KR20210077704A - 차지 기반 스위치드 매트릭스 및 그 방법 - Google Patents
차지 기반 스위치드 매트릭스 및 그 방법 Download PDFInfo
- Publication number
- KR20210077704A KR20210077704A KR1020217013786A KR20217013786A KR20210077704A KR 20210077704 A KR20210077704 A KR 20210077704A KR 1020217013786 A KR1020217013786 A KR 1020217013786A KR 20217013786 A KR20217013786 A KR 20217013786A KR 20210077704 A KR20210077704 A KR 20210077704A
- Authority
- KR
- South Korea
- Prior art keywords
- charge
- input
- storage device
- output
- charge storage
- Prior art date
Links
Images























Classifications
-
- G06N3/0635—
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03K—PULSE TECHNIQUE
- H03K5/00—Manipulating of pulses not covered by one of the other main groups of this subclass
- H03K5/01—Shaping pulses
- H03K5/04—Shaping pulses by increasing duration; by decreasing duration
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G06N3/0445—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
- G06N3/065—Analogue means
-
- H—ELECTRICITY
- H02—GENERATION; CONVERSION OR DISTRIBUTION OF ELECTRIC POWER
- H02M—APPARATUS FOR CONVERSION BETWEEN AC AND AC, BETWEEN AC AND DC, OR BETWEEN DC AND DC, AND FOR USE WITH MAINS OR SIMILAR POWER SUPPLY SYSTEMS; CONVERSION OF DC OR AC INPUT POWER INTO SURGE OUTPUT POWER; CONTROL OR REGULATION THEREOF
- H02M3/00—Conversion of dc power input into dc power output
- H02M3/02—Conversion of dc power input into dc power output without intermediate conversion into ac
- H02M3/04—Conversion of dc power input into dc power output without intermediate conversion into ac by static converters
- H02M3/06—Conversion of dc power input into dc power output without intermediate conversion into ac by static converters using resistors or capacitors, e.g. potential divider
- H02M3/07—Conversion of dc power input into dc power output without intermediate conversion into ac by static converters using resistors or capacitors, e.g. potential divider using capacitors charged and discharged alternately by semiconductor devices with control electrode, e.g. charge pumps
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03K—PULSE TECHNIQUE
- H03K5/00—Manipulating of pulses not covered by one of the other main groups of this subclass
- H03K5/22—Circuits having more than one input and one output for comparing pulses or pulse trains with each other according to input signal characteristics, e.g. slope, integral
- H03K5/24—Circuits having more than one input and one output for comparing pulses or pulse trains with each other according to input signal characteristics, e.g. slope, integral the characteristic being amplitude
- H03K5/2472—Circuits having more than one input and one output for comparing pulses or pulse trains with each other according to input signal characteristics, e.g. slope, integral the characteristic being amplitude using field effect transistors
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03K—PULSE TECHNIQUE
- H03K5/00—Manipulating of pulses not covered by one of the other main groups of this subclass
- H03K5/156—Arrangements in which a continuous pulse train is transformed into a train having a desired pattern
- H03K5/1565—Arrangements in which a continuous pulse train is transformed into a train having a desired pattern the output pulses having a constant duty cycle
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02E—REDUCTION OF GREENHOUSE GAS [GHG] EMISSIONS, RELATED TO ENERGY GENERATION, TRANSMISSION OR DISTRIBUTION
- Y02E60/00—Enabling technologies; Technologies with a potential or indirect contribution to GHG emissions mitigation
- Y02E60/10—Energy storage using batteries
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Data Mining & Analysis (AREA)
- Computing Systems (AREA)
- Computational Linguistics (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Nonlinear Science (AREA)
- Neurology (AREA)
- Power Engineering (AREA)
- Electronic Switches (AREA)
- Analogue/Digital Conversion (AREA)
Abstract
가변구조형, 예를 들어 시간과 함께, 네트워크 스위치 매트릭스 연결 스위치 차지 회로는 네트워크 내의 크로스바를 통해 차지 펄스에 비례하여 수신 및 출력할 수 있는 곱셈 및 덧셈 회로(MACs) 및 뉴런(활성화된 MACs)을 나타내고, 이 크로스바는 크로스바 통신을 셋업하기 위해 로컬 컨트롤러 및 상위 레벨 컨트롤러에 의해 제어된다.
Description
본 발명은 전체적으로 아날로그 머신 러닝에 관한 것으로, 더욱 상세하게는, 뉴런으로 구성된 스위치 매트릭스를 사용하는 아날로그 뉴런 네트워크에 관한 것이며, 스위치 매트릭스는 다음을 허용한다: i) 통신 경로의 신속한 재 연결; ii) 유한 루프 대역폭에 의해 제한되지 않는 통신; iii) 물리적 연결에 의해 제한되지 않는 연결 수단; iv) 장치 값, 환경, 온도 및 기타 매칭 효과와 관계없는 연결 수단, 그리고 v) 상당한 튜닝, 조정 또는 글로벌 파라미터 매칭 또는 특수 장치가 요구되지 않는 연결 수단.
아날로그 머신 러닝은 디지털 구현과 비교하여 상당한 전력 절감, 성능 개선, 정확도 개선 및 노이즈 감소의 가능성을 가진다. 일반적으로, 머신 러닝은 편향이라고하는 선형 이동과, 더하여 출력을 생성하기 위한 활성화 또는 결정 수단을 가질 수 있는, 가중치 합산기의 구현을 필요로 한다. 각 출력은 많은 다른 가중 합산기에 연결될 수 있고 이들 연결은, 예를 들어 모든 네트워크의 가중치 및 편향 값과 마찬가지로, 반복되는 네트워크, 또는 가상 뉴런 스킴(schemes)에서 동적으로 프로그래밍 가능할 필요가 있을 수 있다.
아날로그 구현 수단은 몇 가지 가능한 방법을 포함한다: i) 전압과 같은 입력에 대한 가중치로서, 3극 모드 저항과 같은, 트랜지스터 동작 점의 변조 그리고 가중 합을 생성하기 위한 이러한 여러 경로의 합산; ii) 곱셈 결과를 생성하기 위해 아날로그 멀티플라이어(예 : Gilbert 타입 멀티플라이어)와 같은 트랜스 선형 루프의 사용; iii) 전압 또는 전류 입력에 대해 가중 입력을 생성하기 위한 멤리스터(memristor)와 같은 특수 장치의 사용; iv) 가중 전류 DAC를 사용한 전류의 곱셈; v) 스위치드 커패시터가 입력 커패시터 유닛 셀과 스위치를 사용하여 크기가 변화되는 스위치드 커패시터 회로의 사용.
상기 아날로그 구현 수단 각각은 상당한 단점을 가진다. 예를 들어(상기 방법을 참조하는 인덱스와 함께), i)멀티플렉서 및 크로스-바의 고정 임피던스가 변조와 관련없는 장치 임피던스를 추가하고, 그의 자체 환경(예, 온도) 및 처리 종속성이 장치 변조 결과를 방해하며 튜닝 조치가 필요한 왜곡을 유발하기 때문에 프로그래밍 가능한 스위치 매트릭스 연결을 생성하기가 매우 어렵다.
또한, 전류의 합산은 대역폭 제한을 가지고 3극관 모드는 단기간만 사용되더라도 고전력이다. ii) 트랜스 선형 루프는 상당한 셋업 시간이 필요하며 전력 낭비를 동적으로 게이트할 수 없다. 또한 대역폭이 제한된다. iii) 이러한 특수 장치를 안정적으로 제조하고 사용하는 것이 어렵고 일반적으로 룩업 테이블 등의 사용을 통해 상당한 튜닝 및 조정이 필요하지만 왜곡 및 속도 제한이 발생한다. iv) 가중 DAC는 학습 및 작동 중에 전력 비효율적이며 또한 왜곡 문제 및 대역폭 제한이 있는 디지털 비트 스토리지가 요구된다. v) 스위치드 커패시터 회로는 많은 실리콘 영역을 사용하고 일치하기가 매우 어려워 해상도를 제한하고 왜곡을 강화하는 유닛 커패시터가 요구된다.
매우 높은 데이터 속도로 정보를 전달할 수 있고, 또한 스위치 매트릭스 또는 통신 네트워크의 빠른 동적 재 연결을 가능하게 하는 뉴런 네트워크는 뉴런을 매우 빠르게 재 연결하고 시간 프레임 접근을 기반으로 그들을 재사용하는 것에 의해 효과적인 뉴런의 수를 증가시키는데 사용될 수 있다. 이것은 사용되는 프레임 수만큼 효과적인 뉴런의 수를 증가시킬 수 있다. 그것은 반복적인 네트워크 기능을 대안적으로 또는 마찬가지로 허용할 수 있다. 예를 들어, 16개의 시간 프레임 또는 시간 슬롯이 있는 경우, 첫 번째 프레임에 하나의 네트워크 연결이 있을 수 있고, 두 번째 시간 프레임에 다른 네트워크 연결이 있을 수 있다. 그 결과는 사용자에게 16배 크기인 네트워크처럼 보일 것이다.
따라서, 상기 문제점을 극복한 시스템 및 방법을 제공하는 것이 바람직할 것이다. 그 시스템 및 방법은 다음을 허용하는 뉴런(가중 가산기 및 활성화 함수)으로 구성된 스위치 매트릭스를 생성한다. i) 통신 경로의 신속한 재 연결; ii) 유한 루프 대역폭에 의해 제한되지 않는 통신; iii) 물리적 연결에 의해 제한되지 않는 연결 수단; iv) 장치 값, 환경, 온도 및 기타 매칭 효과와 관계없는 연결 수단, 그리고 v) 상당한 튜닝, 조정 또는 글로벌 파라미터 매칭 또는 특수 장치가 요구되지 않는 연결 수단.
본 발명은 통신 경로의 신속한 재 연결, 유한 루프 대역폭에 의해 제한되지 않는 통신, 물리적 연결에 의해 제한되지 않는 연결 수단, 장치 값, 환경, 온도 및 기타 매칭 효과와 관계없는 연결 수단, 그리고 상당한 튜닝, 조정 또는 글로벌 파라미터 매칭 또는 특수 장치가 요구되지 않는 연결 수단이 가능한 차지 기반 스위치드 매트릭스 및 그 방법을 제공함에 목적이 있다.
본 발명에 따른 스위치드 차지 회로는, 초기 페이스(phase) 동안 차지(charge)를 수신하기 위해 입력에 연결된 적어도 하나의 입력 차지 저장 장치-상기 적어도 하나의 입력 차지 저장 장치는 초기에 전위 또는 차지 임계치 중 하나로 리셋됨; 출력 및 상기 적어도 하나의 입력 차지 저장 장치에 연결된 적어도 하나의 출력 차지 저장 장치-상기 적어도 하나의 출력 차지 저장 장치는 초기에 차지 레벨로 리셋됨; 상기 적어도 하나의 입력 차지 저장 장치와 상기 적어도 하나의 출력 차지 저장 장치를 연결하는 공유 노드에 연결된 비교 장치; 상기 적어도 하나의 출력 차지 저장 장치에 연결된 적어도 하나의 제1 전류 소스; 상기 적어도 하나의 출력 차지 저장 장치 상에 차지 곱셈 또는 나눗셈 중 하나를 생성하도록, 상기 적어도 하나의 입력 차지 저장 장치 및 상기 적어도 하나의 출력 차지 저장 장치를 상기 적어도 하나의 제1 전류 소스에 크기에 비례해 연결하여 공유 노드에 연결된 적어도 하나의 제2 전류 소스를 포함하고, 상기 적어도 하나의 제1 전류 소스 및 상기 적어도 하나의 제2 전류 소스는 제2 페이스의 시작에서 켜지고 상기 공유 노드가 차지 곱셈 또는 나눗셈 중 하나의 크기에 비례하는 출력 펄스를 생성하는 전위 또는 차지 임계치 중 하나에 도달하면 꺼질 수 있다.
본 발명의 차지 기반 스위치드 매트릭스 및 그 방법은, 통신 경로의 신속한 재 연결, 유한 루프 대역폭에 의해 제한되지 않는 통신, 물리적 연결에 의해 제한되지 않는 연결 수단, 장치 값, 환경, 온도 및 기타 매칭 효과와 관계없는 연결 수단, 그리고 상당한 튜닝, 조정 또는 글로벌 파라미터 매칭 또는 특수 장치가 요구되지 않는 연결 수단으로서 가능한 효과가 있다.
본 출원은 이하의 도면을 참조하여 더욱 상세하게 설명된다. 이들 도면은 본 출원의 범위를 제한하려는 것이 아니라 그 특정 속성을 예시하는 것이다. 동일하거나 유사한 부분을 지칭하기 위하여 도면 전체에 걸쳐 동일한 참조 번호가 사용된다.
도 1a는 스필 및 필 회로(spill and fill circuit)를 나타낸다.
도 1b는 도 1A의 스필 및 필 회로에서 저장 웰 SW 차지 저장소로부터 플로팅 확산 FD 차지 저장소로의 에너지 다이어그램을 나타낸다.
도 2는 "단일 트랜지스터" 차지 멀티플라이어 회로의 블록 다이어그램을 나타낸다.
도 3은 본 출원의 일 형태에 따른 뉴런(MAC + 활성화)의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 4는 본 출원의 일 형태에 따른, 플로팅 커패시터가 필요하지 않은 경우 단순 비례 차지 펄스 스위치 매트릭스에 호환되는 뉴런의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 5는 본 출원의 일 형태에 따른 코어의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 6은 본 출원의 일 형태에 따른 뉴런 네트워크 연결의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 7은 본 출원의 일 형태에 따른 차지 펄스 크로스바의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 8은 본 출원의 일 형태에 따른 4 개의 코어를 가지는 로컬 그룹의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 9는 본 출원의 일 형태에 따른 추가 코어에 연결되는 4 개의 코어의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 10은 본 출원의 일 형태에 따른 최대 풀링 회로 코어의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 11은 본 출원의 일 형태에 따른 차지 범위의 예시적인 실시예를 나타내는 다이어그램이다.
도 12는 본 출원의 일 형태에 따른 팩토리 프로그래밍 경로를 허용하기 위한 Zcell의 사용의 예시적인 실시예를 나타내는 블록도이다.
도 13은 본 출원의 일 형태에 따른 단축 조작에 사용될 수 있는 2D CCD 시프트 레지스터에 연결된 포토 다이오드의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 14는 본 출원의 일 형태에 따른 차지 투입을 감소시킬 수 있는 공핍된 차지 스위치의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 15는 본 출원의 일 형태에 따른 로컬 정확도 조정을 위해 뉴런 주소에 추가될 수 있는 로컬 비트를 생성할 수 있는 연속 시간 Δ∑의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 16은 본 출원의 일 형태에 따른 로컬 단기 동적 메모리의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 17은 본 출원의 일 형태에 따른 아날로그 NVM 차지 트랩 전류 소스의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 18은 본 출원의 일 형태에 따른 정류된 선형 타입 결정 회로의 예시적인 실시예의 그래프이다.
도 19는 본 출원의 일 형태에 따른 RELU 기능의 예시적인 실시예를 나타내는 그래프이다.
도 20은 본 출원의 일 형태에 따른 양면 차지 추가 또는 제거를 위한 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 21은 본 출원의 일 형태에 따른 차지 입력에 바이어스를 추가하기 위한 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 22는 본 출원의 일 형태에 따른 커패시터에 저장된 차지에 포지티브/네거티브 바이어스를 구현하기 위한 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 23은 본 출원의 일 형태에 따른 다중 입력 차지로부터 시간 펄스 합이 어떻게 생성되는지의 예시적인 실시예를 나타내는 그래프이다.
도 24는 본 출원의 일 형태에 따른 VREF 레벨을 시프트하는 것에 의해 바이어스를 추가하기 위한 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 25는 본 출원의 일 형태에 따른 공통 소스 스테이지의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 26은 본 출원의 일 형태에 따른 레벨 시프팅에 의한 차지 범위 확장의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 27은 스위치 누설을 줄이는 샘플 및 홀드 타임을 개선하는 단기 메모리 스킴의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 28은 본 출원의 일 형태에 따른 MOS 스위치의 게이트 전압을 제한하기 위한 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다. 그리고
도 29는 본 출원의 일 형태에 따른 빠른 시동을 위한 조향 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 1a는 스필 및 필 회로(spill and fill circuit)를 나타낸다.
도 1b는 도 1A의 스필 및 필 회로에서 저장 웰 SW 차지 저장소로부터 플로팅 확산 FD 차지 저장소로의 에너지 다이어그램을 나타낸다.
도 2는 "단일 트랜지스터" 차지 멀티플라이어 회로의 블록 다이어그램을 나타낸다.
도 3은 본 출원의 일 형태에 따른 뉴런(MAC + 활성화)의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 4는 본 출원의 일 형태에 따른, 플로팅 커패시터가 필요하지 않은 경우 단순 비례 차지 펄스 스위치 매트릭스에 호환되는 뉴런의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 5는 본 출원의 일 형태에 따른 코어의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 6은 본 출원의 일 형태에 따른 뉴런 네트워크 연결의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 7은 본 출원의 일 형태에 따른 차지 펄스 크로스바의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 8은 본 출원의 일 형태에 따른 4 개의 코어를 가지는 로컬 그룹의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 9는 본 출원의 일 형태에 따른 추가 코어에 연결되는 4 개의 코어의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 10은 본 출원의 일 형태에 따른 최대 풀링 회로 코어의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 11은 본 출원의 일 형태에 따른 차지 범위의 예시적인 실시예를 나타내는 다이어그램이다.
도 12는 본 출원의 일 형태에 따른 팩토리 프로그래밍 경로를 허용하기 위한 Zcell의 사용의 예시적인 실시예를 나타내는 블록도이다.
도 13은 본 출원의 일 형태에 따른 단축 조작에 사용될 수 있는 2D CCD 시프트 레지스터에 연결된 포토 다이오드의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 14는 본 출원의 일 형태에 따른 차지 투입을 감소시킬 수 있는 공핍된 차지 스위치의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 15는 본 출원의 일 형태에 따른 로컬 정확도 조정을 위해 뉴런 주소에 추가될 수 있는 로컬 비트를 생성할 수 있는 연속 시간 Δ∑의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 16은 본 출원의 일 형태에 따른 로컬 단기 동적 메모리의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 17은 본 출원의 일 형태에 따른 아날로그 NVM 차지 트랩 전류 소스의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 18은 본 출원의 일 형태에 따른 정류된 선형 타입 결정 회로의 예시적인 실시예의 그래프이다.
도 19는 본 출원의 일 형태에 따른 RELU 기능의 예시적인 실시예를 나타내는 그래프이다.
도 20은 본 출원의 일 형태에 따른 양면 차지 추가 또는 제거를 위한 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 21은 본 출원의 일 형태에 따른 차지 입력에 바이어스를 추가하기 위한 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 22는 본 출원의 일 형태에 따른 커패시터에 저장된 차지에 포지티브/네거티브 바이어스를 구현하기 위한 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 23은 본 출원의 일 형태에 따른 다중 입력 차지로부터 시간 펄스 합이 어떻게 생성되는지의 예시적인 실시예를 나타내는 그래프이다.
도 24는 본 출원의 일 형태에 따른 VREF 레벨을 시프트하는 것에 의해 바이어스를 추가하기 위한 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 25는 본 출원의 일 형태에 따른 공통 소스 스테이지의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 26은 본 출원의 일 형태에 따른 레벨 시프팅에 의한 차지 범위 확장의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 27은 스위치 누설을 줄이는 샘플 및 홀드 타임을 개선하는 단기 메모리 스킴의 예시적인 실시예를 나타내는 블록 다이어그램이다.
도 28은 본 출원의 일 형태에 따른 MOS 스위치의 게이트 전압을 제한하기 위한 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다. 그리고
도 29는 본 출원의 일 형태에 따른 빠른 시동을 위한 조향 회로의 예시적인 실시예를 나타내는 블록 다이어그램이다.
첨부된 도면과 관련하여 아래에 개진된 설명은 본 개시 내용의 현재 바람직한 실시예의 설명으로서 의도되고 본 개시 내용이 구성 및/또는 이용될 수 있는 유일한 형태를 나타내는 것으로 의도되지는 않는다. 설명은 예시된 실시예와 관련하여 개시 내용을 구성하고 운영하기 위한 기능 및 단계의 순서를 설명한다. 그러나, 동일하거나 동등한 기능 및 순서가 또한 본 개시 내용의 사상 및 범위 내에 포함되도록 역시 의도된 상이한 실시예에 의해 달성될 수 있다는 것이 이해되어야 한다.
아날로그 머신 러닝은 디지털 구현에 비해 상당한 전력 절감, 성능 개선, 정확도 개선 및 노이즈 감소를 약속한다. 하지만, 현재의 아날로그 구현 수단은 위에 설명된 것처럼 상당한 단점을 가진다.
이러한 아날로그 뉴런 네트워크에 대한 하나의 솔루션은 스위치드 차지(switched charge)의 개념을 기반으로 구축된다. 스위치드 차지 회로는 전압 또는 전류를 연결하는 스위치드 커패시터 회로와 매우 다른데, 스위치드 차지 회로는 커패시터 매칭에 의존하지 않거나 일부 구현에서 오퍼레이셔널 앰플리파이어(operational amplifiers)와 같은 유한 대역폭 장치에 의존하지 않기 때문이다. 커패시터에 대한 유일한 요구 사항은 커패시터가 그들에 연결된 차지를 저장할 만큼 충분히 큰 것이다. 매칭된 커패시터 값, 선형성, 평탄도 및 전압 또는 전류 스위치드 커패시터 도메인에서 오류를 생성하는 기타 요인은 스위치드 차지 회로 도메인과 관련이 없다.
스위치 차지 회로는 차지 저장 장치 및 차지의 추가 또는 제거를 위한 전류 소스로서 커패시터를 사용하여 구현될 수 있다. 차지 저장은 또한 센서 분야의 당업자에 의해 사용될 수 있는 고정된 포토 다이오드, 플로팅 확산, mems 멤브레인 또는 차지 결합 장치와 같은 다른 차지 저장 장치로 구현될 수 있다. 유사하게, 차지 추가 또는 제거는 도 1A에 도시된 것과 같은 스필 및 필 회로(spill and fill circuits)의 사용을 통해 구현될 수 있다. 차지 추가 또는 제거의 추가 수단은 당업자에게 알려져 있다. 다양한 스위치 차지 구현으로 인해 우리는 때때로 스위치 차지 회로를 zcells라고 부를 것이다.
스필 및 필 회로(10)는 전송 게이트 TG(transfer gate) 앞에 전자를 보유하는 PPD(pinned photodiode) 차지 리셉터클(receptacle)의 개념을 사용한다. 전송 게이트 TG는 필요한 전자 흐름에 따라 하강되고 상승된다. 어떤 지점에서 전송 게이트 TG는 전위 장벽을 낮추고 전자는 저장 웰 SW(storage well) 차지 저장소로부터 플로팅 확산 FD(floating diffusion) 차지 저장소로 유출된다. 모든 전자가 저장 웰 SW 차지 저장소로부터 플로팅 확산 FD 차지 저장소로 이동하도록 장치가 생성된다. 도 1B는 저장 웰 SW 차지 저장소로부터 플로팅 확산 FD 차지 저장소로의 에너지 다이어그램을 보여준다.
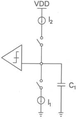
효율적인 아날로그 멀티플라이어(multiplier)는 도 2에 도시된 것과 유사한, 차지 멀티플라이어로서 구현될 수 있다. 도 2에 도시된 차지 멀티플라이어(20)(이하 멀티플라이어(20))는 본 발명자의 이름으로, 일련 번호 16/291,311를 가지는, "단일 트랜지스터 멀티플라이어 및 그의 방법"이라는 제목의 미국 특허 출원에 도시된 것과 동일하며, 여기에 통합된다.
멀티플라이어(20)는 감소된 수의 트랜지스터를 가질 수 있다. 일 실시예에 따르면, 멀티플라이어(20)는 MOSFET MN1을 가질 수 있다. MOSFET MN1은 공통 소스 구성으로 배열될 수 있다. 전류 소스 IMN1은 MOSFET MN1의 드레인에 연결될 수 있다. 인버터(22)는 MOSFET MN1의 드레인 단자에 연결될 수 있다. 인버터(22)의 출력은 전류 크기가 비례할 수 있는 두 전류 소스 I1 및 I2를 게이팅하기 위해 사용될 수 있다.
커패시터 C1은 제1 전류 소스 I1 및 MOSFET MN1의 게이트에 연결된 단자를 가질 수 있다. 커패시터 C1의 타단은 접지될 수 있다. 제1 전류 소스 I1은 커패시터 C2의 제2 단자 및 MOSFET MN1의 게이트에 연결될 수 있다. 제2 전류 소스 I2는 제2 커패시터 C2의 제1 단자에 연결될 수 있다.
리셋 스위치는 MOSFET MN1의 게이트에 연결될 수 있다. 일 실시예에 따르면, 리셋 스위치는 리셋 트랜지스터 MOSFET MNR일 수 있다. 본 실시예에서, MOSFET MNR은 공통 소스 구성으로 구성될 수 있다. MOSFET MNR의 게이트 단자는 리셋 신호 RESET에 연결될 수 있다. 전송 게이트 TG는 MOSFET MN1의 게이트 단자, 커패시터 C1의 제1 단자, C2의 제2 단자 및 전류 소스 I1에 연결될 수 있다.
기본 아이디어는 차지 이동 수단을 제1 차지 저장 저장소에 연결하는 것이며, 이 경우에 커패시터 C1과 다른 커패시턴스가 게이트 입력 노드에 연결되고, 제2 차지 이동 수단을 제2차지 저장소에, 이 경우에 차지 이동 수단의 이동 속도가 비례하고 둘 다 동일한 비교기에 의해 게이트되는 플로팅 커패시터 C2, 즉 비교기로 사용되는 공통 소스 구성의 MOSFET MN1은 Vt 비교기 임계치와 상관 관계가 있다.
멀티플라이어(20)는 다음과 같이 동작할 수 있다. 처음에는 전송 게이트 TG가 열려 있고 I1 및 I2를 생성하는 전류 소스 MOSFET은 커패시터 C2를 레일로 끌어 당겨 방전하거나 추가 스위치가 커패시터 C2의 제2 단자에 연결되고 MOSFET MNR은 낮게 유지된다. 이들 방법은 커패시터 C2가 방전되도록 한다. 커패시터 C2가 방전되면 다른 트랜지스터(전류 소스 포함)는 꺼진다. 또는, C2의 제1 단자가 접지된 다음 리셋 트랜지스터 MOSFET MNR이 게이트를 트립 임계치 Vt 아래로 당기고 전류 소스 I1이 활성화되어 MN1 게이트 노드를 충전하기를 시작할 수 있다. 어느 시점에서 MOSFET MN1의 게이트 상의 전압은 MOSFET MN1의 드레인을 반전시키고 인버터(22)의 출력은 전류 소스 I1을 끈다. MOSFET MN1의 게이트 단자는 이제 비교기 임계치 Vt에 해당하는 전압이다. C2 역시 Vt를 유지하거나 선택된 리셋 방법에 따라 전압을 가지지 않는다. 또는, C2가 두 번 리셋될 수 있고 Vt 임계치를 설정하여 일정한 충전 전류를 유지하고 슬로프(공통 소스 비교기 오버 슈트) 관련 오류를 줄이도록 I1+I2가 사용될 수 있다.
도 2에 도시된 바와 같이, 차지 패킷은 전송 게이트 TG의 좌측에 도입될 수 있다. 일 실시예에 따르면, 차지 패킷은 음의 차지 패킷이다. 전류 소스 I1 및 I2는 원하는 멀티플리컨트(multiplicand)를 형성하기 위해 서로에 비례하여 프로그래밍될 수 있다. 전송 게이트 TG가 켜지면 전자가 MN1 게이트 노드에 결합되어 그의 전압 전위가 감소한다.
차지 패킷은 MN1 게이트 커패시턴스를 방전하는 전류 소스일 수 있다. 차지 패킷은 또한 활성 픽셀로부터의 고정된 포토 다이오드의 차지 저장소에 저장된 차지 또는 활성 픽셀로부터의 플로팅 확산 또는 CCD 시프트 레지스터의 출력에 따라 제거된 차지일 수 있다. 그것은 예를 들어 마이크로폰의 음향 커패시터에 비례하여 형성되는 MEM 멤브레인에 의해 형성된 이 노드와 병렬인 커패시터일 수도 있다. 일부 경우에는, MN1 게이트 커패시턴스를 방전하는(차지 입력 정보를 제공함) 게이트 전류 소스와 같은, 전송 게이트가 필요하지 않다.
전송 게이트 TG가 켜지고 MOSFET MN1의 게이트 상의 전압이 Vt 비교기 임계치 아래에 입력 차지에 비례하여 떨어지면, 전류 소스 I1 및 I2가 켜진다. 커패시터 C1은 Vt 비교기 임계치에 도달할 때까지 I1+I2에 의해 충전되며, 이때 인버터(22)는 전류 소스 I1 및 I2를 끈다. 커패시터 C1을 Vt 비교기 임계치까지 충전하기 위하여 걸리는 시간은 방정식 tcharge=Qin/(I1+I2)로 나타낼 수 있다. 이 시간 동안 커패시터 C2는 전류 소스 I2에 의해서만 충전된다. 이것은 Qin/(I1+I2) 동안 Qin*I2/(I1+I2)의 차지를 커패시터 C2에 넣는 동안 발생한다. 따라서, 입력 차지는 I2/(I1+I2)에 의해 곱해지고 커패시터 C2에 저장된다.
플로팅 커패시터 C2의 차지는 제2 차지 이동 수단에 의해서만 조정되므로 그것은 차지 ΔQout=I2*Δt만큼 이동하고, 제1 차지는 ΔQin=(I1+I2)*Δt만큼 이동하므로, ΔQout=I2/(I1+I2)*ΔQin은 차지 이동 비율 만의 함수이다.
먼저 커패시터 C1 및 C2를 MN1 비교기 트립 포인트(MN1 comparator trip point)로 초기화한 다음, 차지를 제거하는 것은 오프셋 및 특정 노이즈를 제거하는 상관 이중 샘플링(CDS, correlated double sampling) 기능을 수행한다. 이를 최적화하려면, 공통 소스 비교기 MN1 게이트의 상승 슬로프(slope)가 일정해야 한다. 이것은 I1 대 I2의 비율을 조정하면서 I1+I2=일정하게 유지함으로써 달성될 수 있다. 공통 소스 비교기(common source comparator) 주변의 Schmidt 트리거 타입 동작(Schmidt trigger type action)과 유사한 포지티브 피드백(positive feedback)을 추가하는 것에 의해 개선될 수도 있다. 초기 리셋은 동일한 정전류(constant current)로 수행될 수 있다. 차지 이동 수단은 전류 소스 또는 스필 및 필 타입 회로일 수 있거나, 당업자에게 알려진 다른 타입의 차지 이동 수단일 수 있다. 차지 저장 수단은 커패시터, 고정된 포토 다이오드, 플로팅 확산, 차지 결합 장치, mems 마이크로폰에 사용되는 것들과 같은 mems 마이크로폰 또는 당업자에게 알려진 다른 차지 저장 수단일 수 있다. 플로팅 커패시터는 그것을 Vt로 사전 충전하기 위해 오른편 단자를 접지하여 먼저 충전되면, 플로팅에 걸친 전압(voltage across floating)은 wp2 페이스(phase)에서 감소하고 곱해진 충전 결과는 플로팅 커패시터 커패시턴스로 나누어진 곱하거나 나누어진 입력 차지 변화와 연관된 전압을 뺀 공통 소스 비교기 MN1의 스위치 포인트이다-동일한 공통 소스 비교기 스위치 포인트를 사용하는 추가 작업에 호환됨. 리셋 방법이 모든 차지를 제거하면 C2에 걸친 전압은 오직 플로팅 커패시턴스에 의해 나누어진 곱해진 입력 차지 변화이다. 곱셈 또는 나눗셈은 전류 크기 및 본질적으로 동일한 것에 의해 세팅된다.
제1 및 제2 차지 저장 수단(즉, 커패시터 C1 및 C2 각각)을 다음 회로에 직접 연결하는 대신에, 곱해진 차지 출력은 차지에 폭이 비례하는 펄스와 같은 다른 방식으로 연결될 수 있다. 도 3 및 4에는 이러한 방법이 도시되어 있다.
도 3에, 뉴런의 한 구현의 빌딩 블록이 나타내진다. 도 3의 상부에서, m1과 m2는 그들의 입력으로서 차지를 받아들이는 멀티플라이어를 나타낸다. 단지 두 개의 멀티플라이어만 나타나 있으나, 여러 멀티플라이어가 있을 수 있다. 도 2의 멀티플라이어(20)에 대한 설명과 함께, m1 및 m2는 차지 이동 수단(이 경우 전류 소스)이 입력 차지가 로딩된 후에 공통 소스 비교기를 그의 원래 스위치로 복원하는 동안 펄스를 출력하는 것에 의해 곱해진 차지에 비례하는 펄스를 생성한다.
이들 펄스는 임의의 수의 추가적인 차지 입력 장치에, 동적으로 연결될 수 있다. 예를 들어, 도 19에 ReLU 활성화 기능이 나타나 있다. 이 기능은 도 3의 하부에 있는 "Replica" 블록에 나타난 m1 및 m2에 의해 생성된 펄스를 가져와서 구현될 수 있으며, 이는 프로그래밍 가능한 레퍼런스(reference)를 통해 비교기에 더 연결된다. 또한, m1 및 m2는 또 다른 단일 트랜지스터 멀티플라이어에 연결된다. "Replica" 기능은 이 최소 "정류된" 차지를 m1 및 m2의 차지 다중 차지 펄스와 효과적으로 OR하여(OR’ing) 최소 "정류된" 시간이 경과할 때까지 출력 펄스가 종료되지 않도록 할 수 있다. C2의 차지가 필요하지 않으면 도 4와 같이 C2가 생략될 수 있다.
결과적인 펄스, m3는 다음 단계에서, 차지 이동 수단이 이전 단계의 전류 이동 수단에 매칭될 필요가 없도록 차지 정보를 포함할 것이다. m3를 ReLU 결정 펄스로 전환하려면 출력 펄스가 동등한 임계 차지 펄스 폭보다 작지 않은지 확인하기만 하면 된다. 이 경우, 임계 차지는 임계 차지를 설정하는데 사용될 수 있는 전류 DAC로 표시되지만, 게이트된 입력 펄스의 통합 차지가 비교될 수 있는 임계 차지를 생성하는 모든 수단이 제공되는데, 결정 인테그레이터(decision integrator)를 위한 차지 이동 수단은 결정 회로 출력단에 사용되는 단일 트랜지스터 차지 멀티플라이어의 것과 비례한다. 결과는 결정 회로의 단일 트랜지스터 차지 멀티플라이어 단계와 비활성된 트랜지스터 및 DAC에 의해 구현된 통합 블랭킹 단계(integrated blanking stage) 모두에서 게이트된 입력 전류에 대해 출력 페이스(phase) 동안 차지 전류를 조정하여 정규화될 수 있다. 임계 차지는 절반 차지, 또는 학습을 최적화하는 다른 차지일 수 있다. 임계치 또는 절반 차지도 학습 과정의 일부로 설정될 수 있다. 임계 차지는 차지가 종료되기 전에 극복해야 할 최소 차지를 나타내는 사전-로딩된 바이어스로 구현될 수도 있다(m1+m2가 제로의 입력 차지를 가진다면). 차지 이동 수단이 켜진 시간 동안 펄스를 출력함으로써, 다음 단계에 활성화 출력으로서 차지 정보를 전달할 수 있다.
추가 비교기 임계치(들)을 추가함으로써, 예를 들어 구분 선형 구현을 기반으로 하여, 비교기 출력을 기반으로 하는 합산 회로의 전류를 변화하는 것에 의해 SeLU, softplus, sigmoid, leakly ReLU, swish 등과 같은 다른 결정 함수를 근사화할 수 있다. leaky ReLU의 경우, 누설 부분의 슬로프(slope)도 학습 과정의 일부가 될 수 있다.
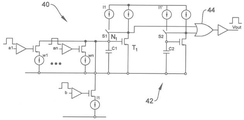
도 4에서, 차지 비례 펄스로서 정보를 수용하고 출력할 수 있고, 따라서 간단한 스위치 매트릭스 구현과 호환되는 대안적인 뉴런(40)이 도시되어 있다. 이 구현은 플로팅 커패시터 회로가 요구되지 않는 것으로 나타난다(그러나 그들이 다른 목적으로 원해지는 경우 사용될 수 있음). 이 경우 가중치는 스위치 a1... an 및 b에 의해 게이트된 입력 전류 소스의 크기의 비율에 의해 I1의 크기로 세팅된다. 입력 데이터에 비례하는 시간 동안 비례하는 전류 크기에 의해 가중치 값 세트에 따라 출력 전류에 각각 비례하는 이들 전류 소스 입력을 켜면, 여러 동시 입력, 심지어 중첩 입력에 대해 차지 곱셈 및 합산을 수행할 수 있다. 사실, 각 뉴런은 자체 최대, 최소 또는 임계치(예 : 중간 범위) 차지 레벨을 가질 수 있는데, 각 게이트된 펄스가 최대 펄스에 상대적이고, 로컬 최대 차지에 비례하는 차지를 생성하므로 글로벌 상관 관계가 필요하지 않다. Ie. 1의 가중치를 위한 출력 펄스는 전류 소스 I1, w1...wn의 크기를 조정하는 것에 의해 글로벌(최대) 마스터 펄스에 매칭될 수 있다.
최대 차지 범위를 설정하는 것에 의해, 소프트 최대값을 구현할 수도 있다. 이는 또한, 예를 들어 팔로워 또는 다른 DC 회로를 사용하여, 최소 게이트 전압을 제한하고, 최소 게이트 전압을 전위로 유지하거나, 다이오드가 접지 노드 또는 레벨 시프터 전위로 클램핑에 의해 구현될 수 있다.
상기 논의에서 차지 이동 수단은 모든 입력이 로딩될 때까지 도 4의 S1과 같은 스위치 또는 도 2의 MN1 비교기 드레인의 드레인에서 접지로의 트랜지스터(미도시)에 의해 억제될 수 있음에 유의하는 것이 중요하다. 이는 이 비활성 트랜지스터를 끄기 전에 최소 시간이 지나도록 하는 것에 의해 또는 모든 입력이 로딩될 때 플래그를 지정하는 컨트롤러를 통해 수행된다. 즉, 입력 차지가 입력 시간 창 중에 그리하는 한 언제 입력 차지가 도착하는지 알 수 없다. 출력 회로는 또한 컨트롤러처럼, 차지 수집(합계) 입력 페이스를 종료하고 출력 펄스를 시작하는 I1 재충전 페이스를 시작하기 위해, 원하는 경우 펄스를 요청할 수 있다.
도 4에서, 모든 입력 및 바이어스(사용되는 경우)가 수집되고 스위치 S1이 I1이 공통 소스 비교기 게이트 노드 N1을 충전할 수 있게 하기 전에 레벨에 도달할 필요가 있다. 이는 충분히 변경되지 않는 뉴런과 같은, 이벤트 구동 작업이 너무 적은 차지가 수집되는 경우 업데이트에 포함되지 않도록 한다. 때때로 이는 차지 범위의 일부를 제거하고 이 최소 레벨이 사용되지 않으므로 바람직하지 않다. 값이 0에 이르는 전체 범위가 필요한 경우 제로 펄스에 해당하는 최소 차지로 로딩해야 할 수 있다. 예를 들어 1ns 펄스는 0을 나타내고 8ns는 256을 나타낼 수 있다. 이들 두 레벨이 설정되었지만 1ns와 8ns 사이의 레졸루션(resolution)은 여전히 8 비트 이상일 수 있다. 이 최소 차지는 글로벌 마스터(최소) 펄스에 대한 저장된 바이어스 값 세트로 구현될 수 있다. 다른 경우에는, 뉴런 구현과 같이 - 전력을 절약하기 위해 너무 적은 변화를 가진 뉴런이 참여하지 않는 것이 바람직하다. 도 4에 설명된 방법은 두 가지 타입의 기능을 모두 허용한다. 공통 소스 비교기 게이트 노드 N1이 스위치 포인트로 리셋되고 그 후, 모든 입력이 로딩되면, 스위치 S1이 펄스를 생성하는 것이 가능해진다. 스위치 S1의 사용은 회로(40)가 펄스가 생성되는 시기를 결정할 수 있게 한다. 이를 통해 비동기 입력이 수집될 수 있다. 이 예에서, 가중치는 w1에서 wn (I1에 부분적으로 비례)으로 표시된 전류 크기로 설정되고, 게이트 입력이 있는 전체 I1이 예제 바이어스 입력으로 표시된다. 입력의 수는 추가 드레인 커패시턴스와 회로(40)의 원하는 응답 시간에 의해서만 제한된다. 바이어스 입력 I1과 가중치 w1 내지 wn은 이전과 같이 전류 비율에 의해 설정된다. 그 결과 펄스 입력로만 작으동하고 펄스 출력 정보를 생성하며, 간략화된 스위치 매트릭스가 가능한 매우 강력한 곱셈 및 합셈 회로가 생성된다.
또한, 도 4에는 새로운 결정 또는 활성화 회로(42)가 도시되어 있다. 커패시터 C2가 이전에 리셋되고, 그 후에 절반 차지 또는 다른 임계치가 제거된 경우(차지로 인해 전압 전위가 트립 포인트 아래로 감소됨), I1과 동일한 크기의 제2 전류 소스 I1 '은 I1 차지 출력 복구가 시작될 때 리셋 레벨로 활성화되고 예를 들어 게이트(44)에 의해 OR된(OR’ed) 다음 노드 Vout의 출력 펄스는 ReLU(rectified linear) 결정 회로가 된다. 다른 타입의 결정 회로는 도 18 및 19에 도시된 바와 같이 42와 협력하여 2 사분 오퍼레이션(quadrant operation)을 사용하여 조작함으로써 생성될 수 있다.
공통 소스 비교기를 사용하는 방법은 또한 도 20에 도시된 바와 같이 비교기 트립 포인트로부터 차지가 더해지거나 차감되는 2 사분면에서 구현될 수 있다. 이 방법에서 오퍼레이션의 사분면(스위칭 동작을 생성하기 위한 전압 상승 또는 전압 하강)을 위해 비교기 게이트 노드는 먼저 정확한 초기 임계치로 리셋된다. 이 클래스 B 구현의 "데드존"을 극복하기 위해, 당업자는 클래스 AB 기술을 사용하여 "데드존"을 극복하기 위한 많은 전략이 존재하고 따라서 상기 "데드존" 없이 2 사분 오퍼레이션이 가능하다는 것을 알고있다. 이 경우 단일 "리셋 레벨"이 양 사분면을 위해 사용될 수 있다.
차지 이동 수단은 차지 트랩 장치의 사용을 통해 구현될 수 있다. 차지 트랩 장치(170)의 일 실시예가 도 17에 나타나 있다. 차지 트랩 장치의 컨트롤 노드는 다중 비트 디지털 스킴(multiple bit digital schemes)에 비해 전력을 절약하는 단일 등가 비트에서 차지 배수의 조정을 허용하는 차지 펄스를 사용하여 연속적으로 조정될 수 있다. 차지 트랩 장치에 대한 작은 조정은 전체 디지털 쓰기 또는 지우기가 수행하는 비 휘발성 메모리에 대한 동일한 저하 효과를 갖지 않는 것으로 나타났다. 이는 단기 동적 메모리없이 뉴런 네트워크 학습을 위해 차지 트랩 장치를 사용할 수 있는 가능성을 열어준다. 대안적으로, 도 16에 도시된 것과 같은 단기 메모리(70)가 사용될 수 있다. 이 메모리(70)는 비 휘발성 메모리(NVM)로부터 값을 복사한 다음 조정에 사용되고 필요에 따라 NVM에 다시 기록된다. 공핍 접합 전송 게이트(depleted junction transfer gates) 및 플로팅 확산과 같은 CIS 기술(cmos 이미지 센서)은 차지 커플 장치 메모리와 같이 이 단기 메모리를 위해 대안으로 사용될 수 있다.
각 뉴런의 절대 차지 범위는 일치할 필요가 없다. 일 실시예에서, 로컬 레벨에서 요구되는 유일한 캘리브레이션(calibration)은 차지 범위를 설정하기 위해 최대 펄스를 제공하고, 선택적으로 차지 범위(그 후에 고정된 최소 차지에 의해 매 사이클마다 추가될 수 있음) 의 최소 또는 0을 설정하기 위해 최소 펄스를 제공하는 것이다. 이는 공통 소스 비교기 스위치 포인트 근처의 불확실한 "데드존"을 극복하기 위하여 필요할 수 있다. 개선된 Schmidt 타입 아키텍처의 라인에 따른 포지티브 피드백은 클래스 AB 바이어스 기술처럼 "데드존"을 줄이는데도 도움이 될 수 있다. 서브임계치 오퍼레이션은 또한 공통 소스 MOSFET의 이득을 증가시키고 그리하여 이들 다른 기술을 따라 또는 이와 함께 스위칭을 개선한다. 이미징 시스템에서 이는 입력 단계를 최대 글로벌 셔터 노출에 노출시키고 네트워크를 통해 가득한 차지로 전파함으로써 달성될 수 있다. 이 개념은 도 11에 도시되어 있다. 각 MAC(예를 들어, 42없는 도 4) 또는 뉴런(42 포함)에서, 최대 폭이 수신되고 최대 차지는 로컬 차지 이동 수단을 합리적인 동적 범위로 조정하는 것에 의해 기록될 수 있다. ReLU 또는 유도 타입 회로가 사용되는 경우 최대 펄스 출력이 되는 임계 레벨 또는 다른 임계 차지만 통신될 필요가 있다. 선택적으로, 이벤트 구동 뉴런 스위치 매트릭스를 생성하여 전력을 절약하는 임계 차지가 설정될 수 있다. 특히, 입력이 그보다 더 큰 차지를 생성하지 않는 한 뉴런은 펄스 출력을 전혀 생성하지 않는다.
이 접근 방식은 다음과 같은 몇 가지 이점을 제공한다: i) 고정된 포토 다이오드와 같은 센서에 직접 연결될 수 있다. ii) 매우 적은 차지가 요구된다. iii) 오프셋 및 특정 노이즈를 제거하기 위해 스위치드 차지 회로를 사용하여 상관 이중 샘플링(CDS, correlated double sampling) 토폴로지를 구축할 수 있다. iv) 따라서 매우 작은 커패시터를 사용하여 전력을 줄이고 성능을 높일 수 있다(커패시터가 매우 빨리 충전되기 때문에). v) 유한 루프 대역폭을 갖는 증폭기 또는 컴포넌트가 없으며, 전파(propagations)는 장치의 개방 루프 물리학에 의해 제한된다. vi) 차지 이동 비율은 정확하게 제어하기 쉽고 로컬 매칭만 필요하다. vii) 전송 게이트, 공핍 접합 및 플로팅 확산 기술을 사용하면 스위치드 차지 회로를 사용할 때 스위치드 커패시터 회로와 일반적으로 관련된 차지 투입을 줄일 수 있다. viii) 큰 왜곡없이 여러 경로로 쉽게 복제될 수 있는 차지에 비례하는 펄스를 생성할 수 있다. ix) 차지 펄스 출력이 있는 차지 기반 결정 회로를 생성하도록 차지 회로를 확장할 수 있다. ix) 비동기 오퍼레이션 및; x) 이벤트/임계치 구동 뉴런 오퍼레이션; x) 차지(펄스 입력을 받아들이고 펄스 출력을 출력함)에 비례하는 펄스에 응답하는 간단한 스위치 매트릭스를 사용하여, ADCs / DACs 또는 다른 컴플렉스인터페이스 전기 회로망을 제거한다. xii) 다른 솔루션의 고유한 소음 한계를 극복한다. xiii) 임의 정밀성의 스킴과 호환된다.
초소형 커패시터가 사용될 수 있다는 것은 앞서 언급되었다. CMOS 이미지 센서 분야의 당업자는 전송 게이트, 플로팅 확산, 차지 결합 장치 어레이 및/또는 10fF 미만 또는 수천 개의 커패시턴스를 사용하는 고정된 포토 다이오드를 사용하는 상관 이중 샘플링에 사용되는 스위치드 플로팅 확산 회로로 14 비트 정확도를 입증했다. 임의의 정밀도는 오버 샘플링 기술을 사용하거나 낮은 정밀도에 대해 다중 MSB 및 LSB 경로를 유지하고 나중에 그들을 결합하는 것에 의해 구현될 수 있다. 예를 들어 이것은 러닝 애플리케이션(learning applications)에서 유용할 수 있다. 이러한 회로는 많은 픽셀을 디지털 값으로 변환하는데 관련된 시간으로 인해 입력의 여러 시간 노출 샘플을 저장하기 위해 차지 결합 시프트 레지스터에 연결되었다. 도 13은 다중 노출 또는 단축 계산을 위한 가중치의 재정렬에 사용될 수 있는 이러한 차지 결합 장치를 예시한다. 차지 결합 장치는 일련 번호 16/291,864를 가지고, 본 발명자의 이름으로, 그리고 여기에 포함된 "Charge Domain Mathematical Engine and Method"라는 제목의 미국 특허 출원에 나타난 것과 동일하다. 도 14는 예를 들어 종래의 스위치드 커패시터 구현에서 기대할 수 있는 중첩 커패시턴스를 공핍시킴으로써 스위칭과 관련된 차지 투입을 감소시키는 그러한 공핍 접합 전송 게이트(depletion junction transfer gate)를 나타낸다.
픽셀에 다중 입력 노출을 저장하기 위하여 이러한 시프트 레지스터를 사용하는 대신에, 도 13에 도시된 CCD 시프트 레지스터의 뉴런 내장 버전(neuron embedded versions)을 사용하여 다른 뉴런에 대한 다중 가중 입력과 함께 사용하기 위해 입력 데이터의 여러 사본 또는 도 16에 도시된 단기 메모리를 빠르게 저장할 수 있다. 추가적으로, 플로팅 확산, 전송 게이트 및 유사한 cmos 이미지 센서 도메인 회로와 함께 상관 이중 샘플링(CDS) 기술을 사용하여 멀티플라이어, 결정 회로 및 합산기를 구현할 수 있다. 이러한 회로의 차지 투입이 기존의 스위치드 커패시터 회로와 비교하여 극적으로 감소됨에 따라, 차지 저장 수단(예를 들어 커패시턴스 또는 플로팅 확산의 차지 저장 커패시터)의 등가의 크기가 차례로 감소될 수 있다. 이것은 차지 저장소를 채우기 위하여 요구되는 차지(더 빠르게 함) 및 사용되야하는 차지량(전력을 절약함)을 감소시킨다.
CDS는 플리커 노이즈(flicker noise)와 같은 오프셋 및 노이즈를 줄이고 유한 펄스 기반 입력 샘플링(finite pulse-based input sampling)은 등가 노이즈 대역폭을 줄여 kT/C 노이즈를 줄여주는데, 그렇지 않으면 이러한 작은 차지 저장소가 기존의 스위치드 커패시터 구현에서 스위치드 차지 기능에 바람직하지 않게 만들 수 있다. 상기를 구현하는 새로운 방법은 차지 이동 수단을 차례로 제어하는 입력 장치로서, 부하를 가지는, 공통 소스 트랜지스터(common source transistor)를 사용하는 것이다. 이를 통해 CDS를 포함하는 매우 작고, 매우 빠른 비교기 수단을 만들 수 있다. CDS 동작을 이해하기 위해 도 4에 나타난 공통 소스 트랜지스터 T1이 초기에 트립 포인트에 있는 것을 고려한다. 그 후, 입력 차지 정보 이외에도, 플리커 노이즈와 같은 노이즈가 입력 차지의 부하 중에 축적된다. 게이트 전압이 출력 펄스 기간 동안 공통 소스 트랜지스터 T1의 스위치 포인트로 다시 충전될 때 방전 및 충전 전류 소스(예를 들어, w1..주 b vs I1)의 등가 노이즈 크기와 일치하도록 노력한다면 이전에 로드된 플리커 노이즈를 효과적으로 제거할 수 있다. 활성화 출력 수단(도 4의 42)은 그것의 트립 포인트로 리셋되고 차지가 제거된 다음 트립 포인트로 돌아 가기 위해 추가되는 경우 유사한 효과를 가진다. 뉴런 출력 버퍼(도 4에서 44의 오른쪽)는 버퍼는 다양한 연결 수(동적 로드)에 대한 에지 효과를 제거하기 위한 적응형 버퍼(adaptive buffer)일 수 있다.
이러한 작은 커패시터를 사용할 수 있는 회로를 사용하면 장치의 기생(parasitics)만을 사용하거나, 필요에 따라 요구되는 것보다 더 작은 커패시터에 의해 증가된 기생을 대신 사용하여, 다이 면적(die area)을 줄일 수 있다. 스위치드 차지 회로에서 커패시터의 절대 값과 선형성은 중요하지 않으므로, 이러한 기생과 관련된 장치 변동은 무시될 수 있다. 또한, 전송 게이트 및 공핍 접합 장치와 플로팅 확산을 사용하면 종래의 스위치드 커패시터 회로에 더 큰 커패시터를 강제하는 차지 투입 효과(charge injection effects)가 감소한다. 공통 소스 스킴(common source scheme)에서 CDS 및 유한 노이즈 대역폭 입력 샘플링(전체 기간에 비해 펄스 샘플이 작음)을 사용하면 오프셋, 장치, 온도 및 다른 비 이상적 요소뿐만 아니라 플리커(flicker)와 같은 노이즈가 제거되고 기존의 스위치드 커패시터 회로와 비교하여 kT/C 노이즈가 크게 감소한다. 동시에 공핍 접합 전송 게이트는 차지 투입을 줄인다.
그 결과 스위치드 차지 회로는 기존의 아날로그 방식보다 더 효율적이고 매우 작은 차지 저장 요소로부터 차지를 추가하거나 제거하는 데 걸리는 시간이 적고 유한 대역폭 응답 프로파일(finite bandwidth response profiles)을 가진 opamp와 같은 구성 요소 제거 때문에 GHz 또는 10GHz 범위 내에서 잠재적으로 잘, 극히 높은 작동 속도로 작동할 수 있다. 사실, 멀티플라이어가 매우 빨라서, 데이터 속도는 펄스가 여러 경로에 복사되는 경우 적응형 드라이버 및 리피터를 추가로 필요로 하는 전송 라인 및 기타 매칭 효과를 고려해야 할 수 있다.
위의 모든 사항을 통해 다른 아날로그 수단에서 종종 요구되는 것처럼 최소의 캘리브레이션이 필요하고 지속적인 튜닝이 필요하지 않은 장치 및 온도 독립적인 차지-기반 수단을 구현할 수 있다. 이러한 장치에 의해 생성된 펄스는 각 로컬 뉴런의 차지 및 최대 차지 범위에 비례하므로, 최대 펄스 및 선택적으로 최소 또는 임계 차지(잠재적으로 한 번만) 이외의 뉴런 캘리브레이션 또는 튜닝을 어떤 뉴런에도 제공할 필요가 없다. 이를 통해 우리는 매우 강력한 스위치 매트릭스를 개발할 수 있다.
본 스위치 매트릭스(80)는 도 8에 예시된 것과 유사한, 메모리, 바이어싱(biasing) 및 뉴런의 뱅크(bank)를 포함하는 로컬 코어(82)로 구성될 수 있다. 로컬 컨트롤러(84)는 같은 뱅크 또는 다른 4개의 뱅크에서 뉴런 사이의 로컬 연결을 생성하는 도 7에 추가로 예시된, 크로스바를 제어한다. 이것은 도 9에 예시되어 있다. 각 로컬 컨트롤러(84)는 다른 로컬 컨트롤러(84)와 통신하는 로컬 크로스바(86)를 제어할 것이다. 로컬 컨트롤러(84)는 네트워크의 라우터를 나타낸다. 연결된 레이어와 관련된 것들과 같은 뉴런의 그룹은, 입력의 세트(a set of inputs)를 필요로 할 것이고, 적절한 뉴런과 관련된 로컬 컨트롤러(84)는 프레임에 연관되고 참여하는 모든 뉴런이 그들의 입력 데이터를 수신할 때까지 크로스바(고 7)를 통해 통신하고 프레임을 유지할 것이다.
제2 프레임 정보는 초기 프레임 이후 차지 저장소 또는 단기 메모리에 저장되며, 마지막 컨트롤러(84)가 그것의 제1 프레임 활동으로 완료되었음을 표시한 경우에만 컨트롤러(84)가 제2 프레임을 시작할 것이다. 컨트롤러(84)는 또한 가상 뉴런(재사용 뉴런)을 나타내는 뉴런 연결이 순차적으로 연결되도록 실행 제어를 처리할 것이다. 이런 식으로 스위치 차지(뉴런에 연결된 펄스 네트워킹) 개념을 사용하여 얻을 수 있는 속도로 인해 더 적은 수의 뉴런이 훨씬 더 큰 뉴런 네트워크를 시뮬레이션할 수 있다.
프레이밍(framing) 동안 스위치 매트릭스 연결 제어를 개방하기 위해, 컨트롤러(84)는 주소를 참여 뉴런과 연관시킬 것이다. 이 주소는 디지털이지만 로컬 클러스터 또는 그룹에 연관되는 것에 의해 크기가 제한되며 각 프레임의 펄스 스위치 연결의 개방에만 관련된다. 각 뉴런 뱅크의 상대적 주소 지정(addressing) 및 제한된 수의 컨트롤러(84)로 인해 주소가 작을 수 있다.
뉴런 네트워크의 사용자는 향상된 정확도를 요구할 수 있다. 연속적인 시간 델타 시그마 조정 수단(오버샘플링)에 의해 가중치 로딩 중에 로컬로 저장된 조정에 해당하는 선택적인 비트 세트를 추가함으로써 향상된 정밀도를 생성할 수 있다. 이러한 연속적인 시간 델타 시그마 컨버터(90)는 도 15에 보여질 수 있다. 델타 시그마 컨버터(90)는 결과가 일치함을 보장하기 위해 알려진 가중치에 대해 테스트 차지를 곱함으로써 정확도와 시간을 교환할 수 있다. 오버 샘플링된 속도(스위치 차지 회로 스위칭보다 빠름)로 구현된 비트 스트림에 대해 게이트된 로컬 전류 소스를 제어함으로써 로컬에서 수정된 더 높은 정확도의 결과를 생성하고, 이 정보를 디지털로 저장할 수 있는데, 예를 들어 로컬 컨트롤러(84)가 비트를 뉴런 주소와 연관시킬 수 있다. 또한 이 회로는 디지털 캘리브레이션 입력으로부터 가중치를 로드하고 초기 입력 벡터의 팩토리 로드에 잘 매칭되도록 다시 사용될 수 있다. 또는, 감소된 정밀도의 별도의 LSB 및 MSB 경로를 유지하고 나중에 정밀도를 높이기 위해 그들을 결합할 수 있다. 어느 쪽이든 뉴럴 네트워크의 교육된 구현은 많은 아날로그 구현과 달리 디지털 구현과 유사한 프로세스 또는 정밀도 제한이 없다. 이를 통해 아날로그 구현은 추가 정밀도가 요구되는 딥 러닝 애플리케이션에 참여할 수 있으며, 대부분의 경쟁 아날로그 구현은 추론으로 제한된다.
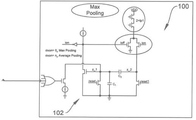
많은 뉴런 네트워크 구현에서, 가장 작은 결과와 가장 큰 결과를 취하고 이들 결과에 대해 시스템을 리스케일링(re-scaling)하여, 컨벌루션(convolution)의 결과와 같은, 값 그룹을 정규화할 필요가 있다. 새로운 구현에서 이것은 이들의 레벨과 관련된 이들의 최대, 임계치 및 최소 값을 사용하여 최대 차지 범위, 임계치(예를 들어, 절반 차지) 범위 및/또는 최소 차지 범위를 리캘리브레이팅(re-calibrating)함으로써 달성될 수 있다. 이것는 로컬 전류 소스를 조정하거나 고정 입력 바이어스를 조정하여 뉴런 그룹의 로컬 최소 및 최대를 조정하기 위해 DLL을 사용하여 의해 수행될 수 있다. 최대 풀링(Max pooling)은 도 10에 나타난 회로(100)에 보여지는 바와 같이 달성될 수 있다. 회로(100)에서, 입력은 함께 OR된(OR’ed) 다음 차지 멀티플라이어 회로(102)에 인가된다.
도 5는 펄스 기반 뉴런(50)을 나타낸다. 입력 및 출력은 최대에서 상관된 펄스이고, 선택적으로 "데드존"을 극복하기 위한 최소 또는 임계 차지 레벨이며, 물리적 연결 제약이 없다. 또한, 시간이 지남에 따라 연결의 변경에 의존하는 반복 네트워크(recurrent networks)는 앞에서 설명된 시간 프레임 접근 방식을 사용하여 구현될 수 있다. 도 5는 단기 메모리, 장기 비 휘발성 메모리, 로컬 바이어스, 인터페이스, zcell 회로(3 또는 4의 회로로부터 구축될 수 있는 회로), 그리고 크로스바를 포함하여 로컬로 함께 그룹화될 수 있는 "클러스터"인 회로 그룹을 보여준다. 도 5의 크로스바는 동일한 펄스로 구동될 수 있는 라인을 함께 연결하는 것에 의해 작동한다. 삼각형은 만들어진 연결 수에 관계없이 일정한 에지 속도를 유지하는 적응형 드라이브를 나타낸다. 검은 색 원은 연결을 나타내며 열린 원은 연결되지 않는다.
도 6은 뉴런 네트워크에서 가능한 많은 다른 연결 타입을 보여준다. zcell을 재사용하여 가상 뉴런을 생성하거나, 동적 방식으로 반복되는 뉴런 네트워크를 위해 이러한 연결을 만들 수 있는 것이 바람직하다. 도 7은 거리에 걸쳐 동시에 많은 뉴런을 함께 연결하기 위해 연속된 크로스바가 어떻게 사용될 수 있는지를 보여준다. 공통 스레드(common thread)는 다른 뉴런의 수로 구동되는 동시 펄스(simultaneous pulse)이다. 시간 프레임을 활용하는 것에 의해, 서로 다른 뉴런이 서로 다른 시간에 동적으로 연결될 수 있고 펄스는 도 6에 예시된 기능을 구현할 수 있도록 서로 다른 방향으로 이동할 수 있다.
도 8은 로컬 컨트롤러(84)가 4개의 클러스터 영역의 로컬 연결을 개방하는 것을 어떻게 책임질 수 있는지를 예시한다. 이 구성을 코어(82)라 부를 수 있다. 도 9는 동적으로 서로 다른 프레임 동안 상이한 연결을 개방하기 위해 로컬 컨트롤러(84) 사이의 글로벌 크로스바(86)를 개방하기 위해 이들 코어(82)가 서로 어떻게 통신할 수 있는지 보여준다.
뉴런 네트워크 또는 머신 러닝 시스템의 팩토리 로딩 및 캘리브레이션은 대규모 네트워크에 로딩될 필요가 있는 많은 수의 가중치와 바이어스로 인해 상당한 시간이 걸릴 수 있다. 뉴런 네트워크를 픽셀 어레이에 통합하고 로컬 차지 도메인 메모리를 제공하는 것에 의해 데이터를 매우 빠르게 병렬 로딩할 수 있어, 팩토리 캘리브레이션 또는 학습 상황에서 시간과 비용을 절약할 수 있다. 특히, 로딩하려는 데이터에 해당하는 픽셀 데이터를 제공하는 테스트 픽스처(test fixture)가 개발된 경우(주어진 픽셀에 대한 빛의 강도에 의해 세팅된 가중치 및 바이어스와 같은) 픽셀 수 많큼 많은 가중치 또는 바이어스를 병렬로 로딩할 수 있다. 예를 들어, 1,200 만 픽셀 어레이는 1,200 만 개의 정보를 병렬로 로딩할 수 있다. 1us보다 적은 차지 축적 시간으로 이는 초당 12M*1e6=12e12 또는 12 terabytes의 데이터를 로딩할 수 있음을 의미한다. 14 비트의 추정 정확도에서 이는 다른 수단을 사용하여 일치시키기 어려운 초당 12*12=144 terabits의 데이터 속도로 로딩하는 것과 동일하다.
스위치드 차지 회로에서 전류 소스를 구현하기 위해 MOSFET이 사용되는 경우, 포화 또는 서브임계치 오퍼레이션(subthreshold operation)이 활용될 수 있다. 서브임계치 영역 오퍼레이션은 속도를 희생하면서 전력을 감소시킨다. 이 방법은 또한 당업자에게 익숙한 바와 같이 pHEMT, finfets, 그리고 backgate control과 같은 다른 타입의 장치로 확장될 수 있다.
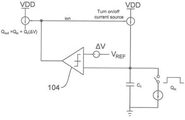
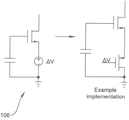
메모리 소자 또는 커패시터와 같은 제어 레지스터에 양전하 또는 음전하를 추가하기 위한 방법 및 장치는 도 16에서 I12로 표시되는 그림 22에 나타나 있다.이 경우 커패시터 C22의 전압은, 예를 들어 학습 애플리케이션의 가중치 값을 조절하기 위한 짧은 펄스를 사용하여 증가 또는 감소될 수 있다. 예를 들어 i*tpulse는 양의 펄스가 적용되는 경우 증가 전하이고 -i*tpulse는 음전하 펄스를 가지는 있는 감소 펄스이다. 적용된 바이어스 단계의 크기는 펄스 폭 또는 전류 바이어스 레벨을 변경하는 것에 의해 조정될 수 있다. 이것은 도 22에 나와 있다. 도 23은 펄스 기반의 전하 부하 및 스위치드 차지 MAC(곱셈 및 누적 회로) 또는 zcell의 출력 펄스 개념을 나타내고, 입력 차지가 로드될 때 기준 레벨에서 차지 레벨의 변화를 보여주며, 시스템이 기준 레벨로 돌아갈 때 차지에 비례하는 펄스 출력 시간을 나타낸다.
이것은 예를 들어 학습 과정 동안 가중치를 변경하거나 뉴런에 바이어스를 구현하기 위해 사용될 수 있다. 도 24는 캘리브레이션 사이클 후에 비교기(104)에 인가되는 기준 전압의 레벨을 시프팅하는 것에 의해 뉴런 바이어스를 구현하는 방법을 나타낸다. 위의 설명에서 VREF 및 ΔV는 QREF 및 ΔQ를 대체할 수 있다는 점에 유의해야한다.
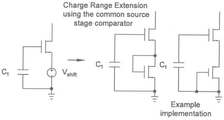
게이트 노드가 차지를 로딩하기 위해 사용되는 공통 소스 비교기를 사용하면 게이트 전압에 의해 제한되는 동적 범위가 생성되거나 게이트가 음 전압으로 전환될 수 있도록 절연이 요구된다. 범위를 확장하기 위해 도 25 또는 도 26에 나타난 방법이 사용될 수 있다. 공통 소스 트립 포인트를 더 높게 시프팅하면, 차지를 로딩할 때 게이트 노드의 동적 범위를 증가시킬 수 있다. 공통 소스 비교기의 스위치 성능을 향상시키려면 gm을 증가시키기 위하여 그것의 크기를 증가시키는 것이 바람직하다. 불행히도 그렇게 하면 트립 전압이 감소하고, 전압 범위가 더욱 제한된다. 따라서, 공통 소스 비교기의 소스와 접지 사이에 다이오드 연결 장치 또는 도 25에 도시된 팔로워(follower)와 같은, 레벨 시프트를 사용하면 gm 및 동적 차지 범위를 모두 높일 수 있다. 스위칭 기술과 같은 Schmidt 같은 포지티브 피드백의 사용은 스위치 포인트를 최적화하고 유한 비교기 스위칭 시간 및 오버 슈트와 관련된 어떠한 "데드존"이라도 최소화하기 위해 이들 기술과 함께 사용될 수도 있다.
예를 들어 가중치를 임시로 저장하거나 정보를 입력하는데 사용될 수 있는, 단기 메모리와 관련하여, 도 27에 도시된 방법이 사용될 수 있다. 이 경우 M1 제어 게이트를 접지 또는 접지 아래로 당기고 M0및 M1 사이에 공유되는 노드를 올리면 이 공유 노드의 전압이 Vmem에 가까울 경우 채널 누설이 최소화된다. 매칭이 정확하지 않더라도, 채널의 전압을 줄이는 것에 의해 채널 누설이 감소된다. 도 16은 또한 채널 누설을 최소화하기 위해 스위칭 엘리먼트 M5의 백게이트(backgate)를 이동하는 방법을 보여준다.
도 28에는 샘플링 스위치가 꺼지는 동안 차지 주입 및 커패서티브 피드스루(capacitive feedthrough)를 감소시키기 위한 방법이 보여진다. 이러한 아이디어는 게이트 전압 범위를 제한하는 것이다. 다른 부스트 전압이 전압 스위치 범위를 최소화하거나 차지를 피하기 위한 경로를 제공하기 위한 시도로 사용될 수 있다. 또한, MOS 스위치(108) 및 커패서티브 피드스루의 반전 및 중첩 커패시턴스 차지는 모두 게이트 전압에 비례한다. 더 긴 게이트는 누설이 적지만 반전 및 중첩 차지가 많은 것을 의미하는데, 사용될 수 있는 최대 전압을 제한하는 대신, 감소된 출력 전압 레벨을 가지는 디지털 드라이버를 사용하면 투입을 줄일 수 있다. 이 스킴은 저장된 전압에 적응하는 플로팅 드라이버로서 구현될 수도 있다.
뉴런에 대한 바이어스의 구현은 뉴런 네트워크의 표준 방법이다. 도 21은 프로그래밍 가능한 지연 라인이 바이어스를 생성하기 위해 사용될 수 있는 방법을 예시한다. 이 바이어스는 단기 또는 장기 메모리에 저장된 값에 따라 생성될 수 있다.
입력 신호 레이어는 스위치드 차지 장치를 사용할 때 매우 유연하다는 점에 유의해야 한다. 이미징 애플리케이션의 경우, 차지 전송 수단이 스위치드 차지 회로(예. 도 2, 3 또는 4)에 결합되는 입력 저장 수단으로서 고정 플로팅 다이오드가 사용될 수 있다. 글로벌 셔터 및 차지 멀티플라이어 수단은 입력 차지를 곱하거나 시스템을 정규화하기 위하여 사용될 수 있다. 대안적으로, 시스템은 먼저 차지 비례 펄스로 변환함으로써 다른 방식으로 차지를 수용할 수 있으며, 그 후 도 3 및 도 4에 도시된 공통 소스 비교기의 게이트와 같은 스위치 차지 회로에 연결된다. 예로는 MEM 또는 다른 타입의 마이크로폰의 차지, 전압, 또는 전류 입력일 수 있으며, 또는 MEMs 마이크로폰의 MEMs 멤브레인에 의해 형성된 커패시턴스는 공통 소스 비교기 게이트와 병렬로 배치되거나, 입력은 이미지 센서, 초음파, APD 포토디텍터, 레이더, 가속도계, 자이로, 압력 게이지 또는 기타 센서 입력일 수 있다.
도 29는 단일 트랜지스터 차지 멀티플라이어 또는 zcell의 빠른 오퍼레이션을 허용하기 위해 사용되는 스티어링 회로(110)를 도시한다. 전류 소스의 한정된 안정화 시간으로 인해, 이미 설정된 전류 소스를 가지는 스티어링 회로(110)의 사용은 단일 트랜지스터 차지 멀티플라이어에 사용되는 것과 같은 비교기를 사용하여 전류 또는 차지 이동 수단의 신속한 리-디렉션(re-direction)을 허용한다. 전류 소스는 정적 전력을 절약하기 위해 오퍼레이션 사이에 여전히 꺼져있을 수 있지만, 도 2, 3 또는 4에 도시된 것과 같은 zcell 오퍼레이션의 제1 페이스에서 제2 페이스로 이동하는 것과 같은 구동 중에, 스티어링 회로(110)가 사용되면 사용되지 않을 경우 충전 비율을 저하시킬 수 있는 스위칭과 관련된 오류가 감소된다. 이는 동적으로 가능한 다른 차지 이동 수단으로 확장될 수 있는데, - 즉, 차지 소스가 사용 직전에 최소 차지로 충전될 수 있어 소스를 작동시키고 불능화하는 대신 자동으로 전력 손실을 제한한다. 또한, 예를 들어 스티어링 회로(steering circuits)는 "온데크(on deck)"에 있는 다음 가중치에서 번갈아 스위칭하여 그것을 순차적으로 로딩하고 안정화될 때까지 기다리는 대신에 뉴런 또는 MAC 재사용을 위한 빠른 애플리케이션을 준비할 수 있다. 스티어링 회로는 로컬 버퍼 파이프 라인의 끝에서 "메모리의 프로세스" 전력 소비를 최적화하기 위해 "온데크" 위치에 가중치를 부여 할 수 있다.
펄스가 스위치드 차지 회로에서 커패시터를 매칭할 필요가 없도록 차지 정보를 전달하는 것을 당업자는 알 수 있다. 또한 스테이지 간 튜닝이 필요하지 않다. 주어진 멀티플라이어 또는 결정 회로에 대한 차지 범위를 최적화하기 위하여 로컬 튜닝만이 필요하다.
일 실시예에 따르면, ReLU 결정 회로가 개시된다. ReLU 결정 회로는 임계 차지에 해당하는 최소 펄스 폭을 출력하고 스위치드 차지 회로에서 적어도 임계 차지 레벨에 도달할 때까지 추가 펄스 확장을 억제한다.
일 실시예에 따르면, 단기 메모리/샘플 및 홀드 회로가 개시된다. 단기 메모리/샘플 및 홀드 회로는 공통 노드를 직렬로 공유하는 한 쌍의 스위치를 가지고, 여기서 제1 스위치는 샘플링되기 위한 입력 전압에 연결되고 제2 스위치는 샘플링된 입력 전압을 저장하기위한 차지 저장 장치 출력에 연결된다. 바이어싱 장치는 공통 노드의 전위를 프로그래밍하기 위해 공통 노드에 연결된다. 이 바이어싱을 통해 스위치 내 접합의 전압을 최소화함으로써, 단기 메모리/샘플 및 홀드 회로는 채널 누설 및 다른 접합 누설을 최소화하여 차지 저장 장치 출력의 유지 시간을 최대화한다.
일 실시예에 따르면, 샘플링 스위치를 위한 드라이버 회로가 개시된다. 레벨 시프팅 소자에 연결된 cmos 인버터를 포함하는 샘플링 스위치를 위한 드라이버 회로로서, cmos 인버터는 샘플링 스위치에 연결되어 cmos 인버터의 전압 범위가 샘플링 스위치에 의해 요구되는 전압에 비례하여 제한된다.
일 실시예에 따르면, 입력 레이어가 개시된다. 입력 레이어는, 다음의 레이어를 적용하기 전에 이를 정규화하기 위해 고정된, 프로그래밍 가능한 또는 학습된 양 중 하나에 의해 입력이 먼저 곱해진다.
본 특허 출원은 David Schie의 이름으로 "차지 기반 스위치드 매트릭스"라는 제목의, 그리고 그 전체가 참조로서 여기에 포함되는, 2019년 10월 10일에 출원된 미국 가출원 번호 62/743,130과 관련이 있다. 본 특허 출원은 35 U.S.C §119(e)에 따라 혜택을 주장한다.
당업자에게 공지된 상기 수단 및 방법의 다양한 구현은, 특히 설명된 상이한 스위치, 차지 저장 수단, 또는 차지 이동 수단이 삽입되고 상이한 타이밍 수단 또는 차지 펄스 통신의 변형이 구현될 때 당업자에게 공지될 것이다.
본 개시의 실시예가 다양한 특정 실시예의 관점에서 설명되었지만, 당업자는 본 개시의 실시예가 청구 범위의 사상 및 범위 내에서 수정으로 실시될 수 있음을 알 것이다.
20: 멀티플라이어 40: 뉴런
80: 스위치 매트릭스
80: 스위치 매트릭스
Claims (30)
- 초기 페이스(phase) 동안 차지(charge)를 수신하기 위해 입력에 연결된 적어도 하나의 입력 차지 저장 장치-상기 적어도 하나의 입력 차지 저장 장치는 초기에 전위 또는 차지 임계치 중 하나로 리셋됨;
출력 및 상기 적어도 하나의 입력 차지 저장 장치에 연결된 적어도 하나의 출력 차지 저장 장치-상기 적어도 하나의 출력 차지 저장 장치는 초기에 차지 레벨로 리셋됨;
상기 적어도 하나의 입력 차지 저장 장치와 상기 적어도 하나의 출력 차지 저장 장치를 연결하는 공유 노드에 연결된 비교 장치;
상기 적어도 하나의 출력 차지 저장 장치에 연결된 적어도 하나의 제1 전류 소스;
상기 적어도 하나의 출력 차지 저장 장치 상에 차지 곱셈 또는 나눗셈 중 하나를 생성하도록, 상기 적어도 하나의 입력 차지 저장 장치 및 상기 적어도 하나의 출력 차지 저장 장치를 상기 적어도 하나의 제1 전류 소스에 크기에 비례해 연결하여 공유 노드에 연결된 적어도 하나의 제2 전류 소스
를 포함하고,
상기 적어도 하나의 제1 전류 소스 및 상기 적어도 하나의 제2 전류 소스는 제2 페이스의 시작에서 켜지고 상기 공유 노드가 차지 곱셈 또는 나눗셈 중 하나의 크기에 비례하는 출력 펄스를 생성하는 전위 또는 차지 임계치 중 하나에 도달하면 꺼지는 것을 특징으로 하는 스위치드 차지 회로.
- 초기 페이스(phase) 동안 차지를 수신하도록 초기에 차지 임계치로 리셋되고 입력에 연결되는 적어도 하나의 입력 스위치드 차지 저장소;
펑셔널 시리즈(functional series)로 출력 및 제1 입력 차지 저장소에 연결된, 초기에 차지 임계치로 리셋된 적어도 하나의 출력 스위치드 차지 저장소;
상기 적어도 하나의 입력 스위치드 차지 저장소 및 상기 적어도 하나의 출력 스위치드 차지 저장소를 연결하는 공유 노드에 연결된 비교 장치;
상기 적어도 하나의 출력 스위치드 차지 저장소에 연결된 적어도 하나의 제1 차지 이동 장치;
차지 곱셈 또는 나눗셈 중 하나를 생성하기 위해 비례 차지 레이트(proportional charge rates)로 상기 적어도 하나의 입력 스위치드 차지 저장소 및 상기 적어도 하나의 출력 스위치드 차지 저장소를 충전하도록 상기 적어도 하나의 제1 차지 이동 장치에 크기에 비례하여 공유 노드에 연결되는 적어도 하나의 제2 차지 이동 장치; 및
상기 적어도 하나의 제1 차지 이동 장치 및 상기 적어도 하나의 제2 차지 이동 장치가 제2 페이스 동안 온(on)되는 시간 동안 출력 펄스를 구동함으로써 차지 곱셈 또는 나눗셈 중 하나의 크기에 비례하여 출력 펄스를 생성하는 드라이버
를 포함하고,
상기 적어도 하나의 제1 차지 이동 장치 및 상기 적어도 하나의 제2 차지 이동 장치는 제2 페이스(phase)의 시작에서 켜지고 상기 공유 노드가 기준 전위 또는 차지 임계치 중 하나에 도달할 때 꺼지는 것을 특징으로 하는 스위치드 차지 회로.
- 제1 전위 또는 제1 차지 임계치 중 하나로 초기에 리셋되고 초기 페이스(phase) 동안 입력 차지를 수신하기 위해 입력에 연결되는 제1 차지 저장 장치;
상기 제1 차지 저장 장치는 적어도 차지 펄스에 의해 게이트된 프로그래밍 가능한 크기의 제1 차지 이동 장치를 구성하는 상기 입력으로부터 차지를 수신하고, 여기서 상기 펄스 폭은 차지 비례 입력값을 구성하며 상기 차지 이동 장치 크기는 가중치를 구성하고;
상기 차지 비례 입력값에 의한 상기 차지 이동 장치의 게이팅은 상기 제1 차지 저장 장치에서 합산되는 값 차지 입력에 의해 곱해진 가중치를 생성하며;
상기 가중값 차지 입력이 상기 제 1 차지 저장 장치에 연결된 후, 상기 적어도 제1 차지 이동 장치에 비례하는 출력 차지 이동 장치가 제2 페이스 동안 활성화되어 상기 제1 차지 저장 장치를 상기 제1 전위 또는 상기 제1 차지 임계치 중 하나로 복귀시키고, 꺼지며,
드라이버는 상기 적어도 하나의 차지 이동 장치가 활성화되는 시간 동안 펄스를 생성하여 그 주기가 입력 값의 가중 합을 나타내는 펄스 출력을 생성하는 것을 특징으로 하는 스위치드 차지 회로.
- 제3항에 있어서,
상기 출력 차지 이동 장치는 모든 차지 입력이 도달할 때까지 제어 신호에 의해 비활성화되는 스위치드 차지 회로.
- 제3항에 있어서,
제2 전위 또는 제2 차지 임계치 중 하나로 초기에 리셋되는 제 2 차지 저장 장치-결정 회로 임계치에 대응하는 차지는 상기 제2 차지 저장 장치 상에 추가로 로딩됨;
제2 차지 저장 장치 상기 제2 전위 또는 제2 차지 임계치에 도달할 때 종료되는 상기 제 1 차지 이동 장치와 동시에 작동될 수 있는 제 2 차지 이동 장치-각각의 상기 차지 이동 장치가 켜있는 동안 켜있는 펄스의 동시 출력을 OR’ing에 의해 출력이 생성됨
을 더 포함하고,
상기 OR'ing의 출력은 차지 형태에 비례하는 펄스의 ReLU 출력인 것을 특징으로 하는 스위치드 차지 회로.
- 입력 차지 저장 장치;
출력 차지 저장 장치;
상기 입력 차지 저장 장치에 연결된 적어도 하나의 입력 차지; 및
상기 입력 차지 저장 장치와 상기 출력 차지 저장 장치를 연결하는 차지 전송 장치
를 포함하고,
입력 차지에 비례하는 출력에 상기 차지 전송 장치에 의해 공급된 차지의 비율로 곱해진 입력 차지에 비례하는 출력이 생성되고;
상기 입력 차지 저장 장치 및 상기 출력 차지 저장 장치로의 차지의 소싱(sourcing)은 입력 차지의 연결 후에 개시되고 상기 입력 차지 저장 장치가 초기 차지 레벨로 복귀한 후에 상기 차지의 소싱을 중지하는 것을 특징으로 하는 입력 가중 합산기 출력(input(s) weighted summer output)을 생성하기 위한 장치.
- 제6항에 있어서,
출력 펄스는 상기 입력 차지 저장 장치를 초기 차지 레벨로 되돌리는데 걸리는 시간에 비례하는 것을 특징으로 하는 입력 가중 합산기 출력을 생성하기 위한 장치.
- 네트워크에서, 유효 뉴런 수를 증가시키거나, 가상 뉴런을 생성하기 위한 장치로서, 이 장치는 뉴런 오퍼레이션(operations)을 시간 프레임으로 분리하고, 각 프레임에서 펄스 연결이 수정되어 새로운 연결이 그것이 독립적인 뉴런인 것처럼 뉴런을 재사용하는 것을 특징으로 하는 장치.
- 입력에 연결된 차지 저장 장치;
상기 차지 저장 장치에 연결된 비교기; 및
상기 차지 저장 장치에 연결된 차지 이동 장치
를 포함하고,
상기 차지 저장 장치는 상기 비교기의 스위치 포인트가 한 페이스(phase)에 도달할 때까지 상기 차지 이동 장치에 의해 조정되며, 그 후 제2 페이스 동안 입력 차지는 상기 차지 저장 장치에서 차지 레벨을 조정하는 상기 차지 저장 장치로부터 제거되고, 그 후 상기 비교기의 스위치 포인트에 다시 도달할 때까지 상기 차지 이동 장치가 출력 페이스에 작동 가능하도록 되며,
노이즈 및 오프셋은 상기 제2 페이스 동안 과도한 차지 제거를 나타내고, 상기 출력 페이스 동안 다시 추가되어 상기 노이즈 및 오프셋을 제거하는 것을 특징으로 하는 상관 이중 샘플링 리셋 메커니즘(correlated double sampling reset mechanism).
- 적어도 하나의 게이트된 입력 차지 이동 장치에 연결된 제1 차지 저장 장치-상기 적어도 하나의 게이트된 입력 차지 이동 장치는 게이트된 마스터 차지 이동 장치에 대해 크기로 프로그래밍 가능하며, 상기 적어도 하나의 게이트된 입력 차지 이동 장치는 입력 차지 값에 시간적으로 비례하는 입력 펄스에 의해 게이트됨;
상기 제1 차지 저장 장치에 연결된 제1 비교기 장치-상기 제1 차지 저장 장치는 초기에 상기 제1 비교기 장치의 스위치 포인트에 충전됨;
제2 차지 저장 장치;
제 2 비교기 장치-상기 제2 차지 저장 장치는 초기에 상기 제2 비교기의 스위치 포인트로 충전된 다음 상기 제2 차지 저장 장치로부터 제거된 임계치에 비례하는 차지로 충전됨; 및
상기 제2 비교기 장치에 의해 게이트된 상기 마스터 차지 이동 장치에 크기가 비례하는 제2 차지 이동 장치
를 포함하고,
상기 마스터 차지 이동 장치 및 상기 제 2 차지 이동 장치는 입력 차지가 로딩된 후에 작동 가능하며, 상기 마스터 차지 이동 장치는 상기 제1 비교기의 스위치 포인트에 도달할 때까지 켜져 있고, 상기 제2 차지 이동 장치는 상기 제2 비교기 장치의 스위치 포인트에 도달할 때까지 켜져 있으며;
상기 제1 비교기 장치의 스위치 포인트 또는 상기 제2 비교기 장치의 스위치 포인트 중 후자에 도달하는 데 걸리는 시간이 OR되고(OR’ed) 버퍼링되어 차지 출력 형태에 비례하는 ReLU 결정 출력을 생성하는 것을 특징으로 하는 차지 비례 펄스 기반 뉴런.
- 제1항, 제2항, 제3항 또는 제10항에 있어서,
상기 비교 장치는 공통 소스 MOSFET인 스위치드 차지 회로.
- 제1항, 제2항, 제3항 또는 제10항에 있어서,
상기 비교 장치는 접지에 대해 소스 레벨이 시프트된 공통 소스 MOSFET인 스위치드 차지 회로.
- 제1항, 제2항, 제3항 또는 제10항에 있어서,
상기 공통 소스 MOSFET의 소스와 접지 사이에 연결된 다이오드 연결 MOSFET을 더 포함하는 스위치드 차지 회로.
- 제11항, 12항 또는 제13항에 있어서,
포지티브 피드백은 스위칭 발생에 요구되는 오버드라이브를 감소시켜 오퍼레이션의 "데드존"을 감소시키기 위하여 사용되는 스위치드 차지 회로.
- 제12항에 있어서,
상기 공통 소스 MOSFET의 소스는 상기 스위치 포인트 전압을 제어하기 위해 팔로워(follower)에 의해 상승되는 스위치드 차지 회로.
- 제1항, 제2항, 제3항 또는 제10항에 있어서,
상기 드라이버는 복제 차지 펄스를 생성하고, 복제된 차지 펄스는 크기 및 에지가 로드에 상관없이 복제되는 펄스와 동일하도록 적응적으로 구동되는 스위치드 차지 회로.
- 최대 차지 펄스 폭이 곱셈 및 덧셈 스위치 차지 회로 또는 뉴런에 제공되고, 1의 가중 크기를 위해 상기 최대 펄스 폭을 복제하기 위하여 로컬 차지 이동 장치 크기가 상기 최대 펄스 폭에 대해 조정되는 캘리브레이션 회로(calibration circuit).
- 제17항에 있어서,
최소 차지 폭은 최소 비례 펄스 폭 및
차지 제로 또는 다른 최소 차지 값과 연관성이 있는 상기 펄스 폭과 매칭하기 위하여, 바이어스 입력 또는 고정된 지연 앨리먼트를 통해, 최소 비례 펄스 폭을 세팅하도록 로컬 뉴런에 제공되는 캘리브레이션 회로.
- 제17항에 있어서,
상기 최대 펄스 폭은 CMOS 이미지 센서 글로벌 셔터 장치에 따라 설정되는 캘리브레이션 회로.
- 동적 드라이버에 의해 구동되고 차지 비례 펄스를 결합할 수 있는 크로스바.
- 제20항에 있어서,
상기 크로스바는 프레임 시간에 응답하는 동적 크로스바 연결을 만들 수 있는 로컬 컨트롤러에 결합되는 크로스바.
- 제21항에 있어서,
상기 로컬 컨트롤러는 다른 로컬 컨트롤러에 더 연결되는 크로스바.
- 제1항, 제2항, 제3항 또는 제10항에 있어서,
상기 스위치 차지 회로는 전력을 감소시키기 위해 서브임계치에서 바이어스되는 스위치드 차지 회로.
- 제1항, 제2항, 제3항 또는 제10항에 있어서,
2 사분면 오퍼레이션은 초기 리셋 후 차지를 추가하거나 제거하는 것 중 하나에 의해 구현되는 스위치드 차지 회로.
- 제24항에 있어서,
클래스 AB 스위치오버 기술은 상기 공통 소스 MOSFET 비교기의 스위치 포인트 주변의 2 사분면 오퍼레이션과 관련된 데드존을 극복하기 위해 사용되는 스위치드 차지 회로.
- 제24항 또는 제25항에 있어서,
작동할 사분면을 파악하는 것에 의해 상기 비교 장치의 적절한 사전 설정 및 리셋을 허용하기 위하여 부호 비트(sign bit)가 통신되는 스위치드 차지 회로.
- 제1항, 제2항, 제3항 또는 제10항에 있어서,
상기 입력 또는 후속 레이어는 상기 제2 차지 이동 장치의 크기를 조정하는 것에 의해 정규화되는 회로.
- 제1항, 제2항, 제3항 또는 제10항에 있어서,
비교기를 위해 고정된 오버슈트를 유지하기 위하여 상기 적어도 하나의 제1 전류 소스 및 상기 적어도 하나의 제2 전류 소스의 합은 상기 적어도 하나의 제1 전류 소스와 상기 적어도 하나의 제2 전류 소스 사이의 비율을 변화시키는 동안 일정한 크기를 가지는 스위치드 차지 회로.
- 여러 전류 크기를 셋업하고 그들 사이를 빠르게 스위칭하기 위해 스티어링 회로를 사용하여 차지 이동 무게 안정화 시간을 줄이는 회로.
- 크로스바
를 포함하고,
상기 크로스바는 동적 드라이버에 의해 구동되고 차지 비례 펄스를 연결할 수 있으며, 상기 크로스바는 프레임 시간에 응답하는 동적 크로스바 연결을 만들 수 있는 로컬 컨트롤러에 연결되고, 연결은 반복적인 뉴런 네트워크 구현에 상응하는 시간 기반 연결의 필요에 따라 만들어진 반복적인 뉴런 네트워크.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862743130P | 2018-10-09 | 2018-10-09 | |
| US62/743,130 | 2018-10-09 | ||
| US16/597,522 | 2019-10-09 | ||
| PCT/US2019/055421 WO2020076966A1 (en) | 2018-10-09 | 2019-10-09 | Charge based switched matrix and method therefor |
| US16/597,522 US20200110987A1 (en) | 2018-10-09 | 2019-10-09 | Charge based switched matrix and method therefor |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210077704A true KR20210077704A (ko) | 2021-06-25 |
Family
ID=70051760
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217013786A KR20210077704A (ko) | 2018-10-09 | 2019-10-09 | 차지 기반 스위치드 매트릭스 및 그 방법 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20200110987A1 (ko) |
| EP (1) | EP3864744A4 (ko) |
| JP (1) | JP7465563B2 (ko) |
| KR (1) | KR20210077704A (ko) |
| WO (1) | WO2020076966A1 (ko) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20200128109A (ko) * | 2018-03-02 | 2020-11-11 | 에이아이스톰, 아이엔씨. | 전하 도메인 수학적 엔진 및 방법 |
| US11487507B2 (en) | 2020-05-06 | 2022-11-01 | Qualcomm Incorporated | Multi-bit compute-in-memory (CIM) arrays employing bit cell circuits optimized for accuracy and power efficiency |
| US11567730B2 (en) * | 2021-01-31 | 2023-01-31 | Ceremorphic, Inc. | Layout structure for shared analog bus in unit element multiplier |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE3329269A1 (de) * | 1983-08-12 | 1985-02-28 | Siemens AG, 1000 Berlin und 8000 München | Schaltungsanordnung zum erzeugen von rechtecksignalen |
| AU633812B2 (en) * | 1988-08-31 | 1993-02-11 | Fujitsu Limited | Neurocomputer |
| US5148514A (en) * | 1989-05-15 | 1992-09-15 | Mitsubishi Denki Kabushiki Kaisha | Neural network integrated circuit device having self-organizing function |
| US5039870A (en) * | 1990-05-21 | 1991-08-13 | General Electric Company | Weighted summation circuits having different-weight ranks of capacitive structures |
| US5261035A (en) * | 1991-05-31 | 1993-11-09 | Institute Of Advanced Study | Neural network architecture based on summation of phase-coherent alternating current signals |
| US5483184A (en) * | 1993-06-08 | 1996-01-09 | National Semiconductor Corporation | Programmable CMOS bus and transmission line receiver |
| WO1999021278A1 (en) * | 1997-10-17 | 1999-04-29 | Photobit Corporation | Low-voltage comparator with wide input voltage swing |
| US6445623B1 (en) * | 2001-08-22 | 2002-09-03 | Texas Instruments Incorporated | Charge pumps with current sources for regulation |
| US7053684B1 (en) * | 2004-04-28 | 2006-05-30 | Cirrus Logic, Inc. | Reduced jitter charge pumps and circuits and systems utilizing the same |
| US7907429B2 (en) * | 2007-09-13 | 2011-03-15 | Texas Instruments Incorporated | Circuit and method for a fully integrated switched-capacitor step-down power converter |
| GB2455524B (en) * | 2007-12-11 | 2010-04-07 | Wolfson Microelectronics Plc | Charge pump circuit and methods of operation thereof and portable audio apparatus including charge pump circuits |
| JP2010061428A (ja) | 2008-09-04 | 2010-03-18 | Yazaki Corp | 掛算回路 |
| US9606302B2 (en) * | 2013-03-15 | 2017-03-28 | Commscope Technologies Llc | Ferrules for fiber optic connectors |
| US9793260B2 (en) * | 2015-08-10 | 2017-10-17 | Infineon Technologies Austria Ag | System and method for a switch having a normally-on transistor and a normally-off transistor |
| US11263522B2 (en) * | 2017-09-08 | 2022-03-01 | Analog Devices, Inc. | Analog switched-capacitor neural network |
| JP7412010B2 (ja) | 2018-03-02 | 2024-01-12 | エーアイストーム インコーポレイテッド | 単一のトランジスタ乗算器およびその方法 |
| US10700695B1 (en) * | 2018-04-17 | 2020-06-30 | Ali Tasdighi Far | Mixed-mode quarter square multipliers for machine learning |
| US10522226B2 (en) * | 2018-05-01 | 2019-12-31 | Silicon Storage Technology, Inc. | Method and apparatus for high voltage generation for analog neural memory in deep learning artificial neural network |
-
2019
- 2019-10-09 EP EP19870700.2A patent/EP3864744A4/en active Pending
- 2019-10-09 JP JP2021519141A patent/JP7465563B2/ja active Active
- 2019-10-09 US US16/597,522 patent/US20200110987A1/en active Pending
- 2019-10-09 WO PCT/US2019/055421 patent/WO2020076966A1/en unknown
- 2019-10-09 KR KR1020217013786A patent/KR20210077704A/ko unknown
Also Published As
| Publication number | Publication date |
|---|---|
| CN112805912A (zh) | 2021-05-14 |
| US20200110987A1 (en) | 2020-04-09 |
| EP3864744A1 (en) | 2021-08-18 |
| WO2020076966A1 (en) | 2020-04-16 |
| JP7465563B2 (ja) | 2024-04-11 |
| JP2022504469A (ja) | 2022-01-13 |
| EP3864744A4 (en) | 2022-07-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20210077704A (ko) | 차지 기반 스위치드 매트릭스 및 그 방법 | |
| CN207099208U (zh) | 图像传感器 | |
| CN108476297B (zh) | 具有扩展的动态范围的图像传感器 | |
| CN1659860B (zh) | 图像传感器电路及其方法 | |
| CN207083171U (zh) | 图像传感器 | |
| US7675015B2 (en) | CMOS image sensor with boosted voltage signal and related method of operation | |
| KR100961052B1 (ko) | 이미저를 위한 칼럼-병렬 시그마-델타 아날로그-디지털변환 | |
| US20170352696A1 (en) | Charge packet signal processing using pinned photodiode devices | |
| US8450673B2 (en) | Pixel circuit, imaging integrated circuit, and method for image information acquisition | |
| EP1158789A1 (en) | Photodetector device | |
| US11755850B2 (en) | Single transistor multiplier and method therefor | |
| CN110875004A (zh) | 像素电路 | |
| EP3319311A1 (fr) | Capteur d'images synchrone à codage temporel | |
| TWI613917B (zh) | 像素單元、成像系統及控制像素單元之全域快門之方法 | |
| US20240030923A1 (en) | Control of semiconductor devices | |
| US9160948B2 (en) | Replica noise generator using pixel modeling and ramp signal generator including the same | |
| CN112805912B (zh) | 基于电荷的开关矩阵及其方法 | |
| EP1743427A1 (en) | An analog-to-digital converter | |
| US7671644B2 (en) | Process insensitive delay line | |
| CN115087990A (zh) | 神经放大器、神经网络和传感器设备 | |
| JP7465350B2 (ja) | センサフロントエンドのための電荷感受性増幅器回路 | |
| JP7292054B2 (ja) | 画素信号読み出し回路および積層型固体撮像装置 | |
| KR102170758B1 (ko) | 아날로그 신호 생성 회로 |