KR20230066095A - 항-b7h4 항체-약물 접합체 요법에 대한 점수산정 방법 - Google Patents
항-b7h4 항체-약물 접합체 요법에 대한 점수산정 방법 Download PDFInfo
- Publication number
- KR20230066095A KR20230066095A KR1020237012322A KR20237012322A KR20230066095A KR 20230066095 A KR20230066095 A KR 20230066095A KR 1020237012322 A KR1020237012322 A KR 1020237012322A KR 20237012322 A KR20237012322 A KR 20237012322A KR 20230066095 A KR20230066095 A KR 20230066095A
- Authority
- KR
- South Korea
- Prior art keywords
- adc
- cancer
- cell
- antibody
- seq
- Prior art date
Links
- 239000000611 antibody drug conjugate Substances 0.000 title claims abstract description 358
- 229940049595 antibody-drug conjugate Drugs 0.000 title claims abstract description 358
- 238000002560 therapeutic procedure Methods 0.000 title claims abstract description 42
- 238000013077 scoring method Methods 0.000 title description 3
- 210000004027 cell Anatomy 0.000 claims abstract description 406
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 331
- 201000011510 cancer Diseases 0.000 claims abstract description 288
- 239000012528 membrane Substances 0.000 claims abstract description 181
- 238000000034 method Methods 0.000 claims abstract description 177
- 238000010186 staining Methods 0.000 claims abstract description 104
- 210000001519 tissue Anatomy 0.000 claims abstract description 84
- 238000011282 treatment Methods 0.000 claims abstract description 83
- 230000004044 response Effects 0.000 claims abstract description 77
- 210000000805 cytoplasm Anatomy 0.000 claims abstract description 71
- 238000004364 calculation method Methods 0.000 claims abstract description 20
- 230000004931 aggregating effect Effects 0.000 claims abstract description 11
- 230000003287 optical effect Effects 0.000 claims description 120
- SXEHKFHPFVVDIR-UHFFFAOYSA-N [4-(4-hydrazinylphenyl)phenyl]hydrazine Chemical compound C1=CC(NN)=CC=C1C1=CC=C(NN)C=C1 SXEHKFHPFVVDIR-UHFFFAOYSA-N 0.000 claims description 68
- 239000000975 dye Substances 0.000 claims description 65
- 102100038929 V-set domain-containing T-cell activation inhibitor 1 Human genes 0.000 claims description 61
- 108010079206 V-Set Domain-Containing T-Cell Activation Inhibitor 1 Proteins 0.000 claims description 54
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 50
- 108090000623 proteins and genes Proteins 0.000 claims description 50
- 102000004169 proteins and genes Human genes 0.000 claims description 49
- 230000006870 function Effects 0.000 claims description 39
- 239000003534 dna topoisomerase inhibitor Substances 0.000 claims description 27
- 229940044693 topoisomerase inhibitor Drugs 0.000 claims description 27
- 206010006187 Breast cancer Diseases 0.000 claims description 26
- 208000026310 Breast neoplasm Diseases 0.000 claims description 26
- 229940123780 DNA topoisomerase I inhibitor Drugs 0.000 claims description 25
- 239000000365 Topoisomerase I Inhibitor Substances 0.000 claims description 25
- 230000002776 aggregation Effects 0.000 claims description 25
- 238000004220 aggregation Methods 0.000 claims description 25
- 101000955999 Homo sapiens V-set domain-containing T-cell activation inhibitor 1 Proteins 0.000 claims description 18
- 206010033128 Ovarian cancer Diseases 0.000 claims description 17
- 208000006990 cholangiocarcinoma Diseases 0.000 claims description 16
- 206010014733 Endometrial cancer Diseases 0.000 claims description 12
- 206010014759 Endometrial neoplasm Diseases 0.000 claims description 12
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 12
- 210000000481 breast Anatomy 0.000 claims description 11
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 10
- 230000001086 cytosolic effect Effects 0.000 claims description 10
- 201000005202 lung cancer Diseases 0.000 claims description 10
- 208000020816 lung neoplasm Diseases 0.000 claims description 10
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 9
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 9
- 201000002528 pancreatic cancer Diseases 0.000 claims description 9
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 9
- 230000004083 survival effect Effects 0.000 claims description 9
- HSTOKWSFWGCZMH-UHFFFAOYSA-N 3,3'-diaminobenzidine Chemical group C1=C(N)C(N)=CC=C1C1=CC=C(N)C(N)=C1 HSTOKWSFWGCZMH-UHFFFAOYSA-N 0.000 claims description 8
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 8
- 206010017758 gastric cancer Diseases 0.000 claims description 8
- 201000011549 stomach cancer Diseases 0.000 claims description 8
- 230000008685 targeting Effects 0.000 claims description 6
- 201000008275 breast carcinoma Diseases 0.000 claims description 5
- 230000002357 endometrial effect Effects 0.000 claims description 5
- 230000002611 ovarian Effects 0.000 claims description 5
- 230000008901 benefit Effects 0.000 claims description 4
- 201000003914 endometrial carcinoma Diseases 0.000 claims description 4
- 201000004228 ovarian endometrial cancer Diseases 0.000 claims description 4
- 230000009467 reduction Effects 0.000 claims description 4
- 238000012303 cytoplasmic staining Methods 0.000 claims 4
- 210000004379 membrane Anatomy 0.000 description 141
- 230000027455 binding Effects 0.000 description 105
- 239000000427 antigen Substances 0.000 description 93
- 102000036639 antigens Human genes 0.000 description 93
- 108091007433 antigens Proteins 0.000 description 93
- 239000012634 fragment Substances 0.000 description 91
- 239000000523 sample Substances 0.000 description 61
- 210000004881 tumor cell Anatomy 0.000 description 56
- 125000005647 linker group Chemical group 0.000 description 45
- 241000282414 Homo sapiens Species 0.000 description 39
- 150000001875 compounds Chemical class 0.000 description 37
- 235000001014 amino acid Nutrition 0.000 description 36
- 150000001413 amino acids Chemical class 0.000 description 32
- 238000010191 image analysis Methods 0.000 description 29
- 235000018102 proteins Nutrition 0.000 description 25
- 229940079593 drug Drugs 0.000 description 23
- 239000003814 drug Substances 0.000 description 23
- 210000002919 epithelial cell Anatomy 0.000 description 23
- 230000001965 increasing effect Effects 0.000 description 23
- 208000037821 progressive disease Diseases 0.000 description 22
- 239000003446 ligand Substances 0.000 description 20
- 210000004940 nucleus Anatomy 0.000 description 18
- 108090000765 processed proteins & peptides Proteins 0.000 description 18
- 238000009826 distribution Methods 0.000 description 16
- 230000000694 effects Effects 0.000 description 16
- 102000004196 processed proteins & peptides Human genes 0.000 description 15
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 13
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 12
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 12
- 125000000217 alkyl group Chemical group 0.000 description 12
- 230000011218 segmentation Effects 0.000 description 12
- 108010016626 Dipeptides Chemical group 0.000 description 11
- 108060003951 Immunoglobulin Proteins 0.000 description 11
- 210000000170 cell membrane Anatomy 0.000 description 11
- 102000018358 immunoglobulin Human genes 0.000 description 11
- 102000005600 Cathepsins Human genes 0.000 description 10
- 108010084457 Cathepsins Proteins 0.000 description 10
- 241001465754 Metazoa Species 0.000 description 10
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 10
- 101710117290 Aldo-keto reductase family 1 member C4 Proteins 0.000 description 9
- 230000005778 DNA damage Effects 0.000 description 9
- 231100000277 DNA damage Toxicity 0.000 description 9
- 102000055298 human VTCN1 Human genes 0.000 description 9
- 238000006467 substitution reaction Methods 0.000 description 9
- 150000001721 carbon Chemical group 0.000 description 8
- 229910052799 carbon Inorganic materials 0.000 description 8
- 238000013527 convolutional neural network Methods 0.000 description 8
- 230000004048 modification Effects 0.000 description 8
- 238000012986 modification Methods 0.000 description 8
- 102000003952 Caspase 3 Human genes 0.000 description 7
- 108090000397 Caspase 3 Proteins 0.000 description 7
- 108020004414 DNA Proteins 0.000 description 7
- 102000009109 Fc receptors Human genes 0.000 description 7
- 108010087819 Fc receptors Proteins 0.000 description 7
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 7
- 241000699670 Mus sp. Species 0.000 description 7
- 238000004422 calculation algorithm Methods 0.000 description 7
- 230000008569 process Effects 0.000 description 7
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 6
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 6
- 241000282567 Macaca fascicularis Species 0.000 description 6
- 125000000539 amino acid group Chemical group 0.000 description 6
- 230000030833 cell death Effects 0.000 description 6
- 239000000562 conjugate Substances 0.000 description 6
- 238000012217 deletion Methods 0.000 description 6
- 230000037430 deletion Effects 0.000 description 6
- 201000010099 disease Diseases 0.000 description 6
- 239000012636 effector Substances 0.000 description 6
- 210000004408 hybridoma Anatomy 0.000 description 6
- 238000002347 injection Methods 0.000 description 6
- 239000007924 injection Substances 0.000 description 6
- 239000008194 pharmaceutical composition Substances 0.000 description 6
- 150000003839 salts Chemical class 0.000 description 6
- 239000012453 solvate Substances 0.000 description 6
- -1 -CH=CH 2 ) Chemical group 0.000 description 5
- 241000880493 Leptailurus serval Species 0.000 description 5
- 230000009471 action Effects 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 5
- 239000000090 biomarker Substances 0.000 description 5
- 125000004432 carbon atom Chemical group C* 0.000 description 5
- 210000003855 cell nucleus Anatomy 0.000 description 5
- 125000004976 cyclobutylene group Chemical group 0.000 description 5
- 125000004980 cyclopropylene group Chemical group 0.000 description 5
- 231100000599 cytotoxic agent Toxicity 0.000 description 5
- 230000007423 decrease Effects 0.000 description 5
- 108010015792 glycyllysine Proteins 0.000 description 5
- 230000002055 immunohistochemical effect Effects 0.000 description 5
- 238000000338 in vitro Methods 0.000 description 5
- 239000003112 inhibitor Substances 0.000 description 5
- 230000004807 localization Effects 0.000 description 5
- 210000004698 lymphocyte Anatomy 0.000 description 5
- 238000004519 manufacturing process Methods 0.000 description 5
- 230000035772 mutation Effects 0.000 description 5
- 229920001184 polypeptide Polymers 0.000 description 5
- 230000002062 proliferating effect Effects 0.000 description 5
- 125000006413 ring segment Chemical group 0.000 description 5
- 210000002966 serum Anatomy 0.000 description 5
- 238000012549 training Methods 0.000 description 5
- 230000004614 tumor growth Effects 0.000 description 5
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 4
- 102000012745 Immunoglobulin Subunits Human genes 0.000 description 4
- 108010079585 Immunoglobulin Subunits Proteins 0.000 description 4
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 4
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 4
- 241000283973 Oryctolagus cuniculus Species 0.000 description 4
- 241000700159 Rattus Species 0.000 description 4
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 4
- 125000003342 alkenyl group Chemical group 0.000 description 4
- 125000000304 alkynyl group Chemical group 0.000 description 4
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 4
- 125000000732 arylene group Chemical group 0.000 description 4
- 230000008878 coupling Effects 0.000 description 4
- 238000010168 coupling process Methods 0.000 description 4
- 238000005859 coupling reaction Methods 0.000 description 4
- 231100000433 cytotoxic Toxicity 0.000 description 4
- 230000001472 cytotoxic effect Effects 0.000 description 4
- 239000002619 cytotoxin Substances 0.000 description 4
- 239000003085 diluting agent Substances 0.000 description 4
- 208000035475 disorder Diseases 0.000 description 4
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 4
- 230000005847 immunogenicity Effects 0.000 description 4
- 230000008676 import Effects 0.000 description 4
- 239000000203 mixture Substances 0.000 description 4
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 4
- 239000002773 nucleotide Substances 0.000 description 4
- 125000003729 nucleotide group Chemical group 0.000 description 4
- 230000036961 partial effect Effects 0.000 description 4
- 239000013610 patient sample Substances 0.000 description 4
- 230000003285 pharmacodynamic effect Effects 0.000 description 4
- 125000006239 protecting group Chemical group 0.000 description 4
- 102000005962 receptors Human genes 0.000 description 4
- 108020003175 receptors Proteins 0.000 description 4
- 229920006395 saturated elastomer Polymers 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 4
- 108010071635 tyrosyl-prolyl-arginine Proteins 0.000 description 4
- OVSKIKFHRZPJSS-UHFFFAOYSA-N 2,4-D Chemical compound OC(=O)COC1=CC=C(Cl)C=C1Cl OVSKIKFHRZPJSS-UHFFFAOYSA-N 0.000 description 3
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 3
- WUHBLPVELFTPQK-KKUMJFAQSA-N Leu-Tyr-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O WUHBLPVELFTPQK-KKUMJFAQSA-N 0.000 description 3
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 3
- 241001529936 Murinae Species 0.000 description 3
- 241000699666 Mus <mouse, genus> Species 0.000 description 3
- 101000956000 Mus musculus V-set domain containing T-cell activation inhibitor 1 Proteins 0.000 description 3
- 206010035226 Plasma cell myeloma Diseases 0.000 description 3
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 3
- 208000003837 Second Primary Neoplasms Diseases 0.000 description 3
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 3
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 3
- XZSJDSBPEJBEFZ-QRTARXTBSA-N Trp-Asn-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O XZSJDSBPEJBEFZ-QRTARXTBSA-N 0.000 description 3
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 3
- 230000004075 alteration Effects 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 239000003795 chemical substances by application Substances 0.000 description 3
- 238000003776 cleavage reaction Methods 0.000 description 3
- 125000000753 cycloalkyl group Chemical group 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- 108010037850 glycylvaline Proteins 0.000 description 3
- 230000012010 growth Effects 0.000 description 3
- 230000003053 immunization Effects 0.000 description 3
- 238000002649 immunization Methods 0.000 description 3
- 230000002163 immunogen Effects 0.000 description 3
- 229940072221 immunoglobulins Drugs 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 108010034529 leucyl-lysine Proteins 0.000 description 3
- 238000011068 loading method Methods 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 201000000050 myeloid neoplasm Diseases 0.000 description 3
- 238000011275 oncology therapy Methods 0.000 description 3
- 238000005457 optimization Methods 0.000 description 3
- 125000000843 phenylene group Chemical group C1(=C(C=CC=C1)*)* 0.000 description 3
- 108091033319 polynucleotide Proteins 0.000 description 3
- 102000040430 polynucleotide Human genes 0.000 description 3
- 239000002157 polynucleotide Substances 0.000 description 3
- YUOCYTRGANSSRY-UHFFFAOYSA-N pyrrolo[2,3-i][1,2]benzodiazepine Chemical class C1=CN=NC2=C3C=CN=C3C=CC2=C1 YUOCYTRGANSSRY-UHFFFAOYSA-N 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 230000007017 scission Effects 0.000 description 3
- 238000000926 separation method Methods 0.000 description 3
- 125000006850 spacer group Chemical group 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 230000001225 therapeutic effect Effects 0.000 description 3
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 3
- 231100000331 toxic Toxicity 0.000 description 3
- 230000002588 toxic effect Effects 0.000 description 3
- 125000006645 (C3-C4) cycloalkyl group Chemical group 0.000 description 2
- 125000003903 2-propenyl group Chemical group [H]C([*])([H])C([H])=C([H])[H] 0.000 description 2
- 125000001494 2-propynyl group Chemical group [H]C#CC([H])([H])* 0.000 description 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 2
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 2
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 2
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 2
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 2
- AITGTTNYKAWKDR-CIUDSAMLSA-N Asn-His-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O AITGTTNYKAWKDR-CIUDSAMLSA-N 0.000 description 2
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 2
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 2
- YFSLJHLQOALGSY-ZPFDUUQYSA-N Asp-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N YFSLJHLQOALGSY-ZPFDUUQYSA-N 0.000 description 2
- OZBXOELNJBSJOA-UBHSHLNASA-N Asp-Ser-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N OZBXOELNJBSJOA-UBHSHLNASA-N 0.000 description 2
- 229940126062 Compound A Drugs 0.000 description 2
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 description 2
- 102000003915 DNA Topoisomerases Human genes 0.000 description 2
- 108090000323 DNA Topoisomerases Proteins 0.000 description 2
- 238000002965 ELISA Methods 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- 241000283086 Equidae Species 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 2
- DQPOBSRQNWOBNA-GUBZILKMSA-N Gln-His-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O DQPOBSRQNWOBNA-GUBZILKMSA-N 0.000 description 2
- UESYBOXFJWJVSB-AVGNSLFASA-N Gln-Phe-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O UESYBOXFJWJVSB-AVGNSLFASA-N 0.000 description 2
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 2
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 2
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 2
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 2
- STVHDEHTKFXBJQ-LAEOZQHASA-N Gly-Glu-Ile Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O STVHDEHTKFXBJQ-LAEOZQHASA-N 0.000 description 2
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 2
- UHPAZODVFFYEEL-QWRGUYRKSA-N Gly-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN UHPAZODVFFYEEL-QWRGUYRKSA-N 0.000 description 2
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 2
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 2
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 2
- DBUNZBWUWCIELX-JHEQGTHGSA-N Gly-Thr-Glu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DBUNZBWUWCIELX-JHEQGTHGSA-N 0.000 description 2
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 2
- NLDMNSXOCDLTTB-UHFFFAOYSA-N Heterophylliin A Natural products O1C2COC(=O)C3=CC(O)=C(O)C(O)=C3C3=C(O)C(O)=C(O)C=C3C(=O)OC2C(OC(=O)C=2C=C(O)C(O)=C(O)C=2)C(O)C1OC(=O)C1=CC(O)=C(O)C(O)=C1 NLDMNSXOCDLTTB-UHFFFAOYSA-N 0.000 description 2
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 2
- BOTVMTSMOUSDRW-GMOBBJLQSA-N Ile-Arg-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(N)=O)C(O)=O BOTVMTSMOUSDRW-GMOBBJLQSA-N 0.000 description 2
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 2
- RHGKLRLOHDJJDR-BYPYZUCNSA-N L-citrulline Chemical group NC(=O)NCCC[C@H]([NH3+])C([O-])=O RHGKLRLOHDJJDR-BYPYZUCNSA-N 0.000 description 2
- KVRKAGGMEWNURO-CIUDSAMLSA-N Leu-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N KVRKAGGMEWNURO-CIUDSAMLSA-N 0.000 description 2
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 2
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 2
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 2
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 2
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 2
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 2
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 2
- YNNPKXBBRZVIRX-IHRRRGAJSA-N Lys-Arg-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O YNNPKXBBRZVIRX-IHRRRGAJSA-N 0.000 description 2
- WRODMZBHNNPRLN-SRVKXCTJSA-N Lys-Leu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O WRODMZBHNNPRLN-SRVKXCTJSA-N 0.000 description 2
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 2
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 2
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 2
- RHGKLRLOHDJJDR-UHFFFAOYSA-N Ndelta-carbamoyl-DL-ornithine Natural products OC(=O)C(N)CCCNC(N)=O RHGKLRLOHDJJDR-UHFFFAOYSA-N 0.000 description 2
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 2
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 2
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 2
- LNICFEXCAHIJOR-DCAQKATOSA-N Pro-Ser-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LNICFEXCAHIJOR-DCAQKATOSA-N 0.000 description 2
- 102000001708 Protein Isoforms Human genes 0.000 description 2
- 108010029485 Protein Isoforms Proteins 0.000 description 2
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 2
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 2
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 2
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 2
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 2
- HDBOEVPDIDDEPC-CIUDSAMLSA-N Ser-Lys-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O HDBOEVPDIDDEPC-CIUDSAMLSA-N 0.000 description 2
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 2
- PQEQXWRVHQAAKS-SRVKXCTJSA-N Ser-Tyr-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)N)CC1=CC=C(O)C=C1 PQEQXWRVHQAAKS-SRVKXCTJSA-N 0.000 description 2
- KIEIJCFVGZCUAS-MELADBBJSA-N Ser-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CO)N)C(=O)O KIEIJCFVGZCUAS-MELADBBJSA-N 0.000 description 2
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 2
- 210000001744 T-lymphocyte Anatomy 0.000 description 2
- YTPLMLYBLZKORZ-UHFFFAOYSA-N Thiophene Chemical compound C=1C=CSC=1 YTPLMLYBLZKORZ-UHFFFAOYSA-N 0.000 description 2
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 2
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 2
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 2
- BPGDJSUFQKWUBK-KJEVXHAQSA-N Thr-Val-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BPGDJSUFQKWUBK-KJEVXHAQSA-N 0.000 description 2
- 101710183280 Topoisomerase Proteins 0.000 description 2
- 208000003721 Triple Negative Breast Neoplasms Diseases 0.000 description 2
- FEZASNVQLJQBHW-CABZTGNLSA-N Trp-Gly-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O)=CNC2=C1 FEZASNVQLJQBHW-CABZTGNLSA-N 0.000 description 2
- GQHAIUPYZPTADF-FDARSICLSA-N Trp-Ile-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 GQHAIUPYZPTADF-FDARSICLSA-N 0.000 description 2
- VCXWRWYFJLXITF-AUTRQRHGSA-N Tyr-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 VCXWRWYFJLXITF-AUTRQRHGSA-N 0.000 description 2
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 2
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 2
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 2
- SINRIKQYQJRGDQ-MEYUZBJRSA-N Tyr-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SINRIKQYQJRGDQ-MEYUZBJRSA-N 0.000 description 2
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 2
- YMZYSCDRTXEOKD-IHPCNDPISA-N Tyr-Trp-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N YMZYSCDRTXEOKD-IHPCNDPISA-N 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 2
- JVYIGCARISMLMV-HOCLYGCPSA-N Val-Gly-Trp Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N JVYIGCARISMLMV-HOCLYGCPSA-N 0.000 description 2
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- 108010047495 alanylglycine Proteins 0.000 description 2
- 125000002723 alicyclic group Chemical group 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 125000006242 amine protecting group Chemical group 0.000 description 2
- 108010008355 arginyl-glutamine Proteins 0.000 description 2
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 2
- 108010077245 asparaginyl-proline Proteins 0.000 description 2
- 210000003719 b-lymphocyte Anatomy 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 239000011203 carbon fibre reinforced carbon Substances 0.000 description 2
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 2
- 230000004663 cell proliferation Effects 0.000 description 2
- 229960002173 citrulline Drugs 0.000 description 2
- 235000013477 citrulline Nutrition 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 2
- 230000002596 correlated effect Effects 0.000 description 2
- 230000000875 corresponding effect Effects 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 239000000104 diagnostic biomarker Substances 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 229940088598 enzyme Drugs 0.000 description 2
- NLFBCYMMUAKCPC-KQQUZDAGSA-N ethyl (e)-3-[3-amino-2-cyano-1-[(e)-3-ethoxy-3-oxoprop-1-enyl]sulfanyl-3-oxoprop-1-enyl]sulfanylprop-2-enoate Chemical group CCOC(=O)\C=C\SC(=C(C#N)C(N)=O)S\C=C\C(=O)OCC NLFBCYMMUAKCPC-KQQUZDAGSA-N 0.000 description 2
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 230000001747 exhibiting effect Effects 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- 108010049041 glutamylalanine Proteins 0.000 description 2
- 150000004676 glycans Chemical class 0.000 description 2
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 2
- 108010010147 glycylglutamine Proteins 0.000 description 2
- 108010087823 glycyltyrosine Proteins 0.000 description 2
- 125000005549 heteroarylene group Chemical group 0.000 description 2
- 125000005842 heteroatom Chemical group 0.000 description 2
- 150000002430 hydrocarbons Chemical class 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 238000001802 infusion Methods 0.000 description 2
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 2
- 208000032839 leukemia Diseases 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 210000004072 lung Anatomy 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 230000007935 neutral effect Effects 0.000 description 2
- 210000001672 ovary Anatomy 0.000 description 2
- 108010051242 phenylalanylserine Proteins 0.000 description 2
- 239000002504 physiological saline solution Substances 0.000 description 2
- 229920001223 polyethylene glycol Polymers 0.000 description 2
- 229920001282 polysaccharide Polymers 0.000 description 2
- 239000005017 polysaccharide Substances 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 2
- 108010070643 prolylglutamic acid Proteins 0.000 description 2
- 238000000159 protein binding assay Methods 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 238000002054 transplantation Methods 0.000 description 2
- 208000022679 triple-negative breast carcinoma Diseases 0.000 description 2
- 108010038745 tryptophylglycine Proteins 0.000 description 2
- 108010017949 tyrosyl-glycyl-glycine Proteins 0.000 description 2
- 108010003137 tyrosyltyrosine Proteins 0.000 description 2
- 125000000391 vinyl group Chemical group [H]C([*])=C([H])[H] 0.000 description 2
- 238000012447 xenograft mouse model Methods 0.000 description 2
- IESDGNYHXIOKRW-YXMSTPNBSA-N (2s)-2-[[(2s)-1-[(2s)-6-amino-2-[[(2s,3r)-2-amino-3-hydroxybutanoyl]amino]hexanoyl]pyrrolidine-2-carbonyl]amino]-5-(diaminomethylideneamino)pentanoic acid Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IESDGNYHXIOKRW-YXMSTPNBSA-N 0.000 description 1
- DIBLBAURNYJYBF-XLXZRNDBSA-N (2s)-2-[[(2s)-2-[[2-[[(2s)-6-amino-2-[[(2s)-2-amino-3-methylbutanoyl]amino]hexanoyl]amino]acetyl]amino]-3-phenylpropanoyl]amino]-3-(4-hydroxyphenyl)propanoic acid Chemical compound C([C@H](NC(=O)CNC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 DIBLBAURNYJYBF-XLXZRNDBSA-N 0.000 description 1
- JBFQOLHAGBKPTP-NZATWWQASA-N (2s)-2-[[(2s)-4-carboxy-2-[[3-carboxy-2-[[(2s)-2,6-diaminohexanoyl]amino]propanoyl]amino]butanoyl]amino]-4-methylpentanoic acid Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)C(CC(O)=O)NC(=O)[C@@H](N)CCCCN JBFQOLHAGBKPTP-NZATWWQASA-N 0.000 description 1
- DLKUYSQUHXBYPB-NSSHGSRYSA-N (2s,4r)-4-[[2-[(1r,3r)-1-acetyloxy-4-methyl-3-[3-methylbutanoyloxymethyl-[(2s,3s)-3-methyl-2-[[(2r)-1-methylpiperidine-2-carbonyl]amino]pentanoyl]amino]pentyl]-1,3-thiazole-4-carbonyl]amino]-2-methyl-5-(4-methylphenyl)pentanoic acid Chemical class N([C@@H]([C@@H](C)CC)C(=O)N(COC(=O)CC(C)C)[C@H](C[C@@H](OC(C)=O)C=1SC=C(N=1)C(=O)N[C@H](C[C@H](C)C(O)=O)CC=1C=CC(C)=CC=1)C(C)C)C(=O)[C@H]1CCCCN1C DLKUYSQUHXBYPB-NSSHGSRYSA-N 0.000 description 1
- IGKWOGMVAOYVSJ-ZDUSSCGKSA-N (4s)-4-ethyl-4-hydroxy-7,8-dihydro-1h-pyrano[3,4-f]indolizine-3,6,10-trione Chemical compound C1=C2C(=O)CCN2C(=O)C2=C1[C@](CC)(O)C(=O)OC2 IGKWOGMVAOYVSJ-ZDUSSCGKSA-N 0.000 description 1
- JYEUMXHLPRZUAT-UHFFFAOYSA-N 1,2,3-triazine Chemical compound C1=CN=NN=C1 JYEUMXHLPRZUAT-UHFFFAOYSA-N 0.000 description 1
- 125000006017 1-propenyl group Chemical group 0.000 description 1
- IEMAOEFPZAIMCN-UHFFFAOYSA-N 1H-pyrazole Chemical compound C=1C=NNC=1.C=1C=NNC=1 IEMAOEFPZAIMCN-UHFFFAOYSA-N 0.000 description 1
- MREIFUWKYMNYTK-UHFFFAOYSA-N 1H-pyrrole Chemical compound C=1C=CNC=1.C=1C=CNC=1 MREIFUWKYMNYTK-UHFFFAOYSA-N 0.000 description 1
- HUEXNHSMABCRTH-UHFFFAOYSA-N 1h-imidazole Chemical compound C1=CNC=N1.C1=CNC=N1 HUEXNHSMABCRTH-UHFFFAOYSA-N 0.000 description 1
- NRKYWOKHZRQRJR-UHFFFAOYSA-N 2,2,2-trifluoroacetamide Chemical group NC(=O)C(F)(F)F NRKYWOKHZRQRJR-UHFFFAOYSA-N 0.000 description 1
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 1
- NXSFUECZFORGOG-CIUDSAMLSA-N Ala-Asn-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXSFUECZFORGOG-CIUDSAMLSA-N 0.000 description 1
- SHYYAQLDNVHPFT-DLOVCJGASA-N Ala-Asn-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SHYYAQLDNVHPFT-DLOVCJGASA-N 0.000 description 1
- WCBVQNZTOKJWJS-ACZMJKKPSA-N Ala-Cys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O WCBVQNZTOKJWJS-ACZMJKKPSA-N 0.000 description 1
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 1
- NHLAEBFGWPXFGI-WHFBIAKZSA-N Ala-Gly-Asn Chemical compound C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N NHLAEBFGWPXFGI-WHFBIAKZSA-N 0.000 description 1
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 1
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 1
- WUHJHHGYVVJMQE-BJDJZHNGSA-N Ala-Leu-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WUHJHHGYVVJMQE-BJDJZHNGSA-N 0.000 description 1
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 1
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 1
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 1
- WQLDNOCHHRISMS-NAKRPEOUSA-N Ala-Pro-Ile Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WQLDNOCHHRISMS-NAKRPEOUSA-N 0.000 description 1
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 1
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 1
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 1
- WNHNMKOFKCHKKD-BFHQHQDPSA-N Ala-Thr-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O WNHNMKOFKCHKKD-BFHQHQDPSA-N 0.000 description 1
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 1
- UISQLSIBJKEJSS-GUBZILKMSA-N Arg-Arg-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(O)=O UISQLSIBJKEJSS-GUBZILKMSA-N 0.000 description 1
- WESHVRNMNFMVBE-FXQIFTODSA-N Arg-Asn-Asp Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)CN=C(N)N WESHVRNMNFMVBE-FXQIFTODSA-N 0.000 description 1
- GDVDRMUYICMNFJ-CIUDSAMLSA-N Arg-Cys-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O GDVDRMUYICMNFJ-CIUDSAMLSA-N 0.000 description 1
- GMFAGHNRXPSSJS-SRVKXCTJSA-N Arg-Leu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GMFAGHNRXPSSJS-SRVKXCTJSA-N 0.000 description 1
- UZGFHWIJWPUPOH-IHRRRGAJSA-N Arg-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UZGFHWIJWPUPOH-IHRRRGAJSA-N 0.000 description 1
- ASQKVGRCKOFKIU-KZVJFYERSA-N Arg-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ASQKVGRCKOFKIU-KZVJFYERSA-N 0.000 description 1
- 206010003210 Arteriosclerosis Diseases 0.000 description 1
- 206010003445 Ascites Diseases 0.000 description 1
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 1
- GZXOUBTUAUAVHD-ACZMJKKPSA-N Asn-Ser-Glu Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GZXOUBTUAUAVHD-ACZMJKKPSA-N 0.000 description 1
- MYTHOBCLNIOFBL-SRVKXCTJSA-N Asn-Ser-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MYTHOBCLNIOFBL-SRVKXCTJSA-N 0.000 description 1
- AMGQTNHANMRPOE-LKXGYXEUSA-N Asn-Thr-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O AMGQTNHANMRPOE-LKXGYXEUSA-N 0.000 description 1
- KZYSHAMXEBPJBD-JRQIVUDYSA-N Asn-Thr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KZYSHAMXEBPJBD-JRQIVUDYSA-N 0.000 description 1
- LGCVSPFCFXWUEY-IHPCNDPISA-N Asn-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N LGCVSPFCFXWUEY-IHPCNDPISA-N 0.000 description 1
- LTDGPJKGJDIBQD-LAEOZQHASA-N Asn-Val-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LTDGPJKGJDIBQD-LAEOZQHASA-N 0.000 description 1
- XOQYDFCQPWAMSA-KKHAAJSZSA-N Asn-Val-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XOQYDFCQPWAMSA-KKHAAJSZSA-N 0.000 description 1
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 1
- VHQOCWWKXIOAQI-WDSKDSINSA-N Asp-Gln-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VHQOCWWKXIOAQI-WDSKDSINSA-N 0.000 description 1
- ZSJFGGSPCCHMNE-LAEOZQHASA-N Asp-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N ZSJFGGSPCCHMNE-LAEOZQHASA-N 0.000 description 1
- HSWYMWGDMPLTTH-FXQIFTODSA-N Asp-Glu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HSWYMWGDMPLTTH-FXQIFTODSA-N 0.000 description 1
- LTXGDRFJRZSZAV-CIUDSAMLSA-N Asp-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N LTXGDRFJRZSZAV-CIUDSAMLSA-N 0.000 description 1
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 1
- UZFHNLYQWMGUHU-DCAQKATOSA-N Asp-Lys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UZFHNLYQWMGUHU-DCAQKATOSA-N 0.000 description 1
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 1
- DONWIPDSZZJHHK-HJGDQZAQSA-N Asp-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)O DONWIPDSZZJHHK-HJGDQZAQSA-N 0.000 description 1
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 1
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 1
- 206010003571 Astrocytoma Diseases 0.000 description 1
- 208000037260 Atherosclerotic Plaque Diseases 0.000 description 1
- 206010005003 Bladder cancer Diseases 0.000 description 1
- 208000020084 Bone disease Diseases 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 208000003174 Brain Neoplasms Diseases 0.000 description 1
- 241000282461 Canis lupus Species 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 206010009944 Colon cancer Diseases 0.000 description 1
- 102000014447 Complement C1q Human genes 0.000 description 1
- 108010078043 Complement C1q Proteins 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- PMPVIKIVABFJJI-UHFFFAOYSA-N Cyclobutane Chemical compound C1CCC1 PMPVIKIVABFJJI-UHFFFAOYSA-N 0.000 description 1
- LVZWSLJZHVFIQJ-UHFFFAOYSA-N Cyclopropane Chemical compound C1CC1 LVZWSLJZHVFIQJ-UHFFFAOYSA-N 0.000 description 1
- ZXCAQANTQWBICD-DCAQKATOSA-N Cys-Lys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N ZXCAQANTQWBICD-DCAQKATOSA-N 0.000 description 1
- PEZINYWZBQNTIX-NAKRPEOUSA-N Cys-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)N PEZINYWZBQNTIX-NAKRPEOUSA-N 0.000 description 1
- 101710112752 Cytotoxin Proteins 0.000 description 1
- 239000003155 DNA primer Substances 0.000 description 1
- 206010059866 Drug resistance Diseases 0.000 description 1
- 102000002322 Egg Proteins Human genes 0.000 description 1
- 108010000912 Egg Proteins Proteins 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 206010053717 Fibrous histiocytoma Diseases 0.000 description 1
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 201000003741 Gastrointestinal carcinoma Diseases 0.000 description 1
- 206010017993 Gastrointestinal neoplasms Diseases 0.000 description 1
- 208000032612 Glial tumor Diseases 0.000 description 1
- 206010018338 Glioma Diseases 0.000 description 1
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 1
- DHNWZLGBTPUTQQ-QEJZJMRPSA-N Gln-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N DHNWZLGBTPUTQQ-QEJZJMRPSA-N 0.000 description 1
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 1
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 1
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 1
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 1
- YKLNMGJYMNPBCP-ACZMJKKPSA-N Glu-Asn-Asp Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YKLNMGJYMNPBCP-ACZMJKKPSA-N 0.000 description 1
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 1
- HNVFSTLPVJWIDV-CIUDSAMLSA-N Glu-Glu-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HNVFSTLPVJWIDV-CIUDSAMLSA-N 0.000 description 1
- KASDBWKLWJKTLJ-GUBZILKMSA-N Glu-Glu-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O KASDBWKLWJKTLJ-GUBZILKMSA-N 0.000 description 1
- HILMIYALTUQTRC-XVKPBYJWSA-N Glu-Gly-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HILMIYALTUQTRC-XVKPBYJWSA-N 0.000 description 1
- CXRWMMRLEMVSEH-PEFMBERDSA-N Glu-Ile-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O CXRWMMRLEMVSEH-PEFMBERDSA-N 0.000 description 1
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 1
- QDMVXRNLOPTPIE-WDCWCFNPSA-N Glu-Lys-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QDMVXRNLOPTPIE-WDCWCFNPSA-N 0.000 description 1
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 1
- YQAQQKPWFOBSMU-WDCWCFNPSA-N Glu-Thr-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O YQAQQKPWFOBSMU-WDCWCFNPSA-N 0.000 description 1
- BPCLDCNZBUYGOD-BPUTZDHNSA-N Glu-Trp-Glu Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 BPCLDCNZBUYGOD-BPUTZDHNSA-N 0.000 description 1
- UZWUBBRJWFTHTD-LAEOZQHASA-N Glu-Val-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O UZWUBBRJWFTHTD-LAEOZQHASA-N 0.000 description 1
- QXUPRMQJDWJDFR-NRPADANISA-N Glu-Val-Ser Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXUPRMQJDWJDFR-NRPADANISA-N 0.000 description 1
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 1
- MZZSCEANQDPJER-ONGXEEELSA-N Gly-Ala-Phe Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MZZSCEANQDPJER-ONGXEEELSA-N 0.000 description 1
- JPXNYFOHTHSREU-UWVGGRQHSA-N Gly-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN JPXNYFOHTHSREU-UWVGGRQHSA-N 0.000 description 1
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 1
- GRIRDMVMJJDZKV-RCOVLWMOSA-N Gly-Asn-Val Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O GRIRDMVMJJDZKV-RCOVLWMOSA-N 0.000 description 1
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 1
- FIQQRCFQXGLOSZ-WDSKDSINSA-N Gly-Glu-Asp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FIQQRCFQXGLOSZ-WDSKDSINSA-N 0.000 description 1
- BIRKKBCSAIHDDF-WDSKDSINSA-N Gly-Glu-Cys Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O BIRKKBCSAIHDDF-WDSKDSINSA-N 0.000 description 1
- UESJMAMHDLEHGM-NHCYSSNCSA-N Gly-Ile-Leu Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O UESJMAMHDLEHGM-NHCYSSNCSA-N 0.000 description 1
- IGOYNRWLWHWAQO-JTQLQIEISA-N Gly-Phe-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 IGOYNRWLWHWAQO-JTQLQIEISA-N 0.000 description 1
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 1
- NGBGZCUWFVVJKC-IRXDYDNUSA-N Gly-Tyr-Tyr Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NGBGZCUWFVVJKC-IRXDYDNUSA-N 0.000 description 1
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 1
- WMKXFMUJRCEGRP-SRVKXCTJSA-N His-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N WMKXFMUJRCEGRP-SRVKXCTJSA-N 0.000 description 1
- HIAHVKLTHNOENC-HGNGGELXSA-N His-Glu-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HIAHVKLTHNOENC-HGNGGELXSA-N 0.000 description 1
- WEIYKCOEVBUJQC-JYJNAYRXSA-N His-Glu-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC2=CN=CN2)N WEIYKCOEVBUJQC-JYJNAYRXSA-N 0.000 description 1
- UROVZOUMHNXPLZ-AVGNSLFASA-N His-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 UROVZOUMHNXPLZ-AVGNSLFASA-N 0.000 description 1
- TVMNTHXFRSXZGR-IHRRRGAJSA-N His-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O TVMNTHXFRSXZGR-IHRRRGAJSA-N 0.000 description 1
- ZHHLTWUOWXHVQJ-YUMQZZPRSA-N His-Ser-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZHHLTWUOWXHVQJ-YUMQZZPRSA-N 0.000 description 1
- 208000017604 Hodgkin disease Diseases 0.000 description 1
- 208000021519 Hodgkin lymphoma Diseases 0.000 description 1
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000690301 Homo sapiens Aldo-keto reductase family 1 member C4 Proteins 0.000 description 1
- 101001019455 Homo sapiens ICOS ligand Proteins 0.000 description 1
- 101001117317 Homo sapiens Programmed cell death 1 ligand 1 Proteins 0.000 description 1
- 101001116548 Homo sapiens Protein CBFA2T1 Proteins 0.000 description 1
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 1
- 102100034980 ICOS ligand Human genes 0.000 description 1
- RWIKBYVJQAJYDP-BJDJZHNGSA-N Ile-Ala-Lys Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN RWIKBYVJQAJYDP-BJDJZHNGSA-N 0.000 description 1
- MKWSZEHGHSLNPF-NAKRPEOUSA-N Ile-Ala-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O)N MKWSZEHGHSLNPF-NAKRPEOUSA-N 0.000 description 1
- FADXGVVLSPPEQY-GHCJXIJMSA-N Ile-Cys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N FADXGVVLSPPEQY-GHCJXIJMSA-N 0.000 description 1
- TWPSALMCEHCIOY-YTFOTSKYSA-N Ile-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)O)N TWPSALMCEHCIOY-YTFOTSKYSA-N 0.000 description 1
- AXNGDPAKKCEKGY-QPHKQPEJSA-N Ile-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N AXNGDPAKKCEKGY-QPHKQPEJSA-N 0.000 description 1
- IOVUXUSIGXCREV-DKIMLUQUSA-N Ile-Leu-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IOVUXUSIGXCREV-DKIMLUQUSA-N 0.000 description 1
- NZGTYCMLUGYMCV-XUXIUFHCSA-N Ile-Lys-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N NZGTYCMLUGYMCV-XUXIUFHCSA-N 0.000 description 1
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 1
- AGGIYSLVUKVOPT-HTFCKZLJSA-N Ile-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N AGGIYSLVUKVOPT-HTFCKZLJSA-N 0.000 description 1
- KXUKTDGKLAOCQK-LSJOCFKGSA-N Ile-Val-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O KXUKTDGKLAOCQK-LSJOCFKGSA-N 0.000 description 1
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 1
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 1
- 206010061218 Inflammation Diseases 0.000 description 1
- 108010065920 Insulin Lispro Proteins 0.000 description 1
- 238000010824 Kaplan-Meier survival analysis Methods 0.000 description 1
- 208000007766 Kaposi sarcoma Diseases 0.000 description 1
- 208000008839 Kidney Neoplasms Diseases 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 1
- WCTCIIAGNMFYAO-DCAQKATOSA-N Leu-Cys-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O WCTCIIAGNMFYAO-DCAQKATOSA-N 0.000 description 1
- BOFAFKVZQUMTID-AVGNSLFASA-N Leu-Gln-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N BOFAFKVZQUMTID-AVGNSLFASA-N 0.000 description 1
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 1
- FIYMBBHGYNQFOP-IUCAKERBSA-N Leu-Gly-Gln Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N FIYMBBHGYNQFOP-IUCAKERBSA-N 0.000 description 1
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 1
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 1
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 1
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 1
- DDVHDMSBLRAKNV-IHRRRGAJSA-N Leu-Met-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O DDVHDMSBLRAKNV-IHRRRGAJSA-N 0.000 description 1
- KWLWZYMNUZJKMZ-IHRRRGAJSA-N Leu-Pro-Leu Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O KWLWZYMNUZJKMZ-IHRRRGAJSA-N 0.000 description 1
- ICYRCNICGBJLGM-HJGDQZAQSA-N Leu-Thr-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(O)=O ICYRCNICGBJLGM-HJGDQZAQSA-N 0.000 description 1
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 1
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 1
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 1
- NTBFKPBULZGXQL-KKUMJFAQSA-N Lys-Asp-Tyr Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTBFKPBULZGXQL-KKUMJFAQSA-N 0.000 description 1
- DZQYZKPINJLLEN-KKUMJFAQSA-N Lys-Cys-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N)O DZQYZKPINJLLEN-KKUMJFAQSA-N 0.000 description 1
- GCMWRRQAKQXDED-IUCAKERBSA-N Lys-Glu-Gly Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)N[C@@H](CCC([O-])=O)C(=O)NCC([O-])=O GCMWRRQAKQXDED-IUCAKERBSA-N 0.000 description 1
- ODUQLUADRKMHOZ-JYJNAYRXSA-N Lys-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)O ODUQLUADRKMHOZ-JYJNAYRXSA-N 0.000 description 1
- QZONCCHVHCOBSK-YUMQZZPRSA-N Lys-Gly-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O QZONCCHVHCOBSK-YUMQZZPRSA-N 0.000 description 1
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 1
- CTJUSALVKAWFFU-CIUDSAMLSA-N Lys-Ser-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N CTJUSALVKAWFFU-CIUDSAMLSA-N 0.000 description 1
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 1
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 1
- IKXQOBUBZSOWDY-AVGNSLFASA-N Lys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCCCN)N IKXQOBUBZSOWDY-AVGNSLFASA-N 0.000 description 1
- 241000282553 Macaca Species 0.000 description 1
- WXHHTBVYQOSYSL-FXQIFTODSA-N Met-Ala-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O WXHHTBVYQOSYSL-FXQIFTODSA-N 0.000 description 1
- 241000699660 Mus musculus Species 0.000 description 1
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 1
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 1
- DBRANXPIWBDHCD-UHFFFAOYSA-N NC1=CC=C(C=2C(CCCC1=2)=O)NC(C(F)(F)F)=O Chemical compound NC1=CC=C(C=2C(CCCC1=2)=O)NC(C(F)(F)F)=O DBRANXPIWBDHCD-UHFFFAOYSA-N 0.000 description 1
- 206010061309 Neoplasm progression Diseases 0.000 description 1
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 1
- ZCQWOFVYLHDMMC-UHFFFAOYSA-N Oxazole Chemical compound C1=COC=N1 ZCQWOFVYLHDMMC-UHFFFAOYSA-N 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- 108090000284 Pepsin A Proteins 0.000 description 1
- 206010057249 Phagocytosis Diseases 0.000 description 1
- DFEVBOYEUQJGER-JURCDPSOSA-N Phe-Ala-Ile Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O DFEVBOYEUQJGER-JURCDPSOSA-N 0.000 description 1
- CGOMLCQJEMWMCE-STQMWFEESA-N Phe-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 CGOMLCQJEMWMCE-STQMWFEESA-N 0.000 description 1
- HXSUFWQYLPKEHF-IHRRRGAJSA-N Phe-Asn-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HXSUFWQYLPKEHF-IHRRRGAJSA-N 0.000 description 1
- KJJROSNFBRWPHS-JYJNAYRXSA-N Phe-Glu-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KJJROSNFBRWPHS-JYJNAYRXSA-N 0.000 description 1
- CSDMCMITJLKBAH-SOUVJXGZSA-N Phe-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O CSDMCMITJLKBAH-SOUVJXGZSA-N 0.000 description 1
- BWTKUQPNOMMKMA-FIRPJDEBSA-N Phe-Ile-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BWTKUQPNOMMKMA-FIRPJDEBSA-N 0.000 description 1
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 1
- JDMKQHSHKJHAHR-UHFFFAOYSA-N Phe-Phe-Leu-Tyr Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)CC1=CC=CC=C1 JDMKQHSHKJHAHR-UHFFFAOYSA-N 0.000 description 1
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 1
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 1
- IIEOLPMQYRBZCN-SRVKXCTJSA-N Phe-Ser-Cys Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O IIEOLPMQYRBZCN-SRVKXCTJSA-N 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- ZSKJPKFTPQCPIH-RCWTZXSCSA-N Pro-Arg-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZSKJPKFTPQCPIH-RCWTZXSCSA-N 0.000 description 1
- TUYWCHPXKQTISF-LPEHRKFASA-N Pro-Cys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N2CCC[C@@H]2C(=O)O TUYWCHPXKQTISF-LPEHRKFASA-N 0.000 description 1
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 1
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 1
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 1
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 1
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 1
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 1
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 1
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 1
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 1
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 1
- CXGLFEOYCJFKPR-RCWTZXSCSA-N Pro-Thr-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O CXGLFEOYCJFKPR-RCWTZXSCSA-N 0.000 description 1
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 201000004681 Psoriasis Diseases 0.000 description 1
- 206010038389 Renal cancer Diseases 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 208000034189 Sclerosis Diseases 0.000 description 1
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 1
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 1
- MPPHJZYXDVDGOF-BWBBJGPYSA-N Ser-Cys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CO MPPHJZYXDVDGOF-BWBBJGPYSA-N 0.000 description 1
- HVKMTOIAYDOJPL-NRPADANISA-N Ser-Gln-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVKMTOIAYDOJPL-NRPADANISA-N 0.000 description 1
- YQQKYAZABFEYAF-FXQIFTODSA-N Ser-Glu-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQQKYAZABFEYAF-FXQIFTODSA-N 0.000 description 1
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 1
- ZOPISOXXPQNOCO-SVSWQMSJSA-N Ser-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CO)N ZOPISOXXPQNOCO-SVSWQMSJSA-N 0.000 description 1
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 1
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 1
- OWCVUSJMEBGMOK-YUMQZZPRSA-N Ser-Lys-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O OWCVUSJMEBGMOK-YUMQZZPRSA-N 0.000 description 1
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 1
- ZSLFCBHEINFXRS-LPEHRKFASA-N Ser-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N ZSLFCBHEINFXRS-LPEHRKFASA-N 0.000 description 1
- XGQKSRGHEZNWIS-IHRRRGAJSA-N Ser-Pro-Tyr Chemical compound N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O XGQKSRGHEZNWIS-IHRRRGAJSA-N 0.000 description 1
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 1
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 1
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 1
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 1
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 1
- PCJLFYBAQZQOFE-KATARQTJSA-N Ser-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N)O PCJLFYBAQZQOFE-KATARQTJSA-N 0.000 description 1
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 1
- STIAINRLUUKYKM-WFBYXXMGSA-N Ser-Trp-Ala Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CO)=CNC2=C1 STIAINRLUUKYKM-WFBYXXMGSA-N 0.000 description 1
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 1
- RCOUFINCYASMDN-GUBZILKMSA-N Ser-Val-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O RCOUFINCYASMDN-GUBZILKMSA-N 0.000 description 1
- 206010041067 Small cell lung cancer Diseases 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 230000006044 T cell activation Effects 0.000 description 1
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 1
- 208000024313 Testicular Neoplasms Diseases 0.000 description 1
- 206010057644 Testis cancer Diseases 0.000 description 1
- FZWLAAWBMGSTSO-UHFFFAOYSA-N Thiazole Chemical compound C1=CSC=N1 FZWLAAWBMGSTSO-UHFFFAOYSA-N 0.000 description 1
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 1
- KWQBJOUOSNJDRR-XAVMHZPKSA-N Thr-Cys-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N)O KWQBJOUOSNJDRR-XAVMHZPKSA-N 0.000 description 1
- DSLHSTIUAPKERR-XGEHTFHBSA-N Thr-Cys-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O DSLHSTIUAPKERR-XGEHTFHBSA-N 0.000 description 1
- GKWNLDNXMMLRMC-GLLZPBPUSA-N Thr-Glu-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O GKWNLDNXMMLRMC-GLLZPBPUSA-N 0.000 description 1
- ONNSECRQFSTMCC-XKBZYTNZSA-N Thr-Glu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ONNSECRQFSTMCC-XKBZYTNZSA-N 0.000 description 1
- PAXANSWUSVPFNK-IUKAMOBKSA-N Thr-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N PAXANSWUSVPFNK-IUKAMOBKSA-N 0.000 description 1
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 1
- BDGBHYCAZJPLHX-HJGDQZAQSA-N Thr-Lys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BDGBHYCAZJPLHX-HJGDQZAQSA-N 0.000 description 1
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 1
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 1
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 1
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 1
- DQDXHYIEITXNJY-BPUTZDHNSA-N Trp-Gln-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N DQDXHYIEITXNJY-BPUTZDHNSA-N 0.000 description 1
- RRVUOLRWIZXBRQ-IHPCNDPISA-N Trp-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N RRVUOLRWIZXBRQ-IHPCNDPISA-N 0.000 description 1
- NLWCSMOXNKBRLC-WDSOQIARSA-N Trp-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLWCSMOXNKBRLC-WDSOQIARSA-N 0.000 description 1
- CSOBBJWWODOYGW-ILWGZMRPSA-N Trp-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CNC4=CC=CC=C43)N)C(=O)O CSOBBJWWODOYGW-ILWGZMRPSA-N 0.000 description 1
- UMIACFRBELJMGT-GQGQLFGLSA-N Trp-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N UMIACFRBELJMGT-GQGQLFGLSA-N 0.000 description 1
- 102000007537 Type II DNA Topoisomerases Human genes 0.000 description 1
- 108010046308 Type II DNA Topoisomerases Proteins 0.000 description 1
- VTFWAGGJDRSQFG-MELADBBJSA-N Tyr-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O VTFWAGGJDRSQFG-MELADBBJSA-N 0.000 description 1
- SCCKSNREWHMKOJ-SRVKXCTJSA-N Tyr-Asn-Ser Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O SCCKSNREWHMKOJ-SRVKXCTJSA-N 0.000 description 1
- JRXKIVGWMMIIOF-YDHLFZDLSA-N Tyr-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JRXKIVGWMMIIOF-YDHLFZDLSA-N 0.000 description 1
- SLCSPPCQWUHPPO-JYJNAYRXSA-N Tyr-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SLCSPPCQWUHPPO-JYJNAYRXSA-N 0.000 description 1
- NHOVZGFNTGMYMI-KKUMJFAQSA-N Tyr-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NHOVZGFNTGMYMI-KKUMJFAQSA-N 0.000 description 1
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 1
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 1
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 1
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 1
- GNWUWQAVVJQREM-NHCYSSNCSA-N Val-Asn-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N GNWUWQAVVJQREM-NHCYSSNCSA-N 0.000 description 1
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 1
- COSLEEOIYRPTHD-YDHLFZDLSA-N Val-Asp-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 COSLEEOIYRPTHD-YDHLFZDLSA-N 0.000 description 1
- WDIGUPHXPBMODF-UMNHJUIQSA-N Val-Glu-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N WDIGUPHXPBMODF-UMNHJUIQSA-N 0.000 description 1
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 1
- ZIGZPYJXIWLQFC-QTKMDUPCSA-N Val-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N)O ZIGZPYJXIWLQFC-QTKMDUPCSA-N 0.000 description 1
- WNZSAUMKZQXHNC-UKJIMTQDSA-N Val-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N WNZSAUMKZQXHNC-UKJIMTQDSA-N 0.000 description 1
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 1
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- HPANGHISDXDUQY-ULQDDVLXSA-N Val-Lys-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N HPANGHISDXDUQY-ULQDDVLXSA-N 0.000 description 1
- LJSZPMSUYKKKCP-UBHSHLNASA-N Val-Phe-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 LJSZPMSUYKKKCP-UBHSHLNASA-N 0.000 description 1
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 1
- KRAHMIJVUPUOTQ-DCAQKATOSA-N Val-Ser-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KRAHMIJVUPUOTQ-DCAQKATOSA-N 0.000 description 1
- SDHZOOIGIUEPDY-JYJNAYRXSA-N Val-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 SDHZOOIGIUEPDY-JYJNAYRXSA-N 0.000 description 1
- TVGWMCTYUFBXAP-QTKMDUPCSA-N Val-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N)O TVGWMCTYUFBXAP-QTKMDUPCSA-N 0.000 description 1
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 1
- JAIZPWVHPQRYOU-ZJDVBMNYSA-N Val-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O JAIZPWVHPQRYOU-ZJDVBMNYSA-N 0.000 description 1
- IRAUYEAFPFPVND-UVBJJODRSA-N Val-Trp-Ala Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 IRAUYEAFPFPVND-UVBJJODRSA-N 0.000 description 1
- ZLNYBMWGPOKSLW-LSJOCFKGSA-N Val-Val-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLNYBMWGPOKSLW-LSJOCFKGSA-N 0.000 description 1
- ZHWZDZFWBXWPDW-GUBZILKMSA-N Val-Val-Cys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O ZHWZDZFWBXWPDW-GUBZILKMSA-N 0.000 description 1
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 1
- DONIIAXVJUFSOY-FJTITLMZSA-N [H][C@](C)(CC)[C@H](NC(=O)[C@H]1C[C@H](C)CCN1C)C(=O)N(CC)[C@H](C[C@@H](OC(C)=O)C1=NC(=CS1)C(=O)N[C@H](C[C@H](C)C(O)=O)CC1=CC=C(NC(=O)[C@H](CCCCN)NC(=O)CCCCCN2C(=O)C=CC2=O)C=C1)C(C)C Chemical compound [H][C@](C)(CC)[C@H](NC(=O)[C@H]1C[C@H](C)CCN1C)C(=O)N(CC)[C@H](C[C@@H](OC(C)=O)C1=NC(=CS1)C(=O)N[C@H](C[C@H](C)C(O)=O)CC1=CC=C(NC(=O)[C@H](CCCCN)NC(=O)CCCCCN2C(=O)C=CC2=O)C=C1)C(C)C DONIIAXVJUFSOY-FJTITLMZSA-N 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 238000007792 addition Methods 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 208000009956 adenocarcinoma Diseases 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- HSFWRNGVRCDJHI-UHFFFAOYSA-N alpha-acetylene Natural products C#C HSFWRNGVRCDJHI-UHFFFAOYSA-N 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 210000000612 antigen-presenting cell Anatomy 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 1
- 150000001491 aromatic compounds Chemical class 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 210000003567 ascitic fluid Anatomy 0.000 description 1
- 108010047857 aspartylglycine Proteins 0.000 description 1
- 238000003556 assay Methods 0.000 description 1
- 238000011717 athymic nude mouse Methods 0.000 description 1
- 125000004429 atom Chemical group 0.000 description 1
- 230000008512 biological response Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 125000004369 butenyl group Chemical group C(=CCC)* 0.000 description 1
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 230000000981 bystander Effects 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 230000009702 cancer cell proliferation Effects 0.000 description 1
- 230000005907 cancer growth Effects 0.000 description 1
- 125000002837 carbocyclic group Chemical group 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 230000022131 cell cycle Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- 235000013330 chicken meat Nutrition 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 208000029742 colonic neoplasm Diseases 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 229940125890 compound Ia Drugs 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000001268 conjugating effect Effects 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 208000018631 connective tissue disease Diseases 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000000139 costimulatory effect Effects 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- CFBGXYDUODCMNS-UHFFFAOYSA-N cyclobutene Chemical compound C1CC=C1 CFBGXYDUODCMNS-UHFFFAOYSA-N 0.000 description 1
- OOXWYYGXTJLWHA-UHFFFAOYSA-N cyclopropene Chemical compound C1C=C1 OOXWYYGXTJLWHA-UHFFFAOYSA-N 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 150000001944 cysteine derivatives Chemical class 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 206010012818 diffuse large B-cell lymphoma Diseases 0.000 description 1
- 238000009792 diffusion process Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 238000007865 diluting Methods 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 238000010494 dissociation reaction Methods 0.000 description 1
- 230000005593 dissociations Effects 0.000 description 1
- 235000013345 egg yolk Nutrition 0.000 description 1
- 210000002969 egg yolk Anatomy 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 125000002534 ethynyl group Chemical group [H]C#C* 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000013604 expression vector Substances 0.000 description 1
- 230000000893 fibroproliferative effect Effects 0.000 description 1
- 230000003325 follicular Effects 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- WCVXAYSKMJJPLO-UHFFFAOYSA-N furan Chemical compound C=1C=COC=1.C=1C=COC=1 WCVXAYSKMJJPLO-UHFFFAOYSA-N 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 108010078144 glutaminyl-glycine Proteins 0.000 description 1
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 1
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 1
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 1
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 1
- 108010077435 glycyl-phenylalanyl-glycine Proteins 0.000 description 1
- 230000005484 gravity Effects 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 125000005843 halogen group Chemical group 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 230000002489 hematologic effect Effects 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 108010018006 histidylserine Proteins 0.000 description 1
- 201000000284 histiocytoma Diseases 0.000 description 1
- 108091008039 hormone receptors Proteins 0.000 description 1
- 102000048776 human CD274 Human genes 0.000 description 1
- 102000054751 human RUNX1T1 Human genes 0.000 description 1
- 230000008348 humoral response Effects 0.000 description 1
- 206010020718 hyperplasia Diseases 0.000 description 1
- 230000002390 hyperplastic effect Effects 0.000 description 1
- 210000002865 immune cell Anatomy 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 238000011532 immunohistochemical staining Methods 0.000 description 1
- 238000003364 immunohistochemistry Methods 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 201000002313 intestinal cancer Diseases 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 125000000959 isobutyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])* 0.000 description 1
- 108010078274 isoleucylvaline Proteins 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- ZLTPDFXIESTBQG-UHFFFAOYSA-N isothiazole Chemical compound C=1C=NSC=1 ZLTPDFXIESTBQG-UHFFFAOYSA-N 0.000 description 1
- CTAPFRYPJLPFDF-UHFFFAOYSA-N isoxazole Chemical compound C=1C=NOC=1 CTAPFRYPJLPFDF-UHFFFAOYSA-N 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 201000010982 kidney cancer Diseases 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 238000011031 large-scale manufacturing process Methods 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 1
- 108010057821 leucylproline Proteins 0.000 description 1
- 201000007270 liver cancer Diseases 0.000 description 1
- 208000014018 liver neoplasm Diseases 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 108010009298 lysylglutamic acid Proteins 0.000 description 1
- 108010064235 lysylglycine Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 210000003519 mature b lymphocyte Anatomy 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- 108010016686 methionyl-alanyl-serine Proteins 0.000 description 1
- 229940126619 mouse monoclonal antibody Drugs 0.000 description 1
- 102000051367 mu Opioid Receptors Human genes 0.000 description 1
- 125000004108 n-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000004123 n-propyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 230000001613 neoplastic effect Effects 0.000 description 1
- 125000000449 nitro group Chemical group [O-][N+](*)=O 0.000 description 1
- 150000002482 oligosaccharides Polymers 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 208000008798 osteoma Diseases 0.000 description 1
- 201000008968 osteosarcoma Diseases 0.000 description 1
- GHCAUEMXBSLMGU-UHFFFAOYSA-N oxadiazole;1,2,5-oxadiazole Chemical compound C=1C=NON=1.C1=CON=N1 GHCAUEMXBSLMGU-UHFFFAOYSA-N 0.000 description 1
- CQDAMYNQINDRQC-UHFFFAOYSA-N oxatriazole Chemical compound C1=NN=NO1 CQDAMYNQINDRQC-UHFFFAOYSA-N 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 238000010647 peptide synthesis reaction Methods 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 230000008782 phagocytosis Effects 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 1
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 1
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 1
- 150000004713 phosphodiesters Chemical group 0.000 description 1
- 230000003169 placental effect Effects 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 239000000244 polyoxyethylene sorbitan monooleate Substances 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- 229940068968 polysorbate 80 Drugs 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 210000002307 prostate Anatomy 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- CRTBNOWPBHJICM-UHFFFAOYSA-N pyrazine Chemical compound C1=CN=CC=N1.C1=CN=CC=N1 CRTBNOWPBHJICM-UHFFFAOYSA-N 0.000 description 1
- IOXGEAHHEGTLMQ-UHFFFAOYSA-N pyridazine Chemical compound C1=CC=NN=C1.C1=CC=NN=C1 IOXGEAHHEGTLMQ-UHFFFAOYSA-N 0.000 description 1
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 description 1
- YMXFJTUQQVLJEN-UHFFFAOYSA-N pyrimidine Chemical compound C1=CN=CN=C1.C1=CN=CN=C1 YMXFJTUQQVLJEN-UHFFFAOYSA-N 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 230000008261 resistance mechanism Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 125000002914 sec-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 108010048818 seryl-histidine Proteins 0.000 description 1
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 1
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 208000000587 small cell lung carcinoma Diseases 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000007480 spreading Effects 0.000 description 1
- 238000003892 spreading Methods 0.000 description 1
- 206010041823 squamous cell carcinoma Diseases 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 239000004094 surface-active agent Substances 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 201000003120 testicular cancer Diseases 0.000 description 1
- 150000003573 thiols Chemical class 0.000 description 1
- 229930192474 thiophene Natural products 0.000 description 1
- 108010061238 threonyl-glycine Proteins 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 238000011830 transgenic mouse model Methods 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- 150000003852 triazoles Chemical class 0.000 description 1
- 108010080629 tryptophan-leucine Proteins 0.000 description 1
- 230000005751 tumor progression Effects 0.000 description 1
- 108010051110 tyrosyl-lysine Proteins 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- 210000003932 urinary bladder Anatomy 0.000 description 1
- 201000005112 urinary bladder cancer Diseases 0.000 description 1
- 108010052774 valyl-lysyl-glycyl-phenylalanyl-tyrosine Proteins 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 229920002554 vinyl polymer Polymers 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 239000008215 water for injection Substances 0.000 description 1
- 230000003442 weekly effect Effects 0.000 description 1
- 108010027345 wheylin-1 peptide Proteins 0.000 description 1
- 108020001612 μ-opioid receptors Proteins 0.000 description 1
Images





















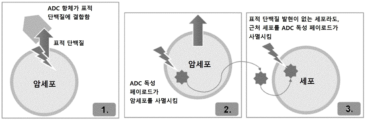


































Classifications
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57484—Immunoassay; Biospecific binding assay; Materials therefor for cancer involving compounds serving as markers for tumor, cancer, neoplasia, e.g. cellular determinants, receptors, heat shock/stress proteins, A-protein, oligosaccharides, metabolites
- G01N33/57492—Immunoassay; Biospecific binding assay; Materials therefor for cancer involving compounds serving as markers for tumor, cancer, neoplasia, e.g. cellular determinants, receptors, heat shock/stress proteins, A-protein, oligosaccharides, metabolites involving compounds localized on the membrane of tumor or cancer cells
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2827—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against B7 molecules, e.g. CD80, CD86
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2413—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on distances to training or reference patterns
- G06F18/24133—Distances to prototypes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/254—Fusion techniques of classification results, e.g. of results related to same input data
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/44—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components
- G06V10/443—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components by matching or filtering
- G06V10/449—Biologically inspired filters, e.g. difference of Gaussians [DoG] or Gabor filters
- G06V10/451—Biologically inspired filters, e.g. difference of Gaussians [DoG] or Gabor filters with interaction between the filter responses, e.g. cortical complex cells
- G06V10/454—Integrating the filters into a hierarchical structure, e.g. convolutional neural networks [CNN]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/60—Type of objects
- G06V20/69—Microscopic objects, e.g. biological cells or cellular parts
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/60—Type of objects
- G06V20/69—Microscopic objects, e.g. biological cells or cellular parts
- G06V20/695—Preprocessing, e.g. image segmentation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/60—Type of objects
- G06V20/69—Microscopic objects, e.g. biological cells or cellular parts
- G06V20/698—Matching; Classification
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2800/00—Detection or diagnosis of diseases
- G01N2800/52—Predicting or monitoring the response to treatment, e.g. for selection of therapy based on assay results in personalised medicine; Prognosis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/03—Recognition of patterns in medical or anatomical images
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Theoretical Computer Science (AREA)
- Immunology (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Chemical & Material Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Data Mining & Analysis (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Multimedia (AREA)
- Organic Chemistry (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Medicinal Chemistry (AREA)
- Biochemistry (AREA)
- Cell Biology (AREA)
- Genetics & Genomics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Urology & Nephrology (AREA)
- Hematology (AREA)
- Oncology (AREA)
- Biodiversity & Conservation Biology (AREA)
- Hospice & Palliative Care (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Biotechnology (AREA)
- Epidemiology (AREA)
- Microbiology (AREA)
- Veterinary Medicine (AREA)
- Food Science & Technology (AREA)
Abstract
본 발명은 항체-약물 접합체(ADC) 요법에 암 환자가 어떻게 반응할지 예측하는 방법으로서, 각각의 암세포에 대한 단일세포 ADC 점수를 기반으로 예측 반응 점수를 계산하는 단계를 포함하는 방법에 관한 것이다. 각각의 암세포에 대해, 단일세포 ADC 점수는 암세포의 막과 세포질 및 인접 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 계산된다. 본 발명은 또한 통계 연산을 사용하여 조직 샘플의 모든 단일세포 ADC 점수를 집계하여 ADC 요법에 대한 암 환자의 반응을 예측하고, 관련 항체-약물 접합체를 이용한 암의 후속 치료를 예측하는 것에 관한 것이다.
Description
관련 출원에 대한 상호 참조
본 출원은 2020년 9월 12일에 출원된 미국 특허가출원 63/077,607호의 우선권 이익을 주장한다. 상기 열거된 각 출원은 모든 목적을 위해 전문이 본원에 참조로 포함된다.
전자적으로 제출된 자료의 참조에 의한 포함
본 출원과 동시에 제출되고 다음과 같이 확인되는 컴퓨터 판독가능한 뉴클레오티드/아미노산 서열 목록은 전체가 본원에 참조로 포함된다: 2021년 9월 2일자로 생성된 "B7H4-400-WO-PCT_seq-listing.txt"라는 파일명의 14,351 바이트 ASCII(텍스트) 파일 1개.
기술분야
본 발명은 항-B7H4 항체-약물 접합체를 사용하는 요법에 암 환자가 어떻게 반응할지를 나타내는 점수를 계산하는 방법에 관한 것이다.
주어진 치료에 대한 암 환자의 반응 확률을 평가하는 것은 암 환자의 치료 요법을 결정하는 데 필수적인 단계이다. 이러한 평가는 대개 암 환자의 조직 샘플에 대한 조직학적 분석을 기반으로 하며 표준 등급 체계를 사용하여 암을 식별하고 분류하는 것을 수반한다. 특정 단백질을 발현하는 마커-양성 세포와 단백질을 발현하지 않는 마커-음성 세포를 구별하기 위해 면역조직화학(IHC) 염색을 사용할 수 있다. IHC 염색은 일반적으로 단백질 특이적 항체에 연결된 하나 이상의 염료 및 반대 염색인 다른 염료를 포함하는 여러 염료를 수반한다. 일반적인 반대염색은 DNA를 표지하여 핵을 염색하는 헤마톡실린이다.
소정 요법에 대한 반응을 나타낼 가능성이 있는 암 환자의 조직 영역을 식별하기 위해 단백질 특이적 염색 또는 바이오마커를 사용할 수 있다. 예를 들어, 상피세포를 염색하는 바이오마커는 의심되는 종양 영역을 식별하는 데 도움이 될 수 있다. 이어서, 다른 단백질 특이적 바이오마커를 사용하여 암 조직 내의 세포를 특성화한다. 특정 바이오마커에 의해 염색된 세포를 식별하고 정량화할 수 있으며, 이후 양성으로 염색된 세포와 음성으로 염색된 세포의 수를 나타내는 점수를 병리학자가 시각적으로 추정할 수 있다. 이어서, 이 점수는 같은 방식으로 계산된 다른 암 환자의 점수와 비교될 수 있다. 주어진 암 치료에 대한 이러한 다른 환자들의 반응이 알려지면, 병리학자는 암 환자에 대해 계산된 점수와 다른 환자의 점수의 비교를 기반으로 암 환자가 주어진 치료에 반응할 가능성이 얼마나 되는지 예측할 수 있다. 그러나, 병리학자의 시각적 평가는 가변성과 주관성의 경향이 있다.
유망한 암 치료법 중 하나는 항원이 암세포 표면에서 발현되는 항체에 세포독성을 가진 약물이 접합된 항체-약물 접합체(ADC)를 수반한다. ADC는 항원에 결합하고 세포 내재화를 거쳐 암세포에 선택적으로 약물을 전달하고 해당 암세포 내에 약물을 축적하여 암세포를 사멸시킨다. 치료용 B7-H4 항체-약물 접합체를 수반하는 치료에 대한 암 환자의 반응을 나타내는 반복가능한 객관적인 점수를 생성하기 위한 컴퓨터 기반 방법이 모색된다.
항체-약물 접합체(ADC)를 수반하는 요법에 암 환자가 어떻게 반응할지 예측하는 방법은 각각의 암세포에 대한 단일세포 ADC 점수를 기반으로 반응 점수를 계산하는 단계를 포함한다. ADC는 각각의 암세포 상의 단백질을 표적화하는 ADC 항체 및 ADC 페이로드를 포함한다. 조직 샘플의 암세포 상의 단백질에 결합하는 진단 항체에 연결된 염료를 사용하여 조직 샘플을 면역조직화학적으로 염색한다. 조직 샘플의 디지털 이미지를 획득한다. 컨벌루션 뉴럴 네트워크를 사용하여 암세포를 검출하기 위해 디지털 이미지에 대해 이미지 분석을 수행한다. 각각의 암세포에 대해, 암세포의 막 및/또는 세포질, 및/또는 미리 정의된 거리보다 상기 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 단일세포 ADC 점수를 계산한다. 통계 연산을 사용하여 조직 샘플의 모든 단일세포 ADC 점수를 집계하여 ADC 요법에 대한 암 환자의 반응을 예측하는 반응 점수를 생성한다. 소정의 임계값보다 높은 반응 점수를 갖는 환자에게 ADC를 수반하는 요법이 권장된다.
일 구현예에서, 항체-약물 접합체(ADC)로 치료받은 암 환자의 생존 확률을 나타내는 점수를 생성하는 방법은 단일세포 ADC 점수를 계산하는 단계를 포함한다. 진단 항체에 연결된 염료를 사용하여 암 환자의 조직 샘플을 면역조직화학적으로 염색한다. ADC는 암세포 상의 B7-H4 단백질을 표적화하는 ADC 항체 및 ADC 페이로드를 포함한다. 진단 항체는 조직 샘플의 암세포 상의 B7-H4 단백질에 결합한다. 조직 샘플의 디지털 이미지를 획득하고, 이미지 분석을 사용하여 디지털 이미지의 암세포를 검출한다. 각각의 암세포에 대해, 막에서의 염료의 염색 강도를 기반으로 단일세포 ADC 점수를 계산한다. 단일세포 ADC 점수는 또한 임의로, 암세포의 세포질에서의 염료의 염색 강도, 뿐만 아니라 미리 정의된 거리보다 상기 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 할 수 있다. 이에 따른 정량적 연속 점수(QCS)는 암 환자의 생존 확률을 나타내며, 통계 연산을 사용하여 조직 샘플의 모든 단일세포 ADC 점수를 집계하여 생성된다. 모든 단일세포 ADC 점수의 집계는 평균 결정, 중앙값 결정, 및 미리 정의된 백분율의 분위수 결정에 의해 수행된다. 다른 양태에서, 모든 단일세포 ADC 점수의 집계는 미리 정의된 임계값을 사용하는 임계값 연산을 포함한다. 미리 정의된 임계값보다 큰 단일세포 ADC 점수를 갖는 모든 세포는 단일세포 ADC 양성으로 표지된다. 집계는 단일세포 ADC 양성 세포의 수를 모든 암세포의 수로 나눈 값을 구하여 수행된다.
일 구현예에서, 항체-약물 접합체(ADC)에 대한 암 환자의 반응을 예측하는 방법은 암세포를 검출하는 단계 및 각각의 암세포에 대한 단일세포 ADC 점수를 계산하는 단계를 포함한다. ADC는 암세포 상의 단백질을 표적화하는 ADC 항체 및 ADC 페이로드를 포함한다. 단백질은 B7-H4이다. 진단 항체에 연결된 염료를 사용하여 조직 샘플을 면역조직화학적으로 염색한다. 진단 항체는 조직 샘플의 암세포 상의 단백질에 결합한다. 조직 샘플의 디지털 이미지를 획득하고, 디지털 이미지에서 암세포를 검출한다. 각각의 암세포에 대해, 막에서의 염료의 염색 강도를 기반으로 단일세포 ADC 점수를 계산한다. 단일세포 ADC 점수는 또한 임의로, 암세포의 세포질에서의 염료의 염색 강도, 및 미리 정의된 거리보다 상기 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 할 수 있다. 각각의 막의 염색 강도는 막 픽셀에서의 갈색 디아미노벤지딘(DAB) 신호의 평균 광학 밀도를 기반으로 계산되고, 각각의 세포질의 염색 강도는 세포질 픽셀에서의 갈색 DAB 신호의 평균 광학 밀도를 기반으로 계산된다. ADC에 대한 암 환자의 반응은 통계 연산을 사용한 조직 샘플의 모든 단일세포 ADC 점수의 집계를 기반으로 예측된다.
일부 구현예에서, 종양 세포의 90% 이상이 5 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 90% 이상이 6 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 90% 이상이 7 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 90% 이상이 8 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 90% 이상이 9 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 90% 이상이 10 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 90% 이상이 15 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 90% 이상이 20 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 90% 이상이 25 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다.
일부 구현예에서, 종양 세포의 50% 이상이 5 이상, 8 이상, 또는 25 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 50% 이상이 8 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 60% 이상이 5 이상, 8 이상, 또는 25 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 60% 이상이 8 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 70% 이상이 5 이상, 8 이상, 또는 25 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 70% 이상이 8 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 80% 이상이 5 이상, 8 이상, 또는 25 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 80% 이상이 8 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 90% 이상이 5 이상, 8 이상, 또는 25 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 90% 이상이 8 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 95% 이상이 5 이상, 8 이상, 또는 25 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다. 일부 구현예에서, 종양 세포의 95% 이상이 8 이상의 막 광학 밀도를 갖는 경우 환자는 점수-양성이다.
일부 구현예에서, 8 이상의 막 광학 밀도를 갖는 종양 세포의 밀도가 500개 세포/mm2 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 8 이상의 막 광학 밀도를 갖는 종양 세포의 밀도가 1000개 세포/mm2 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 8 이상의 막 광학 밀도를 갖는 종양 세포의 밀도가 1250개 세포/mm2 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 8 이상의 막 광학 밀도를 갖는 종양 세포의 밀도가 1500개 세포/mm2 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 8 이상의 막 광학 밀도를 갖는 종양 세포의 밀도가 1600개 세포/mm2 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 8 이상의 막 광학 밀도를 갖는 종양 세포의 밀도가 1670개 세포/mm2 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 8 이상의 막 광학 밀도를 갖는 종양 세포의 밀도가 1700개 세포/mm2 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 8 이상의 막 광학 밀도를 갖는 종양 세포의 밀도가 1800개 세포/mm2 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 8 이상의 막 광학 밀도를 갖는 종양 세포의 밀도가 1900개 세포/mm2 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 8 이상의 막 광학 밀도를 갖는 종양 세포의 밀도가 2000개 세포/mm2 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 8 이상의 막 광학 밀도를 갖는 종양 세포의 밀도가 3000개 세포/mm2 이상인 경우 환자는 점수-양성이다.
일부 구현예에서, 공간 근접성 점수가 90 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 공간 근접성 점수가 91 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 공간 근접성 점수가 92 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 공간 근접성 점수가 93 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 공간 근접성 점수가 94 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 공간 근접성 점수가 95 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 공간 근접성 점수가 96 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 공간 근접성 점수가 97 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 공간 근접성 점수가 98 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 공간 근접성 점수가 99 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 공간 근접성 점수가 99.5 이상인 경우 환자는 점수-양성이다. 일부 구현예에서, 공간 근접성 점수가 99.8 이상인 경우 환자는 점수-양성이다. 상기 구현예에서, 공간 근접성 점수는 다음과 같이 계산된다: 공간 근접성 점수 = ([OD가 8보다 큰 종양 세포의 수] + [OD가 8보다 큰 적어도 하나의 종양 세포의 25 um 근처에 있는 OD가 8 이하인 종양 세포의 수])/[모든 종양 세포의 수].
다른 구현예에서, 항체-약물 접합체(ADC)에 대해 소정의 반응을 나타낼 암 환자를 식별하는 방법은 반응 점수를 생성하는 단계를 포함한다. ADC는 암세포 상의 단백질을 표적화하는 ADC 항체 및 ADC 페이로드를 포함한다. 조직 샘플의 암세포 상의 단백질에 결합하는 진단 항체에 연결된 염료를 사용하여 암 환자의 조직 샘플을 면역조직화학적으로 염색한다. 조직 샘플의 디지털 이미지를 획득하고, 컨벌루션 뉴럴 네트워크를 사용하여 디지털 이미지의 암세포를 검출한다. 각각의 암세포에 대해, 막에서의 염료의 염색 강도를 기반으로 단일세포 ADC 점수를 계산한다. 단일세포 ADC 점수는 또한 임의로, 암세포의 세포질에서의 염료의 염색 강도, 및 미리 정의된 거리보다 단일세포 점수가 계산되는 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 할 수 있다. QCS 점수는 통계 연산을 사용하여 조직 샘플의 모든 단일세포 ADC 점수를 집계하여 생성되는 반응 점수이다. 암 환자는 QCS 점수가 임계값을 초과하는지 여부에 따라 ADC에 대해 소정의 반응을 나타낼 환자로 식별된다. 임계값보다 큰 QCS 점수를 나타내는 환자는 QCS 점수 양성으로 간주되고, 다른 모든 환자는 QCS 점수 음성으로 간주된다. 소정의 반응은 평균 종양 크기의 감소이다. 다른 양태에서, 임계값에 대한 QCS 점수의 차이는 암 환자가 ADC에 대해 소정의 반응을 나타낼 환자로 정확하게 식별될 확률을 나타낸다. 적은 차이는 낮은 확률을 나타내는 반면, 큰 차이는 암 환자가 정확히 식별될 확률이 높다는 것을 나타낸다.
일 구현예에서, 항체-약물 접합체(ADC)로 암 환자를 치료하는 방법은 치료 점수 형태로 QCS 점수를 생성하는 단계를 포함한다. ADC는 암세포 상의 단백질을 표적화하는 ADC 항체 및 ADC 페이로드를 포함한다. 단백질은 B7-H4이다. 조직 샘플의 암세포 상의 단백질에 결합하는 진단 항체에 연결된 염료를 사용하여 암 환자의 조직 샘플을 면역조직화학적으로 염색한다. 조직 샘플의 디지털 이미지를 획득하고, 디지털 이미지의 암세포를 검출한다. 각각의 암세포에 대해, 막에서의 염료의 염색 강도를 기반으로 단일세포 ADC 점수를 계산한다. 단일세포 ADC 점수는 또한 임의로, 암세포의 세포질에서의 염료의 염색 강도, 뿐만 아니라 미리 정의된 거리보다 상기 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 할 수 있다. 치료 점수는 통계 연산을 사용하여 조직 샘플의 모든 단일세포 ADC 점수를 집계하여 생성된다. 치료 점수가 소정의 임계값을 초과하는 경우 암 환자에게 ADC를 수반하는 요법이 투여된다.
다른 구현예에서, 항체-약물 접합체(ADC)로 암 환자를 치료하는 방법은 요법을 투여하는 임상의에 의해 수행된다. ADC는 암세포 상의 단백질을 표적화하는 ADC 항체 및 ADC 페이로드를 포함한다. 단백질은 B7-H4이다. ADC를 수반하는 요법은 반응 점수가 소정의 임계값을 초과하는 경우 암 환자에게 투여된다. QCS 반응 점수는 통계 연산을 사용하여 암 환자의 조직 샘플의 단일세포 ADC 점수를 집계하여 생성된다. 각각의 단일세포 ADC 점수는 각각의 암세포에 대해 막에서의 염료의 염색 강도를 기반으로 계산된다. 단일세포 ADC 점수는 또한 임의로, 각각의 암세포의 세포질에서의 염료의 염색 강도, 및 또한 미리 정의된 거리보다 단일세포 ADC 점수가 계산된 각각의 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 할 수 있다. 암 환자의 조직 샘플의 디지털 이미지에서 암세포를 검출하였다. 조직 샘플의 암세포 상의 단백질에 결합하는 진단 항체에 연결된 염료를 사용하여 조직 샘플을 면역조직화학적으로 염색하였다.
다른 구현예 및 이점은 아래 상세한 설명에서 설명된다. 이 요약은 발명을 정의하려는 것이 아니다. 본 발명은 청구범위에 의해 정의된다.
동일한 참조번호가 동일한 구성요소를 나타내는 첨부 도면은 본 발명의 구현예를 예시한다.
도 1은 인간 B7-H4를 암호화하는 전체 뉴클레오티드 서열(서열번호 1)을 보여준다.
도 2는 인간 B7-H4에 대한 뉴클레오티드 암호화 서열(서열번호 2)을 보여준다.
도 3은 인간 B7-H4의 폴리펩티드 서열(서열번호 3)을 보여준다.
도 4는 항-B7H4 항체의 중쇄 HCDR1의 아미노산 서열(서열번호 4)을 보여준다.
도 5는 항-B7H4 항체의 중쇄 HCDR2의 아미노산 서열(서열번호 5)을 보여준다.
도 6은 항-B7H4 항체의 중쇄 HCDR3의 아미노산 서열(서열번호 6)을 보여준다.
도 7은 항-B7H4 항체의 경쇄 LCDR1의 아미노산 서열(서열번호 7)을 보여준다.
도 8은 항-B7H4 항체의 경쇄 LCDR2의 아미노산 서열(서열번호 8)을 보여준다.
도 9는 항-B7H4 항체의 경쇄 LCDR3의 아미노산 서열(서열번호 9)을 보여준다.
도 10은 항-B7H4 항체의 중쇄 가변 영역(VH)의 아미노산 서열(서열번호 10)을 보여준다.
도 11은 항-B7H4 항체의 경쇄 가변 영역(VL)의 아미노산 서열(서열번호 11)을 보여준다.
도 12는 항-B7H4 항체의 중쇄의 아미노산 서열(서열번호 12)을 보여준다.
도 13은 항-B7H4 항체의 경쇄의 아미노산 서열(서열번호 13)을 보여준다.
도 14는 분석 시스템이 암 환자 조직의 디지털 이미지를 분석하고 항-B7H4 항체-약물 접합체를 수반하는 요법에 암 환자가 어떻게 반응할지 예측하는 단계의 순서도이다.
도 15는 도 14의 단계 2의 이미지 분석 프로세스를 예시하는 디지털 이미지를 보여준다.
도 16은 암세포의 핵 객체를 검출하는 이미지 분석 단계를 예시한다.
도 17은 핵 객체를 사용하여 막을 검출하는 이미지 분석 단계를 예시한다.
도 18은 암세포의 막 객체를 검출하는 이미지 분석 단계를 예시한다.
도 19는 이미지 분석 소프트웨어 환경에서 이미지 분석 단계의 결과에 대한 스크린샷이다.
도 20은 이미지 분석 분할에 사용된 스크립트 및 스크립트를 사용하여 얻은 세포 객체 측정을 보여준다.
도 21은 막 및 세포질 픽셀의 회색 값을 사용하여 이미지 분석으로부터 얻은 염색 강도의 샘플 정량 결과를 보여준다.
도 22는 도 21 이미지의 막 및 세포질에서의 예시적인 정량적 염색량을 보여준다.
도 23은 항-B7H4 ADC 요법이 암세포를 사멸시키는 메커니즘을 예시한다.
도 24는 ADC 페이로드의 인접 세포로의 흡수를 반영하기 위한 세포 분리 기반의 도 22에 나타낸 3개의 세포 각각에 대한 단일세포 ADC 점수 계산을 예시한다.
도 25는 단일세포 점수를 계산하는 식을 보여준다.
도 26은 PDX 유방 연구의 15개 샘플의 실제 결과와 반응 카테고리별로 나열된 수동 H 점수 간의 상관관계를 보여준다.
도 27은 수동 비율 점수를 평균 H 점수와 비교하는 그래프이다.
도 28은 수동 비율 점수를 B7H4 막 염색의 광학 밀도에 대한 중앙값 QCS 점수와 비교하는 그래프이다.
도 29는 수동 강도 점수를 평균 H 점수와 비교하는 그래프이다.
도 30은 수동 강도 점수를 B7H4 막 염색의 광학 밀도에 대한 중앙값 QCS 점수와 비교하는 그래프이다.
도 31은 3개의 반응 카테고리 PD, R, 및 SD에 속하는 PDX 유방 연구 샘플의 평균 H 점수를 보여준다.
도 32는 3개의 반응 카테고리 PD, R, 및 SD에 속하는 PDX 유방 연구 샘플의 중앙값 QCS 점수를 보여준다.
도 33은 반응 카테고리 R, SD, 및 PD에 대한 샘플의 수동 H 점수의 박스 플롯 분포를 보여준다.
도 34는 반응 카테고리 R, SD, 및 PD에 대한 샘플의 중앙값 막 광학 밀도에 의해 정의되는 QCS 점수의 박스 플롯 분포를 보여준다.
도 35는 종양 성장 퍼센트와 QCS 점수(샘플 내 모든 종양 세포의 막 광학 밀도의 중앙값/50% 분위수) 간의 관계를 보여준다.
도 36은 종양 성장 퍼센트와 QCS 점수 간의 관계를 추가 상관 관계선과 함께 보여준다.
도 37은 항-B7H4 ADC의 약동학 및 약력학을 연구하기 위해 이미지 분석 및 정량적 연속 점수와 함께 이종이식 마우스 모델이 어떻게 사용되었는지를 예시한다.
도 38의 A는 모든 상피세포에 대한 ADC-IgG 염색된 상피세포의 세포 비율을 보여주는 그래프이며, 표적 세포에 대한 ADC 결합의 농도 의존성 및 동역학을 보여준다.
도 38의 B는 gH2AX 양성 상피세포 백분율을 보여주는 그래프이며, 상이한 ADC 농도에서 ADC 처치 후 시간 경과에 따라 증가하는 DNA 손상을 보여준다.
도 38의 C는 절단된 카스파제-3(CC-3) 양성 종양 면적의 백분율에 근거하여 ADC 처치 후 시간 경과에 따라 증가하는 DNA 손상을 보여주는 그래프이다.
도 38의 D는 모든 상피세포의 세포 밀도 감소에 근거하여 ADC 처치 후 시간 경과에 따라 증가하는 종양 세포 사멸을 보여주는 그래프이다.
도 39의 A는 마우스에 이식하여 복제한 28명의 유방암 환자의 종양 조직의 막 염색의 중앙값 광학 밀도를 보여준다.
도 39의 B는 진단 항체 D11에 의한 막 염색이 진단 항체 A57.1 및 Cal63에 의한 염색보다 훨씬 적은, 도 39의 A의 샘플 #21의 염색된 조직을 보여준다.
도 39의 C는 진단 항체 A57.1에 의한 막 염색이 진단 항체 D11 및 Cal63에 의한 염색보다 훨씬 많은, 도 39의 A의 샘플 #28의 염색된 조직을 보여준다.
도 40a는 진단 항체 Cal63을 사용하여 염색된 도 39의 A의 샘플 #26의 디지털 이미지이다.
도 40b는 진단 항체 Cal63을 사용하여 염색된 도 39의 A의 샘플 #4의 디지털 이미지이다.
도 41a는 페이로드 없이 다양한 농도의 ADC로 처치하기 전과 후의 샘플 #26에 대한 세포당 막 염색의 분포를 보여준다.
도 41b는 ADC E02-GL-SG3932로 처치하기 전과 후의 샘플 #4에 대한 세포당 막 염색의 분포를 보여준다.
도 42a는 샘플 #26에 대한 ADC 처치 전과 후의 결합된 IgG의 세포당 분포를 보여준다.
도 42b는 샘플 #4에 대한 ADC 처치 전과 후의 결합된 IgG의 세포당 분포를 보여준다.
도 42c는 ADC E02-GL-SG3932의 다양한 투여량 수준에서의 결합된 IgG의 최대 막 광학 밀도에 대한 그래프이다.
도 42d는 ADC E02-GL-SG3932의 다양한 투여량 수준에서의 샘플 #26에 대한 절단된 카스파제-3(CC-3) 양성 종양의 백분율을 보여준다.
도 43a는 다양한 투여량의 ADC 처치 후 다양한 시간에서의 클론 샘플 #26 및 #4에 대한 IgG의 막 광학 밀도를 보여주는 그래프이다.
도 43b는 7 mg/kg의 ADC E02-GL-SG3932 처치 후 다양한 시간에서의 샘플 #26의 중앙값 광학 밀도를 보여준다.
도 44a는 샘플 #26에 대해, ADC 처치 후 다양한 시간에서의 염색된 상피세포의 밀도, 및 절단된 카스파제-3(CC-3) 양성 종양 세포의 백분율에 근거하여 ADC 처치 후 시간 경과에 따라 증가하는 DNA 손상을 보여준다.
도 44b는 샘플 #4에 대해, ADC 처치 후 다양한 시간에서의 염색된 상피세포의 밀도, 및 CC-3 양성 종양 세포의 백분율에 근거하여 ADC 처치 후 시간 경과에 따라 증가하는 DNA 손상을 보여준다.
도 45a는 샘플 #26에 대해 ADC 처치 후 다양한 시간에서의 막 광학 밀도에 대한 이진 공간 근접성의 관계를 보여준다.
도 45b는 샘플 #4에 대해 ADC 처치 후 다양한 시간에서의 막 광학 밀도에 대한 이진 공간 근접성의 관계를 보여준다.
도 46a는 샘플 #26에 대해 ADC 처치 후 다양한 시간에서의 막 광학 밀도에 대한 연속 공간 근접성의 관계를 보여준다.
도 46b는 샘플 #4에 대해 ADC 처치 후 다양한 시간에서의 막 광학 밀도에 대한 연속 공간 근접성의 관계를 보여준다.
도 47a는 샘플 #26에 대해 ADC 처치 후 다양한 시간에서의 상피세포 밀도에 대한 연속 공간 근접성의 관계를 보여준다.
도 47b는 샘플 #4에 대해 ADC 처치 후 다양한 시간에서의 상피세포 밀도에 대한 연속 공간 근접성의 관계를 보여준다.
도 1은 인간 B7-H4를 암호화하는 전체 뉴클레오티드 서열(서열번호 1)을 보여준다.
도 2는 인간 B7-H4에 대한 뉴클레오티드 암호화 서열(서열번호 2)을 보여준다.
도 3은 인간 B7-H4의 폴리펩티드 서열(서열번호 3)을 보여준다.
도 4는 항-B7H4 항체의 중쇄 HCDR1의 아미노산 서열(서열번호 4)을 보여준다.
도 5는 항-B7H4 항체의 중쇄 HCDR2의 아미노산 서열(서열번호 5)을 보여준다.
도 6은 항-B7H4 항체의 중쇄 HCDR3의 아미노산 서열(서열번호 6)을 보여준다.
도 7은 항-B7H4 항체의 경쇄 LCDR1의 아미노산 서열(서열번호 7)을 보여준다.
도 8은 항-B7H4 항체의 경쇄 LCDR2의 아미노산 서열(서열번호 8)을 보여준다.
도 9는 항-B7H4 항체의 경쇄 LCDR3의 아미노산 서열(서열번호 9)을 보여준다.
도 10은 항-B7H4 항체의 중쇄 가변 영역(VH)의 아미노산 서열(서열번호 10)을 보여준다.
도 11은 항-B7H4 항체의 경쇄 가변 영역(VL)의 아미노산 서열(서열번호 11)을 보여준다.
도 12는 항-B7H4 항체의 중쇄의 아미노산 서열(서열번호 12)을 보여준다.
도 13은 항-B7H4 항체의 경쇄의 아미노산 서열(서열번호 13)을 보여준다.
도 14는 분석 시스템이 암 환자 조직의 디지털 이미지를 분석하고 항-B7H4 항체-약물 접합체를 수반하는 요법에 암 환자가 어떻게 반응할지 예측하는 단계의 순서도이다.
도 15는 도 14의 단계 2의 이미지 분석 프로세스를 예시하는 디지털 이미지를 보여준다.
도 16은 암세포의 핵 객체를 검출하는 이미지 분석 단계를 예시한다.
도 17은 핵 객체를 사용하여 막을 검출하는 이미지 분석 단계를 예시한다.
도 18은 암세포의 막 객체를 검출하는 이미지 분석 단계를 예시한다.
도 19는 이미지 분석 소프트웨어 환경에서 이미지 분석 단계의 결과에 대한 스크린샷이다.
도 20은 이미지 분석 분할에 사용된 스크립트 및 스크립트를 사용하여 얻은 세포 객체 측정을 보여준다.
도 21은 막 및 세포질 픽셀의 회색 값을 사용하여 이미지 분석으로부터 얻은 염색 강도의 샘플 정량 결과를 보여준다.
도 22는 도 21 이미지의 막 및 세포질에서의 예시적인 정량적 염색량을 보여준다.
도 23은 항-B7H4 ADC 요법이 암세포를 사멸시키는 메커니즘을 예시한다.
도 24는 ADC 페이로드의 인접 세포로의 흡수를 반영하기 위한 세포 분리 기반의 도 22에 나타낸 3개의 세포 각각에 대한 단일세포 ADC 점수 계산을 예시한다.
도 25는 단일세포 점수를 계산하는 식을 보여준다.
도 26은 PDX 유방 연구의 15개 샘플의 실제 결과와 반응 카테고리별로 나열된 수동 H 점수 간의 상관관계를 보여준다.
도 27은 수동 비율 점수를 평균 H 점수와 비교하는 그래프이다.
도 28은 수동 비율 점수를 B7H4 막 염색의 광학 밀도에 대한 중앙값 QCS 점수와 비교하는 그래프이다.
도 29는 수동 강도 점수를 평균 H 점수와 비교하는 그래프이다.
도 30은 수동 강도 점수를 B7H4 막 염색의 광학 밀도에 대한 중앙값 QCS 점수와 비교하는 그래프이다.
도 31은 3개의 반응 카테고리 PD, R, 및 SD에 속하는 PDX 유방 연구 샘플의 평균 H 점수를 보여준다.
도 32는 3개의 반응 카테고리 PD, R, 및 SD에 속하는 PDX 유방 연구 샘플의 중앙값 QCS 점수를 보여준다.
도 33은 반응 카테고리 R, SD, 및 PD에 대한 샘플의 수동 H 점수의 박스 플롯 분포를 보여준다.
도 34는 반응 카테고리 R, SD, 및 PD에 대한 샘플의 중앙값 막 광학 밀도에 의해 정의되는 QCS 점수의 박스 플롯 분포를 보여준다.
도 35는 종양 성장 퍼센트와 QCS 점수(샘플 내 모든 종양 세포의 막 광학 밀도의 중앙값/50% 분위수) 간의 관계를 보여준다.
도 36은 종양 성장 퍼센트와 QCS 점수 간의 관계를 추가 상관 관계선과 함께 보여준다.
도 37은 항-B7H4 ADC의 약동학 및 약력학을 연구하기 위해 이미지 분석 및 정량적 연속 점수와 함께 이종이식 마우스 모델이 어떻게 사용되었는지를 예시한다.
도 38의 A는 모든 상피세포에 대한 ADC-IgG 염색된 상피세포의 세포 비율을 보여주는 그래프이며, 표적 세포에 대한 ADC 결합의 농도 의존성 및 동역학을 보여준다.
도 38의 B는 gH2AX 양성 상피세포 백분율을 보여주는 그래프이며, 상이한 ADC 농도에서 ADC 처치 후 시간 경과에 따라 증가하는 DNA 손상을 보여준다.
도 38의 C는 절단된 카스파제-3(CC-3) 양성 종양 면적의 백분율에 근거하여 ADC 처치 후 시간 경과에 따라 증가하는 DNA 손상을 보여주는 그래프이다.
도 38의 D는 모든 상피세포의 세포 밀도 감소에 근거하여 ADC 처치 후 시간 경과에 따라 증가하는 종양 세포 사멸을 보여주는 그래프이다.
도 39의 A는 마우스에 이식하여 복제한 28명의 유방암 환자의 종양 조직의 막 염색의 중앙값 광학 밀도를 보여준다.
도 39의 B는 진단 항체 D11에 의한 막 염색이 진단 항체 A57.1 및 Cal63에 의한 염색보다 훨씬 적은, 도 39의 A의 샘플 #21의 염색된 조직을 보여준다.
도 39의 C는 진단 항체 A57.1에 의한 막 염색이 진단 항체 D11 및 Cal63에 의한 염색보다 훨씬 많은, 도 39의 A의 샘플 #28의 염색된 조직을 보여준다.
도 40a는 진단 항체 Cal63을 사용하여 염색된 도 39의 A의 샘플 #26의 디지털 이미지이다.
도 40b는 진단 항체 Cal63을 사용하여 염색된 도 39의 A의 샘플 #4의 디지털 이미지이다.
도 41a는 페이로드 없이 다양한 농도의 ADC로 처치하기 전과 후의 샘플 #26에 대한 세포당 막 염색의 분포를 보여준다.
도 41b는 ADC E02-GL-SG3932로 처치하기 전과 후의 샘플 #4에 대한 세포당 막 염색의 분포를 보여준다.
도 42a는 샘플 #26에 대한 ADC 처치 전과 후의 결합된 IgG의 세포당 분포를 보여준다.
도 42b는 샘플 #4에 대한 ADC 처치 전과 후의 결합된 IgG의 세포당 분포를 보여준다.
도 42c는 ADC E02-GL-SG3932의 다양한 투여량 수준에서의 결합된 IgG의 최대 막 광학 밀도에 대한 그래프이다.
도 42d는 ADC E02-GL-SG3932의 다양한 투여량 수준에서의 샘플 #26에 대한 절단된 카스파제-3(CC-3) 양성 종양의 백분율을 보여준다.
도 43a는 다양한 투여량의 ADC 처치 후 다양한 시간에서의 클론 샘플 #26 및 #4에 대한 IgG의 막 광학 밀도를 보여주는 그래프이다.
도 43b는 7 mg/kg의 ADC E02-GL-SG3932 처치 후 다양한 시간에서의 샘플 #26의 중앙값 광학 밀도를 보여준다.
도 44a는 샘플 #26에 대해, ADC 처치 후 다양한 시간에서의 염색된 상피세포의 밀도, 및 절단된 카스파제-3(CC-3) 양성 종양 세포의 백분율에 근거하여 ADC 처치 후 시간 경과에 따라 증가하는 DNA 손상을 보여준다.
도 44b는 샘플 #4에 대해, ADC 처치 후 다양한 시간에서의 염색된 상피세포의 밀도, 및 CC-3 양성 종양 세포의 백분율에 근거하여 ADC 처치 후 시간 경과에 따라 증가하는 DNA 손상을 보여준다.
도 45a는 샘플 #26에 대해 ADC 처치 후 다양한 시간에서의 막 광학 밀도에 대한 이진 공간 근접성의 관계를 보여준다.
도 45b는 샘플 #4에 대해 ADC 처치 후 다양한 시간에서의 막 광학 밀도에 대한 이진 공간 근접성의 관계를 보여준다.
도 46a는 샘플 #26에 대해 ADC 처치 후 다양한 시간에서의 막 광학 밀도에 대한 연속 공간 근접성의 관계를 보여준다.
도 46b는 샘플 #4에 대해 ADC 처치 후 다양한 시간에서의 막 광학 밀도에 대한 연속 공간 근접성의 관계를 보여준다.
도 47a는 샘플 #26에 대해 ADC 처치 후 다양한 시간에서의 상피세포 밀도에 대한 연속 공간 근접성의 관계를 보여준다.
도 47b는 샘플 #4에 대해 ADC 처치 후 다양한 시간에서의 상피세포 밀도에 대한 연속 공간 근접성의 관계를 보여준다.
본 발명은 B7-H4 항체-약물 접합체를 사용하는 요법에 암 환자가 어떻게 반응할지를 나타내는 점수를 계산하는 새로운 방법을 제공한다. 본 발명의 다른 양태는 ADC로 치료받은 암 환자의 생존 확률을 나타내는 암 환자에 대한 점수를 계산하는 방법에 관한 것이다. 본 발명의 다른 양태는 ADC에 대한 암 환자의 반응을 예측하는 방법에 관한 것이다. 본 발명의 다른 양태는 ADC에 대한 소정의 반응을 나타낼 암 환자를 식별하는 것에 관한 것이다. 본 발명의 또 다른 양태는 치료 점수가 소정의 임계값을 초과하는 경우 ADC를 수반하는 요법을 투여하여 암 환자를 치료하는 방법에 관한 것이다.
I. 정의.
본 발명의 이해를 용이하게 하기 위해, 다수의 용어 및 어구를 아래에 정의한다. "암"이라는 용어는 "종양"이라는 용어와 동일한 의미로 사용된다.
본 발명에서, "B7-H4"는 VTCN1 유전자에 의해 암호화되는 V-세트 도메인 함유 T 세포 활성화 억제제 1과 동의어이다. B7-H4는 B7 계열 공동자극 단백질의 막관통 폴리펩티드이다. B7-H4는 T-림프구와 같은 면역 세포의 리간드와의 상호작용을 위해 항원 제시 세포의 표면에서 발현되는 것으로 이해되며, CD28이 잠재적인 리간드이다. 다양한 암 유형의 세포에서 B7-H4가 높게 발현되는 것으로 관찰되는 것은 이 분자가 종양 관련 항원임을 시사한다. B7-H4 발현은 특정 암 유형에 국한되지 않고 오히려 광범위한 암 유형을 치료하기 위한 표적 항원을 나타낸다. B7-H4 단백질의 발현은 면역조직화학법(IHC)과 같은 당업자에게 잘 알려진 방법을 사용하여 검출할 수 있다.
B7-H4의 RNA, DNA, 및 아미노산 서열은 당업자에게 알려져 있으며, 여러 데이터베이스, 예를 들어 미국 국립생물정보센터(NCBI)의 데이터베이스 및 UniProt에서 확인할 수 있다. UniProt에서 확인되는 이들 서열의 예는 인간 B7-H4에 대한 Q7Z7D3(VTCN1_HUMAN) 및 마우스 B7-H4에 대한 Q7TSP5(VTCN1_MOUSE)이다. 인간 B7-H4를 암호화하는 뉴클레오티드 서열은 서열번호 1(도 1) 또는 보다 바람직하게는 서열번호 2(도 2)일 수 있다. 인간 B7-H4의 폴리펩티드 서열은 바람직하게는 서열번호 3(도 3)이다.
본 발명에서, "항-B7H4 항체"는 B7-H4에 특이적으로 결합하는 항체로서, 바람직하게는 B7-H4에 대한 결합 활성을 가져 B7-H4 발현 세포에 내재화되는 항체를 의미한다. 즉, "항-B7H4 항체"는 B7-H4에 결합한 후 B7-H4 발현 세포로 이동하는 활성을 갖는 항체를 의미한다.
항-B7H4 항체는 서열번호 4(도 4)의 아미노산 서열을 갖는 중쇄 HCDR1, 서열번호 5(도 5)의 아미노산 서열을 갖는 중쇄 HCDR2, 서열번호 6(도 6)의 아미노산 서열을 갖는 중쇄 HCDR3, 서열번호 7(도 7)의 아미노산 서열을 갖는 경쇄 LCDR1, 서열번호 8(도 8)의 아미노산 서열을 갖는 경쇄 LCDR2, 및 서열번호 9(도 9)의 아미노산 서열을 갖는 경쇄 LCDR3을 포함한다. 항-B7H4 항체는 서열번호 10(도 10)의 아미노산 서열을 포함하는 가변 중쇄, 및 서열번호 11(도 11)의 아미노산 서열을 포함하는 가변 경쇄를 포함한다. 항-B7H4 항체는 서열번호 12(도 12)의 아미노산 서열을 포함하는 중쇄(예를 들어, VH 및 불변 중쇄 포함) 및 서열번호 13(도 13)의 아미노산 서열을 포함하는 경쇄(예를 들어, VL 및 불변 경쇄 포함)를 포함한다.
용어 "대상체", "개체", 및 "환자"는 포유동물 대상체를 지칭하기 위해 본원에서 상호교환적으로 사용된다. 일 구현예에서, "대상체"는 인간, 가축, 농장 동물, 스포츠 동물, 및 동물원 동물, 예를 들어 인간, 비인간 영장류, 개, 고양이, 기니피그, 토끼, 래트, 마우스, 말, 소 등이다. 일 구현예에서, 대상체는 시노몰구스 원숭이(마카카 파시쿨라리스)이다. 바람직한 구현예에서, 대상체는 인간이다. 본 발명의 방법에서, 환자는 암이 있는 것으로 이전에 진단된 적이 없을 수 있다. 대안적으로, 환자는 암이 있는 것으로 이전에 진단된 적이 있을 수 있다. 환자는 또한 질환 위험 인자를 나타내는 자이거나 암에 대해 무증상인 자일 수 있다. 환자는 또한 암을 앓고 있거나 암이 발생할 위험이 있는 자일 수 있다. 따라서, 일 구현예에서, 본 발명의 방법은 환자의 암 존재를 확인하는 데 사용될 수 있다. 예를 들어, 환자는 이전에 다른 방법으로 암 진단을 받았을 수 있다. 일 구현예에서, 환자는 이전에 암 요법을 받은 적이 있다.
본 발명에서, "QCS 양성"이라는 용어는 항-B7H4 ADC 요법에 반응을 보일 가능성이 있는 암을 나타낸다. "QCS 음성"이라는 용어는 항-B7H4 ADC 요법에 반응을 보일 가능성이 없는 암을 나타낸다. 약어 QCS는 정량적 연속 점수(Quantitative Continuous Score)를 나타낸다. 본 발명의 신규 예측 방법의 결과는 일반적으로 정량적 연속 점수로 언급되며, 반응 점수이거나 예측 생존 시간의 지표일 수 있다.
II. 항-B7H4 항체-약물 접합체.
본 발명에서 사용되는 항-B7H4 항체-약물 접합체는 토포이소머라제 I 억제제, 튜불리신 유도체, 피롤로벤조디아제핀, 또는 이들의 조합으로부터 선택되는 하나 이상의 세포독소에 접합된 항-B7H4 항체 또는 항원 결합 단편을 포함한다. 예를 들어, 항체 또는 이의 항원 결합 단편은 토포이소머라제 I 억제제 SG3932, SG4010, SG4057, 또는 SG4052(이들의 구조는 아래에 제공); 튜불리신 AZ1508, 피롤로벤조디아제핀 SG3315, 피롤로벤조디아제핀 SG3249, 또는 이들의 조합으로 이루어진 군으로부터 선택되는 하나 이상의 세포독소에 접합된다.
항체 또는 이의 항원 결합 단편은 토포이소머라제 I 억제제에 접합되는 것이 바람직하다. 토포이소머라제 억제제는 정상적인 세포 주기 동안 DNA 가닥의 포스포디에스테르 백본의 파단 및 재결합에 촉매작용을 함으로써 DNA 구조의 변화를 제어하는 효소 유형인 토포이소머라제(토포이소머라제 I 및 II)의 작용을 차단하는 화합물이다.
적합한 토포이소머라제 I 억제제의 일반적인 예는 하기 화합물로 표시된다:
[화학식 1]

상기 화합물은 A*로 표시되며, 본원에서 "약물 단위"로 지칭될 수 있다. 화합물 A*에는 바람직하게는 본원에 기재된 항체 또는 항원 결합 단편("리간드 단위"로 지칭될 수 있음)에 연결(바람직하게는 접합)하기 위한 링커가 제공되는 것이 바람직하다. 적합하게, 링커는 본원에 기재된 항체 또는 항원 결합 단편의 아미노 잔기, 예를 들어 아미노산에 절단가능한 방식으로 부착(예를 들어, 접합)된다.
보다 구체적으로, 적합한 토포이소머라제 I 억제제의 예는 "I"로 나타내는 하기 화합물로 표시된다:
[화학식 2]

화합물 I는 이의 염 및 용매화물을 포함하며, RL은 본원에 기재된 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)에 연결하기 위한 링커이고, 상기 링커 "Ia"는 바람직하게는 다음으로부터 선택된다:
[화학식 3]

Q는 다음과 같고:
[화학식 4]

QX는 Q가 아미노산 잔기, 디펩티드 잔기, 트리펩티드 잔기, 또는 테트라펩티드 잔기가 되도록 하는 것이고, 화학식 3에서 X는 다음과 같고:
[화학식 5]

a는 0 내지 5이고, b1은 0 내지 16이고, b2는 0 내지 16이고, c1은 0 또는 1이고, c2는 0 또는 1이고, d는 0 내지 5이고, 적어도 b1 또는 b2는 0(즉, b1과 b2 중 하나만 0이 아닐 수 있음)이고, 적어도 c1 또는 c2는 0(즉, c1과 c2 중 하나만 0이 아닐 수 있음)이다. 화학식 3에서 GL은 본원에 기재된 바와 같은 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)에 연결하기 위한 링커이다. 대안적으로, 화학식 3에서 GL은 "Ib"로 표시되는 화합물이고:
[화학식 6]

RL1 및 RL2는 독립적으로 H 및 메틸로부터 선택되거나, 이들이 결합되는 탄소 원자와 함께 시클로프로필렌 또는 시클로부틸렌 기를 형성한다. 화학식 6에서, e는 0 또는 1이다.
당업자라면 상기 제제(예를 들어, 토포이소머라제 I 억제제) 중 둘 이상이 항체 또는 이의 항원 결합 단편에 접합될 수 있음을 이해할 것이다. 예를 들어, 본 발명의 접합체(예를 들어, 항체-약물 접합체)는 일반식 L-(DL)p를 갖는 것 또는 이의 약학적으로 허용가능한 염 또는 용매화물일 수 있으며, L은 본원에 기재된 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)이고, p는 1 내지 20의 정수이고, DL은 하기 화학식으로 표시되는 링커(예를 들어, 약물 링커 단위)를 갖는 토포이소머라제 I 억제제이다:
[화학식 7]

화학식 7에서, RLL은 본원에 기재된 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)에 연결된 링커이고, 링커는 바람직하게는 "Ia'" 또는 "Ib'"로부터 선택되고:
[화학식 8]

Q 및 X는 상기 정의된 바와 같고, GLL은 본원에 기재된 바와 같은 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)에 연결된 링커이다. Ib'는 하기 화학식으로 표시되며:
[화학식 9]

RL1 및 RL2는 상기에 정의된 바와 같다. 항체-약물 접합체에 대한 화학식 L-(DL)p에서 "p"는 약물 로딩을 나타내고, 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)당 토포이소머라제 I 억제제(예를 들어, 약물 단위)의 수이다. 약물 로딩 범위는 리간드 단위당 1 내지 20 약물 단위(D)이다. 각각의 약물 링커 단위는 항-B7H4 항체에 접합된다. 조성물의 경우, "p"는 조성물에서 접합체의 평균 약물 로딩을 나타내고, "p"의 범위는 1 내지 20이다. "p"의 의미는 소위 접합된 약물 분자의 평균 수(약물 대 항체 비 DAR)와 동일하고, 항체 분자당 접합된 약물-링커 단위의 평균 수를 나타낸다.
따라서, 본원에 기재된 항체-약물 접합체는 적어도 하나의 토포이소머라제 I 억제제(예를 들어, 상기 예시한 A*와 같은 약물 단위)에 공유 연결된 본원에 기재된 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)을 포함하는 접합체를 포괄한다. 상기 억제제는 바람직하게는 링커(예를 들어, 링커 단위), 예컨대 상기 RL 및/또는 RLL로 기재된 링커에 의해 항체 또는 이의 항원 결합 단편에 연결된다. 즉, 본원에 기재된 항체-약물 접합체는 바람직하게는 링커(예를 들어, 약물 링커 단위)를 통해, 하나 이상의 토포이소머라제 I 억제제가 부착된 본원에 기재된 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)을 포괄한다. 상기에서 보다 충분히 기재된 항체 또는 이의 항원 결합 단편(리간드 단위를 나타냄)은 표적 모이어티에 결합하는 표적화제이다. 보다 구체적으로, 이 리간드 단위는 예를 들어, 약물 단위가 전달되는 표적 세포 상의 B7-H4 단백질에 특이적으로 결합할 수 있다. 따라서, 본 발명은 또한 예를 들어 ADC로 다양한 암 및 기타 장애(예를 들어, B7-H4를 발현하는 세포, 바람직하게는 암세포의 존재와 관련된 암/장애)를 치료하는 방법을 제공한다.
본 발명에서 사용되는 항-B7H4 항체-약물 접합체는 암세포로의 세포 내재화를 거친 후, 링커 단위에서 절단되어 암세포 내로 약물 단위를 방출한다. 본 발명에서 사용되는 항-B7H4 항체-약물 접합체는 또한, 표적 단백질 B7-H4를 발현하는 암세포에 항-B7H4 항체-약물 접합체가 내재화되어, 표적 단백질 B7-H4를 발현하지 않는 인접 암세포에도 약물 단위가 항종양 효과를 발휘하는 방관자 효과가 있다.
III. 바람직한 구현예의 추가 바람직한 예.
하기 바람직한 예는 전술한 바와 같은 본 발명의 모든 양태에 적용될 수 있거나, 단일 양태와 관련될 수 있다. 바람직한 예는 임의의 조합으로 함께 결합될 수 있다. 이 섹션의 특정 용어와 관련된 다양한 정의는 아래에 제시된 "추가 화학적 정의"라는 제목으로 제공된다.
전술한 토포이소머라제 I 억제제의 특정 특징이 특히 바람직하며 이하 보다 상세히 정의된다. 예로서, 화학식 4의 링커의 특징 QX의 바람직한 구현예를 요약한다. 일 구현예에서, Q는 아미노산 잔기이다. 아미노산은 천연 아미노산 또는 비천연 아미노산일 수 있다. 예를 들어, Q는 Phe, Lys, Val, Ala, Cit, Leu, Ile, Arg, 및 Trp로부터 선택될 수 있고, Cit는 시트룰린이다. 일 구현예에서, Q는 디펩티드 잔기를 포함한다. 디펩티드의 아미노산은 천연 아미노산과 비천연 아미노산의 임의의 조합일 수 있다. 일부 구현예에서, 디펩티드는 천연 아미노산을 포함한다. 링커가 카텝신 불안정성 링커인 경우, 디펩티드는 카텝신 매개 절단에 대한 작용 부위이다. 즉 디펩티드는 카텝신에 대한 인식 부위이다.
일 구현예에서, Q는 다음으로부터 선택되고:
NH-Phe-Lys-C=O,
NH-Val-Ala-C=O,
NH-Val-Lys-C=O,
NH-Ala-Lys- C=O,
NH-Val-Cit-C=O,
NH-Phe-Cit-C=O,
NH-Leu-Cit-C=O,
NH-Ile-Cit-C=O,
NH-Phe-Arg-C=O,
NH-Trp-Cit-C=O, 및
NH-Gly-Val-C=O;
Cit는 시트룰린이다. 바람직하게는, Q는 다음으로부터 선택된다:
NH-Phe-Lys-C=O,
NH-Val-Ala-C=O,
NH-Val-Lys-C=O,
NH-Ala-Lys-C=O, 및
NH-Val-Cit-C=O.
보다 바람직하게는, Q는 NH-Phe-Lys-C=O, NH-Val-Cit-C=O, 또는 NH-Val-Ala-C=O로부터 선택된다. 기타 적합한 디펩티드 조합은 다음을 포함한다:
NH-Gly-Gly-C=O,
NH-Gly-Val-C=O,
NH-Pro-Pro-C=O, 및
NH-Val-Glu-C=O.
본원에 참조로 포함되는 문헌[Dubowchik et al., Bioconjugate Chemistry, 2002, 13,855-869]에 기술된 것들을 포함하여 다른 디펩티드 조합이 사용될 수 있다.
일부 구현예에서, Q는 트리펩티드 잔기이다. 트리펩티드의 아미노산은 천연 아미노산과 비천연 아미노산의 임의의 조합일 수 있다. 일부 구현예에서, 트리펩티드는 천연 아미노산을 포함한다. 링커가 카텝신 불안정성 링커인 경우, 트리펩티드는 카텝신 매개 절단에 대한 작용 부위이다. 즉 트리펩티드는 카텝신에 대한 인식 부위이다. 특히 관심 대상인 트리펩티드 링커는 다음과 같다:
NH-Glu-Val-Ala-C=O,
NH-Glu-Val-Cit-C=O,
NH-αGlu-Val-Ala-C=O, 및
NH-αGlu-Val-Cit-C=O.
일부 구현예에서, Q는 테트라펩티드 잔기이다. 테트라펩티드의 아미노산은 천연 아미노산과 비천연 아미노산의 임의의 조합일 수 있다. 일부 구현예에서, 테트라펩티드는 천연 아미노산을 포함한다. 링커가 카텝신 불안정성 링커인 경우, 테트라펩티드는 카텝신 매개 절단에 대한 작용 부위이다. 즉 테트라펩티드는 카텝신에 대한 인식 부위이다. 특히 관심 대상인 테트라펩티드 링커는 다음과 같다:
NH-Gly-Gly-Phe-Gly C=O, 및
NH-Gly-Phe-Gly-Gly C=O.
일부 구현예에서, 테트라펩티드는 다음과 같다:
NH-Gly-Gly-Phe-Gly C=O.
펩티드 잔기의 상기 표현에서, NH-는 N-말단을 나타내고, -C=O는 잔기의 C-말단을 나타낸다. C-말단은 화학식 1로 표시되는 화합물 A*의 NH에 결합한다. Glu는 글루탐산의 잔기를 나타낸다. 즉:
[화학식 10]

αGlu는 α-쇄를 통해 결합될 때의 글루탐산의 잔기를 나타낸다. 즉:
[화학식 11]

일 구현예에서, 아미노산 측쇄는 적절한 경우 화학적으로 보호된다. 측쇄 보호기는 상기 논의된 바와 같은 기일 수 있다. 보호된 아미노산 서열은 효소에 의해 절단될 수 있다. 예를 들어, Boc 측쇄-보호된 Lys 잔기를 포함하는 디펩티드 서열은 카텝신에 의해 절단될 수 있다.
아미노산의 측쇄에 대한 보호기는 당업계에 잘 알려져 있으며, Novabiochem 카탈로그에 기술되어 있으며, 전술된 바와 같다.
화학식 3의 링커의 GL은 다음으로부터 선택될 수 있다:


상기 표에서, Ar은 C5-6 아릴렌기(예를 들어, 페닐렌)을 나타내고, X는 C1-4 알킬을 나타낸다.
일부 구현예에서, GL은 GL1-1 및 GL1-2로부터 선택된다. 이러한 구현예 중 일부 구현예에서, GL은 GL1-1이다. GLL은 다음으로부터 선택될 수 있다:

상기 표에서, Ar은 C5-6 아릴렌기(예를 들어, 페닐렌)을 나타내고, X는 C1-4 알킬을 나타낸다. 일부 구현예에서, GLL은 GLL1-1 및 GLL1-2로부터 선택된다. 이러한 구현예 중 일부 구현예에서, GLL은 GLL1-1이다.
X는 바람직하게는 다음과 같고:
[화학식 12]

a는 0 내지 5이고, b1은 0 내지 16이고, b2는 0 내지 16이고, c는 0 또는 1이고, d는 0 내지 5이고, 적어도 b1 또는 b2는 0이고, 적어도 c1 또는 c2는 0이다.
"a"는 0, 1, 2, 3, 4, 또는 5일 수 있다. 일부 구현예에서, a는 0 내지 3이다. 이러한 구현예 중 일부 구현예에서, a는 0 또는 1이다. 추가 구현예에서, a는 0이다.
"b1"은 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 또는 16일 수 있다. 일부 구현예에서, "b1"은 0 내지 12이다. 이러한 구현예 중 일부 구현예에서, "b1"은 0 내지 8이고, 0, 2, 3, 4, 5, 또는 8일 수 있다.
"b2"는 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 또는 16일 수 있다. 일부 구현예에서, "b2"는 0 내지 12이다. 이러한 구현예 중 일부 구현예에서, "b2"는 0 내지 8이고, 0, 2, 3, 4, 5, 또는 8일 수 있다. 바람직하게는, b1과 b2 중 하나만 0이 아닐 수 있다.
"c1"은 0 또는 1일 수 있다. "c2"는 0 또는 1일 수 있다. 바람직하게는, "c1"과 "c2" 중 하나만 0이 아닐 수 있다.
"d"는 0, 1, 2, 3, 4, 또는 5일 수 있다. 일부 구현예에서, "d"는 0 내지 3이다. 이러한 구현예 중 일부 구현예에서, "d"는 1 또는 2이다. 추가 구현예에서, "d"는 2이다. 추가 구현예에서, "d"는 5이다.
X의 일부 구현예에서, a는 0이고, b1은 0이고, c1은 1이고, c2는 0이고, d는 2이고, b2는 0 내지 8일수 있다. 이러한 구현예 중 일부 구현예에서, b2는 0, 2, 3, 4, 5, 또는 8이다. X의 일부 구현예에서, a는 1이고, b2는 0이고, c1은 0이고, c2는 0이고, d는 0이고, b1은 0 내지 8일수 있다. 이러한 구현예 중 일부 구현예에서, b1은 0, 2, 3, 4, 5, 또는 8이다. X의 일부 구현예에서, a는 0이고, b1은 0이고, c1은 0이고, c2는 0이고, d는 1이고, b2는 0 내지 8일수 있다. 이러한 구현예 중 일부 구현예에서, b2는 0, 2, 3, 4, 5, 또는 8이다. X의 일부 구현예에서, b1은 0이고, b2는 0이고, c1은 0이고, c2는 0이고, a와 d 중 하나는 0이다. a와 d 중 다른 하나는 1 내지 5이다. 이러한 구현예 중 일부 구현예에서, a와 d 중 다른 하나는 1이다. 이러한 구현예 중 다른 구현예에서, a와 d 중 다른 하나는 5이다. X의 일부 구현예에서, a는 1이고, b2는 0이고, c1은 0이고, c2는 1이고, d는 2이고, b1은 0 내지 8일수 있다. 이러한 구현예 중 일부 구현예에서, b2는 0, 2, 3, 4, 5, 또는 8이다.
일부 구현예에서, RL은 화학식 6의ㅣ Ib이다. 일부 구현예에서, RLL은 화학식 9의 Ib' 기이다. RL1 및 RL2는 독립적으로 H 및 메틸로부터 선택되거나, 이들이 결합되는 탄소 원자와 함께 시클로프로필렌 또는 시클로부틸렌 기를 형성할 수 있다.
일부 구현예에서, RL1 및 RL2는 둘 다 H이다. 일부 구현예에서, RL1은 H이고 RL2는 메틸이다. 일부 구현예에서, RL1 및 RL2는 둘 다 메틸이다.
일부 구현예에서, RL1 및 RL2는 이들이 결합되는 탄소 원자와 함께 시클로프로필렌기를 형성한다. 일부 구현예에서, RL1 및 RL2는 이들이 결합되는 탄소 원자와 함께 시클로부틸렌기를 형성한다.
화학식 6의 Ib 기의 일부 구현예에서, e는 0이다. 다른 구현예에서, e는 1이고, 니트로기는 고리의 임의의 이용가능한 위치에 있을 수 있다. 이러한 구현예 중 일부 구현예에서, 이는 오르토 위치에 있다. 이러한 구현예 중 다른 구현예에서, 이는 파라 위치에 있다.
본원에 기재된 화합물이 단일 거울상이성질체로 또는 거울상이성질체가 풍부한 형태로 제공되는 일부 구현예에서, 거울상이성질체가 풍부한 형태는 60:40, 70:30; 80:20, 또는 90:10보다 큰 거울상이성질체 비를 갖는다. 추가 구현예에서, 거울상이성질체 비는 95:5, 97:3, 또는 99:1보다 크다.
일부 구현예에서, 화학식 2의 RL은 다음으로부터 선택된다:


일부 구현예에서, RLL은 상기 RL 기로부터 유래된 기이다.
상기 바람직한 예를 위에서 요약했으므로, 특정 바람직한 토포이소머라제 I 링커 화학식(예를 들어, 약물 링커 단위의 화학식)을 이제 설명한다. 일부 구현예에서, 화학식 2의 화합물 I는 화합물 I P :
[화학식 13]

및 이의 염 및 용매화물이다. RLP는 본원에 기재된 항체 또는 이의 항원 결합 단편에 연결하기 위한 링커이고, 상기 링커는 Ia 또는 Ib 기로부터 선택된다. Ia 기는 하기 화학식으로 표시되며:
[화학식 14]

QP는 다음과 같고:

QXP는 QP가 아미노산 잔기, 디펩티드 잔기, 또는 트리펩티드 잔기가 되도록 하는 것이다. 화학식 14에서 XP는 다음과 같고:
[화학식 15]

aP는 0 내지 5, bP는 0 내지 16, cP는 0 또는 1, dP는 0 내지 5이다. 화학식 14에서 GL은 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)에 연결하기 위한 링커이다. aP는 0, 1, 2, 3, 4, 또는 5일 수 있다. 일부 구현예에서, aP는 0 내지 3이다. 이러한 구현예 중 일부 구현예에서, aP는 0 또는 1이다. 추가 구현예에서, aP는 0이다. bP는 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 또는 16일 수 있다. 일부 구현예에서, b는 0 내지 12이다. 이러한 구현예 중 일부 구현예에서, bP는 0 내지 8이고, 0, 2, 4, 또는 8일 수 있다. cP는 0 또는 1일 수 있다. dP는 0, 1, 2, 3, 4, 또는 5일 수 있다. 일부 구현예에서, dP는 0 내지 3이다. 이러한 구현예 중 일부 구현예에서, dP는 1 또는 2이다. 추가 구현예에서, dP는 2이다.
Ib 기는 하기 화학식으로 표시되며:
[화학식 16]

RL1 및 RL2는 독립적으로 H 및 메틸로부터 선택되거나, 이들이 결합되는 탄소 원자와 함께 시클로프로필렌 또는 시클로부틸렌 기를 형성한다. 화학식 16에서 "e"는 0 또는 1이다.
화학식 14의 XP의 일부 구현예에서, aP는 0이고, cP는 1이고, dP는 2이고, bP는 0 내지 8일수 있다. 이러한 구현예 중 일부 구현예에서, bP는 0, 4, 또는 8이다.
화합물 I에 대한 화학식 4의 QX에 대한 바람직한 예는 화학식 14의 QXP에 적용될 수 있다. 화학식 2의 화합물 I에 대한 상기 GL, RL1, RL2, 및 e에 대한 바람직한 예는 화학식 13의 화합물 I P 에 적용될 수 있다.
일부 구현예에서, 항체-약물 접합체 L-(DL)p의 접합체는 화합물 L-(DLP)p 또는 이의 약학적으로 허용가능한 염 또는 용매화물이며, L은 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)이고, DLP는 하기 화합물 IIIP인 토포이소머라제 I 억제제(예를 들어, 약물 링커 단위)이고:
[화학식 17]

RLLP는 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)에 연결된 링커이고, 상기 링커는 Ia' 또는 Ib' 기로부터 선택된다. Ia' 기는 하기 화학식으로 표시되며:
[화학식 18]

QP 및 XP는 상기 정의된 바와 같고, GLL은 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)에 연결된 링커이다. Ib' 기는 하기 화학식으로 표시되며:
[화학식 19]

RL1 및 RL2는 상기 정의된 바와 같고; p는 1 내지 20의 정수이다.
일부 구현예에서, 화학식 2의 화합물 I는 화합물 I P2 :
[화학식 20]

및 이의 염 및 용매화물이다. RLP2는 항체 또는 이의 항원 결합 단편에 연결하기 위한 링커이고, 상기 링커는 Ia 또는 Ib 기로부터 선택된다. Ia 기는 하기 화학식으로 표시되며:
[화학식 21]

Q는 다음과 같고:

QX는 Q가 아미노산 잔기, 디펩티드 잔기, 트리펩티드 잔기, 또는 테트라펩티드 잔기가 되도록 하는 것이다. XP2는 다음과 같고:

aP2는 0 내지 5이고, b1P2는 0 내지 16이고, b2P2는 0 내지 16이고, cP2는 0 또는 1이고, dP2는 0 내지 5이고, 적어도 b1P2 또는 b2P2는 0(즉, b1과 b2 중 하나만 0이 아닐 수 있음)이다. 화학식 21의 GL은 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)에 연결하기 위한 링커이다.
aP2는 0, 1, 2, 3, 4, 또는 5일 수 있다. 일부 구현예에서, aP2는 0 내지 3이다. 이러한 구현예 중 일부 구현예에서, aP2는 0 또는 1이다. 추가 구현예에서, aP2는 0이다. b1P2는 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 또는 16일 수 있다. 일부 구현예에서, b1P2는 0 내지 12이다. 이러한 구현예 중 일부 구현예에서, b1P2는 0 내지 8이고, 0, 2, 3, 4, 5, 또는 8일 수 있다. b2P2는 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 또는 16일 수 있다. 일부 구현예에서, b2P2는 0 내지 12이다. 이러한 구현예 중 일부 구현예에서, b2P2는 0 내지 8이고, 0, 2, 3, 4, 5, 또는 8일 수 있다. 바람직하게는, b1P2과 b2P2 중 하나만 0이 아닐 수 있다. cP2는 0 또는 1일 수 있다. dP2는 0, 1, 2, 3, 4, 또는 5일 수 있다. 일부 구현예에서, dP2는 0 내지 3이다. 이러한 구현예 중 일부 구현예에서, dP2는 1 또는 2이다. 추가 구현예에서, dP2는 2이다. 추가 구현예에서, dP2는 5이다.
Ib 기는 하기 화학식으로 표시되며:
[화학식 22]

RL1 및 RL2는 독립적으로 H 및 메틸로부터 선택되거나, 이들이 결합되는 탄소 원자와 함께 시클로프로필렌 또는 시클로부틸렌 기를 형성하고; e는 0 또는 1이다.
화학식 21의 XP2의 일부 구현예에서, aP2는 0이고, b1P2는 0이고, cP2는 1이고, dP2는 2이고, b2P2는 0 내지 8일수 있다. 이러한 구현예 중 일부 구현예에서, b2P2는 0, 2, 3, 4, 5, 또는 8이다. XP2의 일부 구현예에서, aP2는 1이고, b2P2는 0이고, cP2는 0이고, dP2는 0이고, b1P2는 0 내지 8일수 있다. 이러한 구현예 중 일부 구현예에서, b1P2는 0, 2, 3, 4, 5, 또는 8이다. XP2의 일부 구현예에서, aP2는 0이고, b1P2는 0이고, cP2는 0이고, dP2는 1이고, b2P2는 0 내지 8일수 있다. 이러한 구현예 중 일부 구현예에서, b2P2는 0, 2, 3, 4, 5, 또는 8이다. XP2의 일부 구현예에서, b1P2는 0이고, b2P2는 0이고, cP2는 0이고, aP2와 dP2 중 하나는 0이다. aP2와 d 중 다른 하나는 1 내지 5이다. 이러한 구현예 중 일부 구현예에서, aP2와 d 중 다른 하나는 1이다. 이러한 구현예 중 다른 구현예에서, aP2와 dP2 중 다른 하나는 5이다.
화학식 2의 화합물 I에 대한 상기 QX에 대한 바람직한 예는 화학식 21의 IaP2 기의 QX에 적용될 수 있다. 화학식 2의 화합물 I에 대한 상기 GL, RL1, RL2, 및 e에 대한 바람직한 예는 화학식 21의 화합물 IaP2에 적용될 수 있다.
일부 구현예에서, 접합체 L-(DL)p의 접합체는 화합물 L-(DLP2)p 또는 이의 약학적으로 허용가능한 염 또는 용매화물이며, L은 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)이고, DLP2는 하기 화합물 IIIP2인 토포이소머라제 I 억제제(예를 들어, 약물 링커 단위)이고:
[화학식 23]

RLLP2는 항체 또는 이의 항원 결합 단편(예를 들어, 리간드 단위)에 연결된 링커이고, 상기 링커는 Ia' 또는 Ib' 기로부터 선택된다. Ia' 기는 하기 화학식으로 표시되며:
[화학식 24]

Q 및 XP2는 상기 정의된 바와 같고, GLL은 항체 또는 이의 항원 결합 단편에 연결된 링커이다.
Ib' 기는 하기 화학식으로 표시되며:
[화학식 25]

RL1 및 RL2는 상기 정의된 바와 같고; p는 1 내지 20의 정수이다.
특히 적합한 토포이소머라제 I 억제제는 하기 화학식을 갖는 것들을 포함한다:
[화학식 26]

[화학식 27]

[화학식 28]

[화학식 29]

[화학식 30]

억제제 SG3932가 특히 바람직하다. 따라서, 바람직한 구현예에서, 항체 또는 이의 항원 결합 단편은 SG3932의 하기 화학식을 갖는 토포이소머라제 I 억제제에 접합된다:
[화학식 26]

의심의 여지를 없애기 위해, 화학식 26의 숫자 "8"은 박스 괄호 안의 구조가 8번 반복됨을 지정한다. 따라서, SG3932의 다른 표현은 다음과 같다:
[화학식 31]

SG4010의 다른 표현은 다음과 같다:
[화학식 32]

SG4057의 다른 표현은 다음과 같다:
[화학식 33]

SG4052의 다른 표현은 다음과 같다:
[화학식 34]

본원에 기재된 임의의 항체 또는 이의 항원 결합 단편이 상기 토포이소머라제 I 억제제 중 하나 이상에 접합될 수 있다.
IV. 추가 화학적 정의.
하기 정의는 특히 상기 토포이소머라제 I 억제제의 설명에 관한 것이며, 더욱 더 구체적으로 "바람직한 구현예의 추가 바람직한 예"라는 제목의 섹션에 관한 것일 수 있다.
C5-6 아릴렌: 본원에서 사용되는 용어 "C5-6 아릴렌"은 방향족 화합물의 방향족 고리 원자로부터 2개의 수소 원자를 제거하여 얻은 2가 모이어티에 관한 것이다.
이러한 맥락에서, 접두사(예를 들어, C5-6)는 탄소 원자이든 헤테로원자이든, 고리 원자의 수, 또는 고리 원자 수의 범위를 나타낸다. 고리 원자는 "카보아릴렌기"에서와 같이 모두 탄소 원자일 수 있고, 이 경우 기는 페닐렌(C6)이다. 대안적으로, 고리 원자는 "헤테로아릴렌기"에서와 같이 하나 이상의 헤테로원자를 포함할 수 있다. 헤테로아릴렌기의 예는 다음으로부터 유래된 것을 포함하나 이에 한정되지 않는다:
N1: 피롤(아졸)(C5), 피리딘(아진)(C6);
O1: 푸란(옥솔)(C5);
S1: 티오펜(티올)(C5);
N1O1: 옥사졸(C5), 이속사졸(C5), 이속사진(C6);
N2O1: 옥사디아졸(푸라잔)(C5);
N3O1: 옥사트리아졸(C5);
N1S1: 티아졸(C5), 이소티아졸(C5);
N2: 이미다졸(1,3-디아졸)(C5), 피라졸(1,2-디아졸)(C5), 피리다진(1,2-디아진)(C6), 피리미딘(1,3-디아진)(C6)(예를 들어, 시토신, 티민, 우라실), 피라진(1,4-디아진)(C6); 및
N3: 트리아졸(C5), 트리아진(C6).
C1-4 알킬: 본원에서 사용되는 용어 "C1-4 알킬"은 1 내지 4개의 탄소 원자를 갖는 탄화수소 화합물의 탄소 원자로부터 수소 원자를 제거하여 얻은 1가 모이어티에 관한 것으로, 지방족 또는 지환족일 수 있고, 포화 또는 불포화(예를 들어, 부분 불포화, 완전 불포화)일 수 있다. 본원에서 사용되는 용어 "C1-n 알킬"은 1 내지 n개의 탄소 원자를 갖는 탄화수소 화합물의 탄소 원자로부터 수소 원자를 제거하여 얻은 1가 모이어티에 관한 것으로, 지방족 또는 지환족일 수 있고, 포화 또는 불포화(예를 들어, 부분 불포화, 완전 불포화)일 수 있다. 따라서, 용어 "알킬"은 이하에서 논의되는 하위 부류인 알케닐, 알키닐, 시클로알킬 등을 포함한다.
포화 알킬기의 예는 메틸(C1), 에틸(C2), 프로필(C3), 및 부틸(C4)을 포함하나 이에 한정되지 않는다. 포화 선형 알킬기의 예는 메틸(C1), 에틸(C2), n-프로필(C3), 및 n-부틸(C4)을 포함하나 이에 한정되지 않는다. 포화 분지형 알킬기의 예는 이소-프로필(C3), 이소-부틸(C4), sec-부틸(C4), tert-부틸(C4)을 포함한다.
C2-4 알케닐: 본원에서 사용되는 용어 "C2-4 알케닐"은 하나 이상의 탄소-탄소 이중 결합을 갖는 알킬기에 관한 것이다. 불포화 알케닐기의 예는 에테닐(비닐, -CH=CH2), 1-프로페닐(-CH=CH-CH3), 2-프로페닐(알릴, -CH-CH=CH2), 이소프로페닐(1-메틸비닐, -C(CH3)=CH2), 및 부테닐(C4)을 포함하나 이에 한정되지 않는다.
C2-4 알키닐: 본원에서 사용되는 용어 "C2-4 알키닐"은 하나 이상의 탄소-탄소 삼중 결합을 갖는 알킬기에 관한 것이다. 불포화 알키닐기의 예는 에티닐(-C≡CH) 및 2-프로피닐(프로파길, -CH2-C≡CH)을 포함하나 이에 한정되지 않는다.
C3-4 시클로알킬: 본원에서 사용되는 용어 "C3-4 시클로알킬"은 시클릴기이기도 한 알킬기, 즉 환형 탄화수소(카보시클릭) 화합물의 지환족 고리 원자로부터 수소 원자를 제거하여 얻은 1가 모이어티에 관한 것으로, 이 모이어티는 3 내지 7개의 고리 원자를 포함하여 3 내지 7개의 탄소 원자를 갖는다. 시클로알킬기의 예는 시클로프로판(C3) 및 시클로부탄(C4)과 같은 포화 단환 탄화수소 화합물; 및 시클로프로펜(C3) 및 시클로부텐(C4)과 같은 불포화 단환 탄화수소 화합물로부터 유래된 것들을 포함하나 이에 한정되지 않는다.
연결 표시: 아래 화학식 35에서, 위첨자 표시 C(=O) 및 NH는 원자가 결합되는 기를 나타낸다.
[화학식 35]

예를 들어, NH기는 (예시된 모이어티의 일부가 아닌) 카보닐에 결합되는 것으로 표시되고, 카보닐은 (예시된 모이어티의 일부가 아닌) NH기에 결합되는 것으로 표시된다.
V. 토포이소머라제 I 억제제의 합성.
RL이 화학식 3의 Ia 기인 화학식 2의 화합물 I는 화학식 36의 화합물:
[화학식 36]

(RL*은 -QH임)로부터, 화학식 37의 화합물:
[화학식 37]

또는 이의 활성화 버전을 연결함으로써 합성될 수 있다. 이러한 반응은 아미드 커플링 조건 하에서 수행될 수 있다. 화학식 36의 화합물은 화학식 38의 화합물:
[화학식 38]

(RL*prot는 -Q-ProtN이고, ProtN은 아민 보호기임)을 탈보호함으로써 합성될 수 있다. 화학식 38의 화합물은 Friedlander 반응을 이용하여 화학식 39의 화합물:
[화학식 39]

을 화합물 A3과 커플링함으로써 합성될 수 있다. 화합물 A3은 (S)-4-에틸-4-하이드록시-7,8-디하이드로-1H-피라노[3,4-f]인돌리진-3,6,10(4H)-트리온이다. 화학식 39의 화합물은 화학식 40의 화합물:
[화학식 40]

로부터 트리플루오로아세트아미드 보호기를 제거함으로써 합성될 수 있다. 화학식 40의 화합물은 RL*prot-OH를 화합물 I7에 커플링함으로써 합성될 수 있다. 화합물 I7은 N-(4-아미노-8-옥소-5,6,7,8-테트라하이드로나프탈렌-1-일)-2,2,2-트리플루오로아세트아미드이다. RL이 화학식 3의 Ia 기 또는 화학식 6의 Ib 기인 화학식 2의 화합물 I는 화합물 RL-OH 또는 이의 활성화 형태의 커플링에 의해 화합물 I11로부터 합성될 수 있다. 화합물 I11은 (S)-4-아미노-9-에틸-9-하이드록시-1,2,3,9,12,15-헥사하이드로-10H,13H-벤조[데]피라노[3',4':6,7]인돌리지노[1,2-b]퀴놀린-10,13-디온이다.
아민 보호기는 당업자에게 잘 알려져 있다. 특히 문헌[Greene's Protecting Groups in Organic Synthesis, Fourth Edition, John Wiley & Sons, 2007 (ISBN 978-0-471-69754-1), pages 696-871]의 적합한 보호기에 대한 개시내용을 참조한다.
VI. 항-B7H4 항체.
용어 "항체"는 (예를 들어, 원하는 생물학적 활성을 나타내는) 단일클론 항체 및 이의 단편을 포함한다. 바람직한 구현예에서, 본원에 기재된 항체는 단일클론 항체이다. 보다 바람직한 구현예에서, 항체는 완전 인간 단일클론 항체이다. 일 구현예에서, 본 발명의 방법은 다클론 항체를 사용할 수 있다.
특히, 항체는 적어도 1개 또는 2개의 중(H)쇄 가변 영역(본원에서 VHC로 약칭함), 및 적어도 1개 또는 2개의 경(L)쇄 가변 영역(본원에서 VLC로 약칭함)을 포함하는 단백질이다. VHC 및 VLC 영역은 "프레임워크 영역"(FR)이라고 하는 더 보존된 영역이 산재된, "상보성 결정 영역"("CDR")이라고 하는 초가변성 영역으로 더 세분화될 수 있다. 프레임워크 영역 및 CDR의 범위는 정확하게 정의되어 있다(문헌[Kabat, E.A., et al. Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242, 1991, 및 Chothia, C. et al, J. MoI. Biol. 196:901-917, 1987] 참조).
바람직하게, 각각의 VHC 및 VLC은 아미노-말단에서 카복시-말단으로 FRl, CDRl, FR2, DR2, FR3, CDR3, FR4의 순서로 배열된 3개의 CDR 및 4개의 FR로 구성된다. 항체의 VHC 또는 VLC 사슬은 중쇄 또는 경쇄 불변 영역의 전부 또는 일부를 추가로 포함할 수 있다. 일 구현예에서, 2개의 중쇄 면역글로불린 사슬 및 2개의 경쇄 면역글로불린 사슬의 사량체이며, 중쇄 및 경쇄 면역글로불린 사슬은 예를 들어 이황화 결합에 의해 상호연결된다. 중쇄 불변 영역은 3개의 도메인 CH1, CH2, 및 CH3을 포함한다. 경쇄 불변 영역은 하나의 도메인 CL로 구성된다. 중쇄 및 경쇄의 가변 영역은 항원과 상호작용하는 결합 도메인을 포함한다.
용어 "항체"는 IgA, IgG, IgE, IgD, IgM 유형(및 그 하위 유형)의 온전한 면역글로불린을 포함하며, 면역글로불린의 경쇄는 카파 또는 람다 유형일 수 있다. 본원에서 사용되는 용어 "항체"는 또한 상기 언급된 마커 중 하나에 결합하는 항체의 일부, 예를 들어 하나 이상의 면역글로불린 사슬이 전체 길이는 아니지만 마커에 결합하는 분자를 지칭한다. 용어 "항체"에 포함되는 결합 부분의 예는 (i) VLC, VHC, CL, 및 CH1 도메인으로 구성된 1가 단편인 Fab 단편; (ii) 힌지 영역에서 이황화 가교에 의해 연결된 2개의 Fab 단편을 포함하는 2가 단편인 F(ab')2 단편; (iii) VHC 및 CH1 도메인으로 구성된 Fc 단편; (iv) 항체의 단일 아암의 VLC 및 VHC 도메인으로 구성된 Fv 단편; (v) VHC 도메인으로 구성된 dAb 단편(Ward et al, Nature 341:544-546, 1989); 및 (vi) 결합하기에 충분한 프레임워크를 갖는 단리된 상보성 결정 영역(CDR), 예를 들어 가변 영역의 항원 결합 부분을 포함한다. 경쇄 가변 영역의 항원 결합 부분 및 중쇄 가변 영역의 항원 결합 부분, 예를 들어 Fv 단편의 2개의 도메인, VLC 및 VHC는 재조합 방법을 사용하여, VLC와 VHC 영역이 쌍을 이루어 1가 분자를 형성하는 단일 단백질 사슬(단일쇄 Fv(scFv)로 알려짐; 예를 들어 문헌[Bird et al. (1988) Science lAl-ATi-Alβ; 및 Huston et al. (1988) Proc. Natl. Acad. ScL USA 85:5879-5883] 참조)로 되도록 할 수 있는 합성 링커에 의해 연결될 수 있다. 이러한 단일쇄 항체도 용어 "항체"에 포함된다. 이러한 것들은 당업자에게 알려진 통상적인 기술을 사용하여 얻을 수 있으며, 이들 부분은 온전한 항체와 동일한 방식으로 유용성을 위해 스크리닝된다.
일 구현예에서, 항체 또는 항원 결합 단편은 뮤린 항체, 인간화 항체, 키메라 항체, 단일클론 항체, 다클론 항체, 재조합 항체, 다중특이적 항체, 또는 이들의 조합으로부터 선택되는 하나 이상이다.
일 구현예에서, 항원 결합 단편은 Fv 단편, Fab 단편, F(ab')2 단편, Fab' 단편, dsFv 단편, scFv 단편, sc(Fv)2 단편, 또는 이들의 조합으로부터 선택되는 하나 이상이다.
바람직한 구현예에서, 항체 또는 이의 항원 결합 단편은 단일클론 항체(mAb)이다. 일 구현예에서, 본 발명의 항체 또는 이의 항원 결합 단편(예를 들어, mAb)은 scFv이다.
일 구현예에서, 항체 또는 이의 항원 결합 단편은 종에 걸쳐 B7-H4 분자에 결합할 수 있다. 예를 들어, 항체 또는 단편은 마우스 B7-H4, 래트 B7-H4, 토끼, 인간 B7-H4, 및/또는 시노몰구스 원숭이 B7-H4에 결합할 수 있다. 일 구현예에서, 항체 또는 단편은 인간 B7-H4 및 시노몰구스 원숭이 B7-H4에 결합할 수 있다. 일 구현예에서, 항체 또는 항원 결합 단편은 또한 마우스 B7-H4에 결합할 수 있다. 일 구현예에서, 항체 또는 이의 항원 결합 단편은 B7-H4, 예를 들어 인간 B7-H4 및 시노몰구스 원숭이 B7-H4에 특이적으로 결합할 수 있지만, 인간 B7-H1, B7-H2, 및/또는 B7-H3에는 특이적으로 결합하지 않는다.
일 구현예에서, 항체 또는 이의 항원 결합 단편은 VH 및 VL 외에도 중쇄 불변 영역 또는 이의 단편을 포함할 수 있다. 일 구현예에서, 중쇄 불변 영역은 인간 중쇄 불변 영역, 예를 들어 인간 IgG 불변 영역, 예를 들어 인간 IgG1 불변 영역이다. 일 구현예에서(바람직하게는 항체 또는 이의 항원 결합 단편이 세포독성제와 같은 제제에 접합된 경우), IgG1의 CH2 영역에서 아미노산 S239와 V240 사이에 시스테인 잔기가 삽입된다. 이 시스테인은 "239 삽입" 또는 "239i"로 지칭된다.
VII. 항-B7H4 항체의 제조.
본원에 기재된 항체는 당업자에게 알려진 통상적인 기술 및 통상적인 결합 연구에 의해 확인된 그 유용성을 사용하여 얻을 수 있다. 예로서, 간단한 결합 분석은 항원 발현 세포를 항체와 함께 인큐베이션하는 것이다. 항체가 형광단으로 태깅된 경우, 항원에 대한 항체의 결합은 FACS 분석에 의해 검출될 수 있다.
본원에 기재된 항체는 마우스, 래트, 토끼, 염소, 양, 원숭이, 또는 말을 비롯한 다양한 동물에서 생성될 수 있다. 항체는 개별 협막 다당류 또는 복수의 협막 다당류로 면역화한 후 생성될 수 있다. 이러한 동물로부터 단리된 혈액은 동일 항원에 결합하는 다중 항체인 다클론 항체를 포함한다. 난황에서의 다클론 항체의 생성을 위해 항원을 닭에 주입할 수도 있다. 항원의 단일 에피토프에 특이적인 단일클론 항체를 얻기 위해, 항체-분비 림프구를 동물로부터 단리하고 암 세포주와 융합시켜 불멸화시킨다. 융합된 세포는 하이브리도마라고 불리며, 배양에서 지속적으로 성장하고 항체를 분비한다. 단일 하이브리도마 세포는 희석 클로닝에 의해 단리되어 모두 동일한 항체를 생산하는 세포 클론을 생성하며; 이러한 항체를 단일클론 항체라고 한다. 단일클론 항체를 생성하는 방법은 당업자에게 알려진 통상적인 기술이다(예를 들어, 문헌[Making and Using Antibodies: A Practical Handbook. GC Howard. CRC Books. 2006. ISBN 0849335280] 참조). 다클론 및 단일클론 항체는 흔히 단백질 A/G 또는 항원 친화성 크로마토그래피를 사용하여 정제된다.
본원에 기재된 항체 또는 항원 결합 단편은 문헌[Kohler and Milstein, Nature 256:495 (1975)]에 기재된 것과 같은 하이브리도마 방법을 사용하여 제조될 수 있는 단일클론 항-B7H4 항체로서 제조될 수 있다. 하이브리도마 방법을 사용하여, 마우스, 햄스터, 또는 다른 적절한 숙주 동물을 전술한 바와 같이 면역화시켜, 면역화 항원에 특이적으로 결합할 항체의 림프구에 의한 생성을 유도한다. 림프구는 시험관내에서 면역화될 수도 있다. 면역화 후, 림프구는 단리되고 예를 들어 폴리에틸렌 글리콜을 사용하여 적합한 골수종 세포주와 융합되어 하이브리도마 세포를 형성하며, 이는 이후 융합되지 않은 림프구 및 골수종 세포로부터 선별될 수 있다. 면역침전, 면역블롯팅 또는 시험관내 결합 분석법, 예를 들어 방사성면역분석법(RIA) 또는 효소결합 면역흡착 분석법(ELISA)으로 측정시 선택된 항원에 대해 특이적으로 유도된 단일클론 항체를 생성하는 하이브리도마는 이어서 표준 방법(Goding, Monoclonal Antibodies: Principles and Practice, Academic Press, 1986)을 사용하여 시험관내 증식되거나 동물에서 복수 종양으로서 생체내 증식될 수 있다. 이어서 단일클론 항체는 알려진 방법을 사용하여 배양 배지 또는 복수액으로부터 정제될 수 있다.
대안적으로, 항체 또는 이의 항원 결합 단편(예를 들어, 단일클론 항체)은 미국 특허번호 4,816,567에 기재된 바와 같은 재조합 DNA 방법을 사용하여 제조될 수도 있다. 단일클론 항체를 암호화하는 폴리뉴클레오티드는 예컨대 항체의 중쇄 및 경쇄를 암호화하는 유전자를 특이적으로 증폭시키는 올리고뉴클레오티드 프라이머를 이용한 RT-PCR에 의해 성숙한 B 세포 또는 하이브리도마 세포로부터 단리되고, 그 서열은 통상적인 절차를 사용하여 결정된다.
중쇄 및 경쇄를 암호화하는 단리된 폴리뉴클레오티드는 이어서 적합한 발현 벡터에 클로닝되어, 대장균 세포, 유인원 COS 세포, 중국 햄스터 난소(CHO) 세포, 또는 달리 면역글로불린 단백질을 생성하지 않는 골수종 세포와 같은 숙주 세포 내로 형질주입될 경우, 숙주 세포에 의해 단일클론 항체가 생성된다. 또한, 원하는 종의 재조합 단일클론 항체 또는 이의 항원 결합 단편은 문헌[McCafferty et al., Nature 348:552-554 (1990); Clackson et al., Nature, 352:624-628 (1991); 및 Marks et al., J. Mol. Biol. 222:581-597 (1991)]에 기재된 바와 같이 원하는 종의 CDR을 발현하는 파지 디스플레이 라이브러리로부터 단리될 수 있다.
본 발명의 항체 또는 이의 항원 결합 단편을 암호화하는 폴리뉴클레오티드(들)는 재조합 DNA 기술을 사용하여 다양한 방식으로 추가로 변형되어 대안적인 항체를 생성할 수 있다. 일부 구현예에서, 예를 들어 마우스 단일클론 항체의 경쇄 및 중쇄의 불변 도메인은 (1) 예를 들어 인간 항체의 해당 영역을 대체하여 키메라 항체를 생성하거나, (2) 비면역글로불린 폴리펩티드를 대체하여 융합 항체를 생성할 수 있다. 일부 구현예에서, 불변 영역은 단일클론 항체의 원하는 항체 단편을 생성하기 위해 절단되거나 제거된다. 단일클론 항체의 특이성, 친화성 등을 최적화하기 위해 가변 영역의 부위 지정 돌연변이 유발 또는 고밀도 돌연변이 유발이 이용될 수 있다.
일 구현예에서, 항체 또는 이의 항원 결합 단편은 인간 항체 또는 이의 항원 결합 단편이다. 인간 항체는 당업계에 알려진 다양한 기술을 사용하여 직접 제조될 수 있다. 표적 항원에 대한 항체를 생성하는 시험관내 면역화되거나 면역 개체로부터 단리된 불멸화 인간 B 림프구가 생성될 수 있다. 예를 들어, 문헌[Cole et al., Monoclonal Antibodies and Cancer Therapy, Alan R. Liss, p. 77 (1985); Boemer et al., J. Immunol. 147 (1):86-95 (1991); 미국 특허 5,750,373] 참조.
일 구현예에서, 항체 또는 이의 항원 결합 단편은 파지 라이브러리로부터 선택될 수 있으며, 해당 파지 라이브러리는 예를 들어 문헌[Vaughan et al., Nat. Biotech. 14:309-314 (1996); Sheets et al., Proc. Natl. Acad. Sci. USA, 95:6157-6162 (1998); Hoogenboom and Winter, J. Mol. Biol. 227:381 (1991); 및 Marks et al., J. Mol. Biol. 222:581 (1991)]에 기재된 바와 같이 인간 항체를 발현한다. 항체 파지 라이브러리의 생성 및 사용 기술은 또한 문헌[미국 특허번호 5,969,108, 6,172,197, 5,885,793, 6,521,404; 6,544,731; 6,555,313; 6,582,915; 6,593,081; 6,300,064; 6,653,068; 6,706,484; 및 7,264,963; 및 Rothe et al., J. Molec. Biol. 376:1182-1200 (2008)]에 기술되어 있으며, 각각의 문헌은 전체가 참조로 포함된다.
친화성 성숙 전략 및 사슬 셔플링 전략이 당업계에 알려져 있고 고친화성 인간 항체 또는 이의 항원 결합 단편을 생성하기 위해 사용될 수 있다. 전체가 참조로 포함되는 문헌[Marks et al., BioTechnology 10:779-783 (1992)] 참조.
일 구현예에서, 항체 또는 이의 항원 결합 단편(예를 들어, 단일클론 항체)은 인간화 항체일 수 있다. 비인간 또는 인간 항체의 조작, 인간화, 또는 표면변형(resurfacing) 방법이 또한 사용될 수 있고 당업계에 잘 알려져 있다. 인간화, 표면변형, 또는 유사하게 조작된 항체는 비인간(비제한적인 예로서, 마우스, 래트, 토끼, 비인간 영장류, 또는 기타 포유동물)인 공급원으로부터의 하나 이상의 아미노산 잔기를 가질 수 있다. 이러한 비인간 아미노산 잔기는 알려진 인간 서열의 "유입" 가변, 불변, 또는 기타 도메인으로부터 취해지는 것이 일반적인 "유입" 잔기로 종종 지칭되는 잔기에 의해 대체된다. 이러한 유입 서열은 당업계에 알려진 바와 같이, 면역원성의 감소, 또는 결합, 친화성, 결합률, 해리율, 결합활성, 특이성, 반감기, 또는 기타 임의의 적합한 특성의 감소, 향상, 또는 변경을 위해 사용될 수 있다. 적합하게는, CDR 잔기는 B7-H4 결합에 영향을 미치는 데 직접적으로 그리고 가장 실질적으로 관여할 수 있다. 따라서, 비인간 또는 인간 CDR 서열의 일부 또는 전부는 유지되는 것이 바람직한 반면, 가변 및 불변 영역의 비인간 서열은 인간 또는 다른 아미노산으로 대체될 수 있다.
항체는 또한 임의로, 항원 B7-H4에 대한 높은 친화도 및 기타 유리한 생물학적 특성을 보유하도록 인간화, 표면변형, 조작될 수 있거나, 또는 조작된 인간 항체일 수 있다. 이러한 목표를 달성하기 위해, 인간화(또는 인간) 또는 조작된 항-B7H4 항체 및 표면변형 항체는 임의로, 모체 서열, 조작된 서열, 및 인간화 서열의 3차원 모델을 사용하여 모체 서열 및 다양한 개념적인 인간화 및 조작된 생성물을 분석하는 프로세스에 의해 제조될 수 있다. 3차원 면역글로불린 모델은 일반적으로 이용가능하고 당업자에게 잘 알려져 있다. 선택된 후보 면역글로불린 서열의 가능한 3차원 입체 구조를 예시하고 디스플레이하는 컴퓨터 프로그램을 이용할 수 있다. 이러한 디스플레이의 검사는 후보 면역글로불린 서열의 기능에 있어서 잔기의 가능한 역할의 분석, 즉 B7-H4와 같은 항원에 결합하는 후보 면역글로불린의 능력에 영향을 미치는 잔기의 분석을 가능하게 한다. 이러한 방식으로, 표적 항원(들)에 대한 증가된 친화도와 같은 원하는 항체 특성이 달성되도록 공통 서열 및 유입 서열로부터 FW 잔기가 선택되고 조합될 수 있다.
본 발명의 항-B7H4 항체 또는 이의 항원 결합 단편의 인간화, 표면변형, 또는 조작은 문헌[Jones et al., Nature 321:522 (1986); Riechmann et al., Nature 332:323 (1988); Verhoeyen et al., Science 239:1534 (1988); Sims et al., J. Immunol. 151: 2296 (1993); Chothia and Lesk, J. Mol. Biol. 196:901 (1987); Carter et al., Proc. Natl. Acad. Sci. USA 89:4285 (1992); Presta et al., J. Immunol. 151:2623 (1993); 미국 특허번호 5,639,641, 5,723,323; 5,976,862; 5,824,514; 5,817,483; 5,814,476; 5,763,192; 5,723,323; 5,766,886; 5,714,352; 6,204,023; 6,180,370; 5,693,762; 5,530,101; 5,585,089; 5,225,539; 4,816,567, 7,557,189; 7,538,195; 및 7,342,110; 국제 출원번호 PCT/US98/16280; PCT/US96/18978; PCT/US91/09630; PCT/US91/05939; PCT/US94/01234; PCT/GB89/01334; PCT/GB91/01134; PCT/GB92/01755; 국제 특허출원 공개번호 WO90/14443; WO90/14424; WO90/14430; 및 유럽 특허 공개번호 EP 229246]에 기재된 것과 같은(이에 한정되지 않음) 임의의 알려진 방법을 사용하여 수행될 수 있으며, 각각의 문헌은 그 안에 인용된 참고문헌을 포함하여 전체가 본원에 참조로 포함된다.
항-B7H4 인간화 항체 및 이의 항원 결합 단편은 내인성 면역글로불린의 부재 하에 면역화시 인간 항체의 전체 레퍼토리를 생성할 수 있는 인간 면역글로불린 유전자좌를 포함하는 유전자이식 마우스에서도 제조될 수 있다. 이 접근법은 미국 특허번호 5,545,807; 5,545,806; 5,569,825; 5,625,126; 5,633,425; 및 5,661,016에 기술되어 있다.
일 구현예에서, 항체(예를 들어, 항-B7H4 항체)의 단편(예를 들어, 항체 단편)이 제공된다. 항체 단편 생성을 위한 다양한 기술이 알려져 있다. 통상적으로, 이러한 단편은 예를 들어 문헌[Morimoto et al., J. Biochem. Biophys. Meth. 24:107-117 (1993) 및 Brennan et al., Science 229:81 (1985)]에 기술된 바와 같이, 온전한 항체의 단백질 분해를 통해 파생된다. 일 구현예에서, 항-B7H4 항체 단편은 재조합적으로 생성된다. Fab, Fv, 및 scFv 항체 단편은 모두 대장균 또는 다른 숙주 세포에서 발현되어 분비될 수 있으므로, 이러한 단편의 대량 생산이 가능하다. 이러한 항-B7-H4 항체 단편은 상기 논의된 항체 파지 라이브러리로부터 단리될 수도 있다. 이러한 항-B7-H4 항체 단편은 미국 특허번호 5,641,870에 기재된 바와 같이 선형 항체일 수도 있다. 항체 단편의 생성을 위한 다른 기술은 당업자에게 명백할 것이다.
본 발명에 따르면, B7-H4에 특이적인 단일쇄 항체 생성을 위한 기술이 채택될 수 있다(예를 들어, 미국 특허번호 4,946,778 참조). 또한, B7-H4에 대한 원하는 특이성을 갖는 단일클론 Fab 단편, 또는 이의 유도체, 단편, 유사체, 또는 상동체의 신속하고 효과적인 확인을 가능하게 하기 위해 Fab 발현 라이브러리를 구성하는 방법이 채택될 수 있다. 예를 들어, 문헌[Huse et al., Science 246:1275-1281 (1989)] 참조. 항체 분자의 펩신 분해에 의해 생성되는 F(ab')2 단편; F(ab')2 단편의 이황화 가교를 환원시켜 생성되는 Fab 단편; 항체 분자를 파파인 및 환원제로 처리하여 생성되는 Fab 단편; 또는 Fv 단편을 포함하는(이에 한정되지 않음) 항체 단편이 당업계에 알려진 기술에 의해 생성될 수 있다.
일 구현예에서, 본원에 기재된 항체 또는 이의 항원 결합 단편은 혈청 반감기를 증가시키기 위해 변형될 수 있다. 이는 예를 들어 회수(salvage) 수용체 결합 에피토프를 항체 또는 항체 단편에 통합함으로써, 항체 또는 항체 단편의 적절한 영역의 돌연변이에 의해, 또는 에피토프를 펩티드 태그에 통합한 후 말단 또는 중간에서 항체 또는 항체 단편에 융합시킴으로써(예를 들어, DNA 또는 펩티드 합성에 의해), 또는 YTE 돌연변이에 의해 달성될 수 있다. 항체 또는 이의 항원 결합 단편의 혈청 반감기를 증가시키는 다른 방법, 예를 들어 PEG와 같은 이종 분자에 대한 접합은 당업계에 알려져 있다.
본원에 제공된 바와 같은 변형된 항체 또는 이의 항원 결합 단편은 항체 또는 폴리펩티드와 B7-H4의 회합을 제공하는 임의의 유형의 가변 영역을 포함할 수 있다. 이와 관련하여, 가변 영역은 체액성 반응을 일으키고 원하는 항원에 대한 면역글로불린을 생성하도록 유도될 수 있는 포유동물의 임의의 유형을 포함하거나 이로부터 유래될 수 있다. 이와 같이, 항-B7H4 항체 또는 이의 항원 결합 단편의 가변 영역은 예를 들어 인간, 뮤린, 비인간 영장류(예를 들어, 시노몰구스 원숭이, 마카크 등), 또는 이리 기원의 것일 수 있다. 일 구현예에서, 변형된 항체 또는 이의 항원 결합 단편의 가변 영역 및 불변 영역은 둘 다 인간이다. 일 구현예에서, 적합한 항체의 가변 영역(일반적으로 비인간 공급원으로부터 유래)은 분자의 결합 특성을 개선하거나 면역원성을 감소시키도록 조작되거나 특이적으로 조정될 수 있다. 이와 관련하여, 본 발명에 유용한 가변 영역은 유입된 아미노산 서열의 포함을 통해 인간화되거나 달리 변경될 수 있다.
일 구현예에서, 항체 또는 이의 항원 결합 단편의 중쇄 및 경쇄 둘 다의 가변 도메인은 하나 이상의 CDR의 적어도 부분적인 대체 및/또는 부분적인 프레임워크 영역 대체 및 서열 바꿈에 의해 변경된다. 프레임워크 영역이 유래된 항체와 동일한 부류 또는 심지어 하위 부류의 항체로부터 CDR이 유래될 수 있지만, CDR은 상이한 부류의 항체로부터, 특정 구현예에서는 상이한 종의 항체로부터 유래될 것으로 예상된다. 한 가변 도메인의 항원 결합 능력을 다른 가변 도메인으로 전달하기 위해 모든 CDR을 공여체 가변 영역의 완전한 CDR로 대체할 필요는 없다. 오히려, 항원 결합 부위의 활성을 유지하는 데 필요한 잔기를 옮기는 것만이 필요하다. 미국 특허번호 5,585,089, 5,693,761, 및 5,693,762에 기재된 설명을 고려하면, 통상적인 실험을 수행하여 면역원성이 감소된 기능적 항체를 얻는 것은 당업자의 능력 범위 내에 해당할 것이다.
가변 영역에 대한 변경에도 불구하고, 당업자는 본원에 기재된 변형된 항체 또는 이의 항원 결합 단편이, 천연 또는 변경되지 않은 불변 영역을 포함하는 거의 동일한 면역원성의 항체와 비교하여 증가된 종양 국소화 또는 감소된 혈청 반감기와 같은 원하는 생화학적 특성을 제공하도록 하나 이상의 불변 영역 도메인의 적어도 일부가 결실되거나 달리 변경된 항체(예를 들어, 전장 항체 또는 이의 항원 결합 단편)를 포함할 것임을 인식할 것이다. 일 구현예에서, 변형된 항체의 불변 영역은 인간 불변 영역을 포함할 것이다. 본 발명에 적합한 불변 영역에 대한 변형은 하나 이상의 도메인에서의 하나 이상의 아미노산의 부가, 결실, 또는 치환을 포함한다. 즉, 본원에 개시된 변형된 항체는 3개의 중쇄 불변 도메인(CH1, CH2, 또는 CH3) 중 하나 이상 및/또는 경쇄 불변 도메인(CL)에 대한 변경 또는 변형을 포함할 수 있다. 일 구현예에서, 하나 이상의 도메인이 부분적으로 또는 전체적으로 결실된 변형된 불변 영역이 고려된다. 일 구현예에서, 변형된 항체는 전체 CH2 도메인이 제거된 도메인 결실 구성체 또는 변이체(ΔCH2 구성체)를 포함할 것이다. 일 구현예에서, 생략된 불변 영역 도메인은 부재 불변 영역에 의해 전형적으로 부여되는 분자 유연성의 일부를 제공하는 짧은 아미노산 스페이서(예를 들어, 10개의 잔기)에 의해 대체될 수 있다.
이들의 구성 외에도, 불변 영역이 여러 이펙터 기능을 매개한다는 것이 당업계에 알려져 있다. 예를 들어, 항체는 Fc 영역을 통해 세포에 결합하며, 항체 Fc 영역 상의 Fc 수용체 부위가 세포 상의 Fc 수용체(FcR)에 결합한다. IgG(감마 수용체), IgE(에타 수용체), IgA(알파 수용체), 및 IgM(뮤 수용체)를 비롯한 다양한 부류의 항체에 특이적인 Fc 수용체가 다수 존재한다. 세포 표면의 Fc 수용체에 대한 항체의 결합은 항체-코팅 입자의 포식 및 파괴, 면역 복합체의 제거, 킬러 세포에 의한 항체-코팅 표적 세포의 용해(항체 의존적 세포매개 세포독성 또는 ADCC라고 함), 염증 매개자의 방출, 태반 통과, 및 면역글로불린 생성 제어를 포함한 다수의 중요하고 다양한 생물학적 반응을 유발한다.
일 구현예에서, 항체 또는 이의 항원 결합 단편은 투여된 항체 또는 이의 항원 결합 단편의 생물학적 프로파일에 결과적으로 영향을 미치는 변경된 이펙터 기능을 제공한다. 예를 들어, 불변 영역 도메인의 (점 돌연변이 또는 다른 수단을 통한) 결실 또는 비활성화는 순환하는 변형된 항체의 Fc 수용체 결합을 감소시킬 수 있다. 다른 경우에, 본 발명과 일치하는 불변 영역 변형은 보체 결합을 완화시켜, 접합된 세포독소의 혈청 반감기 및 비특이적 회합을 감소시킬 수 있다. 항원 특이성 또는 항체 유연성의 증가로 인해 향상된 국소화를 가능하게 하는 이황화 결합 또는 올리고당 모이어티를 제거하기 위한 불변 영역의 또 다른 변형이 사용될 수 있다. 유사하게, 본 발명에 따른 불변 영역에 대한 변형은 당업자의 견지에서 잘 알려진 생화학 또는 분자 공학 기술을 사용하여 용이하게 이루어질 수 있다.
일 구현예에서, 항체 또는 이의 항원 결합 단편은 하나 이상의 이펙터 기능을 갖지 않는다. 예를 들어, 일 구현예에서, 항체 또는 이의 항원 결합 단편은 항체 의존적 세포매개 세포독성(ADCC) 활성 및/또는 보체 의존적 세포독성(CDC) 활성을 갖지 않는다. 일 구현예에서, 항체 또는 이의 항원 결합 단편은 Fc 수용체 및/또는 보체 인자와 결합하지 않는다. 일 구현예에서, 항체 또는 이의 항원 결합 단편은 이펙터 기능을 갖지 않는다.
일 구현예에서, 항체 또는 이의 항원 결합 단편은 각각의 변형된 항체 또는 이의 단편의 힌지 영역에 CH3 도메인을 직접 융합하도록 조작될 수 있다. 다른 구성체에서, 힌지 영역과 변형된 CH2 및/또는 CH3 도메인 사이에 펩티드 스페이서가 삽입될 수 있다. 예를 들어, CH2 도메인이 결실되고 나머지 CH3 도메인(변형 또는 비변형)이 5~20개의 아미노산 스페이서를 사용하여 힌지 영역에 연결된 적합한 구성체가 발현될 수 있다. 이러한 스페이서는 예를 들어 불변 도메인의 조절 요소가 자유롭고 접근가능한 상태로 유지되도록 하기 위해 또는 힌지 영역이 유연한 상태로 유지되도록 하기 위해 추가될 수 있다. 아미노산 스페이서는 경우에 따라 면역원성이어서 구성체에 대해 원치 않는 면역 반응을 유도할 수 있는 것으로 입증될 수 있다. 일 구현예에서, 구성체에 추가되는 임의의 스페이서는 상대적으로 비면역원성이거나 심지어 전부 생략되어, 변형된 항체의 원하는 생화학적 성질을 유지할 수 있다.
전체 불변 영역 도메인의 결실 외에도, 본원에 제공된 항체 또는 이의 항원 결합 단편은 불변 영역의 일부 아미노산 또는 심지어 단일 아미노산의 부분적 결실 또는 치환에 의해 변형될 수 있다. 예를 들어, CH2 도메인의 선택된 영역의 단일 아미노산의 돌연변이는 Fc 결합을 실질적으로 감소시켜 종양 국소화를 증가시키기에 충분할 수 있다. 유사하게, 이펙터 기능(예를 들어, 보체 C1Q 결합)을 제어하는 하나 이상의 불변 영역 도메인이 완전히 또는 부분적으로 결실될 수 있다. 불변 영역의 이러한 부분적 결실은 대상 불변 영역 도메인과 관련된 다른 바람직한 기능을 온전하게 남겨두면서 항체 또는 이의 항원 결합 단편의 선택된 특징(예를 들어, 혈청 반감기)을 개선할 수 있다. 또한, 항체 및 이의 항원 결합 단편의 불변 영역은 생성된 구성체의 프로파일을 향상시키는 하나 이상의 아미노산의 돌연변이 또는 치환을 통해 변형될 수 있다. 이와 관련하여, 변형된 항체 또는 이의 항원 결합 단편의 구성 및 면역원성 프로파일을 실질적으로 유지하면서, 보존된 결합 부위(예를 들어, Fc 결합)에 의해 제공되는 활성을 파괴하는 것이 가능하다. 일 구현예에서, 이펙터 기능의 감소 또는 증가와 같은 바람직한 특성을 향상시키기 위해 또는 더 많은 세포독소 또는 탄수화물 부착을 제공하기 위해 불변 영역에 하나 이상의 아미노산이 추가될 수 있다. 일 구현예에서, 선택된 불변 영역 도메인으로부터 유래된 특정 서열을 삽입하거나 복제하는 것이 바람직할 수 있다.
본원에 기재된 항체 및 항체 결합 단편은 또한 본원에 구체적으로 기재된 항체 또는 항원 결합 단편(예를 들어, 뮤린, 키메라, 인간화 또는 인간 항체, 또는 이의 항원 결합 단편)과 실질적으로 상동성인 변이체 및 등가물을 포함한다. 이들은 예를 들어 보존적 치환 돌연변이, 즉 유사한 아미노산에 의한 하나 이상의 아미노산의 치환을 포함할 수 있다. 예를 들어, 보존적 치환은 아미노산을 동일한 일반 부류 내의 다른 아미노산으로 치환하는 것, 예를 들어 하나의 산성 아미노산을 다른 산성 아미노산으로, 하나의 염기성 아미노산을 다른 염기성 아미노산으로, 또는 하나의 중성 아미노산을 다른 중성 아미노산으로 치환하는 것을 의미한다. 보존적 아미노산 치환이 의도하는 바는 당업계에 잘 알려져 있다.
일 구현예에서, 항체 또는 이의 항원 결합 단편은 보통은 단백질의 일부가 아닌 추가적인 화학 모이어티를 포함하도록 추가로 변형될 수 있다. 이러한 유도체화된 모이어티는 단백질의 용해도, 생물학적 반감기, 또는 흡수를 향상시킬 수 있다. 모이어티는 또한 단백질 등의 임의의 바람직한 부작용을 감소시키거나 제거할 수 있다. 이러한 모이어티에 대한 개요는 문헌[Remington's Pharmaceutical Sciences, 22nd ed., Ed. Lloyd V. Allen, Jr. (2012)]에서 확인할 수 있다.
VIII. 항-B7H4 항체-약물 접합체의 용도.
바람직하게는, 접합체는 증식성 질환을 치료하기 위해 사용될 수 있다. 용어 "증식성 질환"은 시험관내에서든 생체내에서든, 신생물 또는 과형성 성장과 같은 바람직하지 않은 과도하거나 비정상적인 세포의 원치 않는 또는 제어되지 않는 세포 증식에 관한 것이다. 용어 "증식성 질환"은 대안적으로 "암"으로 지칭될 수 있다.
적합한 증식성 질환(예를 들어, 암)은 바람직하게는 B7-H4를 발현하는 암성 세포의 존재를 특징으로 할 것이다.
증식성 병태의 예는 신생물 및 종양(예를 들어, 조직구종, 신경아교종, 성상세포종, 골종), 암(예를 들어, 폐암, 소세포폐암, 위장암, 장암, 결장암, 유방 암종, 난소 암종, 전립선암, 고환암, 간암, 신장암, 방광암, 췌장암, 뇌암, 육종, 골육종, 카포시 육종, 흑색종), 백혈병, 건선, 골 질환, 섬유증식성 장애(예를 들어, 결합 조직 장애), 및 죽상경화증을 포함하는(이에 한정되지 않음) 양성, 전악성, 및 악성 세포 증식을 포함하나 이에 한정되지 않는다. 관심 대상의 다른 암은 혈액암; 악성종양, 예컨대 백혈병 및 림프종, 예컨대 비호지킨 림프종, 및 하위 유형, 예컨대 DLBCL, 변연부, 외투층, 및 여포성, 호지킨 림프종, AML, 및 B 또는 T 세포 기원의 다른 암을 포함하나 이에 한정되지 않는다. 폐, 위장(예를 들어, 장, 결장을 포함), 유방(유방 관련), 난소, 전립선, 간(간 관련), 신장(신장 관련), 방광, 췌장, 뇌, 및 피부를 포함하나 이에 한정되지 않는 임의의 유형의 세포가 치료될 수 있다.
일부 구현예에서, 본원에 기재된 항체-약물 접합체는 유방암, 난소암, 자궁내막암, 담관암종, 폐암, 췌장암, 및 위암을 포함하는 목록으로부터 선택되는 암을 치료하는 데 사용된다. 일부 구현예에서, 본원에 기재된 항체-약물 접합체는 유방암, 난소암, 자궁내막암, 및 담관암종을 포함하는 목록으로부터 선택되는 암을 치료하는 데 사용된다. 일부 구현예에서, 유방암은 호르몬 수용체 양성(HR+) 유방암이다. 일부 구현예에서, 유방암은 인간 표피 성장 인자 수용체 2 양성(HER2+) 유방암이다. 다른 구현예에서, 유방암은 삼중음성 유방암(TNBC)이다. 일부 구현예에서, 폐암은 비소세포폐암(NSCLC)이다. 일부 구현예에서, NSCLC는 편평세포 암종이다. 다른 구현예에서, NSCLC는 선암종이다.
본 발명의 항체-약물 접합체는 암세포의 성장을 지연시키고 증식을 억제하며 암세포를 더욱 파괴할 수 있다. 이러한 작용은 암으로 인한 증상의 완화, 암 환자의 삶의 질(QOL) 향상을 달성하고, 암 환자의 생명을 보존하여 치료 효과를 얻을 수 있다. 암세포의 파괴로 이어지지 않더라도, 암세포 증식의 억제 또는 제어는 암 환자에서 더 높은 QOL을 달성할 뿐만 아니라 더 긴 기간의 생존을 달성할 수 있다.
본 발명의 항-H7B4 ADC는 환자에게 전신 요법으로 적용하고, 추가적으로 암 조직에 국소 적용함으로써 치료 효과를 발휘할 것으로 기대할 수 있다.
항-H7B4 ADC는 하나 이상의 약학적으로 적합한 성분이 함유된 약학적 조성물로서 투여될 수 있다. 약학적으로 적합한 성분은 항-H7B4 ADC의 투여량, 투여 농도 등을 고려하여 당업계에서 일반적으로 사용되는 제형 첨가제 등으로부터 적절히 선택될 수 있다. 예를 들어, 본 발명에서 사용되는 항-H7B4 ADC는 히스티딘 완충제와 같은 완충제, 수크로스와 같은 부형제, 및 폴리소르베이트 80과 같은 계면활성제를 함유하는 약학적 조성물로서 투여될 수 있다. 본 발명에서 사용되는 항-H7B4 ADC를 함유하는 약학적 조성물은 주사제로, 수성 주사제 또는 동결건조 주사제로, 또는 심지어 동결건조 주사제로도 사용될 수 있다.
본 발명에서 사용되는 항-H7B4 ADC를 함유하는 약학적 조성물이 수성 주사제인 경우, 적합한 희석제로 희석한 후 정맥내 주입으로 투여할 수 있다. 희석제의 예는 덱스트로스 용액 및 생리 식염수를 포함할 수 있다.
본 발명에서 사용되는 항-H7B4 항체-약물 접합체를 함유하는 약학적 조성물이 동결건조 주사제인 경우, 주사용수에 용해시킨 후 적합한 희석제로 필요한 양만큼 희석한 후 정맥내 주입으로 투여할 수 있다. 희석제의 예는 덱스트로스 용액 및 생리 식염수를 포함한다.
본원에 기재된 약학적 조성물을 투여하기 위해 사용될 수 있는 투여 경로의 예는 정맥내, 피내, 피하, 근육내, 및 복강내 경로를 포함할 수 있다.
IX. 항-B7H4 항체-약물 접합체에 대한 환자 반응을 예측하는 방법.
도 14는 분석 시스템이 암 환자 조직의 디지털 이미지를 분석하고 항-B7H4 항체-약물 접합체(ADC)를 수반하는 요법에 암 환자가 어떻게 반응할지 예측하는 방법(7)의 단계 1~6의 순서도이다. 일 구현예에서, 상기 방법은 유방암, 난소암, 자궁내막암, 담관암종, 폐암, 췌장암, 및 위암으로 이루어진 군으로부터 선택되는 암을 갖는 환자의 ADC에 대한 반응을 예측한다. 일 구현예에서, 상기 방법은 유방암, 난소암, 자궁내막암, 및 담관암종으로 이루어진 군으로부터 선택되는 암을 갖는 환자의 ADC에 대한 반응을 예측한다. 일 구현예에서, 상기 방법은 유방암 환자의 ADC에 대한 반응을 예측한다. 일 구현예에서, 상기 방법은 난소암 환자의 ADC에 대한 반응을 예측한다. 일 구현예에서, 상기 방법은 자궁내막암 환자의 ADC 반응을 예측한다.
첫 번째 단계 1에서, 하나 이상의 바이오마커 또는 염색을 사용하여 염색된 암 환자의 조직 절편의 고해상도 디지털 이미지를 획득한다.
ADC 요법의 효능을 예측하기 위해, ADC 요법의 표적 단백질과 동일한 단백질을 표적화하는 염료가 부착된 진단 바이오마커가 사용된다. 일 구현예에서, 점수산정 대상인 항-B7H4 ADC 요법은 토포이소머라제 I 억제제에 접합된 항-B7H4 항체이다. 일 구현예에서, 항-B7H4 ADC는 다음으로부터 선택되는 토포이소머라제 I 억제제에 접합된 항-B7H4 항체를 포함한다:




일 구현예에서, 항-B7H4 ADC는 하기 구조로 표시되는, 토포이소머라제 억제제 SG3932에 접합된 항-B7H4 항체를 포함한다:

따라서, 구현예에서, 진단 바이오마커는 또한 B7-H4 단백질을 표적화한다.
단계 2에서, 미리 학습된 컨벌루션 뉴럴 네트워크가 3,3'-디아미노벤지딘(DAB)과 같은 염료에 연결된 진단 항체로 염색된 암 환자의 조직의 디지털 이미지를 처리한다. 암세포의 막에서의 염료의 염색 강도는 상응하는 분할된 막 객체와 관련된 모든 픽셀의 염료의 평균 염색 강도를 기반으로 결정된다. 또한, 단일 픽셀에서 염료의 염색 강도는 픽셀의 적색, 녹색, 및 청색 구성요소를 기반으로 계산된다. 이미지 분석 처리의 결과는 디지털 이미지의 각 픽셀에 대해 픽셀이 세포핵에 속할 확률과 픽셀이 세포막에 속할 확률을 나타내는 2개의 사후 이미지 레이어이다.
단계 2의 다른 구현예에서, 2개의 미리 학습된 컨벌루션 네트워크가 조직의 디지털 이미지를 처리한다. 제1 네트워크에 의한 처리의 결과는 디지털 이미지의 각 픽셀에 대해 픽셀이 세포핵에 속할 가능성을 나타내는 사후 이미지 레이어이다. 제2 네트워크에 의한 처리의 결과는 디지털 이미지의 각 픽셀에 대해 픽셀이 세포막에 속할 가능성을 나타내는 사후 이미지 레이어이다.
단계 3에서, 핵 및 막에 대한 사후 레이어의 휴리스틱 이미지 분석을 기반으로 개별 암세포를 검출한다. 세포막 객체 및 임의로 또한 세포질 객체를 포함하는 암세포 객체가 생성된다.
단계 4에서, 각각의 암세포에 대해 단일세포 ADC 점수를 결정한다. 단일세포 ADC 점수는 (1) 세포막의 DAB 양, 및 (2) ADC 페이로드 흡수량을 기반으로 한다. DAB의 양은 막의 픽셀에서 갈색 디아미노벤지딘(DAB) 신호의 평균 광학 밀도를 기반으로 각각의 막의 염색 강도에 의해 결정된다. ADC 페이로드 흡수량은 세포막의 DAB 양 및 임의로 또한 세포질의 DAB 양을 기반으로, 추가로 임의로 또한 점수가 결정되는 세포에 인접한 세포의 막과 세포질의 DAB 양을 기반으로 추정된다. 세포질의 DAB 양은 세포질의 픽셀에서 갈색 DAB 신호의 평균 광학 밀도를 기반으로 계산되는 각각의 세포질의 염색 강도에 의해 결정된다. 인접 세포의 DAB 양은 점수가 결정되는 세포의 미리 정의된 거리 내의 암세포에 대해 결정된다.
단계 5에서, 디지털 이미지의 모든 암세포의 단일세포 ADC 점수에 대한 통계 연산을 기반으로 조직의 디지털 이미지에 대한 환자 점수를 계산한다. 환자 점수는 항-B7H4 ADC를 수반하는 요법에 암 환자가 어떻게 반응할지를 나타낸다. 단계 4의 단일세포 ADC 점수의 매개변수 및 단계 5의 통계 연산 유형은 ADC 요법에 대한 반응이 알려진 학습 환자 코호트를 사용하여 최적화된다. 최적화 목표는 학습 코호트에서 점수-양성 환자 대 점수-음성 환자 그룹의 Kaplan Meier 분석에서 낮은 p-값이다.
단계 6에서, 점수가 소정의 임계값보다 큰 경우, 점수-양성 환자에게 항-B7H4 ADC를 수반하는 요법을 권장한다.
X. 예측 및 점수산정 방법의 예.
A. 염색된 조직의 이미지 분석.
이제 도 14의 방법을 염색된 암 조직의 특정 이미지와 관련하여 설명한다.
단계 1에서, 조직 샘플의 암세포 상의 관련 단백질에 결합하는 진단 항체에 연결된 염료를 사용하여 조직 샘플을 면역조직화학적으로 염색한다. 도 15(좌측 상단 이미지)는 단계 1에서 획득된 염색된 조직의 일부의 디지털 이미지(8)이다. 이미지(8)는 염료에 연결된 항-B7H4 진단 항체로 면역조직화학적으로 염색된 암 환자의 조직을 보여준다. 이 예에서, 진단 항체는 마우스 항-인간 B7H4 IgG1 클론으로 재포맷된 항-B7H4 생성 클론(B7H4 IHC 도구 Ab로 표시)이다. IgG1은 항-B7H4 항체의 이소형을 나타낸다. 염색 프로토콜은 Dako Autostainer 플랫폼을 사용하여 개발하였다. 항-B7H4 항체는 막 단백질 B7-H4에 결합하여 3,3'-디아미노벤지딘(DAB) 염색이 조직 샘플에서 단백질 B7-H4의 위치를 나타낸다.
단계 2에서, 컨벌루션 뉴럴 네트워크를 사용하여 암세포 핵과 막의 사후 이미지 레이어를 생성하기 위해 디지털 이미지(8)에 대해 이미지 분석을 수행한다. 이미지 분석을 사용하여 암세포 및 그 구성요소, 예컨대 핵, 막, 및 세포질을 검출한다. 도 15는 단계 2의 이미지 분석 프로세스를 예시한다. 컨벌루션 뉴럴 네트워크는 디지털 이미지(8)의 각 픽셀에 대해 각 픽셀이 세포의 핵(도 15, 우측 상단 이미지) 및 막(도 15, 좌측 하단 이미지)에 속할 확률을 나타내는 사후 레이어(회색 값 이미지)를 생성한다. 높은 확률은 검은색으로, 낮은 확률은 흰색으로 표시된다.
일 구현예에서, 컨벌루션 뉴럴 네트워크는 입력 이미지(8)로부터의 매우 작은 공간 크기(1 내지 16 픽셀)의 병목 레이어를 향한 일련의 컨벌루션 레이어, 및 입력 이미지(8)와 동일한 크기의 사후 레이어를 향한 일련의 디컨벌루션 레이어를 포함한다. 이러한 네트워크 구조를 U-Net라고 한다. 컨벌루션 뉴럴 네트워크의 가중치 학습은 여러 학습 이미지의 핵과 막에 대한 수동 주석 레이어를 생성한 다음, 생성된 사후 레이어가 수동 생성 주석 레이어와 가장 유사하도록 네트워크 가중치를 최적화 알고리즘으로 조정하여 수행된다.
다른 구현예에서, 핵과 막에 대한 주석 레이어는 자동으로 생성되며 여러 학습 이미지에서 수동으로 수정된다. 상피 영역과 핵 중심은 수동으로 각각 영역과 점으로 주석 처리된다. 각각의 학습 이미지에 대해, 막 분할은 주석이 달린 핵 중심에 의해 시드되고 주석이 달린 상피 영역의 범위에 의해 제한되는 영역 성장-유사 알고리즘(예를 들어, 유역 분할)을 적용하여 자동으로 생성된다. 학습 이미지가 주어지면, 핵 분할은 블럽(blob) 검출 알고리즘(예를 들어, 최대 안정 극단 영역 MSER 알고리즘)을 적용하고 주석이 달린 핵 중심을 포함하는 검출된 블럽만 핵으로 선택하여 자동으로 생성된다. 자동으로 생성된 막 및 핵 분할은 시각적으로 검토되고 필요한 경우 수동으로 수정된다. 수정 단계는 다음 방법 중 하나를 수반한다: 부정확하게 분할된 막 또는 핵의 거부, 정확하게 주석이 달린 막 또는 핵의 명시적 수용, 또는 막 또는 핵 형상의 수정. 주석이 달린 막 또는 핵이 있는 각각의 이미지의 경우, 주석 레이어가 생성된다. 일 구현예에서, 주석 레이어의 각 픽셀은 주석이 달린 객체(막 또는 핵)에 속하는 경우 "1"이 할당되고, 그렇지 않을 경우 "0"이 할당된다. 다른 구현예에서, 주석 레이어의 픽셀은 주석이 달린 가장 가까운 객체까지의 거리를 나타낸다. 네트워크 가중치는 생성된 사후 레이어가 자동으로 생성된 막 및 핵 주석 레이어와 가장 유사하도록 최적화 알고리즘에 의해 조정된다.
도 16은 각각 세포막 및 세포질을 포함하는 개별 암세포 객체를 검출하는 단계 3을 예시한다. 휴리스틱 이미지 분석 프로세스는 컨벌루션 뉴럴 네트워크에 의해 생성된 핵 사후 레이어를 사용하여 세포핵을 분할하기 위해 유역 분할을 사용한다. 분할은 핵 객체를 생성한다. 각각의 핵 객체에는 고유 식별자(UID)가 할당된다. 개별적으로 식별된 핵은 도 16(우측 하단 이미지)에서 어두운 객체로 표시되어 있다. 검출된 핵은 또한 입력 이미지(8)(좌측 상단 이미지)에서 그리고 핵(우측 상단 이미지) 및 막(좌측 하단 이미지)에 대한 사후 레이어에서 오버레이로 표시되어 있다.
일 구현예에서, 유역 분할은 미리 정의된 제1 크기 임계값을 사용한 핵 사후 레이어의 이진화(thresholding)를 수반한다. 제1 크기 임계값을 초과하는 모든 단일 연결 픽셀은 핵 객체에 속하는 것으로 간주된다. 면적이 16 um^2보다 작은 핵 객체는 폐기된다. 각각의 핵 객체에 UID가 할당된다. 후속 단계에서, 핵 객체는 더 작은 사후 핵을 향해 성장하며, 추가된 핵 사후 픽셀은 미리 정의된 제2 임계값보다 커야 한다.
도 17은 핵 객체를 사용하여 막의 분할을 검출하고 개선하는 추가 분할 단계를 예시한다. 영역 성장 알고리즘은 검출된 핵 객체를 시드로 사용하여 막 사후 레이어에서 막의 능선(대략 세포 경계)까지 성장시킨다. 검출된 막(우측 하단 이미지)은 입력 이미지(8)(좌측 상단 이미지)에서 그리고 핵(우측 상단 이미지) 및 막(좌측 하단 이미지)에 대한 사후 레이어에서 오버레이로 표시되어 있다.
도 18은 검출된 세포의 경계 픽셀 영역을 바깥쪽으로 막 확률 레이어까지 그리고 미리 정의된 막 레이어 사후 임계값까지 성장시켜 분할되는 막 객체의 검출 및 분할을 예시한다. 더 두꺼운 경계 영역이 막 객체가 된다. 각각의 막 객체에는 관련된 핵 객체와 동일한 UID가 할당된다.
막과 핵 사이의 공간은 핵의 UID를 사용하여 세포질로 할당된다. 각각의 막(도 18 좌측 상단 이미지 참조) 및 세포질(도 18 좌측 상단 이미지 참조)에 대해, DAB 염색의 평균 광학 밀도는 UID와 함께 하드 드라이브의 파일로 내보내진다. (핵, 세포질, 및 막을 포함하는 것으로 정의된) 각각의 세포에 대해, 슬라이드 내 세포의 무게 중심(x,y)의 위치도 내보내진다. 파일은 컴퓨터 시스템의 하드 디스크, 솔리드 스테이트 디스크, 또는 전용 RAM 부분에 상주할 수 있다.
도 19는 이미지 분석 소프트웨어 환경에서 이미지 분석의 결과를 예시한다. 도 19(좌측 상단 이미지)는 염색된 조직의 디지털 이미지에 오버레이로 핵 객체와 막 객체의 분할을 보여준다. 도 19(좌측 하단 이미지)는 디지털 이미지의 광학 밀도 표현에 오버레이로 핵 객체의 분할을 보여준다. 어두운 광학 밀도 픽셀은 많은 양의 DAB와 관련되고, 밝은 광학 밀도 픽셀은 적은 양의 DAB와 관련된다. 각 이미지 픽셀의 DAB 광학 밀도는 갈색 DAB 구성요소가 독립적인 색상이 되도록 적녹청 색 공간을 변환하고 해당 갈색 구성요소의 로그를 취함으로써 이미지 픽셀의 적녹청 표현으로부터 계산된다. 도 19(우측 상단 이미지) 및 도 20(상단)은 Definiens Developer XD 플랫폼 내에서 분할된 이미지를 생성하는 데 사용되는 이미지 분석 스크립트를 보여준다. 도 19(우측 하단 이미지) 및 도 20(하단)은 이미지(8)의 모든 세포막 객체 및 세포질 객체에 대해 내보내진 측정값을 보여준다.
B. 예측 ADC 점수의 계산.
막 객체 및 임의로 세포질 객체 내의 DAB 염색의 광학 밀도를 기반으로, 디지털 이미지(8)의 각 암세포에 대해 단일세포 ADC 점수가 계산된다. 단일세포 ADC 점수는 또한 임의로, 미리 정의된 거리보다 단일세포 ADC 점수가 계산되는 암세포에 더 가까운 인접 암세포의 막 객체 및 세포질 객체에서의 DAB 염료의 염색 강도를 기반으로 한다. 단일세포 ADC 점수의 집계는 항-B7H4 ADC 요법에 대한 암 환자의 반응을 예측한다.
도 21은 막 및 세포질 픽셀의 회색 값을 사용한 개략도로 단계 2~3의 이미지 분석으로부터의 염색 광학 밀도의 예시적인 정량적 결과를 예시한다. 도 15 내지 20에 예시된 휴리스틱 이미지 분석 단계를 사용하여 도 21의 세포핵, 세포막, 및 세포질로의 예시적인 분할을 얻는다. 도 21의 밝은 회색 값은 높은 DAB 광학 밀도와 관련이 있으므로, 진단 항체에 의해 표적화된 많은 양의 단백질과 관련이 있다. 어두운 회색 값은 낮은 DAB 광학 밀도와 관련된다. 더 밝은 픽셀은 더 높은 DAB 광학 밀도에 해당한다.
도 22는 도 22에 부분적으로 재현된 도 21 이미지의 막 및 세포질에서의 예시적인 정량적 염색량을 보여준다. 제1, 제2, 및 제3 세포의 막으로부터의 갈색 DAB 신호의 광학 밀도는 각각 0.949, 0.369, 및 0.498이다. 제1, 제2, 및 제3 세포의 세포질로부터의 갈색 DAB 신호의 광학 밀도는 각각 0.796, 0.533, 및 0.369이다. 도 22의 개략도에서, 제1 암세포(9)는 많은 양의 표적 단백질 B7-H4를 발현하며, ADC 항체에 연결된 세포로 유입되는 ADC 페이로드에 의해 사멸될 가능성이 매우 높다(도 23의 효과 1). 제2 암세포(10) 및 제3 암세포(11)는 항-B7H4 ADC에 의해 직접 사멸될 정도의 충분한 양의 표적 단백질 B7-H4를 발현하지 않는다. 그러나, 제2 암세포(10)가 제1 암세포(9) 근처에 있기 때문에, 제1 암세포로부터 방출되는 독성 페이로드가 제2 암세포(10)도 사멸시킬 것이다(도 23의 효과 3). 제3 암세포(11)는 활성 상태를 유지하고 약물 내성 메커니즘의 기원이 될 수 있으며, 이는 결국 환자의 사망을 초래할 수 있다.
도 23은 항-B7H4 ADC 요법이 암세포를 사멸시키는 메커니즘을 예시한다. 제1 단계에서, ADC 항체는 표적 단백질 B7-H4에 결합하고 표적 단백질의 자연적 기능을 억제하여, 세포 사멸을 유발할 수 있다. 제2 단계에서, 페이로드(예를 들어, 유형 I 토포이소머라제 억제제)가 세포에 내재화되고 페이로드의 독성으로 세포를 사멸시킨다. 페이로드의 이러한 흡수는 막에 있는 표적 단백질의 양에 따라, 그리고 막과 세포질에 있는 표적 단백질의 양의 차이에 따라 달라진다. 흡수 후, 페이로드는 세포로부터 주변 조직으로 방출될 수 있다. 제3 단계에서, 페이로드는 근처의 세포로 들어가 세포를 사멸시킬 수도 있다. 조직에서 페이로드의 공간적 분포는 수동 확산에 의해 확산된다.
통상적인 IHC 점수산정은 ADC 결합으로 인한 표적 단백질의 억제 효과, 및 ADC 항체와 함께 암세포에 유입되는 세포독성 페이로드의 효과 둘 다를 반영한다. 따라서, ADC 요법에 대한 통상적인 점수산정은 세포질 내 표적 단백질 존재의 중요성 및 사멸된 제1 암세포로부터 방출된 후 조직으로 확산되는 세포독성 페이로드의 효과를 반영하지 않는다. 이에 비해, 신규 예측 ADC 점수는 인접 암세포에 대한 세포독성 페이로드의 방출 효과를 측정한다.
도 14의 방법의 단계 4에서, 각각의 암세포에 대해 단일세포 ADC 점수를 결정한다. 도 24는 도 22에 나타낸 3개의 세포 각각에 대한 단일세포 ADC 점수 계산을 예시하며, ADC 페이로드의 인접 세포로의 흡수를 반영하기 위해 세포 분리에 기반한 지수 가중 계수를 통합한다. 단일세포 점수는 도 25에 나타낸 식 또는 청구항 4에 기재된 식에 기초하여 계산될 수 있다. 도 22에 열거된, 세포막으로부터의 DAB 신호에 대한 광학 밀도(0.949, 0.369, 및 0.498) 및 세포질로부터의 DAB 신호에 대한 광학 밀도(0.796, 0.533, 및 0.369)가 도 24에 예시된 계산에 대한 입력이다. 제1, 제2, 및 제3 세포(9~11)는 각각 0.145, 0.012, 및 0.064의 단일세포 점수를 갖는다.
따라서, 단일세포 ADC 점수는 DAB 광학 밀도를 사용한 세포막에 있는 표적 단백질의 양의 측정 및 임의로 ADC 페이로드 흡수량의 추정을 통합한다. 도 23에 도시된 바와 같이, 제1 세포에 대한 ADC 페이로드의 흡수는 제1 세포의 막과 세포질에서의 염료의 양뿐만 아니라, 제1 세포 근처에 있는 제2 세포의 막과 세포질에서의 염료의 양에 따라 달라진다. 보다 구체적으로, 근처는 제1 암세포 주위의 미리 정의된 반경을 갖는 원형 디스크일 수 있다. 일 구현예에서, 제1 암세포에 대한 단일세포 ADC 점수는 관련 암세포 중심이 미리 정의된 거리보다 제1 암세포 중심에 더 가까운 막 및 세포질 객체의 DAB 광학 밀도의 여러 거듭제곱의 거리 가중 합에 의해 결정된다. 일 구현예에서, 미리 정의된 거리는 도 24의 계산에 사용된 바와 같이 50 um이다. 다른 구현예에서, 거리는 20 um이다. 또 다른 구현예에서, 거리 가중은 제1 암세포 중심으로부터 다른 암세포 중심까지의 스케일링된 음의 유클리드 거리의 지수를 합계에서 계산하는 것을 수반한다. 다른 구현예에서, 합계에서 거듭제곱은 0, 1, 및 2(상수, 선형 항, 제곱)로 제한된다.
도 25는 단일세포 ADC 점수를 계산하기 위한 식의 일 구현예를 보여준다. 식에서 함수 akl은 세포 j에서 세포 i까지의 거리 |rj - ri|에 따라 달라진다. ODMj는 세포 j의 막의 DAB 광학 밀도이고, ODCj는 세포 j의 세포질의 DAB 광학 밀도이다. 상수 A_ij, r_norm, 및 d는 모든 유형의 암에 대해 동일하다. 그러나, 환자가 ADC 요법에 적격인지 여부를 결정하기 위한 점수의 임계값은 서로 다른 유형의 암에 대해 동일하지 않다.
특정 암 환자가 ADC 요법에 어떻게 반응할지를 나타내는 방법의 단계 5에서, 표적 단백질 B7-H4의 염색을 기반으로 암 환자 조직의 디지털 이미지(8)에 대한 반응 점수를 계산하여 점수가 항-B7H4 ADC 요법에 암 환자가 어떻게 반응할지를 나타낸다. 반응 점수는 통계 연산을 사용하여 조직 샘플의 모든 단일세포 ADC 점수를 집계하여 생성된다. 따라서, 점수는 디지털 이미지에서 검출된 모든 암세포에 대한 단일세포 ADC 점수의 통계를 기반으로 계산된다. 일 구현예에서, 통계는 이미지(8)에서 모든 암세포의 ADC 페이로드 흡수 추정치의 미리 정의된 분위수이다.
다른 구현예에서, 단일세포 ADC 점수를 계산하기 위한 식은 각각의 암세포의 염색된 막의 광학 밀도만을 고려하며, 세포질의 염색, 또는 단일세포 ADC 점수가 계산되는 암세포의 소정 거리 내에 다른 암세포가 위치하는지 여부를 고려하지 않는다.
상기 방법의 단계 6에서, 반응 점수가 소정의 임계값보다 큰 경우, 암 환자에게 항-B7H4 ADC 요법을 권장한다. 단계 6의 소정의 임계값 및 단계 5의 분위수는 단일세포 ADC 점수 및 요법 반응 매개변수가 알려진 환자 코호트를 사용하여 양성 예측 값, 음성 예측 값, 및 양성 권장의 출현율을 최적화하여 결정된다.
단계 5의 반응 점수 계산의 또 다른 예에서, 암 환자 조직 샘플의 디지털 이미지를 획득하고 진단 항체(dAB)로 염색한다. 디지털 이미지에 대해 이미지 분석을 수행하여 N개의 암세포(ci) 0≤i<N 를 검출한다. 세포 c i 의 분할된 막에서의 광학 밀도는 OD M i 로 표시되고, 분할된 세포질에서의 광학 밀도는 OD C i 로 표시된다. 디지털 이미지와 관련된 반응 점수 S S 는 항-B7H4 ADC 요법에 암 환자가 반응할 가능성을 나타낸다. ADC는 진단 항체와 동일한 B7-H4 단백질에 특이적으로 결합한다. 반응 점수 S S 는 다음과 같이 표현될 수 있다:
[식 41]
식에서  는 디지털 이미지에서 검출된 일련의 세포에 대한 집계 연산자이다. 집계 연산은 검출된 세포와 관련된 양성 값 p(c i )를 나타내는 단일 숫자이다. 하나의 예에서, 집계 연산은 산술 평균이다. 다른 예에서, 집계 연산은 조화 평균 또는 기하 평균과 같은 여러 종류의 평균 중 하나이다. 다른 예에서, 집계 연산은 검출된 세포의 하위 그룹의 빈도이다. 다른 예에서, 집계 연산은 합계이다. 일 구현예에서, 집계 연산은 세포 하위 세트의 여러 종류의 평균 중 하나이다. 또 다른 예에서, 집계 연산은 분위수이다.
는 디지털 이미지에서 검출된 일련의 세포에 대한 집계 연산자이다. 집계 연산은 검출된 세포와 관련된 양성 값 p(c i )를 나타내는 단일 숫자이다. 하나의 예에서, 집계 연산은 산술 평균이다. 다른 예에서, 집계 연산은 조화 평균 또는 기하 평균과 같은 여러 종류의 평균 중 하나이다. 다른 예에서, 집계 연산은 검출된 세포의 하위 그룹의 빈도이다. 다른 예에서, 집계 연산은 합계이다. 일 구현예에서, 집계 연산은 세포 하위 세트의 여러 종류의 평균 중 하나이다. 또 다른 예에서, 집계 연산은 분위수이다.
p () 항은 각각의 세포에 대해 항-B7H4 ADC 요법에 반응할 확률을 나타내는 양성 함수를 나타낸다. 세포에 대한 양성 함수는 세포의 인접 세포와 관련된 dAB 양성 값의 집계에 대해 양성이다. 세포 c i 와 관련된 양성 값 p(c i )는 다음과 같이 표현된다:
[식 42]
식에서 π i 는 세포 c i 까지의 거리가 미리 정의된 상수보다 작은 암세포로 정의되는, 세포 c i 를 포함하는, 세포 c i 근처에 있는 인접 암세포의 세트이다. 하나의 예에서, c i 와 c j 사이의 거리는 두 세포 중심 사이의 유클리드 거리이다. 다른 예에서, 거리는 c i 와 c j 의 막 사이의 최소 거리이다. 식 42에서, p dAB ( c j )는 막에서의 광학 밀도 및 세포질에서의 광학 밀도 기반의 세포 c j 와 관련된 양성 값이다. 하나의 예에서, p dAB (c j )는 다음에 해당하는 경우 세포에 1을 결부시키고,
[식 43]
그렇지 않을 경우 0을 결부시키는 함수로 정의된다. 식 43에서, α 1, α 2, α 3, γ 1, γ 2, γ 3, 및 T p 는 미리 정의된 상수이고,  는 OD M j 와 OD C j 의 차이를 측정하는 함수이다. 미리 정의된 상수는 항-B7H4 ADC 요법에 대한 치료 반응이 알려진 암 환자 코호트의 통계 분석에 의해 결정된다. 다른 예에서, p dAB (c j )는 다음과 같이 표현된다:
는 OD M j 와 OD C j 의 차이를 측정하는 함수이다. 미리 정의된 상수는 항-B7H4 ADC 요법에 대한 치료 반응이 알려진 암 환자 코호트의 통계 분석에 의해 결정된다. 다른 예에서, p dAB (c j )는 다음과 같이 표현된다:
[식 44]
하나의 예에서, 함수  는
는  로 표현되는, OD M j 와 OD C j 의 차이와 같다. 다른 예에서, 함수
로 표현되는, OD M j 와 OD C j 의 차이와 같다. 다른 예에서, 함수  는
는  로 표현되는, OD M j 와 OD C j 사이의 양의 차이만 고려한다. 또 다른 예에서, 함수
로 표현되는, OD M j 와 OD C j 사이의 양의 차이만 고려한다. 또 다른 예에서, 함수  는
는  로 표현되는, OD C j 와 OD M j 사이의 대비와 같다.
로 표현되는, OD C j 와 OD M j 사이의 대비와 같다.
식 42에서,  는 인접 암세포 세트에 대한 집계 연산자이다. 집계 연산은 인접 세포와 관련된 dAB 양성 값을 나타내는 단일 숫자이다. 하나의 예에서, 집계 연산은 dAB 양성의 가중 산술 평균으로 다음과 같이 표현된다:
는 인접 암세포 세트에 대한 집계 연산자이다. 집계 연산은 인접 세포와 관련된 dAB 양성 값을 나타내는 단일 숫자이다. 하나의 예에서, 집계 연산은 dAB 양성의 가중 산술 평균으로 다음과 같이 표현된다:
[식 45]

식에서  는 세포 c i 가 인접 세포 c j 에 의해 영향을 받을 가능성을 계산하는 가중치 함수를 나타낸다. 다른 예에서, 집계 연산은 인접 세포의 dAB 양성 값의 합이 임의의 실수 상수 T n 보다 클 경우 세포에 1을 결부시키고, 그렇지 않을 경우 0을 결부시킨다. 다른 예에서, 집계 연산은 분위수, 빈도 측정, 또는 조화 평균 또는 기하 평균과 같은 여러 종류의 평균 중 하나이다. 하나의 예에서, 가중치 함수
는 세포 c i 가 인접 세포 c j 에 의해 영향을 받을 가능성을 계산하는 가중치 함수를 나타낸다. 다른 예에서, 집계 연산은 인접 세포의 dAB 양성 값의 합이 임의의 실수 상수 T n 보다 클 경우 세포에 1을 결부시키고, 그렇지 않을 경우 0을 결부시킨다. 다른 예에서, 집계 연산은 분위수, 빈도 측정, 또는 조화 평균 또는 기하 평균과 같은 여러 종류의 평균 중 하나이다. 하나의 예에서, 가중치 함수  는 세포 c i 와 세포 c j 사이의 공간 거리 d(c i ,c j )의 가우시안 함수이다.
는 세포 c i 와 세포 c j 사이의 공간 거리 d(c i ,c j )의 가우시안 함수이다.
[식 46]
식에서 σ 및 α는 미리 정의된 상수이다. 다른 예에서, 가중치 함수는 공간 거리의 시그모이드이다:
[식 47]

식에서 σ, α, 및 β는 미리 정의된 상수이다. 다른 예에서, 가중치 함수는 세포 c i 와 세포 c j 사이의 유클리드 거리의 감소 함수이다. 또 다른 예에서, 가중치 함수는 거리가 미리 정의된 상수 T d 보다 작을 경우 1을 결부시키고 그렇지 않을 경우 0을 결부시키는, 세포 c i 와 세포 c j 사이의 거리의 Heaviside 함수이다.
양성 함수 p(c i )의 하나의 특정 예는 다음에 해당하는 경우 세포에 1을 결부시키고,
[식 48]
그렇지 않을 경우 0을 결부시킨다.
C. 예측 방법의 검증.
도 14의 방법에 따라 생성된 신규 예측 ADC 점수의 정확도를 수동 "H 점수"로 표시되는 바와 같이 다양한 B7-H4 발현 수준을 가진 15명의 환자에 대한 환자 유래 이종이식(PDX) 연구를 기반으로 검증하였다. 간략하게, 종양 조직 단편을 6~8주령의 암컷 무흉선 누드 마우스에 피하 이식하였다. 종양이 적절한 종양 부피 범위(일반적으로 150~300 mm)에 도달했을 때, 동물을 처치군과 대조군으로 무작위 배정하고 B7H4-SG3932 ADC 투약을 시작하였다. 종양 보유 마우스에게 정맥 주사를 통해 B7H4-SG3932 ADC의 단회 용량을 투여하였다. 동물을 매일 관찰하고, 종양 치수 및 체중을 매주 2회 측정하고 기록하였다. 종양 체적은 디지털 캘리퍼스로 측정하고 종양 체적은 다음 식을 사용하여 계산하였다: 종양 부피 = [길이(mm) x 너비(mm)2 x 0.52], 여기서 길이와 너비는 각각 종양의 가장 긴 직경과 가장 짧은 직경이다.
도 26은 PDX 유방 연구의 15명 환자의 실제 결과와 반응 카테고리별로 나열된 수동 H 점수 간의 상관관계를 보여준다. 반응 카테고리는 진행성 질환의 경우 PD, 안정성 질환의 경우 SD, 반응의 경우 R이다. 도 26에서 분석된 조직은 15명의 인간 암 환자의 종양 세포를 가진 마우스의 것이었다.
도 27 및 28은 수동 평가 H 점수와 QCS 점수 간의 비율 점수 결과의 상관관계를 보여준다. 도 27은 수동 비율 점수를 평균 H 점수와 비교한다. 도 28은 수동 비율 점수를 B7H4 막 염색의 광학 밀도에 대한 중앙값 QCS 점수(q50)와 비교한다. 비율 점수의 경우, QCS 점수(q50)와 수동 평가 H 점수 간에 강한 상관관계가 있다.
도 29 및 30은 수동 평가 H 점수와 QCS 점수 간의 강도 점수 결과의 상관관계를 보여준다. 도 29는 수동 강도 점수를 평균 H 점수와 비교한다. 도 30은 수동 강도 점수를 B7H4 막 염색의 광학 밀도에 대한 중앙값 QCS 점수와 비교한다. 강도 점수의 경우, QCS 점수와 수동 평가 H 점수 간에 더 약한 상관관계가 있다.
도 31 및 32는 중앙값 QCS 점수(q50)의 함수로서 환자의 실제 반응 카테고리와 비교하여 평균 H 점수의 함수로서 각 환자의 실제 반응 카테고리의 상관관계를 예시한다. 도 31은 3개의 반응 카테고리 PD(진행성 질환), R(반응), 및 SD(안정성 질환) 각각에서 환자의 평균 H 점수를 보여준다. 도 32는 3개의 반응 카테고리 PD, R, 및 SD 각각에서 환자의 중앙값 QCS 점수(q50)를 보여준다. 평균 H 점수는 PD 및 R 반응 카테고리에서 환자의 덜 최적화된 구분자였지만, 더 낮은 QCS 점수는 진행성 질환과 관련이 있었고, 더 높은 QCS 점수는 항-H7B4 ADC에 대한 반응과 관련되는 경향이 있었다.
도 33 및 34는 QCS 점수와 H 점수 둘 다를 사용하여 PD와 R 반응 카테고리 간의 기준선 B7-H4 수준의 차이가 유의미함을 보여준다. 도 33은 환자 샘플의 PD(진행성 질환)와 R(반응) 그룹 간의 T 검정의 p 값이 H 점수를 사용하여 0.019임을 보여준다. 도 34는 환자 샘플의 PD와 R 그룹 간의 T 검정의 p 값이 QCS 점수를 사용하여 0.011임을 보여준다.
도 35는 종양 성장 퍼센트와 QCS 점수(샘플 내 모든 종양 세포의 막 광학 밀도의 중앙값/50% 분위수) 간의 관계를 보여준다. 0보다 큰 X축 값은 관찰하는 동안 종양 크기가 커진 것을 나타내고, 0보다 작은 값은 관찰하는 동안 종양 크기가 줄어든 것을 나타낸다.
각 환자 샘플에 대한 QCS q50 점수는 환자 샘플로부터 획득한 B7H4-염색된 디지털 조직 이미지에서 모든 종양 세포의 중앙값 막 광학 밀도를 측정하여 계산된다.
도 36은 QCS 점수와 종양 성장 간의 상관관계를 보여준다. QCS 점수를 사용하여 평가된 기준선 B7-H4 광학 밀도 염색 수준과 처치 후 종양 크기의 변화 간에 음의 상관관계가 있었다. 도 36의 그래프에서, Spearman의 ρ는 -0.65이고 p는 0.011이다. 따라서, 종양 크기의 더 큰 감소는 B7-H4 염색의 더 높은 광학 밀도와 관련이 있었다.
D. 진단 항체 염색에서 더 높은 QCS 점수가 ADC로 처치한 후의 종양 세포 밀도 감소와 상관관계가 있음을 보여주는 예.
정량적 연속 점수(QCS)의 적용을 보여주는 예는 점수 및 관련 이미지 분석을 사용하여 항-H7B4 ADC E02-GL-SG3932의 약동학(PK) 및 약력학(PD)을 평가하는 것을 포함하였다. 도 37은 PK 및 PD 연구가 어떻게 수행되었는지를 예시한다. ADC가 인간 유방암 조직의 종양 성장을 어떻게 감소시키는지를 연구하기 위해 이종이식 마우스 모델을 사용하였다. 28명의 유방암 환자의 인간 종양 세포를 마우스에 이식하고 복제하였다. ADC E02-GL-SG3932의 항체와 관련된 이미지 분석 및 염색된 진단 항체를 사용하여 이식된 종양 세포의 시간 경과에 따른 성장을 추적하였다.
도 38의 A 내지 D는 PK 및 PD 결과를 요약한 그래프이다. 단회 용량의 ADC로 처치한 후 상이한 시간에 종양 샘플을 채취한 다음, 면역조직화학적으로 염색하였다. 딥 러닝 기반 QCS 알고리즘을 사용하여 ADC를 정량화하고 맞춤형 HALO 솔루션을 사용하여 종양 세포에서 gH2AX 및 절단된 카스파제 3의 출현율을 확인하였다.
도 38의 A는 모든 상피세포에 대한 ADC-IgG(인간 면역글로불린 G1) 막 염색이 있는 상피세포의 세포 비율을 기반으로 상피세포에서 ADC의 결합 및 흡수를 보여준다. 대조군에서 관찰된 최대값보다 높은 염색을 나타내는 경우에만 세포를 염색된 것으로 계수하였다. 도 38의 A는 ADC 흡수가 ADC 처치 후 96시간까지 시간 경과에 따라 증가했고 ADC 투여량이 높을수록 더 많이 증가했음을 보여준다.
도 38의 B는 ADC 처치 후 시간 경과에 따라 증가하는 DNA 손상(gH2AX)을 보여준다. DNA 손상은 gH2AX 분석에서 병소에 대해 양성으로 확인된 상피세포의 분율로 표시된다. 상업적으로 입수가능한 이미지 분석 시스템 Halo(Indica Labs, Albuquerque, USA)를 사용하여 슬라이드를 분석하여 γH2AX의 출현율을 확인하였다. 도 38의 B는 ADC 처치 약 168시간 후 DNA 손상이 정점에 도달했음을 보여준다.
도 38의 C는 절단된 카스파제-3 양성 종양 세포의 백분율에 근거하여 ADC 처치 후 시간 경과에 따라 증가하는 DNA 손상을 보여준다. HALO 이미지 분석 시스템을 사용하여 슬라이드를 분석하였다.
도 38의 D는 모든 상피세포의 세포 밀도 감소에 근거하여 ADC 처치 후 시간 경과에 따라 증가하는 종양 세포 사멸을 보여준다. E02-GL-SG3932를 사용한 처치는 이소형 ADC를 사용한 처치와 비교하여 세포 사멸을 나타내는 세포 수의 감소를 유발한다.
염색된 조직에 대한 이미지 분석을 수행하기 전에, 먼저 ADC E02-GL-SG3932의 항체와 밀접하게 관련된 진단 항체를 선택하였다. 이어서 진단 항체를 염색에 사용하였다. 먼저, 이종이식 모델을 사용하여 D11, A57.1, 및 Cal63의 3가지 진단 항체에 연결된 염료에 의한 종양 세포의 막 염색이 3가지 사이에서 높은 상관관계가 있음을 확인했다. 도 39의 A는 마우스에 이식하여 복제한 28명의 유방암 환자의 종양 조직의 막 염색의 중앙값 광학 밀도를 보여준다. 3개의 진단 항체로부터 생성된 28개의 별개의 종양 샘플의 높은 상관관계가 있는 염색 정도는 종양 진행 정도가 진단 항체에 의해 일관되게 측정되었음을 입증한다. 28개의 종양 샘플 중 2개에서만, 진단 항체 중 하나가 다른 2개의 진단 항체와 상당히 다른 염색 수준을 생성했다.
도 39의 B는 종양 클론 샘플 #21의 경우 진단 항체 D11에 의한 막 염색이 진단 항체 A57.1 및 Cal63에 의한 염색보다 훨씬 적었음을 보여준다. 도 39의 C는 종양 샘플 #28의 경우 진단 항체 A57.1에 의한 막 염색이 진단 항체 D11 및 Cal63에 의한 염색보다 훨씬 컸음을 보여준다. 따라서, 진단 항체 Cal63이 종양 샘플의 가장 일관된 막 염색을 제공했으며 이를 PK 및 PD 연구에 사용하였다.
도 40a 및 40b는 염료에 연결된 진단 항체 Cal63을 사용하여 염색된 클론 샘플 #26 및 #4의 디지털 이미지를 보여준다. 이미지 분석 및 QCS 방법을 사용하여, 디지털 이미지의 각각의 종양 세포에 대해 막 염색을 기반으로 단일세포 점수를 결정하였다. 이어서, 유사하게 염색된 세포의 분포를 결정하였다. ADC E02-GL-SG3932의 약동학(PK) 및 약력학(PD)을 연구하기 위해 QCS 점수를 사용하였다.
도 41a 및 41b는 세포독성 페이로드 없이 다양한 투여량의 E02-GL-SG3932 또는 ADC로 처치한 후 항-B7H4 진단 항체 Cal63을 사용하여 염색한 샘플의 막 광학 밀도 분포를 보여준다. 도 41a 및 41b의 그래프는 ADC 처치가 표적 발현 수준을 증가시켰고 테스트된 수준에서 ADC 농도와 무관하다는 것을 보여준다.
도 41a는 페이로드 없이 다양한 농도의 ADC로 처치하기 전과 후의 클론 샘플 #26에 대한 세포당 막 염색(막 광학 밀도)의 분포를 보여준다. 위쪽 그래프는 시간 0에서의 그래프이고, 아래쪽 그래프는 처치 168시간 후의 그래프이다. 이소형 대조군은 시간 0에서 비처치 샘플과 거의 동일한 염색 분포를 갖는다. 처치 168시간 후, 막 염색 수준이 더 높은 세포의 수가 증가했다. 증가된 염색은 ADC 농도와 비교적 무관했다. ADC 처치 후 증가된 염색은 ADC가 상피 세포막에서 B7H4-항체의 표적 수준을 상승시켰음을 입증한다.
도 41b는 ADC E02-GL-SG3932로 처치하기 전과 후의 클론 샘플 #4에 대한 세포당 막 염색의 분포를 보여준다. 위쪽 그래프는 시간 0에서의 그래프이고, 아래쪽 그래프는 처치 168시간 후의 그래프이다. 위쪽 그래프는 시간 0에서 클론 샘플 #4의 막 염색의 중앙값 광학 밀도가 도 41a의 클론 샘플 #26의 약 60%임을 보여준다. 처치 168시간 후, 막 염색 수준이 더 높은 세포의 수가 증가했다. 이러한 낮은 출현율의 종양 세포 막 염색에서 시작해도, ADC 처치는 높은 표적 수준을 유발했다.
도 42a 및 42b는 클론 샘플 #26 및 #4에 대한 ADC 처치 전과 후의 결합된 IgG의 세포당 분포를 보여준다. 도 42a 및 42b의 위쪽 그래프는 샘플 #26이 샘플 #4보다 더 높은 결합된 IgG 기준선 분포를 가짐을 보여준다. 도 42a 및 42b의 아래쪽 그래프는 ADC 처치 후 결합된 IgG의 분포를 보여주며, 샘플 #26의 더 높은 기준선 표적 수준이 샘플 #4에 비해 더 높은 ADC 결합을 유발했음을 입증한다. 따라서, 표적 세포에 대한 ADC 결합은 표적 발현에 의존한다.
도 42c는 E02-GL-SG3932의 다양한 투여량 수준에서의 결합된 IgG의 최대 막 광학 밀도에 대한 그래프이다. 도 42c는 페이로드 없이 ADC의 투여량 수준이 증가함에 따라, 결합된 IgG의 막 광학 밀도 분포의 평균 값이 증가했음을 보여준다.
도 42d는 1 내지 7 mg/kg의 ADC E02-GL-SG3932 투여량 수준에서의 클론 샘플 #26에 대한 절단된 카스파제-3 양성 종양의 백분율을 보여준다. 도 42d는 7 mg/kg의 투여량 수준에서 양성 종양 백분율 값이 클론 #4의 경우보다 클론 #26의 경우 더 높음을 보여준다.
도 43a 및 43b는 다양한 투여량에서 E02-GL-SG3932의 약동학(PK) 및 약력학(PD)에 대한 표적 발현의 효과를 보여주는 그래프이다.
도 43a는 E02-GL-SG3932의 막 결합 동역학을 예시한다. 도 43a는 페이로드 없이 다양한 투여량의 ADC로 처치한 후 다양한 시간에서의 클론 #26 및 #4에 대한 IgG의 중앙값 막 광학 밀도를 차트로 나타낸다. 중앙값 막 광학 밀도는 처치 후 시간 경과에 따라 증가했고 처치 약 96시간 후에 최대에 도달했다.
도 43b는 막 대 세포질에서 ADC 존재의 동역학을 예시한다. 도 43b의 그래프는 7 mg/kg의 E02-GL-SG3932 처치 후 다양한 시간에서의 클론 #26의 중앙값 광학 밀도를 보여준다. 광학 밀도는 표적 발현의 지표이다. 도 43b의 그래프는 막 및 세포질에서의 광학 밀도를 보여준다. 처치로부터 약 24시간 후, 세포질에서의 표적 발현보다 막에서의 표적 발현이 더 빠른 속도로 증가한다. 따라서, ADC 결합은 투여량 및 표적 발현 둘 다에 의존하였다.
도 44a 및 44b는 다양한 투여량에서 E02-GL-SG3932의 PK 및 PD에 대한 표적 발현의 효과를 보여주는 그래프이다. 도 44a 및 44b는 ADC가 더 낮은 표적 발현 세포주에도 효과적임을 보여준다. 도 44a는 클론 #26에 관한 것이고 도 44b는 클론 #4에 관한 것이다.
도 44a 및 44b의 위쪽 그래프는 페이로드 없이 ADC로 처치한 후 다양한 시간에서의 염색된 상피세포의 밀도를 보여준다. 도 44a의 위쪽 그래프는 이소형 대조군 처치와 비교하여 페이로드 없이 7 mg/kg의 ADC로 클론 #26을 처치한 후 288시간까지 상피세포 밀도가 51.2%만큼 감소했음을 보여준다. 도 44b의 위쪽 그래프는 이소형 대조군 처치와 비교하여 페이로드 없이 7 mg/kg의 ADC로 클론 #4를 처치한 후 288시간까지 상피세포 밀도가 44.7%만큼 감소했음을 보여준다.
도 44a 및 44b의 아래쪽 그래프는 절단된 카스파제-3(CC-3) 양성 종양 세포의 백분율에 근거하여 ADC 처치 후 시간 경과에 따라 증가하는 DNA 손상을 보여준다. 슬라이드의 이미지 분석은 맞춤형 HALO 솔루션을 사용하여 수행하였다. 도 44a의 아래쪽 그래프는 클론 #26의 손상된 종양 세포의 CC-3 양성 면적이 처치 96시간 후 유의하게 증가했음을 보여준다. CC-3 양성 조직의 면적은 페이로드가 없는 더 높은 투여량의 ADC 대해 더 높았다. 도 44b의 아래쪽 그래프는 클론 #4의 손상된 종양 세포의 CC-3 양성 면적이 페이로드 없는 ADC 7mg/kg의 더 높은 투여량에서도 처치로부터 약 48시간 후에 시작하여 단지 완만하게 증가했음을 보여준다. 그리고 CC-3 양성 조직의 증가는 이소형 ADC의 증가와 거의 동일했다.
도 45a, 45b, 46a, 46b, 47a, 및 47b는 E02-GL-SG3932의 약동학(PK)에 대한 염색된 상피세포의 공간 근접성의 효과를 예시한다. 염색된 종양 세포의 더 가까운 공간 근접성으로 인해, 표적 단백질 발현이 있는 암세포에 결합하는 ADC의 독성 페이로드는 또한 표적 단백질을 발현하지 않는 근접한 세포를 사멸시킬 수 있다. 따라서, 염색된 상피세포에 더 근접한 영역에서 세포 사멸률이 더 높고 이에 따라 표적 단백질의 발현이 더 높다.
도 45a 및 45b는 ADC로 처치한 후 312시간까지 다양한 시간에서의 막 광학 밀도에 대한 이진 공간 근접성(25 um에서의 SPS)의 관계를 보여준다. 클론 샘플 #26에 대해, 도 45a는 이진 SPS와 중앙값 막 광학 밀도 간의 관계가 시간 경과에 따라 변함에 따라 해당 관계에 강한 선형 상관관계가 있음을 보여준다. 상관 계수 r은 도 45a의 산점도에 대해 0.914이다. 도 45b는 이진 SPS와 막 광학 밀도 간의 관계가 시간 경과에 따라 변함에 따라 해당 관계에서 클론 #4에 대해 훨씬 더 강한 선형 상관관계가 있음을 보여준다. 상관 계수 r은 도 45b의 산점도에 대해 0.925이다.
도 46a 및 46b는 ADC로 처치한 후 다양한 시간에서의 막 광학 밀도에 대한 연속 공간 근접성(25 um에서의 연속 SPS)의 관계를 보여준다. 클론 샘플 #26에 대해, 도 46a는 연속 SPS와 중앙값 막 광학 밀도 간의 관계가 시간 경과에 따라 변함에 따라 해당 관계에 약한 선형 상관관계가 있음을 보여준다. 도 46a는 실제로 염색의 막 광학 밀도가 높은 클론 #26의 경우, 처치 약 168시간 후 연속 공간 근접성이 감소함에 따라 광학 밀도가 증가함을 보여준다. 이는 산점도를 2개의 별개 그룹으로 나눈다. 따라서, 표적 발현 수준이 높은 클론 #26의 경우, 더 낮은 연속 공간 근접성의 종양 영역에서 처치 후 시간 경과에 따라 표적 발현이 증가하였다.
그러나, 표적 발현 수준이 낮은 클론 #4의 경우, 도 46b는 처치 후 더 긴 시간이 경과한 후에 산점도 형태의 두 번째 별개 그룹을 나타내지 않는다. 대신, 연속 SPS와 막 광학 밀도 간의 관계가 시간 경과에 따라 변함에 따라 해당 관계에 중등의 선형 상관관계가 남아 있다. 상관 계수 r은 도 46b의 산점도에 대해 0.617이다.
도 47a 및 47b는 ADC로 처치한 후 312시간까지 다양한 시간에서의 상피세포 밀도에 대한 연속 공간 근접성(25 um에서의 연속 SPS)의 관계를 보여준다. 클론 샘플 #26에 대해, 도 47a는 연속 SPS와 상피 밀도 간의 관계가 시간 경과에 따라 변함에 따라 해당 관계에 중등의 선형 상관관계가 있음을 보여준다. 상관 계수 r은 도 47a의 산점도에 대해 0.798이다. 도 47b는 연속 SPS와 상피세포 밀도 간의 관계가 시간 경과에 따라 변함에 따라 해당 관계에서 클론 #4에 대해 더 약한 선형 상관관계가 있음을 보여준다. 상관 계수 r은 도 47b의 산점도에 대해 0.686이다. 도 47a 및 47b는 ADC 처치 후 시간 경과에 따라, 염색된 종양 세포 사이의 연속 공간 근접성이 더 가까운 영역에서 세포 사멸률이 더 높음(이에 따라 세포 밀도가 더 낮음)을 보여준다. 염색된 상피세포에 더 근접한 영역에서 관찰된 더 높은 세포 사멸률 및 이에 따른 표적 단백질의 더 높은 발현은 ADC의 표적 세포 근처에 있는 비발현 암세포도 ADC의 독성 페이로드에 의해 사멸되는 도 23에 예시된 제안된 제3 효과를 뒷받침한다. 또한, 이는 인접 세포로의 ADC 페이로드 흡수를 반영하기 위해 세포 분리를 고려하는 도 24 및 25에 나타낸 단일세포 ADC 점수에 대한 식에 지수 가중 계수를 포함시키는 것을 뒷받침한다.
설명 목적을 위해 특정의 구체적인 구현예와 관련하여 본 발명을 설명하였지만, 본 발명은 이에 제한되지 않는다. 설명된 구현예의 다양한 특징의 다양한 변형, 응용, 및 조합이 청구범위에 기재된 본 발명의 범위를 벗어남이 없이 실시될 수 있다.
SEQUENCE LISTING
<110> MEDIMMUNE LIMITED
<120> A Scoring Method for an Anti-B7H4 Antibody-Drug Conjugate Therapy
<130> B7H4-400-WO-PCT
<150> US 63/077607
<151> 2020-09-12
<160> 13
<170> PatentIn version 3.5
<210> 1
<211> 282
<212> PRT
<213> Homo sapiens
<400> 1
Met Ala Ser Leu Gly Gln Ile Leu Phe Trp Ser Ile Ile Ser Ile Ile
1 5 10 15
Ile Ile Leu Ala Gly Ala Ile Ala Leu Ile Ile Gly Phe Gly Ile Ser
20 25 30
Gly Arg His Ser Ile Thr Val Thr Thr Val Ala Ser Ala Gly Asn Ile
35 40 45
Gly Glu Asp Gly Ile Leu Ser Cys Thr Phe Glu Pro Asp Ile Lys Leu
50 55 60
Ser Asp Ile Val Ile Gln Trp Leu Lys Glu Gly Val Leu Gly Leu Val
65 70 75 80
His Glu Phe Lys Glu Gly Lys Asp Glu Leu Ser Glu Gln Asp Glu Met
85 90 95
Phe Arg Gly Arg Thr Ala Val Phe Ala Asp Gln Val Ile Val Gly Asn
100 105 110
Ala Ser Leu Arg Leu Lys Asn Val Gln Leu Thr Asp Ala Gly Thr Tyr
115 120 125
Lys Cys Tyr Ile Ile Thr Ser Lys Gly Lys Gly Asn Ala Asn Leu Glu
130 135 140
Tyr Lys Thr Gly Ala Phe Ser Met Pro Glu Val Asn Val Asp Tyr Asn
145 150 155 160
Ala Ser Ser Glu Thr Leu Arg Cys Glu Ala Pro Arg Trp Phe Pro Gln
165 170 175
Pro Thr Val Val Trp Ala Ser Gln Val Asp Gln Gly Ala Asn Phe Ser
180 185 190
Glu Val Ser Asn Thr Ser Phe Glu Leu Asn Ser Glu Asn Val Thr Met
195 200 205
Lys Val Val Ser Val Leu Tyr Asn Val Thr Ile Asn Asn Thr Tyr Ser
210 215 220
Cys Met Ile Glu Asn Asp Ile Ala Lys Ala Thr Gly Asp Ile Lys Val
225 230 235 240
Thr Glu Ser Glu Ile Lys Arg Arg Ser His Leu Gln Leu Leu Asn Ser
245 250 255
Lys Ala Ser Leu Cys Val Ser Ser Phe Phe Ala Ile Ser Trp Ala Leu
260 265 270
Leu Pro Leu Ser Pro Tyr Leu Met Leu Lys
275 280
<210> 2
<211> 858
<212> DNA
<213> Homo sapiens
<400> 2
gccaccatgg cttccctggg gcagatcctc ttctggagca taattagcat catcattatt 60
ctggctggag caattgcact catcattggc tttggtattt cagggagaca ctccatcaca 120
gtcactactg tcgcctcagc tgggaacatt ggggaggatg gaatcctgag ctgcactttt 180
gaacctgaca tcaaactttc tgatatcgtg atacaatggc tgaaggaagg tgttttaggc 240
ttggtccatg agttcaaaga aggcaaagat gagctgtcgg agcaggatga aatgttcaga 300
ggccggacag cagtgtttgc tgatcaagtg atagttggca atgcctcttt gcggctgaaa 360
aacgtgcaac tcacagatgc tggcacctac aaatgttata tcatcacttc taaaggcaag 420
gggaatgcta accttgagta taaaactgga gccttcagca tgccggaagt gaatgtggac 480
tataatgcca gctcagagac cttgcggtgt gaggctcccc gatggttccc ccagcccaca 540
gtggtctggg catcccaagt tgaccaggga gccaacttct cggaagtctc caataccagc 600
tttgagctga actctgagaa tgtgaccatg aaggttgtgt ctgtgctcta caatgttacg 660
atcaacaaca catactcctg tatgattgaa aatgacattg ccaaagcaac aggggatatc 720
aaagtgacag aatcggagat caaaaggcgg agtcacctac agctgctaaa ctcaaaggct 780
tctctgtgtg tctcttcttt ctttgccatc agctgggcac ttctgcctct cagcccttac 840
ctgatgctaa aataataa 858
<210> 3
<211> 846
<212> DNA
<213> Homo sapiens
<400> 3
atggcttccc tggggcagat cctcttctgg agcataatta gcatcatcat tattctggct 60
ggagcaattg cactcatcat tggctttggt atttcaggga gacactccat cacagtcact 120
actgtcgcct cagctgggaa cattggggag gatggaatcc tgagctgcac ttttgaacct 180
gacatcaaac tttctgatat cgtgatacaa tggctgaagg aaggtgtttt aggcttggtc 240
catgagttca aagaaggcaa agatgagctg tcggagcagg atgaaatgtt cagaggccgg 300
acagcagtgt ttgctgatca agtgatagtt ggcaatgcct ctttgcggct gaaaaacgtg 360
caactcacag atgctggcac ctacaaatgt tatatcatca cttctaaagg caaggggaat 420
gctaaccttg agtataaaac tggagccttc agcatgccgg aagtgaatgt ggactataat 480
gccagctcag agaccttgcg gtgtgaggct ccccgatggt tcccccagcc cacagtggtc 540
tgggcatccc aagttgacca gggagccaac ttctcggaag tctccaatac cagctttgag 600
ctgaactctg agaatgtgac catgaaggtt gtgtctgtgc tctacaatgt tacgatcaac 660
aacacatact cctgtatgat tgaaaatgac attgccaaag caacagggga tatcaaagtg 720
acagaatcgg agatcaaaag gcggagtcac ctacagctgc taaactcaaa ggcttctctg 780
tgtgtctctt ctttctttgc catcagctgg gcacttctgc ctctcagccc ttacctgatg 840
ctaaaa 846
<210> 4
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Sythetic Peptide
<400> 4
Gly Tyr Tyr Trp Asn
1 5
<210> 5
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Sythetic Peptide
<400> 5
Glu Ile Asn His Ser Gly Ser Thr Ser Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 6
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Sythetic Peptide
<400> 6
Val Leu Tyr Asn Trp Asn Val Asp Ser
1 5
<210> 7
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Sythetic Peptide
<400> 7
Arg Ala Ser Gln Asp Ile Arg Asn Asp Val Gly
1 5 10
<210> 8
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Sythetic Peptide
<400> 8
Ala Ala Ser Arg Leu Gln Ser
1 5
<210> 9
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Sythetic Peptide
<400> 9
Leu Gln His Asn Ser Tyr Pro Arg Thr
1 5
<210> 10
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Sythetic Peptide
<400> 10
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Ala Cys Thr Val Tyr Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Thr Ser Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Val Leu Tyr Asn Trp Asn Val Asp Ser Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 11
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Sythetic Peptide
<400> 11
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Arg Asn Asp
20 25 30
Val Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ser Tyr Pro Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 12
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> Sythetic Peptide
<400> 12
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Ala Cys Thr Val Tyr Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Thr Ser Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Val Leu Tyr Asn Trp Asn Val Asp Ser Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 13
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Sythetic Peptide
<400> 13
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Arg Asn Asp
20 25 30
Val Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ser Tyr Pro Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
Claims (116)
- 암세포 상의 B7-H4 단백질을 표적화하는 ADC 항체 및 ADC 페이로드를 포함하는 항체-약물 접합체(ADC)에 대한 암 환자의 반응을 예측하기 위한 반응 점수 생성 방법으로서,
진단 항체에 연결된 염료를 사용하여 면역조직화학적으로 조직 샘플을 염색하는 단계(진단 항체는 조직 샘플의 암세포 상의 단백질에 결합함);
조직 샘플의 디지털 이미지를 획득하는 단계;
디지털 이미지에서 암세포를 검출하는 단계;
각각의 암세포에 대해 암세포의 막과 세포질에서의 염료의 염색 강도, 및 미리 정의된 거리보다 상기 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 단일세포 ADC 점수를 계산하는 단계; 및
통계 연산을 사용하여 조직 샘플의 모든 단일세포 ADC 점수를 집계하여 반응 점수를 생성하는 단계
를 포함하는 방법. - 제1항에 있어서, 암세포를 검출하는 단계는 각각의 암세포에 대해 막에 속하는 픽셀 및 세포질에 속하는 픽셀을 검출하는 단계를 포함하는, 방법.
- 제1항 또는 제2항에 있어서, 각각의 막의 염색 강도는 막 픽셀에서의 갈색 디아미노벤지딘(DAB) 신호의 평균 광학 밀도를 기반으로 계산되고, 각각의 세포질의 염색 강도는 세포질 픽셀에서의 갈색 DAB 신호의 평균 광학 밀도를 기반으로 계산되는, 방법.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 세포 i에 대한 단일세포 ADC 점수는
|rj - ri|<d인 모든 세포 j에 대한 {a20(|rj - ri|) x ODMj 2 + a11(|rj - ri|) x ODMj x ODCj + a02(|rj - ri|) x ODCj 2 + a00(|rj - ri|)}의 합으로서 계산되며,
식에서 함수 akl은 각각의 세포 j에서 각각의 세포 i까지의 거리 |rj - ri|에 따라 달라지고, ODMj는 세포 j의 막에서의 갈색 DAB 신호의 광학 밀도이고, ODCj는 세포 j의 세포질에서의 갈색 DAB 신호의 광학 밀도인, 방법. - 제4항에 있어서, 함수 akl은 akl(|rj - ri|) = Akl x exp(- |rj - ri| / rnorm)의 관계(상수 계수 Aoo, A1o, Ao1, A11, A20, Ao2는 미리 정의됨)로 세포 j에서 세포 i까지의 거리 |rj - ri|에 따라 달라지는, 방법.
- 제5항에 있어서, 계수 Aoo, A1o, Ao1, A11, A20, Ao2, d, 및 rnorm은 학습 환자 코호트의 치료 반응과 반응 점수의 상관관계를 최적화함으로써 결정되는, 방법.
- 제1항 내지 제6항 중 어느 한 항에 있어서, 모든 단일세포 ADC 점수의 집계는 평균 결정, 중앙값 결정, 및 미리 정의된 백분율의 분위수 결정으로 이루어진 군으로부터 선택되는, 방법.
- 제1항 내지 제7항 중 어느 한 항에 있어서, ADC 항체는 서열번호 4, 서열번호 5, 서열번호 6, 서열번호 7, 서열번호 8, 및 서열번호 9의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 HCDR1, HCDR2, HCDR3, LCDR1, LCDR2, 및 LCDR3을 포함하는, 방법.
- 제8항에 있어서, ADC 항체는 서열번호 10 및 서열번호 11의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 VH쇄 및 VL쇄를 포함하는, 방법.
- 제9항에 있어서, ADC 항체는 서열번호 12의 아미노산 서열을 포함하는 중쇄; 및 서열번호 13의 아미노산 서열을 포함하는 경쇄를 포함하는, 방법.
- 제1항 내지 제10항 중 어느 한 항에 있어서, 소정의 임계값보다 높은 반응 점수를 갖는 환자에게 ADC를 수반하는 요법이 권장되는, 방법.
- 제1항 내지 제11항 중 어느 한 항에 있어서, ADC 항체는 인간화 IgG1 단일클론 항체인, 방법.
- 제1항 내지 제12항 중 어느 한 항에 있어서, ADC 페이로드는 토포이소머라제 I 억제제인, 방법.
- 제1항 내지 제13항 중 어느 한 항에 있어서, 염료는 3,3'-디아미노벤지딘(DAB)인, 방법.
- 제1항 내지 제14항 중 어느 한 항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 담관암종, 폐암, 췌장암, 및 위암으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 제15항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 및 담관암종으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 제1항 내지 제16항 중 어느 한 항에 있어서, ADC는 약물-링커에 접합된 항-B7H4 항체이고, 약물-링커는 하기 화학식:

으로 표시되는(식에서, RLL은 항-B7H4 항체에 연결되는 링커임), 방법. - 제1항 내지 제17항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
;
;
; 및/또는

로부터 선택되는, 방법. - 제1항 내지 제17항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
인, 방법.
- 항체-약물 접합체(ADC)로 치료받은 암 환자의 생존 확률을 나타내는 점수를 생성하는 방법으로서,
진단 항체에 연결된 염료를 사용하여 면역조직화학적으로 암 환자의 조직 샘플을 염색하는 단계(ADC는 암세포 상의 B7-H4 단백질을 표적화하는 ADC 항체 및 ADC 페이로드를 포함하고, 진단 항체는 조직 샘플의 암세포 상의 B7-H4 단백질에 결합함);
조직 샘플의 디지털 이미지를 획득하는 단계;
디지털 이미지에서 암세포를 검출하는 단계;
각각의 암세포에 대해 암세포의 막과 세포질에서의 염료의 염색 강도, 및 미리 정의된 거리보다 상기 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 단일세포 ADC 점수를 계산하는 단계; 및
통계 연산을 사용하여 조직 샘플의 모든 단일세포 ADC 점수를 집계하여 암 환자의 생존 확률을 나타내는 점수를 생성하는 단계
를 포함하는 방법. - 제20항에 있어서, 암세포를 검출하는 단계는 각각의 암세포에 대해 막에 속하는 픽셀 및 세포질에 속하는 픽셀을 검출하는 단계를 포함하는, 방법.
- 제20항 또는 제21항에 있어서, 각각의 막의 염색 강도는 막 픽셀에서의 갈색 디아미노벤지딘(DAB) 신호의 평균 광학 밀도를 기반으로 계산되고, 각각의 세포질의 염색 강도는 세포질 픽셀에서의 갈색 DAB 신호의 평균 광학 밀도를 기반으로 계산되는, 방법.
- 제22항에 있어서, 세포 i에 대한 단일세포 ADC 점수는
|rj - ri|<d인 모든 세포 j에 대한 {a20(|rj - ri|) x ODMj 2 + a11(|rj - ri|) x ODMj x ODCj + a02(|rj - ri|) x ODCj 2 + a00(|rj - ri|)}의 합으로서 계산되며,
식에서 함수 akl은 각각의 세포 j에서 각각의 세포 i까지의 거리 |rj - ri|에 따라 달라지고, ODMj는 세포 j의 막에서의 갈색 DAB 신호의 광학 밀도이고, ODCj는 세포 j의 세포질에서의 갈색 DAB 신호의 광학 밀도인, 방법. - 제23항에 있어서, 함수 akl은 akl(|rj - ri|) = Akl x exp(- |rj - ri| / rnorm)의 관계(상수 계수 Aoo, A1o, Ao1, A11, A20, Ao2는 미리 정의됨)로 세포 j에서 세포 i까지의 거리 |rj - ri|에 따라 달라지는, 방법.
- 제24항에 있어서, 계수 Aoo, A1o, Ao1, A11, A20, Ao2, d, 및 rnorm은 학습 환자 코호트의 치료 반응과 반응 점수의 상관관계를 최적화함으로써 결정되는, 방법.
- 제20항 내지 제25항 중 어느 한 항에 있어서, 모든 단일세포 ADC 점수의 집계는 평균 결정, 중앙값 결정, 및 미리 정의된 백분율의 분위수 결정으로 이루어진 군으로부터 선택되는, 방법.
- 제20항 내지 제26항 중 어느 한 항에 있어서, 점수가 암 환자의 생존 확률이 소정의 임계값을 초과함을 나타내는 경우 암 환자에게 ADC를 수반하는 요법이 권장되는, 방법.
- 제20항 내지 제27항 중 어느 한 항에 있어서, ADC 항체는 인간화 IgG1 단일클론 항체인, 방법.
- 제20항 내지 제28항 중 어느 한 항에 있어서, ADC 항체는 서열번호 4, 서열번호 5, 서열번호 6, 서열번호 7, 서열번호 8, 및 서열번호 9의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 HCDR1, HCDR2, HCDR3, LCDR1, LCDR2, 및 LCDR3을 포함하는, 방법.
- 제29항에 있어서, ADC 항체는 서열번호 10 및 서열번호 11의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 VH쇄 및 VL쇄를 포함하는, 방법.
- 제30항에 있어서, ADC 항체는 서열번호 12의 아미노산 서열을 포함하는 중쇄; 및 서열번호 13의 아미노산 서열을 포함하는 경쇄를 포함하는, 방법.
- 제20항 내지 제31항 중 어느 한 항에 있어서, ADC 페이로드는 토포이소머라제 I 억제제인, 방법.
- 제20항 내지 제32항 중 어느 한 항에 있어서, 염료는 3,3'-디아미노벤지딘(DAB)인, 방법.
- 제20항 내지 제33항 중 어느 한 항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 담관암종, 폐암, 췌장암, 및 위암으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 제34항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 및 담관암종으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 제20항 내지 제35항 중 어느 한 항에 있어서, ADC는 약물-링커에 접합된 항-B7H4 항체이고, 약물-링커는 하기 화학식:
,
으로 표시되는(식에서, RLL은 항-B7H4 항체에 연결되는 링커임), 방법. - 제20항 내지 제36항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
;
;
; 및/또는

로부터 선택되는, 방법. - 제20항 내지 제36항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
인, 방법.
- ADC 항체가 암세포 상의 단백질을 표적화하는, ADC 항체 및 ADC 페이로드를 포함하는 항체-약물 접합체(ADC)에 대한 암 환자의 반응을 예측하는 방법으로서,
진단 항체에 연결된 염료를 사용하여 면역조직화학적으로 조직 샘플을 염색하는 단계(진단 항체는 조직 샘플의 암세포 상의 단백질에 결합하고, 단백질은 B7-H4임);
조직 샘플의 디지털 이미지를 획득하는 단계;
디지털 이미지에서 암세포를 검출하는 단계;
각각의 암세포에 대해 막에서의 염료의 염색 강도를 기반으로 단일세포 ADC 점수를 계산하는 단계; 및
통계 연산을 사용한 조직 샘플의 모든 단일세포 ADC 점수의 집계를 기반으로 ADC에 대한 암 환자의 반응을 예측하는 단계
를 포함하는 방법. - 제39항에 있어서, 각각의 암세포에 대한 단일세포 ADC 점수는 또한 세포질에서의 염료의 염색 강도, 및 미리 정의된 거리보다 상기 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 계산되는, 방법.
- 제39항 또는 제40항에 있어서, 암세포를 검출하는 단계는 각각의 암세포에 대해 막에 속하는 픽셀 및 세포질에 속하는 픽셀을 검출하는 단계를 포함하는, 방법.
- 제39항 내지 제41항 중 어느 한 항에 있어서, 각각의 막의 염색 강도는 막 픽셀에서의 갈색 디아미노벤지딘(DAB) 신호의 평균 광학 밀도를 기반으로 계산되고, 각각의 세포질의 염색 강도는 세포질 픽셀에서의 갈색 DAB 신호의 평균 광학 밀도를 기반으로 계산되는, 방법.
- 제39항 내지 제42항 중 어느 한 항에 있어서, 세포 i에 대한 단일세포 ADC 점수는
|rj - ri|<d인 모든 세포 j에 대한 {a20(|rj - ri|) x ODMj 2 + a11(|rj - ri|) x ODMj x ODCj + a02(|rj - ri|) x ODCj 2 + a00(|rj - ri|)}의 합으로서 계산되며,
식에서 함수 akl은 각각의 세포 j에서 각각의 세포 i까지의 거리 |rj - ri|에 따라 달라지고, ODMj는 세포 j의 막에서의 갈색 DAB 신호의 광학 밀도이고, ODCj는 세포 j의 세포질에서의 갈색 DAB 신호의 광학 밀도인, 방법. - 제43항에 있어서, 함수 akl은 akl(|rj - ri|) = Akl x exp(- |rj - ri| / rnorm)의 관계(상수 계수 Aoo, A1o, Ao1, A11, A20, Ao2는 미리 정의됨)로 세포 j에서 세포 i까지의 거리 |rj - ri|에 따라 달라지는, 방법.
- 제44항에 있어서, 계수 Aoo, A1o, Ao1, A11, A20, Ao2, d, 및 rnorm은 학습 환자 코호트의 치료 반응과 반응 점수의 상관관계를 최적화함으로써 결정되는, 방법.
- 제39항 내지 제45항 중 어느 한 항에 있어서, 모든 단일세포 ADC 점수의 집계는 평균 결정, 중앙값 결정, 및 미리 정의된 백분율의 분위수 결정으로 이루어진 군으로부터 선택되는 연산에 의해 수행되는, 방법.
- 제39항 내지 제46항 중 어느 한 항에 있어서, ADC 항체는 서열번호 4, 서열번호 5, 서열번호 6, 서열번호 7, 서열번호 8, 및 서열번호 9의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 HCDR1, HCDR2, HCDR3, LCDR1, LCDR2, 및 LCDR3을 포함하는, 방법.
- 제47항에 있어서, ADC 항체는 서열번호 10 및 서열번호 11의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 VH쇄 및 VL쇄를 포함하는, 방법.
- 제48항에 있어서, ADC 항체는 서열번호 12의 아미노산 서열을 포함하는 중쇄; 및 서열번호 13의 아미노산 서열을 포함하는 경쇄를 포함하는, 방법.
- 제39항 내지 제49항 중 어느 한 항에 있어서, 점수가 암 환자의 생존 확률이 소정의 임계값을 초과함을 나타내는 경우 암 환자에게 ADC를 수반하는 요법이 권장되는, 방법.
- 제39항 내지 제50항 중 어느 한 항에 있어서, ADC 항체는 인간화 IgG1 단일클론 항체인, 방법.
- 제39항 내지 제51항 중 어느 한 항에 있어서, ADC 페이로드는 토포이소머라제 I 억제제인, 방법.
- 제39항 내지 제52항 중 어느 한 항에 있어서, 염료는 3,3'-디아미노벤지딘(DAB)인, 방법.
- 제39항 내지 제53항 중 어느 한 항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 담관암종, 폐암, 췌장암, 및 위암으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 제54항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 및 담관암종으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 제39항 내지 제55항 중 어느 한 항에 있어서, ADC는 약물-링커에 접합된 항-B7H4 항체이고, 약물-링커는 하기 화학식:
,
으로 표시되는(식에서, RLL은 항-B7H4 항체에 연결되는 링커임), 방법. - 제39항 내지 제56항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
;
;
; 및/또는

로부터 선택되는, 방법. - 제39항 내지 제56항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
인, 방법.
- 암세포 상의 단백질을 표적화하는 ADC 항체 및 ADC 페이로드를 포함하는 항-B7H4 항체-약물 접합체(ADC)로 치료하기 위한 암 환자를 식별하는 방법으로서,
진단 항체에 연결된 염료를 사용하여 면역조직화학적으로 암 환자의 조직 샘플을 염색하는 단계(진단 항체는 조직 샘플의 암세포 상의 단백질에 결합하고, 단백질은 B7-H4임);
조직 샘플의 디지털 이미지를 획득하는 단계;
디지털 이미지에서 암세포를 검출하는 단계;
각각의 암세포에 대해 막에서의 염료의 염색 강도를 기반으로 단일세포 ADC 점수를 계산하는 단계;
통계 연산을 사용하여 조직 샘플의 모든 단일세포 ADC 점수를 집계하여 반응 점수를 생성하는 단계; 및
반응 점수가 임계값을 초과하는 경우 암 환자를 ADC의 투여로부터 이익을 얻을 가능성이 있는 환자로 식별하는 단계
를 포함하는 방법. - 제59항에 있어서, 가능성 있는 이익은 평균 종양 크기의 감소인, 방법.
- 제59항 또는 제60항에 있어서, 각각의 암세포에 대한 단일세포 ADC 점수는 또한 세포질에서의 염료의 염색 강도, 및 미리 정의된 거리보다 상기 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 계산되는, 방법.
- 제59항 내지 제61항 중 어느 한 항에 있어서, 암세포를 검출하는 단계는 각각의 암세포에 대해 막에 속하는 픽셀 및 세포질에 속하는 픽셀을 검출하는 단계를 포함하는, 방법.
- 제59항 내지 제62항 중 어느 한 항에 있어서, 각각의 막의 염색 강도는 막 픽셀에서의 갈색 디아미노벤지딘(DAB) 신호의 평균 광학 밀도를 기반으로 계산되고, 각각의 세포질의 염색 강도는 세포질 픽셀에서의 갈색 DAB 신호의 평균 광학 밀도를 기반으로 계산되는, 방법.
- 제59항 내지 제63항 중 어느 한 항에 있어서, 세포 i에 대한 단일세포 ADC 점수는
|rj - ri|<d인 모든 세포 j에 대한 {a20(|rj - ri|) x ODMj 2 + a11(|rj - ri|) x ODMj x ODCj + a02(|rj - ri|) x ODCj 2 + a00(|rj - ri|)}의 합으로서 계산되며,
식에서 함수 akl은 각각의 세포 j에서 각각의 세포 i까지의 거리 |rj - ri|에 따라 달라지고, ODMj는 세포 j의 막에서의 갈색 DAB 신호의 광학 밀도이고, ODCj는 세포 j의 세포질에서의 갈색 DAB 신호의 광학 밀도인, 방법. - 제64항에 있어서, 함수 akl은 akl(|rj - ri|) = Akl x exp(- |rj - ri| / rnorm)의 관계(상수 계수 Aoo, A1o, Ao1, A11, A20, Ao2는 미리 정의됨)로 세포 j에서 세포 i까지의 거리 |rj - ri|에 따라 달라지는, 방법.
- 제65항에 있어서, 계수 Aoo, A1o, Ao1, A11, A20, Ao2, d, 및 rnorm은 학습 환자 코호트의 치료 반응과 반응 점수의 상관관계를 최적화함으로써 결정되는, 방법.
- 제59항 내지 제66항 중 어느 한 항에 있어서, 모든 단일세포 ADC 점수의 집계는 평균 결정, 중앙값 결정, 및 미리 정의된 백분율의 분위수 결정으로 이루어진 군으로부터 선택되는, 방법.
- 제59항 내지 제67항 중 어느 한 항에 있어서, ADC 항체는 서열번호 4, 서열번호 5, 서열번호 6, 서열번호 7, 서열번호 8, 및 서열번호 9의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 HCDR1, HCDR2, HCDR3, LCDR1, LCDR2, 및 LCDR3을 포함하는, 방법.
- 제68항에 있어서, ADC 항체는 서열번호 10 및 서열번호 11의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 VH쇄 및 VL쇄를 포함하는, 방법.
- 제69항에 있어서, ADC 항체는 서열번호 12의 아미노산 서열을 포함하는 중쇄; 및 서열번호 13의 아미노산 서열을 포함하는 경쇄를 포함하는, 방법.
- 제59항 내지 제70항 중 어느 한 항에 있어서, 소정의 임계값보다 높은 반응 점수를 갖는 환자에게 ADC를 수반하는 요법이 권장되는, 방법.
- 제59항 내지 제71항 중 어느 한 항에 있어서, ADC 항체는 인간화 IgG1 단일클론 항체인, 방법.
- 제59항 내지 제72항 중 어느 한 항에 있어서, ADC 페이로드는 토포이소머라제 I 억제제인, 방법.
- 제59항 내지 제73항 중 어느 한 항에 있어서, 염료는 3,3'-디아미노벤지딘(DAB)인, 방법.
- 제59항 내지 제74항 중 어느 한 항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 담관암종, 폐암, 췌장암, 및 위암으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 제75항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 및 담관암종으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 제59항 내지 제76항 중 어느 한 항에 있어서, ADC는 약물-링커에 접합된 항-B7H4 항체이고, 약물-링커는 하기 화학식:
,
으로 표시되는(식에서, RLL은 항-B7H4 항체에 연결되는 링커임), 방법. - 제59항 내지 제77항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
;
;
; 및/또는

로부터 선택되는, 방법. - 제59항 내지 제77항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
인, 방법.
- 암세포 상의 B7-H4 단백질을 표적화하는 ADC 항체 및 ADC 페이로드를 포함하는 항체-약물 접합체(ADC)를 암 환자에게 투여하는 단계를 포함하는 암 치료 방법으로서,
진단 항체에 연결된 염료를 사용하여 면역조직화학적으로 암 환자의 조직 샘플을 염색하는 단계(진단 항체는 조직 샘플의 암세포 상의 단백질에 결합함);
조직 샘플의 디지털 이미지를 획득하는 단계;
디지털 이미지에서 암세포를 검출하는 단계;
각각의 암세포에 대해 막에서의 염료의 염색 강도를 기반으로 단일세포 ADC 점수를 계산하는 단계;
통계 연산을 사용하여 조직 샘플의 모든 단일세포 ADC 점수를 집계하여 치료 점수를 생성하는 단계; 및
치료 점수가 소정의 임계값을 초과하는 경우 암 환자에게 ADC를 수반하는 요법을 투여하는 단계
를 포함하는 방법. - 제80항에 있어서, 각각의 암세포에 대한 단일세포 ADC 점수는 또한 세포질에서의 염료의 염색 강도, 및 미리 정의된 거리보다 상기 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 계산되는, 방법.
- 제80항 또는 제81항에 있어서, 암세포를 검출하는 단계는 각각의 암세포에 대해 막에 속하는 픽셀 및 세포질에 속하는 픽셀을 검출하는 단계를 포함하는, 방법.
- 제80항 내지 제82항 중 어느 한 항에 있어서, 각각의 막의 염색 강도는 막 픽셀에서의 갈색 디아미노벤지딘(DAB) 신호의 평균 광학 밀도를 기반으로 계산되고, 각각의 세포질의 염색 강도는 세포질 픽셀에서의 갈색 DAB 신호의 평균 광학 밀도를 기반으로 계산되는, 방법.
- 제80항 내지 제83항 중 어느 한 항에 있어서, 세포 i에 대한 단일세포 ADC 점수는
|rj - ri|<d인 모든 세포 j에 대한 {a20(|rj - ri|) x ODMj 2 + a11(|rj - ri|) x ODMj x ODCj + a02(|rj - ri|) x ODCj 2 + a00(|rj - ri|)}의 합으로서 계산되며,
식에서 함수 akl은 각각의 세포 j에서 각각의 세포 i까지의 거리 |rj - ri|에 따라 달라지고, ODMj는 세포 j의 막에서의 갈색 DAB 신호의 광학 밀도이고, ODCj는 세포 j의 세포질에서의 갈색 DAB 신호의 광학 밀도인, 방법. - 제84항에 있어서, 함수 akl은 akl(|rj - ri|) = Akl x exp(- |rj - ri| / rnorm)의 관계(상수 계수 Aoo, A1o, Ao1, A11, A20, Ao2는 미리 정의됨)로 세포 j에서 세포 i까지의 거리 |rj - ri|에 따라 달라지는, 방법.
- 제85항에 있어서, 계수 Aoo, A1o, Ao1, A11, A20, Ao2, d, 및 rnorm은 학습 환자 코호트의 치료 반응과 반응 점수의 상관관계를 최적화함으로써 결정되는, 방법.
- 제80항 내지 제86항 중 어느 한 항에 있어서, 모든 단일세포 ADC 점수의 집계는 평균 결정, 중앙값 결정, 및 미리 정의된 백분율의 분위수 결정으로 이루어진 군으로부터 선택되는, 방법.
- 제80항 내지 제87항 중 어느 한 항에 있어서, ADC 항체는 인간화 IgG1 단일클론 항체인, 방법.
- 제80항 내지 제88항 중 어느 한 항에 있어서, ADC 항체는 서열번호 4, 서열번호 5, 서열번호 6, 서열번호 7, 서열번호 8, 및 서열번호 9의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 HCDR1, HCDR2, HCDR3, LCDR1, LCDR2, 및 LCDR3을 포함하는, 방법.
- 제89항에 있어서, ADC 항체는 서열번호 10 및 서열번호 11의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 VH쇄 및 VL쇄를 포함하는, 방법.
- 제90항에 있어서, ADC 항체는 서열번호 12의 아미노산 서열을 포함하는 중쇄; 및 서열번호 13의 아미노산 서열을 포함하는 경쇄를 포함하는, 방법.
- 제80항 내지 제91항 중 어느 한 항에 있어서, ADC 페이로드는 토포이소머라제 I 억제제인, 방법.
- 제80항 내지 제92항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
;
;
; 및/또는

로부터 선택되는, 방법. - 제80항 내지 제92항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
인, 방법.
- 제80항 내지 제94항 중 어느 한 항에 있어서, 염료는 3,3'-디아미노벤지딘(DAB)인, 방법.
- 제80항 내지 제95항 중 어느 한 항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 담관암종, 폐암, 췌장암, 및 위암으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 제96항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 및 담관암종으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 암세포 상의 B7H4 단백질을 표적화하는 ADC 항체 및 ADC 페이로드를 포함하는 항체-약물 접합체(ADC)를 암 환자에게 투여하는 단계를 포함하는 암 치료 방법으로서,
반응 점수가 소정의 임계값을 초과하는 경우 암 환자에게 ADC를 수반하는 요법을 투여하는 단계를 포함하고, 반응 점수는 통계 연산을 사용하여 암 환자의 조직 샘플의 단일세포 ADC 점수를 집계하여 생성되었고, 각각의 단일세포 ADC 점수는 각각의 암세포에 대해 막에서의 염료의 염색 강도를 기반으로 계산되었고, 암세포는 암 환자의 조직 샘플의 디지털 이미지에서 검출되었고, 조직 샘플은 진단 항체에 연결된 염료를 사용하여 면역조직화학적으로 염색되었고, 진단 항체는 조직 샘플의 암세포 상의 단백질에 결합하는, 방법. - 제98항에 있어서, 각각의 암세포에 대한 단일세포 ADC 점수는 또한 세포질에서의 염료의 염색 강도, 및 미리 정의된 거리보다 상기 암세포에 더 가까운 다른 암세포의 막과 세포질에서의 염료의 염색 강도를 기반으로 계산된, 방법.
- 제98항 또는 제99항에 있어서, 암세포를 검출하는 단계는 각각의 암세포에 대해 막에 속하는 픽셀 및 세포질에 속하는 픽셀을 검출하는 단계를 포함한, 방법.
- 제98항 내지 제100항 중 어느 한 항에 있어서, 각각의 막의 염색 강도는 막 픽셀에서의 갈색 디아미노벤지딘(DAB) 신호의 평균 광학 밀도를 기반으로 계산되고, 각각의 세포질의 염색 강도는 세포질 픽셀에서의 갈색 DAB 신호의 평균 광학 밀도를 기반으로 계산되는, 방법.
- 제98항 내지 제101항 중 어느 한 항에 있어서, 세포 i에 대한 단일세포 ADC 점수는
|rj - ri|<d인 모든 세포 j에 대한 {a20(|rj - ri|) x ODMj 2 + a11(|rj - ri|) x ODMj x ODCj + a02(|rj - ri|) x ODCj 2 + a00(|rj - ri|)}의 합으로서 계산되며,
식에서 함수 akl은 각각의 세포 j에서 각각의 세포 i까지의 거리 |rj - ri|에 따라 달라지고, ODMj는 세포 j의 막에서의 갈색 DAB 신호의 광학 밀도이고, ODCj는 세포 j의 세포질에서의 갈색 DAB 신호의 광학 밀도인, 방법. - 제102항에 있어서, 함수 akl은 akl(|rj - ri|) = Akl x exp(- |rj - ri| / rnorm)의 관계(상수 계수 Aoo, A1o, Ao1, A11, A20, Ao2는 미리 정의됨)로 세포 j에서 세포 i까지의 거리 |rj - ri|에 따라 달라지는, 방법.
- 제103항에 있어서, 계수 Aoo, A1o, Ao1, A11, A20, Ao2, d, 및 rnorm은 학습 환자 코호트의 치료 반응과 반응 점수의 상관관계를 최적화함으로써 결정되는, 방법.
- 제98항 내지 제104항 중 어느 한 항에 있어서, 모든 단일세포 ADC 점수의 집계는 평균 결정, 중앙값 결정, 및 미리 정의된 백분율의 분위수 결정으로 이루어진 군으로부터 선택되는, 방법.
- 제98항 내지 제105항 중 어느 한 항에 있어서, ADC 항체는 인간화 IgG1 단일클론 항체인, 방법.
- 제98항 내지 제106항 중 어느 한 항에 있어서, ADC 항체는 서열번호 4, 서열번호 5, 서열번호 6, 서열번호 7, 서열번호 8, 및 서열번호 9의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 HCDR1, HCDR2, HCDR3, LCDR1, LCDR2, 및 LCDR3을 포함하는, 방법.
- 제107항에 있어서, ADC 항체는 서열번호 10 및 서열번호 11의 아미노산 서열 각각 또는 이의 기능적 변이체를 포함하는 VH쇄 및 VL쇄를 포함하는, 방법.
- 제108항에 있어서, ADC 항체는 서열번호 12의 아미노산 서열을 포함하는 중쇄; 및 서열번호 13의 아미노산 서열을 포함하는 경쇄를 포함하는, 방법.
- 제98항 내지 제109항 중 어느 한 항에 있어서, ADC 페이로드는 토포이소머라제 I 억제제인, 방법.
- 제98항 내지 제110항 중 어느 한 항에 있어서, 염료는 3,3'-디아미노벤지딘(DAB)인, 방법.
- 제98항 내지 제111항 중 어느 한 항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 담관암종, 폐암, 췌장암, 및 위암으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 제112항에 있어서, 암 환자는 유방암, 난소암, 자궁내막암, 및 담관암종으로 이루어진 군으로부터 선택되는 암을 갖는, 방법.
- 제98항 내지 제113항 중 어느 한 항에 있어서, ADC는 약물-링커에 접합된 항-B7H4 항체이고, 약물-링커는 하기 화학식:
,
으로 표시되는(식에서, RLL은 항-B7H4 항체에 연결되는 링커임), 방법. - 제98항 내지 제114항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
;
;
; 및/또는

로부터 선택되는, 방법. - 제98항 내지 제114항 중 어느 한 항에 있어서, ADC는 토포이소머라제 억제제에 접합된 항-B7H4 항체이고, 토포이소머라제 억제제는
인, 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063077607P | 2020-09-12 | 2020-09-12 | |
| US63/077,607 | 2020-09-12 | ||
| PCT/EP2021/075116 WO2022053685A2 (en) | 2020-09-12 | 2021-09-13 | A scoring method for an anti-b7h4 antibody-drug conjugate therapy |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230066095A true KR20230066095A (ko) | 2023-05-12 |
Family
ID=77913114
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237012322A KR20230066095A (ko) | 2020-09-12 | 2021-09-13 | 항-b7h4 항체-약물 접합체 요법에 대한 점수산정 방법 |
Country Status (8)
| Country | Link |
|---|---|
| EP (1) | EP4211663A2 (ko) |
| JP (1) | JP2023542301A (ko) |
| KR (1) | KR20230066095A (ko) |
| CN (1) | CN116615455A (ko) |
| AU (1) | AU2021342349A1 (ko) |
| CA (1) | CA3194182A1 (ko) |
| IL (1) | IL301264A (ko) |
| WO (1) | WO2022053685A2 (ko) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115160403A (zh) * | 2022-07-05 | 2022-10-11 | 上海彩迩文生化科技有限公司 | 特异性拓扑异构酶抑制剂和可用于抗体药物偶联物及其制备方法 |
Family Cites Families (38)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6492107B1 (en) | 1986-11-20 | 2002-12-10 | Stuart Kauffman | Process for obtaining DNA, RNA, peptides, polypeptides, or protein, by recombinant DNA technique |
| DE3546807C2 (ko) | 1985-03-30 | 1991-03-28 | Marc Genf/Geneve Ch Ballivet | |
| US5618920A (en) | 1985-11-01 | 1997-04-08 | Xoma Corporation | Modular assembly of antibody genes, antibodies prepared thereby and use |
| DE3600905A1 (de) | 1986-01-15 | 1987-07-16 | Ant Nachrichtentech | Verfahren zum dekodieren von binaersignalen sowie viterbi-dekoder und anwendungen |
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| US4946778A (en) | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| GB8823869D0 (en) | 1988-10-12 | 1988-11-16 | Medical Res Council | Production of antibodies |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| CA2016841C (en) | 1989-05-16 | 1999-09-21 | William D. Huse | A method for producing polymers having a preselected activity |
| CA2016842A1 (en) | 1989-05-16 | 1990-11-16 | Richard A. Lerner | Method for tapping the immunological repertoire |
| EP0478627A4 (en) | 1989-05-16 | 1992-08-19 | William D. Huse | Co-expression of heteromeric receptors |
| GB9015198D0 (en) | 1990-07-10 | 1990-08-29 | Brien Caroline J O | Binding substance |
| US6172197B1 (en) | 1991-07-10 | 2001-01-09 | Medical Research Council | Methods for producing members of specific binding pairs |
| US5545806A (en) | 1990-08-29 | 1996-08-13 | Genpharm International, Inc. | Ransgenic non-human animals for producing heterologous antibodies |
| ES2108048T3 (es) | 1990-08-29 | 1997-12-16 | Genpharm Int | Produccion y utilizacion de animales inferiores transgenicos capaces de producir anticuerpos heterologos. |
| US5661016A (en) | 1990-08-29 | 1997-08-26 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| US5633425A (en) | 1990-08-29 | 1997-05-27 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5625126A (en) | 1990-08-29 | 1997-04-29 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| ES2113940T3 (es) | 1990-12-03 | 1998-05-16 | Genentech Inc | Metodo de enriquecimiento para variantes de proteinas con propiedades de union alteradas. |
| WO1993011236A1 (en) | 1991-12-02 | 1993-06-10 | Medical Research Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| JP4157160B2 (ja) | 1991-12-13 | 2008-09-24 | ゾーマ テクノロジー リミテッド | 改変抗体可変領域の調製のための方法 |
| US5639641A (en) | 1992-09-09 | 1997-06-17 | Immunogen Inc. | Resurfacing of rodent antibodies |
| US5641870A (en) | 1995-04-20 | 1997-06-24 | Genentech, Inc. | Low pH hydrophobic interaction chromatography for antibody purification |
| EP0859841B1 (en) | 1995-08-18 | 2002-06-19 | MorphoSys AG | Protein/(poly)peptide libraries |
| US6706484B1 (en) | 1995-08-18 | 2004-03-16 | Morphosys Ag | Protein/(poly)peptide libraries |
| US5714352A (en) | 1996-03-20 | 1998-02-03 | Xenotech Incorporated | Directed switch-mediated DNA recombination |
| WO2001002588A2 (en) | 1999-07-02 | 2001-01-11 | Morphosys Ag | Generation of specific binding partners binding to (poly)peptides encoded by genomic dna fragments or ests |
| US7538195B2 (en) | 2002-06-14 | 2009-05-26 | Immunogen Inc. | Anti-IGF-I receptor antibody |
| ZA200503075B (en) | 2002-11-07 | 2006-09-27 | Immunogen Inc | Anti-CD33 antibodies and method for treatment of acute myeloid leukemia using the same |
| JP5470817B2 (ja) | 2008-03-10 | 2014-04-16 | 日産自動車株式会社 | 電池用電極およびこれを用いた電池、並びにその製造方法 |
| WO2013147114A1 (ja) * | 2012-03-30 | 2013-10-03 | 公益財団法人神奈川科学技術アカデミー | イメージングセルソーター |
| JP6136279B2 (ja) | 2013-01-15 | 2017-05-31 | 株式会社ジェイテクト | 転がり軸受装置 |
| TWI503850B (zh) | 2013-03-22 | 2015-10-11 | Polytronics Technology Corp | 過電流保護元件 |
| TWI510996B (zh) | 2013-10-03 | 2015-12-01 | Acer Inc | 控制觸控面板的方法以及使用該方法的可攜式電腦 |
| WO2015124777A1 (en) * | 2014-02-21 | 2015-08-27 | Ventana Medical Systems, Inc. | Medical image analysis for identifying biomarker-positive tumor cells |
| US9816280B1 (en) | 2016-11-02 | 2017-11-14 | Matthew Reitnauer | Portable floor |
| WO2019197509A1 (en) * | 2018-04-13 | 2019-10-17 | Ventana Medical Systems, Inc. | Systems for cell shape estimation |
| WO2020081343A1 (en) * | 2018-10-15 | 2020-04-23 | Ventana Medical Systems, Inc. | Systems and methods for cell classification |
-
2021
- 2021-09-13 IL IL301264A patent/IL301264A/en unknown
- 2021-09-13 CA CA3194182A patent/CA3194182A1/en active Pending
- 2021-09-13 CN CN202180075699.6A patent/CN116615455A/zh active Pending
- 2021-09-13 WO PCT/EP2021/075116 patent/WO2022053685A2/en active Application Filing
- 2021-09-13 EP EP21777496.7A patent/EP4211663A2/en active Pending
- 2021-09-13 KR KR1020237012322A patent/KR20230066095A/ko unknown
- 2021-09-13 JP JP2023516505A patent/JP2023542301A/ja active Pending
- 2021-09-13 AU AU2021342349A patent/AU2021342349A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| EP4211663A2 (en) | 2023-07-19 |
| JP2023542301A (ja) | 2023-10-06 |
| CN116615455A (zh) | 2023-08-18 |
| AU2021342349A1 (en) | 2023-05-25 |
| WO2022053685A3 (en) | 2022-04-21 |
| IL301264A (en) | 2023-05-01 |
| CA3194182A1 (en) | 2022-03-17 |
| WO2022053685A2 (en) | 2022-03-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102610592B1 (ko) | 당화 pd-l1에 특이적인 항체 및 그의 사용 방법 | |
| US11046759B2 (en) | Matrix metalloprotease-cleavable and serine protease-cleavable substrates and methods of use thereof | |
| US8557964B2 (en) | Anti CXCR4 antibodies and their use for the treatment of cancer | |
| EP2588497B1 (en) | Novel antibody for the diagnosis and/or prognosis of cancer | |
| JP2017532025A (ja) | 交差反応性siglec抗体 | |
| RU2595394C2 (ru) | Гуманизированные антитела к cxcr4 для лечения рака | |
| EA039377B1 (ru) | Антитела к ceacam5 и их применения | |
| MX2011004684A (es) | Anticuerpos que bloquean espicificamente la actividad biologica de un antigeno de tumor. | |
| WO2012145568A1 (en) | Antibodies to human b7x for treatment of metastatic cancer | |
| JP2022511337A (ja) | 免疫チェックポイント治療に抵抗性のある癌の治療のための方法および医薬組成物 | |
| KR20230066095A (ko) | 항-b7h4 항체-약물 접합체 요법에 대한 점수산정 방법 | |
| KR20230106607A (ko) | 191p4d12 단백질에 결합하는 항체 약물 접합체(adc)로 암을 치료하는 방법 | |
| RU2706967C2 (ru) | Антитело к igf-1r и его применение для диагностики рака | |
| US20200400675A1 (en) | Progastrin as a biomarker for immunotherapy | |
| KR20230066094A (ko) | 항-her2 항체-약물 접합체 치료법을 위한 채점 방법 | |
| RU2706959C2 (ru) | Антитело к igf-1r и его применение для диагностики рака | |
| JP7485274B2 (ja) | 免疫療法のためのバイオマーカーとしてのプロガストリン | |
| TWI703155B (zh) | 特異性結合至pauf蛋白質的抗體及其用途 | |
| CN117177771A (zh) | 一种诊断和治疗t细胞淋巴瘤的方法 | |
| OA19972A (en) | Receptor for VISTA |