KR20210061995A - Adam9를 표적으로 하는 면역콘쥬게이트 및 이를 이용하는 방법들 - Google Patents
Adam9를 표적으로 하는 면역콘쥬게이트 및 이를 이용하는 방법들 Download PDFInfo
- Publication number
- KR20210061995A KR20210061995A KR1020217002564A KR20217002564A KR20210061995A KR 20210061995 A KR20210061995 A KR 20210061995A KR 1020217002564 A KR1020217002564 A KR 1020217002564A KR 20217002564 A KR20217002564 A KR 20217002564A KR 20210061995 A KR20210061995 A KR 20210061995A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- ala
- adam9
- domain
- immunoconjugate
- Prior art date
Links
Images




















Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6871—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting an enzyme
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/33—Heterocyclic compounds
- A61K31/395—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins
- A61K31/535—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having six-membered rings with at least one nitrogen and one oxygen as the ring hetero atoms, e.g. 1,2-oxazines
- A61K31/5365—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having six-membered rings with at least one nitrogen and one oxygen as the ring hetero atoms, e.g. 1,2-oxazines ortho- or peri-condensed with heterocyclic ring systems
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/06—Organic compounds, e.g. natural or synthetic hydrocarbons, polyolefins, mineral oil, petrolatum or ozokerite
- A61K47/22—Heterocyclic compounds, e.g. ascorbic acid, tocopherol or pyrrolidones
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/6811—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a protein or peptide, e.g. transferrin or bleomycin
- A61K47/6817—Toxins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6889—Conjugates wherein the antibody being the modifying agent and wherein the linker, binder or spacer confers particular properties to the conjugates, e.g. peptidic enzyme-labile linkers or acid-labile linkers, providing for an acid-labile immuno conjugate wherein the drug may be released from its antibody conjugated part in an acidic, e.g. tumoural or environment
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2896—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against molecules with a "CD"-designation, not provided for elsewhere
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/40—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against enzymes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/77—Internalization into the cell
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Immunology (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Organic Chemistry (AREA)
- Epidemiology (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Oil, Petroleum & Natural Gas (AREA)
- Toxicology (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Peptides Or Proteins (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Medicinal Preparation (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
본 발명은 적어도 한 개의 메이탄시노이드 화합물에 콘쥬게이트된 "디스인테그린 및 금속단백분해효소 도메인-함유하는 단백질 9" ("ADAM9")에 특이적으로 결합할 수 있는 항체 또는 이의 단편을 포함하는 면역콘쥬게이트에 관계한다. 본 발명 구체적으로 인간 ADAM9 및 비-인간 영장류 (이를 테면, 시노몰구스 원숭이)의 ADAM9와 교차-반응성이 있는 이러한 면역콘쥬게이트에 관계한다. 본 발명 추가적으로, 이러한 면역콘쥬게이트를 수령 대상체에게 투여할 때, 면역원성을 감소시키도록 하기 위해, 인간화된 및/또는 탈면역화된 경쇄 가변 (VL) 도메인 및/또는 중쇄 가변 (VH) 도메인을 포함하는 이러한 모든 면역콘쥬게이트에 관계한다. 본 발명은 이러한 면역콘쥬게이트중 임의의 것을 함유하는 약제학적 조성물, 그리고 암과 기타 질환 및 병태의 치료에 이러한 임의의 면역콘쥬게이트의 사용과 관련된 방법에 또한 관계한다.
Description
관련된 출원들
본 출원은 2018년 6월 26일자로 제출된 U.S. 가출원 번호.: 62/690,052, 2018년 6월 28일자로 제출된 U.S. 가출원 번호.: 62/691,342, 그리고 2019년 2월 26일자로 제출된 U.S. 가출원 번호.: 62/810,703에 대해 우선권을 주장한다. 이들 출원의 내용은 본 명세서에 전문이 참고자료에 편입된다.
서열 목록
본 출원은 ASCII 포멧으로 전자적으로 제출된 서열 목록을 포함하며, 이의 전문이 본 명세서의 참고자료에 편입된다. 전술한 ASCII 사본은 2019년 5월 16일자로 생성되었으며, 화일명은 121162-04820_SL.txt이며, 크기는 163,070바이트이다.
발명의 분야
본 발명은 적어도 한 개의 약학적 제제에 콘쥬게이트된 "디스인테그린 및 메탈로프로테아제 도메인-함유하는 단백질 9" ("ADAM9")에 특이적으로 결합할 수 있는 항체 또는 이의 단편을 포함하는 면역콘쥬게이트에 관계한다. 본 발명 구체적으로 인간 ADAM9 및 비-인간 영장류 (이를 테면, 시노몰구스 원숭이)의 ADAM9와 교차-반응성이 있는 이러한 면역콘쥬게이트에 관계한다. 본 발명 추가적으로, 이러한 면역콘쥬게이트를 수령 대상체에게 투여할 때, 면역원성을 감소시키도록 하기 위해, 인간화된 및/또는 탈면역화된 경쇄 가변 (VL) 도메인 및/또는 중쇄 가변 (VH) 도메인을 포함하는 이러한 모든 면역콘쥬게이트에 관계한다. 본 발명은 이러한 면역콘쥬게이트중 임의의 것을 함유하는 약제학적 조성물, 그리고 암과 기타 질환 및 병태의 치료에 이러한 임의의 면역콘쥬게이트의 사용과 관련된 방법에 또한 관계한다.
발명의 배경
ADAM은 다양한 생리적 및 병리적 과정에 관여하는 단백질 패밀리다 (Amendola, R.S. et al. (2015) "ADAM9 Disintegrin Domain Activates Human Neutrophils Through An Autocrine Circuit Involving Integrins And CXCR2," J. Leukocyte Biol. 97(5):951-962; Edwars, D.R. et al. (2008) ''The ADAM Metalloproteases" Molec. Aspects Med. 29:258-289). 상기 패밀리의 적어도 40 가지 유전자 구성원이 확인되었으며, 이러한 구성원 중 최소한 21 개는 인간에서 기능하는 것으로 여겨진다(Li, J. et al. (2016) "Overexpression of ADAM9 Promotes Colon Cancer Cells Invasion," J. Invest. Surg. 26(3):127-133; Duffy, M.J. et al. (2011) "The ADAMs Family Of Proteases: New Biomarkers And Therapeutic Targets For Cancer!," Clin. Proteomics 8:9:1-13; US 특허 공개 번호. 2013/0045244 참고).
ADAM 패밀리 구성원은 8 개의 도메인으로 잘-보존된 구조를 가지고 있으며, 그 중 메탈로프로테아제 도메인과 인테그린-결합 (디스인테그린) 도메인이 그것이다 (Duffy, M.J. et al. (2009) "The Role Of ADAMs In Disease Pathophysiology," Clin. Chim. Acta 403:31-36). 상기 ADAM 메탈로프로테아제 도메인은 쉐다제(sheddase)로 작용하고, 막경유 단백질들을 절단하고, 그 다음 가용성 리간드들로 작용하여, 세포의 신호전달을 제어할 수 있는 일련의 생물학적 공정을 조절하는 것으로 보고된 바 있다 (Amendola, R.S. et al. (2015) "ADAM9 Disintegrin Domain Activates Human Neutrophils Through An Autocrine Circuit Involving Integrins And CXCR2," J. Leukocyte Biol. 97(5):951-962; Ito, N. et al. (2004) "ADAMs, A Disintegrin And Metalloproteinases, Mediate Shedding Of Oxytocinase," Biochem. Biophys. Res. Commun. 314 (2004) 1008-1013).
ADAM9는 ADAM 패밀리의 분자 구성원이다. 그것은 비활성 형태로 합성되고, 활성 효소를 생성하기 위해 단백질 분해로 절단된다. 상류(upstream) 부위에서의 공정은 프로엔자임(proenzyme) 활성화에 특히 중요하다. ADAM9는 섬유모세포 (Zigrino, P. et al. (2011) "The Disintegrin-Like And Cysteine-Rich Domains Of ADAM-9 Mediate Interactions Between Melanoma Cells And Fibroblasts," J. Biol. Chem. 286:6801-6807), 활성화된 맥관 평활근 세포 (Sun, C. et al. (2010) "ADAM 15 Regulates Endothelial Permeability And Neutrophil Migration Via Src/ERKl/2 Signalling," Cardiovasc. Res. 87:348-355), 단핵구 (Namba, K. et al. (2001) "Involvement Of ADAM9 In Multinucleated Giant Cell Formation Of Blood Monocytes," Cell. Immunol. 213:104-113), 활성화된 대식세포 (Oksala, N. et al. (2009) "ADAM-9, ADAM-15, And ADAM-17 Are Upregulated In Macrophages In Advanced Human Atherosclerotic Plaques In Aorta And Carotid And Femoral Arteries - Tampere Vascular Study," Ann. Med. 41:279-290)에서 발현된다.
ADAM9의 메탈로프로테아제 활성은 기질 성분의 분해에 참여하여, 종양 세포의 이동을 허용하다 (Amendola, R.S. et al. (2015) "ADAM9 Disintegrin Domain Activates Human Neutrophils Through An Autocrine Circuit Involving Integrins And CXCR2," J. Leukocyte Biol. 97(5):951-962). 이의 디스인테그린 도메인 (많은 뱀-독 디스인테그린과 매우 상동성임)은 ADAM9와 인테그린 간의 상호 작용을 허용하고, ADAM9가 세포 부착 이벤트를 양성적으로 또는 음성적으로 조절할 수 있도록 한다(Zigrino, P. et al. (2011) "The Disintegrin-Like And Cysteine-Rich Domains Of ADAM-9 Mediate Interactions Between Melanoma Cells And Fibroblasts," J. Biol. Chem. 286:6801-6807; Karadag, A. et al. (2006) "ADAM-9 (MDC- 9/Meltringamma), A Member Of The A Disintegrin And Metalloproteinase Family, Regulates Myeloma-Cell-Induced Interleukin-6 Production In Osteoblasts By Direct Interaction With The Alpha(v)Beta5 Integrin," Blood 107:3271-3278; Cominetti, M.R. et al. (2009) "Inhibition Of Platelets And Tumor Cell Adhesion By The Disintegrin Domain Of Human ADAM9 To Collagen I Under Dynamic Flow Conditions," Biochimie, 91:1045- 1052). ADAM9 디스인테그린 도메인은 α6β1, α6β4, αvβ5 및 α9β1 인테그린과 상호작용하는 것으로 나타났다.
ADAM9의 발현은 질환, 특히 암과 관련이 있는 것으로 밝혀졌다. ADAM9는 TEK, KDR, EPHB4, CD40, VCAM1 및 CDH5와 같은 종양 형성 및 맥관신생에 중요한 역할을 하는 다수의 분자를 절단 및 방출하는 것으로 밝혀졌다. ADAM9는 유방암, 결장암, 위암, 신경교종, 간암, 비-소 세포 폐암, 흑색종, 골수종, 췌장암 및 전립선 암과 같은 종양 세포를 포함한 다양한 유형의 종양 세포에서 발현된다 (Yoshimasu, T. et al. (2004) "Overexpression Of ADAM9 In Non-Small Cell Lung Cancer Correlates With Brain Metastasis," Cancer Res. 64:4190-4196; Peduto, L. et al. (2005) "Critical Function For ADAM9 In Mouse Prostate Cancer," Cancer Res. 65:9312-9319; Zigrino, P. et al. (2005) "ADAM-9 Expression And Regulation In Human Skin Melanoma And Melanoma Cell Lines," Int. J. Cancer 116:853-859; Fritzsche, F.R. et al. (2008) "ADAM9 Is Highly Expressed In Renal Cell Cancer And Is Associated With Tumour Progression," BMC Cancer 8:179:1-9; Fry, J.L. et al. (2010) "Secreted And Membrane-Bound Isoforms Of Protease ADAM9 Have Opposing Effects On Breast Cancer Cell Migration," Cancer Res. 70, 8187-8198; Chang, L. et al. (2016) "Combined Rnai Targeting Human Stat3 And ADAM9 As Gene Therapy For Non -Small Cell Lung Cancer," Oncology Letters 11:1242- 1250; Fan, X. et al. (2016) "ADAM9 Expression Is Associate with Glioma Tumor Grade and Histological Type, and Acts as a Prognostic Factor in Lower-Grade Gliomas," Int. J. Mol. Sci. 17:1276:1-11).
유의적으로, ADAM9 발현 증가는 악성 종양 및 전이 가능성과 양성 상관관계가 있는 것으로 밝혀졌다(Amendola, R.S. et al. (2015) "ADAM9 Disintegrin Domain Activates Human Neutrophils Through An Autocrine Circuit Involving Integrins And CXCR2," J. Leukocyte Biol. 97(5):951-962; Fan, X. et al. (2016) "ADAM9 Expression Is Associate with Glioma Tumor Grade and Histological Type, and Acts as a Prognostic Factor in Lower-Grade Gliomas," Int. J. Mol. Sci. 17:1276:1-11; Li, J. et al. (2016) "Overexpression ofADAM9 Promotes Colon Cancer Cells Invasion," J. Invest. Surg. 26(3): 127-133). 추가적으로, ADAM9와 이의 분비된 용해성 아이소폼(isoform)은 암 세포가 전파하는 데 결정적인 것으로 보인다 (Amendola, R.S. et al. (2015) "ADAM9 Disintegrin Domain Activates Human Neutrophils Through An Autocrine Circuit Involving Integrins And CXCR2," J. Leukocyte Biol. 97(5):951-962; Fry, J.L. et al. (2010) "Secreted And Membrane-Bound Isoforms Of Protease ADAM9 Have Opposing Effects On Breast Cancer Cell Migration," Cancer Res. 70, 8187-8198; Mazzocca, A. (2005) "A Secreted Form Of ADAM9 Promotes Carcinoma Invasion Through Tumor-Stromal Interactions," Cancer Res. 65:4728-4738; US 특허 번호. 9,150,656; 7,585,634; 7,829,277; 8,101,361; 및 8,445,198, 그리고 US 특허 공개 번호. 2009/0023149 또한 참고).
따라서, 많은 연구에서 ADAM9를 항암 치료요법의 잠재적 표적으로 확인했다 (Peduto, L. (2009) "ADAM9 As A Potential Target Molecule In Cancer," Curr. Pharm. Des. 15:2282-2287; Duffy, M.J. et al. (2009) "Role Of ADAMs In Cancer Formation And Progression," Clin. Cancer Res. 15:1140-1144; Duffy, M.J. et al. (2011) "The ADAMs Family Of Proteases: New Biomarkers And Therapeutic Targets For Cancer?," Clin. Proteomics 8:9:1-13; Josson, S. et al. (2011) "Inhibition of ADAM9 Expression Induces Epithelial Phenotypic Alterations and Sensitizes Human Prostate Cancer Cells to Radiation and Chemotherapy," Prostate 71(3):232-240; US 특허 공개 번호 2016/0138113, 2016/0068909, 2016/0024582, 2015/0368352, 2015/0337356, 2015/0337048, 2015/0010575, 2014/0342946, 2012/0077694, 2011/0151536, 2011/0129450, 2010/0291063, 2010/0233079, 2010/0112713, 2009/0285840, 2009/0203051, 2004/0092466, 2003/0091568, 및 2002/0068062, 그리고 PCT 공개 번호. WO 2016/077505, WO 2014/205293, WO 2014/186364, WO 2014/124326, WO 2014/108480, WO 2013/119960, WO 2013/098797, WO 2013/049704, 및 WO 2011/100362). 추가적으로, ADAM9의 발현은 또한 폐 질환 및 염증과 관련이 있는 것으로 밝혀졌다 (이를 테면, US 특허 공개 번호 2016/0068909; 2012/0149595; 2009/0233300; 2006/0270618; 및 2009/0142301). ADAM9에 결합하는 항체는 Abeam, Thermofisher, Sigma-Aldrich 및 기타 회사에서 시판된다.
그러나, 모든 기존의 발전에도 불구하고, 정상 조직에는 최저 결합을 나타내고, 유사한 높은 친화력으로 인간 및 비-인간 ADAM9에 결합할 수 있는 높은 친화력 ADAM9 면역콘쥬게이트가 여전히 필요하다. 본 발명은 이러한 요구 및 암에 대한 개선된 치료요법제의 필요성을 해결한다.
본 발명의 요약
본 발명은 본원에서 기술된 적어도 한 가지 메이탄시노이드(maytansinoid)에 콘쥬게이트된 "디스인테그린 및 메탈로프로테아제 도메인-함유하는 단백질 9" ("ADAM9")에 특이적으로 결합할 수 있는 항체 또는 이의 단편을 포함하는 면역콘쥬게이트에 관계한다. 본 발명 구체적으로 인간 ADAM9 및 비-인간 영장류 (이를 테면, 시노몰구스 원숭이)의 ADAM9와 교차-반응성이 있는 이러한 면역콘쥬게이트에 관계한다. 본 발명 추가적으로, 이러한 면역콘쥬게이트를 수령 대상체에게 투여할 때, 면역원성을 감소시키도록 하기 위해, 인간화된 및/또는 탈면역화된 경쇄 가변 (VL) 도메인 및/또는 중쇄 가변 (VH) 도메인을 포함하는 이러한 모든 면역콘쥬게이트에 관계한다. 본 발명은 이러한 면역콘쥬게이트중 임의의 것을 함유하는 약제학적 조성물, 그리고 암과 기타 질환 및 병태의 치료에 이러한 임의의 면역콘쥬게이트의 사용과 관련된 방법에 또한 관계한다.
상술하면, 본 발명은 면역콘쥬게이트 (다음의 화학식으로 나타냄):

또는 이의 약제학적으로 허용되는 염을 제공하며, 이때:
CB는 항-ADAM9 항체 또는 이의 ADAM9-결합 단편이며;
L2는 다음의 화학식중 하나로 표시되며:


이때:
각 경우들에서 Rx, Ry, Rx' 및 Ry'는 독립적으로 H,-OH, 할로겐,-O-(C1-4 알킬),-SO3H,-NR40R41R42 +, 또는 OH, 할로겐, SO3H 또는 NR40R41R42 +로 임의선택적으로 치환된 C1-4 알킬이며, 이때 R40, R41 및 R42는 각각 독립적으로 H 또는 C1-4 알킬이며;
l 및 k는 각각 독립적으로 1 내지 10의 정수이며;
l1은 2 내지 5의 정수이며;
k1은 1 내지 5의 정수이며; 그리고
s1은 세포-결합 제제 CB에 연결된 부위를 나타내며, s3은 A 기에 연결된 부위를 나타낸다;
A는 아미노산 잔기 또는 2 내지 20개 아미노산 잔기들을 포함하는 펩티드이며;
R1 및 R2는 각각 독립적으로 H 또는 C1-3 알킬이며;
L1은 다음의 화학식으로 나타내고:
-CR3R4-(CH2)1-8-C(=O)-
이때 R3 및 R4는 각각 독립적으로 H 또는 Me이며, L1에서-C(=O)-모이어티는 D에 연결되며;
D는 다음의 화학식으로 나타내고:

q는 1 내지 20의 정수다.
특정 구체예들에서, 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 경쇄 가변 (VL) 도메인과 중쇄 가변 (VH) 도메인을 포함하며, 이때 상기 중쇄 가변 도메인은 CDRH1 도메인, CDRH2 도메인 및 CDRH3 도메인을 포함하며, 그리고 상기 경쇄 가변 도메인은 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 포함하며, 이때:
(A)
전술한 CDRH1 도메인, CDRH2 도메인 및 CDRH3 도메인은 MAB-A의 최적화된 변이체의 중쇄 가변 (VH) 도메인의 CDRH1 도메인, CDRH2 도메인 및 CDRH3 도메인의 아미노산 서열을 갖고; 그리고 전술한 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인은 MAB-A의 경쇄 가변 (VL) 도메인의 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인의 아미노산 서열을 갖고; 또는
(B)
전술한 CDRH1 도메인, CDRH2 도메인 및 CDRH3 도메인은 MAB-A의 중쇄 가변 (VH) 도메인의 CDRH1 도메인, CDRH2 도메인 및 CDRH3 도메인의 아미노산 서열을 갖고; 그리고 전술한 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인은 MAB-A의 경쇄 가변 (VL) 도메인의 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인의 아미노산 서열을 갖고; 또는
(C)
전술한 CDRH1 도메인, CDRH2 도메인 및 CDRH3 도메인은 MAB-A의 최적화된 변이체의 중쇄 가변 (VH) 도메인의 CDRH1 도메인, CDRH2 도메인 및 CDRH3 도메인의 아미노산 서열을 갖고; 그리고 전술한 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인은 MAB-A의 최적화된 변이체의 경쇄 가변 (VL) 도메인의 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인의 아미노산 서열을 갖는다.
특정 구체예들에서, 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 다음을 포함한다:
(A)
(1) MAB-A의 중쇄 가변 (VH) 도메인의 CDRH1 도메인, CDRH2 도메인 및 CDRH3 도메인; 그리고
(2) MAB-A의 인간화된 변이체의 VH 도메인의 FR1, FR2, FR3 및 FR4; 또는
(B)
(1) 상기 경쇄 가변 (VL) 도메인 MAB-A의 CDRL1 도메인, CDRL2 도메인 및 CDRL3 도메인; 그리고
(2) MAB-A의 인간화된 변이체의 VL 도메인의 FR1, FR2, FR3 및 FR4; 또는
(C)
(1) MAB-A의 최적화된 변이체의 중쇄 가변 (VH) 도메인의 CDRH1 도메인, CDRH2 도메인 및 CDRH3 도메인; 그리고
(2) MAB-A의 인간화된 변이체의 VH 도메인의 FR1, FR2, FR3 및 FR4 또는
(D)
(1) MAB-A의 최적화된 변이체의 경쇄 가변 (VL) 도메인의 CDRL1 도메인, CDRL2 도메인 및 CDRL3 도메인; 그리고
(2) MAB-A의 인간화된 변이체의 VL 도메인의 FR1, FR2, FR3 및 FR4; 또는
(E)
(1) MAB-A의 인간화된/최적화된 변이체의중쇄 가변 (VH) 도메인; 그리고
(2) MAB-A의 인간화된/최적화된 변이체의 VL 경쇄 가변 (VL) 도메인.
특정 구체예들에서, MAB-A의 최적화된 변이체의 중쇄 가변 (VH) 도메인의 CDRH1 도메인, CDRH2 도메인 및 CDRH3 도메인은 다음의 아미노산 서열을 갖는다:
(1)
서열 식별 번호:47 (SYWX1H)
이때: X1는 M 또는 I이며;
(2)
서열 식별 번호:48 (EIIPIX2GHTNYNEX3FX4X5)
이때: X 2 , X 3 , X 4 , 그리고 X 5 는 독립적으로 선택되며, 그리고
이때: X 2 는 N 또는 F이며;
X 3 은 K 또는 R이며;
X 4 는 K 또는 Q이며; 그리고
X 5 는 S 또는 G이며; 그리고
(3)
서열 식별 번호:49 (GGYYYYX6X7X8X9X10X11DY)
이때: X 6 은 P, F, Y, W, I, L, V, T, G 또는 D이며, 그리고 X 7 , X 8 , X 9 , X 10 , 그리고 X 11 은 다음과 같이 선택된다:
(A)
X 6 이 P인 경우:
X 7 은 K 또는 R이며;
X 8 은 F 또는 M이며;
X 9 는 G이며;
X 10 은 W 또는 F이며; 그리고
X 11 은 M, L 또는 K이고;
(B)
X 6 이 F, Y 또는 W인 경우:
X 7 은 N 또는 H이며;
X 8 은 S 또는 K이며;
X 9 는 G 또는 A이며;
X 10 은 T 또는 V이며; 그리고
X 11 은 M, L 또는 K이며;
(C)
X 6 이 I, L 또는 V인 경우:
X 7 은 G이며;
X 8 은 K이며;
X 9 는 G 또는 A이며;
X 10 은 V이며; 그리고
X 11 은 M, L 또는 K이고;
(D)
X 6 이 T인 경우:
X 7 은 G이며;
X 8 은 K, M 또는 N이며;
X 9 는 G이며;
X 10 은 V 또는 T이며; 그리고
X 11 은 L 또는 M이고;
(E)
X 6 이 G인 경우:
X 7 은 G이며;
X 8 은 S이며;
X 9 는 G이며;
X 10 은 V이며; 그리고
X 11 은 L이고; 그리고
(F)
X 6 이 D인 경우:
X 7 는 S이며;
X 8 은 N이며;
X 9 는 A이며;
X 10 은 V이며; 그리고
X 11 은 L이다.
특정 구체예들에서, 상기 MAB-A의 최적화된 변이체의 중쇄 가변 (VH) 도메인은 서열 식별 번호:15:의 아미노산 서열을 포함한다:

이때:
X 1 , X 2 , X 3 , X 4 , X 5 , 그리고 X 6 은 독립적으로 선택되며,
이때:
X 1 은 M 또는 I이며;
X 2 는 N 또는 F이며;
X 3 은 K 또는 R이며;
X 4 는 K 또는 Q이며;
X 5 는 S 또는 G이며, 그리고
X 6 은 P, F, Y, W, I, L, V, T, G 또는 D이며;
이때: X 7 , X 8 , X 9 , X 10 , 그리고 X 11 은 다음과 같이 선택되며:
X 6 이 P인 경우; X 7 은 K 또는 R이며; X 8 은 F 또는 M이며; X 9 는 G이며; X 10 은 W 또는 F이며; 그리고 X 11 은 M, L 또는 K이고;
X 6 이 F, Y 또는 W인 경우; X 7 은 N 또는 H이며; X 8 은 S 또는 K이며; X 9 는 G 또는 A이며; X 10 은 T 또는 V이며; 그리고 X 11 은 M, L 또는 K이고;
X 6 이 I, L 또는 V인 경우; X 7 은 G이며; X 8 은 K이며; X 9 는 G 또는 A이며; X 10 은 V이며; 그리고 X 11 은 M, L 또는 K이고;
X 6 이 T인 경우; X 7 은 G이며; X 8 은 K, M 또는 N이며; X 9 는 G이며; X 10 은 V 또는 T이며; 그리고 X 11 은 L 또는 M이고;
X 6 이 G인 경우; X 7 은 G이며; X 8 은 S이며; X 9 는 G이며; X 10 은 V이며; 그리고 X 11 은 L이고;
X 6 이 D인 경우; X 7 은 S이며; X 8 은 N이며; X 9 는 A이며; X 10 은 V이며; 그리고 X 11 은 L이다.
특정 구체예들에서, 상기 MAB-A의 최적화된 변이체의 중쇄 가변 (VH) 도메인은 다음으로 구성된 군에서 선택되며:
(1)
hMAB-A VH(1) (서열 식별 번호:16);
(2)
hMAB-A VH(2) (서열 식별 번호:17);
(3)
hMAB-A VH(3) (서열 식별 번호:18);
(4)
hMAB-A VH(4) (서열 식별 번호:19);
(5)
hMAB-A VH(2A) (서열 식별 번호:20);
(6)
hMAB-A VH(2B) (서열 식별 번호:21);
(7)
hMAB-A VH(2C) (서열 식별 번호:22);
(8)
hMAB-A VH(2D) (서열 식별 번호:23);
(9)
hMAB-A VH(2E) (서열 식별 번호:24);
(10)
hMAB-A VH(2F) (서열 식별 번호:25);
(11)
hMAB-A VH(2G) (서열 식별 번호:26);
(12)
hMAB-A VH(2H) (서열 식별 번호:27);
(13)
hMAB-A VH(2I) (서열 식별 번호:28); 그리고
(14)
hMAB-A VH(2J) (서열 식별 번호:29).
특정 구체예들에서, 상기 MAB-A의 최적화된 변이체의 경쇄 가변 (VL) 도메인의 CDRL1 도메인, CDRL2 도메인 및 CDRL3 도메인은 다음의 아미노산 서열을 갖고:
(1)
서열 식별 번호:66 (X12ASQSVDYX13GDSYX14N)
이때: X 12 , X 13 , X 14 는 독립적으로 선택되며, 그리고
이때: X 12 은 K 또는 R이며;
X 13 은 D 또는 S이며; 그리고
X 14 은 M 또는 L이고;
(2)
서열 식별 번호:13 (AASDLES); 그리고
(3)
서열 식별 번호:67 (QQSX15X16X17PFT)
이때: X 15 , X 16 , 그리고 X 17 은 독립적으로 선택되며, 그리고
이때: X 15 은 H 또는 Y이며; X 16 은 E 또는 S이며; 그리고 X 17 은 D 또는 T이다.
특정 구체예들에서, 상기 경쇄 가변 (VL) 도메인은 서열 식별 번호:53의 아미노산 서열을 포함한다:

이때 X 12 , X 13 , X 14 , X 15 , X 16 , 그리고 X 17 은 독립적으로 선택되며, 그리고
이때 X 12 는 K 또는 R이며;
X 13 은 D 또는 S이며;
X 14 는 M 또는 L이며;
X 15 는 H 또는 Y이며;
X 16 은 E 또는 S이며; 그리고
X 17 은 D 또는 T이다.
특정 구체예들에서, 상기 MAB-A의 최적화된 변이체의 경쇄 가변 (VL) 도메인은 다음으로 구성된 군에서 선택되며:
(1)
hMAB-A VL(1) (서열 식별 번호:54);
(2)
hMAB-A VL(2) (서열 식별 번호:55);
(3)
hMAB-A VL(3) (서열 식별 번호:56);
(4)
hMAB-A VL(4) (서열 식별 번호:57);
(5)
hMAB-A VL(2A) (서열 식별 번호:20).
특정 구체예들에서, 상기CDRH1 도메인은 아미노산 서열 SYWMH (서열 식별 번호:8)을 포함하며, CDRH2 도메인은 아미노산 서열 EIIPIFGHTNYNEKFKS (서열 식별 번호:35)을 포함하며, 그리고 CDRH3 도메인은 아미노산 서열 GGYYYYPRQGFLDY (서열 식별 번호:45)을 포함한다.
특정 구체예들에서, 상기 CDRL1 도메인은 아미노산 서열 KASQSVDYSGDSYMN (서열 식별 번호:62)을 포함하며, CDRL2 도메인은 아미노산 서열 AASDLES (서열 식별 번호:13)을 포함하며, 그리고 CDRL3 도메인은 아미노산 서열 QQSHEDPFT (서열 식별 번호:14)을 포함한다.
특정 구체예들에서, 상기 면역콘쥬게이트는 다음을 포함한다:
(A) hMAB-A (2I.2)의 중쇄 가변 (VH) 도메인 (서열 식별 번호:28) 또는
(B) hMAB-A (2I.2)의 경쇄 가변 (VL) 도메인 (서열 식별 번호:55); 또는
(C) hMAB-A (2I.2)의 중쇄 가변 (VH) 도메인 (서열 식별 번호:28) 및 hMAB-A(2I.2)의 경쇄 가변 (VL) 도메인 (서열 식별 번호:55)
특정 구체예들에서, 상기 면역콘쥬게이트는 Fc 영역을 포함한다. 일부 구체예들에서, 상기 Fc 영역은 다음을 포함하는 변이체 Fc 영역이다: (a) FcγR에 대한 변이체 Fc 영역의 친화력을 감소시키는 하나 또는 그 이상의 아미노산 변형(들); 및/또는 (b) 시스테인 잔기를 도입시키는 하나 또는 그 이상의 아미노산 변형(들). 일부 구체예들에서, 상기 FcγR에 대한 변이체 Fc 영역의 친화력을 감소시키는 하나 또는 그 이상의 아미노산 변형(들)은 다음을 포함한다: (A) L234A; (B) L235A; 또는 (C) L234A 및 L235A; 이때 전술한 번호매김은 Kabat와 같은 EU 색인의 번호매김이다 일부 구체예들에서, 상기 시스테인 잔기를 도입시키는 하나 또는 그 이상의 아미노산 변형(들)은 S442C을 포함하며, 이때 전술한 번호매김은 Kabat와 같은 EU 색인의 번호매김이다
특정 구체예들에서, 본 발명의 면역콘쥬게이트는 인간 ADAM9 및 cyno ADAM9에 특이적으로 결합하는 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편을 포함하며, 이때 상기 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 약학적 제제에 콘쥬게이트된다.
일부 구체예들에서, 상기 인간화된 항-ADAM9 항체 또는 ADAM9-결합 이의 단편은 다음으로 구성된 군에서 선택된 서열을 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 포함한다:
(a)
차례로 서열 식별 번호:8, 35, 및 10, 그리고 서열 식별 번호:62, 13, 14;
(b)
차례로 서열 식별 번호:8, 35, 및 10, 그리고 서열 식별 번호:63, 13, 14;
(c)
차례로 서열 식별 번호:8, 36, 및 10 그리고 서열 식별 번호:63, 13, 14; 그리고
(d)
차례로 서열 식별 번호:34, 36, 및 10 그리고 서열 식별 번호:64, 13, 65.
일부 구체예들에서, 상기 인간화된 항-ADAM9 항체 또는 ADAM9-결합 이의 단편은 다음으로 구성된 군에서 선택된 서열에 대해 적어도 90%, 적어도 95%, 또는 적어도 99% 동일성인 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함한다:
(a)
차례로 서열 식별 번호:17 및 서열 식별 번호:55;
(b)
차례로 서열 식별 번호:17 및 서열 식별 번호:56;
(c)
차례로 서열 식별 번호:18 및 서열 식별 번호:56; 그리고
(d)
차례로 서열 식별 번호:19 및 서열 식별 번호:57.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체 또는 ADAM9-결합 이의 단편은 다음으로 구성된 군에서 선택된 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함한다:
(a)
차례로 서열 식별 번호:17 및 서열 식별 번호:55;
(b)
차례로 서열 식별 번호:17 및 서열 식별 번호:56;
(c)
차례로 서열 식별 번호:18 및 서열 식별 번호:56; 그리고
(d)
차례로 서열 식별 번호:19 및 서열 식별 번호:57.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체 또는 ADAM9-결합 이의 단편은 키메라 또는 뮤린 부계 항체와 비교하였을 때, cyno ADAM9에 대한 결합 친화력은 적어도 100-배 강화되고, 인간 ADAM9에 대해 높은 결합 친화력을 유지하되도록 최적화된다.
특정 구체예들에서, 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 다음으로 구성된 군에서 선택된 서열을 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 포함한다:
(a)
차례로 서열 식별 번호:8, 35, 및 37, 그리고 서열 식별 번호:62, 13, 14;
(b)
차례로 서열 식별 번호:8, 35, 및 38, 그리고 서열 식별 번호:62, 13, 14;
(c)
차례로 서열 식별 번호:8, 35, 및 39, 그리고 서열 식별 번호:62, 13, 14;
(d)
차례로 서열 식별 번호:8, 35, 및 40, 그리고 서열 식별 번호:62, 13, 14;
(e)
차례로 서열 식별 번호:8, 35, 및 41, 그리고 서열 식별 번호:62, 13, 14;
(f)
차례로 서열 식별 번호:8, 35, 및 42, 그리고 서열 식별 번호:62, 13, 14;
(g)
차례로 서열 식별 번호:8, 35, 및 43, 그리고 서열 식별 번호:62, 13, 14;
(h)
차례로 서열 식별 번호:8, 35, 및 44, 그리고 서열 식별 번호:62, 13, 14;
(i)
차례로 서열 식별 번호:8, 35, 및 45, 그리고 서열 식별 번호:62, 13, 14; 그리고
(j)
차례로 서열 식별 번호:8, 35, 및 46, 그리고 서열 식별 번호:62, 13, 14.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체 또는 ADAM9-결합 이의 단편은 다음으로 구성된 군에서 선택된 서열에 대해 적어도 90%, 적어도 95%, 또는 적어도 99% 동일성인 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함한다:
(a)
차례로 서열 식별 번호:20 및 서열 식별 번호:55;
(b)
차례로 서열 식별 번호:21 및 서열 식별 번호:55;
(c)
차례로 서열 식별 번호:22 및 서열 식별 번호:55;
(d)
차례로 서열 식별 번호:23 및 서열 식별 번호:55;
(e)
차례로 서열 식별 번호:24 및 서열 식별 번호:55;
(f)
차례로 서열 식별 번호:25 및 서열 식별 번호:55;
(g)
차례로 서열 식별 번호:26 및 서열 식별 번호:55;
(h)
차례로 서열 식별 번호:27 및 서열 식별 번호:55;
(i)
차례로 서열 식별 번호:28 및 서열 식별 번호:55; 그리고
(j)
차례로 서열 식별 번호:29 및 서열 식별 번호:55.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체 또는 ADAM9-결합 이의 단편은 다음으로 구성된 군에서 선택된 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함한다:
(a)
차례로 서열 식별 번호:20 및 서열 식별 번호:55;
(b)
차례로 서열 식별 번호:21 및 서열 식별 번호:55;
(c)
차례로 서열 식별 번호:22 및 서열 식별 번호:55;
(d)
차례로 서열 식별 번호:23 및 서열 식별 번호:55;
(e)
차례로 서열 식별 번호:24 및 서열 식별 번호:55;
(f)
차례로 서열 식별 번호:25 및 서열 식별 번호:55;
(g)
차례로 서열 식별 번호:26 및 서열 식별 번호:55;
(h)
차례로 서열 식별 번호:27 및 서열 식별 번호:55;
(i)
차례로 서열 식별 번호:28 및 서열 식별 번호:55; 그리고
(j)
차례로 서열 식별 번호:29 및 서열 식별 번호:55.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체는 Fc 영역을 포함하는 전장의 항체다. 일부 구체예들에서, 상기 Fc 영역은 다음을 포함하는 변이체 Fc 영역이다:
(a)
FcγR에 대한 변이체 Fc 영역의 친화력을 감소시키는 다음으로 구성된 군에서 선택된 하나 또는 그 이상의 아미노산 변형(들): L234A, L235A, 그리고 L234A 및 L235A이며; 및/또는
(b)
S442에 시스테인 잔기를 도입시키는 아미노산 변형, 이때 전술한 번호매김은 Kabat와 같은 EU 색인의 번호매김; 및/또는
(c)
FcRn에 대한 변이체 Fc 영역의 반감기를 연장시키는, 다음으로 구성된 군에서 선택된 하나 또는 그 이상의 아미노산 치환(들): M252Y, S254T, 그리고 T256E.
일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 다음으로 구성된 군에서 선택된 서열을 갖는 중쇄와 경쇄를 포함한다:
(a)
서열 식별 번호:50 및 서열 식별 번호:68;
(b)
서열 식별 번호:51 및 서열 식별 번호:68; 그리고
(c)
서열 식별 번호:52 및 서열 식별 번호:68.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체는 다음으로 구성된 군에서 선택된 서열을 갖는 중쇄와 경쇄를 포함한다:
(a)
차례로 서열 식별 번호:141 및 서열 식별 번호:68;
(b)
차례로 서열 식별 번호:142 및 서열 식별 번호:68;
(c)
차례로 서열 식별 번호:143 및 서열 식별 번호:68;
(d)
차례로 서열 식별 번호:151 및 서열 식별 번호:68;
(e)
차례로 서열 식별 번호:152 및 서열 식별 번호:68;
(f)
차례로 서열 식별 번호:153 및 서열 식별 번호:68; 그리고
(g)
차례로 서열 식별 번호:154 및 서열 식별 번호:68.
특정 구체예들에서, 서열 식별 번호:141, 서열 식별 번호:142, 서열 식별 번호:143, 서열 식별 번호:151, 서열 식별 번호:152, 서열 식별 번호:153 또는 서열 식별 번호:154에서 X는 리신이다.
특정 구체예들에서, 서열 식별 번호:141, 서열 식별 번호:142, 서열 식별 번호:143, 서열 식별 번호:151, 서열 식별 번호:152, 서열 식별 번호:153 또는 서열 식별 번호:154에서 X는 존재하지 않는다.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:156 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다. 특정 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:155 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:157에 의해 인코드된 경쇄, 그리고 (i) 서열 식별 번호:159, (ii) 서열 식별 번호:160, (iii) 서열 식별 번호:161, 또는 (iv) 서열 식별 번호:162에 의해 인코드된 중쇄를 포함한다.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:158에 의해 인코드된 경쇄, 그리고 (i) 서열 식별 번호:159, (ii) 서열 식별 번호:160, (iii) 서열 식별 번호:161, 또는 (iv) 서열 식별 번호:162에 의해 인코드된 중쇄를 포함한다.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:157에 의해 인코드된 경쇄와 서열 식별 번호:161에 의해 인코드된 중쇄를 포함한다.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:157에 의해 인코드된 경쇄와 서열 식별 번호:162에 의해 인코드된 중쇄를 포함한다.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:158에 의해 인코드된 경쇄와 서열 식별 번호:161에 의해 인코드된 중쇄를 포함한다.
특정 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:158에 의해 인코드된 경쇄와 서열 식별 번호:162에 의해 인코드된 중쇄를 포함한다.
특정 구체예들에서, 본 발명의 면역콘쥬게이트는 다음의 화학식으로 나타낸다:

이때:
CBA은 서열 식별 번호:8, 35, 그리고 45 및 서열 식별 번호:62, 13, 14를 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 포함하는 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편이며;
q은 1 또는 2이며;
D1은 다음의 화학식으로 나타낸다:

특정 구체예들에서, 상기 인간화된 항-ADAM9 항체 또는 ADAM9-결합 이의 단편은 서열 식별 번호:28 및 서열 식별 번호:55의 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함한다. 일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:142 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다. 일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:152 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다. 일부 구체예들에서, 일부 구체예들에서, 서열 식별 번호:142 또는 서열 식별 번호:152에서 X는 리신이다. 일부 구체예들에서, 일부 구체예들에서, 서열 식별 번호:142 또는 서열 식별 번호:152에서 X는 존재하지 않는다. 일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:156 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다. 일부 구체예들에서, 상기 면역콘쥬게이트를 포함하는 조성물(이를 테면, 약제학적 조성물)의 DAR 값은 1.0 내지 2.5, 1.5 내지 2.5, 1.8 내지 2.2, 또는 1.9 내지 2.1의 범위에 있다. 일부 구체예들에서, 상기 DAR은 1.8, 1.9, 2.0 또는 2.1이다.
특정 구체예들에서, 본 발명의 면역콘쥬게이트는 다음의 화학식으로 나타낸다:

이때:
CBA은 서열 식별 번호:8, 35, 그리고 45 및 서열 식별 번호:62, 13, 14를 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 포함하는 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편이며;
q은 1 또는 10의 정수이며;
D1은 다음의 화학식으로 나타낸다:

특정 구체예들에서, 상기 인간화된 항-ADAM9 항체 또는 ADAM9-결합 이의 단편은 서열 식별 번호:28 및 서열 식별 번호:55의 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함한다. 일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:52 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다. 일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:151 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다. 일부 구체예들에서, 서열 식별 번호:52 및 서열 식별 번호:151에서 X는 리신이다. 일부 구체예들에서, 서열 식별 번호:52 및 서열 식별 번호:151에서 X는 존재하지 않는다. 일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:155 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다. 일부 구체예들에서, 상기 면역콘쥬게이트를 포함하는 조성물(이를 테면, 약제학적 조성물)의 DAR 값은 1.0 내지 5.0, 1.0 내지 4.0, 1.5 내지 4.0, 2.0 내지 4.0, 2.5 내지 4.0, 2.9 내지 3.3, 3.3 내지 3.8, 1.5 내지 2.5, 또는 1.8 내지 2.2의 범위에 있다. 일부 구체예들에서, 상기 DAR은 4.0 미만, 3.8 미만, 3.6 미만, 3.5 미만, 3.0 미만 또는 2.5 미만이다. 일부 구체예들에서, 상기 DAR은 3.0 내지 3.2의 범위 안에 있다. 일부 구체예들에서, 상기 DAR은 3.5 내지 3.7의 범위 안에 있다. 일부 구체예들에서, 상기 DAR은 3.1, 3.2, 3.3, 3.4, 3.5, 3.6 또는 3.7이다. 일부 구체예들에서, 상기 DAR은 1.9 내지 2.1의 범위 안에 있다. 일부 구체예들에서, 상기 DAR은 1.9, 2.0 또는 2.1이다.
본 발명의 또다른 측면은 본원에서 기술된 본 발명의 면역콘쥬게이트의 효과량과 약제학적으로 허용되는 운반체, 부형제 또는 희석제를 포함하는 약제학적 조성물을 제공한다.
또다른 측면에 있어서, 본 발명은 대상체에서 ADAM9의 발현과 연합된, 또는 이를 특징으로 하는 질환 또는 병태를 치료하는 방법을 제공하는데, 이 방법은 전술한 대상체에게 효과량의 상기 면역콘쥬게이트 또는 본 발명에서 기술된 약제학적 조성물을 투여하는 것을 포함한다. 대상체에서 ADAM9의 발현과 연합된, 또는 이를 특징으로 하는 질환 또는 병태의 치료에 있어서 본 발명에서 기술된 면역콘쥬게이트 또는 약제학적 조성물의 용도를 또한 본 발명에서 제공한다. 본 발명은 대상체에서 ADAM9의 발현과 연합된, 또는 이를 특징으로 하는 질환 또는 병태 치료용 약물로써 본 발명에서 기술된 면역콘쥬게이트 또는 약제학적 조성물의 용도를 또한 본 발명에서 제공한다.
특정 구체예들에서, ADAM9의 발현과 연합된, 또는 이를 특징으로 하는 질환 또는 병태는 암이다. 일부 구체예들에서, 상기 암은 비-소(small)-세포 폐암, 결장직장암, 위암, 췌장암, 신장 세포 암종, 전립선암, 식도암, 유방암, 두경부암, 난소암, 간암, 자궁경부암, 갑상선암, 고환암, 골수암, 흑색종 및 림프 암으로 구성된 군에서 선택된다. 특정 구체예들에서, 상기 암은 비-소-세포 폐암, 위암, 췌장암 또는 결장직장암이다. 특정 구체예들에서, 상기 비-소-세포 폐암은 편평 세포 암종, 선암종, 또는 거대-세포 미분화된 암종이다. 특정 구체예들에서, 상기 결장직장암은 선암종, 위장관 카르시노이드 종양, 위장 기질 종양, 원발성 결장직장 림프종, 평활근육종, 또는 편평 세포 암종이다.
도 1A-1C는 면역조직화학 (IHC) 연구의 결과를 제시하는데, 다양한 비-소 세포 폐암 유형 (도 1A), 유방암 세포, 전립선암 세포, 위암 세포 (도 IB), 그리고 결장암 세포 (도 1C)를 특이적으로 라벨시키는 MAB-A의 능력을 보여주며, 한편 아이소타입 대조군은 이들 암 세포 유형중 임의의 것에도 특이적으로 라벨되지 못했다 (도 1A-1C).
도 2는 세포 착색 연구 결과를 제시하는데, MAB-A는 인간 ADAM9에 결합하고, 그리고 다소 적은 수준이지만, 293-FT 및 CHO-K 세포 (차례로 상부 패널 및 하부 패널)의 표면에서 일과적으로 발현된 시노몰구스 원숭이 ADAM9에 결합한다는 것을 보여준다.
도 3A-3B는 MAB-A의 몇 가지 인간화된/최적화된 변이체와 함께 나란히 배열된 (도 3A, 서열 식별 번호:7, 16,17, 18, 19, 21, 22, 23 및 28) 뮤린 항-ADAM9-VH 도메인의 아미노산 서열, 그리고 몇 가지 MAB-A의 인간화된/최적화된 변이체와 나란히 배열된 (도 3B, 서열 식별 번호:11, 54, 55, 56 및 57) 뮤린 항-ADAM9-VH 도메인을 도시한다. 초기 최적화 동안 CDRs내에서 치환된 위치는 다음과 같이 밑줄있다: 잠재적인 탈아미드화(deamidation) 부위 및 이성질체화(isomeration) 부위는 단일 밑줄로 표시되고, 리신 잔기는 이중 밑줄로 표시되며, 추가 불안정한 잔기는 점선 밑줄로 표시된다.
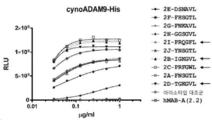
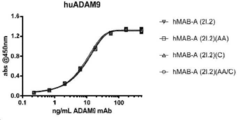
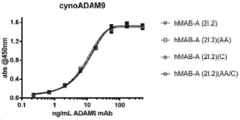
도 4A-4B는 CDRH3 변이체, 부계 hMAB-A (2.2), 그리고 아이소타입 대조군 항체를 포함하는 10개의 선택된 최적화 hMAB-A 클론의 ELISA 결합 곡선을 나타낸다. 도 4A는 cynoADAM9의 결합 곡선을 나타내며, 도 4B는 huADAM9의 결합 곡선을 나타낸다.
도 5A-5B는 상기 Fc 변이체의 ELISA 결합 곡선을 나타낸다. 도 5A는 huADAM9의 결합 곡선을 나타내며, 도 5B는cynoADAM9의 결합 곡선을 나타낸다.
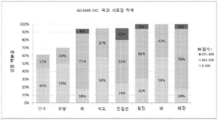
도 6A-6B는 차례로 20 개의 암종 조직 마이크로어레이에서 ADAM9 IHC 막 착색과 8 개의 선택된 징후에서 각각 ADAM IHC 막 및 세포질 염색을 나타낸다.
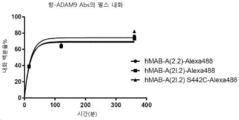
도 7A-7B는 차례로 다양한 항-ADAM9 항체 콘쥬게이트의 펄스 내화(internalization) 및 연속적 내화를 보여준다.
도 8A는 pH 6.0에서 YTE 돌연변이를 갖는, 그리고 이 돌연변이가 없는 포획된 항-ADAM9 항체에 대한 250nM & 1000nM huFcRn의 결합을 보여준다.
도 8B는 pH 6.0에서 고정된 FcRn에 대한 YTE 돌연변이를 갖는, 그리고 이 돌연변이가 없는 포획된 25nM & 100nM 항-ADAM9 항체의 결합을 보여준다.
도 9A, 9B 및 9C에서는 예시적인 메이탄시노이드 화합물들과 본 발명의 면역콘쥬게이트를 준비하는 합성 도해를 보여준다.
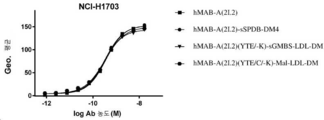
도 10는 hMAB-A(2I.2), hMAB-A(2I.2)-sSPDB-DM4, hMAB-A(2I.2)(YTE/-K)-LDL-DM 및 hMAB-A(2I.2)(YTE/C/-K)-LDL-DM의 FACS 결합 곡선을 나타낸다.
도 11A 및 11B는 다양한 비-소 세포 폐암 세포주에 대항하는 다양한 항-ADAM9 면역콘쥬게이트의 시험관내 세포독성을 나타낸다. 비-표적화된 IgG1 기반-접합체는 음성 대조군으로 포함된다.
도 12는 Calu-3 인간 비-소 세포 폐 선암종 이종이식편 모델에서 hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR)의 항-종양 활성을 나타낸다.
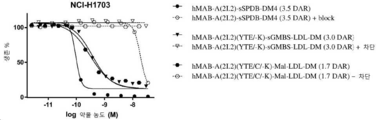
도 13은 H1703 인간 비-소 세포 폐 편평 세포 암종 이종이식편에서 hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR)의 항-종양 활성을 나타낸다.
도 14는 SNU-5 인간 위 암종 이종이식편에서 hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR)의 항-종양 활성을 나타낸다.
도 15는 EBC-1 인간 비-소 세포 폐 편평 세포 암종 이종이식편을 품고 있는 SCID 마우스에서 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR) 및 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드의 항-종양 활성을 나타낸다.
도 16은 SW48 인간 결장직장 선암종 이종이식편을 품고 있는 CD1 누드 마우스에서 hMAB-A(2I.2)(YTE/C/-K)-Ma1-LDL-DM 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드와 비-결합 대조군 huKTI-Ma1-LDL-DM (2.0 DAR) 콘쥬게이트의 100μg/kg의 DM 페이로드의 항-종양 활성을 나타낸다.
도 17은 HPAF-II 인간 췌장 선암종 이종이식편을 품고 있는 CD1 누드 마우스에서 hMAB-A(2I.2)(YTE/C/-K)-Ma1-LDL-DM 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드와 비-결합 대조군 huKTI-Ma1-LDL-DM (2.0 DAR) 콘쥬게이트의 100μg/kg의 DM 페이로드의 항-종양 활성을 나타낸다.
도 18은 H1975 인간 비-소 세포 폐 선암종 이종이식편을 품고 있는 CD1 누드 마우스에서 hMAB-A(2I.2)-sSPDB-DM4(2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드와 hMAB-A(2I.2)-S442C-Ma1-LDL-DM (2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드의 항-종양 활성을 나타낸다.
도 19는 Hs 746T 인간 위 암종 이종이식편을 품고 있는 CD1 누드 마우스에서 hMAB-A(2I.2)-sSPDB-DM4(2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드와 hMAB-A(2I.2)-S442C-Ma1-LDL-DM (2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드의 항-종양 활성을 나타낸다.
도 2는 세포 착색 연구 결과를 제시하는데, MAB-A는 인간 ADAM9에 결합하고, 그리고 다소 적은 수준이지만, 293-FT 및 CHO-K 세포 (차례로 상부 패널 및 하부 패널)의 표면에서 일과적으로 발현된 시노몰구스 원숭이 ADAM9에 결합한다는 것을 보여준다.
도 3A-3B는 MAB-A의 몇 가지 인간화된/최적화된 변이체와 함께 나란히 배열된 (도 3A, 서열 식별 번호:7, 16,17, 18, 19, 21, 22, 23 및 28) 뮤린 항-ADAM9-VH 도메인의 아미노산 서열, 그리고 몇 가지 MAB-A의 인간화된/최적화된 변이체와 나란히 배열된 (도 3B, 서열 식별 번호:11, 54, 55, 56 및 57) 뮤린 항-ADAM9-VH 도메인을 도시한다. 초기 최적화 동안 CDRs내에서 치환된 위치는 다음과 같이 밑줄있다: 잠재적인 탈아미드화(deamidation) 부위 및 이성질체화(isomeration) 부위는 단일 밑줄로 표시되고, 리신 잔기는 이중 밑줄로 표시되며, 추가 불안정한 잔기는 점선 밑줄로 표시된다.
도 4A-4B는 CDRH3 변이체, 부계 hMAB-A (2.2), 그리고 아이소타입 대조군 항체를 포함하는 10개의 선택된 최적화 hMAB-A 클론의 ELISA 결합 곡선을 나타낸다. 도 4A는 cynoADAM9의 결합 곡선을 나타내며, 도 4B는 huADAM9의 결합 곡선을 나타낸다.
도 5A-5B는 상기 Fc 변이체의 ELISA 결합 곡선을 나타낸다. 도 5A는 huADAM9의 결합 곡선을 나타내며, 도 5B는cynoADAM9의 결합 곡선을 나타낸다.
도 6A-6B는 차례로 20 개의 암종 조직 마이크로어레이에서 ADAM9 IHC 막 착색과 8 개의 선택된 징후에서 각각 ADAM IHC 막 및 세포질 염색을 나타낸다.
도 7A-7B는 차례로 다양한 항-ADAM9 항체 콘쥬게이트의 펄스 내화(internalization) 및 연속적 내화를 보여준다.
도 8A는 pH 6.0에서 YTE 돌연변이를 갖는, 그리고 이 돌연변이가 없는 포획된 항-ADAM9 항체에 대한 250nM & 1000nM huFcRn의 결합을 보여준다.
도 8B는 pH 6.0에서 고정된 FcRn에 대한 YTE 돌연변이를 갖는, 그리고 이 돌연변이가 없는 포획된 25nM & 100nM 항-ADAM9 항체의 결합을 보여준다.
도 9A, 9B 및 9C에서는 예시적인 메이탄시노이드 화합물들과 본 발명의 면역콘쥬게이트를 준비하는 합성 도해를 보여준다.
도 10는 hMAB-A(2I.2), hMAB-A(2I.2)-sSPDB-DM4, hMAB-A(2I.2)(YTE/-K)-LDL-DM 및 hMAB-A(2I.2)(YTE/C/-K)-LDL-DM의 FACS 결합 곡선을 나타낸다.
도 11A 및 11B는 다양한 비-소 세포 폐암 세포주에 대항하는 다양한 항-ADAM9 면역콘쥬게이트의 시험관내 세포독성을 나타낸다. 비-표적화된 IgG1 기반-접합체는 음성 대조군으로 포함된다.
도 12는 Calu-3 인간 비-소 세포 폐 선암종 이종이식편 모델에서 hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR)의 항-종양 활성을 나타낸다.
도 13은 H1703 인간 비-소 세포 폐 편평 세포 암종 이종이식편에서 hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR)의 항-종양 활성을 나타낸다.
도 14는 SNU-5 인간 위 암종 이종이식편에서 hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR)의 항-종양 활성을 나타낸다.
도 15는 EBC-1 인간 비-소 세포 폐 편평 세포 암종 이종이식편을 품고 있는 SCID 마우스에서 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR) 및 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드의 항-종양 활성을 나타낸다.
도 16은 SW48 인간 결장직장 선암종 이종이식편을 품고 있는 CD1 누드 마우스에서 hMAB-A(2I.2)(YTE/C/-K)-Ma1-LDL-DM 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드와 비-결합 대조군 huKTI-Ma1-LDL-DM (2.0 DAR) 콘쥬게이트의 100μg/kg의 DM 페이로드의 항-종양 활성을 나타낸다.
도 17은 HPAF-II 인간 췌장 선암종 이종이식편을 품고 있는 CD1 누드 마우스에서 hMAB-A(2I.2)(YTE/C/-K)-Ma1-LDL-DM 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드와 비-결합 대조군 huKTI-Ma1-LDL-DM (2.0 DAR) 콘쥬게이트의 100μg/kg의 DM 페이로드의 항-종양 활성을 나타낸다.
도 18은 H1975 인간 비-소 세포 폐 선암종 이종이식편을 품고 있는 CD1 누드 마우스에서 hMAB-A(2I.2)-sSPDB-DM4(2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드와 hMAB-A(2I.2)-S442C-Ma1-LDL-DM (2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드의 항-종양 활성을 나타낸다.
도 19는 Hs 746T 인간 위 암종 이종이식편을 품고 있는 CD1 누드 마우스에서 hMAB-A(2I.2)-sSPDB-DM4(2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드와 hMAB-A(2I.2)-S442C-Ma1-LDL-DM (2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드의 항-종양 활성을 나타낸다.
발명의 상세한 설명
본 발명은 본원에서 기술된 적어도 한 가지 메이탄시노이드 화합물에 콘쥬게이트된 "디스인테그린 및 메탈로프로테아제 도메인-함유하는 단백질 9" ("ADAM9") 에 특이적으로 결합할 수 있는 항체 또는 이의 단편을 포함하는 면역콘쥬게이트에 관계한다. 본 발명 구체적으로 인간 ADAM9 및 비-인간 영장류 (이를 테면, 시노몰구스 원숭이)의 ADAM9와 교차-반응성이 있는 이러한 면역콘쥬게이트에 관계한다. 본 발명 추가적으로, 이러한 면역콘쥬게이트를 수령 대상체에게 투여할 때, 면역원성을 감소시키도록 하기 위해, 인간화된 및/또는 탈면역화된 경쇄 가변 (VL) 도메인 및/또는 중쇄 가변 (VH) 도메인을 포함하는 이러한 모든 면역콘쥬게이트에 관계한다. 본 발명은 이러한 면역콘쥬게이트중 임의의 것을 함유하는 약제학적 조성물, 그리고 암과 기타 질환 및 병태의 치료에 이러한 임의의 면역콘쥬게이트의 사용과 관련된 방법에 또한 관계한다.
I.
항체 및 이들의 결합 도메인
본 발명의 면역콘쥬게이트는 ADAM9 또는 이의 ADAM9-결합 단편에 결합하는 항체를 포함한다. "항체"란 면역글로불린 분자의 가변 도메인에 위치하는 적어도 한 개의 항원 인지 부위를 통하여, 탄수화물, 폴리뉴클레오티드, 지질, 폴리펩티드, 등등과 같은 표적에 특이적으로 결합할 수 있는 면역글로불린 분자들이다. 본원에서 사용된 바와 같이, "항체" 및 "항체"란 단일클론 항체, 다중특이적 항체, 인간 항체, 인간화된 항체, 합성 항체, 키메라 항체, 다중클론 항체, 카멜화된(camelized) 항체, 단일-쇄 Fvs (scFv), 단일-쇄 항체, Fab 단편들, F(ab') 단편들, 인트라바디, 그리고 상기 것들중 임의의 것의 에피토프-결합 단편들을 지칭한다. 특히, 용어 "항체"에는 면역글로불린 분자들과 면역글로불린 분자들의 면역학적으로 활성 단편들, 에피토프-결합 부위를 함유하는 분자들이 내포된다. 면역글로불린 분자들은 임의의 유형의 (이를 테면, IgG, IgE, IgM, IgD, IgA 및 IgY), 클래스 (이를 테면, IgG1, IgG2, IgG3, IgG4, IgA1 및 IgA2) 또는 서브클래스일 수 있다. 지난 수십 년 동안 항체의 치료 잠재력에 대한 관심이 다시 부활했으며, 항체는 생명공학-유래 약물의 선도적인 클래스 중 하나가 되었다 (Chan, C.E. et al. (2009) "The Use Of Antibodies In The Treatment Of Infectious Diseases," Singapore Med. J. 50(7):663-666). 진단에 사용하는 것 외에도, 항체는 치료요법제로 유용한 것으로 나타났다. 200 개 이상의 항체-기반 약물 사용이 승인되었거나 또는 개발 중이다.
항체는 폴리펩티드 또는 단백질 또는 비-단백질 분자에 존재하는 특정 도메인 또는 모이어티 또는 입체형태 ("에피토프")의 존재로 인하여 이들에게 "면역특이적으로 결합"할 수 있다. 에피토프-함유하는 분자는 면역원성 활성을 보유할 수 있으며, 이로 인하여 이 분자는 동물에서 항체 생산 반응을 유도하며; 이러한 분자들을 "항원"이라고 한다. 본원에서 사용된 바와 같이, 항체는 다른 분자의 영역 (가령, 에피토프)에 더 빈번하게, 더 빠르게, 더 오랜 지속 시간으로, 및/또는 대체 분자에 비교하여 더 큰 친화력으로 반응하거나 또는 결합하는 경우 "면역특이적으로"결합한다라고 한다. 예를 들면, 바이러스성 에피토프에 면역특이적으로 결합하는 항체는 다른 바이러스성 에피토프 또는 비-바이러스성 에피토프에 이것이 면역특이적으로 결합하는 것보다 더 큰 친화력, 항원항체결합력(avidity), 더욱 즉각적으로, 및/또는 더 오랜 기간 동안 당해 바이러스성 에피토프에 결합하는 항체다. 예를 들어, 제 1 표적에 면역특이 적으로 결합하는 항체 (또는 모이어티 또는 에피토프)는 제 2 표적에 특이적으로 또는 선호적으로 결합할 수 있거나 또는 결합하지 않을 수 있다는 것을 이 정의를 읽음으로써 또한 이해할 수 있다. 이와 같이, 특정 에피토프에 "면역특이적 결합"이 당해 에피토프에 배타적인 결합을 반드시 요구하는 것은 아니다(비록 이러한 것을 포함할 지라도). 일반적으로, 반드시 그런 것은 아니지만, 결합을 언급할 때, 이 결합은 "면역특이적" 결합을 의미한다. 두 분자는 이들 분자의 수용체가 각각의 리간드에 결합하는 특이성을 나타내는 경우, "물리특이적" 방식으로 서로에 대해 결합할 수 있다고 한다.
용어 "단일클론 항체"란 단일클론 항체가 항원의 선택적 결합에 관여하는 아미노산 (자연 발생적 또는 비-자연 발생적)으로 구성되는 동종 항체 집단을 의미한다. 단일클론 항체는 단일 에피토프(또는 항원 부위)로 지향되는 매우 특이적이다. 용어 "단일클론 항체"에는 무손상 단일클론 항체 및 전장(full-length)의 단일클론 항체, 뿐만 아니라 이의 단편들 (이를 테면, Fab, Fab', F(ab')2 Fv), 단일-쇄 (scFv), 이의 돌연변이체들, 항체 부분을 포함하는 융합 단백질들, 인간화된 단일클론 항체, 키메라 단일클론 항체, 그리고 항원에 결합하는 요구되는 특이성 및 능력을 갖는 항원 인지 부위를 포함하는 면역글로불린 분자의 임의의 기타 변형된 입체형태가 포괄된다. 이 용어는 항체의 공급원 또는 그것이 만들어지는 방식 (예를 들어, 하이브리도마, 파아지 선택, 재조합 발현, 유전자이식된(transgenic) 동물들 등,)과 관련하여 제한되는 것으로 의도되지 않는다. 이 용어는 전체 면역글로불린 및 "항체"의 정의 하에 상기 기재된 단편 등을 포함한다. 단일클론 항체를 만드는 방법은 당업계에 알려져 있다. 이용할 수 있는 한 가지 방법은 Kohler, G. et al. (1975) "Continuous Cultures Of Fused Cells Secreting Antibody Of Predefined Specificity," Nature 256:495-497의 방법이거나, 또는 이의 변형된 방법이다. 일반적으로, 단일클론 항체는 마우스, 렛(rats) 또는 토끼에서 발생된다. 항체는 원하는 에피토프를 포함하는 면역원성 양의 세포, 세포 추출물 또는 단백질 조제물(preparations)로 동물을 면역화시켜 만든다. 상기 면역원은 일차 세포, 배양된 세포주, 암 세포, 단백질, 펩티드, 핵산 또는 조직이 될 수 있지만, 이에 국한되지 않는다. 면역화에 사용되는 세포는 면역원으로 사용되기 전, 일정 기간 (예를 들어, 적어도 24 시간) 동안 배양될 수 있다. 세포는 자체적으로 또는 비-변성 어쥬번트, 이를 테면, Ribi (이를 테면, Jennings, V.M. (1995) "Review of Selected Adjuvants Used in Antibody Production," ILAR J. 37(3): 119-125 참고)와 함께 면역원으로 사용될 수 있다. 일반적으로, 세포는 손상되지 않은 상태(intact)로 유지되어야 하며, 면역원으로 사용될 때 가급적 생존 가능해야 한다. 무손상 세포는 면역화된 동물에 의해 파열된 세포보다 항원이 더 잘 검출되도록 할 수 있다. 변성 또는 까다로운(harsh) 어쥬번트 (예: Freund의 어쥬번트)를 사용하면 세포가 파열될 수 있으므로, 권장되지 않는다. 면역원은 주기적 간격, 이를 테면, 격주로 또는 매주 여러 번 투여될 수 있거나, 또는 동물에서 생존력을 유지하는 방식으로 투여될 수 있다 (예를 들어, 조직 재조합체에서). 대안적으로, 기존의 단일클론 항체 및 원하는 병원성 에피토프에 대해 면역 특이적인 임의의 다른 등가 항체는 당업계에 공지된 임의의 수단에 의해 서열화되고, 재조합적으로 생성될 수 있다. 한 구체예에서, 그러한 항체는 서열화되고, 그 다음 폴리뉴클레오티드 서열은 발현 또는 증식을 위해 벡터로 클로닝된다. 관심 항체를 인코딩하는 서열은 숙주 세포의 벡터에서 유지될 수 있고, 숙주 세포는 이후 사용을 위해 확장 및 동결될 수 있다. 이러한 항체의 폴리뉴클레오티드 서열은 친화력 최적화된, 키메라 항체, 인간화된 항체, 및/또는 캐니나이져화된(caninized) 항체를 만들기 위해, 상기 항체의 친화력 및 기타 특징을 개선시키기 위해 유전적 조작에 이용되고, 뿐만 아니라 본 발명의 면역콘쥬게이트를 만들기 위해 이용될 수 있다. 항체를 인간화시키는 일반적인 원리는 항체의 항원-결합 부분의 기본 서열을 유지하면서, 한편 항체의 나머지 비-인간 부분을 인간 항체 서열로 교체하는 것이다.
천연 항체 (이를 테면, 천연 IgG 항체)는 두 개의 "중쇄"와 복합된 두 개의 "경쇄"로 구성된다. 각 경쇄는 가변 도메인 ("VL")과 불변 도메인 ("CL")을 함유한다. 각 중쇄는 가변 도메인 ("VH"), 세 개의 불변 도메인 ("CH1","CH2" 및 "CH3"), 그리고 당해 CH1과 CH2 도메인 사이에 위치한 "힌지"("H") 영역을 함유한다. 대조적으로, scFv는 짧은 연결 펩티드를 통해 경쇄 도메인과 중쇄 가변 도메인을 함께 연결시켜 만든 단일 사슬 분자다.
따라서, 자연 발생적 면역글로불린 (예, IgG)의 기본 구조 단위는 일반적으로 약 150,000 Da의 당 단백질로 발현되는 두 개의 경쇄와 두 개의 중쇄를 갖는 사량체다. 각 쇄의 아미노-말단 ("N-말단")부분은 주로 항원 인식을 담당하는 약 100 내지 110 개 이상의 아미노산의 가변 도메인을 포함한다. 각 쇄의 카르복시-말단 ("C-말단") 부분은 불변 영역으로 특정되며, 경쇄는 단일 불변 도메인을 갖고, 그리고 중쇄는 보통 세 개의 불변 도메인과 힌지 영역을 갖는다. 따라서, IgG 분자의 경쇄 구조는 n-VL-CL-c이며, IgG 중쇄 구조는 n-VH-CH1-H-CH2-CH3-c (여기에서 n 및 c는 차례로, 당해 폴리펩티드의 N-말단부와 C-말단부를 나타낸다).
A.
항체 가변 도메인의 특징
IgG 분자의 가변 도메인은 1개, 2개, 그리고 가장 흔하게 3개의 상보성 결정 영역 ("CDR", 예를 들면, 차례로, CDR1, CDR2 및 CDR3)으로 구성되며, 이들은 에피토프와 접촉되는 잔기들과, 그리고 비-CDR 세그먼트, 이는 프레임워크 영역 ("FR")이라 지칭됨, 이것은 당해 CDR 영역의 구조 및 위치를 일반적으로 유지시켜, 이러한 접촉이 가능하도록 함(비록, 일부 프레임워크는 또한 당해 에피토프와 접촉할 수 있음)-을 함유한다. 따라서, 상기 VL 및 VH 도메인은 전형적으로 다음의 구조를 갖는다: n-FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4-c (여기에서 "n"은 N-말단부를 나타내며, "c"는 C-말단부를 나타낸다). 항체 경쇄의 첫 번째, 두 번째, 세 번째 그리고 네 번째 FR인 (또는 이러한 것들로 작용하는) 폴리펩티드는 본원에서 차례로 다음과 같이 지칭된다: FR L 1 도메인, FR L 2 도메인, FR L 3 도메인, 그리고 FR L 4 도메인. 유사하게, 항체 중쇄의 첫 번째, 두 번째, 세 번째 그리고 네 번째 FR인 (또는 이러한 것들로 작용하는) 폴리펩티드는 본원에서 차례로 다음과 같이 지칭된다: FR H 1 도메인, FR H 2 도메인, FR H 3 도메인 및 FR H 4 도메인. 항체 경쇄의 첫 번째, 두 번째, 그리고 세 번째 CDR인 (또는 이러한 것들로 작용하는) 폴리펩티드는 본원에서 차례로 다음과 같이 지칭된다: CDR L 1 도메인, CDR L 2 도메인, 그리고 CDR L 3 도메인. 유사하게, 항체 중쇄의 첫 번째, 두 번째, 그리고 세 번째 CDR인 (또는 이러한 것들로 작용하는) 폴리펩티드는 본원에서 차례로 다음과 같이 지칭된다: CDR H 1 도메인, CDR H 2 도메인, 그리고 CDR H 3 도메인. 따라서, 용어 CDRL1 도메인, CDRL2 도메인, CDRL3 도메인, CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인은 이들 폴리펩티드가 항체에 통합될 때, 당해 항체가 특정 에피토프에 결합할 수 있도록 이 폴리펩티드로 지향한다.
본 명세서 전반에 걸쳐, 면역글로불린의 성숙한 중쇄 및 경쇄의 가변 도메인에 있는 잔기의 번호매김은 쇄서 아미노산의 위치에 의해 지정된다. Kabat는 항체에 대한 수많은 아미노산 서열을 설명하고, 각 하위그룹에 대한 아미노산 컨센수스(consensus) 서열을 식별해내었으며, 각 아미노산에 잔기 번호를 할당했으며, CDR은 Kabat에 의해 정의된 바와 같이 식별된다(Chothia에 의해 정의된 CDRH1은 Chothia, C. & Lesk, A. M. ((1987) "Canonical structures for the hypervariable regions of immunoglobulins," J. Mol. Biol. 196:901-917) 5개 잔기 앞에서 시작된다). Kabat의 번호매김 체계는 보존된 아미노산을 참조하여 문제의 항체를 Kabat의 컨센수스 서열 중 하나와 정렬함으로써 그의 개요에 포함되지 않은 항체로 확장시킬 수 있다. 잔기 번호를 할당하는 이 방법은 현장에서 표준이 되었으며, 키메라 또는 인간화된 변이체를 비롯한 다른 항체의 대등한 위치에 있는 아미노산을 용이하게 식별한다. 예를 들면, 인간 항체 경쇄의 위치 50에 있는 아미노산은 마우스 항체 경쇄 위치 50의 아미노산에 대해 등가의 위치를 점유한다.
항원의 에피토프에 결합하는 항체의 능력은 당해 항체의 VL 도메인과 VH 도메인의 존재 및 아미노산 서열에 따라 달라진다. 항체의 경쇄와 중쇄의 상호작용, 특히, 이의 VL 도메인과 VH 도메인의 상호작용은 천연 항체, 이를 테면, IgG의 두 개의 에피토프-결합 부위를 형성한다. 천연 항체는 비록 에피토프 종의 다수 복사체에 결합할 수 있지만 (이를 테면, 이가결합가(bivalency) 또는 다가결합가(multivalency)를 나타냄), 천연 항체는 오직 하나의 에피토프 종 (이를 테면, 이들은 단일특이성임)에만 결합할 수 있다.
따라서, 본원에서 사용된 바와 같이, 용어 "에피토프-결합 단편" 이란 에피토프에 면역특이적으로 결합할 수 있는 항체의 단편이며, 용어 "에피토프-결합 부위"이란 에피토프-결합 단편을 포함하는 분자의 부분을 지칭한다. 에피토프-결합 단편은 항체의 임의의 1개, 2개, 3개, 4개, 또는 5개의CDR 도메인을 함유할 수 있거나, 또는 항체의 6개 모든 CDR 도메인을 함유할 수 있고, 이러한 에피토프에 면역특이적으로 결합하지만, 이러한 항체의 것과는 상이한 이러한 항체에 대한 면역특이성, 친화력 또는 선택성을 나타낼 수 있다. 선호적으로, 그러나, 에피토프-결합 단편은 이러한 항체의 CDR 도메인 6개 모두를 함유하는 것이다. 항체의 에피토프-결합 단편은 단일 폴리펩티드 쇄 (이를 테면, scFv), 또는 두 개 또는 그 이상의 폴리펩티드 쇄를 포함할 수 있으며, 각 쇄는 아미노 말단부와 카르복시 말단부 (이를 테면, Fab 단편, Fab2 단편, 등등,)를 갖는다. 명시적으로 언급되지 않는 한, 본원에서 기술된 단백질 분자들의 도메인 순서는 "N-말단으로부터 C-말단" 방향이다.
본 발명은 본 발명의 항-ADAM9-VL 및/또는 VH 도메인을 포함하는 단일-쇄 가변 도메인 단편들 ("scFv")을 포함하는 면역콘쥬게이트 또한 포괄한다. 단일-쇄 가변 도메인 단편들은 짧은 "링커" 펩티드를 이용하여 서로 연계된 VL 도메인과 VH 도메인을 포함한다. 이러한 링커들은 추가적인 기능을 제공하도록, 이를 테면, 약물의 부착을 허용하도록, 또는 고형 지지대에 부착이 되도록, 변형될 수 있다. 상기 단일-쇄 변이체는 재조합에 의해 또는 합성에 의해 만들어질 수 있다. scFv의 합성에 의한 생산을 위해, 자동화 합성기가 이용될 수 있다. scFv의 재조합적 생산을 위해, scFv를 인코드하는 폴리뉴클레오티드를 함유하는 적합한 플라스미드가 적합한 숙주 세포, 진핵세포, 이를 테면, 효모, 식물, 곤충 또는 포유류 세포이거나, 또는 원핵세포, 이를 테면, 대장균(E. coli)으로 도입될 수 있다. 관심대상의 scFv를 인코드하는 폴리뉴클레오티드는 통상적인 조작, 이를 테면, 폴리뉴클레오티드의 결찰에 의해 만드어질 수 있다. 결과적으로 생성된 scFv는 당분야에 공지된 표준 단백질 정제 기술을 이용하여 단리될 수 있다.
본 발명은 본 발명의 항-ADAM9 항체의 인간화된/최적화된 변이체의 CDRH1, CDRH2, CDRH3, CDRL1, CDRL2, 그리고 CDRL3 도메인을 포함하는, 뿐만 아니라 이러한 CDRL를 임의의 1개, 2개, 또는 3개를 함유하는 VL 도메인과 임의의 1개, 2개, 또는 3개의 이러한 CDRH를 함유하는 VH 도메인을 포함하는 면역콘쥬게이트를 포괄하고, 뿐만 아니라 이러한 동일한 것을 포함하는 다중특이적-결합 분자들을 또한 포괄한다. 용어 "인간화된" 항체란 비-인간 종의 면역글로불린의 에피토프-결합 부위를 갖고, 인간 면역글로불린의 구조 및/또는 서열에 기반을 둔 나머지 면역글로불린 구조를 갖는 키메라 분자를 지칭한다. 인간화된 항체는 일반적으로 재조합 기술을 이용하여 만들어진다. 본 발명의 면역콘쥬게이트는 항체의 인간화된, 키메라 또는 캐니나이져화된 변이체를 포함할 수 있는데, 이는 본원에서 "MAB-A"로 명명된다. MAB-A의 가변 도메인을 인코드하는 폴리뉴클레오티드 서열은 개선된 또는 변경된 특징 (이를 테면, 친화력, 교차-반응성, 특이성, 등등,)을 소유하는 MAB-A 유도체들을 만들기 위한 유전자 조작에 이용될 수 있다. 항체를 인간화시키는 일반적인 원리는 항체의 에피토프-결합 부분의 기본 서열을 유지하면서, 한편 항체의 나머지 비-인간 부분을 인간 항체 서열로 교체하는 것이다. 단일클론 항체를 인간화시키는데 네 가지 단계가 있다. 이들 단계는 다음과 같다: (1) 출발 항체 경쇄 및 중쇄 가변 도메인의 뉴클레오티드 및 예상 아미노산 서열을 결정하고; (2) 상기 인간화된 항체 또는 캐니나이져화된 항체를 기획하고, 이를 테면, 인간화 또는 캐노나이징 공정 동안 이용하기 위한 항체 프레임워크 영역을 결정하고; (3) 실질적인 인간화 또는 캐노나이징 방법/기술을 이용하고; 그리고 (4) 상기 인간화된 항체를 형질감염 및 발현시킨다. 예를 들면, U.S. 특허 번호. 4,816,567; 5,807,715; 5,866,692; 그리고 6,331,415 참고. 용어 "최적화된" 항체란 경쇄 또는 중쇄 가변 영역에서 적어도 한 개의 상보성 결정 영역 (CDR)이 부계 항체와 상이한 적어도 한 개의 아미노산을 갖는 항체를 지칭하며, 이러한 차이는 부계 항체와 비교하였을 때, 인간 ADAM9 및/또는 시노몰구스 원숭이에 대해 더 높은 결합 친화력, (이를 테면, 2-배 또는 그 이상의 배수) 더 높은 결합 친화력을 부여한다. 본원에서 제공된 기술로부터 본 발명의 항체는 인간화되거나, 최적화되거나, 또는 인간화 및 최적화 모두 된 것일 수 있음을 이해할 것이다.
상기 에피토프-결합 부위는 하나 또는 그 이상의 불변 도메인에 융합된 완벽한 가변 도메인을 포함할 수 있거나, 또는 적절한 프레임워크 영역에 접합된 이러한 가변 도메인의 오로지 CDRs만을 포함할 수 있다. 에피토프-결합 부위들은 야생형이거나, 또는 하나 또는 그 이상의 아미노산 치환, 삽입 또는 결손에 의해 변형될 수 있다. 이러한 작용에 의해 당해 불변 영역이 수령체 (이를 테면, 인간 개체)에서 면역원으로써 작용하는 능력이 부분적으로 또는 완전하게 제거하거나, 그러나, 외부 가변 도메인에 대한 면역 반응 가능성은 남아있다 (LoBuglio, A.F. et al. (1989) "Mouse/Human Chimeric Monoclonal Antibody In Man: Kinetics And Immune Response," Proc. Natl. Acad. Sci. (U.S.A.) 86:4220-4224). 또다른 접근법은 인간-유래된 불변 영역을 제공하는 것 뿐만 아니라, 가변 도메인을 변형시켜 인간 면역글로불린에서 발견되는 형태에 최대한 가깝게 재구성하는데 중점을 둔다. 항체의 중쇄 및 경쇄 모두의 가변 도메인은 해당 항원에 반응하여 변화하고, 결합 능력을 결정하는 3 개의 CDRs을 함유하는데, 이들은 주어진 종에서 상대적으로 보존된 4 개의 프레임 워크 영역에 의해 측면에 위치하며, 이들은 추정적으로 CDRs를 위한 스캐폴딩을 제공한다. 비-인간 항체가 특정 항원에 대해 준비될 때, 당해 가변 도메인은 변형될 인간 항체에 존재하는 FR에 비-인간 항체로부터 유래된 CDRs을 접목시킴으로써 "재-성형" 또는 "인간화"될 수 있다. 다양한 항체에 대한 이러한 방식의 적용은 Sato, K. et al. (1993) Cancer Res 53:851-856. Riechmann, L. et al. (1988) "Reshaping Human Antibodies for Therapy," Nature 332:323-327; Verhoeyen, M. et al. (1988) "Reshaping Human Antibodies: Grafting An Antilysozyme Activity," Science 239:1534-1536; Kettleborough, C. A. et al. (1991) "Humanization Of A Mouse Monoclonal Antibody By CDR-Grafting: The Importance Of Framework Residues On Loop Conformation," Protein Engineering 4:773-3783; Maeda, H. et al. (1991) "Construction Of Reshaped Human Antibodies With HIV-Neutralizing Activity," Human Antibodies Hybridoma 2:124-134; Gorman, S. D. et al. (1991) "Reshaping A Therapeutic CD4 Antibody," Proc. Natl. Acad. Sci. (U.S.A.) 88:4181-4185; Tempest, P.R. et al. (1991) "Reshaping A Human Monoclonal Antibody To Inhibit Human Respiratory Syncytial Virus Infection in vivo," Bio/Technology 9:266-271; Co, M. S. et al. (1991) "Humanized Antibodies For Antiviral Therapy," Proc. Natl. Acad. Sci. (U.S.A.) 88:2869-2873; Carter, P. et al. (1992) "Humanization Of An Anti-pl85her2 Antibody For Human Cancer Therapy," Proc. Natl. Acad. Sci. (U.S.A.) 89:4285-4289; 그리고 Co, M.S. et al. (1992) "Chimeric And Humanized Antibodies With Specificity For The CD33 Antigen," J. Immunol. 148:1149-1154에서 보고된 바 있다. 일부 구체예들에서, 인간화 항체는 모든 CDR 서열을 보존하고 있다 (예를 들어, 뮤린 항체에 존재하는 6 개의 CDRs 모두를 포함하는 인간화된 뮤린 항체). 다른 구체예들에서, 인간화된 항체는 원래 항체의 CDRs와 비교하여 서열이 상이한 하나 또는 그 이상의 CDRs (1개, 2개, 3개, 4개, 5개 또는 6개)을 갖는다.
비-인간 면역글로불린으로부터 유래된 에피토프-결합 부위를 포함하는 다수의 인간화된 항체 분자들이 기술되는데, 인간 불변 도메인에 융합된 설치류 또는 변형된 설치류 가변 도메인 그리고 이들의 연합된 연합된 상보성 결정 영역 (CDRs)들이 포함된다 (예를 들면, Winter et al. (1991) "Man-made Antibodies" Nature 349:293-299; Lobuglio et al. (1989) "Mouse/Human Chimeric Monoclonal Antibody In Man: Kinetics And Immune Response," Proc. Natl. Acad. Sci. (U.S.A.) 86:4220-4224; Shaw et al. (1987) "Characterization Of A Mouse/Human Chimeric Monoclonal Antibody (17-1 A) To A Colon Cancer Tumor-Associated Antigen," J. Immunol. 138:4534-4538; 및 Brown et al. (1987) "Tumor-Specific Genetically Engineered Murine/Human Chimeric Monoclonal Antibody," Cancer Res. 47:3577-3583참고). 다른 참고 문헌들에서는 적절한 인간 항체 불변 도메인과의 융합 전, 인간 지원-프레임 워크 영역 (FR)에 접합된 설치류 CDRs이 기술되어 있다 (예를 들면, Riechmann, L. et al. (1988) "Reshaping Human Antibodies for Therapy," Nature 332:323-327; Verhoeyen, M. et al. (1988) "Reshaping Human Antibodies: Grafting An Antilysozyme Activity," Science 239:1534-1536; 그리고 Jones et al. (1986) "Replacing The Complementarity-Determining Regions In A Human Antibody With Those From A Mouse," Nature 321:522-525 참고). 또 다른 참고 문헌에 재조합적으로 붙여진 설치류 프레임워크 영역에 의해 지지되는 설치류 CDRs들이 기술된다 (예를 들면, 유럽 특허 공개 번호. 519,596 참고). 이러한 "인간화된" 분자들은 설치류 항-인간 항체 분자를 향한 원치 않는 면역 반응을 최소화하도록 설계되었으며, 이는 인간 수령자에서 이러한 모이어티의 치료요법적 응용 기간 및 효과를 제한시킨다. 또한 이용될 수 있는 항체를 인간화하는 다른 방법들이Daugherty et al. (1991) "Polymerase Chain Reaction Facilitates The Cloning, CDR-Grafting, And Rapid Expression Of A Murine Monoclonal Antibody Directed Against The CD18 Component Of Leukocyte Integrins," Nucl. Acids Res. 19:2471- 2476 및 U.S. 특허 번호. 6,180,377; 6,054,297; 5,997,867; 및 5,866,692에서 개시된다.
B.
항체 불변 도메인의 특징
명세서 전반에 걸쳐, IgG 중쇄의 불변 영역에 있는 잔기들의 번호매김은 Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, NH1, MD (1991) ("Kabat"), 에서와 같이 EU 색인의 번호매김에 따른다(이들 문헌은 본원의 참고자료에 명시적으로 편입된다). 용어 "Kabat에서와 같은 EU 색인"이란 Kabat에서 제공된 인간 IgG1 EU 항체의 불변 도메인의 번호매김을 지칭한다. 잔기 번호를 할당하는 이 방법은 현장에서 표준이 되었으며, 상이한 항체 아이소타입의 불변 영역에 있는 등가의 위치에 있는 아미노산을 용이하게 식별한다.
1.
경쇄의 불변 영역
상기에서 나타낸 것과 같이, 항체의 각 경쇄는 가변 도메인 ("VL") 및 불변 도메인 ("CL")을 함유한다.
선호되는 CL 도메인은 인간 IgG CL 카파 도메인이다. 예시적인 인간 CL 카파 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:69):

대안으로, 예시적인 CL 도메인은 인간 IgG CL 람다 도메인이다. 예시적인 인간 CL 람다 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:70):

2.
중쇄의 불변 영역
a.
자연-발생적 Fc 영역
본원에서 제공된 바와 같이, 본 발명의 면역콘쥬게이트는 Fc 영역을 포함할 수 있다. 본 발명의 이러한 면역콘쥬게이트의 Fc 영역은 임의의 아이소타입 (이를 테면, IgG1, IgG2, IgG3, 또는 IgG4)일 수 있다. 본 발명의 면역콘쥬게이트는 CH1 도메인 및/또는 힌지 영역을 더 포함할 수 있다. CH1 도메인 및/또는 힌지 영역이 존재하는 경우, 이들은 임의의 아이소타입 (이를 테면, IgG1, IgG2, IgG3, 또는 IgG4)이며, 원하는 Fc 영역과 동일한 아이소타입의 것들이 바람직하다.
본 발명의 상기 Fc 영역-함유하는 면역콘쥬게이트에서 당해 Fc 영역은 완전한 Fc 영역 (이를 테면, 완전한 IgG Fc 영역)이거나, 또는 당해 Fc 영역의 오로지 단편만일 수도 있다. 임의선택적으로, 본 발명의 상기 Fc 영역-함유하는 면역콘쥬게이트에서 당해 Fc 영역은 C-말단 리신 아미노산 잔기가 결여된다.
항체 복합체의 두 개 중쇄의 CH1 도메인은 당해 항체의 경쇄의 "CL" 불변 영역과 복합체를 이루고, 그리고 중간에 끼인 힌지 도메인을 통하여 당해 중쇄 CH2 도메인에 부착된다.
예시적인 CH1 도메인은 인간 IgG1 CH1 도메인이다. 예시적인 인간 IgG1 CH1 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:71):
예시적인 CH1 도메인은 인간 IgG2 CH1 도메인이다. 예시적인 인간 IgG2 CH1 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:72):
예시적인 CH1 도메인은 인간 IgG4 CH1 도메인이다. 예시적인 인간 IgG4 CH1 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:73):
예시적인 하나의 힌지 영역은 인간 IgG1 힌지 영역이다. 예시적인 인간 IgG1 힌지 영역의 아미노산 서열은 다음과 같다 (서열 식별 번호:74): 
또다른 예시적인 힌지 영역은 인간 IgG2 힌지 영역이다. 예시적인 인간 IgG2 힌지 영역의 아미노산 서열은 다음과 같다 (서열 식별 번호:75): 
또다른 예시적인 힌지 영역은 인간 IgG4 힌지 영역이다. 예시적인 인간 IgG4 힌지 영역의 아미노산 서열은 다음과 같다 (서열 식별 번호:76):  상기에서 기술된 바와 같이, IgG4 힌지 영역은 안정화 돌연변이, 이를 테면, S228P 치환을 포함할 수 있다. 예시적인 안정화된 IgG4 힌지 영역의 아미노산 서열은 다음과 같다 (서열 식별 번호:77):
상기에서 기술된 바와 같이, IgG4 힌지 영역은 안정화 돌연변이, 이를 테면, S228P 치환을 포함할 수 있다. 예시적인 안정화된 IgG4 힌지 영역의 아미노산 서열은 다음과 같다 (서열 식별 번호:77): 
항체의 두 개 중쇄의 CH2 도메인과 CH3 도메인은 "Fc 영역"을 형성하기 위해 상호작용하고, 이것은 Fc 감마 수용체 ("FcγRs")를 포함하나, 이에 국한되지 않는 세포의 "Fc 수용체"에 의해 인지된다. 본원에서 사용된 바와 같이, 용어 "Fc 영역"은 IgG 중쇄의 CH2 도메인 및 CH3 도메인의 C-말단 영역을 특정하는데 이용된다. Fc 영역은 아미노산 서열이 다른 IgG 아이소타입에 비해 당해 아이소타입에 가장 상동적인 경우, 특정 IgG 아이소타입의 클래스 또는 서브클래스라고 한다.
예시적인 인간 IgG1의 CH2-CH3 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:1):

이때 Kabat에서 제시된 바와 같은 EU 색인에 의해 번호매김되며, 이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
예시적인 인간 IgG2의 CH2-CH3 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:2):

이때 Kabat에서 제시된 바와 같은 EU 색인에 의해 번호매김되며, 이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
예시적인 인간 IgG3의 CH2-CH3 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:3):

이때 Kabat에서 제시된 바와 같은 EU 색인에 의해 번호매김되며, 이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
예시적인 인간 IgG4의 CH2-CH3 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:4):

이때 Kabat에서 제시된 바와 같은 EU 색인에 의해 번호매김되며, 이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
항체 불변 영역 (예를 들어, Kabat에 명시된 바와 같이 EU 색인에 의해 번호매김된, 위치 270, 272, 312, 315, 356 및 358을 포함하지만 이에 국한되지 않는 Fc 위치)에서 다형성이 관찰되었고, 그리고 따라서 제시된 서열과 선행 기술의 서열 사이에 약간의 차이가 있을 수 있다. 인간 면역글로불린의 다형성 형태는 잘-특성화되어 있다. 현재, 18개의 Gm 동종이형(allotypes)이 공지되어 있다: G1m (1, 2, 3, 17) 또는 G1m (a, x, f, z), G2m (23) 또는 G2m (n), G3m (5, 6, 10, 11, 13, 14, 15, 16, 21, 24, 26, 27, 28) 또는 G3m (b1, c3, b3, b0, b3, b4, s, t, g1, c5, u, v, g5) (Lefranc, et al., "The Human IgG Subclasses: Molecular Analysis of Structure, Function And Regulation." Pergamon, Oxford, pp. 43-78 (1990); Lefranc, G. etal., 1979, Hum. Genet.: 50, 199-211). 본 발명의 항체는 임의의 면역글로불린 유전자의 임의의 동종이형, 동종동질이형(isoallotype), 또는 하플로타입을 포함 할 수 있으며, 본원에 제공된 서열의 동종이형, 동종동질이형 또는 하플로타입으로 국한되지 않는다. 더욱이, 일부 발현 시스템에서, CH3 도메인의 C-말단 아미노산 잔기 (상기에서 굵게 표시됨)는 해독-후 제거될 수 있다. 따라서, CH3 도메인의 C-말단 잔기는 본 발명의 면역콘쥬게이트에서 임의선택적인 아미노산 잔기다. CH3 도메인의 C-말단 잔기가 부족한 면역콘쥬게이트는 본 발명에서 특별히 포괄된다. CH3 도메인의 C-말단 리신 잔기를 포함하는 구조체 또한 본 발명에서 특별히 포괄된다.
b.
Fcγ 수용체 (FcγRs)
전통적인 면역 기능에서 항체-항원 복합체와 면역계 세포의 상호작용은 항체 의존성 세포독성, 비만 세포 탈과립화 및 식균작용과 같은 작동체 기능에서 림프구 증식 및 항체 분비 조절과 같은 면역조절 신호에 이르기까지 광범위한 반응을 초래한다. 이러한 모든 상호작용은 항체 또는 면역 복합체의 Fc 영역이 조혈 세포의 특수 세포 표면 수용체, 구체적으로 여러 유형의 면역계 세포 (예: B 림프구, 여포 수지상 세포, 천연 살해 세포, 대식세포, 호중구, 호산구, 호염기구 및 비만 세포)의 표면에서 발견되는 수용체 (단독적으로 "Fc 감마 수용체" 또는 "FcγR"로 지칭되며, 집합적으로 "FcγRs"로 지칭됨 ")의 결합을 통해 개시된다.
항체와 면역 복합체에 의해 촉발되는 세포 반응의 다양성은 세 가지 Fc 수용체의 구조적 이질성에서 기인한다: FcγRI (CD64), FcγRII (CD32), 그리고 FcγRIII (CD16). FcγRI (CD64), FcγRIIA (CD32A) 및 FcγRIII (CD16)은 활성 (이를 테면, 면역계 강화) 수용체이며; FcγRIIB (CD32B)은 저해성 (이를 테면, 면역계 감쇠) 수용체이다. 또한, 신생아 Fc 수용체 (FcRn)와의 상호 작용은 IgG 분자를 엔도좀으로부터 세포 표면으로 재순환시켜, 혈액으로 방출되는 것을 매개한다. 예시적인 야생형 IgG1 (서열 식별 번호:1), IgG2 (서열 식별 번호:2), IgG3 (서열 식별 번호:3), 그리고 IgG4 (서열 식별 번호:4)의 아미노산 서열은 하기에 제시된다.
정반대 기능을 매개하는 상이한 FcγR들의 능력은 상이한 FcγR들 간의 구조적 차이를 반영하고, 특히 결합된 FcγR이 면역수용체 티로신-기반 활성화 모티프 ("ITAM") 또는 면역수용체 티로신-기반 억제 모티프 ("ITIM")를 소요하는 지를 반형한다. 이들 구조에 대한 상이한 세포질 효소의 동원은 FcγR-매개된 세포 반응의 결과를 나타낸다. ITAM-함유 FcγR들은 FcγRI, FcγRIIA, FcγRIIIA를 포함하고, Fc 영역 (예를 들어, 면역 복합체에 존재하는 응집된 Fc 영역)에 결합될 때, 면역계를 활성화시킨다. FcγRIIB는 현재 알려진 유일한 천연 ITIM-함유 FcγR이며; 응집된 Fc 영역에 결합될 때, 면역계를 약화시키거나 또는 억제하는 역할을 한다. 인간 호중구는 FcγRIIA 유전자를 발현시킨다. 면역 복합체 또는 특정 항체-교를 통한 FcγRIIA 클러스터링(clustering)은 ITAM 인산화를 촉진하는 수용체-연합된 키나제와 ITAM을 응집시키는 역할을 한다. ITAM 인산화는 Syk 키나아제의 도킹 부위 역할을 하며, 그이의 활성화로 인해 하류 기질(이를 테면, PI3K)의 활성화를 초래한다. 세포의 활성화는 전-염증성 매개체들의 방출로 이어진다. 상기 FcγRIIB 유전자는 B 림프구에서 발현되며; 이의 세포외 도메인은 FcγRIIA와 96% 동일하며, 구별-불가능한 방식으로 IgG 복합체에 결합한다. FcγRIIB의 세포질 도메인에서 ITIM의 존재는 이러한 Fcγ의 억제성 서브클래스를 특정한다. 최근, 이러한 억제의 분자적 근거가 확립되었다. 활성화 FcγR과 함께 공동-결찰되면, FcγRIIB의 ITIM은 인산화되고, 이노시톨 폴리포스페이트 5'-포스파타제 (SHIP)의 SH2 도메인을 끌어당겨, ITAM-함유 FcγR-매개된 티로신 키나제의 활성화 결과로 방출된 포스포이노시톨 메신저를 가수 분해하고, 결과적으로 세포내 Ca++의 유입을 방지한다. 따라서, FcγRIIB의 가교는 FcγR 결찰에 대한 활성화 반응을 약화시키고, 세포 반응성을 억제시킨다. B-세포 활성화, B-세포 증식 및 항체 분비는 따라서 중단된다.
c.
변이체 Fc 영역
상기 Fc 영역의 변형은 변경된 표현형, 예를 들면, 변경된 혈청 반감기, 변경된 안정성, 세포의 효소에 대한 변경된 민감성 또는 변경된 작동체으로 이어질 수 있다. 따라서, 예를 들면, 암 치료에 이와 같은 Fc 영역-함유하는 분자의 효과를 강화시키기 위해, 작동체 기능에 있어서 이러한 본 발명의 분자를 변형시키는 것이 바람직할 수 있다. 작동체 기능의 감소 또는 제거는 특정 경우, 예를 들어. 항체의 작용 기전이 차단 또는 길항 작용을 포함하지만, 표적 항원을 품고 있는 세포를 죽이지 않는 항체가 바람직하다. 증가된 작동체 기능은 원치않는 세포, 이를 테면, 종양 및 외래 세포로 지향될 때 일반적으로 바람직하며, 여기에서 상기 FcγR들은 낮은 수준, 예를 들면, 낮은 수준의 FcγRIIB를 갖는 종양-특이적 B 세포 (이를 테면, 비-Hodgkin의 림프종, 그리고 Burkitt의 림프종)으로 발현된다. 이러한 부여된 또는 변경된 작동체 기능 활성을 소유한 본 발명의 면역콘쥬게이트는 작동체 기능 활성이 강화된 효과를 갖는 것이 바람직한 질환, 장애 또는 감염 치료 및/또는 예방에 유용하다.
따라서, 특정 구체예들에서, 본 발명의 Fc 영역을 함유하는 면역콘쥬게이트의 Fc 영역은 공작된 변이체 Fc 영역일 수 있다. 상기 본 발명의 면역콘쥬게이트의 Fc 영역은 하나 또는 그 이상의 Fc 수용체 (이를 테면, FcγR(s))에 결합하는 능력을 소유할 수 있지만, 더 선호적으로 이러한 변이체 Fc 영역은 (야생형 Fc 영역에 의해 나타내는 결합과 비교하여), FcγRIA (CD64), FcγRIIA (CD32A), FcγRIIB (CD32B), FcγRIIIA (CD16a) 또는 FcγRIIIB (CD16b)에 대해 변경된 결합을 갖고, 이를 테면, 활성화 수용체에 대해 강화된 결합을 가지며 및/또는 억제 수용체(들)에 대해 실질적으로 결합하는 능력이 감소되거나, 또는 결합하는 능력이 없게 될 것이다. 따라서, 본 발명의 면역콘쥬게이트의 Fc 영역은 완전한 Fc 영역에서 CH2 도메인의 일부 또는 전부 및/또는 CH3 도메인의 일부 또는 전부를 내포할 수 있거나, 또는 변이체 CH2 및/또는 변이체 CH3 서열을 포함할 수 있다 (예를 들면, 완전한 Fc 영역의 CH2 또는 CH3 도메인에 대해 하나 또는 그 이상의 삽입 및/또는 하나 또는 그 이상의 결손을 내포할 수 있다). 이러한 Fc 영역은 비-Fc 폴리펩티드 부분을 포함할 수 있거나, 또는 비-자연적 완전한 Fc 영역의 부분을 포함할 수 있거나, 또는 CH2 및/또는 CH3 도메인의 비-자연 발생적 방향 (이를 테면, 예를 들면, 두 개의 CH2 도메인 또는 두 개의 CH3 도메인, 또는 N-말단으로부터 C-말단 방향으로, CH2 도메인에 연계된 CH3 도메인, 등등,)을 포함할 수 있다.
활성화 수용체에 대한 결합을 증가시키는 변형 (이를 테면, FcγRIIA (CD16A), 그리고 억제 수용체에 대한 결합을 감소시키는 변형 (이를 테면, FcγRIIB (CD32B)을 비롯하여, 작동체 기능이 변경된 것으로 확인되는 Fc 영역 변형은 당분야에 공지되어 있다 (이를 테면, Stavenhagen, J.B. et al. (2007) "Fc Optimization Of Therapeutic Antibodies Enhances Their Ability To Kill Tumor Cells In Vitro And Controls Tumor Expansion In Vivo Via Low- Affinity Activating Fcgamma Receptors," Cancer Res. 57(18):8882-8890 참고). 표 1에서는 활성화 수용체에 대한 결합을 증가시키는 및/또는 억제 수용체에 대한 결합을 감소시키는 예시적인 변형에 있어서, 예시적으로 단일, 이중, 삼중, 사중 및 오중 치환 (번호매김은 Kabat와 같은 EU 색인의 번호매김, 치환은 서열 식별 번호:1의 아미노산 서열 근거)을 열거하고 있다.

CD32B에 대해 감소된 결합을 갖고, 및/또는 CD16A에 대해 증가된 결합을 갖는 인간 IgG1 Fc 영역의 예시적인 변이체는 F243L, R292P, Y300E, V305I 또는 P396E 치환을 함유하며, 이때 상기 번호매김은 Kabat와 같은 EU 색인의 번호매김이다. 이들 아미노산 치환은 임의의 조합에 의해 인간 IgG1 Fc 영역 안에 존재할 수 있다. 한 구체예에서, 상기 변이체 인간 IgG1 Fc 영역은 F243E, R292P 및 Y300L 치환을 함유한다. 또다른 구체예에서, 상기 변이체 인간 IgG1 Fc 영역은 F243L, R292P, Y300L, V305I 및 P396L 치환을 함유한다.
특정 구체예들에서, 본 발명의 면역콘쥬게이트의 Fc 영역의 경우, (야생형 IgG1 Fc 영역 (서열 식별 번호:1)에 의해 나타나는 결합과 비교하여) FcγRIA (CD64), FcγRIIA (CD32A), FcγRIIB (CD32B), FcγRIIIA (CD16a) 또는 FcγRIIIB (CD 16b)에 대한 결합이 감소 (또는 실질적으로 결합이 없음)되는 것이 바람직하다. 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 ADCC 작동체 기능이 감소된 IgG Fc 영역을 포함한다. 바람직한 구체예에서, 면역콘쥬게이트의 CH2-CH3 도메인은 다음 치환중 임의의 1개, 2개, 3개, 또는 4개를 내포한다: E234A, E235A, D265A, N297Q, 그리고 N297G, 이때 상기 번호매김은 Kabat와 같은 EU 색인의 번호매김이다. 또다른 구체예에서, 상기 CH2-CH3 도메인은 N297Q 치환, N297G 치환, E234A 및 E235A 치환 또는 D265A 치환을 함유하는데, 이들 돌연변이는 FcR 결합을 없애버린다. 대안으로, FcγRIIIA (CD 16a)에 대한 결합이 본질적으로 감소된 (또는 실질적으로 결합이 없는 및/또는 감소된 작동체 기능 (야생형 IgG1 Fc 영역 (서열 식별 번호:1)에 의해 나타나는 결합 및 작동체 기능에 비교하여) 을 나타내는 자연 발생적 Fc 영역의 CH2-CH3 도메인이 이용된다. 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 IgG2 Fc 영역 (서열 식별 번호:2) 또는 IgG4 Fc 영역 (서열 식별:번호:4)을 포함한다. IgG4 Fc 영역이 이용될 때, 본 발명은 안정화 돌연변이, 이를 테면, 상기에서 기술된 힌지 영역 S228P 치환(이를 테면, 서열 식별 번호:77 참고)의 도입을 또한 포괄한다. N297G, N297Q, E234A, E235A 및 D265A 치환으로 작동체 기능이 폐기되며, 작동체 기능은 필요한 경우, 이들 치환은 선호적으로 이용되지 않는다.
감소된 또는 폐기된 작동체 기능을 갖는 본 발명의 Fc 영역을 함유하는 면역콘쥬게이트의 CH2 및 CH3 도메인에 대한 선호되는 IgG1 서열은 치환 E234A/E235A (밑줄로 표시됨)을 포함할 것이다 (서열 식별 번호:78):

이때, X는 리신 (K)이거나, 또는 존재하지 않는다.
본 발명의 Fc 영역을 함유하는 면역콘쥬게이트의 CH2 및 CH3 도메인에 대한 두 번째 선호되는 IgG1 서열은 S442C 치환 (밑줄로 표시됨)을 포함하는데, 이들은 두 개의 CH3 도메인이 이황화결합을 통하여 서로 공유적으로 결합되거나, 또는 약제학적 제제에 이황화 결합 또는 콘쥬게이션할 수 있도록 한다. 이러한 분자의 아미노산 서열은 다음과 같다 (서열 식별 번호:79):

이때, X는 리신 (K)이거나, 또는 존재하지 않는다.
본 발명의 Fc 영역을 함유하는 면역콘쥬게이트의 CH2 및 CH3 도메인에 대한 세번째 선호되는 IgG1 서열은 작동체 기능을 감소 또는 폐시하는 L234A/L235A 치환 (밑줄로 표시됨), 그리고 두 개의 CH3 도메인이 이황화결합을 통하여 서로 공유적으로 결합되거나, 또는 약제학적 제제에 이황화 결합 또는 콘쥬게이션할 수 있도록 하는 S442C 치환 (밑줄로 표시됨)을 포함한다. 이러한 분자의 아미노산 서열은 다음과 같다 (서열 식별 번호:80):

이때, X는 리신 (K)이거나, 또는 존재하지 않는다.
Fc 영역을 포함하는 단백질들의 혈청 반감기는 FcRn에 대한 Fc 영역의 결합 친화력을 증가시킴으로써, 증가될 수 있다. 본원에서 사용된 바와 같이, 용어 "반감기"란 투여 후, 분자의 평균 생존 시간을 측정하는 분자의 약동학적 특성을 의미한다. 반감기는 대상체(이를 테면, 인간 환자 또는 기타 포유류)의 신체 또는 이의 특정 구획, 혈청에서 측정하였을 때, 순환 반감기, 또는 다른 조직들에서 분자의 공지된 양의 50 퍼센트 (50%)를 제거하는데 필요한 시간으로 표현할 수 있다. 일반적으로, 반감기가 증가하면 투여된 분자의 순환에서 평균 체류 시간 (MRT)은 증가된다.
일부 구체예들에서, 본 발명의 면역콘쥬게이트는 야생형 Fc 영역에 대해 적어도 한 개의 아미노산 변형을 포함하는 변이체 Fc 영역을 포함하는데, 전술한 분자는 증가된 반감기 (야생형 Fc 영역을 포함하는 분자와 비교하였을 때)를 갖는다. 일부 구체예들에서, 본 발명의 면역콘쥬게이트는 변이체 IgG Fc 영역을 포함하며, 이때 전술한 변이체 Fc 영역은 다음으로 구성된 군에서 선택된 하나 또는 그 이상의 위치에서 반감기 연장 아미노산 치환을 포함하며: 238, 250, 252, 254, 256, 257, 256, 265, 272, 286, 288, 303, 305, 307, 308, 309, 311, 312, 317, 340, 356, 360, 362, 376, 378, 380, 382, 413, 424, 428, 433, 434, 435, 그리고 436, 이때 상기 번호매김은 Kabat와 같은 EU 색인의 번호매김이다. Fc 영역-함유하는 분자의 반감기를 증가시킬 수 있는 다수의 돌연변이가 당분야에 공지되어 있으며, 예를 들면 M252Y, S254T, T256E, 그리고 이의 조합들이 내포된다. 예를 들면, U.S. 특허 번호. 6,277,375, 7,083,784; 7,217,797, 8,088,376; U.S. 공개 번호. 2002/0147311; 2007/0148164; 그리고 PCT 공개 번호. WO 98/23289; WO 2009/058492; 그리고 WO 2010/033279에서 기술된 돌연변이 참고, 이들은 이들의 전문이 본원의 참고자료에 편입되어 있다. 강화된 반감기를 갖는 면역콘쥬게이트에는 Fc 영역 잔기 250, 252, 254, 256, 257, 288, 307, 308, 309, 311, 378, 428, 433, 434, 435 및 436중 두개 또는 그 이상의 위치에서 치환을 포함하는 변이체 Fc 영역을 소유한 것들이 내포되며, 이때 상기 번호매김은 Kabat와 같은 EU 색인의 번호매김이다. 특히, 두 개 또는 그 이상의 치환은 다음에서 선택되며: T250Q, M252Y, S254T, T256E, K288D, T307Q, V308P, A378V, M428L, N434A, H435K, 그리고 Y436I, 이때 상기 번호매김은 Kabat와 같은 EU 색인의 번호매김이다.
특이적 구체예에서, 본 발명의 면역콘쥬게이트는 다음 치환을 포함하는 변이체 IgG Fc 영역을 소유한다:
(A)
M252Y, S254T 및 T256E;
(B)
M252Y
및 S254T;
(C)
M252Y 및 T256E;
(D)
T250Q
및 M428L;
(E)
T307Q
및 N434A;
(F)
A378V 및 N434A;
(G)
N434A 및 Y436I;
(H)
V308P 및 N434A; 또는
(I)
K288D 및 H435K.
바람직한 구체예에서, 본 발명의 면역콘쥬게이트는 다음 치환중 임의의 1개, 2개, 또는 3개의 치환을 포함하는 변이체 Fc 영역을 소유한다: M252Y, S254T 및 T256E. 본 발명은 다음을 포함하는 변이체 Fc 영역을 소유하는 면역콘쥬게이트를 더 포괄한다:
(A)
작동체 기능 및/또는 FcγR를 변경시키는 하나 또는 그 이상의 돌연변이; 그리고
(B)
혈청 반감기를 연장시키는 하나 또는 그 이상의 돌연변이.
본 발명의 Fc 영역을 함유하는 면역콘쥬게이트의 CH2 및 CH3 도메인에 대해 네 번째 선호되는 IgG1 서열은 혈청 반감기를 연장시키기 위해 M252Y, S254T 및 T256E 치환 (밑줄로 표시됨)을 포함한다. 이러한 분자의 아미노산 서열은 다음과 같다 (서열 식별 번호:147):

이때, X는 리신 (K)이거나, 또는 존재하지 않는다.
본 발명의 Fc 영역을 함유하는 면역콘쥬게이트의 CH2 및 CH3 도메인에 대한 다섯 번째 선호되는 IgG1 서열은 혈청 반감기를 연장시키기 위한 M252Y, S254T 및 T256E 치환 (밑줄로 표시됨), 그리고 두 개의 CH3 도메인이 이황화결합을 통하여 서로 공유적으로 결합되거나, 또는 약물 모이어티에 콘쥬게이션할 수 있도록 하는 S442C 치환 (밑줄로 표시됨)을 포함한다. 이러한 분자의 아미노산 서열은 다음과 같다 (서열 식별 번호:148):

이때, X는 리신 (K)이거나, 또는 존재하지 않는다.
본 발명의 Fc 영역을 함유하는 면역콘쥬게이트의 CH2 및 CH3 도메인에 대한 여섯 번째 선호되는 IgG1 서열은 작동체 기능을 감소 또는 폐기하기 위한 L234A/L235A 치환 (밑줄로 표시됨)과 혈청 반감기를 연장시키기 위한 M252Y, S254T 및 T256E 치환 (밑줄로 표시됨)을 포함한다. 이러한 분자의 아미노산 서열은 다음과 같다 (서열 식별 번호:149):

이때, X는 리신 (K)이거나, 또는 존재하지 않는다.
본 발명의 Fc 영역을 함유하는 면역콘쥬게이트의 CH2 및 CH3 도메인에 대한 일곱 번째 선호되는 IgG1 서열은 작동체 기능을 감소 또는 폐기하기 위한 L234A/L235A 치환 (밑줄로 표시됨), 혈청 반감기를 연장시키기 위한 M252Y, S254T 및 T256E 치환 (밑줄로 표시됨), 그리고 두 개의 CH3 도메인이 이황화결합을 통하여 서로 공유적으로 결합되거나, 또는 약물 모이어티에 콘쥬게이션할 수 있도록 하는 S442C 치환 (밑줄로 표시됨)을 포함한다. 이러한 분자의 아미노산 서열은 다음과 같다 (서열 식별 번호:150):

이때, X는 리신 (K)이거나, 또는 존재하지 않는다.
II.
예시적인 항-ADAM9 항체
본 발명은 본 발명의 면역콘쥬게이트를 만들 때 유용한 ADAM9에 특이적으로 결합할 수 있는 특정 항체 및 이의 항원-결합 단편들을 제공한다.
대표적인 인간 ADAM9 폴리펩티드 (NCBI 서열 NP_003807, 28개의 아미노산 잔기 신호 서열을 포함, 밑줄로 표시됨)는 다음의 아미노산 서열을 갖는다 (서열 식별 번호:5):

ADAM9의 819개 아미노산 잔기 (서열 식별 번호:5) 잔기중 잔기 1-28은 신호 서열이며, 잔기 29-697은 세포외 도메인이며, 잔기 698-718은 막경유 도메인이며, 그리고 잔기 719-819는 세포내 도메인이다. 다음의 세 개의 구조적 도메인은 세포외 도메인 안에 위치한다: 레로리신 (M12B) 패밀리 아연 메탈로프로테아제 도메인 (대략적으로 잔기 212-406에서); 디스인테그린 도메인 (대략적으로 잔기 423-497에서); 그리고 EGF-유사 도메인 (대략적으로 잔기 644-697에서). 많은 해독-후 변형 및 아이소폼들이 확인되었으며, 단백질은 형질 막에 도달하여 성숙한 단백질을 생성하기 전, 트랜스-골지(Golgi) 네트워크에서 단백질 분해로 절단된다. 프로-도메인의 제거는 두 개의 다른 부위에서 절단을 통해 발생한다. 프로-도메인과 촉매 도메인 사이(Arg-205/Ala-206)의 경계에서 퓨린과 같은 전-단백질 전환효소에 의해 대부분 처리된다. 추가적인 상류 절단 전-단백질 전환효소 부위 (Arg-56/Glu-57)는 ADAM9의 활성화에 중요한 역할을 한다.
대표적인 시노몰구스 원숭이 ADAM9 폴리펩티드 (NCBI 서열 XM_005563126.2, 아마도 28개 아미노산 잔기 신호 서열 포함, 밑줄로 표시됨)는 다음의 아미노산 서열을 갖는다 (서열 식별 번호:6):

당해 단백질의 레프로리신 (M12B) 패밀리 아연 메탈로프로테아제 도메인은 대략적으로 잔기 212-406에 있고); 당해 단백질의 디스인테그린 도메인은 대략적으로 잔기 423-497에 있다.
특정 구체예들에서, 본 발명의 항-ADAM9 항체 및 ADAM9-결합 단편들은 다음 기준중 임의의 하나, 둘, 셋, 넷, 다섯, 여섯, 일곱, 여덟, 또는 아홉가지 기준에 의해 특징화된다:
(1)
암 세포의 표면 상에서 내생적으로 발현될 때 인간 ADAM9에 면역특이적으로 결합하는 능력;
(2)
유사한 결합 친화력으로 인간 및 비-인간 영장류 ADAM9 (이를 테면, 시노몰구스 원숭이의 ADAM9)에 특이적으로 결합;
(3)
4 nM 또는 그 미만의 평형 결합 불변 (KD) 으로 인간 ADAM9에 특이적으로 결합;
(4)
4 nM 또는 그 미만의 평형 결합 불변 (KD) 으로 비-인간 영장류 ADAM9에 특이적으로 결합;
(5)
5 x 105 M-1분-1 또는 그 이상의 결합 상수(ka)로 인간 ADAM9에 특이적으로 결합;
(6)
1 x 106 M-1분-1 또는 그 이상의 결합 상수(ka)로 비-인간 영장류 ADAM9에 특이적으로 결합;
(7)
1 x 10-3 분-1 또는 그 미만의 해리 상수(KD)로 인간 ADAM9에 특이적으로 결합;
(8)
9 x 10-4 분-1또는 그 미만의 해리 상수(KD)로 비-인간 영장류 ADAM9에 특이적으로 결합;
(9)
키메라 또는 뮤린 부계 항체와 비교하였을 때, cyno ADAM9에 대한 결합 친화력 (이를 테면, BIACORE® 분석에 의해 측정하였을 때)에서 적어도 100-배 강화 (이를 테면, 적어도 100-배, 적어도 150-배, 적어도 200-배, 적어도 250-배, 적어도 300-배, 적어도 350-배, 적어도 400-배, 적어도 450-배, 적어도 500-배, 적어도 550-배수, 또는 적어도 600-배 강화)를 갖도록 최적화되며, 그리고 인간 ADAM9에 대해 높은 결합 친화력을 유지한다 (이를 테면, BIACORE® 분석).
본원에서 기술된 바와 같이, 항-ADAM9 항체 또는 이의 ADAM9-결합 단편의 결합 상수는 표면 플라스몬 공명 이를 테면, BIACORE® 분석을 통하여 결정될 수 있다. 표면 플라스몬 공명 데이터는 1:1 Langmuir 결합 모델 (동시 ka kd) 및 속도 상수 kd/ka 비율로부터 산출된 평형 결합 불변 KD에 피팅될 수 있다. 단가(monovalent) 항-ADAM9 항체 또는 이의 ADAM9-결합 단편 (이를 테면, 단일 ADAM9 에피토프-결합 부위를 포함하는 분자, 이가(bivalent) 항-ADAM9 항체 또는 이의 ADAM9-결합 단편 (이를 테면, 두 개의 ADAM9 에피토프-결합 부위를 포함하는 분자), 또는 더 높은 결합가를 갖는 항-ADAM9 항체 및 이의 ADAM9-결합 단편들 (이를 테면, 세 개, 네 개, 또는 그 이상의 ADAM9 에피토프결합 부위를 포함하는 분자)에 대해서도 이러한 결합 상수가 결정될 수 있다.
본 발명은 구체적으로 인간 ADAM9 폴리펩티드의 에피토프에 면역특이적으로 결합하는 항-ADAM9 경쇄 가변 (VL) 도메인 및 항-ADAM9 중쇄 가변 (VH) 도메인을 포함하는 항-ADAM9 항체 또는 이의 ADAM9-결합 단편을 소유한 면역콘쥬게이트를 포괄한다. 다른 언급이 없는 한, 이러한 모든 항-ADAM9 항체 및 이의 ADAM9-결합 단편은 인간 ADAM9에 면역특이적으로 결합할 수 있다. 본원에서 사용된 바와 같이, 이러한 ADAM9 가변 도메인은 차례로 "항-ADAM9-VL" 및 "항-ADAM9-VH"로 지칭된다.
A. 뮤린 항-인간 ADAM9 항체
ADAM9의 표적 단백질 프로세싱 활성을 차단시키는 뮤린 항-ADAM9 항체는 내화되며, 항-종양 활성을 갖는 것으로 확인되었다 (이를 테면, US 특허 번호. 8,361,475 참고). US 특허 번호. 7,674,619 및 8,361,475에서 하이브리도마 클론 ATCC PTA-5174에 의해 만들어진 "항-KID24" 항체로 지명된 이 항체는 본원에서 "MAB-A"로 지칭된다. MAB-A는 정상 조직과 비교하여 종양에 대해 강력한 선호적인 결합을 나타낸다 (참고, 도 7A-7C). MAB-A는 상당한 패널의 정상 세포에 걸쳐 착색이 거의 없거나 또는 전혀 없었다 (표 2).


도 2에 나타낸 것과 같이, MAB-A는 높은 친화력으로 인간 ADAM9에 결합하지만, 그러나 비-인간 영장류 (이를 테면, 시노몰구스 원숭이) ADAM9에는 이보다 다소 낮은 친화력으로 결합한다.
MAB-A의 VL 도메인과 VH 도메인의 아미노산 서열은 하기에서 제공된다. MAB-A의 VH 도메인과 VL 도메인은 인간화되었고, CDR들은 친화력을 개선시키기 위해 및/또는 잠재적 아미노산 우발성(liabilities)을 제거하기 위해 최적화된다. CDRH3 은 인간 ADAM9에 대한 이의 높은 친화력은 유지하면서, 한편으로 비-인간 영장류 ADAM9에 결합을 강화시키기 위해 추가 최적화되었다.
선호되는 본 발명의 면역콘쥬게이트는 VH 도메인의 CDRH들중 1개, 2개 또는 3개 모두 및/또는 MAB-A의 최적화된 변이체의 VL 도메인의 CDRL들중 1개, 2개 또는 3개를 포함하고, 그리고 선호적으로 상기 인간화된 MAB-A의 VH 및/또는 VL 도메인의 인간화된 프레임워크 영역 ("FRs")을 더 소유한다. 기타 선호되는 본 발명의 면역콘쥬게이트는 MAB-A의 인간화된/최적화된 변이체의 전체 VH 및/또는 VL 도메인을 소유한다.
본 발명은 구체적으로 다음을 포함하는 면역콘쥬게이트에 관계한다:
(A)
(1) MAB-A의 VH 도메인의 세 개의 CDRH; 그리고
(2) MAB-A의 인간화된 변이체의 VH 도메인의 네 개의 FR; 또는
(B)
(1) MAB-A의 VL 도메인의 세 개의 CDRL; 그리고
(2) MAB-A의 인간화된 변이체의 VL 도메인의 네 개의 FR; 또는
(C)
MAB-A의 최적화된 변이체의 VH 도메인의 세 개의 CDRH; 그리고 MAB-A의 VL 도메인의 세 개의 CDRL; 또는
(D)
MAB-A의 VH 도메인의 세 개의 CDRH; 그리고 최적화된 변이체 MAB-A의 VL 도메인의 세 개의 CDRL; 또는
(E)
MAB-A의 최적화된 변이체의 VH 도메인의 세 개의 CDRH; 그리고 최적화된 MAB-A의 VL 도메인의 세 개의 CDRL; 또는
(F)
(1) MAB-A의 최적화된 변이체의 VH 도메인의 세 개의 CDRH;
그리고
(2) MAB-A의 인간화된 변이체의 VH 도메인의 네 개의 FR; 또는
(G)
(1) MAB-A의 최적화된 변이체의 VL 도메인의 세 개의 CDRL;
그리고
(2) MAB-A의 인간화된 변이체의 VL 도메인의 네 개의 FR; 또는
(H)
(1) MAB-A의 인간화된/최적화된 변이체의 VH 도메인; 그리고
(2) MAB-A의 인간화된/최적화된 변이체의 VL 도메인. 뮤린 항체 "MAB-A"
뮤린 항-ADAM9 항체 MAB-A의 VH 도메인의 아미노산 서열은 다음과 같다: 서열 식별 번호:7 (CDRH 잔기들은 밑줄로 표시됨):

MAB-A CDRH1 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:8): 
MAB-A의 CDRH2 도메인의 아미노산 서열은 다음과 같다(서열 식별 번호:9): 
MAB-A의 CDRH3 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:10): 
뮤린 항-ADAM9 항체 MAB-A의 VL 도메인의 아미노산 서열은 다음과 같다: 서열 식별 번호:11 (CDRL 잔기들은 밑줄로 표시됨):

MAB-A의 CDRL1 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:12): 
MAB-A의 CDRL2 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:13): 
MAB-A의 CDRL3 도메인의 아미노산 서열은 다음과 같다 (서열 식별 번호:14): 
B. 예시적인 인간화된/최적화된 항-ADAM9-VH 도메인 및 VL 도메인
1.
변이체 MAB-A의 VH 도메인
MAB-A의 특정 선호되는 인간화된/최적화된 항-ADAM9-VH 도메인의 아미노산 서열은 MAB-A의 ADAM9-VH 도메인의 변이체 (서열 식별 번호:7)이며, 이들은 다음의 서열 식별 번호:15로 나타낸다 (CDRH 잔기들은 밑줄로 표시됨):

이때 X 1 , X 2 , X 3 , X 4 , X 5 , 그리고 X 6 은 독립적으로 선택되며,
이때 X 1 은 M 또는 I이며;
X 2 은 N 또는 F이며;
X 3 은 K 또는 R이며;
X 4 는 K 또는 Q이며;
X 5 는 S 또는 G이며, 그리고
X 6 은 P, F, Y, W, I, L, V, T, G 또는 D이며;
이때: X 7 , X 8 , X 9 , X 10 , 그리고 X 11 은 다음과 같이 선택된다:
(A)
X 6 이 P인 경우:
X 7 은 K 또는 R이며; X 8 은 F 또는 M이며; X 9 는 G이며;
X 10 은 W 또는 F이며; 그리고 X 11 은 M, L 또는 K이고;
(B)
X 6 이 F, Y 또는 W인 경우:
X 7 은 N 또는 H이며;
X 8 은 S 또는 K이며;
X 9 는 G 또는 A이며;
X 10 은 T 또는 V이며; 그리고
X 11 은 M, L 또는 K이며;
(C)
X 6 이 I, L 또는 V인 경우:
X 7 은 G이며;
X 8 은 K이며;
X 9 는 G 또는 A이며;
X 10 은 V이며; 그리고
X 11 은 M, L 또는 K이고;
(D)
X 6 이 T인 경우:
X 7 은 G이며;
X 8 은 K, M 또는 N이며;
X 9 는 G이며;
X 10 은 V 또는 T이며; 그리고
X 11 은 L 또는 M이고;
(E)
X 6 이 G인 경우:
X 7 은 G이며;
X 8 은 S이며;
X 9 는 G이며;
X 10 은 V이며; 그리고
X 11 은 L이고; 그리고
(F)
X 6 이 D인 경우:
X 7 는 S이며;
X 8 은 N이며;
X 9 는 A이며;
X 10 은 V이며; 그리고
X 11 은 L이다.
선호되는 인간화된 항-ADAM9 MAB-A의 VH 도메인의 아미노산 서열: hMAB-A VH(1) (서열 식별 번호:16) 그리고 MAB-A의 특정 선호되는 인간화된/최적화된 항-ADAM9-VH 도메인의 아미노산 서열:

및  은 하기에서 제시되며 (CDRH 잔기들은 한줄의 밑줄로 표시됨; hMAB-A VH(1) (서열 식별 번호:7)에 대해 차이는 이중 밑줄로 표시됨).
은 하기에서 제시되며 (CDRH 잔기들은 한줄의 밑줄로 표시됨; hMAB-A VH(1) (서열 식별 번호:7)에 대해 차이는 이중 밑줄로 표시됨).
hMAB-A VH(1) (서열 식별 번호:16):

hMAB-A VH(2) (서열 식별 번호:17):

hMAB-A VH(3) (서열 식별 번호:18):

hMAB-A VH(4) (서열 식별 번호:19):

hMAB-A VH(2A) (서열 식별 번호:20):

hMAB-A VH(2B) (서열 식별 번호:21):

hMAB-A VH(2C) (서열 식별 번호:22):

hMAB-A VH(2D) (서열 식별 번호:23):

hMAB-A VH(2E) (서열 식별 번호:24):

hMAB-A VH(2F) (서열 식별 번호:25):

hMAB-A VH(2G) (서열 식별 번호:26):

hMAB-A VH(2H) (서열 식별 번호:27):

hMAB-A VH(2I) (서열 식별 번호:28):

hMAB-A VH(2J) (서열 식별 번호:29):

MAB-A의의 인간화된 및/또는 최적화된 항-ADAM9-VH 도메인의 FR들에 대한 적합한 아미노산 서열은 다음과 같다:
FRH1 도메인 (서열 식별 번호:30):

FRH2 도메인 (서열 식별 번호:31):

FRH3 도메인 (서열 식별 번호:32):

FRH4 도메인 (서열 식별 번호:33):

항-ADAM9-VH 도메인의 CDRH1 도메인에 대한 적합한 대체 아미노산 서열에는 다음이 내포된다:
서열 식별 번호:8:
SYWMH
서열 식별 번호:34:SYWIH
항-ADAM9-VH 도메인의 CDRH2 도메인에 대한 적합한 대체 아미노산 서열에는 다음이 내포된다:
서열 식별 번호:9:

서열 식별 번호:35:

서열 식별 번호:36:

항-ADAM9-VH 도메인의 CDRH3 도메인에 대한 적합한 대체 아미노산 서열에는 다음이 내포된다:
서열 식별 번호:10:

서열 식별 번호:37:

서열 식별 번호:38:

서열 식별 번호:39:

서열 식별 번호:40:

서열 식별 번호:41:

서열 식별 번호:42:

서열 식별 번호:43:

서열 식별 번호:44:

서열 식별 번호:45:

서열 식별 번호:46:

따라서, 본 발명은 다음을 포함하는 VH 도메인을 갖는 ADAM9 결합 분자들을 포괄한다:
(1)
다음 아미노산 서열을 갖는 CDRH1 도메인:
서열 식별 번호:47 :SYWX1H
이때: X 1 은 M 또는 I이며;
(2)
다음 아미노산 서열을 갖는 CDRH2 도메인:
서열 식별 번호:48: EIIPIX2GHTNYNEX3FX4X5
이때: X 2 , X 3 , X 4 , 그리고 X 5 는 독립적으로 선택되며, 그리고
이때: X 2 는 N 또는 F이며;
X 3 은 K 또는 R이며;
X 4 는 K 또는 Q이며; 그리고
X 5 는 S 또는 G이고,
그리고
(3)
다음 아미노산 서열을 갖는 CDRH3 도메인:
서열 식별 번호:49: GGYYYYX6X7X8X9X10X11DY
이때: X 6 은 P, F, Y, W, I, L, V, T, G 또는 D이며, 그리고 X 7 , X 8 , X 9 , X 10 그리고 X 11 은 다음과 같이 선택된다:
(A)
X 6 이 P인 경우:
X 7 은 K 또는 R이며;
X 8 은 F 또는 M이며;
X 9 는 G이며;
X 10 은 W 또는 F이며; 그리고
X 11 은 M, L 또는 K이고;
(B)
X 6 이 F, Y 또는 W인 경우:
X 7 은 N 또는 H이며;
X 8 은 S 또는 K이며;
X 9 는 G 또는 A이며;
X 10 은 T 또는 V이며; 그리고
X 11 은 M, L 또는 K이고;
(C)
X 6 이 I, L 또는 V인 경우:
X 7 은 G이며;
X 8 은 K이며;
X 9 는 G 또는 A이며;
X 10 은 V이며; 그리고
X 11 은 M, L 또는 K이고;
(D)
X 6 이 T인 경우:
X 7 은 G이며;
X 8 은 K, M 또는 N이며;
X 9 는 G이며;
X 10 은 V 또는 T이며; 그리고
X 11 은 L 또는 M이고;
(E)
X 6 이 G인 경우:
X 7 은 G이며;
X 8 은 S이며;
X 9 는 G이며;
X 10 은 V이며; 그리고
X 11 은 L이고; 그리고
(F)
X 6 이 D인 경우:
X 7 은 S이며;
X 8 은 N이며;
X 9 는 A이며;
X 10 은 V이며; 그리고
X 11 은 L이다.
MAB-A의 유도체/변이체의 첫 번째 예시적인 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2) 도메인 (서열 식별 번호:17)을 함유하고, 다음 아미노산 서열을 갖는다 (서열 식별 번호:50):

이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
MAB-A의 유도체/변이체의 두 번째 예시적인 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2C) 도메인 (서열 식별 번호:22)을 함유하고, 다음 아미노산 서열을 갖는다 (서열 식별 번호:51):

이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
MAB-A의 유도체/변이체의 세 번째 예시적인 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2I) 도메인 (서열 식별 번호:28)을 함유하고, 다음 아미노산 서열을 갖는다 (서열 식별 번호:52):

이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
상기에서 제공된 바와 같이, 상기 Fc 영역의 CH2-CH3 도메인은 예를 들면, 작동체 기능을 감소시키기 위해 및/또는 콘쥬게이션 부위를 도입시키기 위해 및/또는 혈청 반감기를 연장시키기 위해 공작될 수 있다. 특정 구체예들에서, 본 발명의 예시적인 인간화된/최적화된 IgG1 중쇄의 CH2-CH3 도메인은 다음에서 선택된 하나 또는 그 이상의 치환을 포함한다: L234A, L235A, M252Y, S254T, T256E 및 S442C.
따라서, MAB-A의 유도체/변이체의 네 번째 예시적인 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2I) 도메인 (서열 식별 번호:28)을 함유하고, 상기 Fc 영역의 CH2-CH3 도메인에서 치환 L234A, 그리고 L235A을 더 포함하고 (서열 식별 번호:78), 다음 아미노산 서열을 갖는다 (서열 식별 번호:141):

이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
MAB-A의 유도체/변이체의 다섯 번째 예시적인 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2I) 도메인 (서열 식별 번호:28)을 함유하고, 상기 Fc 영역의 CH2-CH3 도메인에서 S442C 치환을 더 포함하고 (서열 식별 번호:79), 다음 아미노산 서열을 갖는다 (서열 식별 번호:142):

이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
MAB-A의 유도체/변이체의 여섯 번째 예시적인 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2I) 도메인 (서열 식별 번호:28)을 함유하고, 상기 Fc 영역의 CH2-CH3 도메인에서 치환 L234A, L235A 및 S442C를 더 포함하고 (서열 식별 번호:80), 다음 아미노산 서열을 갖는다 (서열 식별 번호:143):

이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
MAB-A의 유도체/변이체의 일곱 번째 예시적인 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2I) 도메인 (서열 식별 번호:28)을 함유하고, 상기 Fc 영역의 CH2-CH3 도메인에서 치환 M252Y, S254T 및 T256E를 더 포함하고 (서열 식별 번호:147), 다음 아미노산 서열을 갖는다 (서열 식별 번호:151):

이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
한 구체예에서, MAB-A의 유도체/변이체의 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2I) 도메인 (서열 식별 번호:28)을 함유하고, 상기 Fc 영역의 CH2-CH3 도메인에서 치환 M252Y, S254T 및 T256E를 더 포함하고 (서열 식별 번호:147), 다음 아미노산 서열을 갖는다 (서열 식별 번호:155):

MAB-A의 유도체/변이체의 여덟 번째 예시적인 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2I) 도메인 (서열 식별 번호:28)을 함유하고, 상기 Fc 영역의 CH2-CH3 도메인에서 치환 M252Y, S254T, T256E, 그리고 S442C를 더 포함하고 (서열 식별 번호:148), 다음 아미노산 서열을 갖는다 (서열 식별 번호:152):

이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
한 구체예에서, MAB-A의 유도체/변이체의 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2I) 도메인 (서열 식별 번호:28)을 함유하고, 상기 Fc 영역의 CH2-CH3 도메인에서 치환 M252Y, S254T, T256E, 그리고 S442C를 더 포함하고 (서열 식별 번호:148), 다음 아미노산 서열을 갖는다 (서열 식별 번호:156):

MAB-A의 유도체/변이체의 아홉 번째 예시적인 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2I) 도메인 (서열 식별 번호:28)을 함유하고, 상기 Fc 영역의 CH2-CH3 도메인에서 치환 L234A, L235A, M252Y, S254T 및 T256E를 더 포함하고 (서열 식별 번호:149), 다음 아미노산 서열을 갖는다 (서열 식별 번호:153):

이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
MAB-A의 유도체/변이체의 열 번째 예시적인 인간화된/최적화된 IgG1 중쇄는 hMAB-A VH (2I) 도메인 (서열 식별 번호:28)을 함유하고, 상기 Fc 영역의 CH2-CH3 도메인에서 치환 L234A, L235A, M252Y, S254T, T256E, 그리고 S442C를 더 포함하고 (서열 식별 번호:150), 다음 아미노산 서열을 갖는다 (서열 식별 번호:154):

이때 X는 리신 (K)이거나, 또는 존재하지 않는다.
2.
변이체 MAB-A의 VL 도메인
MAB-A의 선호되는 인간화된/최적화된 항-ADAM9-VL 도메인의 아미노산 서열은 ADAM9-MAB-A의 VL 도메인의 변이체이며 (서열 식별 번호:11), 다음의 서열 식별 번호:53로 나타낸다 (CDRL 잔기들은 밑줄로 표시됨):

이때: X 12 , X 13 , X 14 , X 15 , X 16 , 그리고 X 17 은 독립적으로 선택되며, 그리고
이때; X 12 는 K 또는 R이며;
X 13 은 D 또는 S이며;
X 14 는 M 또는 L이며;
X 15 는 H 또는 Y이며;
X 16 은 E 또는 S이며; 그리고
X 17 은 D 또는 T이다.
선호되는 인간화된 항-ADAM9-MAB-A의 VL 도메인의 아미노산 서열: hMAB-A VL(1) (서열 식별 번호:54), 그리고 특정 선호되는 인간화된/최적화된 항-ADAM9-MAB-A의 VL 도메인의 아미노산 서열: hMAB-A VL(2) (서열 식별 번호:55), hMAB-A VL(3) (서열 식별 번호:56), 그리고 hMAB-A VL(4) (서열 식별 번호:57)은 하기에서 제시되며 (CDRL 잔기들은 한줄의 밑줄로 표시됨; hMAB-A VL(1) (서열 식별 번호:54)에 대해 차이는 이중 밑줄로 표시됨).
hMAB-A VL(1) (서열 식별 번호:54):

hMAB-A VL(2) (서열 식별 번호:55):

hMAB-A VL(3) (서열 식별 번호:56):

hMAB-A VL(4) (서열 식별 번호:57):

따라서, 인간화된 및/또는 최적화된 항-ADAM9-MAB-A의 VL 도메인의 FR들에 대한 적합한 아미노산 서열은 다음과 같다:
FRL1 도메인 (서열 식별 번호:58):

FRL2 도메인 (서열 식별 번호:59):

FRL3 도메인 (서열 식별 번호:60):

FRL4 도메인 (서열 식별 번호:61):

항-ADAM9-VL 도메인의 CDRL1 도메인에 대한 적합한 대체 아미노산 서열에는 다음이 내포된다:
서열 식별 번호:12:

서열 식별 번호:62:

서열 식별 번호:63:

서열 식별 번호:64:

항-ADAM9-VL 도메인의 CDRL3 도메인에 대한 적합한 대체 아미노산 서열에는 다음이 내포된다:
서열 식별 번호:14:

서열 식별 번호:65:

따라서, 본 발명은 다음을 포함하는 항-ADAM9 항체 VL 도메인을 포괄한다:
(1)
다음 아미노산 서열을 갖는 CDRL1 도메인:
서열 식별 번호:66: X12ASQSVDYX13GDSYX14N
이때: X 12 , X 13 , X 14 는 독립적으로 선택되며, 그리고
이때: X 12 는 K 또는 R이며; X 13 은 D 또는 S이며; 그리고 X 14 은 M 또는 L이고;
(2)
다음 아미노산 서열을 갖는 CDRL2 도메인:
서열 식별번호:13: AASDLES
그리고
(3)
다음 아미노산 서열을 갖는 CDRL3 도메인:
서열 식별번호:67: QQSX15X16X17PFT
이때: X 15 , X 16 , 그리고 X17은 독립적으로 선택되며, 그리고
이때: X 15 는 H 또는 Y이며; X 16 은 E 또는 S이며; 그리고 X 17 은 D 또는 T이다.
MAB-A의 유도체/변이체의 예시적인 인간화된/최적화된 IgG1 경쇄는 hMAB-A VL (2) 도메인 (서열 식별 번호:55)을 함유하고, 다음 아미노산 서열을 갖는다 (서열 식별 번호:68):

본 발명은 인간 ADAM9 폴리펩티드의 에피토프에 면역특이적으로 결합하고, 상기-제공된 MAB-A CDRH1, CDRH2, CDRH3, CDRL1, CDRL2, 또는 CDRL3중 임의의 것을 포함하는 면역콘쥬게이트를 추가적으로 명시적으로 고려하며, 그리고 구체적으로 상기-제공된 MAB-A CDRH1중의 하나, 상기-제공된 MAB-A CDRH2중의 하나, 상기-제공된 MAB-A CDRH3중의 하나, 상기-제공된 MAB-A CDRL1중의 하나, 상기-제공된 MAB-A CDRL2, 그리고 상기-제공된 MAB-A CDRL3중의 하나를 포함하는 이러한 면역콘쥬게이트를 고려한다. 본 발명은 상기-제공된 인간화된 MAB-A FRH1, FRH2, FRH3, 또는 FRH4, FRL1, FRL2, FRL3, 또는 FRL4중 임의의 것을 더 포함하는 이러한 면역콘쥬게이트를 더 고려하며, 그리고 구체적으로 FRH1, FRH2, FRH3, 그리고 FRH4를 포함하고, 및/또는 FRL1, FRL2, FRL3, FRL4 및 FRH1을 포함하는 이러한 면역콘쥬게이트를 더 고려한다.
일부 구체예들에서, 상기 인간화된/최적화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 다음으로 구성된 군에서 선택된 서열을 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 내포한다:
(a)
차례로 서열 식별 번호:8, 35, 및 10 그리고 서열 식별 번호:62, 13, 14;
(b)
차례로 서열 식별 번호:8, 35, 및 10 그리고 서열 식별 번호:63, 13, 14;
(c)
차례로 서열 식별 번호:8, 36, 및 10 그리고 서열 식별 번호:63, 13, 14;
(d)
차례로 서열 식별 번호:34, 36, 및 10 그리고 서열 식별 번호:64, 13, 65, 제각기
(e)
차례로 서열 식별 번호:8, 35, 및 37, 그리고 서열 식별 번호:62, 13, 14;
(f)
차례로 서열 식별 번호:8, 35, 및 38, 그리고 서열 식별 번호:62, 13, 14;
(g)
차례로 서열 식별 번호:8, 35, 및 39, 그리고 서열 식별 번호:62, 13, 14;
(h)
차례로 서열 식별 번호:8, 35, 및 40, 그리고 서열 식별 번호:62, 13, 14;
(i)
차례로 서열 식별 번호:8, 35, 및 41, 그리고 서열 식별 번호:62, 13, 14;
(j)
차례로 서열 식별 번호:8, 35, 그리고 42 및 서열 식별 번호:62, 13, 14;
(k)
차례로 서열 식별 번호:8, 35, 그리고 43 및 서열 식별 번호:62, 13, 14;
(l)
차례로 서열 식별 번호:8, 35, 그리고 44 및 서열 식별 번호:62, 13, 14;
(m)
차례로 서열 식별 번호:8, 35, 그리고 45 및 서열 식별 번호:62, 13, 14; 그리고
(n)
차례로 서열 식별 번호:8, 35, 그리고 46 및 서열 식별 번호:62, 13, 14.
특정 구체예들에서, 상기 인간화된/최적화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 차례로 서열 식별 번호:8, 35, 그리고 45 및 서열 식별 번호:62, 13, 14를 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 내포한다.
일부 구체예들에서, 상기 인간화된/최적화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 다음의 서열에 대해 적어도 90%, 적어도 95%, 적어도 99%, 또는 100% 동일한 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 내포한다:
(a)
차례로 서열 식별 번호:17 및 서열 식별 번호:55;
(b)
차례로 서열 식별 번호:17 및 서열 식별 번호:56;
(c)
차례로 서열 식별 번호:18 및 서열 식별 번호:56;
(d)
차례로 서열 식별 번호:19 및 서열 식별 번호:57,
(e)
차례로 서열 식별 번호:20 및 서열 식별 번호:55;
(f)
차례로 서열 식별 번호:21 및 서열 식별 번호:55;
(g)
차례로 서열 식별 번호:22 및 서열 식별 번호:55;
(h)
차례로 서열 식별 번호:23 및 서열 식별 번호:55;
(i)
차례로 서열 식별 번호:24 및 서열 식별 번호:55;
(j)
차례로 서열 식별 번호:25 및 서열 식별 번호:55;
(k)
차례로 서열 식별 번호:26 및 서열 식별 번호:55;
(l)
차례로 서열 식별 번호:27 및 서열 식별 번호:55;
(m)
차례로 서열 식별 번호:28 및 서열 식별 번호:55; 그리고
(n)
차례로 서열 식별 번호:29 및 서열 식별 번호:55.
"실질적으로 동일한" 또는 "동일한"이란 기준 아미노산 서열 (예를 들면, 본원에서 기술된 아미노산 서열중 임의의 하나)에 대해 적어도 50% 동일성을 나타내는 폴리펩티드를 의미한다. 선호적으로, 이러한 서열은 비교용으로 이용된 서열에 대해 아미노산 수준 또는 핵산 수준에서 적어도 60%, 더욱 선호적으로 적어도 80% 또는 적어도 85%, 그리고 더욱 선호적으로 적어도 90%, 적어도 95% 적어도 99%, 또는 심지어 100% 동일하다.
서열 동일성은 전형적으로 서열 분석 소프트웨어 (예를 들면, Sequence Analysis Software Package of the Genetics Computer Group, University of Wisconsin Biotechnology Center, 1710 University Avenue, Madison, Wis. 53705, BLAST, BESTFIT, GAP, 또는 PILEUP/PRETTYBOX 프로그램)을 이용하여 측정된다. 이러한 소프트웨어는 다양한 치환, 결손, 및/또는 기타 변형에 대해 상동성 정도를 할당함으로써, 동일하거나 또는 유사한 서열을 매치시킨다. 보존적 치환은 다음 그룹 안에서의 치환이 전형적으로 내포된다: 글리신, 알라닌; 발린, 이소류신, 류신; 아스파르트산, 글루탐산, 아스파라긴, 글루타민; 세린, 트레오닌; 리신, 아르기닌; 그리고 페닐알라닌, 티로신. 동일성의 정도를 결정하는 예시적인 접근법에서, BLAST 프로그램이 사용될 수 있는데, 밀접하게 관련된 서열임을 표시하는 e-3과 e-100 사이의 확률 점수를 이용한다.
특정 구체예들에서, 상기 인간화된/최적화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 차례로 서열 식별 번호:28 및 서열 식별 번호:55의 서열에 대해 적어도 90%, 적어도 95%, 적어도 99%, 또는 100% 동일한 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 내포한다.
특정 구체예들에서, 상기 인간화된/최적화된 항-ADAM9 항체는 다음의 중쇄와 경쇄 서열을 포함한다:
(a)
차례로 서열 식별 번호:50 및 서열 식별 번호:68;
(b)
차례로 서열 식별 번호:51 및 서열 식별 번호:68;
(c)
차례로 서열 식별 번호:52 및 서열 식별 번호:68,
(d)
차례로 서열 식별 번호:141 및 서열 식별 번호:68;
(e)
차례로 서열 식별 번호:142 및 서열 식별 번호:68;
(f)
차례로 서열 식별 번호:143 및 서열 식별 번호:68;
(g)
차례로 서열 식별 번호:151 및 서열 식별 번호:68;
(h)
차례로 서열 식별 번호:152 및 서열 식별 번호:68;
(i)
차례로 서열 식별 번호:153 및 서열 식별 번호:68; 그리고
(j)
차례로 서열 식별 번호:154 및 서열 식별 번호:68.
특정 구체예들에서, 상기 인간화된/최적화된 항-ADAM9 항체는 서열 식별 번호:52의 서열을 갖는 중쇄와 서열 식별 번호:68의 서열을 갖는 경쇄를 포함한다. 다른 특정 구체예들에서, 상기 인간화된/최적화된 항-ADAM9 항체는 서열 식별 번호:142의 서열을 갖는 중쇄와 서열 식별 번호:68의 서열을 갖는 경쇄를 포함한다. 다른 구체예들에서, 상기 인간화된/최적화된 항-ADAM9 항체는 혈청 반감기 연장을 위해 공작되며, 서열 식별 번호:151의 서열을 갖는 중쇄와 서열 식별 번호:68의 서열을 갖는 경쇄를 포함한다. 다른 특정 구체예들에서, 상기 인간화된/최적화된 항-ADAM9 항체는 혈청 반감기 연장을 위해 공작되며, 서열 식별 번호:155의 서열을 갖는 중쇄와 서열 식별 번호:68의 서열을 갖는 경쇄를 포함한다. 다른 특정 구체예들에서, 상기 인간화된/최적화된 항-ADAM9 항체는 혈청 반감기 연장을 위해 그리고 부위 특이적 콘쥬게이션을 위해 공작되며, 서열 식별 번호:152의 서열을 갖는 중쇄와 서열 식별 번호:68의 서열을 갖는 경쇄를 포함한다. 다른 특정 구체예들에서, 상기 인간화된/최적화된 항-ADAM9 항체는 혈청 반감기 연장을 위해 그리고 부위 특이적 콘쥬게이션을 위해 공작되며, 서열 식별 번호:156의 서열을 갖는 중쇄와 서열 식별 번호:68의 서열을 갖는 경쇄를 포함한다.
본 발명은 인간 ADAM9 폴리펩티드의 에피토프에 면역특이적으로 결합하고, 그리고 상기-제공된 인간화된/최적화된 항-ADAM9 MAB-A VL 또는 VH 도메인중 임의의 것을 포함하는 면역콘쥬게이트를 또한 명시적으로 고려한다. 본 발명은 인간화된/최적화된 항-ADAM9 VL 또는 VH 도메인의 다음 조합들중 임의의 것을 포함하는 이러한 항-ADAM9 항체 및 이의 ADAM9-결합 단편들을 특히 고려한다:

본 발명은 상기에서 제공된 바와 같이, 인간화된/최적화된 항-ADAM9-VL 및/또는 VH 도메인을 포함하는 면역콘쥬게이트를 특히 포괄한다. 특정 구체예들에서, 본 발명의 면역콘쥬게이트는 (i) 상기에서 제공된 바와 같이, 인간화된/최적화된 항-ADAM9-VL 및/또는 VH 도메인 그리고 (ii) Fc 영역을 포함한다.
항-ADAM9 VH 도메인 및 VL 도메인에 대한 특정 변형이 상기에서 요약되고, 도 3A-3B에서 비교되고 있지만, 본 발명의 인간화된 및/또는 최적화된 항-ADAM9-VH 또는 VL 도메인을 공작할 때, 이들 잔기 모두 또는 대부분이 변형될 필요는 없다. 본 발명은 서브클로닝을 용이하게 하기 위해 도입될 수 있는, 예를 들면, C-말단 및/또는 N-말단 아미노산 잔기들의 아미노산 치환을 비롯한 VH 서열 및 VL 서열의 최소한 변이 또한 포괄한다.
III.
항체 약물 콘쥬게이트
정의
본원에서 사용된 바와 같이, 용어 "면역콘쥬게이트", "콘쥬게이트", 또는 "ADC"란 세포 결합 제제에 연계되거나 또는 콘쥬게이트된 본원에서 기술된 메이탄시노이드 화합물 (이를 테면, 본원에서 기술된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편)을 지칭한다.
"링커"란 본원에서 기술된 메이탄시노이드 화합물을 세포-결합 제제, 이를 테면, 항-ADAM9 항체 또는 이의 ADAM9-결합 단편에 안정적이며, 공유적인 방식으로 연계시킬 수 있는 임의의 화학 모이어티다. 링커는 당해 화합물 또는 당해 항체가 활성을 유지하는 조건 하에서, 산-유도된 절단, 광-유도된 절단, 펩티다제-유도된 절단, 에스테라제-유도된 절단, 그리고 이황화물 결합 절단에 예민하거나(susceptible), 또는 실질적으로 저항성일 수 있다. 적합한 링커는 당업계에 잘 알려져 있으며, 예를 들어 디설파이드기, 티오에테르 기, 산-불안정 기, 광-불안정 기, 펩티다제-불안정 기 및 에스테라제-불안정 기를 포함한다. 링커는 또한 본원에 기술되고, 당업계에 공지된 하전된 링커 및 그의 친수성 형태를 포함한다.
본원에 사용된 "알킬"은 1 내지 20 개의 탄소 원자의 포화 선형 또는 분지-쇄 단가(monovalent) 탄화수소 라디칼을 지칭한다. 알킬의 예로는 메틸, 에틸, 1-프로필, 2-프로필, 1-부틸, 2-메틸-1-프로필,-CH2CH(CH3)2), 2-부틸, 2-메틸-2-프로필, 1-펜틸, 2-펜틸 3-펜틸, 2-메틸-2-부틸, 3-메틸-2-부틸, 3-메틸-1-부틸, 2-메틸-1-부틸, 1-헥실), 2-헥실, 3-헥실, 2-메틸-2-펜틸, 3-메틸-2-펜틸, 4-메틸-2-펜틸, 3-메틸-3-펜틸, 2-메틸-3-펜틸, 2,3-디메틸-2-부틸, 3,3-디메틸-2-부틸, 1-헵틸, 1-옥틸, 그리고 이와 유사한 것들을 포함하나, 이에 국한되지 않는다. 바람직하게는, 알킬은 1 내지 10개의 탄소 원자를 갖는다. 더욱 바람직하게는, 알킬은 1 내지 4개의 탄소 원자를 갖는다.
그룹 내의 탄소 원자의 수는 본원에서 접두사 "Cx_xx"로 지정될 수 있으며, 여기서 x 및 xx는 정수이다. 예를 들면, "C1-4 알킬"은 1 내지 4개의 탄소 원자를 갖는 알킬기다.
용어 "화합물" 또는 "세포독성 화합물", 또는 "세포독성 제제"는 호환사용된다. 이들은 구조 또는 화학식 또는 이의 임의의 유도체가 본 발명에 개시된 화합물 또는 참고자료에 편입된 구조 또는 화학식 또는 이의 임의의 유도체를 포함하고자 한다. 상기 용어는 또한 본 발명에 개시된 모든 화학식의 화합물의 입체이성질체, 기하 이성질체, 호변체(tautomers), 용매화물(solvates), 대사산물(metabolites) 및 염 (예를 들어, 약제적으로 허용되는 염)을 포함한다. 상기 용어는 또한 상기 중 임의의 것의 임의의 용매화물, 수화물(hydrates) 및 다형체(polymorphs)를 포함한다. 본 출원에서 기술된 본 발명의 특정 측면들에서 "입체이성질체", "기하 이성질체", "호변체", "용매화물", "대사체", "접합체", "접합체 염", "용매화물", "수화물" 또는 "다형체"의 구체적 언급은 상기 용어 "화합물"이 이러한 다른 형태의 언급없이 사용되는 경우, 본 발명의 다른 측면들에서 이러한 형태의 의도된 생략으로 간주 해석되어서는 안된다.
용어 "키랄(chiral)"이라는 용어는 거울상 짝의 비-중첩성 특성을 갖는 분자를 지칭하는 반면, "아키랄(achiral)"이라는 용어는 그들의 거울상 짝에 중첩가능한 분자를 지칭한다.
용어 "입체이성질체(stereoisomer)"는 동일한 화학적 구성 및 연결성(connectivity)을 갖지만, 단일 결합에 대한 회전에 의해 상호전환될 수 없는 공간에서 원자의 상이한 배향(orientations)을 갖는 화합물을 지칭한다.
"부분입체이성질체(diastereomer)"는 둘 또는 그 이상의 키랄 중심을 가지며, 이들 분자는 서로 거울상이 아닌 입체 이성질체를 지칭한다. 부분입체이성질체는 상이한 물리적 성질, 예를 들어, 상이한 융점, 비점, 스펙트럼 특성 및 반응성을 갖는다. 부분입체이성질체의 혼합물은 결정화, 전기영동 및 크로마토그래피와 같은 고해상도 분석 절차 하에서 분리될 수 있다.
"거울상이성질체(enantiomers)"는 서로 중첩될 수 없는 거울상인 화합물의 2 개 입체이성질체를 지칭한다.
본원에 사용된 입체화학적 정의 및 규칙은 일반적으로 다음과 같다 S. P. Parker, Ed., McGraw-Hill, Dictionary of Chemical Terms (1984) McGraw-Hill Book Company, New York; 그리고 Eliel, E. and Wilen, S., Stereochemistry of Organic Compounds, John Wiley & Sons, Inc., New York, 1994. 본 발명의 화합물은 비대칭 또는 키랄 중심을 함유할 수 있으며, 따라서 상이한 입체이성질체 형태로 존재한다. 부분입체이성질체, 거울상이성질체 및 회전장애이성질체(atropisomers) 뿐만 아니라, 라셈체(racemic) 혼합물과 같은 이들의 혼합물을 포함하는 본 발명의 화합물의 모든 입체이성질체 형태는 본 발명의 일부를 형성하는 것으로 의도된다. 많은 유기 화합물이 광학 활성 형태로 존재하는데, 즉, 이들은 평면-편광(plane-polarized light)을 회전시키는 능력을 갖는다. 광학 활성 화합물을 기술함에 있어서, 접두사 D와 L, 또는 R과 S는 키랄 중심(들)에 대한 분자의 절대적 배열을 나타내기 위해 사용된다. 접두사 d와 l, 또는 (+)와 (-)는 화합물에 의한 평면-편광의 회전의 표시를 나타내기 위해 사용되며, (-) 또는 l은 화합물이 좌회전성(levorotatory)임을 의미한다. (+) 또는 d의 접두사가 붙은 화합물은 우회전성(dextrorotatory)이다. 주어진 화학 구조에 대해, 이들 입체이성질체는 서로 거울상 인 점을 제외하고는 동일하다. 특정 입체이성질체는 또한 거울상이성질체로 지칭될 수 있고, 이러한 이성질체의 혼합물은 종종 거울상이성질체 혼합물로 불린다. 거울상이성질체의 50:50 혼합물은 라셈체 혼합물 또는 라셈체로 지칭되며, 이는 화학 반응 또는 공정에서 입체선택 또는 입체 특이성이 없는 경우에 발생할 수 있다. 용어 "라셈체 혼합물" 및 "라셈체"는 광학 활성이 없는, 2 개의 거울상이성질체 종(species)의 등몰(equimolar) 혼합물을 지칭한다.
용어 "호변체(tautomer)"또는 "호변체 형태"는 낮은 에너지 장벽을 통해 상호전환 가능한 상이한 에너지의 구조적 이성질체를 지칭한다. 예를 들면, 양성자 호변체(양성자 이전성(prototropic) 호변체로도 알려져 있음)는 케토-에놀(keto-enol) 및 이민-에나민(imine-enamine) 이성질화와 같은 양성자의 이동을 통한 상호전환을 포함한다. 원자가(valence) 호변체는 일부 결합 전자의 재구성에 의한 상호전환을 포함한다.
용어 "양이온"은 양전하를 갖는 이온을 지칭한다. 양이온은 단가 (가령, Na+, K+, NH4+ 등), 2-가(가령, Ca2+, Mg2+, 등) 또는 다-가 (가령, Al3+ 등)일 수 있다. 바람직하게는, 상기 양이온은 단가이다.
본원에 사용된 어구 "약제학적으로 허용되는 염"은 본 발명의 화합물의 약제학적으로 허용되는 유기 또는 무기 염을 지칭한다. 예시적인 염은 설페이트, 시트레이트, 아세테이트, 옥살레이트, 클로라이드, 브롬화물, 요오드화물, 질산염, 중황산염, 포스페이트, 산 포스페이트, 이소니코티네이트, 락테이트, 살리실레이트, 산 시트레이트, 타르트레이트, 올레에이트, 탄네이트, 판토테네이트, 바이타르트레이트, 아스코르베이트, 숙시네이트, 말레이트, 젠티지네이트, 푸마레이트, 글루코네이트, 글루코루네이트, 사카레이트, 포르메이트, 벤조에이트, 글루타메이트, 메탄설포네이트 "메실레이트", 에탄설포네이트, 벤젠설포 네이트, p-톨루엔설포네이트, 파모에이트(가령, 1,1'-메틸렌-비스-(2-하이드록시-3-나프토에이트)) 염, 알칼리 금속(가령, 나트륨 및 칼륨) 염, 알칼리 토금속(가령, 마그네슘) 염, 그리고 암모늄 염을 포함하나, 이에 국한되지 않는다. 약제학적으로 허용되는 염은 아세테이트 이온, 숙시네이트 이온 또는 다른 반대 이온(counter ion)과 같은 또다른 분자의 함입과 관련될 수 있다. 상기 반대 이온은 부모 화합물의 전하를 안정화시키는 임의의 유기 또는 무기 부분일 수 있다. 또한, 약제학적으로 허용되는 염은 이의 구조에서 하나 이상의 하전된 원자를 가질 수 있다. 다수의 하전된 원자가 약제학적으로 허용되는 염의 일부인 경우에는 다수의 반대 이온을 가질 수 있다. 그런 이유로, 약제학적으로 허용되는 염은 하나 또는 그 이상의 하전된 원자 및/또는 하나 또는 그 이상의 반대 이온을 가질 수 있다.
본 발명의 화합물이 염기라면, 원하는 약제학적으로 허용되는 당분야에서 이용가능한 임의의 적합한 방법에 의해 준비될 수 있는데, 예를 들면, 자유 염기를 무기 산, 이를 테면, 염산, 브롬화수소산, 황산, 질산, 메탄설폰산, 인산 및 이와 유사한 것들로 처리, 또는 유기 산, 이를 테면, 아세트산, 말레산, 숙신산, 만델산, 푸마르산, 말론산, 피루브산, 옥살산, 글리콜산, 살리실산, 피라노시딜산, 예컨대 글루쿠론산 또는 갈락투론산, 알파 하이드록시산, 이를 테면, 시트르산 또는 타르타르산, 아미노산, 이를 테면, 아스파르트산 또는 글루타민산, 방향족산, 이를 테면, 벤조산 또는 시남산, 술포산, 이를 테면, p-톨루렌술폰산 또는 에탄술폰산, 또는 이와 유사한 것들로 처리함으로써, 준비될 수 있다.
본 발명의 화합물이 산인 경우, 바람직한 약제학적으로 허용되는 염은 임의의 적합한 방법, 예를 들어 자유 산을 무기 또는 유기 염기, 예컨대, 아민 (1 차, 2 차 또는 3 차), 알칼리 금속 수산화물 또는 알칼리 토금속 수산화물, 또는 이와 유사한 것으로 처리함으로써, 준비될 수 있다. 적합한 염의 예시적인 예는 아미노산, 이를 테면, 글리신 및 아르기닌, 암모니아, 1 차, 2 차 및 3 차 아민, 그리고 사이클릭 아민, 이를 테면, 피페리딘, 몰폴린 및 피페라진 그리고 나트륨, 칼슘, 칼륨, 마그네슘, 망간, 철, 구리, 아연, 알루미늄 및 리튬으로부터 유도된 무기 염을 포함하지만, 이에 국한되지는 않는다.
본원에 사용된 바와 같이, 용어 "용매화물(solvate)"은 비-공유 분자간 힘에 의해 결합된, 화학량론적 또는 비-화학량론적 양의 용매, 이를 테면, 물, 이소프로판올, 아세톤, 에탄올, 메탄올, DMSO, 에틸 아세테이트, 아세트산 및 에탄올아민 디클로로메탄, 2-프로판올, 또는 이와 유사한 것들을 추가로 포함하는 화합물을 의미한다. 화합물의 용매화물 또는 수화물은 메탄올, 에탄올, 1-프로판올, 2-프로판올 또는 물과 같은 최소한 한 가지의 몰 당량을 당해 화합물에 추가함으로써, 이민 모이어티의 용해화 또는 수화를 야기하여 용이하게 준비된다.
"대사산물" 또는 "분해대사산물(catabolite)"은 특정 화합물, 이의 유도체 또는 이의 접합체 또는 이의 염이 신체에서 대사 또는 이화 작용을 통해 생성된 산물이다. 화합물의 대사산물, 이의 유도체 또는 이의 접합체는 당업계에 공지된 일상적인 기술을 사용하여 확인될 수 있으며, 여기에 기술된 것과 같은 테스트를 사용하여 그 활성을 측정할 수 있다. 이러한 산물은 예를 들어, 투여된 화합물의 산화, 히드록 실화, 환원, 가수 분해, 아미드화, 탈아미드화, 에스테르화, 탈에스테르화, 효소적 절단 등으로부터 발생할 수 있다. 따라서, 본 발명은 화합물, 이의 유도체 또는 이의 접합체의 대사 산물을 생성하기에 충분한 시간 동안 포유 동물에게 본 발명의 화합물, 이의 유도체, 또는 이의 콘쥬게이트를 접촉시키는 것을 포함하는 공정에 의해 생산된 본 발명의 화합물, 이의 유도체 또는 이의 콘쥬게이트의 대사산물을 내포한다.
"약제학적으로 허용되는"이라는 문구는 물질 또는 조성물이 제제를 포함하는 다른 성분 및/또는 이런 것들로 처리되는 포유 동물과 화학적으로 및/또는 독성학적으로 양립가능해야 함을 나타낸다.
용어 "보호 기" 또는 "보호 모이어티"란 화합물, 이의 유도체 또는 이의 콘쥬게이트 상의 다른 작용기와 반응하면서, 특정 작용기를 차단시키거나 또는 보호하기 위해 일반적으로 사용되는 치환기를 의미한다. 예를 들면, "아민-보호 기" 또는 "아미노-보호 모이어티"는 화합물에서 아미노 작용기를 차단하거나 또는 보호하는 아미노기에 부착된 치환기다. 이러한 기들은 당업계에 잘 알려져 있고 (예를 들면 P. Wuts and T. Greene, 2007, Protective Groups in Organic Synthesis, Chapter 7, J. Wiley & Sons, NJ), 카바메이트, 이를 테면, 메틸 및 에틸 카바메이트, FMOC, 치환된 에틸 카바메이트, 1,6-β-제거에 의해 절단된 카바메이트 ("자기-희생기(immolative)"라고도 함), 우레아, 아미드, 펩티드, 알킬 및 아릴 유도체로 예시된다. 적합한 아미노-보호 기는 아세틸, 트리플루오로아세틸, t-부톡시카르보닐 (BOC), 벤질옥시카르보닐 (CBZ) 및 9-플루오레닐메틸렌옥시카르보닐 (Fmoc)을 포함한다. 보호 그룹 및 그 용도에 대한 일반적인 설명은 P. G.M. Wuts & T. W. Greene, Protective Groups in Organic Synthesis, John Wiley & Sons, New York, 2007을 참고한다.
용어 "아미노산"이란 자연 발생적 아미노산 또는 비-자연 발생적 아미노산을 지칭한다. 한 구체예에서, 아미노산은 NH2-C(Raa'Raa)-C(=O)OH이며, 이때 Raa 및 Raa'는 각각 독립적으로 H, 1 내지 10개 탄소원자를 갖는 임의선택적으로 치환된 선형, 분기형 또는 사이클릭 알킬, 알케닐 또는 알키닐, 아릴, 헤테로아릴 또는 헤테로사이클릴이며, 또는 Raa과 N-말단 질소원자는 함께 헤테로사이클릭 고리(가령, 프롤린에서와 같은)를 형성할 수 있다. 용어 "아미노산 잔기"란 아미노산, 이를 테면,-NH-C(Raa'Raa)-C(=O)-의 아민 단부 및/또는 아미노산의 카르복시 단부의 히드록실 기가 제거된 대응하는 잔기를 지칭한다. 알파 탄소의 특정 입체 화학을 나타내지 않고, 아미노산 또는 아미노산 잔기를 언급하는 경우, 이는 L- 및 R-이성체를 모두 포함하는 것을 의미한다. 예를 들면, "Ala"에는 L-알라닌 및 R-알라닌이 모두 내포된다.
용어 "펩티드"란 펩티드 (아미드) 결합에 의해 연계된 짧은 쇄 아미노산 단량체를 지칭한다. 일부 구체예들에서, 상기 펩티드는 2개 내지 20개 아미노산 잔기를 함유한다. 다른 구체예들에서, 상기 펩티드는 2개 내지 10개 아미노산 잔기를 함유한다. 여전히 다른 구체예들에서, 상기 펩티드는 2 내지 5개 아미노산 잔기를 함유한다. 본원에서 사용된 바와 같이, 펩티드가 특이적 서열의 아미노산으로 제시되는 본원에서 기술된 세포독성 제제 또는 링커의 일부분인 경우, 상기 펩티드는 세포독성 제제 또는 상기 링커의 나머지 부분에 양 방향으로 연결될 수 있다. 예를 들면, 디펩티드 X1-X2에는 X1-X2 및 X2-X1이 내포된다. 유사하게, 트리펩티드 X1-X2-X3에는 X1-X2-X3 및 X3-X2-X1이 내포되며, 테트라펩티드 X1-X2-X3-X4에는 X1-X2-X3-X4 및 X4-X2-X3-X1이 내포된다. X1, X2, X3 및 X4는 아미노산 잔기를 나타낸다. 펩티드 또는 펩티드 잔기가 각 아미노산의 입체화학 또는 아미노산 잔기를 나타내지 않고 언급되는 경우, 이는 L- 및 R-이성체를 모두 포함하는 것을 의미한다. 그러나, 펩티드 또는 펩티드 잔기에서 하나 또는 그 이상의 아미노산 또는 아미노산 잔기의 입체 화학이 D-이성질체로 특정될 때, 특정 입체화학의 명시 없는 펩티드 또는 펩티드 잔기의 다른 아미노산 또는 아미노산 잔기는 오로지 천연물 L-이성질체만을 포함하는 것을 의미한다. 예를 들면, "Ala-Ala-Ala"란 각 Ala이 L- 또는 R-이성질체인 펩티드 또는 펩티드 잔기를 내포하지만; 한편 "Ala-D-Ala-Ala"는 L-Ala-D-Ala-L-Ala를 내포하는 것을 의미한다.
용어 "반응성 에스테르 기"란 아미드 결합을 형성하기 위해 아민 기와 바로 반응할 수 있는 에스테르 기를 지칭한다. 예시적인 반응성 에스테르 기에는 N-하이드록시숙시니미드 에스테르, N-하이드록시프탈리미드 에스테르, N-하이드록시 술포-숙시니미드 에스테르, 파라-니트로페닐 에스테르, 디니트로페닐 에스테르, 펜타플루오르페닐 에스테르 및 이들의 유도체들이 포함되나 이에 국한되지 않으며, 이때 전술한 유도체들은 아미드 결합 형성을 촉진시킨다. 특정 구체예들에서, 상기 반응성 에스테르 기는 N-하이드록시숙시니미드 에스테르 또는 N-하이드록시 술포-숙시니미드 에스테르이다.
용어 "아민-반응성 기"란 공유 결합을 형성하기 위해 아민 기와 반응할 수 있는 기를 지칭한다. 예시적인 아민-반응성 기에는 반응성 에스테르 기, 아실 할라이드, 술포닐 할라이드, 이미도에스테르, 또는 반응성 티오에스테르 기가 내포되나, 이에 국한되지 않는다. 특정 구체예들에서, 상기 아민 반응성 기는 반응성 에스테르 기다. 한 구체예에서, 상기 아민 반응성 기는 N-하이드록시숙시니미드 에스테르 또는 N-하이드록시 술포-숙시니미드 에스테르이다.
용어 "티올-반응성 기"란 공유 결합을 형성하기 위해 티올 (-SH) 기와 반응할 수 있는 기를 지칭한다. 예시적인 티올-반응성 기에는 말레이미드, 할로아세틸, 알로아세트아미드, 비닐 술폰, 비닐 술폰아미드 또는 비닐 피리딘을 포함하나, 이에 국한되지 않는다. 한 구체예에서, 상기 티올-반응성 기는 말레이미드이다.
본 명세서와 청구범위에서 사용된 바와 같이, 단수("a", "an" 및 "the")형은 다른 명시적인 언급이 없는 한 복수 개념을 포함한다는 것으로 주지되어야 한다.
본 명세서에서 "포함하는"이라는 언어는 구체예들이 기술되는 경우, 그렇지 않으면 "~구성되는" 및/또는 "본질적으로 ~구성되는"의 관점에서 설명된 유사한 구체예들이 또한 제공되는 것으로 이해된다.
A. 예시적인 면역콘쥬게이트
본 발명의 메이탄시노이드 화합물들은 "면역콘쥬게이트", "콘쥬게이트", 또는 "ADC"를 만들기 위해, 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편에 직접적으로, 또는 당분야에 공지된 기술을 이용하여 링커를 통하여 간접적으로 결합되거나 또는 콘쥬게이트될 수 있다.
첫 번째 구체예에서, 본 발명의 면역콘쥬게이트는 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편 상에 위치한 하나 또는 그 이상의 리신 잔기의 ε-아미노기를 통하여, 또는 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편 상에 위치한 하나 또는 그 이상의 시스테인 잔기의 티올 기를 통하여 본원에서 기술된 메이탄시노이드 화합물에 공유적으로 연계된 본원에 기술된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편을 포함한다.
상기 첫 번째 구체예의 제1 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 상기에서 기재된 화학식 (I)로 나타내며, 이때 Rx, Ry, Rx' 및 Ry' 는 모두 H이며; 그리고 l 및 k는 각각 독립적으로 2 내지 6의 정수이며; 그리고 나머지 변수들은 화학식 (I)에 대해 상기에서 기술된 바와 같다.
상기 첫 번째 구체예의 제 2 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 상기에서 기재된 화학식 (I)로 나타내며, 이때 A는 2개 내지 5개 아미노산 잔기를 함유하는 펩티드이며; 그리고 나머지 변수들은 화학식 (I)에 대해 상기에서 기술된 바와 같거나, 또는 제 1 특이적 구체예에서 기술된 것과 같다. 일부 구체예들에서, A는 프로테아제에 의해 절단가능한 펩티드이다. 일부 구체예들에서, 프로테아제에 의해 절단가능한 펩티드는 종양 조직에서 발현된다. 일부 구체예들에서, A는 다음의 Ala, Arg, Asn, Asp, Cit, Cys, 셀리노-Cys, Gin, Glu, Gly, Ile Leu, Lys, Met, Phe, Pro, Ser, Thr, Trp, Tyr 및 Val (각각 독립적으로 L- 또는 D-이성질체임)으로부터 선택된 -NH-CR1R2-S-L1-D에 공유적으로 연계된 아미노산을 갖는 펩티드이다. 일부 구체예들에서, -NH-CR1R2-S-L1-D에 연결된 아미노산은 L-아미노산이다.
첫 번째 구체예의 제 3 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 상기에서 기재된 화학식 (I)로 나타내며, 이때 A는 다음으로 구성된 군에서 선택되며 Gly-Gly-Gly, Ala-Val, Val-Ala, D-Val-Ala, Val-Cit, D-Val-Cit, Val-Lys, Phe-Lys, Lys-Lys, Ala-Lys, Phe-Cit, Leu-Cit, Ile-Cit, Phe-Ala, Phe-N9-토실-Arg, Phe-N9-니트로-Arg, Phe-Phe-Lys, D-Phe-Phe-Lys, Gly-Phe-Lys, Leu-Ala-Leu, Ile-Ala-Leu, Val-Ala-Val, Ala-Ala-Ala, D-Ala-Ala-Ala, Ala-D-Ala-Ala, Ala-Ala-D-Ala, Ala-Leu-Ala-Leu (서열 식별 번호:144), β-Ala-Leu-Ala-Leu (서열 식별 번호:145), Gly-Phe-Leu-Gly (서열 식별 번호:146), Val-Arg, Arg-Arg, Val-D-Cit, Val-D-Lys, Val-D-Arg, D-Val-Cit, D-Val-Lys, D-Val-Arg, D-Val-D-Cit, D-Val-D-Lys, D-Val-D-Arg, D-Arg-D-Arg, Ala-Ala, Ala-D-Ala, D-Ala-Ala, D-Ala-D-Ala, Ala-Met, Gln-Val, Asn-Ala, Gln-Phe, Gln-Ala, D-Ala-Pro, 그리고 D-Ala-tBu-Gly, 이때 각 펩티드에서 첫 번째 아미노산은 L2기에 연결되며, 각 펩티드에서 마지막 아미노산은-NH-CR1R2-S-L1-D에 연결되며; 그리고 나머지 변수들은 화학식 (I)에 대해 기술된 바와 같거나, 또는 제 1 특이적 구체예에서 기술된 것과 같다.
첫 번째 구체예의 제 4 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 상기에서 기재된 화학식 (I)로 나타내며, 이때 R1 및 R2는 모두 H이며; 그리고 나머지 변수들은 화학식 (I)에 대해 기술된 바와 같거나, 또는 제1, 제 2, 또는 제 3 특이적 구체예에서 기술된 바와 같다.
첫 번째 구체예의 제 5 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 상기에서 기재된 화학식 (I)로 나타내며, 이때 L1은 -(CH2)4-6-C(=O)-이며; 그리고 나머지 변수들 화학식 (I)에 대해 기술된 바와 같거나, 또는 제1, 제 2, 제 3, 또는 제 4 특이적 구체예에서 기술된 바와 같다.
첫 번째 구체예의 제 6 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 상기에서 기재된 화학식 (I)로 나타내며, 이때 D은 다음의 화학식으로 나타내고:

그리고, 나머지 변수들은 화학식 (I)에 대해 기술된 바와 같거나, 또는 제1, 제 2, 제 3, 제 4, 또는 제 5 특이적 구체예에서 기술된 것과 같다.
제 7 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 다음의 화학식으로 나타내거나: 또는 이의 약제학적으로 허용되는 염이며, 이때:

R3 및 R4는 각각 독립적으로 H 또는 Me이며;
m1, m3, n1, r1, s1 및 t1는 각각 독립적으로 1 내지 6의 정수이며;
m2, n2, r2, s2 및 t2는 각각 독립적으로 1 내지 7의 정수이며;
t3은 1 내지 12의 정수이며;
D1은 다음의 화학식으로 나타내고:

q는 1 내지 20의 정수다. 더욱 특이적 구체예에서, D1은 다음의 화학식으로 나타낸다:

제 8 특이적 구체예에서, 본 발명의 면역콘쥬게이트는
다음의 화학식으로 나타내거나:

이때:
m1 및 m3은 각각 독립적으로 2 내지 4의 정수이며;
m2는 2 내지 5의 정수이며;
r1은 2 내지 6의 정수이며;
r2는 2 내지 5의 정수이며; 그리고
나머지 변수들은 제 7 특이적 구체예에서 기술된 것과 같다.
제 9 특이적 구체예에서, 제 7 또는 제 8 특이적 구체예에서 기술된 면역콘쥬게이트의 경우, A는 Ala-Ala-Ala, Ala-D-Ala-Ala, Ala-Ala, D-Ala-Ala, Val-Ala, D-Val-Ala, D-Ala-Pro, 또는 D-Ala-tBu-Gly이다. 더욱 특이적 구체예에서, 제 7 또는 제 8 특이적 구체예에서 기술된 면역콘쥬게이트의 경우, A는 L-Ala-D-Ala-L-Ala이다.
제 10 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 다음의 화학식으로 나타내거나:








또는 이의 약제학적으로 허용되는 염이며, 이때:
이때
A는 Ala-Ala-Ala, Ala-D-Ala-Ala, Ala-Ala, D-Ala-Ala, Val-Ala, D-Val-Ala, D-Ala-Pro, 또는 D-Ala-tBu-Gly이며, 그리고
D1은 다음의 화학식으로 나타내고:

그리고 나머지 변수들은 제7, 제 8 또는 제 9특이적 구체예에서 기술된 것과 같다. 더욱 특이적 구체예에서, A는 L-Ala-D-Ala-L-Ala이다. 더욱 특이적 구체예에서, D1은 다음의 화학식으로 나타낸다:

제 11 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 다음의 화학식으로 나타내며:

이때 D1은 다음의 화학식으로 나타낸다:

제 12 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 다음의 화학식으로 나타낸다:

이때:
CBA은 서열 식별 번호:8, 35, 그리고 45 및 서열 식별 번호:62, 13, 14를 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 포함하는 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편이며;
q은 1 또는 2이며;
D1은 다음의 화학식으로 나타낸다:

일부 구체예들에서, 상기 인간화된 항-ADAM9 항체 또는 ADAM9-결합 이의 단편은 서열 식별 번호:28 및 서열 식별 번호:55의 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함한다. 일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:142 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다. 일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:152 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다. 일부 구체예들에서, 서열 식별 번호:142 또는 서열 식별 번호:152에서 X는 리신이다. 일부 구체예들에서, 서열 식별 번호:142 또는 서열 식별 번호:152에서 X는 존재하지 않는다. 일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:156 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다.
제 13 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 다음의 화학식으로 나타낸다:

이때:
CBA은 서열 식별 번호:8, 35, 그리고 45 및 서열 식별 번호:62, 13, 14를 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 포함하는 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편이며;
q은 1 또는 10의 정수이며;
D1은 다음의 화학식으로 나타낸다:

특정 구체예들에서, 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 서열 식별 번호:28 및 서열 식별 번호:55의 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함한다. 일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:52 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다. 일부 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:151 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다. 일부 구체예에서, 서열 식별 번호:52 또는 서열 식별 번호:151에서 X는 리신이다. 일부 구체예들에서, 서열 식별 번호:52 또는 서열 식별 번호:151에서 X는 존재하지 않는다. 특정 구체예들에서, 상기 인간화된 항-ADAM9 항체는 서열 식별 번호:155 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함한다.
제 14 구체예에서, 본 발명의 면역콘쥬게이트는 다음의 구조적 화학식으로 나타낸 메이탄시노이드 화합물 DM21C (또한 Mal-LDL-DM 또는 MalC5-LDL-DM 또는 화합물 17a로 지칭됨)에 결합된 항-ADAM9 항체, hMAB-A(2I.2)(YTE/C/-K))을 포함하며:

이때 D1은 다음의 화학식으로 나타낸다:

상기 항-ADAM9 항체 hMAB-A(2I.2)(YTE/C/-K))는 차례로 서열 식별 번호:156 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 갖는다. 일부 구체예들에서, 상기 면역콘쥬게이트는 본원에서 hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM로 언급된다.
한 구체예에서, 상기 면역콘쥬게이트 hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM은 다음의 구조적 화학식으로 나타내며:

이때: CBA는 상기 항-ADAM9 항체 hMAB-A(2I.2)(YTE/C/-K)는 Cys 티올 기를 통하여 메이탄시노이드 화합물에 연결되며; 그리고
q은 1 또는 2이다.
특정 구체예들에서, 제 14 특이적 구체예의 면역콘쥬게이트를 포함하는 조성물(이를 테면, 약제학적 조성물)의 경우 DAR은 1.5 내지 2.2, 1.7 내지 2.2 또는 1.9 내지 2.1의 범위에 있다. 일부 구체예에서, 상기 DAR은 1.7, 1.8, 1.9, 2.0 또는 2.1이다.
제 15 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 다음의 구조적 화학식으로 나타낸, 메이탄시노이드 화합물 DM21L (LDL-DM 또는 화합물 14c로도 지칭됨)에 γ-말레이미도부틸산 N-숙시니미딜 에스테르 (GMBS) 또는 N-(γ-말레이미도부티릴옥시)술포숙시니미드 에스테르 (술포-GMBS 또는 sGMBS) 링커를 통하여 결합된 항-ADAM9 항체, hMAB-A(2I.2)(YTE/-K))를 포함한다:

상기 항-ADAM9 항체 hMAB-A(2I.2)(YTE/-K))는 차례로 서열 식별 번호:155 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 갖는다. 일부 구체예들에서, 상기 콘쥬게이트는 본원에서 hMAB-A(2I.2)(YTE/-K)-sGMBS-LDL-DM로 언급된다. 상기 콘쥬게이트는 또한 hMAB-A(2I.2)(YTE/-K)-GMBS-LDL-DM로도 또한 언급될 수 있으며, 이는 hMAB-A(2I.2)(YTE/-K)-sGMBS-LDL-DM과 호환이용될 수 있다.
GMBS 및 술포-GMBS (또는 sGMBS) 링커들은 당분야에 공지된 것이며, 다음의 구조적 화학식으로 나타낼 수 있다:

한 구체예에서, 상기 면역콘쥬게이트는 다음의 화학식으로 나타내며:

이때: CBA는 상기 항-ADAM9 항체 hMAB-A(2I.2)(YTE/-K))는 Lys 아민 기를 통하여 메이탄시노이드 화합물에 연결되며; 그리고 q은 1 또는 10의 정수다.
특정 구체예들에서, 제 15 특이적 구체예의 면역콘쥬게이트를 포함하는 조성물(이를 테면, 약제학적 조성물)의 경우 DAR은 3.0 내지 4.0, 3.2 내지 3.8, 또는 3.4 내지 3.7의 범위에 있다. 일부 구체예들에서, 상기 DAR은 3.2, 3.3, 3.4, 3.5, 3.5, 3.7, 또는 3.8이다.
특정 구체예들에서, 첫 번째 구체예, 또는 제 1, 제 2, 제 3, 제 4, 제 5, 제 6, 제 7, 제 8, 제 9, 제 10, 제 11, 제 12, 제 13, 제 14 또는 제 15 특이적 구체예의 면역콘쥬게이트를 포함하는 조성물(이를 테면, 약제학적 조성물)의 경우, 조성물에서 약물-항체 비율 (DAR)로 알려진, 항체 분자 당 세포독성 제제의 수 (이를 테면, q의 평균 값)은 1.0 내지 8.0 범위에 있다. 일부 구체예들에서, DAR은 1.0 내지 5.0, 1.0 내지 4.0, 1.5 내지 4.0, 2.0 내지 4.0, 2.5 내지 4.0, 1.0 내지 3.4, 1.0 내지 3.0, 2.9 내지 3.3, 3.3 내지 3.8, 1.5 내지 2.5, 2.0 내지 2.5, 1.7 내지 2.3, 또는 1.8 내지 2.2의 범위에 있다. 일부 구체예들에서, 상기 DAR은 4.0 미만, 3.8 미만, 3.6 미만, 3.5 미만, 3.0 미만 또는 2.5 미만이다. 일부 구체예들에서, 상기 DAR은 3.2 내지 3.4의 범위에 있다. 일부 구체예들에서, 상기 DAR은 3.0 내지 3.2의 범위 안에 있다. 일부 구체예들에서, 상기 DAR은 3.5 내지 3.7의 범위 안에 있다. 일부 구체예들에서, 상기 DAR은 3.1, 3.2, 3.3, 3.4, 3.5, 3.6 또는 3.7이다. 일부 구체예들에서, 상기 DAR은 1.8 내지 2.0의 범위 안에 있다. 일부 구체예들에서, 상기 DAR은 1.7 내지 1.9의 범위 안에 있다. 일부 구체예들에서, 상기 DAR은 1.9 내지 2.1의 범위 안에 있다. 일부 구체예들에서, 상기 DAR은 1.9, 2.0 또는 2.1이다. 일부 구체예들에서, 하나 또는 그 이상의 시스테인 티올 기를 통하여 메이탄시노이드 화합물에 연계된 항-ADAM9 항체 또는 항-이의 ADAM9-결합 단편을 포함하는 본 발명의 면역콘쥬게이트의 경우, 상기 DAR은 1.5 내지 2.5, 1.8 내지 2.2, 1.1 내지 1.9 또는 1.9 내지 2.1의 범위에 있다. 일부 구체예들에서, 상기 DAR은 1.8, 1.9, 2.0 또는 2.1이다.
C.
예시적인 링커 분자
당분야에 공지된 임의의 적합한 링커를 본 발명의 면역콘쥬게이트를 만드는데 이용할 수 있다. 특정 구체예들에서, 상기 링커는 이중기능성 링커다. 본원에서 사용된 바와 같이, 용어 "이중기능성 링커"란 2 개의 반응성기를 갖는 개질성 제제를 의미하고; 그중 하나는 세포 결합제와 반응할 수 있는 반면, 다른 하나는 메이탄시노이드 화합물과 반응하여 두 모이어티를 함께 연계시킨다. 이러한 이중기능성 가교-링커들은 당분야에 잘 공지되어 있다 (예를 들면, Isalm and Dent in Bioconjugation chapter 5, p218-363, Groves Dictionaries Inc. New York, 1999 참고). 예를 들면, 티오에테르 결합을 통하여 링키지를 할 수 있는 이중기능성 가교성 제제에는 말레이미도 기를 도입시키기 위한 N-숙시니미딜-4-(N-말레이미도메틸)-시클로헥산-1-카르복실레이트 (SMCC), 또는 요오드아세틸 기를 도입시키기 위한 N-숙시니미딜-4-(요오드아세틸)-아미노벤조에이트 (SIAB)가 내포된다. 말레이미도 기 또는 할로아세틸 기를 세포 결합 제제로 도입시키는 기타 이중기능성 가교성 제제는 당분야에 공지되어 있으며 (US 특허 공개 번호. 2008/0050310, 20050169933, Pierce Biotechnology Inc. P.O. Box 117, Rockland, IL 61105, USA), 비스-말레이미도폴리에틸렌글리콜 (BMPEO), BM(PEO)2, BM(PEO)3, N-(β-말레이미도프로필옥시)숙시니미드 에스테르 (BMPS), γ-말레이미도부틸산 N-숙시니미딜 에스테르 (GMBS), ε-말레이미도카프론산 N-하이드록시숙시니미드 에스테르 (EMCS), 5-말레이미도발레르산 NHS, HBVS, N-숙시니미딜-4-(N-말레이미도메틸)-시클로헥산-1-카르복시-(6-아미도카프로에이트) (이것은 SMCC의 "장(long)쇄" 유사체임), m-말레이미도벤조일-N-하이드록시숙시니미드 에스테르 (MBS), 4-(4-N-말레이미도페닐)-부틸산 하이드라지드 또는 HC1 염 (MPBH), N-숙시니미딜 3-(브로모아세트아미도)프로피오네이트 (SBAP), N-숙시니미딜 요오드아세테이트 (SIA), κ-말레이미도운데카논산 N-숙시니미딜 에스테르 (KMUA), N-숙시니미딜 4-(p-말레이미도페닐)-부티레이트 (SMPB), 숙시니미딜-6-(β-말레이미도프로피온아미도)헥사노에이트 (SMPH), 숙시니미딜-(4-비닐술포닐)벤조에이트 (SVSB), 디티오비스-말레이미도에탄 (DTME), 1,4-비스-말레이미도부탄 (BMB), 1,4-비스말레이미딜-2,3-디하이드록시부탄 (BMDB), 비스-말레이미도헥산 (BMH), 비스-말레이미도에탄 (BMOE), 술포숙시니미딜 4-(N-말레이미도-메틸)시클로헥산-1-카르복실레이트 (술포-SMCC), 술포숙시니미딜(4-요오드-아세틸)아미노벤조에이트 (술포-SIAB), m-말레이미도벤조일-N-하이드록시술포숙시니미드 에스테르 (술포-MBS), N-(γ-말레이미도부티릴옥시)술포숙시니미드 에스테르 (술포-GMBS 또는 sGMBS), N-(ε-말레이미도카프로일옥시)술포숙시이미도 에스테르 (술포-EMCS), N-(κ-말레이미도운데카노일옥시)술포숙시니미드 에스테르 (술포-KMUS), 그리고 술포숙시니미딜 4-(p-말레이미도페닐)부티레이트 (술포-SMPB)를 포함하나, 이에 국한되지 않는다.
이형(hetero)-이중기능성 가교성 제제는 두 개의 상이한 반응성 기를 갖는 이중기능성 가교성 제제다. 아민-반응성 N-하이드록시숙시니미드 기 (NHS 기)와 카르보닐-반응성 히드라진 기를 모두 함유하는 이형이중기능성 가교성 제제를 또한 이용하여 본원에서 기술되는 세포독성 화합물들을 세포-결합 제제 (이를 테면, 항체)에 연계시킬 수 있다. 이러한 시판되는 이용가능한 이형이중기능성 가교성 제제의 예로는 숙시니미딜 6-히드라지노니코틴아미드 아세톤 히드라존 (SANH), 숙시니미딜 4-히드라지도테레프탈레이트 히드로클로라이드 (SHTH) 및 숙시니미딜 히드라지니움 니코틴에이트 히드로클로라이드 (SHNH)들이 내포된다. 산-불안정 링키즈를 품고 있는 콘쥬게이트는 또한 본 발명의 히드라진-함유 벤조디아제핀 유도체를 사용하여 제조할 수 있다. 이용될 수 있는 이중기능성 가교성 제제의 예로는 숙시니미딜-p-포르밀 벤조에이트 (SFB) 및 숙시니미딜-p-포르밀펜옥시아세테이트 (SFPA)가 내포된다.
이황화 결합을 통하여 세포독성 화합물들을 세포 결합 제제에 링키지시킬 수 있는 이중기능성 가교성 제제들은 당분야에 공지되어 있으며, 디티오피리딜 기를 도입시키기 위한 N-숙시니미딜-3-(2-피리딜디티오)프로피오네이트(SPDP), N-숙시니미딜-4-(2-피리딜디티오)펜타노에이트 (SPP), N-숙시니미딜-4-(2-피리딜디티오)부타노에이트 (SPDB), N-숙시니미딜-4-(2-피리딜디티오)2-술포 부타노에이트 (술포-SPDB 또는 sSPDB)가 내포된다. 이황화물 기를 도입시키는데 이용될 수 있는 기타 이중기능성 가교성 제제들은 당분야에 공지되어 있으며, U.S. 특허 6,913,748, 6,716,821, 그리고 US 특허 공개 20090274713 및 20100129314(이들 모두는 참고자료로 본원에 편입됨)에서 기술된다. 대안으로, 티올 기를 도입시키는 가교성 제제, 이를 테면, 2-이미노티올란, 호모시스테인 티올락톤 또는 S-아세틸숙신 무수물이 또한 이용될 수 있다.
D.
예시적인 메이탄시노이드
두 번째 구체예에서, 본 발명은 본 발명의 면역콘쥬게이트를 만드는데 이용될 수 있는 메이탄시노이드 화합물들을 제공한다.
일부 구체예들에서, 상기 메이탄시노이드 화합물은 다음의 화학식으로 나타낸다:
또는 이의 약제학적으로 허용되는 염이며, 이때:
L2'는 다음의 구조적 화학식으로 나타내며:

이때:
각 경우들에서 Rx, Ry, Rx' 및 Ry'는 독립적으로 H,-OH, 할로겐, -O-(C1-4알킬),-SO3H,-NR40R41R42 +, 또는 OH, 할로겐, SO3H 또는 NR40R41R42 +로 임의선택적으로 치환된 C1-4 알킬이며, 이때 R40, R41 및 R42는 각각 독립적으로 H 또는 C1-4알킬이며;
l 및 k는 각각 독립적으로 1 내지 10의 정수이며;
JCB'는-C(=O)OH 또는 -COE이며, 이때 -COE은 반응성 에스테르이며;
A는 아미노산 또는 2 내지 20개 아미노산 잔기를 포함하는 펩티드이며;
R1 및 R2는 각각 독립적으로 H 또는 C1-3알킬이며;
L1은 다음의 화학식으로 나타낸다:
-CR3R4-(CH2)1-8-C(=O)-;
이때 R3 및 R4는 각각 독립적으로 H 또는 Me이며, L1에서-C(=O)- 모이어티는 D에 연결되며;
D는 다음의 화학식으로 나타내고:

q는 1 내지 20의 정수다.
일부 구체예들에서, 본 발명의 메이탄시노이드는 다음의 화학식으로 나타낸다:
또는 이의 약제학적으로 허용되는 염이며, 이때:
A'는 아미노산 또는 2 내지 20개 아미노산 잔기를 포함하는 펩티드(이를 테면, A-NH2)이며;
R1 및 R2는 각각 독립적으로 H 또는 C1-3알킬이며;
L1은-CR3R4-(CH2)1-8-C(=O)-이며; R3 및 R4는 각각 독립적으로 H 또는 Me이며;
D은 다음의 화학식으로 나타낸다:

q는 1 내지 20의 정수다.
일부 구체예들에서, 본 발명의 메이탄시노이드 다음의 화학식으로 나타낸다:
또는 이의 약제학적으로 허용되는 염이며, 이때:
각 경우들에서 Rx' 및 Ry'는 독립적으로 H,-OH, 할로겐,-O-(C1-4알킬),-SO3H,-NR40R41R42 +, 또는 OH, 할로겐, SO3H 또는 NR40R41R42 +로 임의선택적으로 치환된 C1-4 알킬이며, 이때 R40, R41 및 R42는 각각 독립적으로 H 또는 C1-4알킬이며;
k은 1 내지 10의 정수이고
A는 아미노산 잔기 또는 2 내지 20개 아미노산 잔기들을 포함하는 펩티드이며;
R1 및 R2는 각각 독립적으로 H 또는 C1-3알킬이며;
L1은-CR3R4-(CH2) 1-8-C(=O)-이며; R3 및 R4는 각각 독립적으로 H 또는 Me이며;
D는 다음의 화학식으로 나타내고:

q는 1 내지 20의 정수다.
일부 구체예들에서, 화학식 (II), (III) 또는 (IV)의 메이탄시노이드 화합물들의 경우 변수들은 상기 첫 번째 구체예, 또는 상기 첫 번째 구체예의 제 1, 제 2, 제 3, 제 4, 제 5, 제 6, 제 7, 제 8, 제 9, 제 10 또는 제 11 특이적 구체예에서 기술된 것과 같다.
특이적 구체예에서, 상기 메이탄시노이드 화합물은 다음의 화학식으로 나타낸다:

이때 D1은 다음의 화학식으로 나타낸다:

IV.
생산 방법
본 발명의 항-ADAM9 항체 및 이의 ADAM9-결합 단편들은 당업계에 공지된 바와 같이 이러한 폴리펩티드를 인코딩하는 핵산 분자의 재조합 발현을 통해 생산하는 것이 가장 바람직하다.
본 발명의 폴리펩티드는 고형 상(phase) 펩티드 합성을 통하여 편리하게 만들 수 있다 (Merrifield, B. (1986) "Solid Phase Synthesis," Science 232(4748):341- 347; Houghten, R.A. (1985) "General Method For The Rapid Solid-Phase Synthesis Of Large Numbers Of Peptides: Specificity Of Antigen-Antibody Interaction At The Level Of Individual Amino Acids," Proc. Natl. Acad. Sci. (U.S.A.) 82(15):5131-5135; Ganesan, A. (2006) "Solid-Phase Synthesis In The Twenty-First Century" Mini Rev. Med. Chem. 6(1):3-10).
대안으로, 항체는 당업계에 공지된 임의의 방법을 사용하여 재조합적으로 제조 및 발현될 수 있다. 항체는 숙주 동물로부터 만들어진 항체를 먼저 단리시키고, 유전자 서열을 획득하고, 그리고 당해 유전자 서열을 사용하여 숙주 세포 (예를 들어, CHO 세포)에서 항체를 재조합적으로 발현시킴으로써 재조합적으로 제조될 수 있다. 사용할 수 있는 또 다른 방법은 식물{이를 테면, 담배) 또는 유전자이식된 우유에서 항체 서열을 발현시키는 것이다. 식물 또는 우유에서 재조합적으로 항체를 발현시키기 위한 적합한 방법들이 기술되었다(예를 들면, Peeters et al. (2001) "Production Of Antibodies And Antibody Fragments In Plants," Vaccine 19:2756; Lonberg, N. et al. (1995) "Human Antibodies From Transgenic Mice," Int. Rev. Immunol 13:65-93; 그리고 Pollock et al. (1999) "Transgenic Milk As A Method For The Production Of Recombinant Antibodies," J. Immunol Methods 231:147-157 참고). 항체의 유도체, 이를 테면, 인간화된, 단일-쇄, 등등,을 만드는 적합한 방법들이 당분야에 공지되어 있으며, 그리고 상기에 기술되어 있다. 또다른 대안에서, 항체는 파아지 디스플레이 기술에 의해 재조합적으로 만들어질 수 있다 (예를 들면, U.S. 특허 번호. 5,565,332; 5,580,717; 5,733,743; 6,265,150; 그리고 Winter, G. et al. (1994) "Making Antibodies By Phage Display Technology," Annu. Rev. Immunol. 12.433-455).
관심대상의 폴리뉴클레오티드 (예를 들어, 본 발명의 항-ADAM9 항체 및 이의 ADAM9- 결합 단편의 폴리펩티드 쇄를 인코드하는 폴리뉴클레오티드)를 함유하는 벡터는 전기천공, 염화칼슘, 염화루비듐, 인산 칼슘, DEAE-덱스트란 또는 기타 기질을 사용한 형질감염; 미세-발사체 투하; 리포펙션; 및 감염 (예: 이때 벡터가 백시니아 바이러스와 같은 감염성 제제인 경우)을 포함한 여러 적절한 수단중 임의의 수단에 의해 숙주 세포로 도입시킬 수 있다. 벡터 또는 폴리뉴클레오티드 도입의 선택은 종종 숙주 세포의 특징에 따라 달라진다.
이종성(heterologous) DNA를 과다발현시킬 수 있는 임의의 숙주 세포는 관심대상 폴리펩티드 또는 단백질을 발현시킬 목적으로 사용될 수 있다. 적합한 포유류 숙주 세포의 비-제한적 예로는 COS, HeLa, 그리고 CHO 세포가 포함되나, 이에 국한되지 않는다.
본 발명은 본 발명의 항-ADAM9 항체 또는 이의 ADAM9-결합 단편의 아미노산 서열을 포함하는 면역콘쥬게이트를 내포한다. 본 발명의 폴리펩티드는 당업계에 공지된 절차에 의해 제조될 수 있다. 상기 폴리펩티드는 항체의 단백질 분해 또는 기타 분해에 의해, 상기 기재된 바와 같은 재조합 방법 (즉, 단일 또는 융합 폴리펩티드) 또는 화학적 합성에 의해 생성될 수 있다. 항체의 폴리펩티드, 특히 최대 약 50개 아미노산의 짧은 폴리펩티드는 화학적 합성에 의해 편리하게 만들어진다. 화학적 합성 방법은 당업계에 공지되어 있으며, 상업적으로 이용가능하다.
본 발명은 항-ADAM9 항체의 변이체들 및 그의 단편을 포함하는 면역콘쥬게이트를 포함하는데, 이러한 분자의 특성에 유의적으로 영향을 미치지 않는 기능적으로 등가의 폴리펩티드 및 활성이 향상되거나 또는 감소된 변이체가 포함된다. 폴리펩티드의 변형은 당업계에서 일상적인 작업이므로, 본원에서 자세히 설명될 필요는 없다. 변형된 폴리펩티드의 예는 아미노산 잔기의 보존적 치환을 갖는 폴리펩티드, 기능적 활성이 유의적으로 유해하게 변경하지 않는 아미노산의 하나 또는 그 이상의 결실 또는 첨가, 또는 화학적 유사체의 사용이 내포된다. 서로 보존적으로 치환될 수 있는 아미노산 잔기에는 글리신/알라닌; 세린/트레오닌; 발린/이소류신/류신; 아스파라긴/글루타민; 아스파르트산/글루탐산; 리신/아르기닌; 및 페닐알라닌/티로신이 포함되나, 이에 국한되지 않는다. 이들 폴리펩티드는 또한 글리코실화된 폴리펩티드 및 비-글리코실화 폴리펩티드, 뿐만 아니라 다른 해독-후 변형, 예를 들어, 상이한 당을 사용한 글리코실화, 아세틸화 및 인산화를 갖는 폴리펩티드를 또한 내포한다. 선호적으로, 아미노산 치환은 보존적일 것이며, 즉, 치환된 아미노산은 원래 아미노산과 유사한 화학적 특성을 소유할 것이다. 이러한 보존적 치환은 당분야에 공지되어 있으며, 그리고 예시들이 상기에서 제시되었다. 아미노산 변형은 하나 또는 그 이상의 아미노산을 변경하거나 또는 변형하는 것에서부터 영역, 이를 테면, 가변 도메인의 완전한 재설계에 이르기까지 다양하다. 상기 가변 도메인의 변경으로 결합 친화력 및/또는 특이성이 바뀔 수 있다. 다른 변형 방법은 효소적 수단, 산화적 치환 및 킬레이트화를 포함하나, 이에 국한되지 않는 당업계에 공지된 커플링 기술의 사용이 내포된다. 예를 들어, 방사면역검정을위한 방사성활성 모이어티의 부착과 같은 면역검정을위한 라벨 부착을 위해 변형이 사용될 수 있다. 변형된 폴리펩티드는 당업계에서 확립된 절차를 사용하여 제조되고, 당업계에 공지된 표준 검정을 사용하여 스크리닝할 수 있다.
본 발명 본 발명은 본 발명의 항-ADAM9-VL 및/또는 VH 중 하나 또는 그 이상을 갖는 융합 단백질을 포함하는 면역콘쥬게이트를 포함한다. 한 구체예에서, 경쇄, 중쇄 또는 경쇄와 중쇄 둘 모두다 포함하는 융합 폴리펩티드가 제시된다. 또다른 구체예에서, 상기 융합 폴리펩티드는 이종성 면역글로불린 불변 영역을 함유한다. 또다른 구체예에서, 상기 융합 폴리펩티드는 공개적으로-기탁된 하이브리도마로부터 만들어진 항체의 경쇄 가변 도메인 및 중쇄 가변 도메인을 함유한다. 본 발명의 목적을 위해, 항체 융합 단백질은 ADAM9 및 태생적 분자, 예를 들면, 또다른 영역의 이종성 서열 또는 상동성 서열에 부착되지 않는 또다른 아미노산 서열에 특이적으로 결합하는 하나 또는 그 이상의 폴리펩티드 도메인을 함유한다.
본 발명은 본 발명의 항-ADAM9 항체 또는 이의 ADAM9-결합 단편을 인코드하는 뉴클레오티드 서열을 포함하는 폴리뉴클레오티드를 또한 제공한다.
특정 구체예들에서, 본 발명은 서열 식별 번호:68의 아미노산 서열을 갖는 hMAB-A VL (2) 경쇄를 인코드하는 폴리뉴클레오티드를 제공하는데, 이때 상기 폴리뉴클레오티드는 다음의 서열 식별 번호:157의 뉴클레오티드 서열을 갖는다:

특정 구체예들에서, 본 발명은 서열 식별 번호:68의 아미노산 서열을 갖는 hMAB-A VL (2) 경쇄를 인코드하는 폴리뉴클레오티드를 제공하는데, 이때 상기 폴리뉴클레오티드은 코돈 최적화되고, 다음의 서열 식별 번호:158의 뉴클레오티드 서열을 갖는다.

특정 구체예들에서, 본 발명은 서열 식별 번호:151의 아미노산 서열을 갖는 hMAB-A VH (2I) 중쇄를 인코드하는 폴리뉴클레오티드를 제공하는데, 이때 상기 폴리뉴클레오티드는 다음의 서열 식별 번호:159의 뉴클레오티드 서열을 갖는다:

이때 xxx는 aaa이거나 또는 존재하지 않는다.
특정 구체예들에서, 본 발명은 서열 식별 번호:155의 아미노산 서열을 갖는 hMAB-A VH (2I) 중쇄를 인코드하는 폴리뉴클레오티드를 제공하는데, 이때 상기 폴리뉴클레오티드는 다음의 서열 식별 번호:160의 뉴클레오티드 서열을 갖는다:

특정 구체예들에서, 본 발명은 서열 식별 번호:156의 아미노산 서열을 갖는 hMAB-A VH (2I) 중쇄를 인코드하는 폴리뉴클레오티드를 제공하는데, 이때 상기 폴리뉴클레오티드는 다음의 서열 식별 번호:161의 뉴클레오티드 서열을 갖는다:

특정 구체예들에서, 본 발명은 서열 식별 번호:156의 아미노산 서열을 갖는 hMAB-A VH (2I) 중쇄를 인코드하는 폴리뉴클레오티드를 제공하는데, 이때 상기 폴리뉴클레오티드는 다음의 서열 식별 번호:162의 뉴클레오티드 서열을 갖는다:

V.
약물 콘쥬게이션
본원에 기재된 메이탄시노이드 화합물에 공유적으로 연계된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편을 포함하는 면역콘쥬게이트는 당업계에 공지된 임의의 적합한 방법에 따라 제조될 수 있다.
특정 구체예들에서, 첫 번째 구체예의 면역콘쥬게이트는 항-ADAM9 항체 또는 이의 ADAM9-결합 단편을 두 번째 구체예에 기재된 화학식 (II)의 메이탄시노이드 화합물과 반응시키는 단계를 포함하는 제 1 방법에 의해 제조될 수 있다.
특정 구체예들에서, 첫 번째 구체예의 면역콘쥬게이트는 다음의 단계들을 포함하는 제 2 방법에 의해 제조될 수 있다:
(a)
항-ADAM9 항체 또는 이의 ADAM9-결합 단편 (또는 CBA)에 공유적으로 연계될 수 있는 이에 결합된 아민-반응성 기 또는 티올-반응성 기를 갖는 세포독성 제제-메이탄시노이드 화합물을 만들기 위해 본원에서 기술된 화학식 (III) 또는 (IV)의 메이탄시노이드 화합물과 링커 화합물을 반응시키고; 그리고
(b)
상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편과 상기 메이탄시노이드-링커 화합물을 반응시켜, 상기 면역콘쥬게이트를 만든다.
특정 구체예들에서, 첫 번째 구체예의 면역콘쥬게이트는 다음의 단계들을 포함하는 제 3 방법에 의해 제조될 수 있다:
(a)
화학식 (III) 또는 (IV)의 메이탄시노이드 화합물에 공유적으로 연계될 수 있는 화합물 (이를 테면, 화학식 (II)의 화합물)에 결합된 아민-반응성 기 또는 티올-반응성 기를 갖는 변형된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편을 만들기 위해 본원에서 기술된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편과 링커 화합물을 반응시키고; 그리고
(b)
상기 변형된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편과 상기 화학식 (III) 또는 (IV)의 메이탄시노이드 화합물을 반응시켜, 상기 면역콘쥬게이트를 만든다.
특정 구체예들에서, 첫 번째 구체예의 면역콘쥬게이트는 제 3 방법에 의해 제조될 수 있는데, 이 방법은 항-ADAM9 항체 또는 ADAM9-결합 이의 단편, 링커 화합물 및 화학식 (III) 또는 (IV)의 메이탄시노이드 화합물을 반응시켜, 상기 면역콘쥬게이트를 만드는 것을 포함한다. 한 구체예에서, 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편 및 상기 화학식 (III) 또는 (IV)의 메이탄시노이드 화합물을 우선 혼합하고, 이어서 상기 링커 화합물을 추가한다.
특정 구체예들에서, 상기에서 기술된 제 2 방법, 제 3 방법 또는 제 4 방법의 경우, 상기 링커 화합물은 화학식 (a1L)-(a10L)중 임의의 하나로 나타내거나, 또는 이의 약제학적으로 허용되는 염이다:

이때 X는 할로겐; JD-SH, 또는-SSRd이며; Rd은 페닐, 니트로페닐, 디니트로페닐, 카르복시니트로페닐, 피리딜 또는 니트로피리딜이며; Rg는 알킬이며; 그리고 U는 -H 또는 SO3H이다.
한 구체예에서, 상기 링커 화합물은 화학식 (a9L)로 나타내거나, 또는 이의 약제학적으로 허용되는 염인, GMBS 또는 술포-GMBS이며, 이때 U는 -H 또는 SO3H이다.
특이적 구체예에서, 본 발명의 면역콘쥬게이트는 다음의 화학식으로 나타내고:


상기 면역콘쥬게이트는 상기에서 기술된 제 2 방법, 제 3 방법, 또는 제 4 방법에 의해 만들어질 수 있고, 이때 상기 링커 화합물은 화학식 (a9L)로 나타내거나, 또는 이의 약제학적으로 허용되는 염인, GMBS 또는 술포-GMBS이며, 이때 U는 -H 또는 SO3H이며; 그리고 상기 메이탄시노이드 화합물은 상기에서 기술된 화학식 (D-1)로 나타낸다. 더욱 특이적 구체예에서, 화학식 (I-1)의 면역콘쥬게이트는 화학식 (D-1)의 메이탄시노이드 화합물과 상기 링커 화합물 GMBS 또는 술포-GMBS를 반응시켜, 메이탄시노이드-링커 화합물을 만들고, 이어서 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편과 상기 메이탄시노이드-링커 화합물을 반응시킴으로써, 만들어진다. 더더욱 특이적 구체예에서, 상기 메이탄시노이드 링커 화합물은 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편과 반응 전, 당해 화합물을 정제하지 않는다.
또다른 특이적 구체예에서, 상기 면역콘쥬게이트는 다음의 화학식으로 나타낸다:

그리고 상기 면역콘쥬게이트는 상기에서 기술된 제 2 방법, 제 3 방법, 또는 제 4 방법에 의해 만들 수 있으며, 이때 상기 링커 화합물은 화학식 (a9L)로 나타내거나, 또는 이의 약제학적으로 허용되는 염인, GMBS 또는 술포-GMBS이며, 이때 U는-H 또는 SO3H이며; 그리고 상기 메이탄시노이드 화합물은 상기에서 기술된 화학식 (D-2)로 나타낸다. 더욱 특이적 구체예에서, 화학식 (I-2)의 면역콘쥬게이트는 화학식 (D-2)의 메이탄시노이드 화합물과 상기 링커 화합물 GMBS 또는 술포-GMBS를 반응시켜, 메이탄시노이드-링커 화합물을 만들고, 이어서 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편과 상기 메이탄시노이드-링커 화합물을 반응시킴으로써, 만들어진다. 더더욱 특이적 구체예에서, 상기 메이탄시노이드 링커 화합물은 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편과 반응 전, 당해 화합물을 정제하지 않는다.
또다른 특이적 구체예에서, 상기 면역콘쥬게이트는 다음의 화학식으로 나타내고:

상기 면역콘쥬게이트는 상기에서 기술된 제 1 방법에 따라 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편과 상기에서 기술된 화학식 (D-3)의 메이탄시노이드 화합물과 반응시킴으로써, 만든다.
또다른 특이적 구체예에서, 상기 면역콘쥬게이트는 다음의 화학식으로 나타내며:

그리고 상기 면역콘쥬게이트는 상기에서 기술된 제 1 방법에 따라 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편과 상기에서 기술된 화학식 (D-4)의 메이탄시노이드 화합물과 반응시킴으로써, 만든다.
또다른 특이적 구체예에서, 상기 면역콘쥬게이트는 다음의 화학식으로 나타내고:

상기 면역콘쥬게이트는 상기에서 기술된 제 1 방법에 따라 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편과 상기에서 기술된 화학식 (D-5)의 메이탄시노이드 화합물과 반응시킴으로써, 만든다.
또다른 특이적 구체예에서, 상기 면역콘쥬게이트는 다음의 화학식으로 나타내고:

상기 면역콘쥬게이트는 상기에서 기술된 제 1 방법에 따라 상기 항-ADAM9 항체 또는 이의 ADAM9-결합 단편과 상기에서 기술된 화학식 (D-6)의 메이탄시노이드 화합물과 반응시킴으로써, 만든다.
일부 구체예들에서, 상기에서 기술된 임의의 방법에 의해 만들어진 면역콘쥬게이트는 정제 단계를 거친다. 이와 관련하여, 면역콘쥬게이트는 접선 유동 여과 (TFF), 비-흡착성 크로마토그래피, 흡착성 크로마토그래피, 흡착성 여과, 선택적 침전 또는 임의의 다른 적절한 정제 공정, 뿐만 아니라 이들의 조합을 사용하여, 혼합물의 다른 성분으로부터 정제시킬 수 있다.
일부 구체예들에서, 상기 면역콘쥬게이트는 단일 정제 단계 (이를 테면, TFF)를 이용하여 정제된다. 선호적으로, 상기 콘쥬게이트는 단일 정제 단계 (이를 테면, TFF)를 이용하여 정제되고, 적절한 제형(formulation)으로 교환된다. 본 발명의 다른 구체예들에서, 상기 면역콘쥬게이트는 두 가지 순차적 정제 단계를 이용하여 정제된다. 예를 들면, 상기 면역콘쥬게이트는 먼저 선택적 침전, 흡착성 여과, 흡착성 크로마토그래피 또는 비-흡착성 크로마토그래피에 의해 정제된 다음, TFF로 정제될 수 있다. 당업자는 콘쥬게이트의 정제로 인해, 세포독성 제제에 화학적으로 결합된 세포-결합 제제를 포함하는 안정한 면역콘쥬게이트를 분리할 수 있다는 사실을 이해할 것이다.
정제에 적합한 임의의 TFF 시스템을 사용할 수 있는데, Pellicon 유형 시스템 (Millipore, Billerica, Mass.), Sartocon Cassette 시스템 (Sartorius AG, Edgewood, N.Y.), 그리고 Centrasette 유형 시스템 (Pall Corp., East Hills, N.Y.)이 포함된다.
임의의 적합한 흡착성 크로마토그래피 수지가 정제에 사용될 수 있다. 바람직한 흡착성 크로마토그래피 수지는 하이드록시아파타이트 크로마토그래피, 소수성 전하 유도 크로마토그래피 (HCIC), 소수성 상호작용 크로마토그래피 (HIC), 이온 교환 크로마토그래피, 혼합 모드 이온 교환 크로마토그래피, 고정된 금속 친화력 크로마토그래피 (IMAC), 염료 리간드 크로마토그래피, 친화력 크로마토그래피, 역상 크로마토그래피 및 이들의 조합을 포함한다. 적합한 하이드록시아파타이트 수지는 세라믹 하이드록시아파타이트 (CHT 유형 I 및 유형 II, Bio-Rad Laboratories, Hercules, Calif.), HA Ultrogel 하이드록시아파타이트 (Pall Corp., East Hills, N.Y.), 그리고 세라믹 플루오르아파타이트 (CFT 유형 I 및 유형 II, Bio-Rad Laboratories, Hercules, Calif.)를 포함한다. 적합한 HCIC 수지의 예로는 MEP Hypercel 수지 (Pall Corp., East Hills, N.Y.)이다. 적합한 HIC 수지의 예시에는 부틸-Sepharose, 헥실-Sepharose, 페닐-Sepharose, 그리고 옥틸 Sepharose 수지 (all from GE Healthcare, Piscataway, N.J.), 뿐만 아니라 Macro-prep 메틸 및 Macro-Prep t-부틸 수지 (Biorad Laboratories, Hercules, Calif.)가 내포된다. 적합한 이온 교환 수지의 예시에는 SP-Sepharose, CM-Sepharose, 그리고 Q-Sepharose 수지 (모두 GE Healthcare, Piscataway, N.J.의 제품), 그리고 Unosphere S 수지 (Bio-Rad Laboratories, Hercules, Calif.)가 내포된다. 적합한 혼합 모드 이온 교환기의 예시에는 Bakerbond ABx 수지 (JT Baker, Phillipsburg N.J.)가 내포된다. 적합한 IMAC 수지의 예시에는 Chelating Sepharose 수지 (GE Healthcare, Piscataway, N.J.) 및 Profinity IMAC 수지 (Bio-Rad Laboratories, Hercules, Calif.)가 내포된다. 적합한 염료 리간드 수지의 예시에는 Blue Sepharose 수지 (GE Healthcare, Piscataway, N.J.) 및 Affi-gel Blue 수지 (Bio-Rad Laboratories, Hercules, Calif.)가 내포된다. 적합한 친화력 수지의 예시에는 Protein A Sepharose 수지 (이를 테면, MabSelect, GE Healthcare, Piscataway, N.J.)-여기에서 상기 세포-결합 제제는 항체이며-, 그리고 렉틴 친화력 수지, 이를 테면, Lentil Lectin Sepharose 수지 (GE Healthcare, Piscataway, N.J.)(여기에서 상기 세포-결합 제제는 적절한 렉틴 결합 부위를 품고 있음)가 내포된다. 대안으로, 상기 세포-결합 제제에 특이적 항체가 이용될 수 있다. 이러한 항체는 예를 들면, Sepharose 4 Fast Flow 수지 (GE Healthcare, Piscataway, N.J.)에 고정될 수 있다. 적합한 역-상 수지의 예에는 C4, C8, 그리고 C18 수지 (Grace Vydac, Hesperia, Calif.)가 내포된다.
정제를 위해 임의의 적합한 비-흡착성 크로마토그래피 수지가 이용될 수 있다. 적합한 비-흡착성 크로마토그래피 수지의 예시로는 SEPHADEXTM G-25, G-50, G-100, SEPHACRYLTM 수지 (이를 테면, S-200 및 S-300), SUPERDEXTM 수지 (이를 테면, SUPERDEXTM 75 및 SUPERDEXTM 200), BIO-GEL® 수지 (이를 테면, P-6, P-10, P-30, P-60, 및 P-100), 그리고 당분야의 당업자에게 공지된 기타 다른 것들이 내포되지만, 이에 국한되지 않는다.
VI.
본 발명의 면역콘쥬게이트의 용도
본 발명은 본 발명의 면역콘쥬게이트를 포함하는 약제학적 조성물을 비롯한 조성물을 포괄한다.
본원에서 제공된 바와 같이, 본원에서 제공되는 상기 인간화된/최적화된 항-ADAM9-VL 및/또는 VH 도메인을 포함하는 본 발명의 면역콘쥬게이트는 세포 표면에 존재하는 ADAM9에 결합하고, 세포 사멸을 중개하는 능력을 갖는다. 특히, 약학적 제제를 포함하는 본 발명의 면역콘쥬게이트는 당해 약학적 제제의 활성을 통해 내화되고, 세포 사멸을 매개한다. 항체-의존적 세포-중개된 세포독성 (ADCC) 및/또는 보체 의존적 세포독성 (CDC)을 유도하는 면역콘쥬게이트에 의해 이러한 세포 사멸 활성이 증가될 수 있다.
따라서, 본원에서 제공된 인간화된/최적화된 항-ADAM9-VL 및/또는 VH 도메인을 포함하는 본 발명의 면역콘쥬게이트는 ADAM9의 발현과 연합되거나, 또는 이를 특징으로 하는 임의의 질환 또는 병태를 치료하는 능력을 갖는다. 상기에서 논의된 바와 같이, ADAM9은 덜-분화된 형태(morphology)를 나타내는 고급-종양과 관련된 수많은 혈액 악성 종양 및 고형 악성 종양에서 발현되는 종양-배아 항원이며, 불량한 임상 결과와 상관관계가 있다. 따라서, 제한없이, 본 발명의 면역콘쥬게이트는 암, 구체적으로 ADAM9의 발현을 특징으로 하는 암 치료에 이용될 수 있다.
다른 특정 구체예들에서, 본 발명의 면역콘쥬게이트는 암 (이를 테면, 비-소-세포 폐암), 결장직장암, 방광암, 위암, 췌장암, 신장 세포 암종, 전립선암, 식도암, 유방암, 두경부암, 자궁암, 난소암, 간암, 자궁경부암, 갑상선암, 고환암, 골수암, 흑색종 및 림프 암의 치료에 유용할 수 있다. 다른 특정 구체예들에서, 본 발명의 면역콘쥬게이트는 비-소-세포 폐암, 결장직장암, 위암, 유방암 (이를 테면, 삼중 음성 유방암 (TNBC)), 또는 췌장암의 치료에 유용할 수 있다.
추가 구체예들에서, 본 발명의 면역콘쥬게이트는 비-소-세포 폐암 (편평 세포, 비-편평 세포, 선암종, 또는 거대-세포 미분화된 암종), 결장직장암 (선암종, 위장관 카르시노이드 종양, 위장 기질 종양, 원발성 결장직장 림프종, 평활근육종, 또는 편평 세포 암종) 또는 유방암 (이를 테면, 삼중 음성 유방암 (TNBC)) 암의 치료에 유용할 수 있다.
치료요법에서의 용도에 더하여, 본 발명의 면역콘쥬게이트는 암 진단 또는 종양 및 종양 세포의 영상화에서 검출가능하게 라벨되어 사용될 수 있다.
VII.
약제학적 조성물
본 발명의 조성물에는 약제학적 조성물 (이를 테면, 미정제 조성물 또는 비-살균 조성물) 및 약제학적 조성물 (이를 테면, 대상체 또는 환자에게 투여하기에 적합한 조성물)의 제작에 유용한 벌크 약학 조성물이 내포되며, 이들은 단위 투약형의 조제물에 이용될 수 있다. 이러한 조성물은 본 발명의 면역콘쥬게이트, 또는 이러한 제제들과 약제학적으로 허용되는 운반체의 조합의 예방적, 또는 치료요법적 효과량을 포함한다. 선호적으로, 본 발명의 조성물은 본 발명의 면역콘쥬게이트 및 약제학적으로 허용되는 운반체의 예방적, 또는 치료요법적 효과량을 포함한다. 본 발명은 추가적으로 특정 암 항원에 특이적인 제 2의 치료요법적 항체 (이를 테면, 종양-특이적 단일클론 항체)와 약제학적으로 허용되는 운반체를 포함하는 이러한 약제학적 조성물을 또한 포괄한다.
특이적 구체예에서, 용어 "약학적으로 허용되는"이란 U.S. 약전에 열거된 연방 또는 주정부의 관리가 승인한 또는 동물, 더욱 구체적으로 인간에 사용할 수 있는 것으로 일반적으로 인지된 다른 약전에서 승인되었다는 것을 의미한다. 용어 "운반체"란 치료요법제와 함께 투여되는 희석제, 어쥬번트 (이를 테면, Freund의 (완전한, 그리고 불완전한) 어쥬번트, 부형제, 또는 비히클을 지칭한다. 일반적으로, 본 발명의 조성물의 이들 성분은 별도로 공급되거나 또는 단위 투약형, 예를 들면, 건조 동결건조된 분말 또는 밀봉된 용기, 이를 테면 활성 물질의 양이 표시된 앰플 또는 사세(sachette)에 함께 혼합될 수 있다. 상기 조성물이 주입에 의해 투여될 때, 약학 등급의 멸균 물 또는 염수가 포함된 주입 병 안에 분배될 수 있다. 상기 조성물이 주사에 의해 투여될 때, 주사용 멸균 수 또는 염수 앰플이 제공되고, 상기 성분들은 투여 전 혼합될 수 있다.
본 발명은 본 발명의 면역콘쥬게이트 단독으로, 또는 이러한 약제학적으로 허용되는 운반체와 함께 채워진 하나 또는 그 이상의 용기를 포함하는 약제 학적 팩 또는 키트를 또한 제공한다. 추가적으로, 질환 치료에 유용한 하나 또는 그 이상의 다른 기타 예방제 또는 치료요법제가 또한 상기 약제학적 팩 또는 키트에 포함될수 있다. 본 발명은 본 발명의 약제학적 조성물의 성분 중 하나 또는 그 이상으로 채워진 하나 또는 그 이상의 용기를 포함하는 약제학적 팩 또는 키트를 또한 제공한다. 의약품 또는 생물학적 제품의 제조, 사용 또는 판매를 규제하는 정부 기관이 규정한 형식의 통지가 임의선택적으로 이러한 용기(들)에 부착될 수 있으며, 이러한 통지는 인간에게 투여하기 위한 제조, 사용 또는 판매 기관의 승인을 반영한다.
본 발명은 상기 방법에 사용될 수 있는 키트를 제공한다. 키트는 본 발명의 임의의 면역콘쥬게이트를 포함할 수 있다. 상기 키트는 암 치료에 유용한 하나 또는 그 이상의 다른 예방제 및/또는 치료요법제를 하나 또는 그 이상의 용기에 추가로 포함할 수 있다.
VIII.
투여 방법
본 발명의 조성물은 본 발명의 면역콘쥬게이트의 유효량을 대상체에게 투여함으로써 질환, 장애와 관련된 하나 또는 그 이상의 증상의 치료, 예방 및 개선을 위해 제공될 수 있다. 바람직한 측면에서, 이러한 조성물은 실질적으로 정제된다 (이를 테면, 이의 효과를 제한하거나 또는 바람직하지 않은 부작용을 생성하는 물질이 실질적으로 없음). 특이적 구체예에서, 상기 대상체는 동물, 선호적으로 포유류 이를 테면, 비-영장류 (이를 테면, 소, 말, 고양이, 개, 설치류, 등등,) 또는 영장류 (이를 테면, 원숭이 이를 테면, 시노몰구스 원숭이, 인간, 등등,)이다. 바람직한 구체예에서, 상기 대상체는 인간이다.
다양한 전달 시스템이 공지되어 있으며, 예를 들어 본 발명의 조성물을 투여하기 위해 리포좀, 마이크로입자, 마이크로캡슐, 돌연변이 바이러스를 발현시킬 수 있는 재조합 세포에 의한 포집화, 수용체-매개된 엔도사이토시스 (가령, Wu et al. (1987) "Receptor-Mediated In Vitro Gene Transformation By A Soluble DNA Carrier System, " J. Biol. Chem. 262:4429-4432), 레트로바이러스 벡터 또는 기타 벡터의 일부분으로써 핵사의 구축, 등,이 이용될 수 있다.
본 발명의 면역콘쥬게이트를 투여하는 방법은 비경 구 투여 (예를 들어, 피내, 근육내, 복강내, 정맥 및 피하), 경막외 투여 및 점막 투여 (예를 들어, 비강 및 경구 경로)을 포함하지만, 이에 국한되지는 않는다. 특이적 구체예에서, 본 발명의 면역콘쥬게이트는 근육내로, 정맥내로, 또는 피하로 투여된다. 상기 조성물은 임의의 편리한 경로, 예를 들어, 주입 또는 볼루스(bolus) 주사에 의해 투여될 수 있고, 그리고 다른 생물학적 활성제와 함께 투여될 수 있다. 투여는 전신으로 또는 국소적으로 이루어질 수 있다.
본 발명은 본 발명의 면역콘쥬게이트 조제물이 분자의 양을 표시하는 앰플 또는 사세(sachette)와 같은 밀폐 용기에 포장된 것을 또한 제공한다. 한 구체예에서, 이러한 분자는 밀폐된 용기에 건조 멸균된 동결 건조 분말 또는 물이 없는 농축물로 공급되며, 예를 들어, 대상체에게 투여하기에 적절한 농도로 물 또는 식염수를 이용하여 재구성될 수 있다. 선호적으로, 본 발명의 면역콘쥬게이트는 밀폐된 용기에 건조 멸균 동결 건조 분말로 공급된다.
본 발명의 면역콘쥬게이트의 동결 건조된 조제물은 원래 용기에 2℃에서 8℃ 사이에 보관되어야 하며, 당해 분자는 재구성 후 12 시간 이내, 바람직하게는 6 시간 이내, 5 시간 이내, 3 시간 이내, 또는 1 시간 이내 투여되어야 한다. 대안으로 구체예, 이러한 분자는 분자, 융합 단백질 또는 콘쥬게이트된 분자의 양과 농도를 표시하는 밀폐 용기에 액체 형태로 공급된다. 선호적으로, 액체 형태로 제공되는 경우, 이러한 면역콘쥬게이트는 밀폐된 용기에 담아 제공된다.
본원에서 사용된 바와 같이, 약제학적 조성물의 "효과량"은 질병으로 인한 증상의 감소, 감염 증상 (예: 바이러스 부하, 발열, 통증, 패혈증 등)의 감쇠 또는 암의 증상 (예: 증식, 암세포, 종양 존재, 종양 전이 등)의 감쇠를 비롯한 유익한 결과 또는 원하는 결과를 얻고, 따라서 질환을 앓고 있는 자들의 삶의 질을 높이고, 질병을 치료하는 데 필요한 다른 약물의 용량을 줄이고, 표적화 및/또는 내화를 통해 다른 약물의 효과를 강화시키고, 질환의 진행을 지연시키고, 및/또는 개체의 생존 연장시키는데 충분한 양이다. 효과량은 하나 또는 그 이상의 투여로 투여될 수 있다. 본 발명의 목적을 위해, 약물, 화합물, 또는 약제학적 조성물의효과량은 암 세포를 죽이거나 또는 암 세포의 증식을 감소시키고 및/또는 암의 원발성 부위로부터 전이의 발생을 제거, 감소 및/또는 지연시키기에 충분한 양이다.
본 발명의 약제학적 조성물은 치료가 필요한 부위에 국소적으로 투여될 수 있는데; 이는 예를 들어, 국소 주입, 주사, 또는 임플란트에 의해 이루어질 수 있지만, 이에 국한되지 않으며, 상기 임플란트는 시알라스틱 막 또는 섬유와 같은 막을 비롯한, 다공성, 비-다공성 또는 젤라틴성 물질로 구성된다. 선호적으로, 본 발명의 면역콘쥬게이트를 투여할 때, 분자가 흡수하지 않는 물질을 사용하도록 주의를 해야 한다.
본 발명의 조성물은 소포, 특히 리포솜으로 운반될 수 있다.(Langer (1990) "New Methods Of Drug Delivery," Science 249:1527-1533); Treat et al., in Liposomes in the Therapy of Infectious Disease and Cancer, Lopez- Berestein and Fidler (eds.), Liss, New York, pp. 353- 365 (1989); Lopez-Berestein, ibid., pp. 3 17-327 참고).
실시예
이제까지, 본 발명을 일반적으로 설명하였고, 본 발명은 하기 실시예들을 참조하여 보다 쉽게 이해될 수 있다. 다음 실시예들은 본 발명의 진단 또는 치료 방법에서 조성물에 대한 다양한 방법을 설명한다. 실시예들은 본 발명의 범위를 예시하기 위한 것이지, 결코 이들에 국한시키고자 함은 아니다.
실시예 1
항-ADAM9 항체 MAB-A의 종양 세포 특이성
뮤린 항-ADAM9 항체 (본원에서 MAB-A로 지칭됨)는 다음과 같이 식별되었다: (1) ADAM9의 표적 단백질 프로세싱 활성을 차단시키고; (2) 내화되며; 그리고 (3) 항-종양 활성을 보유한다 (이를 테면, US 특허 번호. 8361475 참고). MAB-A의 종양 세포 특이성은 IHC에 의해 조사되었다. 종양 조직에 MAB-A (0.4μg/mL) 또는 아이소타입 대조군 (0.4μg/mL)을 접촉시키고, 착색 정도를 시각화하였다. MAB-A는 다양한 거대 세포 암종, 편평 세포 암종, 그리고 선암종 비-소 세포 폐암 세포 유형 (도 1A), 유방암 세포, 전립선암 세포, 위암 세포 (도 1B), 뿐만 아니라 결장암 샘플 (도 1C)을 강하게 라벨시키는 것으로 나타났다. 정상 조직에 MAB-A (1.25μg/mL)를 접촉시키고, 착색 정도를 시각화했다. 상기 표 2에서 요약된 바와 같이, MAB-A는 광범위하게 다양한 정상 조직을 착색시키지 못하거나, 또는 거의 착색시키지 못했다. 이 연구에 사용된 MAB-A의 농도는 종양 세포의 착색에 사용 된 농도의 거의 3 배라는 것을 알 수 있다. 이러한 IHC 연구의 결과는 MAB-A가 정상 세포보다 종양 세포에 대한 강력한 우선 결합을 나타냄을 보여준다.
실시예 2
종 교차 반응성
인간 ADAM9 (huADAM9) 및 시노몰구스 원숭이 ADAM9 (cynoADAM9)에 대한 MAB-A의 결합을 조사하였다. 간단히 말해서, huADAM9, cynoADAM9, 무관한 항원을 일시적으로 발현시키는 293-FT 및 CHO-K 세포, 또는 형질감염되지 않은 부계 세포를 MAB-A와 함께 항온처리하였고, 이어서 염소 항-뮤린-PE 2 차 항체와 함께 항온처리하였고, FACS로 분석했다. 도 2에 나타낸 바와 같이, MAB-A는 두 세포 유형 모두에서 일시적으로 발현된 huADAM9에 강력하게 결합하였다. MAB-A는 cynoADAM9에는 잘 결합하지 못한다. MAB-A는 무관한 부계 세포, 또는 무관한 항원을 발현시키는 세포에는 결합하지 않았다. cynoADAM에 대한 유사한 낮은 수준의 결합이 ELISA 검정에서 관찰되었다.
실시예 3
인간화 및 초기 최적화
MAB-A의 인간화로 인간화된 VH 도메인(본원에서 "hMAB-A VH(1)"로 명시됨)과 인간화된 VL 도메인 (본원에서 "hMAB-A VL(1)"로 명시됨)이 수득되었다. 그 다음, 하기에서 더욱 상세하게 기술된 것과 같이, 상기 인간화된 가변 도메인을 최적화시켜 결합 활성을 강화시키고 및/또는 잠재적 불안정한 아미노산 잔기들을 제거하였다. 이러한 제 1 라운드의 최적화(optimization)로 세 개의 추가적인 인간화된 VH 도메인, 즉 본원에서 명시된 "hMAB-A VH(2)", "hMAB-A VH(3)", 및 "hMAB-A VH(4)", 그리고 세 개의 추가적인 인간화된 VL 도메인, 즉 본원에서 명시된 "hMAB-A VL(2)", "hMAB-A VL(3)", 및 "hMAB-A VL(4)"이 수득되었다. 또한, 뮤린 VH 도메인 및 VL 도메인, 그리고 인간 불변 영역을 갖는 키메라 형태의 MAB-A ("chMAB-A")가 생성되었다. 상기 뮤린 및 인간화된/최적화된 VH 도메인 및 VL 도메인의 아미노산 서열들은 상기에서 제시되며, 이들은 도 3A 및 3B정렬되어 있다. 이들 인간화된/최적화된 VH 도메인 및 VL 도메인의 콘센수스 서열은 상기에서 제공된다. 여기에서 다수의 인간화된 가변 도메인이 생성될 때, 상기 특정 항-ADAM9 항체 (이를 테면, MAB-A)의 인간화된 중쇄 및 경쇄 가변 도메인은 임의의 조합으로 이용될 수 있고, 인간화된 쇄의 특정 조합은 특이적 VH/VL 도메인을 참고하여 대해 언급되는데, 예를 들면, hMAB-A VH(1) 및 hMAB-A VL(2)를 포함하는 항체는 "hMAB-A (1.2)"로 특별히 지칭된다.
인간 생식계 VH3-21 및 VH3-64로부터 유래된 프레임워크 영역을 갖는 hMAB-A VH(1)이 생성되었고, 그리고 인간 생식계 B3 및 L6로부터 유래된 프레임워크 영역을 갖는 hMAB-A VL(1)이 생성되었다. 상기 뮤린 CDRs은 이들 인간화된 가변 도메인 안에 유지되었다.
잠재적 탈아미드화 부위는 CDRH2 (도 3A에서 한줄로 표시됨)에서 확인되었으며, 잠재적 아스파르트산 이성질체화 부위는 CDRL1 (도 3B에서 한줄로 표시됨)에서 확인되었다. 이들 위치에서의 아미노산 치환을 조사하여 결합 친화력을 유지하면서 이들 부위를 제거하기 위한 치환을 확인하였다. CDRH2의 위치 54 (N54F) (hMAB-A VH(2)에 존재하는)에서 페닐알라닌 그리고 CDRL1의 위치 28 (D28S)(hMAB-A VL(2)에 존재하는)에서 세린의 치환이 선택되며, 이때 상기 번호매김은 Kabat에 따른 번호매김이다. 식별된 치환들은 별도로 이용되거나, 또는 조합에 의해 이용될 수 있다. 놀랍게도, N54F 치환을 포함하는 항체는 인간 ADAM9에 대한 친화력이 약 2 배 증가하고 (예를 들어, 아래 표 3 참조) 사노몰구스 ADAM9에 대한 결합이 약간 개선된 것으로 밝혀졌다.
추가적인, CDRs에 존재하는 리신 잔기의 수를 최소화하기 위해, 최적화된 변이체가 생성되었다. 두 개 리신 잔기는 CDRH2에 존재하고 (도 3A에서 이중 밑줄로 표시됨), 그리고 CDRL1에는 한 개 리신이 존재한다 (도 3B에서 이중 밑줄로 표시됨). 이들 위치에서의 아미노산 치환을 조사하여 결합 친화력을 유지하는 치환을 확인하였다. CDRH2 (hMAB-A VH(3)에 존재)의 경우, 위치 62 (K62R)에서 아르기닌, 위치 64에서 글루카민 (K64Q), 그리고 위치 65에서 세린 (S65G)의 치환이 선택되었으며, 이때 상기 번호매김은 Kabat에 따른 번호매김이다. CDRL1 (hMAB-A VL(3)에 존재)의 경우 위치 24 (K24R)에서 아르기닌의 치환이 선택되었다. 식별된 치환들은 별도로 이용되거나, 또는 조합에 의해 이용될 수 있다.
CDRs에 존재하는 기타 잠재적 불안정한 잔기들이 식별되었고 (도 3A-3B에서 점선 밑줄로 표시됨), 이들은 CDRH1안의 위치 34에서 한 개 메티오닌 잔기 (M34), CDRL1 안의 위치 33에서 한 개 메티오닌 잔기 (M33), 그리고 CDRL3 안에 위치 92 (H93), 위치 93 (E93), 그리고 위치 94 (D94)에서 히스티딘, 글루타민 그리고 아스파르트산 잔기이며, 이때 상기 번호매김은 Kabat에 따른 번호매김이다. 이들 위치에서의 아미노산 치환을 조사하여 결합 친화력을 유지하는 치환을 확인하였다. CDRH1의 경우 위치 34(M34I)에서 이소류신의 치환이 선택되었으며, CDRL3의 경우 위치 33 (M33L), 위치 92 (H93Y), 위치 93 (E93S), 그리고 위치 94 (D94T)에서 류신, 티로신, 세린 및 트레오닌의 치환이 선택되었으며, 이때 번호매김은 Kabat에 따른 번호매김이다. 이러한 각 위치는 hMAB-A VH (4) 및 hMAB-A VL (4)를 생성하기 위해, 상기 설명된 모든 치환과 조합적으로 용이하게 치환될 수 있고, 이로 인하여 짝을 이룰 때 부계 뮤린 항체에 비해 친화략이 약간 개선된 항체를 생성하고, 탈아미드화 또는 산화 가능성이 크게 감소하고, CDRs에 리신 잔기가 없는 항체가 생성된다.
상기 인간화된/최적화된 항체 hMAB-A (1.1), hMAB-A (2.2), hMAB-A (2.3), hMAB-A (3.3), hMAB-A (4.4) 및 키메라 chMAB-A (뮤린 VH/VL 도메인을 갖는)의 huADAM에 대한 상대적 결합 친화력은 BIACORE® 분석을 이용하여 조사되었으며, 이때 His-테그된 가용성 인간 ADAM9 ("shADAM9-His", 히스티딘-함유하는 단백질에 융합된 인간 ADAM9의 세포외 부분을 함유)는 고정된 항체로 피복된 표면 위를 통과하였다. 간략하게 설명하자면, 각 항체를 Fab2 염소 항-인간 Fc 표면에 포획시킨 다음, shADAM9-His 단백질의 상이한 농도 (6.25-100 nM)의 존재 하에 항온처리하였다. 결합 역학은 BIACORE® 분석 결합을 통해 결정되었다 (정상화된 1:1 Langmuir 결합 모델). 이들 연구로부터 산출된 ka, kd 및 KD는 표 3에 제시된다. cynoADAM9에 대한 결합은 상기에서 기술된 바와 같이 FACS 및 ELISA에 의해 검사되었다.

이들 연구 결과는 상기 인간화된/최적화된 항체가 부계 뮤린 항체와 비교하여 인간 ADAM9에 동일한 또는 더 높은 결합 친화력을 갖는다는 것을 실증한다. 특히, N54F 돌연변이를 상기 인간화된 항체로 도입시키면 huADAM9 (이를 테면, hMAB-A(2.2), hMAB-A (2.3), 그리고 hMAB-A (3.3))에 대한 결합이 개선되었음이 관찰되었다. 이 돌연변이는 FACS 및 ELISA를 통하여 측정하였을 때, cynoADAM9에 대한 결합이 약간 개선되었지만, 그러나, 이들 항체는 cynoADAM9에 대한 결합은 여전히 불량하였다. 이들 연구에서는 친화력 감소 없이 CDRs로부터 리신 잔기를 제거하기 위해 도입될 수 있는 추가 치환을 또한 확인하였다. 친화력에는 최소한의 영향을 끼치면서, 기타 잠재적 불안정 잔기를 제거하는 추가 치환이 확인되었다.
실시예 4
비-인간 영장류 ADAM9에 대한 결합 최적화
무작위 돌연변이유발을 이용하여 hMAB-A (2.2)의 중쇄 CDRH2 (Kabat 위치 53-58)와 CDRH3 (Kabat 위치 95-100 및 100a-100f) 도메인 안에 치환을 도입시켰다. 비-인간 영장류 ADAM9 (이를 테면, cynoADAM9)에 대해 강화된 결합을 가지면서, huADAM9에 대한 높은 친화력 결합을 유지하는 클론을 식별하기 위해 상기 돌연변이체들을 스크리닝하였다. CDRH3 (Kabat 위치 100a-100f) 안에서 두 차례 독립적으로 돌연변이들의 스크린으로부터 48개 클론이 선택되었다. 두 차례 독립적인 스크린으로부터 cynoADAM9에 대한 강화된 결합에 대해 선별된 hMAB-A (2.2) 클론으로부터 CDRH3 Kabat 잔기들 100a-f의 아미노산 서열의 정렬을 표 4에서 제공한다. 표 5에서는 추가적인 클론 정렬을 제공한다. 이들 표에서 나타낸 것과 같이, 유사한 클론들이 각 실험에서 출현되었으며, 이들은 별개의 치환 패턴에 속하였다.


검사한 모든 클론에 대해, Gly 및 Ala는 위치 4 (P4)에서 선호되는 아미노산 잔기이며; Leu, Met 및 Phe는 위치 6 (P6)에서 선호되는 아미노산 잔기다. 다른 위치 (예를 들어, 위치 2 (P2), 위치 3 (P3) 및 위치 5 (P5))에서 선호되는 아미노산 잔기는 P1에서 발견되는 아미노산 잔기에 따라 달라진다. 위치 1 (P1)에 Pro 잔기를 갖는 클론의 경우, Lys 및 Arg는 P2에서 선호되었으며, Phe 및 Met는 P3에서 선호되었으며, Gly는 P4에서 선호되었으며, 그리고 Trp 또는 Phe는 P5에서 선호되었다. P1에 Phe, Tyr 또는 Trp를 갖는 클론의 경우, Asn 및 His는 P2에서 선호되었으며, Ser 및 His는 P3에서 선호되었으며, 그리고 Leu는 P6에서 선호되었다. P1에 Ile Leu 또는 Val을 갖는 클론의 경우, Gly는 P2에서 선호되었으며, Lys는 P3에서 선호되었으며, Val은 P5에서 선호되었으며, 그리고 소수성은 P6에서 선호되었다. 또한, 표 4에서 볼 수 있는 것과 같이, P1에서 Thr 잔기를 갖는 클론의 경우, Gly는 P2에서 선호되었으며, Lys, Met 및 Asn은 P3에서 선호되었으며, Gly는 P4에서 선호되었으며, Val 또는 Thr은 P5에서 선호되었으며, 그리고 Leu 및 Met는 P6에서 선호되었다. P1에 Asp, Gly, Arg, His 또는 Ser 잔기를 갖는 추가 클론들 또한 더 낮은 빈도로 확인되었다 (참고, 표 4 및 표5).
표 5에 표시된 10 개의 클론의 VH 도메인을 사용하여, hMAB-A (2A.2)-(2J.2)로 지정된 hMAB-A (2.2)의 추가 최적화된 변이체를 만들었다. 선택된 클론의 결합은 ELISA 검정에 의해 조사되었다. 간략하게 설명하자면, 히스티딘-함유하는 펩티드에 결합하고, 미량적정 플레이트 상에 피복시킨 항체를 이용하여, His 펩티드-테그된 가용성 cynoADAM9 ("cynoADAM9-His") (1μg/mL) 또는 His 펩티드-테그된 가용성 huADAM9 (1μg/mL)를 포획하였고, 그리고 부계 hMAB-A (2.2) 및 10개의 CDRH3 hMAB-A (2A.2) 변이체의 일련의 희석물의 결합을 검사하였다. cynoADAM9 및 huADAM9에 대한 결합 곡선은 도 4A 및 도 4B에서 제시된다. 선택된 각 VH 도메인을 포함하는 hMAB-A (2A.2) 변이체들은 cynoADAM9에 대해 개선된 결합을 나타내었고, MAB-A VH(2B), MAB-A VH(2C), MAB-A VH(2D), 그리고 MAB-A VH(2I)들은 cynoADAM9 결합에 있어서 최대의 강화를 보여주었지만, 한편 huADAM9에 대해서는 부계 hMAB-A (2.2) 항체와 유사한 결합을 유지하였다.
huADAM9-His 및 cynoADAM9-His에 대한 상기 인간화된/추가 최적화된 항체 MAB-A VH(2B.2), MAB-A VH(2C.2), MAB-A VH(2D.2), 그리고 MAB-A VH(2I.2), 그리고 부계 hMAB-A (2.2)들의 결합 친화력은 상기에서 기술된 바와 같이, 필수적으로 BIACORE® 분석을 이용하여 조사되었다. 이들 연구로부터 산출된 ka, kd 및 KD는 표 6에 제시된다.

상기 결합 연구로부터 4 개의 상위 클론이 한편으로 부계 항체와 동일한 높은 친화력 결합을 huADAM9에 유지하면서, cynoADAM9에 대한 결합 친화력은 150-550 배 향상되었음이 입증된다. hMAB-A (2C.2) 및 hMAB-A(2I.2)는 추가 연구를 위해 선택되었다.
실시예 5
항체 hMAB-A (2I.2)의 면역조직화학 연구
hMAB-A (2I.2)의 세포 특이성은 IHC에 의해 조사되었다. 양성 및 음성 대조군 세포, 그리고 정상 인간 및 시노몰구스 원숭이 조직에 hMAB-A (2I.2) (2.5μg/mL) 또는 아이소타입 대조군 (2.5μg/mL)을 접촉시켜기고, 착색 정도를 시각화하였다. 상기 연구의 결과는 표 7에 요약되어 있다.


또한 12.5μg/mL의 농도 (5x 최적 착색 농도)에서 인간화/최적화된 hMAB-A (2I.2)의 결합을 평가하기 위해, IHC 연구가 수행되었다. 양성 및 음성 대조군 세포, 그리고 정상 인간 및 시노몰구스 원숭이 조직이 본 연구에 이용되었다. 상기 연구의 결과는 표 8에 요약되어 있다.


2.5μg/mL 또는 5μg/mL에서 hMAB-A (2.2), hMAB-A (2.3), hMAB-A (2C.2), 그리고 hMAB-A (2I.2)에 의한 결합의 차이를 평가하기 위해 비교 IHC 연구를 실행하였다. 양성 및 음성 대조군 세포, 그리고 정상 인간 및 시노몰구스 원숭이 조직이 본 연구에 이용되었다. 상기 연구의 결과는 표 9에 요약되어 있다.


2.5μg/mL, 5μg/mL 또는 12.5μg/mL에서 hMAB-A (2.2), hMAB-A (2.3), hMAB-A (2C.2), 그리고 hMAB-A (2I.2) 및 뮤린 MAB-A에 의한 결합의 차이를 평가하기 위해 추가 비교 IHC 연구를 실행하였다. 양성 및 음성 대조군 세포, 그리고 정상 인간 및 시노몰구스 원숭이 조직이 본 연구에 이용되었다. 상기 연구의 결과는 표 10에 요약되어 있다.


따라서, 상기 결과로부터 최적 농도에서 hMAB-A (2.2)는 인간 간세포 및 신장 세관에서 전체적으로 낮은 수준의 착색을 나타내었으며, 음성 대조군에서 관찰된 간세포 및 신장 세관에서 낮은 착색 강도/반응 빈도를 나타냄이 실증되었다. 최적 농도의 hMAB-A (2.2)는 cyno 간세포 및 신장 세관에서 유사하게 낮은 수준의 착색을 나타냈으며, 음성 대조군에서 관찰된 신장 세관에서 낮은 착색 강도/반응 빈도를 나타냈다.
따라서, 상기 결과로부터 최적 농도에서 hMAB-A (2C.2)는 인간 간세포 및 신장 세관에서 전체적으로 낮은 수준의 착색을 나타내었으며, 음성 대조군에서 관찰된 간세포 및 신장 세관에서 낮은 착색 강도/반응 빈도를 나타 냈음이 실증되었다. 최적 농도의 hMAB-A (2C.2)는 cyno 간세포 및 신장 세관에서 유사하게 낮은 수준의 착색을 나타냈다. hMAB-A (2C.2)에 대한 cyno 폐 상피, 췌장 섬/상피 및 방광 상피에서 추가적인 최소 발견은 해당 인간 조직에서 관찰되지 않았고; 낮은 착색 강도/반응 빈도는 음성 대조군에서 폐 상피, 신장 세관, 방광 상피에서 관찰되었다. 상기 결과에서 또한, 최적 농도의 hMAB-A (2I.2)는 인간 또는 cyno 조직에서 착색을 나타내지 않았는데, 방광 이행 세포 상피 착색은 드문 +/-을 나타낸다. 5 배 최적 농도에서 hMAB-A (2I.2)는 또한 인간 폐 폐포 세포, 췌장 관 상피, 신장 세관, 방광 이행 세포 상피에서 전체적으로 낮은 수준 및 빈도 착색을 나타냈으며, cyno 기관지 상피 및 방광 이행에서 전반적으로 낮은 수준의 착색을 나타냈다. hMAB-A (2I.2)는 시험된 인간 정상 조직에서 전반적으로 유리한 IHC 프로파일을 나타내고, 상응하는 시노몰구스 원숭이 조직에서 유사한 프로파일을 나타낸다.
실시예 6
변이체 Fc 영역을 포함하는 hMAB-A (2I.2)
hMAB-A(2I.2)는 카파 경쇄 불변 영역을 갖는 경쇄 (서열 식별 번호:68) 및 야생형 IgG 중쇄 불변 영역을 갖는 중쇄 (서열 식별 번호:52)를 포함한다. Fc 영역에 다음 치환을 도입하기 위해, Fc 변이체를 만들었다: L234A/L235A (이를 테면, 서열 식별 번호:78) -hMAB-A (2I.2)(AA)로 지칭됨; S442C (이를 테면, 서열 식별 번호:79) -hMAB-A (2I.2)(C)로 지칭됨; 그리고 L234A/L235A/S442C (이를 테면, 서열 식별 번호:80) -hMAB-A (2I.2)(AA/C)로 지칭됨. huADAM9-His 및 cynoADAM9-His에 대한 각 Fc 변이체의 결합을 ELISA 검정으로 조사하였다. 간략하게 설명하자면, 히스티딘-함유하는 펩티드에 결합하고, 미량적정 플레이트 상에 피복시킨 항체를 이용하여, His 펩티드-테그된 가용성 cynoADAM9 또는 His 펩티드-테그된 가용성 huADAM9 (0.5μg/mL)를 포획하였고, 그리고 부계 hMAB-A (2.2) 및 Fc 변이체들의 일련의 희석물의 결합을 검사하였다. huADAM9 및 cynoADAM9에 대한 결합 곡선은 도 5A 및 도 5B에 차례로 제시되며, 상기 각 Fc 변이체는 야생형 Fc 영역을 갖는 hMAB-A(2I.2)의 결합 친화력을 유지고 있음을 보여준다.
실시예 7
표적 발현 분석
다양한 징후에 걸쳐 ADAM9 발현을 평가하기 위해, 예비 연구용으로 ImmunoGen에서 개발한 ADAM9 IHC 분석을 사용하여 20 가지 상이한 종양 유형을 가진 조직 마이크로 어레이 (TMA)를 우선 평가했다.
분석된 모든 샘플은 FFPE (포르말린 고정된 & 파라핀 매립된) 샘플이다. 500개 코어 20 암종 TMA는 Folio Biosciences(Cat# ARY-HH0212)에서 구입했다. 선암종에 대한 80개의 코어와 편평세포 암종에 대한 80개 코어가 있는 NSCLC TMA는 US Biomax (Cat # LC1921A)에서 구입했다. 선암종에 대한 80개 코어와 함께 결장직장암 암 TMA는 Pantomics Inc에서 구입했다. (Cat# COC1261). 위암 샘플은 Avaden Biosciences에서 구입했다.
ADAM9에 대한 면역조직화학 착색은 Ventana Discovery Ultra 자동착색기를 사용하여 수행되었다. ADAM9에 대한 원발성 항체는 시판되는 토끼 단일클론 항체다. 모든 샘플은 채점 방식(scoring algorithm)으로 면허를 갖고 있는 병리학자들에 의해 평가 및 채점되었다. 채점을 위해 적어도 100 개의 생존가능한 종양 세포가 필요했다. 착색 강도는 0에서 3까지의 반-정량적 정수 척도로 점수를 매겼으며, 0은 착색 없음, 1은 약한 착색, 2는 보통 착색, 3은 강한 착색을 나타낸다. 각 강도 수준에서 양성으로 착색된 세포의 백분율을 기록했다. 점수는 Adam9의 세포 막에만 국한된 것, 뿐만 아니라 세포질과 막 모두에 대한 국소화 평가를 기반으로 했다. 착색 결과는 H 점수로 분석되었고, 이는 착색 강도의 구성 요소와 양성 세포의 비율과 결합된다. 이 결과는 0에서 300 사이의 값을 가지며, 다음과 같이 정의된다:
1 * (1+ 강도에서의 세포 착색 백분율)
+ 2 * (2+ 강도에서의 세포 착색 백분율)
+ 3 * (3+ 강도에서의 세포 착색 백분율)
= H 점수.
각 종양 유형에 대해 5 개의 정상 조직 대조군과 함께, 500 개의 코어 20 암종 TMA를 착색시키고, 두 가지 다른 방식으로 점수를 매겼다: (1) 오로지 막 착색 단독, 또는 (2) 막 및 세포질 염색을 기반. 아래 표 11 및 도 6A는 20 가지 징후 모두에 대한 막 착 색에 기초한 ADAM9의 유병률을 요약하고, 표 12 및 도 6B는 8 개의 선택된 징후에 대한 막 및 세포질 염색의 결과를 요약한다.
다수의 암종 TMA의 결과를 기반으로, 확장된 유병률 분석에 대한 세 가지 징후가 선택되었다: 비-소 세포 폐암 (NSCLC), 결장 직장암 (CRC) 및 위암. NSCLC의 경우, 선암종에 대한 80 개의 코어와 편평 세포 암종에 대한 80 개의 코어를 갖는 하나의 TMA를 착색하고, 평가했다. CRC의 경우, 선암종에 대한 80 개의 코어를 갖는 하나의 TMA가 분석되었으며, 이 중 78 개가 평가가능했다. 위암의 경우, 선암종의 15 개 전체 조직 절편을 분석했다. 이들 샘플 모두에 대해 막 및 세포질 착색에 대한 점수를 매겼으며, 결과는 표 13에 요약되어 있다. 이러한 예비 연구의 결과로부터 ADAM9가 광범위한 고형암에서 발현되고, ADAM9-발현시키는 다양한 고형 종양에서 항-ADAM9 약물 콘쥬게이트의 사용이 뒷받침된다는 것을 보여준다.



실시예 8
항-ADAM9 항체 내화 연구
본 발명의 항-ADAM9 항체의 내화를 평가하기 위해, Alexa Fluor 488에 콘쥬게이트된 hMAB-A (2.2), hMAB-A (2I.2) 및 hMAB-A (2I.2)-S442C에서 유동세포측정-기반 내화 실험을 수행했다.
hMAB-A(2.2), hMAB-A(2I.2), hMAB-A(2I.2)-S442C에 대한 항-ADAM9 Alexa488 항체 콘쥬게이트는 제조업자 (Thermofisher)의 지침에 따라 Alexa Fluor 488 tetra플루오르페닐 에스테르를 이용하여 만들었다. 상기 콘쥬게이트는 내화 분석을 가능하도록 아지드화 나트륨이 없는 PBS, pH 7.2에서 용리되었다. 라벨링 농도 및 정도는 280 nm 및 494 nm에서의 흡수 측정으로부터 계산되었다. Alexa488-라벨링이 표적 결합에 악영향을 미치지 않음을 확인하기 위해 FACS 결합 분석을 수행했다.
항-ADAM9-Alexa488 콘쥬게이트의 내화는 형광 콘쥬게이트에 대한 연속 모출 및 펄스 노출 모두에 따라 결정되었다. 연속 실험을 위해, NCI-H1703 세포를 표시된 Alexa488-라벨된 항체의 포화 농도로 얼음 상에서, 또는 표시된 전체 시간 동안 37℃에서 처리했다. 한편 펄스 실험의 경우, 항-ADAM9-Alexa488 콘쥬게이트는 얼음 상에서 세포에 사전-결합되었고, 과량의 콘쥬게이트는 씻어낸 후, 37℃로 변이시키고, 내화를 모니터링하였다. 연속 또는 펄스 노출 후, 지정된 시점에서 세포를 베르센(versene) (Thermofisher)으로 들어 올리고, 얼음-냉각시킨 PBS로 두 차례 세척하고, 복제 웰을 얼음-냉각시킨 PBS에 재현탁하거나 (소거되지 않은 샘플) 또는 300nM의 항-A488 항체 (소거된 샘플)로 재현탁했다. 모든 샘플은 얼음에서 30m 동안 항온처리되었다. 그런 다음, 세포를 펠릿화하고, 1% 파라포름알데히드에 고정하고, 유동세포측정 분석으로 분석했다. 얼음에서 30 분 동안 항온처리한 다음, 항-Alexa488 항체와 함께 항온처리된 세포의 형광은 비-소거성(unquenchable) 형광 분획을 나타내며, 내화 산출에 앞서 다른 모든 샘플로부터 차감시켰다. 내화 백분율은 불완전한 표면 소거 (세포내 형광)에 대해 보정된 소거된 샘플의 형광을 소거되지 않은 세포의 형광 (총 형광)으로 나눈 값으로 산출되었다. 항-ADAM9 항체 콘쥬게이트의 내화를 그래프로 만들고, 데이터를 단상(singlephase) 지수적괴 방정식 (GraphPad Prism, ver. 5.01)을 사용하여 피팅했다.
표면 결합 Alexa488-라벨된 항-ADAM9 항체의 내화는 NCI-H1703 세포에서 펄스 및 연속 처리 후 평가되었다. 테스트된 항-ADAM9-Alexa488 콘쥬게이트 3 개 모두다 빠른 내화를 보였으며, 콘쥬게이트의 ~39%는 처음 15 분 안에 내화되었고, 6 시간 후 총 ~77%가 내화되었다 (도 7A). 흥미롭게도, 24 시간 연속 노출 후, 내화된 형광 신호는 30 분 후 세포 표면에 결합된 초기 전체 형광 신호보다 ~7 배 더 컸다 (도 7B). 따라서, ADAM9은 37℃에서 항온처리하는 동안 세포내 모둠(pool)에서 세포 표면에 보충될 가능성이 높으므로, 항-ADAM9 항체 콘쥬게이트의 여러 라운드의 내화가 허용된다. 항-ADAM9 면역콘쥬게이트의 효능은 당해 면역콘쥬게이트의 내화, 세포내 트래피킹(trafficking) 및 분해에 의존적이다. 항-ADAM9 면역콘쥬게이트의 효능은 부분적으로 항 -ADAM9 면역콘쥬게이트의 높은 내화에 의해 설명될 수 있으며, 이는 다량의 세포독성 분해대사산물의 생성으로 이어질 것 같다.
실시예 9
항-ADAM9 항체 세포 프로세싱 연구
chMAB-A의 세포-상 표적 결합, 흡수 및 리소좀 분해를 평가하기 위해, 이미-설명된 3H-프로피온아미드-라벨된 항체 프로세싱 방법을 사용했다(Lai et al., Pharm Res. 2015 Nov; 32(11):3593-603). 이 방법을 사용하여, ADAM9-표적화 chMAB-A 항체를 리신 잔기를 통해 삼중수소화된 프로피오네이트로 흔적(trace) 라벨하였다. 세포 결합, 취입 및 리소좀으로의 트래피킹시 [3H]프로피오 네이트-라벨된-Ab (3H-Ab)가 분해되고, 리신-[3H]프로피온아미드가 세포 성장 배지로 방출되는 것은 이미 밝혀졌다. 유기 용매를 첨가하면, 무손상 라벨된 항체가 침전되고, 리신-[3H]프로피노아미드가 용액에 남게 되어, 항체 처리 범위를 편리하고 정확하게 측정할 수 있다.
chMAB-A는 이미 설명된 바와 같이 [3H]-프로피오네이트로 라벨되었다. NSCLC 계통, NCI-H1703, 그리고 CRC 계통, DLD-1은 10 nM 3H-chMAB-A 항체로 처리하였고, 결합 곡선을 통하여 항원 포화를 결정하였다. 일부 세포 샘플 은 비-표적화된, 삼중수소화된 아이소타입 대조군 항체, 3H-chKTI로 처리되었고, 한편 다른 것들은 처리되지 않았다. 세포를 6-웰 플레이트에서 플레이팅시키고, 하룻밤 동안 성장시킨 다음, 이미 설명한 바와 같이, 시약(들)으로 펄스 처리했다. 간단히 말해서, 세포를 3H-chMAB-A 항체 또는 3H-chKTI와 함께 20 분 동안 항온처리한 후, 새로운 배지에서 3 회 세척했다. 세포를 5% CO2와 함께 37℃에서 하룻밤 동안 항온처리하였다. 20-24 시간 항온처리 후, 세포를 수거하였고, 단백질을 4:3 부피의 아세톤:배지/세포 혼합물로 침전시켰다. 샘플을 해동 및 원심 분리기로 분리하기 전, 최소 1 시간 동안 -80℃에서 냉동시켰다. TriCarb 액체 섬광 계수기 (LSC)에서 5 분 동안 계수하기 전, 펠렛을 처리하여 단백질을 용해시켰다. 제조업체의 프로토콜에 따라, 1mL의 SOLVABLE (Perkin Elmer)을 각 펠릿 샘플에 첨가하고, 50℃ 수조에서 밤새 항온처리했다. 샘플을 수조에서 제거하고, 20 mL 유리 섬광 바이알로 옮기고, EDTA 및 H2O2를 샘플에 첨가한 다음, 추가 1 시간 50℃에서 항온처리했다. 샘플을 HCl로 소거시키고, 15 mL의 Optima Gold 액체 섬광 유체 (Perkin Elmer)를 첨가하고, 샘플을 완전하게 와류시켰다. LSC로 계수하기 전, 샘플을 최소 4 시간 동안 어둠 속에 방치하였다. 단백질-없는 아세톤 추출물 샘플을 진공 하에서 <1 mL 부피로 건조시키고, LSC 실행 전, 위에서 설명한대로 Solvable을 사용하여 처리했다. 결합된, 분해된 및 무손상 라벨된 항체의 양은 결과 샘플 CPM 값으로부터 산출되었다.
3H-chMAB-A 항체의 프로세싱 수준은 펄스 처리 및 37℃에서 하룻밤 동안 항온처리 후 결정되었다 NCI-H1703 세포에서는 3H-chMAB-A의 93가 24 시간 이내에 프로세싱되었고, 그리고 DLD-1 세포에서는 동일한 기간 동안 3H-chMAB-A의 92%가 프로세싱됨을 보여주었다. 3H-chKTI의 결합 및 프로세싱은 무시할 수준이었다 (표적화된 항체의 경우보다 총 CPM에서 >100-배 더 낮다). 특히 본 발명의 항-ADAM9 항체가 효과적인 약물 콘쥬게이트임을 뒷받침하는 다른 ADC 표적/항체에 대한 이전 보고된 24 시간 펄스 처리 값과 비교할 때, 이들 세포주에 대한 프로세싱 값은 높다.
실시예 10.
본 발명의 메이탄시노이드 유도체들의 합성
실시예 10a. DM-H (7) 원액 준비

메이탄시놀 (5.0g, 8.85mmol)을 무수 DMF (125mL)에 용해시킨 다음, 얼음조에서 냉각시켰다. N-메틸 알라닌의 N-카르복시 무수물 (5.7g, 44.25mmol), 무수 DIPEA (7.70mL, 44.25mmol) 및 아연 트리플루오로메탄 설포네이트 (22.5g, 62mmol)을 아르곤 대기 하에서 자석 교반하면서 첨가하였다. 얼음조를 제거하고, 반응물을 교반시키면서 데워지도록 하였다. 16 시간 후, 탈-이온수 (10 mL)를 첨가하였다. 30 분 후, 포화된 수성 중탄산나트륨:포화 수성 염화나트륨 (190mL)의 1:1 용액과 에틸 아세테이트 (250mL)을 격렬하게 교반하면서, 첨가하였다. 혼합물을 분별 깔때기로 옮기고, 유기 층은 유지시켰다. 수성 층을 에틸 아세테이트 (100 mL)로 추출한 다음, 유기 층에 복합시키고, 포화 수성 염화나트륨 (50 mL)으로 세척 하였다. 유기층은 증발조를 가열하지 않고, 진공 하에서 회전 증발에 의해 대략적으로 1/4의 부피로 농축되었고, 정제는 수행되지 않았다. 이 용액의 농도는 반응에 사용된 메이탄시놀의 mmoles(1.77 mmol)을 부피 (150 mL)로 나누어, DM-H 원액 (0.06 mmol/ml)을 제공함으로써 추정되었다. 상기 원액의 분취액은 즉시 분배된 후 반응에 사용되거나, 또는 -80 C 냉동고에 보관한 다음, 필요할 때 해동시켰다.
실시예 10b. 티오-펩티드-메이탄시노이드의 합성
1.
FMoc-펩티드-NH-CH
2
-OAc 화합물들 (화합물 9a-j)
FMoc-L-Ala-D-Ala-L-Ala-NH-CH
2
-OAc(9c)의 합성

단계 1: FMoc-L-Ala-D-Ala-OtBu (3c):
FMoc-L-알라닌 (10g, 32.1 mmol) 및 D-Ala-OtBu, HCl (7.00 g, 38.5 mmol)은 CH2Cl2 (100 ml)에 용해시키고, COMU (20.63 g, 48.2 mmol) 및 DIPEA (11.22 ml, 64.2 mmol)로 처리하였다. 반응은 실온에서 아르곤 하에 진행시켰다. 2 시간 후, 반응은 UPLC에 의해 완료되었음이 확인되었으며, 2-MeTHF (50ml)로 희석하고 10% 수성 시트르산 (2x100mL), 물 (100mL), 염수 (100mL)로 세척하였다. 유기층을 황산 마그네슘상에서 건조시키고, 여과하고 농축하여, 미정제 FMoc-L-Ala-D-Ala-OtBu (100% 추정 수율)를 얻었다.
단계 2: FMoc-E-Ala-D-Ala (4c)
FMoc-LAla-DAla-OtBu (11.25g, 25.7 mmol)은 TFA:물 (95:5) (50ml)로 처리하였다. 반응을 아르곤 대기 하에 실온에서 진행시켰다. 4 시간 후, 반응은 UPLC에 의해 완료되었음이 확인되었으며, 톨루엔 (25mL)으로 희석하고, 3x 공동-증발시켜, FMoc-L-Ala-D-Ala를 수득하였다(100% 추정 수율).
단계 3: FMoc-E-Ala-Gly-OtBu
(5c)
Z-L-Ala-ONHS (10 g, 31.2 mmol) 및 tert-부틸 글리시네이트, (6.28 g, 37.5 mmol)는 CH2Cl2 (100 ml)에 용해시키고, DIPEA (10.91 ml, 62.4 mmol)로 처리하였다. 반응은 실온에서 아르곤 하에 진행시켰다. 2 시간 후, UPLC에서 반응 완료를 확인하였고, 반응물을 2-MeTHF (50mL)로 희석하고, 10% 수성 시트르산(100mL), 포화 중탄산 나트륨 (2x100mL), 물 (100mL), 염수 (100mL)로 세척했다. 유기층을 황산 마그네슘으로 건조시키고, 여과하고 농축하여, Z-L-Ala-Gly-OtBu (수율 100%로 추정)를 얻었다.
단계 4. L-Ala-Gly-OtBu
(6c)
Z-Ala-Gly-OtBu (10.05 g, 29.9 mmol)를 95:5 MeOH:물 (50ml)에 용해시키고, 수소화 플라스크로 옮기고, Pd/C (1.272g, 11.95mmol)로 처리했다. 수소화 플라스크를 진탕기에 놓고, 플라스크를 흔들면서 진공으로 공기를 제거했다. 30psi까지 수소가 채워진 플라스크를 2 분 동안 교반시키고, 진공을 이용하여 수소를 제거했다. 이 과정은 2 번 더 반복되었다. 수소를 플라스크에 30psi로 채우고, 교반되도록 두었다. 4 시간 후, UPLC에서 반응 완료를 확인하였고, 반응을 셀라이트 플러그를 통해 진공 상태로 여과하고, 2-MeTHF에 재용해하고 농축시켜, LAla-Gly-OtBu를 산출(100% 추정 수율)하였다.
단계 5: FMoc-L-Ala-D-Ala-L-Ala-Gly-OtBu (
7c
)
FMoc-LAla-D-ALa-OH (0.959 g, 2.508 mmol) 및 L-Ala-Gly-OtBu (0.718 g, 3.01 mmol)는 CH2Cl2 (10 ml)에 용해시키고, COMU (1.181 g, 2.76 mmol) 및 DIPEA (0.876 ml, 5.02 mmol)로 처리하였다. 반응은 실온에서 아르곤 하에 진행시켰다. 2 시간 후, 반응이 완료되었다. 반응물l 농축하여 CH2C12를 제거하고, 2mL DMF에 재용해하고, 선형 구배를 사용하여 C18 combiflash로 정제하고, 생성물을 복합하여 FMoc-L-Ala-D-Ala-L-Ala-Gly-OtBu를 얻었다(660mg, 46% 수율).
단계 6. FMoc-L-Ala-D-Ala-L-Ala-Gly-OH (
8c)
FMoc-LAla-DAla-LAla-GlyOtBu (200mg, 0.353 mmol)는 TFA: 물 (95:5) (2 ml)로 처리하였다. 반응은 실온에서 아르곤 하에 진행시켰다. 1 시간 후, UPLC를 통하여 반응이 완료됨을 확인하였다. 미정제 생성물을 톨루엔 (1mL)으로 희석하고, 톨루엔과 2x 공 증발시켜 FMoc-L-Ala-D-Ala-L-Ala-Gly-OH를 얻었다(100% 수율 추정).
단계 7. FMoc-L-Ala-D-Ala-L-Ala-CFF-OAc ( 9c )
FMoc-L-Ala-D-Ala-L-Ala-Gly-OH (2.65 g, 5.19 mmol)를 DMF (20mL)에 용해시키고, 아세테이트 구리 (II) (0.094 g, 0.519 mmol) 및 아세트산 (0.446 ml, 7.79 mmol)으로 처리하고, 일단 모든 시약에 용해되면, 반응물은 테트라아세테이트 납(3.45 g, 7.785 mmol)으로 처리하였다. 반응을 아르곤 하에 60℃에서 30 분 동안 진행시켰다. 미정제 반응물은 구배 (시간-분, 아세토니트릴 백분율) (0,5) (8,50) (26, 55)를 사용하여 용매로서 0.1% 포름산 및 아세토니트릴을 함유하는 탈-이온수와 함께, 125mL/min의 유속으로 C18 450g 컬럼을 사용하여 Combiflash Rf 200i를 통해 정제시켰다. 원하는 산물은 11 분의 정체 시간(retention time)을 갖고, 산물 분획을 즉시 동결 및 동결 건조시켜, FMoc-L-Ala-D-Ala-L-Ala-CH2-OAc (843mg, 1.607 mmol, 31.0% 수율)을 수득하였다. HRMS (M+Na)+ 산출값 547.2163, 수득값 547.2167. 1H NMR (400 MHz, DMSO-d6) δ 1.23 (dd, J = 12.5, 7.4 Hz, 9H), 1.95 (s, 2H), 4.00 - 4.13 (m, 1H), 4.17 - 4.38 (m, 6H), 5.06 (q, J = 8.8 Hz, 2H), 7.33 (t, J = 7.3 Hz, 2H), 7.42 (t, J = 7.4 Hz, 2H), 7.62 (d, J = 6.8 Hz, 1H), 7.71 (t, J = 8.6 Hz, 2H), 7.85 - 8.01 (m, 3H), 8.21 (d, J = 7.0 Hz, 1H), 8.69 (d, J = 6.9 Hz, 1H).
FMoc-펩티드-NH-CH2-OAc 유형의 다음 화합물들은 도 9A에 나타낸 것과 같이 준비하였고, 그리고 상기 FMoc-L-Ala-D-Ala-L-Ala-NH-CH2-OAc (9c)로 구체예화되었다.
FMoc-L-Ala-L-Ala-L-Ala-NH-CH 2 -OAc (9a): FMoc-L-Ala-L-Ala-L-Ala-Gly-OH (서열 식별 번호:163) (500 mg, 0.979 mmol)은 DMF (2 mL)에 용해시켰으며, 여기에 아세테이트 구리 (II) (17.8 mg, 0.098 mmol) 및 아세트산 (84 μL, 1.47 mmol)를 아르곤 하에서 자석 교반시키면서 추가하였다. 일단 고체들이 용해되었다면, 테트라아세테이트 납 (434 mg, 0.979 mmol)을 추가하였고, 반응물은 60℃에서 20 분 동안 진행되도록 두고, 그 다음 C18, 30 미크론 450 g 컬럼 카트릿지 상에서 0.1% 포름산을 함유하는 탈이온 수로 용리시키고, 125 mL/분의 유속으로 26분에 걸쳐 5% 내지 55%의 선형 아세토니트릴 구배를 이용하여 정제시켰다. 순수한 원하는 산물이 함유된 분획을 냉동 및 동결건조시켜, 백색 고체 178 mg (34% 수율)를 얻었다. HRMS (M + Na)+ 산출값. 547.2163; 수득값 547.2160. 1H NMR (400 MHz, DMSO-d6) δ 1.20 (qd, J = 7.5, 6.9, 4.2 Hz, 9H), 1.91 - 2.05 (m, 3H), 3.26 - 3.38 (m, 1H), 4.05 (q, J = 7.3 Hz, 1H), 4.23 (td, J = 11.9, 10.7, 6.4 Hz, 5H), 5.07(ddd, J = 11.2, 6.9, 4.3 Hz, 2H), 7.32 (q, J = 7.5 Hz, 2H), 7.41 (q, J = 7.4 Hz, 2H), 7.52 (t, J = 6.8 Hz, 1H), 7.71 (q, J = 7.5, 7.0 Hz, 2H), 7.82 - 8.08 (m, 4H), 8.84 (q, J = 7.1 Hz, 1H).
FMoc-D-Ala-L-Ala-L-Ala-NH-CH 2 -OAc (9b): HRMS (M+Na)+ 산출값. 547.2163, 수득값 547.2167. 1H NMR (400 MHz, DMSO-d6) δ 1.23 (dd, J = 12.5, 7.4 Hz, 9H), 1.95 (s, 2H), 4.00 - 4.13 (m, 1H), 4.17 - 4.38 (m, 6H), 5.06 (q, J = 8.8 Hz, 2H), 7.33 (t, J = 7.3 Hz, 2H), 7.42 (t, J = 7.4 Hz, 2H), 7.62 (d, J = 6.8 Hz, 1H), 7.71 (t, J = 8.6 Hz, 2H), 7.85 - 8.01 (m, 3H), 8.21 (d, J = 7.0 Hz, 1H), 8.69 (d, J = 6.9 Hz, 1H).
FMoc-L-Ala-L-Ala-D-Ala-NH-CH 2 -OAc (9d): HRMS (M+Na)+ 산출값. 547.2163, 수득값 547.2167. 1H NMR (400 MHz, DMSO-d6) δ 1.18 - 1.25 (m, 9H), 1.97 (s, 3H), 3.96 - 4.15 (m, 1H), 4.17 - 4.36 (m, 5H), 5.09 (d, J = 6.9 Hz, 2H), 7.34 (t, J = 7.4 Hz, 2H), 7.42 (t, J = 7.4 Hz, 2H), 7.57 (d, J = 7.2 Hz, 1H), 7.71 (d, J = 7.3 Hz, 2H), 7.90 (d, J = 7.5 Hz, 2H), 8.07 (s, 2H), 8.86 (s, 1H).
FMoc-L-Ala-D-Ala-NH-CH 2 -OAc (9f): HRMS (M+Na)+ 산출값. 476.1792, 수득값 476.1786.1H NMR (400 MHz, DMSO-d6) δ 1.13 (dd, J = 7.1, 1.4 Hz, 6H), 1.89 (s, 3H), 3.99 (q, J = 7.1 Hz, 1H), 4.10 - 4.29 (m, 4H), 4.95 - 5.08 (m, 2H), 7.26 (t, J = 7.4, 1.3 Hz, 2H), 7.35 (t, J = 7.4 Hz, 2H), 7.49 (d, J = 7.2 Hz, 1H), 7.66 (t, J = 7.6 Hz, 2H), 7.82 (d, J = 7.5 Hz, 2H), 8.11 (d, J = 7.7 Hz, 1H), 8.76 (t, J = 7.0 Hz, 1H).
FMoc-D-Ala-L-Ala-NH-CH 2 -OAc (9g): HRMS (M+Na)+ 산출값. 476.1792, 수득값 476.1788. 1H NMR (400 MHz, DMSO-d6) δ 1.21 (dd, J = 7.1, 1.4 Hz, 6H), 1.96 (s, 3H), 4.08 (t, J = 7.1 Hz, 1H), 4.17 - 4.36 (m, 4H), 5.05 - 5.14 (m, 2H), 7.26 - 7.38 (m, 2H), 7.42 (t, J = 7.4 Hz, 2H), 7.56 (d, J = 7.3 Hz, 1H), 7.73 (t, J = 7.6 Hz, 2H), 7.90 (d, J = 7.6 Hz, 2H), 8.18 (d, J = 7.8 Hz, 1H), 8.83 (t, J = 6.9 Hz, 1H).
FMoc-D-Ala-D-Ala-NH-CH 2 -OAc (9h): HRMS (M+H)+ 산출값. 455.4877, 수득값 455.2051 1H NMR (400 MHz, DMSO-d6) δ 1.14 (dd, J = 7.1, 3.3 Hz, 6H), 1.21 (d, J = 7.2 Hz, 1H), 1.81 (s, 1H), 1.91 (s, 2H), 4.01 (q, J = 7.7 Hz, 1H), 4.09 - 4.27 (m, 5H), 4.95 - 5.10 (m, 1H), 7.26 (td, J = 7.4, 1.2 Hz, 3H), 7.35 (t, J = 7.4 Hz, 3H), 7.45 (d, J = 7.6 Hz, 1H), 7.65 (t, J = 7.1 Hz, 3H), 7.82 (d, J = 6.4 Hz, 2H), 7.96 (d, J = 7.4 Hz, 1H), 8.78 (t, J = 7.0 Hz, 1H).
2.
FMoc-펩티드-COOH 화합물들 (화합물 10a-10j)
FMoc-펩티드-NH-CH2-S-(CH2)n-CO2H 유형의 화합물들은 도 9A에 나타낸 것과 같이 준비하였고, 그리고 FMoc-L-Ala-L-Ala-L-Ala-NH-CH2-S-(CH 2 )5-CO2H로 구체예화되었다.
FMoc-L-Ala-L-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO 2 H (10a): 6-멀캅토헥사논산 (287 μL, 2.07 mmol)은 1:4 TFA: 디클로로메탄 (5 mL) 용액에 용해시켰고, 그 다음 함유하는 FMoc-L-Ala-L-Ala-L-Ala-NH-CH2-OAc (178 mg, 0.339 mmol)을 함유하고 있는 바이알에 추가하였다. 반응을 아르곤 대기 하에서 실온에서 20 분 동안 자기 교반하면서 진행시켰다. 미정제 재료를 진공에서 농축시켜 최소 부피의 DMF에 재용해시키고, C18 30 마이크론, 30g 카트리지에서 0.1% 포름산을 함유하는 탈이온수로 용리시키고, 13 분에 걸쳐 35 mL/분의 유속으로 5%에서 95%까지의 아세토니트릴의 선형 구배로 용리시켜, 정제하였다. 순수한 원하는 산물이 함유된 분획을 냉동 및 동결건조시켜, 백색 고체 200 mg (96% 수율)를 얻었다. HRMS (M + H)+ 산출값. 613.2690; 수득값 613.2686. 1H NMR (400 MHz, DMSO-d6) δ 1.20 (dt, J = 7.1, 4.9 Hz, 10H), 1.31 (tt, J = 10.1, 6.0 Hz, 2H), 1.49 (dq, J = 12.5, 7.4 Hz, 4H), 2.18 (t, J = 7.3 Hz, 2H),4.05 (t, J = 7.3 Hz, 1H), 4.16 - 4.30 (m, 7H), 7.33 (td, J = 7.4, 1.2 Hz, 2H), 7.42 (td, J = 7.3, 1.1 Hz, 2H), 7.54 (d, J = 7.4 Hz, 1H), 7.72 (t, J = 7.0 Hz, 2H), 7.89 (d, J = 7.5 Hz, 2H), 7.94 - 8.07 (m, 2H), 8.44 (t, J = 6.1 Hz, 1H).
FMoc-D-Ala-L-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO 2 H (10b): HRMS (M+Na)+ 산출값 635.2510, 수득값 635.2515. 1H NMR (400 MHz, DMSO-d6) δ 1.15 (d, J = 6.8 Hz, 3H), 1.18 - 1.25 (m, 10H), 2.18 (q, J = 7.5 Hz, 4H), 2.40 - 2.48 (m, 1H), 2.70 (t, J = 7.2 Hz, 1H), 4.15 - 4.30 (m, 6H), 6.29 (s, 2H), 7.34 (q, J = 7.3 Hz, 3H), 7.42 (t, J = 7.4 Hz, 3H), 7.63 - 7.78 (m, 1H), 7.85 (d, J = 7.3 Hz, 2H), 7.89 (d, J = 7.5 Hz, 3H), 8.37 - 8.46 (m, 1H).
FMoc-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO 2 H (10c): HRMS (M+Na)+ 산출값 635.2510, 수득값 635.2514. 1H NMR (400 MHz, DMSO-d6) δ 1.18 - 1.23 (m, 10H), 1.34 (q, J = 3.4 Hz, 5H), 2.24 (s, 2H), 2.44 (s, 2H), 4.05 (t, J = 7.1 Hz, 1H), 4.16 - 4.35 (m, 8H), 7.33 (t, J = 7.4 Hz, 2H), 7.42 (t, J = 7.5 Hz, 2H), 7.58 (d, J = 7.0 Hz, 1H), 7.71 (t, J = 8.4 Hz, 2H), 7.90 (s, 1H), 7.98 (d, J = 7.5 Hz, 1H), 8.15 (d, J = 7.3 Hz, 1H), 8.39 (t, J = 6.2 Hz, 1H), 11.98 (s, 1H).
FMoc-L-Ala-L-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO 2 H (10d): HRMS (M+Na)+ 산출값 635.2510, 수득값 635.2510. 1H NMR (400 MHz, DMSO-d6) δ 1.15 (d, J = 6.9 Hz, 3H), 1.21 (d, J = 7.1 Hz, 9H), 1.28 - 1.38 (m, 3H), 1.44 - 1.60 (m, 5H), 2.13 - 2.22 (m, 3H), 3.33 (q, J = 6.9 Hz, 1H), 4.20 (s, 2H), 6.29 (s, 2H), 7.29 - 7.40 (m, 3H), 7.38 - 7.47 (m, 3H), 7.85 (d, J = 7.5 Hz, 2H), 7.89 (d, J = 7.5 Hz, 2H), 8.26 (d, J = 7.6 Hz, 1H), 8.48 (d, J = 6.2 Hz, 1H).
FMoc-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO 2 H (10g): HRMS (M+H)+ 산출값 542.2319, 수득값 542.2316. 1H NMR (400 MHz, DMSO-d6) δ 1.13 (dd, J = 7.1, 1.7 Hz, 6H), 1.16 - 1.25 (m, 2H), 1.32 - 1.47 (m, 4H), 2.08 (t, J = 7.3 Hz, 2H), 3.25 (s, 2H), 3.99 (p, J = 7.0 Hz, 1H), 4.07 - 4.27 (m, 6H), 7.26 (t, J = 7.4, 1.2 Hz, 2H), 7.35 (t, J = 7.4 Hz, 2H), 7.52 (d, J = 7.0 Hz, 1H), 7.65 (t, J = 7.3 Hz, 2H), 7.82 (d, J = 7.5 Hz, 2H), 8.08 (d, J = 7.7 Hz, 1H), 8.27 (t, J = 6.2 Hz, 1H), 11.82 (s, 1H).
FMoc-L-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO 2 H (10f): HRMS (M+H)+ 산출값 542.2319, 수득값 542.2321. 1H NMR (400 MHz, DMSO-d6) δ 1.13 (dd, J = 7.1, 1.8 Hz, 7H), 1.17 - 1.26 (m, 2H), 1.32 - 1.48 (m, 5H), 2.08 (t, J = 7.3 Hz, 2H), 3.99 (p, J = 7.1 Hz, 1H), 4.07 - 4.26 (m, 7H), 7.26 (t, J = 7.4 Hz, 2H), 7.35 (t, J = 7.4 Hz, 2H), 7.53 (d, J = 7.1 Hz, 1H), 7.65 (t, J = 7.3 Hz, 2H), 7.82 (d, J = 7.4 Hz, 2H), 8.10 (d, J = 7.7 Hz, 1H), 8.28 (t, J = 6.3 Hz, 1H).
FMoc-D-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO 2 H (10h): (16.7 mg, 0.031 mmol, 70% yield). HRMS (M+H)+ 산출값 542.2319, 수득값 542.2318.
FMoc-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 3 -CO 2 H(10j): HRMS (M+H)+ 산출값 585.2377, 수득값 585.2367. 1H NMR (400 MHz, DMSO-d6) δ 1.14 - 1.26 (m, 9H), 1.75 (p, J = 7.3 Hz, 2H), 2.27 (t, J = 7.3 Hz, 2H), 2.54 (d, J = 7.7 Hz, 2H), 3.97 - 4.10 (m, 1H), 4.13 - 4.34 (m, 7H), 7.33 (t, J = 7.5 Hz, 2H), 7.42 (t, J = 7.5 Hz, 2H), 7.57 (d, J = 6.9 Hz, 1H), 7.71 (t, J = 8.4 Hz, 2H), 7.89 (d, J = 7.6 Hz, 2H), 7.97 (d, J = 7.5 Hz, 1H), 8.14 (d, J = 7.0 Hz, 1H), 8.41 (s, 1H), 12.06 (s, 1H).
FMoc-D-Ala-L-Ala-NH-CH 2 -S-(CH) 2 -CO 2 H (10i): HRMS (M+H)+ 산출값 500.1850, 수득값 500.1843. 1H NMR (400 MHz, DMSO-d6) δ 1.20 (dd, J = 7.2, 1.9 Hz, 6H), 2.53 (d, J = 7.1 Hz, 2H), 2.70 (t, J = 7.1 Hz, 2H), 4.07 (q, J = 7.0 Hz, 1H), 4.17 - 4.26 (m, 4H), 4.29 (d, J = 6.8 Hz, 2H), 7.33 (t, J = 7.4 Hz, 2H), 7.41 (t, J = 7.5 Hz, 2H), 7.56 (d, J = 7.1 Hz, 1H), 7.72 (t, J = 7.7 Hz, 2H), 7.89 (d, J = 7.5 Hz, 2H), 8.14 (d, J = 7.6 Hz, 1H), 8.42 (t, J = 6.3 Hz, 1H), 12.22 (s, 1H).
3.
FMoc-펩티드-May-NMA 화합물들 (화합물 11a-11j)
FMoc-펩티드-NH-CH2-S-(CH2)n-CO2-DM 유형의 화합물들은 도 9A에 나타낸 것과 같이 준비하였고, FMoc-L-Ala-L-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-DM로 구체예화되었다.
FMoc-L-Ala-L-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (11a): DM-H 원액 (8.2 mL, 0.49 mmol)에 FMoc-L-Ala-L-Ala-L-Ala-NH-CH2-S-(CH2)5-COOH (300 mg, 0.49 mmol), EDC (94 mg, 0.490 mmol) 및 DIPEA (90 μL, 0.49 mmol)이 추가되었다. 반응을 아르곤 대기 하에 실온에서 2 시간 동안 자기 교반하면서 진행시켰다. 미정제 재료를 진공 하에 회전 증발에 의해 농축시켰고, 그 다음 C18, 30 미크론, 30 g 카트릿지 상에서 0.1% 포름산을 함유하는 탈이온 수 및 25분에 걸쳐 5%에서 50%까지의 아세토니트릴의 선형 구배로 용리시켜, 정제하였다. 순수한 원하는 산물을 함유하는 분획 냉동 및 동결건조시켜, 백색 고체 151 mg, (37.2% 수율)을 얻었다. HRMS (M + Na)+ 산출값 1266.5170; 수득값 1266.5141. 1H NMR (400 MHz, DMSO-d6) δ 0.77 (s, 3H), 1.12 (d, J = 6.4 Hz, 3H), 1.14 - 1.22 (m, 12H), 1.22 - 1.30 (m, 3H), 1.35 - 1.49 (m, 4H), 1.50 - 1.55 (m, 1H), 1.59 (s, 3H), 2.00 - 2.07 (m, 1H), 2.14 (ddd, J = 15.6, 8.7, 5.9 Hz, 1H), 2.40 (dtd, J = 17.0, 7.9, 7.0, 4.9 Hz, 3H), 2.69 (s, 3H), 2.79 (d, J = 9.6 Hz, 1H), 3.08 (s, 3H), 3.20 (d, J = 12.6 Hz, 1H), 3.24 (s, 3H), 3.43 (d, J = 12.4 Hz, 2H), 3.48 (d, J = 8.9 Hz, 1H), 3.92 (s, 3H), 4.08 (ddd, J = 20.8, 10.8, 5.0 Hz, 3H), 4.14 - 4.24 (m, 4H), 4.26 (d, J = 6.0 Hz, 3H), 4.52 (dd, J = 12.0, 2.8 Hz, 1H), 5.34 (q, J = 6.7 Hz, 1H), 5.56 (dd, J = 14.7, 9.0 Hz, 1H), 5.91 (s, 1H), 6.50 - 6.66 (m, 3H), 6.88 (s, 1H), 7.17 (d, J = 1.8 Hz, 1H), 7.33 (td, J = 7.5, 1.2 Hz, 2H), 7.41 (t, J = 7.4 Hz, 2H), 7.53 (d, J = 7.4 Hz, 1H), 7.72 (t, J = 7.0 Hz, 2H), 7.89 (d, J = 7.5 Hz, 3H), 7.99 (d, J = 7.3 Hz, 1H), 8.36 (t, J = 6.3 Hz, 1H).
FMoc-D-Ala-L-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (11b): HRMS (M+Na)+ 산출값 1266.5170, 수득값 1266.5164. 1H NMR (400 MHz, DMSO-d6) δ 0.78 (s, 3H), 1.14 (dd, J = 14.6, 6.5 Hz, 6H), 1.22 (t, J = 6.8 Hz, 10H), 1.33 - 1.57 (m, 4H), 1.59 (s, 3H), 2.04 (d, J = 13.5 Hz, 1H), 2.27 - 2.44 (m, 1H), 2.69 (s, 3H), 2.80 (d, J = 9.7 Hz, 1H), 3.08 (s, 3H), 3.14 - 3.28 (m, 5H), 3.37 - 3.55 (m, 3H), 3.92 (s, 3H), 3.98 - 4.16 (m, 3H), 4.20 (dd, J = 15.6, 7.6 Hz, 7H), 4.52 (d, J = 12.7 Hz, 1H), 5.34 (d, J = 6.9 Hz, 1H), 5.57 (dd, J = 14.7, 9.0 Hz, 1H), 5.92 (s, 1H), 6.46 - 6.72 (m, 4H), 6.88 (s, 1H), 7.17 (s, 1H), 7.33 (t, J = 7.5 Hz, 3H), 7.41 (t, J = 7.4 Hz, 3H), 7.60 - 7.75 (m, 4H), 7.80 - 7.93 (m, 4H), 8.12 (t, 1H), 8.29 (d, J = 6.9 Hz, 1H).
FMoc-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (11c): HRMS (M+Na)+ 산출값 1266.5170, 수득값 1266.5170. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 0.96 - 1.16 (m, 10H), 1.16 - 1.51 (m, 10H), 1.52 (s, 4H), 1.82 - 2.16 (m, 1H), 2.17 - 2.56 (m, 11H), 2.62 (d, J = 5.8 Hz, 4H), 2.68 - 2.87 (m, 3H), 2.92 - 3.04 (m, 4H), 3.09 - 3.22 (m, 7H), 3.24 (d, J = 7.4 Hz, 1H), 3.33 - 3.50 (m, 2H), 3.73 - 3.89 (m, 4H), 3.92 - 4.07 (m, 2H), 4.07 - 4.25 (m, 2H), 4.45 (dd, J = 12.0, 2.8 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.40 - 5.55 (m, 1H), 5.85 (s, 1H), 6.33 - 6.66 (m, 4H), 6.81 (s, 2H), 7.03 - 7.19 (m, 1H), 7.19 - 7.43 (m, 2H), 7.62 (d, J = 11.6 Hz, 1H), 7.73 - 7.85 (m, 1H).
FMoc-L-Ala-L-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (11d): HRMS (M+Na)+ 산출값 1266.5170, 수득값 1266.5158. 1H NMR (400 MHz, DMSO-d6) δ 0.78 (s, 3H), 1.06 - 1.33 (m, 16H), 1.44 (d, J = 10.3 Hz, 11H), 1.59 (s, 3H), 1.99 - 2.22 (m, 3H), 2.35 - 2.45 (m, 2H), 2.55 (d, J = 1.8 Hz, 1H), 2.69 (s, 3H), 2.80 (d, J = 9.6 Hz, 1H), 3.08 (s, 2H), 3.25 (s, 3H), 3.39 - 3.52 (m, 3H), 3.92 (s, 3H), 3.99 - 4.40 (m, 4H), 4.52 (d, J = 11.1 Hz, 1H), 5.34 (d, J = 6.8 Hz, 1H), 5.57 (dd, J = 14.5, 9.2 Hz, 1H), 5.92 (s, 1H), 6.53 - 6.64 (m, 2H), 6.88 (s, 2H), 7.17 (d, J = 1.9 Hz, 1H), 7.33 (t, J = 7.3 Hz, 3H), 7.42 (t, J = 7.4 Hz, 3H), 7.57 (d, J = 7.4 Hz, 1H), 7.72 (s, 3H), 7.89 (d, J = 7.6 Hz, 3H), 7.99 (d, J = 7.6 Hz, 1H), 8.07 (s, 1H), 8.35 (s, 1H).
FMoc-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (11g): HRMS (M+H)+ 산출값 1173.4980, 수득값 1173.4964. 1H NMR (400 MHz, DMSO-d6) δ 0.79 (s, 3H), 1.06 - 1.34 (m, 13H), 1.36 - 1.54 (m, 4H), 1.60 (s, 2H), 1.88 - 2.10 (m, 1H), 2.10 - 2.23 (m, 1H), 2.31 - 2.51 (m, 13H), 2.71 (s, 3H), 2.80 (d, J = 9.6 Hz, 1H), 3.10 (s, 3H), 3.26 (s, 4H), 3.33 - 3.66 (m, 3H), 3.98 - 4.32 (m, 4H), 4.53 (dd, J = 12.0, 2.8 Hz, 1H), 5.35 (q, J = 6.7 Hz, 1H), 5.49 - 5.65 (m, 1H), 6.51 - 6.67 (m, 3H), 6.89 (s, 1H), 7.19 (d, J = 1.8 Hz, 1H), 8.25 (s, 2H), 8.34 (d, J = 7.1 Hz, 1H), 8.58 (t, J = 6.3 Hz, 1H).
FMoc-L-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (11f): HRMS (M+H)+ 산출값 1173.4980, 수득값 1173.4969.
FMoc-D-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (11h): HRMS (M+Na)+ 산출값 1195.4907, 수득값 1195.4799. 1H NMR (400 MHz, DMSO-d 6) δ 0.71 (s, 3H), 1.00 - 1.22 (m, 13H), 1.28 - 1.45 (m, 2H), 1.52 (s, 3H), 1.91 - 2.14 (m, 1H), 2.26 (t, J = 1.9 Hz, 5H), 2.48 (t, J = 1.8 Hz, 2H), 2.62 (s, 3H), 2.66 - 2.77 (m, 2H), 3.01 (s, 2H), 3.10 - 3.21 (m, 5H), 3.28 - 3.47 (m, 2H), 3.86 (d, J = 6.7 Hz, 4H), 3.93 - 4.25 (m, 10H), 4.37 - 4.54 (m, 1H), 5.27 (d, J = 6.7 Hz, 1H), 5.40 - 5.56 (m, 1H), 5.85 (s, 1H), 6.31 - 6.66 (m, 3H), 6.81 (s, 1H), 7.11 (d, J = 1.8 Hz, 1H), 7.26 (t, J = 7.4 Hz, 2H), 7.35 (t, J = 7.4 Hz, 2H), 7.45 (d, J = 7.5 Hz, 1H), 7.65 (t, J = 7.1 Hz, 2H), 7.82 (d, J = 7.5 Hz, 2H), 7.89 (d, J = 7.3 Hz, 1H).
FMoc-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 3 -CO-DM (11j): HRMS (M+H)+ 산출값 1216.5038, 수득값 1216.4999. 1H NMR (400 MHz, DMSO-d6) δ 0.78 (s, 3H), 0.95 - 1.29 (m, 16H), 1.37 (d, J = 3.4 Hz, 1H), 1.46 (t, J = 12.5 Hz, 2H), 1.59 (s, 3H), 1.62 - 1.90 (m, 1H), 1.99 - 2.07 (m, 1H), 2.08 (s, 2H), 2.18 - 2.43 (m, 1H), 2.50 - 2.59 (m, 1H), 2.69 (s, 3H), 2.73 - 2.83 (m, 1H), 3.10 (s, 2H), 3.25 (s, 3H), 3.38 - 3.55 (m, 2H), 3.91 (s, 3H), 3.99 - 4.13 (m, 4H), 4.12 - 4.35 (m, 7H), 4.52 (dd, J = 12.0, 2.9 Hz, 1H), 5.34 (q, J = 6.7 Hz, 1H), 5.48 - 5.65 (m, 1H), 5.92 (s, 1H), 6.48 - 6.70 (m, 3H), 6.88 (s, 1H), 7.17 (d, J = 1.7 Hz, 1H), 7.33 (t, J = 7.5 Hz, 2H), 7.41 (t, J = 7.4 Hz, 2H), 7.58 (d, J = 7.0 Hz, 1H), 7.71 (t, J = 8.3 Hz, 2H), 7.89 (d, J = 7.5 Hz, 3H), 7.95 (d, J = 7.6 Hz, 1H), 8.15 (d, J = 7.2 Hz, 1H), 8.29 - 8.38 (m, 1H), 8.41 (s, 1H).
FMoc-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 2 -CO-DM (11i): HRMS (M+H)+ 산출값 1131.4510, 수득값 1131.4507.1H NMR (400 MHz, DMSO-d6) δ 0.76 (s, 3H), 1.08 - 1.21 (m, 12H), 1.24 (d, J = 13.9 Hz, 1H), 1.38 - 1.52 (m, 2H), 1.58 (s, 3H), 1.99 - 2.09 (m, 1H), 2.33 - 2.44 (m, 1H), 2.68 (s, 3H), 2.80 (dd, J = 14.4, 8.6 Hz, 2H), 3.08 (s, 3H), 3.17 (d, J = 12.5 Hz, 1H), 3.23 (s, 3H), 3.46 (t, J = 10.3 Hz, 2H), 3.91 (s, 3H), 4.00 - 4.13 (m, 3H), 4.13 - 4.34 (m, 5H), 4.52 (dd, J = 12.0, 2.9 Hz, 1H), 5.30 (q, J = 6.8 Hz, 1H), 5.55 (dd, J = 13.4, 9.1 Hz, 1H), 5.91 (s, 1H), 6.55 (dd, J = 7.4, 5.7 Hz, 3H), 6.87 (s, 1H), 7.16 (d, J = 1.8 Hz, 1H), 7.32 (tt, J = 7.4, 1.5 Hz, 2H), 7.41 (tt, J = 7.5, 1.5 Hz, 2H), 7.57 (d, J = 7.0 Hz, 1H), 7.71 (dd, J = 10.5, 7.5 Hz, 2H), 7.88 (d, J = 7.5 Hz, 2H), 8.14 (d, J = 7.6 Hz, 1H), 8.37 (t, J = 6.3 Hz, 1H).
4.
아미노-펩티드-메이탄시노이드 (화합물 12a-12j)
H2N-펩티드-NH-CH2-S-(CH2)n-CO2-DM 유형의 화합물들을 도 9A에 나타낸 것과 같이 준비하였고, H2N-L-Ala-L-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-DM로 구체예화되었다.
H 2 N-L-Ala-L-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (12a): FMoc-L-Ala-L-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-DM (151 mg, 0.121 mmol)은 DMF (2 mL)에서 20% 몰포린으로 처리하였다. 반응을 아르곤 하에서 자석 교반시키면서 실온에서 1시간 동안 자기 교반하면서 진행시켰다. 미정제 재료는 C18, 30 미크론, 150 g 카트릿지 상에서 0.1% 포름산을 함유하는 탈이온 수로 용리시키고, 26분에 걸쳐 5%에서 50%까지의 아세토니트릴의 선형 구배로 용리시켜 정제하였다. 원하는 산물을 함유하는 분획 즉시 냉동 및 동결건조시켜, 무색 오일 46 mg (37.1% 수율)을 얻었다. HRMS (M + H)+ 산출값 1022.4670; 수득값 1022.4669. 1H NMR (400 MHz, DMSO-d6) δ 0.78 (s, 3H), 1.12 (d, J = 6.3 Hz, 3H), 1.13 - 1.21 (m, 10H), 1.21 - 1.31 (m, 3H), 1.37 - 1.50 (m, 4H), 1.51 - 1.57 (m, 1H), 1.59 (s, 3H), 2.04 (dd, J = 14.4, 2.8 Hz, 1H), 2.15 (ddd, J = 15.9, 8.7, 6.0 Hz, 1H), 2.38 (td, J = 7.0, 3.6 Hz, 2H), 2.70 (s, 3H), 2.79 (d, J = 9.6 Hz, 1H), 3.09 (s, 3H), 3.21 (d, J = 12.5 Hz, 1H), 3.25 (s, 3H), 3.33-3.55 (m, 8H), 3.93 (s, 3H), 4.01 - 4.33 (m, 5H), 4.52 (dd, J = 12.0, 2.8 Hz, 1H), 5.34 (q, J = 6.7 Hz, 1H), 5.57 (dd, J = 14.6, 9.0 Hz, 1H), 5.95 (s, 1H), 6.48 - 6.65 (m, 3H), 6.89 (s, 1H), 7.18 (d, J = 1.8 Hz, 1H), 8.07 (d, J = 7.5 Hz, 1H), 8.13 (s, 1H), 8.31 (s, 1H), 8.40 (t, J = 6.3 Hz, 1H).
H 2 N-D-Ala-L-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (12b): HRMS (M+H)+ 산출값 1022.4670, 수득값 1022.4675. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.05 (dd, J = 6.7, 3.1 Hz, 7H), 1.08 - 1.16 (m, 10H), 1.19 (t, J = 8.1 Hz, 3H), 1.30 - 1.50 (m, 6H), 1.52 (s, 3H), 1.97 (d, J = 13.3 Hz, 1H), 2.01 - 2.21 (m, 2H), 2.34 (s, 3H), 2.63 (s, 3H), 2.73 (d, J = 9.8 Hz, 1H), 3.02 (s, 3H), 3.14 (d, J = 12.5 Hz, 1H), 3.33 - 3.48 (m, 2H), 3.86 (s, 3H), 3.95 - 4.23 (m, 7H), 4.45 (dd, J = 13.1 Hz, 1H), 5.27 (q, J = 6.8 Hz, 1H), 5.41 - 5.58 (m, 1H), 5.85 (s, 1H), 6.39 - 6.63 (m, 4H), 6.81 (s, 1H), 7.12 (d, J = 1.8 Hz, 1H), 8.02 (s, 1H), 8.13 (d, J = 7.7 Hz, 1H), 8.26 (s, 1H), 8.36 (t, J = 6.2 Hz, 1H).
H 2 N-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (12c): HRMS (M+H)+ 산출값 1022.4670, 수득값 1022.4680. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.01 - 1.26 (m, 19H), 1.25 - 1.50 (m, 6H), 1.52 (s, 3H), 1.97 (d, J = 13.7 Hz, 1H), 2.02 - 2.22 (m, 1H), 2.35 (dd, J = 17.2, 9.5 Hz, 2H), 2.47 (d, J = 11.5 Hz, 1H), 2.63 (s, 4H), 2.73 (d, J = 9.6 Hz, 1H), 3.02 (s, 3H), 3.10 - 3.24 (m, 6H), 3.32 - 3.50 (m, 2H), 3.86 (s, 3H), 3.95 - 4.18 (m, 4H), 4.45 (dd, J = 12.1, 2.6 Hz, 1H), 5.27 (q, J = 6.9 Hz, 1H), 5.44 - 5.55 (m, 1H), 5.85 (s, 1H), 6.42 - 6.59 (m, 4H), 6.81 (s, 1H), 7.12 (d, J = 1.7 Hz, 1H), 8.02 (s, 1H), 8.13 (d, J = 7.7 Hz, 1H), 8.36 (t, J = 6.3 Hz, 1H).
H 2 N-L-Ala-L-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (12d): HRMS (M+H)+ 산출값 1022.4670, 수득값 1022.4675. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 0.98 - 1.14 (m, 13H), 1.14 - 1.26 (m, 2H), 1.30 - 1.49 (m, 4H), 1.52 (s, 3H), 2.24 - 2.41 (m, 2H), 2.44 (d, J = 1.8 Hz, 16H), 2.63 (s, 2H), 2.73 (d, J = 9.6 Hz, 1H), 3.02 (s, 2H), 3.08 - 3.21 (m, 4H), 3.32 - 3.49 (m, 2H), 3.86 (s, 3H), 3.92 - 4.23 (m, 3H), 4.45 (d, J = 11.8 Hz, 1H), 5.26 (t, J = 6.7 Hz, 1H), 5.40 - 5.57 (m, 1H), 5.86 (s, 1H), 6.41 - 6.66 (m, 3H), 6.81 (s, 1H), 7.12 (d, J = 1.7 Hz, 1H), 8.02 (s, 1H), 8.10 (d, J = 7.7 Hz, 1H), 8.35 (t, J = 6.3 Hz, 1H).
H 2 N-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (12g): HRMS (M+H)+ 산출값 951.4299, 수득값 951.4289. 1H NMR (400 MHz, DMSO-d6) δ 0.79 (s, 3H), 1.06 - 1.34 (m, 13H), 1.36 - 1.54 (m, 4H), 1.60 (s, 2H), 1.88 - 2.10 (m, 1H), 2.10 - 2.23 (m, 1H), 2.31 - 2.51 (m, 13H), 2.71 (s, 3H), 2.80 (d, J = 9.6 Hz, 1H), 3.10 (s, 3H), 3.26 (s, 4H), 3.33 - 3.66 (m, 3H), 3.98 - 4.32 (m, 4H), 4.53 (dd, J = 12.0, 2.8 Hz, 1H), 5.35 (q, J = 6.7 Hz, 1H), 5.49 - 5.65 (m, 1H), 6.51 - 6.67 (m, 3H), 6.89 (s, 1H), 7.19 (d, J = 1.8 Hz, 1H), 8.25 (s, 2H), 8.34 (d, J = 7.1 Hz, 1H), 8.58 (t, J = 6.3 Hz, 1H).
H 2 N-L-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (12f): HRMS (M+H)+ 산출값 951.4226, 수득값 951.1299. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.00 - 1.13 (m, 11H), 1.19 (t, J = 8.9 Hz, 3H), 1.29 - 1.45 (m, 4H), 1.52 (s, 3H), 1.92 - 2.03 (m, 1H), 2.07 (dd, J = 15.7, 8.7 Hz, 1H), 2.23 - 2.39 (m, 1H), 2.63 (s, 3H), 2.73 (d, J = 9.7 Hz, 1H), 3.02 (s, 3H), 3.07 - 3.32 (m, 14H), 3.34 - 3.47 (m, 2H), 3.86 (s, 3H), 3.95 - 4.21 (m, 4H), 4.45 (dd, J = 11.9, 2.8 Hz, 1H), 5.27 (q, J = 6.8 Hz, 1H), 5.50 (dd, J = 14.7, 9.0 Hz, 1H), 5.85 (s, 1H), 6.40 - 6.61 (m, 3H), 6.81 (s, 1H), 7.12 (d, J = 1.8 Hz, 1H), 8.41 (t, J = 6.1 Hz, 1H).
H 2 N-D-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (12h): HRMS (M+H)+ 산출값 950.4226, 수득값 951.4299. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 0.96 - 1.14 (m, 14H), 1.19 (t, J = 8.9 Hz, 3H), 1.38 (q, J = 10.5, 7.0 Hz, 5H), 1.52 (s, 3H), 1.88 - 2.02 (m, 1H), 2.02 - 2.18 (m, 1H), 2.22 - 2.41 (m, 2H), 2.48 (s, 1H), 2.63 (s, 3H), 2.73 (d, J = 9.6 Hz, 1H), 3.02 (s, 3H), 3.08 - 3.22 (m, 4H), 3.34 - 3.48 (m, 2H), 3.86 (s, 4H), 3.95 - 4.23 (m, 5H), 4.45 (dd, J = 11.9, 2.8 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.41 - 5.60 (m, 1H), 5.85 (s, 1H), 6.40 - 6.65 (m, 4H), 6.81 (s, 1H), 7.12 (d, J = 1.8 Hz, 1H), 8.44 (t, J = 6.1 Hz, 1H).
H 2 N-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 3 -CO-DM (12j): HRMS (M+H)+ 산출값 994.4357, 수득값 994.4330.
H 2 N-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 2 -CO-DM (12i): HRMS (M+H)+ 산출값 909.3830, 수득값 909.3826. 1H NMR (400 MHz, DMSO-d6) δ 0.77 (s, 3H), 1.12 (d, J = 6.7 Hz, 6H), 1.17 (dd, J = 7.0, 5.2 Hz, 6H), 1.25 (d, J = 13.3 Hz, 1H), 1.40 - 1.51 (m, 2H), 1.59 (s, 3H), 2.04 (dd, J = 14.4, 2.9 Hz, 1H), 2.41 (ddt, J = 18.6, 10.1, 5.4 Hz, 1H), 2.61 - 2.70 (m, 1H), 2.72 (s, 3H), 2.76 - 2.90 (m, 3H), 3.09 (s, 3H), 3.20 (d, J = 12.4 Hz, 1H), 3.25 (s, 3H), 3.33 (q, J = 6.9 Hz, 1H), 3.39 - 3.64 (m, 3H), 3.93 (s, 3H), 4.03 - 4.16 (m, 2H), 4.24 (dt, J = 15.1, 7.6 Hz, 2H), 4.53 (dd, J = 12.0, 2.9 Hz, 1H), 5.32 (q, J = 6.8 Hz, 1H), 5.51 - 5.64 (m, 1H), 5.93 (s, 1H), 6.49 - 6.62 (m, 2H), 6.88 (s, 1H), 7.19 (d, J = 1.8 Hz, 1H), 8.10 (s, 1H), 8.55 (t, J = 6.3 Hz, 1H).
5.
SPDB-펩티드-메이탄시노이드 (화합물 13a-13j)
SPDB-펩티드-NH-CH2-S-(CH2)n-CO2-DM 유형의 화합물들은 도 9A에 나타낸 것과 같이 준비하였고, SPDB-L-Ala-L-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-DM로 구체예화되었다.
SPDB-L-Ala-L-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (13a): H2N-L-Ala-L-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-DM (46 mg, 0.045 mmol)는 DMF (2 mL)에 용해시켰고, 여기에 SPDB (14.7 mg, 0.045 mmol)를 추가하고, 그리고 실온에서 아르곤 대기하에 자석 교반시키면서 1시간 동안 반응시켰다. 미정제 재료는 C18, 430 마이크로, 30g 카트릿지 상에서 0.1% 포름산을 함유하는 탈이온 수로 용리시키고, 35분에 걸쳐 5%에서 95%까지의 아세토니트릴의 선형 구배로 용리시켜 정제하였다. 순수한 원하는 산물을 함유하는 분획은 냉동 및 동결건조시켜, 백색 고체 38 mg, (68.5% 수율)를 얻었다. HRMS (M + H)+ 산출값 1233.4796; 수득값 1233.4783. 1H NMR (400 MHz, DMSO-d6) δ 0.78 (s, 3H), 1.12 (d, J = 6.4 Hz, 3H), 1.14 - 1.21 (m, 10H), 1.22 - 1.30 (m, 3H), 1.44 (qd, J = 10.2, 4.5 Hz, 5H), 1.50 - 1.56 (m, 1H), 1.59 (s, 3H), 1.84 (p, J = 7.3 Hz, 2H), 2.04 (dd, J = 14.4, 2.7 Hz, 1H), 2.15 (ddd, J = 15.8, 8.6, 5.9 Hz, 2H), 2.24 (t, J = 7.2 Hz, 2H), 2.39 (dtdd, J = 18.1, 13.2, 8.1, 4.7 Hz, 3H), 2.70 (s, 3H), 2.76 - 2.86 (m, 3H), 3.09 (s, 3H), 3.21 (d, J = 12.5 Hz, 1H), 3.25 (s, 3H), 3.43 (d, J = 12.4 Hz, 1H), 3.48 (d, J = 9.0 Hz, 1H), 3.92 (s, 3H), 4.13 (s, 2H), 4.19 (h, J = 6.6 Hz, 4H), 4.52 (dd, J = 12.1, 2.8 Hz, 1H), 5.34 (q, J = 6.8 Hz, 1H), 5.56 (dd, J = 14.7, 9.0 Hz, 1H), 5.92 (s, 1H), 6.49 - 6.66 (m, 3H), 6.85 - 6.97 (m, 2H), 7.18 (d, J = 1.8 Hz, 1H), 7.23 (ddd, J = 7.3, 4.8, 1.2 Hz, 1H), 7.76 (dt, J = 8.1, 1.2 Hz, 1H), 7.78 - 7.91 (m, 2H), 8.00 (d, J = 7.1 Hz, 1H), 8.09 (d, J = 7.0 Hz, 1H), 8.33 (t, J = 6.3 Hz, 1H), 8.44 (dt, J = 4.7, 1.3 Hz, 1H), 8.50 (s, 1H).
SPDB-D-Ala-L-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (13b): HRMS (M+H)+ 산출값 1233.4796, 수득값 1233.4799. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.01 - 1.22 (m, 13H), 1.27 - 1.45 (m, 2H), 1.52 (s, 3H), 1.91 - 2.16 (m, 1H), 2.26 (d, J = 7.4 Hz, 7H), 2.26 (t, J = 1.9 Hz, 4H), 2.48 (t, J = 1.8 Hz, 2H), 2.57 - 2.65 (m, 3H), 2.65 - 2.77 (m, 2H), 3.01 (s, 2H), 3.13 (d, J = 12.2 Hz, 1H), 3.18 (s, 3H), 3.32 - 3.47 (m, 2H), 3.86 (d, J = 6.7 Hz, 4H), 3.93 - 4.11 (m, 3H), 4.18 (t, J = 11.2 Hz, 7H), 4.39 - 4.50 (m, 1H), 5.27 (d, J = 6.7 Hz, 1H), 5.50 (dd, J = 14.7, 8.8 Hz, 1H), 5.85 (s, 1H), 6.37 - 6.61 (m, 3H), 6.81 (s, 1H), 7.11 (d, J = 1.8 Hz, 1H), 7.26 (t, J = 7.4 Hz, 2H), 7.35 (t, J = 7.4 Hz, 2H), 7.45 (d, J = 7.5 Hz, 1H), 7.65 (t, J = 7.1 Hz, 2H), 7.82 (d, J = 7.5 Hz, 2H), 7.89 (d, J = 7.3 Hz, 1H).
SPDB- L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (13c): HRMS (M+H)+ 산출값 1233.4796, 수득값 1233.4795. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.02 - 1.25 (m, 18H), 1.29 - 1.50 (m, 6H), 1.52 (s, 3H), 1.70 - 1.87 (m, 2H), 1.87 - 2.14 (m, 2H), 2.13 - 2.22 (m, 2H), 2.27 - 2.40 (m, 3H), 2.63 (s, 3H), 2.69 - 2.84 (m, 4H), 3.02 (s, 3H), 3.14 (d, J = 12.3 Hz, 1H), 3.18 (s, 3H), 3.32 - 3.45 (m, 2H), 3.85 (s, 3H), 3.95 - 4.07 (m, 2H), 4.07 - 4.19 (m, 4H), 4.45 (dd, J = 11.9, 2.7 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.44 - 5.55 (m, 1H), 5.85 (s, 1H), 6.42 - 6.59 (m, 3H), 6.81 (s, 1H), 7.11 (s, 1H), 7.13 - 7.19 (m, 1H), 7.68 (d, J = 8.2, 2.7 Hz, 1H), 7.72 - 7.80 (m, 1H), 7.88 (t, J = 6.6 Hz, 1H), 8.04 (d, J = 6.4 Hz, 1H), 8.09 (d, J = 7.4 Hz, 1H), 8.25 (t, J = 6.3 Hz, 1H), 8.37 (dd, J = 5.0, 1.9 Hz, 1H).
SPDB- L-Ala-L-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (13d): HRMS (M+H)+ 산출값 1233.4796, 수득값 1233.4797. 1H NMR (400 MHz, DMSO-d6) δ 0.72 (d, J = 3.3 Hz, 3H), 0.98 - 1.28 (m, 22H), 1.30 - 1.46 (m, 3H), 1.53 (s, 3H), 1.78 (q, J = 7.1 Hz, 2H), 1.86 - 2.16 (m, 2H), 2.19 (q, J = 7.4, 5.6 Hz, 2H), 2.26 - 2.41 (m, 2H), 2.41 - 2.55 (m, 4H), 2.64 (d, J = 3.2 Hz, 2H), 2.81 - 2.92 (m, 1H), 3.02 (s, 2H), 3.14 (d, J = 12.0 Hz, 1H), 3.26 (s, 1H), 3.31 - 3.48 (m, 2H), 3.86 (s, 3H), 3.97 - 4.30 (m, 7H), 4.46 (dd, J = 11.8, 3.2 Hz, 1H), 5.24 - 5.36 (m, 1H), 5.45 - 5.62 (m, 1H), 5.86 (s, 1H), 6.40 - 6.65 (m, 3H), 6.82 (d, J = 3.4 Hz, 1H), 7.11 (d, J = 3.2 Hz, 1H), 7.18 (d, J = 12.1, 6.1, 4.9 Hz, 2H), 7.69 (d, J = 8.1 Hz, 1H), 7.75 (t, J = 7.6 Hz, 2H), 7.89 (d, J = 7.8, 3.2 Hz, 1H), 7.95 - 8.04 (m, 2H), 8.26 (d, J = 6.1 Hz, 1H), 8.33 - 8.47 (m, 1H).
SPDB-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (13g): HRMS (M+H)+ 산출값 1162.4425, 수득값 1162.4405. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.08 (dt, J = 13.9, 6.9 Hz, 15H), 1.15 - 1.25 (m, 3H), 1.28 - 1.44 (m, 5H), 1.52 (s, 3H), 1.77 (p, J = 7.2 Hz, 2H), 1.91 - 2.02 (m, 1H), 2.02 - 2.13 (m, 1H), 2.17 (t, J = 7.2 Hz, 2H), 2.22 - 2.40 (m, 2H), 2.63 (s, 3H), 2.68 - 2.80 (m, 3H), 3.02 (s, 3H), 3.13 (d, J = 12.3 Hz, 1H), 3.18 (s, 3H), 3.33 - 3.45 (m, 2H), 3.85 (s, 3H), 3.95 - 4.16 (m, 5H), 4.45 (dd, J = 12.1, 2.8 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.44 - 5.56 (m, 1H), 5.85 (s, 1H), 6.43 - 6.60 (m, 3H), 6.82 (s, 1H), 7.11 (d, J = 1.8 Hz, 1H), 7.12 - 7.18 (m, 1H), 7.65 - 7.79 (m, 2H), 8.06 - 8.16 (m, 2H), 8.30 (t, J = 6.3 Hz, 1H), 8.35 - 8.40 (m, 1H).
SPDB-L-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (13f): HRMS (M+H)+ 산출값 1162.4399, 수득값 1162.455. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.02 - 1.13 (m, 12H), 1.14 - 1.25 (m, 3H), 1.31 - 1.44 (m, 5H), 1.52 (s, 3H), 1.77 (p, J = 7.3 Hz, 2H), 1.97 (d, J = 14.3, 2.7 Hz, 1H), 2.02 - 2.13 (m, 1H), 2.17 (t, J = 7.2 Hz, 2H), 2.28 - 2.40 (m, 3H), 2.43 (m, J = 3.2 Hz, 3H), 2.63 (s, 3H), 2.69 - 2.80 (m, 3H), 3.02 (s, 3H), 3.13 (d, J = 12.4 Hz, 1H), 3.18 (s, 3H), 3.39 (dd, J = 21.0, 10.7 Hz, 2H), 3.85 (s, 3H), 3.96 - 4.18 (m, 5H), 4.45 (dd, J = 12.1, 2.8 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.45 - 5.55 (m, 1H), 5.85 (s, 1H), 6.43 - 6.60 (m, 3H), 6.81 (s, 1H), 7.10 (d, J = 1.8 Hz, 1H), 7.16 (t, J = 7.2, 4.9 Hz, 1H), 7.68 (d, J = 8.1 Hz, 1H), 7.71 - 7.79 (m, 1H), 8.02 - 8.15 (m, 2H), 8.28 (t, J = 6.3 Hz, 1H), 8.37 (d, J = 4.8, 1.7 Hz, 1H).
SPDB-D-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (13h): HRMS (M+H)+ 산출값 1162.4399, 수득값 1162.455. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.02 - 1.16 (m, 13H), 1.14 - 1.25 (m, 3H), 1.28 - 1.49 (m, 5H), 1.52 (s, 3H), 1.77 (p, J = 7.2 Hz, 2H), 1.92 - 2.14 (m, 2H), 2.17 (t, J = 7.2 Hz, 2H), 2.23 - 2.40 (m, 2H), 2.46 - 2.54 (m, 1H), 2.63 (s, 3H), 2.65 - 2.85 (m, 4H), 3.02 (s, 3H), 3.03 - 3.16 (m, 2H), 3.18 (s, 3H), 3.28 - 3.45 (m, 2H), 3.85 (s, 3H), 3.95 - 4.20 (m, 5H), 4.45 (dd, J = 12.1, 2.8 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.44 - 5.55 (m, 1H), 5.82 - 5.88 (m, 1H), 6.42 - 6.59 (m, 3H), 6.81 (s, 1H), 7.11 (d, J = 1.9 Hz, 1H), 7.14 - 7.20 (m, 1H), 7.67 - 7.72 (m, 1H), 7.72 - 7.80 (m, 1H), 7.88 (d, J = 7.6 Hz, 1H), 7.99 (d, J = 7.1 Hz, 1H), 8.28 (t, J = 6.3 Hz, 1H), 8.35 - 8.40 (m, 1H).
SPDB-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 3 -CO-DM (13j): HRMS (M+H)+ 산출값 1203.4337, 수득값 1203.4315. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 0.94 - 1.24 (m, 20H), 1.38 (s, 3H), 1.52 (s, 3H), 1.57 - 1.87 (m, 1H), 1.89 - 2.08 (m, 1H), 2.26 (t, J = 15.1 Hz, 1H), 2.50 (d, J = 5.2 Hz, 2H), 2.54 - 2.79 (m, 7H), 3.05 (d, J = 3.8 Hz, 3H), 3.18 (s, 5H), 3.29 - 3.46 (m, 3H), 3.86 (d, J = 6.1 Hz, 4H), 4.00 (s, 3H), 4.05 - 4.24 (m, 4H), 4.33 - 4.54 (m, 1H), 5.17 - 5.38 (m, 1H), 5.39 - 5.58 (m, 1H), 5.85 (s, 1H), 6.29 - 6.58 (m, 4H), 6.63 (s, 1H), 6.81 (s, 1H), 7.04 - 7.19 (m, 1H), 7.90 (s, 1H), 8.14 - 8.39 (m, 1H), 8.45 (s, 1H).
SPDB-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 2 -CO-DM (13i): HRMS (M+H)+ 산출값 1120.3955, 수득값 1120.3951. 1H NMR (400 MHz, DMSO-d6) δ 0.74 - 0.82 (m, 3H), 1.10 - 1.22 (m, 13H), 1.25 (d, J = 14.1 Hz, 1H), 1.46 (t, J = 10.9 Hz, 2H), 1.56 - 1.63 (m, 3H), 1.85 (ddd, J = 14.4, 9.0, 5.1 Hz, 2H), 2.00 (ddd, J = 14.7, 9.3, 5.4 Hz, 9H), 2.24 (dt, J = 10.8, 5.0 Hz, 2H), 2.72 (d, J = 3.6 Hz, 2H), 2.94 (dq, J = 10.7, 7.2, 5.7 Hz, 9H), 3.10 (d, J = 3.7 Hz, 3H), 3.20 (d, J = 3.4 Hz, 1H), 3.25 (d, J = 3.6 Hz, 3H), 3.32 (d, J = 3.7 Hz, 1H), 3.47 (td, J = 10.7, 10.0, 3.8 Hz, 2H), 3.93 (t, J = 4.6 Hz, 3H), 4.02 - 4.25 (m, 6H), 4.49 - 4.57 (m, 1H), 5.28 - 5.37 (m, 1H), 5.53 - 5.62 (m, 1H), 5.92 (d, J = 3.6 Hz, 1H), 6.57 (q, J = 5.4, 4.5 Hz, 3H), 6.85 - 6.93 (m, 1H), 7.17 (d, J = 3.3 Hz, 1H), 7.25 (dq, J = 8.0, 4.9 Hz, 6H), 7.72 - 7.87 (m, 11H), 8.16 (dt, J = 15.4, 4.9 Hz, 2H), 8.45 (tt, J = 9.9, 5.9 Hz, 6H).
6.
티오-펩티드-메이탄시노이드 (화합물들 14a-14j)
HS-(CH2) 3 CO-펩티드-NH-CH2-S-(CH2)n-CO2-DM 유형의 화합물들은 도 9A에 나타낸 것과 같이 준비하였고, HS-(CH2) 3 CO-L-Ala-L-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-DM로 구체예화되었다.
HS-(CH 2 ) 3 CO-L-Ala-L-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (14a): SPDB-L-Ala-L-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-DM (38 mg, 0.031 mmol)를 DMSO (1 mL)에 용해시키고, 여기에 100 mM 인산 칼륨, 2mM EDTA pH 7.5 완충제 (1mL)에서 DTT (19 mg, 0.12 mmol) 용액을 추가하였다. 반응을 아르곤 하에서 자석 교반시키면서 실온에서 1시간 동안 자기 교반하면서 진행시켰다. 미정제 반응물은 C18, 30 미크론, 30g 카트릿지 0.1% 상에서 포름산을 함유하는 탈이온 수로 용리시키고, 35분에 걸쳐 5%에서 95%까지의 아세토니트릴의 선형 구배로 용리시켜 정제하였다. 원하는 산물을 함유하는 분획은 즉시 냉동 및 동결건조시켜, 백색 고체 18.2 mg, (52.5% 수율)를 얻었다. HRMS (M + H)+ 산출값 1124.4809; 수득값 1124.4798. 1H NMR (400 MHz, DMSO-d6) δ 0.78 (s, 3H), 1.12 (d, J = 6.4 Hz, 3H), 1.14 - 1.21 (m, 10H), 1.22 - 1.30 (m, 3H), 1.37 - 1.50 (m, 5H), 1.51 - 1.57 (m, 1H), 1.59 (s, 3H), 1.74 (p, J = 7.2 Hz, 2H), 2.04 (dd, J = 14.4, 2.8 Hz, 1H), 2.09 - 2.18 (m, 1H), 2.18 - 2.24 (m, 2H), 2.27 (t, J = 7.6 Hz, 1H), 2.38 (td, J = 7.1, 4.7 Hz, 2H), 2.44 (t, J = 7.3 Hz, 2H), 2.70 (s, 3H), 2.79 (d, J = 9.6 Hz, 1H), 3.09 (s, 3H), 3.21 (d, J = 12.6 Hz, 1H), 3.25 (s, 3H), 3.43 (d, J = 12.4 Hz, 1H), 3.49 (d, J = 9.0 Hz, 1H), 3.93 (s, 3H), 4.08 (ddd, J = 21.6, 11.4, 4.1 Hz, 2H), 4.13 - 4.28 (m, 4H), 4.52 (dd, J = 12.1, 2.8 Hz, 1H), 5.34 (q, J = 6.7 Hz, 1H), 5.56 (dd, J = 14.7, 9.0 Hz, 1H), 5.91 (d, J = 1.4 Hz, 1H), 6.48 - 6.66 (m, 3H), 6.88 (s, 1H), 7.18 (d, J = 1.8 Hz, 1H), 7.86 (d, J = 7.5 Hz, 1H), 7.96 (d, J = 7.3 Hz, 1H), 8.05 (d, J = 7.1 Hz, 1H), 8.33 (t, J = 6.3 Hz, 1H).
HS-(CH 2 ) 3 CO-D-Ala-L-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (14b): HRMS (M+Na)+ 산출값 1146.4629, 수득값 1146.4591. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.03 - 1.25 (m, 19H), 1.30 - 1.45 (m, 6H), 1.52 (s, 4H), 1.65 (p, J = 7.3 Hz, 2H), 1.91 - 2.02 (m, 1H), 2.02 - 2.13 (m, 1H), 2.12 - 2.19 (m, 4H), 2.29 - 2.39 (m, 4H), 2.63 (s, 3H), 2.73 (d, J = 9.6 Hz, 1H), 3.02 (s, 3H), 3.14 (d, J = 12.5 Hz, 1H), 3.33 - 3.47 (m, 2H), 3.86 (s, 3H), 4.01 (td, J = 10.4, 9.7, 4.3 Hz, 2H), 4.04 - 4.16 (m, 5H), 4.45 (dd, J = 12.0, 2.9 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.43 - 5.56 (m, 1H), 5.85 (s, 1H), 6.38 - 6.61 (m, 4H), 6.81 (s, 1H), 7.11 (d, J = 1.8 Hz, 1H), 7.82 (d, J = 7.7 Hz, 1H), 7.97 (t, J = 6.3 Hz, 1H), 8.10 (d, J = 6.0 Hz, 1H), 8.25 (d, J = 6.9 Hz, 1H).
HS-(CH 2 ) 3 CO-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (14c): HRMS (M+Na)+ 산출값 1146.4629, 수득값 1146.4553. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 0.99 - 1.26 (m, 21H), 1.31 - 1.45 (m, 5H), 1.52 (s, 3H), 1.67 (p, J = 7.2 Hz, 2H), 1.89 - 2.02 (m, 1H), 2.02 - 2.24 (m, 4H), 2.25 - 2.46 (m, 3H), 2.63 (s, 3H), 2.73 (d, J = 9.7 Hz, 1H), 3.02 (s, 3H), 3.18 (s, 3H), 3.32 - 3.51 (m, 2H), 3.86 (s, 3H), 3.96 - 4.18 (m, 7H), 4.45 (dd, J = 12.0, 2.9 Hz, 1H), 5.27 (q, J = 6.8 Hz, 1H), 5.44 - 5.63 (m, 1H), 5.85 (s, 1H), 6.37 - 6.59 (m, 4H), 6.81 (s, 1H), 7.11 (d, J = 1.8 Hz, 1H), 7.89 (d, J = 7.7 Hz, 1H), 8.03 (d, J = 6.5 Hz, 1H), 8.08 (d, J = 7.3 Hz, 1H), 8.27 (t, J = 6.3 Hz, 1H).
HS-(CH 2 ) 3 CO-L-Ala-L-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (14d): HRMS (M+Na)+ 산출값 1146.4629, 수득값 1146.4519. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 0.95 - 1.24 (m, 20H), 1.27 - 1.45 (m, 5H), 1.52 (s, 3H), 1.67 (p, J = 7.3 Hz, 2H), 1.93 - 2.01 (m, 1H), 2.02 - 2.22 (m, 4H), 2.22 - 2.41 (m, 5H), 2.63 (s, 3H), 2.73 (d, J = 9.6 Hz, 1H), 3.02 (s, 3H), 3.18 (s, 4H), 3.39 (dd, J = 21.4, 10.7 Hz, 2H), 3.86 (s, 3H), 3.94 - 4.24 (m, 6H), 4.45 (dd, J = 12.0, 2.8 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.44 - 5.57 (m, 1H), 5.85 (s, 1H), 6.37 - 6.65 (m, 3H), 6.81 (s, 1H), 7.11 (d, J = 1.8 Hz, 1H), 7.89 (d, J = 7.6 Hz, 1H), 7.93 - 8.05 (m, 2H), 8.26 (t, J = 6.4 Hz, 1H).
HS-(CH 2 ) 3 CO-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (14g): HRMS (M+H)+ 산출값 1053.4438, 수득값 1053.4426. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.01 - 1.15 (m, 13H), 1.15 - 1.27 (m, 3H), 1.31 - 1.44 (m, 5H), 1.53 (s, 3H), 1.67 (p, J = 7.1 Hz, 2H), 1.93 - 2.03 (m, 1H), 2.03 - 2.23 (m, 4H), 2.22 - 2.41 (m, 5H), 2.63 (s, 3H), 2.73 (d, J = 9.7 Hz, 1H), 3.02 (s, 3H), 3.14 (d, J = 12.5 Hz, 1H), 3.18 (s, 3H), 3.32 - 3.46 (m, 2H), 3.86 (s, 3H), 3.92 - 4.20 (m, 6H), 4.45 (dd, J = 11.9, 2.8 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.42 - 5.58 (m, 1H), 5.85 (s, 1H), 6.42 - 6.60 (m, 3H), 6.81 (s, 1H), 7.12 (d, J = 1.8 Hz, 1H), 8.05 (d, J = 6.5 Hz, 1H), 8.10 (d, J = 7.8 Hz, 1H), 8.30 (t, J = 6.3 Hz, 1H).
HS-(CH 2 ) 3 CO-L-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (14f): HRMS (M+H)+ 산출값 1053.4366, 수득값 1053.4438. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.02 - 1.14 (m, 13H), 1.19 (t, J = 9.7 Hz, 3H), 1.31 - 1.43 (m, 6H), 1.53 (s, 3H), 1.67 (p, J = 7.3 Hz, 2H), 1.91 - 2.02 (m, 1H), 2.02 - 2.22 (m, 4H), 2.34 - 2.39 (m, 4H), 2.63 (s, 3H), 2.73 (d, J = 9.5 Hz, 1H), 3.02 (s, 3H), 3.19 (d, J = 4.2 Hz, 4H), 3.30 - 3.47 (m, 2H), 3.86 (s, 3H), 3.94 - 4.20 (m, 6H), 4.45 (d, J = 11.8, 2.8 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.44 - 5.56 (m, 1H), 5.85 (s, 1H), 6.40 - 6.61 (m, 3H), 6.81 (s, 1H), 7.12 (s, 1H), 8.03 (d, J = 6.5 Hz, 1H), 8.08 (d, J = 7.8 Hz, 1H), 8.29 (t, J = 6.2 Hz, 1H).
HS-(CH 2 ) 3 CO-D-Ala-D-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (14h): HRMS (M+H)+ 산출값 1053.4366, 수득값 1053.4438. 1H NMR (400 MHz, DMSFO-d6) δ 0.71 (s, 3H), 1.02 - 1.15 (m, 13H), 1.14 - 1.24 (m, 3H), 1.30 - 1.45 (m, 5H), 1.53 (s, 3H), 1.67 (p, J = 7.1 Hz, 2H), 1.90 - 2.01 (m, 1H), 2.01 - 2.24 (m, 4H), 2.27 - 2.33 (m, 1H), 2.33 - 2.42 (m, 4H), 2.63 (s, 3H), 2.73 (d, J = 9.7 Hz, 1H), 3.02 (s, 3H), 3.10 - 3.21 (m, 4H), 3.33 - 3.46 (m, 2H), 3.86 (s, 3H), 3.95 - 4.18 (m, 6H), 4.45 (dd, J = 11.9, 2.8 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.44 - 5.55 (m, 1H), 5.85 (s, 1H), 6.42 - 6.59 (m, 3H), 6.81 (s, 1H), 7.12 (d, J = 1.8 Hz, 1H), 8.05 (d, J = 6.5 Hz, 1H), 8.10 (d, J = 7.8 Hz, 1H), 8.30 (t, J = 6.3 Hz, 1H).
HS-(CH 2 ) 3 CO-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 3 -CO-DM (14j): HRMS (M+H)+ 산출값 1096.4496, 수득값 1096.4464. 1H NMR (400 MHz, DMSO-d6) δ 0.78 (s, 3H), 1.02 - 1.31 (m, 19H), 1.35 - 1.55 (m, 2H), 1.60 (s, 3H), 1.74 (p, J = 7.4 Hz, 3H), 1.78 - 1.93 (m, 1H), 2.14 - 2.33 (m, 4H), 2.41 - 2.49 (m, 2H), 2.71 (s, 3H), 2.80 (d, J = 9.6 Hz, 1H), 3.12 (s, 3H), 3.22 (d, J = 12.7 Hz, 1H), 3.26 (s, 3H), 3.47 (dd, J = 21.3, 10.6 Hz, 2H), 3.93 (s, 4H), 4.03 - 4.13 (m, 3H), 4.13 - 4.25 (m, 3H), 4.52 (dd, J = 12.0, 2.8 Hz, 1H), 5.35 (q, J = 6.8 Hz, 1H), 5.50 - 5.64 (m, 1H), 5.92 (s, 1H), 6.47 - 6.69 (m, 4H), 6.88 (s, 1H), 7.18 (d, J = 1.7 Hz, 1H), 7.94 (d, J = 7.3 Hz, 1H), 8.09 (d, J = 6.4 Hz, 1H), 8.15 (d, J = 7.3 Hz, 1H), 8.32 (t, J = 6.3 Hz, 1H).
HS-(CH 2 ) 3 CO-(CH 2 ) 3 -CO-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 2 -CO-DM (14i): HRMS (M+H)+ 산출값 1011.3969, 수득값 1011.3961. 1H NMR (400 MHz, DMSO-d6) δ 0.77 (s, 3H), 1.12 (d, J = 6.4 Hz, 3H), 1.17 (dd, J = 7.0, 5.1 Hz, 9H), 1.25 (d, J = 13.0 Hz, 1H), 1.40 - 1.51 (m, 2H), 1.59 (s, 3H), 1.74 (q, J = 7.2 Hz, 2H), 2.00 - 2.08 (m, 1H), 2.23 (dt, J = 16.8, 7.6 Hz, 3H), 2.43 (q, J = 7.4 Hz, 2H), 2.62 - 2.69 (m, 1H), 2.72 (s, 3H), 2.76 - 2.88 (m, 2H), 3.10 (s, 3H), 3.20 (d, J = 12.6 Hz, 1H), 3.25 (s, 3H), 3.31 (s, 3H), 3.39 - 3.54 (m, 2H), 3.93 (s, 3H), 4.01 - 4.26 (m, 5H), 4.53 (dd, J = 12.0, 2.8 Hz, 1H), 5.32 (q, J = 6.8 Hz, 1H), 5.49 - 5.63 (m, 1H), 5.92 (d, J = 1.4 Hz, 1H), 6.48 - 6.62 (m, 3H), 6.88 (s, 1H), 7.18 (d, J = 1.8 Hz, 1H), 8.10 (d, J = 6.5 Hz, 1H), 8.16 (d, J = 7.7 Hz, 1H), 8.41 (t, J = 6.3 Hz, 1H).
7.
HOOC-(CH
2
)
3
-CO-펩티드-NH-CH
2
-S-(CH
2
)
n
-CO
2
-DM (화합물들 19a-19j)
HOOC-(CH2)3-CO-펩티드-NH-CH2-S-(CH2)n-CO2-DM 유형의 화합물들은 도 9B에 나타낸 것과 같이 준비하였고, HOOC-(CH2)3-CO-L-Ala-D-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-DM로 구체예화되었다.
HOOC-(CH 2 ) 3- CO-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM(19a): L-Ala-D-Ala-
L-Ala-NH-CH2-S-(CH2)5-CO-DM (17.25 mg, 0.017 mmol)을 글루타르 무수물 (38.5 mg, 0.337 mmol)로 처리하고, 실온에서 아르곤 하에서 자석 교반시키면서 하룻밤 동안 반응시켰다. 미정제 반응물은 XDB-C18, 21.2 x 5 mm, 5 미크론 컬럼을 이용하여 HPLC에 의해 0.1% 포름산을 함유하는 탈이온 수로 용리시키고, 30분에 걸쳐 20ml/분의 유속으로 5%에서 95%까지의 아세토니트릴의 선형 구배로 용리시켜 정제시켰다. 순수한 원하는 산물을 함유하는 분획은 즉시 복합시키고, 냉동 및 동결건조시켜, 백색 고체 3 mg, (15% 수율)를 얻었다. HRMS (M+H)+ 산출값 1136.4987, 수득값 1136.4954. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 0.92 - 1.27 (m, 20H), 1.26 - 1.48 (m, 5H), 1.52 (s, 3H), 1.63 (q, J = 7.1 Hz, 2H), 1.83 - 2.20 (m, 7H), 2.23 - 2.41 (m, 5H), 2.63 (s, 4H), 2.73 (d, J = 9.5 Hz, 1H), 3.02 (s, 3H), 3.36 - 3.50 (m, 2H), 3.86 (s, 3H), 3.91 - 4.24 (m, 7H), 4.45 (d, J = 11.8 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.41 - 5.57 (m, 1H), 5.86 (s, 1H), 6.32 - 6.66 (m, 3H), 6.81 (s, 1H), 7.12 (s, 1H), 8.06 (t, J = 9.1 Hz, 2H), 8.35 (d, J = 11.6 Hz, 1H), 8.62 (s, 1H).
HOOC-(CH 2 ) 3- CO-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (19g): HRMS (M+H)+ 산출값 1136.4987, 수득값 1136.4962.1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 0.97 - 1.14 (m, 13H), 1.14 - 1.26 (m, 3H), 1.28 - 1.45 (m, 5H), 1.52 (s, 3H), 1.62 (p, J = 7.5 Hz, 2H), 1.93 - 2.00 (m, 1H), 2.08 (dt, J = 13.1, 7.4 Hz, 6H), 2.25 - 2.41 (m, 3H), 2.63 (s, 3H), 2.73 (d, J = 9.5 Hz, 1H), 3.02 (s, 3H), 3.18 (s, 3H), 3.31 - 3.48 (m, 2H), 3.86 (s, 3H), 3.93 - 4.19 (m, 6H), 4.45 (dd, J = 12.0, 2.8 Hz, 1H), 5.27 (q, J = 6.8 Hz, 1H), 5.43 - 5.58 (m, 1H), 5.85 (s, 1H), 6.40 - 6.61 (m, 3H), 6.81 (s, 1H), 7.11 (d, J = 1.8 Hz, 1H), 8.03 (d, J = 6.5 Hz, 1H), 8.13 (d, J = 7.8 Hz, 1H), 8.34 (t, J = 6.3 Hz, 1H), 11.94 (s, 1H).
HOOC-(CH 2 ) 3 -CO-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 3 -CO-DM (19i): HRMS (M+H)+ 산출값 1108.4674, 수득값 1108.4634. 1H NMR (400 MHz, DMSO-d6) δ 0.78 (s, 3H), 1.04 - 1.32 (m, 16H), 1.45 (d, J = 12.6 Hz, 2H), 1.60 (s, 3H), 1.69 (p, J = 7.2 Hz, 3H), 1.77 - 1.95 (m, 1H), 1.99 - 2.07 (m, 1H), 2.11 - 2.20 (m, 4H), 2.20 - 2.39 (m, 1H), 2.55 (s, 1H), 2.71 (s, 3H), 2.80 (d, J = 9.5 Hz, 1H), 3.12 (s, 3H), 3.40 (d, J = 21.0 Hz, 8H), 3.49 (d, J = 9.1 Hz, 1H), 3.93 (s, 3H), 4.02 - 4.27 (m, 6H), 4.48 - 4.61 (m, 1H), 5.34 (q, J = 6.6 Hz, 1H), 5.48 - 5.65 (m, 1H), 5.92 (s, 1H), 6.50 - 6.71 (m, 3H), 6.88 (s, 1H), 7.18 (s, 1H), 7.99 (d, J = 7.6 Hz, 1H), 8.08 (d, J = 6.5 Hz, 1H), 8.22 (d, J = 7.4 Hz, 1H), 8.30 (s, 1H), 8.42 (s, 1H).
8. NHS-OOC-(CH 2 ) 3- CO-펩티드-NH-CH 2 -S-(CH 2 ) n -CO 2 -DM (화합물 20a-20j) NHS-OOC-(CH2)3-CO-펩티드-NH-CH2-S-(CH2)n-CO2-DM 유형의 화합물들은 도 9B에 나타낸 것과 같이 준비하였고, NHS-OOC-(CH2)3-CO-D-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-DM로 구체예화되었다.
NHS-OOC-(CH 2 ) 3 -CO-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (20g): HOOC-(CH2)3 -CO-D-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-DM (8 mg 7.5 μmol) DMSO (1 mL)에 용해시키고, NHS (0.9 mg, 7.51 μmol) 및 EDC (1.4 mg, 7.51 μmol)로 처리하였다. 반응을 아르곤 대기 하에서 자석 교반시키면서 실온에서 2시간 동안 자기 교반하면서 진행시켰다. 미정제 재료는 HPLC을 통하여 XDB-C18, 21.2 x 5mm, 5 μm 컬럼을 이용하여 0.1% 포름산을 함유하는 탈이온 수로 용리시키고, 20ml/분의 유속으로 30분에 걸쳐 5%에서 95%까지의 아세토니트릴의 선형 구배로 용리시켜 정제하였다. 원하는 산물을 함유하는 분획 복합시키고, 즉시 냉동시키고, 그 다음 동결건조시켜, 백색 고체 6.5 mg (74% 수율)를 얻었다. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.00 - 1.14 (m, 13H), 1.14 - 1.25 (m, 3H), 1.29 - 1.46 (m, 5H), 1.52 (s, 3H), 1.75 (p, J = 7.5 Hz, 2H), 1.92 - 2.12 (m, 2H), 2.16 (t, J = 7.3 Hz, 2H), 2.22 - 2.39 (m, 3H), 2.62 (d, J = 10.8 Hz, 5H), 2.73 (d, J = 10.5 Hz, 5H), 3.02 (s, 3H), 3.18 (s, 3H), 3.32 - 3.47 (m, 2H), 3.86 (s, 3H), 3.95 - 4.19 (m, 6H), 4.45 (dd, J = 12.0, 2.8 Hz, 1H), 5.27 (q, J = 6.8 Hz, 1H), 5.42 - 5.57 (m, 1H), 5.82 - 5.87 (m, 1H), 6.41 - 6.60 (m, 4H), 6.81 (s, 1H), 7.11 (d, J = 1.7 Hz, 1H), 8.05 (d, J = 6.5 Hz, 1H), 8.10 (d, J = 7.7 Hz, 1H), 8.20 (d, J = 4.8 Hz, 1H), 8.29 (t, J = 6.3 Hz, 1H).
NHS-OOC-(CH 2 ) 3 -CO-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM (20g): HRMS (M+H)+ 산출값 1233.5151, 수득값 1233.5135.
NHS-OOC-(CH 2 ) 3 -CO-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 3 -CO-DM (20i): HRMS (M+H)+ 산출값 1205.4838, 수득값 1205.4808.
9.
Mal-(CH
2
)
3
-CO-펩티드-NH-CH
2
-S-(CH
2
)
n
-CO-DM (화합물들 23a-23j)
화합물들 23a-23j은 도 9B에 나타낸 것과 같이 준비하였고, 화합물 23c로 구체예화되었다.
Mal-(CH 2 ) 3 -CO-L-Ala-D-Ala-L-Ala-NH-CH 2 -S-(CH 2 ) 5 -CO-DM 또는 Mal-LDL-DM (23c): H2N-L-Ala-D-Ala-L-Ala-CH2-S-(CH2) 5 -CO-DM (8 mg, 7.82 μmol)는 DMF (2 mL)에 용해시켰고, 3-말레이미도프로파논산 (1.32 mg, 7.82 μmol), EDC (2.25 mg, 0.012 mmol) 및 HOBt (1.198 mg, 7.82 μmol)로 처리하였다. 반응을 아르곤 대기 하에서 자석 교반시키면서 실온에서 2시간 동안 자기 교반하면서 진행시켰다. 미정제 재료는 세미-예비 HPLC를 통하여 XDB-C18, 21.2x5mm, 5 μm을 이용하여 0.1% 포름산을 함유하는 탈이온 수로 용리시키고, 20ml/분의 유속으로 30분에 걸쳐 5%에서 95%까지의 아세토니트릴의 선형 구배로 용리시켜 정제하였다. 원하는 산물을 함유하는 분획은 즉시 복합시키고, 및 냉동시키고, 그 다음 동결건조시켜, 백색 고체 1.8 mg (19.60% 수율)를 얻었다. HRMS (M+H)+ 산출값. 1173.4940, 수득값 1173.4931. HRMS (M+H)+ 산출값 1173.4940, 수득값 1173.4931. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.02 - 1.14 (m, 15H), 1.16 - 1.25 (m, 3H), 1.30 - 1.44 (m, 5H), 1.52 (s, 3H), 1.92 - 2.03 (m, 1H), 2.03 - 2.17 (m, 1H), 2.23 - 2.39 (m, 4H), 2.63 (s, 3H), 2.73 (d, J = 9.6 Hz, 1H), 3.02 (s, 3H), 3.18 (s, 4H), 3.33 - 3.46 (m, 2H), 3.52 (t, J = 7.3 Hz, 2H), 3.86 (s, 3H), 3.95 - 4.17 (m, 7H), 4.45 (dd, J = 12.0, 2.9 Hz, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.44 - 5.56 (m, 1H), 5.85 (s, 1H), 6.39 - 6.64 (m, 3H), 6.81 (s, 1H), 6.86 (s, 1H), 6.92 (s, 2H), 7.11 (d, J = 1.7 Hz, 1H), 7.89 (d, J = 7.4 Hz, 1H), 8.10 (d, J = 7.3 Hz, 1H), 8.17 (d, J = 6.7 Hz, 1H), 8.28 (t, J = 6.3 Hz, 1H), 8.43 (s, 1H).
10.
기타 화합물들

Mal2-LAla-D-Ala-L-Ala-Imm-C6-May

Mal-C5-L-Ala-D-Ala-L-Ala-Imm-C6-May: L-Ala-D-Ala-L-Ala-CH2-S-(CH2)5-CO-MayNMA (화합물 I-1a) (25mg, 0.024 mmol), 그리고 2,5-디옥소피롤리딘-1-일 6-(2,5-디옥소-2,5-디하이드로-1H-피롤-1-일)헥사노에이트 (7.54 mg, 0.024 mmol) 간의 반응으로 Mal-C5-L-Ala-D-Ala-L-Ala-Imm-C6-May (화합물 I-2a) (20.8mg, 0.017 mmol, 70.0% 수율)를 얻었다. LRMS (M+H)+ 산출값 1215.52, 수득값 1216.4. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 3H), 1.05 (d, J = 6.4 Hz, 3H), 1.07 - 1.14 (m, 14H), 1.15 - 1.25 (m, 3H), 1.39 (t, J = 9.2 Hz, 10H), 1.52 (s, 3H), 2.01 (t, J = 7.6 Hz, 3H), 2.26 (t, J = 1.9 Hz, 1H), 2.28 - 2.38 (m, 2H), 2.57 - 2.62 (m, 1H), 2.63 (s, 3H), 2.73 (d, J = 9.6 Hz, 1H), 3.02 (s, 3H), 3.14 (d, J = 12.5 Hz, 1H), 3.18 (s, 3H), 3.29 (t, J = 7.1 Hz, 2H), 3.36 (d, J = 12.5 Hz, 1H), 3.42 (d, J = 9.0 Hz, 1H), 3.86 (s, 3H), 3.96 - 4.05 (m, 1H), 4.04 - 4.15 (m, 4H), 4.41 - 4.48 (m, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.46 - 5.54 (m, 1H), 5.82 - 5.88 (m, 1H), 6.47 - 6.50 (m, 2H), 6.54 (t, J = 11.4 Hz, 2H), 6.82 (s, 1H), 6.92 (s, 2H), 7.11 (d, J = 1.8 Hz, 1H), 7.86 - 7.93 (m, 2H), 7.95 (s, 1H), 8.05 (d, J = 7.4 Hz, 1H), 8.24 (t, J = 6.2 Hz, 1H).
Mal-(CH
2
)
2
-PEG
2
-CO-L-Ala-D-Ala-L-ALa-NH-CH2-S-(CH2)5-CO-MayNMA

Mal-(CH
2
)
2
-PEG
2
-CO-L-Ala-D-Ala-L-ALa-NH-CH
2
-S-(CH
2
)
5
-CO-MayNMA:
L-Ala-D-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-MayNMA (화합물 I-1a) (25mg, 0.024 mmol)와 Mal-아미도-PEG2-NHS (10.40 mg, 0.024 mmol) 간의 반응으로 Mal-(CH2)2-PEG2-CO2-L-Ala-D-Ala-L-ALa-NH-CH2-S-(CH2)5-CO-MayNMA (화합물 I-3a) (14.1mg, 10.58 μmol, 43.3% 수율)을 얻었다. LRMS (M+H)+ 산출값 1332.58, 수득값 1332.95. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 4H), 1.05 (d, J = 6.3 Hz, 4H), 1.07 - 1.14 (m, 15H), 1.18 (d, J = 9.0 Hz, 2H), 1.37 (d, J = 11.8 Hz, 6H), 1.52 (s, 3H), 2.23 - 2.38 (m, 5H), 2.63 (s, 4H), 2.72 (d, J = 9.7 Hz, 1H), 3.02 (s, 3H), 3.07 (q, J = 5.7 Hz, 2H), 3.18 (s, 3H), 3.39 (s, 4H), 3.41 (d, J = 9.9 Hz, 2H), 3.47 - 3.56 (m, 4H), 3.86 (s, 4H), 3.95 - 4.08 (m, 2H), 4.08 - 4.19 (m, 3H), 4.41 - 4.51 (m, 1H), 5.23 - 5.31 (m, 1H), 5.44 - 5.54 (m, 1H), 5.85 (s, 1H), 6.46 - 6.50 (m, 2H), 6.54 (t, J = 11.3 Hz, 2H), 6.83 (s, 1H), 6.93 (s, 2H), 7.12 (s, 1H), 7.88 - 8.00 (m, 2H), 8.01 - 8.08 (m, 2H), 8.27 (t, J = 6.2 Hz, 1H).
Mal-(CH
2
)
2
-PEG
4
-CO-L-Ala-D-Ala-L-ALa-NH-CH
2
-S-(CH
2
)
5
-CO-MayNMA

Mal-(CH
2
)
2
-PEG
4
-CO
2
-L-Ala-D-Ala-L-ALa-NH-CH
2
-S-(CH
2
)
5
-CO-MayNMA:
L-Ala-D-Ala-L-Ala-NH-CH2-S-(CH2)5-CO-MayNMA (화합물 I-la) (25mg, 0.024 mmol)와 Mal-아미도-PEG4-NHS (12.55 mg, 0.024 mmol) 간의 반응으로 Mal-(CH2)2-PEG4-CO2-L-Ala-D-Ala-L-ALa-NH-CH2-S-(CH2)5-CO-MayNMA Mal-PEG4-CO2-C6-LDL-DM (화합물 I-3b) (22.3mg, 0.016 mmol, 64.2% 수율)를 얻었다. LRMS (M+H)+ 산출값 1420.63, 수득값 1420.06. 1H NMR (400 MHz, DMSO-d6) δ 0.71 (s, 4H), 1.05 (d, J = 6.4 Hz, 3H), 1.07 - 1.16 (m, 14H), 1.19 (t, J = 8.1 Hz, 2H), 1.31 - 1.50 (m, 2H), 1.52 (s, 4H), 1.98 (s, 1H), 2.02 - 2.17 (m, 2H), 2.20 - 2.40 (m, 7H), 2.63 (s, 4H), 2.73 (d, J = 9.6 Hz, 1H), 3.02 (s, 3H), 3.05 - 3.12 (m, 2H), 3.18 (s, 3H), 3.28 - 3.36 (m, 1H), 3.37 - 3.45 (m, 15H), 3.47 - 3.57 (m, 4H), 3.86 (s, 4H), 3.94 - 4.08 (m, 2H), 4.12 (ddt, J = 14.5, 7.3, 3.6 Hz, 4H), 4.41 - 4.49 (m, 1H), 5.27 (q, J = 6.7 Hz, 1H), 5.45 - 5.55 (m, 1H), 5.86 (s, 1H), 6.42 - 6.60 (m, 4H), 6.83 (s, 1H), 6.94 (s, 1H), 7.12 (d, J = 1.8 Hz, 1H), 7.89 - 8.00 (m, 2H), 8.00 - 8.09 (m, 2H), 8.26 (t, J = 6.2 Hz, 1H).
실시예 11
항-ADAM9 항체의 리신-연계된 DM 콘쥬게이트 준비
a.
hMAB-A(2I.2)-sSPDB-DM4 준비
hMAB-A(2I.2)은 서열 식별 번호:68의 경쇄 서열과 서열 식별 번호:52의 경쇄 서열을 갖는 (서열 식별 번호:52에서 X는 K임) 인간화된/최적화된 항체다.
hMAB-A(2I.2)-sSPDB-DM4 콘쥬게이트를 준비하기 위해, 단계-별 방식으로 술포-SPDB (sSPDB) 및 DM4 추가되었다. 우선, 50 mM 4-(2-하이드록시에틸)-1-피페라진프로판술폰산 (EPPS), 50 mM 염화나트륨으로 pH 8.1에서 완충된 hMAB-A(2I.2) 항체를 함유하는 용액에 DMA 및 DMA 원액에서 11.5 당량의 sSPDB와 혼합하여, 최종 용매 조성물은 10% (v/v) DMA 및 90% (v/v) 수성 완충제였다. 첫 번째 반응 단계가 4 시간 동안 25℃에서 진행되도록 한 후, DMA 원액으로부터 17.3 당량의 DM4, DMA, 그리고 500 mM EPPS/500 mM 염화나트륨 pH 8.1 완충제를 이 반응 혼합물에 추가하여, 첫 번째 반응 단계에서 10% (v/v) DMA 및 90% (v/v) 수성 완충제의 최종 용매 조성물이 유지되었다. 두 번째 반응 단계는 25℃에서 하룻밤 동안 진행되도록 하였다.
상기 콘쥬게이트는 Sephadex G-25 탈염 컬럼 상에서 10 mM 숙시네이트, 250 mM 글리신, 0.5% 수크로스, 0.01% Tween-20, pH 5.5로 정제되었으며, 10 kDa 분자량 컷오프 막을 이용하여 이 완충제에 대해 투석되었고, 그리고 0.22 μm 주시기 필터를 통하여 여과시켰다.
상기 콘쥬게이트는 UV-vis에 의하면 평균 3.5 mol DM4/mol 항체를 보유하며, SEC에 의하면 99.2% 단량체를 갖고, 그리고 혼합-모드 HPLC에 의하면 ≤ 1.7% 콘쥬게이트안된 DM4를 갖는다. 탈글리코실화된 콘쥬게이트의 LC-MS는 나타내지 않는다.
b.
hMAB-A(2I.2)-S442C-Mal-LDL-DM의 준비
hMAB-A(2I.2)-S442C은 서열 식별 번호:68의 경쇄 서열과 서열 식별 번호:142의 중쇄 서열을 갖는 (이때 X는 K임) 인간화된/최적화된 항체다.
환원된 상태에서 2개의 짝을 이루지 않은 시스테인 잔기들 (중쇄 CH3 영역에서 C442 위치)을 품고 있는 hMAB-A(2I.2)-S442C 항체는 표준 절차를 이용하여 준비하였고, 인산염 완충된 염수 (PBS) pH 7.4, 2 mM EDTA로 정제되었다. 환원된, 그리고 재-산화된 항체 용액을 Mal-LDL-DM (화합물 17a)에 콘쥬게이션에 즉시 이용하였다.
재-산화된 hMAB-A(2I.2)-S442C 항체는 PBS pH 6.0, 2 mM EDTA로 스파이크되었으며, 콘쥬게이션은 10% N-N-디메틸아세트아미드 (DMA, SAFC) 및 5 당량의 Mal-LDL-DM (화합물 17a)을 이용하여 90% 수성 용액에서 실시되었다. 상기 반응물은 25℃에서 하룻밤 동안 항온처리되었다.
반응-후, 상기 콘쥬게이트는 NAP 탈염 컬럼 (GE Healthcare)을 이용하여 10 mM 아세테이트, 9% 수크로스, 0.01% Tween-20, pH 5.0 제형 완충제로 정제되었으며, 0.22 μm PVDF 막을 이용한 주사기 필터를 통하여 여과시켰다.
상기 정제된 콘쥬게이트는 UV-Vis에 의하면 2.1 mol LDL-DM/mol 항체를 갖고, SEC에 의하면 95% 단량체를 갖고, 그리고 SEC/역-상 HPLC 듀얼 컬럼 분석에 의하면 1% 미만의 자유 약물을 갖는다.
c.
hMAB-A(2I.2)-sGMBS-LDL-DM, 3.1 DAR의 준비
콘쥬게이션에 앞서, 60:40 유기:수성 용액 및 최종 농도 3 mM의 술포-GMBS 및 3.9 mM의 LDL-DM을 획득하기 위해, N-N-디메틸아세트아미드 (DMA, SAFC)에서 sGMBS 원액 용액(도 9C)을 LDL-DM (화합물 14c, 도 9A)/DMA 원액과 숙시네이트 완충제 pH 5.0 존재 하에서 혼합하여, sGMBS-LDL-DM을 준비하였다. 이 반응물은 2h 동안 25℃에서 항온처리하였다. 1 mol의 hMAB-A (2I.2)항체에 대해 7.8 mol의 최종 비율의 술포-GMBS-LDL-DM으로, 300 mM 4-(2-하이드록시에틸)-1-피페라진프로판술폰산 (EPPS) pH 8.5 및 10% DMA (v/v)의 5x 용액으로 스파이크된 인산염 완충된 염수 (PBS) pH 7.4 안에 hMAB-A(2I.2) 항체를 함유하는 용액에 미정제 sGMBS-LDL-DM 혼합물을 추가하였다. 상기 반응물은 25℃에서 하룻밤 동안 항온처리되었다.
상기 반응물은 NAP 탈염 컬럼 (GE Healthcare)을 이용하여 10 mM 히스티딘, 250 mM 글리신, 1% 수크로스, 0.01% Tween20, pH 5.5 제형 완충제로 정제시키고, 0.22 μm PVDF 막을 이용한 주사기 필터를 통하여 여과시켰다.
상기 정제된 콘쥬게이트는 UV-Vis에 의하면 3.1 mol LDL-DM/mol 항체를 갖고, SEC에 의하면 97% 단량체를 갖고, 그리고 SEC/역-상 HPLC 듀얼 컬럼 분석에 의하면 4% 미만의 자유 약물을 갖는다.
d.
hMAB-A(2I.2)-sGMBS-LDL-DM, 2.0 DAR의 준비
콘쥬게이션에 앞서, 60/40의 유기/수성 용액 및 최종 농도 3 mM의 술포-GMBS 및 3.9 mM의 LDL-DM을 획득하기 위해, N-N-디메틸아세트아미드 (DMA, SAFC)에서 sGMBS 원액 용액을 숙시네이트 완충제 pH 5.0 존재 하에서 DMA에서 LDL-DM (화합물 14c, 도 9A)의 원액과 혼합하여, sGMBS-LDL-DM을 준비하였다. 이 반응물은 2h 동안 25℃에서 항온처리하였다. 1 mol의 hMAB-A (2I.2)항체에 대해 3 mol의 최종 비율의 sGMBS-LDL-DM으로, 300 mM 4-(2-하이드록시에틸)-1-피페라진프로판술폰산 (EPPS) pH 8.5 및 10% DMA (v/v)의 5x 용액으로 스파이크된 인산염 완충된 염수 (PBS) pH 7.4내 hMAB-A(2I.2) 항체를 함유하는 용액에 미정제 sGMBS-LDL-DM 혼합물을 추가하였다. 상기 반응물은 25℃에서 하룻밤 동안 항온처리되었다.
상기 반응물은 NAP 탈염 컬럼 (GE Healthcare)을 이용하여 10 mM 아세테이트, 9% 수크로스, 0.01% Tween20, pH 5.0 제형 완충제로 정제시키고, 0.22 μm PVDF 막을 이용한 주사기 필터를 통하여 여과시켰다.
상기 정제된 콘쥬게이트는 UV-Vis에 의하면 2.0 mol LDL-DM/mol 항체를 갖고, SEC에 의하면 99% 단량체를 갖고, 그리고 SEC/역-상 HPLC 듀얼 컬럼 분석에 의하면 1% 미만의 자유 약물을 갖는다.
e.
hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM의 준비
hMAB-A(2I.2)(YTE/C/-K)은 서열 식별 번호:68의 경쇄 서열과 서열 식별 번호:156의 중쇄 서열을 갖는 인간화된 항체다.
환원된 상태에서 2개의 짝을 이루지 않은 시스테인 잔기들 (중쇄 CH3 영역에서 C442 위치)을 품고 있는 hMAB-A(2I.2)(YTE/C/-K) 항체는 표준 절차를 이용하여 준비하였고, 인산염 완충된 염수 (PBS) pH 7.4, 2 mM EDTA로 정제되었다. 환원된, 그리고 재-산화된 항체 용액을 Mal-LDL-DM에 콘쥬게이션에 즉시 이용하였다.
재-산화된 hMAB-A(2I.2)(YTE/C/-K) 항체는 PBS pH 6.0, 2 mM EDTA로 스파이크되었으며, 콘쥬게이션은 10% N-N-디메틸아세트아미드 (DMA, SAFC) 및 5 당량의 Mal-LDL-DM (화합물 17a)을 이용하여 90% 수성 용액에서 실시되었다. 상기 반응물은 25℃에서 하룻밤 동안 항온처리되었다.
반응-후, 상기 콘쥬게이트는 NAP 탈염 컬럼 (GE Healthcare)을 이용하여 10 mM 아세테이트, 9% 수크로스, 0.01% Tween-20, pH 5.0 제형 완충제로 정제되었으며, 0.22 μm PVDF 막을 이용한 주사기 필터를 통하여 여과시켰다.
상기 정제된 콘쥬게이트는 UV-Vis에 의하면 2.0 mol LDL-DM/mol 항체를 갖고, SEC에 의하면 99% 단량체를 갖고, 그리고 SEC/역-상 HPLC 듀얼 컬럼 분석에 의하면 5% 미만의 자유 약물을 갖는다.
f.
hMAB-A(2I.2)(YTE/-K)-sGMBS-LDL-DM의 준비
hMAB-A(2I.2)(YTE/-K) 항체는 서열 식별 번호:68의 경쇄 서열과 서열 식별 번호:155의 중쇄 서열을 갖는 인간화된 항체다.
콘쥬게이션에 앞서, 60/40의 유기/수성 용액 및 최종 농도 3 mM의 술포-GMBS 및 3.9 mM의 LDL-DM을 획득하기 위해(화합물 14c), N-N-디메틸아세트아미드 (DMA, SAFC)에서 술포-GMBS 원액 용액을 숙시네이트 완충제 pH 5.0 존재 하에서 DMA에서 LDL-DM 원액과 혼합하여, sGMBS-LDL-DM 을 준비하였다. 이 반응물은 2h 동안 25℃에서 항온처리하였다. 1 mol의 hMAB-A(2I.2)(YTE/-K) 항체에 대해 5 mol의 최종 비율의 sGMBS-LDL-DM으로, 300 mM 4-(2-하이드록시에틸)-1-피페라진프로판술폰산 (EPPS) pH 8.5 및 10% DMA (v/v)의 5x 용액으로 스파이크된 인산염 완충된 염수 (PBS) pH 7.4내 hMAB-A(2I.2)(YTE/-K) 항체를 함유하는 용액에 미정제 sGMBS-LDL-DM 혼합물을 추가하였다. 상기 반응물은 25℃에서 하룻밤 동안 항온처리되었다.
상기 반응물은 NAP 탈염 컬럼 (GE Healthcare)을 이용하여 10 mM 아세테이트, 9% 수크로스, 0.01% Tween20, pH 5.0 제형 완충제로 정제시키고, 0.22 μm PVDF 막을 이용한 주사기 필터를 통하여 여과시켰다.
상기 정제된 콘쥬게이트는 UV-Vis에 의하면 3.6 mol LDL-DM/mol 항체를 갖고, SEC에 의하면 99% 단량체를 갖고, 그리고 SEC/역-상 HPLC 듀얼 컬럼 분석에 의하면 4% 미만의 자유 약물을 갖는다.
실시예 12
항-ADAM9 항체 약물 콘쥬게이트의 결합 친화력
항원 결합에 있어서 콘쥬게이션 결과를 평가하기 위하여, ADAM9에 대한 각 항-ADAM9 ADC 및이의 각각의 콘쥬게이트안된 항체의 상대적인 결합 친화력은 인간 ADAM9를 내생적으로 발현시키는 NCI-H1703 세포 상에서 FACS 분석을 통하여 결정하였다. 간략하게 설명하자면, ADAM9-발현시키는 NCI-H1703 세포는 FACS 완충제 (PBS, 0.1% BSA, 0.01% NaN3)에서 4℃에서 30분 동안 항-ADAM9 항체 또는 ADCs의 일련의 희석물과 함께 항온처리하였다. 그 다음 샘플을 세척하였고, 형광-라벨된 제 2 항체와 함께 30 분 동안 4℃에서 항온처리되었다. 각 농도에서 형광 강도의 정상화된 평균을 플로팅하고, 비-선형 회귀 분석(GraphPad Prism 7.0)을 사용하여 결합의 EC50을 계산했다. 이들 연구의 결과는 표 14에 요약되어 있다.
항-ADAM9 항체 및 ADCs는 모두 유동세포측정 분석에 의해 측정하였을 때 대략적으로 0.3 nM의 EC50으로 인간 ADAM9에 유사한 친화력으로 결합되었으며, 이는 콘쥬게이션이 항체 결합 친화력을 현저하게 변경하지 않았음을 나타낸다, 도 10.

실시예 13
항-ADAM9 항체 약물 콘쥬게이트의
시험관내
세포독성
세 개의 ADAM9-발현시키는 폐 암 세포주에 대항하여 LDL-DM 링커/페이로드를 이용한 항-ADAM9 ADCs의 시험관내 세포독성은 비-표적화된 IgG1 ADCs 또는 콘쥬게이트안된 항체로 우선적으로 차단된 세포와 비교하였다. DM4 페이로드를 이용한 항-ADAM9 ADC 또한 비교에 내포시켰다. 구체적으로, 500개 내지 2000개의 세포/웰을 96-웰 플레이트 상에 상기 처리 전, 플레이팅하였다. 콘쥬게이트를 일련의 3-배 희석을 사용하여 배양 배지로 희석시키고, 웰당 100μL을 첨가했다. 콘쥬게이트가 내포되지 않은 세포를 함유하는 웰, 그리고 배지만을 함유하는 웰을 대조군으로 각 분석 플레이트에 포함시켰다. 분석은 각 데이터 포인트에 대해 3 회 수행되었다. 플레이트는 가습된 5% CO2 인큐베이터에서 5 일 동안 37℃에서 항온처리되었다. 그런 다음 WST-8 기반 Cell Counting Kit-8을 사용하여, 각 웰에서 상대적인 생존 세포 수를 결정했다. 먼저 중간 배경 흡광도를 보정한 다음, 각 값을 대조군(비-처리된 세포) 웰 값의 평균으로 나누어 각 웰에서 세포의 생존 분획을 계산했다. 생존 세포의 백분율을 접합체 농도에 대해 플롯하고, 활성의 EC50을 비-선형 회귀 분석(GraphPad Prism 7.0)을 사용하여 계산했다. 표 15, 그리고 도 11A 및 11B에 이들 결과를 제시한다. LDL-DM 콘쥬게이트는 DM4 콘쥬게이트와 비교하여 훨씬 더 큰 특이성 창을 보여준다.

실시예 14
Calu-3 인간 비-소 세포 폐 선암종 이종이식편을 품고 있는 SCID 마우스에서 항-ADAM9 항체 약물 콘쥬게이트의 항-종양 활성
Calu-3 세포를 품고 있는 SCID 암컷 마우스, 인간 폐 선암종 이종이식편 모델에서 hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR) 콘쥬게이트들에 50μg/kg의 DM (메이탄시노이드) 페이로드의 항-종양 활성이 평가되었다. 면역콘쥬게이트 hMAB-A(2I.2)-S442C-Mal-SPBD-DM4는 Mal-SPDB 링커를 통하여 DM4에 결합된 hMAB-A(2I.2)-S442C 항체를 포함한다:

Calu-3 세포를 접종을 위해 수확하였고, 트립판 블루 배제에 의해 100% 생존력을 결정하였다. 마우스의 오른쪽 뒷 옆구리 영역에 피하 주사를 통하여 0.2ml 50% Matrigel/50% 무 혈청 배지에서 5 x 106 Calu-3 세포를 접종했다. 88-마리의 암컷 CB.17 SCID 마우스 (6주령)를 구했다. 이들 동물 수령 당시, 연구 개시 전 7 일 동안 당해 동물들을 관찰했다. 이들 동물은 도착 시 또는 치료 전, 질환이나 질병의 징후를 보이지 않았다.
56 마리의 마우스를 종양 부피에 따라 7 개 그룹 (그룹당 8 마리의 마우스)으로 무작위 배치했다. 당해 종양 부피는 78.92에서 123.62 (98.60 ± 12.90, 평균 ± SD) mm3 범위였다. 이식 후, 7 일 시점에 종양 부피를 기준으로 마우스를 계측하고, 무작위화하였다. 마우스는 이식 후 7 일 시점에 투여되었다(12/19/17). 마우스의 체중은 16.99에서 21.57 그램 (18.89 ± 0.93, 평균 ± SD) 범위였다. 각 그룹의 마우스는 펀치 방법으로 식별되었다. 27 게이지, ½ 인치 바늘이 장착된 1.0 ml 주사기를 사용하여, 시험 제제 및 비히클을 정맥 내로 투여하였다. 항체 약물 콘쥬게이트 시험 제제는 50μg/kg의 DM 페이로드로 qd x1로 투여되며, 이는 DAR ~3.5 콘쥬게이트의 경우 ~2.5 mg/kg 항체에 해당되며, DAR ~2.0 콘쥬게이트의 경우 ~4.3 mg/kg 항체에 해당된다. 그룹에는 다음이 내포된다: 비히클 (PBS, 150 μL)이 투여된 대조군 그룹, hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), 2.6 mg/kg 항체, hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), 2.9 mg/kg 항체, hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), 4.3 mg/kg 항체, hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), 5.1 mg/kg 항체, hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 5.3 mg/kg 항체, 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR), 5.3 mg/kg 항체.
캘리퍼(caliper)를 사용하여 3 차원으로 종양 크기를 주 2 회 측정하였다. 종양 부피는 다음의 공식을 사용하여 나타낸다: 부피 (mm3) = 길이 x 폭 x 높이 x ½. 마우스는 종양 부피가 50% 또는 그 이상 감소될 때, 부분 회귀 (PR)로 간주되며, 만져질 수 있는 종양이 발견되지 않을 때 완전한 종양 회귀 (CR)로 간주되고, 그리고 연구 종료 시점에서 만져질 수 있는 종양이 발견되지 않는 종양-없이 생존한 경우 (TFS)로 간주되었다. 종양 부피는 StudyLog 소프트웨어에 의해 결정되었다.
종양 성장 억제 (T/C%)는 미리-정해둔 시점 (이를 테면, 마우스를 안락사 시켰을 시점에서 당해 대조군 종양의 정중 TV가 최대 종양 부피 ~1000mm3에 이른 시점)에서 대조군 그룹(C)의 정중 TV에 대한 처리 그룹(T)의 정중 종양 부피(TV)의 비율이다. T/C%는 당해 대조군 그룹의 정중 TV가 953 mm3에 이를 때, 접종 후 58일 시점에서 산출되었다. NCI 표준에 따르면 T/C ≤42%는 항-종양 활성의 최소 수준이며, 따라서 T/C <10%는 높은 항-종양 활성 수준으로 간주된다. 종양 성장 지연 (T-C)은 1000 mm3의 예정된 크기에 도달하기 위해, 처리 그룹 (T)과 대조군 그룹 종양 (C)에 대한 정중 시점(일자) 간에 차이다 (종양-없는 생존개체들은 배제됨). 종양 배가 시간 (Td)은 대조군 종양 성장의 일일 정중 값의 비-선형 지수 곡선 맞춤으로부터 추정되며, StudyLog 소프트웨어에 의해 결정된다. Td는 16.9일이었으며, R2=0.998이다. Log10 세포 사멸 (LCK)은 공식 LCK = (T-C)/Td x 3.32로 계산되며, 여기서 3.32는 세포 성장 로그 당 세포 배가 수치다. LCK에 대한 Southern Research Institute (SRI) 활성 기준은 다음과 같다: <0.7:-(비활성), 0.7-1.2: +, 1.3-1.9: ++, 2.0-2.8: +++, >2.8: ++++ (매우 활성).
모든 마우스의 체중 (BW)은 약물 독성의 대략적인 지표로 주당 2 회 측정되었으며, StudyLog 소프트웨어에 의해 결정되었다. 마우스의 체중은 다음과 같이 처치 전 체중으로부터 체중 변화 퍼센트로 표현되었다: BW 변화%= [(BWpost/BWpre)-1] x 100, 여기서 BWpost는 처치-후 체중이고, BWpre은 출발 체중이다. 체중 감소 백분율 (BWL)은 치료 후 체중의 평균 변화로 표현되었다. 종양 부피가 1000 mm3이상이 되거나 또는 종양의 괴사가 시작되거나, 마우스가 초기 체중의 >20%으로 상실하거나 또는 마우스가 연구 중 언제라도 빈사 상태인 경우, 당해 동물을 안락사시켰다.
상기 연구의 결과는 도 12에 나타낸다. LDL-DM ADCs는 모두다 SPDB-DM4 대응부에 비해 더 활성이 있었다. hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR) 콘쥬게이트의 종양 성장 억제 (T/C) 값은 30% (활성), 종양 성장 지연 (T-C) 값은 34일, 그리고 log 10 세포 사멸 (LCK) 값은 6.7 (++++)을 갖고, 그리고 8 마리의 마우스에서 1 마리는 부분 종양 회귀를 가졌으며, 완전한 회귀는 없었다. hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR) 콘쥬게이트의 종양 T/C 값은 7% (매우 활성), T-C) 값은 >66일, LCK 값은 13.0 (++++)을 갖고, 그리고 8 마리의 마우스에서 6 마리는 부분 종양 회귀를 가졌으며, 완전한 회귀는 없었다. 이것은 hMAB-A(2I.2)-sGMBS-LDL-DM이 ~3.5 DAR에서 hMAB-A(2I.2)-sSPDB-DM4보다 더 활성이 있음을 설명하는 것이다. hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)는 T/C 값 58% (비활성), T-C 값 20일, 그리고 LCK 값 4.0 (++++)을 갖고, 그리고 8 마리 마우스중 부분적인 종양 회귀는 0이며, 그리고 완전 회귀는 0이다. hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR)은 T/C 값 15% (활성), T-C 값 47 일, 그리고 LCK 값 9.2 (++++), 그리고 8 마리의 마우스에서 6 마리는 부분 종양 회귀를 가졌으며, 완전한 회귀는 1 마리였다. 이것은 hMAB-A(2I.2)-sGMBS-LDL-DM은 ~2.0 DAR에서 hMAB-A(2I.2)-sSPDB-DM4보다 더 활성이 있음을 설명한다. hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR)는 T/C 값 97% (비활성), T-C 값 3 일, 그리고 LCK 값 0.6 (-)을 갖고, 8 마리 마우스중 부분적인 종양 회귀는 0이며, 그리고 완전 회귀는 0이다. hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR)는 T/C 값 15% (활성), T-C 값 39 일, 그리고 LCK 값 7.7 (++++)을 갖고, 그리고 8 마리의 마우스에서 6 마리는 부분 종양 회귀를 가졌으며, 완전한 회귀는 2 마리였다. 이것은 hMAB-A(2I.2)-S442C-Mal-LDL-DM이 부위 특이적 콘쥬게이션을 갖는 DAR ~2.0에서 hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 보다 더 활성이 있음을 설명하는 것이다. 표시된 용량에서 ADCs중 어느 것에서도 유의적인 체중 감소가 관찰되지 않았으며, 따라서 이 연구에서 6 개의 콘쥬게이트 모두가 마우스에서 잘 용인되었다.
또한, DAR ~2.0 ADCs는 DAR ~3.5 대응부와 필적되는 활성이 있었다. 구체적으로, hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR)는 hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR) 및 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR) 만큼 활성을 가졌다. 내약성과 독성은 페이로드 농도에 의해 결정되기 때문에 DAR 2.0이 있는 ADC는 DAR 3.5가 있는 ADC보다 더 높은 항체 농도로 투여될 수 있다. DAR 2.0 ADC의 증가된 노출은 표적-매개된 약물 배치 (TMDD)를 포화시키고 및/또는 종양 침투를 증가시킴으로써 효능을 향상시킬 수 있다. 이 연구의 결과는 hMAB-A (2I.2)-S442C-Mal-LDL-DM (1.8 DAR) 콘쥬게이트가 강력한 항-종양 활성을 보여주며, Calu-3 비-소 세포 폐 선암종 종양 이종이식편 모델에서 매우 효과적임을 시사한다.
실시예 15
H1703 인간 비-소 세포 폐 편평 세포 암종 이종이식편을 품고 있는 누드 마우스에서 항-ADAM9 항체 약물 콘쥬게이트의 항-종양 활성
H1703 세포를 품고 있는 암컷 누드 마우스의 인간 비-소 세포 폐 편평 세포 암종 이종이식편 모델에서 hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR)의 50μg/kg의 DM 페이로드의 항-종양 활성이 평가되었다.
H1703 세포를 접종을 위해 수확하였고, 트립판 블루 배제에 의해 100% 생존력을 결정하였다. 마우스의 오른쪽 뒷 옆구리 영역에 피하 주사를 통하여 0.2ml 50% Matrigel/50% 무 혈청 배지에서 5 x 106 H1703 세포를 접종했다. 66-마리 암컷 무-흉선 Nude-Foxn1nu 마우스 (6주령)를 구했다. 이들 동물 수령 당시, 연구 개시 전 3 일 동안 당해 동물들을 관찰했다. 이들 동물은 도착 시 또는 치료 전, 질환이나 질병의 징후를 보이지 않았다.
42-마리 마우스를 종양 부피에 따라 7 개 그룹 (그룹당 6 마리의 마우스)으로 무작위 배치했다. 당해 종양 부피는 61.84 내지 310.17 mm3 (128.05 ± 46.61, 평균 ± SD) 범위였다. 이식 후, 26 일 시점에 종양 부피를 기준으로 마우스를 계측하고, 무작위화하였다. 마우스는 이식 후 27 일 시점에 투여되었다(12/19/17). 마우스의 체중은 19.69 내지 26.59 (23.54 ± 1.61, 평균 ± SD) 그램 범위였다. 각 그룹의 마우스는 펀치 방법으로 식별되었다. 27 게이지, ½ 인치 바늘이 장착된 1.0 ml 주사기를 사용하여, 시험 제제 및 비히클을 정맥 내로 투여하였다. 항체 약물 콘쥬게이트 시험 제제는 50μg/kg의 DM 페이로드로 qd x1로 투여되며, 이는 DAR ~3.5 콘쥬게이트의 경우 ~2.5 mg/kg 항체에 해당되며, DAR ~2.0 콘쥬게이트의 경우 ~4.3 mg/kg 항체에 해당된다. 그룹에는 다음이 내포된다: 비히클 (PBS, 150 μL)이 투여된 대조군 그룹, hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), 2.6 mg/kg 항체, hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), 2.9 mg/kg 항체, hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), 4.3 mg/kg 항체, hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), 5.1 mg/kg 항체, hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 5.3 mg/kg 항체, 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR), 5.3 mg/kg 항체.
캘리퍼를 사용하여 3 차원으로 종양 크기를 주 2 회 측정하였다. 종양 부피는 다음의 공식을 사용하여 나타낸다: 부피 (mm3) = 길이 x 폭 x 높이 x ½. 마우스는 종양 부피가 50% 또는 그 이상 감소될 때, 부분 회귀 (PR)로 간주되며, 만져질 수 있는 종양이 발견되지 않을 때 완전한 종양 회귀 (CR)로 간주되고, 그리고 연구 종료 시점에서 만져질 수 있는 종양이 발견되지 않는 종양-없이 생존한 경우 (TFS)로 간주되었다. 종양 부피는 StudyLog 소프트웨어에 의해 결정되었다.
종양 성장 억제 (T/C%)는 미리-정해둔 시점 (이를 테면, 마우스를 안락사 시켰을 시점에서 당해 대조군 종양의 정중 TV가 최대 종양 부피 ~1000mm3에 이른 시점)에서 대조군 그룹(C)의 정중 TV에 대한 처리 그룹(T)의 정중 종양 부피(TV)의 비율이다. T/C%는 당해 대조군 그룹의 정중 TV가 1206 mm3에 이를 때, 접종 후 44일 시점에서 산출되었다. NCI 표준에 따르면 T/C ≤42%는 항-종양 활성의 최소 수준이며, 따라서 T/C <10%는 높은 항-종양 활성 수준으로 간주된다. 종양 성장 지연 (T-C)은 1000 mm3의 예정된 크기에 도달하기 위해, 처리 그룹 (T)과 대조군 그룹 종양 (C)에 대한 정중 시점(일자) 간에 차이다 (종양-없는 생존개체들은 배제됨). 종양 배가 시간 (Td)은 대조군 종양 성장의 일일 정중 값의 비-선형 지수 곡선 맞춤으로부터 추정되며, StudyLog 소프트웨어에 의해 결정된다. Td는 7.60일이었으며, R2=0.994이다. Log10 세포 사멸 (LCK)은 공식 LCK = (T-C)/Td x 3.32로 계산되며, 여기서 3.32는 세포 성장 로그 당 세포 배가 수치다. LCK에 대한 Southern Research Institute (SRI) 활성 기준은 다음과 같다: <0.7:-(비활성), 0.7-1.2: +, 1.3-1.9: ++, 2.0-2.8: +++, >2.8: ++++ (매우 활성).
모든 마우스의 체중 (BW)은 약물 독성의 대략적인 지표로 주당 2 회 측정되었으며, StudyLog 소프트웨어에 의해 결정되었다. 마우스의 체중은 다음과 같이 처치 전 체중으로부터 체중 변화 퍼센트로 표현되었다: BW 변화%= [(BWpost/BWpre)-1] x 100, 여기서 BWpost는 처치-후 체중이고, BWpre은 출발 체중이다. 체중 감소 백분율 (BWL)은 치료 후 체중의 평균 변화로 표현되었다. 종양 부피가 1000 mm3이상이 되거나 또는 종양의 괴사가 시작되거나, 마우스가 초기 체중의 >20%으로 상실하거나 또는 마우스가 연구 중 언제라도 빈사 상태인 경우, 당해 동물을 안락사시켰다.
상기 연구의 결과는 도 13에 나타낸다. LDL-DM ADCs는 모두다 SPDB-DM4 대응부에 비해 더 활성이 있었다. hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR) 콘쥬게이트의 종양 성장 억제 (T/C) 값은 5% (매우 활성)이며, 종양 성장 지연 (T-C) 값은 32 일이며, 그리고 log 10 세포 사멸 (LCK) 값은 1.3 (++)이며, 그리고 6 마리의 마우스에서 3 마리는 부분 종양 회귀를 가졌으며, 1 마리는 완전환 회귀, 1 마리는 종양-없는 생존 개체다. hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR) 콘쥬게이트의 T/C 값은 0% (매우 활성)이며, T-C 값은 >85 일이며, 그리고 LCK 값은 >3.4 (++++)이고, 그리고 6 마리의 마우스에서 6 마리는 부분 종양 회귀를 가졌으며, 6 마리는 완전환 회귀, 5 마리는 종양-없는 생존 개체다. 이것은 hMAB-A(2I.2)-sGMBS-LDL-DM이 ~3.5 DAR에서 hMAB-A(2I.2)-sSPDB-DM4보다 더 활성이 있음을 설명하는 것이다. hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)는 T/C 값 1% (매우 활성), T-C 값 >66 일, 그리고 LCK 값 >2.6 (+++)을 갖고, 6 마리의 마우스에서 6 마리는 부분 종양 회귀를 가졌으며, 6 마리는 완전환 회귀, 2 마리는 종양-없는 생존 개체다. hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR)는 T/C 값 1% (매우 활성), T-C 값 64 일, 그리고 LCK 값 2.5 (+++)을 갖고, 6 마리의 마우스에서 6 마리는 부분 종양 회귀를 가졌으며, 5 마리는 완전환 회귀, 1 마리는 종양-없는 생존 개체다. 이것은 hMAB-A(2I.2)-sGMBS-LDL-DM은 ~2.0 DAR에서 hMAB-A(2I.2)-sSPDB-DM4 만큼 활성이 있음을 설명한다. hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR)는 T/C 값 36% (활성), T-C 값 13 일, 그리고 LCK 값 0.5 (-)을 갖고, 6 마리 마우스중 부분적인 종양 회귀는 1이며, 완전한 회귀는 없다. hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR)는 T/C 값 1% (매우 활성), T-C 값 38 일, 그리고 LCK 값 1.5 (++)을 갖고, 6 마리의 마우스에서 6 마리는 부분 종양 회귀를 가졌으며, 5 마리는 완전환 회귀, 그리고 4 마리는 종양-없는 생존 개체다. 이것은 hMAB-A(2I.2)-S442C-Mal-LDL-DM이 부위 특이적 콘쥬게이션을 갖는 DAR ~2.0에서 hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 보다 더 활성이 있음을 설명하는 것이다. 표시된 용량에서 ADCs 중 어느 것에서도 유의적인 체중 감소가 관찰되지 않았으며, 따라서 이 연구에서 6 개의 콘쥬게이트 모두가 마우스에서 잘 용인되었다.
또한, DAR ~2.0 ADCs는 DAR ~3.5 대응부와 필적되는 활성이 있었다. 구체적으로, hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR)는 hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR) 및 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR) 만큼 활성을 가졌다. 내약성과 독성은 페이로드 농도에 의해 결정되기 때문에 DAR 2.0이 있는 ADC는 DAR 3.5가 있는 ADC보다 더 높은 항체 농도로 투여될 수 있다. DAR 2.0 ADC의 증가된 노출은 표적-매개된 약물 배치 (TMDD)를 포화시키고 및/또는 종양 침투를 증가시킴으로써 효능을 향상시킬 수 있다. 이 연구의 결과는 hMAB-A (2I.2)-S442C-Mal-LDL-DM (1.8 DAR) 콘쥬게이트가 강력한 항-종양 활성을 보여주며, H1703 비-소 세포 편평 폐 암 종양 이종이식편 모델에서 매우 효과적임을 시사한다.
실시예 16
SNU-5 인간 위 암종 이종이식편을 품고 있는 누드 마우스에서 항-ADAM9 항체 약물 콘쥬게이트의 항-종양 활성
SNU-5 세포를 품고 있는 암컷 누드 마우스의 인간 위 암종 이종이식편 모델에서 hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR) 콘쥬게이트의 50μg/kg의 DM 페이로드의 항-종양 활성이 평가되었다.
SNU-5 세포를 접종을 위해 수확하였고, 트립판 블루 배제에 의해 100% 생존력을 결정하였다. 마우스의 오른쪽 뒷 옆구리 영역에 피하 주사를 통하여 0.1ml 50% Matrigel/50% 무 혈청 배지에서 5 x 106 SNU-5 세포를 접종했다. 66-마리 암컷 무-흉선 Nude-Foxn1nu 마우스 (6주령)를 구했다. 이들 동물 수령 당시, 연구 개시 전 6 일 동안 당해 동물들을 관찰했다. 이들 동물은 도착 시 또는 치료 전, 질환이나 질병의 징후를 보이지 않았다.
42-마리 마우스를 종양 부피에 따라 7 개 그룹 (그룹당 6 마리의 마우스)으로 무작위 배치했다. 당해 종양 부피는 61.84 내지 310.17 (128.05 ± 46.61, 평균 ± SD)mm3 범위였다. 이식 후, 18 일 시점에 종양 부피를 기준으로 마우스를 계측하고, 무작위화하였다. 마우스는 이식 후 20 일 시점에 투여되었다(1/7/18). 마우스의 체중은 19.69 내지 26.59 그램 (23.63 ± 1.57, 평균 ± SD) 범위였다. 각 그룹의 마우스는 펀치 방법으로 식별되었다. 27 게이지, ½ 인치 바늘이 장착된 1.0 ml 주사기를 사용하여, 시험 제제 및 비히클을 정맥 내로 투여하였다. 항체 약물 콘쥬게이트 시험 제제는 50μg/kg의 DM 페이로드로 qdx1로 투여되며, 이는 DAR ~3.5 콘쥬게이트의 경우 ~2.5 mg/kg 항체에 해당되며, DAR ~2.0 콘쥬게이트의 경우 ~4.3 mg/kg 항체에 해당된다. 그룹에는 다음이 내포된다: 비히클 (PBS, 150 μL)이 투여된 대조군 그룹, hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR), 2.6 mg/kg 항체, hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR), 2.9 mg/kg 항체, hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), 4.3 mg/kg 항체, hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR), 5.1 mg/kg 항체, hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR), 5.3 mg/kg 항체, 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR), 5.3 mg/kg 항체.
캘리퍼를 사용하여 3 차원으로 종양 크기를 주 2 회 측정하였다. 종양 부피는 다음의 공식을 사용하여 나타낸다: 부피 (mm3) = 길이 x 폭 x 높이 x ½. 마우스는 종양 부피가 50% 또는 그 이상 감소될 때, 부분 회귀 (PR)로 간주되며, 만져질 수 있는 종양이 발견되지 않을 때 완전한 종양 회귀 (CR)로 간주되고, 그리고 연구 종료 시점에서 만져질 수 있는 종양이 발견되지 않는 종양-없이 생존한 경우 (TFS)로 간주되었다. 종양 부피는 StudyLog 소프트웨어에 의해 결정되었다.
종양 성장 억제 (T/C%)는 미리-정해둔 시점 (이를 테면, 마우스를 안락사 시켰을 시점에서 당해 대조군 종양의 정중 TV가 최대 종양 부피 ~1000mm3에 이른 시점)에서 대조군 그룹(C)의 정중 TV에 대한 처리 그룹(T)의 정중 종양 부피(TV)의 비율이다. T/C%는 당해 대조군 그룹의 정중 TV가 1122 mm3에 이를 때, 접종 후 70일 시점에서 산출되었다. NCI 표준에 따르면 T/C ≤42%는 항-종양 활성의 최소 수준이며, 따라서 T/C <10%는 높은 항-종양 활성 수준으로 간주된다. 종양 성장 지연 (T-C)은 1000 mm3의 예정된 크기에 도달하기 위해, 처리 그룹 (T)과 대조군 그룹 종양 (C)에 대한 정중 시점(일자) 간에 차이다 (종양-없는 생존개체들은 배제됨). 종양 배가 시간 (Td)은 대조군 종양 성장의 일일 정중 값의 비-선형 지수 곡선 맞춤으로부터 추정되며, StudyLog 소프트웨어에 의해 결정된다. Td는 19.7일이었으며, R2=0.986이다. Log10 세포 사멸 (LCK)은 공식 LCK = (T-C)/Td x 3.32로 계산되며, 여기서 3.32는 세포 성장 로그 당 세포 배가 수치다. LCK에 대한 Southern Research Institute (SRI) 활성 기준은 다음과 같다: <0.7:-(비활성), 0.7-1.2: +, 1.3-1.9: ++, 2.0-2.8: +++, >2.8: ++++ (매우 활성).
모든 마우스의 체중 (BW)은 약물 독성의 대략적인 지표로 주당 2 회 측정되었으며, StudyLog 소프트웨어에 의해 결정되었다. 마우스의 체중은 다음과 같이 처치 전 체중으로부터 체중 변화 퍼센트로 표현되었다: BW 변화%= [(BWpost/BWpre)-1] x 100, 여기서 BWpost는 처치-후 체중이고, BWpre은 출발 체중이다. 체중 감소 백분율 (BWL)은 치료 후 체중의 평균 변화로 표현되었다. 종양 부피가 1000 mm3이상이 되거나 또는 종양의 괴사가 시작되거나, 마우스가 초기 체중의 >20%으로 상실하거나 또는 마우스가 연구 중 언제라도 빈사 상태인 경우, 당해 동물을 안락사시켰다.
상기 연구의 결과는 도 14에 나타낸다. LDL-DM ADCs는 모두다 SPDB-DM4 대응부에 비해 더 활성이 있었다. hMAB-A(2I.2)-sSPDB-DM4 (3.6 DAR) 콘쥬게이트의 종양 성장 억제 (T/C) 값은 66% (비활성), 종양 성장 지연 (T-C) 값은 0 일, 그리고 log 10 세포 사멸 (LCK) 값은 0.0 (-)을 갖고, 그리고 6 마리의 마우스에서 2 마리는 부분 종양 회귀를 가졌으며, 완전한 회귀는 없었다. hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR) 콘쥬게이트의 T/C 값은 14% (활성), T-C 값은 45 일, 그리고 LCK 값은 0.7 (+)이며, 6 마리의 마우스에서 4 마리는 부분 종양 회귀를 가졌으며, 1 마리는 완전환 회귀, 그리고 1 마리는 종양-없는 생존 개체다. 이것은 hMAB-A(2I.2)-sGMBS-LDL-DM이 ~3.5 DAR에서 hMAB-A(2I.2)-sSPDB-DM4보다 더 활성이 있음을 설명하는 것이다. hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)는 T/C 값 47% (비활성), T-C 값 10 일, 그리고 LCK 값 0.2 (-)을 갖고, 6 마리의 마우스에서 1 마리는 부분 종양 회귀를 가졌으며, 1 마리는 완전환 회귀, 1 마리는 종양-없는 생존 개체다. hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR)는 T/C 값 41% (활성), T-C 값 10 일, 그리고 LCK 값 0.2 (-)을 갖고, 6 마리의 마우스에서 2 마리는 부분 종양 회귀를 가졌으며, 1 마리는 완전환 회귀, 그리고 1 마리는 종양-없는 생존 개체다. 이것은 hMAB-A(2I.2)-sGMBS-LDL-DM은 ~2.0 DAR에서 hMAB-A(2I.2)-sSPDB-DM4 보다 더 활성이 있음을 설명한다. hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 (1.8 DAR)는 T/C 값 107% (비활성), T-C 값 -11 일, 그리고 LCK 값 -0.2 (-)를 갖고, 6 마리의 마우스에서 1 마리는 부분 종양 회귀를 가졌으며, 1 마리는 완전환 회귀, 그리고 1 마리는 종양-없는 생존 개체다. hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR)는 T/C 값 22% (활성), T-C 값 28 일, 그리고 LCK 값 0.4 (-)을 갖고, 그리고 6 마리의 마우스에서 2 마리는 부분 종양 회귀를 가졌으며, 1 마리는 완전환 회귀, 그리고 1 마리는 종양-없는 생존 개체다. 이것은 hMAB-A(2I.2)-S442C-Mal-LDL-DM이 부위 특이적 콘쥬게이션을 갖는 DAR ~2.0에서 hMAB-A(2I.2)-S442C-Mal-SPBD-DM4 보다 더 활성이 있음을 설명하는 것이다. 표시된 용량에서 ADCs 중 어느 것에서도 유의적인 체중 감소가 관찰되지 않았으며, 따라서 이 연구에서 6 개의 콘쥬게이트 모두가 마우스에서 잘 용인되었다.
또한, DAR ~2.0 ADCs는 DAR ~3.5 대응부와 필적되는 활성이 있었다. 구체적으로, hMAB-A(2I.2)-sGMBS-LDL-DM (3.3 DAR)는 hMAB-A(2I.2)-sGMBS-LDL-DM (1.9 DAR) 및 hMAB-A(2I.2)-S442C-Mal-LDL-DM (1.8 DAR) 만큼 활성을 가졌다. 내약성과 독성은 페이로드 농도에 의해 결정되기 때문에 DAR 2.0이 있는 ADC는 DAR 3.5가 있는 ADC보다 더 높은 항체 농도로 투여될 수 있다. DAR 2.0 ADC의 증가된 노출은 표적-매개된 약물 배치 (TMDD)를 포화시키고 및/또는 종양 침투를 증가시킴으로써 효능을 향상시킬 수 있다. 이 연구의 결과는 hMAB-A (2I.2)-S442C-Mal-LDL-DM (1.8 DAR) 콘쥬게이트가 항-종양 활성을 보여주며, SNU-5 위 암종 종양 이종이식편 모델에서 효과적임을 시사한다.
실시예 17
EBC-1 인간 비-소 세포 폐 편평 세포 암종 이종이식편을 품고 있는 SCID 마우스에서 항-ADAM9 항체 약물 콘쥬게이트의 항-종양 활성
EBC-1 세포를 품고 있는 암컷 SCID 마우스의 인간 비-소 세포 폐 편평 세포 암종 이종이식편 모델에서 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR) 및 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg DM 페이로드의 항-종양 활성을 나타낸다.
EBC-1 세포를 접종을 위해 수확하였고, 트립판 블루 배제에 의해 100% 생존력을 결정하였다. 마우스의 오른쪽 뒷 옆구리 영역에 피하 주사를 통하여 0.2ml 50% Matrigel/50% 무 혈청 배지에서 5 x 106 EBC-1 세포를 접종했다. 66-마리의 암컷 CB.17 SCID 마우스 (6주령)를 구했다. 이들 동물 수령 당시, 연구 개시 전 6 일 동안 당해 동물들을 관찰했다. 이들 동물은 도착 시 또는 치료 전, 질환이나 질병의 징후를 보이지 않았다.
42-마리 마우스를 종양 부피에 따라 7 개 그룹 (그룹당 6 마리의 마우스)으로 무작위 배치했다. 당해 종양 부피는 79.38 내지 124.29 (95.81 ± 11.83, 평균 ± SD) mm3 범위였다. 이식 후, 7 일 시점에 종양 부피를 기준으로 마우스를 계측하고, 무작위화하고, 투여하였다 (4/16/18). 마우스의 체중은 15.94 내지 21.10 그램 (18.55 ± 1.17, 평균 ± SD) 범위였다. 각 그룹의 마우스는 펀치 방법으로 식별되었다. 27 게이지, ½ 인치 바늘이 장착된 1.0 ml 주사기를 사용하여, 시험 제제 및 비히클을 정맥 내로 투여하였다. 항체 약물 콘쥬게이트 시험 제제는 25, 50, 또는 100μg/kg DM 페이로드로 qd x1로 투여되며, 이는 DAR ~2.0 콘쥬게이트의 경우 ~2, 4, 그리고 9 mg/kg 항체 (Ab)에 해당된다. 그룹에는 다음이 내포된다: 비히클 (PBS, 200 μL)이 투여되는 대조군 그룹, hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR) 2.18, 4.36, 그리고 8.76 mg/kg Ab, 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR) 2.14, 4.28, 그리고 8.57 mg/kg Ab.
캘리퍼를 사용하여 3 차원으로 종양 크기를 주 2 회 측정하였다. 종양 부피는 다음의 공식을 사용하여 나타낸다: 부피 (mm3) = 길이 x 폭 x 높이 x ½. 마우스는 종양 부피가 50% 또는 그 이상 감소될 때, 부분 회귀 (PR)로 간주되며, 만져질 수 있는 종양이 발견되지 않을 때 완전한 종양 회귀 (CR)로 간주되고, 그리고 연구 종료 시점에서 만져질 수 있는 종양이 발견되지 않는 종양-없이 생존한 경우 (TFS)로 간주되었다. 종양 부피는 StudyLog 소프트웨어에 의해 결정되었다.
종양 성장 억제 (T/C%)는 미리-정해둔 시점 (이를 테면, 마우스를 안락사 시켰을 시점에서 당해 대조군 종양의 정중 TV가 최대 종양 부피 ~1000mm3에 이른 시점)에서 대조군 그룹(C)의 정중 TV에 대한 처리 그룹(T)의 정중 종양 부피(TV)의 비율이다. T/C%는 당해 대조군 그룹의 정중 TV가 1279 mm3에 이를 때, 접종 후 28일 시점에서 산출되었다. NCI 표준에 따르면 T/C ≤42%는 항-종양 활성의 최소 수준이며, 따라서 T/C <10%는 높은 항-종양 활성 수준으로 간주된다. 종양 성장 지연 (T-C)은 1000 mm3의 예정된 크기에 도달하기 위해, 처리 그룹 (T)과 대조군 그룹 종양 (C)에 대한 정중 시점(일자) 간에 차이다 (종양-없는 생존개체들은 배제됨). 종양 배가 시간 (Td)은 대조군 종양 성장의 일일 정중 값의 비-선형 지수 곡선 맞춤으로부터 추정되며, StudyLog 소프트웨어에 의해 결정된다. Td는 6.04일이었으며, R2=0.995이다. Log10 세포 사멸 (LCK)은 공식 LCK = (T-C)/Td x 3.32로 계산되며, 여기서 3.32는 세포 성장 로그 당 세포 배가 수치다. LCK에 대한 Southern Research Institute (SRI) 활성 기준은 다음과 같다: <0.7:-(비활성), 0.7-1.2: +, 1.3-1.9: ++, 2.0-2.8: +++, >2.8: ++++ (매우 활성).
모든 마우스의 체중 (BW)은 약물 독성의 대략적인 지표로 주당 2 회 측정되었으며, StudyLog 소프트웨어에 의해 결정되었다. 마우스의 체중은 다음과 같이 처치 전 체중으로부터 체중 변화 퍼센트로 표현되었다: BW 변화%= [(BWpost/BWpre)-1] x 100, 여기서 BWpost는 처치-후 체중이고, BWpre은 출발 체중이다. 체중 감소 백분율 (BWL)은 치료 후 체중의 평균 변화로 표현되었다. 종양 부피가 1000 mm3이상이 되거나 또는 종양의 괴사가 시작되거나, 마우스가 초기 체중의 >20%으로 상실하거나 또는 마우스가 연구 중 언제라도 빈사 상태인 경우, 당해 동물을 안락사시켰다.
상기 연구의 결과는 도 15에 나타낸다. LDL-DM ADC는 SPDB-DM4 대응부 보다 더 활성이 컸다. 25μg/kg의 DM (2.18 mg/kg Ab)에서 투여된 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)는 T/C 값 17% (활성), T-C 값 21 일, 그리고 LCK 값 1.06 (+)을 갖고, 그리고 종양 회귀 또는 종양-없는 생존개체는 없었다. 50μg/kg의 DM (4.36 mg/kg Ab)에서 투여된 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)는 T/C 값 2% (매우 활성), T-C 값 34 일, 그리고 LCK 값 1.68 (++)을 갖고, 그리고 6 마리 마우스중 6마리가 부분 종양 회귀, 1 마리는 완전한 회귀이며, 그리고 종양-없는 생존개체는 없었다. 100μg/kg의 DM (8.76 mg/kg Ab)에서 투여된 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)는 T/C 값 2% (매우 활성), T-C 값 >65 일, 그리고 LCK 값 >3.26 (++++)을 갖고, 그리고 6 마리중 6마리는 부분 종양 회귀, 6 마리는 완전한 회귀, 그리고 2 마리는 종양-없는 생존개체였다. 25μg/kg의 DM (2.14 mg/kg Ab)에서 투여된 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR)는 T/C 값 2% (매우 활성), T-C 값 56 일, 그리고 LCK 값 2.79 (+++)을 갖고, 그리고 6 마리 마우스중 6 마리는 부분 종양 회귀, 3 마리는 완전한 회귀, 그리고 종양-없는 생존개체는 없었다. 50μg/kg의 DM (4.28 mg/kg Ab)에서 투여된 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR)는 T/C 값 2% (매우 활성), T-C 값 >65 일, 그리고 LCK 값 >3.26 (++++)을 갖고, 6 마리 마우스중 6 마리는 부분 종양 회귀, 6 마리는 완전한 회귀, 그리고 종양-없는 생존개체는 없었다. 100μg/kg DM (8.57 mg/kg Ab)에서 투여된 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR)는 T/C 값 1% (매우 활성), T-C 값 >65 일, 그리고 LCK 값 >3.26 (++++)를 갖고, 6마리 마우스중 6 마리는 부분 종양 회귀, 6 마리는 완전한 회귀, 그리고 6마리는 종양-없는 생존개체였다. 표시된 용량에서 ADCs 중 어느 것에서도 유의적인 체중 감소가 관찰되지 않았으며, 따라서 이 연구에서 6 개의 콘쥬게이트 모두가 마우스에서 잘 용인되었다. 이 연구의 결과로부터 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR) 및 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR) 콘쥬게이트는 모두 투여량 의존적 항-종양 활성을 나타내며, EBC-1 비-소 세포 폐 편평 세포 암종 종양 이종이식편 모델에서 효과적임을 시사한다.
실시예 18
SW48 인간 결장직장 선암종 이종이식편을 품고 있는 CD1 누드 마우스에서 항-ADAM9 항체 약물 콘쥬게이트의 항-종양 활성
hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR)의 25, 50, 및 100μg/kg의 DM 페이로드 및 비-결합 대조군 huKTI-Mal-LDL-DM (2.0 DAR) 콘쥬게이트의 100 ug/kg의 DM 페이로드의 항-종양 활성은 SW48 세포를 품고 있는 CD1 암컷 누드 면역결핍 마우스의 인간 결장직장 선암종 이종이식편 모델에서 평가되었다.
SW48 (ATCC CCL-231) 세포를 접종을 위해 수확하였고, 트립판 블루 배제에 의해 90% 이상의 생존력을 결정하였다. 마우스의 오른쪽 뒷 옆구리 영역에 피하 주사를 통하여 0.1ml 50% Matrigel/50% 무 혈청 배지에서 5 x 106 SW48 세포를 접종했다. Charles Rivers Laboratories으로부터 암컷 CD1 누드 마우스 (5-7 주령)를 구하였다. 이들 동물 수령 당시, 연구 개시 전, 3-4 일 동안 당해 동물들을 관찰했다. 이들 동물은 도착 시 또는 치료 전, 질환이나 질병의 징후를 보이지 않았다.
40 마리 마우스를 종양 부피에 따라 5 개 그룹 (그룹당 8 마리의 마우스)으로 무작위 배치했다. 이식 후, 19일차 종양 부피의 범위는 121.33 내지 186.59 (152.49 ± 18.50, 평균 ± SD)mm3 이었다. 19일차 시점에서 종양 부피를 기준으로 마우스를 계측하고, 무작위화하였고, 이식 후 21일차에 투여하였다. 19일차 마우스 체중은 18.80 내지 29.90 (25.75 ± 2.50, 평균 ± SD) 그램 범위였다. 각 그룹의 마우스는 귀 테그 방법으로 식별되었다. 28 게이지, ½ 인치 바늘이 장착된 0.5 ml 주사기를 사용하여, 시험 제제 및 비히클을 꼬리 정맥 주사를 통하여 정맥내로 투여하였다. 항체 약물 콘쥬게이트 시험 제제는 25, 50, 또는 100μg/kg의 DM 페이로드에서 qdxl로 투여되었으며, 이는 상기 DAR ~2.0 콘쥬게이트의 경우 ~2, 4, 그리고 9 mg/kg 항체 (Ab)에 해당된다. 이 그룹에는 다음이 내포된다: 비히클 (IX PBS, 100 μL)이 투여된 대조군, hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR), 2.18, 4.36, 그리고 8.57 mg/kg Ab, 그리고 huKTI-Mal-LDL-DM (2.0 DAR), 8.57 mg/kg Ab.
종양 크기는 전자 캘리퍼스를 사용한 직교 측정에 의해 주 1 회 측정되었고, 당해 그룹에 투여되면 주당 2 회 측정되었다. 종양 부피는 다음의 공식을 사용하여 나타낸다: 부피 (mm3) = 길이 x 폭 x 높이 x ½. 마우스는 투여한 날로부터 종양 부피가 50% 또는 그 이상 감소될 때, 부분 회귀 (PR)로 간주되며, 3 내지 4회 연속 측정에서 만져질 수 있는 종양(≤14.08 mm3)이 발견되지 않을 때 완전한 종양 회귀 (CR)로 간주되고, 그리고 연구 종료 시점에서 만져질 수 있는 종양이 발견되지 않는 종양 (≤14.08 mm3)-없이 생존한 경우 (TFS)로 간주되었다. 종양 부피는 Study Director 소프트웨어 안에서 기록되었다.
종양 성장 억제 (T/C%)은 미리-정해둔 시점 (이를 테면, 연구에서 모든 비히클 대조군 동물이 남아있는 시점)에서 대조군 그룹(C)의 정중 TV에 대한 처리 그룹(T)의 정중 종양 부피(TV)의 비율이다. T/C%는 당해 대조군 그룹의 정중 TV가 663.04mm3에 이를 때, 접종 후 56일 시점에서 산출되었다. NCI 표준에 따르면, T/C ≤42%는 항-종양 활성의 최소 수준이며, 따라서 T/C <10%는 높은 항-종양 활성 수준으로 간주된다.
모든 마우스의 체중 (BW)을 투여 전, 주 1 회 측정하고, 약물 독성의 대략적인 지표로 투여 후 주당 2 회 측정하고, Study Director 소프트웨어 내에 기록되었다. 마우스의 체중은 다음과 같이 처치 전 체중으로부터 체중 변화 퍼센트로 표현되었다: BW 변화%= [(BWpost/BWpre)-1] x 100, 여기서 BWpost는 처치-후 체중이고, BWpre은 출발 체중이다. 체중 감소 백분율 (BWL)은 치료 후 체중의 평균 변화로 표현되었다. 종양 부피가 2000 mm3이상이 되고, 종양이 심각한 궤양 또는 괴사의 징후를 보였고, 마우스가 초기 체중의 >20%으로 상실한 경우, 당해 동물을 안락사시켰다.
연구 결과는 도 16에 나타낸다. hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR)는 100μg/kg DM (8.57 mg/kg Ab)의 투여량에서 매우 활성적이었으며, 부분 회귀는 8/8의 마우스, 완전한 회귀는 7/8의 마우스, 종양-없는 생존개체는 7/8의 마우스, 그리고 T/C%는 1%였다. 50μg/kg의 DM (4.36 mg/kg Ab) 투여 수준에서, hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR)는 활성적이었으며, 부분 회귀는 5/8의 마우스, 완전한 회귀 2/8의 마우스, 종양-없는 생존개체는 2/8의 마우스이었으며, 그리고 T/C%는 15%였다. hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR)는 NCI 표준에 따르면 25μg/kg의 DM (2.18 mg/kg Ab)에서 비활성으로 간주되었으며, 부분 회귀는 1/8의 마우스, 완전한 회귀는 0/8의 마우스, 종양-없는 생존개체는 0/8의 마우스, 그리고 T/C%는 51%였다. 결과로부터 상기 비-결합 대조군 huKTI-Mal-LDL-DM (2.0 DAR) 콘쥬게이트가 100μg/kg의 DM (8.57 mg/kg Ab)에서 비활성적이었기 때문에, hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR)는 ADAM9-표적화되었다는 것이 설명되었으며, 0/8은 부분 회귀, 0/8은 완전한 회귀, 0/8은 종양-없는 생존개체이며, 그리고 T/C%는 93%였다. 표시된 용량에서 ADCs 중 어느 것에서도 유의적인 체중 감소가 관찰되지 않았으며, 따라서 이 연구에서 모든 콘쥬게이트가 마우스에서 잘 용인되었다. 이 연구로부터 hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR) 콘쥬게이트는 용량 의존적 표적화된 항-종양 활성을 실증하였고, SW48 결장직장 선암종 이종이식편 모델에서 효과적임을 시사한다.
실시예 19
HPAF-II 인간 췌장 선암종 이종이식편을 품고 있는 CD1 누드 마우스에서 항-ADAM9 항체 약물 콘쥬게이트의 항-종양 활성
hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR)의 25, 50, 및 100μg/kg의 DM 페이로드 및 비-결합 대조군 huKTI-Mal-LDL-DM (2.0 DAR) 콘쥬게이트의 100 ug/kg의 DM 페이로드의 항-종양 활성은 HPAF-II 세포를 품고 있는 CD1 암컷 누드 면역결핍 마우스의 인간 췌장 선암종 이종이식편 모델에서 평가되었다.
HPAF-II (ATCC CRL-1997) 세포를 접종을 위해 수확하였고, 트립판 블루 배제에 의해 90% 이상의 생존력을 결정하였다. 마우스의 오른쪽 뒷 옆구리 영역에 피하 주사를 통하여 0.1ml 50% Matrigel/50% 무 혈청 배지에서 5 x 106 HPAF-II세포를 접종했다. Charles Rivers Laboratories으로부터 암컷 CD1 누드 마우스 (5-7 주령)를 구하였다. 이들 동물 수령 당시, 연구 개시 전, 3-4 일 동안 당해 동물들을 관찰했다. 이들 동물은 도착 시 또는 치료 전, 질환이나 질병의 징후를 보이지 않았다.
35-마리 마우스를 종양 부피에 따라 5 개 그룹 (그룹당 7 마리의 마우스)으로 무작위 배치했다. 이식 후, 15일차 종양 부피의 범위는 81.64 내지 136.77 (104.94 ± 13.89, 평균 ± SD)mm3 이었다. 15일차 시점에서 종양 부피를 기준으로 마우스를 계측하고, 무작위화하였고, 이식 후 16일차에 투여하였다. 15일차 마우스 체중은 21.00 내지 28.60 (25.21 ± 1.70, 평균 ± SD) 그램 범위였다. 각 그룹의 마우스는 귀 테그 방법으로 식별되었다. 28 게이지, ½ 인치 바늘이 장착된 0.5 ml 주사기를 사용하여, 시험 제제 및 비히클을 꼬리 정맥 주사를 통하여 정맥내로 투여하였다. 항체 약물 콘쥬게이트 시험 제제는 25, 50, 또는 100μg/kg의 DM 페이로드로 에서 qdxl로 투여되었으며, 이는 상기 DAR ~2.0 콘쥬게이트의 경우 ~2, 4, 그리고 9 mg/kg 항체 (Ab)에 해당된다. 이 그룹에는 다음이 내포된다: 비히클 (IX PBS, 100 μL)이 투여된 대조군, hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR), 2.18, 4.36, 그리고 8.57 mg/kg Ab, 그리고 huKTI-Mal-LDL-DM (2.0 DAR), 8.57 mg/kg Ab.
종양 크기는 전자 캘리퍼스를 사용한 직교 측정에 의해 주 1 회 측정되었고, 당해 그룹에 투여되면 주당 2 회 측정되었다. 종양 부피는 다음의 공식을 사용하여 나타낸다: 부피 (mm3) = 길이 x 폭 x 높이 x ½. 마우스는 투여한 날로부터 종양 부피가 50% 또는 그 이상 감소될 때, 부분 회귀 (PR)로 간주되며, 3 내지 4회 연속 측정에서 만져질 수 있는 종양(≤14.08 mm3)이 발견되지 않을 때 완전한 종양 회귀 (CR)로 간주되고, 그리고 연구 종료 시점에서 만져질 수 있는 종양이 발견되지 않는 종양 (≤14.08 mm3)-없이 생존한 경우 (TFS)로 간주되었다. 종양 부피는 Study Director 소프트웨어 안에서 기록되었다.
종양 성장 억제 (T/C%)은 미리-정해둔 시점 (이를 테면, 연구에서 모든 비히클 대조군 동물이 남아있는 시점)에서 대조군 그룹(C)의 정중 TV에 대한 처리 그룹(T)의 정중 종양 부피(TV)의 비율이다. T/C%는 당해 대조군 그룹의 정중 TV가 882.83mm3에 이를 때, 접종 후 47일 시점에서 산출되었다. NCI 표준에 따르면, T/C ≤42%는 항-종양 활성의 최소 수준이며, 따라서 T/C <10%는 높은 항-종양 활성 수준으로 간주된다.
모든 마우스의 체중 (BW)을 투여 전, 주 1 회 측정하고, 약물 독성의 대략적인 지표로 투여 후 주당 2 회 측정하고, Study Director 소프트웨어 내에 기록되었다. 마우스의 체중은 다음과 같이 처치 전 체중으로부터 체중 변화 퍼센트로 표현되었다: BW 변화%= [(BWpost/BWpre)-1] x 100, 여기서 BWpost는 처치-후 체중이고, BWpre은 출발 체중이다. 체중 감소 백분율 (BWL)은 치료 후 체중의 평균 변화로 표현되었다. 종양 부피가 2000 mm3이상이 되고, 종양이 심각한 궤양 또는 괴사의 징후를 보였고, 마우스가 초기 체중의 >20%으로 상실한 경우, 당해 동물을 안락사시켰다.
연구 결과는 도 17에 나타낸다.hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR)는 100μg/kg의 DM (8.57 mg/kg Ab)에서 매우 활성적이며, 부분 회귀는 7/7의 마우스, 완전한 회귀는 3/7의 마우스, 종양-없는 생존개체는 3/7의 마우스이었으며, 그리고 T/C%는 3%이었다. 50μg/kg의 DM (4.36 mg/kg Ab)의 투여 수준에서, hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR)는 활성이었으며, 부분 회귀는 5/7의 마우스, 완전한 회귀는 1/7의 마우스, 종양-없는 생존개체는 1/7의 마우스이었으며, 그리고 T/C%는 11%이었다. hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR)는 NCI 표준에 따르면 25μg/kg의 DM (2.18 mg/kg Ab)에서 비활성으로 간주되었으며, 부분 회귀는 0/7의 마우스, 완전한 회귀는 0/7의 마우스, 종양-없는 생존개체는 0/7의 마우스이었으며, 그리고 T/C%는 56%이었다. 결과로부터 비-결합 대조군 huKTI-Mal-LDL-DM (2.0 DAR) 콘쥬게이트가 NCI 표준에 따르면, 100μg/kg의 DM (8.57 mg/kg Ab) 투여량에서 비활성으로 간주되었기 때문에, hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR)는 ADAM9-표적화되었으며, 부분 회귀는 0/7, 완전한 회귀는 0/7, 종양-없는 생존개체는 0/7이었으며, 그리고 T/C%는 48%이었다. 표시된 용량에서 ADCs 중 어느 것에서도 유의적인 체중 감소가 관찰되지 않았으며, 따라서 이 연구에서 모든 콘쥬게이트가 마우스에서 잘 용인되었다. 이 연구로부터 hMAB-A(2I.2)(YTE/C/-K)-Mal-LDL-DM (1.8 DAR) 콘쥬게이트는 용량 의존적 표적화된 항-종양 활성을 실증하였고, HPAF-II 췌장 선암종 이종이식편 모델에서 효과적임을 시사한다.
실시예 20
H1975 인간 비-소 세포 폐 선암종 이종이식편을 품고 있는 누드 마우스에서 항-ADAM9 항체 약물 콘쥬게이트의 항-종양 활성
hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR) 및 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드의 항-종양 활성은 H1975 세포를 품고 있는 암컷 누드 마우스의 인간 비-소 세포 폐 선암종 이종이식편 모델에서 평가되었다.
Hl975 세포를 접종을 위해 수확하였고, 트립판 블루 배제에 의해 100% 생존력을 결정하였다. 마우스의 오른쪽 뒷 옆구리 영역에 피하 주사를 통하여 0.2ml 50% Matrigel/50% 무 혈청 배지에서 3 x 106 H1975세포를 접종했다. 66-마리 암컷 무흉선 Foxn1nu 마우스 (6주령)를 구했다. 이들 동물 수령 당시, 연구 개시 전 7 일 동안 당해 동물들을 관찰했다. 이들 동물은 도착 시 또는 치료 전, 질환이나 질병의 징후를 보이지 않았다.
42-마리 마우스를 종양 부피에 따라 7 개 그룹 (그룹당 6 마리의 마우스)으로 무작위 배치했다. 당해 종양 부피는 79.43 내지 119.61 (92.44 ± 10.36, 평균 ± SD) mm3 범위였다. 이식 후, 7 일 시점에 종양 부피를 기준으로 마우스를 계측하고, 무작위화하고, 투여하였다 (4/10/18). 마우스의 체중은 18.87 내지 26.30 (22.92 ± 1.50, 평균 ± SD) 그램 범위였다. 각 그룹의 마우스는 펀치 방법으로 식별되었다. 27 게이지, ½ 인치 바늘이 장착된 1.0 ml 주사기를 사용하여, 시험 제제 및 비히클을 정맥 내로 투여하였다. 항체 약물 콘쥬게이트 시험 제제는 25, 50, 또는 100μg/kg의 DM 페이로드로 에서 qdxl로 투여되었으며, 이는 상기 DAR ~2.0 콘쥬게이트의 경우 ~2, 4, 그리고 9 mg/kg 항체 (Ab)이다. 그룹에는 다음이 내포된다: 비히클 (PBS, 200 μL)이 투여되는 대조군 그룹, hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR) at 2.18, 4.36, 그리고 8.76 mg/kg Ab, 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR) at 2.14, 4.28, 그리고 8.57 mg/kg Ab.
캘리퍼를 사용하여 3 차원으로 종양 크기를 주 2 회 측정하였다. 종양 부피는 다음의 공식을 사용하여 나타낸다: 부피 (mm3) = 길이 x 폭 x 높이 x ½. 마우스는 종양 부피가 50% 또는 그 이상 감소될 때, 부분 회귀 (PR)로 간주되며, 만져질 수 있는 종양이 발견되지 않을 때 완전한 종양 회귀 (CR)로 간주되고, 그리고 연구 종료 시점에서 만져질 수 있는 종양이 발견되지 않는 종양-없이 생존한 경우 (TFS)로 간주되었다. 종양 부피는 StudyLog 소프트웨어에 의해 결정되었다.
종양 성장 억제 (T/C%)는 미리-정해둔 시점 (이를 테면, 마우스를 안락사 시켰을 시점에서 당해 대조군 종양의 정중 TV가 최대 종양 부피 ~1000mm3에 이른 시점)에서 대조군 그룹(C)의 정중 TV에 대한 처리 그룹(T)의 정중 종양 부피(TV)의 비율이다. T/C%는 당해 대조군 그룹의 정중 TV가 729 mm3에 이를 때, 접종 후 20일 시점에서 산출되었다. NCI 표준에 따르면 T/C ≤42%는 항-종양 활성의 최소 수준이며, 따라서 T/C <10%는 높은 항-종양 활성 수준으로 간주된다. 종양 성장 지연 (T-C)은 1000 mm3의 예정된 크기에 도달하기 위해, 처리 그룹 (T)과 대조군 그룹 종양 (C)에 대한 정중 시점(일자) 간에 차이다 (종양-없는 생존개체들은 배제됨). 종양 배가 시간 (Td)은 대조군 종양 성장의 일일 정중 값의 비-선형 지수 곡선 맞춤으로부터 추정되며, StudyLog 소프트웨어에 의해 결정된다. Td는 3.84일이었으며, R2=0.998이다. Log10 세포 사멸 (LCK)은 공식 LCK = (T-C)/Td x 3.32로 계산되며, 여기서 3.32는 세포 성장 로그 당 세포 배가 수치다. LCK에 대한 Southern Research Institute (SRI) 활성 기준은 다음과 같다: <0.7:-(비활성), 0.7-1.2: +, 1.3-1.9: ++, 2.0-2.8: +++, >2.8: ++++ (매우 활성).
모든 마우스의 체중 (BW)은 약물 독성의 대략적인 지표로 주당 2 회 측정되었으며, StudyLog 소프트웨어에 의해 결정되었다. 마우스의 체중은 다음과 같이 처치 전 체중으로부터 체중 변화 퍼센트로 표현되었다: BW 변화%= [(BWpost/BWpre)-1] x 100, 여기서 BWpost는 처치-후 체중이고, BWpre은 출발 체중이다. 체중 감소 백분율 (BWL)은 치료 후 체중의 평균 변화로 표현되었다. 종양 부피가 1000 mm3이상이 되거나 또는 종양의 괴사가 시작되거나, 마우스가 초기 체중의 >20%으로 상실하거나 또는 마우스가 연구 중 언제라도 빈사 상태인 경우, 당해 동물을 안락사시켰다.
상기 연구의 결과는 도 18에 나타낸다. LDL-DM ADC는 SPDB-DM4 ADC 대응부 보다 더 활성적이었다. 25μg/kg의 DM (2.18 mg/kg Ab)의 투여량에서 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)의 T/C 값은 26% (활성), T-C 값은 10 일, 그리고 LCK 값은 0.79 (+)이었으며, 종양 회귀 또는 종양-없는 생존개체는 없었다. 50μg/kg의 DM (4.36 mg/kg Ab)의 투여량에서 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)의 T/C 값은 8% (매우 활성), T-C 값은 35 일, 그리고 LCK 값은 2.72 (+++)이었으며, 6 마리 마우스중 5마리가 부분 종양 회귀, 1 마리가 완전한 회귀였으며, 그리고 종양-없는 생존개체는 없었다. 100μg/kg의 DM (8.76 mg/kg Ab)의 투여량에서 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)의 T/C 값은 7% (매우 활성), T-C 값은 >38 일, 그리고 LCK 값은 >2.98 (++++)이었으며, 6 마리 마우스중 6마리가 부분 종양 회귀를, 완전한 회귀는 없었고, 그리고 종양-없는 생존개체도 없었다. 25μg/kg의 DM (2.14 mg/kg Ab)의 투여량에서 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR)의 T/C 값은 6% (매우 활성)이었으며, 6 마리 마우스중 4 마리가 부분 종양 회귀이며, 1 마리가 완전한 회귀이며, 그리고 종양-없는 생존개체는 없었다. 종양 괴사로 인하여 당해 그룹의 동물을 잃거나, 또는 최저점에서의 7% 체중 감소로 인해, TC 값과 LCK 값은 계산할 수 없을 수도 있다 (주사 후 10 일 시점에서 이 그룹의 한 마리는 > 20% 체중 감소로 인해 안락사시켜야만 했다). 50μg/kg의 DM (4.28 mg/kg Ab)의 투여량에서 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR)의 T/C 값은 4% (매우 활성)였고, 6마리 마우스중 5 마리는 부분 종양 회귀였고, 완전한 회귀는 없었고, 그리고 종양-없는 생존개체도 없었다. 종양 괴사로 인하여 당해 그룹의 동물을 잃거나, 또는 최저점에서의 35% 체중 감소로 인해, TC 값과 LCK 값은 계산할 수 없을 수도 있다 (주사 후 20 일 시점에서 이 그룹의 모든 동물은 물병 마개로 인한 > 20% 체중 감소로 인해 안락사시켜야만 했다). 100μg/kg의 DM (8.57 mg/kg Ab) 투여량에서 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR)의 T/C 값은 6% (매우 활성), T-C 값은 >38 일, 그리고 LCK 값은 >2.98 (++++)이었으며, 6마리 마우스중 6 마리는 부분 종양 회귀였고, 2 마리는 완전한 회귀, 그리고 2마리는 종양-없는 생존개체였다. 임의의 투여량에서 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR) 또는 100μg/kg의 최대 투여량의 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR)에서 유의적인 체중 감소가 관찰되지 않았고, 따라서 이 연구에서 두 콘쥬게이트는 모두 마우스에서 잘 용인되었다. 이 연구의 결과로부터 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR) 및 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR) 콘쥬게이트 둘 모두다 투여량 의존적 항-종양 활성을 나타내며, H1975 비-소 세포 폐 선암종 종양 이종이식편 모델에서 효과적임을 시사한다.
실시예 21
Hs 746T 인간 위 암종 이종이식편을 품고 있는 SCID 마우스에서 항-ADAM9 항체 약물 콘쥬게이트의 항-종양 활성
hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR) 및 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR) 콘쥬게이트의 25, 50, 및 100μg/kg의 DM 페이로드의 항-종양 활성은 746T 세포를 품고 있는 암컷 SCID 마우스의 인간 비-소 세포 폐 선암종 이종이식편 모델에서 평가되었다.
Hs 746T 세포를 접종을 위해 수확하였고, 트립판 블루 배제에 의해 100% 생존력을 결정하였다. 마우스의 오른쪽 뒷 옆구리 영역에 피하 주사를 통하여 0.1ml 무 혈청 배지에서 5 x 106 Hs 746T 세포 접종했다. 60-마리 암컷 CB.17 SCID 마우스 (6주령)를 구했다. 이들 동물 수령 당시, 연구 개시 전 7 일 동안 당해 동물들을 관찰했다. 이들 동물은 도착 시 또는 치료 전, 질환이나 질병의 징후를 보이지 않았다.
42-마리 마우스를 종양 부피에 따라 7 개 그룹 (그룹당 6 마리의 마우스)으로 무작위 배치했다. 당해 종양 부피는 69.09 내지 136.75 (101.40 ± 19.16, 평균 ± SD)mm3 범위였다. 이식 후, 13 일 시점에 종양 부피를 기준으로 마우스를 계측하고, 무작위화하고, 투여하였다 (7/11/18). 마우스의 체중은 18.03 내지 23.21 (19.66 ± 1.21, 평균 ± SD) 그램 범위였다. 각 그룹의 마우스는 펀치 방법으로 식별되었다. 27 게이지, ½ 인치 바늘이 장착된 1.0 ml 주사기를 사용하여, 시험 제제 및 비히클을 정맥 내로 투여하였다. 항체 약물 콘쥬게이트 시험 제제는 25, 50, 또는 100μg/kg의 DM 페이로드에서 qdxl로 투여되었으며, 이는 상기 DAR ~2.0 콘쥬게이트의 경우 ~2, 4, 그리고 9 mg/kg 항체 (Ab)이다. 그룹에는 다음이 내포된다: 비히클 (PBS, 200 μL)이 투여된 대조군 그룹, hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR), 2.18, 4.36, 그리고 8.76 mg/kg Ab, 그리고 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR), 2.14, 4.28, 그리고 8.57 mg/kg Ab.
캘리퍼를 사용하여 3 차원으로 종양 크기를 주 2 회 측정하였다. 종양 부피는 다음의 공식을 사용하여 나타낸다: 부피 (mm3) = 길이 x 폭 x 높이 x ½. 마우스는 종양 부피가 50% 또는 그 이상 감소될 때, 부분 회귀 (PR)로 간주되며, 만져질 수 있는 종양이 발견되지 않을 때 완전한 종양 회귀 (CR)로 간주되고, 그리고 연구 종료 시점에서 만져질 수 있는 종양이 발견되지 않는 종양-없이 생존한 경우 (TFS)로 간주되었다. 종양 부피는 StudyLog 소프트웨어에 의해 결정되었다.
종양 성장 억제 (T/C%)는 미리-정해둔 시점 (이를 테면, 마우스를 안락사 시켰을 시점에서 당해 대조군 종양의 정중 TV가 최대 종양 부피 ~1000mm3에 이른 시점)에서 대조군 그룹(C)의 정중 TV에 대한 처리 그룹(T)의 정중 종양 부피(TV)의 비율이다. T/C%는 당해 대조군 그룹의 정중 TV가 1536 mm3에 이를 때, 접종 후 25일 시점에서 산출되었다. NCI 표준에 따르면 T/C ≤42%는 항-종양 활성의 최소 수준이며, 따라서 T/C <10%는 높은 항-종양 활성 수준으로 간주된다. 종양 성장 지연 (T-C)은 1000 mm3의 예정된 크기에 도달하기 위해, 처리 그룹 (T)과 대조군 그룹 종양 (C)에 대한 정중 시점(일자) 간에 차이다 (종양-없는 생존개체들은 배제됨). 종양 배가 시간 (Td)은 대조군 종양 성장의 일일 정중 값의 비-선형 지수 곡선 맞춤으로부터 추정되며, StudyLog 소프트웨어에 의해 결정된다. Td는 3.38일이었으며, R2=0.991이다. Log10 세포 사멸 (LCK)은 공식 LCK = (T-C)/Td x 3.32로 계산되며, 여기서 3.32는 세포 성장 로그 당 세포 배가 수치다. LCK에 대한 Southern Research Institute (SRI) 활성 기준은 다음과 같다: <0.7:-(비활성), 0.7-1.2: +, 1.3-1.9: ++, 2.0-2.8: +++, >2.8: ++++ (매우 활성).
모든 마우스의 체중 (BW)은 약물 독성의 대략적인 지표로 주당 2 회 측정되었으며, StudyLog 소프트웨어에 의해 결정되었다. 마우스의 체중은 다음과 같이 처치 전 체중으로부터 체중 변화 퍼센트로 표현되었다: BW 변화%= [(BWpost/BWpre)-1] x 100, 여기서 BWpost는 처치-후 체중이고, BWpre은 출발 체중이다. 체중 감소 백분율 (BWL)은 치료 후 체중의 평균 변화로 표현되었다. 종양 부피가 1000 mm3이상이 되거나 또는 종양의 괴사가 시작되거나, 마우스가 초기 체중의 >20%으로 상실하거나 또는 마우스가 연구 중 언제라도 빈사 상태인 경우, 당해 동물을 안락사시켰다.
상기 연구의 결과는 도 19에 나타낸다. LDL-DM ADC는 SPDB-DM4 ADC 대응부 보다 더 활성이 컸다. 25μg/kg의 DM (2.18 mg/kg Ab)의 투여량에서 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)의 T/C 값은 77% (비활성), T-C 값은 1 일, 그리고 LCK 값은 0.12 (-)이며, 종양 회귀 또는 종양-없는 생존개체는 없었다. 50μg/kg의 DM (4.36 mg/kg Ab)의 투여량에서 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)의 T/C 값은 67% (비활성), T-C 값은 3 일, 그리고 LCK 값은 0.24 (-)이었으며, 종양 회귀 또는 종양-없는 생존개체는 없었다. 100μg/kg의 DM (8.76 mg/kg Ab)의 투여량에서 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR)의 T/C 값은 12% (활성), T-C 값은 15 일, 그리고 LCK 값은 1.35 (++)이었으며, 6 마리 마우스중 1 마리는 부분 종양 회귀였고, 완전한 회귀는 없었고, 그리고 종양-없는 생존개체도 없었다. 25μg/kg의 DM (2.14 mg/kg Ab)의 투여량에서 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR)의 T/C 값은 58% (비활성), T-C 값은 4 일, 그리고 LCK 값은 0.33 (-)이었으며, 종양 회귀 또는 종양-없는 생존개체는 없었다. 50μg/kg의 DM (4.28 mg/kg Ab)의 투여량에서 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR)의 T/C 값은 26% (활성), T-C 값은 12 일, 그리고 LCK 값은 1.09 (+)이었으며, 종양 회귀 또는 종양-없는 생존개체는 없었다. 100μg/kg의 DM (8.57 mg/kg Ab)의 투여량에서 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR)의 T/C 값은 6% (매우 활성), T-C 값은 29 일, 그리고 LCK 값은 2.59 (+++)이었으며, 6 마리 마우스중 4 마리는 부분 종양 회귀였고, 완전한 회귀는 없었고, 그리고 종양-없는 생존개체도 없었다. 표시된 용량에서 ADCs 중 어느 것에서도 유의적인 체중 감소가 관찰되지 않았으며, 따라서 이 연구에서 6 개의 콘쥬게이트 모두가 마우스에서 잘 용인되었다. 이 연구의 결과로부터 hMAB-A(2I.2)-sSPDB-DM4 (2.1 DAR) 및 hMAB-A(2I.2)-S442C-Mal-LDL-DM (2.1 DAR) 콘쥬게이트는 모두 투여량 의존적 항-종양 활성을 나타내며, Hs 746T 위 암종 종양 이종이식편 모델에서 효과적임을 시사한다.
본 명세서에 언급된 모든 공보 및 특허는 각각의 개별 공보 또는 특허 출원이 구체적이고 개별적으로 참조로 포함된 것으로 표시되는 것과 동일한 정도로 본원에 이의 전문이 참고자료로 편입된다. 본 발명은 본 명세서의 특정 구체예들과 연계되어 설명되지만, 추가 변형이 가능하며, 본 출원은 일반적으로 본 발명의 원리에 따라 발명의 임의의 변형, 사용 또는 채택을 포괄하도록 의도되며, 본 발명으로부터 이러한 벗어남은 본 발명이 속하는 분야내 공지의 또는 관습적 실행 범위 안에 있고, 그리고 본 명세서에서 앞서 제공된 필수 특징에 적용될 수 있기 때문에 이러한 것들을 포함하는 것으로 의도된다.
SEQUENCE LISTING
<110> IMMUNOGEN, INC.
MACROGENICS, INC.
<120> IMMUNOCONJUGATES TARGETING ADAM9 AND METHODS OF USE THEREOF
<130> 121162-04820
<140>
<141>
<150> 62/810,703
<151> 2019-02-26
<150> 62/691,342
<151> 2018-06-28
<150> 62/690,052
<151> 2018-06-26
<160> 163
<170> PatentIn version 3.5
<210> 1
<211> 217
<212> PRT
<213> Homo sapiens
<220>
<221> VARIANT
<222> (217)..(217)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(217)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 1
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Ser Leu Ser Pro Gly Lys
210 215
<210> 2
<211> 216
<212> PRT
<213> Homo sapiens
<220>
<221> VARIANT
<222> (216)..(216)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(216)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 2
Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
1 5 10 15
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
20 25 30
Val Asp Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val
35 40 45
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
50 55 60
Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val His Gln
65 70 75 80
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly
85 90 95
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro
100 105 110
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr
115 120 125
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
130 135 140
Asp Ile Ser Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
145 150 155 160
Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
165 170 175
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
180 185 190
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
195 200 205
Ser Leu Ser Leu Ser Pro Gly Lys
210 215
<210> 3
<211> 217
<212> PRT
<213> Homo sapiens
<220>
<221> VARIANT
<222> (217)..(217)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(217)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 3
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln Phe Lys Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Ser Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Asn Thr Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Ile
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn Arg Phe Thr Gln
195 200 205
Lys Ser Leu Ser Leu Ser Pro Gly Lys
210 215
<210> 4
<211> 217
<212> PRT
<213> Homo sapiens
<220>
<221> VARIANT
<222> (217)..(217)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(217)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 4
Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Ser Leu Ser Leu Gly Lys
210 215
<210> 5
<211> 819
<212> PRT
<213> Homo sapiens
<400> 5
Met Gly Ser Gly Ala Arg Phe Pro Ser Gly Thr Leu Arg Val Arg Trp
1 5 10 15
Leu Leu Leu Leu Gly Leu Val Gly Pro Val Leu Gly Ala Ala Arg Pro
20 25 30
Gly Phe Gln Gln Thr Ser His Leu Ser Ser Tyr Glu Ile Ile Thr Pro
35 40 45
Trp Arg Leu Thr Arg Glu Arg Arg Glu Ala Pro Arg Pro Tyr Ser Lys
50 55 60
Gln Val Ser Tyr Val Ile Gln Ala Glu Gly Lys Glu His Ile Ile His
65 70 75 80
Leu Glu Arg Asn Lys Asp Leu Leu Pro Glu Asp Phe Val Val Tyr Thr
85 90 95
Tyr Asn Lys Glu Gly Thr Leu Ile Thr Asp His Pro Asn Ile Gln Asn
100 105 110
His Cys His Tyr Arg Gly Tyr Val Glu Gly Val His Asn Ser Ser Ile
115 120 125
Ala Leu Ser Asp Cys Phe Gly Leu Arg Gly Leu Leu His Leu Glu Asn
130 135 140
Ala Ser Tyr Gly Ile Glu Pro Leu Gln Asn Ser Ser His Phe Glu His
145 150 155 160
Ile Ile Tyr Arg Met Asp Asp Val Tyr Lys Glu Pro Leu Lys Cys Gly
165 170 175
Val Ser Asn Lys Asp Ile Glu Lys Glu Thr Ala Lys Asp Glu Glu Glu
180 185 190
Glu Pro Pro Ser Met Thr Gln Leu Leu Arg Arg Arg Arg Ala Val Leu
195 200 205
Pro Gln Thr Arg Tyr Val Glu Leu Phe Ile Val Val Asp Lys Glu Arg
210 215 220
Tyr Asp Met Met Gly Arg Asn Gln Thr Ala Val Arg Glu Glu Met Ile
225 230 235 240
Leu Leu Ala Asn Tyr Leu Asp Ser Met Tyr Ile Met Leu Asn Ile Arg
245 250 255
Ile Val Leu Val Gly Leu Glu Ile Trp Thr Asn Gly Asn Leu Ile Asn
260 265 270
Ile Val Gly Gly Ala Gly Asp Val Leu Gly Asn Phe Val Gln Trp Arg
275 280 285
Glu Lys Phe Leu Ile Thr Arg Arg Arg His Asp Ser Ala Gln Leu Val
290 295 300
Leu Lys Lys Gly Phe Gly Gly Thr Ala Gly Met Ala Phe Val Gly Thr
305 310 315 320
Val Cys Ser Arg Ser His Ala Gly Gly Ile Asn Val Phe Gly Gln Ile
325 330 335
Thr Val Glu Thr Phe Ala Ser Ile Val Ala His Glu Leu Gly His Asn
340 345 350
Leu Gly Met Asn His Asp Asp Gly Arg Asp Cys Ser Cys Gly Ala Lys
355 360 365
Ser Cys Ile Met Asn Ser Gly Ala Ser Gly Ser Arg Asn Phe Ser Ser
370 375 380
Cys Ser Ala Glu Asp Phe Glu Lys Leu Thr Leu Asn Lys Gly Gly Asn
385 390 395 400
Cys Leu Leu Asn Ile Pro Lys Pro Asp Glu Ala Tyr Ser Ala Pro Ser
405 410 415
Cys Gly Asn Lys Leu Val Asp Ala Gly Glu Glu Cys Asp Cys Gly Thr
420 425 430
Pro Lys Glu Cys Glu Leu Asp Pro Cys Cys Glu Gly Ser Thr Cys Lys
435 440 445
Leu Lys Ser Phe Ala Glu Cys Ala Tyr Gly Asp Cys Cys Lys Asp Cys
450 455 460
Arg Phe Leu Pro Gly Gly Thr Leu Cys Arg Gly Lys Thr Ser Glu Cys
465 470 475 480
Asp Val Pro Glu Tyr Cys Asn Gly Ser Ser Gln Phe Cys Gln Pro Asp
485 490 495
Val Phe Ile Gln Asn Gly Tyr Pro Cys Gln Asn Asn Lys Ala Tyr Cys
500 505 510
Tyr Asn Gly Met Cys Gln Tyr Tyr Asp Ala Gln Cys Gln Val Ile Phe
515 520 525
Gly Ser Lys Ala Lys Ala Ala Pro Lys Asp Cys Phe Ile Glu Val Asn
530 535 540
Ser Lys Gly Asp Arg Phe Gly Asn Cys Gly Phe Ser Gly Asn Glu Tyr
545 550 555 560
Lys Lys Cys Ala Thr Gly Asn Ala Leu Cys Gly Lys Leu Gln Cys Glu
565 570 575
Asn Val Gln Glu Ile Pro Val Phe Gly Ile Val Pro Ala Ile Ile Gln
580 585 590
Thr Pro Ser Arg Gly Thr Lys Cys Trp Gly Val Asp Phe Gln Leu Gly
595 600 605
Ser Asp Val Pro Asp Pro Gly Met Val Asn Glu Gly Thr Lys Cys Gly
610 615 620
Ala Gly Lys Ile Cys Arg Asn Phe Gln Cys Val Asp Ala Ser Val Leu
625 630 635 640
Asn Tyr Asp Cys Asp Val Gln Lys Lys Cys His Gly His Gly Val Cys
645 650 655
Asn Ser Asn Lys Asn Cys His Cys Glu Asn Gly Trp Ala Pro Pro Asn
660 665 670
Cys Glu Thr Lys Gly Tyr Gly Gly Ser Val Asp Ser Gly Pro Thr Tyr
675 680 685
Asn Glu Met Asn Thr Ala Leu Arg Asp Gly Leu Leu Val Phe Phe Phe
690 695 700
Leu Ile Val Pro Leu Ile Val Cys Ala Ile Phe Ile Phe Ile Lys Arg
705 710 715 720
Asp Gln Leu Trp Arg Ser Tyr Phe Arg Lys Lys Arg Ser Gln Thr Tyr
725 730 735
Glu Ser Asp Gly Lys Asn Gln Ala Asn Pro Ser Arg Gln Pro Gly Ser
740 745 750
Val Pro Arg His Val Ser Pro Val Thr Pro Pro Arg Glu Val Pro Ile
755 760 765
Tyr Ala Asn Arg Phe Ala Val Pro Thr Tyr Ala Ala Lys Gln Pro Gln
770 775 780
Gln Phe Pro Ser Arg Pro Pro Pro Pro Gln Pro Lys Val Ser Ser Gln
785 790 795 800
Gly Asn Leu Ile Pro Ala Arg Pro Ala Pro Ala Pro Pro Leu Tyr Ser
805 810 815
Ser Leu Thr
<210> 6
<211> 819
<212> PRT
<213> Macaca fascicularis
<400> 6
Met Gly Ser Gly Val Gly Ser Pro Ser Gly Thr Leu Arg Val Arg Trp
1 5 10 15
Leu Leu Leu Leu Cys Leu Val Gly Pro Val Leu Gly Ala Ala Arg Pro
20 25 30
Gly Phe Gln Gln Thr Ser His Leu Ser Ser Tyr Glu Ile Ile Thr Pro
35 40 45
Trp Arg Leu Thr Arg Glu Arg Arg Glu Ala Pro Arg Pro Tyr Ser Lys
50 55 60
Gln Val Ser Tyr Leu Ile Gln Ala Glu Gly Lys Glu His Ile Ile His
65 70 75 80
Leu Glu Arg Asn Lys Asp Leu Leu Pro Glu Asp Phe Val Val Tyr Thr
85 90 95
Tyr Asn Lys Glu Gly Thr Val Ile Thr Asp His Pro Asn Ile Gln Asn
100 105 110
His Cys His Phe Arg Gly Tyr Val Glu Gly Val Tyr Asn Ser Ser Val
115 120 125
Ala Leu Ser Asn Cys Phe Gly Leu Arg Gly Leu Leu His Leu Glu Asn
130 135 140
Ala Ser Tyr Gly Ile Glu Pro Leu Gln Asn Ser Ser His Phe Glu His
145 150 155 160
Ile Ile Tyr Arg Met Asp Asp Val His Lys Glu Pro Leu Lys Cys Gly
165 170 175
Val Ser Asn Lys Asp Ile Glu Lys Glu Thr Thr Lys Asp Glu Glu Glu
180 185 190
Glu Pro Pro Ser Met Thr Gln Leu Leu Arg Arg Arg Arg Ala Val Leu
195 200 205
Pro Gln Thr Arg Tyr Val Glu Leu Phe Ile Val Val Asp Lys Glu Arg
210 215 220
Tyr Asp Met Met Gly Arg Asn Gln Thr Ala Val Arg Glu Glu Met Ile
225 230 235 240
Leu Leu Ala Asn Tyr Leu Asp Ser Met Tyr Ile Met Leu Asn Ile Arg
245 250 255
Ile Val Leu Val Gly Leu Glu Ile Trp Thr Asn Gly Asn Leu Ile Asn
260 265 270
Ile Ala Gly Gly Ala Gly Asp Val Leu Gly Asn Phe Val Gln Trp Arg
275 280 285
Glu Lys Phe Leu Ile Thr Arg Arg Arg His Asp Ser Ala Gln Leu Val
290 295 300
Leu Lys Lys Gly Phe Gly Gly Thr Ala Gly Met Ala Phe Val Gly Thr
305 310 315 320
Val Cys Ser Arg Ser His Ala Gly Gly Ile Asn Val Phe Gly His Ile
325 330 335
Thr Val Glu Thr Phe Ala Ser Ile Val Ala His Glu Leu Gly His Asn
340 345 350
Leu Gly Met Asn His Asp Asp Gly Arg Asp Cys Ser Cys Gly Ala Lys
355 360 365
Ser Cys Ile Met Asn Ser Gly Ala Ser Gly Ser Arg Asn Phe Ser Ser
370 375 380
Cys Ser Ala Glu Asp Phe Glu Lys Leu Thr Leu Asn Lys Gly Gly Asn
385 390 395 400
Cys Leu Leu Asn Ile Pro Lys Pro Asp Glu Ala Tyr Ser Ala Pro Ser
405 410 415
Cys Gly Asn Lys Leu Val Asp Ala Gly Glu Glu Cys Asp Cys Gly Thr
420 425 430
Pro Lys Glu Cys Glu Leu Asp Pro Cys Cys Glu Gly Ser Thr Cys Lys
435 440 445
Leu Lys Ser Phe Ala Glu Cys Ala Tyr Gly Asp Cys Cys Lys Asp Cys
450 455 460
Arg Phe Leu Pro Gly Gly Thr Leu Cys Arg Gly Lys Thr Ser Glu Cys
465 470 475 480
Asp Val Pro Glu Tyr Cys Asn Gly Ser Ser Gln Phe Cys Gln Pro Asp
485 490 495
Val Phe Ile Gln Asn Gly Tyr Pro Cys Gln Asn Asn Lys Ala Tyr Cys
500 505 510
Tyr Asn Gly Met Cys Gln Tyr Tyr Asp Ala Gln Cys Gln Val Ile Phe
515 520 525
Gly Ser Lys Ala Lys Ala Ala Pro Lys Asp Cys Phe Ile Glu Val Asn
530 535 540
Ser Lys Gly Asp Arg Phe Gly Asn Cys Gly Phe Ser Gly Asn Glu Tyr
545 550 555 560
Lys Lys Cys Ala Thr Gly Asn Ala Leu Cys Gly Lys Leu Gln Cys Glu
565 570 575
Asn Val Gln Glu Ile Pro Val Phe Gly Ile Val Pro Ala Ile Ile Gln
580 585 590
Thr Pro Ser Arg Gly Thr Lys Cys Trp Gly Val Asp Phe Gln Leu Gly
595 600 605
Ser Asp Val Pro Asp Pro Gly Met Val Asn Glu Gly Thr Lys Cys Gly
610 615 620
Ala Asp Lys Ile Cys Arg Asn Phe Gln Cys Val Asp Ala Ser Val Leu
625 630 635 640
Asn Tyr Asp Cys Asp Ile Gln Lys Lys Cys His Gly His Gly Val Cys
645 650 655
Asn Ser Asn Lys Asn Cys His Cys Glu Asn Gly Trp Ala Pro Pro Asn
660 665 670
Cys Glu Thr Lys Gly Tyr Gly Gly Ser Val Asp Ser Gly Pro Thr Tyr
675 680 685
Asn Glu Met Asn Thr Ala Leu Arg Asp Gly Leu Leu Val Phe Phe Phe
690 695 700
Leu Ile Val Pro Leu Ile Val Cys Ala Ile Phe Ile Phe Ile Lys Arg
705 710 715 720
Asp Gln Leu Trp Arg Arg Tyr Phe Arg Lys Lys Arg Ser Gln Thr Tyr
725 730 735
Glu Ser Asp Gly Lys Asn Gln Ala Asn Pro Ser Arg Gln Pro Val Ser
740 745 750
Val Pro Arg His Val Ser Pro Val Thr Pro Pro Arg Glu Val Pro Ile
755 760 765
Tyr Ala Asn Arg Phe Pro Val Pro Thr Tyr Ala Ala Lys Gln Pro Gln
770 775 780
Gln Phe Pro Ser Arg Pro Pro Pro Pro Gln Pro Lys Val Ser Ser Gln
785 790 795 800
Gly Asn Leu Ile Pro Ala Arg Pro Ala Pro Ala Pro Pro Leu Tyr Ser
805 810 815
Ser Leu Thr
<210> 7
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 7
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Ile Pro Ile Asn Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Lys Ala Thr Leu Thr Leu Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Ala Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Gly Ser Arg Asp Tyr Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 8
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 8
Ser Tyr Trp Met His
1 5
<210> 9
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 9
Glu Ile Ile Pro Ile Asn Gly His Thr Asn Tyr Asn Glu Lys Phe Lys
1 5 10 15
Ser
<210> 10
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 10
Gly Gly Tyr Tyr Tyr Tyr Gly Ser Arg Asp Tyr Phe Asp Tyr
1 5 10
<210> 11
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 11
Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Cys Lys Ala Ser Gln Ser Val Asp Tyr Asp
20 25 30
Gly Asp Ser Tyr Met Asn Trp Tyr Gln Gln Ile Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Asp Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Asn Ile His
65 70 75 80
Pro Val Glu Glu Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Ser His
85 90 95
Glu Asp Pro Phe Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 12
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 12
Lys Ala Ser Gln Ser Val Asp Tyr Asp Gly Asp Ser Tyr Met Asn
1 5 10 15
<210> 13
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 13
Ala Ala Ser Asp Leu Glu Ser
1 5
<210> 14
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 14
Gln Gln Ser His Glu Asp Pro Phe Thr
1 5
<210> 15
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (34)..(34)
<223> /replace="Ile"
<220>
<221> VARIANT
<222> (55)..(55)
<223> /replace="Phe"
<220>
<221> VARIANT
<222> (63)..(63)
<223> /replace="Arg"
<220>
<221> VARIANT
<222> (65)..(65)
<223> /replace="Gln"
<220>
<221> VARIANT
<222> (66)..(66)
<223> /replace="Gly"
<220>
<221> VARIANT
<222> (105)..(105)
<223> /replace="Phe" or "Tyr" or "Trp" or "Ile" or "Leu"
"Val" or "Thr" or "Gly" or "Asp"
<220>
<221> VARIANT
<222> (106)..(106)
<223> /replace="Arg" or "Asn" or "His" or "Gly" or "Ser"
<220>
<221> VARIANT
<222> (107)..(107)
<223> /replace="Met" or "Ser" or "Lys" or "Asn"
<220>
<221> VARIANT
<222> (108)..(108)
<223> /replace="Ala"
<220>
<221> VARIANT
<222> (109)..(109)
<223> /replace="Phe" or "Thr" or "Val"
<220>
<221> VARIANT
<222> (110)..(110)
<223> /replace="Leu" or "Lys"
<220>
<221> SITE
<222> (1)..(123)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<220>
<221> source
<223> /note="See specification as filed for detailed description of
substitutions and preferred embodiments"
<400> 15
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Asn Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Lys Phe Gly Trp Met Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 16
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 16
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Asn Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Gly Ser Arg Asp Tyr Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 17
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 17
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Gly Ser Arg Asp Tyr Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 18
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 18
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Arg Phe
50 55 60
Gln Gly Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Gly Ser Arg Asp Tyr Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 19
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 19
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Arg Phe
50 55 60
Gln Gly Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Gly Ser Arg Asp Tyr Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 20
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 20
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Phe Asn Ser Gly Thr Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 21
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 21
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Ile Gly Lys Gly Val Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 22
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 22
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Phe Gly Trp Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 23
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 23
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Thr Gly Lys Gly Val Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 24
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 24
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Asp Ser Asn Ala Val Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 25
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 25
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Phe His Ser Gly Thr Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 26
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 26
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Phe Asn Lys Ala Val Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 27
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 27
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Gly Gly Ser Gly Val Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 28
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 28
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 29
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 29
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Tyr Asn Ser Gly Thr Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 30
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 30
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser
20 25 30
<210> 31
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 31
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Gly
1 5 10
<210> 32
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 32
Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg
20 25 30
<210> 33
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 33
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
1 5 10
<210> 34
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 34
Ser Tyr Trp Ile His
1 5
<210> 35
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 35
Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe Lys
1 5 10 15
Ser
<210> 36
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 36
Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Arg Phe Gln
1 5 10 15
Gly
<210> 37
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 37
Gly Gly Tyr Tyr Tyr Tyr Phe Asn Ser Gly Thr Leu Asp Tyr
1 5 10
<210> 38
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 38
Gly Gly Tyr Tyr Tyr Tyr Ile Gly Lys Gly Val Leu Asp Tyr
1 5 10
<210> 39
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 39
Gly Gly Tyr Tyr Tyr Tyr Pro Arg Phe Gly Trp Leu Asp Tyr
1 5 10
<210> 40
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 40
Gly Gly Tyr Tyr Tyr Tyr Thr Gly Lys Gly Val Leu Asp Tyr
1 5 10
<210> 41
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 41
Gly Gly Tyr Tyr Tyr Tyr Asp Ser Asn Ala Val Leu Asp Tyr
1 5 10
<210> 42
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 42
Gly Gly Tyr Tyr Tyr Tyr Phe His Ser Gly Thr Leu Asp Tyr
1 5 10
<210> 43
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 43
Gly Gly Tyr Tyr Tyr Tyr Phe Asn Lys Ala Val Leu Asp Tyr
1 5 10
<210> 44
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 44
Gly Gly Tyr Tyr Tyr Tyr Gly Gly Ser Gly Val Leu Asp Tyr
1 5 10
<210> 45
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 45
Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
1 5 10
<210> 46
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 46
Gly Gly Tyr Tyr Tyr Tyr Tyr Asn Ser Gly Thr Leu Asp Tyr
1 5 10
<210> 47
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> VARIANT
<222> (4)..(4)
<223> /replace="Ile"
<220>
<221> SITE
<222> (1)..(5)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 47
Ser Tyr Trp Met His
1 5
<210> 48
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> VARIANT
<222> (6)..(6)
<223> /replace="Phe"
<220>
<221> VARIANT
<222> (14)..(14)
<223> /replace="Arg"
<220>
<221> VARIANT
<222> (16)..(16)
<223> /replace="Gln"
<220>
<221> VARIANT
<222> (17)..(17)
<223> /replace="Gly"
<220>
<221> SITE
<222> (1)..(17)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 48
Glu Ile Ile Pro Ile Asn Gly His Thr Asn Tyr Asn Glu Lys Phe Lys
1 5 10 15
Ser
<210> 49
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> VARIANT
<222> (7)..(7)
<223> /replace="Phe" or "Tyr" or "Trp" or "Ile" or "Leu"
"Val" or "Thr" or "Gly" or "Asp"
<220>
<221> VARIANT
<222> (8)..(8)
<223> /replace="Arg" or "Asn" or "His" or "Gly" or "Ser"
<220>
<221> VARIANT
<222> (9)..(9)
<223> /replace="Met" or "Ser" or "Lys" or Asn"
<220>
<221> VARIANT
<222> (10)..(10)
<223> /replace="Ala"
<220>
<221> VARIANT
<222> (11)..(11)
<223> /replace="Phe" or "Thr" or "Val"
<220>
<221> VARIANT
<222> (12)..(12)
<223> /replace="Leu" or "Lys"
<220>
<221> SITE
<222> (1)..(14)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<220>
<221> source
<223> /note="See specification as filed for detailed description of
substitutions and preferred embodiments"
<400> 49
Gly Gly Tyr Tyr Tyr Tyr Pro Lys Phe Gly Trp Met Asp Tyr
1 5 10
<210> 50
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (453)..(453)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(453)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 50
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Gly Ser Arg Asp Tyr Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 51
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (453)..(453)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(453)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 51
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Phe Gly Trp Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 52
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (453)..(453)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(453)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 52
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 53
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (24)..(24)
<223> /replace="Arg"
<220>
<221> VARIANT
<222> (32)..(32)
<223> /replace="Ser"
<220>
<221> VARIANT
<222> (37)..(37)
<223> /replace="Leu"
<220>
<221> VARIANT
<222> (96)..(96)
<223> /replace="Tyr"
<220>
<221> VARIANT
<222> (97)..(97)
<223> /replace="Ser"
<220>
<221> VARIANT
<222> (98)..(98)
<223> /replace="Thr"
<220>
<221> SITE
<222> (1)..(111)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 53
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Ser Cys Lys Ala Ser Gln Ser Val Asp Tyr Asp
20 25 30
Gly Asp Ser Tyr Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Asp Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser His
85 90 95
Glu Asp Pro Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 54
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 54
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Ser Cys Lys Ala Ser Gln Ser Val Asp Tyr Asp
20 25 30
Gly Asp Ser Tyr Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Asp Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser His
85 90 95
Glu Asp Pro Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 55
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 55
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Ser Cys Lys Ala Ser Gln Ser Val Asp Tyr Ser
20 25 30
Gly Asp Ser Tyr Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Asp Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser His
85 90 95
Glu Asp Pro Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 56
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 56
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Ser Cys Arg Ala Ser Gln Ser Val Asp Tyr Ser
20 25 30
Gly Asp Ser Tyr Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Asp Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser His
85 90 95
Glu Asp Pro Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 57
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 57
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Ser Cys Arg Ala Ser Gln Ser Val Asp Tyr Ser
20 25 30
Gly Asp Ser Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Asp Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr
85 90 95
Ser Thr Pro Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 58
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 58
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Ser Cys
20
<210> 59
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 59
Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile Tyr
1 5 10 15
<210> 60
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 60
Gly Ile Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Glu Pro Glu Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 61
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 61
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
1 5 10
<210> 62
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 62
Lys Ala Ser Gln Ser Val Asp Tyr Ser Gly Asp Ser Tyr Met Asn
1 5 10 15
<210> 63
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 63
Arg Ala Ser Gln Ser Val Asp Tyr Ser Gly Asp Ser Tyr Met Asn
1 5 10 15
<210> 64
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 64
Arg Ala Ser Gln Ser Val Asp Tyr Ser Gly Asp Ser Tyr Leu Asn
1 5 10 15
<210> 65
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 65
Gln Gln Ser Tyr Ser Thr Pro Phe Thr
1 5
<210> 66
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> VARIANT
<222> (1)..(1)
<223> /replace="Arg"
<220>
<221> VARIANT
<222> (9)..(9)
<223> /replace="Ser"
<220>
<221> VARIANT
<222> (14)..(14)
<223> /replace="Leu"
<220>
<221> SITE
<222> (1)..(15)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 66
Lys Ala Ser Gln Ser Val Asp Tyr Asp Gly Asp Ser Tyr Met Asn
1 5 10 15
<210> 67
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> VARIANT
<222> (4)..(4)
<223> /replace="Tyr"
<220>
<221> VARIANT
<222> (5)..(5)
<223> /replace="Ser"
<220>
<221> VARIANT
<222> (6)..(6)
<223> /replace="Thr"
<220>
<221> SITE
<222> (1)..(9)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 67
Gln Gln Ser His Glu Asp Pro Phe Thr
1 5
<210> 68
<211> 218
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 68
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Ser Cys Lys Ala Ser Gln Ser Val Asp Tyr Ser
20 25 30
Gly Asp Ser Tyr Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Asp Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser His
85 90 95
Glu Asp Pro Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 69
<211> 107
<212> PRT
<213> Homo sapiens
<400> 69
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 70
<211> 104
<212> PRT
<213> Homo sapiens
<400> 70
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
1 5 10 15
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
20 25 30
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
35 40 45
Lys Ala Gly Val Glu Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
50 55 60
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
65 70 75 80
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
85 90 95
Thr Val Ala Pro Thr Glu Cys Ser
100
<210> 71
<211> 98
<212> PRT
<213> Homo sapiens
<400> 71
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val
<210> 72
<211> 98
<212> PRT
<213> Homo sapiens
<400> 72
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val
<210> 73
<211> 98
<212> PRT
<213> Homo sapiens
<400> 73
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val
<210> 74
<211> 15
<212> PRT
<213> Homo sapiens
<400> 74
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
1 5 10 15
<210> 75
<211> 12
<212> PRT
<213> Homo sapiens
<400> 75
Glu Arg Lys Cys Cys Val Glu Cys Pro Pro Cys Pro
1 5 10
<210> 76
<211> 12
<212> PRT
<213> Homo sapiens
<400> 76
Glu Ser Lys Tyr Gly Pro Pro Cys Pro Ser Cys Pro
1 5 10
<210> 77
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 77
Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro
1 5 10
<210> 78
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (217)..(217)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(217)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 78
Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Ser Leu Ser Pro Gly Lys
210 215
<210> 79
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (217)..(217)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(217)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 79
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Cys Leu Ser Pro Gly Lys
210 215
<210> 80
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (217)..(217)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(217)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 80
Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Cys Leu Ser Pro Gly Lys
210 215
<210> 81
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 81
Gly Ser Arg Asp Tyr Phe
1 5
<210> 82
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 82
Asp Gly Glu Gly Val Met
1 5
<210> 83
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 83
Phe His Ser Gly Leu Leu
1 5
<210> 84
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 84
Phe Asn Ser Ala Thr Leu
1 5
<210> 85
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 85
Phe Asn Ser Gly Thr Leu
1 5
<210> 86
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 86
Phe Asn Ser Ser Thr Leu
1 5
<210> 87
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 87
Gly Lys Ser Lys Trp Leu
1 5
<210> 88
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 88
Gly Met Gly Gly Thr Leu
1 5
<210> 89
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 89
His Ala Lys Gly Gly Met
1 5
<210> 90
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 90
Ile Gly Glu Ala Val Leu
1 5
<210> 91
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 91
Ile Gly Lys Gly Val Phe
1 5
<210> 92
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 92
Ile Gly Lys Gly Val Leu
1 5
<210> 93
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 93
Lys His Asp Ser Val Leu
1 5
<210> 94
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 94
Leu Asn Thr Ala Val Met
1 5
<210> 95
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 95
Asn Gly Glu Gly Thr Leu
1 5
<210> 96
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 96
Asn Gly Lys Asn Thr Leu
1 5
<210> 97
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 97
Asn Ser Ala Gly Ile Leu
1 5
<210> 98
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 98
Pro Lys Glu Gly Trp Met
1 5
<210> 99
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 99
Pro Lys Phe Gly Trp Lys
1 5
<210> 100
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 100
Pro Lys Met Gly Trp Val
1 5
<210> 101
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 101
Pro Arg Leu Gly His Leu
1 5
<210> 102
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 102
Pro Ser Phe Gly Trp Ala
1 5
<210> 103
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 103
Gln Ala Lys Gly Thr Met
1 5
<210> 104
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 104
Arg Gly Met Gly Val Met
1 5
<210> 105
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 105
Arg Lys Glu Gly Trp Met
1 5
<210> 106
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 106
Thr Gly Lys Gly Val Leu
1 5
<210> 107
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 107
Thr Gly Met Gly Thr Leu
1 5
<210> 108
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 108
Thr Gly Asn Gly Val Met
1 5
<210> 109
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 109
Trp Asn Ala Gly Thr Phe
1 5
<210> 110
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 110
Tyr His His Thr Pro Leu
1 5
<210> 111
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 111
Tyr Gln Ser Ala Thr Leu
1 5
<210> 112
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 112
Asp Gly Lys Ala Val Leu
1 5
<210> 113
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 113
Phe Asn Lys Ala Val Leu
1 5
<210> 114
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 114
Phe Asn Ser Gly Thr Trp
1 5
<210> 115
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 115
Phe Asn Thr Gly Val Phe
1 5
<210> 116
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 116
Gly Lys Ser Arg Phe His
1 5
<210> 117
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 117
Ile Gly Lys Asn Val Tyr
1 5
<210> 118
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 118
Met Gly Lys Gly Val Met
1 5
<210> 119
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 119
Asn Gly Glu Ser Val Phe
1 5
<210> 120
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 120
Pro Asp Phe Gly Trp Met
1 5
<210> 121
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 121
Pro Gly Ser Gly Val Met
1 5
<210> 122
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 122
Pro Lys Asp Ala Trp Leu
1 5
<210> 123
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 123
Pro Lys Phe Gly Trp Leu
1 5
<210> 124
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 124
Pro Lys Ile Gly Trp His
1 5
<210> 125
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 125
Pro Lys Met Gly Trp Ala
1 5
<210> 126
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 126
Pro Lys Met Gly Trp Met
1 5
<210> 127
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 127
Pro Gln Met Gly Trp Leu
1 5
<210> 128
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 128
Pro Arg Phe Gly Trp Leu
1 5
<210> 129
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 129
Pro Arg Met Gly Phe Leu
1 5
<210> 130
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 130
Pro Arg Met Gly Phe Met
1 5
<210> 131
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 131
Pro Ser Phe Gly Trp Met
1 5
<210> 132
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 132
Arg Arg Glu Gly Trp Met
1 5
<210> 133
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 133
Ser Gly Glu Gly Val Leu
1 5
<210> 134
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 134
Ser Gly Asn Gly Val Met
1 5
<210> 135
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 135
Val Gly Lys Ala Val Leu
1 5
<210> 136
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 136
Asp Ser Asn Ala Val Leu
1 5
<210> 137
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 137
Phe His Ser Gly Thr Leu
1 5
<210> 138
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 138
Gly Gly Ser Gly Val Leu
1 5
<210> 139
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 139
Pro Arg Gln Gly Phe Leu
1 5
<210> 140
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 140
Tyr Asn Ser Gly Thr Leu
1 5
<210> 141
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (453)..(453)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(453)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 141
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala
225 230 235 240
Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 142
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (453)..(453)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(453)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 142
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Cys
435 440 445
Leu Ser Pro Gly Lys
450
<210> 143
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (453)..(453)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(453)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 143
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala
225 230 235 240
Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Cys
435 440 445
Leu Ser Pro Gly Lys
450
<210> 144
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 144
Ala Leu Ala Leu
1
<210> 145
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> MOD_RES
<222> (1)..(1)
<223> Beta-Ala
<400> 145
Ala Leu Ala Leu
1
<210> 146
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 146
Gly Phe Leu Gly
1
<210> 147
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (217)..(217)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(217)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 147
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Tyr Ile Thr Arg Glu Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Ser Leu Ser Pro Gly Lys
210 215
<210> 148
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (217)..(217)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(217)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 148
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Tyr Ile Thr Arg Glu Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Cys Leu Ser Pro Gly Lys
210 215
<210> 149
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (217)..(217)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(217)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 149
Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Tyr Ile Thr Arg Glu Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Ser Leu Ser Pro Gly Lys
210 215
<210> 150
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (217)..(217)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(217)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 150
Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Tyr Ile Thr Arg Glu Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Cys Leu Ser Pro Gly Lys
210 215
<210> 151
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (453)..(453)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(453)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 151
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Tyr Ile Thr Arg Glu Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 152
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (453)..(453)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(453)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 152
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Tyr Ile Thr Arg Glu Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Cys
435 440 445
Leu Ser Pro Gly Lys
450
<210> 153
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (453)..(453)
<223> /replace=" "
<220>
<221> SITE
<222> (1)..(453)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 153
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala
225 230 235 240
Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Tyr Ile Thr Arg Glu Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Xaa
450
<210> 154
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<220>
<221> VARIANT
<222> (453)..(453)
<223> /replace="
<220>
<221> SITE
<222> (1)..(453)
<223> /note="Variant residues given in the sequence have no
preference with respect to those in the annotations
for variant positions"
<400> 154
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala
225 230 235 240
Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Tyr Ile Thr Arg Glu Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Cys
435 440 445
Leu Ser Pro Gly Lys
450
<210> 155
<211> 452
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 155
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Tyr Ile Thr Arg Glu Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly
450
<210> 156
<211> 452
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 156
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Ile Pro Ile Phe Gly His Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Arg Phe Thr Ile Ser Leu Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Gly Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Tyr Tyr Tyr Pro Arg Gln Gly Phe Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Tyr Ile Thr Arg Glu Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Cys
435 440 445
Leu Ser Pro Gly
450
<210> 157
<211> 654
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 157
gacattgtga tgacccaatc tccagattct ttggctgtgt ctctagggga gagggccacc 60
atctcctgca aggccagcca aagtgttgat tactctggtg atagttatat gaactggtac 120
caacagaaac caggacagcc acccaaactc ctcatctatg ctgcatccga cctagaatct 180
ggaatcccag ccaggtttag tggcagtggg tctgggacag acttcaccct cactatctct 240
agcctggagc ctgaggattt cgcaacctat tactgtcagc aaagtcatga agacccgttc 300
acgttcggac aagggaccaa gctcgaaatc aaacgtacgg tggctgcacc atctgtcttc 360
atcttcccgc catctgatga gcagttgaaa tctggaactg cctctgttgt gtgcctgctg 420
aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc cctccaatcg 480
ggtaactccc aggagagtgt cacagagcag gacagcaagg acagcaccta cagcctcagc 540
agcaccctga cgctgagcaa agcagactac gagaaacaca aagtctacgc ctgcgaagtc 600
acccatcagg gcctgagctc gcccgtcaca aagagcttca acaggggaga gtgt 654
<210> 158
<211> 654
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 158
gacattgtga tgacgcagtc ccccgactcc ctggccgtgt ccttgggcga aagggccaca 60
atcagctgca aggcatcaca gagcgtggac tactctgggg acagctacat gaattggtac 120
cagcagaagc ccgggcagcc tccaaagctg ctgatctacg ccgcatccga cctggagtcc 180
ggcatcccgg cgcggttctc gggttcggga tccggcactg acttcaccct gaccatctca 240
agcctggagc ccgaggactt tgcgacctac tactgccaac agtcccacga agatccgttt 300
accttcggac aaggcaccaa gctcgagatc aagagaactg tggccgcccc gagcgtgttc 360
attttcccgc catcggatga gcaactgaag tccggaactg cgagcgtggt ctgcctcctc 420
aacaacttct atcctcggga agccaaagtg cagtggaagg tcgacaacgc tctgcagtcc 480
ggaaactccc aagagagcgt gaccgaacag gattccaagg actcgaccta ctcgctgtca 540
tccactctga ccctgagcaa ggccgattac gaaaagcaca aagtgtacgc ttgcgaagtg 600
acccaccagg gactgtcatc ccctgtgacc aagtcgttca accgcggcga atgc 654
<210> 159
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> SITE
<222> (1357)..(1359)
<223> /note="This region may or may not be present in its entirety"
<400> 159
gaggtccaac tggtggaatc tgggggaggc ctggtgaagc ctgggggctc actgagactg 60
tcttgcgctg cttctggttt taccttctct agctactgga tgcactgggt gagacaggca 120
cctggaaagg gccttgagtg ggttggagag attattccta tctttggtca tactaactac 180
aatgagaagt tcaagagcag gttcacaatt tctttagaca actccaagaa tacactgtac 240
ctccaaatgg gaagcctgag ggcagaggac acagcggtct attactgtgc aagagggggt 300
tattattatt acccccggca gggcttcctg gactactggg gccaaggcac cactgtgaca 360
gtctcctcag cctccaccaa gggcccatcg gtcttccccc tggcaccctc ctccaagagc 420
acctctgggg gcacagcggc cctgggctgc ctggtcaagg actacttccc cgaaccggtg 480
acggtgtcgt ggaactcagg cgccctgacc agcggcgtgc acaccttccc ggctgtccta 540
cagtcctcag gactctactc cctcagcagc gtggtgaccg tgccctccag cagcttgggc 600
acccagacct acatctgcaa cgtgaatcac aagcccagca acaccaaggt ggacaagaga 660
gttgagccca aatcttgtga caaaactcac acatgcccac cgtgcccagc acctgaactc 720
ctggggggac cgtcagtctt cctcttcccc ccaaaaccca aggacaccct ctatatcacc 780
cgggagcctg aggtcacatg cgtggtggtg gacgtgagcc acgaagaccc tgaggtcaag 840
ttcaactggt acgtggacgg cgtggaggtg cataatgcca agacaaagcc gcgggaggag 900
cagtacaaca gcacgtaccg tgtggtcagc gtcctcaccg tcctgcacca ggactggctg 960
aatggcaagg agtacaagtg caaggtctcc aacaaagccc tcccagcccc catcgagaaa 1020
accatctcca aagccaaagg gcagccccga gaaccacagg tgtacaccct gcccccatcc 1080
cgggaggaga tgaccaagaa ccaggtcagc ctgacctgcc tggtcaaagg cttctatccc 1140
agcgacatcg ccgtggagtg ggagagcaat gggcagccgg agaacaacta caagaccacg 1200
cctcccgtgc tggactccga cggctccttc ttcctctaca gcaagctcac cgtggacaag 1260
agcaggtggc agcaggggaa cgtcttctca tgctccgtga tgcatgaggc tctgcacaac 1320
cactacacgc agaagagcct ctccctgtct ccgggtaaa 1359
<210> 160
<211> 1356
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 160
gaggtccaac tggtggaatc tgggggaggc ctggtgaagc ctgggggctc actgagactg 60
tcttgcgctg cttctggttt taccttctct agctactgga tgcactgggt gagacaggca 120
cctggaaagg gccttgagtg ggttggagag attattccta tctttggtca tactaactac 180
aatgagaagt tcaagagcag gttcacaatt tctttagaca actccaagaa tacactgtac 240
ctccaaatgg gaagcctgag ggcagaggac acagcggtct attactgtgc aagagggggt 300
tattattatt acccccggca gggcttcctg gactactggg gccaaggcac cactgtgaca 360
gtctcctcag cctccaccaa gggcccatcg gtcttccccc tggcaccctc ctccaagagc 420
acctctgggg gcacagcggc cctgggctgc ctggtcaagg actacttccc cgaaccggtg 480
acggtgtcgt ggaactcagg cgccctgacc agcggcgtgc acaccttccc ggctgtccta 540
cagtcctcag gactctactc cctcagcagc gtggtgaccg tgccctccag cagcttgggc 600
acccagacct acatctgcaa cgtgaatcac aagcccagca acaccaaggt ggacaagaga 660
gttgagccca aatcttgtga caaaactcac acatgcccac cgtgcccagc acctgaactc 720
ctggggggac cgtcagtctt cctcttcccc ccaaaaccca aggacaccct ctatatcacc 780
cgggagcctg aggtcacatg cgtggtggtg gacgtgagcc acgaagaccc tgaggtcaag 840
ttcaactggt acgtggacgg cgtggaggtg cataatgcca agacaaagcc gcgggaggag 900
cagtacaaca gcacgtaccg tgtggtcagc gtcctcaccg tcctgcacca ggactggctg 960
aatggcaagg agtacaagtg caaggtctcc aacaaagccc tcccagcccc catcgagaaa 1020
accatctcca aagccaaagg gcagccccga gaaccacagg tgtacaccct gcccccatcc 1080
cgggaggaga tgaccaagaa ccaggtcagc ctgacctgcc tggtcaaagg cttctatccc 1140
agcgacatcg ccgtggagtg ggagagcaat gggcagccgg agaacaacta caagaccacg 1200
cctcccgtgc tggactccga cggctccttc ttcctctaca gcaagctcac cgtggacaag 1260
agcaggtggc agcaggggaa cgtcttctca tgctccgtga tgcatgaggc tctgcacaac 1320
cactacacgc agaagagcct ctccctgtct ccgggt 1356
<210> 161
<211> 1356
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 161
gaggtccaac tggtggaatc tgggggaggc ctggtgaagc ctgggggctc actgagactg 60
tcttgcgctg cttctggttt taccttctct agctactgga tgcactgggt gagacaggca 120
cctggaaagg gccttgagtg ggttggagag attattccta tctttggtca tactaactac 180
aatgagaagt tcaagagcag gttcacaatt tctttagaca actccaagaa tacactgtac 240
ctccaaatgg gaagcctgag ggcagaggac acagcggtct attactgtgc aagagggggt 300
tattattatt acccccggca gggcttcctg gactactggg gccaaggcac cactgtgaca 360
gtctcctcag cctccaccaa gggcccatcg gtcttccccc tggcaccctc ctccaagagc 420
acctctgggg gcacagcggc cctgggctgc ctggtcaagg actacttccc cgaaccggtg 480
acggtgtcgt ggaactcagg cgccctgacc agcggcgtgc acaccttccc ggctgtccta 540
cagtcctcag gactctactc cctcagcagc gtggtgaccg tgccctccag cagcttgggc 600
acccagacct acatctgcaa cgtgaatcac aagcccagca acaccaaggt ggacaagaga 660
gttgagccca aatcttgtga caaaactcac acatgcccac cgtgcccagc acctgaactc 720
ctggggggac cgtcagtctt cctcttcccc ccaaaaccca aggacaccct ctatatcacc 780
cgggagcctg aggtcacatg cgtggtggtg gacgtgagcc acgaagaccc tgaggtcaag 840
ttcaactggt acgtggacgg cgtggaggtg cataatgcca agacaaagcc gcgggaggag 900
cagtacaaca gcacgtaccg tgtggtcagc gtcctcaccg tcctgcacca ggactggctg 960
aatggcaagg agtacaagtg caaggtctcc aacaaagccc tcccagcccc catcgagaaa 1020
accatctcca aagccaaagg gcagccccga gaaccacagg tgtacaccct gcccccatcc 1080
cgggaggaga tgaccaagaa ccaggtcagc ctgacctgcc tggtcaaagg cttctatccc 1140
agcgacatcg ccgtggagtg ggagagcaat gggcagccgg agaacaacta caagaccacg 1200
cctcccgtgc tggactccga cggctccttc ttcctctaca gcaagctcac cgtggacaag 1260
agcaggtggc agcaggggaa cgtcttctca tgctccgtga tgcatgaggc tctgcacaac 1320
cactacacgc agaagagcct ctgcctgtct ccgggt 1356
<210> 162
<211> 1356
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 162
gaagtccaac tggtggaatc ggggggcggc ctcgtgaagc ccggaggatc cctgaggctc 60
tcctgcgccg cctccgggtt cactttttcg tcatactgga tgcattgggt ccgccaggcc 120
ccggggaagg gactggaatg ggtcggagag atcatcccca ttttcggcca cacaaactac 180
aacgaaaagt tcaagagccg ctttactatt tccttggaca attcaaagaa caccctgtat 240
ctgcaaatgg gaagcctgcg ggccgaggac accgctgtgt actactgcgc ccggggtggc 300
tactattact acccgagaca gggtttcctc gattactggg gccagggaac caccgtgacc 360
gtgtcctctg cctcgaccaa aggcccctcg gtgttcccgc ttgcgccatc ctccaaatcc 420
acctccggcg gcaccgccgc tctgggatgc ctggtcaaag attacttccc ggagcctgtg 480
acggtgtcgt ggaactctgg agccctcacg agcggagtgc ataccttccc tgcggtgctc 540
caatcgtccg gactgtacag cctgagcagc gtcgtcactg tgcctagctc gtccctgggc 600
acccagacct acatttgcaa cgtgaaccat aagccttcaa acactaaggt cgacaaacgg 660
gtggaaccca agtcgtgcga taagactcat acttgcccgc cttgccccgc gcctgaactt 720
ttgggagggc cgtccgtgtt cctgttcccg ccaaagccaa aggacactct gtacatcact 780
cgcgaacccg aagtgacctg tgtggtcgtg gacgtgtccc acgaggatcc ggaagtcaag 840
ttcaattggt acgtggacgg tgtcgaggtg cacaacgcaa agaccaagcc gcgcgaggaa 900
cagtacaact ccacataccg ggtggtgtca gtgctgaccg tgttgcacca ggactggctc 960
aacggaaagg agtacaagtg caaagtgtcc aacaaggccc tgcctgcacc aatcgaaaag 1020
accattagca aggccaaggg gcagccccgg gagccccaag tgtacactct gcccccgtca 1080
cgggaagaaa tgaccaagaa ccaagtgtca ctgacctgtc ttgtgaaggg tttctacccc 1140
tccgacatcg ccgtggagtg ggagtccaac ggacagccgg agaacaatta caagactacc 1200
ccgccggtgc tggatagcga cggctccttc ttcctgtact ccaagctgac cgtggacaag 1260
tcgagatggc agcaggggaa cgtgttctcg tgctccgtga tgcacgaagc gctgcacaac 1320
cactataccc agaagtccct gtgcctgtcc cctgga 1356
<210> 163
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 163
Ala Ala Ala Gly
1
Claims (47)
- 다음의 화학식으로 나타낸 면역콘쥬게이트:

또는 이의 약제학적으로 허용되는 염이며, 이때:
CB는 항-ADAM9 항체 또는 이의 ADAM9-결합 단편이며; L2는 다음의 화학식중 하나로 표시되며:

이때:
각 경우들에서 Rx, Ry, Rx' 및 Ry'는 독립적으로 H, -OH, 할로겐, -O-(C1-4 알킬), -SO3H, -NR40R41R42 +, 또는 OH, 할로겐, SO3H 또는 NR40R41R42 +로 임의선택적으로 치환된 C1-4 알킬이며, 이때 R40, R41 및 R42는 각각 독립적으로 H 또는 C1-4 알킬이며;
l 및 k는 각각 독립적으로 1 내지 10의 정수이며;
l1은 2 내지 5의 정수이며;
k1은 1 내지 5의 정수이며; 그리고
s1은 세포-결합 제제 CB에 연결된 부위를 나타내며, s3은 A 기에 연결된 부위를 나타낸다;
A는 아미노산 잔기 또는 2 내지 20개 아미노산 잔기들을 포함하는 펩티드이며;
R1 및 R2는 각각 독립적으로 H 또는C1-3 알킬이며;
L1은 다음의 화학식으로 나타내고:
-CR3R4-(CH2)1-8-C(=O)-
이때 R3 및 R4는 각각 독립적으로 H 또는 Me이며, L1에서-C(=O)-모이어티는 D에 연결되며;
D는 다음의 화학식으로 나타내고:
;그리고
q는 1 내지 20의 정수다. - 청구항 1에 있어서, 이때 Rx, Ry, Rx' 및 Ry'는 모두 H이며; 그리고 l 및 k는 각각 독립적으로 2 내지 6의 정수인 면역콘쥬게이트.
- 청구항 1 또는 2에 있어서, 이때 A는 2개 내지 5개 아미노산 잔기를 함유하는 펩티드인, 면역콘쥬게이트.
- 청구항 3에 있어서, 이때 A는 다음 Gly-Gly-Gly, Ala-Val, Val-Ala, D-Val-Ala, Val-Cit, D-Val-Cit, Val-Lys, Phe-Lys, Lys-Lys, Ala-Lys, Phe-Cit, Leu-Cit, Ile-Cit, Phe-Ala, Phe-N9-토실-Arg, Phe-N9-니트로-Arg, Phe-Phe-Lys, D-Phe-Phe-Lys, Gly-Phe-Lys, Leu-Ala-Leu, Ile-Ala-Leu, Val-Ala-Val, Ala-Ala-Ala, D-Ala-Ala-Ala, Ala-D-Ala-Ala, Ala-Ala-D-Ala, Ala-Leu-Ala-Leu (서열 식별 번호:144), β-Ala-Leu-Ala-Leu (서열 식별 번호:145), Gly-Phe-Leu-Gly (서열 식별 번호:146), Val-Arg, Arg-Arg, Val-D-Cit, Val-D-Lys, Val-D-Arg, D-Val-Cit, D-Val-Lys, D-Val-Arg, D-Val-D-Cit, D-Val-D-Lys, D-Val-D-Arg, D-Arg-D-Arg, Ala-Ala, Ala-D-Ala, D-Ala-Ala, D-Ala-D-Ala, Ala-Met, Gln-Val, Asn-Ala, Gln-Phe, Gln-Ala, D-Ala-Pro, 그리고 D-Ala-tBu-Gly으로 구성된 군에서 선택되며, 이때 각 펩티드에서 첫 번째 아미노산은 L2기에 연결되며, 각 펩티드에서 마지막 아미노산은 -NH-CR1R2-S-L1-D에 연결되는, 면역콘쥬게이트.
- 청구항 1-4중 임의의 한 항에 있어서, 이때 R1 및 R2 는 모두 H인, 면역콘쥬게이트.
- 청구항 1-5중 임의의 한 항에 있어서, 이때 L1은 -(CH2)4-6-C(=O)-인, 면역콘쥬게이트.
- 청구항 1-6중 임의의 한 항에 있어서, 이때 D은 다음의 화학식으로 나타내는, 코면역콘쥬게이트:

- 청구항 1-7중 임의의 한 항에 있어서, 이때 상기 면역콘쥬게이트는 다음의 화학식으로 나타내거나:

또는 이의 약제학적으로 허용되는 염이며, 이때:
는 Lys 아민 기를 통하여 L2 기에 연결된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편이며;
는 Cys 티올 기를 통하여 L2 기에 연결된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편이며;
R3 및 R4는 각각 독립적으로 H 또는 Me이며;
M1, m3, n1, r1, s1 및 t1는 각각 독립적으로 1 내지 6의 정수이며;
m2, n2, r2, s2 및 t2는 각각 독립적으로 1 내지 7의 정수이며;
t3은 1 내지 12의 정수이며;
D1은 다음의 화학식으로 나타낸다:

- 청구항 8에 있어서, 이때 상기 면역콘쥬게이트는 다음의 화학식으로 나타내는, 면역콘쥬게이트:

이때:
m1 및 m3는 각각 독립적으로 2 내지 4의 정수이며;
m2는 2 내지 5의 정수이며;
r1은 2 내지 6의 정수이며; 그리고
r2는 2 내지 5의 정수이다. - 청구항 8 또는 9에 있어서, 이때 A는 Ala-Ala-Ala, Ala-D-Ala-Ala, Ala-Ala, D-Ala-Ala, Val-Ala, D-Val-Ala, D-Ala-Pro, 또는 D-Ala-tBu-Gly인, 면역콘쥬게이트.
- 청구항 8에 있어서, 이때 상기 면역콘쥬게이트는 다음의 화학식으로 나타내거나,

,





또는 이의 약제학적으로 허용되는 염이며, 이때:
A는 Ala-Ala-Ala, Ala-D-Ala-Ala, Ala-Ala, D-Ala-Ala, Val-Ala, D-Val-Ala,
D-Ala-Pro, 또는 D-Ala-tBu-Gly이며, 그리고
D1은 다음의 화학식으로 나타낸다:

- 청구항 11에 있어서, 이때 다음의 화학식으로 나타내는 상기 면역콘쥬게이트:

이때 D1은 다음의 화학식으로 나타낸다:

- 청구항 1-12중 임의의 한 항에 있어서, 이때 상기 면역콘쥬게이트는 인간 ADAM9 및 cyno ADAM9에 특이적으로 결합하는 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편을 포함하며, 이때 전술한 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 약학적 제제에 콘쥬게이트되는, 면역콘쥬게이트.
- 청구항 13에 있어서, 이때 전술한 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 다음으로 구성된 군에서 선택된 서열을 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 포함하는 면역콘쥬게이트:
(a) 차례로 서열 식별 번호:8, 35, 및 10 그리고 서열 식별 번호:62, 13, 14;
(b) 차례로 서열 식별 번호:8, 35, 및 10 그리고 서열 식별 번호:63, 13, 14;
(c) 차례로 서열 식별 번호:8, 36, 및 10 그리고 서열 식별 번호:63, 13, 14; 그리고
(d) 차례로 서열 식별 번호:34, 36, 및 10 그리고 서열 식별 번호:64, 13, 65. - 청구항 13 또는 14에 있어서, 이때 전술한 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 다음으로 구성된 군에서 선택된 서열에 대해 적어도 90%, 적어도 95%, 또는 적어도 99% 동일성을 갖는 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함하는, 면역콘쥬게이트:
(a) 차례로 서열 식별 번호:17 및 서열 식별 번호:55;
(b) 차례로 서열 식별 번호:17 및 서열 식별 번호:56;
(c) 차례로 서열 식별 번호:18 및 서열 식별 번호:56; 그리고
(d) 차례로 서열 식별 번호:19 및 서열 식별 번호:57. - 청구항 15에 있어서, 이때 전술한 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 다음으로 구성된 군에서 선택된 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함하는 면역콘쥬게이트:
(a) 차례로 서열 식별 번호:17 및 서열 식별 번호:55;
(b) 차례로 서열 식별 번호:17 및 서열 식별 번호:56;
(c) 차례로 서열 식별 번호:18 및 서열 식별 번호:56; 그리고
(d) 차례로 서열 식별 번호:19 및 서열 식별 번호:57. - 청구항 13에 있어서, 이때 전술한 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 키메라 또는 뮤린 부계 항체와 비교하였을 때, cyno ADAM9에 대한 결합 친화력은 적어도 100-배 강화되고, 인간 ADAM9에 대해 높은 결합 친화력을 유지하되도록 최적화되는, 면역콘쥬게이트.
- 청구항 17에 있어서, 이때 전술한 항-ADAM9 항체 또는 ADAM9-결합 이의 단편은 다음으로 구성된 군에서 선택된 서열을 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 포함하는, 면역콘쥬게이트:
(a) 차례로 서열 식별 번호:8, 35, 및 37, 그리고 서열 식별 번호:62, 13, 14;
(b) 차례로 서열 식별 번호:8, 35, 및 38, 그리고 서열 식별 번호:62, 13, 14;
(c) 차례로 서열 식별 번호:8, 35, 및 39, 그리고 서열 식별 번호:62, 13, 14;
(d) 차례로 서열 식별 번호:8, 35, 및 40, 그리고 서열 식별 번호:62, 13, 14;
(e) 차례로 서열 식별 번호:8, 35, 및 41, 그리고 서열 식별 번호:62, 13, 14;
(f) 차례로 서열 식별 번호:8, 35, 그리고 42 및 서열 식별 번호:62, 13, 14;
(g) 차례로 서열 식별 번호:8, 35, 그리고 43 및 서열 식별 번호:62, 13, 14;
(h) 차례로 서열 식별 번호:8, 35, 그리고 44 및 서열 식별 번호:62, 13, 14;
(i) 차례로 서열 식별 번호:8, 35, 그리고 45 및 서열 식별 번호:62, 13, 14; 그리고
(j) 차례로 서열 식별 번호:8, 35, 그리고 46 및 서열 식별 번호:62, 13, 14. - 청구항 18에 있어서, 이때 전술한 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 다음으로 구성된 군에서 선택된 서열에 대해 적어도 90%, 적어도 95%, 또는 적어도 99% 동일성을 갖는 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함하는, 면역콘쥬게이트:
(a) 차례로 서열 식별 번호:20 및 서열 식별 번호:55;
(b) 차례로 서열 식별 번호:21 및 서열 식별 번호:55;
(c) 차례로 서열 식별 번호:22 및 서열 식별 번호:55;
(d) 차례로 서열 식별 번호:23 및 서열 식별 번호:55;
(e) 차례로 서열 식별 번호:24 및 서열 식별 번호:55;
(f) 차례로 서열 식별 번호:25 및 서열 식별 번호:55;
(g) 차례로 서열 식별 번호:26 및 서열 식별 번호:55;
(h) 차례로 서열 식별 번호:27 및 서열 식별 번호:55;
(i) 차례로 서열 식별 번호:28 및 서열 식별 번호:55; 그리고
(j) 차례로 서열 식별 번호:29 및 서열 식별 번호:55. - 청구항 19에 있어서, 이때 전술한 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 다음으로 구성된 군에서 선택된 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함하는, 면역콘쥬게이트:
(a) 차례로 서열 식별 번호:20 및 서열 식별 번호:55;
(b) 차례로 서열 식별 번호:21 및 서열 식별 번호:55;
(c) 차례로 서열 식별 번호:22 및 서열 식별 번호:55;
(d) 차례로 서열 식별 번호:23 및 서열 식별 번호:55;
(e) 차례로 서열 식별 번호:24 및 서열 식별 번호:55;
(f) 차례로 서열 식별 번호:25 및 서열 식별 번호:55;
(g) 차례로 서열 식별 번호:26 및 서열 식별 번호:55;
(h) 차례로 서열 식별 번호:27 및 서열 식별 번호:55;
(i) 차례로 서열 식별 번호:28 및 서열 식별 번호:55; 그리고
(j) 차례로 서열 식별 번호:29 및 서열 식별 번호:55. - 청구항 13-20중 임의의 한 항에 있어서, 이때 전술한 인간화된 항-ADAM9 항체는 Fc 영역을 포함하는 전장의 항체인, 면역콘쥬게이트.
- 청구항 21에 있어서, 이때 전술한 인간화된 항-ADAM9 항체는 다음으로 구성된 군에서 선택된 서열을 갖는 중쇄와 경쇄를 포함하는 면역콘쥬게이트:
(a) 차례로 서열 식별 번호:50 및 서열 식별 번호:68;
(b) 차례로 서열 식별 번호:51 및 서열 식별 번호:68; 그리고
(c) 차례로 서열 식별 번호:52 및 서열 식별 번호:68. - 청구항 13-22중 임의의 한 항에 있어서, 이때 전술한 Fc 영역은 다음을 포함하는 변이체 Fc 영역인, 면역콘쥬게이트:
(a) FcγR에 대한 변이체 Fc 영역의 친화력을 감소시키는 다음으로 구성된 군에서 선택된 하나 또는 그 이상의 아미노산 변형(들): L234A, L235A, 그리고 L234A 및 L235A이며; 및/또는
(b) S442에 시스테인 잔기를 도입시키는 아미노산 변형, 이때 전술한 번호매김은 Kabat와 같은 EU 색인의 번호매김; 및/또는
(c) FcRn에 대한 변이체 Fc 영역의 반감기를 연장시키는, 다음으로 구성된 군에서 선택된 하나 또는 그 이상의 아미노산 치환(들): M252Y, S254T, 그리고 T256E. - 청구항 18에 있어서, 이때 전술한 인간화된 항-ADAM9 항체는 다음으로 구성된 군에서 선택된 서열을 갖는 중쇄와 경쇄를 포함하는, 면역콘쥬게이트:
(a) 차례로 서열 식별 번호:141 및 서열 식별 번호:68;
(b) 차례로 서열 식별 번호:142 및 서열 식별 번호:68;
(c) 차례로 서열 식별 번호:143 및 서열 식별 번호:68;
(d) 차례로 서열 식별 번호:151 및 서열 식별 번호:68;
(e) 차례로 서열 식별 번호:152 및 서열 식별 번호:68;
(f) 차례로 서열 식별 번호:153 및 서열 식별 번호:68; 그리고
(g) 차례로 서열 식별 번호:154 및 서열 식별 번호:68. - 청구항 24에 있어서, 이때 서열 식별 번호:141, 서열 식별 번호:142, 서열 식별 번호:143, 서열 식별 번호:151, 서열 식별 번호:152, 서열 식별 번호:153 또는 서열 식별 번호:154에서 X는 리신인, 면역콘쥬게이트.
- 청구항 24에 있어서, 이때 서열 식별 번호:141, 서열 식별 번호:142, 서열 식별 번호:143, 서열 식별 번호:151, 서열 식별 번호:152, 서열 식별 번호:153 또는 서열 식별 번호:154에서 X는 존재하지 않는, 면역콘쥬게이트.
- 청구항 1에 있어서, 이때 상기 면역콘쥬게이트는 다음의 화학식으로 나타내는, 면역콘쥬게이트:

이때:
CBA은 서열 식별 번호:8, 35, 그리고 45 및 서열 식별 번호:62, 13, 14를 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 포함하는 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편이며;
q은 1 또는 2이며;
D1은 다음의 화학식으로 나타낸다:

- 청구항 27에 있어서, 이때 전술한 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 서열 식별 번호:28 및 서열 식별 번호:55의 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함하는, 면역콘쥬게이트.
- 청구항 27에 있어서, 이때 전술한 인간화된 항-ADAM9 항체는 서열 식별 번호:142 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함하는, 면역콘쥬게이트.
- 청구항 27에 있어서, 이때 전술한 인간화된 항-ADAM9 항체는 서열 식별 번호:152 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함하는, 면역콘쥬게이트.
- 청구항 29 또는 30에 있어서, 이때 서열 식별 번호:142 또는 서열 식별 번호:152에서 X는 리신인, 면역콘쥬게이트.
- 청구항 29에 있어서, 이때 서열 식별 번호:142에서 X는 존재하지 않는, 면역콘쥬게이트.
- 청구항 27에 있어서, 이때 전술한 인간화된 항-ADAM9 항체는 서열 식별 번호:156 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함하는, 면역콘쥬게이트.
- 청구항 1에 있어서, 이때 다음의 화학식으로 나타내는 면역콘쥬게이트:

이때:
CBA은 서열 식별 번호:8, 35, 그리고 45 및 서열 식별 번호:62, 13, 14를 갖는 CDRH1 도메인, CDRH2 도메인, 그리고 CDRH3 도메인 및 CDRL1 도메인, CDRL2 도메인, 그리고 CDRL3 도메인을 포함하는 인간화된 항-ADAM9 항체 또는 이의 ADAM9-결합 단편이며;
q은 1 또는 10의 정수이며;
D1은 다음의 화학식으로 나타낸다:

- 청구항 33에 있어서, 이때 전술한 항-ADAM9 항체 또는 이의 ADAM9-결합 단편은 서열 식별 번호:28 및 서열 식별 번호:55의 서열을 갖는 중쇄 가변 도메인 (VH)과 경쇄 가변 도메인 (VL)을 포함하는, 면역콘쥬게이트.
- 청구항 35에 있어서, 이때 전술한 인간화된 항-ADAM9 항체는 서열 식별 번호:52 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함하는, 면역콘쥬게이트.
- 청구항 34에 있어서, 이때 전술한 인간화된 항-ADAM9 항체는 서열 식별 번호:151 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함하는, 면역콘쥬게이트.
- 청구항 36 또는 37에 있어서, 이때 서열 식별 번호:52 또는 서열 식별 번호:151에서 X는 리신인, 면역콘쥬게이트.
- 청구항 36에 있어서, 이때 서열 식별 번호:52에서 X는 존재하지 않는, 면역콘쥬게이트.
- 청구항 34에 있어서, 이때 전술한 인간화된 항-ADAM9 항체는 서열 식별 번호:155 및 서열 식별 번호:68의 서열을 갖는 중쇄와 경쇄를 포함하는, 면역콘쥬게이트.
- 청구항 1-40중 임의의 한 항의 면역콘쥬게이트 효과량과 약제학적으로 허용되는 운반체, 부형제 또는 희석제를 포함하는 약제학적 조성물.
- 대상체에서 ADAM9의 발현과 연합된, 또는 이를 특징으로 하는 질환 또는 병태를 치료하는 방법에 있어서, 이 방법은 전술한 대상체에게 청구항 1-40항의 면역콘쥬게이트 또는 청구항 41의 약제학적 조성물의 효과량을 투여하는 것을 포함하는 치료 방법.
- 청구항 42에 있어서, 이때 ADAM9의 발현과 연합된, 또는 이를 특징으로 하는 전술한 질환 또는 병태는 암인, 방법.
- 청구항 43에 있어서, 이때 전술한 암은 다음으로 구성된 군에서 선택되며 비-소-세포 폐암, 결장직장암, 방광 암, 위암, 췌장암, 신장 세포 암종, 전립선암, 식도 암, 유방암, 두경부 암, 자궁 암, 난소암, 간암, 자궁경부암, 갑상선암, 고환암, 골수암, 흑색종 및 림프 암으로 구성된 군에서 선택된, 방법.
- 청구항 44에 있어서, 이때 전술한 비-소-세포 폐암은 편평 세포 암종, 비편평 세포 암종, 선암종, 또는 거대-세포 미분화된 암종인, 방법.
- 청구항 44에 있어서, 이때 전술한 결장직장암은 선암종, 위장관 카르시노이드 종양, 위장 기질 종양, 원발성 결장직장 림프종, 평활근육종, 또는 편평 세포 암종인, 방법.
- 청구항 42에 있어서, 이때 상기 방법은 비-소-세포 폐암, 위암, 췌장암, 삼중 음성 유방암 (TNBC) 또는 결장직장암 치료를 위한, 방법.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862690052P | 2018-06-26 | 2018-06-26 | |
| US62/690,052 | 2018-06-26 | ||
| US201862691342P | 2018-06-28 | 2018-06-28 | |
| US62/691,342 | 2018-06-28 | ||
| US201962810703P | 2019-02-26 | 2019-02-26 | |
| US62/810,703 | 2019-02-26 | ||
| PCT/US2019/038992 WO2020005945A1 (en) | 2018-06-26 | 2019-06-25 | Immunoconjugates targeting adam9 and methods of use thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210061995A true KR20210061995A (ko) | 2021-05-28 |
Family
ID=67513726
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217002564A KR20210061995A (ko) | 2018-06-26 | 2019-06-25 | Adam9를 표적으로 하는 면역콘쥬게이트 및 이를 이용하는 방법들 |
Country Status (13)
| Country | Link |
|---|---|
| US (1) | US20210275685A1 (ko) |
| EP (1) | EP3814378A1 (ko) |
| JP (1) | JP2021528471A (ko) |
| KR (1) | KR20210061995A (ko) |
| CN (1) | CN112543770A (ko) |
| AU (1) | AU2019294510A1 (ko) |
| BR (1) | BR112020025346A2 (ko) |
| CA (1) | CA3104511A1 (ko) |
| IL (1) | IL279633A (ko) |
| MX (1) | MX2020013466A (ko) |
| SG (1) | SG11202012257VA (ko) |
| TW (1) | TWI831797B (ko) |
| WO (1) | WO2020005945A1 (ko) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2020240310A1 (en) | 2019-03-21 | 2021-10-07 | Immunogen, Inc. | Methods of preparing cell-binding agent-drug conjugates |
| US20240165256A1 (en) | 2021-03-08 | 2024-05-23 | Immunogen, Inc. | Methods for increasing efficacy of immunoconjugates targeting adam9 for the treatment of cancer |
| WO2024059263A1 (en) * | 2022-09-15 | 2024-03-21 | Immunogen, Inc. | Methods for preparing maytansinoid derivatives with self-immolative peptide linkers |
Family Cites Families (62)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US5807715A (en) | 1984-08-27 | 1998-09-15 | The Board Of Trustees Of The Leland Stanford Junior University | Methods and transformed mammalian lymphocyte cells for producing functional antigen-binding protein including chimeric immunoglobulin |
| US5427908A (en) | 1990-05-01 | 1995-06-27 | Affymax Technologies N.V. | Recombinant library screening methods |
| DE69233482T2 (de) | 1991-05-17 | 2006-01-12 | Merck & Co., Inc. | Verfahren zur Verminderung der Immunogenität der variablen Antikörperdomänen |
| WO1994004679A1 (en) | 1991-06-14 | 1994-03-03 | Genentech, Inc. | Method for making humanized antibodies |
| GB9115364D0 (en) | 1991-07-16 | 1991-08-28 | Wellcome Found | Antibody |
| AU669124B2 (en) | 1991-09-18 | 1996-05-30 | Kyowa Hakko Kirin Co., Ltd. | Process for producing humanized chimera antibody |
| US5565332A (en) | 1991-09-23 | 1996-10-15 | Medical Research Council | Production of chimeric antibodies - a combinatorial approach |
| US5733743A (en) | 1992-03-24 | 1998-03-31 | Cambridge Antibody Technology Limited | Methods for producing members of specific binding pairs |
| US6180377B1 (en) | 1993-06-16 | 2001-01-30 | Celltech Therapeutics Limited | Humanized antibodies |
| US6265150B1 (en) | 1995-06-07 | 2001-07-24 | Becton Dickinson & Company | Phage antibodies |
| WO1998023289A1 (en) | 1996-11-27 | 1998-06-04 | The General Hospital Corporation | MODULATION OF IgG BINDING TO FcRn |
| US6277375B1 (en) | 1997-03-03 | 2001-08-21 | Board Of Regents, The University Of Texas System | Immunoglobulin-like domains with increased half-lives |
| US7091321B2 (en) | 2000-02-11 | 2006-08-15 | Emd Lexigen Research Center Corp. | Enhancing the circulating half-life of antibody-based fusion proteins |
| EP1142910A1 (en) | 2000-04-07 | 2001-10-10 | Jürgen Prof. Dr. Frey | Inhibitors for the formation of soluble human CD23 |
| US20030091568A1 (en) | 2000-04-07 | 2003-05-15 | Jurgen Frey | Inhibitors for the formation of soluble human CD23 |
| PT1355919E (pt) | 2000-12-12 | 2011-03-02 | Medimmune Llc | Moléculas com semivida longa, composições que as contêm e suas utilizações |
| JP2005528082A (ja) | 2001-12-18 | 2005-09-22 | モンドバイオテック・ラボラトリーズ・アンスタルト | 間質性肺疾患の治療を向上させるためのインターフェロンγ又はパーフェニドンと分子診断薬との新規医薬組成物 |
| US6716821B2 (en) | 2001-12-21 | 2004-04-06 | Immunogen Inc. | Cytotoxic agents bearing a reactive polyethylene glycol moiety, cytotoxic conjugates comprising polyethylene glycol linking groups, and methods of making and using the same |
| US20040092466A1 (en) | 2002-11-11 | 2004-05-13 | Isis Pharmaceuticals Inc. | Modulation of ADAM9 expression |
| DE60336149D1 (de) | 2002-08-16 | 2011-04-07 | Immunogen Inc | Vernetzer mit hoher reaktivität und löslichkeit und ihre verwendung bei der herstellung von konjugaten für die gezielte abgabe von kleinmolekularen arzneimitteln |
| US7217797B2 (en) | 2002-10-15 | 2007-05-15 | Pdl Biopharma, Inc. | Alteration of FcRn binding affinities or serum half-lives of antibodies by mutagenesis |
| US8088387B2 (en) | 2003-10-10 | 2012-01-03 | Immunogen Inc. | Method of targeting specific cell populations using cell-binding agent maytansinoid conjugates linked via a non-cleavable linker, said conjugates, and methods of making said conjugates |
| DE10337368A1 (de) * | 2003-08-08 | 2005-03-03 | Technische Universität Dresden | Verfahren und Mittel zur Diagnose und Behandlung von Pankreastumoren |
| WO2005047327A2 (en) | 2003-11-12 | 2005-05-26 | Biogen Idec Ma Inc. | NEONATAL Fc RECEPTOR (FcRn)-BINDING POLYPEPTIDE VARIANTS, DIMERIC Fc BINDING PROTEINS AND METHODS RELATED THERETO |
| WO2005091823A2 (en) | 2004-03-01 | 2005-10-06 | The Regents Of The University Of California | The use of lunasin peptide as a transcriptional activator to prevent cancer and related methods for treatment, monitoring and prognosis |
| US8367805B2 (en) | 2004-11-12 | 2013-02-05 | Xencor, Inc. | Fc variants with altered binding to FcRn |
| US8802820B2 (en) | 2004-11-12 | 2014-08-12 | Xencor, Inc. | Fc variants with altered binding to FcRn |
| WO2006084075A2 (en) | 2005-02-02 | 2006-08-10 | Raven Biotechnologies, Inc. | Adam-9 modulators |
| US8445198B2 (en) | 2005-12-01 | 2013-05-21 | Medical Prognosis Institute | Methods, kits and devices for identifying biomarkers of treatment response and use thereof to predict treatment efficacy |
| DK2032606T3 (da) | 2006-05-30 | 2014-02-03 | Genentech Inc | Antistoffer og immunkonjugater og anvendelser deraf |
| WO2007143752A2 (en) | 2006-06-09 | 2007-12-13 | The Regents Of The University Of California | Targets in breast cancer for prognosis or therapy |
| KR101443214B1 (ko) | 2007-01-09 | 2014-09-24 | 삼성전자주식회사 | 폐암 환자 또는 폐암 치료를 받은 폐암 환자의 폐암 재발 위험을 진단하기 위한 조성물, 키트 및 마이크로어레이 |
| GB2453589A (en) | 2007-10-12 | 2009-04-15 | King S College London | Protease inhibition |
| GB0724357D0 (en) * | 2007-12-14 | 2008-01-23 | Glaxosmithkline Biolog Sa | Method for preparing protein conjugates |
| WO2009114532A2 (en) | 2008-03-10 | 2009-09-17 | National Jewish Health | Markers for diagnosis of pulmonary inflammation and methods related thereto |
| EP2271675A4 (en) | 2008-04-07 | 2011-08-24 | Zymogenetics Inc | THROMBIN ACTIVATOR COMPOSITION AND METHOD FOR THE PRODUCTION AND USE THEREOF |
| US20090285840A1 (en) * | 2008-04-29 | 2009-11-19 | New York Society For The Ruptured And Crippled Maintaining The Hospital For Special Surgery | Methods for treating pathological neovascularization |
| BRPI0910746B8 (pt) | 2008-04-30 | 2021-05-25 | Immunogen Inc | agente de reticulação, conjugado de agente de ligação celular-fármaco, seu uso, composto e composição farmacêutica |
| UA108598C2 (xx) | 2008-04-30 | 2015-05-25 | Високоефективні кон'югати та гідрофільні зшиваючі агенти (лінкери) | |
| CA2726845C (en) | 2008-06-04 | 2017-09-26 | Macrogenics, Inc. | Antibodies with altered binding to fcrn and methods of using same |
| US20110129450A1 (en) | 2008-08-01 | 2011-06-02 | Orly Lazarov | Method of promoting neurogenesis by modulating secretase activities |
| WO2010053539A2 (en) | 2008-11-05 | 2010-05-14 | The Texas A&M University System | Methods for detecting colorectal diseases and disorders |
| CA2745271A1 (en) | 2008-12-04 | 2010-06-10 | Abbott Laboratories | Dual variable domain immunoglobulins and uses thereof |
| EP2486023A4 (en) * | 2009-10-06 | 2014-05-07 | Immunogen Inc | EFFICIENT CONJUGATES AND HYDROPHILIC BINDER |
| US20110097345A1 (en) * | 2009-10-21 | 2011-04-28 | Immunogen Inc. | Novel dosing regimen and method of treatment |
| EP2534171A4 (en) | 2010-02-11 | 2013-07-17 | Univ Southern California | MODIFIED POLYPEPTIDES OF THE DEINDEGRINE ADAM DOMAIN, AND USES THEREOF |
| PH12018501083A1 (en) | 2010-03-04 | 2019-02-18 | Macrogenics Inc | Antibodies reactive with b7-h3, immunologically active fragments thereof and uses thereof |
| US20130058947A1 (en) | 2011-09-02 | 2013-03-07 | Stem Centrx, Inc | Novel Modulators and Methods of Use |
| US20130130355A1 (en) | 2011-09-28 | 2013-05-23 | Armune Biosciences, Inc. | Method and system of particle-phage epitope complex |
| WO2013098797A2 (en) | 2011-12-31 | 2013-07-04 | Kuriakose Moni Abraham | Diagnostic tests for predicting prognosis, recurrence, resistance or sensitivity to therapy and metastatic status in cancer |
| US9534058B2 (en) | 2012-02-08 | 2017-01-03 | Abbvie Stemcentrx Llc | Anti-CD324 monoclonal antibodies and uses thereof |
| US10851402B2 (en) | 2013-01-09 | 2020-12-01 | Friedrich-Alexander-Universitaet Erlangen-Nuernberg | Method for in vitro detection and monitoring of a disease by measuring disease-associated protease activity in extracellular vesicles |
| JP2016509014A (ja) | 2013-02-08 | 2016-03-24 | ステムセントリックス, インコーポレイテッド | 新規の多特異的構成物 |
| JP6847388B2 (ja) * | 2013-03-15 | 2021-03-31 | レゲネロン ファーマシューティカルス,インコーポレーテッド | 生物活性分子、そのコンジュゲート、及び治療用途 |
| WO2014168154A1 (ja) | 2013-04-08 | 2014-10-16 | 三菱レイヨン株式会社 | 眼疾患を評価するためのマイクロアレイ及び眼疾患の評価方法 |
| ES2902420T3 (es) | 2013-05-13 | 2022-03-28 | Univ Tufts | Composiciones para el tratamiento del cáncer que expresa ADAM8 |
| US20160138113A1 (en) | 2013-06-19 | 2016-05-19 | Memorial Sloan-Kettering Cancer Center | Methods and compositions for the diagnosis, prognosis and treatment of brain metastasis |
| US9567641B2 (en) | 2013-07-03 | 2017-02-14 | Samsung Electronics Co., Ltd. | Combination therapy for the treatment of cancer using an anti-C-met antibody |
| EA201790871A1 (ru) | 2014-11-11 | 2017-11-30 | Амуникс Оперэйтинг Инк. | Нацеленные конъюгатные композиции xten и способы их получения |
| WO2017136623A1 (en) * | 2016-02-05 | 2017-08-10 | Immunogen, Inc. | Efficient process for preparing cell-binding agent-cytotoxic agent conjugates |
| RS63154B1 (sr) * | 2016-12-23 | 2022-05-31 | Immunogen Inc | Imunokonjugati koji ciljano deluju na adam9 i postupci za njihovu upotrebu |
-
2019
- 2019-06-25 TW TW108122055A patent/TWI831797B/zh active
- 2019-06-25 MX MX2020013466A patent/MX2020013466A/es unknown
- 2019-06-25 AU AU2019294510A patent/AU2019294510A1/en active Pending
- 2019-06-25 JP JP2020573007A patent/JP2021528471A/ja active Pending
- 2019-06-25 WO PCT/US2019/038992 patent/WO2020005945A1/en unknown
- 2019-06-25 BR BR112020025346-4A patent/BR112020025346A2/pt unknown
- 2019-06-25 EP EP19748615.2A patent/EP3814378A1/en active Pending
- 2019-06-25 US US17/255,064 patent/US20210275685A1/en not_active Abandoned
- 2019-06-25 CA CA3104511A patent/CA3104511A1/en active Pending
- 2019-06-25 KR KR1020217002564A patent/KR20210061995A/ko unknown
- 2019-06-25 SG SG11202012257VA patent/SG11202012257VA/en unknown
- 2019-06-25 CN CN201980049672.2A patent/CN112543770A/zh active Pending
-
2020
- 2020-12-21 IL IL279633A patent/IL279633A/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| EP3814378A1 (en) | 2021-05-05 |
| CA3104511A1 (en) | 2020-01-02 |
| MX2020013466A (es) | 2021-04-19 |
| TW202019960A (zh) | 2020-06-01 |
| WO2020005945A1 (en) | 2020-01-02 |
| AU2019294510A1 (en) | 2021-01-21 |
| JP2021528471A (ja) | 2021-10-21 |
| IL279633A (en) | 2021-03-01 |
| TWI831797B (zh) | 2024-02-11 |
| BR112020025346A2 (pt) | 2021-05-25 |
| CN112543770A (zh) | 2021-03-23 |
| US20210275685A1 (en) | 2021-09-09 |
| SG11202012257VA (en) | 2021-01-28 |
| AU2019294510A8 (en) | 2021-04-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20210171637A1 (en) | Anti-b7-h3 antibodies and antibody drug conjugates | |
| AU2022291603A1 (en) | Anti-CD123 antibodies and conjugates and derivatives thereof | |
| AU2018279105A1 (en) | Antibody conjugates of immune-modulatory compounds and uses thereof | |
| TWI783957B (zh) | 靶向adam9之免疫共軛物及其使用方法 | |
| CA3049791A1 (en) | Tumor targeting conjugates and methods of use thereof | |
| KR20180130574A (ko) | 신규 b7-h3-결합 분자, 그것의 항체 약물 콘쥬게이트 및 그것의 사용 방법 | |
| CA3049842A1 (en) | Construct-peptide compositions and methods of use thereof | |
| US20220135701A1 (en) | Anti-mertk antibodies and their methods of use | |
| CA3137373A1 (en) | Amatoxin antibody-drug conjugates and uses thereof | |
| KR20210061995A (ko) | Adam9를 표적으로 하는 면역콘쥬게이트 및 이를 이용하는 방법들 | |
| CA3131104A1 (en) | Cyclic amino-pyrazinecarboxamide compounds and uses thereof | |
| CA3138272A1 (en) | Biparatopic fr-alpha antibodies and immunoconjugates | |
| WO2022006340A1 (en) | Alk5 inhibitors, conjugates, and uses thereof | |
| CA3231039A1 (en) | Linkers for use in antibody drug conjugates | |
| JPWO2020219748A5 (ko) | ||
| JPWO2020219770A5 (ko) |