GENOME DE LACTOCOCCUS LACTIS, POLYPEFTTOES ET UTILISATIONS
La présente invention a pour objet la séquence génomique et des séquences nucléotidiques codant pour des polypeptides de Lactococcus lactis 1L1403. Les polypeptides décrits dans la présente invention sont, de façon non limitative, des polypeptides d'enveloppe cellulaire, des polypeptides impliqués dans les différents cycles du métabolisme de Lactococcus lactis ou dans les processus de réplication et de sensibilité ou de résistance aux phages, ou sécrétés.
L'invention concerne également l'utilisation de la séquence génomique et/ou des séquences nucléotidiques et/ou polypeptidiques décrites dans la présente invention pour l'analyse de l'expression de gènes, et l'identification de gènes homologues chez des espèces proches de Lactococcus lactis.
L'invention concerne également différents outils qui permettent d'identifier la présence de Lactococcus lactis ou d'espèces avoisinantes dans des échantillons biologiques.
Par ailleurs, l'invention concerne également des souches de Lactococcus lactis ou d'espèces proches de Lactococcus lactis, modifiées par mutagenèse et/ou introduction de gènes spécifiques de L. lactis, afin d'augmenter les propriétés industrielles desdites souches.
Lactococcus lactis est une bactérie gram positive à bas GC%, catalase négative, asporogène et anaérobie facultative. Elle est membre du groupe des Streptococceae auquel appartient aussi entre autre les bactéries des genres Enterococcus, Streptococcus, Leuconostoc, Pediococcus. De nombreuses souches de ces genres sont utilisées dans l'industrie alimentaire, mais aussi dans des fabrications spécialisées. Lactococcus est l'une des bactéries les mieux caractérisées de ce groupe, tant au niveau métabolique que génétique. Ces bactéries produisent
principalement du lactate à partir des sucres lors des fermentation alimentaires et sont donc couramment nommées "bactéries lactiques". Les bactéries lactiques sont en général non pathogènes et sont ajoutées comme ferments pour la production d'aliments fermentes. En particulier, L. lactis est utilisé comme ferment pour la production de fromages, de beurre et de nombreux autres produits laitiers. Les souches de L. lactis sont en général capables de pousser rapidement dans le lait. Cette propriété est conférée entre autre par leur capacité à utiliser le lactose comme source de sucre et les protéines du lait comme source d'acides aminés. Ces gènes sont portés par des plasmides dont la perte provoque un chute de la vitesse de croissance des souches dans le lait.
L'importance de L. lactis pour l'industrie a suscité de nombreuses études en particulier durant ces 15 dernières années. Cela a conduit à la construction de nombreux outils d'étude et de modification génétique pour cette bactérie. Ces études ont aussi permis d'accumuler de nombreuses connaissances sur sa génétique et sa physiologie. La plupart de ces études furent conduites sur deux groupes de souches dont les représentants de laboratoire les plus connus sont les souches IL 1403 et MG1363. Ces deux souches sont génétiquement représentatives des deux principales sous espèces utilisées dans l'industrie, L. lactis subsp. lactis et subsp. cremoris. Une étude décrivant la variabilité génétique au sein de l'espèce L. lactis a été publiée (Tailliez et al, System. Appl. Microbiol., 21: 530-538, 1998). Elle révèle que les souches industrielles peuvent être réparties en 3 groupes. La souche IL 1403 (déposée à la CNCM sous le numéro 1-2438) dont la séquence est un objet de la présente invention appartient au groupe de souches le plus représenté.
De nombreuses études ont été réalisées pour comprendre le métabolisme et la physiologie des lactocoques dans le but d'améliorer leur utilisation dans l'industrie et de développer de nouvelles applications. Ces études ont permis, entre autre de développer des applications permettant l'accélération de l'affinage, la production
d'arôme ou la résistance aux phages. Il a été aussi mis au point des procédés biotechnologiques permettant de produire avantageusement des produits tel la L- alanine.
La recherche actuelle cherche donc à maîtriser et améliorer les performances des bactéries lactiques pour optimiser les transformations agroalimentaires, en particulier la fabrication des yaourts et des fromages.
A titre d'exemple, le goût de noisette du beurre, le goût frais des fromages blancs est apporté par le diacétyle, molécule produite par les bactéries lactiques. Or, l'addition de diacétyle est interdite en France. Il serait par conséquent intéressant d'utiliser des souches naturellement ou artificiellement surproductrices de diacétyle pour obtenir des produits ayant un goût plus typé.
Les bactéries lactiques sécrètent des enzymes et autres protéines qui contribuent aux qualités organoleptiques (texture et arôme) des fromages. La connaissance des mécanismes facilitant la sécrétion devrait permettre d'accélérer l'affinage ou de faire produire par les bactéries des molécules intéressantes : enzymes digestives, antigènes pour la fabrication de vaccins...
On estime que 10% de la fabrication fromagère est perdue ou fortement déclassée du fait de l'attaque par des phages. Si on comprenait les raisons de la résistance de certaines bactéries, on pourrait améliorer la survie des ferments utilisés par l'industrie.
L'ensemble des études menées sur L. lactis a conduit à la publication de 420 séquences dans GenBank correspondant à 1317 peptides traduits. Ces séquences sont largement redondantes par le fait que de nombreux gènes ont été séquences plusieurs fois dans des souches différentes. De plus, de nombreuses séquences correspondent à une information plasmidique. Il en découle que ces séquences correspondent à environ 500 gènes chromosomiques chez L. lactis, ce qui représente entre un cinquième et un quart du génome.
Un certain nombre d'approches a été utilisé pour identifier des gènes de L. lactis. Une première approche consiste à isoler dans un premier temps des mutants
affectés dans une fonction, et de rechercher par la suite des fragments d'ADN qui permettent de restaurer cette fonction (Renault, P et al. 1989. Product of the Lactococcus lactis gène required for malolactic fermentation is homologous to a family of positive regulators. J. Bacteriol. , no. 171 : 3108-14). Une deuxième approche est de complémenter des mutants d'autres bactéries comme E. coli ou B. subtilis pour un gène de fonction connue (Bardowski, J., S. D. Ehrlich, and A. Chopin. 1992. Tryptophan biosynthesis gènes in Lactococcus lactis subsp. lactis. J. Bacteriol. 174: 6563-70.). Une troisième approche est de rechercher des mutants obtenus par insertion de transposons ou de plasmides portant des courtes séquences homologues, ce qui permet ensuite de caractériser le ou les gènes inactivés en clonant des fragments adjacents (Rallu, F., A. Gruss, and E. aguin. 1996. Lactococcus lactis and stress. Antonie Van Leeuwenhoek 70, no. 2-4: 243-51). Des approches génomiques permettent aussi de définir des segments de gènes qui sont conservés dans différents organismes, et d'en déduire des amorces dont l'utilisation en PCR permet d'amplifier et d'isoler un fragment d'un gène connu par ailleurs (Duwat, P., S. D. Ehrlich, and A. Gruss. 1995. The recA gène of Lactococcus lactis: characterization and involvement in oxidative and thermal stress. Molecular Microbiology 17: 1121-31). Différentes variantes de ces techniques existent et peuvent être utilisées avantageusement. L'étude de Lactococcus lactis demande de nouvelles approches, en particulier génétiques, afin d'améliorer la compréhension des différentes voies métaboliques de cet organisme.
Ainsi, c'est un objet de la présente invention que de divulguer la séquence complète du génome de Lactococcus lactis IL 1403 ainsi que de tous les gènes contenus dans cedit génome.
En effet, la connaissance du génome de cet organisme permet de mieux définir les interactions entre les différents gènes, les différentes protéines, et par là-même, les différentes voies métaboliques. En effet, et contrairement à la divulgation de séquences isolées, la séquence génomique complète d'un organisme forme un tout, permettant d'obtenir immédiatement toutes les
informations nécessaires à cet organisme pour croître et fonctionner.
La présente invention concerne donc une séquence nucléotidique de Lactococcus lactis caractérisée en ce qu'elle correspond à SEQ ID N° 1.
La présente invention concerne également une séquence nucléotidique de Lactococcus lactis caractérisée en ce qu'elle est choisie parmi : a) une séquence nucléotidique comportant au moins 80 %, 85 %, 90 %, 95 % ou 98 % d'identité avec SEQ ID N° 1 ; b) une séquence nucléotidique hybridant dans des conditions de forte stringence avec SEQ ID N° 1 ; c) une séquence nucléotidique complémentaire de SEQ ID
N° 1 ou complémentaire d'une séquence nucléotidique telle que définie en a), ou b), ou une séquence nucléotidique de TARN correspondant ; d) une séquence nucléotidique de fragment représentatif de SEQ ID N° 1, ou de fragment représentatif d'une séquence nucléotidique telle que définie en a), b) ou c); e) une séquence nucléotidique comprenant une séquence telle que définie en a), b), c) ou d) ; et f) une séquence nucléotidique modifiée d'une séquence nucléotidique telle que définie en a), b), c), d) ou e).
De façon plus particulière, la présente invention a également pour objet les séquences nucléotidiques caractérisées en ce qu'elles sont issues de SEQ ID N° 1 et en ce qu'elles codent pour un polypeptide choisi parmi les séquences SEQ ID N° 2 à SEQ ID N° 2323. De plus, les séquences nucléotidiques caractérisées en ce qu'elles comprennent une séquence nucléotidique choisie parmi : a) une séquence nucléotidique codant pour un polypeptide choisi parmi les séquences SEQ ID N° 2 à SEQ ID N° 2323; b) une séquence nucléotidique comportant au moins 80 %, 85 %, 90 %,
95 % ou 98 % d'identité avec une séquence nucléotidique codant pour un polypeptide choisi parmi les séquences SEQ ID N° 2 à SEQ ID N° 2323 ; c) une séquence nucléotidique s'hybridant dans des conditions de forte stringence avec une séquence nucléotidique codant pour un polypetide choisi parmi les séquences SEQ ID N° 2 à SEQ ID N° 2323 ; d) une séquence nucléotidique complémentaire ou d'ARN correspondant à une séquence telle que définie en a), b) ou c) ; e) une séquence nucléotidique de fragment représentatif d'une séquence telle que définie en a), b), c) ou d) ; et f) une séquence nucléotidique modifiée d'une séquence telle que définie en a), b), c), d) ou e), sont également des objets de l'invention. Par acide nucléique, séquence nucléique ou d'acide nucléique, polynucléotide, oligonucléotide, séquence de polynucléotide, séquence nucléotidique, termes qui seront employés indifféremment dans la présente description, on entend désigner un enchaînement précis de nucléotides, modifiés ou non, permettant de définir un fragment ou une région d'un acide nucléique, comportant ou non des nucléotides non naturels, et pouvant correspondre aussi bien à un ADN double brin, un ADN simple brin que des produits de transcription desdits ADNs. Ainsi, les séquences nucléiques selon l'invention englobent également les PNA (Peptid Nucleic Acid), ou analogues.
Il doit être compris que la présente invention ne concerne pas les séquences nucléotidiques dans leur environnement chromosomique naturel, c'est-à-dire à l'état naturel. Il s'agit de séquences qui ont été isolées et/ou purifiées, c'est-à-dire qu'elles ont été prélevées directement ou indirectement, par exemple par copie, leur environnement ayant été au moins partiellement modifié. On entend ainsi également désigner les acides nucléiques obtenus par synthèse chimique.
Par « pourcentage d'identité » entre deux séquences d'acides nucléiques ou d'acides aminés au sens de la présente invention, on entend désigner un pourcentage de nucléotides ou de résidus d'acides aminés identiques entre les deux séquences à comparer, obtenu après le meilleur alignement, ce pourcentage étant purement statistique et les différences entre les deux séquences étant réparties au hasard et sur toute leur longueur. On entend désigner par "meilleur alignement" ou "alignement optimal", l'alignement pour lequel le pourcentage d'identité déterminé comme ci- après est le plus élevé. Les comparaisons de séquences entre deux séquences d'acides nucléiques ou d'acides aminés sont traditionnellement réalisées en comparant ces séquences après les avoir alignées de manière optimale, ladite comparaison étant réalisée par segment ou par « fenêtre de comparaison » pour identifier et comparer les régions locales de similarité de séquence. L'alignement optimal des séquences pour la comparaison peut être réalisé, outre manuellement, au moyen de l'algorithme d'homologie locale de Smith et Waterman (1981, Ad. App. Math. 2 : 482), au moyen de l'algorithme d'homologie locale de Neddleman et Wunsch (1970, J. Mol. Biol. 48 : 443), au moyen de la méthode de recherche de similarité de Pearson et Lipman (1988, Proc. Natl. Acad. Sci. USA 85 : 2444), au moyen de logiciels informatiques utilisant ces algorithmes (GAP, BESTFIT, BLAST P, BLAST N, FASTA et TFASTA dans le Wisconsin Genetics Software Package, Genetics Computer Group, 575 Science Dr., Madison, WI). Afin d'obtenir l'alignement optimal, on utilise de préférence le programme BLAST, avec la matrice BLOSUM 62. On peut également utiliser les matrices PAM ou PAM250.
Le pourcentage d'identité entre deux séquences d'acides nucléiques ou d'acides aminés est déterminé en comparant ces deux séquences alignées de manière optimale dans laquelle la séquence d'acides nucléiques ou d'acides aminés à comparer peut comprendre des additions ou des délétions par rapport à la séquence de référence pour un alignement optimal entre ces deux séquences. Le pourcentage d'identité est calculé en déterminant le nombre de positions identiques pour lesquelles le nucléotide ou le résidu d'acide aminé est identique entre les deux
séquences, en divisant ce nombre de positions identiques par le nombre total de positions comparées et en multipliant le résultat obtenu par 100 pour obtenir le pourcentage d'identité entre ces deux séquences.
Par séquences nucléiques présentant un pourcentage d'identité d'au moins 80 %, de préférence 85 % ou 90 %, de façon plus préférée 95 % voire 98 %, après alignement optimal avec une séquence de référence, on entend désigner les séquences nucléiques présentant, par rapport à la séquence nucléique de référence, certaines modifications comme en particulier une délétion, une troncation, un allongement, une fusion chimérique et/ou une substitution, notamment ponctuelle, et dont la séquence nucléique présente au moins 80 %, de préférence 85 %, 90 %, 95 % ou 98 %, d'identité après alignement optimal avec la séquence nucléique de référence. Il s'agit de préférence de séquences dont les séquences complémentaires sont susceptibles de s'hybrider spécifiquement avec les séquences de référence. De préférence, les conditions d'hybridation spécifiques ou de forte stringence seront telles qu'elles assurent au moins 80 %, de préférence 85 %, 90 %, 95 % ou 98 % d'identité après alignement optimal entre l'une des deux séquences et la séquence complémentaire de l'autre.
Une hybridation dans des conditions de forte stringence signifie que les conditions de température et de force ionique sont choisies de telle manière qu'elles permettent le maintien de l'hybridation entre deux fragments d'ADN complémentaires. A titre illustratif, des conditions de forte stringence de l'étape d'hybridation aux fins de définir les fragments polynucléotidiques décrits ci-dessus, sont avantageusement les suivantes.
L'hybridation ADN- ADN ou ADN-ARN est réalisée en deux étapes : (1) préhybridation à 42°C pendant 3 heures en tampon phosphate (20 mM, pH 7,5) contenant 5 x SSC (1 x SSC correspond à une solution 0,15 M NaCl + 0,015 M citrate de sodium), 50 % de formamide, 7 % de sodium dodécyl sulfate (SDS), 10 x Denhardt's, 5 % de dextran sulfate et 1 % d'ADN de sperme de saumon ; (2) hybridation proprement dite pendant 20 heures à une température dépendant de la
taille de la sonde (i.e. : 42°C, pour une sonde de taille > 100 nucléotides) suivie de 2 lavages de 20 minutes à 20°C en 2 x SSC + 2 % SDS, 1 lavage de 20 minutes à 20°C en 0,1 x SSC + 0,1 % SDS. Le dernier lavage est pratiqué en 0,1 x SSC + 0,1 % SDS pendant 30 minutes à 60°C pour une sonde de taille > 100 nucléotides. Les conditions d'hybridation de forte stringence décrites ci-dessus pour un polynucléotide de taille définie, peuvent être adaptées par l'homme du métier pour des oligonucléotides de taille plus grande ou plus petite, selon l'enseignement de Sambrook et al., (1989, Molecular cloning : a laboratory manual. 2n Ed. Cold Spring Harbor). De plus, par fragment représentatif de séquences selon l'invention, on entend désigner tout fragment nucléotidique présentant au moins 15 nucléotides, de préférence au moins 30, 75, 150, 300 et 450 nucléotides consécutifs de la séquence dont il est issu.
Par fragment représentatif, on entend en particulier une séquence nucléique codant pour un fragment biologiquement actif d'un polypeptide, tel que défini plus loin.
Par fragment représentatif, on entend également les séquences intergéniques, et en particulier les séquences nucléotidiques portant les signaux de régulation (promoteurs, terminateurs, voire enhancers...). Parmi lesdits fragments représentatifs, on préfère ceux ayant des séquences nucléotidiques correspondant à des cadres ouverts de lecture, dénommés séquences ORFs (ORF pour « Open Reading Frame »), compris en général entre un codon d'initiation et un codon stop, ou entre deux codons stop, et codant pour des polypeptides, de préférence d'au moins 100 acides aminés, tel que par exemple, sans s'y limiter, les séquences ORFs qui seront décrites par la suite.
La numérotation des séquences nucléotidiques ORFs qui sera utilisée par la suite dans la présente description correspond à la numérotation des séquences d'acides aminés des protéines codées par lesdites ORFs.
Ainsi, les séquences nucléotidiques ORF2, ORF3..., ORF2322 et ORF2323 codent respectivement pour les protéines de séquences d'acides aminés SEQ ID N° 2, SEQ ID N° 3..., SEQ ID N° 2322 et SEQ ID N° 2323 figurant dans la liste de séquences de la présente invention. Les séquences nucléotidiques détaillées des séquences ORF2, ORF3... , ORF2322 et ORF2323 sont déterminées par leur position respective sur la séquence génomique SEQ ID N° 1. Le tableau I fournit les coordonnées des différentes ORFs par rapport à la séquence nucléotidique SEQ ID N° 1, en donnant le nucléotide de départ, le nucléotide de fin d'ORF, ainsi que le nucléotide estimé pour lequel la protéine débute.
Ainsi, ORF N° 2 s'étend du nucléotide 349 au nucléotide 1722, la protéine SEQ ID N° 2 s'étendant quant à elle du nucléotide 358 au nucléotide 1722. De même, OFR N° 6 s'étend du nucléotide 10283 au nucléotide 10846, la protéine débutant au nucléotide 10837, car elle est située sur le brin complémentaire. Ainsi, à la lecture du Tableau I, on voit bien que ORF N° 6 est la séquence complémentaire s'étendant entre les nucléotides 10283 et 10846, extrémités comprises, de la séquence SEQ ID N° 1.
Les fragments représentatifs selon l'invention peuvent être obtenus par exemple par amplification spécifique telle que la PCR ou après digestion par des enzymes de restriction appropriés de séquences nucléotidiques selon l'invention, cette méthode étant décrite en particulier dans l'ouvrage de Sambrook et al.. Lesdits fragments représentatifs peuvent également être obtenus par synthèse chimique lors que leur taille n'est pas trop importante, selon des méthodes bien connues de l'homme du métier. Parmi les séquences contenant des séquences de l'invention, ou des fragments représentatifs, on entend également les séquences qui sont naturellement encadrées par des séquences qui présentent au moins 80 %, 85 %, 90 %, 95 % ou 98 % d'identité avec les séquences selon l'invention.
Par séquence nucléotidique modifiée, on entend toute séquence
nucléotidique obtenue par mutagenèse selon des techniques bien connues de l'homme du métier, et comportant des modifications par rapport aux séquences normales, par exemple des mutations dans les séquences régulatrices et/ou promotrices de l'expression du polypeptide, notamment conduisant à une modification du taux d'expression ou de l'activité dudit polypeptide.
Par séquence nucléotidique modifiée, on entend également toute séquence nucléotidique codant pour un polypeptide modifié tel que définit ci- après.
Les fragments représentatifs selon l'invention peuvent également être des sondes ou amorces, qui peuvent être utilisées dans des procédés de détection, d'identification, de dosage ou d'amplification de séquences nucléiques.
Une sonde ou amorce se définit, au sens de l'invention, comme étant un fragment d'acides nucléiques simple brin ou un fragment double brin dénaturé comprenant par exemple de 12 bases à quelques kb, notamment de 15 à quelques centaines de bases, de préférence de 15 à 50 ou 100 bases, et possédant une spécificité d'hybridation dans des conditions déterminées pour former un complexe d'hybridation avec un acide nucléique cible.
Les sondes et amorces selon l'invention peuvent être marquées directement ou indirectement par un composé radioactif ou non radioactif par des méthodes bien connues de l'homme du métier, afin d'obtenir un signal détectable et/ou quantifiable.
Les séquences de polynucléotides selon l'invention non marquées peuvent être utilisées directement comme sonde ou amorce.
Les séquences sont généralement marquées pour obtenir des séquences utilisables pour de nombreuses applications. Le marquage des amorces ou des sondes selon l'invention est réalisé par des éléments radioactifs ou par des molécules non radioactives.
Parmi les isotopes radioactifs utilisés, on peut citer le P, le P, le S, le H
125 • ou le I. Les entités non radioactives sont sélectionnées parmi les ligands tels la
biotine, l'avidine, la streptavidine, la dioxygénine, les haptènes, les colorants, les agents luminescents tels que les agents radioluminescents, chémoluminescents, bioluminescents, fluorescents, phosphorescents.
Les polynucléotides selon l'invention peuvent ainsi être utilisés comme amorce et/ou sonde dans des procédés mettant en oeuvre notamment la technique de PCR (amplification en chaîne par polymérase) (Rolfs et al., 1991, Berlin : Springer-Verlag). Cette technique nécessite le choix de paires d'amorces oligonucléotidiques encadrant le fragment qui doit être amplifié. On peut, par exemple, se référer à la technique décrite dans le brevet américain U.S. N° 4,683,202. Les fragments amplifiés peuvent être identifiés, par exemple après une électrophorèse en gel d'agarose ou de polyacrylamide, ou après une technique chromatographique comme la filtration sur gel ou la chromatographie échangeuse d'ions, puis séquences. La spécificité de l'amplification peut être contrôlée en utilisant comme amorce les séquences nucléotidiques de polynucléotides de l'invention comme matrice, des plasmides contenant ces séquences ou encore les produits d'amplification dérivés. Les fragments nucléotidiques amplifiés peuvent être utilisés comme réactifs dans des réactions d'hybridation afin de mettre en évidence la présence, dans un échantillon biologique, d'un acide nucléique cible de séquence complémentaire à celle desdits fragments nucléotidiques amplifiés. L'invention vise également les acides nucléiques susceptibles d'être obtenus par amplification à l'aide d'amorces selon l'invention.
D'autres techniques d'amplification de l'acide nucléique cible peuvent être avantageusement employées comme alternative à la PCR (PCR-like) à l'aide de couple d'amorces de séquences nucléotidiques selon l'invention. Par PCR-like on entend désigner toutes les méthodes mettant en œuvre des reproductions directes ou indirectes des séquences d'acides nucléiques, ou bien dans lesquelles les systèmes de marquage ont été amplifiés, ces techniques sont bien entendu connues, en général il s'agit de l'amplification de l'ADN par une polymérase ; lorsque l'échantillon d'origine est un ARN il convient préalablement d'effectuer une transcription reverse.
Il existe actuellement de très nombreux procédés permettant cette amplification, comme par exemple la technique SDA (Strand Displacement Amplification) ou technique d'amplification à déplacement de brin (Walker et al., 1992, Nucleic Acids Res. 20 : 1691), la technique TAS (Transcription-based Amplification System) décrite par Kwoh et al. (1989, Proc. Natl. Acad. Sci. USA, 86, 1173), la technique 3SR (Self-Sustained Séquence Replication) décrite par Guatelli et al. (1990, Proc. Natl. Acad. Sci. USA 87: 1874), la technique NASBA (Nucleic Acid Séquence Based Amplification) décrite par Kievitis et al. (1991, J. Virol. Methods, 35, 273), la technique TMA (Transcription Mediated Amplification), la technique LCR (Ligase Chain Reaction) décrite par Landegren et al. (1988, Science 241, 1077), la technique de RCR (Repair Chain Reaction) décrite par Segev (1992, Kessler C. Springer Verlag, Berlin, New- York, 197-205), la technique CPR (Cycling Probe Reaction) décrite par Duck et al. (1990, Biotechniques, 9, 142), la technique d'amplification à la Q-béta-réplicase décrite par Miele et al. (1983, J. Mol. Biol., 171, 281). Certaines de ces techniques ont depuis été perfectionnées.
Dans le cas où le polynucléotide cible à détecter est un ARNm, on utilise avantageusement, préalablement à la mise en oeuvre d'une réaction d'amplification à l'aide des amorces selon l'invention ou à la mise en œuvre d'un procédé de détection à l'aide des sondes de l'invention, une enzyme de type transcriptase inverse afin d'obtenir un ADNc à partir de l'ARNm contenu dans l'échantillon biologique. L'ADNc obtenu servira alors de cible pour les amorces ou les sondes mises en oeuvre dans le procédé d'amplification ou de détection selon l'invention.
La technique d'hybridation de sondes peut être réalisée de manières diverses (Matthews et al., 1988, Anal. Biochem., 169, 1-25). La méthode la plus générale consiste à immobiliser l'acide nucléique extrait des cellules de différents tissus ou de cellules en culture sur un support (tels que la nitrocellulose, le nylon, le polystyrène) et à incuber, dans des conditions bien définies, l'acide nucléique cible immobilisé avec la sonde. Après l'hybridation, l'excès de sonde est éliminé et les molécules hybrides formées sont détectées par la méthode appropriée (mesure de la
radioactivité, de la fluorescence ou de l'activité enzymatique liée à la sonde).
Selon un autre mode de mise en œuvre des sondes nucléiques selon l'invention, ces dernières peuvent être utilisées comme sondes de capture. Dans ce cas, une sonde, dite « sonde de capture », est immobilisée sur un support et sert à capturer par hybridation spécifique l'acide nucléique cible obtenu à partir de l'échantillon biologique à tester et l'acide nucléique cible est ensuite détecté grâce à une seconde sonde, dite « sonde de détection », marquée par un élément facilement détectable.
Parmi les fragments d'acides nucléiques intéressants, il faut ainsi citer en particulier les oligonucléotides anti-sens, c'est-à-dire dont la structure assure, par hybridation avec la séquence cible, une inhibition de l'expression du produit correspondant. Il faut également citer les oligonucléotides sens qui, par interaction avec des protéines impliquées dans la régulation de l'expression du produit correspondant, induiront soit une inhibition, soit une activation de cette expression. De façon préférée, les sondes ou amorces selon l'invention sont immobilisées sur un support, de manière covalente ou non covalente. En particulier, le support peut être une puce à ADN ou un filtre à haute densité, également objets de la présente invention.
On entend désigner par puce à ADN ou filtre haute densité, un support sur lequel sont fixées des séquences d'ADN, chacune d'entre elles pouvant être repérée par sa localisation géographique. Ces puces ou filtres diffèrent principalement par leur taille, le matériau du support, et éventuellement le nombre de séquences d'ADN qui y sont fixées.
On peut fixer les sondes ou amorces selon la première invention sur des supports solides, en particulier les puces à ADN, par différents procédés de fabrication. En particulier, on peut effectuer une synthèse in situ par adressage photochimique ou par jet d'encre. D'autres techniques consistent à effectuer une synthèse ex situ et à fixer les sondes sur le support de la puce à ADN par adressage mécanique, électronique ou par jet d'encre. Ces différents procédés
sont bien connus de l'homme du métier.
Une séquence nucléotidique (sonde ou amorce) selon l'invention permet donc la détection et/ou l'amplification de séquences nucléiques spécifiques. En particulier, la détection de cesdites séquences est facilitée lorsque la sonde est fixée sur une puce à ADN, ou à un filtre haute densité.
L'utilisation de puces à ADN ou de filtres à haute densité permet en effet de déterminer l'expression de gènes dans un organisme présentant une séquence génomique proche de L. lactis IL 1403.
La séquence génomique de L. lactis IL 1403, complétée par l'identification de tous les gènes de cet organisme, telle que présentée dans la présente invention, sert de base à la construction de ces puces à ADN ou filtre.
La préparation de ces filtres ou puces consiste à synthétiser des oligonucléotides, correspondant aux extrémités 5' et 3' des gènes. Ces oligonucléotides sont choisis en utilisant la séquence génomique et ses annotations divulguées par la présente invention. La température d'appariement des ces oligonucléotides aux places correspondantes sur l'ADN doit être approximativement la même pour chaque oligonucleotide. Ceci permet de préparer des fragments d'ADN correspondants à chaque gène par l'utilisation de condition de PCR appropriées dans un environnement hautement automatisée. Les fragments amplifiés sont ensuite immobilisés sur des filtres ou des supports en verre, silicium ou polymères synthétiques et ces milieux sont utilisés pour l'hybridation.
La disponibilité de tels filtres et/ou puces et de la séquence génomique correspondante annotée permet d'étudier l'expression de grands ensembles, voire de la totalité des gènes dans les micro-organismes associés à Lactococcus lactis, en préparant les ADN complémentaires, et en les hybridant à l'ADN ou aux oligonucléotides immobilisés sur les filtres ou les puces. Egalement, les filtres et/ou les puces permettent d'étudier la variabilité des souches ou des espèces, en préparant l'ADN de ces organismes et en les hybridant à l'ADN ou aux oligonucléotides immobilisés sur les filtres ou les puces.
Les différences entre les séquences génomiques des différentes souches ou espèces peuvent grandement affecter l'intensité de l'hybridation et, par conséquent, perturber l'interprétation des résultats. Il peut donc être nécessaire d'avoir la séquence précise des gènes de la souche que l'on souhaite étudier. La méthode de détection des gènes décrite plus loin en détail, impliquant la détermination de la séquence de fragments aléatoires d'un génome, et les organisant d'après la séquence du génome complet de Lactococcus lactis TL 1403 divulgué dans la présente invention, peut être très utile.
L'utilisation des filtres à haute densité et/ou des puces permet ainsi d'obtenir des connaissances nouvelles sur la régulation des gènes dans les organismes d'importance industrielle, et en particulier les bactéries lactiques propagées dans diverses conditions. Elle permet aussi une identification rapide des différences entre les génomes des souches utilisées dans de multiples applications industrielles. En outre, une puce à ADN ou un filtre peut être un outil extrêmement intéressant pour la détermination, la détection et/ou l'identification d'un microorganisme. Ainsi, on préfère également les puces à ADN selon l'invention qui contiennent en outre au moins une séquence nucléotidique d'un microorganisme autre de Lactococcus lactis, immobilisée sur le support de ladite puce. De préférence, le microorganisme choisi l'est parmi les microorganismes associés à Lactococcus lactis, les bactéries du genre Lactococcus, ou les variants de Lactococcus lactis. Par bactérie associée à Lactococcus lactis, on entend, comme ceci a déjà été défini plus haut, les bactéries membres du groupe des Streptocoques. Une puce à ADN ou un filtre selon l'invention est un élément très utile de certains kits ou nécessaires pour la détection et/ou l'identification de microorganismes, en particulier les bactéries appartenant à l'espèce Lactococcus lactis ou les microorganismes associés, également objets de l'invention.
Par ailleurs, les puces à ADN ou les filtres selon l'invention, contenant
des sondes ou amorces spécifiques de Lactococcus lactis, sont des éléments très avantageux de kits ou nécessaires pour la détection et/ou la quantification de l'expression de gènes de Lactococcus lactis (ou de microorganismes associés). En effet, le contrôle de l'expression des gènes est un point critique pour optimiser la croissance et le rendement d'une souche, soit en permettant l'expression d'un ou plusieurs gènes nouveaux, soit en modifiant l'expression de gènes déjà présents dans la cellule. La présente invention fournit l'ensemble des séquences naturellement actives chez L. lactis permettant l'expression des gènes. Elle permet ainsi la détermination de l'ensemble des séquences exprimées chez L. lactis. Elle fournit également un outil permettant de repérer les gènes dont l'expression suit un schéma donné. Pour réaliser cela, l'ADN de tout ou partie des gènes de L. lactis peut être amplifié grâce à des amorces selon l'invention, puis fixé à un support comme par exemple le verre ou le nylon ou une puce à ADN, afin de construire un outil permettant de suivre le profil d'expression de ces gènes. Cet outil, constitué de ce support contenant les séquences codantes sert de matrice d'hybridation à un mélange de molécules marquées reflétant les ARN messagers exprimés dans la cellule (en particulier les sondes marquées selon l'invention). En répétant cette expérience à différents instants et en combinant l'ensemble de ces données par un traitement approprié, on obtient alors les profils d'expression de l'ensemble de ces gènes. La connaissance des séquences qui suivent un schéma de régulation donnée peut aussi être mise à profit pour rechercher de manière dirigée, par exemple par homologie, d'autres séquences suivant globalement, mais de manière légèrement différente le même schéma de régulation. En complément, il est possible d'isoler chaque séquence de contrôle présente en amont des segments servant de sondes et d'en suivre l'activité à l'aide de moyen approprié comme un gène raporteur (luciférase, β-galactosidase, GFP). Ces séquences isolées peuvent ensuite être modifiées et assemblées par ingénierie métabolique avec des séquences d'intérêt en vue de leur expression optimale.
La présente invention donne la liste de nombreux gènes codant pour des
protéines régulant la transcription des gènes de L. lactis (Tableau II). Modifier la structure ou l'intégrité de ces gènes pourra permettre de modifier l'expression des gènes cibles contrôlés par des promoteurs cibles de ces régulateurs. Les indications données par le Tableau II permettent de plus à l'homme du métier de choisir le ou les régulateurs pertinents pour l'application recherchée ainsi que leur cible, ce qui permet l'optimisation de l'expression de gènes d'intérêt. Par exemple l'inactivation du gène kdgR augmente la transcription des gènes de la voie d'Entner Dodouroff, codés par les gènes qui lui sont contigus, et transcrits dans le sens opposé (ORF 1674 et 1675). L'utilisation des outils précédemment décrits tels les puces à ADN, permet aussi de repérer l'ensemble des gènes dont la régulation est modifiée par cette inactivation. Il est ainsi possible de sélectionner un ensemble de séquence de contrôle répondant, à des nuances près, à un même type de régulation. Ces séquences peuvent être alors utilisées pour contrôler l'expression de gènes d'intérêt.
L'invention concerne également les polypeptides codés par une séquence nucléotidique selon l'invention, de préférence, par un fragment représentatif de la séquence SEQ ID N° 1 et correspondant à une séquence ORF. En particulier, les polypeptides de Lactococcus lactis caractérisés en ce qu'ils sont choisis parmi les séquences SEQ ID N° 2 à SEQ ID N° 2323 sont objet de l'invention.
L'invention comprend également les polypeptides caractérisés en ce qu'ils comprennent un polypeptide choisi parmi : a) un polypeptide selon l'invention ; b) un polypeptide présentant au moins 80 % de préférence 85 %, 90 %, 95 % et 98 % d'identité avec un polypeptide selon l'invention ; c) un fragment d'au moins 5 acides aminés d'un polypeptide selon l'invention, ou tel que défini en b) ; d) un fragment biologiquement actif d'un polypeptide selon l'invention, ou tel que défini en b) ou c) ; et e) un polypeptide modifié d'un polypeptide selon l'invention, ou tel que défini en b), c) ou d).
Les séquences nucléotidiques codant pour les polypeptides décrits précédemment sont également objet de l'invention.
Dans la présente description, les termes polypeptides, séquences polypeptidiques, peptides et protéines sont interchangeables. II doit être compris que l'invention ne concerne pas les polypeptides sous forme naturelle, c'est-à-dire qu'ils ne sont pas pris dans leur environnement naturel mais qu'ils ont pu être isolés ou obtenus par purification à partir de sources naturelles, ou bien obtenus par recombinaison génétique, ou par synthèse chimique, et qu'ils peuvent alors comporter des acides aminés non naturels comme cela sera décrit plus loin.
Par polypeptide présentant un certain pourcentage d'identité avec un autre, que l'on désignera également par polypeptide homologue, on entend désigner les polypeptides présentant par rapport aux polypeptides naturels, certaines modifications, en particulier une délétion, addition ou substitution d'au moins un acide aminé, une troncation, un allongement, une solution chimérique et/ou une mutation, ou les polypeptides présentant des modifications post- traductionnelles. Parmi les polypeptides homologues, on préfère ceux dont la séquence d'acides aminés présentent au moins 80 %, de préférence 85 %, 90 %, 95 % et 98 % d'homologie avec les séquences d'acides aminés des polypeptides selon l'invention. Dans le cas d'une substitution, un ou plusieurs acide(s) aminé(s) consécutifs) ou non consécutifs) sont remplacés par des acides aminés « équivalents ». L'expression « acides aminés équivalents » vise ici à désigner tout acide aminé susceptible d'être substitué à l'un des acides aminés de la structure de base sans cependant modifier essentiellement les activités biologiques des peptides correspondant et telles qu'elles seront définies par la suite.
Ces acides aminés équivalents peuvent être déterminés soit en s'appuyant sur leur homologie de structure avec les acides aminés auxquels ils se substituent, soit sur des résultats d'essais comparatifs d'activité biologique
entre les différents polypeptides susceptibles d'être effectués.
A titre d'exemple, on mentionne les possibilités de substitution susceptibles d'être effectuées sans qu'il résulte en une modification approfondie de l'activité biologique du polypeptide modifié correspondant. On peut remplacer ainsi la leucine par la valine ou l'isoleucine, l'acide aspartique par l'acide glutamine, la glutamine par l'asparagine, l'arginine par la lysine, etc... les substitutions inverses étant naturellement envisageables dans les mêmes conditions.
Les polypeptides homologues correspondent également aux polypeptides codés par les séquences nucléotidiques homologues ou identiques, telles que définies précédemment et comprennent ainsi dans la présente définition des polypeptides mutés ou correspondant à des variations inter ou intra espèces, pouvant exister chez Lactococcus, et qui correspondent notamment à des troncatures, substitutions, délétions et/ou additions, d'au moins un résidu d'acides aminés.
Il est entendu que l'on calcule le pourcentage d'identité entre deux polypeptides de la même façon qu'entre deux séquences d'acides nucléiques. Ainsi, le pourcentage d'identité entre deux polypeptides est calculé après alignement optimal de ces deux séquences, sur une fenêtre d'homologie maximale. Pour définir ladite fenêtre d'homologie maximale, on peut utiliser les mêmes algorithmes que pour les séquences d'acide nucléique.
Par fragment biologiquement actif d'un polypeptide selon l'invention, on entend désigner en particulier un fragment de polypeptide, tel que défini ci- après, présentant au moins une des caractéristiques biologiques des polypeptides selon l'invention, notamment en ce qu'il est capable d'exercer de manière générale une activité même partielle, tel que par exemple :
- une activité enzymatique (métabolique) ou une activité pouvant être impliquée dans la biosynthèse ou la biodégradation de composés organiques ou inorganiques ;
- une activité structurelle (enveloppe cellulaire, molécule chaperonne, ribosome) ;
- une activité de transport (d'énergie, d'ion) ; ou dans la sécrétion de protéine ; - une activité dans le processus de réplication, amplification, préparation, transcription, traduction ou maturation, notamment de l'ADN, de l'ARN ou des protéines.
Par fragment de polypeptides selon l'invention, on entend désigner un polypeptide comportant au minimum 5 acides aminés, de préférence 10, 15, 25, 50, 100 et 150 acides aminés.
Les fragments de polypeptides peuvent correspondre à des fragments isolés ou purifiés naturellement présents dans les souches de Lactococcus, ou à des fragments qui peuvent être obtenus par clivage dudit polypeptide par une enzyme protéolitique telle que la trypsine ou la chymotrypsine ou la collagénase, par un réactif chimique (bromure de cyanogène, CNBr) ou en plaçant ledit polypeptide dans un environnement très acide (par exemple à pH = 2,5). Des fragments polypeptidiques peuvent également être préparés par synthèse chimique, à partir d'hôtes transformés par un vecteur d'expression selon l'invention qui contiennent un acide nucléique permettant l'expression dudit fragment, et placé sous le contrôle des éléments de régulation et/ou d'expression appropriés.
Par « polypeptide modifié » d'un polypeptide selon l'invention, on entend désigner un polypeptide obtenu par recombinaison génétique ou par synthèse chimique comme décrit plus loin, qui présente au moins une modification par rapport à la séquence normale. Ces modifications peuvent être notamment portées sur des acides aminés nécessaires pour la spécificité ou l'efficacité de l'activité, ou à l'origine de la conformation structurale, de la charge, ou de l'hydrophobicité du polypeptide selon l'invention. On peut ainsi créer des polypeptides d'activité équivalente, augmentée ou diminuée, ou de
spécificité équivalente, plus étroite ou plus large. Parmi les polypeptides modifiés, il faut citer les polypeptides dans lesquels jusqu'à cinq acides aminés peuvent être modifiés, tronqués à l'extrémité N ou C-terminale, ou bien délétés, ou ajoutés. Comme cela est indiqué, les modifications d'un polypeptide ont pour objectif notamment :
- de permettre sa mise en œuvre dans des procédés de biosynthèse ou de biodégradation de composés organiques ou inorganiques,
- de permettre sa mise en œuvre dans des procédés de réplication, d'amplification, de réparation et règle de transcription, de traduction, ou de maturation notamment de l'ADN, l'ARN, ou de protéines,
- de permettre sa sécrétion améliorée, de modifier sa solubilité, l'efficacité ou la spécificité de son activité, ou encore de faciliter sa purification. La synthèse chimique présente également l'avantage de pouvoir utiliser des acides aminés non naturels ou des liaisons non peptidiques. Ainsi, il peut être intéressant d'utiliser des acides aminés non naturels, par exemple sous forme D, ou des analogues d'acides aminés, notamment des formes souffrées.
La présente invention fournit toutes les séquences nucléotidiques et polypeptidiques du génome de Lactococcus lactis IL 1403. Par ailleurs, il est un objet de la présente invention que de divulguer les fonctions de ces gènes et protéines (Tableau II).
Ainsi, à chaque cadre ouvert de lecture présenté dans le Tableau I est assigné un descriptif sur son rôle (Tableau II). Les gènes ont ensuite été classés en catégories selon une classification adaptée des gènes de E. coli (Riley, Functions of the gène products of Escherichia coli, Microbiology Reviews 57: 862, 1993). Cela permet à l'homme du métier de repérer les gènes utilisés dans une fonction métabolique donnée, puis d'isoler ce ou ces gènes dans des buts d'application en relation avec sa problématique, en y incluant des applications
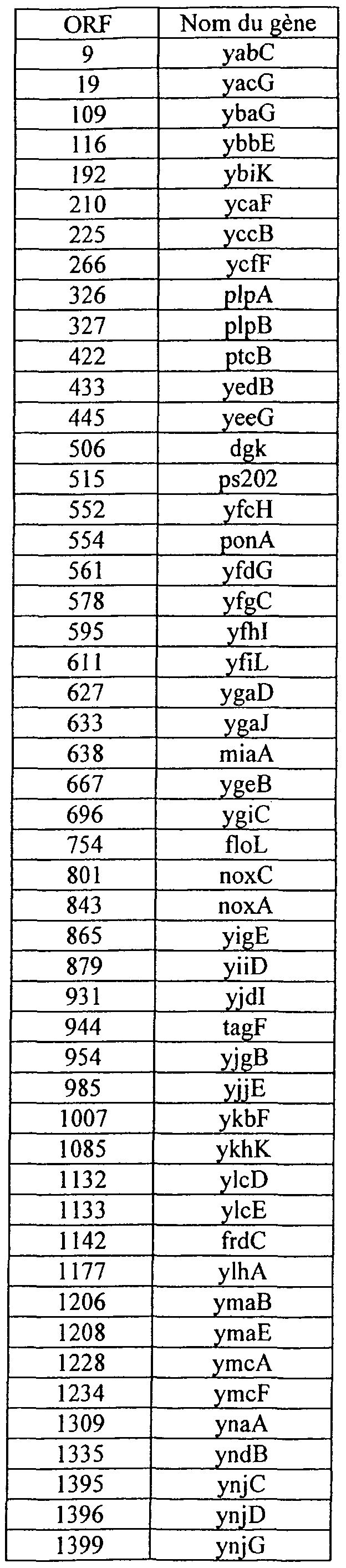
industrielles directes (modification des souches) ou indirectes (outil de diagnostique et ses applications). Les gènes décrits dans l'invention ont été isolés sur des fragment d'ADN grâce à des amorces déduites de la séquence de L. lactis IL1403. Le Tableau III donne les noms des gènes correspondants aux ORF, ainsi que les protéines correspondantes d'autres organismes après comparaison avec la banque de données Swiss prot.
Les enzymes de biosynthèses d'acides aminés
Dans cette partie sont groupés les cadres ouverts de lecture correspondant aux protéines impliquées dans les réactions catalytiques des voies du métabolisme primaire, intermédiaire, secondaire, la fabrication de molécules complexes ou plus simples. Les voies identifiées ont été déterminées d'après les connaissances relatives aux besoins nutritionnels de ces bactéries et leurs possibilités métaboliques. L'ensemble des gènes impliqués dans les voies de biosynthèse des acides aminés est divulgué. Certaines de ces voies ont été identifiées auparavant tel que les voies de biosynthèse de l'histidine, du tryptophane, des acides aminés branchés ainsi que quelques gènes impliqués dans différentes autres voies.
La synthèse de vitamines La synthèse de vitamines peut avoir un intérêt certain pour une bactérie alimentaire comme L. lactis. Cette bactérie est capable de synthétiser naturellement un certain nombre de vitamines, et la connaissance des gènes menant à leur synthèse permet à l'homme du métier d'optimiser l'expression de ces gènes ou de les modifier en vue d'augmenter la production de ces vitamines. Les bactéries ainsi modifiées peuvent être utilisées soit dans des procédés de fabrication de concentré de vitamines, soit directement dans l'alimentation afin d'obtenir un produit enrichi en vitamine. Comme il est indiqué au Tableau II, les gènes nécessaires à la synthèse de quatre cofacteurs, l'acide folique, la ménaquinone, la riboflavine et la thiorédoxine ont été identifiés.
Les gènes à activité peptidolytique
Les gènes codant pour des enzymes protéolytiques ont été systématiquement recherchés. Un certains nombre d'entre eux avaient déjà été caractérisés et leur fonction décrite tel pepN, pepC, pepF, pepO, pepA, pepP, pepV, pepXclpP and clpY et d'autres étaient encore inconnus du public tels pepQ, pepM, pepDAl, pepDA2, ycjE, htrA. Ces enzymes ont un rôle crucial dans la nutrition azotée des bactéries lactiques et participent à la dégradation des peptides dans les produits fermentes, en particulier les fromages. Cet enzyme participe aussi à d'autres processus cellulaires comme la dégradation de protéines permettant le renouvellement des protéines ou même de protéines héterologues limitant ainsi leur production. D'autres protéines participent à la formation de la paroi comme vanY ou à des processus plus généraux comme la dégradation de protéines entrant dans divers processus cellulaires pour pi 136, yudC, yudDyu B anάyufD.
Les gènes de la glycolyse
Les enzymes impliqués dans la glycolyse ont été plus particulièrement étudiés. Les gènes impliqués dans la glycolyse ont été détectés dans différentes parties du chromosome de la souche IL 1403. Ce sont enoA (633 kb) et enoB (274 kb) codant pour l'énolase, pgk (242 kb) codant pour la phosphoglycérate kinase, pgm (332 kb) codant pour la phosphoglycérate mutase, pgmB (442 kb) codant pour la betta-phosphoglycomutase, gapA (554 kb) et gapB (2315 kb) codant pour la glycéraldéhyde 3-phosphate déhydrogénase, tpiA (1148 kb) codant pour la trioséphosphate isomérase, pyk (1370 kb) codant pour la pyruvate kinase, fbaA (1963 kb) codant pour la fructose-bisphosphate aldolase, pgiA (2228 kb) codant pour la glucose-6-phosphate isomérase. En synthétisant des oligonucléotides homologues aux séquences de contigs proches des zones où ces gènes ont été détectés dans IL 1403, et en effectuant des amplifications de type LR PCR sur l'ADN chromosomique de MG1363, des produits
d'amplification contenant les gènes de la glycolyse ont été obtenus. Ces gènes représentent l'ensemble complet des gènes de la glycolyse ayant pu être trouvés chez L. lactis. Cette méthode peut être appliquées aux autres souches de L. Lactis pour la détection des gènes de la glycolyse dans l'environnement génétique le plus adéquat pour l'industrie. La modification des ces gènes par mutagenèse a permis la construction de nouvelles souches dites « food-grade », qui ont de nombreuses applications dans l'industrie alimentaire et l'agriculture.
En particulier, il a montré qu'il existait 2 copies des gènes gap codant pour la glyceraldehyde 3 phosphate dehydrogénase et eno codant pour l'énolase. Il a été aussi montré que le gène gap précédemment isolé n'était pas exprimé de manière significative lors de croissances dans différents milieux, et ne codait donc pas pour le gène réellement impliqué dans la glycolyse. Une analyse détaillée de la séquence montre que le second gène gap identifié possède des propriétés qui suggèrent fortement qu'il s'agit du gène réellement actif lors de la glycolyse. Premièrement, son biais de codon est très fort et semblable aux autres gènes de la glycolyse tels ceux de l'opéron las, pgi, fdp et tpi. Deuxièmement, il possède une séquence de régulation (boîte CRE) en amont de la boîte -35 de son promoteur, permettant son activation lors de l'assimilation du sucre rapide. Enfin, il a été démontré expérimentalement que ce gène était fortement exprimé lors de croissance exponentielle, et qu'il était indispensable à la croissance cellulaire (son inactivation est létale). Le gène gap de la glycolyse a été isolé sur un plasmide de E. coli (pGEM) et son expression dans E. coli restaure la croissance de mutants gap dans les milieux appropriés. Ce gène pourrait donc être utilisé pour augmenter l'activité GAPDH dans des souches où cette activité est limitante pour la vitesse d'acidification. Une telle construction mènera à l'obtention d'une souche acidifiant plus vite le lait, une propriété recherchée dans certains procédés industriels. Un travail comparable peut être réalisé sur les autres enzymes de cette voie.
Les voies d'assimilation secondaire des sucres
L. lactis est capable d'utiliser un grand nombre de carbohydrates (de manière non limitative: L-arabinose, ribose, D-xylose, galactose, glucose, fructose, mannose, mannitol, N-acetyl glucoseamine, amygdaline, arbutine, esculine, salicine, cellobiose, maltose, lactose, melibiose, saccharose, trehalose, raffinose, amidon, gentiobiose, gluconate). Les gènes impliqués dans l'entrée de ces sucres et leur transformation pour rejoindre une des étapes de la glycolyse sont présentés au Tableau II. Pour illustrer, deux gènes impliqués dans la voie des pentoses phosphates ont été identifiés : la transkétolase (YqgF) et la phosphokétolase (YpdE). Un fragment interne a été utilisé pour inactiver l'un ou l'autre de ces gènes dans la souche de L. lactis ~NCD02\ 18. Les mutants ainsi obtenus sont affectés dans le métabolisme des sucres et accusent des retards de croissance, en particulier en présence de xylose pour la souche ypdE. L'activité de ces gènes peut également être amplifiée en plaçant l'un ou l'autre de ces gènes sous contrôle d'un promoteur régulé différemment. Un travail similaire avec les autres gènes de ces voies permettra de construire des souches de L. lactis avec des capacités fermentaires nouvelles. En particulier, la modification additionnelle de l'expression des gènes codant (i) pour la glucose 6-phosphate dehydrogénase (zwf), la gluconate déshydrogénase (gnd), la ribulose phosphate isomérase (rpiA) ou pour (ii) des gènes de la voie d'Entner- Dodouroff (kdg, uxu etyqhA présent en amont de la transkétolase) et la gluconate phosphate déshydrogénase devrait permettre de produire des souches de L. lactis hétérofermentaires vraies à partir de sucre métabolisé en glucose 6-phosphate.
Les gènes impliqués dans la formation et la régulation de l'ensemble des produits de fermentation
Les produits de fermentation sont ce qu'il y a de plus important pour la formation de l'arôme du fromage par Lactococcus lactis. Dans les conditions habituellement appliquées pour la production fromagère, 95 % du sucre utilisé est converti en acide lactique. D'autres produits importants pour la fermentation sont
l'éthanol, le fumarate et l'acétate. Une petite partie, habituellement moins de 1 %, du pyruvate produit durant la glycolyse est convertie en alpha-acétolactate, qui est distribué entre les acides aminés branchés et les produits de la branche de formation des acétoïnes : diacétyl, acétoïne ou 2,3-butanediol. L'interaction de ces gènes et leur régulation sont importantes pour la formation de l'ensemble des produits de fermentation. La présente invention fournie les outils pour détecter tous les gènes chromosomiques des bactéries du genre lactococci, impliquées dans la formation de produits de fermentation. Ces produits sont importants pour l'arôme du produit fromager final. Plusieurs gènes ont déjà été détectés auparavant. Ceux-ci incluent la lactate dehydrogénase, la pyruvate formate lyase, α-acétolactate synthase, α- acétolactate décarboxylase. De nouveaux gènes potentiels impliqués dans cette voie, sont fournis par cette invention, détectés durant l'annotation. Ce sont d'autres putatives alpha-acétolactate décarboxylase (aldC gène), diacétyl réductase (butB), acétoïne réductase (put A), pyruvate dehydrogénase (pdhABCD), acétate kinase (acdAl, acdA2), alcool dehydrogénase (adhA, adhE). En manipulant ces gènes par des méthodes de génie génétique ou de génétique, l'homme du métier peut influencer l'arôme du produit final fromager de la façon désirée. D'autres enzymes, qui peuvent être utilisées pour changer l'emsemble des produits de fermentation, sont les NADH oxidases. Ces gènes sont codés par ndhA, yieA, yieB, yphA, ydjE, yhjd, yr/B, nox. La présente invention fournit les outils pour détecter ces gènes dans les différentes souches de L. lactis et pour créer des bactéries « food-grade » capables de produire ces métabolites importants pour les arômes comme le diacétyl.
Les gènes liés à l'activité des bactériophages Les bactériophages constituent l'un des problèmes majeurs de l'industrie laitière. Ils sont à l'origine de perturbations importantes de les fermentations et par ce biais, de pertes économiques. De nombreux efforts ont été consacrés au développement de méthodes permettant de contrôler leur développement au cours des procédés de fabrication fromagère. On peut
envisager en particulier de cloner sur un plasmide ou dans le chromosome de souches à utilisation industrielle, des gènes bactériens et/ou de bactériophages dont les produits limitent le développement de phages infectants On peut également développer des systèmes artificiels de résistance mimant les mécanismes naturels dits d'infection abortive, dans lesquels les cellules infectées meurent sans multiplier les phages. Dans ce but, un gène toxique pour la bactérie, placé sous le contrôle d'un promoteur de phage dont l'expression est induite après infection par un phage similaire est clone sur un plasmide (Djordjevic, G. M., and Klaenhammer, T. R. (1997) Bacteriophage-triggered défense Systems : phage adaptation and design improvements. Appl Environ Microbiol 63 :4370-4376 ; Walker, S. A., and Klaenhammer, T. R. (1998) Molecular characterization of a phage-inducible middle promoter and its transcriptional activator from the lactococcal bacteriophage Φ31. J Bacteriol 180 : 921-931) ou sur le chromosome bactérien. La présente invention, décrit les gènes de la souche IL 1403 et de six prophages identifiés sur son chromosome. Cinq de ces prophages ont été identifiés expérimentalement par induction de leur cycle de croissance lytique après exposition à un agent endommageant l'ADN (Ultra- Violets ou Mitomycine C). La présente invention apporte donc la possibilité d'identifier des gènes de bactérie ou de phage répondant à l'une ou l'autre des propriétés citées ci-dessus. A savoir : des gènes qui perturbent le développement d'un phage infectant, des gènes toxiques pour la bactérie, des circuits de régulation induits après infection par un phage.
Il est à noter que les signaux de transcription et traduction des phages ainsi que leurs circuits de régulation peuvent aussi être utilisés pour développer des systèmes d'expression conditionnelle (WO95/31563) ou de surexpression (O' Sullivan, D. J., Walker, S. A., West, G, and Klaenhammer, T. R. (1996) Development of an expression strategy using a lytic phage to trigger explosive plasmid amplification and gène expression. Biotechnology 14 : 82-87) de protéines d'intérêt. La présente invention peut donc aussi être utilisée dans ce
but.
Les gènes impliqués dans les systèmes de régulation correspondent aux ORF 38, 41, 448, 452, 518, 1461 et 1472.
Les gènes de réponse au stress
Les lactocoques sont soumis à de nombreux changements environnementaux dans les procédés industriels on peut citer parmi d'autres, des changements de température (chaleur, froid), d'osmolarité (salinité, activité en eau), de pH, d'oxygénation, de conditions redox etc. Une survie optimale de L. lactis à ces changements environnementaux, parfois brusques, est recherchée afin d'améliorer la reproductibilité et le rendement des procédés de fabrication et d'utilisation de ces ferments lactiques. Les lactocoques possèdent des réponses inductibles aux stress notamment aux UV, à la chaleur, au froid, au NaCl, à la présence d'H2O2, à la carence en sucre, à la bile, à l'acidité. Il faut noter que certains résultats (Kim et al, 1999, FEMS Microbiol Lett, 171, 57) soulignent des différences dans les capacités de résistance et d'adaptation aux stress de 2 sous-espèces de lactocoques : L. lactis ssp. lactis et L. lactis ssp. cremoris. Des études protéomiques montrent qu'un certain nombre de protéines sont induites dans plusieurs conditions de stress. Cependant, les protéines impliquées dans la résistance à un ou plusieurs stress ont été, à ce jour rarement identifiées en particulier du fait de l'absence de l'invention qui limitait les possibilités d'identification des spots protéiques. Il est important de souligner néanmoins, que certaines conditions de stress semblent modifier l'expression d'enzymes métaboliques notamment impliqués dans la glycolyse. D'autres études biochimiques, moins globales, corrèlent l'augmentation de certaines activités enzymatiques à une meilleure survie et/ou à l'adaptation des lactocoques à certains stress. Ainsi, la H+-ATPase, la désimination de l'arginine, le transport du citrate dans la sous espèce diacetylactis, le transport de solutés compatibles, les NADH-peroxidase et NADH-oxidase sont probablement
impliquées dans des mécanismes d'adaptation aux stress et pour certains, dans la survie en fin de fermentation.
Des études génétiques (recherche de gènes conservés ou mutagenèse) ont permis la caractérisation de certains gènes impliqués dans les résistances aux stress. Ceux-ci restent néanmoins peu nombreux et le lien avec les études biochimiques a rarement été établi. Parmi les gènes identifiés on peut notamment citer :
- stress oxydatif : recA,fpg, sodA, nox,pox (NADH peroxidase),y7 et flpB,
- stress mutagène : recA, polA, hexB, deoB, gerC, dltD, arcD, bglA, gidA, hgrP, metB, proA et sept orf non identifiées par recherche d'homologie avec les banques de données,
- stress thermique, dénaturation protéique : recA, groES, groEL, dnaK, dnaJ.ftsH, grpE, hrcA, ctsR, clpP, clpB, clpE, htrA,
- stress froid : cspABCDE, - stress osmotique : bus A, gadBCR,
- stress acide : gadBCR, clpP, groES, groEL, dnaK.
De plus, deux études génétiques (Duwat et al., 1999, Mol Microbiol., 31, 845 ; Rallu et al, 2000, Mol Microbiol., 35, 517 ; FR27 53201) ont permis d'isoler des mutants plus résistants que la souche initiale (MG1363) à une ou plusieurs conditions de stress et suggèrent fortement que des pools intracellulaires notamment de composés puriques et de phosphate constituent des détecteurs intracellulaires de stress.
La séquence annotée de L. lactis IL 1403 apporte une base moléculaire pour l'étude systématique des réponses aux stress des lactocoques. Les gènes détectés pendant l'annotation du génome de 111403 sont fournis dans les Tableaux II et III de la présente demande. La méthode de détection des gènes équivalents dans d'autres bactéries proches de L. lactis IL1403 est fournie dans la présente invention et permet d'exploiter les résultats obtenus durant l'étude
des réponses aux stress d'autres souches de L. lactis. En effet, les réponses aux stress ont préférentiellement été étudiées avec L. lactis MG1363 qui contrairement à IL 1403 ne contient pas de prophage inductible en condition de stress.
Les gènes des protéines sécrétés ou dont l'activité est liée à la sécrétion des protéines
L. lactis est capable de sécréter un certain nombre de protéines dans le milieu extérieur et à la surface de la cellule. Cette capacité peut être mise à profit pour sécréter des molécules d'intérêt comme des enzymes d'intérêt technologique ou des molécules d 'intérêt médical ou pharmaceutique. L'invention présente permet d'isoler rapidement différents signaux d'exportation de L. lactis afin de tester celui ou ceux qui donnent les meilleurs résultats avec le gène d'intérêt à exporter. La liste des protéines et des gènes susceptibles de fournir de tels signaux est fournie Tableau π. Ces protéines ont été extraites par une méthode informatique avec le logiciel PSORT (Nakai & Horton, PSORT: a program for detecting sorting signais in proteins and predicting their subcellular localization, Trends Biochem Sci, 24: 34-6, 1999). D'autres méthodes pourraient être employées pour compléter ce tableau en utilisant une partie des données de l'invention, comme la liste des protéines potentiellement traduites chez L. lactis ou directement la séquence nucléotidique traduite dans toutes les phases.
De plus, l'outil fourni dans l'invention donne toutes les informations de base sur les gènes qui peuvent limiter certaines étapes de la sécrétion. Une liste de ces gènes est présentée Tableau IV. Par exemple, l'intégralité du gène codant pour une lipoprotéine qui permet d'accélérer le repliement correct des protéines sécrétées a été isolé grâce aux enseignements de l'invention. Des homologues de cette protéine ont été caractérisés précédemment chez d'autre organismes comme B. subtilis. Cependant, il peut exister plusieurs gènes de ce type dans un organisme, ce qui complique la tache de l'expérimentateur conf onté soit à une recherche exhaustive
de toutes les protéines homologues afin de réaliser le choix le plus judicieux, soit à développer une expérimentation lourde afin d'isoler le facteur pertinent dans son procédé. La présente invention permet donc à l'homme du métier de choisir en fonction de son expertise le ou les gènes nécessaires à l'accomplissement de son travail. Dans le cas de L. lactis, il a été possible d'isoler le gène codant pour l'homologue vrai de prsA de B. subtilis et de l'exprimer plus fortement dans des cellules surproduisant un enzyme d'intérêt industriel à partir du gène lip de Staphylococcus hyicus. En condition normale, une grande partie de la lipase est dégradée par limitation de la protéine type prsA. Sa surproduction préserve la lipase de toute dégradation de cet enzyme lors ou après son exportation.
Les gènes impliqués dans la compétence des transformations génétiques La compétence génétique naturelle est la capacité des bactéries à transporter de l'ADN étranger dans la cellule, le processer et à l'intégrer dans le chromosome ou à établire des éléments à réplication autonome. Les gènes, qui permettent à la bactérie de développer cette capacité, sont divisés en ce qu'on appelle des gènes précoces, qui sont des gènes de régulation, et en gènes tardifs, représentant le système de compétence lui-même. L'étude des séquences des gènes tardifs de compétence montre qu'ils sont fortement similaires dans les différentes bactéries AT- riches gram positifs, comme B. subtilis ou Streptococci . Une grande différence existe dans les méchanismes moléculaires qui régulent le développement de ce processus dans Streptococci et Bacilli. Dans B. subtilis, le régulateur ComK existe, qui assemble les signaux des étapes précoces du développement de compétence. Un pendant fonctionnel de ce régulateur a été trouvé chez Streptococci. Il code pour le facteur sigma de l'ARN polymérase. Les conditions de compétence naturelle ne sont pas connues pour l'espèce L. lactis. Cependant, des recherches d'homologies dans le génome de L. lactis révellent 4 opérons (comE, comF, comC et comG) contenant 8 gènes ayant une forte similarité avec les gènes tardifs de
compétence de B. subtilis en S. pneumoniae. Comme L. lactis semble pouvoir posséder un ensemble complet des gènes tardifs de compétence, il peut acquérir une compétence naturelle. Une manière de découvrir les conditions pour acquérir la compétence peut être l'étude de la régulation des gènes tardifs. Le gène, correspondant au régulateur de la compétence, ywcA, existe aussi dans L. lactis IL 1403. La surproduction de cette protéine dans L. lactis permettra l'induction des gènes tardifs de compétence dans ces cellules. La présente invention fournit la manière de détecter le système complet des gènes de compétence dans les plusieurs souches de L. lactis différentes de d'IL1403. La connaissance des structures des régions de régulation dans ces bactéries et des régulateurs correspondants donnera la possibilité d'induire la compétence dans ces souches. Cette méthode peut être utilisée pour les souches ne pouvant pas être manipulées par les autres méthodes de génie génétique.
D'une manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention, caractérisées en ce qu'elle pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans la biosynthèse des acides aminés et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 1507 1508 1511 1512 1513 1514 1515 796 1178 1179 1275 1881 1251 1252 1254 1255 1257 1258 1259 1260 1261 683 1238 1240 1241 1243 1245 1246 1247 1248 1249 860 797, de préférence 500 120 1291 1690 1793 1794 1795 1796 1803 1807 1808 166 361 755 1292 1293 1323 1609 1668 1670 1972 1973 2159 2285 128 129 575 812 813 814 815 1324 1325 1656 1657 1935 2257 75 551 613 615 616 617 1904 et un de leurs fragments représentatifs. De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans la biosynthèse des cofacteurs, groupes prosthétiques et transporteurs et en ce qu'elle est choisie parmi les séquences suivantes : ORF 1169 1383 398 1405, de
préférence 871 953 1172 1173 1174 1176 1353 1354 610 1157 1615 187 743 744 745 746 747 875 584 585 1362 1487 101 1 1012 1013 1014 1123 1145 1871 862 958 1692 1695 497 1130 1300 1301 1302 1526 1 120 et un de leurs fragments représentatifs. De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide d'enveloppe cellulaire de Lactococcus lactis ou un de ses fragments, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 328 329 2288 2320 1296, de préférence 326 327 631 978 1105 1193 1481 2025 2185 280 320 348 350 351 395 552 554 560 885 886 968 1181 1321 1406 1637 1638 1857 1934 1960 2096 2164 2283 2287 153 206 207 212 213 217 218 219 220 221 222 223 224 693 695 697 754 894 930 936 937 939 940 942 944 945 973 1297 1298 1299 1304 1380 1499 1500 1618 1845 2218 2279 2280 et un de leurs fragments représentatifs. De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans la machinerie cellulaire, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 20 22 681 1898 1920 1921 402 403 972 417 1015 2134 1779 2206, de préférence 100 818 828 902 914 990 991 1267 1384 1636 1704 2207 508 126 119 562 959 1664 2161 2315 1107 1108 1265 1823 1824 1859 2084 2120 2176 2177 2178 2179 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le métabolisme intermédiaire central, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 728 155, de préférence 434 1024 1 162 1376 1537 1621 291 716 1289 1538 1539 1728
1729 1732 2005 1663 215 586 712 713 714 715 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le métabolisme énergétique, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 1785 2042 59 1329 1814 1815 1816 1817 1818 1819 1820 994 995 677 918 1205 1262 2211 284 345 439 570 656 682 1152 1372 1373 1374 634 1552 1553 1554 2034 2035 2036 2037 2038 2039 684, de préférence 76 136 151 186 242 273 276 342 347 400 643 768 801 843 844 1281 1348 1572 1574 1583 1596 1601 1604 1746 1784 1925 2100 2182 2307 290 502 548 742 751 816 845 846 974 1327 1343 1747 1751 1971 1985 2088 2089 2090 2092 2093 254 256 257 1127 1283 1379 431 609 620 719 720 732 1756 2167 1674 1675 915 916 1 125 1142 1207 1290 1707 1858 1864 2068 2069 265 253 385 967 1 146 1792 1962 2224 2303 1673 1723 1979 2277 2290 61 62 63 64 26 181 426 440 71 1 784 834 976 1326 1504 1532 1533 1534 1543 1546 1549 1550 1676 1679 1680 1687 1721 1730 1731 2079 2241 2242 685 1212 1213 1214 1215 1216 et un de leurs fragments représentatifs. De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le métabolisme des acides gras et des phospholipides et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 65 72 1 18 390 413 414 415 576 577 675 786 787 788 789 790 791 792 793 794 795 859 1284 1834 1837 1955 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le
3o
métabolisme des nucléotides, des purines, des pyrimidines ou nucléosides et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 2066 1531 1556 1557 1558 1569 1573 1575 1576 1578 501 1386 1387 1404 1586 1599 21 281 282 947 949 1969 2133 200, de préférence 182 506 992 993 1159 1177 311 11 12 1754 226 1164 1563 1564 1568 1689 2007 407 1086 1087 1388 1649 1650 295 605 645 829 854 1 165 1482 1483 1485 1708 1908 1950 202 204 205 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans les fonctions de régulation, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 1263 1331 1559 2041 2316 405 406 908 909 1022 1478 1641 1725 1696 1726 890 1555 1506 7, de préférence 6 8 110 131 137 154 167 243 245 261 324 335 421 424 429 445 541 565 622 674 771 832 847 877 905 929 946 982 1084 1151 1186 1197 1233 1294 1310 1349 1490 1494 1521 1524 1566 1624 1639 1652 1654 1717 1745 1753 1766 1830 1831 1846 1852 1853 1928 1956 2001 2032 2043 2059 2095 2216 2243 2258 2262 2270 2291 2296 2306 1020 1477 1642 1724 1752 1797 1798 740 1545 1688 2200 2205 24 340 383 386 1274 1345 1603 1927 543 435 1480 1498 1681 804 975 1211 1336 1 17 603 723 757 785 926 1344 1517 1527 1585 2172 227 229 360 770 1171 1333 1635 2071 2299 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le processus de réplication, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 4 5 2 3 362 363 563 600 663 664 665 2030 2180 2198 2265 2281, de préférence 573 644 806 856 872 873 1089 1360 1361 1869 101 102 240 349 401 408 428 507 513 542 572 657 761 766
767 857 878 898 923 997 1000 1002 1025 1088 1129 1138 1139 1140 1266 1270 1693 1791 1883 1948 2098 2247 2251 2263 2264 2267 2301 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le processus de transcription, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 1237 1332 564, de préférence 817 960 1906 2314 14 619 646 648 709 779 1314 1367 1368 1607 1612 1623 1850 1851 2124 2160 2222 2297 359 419 1613 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le processus de traduction, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 1239 313 396 706 858 1778 1854 1861 1929 2105 571 1776 97 98 680 2127 782 783 2128, de préférence 68 382 394 807 831 1113 1114 1763 1775 1879 1902 1914 1964 1983 1984 2020 2022 2094 2109 2183 2229 260 303 624 1606 1697 2027 2028 2045 2047 2192 374 911 1600 2062 107 135 198 246 292 301 302 748 760 781 805 853 892 906 1097 1099 1307 1308 1617 1644 1790 1893 1894 1937 2056 2057 2123 2125 2126 2135 2136 2137 2138 2139 2140 2142 2143 2144 2145 2146 2147 2148 2149 2150 2151 2152 2153 2154 2155 2156 2162 2209 2246 2248 2310 2311 2318 2319 13 132 158 168 169 171 496 638 705 852 1144 1923 1944 358 607 707 989 1126 1895 1912 2065 2208 2317 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le
processus de transport et de liaison des protéines, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 1256 1787 330 550 699 717 1330 1496 1497 1810 1888 1889 1890 1891 1892 2091 1771 566 919 1551 2040 2104 635 676 1970 121 122 437 81 82 726 927 2221, de préférence 11 74 104 262 263 269 270 271 285 286 287 318 319 333 334 544 545 579 580 672 673 729 855 881 888 889 917 983 984 1080 1121 1122 1203 1311 1312 1366 1567 1602 1667 1800 1801 1825 1826 1844 1926 2051 2052 2074 2157 2260 2261 2313 2321 70 115 331 352 353 354 355 356 357 364 365 375 574 698 824 863 864 955 956 957 1 128 1182 1183 1 184 1185 1750 1811 1847 1848 1873 2087 2107 2250 52 308 309 310 1767 1768 1769 1770 1772 208 209 259 430 933 934 1282 1369 1370 1371 1530 1540 1541 1542 1548 1671 1678 1683 1684 1685 1686 1733 1734 1735 2239 99 193 194 316 336 337 338 339 341 392 587 636 691 848 849 869 932 1194 1195 1295 1341 1355 1356 1357 1407 1528 1640 1655 2058 2169 2170 2171 2305 896 1166 1651 23 25 180 422 423 425 630 833 977 1 149 1 150 1505 1757 1758 1759 127 130 160 244 314 389 621 679 721 722 1389 1561 1584 1682 2220 2292 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans l'adaptation aux conditions atypiques, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 174 540 568 654 686 970 1570, de préférence 69 173 195 312 346 418 653 912 971 1 102 1170 1414 2085 et un de leurs fragments représentatifs. De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments dans la sensibilité aux médicaments et analogues, et en ce qu'elle comprend une séquence
nucléotidique choisie parmi les séquences suivantes : ORF 1244, de préférence 1860 2249 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans les fonctions relatives aux phages et prophages, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 448 449 452 455 465 471 493 494 1026 1027 1028 1029 1030 1031 1032 1033 1034 1035 1036 1037 1038 1039 1040 1041 1046 1051 1075 1076 1077 1420 1422 1423 1424 1425 1426 1448 1450 1455 1456 1458 1465 1466 1467 1468 1470 1720, de préférence 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 446 447 450 451 453 454 456 457 458 459 460 461 462 463 464 466 467 468 469 470 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 531 532 533 534 1042 1043 1044 1045 1047 1048 1049 1050 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 1067 1068 1069 1070 1071 1072 1073 1074 1200 1217 1416 1417 1418 1419 1421 1427 1428 1429 1430 1431 1432 1433 1434 1435 1436 1437 1438 1439 1440 1441 1442 1443 1444 1445 1446 1447 1449 1451 1452 1453 1454 1457 1459 1460 1461 1462 1463 1464 1469 1471 1472 1473 1474 1475 1647 1998 2003 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans les fonctions relatives aux transposons et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 53 54 55 56 90 91 93 94 141 142 143 144 145 146 378 379 380 381 649 650 651 652 662 670 737 738 837 838 839 841 842 1224 1225 1231 1232 1236 1286 1287 1591 1741 1742 2082 2083 2129 2130 2131 2132 2201 2202 2203 2204, de préférence
61469471895012681342140015601749193619611986199220602118 21912240 et un de leurs fragments représentatifs.
De manière préférée, l'invention est relative à une séquence nucléotidique selon l'invention caractérisées en ce qu'elle code pour un polypeptide spécifique de Lactococcus lactis ou un de ses fragments, et en ce qu'elle comprend une séquence nucléotidique choisie parmi les séquences suivantes : ORF 416172718228788279332569671700701727840850 8848919001204 12421277 1382 1592 1605 1718 1719176217771780 19071917191819191930193819391940210221062174221012501328 2199666948 1381 1990, de préférence 591618710835 1153 1910 1931 195320311718505758607879808492113 114116124125133134 139140148149150157159161162170172175176179183184185188 189196197214230231232233234235236238247255258264266267 268274277283288289293294298299300315317321323325343344 366367369370371372373376377384387388399404409410411420 433436438443444498499503510512546549553555556557558582 583588589592594597599611625637655678688703704708725730 735741749756759762763764765769774780798799800803809810 811819827830861865880882883899913920924951963964965986 9879991001 1004101610191023 1078 107910901091 109410981100 11031104110611091110111511161117111911241131113711411147 1148115511561160116111681175118711881201 1202120812091223 12761278128013031313131513161318131913221340135213581359 1363139113921393140814091411 14121476148614891491 14921493 15011518151915201522152315251529154415471565157715791581 15951597161416191620162216481658166116621666166916771694 169917011702170917101711 17121722174817601761 176417651773 17741781178217861788178918021805180918271828182918321833 18381839184018421843184918551856186318651866186718681872
18741875187618851886188719001901190319151916192419331941 19461951195219541958195919631966196719681976197719781981 19822004200620082011201420152016201720182019202620292033 20442049205020542061206320702080208121012108211021152158 21632165216821732175218421862190219321942197221722192226 22272232223522382245225322542259227222752278228222842286 2289229422952298230223042308231223222323 1666677377108 109111112252391432505509511559581593598604612640642647 702733734736739750752758776777778802820826874876897901 9109229529549619799809819961017109311111118113511961199 12731320137714131562161017051783180418841897190919222117 22939101215195171838586899596103105106123138147152 156163164165177178190191192199201203210211216225228237 239241248249250251272275278296297304305306307322368393 397412427441442495504530535536537538539547561567578590 595596601602606608623626627628629632633639641658659660 661667668669687689690692696724731753772773775808821822 823825836851866867868870879887893895903904907921925928 9319359389419439629669699859889981003 1005100610071008 10091010101810211081108210831085109210951096110111321133 11341136114311541158116311671180118911901191 119211981206 12101218121912201221122212261227122812291230123412351253 126412691271 12721279128512881305130613091317133413351337 13381339134613471350135113641365137513781385139013941395 13961397139813991401140214031410141514791484148814951502 1503150915101516153515361571 1580158215871588158915901593 15941598160816111616162516261627162816291630163116321633 1634164316451646165316591660166516721691 1698170017031706 17131714171517161736173717381739174017431744175517991806
1812 1813 1821 1835 1836 1841 1862 1870 1877 1878 1880 1882 1896 1899 1905 1911 1913 1932 1942 1943 1945 1947 1949 1957 1965 1974 1975 1980 1987 1988 1989 1991 1993 1994 1995 1996 1997 1999 2000 2002 2009 2010 2012 2013 2021 2023 2024 2046 2048 2053 2055 2064 2067 2072 2073 2075 2076 2077 2078 2086 2097 2099 2103 2111 2112 2113 2114 2116 2119 2121 2122 2141 2166 2181 2187 2188 2189 2195 2196 2212 2213 2214 2215 2223 2225 2228 2230 2231 2233 2234 2236 2237 2244 2252 2255 2256 2266 2268 2269 2271 2273 2274 et un de leurs fragments représentatifs.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans la biosynthèse des acides aminés, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 1507 1508 1511 1512 1513 1514 1515 796 1178 1179 1275 1881 1251 1252 1254 1255 1257 1258 1259 1260 1261 683 1238 1240 1241 1243 1245 1246 1247 1248 1249 860 797, de préférence 500 120 1291 1690 1793 1794 1795 1796 1803 1807 1808 166 361 755 1292 1293 1323 1609 1668 1670 1972 1973 2159 2285 128 129 575 812 813 814 815 1324 1325 1656 1657 1935 2257 75 551 613 615 616 617 1904 et un de leurs fragments. Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans la biosynthèse des cofacteurs, groupes prosthétiques et transporteurs, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 1169 1383 398 1405, de préférence 871 953 1 172 1173 1174 1 176 1353 1354 610 1 157 1615 187 743 744 745 746 747 875 584 585 1362 1487 1011 1012 1013 1014 1 123 1145 1871 862 958 1692 1695 497 1 130 1300 1301 1302 1526 1120 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un
polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide d'enveloppe cellulaire de Lactococcus lactis ou un de ses fragments, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 328 329 2288 2320 1296, de préférence 326 327 631 978 1105 1 193 1481 2025 2185 280 320 348 350 351 395 552 554 560 885 886 968 1181 1321 1406 1637 1638 1857 1934 1960 2096 2164 2283 2287 153 206 207 212 213 217 218 219 220 221 222 223 224 693 695 697 754 894 930 936 937 939 940 942 944 945 973 1297 1298 1299 1304 1380 1499 1500 1618 1845 2218 2279 2280 et un de leurs fragments. Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans la machinerie cellulaire, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 20 22 681 1898 1920 1921 402 403 972 417 1015 2134 1779 2206, de préférence 100 818 828 902 914 990 991 1267 1384 1636 1704 2207 508 126 119 562 959 1664 2161 2315 1107 1108 1265 1823 1824 1859 2084 2120 2176 2177 2178 2179 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le métabolisme intermédiaire central, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 728 155, de préférence 434 1024 1162 1376 1537 1621 291 716 1289 1538 1539 1728 1729 1732 2005 1663 215 586 712 713 714 715 et un de leurs fragments. Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le métabolisme énergétique, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 1785 2042 59 1329 1814 1815 1816 1817 1818 1819
1820 994 995 677 918 1205 1262 221 1 284 345 439 570 656 682 1152 1372 1373 1374 634 1552 1553 1554 2034 2035 2036 2037 2038 2039 684, de préférence 76 136 151 186 242 273 276 342 347 400 643 768 801 843 844 1281 1348 1572 1574 1583 1596 1601 1604 1746 1784 1925 2100 2182 2307 290 502 548 742 751 816 845 846 974 1327 1343 1747 1751 1971 1985 2088 2089 2090 2092 2093 254 256 257 1 127 1283 1379 431 609 620 719 720 732 1756 2167 1674 1675 915 916 1125 1142 1207 1290 1707 1858 1864 2068 2069 265 253 385 967 1146 1792 1962 2224 2303 1673 1723 1979 2277 2290 61 62 63 64 26 181 426 440 711 784 834 976 1326 1504 1532 1533 1534 1543 1546 1549 1550 1676 1679 1680 1687 1721 1730 1731 2079 2241 2242 685 1212 1213 1214 1215 1216 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le métabolisme des acides gras et des phospholipides, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 65 72 118 390 413 414 415 576 577 675 786 787 788 789 790 791 792 793 794 795 859 1284 1834 1837 1955 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le métabolisme des nucléotides, des purines, des pyrimidines ou nucléosides, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 2066 1531 1556 1557 1558 1569 1573 1575 1576 1578 501 1386 1387 1404 1586 1599 21 281 282 947 949 1969 2133 200, de préférence 182 506 992 993 1159 1177 311 1 112 1754 226 1164 1563 1564 1568 1689 2007 407 1086 1087 1388 1649 1650 295 605 645 829 854 1165 1482 1483 1485 1708 1908 1950 202 204 205 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un
polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans les fonctions de régulation, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 1263 1331 1559 2041 2316 405 406 908 909 1022 1478 1641 1725 1696 1726 890 1555 1506 7, de préférence 6 8 110 131 137 154 167 243 245 261 324 335 421 424 429 445 541 565 622 674 771 832 847 877 905 929 946 982 1084 1151 1186 1197 1233 1294 1310 1349 1490 1494 1521 1524 1566 1624 1639 1652 1654 1717 1745 1753 1766 1830 1831 1846 1852 1853 1928 1956 2001 2032 2043 2059 2095 2216 2243 2258 2262 2270 2291 2296 2306 1020 1477 1642 1724 1752 1797 1798 740 1545 1688 2200 2205 24 340 383 386 1274 1345 1603 1927 543 435 1480 1498 1681 804 975 1211 1336 117 603 723 757 785 926 1344 1517 1527 1585 2172 227 229 360 770 1171 1333 1635 2071 2299 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le processus de réplication, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 4 5 2 3 362 363 563 600 663 664 665 2030 2180 2198 2265 2281, de préférence 573 644 806 856 872 873 1089 1360 1361 1869 101 102 240 349 401 408 428 507 513 542 572 657 761 766 767 857 878 898 923 997 1000 1002 1025 1088 1129 1138 1139 1140 1266 1270 1693 1791 1883 1948 2098 2247 2251 2263 2264 2267 2301 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le processus de transcription, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 1237 1332 564, de préférence 817 960 1906 2314 14 619 646 648 709 779 1314 1367 1368 1607 1612 1623 1850 1851 2124 2160 2222 2297 359 419 1613 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le processus de traduction, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N0 1239 313 396 706 858 1778 1854 1861 1929 2105 571 1776 97 98 680 2127 782 783 2128, de préférence 68 382 394 807 831 11 13 1114 1763 1775 1879 1902 1914 1964 1983 1984 2020 2022 2094 2109 2183 2229 260 303 624 1606 1697 2027 2028 2045 2047 2192 374 911 1600 2062 107 135 198 246 292 301 302 748 760 781 805 853 892 906 1097 1099 1307 1308 1617 1644 1790 1893 1894 1937 2056 2057 2123 2125 2126 2135 2136 2137 2138 2139 2140 2142 2143 2144 2145 2146 2147 2148 2149 2150 2151 2152 2153 2154 2155 2156 2162 2209 2246 2248 2310 2311 2318 2319 13 132 158 168 169 171 496 638 705 852 1144 1923 1944 358 607 707 989 1126 1895 1912 2065 2208 2317 et un de leurs fragments. Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans le processus de transport et de liaison des protéines, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 1256 1787 330 550 699 717 1330 1496 1497 1810 1888 1889 1890 1891 1892 2091 1771 566 919 1551 2040 2104 635 676 1970 121 122 437 81 82 726 927 2221, de préférence 1 1 74 104 262 263 269 270 271 285 286 287 318 319 333 334 544 545 579 580 672 673 729 855 881 888 889 917 983 984 1080 1 121 1 122 1203 131 1 1312 1366 1567 1602 1667 1800 1801 1825 1826 1844 1926 2051 2052 2074 2157 2260 2261 2313 2321 70 1 15 331 352 353 354 355 356 357 364 365 375 574 698 824 863 864 955 956 957 1128 1182 1183 1184 1185 1750 1811 1847 1848 1873 2087 2107 2250 52 308 309 310 1767 1768 1769 1770 1772 208 209 259 430 933 934 1282 1369 1370 1371 1530 1540 1541 1542 1548 1671 1678 1683 1684 1685 1686 1733 1734 1735 2239 99 193 194 316 336 337 338
339 341 392 587 636 691 848 849 869 932 1194 1195 1295 1341 1355 1356 1357 1407 1528 1640 1655 2058 2169 2170 2171 2305 896 1166 1651 23 25 180 422 423 425 630 833 977 1149 1150 1505 1757 1758 1759 127 130 160 244 314 389 621 679 721 722 1389 1561 1584 1682 2220 2292 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans l'adaptation aux conditions atypiques, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 174 540 568 654 686 970 1570, de préférence 69 173 195 312 346 418 653 912 971 1102 1170 1414 2085 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments dans la sensibilité aux médicaments et analogues, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 1244, de préférence 1860 2249 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans les fonctions relatives aux phages et prophages, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 448 449 452 455 465 471 493 494 1026 1027 1028 1029 1030 1031 1032 1033 1034 1035 1036 1037 1038 1039 1040 1041 1046 1051 1075 1076 1077 1420 1422 1423 1424 1425 1426 1448 1450 1455 1456 1458 1465 1466 1467 1468 1470 1720, de préférence 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 446 447 450 451 453 454 456 457 458 459 460 461 462 463 464 466 467 468 469 470 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 531 532 533
534 1042 1043 1044 1045 1047 1048 1049 1050 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 1067 1068 1069 1070 1071 1072 1073 1074 1200 1217 1416 1417 1418 1419 1421 1427 1428 1429 1430 1431 1432 1433 1434 1435 1436 1437 1438 1439 1440 1441 1442 1443 1444 H45 1446 1447 1449 1451 1452 1453 1454 1457 1459 1460 1461 1462 1463 1464 1469 1471 1472 1473 1474 1475 1647 1998 2003 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide de Lactococcus lactis ou un de ses fragments impliqué dans les fonctions relatives aux transposons, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 53 54 55 56 90 91 93 94 141 142 143 144 145 146 378 379 380 381 649 650 651 652 662 670 737 738 837 838 839 841 842 1224 1225 1231 1232 1236 1286 1287 1591 1741 1742 2082 2083 2129 2130 2131 2132 2201 2202 2203 2204, de préférence 614 694 718 950 1268 1342 1400 1560 1749 1936 1961 1986 1992 2060 21 18 2191 2240 et un de leurs fragments.
Sous un autre aspect, de manière préférée, l'invention a pour objet un polypeptide selon l'invention, caractérisé en ce qu'il s'agit d'un polypeptide spécifique de Lactococcus lactis ou un de ses fragments, et en ce qu'il est choisi parmi les polypeptides de séquences suivantes : SEQ ID N° 416 1727 1822 87 88 279 332 569 671 700 701 727 840 850 884 891 900 1204 1242 1277 1382 1592 1605 1718 1719 1762 1777 1780 1907 1917 1918 1919 1930 1938 1939 1940 2102 2106 2174 2210 1250 1328 2199 666 948 1381 1990, de préférence 591 618 710 835 1153 1910 1931 1953 2031 17 18 50 57 58 60 78 79 80 84 92 113 114 1 16 124 125 133 134 139 140 148 149 150 157 159 161 162 170 172 175 176 179 183 184 185 188 189 196 197 214 230 231 232 233 234 235 236 238 247 255 258 264 266 267 268 274 277 283 288 289 293 294 298 299 300 315 317 321 323 325 343 344 366 367 369 370 371 372 373 376 377 384
387388399404409410411420433436438443444498499503510512 546549553555556557558582583588589592594597599611625637 655678688703704708725730735741749756759762763764765769 774780798799800803809810811819827830861865880882883899 9139209249519639649659869879991001 10041016101910231078 107910901091 10941098110011031104110611091110111511161117 111911241131 11371141114711481155115611601161116811751187 11881201120212081209122312761278128013031313131513161318 1319132213401352135813591363139113921393140814091411 1412 1476148614891491149214931501 1518151915201522152315251529 15441547156515771579158115951597161416191620162216481658 16611662166616691677169416991701170217091710171117121722 17481760176117641765177317741781178217861788178918021805 18091827182818291832183318381839184018421843184918551856 18631865186618671868187218741875187618851886188719001901 19031915191619241933194119461951195219541958195919631966 19671968197619771978198119822004200620082011201420152016 20172018201920262029203320442049205020542061206320702080 20812101210821102115215821632165216821732175218421862190 21932194219722172219222622272232223522382245225322542259 22722275227822822284228622892294229522982302230423082312 232223231666677377108109111112252391432505509511559581 593598604612640642647702733734736739750752758776777778 8028208268748768979019109229529549619799809819961017 10931111 111811351196119912731320137714131562161017051783 18041884189719091922211722939101215195171838586899596 103105106123138147152156163164165177178190191192199201 203210211216225228237239241248249250251272275278296297 304305306307322368393397412427441442495504530535536537
538539547561567578590595596601602606608623626627628629 632633639641658659660661667668669687689690692696724731 753772773775808821822823825836851866867868870879887893 895903904907921925928931935938941943962966969985988998 10031005100610071008100910101018102110811082108310851092 10951096110111321133113411361143115411581163116711801189 11901191 119211981206121012181219122012211222122612271228 12291230123412351253126412691271 127212791285128813051306 13091317133413351337133813391346134713501351136413651375 13781385139013941395139613971398139914011402140314101415 14791484148814951502150315091510151615351536157115801582 158715881589159015931594159816081611 16161625162616271628 16291630163116321633163416431645164616531659166016651672 16911698170017031706171317141715171617361737173817391740 17431744175517991806181218131821183518361841 186218701877 18781880188218961899190519111913193219421943194519471949 19571965197419751980198719881989199119931994199519961997 19992000200220092010201220132021202320242046204820532055 20642067207220732075207620772078208620972099210321112112 21132114211621192121212221412166218121872188218921952196 22122213221422152223222522282230223122332234223622372244 225222552256226622682269227122732274 et un de leurs fragments.
II est important de noter toutefois qu'un organisme vivant est un tout et doit être pris comme tel. Ainsi, afin de pouvoir se développer et d'exhiber ses propriétés, tout organisme a besoin d'interactions entre les différentes voies métaboliques. Ainsi, la classification énoncée ci-dessus ne doit pas être considérée comme limitative, un gène pouvant être impliqué dans deux voies métaboliques distinctes.
La présente invention a également pour objet les séquences
nucléotidiques et/ou de polypeptides selon l'invention, caractérisées en ce que lesdites séquences sont enregistrées sur un support d'enregistrement dont la forme et la nature facilitent la lecture, l'analyse et/ou l'exploitation de ladite ou desdites séquence(s). Ces supports peuvent également contenir d'autres informations extraites de la présente invention, notamment les analogies avec des séquences déjà connues, comme mentionné dans le Tableau III et/ou des informations concernant les séquences nucléotidiques et/ou de polypeptides d'autres microorganismes afin de faciliter l'analyse comparative et l'exploitation des résultats obtenus. Parmi cesdits supports d'enregistrement, on préfère en particulier les supports lisibles par un ordinateur, tels les supports magnétiques, optiques, électriques ou hybrides, en particulier les disquettes informatiques, les CD- ROM, les serveurs informatiques. De tels supports d'enregistrement sont également objet de l'invention. Les supports d'enregistrement selon l'invention, avec les informations apportées, sont très utiles pour le choix d'amorces ou de sondes nucléotidiques pour la détermination de gènes dans Lactococcus lactis ou souches proches de cet organisme. De même, l'utilisation de ces supports pour l'étude du polymorphisme génétique de souche proche de Lactococcus lactis, en particulier par la détermination des régions de colinéarité, est très utile dans la mesure où ces supports fournissent non seulement la séquence nucléotidique du génome de Lactococcus lactis IL1403, mais également l'organisation génomique dans ladite séquence. Ainsi, les utilisations de supports d'enregistrement selon l'invention sont également des objets de l'invention. Un procédé d'étude du polymorphisme génétique entre les souches proches de Lactococcus lactis, par détermination des régions de colinéarité, peut comprendre les étapes de
- fragmentation de l'ADN chromosomal de ladite autre souche (sonication, digestion),
séquence des fragments d'ADN, analyse d'homologie avec le génome de Lactococcus lactis IL 1043 (SEQ ID N° 1). Ce procédé qui comprend une étape d'analyse d'homologie avec le génome de Lactococcus lactis IL1403, en particulier grâce à l'aide d'un support d'enregistrement, est également l'objet de l'invention.
L'analyse d'homologie entre différentes séquences s'effectue en effet avantageusement à l'aide de logiciels de comparaisons de séquences, tels le logiciel Blast, ou les logiciels de la trousse GCG, décrits précédemment. L'invention vise également les vecteurs de clonage et/ou d'expression, qui contiennent une séquence nucléotidique selon l'invention. On préfère en particulier, les séquences nucléotidiques codant pour des polypeptides impliqués dans la machinerie cellulaire, en particulier la sécrétion, le métabolisme intermédiaire central, en particulier la production de sucre, le métabolisme énergétique, les processus de synthèse des acides aminés, de transcription et de traduction, de synthèse de polypeptides, ou les séquences nucléiques impliquées dans les fonctions relatives aux phages et prophages.
Les vecteurs selon l'invention sont avantageusement utilisés pour la génération de souches bactériennes qui présentent des propriétés de fermentation améliorée et/ou une stabilité accrue. En particulier, on recherche les souches bactériennes, de préférence de Lactococcus lactis, qui présentent une résistance accrue aux phages, ou des capacités de sécrétion améliorées.
Les vecteurs selon l'invention comportent de préférence des éléments qui permettent l'expression et/ou la sécrétion des séquences nucléotidiques dans une cellule hôte déterminée.
Le vecteur doit alors comporter un promoteur, des signaux d'initiation et de terminaison de la traduction, ainsi que des régions appropriées de régulation de la transcription. Il doit pouvoir être maintenu de façon stable dans la cellule hôte et peut éventuellement posséder des signaux particuliers qui
spécifient la sécrétion de la protéine traduite. Ces différents éléments sont choisis et optimisés par l'homme du métier en fonction de l'hôte cellulaire utilisé. A cet effet, les séquences nucléotidiques selon l'invention peuvent être insérées dans des vecteurs à réplication autonome au sein de l'hôte choisi, ou être des vecteurs intégratifs de l'hôte choisi.
De tels vecteurs sont préparés par des méthodes couramment utilisées par l'homme du métier, et les clones résultant peuvent être introduits dans un hôte approprié par des méthodes standards, telle que la lipofection, l'électroporation, le choc thermique, ou des méthodes chimiques. Les vecteurs selon l'invention sont par exemple des vecteurs d'origine plasmidique ou virale. Ils sont utiles pour transformer des cellules hôtes afin de cloner ou d'exprimer les séquences nucléotidiques selon l'invention.
L'invention comprend également les cellules hôtes transformées par un vecteur selon l'invention. L'hôte cellulaire peut être choisi parmi des systèmes procaryotes ou eucaryotes, par exemple les cellules bactériennes mais également les cellules de levure ou les cellules animales, en particulier les cellules de mammifères. On peut également utiliser des cellules d'insectes ou des cellules de plantes. Les cellules hôtes préférées selon l'invention sont en particulier les cellules procaryotes, de préférence les bactéries appartenant au genre Lactococcus, à l'espèce Lactococcus lactis, ou les microorganismes associés à l'espèce Lactococcus lactis. L'invention concerne également les animaux et végétaux, excepté l'homme, qui comprennent une cellule transformée selon l'invention. Les cellules transformées selon l'invention sont utilisables dans des procédés de préparation de polypeptides recombinants selon l'invention. Les procédés de préparation d'un polypeptide selon l'invention sous forme recombinante, caractérisés en ce qu'ils mettent en œuvre un vecteur et/ou une cellule transformée par un vecteur selon l'invention sont eux-mêmes compris dans la présente invention. De préférence, on cultive une cellule transformée par un
vecteur selon l'invention dans des conditions qui permettent l'expression dudit polypeptide et on récupère ledit peptide recombinant. Les cellules hôtes selon l'invention peuvent également être utilisées pour la préparation de compositions alimentaires, qui sont elles-mêmes objet de la présente invention. Ainsi qu'il a été dit, l'hôte cellulaire peut être choisi parmi des systèmes procaryotes ou eucaryotes. En particulier, il est possible d'identifier des séquences nucléotidiques selon l'invention, facilitant la sécrétion dans un tel système procaryote ou eucaryote. Un vecteur selon l'invention portant une telle séquence peut donc être avantageusement utilisé pour la production de protéines recombinantes, destinées à être sécrétées. En effet, la purification de ces protéines recombinantes d'intérêt sera facilité par le fait qu'elles sont présentent dans le surnageant de la culture cellulaire plutôt qu'à l'intérieur des cellules hôtes.
On peut également préparer les polypeptides selon l'invention par synthèse chimique. Un tel procédé de préparation est également un objet de l'invention. L'homme du métier connaît les procédés de synthèse chimique, par exemple les techniques mettant en œuvre des phases solides (voir notamment Steward et al., 1984, Solid phase peptides synthesis, Pierce Chem. Company, Rockford, 111, 2ème éd., (1984)) ou des techniques utilisant des phases solides partielles, par condensation de fragments ou par une synthèse en solution classique. Les polypeptides obtenus par synthèse chimique et pouvant comporter des acides aminés non naturels correspondant sont également compris dans l'invention.
L'invention comprend également les polypeptides hybrides qui comprennent au moins la séquence d'un polypeptide selon l'invention, et la séquence d'un polypeptide susceptible d'induire une réponse immunitaire chez l'homme ou l'animal. L'invention comprend également les séquences nucléotidiques qui codent pour de tels polypeptides hybrides, ou les vecteurs qui contiennent ces séquences nucléotidiques. Ce couplage entre un polypeptide
selon l'invention et un polypeptide immunogène, peut être effectué par voie chimique, ou par voie biologique. Ainsi, selon l'invention, il est possible d'introduire un ou plusieurs élément(s) de liaison, notamment des acides aminés pour faciliter les réactions de couplage entre le polypeptide selon l'invention, et le polypeptide immunostimulateur, le couplage covalent de l'antigène immunostimulateur pouvant être réalisé à l'extrémité N ou C-terminale du polypeptide selon l'invention. Les réactifs bifonctionnels permettant ce couplage sont déterminés en fonction de l'extrémité choisie pour réaliser ce couplage, et les techniques de couplage sont bien connues de l'homme du métier. Les conjugués issus d'un couplage de peptides peuvent être également préparés par recombinaison génétique. Le peptide hybride (conjugué) peut en effet être produit par des techniques d'ADN recombinant, par insertion ou addition à la séquence d'ADN codant pour le polypeptide selon l'invention, d'une séquence codant pour le ou les peptide(s) antigène(s), immunogène(s) ou haptène(s). Ces techniques de préparation de peptides hybrides par recombinaison génétique sont bien connues de l'homme du métier (voir par exemple Makrides, 1996, Microbiological Reviews 60,512-538).
De préférence, ledit polypeptide immunitaire est choisi dans le groupe des peptides contenant les anatoxines, notamment le toxoïde diphtérique ou le toxoïde tétanique, les protéines dérivées du Streptocoque (comme la protéine de liaison à la séralbumine humaine), les protéines membranaires OMPA et les complexes de protéines de membranes externes, les vésicules de membranes externes ou les protéines de chocs thermiques.
Les séquences nucléotidiques et vecteurs, codant pour un polypeptide hybride selon l'invention sont également objet de l'invention.
Les polypeptides hybrides selon l'invention sont très utiles pour obtenir des anticorps monoclonaux ou polyclonaux, capables de reconnaître spécifiquement les polypeptides selon l'invention. En effet, un polypeptide hybride selon l'invention permet la potentiation de la réponse immunitaire,
J>0
contre le polypeptide selon l'invention couplé à la molécule immunogène. De tels anticorps monoclonaux ou polyclonaux, leurs fragments, ou les anticorps chimériques, reconnaissant les polypeptides selon l'invention, sont également objets de l'invention. Les anticorps monoclonaux spécifiques peuvent être obtenus selon la méthode classique de culture d'hybridome décrite par Kôhler et Milstein (1975,
Nature 256, 495).
Les anticorps selon l'invention sont par exemple des anticorps chimériques, des anticorps humanisés, des fragments Fab, ou F(ab') . Il peut également se présenter sous forme d'immunoconjugué ou d'anticorps marqué afin d'obtenir un signal détectable et/ou quantifiable.
Ainsi, les anticorps selon l'invention peuvent être employés dans un procédé pour la détection et/ou l'identification de bactéries appartenant à l'espèce Lactococcus lactis ou à un microorganisme associé dans un échantillon biologique, caractérisé en ce qu'il comprend les étapes suivantes : a) mise en contact de l'échantillon biologique avec un anticorps selon l'invention ; b) mise en évidence du complexe antigène-anticorps éventuellement formé. Les anticorps selon la présente invention sont également utilisables afin de détecter une expression d'un gène de Lactococcus lactis ou de microorganismes associés. En effet, la présence du produit d'expression d'un gène reconnu par un anticorps spécifique dudit produit expression peut être détectée par la présence d'un complexe antigène-anticorps formé après la mise en contact de la souche de Lactococcus lactis ou du microorganisme associé avec un anticorps selon l'invention. La souche bactérienne utilisée peut avoir été « préparée », c'est-à-dire centrifugée, lysée, placée dans un réactif approprié pour la constitution du milieu propice à la réaction immunologique. En particulier, on préfère un procédé de détection de l'expression dans le gène,
correspondant à un Western blot, pouvant être effectué après une électrophorèse sur gel de polyacrylamide d'un lysat de la souche bactérienne, en présence ou en l'absence de conditions réductrices (SDS-PAGE). Après migration et séparation des protéines sur le gel de polyacrylamide, on transfère lesdites protéines sur une membrane appropriée (par exemple en nylon) et on détecte la présence de la protéine ou du polypeptide d'intérêt, par mise en contact de ladite membrane avec un anticorps selon l'invention.
Ainsi, la présente invention comprend également les kits ou nécessaires pour la mise en œuvre d'un procédé tel que décrit (de détection de l'expression d'un gène de Lactococcus lactis ou d'un microorganisme associé, ou pour la détection et/ou l'identification de bactéries appartenant à l'espèce Lactococcus lactis ou un microorganisme associé), comprenant les éléments suivants : a) un anticorps polyclonal ou monoclonal selon l'invention ; b) éventuellement, les réactifs pour la constitution du milieu propice à la réaction immunologique ; c) éventuellement, les réactifs permettant la mise en évidence des complexes antigène-anticorps produits par la réaction immunologique.
Les polypeptides et les anticorps selon l'invention peuvent avantageusement être immobilisés sur un support, notamment une puce à protéines. Une telle puce à protéines est un objet de l'invention, et peut également contenir au moins un polypeptide d'un microorganisme autre que Lactococcus lactis ou un anticorps dirigé contre un composé d'un microorganisme autre que Lactococcus lactis.
Les puces à protéines ou filtres à haute densité contenant des protéines selon l'invention peuvent être construits de la même manière que les puces à ADN selon l'invention. En pratique, on peut effectuer la synthèse des polypeptides fixés directement sur la puce à protéines, ou effectuer une synthèse ex situ suivie d'une étape de fixation du polypeptide synthétisé sur ladite puce. Cette dernière méthode est préférable, lorsque l'on désire fixer des protéines de
taille importante sur le support, qui sont avantageusement préparées par génie génétique. Toutefois, si l'on ne désire fixer que des peptides sur le support de ladite puce, il peut être plus intéressant de procéder à la synthèse desdits peptides directement in situ. Les puces à protéines selon l'invention peuvent être avantageusement utilisées dans des kits ou nécessaires pour la détection et/ou l'identification de bactéries associées à l'espèce Lactococcus lactis ou à un microorganisme, ou de façon plus générale dans des kits ou nécessaires pour la détection et/ou l'identification de microorganismes. Lorsque l'on fixe les polypeptides selon l'invention sur les puces à ADN, on recherche la présence d'anticorps dans les échantillons testés, la fixation d'un anticorps selon l'invention sur le support de la puce à protéines permettant l'identification de la protéine dont ledit anticorps est spécifique.
De préférence, on fixe un anticorps selon l'invention sur le support de la puce à protéines, et on détecte la présence de l'antigène correspondant, spécifique de Lactococcus lactis ou d'un microorganisme associé.
Une puce à protéines ci-dessus décrite peut être utilisée pour la détection de produits de gènes, pour établir un profil d'expression desdits gènes, en complément d'une puce à ADN selon l'invention. Les puces à protéines selon l'invention sont également extrêmement utiles pour les expériences de protéomique, qui étudie les interactions entre les différentes protéines d'un microorganisme donné. De façon simplifiée, on fixe des peptides représentatifs des différentes protéines d'un organisme sur un support. Puis, on met ledit support en contact avec des protéines marquées, et après une étape optionnelle de rinçage, on détecte des interactions entre lesdites protéines marquées et les peptides fixés sur la puce à protéines.
Ainsi, les puces à protéines comprenant une séquence polypeptidique selon l'invention ou un anticorps selon l'invention sont objet de l'invention, ainsi que les kits ou nécessaires les contenant.
La présente invention couvre également un procédé de détection et/ou d'identification de bactéries appartenant à l'espèce Lactococcus lactis ou à un microorganisme associé dans un échantillon biologique, qui met en œuvre une séquence nucléotidique selon l'invention. II doit être entendu que le terme échantillon biologique concerne dans la présente invention les échantillons prélevés à partir d'un organisme vivant (en particulier sang, tissus, organes ou autres prélevés à partir d'un mammifère) ou un échantillon contenant du matériel biologique, c'est-à-dire de l'ADN. Un tel échantillon biologique englobe donc les compositions alimentaires contenant des bactéries (par exemple les fromages, les produits laitiers), mais également des compositions alimentaires contenant des levures (bières, pains) ou autres.
Le procédé de détection et/ou d'identification mettant en œuvre les séquences nucléotidiques selon l'invention peut être de diverse nature. On préfère un procédé comportant les étapes suivantes : a) éventuellement, isolement de l'ADN à partir de l'échantillon biologique à analyser, ou obtention d'un ADNc à partir de l'ARN de l'échantillon biologique ; b) amplification spécifique de l'ADN de bactéries appartenant à l'espèce Lactococcus lactis ou à un micro-organisme associé à l'aide d'au moins une amorce selon l'invention ; c) mise en évidence des produits d'amplification.
Ce procédé est basé sur l'amplification spécifique de l'ADN, en particulier par une réaction d'amplification en chaîne.
On préfère également un procédé comprenant les étapes suivantes : a) mise en contact d'une sonde nucléotidique selon l'invention avec un échantillon biologique, l'acide nucléique contenu dans l'échantillon biologique ayant, le cas échéant, préalablement été rendu accessible à l'hybridation, dans des conditions permettant l'hybridation de la sonde à l'acide nucléique d'une bactérie
appartenant à l'espèce Lactococcus lactis ou à un microorganisme associé ; b) mise en évidence de l'hybride éventuellement formé entre la sonde nucléotidique et l'ADN de l'échantillon biologique. Un tel procédé ne doit pas être limité à la détection de la présence de l'ADN contenu dans l'échantillon biologique attesté, il peut être également mis en œuvre pour détecter l'ARN contenu dans ledit échantillon. Ce procédé englobe en particulier les Southern et Northern blot.
Un autre procédé préféré selon l'invention comprend les étapes suivantes : a) mise en contact d'une sonde nucléotidique immobilisée sur un support selon l'invention avec un échantillon biologique, l'acide nucléique de l'échantillon, ayant, le cas échéant, été préalablement rendu accessible à l'hybridation, dans des conditions permettant l'hybridation de la sonde à l'acide nucléique d'une bactérie appartenant à l'espèce Lactococcus lactis ou à un micro-organisme associé ; b) mise en contact de l'hybride formé entre la sonde nucléotidique immobilisée sur un support et l'acide nucléique contenu dans l'échantillon biologique, le cas échéant après élimination de l'ADN de l'échantillon biologique n'ayant pas hybride avec la sonde, avec une sonde nucléotidique marquée selon l'invention ; c) mise en évidence du nouvel hybride formé à l'étape b).
Ce procédé est avantageusement utilisé avec une puce à ADN selon l'invention, l'acide nucléique recherché s'hybridant avec une sonde présente à la surface de ladite puce, et étant détecté par l'utilisation d'une sonde marquée. Ce procédé est avantageusement mis en œuvre en combinant une étape préalable d'amplification de l'ADN ou de l'ADN complémentaire obtenu éventuellement par transcription inverse, à l'aide d'amorces selon l'invention.
Ainsi, la présente invention englobe également les kits ou nécessaires pour la détection et/ou l'identification de bactéries appartenant à l'espèce Lactococcus lactis ou à un micro-organisme associé, caractérisé en ce qu'il comprend les éléments suivants : a) une sonde nucléotidique selon l'invention ; b) éventuellement, les réactifs nécessaires à la mise en œuvre d'une réaction d'hybridation ; c) éventuellement, au moins une amorce selon l'invention ainsi que les réactifs nécessaires à une réaction d'amplification de l'ADN. De même, la présente invention englobe également les kits ou nécessaires pour la détection et/ou l'identification de bactéries appartenant à l'espèce Lactococcus lactis ou à un micro-organisme associé, caractérisé en ce qu'il comprend les éléments suivants : a) une sonde nucléotidique, dite sonde de capture, selon l'invention; b) une sonde oligonucléotidique, dite sonde de révélation, selon l'invention ; c) éventuellement, au moins une amorce selon l'invention ainsi que les réactifs nécessaires à une réaction d'amplification de l'ADN. Enfin, les kits ou nécessaires pour la détection et/ou l'identification de bactéries appartenant à l'espèce Lactococcus lactis ou à un micro-organisme associé, caractérisé en ce qu'il comprend les éléments suivants : a) au moins une amorce selon l'invention ; b) éventuellement, les réactifs nécessaires pour effectuer une réaction d'amplification d'ADN ; c) éventuellement, un composant permettant de vérifier la séquence du fragment amplifié, plus particulièrement une sonde oligonucléotidique selon l'invention, sont également objets de la présente invention.
De préférence, lesdites amorces et/ou sondes et/ou polypeptides et/ou
anticorps selon la présente invention utilisés dans les procédés et/ou kits ou nécessaires selon la présente invention sont choisis parmi les amorces et/ou sondes et/ou polypeptides et/ou anticorps spécifiques de l'espèce Lactococcus lactis. De manière préférée, ces éléments sont choisis parmi les séquences nucléotidiques condant pour une protéine sécrétée, parmi les polypeptides sécrétés, ou parmi les anticorps dirigés contre des polypeptides sécrétés de Lactococcus lactis.
La présente invention a également pour objet les souches de
Lactococcus lactis et/ou de microorganismes associés contenant une ou plusieurs mutation(s) dans une séquence nucléotidique selon l'invention, en particulier une séquence ORF, ou leurs éléments régulateurs (en particulier promoteurs).
On préfère, selon la présente invention, les souches de Lactococcus lactis présentant une ou plusieurs mutation(s) dans les séquences nucléotidiques codant pour des polypeptides impliqués dans la machine cellulaire, en particulier la sécrétion, le métabolisme intermédiaire central, en particulier la production de sucres, le métabolisme énergétique, les processus de synthèse des acides aminés, de transcription et de traduction, de synthèse des polypeptides, ou dans la résistance et/ou l'adaptation au stress ou les séquences nucléiques impliquées dans les fonctions relatives aux phages et prophages.
Lesdites mutations peuvent mener à une inactivation du gène, ou en particulier lorsqu'elles sont situées dans les éléments régulateurs dudit gène, à une surexpression de celui-ci.
Ainsi, on recherche en particulier des souches de Lactococcus lactis présentant une résistance accrue à l'infection et/ou la propagation des phages, sur-exprimant ou sous-exprimant (en particulier n'exprimant plus du tout) un polypeptide selon l'invention, impliquées dans les fonctions relatives aux phages et prophages. Une souche de Lactococcus lactis qui présente une résistance accrue à l'infection et/ou la propagation des phages, contenant un gène toxique sous le contrôle d'un agent régulateur de l'expression des gènes codant pour les
fonctions relatives aux phages et prophages, est également un objet de l'invention.
De telles souches de Lactococcus lactis modifiées sont très utiles pour augmenter la biosynthèse ou la biodégradation de composés d'intérêt. En particulier, on recherche une amélioration de la biosynthèse du diacétyle, lorsque l'on désire fabriquer du beurre ou du fromage blanc. Il peut également être intéressant d'améliorer la biodégradation des sucres en particulier les lactoses, présents dans les compositions alimentaires dans lesquelles on rajoute les souches selon l'invention. On peut également utiliser un polypeptide selon l'invention, une cellule transformée selon l'invention, et/ou un animal selon l'invention dans un procédé de biosynthèse ou de biodégradation d'un composé d'intérêt, lui-même également objet de la présente invention.
Enfin, une méthode de diagnostic de la présence de phages dans les levains lactiques et dans les produits laitiers, par l'étude de la présence de l'acide nucléique qui code pour un polypeptide impliqué dans les fonctions relatives aux phages et prophages, est également un objet de l'invention.
MATERIELS ET METHODES
1. Le séguençaεe du génome Ldactis IL1403.
La stratégie de séquençage du génome de L. lactis IL 1403 comportait deux étapes principales. Premièrement, la séquence diagnostique a été établie, avec une redondance de séquençage de seulement 2. Deuxièmement, la qualité de la séquence a été améliorée par séquençage de matrices aléatoires jusqu'à obtenir une redondance de 6. Toute partie du génome qui n'a été séquence que sur un brin a été re-séquencé, en utilisant des matrices générées par PCR à longue distance (Long Range ou LR PCR), afin d'obtenir un taux d'erreur
inférieur à 0,01% (moins d'une erreur pour 10.000 bases).
La stratégie de séquençage avec une faible redondance, du génome de L. lactis, est présentée dans le Tableau 2. Cette stratégie est un compromis entre une approche de séquençage direct et une approche de séquençage au hasard. L'objectif étant de réduire le temps et l'effort nécessaire pour obtenir l'organisation du génome et connaître les gènes qui le compose. Dans un premier temps, un nombre limité de clones choisis au hasard est séquence, ainsi le taux d'accumulation de nouvelles séquences reste approximativement constant. Cette condition s'arrête quand le génome a été couvert à peu près une fois. Dans un second temps, des clones choisis au hasard, et portant un grand insert, sont séquences par « primer walking ». On peut garder alors une redondance faible en choisissant les oligonucléotides correspondant aux extrémités des contigs prolongés, pour l'étape suivante de « primer walking ». Cette étape est poursuivie jusqu'à ce que l'obtention d'une nouvelle séquence soit supérieure à l'obtention d'1 nouvelle base pour 3 bases séquencées. L'étape finale du séquençage s'achève par l'utilisation d'une autre méthode directe, qui est appelée « multiplex long accurate PCR » (MLA PCR) (Sorokin et al, 1996, A new approach using multiplex long accurate PCR and yeast artificial chromosomes for bacterial chromosome mapping and sequencing, Génome Res, 6: 448-53). Celle-ci implique le mélange d'un grand nombre d'oligonucléotides correspondant aux extrémités des contigs. Un produit sera obtenu chaque fois que la distance entre 2 sites sur le génome, correspondant aux extrémités de deux contigs, est inférieure à la taille maximale pouvant être synthétisée par LR PCR. Pour la taille du génome de L. lactis, la probabilité d'obtenir ce type de produit est entre 0,5 et 1, si 20 oligonucléotides sont mélangés (au moins la moitié des réactions de PCR contenant 20 oligonucléotides choisis au hasard, donneront un produit d'amplification). Les données statistiques de l'application de cette stratégie pour le séquençage de L. lactis sont présentées dans le tableau 3. Une banque contenant 2854 clones avec des inserts d'une taille comprise
entre 1 et 2 Kb, a été construite en utilisant les vecteurs pBluescript II KS+ (Stratagène) ou pSGMU2 (Errington J, 1986, A gênerai method for fusion of the Escherichia coli lacZ gène to chromosomal gènes in Bacillus subtilis, J Gen Microbiol, 132 :2953-66). 2625 clones ont été séquences avec l' oligonucleotide direct (M13-21) et 2168 avec l' oligonucleotide réverse (M13RP1), avec un taux de séquences réussies d'environ 90 %. Après l'obtention d'environ 2100 kb de séquences, 2357 oligonucléotides ont été synthétisés pour fermer les espaces entres les séquences directes et réverses. Un total d'environ 3,3 Mb de séquences a ainsi été obtenu. Le vecteur λ-FIXII (Stratagène) a été utilisé pour construire une banque de grands inserts. Le chromosome de L. lactis a été partiellement digéré avec Sau3A, fractionné par centrifugation en gradient de sucrose, traité avec la Klenow polymérase en présence de dGTP et de dATP, et ligaturé avec le vecteur λ-FIXII lui-même digéré par Xhol et traité avec la Klenow polymérase en présence de dCTP et de dTTP. 262 phages ont été choisis au hasard et les extrémités des inserts ont été séquencées avec l' oligonucleotide T7 (Stratagène). Parmis ces 262 phages séquences, 122 phages ayant permis d'obtenir une séquence unique avec l' oligonucleotide T7, ont alors été séquences avec l'oligonucléotide T3 (Stratagène). Environ 250 kb de séquences ont ainsi été obtenues de cette façon.
La MLA PCR a été utilisée pour obtenir des produits pour de nouvelles séquences. L'étape critique de la méthode a été de déterminer quels mélanges de 2 oligonucléotides donnaient un produit utilisable pour le séquençage. Le protocole développé précédemment et qui requérait deux étapes pour l'identification (Sorokin et al, 1996, A new approach using multiplex long accurate PCR and yeast artificial chromosomes for bacterial chromosome mapping and sequencing, Génome Res, 6: 448-53), a été modifié ici de façon à ce qu'une seule étape soit requise. Au total, 1641 réactions de séquençage sur des produits de tailles variant entre 1 et 20 kb ont été obtenues, et environ 0,77 Mb de séquences ont été lues. Cette étape a permis de
finir l'assemblage complet du chromosome, donnant un contig de 2,34 Mb. La redondance totale est proche de 2. Pour vérifier que l'assemblage est correct, les Inventeurs ont effectué des amplifications de type LR PCR sur le génome entier, en utilisant 266 oligonucléotides, séparés par des distances prédites entre 10 et 20 kb. Les produits espérés ont été obtenus, indiquant que l'assemblage est correct.
Pour améliorer la qualité de la séquence finale, et ainsi faciliter l'étape suivante d'annotation, une autre banque de plasmides contenant des petits inserts (1-2 kb) du génome de L. lactis IL 1403, a été construite et les inserts obtenus séquences avec les oligonucléotides directs (Ml 3-21) et réverses (M13RP1). Au total 7665 plasmides ont été séquences avec succès, ce qui a permis d'obtenir 15310 gels lus, contenant 9671085 caractères. Ces séquences couvrent 93 % de la séquence contiguë obtenue lors de l'étape de séquençage basse-redondance, et sont distribuées dans 358 groupes le long de la séquence contiguë. 978 oligonucléotides ont alors été synthétisés pour séquencer les produits de LR PCR générés en utilisant la séquence connue d'IL1403. La base de données de la séquence finale contient 26036 gels lus, contenant 14842630 caractères. La taille moyenne des gels lus est donc de 570 bases. La longueur de la séquence génomique d'IL1403 est de 2365589 bases, la redondance de la séquence finale est 6,27.
2. annotation du génome d'IL1403
2.1. Prédiction des gènes codant pour les protéines dans L. lactis
IL1403.
Les fenêtres ouvertes de lecture prédites ont d'abord été identifiées en utilisant TGA, TAA et TAG comme codons stops et en utilisant le code génétique bactérien standard. La région codante pouvant coder pour une protéine a été considérée comme ayant une taille de plus de 60 acides aminés. Les séquences homologues à l'extrémité 3' de l'ARNr 16S de L.lactis (3' UCUUUCCUCCA...5') en amont des codons potentiels d'initation, qui sont
ATG, GTG, ou TTG, ont été systématiquement recherchées pour assurer la fonctionnalité du gène putatif trouvé Plusieurs gènes dans L. lactis IL 1403 ont ainsi été trouvés, ils ont été appelés ARNm « leaderless » et démarrent au codon ATG de l'extrémité 5' Ceci est applicable en particulier aux gènes impliqués dans le processus de transformation génétique Ceci peut expliquer que L. lactis est protégé de cette façon de l'expression de gènes occasionnels due à une mutation ou à une insertion d'une séquence ayant une activité promotrice
Les protéines prédites sont ensuite systématiquement testées au niveau de leur homologie avec les protéines connues contenues dans les bases de données Finalement, ceci a révélé 2323 gènes avec ou sans fonctions assignées, présentés dans le tableau 1 Les gènes sont classés selon un schéma de classification proposé par M Riley (Riley M, 1993, Functions of the gène products of Escherichia coli, Microbiol Rev, 57 862-952) Plusieurs catégories de gènes de L. lactis IL 1403 sont décrits ci-dessous 2.2 Les éléments IS et les prophages chez L. lactis IL1403.
Trois éléments IS étaient déjà connus dans le génome de L. lactis IL 1403, désignés IS981, IS982 et IS1076 Leur nombre de copies (respectivement dix, une et sept) et leur localisation approximative sont rapportés Les données de séquençage des Inventeurs révèlent que dans toutes les localisations chromosomiques où IS1076 a été cartographie, la séquence nucléotidique identique à IS904 est présente Le dernier nom est gardé sur la carte Un autre élément, appelé IS1077, était présent dans chacun de ces sept sites Quinze copies d'un élément, qui n'avait pas été décrit précédemment pour l'espèce Lactococcus et appelé IS983, ont été détectées dans le génome de IL1403 L'élément le plus proche relativement d'une autre bactérie lactique, qui est IS1070, a été découvert dans le plasmide pNZ63 de Leuconostoc lactis NZ6009
Pour identifier les prophages potentiels présents dans le chromosome, les Inventeurs ont utilisé la recherche d'homologies dans les bases de données
contenant des séquences protéiques de phages connus. La base de données est composée de 1219 séquences protéiques, comprenant l'ensemble complet des 50 protéines putatives dérivées de la séquence du phage tempéré rit de L. lactis (Van Sinderen, D., Karsens, H., Kok, J., Terpstra, P., Ruiters, M.H., Venema, G, & Nauta, A., 1996, Séquence analysis and molecular characterization of the temperate lactococcal bacteriophage rit, Mol Microbiol 19: 1343-1355). Une distribution des homologies non redondantes lancées sur le génome de L. lactis a été générée. Cette distribution indique la présence de trois régions, autour de 470, 1060 et 1430 Kb, qui contiennent les prophages identifiés précédemment par des tests biologiques. Deux sites, autour de 45 et 2020 Kb, indiquent un quatrième et un cinquième prophages.
2.3. Le biais GC, l'origine de réplication et le terminus. Pour prédire les sites de l'origine de la réplication et le terminus, les Inventeurs ont utilisé les biais GC et AT dans des schémas similaires (Lobry, J.R., 1996, Asymmetric substitution patterns in the two DNA strands of bacteria, Mol Biol Evol, 13: 660-665). Les distributions des valeurs (C- G)/(C+G) et (A-T)/(A+T) le long de la région chromosomique montre une transition bien franche entre les valeurs positives et négatives, et indique la présence de l'origine de réplication dans le voisinage de gène dnaA. Cette région contient quatre boites DnaA, qui indiquent aussi la présence de l'origine de réplication. Les Inventeurs ont choisi le point de départ de la présentation circulaire du génome de L. lactis au milieu du site Hindlll près de l'origine de réplication et la carte est orientée de façon avec la direction de transcription des gènes dnaA et dnaN. Les biais GC et AT indiquent aussi la localisation du terminus de réplication. La transition entre les valeurs positives et négatives se produit près de la position 1260 K. Ceci est en corrélation avec la localisation du terminus de réplication basée sur l'orientation des gènes potentiels de transcription et la distribution des sites chi le long du génome.
3 Description des catégories de gènes
3.1. Biosynthèses d'acides aminés de vitamines et de nucléotides.
Les analyses des Inventeurs ont montré que L. lactis a un potentiel génétique pour synthétiser les 20 acides aminés standards et au moins 4 co-facteurs (l'acide folique, la ménaquinone, la riboflavine et la thiorédoxine). Cependant, cette bactérie est délicate d'un point de vue nutritionnel et nécessite de nombreux métabolites qu'il faut ajouter au milieu synthétique (Jensen & Hammer, 1993, Minimal requirements for exponential growth of lactococcus lactis, Appl Env Microbiol, 59:4363-4366). Le problème des exigences nutritionnelles délicates des souches L. lactis a récemment été abordé par l'application de la techique de simple omission (Cocaign-Bousquet, M., Garrigues, C, Novak, L., Lindley, N.D., & Loubiere, P., 1995, Rational development of a simple synthetic médium for the sustained growth of Lactococcus lactis, J Appl Bacteriol, 79: 108-116) et des approches génétiques. Il a également été montré que l'auxotrophie de EL 1403, utilisée comme une souche laitière, pour l'histidine et les acides aminés à chaine ramifiée est due à des mutations récemment acquises. La mise à disposition du complément complet des gènes biosynthétiques présents dans L. lactis fournira de nombreux éléments pour la compréhension et l'utilisation efficace du métabolisme biosynthétique dans ces bactéries.
Les Inventeurs ont détecté 60 gènes impliqués dans la biosynthèse et la préservation des nucléotides et nucléosides. La plupart des gènes pour la biosynthèse des purines sont regroupés près de l'opéron purDEK, qui a été récemment caractérisé. Une copie de IS983 a été détectée entre l'opéron purDEK et d'autres gènes de la biosynthèse des purines.
3.2. Métabolisme énergétique et transporteurs.
Le potentiel génétique de L. lactis à croître sur différentes sources carbonées peut être estimé à partir de la présence des gènes de biodégradation et des transporteurs adéquats. EL 1403 a des gènes qui peuvent être utilisés pour la
croissance sur différentes sources de carbone : le glucose (les gènes de glycolyse), le fructose (positions 1519 et 2230 kb, fructokinase and glucoso-6P-isomérase, scrK et pgiA), la N-acétyl glucosamine (1032 kb, gène codant pour la glucosamine- fructoso-6P aminotransférase, glmS), le xylose (1550 kb, opéron xyl), le ribose (1685 kb, opéron rbs), le mannose (779 kb, mannose-6P isomérase, pmi), le gluconate (608, 2254 et 2254 kb, 6P gluconate déshydrogénases et gluconate kinase, gnd, gntZ and gntK), maltose (692, 700 et 1526 kb, maltodextrine glucosidases and 4-α-glucanotransférase, malQ), le lactose (2041 kb, β- galactosidase, lacZ), le galactose (2045 kb, opéron gai), le mannitol (33 kb, mannitol-lP 5-déshydrogénase, mtlD), les différents β-glucosides (186, 419, 830, 1490 et 1520 kb, glucosidases, 6P β-glucosidases, bglS, bglA, yidC, bglH, dexB). L'opéron catabolique du glucuronate ou du galacturonate (1670 kb, opéron uxu- kdg) peut être utilisé pour l'utilisation des produits de dégradation de la pectine comme une source supplémentaire d'énergie et de carbone. Les composants des systèmes de transports dépendant de l'enzyme II sucre-spécifique du phosphoénol- pyruvate ont été trouvés pour le mannitol (30 kb, mtlAF), le sucrose ou le tréhalose (435 kb,yedF), le fructose (9S4,fruA), le mannose (1748 kb, opéron ptri) et des β- glucosides (175, 416, 830, 1144 et 1489 kb, celB, opéron ptc, yidB, yleDE, ptbA). L'analyse de la séquence du chromosome de IL1403 a révélé que les gènes codant pour la voie PTS-dépendante de l'utilisation du lactose étaient absents dans cette souche. Le chromosome contient cependant un autre système pour l'utilisation du lactose dépendant du transport par le produit du gène lacS, codant pour un symporteur H+ ou un anti-porteur galactose-lactose. L'analyse des Inventeurs a détecté 19 gènes impliqués dans la glycolyse, complétant la description de ce système et a révélé un second gène de déshydrogénase glyceraldéhyde-phosphate. Ceci a également confirmé l'absence d'un cycle complet de l'acide citrique. Un gène impliqué dans la gluconéogenèse a été identifié ; il s'agit du gène codant pour la fructose 1,6 bisphosphatase. Aucun gène codant pour la phosphoénolpyruvate carboxykinase ou la phosphoénolpyruvate synthétase n'a été trouvé.
Les importeurs et exporteurs de différents métabolites sont largement représentés dans les bactéries par les transporteurs ABC. Les importeurs sont impliqués dans le transport vers l'intérieur de la cellule de différents sucres ainsi que d'oligosacharides, oligopeptides et acides aminés, anions et cations. Les exporteurs sont impliqués dans l'excrétion des métabolites dangereux pour la cellule et sont donc souvent impliqués dans la résistance de la cellule à différents antibiotiques ou autres drogues. L'inventaire complet de tels transporteurs a été réalisé à partir du séquençage complet de plusieurs microorganismes, y compris de levures telles que Sacharomyces cerevisiae, Escherichia coli et Bacillus subtilis. Dans L. lactis plusieurs systèmes codant pour les transporteurs ABC ont été caractérisés. L'un d'entre eux, oppDFBCA, code pour un transporteur d' oligopeptides et semble être important pour la croissance dans un milieu contenant des oligopeptides. Le système codé par l'opéron IcnCD est impliqué dans la sécrétion et la maturation de lactococcine A et est important dans le développement de la résistance à cet antibiotique. Il a été montré que le gène I rA, impliqué dans la résistance multi-drogues, est capable de complémenter le gène humain MDR1, responsable de la résistance à la chimiothérapie dans plusieurs formes de cancers. Il a été montré que les gènes busAA et busAB responsables du transport de la bétaïne sont importants pour la résistance aux chocs osmotiques. L'inventaire complet des transporteur ABC dans le chromosome de L. lactis EL 1403 est présenté dans le Tableau ABC. La présente invention fournit les moyens pour détecter les gènes correspondants dans différentes souches de L. lactis et apparentés de façon étroite aux Streptocoques. Dans ces derniers, les transporteurs correspondants peuvent être impliqués dans le développement de la pathogénicité. 3.4. Enveloppe cellulaire.
L'analyse des Inventeurs a révélé 81 gènes impliqués dans les fonctions de l'enveloppe cellulaire, y compris 10 protéines de membrane, 28 gènes de la biosynthèse des peptidoglycanes et muréine succulus et 43 gènes de la biosynthèse des polysaccharides de surface.
3.5. Machinerie cellulaire.
Parmi les gènes impliqués dans le fonctionnement de la machinerie cellulaire, listés dans le Tableau 1, les plus importants pour les applications portentielles sont ceux impliqués dans la sécrétion protéique et le développement de la compétence génétique. La liste complète des gènes détectés pertinents est présentée dans le Tableau 1. Leur présentation est détaillée en partie ci-dessus. L'exemple correspondant d'isolement de tels gènes par la mise en œuvre de la présente invention est fourni ci-après.
3.6. Fonctions de régulation. L'analyse a révélé 126 gènes potentiellement impliqués dans la régulation, qui représentent à peu près 5,6 % du nombre total des ORFs identifiés.
3.7. Réplication, transcription et traduction.
65, 27 et 128 gènes ont été attribués aux catégories fonctionnelles de réplication, transcription et traduction respectivement. Il apparaît que le système de réplication de L. lactis est très similaire à celui de B. subtilis. La contrepartie des gènes de dnaB et dnaD, essentiels pour la réplication de l'ADN chez B. subtilis et non présents dans les bactéries gram négatives, ont été détectés. Deux gènes d'ADN-polymérase IEf de chaîne α, l'un correspondant àpolC et un autre à dnαE de B. subtilis, ont également été détectés chez L. lactis. E. coli possède seulement ce dernier gène. La machinerie transcriptionnelle et traductionnelle ne semble pas présenter de différence remarquable avec celle de B. subtilis. Il semble que B. subtilis, avec ses outils génétiques bien développés, puisse être un organisme hôte convenable pour étudier la régulation des gènes dans les systèmes de L. lactis.
EXEMPLES
1. Détection des régions de longue colinéarité et établissement de l'organisation correspondante des gènes dans la souche L. lactis
MG1363 étroitement apparentée à L. lactis IL1403.
Comme base pour la détection de gènes chez une bactérie qui est proche de L. lactis EL1403, la présente invention propose le séquençage d'un nombre limité de fragments d'ADN pris au hasard. Leur nombre doit être défini de façon à permettre une densité suffisamment élevée de distribution de leur site d'homologie par rapport au génome de L. lactis EL 1403. Dans cet exemple, pour la souche L. lactis MG1363, il y a 513 séquences qui ont en moyenne un site sur chaque 5 kb. Les séquences des fragments d'ADN correspondant à 2 sites les plus proches du gène d'intérêt sur le génome de EL 1403 sont utilisées pour choisir les oligonucléotides pour l'amplification par PCR de la zone correspondante à partir du génome de MG1363. Dans les régions des génomes considérées comme colinéaires, le fragment amplifié devra contenir le gène d'intérêt de MG1363, du fait de la colinéarité des génomes.
L'ADN chromosomique de la souche MG1363 est digéré par l'enzyme de restriction Alul ou par sonication randomisée. Après séparation dans un gel d'agarose à 0,8 %, une fraction contenant des fragments ayant une taille de 500 bp à 1 kb est isolée. Cet ADN est ligaturé au plasmide pSGMU2, digéré par Smal et déphosphorylé par la phosphatase alkaline de E. coli. La déphosphorylation du vecteur d'ADN était nécessaire pour empêcher une auto-ligature et ainsi augmenter le nombre de colonies qui portent l'ADN chromosomique de MG1363 inséré dans le vecteur. L'ADN ligaturé a été transformé dans des cellules TG1 de E. coli, qui ont été rendues compétentes par un traitement avec une solution de CaCbà 50 mM. Les cellules ont été étalées sur un milieu d'agar, qui contenait 50 μg/ml d'ampicilline, 20 μg/ml de X-gal et 20 μg/ml d'EPTG Les colonies blanches ont été prises pour le séquençage des inserts par des amorces sens (M13-21) et reverses (M13RP1). 665 plasmides au total ont été séquences et ils ont donnés 882 gels lus contenant 258919 caractères. Ces séquences ont été réparties dans 539 groupes de liaison, chacun correspondant à une unique séquence de l'ADN génomique de MG1363 avec une taille moyenne de 348 bp et une longueur totale de 185292 bp.
L'analyse de l'homologie avec le génome de L. lactis EL 1403 a été réalisée en utilisant les algorithmes de FASTA et de BLASTx. Les résultats de cette analyse ont été utilisés pour détecter les zones de forte homologie entre les deux génomes et pour détecter les régions de colinéarité potentielle dans les organisations de génome. L'estimation d'un niveau d'homologie statistiquement significatif a été donnée par le calcul de la distribution des contigs (tags ou étiquettes) séquences avec un pourcentage donné d'homologie par rapport au génome de la souche EL 1403. Le niveau d'homologie entre les différentes parties des génomes de MG1363 et EL1403 qui peuvent être considérées comme des contreparties est compris entre 65 et 100 %, avec un nombre maximum de régions homologues proche de 85 %.
240 oligonucléotides (SEQ ED N° 2324 à 2563) ont été synthétisés et utilisés dans des réactions de Long Range PCR, dans le but de confirmer la colinéarité des régions détectées. Les zones correspondant aux zones de colinéarité peuvent être facilement amplifiées par LR PCR en utilisant les oligonucléotides correspondants comme amorces. L'organisation des gènes dans ces zones de colinéarité est conservée dans ces deux souches. Ce fait peut donc être utilisé pour amplifier les gènes désirés à partir d'autres souches de Lactocoques et les utiliser pour des manipulations génétiques. Certains systèmes génétiques particuliers, amplifiés à partir de la souche MG1363 par utilisation de l'information génomique pour EL 1403 et l'approche décrite dans cet exemple, sont décrits dans les exemples 2 et 3.
La présente invention fournit donc les séquences pour le génome de L. lactis MG1363, qui permet la détection d'un gène quelconque existant dans les deux souches : EL1403 et MG1363. Puisque l'homologie et la colinéarité des deux génomes sont estimées à 65 %, il y a 65 % de tous les gènes listés dans les Tableaux I et H, représentant une annotation fonctionnelle du génome de EL 1403.
L'invention concerne une méthode pour l'estimation de la colinéarité entre l'organisation chromosomique de deux génomes. Les parties de deux génomes sont colinéaires si les régions homologues sont situées à égale distance dans les deux
génomes. Ceci signifie en premier lieu que dans les régions colinéaires pour deux génomes donnés, l'organisation des gènes est conservée. Ceci signifie en second lieu que les oligonucléotides homologues des régions colinéaires devraient donner, par amplification PCR, des fragments de taille similaire pour les deux génomes. Ainsi, pour les régions colinéaires, la similarité de l'amplification PCR devrait indiquer la similarité de l'organisation des gènes. Dans les parties des génomes considérées comme colinéaires, estimées par amplification PCR, les fragments amplifiés devraient contenir des gènes similaires pour les deux génomes, du fait de la colinéarité des génomes. La présente invention fournit donc les moyens de déterminer les séquences du génome de L. lactis MG1363 et permet la détection d'un gène quelconque qui existe dans les deux souches : EL1403 et MG1363. L'homologie des deux génomes est estimée à 85 %. Les Inventeurs ont estimé que les régions de non-colinéarité, qui sont une partie du génome et dont la densité de distribution de tags séquences inférieure à celle attendue à partir d'une distribution randomisée, est d'environ 800 kb. Ces régions ne peuvent pas être amplifiées par PCR utilisant la méthode basée sur l'estimation de la colinéarité entre les deux génomes, fournis par la présente invention. D'autres régions peuvent être amplifiées en utilisant cette méthode. Ainsi, en utilisant cette méthode, 65 % de tous les gènes L. lactis peuvent être détectés dans une autre souche de L. lactis que EL 1403. Ceci signifie également que la préparation de tous les fragments représentatifs à partir de l'ADN de la souche EL 1403, ou à partir d'une quelconque autre souche d'intérêt, en utilisant les méthodes décrites ci-dessus, donnera au minimum 65 % de tous les gènes d'une quelconque souche de L. lactis. Cet ensemble représentatif de fragments peut être utilisé pour détecter des différences entre les génomes entiers de souches de L. lactis ou pour étudier l'expression de gènes par hybridation à de l'ARN extrait. Cette détection de 65 % des gènes ou de leur expression dans L. lactis est également basée sur la séquence génomique de EL 1403 présentée à la Figure 1 , sur l'annotation fonctionnelle de ce génome fournie au Tableau 1 et sur la méthode de la détection
de gènes selon la présente invention.
2. Détection des gènes impliqués dans la biosynthèse de l'arginine dans la souche L lactis MG1363. Un opéron codant pour cinq gènes nécessaires à la biosynthèse de l'arginine a été détecté aux environs de 805 kb du génome de L. lactis EL 1403. Bien que le séquençage généré à partir de l'ADN génomique de L. lactis MG1363 n'a pas révélé un tag séquence homologue à un quelconque gène de la biosynthèse de l'arginine, on peut s'attendre à ce que de tels gènes soient localisés dans le génome de MG1363 dans la région à partir de 800 à 850 kb, qui est colinéaire entre les deux souches. Les Inventeurs ont choisi deux tags séquences, les plus proches de la zone, qui doivent contenir des gènes de la biosynthèse de l'arginine dans le génome de MG1363. Il s'agit de contigs séquences qui ont révélé une homologie avec les gènes yhjD et yibC. En synthétisant les homologues oligonucléotides des séquences à partir de ces deux contigs, ma86 (SEQ ID N° 2564) et ma87 (SEQ ED N° 2565), et en réalisant une amplification par LR PCR sur l'ADN chromosomique de MG1363, un produit d'amplification d'une taille de 19 kb, ou proche de cela, contenant des gènes de la biosynthèse de l'arginine était attendu. L'amplification a donné lieu à un fragment de la taille de 19 kb. Le séquençage des extrémités de ce fragment a montré que le fragment correspondait effectivement à la zone attendue et que les gènes de la biosynthèse de l'arginine étaient contenus dans cette zone du génome de MG1363. Cette méthode peut être appliquée à d'autres souches de L. lactis pour détecter les gènes de l'arginine dans la plupart des environnements génétiques recherchés. Les gènes argG et argH, codant pour la synthase arginosuccinate et la lyase respectivement, peuvent également être détectés de la même façon. Ils ont été détectés dans le génome de la souche EL 1403 proche de 130 kb. Des manipulations génétiques avec ces gènes peuvent être mises en œuvre pour augmenter ou diminuer le niveau de production de l'arginine, ce qui a de nombreuses applications dans l'industrie alimentaire, l'agriculture ou la médecine.
3. Détection des gènes de la déshydrogénase pyruvate dans la souche de L. lactis MG1363.
La déshydrogénase pyruvate est l'une des enzymes importantes dans la régulation des flux du métabolisme du pyruvate dans les microorganismes. En manipulant les niveaux d'activité de cette enzyme dans la cellule, il est possible de faire passer une bactérie de fermentation homolactique en fermentation acide mixte et ainsi influencer les rendements les différents produits de fermentation, ce qui peut influencer la saveur du produit final alimentaire. Un opéron codant pour quatre gènes nécessaires à la biosynthèse de la déshydrogénase pyruvate a été détecté aux environs de 60 kb dans le génome de L. lactis EL 1403. Le séquençage généré à partir de l'ADN génomique de L. lactis MG1363 a révélé un contig, homologue du gène pdhD, codant pour une sous-unité de la désydrogénase pyruvate. Un autre tag séquence qui peut être utilisé pour amplifier ces gènes a été détecté comme homologue du gène yahG dans le génome annoté de EL 1403. Par synthèse des oligonucléotides homologues aux séquences à partir de ces deux contigs, ma08 (SEQ LD N° 2566) et ma09 (SEQ ED N° 2567), et par la mise en œuvre d'une amplification par LR PCR sur l'ADN chromosomique de MG1363, un produit d'amplification de la taille de 15 kb, ou proche de cela, contenant les gènes de la biosynthèse de la déshydrogénase pyruvate était attentdu. L'amplification a effectivement donné un fragment de la taille de 15 kb.Le séquençage des extrémités de ce fragment a montré que ce fragment correspondait bien à la zone attendue et que les gènes de la biosynthèse de la déshydrogénase pyruvate étaient contenus dans cette zone du génome de MG1363. Cette méthode peut être appliquée à d'autres souches de L. lactis pour la détection des gènes de la déshydrogénase de pyruvate dans les environnements génétiques les plus recherchés. D'autres gènes également impliqués dans la glycolyse ont été détectés dans différentes parties du chromosome de la souche EL1403. Il s'agit de enoA (633 kb) et enoB (274 kb), tous deux codant pour une énolase, de pgk (242 kb) codant pour une phosphoglycératekinase, depg
(332 kb) codant pour une phosphoglycérate mutase, depgmB (442 kb) codant pour une betta-phosphoglycomutase, de gapA (554 kb) et de gapB (2315 kb) les deux codant pour une déshydrogénase de glycéraldéhyde 3-phosphate, de tpiA (1148 kb) codant pour une isomérase triosephosphate, de pyk (1370 kb) codant pour une pyruvate kinase, deflaA (1963 kb) codant pour une aldolase fructose-bisphosphate, depgiA (2228 kb) codant pour une glucose-6-phosphate isomérase. Par la synthèse des oligonucléotides homologues des séquences à partir des contigs proches des zones où ces gènes étaient détectés dans EL1403, et la mise en œuvre d'une amplification par LR PCR sur l'ADN chromosomique de MG1363, un produit d'amplification contenant les gènes de la glycolyse était attendu. Ces gènes représentent l'ensemble complet des gènes de la glycolyse et peuvent être trouvés dans Lactococcus lactis.
Cette méthode peut être appliquée à d'autres souches de L. lactis pour la détection des gènes de la glycolyse dans la plupart des environnements génétiques recherchés. La modification de ces gènes par mutagenèse pourrait donner lieu à la construction de nouvelles souches de niveau alimentaire qui auraient de nombreuses applications dans l'industrie alimentaire et l'agriculture.
4. Isolement et surproduction d'une chaperone extracytoplasmique Les protéines sécrétées sont souvent dégradées au cours ou après leur sécrétion par des protéases présentes à la surface des cellules. Cette dégradation est souvent d'autant plus importante que la protéine sécrétée est d'origine étrangère, et ceci probablement parce que leur repliement est soit trop lent, soit mal synchronisé avec la synthèse et/ou la sécrétion. L'expression amplifiée de certains enzymes dont le rôle est de faciliter leur repliement permet parfois de protéger ces protéines de cette dégradation. Dans l'exemple suivant, les Inventeurs ont isolé la séquence complète d'un gène dont le meilleur homologue dans les bases de donnée est prsA de B. subtilis et dont l'activité semble être celle d'aider les protéines sécrétées à mieux se replier.
Deux amorces PCR (SEQ ID N° 2568 et SEQ ID N° 2569) ont été déduites de la séquence de L. lactis EL1403 et ont permis d'amplifier le gène correspondant à prsA chez L. lactis. Ce gène a été clone dans le vecteur pGEMT (Promega) et sa séquence vérifiée. Le plasmide obtenu a ensuite été fusionné au site Ncol au plasmide pNZ8037 contenant le promoteur de l'opéron nisine de L. lactis. La partie pGEMT de cet hybride a ensuite été délétée par coupure PstI et recircularisation avec la T4-ligase. Ce plasmide a ensuite été transformé dans la souche NZ9000, un dérivé de L. lactis subsp. cremoris MG1363 contenant le système permettant d'induire le promoteur placé en amont du gène homologue deprsA de L. lactis.
Cette souche a ensuite été testée pour la production de la lipase de Staphylococcus hyicus qui est dégradée en plusieurs formes tronquées lors de sa sécrétion chez L. lactis (Drouault et al. 2000, Appl Environ Microbiol., 66, 588). Dans cette souche, aucune forme dégradée de la lipase n'a pu être visualisée montrant que la production sur plasmide de l'homologue de prsA de L. lactis IL 1403 permet d'éviter l'accumulation de forme dégradée d'un enzyme hétérologue sécrété par une souche de L. lactis subsp. cremoris
5. Contrôle du métabolisme des sucres La majeure partie du galactose métabolisé par L. lactis et en général les bactéries lactiques est transformé dans la voie de la glycolyse via la voie de Leloir. En effet, du fait du métabolisme fermentaire des bactéries lactiques, ces réactions sont plus actives que celles ayant trait à la synthèse de sucres nucléotides, précurseur du glycogène, d'acide lipotechoique et d'exopolysaccharides. Une des étapes limitant la synthèse dΕPS, en particulier chez Streptococcus thermophilus, bactéries du yaourt, est la réaction glucose-6-phosphate vers le glucose 1 -phosphate par la phosphoglucomutase (cPGM). Son amplification est donc souhaitable pour permettre d'augmenter la production des EPS.
Le gène codant pour αPGM, pgm, a été caractérisé pour en obtenir une
surexpression. Aucun gène PGM de bactérie gram positive, et en particulier de bactérie lactique, n'avait été encore caractérisé génétiquement. Les Inventeurs ont donc recherché des séquences potentielles codant pour de tels gènes chez L. lactis sur la base de motifs court du site actif des protéines de cette famille comprenant des phosphoglucomutases, des phosphomannomutases, des phosphoNacetylglucosamine-mutases et des gènes de fonction inconnue dont mrsA de E coli (Swissprot p31120). Les Inventeurs ont ensuite réalisé des alignements multiples des protéines homologues aux gènes homologues chez L. lactis et défini pour chacun des régions conservées afin de faire la synthèse d'oligonucléotides dégénérés permettant d'amplifier les régions correspondantes du génome de différente bactéries comme par exemple Streptococcus thermophilus. Une PCR dégénérée a été réalisée avec ces oligonucléotides SEQ D N° 2570 et SEQ ED N° 2571 sur l'ADN total d'une souche de Streptococcus thermophilus. Il ont permis d'amplifier un fragment de 1.2 kb dont la séquence a montré qu'il contenait un gène homologue à celui de L. lactis.
Le reste du gène a ensuite été obtenu par PCR inverse (Ochman et al., 1990, Biotechnology, 8, 759). L'ADN chromosomique est digérée avec des enzymes de restriction puis les produits de coupure sont circularisés par ligation avec la ligase puis amplifiés par PCR "Long Range" en utilisant des primers complémentaires au brin opposé. Les bandes obtenues sont extraites du gel et séquencées. La taille du gène pgm de Streptococcus thermophilus est de 1350 pb. Les Inventeurs ont montré par la suite que ce gène correspond bien à l'α-PGM de S. thermophilus bien qu'il ait été isolé à partir de séquence supposée être codante pour les mannomutases. Pour montrer que ce gène codait pour l' -PGM, les Inventeurs ont adopté une stratégie d'inactivation par insertion d'un vecteur dans le gène par recombinaison homologue. Dans un premier temps, des plasmides dont la réplication est thermosensible contenant des fragments internes au gènepgm (Biswas et al., 1993, J Bacteriol., 175, 3628) ont été construits. Une souche de Streptococcus
thermophilus contenant le plasmide pG+host contenant l'insert interne a pgm a été mise à pousser à 42°C sur boites Ml 7 lactose contenant l'erythromycine pour détecter les événements d'intégration. L'ADN chromosomique préparée à partir d'une souches ainsi obtenue a été digéré par Kpnl puis analysé par Southern en utilisant une sonde PCR couvrant le gène pgm. La bande correspondant à l'hybridation avec le gène pgm du chromosome est transformée en deux bandes correspondant à l'intégration du vecteur dans le gène pgm. Ce plasmide est donc bien intégré par recombinaison homologue. Il est attendu qu'une souche contenant une mutation dans le gène pgm pousse normalement sur milieu contenant du glucose et du galactose mais pas sur milieu contenant du galactose ou glucose seul.
Le clone obtenu après intégration ne pousse pas sur glucose ou galactose seul, mais normalement en lactose ou sur un mélange glucose et galactose. Ceci montre que le métabolisme du glucose et du galactose a bien été découplé dans cette souche et que le gène dont l'activité a été affectée est bien pgm. Le travail réalisé dans la présente invention permet de montrer que le gène inactivé code bien pour l'enzyme connectant la voie des EPS et la glycolyse. Il code donc probablement pour l'α-PGM dont la séquence n'était pas encore caractérisée expérimentalement chez les bactéries lactiques. Ces expériences montrent aussi que l'on peut, en s'appuyant sur les séquences du génome de L. lactis, isoler des gènes d'autres bactéries et notamment des Streptococcus.
6. Résistance au stress
L'annotation de IL1403 par comparaison avec d'autres bactéries telles que B. subtilis ou E. coli, permet d'identifier les gènes codant pour des activités répertoriées comme importantes en conditions de stress à la suite d'études biochimiques. Ainsi, l'invention permet l'identification de protéines mises en évidence par analyse protéomique quelle que soit la souche de L. lactis étudiée. Par exemple, la comparaison de certaines séquences N-terminales rapportées par Kilstrup et al. (1997, Appl Environ Microbiol., 63, 1826, souche MG1363)
et Frees et Ingmer (1999, Mol Microbiol., 31, 79, souche MG1363) avec les orfs détectées dans la séquence de EL 1403 permet de confirmer les fonctions assignées ou d'en attribuer. Ce type d'analyse devrait permettre d'identifier des gènes appartenant aux différents régulons de stress. Il deviendra possible de rechercher des séquences régulatrices communes entre les gènes d'un régulon puis dans l'ensemble de la séquence génomique afin d'en identifier tous les éléments. Les gènes codant pour la H+-ATPase ou la désimination de l'arginine dont les activités augmentent en condition de stress, sont désormais identifiés chez EL 1403. On peut envisager de les modifier pour renforcer ou réduire la résistance des souches aux conditions acides.
Cette annotation comparée permet aussi de bénéficier des connaissances acquises chez d'autres micro-organismes sur les réponses aux stress. En exemple, il peut être mentionné l'identification chez IL 1403 d'un homologue du gène pexB de B. subtilis aussi appelé dps chez B. subtilis et E. coli. Ce gène a chez ces deux bactéries un rôle majeur dans la protection contre des dommages oxydatifs de l'ADN. Il est extrêmement probable, au vu de sa conservation, qu'il remplisse la même fonction chez L. lactis et soit important pour la survie au stress oxydatif et en phase stationnaire. Cette annotation révèle aussi des gènes de métabolisme du glycogène, de polyphosphate et de tréhalose dont il est bien établi qu'ils ont des rôles importants dans la survie en condition de phase stationnaire et de carence. Mais l'annotation révèle aussi des différences majeures entre EL 1403 et B. subtilis : le facteur sigma-B contrôle chez B. subtilis une centaine de gènes de stress, la séquence de EL 1403 ne révèle aucun homologue de ce facteur sigma. L'identification des régulateurs de stress doit donc reposer sur d'autres voies que la stricte comparaison. Là encore, la séquence permet d'envisager plusieurs solutions d'une part, elle révèle un certains nombre de régulateurs dont on peut désormais déterminer l'implication dans les phénomènes de résistance aux stress, d'autre part, elle permet le développement d'outils
(notamment des puces à ADN) qui faciliteront cette étude. L'identification des régulateurs est très importante pour le développement d'applications puisque la modification d'un seul gène (le régulateur) affectera l'expression de l'ensemble des gènes appartenant à 1 régulon de stress. La présente invention permet d'identifier les réseaux de gènes de résistance aux stress de L. lactis, leur régulateurs et leurs interactions. Des applications potentielles sont i) de trouver des marqueurs de stress pertinents, ii) de modifier ces gènes et/ou leur expression pour changer la capacité de résistance/sensibilité aux stress des Lactocoques et iii) de complémenter de façon pertinente l'absence de certains systèmes chez les Lactocoques éventuellement en implémentant de nouvelles fonctions.
Enfin, cette invention constitue un outil de diagnostic i) des stress réellement perçus par les Lactocoques au cours d'un procédé donné, ii) du potentiel de résistance/sensibilité d'une nouvelle souche et de son adéquation à un procédé, iii) pour choisir entre l'utilisation d'OGM ou de mutants naturels ou chimiques plus résistants aux stress et le cas échéant, identifier et contrôler la(es) mutation(s).
7. Cycle des phages L'analyse de la séquence du chromosome de la souche IL1403 a permis d'identifier 6 prophages et de caractériser les régions du génome dans lesquelles ils sont insérés. Au total, 256 orfs ont été identifiées, ainsi que les régions putatives de régulation de leur expression. Sur les 256 protéines codées par ces orfs, 186 sont homologues à des protéines de bactériophages ou de bactéries présentes dans les banques de données, mais 70 sont nouvelles, sans homologie avec des protéines déjà décrites. De plus, l'analyse des Inventeurs a permis d'établir que certaines protéines ont une structure modulaire. Ceci implique que ces protéines, bien qu'homologues sur une partie de leur longueur à des protéines déjà décrites, puissent néanmoins présenter des spécificités
d'action différentes. C'est le cas en particulier des protéines d'initiation de la réplication de l'ADN (Orflό, Orfl5 et Orfl4 respectivement pour les phages bIL285, bEL286 et bIL309) qui, bien qu'ayant des domaines homologues, reconnaissent vraisemblablement des origines de réplication différentes sur l'ADN.
L'analyse de la séquence du chromosome de la souche EL 1403 a permis d'identifier des gènes codant pour des protéines impliquées dans des étapes clé de la multiplication des phages telles que la régulation du choix entre cycle lytique et cycle tempéré, la réplication de l'ADN, la recombinaison, la moφhogenèse et la lyse cellulaire. En perturbant l'expression ou la fonction de certaines de ces protéines, il serait possible de développer des systèmes de résistance aux phages. Deux stratégies seraient utilisables :
1) le développement de phages infectants pourrait être gravement perturbé en changeant la concentration de l'une ou plusieurs des ces protéines ; ceci pourrait être fait en surproduisant, ou au contraire en titrant ces protéines et/ou leurs régulateurs ;
2) les systèmes de contrôle temporel d'expression des gènes de phages pourraient être utilisés ; en plaçant des gènes toxiques sous le contrôle de tels systèmes d'expression, il serait possible de développer des «systèmes suicides » dans lesquels l'infection par un phage entraînerait la mort des cellules infectées avant qu'elles ne puissent libérer de nouveaux phages.
La présente invention a également permis de mieux décrire la variété des génomes existant parmi les phages du groupe P335. Cette connaissance pourrait être utilisée pour développer de meilleurs systèmes de diagnostic des phages présents dans les levains lactiques et les produits laitiers.
8. Expression des gènes et milieu d'identification des souches.
L'une des applications directes de l'information découlant de la séquence
génomique est la construction de filtres à haute densité ou de puces, qui peuvent être utilisés pour étudier l'expression des gènes de la cellule entière ou pour comparer des génomes de souches différentes. La base pour la construction d'une telle expression de gènes et les milieux d'identification de souches est la séquence génomique et son annotation. Ansi, l'information nécessaire pour la constmction de filtres à haute densité et de puces pour L. lactis EL 1403 est la séquence génomique (SEQ ED N° 1) et son annotation présentée dans le Tableau II. La préparation de tels filtres ou puces consiste à synthétiser des oligonucléotides qui correspondent aux parties terminales 5' et 3' des gènes. Ces oligonucléotides sont sélectionnés en utilisant la séquence génomique et son annotation telle que fournie par la présente invention. La température d'annelage des oligonucléotides aux endroits correspondants sur l'ADN doit être approximativement la même pour chaque nucléotide. Ceci permet de préparer les fragments correspondants d'ADN pour chaque gène en utilisant des conditions standards de PCR dans des expérimentations par PCR automatisée à haut débit. Les fragments amplifiés sont ensuite immobilisés sur les filtres ou des supports de verre et ces milieux sont utilisés pour l'hybridation.
La disponibilité de tels filtres et la séquence annotée correspondante permet d'étudier l'expression de l'ensemble des gènes dans le microorganisme en préparant l'ADNc correspondant et en l'hybridant à de l'ADN immobilisé sur le filtre. L'hybridation de l'ADN immobilisé sur le filtre avec l'ADN total de différentes souches permet également d'étudier la divergence de l'organisation génomique chez différentes souches.
Les différences des séquences de gènes chez différentes souches peuvent largement influencer l'intensité de l'hybridation et ainsi influencer la précision de l'inteφrétation des données. Il est donc nécessaire d'avoir exactement l'ADN de la souche qui est étudiée pour l'immobiliser sur le filtre. Dans ce but, la méthode de la détection des gènes telle que fournie par la présente invention est utile. La procédure consiste dans ce cas à amplifier l'ADN de la souche d'intérêt en utilisant l'information sur la cartographie des régions colinéaires et la méthode de détection
des gènes conformément à l'invention.
L'utilisation de l'expression des gènes et le milieu d'identification de la souche fournira un ensemble de nouvelles connaissances sur la régulation des gènes des souches de L. lactis présentant un intérêt industriel et dans différentes conditions de croissance. Ceci permettra également l'identification rapide des différences génomiques dans les souches utilisées pour des applications industrielles multiples.
La souche de Lactococcus lactis EL 1403 a été déposée le 7 avril 2000 à la Collection National de Cultures de Microorganismes, Instimt Pasteur, 25 rue du Dr Roux, 75724 PARIS Cedex 15, France, selon les provisions du traité de Budapest, et a été enregistrée sous le numéro d'ordre 1-2438.
TABLEAU I Coordonnées des ORE par rapport à SEO ID N° 1
TABLEAU II. Classif cation des protéines de L. lactis (SEQ IDs) en groupes fonctionnels
BIOSYNTHESE DES ACIDES AMINES
Général SEQ ID: 500
Famille acides aminés Aromatiques SEQ IDs: 120 1291 1507 1508 1511 1512 1513 1514 1515 1690 SEQ IDs: 1793 1794 1795 1796 1803 1807 1808
Famille Aspartate SEQ IDs: 166 361 755 796 1178 1179 1275 1292 1293 1323 SEQ IDs: 1609 1668 1670 1881 1972 1973 2159 2285
Famille Chaîne ramifiée SEQ IDs: 1251 1252 1254 1255 1257 1258 1259 1260 1261
Famille Glutamate SEQ IDs: 128 129 575 683 812 813 814 815 1324 1325 SEQ IDs: 1656 1657 1935 2257
Famille Histidine SEQ IDs: 1238 1240 1241 1243 1245 1246 1247 1248 1249
Famille Pyruvate SEQ IDs: 860
Famille Serine SEQ IDs: 75 551 613 615 616 617 797 1904
BIOSYNTHESE de COFACTEURS, GROUPES PROSTHETIQUES, et TRANSPORTEURS acide folique SEQ IDs: 871 953 1169 1172 1173 1174 1176 1353 1354
Hème et porphyrine SEQ IDs: 610 1157 1615
Ménaquinone et ubiquinone SEQ IDs: 187 743 744 745 746 747 875 1383
Pantothénate SEQ IDs: 584 585 1362 1487
Riboflavine et cobalamine SEQ IDs: 1011 1012 1013 1014 1123 1145 1871
Thiorédoxine, glutarédoxine, et glutathione SEQ IDs: 398 862 958 1405 1692 1695
Thiamine SEQ IDs: 497 1130 1300 1301 1302 1526
Nucléotides Pyridine SEQ IDs: 1120
ENVELOPPE CELLULAIRE
Membranes, lipoprotéines, et porines SEQ IDs: 326 327 328 329 631 978 1105 1193 1481 2025 SEQ IDs: 2185
Muréine sacculus et peptidoglycane
SEQ IDs 280 320 348 350 351 395 552 554 560 885 SEQ IDs 886 968 1181 1321 1406 1637 1638 1857 1934 1960 SEQ IDs 2096 2164 2283 2287 2288 2320
Polysaccharides de Surface, lipopolysaccharides et antigènes SEQ IDs: 153 206 207 212 213 217 218 219 220 221 SEQ IDs: 222 223 224 693 695 697 754 894 930 936 SEQ IDs: 937 939 940 942 944 945 973 1296 1297 1298 SEQ IDs: 1299 1304 1380 1499 1500 1618 1845 2218 2279 2280
MACHINERIE CELLULAIRE
Division cellulaire SEQ IDs: 20 22 100 681 818 828 902 914 990 991 SEQ IDs: 1267 1384 1636 1704 1898 1920 1921 2207
Mort cellulaire
SEQ IDs: 508
Chaperones
SEQ IDs: 126 402 403 972
Détoxification
SEQ IDs: 417
Sécrétion des Protéines et peptides
SEQ IDs: 119 562 959 1015 1664 2134 2161 2315
Transformation SEQ IDs: 1107 1108 1265 1779 1823 1824 1859 2084 2120 2176 SEQ IDs: 2177 2178 2179 2206
METABOLISME INTERMEDIAIRE CENTRAL
Sucres aminés
SEQ IDs: 434 1024 1162 1376 1537 1621
Dégradation des polysaccharides
SEQ IDs: 291 716 1289 1538 1539 1728 1729 1732 2005
Composés phosphores SEQ IDs: 728
Biosynthèse de la Polyamine
SEQ IDs: 1663
Autres
SEQ IDs: 155 215 586 712 713 714 715
METABOLISME ENERGETIQUE
Aérobique SEQ IDs: 76 136 151 186 242 273 276 342 347 400 SEQ IDs: 643 768 801 843 844 1281 1348 1572 1574 1583 SEQ IDs: 1596 1601 1604 1746 1784 1785 1925 2042 2100 2182 SEQ IDs: 2307
Acides aminés et aminés SEQ IDs: 59 290 502 548 742 751 816 845 846 974 SEQ IDs: 1327 1329 1343 1747 1751 1971 1985 2088 2089 2090 SEQ IDs: 2092 2093
Anaérobique SEQ IDs: 254 256 257 1127 1283 1379
Interconversion force motrice ATP-proton SEQ IDs: 1814 1815 1816 1817 1818 1819 1820
Transport d' Electron SEQ IDs: 431 609 620 719 720 732 994 995 1756 2167
Entner-Doudoroff SEQ IDs: 1674 1675
Fermentation SEQ IDs: 677 915 916 918 1125 1142 1205 1207 1262 1290 SEQ IDs: 1707 1858 1864 2068 2069 2211
Gluconéogenèse SEQ IDs: 265
Glycolyse SEQ IDs: 253 284 345 385 439 570 656 682 967 1146 SEQ IDs: 1152 1372 1373 1374 1792 1962 2224 2303
Voie Pentose phosphate SEQ IDs: 634 1673 1723 1979 2277 2290
Pyruvate dehydrogénase SEQ IDs: 61 62 63 64
Sucres SEQ IDs: 26 181 426 440 711 784 834 976 1326 1504 SEQ IDs: 1532 1533 1534 1543 1546 1549 1550 1552 1553 1554 SEQ IDs: 1676 1679 1680 1687 1721 1730 1731 2034 2035 2036 SEQ IDs: 2037 2038 2039 2079 2241 2242
Cycle TCA SEQ IDs: 684 685 1212 1213 1214 1215 1216
METABOLISME DES ACIDES GRAS ET PHOSPHOLIPIDES
Général
SEQ IDs: 65 72 118 390 413 414 415 576 577 675
SEQ IDs: 786 787 788 789 790 791 792 793 794 795
SEQ IDs: 859 1284 1834 1837 1955
PURINES, PYRIMIDINES, NUCLEOSIDES ET NUCLEOTIDES métabolisme 2 ' -deoxyribonucleotide SEQ IDs: 182 506 992 993 1159 1177
Interconversions Nucléotide et nucléoside SEQ IDs: 311 1112 1754 2066
Biosynthèse des ribonucléotides Purine SEQ IDs: 226 1164 1531 1556 1557 1558 1563 1564 1568 1569 SEQ IDs: 1573 1575 1576 1578 1689 2007 biosynthèse des ribonucléotides Pyrimidine SEQ IDs: 407 501 1086 1087 1386 1387 1388 1404 1586 1599 SEQ IDs: 1649 1650
Récupération des nucléosides et nucléotides SEQ IDs: 21 281 282 295 605 645 829 854 947 949 SEQ IDs: 1165 1482 1483 1485 1708 1908 1950 1969 2133 biosynthèse Sucre-nucléotide et interconversions SEQ IDs: 200 202 204 205
FONCTIONS DE REGULATION
Général
SEQ IDs: 6 8 110 131 137 154 167 243 245 261 SEQ IDs: 324 335 421 424 429 445 541 565 622 674 SEQ IDs: 771 832 847 877 905 929 946 982 1084 1151 SEQ IDs: 1186 1197 1233 1263 1294 1310 1331 1349 1490 1494 SEQ IDs: 1521 1524 1559 1566 1624 1639 1652 1654 1717 1745 SEQ IDs: 1753 1766 1830 1831 1846 1852 1853 1928 1956 2001 SEQ IDs: 2032 2041 2043 2059 2095 2216 2243 2258 2262 2270 SEQ IDs: 2291 2296 2306 2316
Systèmes deux-composants SEQ IDs: 405 406 908 909 1020 1022 1477 1478 1641 1642 SEQ IDs: 1724 1725 1752 1797 1798
Régulateurs de la famille Lad
SEQ IDs: 740 1545 1688 1696 1726 2200 2205
Régulateurs de la famille LysR
SEQ IDs: 24 340 383 386 890 1274 1345 1603 1927
Régulateurs de la famille AraC
SEQ IDs: 543 1555
Régulateurs de la famille GntR
SEQ IDs: 435 1480 1498 1681
Régulateurs de la famille DeoR
SEQ IDs: 804 975 1211 1336
Régulateurs de la famille MarR SEQ IDs: 117 603 723 757 785 926 1344 1517 1527 1585 SEQ IDs: 2172
Régulateurs de la famille BglG
SEQ IDs: 1506
Protéines liant le GTP
SEQ IDs: 7 227 229 360 770 1171 1333 1635 2071 2299
REPLICATION
Dégradation de l'ADN
SEQ IDs: 4 5 573 644 806 856 872 873 1089 1360
SEQ IDs: 1361 1869
Réplication, Restriction, modification, recombination, et réparation de l'ADN
SEQ IDs: 2 3 101 102 240 349 362 363 401 408
SEQ IDs: 428 507 513 542 563 572 600 657 663 664
SEQ IDs: 665 761 766 767 857 878 898 923 997 1000
SEQ IDs: 1002 1025 1088 1129 1138 1139 1140 1266 1270 1693
SEQ IDs: 1791 1883 1948 2030 2098 2180 2198 2247 2251 2263 SEQ IDs: 2264 2265 2267 2281 2301
TRANSCRIPTION
Dégradation de l'ARN
SEQ IDs: 817 960 1237 1332 1906 2314
Synthèse, modification de l'ARN, et transcription de l'ADN SEQ IDs: 14 564 619 646 648 709 779 1314 1367 1368 SEQ IDs: 1607 1612 1623 1850 1851 2124 2160 2222 2297
Maturation moléculaire de l'ARN
SEQ IDs: 359 419 1613
TRADUCTION synthétases d'ARNt amino acyl
SEQ IDs: 68 382 394 807 831 1113 1114 1239 1763 1775
SEQ IDs: 1879 1902 1914 1964 1983 1984 2020 2022 2094 2109 SEQ IDs: 2183 2229
Dégradation des protéines, peptides, et glycopeptides
SEQ IDs: 260 303 313 396 624 706 858 1606 1697 1778
SEQ IDs: 1854 1861 1929 2027 2028 2045 2047 2105 2192
Modification des protéines
SEQ IDs: 374 571 911 1600 1776 2062
Protéines Ribosomales: synthèse et modification
SEQ IDs: 97 98 107 135 198 246 292 301 302 680 SEQ IDs: 748 760 781 805 853 892 906 1097 1099 1307 SEQ IDs: 1308 1617 1644 1790 1893 1894 1937 2056 2057 2123 SEQ IDs: 2125 2126 2127 2135 2136 2137 2138 2139 2140 2142 SEQ IDs: 2143 2144 2145 2146 2147 2148 2149 2150 2151 2152 SEQ IDs: 2153 2154 2155 2156 2162 2209 2246 2248 2310 2311 SEQ IDs: 2318 2319
Modification de l'ARNt
SEQ IDs: 13 132 158 168 169 171 496 638 705 852
SEQ IDs: 1144 1923 1944
Facteurs de traduction SEQ IDs: 358 607 707 782 783 989 1126 1895 1912 2065 SEQ IDs: 2128 2208 2317
TRANSPORT ET LIAISON DES PROTEINES
Général
SEQ IDs 11 74 104 262 263 269 270 271 285 286 SEQ IDs 287 318 319 333 334 544 545 579 580 672 SEQ IDs 673 729 855 881 888 889 917 983 984 1080 SEQ IDs 1121 1122 1203 1256 1311 1312 1366 1567 1602 1667 SEQ IDs 1787 1800 1801 1825 1826 1844 1926 2051 2052 2074 SEQ IDs 2157 2260 2261 2313 2321
Acides aminés, peptides et aminés
SEQ IDs: 70 115 330 331 352 353 354 355 356 357
SEQ IDs: 364 365 375 550 574 698 699 717 824 863
SEQ IDs: 864 955 956 957 1128 1182 1183 1184 1185 1330
SEQ IDs: 1496 1497 1750 1810 1811 1847 1848 1873 1888 1889 SEQ IDs: 1890 1891 1892 2087 2091 2107 2250
Anions
SEQ IDs: 52 308 309 310 1767 1768 1769 1770 1771 1772
Hydrates de Carbone, alcools organiques et acides
SEQ IDs 208 209 259 430 566 919 933 934 1282 1369 SEQ IDs 1370 1371 1530 1540 1541 1542 1548 1551 1671 1678 SEQ IDs 1683 1684 1685 1686 1733 1734 1735 2040 2104 2239
Cations
SEQ IDs 99 193 194 316 336 337 338 339 341 392 SEQ IDs 587 635 636 676 691 848 849 869 932 1194 SEQ IDs 1195 1295 1341 1355 1356 1357 1407 1528 1640 1655 SEQ IDs 1970 2058 2169 2170 2171 2305
Nucléosides, purines et pyrimidines
SEQ IDs: 896 1166 1651
Système PTS SEQ IDs: 23 25 121 122 180 422 423 425 437 630 SEQ IDs: 833 977 1149 1150 1505 1757 1758 1759
Résistance Multidrogue
SEQ IDs 81 82 127 130 160 244 314 389 621 679 SEQ IDs 721 722 726 927 1389 1561 1584 1682 2220 2221 SEQ IDs 2292
AUTRES CATEGORIES
Adaptations aux conditions atypiques SEQ IDs: 69 173 174 195 312 346 418 540 568 653 SEQ IDs: 654 686 912 970 971 1102 1170 1414 1570 2085
Sensibilité aux médicaments et analogues
SEQ IDs 1244 1860 2249
Fonctions relatives aux phages ; et prophages
SEQ IDs 27 28 29 30 31 32 33 34 35 36
SEQ IDs 37 38 39 40 41 42 43 44 45 46
SEQ IDs 47 48 49 446 447 448 449 450 451 452
SEQ IDs 453 454 455 456 457 458 459 460 461 462
SEQ IDs 463 464 465 466 467 468 469 470 471 472
SEQ IDs 473 474 475 476 477 478 479 480 481 482
SEQ IDs 483 484 485 486 487 488 489 490 491 492
SEQ IDs 493 494 514 515 516 517 518 519 520 521
SEQ IDs 522 523 524 525 526 527 528 529 531 532
SEQ IDs 533 534 1026 1027 1028 1029 1030 1031 1032 1033
SEQ IDs 1034 1035 1036 1037 1038 1039 1040 1041 1042 1043
SEQ IDs 1044 1045 1046 1047 1048 1049 1050 1051 1052 1053
SEQ IDs 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063
SEQ IDs 1064 1065 1066 1067 1068 1069 1070 1071 1072 1073
SEQ IDs 1074 1075 1076 1077 1200 1217 1416 1417 1418 1419
SEQ IDs 1420 1421 1422 1423 1424 1425 1426 1427 1428 1429
SEQ IDs 1430 1431 1432 1433 1434 1435 1436 1437 1438 1439
SEQ IDs 1440 1441 1442 1443 1444 1445 1446 1447 1448 1449
SEQ IDs 1450 1451 1452 1453 1454 1455 1456 1457 1458 1459
SEQ IDs 1460 1461 1462 1463 1464 1465 1466 1467 1468 1469
SEQ IDs 1470 1471 1472 1473 1474 1475 1647 1720 1998 2003
Fonctions relatives aux Transposons
SEQ IDs: 53 54 55 56 90 91 93 94 141 142 SEQ IDs: 143 144 145 146 378 379 380 381 614 649 SEQ IDs: 650 651 652 662 670 694 718 737 738 837 SEQ IDs: 838 839 841 842 950 1224 1225 1231 1232 1236 SEQ IDs: 1268 1286 1287 1342 1400 1560 1591 1741 1742 1749 SEQ IDs: 1936 1961 1986 1992 2060 2082 2083 2118 2129 2130 SEQ IDs: 2131 2132 2191 2201 2202 2203 2204 2240
Autres
SEQ IDs: 416 591 618 710 835 1153 1727 1822 1910 1931 SEQ IDs: 1953 2031
HYPOTHETIQUES
Général
SEQ IDs 17 18 50 57 58 60 78 79 80 84
SEQ IDs 87 88 92 113 114 116 124 125 133 134
SEQ IDs 139 140 148 149 150 157 159 161 162 170
SEQ IDs 172 175 176 179 183 184 185 188 189 196
SEQ IDs 197 214 230 231 232 233 234 235 236 238
SEQ IDs 247 255 258 264 266 267 268 274 277 279
SEQ IDs 283 288 289 293 294 298 299 300 315 317
SEQ IDs 321 323 325 332 343 344 366 367 369 370
SEQ IDs 371 372 373 376 377 384 387 388 399 404
SEQ IDs 409 410 411 420 433 436 438 443 444 498
SEQ IDs 499 503 510 512 546 549 553 555 556 557
SEQ IDs 558 569 582 583 588 589 592 594 597 599
SEQ IDs 611 625 637 655 671 678 688 700 701 703
SEQ IDs 704 708 725 727 730 735 741 749 756 759
SEQ IDs 762 763 764 765 769 774 780 798 799 800
SEQ IDs 803 809 810 811 819 827 830 840 850 861
SEQ IDs 865 880 882 883 884 891 899 900 913 920
SEQ IDs 924 951 963 964 965 986 987 999 1001 1004
SEQ IDs 1016 1019 1023 1078 1079 1090 1091 1094 1098 1100
SEQ IDs 1103 1104 1106 1109 1110 1115 1116 1117 1119 1124
SEQ IDs 1131 1137 1141 1147 1148 1155 1156 1160 1161 1168
SEQ IDs 1175 1187 1188 1201 1202 1204 1208 1209 1223 1242
SEQ IDs 1276 1277 1278 1280 1303 1313 1315 1316 1318 1319
SEQ IDs 1322 1340 1352 1358 1359 1363 1382 1391 1392 1393
SEQ IDs 1408 1409 1411 1412 1476 1486 1489 1491 1492 1493
SEQ IDs 1501 1518 1519 1520 1522 1523 1525 1529 1544 1547
SEQ IDs 1565 1577 1579 1581 1592 1595 1597 1605 1614 1619
SEQ IDs 1620 1622 1648 1658 1661 1662 1666 1669 1677 1694
SEQ IDs 1699 1701 1702 1709 1710 1711 1712 1718 1719 1722
SEQ IDs 1748 1760 1761 1762 1764 1765 1773 1774 1777 1780
SEQ IDs 1781 1782 1786 1788 1789 1802 1805 1809 1827 1828
SEQ IDs 1829 1832 1833 1838 1839 1840 1842 1843 1849 1855
SEQ IDs 1856 1863 1865 1866 1867 1868 1872 1874 1875 1876
SEQ IDs 1885 1886 1887 1900 1901 1903 1907 1915 1916 1917
SEQ IDs 1918 1919 1924 1930 1933 1938 1939 1940 1941 1946
SEQ IDs 1951 1952 1954 1958 1959 1963 1966 1967 1968 1976
SEQ IDs 1977 1978 1981 1982 2004 2006 2008 2011 2014 2015
SEQ IDs 2016 2017 2018 2019 2026 2029 2033 2044 2049 2050
SEQ IDs 2054 2061 2063 2070 2080 2081 2101 2102 2106 2108
SEQ IDs 2110 2115 2158 2163 2165 2168 2173 2174 2175 2184
SEQ IDs 2186 2190 2193 2194 2197 2210 2217 2219 2226 2227
SEQ IDs 2232 2235 2238 2245 2253 2254 2259 2272 2275 2278
SEQ IDs 2282 2284 2286 2289 2294 2295 2298 2302 2304 2308
SEQ IDs 2312 2322 2323
Conservées
SEQ IDs 16 66 67 73 77 108 109 111 112 252
SEQ IDs 391 432 505 509 511 559 581 593 598 604
SEQ IDs 612 640 642 647 702 733 734 736 739 750
SEQ IDs 752 758 776 777 778 802 820 826 874 876
SEQ IDs 897 901 910 922 952 954 961 979 980 981
SEQ IDs 996 1017 1093 1111 1118 1135 1196 1199 1250 1273
SEQ IDs 1320 1328 1377 1413 1562 1610 1705 1783 1804 1884
SEQ IDs 1897 1909 1922 2117 2199 2293
INCONNU! :s
Général
SEQ IDs 9 10 12 15 19 51 71 83 85 86
SEQ IDs 89 95 96 103 105 106 123 138 147 152
SEQ IDs 156 163 164 165 177 178 190 191 192 199
SEQ IDs 201 203 210 211 216 225 228 237 239 241
SEQ IDs 248 249 250 251 272 275 278 296 297 304
SEQ IDs 305 306 307 322 368 393 397 412 427 441
SEQ IDs 442 495 504 530 535 536 537 538 539 547
SEQ IDs 561 567 578 590 595 596 601 602 606 608
SEQ IDs 623 626 627 628 629 632 633 639 641 658
SEQ IDs 659 660 661 666 667 668 669 687 689 690
SEQ IDs 692 696 724 731 753 772 773 775 808 821
SEQ IDs 822 823 825 836 851 866 867 868 870 879
SEQ IDs 887 893 895 903 904 907 921 925 928 931
SEQ IDs 935 938 941 943 948 962 966 969 985 988
SEQ IDs 998 1003 1005 1006 1007 1008 1009 1010 1018 1021
SEQ IDs 1081 1082 1083 1085 1092 1095 1096 1101 1132 1133
SEQ IDs 1134 1136 1143 1154 1158 1163 1167 1180 1189 1190
SEQ IDs 1191 1192 1198 1206 1210 1218 1219 1220 1221 1222
SEQ IDs 1226 1227 1228 1229 1230 1234 1235 1253 1264 1269
SEQ IDs 1271 1272 1279 1285 1288 1305 1306 1309 1317 1334
SEQ IDs 1335 1337 1338 1339 1346 1347 1350 1351 1364 1365
SEQ IDs 1375 1378 1381 1385 1390 1394 1395 1396 1397 1398
SEQ IDs 1399 1401 1402 1403 1410 1415 1479 1484 1488 1495
SEQ IDs 1502 1503 1509 1510 1516 1535 1536 1571 1580 1582
SEQ IDs 1587 1588 1589 1590 1593 1594 1598 1608 1611 1616
SEQ IDs 1625 1626 1627 1628 1629 1630 1631 1632 1633 1634
SEQ IDs 1643 1645 1646 1653 1659 1660 1665 1672 1691 1698
SEQ IDs 1700 1703 1706 1713 1714 1715 1716 1736 1737 1738
SEQ IDs 1739 1740 1743 1744 1755 1799 1806 1812 1813 1821
SEQ IDs 1835 1836 1841 1862 1870 1877 1878 1880 1882 1896
SEQ IDs 1899 1905 1911 1913 1932 1942 1943 1945 1947 1949
SEQ IDs 1957 1965 1974 1975 1980 1987 1988 1989 1990 1991
SEQ IDs 1993 1994 1995 1996 1997 1999 2000 2002 2009 2010
SEQ IDs 2012 2013 2021 2023 2024 2046 2048 2053 2055 2064
SEQ IDs 2067 2072 2073 2075 2076 2077 2078 2086 2097 2099
SEQ IDs 2103 2111 2112 2113 2114 2116 2119 2121 2122 2141
SEQ IDs 2166 2181 2187 2188 2189 2195 2196 2212 2213 2214
SEQ IDs 2215 2223 2225 2228 2230 2231 2233 2234 2236 2237
SEQ IDs 2244 2252 2255 2256 2266 2268 2269 2271 2273 2274
TABLEAU III. Homologies des protéines de L.lactis IL1403 avec des protéines connues
SEQID Nom Identittéé Numéro Meilleur homologue d' accession
2 dnaA 95% 054375 dnaa; Lactococcus lactis
3 dnaN 97% 054376 dna polymérase iii, beta chain; Lactococcus lactis
4 rexB 87% 054377 exonuclease rexb; Lactococcus lactis
5 rexA 88% 054378 exonuclease rexa; Lactococcus lactis
6 yabA 68% 054379 hypothetical 21.4 kd protein; Lactococcus lactis
7 yyaL 99% 054380 putative gtp binding protein; Lactococcus lactis
8 yabB 39% Q46240 nanh gène & orfl,2,3 & 4; Clostridium perfringens
9 yabC putative
10 yabD putative
11 yabE 36% Q9ZHB1 hypothetical 24.0 kd protein; Streptococcus pneumoniae
12 yabF 31% Q47838 copa, copy and copz gènes; Enterococcus hirae
13 pth 52% 085235 hypothetical 19.6 kd protein; Lactobacillus sake
14 mfd 47% P37474 transcription-repair coupling factor; Bacillus subtilis
15 yacl putative
16 yacB 62% P37557 hypothetical 9.7 kd protein in mfd-divic intergenic région; Bacillus subtilis
17 yacC 30% P37471 cell division protein divic; Bacillus subtilis
18 yacD putative
19 yacG 21% 087489 beta-lactamase cef-1 precursor; Pseudomonas aeruginosa, and escherichia coli
20 esJ 99% Q48646 partial orf; Lactococcus lactis
21 hpt 87% Q02522 hypoxanthine-guanine phosphoribosyltransferase; Lactococcus lactis
22 ftsH 92% P46469 cell division protein ftsh homolog; Lactococcus lactis
23 mtlA 49% P50852 pts System, mannitol-specific iibc component (ec 2.7.1.6. Bacillus stearothermophilus
24 mtlR 36% Q02425 hypothetical protein in mtlf 5 'région; Streptococcus mutans
25 mtlF 71% Q02420 pts System, mannitol-specific iia component (eiii-mt. Streptococcus mutans
26 mtlD 61% Q02418 mannitol-1-phosphate 5-dehydrogénase; Streptococcus mutans
27 pslOl putative
28 psl02 49% 053060 hypothetical 16.9 kd protein; Lactococcus lactis
29 psl03 45% 003926 lactobacillus bacteriophage phigle complète genomic dna; Bacteriophage phigle
30 psl04 putative 31 psl05 45% Q9XJC9 putative primase; Streptococcus thermophilus bacteriophage dtl
32 psl06 25% Q38605 orfl; Streptococcus thermophilus bacteriophage sfilδ, and streptococcus thermophilus bacteriophage sfil9
33 psl07 putative 34 psl08 putative 35 psl09 putative 36 psllO putative 37 pslll putative 38 psll2 25% P33537 probable dna polymérase; Neurospora crassa
psll3 putative psll4 27% 034449 yoqd protein; Bacillus subtilis psll5 31% AAF12710 repressor protein; Bacteriophage tpw22 psll6 37% AAF12709 hypothetical 21.8 kd protein; Bacteriophage tpw22 psll7 putative psllδ putative psll9 putative psl20 putative psl21 putative psl22 33% Q00561 lactococcin a i munity protein; Lactococcus lactis , and lactococcus lactis psl23 27% Q38159 integrase; Bacteriophage t2 yafE 34% BAA77903 hypothetical 15.5 kd protein in dinp-rrfh intergenic région; ; Escherichia coli yafF putative yafB 25% P40877 hypothetical 58.4 kd protein in pth-prsa intergenic région; Escherichia coli yafG 100% 032786 hypothetical 21.3 kd protein; Lactococcus lactis tral077A 96% 032787 transposase; Lactococcus lactis tra904A 99% CAA55220 isl069 gène; Lactococcus lactis yafl 100% Q48713 dna for the transposon-like élément on the lactose plasmid; Lactococcus lactis yafJ putative yafC 34% CAB62759 putative acetyltransferase; Streptomyces coelicolor araT 97% AAF06954 aromatic amino acid a inotransferase; Lactococcus lactis yafD 29% P42095 hypothetical 29.3 kd protein in bex-dnag/dnae intergenic région; Bacillus subtilis pdhD 50% P11959 dihydrolipoamide dehydrogénase; Bacillus stearothermophilus pdhC 39% P11961 dihydrolipoamide acetyltransferase component of pyruvate dehydrogénase complex; Bacillus stearothermophilus pdhB 58% P21874 pyruvate dehydrogénase el component, beta subunit; Bacillus stearothermophilus pdhA 51% P21881 pyruvate dehydrogénase el component, alpha subunit; Bacillus subtilis lplL 38% 007608 hypothetical 38.0 kd protein; Bacillus subtilis yagA 34% 007592 hypothetical 27.5 kd protein; Bacillus subtilis yagB 32% P54168 hypothetical 23.1 kd protein in bsaa-ilvd intergenic région; Bacillus subtilis trpS 66% Q46127 tryptophanyl-trna synthetase; Clostridium longisporum osmC 49% , P23929 osmotically inducible protein c; Escherichia coli yagE 24% 026646 cationic amino acid transporter related protein; Methanobacterium thermoautotrophicum yahC putative plsX 42% P71018 fatty acid/phospholipid synthesis protein plsx homolog; Bacillus subtilis yahA 30% P75792 hypothetical protein 1; Escherichia coli yahG 61% 031716 ykpa protein; Bacillus subtilis cysD 55% Q9WZY4 o-acetylhomoserine sulfhydrylase; Ther otoga maritima yahl 33% Q9ZK 1 putative; Helicobacter pylori j 99 yahB 32% 026984 conserved protein; Methanobacterium thermoautotrophicum yahD 32% 034842 yolf; Bacillus subtilis
79 yaiA 32% 034689 ykca protein; Bacillus subtilis
80 yaiB 43% 005220 hypothetical protein ywrf; Bacillus subtilis
81 lcnC 89% Q00564 lactococcin a transport atp-binding protein lcnc; Lactococcus lactis
82 lcnD 93% Q00565 lactococcin a sécrétion protein lcnd; Lactococcus lactis , and lactococcus lactis
83 yaiE putative
84 yaiF 37% Q48724 abortive infection proteins gènes, complète cds; Lactococcus lactis
85 yail putative
86 yaiJ putative
87 yaiG 92% Q00565 lactococcin a sécrétion protein lcnd; Lactococcus lactis , and lactococcus lactis
88 yaiH 76% Q48724 abortive infection proteins gènes, complète cds; Lactococcus lactis
89 yajA putative
90 tra981A 92% Q48668 insertion séquence is981; Lactococcus lactis
91 yajE 100% Q48667 insertion séquence is981; Lactococcus lactis
92 yajF 28% Q48724 abortive infection proteins gènes, complète cds; Lactococcus lactis
93 tra981B 92% Q48668 insertion séquence is981; Lactococcus lactis
94 yajG 97% Q48667 insertion séquence is981; Lactococcus lactis
95 yajB putative
96 yajH putative
97 rp GB 100% 034102 50s ribosomal protein 133; Lactococcus lactis
98 rpmF 100% 034101 50s ribosomal protein 132; Lactococcus lactis
99 cadA 36% CAB53131 putative cation-transporting atpase; Streptomyceβ coelicolor
100 parA 50% 006671 spspoj ; Streptococcus pneumoniae
101 cshA 59% 034528 yrvn protein; Bacillus subtilis
102 ybaH 44% CAB51273 putative acetyltransferase; Streptomyces coelicolor
103 ybaA putative
104 ybaB 58% 034512 yfmm protein; Bacillus subtilis
105 ybaC putative
106 ybaD putative
107 pr A 44% BAA82791 orf35 protein; Listeria monocytogenes
108 ybaF 42% P54461 hypothetical 28.8 kd protein in dnaj-rpsu interegenic région; Bacillus subtilis
109 ybaG 37% P94361 homologous to swissprot : yade_ecoli; Bacillus subtilis
110 relA 67% Q54089 putative gtp pyrophosphokinase; Streptococcus equisimilis
111 ybal 37% Q45539 csbb protein; Bacillus subtilis
112 ybbA 71% Q54088 dexb, abc, lrp, skc, rel gènes and orfl; Streptococcus equisimilis
113 ybbB putative
114 ybbC 27% Q9WZA8 conserved hypothetical protein; Ther otoga maritima
115 ctrA 29% 007576 hypothetical 49.7 kd protein; Bacillus subtilis
116 ybbE 35% 007584 hypothetical 21.9 kd protein; Bacillus subtilis
117 rmaD 26% 034692 yvna; Bacillus subtilis
118 acpD 42% Q9X4K2 nadh dehydrogénase; Bacillus stearothermophilus
119 secA 56% P28366 preprotein translocase seca subunit; Bacillus subtilis
120 aroF 41% 054459 phospho-2-dehydro-3-deoxyheptonate aldolase, trp-sensitive (3-deoxy-d-arabino-he. Erwinia herbicola
121 ptsH 96% Q9ZAD9 histidine containing protein; Lactococcus lactis
122 ptsl 96% Q9zad8 phosphoénolpyruvate-protein phosphotransferase; Lactococcus lactis
123 ybcC putative
124 ybcG 38% Q9XAI3 hypothetical 11.7 kd protein; Streptomyces coelicolor
125 ybcH 27% CAB49187 hypothetical 2-acetyl-l-alkylglycerophosph ocholine esterase; Pyrococcus abyssi
126 sugE 46% P30743 suge protein; Escherichia coli
127 bit 40% P39843 multidrug résistance protein 2; Bacillus subtilis
128 argG 64% 034347 argininosuccinate synthase; Bacillus subtilis
129 argH 59% 034858 arginine succinate lyase; Bacillus subtilis
130 pmrB 43% BAA35851 probable intégral membrane protein; ; Escherichia coli
131 ybdA 35% P03039 tetracycline repressor protein class c; Escherichia coli
132 rnpA 48% BAA82683 rnpa protein; Bacillus sp
133 ybdC 40% 032298 spoiiij protein; Bacillus subtilis
134 ybdD 31% Q9X1H1 jag protein, putative; Thermotoga maritima
135 rpmH 77% P45647 50s ribosomal protein 134; Coxiella burnetii
136 ybdE 36% P42972 hypothetical oxidoreductase in pbpc-lrpc intergenic région; Bacillus subtilis
137 ybdG 35% 028481 hypothetical transcriptional regulator afl793; Archaeoglobus fulgidus
138 ybdH putative
139 ybdl 31% Q48724 abortive infection proteins gènes, complète cds; Lactococcus lactis
140 ybdJ 33% Q48724 abortive infection proteins gènes, complète cds; Lactococcus lactis
141 ybdK 100% Q48710 span gène encoding nisin and insertion séquence is904; Lactococcus lactis
142 tra904B 100% CAA55220 isl069 gène; Lactococcus lactis
143 ybdL 99% 032786 hypothetical 21.3 kd protein; Lactococcus lactis
144 tral077B 97% 032787 transposase; Lactococcus lactis
145 tra904C 100% CAA55220 isl069 gène; Lactococcus lactis 146 ybeG 100% Q48710 span gène encoding nisin and insertion séquence is904; Lactococcus lactis
147 ybeA putative
148 ybeB 53% 034634 hypothetical 15.2 kd protein in udk-alas intergenic région; Bacillus subtilis
149 ybeC 46% 034828 yrzb protein; Bacillus subtilis
150 ybeH 17% AAF10767 hypothetical 23.9 kd protein; Deinococcus radiodurans
151 cbr 28% P48758 carbonyl réductase [nadph] ; Mus musculus
152 ybel putative
153 ybeE 32% CAB53277 putative oxidoreductase; Streptomyces coelicolor
154 ybeD 43% 067157 transcriptional regulator; Aquifex aeolicus
155 glgB 47% P30924 1, 4-alpha-glucan branching enzyme; Solanum tuberosum
156 ybeM putative
157 ybeF 21% Q9X3M7 fibronectin-binding protein i; Streptococcus pyogenes
158 tgt 71% 032053 queuine trna-ribosyltransferase; Bacillus subtilis
159 ybfA 29% Q06073 hypothetical 25.7 kd protein in cytochrome p450meg gène 5 'région; Bacillus megaterium
160 ybfD 30% P94577 hypothetical 43.1 kd protein; Bacillus subtilis
161 ybfE 47% Q45065 ynet; Bacillus subtilis
162 ybfB 25% 033735 streptodornase; Streptococcus pyogenes
163 ybfC putative
164 ybgA putative
165 ybgB putative
166 aspC 63% P71348 probable aminotransferase hi0286; Haemophilus influenzae
167 codY 48% P39779 cody protein; Bacillus subtilis
168 gatC 45% 006492 glutamyl-trna amidotransferase subunit c; Bacillus subtilis
169 gatA 58% 006491 glutamyl-trna amidotransferase subunit a; Bacillus subtilis
170 ybgD 43% Q9ZHC2 mutt; Streptococcus pneumoniae
171 gatB 62% Q45486 petll2-like protein; Bacillus subtilis
172 ybgE 28% AAF09821 6-aminohexanoate-cyclic-dimer hydrolase; Deinococcus radiodurans
173 dinF 34% 033729 dinf protein; Streptococcus pneumoniae
174 cspE 98% Q9ZAG9 cold shock protein e; Lactococcus lactis
175 ybhA 41% 066124 hypothetical protein; Streptococcus mutans 176 ybhB 32% 059166 197aa long hypothetical protein; Pyrococcus horikoshii
177 ybhC putative
178 ybhD putative
179 ybhE 40% 050983 outer surface protein, putative; Borrelia burgdorferi
180 celB 30% P17334 pts System, cellobiose-specific iic component; Escherichia coli
181 bglS 59% P42403 probable beta-glucosidase; Bacillus subtilis 182 dut 52% Q38106 dutpase; Bacteriophage rit 183 ybiB 33% 032133 yund protein; Bacillus subtilis 184 ybiC 53% 032127 yutd protein; Bacillus subtilis 185 ybiD 54% 034617 hypothetical 41.6 kd protein in fmt-spovm intergenic région; Bacillus subtilis
186 ybiE 32% Q50261 this orf is homologous to nitroreductase from enterobacter cloacae; Phytoplasma sp
187 preA 30% P31114 probable heptaprenyl diphosphate synthase component ii; Bacillus subtilis
188 ybiG 21% P39582 probable 1, 4-dihydroxy-2-naphthoate octaprenyltransferase; Bacillus subtilis
189 ybiH 46% P71468 plni; Lactobacillus plantarum 190 ybil putative 191 ybiJ putative 192 ybiK putative 193 feoB 36% 027414 ferrous iron transport protein b; Methanobacterium thermoautotrophicum
194 feoA 42% 027415 hypothetical 8.2 kd protein; Methanobacterium thermoautotrophicum
195 ybjA 65% Q9XB39 csrl4 protein; Enterococcus faecalis
196 ybjJ 43% 034751 ylov protein; Bacillus subtilis
197 ybjK 41% 034318 ylou protein; Bacillus subtilis
198 rpmB 56% P37807 50s ribosomal protein 128; Bacillus subtilis
199 ybjB putative
200 rmlA 90% 054574 glucose-1-phosphate thymidyl transferase; Streptococcus pneumoniae
201 ybjD putative
202 cpsM 88% P97005 dtdρ-4-keto-6-deoxyglucose-3, 5-epimerase; Streptococcus pneumoniae
203 ybjF putative
204 rmlB 75% AAC78676 dtdp-glucose-4 , 6-dehydratase cpsl9an; Streptococcus pneumoniae
205 rmlC 72% AAC78677 dtdp-1-rhamnose synthase cpsl9ao; Streptococcus pneumoniae
206 rgpA 54% 082873 rgpac protein; Streptococcus mutans 207 rgpB 53% 082874 rha nosyltransferase; Streptococcus mutans 208 rgpC 46% 082875 abc-transporter; Streptococcus mutans
209 rgpD 70% 082876 abc-transporter; Streptococcus mutans
210 ycaF putative
211 ycaG putative
212 rgpE 34% 006035 epsg protein; Lactococcus lactis
213 rgpF 52% 082878 rgpfc protein; Streptococcus mutans
214 ycbA 23% 005375 unnamed protein product; Actinobacillus actinomycetemcomitans
215 ycbB 52% 088085 putative glycosyl transferase; Enterococcus faecalis
216 ycbC putative
217 ycbD 40% CAB49227 udp-glucose 4-epimerase; Pyrococcus abyssi
218 ycbK 18% 032273 tuab protein; Bacillus subtilis
219 ycbF 25% Q08918 chromosome xvi reading frame orf ypll75w; Saccharomyces cerevisiae
220 ycbG 32% Q9X4D4 licdl; Streptococcus pneumoniae
221 ycbH 34% 085000 galactosyl transferase; Streptococcus pneumoniae
222 ycbl 30% Q57022 putative glycosyl transferase hi0868; Haemophilus influenzae
223 ycbJ 30% P37965 glycerophosphoryl diester phosphodiesterase; Bacillus subtilis
224 tagDl 55% 005155 tagd; Staphylococcus aureus
225 yccB 40% 066077 putative extracellular protein exp3 precursor; Lactococcus lactis
226 guaB 83% P50099 inosine-5 ' -monophosphate dehydrogénase; Streptococcus pyogenes
227 yqeL 51% P54453 hypothetical 41.0 kd protein in nucb-arod intergenic région; Bacillus subtilis
228 yccE putative
229 hflX 54% P94478 ynba; Bacillus subtilis
230 yccF 44% P54454 hypothetical 10.8 kd protein in arod-comer intergenic région; Bacillus subtilis
231 yccG 34% P54455 hypothetical 22.2 kd protein in arod-comer intergenic région; Bacillus subtilis
232 yccH 37% P54456 hypothetical 21.3 kd protein in arod-comer intergenic région; Bacillus subtilis
233 yccl 29% P16691 phno protein; Escherichia coli
234 yccJ 41% P54457 hypothetical 13.3 kd protein in arod-comer intergenic région; Bacillus subtilis
235 yccK 40% P54458 hypothetical 28.3 kd protein in arod-comer intergenic région; Bacillus subtilis
236 yccL 41% Q58361 hypothetical protein mj0951; Methanococcus jannaschii
237 ycdA putative
238 ycdB 94 % P76351 hypothetical 25.9 kd protein in amn-cbl intergenic regiion; Escherichia coli
239 ycdC putative
240 ung 54 Q9XDS 8 uracil dna glycosylase; Streptococcus agalactiae
241 ycdE putative
242 ycdG putative
243 ycdF 36% CAB58281 putative tetr family transcriptional regulator; Streptomyces coelicolor
244 ycdH 27% 032182 yusp protein; Bacillus subtilis
245 ycdl 38% P4 4 617 hypothetical transcriptional regulator hi0293; Haemophilus influenzae
246 rpsU 83% BAA82793 30s ribosomal protein s21; Listeria monocytogenes
247 ycdJ putative 248 yceA putative 249 yceB putative
250 yceC putative 251 yceD putative 252 yceE 29% Q9WZB9 conserved hypothetical protein; Thermotoga maritima
253 pgk 57% Q9Z5C4 phosphoglycérate kinase; Staphylococcus aureus
254 dhaK 37% 004059 putative 3, 4-dihydroxy-2-butanone kinase; Lycopersicon esculentum
255 yceG 41% 053054 hypothetical transcriptional regulator in inlc 3 'région; Listeria ivanovii
256 dhaL 41% P76015 hypothetical 24.0k protein; Escherichia coli 257 dhaM 37% P76014 orf o246#l; Escherichia coli 258 yceJ 32% AAF12590 conserved hypothetical protein; Deinococcus radiodurans
259 glpFl 47% P52281 glycerol uptake facilitator protein; Streptococcus pneumoniae
260 pepDA 55% Q48558 dipeptidase; Lactobacillus helveticus
261 ycfA 45% 008306 30s ribosomal protein s21; Nocardioides simplex
262 ycfB 39% 029256 abc transporter, atp-binding protein; Archaeoglobus fulgidus
263 ycfC 36% 033188 hypothetical 24.4 kd protein; Mycobacterium tuberculosis
264 ycfD 44% P39587 hypothetical 44.4 kd protein in epr-galk intergenic région; Bacillus subtilis
265 fbp 52% Q45597 function unknown; Bacillus subtilis
266 ycfF 50% 030505 ytfp; Bacillus subtilis
267 ycfG 43% P96051 hypothetical 29.9 kd protein in fold-pbp2b intergenic région; Streptococcus thermophilus
268 ycfH 48% Q10845 hypothetical 18.2 kd protein cy39.05c; Mycobacterium tuberculosis
269 ycfl 34% Q11046 hypothetical abc transporter atp-binding protein rvl273c; Mycobacterium tuberculosis
270 ycgA 26% Q9WYC4 abc transporter, atp-binding protein; Thermotoga maritima
271 ycgB 50% Q11047 hypothetical abc transporter atp-binding protein cy50.10; Mycobacterium tuberculosis
272 ycgC 30% Q9ZL99 putative; Helicobacter pylori j99
273 ycgD 43% P46853 hypothetical oxidoreductase in gntr-ggt intergenic région; Escherichia coli
274 ycgE 47% AAF11932 conserved hypothetical protein; Deinococcus radiodurans
275 ycgF putative
276 ycgG 49% P22045 probable réductase; Leishmania major
277 ycgH 31% Q9ZF59 nicotinamidase/pyrazinamidase; Mycobacterium smegmatis
278 ycgl 25% 053298 hypothetical 45.8 kd protein; Mycobacterium tuberculosis 79 ycgJ 90% Q48604 hypothetical 11.3 kd protein; Lactococcus lactis 80 acmA 65% Q48603 n-acetylmuramidase precursor; Lactococcus lactis 81 nrdD 95% Q9ZAX6 anaérobie ribonucleotide réductase; Lactococcus lactis 82 nrdG 87% Q9ZAX5 anaérobie ribonucleotide réductase activator protein; Lactococcus lactis 83 ychC 45% Q9ZAX4 hypothetical 7.3 kd protein; Lactococcus lactis 84 enoB 91% 052191 enolase; Streptococcus thermophilus 85 ychD 57% 087533 abc transporter atp-binding protein; Streptococcus pyogenes 86 ychE 53% P70970 hypothetical 30.6 kd protein; Bacillus subtilis 87 ychF 44% P70972 ybaf protein; Bacillus subtilis 88 ychG putative
289 ychH 43% Q9X1K7 2,3,4, 5-tetrahydropyridine-2-carboxylate n- succinyltransferase-related protein; Thermotoga maritima
290 yciA 44% 034916 ykur protein; Bacillus subtilis
291 xynD 40% P04339 chitooligosaccharide deacetylase; Rhizobium leguminosarum
292 rpsD 66% P21466 30s ribosomal protein s4; Bacillus subtilis
293 yciC 44% Q51152 hypothetical 83.1 kd protein in région e;
Neisseria meningitidis
294 yciD 42% P96628 ydck protein; Bacillus subtilis
295 add 31% Q9X7T2 putative adenosine deaminase; Streptomyces coelicolor
296 yciF putative
297 yciG putative
298 yciH 60% Q45493 hypothetical 61.5 kd protein in adec-pdha intergenic région; Bacillus subtilis
299 ycjA 32% 031718 ykzg protein; Bacillus subtilis
300 ycjB 32% 005516 h. influenzae hypothetical protein; Bacillus subtilis
301 ycjC 36% 005517 h. influenzae; Bacillus subtilis
302 ycjD 37% 005517 h. influenzae; Bacillus subtilis
303 gcp 54% 005518 hypothetical 36.8 kd protein in phob-groes intergenic région; Bacillus subtilis
304 ycjF putative
305 ycjG putative
306 ycjH putative
307 ycjl putative
308 phnC 40% 069063 atpase component htxd; Pseudomonas stutzeri
309 phnB 33% 069053 ptxc; Pseudomonas stutzeri
310 phnE 37% 069053 ptxc; Pseudomonas stutzeri
311 ycjM 26% P44764 2 ' , 3 ' -cyclic-nucleotide 2 ' -phosphodiesterase precursor; Haemophilus influenzae
312 tpx 40% P80864 probable thiol peroxidase; Bacillus subtilis
313 pepN 96% P37897 aminopeptidase n; Lactococcus lactis
314 napC 49% 032603 napc protein; Enterococcus hirae
315 napB 39% 032602 napb protein; Enterococcus hirae
316 ydaE 43% P46348 hypothetical 31.8 kd protein in gabp-guaa intergenic région; Bacillus subtilis
317 ydaF 36% P39044 30s ribosomal protein sl4 homolog; Bacillus sphaericus
318 ydaG 38% Q9 YC3 abc transporter, atp-binding protein; Thermotoga maritima
319 ydbA 58% Q9ZIC7 abc transporter homolog z; Listeria monocytogenes
320 urAl 55% P19670 probable udp-n-acetylglucosamine 1- carboxyvinyltransferase; Bacillus subtilis
321 ydbC 46% 083371 hypothetical protein tp0352; Treponema pallidum
322 ydbD putative
323 ydbE 34% 057898 162aa long hypothetical protein; Pyrococcus horikoshii
324 ydbF 37% P36922 ebsc protein; Enterococcus faecalis
325 ydbH 34% 032074 yuaj protein; Bacillus subtilis
326 plpA 56% CAB59827 hypothetical 32.0 kd protein; Lactococcus lactis
327 plpB 61% CAB59827 hypothetical 32.0 kd protein; Lactococcus lactis
328 plpC 89% CAB59825 hypothetical 31.6 kd protein; Lactococcus lactis
329 plpD 94% CAB59827 hypothetical 32.0 kd protein; Lactococcus lactis
330 ydcB 95% CAB59828 hypothetical 41.0 kd protein; Lactococcus lactis
331 ydcC 65% CAB59829 hypothetical 24.8 kd protein; Lactococcus lactis
332 ydcD 90% CAB59830 hypothetical 19.4 kd protein; Lactococcus lactis
333 ydcE 37% 059479 284aa long hypothetical cobalt transport atp- binding protein; Pyrococcus horikoshii
334 ydcF 24% Q50292 hypothetical protein mgl81 homolog; Mycoplasma pneumoniae
335 ydcG 50% Q57720 hypothetical transcriptional regulator mj0272; Methanococcus jannaschii
336 fhuC 43% Q9X665 fhua; Staphylococcus aureus
337 fhuB 25% P49936 ferrichrome transport permease protein fhub; Bacillus subtilis
338 fhuG 32% P49937 ferrichrome transport permease protein fhug; Bacillus subtilis
339 fhuD 32% P54941 probable abc transporter binding protein in idh- deor intergenic région precursor; Bacillus subtilis
340 fhuR 31% CAB36982 epsy protein; Streptococcus agalactiae
341 yddA 45% 034367 ytbd; Bacillus subtilis
342 yddB 54% 032210 yvgn protein; Bacillus subtilis
343 yddC 61% 034533 hypothetical 14.5 kd protein in gapb-mutm intergenic région; Bacillus subtilis
344 yddD hypothetical 14.8 kd protein in tdk-prfa intergenic région; Bacillus subtilis
345 pmg 86% Q9X9S2 phosphoglyceromutase; Streptococcus pneumoniae 346 aphC 70% P80239 alkyl hydroperoxide réductase c22 protein; Bacillus subtilis
347 ahpF 61% P42974 nadh dehydrogénase; Bacillus subtilis 348 pbp2B 45% P10524 penicillin-binding protein 2b; Streptococcus pneumoniae
349 recM 78% Q9ZHC4 recra; Streptococcus pneumoniae 350 ddl 63% 054631 d-ala-d-ala ligase; Streptococcus pneumoniae 351 murF 59% Q9ZHC3 d-ala-d-ala adding enzyme; Streptococcus pneumoniae
352 optS 42% Q9Z692 hyaluronate-associated protein precursor; Streptococcus equi
353 optA 45% Q9Z692 hyaluronate-associated protein precursor; Streptococcus equi
354 optB 41% 031598 oligopeptide abc transporter; Bacillus subtilis 355 optC 39% P94895 transport System permease homolog; Listeria monocytogenes
356 optD 62% P24136 oligopeptide transport atp-binding protein oppd; Bacillus subtilis
357 optF 57% 031599 oligopeptide abc transporter; Bacillus subtilis 358 prfC 57% 086490 peptide chain release factor 3; Staphylococcus aureus
359 rheA 59% Q9Z6C9 autoaggregation-mediating protein; Lactobacillus reuteri
360 eraL 77% Q9XDG9 gtpase era; Streptococcus pneumoniae
361 asnB 38% Q61024 asparagine synthetase; Mus usculus
362 mutM 89% P42371 formamidopyrimidine-dna glycosylase; Lactococcus lactis
363 recA 93% Q01840 reca protein; Lactococcus lactis
364 ydgB 39% P96704 hypothetical transport protein in expz-dinb intergenic région; Bacillus subtilis
365 ydgC 40% 006005 amino acid permease aapa; Bacillus subtilis
366 ydgD 25% 034412 ylbf protein; Bacillus subtilis
367 ydgE putative
368 ydgG putative
369 ydgF 29% 031609 yjbk protein; Bacillus subtilis
370 ydgH 32% 034535 yoat; Bacillus subtilis
371 ydgl 53% 031611 yjbm protein; Bacillus subtilis
372 ydgJ 43% 031612 yjbn protein; Bacillus subtilis
373 ydgK 42% 031613 hypothetical 31.5 kd protein in meca-tena intergenic région; Bacillus subtilis
374 ppiA 39% 074942 peptidyl prolyl cis/trans isomérase; Schizosaccharomyces pombe
375 lysQ 47% P25737 lysine-specific permease; Escherichia coli
376 ydhB 31% P31465 hypothetical 20.4 kd protein in tnab-bglb intergenic région; Escherichia coli
377 ydhC 30% 083774 thiamine biosynthesis lipoprotein apbe precursor; Treponema pallidum
378 y hD 100% Q48713 dna for the transposon-like élément on the lactose plasmid; Lactococcus lactis
379 tra904D 99% CAA55220 isl069 gène; Lactococcus lactis
380 ydhE 99% 032786 hypothetical 21.3 kd protein; Lactococcus lactis
381 tral077C 98% 032787 transposase; Lactococcus lactis
382 lysS 65% P37477 lysyl-trna synthetase; Bacillus subtilis
383 rlrG 29% 067145 transcriptional regulator; Aquifex aeolicus
384 ydhF 27% P33019 hypothetical 36.9 kd protein in lysp-nfo intergenic région; Escherichia coli
385 ldhB 53% P13714 1-lactate dehydrogénase; Bacillus subtilis
386 rlrD 29% 067145 transcriptional regulator; Aquifex aeolicus
387 ydiA 23% Q58172 hypothetical protein mj0762; Methanococcus jannaschii
388 ydiB 49% 034595 probable thiamine biosynthesis protein thii; Bacillus subtilis
389 ydiC 27% Q00538 methylenomycin a résistance protein; Bacillus subtilis
390 ydiD 39% Q9X4K2 nadh dehydrogénase; Bacillus stearothermophilus
391 ydiE 56% 031790 ymad protein; Bacillus subtilis
392 ydiF 29% P32703 putative na/h exchanger yjce; Escherichia coli
393 ydiG putative
394 tyrS 53% P22326 tyrosyl-trna synthetase 1; Bacillus subtilis
395 pbplB 48% 070038 penicillin-binding protein lb; Streptococcus pneumoniae
396 pepA 93% Q48677 glutamyl-aminopeptidase; Lactococcus lactis
397 ydjB putative
398 trxH 95% Q48676 pepa gène; Lactococcus lactis
399 ydjD 45% 034943 ytpr; Bacillus subtilis
400 noxE 51% 083891 nadh oxidase; Treponema pallidum
401 ssbA 49% Q9XJE5 putative single stranded binding protein; Bacteriophage tuc2009
402 groES 84% P37283 10 kd chaperonin; Lactococcus lactis
403 groEL 94% P37282 60 kd chaperonin; Lactococcus lactis
404 yeaA 50% Q45611 function unknown; Bacillus subtilis
405 kinC 88% 007384 histidine kinase; Lactococcus lactis
406 IrrC 87% 086269 arca protein; Lactococcus lactis
407 yeaB 49% P37537 thymidylate kinase; Bacillus subtilis
408 holB 34% 067707 dna polymérase iii gamma subunit; Aquifex aeolicus
409 yeaC 37% P37541 hypothetical 31.2 kd protein in xpac-abrb intergenic région; Bacillus subtilis
410 yeaD 29% P37542 hypothetical 14.1 kd protein in xpac-abrb intergenic région; Bacillus subtilis
411 yeaE 48% P37544 hypothetical 33.0 kd protein in xpac-abrb intergenic région; Bacillus subtilis
412 yeaF putative
413 yeaG 32% 059291 335aa long hypothetical protein; Pyrococcus horikoshii
414 yeaH 28% P32377 diphosphomevalonate décarboxylase; Saccharomyces cerevisiae
415 yebA 26% 027995 mevalonate kinase; Archaeoglobus fulgidus
416 yebB 84% Q48601 hypothetical 15.1 kd protein; Lactococcus lactis
417 sodA 92% P50911 superoxide dismutase [mn] ; Lactococcus lactis
418 CStA 47% P95095 carbon starvation protein a homolog;
Mycobacterium tuberculosis
419 rheB 48% P54475 probable rna helicase in ccca-soda intergenic région; Bacillus subtilis
420 yebE 32% 007474 gdmh; Staphylococcus gallinarum
421 yebF 29% Q9X0V5 transcriptional regulator, rpir family;
Thermotoga maritima
422 ptcB 52% P46318 pts system, cellobiose-specific iib component;
Bacillus subtilis
423 ptcA 43% P46319 pts system, cellobiose-specific iia component
(eiii-c. Bacillus subtilis
424 yecA 25% Q9ZB19 hypothetical 27.6 kd protein; Lactococcus lactis
425 ptcC 34% P39584 hypothetical 47.6 kd protein in epr-galk intergenic région; Bacillus subtilis
426 bglA 63% P42973 6-phospho-beta-glucosidase; Bacillus subtilis
427 yecD putative
428 ligA 52% 031498 yerg protein; Bacillus subtilis
429 yecE 50% 031502 yerq protein; Bacillus subtilis
430 rasmK 73% Q00752 multiple sugar-binding transport atp-binding protein msmk; Streptococcus mutans
431 nifJ 55% Q9X716 pyruvate ferredoxin oxidoreductase; Clostridium pasteurianum
432 yedA 48% P47351 hypothetical protein mgl05; Mycoplasma genitalium
433 yedB 28% Q9ZAI5 hypothetical 34.6 kd protein; Staphylococcus aureus
434 femD 59% 034824 ybbt protein; Bacillus subtilis
435 rgrA 40% P39796 trehalose opéron transcriptional repressor; Bacillus subtilis
436 yedE 43% P12655 pts system, sucrose-specific iiabc component (e. Streptococcus mutans
437 yedF 90% Q9ZAG2 hypothetical 35.3 kd protein; Lactococcus lactis
438 yeeA 99% Q9ZAG0 hypothetical 87.3 kd protein; Lactococcus lactis
439 pgmB 99% P71447 beta-phosphoglucomutase; Lactococcus lactis
440 yeeB 27% P26223 endo-1, 4-beta-xylanase b; Butyrivibrio fibrisolvens
441 yeeC putative
442 yeeD putative
443 yeeE 43% 005515 hypothetical 17.9 kd protein in phob-groes intergenic région; Bacillus subtilis
444 yeeF 31% Q9 Z46 conserved hypothetical protein; Thermotoga maritima
445 yeeG 27% P96499 putative transcriptional regulator; Bacillus subtilis
446 pilOl 39% Q38325 integrase; Lactococcus lactis phage bk5-t
447 pil02 66% Q38183 orf 3; Bacteriophage tρ901-l
448 pil03 97% Q38089 repressor protein; Bacteriophage rit
449 pil04 94% Q38328 cro repressor protein; Lactococcus lactis phage bk5-t
450 pil05 putative
451 pil06 putative
452 pil07 100% Q38090 integrase, repressor protein , dutpase, holin and lysin gènes, complète cds; Bacteriophage rit
453 pil08 40% P44189 hypothetical protein hil418; Haemophilus influenzae
454 pil09 75% Q38092 orf6; Bacteriophage rit 455 pillO 96% Q38094 orf8; Bacteriophage rit 456 pilll 45% CAB53838 putative recombinase; Bacteriophage all8 457 pill2 putative 458 pill3 52% Q9XJE6 putative replisome organiser protein; Bacteriophage tuc2009
459 pill4 36% 003914 zinc finger protein; Bacteriophage phigle
460 pill5 putative
461 pill6 43% Q9XJF1 hypothetical 22.4 kd protein; Bacteriophage tuc2009
462 pill7 putative
463 pill8 putative
464 pil!9 72% Q9XJF3 hypothetical 14 kd protein; Bacteriophage tuc2009
465 pil20 97% Q38106 dutpase Bacteriophage rit 466 pil21 putative 467 pil22 putative 468 pil23 putative 469 pil24 putative 470 pil25 putative 471 pil26 85% 053058 hypothetical 11.0 kd protein Lactococcus lactis
472 pil27 41% 034051 orf20; Streptococcus thermophilus
473 pil28 32% 053058 hypothetical 11.0 kd protein; Lactococcus lactis
474 pil29 40% Q05277 gène 64 protein; Mycobacteriophage 15
475 pil30 putative
476 pil31 68% 053060 hypothetical 16.9 kd protein; Lactococcus lactis
477 pil32 putative
478 pil33 45% Q9XJ95 hypothetical 17.4 kd protein; Streptococcus thermophilus bacteriophage dtl
479 pil34 37% Q9XJ75 orf623 gp; Streptococcus thermophilus bacteriophage sfi21
480 pil35 31% CAB52519 hypothetical 43.3 kd protein; Lactobacillus bacteriophage phi adh
481 pil36 36% Q9ZXF7 orf26; Bacteriophage phi-105
482 pil37 24% 080046 capsid protein; Bacteriophage phi pvl
483 pil38 putative
484 pil39 33% 064288 hypothetical 13.5 kd protein; Streptococcus thermophilus bacteriophage sfil9
485 pil40 42% Q38219 orfa; Bacteriophage 110
486 pil41 31% Q38220 orfi; Bacteriophage 110
487 pil42 46% 036159 s all major structural protein; Streptococcus phage phi7201
488 pil43 putative
489 pil44 40% P45931 hypothetical 171.0 kd protein in spoiiic-cwla intergenic région; Bacillus subtilis
490 pil45 38% Q38318 orf 10; Lactococcus lactis phage bk5-t 491 pil46 51% Q38319 orf1904; Lactococcus lactis phage bk5-t 492 pil47 putative 493 pil48 98% Q38322 orf95; Lactococcus lactis phage bk5-t 494 pil49 97% Q38323 orf259; Lactococcus lactis phage bk5-t 495 yeiD putative 496 truA 43% Q9Z9J0 trua protein; Bacillus sp
497 thiD2 37% 023128 probable thiamin biosynthetic enzyme;
Arabidopsis thaliana
498 yeiE 33% P20298 hypothetical protein in gapdh 3 'région;
Pyrococcus woesei
499 yeiF 44% P39157 hypothetical 19.4 kd protein in spoiir-glyc intergenic région; Bacillus subtilis
500 yeiG 35% Q59569 aspartate aminotransferase; Methanobacterium thermoformicicum
501 pyrG 94% 087761 ctp synthetase; Lactococcus lactis
502 hicD 38% P14295 1-2-hydroxyisocaproate dehydrogénase ;
Lactobacillus confusus
503 yejC 36% 086314 hypothetical 20.4 kd protein; Mycobacterium tuberculosis
504 yejD 27% G1017854 nucleoside 2-deoxyribosyltransferase=ntd product
{ec 2.4.2.6}; Escherichia coli
505 yejE 29% 006986 hypothetical 21.1 kd protein; Bacillus subtilis
506 dgk 62% Q59484 bifunctional deoxy-adenosine/guanosine kinase subunit 2 [includes: deoxyguanosine kinase ; deoxyadenosine kinase ] ; Lactobacillus acidophilus
507 dnaE 33% 034623 dna polymérase iii, alpha chain; Bacillus subtilis
508 hly 38% P54176 hemolysin iii; Bacillus cereus
509 yejH 39% Q53667 hypothetical 21.2 kd protein; Staphylococcus aureus
510 yejl 44% P96043 hypothetical 31.7 kd protein; Streptococcus thermophilus
511 yejj 31% 082840 beta-n-acetylglucosaminidase precursor;
Streptomyces thermoviolaceus
512 yfaA 34% P54179 hypothetical 21.1 kd protein in ilva 3 'région;
Bacillus subtilis
513 hslA 78% Q9XB20 histone-like dna-binding protein; Streptococcus gordonii
514 ps201 33% 054477 integrase; Staphylococcus aureus
515 ps202 putative
516 ps203 putative
517 ps204 36% AAF12709 hypothetical 21.8 kd protein; Bacteriophage tp 22
518 ps205 53% AAF12710 repressor protein; Bacteriophage tpw22
519 ps206 40% CAB52490 hypothetical 7.4 kd protein; Lactobacillus bacteriophage phi adh
520 ps207 50% Q54879 excisionase; Streptococcus pneumoniae
521 ps208 putative
522 ps209 putative
523 ps210 putative
524 ps211 putative
525 ps212 putative
526 ps213 putative
527 ps214 putative
528 ps215 32% 054471 orfll; Staphylococcus aureus
529 ps216 putative
530 yfbB putative
531 ps218 putative
532 ps219 37% Q9ZXB1 gp35; Bacteriophage phi-c31
533 ps220 putative
534 ps221 putative
535 yfbG putative
536 yfbH putative
537 yfbl putative
538 yfbJ putative
539 yfbK putative
540 cspD 93% Q9ZAH0 cold shock protein d; Lactococcus lactis 541 yfbM 29% 032075 yuai protein; Bacillus subtilis 542 ogt 48% Q9ZBT7 putative methylated-dna-protein-cysteine methyltransferase; Streptomyces coelicolor
543 adaA 42% P19219 methylphosphotriester-dna alkyltransferase; Bacillus subtilis
544 yfcA 37% P08720 nodulation atp-binding protein i; Rhizobium leguminosarum
545 yfcB putative 546 yfcC 27% Q9 WI2 alginate biosynthesis regulatory protein; Pseudomonas syringae
547 yfcD putative 548 yfcE 53% P31672 nifs protein homolog; Lactobacillus delbrueckii 549 yfcF 38% 006969 hypothetical 51.0 kd protein; Bacillus subtilis 550 yfcG 93% CAB61245 lipoprotein precursor; Lactococcus lactis 551 cysM 66% BAA88310 o-acetylserine lyase; Streptococcus suis 552 yfcH 35% P37710 autolysin; Enterococcus faecalis 553 yfcl 45% P54501 hypothetical 23.2 kd protein in soda-comga intergenic région; Bacillus subtilis
554 ponA 53% Q00573 penicillin-binding protein la; Streptococcus oralis
555 yfdA 72% Q00579 hypothetical 23.1 kd protein in pona 5'region; Streptococcus oralis
556 yfdB 40% P50838 hypothetical 21.1 kd protein in cotd-kdud intergenic région; Bacillus subtilis
557 yfdC 57% 031602 yjbd protein; Bacillus subtilis 558 yfdD 44% Q45497 hypothetical 10.5 kd protein; Bacillus subtilis 559 yfdE 37% Q45499 extragenic suppressor protein suhb homolog; Bacillus subtilis
560 murA2 55% P70965 udp-n-acetylglucosamine 1- carboxyvinyltransferase; Bacillus subtilis
561 yfdG putative 562 tig 63% 085730 ropa; Streptococcus pyogenes 563 dnaG 96% Q04505 dna primase; Lactococcus lactis 564 rpoD 96% Q04506 rna polymérase sigma factor rpod; Lactococcus lactis
565 yfeA 35% Q9ZB19 hypothetical 27.6 kd protein; Lactococcus lactis
566 glpT 91% Q48705 hexose phosphate transport; Lactococcus lactis 567 yffA putative 568 clpE 94% AAD01782 clpe; Lactococcus lactis 569 yffB 96% Q48660 hypothetical 17.4 kd protein in clpa-gap intergenic région; Lactococcus lactis
570 gapA 97% P52987 glyceraldehyde 3-phosphate dehydrogénase; Lactococcus lactis
571 def 99% Q48661 orf211; Lactococcus lactis 572 yffD 45% Q9ZJZ8 putative dgtp pyrophosphohydrolase; Helicobacter pylori j99
573 uvrB 80% Q54986 excinuclease abc subunit b; Streptococcus pneumoniae
574 gltS 39% P54535 probable amino-acid abc transporter binding protein in bmru-ansr intergenic région precursor; Bacillus subtilis
575 argE 25% Q9ZEY0 succinyl-diaminopimelate desuccinylase; Listeria monocytogenes
576 fabZl 48% P94584 similar to hydroxymyristoyl- dehydratase; Bacillus subtilis
577 fabl 44% 031621 yjbw protein; Bacillus subtilis 578 yfgC 31% AAD45617 laça; Lactococcus lactis 579 yfgE 36% AAD45618 lacf; Lactococcus lactis 580 yfgF 28% AAD45621 lacg; Lactococcus lactis
581 yfgG 39% AAF03934 membrane protein homolog; Listeria monocytogenes 582 yfgH 25% Q9Z2M7 phosphomannomutase; Mus musculus 583 yfgL 30% Q44655 membrane protein; Bacillus acidopullulyticus 584 dfpA 64% Q54433 dna/pantothenate metabolism flavoprotein homolog; Streptococcus mutans
585 dfpB 28% 027284 pantothenate metabolism flavoprotein;
Methanobacterium thermoautotrophicum
586 xylH 35% Q9ZI54 4-oxalocrotonate isomérase; Pseudomonas stutzeri 587 yfgQ 35% Q9Z4 5 putative intégral membrane atpase; Streptomyces coelicolor
588 yfhA 39% P09163 hypothetical 16.4 kd protein in rrfe-meta intergenic région; Escherichia coli
589 yfhB 35% 007859 putative membrane protein; Staphylococcus epidermidis
590 yfhC putative 591 crtK 33% AAF01195 tspo; Rhizobium meliloti 592 yfhF 28% 041106 a624r protein; Paramecium bursaria chlorella virus 1
593 yfhG 30% AAF09965 conserved hypothetical protein; Deinococcus radiodurans
594 yfhH 30% 053731 hypothetical 28.3 kd protein; Mycobacterium tuberculosis
595 yfhl putative 596 yfhJ putative 597 yfhK 34% P94425 hypothetical 10.9 kd protein in phrc-gdh intergenic région; Bacillus subtilis
598 yfhL 30% CAB49143 hypothetical 23.5 kd protein; Pyrococcus abyssi 599 yfiA 75% 087254 hypothetical 11.0 kd protein; Lactococcus lactis
600 umuC 89% 087253 conserved hypothetical protein, orfu; Lactococcus lactis
601 yfiC 32% P13018 streptothricin acetyltransferase; Escherichia coli
602 yfiD 20% 002244 unc-54 protein; Caenorhabditis elegans 603 yfiB 45% 034777 ykma; Bacillus subtilis 604 yfiE 37% 034762 ykla; Bacillus subtilis 605 yfiG 78% P47848 thy idine kinase; Streptococcus gordonii challis 606 yfiH putative 607 prfA 56% P45872 peptide chain release factor 1; Bacillus subtilis
608 yfil putative 609 yfiJ 40% P39605 hypothetical 28.3 kd protein in qoxd-vpr intergenic région; Bacillus subtilis
610 he K 37% P45873 hemk protein homolog; Bacillus subtilis 611 yfiL 29% 032248 yvbk protein; Bacillus subtilis 612 yfjA 36% 073972 340aa long hypothetical protein; Pyrococcus horikoshii
613 glyA 61% P39148 serine hydroxymethyltransferase; Bacillus subtilis
614 yfjB 39% AAF13613 pxo2-08; Bacillus anthracis 615 serC 50% AAD47359 3-phosphoserine aminotransferase; Pseudomonas stutzeri
616 serA 35% AAD51415 3-phosphoglycerate dehydrogénase; Homo sapiens 617 serB 46% CAB50876 putative phosphoserine phosphatase; Streptomyces coelicolor
618 yfjC 47% 035031 putative acylphosphatase; Bacillus subtilis 619 yfjD 42% P94538 hypothetical 26.9 kd protein; Bacillus subtilis 620 yfjE 43% 034589 probable flavodoxin 2; Bacillus subtilis 621 yfjF 31% CAB61606 putative export protein; Streptomyces coelicolor
622 yfjG 36% 050423 transcriptional regulator; Mycobacterium tuberculosis
623 yfjH putative 624 pepM 51% 088076 methionine aminopeptidase a; Enterococcus faecalis
625 ygaB 35% 088169 orfde2; Enterococcus faecalis 626 ygaC 27% AAD54224 mesh; Leuconostoc mesenteroides 627 ygaD putative 628 ygaE putative 629 ygaF putative 630 ptsK 65% Q9ZA56 putative hpr kinase; Streptococcus mutans 631 lgt 65% P72482 prolipoprotein diacylglyceryl transferase; Streptococcus mutans
632 ygal 44% Q9ZA55 hypothetical 14.4 kd protein; Streptococcus mutans
633 ygaJ 76% P96788 hypothetical 20.6 kd protein; Lactococcus lactis
634 gnd 98% P96789 6-phosphogluconate dehydrogénase; Lactococcus lactis
635 kupl 80% P96790 potassium transporter homolog; Lactococcus lactis
636 kup2 31% P76748 from bases 3920310 to 3930455 of the complète génome; Escherichia coli
637 ygbB 30% P54478 hypothetical 32.5 kd protein in ccca-soda intergenic région; Bacillus subtilis
638 miaA 45% 031795 trna delta-isopentenylpyrophosphate transferase; Bacillus subtilis
639 ygbD putative 640 ygbE 44% AAF03497 t22n4.8 protein; Arabidopsis thaliana 641 ygbF putative 642 ygbG 50% P54548 hypothetical 34.0 kd protein in glnq-ansr intergenic région; Bacillus subtilis
643 ygcA 33% P54554 hypothetical oxidoreductase in ansr-bmru intergenic région; Bacillus subtilis
644 recJ 36% 032044 yrve protein; Bacillus subtilis 645 apt 67% 034443 adenine phosphoribosyltransferase; Bacillus subtilis
646 rpoE 36% P12464 dna-directed rna polymérase delta subunit; Bacillus subtilis
647 ygcC 36% 034758 yrrl protein; Bacillus subtilis
648 greA 58% P80240 transcription elongation factor gréa; Bacillus subtilis
649 tra904E 100% CAA55220 isl069 gène; Lactococcus lactis
650 ygcD 100% Q48713 dna for the transposon-like élément on the lactose plasmid; Lactococcus lactis
651 tral077D 98% 032787 transposase; Lactococcus lactis
652 ygcE 100% 032786 hypothetical 21.3 kd protein; Lactococcus lactis
653 ctsR 46% Q48757 clpc atpase; Listeria monocytogenes
654 clpC 90% Q9ZIL9 clpc; Lactococcus lactis
655 ygdA 51% P28368 hypothetical 22.0 kd protein in flit-seca intergenic région; Bacillus subtilis
656 enoA 87% Q9XDS7 enolase; Streptococcus intermedius
657 xerD 29% 026979 integrase-recombinase protein; Methanobacterium thermoautotrophicum
658 ygdC putative
659 ygdD putative
660 ygdF putative
661 ygdE putative
662 tra982 92% 087349 putative transposase; Lactococcus lactis
663 hsdR 98% 068167 hsdr; Lactococcus lactis
664 hsdM 100% 068168 hsdm; Lactococcus lactis
665 hsdS 100% 068169 hsds; Lactococcus lactis
666 ygeA 90% 068170 is982 transposase homolog; Lactococcus lactis
667 ygeB putative
668 ygeC putative
669 ygeD 27% Q9YVT6 orf msvl56 hypothetical protein; Melanoplus sanguinipes entomopoxvirus
670 tra981C 86% Q48668 insertion séquence is981; Lactococcus lactis
671 ygfF 96% Q48667 insertion séquence is981; Lactococcus lactis
672 ygfA 39% Q9 ZG4 abc transporter, atp-binding protein; Thermotoga maritima
673 ygfB 23% AAF12525 hypothetical 37.1 kd protein; Deinococcus radiodurans
674 ygfC 30% P96701 ydgc protein; Bacillus subtilis
675 fadD 25% P29212 long-chain-fatty-acid—coa ligase; Escherichia coli
676 ygfE 96% 032796 orfa protein; Lactococcus lactis
677 pfl 100% 032797 formate acetyltransferase; Lactococcus lactis
678 yggA 43% 034932 hypothetical 22.0 kd protein in gapb-mutm intergenic région; Bacillus subtilis
679 pmrA 48% Q9ZEX9 multi-drug résistance efflux pump; Streptococcus pneumoniae
680 rpmGA 100% P27167 50s ribosomal protein 133; Lactococcus lactis
681 ftsWl 95% P27174 hypothetical protein in rpmg 3 'région; Lactococcus lactis
682 pycA 96% AAF09095 pyruvate carboxylase; Lactococcus lactis
683 gltA 90% AAF09126 citrate synthase; Lactococcus lactis
684 citB 86% AAF09127 aconitate hydratase; Lactococcus lactis
685 icd 56% 006893 isocitrate dehyrogenase; Bacillus israeli
686 clpP 92% Q9ZAB0 protease; Lactococcus lactis
687 yghB putative
688 yghC 54% 031602 yjbd protein; Bacillus subtilis
689 yghD putative
690 yghE putative
691 yghF 39% 034431 ylob protein; Bacillus subtilis
692 yghG putative
693 icaA 38% Q54066 icaa; Staphylococcus epidermidis
694 tra983A 50% 087534 putative transposase; Streptococcus pyogenes
695 icaB 32% Q54067 icab; Staphylococcus epidermidis
696 ygiC putative
697 icaC 35% Q53971 fibronectin binding protein; Streptococcus dysgalactiae
698 ygiE 38% P54104 branched-chain amino acid transport system carrier protein; Lactobacillus delbrueckii
699 brnQ 99% 069437 homologous to branched chain amino acid transporters of liv-ii class; Lactococcus lactis
700 ygiG 94% 069438 yjdj-like protein; Lactococcus lactis
701 ygiH 96% 069439 yjdi-like protein; Lactococcus lactis
702 ygil 42% P37545 hypothetical 29.2 kd protein in mets-ksga intergenic région; Bacillus subtilis
703 ygiJ 40% Q47838 copa, copy and copz gènes; Enterococcus hirae
704 ygiK 42% P37547 hypothetical 20.7 kd protein in mets-ksga intergenic région; Bacillus subtilis
705 ksgA 52% P37468 dimethyladenosine transferase (s- adenosylmethionine-6-n ' , n'-adenosyl (high level kasugamycin re . Bacillus subtilis
706 pepP 91% 008316 aminopeptidase p; Lactococcus lactis
707 efp 40% P49778 elongation factor p; Bacillus subtilis
708 ygjB 39% P54519 hypothetical 14.7 kd protein in accc-fold intergenic région; Bacillus subtilis
709 nusB 45% P54520 n utilization substance protein b homolog;
Bacillus subtilis
710 ygjD 58% 022198 putative 4-alpha-glucanotransferase; Arabidopsis thaliana
711 malQ 40% 022198 putative 4-alpha-glucanotransferase; Arabidopsis thaliana
712 glgC 51% 008326 glucose-1-phosphate adenylyltransferase;
Bacillus stearothermophilus
713 glgD 29% 008327 glycogen biosynthesis protein glgd; Bacillus stearothermophilus
714 glgA 46% P39125 glycogen synthase; Bacillus subtilis
715 glgP 50% P39123 glycogen phosphorylase; Bacillus subtilis
716 amyX 34% P36905 T amylopullulanase precursor [includes: alpha- amylase ; pullulanase (1, 4-alpha-d-glucan ...
717 dtpT 90% P36574 di-/tripeptide transporter; Lactococcus lactis
718 tra983B 50% 087534 putative transposase; Streptococcus pyogenes
719 cydA 46% P94364 cytochrome d ubiquinol oxidase subunit i;
Bacillus subtilis
720 cydB 36% Q9ZBY6 putative cytochrome oxidase subunit ii;
Streptomyces coelicolor
721 cydC 45% P94366 transport atp-binding protein cydc; Bacillus subtilis
722 cydD 41% P94367 transport atp-binding protein cydd; Bacillus subtilis
723 rmaB 35% 050574 hypothetical 16.1 kda transcriptional regulator;
Bacillus firmus
724 yhbE putative
725 yhbF 22% 035264 R platelet-activating factor acetylhydrolase ib beta subunit (pi...
726 lmrA 88% P97046 multidrug résistance protein lmra; Lactococcus lactis
727 yhbH 90% Q48631 hypothetical 13.6 kd protein; Lactococcus lactis
728 api 83% Q48630 alkaline phosphatase like protein; Lactococcus lactis
729 yhcA 38% Q9ZAX8 abc transporter atp binding subunit; Streptococcus mutans
730 yhcC 41% Q58627 hypothetical protein mjl230; Methanococcus jannaschii
731 yhcB putative
732 qor 45% Q9Z3U5 w7. alginate lyase; Pseudomonas sp
733 yhcE 41% P42319 hypothetical 38.3 kd protein in pept-katb intergenic région; Bacillus subtilis
734 yhcG 43% 007607 hypothetical 26.5 kd protein; Bacillus subtilis
735 yhcH 25% 054390 serine/threonine protein phosphatase 1; Microcystis aeruginosa
736 yhcl 49% P21335 hypothetical 17.8 kd protein in sers-dnah intergenic région; Bacillus subtilis
737 tra981D 92% Q48668 insertion séquence is981; Lactococcus lactis
738 yhcJ 100% Q48667 insertion séquence is981; Lactococcus lactis
739 yhcK 26% 059645 alpha-glucosidase; Sulfolobus solfataricus
740 rliC 28% Q56201 maltose opéron transcriptional repressor; Staphylococcus xylosus
741 yhdA 45% P14205 coma opéron protein 2; Bacillus subtilis
742 yhdB 34% 034514 ytfd; Bacillus subtilis
743 menE 35% 034837 osb-coa synthase; Bacillus subtilis
744 menB 76% 034567 dihydroxynaphthoate synthase; Bacillus subtilis
745 menX 34% 034312 ytxm; Bacillus subtilis
746 menD 40% P23970 B menaquinone biosynthesis protein mend [includes: 2-succinyl-6-hydroxy- 2,4-
cyclohexadiene-1-carboxylate synthase ; 2- oxoglutarate décarboxylase (ec...
747 menF 35% P74053 isochorismate synthase; Synechocystis sp
748 yhdC 31% P94482 ynad; Bacillus subtilis
749 yheA 35% 034921 ytoi; Bacillus subtilis
750 yheB 48% 034600 ytqi; Bacillus subtilis
751 ansB 38% AAF11899 1-asparaginase; Deinococcus radiodurans
752 yheD 32% Q45494 hypothetical 28.9 kd protein; Bacillus subtilis
753 yheE putative
754 floL 33% 032076 hypothetical 56.0 kd protein in glgb-gbsb intergenic région; Bacillus subtilis
755 thrA 50% P94417 probable aspartokinase; Bacillus subtilis 756 yheG 33% 053410 hypothetical 29.3 kd protein; Mycobacterium tuberculosis
757 rmaA 33% P96708 ydgj protein; Bacillus subtilis 758 yhfA 30% Q9X0Y1 beta-phosphoglucomutase, putative; Thermotoga maritima
759 yhfB 31% P37484 hypothetical 74.3 kd protein in rpli-cotf intergenic région; Bacillus subtilis
760 rpll 44% P02417 50s ribosomal protein 19; Bacillus stearothermophilus
761 dnaC 52% P37469 replicative dna helicase; Bacillus subtilis 762 yhfC putative 763 yhfD 33% 034935 ytmp; Bacillus subtilis 764 yhfE 54% 034522 ytmq; Bacillus subtilis 765 yhfF 51% P33661 hypothetical 15.2 kd protein in sigg 3 'région; Clostridium acetobutylicum
766 dnaB 20% P07908 réplication initiation and membrane attachment protein; Bacillus subtilis
767 dnal 37% P06567 primosomal protein dnai; Bacillus subtilis
768 yhgA 33% P94424 hypothetical 27.9 kd protein in phrc-gdh intergenic région; Bacillus subtilis
769 yhgB 31% 006733 yisx protein; Bacillus subtilis
770 yphL 65% P50743 hypothetical 48.8 kd gtp-binding protein in c k- gpsa intergenic région; Bacillus subtilis
771 yhgC 27% 030416 positive regulator gadr; Lactococcus lactis
772 yhgD 20% P28968 glycoprotein x precursor; Equine herpesvirus type 1
773 yhgE 27% Q48707 dna for orfl and orf2; Lactobacillus leichmannii
774 yhhA 34% 068213 putative fimbria-associated protein; Actinomyces naeslundii
775 yhhB putative
776 yhhC 29% P39590 hypothetical 25.8 kd protein in epr-galk intergenic région; Bacillus subtilis
777 yhhD 50% 059465 109aa long hypothetical protein; Pyrococcus horikoshii
778 yhhE 36% P32726 hypothetical 17.6 kd protein in nusa 5 'région; Bacillus subtilis
779 nusA 50% 031756 nusa protein; Bacillus subtilis
780 yhhG 47% P32728 hypothetical 10.4 kd protein in nusa-infb intergenic région; Bacillus subtilis
781 yhhH 51% P55768 probable ribosomal protein in infb 5 'région; Enterococcus faecium
782 infB 79% Q9X764 initiation factor 2; Lactococcus lactis 783 rbfA 86% Q9X765 ribosome binding factor a; Lactococcus lactis 784 pmi 65% Q59935 mannose-6-phosphate isomérase; Streptococcus mutans
785 yhiA 34% P70993 hypothetical 15.9 kd protein; Bacillus subtilis 786 fabH 45% 067185 3-oxoacyl- [acyl-carrier-protein] synthase iii; Aquifex aeolicus
787 acpA 47% P80643 acyl carrier protein; Bacillus subtilis 788 fabD 46% 034463 malonyl coa-acyl carrier protein transacylase;
Bacillus subtilis
789 fabGl 47% P51831 3-oxoacyl- [acyl-carrier protein] réductase; Bacillus subtilis
790 fabF 43% 034340 yjay protein; Bacillus subtilis
791 accB 50% Q06881 biotin carboxyl carrier protein of acetyl-coa carboxylase; Anabaena sp
792 fabZ2 58% P94584 similar to hydroxymyristoyl- dehydratase; Bacillus subtilis
793 accC 57% P49787 biotin carboxylase (a subunit of acetyl-coa carboxylase; Bacillus subtilis
794 accD 57% 034571 acetyl-coa carboxylase subunit; Bacillus subtilis
795 accA 54% 034847 acetyl-coenzyme a carboxylase carboxyl transferase subunit alpha; Bacillus subtilis
796 metB2 .00% AAF14693 cystathionine beta-lyase metc; Lactococcus lactis
797 cysK 89% AAF14694 o-acetylserine sulfhydrylase cysk; Lactococcus lactis
798 yhjA 32% 016527 ce-lea; Caenorhabditis elegans
799 yhjB 42% P54510 hypothetical 14.6 kd protein in gcvt-spoiiiaa intergenic région; Bacillus subtilis
800 yhjC 41% P54510 hypothetical 14.6 kd protein in gcvt-spoiiiaa intergenic région; Bacillus subtilis
801 noxC 36% 029847 nadh oxidase; Archaeoglobus fulgidus 802 yhjE 48% BAA86632 hypothetical 9.9 kd protein; Staphylococcus aureus
803 yhjF 51% 032175 yusi protein; Bacillus subtilis 804 rdrA 38% P76034 hypothetical transcriptional regulator in os b- rnb intergenic région; Escherichia coli
805 yhjG 32% P05332 hypothetical p20 protein; Bacillus licheniformis
806 exoA 61% P21998 exodeoxyribonuclease; Streptococcus pneumoniae
807 mets 61% P37465 methionyl-trna synthetase; Bacillus subtilis
808 yiaA putative
809 yiaB 36% Q9X248 3-oxoacyl- réductase; Thermotoga maritima
810 yiaC 31% 005109 cara & orf8 partial cds, argc,j,b,d,f & orf7 citrulline biosynthetic opéron; Lactobacillus plantarum
811 yiaD 42% P71037 hypothetical 23.2 kd protein; Bacillus subtilis
812 argC 41% 008318 n-acetyl-gamma-glutamyl-phosphate réductase; Lactobacillus plantarum
813 argj 48% Q9ZJ14 ornithine acetyltransferase; Bacillus amyloliquefaciens
814 argD 42% 066442 acetylornithine aminotransferase; Aquifex aeolicus
815 argB 40% 028988 acetylglutamate kinase; Archaeoglobus fulgidus
816 argF 62% 053089 ornithine transcarbamoylase; Lactobacillus sake
817 rnc 45% 031734 ribonuclease iii; Bacillus subtilis
818 smc 32% 031735 chromosome ségrégation smc protein homolg; Bacillus subtilis
819 yibB 49% 031735 chromosome ségrégation smc protein homolg; Bacillus subtilis
820 yibC 39% 006487 yfni; Bacillus subtilis
821 yibD putative
822 yibE putative
823 yibF putative
824 yibG 40% 032257 yvbw protein; Bacillus subtilis
825 yicA putative
826 yicB 35% P09997 hypothetical 29.7 kd protein in ibpa-gyrb intergenic région; Escherichia coli
827 yicC 32% Q9WX02 putative membrane protein; Streptomyces coelicolor
828 ftsY 55% P51835 cell division protein ftsy homolog; Bacillus subtilis
829 prsA 66% Q48793 t s and prs gènes, partial cds; Listeria monocytogenes
830 yicE 32% 087552 leucine-rich protein transcriptional regulator;
Bacillus firmus
831 leuS 67% P36430 leucyl-trna synthetase; Bacillus subtilis
832 yidA 26% Q9X0V5 transcriptional regulator, rpir family;
Thermotoga maritima
S33 yidB 25% P39584 hypothetical 47.6 kd protein in epr-galk intergenic région; Bacillus subtilis
834 yidC 39% P42973 6-phospho-beta-glucosidase; Bacillus subtilis 835 cpo 33% CAB60045 citr protein; eissella paramesenteroides 836 yidE putative 837 tra904F 100% CAA55220 isl069 gène; Lactococcus lactis 838 yidF 98% Q48710 span gène encoding nisin and insertion séquence is904; Lactococcus lactis
839 tral077E 98% 032787 transposase; Lactococcus lactis 840 yidG 99% 032786 hypothetical 21.3 kd protein; Lactococcus lactis
841 yidH 100% Q48710 span gène encoding nisin and insertion séquence is904; Lactococcus lactis
842 tra904G 99% CAA55220 isl069 gène; Lactococcus lactis
843 noxA 33% 005267 hypothetical 44.9 kd protein; Bacillus subtilis
844 noxB 33% P32340 rotenone-insensitive nadh-ubiquinone oxidoreductase precursor; Saccharomyces cerevisiae
845 sdhB 47% 034635 probable 1-serine dehydratase, beta chain; Bacillus subtilis
846 sdhA 55% 034607 probable 1-serine dehydratase, alpha chain; Bacillus subtilis
847 copR 40% Q47839 copab atpases metal-fist type repressor; Enterococcus hirae
48 yieF 45% AAC33905 mera, mercuric ion réductase; Escherichia coli
49 copA 45% P32113 copper/potassium-transporting atpase a; Enterococcus hirae
50 yieH 91% 066090 transmembrane protein tmp5; Lactococcus lactis
51 yifA putative
52 trmU 64% 035020 probable trna -methyltransferase; Bacillus subtilis
53 rpsA 49% P50889 40s ribosomal protein si; Leuconostoc lactis
54 udp 35% 083990 uridine phosphorylase; Treponema pallidum
55 yifD 29% Q9ZJT8 nicotinamide mononucleotide transporter; Helicobacter pylori j 99
56 uvrC 50% Q9ZEH3 excinuclease abc, subunit c; Staphylococcus aureus
57 mutY 43% 031584 yfhq protein; Bacillus subtilis
58 pepV 96% 007121 dipeptidase; Lactococcus lactis
59 acpS 54% 007122 hypothetical 8.0 kd protein; Lactobacillus plantarum
60 dal 97% CAB56755 alanine racemase; Lactococcus lactis
61 yigC 50% 031602 yjbd protein; Bacillus subtilis
62 gshR 30% 054279 orf454 protein; Staphylococcus sciuri
63 choQ 60% Q9XBN6 choline transporter; Streptococcus pneumoniae
64 choS 42% Q9XBN5 choline transporter; Streptococcus pneumoniae
65 yigE 16% AAB82017 microfilarial sheath protein shp3; Litomosoides sig odontis
yigF putative yihA putative yihB putative yihC 46% P05425 copper/potassium-transporting atpase b; Enterococcus hirae yihD 21% 080179 putative minor tail protein; Streptococcus thermophilus bacteriophage sfill folD 65% P96050 fold bifunctional protein [includes: methylenetetrahydrofolate dehydrogénase ; methenyltetrahydrofolate cyclohydrolase ] ; Streptococcus thermophilus xseA 37% P54521 putative exodeoxyribonuclease large subunit;
Bacillus subtilis xseB 38% Q9ZDH8 exodeoxyribonuclease small subunit; Rickettsia prowazekii yihF 47% P44507 hypothetical protein hi0091; Haemophilus influenzae ispA 49% 066126 geranyltranstransferase; Micrococcus luteus yiiB 59% P19672 hypothetical 29.7 kd protein in fold-ahrc intergenic région; Bacillus subtilis ahrC 38% 086130 arginine repressor; Bacillus licheniformis recN 40% P17894 dna repair protein recn; Bacillus subtilis yiiD putative yiiE 33% 027534 hypothetical 21.2 kd protein; Methanobacterium thermoautotrophicum yiiF 35% Q56116 Streptococcus thermophilus yiiG 35% Q9ZI22 membrane protein; Streptococcus salivarius yiiH 71% AAC95454 yllc; Streptococcus pneumoniae yiil 85% 066083 putative transmembrane protein tmp2; Lactococcus lactis pbpX 41% P14677 penicillin-binding protein 2x; Streptococcus pneumoniae mraY 50% Q9zha5 phospho-n-acetylmurarnoyl-pentapeptide- transferase; Streptococcus pneumoniae yijB putative yijC 29% P94412 homologue of hypothetical protein in a rapamycin synthesis gène cluster of streptomyces hygroscopicus; Bacillus subtilis yijD 48% P94411 homologue of hypothetical protein in a rapamycin synthesis gène cluster of streptomyces hygroscopicus; Bacillus subtilis mleR 93% P16400 malolactic fermentation system transcriptional activator; Lactococcus lactis yijE 85% Q48663 positive regulator gène; Lactococcus lactis rplS 77% 034031 50s ribosomal protein 119; Streptococcus thermophilus yijF putative yijG 33% P75905 hypothetical 50.8 kd protein in phoh-csgg intergenic région; Escherichia coli yijH putative pnuC 26% 025877 nicotinamide mononucleotide transporter; Helicobacter pylori yjaB 35% Q57951 hypothetical protein mj0531; Methanococcus jannaschii hslB 45% Q9XB21 histone-like dna-binding protein; Streptococcus mutans yjaD 36% CAB55667 putative tetr-family transcriptional regulator; Streptomyces coelicolor yjaE 82% 066092 transmembrane protein tmp7; Lactococcus lactis yjaF 79% 033663 dna for sigma 42 protein, dtdp-4-keto-l-rhamnose réductase, complète cds; Streptococcus mutans
902 ftsW2 45% P27174 hypothetical protein in rpmg 3 ' région; Lactococcus lactis
903 yjaH putat ive
904 yjal putative
905 yjaJ 38% Q56038 epsa; Streptococcus thermophilus
906 rpsN2 63% 031587 yhza protein; Bacillus subtilis
907 yjbB putative
908 kinD 92% 007385 histidine kinase; Lactococcus lactis
909 IrrD 57% CAB54571 response regulator; Streptococcus pneumoniae
910 yjbC 41% P21878 hypothetical protein in pdha 5 'région; Bacillus stearothermophilus
911 ppiB 41% P87051 probable peptidyl-prolyl cis-trans isomérase c57al0.03; Schizosaccharomyces pombe
912 yjbE 37% CAB49760 translation initiation factor aif-2, subun it alpha; Pyrococcus abyssi
913 yjbF 26% 007559 hypothetical 23.3 kd protein; Bacillus subtilis
914 rodA 28% P39604 hypothetical 43.3 kd protein in qoxd-vpr intergenic région; Bacillus subtilis
915 butB 42% 034788 dehydrogénase; Bacillus subtilis
916 butA 67% 002715 acetoin réductase; Bos taurus
917 yjcA 26% Q9ZE86 abc transporter atp-binding protein; Rickettsia prowazekii
918 mleS 95% Q48662 malolactic enzyme; Lactococcus lactis
919 mleP 92% 007032 citrate-sodium symport; Lactococcus lactis
920 yjcD 32% Q9ZF46 hypothetical 32.6 kd protein; Bacillus megaterium
921 yjcE putative
922 yjcF 46% Q57064 unidentified; Streptococcus pneumoniae
923 gyrB 78% Q59957 dna gyrase; Streptococcus pneumoniae
924 yjdA 35% P44074 hypothetical protein hi0912; Haemophilus influenzae
925 yjdB putative
926 yjdD 37% P25150 hypothetical transcriptional regulator in gspa- tyrz intergenic région; Bacillus subtilis
927 yjdE 33% P94422 homologue of multidrug résistance protein b, emrb, of e. coli; Bacillus subtilis
928 yjdF putative
929 tagR 38% 006027 epsr protein; Lactococcus lactis
930 tagL 49% CAB52231 epsl protein; Streptococcus thermophilus
931 yjdl putative
932 yjdJ 26% Q58752 putative potassium channel protein mjl357; Methanococcus jannaschii
933 tagH 48% P42954 teichoic acid translocation atp-binding protein tagh; Bacillus subtilis
934 tagG 30% P42953 teichoic acid translocation permease protein tagg; Bacillus subtilis
935 y eA putative
936 tagZ 33% 006035 epsg protein; Lactococcus lactis
937 tagY 31% AAD56434 tagf; Staphylococcus epidermidis
938 yjeD putative
939 tagX 30% AAD56434 tagf; Staphylococcus epidermidis
940 yjeF 30% P26388 putative colanic acid biosynthesis glycosyl transferase wcal; Salmonella typhimurium
941 yjeG putative
942 tagD2 50% 067380 glycerol-3-phosphate cytidyltransferase; Aquifex aeolicus
943 yjfB putative
944 tagF 41% AAD56434 tagf; Staphylococcus epidermidis
945 tagB 28% P27621 teichoic acid biosynthesis protein b precursor; Bacillus subtilis
946 yj fE 34 % Q9X485 hypothetical 33.8 kd protein; Lactococcus lactis
947 deoB 97% 032808 phosphopentomutase; Lactococcus lactis
948 yjfG 91% 032809 hypothetical 10.3 kd protein; Lactococcus lactis
949 deoD 93% 032810 purine nucleoside phosphorylase; Lactococcus lactis
950 tra983C 50% 087534 putative transposase; Streptococcus pyogenes
951 yjfl 39% 086782 hypothetical 19.8 kd protein; Streptomyces coelicolor
952 yjfj 48% Q9X8J2 hypothetical 11.3 kd protein; Streptomyces coelicolor
953 fhs 65% Q59925 formate—tetrahydrofolate ligase; Streptococcus mutans
954 yjgB 44% Q9X7Z4 putative secreted protein; Streptomyces coelicolor
955 yjgC 29% P54952 probable amino-acid abc transporter binding protein in idh-deor intergenic région precursor;
Bacillus subtilis
956 yjgD 40% P54953 probable amino-acid abc transporter permease protein in idh-deor intergenic région; Bacillus subtilis
957 yjgE 55% 034900 putative amino acid transporter; Bacillus subtilis
958 trxBl 58% 032823 thioredoxin réductase; Listeria monocytogenes
959 secG 32% 032233 probable protein-export membrane protein secg;
Bacillus subtilis
960 vacB 43% 032231 yvaj protein; Bacillus subtilis
961 yjgF 48% P94573 hypothetical 21.1 kd protein; Bacillus subtilis
962 yjhA putative
963 yjhB 23% P39582 probable 1, 4-dihydroxy-2-naphthoate octaprenyltransferase; Bacillus subtilis
964 yjhC 48% Q58953 hypothetical protein mjl558; Methanococcus jannaschii
965 yjhD 59% Q59059 hypothetical protein mjl665; Methanococcus jannaschii
966 yjhE putative
967 yjhF 34% P96121 phosphoglycérate mutase; Treponema pallidum
968 dacB 64% Q9ZAT6 putative d, d-carboxypeptidase; Streptococcus mutans
969 yjhH putative
970 hrcA 97% P42370 heat-inducible transcription repressor hrca; Lactococcus lactis
971 grpE 81% Q9X4R3 heat shock protein grpe; Streptococcus pneumoniae
972 dnaK 87% P42368 dnak protein; Lactococcus lactis
973 mycA 61% Q54525 67 kda myosin-crossreactive streptococcal antigen; Streptococcus pyogenes
974 yjiB 44% 034980 putative hippurate hydrolase; Bacillus subtilis
975 lacR 42% 031713 transcriptional regulator; Bacillus subtilis
976 lacC 47% 031714 fructose-1-phosphate kinase; Bacillus subtilis
977 fruA 43% P71012 phosphotransferase system fructose-specific enzyme iibc component; Bacillus subtilis
978 clsA 47% P71040 hypothetical 55.8 kd protein in spoiiq-mta intergenic région; Bacillus subtilis
979 yjiE 54% 006973 hypothetical 33.9 kd protein in crh-trxb intergenic région; Bacillus subtilis
980 yjiF 42% 006974 hypothetical 34.7 kd protein in crh-trxb intergenic région; Bacillus subtilis
981 yjjA 42% 006975 hypothetical 36.3 kd protein; Bacillus subtilis
982 yjjβ 31% P96222 hypothetical 23.7 kd protein; Mycobacterium tuberculosis
983 yjjc 54% Q9Z9N6 yhaq; Bacillus sp
984 yjjo 26% Q9Z9N5 tnrb3protein; Bacillus sp
985 yjJE putative
986 yjJF 59% AAF04741 hypothetical 18.7 kd protein; Listeria monocytogenes
987 yjjc 60% P71081 hypothetical 12.2 kd protein; Bacillus subtilis
988 yjjH 25% CAB48940 hypothetical 28.0 kd protein; Pyrococcus abyssi
989 prfB 52% P28367 peptide chain release factor 2; Bacillus subtilis
990 ftsE 63% 034814 cell division atp-binding protein; Bacillus subtilis
991 ftsX 38% 034876 cell division protein; Bacillus subtilis
992 nrdF 47% 069274 ribonucleotide réductase subunit r2f; Corynebacterium ammoniagenes
993 nrdE 51% Q9XD63 ribonucleotide réductase alpha-chain; Corynebacterium glutamicum
994 ndrl 93% Q48709 nrdi protein; Lactococcus lactis
995 ndrH 98% Q48708 glutaredoxin-like protein nrdh; Lactococcus lactis
996 ykaC 58% Q9X972 hypothetical 17.9 kd protein; Streptococcus gordonii
997 parE 79% Q59961 topoisomerase iv subunit b; Streptococcus pneumoniae
998 ykaE putative
999 ykaF 37% CAB60666 hypothetical 25.4 kd protein; Bradyrhizobium japonicum
1000 dnaQ 42% Q9zhf6 dna polymérase iii, alpha chain polc-type; Thermotoga maritima
1001 ykbA 39% P52077 elaa protein; Escherichia coli
1002 parC 71% Q9X5Y7 parc; Streptococcus mitis
1003 ykbB 23% Q9WW83 hypothetical 34.5 kd protein; Lactococcus lactis
1004 ykbC 23% P40889 hypothetical 197.6 kd protein in fsp2 5 'région; Saccharomyces cerevisiae
1005 ykbD putative
1006 ykbE putative
1007 ykbF putative
1008 ykcA putative
1009 ykcB putative
1010 ykcC putative
1011 ribG 45% P50853 riboflavin-specific deaminase; Actinobacillus pleuropneumoniae
1012 ribB 58% P50854 riboflavin synthase alpha chain; Actinobacillus pleuropneumoniae
1013 ribA 60% P50855 riboflavin biosynthesis protein riba [includes: gtp cyclohydrolase ii ; 3, 4-dihydroxy-2-butanone 4-ph. Actinobacillus pleuropneumoniae
1014 ribH 67% P50856 6, 7-dimethyl-8-ribityllumazine synthase (riboflavin synthase beta. Actinobacillus pleuropneumoniae
1015 lspA 78% Q48729 signal peptidase type ii; Lactococcus lactis
1016 ykcD 59% Q45480 hypothetical 33.7 kd protein in lsp-pyrr intergenic région; Bacillus subtilis
1017 ykcE 47% P73185 hypothetical 16.0 kd protein; Synechocystis sp
1018 ykcF putative
1019 ykcG 50% 034755 hypothetical 38.5 kd protein in tnra-sspd intergenic région; Bacillus subtilis
1020 IrrE 41% 034903 ykog; Bacillus subtilis
1021 ykdA putative
1022 kinE 73% 007386 histidine kinase; Lactococcus lactis
1023 ykdB 66% 007387 histidine kinase; Lactococcus lactis
1024 glmS 59% P39754 B glucosaminé--fructose-6-phosphate aminotransferase [isomerizing] (1-glutamine...
1025 radC 40% Q02170 dna repair protein rade homolog; Bacillus subtilis
1026 pi201 99% Q38325 integrase; Lactococcus lactis phage bk5-t
1027 pi202 91% Q38183 orf 3; Bacteriophage tp901-l
1028 pi203 95% Q38182 orf2; Bacteriophage tp901-l
1029 pi204 98% 048503 hypothetical 20.8 kd protein; Bacteriophage tp901-l
1030 pi205 100% 048504 hypothetical 8.3 kd protein; Bacteriophage tp901-l
1031 pi206 100% 048505 hypothetical 28.3 kd protein; Bacteriophage tp901-l
1032 pi207 100% Q38331 orflll; Lactococcus lactis phage bk5-t
1033 pi208 98% Q9XJE0 hypothetical 9.9 kd protein; Bacteriophage tuc2009
1034 pi209 100% Q38272 orf71; Lactococcus bacteriophage
1035 pi210 100% Q9XJE3 hypothetical 20.1 kd protein; Bacteriophage tuc2009
1036 pi211 94% Q9XJE4 putative topoisomerase i; Bacteriophage tuc2009
1037 pi212 87% Q9XJE5 putative single stranded binding protein;
Bacteriophage tuc2009
1038 pi213 94% Q9XJE6 putative replisome organiser protein;
Bacteriophage tuc2009
1039 pi214 99% Q9XJE7 hypothetical 27.2 kd protein; Bacteriophage tuc2009
1040 pi215 88% Q9XJE9 hypothetical 15.8 kd protein; Bacteriophage tuc2009
1041 pi216 93% Q38101 orfl5; Bacteriophage rit
1042 pi217 putative
1043 pi218 71% Q9XJF1 hypothetical 22.4 kd protein; Bacteriophage tuc2009
1044 pi219 putative
1045 pi220 72% Q9XJF3 hypothetical 14.3 kd protein; Bacteriophage tuc2009
1046 pi221 99% Q38106 dutpase; Bacteriophage rit
1047 pi222 putative
1048 pi223 putative
1049 pi224 putative
1050 pi225 putative
1051 pi226 84% 053058 hypothetical 11.0 kd protein; Lactococcus lactis
1052 pi227 putative
1053 pi228 31% Q9XJD9 hypothetical 21 kd protein; Streptococcus thermophilus bacteriophage dtl
1054 pi229 putative
1055 pi230 22% Q9XJT6 putative terminase; Bacteriophage d3
1056 pi231 putative
1057 pi232 30% Q9ZXF7 orf26; Bacteriophage phi-105
1058 pi233 31% P25386 intracellular protein transport protein usol; Saccharomyces cerevisiae
1059 pi234 putative
1060 pi235 putative
1061 pi236 putative
1062 pi237 putative
1063 pi238 putative
1064 pi239 24% Q9ZXE9 orf34; Bacteriophage phi-105
1065 pi240 putative
1066 pi241 putative
1067 pi242 22% P26812 hypothetical protein in mep 3' région; Lactococcus lactis bacteriophage f4-l
1068 pi243 26% CAB52531 hypothetical 28.9 kd protein; Lactobacillus bacteriophage phi adh
1069 pi244 41% 051277 conserved hypothetical protein; Borrelia burgdorferi
1070 pi245 putative
1071 pi246 putative
1072 pi247 putative
1073 pi248 putative
1074 pi249 putative
1075 pi250 95% Q38321 orf75; Lactococcus lactis phage bk5-t
1076 pi251 91% Q38322 orf95; Lactococcus lactis phage bk5-t
1077 pi252 98% Q38323 orf259; Lactococcus lactis phage bk5-t
1078 ykhD 48% 005521 hypothetical 24.1 kd protein ydih; Bacillus subtilis
1079 ykhE 45% 031602 yjbd protein; Bacillus subtilis
1080 ykhF 51% 005519 hypothetical abc transporter atp-binding protein ydif; Bacillus subtilis
1081 ykhG putative
1082 ykhH putative
1083 ykhJ putative
1084 ykhl 27% 030416 positive regulator gadr; Lactococcus lactis
1085 ykhK putative
1086 pyrE 72% Q9ZHA6 orotate phosphoribosyltransferase pyre; Streptococcus pneumoniae
1087 pyrC 42% 066990 dihydroorotase; Aquifex aeolicus
1088 dnaD 41% P95775 orf2 protein; Streptococcus mutans
1089 nth 49% P39788 probable endonuclease iii (dna-; Bacillus subtilis
1090 ykiC 49% P95776 orf3 protein; Streptococcus mutans
1091 ykiD 46% P95777 orf4 protein; Streptococcus mutans
1092 ykiE 23% Q9X563 hypothetical 14.2 kd protein; Enterococcus faeciu
1093 ykiF 41% P09997 hypothetical 29.7 kd protein in ibpa-gyrb intergenic région; Escherichia coli
1094 ykiG 51% P39651 hypothetical 51.0 kd protein in pta 3' région; Bacillus subtilis
1095 ykiH putative
1096 ykil putative
1097 rplU 67% P26908 50s ribosomal protein 121; Bacillus subtilis
1098 ykjA 35% P26942 hypothetical 12.3 kd protein in rplu-rpma intergenic région; Bacillus subtilis
1099 rpmA 74% Q44312 ribosomal protein 127; Arthrobacter sp
1100 ykjB 41% AAD46619 nramp protein mnth2 ; Pseudomonas aeruginosa
1101 ykjC putative
1102 phoL 62% P46343 phoh-like protein; Bacillus subtilis
1103 ykjE 40% P46351 hypothetical 45.4 kd protein in thiaminase i 5' région; Bacillus subtilis
1104 ykjF 61% 051806 diacyglycerol kinase; Streptococcus mutans
1105 dgkA 68% Q05888 diacylglycerol kinase; Streptococcus mutans
1106 ykjH 30% Q45226 signal peptidase sips; Bradyrhizobium japonicum
1107 comFC 36% P39147 co f opéron protein 3; Bacillus subtilis
1108 comFA 36% P39145 comf opéron protein 1; Bacillus subtilis
1109 ykjl 46% P32437 hypothetical 24.8 kd protein in degs-tago intergenic région; Bacillus subtilis
1110 ykjj 41% CAB61225 vayz protein; Bacillus circulans
1111 ykjK 39% 006378 hypothetical 39.3 kd protein; Mycobacterium tuberculosis
1112 nucA 30% Q9X6T9 5 '-nucleotidase nuca precursor; Haemophilus influenzae
1113 glySa 71% P54380 glycyl-trna synthetase alpha chain; Bacillus subtilis
1114 glySb 41% P54381 glycyl-trna synthetase beta chain; Bacillus subtilis
1115 ylaC 32% 031818 ynzc protein; Bacillus subtilis
1116 ylaD 30% Q9Z9W7 transposase protein; Bacillus sp
1117 ylaE 45% P54455 hypothetical 22.2 kd protein in arod-comer intergenic région; Bacillus subtilis
1118 ylaF 61% 032090 yuek protein; Bacillus subtilis
1119 ylaG 30% P46854 hypothetical 18.8 kd protein in gntr-ggt intergenic région; Escherichia coli
1120 nadE 65% P18843 nh-dependent nad synthetase; Escherichia coli
1121 ylbA 53% 028456 abc transporter, atp-binding protein;
Archaeoglobus fulgidus
1122 ylbB 24% 028455 hypothetical 89.0 kd protein; Archaeoglobus fulgidus
1123 cobQ 43% Q9ZGG8 cobyric acid synthase cobq; Heliobacillus mobilis
1124 ylbD 33% Q9ZGG7 udp-n-acetylmuramyl tripeptide synthetase mure;
Heliobacillus mobilis
1125 aldC 35% P95676 alpha-acetolactate décarboxylase; Lactococcus lactis
1126 lepA 74% P37949 gtp-binding protein lepa; Bacillus subtilis
1127 ylbE 36% 007609 hypothetical 22.8 kd protein; Bacillus subtilis
1128 ylcA 53% BAA35634 hypothetical 52.1 kd protein in ebgc-uxaa intergenic région; ; Escherichia coli
1129 gyrA 71% CAA06715 dna gyrase subunit a; Streptococcus pneumoniae
1130 apbE 30% Q9X1N9 conserved hypothetical protein; Thermotoga maritima
1131 ylcC 40% P94587 mbl, flh[o,p], rapd, ywp[b, c, d, e, f, g, h, i, j] and ywqa gènes; Bacillus subtilis
1132 ylcD putative
1133 ylcE putative
1134 ylcF putative
1135 ylcG 28% P94974 hypothetical 128.2 kd protein; Mycobacterium tuberculosis
1136 yldA putative
1137 yldB 30% 006251 hypothetical 26.8 kd protein; Mycobacterium tuberculosis
1138 pcrA 53% P56255 atp-dependent helicase pera; Bacillus stearothermophilus
1139 mutX 32% P41354 mutator mutt protein; Streptococcus pneumoniae
1140 tag 46% Q9X6Y6 putative dna-3-methyladenine glycosydase i; Bifidobacterium longum
1141 yldC 66% 032784 hypothetical 16.9 kd protein; Lactococcus lactis
1142 frdC 43% Q9X969 fumarate réductase flavocytochrome c3; Shewanella frigidimarina
1143 yldE putative
1144 truB 73% 032785 hypothetical 19.7 kd protein; Lactococcus lactis
1145 ribC 48% 034127 macrolide-efflux protein; Streptococcus agalactiae
1146 ldhX 35% P94885 1-lactate dehydrogénase; Lactococcus lactis
1147 yleB 29% 050983 outer surface protein, putative; Borrelia burgdorferi
1148 yleC 52% 031420 ybbi protein; Bacillus subtilis
1149 yleD 42% Q45579 ybbf; Bacillus subtilis
1150 yleE 52% P40739 pts system, beta-glucosides-specific iiabc component (ec. Bacillus subtilis
1151 yleF 31% Q45581 hypothetical 33.3 kd protein; Bacillus subtilis
1152 tpiA 99% P50918 triosephosphate isomérase; Lactococcus lactis
1153 yleG 29% P12256 penicillin acylase; Bacillus sphaericus
1154 ylfA putative
1155 ylfB 28% BAA35232 orf id:ol66#5; Escherichia coli
1156 ylfC 47% P77174 hypothetical 23.9 kd protein in csta-dsbg intergenic région; Escherichia coli
1157 hemN 45% CAB61616 hemn protein; Bacillus subtilis 1158 ylfD 25% P34020 autolytic lysozyme; Clostridium acetobutylicum 1159 ylfE 50% CAB49495 demp deaminase, putative; Pyrococcus abyssi 1160 ylfF 25% Q42714 oleoyl-acyl carrier protein thioesterase precursor (s-acyl fatty acid synthase thioeste.
Carthamus tinctorius
1161 ylfG 28% 004792 acyl-acp thioesterase; Garcinia mangostana
1162 ylfH 45% 032125 yutf protein; Bacillus subtilis
1163 ylfl putative
1164 guaC 74% 005269 hypothetical 35.8 kd protein; Bacillus subtilis
1165 xpt 68% CAA13587 xanthine phosphoribosyltransferase; Streptococcus pneumoniae
1166 pbuX 48% P42086 xanthine permease; Bacillus subtilis
1167 ylgB putative
1168 ylgC 57% P32813 hypothetical 18.2 kd protein in glda 3' région; Bacillus stearothermophilus
1169 dfrA 92% Q59487 dihydrofolate réductase; Lactococcus lactis
1170 clpX 64% P50866 atp-dependent clp protease atp-binding subunit clpx; Bacillus subtilis
1171 ysxL 66% P38424 hypothetical gtp-binding protein in lona-hema intergenic région; Bacillus subtilis
1172 folB 32% AAF09757 dihydroneopterin aldolase; Deinococcus radiodurans
1173 folE 48% AAF09628 gtp cyclohydrolase i; Deinococcus radiodurans
1174 folP 36% 067448 dihydropteroate synthase; Aquifex aeolicus
1175 ylgG putative
1176 folC 41% Q05865 folylpolyglutamate synthase; Bacillus subtilis
1177 ylhA 76% Q9ZB43 hypothetical 24.8 kd protein; Streptococcus pyogenes
1178 hom 91% P52985 homoserine dehydrogénase; Lactococcus lactis
1179 thrB 78% P52991 homoserine kinase; Lactococcus lactis
1180 ylhB putative
1181 murB 39% AAD53934 udp-n-acetylenolpyruvoylglucosaminé réductase; Zymomonas mobilis
1182 potA 46% 051587 spermidine/putrescine abc transporter, atp- binding protein; Borrelia burgdorferi
1183 potB 32% 085819 potb; Actinobacillus actinomycetemeomitans 1184 potC 38% 051585 spermidine/putrescine abc transporter, permease protein; Borrelia burgdorferi
1185 potD 43% P23861 spermidine/putrescine-binding periplasmic protein precursor; Escherichia coli
1186 yliA 28% P49330 rgg protein; Streptococcus gordonii challis 1187 yliB 24% 058549 459aa long hypothetical methyltransferase; Pyrococcus horikoshii
1188 yliC 25% CAB49999 multidrug résistance protein; Pyrococcus abyssi 1189 yliD 31% Q9 YH7 permease, putative; Thermotoga maritima 1190 yliE putative 1191 yliF putative 1192 yliG putative 1193 clsB 41% P71040 hypothetical 55.8 kd protein in spoiiq-mta intergenic région; Bacillus subtilis
1194 ylil 33% 008365 probable cation-transporting atpase e; Mycobacterium tuberculosis
1195 yljA 33% Q9Z4W5 putative intégral membrane atpase; Streptomyces coelicolor
1196 yljB 47% 051589 conserved hypothetical protein; Borrelia burgdorferi
1197 yljC 32% P26833 hypothetical 31.2 kd protein in nagh 5 'région; Clostridium perfringens
1198 yljD putative
1199 yljE 43% 031503 yefa protein; Bacillus subtilis
1200 yljF 52% Q55555 orfl; Synechocystis sp
1201 yljG 77% 032813 lactococcus lactis orfa and orfb gènes, partial cds; Lactococcus lactis
1202 yljH 60% 032814 lactococcus lactis orfa and orfb gènes, partial cds; Lactococcus lactis
1203 yljl 79% 032814 lactococcus lactis orfa and orfb gènes, partial cds; Lactococcus lactis
1204 yljj 96% Q48633 alpha-acetolactate synthase; Lactococcus lactis
1205 als 97% Q48634 alpha-acetolactate synthase; Lactococcus lactis
1206 ymaB putative
1207 mae 62% CAB60039 putative malic enzyme; Weissella pa amesenteroides
1208 ymaE 35% Q48797 malate permease; Oenococcus oeni
1209 ymaF 49% CAA57770 malate permease; Oenococcus oeni
1210 ymaG putative
1211 cliR 41% 086289 regulatory protein; Leuconostoc mesenteroides
1212 citC 48% CAB60040 putative citrate lyase ligase; Weissella paramesenteroides
1213 citD 60% CAB60041 putative gamma subunit of citrate lyase; Weissella paramesenteroides
1214 citE 67% 053078 citrate lyase beta chain; Leuconostoc mesenteroides
1215 citF 80% CAB60043 putative alfa subunit of citrate lyase; Weissella paramesenteroides
1216 citG 46% 053080 citg protein; Leuconostoc mesenteroides
1217 ymbA 29% Q54877 integrase; Streptococcus pneumoniae
1218 ymbC putative
1219 ymbD putative
1220 ymbE 26% 005949 dna polymérase i; Rickettsia prowazekii
1221 ymbF putative
1222 ymbG putative
1223 ymbH 23% Q58437 hypothetical protein mjl031; Methanococcus jannaschii
1224 tra981E 91% Q48668 insertion séquence is981; Lactococcus lactis
1225 ymbl 98% Q48667 insertion séquence is981; Lactococcus lactis
1226 ymbJ 32% 032802 x42; Lactococcus lactis
1227 ymbK putative
1228 ymcA putative
1229 ymcB 21% Q9X336 pxol-66; Bacillus anthracis
1230 ymcC putative
1231 ymcD 98% Q48667 insertion séquence is981; Lactococcus lactis
1232 tra981F 91% Q48668 insertion séquence is981; Lactococcus lactis
1233 ymcE 44% 006027 epsr protein; Lactococcus lactis
1234 ymcF 30% P32653 muramidase-released protein precursor; Streptococcus suis
1235 ymcG 31% Q9XAS7 r5 protein precursor; Streptococcus agalactiae
1236 tra905 96% P35881 transposase for insertion séquence élément is905; Lactococcus lactis
1237 ymcH 93% Q02146 hypothetical protein in hisc 5 'région; Lactococcus lactis
1238 hisC 98% Q02135 histidinol-phosphate aminotransferase; Lactococcus lactis
1239 hisX 91% Q02147 hypothetical 38.0 kd protein in hisc-hisg intergenic région; Lactococcus lactis
1240 hisG 98% Q02129 atp phosphoribosyltransferase; Lactococcus lactis
1241 hisD 93% Q02136 histidinol dehydrogénase; Lactococcus lactis
1242 ymdA 87% Q02148 hypothetical 30.7 kd protein in hisd-hisb intergenic région; Lactococcus lactis
1243 hisB 98% Q02134 i idazoleglycerol-phosphate dehydratase;
Lactococcus lactis
1244 ymdC 99% Q02149 probable aminoglycoside 3 ' -phosphotransferase;
Lactococcus lactis
1245 hisH 98% Q02132 amidotransferase hish; Lactococcus lactis
1246 hisA 96% Q02131 phosphoribosylformimino-5-aminoimidazole carboxamide ribotide isomérase; Lactococcus lactis
1247 hisF 89% Q02133 hisf protein; Lactococcus lactis
1248 hisl 99% Q02130 histidine biosynthesis bifunctional protein hisie [includes: phosphoribosyl-amp cyclohydrolase ; phosphori . Lactococcus lactis
1249 hisK 95% Q02150 hypothetical 31.3 kd protein in hisie 3 'région;
Lactococcus lactis
1250 ymdE 99% 034131 hypothetical 36.8 kd protein; Lactococcus lactis
1251 leuA 93% Q02141 2-isopropylmalate synthase; Lactococcus lactis
1252 leuB 99% Q02143 3-isopropylmalate dehydrogénase; Lactococcus lactis
1253 ymeA putative
1254 leuC 93% Q02142 3-isopropylmalate dehydratase large subunit; Lactococcus lactis
1255 leuD 100% Q02144 3-isopropylmalate dehydratase small subunit; Lactococcus lactis
1256 ymeB 86% Q02151 hypothetical abc transporter atp-binding protein in leud 3 'région; Lactococcus lactis
1257 ilvD 95% Q02139 dihydroxy-acid dehydratase; Lactococcus lactis
1258 ilvB 92% Q02137 acetolactate synthase large subunit; Lactococcus lactis
1259 ilvN 98% Q02140 acetolactate synthase small subunit; Lactococcus lactis
1260 ilvC 96% Q02138 ketol-acid reductoisomerase (alpha-keto-beta- hydroxylacil reductoiso. Lactococcus lactis
1261 ilvA 96% 034132 ilva; Lactococcus lactis
1262 aldB 100% P95676 alpha-acetolactate décarboxylase; Lactococcus lactis
1263 aldR 99% 034133 putative regulator aldr; Lactococcus lactis
1264 ymfB putative
1265 dprA 43% P39813 smf protein; Bacillus subtilis
1266 topA 62% P39814 dna topoisomerase i; Bacillus subtilis
1267 gidC 65% P39815 gid protein; Bacillus subtilis
1268 ymfD 70% 069155 hypothetical 41.6 kd protein; Streptococcus mutans
1269 ymfE putative
1270 ymgA 46% 069155 hypothetical 41.6 kd protein; Streptococcus mutans
1271 ymgB putative
1272 ymgD putative
1273 ymgC 30% 005316 hypothetical 62.6 kd protein; Mycobacterium tuberculosis
1274 rlrA 30% 068014 adpl. lysr-type transcriptional activator; Acinetobacter sp
1275 ceo 94% P15244 n5-ornithine synthase (n5--l-ornithine:nadp; Lactococcus lactis
1276 ymgF 62% Q48607 putative 37-kda protein; Lactococcus lactis
1277 ymgG 92% Q48606 putative 20-kda protein; Lactococcus lactis
1278 ymgH 43% Q48605 putative 6-kda protein; Lactococcus lactis
1279 ymgl putative
1280 ymgj 49% P96594 ydas protein; Bacillus subtilis
1281 ymgK 53% Q9XBS1 2, 5-diketo-d-gluconate réductase; Zymomonas mobilis
1282 glpF2 55% P52281 glycerol uptake facilitator protein;
Streptococcus pneumoniae
1283 glpD 53% 087017 alpha-glycerophosphate oxidase; Streptococcus pneumoniae
1284 glpK 74% 034154 glycerol kinase; Enterococcus faecalis
1285 ymhA putative
1286 tra981G 92% Q48668 insertion séquence is981; Lactococcus lactis
1287 ymhB 96% Q48667 insertion séquence is981; Lactococcus lactis
1288 ymhC putative
1289 amyL 47% 031193 alpha amylase; Bacillus stearothermophilus
1290 IctO 45% Q44467 lactate oxidase; Aerococcus viridans
1291 aroH 41% 054459 phospho-2-dehydro-3-deoxyheptonate aldolase, trp-sensitive (3-deoxy-d-arabino-he. Erwinia herbicola
1292 metF 37% 067422 5, 10-methylenetetrahydrofolate réductase; Aquifex aeolicus
1293 metE 45% Q42699 Catharanthus roseus 5- methyltetrahydropteroyltriglutamate— homocysteine methyltransferase ( ...
1294 ymiA 44% 033330 transcriptional repressor; Mycobacterium tuberculosis
1295 mgtA 49% P39168 mg transport atpase, p-type 1; Escherichia coli
1296 dltD 90% 032815 d-alanine carrier homolog dltd; Lactococcus lactis
1297 dltC 41% AAF09203 dite; Lactobacillus rhamnosus
1298 dltB 48% CAB51920 intégral membrane protein; Listeria monocytogenes
1299 dltA 41% AAF09201 dlta; Lactobacillus rhamnosus
1300 thiE 37% P39594 thiamine-phosphate pyrophosphorylase; Bacillus subtilis
1301 thiDl 43% P44697 phosphomethylpyrimidine kinase; Haemophilus influenzae
1302 thiM 34% Q57233 hydroxyethylthiazole kinase; Haemophilus influenzae
1303 ymjE 25% Q54066 icaa; Staphylococcus epidermidis
1304 epsK 50% P97003 udp-n-acetylglucosamine-2-epimerase; Streptococcus pneumoniae
1305 y hG putative
1306 ymhH putative
1307 rplL 50% P02394 50s ribosomal protein 17/112; Bacillus subtilis
1308 rplJ 61% P42923 50s ribosomal protein 110; Bacillus subtilis
1309 ynaA putative
1310 ynaB 34% P45902 hypothetical transcriptional regulator in spoiiic-cwla intergenic région; Bacillus subtilis
1311 ynaC 36% 007549 hypothetical 76.3 kd protein; Bacillus subtilis
1312 ynaD 40% P77265 multidrug resistance-like atp-binding protein mdla; Escherichia coli
1313 ynaE 24% P50726 hypothetical 20.5 kd protein in sera-fer intergenic région; Bacillus subtilis
1314 rsuB 55% P35159 ribosomal large subunit pseudouridine synthase b; Bacillus subtilis
1315 ynaG 42% AAF11414 conserved hypothetical protein; Deinococcus radiodurans
1316 ynaH 37% P35154 hypothetical 29.6 kd protein in ribt-dacb intergenic région; Bacillus subtilis
1317 ynbA putative
1318 ynbB 28% 031698 ykul protein; Bacillus subtilis
1319 ynbC 33% P94559 hypothetical 19.2 kd protein in rph-ilvb intergenic région; Bacillus subtilis
1320 ynbD 50% P94558 hypothetical 21.9 kd protein; Bacillus subtilis
1321 mûri 50% 031338 glutamate racemase; Bacillus cereus
1322 ynbE 37% P45708 hypothetical 8.3 kd protein in ttk-ccda intergenic région; Bacillus subtilis
1323 lysA 39% P31851 taba protein; Pseudomonas syringae
1324 gltD 47% Q51584 small subunit of nadh-dependent glutamate synthase; Plectonema boryanum
1325 gltB 48% P39812 glutamate synthase [nadph] large chain; Bacillus subtilis
1326 yncA 44% P40892 putative acetyltransferase in hxtll-hxt8 intergenic région; Saccharomyces cerevisiae
1327 bcaT 69% P54689 branched-chain amino acid aminotransferase;
Haemophilus influenzae
1328 yncB 94% 030419 hypothetical protein in gadb 3 'région;
Lactococcus lactis
1329 gadB 97% 030418 glutamate décarboxylase; Lactococcus lactis
1330 gadC 90% 030417 amino acid antiporter gadc; Lactococcus lactis
1331 gadR 94% 030416 positive regulator gadr; Lactococcus lactis
1332 rnhB 88% 030415 ribonuclease hii; Lactococcus lactis
1333 ylqL 46% 031743 ylqf protein; Bacillus subtilis
1334 yndA putative
1335 yndB 28% AAF10898 carboxymethylenebutenolidase-related protein; Deinococcus radiodurans
1336 rdrB 41% P94591 similar to phosphotransferase system regulator; Bacillus subtilis
1337 yndC putative
1338 yndD putative
1339 yndE putative
1340 yndF 34% P25146 internalin a precursor; Listeria monocytogenes
1341 yndG 57% 005703 adca protein; Streptococcus pneumoniae
1342 tra983D 50% 087534 putative transposase; Streptococcus pyogenes
1343 ipd 42% P71323 indolepyruvate décarboxylase; Erwinia herbicola
1344 rmaF 32% P31078 petp protein; Rhodobacter capsulatus
1345 rlrC 27% P73862 rubisco opéron transcriptional regulator; Synechocystis sp
1346 yneB 34% AAF10396 lipase, putative; Deinococcus radiodurans
1347 yneC putative
1348 yneD 38% Q9ZKW1 putative; Helicobacter pylori j 99
1349 yneE 38% Q06861 possible virulence-regulating 38 kd protein; Mycobacterium tuberculosis
1350 yneF putative
1351 yneG 36% AAD51848 as4. arsd; Sinorhizobium sp
1352 yneH 29% 031602 yjbd protein; Bacillus subtilis
1353 pabB 38% Q9ZV26 similar to streptomyces papa; Arabidopsis thaliana
1354 pabA 50% P06193 para-aminobenzoate synthase glutamine amidotransferase component ii; Salmonella typhimurium
1355 mtsA 74% Q53891 scba; Streptococcus cristatus
1356 mtsC 59% P42361 29 kd membrane protein in psaa 5 'région; Streptococcus gordonii challis
1357 mtsB 61% 068832 putative atp-binding protein; Streptococcus pneumoniae
1358 ynfC 29% 086747 hypothetical 14.8 kd protein; Streptomyces coelicolor
1359 ynfD 38% 050571 hypothetical 10.1 kda protein; Bacillus firmus
1360 sbcC 22% 067124 hypothetical 115.9 kd protein; Aquifex aeolicus
1361 sbcD 34% 083634 exonuclease, putative; Treponema pallidum
1362 panE 31% CAB49673 probable 2-dehydropantoate 2-reductase; Pyrococcus abyssi
1363 ynfG 44% 031602 yjbd protein; Bacillus subtilis
1364 ynfH 28% Q9X6M3 proline/threonine-rich protein; Salmonella typhi
1365 yngA putative
1366 yngB 59% P95752 fibronectin-binding protein-like protein a; Streptococcus gordonii
1367 yngC 46% P36999 rrna -methyltransferase; Escherichia coli
1368 yngD 27% P36999 rrna -methyltransferase; Escherichia coli
1369 yngE 62% 005253 hypothetical 56.3 kd protein; Bacillus subtilis
1370 yngF 34% 005254 hypothetical 36.8 kd protein; Bacillus subtilis
1371 yngG 47% 005255 hypothetical 33.7 kd protein; Bacillus subtilis
1372 ldh 96% P94885 1-lactate dehydrogénase; Lactococcus lactis
1373 pyk 98% Q07637 pyruvate kinase; Lactococcus lactis
1374 pfk 90% Q07636 6-phosphofructokinase; Lactococcus lactis
1375 ynhA putative
1376 nagA 36% P96166 n-acetylglucosaminé-6-phosphate deacetylase; Vibrio furnissii
1377 ynhC 54% P37535 hypothetical 43.8 kd protein in xpac-abrb intergenic région; Bacillus subtilis
1378 ynhD 18% P37467 xpac protein; Bacillus subtilis
1379 gpdA 51% P46919 glycerol-3-phosphate dehydrogénase [nad+] (nad; Bacillus subtilis
1380 hasC 73% 086882 utp-glucose-1-phosphate uridylyltransferase; Streptococcus pneumoniae
1381 ynhH 77% Q08009 export élément bll; Lactococcus lactis
1382 ynhl 76% 032817 gerça; Lactococcus lactis
1383 ispB 96% 032818 gerce; Lactococcus lactis
1384 gidB 55% P25813 glucose inhibited division protein b; Bacillus subtilis
1385 yniC putative
1386 pyrF 97% P50924 orotidine 5 ' -phosphate décarboxylase; Lactococcus lactis
1387 pyrDb 88% P54322 dihydroorotate dehydrogénase b; Lactococcus lactis
1388 pyrZ 4 411%% P P4466553366 hypothetical 27.6 kd protein in pyrab-pyrd intergenic région; Bacillus caldolyticus
1389 yniG 31% CAB61253 orfb, orfc and hspl8 gène; Oenococcus oeni
1390 yniH 68% CAA76860 hypothetical 44.9 kd protein; Enterococcus faecalis
1391 ynil 51% 086211 hypothetical 43. kd protein; Enterococcus faecalis
1392 yniJ 33% 086210 hypothetical 29. kd protein; Enterococcus faecalis
1393 ynjA 58% BAA35957 hypothetical protein hi0694; Escherichia coli
1394 ynjB putative
1395 ynjC 23% Q9X336 pxol-66; Bacillus anthracis
1396 ynjD 22% 017893 f55bll.3 protein; Caenorhabditis elegans
1397 ynjE putative
1398 ynjF putative
1399 ynjG 22% Q22579 similar to a. faecalis poly depolymerase; Caenorhabditis elegans
1400 tra983E 50% 087534 putative transposase; Streptococcus pyogenes
1401 ynjH putative
1402 ynjl putative
1403 ynjJ 20% 094317 serine-rich protein; Schizosaccharomyces pombe
1404 carB 93% 032771 carbamoylphosphate synthetase; Lactococcus lactis
1405 gpo 93% 032770 glutathione peroxidase; Lactococcus lactis
1406 acmC 48% 032083 yube protein; Bacillus subtilis
1407 yoaB 41% 034431 ylob protein; Bacillus subtilis
1408 yoaD 39% Q9ZCA9 hypothetical 24.9 kd protein; Rickettsia prowazekii
1409 yoaF 30% 006531 hypothetical 21.2 kd protein; Lactobacillus fermentum
1410 yoaG putative
1411 yoaH 33% 027534 hypothetical 21.2 kd protein; Methanobacterium thermoautotrophicum
1412 yoal 27% P17419 possible fimbrial assembly protein fimc; Bacteroides nodosus
1413 yobA 34% Q57951 hypothetical protein mj0531; Methanococcus jannaschii
1414 arsC 58% P45947 putative arsenate réductase; Bacillus subtilis 1415 yobC putative 1416 pi301 41% Q38326 orf258; Lactococcus lactis phage bk5-t 1417 pi302 putative 1418 pi303 putative 1419 pi304 putative 1420 pi305 97% Q38323 orf259; Lactococcus lactis phage bk5-t 1421 pi306 65% Q38322 orf95; Lactococcus lactis phage bk5-t 1422 pi307 83% Q38133 orf47; Bacteriophage rit 1423 pi308 97% Q38321 orf75; Lactococcus lactis phage bk5-t 1424 pi309 78% Q38319 orf1904; Lactococcus lactis phage bk5-t 1425 pi310 78% 080183 gp57; Streptococcus thermophilus bacteriophage sfill
1426 pi311 78% 080182 gp373; Streptococcus thermophilus bacteriophage sfill
1427 pi312 52% Q38319 orf1904; Lactococcus lactis phage bk5-t 1428 pi313 38% Q38318 orf 410; Lactococcus lactis phage bk5-t 1429 pi314 34% 003937 minor capsid protein; Bacteriophage phigle 1430 pi315 putative 1431 pi316 putative 1432 pi317 48% 064291 hypothetical 21.8 kd protein; Streptococcus thermophilus bacteriophage sfil9
1433 pi318 36% Q38220 orfi; Bacteriophage 110
1434 pi319 36% Q38219 orfa; Bacteriophage 110
1435 pi320 29% Q9XJA3 putative head-tail joining protein; Streptococcus thermophilus bacteriophage dtl
1436 pi321 32% 064276 hypothetical 11.8 kd protein; Streptococcus thermophilus bacteriophage sfi21
1437 pi322 60% Q9XJV7 orf397 gp; Streptococcus thermophilus bacteriophage sfil9
1438 pi323 49% Q9XJA0 putative scaffolding protein; Streptococcus thermophilus bacteriophage dtl
1439 pi324 52% Q9XJ81 orf384 gp; Streptococcus thermophilus bacteriophage sfi21
1440 pi325 46% Q9XJ98 putative head-tail joining protein; Streptococcus thermophilus bacteriophage dtl
1441 pi326 62% Q9XJW0 orf623 gp; Streptococcus thermophilus bacteriophage sfil9
1442 pi327 44% Q9XJ95 hypothetical 17.4 kd protein; Streptococcus thermophilus bacteriophage dtl
1443 pi328 42% CAB52516 hypothetical 20.6 kd protein; Lactobacillus bacteriophage phi adh
1444 pi329 putative 1445 pi330 69% 053060 hypothetical 16.9 kd protein; Lactococcus lactis
1446 pi331 putative 1447 pi332 putative 1448 pi333 86% 021897 hypothetical 12.7 kd protein; Bacteriophage ski 1449 pi334 46% Q38107 orf21; Bacteriophage rit 1450 pi335 97% Q38106 dutpase; Bacteriophage rit 1451 pi336 putative 1452 pi337 37% Q38105 orfl9; Bacteriophage rit
1453 pi338 46% Q38444 orf2; Bacteriophage t5
1454 pi339 25% Q90767 atrial-specific myosin heavy-chain; Gallus gallus
1455 pi340 80% Q9XJF1 hypothetical 22.4 kd protein; Bacteriophage tuc2009
1456 pi341 93% Q38103 orfl7; Bacteriophage rit, and bacteriophage tuc2009
1457 pi342 putative
1458 pi343 88% Q38102 orfl6; Bacteriophage rit
1459 pi344 70% Q38101 orfl5; Bacteriophage rit
1460 pi345 putative
1461 pi346 37% 003914 zinc finger protein; Bacteriophage phigle
1462 pi347 35% Q9XJE6 putative replisome organiser protein; Bacteriophage tuc2009
1463 pi348 66% Q9XJE5 putative single stranded binding protein; Bacteriophage tuc2009
1464 pi349 31% AAF10011 hypothetical 23.0 kd protein; Deinococcus radiodurans
1465 pi350 78% 048508 hypothetical 14.7 kd protein; Bacteriophage tp901-l
1466 pi351 100% Q38272 orf71; Lactococcus bacteriophage
1467 pi352 98% Q9XJE0 hypothetical 9.9 kd protein; Bacteriophage tuc2009
1468 pi353 95% Q38333 orfll3; Lactococcus lactis phage bk5-t
1469 pi354 putative
1470 pi355 95% 048505 hypothetical 28.3 kd protein; Bacteriophage tp901-l
1471 pi356 59% 064369 hypothetical 9.2 kd protein; Lactobacillus casei bacteriophage a2
1472 pi357 56% 064370 repressor; Lactobacillus casei bacteriophage a2
1473 pi358 37% AAF12709 hypothetical 21.8 kd protein; Bacteriophage tpw22
1474 pi359 33% 021991 orf203 protein; Streptococcus thermophilus bacteriophage sfi21
1475 pi360 54% Q38159 integrase; Bacteriophage t2
1476 yofM 71% P96468 ylxm; Streptococcus mutans
1477 IrrB 37% Q9ZI97 putative response regulator; Lactobacillus sake
1478 kinB 87% 007383 histidine kinase; Lactococcus lactis
1479 yogA putative
1480 rgrB 34% 034817 yvoa; Bacillus subtilis
1481 bmpA 48% 005252 hypothetical lipoprotein yufn precursor; Bacillus subtilis
1482 cdd 55% CAB51906 cytidine deaminase; Bacillus psychrophilus
1483 deoC 61% P39121 deoxyribose-phosphate aldolase; Bacillus subtilis
1484 yogE putative
1485 pdp 55% P77836 pyrimidine-nucleoside phosphorylase; Bacillus stearothermophilus
1486 yogG 44% Q53753 hypothetical 22.7 kd protein; Staphylococcus aureus
1487 coaA 43% P44793 pantothenate kinase; Haemophilus influenzae
1488 yogi putative
1489 yogJ 30% 085699 hypothetical 35.5 kd protein; Streptomyces lividans
1490 yogL 51% 006027 epsr protein; Lactococcus lactis
1491 yogM 48% P77174 hypothetical 23.9 kd protein in csta-dsbg intergenic région; Escherichia coli
1492 yohA 27% BAA35232 orf_id:ol66#5; Escherichia coli
1493 yohB 30% BAA35232 orf_id:ol66#5; Escherichia coli
1494 yohC 24% 067157 transcriptional regulator; Aquifex aeolicus
1495 yohD putative
14 96 busAB 90 % AAF04259 glycine-betaine binαmg permease protein;
Lactococcus lactis
1497 busAA 96% AAF04258 busaa; Lactococcus lactis 14 98 busR 36% P13669 fatty acyl responsive regulator; Escherichia coli
14 99 yohH 27 % Q56916 trsd; Yersinia enterocolitica 1500 yohJ 28 % Q9WZ 90 lipopolysaccharide biosynthesis protein, putative; Thermotoga maritima
1501 yoiA 20% 096133 hypothetical 237.7 kd protein; Plasmodium falciparum
1502 yoiB 40% Q9X4V4 cps2j; Streptococcus suis
1503 yoiC 27% Q02290 xylanase b; Neocallimastix patriciarum
1504 bglH 64% 086291 beta-glucosidase; Lactobacillus plantarum
1505 ptbA 49% Q46129 pts-dependent enzyme ii; Clostridium longisporum
1506 bglR 98% Q48639 bglr; Lactococcus lactis
1507 trpA 94% Q01997 tryptophan synthase alpha chain; Lactococcus lactis
1508 trpB 100% Q01998 tryptophan synthase beta chain; Lactococcus lactis
1509 yojB 39% AAF10375 acetyltransferase, putative; Deinococcus radiodurans
1510 yojC putative
1511 trpF 100% Q02002 n-anthranilate isomérase; Lactococcus lactis
1512 trpC 100% Q01999 indole-3-glycerol phosphate synthase; Lactococcus lactis
1513 trpD 100% Q02000 anthranilate phosphoribosyltransferase; Lactococcus lactis
1514 trpG 99% Q02003 anthranilate synthase component ii; Lactococcus lactis
1515 trpE 95% Q02001 anthranilate synthase component i; Lactococcus lactis
1516 ypaA 70% Q02009 hypothetical 13.3 kd protein in trpe 5 'région; Lactococcus lactis
1517 rmaC 53% P96707 putative nadh nitroreductase ydgi; Bacillus subtilis
1518 ypaC 29% 087832 methyltransferase; Streptomyces antibioticus
1519 ypaD 31% AAF13747 hypothetical 24.5 kd protein; Zymomonas mobilis
1520 ypaE 31% AAF13747 hypothetical 24.5 kd protein; Zymomonas mobilis
1521 fur 35% AAF00079 ferrie uptake regulator homolog; Staphylococcus aureus
1522 ypaG 37% P54940 hypothetical 13.0 kd protein in idh-deor intergenic région precursor; Bacillus subtilis
1523 ypaH 32% P96661 hypothetical 35.3 kd protein in espe-nap intergenic région; Bacillus subtilis
1524 rmeB 36% P44558 hypothetical transcriptional regulator hi0186; Haemophilus influenzae
1525 ypal 35% 054197 clavulanate-9-aldehyde reducatase; Streptomyces clavuligerus
1526 dxs 35% P26242 probable l-deoxyxylulose-5-phosphate synthase; Rhodobacter capsulatus
1527 rmaE 30% 085850 marr family regulator; Sphingomonas aromatici orans
1528 ypbB 26% AAF12002 transport protein, putative; Deinococcus radiodurans
1529 ypbC 23% CAB50319 dinf related; Pyrococcus abyssi
1530 ypbD 23% P70939 orf protein; Bacteroides ovatus
1531 guaA 94% Q9Z6H4 gmp synthase; Lactococcus lactis
1532 scrK 61% CAB09691 fructokinase; Lactococcus lactis
1533 ypbG 29% 051771 xylose opéron regulatory protein; Borrelia burgdorferi
1534 ypcA 50% 005508 c. thermocellum beta-glucosidase; Bacillus subtilis
1535 ypcB putative
1536 ypcC 32% Q9XBW4 immunoreactive 92 kda antigen pg21; Porphyromonas gingivalis
1537 ypcD 38% Q9ZB22 endo-beta-n-acetylglucosaminidase; Arthrobacter protophormiae
1538 dexB 55% 084995 alpha, 1-6-glucosidase; Streptococcus pneumoniae
1539 lnbA 28% Q9Z4I7 lacto-n-biosidase precursor; Streptomyces sp
1540 ypcG 27% Q9WYP9 sugar abc transporter, periplasmic sugar-binding protein, putative; Thermotoga maritima
1541 ypcH 41% Q44421 sugar-binding transport protein; Anaerocellum thermophilum
1542 ypdA 44% Q44420 sugar-binding transport protein; Anaerocellum thermophilum
1543 ypdB 26% BAA35398 hypothetical protein in hrsa 3 'région; ; Escherichia coli
1544 ypdC 42% CAB52976 hypothetical 47.8 kd protein; Streptomyces coelicolor
1545 rliB 31% Q45831 transcription regulatory protein rega; Clostridium acetobutylicu
1546 ypdD 33% AAD51075 immunoreactive 89kd antigen pg87; Porphyromonas gingivalis
1547 ypdE 41% P74690 hypothetical 92.4 kd protein; Synechocystis sp
1548 xylT 60% 052733 d-xylose-proton symporter; Lactobacillus brevis
1549 xyaX 26% P77862 galactoside o-acetyltransferase; Escherichia coli
1550 xynB 51% 052575 xylosidase/arabinosidase; Selenomonas ruminantium
1551 xynT 97% AAD20246 xyloside transporter; Lactococcus lactis
1552 xylM 99% Q9X417 mutarotase; Lactococcus lactis
1553 xylB 95% Q9X419 xylulokinase; Lactococcus lactis
1554 xylA 93% Q9X416 xylose isomérase; Lactococcus lactis
1555 xylR 94% AAD20248 xylose regulatory protein; Lactococcus lactis
1556 purK 100% Q9ZF42 purk protein; Lactococcus lactis
1557 purE 91% Q9ZF43 pure protein; Lactococcus lactis
1558 purD 99% Q9ZF44 purd protein; Lactococcus lactis
1559 ypfD 90% Q9ZF45 hypothetical 14.0 kd protein; Lactococcus lactis
1560 tra983F 50% 087534 putative transposase; Streptococcus pyogenes
1561 ypfE 26% 035018 lmrb; Bacillus subtilis
1562 ypfF 32% 006480 yfnb; Bacillus subtilis
1563 purH 56% P12048 B bifunctional purine biosynthesis protein purh [includes : phosphoribosylaminoimidazolecarboxamide formyltransferase ; imp cyclohydrolase (ec 3...
1564 hprT 59% P94303 hypoxanthine-guanine phosphoribosyltransferase; Bacillus firmus
1565 ypgB 29% Q19391 similar to dihydroflavonol-4-reductase; Caenorhabditis elegans
1566 ypgC putative
1567 ypgD 28% Q48569 abc transporter; Lactobacillus helveticus
1568 purN 47% AAF08602 phosphoribosylglycinamide formyltransferase homolog; Streptococcus pyogenes
1569 purM 90% 068186 phosphoribosylformylglycinamide cyclo-ligase; Lactococcus lactis
1570 clpB 94% 068185 clpb chaperone homolog; Lactococcus lactis
1571 ypgH putative
1572 yphA putative
1573 purF 94% Q9ZB05 phosphoribosylpyrophosphate amidotransferase; Lactococcus lactis
1574 yphC 41% CAB53269 putative oxidoreductase; Streptomyces coelicolor
1575 purL 94% Q9ZB06 phosphoribosylformylglycinamidine synthetase ii;
Lactococcus lactis
1576 purQ 95% Q9ZB07 phosphoribosylformylglycinamidine synthetase i;
Lactococcus lactis
1577 yphF 71% Q9ZB08 hypothetical 9.9 kd protein; Lactococcus lactis
1578 purC 92% AAD12623 phosphoribosylaminoimidazolesuccinocarboxamide synthetase; Lactococcus lactis
1579 yphH 41% Q9X0A3 hypothetical 15.1 kd protein; Thermotoga maritima
1580 yphl putative
1581 yphJ 37% Q9XD79 2065. 4-carboxymuconolactone decarboxylase/3- oxoadipate enol-lactone hydrolase; Streptomyces sp
1582 yphK putative
1583 ypiA 73% P25145 hypothetical oxidoreductase in inla 5' région; Listeria monocytogenes
1584 ypiB 31% CAB61253 orfb, orfc and hsplδ gène; Oenococcus oeni
1585 ypiC 35% P97247 hypothetical 17.1 kd protein; Bacillus subtilis
1586 thyA 96% P19368 thymidylate synthase; Lactococcus lactis
1587 ypiE putative
1588 ypiF putative
1589 ypiG putative
1590 ypiH putative
1591 tra981H 92% Q48668 insertion séquence is981; Lactococcus lactis
1592 ypil 100% Q48667 insertion séquence is981; Lactococcus lactis
1593 ypiJ putative
1594 ypiK putative
1595 ypiL 18% 039307 positional counterpart of hsv-1 gène us5; Equine herpesvirus 4
1596 ypjA 40% 034179 dehydrogénase; Halobacterium volcanii
1597 ypjB putative
1598 ypjC putative
1599 pyrDa 92% P54321 dihydroorotate dehydrogénase a; Lactococcus lactis
1600 ypjE 54% P54154 putative peptide methionine sulfoxide réductase (peptide met; Bacillus subtilis
1601 ypjF 28% CAB61731 putative oxidoreductase; ; Streptomyces coelicolor
1602 ypjG 41% 006476 yfmr; Bacillus subtilis
1603 rlrE 51% CAB36982 cpsy protein; Streptococcus agalactiae
1604 ypjH 32% BAA35229 hypothetical protein in esta 3 'région; ; Escherichia coli
1605 ypjl 80% Q48644 cremoris partial putative open reading frame; Lactococcus lactis
1606 pepDB 53% Q48558 dipeptidase; Lactobacillus helveticus
1607 papL 39% P42977 poly polymérase; Bacillus subtilis
1608 yqaB 29% AAF10345 hypothetical 18.1 kd protein; Deinococcus radiodurans
1609 dapB 50% P42976 dihydrodipicolinate réductase; Bacillus subtilis
1610 yqaC 33% P32436 degv protein; Bacillus subtilis
1611 yqaD putative
1612 trmD 57% 031741 trna -methyltransferase; Bacillus subtilis
1613 ri M ^ 6% 031740 probable 16s rrna processing protein rimm; Bacillus subtilis
1614 yqaG 30% 028521 lysophospholipase; Archaeoglobus fulgidus
1615 hemH 37% P43413 ferrochelatase; Yersinia enterocolitica
1616 yqbA putative
1617 rpsP 65% P21474 30s ribosomal protein sl6; Bacillus subtilis
1618 mvaA 38% 028538 3-hydroxy-3-methy g utaryι-coenzyme a reαuctase;
Archaeoglobus fulgidus
1619 yqbC 47% AAF11511 acetyl-coa acetyltransferase; Deinococcus radiodurans
1620 yqbD 55% Q9ZB67 similar to condensing-enzymes; Staphylococcus carnosus
1621 nagB 49% 031458 hypothetical 27.3 kd protein in gltp-cwlj intergenic région; Bacillus subtilis
1622 yqbF 26% P54567 hypothetical 34.6 kd protein in glnq-ansr intergenic région; Bacillus subtilis
1623 queA 63% 032054 s-adenosylmethionine : trna ribosyltransferase- isomerase; Bacillus subtilis
1624 yqbH 55% 006027 epsr protein; Lactococcus lactis
1625 yqbl putative
1626 yqbJ 29% Q9X336 pxol-66; Bacillus anthracis
1627 yqbK 21% 076602 h02f09.3 protein; Caenorhabditis elegans
1628 yqcA 36% Q54942 orf iota; Streptococcus pyogenes
1629 yqcB putative
1630 yqcC putative
1631 yqcD putative
1632 yqcE putative
1633 yqcF putative
1634 yqcG putative
1635 obgL 59% P20964 spoOb-associated gtp-binding protein; Bacillus subtilis
1636 ftsQ 30% P16655 division initiation protein; Bacillus subtilis
1637 murG 50% 007109 undecaprenyl-pp-n-acetylmuramic acid- pentapeptide n-acetylglucosamine transferase; Enterococcus faecalis
1638 murD 58% Q9ZHB0 d-glutamic acid adding enzyme murd; Streptococcus pneumoniae
1639 glnB 57% 030794 nitrogen regulatory protein p-ii; Nostoc punctiforme
1640 amtB 38% 026759 putative ammonium transporter mth663; Methanobacterium thermoautotrophicum
1641 kinA 87% 007382 histidine kinase llkina; Lactococcus lactis
1642 IrrA 61% 087527 csrr; Streptococcus pyogenes
1643 yqdA 28% 034445 ylbn protein; Bacillus subtilis
1644 rpmE 67% Q9ZH28 ribosomal protein 131; Listeria monocytogenes
1645 yqeA putative
1646 yqeB putative
1647 yqeC 68% Q38326 orf258; Lactococcus lactis phage bk5-t
1648 yqeD 36% 034870 ykue protein; Bacillus subtilis
1649 pyrAA 66% P77885 L glutaminase of carbamoyl-phosphate synthase (carbamoyl-phosphate synthase (carbamoyl- phosphate synthetase (gluta...
1650 pyrB 55% P77883 aspartate carbamoyltransferase; Lactobacillus plantarum
1651 pyrP 51% 052708 putative uracil permease; Enterococcus faecalis
1652 pyrR 60% 052707 atténuation regulatory protein; Enterococcus faecalis
1653 yqeH putative
1654 rarA 26% Q55940 transcriptional repressor smtb homolog; Synechocystis sp
1655 yqel 29% 007084 cation transport protein yrdo; Bacillus subtilis
1656 proA 66% P96489 gamma-glutamyl phosphate réductase; Streptococcus thermophilus
1657 proB 54% P96488 glutamate 5-kinase; Streptococcus thermophilus
1658 yqfA 32% CAB49904 hypothetical 52.3 kd protein; Pyrococcus abyssi
1659 yqfB putative
1660 yqfC putative
1661 yqfD 25% 025889 hypothetical protein hpl331; Helicobacter pylori
1662 yqfE 34% CAB61933 putative réductase; Streptomyces coelicolor
1663 yqfF 48% P37354 spermidine nl-acetyltransferase; Escherichia coli
1664 ffh 65 Q54431 signal récognition particle protein; Streptococcus mutans
1665 yqfG 29% 068831 surface antigen bspa; Bacteroides forsythus
1666 yqgA 37% Q45493 hypothetical 61.5 kd protein in adec-pdha intergenic région; Bacillus subtilis
1667 yqgG 53% P26606 hypothetical 23.2 kd protein in slp-hdeb intergenic région; Escherichia coli
1668 dapA 47% Q04796 dihydrodipicolinate synthase; Bacillus subtilis 1669 yqgC 34% AAF10361 mutt/nudix family protein; Deinococcus radiodurans
1670 asd 69% P10539 aspartate-semialdehyde dehydrogénase; Streptococcus mutans
1671 yqgE 49% P22094 hypothetical 30.9 kd protein in pepx 5 'région. Lactococcus lactis , and lactococcus lactis
1672 yqgF putative 1673 tkt 55% P45694 transkétolase; Bacillus subtilis 1674 kdgA 42% Q9WXS1 2-dehydro-3-deoxyphosphogluconate aldolase/4- hydroxy-2-oxoglutarate aldolase; Thermotoga maritima
1675 kdgK 45% P50845 2-dehydro-3-deoxygluconokinase; Bacillus subtilis
1676 uxaC 47% P42607 uronate isomérase; Escherichia coli
1677 yqhA 40% P73504 hypothetical 33.0 kd protein; Synechocystis sp
1678 uxuT 22% AAD20246 xyloside transporter; Lactococcus lactis
1679 uxuA 57% Q9WXS4 d-mannonate hydrolase; Thermotoga maritima
1680 uxuB 49% Q9WXS3 d-mannonate oxidoreductase, putative; Thermotoga maritima
1681 kdgR 36% Q9ZFL9 regulatory protein; Bacillus stearothermophilus
1682 yqiA 22% Q54806 intégral membrane protein; Streptomyces pristinaespiralis
1683 rbsB 44% P36949 d-ribose-binding protein precursor; Bacillus subtilis
1684 rbsC 53% P96731 membrane transport protein; Bacillus subtilis
1685 rbsA 59% P96732 atp-binding transport protein; Bacillus subtilis
1686 rbsD 56% P36946 high affinity ribose transport protein rbsd; Bacillus subtilis
1687 rbsK 46% P36945 ribokinase; Bacillus subtilis
1688 rbsR 41% P36944 ribose opéron repressor; Bacillus subtilis
1689 purB 74% P12047 adenylosuccinate lyase; Bacillus subtilis
1690 aroD 36% P35146 3-dehydroquinate dehydratase; Bacillus subtilis
1691 yqjA putative
1692 trxA 59% CAB40815 thioredoxin; Listeria monocytogenes
1693 mutS 41% P94545 muts2 protein; Bacillus subtilis
1694 yqjB 30% P94543 hypothetical 19.5 kd protein; Bacillus subtilis
1695 trxB2 39% 005268 thioredoxine réductase; Bacillus subtilis
1696 cepA 98% Q9ZFC9 catabolite control protein; Lactococcus lactis
1697 pepQ 53% 030666 pepq; Streptococcus mutans
1698 yqjD 25% Q23915 protein kinase; Dictyostelium discoideum
1699 yqjE 48% P50840 hypothetical 43.5 kd protein in cotd-kdud intergenic région precursor; Bacillus subtilis
1700 yraA putative
1701 yraB 32% P50839 hypothetical 11.6 kd protein in cotd-kdud intergenic région; Bacillus subtilis
1702 yraC 36% 054085 hypothetical 39.7 kd protein; Streptococcus agalactiae
1703 yraD putative
1704 ftsK 44% P21458 stage iii sporulation protein e; Bacillus subtilis
1705 yraE 30% Q45494 hypothetical 28.9 kd protein; Bacillus subtilis
1706 yraF putative
1707 pta 62% P39646 probable phosphate acetyltransferase; Bacillus subtilis
1708 udk 57% 032033 uridine kinase; Bacillus subtilis
1709 yrbA 34% P42599 hypothetical 36.2 kd protein in ebgc-uxaa intergenic région; Escherichia coli
1710 yrbB 46% P19385 lysozyme; Bacteriophage cp-7
1711 yrbC 20% P39582 probable 1, 4-dihydroxy-2-naphthoate octaprenyltransferase; Bacillus subtilis
1712 yrbD 28% P73745 hypothetical 48.4 kd protein; Synechocystis sp
1713 yrbE putative
1714 yrbF putative
1715 yrbG putative
1716 yrbH putative
1717 yrbl 37% 030416 positive regulator gadr; Lactococcus lactis
1718 yrbJ 97% P49016 probable menaquinone biosynthesis methyltransferase; Lactococcus lactis
1719 yrbK 84% P49016 probable menaquinone biosynthesis methyltransferase; Lactococcus lactis
1720 pip 92% P49022 phage infection protein; Lactococcus lactis
1721 yrcA 58% P24240 6-phospho-beta-glucosidase ascb; Escherichia coli
1722 yrcB 55% Q9X1H3 conserved hypothetical protein; Thermotoga maritima
1723 tktB 34% 067036 hypothetical 69.9 kd protein; Aquifex aeolicus 1724 kinF 42% CAB54565 histidine kinase; Streptococcus pneumoniae 1725 IrrF 99% Q9ZI77 putative response regulator; Lactococcus lactis 1726 rliA 95% Q9ZI78 hypothetical 36.2 kd protein; Lactococcus lactis
1727 mapA 91% Q9ZI79 hypothetical 68.4 kd protein; Lactococcus lactis
1728 agi 42% P94451 exo-alpha-1, 4-glucosidase; Bacillus stearothermophilus
1729 amyY 38% P20845 alpha-amylase precursor; Bacillus megaterium
1730 maa 40% P77862 galactoside o-acetyltransferase; Escherichia coli
1731 malA 64% 084995 alpha, 1-6-glucosidase; Streptococcus pneumoniae
1732 dexC 49% P38940 neopullulanase; Bacillus stearothermophilus
1733 malE 27% 007009 hypothetical 45.5 kd protein; Bacillus subtilis
1734 malF 34% Q48396 cym a, b, c,d, e, f,g, h, i, j gènes; Klebsiella oxytoca
1735 malG 38% Q48397 cym a,b, c,d, e, f, g, h, i, j gènes; Klebsiella oxytoca
1736 yreA putative
1737 yreB putative
1738 yreC putative
1739 yreD 26% P77262 hypothetical 23.0 kd protein in intf-eaeh intergenic région; Escherichia coli
1740 yreE putative 1741 tra981I 92% Q48668 insertion séquence is981; Lactococcus lactis 1742 yrdA 100% Q48667 insertion séquence is981; Lactococcus lactis 1743 yrdB putative 1744 yreF 27% Q9XAS7 r5 protein precursor; Streptococcus agalactiae 1745 yrfA 36% 031245 orfl protein; Agrobacterium radiobacter 1746 yrfB 40% P54524 probable nadh-dependent flavin oxidoreductase yqig; Bacillus subtilis
1747 arcC3 54% 053090 carbamate kinase; Lactobacillus sake
1748 yrfC 49% AAD47622 bg33r. hypothetical 41.0 kd protein;
Pseudomonas sp
1749 tra983G 50% 087534 putative transposase; Streptococcus pyogenes
1750 yrfD 19% BAA84897 orf62 protein; Escherichia coli
1751 otcA 45% 058457 317aa long hypothetical ornithine carbamoyltransferase; Pyrococcus horikoshii
1752 IrrH 45% 087395 two-component response regulator orra; Anabaena sp
1753 yrfE 31% Q47828 psr; Enterococcus hirae
1754 cmk 50% 005386 cytidylate kinase-like protein; Bacillus cereus
1755 yrgA putative
1756 fer 36% P29604 ferredoxin; Thermococcus litoralis
1757 ptnAB 74% AAD46485 mannose-specific phosphotransferase System component iiab; Streptococcus salivarius
1758 ptnC 46% AAD46486 mannose-specific phosphotransferase System component iic; Streptococcus salivarius
1759 ptnD 70% AAD46487 mannose-specific phosphotransferase system component iid; Streptococcus salivarius
1760 yrgE 43% AAD46488 hypothetical 13.7 kd protein; Streptococcus salivarius
1761 yrgF 28% 051049 conserved hypothetical intégral membrane protein; Borrelia burgdorferi
1762 yrgG 85% Q48643 cremoris putative partial open reading frame; Lactococcus lactis
1763 serS 60% P37464 seryl-trna synthetase; Bacillus subtilis
1764 yrgH 38% 035046 yocd; Bacillus subtilis
1765 yrgl 26% P36942 probable phosphoglycérate mutase 2; Escherichia coli
1766 phoU 35% Q9X4T4 phou; Streptococcus pneumoniae
1767 pstA 63% Q58418 probable phosphate transport atp-binding protein pstb; Methanococcus jannaschii
1768 pstB 58% P46341 hypothetical abc transporter atp-binding protein in soda-comga intergenic région; Bacillus subtilis
1769 pstC 51% P46340 probable abc transporter permease protein in soda-comga intergenic région; Bacillus subtilis
1770 pstD 47% P46339 probable abc transporter permease protein in soda-comga intergenic région; Bacillus subtilis
1771 pstE 97% 066079 lipoprotein nlpl precursor; Lactococcus lactis
1772 pstF 56% 066079 lipoprotein nlpl precursor; Lactococcus lactis
1773 yrhG 70% 085201 vacb homolog; Streptococcus pneumoniae
1774 yrhH 29% 080443 fl6ml4.11 protein; Arabidopsis thaliana
1775 alaS 51% 034526 alanyl-trna synthetase; Bacillus subtilis
1776 pmpA 84% 066088 lipoprotein nlp4 precursor; Lactococcus lactis
1777 yriA 88% P94877 methyltransferase; Lactococcus lactis
1778 pepF 96% P54124 oligoendopeptidase f, plasmid; Lactococcus lactis
1779 coiA 74% P94875 transcription factor; Lactococcus lactis
1780 yriB 82% P94874 orf, gènes homologous to vsf-1 and pepf2 and gène encoding protein homologous to methyltransferase; Lactococcus lactis
1781 yriC 41% Q9ZB16 hypothetical 34.5 kd protein; Lactococcus lactis
1782 yriD 38% AAF12190 conserved hypothetical protein; Deinococcus radiodurans
1783 yrjA 31% P70947 hypothetical 30.6 kd protein; Bacillus subtilis
1784 yrjB 57% 007020 hypothetical 26.4 kd protein; Bacillus subtilis
1785 yrjC 97% 069147 putative iron-binding protein; Lactococcus lactis
1786 yrjD 77% 069148 hypothetical 25.1 kd protein; Lactococcus lactis
1787 yrjE 93% 069149 putative membrane spanning protein; Lactococcus lactis
1788 yrjF 28% P39074 bmru protein; Bacillus subtilis
1789 yrjG 31% 067622 hypothetical 64.3 kd protein; Aquifex aeolicus
1790 rpsT 40% BAA01302 ribosomal protein s20; Escherichia coli
1791 recD 40% 034481 yrrc protein; Bacillus subtilis
1792 yrjl 28% Q9X194 phosphoglycérate mutase; Thermotoga maritima
1793 pheA 86% P43909 prephenate dehydratase; Lactococcus lactis
1794 aroK 85% P43906 shikimate kinase; Lactococcus lactis
1795 aroA 89% P43905 3-phosphoshikimate 1-carboxyvinyltransferase (epsp synthas. Lactococcus lactis
1796 tyrA 77% P43901 prephenate dehydrogénase; Lactococcus lactis
1797 kinG 41% CAB54567 histidine kinase; Streptococcus pneumoniae
1798 IrrG 45% CAB54566 response regulator; Streptococcus pneumoniae
1799 ysaA putative
1800 ysaB 20% P42424 hypothetical 70.5 kd protein in idh 3 'région; Bacillus subtilis
1801 ysaC 49% P42423 hypothetical abc transporter atp-binding protein in idh 3 'région; Bacillus subtilis
1802 ysaD 37% P54940 hypothetical 13.0 kd protein in idh-deor intergenic région precursor; Bacillus subtilis
1803 aroC 58% P31104 chorismate synthase; Bacillus subtilis
1804 ysbA 32% Q57064 unidentified; Streptococcus pneumoniae
1805 ysbB 32% Q45498 hypothetical 24.6 kd protein; Bacillus subtilis
1806 ysbC 33% AAF10690 hypothetical 16.7 kd protein; Deinococcus radiodurans
1807 aroB 42% P73997 3-dehydroquinate synthase; Synechocystis sp
1808 aroE 37% CAB49372 shikimate 5-dehydrogenase; Pyrococcus abyssi
1809 ysbD 42% 069601 hypothetical 24.3 kd protein; Mycobacterium leprae
1810 glnP 98% AAF16724 putative intégral membrane protein; Lactococcus lactis
1811 glnQ 62% 029577 glutamine abc transporter, atp-binding protein; Archaeoglobus fulgidus
1812 yscA 21% 076602 h02f09.3 protein; Caenorhabditis elegans
1813 yscB putative
1814 atpE 80% AAF02208 hπ—atpase cytoplasmic fl-part epsilon-subunit ; Lactococcus lactis
1815 atpD 91% AAF02210 h+-atpase cytoplasmic fl-part beta-subunit; Lactococcus lactis
1816 atpG 89% AAF02207 h+-atpase cytoplasmic fl-part gamma-subunit; Lactococcus lactis
1817 atpA 97% AAF02206 h+-atpase cytoplasmic fl-part alpha-subunit; Lactococcus lactis
1818 atpH 92% AAF02205 h+-atpase cytoplasmic fl-part delta-subunit; Lactococcus lactis
1819 atpF 99% AAF02204 h+-atpase fO-part b-subunit; Lactococcus lactis
1820 atpB 94% AAF02203 hπ—atpase fO-part a-subunit; Lactococcus lactis
1821 yscD putative
1822 yscE 94% AAF02201 lipase; Lactococcus lactis
1823 comEC 40% 085198 compétence protein; Streptococcus pneumoniae
1824 comEA 41% P39694 corne opéron protein 1; Bacillus subtilis
1825 ysdA 25% Q48856 hypothetical 46.8 kd protein; Lactobacillus sake
1826 ysdB 4 433%% 008877556644 nata; Bacillus firmus
1827 ysdC putative
1828 ysdD 30% 068850 hypothetical 19.3 kd protein; Vibrio cholerae
1829 ysdE 23% Q57898 hypothetical protein mj0456; MMethanococcus jannaschii
1830 tenA 37% P25052 transcriptional activator tena; Bacillus subtilis
1831 birAl 31% 030162 biotin opéron repressor/biotin-- [acetyl coa carboxylase] ligase; Archaeoglobus fulgidus
1832 yseA 30% 057898 hypothetical protein ph0159; Pyrococcus horikoshii
1833 yseB 27% 007619 hypothetical 52.9 kd protein; Bacillus subtilis 1834 fadA 35% P44873 acetyl-coa acetyltransferase; Haemophilus influenzae
1835 yseC putative
1836 yseD putative
1837 fabG2 40% 067610 3-oxoacyl- [acyl-carrier protein] réductase; Aquifex aeolicus
1838 yseE 37% Q9WZQ7 conserved hypothetical protein; Thermotoga maritima
1839 yseF 65% 032162 yuru protein; Bacillus subtilis
1840 yseG 52% 032163 yurv protein; Bacillus subtilis
1841 yseH putative
1842 ysel 58% 032164 yurw protein; Bacillus subtilis
1843 ysfA 39% 032165 yurx protein; Bacillus subtilis
1844 ysfB 73% P80866 végétative protein 296; Bacillus subtilis
1845 ysfC 57% Q9XDW8 rgpg; Streptococcus mutans
1846 ysfD 27% Q9XDW9 négative regulator of genetic compétence; Streptococcus mutans
1847 gltQ 60% 029577 glutamine abc transporter, atp-binding protein; Archaeoglobus fulgidus
1848 gltP 42% Q9WZ61 amino acid abc transporter, permease protein; Thermotoga maritima
1849 ysfG 28% 034799 ytlr; Bacillus subtilis
1850 rpoC 70% Q9Z9M1 rpoc protein; Bacillus sp
1851 rpoB 69% CAB56706 dna-dependent rna polymérase subunit beta; Listeria monocytogenes
1852 codZ 26% P39779 cody protein; Bacillus subtilis
1853 ysgA 48% 006027 epsr protein; Lactococcus lactis
1854 pepO 99% Q09145 neutral endopeptidase; Lactococcus lactis
1855 ysgB 39% Q50855 putative methylguanine-dna methyltransferase; Myxococcus xanthus
1856 ysgC 31% 034674 ytgp; Bacillus subtilis
1857 murE 28% 067631 udp-murnac-tripeptide synthetase; Aquifex aeolicus
1858 adhA 63% P20368 alcohol dehydrogénase i; Zymomonas mobilis
1859 recQ 49% 034748 recq homolog; Bacillus subtilis
1860 yshA 53% Q9ZJ11 yjem; Salmonella typhimurium
1861 pepT 94% P42020 peptidase t; Lactococcus lactis
1862 yshB 43% 068580 hypothetical 11.4 kd protein; Streptococcus mutans
1863 yshC 70% P95765 intrageneric coaggregation-relevant adhesin; Streptococcus gordonii
1864 pflA 67% 068575 pyruvate formate-lyase activating enzyme; Streptococcus mutans
1865 ysiA 55% 068574 putative hemolysin; Streptococcus mutans
1866 ysiB 43% 068573 putative permease; Streptococcus mutans
1867 ysiC 36% Q9X244 conserved hypothetical protein; Thermotoga maritima
1868 ysiD 54% 086222 hypothetical 25.1 kd protein; Haemophilus influenzae rd
1869 uvrA 63% 034863 excinuclease abc subunit a; Bacillus subtilis
1870 ysiE 24% Q12263 serine/threonine-protein kinase gin4; Saccharomyces cerevisiae
1871 cobC 33% P77109 putative cobalamin synthesis protein; Escherichia coli
1872 ysiG 52% Q51440 d-lactate dehydrogénase; Pediococcus acidilactici
1873 ysjA 35% 032257 yvbw protein; Bacillus subtilis
1874 ysjB 28% BAA35876 mvim protein; Escherichia coli
1875 ysjC 35% 034664 ylos protein; Bacillus subtilis
1876 ysjD 47% Q05247 gène 37 protein; Mycobacteriophage 15
1877 ysjE putative
1878 ysjF putative
1879 asnS 57% P39772 asparaginyl-trna synthetase; Bacillus subtilis
1880 ysjG putative
1881 aspB 87% AAF12702 aspartate aminotransferase; Lactococcus lactis
1882 ysjH putative
1883 dinG 31% 066684 atp-dependent helicase; Aquifex aeolicus
1884 ytaA 33% Q57951 hypothetical protein mj0531; Methanococcus jannaschii
1885 ytaB 41% 005241 hypothetical 49.5 kd protein in tgl-pgi intergenic région; Bacillus subtilis
1886 ytaC 43% P12256 penicillin acylase; Bacillus sphaericus
1887 ytaD 27% Q9X7W7 hypothetical 31.4 kd protein; Streptomyces coelicolor
1888 oppA 87% Q07741 oligopeptide-binding protein oppa precursor; Lactococcus lactis
1889 oppC 94% Q07743 oligopeptide transport system permease protein oppc; Lactococcus lactis , and lactococcus lactis
1890 oppB 95% P50989 oligopeptide transport system permease protein oppb; Lactococcus lactis
1891 oppF 99% Q07734 oligopeptide transport atp-binding protein oppf; Lactococcus lactis , and lactococcus lactis
1892 oppD 99% P50980 oligopeptide transport atp-binding protein oppd; Lactococcus lactis
1893 rplT 54% P55873 50s ribosomal protein 120; Bacillus subtilis
1894 rpml 64% P55874 50s ribosomal protein 135; Bacillus subtilis
1895 infC 55% 053084 translation initiation factor if-3; Listeria monocytogenes
1896 ytbA putative
1897 ytbB 28% 006480 yfnb; Bacillus subtilis
1898 gidA 96% 032806 glucose inhibited division protein a; Lactococcus lactis
1899 ytbC putative
1900 ytbD 49% 006665 putative dna binding protein; Streptococcus gordonii
1901 ytbE 54% 031418 yazc protein; Bacillus subtilis
1902 cysS 47% Q06752 cysteinyl-trna synthetase; Bacillus subtilis
1903 ytcA putative
1904 cysE 50% Q06750 serine acetyltransferase; Bacillus subtilis
1905 ytcB putative
1906 pnpA 60% P50849 polyribonucleotide nucleotidyltransferase; Bacillus subtilis
1907 ytcC 78% 030413 hypothetical 31.2 kd protein; Lactococcus lactis
1908 prsB 51% 033924 prpp synthetase; Corynebacterium ammoniagenes
1909 ytcD 32% 026984 conserved protein; Methanobacterium thermoautotrophicum
1910 nifS 45% 034599 yrvo protein; Bacillus subtilis
1911 ytcE putative
1912 tuf 78% P33170 elongation factor tu; Streptococcus oralis
1913 ytdA putative
1914 ileS 62% Q9ZHB3 isoleucine-trna synthetase; Streptococcus pneumoniae
1915 ytdB 36% Q9ZHB4 cell division protein diviva; Streptococcus pneumoniae
1916 ytdC 35% Q9ZHB5 ylmh; Streptococcus pneumoniae
1917 ytdD 81% Q9ZAI8 hypothetical 10.9 kd protein; Lactococcus lactis
1918 ytdE 85% Q9ZAI9 hypothetical 21.9 kd protein; Lactococcus lactis
1919 ytdF 92% Q9ZAJ0 hypothetical 25.5 kd protein; Lactococcus lactis
1920 ftsZ 83% Q9ZAJ1 cell division protein ftsz; Lactococcus lactis
1921 ftsA 92% Q9ZAJ2 cell division protein ftsa; Lactococcus lactis
1922 yteA 33% P70945 hypothetical 31.3 kd protein; Bacillus subtilis
1923 trmH 45% Q06753 hypothetical trna/rrna methyltransferase yaco;
Bacillus subtilis
1924 yteB 32% 032159 hypothetical 39.4 kd oxidoreductase in hom-mrga intergenic région; Bacillus subtilis
1925 yteC 41% P22045 probable réductase; Leishmania major
1926 yteD 26% 069986 transmembrane efflux protein; Streptomyces coelicolor
1927 rlrB 26% 066882 transcriptional regulator; Aquifex aeolicus
1928 rmeA 37% 006008 mercuric résistance opéron regulatory protein;
Bacillus subtilis
1929 pepC 95% Q04723 aminopeptidase c; Lactococcus lactis
1930 yteE 87% Q04731 hypothetical protein in pepc 5 'région;
Lactococcus lactis
1931 pfs 38% P24247 mta/sah nucleosidase [includes: 5'- methylthioadenosine nucleosidase ; s- adenosylhomocysteine nucleosidase ] ; Escherichia coli
1932 ytfA putative
1933 ytfB 49% P54570 hypothetical 21.0 kd protein in glnq-ansr intergenic région; Bacillus subtilis
1934 glmU 54% P14192 udp-n-acetylglucosamine pyrophosphorylase ; Bacillus subtilis
1935 proC 37% Q04708 pyrroline-5-carboxylate réductase; Pisum sativum 1936 tra983H 50% 087534 putative transposase; Streptococcus pyogenes 1937 rpsO 61% P05766 30s ribosomal protein sl5; Bacillus stearothermophilus
1938 ytfC 86% Q9ZEK3 hypothetical 41.6 kd protein; Lactococcus lactis
1939 ytfD 93% Q9ZEK4 pppl protein; Lactococcus lactis
1940 sunL 92% Q9ZEK5 sunl protein; Lactococcus lactis
1941 ytgH 74% Q48606 putative 20-kda protein; Lactococcus lactis
1942 ytgA putative
1943 ytgB 52% P96594 ydas protein; Bacillus subtilis
1944 fmt 46% P94463 methionyl-trna formyltransferase; Bacillus subtilis
1945 yteG 42% Q9X7R8 hypothetical 17.7 kd protein; Streptomyces coelicolor
1946 ytgC 31% Q58549 adp-ribose pyrophosphatase; Methanococcus jannaschii
1947 ytgD putative
1948 priA 47% P94461 primosomal protein n'; Bacillus subtilis
1949 ytgE 43% 035011 yloh protein; Bacillus subtilis
1950 g k 60% 034328 ylod protein; Bacillus subtilis
1951 ytgF 54% 031774 ymda protein; Bacillus subtilis
1952 ytgG 39% P31470 hypothetical 23.3 kd protein in tnab-bglb intergenic région; Escherichia coli
1953 metK 65% P50307 s-adenosylmethionine synthetase; Staphylococcus aureus
1954 ythD 43% Q9ZKG8 cyclopocyclopropane fatty acid synthase; Helicobacter pylori j99
1955 cfa 43% 025171 cyclopropane fatty acid synthase; Helicobacter pylori
1956 birA2 33% 027938 biotin acetyl-coa carboxylase ligase / biotin opéron repressor bifunctional protein; Methanobacterium thermoautotrophicum
1957 ythA 38% Q9X0P0 conserved hypothetical protein; Thermotoga maritima
1958 ythB 46% Q9X0P0 conserved hypothetical protein; Thermotoga maritima
1959 ythC 23% 034628 yvlb; Bacillus subtilis
1960 acmB 42% 052362 n-acetylmuramidase precursor; Lactococcus lactis
1961 tra983I 50% 087534 putative transposase; Streptococcus pyogenes
1962 fbaA 74% 065944 fructose-bisphosphate aldolase; Streptococcus pneumoniae
1963 ytiA 32% P37027 hypothetical 22.1 kd protein in heml-pfs intergenic région; Escherichia coli
1964 thrS 59% P18255 threonyl-trna synthetase 1; Bacillus subtilis 1965 ytjA putative 1966 ytjB 25% P96593 hypothetical 45.7 kd protein in mutt-gsib intergenic région; Bacillus subtilis
1967 ytjC 36% AAD46617 nramp manganèse transport protein mnth; Escherichia coli
1968 ytj D 34% P37261 hypothetical 21.1 kd protein in fusl-agpl intergenic région; Saccharomyces cerevisiae
1969 upp 99% P50926 uracil phosphoribosyltransferase; Lactococcus lactis
1970 nah 88% Q48731 na/h antiporter homolog; Lactococcus lactis 1971 ytjE 37% Q08432 putative aminotransferase b; Bacillus subtilis 1972 metBl 50% 031631 yjci protein; Bacillus subtilis 1973 metA 53% Q9WZY3 homoserine o-succinyltransferase; Thermotoga maritima
1974 ytjF putative
1975 ytjG 26% Q9WY71 conserved hypothetical protein; Thermotoga maritima
1976 ytjH 37% P42096 lacx protein, chromosomal; Lactococcus lactis
1977 yuaA 38% Q53606 cmp-binding-factor 1; Staphylococcus aureus
1978 yuaB 23% Q9Z6S7 yign family hypothetical protein; Chlamydia pneumoniae
1979 rpe 55% P51012 ribulose-phosphate 3-epimerase; Rhodobacter capsulatus
1980 yuaC putative
1981 yuaD 45% 034530 yloq protein; Bacillus subtilis
1982 yuaE 61% 066078 putative extracellular protein expl precursor; Lactococcus lactis
1983 pheT 44% P17922 phenylalanyl-trna synthetase beta chain; Bacillus subtilis
1984 pheS 60% P17921 phenylalanyl-trna synthetase alpha chain; Bacillus subtilis
1985 pdc 78% P94900 p-coumaric acid décarboxylase; Lactobacillus plantarum
1986 tra983J 50% 087534 putative transposase; Streptococcus pyogenes
1987 yubA 25% P71160 intb, rega, gepa, gepb, and gepc gènes; Bacteroides nodosus
1988 yubB putative
1989 yubK putative
1990 yubD 92% AAF12712 hypothetical 9.1 kd protein; Bacteriophage tpw22
1991 yubE 35% P39909 spermine/spermidine acetyltransferase; Bacillus subtilis
1992 tra983K 50% 087534 putative transposase; Streptococcus pyogenes
1993 yubF 32% P53352 inner centromere protein; Gallus gallus
1994 yubG 27% CAB49281 chromosome ségrégation protein; Pyrococcus abyssi
1995 yubH putative
1996 yubl putative
1997 yubJ putative
1998 yucA 49% Q00370 hypothetical 26.8 kd protein; Bacteriophage 50
1999 yucB putative
2000 yucC 30% P45197 hypothetical protein hil412; Haemophilus influenzae
2001 yucD putative
2002 yucE 30% P03035 repressor protein c2; Bacteriophage p22, and bacteriophage p21
2003 int5 26% P97010 integrase; Bacteriophage tl2 2004 yucF 38% P94443 yfio; Bacillus subtilis 2005 chiA 49% Q9WXD3 chitinase cl; Serratia marcescens
2006 yucG 46% 083009 cbp21 precursor; Serratia marcescens
2007 purA 67% P29726 adenylosuccinate synthetase; Bacillus subtilis
2008 yudA 30% P95773 cadb; Staphylococcus lugdunensis
2009 yudB putative
2010 yudC putative
2011 yudD 30% Q45146 insertion séquence isll68 and nimb gène for 5- nitroimidazole antibiotic résistance protein; Bacteroides fragilis
2012 yudE putative
2013 yudF putative
2014 yudG 57% Q9ZB45 hypothetical 30. kd protein; Streptococcus pyogenes
2015 yudH 40% P45862 hypothetical 19. kd protein in acda 5 'région;
Bacillus subtilis
2016 yudl 59% P37567 hypothetical 37.1 kd protein in folk-lyss intergenic région; Bacillus subtilis
2017 yudJ 43% P42978 hypothetical 23.6 kd protein in qcrc-dapb intergenic région; Bacillus subtilis
2018 yudK 43% P42978 hypothetical 23.6 kd protein in qcrc-dapb intergenic région; Bacillus subtilis
2019 yudL 39% Q48842 gène cluster; Lactobacillus sake
2020 aspS 53% 032038 aspartyl-trna synthetase; Bacillus subtilis
2021 yueA 42% CAB49889 hit-like protein; Pyrococcus abyssi
2022 hisS 63% P30053 histidyl-trna synthetase; Streptococcus equisimilis
2023 yueB 23% 030416 positive regulator gadr; Lactococcus lactis
2024 yueC putative
2025 pgsA 58% 087532 phosphotidylglycerophosphate synthase; Streptococcus pyogenes
2026 yueD 35% P94510 hypothetical 34.7 kd protein; Bacillus subtilis
2027 yueE 43% 031766 ymfh protein; Bacillus subtilis
2028 yueF 36% 087529 hypothetical 48.2 kd protein; Streptococcus pyogenes
2029 yufA 71% Q48692 dna for orfl21 and recf gènes; Lactococcus lactis
2030 recF 99% P50925 recf protein; Lactococcus lactis
2031 pcaC 40% 026336 gamma-carboxymuconolactone décarboxylase; Methanobacterium thermoautotrophicum
2032 yufB 42% AAF11850 transcriptional regulator, merr family; Deinococcus radiodurans
2033 yufC 69% Q9ZB16 hypothetical 34.5 kd protein; Lactococcus lactis
2034 galE 99% 087524 udp-galactose-4-epimerase; Lactococcus lactis
2035 lacZ 98% 087523 beta-galactosidase; Lactococcus lactis
2036 thgA 99% AAC63019 putative galactoside o-acetyltransferase; Lactococcus lactis
2037 galT 99% 087522 galactose-1-phosphate uridylyltransferase; Lactococcus lactis
2038 galK 93% AAD11510 galactokinase; Lactococcus lactis
2039 galM 99% Q9ZB17 aldose 1-epimerase; Lactococcus lactis
2040 lacS 91% Q9ZB18 lactose permease; Lactococcus lactis
2041 yugA 94% Q9ZB19 hypothetical 27.6 kd protein; Lactococcus lactis
2042 yugB 93% Q9ZB20 hypothetical 37.6 kd protein; Lactococcus lactis
2043 nadR 28% P27278 transcriptional regulator nadr; Escherichia coli
2044 yugC 32% Q9X4A4 hypothetical 35.4 kd protein; Staphylococcus aureus
2045 yugD 48% 032034 yrro protein; Bacillus subtilis
2046 yuhA putative
2047 yuhB 32% 032035 yrrn protein; Bacillus subtilis
2048 yuhC putative
2049 yuhD 36% P42313 hypothetical 31.5 kd protein in katb 3 'région; Bacillus subtilis
2050 yuhE 32% Q9Y321 cgi-32 protein; Homo sapiens
2051 ecsB 26% P55340 protein ecsb; Bacillus subtilis
2052 ecsA 60% P55339 abc-type transporter atp-binding protein ecsa; Bacillus subtilis
2053 yuhH 25% 007592 hypothetical 27.5 kd protein; Bacillus subtilis
2054 yuhl 54% 007513 hit protein; Bacillus subtilis
2055 yuhJ putative
2056 rplA 58% Q06797 50s ribosomal protein 11; Bacillus subtilis
2057 rplK 80% P36254 50s ribosomal protein 111; Staphylococcus carnosus
2058 yuiA 38% Q60048 probable cadmium-transporting atpase; Listeria monocytogenes
2059 rcfA 49% CAB53581 fnr-like protein; Lactococcus lactis
2060 tra983L 50% 087534 putative transposase; Streptococcus pyogenes
2061 yuiB 41% 031864 yoze protein; Bacillus subtilis
2062 yuiF 52% P54154 putative peptide methionine sulfoxide réductase (peptide met; Bacillus subtilis
2063 yuiC 35% 006747 yitl protein; Bacillus subtilis
2064 yuiD putative
2065 frr 53% P81101 ribosome recycling factor; Bacillus subtilis
2066 pyrH 94% Q9Z5K8 ump-kinase; Lactococcus lactis
2067 yuiE putative
2068 ackA2 53% P37877 acétate kinase; Bacillus subtilis
2069 ackAl 50% P37877 acétate kinase; Bacillus subtilis
2070 yujA 32% P37876 hypothetical 37.4 kd protein in acka-sspa intergenic région; Bacillus subtilis
2071 typA 70% 007631 gtp-binding protein typa/bipa homolog; Bacillus subtilis
2072 yujB putative
2073 yujC putative
2074 yujD 54% Q9ZHB1 hypothetical 24.0 kd protein; Streptococcus pneumoniae
2075 yujE 23% Q9ZHB2 hypothetical 55.9 kd protein; Streptococcus pneumoniae
2076 yujF putative
2077 yujG 24% Q9X474 entr; Enterococcus faecium
2078 yvaA 35% 031391 orfl protein; Bacillus megaterium
2079 glk 43% 031392 glucose kinase; Bacillus megaterium
2080 yvaB 35% P54510 hypothetical 14.6 kd protein in gcvt-spoiiiaa intergenic région; Bacillus subtilis
2081 yvaC 48% 085254 hypothetical 19.3 kd protein; Streptococcus pneumoniae
2082 tra981J 92% Q48668 insertion séquence is981; Lactococcus lactis
2083 yuil 100% Q48667 insertion séquence is981; Lactococcus lactis
2084 comC 26% P15378 type 4 prepilin-like protein spécifie leader peptidase; Bacillus subtilis
2085 dinP 42% Q47155 dna-damage-inducible protein p; Escherichia coli
2086 yvaD 24% 060155 putative prolyl-trna synthetase;
Schizosaccharomyces pombe
2087 arcD2 62% 032816 arginine/ornithine antiporter homolog arcd;
Lactococcus lactis
2088 arcT 52% 053091 orft; Lactobacillus sake 2089 arcC2 50% 053090 carbamate kinase; Lactobacillus sake 2090 arcCl 51% 053090 carbamate kinase; Lactobacillus sake 2091 arcDl 86% 032816 arginine/ornithine antiporter homolog arcd;
Lactococcus lactis
2092 arcB 72% 053089 ornithine transcarbamoylase; Lactobacillus sake 2093 arcA 60% 053088 arginine deiminase; Lactobacillus sake 2094 argS 37% 074781 putative arginyl-trna synthetase, cytoplasmic;
Schizosaccharomyces pombe
2095 argR 37% Q54870 probable arginine repressor; Streptococcus pneumoniae
2096 murC 56% P40778 udp-n-acetylmuramate--alanine ligase; Bacillus subtilis
2097 y cA putative 2098 yvcB 38% P94295 orfl and snf2 gène; Bacillus cereus 2099 yvcC 28% Q9ZV10 retrotransposon-like protein; Arabidopsis thaliana
2100 poxL 43% P37063 pyruvate oxidase; Lactobacillus plantarum 2101 yvdA 27% CAB61729 possible secreted esterase; Streptomyces coelicolor
2102 yvdB 94% 068177 cypl; Lactococcus lactis 2103 yvdC 31% Q47774 orf8; Enterococcus faecalis 2104 yvdD 92% P22094 hypothetical 30.9 kd protein in pepx 5' région. Lactococcus lactis , and lactococcus lactis
2105 pepXP 89% P22093 xaa-pro dipeptidyl-peptidase (x-p. Lactococcus lactis
2106 yvdE 90% P22347 hypothetical 18.7 kd protein in pepx 3 'région; Lactococcus lactis
2107 yvdF 29% P54952 probable amino-acid abc transporter binding protein in idh-deor intergenic région precursor; Bacillus subtilis
2108 yvdG 48% P77212 probable pyridine nucleotide-disulfide oxidoreductase in eaeh-beta intergenic région; Escherichia coli
2109 gltX 56% 086083 glutamyl-trna synthetase; Lactobacillus delbrueckii
2110 yveA 32% 028131 isochorismatase; Archaeoglobus fulgidus 2111 yveB putative 2112 yveC 27% CAB57420 putative arylalkylamine n-acetyltransferase; Schizosaccharomyces pombe
2113 yveD putative 2114 yveE putative 2115 yveF 38% 087247 conserved hypothetical protein; Lactococcus lactis
2116 yveG putative 2117 yveH 43% AAF10688 conserved hypothetical protein; Deinococcus radiodurans
2118 tra983M 50% 087534 putative transposase; Streptococcus pyogenes 2119 yvel putative 2120 radA 58% 086063 rada homolog; Listeria monocytogenes 2121 yvfA 36% 067432 cation transporting atpase; Aquifex aeolicus 2122 yvfB putative 2123 rplQ 72% P20277 50s ribosomal protein 117; Bacillus subtilis 2124 rpoA 58% BAA75298 rpoa protein; Bacillus sp 2125 rpsK 73% P04969 30s ribosomal protein sll; Bacillus subtilis
2126 rpsM 70% P20282 30s ribosomal protein sl3; Bacillus subtilis
2127 rp J 100% P27146 50s ribosomal protein 136; Lactococcus lactis
2128 infA 100% P27149 translation initiation factor if-1; Lactococcus lactis
2129 tra904H 99% CAA55220 isl069 gène; Lactococcus lactis 2130 yvfD 98% Q48710 span gène encoding nisin and insertion séquence is904; Lactococcus lactis
2131 tral077F 98% 032787 transposase; Lactococcus lactis 2132 yvfC 99% 032786 hypothetical 21.3 kd protein; Lactococcus lactis
2133 adk 98% P27143 adenylate kinase; Lactococcus lactis 2134 secY 96% P27148 preprotein translocase secy subunit; Lactococcus lactis
2135 rplO 58% 006445 50s ribosomal protein 115; Staphylococcus aureus
2136 rpmD 62% 006444 50s ribosomal protein 130; Staphylococcus aureus
2137 rpsE 58% Q9Z9J7 rpse protein; Bacillus sp
2138 rplR 49% P46899 50s ribosomal protein 118; Bacillus subtilis
2139 rplF 63% P02391 50s ribosomal protein 16; Bacillus stearothermophilus
2140 rpsH 71% P12879 30s ribosomal protein s8; Bacillus subtilis
2141 yvgA putative
2142 rpsN 81% P54798 30s ribosomal protein sl4; Bacillus stearothermophilus
2143 rplE 80% P08895 50s ribosomal protein 15; Bacillus stearothermophilus
2144 rplX 75% Q9WV 6 rpl24; Streptococcus pneumoniae 2145 rplN 74% Q9WVZ2 rpll4; Streptococcus pneumoniae 2146 rpsQ 88% Q9WW03 rpsl7; Streptococcus pneumoniae 2147 rpmC 69% Q9WVW8 rpl29; Streptococcus pneumoniae 2148 rplP 89% Q9X5K1 rpllδ; Streptococcus pneumoniae 2149 rpsC 87% Q9WW37 rps3; Streptococcus pneumoniae 2150 rplV 84% Q9WVU5 rpl22; Streptococcus pneumoniae 2151 rpsS 90% Q9WW12 rpsl9; Streptococcus pneumoniae 2152 rplB 76% P42919 50s ribosomal protein 12; Bacillus subtilis 2153 rplW 54% P04454 50s ribosomal protein 123; Bacillus stearothermophilus
2154 rplD 61% P42921 50s ribosomal protein 14; Bacillus subtilis
2155 rplC 69% Q9Z9L4 rplc protein; Bacillus sp
2156 rpsJ 86% P48853 30s ribosomal protein slO; Streptococcus mutans
2157 mscL 44% P94585 large-conductance mechanosensitive channel; Bacillus subtilis
2158 yvhA 27% Q58119 hypothetical protein mj0709; Methanococcus jannaschii
2159 thrC 38% Q42598 threonine synthase; Schizosaccharomyces pombe
2160 nusG 49% Q06795 transcription antitermination protein nusg; Bacillus subtilis
2161 secE putative
2162 rpmGC 57% P51415 50s ribosomal protein 133; Mycoplasma capricolum
2163 yvhB 29% 005402 hypothetical 72.2 kd protein; Bacillus subtilis
2164 pbp2A 50% 070039 penicillin-binding protein 2a; Streptococcus pneumoniae
2165 yviA 33% 032050 yrbg protein; Bacillus subtilis
2166 yviB putative
2167 yviC 39% Q46604 fmn-binding protein; Desulfovibrio vulgaris
2168 yviD 37% P54604 hypothetical 33.7 kd protein in cspb-glpp intergenic région; Bacillus subtilis
2169 zitP 57% 033704 adcb protein; Streptococcus pneumoniae
2170 zitQ 65% 087862 adcc protein; Streptococcus pneumoniae
2171 zitS 43% 034966 ycdh; Bacillus subtilis
2172 zitR 48% 033703 adcr protein; Streptococcus pneumoniae
2173 yviH 57% 086274 hypothetical 9.1 kd protein; Lactococcus lactis
2174 yvil 76% 086275 orfl50 protein; Lactococcus lactis
2175 yviJ 52% 086276 hypothetical 14.8 kd protein; Lactococcus lactis
2176 comGD 31% 085196 compétence protein; Streptococcus pneumoniae
2177 comGC 74% 086277 orfl25 protein; Lactococcus lactis
2178 comGB 70% 086278 orf348 protein; Lactococcus lactis
2179 comGA 76% 086279 orf248 protein; Lactococcus lactis
2180 polC 98% 086280 dna polymérase iii alpha chain-like protein;
Lactococcus lactis
2181 yvjA putative
2182 noxD 33% P37061 nadh oxidase; Enterococcus faecalis
2183 proS 50% 031755 prolyl-trna synthetase; Bacillus subtilis
2184 yvjB 52% AAD47948 eep; Enterococcus faecalis
2185 cdsA 37% Q9ZML7 cdp-diacylglycerol synthase; Helicobacter pylori j99
2186 ywaA 49% 031751 undecaprenyl pyrophosphate synthetase; Bacillus subtilis
2187 ywaB 50% Q47777 orf11; Enterococcus faecalis
2188 ywaC 40% Q9XBL3 dna alkylation repair enzyme; Bacillus cereus
2189 ywaD 45% Q9XBL3 dna alkylation repair enzyme; Bacillus cereus
2190 ywaE 54% Q45601 yyda protein; Bacillus subtilis
2191 tra983N 50% 087534 putative transposase; Streptococcus pyogenes
2192 htrA 58% 006670 putative serine protease; Streptococcus pneumoniae
2193 ywaF 26% 006452 dnag, rpod, cpoa gènes and orf3 and orf5; Streptococcus pneumoniae
2194 ywaG 55% 006453 dnag, rpod, cpoa gènes and orf3 and orf5; Streptococcus pneumoniae
2195 ywaH putative
2196 ywal 23% Q26223 rhoptry protein; Plasmodium berghei yoelii
2197 ywbA 46% P37543 hypothetical 28.3 kd protein in xpac-abrb intergenic région; Bacillus subtilis
2198 polA 93% 032801 dna polymérase i; Lactococcus lactis
2199 ywbB 90% 032800 dna polymérase i; Lactococcus lactis
2200 rliD 43% P37517 hypothetical transcriptional regulator in tetl- exoa intergenic région; Bacillus subtilis
2201 tra904I 100% CAA55220 isl069 gène; Lactococcus lactis
2202 yvjF 98% Q48710 span gène encoding nisin and insertion séquence is904; Lactococcus lactis
2203 tral077G 98% 032787 transposase; Lactococcus lactis 2204 ywbC 99% 032786 hypothetical 21.3 kd protein; Lactococcus lactis
2205 ywbD 27% P37517 hypothetical transcriptional regulator in tetl- exoa intergenic région; Bacillus subtilis
2206 ywcA 76% Q48591 n of 16s rrna gène; Lactococcus lactis
2207 ezrA 21% 034894 ytwp; Bacillus subtilis
2208 tsf 39% Q9ZJ71 elongation factor ts; Helicobacter pylori j 99
2209 rpsB 71% P49668 30s ribosomal protein s2; Pediococcus acidilactici
2210 ywcC 100% 086271 orfb protein; Lactococcus lactis
2211 adhE 98% 086272 alcohol-acetaldehyde dehydrogénase; Lactococcus lactis
2212 ywdA 23% CAB49813 hypothetical 22.1 kd protein; Pyrococcus abyssi
2213 ywdB putative
2214 ywdC 26% 058557 552aa long hypothetical nitrite réductase; Pyrococcus horikoshii
2215 ywdD 29% P07782 coenzyme pqq synthesis protein e; Acinetobacter calcoaceticus
2216 ywdE 30% P49330 rgg protein; Streptococcus gordonii challis
2217 ywdF 34% 034470 ylbl protein; Bacillus subtilis
2218 kdtB 39% Q9WZK0 lipopolysaccharide core biosynthesis protein kdtb, Thermotoga maritima
2219 ywdG 49% 034331 ylbh protein; Bacillus subtilis
2220 yweA 35% Q48658 lmrp intégral membrane protein; Lactococcus lactis
2221 lmrP 91% Q48658 lmrp intégral membrane protein; Lactococcus lactis
2222 sigX 30% 007627 putative rna polymérase sigma factor ylac;
Bacillus subtilis
2223 yweB putative
2224 pgiA 79% Q9X670 glucose-6-phosphate isomérase; Streptococcus mutans
2225 yweC 32% 029764 conserved hypothetical protein; Archaeoglobus fulgidus
2226 yweD 36% P39315 hypothetical 29.7 kd protein in rpli-cpdb intergenic région; Escherichia coli
2227 yweE 53% P70885 orfl08; Butyrivibrio fibrisolvens
2228 yweF putative
2229 valS 60% Q05873 valyl-trna synthetase; Bacillus subtilis
2230 ywfA putative
2231 ywfB putative
2232 ywfC 40% P32699 hypothetical 13.5 kd protein in apha-uvra intergenic région; Escherichia coli
2233 ywfD putative
2234 ywfE 30% CAB57644 hypothetical 25.3 kd protein; Sulfolobus solfataπcus
2235 ywfF 43% 031545 yf o protein; Bacillus subtilis
2236 ywfG 27% Q15333 hr44 protein; Homo sapiens
2237 ywfH 36% CAB61244 secreted protein precursor; Lactococcus lactis
2238 ywgA 31% 031575 yfhg protein; Bacillus subtilis
2239 gntP 50% P46832 gluconate permease; Bacillus licheniformis
2240 tra9830 50% 087534 putative transposase; Streptococcus pyogenes
2241 gntK 48% P12011 gluconokinase; Bacillus subtilis
2242 gntZ 56% P54448 hypothetical 32.8 kd protein in nucb-arod intergenic région; Bacillus subtilis
2243 gntR 29% Q9WYG1 transcriptional regulator, rpir family; Thermotoga maritima
2244 ywhA putative
2245 ywhB 31% 034870 ykue protein; Bacillus subtilis
2246 rpsR 70% P10806 30s ribosomal protein sl8; Bacillus stearothermophilus
2247 ssbD 65% Q9XJE5 putative single stranded bmding protein; Bacteriophage tuc2009
2248 rpsF 59% P21468 30s ribosomal protein s6; Bacillus subtilis
2249 bacA 39% AAD50462 baca; Cytophaga [johnsonae
2250 lysP 45% P25737 lysme-specific permease; Escherichia coli
2251 dnaH 50% Q9WZF2 dna polymérase ni, gamma and tau subunit; Thermotoga maritima
2252 ywiA 33% 005841 hypothetical 51.3 kd protein; Mycobacterium tuberculosis
2253 ywiB 43% P36088 hypothetical 19.7 kd protein m lhsl-nuplOO intergenic région; Saccharomyces cerevisiae
2254 ywiC 31% P39912 B aroa protein [includes: phospho-2-dehydro-3- deoxyheptonate aldolase (3-deoxy-d-arabιno- heptulosona ...
2255 ywiD putative
2256 ywiE putative
2257 glnA 66% P95692 glutamine synthetase type 1, Streptococcus agalactiae
2258 glnR 45% P37582 regulatory protein glnr; Bacillus subtilis
2259 ywiF 45% 035016 yfkj protein; Bacillus subtilis
2260 ywiG 29% Q9WZM4 abc transporter, atp-binding protein;
Thermotoga maritima
2261 y iH putative
2262 ywil 23% 030416 positive regulator gadr; Lactococcus lactis
2263 ruvB 63% 032055 holliday junction dna helicase ruvb; Bacillus subtilis
2264 ruvA 42% 084509 holliday junction helicase; Chlamydia trachomatis
2265 hexB 86% 032819 mismatch repair protein homolog; Lactococcus lactis
2266 ywjA 30% Q17113 80 kda protein; Babesia bovis
2267 hexA 64% P10564 dna mismatch repair protein hexa; Streptococcus pneumoniae
2268 ywjB 24% 031779 ymca protein; Bacillus subtilis
2269 ywjC putative
2270 ywjD 43% 034647 transcription regulator; Bacillus subtilis
2271 ywjE putative
2272 ywjF 52% 034948 hypothetical 30.7 kd protein in mcpc-kina intergenic région; Bacillus subtilis
2273 ywjG putative
2274 ywjH putative
2275 yxaA 25% 028711 conserved hypothetical protein; Archaeoglobus fulgidus
2276 yxaB putative
2277 zwf 49% P54547 glucose-6-phosphate 1-dehydrogenase; Bacillus subtilis
2278 yxaC 38% P54452 hypothetical 20.1 kd protein in nucb-arod intergenic région; Bacillus subtilis
2279 pspA 40% 005166 pcpa; Streptococcus pneumoniae
2280 pspB 40% 005166 pcpa; Streptococcus pneumoniae
2281 dnaJ 86% P35514 dnaj protein; Lactococcus lactis
2282 yxaF putative
2283 racD 53% P29079 aspartate racemase; Streptococcus thermophilus
2284 yxbA putative
2285 asnH 40% 034902 asparagine synthase; Bacillus subtilis
2286 usp45 63% P22865 secreted 45 kd protein precursor; Lactococcus lactis
2287 mreD 25% Q01467 rod shape-determining protein mred; Bacillus subtilis
2288 mreC 95% Q99223 beta-lactamase precursor; Lactococcus lactis
2289 yxbC 40% P46351 hypothetical 45.4 kd protein in thiaminase i 5 'région; Bacillus subtilis
2290 rpiA 45% P72012 probable ribose 5-phosphate isomérase; Methanobacterium thermoautotrophicum
2291 rcfB 27% 086128 fnr protein; Bacillus licheniformis
2292 yxbD 23% P94577 hypothetical 43.1 kd protein; Bacillus subtilis
2293 yxbE 33% 027074 conserved protein; Methanobacterium thermoautotrophicum
2294 yxbF putative
2295 yxcA 29% P11568 activator of -2-hydroxyglutaryl-coa dehydratase; Acidaminococcus fermentans
2296 yxcB 27% CAB55667 putative tetr-family transcriptional regulator; Streptomyces coelicolor
2297 rsuA 42% Q9WYA2 16s pseudouridylate synthase; Thermotoga maritima
2298 yxcD putative
2299 thdF 66% CAB61255 thiophene dégradation protein f; Streptococcus agalactiae
2300 yxcE putative
2301 recG 66% Q54900 atp-dependent dna helicase recg; Streptococcus pneumoniae
2302 yxdA 44% P16680 phna protein; Escherichia coli
2303 gapB 78% P50467 glyceraldehyde 3-phosphate dehydrogénase;
Streptococcus pyogenes
2304 yxdB 24% 015738 zipa; Dictyostelium discoideum
2305 yxdC 37% P37278 cation-transporting atpase pacl; Synechococcus sp
2306 yxdD putative
2307 yxdE 34% AAF12130 oxidoreductase, short-chain dehydrogenase/reductase family; Deinococcus radiodurans
2308 yxdF 30% Q48724 abortive infection proteins gènes, complète cds; Lactococcus lactis
2309 yxdG putative
2310 rpsl 70% P21470 30s ribosomal protein s9; Bacillus subtilis
2311 rplM 63% Q00990 50s ribosomal protein 113; Staphylococcus carnosus
2312 yxeA 29% AAF12525 hypothetical 37.1 kd protein; Deinococcus radiodurans
2313 yxeB 40% 028803 abc transporter, atp-binding protein; Archaeoglobus fulgidus
2314 rnhA 55% 007874 ribonuclease hii; Streptococcus pneumoniae
2315 sipL 53% CAA13401 signal peptidase 1; Streptococcus pneumoniae
2316 purR 100% 053065 purr; Lactococcus lactis
2317 fusA 73% P80868 elongation factor g; Bacillus subtilis
2318 rpsG 72% Q9Z9L8 rpsg protein; Bacillus sp
2319 rpsL 89% P30891 30s ribosomal protein sl2; Streptococcus pneumoniae
2320 dacA 84% 066081 extracellular protein exp2 precursor; Lactococcus lactis
2321 yxfA 55% Q54615 putative multiple membrane domain protein; Streptococcus pyogenes
2322 yxfB 37% 034614 ytqb; Bacillus subtilis
2323 yxfC 59% 035008 ytqa; Bacillus subtilis
Tableau IV. Gènes impliqués dans les phénomènes de sécrétion