that is, “near memory” and “far memory”.
- the latency corresponds to the response time from the memory when the CPU or the like accesses the memory.
- a memory with a low latency is defined as a “near memory”
- a memory with a large latency is defined as a “far memory”. Can do.
- a large-scale multiprocessor system is configured with a large number of CPUs, memories, and I / Os as resources.
- a partitioning technique for dividing a large number of resources into a plurality of partitions and operating an independent OS (Operating System) in each partition is used.
- Patent Documents 1 and 2 disclose a logical partition (soft partition) technique.
- a logical partition technology a plurality of OSs are started for each logical partition on a host OS (control host).
- a logical processor or the like is assigned to each logical partition, and processing by each OS is executed for each logical partition while the host OS associates the logical processor or the like with a physical processor or the like.
- the logical partition technology uses virtual partitions, this case assumes a hard partition technology that uses resources dividedly, that is, a technology that uses physically different resources for each partition.
- partitioning when partitioning is performed in a multiprocessor system adopting the NUMA architecture, a system configuration in which the constituent elements (resources) of the partition do not extend over a plurality of nodes as much as possible is provided so as not to cause deterioration in processing performance. It is desirable. Therefore, partitioning is usually performed in units of nodes. However, after the division, while the CPU and memory are added / reduced / changed due to failure in each partition, the components of the partition may span multiple nodes unexpectedly. (See, for example, FIG. 5).
- the partition configuration is inappropriate, for example, when the partition components span multiple nodes as described above, the following problems occur. That is, the processor (CPU) accesses the “distant memory”, and the memory latency increases. In addition, memory access is performed via more communication paths, and traffic in the entire multiprocessor system is unnecessarily increased. As a result, the processing performance of the entire system is degraded.
- the processor CPU
- One of the objects of the present invention is to optimize the partitioning by realizing resource allocation in consideration of the characteristics of the system, and to improve the processing performance of the entire system.
- the present invention is not limited to the above-described object, and is an operational effect derived from each configuration shown in the best mode for carrying out the invention described later, and has an operational effect that cannot be obtained by conventional techniques. Can be positioned as one of the purposes.
- the multiprocessor system disclosed herein has a plurality of resources, a plurality of partition management units, and a system management unit.
- the plurality of resources can be independently assigned to any one of the plurality of partitions.
- the plurality of partition management units manage resources belonging to each of the plurality of partitions.
- the system management unit manages the plurality of resources and the plurality of partition management units.
- the system management unit has first table storage means, collection means, second table storage means, calculation means, and distribution means.
- the first table storage means stores a first table that defines distance information related to the distance between the plurality of resources.
- the collecting means collects data movement information between the plurality of resources.
- the second table storage means stores a second table that holds the data movement frequency between the plurality of resources based on the data movement information collected by the collection means.
- the calculating means calculates an optimal distribution of the plurality of resources for each partition based on the distance information of the first table and the data movement frequency of the second table.
- the distribution means allocates the plurality of partitions to the plurality of partitions via the plurality of partition management units so that the distribution state of the plurality of resources with respect to the plurality of partitions becomes the state of the optimal distribution calculated by the calculation means. A plurality of resources are allocated.
- the multiprocessor system management apparatus disclosed herein manages the plurality of resources and the plurality of partition managers in the multiprocessor system having the plurality of resources and the plurality of partition managers described above.
- This management apparatus has the first table storage means, collection means, second table storage means, calculation means, and distribution means described above.
- a management program for a multiprocessor system disclosed herein is a management device that manages the plurality of resources and the plurality of partition management units in the multiprocessor system having the plurality of resources and the plurality of partition management units.
- the computer functions.
- This program causes the computer to function as the above-mentioned first table storage means, collection means, second table storage means, calculation means, and distribution means.
- the computer-readable recording medium disclosed herein records the above-described management program for multiprocessor systems.
- the optimal allocation of resources to each partition is statistically calculated based on the distance information between resources in the multiprocessor system and the data movement frequency, and the resource allocation according to the optimal allocation is performed. It is. This realizes resource allocation in consideration of system characteristics, optimizes partitioning, and greatly improves the processing performance of the entire system.
- FIG. 1 It is a block diagram which shows the structure of the multiprocessor system as one Embodiment of this invention. It is a figure which shows an example of the access latency table (1st table) of this embodiment. It is a figure which shows an example of the data movement frequency table between resources (2nd table) of this embodiment.
- 3 is a flowchart for explaining an operation of the multiprocessor system management apparatus shown in FIG. 1. It is a figure which shows the state before the optimization of the system in order to demonstrate the specific example of an optimization operation
- server multiprocessor system
- Server Management Device Multiprocessor System Management Device, System Management Unit
- storage section first table storage means, second table storage means
- Access latency table first table, inter-node distance table
- second table Inter-resource data movement frequency table
- FIG. 1 is a block diagram showing the configuration of a multiprocessor system as an embodiment of the present invention.
- the server 1 which is an example of the multiprocessor system of this embodiment shown in FIG. 1 allocates and divides a plurality of resources such as a CPU and a memory (see resource group 10) into a plurality of partitions, and uses resources belonging to each partition. Thus, data processing is executed for each partition.
- a case where two partitions P1 and P2 are set will be described. However, the number of partitions is not limited to two.
- the multiprocessor system 1 may be simply referred to as “system 1”.
- the multiprocessor system 1 of this embodiment includes a resource group 10, partition management units 21 and 22, and a server management device 30.
- each of the partition management units 21 and 22 and the server management apparatus 30 is configured in units of boards, for example.
- the resource group 10 includes a plurality of resources such as a CPU and a memory that can be independently assigned to any one of a plurality of partitions P1 and P2 in this embodiment. More specifically, in the present embodiment, the resource group 10 includes eight nodes N1 to N8 and crossbar switches CB1 and CB2 that connect the eight nodes N1 to N8 so as to communicate with each other. Yes.
- the four nodes N1 to N4 are connected to the crossbar switch CB1 and can communicate with each other via the crossbar switch CB1.
- the four nodes N5 to N8 are connected to the crossbar switch CB2 and can communicate with each other via the crossbar switch CB2.
- the crossbar switches CB1 and CB2 are connected, and the four nodes N1 to N4 and the four nodes N5 to N8 can communicate with each other via the crossbar switches CB1 and CB2. .
- Each node N1 to N8 is a set of resources obtained by dividing a plurality of resources in the system 1 according to their physical arrangement, and each resource belongs to only one node.
- one memory Mi is configured, for example, as a combination of a plurality of DIMMs (Double Inline Memory Module).
- the memory controller MCi has a function of controlling data movement between the CPUs Ci1 to Ci4, the memory Mi, and the crossbar switch CB1 (or CB2). Further, the memory controller MCi also has a function of recording data movement information on which CPU is a read request in the table Ti when there is a read request for the memory Mi.
- the data movement information recorded in each table Ti is collected by the collection means 32 of the server management device 30 via the inter-resource data movement information collection bus B1 or B2, as will be described later.
- CPUs C31 to C34, C41 to C44, C71 to C74, C81 to C84; memories M3, M4, M7, M8; memory controllers MC3, MC4, MC7, MC8; , T4, T7, and T8 are not shown.
- the CPU may not be possible to separate the CPU from the memory for a specific CPU / memory pair, but here it is possible to separate all CPU / memory pairs.
- the present invention is not limited to whether the CPU and the memory are not separable or separable.
- the number of nodes is 8
- the number of crossbar switches is 2
- the number of CPUs in each node Ni is 4, and the number of memories is 1.
- the present invention is not limited to these numbers.
- the partition management units 21 and 22 are provided corresponding to the partitions P1 and P2, respectively, and manage resources such as CPUs and memories belonging to the partitions P1 and P2. Moreover, each partition management part 21 and 22 recognizes the resource which belongs to each partition P1, P2 based on the condition table about each partition P1, P2. According to the recognition result, the partition management units 21 and 22 allocate and divide a plurality of resources to the partitions P1 and P2, respectively, and manage resources belonging to the partitions P1 and P2. The condition table in each partition management unit 21, 22 is instructed / set by the server management apparatus 30.
- a server management device (multiprocessor system management device, system management unit) 30 manages a plurality of resources and a plurality of partition management units 21 and 22 shown as the resource group 10, and includes a storage unit 31, a collection unit 32, Calculation means 33 and distribution means 34 are provided.
- the storage unit 31 is constituted by, for example, a RAM (Random Access Memory), and stores a first table storage unit that stores an access latency table 31 a as a first table, and an inter-resource data movement frequency table 31 b as a second table. It functions as a second table storage means.
- a RAM Random Access Memory
- the access latency table (internode distance table) 31a defines distance information related to the distance between a plurality of resources belonging to the resource group 10 of the system 1 shown in FIG.
- the distance information for example, as shown in FIG. 2, the distance between nodes to which each resource belongs, more specifically, the actual access latency between nodes (access waiting time; unit: nsec) is defined.
- the distance information defined in the access latency table 31a that is, the access latency, is acquired in advance by a performance test as the performance of the system 1 or the resource group 10 included in the system 1, and is given in advance and stored in the storage unit 31. It is registered in the access latency table 31a.
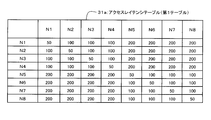
- FIG. 2 is a diagram illustrating an example of the access latency table 31a of the present embodiment.
- the distance between the node N1 and the node N2 is defined as 100 nsec
- the distance between the node N3 and the node N8 is defined as 200 nsec.
- the value in the access latency table 31a as the first table is not limited to the access latency or a value proportional to the access latency as in the present embodiment.
- the value in the access latency table 31a relates to the distance between resources, for example, a value weighted by the throughput of the communication path through which data passes can be used in addition to the actual access latency.
- the inter-resource data movement frequency table 31b holds data movement frequencies between a plurality of resources based on the data movement information collected by the collecting means 32.
- the collecting means 32 receives and collects the data movement information recorded by the memory controller MCi on the table Ti in each node Ni from each table Ti via the buses B1 and B2.
- the data movement information is information indicating which CPU has received the read request from the memory Mi, as described above.
- the collection unit 32 also has a function of integrating the data movement information received from each table Ti by registering it in the inter-resource data movement frequency table 31b.
- the inter-resource data movement frequency table 31b information regarding which CPU has issued a read request to which memory, for example, the number of times of communication / the number of data movements / the number of read accesses, is the data movement frequency.
- data movement information regarding write requests that is, write requests from the CPU to the memory
- data movement information regarding write requests may be collected by the memory controller MCi or the table Ti.
- the inter-resource data movement frequency table 31b information regarding which CPU has issued a write request to which memory, that is, the number of communication times / the number of data movements / the number of write accesses, is the data movement frequency.
- only the number of data movements related to the read request may be counted as the data movement frequency, or only the number of data movements related to the write request may be counted as the data movement frequency, or both the read request and the write request may be counted.
- the total value of the number of data movements may be counted as the data movement frequency.
- the memory controller MCi, the table Ti, the buses B1 and B2, the inter-resource data movement frequency table 31b, and the collecting means 32 constitute the collecting means for collecting data movement information among a plurality of resources. Is done. When communication is performed between resources such as a CPU and a memory using this collection means, it is identified from where to where data movement has been performed, and the data movement frequency is recorded in the inter-resource data movement frequency table 31b.
- FIG. 3 is a diagram showing an example of the inter-resource data movement frequency table 31b of the present embodiment.
- the inter-resource data movement frequency table 31b shown in FIG. 3 a specific example of the number of accesses to each memory of each CPU is recorded. From the inter-resource data movement frequency table 31b, for example, it can be seen that the CPU C11 has made 1000 accesses to the memory M1 and has made 500 accesses to the memory M2. Further, for example, it can be seen that the CPU 23 accesses the memory M2 1000 times.
- the node number i to which each CPU belongs is entered in the #NODE column, and the partition number to which each CPU belongs is written in the #PART column.
- eight CPUs C11, C12, C13, C14, C21, C22, C51, C52 and two memories M1, M5 belong to the partition P1.
- the CPUs C23, C24, C61, C62 and one memory M2 belong to the partition P2.
- D (C61, M2) distance (6, 2), and is 200 when referring to the access latency table 31a shown in FIG.
- the calculating means 33 calculates the optimum distribution of a plurality of resources for each partition P1, P2 based on the distance information (access latency / memory latency) of the access latency table 31a and the data movement frequency of the inter-resource data movement frequency table 31b. To do.
- the calculation means 33 firstly determines all combinations of a plurality of resources allocated to the partitions P1 and P2 based on the distance information of the access latency table 31a and the data movement frequency of the inter-resource data movement frequency table 31b. An average distance, that is, an average memory latency is calculated.
- the calculation unit 33 stores the number of accesses F (Cik, Mn) of each CPU Cik for each memory Mn recorded as the data movement frequency in the inter-resource data movement frequency table 31b and the access latency table 31a.
- the calculation means 33 calculates the value which divided the sum total of the said product by the sum total of the frequency
- the calculation means 33 calculates the average distance, that is, the average memory latency for each combination based on the data in the access latency table 31a and the inter-resource data movement frequency table 31b as follows.
- FIG. 5 the average memory latency for the partition P2 to which four CPUs C23, C24, C61, C62 and one memory M2 are allocated is shown in FIGS. 2 and 3, respectively.
- the case of calculating based on the data of the access latency table 31a and the inter-resource data movement frequency 31b will be specifically described.
- the average memory latency in the partition P2 of the resource combination shown in FIG. 5 is the memory latency recorded in the access latency table 31a shown in FIG. 2 and the number of accesses recorded in the inter-resource data movement frequency table 31b shown in FIG. Is calculated based on [Average memory latency of partition P2 shown in FIG.
- the CPU C23, C24 and the memory M2 shown in FIG. 5 are replaced with the CPU C63, C64 and the memory M6, respectively, as shown in FIG. Is calculated as follows.
- the average memory latency in the partition P2 shown in FIG. 6 is calculated as follows.
- the calculation means 33 calculates an average distance for all resource combinations, and obtains a resource combination that minimizes the average distance as an optimal partition configuration (optimal distribution).
- the calculation means 33 calculates ⁇ : ⁇ CPU set ⁇ ⁇ ⁇ CPU set ⁇ , ⁇ : ⁇ memory set ⁇ ⁇ ⁇ memory set ⁇ .
- Average distance AvgD ( ⁇ , ⁇ ) ⁇ ′D ( ⁇ (C), ⁇ (M)) * F (C, M) / 10000 ⁇ and ⁇ that minimize this are calculated.
- ⁇ a set of CPUs in the partition P2
- ⁇ a set of memories in the partition P2 become an optimal resource configuration (resource allocation) of the partition P2 that minimizes the average latency.
- ⁇ ′ means the sum of D ( ⁇ (C), ⁇ (M)) * F (C, M) calculated for all combinations of CPUs and memories belonging to the partition P2, as described above. ing.
- the calculation means 33 sequentially selects combinations of 12 CPUs and 3 memories belonging to each of the partition P1 and the partition P2, and calculates the average memory latency for each combination in the same manner as described above. Based on the average distance, the optimal allocation, that is, the resource combination that minimizes the average distance is selected.
- the distribution unit 34 sends the CPU Cik to the partitions P1 and P2 via the partition management units 21 and 22 so that the resource distribution state for the partitions P1 and P2 becomes the optimum distribution state calculated by the calculation unit 33. And memory Mn.
- the distribution unit 34 notifies the partition management units 21 and 22 of information regarding the optimal distribution, and rewrites and changes the contents of the condition table for the partitions P1 and P2 in the partition management units 21 and 22.
- the information related to the optimum distribution notified from the distribution means 34 to the partition management units 21 and 21 is information that designates the CPU Cik and the memory Mn to be included in the partitions P1 and P2.
- the distribution change process by the distribution unit 34 is executed after the power of the board including the node to which the resource to be changed belongs is turned off in a time zone where the frequency of use of the system 1 is low, such as at midnight.
- the condition tables are rewritten in the partition management units 21 and 22, and the process of moving the CPU data to be changed and the data stored in the memory to the changed CPU and memory is executed. .
- the resource configuration in each of the partitions P1 and P2 is changed to an optimal partition configuration.
- the present invention is not limited to such a distribution change process, and the distribution change process may be performed by hot replacement of a board or the like.
- the resource allocation change by the distribution unit 34 is executed when there is a partition configuration with an average distance smaller than the average distance in the current partition configuration.
- the resource allocation change is executed when the partition configuration after the distribution change provides a performance improvement equal to or greater than a predetermined standard compared to the current state, that is, the partition configuration before the distribution change. More specifically, when the performance improvement rate [average distance after distribution change] / [average distance before distribution change] calculated as described above is equal to or less than a predetermined value, the resource allocation change may be executed. preferable.
- the processing by the calculating unit 33 and the distributing unit 34 described above is, for example, a time zone where the frequency of use of the system 1 is low, such as midnight, triggered by addition of a new partition, elapse of a predetermined time, a user (server administrator) request, or the like. To be executed.
- the calculation unit 33 selects a resource combination that minimizes the amount of resource allocation change when performing resource allocation by the distribution unit 34 described later as the optimal allocation. It is desirable to do. Thereby, it is possible to efficiently change the allocation by minimizing processing such as rewriting of the condition table in each of the partition management units 21 and 22 and data movement in the CPU / memory accompanying the resource allocation change.
- FIGS. 5 and FIG. 6 are for explaining specific optimization operation examples of partitioning in the system 1 shown in FIG. 1, and FIG. 5 shows a state before optimization of the system 1.
- FIG. 6 and FIG. 6 are views showing a state after optimization of the system 1.
- the CPU and the memory in the same partition are distributed in different nodes, it is necessary to perform communication between nodes, and the memory latency is deteriorated.
- the CPU C61 belonging to the node N6 needs to access the memory M2 in the other node N2, and the memory latency is deteriorated.
- the server management apparatus 30 sets, for example, the access latency table 31 a shown in FIG. 2 or FIG. 3 or the inter-resource data movement frequency 31 b for the resources allocated as shown in FIG. It is the state after optimization obtained as a result of performing the optimization process in the procedure shown in FIG.
- eight CPUs C11, C12, C13, C14, C21, C22, C23, C24 and two memories M1, M2 belong to the partition P1
- four CPUs C61, C62, C63. , C64 and one memory M6 belong to the partition P2.
- the CPU and the memory belonging to the partition P2 are arranged in one node N6. Therefore, when the CPU performs memory access, it always accesses the memory M6 of its own node N6, and the memory latency is minimized.
- the CPU and the memory belonging to the partition P1 are arranged in the two nodes N1 and N2 accommodated in the same crossbar switch CB1. Accordingly, also in this case, when the CPU performs memory access, the memory of the own node or the memory of another node accommodated in the same crossbar switch CB1 is accessed, and the memory latency is minimized.
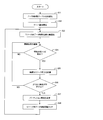
- step S1 when the server management apparatus 30 of this embodiment starts operation
- the access latency table 31a In the initialization of the access latency table 31a, the access latency table 31a corresponding to the resource group 10 of the system 1 is registered and stored in the storage unit 31.
- the table Ti at each node Ni is also initialized (cleared).
- step S3 collection of data movement information between resources is started by the collection means 32 (step S3).
- the data movement information recorded in the table Ti at each node Ni is collected from each table Ti via the buses B1 and B2, and registered in the inter-resource data movement frequency table 31b.
- the inter-resource data movement frequency table 31b in the resource group 10, information regarding which CPU has issued a request to which memory, that is, the number of communications, the number of data movements, the number of read accesses, etc. Is registered as the data movement frequency.
- the collection of data movement information between resources as described above continues (NO route in step S4).
- the calculation means 33 causes the distance information of the access latency table 31a, that is, access. Based on the latency / memory latency and the data movement frequency of the inter-resource data movement frequency table 31b, the optimal resource allocation for each partition P1, P2 is calculated (step S5). That is, as described above, the calculation unit 33 calculates an average distance for all resource combinations, and a resource combination that minimizes the average distance is obtained as an optimal partition configuration (optimal distribution).
- the performance improvement rate [average distance after distribution change] / [average distance before distribution change] as described above is obtained for the optimal partition configuration (optimal distribution) obtained by the calculation means 33. Calculated. And it is judged whether the performance improvement rate is below a predetermined value (Step S6).
- step S6 If the performance improvement rate exceeds a predetermined value, it is determined that there is no better partition configuration than the current partition configuration (NO route in step S6), and the current partition configuration is maintained. That is, the server management apparatus 30 continues to collect data movement information between resources, and proceeds to the process of step S4.
- step S6 if the performance improvement rate is equal to or less than the predetermined value, it is determined that there is a partition configuration better than the current partition configuration (YES route in step S6), and distribution change processing by the distribution unit 34 is executed (step S7). .
- the distribution means 34 rewrites the contents of the condition table for each partition P1, P2 in each partition management unit 21, 22, and changes the CPU data to be changed and the stored data in the memory to the CPU and memory after the change. Moved to. At this time, the data stored in the memory M2 is moved to the memory M6, and the internal data of the CPUs C23 and C24 is moved to the CPUs C63 and C64.
- the data stored in the memory M5 is moved to the memory M2, and the internal data of the CPUs C51 and C52 is moved to the CPUs C23 and C24.
- the nodes N1, N2, N5, and N6 are powered on, and the resource configuration in each partition P1, P2 is changed to an optimal partition configuration (optimal distribution).
- step S8 information such as the data movement frequency and the data movement information related to the resource to be changed is cleared in the inter-resource data movement frequency table 31b and the tables T1, T2, T5, and T6 (step S8).
- the server management apparatus 30 proceeds to the process of step S3.
- the resource information for each partition is based on the distance information between the resources in the multiprocessor system 1 and the data movement frequency.
- the optimal allocation is statistically calculated, and resource allocation according to the optimal allocation is performed. This realizes resource allocation in consideration of the characteristics of the system 1, optimizes partition division, that is, allocation of resources to the partition, and greatly improves the processing performance of the entire system. That is, by performing the resource rearrangement considering the NUMA characteristics of the system 1, the processing performance when the same resource is used can be maximized.
- the present invention is not limited to the above-described embodiment, and various modifications can be made without departing from the spirit of the present invention.
- the functions (all or part of the functions of each unit) as the storage unit (first table storage unit, second table storage unit) 31, collection unit 32, calculation unit 33, and distribution unit 34 described above are computers ( This is realized by a CPU, an information processing apparatus, and various terminals) executing a predetermined application program (multiprocessor system management program).
- the program is, for example, a flexible disk, CD (CD-ROM, CD-R, CD-RW, etc.), DVD (DVD-ROM, DVD-RAM, DVD-R, DVD-RW, DVD + R, DVD + RW, Blu-ray disc, etc.) And the like recorded in a computer-readable recording medium.
- the computer reads the management program for the multiprocessor system from the recording medium, transfers it to the internal storage device or the external storage device, and uses it.
- the program may be recorded in a storage device (recording medium) such as a magnetic disk, an optical disk, or a magneto-optical disk, and provided from the storage device to a computer via a communication line.
- the computer is a concept including hardware and an OS (operating system), and means hardware operating under the control of the OS. Further, when the OS is unnecessary and the hardware is operated by the application program alone, the hardware itself corresponds to the computer.
- the hardware includes at least a microprocessor such as a CPU and means for reading a program recorded on a recording medium.
- the application program as the distributed storage system control program includes a program code for causing the above-described computer to realize the functions as the means 31 to 34. Some of the functions may be realized by the OS instead of the application program.
- a recording medium in the present embodiment in addition to the flexible disk, CD, DVD, magnetic disk, optical disk, and magneto-optical disk described above, an IC card, ROM cartridge, magnetic tape, punch card, computer internal storage device (RAM)
- various computer-readable media such as an external storage device or a printed matter on which a code such as a barcode is printed can be used.
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Multi Processors (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
10 リソース群
21,22 パーティション管理部
30 サーバ管理装置(マルチプロセッサシステム用管理装置,システム管理部)
31 記憶部(第1テーブル記憶手段,第2テーブル記憶手段)
31a アクセスレイテンシテーブル(第1テーブル,ノード間距離テーブル)
31b リソース間データ移動頻度テーブル(第2テーブル)
32 収集手段
33 算出手段
34 配分手段
N1~N8 ノード
CB1,CB2 クロスバスイッチ
Ci1~Ci14(i=1~8) CPU(演算処理部;リソース)
Mi(i=1~8) メモリ(リソース)
MCi(i=1~8) メモリコントローラ(収集手段)
Ti(i=1~8) データ移動情報収集用テーブル(収集手段)
B1,B2 リソース間データ移動情報収集用バス(収集手段)
P1,P2 パーティション
図1は本発明の一実施形態としてのマルチプロセッサシステムの構成を示すブロック図である。この図1に示す本実施形態のマルチプロセッサシステムの例であるサーバ1は、CPU,メモリなどの複数のリソース(リソース群10参照)を複数のパーティションに割り当て分割し、各パーティションに属するリソースを使用してパーティション毎にデータ処理を実行するものである。なお、本実施形態では、2つのパーティションP1,P2が設定されている場合について説明するがパーティションの数は2に限定されるものではない。以下、マルチプロセッサシステム1を単に「システム1」と称する場合がある。
例えば、図2に示すアクセスレイテンシテーブル31aにおいて、ノードN1とノードN2との距離は100nsec、ノードN3とノードN8との距離は200nsecと定義されている。なお、第1テーブルとしてのアクセスレイテンシテーブル31aにおける値は、本実施形態のごとくアクセスレイテンシや、そのアクセスレイテンシに比例した値に限定されるものではない。アクセスレイテンシテーブル31aにおける値は、リソース相互間の距離に係るものであれば、実際のアクセスレイテンシのほかに、例えば、データの通過する通信路のスループットなどによって重み付けした値を使用することもできる。
distance(i, j)= 50 (i=j)
100 ((i≦4 かつ j≦4 かつ i≠j) または
(5≦i かつ 5≦j かつ i≠j))
200 (それ以外)
F(C23, M2)+F(C24, M2)+F(C61, M2)+F(C62, M2)
=1000+4000+3000+2000
=10000
となる。
[図5に示すパーティションP2の平均メモリレイテンシ]
=Σ'D(C,M)*F(C,M)/10000
={D(C23,M2)*F(C23,M2)+D(C24,M2)*F(C24,M2)
+D(C61,M2)*F(C61,M2)+D(C62,M2)*F(C62,M2)}/10000
=(50*1000+50*4000+200*3000+200*2000)/10000
=1250000/10000
=125 nsec
なお、Σ'は、パーティションP2に属するするCPUおよびメモリの全ての組み合わせについて算出されるD(C,M)*F(C,M)の総和を意味している。
F(C63,M6)=F(C23,M2)=1000
F(C64,M6)=F(C24,M2)=4000
であり、図6に示すパーティションP2での平均メモリレイテンシは、以下のように算出される。
=Σ'D(C,M)*F(C,M)/10000
={D(C63,M6)*F(C63,M6)+D(C64,M6)*F(C64,M6)
+D(C61,M6)*F(C61,M6)+D(C62,M6)*F(C62,M6)}/10000
=(50*1000+50*4000+50*3000+50*2000)/10000
=1250000/10000
=50 nsec
平均距離AvgD(τ,ρ)=Σ'D(τ(C),ρ(M))*F(C,M)/10000
を計算し、これを最小にするτ,ρを求める。その結果得られたτ(パーティションP2のCPUの集合)およびρ(パーティションP2のメモリの集合)が、平均レイテンシを最小にする、最適なパーティションP2のリソース構成(リソース配分)になる。なお、Σ'は、上述と同様、パーティションP2に属するするCPUおよびメモリの全ての組み合わせについて算出されるD(τ(C),ρ(M))*F(C,M)の総和を意味している。
また、上述した記憶部(第1テーブル記憶手段,第2テーブル記憶手段)31,収集手段32,算出手段33および配分手段34としての機能(各手段の全部もしくは一部の機能)は、コンピュータ(CPU,情報処理装置,各種端末を含む)が所定のアプリケーションプログラム(マルチプロセッサシステム用管理プログラム)を実行することによって実現される。
Claims (17)
- 複数のパーティションのいずれか一つに対し単独で割当可能な、複数のリソースと、
該複数のパーティションのそれぞれに属するリソースを管理する複数のパーティション管理部と、
該複数のリソースおよび該複数のパーティション管理部を管理するシステム管理部とを有し、
該システム管理部は、
該複数のリソース相互間の距離に係る距離情報を定義する第1テーブルを記憶する第1テーブル記憶手段と、
該複数のリソース相互間のデータ移動情報を収集する収集手段と、
該収集手段によって収集された前記データ移動情報に基づく該複数のリソース相互間のデータ移動頻度を保持する第2テーブルを記憶する第2テーブル記憶手段と、
該第1テーブルの距離情報と該第2テーブルのデータ移動頻度とに基づき、各パーティションに対する、該複数のリソースの最適配分を算出する算出手段と、
該複数のパーティションに対する該複数のリソースの配分状態が該算出手段によって算出された前記最適配分の状態になるように、該複数のパーティション管理部を介して該複数のパーティションに該複数のリソースを配分する配分手段とを有していることを特徴とする、マルチプロセッサシステム。 - 該第1テーブルにおける前記距離情報として、各リソースの属するノード間のアクセスレイテンシが定義されていることを特徴とする、請求項1に記載のマルチプロセッサシステム。
- 該第2テーブルにおける前記データ移動頻度として、前記複数のリソース相互間のデータ移動回数が記録更新されることを特徴とする、請求項1または請求項2に記載のマルチプロセッサシステム。
- 該複数のリソースとして複数の演算処理部と複数のメモリとが含まれ、前記データ移動回数として各演算処理部と各メモリとの間の通信回数が記録更新されることを特徴とする、請求項3に記載のマルチプロセッサシステム。
- 該算出手段は、該第1テーブルの距離情報と該第2テーブルのデータ移動頻度とに基づき、各パーティションに割り当てられる該複数のリソースの全ての組み合わせのそれぞれについて平均距離を算出し、当該平均距離が最小になるリソースの組み合わせを前記最適配分として選択することを特徴とする、請求項1~請求項4のいずれか一項に記載のマルチプロセッサシステム。
- 該算出手段は、前記最適配分として複数の組み合わせが存在する場合には、該配分手段によるリソース配分を行なう際に配分変更量の最も少ない組み合わせを前記最適配分として選択することを特徴とする、請求項5に記載のマルチプロセッサシステム。
- 該複数のリソースとして複数の演算処理部と複数のメモリとが含まれ、
該算出手段は、前記組み合わせ毎に、該第2テーブルに前記データ移動頻度として記録された各メモリに対する各演算処理部のアクセス回数と、該第1テーブルに前記距離情報として定義された対応メモリレイテンシとの積の総和を算出し、当該積の総和を前記アクセス回数の総和で除算した値を、当該組み合わせについての前記平均距離として算出することを特徴とする、請求項5または請求項6に記載のマルチプロセッサシステム。 - 複数のパーティションのいずれか一つに対し単独で割当可能な、複数のリソースと、該複数のパーティションのそれぞれに属するリソースを管理する複数のパーティション管理部とを有するマルチプロセッサシステムにおいて、該複数のリソースおよび該複数のパーティション管理部を管理するマルチプロセッサシステム用管理装置であって、
該複数のリソース相互間の距離に係る距離情報を定義する第1テーブルを記憶する第1テーブル記憶手段と、
該複数のリソース相互間のデータ移動情報を収集する収集手段と、
該収集手段によって収集された前記データ移動情報に基づく該複数のリソース相互間のデータ移動頻度を保持する第2テーブルを記憶する第2テーブル記憶手段と、
該第1テーブルの距離情報と該第2テーブルのデータ移動頻度とに基づき、各パーティションに対する、該複数のリソースの最適配分を算出する算出手段と、
該複数のパーティションに対する該複数のリソースの配分状態が該算出手段によって算出された前記最適配分の状態になるように、該複数のパーティション管理部を介して該複数のパーティションに該複数のリソースを配分する配分手段とを有していることを特徴とする、マルチプロセッサシステム用管理装置。 - 該第1テーブルにおける前記距離情報として、各リソースの属するノード間のアクセスレイテンシが定義されていることを特徴とする、請求項8に記載のマルチプロセッサシステム用管理装置。
- 該第2テーブルにおける前記データ移動頻度として、前記複数のリソース相互間のデータ移動回数が記録更新されることを特徴とする、請求項8または請求項9に記載のマルチプロセッサシステム用管理装置。
- 該複数のリソースとして複数の演算処理部と複数のメモリとが含まれ、前記データ移動回数として各演算処理部と各メモリとの間の通信回数が記録更新されることを特徴とする、請求項10に記載のマルチプロセッサシステム用管理装置。
- 該算出手段は、該第1テーブルの距離情報と該第2テーブルのデータ移動頻度とに基づき、各パーティションに割り当てられる該複数のリソースの全ての組み合わせのそれぞれについて平均距離を算出し、当該平均距離が最小になるリソースの組み合わせを前記最適配分として選択することを特徴とする、請求項8~請求項11のいずれか一項に記載のマルチプロセッサシステム用管理装置。
- 該算出手段は、前記最適配分として複数の組み合わせが存在する場合には、該配分手段によるリソース配分を行なう際に配分変更量の最も少ない組み合わせを前記最適配分として選択することを特徴とする、請求項12に記載のマルチプロセッサシステム用管理装置。
- 該複数のリソースとして複数の演算処理部と複数のメモリとが含まれ、
該算出手段は、前記組み合わせ毎に、該第2テーブルに前記データ移動頻度として記録された各メモリに対する各演算処理部のアクセス回数と、該第1テーブルに前記距離情報として定義された対応メモリレイテンシとの積の総和を算出し、当該積の総和を前記アクセス回数の総和で除算した値を、当該組み合わせについての前記平均距離として算出することを特徴とする、請求項12または請求項13に記載のマルチプロセッサシステム用管理装置。
- 複数のパーティションのいずれか一つに対し単独で割当可能な、複数のリソースと、該複数のパーティションのそれぞれに属するリソースを管理する複数のパーティション管理部とを有するマルチプロセッサシステムにおいて、該複数のリソースおよび該複数のパーティション管理部を管理するマルチプロセッサシステム用管理装置として、コンピュータを機能させるプログラムを記録したコンピュータ読取可能な記録媒体であって、
該プログラムは、
該複数のリソース相互間の距離に係る距離情報を定義する第1テーブルを記憶する第1テーブル記憶手段、
該複数のリソース相互間のデータ移動情報を収集する収集手段、
該収集手段によって収集された前記データ移動情報に基づく該複数のリソース相互間のデータ移動頻度を保持する第2テーブルを記憶する第2テーブル記憶手段、
該第1テーブルの距離情報と該第2テーブルのデータ移動頻度とに基づき、各パーティションに対する、該複数のリソースの最適配分を算出する算出手段、および、
該複数のパーティションに対する該複数のリソースの配分状態が該算出手段によって算出された前記最適配分の状態になるように、該複数のパーティション管理部を介して該複数のパーティションに該複数のリソースを配分する配分手段、として、該コンピュータを機能させることを特徴とする、マルチプロセッサシステム用管理プログラムを記録したコンピュータ読取可能な記録媒体。 - 該プログラムは、該算出手段として該コンピュータを機能させる際に、該第1テーブルの距離情報と該第2テーブルのデータ移動頻度とに基づき、各パーティションに割り当てられる該複数のリソースの全ての組み合わせのそれぞれについて平均距離を算出し、当該平均距離が最小になるリソースの組み合わせを前記最適配分として選択するように、該コンピュータを機能させることを特徴とする、請求項15に記載のマルチプロセッサシステム用管理プログラムを記録したコンピュータ読取可能な記録媒体。
- 該複数のリソースとして複数の演算処理部と複数のメモリとが含まれ、
該プログラムは、該算出手段として該コンピュータを機能させる際に、前記組み合わせ毎に、該第2テーブルに前記データ移動頻度として記録された各メモリに対する各演算処理部のアクセス回数と、該第1テーブルに前記距離情報として定義された対応メモリレイテンシとの積の総和を算出し、当該積の総和を前記アクセス回数の総和で除算した値を、当該組み合わせについての前記平均距離として算出するように、該コンピュータを機能させることを特徴とする、請求項16に記載のマルチプロセッサシステム用管理プログラムを記録したコンピュータ読取可能な記録媒体。
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020117003109A KR101180763B1 (ko) | 2008-08-04 | 2008-08-04 | 멀티프로세서 시스템, 멀티프로세서 시스템용 관리 장치 및 멀티프로세서 시스템용 관리 프로그램을 기록한 컴퓨터 판독 가능한 기록 매체 |
| PCT/JP2008/063977 WO2010016104A1 (ja) | 2008-08-04 | 2008-08-04 | マルチプロセッサシステム,マルチプロセッサシステム用管理装置およびマルチプロセッサシステム用管理プログラムを記録したコンピュータ読取可能な記録媒体 |
| EP08792174A EP2323036A4 (en) | 2008-08-04 | 2008-08-04 | MULTIPROCESSOR SYSTEM, ADMINISTRATION DEVICE FOR A MULTIPROCESSOR SYSTEM AND COMPUTER READABLE RECORDING MEDIUM IN WHICH AN ADMINISTRATIVE PROGRAM FOR A MULTIPROCESSOR SYSTEM IS RECORDED |
| JP2010523663A JP5327224B2 (ja) | 2008-08-04 | 2008-08-04 | マルチプロセッサシステム,マルチプロセッサシステム用管理装置およびマルチプロセッサシステム用管理プログラムを記録したコンピュータ読取可能な記録媒体 |
| CN200880130669.5A CN102112967B (zh) | 2008-08-04 | 2008-08-04 | 多处理器系统、多处理器系统用管理装置以及方法 |
| US13/020,187 US8490106B2 (en) | 2008-08-04 | 2011-02-03 | Apparatus for distributing resources to partitions in multi-processor system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2008/063977 WO2010016104A1 (ja) | 2008-08-04 | 2008-08-04 | マルチプロセッサシステム,マルチプロセッサシステム用管理装置およびマルチプロセッサシステム用管理プログラムを記録したコンピュータ読取可能な記録媒体 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/020,187 Continuation US8490106B2 (en) | 2008-08-04 | 2011-02-03 | Apparatus for distributing resources to partitions in multi-processor system |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2010016104A1 true WO2010016104A1 (ja) | 2010-02-11 |
Family
ID=41663334
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2008/063977 WO2010016104A1 (ja) | 2008-08-04 | 2008-08-04 | マルチプロセッサシステム,マルチプロセッサシステム用管理装置およびマルチプロセッサシステム用管理プログラムを記録したコンピュータ読取可能な記録媒体 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US8490106B2 (ja) |
| EP (1) | EP2323036A4 (ja) |
| JP (1) | JP5327224B2 (ja) |
| KR (1) | KR101180763B1 (ja) |
| CN (1) | CN102112967B (ja) |
| WO (1) | WO2010016104A1 (ja) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013038547A1 (ja) * | 2011-09-15 | 2013-03-21 | 富士通株式会社 | 仮想マシン管理装置、仮想マシン移動制御プログラムおよび仮想マシン移動制御方法 |
| WO2016110950A1 (ja) * | 2015-01-07 | 2016-07-14 | 株式会社日立製作所 | 計算機システム、管理システム、及び、リソース管理方法 |
| JP2018514018A (ja) * | 2015-03-09 | 2018-05-31 | アマゾン・テクノロジーズ・インコーポレーテッド | リソース配置を最適化するための適時性リソース移行 |
| US10616134B1 (en) | 2015-03-18 | 2020-04-07 | Amazon Technologies, Inc. | Prioritizing resource hosts for resource placement |
| US10721181B1 (en) | 2015-03-10 | 2020-07-21 | Amazon Technologies, Inc. | Network locality-based throttling for automated resource migration |
| US11336519B1 (en) | 2015-03-10 | 2022-05-17 | Amazon Technologies, Inc. | Evaluating placement configurations for distributed resource placement |
| WO2023157199A1 (ja) * | 2022-02-17 | 2023-08-24 | 楽天モバイル株式会社 | 妥当性検証システム及び妥当性検証方法 |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012163024A1 (zh) * | 2011-10-27 | 2012-12-06 | 华为技术有限公司 | 针对多步长非一致性内存访问numa架构的内存管理方法及装置 |
| US8830716B2 (en) * | 2012-09-29 | 2014-09-09 | Intel Corporation | Intelligent far memory bandwith scaling |
| US9372907B2 (en) * | 2013-11-26 | 2016-06-21 | Sap Se | Table placement in distributed databases |
| US9830346B2 (en) * | 2013-11-26 | 2017-11-28 | Sap Se | Table redistribution in distributed databases |
| US20160224479A1 (en) * | 2013-11-28 | 2016-08-04 | Hitachi, Ltd. | Computer system, and computer system control method |
| US10523585B2 (en) | 2014-12-19 | 2019-12-31 | Amazon Technologies, Inc. | System on a chip comprising multiple compute sub-systems |
| US9588921B2 (en) * | 2015-02-17 | 2017-03-07 | Amazon Technologies, Inc. | System on a chip comprising an I/O steering engine |
| CN104778077B (zh) * | 2015-04-27 | 2018-03-27 | 华中科技大学 | 基于随机和连续磁盘访问的高速核外图处理方法及系统 |
| KR101637830B1 (ko) | 2015-04-30 | 2016-07-07 | 서울시립대학교 산학협력단 | 헬름홀츠 공명을 이용한 청진기, 그 제어방법 및 그 제조방법 |
| US10140158B2 (en) * | 2016-02-23 | 2018-11-27 | Telefonaktiebolaget Lm Ericsson (Publ) | Methods and modules relating to allocation of host machines |
| US11075801B2 (en) * | 2018-04-17 | 2021-07-27 | Hewlett Packard Enterprise Development Lp | Systems and methods for reconfiguration control using capabilities |
| KR102682740B1 (ko) * | 2019-01-10 | 2024-07-12 | 한국전자통신연구원 | 교통 트래픽 시뮬레이션을 위한 분산 처리 시스템 및 방법 |
| US11556756B2 (en) * | 2019-04-25 | 2023-01-17 | Alibaba Group Holding Limited | Computation graph mapping in heterogeneous computer system |
| US12099391B2 (en) * | 2022-12-22 | 2024-09-24 | Lenovo Enterprise Solutions (Singapore) Pte Ltd. | Independent control of power, clock, and/or reset signals to a partitioned node |
| CN116820687B (zh) * | 2023-08-29 | 2023-12-05 | 银河麒麟软件(长沙)有限公司 | 基于kubelet的NUMA架构资源分配方法及系统 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002202959A (ja) * | 2000-12-28 | 2002-07-19 | Hitachi Ltd | 動的な資源分配をする仮想計算機システム |
| JP2004199561A (ja) * | 2002-12-20 | 2004-07-15 | Hitachi Ltd | 計算機資源割当方法、それを実行するための資源管理サーバおよび計算機システム |
| JP2006003972A (ja) * | 2004-06-15 | 2006-01-05 | Nec Corp | プロセス配置装置、プロセス配置方法及びプロセス配置プログラム |
| JP2007257097A (ja) * | 2006-03-22 | 2007-10-04 | Nec Corp | 仮想計算機システム及びその物理リソース再構成方法並びにプログラム |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6691146B1 (en) * | 1999-05-19 | 2004-02-10 | International Business Machines Corporation | Logical partition manager and method |
| US7143412B2 (en) * | 2002-07-25 | 2006-11-28 | Hewlett-Packard Development Company, L.P. | Method and apparatus for optimizing performance in a multi-processing system |
| US7472246B2 (en) * | 2003-04-30 | 2008-12-30 | International Business Machines Corporation | Method and system for automated memory reallocating and optimization between logical partitions |
| JP4679167B2 (ja) * | 2004-03-05 | 2011-04-27 | 株式会社東芝 | コンピュータシステム解析装置 |
| JP4982971B2 (ja) | 2004-09-29 | 2012-07-25 | ソニー株式会社 | 情報処理装置、プロセス制御方法、並びにコンピュータ・プログラム |
| US7673114B2 (en) * | 2006-01-19 | 2010-03-02 | International Business Machines Corporation | Dynamically improving memory affinity of logical partitions |
-
2008
- 2008-08-04 KR KR1020117003109A patent/KR101180763B1/ko not_active IP Right Cessation
- 2008-08-04 WO PCT/JP2008/063977 patent/WO2010016104A1/ja active Application Filing
- 2008-08-04 CN CN200880130669.5A patent/CN102112967B/zh not_active Expired - Fee Related
- 2008-08-04 EP EP08792174A patent/EP2323036A4/en not_active Withdrawn
- 2008-08-04 JP JP2010523663A patent/JP5327224B2/ja not_active Expired - Fee Related
-
2011
- 2011-02-03 US US13/020,187 patent/US8490106B2/en not_active Expired - Fee Related
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002202959A (ja) * | 2000-12-28 | 2002-07-19 | Hitachi Ltd | 動的な資源分配をする仮想計算機システム |
| JP2004199561A (ja) * | 2002-12-20 | 2004-07-15 | Hitachi Ltd | 計算機資源割当方法、それを実行するための資源管理サーバおよび計算機システム |
| JP2006003972A (ja) * | 2004-06-15 | 2006-01-05 | Nec Corp | プロセス配置装置、プロセス配置方法及びプロセス配置プログラム |
| JP2007257097A (ja) * | 2006-03-22 | 2007-10-04 | Nec Corp | 仮想計算機システム及びその物理リソース再構成方法並びにプログラム |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP2323036A4 * |
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013038547A1 (ja) * | 2011-09-15 | 2013-03-21 | 富士通株式会社 | 仮想マシン管理装置、仮想マシン移動制御プログラムおよび仮想マシン移動制御方法 |
| JPWO2013038547A1 (ja) * | 2011-09-15 | 2015-03-23 | 富士通株式会社 | 仮想マシン管理装置、仮想マシン移動制御プログラムおよび仮想マシン移動制御方法 |
| US9268603B2 (en) | 2011-09-15 | 2016-02-23 | Fujitsu Limited | Virtual machine management device, and virtual machine move control method |
| US10459768B2 (en) | 2015-01-07 | 2019-10-29 | Hitachi, Ltd. | Computer system, management system, and resource management method |
| JPWO2016110950A1 (ja) * | 2015-01-07 | 2017-09-21 | 株式会社日立製作所 | 計算機システム、管理システム、及び、リソース管理方法 |
| WO2016110950A1 (ja) * | 2015-01-07 | 2016-07-14 | 株式会社日立製作所 | 計算機システム、管理システム、及び、リソース管理方法 |
| JP2018514018A (ja) * | 2015-03-09 | 2018-05-31 | アマゾン・テクノロジーズ・インコーポレーテッド | リソース配置を最適化するための適時性リソース移行 |
| JP2020064676A (ja) * | 2015-03-09 | 2020-04-23 | アマゾン・テクノロジーズ・インコーポレーテッド | リソース配置を最適化するための適時性リソース移行 |
| US10715460B2 (en) | 2015-03-09 | 2020-07-14 | Amazon Technologies, Inc. | Opportunistic resource migration to optimize resource placement |
| JP7138126B2 (ja) | 2015-03-09 | 2022-09-15 | アマゾン・テクノロジーズ・インコーポレーテッド | リソース配置を最適化するための適時性リソース移行 |
| US10721181B1 (en) | 2015-03-10 | 2020-07-21 | Amazon Technologies, Inc. | Network locality-based throttling for automated resource migration |
| US11336519B1 (en) | 2015-03-10 | 2022-05-17 | Amazon Technologies, Inc. | Evaluating placement configurations for distributed resource placement |
| US10616134B1 (en) | 2015-03-18 | 2020-04-07 | Amazon Technologies, Inc. | Prioritizing resource hosts for resource placement |
| WO2023157199A1 (ja) * | 2022-02-17 | 2023-08-24 | 楽天モバイル株式会社 | 妥当性検証システム及び妥当性検証方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2323036A1 (en) | 2011-05-18 |
| US20110145831A1 (en) | 2011-06-16 |
| CN102112967A (zh) | 2011-06-29 |
| KR20110034666A (ko) | 2011-04-05 |
| KR101180763B1 (ko) | 2012-09-07 |
| US8490106B2 (en) | 2013-07-16 |
| CN102112967B (zh) | 2014-04-30 |
| JP5327224B2 (ja) | 2013-10-30 |
| JPWO2010016104A1 (ja) | 2012-01-12 |
| EP2323036A4 (en) | 2011-11-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5327224B2 (ja) | マルチプロセッサシステム,マルチプロセッサシステム用管理装置およびマルチプロセッサシステム用管理プログラムを記録したコンピュータ読取可能な記録媒体 | |
| CN102082692B (zh) | 基于网络数据流向的虚拟机迁移方法、设备和集群系统 | |
| US8230432B2 (en) | Defragmenting blocks in a clustered or distributed computing system | |
| CN110120915A (zh) | 高性能计算的三级成本效益分解和具有在线扩展灵活性的高容量存储器 | |
| US9092266B2 (en) | Scalable scheduling for distributed data processing | |
| US20060064441A1 (en) | Storage apparatus, storage control method, and computer product | |
| CN105190567A (zh) | 用于管理存储系统快照的系统和方法 | |
| JP5228988B2 (ja) | 割当制御プログラム及び割当制御装置 | |
| US20170199694A1 (en) | Systems and methods for dynamic storage allocation among storage servers | |
| CN101809551A (zh) | 自动精简配置迁移和清理 | |
| CN113396566B (zh) | 分布式存储系统中基于全面i/o监测的资源分配 | |
| US20030187627A1 (en) | I/O velocity projection for bridge attached channel | |
| JP6056856B2 (ja) | ストレージ制御装置、情報処理装置、ストレージ制御プログラム、及びストレージ制御方法 | |
| JP6269140B2 (ja) | アクセス制御プログラム、アクセス制御方法、およびアクセス制御装置 | |
| US10084860B2 (en) | Distributed file system using torus network and method for configuring and operating distributed file system using torus network | |
| JPWO2008126202A1 (ja) | ストレージシステムの負荷分散プログラム、ストレージシステムの負荷分散方法、及びストレージ管理装置 | |
| TWI795505B (zh) | 記憶體系統、其操作方法和包括該記憶體系統的計算系統 | |
| US20140359215A1 (en) | Storage system and method for controlling storage system | |
| US20160291899A1 (en) | Storage control device and storage system | |
| CN110308865A (zh) | 存储器系统、计算系统及其操作方法 | |
| CN115516436A (zh) | 存储器中的推理 | |
| JP2021149299A (ja) | 計算機システム | |
| JP2002157091A (ja) | ストレージサブシステム及びそのシステムに使用する記憶装置 | |
| JPWO2013145512A1 (ja) | 管理装置及び分散処理管理方法 | |
| JP6836536B2 (ja) | ストレージシステム及びio処理の制御方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 200880130669.5 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 08792174 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2010523663 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 20117003109 Country of ref document: KR Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2008792174 Country of ref document: EP |