KR20210020006A - 암을 진단 및 치료하기 위한 조성물 및 방법 - Google Patents
암을 진단 및 치료하기 위한 조성물 및 방법 Download PDFInfo
- Publication number
- KR20210020006A KR20210020006A KR1020207035142A KR20207035142A KR20210020006A KR 20210020006 A KR20210020006 A KR 20210020006A KR 1020207035142 A KR1020207035142 A KR 1020207035142A KR 20207035142 A KR20207035142 A KR 20207035142A KR 20210020006 A KR20210020006 A KR 20210020006A
- Authority
- KR
- South Korea
- Prior art keywords
- arg
- cys
- gly
- edb
- ile
- Prior art date
Links
- 206010028980 Neoplasm Diseases 0.000 title claims abstract description 227
- 238000000034 method Methods 0.000 title claims description 128
- 201000011510 cancer Diseases 0.000 title claims description 109
- 239000000203 mixture Substances 0.000 title description 15
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 287
- 108010067306 Fibronectins Proteins 0.000 claims abstract description 258
- 102000016359 Fibronectins Human genes 0.000 claims abstract description 258
- 230000008685 targeting Effects 0.000 claims abstract description 14
- 230000027455 binding Effects 0.000 claims description 229
- 210000004027 cell Anatomy 0.000 claims description 162
- 150000007523 nucleic acids Chemical class 0.000 claims description 109
- 150000001413 amino acids Chemical group 0.000 claims description 96
- 102000039446 nucleic acids Human genes 0.000 claims description 91
- 108020004707 nucleic acids Proteins 0.000 claims description 91
- 239000011230 binding agent Substances 0.000 claims description 82
- 239000000126 substance Substances 0.000 claims description 81
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 70
- 239000000523 sample Substances 0.000 claims description 58
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 claims description 56
- 108010016616 cysteinylglycine Proteins 0.000 claims description 42
- UKVGHFORADMBEN-GUBZILKMSA-N Cys-Arg-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UKVGHFORADMBEN-GUBZILKMSA-N 0.000 claims description 40
- LEVWYRKDKASIDU-QWWZWVQMSA-N D-cystine Chemical compound OC(=O)[C@H](N)CSSC[C@@H](N)C(O)=O LEVWYRKDKASIDU-QWWZWVQMSA-N 0.000 claims description 39
- 238000004458 analytical method Methods 0.000 claims description 39
- 229960003067 cystine Drugs 0.000 claims description 39
- WECYRWOMWSCWNX-XUXIUFHCSA-N Ile-Arg-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O WECYRWOMWSCWNX-XUXIUFHCSA-N 0.000 claims description 32
- 230000001225 therapeutic effect Effects 0.000 claims description 32
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 claims description 31
- FRVUYKWGPCQRBL-GUBZILKMSA-N Pro-Met-Cys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@@H]1CCCN1 FRVUYKWGPCQRBL-GUBZILKMSA-N 0.000 claims description 30
- 108010062796 arginyllysine Proteins 0.000 claims description 30
- UDSVWSUXKYXSTR-QWRGUYRKSA-N Asn-Gly-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UDSVWSUXKYXSTR-QWRGUYRKSA-N 0.000 claims description 28
- DNEJSAIMVANNPA-DCAQKATOSA-N Lys-Asn-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DNEJSAIMVANNPA-DCAQKATOSA-N 0.000 claims description 28
- 238000002372 labelling Methods 0.000 claims description 28
- QILPDQCTQZDHFM-HJGDQZAQSA-N Thr-Gln-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QILPDQCTQZDHFM-HJGDQZAQSA-N 0.000 claims description 27
- CEZSLNCYQUFOSL-BQBZGAKWSA-N Cys-Arg-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O CEZSLNCYQUFOSL-BQBZGAKWSA-N 0.000 claims description 25
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 claims description 25
- 108010027338 isoleucylcysteine Proteins 0.000 claims description 25
- NJIFPLAJSVUQOZ-JBDRJPRFSA-N Ala-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C)N NJIFPLAJSVUQOZ-JBDRJPRFSA-N 0.000 claims description 23
- 230000004048 modification Effects 0.000 claims description 23
- 238000012986 modification Methods 0.000 claims description 23
- XGHYKIDVGYYHDC-JBDRJPRFSA-N Cys-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N XGHYKIDVGYYHDC-JBDRJPRFSA-N 0.000 claims description 22
- WRFOZIJRODPLIA-QWRGUYRKSA-N Gly-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN)O WRFOZIJRODPLIA-QWRGUYRKSA-N 0.000 claims description 22
- PNIGSVZJNVUVJA-BQBZGAKWSA-N Arg-Gly-Asn Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O PNIGSVZJNVUVJA-BQBZGAKWSA-N 0.000 claims description 21
- ALNKNYKSZPSLBD-ZDLURKLDSA-N Cys-Thr-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O ALNKNYKSZPSLBD-ZDLURKLDSA-N 0.000 claims description 21
- 230000004927 fusion Effects 0.000 claims description 21
- 239000008194 pharmaceutical composition Substances 0.000 claims description 21
- 239000012472 biological sample Substances 0.000 claims description 20
- 238000003556 assay Methods 0.000 claims description 16
- 239000003112 inhibitor Substances 0.000 claims description 16
- 239000012636 effector Substances 0.000 claims description 13
- 238000012360 testing method Methods 0.000 claims description 13
- 239000007787 solid Substances 0.000 claims description 12
- GGEJHJIXRBTJPD-BYPYZUCNSA-N Gly-Asn-Gly Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GGEJHJIXRBTJPD-BYPYZUCNSA-N 0.000 claims description 11
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 claims description 11
- 210000004881 tumor cell Anatomy 0.000 claims description 11
- NVUIWHJLPSZZQC-CYDGBPFRSA-N Arg-Ile-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NVUIWHJLPSZZQC-CYDGBPFRSA-N 0.000 claims description 10
- 125000002061 L-isoleucyl group Chemical group [H]N([H])[C@]([H])(C(=O)[*])[C@](C([H])([H])[H])([H])C(C([H])([H])[H])([H])[H] 0.000 claims description 10
- 238000012544 monitoring process Methods 0.000 claims description 10
- NFHJQETXTSDZSI-DCAQKATOSA-N Leu-Cys-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NFHJQETXTSDZSI-DCAQKATOSA-N 0.000 claims description 9
- SGZVZUCRAVSPKQ-FXQIFTODSA-N Ser-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N SGZVZUCRAVSPKQ-FXQIFTODSA-N 0.000 claims description 9
- 239000003795 chemical substances by application Substances 0.000 claims description 9
- 230000009870 specific binding Effects 0.000 claims description 9
- SJIGTGZVQGLMGG-NAKRPEOUSA-N Ile-Cys-Arg Chemical compound N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)O SJIGTGZVQGLMGG-NAKRPEOUSA-N 0.000 claims description 8
- 210000002889 endothelial cell Anatomy 0.000 claims description 8
- FQNUWOHNGJWNLM-QWRGUYRKSA-N Tyr-Cys-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)NCC(O)=O FQNUWOHNGJWNLM-QWRGUYRKSA-N 0.000 claims description 7
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 claims description 6
- KVPHTGVUMJGMCX-BIIVOSGPSA-N Asp-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N)C(=O)O KVPHTGVUMJGMCX-BIIVOSGPSA-N 0.000 claims description 6
- GQGAFTPXAPKSCF-WHFBIAKZSA-N Gly-Ala-Cys Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(=O)O GQGAFTPXAPKSCF-WHFBIAKZSA-N 0.000 claims description 6
- 230000015572 biosynthetic process Effects 0.000 claims description 6
- 238000007363 ring formation reaction Methods 0.000 claims description 6
- 238000002560 therapeutic procedure Methods 0.000 claims description 6
- XEXJJJRVTFGWIC-FXQIFTODSA-N Ala-Asn-Arg Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XEXJJJRVTFGWIC-FXQIFTODSA-N 0.000 claims description 5
- 102000014914 Carrier Proteins Human genes 0.000 claims description 5
- 108010078791 Carrier Proteins Proteins 0.000 claims description 5
- NITLUESFANGEIW-BQBZGAKWSA-N Cys-Pro-Gly Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O NITLUESFANGEIW-BQBZGAKWSA-N 0.000 claims description 5
- 101710112927 Trypsin inhibitor 2 Proteins 0.000 claims description 5
- QYLJIYOGHRGUIH-CIUDSAMLSA-N Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](N)CCCNC(N)=N QYLJIYOGHRGUIH-CIUDSAMLSA-N 0.000 claims description 4
- UWMDGPFFTKDUIY-HJGDQZAQSA-N Gln-Pro-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O UWMDGPFFTKDUIY-HJGDQZAQSA-N 0.000 claims description 4
- CXQODNIBUNQWAS-CIUDSAMLSA-N Ala-Gln-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N CXQODNIBUNQWAS-CIUDSAMLSA-N 0.000 claims description 3
- LBFXVAXPDOBRKU-LKTVYLICSA-N Ala-His-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LBFXVAXPDOBRKU-LKTVYLICSA-N 0.000 claims description 3
- OARAZORWIMYUPO-FXQIFTODSA-N Ala-Met-Cys Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CS)C(O)=O OARAZORWIMYUPO-FXQIFTODSA-N 0.000 claims description 3
- ISVACHFCVRKIDG-SRVKXCTJSA-N Arg-Val-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O ISVACHFCVRKIDG-SRVKXCTJSA-N 0.000 claims description 3
- HCZQKHSRYHCPSD-IUKAMOBKSA-N Asn-Thr-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HCZQKHSRYHCPSD-IUKAMOBKSA-N 0.000 claims description 3
- AMRLSQGGERHDHJ-FXQIFTODSA-N Cys-Ala-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMRLSQGGERHDHJ-FXQIFTODSA-N 0.000 claims description 3
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 claims description 3
- RVOMPSJXSRPFJT-DCAQKATOSA-N Lys-Ala-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVOMPSJXSRPFJT-DCAQKATOSA-N 0.000 claims description 3
- LZWNAOIMTLNMDW-NHCYSSNCSA-N Lys-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N LZWNAOIMTLNMDW-NHCYSSNCSA-N 0.000 claims description 3
- ALJGSKMBIUEJOB-FXQIFTODSA-N Pro-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@@H]1CCCN1 ALJGSKMBIUEJOB-FXQIFTODSA-N 0.000 claims description 3
- YMDNFPNTIPQMJP-NAKRPEOUSA-N Ser-Ile-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCSC)C(O)=O YMDNFPNTIPQMJP-NAKRPEOUSA-N 0.000 claims description 3
- MQCPGOZXFSYJPS-KZVJFYERSA-N Thr-Ala-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MQCPGOZXFSYJPS-KZVJFYERSA-N 0.000 claims description 3
- OYTNZCBFDXGQGE-XQXXSGGOSA-N Thr-Gln-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C)C(=O)O)N)O OYTNZCBFDXGQGE-XQXXSGGOSA-N 0.000 claims description 3
- CFMGQWYCEJDTDG-XIRDDKMYSA-N Trp-Lys-Cys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(O)=O)=CNC2=C1 CFMGQWYCEJDTDG-XIRDDKMYSA-N 0.000 claims description 3
- 238000002405 diagnostic procedure Methods 0.000 claims description 3
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 claims description 3
- UYCPJVYQYARFGB-YDHLFZDLSA-N Asn-Phe-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O UYCPJVYQYARFGB-YDHLFZDLSA-N 0.000 claims description 2
- WJHYGGVCWREQMO-GHCJXIJMSA-N Asp-Cys-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WJHYGGVCWREQMO-GHCJXIJMSA-N 0.000 claims description 2
- DFXQCCBKGUNYGG-GUBZILKMSA-N Lys-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCCCN DFXQCCBKGUNYGG-GUBZILKMSA-N 0.000 claims description 2
- 240000001910 Momordica cochinchinensis Species 0.000 claims description 2
- 235000009812 Momordica cochinchinensis Nutrition 0.000 claims description 2
- IBIDRSSEHFLGSD-YUMQZZPRSA-N Val-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-YUMQZZPRSA-N 0.000 claims description 2
- JYVKKBDANPZIAW-AVGNSLFASA-N Val-Arg-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](C(C)C)N JYVKKBDANPZIAW-AVGNSLFASA-N 0.000 claims description 2
- 238000007689 inspection Methods 0.000 claims 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 abstract description 81
- 201000010099 disease Diseases 0.000 abstract description 45
- 238000011282 treatment Methods 0.000 abstract description 27
- 230000033115 angiogenesis Effects 0.000 abstract description 7
- 208000020816 lung neoplasm Diseases 0.000 abstract description 7
- 208000003174 Brain Neoplasms Diseases 0.000 abstract description 6
- 206010006187 Breast cancer Diseases 0.000 abstract description 6
- 208000026310 Breast neoplasm Diseases 0.000 abstract description 6
- 206010009944 Colon cancer Diseases 0.000 abstract description 6
- 206010058467 Lung neoplasm malignant Diseases 0.000 abstract description 6
- 238000003745 diagnosis Methods 0.000 abstract description 6
- 201000010536 head and neck cancer Diseases 0.000 abstract description 6
- 208000014829 head and neck neoplasm Diseases 0.000 abstract description 6
- 201000005202 lung cancer Diseases 0.000 abstract description 6
- 206010060862 Prostate cancer Diseases 0.000 abstract description 5
- 208000000236 Prostatic Neoplasms Diseases 0.000 abstract description 5
- 208000001333 Colorectal Neoplasms Diseases 0.000 abstract description 4
- 230000007838 tissue remodeling Effects 0.000 abstract description 4
- 108090000623 proteins and genes Proteins 0.000 description 129
- 102000004169 proteins and genes Human genes 0.000 description 119
- 235000018102 proteins Nutrition 0.000 description 101
- 235000001014 amino acid Nutrition 0.000 description 91
- 229940024606 amino acid Drugs 0.000 description 87
- 210000001519 tissue Anatomy 0.000 description 64
- 229920002477 rna polymer Polymers 0.000 description 50
- 230000014509 gene expression Effects 0.000 description 47
- 125000003275 alpha amino acid group Chemical group 0.000 description 45
- 125000005647 linker group Chemical group 0.000 description 36
- 210000000056 organ Anatomy 0.000 description 34
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 31
- 239000003814 drug Substances 0.000 description 31
- 150000001875 compounds Chemical class 0.000 description 30
- 238000002965 ELISA Methods 0.000 description 29
- 229940079593 drug Drugs 0.000 description 28
- 239000000463 material Substances 0.000 description 27
- 241000282414 Homo sapiens Species 0.000 description 25
- 241000699670 Mus sp. Species 0.000 description 24
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 24
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 23
- 229940098773 bovine serum albumin Drugs 0.000 description 23
- 239000012634 fragment Substances 0.000 description 22
- 108091028043 Nucleic acid sequence Proteins 0.000 description 21
- -1 for example Proteins 0.000 description 19
- 125000003729 nucleotide group Chemical group 0.000 description 19
- 102100021277 Beta-secretase 2 Human genes 0.000 description 18
- 101710150190 Beta-secretase 2 Proteins 0.000 description 18
- CTRHXXXHUJTTRZ-ZLUOBGJFSA-N Ser-Asp-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N)C(=O)O CTRHXXXHUJTTRZ-ZLUOBGJFSA-N 0.000 description 18
- 238000000338 in vitro Methods 0.000 description 18
- 239000002773 nucleotide Substances 0.000 description 18
- 235000018417 cysteine Nutrition 0.000 description 17
- 239000003446 ligand Substances 0.000 description 17
- 229920001184 polypeptide Polymers 0.000 description 17
- SLUWOCTZVGMURC-BFHQHQDPSA-N Thr-Gly-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O SLUWOCTZVGMURC-BFHQHQDPSA-N 0.000 description 16
- 210000004369 blood Anatomy 0.000 description 16
- 239000008280 blood Substances 0.000 description 16
- 230000000694 effects Effects 0.000 description 16
- 239000013642 negative control Substances 0.000 description 15
- 238000006467 substitution reaction Methods 0.000 description 15
- 238000013518 transcription Methods 0.000 description 15
- 230000035897 transcription Effects 0.000 description 15
- 239000011324 bead Substances 0.000 description 14
- 239000006228 supernatant Substances 0.000 description 14
- 239000013598 vector Substances 0.000 description 14
- 102000004190 Enzymes Human genes 0.000 description 13
- 108090000790 Enzymes Proteins 0.000 description 13
- 102000010834 Extracellular Matrix Proteins Human genes 0.000 description 13
- 108010037362 Extracellular Matrix Proteins Proteins 0.000 description 13
- 239000003153 chemical reaction reagent Substances 0.000 description 13
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 13
- 229940088598 enzyme Drugs 0.000 description 13
- 238000003384 imaging method Methods 0.000 description 13
- 238000012216 screening Methods 0.000 description 13
- 108020004414 DNA Proteins 0.000 description 12
- 102000053602 DNA Human genes 0.000 description 12
- 241000588724 Escherichia coli Species 0.000 description 12
- 239000000872 buffer Substances 0.000 description 12
- 238000002512 chemotherapy Methods 0.000 description 12
- 210000002744 extracellular matrix Anatomy 0.000 description 12
- 238000002347 injection Methods 0.000 description 12
- 239000007924 injection Substances 0.000 description 12
- 230000008569 process Effects 0.000 description 12
- 239000011780 sodium chloride Substances 0.000 description 12
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 11
- 210000001124 body fluid Anatomy 0.000 description 11
- 238000003776 cleavage reaction Methods 0.000 description 11
- 238000001727 in vivo Methods 0.000 description 11
- 239000002245 particle Substances 0.000 description 11
- 230000007017 scission Effects 0.000 description 11
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 11
- 108010061238 threonyl-glycine Proteins 0.000 description 11
- 108091026890 Coding region Proteins 0.000 description 10
- 206010027476 Metastases Diseases 0.000 description 10
- 108010090804 Streptavidin Proteins 0.000 description 10
- 235000004279 alanine Nutrition 0.000 description 10
- 238000003018 immunoassay Methods 0.000 description 10
- 238000003780 insertion Methods 0.000 description 10
- 230000037431 insertion Effects 0.000 description 10
- 108020004999 messenger RNA Proteins 0.000 description 10
- 150000003839 salts Chemical class 0.000 description 10
- 108060002063 Cyclotide Proteins 0.000 description 9
- 241000880493 Leptailurus serval Species 0.000 description 9
- 241000699666 Mus <mouse, genus> Species 0.000 description 9
- 239000002202 Polyethylene glycol Substances 0.000 description 9
- 241000700605 Viruses Species 0.000 description 9
- 238000012217 deletion Methods 0.000 description 9
- 230000037430 deletion Effects 0.000 description 9
- 238000010494 dissociation reaction Methods 0.000 description 9
- 230000005593 dissociations Effects 0.000 description 9
- 238000002474 experimental method Methods 0.000 description 9
- 208000005017 glioblastoma Diseases 0.000 description 9
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 9
- 230000003993 interaction Effects 0.000 description 9
- 230000009401 metastasis Effects 0.000 description 9
- 229920001223 polyethylene glycol Polymers 0.000 description 9
- 230000001105 regulatory effect Effects 0.000 description 9
- 239000013638 trimer Substances 0.000 description 9
- 102000035195 Peptidases Human genes 0.000 description 8
- 108091005804 Peptidases Proteins 0.000 description 8
- 239000007983 Tris buffer Substances 0.000 description 8
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Chemical compound CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 8
- 125000000539 amino acid group Chemical group 0.000 description 8
- 239000000427 antigen Substances 0.000 description 8
- 108091007433 antigens Proteins 0.000 description 8
- 102000036639 antigens Human genes 0.000 description 8
- 210000004899 c-terminal region Anatomy 0.000 description 8
- 231100000433 cytotoxic Toxicity 0.000 description 8
- 230000001472 cytotoxic effect Effects 0.000 description 8
- 238000001514 detection method Methods 0.000 description 8
- 230000003834 intracellular effect Effects 0.000 description 8
- 230000009467 reduction Effects 0.000 description 8
- 239000013074 reference sample Substances 0.000 description 8
- 239000000243 solution Substances 0.000 description 8
- 230000014616 translation Effects 0.000 description 8
- GETQZCLCWQTVFV-UHFFFAOYSA-N trimethylamine Chemical compound CN(C)C GETQZCLCWQTVFV-UHFFFAOYSA-N 0.000 description 8
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 8
- 230000002792 vascular Effects 0.000 description 8
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 7
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 7
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 7
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 7
- 230000002159 abnormal effect Effects 0.000 description 7
- 239000002253 acid Substances 0.000 description 7
- 238000007792 addition Methods 0.000 description 7
- 108010087924 alanylproline Proteins 0.000 description 7
- 239000002246 antineoplastic agent Substances 0.000 description 7
- 108020001507 fusion proteins Proteins 0.000 description 7
- 102000037865 fusion proteins Human genes 0.000 description 7
- 239000002502 liposome Substances 0.000 description 7
- 238000005259 measurement Methods 0.000 description 7
- 235000013336 milk Nutrition 0.000 description 7
- 210000004080 milk Anatomy 0.000 description 7
- 239000008267 milk Substances 0.000 description 7
- 239000000843 powder Substances 0.000 description 7
- 230000035755 proliferation Effects 0.000 description 7
- 238000000746 purification Methods 0.000 description 7
- 241000894007 species Species 0.000 description 7
- 238000010186 staining Methods 0.000 description 7
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 6
- CSCPPACGZOOCGX-UHFFFAOYSA-N Acetone Chemical compound CC(C)=O CSCPPACGZOOCGX-UHFFFAOYSA-N 0.000 description 6
- 241000894006 Bacteria Species 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 6
- 102100024616 Platelet endothelial cell adhesion molecule Human genes 0.000 description 6
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 6
- 238000006243 chemical reaction Methods 0.000 description 6
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 6
- 108010050848 glycylleucine Proteins 0.000 description 6
- 238000003125 immunofluorescent labeling Methods 0.000 description 6
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 6
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 6
- 230000004044 response Effects 0.000 description 6
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 6
- 238000003786 synthesis reaction Methods 0.000 description 6
- 239000012116 Alexa Fluor 680 Substances 0.000 description 5
- 241000282412 Homo Species 0.000 description 5
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 5
- 238000001042 affinity chromatography Methods 0.000 description 5
- 238000012867 alanine scanning Methods 0.000 description 5
- 108010068380 arginylarginine Proteins 0.000 description 5
- 230000001588 bifunctional effect Effects 0.000 description 5
- 229960002685 biotin Drugs 0.000 description 5
- 239000011616 biotin Substances 0.000 description 5
- 210000004556 brain Anatomy 0.000 description 5
- 238000005119 centrifugation Methods 0.000 description 5
- 239000011248 coating agent Substances 0.000 description 5
- 238000000576 coating method Methods 0.000 description 5
- 230000000295 complement effect Effects 0.000 description 5
- 230000021615 conjugation Effects 0.000 description 5
- 229940127089 cytotoxic agent Drugs 0.000 description 5
- 238000011161 development Methods 0.000 description 5
- 230000018109 developmental process Effects 0.000 description 5
- 208000035475 disorder Diseases 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 108010010147 glycylglutamine Proteins 0.000 description 5
- 230000000670 limiting effect Effects 0.000 description 5
- 230000003211 malignant effect Effects 0.000 description 5
- 239000002609 medium Substances 0.000 description 5
- 230000002285 radioactive effect Effects 0.000 description 5
- 238000001542 size-exclusion chromatography Methods 0.000 description 5
- 238000001890 transfection Methods 0.000 description 5
- 238000005406 washing Methods 0.000 description 5
- VQZYZXLBKBUOHE-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(pyridin-2-yldisulfanyl)butanoate Chemical compound C=1C=CC=NC=1SSC(C)CC(=O)ON1C(=O)CCC1=O VQZYZXLBKBUOHE-UHFFFAOYSA-N 0.000 description 4
- JWDFQMWEFLOOED-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(pyridin-2-yldisulfanyl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCSSC1=CC=CC=N1 JWDFQMWEFLOOED-UHFFFAOYSA-N 0.000 description 4
- IAKHMKGGTNLKSZ-INIZCTEOSA-N (S)-colchicine Chemical compound C1([C@@H](NC(C)=O)CC2)=CC(=O)C(OC)=CC=C1C1=C2C=C(OC)C(OC)=C1OC IAKHMKGGTNLKSZ-INIZCTEOSA-N 0.000 description 4
- QAPSNMNOIOSXSQ-YNEHKIRRSA-N 1-[(2r,4s,5r)-4-[tert-butyl(dimethyl)silyl]oxy-5-(hydroxymethyl)oxolan-2-yl]-5-methylpyrimidine-2,4-dione Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O[Si](C)(C)C(C)(C)C)C1 QAPSNMNOIOSXSQ-YNEHKIRRSA-N 0.000 description 4
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 4
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 4
- 240000001980 Cucurbita pepo Species 0.000 description 4
- 108010025905 Cystine-Knot Miniproteins Proteins 0.000 description 4
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 4
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 4
- 102000003886 Glycoproteins Human genes 0.000 description 4
- 108090000288 Glycoproteins Proteins 0.000 description 4
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 4
- 239000004472 Lysine Substances 0.000 description 4
- 102000018697 Membrane Proteins Human genes 0.000 description 4
- 108010052285 Membrane Proteins Proteins 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- 235000009815 Momordica Nutrition 0.000 description 4
- 241000218984 Momordica Species 0.000 description 4
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 4
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 4
- 108010079364 N-glycylalanine Proteins 0.000 description 4
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 4
- 229930012538 Paclitaxel Natural products 0.000 description 4
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 4
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 4
- 108020004511 Recombinant DNA Proteins 0.000 description 4
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 4
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 4
- JQAWYCUUFIMTHE-WLTAIBSBSA-N Thr-Gly-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JQAWYCUUFIMTHE-WLTAIBSBSA-N 0.000 description 4
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 4
- 108090000190 Thrombin Proteins 0.000 description 4
- DTQVDTLACAAQTR-UHFFFAOYSA-N Trifluoroacetic acid Chemical compound OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 description 4
- QYSBJAUCUKHSLU-JYJNAYRXSA-N Tyr-Arg-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O QYSBJAUCUKHSLU-JYJNAYRXSA-N 0.000 description 4
- 230000002378 acidificating effect Effects 0.000 description 4
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 4
- 125000003277 amino group Chemical group 0.000 description 4
- 230000000903 blocking effect Effects 0.000 description 4
- 210000004204 blood vessel Anatomy 0.000 description 4
- 230000004663 cell proliferation Effects 0.000 description 4
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 4
- 239000013068 control sample Substances 0.000 description 4
- 125000004122 cyclic group Chemical group 0.000 description 4
- 150000001945 cysteines Chemical class 0.000 description 4
- 231100000599 cytotoxic agent Toxicity 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 4
- 229960003668 docetaxel Drugs 0.000 description 4
- 210000003527 eukaryotic cell Anatomy 0.000 description 4
- 238000011156 evaluation Methods 0.000 description 4
- 230000009931 harmful effect Effects 0.000 description 4
- 230000002209 hydrophobic effect Effects 0.000 description 4
- 210000003734 kidney Anatomy 0.000 description 4
- 230000002147 killing effect Effects 0.000 description 4
- 108010009298 lysylglutamic acid Proteins 0.000 description 4
- 238000004519 manufacturing process Methods 0.000 description 4
- 230000035772 mutation Effects 0.000 description 4
- 229960001592 paclitaxel Drugs 0.000 description 4
- 230000004962 physiological condition Effects 0.000 description 4
- 210000002381 plasma Anatomy 0.000 description 4
- 238000003752 polymerase chain reaction Methods 0.000 description 4
- 238000002360 preparation method Methods 0.000 description 4
- 108010031719 prolyl-serine Proteins 0.000 description 4
- 238000011321 prophylaxis Methods 0.000 description 4
- 235000019833 protease Nutrition 0.000 description 4
- 102000005962 receptors Human genes 0.000 description 4
- 108020003175 receptors Proteins 0.000 description 4
- 230000002829 reductive effect Effects 0.000 description 4
- 238000004366 reverse phase liquid chromatography Methods 0.000 description 4
- 210000002966 serum Anatomy 0.000 description 4
- 238000003756 stirring Methods 0.000 description 4
- 238000001356 surgical procedure Methods 0.000 description 4
- 239000000725 suspension Substances 0.000 description 4
- 238000007910 systemic administration Methods 0.000 description 4
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 4
- 229960004072 thrombin Drugs 0.000 description 4
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 4
- 238000013519 translation Methods 0.000 description 4
- 108010026382 trypsin inhibitor MCoTI-II Proteins 0.000 description 4
- 241001430294 unidentified retrovirus Species 0.000 description 4
- 210000002700 urine Anatomy 0.000 description 4
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 4
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 3
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- VNFSAYFQLXPHPY-CIQUZCHMSA-N Ala-Thr-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNFSAYFQLXPHPY-CIQUZCHMSA-N 0.000 description 3
- HJDNZFIYILEIKR-OSUNSFLBSA-N Arg-Ile-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HJDNZFIYILEIKR-OSUNSFLBSA-N 0.000 description 3
- QLSRIZIDQXDQHK-RCWTZXSCSA-N Arg-Val-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QLSRIZIDQXDQHK-RCWTZXSCSA-N 0.000 description 3
- DZQKLNLLWFQONU-LKXGYXEUSA-N Asp-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N)O DZQKLNLLWFQONU-LKXGYXEUSA-N 0.000 description 3
- 201000009030 Carcinoma Diseases 0.000 description 3
- 235000009852 Cucurbita pepo Nutrition 0.000 description 3
- LHJDLVVQRJIURS-SRVKXCTJSA-N Cys-Phe-Asp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CS)N LHJDLVVQRJIURS-SRVKXCTJSA-N 0.000 description 3
- 108010092160 Dactinomycin Proteins 0.000 description 3
- 238000012286 ELISA Assay Methods 0.000 description 3
- 241001524679 Escherichia virus M13 Species 0.000 description 3
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 3
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 3
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical class C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 3
- 101001027128 Homo sapiens Fibronectin Proteins 0.000 description 3
- KBDIBHQICWDGDL-PPCPHDFISA-N Ile-Thr-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N KBDIBHQICWDGDL-PPCPHDFISA-N 0.000 description 3
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 3
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 3
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 3
- GQYIWUVLTXOXAJ-UHFFFAOYSA-N Lomustine Chemical compound ClCCN(N=O)C(=O)NC1CCCCC1 GQYIWUVLTXOXAJ-UHFFFAOYSA-N 0.000 description 3
- 101000609452 Momordica cochinchinensis Trypsin inhibitor 1 Proteins 0.000 description 3
- 102000016943 Muramidase Human genes 0.000 description 3
- 108010014251 Muramidase Proteins 0.000 description 3
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 description 3
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 3
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 3
- 206010029113 Neovascularisation Diseases 0.000 description 3
- 239000004365 Protease Substances 0.000 description 3
- 108010029485 Protein Isoforms Proteins 0.000 description 3
- 102000001708 Protein Isoforms Human genes 0.000 description 3
- 241000700159 Rattus Species 0.000 description 3
- ODRUTDLAONAVDV-IHRRRGAJSA-N Ser-Val-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ODRUTDLAONAVDV-IHRRRGAJSA-N 0.000 description 3
- 241000710960 Sindbis virus Species 0.000 description 3
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 3
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 3
- PKUJMYZNJMRHEZ-XIRDDKMYSA-N Trp-Glu-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PKUJMYZNJMRHEZ-XIRDDKMYSA-N 0.000 description 3
- NJNCVQYFNKZMAH-JYBASQMISA-N Trp-Thr-Cys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CS)C(O)=O)=CNC2=C1 NJNCVQYFNKZMAH-JYBASQMISA-N 0.000 description 3
- JRXKIVGWMMIIOF-YDHLFZDLSA-N Tyr-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JRXKIVGWMMIIOF-YDHLFZDLSA-N 0.000 description 3
- YQYFYUSYEDNLSD-YEPSODPASA-N Val-Thr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O YQYFYUSYEDNLSD-YEPSODPASA-N 0.000 description 3
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 3
- 239000004480 active ingredient Substances 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 235000020958 biotin Nutrition 0.000 description 3
- 210000000601 blood cell Anatomy 0.000 description 3
- 210000005013 brain tissue Anatomy 0.000 description 3
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 3
- 230000021164 cell adhesion Effects 0.000 description 3
- 210000000170 cell membrane Anatomy 0.000 description 3
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 3
- 229960004316 cisplatin Drugs 0.000 description 3
- 239000003431 cross linking reagent Substances 0.000 description 3
- 239000002619 cytotoxin Substances 0.000 description 3
- 230000034994 death Effects 0.000 description 3
- 238000010828 elution Methods 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 3
- 229960005420 etoposide Drugs 0.000 description 3
- 230000001747 exhibiting effect Effects 0.000 description 3
- 239000013604 expression vector Substances 0.000 description 3
- 239000007850 fluorescent dye Substances 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- 210000001156 gastric mucosa Anatomy 0.000 description 3
- 238000009396 hybridization Methods 0.000 description 3
- 208000015181 infectious disease Diseases 0.000 description 3
- 230000000977 initiatory effect Effects 0.000 description 3
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 3
- 239000004816 latex Substances 0.000 description 3
- 229920000126 latex Polymers 0.000 description 3
- 108010034529 leucyl-lysine Proteins 0.000 description 3
- 108010057821 leucylproline Proteins 0.000 description 3
- 229960000274 lysozyme Drugs 0.000 description 3
- 239000004325 lysozyme Substances 0.000 description 3
- 235000010335 lysozyme Nutrition 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 3
- 244000005700 microbiome Species 0.000 description 3
- 238000010369 molecular cloning Methods 0.000 description 3
- 238000006384 oligomerization reaction Methods 0.000 description 3
- 238000007911 parenteral administration Methods 0.000 description 3
- 239000008188 pellet Substances 0.000 description 3
- 238000002823 phage display Methods 0.000 description 3
- 239000000546 pharmaceutical excipient Substances 0.000 description 3
- 229910052697 platinum Inorganic materials 0.000 description 3
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 3
- 229920000642 polymer Polymers 0.000 description 3
- 239000003755 preservative agent Substances 0.000 description 3
- 108010004914 prolylarginine Proteins 0.000 description 3
- 125000002652 ribonucleotide group Chemical group 0.000 description 3
- 238000013207 serial dilution Methods 0.000 description 3
- 238000012289 standard assay Methods 0.000 description 3
- 238000002626 targeted therapy Methods 0.000 description 3
- 239000001226 triphosphate Substances 0.000 description 3
- 239000002753 trypsin inhibitor Substances 0.000 description 3
- 241000701161 unidentified adenovirus Species 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- 229960002066 vinorelbine Drugs 0.000 description 3
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 description 3
- 239000013603 viral vector Substances 0.000 description 3
- 238000012447 xenograft mouse model Methods 0.000 description 3
- LLXVXPPXELIDGQ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(2,5-dioxopyrrol-1-yl)benzoate Chemical compound C=1C=CC(N2C(C=CC2=O)=O)=CC=1C(=O)ON1C(=O)CCC1=O LLXVXPPXELIDGQ-UHFFFAOYSA-N 0.000 description 2
- PVGATNRYUYNBHO-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-(2,5-dioxopyrrol-1-yl)butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCN1C(=O)C=CC1=O PVGATNRYUYNBHO-UHFFFAOYSA-N 0.000 description 2
- BQWBEDSJTMWJAE-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[(2-iodoacetyl)amino]benzoate Chemical compound C1=CC(NC(=O)CI)=CC=C1C(=O)ON1C(=O)CCC1=O BQWBEDSJTMWJAE-UHFFFAOYSA-N 0.000 description 2
- PMJWDPGOWBRILU-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[4-(2,5-dioxopyrrol-1-yl)phenyl]butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCC(C=C1)=CC=C1N1C(=O)C=CC1=O PMJWDPGOWBRILU-UHFFFAOYSA-N 0.000 description 2
- WCMOHMXWOOBVMZ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 6-[3-(2,5-dioxopyrrol-1-yl)propanoylamino]hexanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCNC(=O)CCN1C(=O)C=CC1=O WCMOHMXWOOBVMZ-UHFFFAOYSA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 2
- FPKVOQKZMBDBKP-UHFFFAOYSA-N 1-[4-[(2,5-dioxopyrrol-1-yl)methyl]cyclohexanecarbonyl]oxy-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)C1CCC(CN2C(C=CC2=O)=O)CC1 FPKVOQKZMBDBKP-UHFFFAOYSA-N 0.000 description 2
- UHDGCWIWMRVCDJ-UHFFFAOYSA-N 1-beta-D-Xylofuranosyl-NH-Cytosine Natural products O=C1N=C(N)C=CN1C1C(O)C(O)C(CO)O1 UHDGCWIWMRVCDJ-UHFFFAOYSA-N 0.000 description 2
- PNDPGZBMCMUPRI-HVTJNCQCSA-N 10043-66-0 Chemical compound [131I][131I] PNDPGZBMCMUPRI-HVTJNCQCSA-N 0.000 description 2
- UAIUNKRWKOVEES-UHFFFAOYSA-N 3,3',5,5'-tetramethylbenzidine Chemical compound CC1=C(N)C(C)=CC(C=2C=C(C)C(N)=C(C)C=2)=C1 UAIUNKRWKOVEES-UHFFFAOYSA-N 0.000 description 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- QCVGEOXPDFCNHA-UHFFFAOYSA-N 5,5-dimethyl-2,4-dioxo-1,3-oxazolidine-3-carboxamide Chemical compound CC1(C)OC(=O)N(C(N)=O)C1=O QCVGEOXPDFCNHA-UHFFFAOYSA-N 0.000 description 2
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 2
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 2
- 229920001817 Agar Polymers 0.000 description 2
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 2
- FFZJHQODAYHGPO-KZVJFYERSA-N Ala-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N FFZJHQODAYHGPO-KZVJFYERSA-N 0.000 description 2
- NLYYHIKRBRMAJV-AEJSXWLSSA-N Ala-Val-Pro Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N NLYYHIKRBRMAJV-AEJSXWLSSA-N 0.000 description 2
- 102000009027 Albumins Human genes 0.000 description 2
- 108010088751 Albumins Proteins 0.000 description 2
- 239000012114 Alexa Fluor 647 Substances 0.000 description 2
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 2
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 2
- SNYCNNPOFYBCEK-ZLUOBGJFSA-N Asn-Ser-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O SNYCNNPOFYBCEK-ZLUOBGJFSA-N 0.000 description 2
- SPWXXPFDTMYTRI-IUKAMOBKSA-N Asp-Ile-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SPWXXPFDTMYTRI-IUKAMOBKSA-N 0.000 description 2
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 2
- USENATHVGFXRNO-SRVKXCTJSA-N Asp-Tyr-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(O)=O)C(O)=O)CC1=CC=C(O)C=C1 USENATHVGFXRNO-SRVKXCTJSA-N 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- 108010006654 Bleomycin Proteins 0.000 description 2
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 101710132601 Capsid protein Proteins 0.000 description 2
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 2
- 101710094648 Coat protein Proteins 0.000 description 2
- 239000004971 Cross linker Substances 0.000 description 2
- 235000009854 Cucurbita moschata Nutrition 0.000 description 2
- 108010069514 Cyclic Peptides Proteins 0.000 description 2
- 102000001189 Cyclic Peptides Human genes 0.000 description 2
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 2
- IZUNQDRIAOLWCN-YUMQZZPRSA-N Cys-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N IZUNQDRIAOLWCN-YUMQZZPRSA-N 0.000 description 2
- UHDGCWIWMRVCDJ-PSQAKQOGSA-N Cytidine Natural products O=C1N=C(N)C=CN1[C@@H]1[C@@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-PSQAKQOGSA-N 0.000 description 2
- 108090000695 Cytokines Proteins 0.000 description 2
- 102000004127 Cytokines Human genes 0.000 description 2
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 2
- 102000002322 Egg Proteins Human genes 0.000 description 2
- 108010000912 Egg Proteins Proteins 0.000 description 2
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 2
- 108090000371 Esterases Proteins 0.000 description 2
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 2
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 2
- 102000001390 Fructose-Bisphosphate Aldolase Human genes 0.000 description 2
- 108010068561 Fructose-Bisphosphate Aldolase Proteins 0.000 description 2
- VNTGPISAOMAXRK-CIUDSAMLSA-N Gln-Pro-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O VNTGPISAOMAXRK-CIUDSAMLSA-N 0.000 description 2
- STHSGOZLFLFGSS-SUSMZKCASA-N Gln-Thr-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STHSGOZLFLFGSS-SUSMZKCASA-N 0.000 description 2
- NKLRYVLERDYDBI-FXQIFTODSA-N Glu-Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKLRYVLERDYDBI-FXQIFTODSA-N 0.000 description 2
- QJCKNLPMTPXXEM-AUTRQRHGSA-N Glu-Glu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O QJCKNLPMTPXXEM-AUTRQRHGSA-N 0.000 description 2
- FMBWLLMUPXTXFC-SDDRHHMPSA-N Glu-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)O)N)C(=O)O FMBWLLMUPXTXFC-SDDRHHMPSA-N 0.000 description 2
- DAHLWSFUXOHMIA-FXQIFTODSA-N Glu-Ser-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O DAHLWSFUXOHMIA-FXQIFTODSA-N 0.000 description 2
- CAQXJMUDOLSBPF-SUSMZKCASA-N Glu-Thr-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAQXJMUDOLSBPF-SUSMZKCASA-N 0.000 description 2
- PMNHJLASAAWELO-FOHZUACHSA-N Gly-Asp-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PMNHJLASAAWELO-FOHZUACHSA-N 0.000 description 2
- GNPVTZJUUBPZKW-WDSKDSINSA-N Gly-Gln-Ser Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GNPVTZJUUBPZKW-WDSKDSINSA-N 0.000 description 2
- HFXJIZNEXNIZIJ-BQBZGAKWSA-N Gly-Glu-Gln Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFXJIZNEXNIZIJ-BQBZGAKWSA-N 0.000 description 2
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 102100021181 Golgi phosphoprotein 3 Human genes 0.000 description 2
- 108091005904 Hemoglobin subunit beta Proteins 0.000 description 2
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 2
- 241000238631 Hexapoda Species 0.000 description 2
- 108091006905 Human Serum Albumin Proteins 0.000 description 2
- 102000008100 Human Serum Albumin Human genes 0.000 description 2
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 2
- XDXDZDZNSLXDNA-UHFFFAOYSA-N Idarubicin Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XDXDZDZNSLXDNA-UHFFFAOYSA-N 0.000 description 2
- VAXBXNPRXPHGHG-BJDJZHNGSA-N Ile-Ala-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)O)N VAXBXNPRXPHGHG-BJDJZHNGSA-N 0.000 description 2
- UAVQIQOOBXFKRC-BYULHYEWSA-N Ile-Asn-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O UAVQIQOOBXFKRC-BYULHYEWSA-N 0.000 description 2
- HXIDVIFHRYRXLZ-NAKRPEOUSA-N Ile-Ser-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)O)N HXIDVIFHRYRXLZ-NAKRPEOUSA-N 0.000 description 2
- 208000008839 Kidney Neoplasms Diseases 0.000 description 2
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 2
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- KSZCCRIGNVSHFH-UWVGGRQHSA-N Leu-Arg-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O KSZCCRIGNVSHFH-UWVGGRQHSA-N 0.000 description 2
- XYUBOFCTGPZFSA-WDSOQIARSA-N Leu-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 XYUBOFCTGPZFSA-WDSOQIARSA-N 0.000 description 2
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 2
- FBNPMTNBFFAMMH-UHFFFAOYSA-N Leu-Val-Arg Natural products CC(C)CC(N)C(=O)NC(C(C)C)C(=O)NC(C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-UHFFFAOYSA-N 0.000 description 2
- RDIILCRAWOSDOQ-CIUDSAMLSA-N Lys-Cys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N RDIILCRAWOSDOQ-CIUDSAMLSA-N 0.000 description 2
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 2
- 101710125418 Major capsid protein Proteins 0.000 description 2
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 2
- 108010047562 NGR peptide Proteins 0.000 description 2
- PXHVJJICTQNCMI-UHFFFAOYSA-N Nickel Chemical compound [Ni] PXHVJJICTQNCMI-UHFFFAOYSA-N 0.000 description 2
- 101710141454 Nucleoprotein Proteins 0.000 description 2
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- 206010033128 Ovarian cancer Diseases 0.000 description 2
- 206010061535 Ovarian neoplasm Diseases 0.000 description 2
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 2
- MSSXKZBDKZAHCX-UNQGMJICSA-N Phe-Thr-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O MSSXKZBDKZAHCX-UNQGMJICSA-N 0.000 description 2
- JSGWNFKWZNPDAV-YDHLFZDLSA-N Phe-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 JSGWNFKWZNPDAV-YDHLFZDLSA-N 0.000 description 2
- 229920001213 Polysorbate 20 Polymers 0.000 description 2
- 101710193132 Pre-hexon-linking protein VIII Proteins 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 2
- FEPSEIDIPBMIOS-QXEWZRGKSA-N Pro-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEPSEIDIPBMIOS-QXEWZRGKSA-N 0.000 description 2
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 2
- HAEGAELAYWSUNC-WPRPVWTQSA-N Pro-Gly-Val Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAEGAELAYWSUNC-WPRPVWTQSA-N 0.000 description 2
- AJCRQOHDLCBHFA-SRVKXCTJSA-N Pro-His-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O AJCRQOHDLCBHFA-SRVKXCTJSA-N 0.000 description 2
- UREQLMJCKFLLHM-NAKRPEOUSA-N Pro-Ile-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UREQLMJCKFLLHM-NAKRPEOUSA-N 0.000 description 2
- SXMSEHDMNIUTSP-DCAQKATOSA-N Pro-Lys-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O SXMSEHDMNIUTSP-DCAQKATOSA-N 0.000 description 2
- QUBVFEANYYWBTM-VEVYYDQMSA-N Pro-Thr-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O QUBVFEANYYWBTM-VEVYYDQMSA-N 0.000 description 2
- 101710083689 Probable capsid protein Proteins 0.000 description 2
- 206010038389 Renal cancer Diseases 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- 239000008156 Ringer's lactate solution Substances 0.000 description 2
- 206010039491 Sarcoma Diseases 0.000 description 2
- 241000710961 Semliki Forest virus Species 0.000 description 2
- MPPHJZYXDVDGOF-BWBBJGPYSA-N Ser-Cys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CO MPPHJZYXDVDGOF-BWBBJGPYSA-N 0.000 description 2
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 2
- IFPBAGJBHSNYPR-ZKWXMUAHSA-N Ser-Ile-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O IFPBAGJBHSNYPR-ZKWXMUAHSA-N 0.000 description 2
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 2
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 2
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- 229940123237 Taxane Drugs 0.000 description 2
- WDLRUFUQRNWCPK-UHFFFAOYSA-N Tetraxetan Chemical compound OC(=O)CN1CCN(CC(O)=O)CCN(CC(O)=O)CCN(CC(O)=O)CC1 WDLRUFUQRNWCPK-UHFFFAOYSA-N 0.000 description 2
- 102000002933 Thioredoxin Human genes 0.000 description 2
- OHAJHDJOCKKJLV-LKXGYXEUSA-N Thr-Asp-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OHAJHDJOCKKJLV-LKXGYXEUSA-N 0.000 description 2
- ZUUDNCOCILSYAM-KKHAAJSZSA-N Thr-Asp-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ZUUDNCOCILSYAM-KKHAAJSZSA-N 0.000 description 2
- QQWNRERCGGZOKG-WEDXCCLWSA-N Thr-Gly-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O QQWNRERCGGZOKG-WEDXCCLWSA-N 0.000 description 2
- GMXIJHCBTZDAPD-QPHKQPEJSA-N Thr-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N GMXIJHCBTZDAPD-QPHKQPEJSA-N 0.000 description 2
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 2
- JWQNAFHCXKVZKZ-UVOCVTCTSA-N Thr-Lys-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JWQNAFHCXKVZKZ-UVOCVTCTSA-N 0.000 description 2
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 2
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 2
- NHQVWACSJZJCGJ-FLBSBUHZSA-N Thr-Thr-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NHQVWACSJZJCGJ-FLBSBUHZSA-N 0.000 description 2
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 2
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 2
- NJGMALCNYAMYCB-JRQIVUDYSA-N Thr-Tyr-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O NJGMALCNYAMYCB-JRQIVUDYSA-N 0.000 description 2
- 229940122618 Trypsin inhibitor Drugs 0.000 description 2
- 101710162629 Trypsin inhibitor Proteins 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- DXYWRYQRKPIGGU-BPNCWPANSA-N Tyr-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DXYWRYQRKPIGGU-BPNCWPANSA-N 0.000 description 2
- UXUFNBVCPAWACG-SIUGBPQLSA-N Tyr-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N UXUFNBVCPAWACG-SIUGBPQLSA-N 0.000 description 2
- SYFHQHYTNCQCCN-MELADBBJSA-N Tyr-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O SYFHQHYTNCQCCN-MELADBBJSA-N 0.000 description 2
- JHDZONWZTCKTJR-KJEVXHAQSA-N Tyr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JHDZONWZTCKTJR-KJEVXHAQSA-N 0.000 description 2
- VGQOVCHZGQWAOI-UHFFFAOYSA-N UNPD55612 Natural products N1C(O)C2CC(C=CC(N)=O)=CN2C(=O)C2=CC=C(C)C(O)=C12 VGQOVCHZGQWAOI-UHFFFAOYSA-N 0.000 description 2
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- 208000002495 Uterine Neoplasms Diseases 0.000 description 2
- 241000700618 Vaccinia virus Species 0.000 description 2
- CWOSXNKDOACNJN-BZSNNMDCSA-N Val-Arg-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N CWOSXNKDOACNJN-BZSNNMDCSA-N 0.000 description 2
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 2
- KRAHMIJVUPUOTQ-DCAQKATOSA-N Val-Ser-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KRAHMIJVUPUOTQ-DCAQKATOSA-N 0.000 description 2
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 2
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 2
- PFMSJVIPEZMKSC-DZKIICNBSA-N Val-Tyr-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N PFMSJVIPEZMKSC-DZKIICNBSA-N 0.000 description 2
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 2
- 230000001594 aberrant effect Effects 0.000 description 2
- 238000010521 absorption reaction Methods 0.000 description 2
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 239000000853 adhesive Substances 0.000 description 2
- 230000001070 adhesive effect Effects 0.000 description 2
- 239000008272 agar Substances 0.000 description 2
- 150000001299 aldehydes Chemical class 0.000 description 2
- 108010053584 alpha-Globins Proteins 0.000 description 2
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 2
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 2
- 230000006229 amino acid addition Effects 0.000 description 2
- 238000000540 analysis of variance Methods 0.000 description 2
- 239000012491 analyte Substances 0.000 description 2
- VGQOVCHZGQWAOI-HYUHUPJXSA-N anthramycin Chemical compound N1[C@@H](O)[C@@H]2CC(\C=C\C(N)=O)=CN2C(=O)C2=CC=C(C)C(O)=C12 VGQOVCHZGQWAOI-HYUHUPJXSA-N 0.000 description 2
- 230000000340 anti-metabolite Effects 0.000 description 2
- 229940100197 antimetabolite Drugs 0.000 description 2
- 239000002256 antimetabolite Substances 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 108010060035 arginylproline Proteins 0.000 description 2
- 108010077245 asparaginyl-proline Proteins 0.000 description 2
- 108010093581 aspartyl-proline Proteins 0.000 description 2
- 230000002238 attenuated effect Effects 0.000 description 2
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 2
- 229960002170 azathioprine Drugs 0.000 description 2
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- TZCXTZWJZNENPQ-UHFFFAOYSA-L barium sulfate Chemical compound [Ba+2].[O-]S([O-])(=O)=O TZCXTZWJZNENPQ-UHFFFAOYSA-L 0.000 description 2
- 239000002585 base Substances 0.000 description 2
- 238000007413 biotinylation Methods 0.000 description 2
- 230000006287 biotinylation Effects 0.000 description 2
- 210000001185 bone marrow Anatomy 0.000 description 2
- 229960002092 busulfan Drugs 0.000 description 2
- ZEWYCNBZMPELPF-UHFFFAOYSA-J calcium;potassium;sodium;2-hydroxypropanoic acid;sodium;tetrachloride Chemical compound [Na].[Na+].[Cl-].[Cl-].[Cl-].[Cl-].[K+].[Ca+2].CC(O)C(O)=O ZEWYCNBZMPELPF-UHFFFAOYSA-J 0.000 description 2
- FPPNZSSZRUTDAP-UWFZAAFLSA-N carbenicillin Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)C(C(O)=O)C1=CC=CC=C1 FPPNZSSZRUTDAP-UWFZAAFLSA-N 0.000 description 2
- 229960003669 carbenicillin Drugs 0.000 description 2
- 229960004562 carboplatin Drugs 0.000 description 2
- 229960005243 carmustine Drugs 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 239000005018 casein Substances 0.000 description 2
- BECPQYXYKAMYBN-UHFFFAOYSA-N casein, tech. Chemical compound NCCCCC(C(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(CC(C)C)N=C(O)C(CCC(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(C(C)O)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(COP(O)(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(N)CC1=CC=CC=C1 BECPQYXYKAMYBN-UHFFFAOYSA-N 0.000 description 2
- 235000021240 caseins Nutrition 0.000 description 2
- 230000024245 cell differentiation Effects 0.000 description 2
- 230000012292 cell migration Effects 0.000 description 2
- 210000003855 cell nucleus Anatomy 0.000 description 2
- 210000003169 central nervous system Anatomy 0.000 description 2
- 210000002939 cerumen Anatomy 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 229960004630 chlorambucil Drugs 0.000 description 2
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 2
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 2
- 229960002173 citrulline Drugs 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 229960001338 colchicine Drugs 0.000 description 2
- 208000029742 colonic neoplasm Diseases 0.000 description 2
- 230000000052 comparative effect Effects 0.000 description 2
- 238000010668 complexation reaction Methods 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 238000012790 confirmation Methods 0.000 description 2
- 230000001268 conjugating effect Effects 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 229960004397 cyclophosphamide Drugs 0.000 description 2
- 108010060199 cysteinylproline Proteins 0.000 description 2
- 108010069495 cysteinyltyrosine Proteins 0.000 description 2
- 229960003901 dacarbazine Drugs 0.000 description 2
- 229960000640 dactinomycin Drugs 0.000 description 2
- 229960000975 daunorubicin Drugs 0.000 description 2
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 230000002950 deficient Effects 0.000 description 2
- 238000000502 dialysis Methods 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 2
- 108010054812 diprotin A Proteins 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 125000002228 disulfide group Chemical group 0.000 description 2
- 229960004679 doxorubicin Drugs 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 230000004064 dysfunction Effects 0.000 description 2
- 235000014103 egg white Nutrition 0.000 description 2
- 210000000969 egg white Anatomy 0.000 description 2
- 230000008030 elimination Effects 0.000 description 2
- 238000003379 elimination reaction Methods 0.000 description 2
- 210000001163 endosome Anatomy 0.000 description 2
- HESCAJZNRMSMJG-HGYUPSKWSA-N epothilone A Natural products O=C1[C@H](C)[C@H](O)[C@H](C)CCC[C@H]2O[C@H]2C[C@@H](/C(=C\c2nc(C)sc2)/C)OC(=O)C[C@H](O)C1(C)C HESCAJZNRMSMJG-HGYUPSKWSA-N 0.000 description 2
- 239000006167 equilibration buffer Substances 0.000 description 2
- 201000004101 esophageal cancer Diseases 0.000 description 2
- 230000005284 excitation Effects 0.000 description 2
- 238000002866 fluorescence resonance energy transfer Methods 0.000 description 2
- 229960002949 fluorouracil Drugs 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- 238000007306 functionalization reaction Methods 0.000 description 2
- 210000000232 gallbladder Anatomy 0.000 description 2
- 206010017758 gastric cancer Diseases 0.000 description 2
- 230000002496 gastric effect Effects 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 108010078144 glutaminyl-glycine Proteins 0.000 description 2
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 2
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 2
- 108010049041 glutamylalanine Proteins 0.000 description 2
- 108010077515 glycylproline Proteins 0.000 description 2
- 108010037850 glycylvaline Proteins 0.000 description 2
- 239000003102 growth factor Substances 0.000 description 2
- 108010036413 histidylglycine Proteins 0.000 description 2
- 108010025306 histidylleucine Proteins 0.000 description 2
- 229910052739 hydrogen Inorganic materials 0.000 description 2
- 239000001257 hydrogen Substances 0.000 description 2
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 2
- 229960000908 idarubicin Drugs 0.000 description 2
- 230000001900 immune effect Effects 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 230000001976 improved effect Effects 0.000 description 2
- 238000011503 in vivo imaging Methods 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 229940055742 indium-111 Drugs 0.000 description 2
- APFVFJFRJDLVQX-AHCXROLUSA-N indium-111 Chemical compound [111In] APFVFJFRJDLVQX-AHCXROLUSA-N 0.000 description 2
- 230000008595 infiltration Effects 0.000 description 2
- 238000001764 infiltration Methods 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 238000010253 intravenous injection Methods 0.000 description 2
- 238000001948 isotopic labelling Methods 0.000 description 2
- 201000010982 kidney cancer Diseases 0.000 description 2
- 108010053037 kyotorphin Proteins 0.000 description 2
- JJTUDXZGHPGLLC-UHFFFAOYSA-N lactide Chemical compound CC1OC(=O)C(C)OC1=O JJTUDXZGHPGLLC-UHFFFAOYSA-N 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 229960002247 lomustine Drugs 0.000 description 2
- 210000003712 lysosome Anatomy 0.000 description 2
- 230000001868 lysosomic effect Effects 0.000 description 2
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 2
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 2
- 229960004961 mechlorethamine Drugs 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 210000004379 membrane Anatomy 0.000 description 2
- 229960001428 mercaptopurine Drugs 0.000 description 2
- 206010061289 metastatic neoplasm Diseases 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 229960000485 methotrexate Drugs 0.000 description 2
- 238000013508 migration Methods 0.000 description 2
- CFCUWKMKBJTWLW-BKHRDMLASA-N mithramycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@H](O)[C@H](O[C@@H]3O[C@H](C)[C@@H](O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@@H](O)[C@H](O)[C@@H](C)O1 CFCUWKMKBJTWLW-BKHRDMLASA-N 0.000 description 2
- 239000002062 molecular scaffold Substances 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- 239000012120 mounting media Substances 0.000 description 2
- 230000009871 nonspecific binding Effects 0.000 description 2
- 238000012634 optical imaging Methods 0.000 description 2
- 210000003463 organelle Anatomy 0.000 description 2
- 201000002528 pancreatic cancer Diseases 0.000 description 2
- 208000008443 pancreatic carcinoma Diseases 0.000 description 2
- 230000006320 pegylation Effects 0.000 description 2
- 238000010647 peptide synthesis reaction Methods 0.000 description 2
- 210000005259 peripheral blood Anatomy 0.000 description 2
- 239000011886 peripheral blood Substances 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- 239000013612 plasmid Substances 0.000 description 2
- 239000004033 plastic Substances 0.000 description 2
- 229920003023 plastic Polymers 0.000 description 2
- 150000003057 platinum Chemical class 0.000 description 2
- 229960003171 plicamycin Drugs 0.000 description 2
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 2
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 2
- 229910052573 porcelain Inorganic materials 0.000 description 2
- 239000000047 product Substances 0.000 description 2
- 108010015796 prolylisoleucine Proteins 0.000 description 2
- 235000019419 proteases Nutrition 0.000 description 2
- 230000004850 protein–protein interaction Effects 0.000 description 2
- 230000017854 proteolysis Effects 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 238000001959 radiotherapy Methods 0.000 description 2
- 238000011084 recovery Methods 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- YGSDEFSMJLZEOE-UHFFFAOYSA-N salicylic acid Chemical compound OC(=O)C1=CC=CC=C1O YGSDEFSMJLZEOE-UHFFFAOYSA-N 0.000 description 2
- 238000004062 sedimentation Methods 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 210000003491 skin Anatomy 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- 239000008279 sol Substances 0.000 description 2
- 230000003595 spectral effect Effects 0.000 description 2
- 235000020354 squash Nutrition 0.000 description 2
- 201000011549 stomach cancer Diseases 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- DKPFODGZWDEEBT-QFIAKTPHSA-N taxane Chemical class C([C@]1(C)CCC[C@@H](C)[C@H]1C1)C[C@H]2[C@H](C)CC[C@@H]1C2(C)C DKPFODGZWDEEBT-QFIAKTPHSA-N 0.000 description 2
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 125000003396 thiol group Chemical group [H]S* 0.000 description 2
- 108060008226 thioredoxin Proteins 0.000 description 2
- 229940094937 thioredoxin Drugs 0.000 description 2
- 229960003087 tioguanine Drugs 0.000 description 2
- 239000003053 toxin Substances 0.000 description 2
- 231100000765 toxin Toxicity 0.000 description 2
- 108700012359 toxins Proteins 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 241001515965 unidentified phage Species 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- 206010046766 uterine cancer Diseases 0.000 description 2
- 210000005166 vasculature Anatomy 0.000 description 2
- 230000035899 viability Effects 0.000 description 2
- 229960003048 vinblastine Drugs 0.000 description 2
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 2
- 229960004528 vincristine Drugs 0.000 description 2
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 2
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- 210000004916 vomit Anatomy 0.000 description 2
- 230000008673 vomiting Effects 0.000 description 2
- HDTRYLNUVZCQOY-UHFFFAOYSA-N α-D-glucopyranosyl-α-D-glucopyranoside Natural products OC1C(O)C(O)C(CO)OC1OC1C(O)C(O)C(O)C(CO)O1 HDTRYLNUVZCQOY-UHFFFAOYSA-N 0.000 description 1
- AADVCYNFEREWOS-UHFFFAOYSA-N (+)-DDM Natural products C=CC=CC(C)C(OC(N)=O)C(C)C(O)C(C)CC(C)=CC(C)C(O)C(C)C=CC(O)CC1OC(=O)C(C)C(O)C1C AADVCYNFEREWOS-UHFFFAOYSA-N 0.000 description 1
- OZFAFGSSMRRTDW-UHFFFAOYSA-N (2,4-dichlorophenyl) benzenesulfonate Chemical compound ClC1=CC(Cl)=CC=C1OS(=O)(=O)C1=CC=CC=C1 OZFAFGSSMRRTDW-UHFFFAOYSA-N 0.000 description 1
- UFIVODCEJLHUTQ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 2-(1-phenylethyldisulfanyl)-2h-pyridine-1-carboxylate Chemical compound C=1C=CC=CC=1C(C)SSC1C=CC=CN1C(=O)ON1C(=O)CCC1=O UFIVODCEJLHUTQ-UHFFFAOYSA-N 0.000 description 1
- TYKASZBHFXBROF-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 2-(2,5-dioxopyrrol-1-yl)acetate Chemical compound O=C1CCC(=O)N1OC(=O)CN1C(=O)C=CC1=O TYKASZBHFXBROF-UHFFFAOYSA-N 0.000 description 1
- GKSPIZSKQWTXQG-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[1-(pyridin-2-yldisulfanyl)ethyl]benzoate Chemical compound C=1C=C(C(=O)ON2C(CCC2=O)=O)C=CC=1C(C)SSC1=CC=CC=N1 GKSPIZSKQWTXQG-UHFFFAOYSA-N 0.000 description 1
- IHVODYOQUSEYJJ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 6-[[4-[(2,5-dioxopyrrol-1-yl)methyl]cyclohexanecarbonyl]amino]hexanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCNC(=O)C(CC1)CCC1CN1C(=O)C=CC1=O IHVODYOQUSEYJJ-UHFFFAOYSA-N 0.000 description 1
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 1
- JNTMAZFVYNDPLB-PEDHHIEDSA-N (2S,3S)-2-[[[(2S)-1-[(2S,3S)-2-amino-3-methyl-1-oxopentyl]-2-pyrrolidinyl]-oxomethyl]amino]-3-methylpentanoic acid Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JNTMAZFVYNDPLB-PEDHHIEDSA-N 0.000 description 1
- NTEDOEBWPRVVSG-XUXIUFHCSA-N (2s)-1-[(2s)-2-[[(2s)-2-[[2-[[(2s)-2-[(2-aminoacetyl)amino]-5-(diaminomethylideneamino)pentanoyl]amino]acetyl]amino]-3-carboxypropanoyl]amino]-3-hydroxypropanoyl]pyrrolidine-2-carboxylic acid Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N1CCC[C@H]1C(O)=O NTEDOEBWPRVVSG-XUXIUFHCSA-N 0.000 description 1
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 1
- MFRNYXJJRJQHNW-DEMKXPNLSA-N (2s)-2-[[(2r,3r)-3-methoxy-3-[(2s)-1-[(3r,4s,5s)-3-methoxy-5-methyl-4-[methyl-[(2s)-3-methyl-2-[[(2s)-3-methyl-2-(methylamino)butanoyl]amino]butanoyl]amino]heptanoyl]pyrrolidin-2-yl]-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CN[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFRNYXJJRJQHNW-DEMKXPNLSA-N 0.000 description 1
- AXFMEGAFCUULFV-BLFANLJRSA-N (2s)-2-[[(2s)-1-[(2s,3r)-2-amino-3-methylpentanoyl]pyrrolidine-2-carbonyl]amino]pentanedioic acid Chemical compound CC[C@@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AXFMEGAFCUULFV-BLFANLJRSA-N 0.000 description 1
- WOWDZACBATWTAU-FEFUEGSOSA-N (2s)-2-[[(2s)-2-(dimethylamino)-3-methylbutanoyl]amino]-n-[(3r,4s,5s)-1-[(2s)-2-[(1r,2r)-3-[[(1s,2r)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-n,3-dimethylbutanamide Chemical compound CC(C)[C@H](N(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)C1=CC=CC=C1 WOWDZACBATWTAU-FEFUEGSOSA-N 0.000 description 1
- ALBODLTZUXKBGZ-JUUVMNCLSA-N (2s)-2-amino-3-phenylpropanoic acid;(2s)-2,6-diaminohexanoic acid Chemical compound NCCCC[C@H](N)C(O)=O.OC(=O)[C@@H](N)CC1=CC=CC=C1 ALBODLTZUXKBGZ-JUUVMNCLSA-N 0.000 description 1
- GSVQIUGOUKJHRC-YFKPBYRVSA-N (2s)-3-(n-acetyl-3-amino-2,4,6-triiodoanilino)-2-methylpropanoic acid Chemical compound OC(=O)[C@@H](C)CN(C(C)=O)C1=C(I)C=C(I)C(N)=C1I GSVQIUGOUKJHRC-YFKPBYRVSA-N 0.000 description 1
- OJQSISYVGFJJBY-UHFFFAOYSA-N 1-(4-isocyanatophenyl)pyrrole-2,5-dione Chemical compound C1=CC(N=C=O)=CC=C1N1C(=O)C=CC1=O OJQSISYVGFJJBY-UHFFFAOYSA-N 0.000 description 1
- VSNHCAURESNICA-NJFSPNSNSA-N 1-oxidanylurea Chemical compound N[14C](=O)NO VSNHCAURESNICA-NJFSPNSNSA-N 0.000 description 1
- OTLLEIBWKHEHGU-UHFFFAOYSA-N 2-[5-[[5-(6-aminopurin-9-yl)-3,4-dihydroxyoxolan-2-yl]methoxy]-3,4-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-3,5-dihydroxy-4-phosphonooxyhexanedioic acid Chemical compound C1=NC=2C(N)=NC=NC=2N1C(C(C1O)O)OC1COC1C(CO)OC(OC(C(O)C(OP(O)(O)=O)C(O)C(O)=O)C(O)=O)C(O)C1O OTLLEIBWKHEHGU-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- OGHAROSJZRTIOK-KQYNXXCUSA-N 2-amino-9-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-7-methylpurin-9-ium-6-olate Chemical compound C12=NC(N)=NC([O-])=C2N(C)C=[N+]1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OGHAROSJZRTIOK-KQYNXXCUSA-N 0.000 description 1
- OZDAOHVKBFBBMZ-UHFFFAOYSA-N 2-aminopentanedioic acid;hydrate Chemical compound O.OC(=O)C(N)CCC(O)=O OZDAOHVKBFBBMZ-UHFFFAOYSA-N 0.000 description 1
- BFSVOASYOCHEOV-UHFFFAOYSA-N 2-diethylaminoethanol Chemical compound CCN(CC)CCO BFSVOASYOCHEOV-UHFFFAOYSA-N 0.000 description 1
- YZEUHQHUFTYLPH-UHFFFAOYSA-N 2-nitroimidazole Chemical compound [O-][N+](=O)C1=NC=CN1 YZEUHQHUFTYLPH-UHFFFAOYSA-N 0.000 description 1
- 108020005345 3' Untranslated Regions Proteins 0.000 description 1
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 description 1
- WUIABRMSWOKTOF-OYALTWQYSA-N 3-[[2-[2-[2-[[(2s,3r)-2-[[(2s,3s,4r)-4-[[(2s,3r)-2-[[6-amino-2-[(1s)-3-amino-1-[[(2s)-2,3-diamino-3-oxopropyl]amino]-3-oxopropyl]-5-methylpyrimidine-4-carbonyl]amino]-3-[(2r,3s,4s,5s,6s)-3-[(2r,3s,4s,5r,6r)-4-carbamoyloxy-3,5-dihydroxy-6-(hydroxymethyl)ox Chemical compound OS([O-])(=O)=O.N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1NC=NC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C WUIABRMSWOKTOF-OYALTWQYSA-N 0.000 description 1
- BMYNFMYTOJXKLE-UHFFFAOYSA-N 3-azaniumyl-2-hydroxypropanoate Chemical compound NCC(O)C(O)=O BMYNFMYTOJXKLE-UHFFFAOYSA-N 0.000 description 1
- BHPSIKROCCEKQR-UHFFFAOYSA-N 3-sulfanylpyrrole-2,5-dione Chemical compound SC1=CC(=O)NC1=O BHPSIKROCCEKQR-UHFFFAOYSA-N 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- QUHGSDZVAPFNLV-UHFFFAOYSA-N 4-[(5-acetamidofuran-2-carbonyl)amino]-n-[3-(dimethylamino)propyl]-1-propylpyrrole-2-carboxamide Chemical compound C1=C(C(=O)NCCCN(C)C)N(CCC)C=C1NC(=O)C1=CC=C(NC(C)=O)O1 QUHGSDZVAPFNLV-UHFFFAOYSA-N 0.000 description 1
- NCQDNRMSPJIZKR-UHFFFAOYSA-N 4-[[1-(2,5-dioxopyrrolidin-1-yl)-2h-pyridin-2-yl]sulfanyl]pentanoic acid Chemical compound OC(=O)CCC(C)SC1C=CC=CN1N1C(=O)CCC1=O NCQDNRMSPJIZKR-UHFFFAOYSA-N 0.000 description 1
- 108020003589 5' Untranslated Regions Proteins 0.000 description 1
- NMUSYJAQQFHJEW-UHFFFAOYSA-N 5-Azacytidine Natural products O=C1N=C(N)N=CN1C1C(O)C(O)C(CO)O1 NMUSYJAQQFHJEW-UHFFFAOYSA-N 0.000 description 1
- ZAYHVCMSTBRABG-UHFFFAOYSA-N 5-Methylcytidine Natural products O=C1N=C(N)C(C)=CN1C1C(O)C(O)C(CO)O1 ZAYHVCMSTBRABG-UHFFFAOYSA-N 0.000 description 1
- LGZKGOGODCLQHG-CYBMUJFWSA-N 5-[(2r)-2-hydroxy-2-(3,4,5-trimethoxyphenyl)ethyl]-2-methoxyphenol Chemical compound C1=C(O)C(OC)=CC=C1C[C@@H](O)C1=CC(OC)=C(OC)C(OC)=C1 LGZKGOGODCLQHG-CYBMUJFWSA-N 0.000 description 1
- NMUSYJAQQFHJEW-KVTDHHQDSA-N 5-azacytidine Chemical compound O=C1N=C(N)N=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 NMUSYJAQQFHJEW-KVTDHHQDSA-N 0.000 description 1
- ZAYHVCMSTBRABG-JXOAFFINSA-N 5-methylcytidine Chemical group O=C1N=C(N)C(C)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 ZAYHVCMSTBRABG-JXOAFFINSA-N 0.000 description 1
- FVFVNNKYKYZTJU-UHFFFAOYSA-N 6-chloro-1,3,5-triazine-2,4-diamine Chemical group NC1=NC(N)=NC(Cl)=N1 FVFVNNKYKYZTJU-UHFFFAOYSA-N 0.000 description 1
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 1
- 206010000117 Abnormal behaviour Diseases 0.000 description 1
- 108010066676 Abrin Proteins 0.000 description 1
- IMMKUCQIKKXKNP-DCAQKATOSA-N Ala-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CCCN=C(N)N IMMKUCQIKKXKNP-DCAQKATOSA-N 0.000 description 1
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 1
- CVGNCMIULZNYES-WHFBIAKZSA-N Ala-Asn-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CVGNCMIULZNYES-WHFBIAKZSA-N 0.000 description 1
- SHYYAQLDNVHPFT-DLOVCJGASA-N Ala-Asn-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SHYYAQLDNVHPFT-DLOVCJGASA-N 0.000 description 1
- FXKNPWNXPQZLES-ZLUOBGJFSA-N Ala-Asn-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FXKNPWNXPQZLES-ZLUOBGJFSA-N 0.000 description 1
- CSAHOYQKNHGDHX-ACZMJKKPSA-N Ala-Gln-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CSAHOYQKNHGDHX-ACZMJKKPSA-N 0.000 description 1
- RXTBLQVXNIECFP-FXQIFTODSA-N Ala-Gln-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RXTBLQVXNIECFP-FXQIFTODSA-N 0.000 description 1
- PWYFCPCBOYMOGB-LKTVYLICSA-N Ala-Gln-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N PWYFCPCBOYMOGB-LKTVYLICSA-N 0.000 description 1
- WKOBSJOZRJJVRZ-FXQIFTODSA-N Ala-Glu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WKOBSJOZRJJVRZ-FXQIFTODSA-N 0.000 description 1
- HMRWQTHUDVXMGH-GUBZILKMSA-N Ala-Glu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HMRWQTHUDVXMGH-GUBZILKMSA-N 0.000 description 1
- NHLAEBFGWPXFGI-WHFBIAKZSA-N Ala-Gly-Asn Chemical compound C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N NHLAEBFGWPXFGI-WHFBIAKZSA-N 0.000 description 1
- MQIGTEQXYCRLGK-BQBZGAKWSA-N Ala-Gly-Pro Chemical compound C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O MQIGTEQXYCRLGK-BQBZGAKWSA-N 0.000 description 1
- GRPHQEMIFDPKOE-HGNGGELXSA-N Ala-His-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O GRPHQEMIFDPKOE-HGNGGELXSA-N 0.000 description 1
- HQJKCXHQNUCKMY-GHCJXIJMSA-N Ala-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C)N HQJKCXHQNUCKMY-GHCJXIJMSA-N 0.000 description 1
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 1
- AWZKCUCQJNTBAD-SRVKXCTJSA-N Ala-Leu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN AWZKCUCQJNTBAD-SRVKXCTJSA-N 0.000 description 1
- OMNVYXHOSHNURL-WPRPVWTQSA-N Ala-Phe Chemical compound C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OMNVYXHOSHNURL-WPRPVWTQSA-N 0.000 description 1
- CYBJZLQSUJEMAS-LFSVMHDDSA-N Ala-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C)N)O CYBJZLQSUJEMAS-LFSVMHDDSA-N 0.000 description 1
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 1
- FQNILRVJOJBFFC-FXQIFTODSA-N Ala-Pro-Asp Chemical compound C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N FQNILRVJOJBFFC-FXQIFTODSA-N 0.000 description 1
- WQLDNOCHHRISMS-NAKRPEOUSA-N Ala-Pro-Ile Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WQLDNOCHHRISMS-NAKRPEOUSA-N 0.000 description 1
- OLVCTPPSXNRGKV-GUBZILKMSA-N Ala-Pro-Pro Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OLVCTPPSXNRGKV-GUBZILKMSA-N 0.000 description 1
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 1
- RMAWDDRDTRSZIR-ZLUOBGJFSA-N Ala-Ser-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RMAWDDRDTRSZIR-ZLUOBGJFSA-N 0.000 description 1
- MMLHRUJLOUSRJX-CIUDSAMLSA-N Ala-Ser-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN MMLHRUJLOUSRJX-CIUDSAMLSA-N 0.000 description 1
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 1
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 1
- QKHWNPQNOHEFST-VZFHVOOUSA-N Ala-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C)N)O QKHWNPQNOHEFST-VZFHVOOUSA-N 0.000 description 1
- LSMDIAAALJJLRO-XQXXSGGOSA-N Ala-Thr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LSMDIAAALJJLRO-XQXXSGGOSA-N 0.000 description 1
- WNHNMKOFKCHKKD-BFHQHQDPSA-N Ala-Thr-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O WNHNMKOFKCHKKD-BFHQHQDPSA-N 0.000 description 1
- SAHQGRZIQVEJPF-JXUBOQSCSA-N Ala-Thr-Lys Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN SAHQGRZIQVEJPF-JXUBOQSCSA-N 0.000 description 1
- QOIGKCBMXUCDQU-KDXUFGMBSA-N Ala-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C)N)O QOIGKCBMXUCDQU-KDXUFGMBSA-N 0.000 description 1
- KTXKIYXZQFWJKB-VZFHVOOUSA-N Ala-Thr-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O KTXKIYXZQFWJKB-VZFHVOOUSA-N 0.000 description 1
- ZCUFMRIQCPNOHZ-NRPADANISA-N Ala-Val-Gln Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N ZCUFMRIQCPNOHZ-NRPADANISA-N 0.000 description 1
- ANNKVZSFQJGVDY-XUXIUFHCSA-N Ala-Val-Pro-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 ANNKVZSFQJGVDY-XUXIUFHCSA-N 0.000 description 1
- OMSKGWFGWCQFBD-KZVJFYERSA-N Ala-Val-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OMSKGWFGWCQFBD-KZVJFYERSA-N 0.000 description 1
- 206010061424 Anal cancer Diseases 0.000 description 1
- 208000007860 Anus Neoplasms Diseases 0.000 description 1
- 241000239223 Arachnida Species 0.000 description 1
- SGYSTDWPNPKJPP-GUBZILKMSA-N Arg-Ala-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SGYSTDWPNPKJPP-GUBZILKMSA-N 0.000 description 1
- GXCSUJQOECMKPV-CIUDSAMLSA-N Arg-Ala-Gln Chemical compound C[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GXCSUJQOECMKPV-CIUDSAMLSA-N 0.000 description 1
- NABSCJGZKWSNHX-RCWTZXSCSA-N Arg-Arg-Thr Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H]([C@H](O)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N NABSCJGZKWSNHX-RCWTZXSCSA-N 0.000 description 1
- DPXDVGDLWJYZBH-GUBZILKMSA-N Arg-Asn-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O DPXDVGDLWJYZBH-GUBZILKMSA-N 0.000 description 1
- BVBKBQRPOJFCQM-DCAQKATOSA-N Arg-Asn-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BVBKBQRPOJFCQM-DCAQKATOSA-N 0.000 description 1
- IIABBYGHLYWVOS-FXQIFTODSA-N Arg-Asn-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O IIABBYGHLYWVOS-FXQIFTODSA-N 0.000 description 1
- RWCLSUOSKWTXLA-FXQIFTODSA-N Arg-Asp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RWCLSUOSKWTXLA-FXQIFTODSA-N 0.000 description 1
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 1
- OTCJMMRQBVDQRK-DCAQKATOSA-N Arg-Asp-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OTCJMMRQBVDQRK-DCAQKATOSA-N 0.000 description 1
- JTWOBPNAVBESFW-FXQIFTODSA-N Arg-Cys-Asp Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)CN=C(N)N JTWOBPNAVBESFW-FXQIFTODSA-N 0.000 description 1
- JUWQNWXEGDYCIE-YUMQZZPRSA-N Arg-Gln-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O JUWQNWXEGDYCIE-YUMQZZPRSA-N 0.000 description 1
- OBFTYSPXDRROQO-SRVKXCTJSA-N Arg-Gln-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCCN=C(N)N OBFTYSPXDRROQO-SRVKXCTJSA-N 0.000 description 1
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 1
- GOWZVQXTHUCNSQ-NHCYSSNCSA-N Arg-Glu-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O GOWZVQXTHUCNSQ-NHCYSSNCSA-N 0.000 description 1
- AQPVUEJJARLJHB-BQBZGAKWSA-N Arg-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N AQPVUEJJARLJHB-BQBZGAKWSA-N 0.000 description 1
- YNSGXDWWPCGGQS-YUMQZZPRSA-N Arg-Gly-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O YNSGXDWWPCGGQS-YUMQZZPRSA-N 0.000 description 1
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 1
- VRZDJJWOFXMFRO-ZFWWWQNUSA-N Arg-Gly-Trp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O VRZDJJWOFXMFRO-ZFWWWQNUSA-N 0.000 description 1
- YBIAYFFIVAZXPK-AVGNSLFASA-N Arg-His-Arg Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O YBIAYFFIVAZXPK-AVGNSLFASA-N 0.000 description 1
- UAOSDDXCTBIPCA-QXEWZRGKSA-N Arg-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UAOSDDXCTBIPCA-QXEWZRGKSA-N 0.000 description 1
- GXXWTNKNFFKTJB-NAKRPEOUSA-N Arg-Ile-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O GXXWTNKNFFKTJB-NAKRPEOUSA-N 0.000 description 1
- LLUGJARLJCGLAR-CYDGBPFRSA-N Arg-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N LLUGJARLJCGLAR-CYDGBPFRSA-N 0.000 description 1
- PRLPSDIHSRITSF-UNQGMJICSA-N Arg-Phe-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PRLPSDIHSRITSF-UNQGMJICSA-N 0.000 description 1
- WKPXXXUSUHAXDE-SRVKXCTJSA-N Arg-Pro-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O WKPXXXUSUHAXDE-SRVKXCTJSA-N 0.000 description 1
- DNBMCNQKNOKOSD-DCAQKATOSA-N Arg-Pro-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O DNBMCNQKNOKOSD-DCAQKATOSA-N 0.000 description 1
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 1
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 1
- ADPACBMPYWJJCE-FXQIFTODSA-N Arg-Ser-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O ADPACBMPYWJJCE-FXQIFTODSA-N 0.000 description 1
- BECXEHHOZNFFFX-IHRRRGAJSA-N Arg-Ser-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BECXEHHOZNFFFX-IHRRRGAJSA-N 0.000 description 1
- AUZAXCPWMDBWEE-HJGDQZAQSA-N Arg-Thr-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O AUZAXCPWMDBWEE-HJGDQZAQSA-N 0.000 description 1
- MOGMYRUNTKYZFB-UNQGMJICSA-N Arg-Thr-Phe Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MOGMYRUNTKYZFB-UNQGMJICSA-N 0.000 description 1
- INOIAEUXVVNJKA-XGEHTFHBSA-N Arg-Thr-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O INOIAEUXVVNJKA-XGEHTFHBSA-N 0.000 description 1
- QUBKBPZGMZWOKQ-SZMVWBNQSA-N Arg-Trp-Arg Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 QUBKBPZGMZWOKQ-SZMVWBNQSA-N 0.000 description 1
- JBQORRNSZGTLCV-WDSOQIARSA-N Arg-Trp-Lys Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CCCCN)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N)=CNC2=C1 JBQORRNSZGTLCV-WDSOQIARSA-N 0.000 description 1
- CTAPSNCVKPOOSM-KKUMJFAQSA-N Arg-Tyr-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O CTAPSNCVKPOOSM-KKUMJFAQSA-N 0.000 description 1
- XRLOBFSLPCHYLQ-ULQDDVLXSA-N Arg-Tyr-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O XRLOBFSLPCHYLQ-ULQDDVLXSA-N 0.000 description 1
- CNBIWSCSSCAINS-UFYCRDLUSA-N Arg-Tyr-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CNBIWSCSSCAINS-UFYCRDLUSA-N 0.000 description 1
- QTAIIXQCOPUNBQ-QXEWZRGKSA-N Arg-Val-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QTAIIXQCOPUNBQ-QXEWZRGKSA-N 0.000 description 1
- SUMJNGAMIQSNGX-TUAOUCFPSA-N Arg-Val-Pro Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N1CCC[C@@H]1C(O)=O SUMJNGAMIQSNGX-TUAOUCFPSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- NUHQMYUWLUSRJX-BIIVOSGPSA-N Asn-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N NUHQMYUWLUSRJX-BIIVOSGPSA-N 0.000 description 1
- PIWWUBYJNONVTJ-ZLUOBGJFSA-N Asn-Asp-Asn Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)C(=O)N PIWWUBYJNONVTJ-ZLUOBGJFSA-N 0.000 description 1
- WQSCVMQDZYTFQU-FXQIFTODSA-N Asn-Cys-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WQSCVMQDZYTFQU-FXQIFTODSA-N 0.000 description 1
- NNMUHYLAYUSTTN-FXQIFTODSA-N Asn-Gln-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O NNMUHYLAYUSTTN-FXQIFTODSA-N 0.000 description 1
- DDPXDCKYWDGZAL-BQBZGAKWSA-N Asn-Gly-Arg Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N DDPXDCKYWDGZAL-BQBZGAKWSA-N 0.000 description 1
- OPEPUCYIGFEGSW-WDSKDSINSA-N Asn-Gly-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OPEPUCYIGFEGSW-WDSKDSINSA-N 0.000 description 1
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 1
- IBLAOXSULLECQZ-IUKAMOBKSA-N Asn-Ile-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC(N)=O IBLAOXSULLECQZ-IUKAMOBKSA-N 0.000 description 1
- NLRJGXZWTKXRHP-DCAQKATOSA-N Asn-Leu-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NLRJGXZWTKXRHP-DCAQKATOSA-N 0.000 description 1
- HFPXZWPUVFVNLL-GUBZILKMSA-N Asn-Leu-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFPXZWPUVFVNLL-GUBZILKMSA-N 0.000 description 1
- MYCSPQIARXTUTP-SRVKXCTJSA-N Asn-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N MYCSPQIARXTUTP-SRVKXCTJSA-N 0.000 description 1
- GLWFAWNYGWBMOC-SRVKXCTJSA-N Asn-Leu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GLWFAWNYGWBMOC-SRVKXCTJSA-N 0.000 description 1
- JLNFZLNDHONLND-GARJFASQSA-N Asn-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N JLNFZLNDHONLND-GARJFASQSA-N 0.000 description 1
- NLDNNZKUSLAYFW-NHCYSSNCSA-N Asn-Lys-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLDNNZKUSLAYFW-NHCYSSNCSA-N 0.000 description 1
- HPNDKUOLNRVRAY-BIIVOSGPSA-N Asn-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N)C(=O)O HPNDKUOLNRVRAY-BIIVOSGPSA-N 0.000 description 1
- QYRMBFWDSFGSFC-OLHMAJIHSA-N Asn-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QYRMBFWDSFGSFC-OLHMAJIHSA-N 0.000 description 1
- NSTBNYOKCZKOMI-AVGNSLFASA-N Asn-Tyr-Glu Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O NSTBNYOKCZKOMI-AVGNSLFASA-N 0.000 description 1
- QNNBHTFDFFFHGC-KKUMJFAQSA-N Asn-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QNNBHTFDFFFHGC-KKUMJFAQSA-N 0.000 description 1
- LTDGPJKGJDIBQD-LAEOZQHASA-N Asn-Val-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LTDGPJKGJDIBQD-LAEOZQHASA-N 0.000 description 1
- ZAESWDKAMDVHLL-RCOVLWMOSA-N Asn-Val-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O ZAESWDKAMDVHLL-RCOVLWMOSA-N 0.000 description 1
- WSOKZUVWBXVJHX-CIUDSAMLSA-N Asp-Arg-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O WSOKZUVWBXVJHX-CIUDSAMLSA-N 0.000 description 1
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 1
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 1
- CASGONAXMZPHCK-FXQIFTODSA-N Asp-Asn-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N)CN=C(N)N CASGONAXMZPHCK-FXQIFTODSA-N 0.000 description 1
- CELPEWWLSXMVPH-CIUDSAMLSA-N Asp-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O CELPEWWLSXMVPH-CIUDSAMLSA-N 0.000 description 1
- VHWNKSJHQFZJTH-FXQIFTODSA-N Asp-Asp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N VHWNKSJHQFZJTH-FXQIFTODSA-N 0.000 description 1
- QXHVOUSPVAWEMX-ZLUOBGJFSA-N Asp-Asp-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXHVOUSPVAWEMX-ZLUOBGJFSA-N 0.000 description 1
- BFOYULZBKYOKAN-OLHMAJIHSA-N Asp-Asp-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BFOYULZBKYOKAN-OLHMAJIHSA-N 0.000 description 1
- SMZCLQGDQMGESY-ACZMJKKPSA-N Asp-Gln-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)O)N SMZCLQGDQMGESY-ACZMJKKPSA-N 0.000 description 1
- SNAWMGHSCHKSDK-GUBZILKMSA-N Asp-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N SNAWMGHSCHKSDK-GUBZILKMSA-N 0.000 description 1
- DXQOQMCLWWADMU-ACZMJKKPSA-N Asp-Gln-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DXQOQMCLWWADMU-ACZMJKKPSA-N 0.000 description 1
- KIJLEFNHWSXHRU-NUMRIWBASA-N Asp-Gln-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KIJLEFNHWSXHRU-NUMRIWBASA-N 0.000 description 1
- ZSJFGGSPCCHMNE-LAEOZQHASA-N Asp-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N ZSJFGGSPCCHMNE-LAEOZQHASA-N 0.000 description 1
- GHODABZPVZMWCE-FXQIFTODSA-N Asp-Glu-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O GHODABZPVZMWCE-FXQIFTODSA-N 0.000 description 1
- PDECQIHABNQRHN-GUBZILKMSA-N Asp-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O PDECQIHABNQRHN-GUBZILKMSA-N 0.000 description 1
- ZSVJVIOVABDTTL-YUMQZZPRSA-N Asp-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)O)N ZSVJVIOVABDTTL-YUMQZZPRSA-N 0.000 description 1
- PSLSTUMPZILTAH-BYULHYEWSA-N Asp-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O PSLSTUMPZILTAH-BYULHYEWSA-N 0.000 description 1
- UMHUHHJMEXNSIV-CIUDSAMLSA-N Asp-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UMHUHHJMEXNSIV-CIUDSAMLSA-N 0.000 description 1
- RPUYTJJZXQBWDT-SRVKXCTJSA-N Asp-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N RPUYTJJZXQBWDT-SRVKXCTJSA-N 0.000 description 1
- GPPIDDWYKJPRES-YDHLFZDLSA-N Asp-Phe-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O GPPIDDWYKJPRES-YDHLFZDLSA-N 0.000 description 1
- ZBYLEBZCVKLPCY-FXQIFTODSA-N Asp-Ser-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ZBYLEBZCVKLPCY-FXQIFTODSA-N 0.000 description 1
- KGHLGJAXYSVNJP-WHFBIAKZSA-N Asp-Ser-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O KGHLGJAXYSVNJP-WHFBIAKZSA-N 0.000 description 1
- HRVQDZOWMLFAOD-BIIVOSGPSA-N Asp-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N)C(=O)O HRVQDZOWMLFAOD-BIIVOSGPSA-N 0.000 description 1
- KBJVTFWQWXCYCQ-IUKAMOBKSA-N Asp-Thr-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KBJVTFWQWXCYCQ-IUKAMOBKSA-N 0.000 description 1
- JSNWZMFSLIWAHS-HJGDQZAQSA-N Asp-Thr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O JSNWZMFSLIWAHS-HJGDQZAQSA-N 0.000 description 1
- UEFODXNXUAVPTC-VEVYYDQMSA-N Asp-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O UEFODXNXUAVPTC-VEVYYDQMSA-N 0.000 description 1
- GXHDGYOXPNQCKM-XVSYOHENSA-N Asp-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O GXHDGYOXPNQCKM-XVSYOHENSA-N 0.000 description 1
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 1
- KCOPOPKJRHVGPE-AQZXSJQPSA-N Asp-Thr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O KCOPOPKJRHVGPE-AQZXSJQPSA-N 0.000 description 1
- BJDHEININLSZOT-KKUMJFAQSA-N Asp-Tyr-Lys Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(O)=O BJDHEININLSZOT-KKUMJFAQSA-N 0.000 description 1
- WAEDSQFVZJUHLI-BYULHYEWSA-N Asp-Val-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WAEDSQFVZJUHLI-BYULHYEWSA-N 0.000 description 1
- QPDUWAUSSWGJSB-NGZCFLSTSA-N Asp-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N QPDUWAUSSWGJSB-NGZCFLSTSA-N 0.000 description 1
- 108010024976 Asparaginase Proteins 0.000 description 1
- 102000015790 Asparaginase Human genes 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 101710192393 Attachment protein G3P Proteins 0.000 description 1
- 208000023275 Autoimmune disease Diseases 0.000 description 1
- 229930190007 Baccatin Natural products 0.000 description 1
- 244000063299 Bacillus subtilis Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 206010005949 Bone cancer Diseases 0.000 description 1
- 208000018084 Bone neoplasm Diseases 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 229960005532 CC-1065 Drugs 0.000 description 1
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 description 1
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 1
- 244000025254 Cannabis sativa Species 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 108090000565 Capsid Proteins Proteins 0.000 description 1
- 208000005623 Carcinogenesis Diseases 0.000 description 1
- 102000004225 Cathepsin B Human genes 0.000 description 1
- 108090000712 Cathepsin B Proteins 0.000 description 1
- 102000005600 Cathepsins Human genes 0.000 description 1
- 108010084457 Cathepsins Proteins 0.000 description 1
- 102100023321 Ceruloplasmin Human genes 0.000 description 1
- 206010050337 Cerumen impaction Diseases 0.000 description 1
- 206010008342 Cervix carcinoma Diseases 0.000 description 1
- JWBOIMRXGHLCPP-UHFFFAOYSA-N Chloditan Chemical compound C=1C=CC=C(Cl)C=1C(C(Cl)Cl)C1=CC=C(Cl)C=C1 JWBOIMRXGHLCPP-UHFFFAOYSA-N 0.000 description 1
- 102000009016 Cholera Toxin Human genes 0.000 description 1
- 108010049048 Cholera Toxin Proteins 0.000 description 1
- GUTLYIVDDKVIGB-OUBTZVSYSA-N Cobalt-60 Chemical compound [60Co] GUTLYIVDDKVIGB-OUBTZVSYSA-N 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 102000008186 Collagen Human genes 0.000 description 1
- 108010035532 Collagen Proteins 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- 241000557626 Corvus corax Species 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- MIKUYHXYGGJMLM-GIMIYPNGSA-N Crotonoside Natural products C1=NC2=C(N)NC(=O)N=C2N1[C@H]1O[C@@H](CO)[C@H](O)[C@@H]1O MIKUYHXYGGJMLM-GIMIYPNGSA-N 0.000 description 1
- 102100021906 Cyclin-O Human genes 0.000 description 1
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 1
- 108010036949 Cyclosporine Proteins 0.000 description 1
- DEVDFMRWZASYOF-ZLUOBGJFSA-N Cys-Asn-Asp Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O DEVDFMRWZASYOF-ZLUOBGJFSA-N 0.000 description 1
- YZFCGHIBLBDZDA-ZLUOBGJFSA-N Cys-Asp-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YZFCGHIBLBDZDA-ZLUOBGJFSA-N 0.000 description 1
- MGAWEOHYNIMOQJ-ACZMJKKPSA-N Cys-Gln-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CS)N MGAWEOHYNIMOQJ-ACZMJKKPSA-N 0.000 description 1
- YRKJQKATZOTUEN-ACZMJKKPSA-N Cys-Gln-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N YRKJQKATZOTUEN-ACZMJKKPSA-N 0.000 description 1
- PORWNQWEEIOIRH-XHNCKOQMSA-N Cys-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CS)N)C(=O)O PORWNQWEEIOIRH-XHNCKOQMSA-N 0.000 description 1
- ZEXHDOQQYZKOIB-ACZMJKKPSA-N Cys-Glu-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZEXHDOQQYZKOIB-ACZMJKKPSA-N 0.000 description 1
- OXOQBEVULIBOSH-ZDLURKLDSA-N Cys-Gly-Thr Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O OXOQBEVULIBOSH-ZDLURKLDSA-N 0.000 description 1
- ANRWXLYGJRSQEQ-CIUDSAMLSA-N Cys-His-Asp Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(O)=O ANRWXLYGJRSQEQ-CIUDSAMLSA-N 0.000 description 1
- KPENUVBHAKRDQR-GUBZILKMSA-N Cys-His-Glu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O KPENUVBHAKRDQR-GUBZILKMSA-N 0.000 description 1
- XIZWKXATMJODQW-KKUMJFAQSA-N Cys-His-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CS)N XIZWKXATMJODQW-KKUMJFAQSA-N 0.000 description 1
- ZMWOJVAXTOUHAP-ZKWXMUAHSA-N Cys-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N ZMWOJVAXTOUHAP-ZKWXMUAHSA-N 0.000 description 1
- HEPLXMBVMCXTBP-QWRGUYRKSA-N Cys-Phe-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O HEPLXMBVMCXTBP-QWRGUYRKSA-N 0.000 description 1
- BSGXXYRIDXUEOM-IHRRRGAJSA-N Cys-Phe-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CS)N BSGXXYRIDXUEOM-IHRRRGAJSA-N 0.000 description 1
- ZALVANCAZFPKIR-GUBZILKMSA-N Cys-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CS)N ZALVANCAZFPKIR-GUBZILKMSA-N 0.000 description 1
- BCWIFCLVCRAIQK-ZLUOBGJFSA-N Cys-Ser-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N)O BCWIFCLVCRAIQK-ZLUOBGJFSA-N 0.000 description 1
- ZLFRUAFDAIFNHN-LKXGYXEUSA-N Cys-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CS)N)O ZLFRUAFDAIFNHN-LKXGYXEUSA-N 0.000 description 1
- FTTZLFIEUQHLHH-BWBBJGPYSA-N Cys-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N)O FTTZLFIEUQHLHH-BWBBJGPYSA-N 0.000 description 1
- JAHCWGSVNZXHRR-SVSWQMSJSA-N Cys-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CS)N JAHCWGSVNZXHRR-SVSWQMSJSA-N 0.000 description 1
- WTXCNOPZMQRTNN-BWBBJGPYSA-N Cys-Thr-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N)O WTXCNOPZMQRTNN-BWBBJGPYSA-N 0.000 description 1
- LHRCZIRWNFRIRG-SRVKXCTJSA-N Cys-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CS)N)O LHRCZIRWNFRIRG-SRVKXCTJSA-N 0.000 description 1
- JIZRUFJGHPIYPS-SRVKXCTJSA-N Cys-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N)O JIZRUFJGHPIYPS-SRVKXCTJSA-N 0.000 description 1
- MQQLYEHXSBJTRK-FXQIFTODSA-N Cys-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N MQQLYEHXSBJTRK-FXQIFTODSA-N 0.000 description 1
- FNXOZWPPOJRBRE-XGEHTFHBSA-N Cys-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CS)N)O FNXOZWPPOJRBRE-XGEHTFHBSA-N 0.000 description 1
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 1
- 101710112752 Cytotoxin Proteins 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- NYHBQMYGNKIUIF-UHFFFAOYSA-N D-guanosine Natural products C1=2NC(N)=NC(=O)C=2N=CN1C1OC(CO)C(O)C1O NYHBQMYGNKIUIF-UHFFFAOYSA-N 0.000 description 1
- 239000012626 DNA minor groove binder Substances 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- ZNZYKNKBJPZETN-WELNAUFTSA-N Dialdehyde 11678 Chemical compound N1C2=CC=CC=C2C2=C1[C@H](C[C@H](/C(=C/O)C(=O)OC)[C@@H](C=C)C=O)NCC2 ZNZYKNKBJPZETN-WELNAUFTSA-N 0.000 description 1
- 108010016626 Dipeptides Proteins 0.000 description 1
- AADVCYNFEREWOS-OBRABYBLSA-N Discodermolide Chemical compound C=C\C=C/[C@H](C)[C@H](OC(N)=O)[C@@H](C)[C@H](O)[C@@H](C)C\C(C)=C/[C@H](C)[C@@H](O)[C@@H](C)\C=C/[C@@H](O)C[C@@H]1OC(=O)[C@H](C)[C@@H](O)[C@H]1C AADVCYNFEREWOS-OBRABYBLSA-N 0.000 description 1
- 239000012591 Dulbecco’s Phosphate Buffered Saline Substances 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 239000006145 Eagle's minimal essential medium Substances 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 208000001976 Endocrine Gland Neoplasms Diseases 0.000 description 1
- QXRSDHAAWVKZLJ-OXZHEXMSSA-N Epothilone B Natural products O=C1[C@H](C)[C@H](O)[C@@H](C)CCC[C@@]2(C)O[C@H]2C[C@@H](/C(=C\c2nc(C)sc2)/C)OC(=O)C[C@H](O)C1(C)C QXRSDHAAWVKZLJ-OXZHEXMSSA-N 0.000 description 1
- 241000283073 Equus caballus Species 0.000 description 1
- 241001198387 Escherichia coli BL21(DE3) Species 0.000 description 1
- 206010015548 Euthanasia Diseases 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 102000009123 Fibrin Human genes 0.000 description 1
- 108010073385 Fibrin Proteins 0.000 description 1
- BWGVNKXGVNDBDI-UHFFFAOYSA-N Fibrin monomer Chemical compound CNC(=O)CNC(=O)CN BWGVNKXGVNDBDI-UHFFFAOYSA-N 0.000 description 1
- 102000002090 Fibronectin type III Human genes 0.000 description 1
- 108050009401 Fibronectin type III Proteins 0.000 description 1
- 229920001917 Ficoll Polymers 0.000 description 1
- PXGOKWXKJXAPGV-UHFFFAOYSA-N Fluorine Chemical compound FF PXGOKWXKJXAPGV-UHFFFAOYSA-N 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 229910052688 Gadolinium Inorganic materials 0.000 description 1
- GYHNNYVSQQEPJS-YPZZEJLDSA-N Gallium-68 Chemical compound [68Ga] GYHNNYVSQQEPJS-YPZZEJLDSA-N 0.000 description 1
- 108700004714 Gelonium multiflorum GEL Proteins 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- 208000032612 Glial tumor Diseases 0.000 description 1
- 206010018338 Glioma Diseases 0.000 description 1
- RGRMOYQUIJVQQD-SRVKXCTJSA-N Gln-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N RGRMOYQUIJVQQD-SRVKXCTJSA-N 0.000 description 1
- DTMLKCYOQKZXKZ-HJGDQZAQSA-N Gln-Arg-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DTMLKCYOQKZXKZ-HJGDQZAQSA-N 0.000 description 1
- QYTKAVBFRUGYAU-ACZMJKKPSA-N Gln-Asp-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QYTKAVBFRUGYAU-ACZMJKKPSA-N 0.000 description 1
- RKAQZCDMSUQTSS-FXQIFTODSA-N Gln-Asp-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RKAQZCDMSUQTSS-FXQIFTODSA-N 0.000 description 1
- UICOTGULOUGGLC-NUMRIWBASA-N Gln-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UICOTGULOUGGLC-NUMRIWBASA-N 0.000 description 1
- VVWWRZZMPSPVQU-KBIXCLLPSA-N Gln-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCC(=O)N)N VVWWRZZMPSPVQU-KBIXCLLPSA-N 0.000 description 1
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 1
- RBWKVOSARCFSQQ-FXQIFTODSA-N Gln-Gln-Ser Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O RBWKVOSARCFSQQ-FXQIFTODSA-N 0.000 description 1
- NPTGGVQJYRSMCM-GLLZPBPUSA-N Gln-Gln-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NPTGGVQJYRSMCM-GLLZPBPUSA-N 0.000 description 1
- MCAVASRGVBVPMX-FXQIFTODSA-N Gln-Glu-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MCAVASRGVBVPMX-FXQIFTODSA-N 0.000 description 1
- ZNZPKVQURDQFFS-FXQIFTODSA-N Gln-Glu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZNZPKVQURDQFFS-FXQIFTODSA-N 0.000 description 1
- DRDSQGHKTLSNEA-GLLZPBPUSA-N Gln-Glu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DRDSQGHKTLSNEA-GLLZPBPUSA-N 0.000 description 1
- IKFZXRLDMYWNBU-YUMQZZPRSA-N Gln-Gly-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N IKFZXRLDMYWNBU-YUMQZZPRSA-N 0.000 description 1
- CLPQUWHBWXFJOX-BQBZGAKWSA-N Gln-Gly-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O CLPQUWHBWXFJOX-BQBZGAKWSA-N 0.000 description 1
- LTXLIIZACMCQTO-GUBZILKMSA-N Gln-His-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N LTXLIIZACMCQTO-GUBZILKMSA-N 0.000 description 1
- GLEGHWQNGPMKHO-DCAQKATOSA-N Gln-His-Glu Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N GLEGHWQNGPMKHO-DCAQKATOSA-N 0.000 description 1
- HWEINOMSWQSJDC-SRVKXCTJSA-N Gln-Leu-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O HWEINOMSWQSJDC-SRVKXCTJSA-N 0.000 description 1
- MLSKFHLRFVGNLL-WDCWCFNPSA-N Gln-Leu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MLSKFHLRFVGNLL-WDCWCFNPSA-N 0.000 description 1
- ZEEPYMXTJWIMSN-GUBZILKMSA-N Gln-Lys-Ser Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CO)C(O)=O)NC(=O)[C@@H](N)CCC(N)=O ZEEPYMXTJWIMSN-GUBZILKMSA-N 0.000 description 1
- DOMHVQBSRJNNKD-ZPFDUUQYSA-N Gln-Met-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DOMHVQBSRJNNKD-ZPFDUUQYSA-N 0.000 description 1
- FALJZCPMTGJOHX-SRVKXCTJSA-N Gln-Met-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O FALJZCPMTGJOHX-SRVKXCTJSA-N 0.000 description 1
- YGNPTRVNRUKVLA-DCAQKATOSA-N Gln-Met-Met Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCC(=O)N)N YGNPTRVNRUKVLA-DCAQKATOSA-N 0.000 description 1
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 1
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 1
- PAOHIZNRJNIXQY-XQXXSGGOSA-N Gln-Thr-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O PAOHIZNRJNIXQY-XQXXSGGOSA-N 0.000 description 1
- VLOLPWWCNKWRNB-LOKLDPHHSA-N Gln-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VLOLPWWCNKWRNB-LOKLDPHHSA-N 0.000 description 1
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 1
- IIMZHVKZBGSEKZ-SZMVWBNQSA-N Gln-Trp-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(C)C)C(O)=O IIMZHVKZBGSEKZ-SZMVWBNQSA-N 0.000 description 1
- SGVGIVDZLSHSEN-RYUDHWBXSA-N Gln-Tyr-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O SGVGIVDZLSHSEN-RYUDHWBXSA-N 0.000 description 1
- VDMABHYXBULDGN-LAEOZQHASA-N Gln-Val-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O VDMABHYXBULDGN-LAEOZQHASA-N 0.000 description 1
- SZXSSXUNOALWCH-ACZMJKKPSA-N Glu-Ala-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O SZXSSXUNOALWCH-ACZMJKKPSA-N 0.000 description 1
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 1
- VPKBCVUDBNINAH-GARJFASQSA-N Glu-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O VPKBCVUDBNINAH-GARJFASQSA-N 0.000 description 1
- CKRUHITYRFNUKW-WDSKDSINSA-N Glu-Asn-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CKRUHITYRFNUKW-WDSKDSINSA-N 0.000 description 1
- PCBBLFVHTYNQGG-LAEOZQHASA-N Glu-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N PCBBLFVHTYNQGG-LAEOZQHASA-N 0.000 description 1
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 1
- MTAOBYXRYJZRGQ-WDSKDSINSA-N Glu-Gly-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MTAOBYXRYJZRGQ-WDSKDSINSA-N 0.000 description 1
- CUXJIASLBRJOFV-LAEOZQHASA-N Glu-Gly-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUXJIASLBRJOFV-LAEOZQHASA-N 0.000 description 1
- RAUDKMVXNOWDLS-WDSKDSINSA-N Glu-Gly-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O RAUDKMVXNOWDLS-WDSKDSINSA-N 0.000 description 1
- HILMIYALTUQTRC-XVKPBYJWSA-N Glu-Gly-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HILMIYALTUQTRC-XVKPBYJWSA-N 0.000 description 1
- BIHMNDPWRUROFZ-JYJNAYRXSA-N Glu-His-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O BIHMNDPWRUROFZ-JYJNAYRXSA-N 0.000 description 1
- CXRWMMRLEMVSEH-PEFMBERDSA-N Glu-Ile-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O CXRWMMRLEMVSEH-PEFMBERDSA-N 0.000 description 1
- YVYVMJNUENBOOL-KBIXCLLPSA-N Glu-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N YVYVMJNUENBOOL-KBIXCLLPSA-N 0.000 description 1
- VMKCPNBBPGGQBJ-GUBZILKMSA-N Glu-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VMKCPNBBPGGQBJ-GUBZILKMSA-N 0.000 description 1
- AQNYKMCFCCZEEL-JYJNAYRXSA-N Glu-Lys-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AQNYKMCFCCZEEL-JYJNAYRXSA-N 0.000 description 1
- YHOJJFFTSMWVGR-HJGDQZAQSA-N Glu-Met-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YHOJJFFTSMWVGR-HJGDQZAQSA-N 0.000 description 1
- AAJHGGDRKHYSDH-GUBZILKMSA-N Glu-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O AAJHGGDRKHYSDH-GUBZILKMSA-N 0.000 description 1
- SYWCGQOIIARSIX-SRVKXCTJSA-N Glu-Pro-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O SYWCGQOIIARSIX-SRVKXCTJSA-N 0.000 description 1
- BPLNJYHNAJVLRT-ACZMJKKPSA-N Glu-Ser-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O BPLNJYHNAJVLRT-ACZMJKKPSA-N 0.000 description 1
- HMJULNMJWOZNFI-XHNCKOQMSA-N Glu-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N)C(=O)O HMJULNMJWOZNFI-XHNCKOQMSA-N 0.000 description 1
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 1
- RGJKYNUINKGPJN-RWRJDSDZSA-N Glu-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(=O)O)N RGJKYNUINKGPJN-RWRJDSDZSA-N 0.000 description 1
- UMZHHILWZBFPGL-LOKLDPHHSA-N Glu-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O UMZHHILWZBFPGL-LOKLDPHHSA-N 0.000 description 1
- QVXWAFZDWRLXTI-NWLDYVSISA-N Glu-Thr-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O QVXWAFZDWRLXTI-NWLDYVSISA-N 0.000 description 1
- STDOKNKEXOLSII-SZMVWBNQSA-N Glu-Trp-His Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)NC(=O)[C@H](CCC(=O)O)N STDOKNKEXOLSII-SZMVWBNQSA-N 0.000 description 1
- RXJFSLQVMGYQEL-IHRRRGAJSA-N Glu-Tyr-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCC(O)=O)C(O)=O)CC1=CC=C(O)C=C1 RXJFSLQVMGYQEL-IHRRRGAJSA-N 0.000 description 1
- HJTSRYLPAYGEEC-SIUGBPQLSA-N Glu-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCC(=O)O)N HJTSRYLPAYGEEC-SIUGBPQLSA-N 0.000 description 1
- UUTGYDAKPISJAO-JYJNAYRXSA-N Glu-Tyr-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 UUTGYDAKPISJAO-JYJNAYRXSA-N 0.000 description 1
- BKMOHWJHXQLFEX-IRIUXVKKSA-N Glu-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCC(=O)O)N)O BKMOHWJHXQLFEX-IRIUXVKKSA-N 0.000 description 1
- HBMRTXJZQDVRFT-DZKIICNBSA-N Glu-Tyr-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O HBMRTXJZQDVRFT-DZKIICNBSA-N 0.000 description 1
- RMWAOBGCZZSJHE-UMNHJUIQSA-N Glu-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N RMWAOBGCZZSJHE-UMNHJUIQSA-N 0.000 description 1
- SOYWRINXUSUWEQ-DLOVCJGASA-N Glu-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O SOYWRINXUSUWEQ-DLOVCJGASA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- YMUFWNJHVPQNQD-ZKWXMUAHSA-N Gly-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN YMUFWNJHVPQNQD-ZKWXMUAHSA-N 0.000 description 1
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 1
- RQZGFWKQLPJOEQ-YUMQZZPRSA-N Gly-Arg-Gln Chemical compound C(C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)CN)CN=C(N)N RQZGFWKQLPJOEQ-YUMQZZPRSA-N 0.000 description 1
- OGCIHJPYKVSMTE-YUMQZZPRSA-N Gly-Arg-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O OGCIHJPYKVSMTE-YUMQZZPRSA-N 0.000 description 1
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 1
- OCQUNKSFDYDXBG-QXEWZRGKSA-N Gly-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N OCQUNKSFDYDXBG-QXEWZRGKSA-N 0.000 description 1
- KKBWDNZXYLGJEY-UHFFFAOYSA-N Gly-Arg-Pro Natural products NCC(=O)NC(CCNC(=N)N)C(=O)N1CCCC1C(=O)O KKBWDNZXYLGJEY-UHFFFAOYSA-N 0.000 description 1
- XZRZILPOZBVTDB-GJZGRUSLSA-N Gly-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)CN)C(O)=O)=CNC2=C1 XZRZILPOZBVTDB-GJZGRUSLSA-N 0.000 description 1
- UXJHNZODTMHWRD-WHFBIAKZSA-N Gly-Asn-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O UXJHNZODTMHWRD-WHFBIAKZSA-N 0.000 description 1
- JVWPPCWUDRJGAE-YUMQZZPRSA-N Gly-Asn-Leu Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JVWPPCWUDRJGAE-YUMQZZPRSA-N 0.000 description 1
- OCDLPQDYTJPWNG-YUMQZZPRSA-N Gly-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN OCDLPQDYTJPWNG-YUMQZZPRSA-N 0.000 description 1
- FMNHBTKMRFVGRO-FOHZUACHSA-N Gly-Asn-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CN FMNHBTKMRFVGRO-FOHZUACHSA-N 0.000 description 1
- XEJTYSCIXKYSHR-WDSKDSINSA-N Gly-Asp-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN XEJTYSCIXKYSHR-WDSKDSINSA-N 0.000 description 1
- QSTLUOIOYLYLLF-WDSKDSINSA-N Gly-Asp-Glu Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QSTLUOIOYLYLLF-WDSKDSINSA-N 0.000 description 1
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 1
- DTRUBYPMMVPQPD-YUMQZZPRSA-N Gly-Gln-Arg Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DTRUBYPMMVPQPD-YUMQZZPRSA-N 0.000 description 1
- KTSZUNRRYXPZTK-BQBZGAKWSA-N Gly-Gln-Glu Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KTSZUNRRYXPZTK-BQBZGAKWSA-N 0.000 description 1
- LXXANCRPFBSSKS-IUCAKERBSA-N Gly-Gln-Leu Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LXXANCRPFBSSKS-IUCAKERBSA-N 0.000 description 1
- JUBDONGMHASUCN-IUCAKERBSA-N Gly-Glu-His Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O JUBDONGMHASUCN-IUCAKERBSA-N 0.000 description 1
- LHRXAHLCRMQBGJ-RYUDHWBXSA-N Gly-Glu-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)CN LHRXAHLCRMQBGJ-RYUDHWBXSA-N 0.000 description 1
- BEQGFMIBZFNROK-JGVFFNPUSA-N Gly-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)CN)C(=O)O BEQGFMIBZFNROK-JGVFFNPUSA-N 0.000 description 1
- QSVCIFZPGLOZGH-WDSKDSINSA-N Gly-Glu-Ser Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QSVCIFZPGLOZGH-WDSKDSINSA-N 0.000 description 1
- JNGJGFMFXREJNF-KBPBESRZSA-N Gly-Glu-Trp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O JNGJGFMFXREJNF-KBPBESRZSA-N 0.000 description 1
- QPTNELDXWKRIFX-YFKPBYRVSA-N Gly-Gly-Gln Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O QPTNELDXWKRIFX-YFKPBYRVSA-N 0.000 description 1
- GDOZQTNZPCUARW-YFKPBYRVSA-N Gly-Gly-Glu Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O GDOZQTNZPCUARW-YFKPBYRVSA-N 0.000 description 1
- INLIXXRWNUKVCF-JTQLQIEISA-N Gly-Gly-Tyr Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 INLIXXRWNUKVCF-JTQLQIEISA-N 0.000 description 1
- UUWOBINZFGTFMS-UWVGGRQHSA-N Gly-His-Met Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCSC)C(O)=O UUWOBINZFGTFMS-UWVGGRQHSA-N 0.000 description 1
- HMHRTKOWRUPPNU-RCOVLWMOSA-N Gly-Ile-Gly Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O HMHRTKOWRUPPNU-RCOVLWMOSA-N 0.000 description 1
- IUZGUFAJDBHQQV-YUMQZZPRSA-N Gly-Leu-Asn Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IUZGUFAJDBHQQV-YUMQZZPRSA-N 0.000 description 1
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 1
- UHPAZODVFFYEEL-QWRGUYRKSA-N Gly-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN UHPAZODVFFYEEL-QWRGUYRKSA-N 0.000 description 1
- LHYJCVCQPWRMKZ-WEDXCCLWSA-N Gly-Leu-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LHYJCVCQPWRMKZ-WEDXCCLWSA-N 0.000 description 1
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 1
- FXGRXIATVXUAHO-WEDXCCLWSA-N Gly-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN FXGRXIATVXUAHO-WEDXCCLWSA-N 0.000 description 1
- FXLVSYVJDPCIHH-STQMWFEESA-N Gly-Phe-Arg Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FXLVSYVJDPCIHH-STQMWFEESA-N 0.000 description 1
- MTBIKIMYHUWBRX-QWRGUYRKSA-N Gly-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN MTBIKIMYHUWBRX-QWRGUYRKSA-N 0.000 description 1
- 108010009504 Gly-Phe-Leu-Gly Chemical group 0.000 description 1
- YLEIWGJJBFBFHC-KBPBESRZSA-N Gly-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 YLEIWGJJBFBFHC-KBPBESRZSA-N 0.000 description 1
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 1
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 1
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 1
- YOBGUCWZPXJHTN-BQBZGAKWSA-N Gly-Ser-Arg Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YOBGUCWZPXJHTN-BQBZGAKWSA-N 0.000 description 1
- FGPLUIQCSKGLTI-WDSKDSINSA-N Gly-Ser-Glu Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O FGPLUIQCSKGLTI-WDSKDSINSA-N 0.000 description 1
- ABPRMMYHROQBLY-NKWVEPMBSA-N Gly-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)CN)C(=O)O ABPRMMYHROQBLY-NKWVEPMBSA-N 0.000 description 1
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 1
- LLWQVJNHMYBLLK-CDMKHQONSA-N Gly-Thr-Phe Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LLWQVJNHMYBLLK-CDMKHQONSA-N 0.000 description 1
- MYXNLWDWWOTERK-BHNWBGBOSA-N Gly-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN)O MYXNLWDWWOTERK-BHNWBGBOSA-N 0.000 description 1
- FFALDIDGPLUDKV-ZDLURKLDSA-N Gly-Thr-Ser Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O FFALDIDGPLUDKV-ZDLURKLDSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- GWNIGUKSRJBIHX-STQMWFEESA-N Gly-Tyr-Arg Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)CN)O GWNIGUKSRJBIHX-STQMWFEESA-N 0.000 description 1
- KOYUSMBPJOVSOO-XEGUGMAKSA-N Gly-Tyr-Ile Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KOYUSMBPJOVSOO-XEGUGMAKSA-N 0.000 description 1
- NGBGZCUWFVVJKC-IRXDYDNUSA-N Gly-Tyr-Tyr Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NGBGZCUWFVVJKC-IRXDYDNUSA-N 0.000 description 1
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 1
- AFMOTCMSEBITOE-YEPSODPASA-N Gly-Val-Thr Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O AFMOTCMSEBITOE-YEPSODPASA-N 0.000 description 1
- KSOBNUBCYHGUKH-UWVGGRQHSA-N Gly-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN KSOBNUBCYHGUKH-UWVGGRQHSA-N 0.000 description 1
- 108010026389 Gramicidin Proteins 0.000 description 1
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 1
- BIAKMWKJMQLZOJ-ZKWXMUAHSA-N His-Ala-Ala Chemical compound C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O BIAKMWKJMQLZOJ-ZKWXMUAHSA-N 0.000 description 1
- VOKCBYNCZVSILJ-KKUMJFAQSA-N His-Asn-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CN=CN2)N)O VOKCBYNCZVSILJ-KKUMJFAQSA-N 0.000 description 1
- SWSVTNGMKBDTBM-DCAQKATOSA-N His-Gln-Glu Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N SWSVTNGMKBDTBM-DCAQKATOSA-N 0.000 description 1
- TXLQHACKRLWYCM-DCAQKATOSA-N His-Glu-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O TXLQHACKRLWYCM-DCAQKATOSA-N 0.000 description 1
- FIMNVXRZGUAGBI-AVGNSLFASA-N His-Glu-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O FIMNVXRZGUAGBI-AVGNSLFASA-N 0.000 description 1
- RAVLQPXCMRCLKT-KBPBESRZSA-N His-Gly-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O RAVLQPXCMRCLKT-KBPBESRZSA-N 0.000 description 1
- 108010093488 His-His-His-His-His-His Proteins 0.000 description 1
- JBSLJUPMTYLLFH-MELADBBJSA-N His-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC3=CN=CN3)N)C(=O)O JBSLJUPMTYLLFH-MELADBBJSA-N 0.000 description 1
- ORERHHPZDDEMSC-VGDYDELISA-N His-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N ORERHHPZDDEMSC-VGDYDELISA-N 0.000 description 1
- GJMHMDKCJPQJOI-IHRRRGAJSA-N His-Lys-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CN=CN1 GJMHMDKCJPQJOI-IHRRRGAJSA-N 0.000 description 1
- AYUOWUNWZGTNKB-ULQDDVLXSA-N His-Phe-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AYUOWUNWZGTNKB-ULQDDVLXSA-N 0.000 description 1
- XJFITURPHAKKAI-SRVKXCTJSA-N His-Pro-Gln Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(N)=O)C(O)=O)C1=CN=CN1 XJFITURPHAKKAI-SRVKXCTJSA-N 0.000 description 1
- QCBYAHHNOHBXIH-UWVGGRQHSA-N His-Pro-Gly Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)NCC(O)=O)C1=CN=CN1 QCBYAHHNOHBXIH-UWVGGRQHSA-N 0.000 description 1
- UWSMZKRTOZEGDD-CUJWVEQBSA-N His-Thr-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O UWSMZKRTOZEGDD-CUJWVEQBSA-N 0.000 description 1
- VXZZUXWAOMWWJH-QTKMDUPCSA-N His-Thr-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O VXZZUXWAOMWWJH-QTKMDUPCSA-N 0.000 description 1
- CSRRMQFXMBPSIL-SIXJUCDHSA-N His-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CN=CN3)N CSRRMQFXMBPSIL-SIXJUCDHSA-N 0.000 description 1
- WSWAUVHXQREQQG-JYJNAYRXSA-N His-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O WSWAUVHXQREQQG-JYJNAYRXSA-N 0.000 description 1
- 208000017604 Hodgkin disease Diseases 0.000 description 1
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 1
- 101000897441 Homo sapiens Cyclin-O Proteins 0.000 description 1
- 101000899111 Homo sapiens Hemoglobin subunit beta Proteins 0.000 description 1
- 101001099381 Homo sapiens Peroxisomal biogenesis factor 19 Proteins 0.000 description 1
- NKVZTQVGUNLLQW-JBDRJPRFSA-N Ile-Ala-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)O)N NKVZTQVGUNLLQW-JBDRJPRFSA-N 0.000 description 1
- HERITAGIPLEJMT-GVARAGBVSA-N Ile-Ala-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HERITAGIPLEJMT-GVARAGBVSA-N 0.000 description 1
- TZCGZYWNIDZZMR-NAKRPEOUSA-N Ile-Arg-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C)C(=O)O)N TZCGZYWNIDZZMR-NAKRPEOUSA-N 0.000 description 1
- TZCGZYWNIDZZMR-UHFFFAOYSA-N Ile-Arg-Ala Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(C)C(O)=O)CCCN=C(N)N TZCGZYWNIDZZMR-UHFFFAOYSA-N 0.000 description 1
- PJLLMGWWINYQPB-PEFMBERDSA-N Ile-Asn-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PJLLMGWWINYQPB-PEFMBERDSA-N 0.000 description 1
- LEDRIAHEWDJRMF-CFMVVWHZSA-N Ile-Asn-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LEDRIAHEWDJRMF-CFMVVWHZSA-N 0.000 description 1
- UMYZBHKAVTXWIW-GMOBBJLQSA-N Ile-Asp-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UMYZBHKAVTXWIW-GMOBBJLQSA-N 0.000 description 1
- RGSOCXHDOPQREB-ZPFDUUQYSA-N Ile-Asp-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N RGSOCXHDOPQREB-ZPFDUUQYSA-N 0.000 description 1
- QSPLUJGYOPZINY-ZPFDUUQYSA-N Ile-Asp-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N QSPLUJGYOPZINY-ZPFDUUQYSA-N 0.000 description 1
- BSWLQVGEVFYGIM-ZPFDUUQYSA-N Ile-Gln-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N BSWLQVGEVFYGIM-ZPFDUUQYSA-N 0.000 description 1
- KUHFPGIVBOCRMV-MNXVOIDGSA-N Ile-Gln-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(C)C)C(=O)O)N KUHFPGIVBOCRMV-MNXVOIDGSA-N 0.000 description 1
- MVLDERGQICFFLL-ZQINRCPSSA-N Ile-Gln-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 MVLDERGQICFFLL-ZQINRCPSSA-N 0.000 description 1
- DVRDRICMWUSCBN-UKJIMTQDSA-N Ile-Gln-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N DVRDRICMWUSCBN-UKJIMTQDSA-N 0.000 description 1
- MTFVYKQRLXYAQN-LAEOZQHASA-N Ile-Glu-Gly Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O MTFVYKQRLXYAQN-LAEOZQHASA-N 0.000 description 1
- NHJKZMDIMMTVCK-QXEWZRGKSA-N Ile-Gly-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N NHJKZMDIMMTVCK-QXEWZRGKSA-N 0.000 description 1
- LPFBXFILACZHIB-LAEOZQHASA-N Ile-Gly-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)O)C(=O)O)N LPFBXFILACZHIB-LAEOZQHASA-N 0.000 description 1
- GQKSJYINYYWPMR-NGZCFLSTSA-N Ile-Gly-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N1CCC[C@@H]1C(=O)O)N GQKSJYINYYWPMR-NGZCFLSTSA-N 0.000 description 1
- QZZIBQZLWBOOJH-PEDHHIEDSA-N Ile-Ile-Val Chemical compound N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(=O)O QZZIBQZLWBOOJH-PEDHHIEDSA-N 0.000 description 1
- OUUCIIJSBIBCHB-ZPFDUUQYSA-N Ile-Leu-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O OUUCIIJSBIBCHB-ZPFDUUQYSA-N 0.000 description 1
- PARSHQDZROHERM-NHCYSSNCSA-N Ile-Lys-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)O)N PARSHQDZROHERM-NHCYSSNCSA-N 0.000 description 1
- FFAUOCITXBMRBT-YTFOTSKYSA-N Ile-Lys-Ile Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FFAUOCITXBMRBT-YTFOTSKYSA-N 0.000 description 1
- FFJQAEYLAQMGDL-MGHWNKPDSA-N Ile-Lys-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FFJQAEYLAQMGDL-MGHWNKPDSA-N 0.000 description 1
- VLCMCYDZJCWPQT-VKOGCVSHSA-N Ile-Met-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N VLCMCYDZJCWPQT-VKOGCVSHSA-N 0.000 description 1
- IITVUURPOYGCTD-NAKRPEOUSA-N Ile-Pro-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IITVUURPOYGCTD-NAKRPEOUSA-N 0.000 description 1
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 1
- AGGIYSLVUKVOPT-HTFCKZLJSA-N Ile-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N AGGIYSLVUKVOPT-HTFCKZLJSA-N 0.000 description 1
- CNMOKANDJMLAIF-CIQUZCHMSA-N Ile-Thr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O CNMOKANDJMLAIF-CIQUZCHMSA-N 0.000 description 1
- YCKPUHHMCFSUMD-IUKAMOBKSA-N Ile-Thr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCKPUHHMCFSUMD-IUKAMOBKSA-N 0.000 description 1
- YBKKLDBBPFIXBQ-MBLNEYKQSA-N Ile-Thr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)O)N YBKKLDBBPFIXBQ-MBLNEYKQSA-N 0.000 description 1
- KWHFUMYCSPJCFQ-NGTWOADLSA-N Ile-Thr-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N KWHFUMYCSPJCFQ-NGTWOADLSA-N 0.000 description 1
- QHUREMVLLMNUAX-OSUNSFLBSA-N Ile-Thr-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)O)N QHUREMVLLMNUAX-OSUNSFLBSA-N 0.000 description 1
- GVEODXUBBFDBPW-MGHWNKPDSA-N Ile-Tyr-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 GVEODXUBBFDBPW-MGHWNKPDSA-N 0.000 description 1
- WRDTXMBPHMBGIB-STECZYCISA-N Ile-Tyr-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=C(O)C=C1 WRDTXMBPHMBGIB-STECZYCISA-N 0.000 description 1
- YJRSIJZUIUANHO-NAKRPEOUSA-N Ile-Val-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(=O)O)N YJRSIJZUIUANHO-NAKRPEOUSA-N 0.000 description 1
- BCISUQVFDGYZBO-QSFUFRPTSA-N Ile-Val-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O BCISUQVFDGYZBO-QSFUFRPTSA-N 0.000 description 1
- YHFPHRUWZMEOIX-CYDGBPFRSA-N Ile-Val-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)O)N YHFPHRUWZMEOIX-CYDGBPFRSA-N 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 1
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 206010061252 Intraocular melanoma Diseases 0.000 description 1
- ZCYVEMRRCGMTRW-AHCXROLUSA-N Iodine-123 Chemical compound [123I] ZCYVEMRRCGMTRW-AHCXROLUSA-N 0.000 description 1
- OIRFJRBSRORBCM-UHFFFAOYSA-N Iopanoic acid Chemical compound CCC(C(O)=O)CC1=C(I)C=C(I)C(N)=C1I OIRFJRBSRORBCM-UHFFFAOYSA-N 0.000 description 1
- 102100027612 Kallikrein-11 Human genes 0.000 description 1
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 1
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 1
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- 108091026898 Leader sequence (mRNA) Proteins 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 1
- REPPKAMYTOJTFC-DCAQKATOSA-N Leu-Arg-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O REPPKAMYTOJTFC-DCAQKATOSA-N 0.000 description 1
- IBMVEYRWAWIOTN-RWMBFGLXSA-N Leu-Arg-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(O)=O IBMVEYRWAWIOTN-RWMBFGLXSA-N 0.000 description 1
- BAJIJEGGUYXZGC-CIUDSAMLSA-N Leu-Asn-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N BAJIJEGGUYXZGC-CIUDSAMLSA-N 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 1
- DPWGZWUMUUJQDT-IUCAKERBSA-N Leu-Gln-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O DPWGZWUMUUJQDT-IUCAKERBSA-N 0.000 description 1
- GLBNEGIOFRVRHO-JYJNAYRXSA-N Leu-Gln-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GLBNEGIOFRVRHO-JYJNAYRXSA-N 0.000 description 1
- CQGSYZCULZMEDE-SRVKXCTJSA-N Leu-Gln-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CQGSYZCULZMEDE-SRVKXCTJSA-N 0.000 description 1
- CIVKXGPFXDIQBV-WDCWCFNPSA-N Leu-Gln-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CIVKXGPFXDIQBV-WDCWCFNPSA-N 0.000 description 1
- FMEICTQWUKNAGC-YUMQZZPRSA-N Leu-Gly-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O FMEICTQWUKNAGC-YUMQZZPRSA-N 0.000 description 1
- KEVYYIMVELOXCT-KBPBESRZSA-N Leu-Gly-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KEVYYIMVELOXCT-KBPBESRZSA-N 0.000 description 1
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 1
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 1
- CSFVADKICPDRRF-KKUMJFAQSA-N Leu-His-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CN=CN1 CSFVADKICPDRRF-KKUMJFAQSA-N 0.000 description 1
- QJXHMYMRGDOHRU-NHCYSSNCSA-N Leu-Ile-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O QJXHMYMRGDOHRU-NHCYSSNCSA-N 0.000 description 1
- KUIDCYNIEJBZBU-AJNGGQMLSA-N Leu-Ile-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O KUIDCYNIEJBZBU-AJNGGQMLSA-N 0.000 description 1
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 1
- QNTJIDXQHWUBKC-BZSNNMDCSA-N Leu-Lys-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QNTJIDXQHWUBKC-BZSNNMDCSA-N 0.000 description 1
- NJMXCOOEFLMZSR-AVGNSLFASA-N Leu-Met-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O NJMXCOOEFLMZSR-AVGNSLFASA-N 0.000 description 1
- VULJUQZPSOASBZ-SRVKXCTJSA-N Leu-Pro-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O VULJUQZPSOASBZ-SRVKXCTJSA-N 0.000 description 1
- UCBPDSYUVAAHCD-UWVGGRQHSA-N Leu-Pro-Gly Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UCBPDSYUVAAHCD-UWVGGRQHSA-N 0.000 description 1
- YUTNOGOMBNYPFH-XUXIUFHCSA-N Leu-Pro-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YUTNOGOMBNYPFH-XUXIUFHCSA-N 0.000 description 1
- XXXXOVFBXRERQL-ULQDDVLXSA-N Leu-Pro-Phe Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XXXXOVFBXRERQL-ULQDDVLXSA-N 0.000 description 1
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 1
- AKVBOOKXVAMKSS-GUBZILKMSA-N Leu-Ser-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O AKVBOOKXVAMKSS-GUBZILKMSA-N 0.000 description 1
- JIHDFWWRYHSAQB-GUBZILKMSA-N Leu-Ser-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JIHDFWWRYHSAQB-GUBZILKMSA-N 0.000 description 1
- MVHXGBZUJLWZOH-BJDJZHNGSA-N Leu-Ser-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MVHXGBZUJLWZOH-BJDJZHNGSA-N 0.000 description 1
- IWMJFLJQHIDZQW-KKUMJFAQSA-N Leu-Ser-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IWMJFLJQHIDZQW-KKUMJFAQSA-N 0.000 description 1
- ZJZNLRVCZWUONM-JXUBOQSCSA-N Leu-Thr-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O ZJZNLRVCZWUONM-JXUBOQSCSA-N 0.000 description 1
- ZDJQVSIPFLMNOX-RHYQMDGZSA-N Leu-Thr-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZDJQVSIPFLMNOX-RHYQMDGZSA-N 0.000 description 1
- ICYRCNICGBJLGM-HJGDQZAQSA-N Leu-Thr-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(O)=O ICYRCNICGBJLGM-HJGDQZAQSA-N 0.000 description 1
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 1
- VDIARPPNADFEAV-WEDXCCLWSA-N Leu-Thr-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O VDIARPPNADFEAV-WEDXCCLWSA-N 0.000 description 1
- FBNPMTNBFFAMMH-AVGNSLFASA-N Leu-Val-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-AVGNSLFASA-N 0.000 description 1
- TUIOUEWKFFVNLH-DCAQKATOSA-N Leu-Val-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O TUIOUEWKFFVNLH-DCAQKATOSA-N 0.000 description 1
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 1
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 208000007433 Lymphatic Metastasis Diseases 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- DGAAQRAUOFHBFJ-CIUDSAMLSA-N Lys-Asn-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O DGAAQRAUOFHBFJ-CIUDSAMLSA-N 0.000 description 1
- ABHIXYDMILIUKV-CIUDSAMLSA-N Lys-Asn-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ABHIXYDMILIUKV-CIUDSAMLSA-N 0.000 description 1
- HIIZIQUUHIXUJY-GUBZILKMSA-N Lys-Asp-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HIIZIQUUHIXUJY-GUBZILKMSA-N 0.000 description 1
- NRQRKMYZONPCTM-CIUDSAMLSA-N Lys-Asp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NRQRKMYZONPCTM-CIUDSAMLSA-N 0.000 description 1
- ZAENPHCEQXALHO-GUBZILKMSA-N Lys-Cys-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZAENPHCEQXALHO-GUBZILKMSA-N 0.000 description 1
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 1
- MUXNCRWTWBMNHX-SRVKXCTJSA-N Lys-Leu-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O MUXNCRWTWBMNHX-SRVKXCTJSA-N 0.000 description 1
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 1
- PLDJDCJLRCYPJB-VOAKCMCISA-N Lys-Lys-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PLDJDCJLRCYPJB-VOAKCMCISA-N 0.000 description 1
- CNGOEHJCLVCJHN-SRVKXCTJSA-N Lys-Pro-Glu Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O CNGOEHJCLVCJHN-SRVKXCTJSA-N 0.000 description 1
- QBHGXFQJFPWJIH-XUXIUFHCSA-N Lys-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN QBHGXFQJFPWJIH-XUXIUFHCSA-N 0.000 description 1
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 1
- UWHCKWNPWKTMBM-WDCWCFNPSA-N Lys-Thr-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O UWHCKWNPWKTMBM-WDCWCFNPSA-N 0.000 description 1
- JHNOXVASMSXSNB-WEDXCCLWSA-N Lys-Thr-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O JHNOXVASMSXSNB-WEDXCCLWSA-N 0.000 description 1
- BDFHWFUAQLIMJO-KXNHARMFSA-N Lys-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N)O BDFHWFUAQLIMJO-KXNHARMFSA-N 0.000 description 1
- KTINOHQFVVCEGQ-XIRDDKMYSA-N Lys-Trp-Asp Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(=O)N[C@@H](CC(O)=O)C(O)=O KTINOHQFVVCEGQ-XIRDDKMYSA-N 0.000 description 1
- IMDJSVBFQKDDEQ-MGHWNKPDSA-N Lys-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCCCN)N IMDJSVBFQKDDEQ-MGHWNKPDSA-N 0.000 description 1
- SQRLLZAQNOQCEG-KKUMJFAQSA-N Lys-Tyr-Ser Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 SQRLLZAQNOQCEG-KKUMJFAQSA-N 0.000 description 1
- PPNCMJARTHYNEC-MEYUZBJRSA-N Lys-Tyr-Thr Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@H](O)C)C(O)=O)CC1=CC=C(O)C=C1 PPNCMJARTHYNEC-MEYUZBJRSA-N 0.000 description 1
- OHXUUQDOBQKSNB-AVGNSLFASA-N Lys-Val-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O OHXUUQDOBQKSNB-AVGNSLFASA-N 0.000 description 1
- RIPJMCFGQHGHNP-RHYQMDGZSA-N Lys-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCCCN)N)O RIPJMCFGQHGHNP-RHYQMDGZSA-N 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- PHWSCIFNNLLUFJ-NHCYSSNCSA-N Met-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCSC)N PHWSCIFNNLLUFJ-NHCYSSNCSA-N 0.000 description 1
- XKJUFUPCHARJKX-UWVGGRQHSA-N Met-Gly-His Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 XKJUFUPCHARJKX-UWVGGRQHSA-N 0.000 description 1
- PPHLBTXVBJNKOB-FDARSICLSA-N Met-Ile-Trp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O PPHLBTXVBJNKOB-FDARSICLSA-N 0.000 description 1
- HGAJNEWOUHDUMZ-SRVKXCTJSA-N Met-Leu-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O HGAJNEWOUHDUMZ-SRVKXCTJSA-N 0.000 description 1
- DJJBHQHOZLUBCN-WDSOQIARSA-N Met-Lys-Trp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DJJBHQHOZLUBCN-WDSOQIARSA-N 0.000 description 1
- OXIWIYOJVNOKOV-SRVKXCTJSA-N Met-Met-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@H](C(O)=O)CCCNC(N)=N OXIWIYOJVNOKOV-SRVKXCTJSA-N 0.000 description 1
- XGIQKEAKUSPCBU-SRVKXCTJSA-N Met-Met-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCSC)N XGIQKEAKUSPCBU-SRVKXCTJSA-N 0.000 description 1
- RMLLCGYYVZKKRT-CIUDSAMLSA-N Met-Ser-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O RMLLCGYYVZKKRT-CIUDSAMLSA-N 0.000 description 1
- VOAKKHOIAFKOQZ-JYJNAYRXSA-N Met-Tyr-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CCSC)CC1=CC=C(O)C=C1 VOAKKHOIAFKOQZ-JYJNAYRXSA-N 0.000 description 1
- CNFMPVYIVQUJOO-NHCYSSNCSA-N Met-Val-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(N)=O CNFMPVYIVQUJOO-NHCYSSNCSA-N 0.000 description 1
- 241000237852 Mollusca Species 0.000 description 1
- 241000711408 Murine respirovirus Species 0.000 description 1
- 101710135898 Myc proto-oncogene protein Proteins 0.000 description 1
- 102100038895 Myc proto-oncogene protein Human genes 0.000 description 1
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 1
- MBBZMMPHUWSWHV-BDVNFPICSA-N N-methylglucamine Chemical compound CNC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO MBBZMMPHUWSWHV-BDVNFPICSA-N 0.000 description 1
- 238000005481 NMR spectroscopy Methods 0.000 description 1
- GRYLNZFGIOXLOG-UHFFFAOYSA-N Nitric acid Chemical compound O[N+]([O-])=O GRYLNZFGIOXLOG-UHFFFAOYSA-N 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- KYRVNWMVYQXFEU-UHFFFAOYSA-N Nocodazole Chemical compound C1=C2NC(NC(=O)OC)=NC2=CC=C1C(=O)C1=CC=CS1 KYRVNWMVYQXFEU-UHFFFAOYSA-N 0.000 description 1
- 102000015636 Oligopeptides Human genes 0.000 description 1
- 108010038807 Oligopeptides Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 208000000821 Parathyroid Neoplasms Diseases 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 102100038883 Peroxisomal biogenesis factor 19 Human genes 0.000 description 1
- 108010081690 Pertussis Toxin Proteins 0.000 description 1
- CYZBFPYMSJGBRL-DRZSPHRISA-N Phe-Ala-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CYZBFPYMSJGBRL-DRZSPHRISA-N 0.000 description 1
- WMGVYPPIMZPWPN-SRVKXCTJSA-N Phe-Asp-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N WMGVYPPIMZPWPN-SRVKXCTJSA-N 0.000 description 1
- DJPXNKUDJKGQEE-BZSNNMDCSA-N Phe-Asp-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O DJPXNKUDJKGQEE-BZSNNMDCSA-N 0.000 description 1
- MPFGIYLYWUCSJG-AVGNSLFASA-N Phe-Glu-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 MPFGIYLYWUCSJG-AVGNSLFASA-N 0.000 description 1
- KYYMILWEGJYPQZ-IHRRRGAJSA-N Phe-Glu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 KYYMILWEGJYPQZ-IHRRRGAJSA-N 0.000 description 1
- NHCKESBLOMHIIE-IRXDYDNUSA-N Phe-Gly-Phe Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 NHCKESBLOMHIIE-IRXDYDNUSA-N 0.000 description 1
- BYAIIACBWBOJCU-URLPEUOOSA-N Phe-Ile-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BYAIIACBWBOJCU-URLPEUOOSA-N 0.000 description 1
- RFCVXVPWSPOMFJ-STQMWFEESA-N Phe-Leu Chemical group CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 RFCVXVPWSPOMFJ-STQMWFEESA-N 0.000 description 1
- KXUZHWXENMYOHC-QEJZJMRPSA-N Phe-Leu-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUZHWXENMYOHC-QEJZJMRPSA-N 0.000 description 1
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 1
- GOUWCZRDTWTODO-YDHLFZDLSA-N Phe-Val-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O GOUWCZRDTWTODO-YDHLFZDLSA-N 0.000 description 1
- MWQXFDIQXIXPMS-UNQGMJICSA-N Phe-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC1=CC=CC=C1)N)O MWQXFDIQXIXPMS-UNQGMJICSA-N 0.000 description 1
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 description 1
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 description 1
- 208000007913 Pituitary Neoplasms Diseases 0.000 description 1
- 201000005746 Pituitary adenoma Diseases 0.000 description 1
- 206010061538 Pituitary tumour benign Diseases 0.000 description 1
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 1
- 108091036407 Polyadenylation Proteins 0.000 description 1
- AJLVKXCNXIJHDV-CIUDSAMLSA-N Pro-Ala-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O AJLVKXCNXIJHDV-CIUDSAMLSA-N 0.000 description 1
- NHDVNAKDACFHPX-GUBZILKMSA-N Pro-Arg-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O NHDVNAKDACFHPX-GUBZILKMSA-N 0.000 description 1
- HPXVFFIIGOAQRV-DCAQKATOSA-N Pro-Arg-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O HPXVFFIIGOAQRV-DCAQKATOSA-N 0.000 description 1
- GRIRJQGZZJVANI-CYDGBPFRSA-N Pro-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 GRIRJQGZZJVANI-CYDGBPFRSA-N 0.000 description 1
- ICTZKEXYDDZZFP-SRVKXCTJSA-N Pro-Arg-Pro Chemical compound N([C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(O)=O)C(=O)[C@@H]1CCCN1 ICTZKEXYDDZZFP-SRVKXCTJSA-N 0.000 description 1
- SGCZFWSQERRKBD-BQBZGAKWSA-N Pro-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 SGCZFWSQERRKBD-BQBZGAKWSA-N 0.000 description 1
- GDXZRWYXJSGWIV-GMOBBJLQSA-N Pro-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 GDXZRWYXJSGWIV-GMOBBJLQSA-N 0.000 description 1
- KPDRZQUWJKTMBP-DCAQKATOSA-N Pro-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 KPDRZQUWJKTMBP-DCAQKATOSA-N 0.000 description 1
- SFECXGVELZFBFJ-VEVYYDQMSA-N Pro-Asp-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SFECXGVELZFBFJ-VEVYYDQMSA-N 0.000 description 1
- XUSDDSLCRPUKLP-QXEWZRGKSA-N Pro-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 XUSDDSLCRPUKLP-QXEWZRGKSA-N 0.000 description 1
- OZAPWFHRPINHND-GUBZILKMSA-N Pro-Cys-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O OZAPWFHRPINHND-GUBZILKMSA-N 0.000 description 1
- HJSCRFZVGXAGNG-SRVKXCTJSA-N Pro-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 HJSCRFZVGXAGNG-SRVKXCTJSA-N 0.000 description 1
- SKICPQLTOXGWGO-GARJFASQSA-N Pro-Gln-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O SKICPQLTOXGWGO-GARJFASQSA-N 0.000 description 1
- DIFXZGPHVCIVSQ-CIUDSAMLSA-N Pro-Gln-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DIFXZGPHVCIVSQ-CIUDSAMLSA-N 0.000 description 1
- ULIWFCCJIOEHMU-BQBZGAKWSA-N Pro-Gly-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 ULIWFCCJIOEHMU-BQBZGAKWSA-N 0.000 description 1
- WSRWHZRUOCACLJ-UWVGGRQHSA-N Pro-Gly-His Chemical compound C([C@@H](C(=O)O)NC(=O)CNC(=O)[C@H]1NCCC1)C1=CN=CN1 WSRWHZRUOCACLJ-UWVGGRQHSA-N 0.000 description 1
- YTWNSIDWAFSEEI-RWMBFGLXSA-N Pro-His-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)N3CCC[C@@H]3C(=O)O YTWNSIDWAFSEEI-RWMBFGLXSA-N 0.000 description 1
- KWMUAKQOVYCQJQ-ZPFDUUQYSA-N Pro-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 KWMUAKQOVYCQJQ-ZPFDUUQYSA-N 0.000 description 1
- BCNRNJWSRFDPTQ-HJWJTTGWSA-N Pro-Ile-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O BCNRNJWSRFDPTQ-HJWJTTGWSA-N 0.000 description 1
- AUQGUYPHJSMAKI-CYDGBPFRSA-N Pro-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 AUQGUYPHJSMAKI-CYDGBPFRSA-N 0.000 description 1
- CLJLVCYFABNTHP-DCAQKATOSA-N Pro-Leu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O CLJLVCYFABNTHP-DCAQKATOSA-N 0.000 description 1
- GURGCNUWVSDYTP-SRVKXCTJSA-N Pro-Leu-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GURGCNUWVSDYTP-SRVKXCTJSA-N 0.000 description 1
- BRJGUPWVFXKBQI-XUXIUFHCSA-N Pro-Leu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRJGUPWVFXKBQI-XUXIUFHCSA-N 0.000 description 1
- SUENWIFTSTWUKD-AVGNSLFASA-N Pro-Leu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SUENWIFTSTWUKD-AVGNSLFASA-N 0.000 description 1
- ABSSTGUCBCDKMU-UWVGGRQHSA-N Pro-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 ABSSTGUCBCDKMU-UWVGGRQHSA-N 0.000 description 1
- QCMYJBKTMIWZAP-AVGNSLFASA-N Pro-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 QCMYJBKTMIWZAP-AVGNSLFASA-N 0.000 description 1
- MLKVIVZCFYRTIR-KKUMJFAQSA-N Pro-Phe-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLKVIVZCFYRTIR-KKUMJFAQSA-N 0.000 description 1
- WHNJMTHJGCEKGA-ULQDDVLXSA-N Pro-Phe-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O WHNJMTHJGCEKGA-ULQDDVLXSA-N 0.000 description 1
- GFHXZNVJIKMAGO-IHRRRGAJSA-N Pro-Phe-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O GFHXZNVJIKMAGO-IHRRRGAJSA-N 0.000 description 1
- SPLBRAKYXGOFSO-UNQGMJICSA-N Pro-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@@H]2CCCN2)O SPLBRAKYXGOFSO-UNQGMJICSA-N 0.000 description 1
- RFWXYTJSVDUBBZ-DCAQKATOSA-N Pro-Pro-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 RFWXYTJSVDUBBZ-DCAQKATOSA-N 0.000 description 1
- SBVPYBFMIGDIDX-SRVKXCTJSA-N Pro-Pro-Pro Chemical compound OC(=O)[C@@H]1CCCN1C(=O)[C@H]1N(C(=O)[C@H]2NCCC2)CCC1 SBVPYBFMIGDIDX-SRVKXCTJSA-N 0.000 description 1
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 1
- SEZGGSHLMROBFX-CIUDSAMLSA-N Pro-Ser-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O SEZGGSHLMROBFX-CIUDSAMLSA-N 0.000 description 1
- BGWKULMLUIUPKY-BQBZGAKWSA-N Pro-Ser-Gly Chemical compound OC(=O)CNC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 BGWKULMLUIUPKY-BQBZGAKWSA-N 0.000 description 1
- KWMZPPWYBVZIER-XGEHTFHBSA-N Pro-Ser-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWMZPPWYBVZIER-XGEHTFHBSA-N 0.000 description 1
- WVXQQUWOKUZIEG-VEVYYDQMSA-N Pro-Thr-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O WVXQQUWOKUZIEG-VEVYYDQMSA-N 0.000 description 1
- AJJDPGVVNPUZCR-RHYQMDGZSA-N Pro-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1)O AJJDPGVVNPUZCR-RHYQMDGZSA-N 0.000 description 1
- GZNYIXWOIUFLGO-ZJDVBMNYSA-N Pro-Thr-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZNYIXWOIUFLGO-ZJDVBMNYSA-N 0.000 description 1
- CXGLFEOYCJFKPR-RCWTZXSCSA-N Pro-Thr-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O CXGLFEOYCJFKPR-RCWTZXSCSA-N 0.000 description 1
- QHSSUIHLAIWXEE-IHRRRGAJSA-N Pro-Tyr-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O QHSSUIHLAIWXEE-IHRRRGAJSA-N 0.000 description 1
- QKWYXRPICJEQAJ-KJEVXHAQSA-N Pro-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@@H]2CCCN2)O QKWYXRPICJEQAJ-KJEVXHAQSA-N 0.000 description 1
- XDKKMRPRRCOELJ-GUBZILKMSA-N Pro-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 XDKKMRPRRCOELJ-GUBZILKMSA-N 0.000 description 1
- OOZJHTXCLJUODH-QXEWZRGKSA-N Pro-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 OOZJHTXCLJUODH-QXEWZRGKSA-N 0.000 description 1
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 1
- 206010036790 Productive cough Diseases 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- OFOBLEOULBTSOW-UHFFFAOYSA-N Propanedioic acid Natural products OC(=O)CC(O)=O OFOBLEOULBTSOW-UHFFFAOYSA-N 0.000 description 1
- 101000762949 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) Exotoxin A Proteins 0.000 description 1
- 229930185560 Pseudouridine Natural products 0.000 description 1
- PTJWIQPHWPFNBW-UHFFFAOYSA-N Pseudouridine C Natural products OC1C(O)C(CO)OC1C1=CNC(=O)NC1=O PTJWIQPHWPFNBW-UHFFFAOYSA-N 0.000 description 1
- 108020005161 RNA Caps Proteins 0.000 description 1
- 230000026279 RNA modification Effects 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 208000015634 Rectal Neoplasms Diseases 0.000 description 1
- 208000006265 Renal cell carcinoma Diseases 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- KJQFBVYMGADDTQ-UHFFFAOYSA-N S-butyl-DL-homocysteine (S,R)-sulfoximine Chemical compound CCCCS(=N)(=O)CCC(N)C(O)=O KJQFBVYMGADDTQ-UHFFFAOYSA-N 0.000 description 1
- 239000002262 Schiff base Substances 0.000 description 1
- 150000004753 Schiff bases Chemical class 0.000 description 1
- 241000235347 Schizosaccharomyces pombe Species 0.000 description 1
- HBZBPFLJNDXRAY-FXQIFTODSA-N Ser-Ala-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O HBZBPFLJNDXRAY-FXQIFTODSA-N 0.000 description 1
- FCRMLGJMPXCAHD-FXQIFTODSA-N Ser-Arg-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O FCRMLGJMPXCAHD-FXQIFTODSA-N 0.000 description 1
- HZWAHWQZPSXNCB-BPUTZDHNSA-N Ser-Arg-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HZWAHWQZPSXNCB-BPUTZDHNSA-N 0.000 description 1
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 1
- BGOWRLSWJCVYAQ-CIUDSAMLSA-N Ser-Asp-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BGOWRLSWJCVYAQ-CIUDSAMLSA-N 0.000 description 1
- BQWCDDAISCPDQV-XHNCKOQMSA-N Ser-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N)C(=O)O BQWCDDAISCPDQV-XHNCKOQMSA-N 0.000 description 1
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 1
- YRBGKVIWMNEVCZ-WDSKDSINSA-N Ser-Glu-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YRBGKVIWMNEVCZ-WDSKDSINSA-N 0.000 description 1
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 1
- GZBKRJVCRMZAST-XKBZYTNZSA-N Ser-Glu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZBKRJVCRMZAST-XKBZYTNZSA-N 0.000 description 1
- WBINSDOPZHQPPM-AVGNSLFASA-N Ser-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)O WBINSDOPZHQPPM-AVGNSLFASA-N 0.000 description 1
- AEGUWTFAQQWVLC-BQBZGAKWSA-N Ser-Gly-Arg Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O AEGUWTFAQQWVLC-BQBZGAKWSA-N 0.000 description 1
- SNVIOQXAHVORQM-WDSKDSINSA-N Ser-Gly-Gln Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O SNVIOQXAHVORQM-WDSKDSINSA-N 0.000 description 1
- JFWDJFULOLKQFY-QWRGUYRKSA-N Ser-Gly-Phe Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JFWDJFULOLKQFY-QWRGUYRKSA-N 0.000 description 1
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 1
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 1
- MLSQXWSRHURDMF-GARJFASQSA-N Ser-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CO)N)C(=O)O MLSQXWSRHURDMF-GARJFASQSA-N 0.000 description 1
- MOINZPRHJGTCHZ-MMWGEVLESA-N Ser-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N MOINZPRHJGTCHZ-MMWGEVLESA-N 0.000 description 1
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 1
- DOSZISJPMCYEHT-NAKRPEOUSA-N Ser-Ile-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O DOSZISJPMCYEHT-NAKRPEOUSA-N 0.000 description 1
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 1
- NNFMANHDYSVNIO-DCAQKATOSA-N Ser-Lys-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NNFMANHDYSVNIO-DCAQKATOSA-N 0.000 description 1
- CRJZZXMAADSBBQ-SRVKXCTJSA-N Ser-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO CRJZZXMAADSBBQ-SRVKXCTJSA-N 0.000 description 1
- PTWIYDNFWPXQSD-GARJFASQSA-N Ser-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N)C(=O)O PTWIYDNFWPXQSD-GARJFASQSA-N 0.000 description 1
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 1
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 1
- NMZXJDSKEGFDLJ-DCAQKATOSA-N Ser-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CO)N)C(=O)N[C@@H](CCCCN)C(=O)O NMZXJDSKEGFDLJ-DCAQKATOSA-N 0.000 description 1
- DINQYZRMXGWWTG-GUBZILKMSA-N Ser-Pro-Pro Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DINQYZRMXGWWTG-GUBZILKMSA-N 0.000 description 1
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 1
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 1
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 1
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 1
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 1
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 1
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 1
- PURRNJBBXDDWLX-ZDLURKLDSA-N Ser-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N)O PURRNJBBXDDWLX-ZDLURKLDSA-N 0.000 description 1
- ZSDXEKUKQAKZFE-XAVMHZPKSA-N Ser-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N)O ZSDXEKUKQAKZFE-XAVMHZPKSA-N 0.000 description 1
- VLMIUSLQONKLDV-HEIBUPTGSA-N Ser-Thr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VLMIUSLQONKLDV-HEIBUPTGSA-N 0.000 description 1
- STIAINRLUUKYKM-WFBYXXMGSA-N Ser-Trp-Ala Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CO)=CNC2=C1 STIAINRLUUKYKM-WFBYXXMGSA-N 0.000 description 1
- WMZVVNLPHFSUPA-BPUTZDHNSA-N Ser-Trp-Arg Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 WMZVVNLPHFSUPA-BPUTZDHNSA-N 0.000 description 1
- JZRYFUGREMECBH-XPUUQOCRSA-N Ser-Val-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O JZRYFUGREMECBH-XPUUQOCRSA-N 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 108010034546 Serratia marcescens nuclease Proteins 0.000 description 1
- 208000032023 Signs and Symptoms Diseases 0.000 description 1
- 208000000453 Skin Neoplasms Diseases 0.000 description 1
- 208000021712 Soft tissue sarcoma Diseases 0.000 description 1
- ZSJLQEPLLKMAKR-UHFFFAOYSA-N Streptozotocin Natural products O=NN(C)C(=O)NC1C(O)OC(CO)C(O)C1O ZSJLQEPLLKMAKR-UHFFFAOYSA-N 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-N Succinic acid Natural products OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 239000012505 Superdex™ Substances 0.000 description 1
- 241000282898 Sus scrofa Species 0.000 description 1
- 108700026226 TATA Box Proteins 0.000 description 1
- GKLVYJBZJHMRIY-OUBTZVSYSA-N Technetium-99 Chemical compound [99Tc] GKLVYJBZJHMRIY-OUBTZVSYSA-N 0.000 description 1
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 description 1
- DFTCYYILCSQGIZ-GCJQMDKQSA-N Thr-Ala-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DFTCYYILCSQGIZ-GCJQMDKQSA-N 0.000 description 1
- FQPQPTHMHZKGFM-XQXXSGGOSA-N Thr-Ala-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O FQPQPTHMHZKGFM-XQXXSGGOSA-N 0.000 description 1
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 1
- TZKPNGDGUVREEB-FOHZUACHSA-N Thr-Asn-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O TZKPNGDGUVREEB-FOHZUACHSA-N 0.000 description 1
- SKHPKKYKDYULDH-HJGDQZAQSA-N Thr-Asn-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SKHPKKYKDYULDH-HJGDQZAQSA-N 0.000 description 1
- JBHMLZSKIXMVFS-XVSYOHENSA-N Thr-Asn-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JBHMLZSKIXMVFS-XVSYOHENSA-N 0.000 description 1
- LOHBIDZYHQQTDM-IXOXFDKPSA-N Thr-Cys-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LOHBIDZYHQQTDM-IXOXFDKPSA-N 0.000 description 1
- VEWZSFGRQDUAJM-YJRXYDGGSA-N Thr-Cys-Tyr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N)O VEWZSFGRQDUAJM-YJRXYDGGSA-N 0.000 description 1
- DSLHSTIUAPKERR-XGEHTFHBSA-N Thr-Cys-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O DSLHSTIUAPKERR-XGEHTFHBSA-N 0.000 description 1
- GCXFWAZRHBRYEM-NUMRIWBASA-N Thr-Gln-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O GCXFWAZRHBRYEM-NUMRIWBASA-N 0.000 description 1
- DKDHTRVDOUZZTP-IFFSRLJSSA-N Thr-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DKDHTRVDOUZZTP-IFFSRLJSSA-N 0.000 description 1
- VGYBYGQXZJDZJU-XQXXSGGOSA-N Thr-Glu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VGYBYGQXZJDZJU-XQXXSGGOSA-N 0.000 description 1
- XOTBWOCSLMBGMF-SUSMZKCASA-N Thr-Glu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XOTBWOCSLMBGMF-SUSMZKCASA-N 0.000 description 1
- LKEKWDJCJSPXNI-IRIUXVKKSA-N Thr-Glu-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LKEKWDJCJSPXNI-IRIUXVKKSA-N 0.000 description 1
- BNGDYRRHRGOPHX-IFFSRLJSSA-N Thr-Glu-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O BNGDYRRHRGOPHX-IFFSRLJSSA-N 0.000 description 1
- XPNSAQMEAVSQRD-FBCQKBJTSA-N Thr-Gly-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)NCC(O)=O XPNSAQMEAVSQRD-FBCQKBJTSA-N 0.000 description 1
- IMULJHHGAUZZFE-MBLNEYKQSA-N Thr-Gly-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IMULJHHGAUZZFE-MBLNEYKQSA-N 0.000 description 1
- ZTPXSEUVYNNZRB-CDMKHQONSA-N Thr-Gly-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ZTPXSEUVYNNZRB-CDMKHQONSA-N 0.000 description 1
- AHOLTQCAVBSUDP-PPCPHDFISA-N Thr-Ile-Lys Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)[C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O AHOLTQCAVBSUDP-PPCPHDFISA-N 0.000 description 1
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 1
- XYFISNXATOERFZ-OSUNSFLBSA-N Thr-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N XYFISNXATOERFZ-OSUNSFLBSA-N 0.000 description 1
- HOVLHEKTGVIKAP-WDCWCFNPSA-N Thr-Leu-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HOVLHEKTGVIKAP-WDCWCFNPSA-N 0.000 description 1
- MGJLBZFUXUGMML-VOAKCMCISA-N Thr-Lys-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MGJLBZFUXUGMML-VOAKCMCISA-N 0.000 description 1
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 1
- VTMGKRABARCZAX-OSUNSFLBSA-N Thr-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O VTMGKRABARCZAX-OSUNSFLBSA-N 0.000 description 1
- GVMXJJAJLIEASL-ZJDVBMNYSA-N Thr-Pro-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O GVMXJJAJLIEASL-ZJDVBMNYSA-N 0.000 description 1
- YGCDFAJJCRVQKU-RCWTZXSCSA-N Thr-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O YGCDFAJJCRVQKU-RCWTZXSCSA-N 0.000 description 1
- FWTFAZKJORVTIR-VZFHVOOUSA-N Thr-Ser-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O FWTFAZKJORVTIR-VZFHVOOUSA-N 0.000 description 1
- PRTHQBSMXILLPC-XGEHTFHBSA-N Thr-Ser-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PRTHQBSMXILLPC-XGEHTFHBSA-N 0.000 description 1
- IVDFVBVIVLJJHR-LKXGYXEUSA-N Thr-Ser-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O IVDFVBVIVLJJHR-LKXGYXEUSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 1
- HUPLKEHTTQBXSC-YJRXYDGGSA-N Thr-Ser-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUPLKEHTTQBXSC-YJRXYDGGSA-N 0.000 description 1
- NDZYTIMDOZMECO-SHGPDSBTSA-N Thr-Thr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O NDZYTIMDOZMECO-SHGPDSBTSA-N 0.000 description 1
- AAZOYLQUEQRUMZ-GSSVUCPTSA-N Thr-Thr-Asn Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O AAZOYLQUEQRUMZ-GSSVUCPTSA-N 0.000 description 1
- VBMOVTMNHWPZJR-SUSMZKCASA-N Thr-Thr-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VBMOVTMNHWPZJR-SUSMZKCASA-N 0.000 description 1
- BBPCSGKKPJUYRB-UVOCVTCTSA-N Thr-Thr-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O BBPCSGKKPJUYRB-UVOCVTCTSA-N 0.000 description 1
- ZMYCLHFLHRVOEA-HEIBUPTGSA-N Thr-Thr-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ZMYCLHFLHRVOEA-HEIBUPTGSA-N 0.000 description 1
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 1
- CYCGARJWIQWPQM-YJRXYDGGSA-N Thr-Tyr-Ser Chemical compound C[C@@H](O)[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CO)C([O-])=O)CC1=CC=C(O)C=C1 CYCGARJWIQWPQM-YJRXYDGGSA-N 0.000 description 1
- QGVBFDIREUUSHX-IFFSRLJSSA-N Thr-Val-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O QGVBFDIREUUSHX-IFFSRLJSSA-N 0.000 description 1
- KPMIQCXJDVKWKO-IFFSRLJSSA-N Thr-Val-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KPMIQCXJDVKWKO-IFFSRLJSSA-N 0.000 description 1
- AKHDFZHUPGVFEJ-YEPSODPASA-N Thr-Val-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AKHDFZHUPGVFEJ-YEPSODPASA-N 0.000 description 1
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 1
- PWONLXBUSVIZPH-RHYQMDGZSA-N Thr-Val-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O PWONLXBUSVIZPH-RHYQMDGZSA-N 0.000 description 1
- QNXZCKMXHPULME-ZNSHCXBVSA-N Thr-Val-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O QNXZCKMXHPULME-ZNSHCXBVSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- VYVBSMCZNHOZGD-RCWTZXSCSA-N Thr-Val-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O VYVBSMCZNHOZGD-RCWTZXSCSA-N 0.000 description 1
- 108091036066 Three prime untranslated region Proteins 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 208000024770 Thyroid neoplasm Diseases 0.000 description 1
- 101710150448 Transcriptional regulator Myc Proteins 0.000 description 1
- 206010066901 Treatment failure Diseases 0.000 description 1
- HDTRYLNUVZCQOY-WSWWMNSNSA-N Trehalose Natural products O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-WSWWMNSNSA-N 0.000 description 1
- VZBWRZGNEPBRDE-HZUKXOBISA-N Trp-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N VZBWRZGNEPBRDE-HZUKXOBISA-N 0.000 description 1
- QNMIVTOQXUSGLN-SZMVWBNQSA-N Trp-Arg-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 QNMIVTOQXUSGLN-SZMVWBNQSA-N 0.000 description 1
- PXQPYPMSLBQHJJ-WFBYXXMGSA-N Trp-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N PXQPYPMSLBQHJJ-WFBYXXMGSA-N 0.000 description 1
- HJTYJQVRIQXMHM-XIRDDKMYSA-N Trp-Asp-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N HJTYJQVRIQXMHM-XIRDDKMYSA-N 0.000 description 1
- JZHJLBPBQKPTNX-UBHSHLNASA-N Trp-Cys-Ser Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 JZHJLBPBQKPTNX-UBHSHLNASA-N 0.000 description 1
- PTAWAMWPRFTACW-SZMVWBNQSA-N Trp-Gln-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N PTAWAMWPRFTACW-SZMVWBNQSA-N 0.000 description 1
- DXHHCIYKHRKBOC-BHYGNILZSA-N Trp-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O DXHHCIYKHRKBOC-BHYGNILZSA-N 0.000 description 1
- BABINGWMZBWXIX-BPUTZDHNSA-N Trp-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N BABINGWMZBWXIX-BPUTZDHNSA-N 0.000 description 1
- 108090000631 Trypsin Proteins 0.000 description 1
- 102000004142 Trypsin Human genes 0.000 description 1
- 101710152431 Trypsin-like protease Proteins 0.000 description 1
- KDGFPPHLXCEQRN-STECZYCISA-N Tyr-Arg-Ile Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KDGFPPHLXCEQRN-STECZYCISA-N 0.000 description 1
- ADBDQGBDNUTRDB-ULQDDVLXSA-N Tyr-Arg-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O ADBDQGBDNUTRDB-ULQDDVLXSA-N 0.000 description 1
- PZXUIGWOEWWFQM-SRVKXCTJSA-N Tyr-Asn-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O PZXUIGWOEWWFQM-SRVKXCTJSA-N 0.000 description 1
- MBFJIHUHHCJBSN-AVGNSLFASA-N Tyr-Asn-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MBFJIHUHHCJBSN-AVGNSLFASA-N 0.000 description 1
- GAYLGYUVTDMLKC-UWJYBYFXSA-N Tyr-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GAYLGYUVTDMLKC-UWJYBYFXSA-N 0.000 description 1
- BEIGSKUPTIFYRZ-SRVKXCTJSA-N Tyr-Asp-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O BEIGSKUPTIFYRZ-SRVKXCTJSA-N 0.000 description 1
- MNMYOSZWCKYEDI-JRQIVUDYSA-N Tyr-Asp-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MNMYOSZWCKYEDI-JRQIVUDYSA-N 0.000 description 1
- RYSNTWVRSLCAJZ-RYUDHWBXSA-N Tyr-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 RYSNTWVRSLCAJZ-RYUDHWBXSA-N 0.000 description 1
- UNUZEBFXGWVAOP-DZKIICNBSA-N Tyr-Glu-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UNUZEBFXGWVAOP-DZKIICNBSA-N 0.000 description 1
- PMDWYLVWHRTJIW-STQMWFEESA-N Tyr-Gly-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 PMDWYLVWHRTJIW-STQMWFEESA-N 0.000 description 1
- GIOBXJSONRQHKQ-RYUDHWBXSA-N Tyr-Gly-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O GIOBXJSONRQHKQ-RYUDHWBXSA-N 0.000 description 1
- IJUTXXAXQODRMW-KBPBESRZSA-N Tyr-Gly-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)NCC(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O IJUTXXAXQODRMW-KBPBESRZSA-N 0.000 description 1
- RIFVTNDKUMSSMN-ULQDDVLXSA-N Tyr-His-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](Cc1c[nH]cn1)NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(O)=O RIFVTNDKUMSSMN-ULQDDVLXSA-N 0.000 description 1
- HVPPEXXUDXAPOM-MGHWNKPDSA-N Tyr-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HVPPEXXUDXAPOM-MGHWNKPDSA-N 0.000 description 1
- BSCBBPKDVOZICB-KKUMJFAQSA-N Tyr-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BSCBBPKDVOZICB-KKUMJFAQSA-N 0.000 description 1
- GYKDRHDMGQUZPU-MGHWNKPDSA-N Tyr-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CC=C(C=C1)O)N GYKDRHDMGQUZPU-MGHWNKPDSA-N 0.000 description 1
- PYJKETPLFITNKS-IHRRRGAJSA-N Tyr-Pro-Asn Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O PYJKETPLFITNKS-IHRRRGAJSA-N 0.000 description 1
- BIWVVOHTKDLRMP-ULQDDVLXSA-N Tyr-Pro-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O BIWVVOHTKDLRMP-ULQDDVLXSA-N 0.000 description 1
- VXFXIBCCVLJCJT-JYJNAYRXSA-N Tyr-Pro-Pro Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N1CCC[C@H]1C(O)=O VXFXIBCCVLJCJT-JYJNAYRXSA-N 0.000 description 1
- YYLHVUCSTXXKBS-IHRRRGAJSA-N Tyr-Pro-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YYLHVUCSTXXKBS-IHRRRGAJSA-N 0.000 description 1
- KWKJGBHDYJOVCR-SRVKXCTJSA-N Tyr-Ser-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N)O KWKJGBHDYJOVCR-SRVKXCTJSA-N 0.000 description 1
- IEWKKXZRJLTIOV-AVGNSLFASA-N Tyr-Ser-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O IEWKKXZRJLTIOV-AVGNSLFASA-N 0.000 description 1
- NZBSVMQZQMEUHI-WZLNRYEVSA-N Tyr-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N NZBSVMQZQMEUHI-WZLNRYEVSA-N 0.000 description 1
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 1
- TYGHOWWWMTWVKM-HJOGWXRNSA-N Tyr-Tyr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 TYGHOWWWMTWVKM-HJOGWXRNSA-N 0.000 description 1
- DJIJBQYBDKGDIS-JYJNAYRXSA-N Tyr-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(C)C)C(O)=O DJIJBQYBDKGDIS-JYJNAYRXSA-N 0.000 description 1
- KTVKGXZZBQCBGD-UHFFFAOYSA-M Tyropanoate sodium Chemical compound [Na+].CCCC(=O)NC1=C(I)C=C(I)C(CC(CC)C([O-])=O)=C1I KTVKGXZZBQCBGD-UHFFFAOYSA-M 0.000 description 1
- GBOGMAARMMDZGR-UHFFFAOYSA-N UNPD149280 Natural products N1C(=O)C23OC(=O)C=CC(O)CCCC(C)CC=CC3C(O)C(=C)C(C)C2C1CC1=CC=CC=C1 GBOGMAARMMDZGR-UHFFFAOYSA-N 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 201000005969 Uveal melanoma Diseases 0.000 description 1
- YFOCMOVJBQDBCE-NRPADANISA-N Val-Ala-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N YFOCMOVJBQDBCE-NRPADANISA-N 0.000 description 1
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 1
- CVUDMNSZAIZFAE-UHFFFAOYSA-N Val-Arg-Pro Natural products NC(N)=NCCCC(NC(=O)C(N)C(C)C)C(=O)N1CCCC1C(O)=O CVUDMNSZAIZFAE-UHFFFAOYSA-N 0.000 description 1
- DCOOGDCRFXXQNW-ZKWXMUAHSA-N Val-Asn-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N DCOOGDCRFXXQNW-ZKWXMUAHSA-N 0.000 description 1
- ZMDCGGKHRKNWKD-LAEOZQHASA-N Val-Asn-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZMDCGGKHRKNWKD-LAEOZQHASA-N 0.000 description 1
- LIQJSDDOULTANC-QSFUFRPTSA-N Val-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N LIQJSDDOULTANC-QSFUFRPTSA-N 0.000 description 1
- DBOXBUDEAJVKRE-LSJOCFKGSA-N Val-Asn-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N DBOXBUDEAJVKRE-LSJOCFKGSA-N 0.000 description 1
- XLDYBRXERHITNH-QSFUFRPTSA-N Val-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)C(C)C XLDYBRXERHITNH-QSFUFRPTSA-N 0.000 description 1
- YODDULVCGFQRFZ-ZKWXMUAHSA-N Val-Asp-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YODDULVCGFQRFZ-ZKWXMUAHSA-N 0.000 description 1
- COSLEEOIYRPTHD-YDHLFZDLSA-N Val-Asp-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 COSLEEOIYRPTHD-YDHLFZDLSA-N 0.000 description 1
- CFSSLXZJEMERJY-NRPADANISA-N Val-Gln-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CFSSLXZJEMERJY-NRPADANISA-N 0.000 description 1
- QHFQQRKNGCXTHL-AUTRQRHGSA-N Val-Gln-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QHFQQRKNGCXTHL-AUTRQRHGSA-N 0.000 description 1
- NYTKXWLZSNRILS-IFFSRLJSSA-N Val-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N)O NYTKXWLZSNRILS-IFFSRLJSSA-N 0.000 description 1
- AAOPYWQQBXHINJ-DZKIICNBSA-N Val-Gln-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N AAOPYWQQBXHINJ-DZKIICNBSA-N 0.000 description 1
- VVZDBPBZHLQPPB-XVKPBYJWSA-N Val-Glu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O VVZDBPBZHLQPPB-XVKPBYJWSA-N 0.000 description 1
- PMXBARDFIAPBGK-DZKIICNBSA-N Val-Glu-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PMXBARDFIAPBGK-DZKIICNBSA-N 0.000 description 1
- BEGDZYNDCNEGJZ-XVKPBYJWSA-N Val-Gly-Gln Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O BEGDZYNDCNEGJZ-XVKPBYJWSA-N 0.000 description 1
- FXVDGDZRYLFQKY-WPRPVWTQSA-N Val-Gly-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C FXVDGDZRYLFQKY-WPRPVWTQSA-N 0.000 description 1
- KZKMBGXCNLPYKD-YEPSODPASA-N Val-Gly-Thr Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O KZKMBGXCNLPYKD-YEPSODPASA-N 0.000 description 1
- BVWPHWLFGRCECJ-JSGCOSHPSA-N Val-Gly-Tyr Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N BVWPHWLFGRCECJ-JSGCOSHPSA-N 0.000 description 1
- FEFZWCSXEMVSPO-LSJOCFKGSA-N Val-His-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](C)C(O)=O FEFZWCSXEMVSPO-LSJOCFKGSA-N 0.000 description 1
- PTFPUAXGIKTVNN-ONGXEEELSA-N Val-His-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)NCC(=O)O)N PTFPUAXGIKTVNN-ONGXEEELSA-N 0.000 description 1
- LKUDRJSNRWVGMS-QSFUFRPTSA-N Val-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LKUDRJSNRWVGMS-QSFUFRPTSA-N 0.000 description 1
- WNZSAUMKZQXHNC-UKJIMTQDSA-N Val-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N WNZSAUMKZQXHNC-UKJIMTQDSA-N 0.000 description 1
- JZWZACGUZVCQPS-RNJOBUHISA-N Val-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N JZWZACGUZVCQPS-RNJOBUHISA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- XXWBHOWRARMUOC-NHCYSSNCSA-N Val-Lys-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)N)C(=O)O)N XXWBHOWRARMUOC-NHCYSSNCSA-N 0.000 description 1
- PHZGFLFMGLXCFG-FHWLQOOXSA-N Val-Lys-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N PHZGFLFMGLXCFG-FHWLQOOXSA-N 0.000 description 1
- LJSZPMSUYKKKCP-UBHSHLNASA-N Val-Phe-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 LJSZPMSUYKKKCP-UBHSHLNASA-N 0.000 description 1
- YKNOJPJWNVHORX-UNQGMJICSA-N Val-Phe-Thr Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=CC=C1 YKNOJPJWNVHORX-UNQGMJICSA-N 0.000 description 1
- GQMNEJMFMCJJTD-NHCYSSNCSA-N Val-Pro-Gln Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O GQMNEJMFMCJJTD-NHCYSSNCSA-N 0.000 description 1
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 1
- AJNUKMZFHXUBMK-GUBZILKMSA-N Val-Ser-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N AJNUKMZFHXUBMK-GUBZILKMSA-N 0.000 description 1
- JQTYTBPCSOAZHI-FXQIFTODSA-N Val-Ser-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N JQTYTBPCSOAZHI-FXQIFTODSA-N 0.000 description 1
- RYHUIHUOYRNNIE-NRPADANISA-N Val-Ser-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RYHUIHUOYRNNIE-NRPADANISA-N 0.000 description 1
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 1
- QTPQHINADBYBNA-DCAQKATOSA-N Val-Ser-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN QTPQHINADBYBNA-DCAQKATOSA-N 0.000 description 1
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 1
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 1
- MNSSBIHFEUUXNW-RCWTZXSCSA-N Val-Thr-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N MNSSBIHFEUUXNW-RCWTZXSCSA-N 0.000 description 1
- PQSNETRGCRUOGP-KKHAAJSZSA-N Val-Thr-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O PQSNETRGCRUOGP-KKHAAJSZSA-N 0.000 description 1
- DLRZGNXCXUGIDG-KKHAAJSZSA-N Val-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O DLRZGNXCXUGIDG-KKHAAJSZSA-N 0.000 description 1
- UVHFONIHVHLDDQ-IFFSRLJSSA-N Val-Thr-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O UVHFONIHVHLDDQ-IFFSRLJSSA-N 0.000 description 1
- DVLWZWNAQUBZBC-ZNSHCXBVSA-N Val-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N)O DVLWZWNAQUBZBC-ZNSHCXBVSA-N 0.000 description 1
- QPJSIBAOZBVELU-BPNCWPANSA-N Val-Tyr-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N QPJSIBAOZBVELU-BPNCWPANSA-N 0.000 description 1
- DOBHJKVVACOQTN-DZKIICNBSA-N Val-Tyr-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 DOBHJKVVACOQTN-DZKIICNBSA-N 0.000 description 1
- IECQJCJNPJVUSB-IHRRRGAJSA-N Val-Tyr-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CO)C(O)=O IECQJCJNPJVUSB-IHRRRGAJSA-N 0.000 description 1
- BGTDGENDNWGMDQ-KJEVXHAQSA-N Val-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N)O BGTDGENDNWGMDQ-KJEVXHAQSA-N 0.000 description 1
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 1
- JSOXWWFKRJKTMT-WOPDTQHZSA-N Val-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N JSOXWWFKRJKTMT-WOPDTQHZSA-N 0.000 description 1
- 241000863480 Vinca Species 0.000 description 1
- 229940122803 Vinca alkaloid Drugs 0.000 description 1
- 208000027418 Wounds and injury Diseases 0.000 description 1
- VWQVUPCCIRVNHF-OUBTZVSYSA-N Yttrium-90 Chemical compound [90Y] VWQVUPCCIRVNHF-OUBTZVSYSA-N 0.000 description 1
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 1
- 210000001015 abdomen Anatomy 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 238000011481 absorbance measurement Methods 0.000 description 1
- DHKHKXVYLBGOIT-UHFFFAOYSA-N acetaldehyde Diethyl Acetal Natural products CCOC(C)OCC DHKHKXVYLBGOIT-UHFFFAOYSA-N 0.000 description 1
- 150000001241 acetals Chemical class 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 229930183665 actinomycin Natural products 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 201000005188 adrenal gland cancer Diseases 0.000 description 1
- 208000024447 adrenal gland neoplasm Diseases 0.000 description 1
- 150000001294 alanine derivatives Chemical class 0.000 description 1
- 108010047506 alanyl-glutaminyl-glycyl-valine Proteins 0.000 description 1
- 108010044940 alanylglutamine Proteins 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- 108010011559 alanylphenylalanine Proteins 0.000 description 1
- 229910052783 alkali metal Inorganic materials 0.000 description 1
- 229910052784 alkaline earth metal Inorganic materials 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- HDTRYLNUVZCQOY-LIZSDCNHSA-N alpha,alpha-trehalose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-LIZSDCNHSA-N 0.000 description 1
- 230000001668 ameliorated effect Effects 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- ROBVIMPUHSLWNV-UHFFFAOYSA-N aminoglutethimide Chemical compound C=1C=C(N)C=CC=1C1(CC)CCC(=O)NC1=O ROBVIMPUHSLWNV-UHFFFAOYSA-N 0.000 description 1
- 229960003437 aminoglutethimide Drugs 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 230000003698 anagen phase Effects 0.000 description 1
- 239000003098 androgen Substances 0.000 description 1
- 229940030486 androgens Drugs 0.000 description 1
- 230000002491 angiogenic effect Effects 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 229940124650 anti-cancer therapies Drugs 0.000 description 1
- 230000003432 anti-folate effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 230000009830 antibody antigen interaction Effects 0.000 description 1
- 238000011319 anticancer therapy Methods 0.000 description 1
- 229940127074 antifolate Drugs 0.000 description 1
- 229940034982 antineoplastic agent Drugs 0.000 description 1
- 201000011165 anus cancer Diseases 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 108010013835 arginine glutamate Proteins 0.000 description 1
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 1
- 108010008355 arginyl-glutamine Proteins 0.000 description 1
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 1
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 1
- 108010091092 arginyl-glycyl-proline Proteins 0.000 description 1
- 108010059459 arginyl-threonyl-phenylalanine Proteins 0.000 description 1
- 108010036533 arginylvaline Proteins 0.000 description 1
- 210000003567 ascitic fluid Anatomy 0.000 description 1
- 229960003272 asparaginase Drugs 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-M asparaginate Chemical compound [O-]C(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-M 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 229940009098 aspartate Drugs 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 1
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 1
- 108010038633 aspartylglutamate Proteins 0.000 description 1
- 108010092854 aspartyllysine Proteins 0.000 description 1
- 229960002756 azacitidine Drugs 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 229940092690 barium sulfate Drugs 0.000 description 1
- 210000002469 basement membrane Anatomy 0.000 description 1
- 229960000686 benzalkonium chloride Drugs 0.000 description 1
- CADWTSSKOVRVJC-UHFFFAOYSA-N benzyl(dimethyl)azanium;chloride Chemical compound [Cl-].C[NH+](C)CC1=CC=CC=C1 CADWTSSKOVRVJC-UHFFFAOYSA-N 0.000 description 1
- HMFHBZSHGGEWLO-TXICZTDVSA-N beta-D-ribose Chemical group OC[C@H]1O[C@@H](O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-TXICZTDVSA-N 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 1
- WGDUUQDYDIIBKT-UHFFFAOYSA-N beta-Pseudouridine Natural products OC1OC(CN2C=CC(=O)NC2=O)C(O)C1O WGDUUQDYDIIBKT-UHFFFAOYSA-N 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 230000000975 bioactive effect Effects 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000008033 biological extinction Effects 0.000 description 1
- 239000000090 biomarker Substances 0.000 description 1
- 238000001574 biopsy Methods 0.000 description 1
- 201000000053 blastoma Diseases 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 229960004395 bleomycin sulfate Drugs 0.000 description 1
- 230000017531 blood circulation Effects 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 238000010504 bond cleavage reaction Methods 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- KGBXLFKZBHKPEV-UHFFFAOYSA-N boric acid Chemical compound OB(O)O KGBXLFKZBHKPEV-UHFFFAOYSA-N 0.000 description 1
- 239000004327 boric acid Substances 0.000 description 1
- KDYFGRWQOYBRFD-NUQCWPJISA-N butanedioic acid Chemical compound O[14C](=O)CC[14C](O)=O KDYFGRWQOYBRFD-NUQCWPJISA-N 0.000 description 1
- 229940095658 calcium ipodate Drugs 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 159000000007 calcium salts Chemical class 0.000 description 1
- 229940127093 camptothecin Drugs 0.000 description 1
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical compound C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 description 1
- 230000036952 cancer formation Effects 0.000 description 1
- 150000001718 carbodiimides Chemical class 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 229910002091 carbon monoxide Inorganic materials 0.000 description 1
- OKTJSMMVPCPJKN-BJUDXGSMSA-N carbon-11 Chemical compound [11C] OKTJSMMVPCPJKN-BJUDXGSMSA-N 0.000 description 1
- 125000002843 carboxylic acid group Chemical group 0.000 description 1
- 231100000504 carcinogenesis Toxicity 0.000 description 1
- 239000012876 carrier material Substances 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 210000004671 cell-free system Anatomy 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000010001 cellular homeostasis Effects 0.000 description 1
- 230000008614 cellular interaction Effects 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 210000003756 cervix mucus Anatomy 0.000 description 1
- HVZGHKKROPCBDE-HZIJXFFPSA-L chembl2068725 Chemical compound [Ca+2].CN(C)\C=N\C1=C(I)C=C(I)C(CCC([O-])=O)=C1I.CN(C)\C=N\C1=C(I)C=C(I)C(CCC([O-])=O)=C1I HVZGHKKROPCBDE-HZIJXFFPSA-L 0.000 description 1
- NDAYQJDHGXTBJL-MWWSRJDJSA-N chembl557217 Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C)NC(=O)[C@H](NC(=O)CNC(=O)[C@@H](NC=O)C(C)C)CC(C)C)C(=O)NCCO)=CNC2=C1 NDAYQJDHGXTBJL-MWWSRJDJSA-N 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 229960004926 chlorobutanol Drugs 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 229960001265 ciclosporin Drugs 0.000 description 1
- 229940088516 cipro Drugs 0.000 description 1
- MYSWGUAQZAJSOK-UHFFFAOYSA-N ciprofloxacin Chemical compound C12=CC(N3CCNCC3)=C(F)C=C2C(=O)C(C(=O)O)=CN1C1CC1 MYSWGUAQZAJSOK-UHFFFAOYSA-N 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 229920001436 collagen Polymers 0.000 description 1
- 229960005188 collagen Drugs 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- LGZKGOGODCLQHG-UHFFFAOYSA-N combretastatin Natural products C1=C(O)C(OC)=CC=C1CC(O)C1=CC(OC)=C(OC)C(OC)=C1 LGZKGOGODCLQHG-UHFFFAOYSA-N 0.000 description 1
- 238000012875 competitive assay Methods 0.000 description 1
- 230000004154 complement system Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 230000000536 complexating effect Effects 0.000 description 1
- 238000002591 computed tomography Methods 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 239000002872 contrast media Substances 0.000 description 1
- 229920001577 copolymer Polymers 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 239000007822 coupling agent Substances 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 208000030381 cutaneous melanoma Diseases 0.000 description 1
- 229930182912 cyclosporin Natural products 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 229960000684 cytarabine Drugs 0.000 description 1
- UHDGCWIWMRVCDJ-ZAKLUEHWSA-N cytidine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-ZAKLUEHWSA-N 0.000 description 1
- GBOGMAARMMDZGR-TYHYBEHESA-N cytochalasin B Chemical compound C([C@H]1[C@@H]2[C@@H](C([C@@H](O)[C@@H]3/C=C/C[C@H](C)CCC[C@@H](O)/C=C/C(=O)O[C@@]23C(=O)N1)=C)C)C1=CC=CC=C1 GBOGMAARMMDZGR-TYHYBEHESA-N 0.000 description 1
- GBOGMAARMMDZGR-JREHFAHYSA-N cytochalasin B Natural products C[C@H]1CCC[C@@H](O)C=CC(=O)O[C@@]23[C@H](C=CC1)[C@H](O)C(=C)[C@@H](C)[C@@H]2[C@H](Cc4ccccc4)NC3=O GBOGMAARMMDZGR-JREHFAHYSA-N 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 230000001461 cytolytic effect Effects 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 239000000824 cytostatic agent Substances 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000004925 denaturation Methods 0.000 description 1
- 230000036425 denaturation Effects 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 238000010217 densitometric analysis Methods 0.000 description 1
- 238000001212 derivatisation Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 239000000032 diagnostic agent Substances 0.000 description 1
- 229940039227 diagnostic agent Drugs 0.000 description 1
- 238000012631 diagnostic technique Methods 0.000 description 1
- 206010013023 diphtheria Diseases 0.000 description 1
- 229940042399 direct acting antivirals protease inhibitors Drugs 0.000 description 1
- 230000009429 distress Effects 0.000 description 1
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- AMRJKAQTDDKMCE-UHFFFAOYSA-N dolastatin Chemical compound CC(C)C(N(C)C)C(=O)NC(C(C)C)C(=O)N(C)C(C(C)C)C(OC)CC(=O)N1CCCC1C(OC)C(C)C(=O)NC(C=1SC=CN=1)CC1=CC=CC=C1 AMRJKAQTDDKMCE-UHFFFAOYSA-N 0.000 description 1
- 229930188854 dolastatin Natural products 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 239000003937 drug carrier Substances 0.000 description 1
- 239000003118 drug derivative Substances 0.000 description 1
- 241001493065 dsRNA viruses Species 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- VQNATVDKACXKTF-XELLLNAOSA-N duocarmycin Chemical compound COC1=C(OC)C(OC)=C2NC(C(=O)N3C4=CC(=O)C5=C([C@@]64C[C@@H]6C3)C=C(N5)C(=O)OC)=CC2=C1 VQNATVDKACXKTF-XELLLNAOSA-N 0.000 description 1
- 229960005501 duocarmycin Drugs 0.000 description 1
- 229930184221 duocarmycin Natural products 0.000 description 1
- 238000004043 dyeing Methods 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 238000000132 electrospray ionisation Methods 0.000 description 1
- 238000002330 electrospray ionisation mass spectrometry Methods 0.000 description 1
- XOPYFXBZMVTEJF-PDACKIITSA-N eleutherobin Chemical compound C(/[C@H]1[C@H](C(=CC[C@@H]1C(C)C)C)C[C@@H]([C@@]1(C)O[C@@]2(C=C1)OC)OC(=O)\C=C\C=1N=CN(C)C=1)=C2\CO[C@@H]1OC[C@@H](O)[C@@H](O)[C@@H]1OC(C)=O XOPYFXBZMVTEJF-PDACKIITSA-N 0.000 description 1
- XOPYFXBZMVTEJF-UHFFFAOYSA-N eleutherobin Natural products C1=CC2(OC)OC1(C)C(OC(=O)C=CC=1N=CN(C)C=1)CC(C(=CCC1C(C)C)C)C1C=C2COC1OCC(O)C(O)C1OC(C)=O XOPYFXBZMVTEJF-UHFFFAOYSA-N 0.000 description 1
- 201000008184 embryoma Diseases 0.000 description 1
- 210000001671 embryonic stem cell Anatomy 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 230000012202 endocytosis Effects 0.000 description 1
- 210000003060 endolymph Anatomy 0.000 description 1
- 230000003511 endothelial effect Effects 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- HESCAJZNRMSMJG-KKQRBIROSA-N epothilone A Chemical compound C/C([C@@H]1C[C@@H]2O[C@@H]2CCC[C@@H]([C@@H]([C@@H](C)C(=O)C(C)(C)[C@@H](O)CC(=O)O1)O)C)=C\C1=CSC(C)=N1 HESCAJZNRMSMJG-KKQRBIROSA-N 0.000 description 1
- QXRSDHAAWVKZLJ-PVYNADRNSA-N epothilone B Chemical compound C/C([C@@H]1C[C@@H]2O[C@]2(C)CCC[C@@H]([C@@H]([C@@H](C)C(=O)C(C)(C)[C@@H](O)CC(=O)O1)O)C)=C\C1=CSC(C)=N1 QXRSDHAAWVKZLJ-PVYNADRNSA-N 0.000 description 1
- 229960001842 estramustine Drugs 0.000 description 1
- FRPJXPJMRWBBIH-RBRWEJTLSA-N estramustine Chemical compound ClCCN(CCCl)C(=O)OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 FRPJXPJMRWBBIH-RBRWEJTLSA-N 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- 231100000776 exotoxin Toxicity 0.000 description 1
- 239000002095 exotoxin Substances 0.000 description 1
- 229950003499 fibrin Drugs 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 238000011049 filling Methods 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- 235000019634 flavors Nutrition 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- 238000000799 fluorescence microscopy Methods 0.000 description 1
- 238000001215 fluorescent labelling Methods 0.000 description 1
- 229910052731 fluorine Inorganic materials 0.000 description 1
- 239000011737 fluorine Substances 0.000 description 1
- 239000004052 folic acid antagonist Substances 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 238000005194 fractionation Methods 0.000 description 1
- 230000037433 frameshift Effects 0.000 description 1
- 235000011389 fruit/vegetable juice Nutrition 0.000 description 1
- UIWYJDYFSGRHKR-UHFFFAOYSA-N gadolinium atom Chemical compound [Gd] UIWYJDYFSGRHKR-UHFFFAOYSA-N 0.000 description 1
- 210000001035 gastrointestinal tract Anatomy 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 230000008570 general process Effects 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 108060003196 globin Proteins 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 108010085059 glutamyl-arginyl-proline Proteins 0.000 description 1
- 108010073628 glutamyl-valyl-phenylalanine Proteins 0.000 description 1
- 150000002337 glycosamines Chemical group 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- HPAIKDPJURGQLN-UHFFFAOYSA-N glycyl-L-histidyl-L-phenylalanine Natural products C=1C=CC=CC=1CC(C(O)=O)NC(=O)C(NC(=O)CN)CC1=CN=CN1 HPAIKDPJURGQLN-UHFFFAOYSA-N 0.000 description 1
- 108010090037 glycyl-alanyl-isoleucine Proteins 0.000 description 1
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 1
- 108010010096 glycyl-glycyl-tyrosine Proteins 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- 229910052737 gold Inorganic materials 0.000 description 1
- 229940029575 guanosine Drugs 0.000 description 1
- 210000003780 hair follicle Anatomy 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 208000019622 heart disease Diseases 0.000 description 1
- 201000005787 hematologic cancer Diseases 0.000 description 1
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 1
- 229960002897 heparin Drugs 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 125000000487 histidyl group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C([H])=N1 0.000 description 1
- 108010092114 histidylphenylalanine Proteins 0.000 description 1
- 108010085325 histidylproline Proteins 0.000 description 1
- 235000020256 human milk Nutrition 0.000 description 1
- 210000004251 human milk Anatomy 0.000 description 1
- 150000007857 hydrazones Chemical class 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- 229960001101 ifosfamide Drugs 0.000 description 1
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 description 1
- 239000012216 imaging agent Substances 0.000 description 1
- 150000002463 imidates Chemical class 0.000 description 1
- 230000000984 immunochemical effect Effects 0.000 description 1
- 238000010166 immunofluorescence Methods 0.000 description 1
- 238000010569 immunofluorescence imaging Methods 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 230000002458 infectious effect Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 108091006086 inhibitor proteins Proteins 0.000 description 1
- 239000007972 injectable composition Substances 0.000 description 1
- 208000014674 injury Diseases 0.000 description 1
- 102000006495 integrins Human genes 0.000 description 1
- 108010044426 integrins Proteins 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 230000009545 invasion Effects 0.000 description 1
- 231100000745 invertebrate toxin Toxicity 0.000 description 1
- 229960001943 iocetamic acid Drugs 0.000 description 1
- 229910052740 iodine Inorganic materials 0.000 description 1
- 239000011630 iodine Substances 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 239000002555 ionophore Substances 0.000 description 1
- 230000000236 ionophoric effect Effects 0.000 description 1
- 229960002979 iopanoic acid Drugs 0.000 description 1
- 229960004768 irinotecan Drugs 0.000 description 1
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 1
- 239000012948 isocyanate Substances 0.000 description 1
- 150000002513 isocyanates Chemical class 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 108010031424 isoleucyl-prolyl-proline Proteins 0.000 description 1
- 108010060857 isoleucyl-valyl-tyrosine Proteins 0.000 description 1
- 150000002540 isothiocyanates Chemical class 0.000 description 1
- 229930027917 kanamycin Natural products 0.000 description 1
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 1
- 229960000318 kanamycin Drugs 0.000 description 1
- 229930182823 kanamycin A Natural products 0.000 description 1
- 210000002510 keratinocyte Anatomy 0.000 description 1
- 238000012933 kinetic analysis Methods 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 108010077158 leucinyl-arginyl-tryptophan Proteins 0.000 description 1
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- 108700009084 lexitropsin Proteins 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 1
- 201000007270 liver cancer Diseases 0.000 description 1
- 208000014018 liver neoplasm Diseases 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- OHSVLFRHMCKCQY-NJFSPNSNSA-N lutetium-177 Chemical compound [177Lu] OHSVLFRHMCKCQY-NJFSPNSNSA-N 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 108010038320 lysylphenylalanine Proteins 0.000 description 1
- 230000005291 magnetic effect Effects 0.000 description 1
- 239000006249 magnetic particle Substances 0.000 description 1
- 238000002595 magnetic resonance imaging Methods 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- VZCYOOQTPOCHFL-UPHRSURJSA-N maleic acid Chemical compound OC(=O)\C=C/C(O)=O VZCYOOQTPOCHFL-UPHRSURJSA-N 0.000 description 1
- 239000011976 maleic acid Substances 0.000 description 1
- 208000029559 malignant endocrine neoplasm Diseases 0.000 description 1
- 208000026045 malignant tumor of parathyroid gland Diseases 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 229960003194 meglumine Drugs 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- 102000006240 membrane receptors Human genes 0.000 description 1
- 108020004084 membrane receptors Proteins 0.000 description 1
- 206010027191 meningioma Diseases 0.000 description 1
- 230000007102 metabolic function Effects 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- 239000002923 metal particle Substances 0.000 description 1
- 230000001394 metastastic effect Effects 0.000 description 1
- 230000008883 metastatic behaviour Effects 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 108010056582 methionylglutamic acid Proteins 0.000 description 1
- 238000002493 microarray Methods 0.000 description 1
- 238000007392 microtiter assay Methods 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- 229960000350 mitotane Drugs 0.000 description 1
- 229960001156 mitoxantrone Drugs 0.000 description 1
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 1
- 108091005601 modified peptides Proteins 0.000 description 1
- 235000019691 monocalcium phosphate Nutrition 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- 210000003097 mucus Anatomy 0.000 description 1
- 150000002790 naphthalenes Chemical class 0.000 description 1
- 230000007524 negative regulation of DNA replication Effects 0.000 description 1
- 210000005170 neoplastic cell Anatomy 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 238000006386 neutralization reaction Methods 0.000 description 1
- 229910052759 nickel Inorganic materials 0.000 description 1
- 229910017604 nitric acid Inorganic materials 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- OSTGTTZJOCZWJG-UHFFFAOYSA-N nitrosourea Chemical compound NC(=O)N=NO OSTGTTZJOCZWJG-UHFFFAOYSA-N 0.000 description 1
- 229950006344 nocodazole Drugs 0.000 description 1
- 231100000956 nontoxicity Toxicity 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 201000002575 ocular melanoma Diseases 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 150000002905 orthoesters Chemical class 0.000 description 1
- 229940127084 other anti-cancer agent Drugs 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 150000002923 oximes Chemical class 0.000 description 1
- 230000036407 pain Effects 0.000 description 1
- FJKROLUGYXJWQN-UHFFFAOYSA-N papa-hydroxy-benzoic acid Natural products OC(=O)C1=CC=C(O)C=C1 FJKROLUGYXJWQN-UHFFFAOYSA-N 0.000 description 1
- 230000005298 paramagnetic effect Effects 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 210000004049 perilymph Anatomy 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 1
- 108010064486 phenylalanyl-leucyl-valine Proteins 0.000 description 1
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 1
- 108010084572 phenylalanyl-valine Proteins 0.000 description 1
- 108010012581 phenylalanylglutamate Proteins 0.000 description 1
- 108010073101 phenylalanylleucine Proteins 0.000 description 1
- 235000021317 phosphate Nutrition 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 1
- 230000035790 physiological processes and functions Effects 0.000 description 1
- 208000021310 pituitary gland adenoma Diseases 0.000 description 1
- 229940012957 plasmin Drugs 0.000 description 1
- 229940063179 platinol Drugs 0.000 description 1
- 210000004910 pleural fluid Anatomy 0.000 description 1
- 108700028325 pokeweed antiviral Proteins 0.000 description 1
- 229920000889 poly(m-phenylene isophthalamide) Polymers 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920001515 polyalkylene glycol Polymers 0.000 description 1
- 229920002704 polyhistidine Polymers 0.000 description 1
- 239000002861 polymer material Substances 0.000 description 1
- 102000040430 polynucleotide Human genes 0.000 description 1
- 108091033319 polynucleotide Proteins 0.000 description 1
- 239000002157 polynucleotide Substances 0.000 description 1
- 229920001451 polypropylene glycol Polymers 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- XAEFZNCEHLXOMS-UHFFFAOYSA-M potassium benzoate Chemical compound [K+].[O-]C(=O)C1=CC=CC=C1 XAEFZNCEHLXOMS-UHFFFAOYSA-M 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 230000003449 preventive effect Effects 0.000 description 1
- 150000003141 primary amines Chemical class 0.000 description 1
- 229960000624 procarbazine Drugs 0.000 description 1
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 1
- 108010039042 prolyl-histidyl-seryl-arginyl-asparagine Proteins 0.000 description 1
- 108010025826 prolyl-leucyl-arginine Proteins 0.000 description 1
- 108010065320 prolyl-lysyl-glutamyl-lysine Proteins 0.000 description 1
- 108010077112 prolyl-proline Proteins 0.000 description 1
- 108010079317 prolyl-tyrosine Proteins 0.000 description 1
- 108010070643 prolylglutamic acid Proteins 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- 108010053725 prolylvaline Proteins 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- PTJWIQPHWPFNBW-GBNDHIKLSA-N pseudouridine Chemical group O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1C1=CNC(=O)NC1=O PTJWIQPHWPFNBW-GBNDHIKLSA-N 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 125000004076 pyridyl group Chemical group 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 238000011158 quantitative evaluation Methods 0.000 description 1
- UOWVMDUEMSNCAV-WYENRQIDSA-N rachelmycin Chemical compound C1([C@]23C[C@@H]2CN1C(=O)C=1NC=2C(OC)=C(O)C4=C(C=2C=1)CCN4C(=O)C1=CC=2C=4CCN(C=4C(O)=C(C=2N1)OC)C(N)=O)=CC(=O)C1=C3C(C)=CN1 UOWVMDUEMSNCAV-WYENRQIDSA-N 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 239000002534 radiation-sensitizing agent Substances 0.000 description 1
- 238000000763 radioactive isotope labeling Methods 0.000 description 1
- 239000012217 radiopharmaceutical Substances 0.000 description 1
- 229940121896 radiopharmaceutical Drugs 0.000 description 1
- 230000002799 radiopharmaceutical effect Effects 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 206010038038 rectal cancer Diseases 0.000 description 1
- 201000001275 rectum cancer Diseases 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 108091008025 regulatory factors Proteins 0.000 description 1
- 102000037983 regulatory factors Human genes 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000001850 reproductive effect Effects 0.000 description 1
- 238000002271 resection Methods 0.000 description 1
- 238000005096 rolling process Methods 0.000 description 1
- 239000012146 running buffer Substances 0.000 description 1
- 229960004889 salicylic acid Drugs 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 210000002374 sebum Anatomy 0.000 description 1
- 208000011581 secondary neoplasm Diseases 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 210000000582 semen Anatomy 0.000 description 1
- 150000007659 semicarbazones Chemical class 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 108010026333 seryl-proline Proteins 0.000 description 1
- 108010071207 serylmethionine Proteins 0.000 description 1
- 230000001568 sexual effect Effects 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 201000000849 skin cancer Diseases 0.000 description 1
- 201000003708 skin melanoma Diseases 0.000 description 1
- 201000002314 small intestine cancer Diseases 0.000 description 1
- ZEYOIOAKZLALAP-UHFFFAOYSA-M sodium amidotrizoate Chemical compound [Na+].CC(=O)NC1=C(I)C(NC(C)=O)=C(I)C(C([O-])=O)=C1I ZEYOIOAKZLALAP-UHFFFAOYSA-M 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 159000000000 sodium salts Chemical class 0.000 description 1
- 229960003037 sodium tyropanoate Drugs 0.000 description 1
- JJGWLCLUQNFDIS-GTSONSFRSA-M sodium;1-[6-[5-[(3as,4s,6ar)-2-oxo-1,3,3a,4,6,6a-hexahydrothieno[3,4-d]imidazol-4-yl]pentanoylamino]hexanoyloxy]-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].O=C1C(S(=O)(=O)[O-])CC(=O)N1OC(=O)CCCCCNC(=O)CCCC[C@H]1[C@H]2NC(=O)N[C@H]2CS1 JJGWLCLUQNFDIS-GTSONSFRSA-M 0.000 description 1
- PUZPDOWCWNUUKD-ULWFUOSBSA-M sodium;fluorine-18(1-) Chemical compound [18F-].[Na+] PUZPDOWCWNUUKD-ULWFUOSBSA-M 0.000 description 1
- 238000010532 solid phase synthesis reaction Methods 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 208000037959 spinal tumor Diseases 0.000 description 1
- 210000003802 sputum Anatomy 0.000 description 1
- 208000024794 sputum Diseases 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 239000008223 sterile water Substances 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 238000013517 stratification Methods 0.000 description 1
- 229960001052 streptozocin Drugs 0.000 description 1
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 1
- 210000002536 stromal cell Anatomy 0.000 description 1
- 229960002317 succinimide Drugs 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 239000004094 surface-active agent Substances 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 210000004243 sweat Anatomy 0.000 description 1
- 230000008961 swelling Effects 0.000 description 1
- 208000011580 syndromic disease Diseases 0.000 description 1
- 210000002437 synoviocyte Anatomy 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 229920001059 synthetic polymer Polymers 0.000 description 1
- 238000011521 systemic chemotherapy Methods 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 229940056501 technetium 99m Drugs 0.000 description 1
- 229960001278 teniposide Drugs 0.000 description 1
- 210000001550 testis Anatomy 0.000 description 1
- 239000002562 thickening agent Substances 0.000 description 1
- RTKIYNMVFMVABJ-UHFFFAOYSA-L thimerosal Chemical compound [Na+].CC[Hg]SC1=CC=CC=C1C([O-])=O RTKIYNMVFMVABJ-UHFFFAOYSA-L 0.000 description 1
- 229940033663 thimerosal Drugs 0.000 description 1
- SRVJKTDHMYAMHA-WUXMJOGZSA-N thioacetazone Chemical compound CC(=O)NC1=CC=C(\C=N\NC(N)=S)C=C1 SRVJKTDHMYAMHA-WUXMJOGZSA-N 0.000 description 1
- 150000003573 thiols Chemical class 0.000 description 1
- 229960001196 thiotepa Drugs 0.000 description 1
- 201000002510 thyroid cancer Diseases 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- 229960000303 topotecan Drugs 0.000 description 1
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- VZCYOOQTPOCHFL-UHFFFAOYSA-N trans-butenedioic acid Natural products OC(=O)C=CC(O)=O VZCYOOQTPOCHFL-UHFFFAOYSA-N 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 238000011277 treatment modality Methods 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- UNXRWKVEANCORM-UHFFFAOYSA-N triphosphoric acid Chemical compound OP(O)(=O)OP(O)(=O)OP(O)(O)=O UNXRWKVEANCORM-UHFFFAOYSA-N 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
- 108010014563 tryptophyl-cysteinyl-serine Proteins 0.000 description 1
- 231100000588 tumorigenic Toxicity 0.000 description 1
- 230000000381 tumorigenic effect Effects 0.000 description 1
- 108010077037 tyrosyl-tyrosyl-phenylalanine Proteins 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 1
- 229940045145 uridine Drugs 0.000 description 1
- 206010046901 vaginal discharge Diseases 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 108010073969 valyllysine Proteins 0.000 description 1
- KDQAABAKXDWYSZ-PNYVAJAMSA-N vinblastine sulfate Chemical compound OS(O)(=O)=O.C([C@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 KDQAABAKXDWYSZ-PNYVAJAMSA-N 0.000 description 1
- 229960004982 vinblastine sulfate Drugs 0.000 description 1
- AQTQHPDCURKLKT-JKDPCDLQSA-N vincristine sulfate Chemical compound OS(O)(=O)=O.C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C=O)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 AQTQHPDCURKLKT-JKDPCDLQSA-N 0.000 description 1
- 229960002110 vincristine sulfate Drugs 0.000 description 1
- 229960004355 vindesine Drugs 0.000 description 1
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
- 238000005303 weighing Methods 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 1
Images









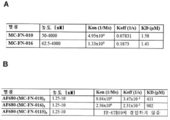







Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/78—Connective tissue peptides, e.g. collagen, elastin, laminin, fibronectin, vitronectin or cold insoluble globulin [CIG]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/81—Protease inhibitors
- C07K14/8107—Endopeptidase (E.C. 3.4.21-99) inhibitors
- C07K14/811—Serine protease (E.C. 3.4.21) inhibitors
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K7/00—Peptides having 5 to 20 amino acids in a fully defined sequence; Derivatives thereof
- C07K7/04—Linear peptides containing only normal peptide links
- C07K7/08—Linear peptides containing only normal peptide links having 12 to 20 amino acids
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K1/00—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length
- C07K1/107—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length by chemical modification of precursor peptides
- C07K1/1072—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length by chemical modification of precursor peptides by covalent attachment of residues or functional groups
- C07K1/1075—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length by chemical modification of precursor peptides by covalent attachment of residues or functional groups by covalent attachment of amino acids or peptide residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/415—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from plants
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57484—Immunoassay; Biospecific binding assay; Materials therefor for cancer involving compounds serving as markers for tumor, cancer, neoplasia, e.g. cellular determinants, receptors, heat shock/stress proteins, A-protein, oligosaccharides, metabolites
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6887—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids from muscle, cartilage or connective tissue
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/81—Protease inhibitors
- G01N2333/8107—Endopeptidase (E.C. 3.4.21-99) inhibitors
- G01N2333/811—Serine protease (E.C. 3.4.21) inhibitors
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Molecular Biology (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Immunology (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- Urology & Nephrology (AREA)
- Hematology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- Analytical Chemistry (AREA)
- Cell Biology (AREA)
- Gastroenterology & Hepatology (AREA)
- Biotechnology (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Food Science & Technology (AREA)
- General Physics & Mathematics (AREA)
- Pathology (AREA)
- Zoology (AREA)
- Toxicology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Oncology (AREA)
- General Chemical & Material Sciences (AREA)
- Hospice & Palliative Care (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Botany (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Bioinformatics & Cheminformatics (AREA)
Abstract
본 발명은 조직 리모델링 및/또는 혈관신생을 특징으로 하는 질환과 같이, 파이브로넥틴 엑스트라 도메인 B (EDB)를 발현하는 질환, 특히 두경부암, 뇌암, 결장직장암, 폐암, 전립선암 및 유방암과 같은 암성 질환의 진단 및 치료에 관한 것이다. 보다 상세하게는, 본 발명은 파이브로넥틴 엑스트라 도메인 B를 표적화하는 펩타이드에 관한 것이다.
Description
본 발명은 조직 리모델링 및/또는 혈관신생을 특징으로 하는 질환과 같이, 파이브로넥틴 엑스트라 도메인 B (Fibronectin Extra Domain B) (EDB)를 발현하는 질환, 특히 두경부암, 뇌암, 결장직장암, 폐암, 전립선암 및 유방암과 같은 암성 질환의 진단 및 치료에 관한 것이다. 보다 상세하게는, 본 발명은 파이브로넥틴 엑스트라 도메인 B를 표적화하는 펩타이드에 관한 것이다.
암은 전세계적으로 심장 질환을 능가하는 주요 사망 원인 중 하나이다. 2012년에는 전 세계적으로 820만명이 암으로 사망하였다 (WHO). 고전적인 항암 요법, 예를 들어, 방사선요법, 화학요법 및 통상적인 외과적인 시술은 대개 선택성이 좋지 않으며, 그래서 건강한 조직에 심각한 독성 부작용을 미치게 된다. 새로운 치료 형태는 종양-관련 항원에 특이적인 결합 분자를 사용해 생리활성 분자 (약물, 사이토카인, 방사핵종 등)를 종양 환경으로 타겟 전달하는 것으로 구성된다. 이로써, 약물을 타겟-양성 종양 조직으로 선택적으로 향하게 하여, 건강한 세포에는 유해하지 않으면서 악성 세포만 효과적으로 사멸시킬 수 있을 것이다. 이는, 개별 암 요법을 위한 합리적인 맞춤형 전략을 사전에 보장하기 위해, 환자에서 타겟-양성 종양을 확인할 수 있는 소위 동반 진단제 (companion diagnostics)의 개발과 함께 진행된다. 이런 점에서, 타겟 특이적인 이미징 기법의 활용은 과거 수십년간 크게 발전한 중요한 진단 단계가 되었다. 이미징 기법은 종양-관련 단백질의 존재 및 양, 위치, 조기 검출, 분포, 환자 계층화 및 치료 모니터링에 대한 임상적인 정보를 제공할 수 있다. 종양 이미징은 암 진단과 암 치료에서 치료학적 성공을 모니터링하기 위한 기본적인 공정이다. 컴퓨터 단층 촬영 스캔 또는 자기 공명 영상과 같이 오랜 기간 확립된 기법들이 수십년간 일상적으로 이용되어 왔다. 그러나, 표적화된 분자 이미징이 암-관련 단백질에 대한 분자 제제를 이용해 종양을 정확하게 가시화하기에, 더 많은 관심을 받고 있다. 종양의 혈관신생 중에 등장하는 바이오마커는, 일반적으로 혈관에서 높은 수준으로 발현되어 혈류로부터 쉽게 접근가능하므로, 매우 유용하다.
파이브로넥틴 (FN)은 타입 I, 타입 II 및 타입 III 도메인들로 구성되는, 세포외 기질의 이황화 결합된 이량체 당단백질이다. 이 단백질은 세포 부착, 이동, 분화 및 항상성 등의 많은 생리학적 과정에 기여한다. FN은 1차 전사체로부터 유래된 복수의 얼터너티브 스플라이싱된 변이체로서 발현된다. 이소형 엑스트라 도메인 B (isoform extra domain B) (EDB)는 아미노산 91개로 된 부가적인 타입 III 도메인을 포함하며, 이것은 FN 도메인 7과 8 사이에 특이적으로 삽입되어 있다. 고도로 보존된 파이브로넥틴 엑스트라 도메인 B 서열은 마우스, 랫, 토끼 및 인간에서 동일하게 존재한다. 파이브로넥틴 엑스트라 도메인 B는 일반적으로 정상 성체 조직에는 존재하진 않지만, 조직 리모델링 및 혈관신생에 관여한다. 또한, 파이브로넥틴 엑스트라 도메인 B는 다수의 여러가지 암 타입들에서 발견되는데, 두경부암, 뇌암 및 유방암과 같이 몇가지 공격적인 고형 인간 종양의 신혈관구조 (neovasculature)에서 강한 발현 패턴을 보인다.
혈관 형성이 좋지 않은 종양을 표적화하는 경우, 크기가 큰 항체, 심지어 이의 단편은 조직 침투 속도를 늦출 수 있으며, 이로써 효율적인 전달을 방해할 수 있다. 더욱이, 항체의 혈액 순환 연장으로 인해, 특히 촬상 개념의 맥락에서는 진단 용도로 최적이 아닌 것으로 보인다. 전술한 바와 더불어, 복잡한 당화 패턴과 이황화 결합을 가진 항체의 분자 구조는 복잡한 비용-집약적인 제조가 요구되며, 예를 들어 이미징 트레이서의 사용에 의해 기능화를 더 복잡하게 만든다. 이러한 한계를 극복하기 위해, 항체에 대한 대안으로서, 소위 단백질 스캐폴드가 지난 수십년간 등장하였다: 스캐폴드는 주어진 타겟을 엄격하고 특이적으로 인지하도록 맞춤화된 상호작용 분자를 정밀하게 조작하기 위한 견고한 구조 프래임워크를 제공해준다. 이들 대부분은 비-환원 조건에서 적절하게 폴딩하여, 변성 및 리폴딩없이 박테리아에서 발현시킬 수 있다. 심지어 화학 합성도 이러한 포맷을 가진 몇종을 제조하기 위한 옵션이 된다. 마지막으로, 이는 다-기능성 결합 분자를 구축하기 위한 추가적인 기능화 (표지, 올리고머화, 다른 펩타이드와의 융합 등)에 매우 적합하다. 여러가지 스캐폴드-기반의 방식들 중에서, 시스틴-노트 미니단백질 (cystine-knot miniprotein)("knottin")은 표적화된 진단제 및 치료학적 제제를 개발하는데 상당한 잠재력을 보여주었다. 미니단백질은 작으며, 동의어 (eponymous) 노티드 구조 (knotted structure)를 형성하는 이황화 결합 3개를 함유한 아미노산 30-50개로 된 폴리펩타이드이다. 슈도노트 시스틴 토폴로지 (pseudoknot cystine topology)는 예외적인 열적 안정성, 단백질 분해에 대한 안정성 및 화학적 안정성에 기여하여, 생체내 생의학적인 용도로 바람직하다. 예를 들어, 미니단백질은 구조적 및 기능적 완전성을 잃지 않으면서 염기성 또는 산성 환경에서 끓일 수 있다. 이황화 결합-제한된 루프 구역 (disulfide-constrained loop region)은 광범위한 서열 다양성을 허용하여, 다양한 생의학적 타겟을 인지하는 단백질을 조작하기 위한 견고한 분자 프래임워크를 제공한다.
진단 및 치료학적 방식에서 유용한 파이브로넥틴 엑스트라 도메인 B 결합성 분자가 당해 기술 분야에서 요구되고 있다.
인간 파이브로넥틴 엑스트라 도메인 B에 대해 높은 특이성과 선택성을 나타내는, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드와 같은 파이브로넥틴 엑스트라 도메인 B 결합제가 본원에 개시된다. 본원에 개시된 파이브로넥틴 엑스트라 도메인 B 결합제는 종양 환경을 효과적으로 표적화함으로써 진단 용도, 특히 종양 이미징, 그리고 치료학적 용도에서 탁월한 도구이다.
Albrecht, Valerie; Richter, Antonia; Pfeiffer, Sarah; Gebauer, Michaela; Lindner, Simon; Gieser, Eugenie et al. (2016): Anticalins directed against the fibronectin extra domain B as diagnostic tracers for glioblastomas. In: International journal of cancer 138 (5), S. 1269-1280. DOI: 10.1002/ijc.29874.
Barbas, Carlos F.; Burton, D. R.; Scott, J. K.; Silverman, G. J. (2004): Phage Display: Cold Spring Harbor Laboratory Pr.
Carnemolla, B.; Balza, E.; Siri, A.; Zardi, L.; Nicotra, M. R.; Bigotti, A.; Natali, P. G. (1989): A tumor-associated fibronectin isoform generated by alternative splicing of messenger RNA precursors. In: The Journal of cell biology 108 (3), S. 1139-1148.
Carnemolla, Barbara; Leprini, Alessandra; Allemanni, Giorgio; Saginati, Marc; Zardi, Luciano (1992): The inclusion of the type III repeat ED-B in the fibronectin molecule generates conformational modifications that unmask a cryptic sequence. In: Journal of Biological Chemistry 267 (34), S. 24689 24692.
Castellani, Patrizia; Viale, Giuseppe; Dorcaratto, Alessandra; Nicolo, Guido; Kaczmarek, Janusz; Querze, Germano; Zardi, Luciano (1994): The fibronectin isoform containing the ed-b oncofetal domain. A marker of angiogenesis. In: Int. J. Cancer 59 (5), S. 612-618. DOI: 10.1002/ijc.2910590507.
Hackel, Benjamin J.; Kimura, Richard H.; Miao, Zheng; Liu, Hongguang; Sathirachinda, Ataya; Cheng, Zhen et al. (2013): 18F-fluorobenzoate-labeled cystine knot peptides for PET imaging of integrin αvβ6. In: Journal of nuclear medicine : official publication, Society of Nuclear Medicine 54 (7), S. 1101-1105. DOI: 10.2967/jnumed.112.110759.
Hernandez, J. F.; Gagnon, J.; Chiche, L.; Nguyen, T. M.; Andrieu, J. P.; Heitz, A. et al. (2000): Squash trypsin inhibitors from Momordica cochinchinensis exhibit an atypical macrocyclic structure. In: Biochemistry 39 (19), S. 5722-5730.
Kimura, Richard H.; Cheng, Zhen; Gambhir, Sanjiv Sam; Cochran, Jennifer R. (2009): Engineered knottin peptides: a new class of agents for imaging integrin expression in living subjects. In: Cancer Research 69 (6), S. 2435 2442. DOI: 10.1158/0008-5472.CAN-08-2495.
Mao, Yong; Schwarzbauer, Jean E. (2005): Fibronectin fibrillogenesis, a cell-mediated matrix assembly process. In: Matrix biology : journal of the International Society for Matrix Biology 24 (6), S. 389-399. DOI: 10.1016/j.matbio.2005.06.008.
Mariani, G.; Lasku, A.; Balza, E.; Gaggero, B.; Motta, C.; Di Luca, L. et al. (1997): Tumor targeting potential of the monoclonal antibody BC-1 against oncofetal fibronectin in nude mice bearing human tumor implants. In: Cancer 80 (12 Suppl), S. 2378-2384.
Miao, Zheng; Ren, Gang; Liu, Hongguang; Kimura, Richard H.; Jiang, Lei; Cochran, Jennifer R. et al. (2009): An engineered knottin peptide labeled with 18F for PET imaging of integrin expression. In: Bioconjugate chemistry 20 (12), S. 2342-2347. DOI: 10.1021/bc900361g.
Mohammadgholi, Mohsen; Sadeghzadeh, Nourollah; Erfani, Mostafa; Abediankenari, Saeid; Abedi, Seyed Mohammad; Emrarian, Iman et al. (2017): Human Fibronectin Extra-Domain B (EDB)-Specific Aptide (APTEDB) Radiolabelling with Technetium-99m as a Potent Targeted Tumour-Imaging Agent. In: Anti-cancer agents in medicinal chemistry. DOI: 10.2174/1871520617666170918125020.
Moore, Sarah J.; Hayden Gephart, Melanie G.; Bergen, Jamie M.; Su, YouRong S.; Rayburn, Helen; Scott, Matthew P.; Cochran, Jennifer R. (2013): Engineered knottin peptide enables noninvasive optical imaging of intracranial medulloblastoma. In: Proceedings of the National Academy of Sciences of the United States of America 110 (36), S. 14598-14603. DOI: 10.1073/pnas.1311333110.
Nielsen, Carsten H.; Kimura, Richard H.; Withofs, Nadia; Tran, Phuoc T.; Miao, Zheng; Cochran, Jennifer R. et al. (2010): PET imaging of tumor neovascularization in a transgenic mouse model with a novel 64Cu-DOTA-knottin peptide. In: Cancer Research 70 (22), S. 9022-9030. DOI: 10.1158/0008-5472.CAN-10-1338.
Pankov, Roumen; Yamada, Kenneth M. (2002): Fibronectin at a glance. In: Journal of cell science 115 (20), S. 3861-3863.
Soroceanu, L.; Gillespie, Y.; Khazaeli, M. B.; Sontheimer, H. (1998): Use of chlorotoxin for targeting of primary brain tumors. In: Cancer Research 58 (21), S. 4871-4879.
Spicer, Christopher D.; Davis, Benjamin G. (2014): Selective chemical protein modification. In: Nature communications 5, S. 4740. DOI: 10.1038/ncomms5740.
Veiseh, Mandana; Gabikian, Patrik; Bahrami, S-Bahram; Veiseh, Omid; Zhang, Miqin; Hackman, Robert C. et al. (2007): Tumor paint: a chlorotoxin:Cy5.5 bioconjugate for intraoperative visualization of cancer foci. In: Cancer Research 67 (14), S. 6882-6888. DOI: 10.1158/0008-5472.CAN-06-3948.
Zhu, Xiaohua; Li, Jinbo; Hong, Yeongjin; Kimura, Richard H.; Ma, Xiaowei; Liu, Hongguang et al. (2014): 99mTc-labeled cystine knot peptide targeting integrin αvβ6 for tumor SPECT imaging. In: Molecular Pharmaceutics 11 (4), S. 1208-1217. DOI: 10.1021/mp400683q.
본 발명에서, 모모르디카 코킨키넨시스 (Momordica cochinchinensis) 유래의 노틴-타입의 트립신 저해제 II (oMCoTI-II)의 오픈-체인 변이체 (open-chain variant)를 파이브로넥틴 엑스트라 도메인 B (EDB) 특이적인 결합 단백질을 조작하기 위한 분자 스캐폴드로서 사용하였다. 이를 위해, 모모르디카 코킨키넨시스 유래의 트립신 저해제 II (oMCoTI-II)에 기반한 파지 라이브러리를 이용해, 재조합 파이브로넥틴 엑스트라 도메인 B에 대한 시스틴-노트 미니단백질을 선별하였다. 조작된 시스틴-노트 미니단백질, MC-FN-010 및 유도체 (derivate) MC-FN-016은 파이브로넥틴 엑스트라 도메인 B에 대한 높은 특이성뿐 아니라 합리적인 친화성을 특징으로 한다. 리간드와 부위-특이적인 형광 염료 접합체의 화학적 올리고머화를 통해, 결합 강도는 크게 증가하면서도 이의 높은 특이성은 유지하고, U-87 MG 기반의 이종이식 교모세포종 마우스 모델에서 생체내 이미징을 달성할 수 있다. 이들 파이브로넥틴 엑스트라 도메인 B-결합성 분자 2종 모두 종양에서 강하게 축적되며, 신장을 제외하고는 백그라운드 신호가 낮다. 이러한 본 발명의 결과는, 종양 이미징 기법에서의 분자 스캐폴드로서의 시스틴-노트 미니단백질의 높은 잠재력을 입증해준다.
본 발명은 일반적으로 암 질환과 같이 파이브로넥틴 엑스트라 도메인 B를 발현하는 질환의 치료 및/또는 진단에 이용가능한 화합물을 제공한다. 이들 화합물은 파이브로넥틴 엑스트라 도메인 B를 발현하는 세포의 선택적인 검출 및/또는 파이브로넥틴 엑스트라 도메인 B를 발현하는 세포의 제거 및/또는 파이브로넥틴 엑스트라 도메인 B를 발현하는 세포와 관련있는 세포와 같이, 파이브로넥틴 엑스트라 도메인 B가 발현되는, 환경과 관련있는 세포의 제거를 제공해준다. 본 발명은 파이브로넥틴 엑스트라 도메인 B를 발현하지 않거나 및/또는 파이브로넥틴 엑스트라 도메인 B가 발현되는 환경과 관련없는 정상 세포에 대한 유해한 효과를 최소화할 수 있다.
본 발명은 아미노산 서열 모티프 Arg-Ile/Val-Arg을 포함하는 파이브로넥틴 엑스트라 도메인 B (EDB) 결합성 펩타이드를 제공한다.
일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 아미노산 서열 모티프 Arg-Ile/Val-Arg-Leu을 포함한다.
일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 하기 아미노산 서열을 포함한다:
(Xaa)n1 Cys (Xaa)n2 Arg Ile/Val Arg (Xaa)n3 Cys (Xaa)n4 Cys (Xaa)n5 Cys (Xaa)n6 Cys (Xaa)n7 Cys (Xaa)n8
상기 서열에서,
Cys 잔기들은 시스틴 노트 구조를 형성하고,
Xaa는 독립적으로 서로 다른 임의의 아미노산이고,
n1, n2, n3, n4, n5, n6, n7 및 n8은 각각의 아미노산 번호이고,
아미노산 Xaa의 특성 및/또는 아미노산 번호 n1, n2, n3, n4, n5, n6, n7 및 n8은 Cys 잔기들 간에 시스틴 노트 구조를 형성할 수 있게 하는 것이다.
파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드에 대한 일 구현예에서:
n1은 0 내지 4, 바람직하게는 1 또는 2이고,
n2는 3 내지 10, 바람직하게는 4, 5, 6 또는 7이고,
n3는 0 내지 4, 바람직하게는 0 또는 1이고,
n4는 3 내지 7, 바람직하게는 4, 5 또는 6이고,
n5는 2 내지 6, 바람직하게는 2, 3 또는 4이고,
n6는 1 내지 3, 바람직하게는 1 또는 2이고,
n7은 3 내지 7, 바람직하게는 4, 5 또는 6이고, 및
n8은 0 내지 4, 바람직하게는 1 또는 2이다.
파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드에 대한 일 구현예에서, (Xaa)n3는 Leu이거나 또는 생략되고, 바람직하게는 (Xaa)n3는 Leu이다. 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드에 대한 일 구현예에서, (Xaa)n2는 (Xaa)n2' Asn이고, 여기서 바람직하게는 n2'은 2 내지 9, 바람직하게는 3, 4, 5 또는 6이다. 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드에 대한 일 구현예에서, (Xaa)n7은 Arg (Xaa)n7'이고, 여기서 바람직하게는 n7'은 2 내지 6, 바람직하게는 3, 4 또는 5이다.
파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드에 대한 일 구현예에서:
n2는 5 또는 6이거나, 또는 n2'은 4 또는 5이고,
n3는 0 또는 1이고,
n4는 5이고,
n5는 3이고,
n6는 1이고, 및
n7은 5이거나, 또는 n7'은 4이다.
일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 하기 아미노산 서열을 포함한다:
(Xaa)n1 Cys (Xaa)n2 Arg Ile/Val Arg (Xaa)n3 Cys Arg Arg Asp Ser Asp Cys (Xaa)n5 Cys Ile Cys Arg Gly Asn Gly Tyr Cys (Xaa)n8.
일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 하기 서열을 포함한다:
(Xaa)n1 Cys (Xaa)n2 Arg Ile/Val Arg (Xaa)n3 Cys Arg Arg Asp Ser Asp Cys (Xaa)n5 Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드에 대한 일 구현예에서, Ile/Val은 Ile이다. 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드에 대한 일 구현예에서, Ile/Val은 Val이다.
일 구현예에서, 본 발명은, 하기 서열들로 이루어진 군으로부터 선택되는 아미노산 서열을 포함하는, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드를 제공한다:
(i) Trp Lys Cys Gln Pro Thr Asn Gly Tyr Arg Ile Arg Cys Arg Arg Asp Ser Asp Cys Pro Gly Asp Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(ii) Ser Val Cys Lys Asn Val Ser Ile Met Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Pro Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(iii) Ser Val Cys Ala His Tyr Asn Thr Ile Arg Val Arg Leu Cys Arg Arg Asp Ser Asp Cys Pro Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(iv) Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(v) Ser Val Cys Lys Gln Ala Asn Phe Val Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Pro Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(vi) Ala Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(vii) Pro Ala Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(viii) Pro Met Cys Ala Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(ix) Pro Met Cys Thr Ala Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(x) Pro Met Cys Thr Gln Ala Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(xi) Pro Met Cys Thr Gln Arg Ala Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(xii) Pro Met Cys Thr Gln Arg Lys Ala Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(xiii) Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Ala Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly, 및
(xiv) Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Ala Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly.
일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 스캐폴드를 형성하거나 또는 이의 일부이다. 일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 공유결합성 변형 (covalent modification)에 의해 안정화된다. 일 구현예에서, 공유결합성 변형은 고리화 (cyclization)이다. 일 구현예에서, 고리화는 하나 이상의 이황화 결합을 통해 형성된다.
일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 시스틴 노트 구조, 바람직하게는 저해제 시스틴 노트 구조를 형성하거나 및/또는 이의 일부이다. 일 구현예에서, 아미노산 서열 모티프는 시스틴 노트 구조, 바람직하게는 저해제 시스틴 노트 구조의 루프 1 내에 위치하고, 바람직하게는 시스틴 노트 구조, 바람직하게는 저해제 시스틴 노트 구조의 루프 1의 C-말단부에 위치한다. 일 구현예에서, 시스틴 노트 구조는 모모르디카 코킨키넨시스로부터 유래한 오픈 체인 트립신 저해제 II (oMCoTI-II)를 토대로 한다.
일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 하나 이상의 융합 파트너를 더 포함한다. 일 구현예에서, 융합 파트너는 이종의 (heterologous) 아미노산 서열을 포함한다.
또한, 본 발명은, 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드를 포함하는 파이브로넥틴 엑스트라 도메인 B (EDB) 결합제를 제공한다. 또한, 본 발명은, 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드를 하나 이상, 예를 들어 2, 3, 4, 5, 6 또는 그 이상으로 포함하되, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드들이 서로 동일하거나 또는 상이할 수 있는, 파이브로넥틴 엑스트라 도메인 B (EDB) 결합제를 제공한다.
파이브로넥틴 엑스트라 도메인 B 결합제에 대한 일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 하나 이상의 추가의 모이어티와 공유결합적으로 및/또는 비-공유결합적으로, 바람직하게는 공유결합적으로 결합된다.
파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 파이브로넥틴 엑스트라 도메인 B 결합제에 대한 일 구현예에서, 융합 파트너 또는 추가의 모이어티는 담체 단백질, 표지물질, 리포터 또는 태그를 포함한다. 일 구현예에서, 리포터는 면역학적 분석을 위한 리포터이며, 리포터는 바람직하게는 알칼라인 포스파타제, 호스래디시 퍼옥시다제 또는 형광 분자로 이루어진 군으로부터 선택된다. 일 구현예에서, 융합 파트너 또는 추가의 모이어티는 His6-카세트, 티오레독신, S-태그, 바이오틴 또는 이들의 조합으로 이루어진 군으로부터 선택된다.
일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합제는, 각각의 서브유닛이 서로 동일하거나 또는 상이할 수 있는 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드를 포함하는, 서로 공유결합적으로 및/또는 비-공유결합적으로 결합된 2 이상의 서브유닛을 포함한다.
본 발명에 따라, 일 구현예에서, 비-공유 결합은 스트렙타비딘을 포함하는 화합물을 통해 형성된다. 본 발명에 따라, 일 구현예에서, 공유 결합은 펩타이드 링커 및/또는 비-펩타이드 링커를 통해 형성된다.
이에, 일 구현예에서, 본 발명의 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 올리고머 형태 또는 멀티머 형태로 존재한다. 이러한 구현예에서, 서로 동일하거나 또는 상이할 수 있는 2 이상의 본 발명의 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는, 바이오틴/스트렙타비딘을 통해서와 같이, 공유 또는 비-공유 결합에 의해 연결 또는 커플링될 수 있다. 즉, 본 발명의 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 이량체, 삼량체, 사량체 등을 형성할 수 있다.
일 구현예에서, 본 발명의 파이브로넥틴 엑스트라 도메인 B 결합제는 4개 이상의 서브유닛을 포함한다. 일 구현예에서, 본 발명의 파이브로넥틴 엑스트라 도메인 B 결합제는 3개 이상의 서브유닛을 포함한다.
또한, 본 발명은, 하나 이상의 검출가능한 표지물질 또는 리포터 및/또는 하나 이상의 치료학적 작동자 모이어티가 공유 및/또는 비-공유결합적으로, 바람직하게는 공유결합적으로 결합된 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제 또는 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드를 포함하는, 파이브로넥틴 엑스트라 도메인 B (EDB) 결합제를 제공한다.
일 구현예에서, 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제는 파이브로넥틴 엑스트라 도메인 B의 고유 에피토프 (native epitope)에 결합한다.
일 구현예에서, 파이브로넥틴 엑스트라 도메인 B는 내피 세포 및/또는 종양 세포에 의해 발현된다.
본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제에 대한 일 구현예에서, 결합은 특이적인 결합이다.
또한, 본 발명은 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드를 암호화하는 재조합 핵산을 제공한다. 일 구현예에서, 재조합 핵산은 벡터 형태 또는 RNA 형태이다.
또한, 본 발명은 본원에 기술된 재조합 핵산을 포함하는 숙주 세포를 제공한다.
본 발명의 다른 과제는 암 질환과 같은 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드를 발현하는 질환을 진단, 검출 또는 모니터링, 즉 퇴행, 진행, 코스 및/또는 개시를 확인하기 위한 수단 및 방법을 제공하는 것이다.
본 발명은 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제를 포함하는 검사 키트를 제공한다. 일 구현예에서, 검사 키트는 면역분석을 수행하기 위한 하나 이상의 부가적인 시약 및/또는 면역분석을 수행하기 위한 키트의 사용 설명서를 더 포함한다. 일 구현예에서, 검사 키트는 진단 검사 키트이다.
본 발명의 진단 검사 키트는 본 발명의 암 진단, 검출 또는 모니터링하는 방법에 사용가능할 수 있다. 이들 키트는 정보 팜플릿 (informative pamphlet), 예를 들어 본원에 기술된 방법을 수행하기 위한 시약의 사용 방법에 대한 정보를 알려주는 팜플릿을 포함할 수 있다.
또한, 본 발명은 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제를 포함하는 분석 장치를 제공한다. 일 구현예에서, 분석 장치는 효소-연계된 면역흡착 분석 장치이다. 분석 장치에 대한 일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 파이브로넥틴 엑스트라 도메인 B 결합제는 고체 지지체 상에 탈착 가능하게 (releasably) 또는 탈착 불가능하게 (non-releasably) 고정된다.
또한, 본 발명은 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제를 이용하는 것을 포함하는 샘플에서 파이브로넥틴 엑스트라 도메인 B (EDB)의 존재 및/또는 양을 분석하는 방법을 제공한다.
또한, 본 발명은 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제를 이용하여 환자에서 파이브로넥틴 엑스트라 도메인 B (EDB)의 존재 및/또는 양을 분석하는 것을 포함하는, 환자에서 암 진단, 검출 또는 모니터링하는 방법을 제공한다.
특정 측면에서, 본 발명은 암 질환의 위치 또는 부위, 예를 들어 특정 조직 또는 장기를 검출, 즉 확인하는 방법에 관한 것이다. 일 구현예에서, 이러한 방법은 검출가능한 표지물질이 커플링된 본 발명의 파이브로넥틴 엑스트라 도메인 B 결합성 화합물, 예를 들어 결합성 펩타이드 또는 제제를 환자에게 투여하는 것을 포함한다.
이러한 환자에서 조직 또는 장기의 표지화는 조직 또는 장기에서 암 질환의 존재 또는 위험성을 의미할 수 있다.
일 구현예에서, 조직 또는 장기는, 조직 또는 장기에 암이 존재하지 않을 경우에는 파이브로넥틴 엑스트라 도메인 B를 실질적으로 발현하지 않는, 조직 또는 장기이다.
본 발명의 방법에 대한 일 구현예에서, 분석은 환자로부터 분리된 생물학적 샘플에 대해 수행한다.
일 구현예에서, 생물학적 샘플은 암 질환을 앓고 있는 환자, 암 질환을 앓고 있거나 또는 걸린 것으로 의심되거나, 또는 암 질환 가능성이 있는 환자로부터 분리된다. 일 구현예에서, 생물학적 샘플은, 조직 또는 장기에 암이 존재하지 않을 경우에는 파이브로넥틴 엑스트라 도메인 B를 실질적으로 발현하지 않는, 조직 또는 장기로부터 유래된다.
전형적으로, 생물학적 샘플 내 파이브로넥틴 엑스트라 도메인 B의 수준을 기준 수준과 비교하고, 이러한 기준 수준으로부터의 차이로 환자에서 암 질환의 존재 및/또는 병기를 나타낸다. 기준 수준은 대조군 샘플 (예, 건강한 조직 또는 개체 유래)에서 확인되는 수준 또는 건강한 개체로부터 확인되는 중간값 수준일 수 있다. 기준 수준으로부터의 "차이"는, 적어도 10%, 20% 또는 30%, 바람직하게는 적어도 40% 또는 50% 또는 그 이상의 증가 또는 감소와 같이, 임의의 유의한 변화를 지정한다. 기준 수준과 비교해, 예를 들어 암 질환이 없는 환자와 비교해, 증가된 파이브로넥틴 엑스트라 도메인 B의 양 및/또는 파이브로넥틴 엑스트라 도메인 B의 존재는, 이 환자에서 암 질환의 존재 또는 위험 (즉, 발병 가능성)을 의미할 수 있다.
일 구현예에서, 생물학적 샘플 및/또는 대조군/기준 샘플은, 암 질환에 의한 영향을 진단, 검출 또는 모니터링할 조직 또는 장기에 해당하는, 조직 또는 장기로부터 유래하며; 예를 들어, 진단, 검출 또는 모니터링할 암 질환은 뇌암이며, 생물학적 샘플 및/또는 대조군/기준 샘플은 뇌 조직이다.
일 구현예에서, 샘플학적 샘플 및/또는 대조군/기준 샘플은, 조직 또는 장기에 암이 없을 경우에 파이브로넥틴 엑스트라 도메인 B를 실질적으로 발현하지 않는 조직 또는 장기로부터 유래한다. 본 발명의 방법을 통한 환자에서 암 질환의 존재 또는 위험성 확인은, 상기한 조직 또는 장기에서 암 질환이 있거나 또는 상기한 조직 또는 장기에서 암 질환 위험성이 있다는 것을 의미할 수 있다.
진단, 검출 또는 모니터링 방법은 타겟 분자, 예를 들어 파이브로넥틴 엑스트라 도메인 B의 발현 수준에 대한 정성적 및/또는 정량적 평가, 예를 들어, 절대 측정 및/또는 상대 측정을 허용한다.
파이브로넥틴 엑스트라 도메인 B의 존재 및/또는 양의 분석을 달성하기 위한 방법은 본원에 기술되며, 당해 기술 분야의 당업자에게 자명할 것이다. 전형적으로, 본 발명의 방법에서 분석은 파이브로넥틴 엑스트라 도메인 B에 특이적으로 결합하는 표지된 리간드, 예를 들어 검출을 위해 제공된 표지물질, 예를 들어 기준효소, 방사성 표지물질, 형광단 또는 상자성 입자가 직접 또는 간접적으로 결합된 파이브로넥틴 엑스트라 도메인 B에 특이적으로 결합하는 본 발명의 화합물의 사용을 수반한다.
일 구현예에서, 암이 없는 기준과 비교해 높은 파이브로넥틴 엑스트라 도메인 B의 양 또는 파이브로넥틴 엑스트라 도메인 B의 존재는 환자가 암에 걸렸다는 것을 의미한다.
본 발명에 따른 모니터링 방법은, 바람직하게는, 제1 시점에 제1 샘플에서, 그리고 제2 시점에 추가의 샘플에서 파이브로넥틴 엑스트라 도메인 B의 존재 및/또는 양을 분석하는 것을 포함하며, 여기서 암 질환의 퇴행, 진행, 과정 및/또는 발병은 이들 2가지 샘플을 비교함으로써 확인할 수 있다.
환자로부터 조기에 수집된 생물학적 샘플과 비교해 생물학적 샘플에서 파이브로넥틴 엑스트라 도메인 B의 양적 감소는, 이 환자에서 암 질환의 퇴행, 긍정적인 코스, 예를 들어 성공적인 치료 또는 발병 위험성 감소를 의미할 수 있다.
환자로부터 조기에 수집된 생물학적 샘플과 비교해 생물학적 샘플에서 파이브로넥틴 엑스트라 도메인 B의 양적 증가는, 이 환자에서 암 질환의 진행, 부정적인 코스, 예를 들어 치료 실패, 재발 또는 전이성 거동, 발병 또는 발병 위험성을 의미할 수 있다.
본 발명의 방법에 대한 일 구현예에서, 파이브로넥틴 엑스트라 도메인 B의 존재 및/또는 양 분석은,
(i)
샘플을 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 파이브로넥틴 엑스트라 도메인 B 결합제와 접촉시키는 단계, 및
(ii)
파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 파이브로넥틴 엑스트라 도메인 B 결합제와 파이브로넥틴 엑스트라 도메인 B 간의 복합체의 형성을 검출하거나 및/또는 복합체의 양을 확인하는 단계를 포함한다.
본 발명의 방법에 대한 일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 파이브로넥틴 엑스트라 도메인 B 결합제는 하나 이상의 검출가능한 표지물질 또는 리포터를 포함하거나 또는 이와 접합된다.
일 구현예에서, 본 발명의 방법은 면역분석 맥락에서 수행된다.
본 발명의 방법에 대한 일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 파이브로넥틴 엑스트라 도메인 B 결합제는 고체 지지체 상에 탈착 가능하게 또는 탈착 불가능하게 고정된다.
파이브로넥틴 엑스트라 도메인 B에 본 발명에 따른 파이브로넥틴 엑스트라 도메인 B 결합성 화합물의 결합은, 파이브로넥틴 엑스트라 도메인 B의 기능을 간섭할 수 있다. 아울러, 파이브로넥틴 엑스트라 도메인 B 결합성 화합물에 치료학적 작동자 모이어티, 예를 들어, 방사성 표지물질, 세포독소, 세포독성 효소 등을 부착시킬 수 있으며, 파이브로넥틴 엑스트라 도메인 B에 이러한 화합물의 결합으로, 파이브로넥틴 엑스트라 도메인 B를 발현하는 세포 또는 파이브로넥틴 엑스트라 도메인 B를 발현하는 세포와 관련있는 세포, 특히 암 세포를, 선택적으로 표적화하여 사멸시킬 수 있다. 일 구현예에서, 이러한 화합물은 종양 세포 증식을 저하하거나 및/또는 종양 세포의 사멸을 유도하며, 따라서 종양-저해 효과 또는 종양-파괴 효과를 보인다. 이에, 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 화합물은, 요법에, 특히 암 질환의 예방학적 및/또는 치료학적 치료에 이용할 수 있다.
본 발명의 방법을 이용한 전술한 암 질환에 대한 긍정적인 진단은, 암 질환을 본원에 기술된 치료 방법으로 치료할 수 있다는 것을 의미할 수 있다.
이에, 본 발명의 다른 과제는 암 질환의 치료학적 및/또는 예방학적 치료를 위한 수단 및 방법을 제공하는 것이다.
또한, 본 발명은 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드, 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제, 본원에 기술된 재조합 핵산 또는 본원에 기술된 숙주 세포를 포함하는 약학적 조성물을 제공한다.
본 발명의 약학적 조성물은 약제학적으로 허용가능한 담체를 포함할 수 있으며, 선택적으로 본원에 기술된 물질을 더 포함할 수 있다.
또한, 본 발명은 요법에 사용하기 위한, 특히 환자에서 암 치료 또는 예방에 사용하기 위한 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드, 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제, 본원에 기술된 재조합 핵산, 본원에 기술된 숙주 세포 또는 본원에 기술된 약학적 조성물을 제공한다.
또한, 본 발명은 환자에서 암을 표적화하는데 사용하기 위한 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제를 제공한다.
또한, 본 발명은 암을 앓고 있거나 또는 암 발병 위험이 있는 환자에게 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드, 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제, 본원에 기술된 재조합 핵산, 본원에 기술된 숙주 세포 또는 본원에 기술된 약학적 조성물을 투여하는 것을 포함하는, 환자의 치료 방법을 제공한다.
전술한 측면들에 대한 일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 파이브로넥틴 엑스트라 도메인 B 결합제는 하나 이상의 치료학적 작동자 모이어티를 포함하거나 또는 이와 접합된다.
전술한 측면들에 대한 일 구현예에서, 암은 파이브로넥틴 엑스트라 도메인 B-양성이거나 및/또는 파이브로넥틴 엑스트라 도메인 B를 발현하는 세포를 수반한다.
본 발명의 모든 측면들에서, 암은 바람직하게는 유방암, 뇌암, 폐암 (pulmonary cancer 또는 lung cancer), 결장직장암, 대장암, 식도암, 두경부암, 위암, 췌장암, 신장암, 자궁경부암, 난소암, 방광암 또는 전립선암으로 이루어진 군으로부터 선택된다.
본 발명의 모든 측면들에서, 파이브로넥틴 엑스트라 도메인 B는 바람직하게는 서열목록의 서열번호 2에 따른 아미노산 서열 또는 이 아미노산 서열의 변이체를 포함한다.
일 측면에서, 본 발명은 본원에 기술된 치료 방법에 사용하기 위한 본원에 기술된 제제를 제공한다. 일 구현예에서, 본 발명은 본원에 기술된 치료 방법에 사용하기 위한 본원에 기술된 약학적 조성물을 제공한다.
본원에 기술된 치료는 외과적 절제 및/또는 방사선 및/또는 전통적인 화학요법과 조합될 수 있다.
본 발명의 다른 특징들과 이점은 후술한 상세한 설명 및 청구항으로부터 명확해질 것이다.
본 발명은 후술한 도면 및 실시예를 들어 상세히 기술하며, 이는 단지 예시하기 위한 것일 뿐 제한되는 것을 의미하지 않는다. 당해 기술 분야의 당업자라면, 설명 및 실시예를 통해, 본 발명에 마찬가지로 포함되는 추가적인 구현예들을 이해할 수 있다.
도면
도 1: A: IMAC 및 SEC 정제 후 FN-단백질의 SDS-PAGE 분석. 단백질 총 10 ㎍을 환원 (+β-머캅토에탄올) 및 비-환원 (-β-머캅토에탄올) 조건 하에 SDS-PAGE에 적용하였다. 단백질 배치의 순도를 비-변형된 SDS-PAGE 이미지로부터 ImageQuant 소프트웨어를 사용해 농도계 분석을 통해 추가적으로 결정하였다. 가시화를 개선하기 위해 이미지에서 대비 및 명도에 변화를 주었다. B: anti-His 항체 및 BC-1 항체를 이용한 FN-6789, FN-67B89 및 FN-B의 효소 연계된 면역흡착 분석 (ELISA)에 기반한 결합 분석. 오차 막대는 2세트 측정값으로부터 구한 표준 편차를 표시하며, 웰 당 각각 단백질 1 ㎍을 코팅하였다.
도 2: MCopt 1.0 및 MCopt 2.0 라이브러리에 대해 파지 스크리닝을 3회 실시한 후 농화된 시스틴-노트 미니단백질 서열. 전체 스크린 클론들의 클론명, 시스틴-노트 미니단백질 서열 및 비율 (proportion)을 각 후보물질에 대해 나타낸다. 가변적인 아미노산은 진한 문자로 표시한다. 식별된 공통적인 R-I/V-R-(L) 모티프는 회색으로 강조 표시한다.
도 3: MCopt 1.0 라이브러리에 대해 파지 디스플레이 스크리닝하여 수득한 EDB 결합성 시스틴-노트 미니단백질 및 후속적인 히트 식별 프로세스. 등급 값은 ELISA를 통해 측정한 신호 (FN-B) : 노이즈 (BSA) 비율을 토대로 계산하였으며, Trx-시스틴-노트 미니단백질의 발현율에 대해 추가적으로 정규화하였다. 가변적인 아미노산은 진한 문자로 나타낸다.
도 4: Trx-시스틴-노트 미니단백질 클론 MCopt 1.0-1/-2/-3 및 MCopt 2.0-1/-2/-3의 특이성 분석. 각 변이체 200 nM을 고정된 FN-B 및 FN-67B89 타겟 단백질뿐 아니라 대조군 단백질 FN-6789, 밀크 분말 및 소 혈청 알부민 (1 ㎍/웰로 코팅)에 적용하였다. HRP-접합된 anti-s-태그 항체를 이용해 결합을 분석하였다. ELISA는 음성 대조군으로서 Trx-MC-Myc-010과 함께 2세트로 수행하였다.
도 5: Trx-시스틴-노트 미니단백질 클론 MCopt 1.0-2/-3 및 MCopt 2.0-1/-2/3에 대한 연장된 특이성 분석. 종합적으로, 각 변이체 200 nM을 FN-B, T7-TEV-B, FN-67B89 및 FN-B(8-14) 타겟 단백질 뿐 아니라 음성 대조군 FN-6789, 밀크 분말, 소 혈청 알부민, 리소자임, 난백알부민 및 알돌라제 (1 ㎍/웰로 코팅)에 적용하였다. ELISA를 2세트로 수행하였으며, 오차 막대는 표준 편차를 표시하고, Trx-MC-Myc-010은 시스틴-노트 미니단백질의 음성 대조군으로 사용하였다.
도 6: MCopt 1.0-2/-3 및 MCopt 2.0-1/-2/-3의 EDB 결합성에 대한 포화-결합 곡선. Trx-시스틴-노트 미니단백질 결합성을 FN-B, FN-67B89 및 FN-B(8-14) 타겟뿐 아니라 FN-6789 대조군 단백질 (1 ㎍/웰로 코팅)에 대해 10가지 농도에서 분석하였다. Trx-시스틴-노트 미니단백질의 결합성은 HRP-접합된 anti-s-태그-항체를 사용해 검출하였다. ELISA는 2세트로 수행하였다 (FN-B(8-14)의 경우, 단일 값).
도 7: A: MC-FN-010 모 서열 (parental sequence)의 제1, 제2 또는 제5 루프에서 해당 아미노산을 알라닌으로 교체하였다. 알라닌 치환은 회색으로 강조 표시한다. B: 모 MC-FN-010 및 Trx-융합 단백질로서 알라닌 스캔 변이체 (50 nM 내지 1.563 nM)를 사전-코팅한 인간 FN-B와 함께 인큐베이션하였다. HRP anti-s-태그-항체 10 ng으로 결합을 검출하였다. ELISA는 2세트로 3가지 독립 분석으로 수행하였다. 각 변이체의 상대적인 결합성은 겉보기 결합 상수 (apparent binding constant)를 결정하고 이를 모 MC-FN-010와 비교함으로써 계산하였다. 오차 막대는 3번의 2세트 측정의 표준 편차를 표시한다. C: MC-FN-010 모 서열. 진한 문자와 묶음표시는 아미노산 시스테인 및 이황화 결합 연결을 표시한다. 연회색으로 강조 표시된 잔기는 타겟-결합과 관련있는 것이고, 회색으로 표시된 것은 결합 상호작용에 기여하지 않거나 또는 최소한으로만 기여하는 것이다.
도 8: 교모세포종 이종이식 종양 단편에 대한 MC-FN-010의 특이적인 결합성. U-87 MG 종양 조직을 EDB 리간드 MC-FN-010 및 음성 대조군 MC-FN-0115로 면역형광 염색한 대표적인 염색 결과. 조직 단편 (5 ㎛)을 시스틴-노트 미니단백질-바이오틴 스트렙타비딘-Cy3 사량체 복합체 (적색) 및 anti-CD31 항체로 염색하여, 혈관구조 (녹색)를 가시화하였다. 스케일 바는 100 ㎛를 표시한다.
도 9: A: ELISA를 이용한 인간 FN-67B89 및 FN-6789에 대한 Trx-MC-FN-010의 특이성 분석. B: ELISA를 이용한 인간 FN-67B89 및 FN-6789에 대한 Trx-MC-FN-016의 특이성 분석. FN-6789와 비교해, 1.56-50 nM의 농도 범위에서 FN-67B89에의 Trx-MC-FN-010 및 Trx-MC-FN-016의 결합성을 HRP-접합된 anti-S-태그-항체 50 ng을 이용해 검출하였다. ELISA는 FN-67B89 또는 FN-6789를 웰당 1 ㎍씩 코팅하여 2세트로 수행하였다.
도 10: A: 표면 플라스몬 공명 분석을 통해 수득한 MC-FN-010 및 MC-FN-016의 동역학적 파라미터. 바이오틴화된 인간 FN-67B89를 스트렙타비딘 센서에 고정하여, 4000 nM에서 시작하는 2배수 연속 희석으로 MC-FN-010 및 MC-FN-016의 친화성 확인을 수행하였다. 동역학적 파라미터는 수득된 센소르그램에 적용한 1:1 랭뮤어 피팅 모델로 계산하였다. B: 싱글 사이클 카이네틱 분석을 이용하여 표면 플라스몬 공명으로부터 수득한 AF680-(MC-FN-010)3 및 AF680-(MC-FN-016)3의 동역학적 파라미터. 바이오틴화된 인간 FN-67B89를 스트렙타비딘 칩에 고정하여, 10 nM에서 시작하는 2배수 연속 희석으로 AF680-(MC-FN-010)3 및 AF680-(MC-FN-016)3의 결합 확인을 수행하였다. 동역학적 파라미터는 수득된 센소르그램에 적용한 1:1 랭뮤어 피팅 모델로 계산하였다.
도 11: A: U-87 MG를 가진 마우스의 생체내 및 생체외 사진. 인간 U-87 MG 세포를 s.c. 주사하여 종양이 생긴 마우스에, 3.36 nmol AF680-(MC-FN-010)3, AF680-(MC-FN-016)3 (EDB 결합제) 및 대조군 AF680-(MC-FN-0115)3를 i.v. 적용한 후, 사진을 촬영하였다. 그룹 당 마우스 3마리씩, 각각 다른 크기의 종양을 가진 그룹으로 계층화하였다. 주사 후 1시간, 2시간 및 6시간 경과한 후 사진을 촬영하였다. 생체내 촬영 후, 장기 및 종양을 적출하여 무게를 측정하였으며, 이를 생체외 형광 신호 분석에 이용하였다. B: 종양, 신장, 간 및 폐에서 경시적인 형광 신호의 전개. 장기의 형광 신호는 Living Image 2.5 이미징 분석 소프트웨어를 사용해 정량하고, 각각의 장기/중양 무게로 정규화하였다. 3세트로부터 수득한 데이터 세트의 평균 ± SE를 나타낸다. 2-웨이 ANOVA로 통계학적 유의성을 계산하였다 (*P < 0.0342; **P < 0.0055; ***P = 0.0001; ****P < 0.0001; n. s. = 유의하지 않음).
도 12: 정상적인 마우스 뇌를 EDB 리간드 MC-FN-010 및 음성 대조군 MC-FN-0115로 염색한 대표적인 면역형광 염색 결과. 조직 단편 (6 ㎛)을 사량체화된 시스틴-노트 미니단백질-바이오틴 / 스트렙타비딘-Cy3 복합체 및 anti-CD31 항체로 염색하여, 혈관 구조를 가시화하였다. 스케일 바, 100 ㎛.
도 13: 마우스 이종이식 종양으로서 인간 U-87 MG 교모세포종 세포주로부터 유래된 조직 단편에 대한 MC- FN -010의 특이적인 결합성. 삼량체성 MC-FN-010 및 음성 대조군 MC-FN-0115를 이용한 U-87 MG 종양 조직에 대한 대표적인 면역형광 염색 결과 (A) 및 정상적인 마우스 뇌 (B)에 대한 대표적인 면역형광 염색 결과. 조직 단편 (6 ㎛)을, 2차 항체로 검출하는 Alexa Fluor 680 접합된 삼량체성 시스틴-노트 미니단백질 및 anti-CD31 항체로 염색하여, 혈관 구조를 가시화하였다. 스케일 바, 20 ㎛.
도 14: A: U-87 MG 보유 마우스의 생체내 사진. Fox n1/nu 마우스의 옆구리에 피하 주사한 인간 U-87 MG 세포로부터 유래된 종양을, 3.34 nmol AF680-(MC-FN-016)3를 단독으로 정맥주사 적용하거나, 또는 3배 및 5배 몰 과량으로 DOTA-(MC-FN-016)3와 동시 (공동-주사)에 주사하거나 또는 30분 전에 (사전-주사) 주사한 후, 사진을 촬영하였다. 트리플 알라닌-돌연변이 펩타이드 AF680-(MC-FN-0115)3를 음성 대조군으로 사용하였다. B: 프로브 정맥 주사하고 6시간 후 장기 사진. C: 종양에서 형광 신호를 정량하고, 각각의 종양 무게에 대해 정규화하였다.
도 15: EDB에 대한 시스틴-노트 미니단백질 변이체들의 SPR 결합성 분석. 표면 플라스몬 공명 분석에 의해 측정하고 1:1 랭뮤어 피팅 모델을 이용해 계산한 EDB-특이적인 시스틴-노트 미니단백질 변이체의 동역학적 파라미터. 바이오틴화된 인간 FN-67B89를 스트렙타비딘 센서에 고정하여, 2배수 연속 희석으로 DOTA-(MC-FN-016)3의 친화성을 측정하였다.
도면
도 1: A: IMAC 및 SEC 정제 후 FN-단백질의 SDS-PAGE 분석. 단백질 총 10 ㎍을 환원 (+β-머캅토에탄올) 및 비-환원 (-β-머캅토에탄올) 조건 하에 SDS-PAGE에 적용하였다. 단백질 배치의 순도를 비-변형된 SDS-PAGE 이미지로부터 ImageQuant 소프트웨어를 사용해 농도계 분석을 통해 추가적으로 결정하였다. 가시화를 개선하기 위해 이미지에서 대비 및 명도에 변화를 주었다. B: anti-His 항체 및 BC-1 항체를 이용한 FN-6789, FN-67B89 및 FN-B의 효소 연계된 면역흡착 분석 (ELISA)에 기반한 결합 분석. 오차 막대는 2세트 측정값으로부터 구한 표준 편차를 표시하며, 웰 당 각각 단백질 1 ㎍을 코팅하였다.
도 2: MCopt 1.0 및 MCopt 2.0 라이브러리에 대해 파지 스크리닝을 3회 실시한 후 농화된 시스틴-노트 미니단백질 서열. 전체 스크린 클론들의 클론명, 시스틴-노트 미니단백질 서열 및 비율 (proportion)을 각 후보물질에 대해 나타낸다. 가변적인 아미노산은 진한 문자로 표시한다. 식별된 공통적인 R-I/V-R-(L) 모티프는 회색으로 강조 표시한다.
도 3: MCopt 1.0 라이브러리에 대해 파지 디스플레이 스크리닝하여 수득한 EDB 결합성 시스틴-노트 미니단백질 및 후속적인 히트 식별 프로세스. 등급 값은 ELISA를 통해 측정한 신호 (FN-B) : 노이즈 (BSA) 비율을 토대로 계산하였으며, Trx-시스틴-노트 미니단백질의 발현율에 대해 추가적으로 정규화하였다. 가변적인 아미노산은 진한 문자로 나타낸다.
도 4: Trx-시스틴-노트 미니단백질 클론 MCopt 1.0-1/-2/-3 및 MCopt 2.0-1/-2/-3의 특이성 분석. 각 변이체 200 nM을 고정된 FN-B 및 FN-67B89 타겟 단백질뿐 아니라 대조군 단백질 FN-6789, 밀크 분말 및 소 혈청 알부민 (1 ㎍/웰로 코팅)에 적용하였다. HRP-접합된 anti-s-태그 항체를 이용해 결합을 분석하였다. ELISA는 음성 대조군으로서 Trx-MC-Myc-010과 함께 2세트로 수행하였다.
도 5: Trx-시스틴-노트 미니단백질 클론 MCopt 1.0-2/-3 및 MCopt 2.0-1/-2/3에 대한 연장된 특이성 분석. 종합적으로, 각 변이체 200 nM을 FN-B, T7-TEV-B, FN-67B89 및 FN-B(8-14) 타겟 단백질 뿐 아니라 음성 대조군 FN-6789, 밀크 분말, 소 혈청 알부민, 리소자임, 난백알부민 및 알돌라제 (1 ㎍/웰로 코팅)에 적용하였다. ELISA를 2세트로 수행하였으며, 오차 막대는 표준 편차를 표시하고, Trx-MC-Myc-010은 시스틴-노트 미니단백질의 음성 대조군으로 사용하였다.
도 6: MCopt 1.0-2/-3 및 MCopt 2.0-1/-2/-3의 EDB 결합성에 대한 포화-결합 곡선. Trx-시스틴-노트 미니단백질 결합성을 FN-B, FN-67B89 및 FN-B(8-14) 타겟뿐 아니라 FN-6789 대조군 단백질 (1 ㎍/웰로 코팅)에 대해 10가지 농도에서 분석하였다. Trx-시스틴-노트 미니단백질의 결합성은 HRP-접합된 anti-s-태그-항체를 사용해 검출하였다. ELISA는 2세트로 수행하였다 (FN-B(8-14)의 경우, 단일 값).
도 7: A: MC-FN-010 모 서열 (parental sequence)의 제1, 제2 또는 제5 루프에서 해당 아미노산을 알라닌으로 교체하였다. 알라닌 치환은 회색으로 강조 표시한다. B: 모 MC-FN-010 및 Trx-융합 단백질로서 알라닌 스캔 변이체 (50 nM 내지 1.563 nM)를 사전-코팅한 인간 FN-B와 함께 인큐베이션하였다. HRP anti-s-태그-항체 10 ng으로 결합을 검출하였다. ELISA는 2세트로 3가지 독립 분석으로 수행하였다. 각 변이체의 상대적인 결합성은 겉보기 결합 상수 (apparent binding constant)를 결정하고 이를 모 MC-FN-010와 비교함으로써 계산하였다. 오차 막대는 3번의 2세트 측정의 표준 편차를 표시한다. C: MC-FN-010 모 서열. 진한 문자와 묶음표시는 아미노산 시스테인 및 이황화 결합 연결을 표시한다. 연회색으로 강조 표시된 잔기는 타겟-결합과 관련있는 것이고, 회색으로 표시된 것은 결합 상호작용에 기여하지 않거나 또는 최소한으로만 기여하는 것이다.
도 8: 교모세포종 이종이식 종양 단편에 대한 MC-FN-010의 특이적인 결합성. U-87 MG 종양 조직을 EDB 리간드 MC-FN-010 및 음성 대조군 MC-FN-0115로 면역형광 염색한 대표적인 염색 결과. 조직 단편 (5 ㎛)을 시스틴-노트 미니단백질-바이오틴 스트렙타비딘-Cy3 사량체 복합체 (적색) 및 anti-CD31 항체로 염색하여, 혈관구조 (녹색)를 가시화하였다. 스케일 바는 100 ㎛를 표시한다.
도 9: A: ELISA를 이용한 인간 FN-67B89 및 FN-6789에 대한 Trx-MC-FN-010의 특이성 분석. B: ELISA를 이용한 인간 FN-67B89 및 FN-6789에 대한 Trx-MC-FN-016의 특이성 분석. FN-6789와 비교해, 1.56-50 nM의 농도 범위에서 FN-67B89에의 Trx-MC-FN-010 및 Trx-MC-FN-016의 결합성을 HRP-접합된 anti-S-태그-항체 50 ng을 이용해 검출하였다. ELISA는 FN-67B89 또는 FN-6789를 웰당 1 ㎍씩 코팅하여 2세트로 수행하였다.
도 10: A: 표면 플라스몬 공명 분석을 통해 수득한 MC-FN-010 및 MC-FN-016의 동역학적 파라미터. 바이오틴화된 인간 FN-67B89를 스트렙타비딘 센서에 고정하여, 4000 nM에서 시작하는 2배수 연속 희석으로 MC-FN-010 및 MC-FN-016의 친화성 확인을 수행하였다. 동역학적 파라미터는 수득된 센소르그램에 적용한 1:1 랭뮤어 피팅 모델로 계산하였다. B: 싱글 사이클 카이네틱 분석을 이용하여 표면 플라스몬 공명으로부터 수득한 AF680-(MC-FN-010)3 및 AF680-(MC-FN-016)3의 동역학적 파라미터. 바이오틴화된 인간 FN-67B89를 스트렙타비딘 칩에 고정하여, 10 nM에서 시작하는 2배수 연속 희석으로 AF680-(MC-FN-010)3 및 AF680-(MC-FN-016)3의 결합 확인을 수행하였다. 동역학적 파라미터는 수득된 센소르그램에 적용한 1:1 랭뮤어 피팅 모델로 계산하였다.
도 11: A: U-87 MG를 가진 마우스의 생체내 및 생체외 사진. 인간 U-87 MG 세포를 s.c. 주사하여 종양이 생긴 마우스에, 3.36 nmol AF680-(MC-FN-010)3, AF680-(MC-FN-016)3 (EDB 결합제) 및 대조군 AF680-(MC-FN-0115)3를 i.v. 적용한 후, 사진을 촬영하였다. 그룹 당 마우스 3마리씩, 각각 다른 크기의 종양을 가진 그룹으로 계층화하였다. 주사 후 1시간, 2시간 및 6시간 경과한 후 사진을 촬영하였다. 생체내 촬영 후, 장기 및 종양을 적출하여 무게를 측정하였으며, 이를 생체외 형광 신호 분석에 이용하였다. B: 종양, 신장, 간 및 폐에서 경시적인 형광 신호의 전개. 장기의 형광 신호는 Living Image 2.5 이미징 분석 소프트웨어를 사용해 정량하고, 각각의 장기/중양 무게로 정규화하였다. 3세트로부터 수득한 데이터 세트의 평균 ± SE를 나타낸다. 2-웨이 ANOVA로 통계학적 유의성을 계산하였다 (*P < 0.0342; **P < 0.0055; ***P = 0.0001; ****P < 0.0001; n. s. = 유의하지 않음).
도 12: 정상적인 마우스 뇌를 EDB 리간드 MC-FN-010 및 음성 대조군 MC-FN-0115로 염색한 대표적인 면역형광 염색 결과. 조직 단편 (6 ㎛)을 사량체화된 시스틴-노트 미니단백질-바이오틴 / 스트렙타비딘-Cy3 복합체 및 anti-CD31 항체로 염색하여, 혈관 구조를 가시화하였다. 스케일 바, 100 ㎛.
도 13: 마우스 이종이식 종양으로서 인간 U-87 MG 교모세포종 세포주로부터 유래된 조직 단편에 대한 MC- FN -010의 특이적인 결합성. 삼량체성 MC-FN-010 및 음성 대조군 MC-FN-0115를 이용한 U-87 MG 종양 조직에 대한 대표적인 면역형광 염색 결과 (A) 및 정상적인 마우스 뇌 (B)에 대한 대표적인 면역형광 염색 결과. 조직 단편 (6 ㎛)을, 2차 항체로 검출하는 Alexa Fluor 680 접합된 삼량체성 시스틴-노트 미니단백질 및 anti-CD31 항체로 염색하여, 혈관 구조를 가시화하였다. 스케일 바, 20 ㎛.
도 14: A: U-87 MG 보유 마우스의 생체내 사진. Fox n1/nu 마우스의 옆구리에 피하 주사한 인간 U-87 MG 세포로부터 유래된 종양을, 3.34 nmol AF680-(MC-FN-016)3를 단독으로 정맥주사 적용하거나, 또는 3배 및 5배 몰 과량으로 DOTA-(MC-FN-016)3와 동시 (공동-주사)에 주사하거나 또는 30분 전에 (사전-주사) 주사한 후, 사진을 촬영하였다. 트리플 알라닌-돌연변이 펩타이드 AF680-(MC-FN-0115)3를 음성 대조군으로 사용하였다. B: 프로브 정맥 주사하고 6시간 후 장기 사진. C: 종양에서 형광 신호를 정량하고, 각각의 종양 무게에 대해 정규화하였다.
도 15: EDB에 대한 시스틴-노트 미니단백질 변이체들의 SPR 결합성 분석. 표면 플라스몬 공명 분석에 의해 측정하고 1:1 랭뮤어 피팅 모델을 이용해 계산한 EDB-특이적인 시스틴-노트 미니단백질 변이체의 동역학적 파라미터. 바이오틴화된 인간 FN-67B89를 스트렙타비딘 센서에 고정하여, 2배수 연속 희석으로 DOTA-(MC-FN-016)3의 친화성을 측정하였다.
본 발명은 아래에서 상세히 기술되지만, 본원에 기술된 특정 방법, 프로토콜 및 시약이 달라질 수 있으므로, 본 발명은 이러한 내용으로 한정되지 않는 것으로 이해되어야 한다. 또한, 본원에 사용된 용어들은 단순히 특정 구현예를 설명하기 위한 목적일 뿐 첨부된 청구항으로부터 제한되는 본 발명의 범위를 한정하고자 하는 것은 아닌 것으로 이해되어야 한다. 달리 정의되지 않은 한, 본원에 사용된 모든 기술 용어 및 과학 용어들은 당해 기술 분야의 당업자가 통상적으로 이해하는 의미와 동일한 의미를 가진다.
이하, 본 발명의 요소들이 설명될 것이다. 이들 요소는 구체적인 구현예를 들어 기술되지만, 이들이 임의의 방식으로 임의의 번호로 조합되어 추가적인 구현예를 구성할 수 있는 것으로 이해되어야 한다. 다양하게 기술된 예 및 바람직한 구현예는 본 발명을 명시적으로 기술된 구현예들로만 한정되는 것으로 해석되어서는 안된다. 이러한 설명은 명시적으로 기술된 구현예를 언급된 및/또는 바람직한 다수의 요소들과 조합하는 구현예들을 뒷받침하고 포괄하는 것으로 이해되어야 한다. 아울러, 본 출원에서 언급된 모든 요소들의 임의 순열 및 조합은 문맥상 그렇지 않은 것으로 지적되지 않은 한 본 출원의 내용에 의해 개시되는 것으로 간주되어야 한다.
바람직하게는, 본원에 사용된 용어들은 "A multilingual glossary of biotechnological terms: (IUPAC Recommendations)", H.G.W. Leuenberger, B. Nagel, and H. Kolbl, Eds., Helvetica Chimica Acta, CH-4010 Basel, Switzerland, (1995)에서 설명된 바와 같이 정의된다.
본 발명을 실시하는 경우, 달리 명시되지 않은 한, 해당 기술 분야의 문헌에 기술된 화학, 생화학, 세포 생물학, 면역학 및 재조합 DNA 기술의 통상적인 방법을 사용할 것이다 (예, Molecular Cloning: A Laboratory Manual, 2nd Edition, J. Sambrook et al. eds., Cold Spring Harbor Laboratory Press, Cold Spring Harbor 1989).
본 명세서와 후술한 청구항 전체에서, 문맥상 달리 요구되지 않은 한, 용어 "들을 포함한다" 및 "를 포함한다"와 "포함하는"과 같은 변형어는 언급된 구성원, 정수 또는 단계 또는 구성원, 정수 또는 단계의 그룹을 망라하며, 일부 구현예에서, 임의의 다른 구성원, 정수 또는 단계 또는 구성원, 정수 또는 단계의 그룹이, 일부 구현예에서 배제될 순 있지만, 이러한 다른 구성원, 정수 또는 단계 또는 구성원, 정수 또는 단계의 그룹을 배제하는 않는 것으로 이해될 것이며, 즉, 대상 내용은 언급된 구성원, 정수 또는 단계 또는 구성원, 정수 또는 단계의 그룹을 포함하는 것으로 구성된다. 본 발명을 설명하는 맥락에서 (특히 청구항에서) 사용되는 정관사 및 부정관사 ("a" 및 "an" 및 "the") 및 유사 언급은, 본원에서 달리 표시되거나 또는 문맥상 명확하게 상충되지 않은 한, 단수 및 복수 둘다를 포괄하는 것으로 해석되어야 한다. 본원에서 값들의 범위 인용은 주로 범위에 속하는 각각의 개별 값들을 개별적으로 언급하는 약칭법으로서 제공되는 것으로 의도된다. 본원에서 달리 지시되지 않은 한, 각각의 개별 값은, 본원에 개별적으로 언급된 바와 같이 명세서에 포함된다. 본원에 언급된 모든 방법들은, 본원에서 달리 지시되거나 또는 문맥상 명확하게 상충되지 않은 한 임의의 적절한 순서로 수행할 수 있다. 본원에 제공된 임의의 모든 예, 또는 예시적인 표현 (예, "와 같은")은 주로 본 발명을 더 잘 예시하기 위한 것이며, 청구된 본 발명의 범위를 제한하는 것은 아니다. 명세서에서 어떤 표현도 본 발명을 실시하는데 필연적인 임의의 청구되지 않은 요소들을 나타내는 것으로 해석되어서는 안된다.
본 명세서 내용에서 몇가지 문헌들이 인용된다. 상기 또는 하기에서 본원에 인용된 문헌들은 각각 (모든 특허, 특허 출원, 과학 간행물, 제조사의 명세서, 설명서 등)은 그 전체 내용이 원용에 의해 본 명세서에 포함된다. 본원에서, 본 발명이 선행 발명으로 인해 이러한 내용을 선행할 자격이 없다는 용인으로서 해석되어서는 안된다.
본 발명은 파이브로넥틴 엑스트라 도메인 B 결합성 화합물 또는 제제 (agent), 예를 들어, 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 하나 이상의 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드를 포함하는 제제에 관한 것이다.
파이브로넥틴 (FN)은, 2개의 이황화 결합에 의해 C-말단에서 연결된 약 250 kDa의 서브유닛 2개로 구성된 이량체로 이루어진, 세포외 기질 (ECM)과 체액에 존재하는 고분자량의 접착성 당단백질이다. 각각의 단량체는 3가지 타입의 반복 유닛으로 구성된다: 타입 I (각각 아미노산 약 40개) FN 반복 유닛 12개, 타입 II (아미노산 약 60개) 2개 및 타입 III (아미노산 약 90개) 15-17개. 파이브로넥틴은 매우 다양한 세포 상호작용을 매개하며, 세포 부착, 정상 세포 형태 확립과 유지, 세포 이동, 성장 및 분화와 같은 다수의 과정들에 참여한다. 이는 수종의 다른 ECM 및 세포 표면 단백질, 예를 들어, 콜라겐, 헤파린, 피브린 및 세포막 수용체와 상호작용한다. 마지막으로, FN은, 반복서열 III-10의 RGD 서열 상의 고전적인 FN 수용체 α5-β1 등의, 다수의 인테그린에 대한 리간드일 수 있다. 파이브로넥틴은 2번 염색체에 위치한 단일 유전자의 산물이지만, 일부 ECM 단백질의 경우 3가지 부위에서 사이토카인 및 세포외/세포내 pH에 의해 조절되는 과정인 pre-mRNA의 얼터너티브 스플라이싱으로부터 여러가지 이소형으로 만들어진다: 타입 III 커넥팅 서열 (IIICS), 컴플리트 타입 III 반복서열, 엑스트라 도메인 A (EDA), 및 컴플리트 타입 III 반복서열, 엑스트라 도메인 B (EDB). 이것들 중 마지막은, 엑손 사용 (exon usage) 또는 엑손 스킵핑 (exon skipping)으로 이들 타입 III 반복서열이 포함 또는 제외된, 아미노산 91개로 구성된 컴플리트 타입 III 상동 반복서열이다. 즉, 이소형 엑스트라 도메인 B (EDB)는, FN 도메인 7과 8 사이에 특이적으로 삽입된, 아미노산 91개로 구성된 부가적인 타입 III 도메인을 포함한다. FN 타입 III 반복서열 7과 8 사이에 EDB의 삽입은 잠복 서열 (cryptic sequence)을 드러내고 다른 것을 방해하는 구조적인 변형을 유도한다. 파이브로넥틴 엑스트라 도메인 B는 일반적으로 정상적인 성체 조직에는 없지만, 조직 리모델링 및 혈관신생에 관여한다. 또한, 파이브로넥틴 엑스트라 도메인 B는 다수의 여러가지 암 타입들에서 발견되는데, 수종의 공격적인 고형 인간 종양의 신혈관 구조에서 다량의 발현 패턴을 나타낸다.
본 발명에서, 용어 "파이브로넥틴 엑스트라 도메인 B"는 바람직하게는 인간 파이브로넥틴 엑스트라 도메인 B를 지칭한다.
바람직하게는, 용어 "파이브로넥틴 엑스트라 도메인 B" 또는 약어 "EDB"는 엑스트라 도메인 B 반복서열을 함유한 특정 파이브로넥틴 이소형을 지칭한다. 일 구현예에서, 용어 "파이브로넥틴 엑스트라 도메인 B" 또는 약어 "EDB"는 서열목록의 서열번호 1의 핵산 서열 또는 상기한 핵산 서열의 변이체를 포함하는, 바람직하게는, 이로 구성되는 핵산 및 이러한 핵산에 의해 암호화된 단백질, 바람직하게는, 서열목록의 서열번호 2의 아미노산 서열 또는 상기한 아미노산 서열의 변이체를 포함하는, 바람직하게는 이로 구성되는 단백질을 지칭한다. 특정 구현예에서, 용어 "파이브로넥틴 엑스트라 도메인 B" 또는 약어 "EDB"는 또한 EDB 파이브로넥틴의 엑스트라 도메인 B 반복서열 영역을 구체적으로 명시하기 위해 본원에서 사용한다. 일 구현예에서, 이러한 EDB 파이브로넥틴의 엑스트라 도메인 B 반복서열 영역은 서열목록의 서열번호 28에 나타낸 아미노산 서열 또는 이러한 아미노산 서열의 변이체를 포함한다.
파이브로넥틴 엑스트라 도메인 B는 두경부암, 뇌암, 결장직장암, 폐암, 전립선암 및 유방암과 같은 다양한 장기의 암에서 발현된다. 파이브로넥틴 엑스트라 도메인 B는 원발성 종양 및 전이를 진단, 예방 및/또는 치료하기 위한 유용한 타겟이다.
본 발명의 파이브로넥틴 엑스트라 도메인 B 결합제는 파이브로넥틴 엑스트라 도메인 B에 결합하는 능력, 즉 파이브로넥틴 엑스트라 도메인 B에 존재하는 에피토프에 결합하는 능력을 가진다. 일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합제는 종양발생과 같은 혈관신생 혈관구조 주변에서 발현된 파이브로넥틴 엑스트라 도메인 B에 결합한다. 일 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합제는 종양 조직의 세포외 기질 내에서와 같이 종양 조직 내 및/또는 그 주변에서 및/또는 종양 신혈관과 같은 종양 혈관 내 및/또는 종양 혈관에서 발현된 파이브로넥틴 엑스트라 도메인 B에 결합한다. 바람직한 특정 구현예에서, 파이브로넥틴 엑스트라 도메인 B 결합제는 파이브로넥틴 엑스트라 도메인 B의 고유 에피토프에 결합한다.
용어 "에피토프"는 결합제에 의해 인지되는 분자 내 한 부분 또는 영역을 지칭한다. 예를 들어, 에피토프는, 결합제에 의해 인지되는, 분자 상의 구분되는 3차원 부위이다. 에피토프는 일반적으로 아미노산 또는 당 측쇄와 같은 분자의 화학적인 활성 표면 그룹들로 구성되며, 일반적으로 특이적인 3차원 구조 특징뿐 아니라 특이적인 전하 특징을 가진다. 입체구조 에피토프 (conformational epitope) 및 비-입체구조 에피토프는, 전자의 경우 변성 용매의 존재시 결합성을 상실하지만 후자의 경우에는 그렇지 않다는 점에서 구분된다. 단백질의 에피토프는, 바람직하게는, 단백질의 연속적인 또는 비-연속적인 영역을 포함하며, 바람직하게는 아미노산 5-100개, 바람직하게는 5-50개, 더 바람직하게는 8-30개, 가장 바람직하게는 10-25개 길이이며, 예를 들어, 에피토프는 바람직하게는 아미노산 8개, 9개, 10개, 11개, 12개, 13개, 14개, 15개, 16개, 17개, 18개, 19개, 20개, 21개, 22개, 23개, 24개 또는 25개 길이일 수 있다.
본 발명에서, 용어 "파이브로넥틴 엑스트라 도메인 B 결합제" 또는 "파이브로넥틴 엑스트라 도메인 B 결합성 화합물"은 파이브로넥틴 엑스트라 도메인 B에 대해 결합력을 가진 임의의 화합물 (분자들의 복합체 포함)을 포함한다. 바람직하게는, 이러한 결합제는 본 발명의 하나 이상의 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드이거나 또는 이를 포함한다. 파이브로넥틴 엑스트라 도메인 B 결합제가 본 발명의 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드를 (동일하거나 또는 상이할 수 있는) 2 이상 포함하는 경우, 이들 펩타이드는 서로 공유결합적으로 또는 비-공유결합적으로 조합 (즉, 결합)된다. 파이브로넥틴 엑스트라 도메인 B 결합제는, 임의의 다른 화합물 또는 모이어티, 예를 들어 표지물질 또는 치료학적 작동자 모이어티가 공유 또는 비-공유 조합된, 하나 이상의 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드를 포함한다.
본 발명에서, 물질이 미리 결정된 타겟에 대해 현저한 친화성을 가지며 표준 분석에서 미리 결정된 타겟에 결합한다면, 이 물질은 파이브로넥틴 엑스트라 도메인 B와 같이 미리 결정된 타겟에 결합할 수 있는 것이다. "친화성" 또는 "결합 친화성"은 평형 해리 상수 (equilibrium dissociation constant, KD)에 의해 흔히 측정한다. 바람직하게는, 용어 "현저한 친화성"은 미리 결정된 타겟에 해리 상수 (KD) 10-5 M 이하, 10-6 M 이하, 10-7 M 이하, 10-8 M 이하, 10-9 M 이하, 10-10 M 이하, 10-11 M 이하 또는 10-12 M 이하로 결합하는 것을 의미한다.
물질이 타겟에 대해 현저한 친화성을 가지지 않고 표준 분석에서 타겟에 현저한 수준으로 결합하지 않는다면, 특히 검출가능하게 결합하지 않는다면, 그 물질은 타겟에 (실질적으로) 결합할 수 없는 것이다. 바람직하게는, 이러한 물질은, 최대 2 ㎍/ml, 바람직하게는 10 ㎍/ml, 더 바람직하게 20 ㎍/ml, 구체적으로 50 ㎍/ml 또는 100 ㎍/ml 또는 그 보다 높은 농도로 존재한다면, 타겟에 검출가능하게 결합하지 않는다. 바람직하게는, 물질이 결합할 수 있는 미리 결정된 타겟에 결합하는 경우의 KD와 비교해, 물질이 적어도 10배, 102배, 103배, 104배, 105배 또는 106배 높은 KD로 타겟에 결합한다면, 그 물질은 타겟에 대해 현저한 친화성을 가지지 않는 것이다. 예를 들어, 물질이 결합할 수 있는 타겟에 물질이 결합하는 경우의 KD가 10-7 M이라면, 그 물질이 현저한 친화성을 가지지 않는 물질에 결합하는 경우의 KD는 적어도 10-6 M, 10-5 M, 10-4 M, 10-3 M, 10-2 M 또는 10-1 M일 것이다.
본 발명에서, 용어 "결합"은 바람직하게는 특이적인 결합을 지칭한다.
"특이적인 결합"은 물질이 다른 타겟에의 결합과 비교해 특이적인 타겟에 더 강하게 결합하는 것을 의미한다. 물질이 제2 타겟에 대한 해리 상수보다 낮은 해리 상수 (KD)로 제1 타겟에 결합한다면, 그 물질은 제2 타겟에 비해 제1 타겟에 더 강하게 결합하는 것이다. 바람직하게는, 물질이 특이적으로 결합하는 타겟에 대한 해리 상수 (KD)는, 물질이 특이적으로 결합하지 않는 타겟에 대한 해리 상수 (KD)보다 102배, 103배, 104배, 105배, 106배, 107배, 108배, 109배 또는 1010배 이상 낮다.
바람직하게는, 물질이 미리 결정된 타겟에 결합할 수 있지만 다른 타겟에는 (실질적으로) 결합할 수 없다면, 즉 다른 타겟에 대해서는 현저한 친화성이 없어 표준 분석에서 다른 타겟에 특이적으로 결합하지 않는다면, 그 물질은 파이브로넥틴 엑스트라 도메인 B와 같이 미리 결정된 타겟에 특이적인 것이다. 바람직하게는, 이러한 다른 타겟에 대한 친화성 및 결합이 소 혈청 알부민 (BSA), 카세인, 인간 혈청 알부민 (HSA) 또는 임의의 그외 명시된 폴리펩타이드 등의 파이브로넥틴 엑스트라 도메인 B와 관련없는 단백질에 대한 친화성 또는 결합을 현저하게 초과하지 않는다면, 그 물질은 파이브로넥틴 엑스트라 도메인 B에 특이적인 것이다. 바람직하게는, 물질이 특이적이지 않은 타겟에 결합하는 KD보다 적어도 102배, 103배, 104배, 105배, 106배, 107배, 108배, 109배 또는 1010배 낮은 KD로 타겟에 결합한다면, 그 물질은 미리 결정된 타겟에 특이적인 것이다.
물질의 타겟에의 결합은 임의의 적절한 방법을 이용해 실험적으로 확인할 수 있다; 예를 들어, Berzofsky et al., "Antibody-Antigen Interactions" In Fundamental Immunology, Paul, W. E., Ed., Raven Press New York, N Y (1984), Kuby, Janis Immunology, W. H. Freeman and Company New York, N Y (1992), 및 본원에 언급된 방법을 참조한다. 친화성은 평형 투석에 의해; 제조사에 의해 제공된 일반적인 공정을 이용한 표면 플라스몬 공명 분석 (예, Biacore)에 의해; 방사성 표지된 타겟 항원을 이용한 방사성 면역분석에 의해; 또는 당해 기술 분야의 당업자에게 공지된 다른 방법에 의해서와 같이, 통상적인 기법을 이용해 쉽게 확인할 수 있다. 친화성 데이터는, 예를 들어, Scatchard et al., Ann N.Y. Acad. ScL, 51:660 (1949)의 방법에 의해 분석할 수 있다. 특정 상호작용에 대해 측정되는 친화성은, 여러가지 조건, 예를 들어, 염 농도, pH에서 측정할 경우, 달라질 수 있다. 따라서, 친화성 및 그외 결합 파라미터, 예를 들어, KD, IC50 측정은 바람직하게는 결합제 및 타겟의 표준화된 용액 및 표준화된 완충제를 사용해 수행한다.
본 발명의 일 구현예에서, 암은 파이브로넥틴 엑스트라 도메인 B-양성 암이다. 본 발명에서, 용어 "파이브로넥틴 엑스트라 도메인 B-양성 암" 또는 유사 표현은 파이브로넥틴 엑스트라 도메인 B가 관여하거나 또는 이와 관련있는 암, 특히 파이브로넥틴 엑스트라 도메인 B를 발현하는 내피 세포 및/또는 종양 세포와 같은 암 관여 세포를 의미한다. 일 구현예에서, 용어 "파이브로넥틴 엑스트라 도메인 B-양성 암" 또는 이의 유사 표현은 파이브로넥틴 엑스트라 도메인 B가 종양 조직의 세포외 기질과 같은 종양 조직 내 및/또는 주변에서 및/또는 종양 신혈관과 같은 종양 혈관 내 및/또는 종양 혈관에서 발현되는 것을 의미한다.
일 구현예에서, 파이브로넥틴 엑스트라 도메인 B가 암과 공간적으로 연관되어 있다면, 특히 파이브로넥틴 엑스트라 도메인 B가 종양 조직의 세포외 기질 내 및/또는 종양 혈관 내 및/또는 종양 혈관에서와 같이 암에 존재한다면, 그 암은 파이브로넥틴 엑스트라 도메인 B가 관여하거나 또는 파이브로넥틴 엑스트라 도메인 B와 관련있는 것이다. 바람직하게는, 파이브로넥틴 엑스트라 도메인 B와 관련있거나 또는 파이브로넥틴 엑스트라 도메인 B가 관여하는 암은 파이브로넥틴 엑스트라 도메인 B를 발현하는 세포를 함유한다. 이러한 세포는 암 세포이거나, 또는 내피 세포와 같이 암과 관련된 세포, 특히 종양 신혈관과 같은 종양 혈관의 내피 세포와 같은 암-연관성 내피 세포 (cancer-associated endothelial cell)일 수 있다.
용어 "일부 (part)" 또는 "단편"은 본원에서 상호 호환적으로 사용되며, 연속적인 요소를 지칭한다. 단백질 서열의 일부 또는 단편은 바람직하게는 단백질 서열의 6개 이상, 특히 8개 이상, 12개 이상, 15개 이상, 20개 이상, 30개 이상, 50개 이상 또는 100개 이상의 연속적인 아미노산을 포함한다.
용어 "일부분 (portion)"은 연속적인 및/또는 비-연속적인 요소를 지칭한다. 단백질 서열의 일부분은 바람직하게는 단백질 서열의 연속적인 및/또는 비-연속적인 아미노산을 6개 이상, 특히 8개 이상, 12개 이상, 15개 이상, 20개 이상, 30개 이상, 50개 이상 또는 100개 이상 포함한다.
본 발명에서, 발현 수준이 검출 한계 보다 낮거나 및/또는 발현 수준이 매우 낮아 파이브로넥틴 엑스트라 도메인 B가 파이브로넥틴 엑스트라 도메인 B-특이적인 결합제에 의한 결합을 허용하지 못하는 경우, 파이브로넥틴 엑스트라 도메인 B는 (실질적으로) 발현되지 않는 것이다.
본 발명에서, 파이브로넥틴 엑스트라 도메인 B는, 발현 수준이 검출 한계보다 높거나 및/또는 발현 수준이 파이브로넥틴 엑스트라 도메인 B-특이적인 결합제에 의한 결합을 허용할 만큼 충분히 높다면, 발현되는 것이다. 바람직하게는, 세포의 의해 발현된 파이브로넥틴 엑스트라 도메인 B는 세포외 기질로 배출되는 바와 같이 세포로부터 배출된다.
용어 "스캐폴드"는 견고성을 부여하는, 예를 들어 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드 또는 아미노산 서열 모티프에 견고성을 부여하는 구조를 의미한다.
시스틴 노트는 적어도 3개의 (시스테인 분자 쌍으로부터 형성된) 이황화 결합을 가진 단백질 구조 모티프이다. 이것은 2개의 이황화 결합에 의해 형성된 임베딩된 고리와, 3번째 이황화 결합에 의해 연결된 커넥팅 백본 세그먼트를 포함한다. 이 구조는 바람직하게는 β-시트 구조와 조합되어 있다. 시스틴 노트를 함유한 펩타이드는 바람직하게는 아미노산 잔기 25-60개, 바람직하게 아미노산 잔기 25-50개 또는 아미노산 잔기 25-40개 길이이다.
시스틴 노트는 다수의 종들에서 많은 펩타이드 또는 단백질들에서 발생하며, 상당한 구조 안정성을 부여한다. 시스틴 노트는 이황화 결합의 토폴로지 차이에 따라 3가지 타입이 존재한다: 성장 인자 시스틴 노트 (GFCK), 저해제 시스틴 노트 (ICK) 및 사이클릭 시스틴 노트, 또는 사이클로티드 (cyclotide).
저해제 시스틴 노트 (inhibitor cystine knot, ICK) 또는 노틴 (knottin)은 이황화 결합 3개를 가진 단백질 구조 모티프이다. (각각 제1 시스테인과 제4 시스테인을 연결하고, 제2 시스테인과 제5 시스테인을 연결하는) 이들 2개의 이황화 결합은 그 사이 위치한 폴리펩타이드 센셕과 함께 루프를 형성하며, (서열에서 제3 시스테인과 제6 시스테인을 연결하는) 3번째 이황화 결합이 루프를 관통하여, 노트를 형성한다. 이 모티프는 거미류 및 연체동물로부터 유래된 것과 같은 무척추동물 독소에서 흔하다. 이 모티프는 식물에서 발견되는 일부 저해제 단백질들에서도 발견된다.
이에, 본 발명에서, ICK 모티프는 인트라시스테인 백본 세그먼트 (intracysteine backbone segment) 2개와 이를 연결하는 이황화 결합 CysIV 및 CysII-CysV를 수반하며, 이황화 결합은 3번째 이황화 결합 CysVI이 관통하는 고리를 형성한다.
ICK 모티프는 사이클릭 시스틴 노트 또는 사이클로티드와 비슷하지만, 사이클로티드 계열에 존재하는 폴리펩타이드 백본의 고리화는 존재하지 않는다. 성장인자 시스틴 노트 (GFCK)는 모티프를 공유하지만, (각각 제2 시스테인과 제5 시스테인 간에, 그리고 제3 시스테인과 제6 시스테인 간에 형성되는) 루프를 관통하는 제1 시스테인과 제4 시스테인 간의 결합이 존재하는 토폴로지를 가진다.
사이클로티드는 2가지 주요 구조 서브패밀리로 나뉜다. 2가지 중 덜 흔한 타입인 뫼비우스 사이클로티드는 국소 180°백본 트위스트를 유도하는 5번 루프에 cis-프롤린을 함유하지만, 팔찌형 사이클로티드 (bracelet cyclotide)는 그렇지 않다. 트립신 저해제 사이클로티드는 서열 변형 및 천연 활성에 따라 자체 패밀리로 분류된다. 트립신 저해제 사이클로티드는, 다른 사이클로티드 보다는, 노틴 또는 저해제 시스틴 노트로 알려진 호박 식물로부터 유래된 비-사이클릭 트립신 저해제 패밀리에 더 상동적이다.
MCoTI-I 및 MCoTI-II는 스피널 고르드 (spinal gourd) 모모르디카 코킨키넨시스 (Momordica cochinchinensis)의 종자로부터 유래된 천연 폴리펩타이드이다. 이들 폴리펩타이드는 트립신-유사 프로테아제의 저해제이며, 아미노 말단과 카르복시 말단을 연결하는 추가적인 루프와 3개의 보존된 이황화 결합으로 된 매듭 배열을 포함한다. 시스틴 노트는 분자간 이황화 결합 3개로 정의되는데, 여기서 선형 펩타이드 서열의 CysICysIV 및 CysII-CysV는 3번째 이황화 결합 CysIII-CysVI이 관통하는 고리를 형성한다. 이러한 배열은, 상당한 열 및 단백질 분해에 대해 안정성을 보이는, 명확하게 정의되고 매우 안정한 스캐폴드를 제공해준다. MCoTI-I 및 MCoTI-II는, 구조 유사성 및 공통적인 생물학적 활성, 즉 트립신 패밀리의 프로테아제에 대한 저해로 인해, 작은 프로테아제 저해제들로 구성된 스쿼시 (squash) 저해제 시스틴-노트 (ICK) 패밀리로 분류된다. 이러한 패밀리에 속하는 구성원은 작은 3중 가닥 β-시트와 짧은 310 나선을 형성하는 오픈-체인 분자로서, 이는 분자내 이황화 결합 3개에 의해 묶여, 시스틴-노트 프래임워크를 형성한다. MCoTI-I 및 MCoTI-II는 사이클 형태인 스쿼시 저해제의 큰 패밀리에 속하는 유일하게 공지된 구성원이다. 고리화 루프가 없는 MCoTI-II의 오픈-체인 변이체들도 합성된 바 있다.
특정 구현예에서, 본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합성 펩타이드는 시스틴 노트 구조, 바람직하게는 저해제 시스틴 노트 구조를 형성하거나 및/또는 이의 일부이다. 특정 구현예에서, 본원에 기술된 아미노 서열은 시스틴 노트 구조, 바람직하게는 저해제 시스틴 노트 구조의 일부이다. 일 구현예에서, 본원에 기술된 아미노산 서열 모티프는 시스틴 노트 구조, 바람직하게는 저해제 시스틴 노트 구조의 1번 루프 내에 위치한다. 일 구현예에서, 본원에 기술된 아미노산 서열 모티프는 시스틴 노트 구조, 바람직하게는 저해제 시스틴 노트 구조의 1번 루프의 C-말단에 위치한다. 일 구현예에서, 시스테인 노트 구조의 첫번째 루프 (1번 루프)는 시스틴 노트 구조의 첫번째 시스테인과 2번째 시스테인 사이에 위치한다.
본 발명에서, 본원에 기술된 펩타이드는 분리된 펩타이드로서 또는 다른 펩타이드 또는 폴리펩타이드의 일부로서 당해 기술 분야에 잘 공지된 화학적 합성 방법에 의해 합성할 수 있다. 대안적으로, 펩타이드는 펩타이드를 생산하는 미생물로부터 생산한 다음 분리할 수 있으며, 적절한 경우 추가적으로 정제할 수 있다. 즉, 펩타이드는 박테리아, 효모 또는 진균과 같은 미생물; 포유류 또는 곤충 세포와 같은 진핵생물 세포; 또는 아데노바이러스, 폭스바이러스 (poxvirus), 헤르페스 바이러스 (herpesvirus), 심리키 포레스트 바이러스 (Simliki forest virus), 바쿨로바이러스 (baculovirus), 박테리오파지 (bacteriophage), 신드비스 바이러스 (sindbis virus) 또는 센다이 바이러스 (sendai virus)와 같은 재조합 바이러스 벡터에서 생산할 수 있다. 펩타이드를 생산하는데 적합한 박테리아로는 대장균 (Escherichia coli), 바실러스 섭틸리스 (Bacillus subtilis) 또는 그외 펩타이드를 발현할 수 있는 임의의 다른 박테리아 등이 있다. 펩타이드를 발현하는데 적합한 효모 타입으로는, 비-제한적으로, 사카로마이세스 세레비지애 (Saccharomyces cerevisiae), 시조사카로마이세스 폼베 (Schizosaccharomyces pombe), 칸디다 (Candida) 또는 펩타이드를 발현할 수 있는 임의의 기타 효모 등이 있다. 전술한 박테리아, 재조합 바이러스 벡터, 진핵생물 세포를 이용해 펩타이드를 생산하는 방법은 당해 기술 분야에 잘 공지되어 있다.
펩타이드를 생산하기 위해, 펩타이드를 암호화하는 핵산은 바람직하게는 플라스미드에 배치되며, 핵산은 미생물에서 펩타이드의 발현에 작용하는 프로모터에 작동가능하게 연결된다. 적합한 프로모터로는, 비-제한적으로, T7 파지 프로모터, T3 파지 프로모터, β-갈락토시다제 프로모터 및 Sp6 파지 프로모터 등이 있다. 펩타이드의 분리 및 정제 방법은 당해 기술 분야에 잘 알려져 있으며, 겔 여과, 친화성 크로마토그래피, 이온 교환 크로마토그래피 또는 원심분리와 같은 방법을 포함한다.
본 발명의 펩타이드는, 그 자체로 또는 융합 펩타이드의 일부로서, 이종의 펩타이드 또는 단백질과 접합할 수 있다. 이러한 이종의 단백질로는, 비-제한적으로, 소 혈청 알부민 (BSA)과 같은 담체 단백질 및 리포터 효소 등이 있으며, 리포터 효소로는, 비-제한적으로, 호스래디시 퍼옥시다제 또는 알칼라인 포스파타제 등이 있다. 아울러, 펩타이드 또는 펩타이드를 포함하는 융합 펩타이드는, 비-제한적으로, 플루오레세인 (fluorescein) 또는 R-피코에리트린 (R-phycoerythrin)을 포함하는, 형광 리포터 분자에 화학적으로 접합될 수 있다. 담체 단백질, 효소 및 형광 리포터 분자를 펩타이드 및 융합 펩타이드에 접합하는 방법은 당해 기술 분야에 잘 공지되어 있다.
펩타이드의 분리를 용이하게 하기 위해, 펩타이드가, 융합 폴리펩타이드를 간단한 회수, 예를 들어 친화성 크로마토그래피 또는 금속 친화성 크로마토그래피, 바람직하게는 니켈 친화성 크로마토그래피에 의한 분리를 가능하게 하는, 이종의 폴리펩타이드 또는 폴리히스티딘, 바람직하게는 히스티딘 잔기 6개와 같이 이종의 태그에 번역시 융합되는 (공유결합적으로 연결된), 융합 폴리펩타이드를 제조할 수 있다. 일부 경우에, 정제한 후 태그는 제거하는 것이 바람직할 수 있다. 따라서, 융합 폴리펩타이드는 펩타이드와 이종의 태그 사이의 정션에 절단부를 포함하는 것이 고려된다. 절단부는 그 부위에서 아미노산 서열 특이적인 효소에 의해 절단되는 아미노산 서열로 구성된다.
본원에 기술된 파이브로넥틴 엑스트라 도메인 B 결합제는 파이브로넥틴 엑스트라 도메인 B 또는 파이브로넥틴 엑스트라 도메인 B 항체의 존재 또는 양을 분석하기 위한 분석에 이용할 수 있다. 이러한 분석은, 비-제한적으로, 면역검출 등의 여러가지 방법으로 수행할 수 있으며, ELISA, 특히 펩타이드 ELISA, 경쟁적인 결합 분석, RIA 등이 있다. 본 발명의 방법은, 파이브로넥틴 엑스트라 도메인 B 또는 파이브로넥틴 엑스트라 도메인 B 항체에 대한 정량적 및/또는 정성적 평가, 예를 들어 절대적인 및/또는 상대적인 평가를 달성할 수 있다.
일반적으로, 이러한 분석은 효소-연계된 면역흡착 분석 (ELISA) 구현예를 이용해 수행한다.
용어 "효소-연계된 면역흡착 분석 또는 ELISA"는, 본원에서, 샘플, 예를 들어 혈액 혈장, 혈청 또는 세포/조직 추출물로부터 단백질 농도를 멀티-웰 플레이트 포맷 (일반적으로 96웰/플레이트)에서 정량적으로 또는 반-정량적으로 측정하는 방법에 관한 것이다. 광의적으로, 용액내 단백질을 ELISA 플레이트에 흡착시킨다. 대상 단백질에 특이적인 항체를 사용해, 플레이트를 탐침할 수 있다. 차단 (blocking) 및 세척 방법을 (IHC에서와 같이) 최적화함으로써 백그라운드를 최소화하고, 양성 대조군 및 음성 대조군의 존재를 통해 특이성을 확보한다. 검출 방법은 일반적으로 비색 (colorimetric) 또는 화학발광 측정을 기반으로 한다.
제1 웰 또는 일련의 웰들에 파이브로넥틴 엑스트라 도메인 B에 대한 단일클론 항체가 표면에 고정된 복수의 웰을 포함하는, 마이크로타이터 플레이트가 제공될 수 있다. 샘플을 단일클론 항체가 결합된 웰에 첨가할 수 있다. 샘플내 파이브로넥틴 엑스트라 도메인 B는 이 단일클론 항체에 결합한다. 항체 복합체가 형성되는 충분한 시간 동안 ELISA를 인큐베이션한다. 본 발명의 펩타이드를 추가적으로 첨가할 수도 있다. 펩타이드는 융합 폴리펩타이드의 일부일 수 있다. 그 후, 웰을 세척하여, 비-결합 물질을 제거한다. 그런 다음, 웰에 표지된 항체 또는 융합 폴리펩타이드에 결합하여 검출가능한 복합체를 형성하는 리포터 분자를 첨가하여 인큐베이션할 수 있다. 표지물질 또는 리포터로부터 발생되는 검출가능한 신호는 샘플이 파이브로넥틴 엑스트라 도메인 B를 함유하고 있다는 것을 의미하는 반면, 신호가 없는 것은 샘플이 파이브로넥틴 엑스트라 도메인 B를 함유하지 않는다는 것을 의미한다. 융합 폴리펩타이드가 표지물질 또는 리포터 효소와 같은 리포터 분자, 예를 들어 알칼라인 포스파타제를 포함하는 경우, 항체 복합체는 표지된 항체없이 직접 검출할 수 있다.
대안적으로, 제1 웰 또는 일련의 웰들에 담체 단백질 또는 융합 폴리펩타이드에 접합될 수 있는 본 발명의 펩타이드가 표면에 고정된, 복수의 웰들을 포함하는 마이크로타이터 플레이트가 제공될 수 있다. 샘플을 펩타이드가 결합된 웰에 첨가할 수 있다. 샘플 내 파이브로넥틴 엑스트라 도메인 B와 웰 표면에 결합된 펩타이드를 복합체가 형성되는 충분한 시간 동안 인큐베이션한다. 그런 후, 웰을 세척하여, 임의의 비-결합 물질을 제거한다. 웰에 표지된 항체 또는 파이브로넥틴 엑스트라 도메인 B에 결합하여 검출가능한 복합체를 형성하는 리포터 분자를 첨가하여 인큐베이션함으로써, 웰에 고정된 펩타이드에 결합된 파이브로넥틴 엑스트라 도메인 B의 양을 측정한다. 리포터로부터 발생되는 검출가능한 신호는 샘플에 파이브로넥틴 엑스트라 도메인 B가 함유되어 있음을 의미하는 반면, 신호가 없다는 것은 샘플에 파이브로넥틴 엑스트라 도메인 B가 함유되어 있지 않다는 것을 의미한다. 신호의 세기는 샘플 내 파이브로넥틴 엑스트라 도메인 B의 농도 추정을 제공할 수 있다.
또한, 본 발명의 펩타이드는 파이브로넥틴 엑스트라 도메인 B에 대한 항체의 존재를 검출하는 방법에 이용할 수 있다. 이러한 방법을 수행하기 위한 적절한 면역분석의 설계는 상당히 변경될 수 있으며, 이러한 다양한 면역분석들은 당해 기술 분야에 공지되어 있다. 적합한 면역분석 프로토콜은, 예를 들어, 경쟁 또는 직접 반응, 또는 샌드위치 타입의 분석을 기반으로 할 수 있다. 또한, 사용되는 면역분석 프로토콜은, 예를 들어, 고체 지지체를 사용할 수 있거나, 또는 면역침강에 의해 수행할 수 있다. 분석은 표지된 펩타이드의 사용을 수반할 수 있으며, 표지물질은 예를 들어 형광 분자, 화학발광 분자, 방사성 분자 또는 염료 분자일 수 있다. 특히 바람직한 분석은 ELISA 분석과 같은 효소-표지된 및 매개된 면역분석이다.
이에, 펩타이드는 샘플 내 파이브로넥틴 엑스트라 도메인 B에 대한 항체를 확인하기 위해 ELISA 분석과 같은 분석에 사용할 수 있다. 이러한 목적을 위해, ELISA 플레이트의 웰을 펩타이드로 코팅할 수 있다. 파이브로넥틴 엑스트라 도메인 B를 웰 표면에 결합된 펩타이드와 복합체를 형성하기에 충분한 시간 동안 인큐베이션할 수 있다. 그런 후, 혈장과 같은 샘플을 첨가하고, 파이브로넥틴 엑스트라 도메인 B 특이적인 항체 (1차 항체)를 1차 항체에 대한 표지된 2차 항체를 사용해 검출할 수 있다.
본 발명의 펩타이드를 본원에 기술된 바와 같은 분석 시약으로서 이용하는 경우, 펩타이드에 표지물질을 접합할 수 있다.
본 발명에서, 표지물질은 존재를 쉽게 검출할 수 있는 임의의 개체 (entity)이다. 바람직하게는, 표지물질은 직접 표지물질이다. 직접 표지물질은, 천연 상태에서 육안으로 쉽게 볼 수 있거나 또는 광학 필터 및/또는 적용된 자극, 예를 들어 형광을 촉진하기 위한 UV 광을 이용해 쉽게 가시화 가능한, 개체이다. 그 예로는, 방사성 화합물, 화학발광 화합물, 전기 활성 화합물 (예, 레독스 표지물질) 및 형광 화합물 등이 있다. 염료 졸 (dye sol), 금속성 졸 (예, 금) 및 유색 라텍스 입자 등의 직접 미립자 표지물질 역시 매우 적합하며, 형광 화합물과 더불어 바람직하다. 이러한 옵션들 중, 유색 라텍스 입자 및 형광 화합물이 가장 바람직하다. 표지물질이 작은 구역 또는 체적으로 농축되면 쉽게 검출가능한 신호, 예를 들어, 강하게 착색된 영역을 형성하여야 한다. 효소, 예를 들어 알칼라인 포스파타제 및 호스래디시 퍼옥시다제와 같은 간접 표지물질은 가시적인 신호를 검출하기 전에 기질로서 하나 이상의 현상 시약 (developing reagent)을 일반적으로 첨가하여야 하지만, 이들 역시 사용할 수 있다.
본 발명에서, 표지물질은 다음과 같은 기능을 수행할 수 있다: (i) 검출가능한 신호 제공; (ii) 제2 표지물질과 상호작용하여, 제1 또는 제2 표지물질에 의해 제공된 검출가능한 신호의 변형, 예를 들어 FRET (형광 공명 에너지 전이); (iii) 전하, 소수성, 형태 또는 그외 물리적 파라미터에 의한 이동성, 예를 들어 전기영동 이동성에 영향을 미침, 또는 (iv) 포획 모이어티, 예를 들어, 친화성, 항체/항원 또는 이온성 착물화 (ionic complexation) 제공. 표지물질로서 적합한 구조는, 형광 표지물질, 발광 표지물질, 발색단 표지물질, 방사성 동위원소 표지물질, 동위원소 표지물질이며, 바람직하게는 안정한 동위원소 표지물질, 동중 표지물질 (isobaric label), 효소 표지물질, 입자 표지물질, 특히 금속 입자 표지물질, 자기 입자 표지물질, 폴리머 입자 표지물질, 소형 유기 분자, 예를 들어, 바이오틴, 수용체의 리간드 또는 세포 부착 단백질 또는 렉틴과 같은 결합 분자, 결합제를 이용하여 검출할 수 있는 아미노산 잔기 및/또는 핵산을 포함하는 표지물질-서열 등이다. 표지물질은, 비-제한적인 방식으로, 바륨 설페이트, 아이오세타민산 (iocetamic acid), 아이오파노익산 (iopanoic acid), 칼슘 이포데이트 (calcium ipodate), 소듐 다이아트리조에이트, 메글루민 디앙트리아조에이트, 메트리즈아미드, 소듐 티로파노에이트 및 방사성 진단제 (radio diagnostic), 예를 들어 불소-18 및 탄소-11과 같은 양전자 방출제 (positron emitter), 요오드-123, 테크네튬-99m, 요오드-131 및 인듐-111과 같은 감마 방출제, 핵 자기 공명에서의 핵종 (nuclide), 예를 들어 불소 및 가돌리늄을 포함한다. 바람직한 구현예에서, 표지물질은 파이브로넥틴 엑스트라 도메인 B 결합제에 결합된 DOTA (1,4,7,10-테트라아자사이클로도데칸-1,4,7,10-테트라아세트산)와 같은 리간드와 복합체를 형성할 수 있는 루테튬-177 또는 갈륨-68과 같은 방사성 핵종을 포함한다.
본 발명의 펩타이드에 표지물질의 접합은 공유 또는 비-공유 (예, 소수성) 결합에 의해 또는 흡착에 의해 수행할 수 있다. 이러한 접합 기법은 당해 기술 분야에서 일반적이며, 사용되는 구체적인 시약에 따라 쉽게 조정할 수 있다.
본원에서, 용어 "샘플"은 환자로부터 분리할 수 있으며 분석 목적으로 사용할 수 있는 모든 생물학적 샘플을 포함한다. 이러한 샘플은 체액 샘플, 조직 샘플 또는 세포 샘플일 수 있다. 예를 들어, 본 발명에 포함되는 샘플은 조직 (예, 단편 또는 외식편) 샘플, 단일 세포 샘플, 세포 콜로니 샘플, 세포 배양 샘플, 혈액 (예, 전혈 또는 혈액 세포 분획, 혈청 또는 혈장과 같은 혈액 분획) 샘플, 뇨 샘플 또는 그외 말초 소스로부터 유래된 샘플일 수 있다. 이러한 샘플은 혼합되거나 또는 합쳐질 (pooling) 수 있으며, 예를 들어, 샘플은 혈액 샘플과 뇨 샘플의 혼합물일 수 있다. 이러한 샘플은 환자로부터 체액, 세포(들), 세포 콜로니, 외식편 또는 단편을 취함으로써 제공될 수 있지만, 또한 이전에 분리된 샘플을 이용하여 제공될 수도 있다. 예를 들어, 조직 샘플은 통상적인 생검 기법에 의해 환자로부터 취할 수 있거나, 혈액 샘플은 통상적인 채혈 기법에 의해 환자로부터 취할 수 있다. 샘플, 예를 들어 조직 샘플 또는 혈액 샘플은, 치료학적 처치를 개시하기 전에, 치료학적 처치 중에 및/또는 치료학적 처치 이후에, 환자로부터 수득할 수 있다.
일 구현예에서, 샘플은 체액 샘플이다. 용어 "체액 샘플"은 본원에서 환자의 신체로부터 유래된 임의의 액체 샘플을 지칭한다. 이러한 체액 샘플은 혈액 샘플, 뇨 샘플, 객담 샘플, 모유 샘플, 뇌척수액 (CSF) 샘플, 귀지 (cerumen 또는 earwax) 샘플, 내림프 샘플 (endolymph sample), 외림프 샘플 (perilymph sample), 위액 샘플 (gastric juice sample), 점액 샘플 (mucus sample), 복막액 샘플, 흉막액 샘플, 타액 샘플, 피지 (피부 지방) 샘플, 정액 샘플, 땀 샘플, 눈물 샘플, 질 분비물 샘플 또는 토사물의 구성 성분 및 분액 등의 토사물 샘플일 수 있다. 이러한 체액 샘플은 혼합되거나 또는 합칠 수 있다. 즉, 체액 샘플은 혈액과 뇨 샘플의 혼합물이거나, 또는 혈액과 뇌척수액 샘플의 혼합물일 수 있다. 이러한 체액 샘플은 환자로부터 체액을 취함으로써 제공될 수 있지만, 또한 이전에 분리된 체액 샘플 물질을 이용해 제공될 수도 있다.
바람직한 일 구현예에서, 샘플은 전혈 샘플이거나, 또는 혈액 세포 분획, 혈액 혈청 또는 혈액 혈장 샘플과 같은 혈액 분획 샘플이다.
일 구현예에서, 생물학적 샘플은 암과 같은 질환에 걸린 것으로 의심되는 조직으로부터 수득한 샘플이다. 일 구현예에서, 생물학적 샘플은 종양 샘플, 예를 들어, 종양으로부터 수득되고, 세포외 기질 또는 세포외 기질 구성성분과 같은 종양 기질 및/또는 종양 세포를 포함하는 샘플이다. 본 발명에서, 용어 "생물학적 샘플"은 또한 생물학적 샘플의 분획 또는 분리물과 같이 가공된 생물학적 샘플, 예를 들어, 핵산 및 펩타이드/단백질 분리물을 포괄한다.
본 발명에서, 기준 샘플 또는 기준 유기체와 같은 "기준"은 검사 샘플 또는 검사 유기체, 즉 환자로부터 수득한 결과들을 본 발명의 방법에서 상호 연관시켜 비교하기 위해 사용할 수 있다. 전형적으로, 기준 유기체는 건강한 유기체, 특히 종양을 앓고 있지 않은 유기체이다.
"기준 값" 또는 "기준 수준"은 충분히 많은 수의 기준을 측정함으로써 기준물로부터 실험적으로 측정할 수 있다. 바람직하게는, 기준 값은 적어도 2, 바람직하게는 적어도 3, 바람직하게는 적어도 5, 바람직하게는 적어도 8, 바람직하게는 적어도 12, 바람직하게는 적어도 20, 바람직하게는 적어도 30, 바람직하게는 적어도 50 또는 바람직하게는 적어도 100개의 기준을 측정함으로써 결정한다.
본원에서 "감소한다", "떨어진다" 또는 "저해한다"는, 수준에서, 예를 들어, 세포의 발현 수준에서 또는 세포의 증식 수준에서, 전반적인 감소, 바람직하게는 5% 이상의 감소, 10% 이상의 감소, 20% 이상의 감소, 더 바람직하게는 50% 이상의 감소, 가장 바람직하게는 75% 이상의 감소를 유발하는 능력 또는 전반적인 감소를 의미한다. 또한, 기준 샘플에서는 검출가능하지만 검사 샘플에서는 없거나 또는 검출불가능하다면, 물질의 양은 기준 샘플과 비교해 생물학적 샘플과 같은 검사 샘플에서 감소된 것이다.
"증가한다" 또는 "강화한다"와 같은 용어는 바람직하게는 약 10% 이상, 바람직하게는 20% 이상, 바람직하게는 30% 이상, 더 바람직하게는 40% 이상, 더 바람직하게는 50% 이상, 보다 더 바람직하게는 80% 이상, 가장 바람직하게는 100% 이상, 200% 이상, 500% 이상, 1000% 이상, 10000% 이상 또는 심지어 그 이상으로의 증가 또는 강화를 의미한다. 검사 샘플에서는 검출가능하지만 기준 샘플에는 없거나 또는 검출불가능하다면, 그 물질의 양은 기준 샘플에 비해 생물학적 샘플과 같은 검사 샘플에서 증가된 것이다.
본 발명의 펩타이드와 같은 파이브로넥틴 엑스트라 도메인 B 결합제는 고체 지지체, 예를 들어 면역분석 웰 또는 딥스틱의 표면에 결합될 수 있거나, 및/또는 적절한 용기에 적절한 시약, 대조군, 설명서 등과 함께 키트로 포장될 수 있다.
이에, 본 발명은 본 발명의 하나 이상의 파이브로넥틴 엑스트라 도메인 B 결합제를 포함하는 키트를 제공한다. 바람직한 구현예에서, 키트는 면역분석을 수행하기 위한 하나 이상의 적절한 시약, 대조군 또는 키트의 사용 설명서와 같은 하나 이상의 부가적인 물질을 더 포함한다.
본 발명은, 본 발명의 하나 이상의 파이브로넥틴 엑스트라 도메인 B 결합제를 포함하는 분석 장치를 또한 제공한다. 일 구현예에서, 분석 장치는 효소-연계된 면역흡착 분석 장치로 이루어진 군으로부터 선택된다.
이러한 장치는 여러가지 형태를 취할 수 있으며, 수행 중인 분석의 엄밀한 특성에 따라 달라질 수 있다. 예를 들어, 본 발명의 펩타이드는 고체 지지체, 전형적으로 니트로셀룰로스 또는 다른 소수성 다공성 물질 상에 코팅할 수 있다. 대안적으로, 펩타이드는 합성 플라스틱 물질, 마이크로타이터 분석 플레이트, 마이크로어레이 칩, 라텍스 비드, 셀룰로직 (cellulosic) 또는 합성 폴리머 물질을 포함하는 필터, 유리 또는 플라스틱 슬라이드, 딥스틱, 모세관 충전 장치 (capillary fill device) 등 상에 코팅할 수 있다. 이들 표면에 펩타이드의 코팅은 당해 기술 분야에 공지된 방법에 의해 달성할 수 있다. 단백질 담체는 전형적으로 복합체 형성 (complexing)에 사용되며, BSA 또는 접착 펩타이드가 가장 바람직하다. 일 구현예에서, 본 발명의 펩타이드는 고체 지지체 상에 탈착 가능하게 고정된다. 다른 바람직한 구현예에서, 본 발명의 펩타이드는 고체 지지체 상에 탈착 불가능하게 고정된다.
본원에 기술된 펩타이드는 펩타이드를 암호화하는 RNA와 같은 핵산을 투여하거나 및/또는 펩타이드를 암호화하는 RNA와 같은 핵산을 포함하는 숙주 세포를 투여함으로써, 환자에게 투여할 수 있는 것으로 이해된다. 즉, 펩타이드를 암호화하는 핵산은, 환자에게 투여시, 네이키드 형태 (naked form)로, 리포좀 또는 바이러스 입자 형태와 같이 적절한 전달 비히클로서, 또는 숙주 세포 내에 존재할 수 있다. 핵산은 지속적인 방식으로 장기간에 걸쳐 펩타이드를 생산할 수 있다. 환자에게 전달될 핵산은 재조합 방식에 의해 생산할 수 있다. 핵산이 환자에게 투여되지만 숙주 세포 내에 존재하지 않는 경우, 이는 바람직하게는 핵산에 의해 암호화된 펩타이드를 발현시키기 위해 환자의 세포에 의해 흡수된다. 핵산이 환자에게 투여되어 숙주 세포 내에 존재한다면, 바람직하게는 이는 핵산에 의해 암호화된 펩타이드를 생산하기 위해 환자 체내에서 숙주 세포에 의해 발현된다.
본원에서, 용어 "핵산"은 데옥시리보뉴클레익산 (DNA) 및 리보뉴클레익산 (RNA), 예를 들어, 게놈 DNA, cDNA, mRNA, 재조합에 의해 제조된 분자 및 화학적으로 합성된 분자를 포괄하는 것으로 의도된다. 핵산은 단일 가닥 또는 이중 가닥일 수 있다. RNA는 시험관내 전사된 RNA (IVT RNA) 또는 합성 RNA를 포괄한다.
본원에서, 용어 "RNA"는 리보뉴클레오티드 잔기를 포함하는 분자를 의미한다. "리보뉴클레오티드"는 β-D-리보-푸라노스 모이어티의 2'-위치에 하이드록시 기를 가진 뉴클레오티드를 의미한다. 이 용어는 이중 가닥 RNA, 단일 가닥 RNA, 분리된 RNA, 예를 들어 부분 정제된 RNA, 기본적으로 순수한 RNA, 합성 RNA, 재조합에 의해 제조된 RNA뿐 아니라 하나 이상의 뉴클레오티드의 부가, 결손, 치환 및/또는 변형에 의해 자연적으로 생성된 RNA와는 다른 변형된 RNA를 포괄한다. 이러한 변형은 RNA의 말단(들)에 또는 내부에, 예를 들어 RNA의 하나 이상의 뉴클레오티드에 비-뉴클레오티드 물질의 부가를 포함할 수 있다. RNA 분자에서 뉴클레오티드는 또한 비-표준 뉴클레오티드, 예를 들어, 비-천연성 뉴클레오티드 또는 화학 합성 뉴클레오티드 또는 데옥시뉴클레오티드를 포함할 수 있다. 이들 변형된 RNA는 유사체 또는 자연적으로 생성된 RNA의 유사체로서 언급될 수 있다.
본 발명에서, 용어 "RNA"는 "메신저 RNA"를 의미하는 "mRNA"를 포함하며 바람직하게는 이를 지칭하는 것이며, 주형으로서 DNA를 이용하여 만들 수 있으며 펩타이드 또는 단백질을 암호화하는 "전사체"를 지칭한다. mRNA는 전형적으로 5' 비-번역 영역 (5'-UTR), 단백질 또는 펩타이드 암호화 영역 및 3' 비-번역 영역 (3'-UTR)을 포함한다. 본 발명의 일 구현예에서, RNA는 시험관내 전사 또는 화학 합성에 의해 수득한다. 바람직하게는, mRNA는 DNA 주형을 이용하여 시험관내 전사에 의해 제조한다. 시험관내 전사 방법은 당해 기술 분야의 당업자에게 공지되어 있다. 예를 들어, 상업적으로 구입가능한 다양한 시험관내 키트들도 존재한다.
본 발명에 따라 사용되는 RNA의 발현 및/또는 안정성을 높이기 위해, 변형할 수 있으며, 바람직하게는 발현되는 펩타이드 또는 단백질의 서열은 변형하지 않으면서 변형할 수 있다.
본 발명에 따라 사용되는 RNA의 맥락에서 용어 "변형"은 RNA에서 천연적으로 존재하지 않는 임의의 RNA 변형을 포함한다.
본 발명의 일 구현예에서, 본 발명에 따라 사용되는 RNA는 캡핑되지 않은 (uncapped) 5'-트리포스페이트를 가지지 않는다. 이러한 캡핑되지 않은 5'-트리포스페이트는 RNA에 포스파타제를 처리함으로써 제거할 수 있다.
본 발명에 따른 RNA는 안정성을 높이거나 및/또는 세포독성을 낮추기 위해 변형된 자연적으로 생성 또는 합성 리보뉴클레오티드를 가질 수 있다. 예를 들어, 일 구현예에서, 본 발명에 따라 사용되는 RNA에서, 시티딘은 5-메틸시티딘으로 일부 또는 완전히, 바람직하게는 완전히 치환된다. 대안적으로 또는 부가적으로, 일 구현예에서, 본 발명에 따라 사용되는 RNA에서, 우리딘은 슈도우리딘으로 일부 또는 완전히, 바람직하게는 완전히 치환된다.
일 구현예에서, 용어 "변형"은 5'-캡 또는 5'-캡 유사체를 가진 RNA를 제공하는 것을 의미한다. 용어 "5'-캡"은 mRNA 분자의 5'-말단에서 발견되는 캡 구조를 의미하는 것으로, 일반적으로 특이한 5' -> 5' 트리포스페이트 연결을 통해 mRNA에 연결된 구아노신 뉴클레오티드로 구성된다. 일 구현예에서, 이 구아노신은 7번 위치에서 메틸화된다. 용어 "통상적인 5'-캡"은 자연적으로 생성된 RNA 5'-캡, 바람직하게는 7-메틸 구아노신 캡 (m7G)을 의미한다. 본 발명의 맥락에서, 용어 "5'-캡"은 RNA 캡 구조와 비슷하며 부착시 RNA를 바람직하게는 생체내 및/또는 세포 내에서 안정시키는 능력을 가지도록 변형된, 5'-캡 유사체를 포함한다.
5'-캡 또는 5'-캡 유사체를 가진 RNA의 제공은 이러한 5'-캡 또는 5'-캡 유사체의 존재 하에 DNA 주형을 시험관내 전사함으로써 달성할 수 있으며, 이러한 5'-캡은 생성된 RNA 가닥에 공동-전사되어 통합되거나, 또는 RNA는 예를 들어 시험관내 전사에 의해 만들 수 있으며, 캡핑 효소, 예를 들어 백시니아 바이러스의 캡핑 효소를 사용하여 전사 후 RNA에 5'-캡을 부착할 수 있다.
RNA는 추가적인 변형을 포함할 수 있다. 예를 들어, 본 발명에서 사용되는 RNA의 추가적 변형은 자연적으로 생성된 폴리(A) 테일의 연장 또는 절단 (truncation) 또는 5'- 또는 3'-비번역 영역 (UTR)의 변형, 예를 들어 RNA의 암호화 영역과 무관한 UTR의 도입, 예를 들어 α2-글로빈, α1-글로빈, β-글로빈, 바람직하게는 β-글로빈, 더 바람직하게 인간 β-글로빈과 같은 글로빈 유전자로부터 유래된 3'-UTR 카피 하나 이상, 바람직하게는 2 이상의 삽입일 수 있다.
본 발명의 맥락에서, 용어 "전사"는, DNA 서열에서 유전자 코드가 RNA로 전사되는 과정을 지칭한다. 이후, RNA는 단백질로 번역될 수 있다. 본 발명에서, 용어 "전사"는 "시험관내 전사"를 포함하며, 여기서 용어 "시험관내 전사"는 RNA 특히 mRNA를 무세포성 시스템에서 바람직하게는 적절한 세포 추출물에서 시험관내 합성하는 과정을 지칭한다. 바람직하게는, 클로닝 벡터가 전사체를 제조하는데 이용된다. 이들 클로닝 벡터는 일반적으로 전사 벡터로서 언급되며, 본 발명에 따라 용어 "벡터"에 포함된다.
본 발명에서 용어 "번역"은 세포의 리보솜에서 메신저 RNA 가닥이 아미노산 서열의 조합을 지시하여 펩타이드 또는 단백질을 만드는 과정을 지칭한다.
본 발명에서, 용어 "발현"은 가장 일반적인 의미로 사용되며, RNA 및/또는 펩타이드 또는 단백질의, 예를 들어 전사 및/또는 번역에 의한 생산을 포괄한다. RNA와 관련하여, 용어 "발현" 또는 "번역"은 특히 펩타이드 또는 단백질을 제조하는 것을 의미한다. 이 용어는 또한 핵산의 부분 발현을 포함한다. 아울러, 발현은 일시적이거나 또는 안정적일 수 있다. 본 발명에서, 용어 발현은 또한 "이상 (aberrant) 발현" 또는 "비정상적인 발현"을 포함한다.
"이상 발현" 또는 "비정상적인 발현"은 본 발명에서 기준, 예를 들어 특정 단백질, 예를 들어 파이브로넥틴 엑스트라 도메인 B의 이상 또는 비정상적인 발현과 관련있는 질환이 없는 개체에서의 상태와 비교해 발현이 변형되는, 바람직하게는 증가되는 것을 의미한다. 발현 증가는 적어도 10%, 구체적으로 적어도 20%, 적어도 50%, 적어도 100%, 적어도 200%, 적어도 500%, 적어도 1000%, 적어도 10000% 또는 그 이상으로의 증가를 의미한다. 일 구현예에서, 발현은 병에 걸린 조직에서만 발견되고, 건강한 조직에서는 발현이 억제된다.
용어 "특이적으로 발현된"은, 단백질이 특정 조직 또는 장기에서만 기본적으로 발현되는 것을 의미한다. 예를 들어, 위 점막에서 특이적으로 발현되는 단백질은 이 단백질이 위 점막에서 주로 발현되고 다른 조직에서는 발현되지 않거나 또는 다른 조직 또는 장기 타입들에서는 유의한 수준으로 발현되지 않는 것을 의미한다. 즉, 위 점막 세포에서만 발현되고, 고환과 같은 임의의 다른 조직에서는 현저하게 낮은 수준으로 발현되는 단백질은, 위 점막 세포 내에서 특이적으로 발현되는 것이다.
본 발명에서, 용어 "암호화 핵산"은, 핵산이 적절한 환경, 바람직하게는 세포 내에 존재할 경우, 발현되어 이것이 암호화하는 단백질 또는 펩타이드를 만들 수 있는 것을 의미한다.
본 발명에 기술된 핵산은 바람직하게는 분리된 것이다. 용어 "단리된 핵산"은 본 발명에서 핵산이 (i) 예를 들어 중합효소 연쇄 반응 (PCR)에 의해 시험관내에서 증폭되었거나, (ii) 클로닝에 의해 재조합에 의해 생산되었거나, (iii) 예를 들어, 절단 및 겔-전기영동 분획화에 의해 정제되었거나, 또는 (iv) 예를 들어 화학 합성에 의해 합성된 것을 의미한다. 분리된 핵산은 재조합 DNA 기법에 의한 조작에 이용가능한 핵산이다.
용어 "변이체"는, 예를 들어 핵산 및 아미노산 서열과 관련하여, 본 발명에서, 임의의 변이체, 특히 돌연변이, 스플라이스 변이체, 입체구조 (conformation), 이소형, 대립유전자 변이체, 종 변이체 및 종 상동체, 특히 자연적으로 존재하는 것을 포괄한다. 대립유전자 변이체는 유전자의 정상 서열에서의 변형이며, 유의성은 대개 불명확하다. 컴플리트 유전잔 서열분석을 통해 종종 주어진 유전자에 대해 수많은 대립유전자 변이체가 동정된다. 종 상동체는 주어진 핵산 또는 아미노산 서열과는 다른 종으로부터 기원하는 핵산 또는 아미노산 서열이다.
핵산 분자와 관련하여, 용어 "변이체"는 축중 (degenerate) 핵산 서열을 포함하며, 본 발명에서 축중 핵산은 유전자 코드의 축중으로 인해 코돈 서열이 기준 핵산과 다른 핵산이다.
아울러, 본 발명에 따른 특정 핵산 서열의 "변이체"는 하나 또는 복수의, 예를 들어 적어도 2개, 적어도 4개 또는 적어도 6개, 바람직하게는 최대 3개, 최대 4개, 최대 5개, 최대 6개, 최대 10개, 최대 15개 또는 최대 20개의 뉴클레오티드 치환, 결손 및/또는 부가를 포함하는 핵산 서열을 포함한다.
바람직하게는, 주어진 핵산 서열과 주어진 핵산 서열의 변이체인 핵산 서열 간의 동일성 정도는 적어도 약 60%, 65%, 70%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%일 것이다. 동일성 정도는 바람직하게는 기준 핵산 서열의 전체 길이의 적어도 약 10%, 적어도 약 20%, 적어도 약 30%, 적어도 약 40%, 적어도 약 50%, 적어도 약 60%, 적어도 약 70%, 적어도 약 80%, 적어도 약 90% 또는 약 100%인 영역에 대해 제공된다. 예를 들어, 기준 핵산 서열이 뉴클레오티드 200개로 이루어진다면, 유사성 또는 동일성 정도는 바람직하게는 적어도 약 20개, 적어도 약 40개, 적어도 약 60개, 적어도 약 80개, 적어도 약 100개, 적어도 약 120개, 적어도 약 140개, 적어도 약 160개, 적어도 약 180개 또는 약 200개의 뉴클레오티드에 대해 제공되며, 바람직하게는 연속적인 뉴클레오티드에 대해 제공된다. 바람직한 구현예에서, 동일성 정도는 기준 핵산 서열의 전장에 대해 제공된다.
2가지 핵산 서열 간의 "서열 동일성"은 이들 서열 간에 동일한 뉴클레오티드의 %를 나타낸다.
용어 "동일성 %"는 비교할 서열 2종을 최적으로 정렬한 서열들 간의 동일한 뉴클레오티드의 %를 나타내는 것으로 의도되며, %는 전적으로 통계에 의한 것이며, 서열 2종 간의 차이는 전체 길이에서 무작위로 분포한다. 뉴클레오티드 서열 2종 간의 서열 비교는 서열을 최적으로 정렬한 다음 이들 서열을 비교함으로써 이루어지며, 비교는 서열 유사성을 가진 국소 영역을 식별 및 비교하기 위해 세그먼트에 의해 또는 "비교 창"에 의해 수행한다. 비교 서열들의 최적의 정렬은 Smith and Waterman, 1981, Ads App. Math. 2, 482의 국소 상동성 알고리즘을 이용하거나, Neddleman and Wunsch, 1970, J. Mol. Biol. 48, 443의 국소 상동성 알고리즘을 이용하거나, Pearson and Lipman, 1988, Proc. Natl Acad. Sci. USA 85, 2444의 유사성 검색 방법을 이용하거나, 또는 이들 알고리즘을 이용하는 컴퓨터 프로그램을 이용함으로써, 생성할 수 있다 (GAP, BESTFIT, FASTA, BLAST P, BLAST N and TFASTA in Wisconsin Genetics Software Package, Genetics Computer Group, 575 Science Drive, Madison, Wis.).
동일성 %는 비교 서열 2종 간에 동일한 위치의 개수를 확인하고, 개수를 비교하는 위치들의 개수로 나눈 다음 그 결과를 100으로 곱하여 계산하여, 이들 서열 2종 간의 동일성 %를 구한다.
바람직하게는, 주어진 핵산 서열과 이러한 주어진 핵산 서열의 변형체인 핵산 서열은 혼성가능할 것이다.
서열 2개가 서로 상보적이라면, 핵산은 다른 핵산에 "혼성할 수 있"거나 또는 "혼성화한다". 서열 2개가 다른 것과 안정적인 두플렉스를 형성할 수 있다면, 그 핵산은 다른 핵산에 "상보적인" 것이다. 본 발명에서, 혼성화는 바람직하게는 폴리뉴클레오티드 간에 특이적인 혼성화를 허용하는 조건 (엄격한 조건) 하에 수행된다. 엄격한 조건은, 예를 들어, Molecular Cloning: A Laboratory Manual, J. Sambrook et al., Editors, 2nd Edition, Cold Spring Harbor Laboratory press, Cold Spring Harbor, New York, 1989 또는 Current Protocols in Molecular Biology, F.M. Ausubel et al., Editors, John Wiley & Sons, Inc., New York에 기술되어 있으며, 예를 들어 혼성 완충제 (3.5 x SSC, 0.02% Ficoll, 0.02% 폴리비닐피롤리돈, 0.02% 소 혈청 알부민, 2.5 mM NaH2PO4 (pH 7), 0.5% SDS, 2 mM EDTA) 중에 65℃에서 혼성화하는 것을 의미한다. SSC는 0.15 M 소듐 클로라이드/0.15 M 소듐 사이트레이트, pH 7이다. 혼성화를 수행한 후, DNA를 옮긴 멤브레인을, 예를 들어, 실온에서 2x SSC로 세척한 다음 최대 68℃의 온도에서 0.1-0.5x SSC/0.1x SDS에서 세척한다.
상보성 %는 핵산 분자에서 제2 핵산 서열과 수소 결합 (예, 왓슨-클릭 염기 쌍 형성)을 형성할 수 있는 연속 잔기들의 %를 나타낸다 (예, 10개 중 5, 6, 7, 8, 9, 10개이면 상보성은 50%, 60%, 70%, 80%, 90% 및 100%임). "완벽한 상보성 (perfectly complementary)" 또는 "완전한 상보성 (fully complementary)"은 핵산 서열의 모든 연속 잔기들이 제2 핵산 서열의 동일한 개수의 연속 잔기와 수소 결합하는 것을 의미한다. 바람직하게는, 본 발명에 따른 상보성 정도는 적어도 70%, 바람직하게는 적어도 75%, 바람직하게는 적어도 80%, 더 바람직하게 적어도 85%, 보다 더 바람직하게 적어도 90% 또는 가장 바람직하게는 적어도 95%, 96%, 97%, 98% 또는 99%이다. 가장 바람직하게는, 본 발명에 따른 상보성 정도는 100%이다.
용어 "유도체"는 뉴클레오티드, 당 또는 포스페이트 상에서 핵산의 모든 화학적 유도체를 포함한다. 또한, 용어 "유도체"는 자연적으로 생성되지 않는 뉴클레오티드 유사체 및 뉴클레오티드를 함유하는 핵산을 포함하며, 바람직하게는 핵산의 유도체화는 이의 안정성을 높인다.
본 발명에서, 핵산은 단독으로 존재하거나 또는 다른 핵산, 구체적으로 이종의 핵산과 조합하여 존재할 수 있다. 바람직하게는, 펩타이드 또는 단백질을 암호화하는 핵산은 이러한 펩타이드 또는 단백질을 발현한다. 바람직한 구현예에서, 핵산은, 이 핵산에 대해 동종 또는 이종일 수 있는, 발현 제어 서열 또는 제어 서열에 기능적으로 연결된다. 암호화 서열 및 조절 서열은, 이것이 암호화 서열의 발현 또는 전사를 조절 서열의 제어 하에 또는 영향 하에 놓이는 방식으로 다른 것에 공유 연결되어 있다면, 이것은 다른 것에 "기능적으로" 연결된 것이다. 만일 암호화 서열이 기능성 단백질로 번역되어야 한다면, 이 암호화 서열에 기능적으로 연결된 조절 서열을 이용하여, 이러한 조절 서열의 도입으로 상기한 암호화 서열의 전사가 암호화 서열에서 프래임 쉬프트의 발생없이 이루어지거나, 또는 상기한 암호화 서열은 원하는 단백질 또는 펩타이드로 번역될 수 없게 된다.
본 발명에서 용어 "발현 제어 서열 (expression control sequence)" 또는 "조절 서열 (regulatory sequence)"은 유전자의 발현을 조절하는 프로모터, 인핸서 및 기타 조절 인자를 포함한다. 본 발명의 특정 구현예에서, 발현 제어 서열은 조절될 수 있다. 조절 서열의 실제 구조는 종 또는 세포 타입의 기능에 따라 달라질 수 있지만, 일반적으로 전사 및 번역의 개시에 각각 참여하는 5' 비-전사되는 서열 및 5' 비-번역되는 서열, 예를 들어 TATA 박스, 캡핑 서열, CAAT 서열 등을 포함한다. 보다 구체적으로, 5' 비-전사되는 조절 서열은 기능적으로 연결된 유전자의 전사 제어를 위한 프로모터 서열을 함유한 프로모터 영역을 포함한다. 조절 서열은 또한 인핸서 서열 또는 상류 활성인자 서열을 포함할 수 있다.
본 발명에서, 핵산은 숙주 세포로부터 유래된 핵산에 의해 암호화되는 단백질 또는 펩타이드의 분비를 제어하는 펩타이드를 암호화하는 다른 핵산과 조합하여 존재할 수 있다. 본 발명에서, 핵산은 또한 암호화된 단백질 또는 펩타이드를 숙주 세포의 세포 막 상에 고정하거나 또는 세포의 특정 소기관으로 구획화하는 펩타이드를 암호화하는 다른 핵산과 조합하여 존재할 수 있다. 마찬가지로, 핵산과의 조합은 리포터 유전자 또는 임의의 "태그"를 나타내는 핵산과의 조합도 가능하다.
바람직한 구현예에서, 재조합 핵산 분자는 본 발명에서 적절한 경우 핵산의 발현을 제어하는 프로모터를 가진 벡터이다. 용어 "벡터"는 본원에서 가장 일반적인 의미로 사용되며, 핵산을 예를 들어 원핵생물 및/또는 진핵생물 세포에 도입하고, 적절한 경우 게놈에 통합시킬 수 있는, 핵산에 대한 임의의 매개 비히클을 포함한다. 이러한 종류의 벡터는 바람직하게는 세포에서 복제 및/또는 발현된다. 매개 비히클은, 예를 들어, 전기천공, 미세 입자 투사법 (bombardment with microprojectile), 리포좀 투여, 아그로박테리아를 이용한 전이 또는 DNA 또는 RNA 바이러스롤 통한 삽입에 사용하도록, 개조될 수 있다. 벡터는 플라스미드, 파지미드, 박테리오파지 또는 바이러스 게놈을 포함한다.
본 발명에 따른 핵산은 숙주 세포의 형질감염에 이용할 수 있다. 본원에서 핵산은 재조합 DNA 및 RNA 둘다를 의미한다. 재조합 RNA는 DNA 주형의 시험관내 전사에 의해 제조할 수 있다. 또한, 이는 사용하기 전에 서열 안정화, 캡핑 및 폴리아데닐화를 통해 변형할 수 있다.
본 발명의 맥락에서, 용어 "재조합"은 "유전자 조작을 통해 제조된" 것을 의미한다. 바람직하게는, 본 발명의 맥락에서 재조합 핵산과 같은 "재조합체"는 자연적으로 생기지 않는다.
본원에서, 용어 "자연적으로 생성된"은 대상을 자연에서 발견할 수 있는 것을 의미한다. 예를 들어, (바이러스를 비롯한) 유기체에 존재하며; 자연계에서 소스로부터 분리할 수 있으며; 실험실에서 사람에 의해 의도적으로 변형되지 않은, 펩타이드 또는 핵산은 자연적으로 생성된 것이다.
용어 "세포" 또는 "숙주 세포"는 바람직하게는 온전한 세포 (intact cell), 즉, 효소, 소기관 또는 유전 물질과 같은 정상적인 세포내 구성성분을 방출하지 않는 온전한 막을 가진 세포를 지칭한다. 온전한 세포는 바람직하게는 생존가능한 세포, 정상적인 대사 기능을 수행할 수 있는 살아있는 세포이다. 바람직하게는, 이 용어는 본 발명에서 외인성 핵산으로 형질감염될 수 있는 임의의 세포를 지칭한다. 바람직하게는, 세포는 외인성 핵산으로 형질감염되었을 때 핵산을 발현할 수 있다.
용어 "숙주 세포"는 원색생물 (예, E. coli) 또는 진핵생물 세포 (예, 수지상 세포, B 세포, CHO 세포, COS 세포, K562 세포, 효모 세포 및 곤충 세포)를 포함한다. 인간, 마우스, 햄스터, 돼지, 염소, 영장류로부터 유래되는 세포와 같은 포유류 세포가 특히 바람직하다. 세포는 다양한 조직 타입들로부터 유래할 수 있으며, 1차 세포 및 세포주를 포함할 수 있다. 구체적인 예로는 각질 형성 세포, 말초혈 백혈구, 골수의 줄기 세포 및 배아 줄기 세포를 포함한다. 핵산은 숙주 세포에 1 카피 형태로 또는 2 카피 이상의 형태로 존재할 수 있으며, 일 구현예에서 숙주 세포에서 발현된다.
용어 "펩타이드"는 올리고펩타이드 및 폴리펩타이드를 포함하며, 이는 펩타이드 결합에 의해 공유 연결된 아미노산 2개 이상, 바람직하게는 3개 이상, 바람직하게는 4개 이상, 바람직하게는 6개 이상, 바람직하게는 8개 이상, 바람직하게는 10개 이상, 바람직하게는 13개 이상, 바람직하게는 16개 이상, 바람직하게는 21개 이상, 바람직하게는 최대 8개, 10개, 20개, 30개, 40개 또는 50개, 특히 100개를 포함하는 물질을 지칭한다. 용어 "단백질"은 큰 펩타이드, 바람직하게는 아미노산 잔기가 100개보다 많은 펩타이드를 지칭하지만, 일반적으로 용어 "펩타이드" 및 "단백질"은 동의어이며, 본원에서 상호 호환적으로 사용된다.
본 발명에서, 펩타이드는 천연 아미노산 및 비-천연 아미노산을 포함할 수 있다. 일 구현예에서, 펩타이드는 주로 천연 아미노산을 포함한다.
본 발명에서, 용어 "비-천연 아미노산"은 천연 아미노산 20종과는 다른 구조를 가진 아미노산을 지칭한다. 비-천연 아미노산은 천연 아미노산과 구조가 비슷하므로, 비-천연 아미노산은 주어진 천연 아미노산의 유사체 또는 유도체로서 분류할 수도 있다.
본 발명에서, 용어 "사이클릭 펩타이드"는 고리를 형성하는 펩타이드 또는 폴리펩타이드 체인을 지칭한다. 펩타이드는 서로 다른 4가지 방법으로 고리를 형성할 수 있다: 머리에서 꼬리 (head-to-tail) (C-말단에서 N-말단), 머리에서 측쇄, 측쇄에서 꼬리 또는 측쇄에서 측쇄. 본 발명에서 분자내 이황화 결합을 형성하여 사이클릭 펩타이드를 형성할 수 있는 시스테인과 같이, 티올 기를 함유한 잔기 2 이상을 가진 펩타이드가 특히 바람직하다.
본 발명에서, 펩타이드는 하나 이상의 다른 화합물에 공유결합적으로 또는 비-공유결합적으로 결합할 수 있다. 이러한 화합물로는 펩타이드 및 단백질과 같은 펩타이드성 화합물뿐 아니라 폴리에틸렌 글리콜 (PEG)과 같은 비-펩타이드성 화합물을 포함한다.
일 구현예에서, 본원에 기술된 펩타이드는 페길화 (PEGylation)된다. 페길화는 폴리에틸렌 글리콜 (PEG) 폴리머 체인을 펩타이드 또는 단백질과 같은 다른 분자에 공유 결합하는 것이다. PEG의 공유 결합은 숙주의 면역 시스템으로부터 물질을 "숨길" 수 있으며 (면역원성 및 항원성 저하), 물질의 유체역학적 크기 (용액 중의 크기)를 증가시켜, 신장 청소율 (renal clearance) 저하로 인해 이의 순환 시간을 연장할 수 있다. 또한, 페길화는 소수성 약물 및 단백질에 수 용해성을 제공할 수 있다.
바람직하게는, 본 발명에 따라 기술된 단백질 및 펩타이드는 분리된 것이다. 용어 "단리된 단백질" 또는 "단리된 펩타이드"는, 단백질 또는 펩타이드가 이의 천연 환경으로부터 분리된 것을 의미한다. 분리된 단백질 또는 펩타이드는 본질적으로 정제된 상태일 수 있다. 용어 "본질적으로 정제된"은, 단백질 또는 펩타이드가 자연에서 또는 생체내에서 조합된 다른 물질이 본질적으로 없는 것을 의미한다. 이러한 단백질 및 펩타이드는, 예를 들어, 면역학적 또는 진단 분석에 또는 치료제로서 사용할 수 있다. 본 발명에 기술된 단백질 및 펩타이드는 조직 또는 세포막과 같은 생물학적 샘플로부터 분리할 수 있으며, 다양한 원핵생물 또는 진핵생물 발현 시스템에서 재조합에 의해 발현할 수 있다.
용어 "항체"는 이황화 결합에 의해 서로 연결된 적어도 2개의 중(H) 쇄와 2개의 경(L) 쇄를 포함하는 당단백질, 및 이러한 당단백질의 항원-결합부를 포함하는 임의 분자를 포괄한다. 용어 "항체"는 단일클론 항체, 재조합 항체, 인간 항체, 인간화된 항체, 키메라 항체, 항체의 결합 단편 또는 유도체를 포함하는 분자, 예를 들어, 비-제한적으로, 단쇄 항체, 예를 들어, scFv 및 항원-결합성 항체 단편, 예를 들어 Fab 및 Fab' 단편을 포함하며, 또한 항체의 모든 재조합 형태, 예를 들어 원핵생물에서 발현된 항체, 비-당화된 항체 및 임의의 항원-결합성 항체 단편 및 본원에 기술된 유도체를 포함한다. 각각의 중쇄는 중쇄 가변부 (본원에서 VH로 약칭함)와 중쇄 불변부로 구성된다. 각각의 경쇄는 경쇄 가변부 (본원에서 VL로 약칭함)와 경쇄 불변부로 구성된다. VH 영역과 VL 영역은 프래임워크 영역 (FR)으로 지칭되는 더 보존적인 영역이 사이에 배치된 상보성 결정부 (CDR)로 지칭되는 과변이 영역들로 추가적으로 분류할 수 있다. 각각의 VH 및 VL은 CDR 3개와 FR 4개로 구성되며, 아미노 말단에서 카르복시 말단 방향으로 다음과 같은 순서로 배열된다: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4. 중쇄 및 경쇄의 가변부들은 항원과 상호작용하는 결합 도메인을 함유하고 있다. 항체의 불변부는 면역계의 다양한 세포 (예, 작동자 세포) 및 고전적인 보체 시스템의 제1 보체 (Clq) 등의 숙주 조직 또는 인자에 면역글로불린이 결합하는 것을 매개할 수 있다.
특정 아미노산 서열, 예를 들어 서열목록에 나타낸 서열에 대해 본원에 제공된 교시 내용은, 특정 서열과 기능적으로 등가인 서열, 예를 들어, 특정 아미노산 서열과 동일한 또는 유사한 특징을 나타내는 아미노산 서열을 형성하는 상기한 특정 서열에 대한 변이체를 지칭하는 것으로도 해석되어야 하다. 중요한 특성은 파이브로넥틴 엑스트라 도메인 B와 같은 타겟에 대해 결합성을 유지하는 것이다.
본 발명의 목적에서, 아미노산 서열의 "변이체"는 아미노산 삽입 변이체, 아미노산 부가 변이체, 아미노산 결손 변이체 및/또는 아미노산 치환 변이체를 포함한다. 단백질의 N-말단 및/또는 C-말단에 결손을 포함하는 아미노산 결손 변이체는 또한 N-말단 및/또는 C-말단 전달 변이체로 지칭된다.
아미노산 삽입 변이체는 특정 아미노산 서열에 아미노산 1개 또는 2개 이상의 삽입을 포함한다. 삽입을 가진 아미노산 서열 변이체의 경우, 제조되는 산물을 적절하게 스크리닝하는 무작위 삽입도 가능하지만, 하나 이상의 아미노산 잔기를 아미노산 서열의 특정 부위에 삽입한다.
아미노산 부가 변이체는 하나 이상의 아미노산, 예를 들어 아미노산 1, 2, 3, 5, 10, 20, 30, 50 또는 그 이상의 개수를 아미노 말단 및/또는 카르복시 말단에 융합하는 것을 포함한다.
아미노산 결손 변이체는 서열에서 하나 이상의 아미노산의 제거, 예를 들어 아미노산 1, 2, 3, 5, 10, 20, 30, 50 또는 그 이상의 개수의 제거를 특징으로 한다. 결손은 펩타이드 또는 단백질의 임의 위치에 존재할 수 있다.
아미노산 치환 변이체는 서열에서 하나 이상의 잔기의 제거 및 그 위치에 다른 잔기의 삽입을 특징으로 한다. 상동적인 단백질 또는 펩타이드 간에 보존적이지 않은 아미노산 서열 내 위치들에서의 변형 및/또는 아미노산을 유사한 특징을 가진 다른 아미노산으로 치환하는 것이 바람직하다. 바람직하게는, 단백질 변이체에서 아미노산 변형은 보존적인 아미노산 변형, 즉 비슷하게 하전된 또는 비하전된 아미노산으로의 치환이다. 보존적인 아미노산 변형은 측쇄가 비슷한 아미노산 계열에 속하는 것으로의 치환을 수반한다. 자연적으로 생성된 아미노산은 일반적으로 4가지 계열로 분류된다: 산성 아미노산 (아스파르테이트, 글루타메이트), 염기성 아미노산 (라이신, 아르기닌, 히스티딘), 비-극성 아미노산 (알라닌, 발린, 루신, 이소루신, 프롤린, 페닐알라닌, 메티오닌, 트립토판), 및 비-하전된 극성 아미노산 (글리신, 아스파라긴, 글루타민, 시스테인, 세린, 트레오닌, 티로신). 페닐알라닌, 트립토판 및 티로신은 때때로 방향족 아미노산으로서 함께 분류된다.
바람직하게는, 유사성 정도, 바람직하게는 주어진 아미노산 서열과 주어진 아미노산 서열의 변이체인 아미노산 서열 간의 동일성은 적어도 약 60%, 65%, 70%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%일 것이다. 유사성 또는 동일성 정도는 바람직하게는 기준 아미노산 서열의 전장의 적어도 약 10%, 적어도 약 20%, 적어도 약 30%, 적어도 약 40%, 적어도 약 50%, 적어도 약 60%, 적어도 약 70%, 적어도 약 80%, 적어도 약 90% 또는 약 100%인 아미노산 영역에 대해 제공된다. 예를 들어, 기준 아미노산 서열이 아미노산 200개로 구성된다면, 유사성 또는 동일성 정도는 바람직하게는 아미노산, 바람직하게는 연속적인 아미노산 적어도 약 20개, 적어도 약 40개, 적어도 약 60개, 적어도 약 80개, 적어도 약 100개, 적어도 약 120개, 적어도 약 140개, 적어도 약 160개, 적어도 약 180개 또는 약 200개에 대해 제공된다. 바람직한 구현예에서, 유사성 또는 동일성 정도는 기준 아미노산 서열의 전장에 대해 제공된다. 서열 유사성, 바람직하게는 서열 동일성을 결정하기 위한 정렬은 당해 기술 분야에 공지된 툴을 사용해, 바람직하게는 최상의 서열 정렬을 적용해, 예를 들어 Align을 표준 세팅으로, 바람직하게는 EMBOSS::needle, Matrix: Blosum62, Gap Open 10.0, Gap Extend 0.5에서 수행할 수 있다.
"서열 유사성"은 동일하거나 또는 보존적인 아미노산 치환인 아미노산의 %를 나타낸다. 2개의 아미노산 서열 간의 "서열 동일성"은 서열 간에 동일한 아미노산의 %를 나타낸다.
용어 "동일성 %"는 비교할 서열 2종을 최적으로 정렬한 서열들 간의 동일한 뉴클레오티드의 %를 나타내는 것으로 의도되며, %는 전적으로 통계에 의한 것이며, 서열 2종 간의 차이는 전체 길이에서 무작위로 분포한다. 아미노산 서열 2종 간의 서열 비교는 서열을 최적으로 정렬한 다음 이들 서열을 비교함으로써 통례적으로 이루어지며, 비교는 서열 유사성을 가진 국소 영역을 식별 및 비교하기 위해 세그먼트에 의해 또는 "비교 창"에 의해 수행된다. 비교 서열들의 최적의 정렬은 Smith and Waterman, 1981, Ads App. Math. 2, 482의 국소 상동성 알고리즘을 이용하거나, Neddleman and Wunsch, 1970, J. Mol. Biol. 48, 443의 국소 상동성 알고리즘을 이용하거나, Pearson and Lipman, 1988, Proc. Natl Acad. Sci. USA 85, 2444의 유사성 검색 방법을 이용하거나, 또는 이들 알고리즘을 이용하는 컴퓨터 프로그램을 이용함으로써, 생성할 수 있다 (GAP, BESTFIT, FASTA, BLAST P, BLAST N and TFASTA in Wisconsin Genetics Software Package, Genetics Computer Group, 575 Science Drive, Madison, Wis.).
동일성 %는 비교 서열 2종 간에 동일한 위치의 개수를 확인하고, 개수를 비교하는 위치들의 개수로 나눈 다음 그 결과를 100으로 곱하여 계산하여, 이들 서열 2종 간의 동일성 %를 구한다.
본원에 기술된 펩타이드 및 아미노산 변이체는 예를 들어 고상 합성 (Merrifield, 1964) 및 유사 방법에 의해, 또는 재조합 DNA 조작에 의해서와 같이, 공지된 펩타이드 합성 기법을 이용해 쉽게 제조할 수 있다. 치환, 삽입 또는 결손을 가진 단백질 및 펩타이드를 제조하기 위한 DNA 서열 조작은, 예를 들어, Sambrook et al. (1989)에 상세히 기술되어 있다.
본 발명에서, 용어 "펩타이드" 또는 "단백질"은 "펩타이드의 유도체 및 단백질의 유도체"를 포함한다. 이러한 유도체는 펩타이드의 변형된 형태 및 단백질의 변형된 형태이다. 이러한 변형은 임의의 화학적 변형을 포함하며, 탄수화물, 지질, 단백질 및/또는 펩타이드와 같이, 펩타이드 및 단백질과 조합된 임의의 분자의 하나 또는 복수의 치환, 결손 및/또는 부가를 포함한다. 용어 "유도체"는 또한 이러한 펩타이드 및 단백질의 모든 기능적 화학 등가체로까지 확장된다. 바람직하게는, 변형된 펩타이드는 증가된 안정성 및/또는 증가된 면역원성을 가진다.
본 발명의 파이브로넥틴 엑스트라 도메인 B 결합제는 치료학적 방식에 사용할 수 있다. 이를 위해, 본 발명의 파이브로넥틴 엑스트라 도메인 B 결합제에 하나 이상의 치료학적 작동자 모이어티를 공유결합적으로 및/또는 비-공유결합적으로 결합시킬 수 있거나, 및/또는 다양한 성분과 조합하여 약제학적으로 허용가능한 조성물로 제조할 수 있다. 본원에 기술된 펩타이드와 같은 물질은 임의의 적절한 약학적 조성물의 형태로 투여할 수 있다.
"표적 세포"는 암 세포와 같은 임의의 부적절한 세포를 의미할 것이다. 바람직한 구현예에서, 표적 세포는, 예를 들어, 파이브로넥틴 엑스트라 도메인 B에 인접하게 공간적으로 결합되어 있거나 또는 이와 조합되며, 예를 들어, 표적 세포는 파이브로넥틴 엑스트라 도메인 B를 발현하는 종양 세포 및/또는 내피 세포와 같은 세포를 수반하는 암 또는 종양 내에 존재한다. 일 구현예에서, 파이브로넥틴 엑스트라 도메인 B는 종양 조직의 세포외 기질에서와 같이 종양 조직 내 및/또는 종양 조직 주변 및/또는 종양 신혈관과 같이 종양 혈관 내 및/또는 종양 혈관에서 발현된다.
본 발명에서, 용어 "치료학적 작동자 모이어티 (therapeutic effector moiety)"는 치료학적 효과를 발휘할 수 있는 임의 분자를 의미한다. 본 발명에서, 치료학적 작동자 모이어티는 바람직하게는 파이브로넥틴 엑스트라 도메인 B 또는 파이브로넥틴 엑스트라 도메인 B와 공간적으로 연결되거나 파이브로넥틴 엑스트라 도메인 B와 조합된 세포로 선택적으로 안내된다. 암 세포에 대해 치료학적 효과를 발휘하는 임의 물질은 파이브로넥틴 엑스트라 도메인 B 결합제에 접합하기 위한 약물로서 사용할 수 있다. 바람직하게는, 약물의 접합은, 본원에 기술된 바와 같이, 파이브로넥틴 엑스트라 도메인 B 결합제의 결합 특징, 특이성을 변형시키지 않거나 또는 현저하게 변형시키지 않는다.
본 발명에서, 치료학적 작동자 모이어티는 항암제, 방사성 동위원소, 예를 들어 방사성 요오드-표지된 화합물, 독소, 세포분열억제 약물 (cytostatic drug) 또는 세포용해 약물 (cytolytic drug) 등을 포함한다. 항암제는, 예를 들어, 아미노글루테티미드, 아자티오프린 (azathioprine), 블레오마이신 (bleomycin) 설페이트, 부설판 (busulfan), 카르무스틴 (carmustine), 클로람부실 (chlorambucil), 시스플라틴 (cisplatin), 사이클로포스파미드 (cyclophosphamide), 사이클로스포린 (cyclosporine), 시타라비딘 (cytarabidine), 다카르바진 (dacarbazine), 닥티노마이신 (dactinomycin), 다우노루빈 (daunorubin), 독소루비신 (doxorubicin), 탁솔 (taxol), 에토포시드 (etoposide), 플루오로우라실, 인터페론-α, 로무스틴 (lomustine), 머캅토퓨린 (mercaptopurine), 메토트렉세이트 (methotrexate), 미토탄 (mitotane), 프로카바진 (procarbazine) HCl, 티오구아닌, 빈블라스틴 (vinblastine) 설페이트 및 빈크리스틴 (vincristine) 설페이트를 포함한다. 다른 항암제들도, 예를 들어, Goodman and Gilman, "The Pharmacological Basis of Therapeutics", 8th Edition, 1990, McGraw-Hill, Inc., 특히 Chapter 52 (Antineoplastic Agents (Paul Calabresi and Bruce A. Chabner)에 기술되어 있다. 독소는 포크위드 (pokeweed) 항-바이러스 단백질, 콜레라 독소, 백일해 독소, 리신, 겔로닌 (gelonin), 아브린 (abrin), 디프테리아 외독소 또는 슈도모나스 외독소와 같은 단백질일 수 있다. 독소 잔기는 코발트-60 등의 고 에너지-방출성 방사핵종일 수 있다.
치료학적 작동자 모이어티로는, 특히 세포독소 또는 세포독성 물질을 포함한다. 세포독소 또는 세포독성 물질로는 세포에 유해하며, 특히 세포를 사멸시키는 임의 물질을 포함한다.
유용한 세포독성 물질 클래스로는, 예를 들어, 항-튜불린제 (antitubulin agent), DNA 작은 고랑 결합제 (DNA minor groove binder) (예, 엔다이인 (enediyne) 및 렉시트롭신 (lexitropsin)), DNA 복제 저해제, 알킬화제 (예, 플라티늄 착물, 예로, cis-플라틴, 모노(플라티늄), 비스(플라티늄) 및 트리-뉴클레어 플라티늄 착물 및 카보플라틴 (carboplatin)), 안트라사이클린, 항생제, 항-폴레이트, 항-대사산물제, 화학요법 감작제 (chemotherapy sensitizer), 두오카르마이신 (duocarmycin), 에토포시드 (etoposide), 불소화 피리미딘, 이오노포어 (ionophore), 니트로소우레아, 플라티놀 (platinol), 기-형성 화합물 (pre-forming compound), 퓨린 항-대사산물제, 푸로마이신 (puromycin), 방사성 감작제 (radiation sensitizer), 스테로이드, 탁산 (예를 들어, 파클리탁셀 (paclitaxel) 및 도세탁셀 (docetaxel)), 토포이소머라제 저해제, 빈카 알칼로이드 또는 유사 물질 등이 있다.
개별 세포독성 물질로는, 예를 들어, 안드로겐, 안트라마이신 (anthramycin, AMC), 아스파라기나제, 5-아자시티딘, 아자티오프린, 블레오마이신, 부설판, 부티오닌 설폭스이민 (buthionine sulfoximine), 캄프토테신 (camptothecin), 카보플라틴 (carboplatin), 카르무스틴 (carmustine) (BSNU), CC-1065, 클로람부실 (chlorambucil), 시스플라틴 (cisplatin), 콜히친, 사이클로포스파미드 (cyclophosphamide), 시타라빈 (cytarabine), 시티딘 아라비노사이드, 시토칼라신 B (cytochalasin B), 다카르바진 (dacarbazine), 닥티노마이신 (dactinomycin) (종래에, 액티노마이신 (actinomycin)), 다우노루비신 (daunorubicin), 데카르바진 (decarbazine), 도세탁셀 (docetaxel), 독소루비신, 에스트로겐, 5-플루오르데옥시우리딘, 5-플루오로우라실, 그라미시딘 D (gramicidin D), 하이드록시우레아, 이다루비신 (idarubicin), 이포스파미드 (ifosfamide), 이리노테칸 (irinotecan), 로무스틴 (lomustine) (CCNU), 메클로르에타민 (mechlorethamine), 멜팔란 (melphalan), 6-머캅토퓨린, 메토트렉세이트 (methotrexate), 미트라마이신 (mithramycin), 미토마이신 (mitomycin) C, 미톡산트론 (mitoxantrone), 니트로이미다졸, 파클리탁셀, 플리카마이신 (plicamycin), 프로카비진 (procarbizine), 스트렙토조톡신 (streptozotocin), 테노포시드 (tenoposide), 6-티오구아닌, 티오TEPA, 토포테칸 (topotecan), 빈블라스틴 (vinblastine), 빈크리스틴 (vincristine), 비노렐빈 (vinorelbine), VP-16 및 VM-26 등이 있다.
항-튜불린제의 예로는, 비-제한적으로, 돌라스타틴 (dolastatin) (예를 들어, 아우리스타틴 (auristatin) E, AFP, MMAF, MMAE, AEB, AEVB), 메이탄시노이드 (maytansinoid), 탁산 (예를 들어, 파클리탁셀, 도세탁셀), T67 (Tularik), 빈카 알킬로이드 (vinca alkyloid) (예를 들어, 빈크리스틴 (vincristine), 빈블라스틴 (vinblastine), 빈데신 (vindesine) 및 비노렐빈 (vinorelbine)), 바카틴 (baccatin) 유도체, 탁산 유사체 (예를 들어, 에포틸론 (epothilone) A 및 B), 노코다졸 (nocodazole), 콜히친 및 콜시미드 (colcimid), 에스트라무스틴 (estramustine), 크립토피신 (cryptophysin), 세마도틴 (cemadotin), 콤브레타스타틴 (combretastatin), 디스코더몰라이드 (discodermolide) 및 엘루테로빈 (eleutherobin) 등이 있다.
세포독성 방사성의약품 (cytotoxic radiopharmaceuticals)을 제조하기 위한 방사성 동위원소로는 예를 들어 요오드-131, 이트륨-90 또는 인듐-111 등이 있다.
치료학적 작동자 모이어티 (약물)를 펩타이드에 접합하는 기법은 잘 알려져 있다. 펩타이드-약물 접합체의 제조는 당해 기술 분야의 당업자에게 공지된 임의 기법으로 달성할 수 있다. 펩타이드 및 약물은 자신의 링커 기를 통해 서로 직접 결합시키거나 또는 링커 또는 다른 물질을 통해 간접적으로 결합시킬 수 있다.
약물을 펩타이드에 공유 결합하기 위해 다수의 여러가지 반응들을 이용할 수 있다. 이는, 대개 라이신의 아민 기, 글루탐산 및 아스파르트산의 유리 카르복시산 기, 시스테인의 설프하이드릴 기 및 방향족 아미노산의 다양한 모이어티 등의, 펩타이드 분자의 아미노산 잔기와의 반응을 통해, 달성된다. 가장 일반적으로 사용되는 비-특이적인 공유 결합 방법들 중 한가지 방법은 펩타이드의 아미노 (또는 카르복시) 기에 화합물의 카르복시 (또는 아미노) 기를 연결하는 카르보디이미드 반응이다. 또한, 다이알데하이드 또는 이미도에스테르와 같은 2 관능성 물질을 사용해 화합물의 아미노 기를 펩타이드 분자의 아미노 기에 연결한다. 또한, 약물을 펩타이드에 부착시키기 위해 시프 염기 (Schiff base) 반응을 이용할 수도 있다. 이 방법은 글리콜 또는 하이드록시 기를 함유한 약물의 과요오드 산화를 수반하며, 이로써 알데하이드가 형성되며, 이후 알데하이드를 펩타이드 분자와 반응시킨다. 결합은 펩타이드 분자의 아미노 기와의 시프 염기의 형성을 통해 이루어진다. 또한, 이소티오시아네이트는 약물을 펩타이드에 공유 결합시키기 위한 커플링제로서 사용할 수 있다. 다른 기법들도 당해 기술 분야의 당업자들에게 공지되어 있으며, 본 발명의 범위에 속한다.
펩타이드-약물 접합체를 제조하기 위한 당해 기술 분야에 공지된 여러가지 연결성 기들이 존재한다. 링커는 바람직하게는 펩타이드 및 약물 중 하나 또는 양쪽과 반응하는 하나 이상의 관능기를 포함한다. 관능기의 예로는 아미노, 카르복실, 머캅토, 말레이미드 및 피리디닐 기 등이 있다.
본 발명의 일 구현예에서, 펩타이드는 2 관능성 가교제 (bifunctional crosslinking reagent)를 통해 약물과 연결된다. 본원에서 "2 관능성 가교제"는 펩타이드와 반응할 수 있는 하나와 펩타이드를 약물에 연결하도록 약물과 반응할 수 있는 하나인 반응성 기 2개를 가지고 있어, 접합체를 형성할 수 있는 시약을 의미한다. 임의의 적합한 2 관능성 가교제는, 링커 시약이 약물, 예를 들어 펩타이드의 세포독성 및 표적화 특징을 유지하는 한, 본 발명과 관련하여 사용할 수 있다. 바람직하게는, 링커 분자는 화학적 결합을 통해 약물을 펩타이드에 연결하며, 그래서 약물과 펩타이드는 서로 화학적으로 커플링된다 (예, 공유 결합된다).
일 구현예에서, 2 관능성 가교제는 절단 불가능한 링커 (non-cleavable linker)를 포함한다. 절단 불가능한 링커는 약물을 펩타이드에 안정적이고 공유적인 방식으로 연결할 수 있는 임의의 화학적 모이어티이다. 바람직하게는, 절단 불가능한 링커는 생리학적 조건에서, 특히 체내에서 및/또는 세포 내에서 절단 불가능하다. 따라서, 절단 불가능한 링커는 펩타이드 또는 약물이 활성인 채 유지되는 조건에서 산-유도성 절단, 빛-유도성 절단, 펩티다제-유도성 절단, 에스테라제-유도성 절단 및 이황화 결합 절단에 대해 실질적으로 내성을 나타낸다. 약물과 펩타이드 간에 절단 불가능한 링커를 형성하는 적절한 가교제들은 당해 기술 분야에 잘 공지되어 있다. 일 구현예에서, 약물은 티오에테르 결합을 통해 펩타이드에 연결된다.
특히 바람직한 일 구현예에서, 링커 시약 (linking reagent)은 절단가능한 링커이다. 바람직하게는, 절단가능한 링커는 생리학적 조건에서, 특히 체내에서 및/또는 세포 내에서 절단가능하다. 적합한 절단가능한 링커의 예로는 다이설파이드 링커, 산 취약성 링커 (acid labile linker), 광 취약성 링커 (photolabile linker), 펩티다제 취약성 링커 및 에스테라제 취약성 링커 등이 있다.
링커의 예로는, 비-제한적으로, N-숙신이미딜-3-(2-피리딜다이티오)부티레이트 (SPDB), N-숙신이미딜-3-(2-피리딜다이티오)프로피오네이트 (SPDP), 설포숙신이미딜-4-(N-말레이미도메틸)사이클로헥산-1-카르복실레이트 (설포-SMCC), N-숙신이미딜-4-(말레이미도메틸)사이클로헥산카르복실레이트 (SMCC), N-숙신이미딜-4-(N-말레이미도메틸)-사이클로헥산-l-카르복시-(6-아미도카프로에이트) (LC-SMCC), 4-말레이미도부티르산 N-하이드록시숙신이미드 에스테르 (GMBS), 3-말레이미도카프로익산 N-하이드록시숙신이미드 에스테르 (EMCS), m-말레이미도벤조일-N-하이드록시숙신이미드 에스테르 (MBS), N-(α-말레이미도아세톡시)-숙신이미드 에스테르 (AMAS), 숙신이미딜-6-(β-말레이미도프로피온아미도)헥사노에이트 (SMPH), N-숙신이미딜-4-(p-말레이미도페닐)-부티레이트 (SMPB), N-(p-말레이미도페닐)이소시아네이트 (PMPI), 6-말레이미도카프로일 (MC), 말레이미도프로파노일 (MP), p-아미노벤질옥시카르보닐 (PAB), N-숙신이미딜-4-(2-피리딜티오)펜타노에이트 (SPP) 및 N-숙신이미딜 (4-요오도아세틸)아미노벤조에이트 (SIAB) 등이 있다. 발린-시트룰린 (Val-Cit) 또는 알라닌-페닐알라닌 (ala-phe)과 같은 펩타이드 링커 역시 사용할 수 있으며, 전술한 임의 링커들을 적절한 조합으로 사용할 수 있다.
다이설파이드 함유 링커는 생리학적 조건에서 발생할 수 있는 다이설파이드 교환을 통해 절단가능한 링커이다. 또 다른 구현예에서, 링커는 환원성 조건에서 절단가능하다 (예, 다이설파이드 링커). 예를 들어, SATA (N-숙신이미딜-5-아세틸티오아세테이트), SPDP (N-숙신이미딜-3-(2-피리딜다이티오)프로피오네이트), SPDB (N-숙신이미딜-3-(2-피리딜다이티오)부티레이트) 및 SMPT (N-숙신이미딜-옥시카르보닐-α-메틸-α-(2-피리딜-다이티오)톨루엔)을 이용해 형성할 수 있는 것들을 비롯하여, 다양한 다이설파이드 링커들이 당해 기술 분야에 공지되어 있다.
산 취약성 링커는 산성 pH에서 절단가능한 링커이다. 예를 들어, 엔도좀 및 리소좀과 같은 특정 세포내 구획은 산성 pH (pH 4-5)를 띠며, 산 취약성 링커를 절단하는데 적합한 조건을 제공한다. 산 취약성 링커는 혈액과 같은 중성 pH 조건에서 비교적 안정적이지만, pH 5.5 또는 5.0 미만에서는 불안정하다. 예를 들어, 하이드라존, 세미카르바존, 티오세미카르바존, cis-아코니틱 아미드, 오르토에스테르, 아세탈, 케탈 또는 유사 물질을 사용할 수 있다.
광 취약성 링커는 신체 표면에서, 그리고 빛이 접근할 수 있는 여러 신체 공동 (body cavity)에서 이용가능하다. 아울러, 적외선은 조직을 침투할 수 있다.
펩티다제 취약성 링커는 세포 내부 또는 세포 외부에서 특정 펩타이드를 절단하기 위해 사용할 수 있다. 일 구현예에서, 절단가능한 링커는 온화한 조건 (mild condition)에서, 즉 세포독성 물질의 활성이 영향을 받지 않는 세포 내 조건에서 절단된다.
링커는, 예를 들어, 비-제한적인 예로, 리소좀 또는 엔도좀 프로테아제 등의, 세포내 펩티다제 또는 프로테아제 효소에 의해 절단되는 펩티딜 링커이거나 또는 이를 포함할 수 있다. 전형적으로, 펩티딜 링커는 아미노산 2개 이상 길이 또는 아미노산 3개 이상 길이이다. 절단제는 카텝신 B 및 D와 플라스민을 함유할 수 있으며, 이들 모두 다이펩타이드 약물 유도체를 가수분해하여, 표적 세포 내부에서 활성 약물을 방출하는 것으로 알려져 있다. 예를 들어, 암성 조직 (cancerous tissue)에서 높은 수준으로 발현되는, 티올-의존적인 프로테아제 카텝신-B에 의해 절단가능한 펩티딜 링커를 사용할 수 있다 (예를 들어, Phe-Leu 또는 Gly-Phe-Leu-Gly 링커). 특정 구현예에서, 세포내 프로테아제에 의해 절단가능한 펩티딜 링커는 발린-시트룰린 (Val-Cit; vc) 링커 또는 페닐알라닌-라이신 (Phe-Lys) 링커이다. 치료학적 물질의 세포내 단백질 분해성 방출 (intracellular proteolytic release)을 이용하는 경우의 한가지 이점은, 전형적으로, 접합시 약독화되고, 접합체의 혈청 안정성이 전형적으로 높다는 점이다.
용어 "개체" 및 "대상"은 본원에서 상호 호환적으로 사용된다. 이들 용어는, 질환 또는 장애 (예를 들어, 암)에 걸릴 수 있거나 또는 걸리기 쉬울 수 있지만, 질환 또는 장애를 앓고 있거나 또는 앓고 있지 않을 수 있는, 인간, 인간을 제외한 영장류 또는 그외 포유류 (예, 마우스, 랫, 토끼, 개, 고양이, 소, 돼지, 양, 말 또는 영장류)를 지칭한다. 다수의 구현예들에서, 개체는 인간이다. 달리 언급되지 않은 한, 용어 "개체" 및 "대상"은 특정 연령을 지칭하는 것은 아니며, 따라서 성인, 노인, 어린이 및 신생아를 망라한다. 본 발명의 바람직한 구현예에서, "개체" 또는 "대상"은 "환자"이다. 용어 "환자"는 본 발명에서 치료하기 위한 대상, 특히 질환에 걸린 대상을 의미한다.
용어 "질환"은 개체의 신체에 영향을 미치는 비정상적인 병태를 지칭한다. 질환은 흔히 특이적인 증상 및 징후가 조합된 의학적인 상태로서 해석된다. 질환은 감염성 질환과 같은 외부적 소스로부터 기원하는 인자에 의해 유발되거나, 또는 자가면역 질환과 같은 내부의 기능 부전으로 인해 유발될 수 있다. 인간의 경우, "질환"은 종종 보다 광의적으로 앓고 있는 개체에게 통증, 기능 부전, 고통, 사회적 문제 또는 사망을 유발하거나 또는 개체와 접촉한 개체에게 유사한 문제를 일으키는 모든 병태를 지칭한다. 이러한 광의적인 의미에서, 이는 때때로 구조 및 기능의 상해, 불안정, 장애, 증후군, 감염, 고립된 증상 (isolated symptom), 비정상적인 거동 및 비정형적인 변형을 포함하나, 다른 맥락 및 다른 목적에서는 이는 구별가능한 범주로 간주될 수 있다. 다수의 질환과 접촉하고 생활하는 것이 삶에 대한 관점과 성격을 바꿀 수 있으므로, 질병은 일반적으로 개체에게 신체적으로뿐만 아니라 감정적으로도 영향을 미친다. 본 발명에서, 용어 "질환"은 암, 특히 본원에 언급된 암 형태를 포함한다. 본원에서 암, 또는 암의 특정 형태는 이의 암 전이를 포함한다. 바람직한 구현예에서, 본 발명에 따라 치료할 질환은 파이브로넥틴 엑스트라 도메인 B를 발현하는 세포를 수반한다.
본 발명에서, "파이브로넥틴 엑스트라 도메인 B를 발현하는 세포를 수반하는 질환" 또는 비슷한 표현은, 파이브로넥틴 엑스트라 도메인 B가 질환에 걸린 조직 또는 장기의 세포에 의해 발현되는 것을 의미한다. 일 구현예에서, 질환에 걸린 조직 또는 장기의 세포에 의한 파이브로넥틴 엑스트라 도메인 B의 발현은 건강한 조직 또는 장기에서의 상태보다 증가한다. 일 구현예에서, 발현은 질환에 걸린 조직에서만 발견되고, 건강한 조직에서의 발현은 억제된다. 본 발명에서, 파이브로넥틴 엑스트라 도메인 B를 발현하는 세포를 수반하는 질환은 암 질환을 포함한다. 아울러, 본 발명에서, 암 질환은 바람직하게는 세포가 파이브로넥틴 엑스트라 도메인 B를 발현하는 질환이다.
용어 "암 질환" 또는 "암"은 개체에서 전형적으로 통제를 벗어난 세포 증식을 특징으로 하는 생리학적 병태를 지칭하거나 또는 나타낸다. 암의 예로는, 비-제한적으로, 암종, 림프종, 모세포종, 육종 및 백혈병 등이 있다. 더 구체적으로, 이러한 암의 예로는 골암, 혈액암, 폐암, 간암, 췌장암, 피부암, 두경부암, 피부 또는 안내 흑색종, 자궁암, 난소암, 직장암, 항문암, 위암, 대장암, 유방암, 전립선암, 자궁암, 생식기 암종 (carcinoma of the sexual and reproductive organ), 호지킨 병, 식도암, 소장암, 내분비계 암, 갑상선암, 부갑상선암, 부신암, 연조직 육종, 방광암, 신장암, 신장 세포 암종, 신우 암종, 중추 신경계 (CNS)의 신생물, 신경외배엽암, 척추 종양, 신경교종, 수막종 및 뇌하수체 선종 등이 있다. 본 발명에서, 용어 "암"은 또한 암 전이를 포함한다. 바람직하게는, "암 질환"은 파이브로넥틴 엑스트라 도메인 B의 발현 또는 존재를 특징으로 한다.
"전이"는 암 세포가 본래의 부위에서 신체의 다른 부위로 퍼지는 것을 의미한다. 전이 발생은 매우 복잡한 과정으로, 원발성 종양으로부터 악성 세포의 탈착, 세포외 기질로의 침입, 체강 및 혈관에 들어가기 위한 내피 기저막 침투 및 이후 혈액에 의해 운반된 후 표적 장기로의 침윤에 의존한다. 마지막으로, 표적 부위에서 새로운 종양의 증식은 혈관신생에 의존한다. 종양 전이는 종종 종양 세포 또는 구성성분이 잔류하여 전이성 상태로 발전할 수 있으므로, 심지어 원발성 종양을 제거한 후에도 발생한다. 일 구현예에서, 본 발명에서 용어 "전이"는 원발성 종양 및 국소 림프절 시스템으로부터 멀리 떨어진 부위로의 전이를 의미하는 "먼거리 전이 (distant metastasis)"를 지칭한다. 일 구현예에서, 본 발명에서 용어 "전이"는 림프절 전이를 지칭한다.
본 발명에서, 용어 "종양" 또는 "종양 질환"은 바람직하게는 종창 (swelling) 또는 병변을 형성하는, 세포의 비정상적인 증식 (신생물성 세포, 종양형성 세포 또는 종양 세포로 지칭됨)을 지칭한다. "종양 세포"는 제어되지 않는 빠른 세포 증식으로 증식하며 개시된 새로운 증식을 중단시키는 자극 후에도 계속 증식하는, 비정상적인 세포를 의미한다. 종양은 정상 조직과의 구조적인 조직화 및 기능적 협조에 일부 또는 완전한 결여를 보이며, 일반적으로 양성, 전-악성 또는 악성일 수 있는 구분되는 조직 덩어리를 형성한다. 본 발명에서, "암 질환"은 바람직하게는 "종양 질환"이다. 그러나, 일반적으로 용어 "암" 및 "종양"은 본원에서 상호 호환적으로 사용된다.
바람직하게는, 본 발명에서 종양 질환은 암 질환, 즉 악성 질환이고, 종양 세포는 암 세포이다. 바람직하게는, 종양 질환 또는 암 질환은 파이브로넥틴 엑스트라 도메인 B의 존재를 특징으로 한다. 일 구현예에서, 암은 파이브로넥틴 엑스트라 도메인 B-양성 암이다.
사람이 과거에 발생한 병태를 다시 앓을 경우 재발 또는 재현이 발생한다. 예를 들어, 환자가 종양 질환을 앓았으며 성공적인 질환 치료를 받았지만 다시 질환이 발생하였다면, 신규 발생한 질환은 재발 또는 재현으로 간주할 수 있다. 그러나, 본 발명에서, 종양 질환의 재발 또는 재현은 오리지널 종양 질환 부위에서 발생할 수 있지만, 반드시 그런 것은 아니다. 종양의 재발 또는 재현은, 오리지널 종양 부위뿐 아니라 오리지널 종양 부위와는 다른 부위에서 종양이 발생하는 경우를 또한 포함한다. 바람직하게는, 환자가 치료받은 오리지널 종양은 원발성 종양이고, 오리지널 종양 부위와는 다른 부위에서의 종양은 이차 또는 전이성 종양이다.
용어 "치료" 또는 "치료학적 치료"는 개체의 건강 상태를 개선하거나 및/또는 수명을 연장하는 (늘이는) 임의의 처치를 의미한다. 이러한 치료는 개체에서 질환을 제거할 수 있거나, 개체에서 질환의 진행을 중단 또는 늦출 수 있거나, 개체에서 질환의 진행을 저해하거나 또는 서행시킬 수 있거나, 또는 개체에서 증상의 진도 및 중증도를 낮출 수 있거나, 및/또는 현재 질환을 앓고 있거나 이전에 질환에 걸렸던 개체에서 재발을 낮출 수 있다.
용어 "예방학적 치료" 또는 "방지적 치료 (preventive treatment)"는 개체에서 질환의 발생을 방지하기 위한 모든 처치를 의미한다. 용어 "예방학적 치료" 또는 "방지적 치료"는 본원에서 상호 호환적으로 사용된다. 예를 들어, 암 발병 위험이 있는 개체는 암을 방지하기 위한 후보일 것이다.
"위험이 있는"은 일반 대중과 비교해 질환, 특히 암의 정상적인 발병 가능성 보다 높은 것으로 동정되는 개체를 의미한다. 또한, 질환, 특히 암을 앓았거나 또는 현재 앓고 있는 개체는, 개체에서 계속 질환이 발생할 수 있으므로, 질환 발병 위험이 높은 개체이다. 현재 또는 과거에 암을 앓았던 개체는 또한 암 전이 위험성이 증가한다.
암의 (치료학적) 치료는 외과적 시술, 화학요법, 방사능 요법 및 타겟 요법 (targeted therapy)으로 이루어진 군으로부터 선택할 수 있다.
본원에서, 용어 "외과적 시술"은 수술에서 종양을 제거하는 것을 포함한다. 이는 암에서 일반적인 치료법이다. 외과의는 국소 절제를 이용해 종양을 제거할 수 있다.
본원에서, 용어 "화학요법"은 화학치료제 또는 화학치료제의 조합을, 바람직하게는 세포를 사멸하거나 또는 세포의 분열을 중단시킴으로써 암 세포의 증식을 정지시키기 위해 사용하는 것을 의미한다. 화학요법을 경구로 복용하거나 또는 정맥 또는 근육으로 주사하는 경우, 약물은 혈류로 들어가, 전신으로 퍼져 암 세포에 도달할 수 있다 (전신성 화학요법). 화학요법이 뇌척수액, 장기 또는 복부와 같은 체강으로 직접 배치되는 경우, 약물은 주로 이들 영역에서 암 세포에 영향을 미친다 (국소 화학요법).
본 발명에 따른 화학치료제는 세포 증식 억제 화합물 및 세포독성 화합물을 포함한다. 전통적인 화학치료제는 대부분의 암 세포의 주요 특징들 중 하나인 빨리 분열하는 세포를 사멸시킴으로써 작용한다. 이는, 화학요법이 골수, 소화관 및 모낭 내 세포와 같이 정상적인 상황에서 빨리 분열하는 세포에도 유해하다는 것을 의미한다. 이는 화학요법의 가장 일반적인 부작용을 야기한다. 암에서 비정상적으로 발현되고 (예, 파이브로넥틴 엑스트라 도메인 B), 물질에 접합된 치료학적 모이어티 또는 물질을 통해 작용하는 물질은, 화학요법의 형태로 볼 수 있다. 그러나, 엄격한 의미에서는, 본 발명에서, 용어 "화학요법"은 표적 요법 (targeted therapy)을 포함하지 않는다.
본 발명에서, 용어 "표적 요법"은 암 조직 또는 세포와 같이 병에 걸린 장기, 조직 또는 세포를 선호적으로 표적화하기 위해 이용할 수 있으며, 병에 걸리지 않은 장기, 조직 또는 세포는 표적화하지 않거나 또는 더 낮은 수준으로 표적화하는, 임의의 요법을 지칭한다. 병에 걸린 장기, 조직 또는 세포를 표적화하여, 바람직하게는 병에 걸린 세포를 죽이거나, 및/또는 병에 걸린 세포의 증식 또는 생존성을 악화시킨다. 이러한 요법은, i) 치료학적 모이어티를 전달하기 위해, 특정 표적, 예를 들어 파이브로넥틴 엑스트라 도메인 B를 표적화하는, 치료학적 모이어티가 접합된 물질 (예, 치료학적 모이어티가 접합된 파이브로넥틴 엑스트라 도메인 B 결합제), 또는 ii) 특정 표적, 예를 들어, 파이브로넥틴 엑스트라 도메인 B를 표적화하며, 병에 걸린 세포의 증식, 전파, 이동 및/또는 생존성을 손상시키는 물질 (예, 치료학적 모이어티가 접합된 또는 치료학적 모이어티가 접합되지 않은 파이브로넥틴 엑스트라 도메인 B 결합제)을 포함한다.
본 발명에 따라 기술된 약학적 조성물 및 치료 방법을 이용해, 본원에 기술된 질환을 치료학적으로 치료 또는 예방할 수 있다. 암에 대한 효과를 검사하기 위해 동물 모델을 이용하는 것도 가능하다. 예를 들어, 인간 암 세포를 마우스에 도입하여 종양을 발생시킬 수 있다. 암 세포에 대한 효과 (예를 들어, 종양 크기의 감소)는 동물에 투여된 물질의 효능 척도로서 측정할 수 있다.
펩타이드는 자체 공지된 방식으로 투여할 수 있다. 일반적으로, 펩타이드 투여량 1 ng 내지 1 mg, 바람직하게는 10 ng 내지 100 ㎍이 제형화되고 투여된다.
핵산 (DNA 및 RNA)을 투여하는 것이 바람직할 경우, 1 ng 내지 0.1 mg의 투여량을 제형화 및 투여할 수 있다.
일 구현예에서, 핵산은 생체외 방법에 의해, 즉 환자로부터 세포를 취하고, 세포를 유전자 변형시켜 핵산을 삽입한 다음 변형된 세포를 환자에게 재도입함으로써, 투여할 수 있다. 이는, 일반적으로, 유전자의 기능성 카피를 환자의 세포에 시험관내에서 도입하고, 유전자 변형된 세포를 환자에게 재도입하는 것을 포함한다. 유전자의 기능성 카피는 유전자 변형된 세포에서 유전자가 발현되도록 할 수 있는 조절 인자의 기능적 제어 하에 배치된다. 형질감염 및 형질도입 방법은 당해 기술 분야의 당업자들에게 공지되어 있다.
또한, 본 발명은 예를 들어 바이러스와 같은 벡터 및 표적-제어성 리포좀 (target-controlled liposomes)을 이용함으로써 핵산을 생체내 투여하기 위해 제공된다.
바람직한 구현예에서, 핵산을 투여하기 위한 바이러스 또는 바이러스 벡터는 아데노바이러스, 아데노-부속 바이러스 (adeno-associated viruse), 백시니아 바이러스 (vaccinia virus) 및 약독화된 폭스 바이러스 (attenuated pox viruse) 등의 폭스 바이러스 (pox viruse), 셈리키 포레스트 바이러스 (Semliki Forest virus), 레트로바이러스, 신드비스 바이러스 (Sindbis virus) 및 Ty 바이러스-유사 입자 (Ty virus-like particle)로 이루어진 군으로부터 선택된다. 특히 바람직하게는, 아데노바이러스 및 레트로바이러스에 제공된다. 레트로바이러스는 전형적으로 복제-결함성 (replication-deficient)이다 (즉, 이는 감염성 입자를 만들지 못함).
핵산을 세포에 시험관내 또는 생체내 도입하는 방법은 핵산 칼슘 포스페이트 침강, DEAE와 조합한 핵산의 형질감염, 대상 핵산을 운반하는 상기한 바이러스를 이용한 형질감염 또는 감염, 리포좀-매개 형질감염 등을 포함한다. 특정 구현예에서, 핵산을 특정 세포로 향하게 하는 것이 바람직하다. 이러한 구현예에서, 핵산을 세포에 투여하기 위해 사용되는 담체 (예, 레트로바이러스 또는 리포좀)는 결합된 표적 제어 분자를 가질 수 있다. 예를 들어, 표적 세포 상의 표면 막 단백질에 특이적인 항체 또는 표적 세포 상의 수용체에 대한 리간드와 같은 분자를 핵산 담체에 부착시키거나 또는 핵산 담체에 병합할 수 있다. 바람직한 항체는 종양 항원에 선택적으로 결합하는 항체를 포함한다. 핵산을 리포좀을 통해 투여하는 것이 바람직할 경우, 엔도사이토시스와 관련된 표면 막 단백질에 결합하는 단백질을 리포좀 제형에 포함시켜, 표적 제어 및/또는 흡수를 가능케할 수 있다. 이러한 단백질은 특정 세포 타입에 특이적인 캡시드 단백질 또는 이의 단편, 내재화되는 단백질에 대한 항체, 세포내 부위로 향하는 단백질 등을 포함한다.
본 발명의 치료학적 활성 화합물은 주사 또는 주입 등의 임의의 통례적인 경로를 통해 투여할 수 있다. 투여는, 예를 들어, 경구, 정맥내, 복막내, 근육내, 피하 또는 경피로 수행할 수 있다. 투여는 국소 또는 전신 투여일 수 있으며, 바람직하게는 전신 투여일 수 있다.
용어 "전신 투여"는 물질이 유의한 함량으로 개체 신체에 널리 퍼지게 하여 원하는 효과를 발생시키도록 물질을 투여하는 것을 의미한다. 예를 들어, 물질은 혈관계를 통해 원하는 작용 부위에 도달하거나 및/또는 혈액에서 원하는 효과를 발휘할 수 있다. 전형적인 전신 투여 경로는 혈관계로의 물질의 직접 도입에 의한 투여, 경구, 폐 또는 근육내 투여를 포함하며, 물질은 흡수되어 혈관계로 유입되며, 혈액을 통해 하나 이상의 원하는 부위(들)로 이동한다.
본 발명에서, 전신 투여는 비경구 투여에 의한 것이 바람직하다. 용어 "비경구 투여"는 물질이 장을 통과하지 않도록 물질을 투여하는 것을 의미한다. 용어 "비경구 투여"는 정맥내 투여, 피하 투여, 진피내 투여 또는 동맥내 투여를 포함하지만, 이들로 한정되는 것은 아니다.
본 발명의 약학적 조성물은 바람직하게는 무균성이며, 원하는 반응 또는 원하는 효과를 발휘하기 위해, 본원에 기술된 물질을 유효량으로, 또한 선택적으로 본원에 기술된 추가적인 물질을 포함한다.
약학적 조성물은 일반적으로 균일한 투약 형태 (uniform dosage form)로 제공되며, 자체 공지된 방식으로 조제할 수 있다. 약학적 조성물은, 예를 들어, 용액 또는 현탁액 형태일 수 있다.
약학적 조성물은 염, 완충제 물질, 보존제, 담체, 희석제 및/또는 부형제를 포함할 수 있으며, 이들 모두 바람직하게는 약제학적으로 허용가능하다. 용어 "약제학적으로 허용가능한"은 약학적 조성물의 활성 성분의 작용과 상호작용하지 않는 물질의 무독성을 의미한다.
약제학적으로 허용가능하지 않은 염도 약제학적으로 허용가능한 염을 제조하기 위해 이용할 수 있으며, 이 역시 본 발명에 포함된다. 이러한 유형의 약제학적으로 허용가능한 염은 다음과 같은 산으로부터 제조된 것을 비-제한적인 방식으로 포함한다: 염산, 브롬화수소산, 황산, 질산, 인산, 말레산, 아세트산, 살리실산, 시트르산, 포름산, 말론산, 숙신산 등. 또한, 약제학적으로 허용가능한 염은 소듐염, 포타슘염 또는 칼슘염과 같은 알칼리 금속염 또는 알칼리 토금속염으로 제조될 수 있다.
약학적 조성물에 사용하기에 적합한 완충제는 염 형태의 아세트산, 염 형태의 구연산, 염 형태의 붕산 및 염 형태의 인산을 포함한다.
약학적 조성물에 사용하기 적합한 보존제는 벤즈알코늄 클로라이드, 클로로부탄올, 파라벤 및 티메로살을 포함한다.
용어 "담체"는, 이용을 용이하게 하거나, 강화하거나 또는 달성하기 위해 활성 성분과 조합되는, 천연 또는 합성 특성의 유기 또는 무기 성분을 지칭한다. 본 발명에서, 용어 "담체"는 또한 환자에게 투여하기 적합한, 하나 이상의 혼용가능한 고체 또는 액체 충전제, 희석제 또는 캡슐화 물질을 포함한다.
비경구 투여에 가능한 담체 물질은, 예를 들어, 멸균수, 링거, 링거 락테이트, 무균성 염화나트륨 수용액, 폴리알킬렌 글리콜, 수소화 나프탈렌 (hydrogenated naphthalene)이며, 특히 생체적합한 락티드 폴리머, 락티드/글리콜라이드 코폴리머 또는 폴리옥시에틸렌/폴리옥시프로필렌 코폴리머이다.
주사가능한 제형은 링거 락테이트와 같은 약제학적으로 허용가능한 부형제를 포함할 수 있다.
본원에서 용어 "부형제"는 약학적 조성물에 존재할 수 있으며, 예를 들어 담체, 결합제, 윤활제, 증점제, 계면활성제, 보존제, 유화제, 완충제, 향미제 또는 착색제와 같이 활성 성분이 아닌, 모든 물질을 지칭하는 것으로 의도된다.
본원에 기술된 물질 및 조성물은 유효량으로 투여한다. "유효량"은 단독으로 또는 추가의 투여량과 함께 원하는 반응 또는 원하는 효과를 달성하는 양을 의미한다. 특정 질환 또는 특정 병태를 치료하는 경우, 원하는 반응은 바람직하게는 질환의 과정 (course)의 저해를 의미한다. 이는 질환의 진행 (progress) 서행, 특히 질환의 진행 중단 또는 반전을 포함한다. 질환 또는 병태의 치료에서 원하는 반응은 또한 질환 또는 병태의 개시 지연 또는 개시 예방일 수 있다.
본원에 기술된 물질 또는 조성물의 유효량은 치료학적 병태, 질환의 중증도, 나이, 신체 조건, 신장 및 체중 등의 환자의 개별 파라미터, 치료 기간, (존재하는 경우) 병용 요법 (accompanying therapy)의 타입, 구체적인 투여 경로 및 유사 인자에 따라 결정될 것이다. 즉, 본원에 기술된 물질이 투여되는 투여량은 이러한 다양한 파라미터에 따라 결정될 수 있다. 환자에서 반응이 초기 투여량으로 충분하지 않을 경우, 더 높은 투여량 (또는 다른 더 국소적인 투여 경로에 의해 달성되는 효과적으로 더 높은 투여량)을 이용할 수 있다.
본원에 기술된 물질 및 조성물은 환자에게, 예를 들어 생체내 투여하여, 본원에 기술된 등의 다양한 장애를 치료 또는 예방할 수 있다. 바람직한 환자는 본원에 기술된 물질 및 조성물을 투여함으로써 교정하거나 또는 개선할 수 있는 장애를 가진 인간 환자를 포함한다. 이는 파이브로넥틴 엑스트라 도메인 B의 발현 패턴 변형을 특징으로 하는 장애를 포함한다.
예를 들어, 일 구현예에서, 본원에 기술된 물질은 암 질환, 예를 들어 파이브로넥틴 엑스트라 도메인 B의 존재를 특징으로 하는 본원에 기술된 암 질환을 앓고 있는 환자를 치료하기 위해 사용할 수 있다.
실시예
본원에 사용되는 기법 및 방법은 본원에 기술되거나, 또는 자체 공지되고 예를 들어 Sambrook et al., Molecular Cloning: A Laboratory Manual, 2nd Edition (1989) Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y.에 언급된 방식으로 수행한다. 키트 및 시약의 사용을 비롯한 모든 방법은 구체적으로 명시되지 않은 한, 제조사의 정보에 따라 수행한다.
실시예
1: 재료 및 방법
표적
발현, 정제 및
바이오틴화
(
biotinylation
)
본 실험에서 재조합 인간 파이브로넥틴 EDB를 단일 도메인 (FN-B, Uniprot ID P02751, 이소형 7, 아미노산 E1265-T1355)으로 또는 이를 둘러싼 타입 III 도메인 (FN-67B89, 아미노산 G1080-E1455)이 측면에 위치한 형태로 표적 단백질로 사용하였으며, EDB (FN-6789) 없는 도메인 6-9를 대조군으로 사용하였다. 모든 변이체들은 E. coli에서 C-말단 헥사히스티딘 (H6) 태그와 함께 발현시키고, 고정된 금속 이온 친화성 크로마토그래피 (IMAC) 및 크기 배제 크로마토그래피 (SEC)를 통해 정제하였다. 이를 위해, 코돈-최적화된 DNA 서열을 Thermo Fisher Scientific 사에서 합성하여, pET-21a 발현 벡터 (Novagen)에 클로닝한 다음 E. coli BL21 (DE3) 세포 (Agilent)에 도입하였다. OD600이 약 0.7에 도달할 때까지 750-mL 규모에서 30℃ 및 120 rpm 조건 하에 단백질을 발현시켰다. 단백질 생산을 유도하기 위해, 1 M IPTG 750 ㎕를 주-배양물에 첨가하여, 25℃에서, 120 rpm 하에 밤새 배양하였다. 세포를 회수하여 10 mL 평형 완충제 (20 mM Tris-HCl pH 8.0, 10% 글리세롤, 500 mM NaCl, 10 mM 이미다졸)에 재현탁하였으며, 음파처리 (sonification) (Branson Digital Sonifier 250)에 의해 세포용해하였다. 상층액을 1 mL HisTrap 컬럼 (GE Healthcare)에서 AKTAprime™ 플러스 시스템 (GE Healthcare) 및 20분간 10-500 mM 이미다졸의 선형 농도구배를 이용한 IMAC에 의해 정제하였다. 그런 후, 단백질을 PBS (14 mM NaCl, 2.7 mM KCl, 10 mM Na2HPO4, 1.8 mM KH2PO4, pH 7.5)에 대해 4℃에서 밤새 투석하고, (FN-67B89 및 FN-6789의 경우) HiLoad 26/600 Superdex 200 pg 또는 (FN-B의 경우) 75 pg 컬럼 (GE Healthcare)을 이용한 크기 배제 크로마토그래피에 의해 추가적으로 정제하였다. 최종 정제된 단백질을 SDS-PAGE, 분석용 SEC 및 EDB 특이적인 BC-1 항체 (ab154210, Abcam)를 이용한 ELISA에 의해 분석하였다. 단백질은 5% 만니톨 및 5% 트레할로스가 첨가된 PBS 중에 분액하여 -20℃에서 보관하였다.
FN-B, FN-67B89 및 FN-6789 단백질을 EZ-Link 설포-NHS-LC-Biotin (Thermo Fisher Scientific)을 제조사의 지침에 따라 사용해 일차 NH2-기를 통해 바이오틴화하였다.
FN
-
67B89
표적 단백질의 품질 관리
발현 및 정제된 FN-67B89 단백질의 품질을 확인하기 위해, 단백질-단백질 상호작용을 분석하기 위한 기법으로서 ELISA를 96웰 포맷으로 사용하였다. 제1 단계에서, 10 ㎍/mL 표적 단백질을 MaxisorbTM 96-웰 플레이트에 100 ㎕로 50 mM Na2CO3 pH 9.4 코팅 완충제를 이용하여 알칼리 조건에서 수동적인 흡수 (passive absorption)를 통해 코팅하였다. ELISA 플레이트의 코팅은 4℃에서 밤새 수행하였다. 코팅 완충제를 제거한 후, 플레이트를 PBS-T 300 ㎕ 및 차단 완충제 (3% BSA/PBS) 300 ㎕로 3번 세척하였다. 차단은 RT에서 2시간 동안 수행하였다. 1차 인큐베이션한 후, 플레이트를 PBS-T 300 ㎕로 3번 헹군 다음 PBS-T에 1:100으로 희석한 C-1 항체 100 ㎕와 함께 1시간 동안 4℃에서 인큐베이션하였다. PBS-T를 100 ㎕ /웰로 사용해 3번 세척한 다음 HRP-접합된 항-마우스 항체 (554002, BD Pharmingen™)를 PBS에 1:5000으로 희석하여 첨가하고, 4℃에서 1시간 동안 인큐베이션하였다. 그런 후, TMB 기질의 HRP 매개 변환을 통해 항원-항체 복합체를 검출하기 전에, 플레이트를 PBS-T로 3번, PBS로 3회 헹구었다. TMB 기질 100 ㎕를 웰에 첨가하였으며, 샘플에 존재하는 분석물의 양에 비례하여 청색이 발색되었다. 발색은 0.2 M HCl 50 ㎕를 첨가하여 정지시키고, 450 nm에서 특이 흡광도를 측정하였다.
파지 디스플레이를 통한 EDB-특이적인 리간드의 선별
EDB-특이적인 시스틴 노트 미니단백질을, 모모르디카 코킨키넨시스의 트립신 저해제 II (oMCoTI-II)의 오픈 체인 변이체를 기반으로 하는 2가지 조합 라이브러리를 이용하여, 파지 디스플레이에 의해 선별하였다. 이들 2가지 라이브러리는 M13 파지미드 시스템을 기반으로 하며, 적용된 무작위 방식에 차이를 가진다. MCopt1.0 라이브러리에서는 루프 1개 (아미노산 6개, 9개 및 12개 길이의 변이 포함) 및 아미노산 3개뿐 아니라 N-말단에서 2개가 무작위 처리된 반면, MCopt2.0 라이브러리는 오직 아미노산 10개를 이용한 루프 1의 무작위화를 통해 구축하였다. 또한, 이들 라이브러리는, MCopt1.0이 주 코트 단백질 pVIII를 통해 제시되는 반면 MCopt2.0은 pIII를 통해 제시된다는 점에서, 제시 타입 측면에서도 상이하다.
종합적으로, 스트렙타비딘-코팅된 (SA) 자기 비드에 기반한 스크리닝을 각 라이브러리를 사용해 3회 수행하였다. 스크리닝 라운드에서, 2 x 50 ㎕ Dynabeads® M-280 스트렙타비딘 (Life Technologies)을 각각 2 mL 튜브로 옮기고, TBS-T (50 mM Tris, 150 mM NaCl, 0.1% Tween-20, pH 7.4) 1 mL로 헹구었다. TBS (50 mM Tris, 150 mM NaCl, pH 7.4) 200 ㎕ 중의 바이오틴화된 FN-B 100 ㎍을 첫번째 튜브에 넣고, 표적 없이 TBS 200 ㎕를 2번째 튜브 (파지의 음성 선별)에 넣었으며, 비드를 롤링 믹서 상에서 20분간 30 rpm으로 인큐베이션하였다. 튜브를 다시 자기에 위치시키고, 남아있는 용액을 버린 후 비드를 TBS-T로 2번 헹구었다. 비드를 TBS 중의 2% 밀크 분말 (Carl Roth)을 사용해 1시간 동안 45℃ 및 30 rpm에서 블록킹하였다. 바이오틴화된 FN-B 코팅 SA-비드는 다시 30분간 블록킹 처리하였다. 파지 7 x 1013 (1차 라운드) 또는 7 x 1012 (2차 및 3차 라운드)를 코팅되지 않은 SA 비드에 TBS 중의 2% 밀크 분말 1 mL 내에 첨가하고, RT에서 30분간 30 rpm으로 인큐베이션하였다 (음성 선별). 표적-코팅된 비드의 블록킹 용액을 폐기하고; 비드를 TBS-T로 2번 헹군 다음 음성 선별로부터 수득한 파지 상층액을 첨가하였다. 표적-코팅된 비드를 파지 현탁물과 1시간 동안 RT에서 30 rpm으로 인큐베이션하였다. 이후, 결합되지 않은 파지를 세척 제거하고, 비드를 TBS-T로 6번, 그리고 TBS로 2번 헹구었다. 결합된 파지를 용출시키기 위해, pH-시프트 용출 (pH-shift elution)을 수행하였으며, 100 mM 트리메틸아민 (TEA) 50 ㎕를 세척한 비드에 첨가하였다. TEA 비드 현탁액을 6분간 3000 rpm에서 인큐베이션하고, 다시 자기로 재배치하였으며, 상층액을 1M Tris/HCl pH 7 100 ㎕이 든 새로운 튜브에 중화를 위해 옮겼다. 2차 용출 단계는, 표적-코팅된 비드에 100 mM 글리신 (pH 2) 50 ㎕를 첨가하고 혼합물을 서모믹서에서 최대 rpm으로 10분간 인큐베이션하여, 수행하였다. 튜브를 다시 자기에 배치하고, 상층액을 1차 용출로부터 수득한 Tris/TEA 혼합물로 옮겼다. 파지 용출물을 사용해, 지수 증식기의 E. coli XL1-Blue (Agilent)에 파지 풀 증폭 (phage pool amplification)을 위해 감염시켰다. OD600 0.5의 E. coli XL1-Blue 세포 1800 ㎕를 용출물에 첨가하여, 37℃에서 교반하지 않고 30분간, 그리고 150 rpm으로 교반하면서 37℃에서 30분간 인큐베이션하였다. 그런 후, 감염시킨 XL1-Blue 세포를 100 ㎍/mL 카르베니실린 (carbenicillin) 및 0.4% 글루코스가 함유된 큰 아가 플레이트 2개에 도말하여, 37℃에서 밤새 인큐베이션한 후, 다음날 파지 회수 (phage rescue)를 수행하였다.
파지 회수를 위해, 플레이트 당 LB 배지 4 mL를 첨가하고, 세포 스크립퍼로 세포를 긁어 회수하였다. 배양물 50 mL을 최종 OD600 0.2로 접종하였다. 세포를 OD600 0.5이 될 때까지 배양하고, 파지미드 벡터로부터 파지 제조를 위해 0.5 x 1012 VCSM13 헬퍼 파지 (Agilent)와 함께 감염시켰다. E. coli XL1-Blue 세포를 30분간 37℃에서 교반하지 않고 인큐베이션한 다음 30분간 37℃에서 150 rpm으로 교반하면서 인큐베이션하였다. 박테리아 상층액을 10분간 RT에서 4500 xg로 원심분리하고, 상층액을 폐기하였다. 박테리아 펠렛을 단백질 생산을 유도하기 위해 (100 ㎍/mL 카르베니실린, 25 ㎍/mL 카나마이신, 1 mM IPTG가 첨가된) LB 배지 50 mL 중에 취하여, 밤새 30℃에서 250 rpm으로 E. coli 파지 생산 배양물을 배양하였다. E. coli 세포를 15분간 4℃에서 4500 x g로 원심분리하여 회수하였다. PEG/NaCl 용액 (25% (w/v) 폴리에틸렌 글리콜, 15% (w/v) NaCl) 10 mL를 파지 함유 상층액 40 mL에 첨가하고, 뒤집어 30분간 얼음 위에 두었다. 이를 20분간 4℃에서 15.000 x g로 원심분리하여 파지 입자를 침강시켰다. 상층액은 버리고, 파지 펠렛은 Tris/HCl (pH 8.0) 1600 ㎕ 중에 취한 후, 이후 10분간 4℃에서 15.000 x g로 원심분리하였다. 파지를 함유한 상층액을 PEG/NaCl 400 ㎕에 다시 첨가하고, 얼음 위에서 20분간 인큐베이션하였다. 2차 PEG/NaCl 침강 후, 튜브를 15분간 4℃에서 15.000 x g로 원심분리하였다. 파지 펠렛을 Tris/HCl 800 ㎕에 재현탁하고, 최종 단계에서 15분간 65℃까지 가열하였다. 파지 현탁물을 RT에서 10분간 15.000 x g로 원심분리하고, 상층액을 취하여, 듀얼 파장 모두스 OD269-OD320를 이용해 광학적으로 파지 입자 농도를 광학적으로 측정하였다. 파지 농도는 M13 파지의 몰 흡광 계수 및 뉴클레오티드 함량에 따라 계산하였다 (Barbas et al. 2004).
선별된 시스틴-노트 미니단백질의 히트 동정 (hit identification)
동정 공정으로, PCR에 의해 시스틴-노트 미니단백질 서열을 증폭하기 위해, 3차 스크리닝 라운드로부터 유래된 농화된 스크리닝 풀 파지미드를 준비하였다. 티오레독신-A 융합 변이체로서 시스틴-노트 미니단백질을 발현시키기 위해 PCR-인서트를 pET-32a (Novagen)의 유도체인 발현 벡터 pET-32-LibEx에 클로닝하였다. 이 벡터는, 세포질에서 효율적인 이황화 결합 형성을 허용하기 위한 E. coli 티오레독신-A, 신속한 정제를 위한 H6-태그, 항체에 의한 검출을 위한 s-태그 및 융합 태그를 제거하기 위한 트롬빈 절단부를 암호화하는 DNA 서열들을 연속적인 순서로 가지고 있다. 시스틴-노트 미니단백질 서열을 암호화하는 DNA 단편을 pET-32-LibEx 벡터의 트롬빈 절단부의 하류에 고유한 Bam HI 및 Kpn I 제한효소 부위를 통해 도입하였다. 벡터를 열 충격에 의해 E. coli SHuffle® T7 Express 세포 (New England BioLabs)에 도입하고, 세포를 선별 아가 플레이트에 접종하였다. 단일 콜로니를 취하여, 서열 분석하고, 1 mL 자동유도 배지 (MagicMedia™, Thermo Fisher Scientific)에서 소규모로 발현시키기 위해 96웰 플레이트로 옮겼다. 30℃에서 밤새 220 rpm으로 단백질 생산을 수행하였다. 이를 15분간 3000 x g로 원심분리하여 세포를 회수하고, 0.1 mg/mL 리소자임 (Merck Millipore) 및 5 U/mL 벤조나제 (Merck Millipore)가 첨가된 완충제 (20 mM Tris, 2 mM MgCl2, 20 mM NaCl, pH 8)에서 냉동-해동 사이클과 조합하여 인큐베이션하였으며, 10분간 80℃에서 열처리하였다. 세포 파편을 제거하기 위해 마지막으로 원심분리 (3000 xg, 15분, 4℃)한 후, 상층액을 E-PAGE™ 및 결합 분석을 위해 수집하였다.
생산 및 열 정제한 단백질의 정량과 병행하여, 96개의 프로브를 동시에 분석하기 위한 고 성능 겔 시스템으로서 E-PAGETM (Life Technologies)을 이용하였다. E-PAGETM 분석은 제조사의 지침에 따라 수행하였다.
ELISA를 단백질-단백질 상호작용을 분석하기 위한 기법으로 사용하였다. 96웰 마이크로타이터 플레이트 (Nunc MaxiSorp™, Thermo Fisher Scientific)의 웰들을 1 ㎍ FN-B, 소 혈청 알부민 (BSA, Eurobio), 밀크 분말, 스트렙타비딘 (Sigma Aldrich), T7-His-TEV-B (LD BioPharma), FN-B(8-14) (R&D Systems), 리소자임, 난백알부민 (GE Healthcare Life Science), 알돌라제 (GE Healthcare Life Science) 또는 0.6 ㎍ 항-c-myc-항체 (M4439, Sigma)로 밤새 4℃에서 코팅하였다. 웰을 PBS-T (1 x PBS + 0.1% (w/v) Tween-20)로 3번 헹군 다음 PBS에 희석한 1x 카세인 완충제 (Sigma Aldrich)로 2시간 동안 RT에서 블록킹하고, 기술한 바와 같이 다시 세척하였다. 각각의 열-정제한 융합 단백질을 함유한 상층액 20 ㎕를, 웰에 적용된, PBS-T 80 ㎕ 또는 200 nM MC-Myc-010 융합 단백질 (항- c-myc-항체가 코팅된 웰)에 첨가하여, 1시간 동안 4℃에서 인큐베이션하였다. PBS-T로 3번 세척한 후, 각각의 변이체의 결합을 호스래디시 퍼옥시다제 (HRP)-접합된 항-S-tag 항체 (ab18589 또는 ab19324, Abcam)를 사용해 검출하였다. 발색단 기질로서 TMB을 사용해 효소 반응을 측정하였으며, 약 5분 후 0.2 M HCl을 첨가하여 반응을 중단시켰다. Infinite M200 PRO Microplate Reader (Tecan)를 사용해 450 nm에서 흡광도 측정을 수행하였다.
여러가지 플레이트에서 결합 신호를 비교하기 위해, ELISA 신호들을 내부 플레이트 대조군 (c-myc 결합)에 대해 표준화하였다. 표준화한 FN-B 신호는 선택된 시스틴-노트 미니단백질의 결합 능력을 평가하기 위해 표준화된 BSA 신호로 언급하였다. 또한, 표적 결합 신호를 단백질 발현율과 연관시켜, 히트 동정의 등급 값을 구하였다.
재조합 시스틴-노트 미니단백질의 생산
재조합 단백질 생산을, 각각의 시스틴-노트 미니단백질 서열을 암호화하는 pET-32-LibEx 벡터를 운반하는 E. coli SHuffle® T7 Express 세포를 이용하여, 750 mL 규모로, 30℃ 및 120 rpm에서 수행하였다. 배양물이 OD600 약 0.7에 도달한 후, 1 M IPTG 750 ㎕를 첨가하여 밤새 25℃에서 120 rpm으로 원심분리함으로써 생산을 유도하였다. E. coli 세포를 회수하고, 이를 평형 완충제 10 mL에 재현탁한 다음 음파처리에 의해 세포용해 후 10분간 80℃까지 가열하였다. 세포 파편을 원심분리 (15.000 xg, 30분, 4℃)한 후, 상층액을 1 mL HisTrap 컬럼에서 AKTAprime™ 플러스 시스템 및 20분간 10-500 mM 이미다졸의 선형 농도구배를 이용한 IMAC에 의해 정제하였다. 시스틴-노트 미니단백질 융합 단백질을 함유한 분획을 수집하여, 트롬빈 절단 완충제 (20 mM Tris, 150 mM NaCl, 1.5 mM CaCl2 및 5% (w/v) 글리세롤, pH 8.45)에 대해 밤새 4℃에서 투석하였다.
융합 단백질은 ELISA를 이용한 분석에 바로 사용하거나 또는 태깅되지 않은 미니단백질이 필요할 경우에는, 예를 들어 SPR 분석하기 위해 추가적으로 가공 처리하였다. 이를 위해, 융합 단백질을 단백질 1 mg 당 0.5 U 트롬빈 (Sigma-Aldrich)을 사용해 절단하고, 밤새 37℃에서 인큐베이션하였다.
단백질 단편들을, Agilent 1260 Infinity Quaternary LC 시스템 (Agilent) 및 3 mL RESOURCE™ RPC 컬럼 (GE Healthcare)을 이용하여, 0.05% 트리플루오로아세트산 (TFA)이 첨가된 H2O 중의 선형 농도구배 2-80% 아세토니트릴을 적용한 역상 크로마토그래피에 의해 분리하였다. 시스틴-노트 미니단백질을 함유한 각각의 분획을 최종 단계로서 RVC 2-18-CD Plus SpeedVac (Christ)에서 동결건조하였다. 시스틴-노트 미니단백질의 양을 무게로 측정하여 확인하고, 펩타이드를 동결건조된 형태로 -20℃에서 보관하였다. 동일성을 LCMS Single Quad G6130B 시스템 (Agilent Technologies)을 표준 전기분무 이온화 프로토콜로 사용한 질량 분석법에 의해 검증하였다.
선별된 MC-
FN
-010의 알라닌 스캐닝 돌연변이 유발 (
alanine
scanning mutagenesis)
EDB-결합에 기여하는 MC-FN-010 내 잔기를 동정하기 위해, 알라닌 스캐닝 돌연변이 유발을 수행하였다. 이 방법은 지정된 위치에서 알라닌을 모두 아미노산 치환한 다음 구축한 돌연변이의 결합성을 분석하는 것을 포함한다. 알라닌 스캐닝 MC-FN-010 유도체를 구축하기 위해, PCR에 의해 돌연변이를 도입하거나 또는 GeneArt™ Strings™ 단편 (Thermo Fisher Scientific)의 직접 합성을 통해 전체 암호화 서열을 조립하였다. 각각의 DNA 단편을 고유한 BamHI 및 KpnI 제한효소 부위를 이용해 pET-32-LibEx 발현 벡터에 클로닝한 다음 E. coli SHuffle® T7 Express 컴피턴트 세포 (New England BioLabs)에 도입하였다. 모든 돌연변이는 DNA 서열분석에 의해 검증하였다. 알라닌 스캔 돌연변이 변이체는 선별적인 자동유도 배지 5 mL을 사용해 24웰 포맷으로 발현시켰다. 융합 단백질 생산 및 정제는 96웰 포맷에서 전술한 바와 같이 수행하였으며, 단 HisPur™ Ni-NTA 스핀 컬럼 (Thermo Fisher Scientific)을 이용한 상층액의 추가적인 정제 단계를 포함시켰다. 표적 및 오프-표적 단백질에 대한 시스틴-노트 융합 단백질의 결합 능력 및 특이성을 전술한 바와 같이 항체-기반의 ELISA 분석으로 수행하였다.
표면
플라스몬
공명
스펙트로스코피
단량체 및 삼량체 시스틴-노트 미니단백질 리간드가 이의 표적 단백질에 결합하는 동역학을 Biacore T-100 장치 (GE Healthcare Life Science)에서 전개 완충제로서 PBS-T를 사용해 측정하였다. 이를 위해, 바이오틴화된 FN-67B89 단백질 (200-300 ㎍/mL)을 SA 센서 칩 (GE Healthcare Life Science)의 플루오 셀에의 결합에 통해 포획하였다. 단량체 리간드의 분석에서는 고정된 표적 밀도 최대 750 RU (response unit)을 적용하였고, 삼량체 변이체의 경우에는 RU 최대 400을 목표로 하였다. 단량체 리간드의 결합 분석을 멀티 사이클 동역학적 방법을 이용해 농도 범위 50 내지 4000 nM에서 수행하였다. 사이클은 결합 시간 90초로 시작하였으며, 그 후 해리 시간 420초 및 마지막 재생 단계를 수행하였다. 동역학적 측정은 유속 20 ㎕/min으로 수행하였다. 삼량체 변이체는 동일한 결합 및 해리 조건 하에 수행하였지만, 일정한 유속 30 ㎕/mL의 싱글 사이클 동역학적 측정 모드를 사용하였다. 이 경우, 분석물의 농도는 1.25 nM 내지 10 nM이었다. 결합 동역학 및 정상 상태 분석을 포괄 동역학 적합 모델(global kinetic fit model)을 적용해 계산하였다 (1:1 랭뮤어, Biacore T-100 Evaluation Software, GE Healthcare Life Science).
면역형광
염색
면역형광 염색을 수행하기 위해, 저온보존 처리한 종양 또는 뇌 조직 조각을 5 ㎛ 두께의 절편으로 자르고, 빙랭한 아세톤에서 5분간 고정한 다음 공기 건조하였다. 그 후, 슬라이드를 3% BSA가 첨가된 PBS에서 5분간 RT에서 차단하였다. EDB로 염색하기 위해, 각각의 바이오틴화된 시스틴-노트 미니단백질 1 ㎍을 스트렙타비딘-Cy3 접합체 (Rockland Immunochemicals) 2.9 ㎍과 함께 RT에서 30분간 인큐베이션하였다. 사전-형성된 복합체를 종양 절편에 첨가하여 30분간 37℃에서 인큐베이션하였다. 그 후, 슬라이드를 1% BSA 함유 PBS로 3번 헹구었다. 그런 다음, 1% BSA가 첨가된 PBS에서 1:100으로 희석한 랫 항-마우스 CD31 IgG 항체 (clone 390, eBioscience)를 사용해 CD31 염색을 수행하였다. 이를 PBS에서 3회 세척 단계를 수행한 후, PBS에서 1:5000으로 희석한 Hochst 33342 (Thermo Fisher Scientific)를 RT에서 30분간 사용해 세포 핵을 염색하였다. 슬라이드를 전술한 바와 같이 다시 헹구고, 얇은 마운팅 매질 (Dako) 층에서 커버슬립으로 덮었다. Zeiss Apotome 현미경 (Carl Zeiss)을 사용해 이미지를 촬영하고, 이는 ZEN 소프트웨어 (Carl Zeiss)로 분석하였다.
펩타이드
합성
리간드 접합된 Trimeric Alexa Fluor 680 (AF680) 및 N-말단 바이오틴화된 미니단백질을 Pepscan 사에서 구입하였다. 입수한 모든 펩타이드 구조체는 100 ㎍ 분액으로서 -20℃에 보관하였다. 실험을 위해, 펩타이드는 모두 DPBS (Gibco) 100 ㎕에 농도 1 ㎍/㎕로 용해하였다. 모든 구조체는 ESI 질량 분석법에 의해 정체 (identity)를 검증하였으며, 분석용 역상 크로마토그래피 (Pepscan)에 의해 순도를 분석하였다. 또한, 삼량체는 표적 결합 특성 (FN-67B89에의 결합) 및 특이성 (FN-67B89에 대한 결합)을 특정하기 위해 SDS-PAGE 및 SPR에 의해 분석하였다.
U-87 MG 이종이식 마우스 모델
인간 교모세포종 U-87 MG (ATCC) 세포주를 10% FCS 첨가된 EMEM 배지 (ATCC)에서 무균 조건 하에 37℃에서 5% CO2 및 습도 95% 하에 배양하였다.
마우스는 BioNTech AG 사의 동물 시설에서 사육하였으며, 모든 동물 프로토콜은 Tierschutzkommision des Landesuntersuchungsamts Rheinland-Pfalz로부터 승인받았다. 체중 약 25-28 g의 4주령의 Fox n1/nu 마우스를 Janvier로부터 입수하였다. 이종이식 마우스 실험을 위해, 인간 U-87 MG 세포 7 x 106개를 Fox n1/nu 마우스의 우측 옆구리에 피하 주사하고, 약 5주간 종양을 증식시켰다. 피하 종양 크기를 타원체 식 ( )으로 구하였다. 종양 체적이 100-1200 mm3에 도달한 동물들은 모두 실험에 포함시켰으며, 마우스를 실험 코호트로 무작위 배정하였다.
)으로 구하였다. 종양 체적이 100-1200 mm3에 도달한 동물들은 모두 실험에 포함시켰으며, 마우스를 실험 코호트로 무작위 배정하였다.
시험관내
및
생체외
이미징
원하는 종양 크기를 가진 마우스를 삼량체 구조체의 생물분포 및 종양 표적화을 분석하기 위해 포함시켰다. 모든 삼량체 구조체는 눈 뒤 정맥 총 (retrobulbar venous plexus)을 통해 최종 부피 PBS 완충제 100 ㎕ (3.34 nmol/마우스)로 정맥내 주사하였다. IVIS 스펙트럼 시스템 (Perkin Elmer)에서 여기 범위 615-665 nm를 적용하고, 그리고 695-770 nm에서의 방출 신호를 모니터링하여, 마우스 (각 구조체에 대해 n=3)에서 이미지를 촬영하였다. 사진 촬영 공정은 주사 후 1시간, 2시간 또는 6시간 경과시 수행하고, 안락사시킨 후 종양 및 특정 장기를 적출하여, 이미지를 촬영하고, 무게를 잰 다음 추가적인 분석을 위해 저온-보존 처리하였다. 대상 영역의 형광 세기를 Living Image® 소프트웨어 (PerkinElmer)로 정량하였다. GraphPad Prism에서 2-웨이 ANOVA 분석을 이용해 트리플리케이트 데이터 세트에 대해 통계학적 유의성을 계산하였다.
실시예
2: EDB-특이적인 리간드의 스크리닝 및 선별
시스틴-노트 미니단백질은 종양 이미지를 촬영하기 위한 물질로서 이상적으로 적합한 것으로 입증된 바 (Kimura et al. 2009; Moore et al. 2013; Miao et al. 2009; Soroceanu et al. 1998; Veiseh et al. 2007, Nielsen et al. 2010; Hackel et al. 2013; Zhu et al. 2014), 본 발명자들은 표적 결합 리간드를 선별하기 위한 조합 파지 라이브러리 구축의 토대로서 모모르디카 코킨키넨시스 트립신 저해제-II (oMCoTI-II)의 오픈 체인 서열을 이용하였다 (Hernandez et al. 2000). 제1 라이브러리 (MCopt 1.0)는 첫번째 루프에 무작위 아미노산, 3번째 루프 내 산재된 위치 및 첫번째 시스테인 앞에 2개의 가변성 잔기를 가진 서열을 포함한다. 시스틴-노트 미니단백질 서열은 M13 파지의 주 코트 단백질 (pVIII)에 유전자 융합하였다. 또한, 서열의 첫번째 루프에서의 무작위화를 포함하며 M13 파지의 마이너 코트 단백질 (pIII)을 통해 단백질을 제시하는 제2 라이브러리 (MCopt 2.0)를 개발하였다. 이에, 라이브러리들은 무작위화된 루프 위치와 서열 길이뿐 아니라 단백질 제시 결합가 (presentation valency) 측면에서 구분되며, 이는 리간드 선별 결과에 차이를 유발할 수 있다. 이들 2종의 라이브러리는, 여러가지 종양에서 높은 수준으로 발현되지만 난소의 간질 또는 활액 세포 등의 대부분의 정상 조직에서는 발현되지 않는 것으로 예상되는, 파이브로넥틴 엑스트라 도메인 B (EDB)에 대한 시스틴-노트 미니단백질을 식별하기 위해 병행하여 사용하였다 (Carnemolla et al. 1989; Castellani et al. 1994).
후속적인 스크리닝 및 히트 식별 공정에 적합한 표적 및 대조군 단백질을 구축하기 위해, 본 발명자들은 싱글 EDB 도메인 (FN-B), 주변 타입 III 도메인이 측면에 위치한 EDB (FN-67B89) 및 EDB가 없는 타입 III 도메인 6-9 (FN-6789)를 재조합에 의해 제조하였다. 도 1A에 나타낸 바와 같이 모든 FN 변이체들의 정확한 단백질 크기를 검증할 수 있었으며, 수득된 순도는 93% 보다 높았다. EDB를 함유한 파이브로넥틴과 EDB가 없는 파이브로넥틴을 구분하는 단일클론 항체 (BC-1)를 사용해 (Carnemolla et al. 1992), FN-67B89 단백질의 고유 폴딩을 조사하였다. 또한, C-말단의 H6-태그가 모든 FN-융합 단백질에서 검출되었다 (도 1B). 2가지 파지 라이브러리를 바이오틴화된 FN-B에 대해 연속적인 3회 라운드로 스크리닝하였으며, 완료 후 싱글 콜로니 46개를 서열분석하였다. MCopt 1.0 스크리닝에서, 시스틴-노트 미니단백질 1종이 강하게 농화되었으며, 이는 풀의 40%를 차지하였다. 또한, 다른 시스틴-노트 미니단백질 클론 2종은 4% 및 2%로 농화되었다 (도 2). MCopt 2.0 스크리닝의 경우, 서로 다른 시스틴-노트 미니단백질 클론 3종이 전체 서열의 13%, 10% 및 2% 비율로 농화되었다. 흥미롭게도, 증폭된 서열 6종 중 5종이 루프 1의 C 말단에 공통적인 R-I/V-R-(L) 모티프를 포함하였다 (도 2).
이러한 발견에 힘입어, 본 발명자들은 MCopt 1.0 라이브러리의 스크리닝으로부터 수득한 농화된 서열의 FN-B 결합 능력을 평가하였다. 이를 위해, 시스틴-노트 미니단백질을, C-말단에 티오레독신, his-태그 및 s-태그 (Trx-시스틴-노트 미니단백질)와 융합시켜, 96웰 미니 스케일 포맷으로 발현시켰다. FN-B 및 BSA에 대한 단백질의 결합을 ELISA로 분석하고, 추가적으로 E-PAGE® 분석을 통해 각 클론의 발현율을 측정하였다. 수득한 신호/노이즈 비율과 발현 값을 토대로, FN-B 상호작용의 척도로서 각 후보물질의 등급 값을 계산하였다. 서로 다른 Trx-시스틴-노트 미니단백질 변이체 3종은 BSA 대조군과 비교해 FN-B에 대해 증가된 상호작용을 나타내었으며 (도 3), 서열은 예상된 바와 같이 스크리닝 풀에서 농화된 클론에 해당하였다. 이들 3가지 후보물질뿐 아니라 MCopt2.0 스크리닝에서 수득한 R-I/V-R-(L) 모티프 함유 클론을 후속적인 심층 결합 분석에 포함시켰다.
실시예
3:
농화된
시스틴-노트 미니단백질 후보물질에 대한 특이성 분석
본 발명자들은 다음으로 사내에서 제조한 EDB 표적 단백질 (FN-B 및 FN-67B89) 및 오프-표적 단백질 (FN-6789) 및 다른 대조군 단백질 (밀크 분말, 스트렙타비딘 및 소 혈청 알부민)을 이용하여 남아있는 시스틴-노트 미니단백질 6종의 표적 결합 특이성에 집중하였다. 엑스트라 도메인 B가 결핍된 파이브로넥틴은 여러가지 다수의 세포 타입들에 의해 발현되므로, FN-6789는 완벽하게 대응되는 오프-표적 단백질이다 (Mao und Schwarzbauer 2005). 후보물질들 모두 재조합 FN-B 및 FN-67B89 표적 단백질에 대해 동일하게 높은 합리적인 EDB 표적 결합성을 나타내었다 (도 4). 공통적인 R-I/V-R-(L) 모티프에 기반하여 선별한 변이체들 (MCopt 1.0-2/-3 및 MCopt 2.0-1/-2/-3)은 오프-표적 단백질 및 대조군 단백질에 대해 중간 내지 낮은 수준의 신호를 나타내었다. MCopt 1.0-2 및 MCopt 1.0-3은 이미 MCopt 1.0 동정에서 식별되었지만, MCopt 2.0-1, -2 및 -3은 이들의 공통 모티프에 기반하여 MCopt 2.0 풀에서만 식별되어, 이전의 FN-B 표적 결합에서는 분석되지 않았다. 그러나, MCopt 1.0-1은 R-I/V-R-(L)-모티프를 함유하지 않으며, 오프-표적 FN-6789뿐 아니라 밀크 분말을 제외한 모든 대조군 단백질에 대해 높은 상호작용이 관찰되어, 특이성 평가에 실패하였다. 이들 데이터는 관찰된 아미노산 모티프가 EDB 결합과 관련있다는 것을 강하게 시사해준다.
이후, 본 발명자들은 또한 상업적으로 입수가능한 T7-TEV-B (LD BioPharma), T7-TEV N-말단 측면에 위치한 EDB 도메인 및 FN-B(8-14) (R&D Systems), C-말단 도메인 8-13 및 도메인 14의 ½을 함유한 EDB를 포함시켜, 5종의 기대되는 후보물질에서 EDB 특이성을 추가적으로 분석하였다. 또다시, 표적 단백질을 함유한 모든 검사 EDB에 대한 결합 신호는 동일하게 높았으며, 오프-표적 신호는 상대적으로 낮았다 (도 5). 이들 모두 다른 포맷, 즉 EDB 단독 (FN-B) 포맷, 인공적인 N-말단 구조체 (T7-His-TEV)가 측면에 위치하는 포맷, 천연적인 C- 및 N-말단 타입 III 도메인이 측면에 위치하는 포맷 (FN-67B89) 및 이웃한 천연적인 C-말단 타입 III 도메인만 측면에 위치하는 포맷 (FN-B(8-14)으로 EDB에 존재하는 표적 단백질을 이용하였으므로, 관찰된 결합 활성이 실제 EDB 중앙부분에 특이적인 것으로 결론내릴 수 있었다.
마지막으로, 본 발명자들은 도 6에 나타낸 바와 같이 여러가지 수용체 포화 농도를 이용하여 FN-B, FN-67B89 및 FN-B(8-14)에 대한 R-I/V-R-(L)-모티프를 함유한 후보물질 4종 (MCopt 1.0-2/-3 및 MCopt2.0 -1/-2)의 농도-의존적인 결합 데이터를 획득하였다. FN-6789 오프-표적에 대해 관찰된 백그라운드 신호는 일반적으로 EDB 함유성 표적 단백질들 전부보다 훨씬 낮았으며, 이는 FN-6789의 파이브로넥틴 타입 III 도메인과 EDB 간의 명확한 구별을 의미한다. 이전의 특이성 ELISA에서 이미 관찰된 바와 같이, 클론 MCopt 2.0-3은 FN-6789 오프-표적에 대해 높은 수준의 비-특이적인 결합성을 나타내었다. 심지어 클론 MCopt 2.0-3은 EDB 표적 결합에서 결정적인 기능을 하는 것으로 보이는 공통적인 R-I/V-R-(L)-모티프를 공유하고 있음에도 불구하고, 무작위화된 시스틴-노트 미니단백질 루프 내 다른 잔기들은 예를 들어 소수성 상호작용으로 인해 비-특이적인 결합을 촉진할 수 있다.
조영제 (imaging agent)로서 계획된 시스틴-노트 미니단백질을 활용하기 위해, 본 발명자들은 표면 플라스몬 공명 (SPR) 분석에 의해 태그-프리 단백질의 결합 능력을 조사하였다. 놀랍게도, 유일하게 MCopt 1.0-3만 검사 농도 범위 50 -1000 nM에서 FN-67B89 표적 단백질에 대한 강한 결합성을 나타내었다 (데이터 도시 안함). 즉, 이하 MC-FN-010으로 지칭되는 MCopt 1.0-3를 선택하여, 추가적인 분석과 광학 이미징 프로브 개발에 이용하였다.
실시예
4: MC-
FN
-010 결합부의 맵핑
여러가지 선택한 시스틴-노트 미니단백질에서 아미노산 모티프 R-I/V-R-(L)에 대한 이전 연구 결과를 통해 EDB 결합에 대한 높은 서열 기여성이 이미 제안되었음에도 불구하고, 본 발명자들은 보다 자세하게 이의 관련성을 실험적으로 조사하였다. MC-FN-010 표적 서열에서 알라닌 단일 치환을 수행하여, 총 14종의 유도 구조체를 만들었다 (도 7a에 나타낸 바와 같이 MC-FN-011에서 MC-FN-0114로 순차적으로 번호를 매김). 구조체들 모두 단일 도메인 FN-B에 대해 검사하였다. 예상된 바와 같이, 서열 상류에 알라닌 치환을 가진 구조체 7종은 여전히 강한 표적 상호작용을 나타내었는 바, 이는 이들 위치가 EDB 결합에 중요하지 않다는 것을 시사해준다. 이와는 대조적으로, 공통 모티프 위치에서 치환된 구조체 4종은 결합성을 상실하는 것으로 확인되었다. 5번째 루프에서 추가적인 알라닌 치환에 의해 표적 상호작용이 감소되었는데, 이는 이러한 관련성을 물론 시사해준다 (도 7b). 이들 결과는, 첫번째 루프 내 아미노산 잔기 4개 (RIRL)와, 또한 5번째 루프 내 아르기닌 잔기가 FN-67B89에의 결합 상호작용에 직접적인 영향을 발휘하거나, 또는 도 7C에 요약 개시된 바와 같이 미니단백질의 입체 구조에 간접적인 영향을 미친다는 것을, 검증해준다.
실시예
5: 종양
조직 상의
모 (parental) MC-
FN
-010 미니단백질의 특이성 분석
본 발명자들은 미세환경에서 천연적인 EDB 단백질을 포함하는 U-87 MG 종양 이종이식 단편을 이용하여 세포 환경에서 모 MC-FN-010의 특이성을 또한 조사하였다. 인간 교모세포종 종양은 혈관 구조에 파이브로넥틴 EDB 이소형을 가지고 있는 것으로 알려져 있다 (Mariani et al. 1997). 본 발명자들은, 알라닌 스캐닝 돌연변이 유발을 기반으로, 3곳에 알라닌 치환을 가진 음성 대조군 구조체 (MC-FN-0115)를 구축하였다 (PMCTQR A NRI AA CRRDSDCTGACICRGNGYCG). 면역형광 이미징 실험에서, MC-FN-010 및 MC-FN-0115은 바이오틴화된 포맷으로서 Cy3-표지된 스트렙타비딘과 함께 사량체화하였다. 사량체화된 MC-FN-010-bio는, 혈관 마커로서 알려진 내피 세포의 도처에서 발현되는 표면 단백질인 C31에 대한 Alexa Fluor 647-접합된 항체를 사용해 검증된 바와 같이, 혈관 주변 영역을 거의 단독으로 표지하였다 (도 8). Cy3 및 Alexa Fluor 647을 병합 사진은 혈관과 관련된 형광 신호 2종이 공동-위치함을 입증해주었다. 또한, 주변 혈관주위 영역 내 사량체화된 MC-FN-010의 국지성도 검출할 수 있었다. 이와는 대조적으로, 음성 대조군 구조체 MC-FN-0115로 염색한 U-87 MG 종양 단편에서는 형광 신호가 전혀 관찰되지 않았다 (도 8). 사량체화된 MC-FN-010 및 MC-FN-0115에 대한 형광 신호는 정상적인 마우스 뇌 단편에서 관찰되지 않았다 (도 12).
실시예
6: FN-67B89에 대한 시스틴-노트 미니단백질의 결합성 및 친화성
단백질을 표적화하는 진단 툴로서 사용하기에 앞서, 여기에 조영제를 특이적으로 접합시켜야 한다 (Spicer und Davis 2014). 본 발명의 리드 후보물질인 MC-FN-010은 루프 1에 라이신을 함유하는데, 이것은 1차 아민에 선별 물질을 연결하는데 좋지 않다. 이전의 분석 결과에 기초하여, 이 아미노산은 EDB 결합성에 적극적으로 기여하지 않으므로, 본 발명자들은 2차 후보물질로서 파생 구조체 MC-FN-016을 선택하였다. 본 발명자들은 Trx-MC-FN-016이 농도-의존적인 방식으로 FN-67B89에 결합하는 것을 관찰하였으며, 그 신호는 모 Trx-MC-FN-010와 비슷하였다 (도 9). 이와는 대조적으로, FN-6789에 대한 전체 백그라운드 신호는 지속적으로 상대적으로 낮았다. 시스틴-노트 미니단백질 후보물질 2종 모두 FN-67B89만 표적화하고, FN-6789와는 상호작용하지 않았으며, 이는 파이브로넥틴이 복수의 세포 타입들에서 광범위하게 발현되므로 중요하다 (Pankov und Yamada 2002). 바이오틴화된 FN-67B89에 대한 태그-프리 MC-FN-010 및 MC-FN-016의 친화성을 SPR 분석으로 평가하였다. 시스틴-노트 미니단백질 2종의 결합 동역학 결과, 한자리 μM 범위에서 낮은 결합 친화성이 확인되었으며, 해리 속도 (off-rate)가 빨랐다 (도 10A).
실시예
7: EDB-특이적인 광학 이미징 프로브의 제작 및 평가
더 강한 결합 세기를 달성하기 위해, 잠재적인 항원-항체 결합 효과 (avidity effect)를 이용하도록 옥심 라이게이션을 통해 리간드를 화학적으로 사량체화하였다. 또한, 마우스에 투여한 후 분포 및 국지성을 관찰할 수 있도록 분자에 근적위선 형광 염료 Alexa Fluor 680을 태깅하였다. 사량체 구조체 3종 모두 화학 합성한 후, 적절한 크기 및 순도를 조절하기 위해 여러가지 분석을 수행하였다. SDS-PAGE 및 역상 크로마토그래피 분석 결과, 모든 구조체들에서 결정적인 특이 사항은 드러나지 않았다 (데이터 도시 안함). 특히, 본 발명의 올리고머화 전략은 EDB 결합성 시스틴-노트 미니단백질 둘다 (AF680-(MC-FN-010)3 및 AF680-(MC-FN-016)3)의 친화성을 상당히 개선하여 세자리 pmol의 친화성 상수가 달성되었으며, 단량체 변이체와 비교해 오프-속도가 현저하게 느려졌다 (도 10B).
이전에, 다른 EDB 표적화 분자들이 교모세포종을 이미징하기 위한 진단 시약으로 적용된 바 있는 것으로 알려져 있다 (Albrecht et al. 2016; Mohammadgholi et al. 2017). 이를 위해, 본 발명자들은 인간 교모세포종을 보유한 Fox n1/nu 마우스를 표적화하는 본 발명의 EDB 결합성 시스틴-노트 미니단백질의 실행 가능성에 초점을 맞추었다. 3.34 nmol AF680-(MC-FN-010)3, AF680-(MC-FN-016)3 및 음성 대조군 AF680-(MC-FN-0115)3을 정맥내 (r. o.) 주사한 후, 전신 및 장기의 생체외 사진 촬영을 수행하였다. 도 11은 음성 대조군 AF680-(MC-FN-0115)3와 비교해 AF680-(MC-FN-010)3 및 AF680-(MC-FN-016)3에서 강한 종양 신호가 발생됨을 보여주는 형광 사진이다. 사량체 구조체들 모두 간, 담낭 및 신장에서 초기 시간대에 검출할 수 있었다. 6시간 후, 담낭을 제외한 여러가지 장기들에서 신호가 감소하였으며, 중요하게도 AF680-(MC-FN-010)3 및 AF680-(MC-FN-016)3로부터 발생되는 종양 신호는 유지되었다. 아울러, 장기의 형광 신호는 도 11B에 나타낸 바와 같이 그 각각의 무게와 관련 있었다. 모 AF680-(MC-FN-010)3는 모든 시점에 음성 대조군과 비교해 현저하게 더 강한 종양 신호를 나타내었다. 그러나, AF680-(MC-FN-016)3는 AF680-(MC-FN-010)3에 비해 신호 강도는 약했지만, 음성 대조군 AF680-(MC-FN-0115)3 보단 더 강하였다.
실시예
8:
마우스 이종이식 종양으로서 증식된 인간 U-87 MG 교모세포종 세포주로부터 유래된 조직에 대한 MC-FN-010의 특이적인 결합성
저온 보존한 종양 또는 뇌 절편을 6 ㎛ 두께로 자르고, 냉랭한 아세톤에서 5분간 고정한 후 공기 건조하였다. 그런 후, 슬라이드를 3% BSA가 첨가된 PBS에서 5분간 RT에서 블록킹하였다. EDB로 염색하기 위해, 1% BSA가 첨가된 PBS에서 1:100으로 희석한 AF680-(MC-FN-010)3 및 항-마우스 CD31 항체 (RB-10333-P1, Thermo Fisher) 0.1 ㎍을 종양 절편에 첨가하여, 37℃에서 30분간 인큐베이션하였다. 그 후, 슬라이드를 1% BSA 함유 PBS로 3번 헹구었다. 그런 다음, 1% BSA가 첨가된 PBS에서 1:400으로 희석한 2차 항-토끼 IgG-Cy3 항체 (111-165-003, Jackson ImmunoResearch)를 사용해, 37℃에서 30분간 1차 항-마우스 CD31 항체의 CD31 염색을 검출하였다. 이를 PBS에서 3회 세척 단계를 수행한 후, PBS에서 1:5000으로 희석한 Hochst 33342 (Thermo Fisher Scientific)를 RT에서 30분간 사용해 세포 핵을 염색하였다. 슬라이드를 전술한 바와 같이 다시 헹구고, 얇은 마운팅 매질 (Dako) 층에서 커버슬립으로 덮었다. Zeiss Apotome 현미경 (Carl Zeiss)을 사용해 이미지를 촬영하고, ZEN 소프트웨어 (Carl Zeiss)로 분석하였다. 도 13은 인간 교모세포종 이종이식 종양 및 정상적인 뇌 조직 샘플을 삼랑체 구조체 (AF680-(MC-FN-010)3 및 대조군 AF680-(MC-FN-0115)3)로 염색한 추가적인 면역형광 염색 결과를 보여준다. AF680-(MC-FN-010)3는 혈관 마커 CD31과 함께 위치하는 U-87 MG 절편의 종양 혈관 주변 영역을 염색시킨 반면, 대조군 AF680-(MC-FN-0115)3는 전혀 염색되지 않았다. 정상적인 마우스 뇌 단편에서는 AF680-(MC-FN-010)3 염색은 관찰되지 않았으며, 이는 종양 혈관 특이성을 의미한다.
실시예
9: 선별된 시스틴-노트 미니단백질을 이용한 특이적인 종양
표적화
U-87 MG 이종이식 마우스 모델을 실시예 1에 기술된 바와 같이 구축하였다 (U-87 MG 이종이식 마우스 모델).
생체내 경쟁 실험으로, 원하는 종양 크기 (~200 mm3)를 가진 마우스에, 비-표지된 삼량체 프로브 (DOTA-(MC-FN-016)3)를 AF680-표지된 삼량체 (3.34 nmol)와 더불어 경쟁자로서 3배 또는 5배 몰 과잉으로 눈 뒷 정맥총을 통해 정맥내 주사하였다. IVIS 스펙트럼 시스템 (Perkin Elmer)에서 여기 범위 615-665 nm를 적용하고, 그리고 695-770 nm에서 방출 신호를 모니터링하여, 마우스에서 이미지를 촬영하였다. 전체 마우스 사진 촬영 공정은 주사 후 1시간, 2시간 또는 6시간 경과시 수행하였다. 6시간 후 마우스를 안락사한 후, 종양 및 특정 장기를 적출하여, 이미지를 촬영하고, 무게를 잰 다음 추가적인 분석을 위해 저온-보존 처리하였다. 대상 영역의 형광 세기를 Living Image® 소프트웨어 (PerkinElmer)로 정량하였다. 이들 마우스에서 종양 형광 세기 동역학을 경쟁자없이 표지된 AF680-(MC-FN-016)3를 처리된 마우스의 생체내 및 생체외 사진 촬영에 의해 비교하였다. DOTA-(MC-FN-016)3는, FN-67B89에 대해 측정한 겉보기 결합 상수가 AF680-(MC-FN-016)3와 비슷하여, 경쟁 실험에 매우 적합하였다 (도 15). 경쟁자 처리된 마우스에서 생체내 측정한 종양 신호는 각 시간대에 실질적으로 감소하였다 (도 14A). 이전 실험 (도 11)에서와 같이, 음성 대조군 펩타이드 AF680-(MC-FN-0115)3는 종양에서 농화되지 않았다. 6시간 후 마우스를 안락사시키고, 종양과 장기를 적출한 다음 생체외 형광 이미징 분석 (도 14B)을 수행하였다. 측정된 형광 세기는 종양 무게에 대해 표준화하였다. 비-표지된 삼량체에 의한 경쟁이 검증되었으며, 경쟁자 농도에 따른 신호 감소 의존성이 관찰되었다 (도 14C). 표지된 삼량체를 주사하기 30분 전에 경쟁자를 주사하는 것이, 동시 주사보다 더 효과적인 것으로 확인되었다.
본 실험은 재조합 EDB에 대한 파지 라이브러리에서 시스틴-노트 미니단백질 (MC-FN-010)의 선별을 기술한다. MC-FN-010 및 이의 유도체 MC-FN-016을 종양 이미징 방식의 분자 스캐폴드로서 조작하였다. 이들 EDB-결합 분자 2종은 U87-MG 이종이식 종양에서 강하게 축적되는 것으로 나타났으며, 신장을 제외하고는 백그라운드 신호가 약하였다. 이들 결과는 종양 진단 기법을 위한 제제로서 MC-FN-010 및 MC-FN-016의 높은 잠재성을 입증해준다.
<110> BioNTech SE
<120> COMPOSITIONS AND METHODS FOR DIAGNOSIS AND TREATMENT OF CANCER
<130> PIPB204312EP
<150> PCT/EP2018/065205
<151> 2018-06-08
<160> 28
<170> KoPatentIn 3.0
<210> 1
<211> 7341
<212> DNA
<213> Homo sapiens
<400> 1
atgcttaggg gtccggggcc cgggctgctg ctgctggccg tccagtgcct ggggacagcg 60
gtgccctcca cgggagcctc gaagagcaag aggcaggctc agcaaatggt tcagccccag 120
tccccggtgg ctgtcagtca aagcaagccc ggttgttatg acaatggaaa acactatcag 180
ataaatcaac agtgggagcg gacctaccta ggcaatgcgt tggtttgtac ttgttatgga 240
ggaagccgag gttttaactg cgagagtaaa cctgaagctg aagagacttg ctttgacaag 300
tacactggga acacttaccg agtgggtgac acttatgagc gtcctaaaga ctccatgatc 360
tgggactgta cctgcatcgg ggctgggcga gggagaataa gctgtaccat cgcaaaccgc 420
tgccatgaag ggggtcagtc ctacaagatt ggtgacacct ggaggagacc acatgagact 480
ggtggttaca tgttagagtg tgtgtgtctt ggtaatggaa aaggagaatg gacctgcaag 540
cccatagctg agaagtgttt tgatcatgct gctgggactt cctatgtggt cggagaaacg 600
tgggagaagc cctaccaagg ctggatgatg gtagattgta cttgcctggg agaaggcagc 660
ggacgcatca cttgcacttc tagaaataga tgcaacgatc aggacacaag gacatcctat 720
agaattggag acacctggag caagaaggat aatcgaggaa acctgctcca gtgcatctgc 780
acaggcaacg gccgaggaga gtggaagtgt gagaggcaca cctctgtgca gaccacatcg 840
agcggatctg gccccttcac cgatgttcgt gcagctgttt accaaccgca gcctcacccc 900
cagcctcctc cctatggcca ctgtgtcaca gacagtggtg tggtctactc tgtggggatg 960
cagtggctga agacacaagg aaataagcaa atgctttgca cgtgcctggg caacggagtc 1020
agctgccaag agacagctgt aacccagact tacggtggca actcaaatgg agagccatgt 1080
gtcttaccat tcacctacaa tggcaggacg ttctactcct gcaccacaga agggcgacag 1140
gacggacatc tttggtgcag cacaacttcg aattatgagc aggaccagaa atactctttc 1200
tgcacagacc acactgtttt ggttcagact cgaggaggaa attccaatgg tgccttgtgc 1260
cacttcccct tcctatacaa caaccacaat tacactgatt gcacttctga gggcagaaga 1320
gacaacatga agtggtgtgg gaccacacag aactatgatg ccgaccagaa gtttgggttc 1380
tgccccatgg ctgcccacga ggaaatctgc acaaccaatg aaggggtcat gtaccgcatt 1440
ggagatcagt gggataagca gcatgacatg ggtcacatga tgaggtgcac gtgtgttggg 1500
aatggtcgtg gggaatggac atgcattgcc tactcgcagc ttcgagatca gtgcattgtt 1560
gatgacatca cttacaatgt gaacgacaca ttccacaagc gtcatgaaga ggggcacatg 1620
ctgaactgta catgcttcgg tcagggtcgg ggcaggtgga agtgtgatcc cgtcgaccaa 1680
tgccaggatt cagagactgg gacgttttat caaattggag attcatggga gaagtatgtg 1740
catggtgtca gataccagtg ctactgctat ggccgtggca ttggggagtg gcattgccaa 1800
cctttacaga cctatccaag ctcaagtggt cctgtcgaag tatttatcac tgagactccg 1860
agtcagccca actcccaccc catccagtgg aatgcaccac agccatctca catttccaag 1920
tacattctca ggtggagacc taaaaattct gtaggccgtt ggaaggaagc taccatacca 1980
ggccacttaa actcctacac catcaaaggc ctgaagcctg gtgtggtata cgagggccag 2040
ctcatcagca tccagcagta cggccaccaa gaagtgactc gctttgactt caccaccacc 2100
agcaccagca cacctgtgac cagcaacacc gtgacaggag agacgactcc cttttctcct 2160
cttgtggcca cttctgaatc tgtgaccgaa atcacagcca gtagctttgt ggtctcctgg 2220
gtctcagctt ccgacaccgt gtcgggattc cgggtggaat atgagctgag tgaggaggga 2280
gatgagccac agtacctgga tcttccaagc acagccactt ctgtgaacat ccctgacctg 2340
cttcctggcc gaaaatacat tgtaaatgtc tatcagatat ctgaggatgg ggagcagagt 2400
ttgatcctgt ctacttcaca aacaacagcg cctgatgccc ctcctgaccc gactgtggac 2460
caagttgatg acacctcaat tgttgttcgc tggagcagac cccaggctcc catcacaggg 2520
tacagaatag tctattcgcc atcagtagaa ggtagcagca cagaactcaa ccttcctgaa 2580
actgcaaact ccgtcaccct cagtgacttg caacctggtg ttcagtataa catcactatc 2640
tatgctgtgg aagaaaatca agaaagtaca cctgttgtca ttcaacaaga aaccactggc 2700
accccacgct cagatacagt gccctctccc agggacctgc agtttgtgga agtgacagac 2760
gtgaaggtca ccatcatgtg gacaccgcct gagagtgcag tgaccggcta ccgtgtggat 2820
gtgatccccg tcaacctgcc tggcgagcac gggcagaggc tgcccatcag caggaacacc 2880
tttgcagaag tcaccgggct gtcccctggg gtcacctatt acttcaaagt ctttgcagtg 2940
agccatggga gggagagcaa gcctctgact gctcaacaga caaccaaact ggatgctccc 3000
actaacctcc agtttgtcaa tgaaactgat tctactgtcc tggtgagatg gactccacct 3060
cgggcccaga taacaggata ccgactgacc gtgggcctta cccgaagagg acagcccagg 3120
cagtacaatg tgggtccctc tgtctccaag tacccactga ggaatctgca gcctgcatct 3180
gagtacaccg tatccctcgt ggccataaag ggcaaccaag agagccccaa agccactgga 3240
gtctttacca cactgcagcc tgggagctct attccacctt acaacaccga ggtgactgag 3300
accaccattg tgatcacatg gacgcctgct ccaagaattg gttttaagct gggtgtacga 3360
ccaagccagg gaggagaggc accacgagaa gtgacttcag actcaggaag catcgttgtg 3420
tccggcttga ctccaggagt agaatacgtc tacaccatcc aagtcctgag agatggacag 3480
gaaagagatg cgccaattgt aaacaaagtg gtgacaccat tgtctccacc aacaaacttg 3540
catctggagg caaaccctga cactggagtg ctcacagtct cctgggagag gagcaccacc 3600
ccagacatta ctggttatag aattaccaca acccctacaa acggccagca gggaaattct 3660
ttggaagaag tggtccatgc tgatcagagc tcctgcactt ttgataacct gagtcccggc 3720
ctggagtaca atgtcagtgt ttacactgtc aaggatgaca aggaaagtgt ccctatctct 3780
gataccatca tcccagaggt gccccaactc actgacctaa gctttgttga tataaccgat 3840
tcaagcatcg gcctgaggtg gaccccgcta aactcttcca ccattattgg gtaccgcatc 3900
acagtagttg cggcaggaga aggtatccct atttttgaag attttgtgga ctcctcagta 3960
ggatactaca cagtcacagg gctggagccg ggcattgact atgatatcag cgttatcact 4020
ctcattaatg gcggcgagag tgcccctact acactgacac aacaaacggc tgttcctcct 4080
cccactgacc tgcgattcac caacattggt ccagacacca tgcgtgtcac ctgggctcca 4140
cccccatcca ttgatttaac caacttcctg gtgcgttact cacctgtgaa aaatgaggaa 4200
gatgttgcag agttgtcaat ttctccttca gacaatgcag tggtcttaac aaatctcctg 4260
cctggtacag aatatgtagt gagtgtctcc agtgtctacg aacaacatga gagcacacct 4320
cttagaggaa gacagaaaac aggtcttgat tccccaactg gcattgactt ttctgatatt 4380
actgccaact cttttactgt gcactggatt gctcctcgag ccaccatcac tggctacagg 4440
atccgccatc atcccgagca cttcagtggg agacctcgag aagatcgggt gccccactct 4500
cggaattcca tcaccctcac caacctcact ccaggcacag agtatgtggt cagcatcgtt 4560
gctcttaatg gcagagagga aagtccctta ttgattggcc aacaatcaac agtttctgat 4620
gttccgaggg acctggaagt tgttgctgcg acccccacca gcctactgat cagctgggat 4680
gctcctgctg tcacagtgag atattacagg atcacttacg gagagacagg aggaaatagc 4740
cctgtccagg agttcactgt gcctgggagc aagtctacag ctaccatcag cggccttaaa 4800
cctggagttg attataccat cactgtgtat gctgtcactg gccgtggaga cagccccgca 4860
agcagcaagc caatttccat taattaccga acagaaattg acaaaccatc ccagatgcaa 4920
gtgaccgatg ttcaggacaa cagcattagt gtcaagtggc tgccttcaag ttcccctgtt 4980
actggttaca gagtaaccac cactcccaaa aatggaccag gaccaacaaa aactaaaact 5040
gcaggtccag atcaaacaga aatgactatt gaaggcttgc agcccacagt ggagtatgtg 5100
gttagtgtct atgctcagaa tccaagcgga gagagtcagc ctctggttca gactgcagta 5160
accaacattg atcgccctaa aggactggca ttcactgatg tggatgtcga ttccatcaaa 5220
attgcttggg aaagcccaca ggggcaagtt tccaggtaca gggtgaccta ctcgagccct 5280
gaggatggaa tccatgagct attccctgca cctgatggtg aagaagacac tgcagagctg 5340
caaggcctca gaccgggttc tgagtacaca gtcagtgtgg ttgccttgca cgatgatatg 5400
gagagccagc ccctgattgg aacccagtcc acagctattc ctgcaccaac tgacctgaag 5460
ttcactcagg tcacacccac aagcctgagc gcccagtgga caccacccaa tgttcagctc 5520
actggatatc gagtgcgggt gacccccaag gagaagaccg gaccaatgaa agaaatcaac 5580
cttgctcctg acagctcatc cgtggttgta tcaggactta tggtggccac caaatatgaa 5640
gtgagtgtct atgctcttaa ggacactttg acaagcagac cagctcaggg agttgtcacc 5700
actctggaga atgtcagccc accaagaagg gctcgtgtga cagatgctac tgagaccacc 5760
atcaccatta gctggagaac caagactgag acgatcactg gcttccaagt tgatgccgtt 5820
ccagccaatg gccagactcc aatccagaga accatcaagc cagatgtcag aagctacacc 5880
atcacaggtt tacaaccagg cactgactac aagatctacc tgtacacctt gaatgacaat 5940
gctcggagct cccctgtggt catcgacgcc tccactgcca ttgatgcacc atccaacctg 6000
cgtttcctgg ccaccacacc caattccttg ctggtatcat ggcagccgcc acgtgccagg 6060
attaccggct acatcatcaa gtatgagaag cctgggtctc ctcccagaga agtggtccct 6120
cggccccgcc ctggtgtcac agaggctact attactggcc tggaaccggg aaccgaatat 6180
acaatttatg tcattgccct gaagaataat cagaagagcg agcccctgat tggaaggaaa 6240
aagacagacg agcttcccca actggtaacc cttccacacc ccaatcttca tggaccagag 6300
atcttggatg ttccttccac agttcaaaag acccctttcg tcacccaccc tgggtatgac 6360
actggaaatg gtattcagct tcctggcact tctggtcagc aacccagtgt tgggcaacaa 6420
atgatctttg aggaacatgg ttttaggcgg accacaccgc ccacaacggc cacccccata 6480
aggcataggc caagaccata cccgccgaat gtaggacaag aagctctctc tcagacaacc 6540
atctcatggg ccccattcca ggacacttct gagtacatca tttcatgtca tcctgttggc 6600
actgatgaag aacccttaca gttcagggtt cctggaactt ctaccagtgc cactctgaca 6660
ggcctcacca gaggtgccac ctacaacatc atagtggagg cactgaaaga ccagcagagg 6720
cataaggttc gggaagaggt tgttaccgtg ggcaactctg tcaacgaagg cttgaaccaa 6780
cctacggatg actcgtgctt tgacccctac acagtttccc attatgccgt tggagatgag 6840
tgggaacgaa tgtctgaatc aggctttaaa ctgttgtgcc agtgcttagg ctttggaagt 6900
ggtcatttca gatgtgattc atctagatgg tgccatgaca atggtgtgaa ctacaagatt 6960
ggagagaagt gggaccgtca gggagaaaat ggccagatga tgagctgcac atgtcttggg 7020
aacggaaaag gagaattcaa gtgtgaccct catgaggcaa cgtgttatga tgatgggaag 7080
acataccacg taggagaaca gtggcagaag gaatatctcg gtgccatttg ctcctgcaca 7140
tgctttggag gccagcgggg ctggcgctgt gacaactgcc gcagacctgg gggtgaaccc 7200
agtcccgaag gcactactgg ccagtcctac aaccagtatt ctcagagata ccatcagaga 7260
acaaacacta atgttaattg cccaattgag tgcttcatgc ctttagatgt acaggctgac 7320
agagaagatt cccgagagta a 7341
<210> 2
<211> 2446
<212> PRT
<213> Homo sapiens
<400> 2
Met Leu Arg Gly Pro Gly Pro Gly Leu Leu Leu Leu Ala Val Gln Cys
1 5 10 15
Leu Gly Thr Ala Val Pro Ser Thr Gly Ala Ser Lys Ser Lys Arg Gln
20 25 30
Ala Gln Gln Met Val Gln Pro Gln Ser Pro Val Ala Val Ser Gln Ser
35 40 45
Lys Pro Gly Cys Tyr Asp Asn Gly Lys His Tyr Gln Ile Asn Gln Gln
50 55 60
Trp Glu Arg Thr Tyr Leu Gly Asn Ala Leu Val Cys Thr Cys Tyr Gly
65 70 75 80
Gly Ser Arg Gly Phe Asn Cys Glu Ser Lys Pro Glu Ala Glu Glu Thr
85 90 95
Cys Phe Asp Lys Tyr Thr Gly Asn Thr Tyr Arg Val Gly Asp Thr Tyr
100 105 110
Glu Arg Pro Lys Asp Ser Met Ile Trp Asp Cys Thr Cys Ile Gly Ala
115 120 125
Gly Arg Gly Arg Ile Ser Cys Thr Ile Ala Asn Arg Cys His Glu Gly
130 135 140
Gly Gln Ser Tyr Lys Ile Gly Asp Thr Trp Arg Arg Pro His Glu Thr
145 150 155 160
Gly Gly Tyr Met Leu Glu Cys Val Cys Leu Gly Asn Gly Lys Gly Glu
165 170 175
Trp Thr Cys Lys Pro Ile Ala Glu Lys Cys Phe Asp His Ala Ala Gly
180 185 190
Thr Ser Tyr Val Val Gly Glu Thr Trp Glu Lys Pro Tyr Gln Gly Trp
195 200 205
Met Met Val Asp Cys Thr Cys Leu Gly Glu Gly Ser Gly Arg Ile Thr
210 215 220
Cys Thr Ser Arg Asn Arg Cys Asn Asp Gln Asp Thr Arg Thr Ser Tyr
225 230 235 240
Arg Ile Gly Asp Thr Trp Ser Lys Lys Asp Asn Arg Gly Asn Leu Leu
245 250 255
Gln Cys Ile Cys Thr Gly Asn Gly Arg Gly Glu Trp Lys Cys Glu Arg
260 265 270
His Thr Ser Val Gln Thr Thr Ser Ser Gly Ser Gly Pro Phe Thr Asp
275 280 285
Val Arg Ala Ala Val Tyr Gln Pro Gln Pro His Pro Gln Pro Pro Pro
290 295 300
Tyr Gly His Cys Val Thr Asp Ser Gly Val Val Tyr Ser Val Gly Met
305 310 315 320
Gln Trp Leu Lys Thr Gln Gly Asn Lys Gln Met Leu Cys Thr Cys Leu
325 330 335
Gly Asn Gly Val Ser Cys Gln Glu Thr Ala Val Thr Gln Thr Tyr Gly
340 345 350
Gly Asn Ser Asn Gly Glu Pro Cys Val Leu Pro Phe Thr Tyr Asn Gly
355 360 365
Arg Thr Phe Tyr Ser Cys Thr Thr Glu Gly Arg Gln Asp Gly His Leu
370 375 380
Trp Cys Ser Thr Thr Ser Asn Tyr Glu Gln Asp Gln Lys Tyr Ser Phe
385 390 395 400
Cys Thr Asp His Thr Val Leu Val Gln Thr Arg Gly Gly Asn Ser Asn
405 410 415
Gly Ala Leu Cys His Phe Pro Phe Leu Tyr Asn Asn His Asn Tyr Thr
420 425 430
Asp Cys Thr Ser Glu Gly Arg Arg Asp Asn Met Lys Trp Cys Gly Thr
435 440 445
Thr Gln Asn Tyr Asp Ala Asp Gln Lys Phe Gly Phe Cys Pro Met Ala
450 455 460
Ala His Glu Glu Ile Cys Thr Thr Asn Glu Gly Val Met Tyr Arg Ile
465 470 475 480
Gly Asp Gln Trp Asp Lys Gln His Asp Met Gly His Met Met Arg Cys
485 490 495
Thr Cys Val Gly Asn Gly Arg Gly Glu Trp Thr Cys Ile Ala Tyr Ser
500 505 510
Gln Leu Arg Asp Gln Cys Ile Val Asp Asp Ile Thr Tyr Asn Val Asn
515 520 525
Asp Thr Phe His Lys Arg His Glu Glu Gly His Met Leu Asn Cys Thr
530 535 540
Cys Phe Gly Gln Gly Arg Gly Arg Trp Lys Cys Asp Pro Val Asp Gln
545 550 555 560
Cys Gln Asp Ser Glu Thr Gly Thr Phe Tyr Gln Ile Gly Asp Ser Trp
565 570 575
Glu Lys Tyr Val His Gly Val Arg Tyr Gln Cys Tyr Cys Tyr Gly Arg
580 585 590
Gly Ile Gly Glu Trp His Cys Gln Pro Leu Gln Thr Tyr Pro Ser Ser
595 600 605
Ser Gly Pro Val Glu Val Phe Ile Thr Glu Thr Pro Ser Gln Pro Asn
610 615 620
Ser His Pro Ile Gln Trp Asn Ala Pro Gln Pro Ser His Ile Ser Lys
625 630 635 640
Tyr Ile Leu Arg Trp Arg Pro Lys Asn Ser Val Gly Arg Trp Lys Glu
645 650 655
Ala Thr Ile Pro Gly His Leu Asn Ser Tyr Thr Ile Lys Gly Leu Lys
660 665 670
Pro Gly Val Val Tyr Glu Gly Gln Leu Ile Ser Ile Gln Gln Tyr Gly
675 680 685
His Gln Glu Val Thr Arg Phe Asp Phe Thr Thr Thr Ser Thr Ser Thr
690 695 700
Pro Val Thr Ser Asn Thr Val Thr Gly Glu Thr Thr Pro Phe Ser Pro
705 710 715 720
Leu Val Ala Thr Ser Glu Ser Val Thr Glu Ile Thr Ala Ser Ser Phe
725 730 735
Val Val Ser Trp Val Ser Ala Ser Asp Thr Val Ser Gly Phe Arg Val
740 745 750
Glu Tyr Glu Leu Ser Glu Glu Gly Asp Glu Pro Gln Tyr Leu Asp Leu
755 760 765
Pro Ser Thr Ala Thr Ser Val Asn Ile Pro Asp Leu Leu Pro Gly Arg
770 775 780
Lys Tyr Ile Val Asn Val Tyr Gln Ile Ser Glu Asp Gly Glu Gln Ser
785 790 795 800
Leu Ile Leu Ser Thr Ser Gln Thr Thr Ala Pro Asp Ala Pro Pro Asp
805 810 815
Pro Thr Val Asp Gln Val Asp Asp Thr Ser Ile Val Val Arg Trp Ser
820 825 830
Arg Pro Gln Ala Pro Ile Thr Gly Tyr Arg Ile Val Tyr Ser Pro Ser
835 840 845
Val Glu Gly Ser Ser Thr Glu Leu Asn Leu Pro Glu Thr Ala Asn Ser
850 855 860
Val Thr Leu Ser Asp Leu Gln Pro Gly Val Gln Tyr Asn Ile Thr Ile
865 870 875 880
Tyr Ala Val Glu Glu Asn Gln Glu Ser Thr Pro Val Val Ile Gln Gln
885 890 895
Glu Thr Thr Gly Thr Pro Arg Ser Asp Thr Val Pro Ser Pro Arg Asp
900 905 910
Leu Gln Phe Val Glu Val Thr Asp Val Lys Val Thr Ile Met Trp Thr
915 920 925
Pro Pro Glu Ser Ala Val Thr Gly Tyr Arg Val Asp Val Ile Pro Val
930 935 940
Asn Leu Pro Gly Glu His Gly Gln Arg Leu Pro Ile Ser Arg Asn Thr
945 950 955 960
Phe Ala Glu Val Thr Gly Leu Ser Pro Gly Val Thr Tyr Tyr Phe Lys
965 970 975
Val Phe Ala Val Ser His Gly Arg Glu Ser Lys Pro Leu Thr Ala Gln
980 985 990
Gln Thr Thr Lys Leu Asp Ala Pro Thr Asn Leu Gln Phe Val Asn Glu
995 1000 1005
Thr Asp Ser Thr Val Leu Val Arg Trp Thr Pro Pro Arg Ala Gln
1010 1015 1020
Ile Thr Gly Tyr Arg Leu Thr Val Gly Leu Thr Arg Arg Gly Gln
1025 1030 1035
Pro Arg Gln Tyr Asn Val Gly Pro Ser Val Ser Lys Tyr Pro Leu
1040 1045 1050
Arg Asn Leu Gln Pro Ala Ser Glu Tyr Thr Val Ser Leu Val Ala
1055 1060 1065
Ile Lys Gly Asn Gln Glu Ser Pro Lys Ala Thr Gly Val Phe Thr
1070 1075 1080
Thr Leu Gln Pro Gly Ser Ser Ile Pro Pro Tyr Asn Thr Glu Val
1085 1090 1095
Thr Glu Thr Thr Ile Val Ile Thr Trp Thr Pro Ala Pro Arg Ile
1100 1105 1110
Gly Phe Lys Leu Gly Val Arg Pro Ser Gln Gly Gly Glu Ala Pro
1115 1120 1125
Arg Glu Val Thr Ser Asp Ser Gly Ser Ile Val Val Ser Gly Leu
1130 1135 1140
Thr Pro Gly Val Glu Tyr Val Tyr Thr Ile Gln Val Leu Arg Asp
1145 1150 1155
Gly Gln Glu Arg Asp Ala Pro Ile Val Asn Lys Val Val Thr Pro
1160 1165 1170
Leu Ser Pro Pro Thr Asn Leu His Leu Glu Ala Asn Pro Asp Thr
1175 1180 1185
Gly Val Leu Thr Val Ser Trp Glu Arg Ser Thr Thr Pro Asp Ile
1190 1195 1200
Thr Gly Tyr Arg Ile Thr Thr Thr Pro Thr Asn Gly Gln Gln Gly
1205 1210 1215
Asn Ser Leu Glu Glu Val Val His Ala Asp Gln Ser Ser Cys Thr
1220 1225 1230
Phe Asp Asn Leu Ser Pro Gly Leu Glu Tyr Asn Val Ser Val Tyr
1235 1240 1245
Thr Val Lys Asp Asp Lys Glu Ser Val Pro Ile Ser Asp Thr Ile
1250 1255 1260
Ile Pro Glu Val Pro Gln Leu Thr Asp Leu Ser Phe Val Asp Ile
1265 1270 1275
Thr Asp Ser Ser Ile Gly Leu Arg Trp Thr Pro Leu Asn Ser Ser
1280 1285 1290
Thr Ile Ile Gly Tyr Arg Ile Thr Val Val Ala Ala Gly Glu Gly
1295 1300 1305
Ile Pro Ile Phe Glu Asp Phe Val Asp Ser Ser Val Gly Tyr Tyr
1310 1315 1320
Thr Val Thr Gly Leu Glu Pro Gly Ile Asp Tyr Asp Ile Ser Val
1325 1330 1335
Ile Thr Leu Ile Asn Gly Gly Glu Ser Ala Pro Thr Thr Leu Thr
1340 1345 1350
Gln Gln Thr Ala Val Pro Pro Pro Thr Asp Leu Arg Phe Thr Asn
1355 1360 1365
Ile Gly Pro Asp Thr Met Arg Val Thr Trp Ala Pro Pro Pro Ser
1370 1375 1380
Ile Asp Leu Thr Asn Phe Leu Val Arg Tyr Ser Pro Val Lys Asn
1385 1390 1395
Glu Glu Asp Val Ala Glu Leu Ser Ile Ser Pro Ser Asp Asn Ala
1400 1405 1410
Val Val Leu Thr Asn Leu Leu Pro Gly Thr Glu Tyr Val Val Ser
1415 1420 1425
Val Ser Ser Val Tyr Glu Gln His Glu Ser Thr Pro Leu Arg Gly
1430 1435 1440
Arg Gln Lys Thr Gly Leu Asp Ser Pro Thr Gly Ile Asp Phe Ser
1445 1450 1455
Asp Ile Thr Ala Asn Ser Phe Thr Val His Trp Ile Ala Pro Arg
1460 1465 1470
Ala Thr Ile Thr Gly Tyr Arg Ile Arg His His Pro Glu His Phe
1475 1480 1485
Ser Gly Arg Pro Arg Glu Asp Arg Val Pro His Ser Arg Asn Ser
1490 1495 1500
Ile Thr Leu Thr Asn Leu Thr Pro Gly Thr Glu Tyr Val Val Ser
1505 1510 1515
Ile Val Ala Leu Asn Gly Arg Glu Glu Ser Pro Leu Leu Ile Gly
1520 1525 1530
Gln Gln Ser Thr Val Ser Asp Val Pro Arg Asp Leu Glu Val Val
1535 1540 1545
Ala Ala Thr Pro Thr Ser Leu Leu Ile Ser Trp Asp Ala Pro Ala
1550 1555 1560
Val Thr Val Arg Tyr Tyr Arg Ile Thr Tyr Gly Glu Thr Gly Gly
1565 1570 1575
Asn Ser Pro Val Gln Glu Phe Thr Val Pro Gly Ser Lys Ser Thr
1580 1585 1590
Ala Thr Ile Ser Gly Leu Lys Pro Gly Val Asp Tyr Thr Ile Thr
1595 1600 1605
Val Tyr Ala Val Thr Gly Arg Gly Asp Ser Pro Ala Ser Ser Lys
1610 1615 1620
Pro Ile Ser Ile Asn Tyr Arg Thr Glu Ile Asp Lys Pro Ser Gln
1625 1630 1635
Met Gln Val Thr Asp Val Gln Asp Asn Ser Ile Ser Val Lys Trp
1640 1645 1650
Leu Pro Ser Ser Ser Pro Val Thr Gly Tyr Arg Val Thr Thr Thr
1655 1660 1665
Pro Lys Asn Gly Pro Gly Pro Thr Lys Thr Lys Thr Ala Gly Pro
1670 1675 1680
Asp Gln Thr Glu Met Thr Ile Glu Gly Leu Gln Pro Thr Val Glu
1685 1690 1695
Tyr Val Val Ser Val Tyr Ala Gln Asn Pro Ser Gly Glu Ser Gln
1700 1705 1710
Pro Leu Val Gln Thr Ala Val Thr Asn Ile Asp Arg Pro Lys Gly
1715 1720 1725
Leu Ala Phe Thr Asp Val Asp Val Asp Ser Ile Lys Ile Ala Trp
1730 1735 1740
Glu Ser Pro Gln Gly Gln Val Ser Arg Tyr Arg Val Thr Tyr Ser
1745 1750 1755
Ser Pro Glu Asp Gly Ile His Glu Leu Phe Pro Ala Pro Asp Gly
1760 1765 1770
Glu Glu Asp Thr Ala Glu Leu Gln Gly Leu Arg Pro Gly Ser Glu
1775 1780 1785
Tyr Thr Val Ser Val Val Ala Leu His Asp Asp Met Glu Ser Gln
1790 1795 1800
Pro Leu Ile Gly Thr Gln Ser Thr Ala Ile Pro Ala Pro Thr Asp
1805 1810 1815
Leu Lys Phe Thr Gln Val Thr Pro Thr Ser Leu Ser Ala Gln Trp
1820 1825 1830
Thr Pro Pro Asn Val Gln Leu Thr Gly Tyr Arg Val Arg Val Thr
1835 1840 1845
Pro Lys Glu Lys Thr Gly Pro Met Lys Glu Ile Asn Leu Ala Pro
1850 1855 1860
Asp Ser Ser Ser Val Val Val Ser Gly Leu Met Val Ala Thr Lys
1865 1870 1875
Tyr Glu Val Ser Val Tyr Ala Leu Lys Asp Thr Leu Thr Ser Arg
1880 1885 1890
Pro Ala Gln Gly Val Val Thr Thr Leu Glu Asn Val Ser Pro Pro
1895 1900 1905
Arg Arg Ala Arg Val Thr Asp Ala Thr Glu Thr Thr Ile Thr Ile
1910 1915 1920
Ser Trp Arg Thr Lys Thr Glu Thr Ile Thr Gly Phe Gln Val Asp
1925 1930 1935
Ala Val Pro Ala Asn Gly Gln Thr Pro Ile Gln Arg Thr Ile Lys
1940 1945 1950
Pro Asp Val Arg Ser Tyr Thr Ile Thr Gly Leu Gln Pro Gly Thr
1955 1960 1965
Asp Tyr Lys Ile Tyr Leu Tyr Thr Leu Asn Asp Asn Ala Arg Ser
1970 1975 1980
Ser Pro Val Val Ile Asp Ala Ser Thr Ala Ile Asp Ala Pro Ser
1985 1990 1995
Asn Leu Arg Phe Leu Ala Thr Thr Pro Asn Ser Leu Leu Val Ser
2000 2005 2010
Trp Gln Pro Pro Arg Ala Arg Ile Thr Gly Tyr Ile Ile Lys Tyr
2015 2020 2025
Glu Lys Pro Gly Ser Pro Pro Arg Glu Val Val Pro Arg Pro Arg
2030 2035 2040
Pro Gly Val Thr Glu Ala Thr Ile Thr Gly Leu Glu Pro Gly Thr
2045 2050 2055
Glu Tyr Thr Ile Tyr Val Ile Ala Leu Lys Asn Asn Gln Lys Ser
2060 2065 2070
Glu Pro Leu Ile Gly Arg Lys Lys Thr Asp Glu Leu Pro Gln Leu
2075 2080 2085
Val Thr Leu Pro His Pro Asn Leu His Gly Pro Glu Ile Leu Asp
2090 2095 2100
Val Pro Ser Thr Val Gln Lys Thr Pro Phe Val Thr His Pro Gly
2105 2110 2115
Tyr Asp Thr Gly Asn Gly Ile Gln Leu Pro Gly Thr Ser Gly Gln
2120 2125 2130
Gln Pro Ser Val Gly Gln Gln Met Ile Phe Glu Glu His Gly Phe
2135 2140 2145
Arg Arg Thr Thr Pro Pro Thr Thr Ala Thr Pro Ile Arg His Arg
2150 2155 2160
Pro Arg Pro Tyr Pro Pro Asn Val Gly Gln Glu Ala Leu Ser Gln
2165 2170 2175
Thr Thr Ile Ser Trp Ala Pro Phe Gln Asp Thr Ser Glu Tyr Ile
2180 2185 2190
Ile Ser Cys His Pro Val Gly Thr Asp Glu Glu Pro Leu Gln Phe
2195 2200 2205
Arg Val Pro Gly Thr Ser Thr Ser Ala Thr Leu Thr Gly Leu Thr
2210 2215 2220
Arg Gly Ala Thr Tyr Asn Ile Ile Val Glu Ala Leu Lys Asp Gln
2225 2230 2235
Gln Arg His Lys Val Arg Glu Glu Val Val Thr Val Gly Asn Ser
2240 2245 2250
Val Asn Glu Gly Leu Asn Gln Pro Thr Asp Asp Ser Cys Phe Asp
2255 2260 2265
Pro Tyr Thr Val Ser His Tyr Ala Val Gly Asp Glu Trp Glu Arg
2270 2275 2280
Met Ser Glu Ser Gly Phe Lys Leu Leu Cys Gln Cys Leu Gly Phe
2285 2290 2295
Gly Ser Gly His Phe Arg Cys Asp Ser Ser Arg Trp Cys His Asp
2300 2305 2310
Asn Gly Val Asn Tyr Lys Ile Gly Glu Lys Trp Asp Arg Gln Gly
2315 2320 2325
Glu Asn Gly Gln Met Met Ser Cys Thr Cys Leu Gly Asn Gly Lys
2330 2335 2340
Gly Glu Phe Lys Cys Asp Pro His Glu Ala Thr Cys Tyr Asp Asp
2345 2350 2355
Gly Lys Thr Tyr His Val Gly Glu Gln Trp Gln Lys Glu Tyr Leu
2360 2365 2370
Gly Ala Ile Cys Ser Cys Thr Cys Phe Gly Gly Gln Arg Gly Trp
2375 2380 2385
Arg Cys Asp Asn Cys Arg Arg Pro Gly Gly Glu Pro Ser Pro Glu
2390 2395 2400
Gly Thr Thr Gly Gln Ser Tyr Asn Gln Tyr Ser Gln Arg Tyr His
2405 2410 2415
Gln Arg Thr Asn Thr Asn Val Asn Cys Pro Ile Glu Cys Phe Met
2420 2425 2430
Pro Leu Asp Val Gln Ala Asp Arg Glu Asp Ser Arg Glu
2435 2440 2445
<210> 3
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<220>
<221> MISC_FEATURE
<222> (2)..(2)
<223> Ile or Val
<400> 3
Arg Xaa Arg Leu
1
<210> 4
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<220>
<221> MISC_FEATURE
<222> (1)..(1)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (1)..(1)
<223> Preferably repeated 0 to 4, preferably 1 or 2 times
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (3)..(3)
<223> Preferably repeated 3 to 10, preferably 4, 5, 6 or 7 times
<220>
<221> MISC_FEATURE
<222> (5)..(5)
<223> Ile or Val
<220>
<221> MISC_FEATURE
<222> (7)..(7)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (7)..(7)
<223> Preferably repeated 0 to 4, preferably 0 or 1 times
<220>
<221> MISC_FEATURE
<222> (9)..(9)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (9)..(9)
<223> Preferably repeated 3 to 7, preferably 4, 5 or 6 times
<220>
<221> MISC_FEATURE
<222> (11)..(11)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (11)..(11)
<223> Preferably repeated 2 to 6, preferably 2, 3 or 4 times
<220>
<221> MISC_FEATURE
<222> (13)..(13)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (13)..(13)
<223> Preferably repeated 1 to 3, preferably 1 or 2 times
<220>
<221> MISC_FEATURE
<222> (15)..(15)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (15)..(15)
<223> Preferably repeated 3 to 7, preferably 4, 5 or 6 times
<220>
<221> MISC_FEATURE
<222> (17)..(17)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (17)..(17)
<223> Preferably repeated 0 to 4, preferably 1 or 2 times
<400> 4
Xaa Cys Xaa Arg Xaa Arg Xaa Cys Xaa Cys Xaa Cys Xaa Cys Xaa Cys
1 5 10 15
Xaa
<210> 5
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<220>
<221> MISC_FEATURE
<222> (1)..(1)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (1)..(1)
<223> Preferably repeated 0 to 4, preferably 1 or 2 times
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (3)..(3)
<223> Preferably repeated 3 to 10, preferably 4, 5, 6 or 7 times
<220>
<221> MISC_FEATURE
<222> (5)..(5)
<223> Ile or Val
<220>
<221> MISC_FEATURE
<222> (7)..(7)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (7)..(7)
<223> Preferably repeated 0 to 4, preferably 0 or 1 times
<220>
<221> MISC_FEATURE
<222> (15)..(15)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (15)..(15)
<223> Preferably repeated 2 to 6, preferably 2, 3 or 4 times
<220>
<221> MISC_FEATURE
<222> (25)..(25)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (25)..(25)
<223> Preferably repeated 0 to 4, preferably 1 or 2 times
<400> 5
Xaa Cys Xaa Arg Xaa Arg Xaa Cys Arg Arg Asp Ser Asp Cys Xaa Cys
1 5 10 15
Ile Cys Arg Gly Asn Gly Tyr Cys Xaa
20 25
<210> 6
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<220>
<221> MISC_FEATURE
<222> (1)..(1)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (1)..(1)
<223> Preferably repeated 0 to 4, preferably 1 or 2 times
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (3)..(3)
<223> Preferably repeated 3 to 10, preferably 4, 5, 6 or 7 times
<220>
<221> MISC_FEATURE
<222> (5)..(5)
<223> Ile or Val
<220>
<221> MISC_FEATURE
<222> (7)..(7)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (7)..(7)
<223> Preferably repeated 0 to 4, preferably 0 or 1 times
<220>
<221> MISC_FEATURE
<222> (15)..(15)
<223> Independently from each other any amino acid
<220>
<221> REPEAT
<222> (15)..(15)
<223> Preferably repeated 2 to 6, preferably 2, 3 or 4 times
<400> 6
Xaa Cys Xaa Arg Xaa Arg Xaa Cys Arg Arg Asp Ser Asp Cys Xaa Cys
1 5 10 15
Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25
<210> 7
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 7
Trp Lys Cys Gln Pro Thr Asn Gly Tyr Arg Ile Arg Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Pro Gly Asp Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 8
<211> 33
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 8
Ser Val Cys Lys Asn Val Ser Ile Met Arg Ile Arg Leu Cys Arg Arg
1 5 10 15
Asp Ser Asp Cys Pro Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys
20 25 30
Gly
<210> 9
<211> 33
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 9
Ser Val Cys Ala His Tyr Asn Thr Ile Arg Val Arg Leu Cys Arg Arg
1 5 10 15
Asp Ser Asp Cys Pro Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys
20 25 30
Gly
<210> 10
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 10
Trp Thr Cys Thr Lys Lys Tyr Pro Asn Thr Ile Ser Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Arg Val Thr Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 11
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 11
Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 12
<211> 33
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 12
Ser Val Cys Lys Gln Ala Asn Phe Val Arg Ile Arg Leu Cys Arg Arg
1 5 10 15
Asp Ser Asp Cys Pro Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys
20 25 30
Gly
<210> 13
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 13
Ala Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 14
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 14
Pro Ala Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 15
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 15
Pro Met Cys Ala Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 16
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 16
Pro Met Cys Thr Ala Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 17
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 17
Pro Met Cys Thr Gln Ala Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 18
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 18
Pro Met Cys Thr Gln Arg Ala Asn Arg Ile Arg Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 19
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 19
Pro Met Cys Thr Gln Arg Lys Ala Arg Ile Arg Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 20
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 20
Pro Met Cys Thr Gln Arg Lys Asn Ala Ile Arg Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 21
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 21
Pro Met Cys Thr Gln Arg Lys Asn Arg Ala Arg Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 22
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 22
Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Ala Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 23
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 23
Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Ala Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 24
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 24
Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Ala Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 25
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 25
Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Ala Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 26
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> EDB binding peptide
<400> 26
Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Ala Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 27
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> Control peptide
<400> 27
Pro Met Cys Thr Gln Arg Ala Asn Arg Ile Ala Ala Cys Arg Arg Asp
1 5 10 15
Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly
20 25 30
<210> 28
<211> 91
<212> PRT
<213> Homo sapiens
<400> 28
Glu Val Pro Gln Leu Thr Asp Leu Ser Phe Val Asp Ile Thr Asp Ser
1 5 10 15
Ser Ile Gly Leu Arg Trp Thr Pro Leu Asn Ser Ser Thr Ile Ile Gly
20 25 30
Tyr Arg Ile Thr Val Val Ala Ala Gly Glu Gly Ile Pro Ile Phe Glu
35 40 45
Asp Phe Val Asp Ser Ser Val Gly Tyr Tyr Thr Val Thr Gly Leu Glu
50 55 60
Pro Gly Ile Asp Tyr Asp Ile Ser Val Ile Thr Leu Ile Asn Gly Gly
65 70 75 80
Glu Ser Ala Pro Thr Thr Leu Thr Gln Gln Thr
85 90
Claims (51)
- 아미노산 서열 모티프 Arg-Ile/Val-Arg를 포함하는, 파이브로넥틴 엑스트라 도메인 B (Fibronectin Extra Domain B) (EDB) 결합성 펩타이드.
- 제1항에 있어서,
아미노산 서열 모티프 Arg-Ile/Val-Arg-Leu를 포함하는, EDB 결합성 펩타이드. - 제1항 또는 제2항에 있어서,
하기 아미노산 서열을 포함하며:
(Xaa)n1 Cys (Xaa)n2 Arg Ile/Val Arg (Xaa)n3 Cys (Xaa)n4 Cys (Xaa)n5 Cys (Xaa)n6 Cys (Xaa)n7 Cys (Xaa)n8
상기 서열에서,
Cys 잔기는 시스틴 노트 구조를 형성하고,
Xaa는 독립적으로 서로 다른 임의의 아미노산으로부터 유래되고,
n1, n2, n3, n4, n5, n6, n7 및 n8은 각각의 아미노산 번호이고,
아미노산 Xaa의 특성 및/또는 아미노산 번호 n1, n2, n3, n4, n5, n6, n7 및 n8은 Cys 잔기들 간에 시스틴 노트 구조가 형성될 수 있게 하는 것인, EDB 결합성 펩타이드. - 제1항 내지 제3항 중 어느 한 항에 있어서,
n1이 0 내지 4, 바람직하게는 1 또는 2이고,
n2가 3 내지 10, 바람직하게는 4, 5, 6 또는 7이고,
n3가 0 내지 4, 바람직하게는 0 또는 1이고,
n4가 3 내지 7, 바람직하게는 4, 5 또는 6이고,
n5가 2 내지 6, 바람직하게는 2, 3 또는 4이고,
n6가 1 내지 3, 바람직하게는 1 또는 2이고,
n7이 3 내지 7, 바람직하게는 4, 5 또는 6이고,
n8이 0 내지 4, 바람직하게는 1 또는 2인, EDB 결합성 펩타이드. - 제3항 또는 제4항에 있어서,
(Xaa)n3가 Leu이거나 또는 생락되고, 바람직하게는 (Xaa)n3가 Leu인, EDB 결합성 펩타이드. - 제3항 내지 제5항 중 어느 한 항에 있어서,
(Xaa)n2가 (Xaa)n2' Asn이고, 바람직하게는 n2'이 2 내지 9, 바람직하게는 3, 4, 5 또는 6인, EDB 결합성 펩타이드. - 제3항 내지 제6항 중 어느 한 항에 있어서,
상기 (Xaa)n7이 Arg (Xaa)n7'이고, 바람직하게는 n7'이 2 내지 6, 바람직하게는 3, 4 또는 5인, EDB 결합성 펩타이드. - 제3항 내지 제7항 중 어느 한 항에 있어서,
n2가 5 또는 6이거나, 또는 n2'이 4 또는 5이고,
n3가 0 또는 1이고,
n4가 5이고,
n5가 3이고,
n6가 1이고,
n7이 5이거나, 또는 n7'이 4인, EDB 결합성 펩타이드. - 제3항 내지 제8항 중 어느 한 항에 있어서,
하기 아미노산 서열을 포함하는, EDB 결합성 펩타이드:
(Xaa)n1 Cys (Xaa)n2 Arg Ile/Val Arg (Xaa)n3 Cys Arg Arg Asp Ser Asp Cys (Xaa)n5 Cys Ile Cys Arg Gly Asn Gly Tyr Cys (Xaa)n8. - 제3항 내지 제9항 중 어느 한 항에 있어서,
하기 아미노산 서열을 포함하는, EDB 결합성 펩타이드:
(Xaa)n1 Cys (Xaa)n2 Arg Ile/Val Arg (Xaa)n3 Cys Arg Arg Asp Ser Asp Cys (Xaa)n5 Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly - 제1항 내지 제10항 중 어느 한 항에 있어서,
Ile/Val이 Ile인, EDB 결합성 펩타이드. - 제1항 내지 제10항 중 어느 한 항에 있어서,
Ile/Val이 Val인, EDB 결합성 펩타이드. - 제1항 내지 제12항 중 어느 한 항에 있어서,
하기 서열들로 이루어진 군으로부터 선택되는 아미노산 서열을 포함하는, EDB 결합성 펩타이드:
(i) Trp Lys Cys Gln Pro Thr Asn Gly Tyr Arg Ile Arg Cys Arg Arg Asp Ser Asp Cys Pro Gly Asp Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(ii) Ser Val Cys Lys Asn Val Ser Ile Met Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Pro Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(iii) Ser Val Cys Ala His Tyr Asn Thr Ile Arg Val Arg Leu Cys Arg Arg Asp Ser Asp Cys Pro Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(iv) Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(v) Ser Val Cys Lys Gln Ala Asn Phe Val Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Pro Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(vi) Ala Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(vii) Pro Ala Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(viii) Pro Met Cys Ala Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(ix) Pro Met Cys Thr Ala Arg Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(x) Pro Met Cys Thr Gln Ala Lys Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(xi) Pro Met Cys Thr Gln Arg Ala Asn Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(xii) Pro Met Cys Thr Gln Arg Lys Ala Arg Ile Arg Leu Cys Arg Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly,
(xiii) Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Ala Arg Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly, 및
(xiv) Pro Met Cys Thr Gln Arg Lys Asn Arg Ile Arg Leu Cys Arg Ala Asp Ser Asp Cys Thr Gly Ala Cys Ile Cys Arg Gly Asn Gly Tyr Cys Gly - 제1항 내지 제13항 중 어느 한 항에 있어서,
스캐폴드 (scaffold)를 형성하거나 또는 스캐폴드의 일부인, EDB 결합성 펩타이드. - 제1항 내지 제14항 중 어느 한 항에 있어서,
공유결합성 변형에 의해 안정화된, EDB 결합성 펩타이드. - 제15항에 있어서,
상기 공유결합성 변형이 고리화인, EDB 결합성 펩타이드. - 제16항에 있어서,
상기 고리화가 하나 이상의 이황화 결합을 통해 형성된, EDB 결합성 펩타이드. - 제1항 내지 제17항 중 어느 한 항에 있어서,
시스틴 노트 구조, 바람직하게는 저해제 시스틴 노트 (inhibitor cystine knot) 구조를 형성하거나 및/또는 그 일부인, EDB 결합성 펩타이드. - 제1항 내지 제18항 중 어느 한 항에 있어서,
아미노산 서열 모티프가 시스틴 노트 구조, 바람직하게는 저해제 시스틴 노트 구조의 루프 1 내에, 바람직하게는 시스틴 노트 구조, 바람직하게는 저해제 시스틴 노트 구조의 루프 1의 C-말단부에 위치하는, EDB 결합성 펩타이드. - 제18항 또는 제19항에 있어서,
상기 시스틴 노트 구조가 모모르디카 코킨키넨시스 (Momordica cochinchinensis)로부터 유래되는 오픈 체인 트립신 저해제 II (oMCoTI-II)를 기본으로 하는, EDB 결합성 펩타이드. - 제1항 내지 제20항 중 어느 한 항에 있어서,
하나 이상의 융합 파트너를 더 포함하는, EDB 결합성 펩타이드. - 제21항에 있어서,
상기 융합 파트너가 이종의 아미노산 서열을 포함하는, EDB 결합성 펩타이드. - 제1항 내지 제22항 중 어느 한 항에 따른 EDB 결합성 펩타이드를 포함하는, 파이브로넥틴 엑스트라 도메인 B (EDB) 결합제.
- 제23항에 있어서,
상기 EDB 결합성 펩타이드가 하나 이상의 추가의 모이어티와 공유결합적으로 및/또는 비-공유결합적으로 결합되고, 바람직하게는 하나 이상의 추가의 모이어티와 공유결합적으로 결합되는, EDB 결합제. - 제21항 또는 제22항 또는 제24항에 있어서,
상기 융합 파트너 또는 상기 추가의 모이어티가 담체 단백질, 표지물질, 리포터 또는 태그를 포함하는, EDB 결합성 펩타이드 또는 EDB 결합제. - 제23항 내지 제25항 중 어느 한 항에 있어서,
공유결합적으로 및/또는 비-공유결합적으로 결합된 2개 이상의 서브유닛을 포함하며,
상기 서브유닛이 각각 제1항 내지 제22항 및 제25항 중 어느 한 항에 따른 EDB 결합성 펩타이드를 포함하고,
상기 EDB 결합성 펩타이드들이 서로 동일하거나 또는 상이할 수 있는, EDB 결합제. - 제26항에 있어서,
4개 이상의 서브유닛을 포함하는, EDB 결합제. - 제26항에 있어서,
3개 이상의 서브유닛을 포함하는, EDB 결합제. - 하나 이상의 검출가능한 표지물질 또는 리포터 및/또는 하나 이상의 치료학적 작동자 모이어티 (therapeutic effector moiety)와 공유결합적으로 및/또는 비-공유결합적으로, 바람직하게는 공유결합적으로 결합된, 제1항 내지 제22항 및 제25항 중 어느 한 항에 따른 EDB 결합성 펩타이드, 또는 제23항 내지 제28항 중 어느 한 항에 따른 EDB 결합제를 포함하는, 파이브로넥틴 엑스트라 도메인 B (EDB) 결합제.
- 제1항 내지 제22항 및 제25항 중 어느 한 항, 또는 제23항 내지 제29항 중 어느 한 항에 있어서,
EDB의 고유 에피토프에 결합하는, EDB 결합성 펩타이드 또는 EDB 결합제. - 제1항 내지 제22항, 제25항 및 제30항 중 어느 한 항, 또는 제23항 내지 제30항 중 어느 한 항에 있어서,
상기 EDB가 내피 세포 및/또는 종양 세포에 의해 발현되는, EDB 결합성 펩타이드. - 제1항 내지 제22항, 제25항, 제30항 및 제31항 중 어느 한 항, 또는 제23항 내지 제31항 중 어느 한 항에 있어서,
상기 결합이 특이적인 결합인, EDB 결합성 펩타이드 또는 EDB 결합제. - 제1항 내지 제22항, 제25항 및 제30항 내지 제32항 중 어느 한 항에 따른 EBD 결합성 펩타이드를 암호화하는 재조합 핵산.
- 제33항의 재조합 핵산을 포함하는 숙주 세포.
- 제1항 내지 제22항, 제25항 및 제30항 내지 제32항 중 어느 한 항에 따른 EDB 결합성 펩타이드, 또는 제23항 내지 제32항 중 어느 한 항에 따른 EDB 결합제를 포함하는, 검사 키트.
- 제35항에 있어서,
진단 검사 키트인, 검사 키트. - 제1항 내지 제22항, 제25항 및 제30항 내지 제32항 중 어느 한 항에 따른 EDB 결합성 펩타이드, 또는 제23항 내지 제32항 중 어느 한 항에 따른 EDB 결합제를 포함하는, 분석 장치.
- 제37항에 있어서,
상기 EDB 결합성 펩타이드 또는 EDB 결합제가 고체 지지체 상에 탈착 가능하게 (releasably) 또는 탈착 불가능하게 (non-releasably) 고정된, 분석 장치. - 제1항 내지 제22항, 제25항 및 제30항 내지 제32항 중 어느 한 항에 따른 EDB 결합성 펩타이드, 또는 제23항 내지 제32항 중 어느 한 항에 따른 EDB 결합제를 이용하는 것을 포함하는, 샘플에서 파이브로넥틴 엑스트라 도메인 B (EDB)의 존재 및/또는 양을 분석하는 방법.
- 제1항 내지 제22항, 제25항 및 제30항 내지 제32항 중 어느 한 항에 따른 EDB 결합성 펩타이드 또는 제23항 내지 제32항 중 어느 한 항에 따른 EDB 결합제를 이용해, 환자에서 파이브로넥틴 엑스트라 도메인 B (EDB)의 존재 및/또는 양을 분석하는 단계를 포함하는, 환자에서 암을 진단, 검출 또는 모니터링하는 방법.
- 제40항에 있어서,
상기 분석이 상기 환자로부터 분리된 생물학적 샘플에 대해 수행되는, 방법. - 제40항 또는 제41항에 있어서,
암이 없는 기준과 비교해 더 높은 EDB의 양 또는 EDB의 존재는 환자가 암에 걸린 것을 의미하는, 방법. - 제39항 내지 제42항 중 어느 한 항에 있어서,
상기 EDB의 존재 및/또는 양 분석을 하는 단계는,
(i) 샘플을 EDB 결합성 펩타이드 또는 EDB 결합제와 접촉시키는 단계, 및
(ii) EDB 결합성 펩타이드 또는 EDB 결합제와 EDB 간의 복합체의 형성을 검출하거나 및/또는 복합체의 양을 확인하는 단계를 포함하는, 방법. - 제39항 내지 제43항 중 어느 한 항에 있어서,
상기 EDB 결합성 펩타이드 또는 EDB 결합제가 하나 이상의 검출가능한 표지물질 또는 리포터를 포함하거나 또는 이에 접합된, 방법. - 제39항 내지 제44항 중 어느 한 항에 있어서,
상기 EDB 결합성 펩타이드 또는 EDB 결합제가 고체 지지체 상에 탈착 가능하게 또는 탈착 불가능하게 고정된, 방법. - 제1항 내지 제22항, 제25항 및 제30항 내지 제32항 중 어느 한 항에 따른 EDB 결합성 펩타이드, 제23항 내지 제32항 중 어느 한 항에 따른 EDB 결합제, 제33항에 따른 재조합 핵산 또는 제34항에 따른 숙주 세포를 포함하는, 약학적 조성물.
- 제1항 내지 제22항, 제25항 및 제30항 내지 제32항 중 어느 한 항, 제23항 내지 제32항 중 어느 한 항, 제33항, 제34항 또는 제46항에 있어서,
요법 (therapy)에 사용하기 위한, 특히 환자에서 암을 치료 또는 예방하는데 사용하기 위한 것인, EDB 결합성 펩타이드, EDB 결합제, 재조합 핵산, 숙주 세포 또는 약학적 조성물. - 제1항 내지 제22항, 제25항 및 제30항 내지 제32항 중 어느 한 항 또는 제23항 내지 제32항 중 어느 한 항에 있어서,
환자에서 암을 표적화하는데 사용하기 위한 것인, EDB 결합성 펩타이드 또는 EDB 결합제. - 제1항 내지 제22항, 제25항 및 제30항 내지 제32항 중 어느 한 항에 따른 EDB 결합성 펩타이드, 제23항 내지 제32항 중 어느 한 항에 따른 EDB 결합제, 제33항에 따른 재조합 핵산, 제34항에 따른 숙주 세포 또는 제46항에 따른 약학적 조성물을 환자에게 투여하는 단계를 포함하고,
바람직하게는, 상기 환자는 암을 앓고 있거나 또는 암 발병 위험성이 있는 환자인, 환자의 치료 방법. - 제46항, 제47항, 제48항 또는 제49항에 있어서,
상기 EDB 결합성 펩타이드 또는 EDB 결합제가 하나 이상의 치료학적 작동자 모이어티를 포함하거나 또는 이에 접합된, 약학적 조성물; EDB 결합성 펩타이드, EDB 결합제, 재조합 핵산, 숙주 세포 또는 약학적 조성물; EDB 결합성 펩타이드 또는 EDB 결합제; 또는 방법. - 제40항 내지 제45항 중 어느 한 항; 제47항 또는 제50항; 제48항 또는 제50항; 또는 제49항 또는 제50항에 있어서,
상기 암이 EDB-양성이거나 및/또는 EDB 발현 세포를 수반하는, 방법; EDB 결합성 펩타이드, EDB 결합제, 재조합 핵산, 숙주 세포 또는 약학적 조성물; EDB 결합성 펩타이드 또는 EDB 결합제; 또는 방법.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020247031593A KR20240142617A (ko) | 2018-06-08 | 2019-06-06 | 암을 진단 및 치료하기 위한 조성물 및 방법 |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/EP2018/065205 WO2019233605A1 (en) | 2018-06-08 | 2018-06-08 | Compositions and methods for diagnosis and treatment of cancer |
| EPPCT/EP2018/065205 | 2018-06-08 | ||
| PCT/EP2019/064872 WO2019234190A1 (en) | 2018-06-08 | 2019-06-06 | Compositions and methods for diagnosis and treatment of cancer |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020247031593A Division KR20240142617A (ko) | 2018-06-08 | 2019-06-06 | 암을 진단 및 치료하기 위한 조성물 및 방법 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210020006A true KR20210020006A (ko) | 2021-02-23 |
Family
ID=62636178
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020247031593A KR20240142617A (ko) | 2018-06-08 | 2019-06-06 | 암을 진단 및 치료하기 위한 조성물 및 방법 |
| KR1020207035142A KR20210020006A (ko) | 2018-06-08 | 2019-06-06 | 암을 진단 및 치료하기 위한 조성물 및 방법 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020247031593A KR20240142617A (ko) | 2018-06-08 | 2019-06-06 | 암을 진단 및 치료하기 위한 조성물 및 방법 |
Country Status (10)
| Country | Link |
|---|---|
| US (2) | US11673939B2 (ko) |
| EP (1) | EP3802585A1 (ko) |
| JP (1) | JP7466466B2 (ko) |
| KR (2) | KR20240142617A (ko) |
| CN (2) | CN116987180A (ko) |
| AU (1) | AU2019282316B2 (ko) |
| BR (1) | BR112020024034A2 (ko) |
| CA (1) | CA3101246A1 (ko) |
| MX (1) | MX2020013205A (ko) |
| WO (2) | WO2019233605A1 (ko) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102649794B1 (ko) * | 2020-10-19 | 2024-03-22 | 고려대학교 산학협력단 | 암 및/또는 뇌질환 바이오마커인 엑스트라-도메인 b 파이브로넥틴 및 이를 이용한 진단 방법 |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2366786A3 (en) * | 2005-05-05 | 2012-08-29 | VALORISATION HSJ, Société en Commandite | Cytokine receptor modulators and uses thereof |
| EP1892248A1 (en) * | 2006-08-21 | 2008-02-27 | Eidgenössische Technische Hochschule Zürich | Specific and high affinity binding proteins comprising modified SH3 domains of FYN kinase |
| AU2009307249B2 (en) * | 2008-10-20 | 2012-11-01 | Gwangju Institute Of Science And Technology | Bipodal peptide binder |
| DK2658872T3 (da) * | 2010-12-27 | 2020-10-12 | Apo T B V | Polypeptid, der binder aberrerende celler og inducerer apoptose |
| WO2014166623A1 (en) * | 2013-04-11 | 2014-10-16 | Merck Patent Gmbh | Potent inhibitors of human matriptase derived from mcoti-ii variants |
| EP3677285B1 (en) * | 2014-08-04 | 2023-12-13 | Case Western Reserve University | Targeting peptides for detecting prostate cancer |
| WO2016146174A1 (en) | 2015-03-17 | 2016-09-22 | Biontech Ag | Compositions and methods for diagnosis and treatment of cancer |
| TWI799366B (zh) * | 2015-09-15 | 2023-04-21 | 美商建南德克公司 | 胱胺酸結骨架平臺 |
| US20170218040A1 (en) * | 2016-02-02 | 2017-08-03 | Julio A. Camarero Palao | Proteolically resistant cyclotides with angiotensin 1-7 like activity |
-
2018
- 2018-06-08 WO PCT/EP2018/065205 patent/WO2019233605A1/en active Application Filing
-
2019
- 2019-06-06 US US16/972,794 patent/US11673939B2/en active Active
- 2019-06-06 EP EP19728093.6A patent/EP3802585A1/en active Pending
- 2019-06-06 BR BR112020024034-6A patent/BR112020024034A2/pt not_active Application Discontinuation
- 2019-06-06 JP JP2020568252A patent/JP7466466B2/ja active Active
- 2019-06-06 CN CN202310907634.4A patent/CN116987180A/zh active Pending
- 2019-06-06 KR KR1020247031593A patent/KR20240142617A/ko active Application Filing
- 2019-06-06 KR KR1020207035142A patent/KR20210020006A/ko active Application Filing
- 2019-06-06 CA CA3101246A patent/CA3101246A1/en active Pending
- 2019-06-06 MX MX2020013205A patent/MX2020013205A/es unknown
- 2019-06-06 AU AU2019282316A patent/AU2019282316B2/en active Active
- 2019-06-06 WO PCT/EP2019/064872 patent/WO2019234190A1/en unknown
- 2019-06-06 CN CN201980045963.4A patent/CN112424220A/zh active Pending
-
2023
- 2023-04-20 US US18/303,642 patent/US20240002471A1/en active Pending
Non-Patent Citations (19)
| Title |
|---|
| Albrecht, Valerie; Richter, Antonia; Pfeiffer, Sarah; Gebauer, Michaela; Lindner, Simon; Gieser, Eugenie et al. (2016): Anticalins directed against the fibronectin extra domain B as diagnostic tracers for glioblastomas. In: International journal of cancer 138 (5), S. 1269-1280. DOI: 10.1002/ijc.29874. |
| Barbas, Carlos F.; Burton, D. R.; Scott, J. K.; Silverman, G. J. (2004): Phage Display: Cold Spring Harbor Laboratory Pr. |
| Carnemolla, B.; Balza, E.; Siri, A.; Zardi, L.; Nicotra, M. R.; Bigotti, A.; Natali, P. G. (1989): A tumor-associated fibronectin isoform generated by alternative splicing of messenger RNA precursors. In: The Journal of cell biology 108 (3), S. 1139-1148. |
| Carnemolla, Barbara; Leprini, Alessandra; Allemanni, Giorgio; Saginati, Marc; Zardi, Luciano (1992): The inclusion of the type III repeat ED-B in the fibronectin molecule generates conformational modifications that unmask a cryptic sequence. In: Journal of Biological Chemistry 267 (34), S. 24689 24692. |
| Castellani, Patrizia; Viale, Giuseppe; Dorcaratto, Alessandra; Nicolo, Guido; Kaczmarek, Janusz; Querze, Germano; Zardi, Luciano (1994): The fibronectin isoform containing the ed-b oncofetal domain. A marker of angiogenesis. In: Int. J. Cancer 59 (5), S. 612-618. DOI: 10.1002/ijc.2910590507. |
| Hackel, Benjamin J.; Kimura, Richard H.; Miao, Zheng; Liu, Hongguang; Sathirachinda, Ataya; Cheng, Zhen et al. (2013): 18F-fluorobenzoate-labeled cystine knot peptides for PET imaging of integrin αvβ6. In: Journal of nuclear medicine : official publication, Society of Nuclear Medicine 54 (7), S. 1101-1105. DOI: 10.2967/jnumed.112.110759. |
| Hernandez, J. F.; Gagnon, J.; Chiche, L.; Nguyen, T. M.; Andrieu, J. P.; Heitz, A. et al. (2000): Squash trypsin inhibitors from Momordica cochinchinensis exhibit an atypical macrocyclic structure. In: Biochemistry 39 (19), S. 5722-5730. |
| Kimura, Richard H.; Cheng, Zhen; Gambhir, Sanjiv Sam; Cochran, Jennifer R. (2009): Engineered knottin peptides: a new class of agents for imaging integrin expression in living subjects. In: Cancer Research 69 (6), S. 2435 2442. DOI: 10.1158/0008-5472.CAN-08-2495. |
| Mao, Yong; Schwarzbauer, Jean E. (2005): Fibronectin fibrillogenesis, a cell-mediated matrix assembly process. In: Matrix biology : journal of the International Society for Matrix Biology 24 (6), S. 389-399. DOI: 10.1016/j.matbio.2005.06.008. |
| Mariani, G.; Lasku, A.; Balza, E.; Gaggero, B.; Motta, C.; Di Luca, L. et al. (1997): Tumor targeting potential of the monoclonal antibody BC-1 against oncofetal fibronectin in nude mice bearing human tumor implants. In: Cancer 80 (12 Suppl), S. 2378-2384. |
| Miao, Zheng; Ren, Gang; Liu, Hongguang; Kimura, Richard H.; Jiang, Lei; Cochran, Jennifer R. et al. (2009): An engineered knottin peptide labeled with 18F for PET imaging of integrin expression. In: Bioconjugate chemistry 20 (12), S. 2342-2347. DOI: 10.1021/bc900361g. |
| Mohammadgholi, Mohsen; Sadeghzadeh, Nourollah; Erfani, Mostafa; Abediankenari, Saeid; Abedi, Seyed Mohammad; Emrarian, Iman et al. (2017): Human Fibronectin Extra-Domain B (EDB)-Specific Aptide (APTEDB) Radiolabelling with Technetium-99m as a Potent Targeted Tumour-Imaging Agent. In: Anti-cancer agents in medicinal chemistry. DOI: 10.2174/1871520617666170918125020. |
| Moore, Sarah J.; Hayden Gephart, Melanie G.; Bergen, Jamie M.; Su, YouRong S.; Rayburn, Helen; Scott, Matthew P.; Cochran, Jennifer R. (2013): Engineered knottin peptide enables noninvasive optical imaging of intracranial medulloblastoma. In: Proceedings of the National Academy of Sciences of the United States of America 110 (36), S. 14598-14603. DOI: 10.1073/pnas.1311333110. |
| Nielsen, Carsten H.; Kimura, Richard H.; Withofs, Nadia; Tran, Phuoc T.; Miao, Zheng; Cochran, Jennifer R. et al. (2010): PET imaging of tumor neovascularization in a transgenic mouse model with a novel 64Cu-DOTA-knottin peptide. In: Cancer Research 70 (22), S. 9022-9030. DOI: 10.1158/0008-5472.CAN-10-1338. |
| Pankov, Roumen; Yamada, Kenneth M. (2002): Fibronectin at a glance. In: Journal of cell science 115 (20), S. 3861-3863. |
| Soroceanu, L.; Gillespie, Y.; Khazaeli, M. B.; Sontheimer, H. (1998): Use of chlorotoxin for targeting of primary brain tumors. In: Cancer Research 58 (21), S. 4871-4879. |
| Spicer, Christopher D.; Davis, Benjamin G. (2014): Selective chemical protein modification. In: Nature communications 5, S. 4740. DOI: 10.1038/ncomms5740. |
| Veiseh, Mandana; Gabikian, Patrik; Bahrami, S-Bahram; Veiseh, Omid; Zhang, Miqin; Hackman, Robert C. et al. (2007): Tumor paint: a chlorotoxin:Cy5.5 bioconjugate for intraoperative visualization of cancer foci. In: Cancer Research 67 (14), S. 6882-6888. DOI: 10.1158/0008-5472.CAN-06-3948. |
| Zhu, Xiaohua; Li, Jinbo; Hong, Yeongjin; Kimura, Richard H.; Ma, Xiaowei; Liu, Hongguang et al. (2014): 99mTc-labeled cystine knot peptide targeting integrin αvβ6 for tumor SPECT imaging. In: Molecular Pharmaceutics 11 (4), S. 1208-1217. DOI: 10.1021/mp400683q. |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7466466B2 (ja) | 2024-04-12 |
| CN112424220A (zh) | 2021-02-26 |
| US11673939B2 (en) | 2023-06-13 |
| AU2019282316B2 (en) | 2023-07-20 |
| WO2019234190A1 (en) | 2019-12-12 |
| BR112020024034A2 (pt) | 2021-02-23 |
| JP2021526808A (ja) | 2021-10-11 |
| US20210246191A1 (en) | 2021-08-12 |
| AU2019282316A1 (en) | 2020-12-24 |
| CA3101246A1 (en) | 2019-12-12 |
| EP3802585A1 (en) | 2021-04-14 |
| KR20240142617A (ko) | 2024-09-30 |
| WO2019233605A1 (en) | 2019-12-12 |
| MX2020013205A (es) | 2021-02-26 |
| US20240002471A1 (en) | 2024-01-04 |
| CN116987180A (zh) | 2023-11-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6739132B2 (ja) | がんの診断及び処置のための組成物及び方法 | |
| Villa et al. | A high‐affinity human monoclonal antibody specific to the alternatively spliced EDA domain of fibronectin efficiently targets tumor neo‐vasculature in vivo | |
| JP5841046B2 (ja) | 制御された血清中薬物動態を有するヒトタンパク質スキャフォールド | |
| ES2352180T3 (es) | Anticuerpo monoclonal de anti-tenascina humana. | |
| JP2015193653A (ja) | プロタンパク質およびその使用方法 | |
| US20240002471A1 (en) | Compositions and Methods for Diagnosis and Treatment of Cancer | |
| BR112017018522B1 (pt) | Peptídeo de ligação a seprase; agente de ligação a seprase compreendendo o dito peptídeo de ligação a seprase; ácido nucleico recombinante, o qual codifica o dito peptídeo de ligação a seprase; método para ensaiar a presença e / ou quantidade de seprase numa amostra; método para diagnóstico, detecção e monitoração do câncer em um paciente, composição farmacêutica e uso dos mesmos | |
| KR20240139054A (ko) | 가교 항체 | |
| NZ734680B2 (en) | Compositions and methods for diagnosis and treatment of cancer | |
| CN118922209A (zh) | 交联抗体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A302 | Request for accelerated examination | ||
| AMND | Amendment | ||
| E902 | Notification of reason for refusal | ||
| AMND | Amendment | ||
| E601 | Decision to refuse application | ||
| AMND | Amendment | ||
| X601 | Decision of rejection after re-examination | ||
| A107 | Divisional application of patent |