KR20200135785A - 인간 pd-l1 및 pd-l2에 대한 이중 특이성 항체 및 이의 사용 방법 - Google Patents
인간 pd-l1 및 pd-l2에 대한 이중 특이성 항체 및 이의 사용 방법 Download PDFInfo
- Publication number
- KR20200135785A KR20200135785A KR1020207026926A KR20207026926A KR20200135785A KR 20200135785 A KR20200135785 A KR 20200135785A KR 1020207026926 A KR1020207026926 A KR 1020207026926A KR 20207026926 A KR20207026926 A KR 20207026926A KR 20200135785 A KR20200135785 A KR 20200135785A
- Authority
- KR
- South Korea
- Prior art keywords
- antibody
- fragment
- ser
- clone
- sequence
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims description 115
- 101001117317 Homo sapiens Programmed cell death 1 ligand 1 Proteins 0.000 title description 10
- 102000048776 human CD274 Human genes 0.000 title description 10
- 101001117312 Homo sapiens Programmed cell death 1 ligand 2 Proteins 0.000 title description 4
- 102000048119 human PDCD1LG2 Human genes 0.000 title description 3
- 108010074708 B7-H1 Antigen Proteins 0.000 claims abstract description 136
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 claims abstract description 128
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 claims abstract description 127
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 97
- 201000011510 cancer Diseases 0.000 claims abstract description 39
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 claims abstract description 5
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 claims abstract 4
- 210000004027 cell Anatomy 0.000 claims description 175
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims description 92
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims description 92
- 230000027455 binding Effects 0.000 claims description 91
- 238000009739 binding Methods 0.000 claims description 89
- 239000000427 antigen Substances 0.000 claims description 55
- 108091007433 antigens Proteins 0.000 claims description 54
- 102000036639 antigens Human genes 0.000 claims description 54
- 239000000203 mixture Substances 0.000 claims description 48
- 241000282414 Homo sapiens Species 0.000 claims description 40
- 210000004408 hybridoma Anatomy 0.000 claims description 26
- 239000012634 fragment Substances 0.000 claims description 25
- 238000001514 detection method Methods 0.000 claims description 24
- 238000003556 assay Methods 0.000 claims description 18
- 238000002965 ELISA Methods 0.000 claims description 16
- 238000009472 formulation Methods 0.000 claims description 14
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 claims description 11
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 claims description 11
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 claims description 9
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 claims description 9
- 206010025323 Lymphomas Diseases 0.000 claims description 9
- 239000013598 vector Substances 0.000 claims description 8
- 238000001262 western blot Methods 0.000 claims description 8
- 230000008629 immune suppression Effects 0.000 claims description 7
- 238000003127 radioimmunoassay Methods 0.000 claims description 7
- 208000026310 Breast neoplasm Diseases 0.000 claims description 5
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 5
- 230000008859 change Effects 0.000 claims description 5
- 206010006187 Breast cancer Diseases 0.000 claims description 4
- 208000006265 Renal cell carcinoma Diseases 0.000 claims description 4
- 230000002068 genetic effect Effects 0.000 claims description 4
- 210000001124 body fluid Anatomy 0.000 claims description 3
- 241000700629 Orthopoxvirus Species 0.000 claims description 2
- 210000002889 endothelial cell Anatomy 0.000 claims description 2
- 210000002536 stromal cell Anatomy 0.000 claims description 2
- 229960005486 vaccine Drugs 0.000 claims 10
- 108010051109 Cell-Penetrating Peptides Proteins 0.000 claims 3
- 102000020313 Cell-Penetrating Peptides Human genes 0.000 claims 3
- 102000008096 B7-H1 Antigen Human genes 0.000 description 132
- 235000001014 amino acid Nutrition 0.000 description 113
- 229940024606 amino acid Drugs 0.000 description 113
- 150000001413 amino acids Chemical class 0.000 description 110
- 108090000623 proteins and genes Proteins 0.000 description 80
- 102000004169 proteins and genes Human genes 0.000 description 68
- 235000018102 proteins Nutrition 0.000 description 66
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 49
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 49
- 239000003446 ligand Substances 0.000 description 40
- 108090000765 processed proteins & peptides Proteins 0.000 description 35
- 239000003795 chemical substances by application Substances 0.000 description 34
- 210000001744 T-lymphocyte Anatomy 0.000 description 29
- 241000699670 Mus sp. Species 0.000 description 28
- 210000001519 tissue Anatomy 0.000 description 27
- 238000011282 treatment Methods 0.000 description 23
- 230000014509 gene expression Effects 0.000 description 22
- 108020004414 DNA Proteins 0.000 description 21
- 239000000523 sample Substances 0.000 description 21
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 20
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 18
- 239000012636 effector Substances 0.000 description 18
- 102000004196 processed proteins & peptides Human genes 0.000 description 18
- 230000006870 function Effects 0.000 description 17
- 102000004190 Enzymes Human genes 0.000 description 16
- 108090000790 Enzymes Proteins 0.000 description 16
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 16
- 230000000903 blocking effect Effects 0.000 description 16
- 230000000694 effects Effects 0.000 description 16
- 229940088598 enzyme Drugs 0.000 description 16
- 238000000684 flow cytometry Methods 0.000 description 16
- 229920001184 polypeptide Polymers 0.000 description 16
- 210000004881 tumor cell Anatomy 0.000 description 16
- 241001465754 Metazoa Species 0.000 description 15
- 108091034117 Oligonucleotide Proteins 0.000 description 15
- 206010035226 Plasma cell myeloma Diseases 0.000 description 15
- 238000004519 manufacturing process Methods 0.000 description 15
- 201000000050 myeloid neoplasm Diseases 0.000 description 15
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 14
- -1 chimeric antibodies Proteins 0.000 description 14
- 230000001225 therapeutic effect Effects 0.000 description 14
- 239000011534 wash buffer Substances 0.000 description 14
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 13
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 13
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 13
- 238000011534 incubation Methods 0.000 description 13
- 239000007924 injection Substances 0.000 description 13
- 238000002347 injection Methods 0.000 description 13
- 239000000243 solution Substances 0.000 description 13
- 238000005406 washing Methods 0.000 description 13
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 12
- KMSHNDWHPWXPEC-BQBZGAKWSA-N Arg-Asp-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KMSHNDWHPWXPEC-BQBZGAKWSA-N 0.000 description 12
- VVJTWSRNMJNDPN-IUCAKERBSA-N Arg-Met-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O VVJTWSRNMJNDPN-IUCAKERBSA-N 0.000 description 12
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 12
- IUVYJBMTHARMIP-PCBIJLKTSA-N Phe-Asp-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O IUVYJBMTHARMIP-PCBIJLKTSA-N 0.000 description 12
- VPBQDHMASPJHGY-JYJNAYRXSA-N Pro-Trp-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CO)C(=O)O VPBQDHMASPJHGY-JYJNAYRXSA-N 0.000 description 12
- OQPNSDWGAMFJNU-QWRGUYRKSA-N Ser-Gly-Tyr Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OQPNSDWGAMFJNU-QWRGUYRKSA-N 0.000 description 12
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 12
- KERCOYANYUPLHJ-XGEHTFHBSA-N Thr-Pro-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O KERCOYANYUPLHJ-XGEHTFHBSA-N 0.000 description 12
- 210000003719 b-lymphocyte Anatomy 0.000 description 12
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 12
- 239000002953 phosphate buffered saline Substances 0.000 description 12
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 11
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 11
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 11
- 108010008355 arginyl-glutamine Proteins 0.000 description 11
- 230000015572 biosynthetic process Effects 0.000 description 11
- 239000003431 cross linking reagent Substances 0.000 description 11
- 239000003814 drug Substances 0.000 description 11
- 230000004927 fusion Effects 0.000 description 11
- 238000009169 immunotherapy Methods 0.000 description 11
- 230000005764 inhibitory process Effects 0.000 description 11
- 238000005259 measurement Methods 0.000 description 11
- 102000005962 receptors Human genes 0.000 description 11
- 108020003175 receptors Proteins 0.000 description 11
- 230000004044 response Effects 0.000 description 11
- 230000004083 survival effect Effects 0.000 description 11
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 10
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 10
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 10
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 10
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 10
- 108060003951 Immunoglobulin Proteins 0.000 description 10
- 241000880493 Leptailurus serval Species 0.000 description 10
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 10
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 10
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 10
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 10
- 108010084389 glycyltryptophan Proteins 0.000 description 10
- 102000018358 immunoglobulin Human genes 0.000 description 10
- 239000012528 membrane Substances 0.000 description 10
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 10
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 9
- 238000011746 C57BL/6J (JAX™ mouse strain) Methods 0.000 description 9
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 description 9
- 238000013459 approach Methods 0.000 description 9
- 229960003852 atezolizumab Drugs 0.000 description 9
- 230000008901 benefit Effects 0.000 description 9
- 229960002685 biotin Drugs 0.000 description 9
- 235000020958 biotin Nutrition 0.000 description 9
- 239000011616 biotin Substances 0.000 description 9
- 229940098773 bovine serum albumin Drugs 0.000 description 9
- 238000006243 chemical reaction Methods 0.000 description 9
- 239000003153 chemical reaction reagent Substances 0.000 description 9
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 9
- 108010087823 glycyltyrosine Proteins 0.000 description 9
- 238000000338 in vitro Methods 0.000 description 9
- 210000004698 lymphocyte Anatomy 0.000 description 9
- 230000008685 targeting Effects 0.000 description 9
- KWKQGHSSNHPGOW-BQBZGAKWSA-N Arg-Ala-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)NCC(O)=O KWKQGHSSNHPGOW-BQBZGAKWSA-N 0.000 description 8
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 8
- JXMSHKFPDIUYGS-SIUGBPQLSA-N Ile-Glu-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N JXMSHKFPDIUYGS-SIUGBPQLSA-N 0.000 description 8
- 241000699666 Mus <mouse, genus> Species 0.000 description 8
- PIQRHJQWEPWFJG-UWJYBYFXSA-N Ser-Tyr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PIQRHJQWEPWFJG-UWJYBYFXSA-N 0.000 description 8
- JWHOIHCOHMZSAR-QWRGUYRKSA-N Tyr-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JWHOIHCOHMZSAR-QWRGUYRKSA-N 0.000 description 8
- UUBKSZNKJUJQEJ-JRQIVUDYSA-N Tyr-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O UUBKSZNKJUJQEJ-JRQIVUDYSA-N 0.000 description 8
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 8
- 239000002246 antineoplastic agent Substances 0.000 description 8
- 239000002609 medium Substances 0.000 description 8
- 230000008569 process Effects 0.000 description 8
- 238000002560 therapeutic procedure Methods 0.000 description 8
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 7
- BDISFWMLMNBTGP-NUMRIWBASA-N Glu-Thr-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O BDISFWMLMNBTGP-NUMRIWBASA-N 0.000 description 7
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 7
- 239000005089 Luciferase Substances 0.000 description 7
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 7
- 108700020796 Oncogene Proteins 0.000 description 7
- 108010090804 Streptavidin Chemical class 0.000 description 7
- 208000003721 Triple Negative Breast Neoplasms Diseases 0.000 description 7
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 7
- 108010047495 alanylglycine Proteins 0.000 description 7
- 230000003321 amplification Effects 0.000 description 7
- 238000004458 analytical method Methods 0.000 description 7
- 230000004663 cell proliferation Effects 0.000 description 7
- 238000002512 chemotherapy Methods 0.000 description 7
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 7
- 229940079593 drug Drugs 0.000 description 7
- 239000000499 gel Substances 0.000 description 7
- 238000003384 imaging method Methods 0.000 description 7
- 229940127121 immunoconjugate Drugs 0.000 description 7
- 230000003993 interaction Effects 0.000 description 7
- 108010034529 leucyl-lysine Proteins 0.000 description 7
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 7
- 238000003199 nucleic acid amplification method Methods 0.000 description 7
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 7
- 208000022679 triple-negative breast carcinoma Diseases 0.000 description 7
- 108010017949 tyrosyl-glycyl-glycine Proteins 0.000 description 7
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 6
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 6
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 6
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 6
- NJLLRXWFPQQPHV-SRVKXCTJSA-N Asp-Tyr-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O NJLLRXWFPQQPHV-SRVKXCTJSA-N 0.000 description 6
- QOJJMJKTMKNFEF-ZKWXMUAHSA-N Asp-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O QOJJMJKTMKNFEF-ZKWXMUAHSA-N 0.000 description 6
- UESYBOXFJWJVSB-AVGNSLFASA-N Gln-Phe-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O UESYBOXFJWJVSB-AVGNSLFASA-N 0.000 description 6
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 6
- MBOAPAXLTUSMQI-JHEQGTHGSA-N Gly-Glu-Thr Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MBOAPAXLTUSMQI-JHEQGTHGSA-N 0.000 description 6
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 6
- UHPAZODVFFYEEL-QWRGUYRKSA-N Gly-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN UHPAZODVFFYEEL-QWRGUYRKSA-N 0.000 description 6
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 6
- BXDLTKLPPKBVEL-FJXKBIBVSA-N Gly-Thr-Met Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O BXDLTKLPPKBVEL-FJXKBIBVSA-N 0.000 description 6
- UMBDRSMLCUYIRI-DVJZZOLTSA-N Gly-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)CN)O UMBDRSMLCUYIRI-DVJZZOLTSA-N 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- 108010002350 Interleukin-2 Proteins 0.000 description 6
- 102000000588 Interleukin-2 Human genes 0.000 description 6
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 6
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 6
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 6
- 108060001084 Luciferase Proteins 0.000 description 6
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 6
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 6
- WRODMZBHNNPRLN-SRVKXCTJSA-N Lys-Leu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O WRODMZBHNNPRLN-SRVKXCTJSA-N 0.000 description 6
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 6
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 6
- 239000004472 Lysine Substances 0.000 description 6
- 241001529936 Murinae Species 0.000 description 6
- LNICFEXCAHIJOR-DCAQKATOSA-N Pro-Ser-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LNICFEXCAHIJOR-DCAQKATOSA-N 0.000 description 6
- 238000011579 SCID mouse model Methods 0.000 description 6
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 6
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 6
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 6
- HDBOEVPDIDDEPC-CIUDSAMLSA-N Ser-Lys-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O HDBOEVPDIDDEPC-CIUDSAMLSA-N 0.000 description 6
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 6
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 6
- FEZASNVQLJQBHW-CABZTGNLSA-N Trp-Gly-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O)=CNC2=C1 FEZASNVQLJQBHW-CABZTGNLSA-N 0.000 description 6
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 6
- GQHAIUPYZPTADF-FDARSICLSA-N Trp-Ile-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 GQHAIUPYZPTADF-FDARSICLSA-N 0.000 description 6
- DDHFMBDACJYSKW-AQZXSJQPSA-N Trp-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O DDHFMBDACJYSKW-AQZXSJQPSA-N 0.000 description 6
- VTFWAGGJDRSQFG-MELADBBJSA-N Tyr-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O VTFWAGGJDRSQFG-MELADBBJSA-N 0.000 description 6
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 6
- QOIKZODVIPOPDD-AVGNSLFASA-N Tyr-Cys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOIKZODVIPOPDD-AVGNSLFASA-N 0.000 description 6
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 6
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 6
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 6
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 6
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 6
- GUIYPEKUEMQBIK-JSGCOSHPSA-N Val-Tyr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)NCC(O)=O GUIYPEKUEMQBIK-JSGCOSHPSA-N 0.000 description 6
- 239000002671 adjuvant Substances 0.000 description 6
- 230000006907 apoptotic process Effects 0.000 description 6
- 108010077245 asparaginyl-proline Proteins 0.000 description 6
- 210000004369 blood Anatomy 0.000 description 6
- 239000008280 blood Substances 0.000 description 6
- 239000000872 buffer Substances 0.000 description 6
- 108010015792 glycyllysine Proteins 0.000 description 6
- 230000002401 inhibitory effect Effects 0.000 description 6
- 239000000463 material Substances 0.000 description 6
- 201000001441 melanoma Diseases 0.000 description 6
- 230000004048 modification Effects 0.000 description 6
- 238000012986 modification Methods 0.000 description 6
- 108010051242 phenylalanylserine Proteins 0.000 description 6
- 238000000746 purification Methods 0.000 description 6
- 230000002441 reversible effect Effects 0.000 description 6
- 150000003839 salts Chemical class 0.000 description 6
- 238000006467 substitution reaction Methods 0.000 description 6
- 238000012360 testing method Methods 0.000 description 6
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 6
- 108010044292 tryptophyltyrosine Proteins 0.000 description 6
- 108010003137 tyrosyltyrosine Proteins 0.000 description 6
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 5
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 5
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 5
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 5
- 206010009944 Colon cancer Diseases 0.000 description 5
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 5
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 5
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 5
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 5
- HXWALXSAVBLTPK-NUTKFTJISA-N Leu-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(C)C)N HXWALXSAVBLTPK-NUTKFTJISA-N 0.000 description 5
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 5
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 5
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 5
- BPIMVBKDLSBKIJ-FCLVOEFKSA-N Phe-Thr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BPIMVBKDLSBKIJ-FCLVOEFKSA-N 0.000 description 5
- 108010004729 Phycoerythrin Proteins 0.000 description 5
- 239000002202 Polyethylene glycol Substances 0.000 description 5
- ZSKJPKFTPQCPIH-RCWTZXSCSA-N Pro-Arg-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZSKJPKFTPQCPIH-RCWTZXSCSA-N 0.000 description 5
- RCYUBVHMVUHEBM-RCWTZXSCSA-N Pro-Pro-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RCYUBVHMVUHEBM-RCWTZXSCSA-N 0.000 description 5
- 241000700159 Rattus Species 0.000 description 5
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 5
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 5
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 5
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 5
- 206010042971 T-cell lymphoma Diseases 0.000 description 5
- 208000027585 T-cell non-Hodgkin lymphoma Diseases 0.000 description 5
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 5
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 5
- VCXWRWYFJLXITF-AUTRQRHGSA-N Tyr-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 VCXWRWYFJLXITF-AUTRQRHGSA-N 0.000 description 5
- WURLIFOWSMBUAR-SLFFLAALSA-N Tyr-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O WURLIFOWSMBUAR-SLFFLAALSA-N 0.000 description 5
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 5
- PGBMPFKFKXYROZ-UFYCRDLUSA-N Val-Tyr-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N PGBMPFKFKXYROZ-UFYCRDLUSA-N 0.000 description 5
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 5
- 230000009824 affinity maturation Effects 0.000 description 5
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 5
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 5
- 229950002916 avelumab Drugs 0.000 description 5
- 230000030833 cell death Effects 0.000 description 5
- 238000002648 combination therapy Methods 0.000 description 5
- 150000001875 compounds Chemical class 0.000 description 5
- 230000009260 cross reactivity Effects 0.000 description 5
- 238000010790 dilution Methods 0.000 description 5
- 239000012895 dilution Substances 0.000 description 5
- 201000010099 disease Diseases 0.000 description 5
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 5
- 238000011156 evaluation Methods 0.000 description 5
- 238000002474 experimental method Methods 0.000 description 5
- 238000001415 gene therapy Methods 0.000 description 5
- 230000012010 growth Effects 0.000 description 5
- 230000002209 hydrophobic effect Effects 0.000 description 5
- 230000003053 immunization Effects 0.000 description 5
- 230000002163 immunogen Effects 0.000 description 5
- 230000001976 improved effect Effects 0.000 description 5
- 230000001939 inductive effect Effects 0.000 description 5
- 239000003112 inhibitor Substances 0.000 description 5
- 108010017391 lysylvaline Proteins 0.000 description 5
- 238000002826 magnetic-activated cell sorting Methods 0.000 description 5
- 230000035772 mutation Effects 0.000 description 5
- 150000007523 nucleic acids Chemical group 0.000 description 5
- 108010073101 phenylalanylleucine Proteins 0.000 description 5
- 229920001223 polyethylene glycol Polymers 0.000 description 5
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 5
- 108010077112 prolyl-proline Proteins 0.000 description 5
- 238000006722 reduction reaction Methods 0.000 description 5
- 229960004641 rituximab Drugs 0.000 description 5
- 241000894007 species Species 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 239000006228 supernatant Substances 0.000 description 5
- 238000001356 surgical procedure Methods 0.000 description 5
- 108010009962 valyltyrosine Proteins 0.000 description 5
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 4
- DVJSJDDYCYSMFR-ZKWXMUAHSA-N Ala-Ile-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O DVJSJDDYCYSMFR-ZKWXMUAHSA-N 0.000 description 4
- WHVNXSBKJGAXKU-UHFFFAOYSA-N Alexa Fluor 532 Chemical compound [H+].[H+].CC1(C)C(C)NC(C(=C2OC3=C(C=4C(C(C(C)N=4)(C)C)=CC3=3)S([O-])(=O)=O)S([O-])(=O)=O)=C1C=C2C=3C(C=C1)=CC=C1C(=O)ON1C(=O)CCC1=O WHVNXSBKJGAXKU-UHFFFAOYSA-N 0.000 description 4
- 102100021569 Apoptosis regulator Bcl-2 Human genes 0.000 description 4
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 4
- 239000004475 Arginine Substances 0.000 description 4
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 4
- JBDLMLZNDRLDIX-HJGDQZAQSA-N Asn-Thr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O JBDLMLZNDRLDIX-HJGDQZAQSA-N 0.000 description 4
- JNNVNVRBYUJYGS-CIUDSAMLSA-N Asp-Leu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O JNNVNVRBYUJYGS-CIUDSAMLSA-N 0.000 description 4
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 4
- 108090001008 Avidin Proteins 0.000 description 4
- GNMQDOGFWYWPNM-LAEOZQHASA-N Gln-Gly-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)CNC(=O)[C@@H](N)CCC(N)=O)C(O)=O GNMQDOGFWYWPNM-LAEOZQHASA-N 0.000 description 4
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 4
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 4
- QBEWLBKBGXVVPD-RYUDHWBXSA-N Gln-Phe-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N QBEWLBKBGXVVPD-RYUDHWBXSA-N 0.000 description 4
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 4
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 4
- RVGMVLVBDRQVKB-UWVGGRQHSA-N Gly-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN RVGMVLVBDRQVKB-UWVGGRQHSA-N 0.000 description 4
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 4
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 4
- WSLHFAFASQFMSK-SFTDATJTSA-N Gly-Trp-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)CN)C(O)=O)=CNC2=C1 WSLHFAFASQFMSK-SFTDATJTSA-N 0.000 description 4
- 239000004471 Glycine Substances 0.000 description 4
- 101000971171 Homo sapiens Apoptosis regulator Bcl-2 Proteins 0.000 description 4
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 description 4
- PRTZQMBYUZFSFA-XEGUGMAKSA-N Ile-Tyr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)NCC(=O)O)N PRTZQMBYUZFSFA-XEGUGMAKSA-N 0.000 description 4
- 102100037850 Interferon gamma Human genes 0.000 description 4
- 108010074328 Interferon-gamma Proteins 0.000 description 4
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 4
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 4
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 4
- POJPZSMTTMLSTG-SRVKXCTJSA-N Leu-Asn-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N POJPZSMTTMLSTG-SRVKXCTJSA-N 0.000 description 4
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 4
- POMXSEDNUXYPGK-IHRRRGAJSA-N Leu-Met-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N POMXSEDNUXYPGK-IHRRRGAJSA-N 0.000 description 4
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 4
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 4
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 4
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 4
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 4
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 4
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 4
- DRXODWRPPUFIAY-DCAQKATOSA-N Met-Asn-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCCN DRXODWRPPUFIAY-DCAQKATOSA-N 0.000 description 4
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 4
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 4
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 4
- 108010079364 N-glycylalanine Proteins 0.000 description 4
- 239000000020 Nitrocellulose Substances 0.000 description 4
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 4
- VCYJKOLZYPYGJV-AVGNSLFASA-N Pro-Arg-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VCYJKOLZYPYGJV-AVGNSLFASA-N 0.000 description 4
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 4
- JLMZKEQFMVORMA-SRVKXCTJSA-N Pro-Pro-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 JLMZKEQFMVORMA-SRVKXCTJSA-N 0.000 description 4
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 4
- 239000004365 Protease Substances 0.000 description 4
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 4
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 4
- XWCYBVBLJRWOFR-WDSKDSINSA-N Ser-Gln-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O XWCYBVBLJRWOFR-WDSKDSINSA-N 0.000 description 4
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 4
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 4
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 4
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 4
- CDEZPHVWBQFJQQ-NKKJXINNSA-N Trp-Trp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CC4=CNC5=CC=CC=C54)N)C(=O)O CDEZPHVWBQFJQQ-NKKJXINNSA-N 0.000 description 4
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 4
- GULIUBBXCYPDJU-CQDKDKBSSA-N Tyr-Leu-Ala Chemical compound [O-]C(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CC1=CC=C(O)C=C1 GULIUBBXCYPDJU-CQDKDKBSSA-N 0.000 description 4
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 4
- UKEVLVBHRKWECS-LSJOCFKGSA-N Val-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](C(C)C)N UKEVLVBHRKWECS-LSJOCFKGSA-N 0.000 description 4
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 4
- 108010087924 alanylproline Proteins 0.000 description 4
- 125000003275 alpha amino acid group Chemical group 0.000 description 4
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 4
- 239000012131 assay buffer Substances 0.000 description 4
- 239000002775 capsule Substances 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 238000005119 centrifugation Methods 0.000 description 4
- 239000011248 coating agent Substances 0.000 description 4
- 238000000576 coating method Methods 0.000 description 4
- 208000029742 colonic neoplasm Diseases 0.000 description 4
- 238000005520 cutting process Methods 0.000 description 4
- 239000000284 extract Substances 0.000 description 4
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 4
- 108010037850 glycylvaline Proteins 0.000 description 4
- 229940022353 herceptin Drugs 0.000 description 4
- FDGQSTZJBFJUBT-UHFFFAOYSA-N hypoxanthine Chemical compound O=C1NC=NC2=C1NC=N2 FDGQSTZJBFJUBT-UHFFFAOYSA-N 0.000 description 4
- 238000002649 immunization Methods 0.000 description 4
- 238000003018 immunoassay Methods 0.000 description 4
- 229940072221 immunoglobulins Drugs 0.000 description 4
- 238000003364 immunohistochemistry Methods 0.000 description 4
- 150000002500 ions Chemical class 0.000 description 4
- 201000005202 lung cancer Diseases 0.000 description 4
- 208000020816 lung neoplasm Diseases 0.000 description 4
- 229960000485 methotrexate Drugs 0.000 description 4
- 210000000822 natural killer cell Anatomy 0.000 description 4
- 229920001220 nitrocellulos Polymers 0.000 description 4
- 239000002773 nucleotide Substances 0.000 description 4
- 125000003729 nucleotide group Chemical group 0.000 description 4
- 239000000047 product Substances 0.000 description 4
- 230000035755 proliferation Effects 0.000 description 4
- 230000002285 radioactive effect Effects 0.000 description 4
- 238000001959 radiotherapy Methods 0.000 description 4
- 230000009467 reduction Effects 0.000 description 4
- 230000002829 reductive effect Effects 0.000 description 4
- 210000003289 regulatory T cell Anatomy 0.000 description 4
- 238000012216 screening Methods 0.000 description 4
- 239000006152 selective media Substances 0.000 description 4
- 238000000926 separation method Methods 0.000 description 4
- 230000004936 stimulating effect Effects 0.000 description 4
- 239000000758 substrate Substances 0.000 description 4
- 125000003396 thiol group Chemical group [H]S* 0.000 description 4
- 239000003053 toxin Substances 0.000 description 4
- 231100000765 toxin Toxicity 0.000 description 4
- 108700012359 toxins Proteins 0.000 description 4
- 108010084932 tryptophyl-proline Proteins 0.000 description 4
- 108010035534 tyrosyl-leucyl-alanine Proteins 0.000 description 4
- 108010073969 valyllysine Proteins 0.000 description 4
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 3
- AGNGYMCLFWQVGX-AGFFZDDWSA-N (e)-1-[(2s)-2-amino-2-carboxyethoxy]-2-diazonioethenolate Chemical compound OC(=O)[C@@H](N)CO\C([O-])=C\[N+]#N AGNGYMCLFWQVGX-AGFFZDDWSA-N 0.000 description 3
- HZAXFHJVJLSVMW-UHFFFAOYSA-N 2-Aminoethan-1-ol Chemical compound NCCO HZAXFHJVJLSVMW-UHFFFAOYSA-N 0.000 description 3
- LLTDOAPVRPZLCM-UHFFFAOYSA-O 4-(7,8,8,16,16,17-hexamethyl-4,20-disulfo-2-oxa-18-aza-6-azoniapentacyclo[11.7.0.03,11.05,9.015,19]icosa-1(20),3,5,9,11,13,15(19)-heptaen-12-yl)benzoic acid Chemical compound CC1(C)C(C)NC(C(=C2OC3=C(C=4C(C(C(C)[NH+]=4)(C)C)=CC3=3)S(O)(=O)=O)S(O)(=O)=O)=C1C=C2C=3C1=CC=C(C(O)=O)C=C1 LLTDOAPVRPZLCM-UHFFFAOYSA-O 0.000 description 3
- TVZGACDUOSZQKY-LBPRGKRZSA-N 4-aminofolic acid Chemical compound C1=NC2=NC(N)=NC(N)=C2N=C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 TVZGACDUOSZQKY-LBPRGKRZSA-N 0.000 description 3
- 229920001817 Agar Polymers 0.000 description 3
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 3
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 3
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 description 3
- 239000004971 Cross linker Substances 0.000 description 3
- 102000004127 Cytokines Human genes 0.000 description 3
- 108090000695 Cytokines Proteins 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 3
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 3
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 3
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 3
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 3
- 102000004457 Granulocyte-Macrophage Colony-Stimulating Factor Human genes 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 3
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 3
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 3
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 3
- 101001117311 Mus musculus Programmed cell death 1 ligand 2 Proteins 0.000 description 3
- QPCDCPDFJACHGM-UHFFFAOYSA-N N,N-bis{2-[bis(carboxymethyl)amino]ethyl}glycine Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(=O)O)CCN(CC(O)=O)CC(O)=O QPCDCPDFJACHGM-UHFFFAOYSA-N 0.000 description 3
- 102000043276 Oncogene Human genes 0.000 description 3
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 108010090931 Proto-Oncogene Proteins c-bcl-2 Proteins 0.000 description 3
- 102000013535 Proto-Oncogene Proteins c-bcl-2 Human genes 0.000 description 3
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 3
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 3
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 3
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 3
- 238000001793 Wilcoxon signed-rank test Methods 0.000 description 3
- 239000008272 agar Substances 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- 229960003896 aminopterin Drugs 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 229960001230 asparagine Drugs 0.000 description 3
- 235000009582 asparagine Nutrition 0.000 description 3
- 229950011321 azaserine Drugs 0.000 description 3
- 239000011230 binding agent Substances 0.000 description 3
- 238000005415 bioluminescence Methods 0.000 description 3
- 230000029918 bioluminescence Effects 0.000 description 3
- 210000002798 bone marrow cell Anatomy 0.000 description 3
- 201000010881 cervical cancer Diseases 0.000 description 3
- 208000013056 classic Hodgkin lymphoma Diseases 0.000 description 3
- 238000012258 culturing Methods 0.000 description 3
- 229940127089 cytotoxic agent Drugs 0.000 description 3
- 230000001472 cytotoxic effect Effects 0.000 description 3
- 210000004443 dendritic cell Anatomy 0.000 description 3
- 230000029087 digestion Effects 0.000 description 3
- 230000002255 enzymatic effect Effects 0.000 description 3
- 125000000524 functional group Chemical group 0.000 description 3
- 206010017758 gastric cancer Diseases 0.000 description 3
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 3
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 3
- 108010089804 glycyl-threonine Proteins 0.000 description 3
- 210000002443 helper t lymphocyte Anatomy 0.000 description 3
- 230000005847 immunogenicity Effects 0.000 description 3
- 238000001727 in vivo Methods 0.000 description 3
- 230000001965 increasing effect Effects 0.000 description 3
- 239000000543 intermediate Substances 0.000 description 3
- 230000002601 intratumoral effect Effects 0.000 description 3
- 239000007788 liquid Substances 0.000 description 3
- 238000011068 loading method Methods 0.000 description 3
- 108010082117 matrigel Proteins 0.000 description 3
- 239000011159 matrix material Substances 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 239000011325 microbead Substances 0.000 description 3
- 230000007935 neutral effect Effects 0.000 description 3
- 108020004707 nucleic acids Proteins 0.000 description 3
- 102000039446 nucleic acids Human genes 0.000 description 3
- 239000003921 oil Substances 0.000 description 3
- 235000019198 oils Nutrition 0.000 description 3
- 238000011275 oncology therapy Methods 0.000 description 3
- 230000037361 pathway Effects 0.000 description 3
- 238000005453 pelletization Methods 0.000 description 3
- 229960002621 pembrolizumab Drugs 0.000 description 3
- 229960003330 pentetic acid Drugs 0.000 description 3
- 239000013612 plasmid Substances 0.000 description 3
- 239000004033 plastic Substances 0.000 description 3
- 229920003023 plastic Polymers 0.000 description 3
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 3
- NLKNQRATVPKPDG-UHFFFAOYSA-M potassium iodide Chemical compound [K+].[I-] NLKNQRATVPKPDG-UHFFFAOYSA-M 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 150000003141 primary amines Chemical group 0.000 description 3
- 102000016914 ras Proteins Human genes 0.000 description 3
- 108010014186 ras Proteins Proteins 0.000 description 3
- 238000002271 resection Methods 0.000 description 3
- 210000002966 serum Anatomy 0.000 description 3
- 108010026333 seryl-proline Proteins 0.000 description 3
- 239000011780 sodium chloride Substances 0.000 description 3
- 238000003756 stirring Methods 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 230000009885 systemic effect Effects 0.000 description 3
- 229940124597 therapeutic agent Drugs 0.000 description 3
- 230000004614 tumor growth Effects 0.000 description 3
- 241001430294 unidentified retrovirus Species 0.000 description 3
- 239000004474 valine Substances 0.000 description 3
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 3
- GKSPIZSKQWTXQG-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[1-(pyridin-2-yldisulfanyl)ethyl]benzoate Chemical group C=1C=C(C(=O)ON2C(CCC2=O)=O)C=CC=1C(C)SSC1=CC=CC=N1 GKSPIZSKQWTXQG-UHFFFAOYSA-N 0.000 description 2
- VBICKXHEKHSIBG-UHFFFAOYSA-N 1-monostearoylglycerol Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(O)CO VBICKXHEKHSIBG-UHFFFAOYSA-N 0.000 description 2
- VGIRNWJSIRVFRT-UHFFFAOYSA-N 2',7'-difluorofluorescein Chemical compound OC(=O)C1=CC=CC=C1C1=C2C=C(F)C(=O)C=C2OC2=CC(O)=C(F)C=C21 VGIRNWJSIRVFRT-UHFFFAOYSA-N 0.000 description 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- LPMXVESGRSUGHW-UHFFFAOYSA-N Acolongiflorosid K Natural products OC1C(O)C(O)C(C)OC1OC1CC2(O)CCC3C4(O)CCC(C=5COC(=O)C=5)C4(C)CC(O)C3C2(CO)C(O)C1 LPMXVESGRSUGHW-UHFFFAOYSA-N 0.000 description 2
- 102000009027 Albumins Human genes 0.000 description 2
- 108010088751 Albumins Proteins 0.000 description 2
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 2
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 2
- RRKCPMGSRIDLNC-AVGNSLFASA-N Asp-Glu-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RRKCPMGSRIDLNC-AVGNSLFASA-N 0.000 description 2
- 208000023275 Autoimmune disease Diseases 0.000 description 2
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 2
- 102100021277 Beta-secretase 2 Human genes 0.000 description 2
- 101710150190 Beta-secretase 2 Proteins 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 241000283707 Capra Species 0.000 description 2
- 208000005623 Carcinogenesis Diseases 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 206010008342 Cervix carcinoma Diseases 0.000 description 2
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 2
- 230000005778 DNA damage Effects 0.000 description 2
- 231100000277 DNA damage Toxicity 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 2
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 2
- 229910052688 Gadolinium Inorganic materials 0.000 description 2
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 2
- IHSGESFHTMFHRB-GUBZILKMSA-N Gln-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(N)=O IHSGESFHTMFHRB-GUBZILKMSA-N 0.000 description 2
- QFXNFFZTMFHPST-DZKIICNBSA-N Gln-Phe-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CCC(=O)N)N QFXNFFZTMFHPST-DZKIICNBSA-N 0.000 description 2
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- 239000004366 Glucose oxidase Substances 0.000 description 2
- 108010015776 Glucose oxidase Proteins 0.000 description 2
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 2
- KSOBNUBCYHGUKH-UWVGGRQHSA-N Gly-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN KSOBNUBCYHGUKH-UWVGGRQHSA-N 0.000 description 2
- 101000721661 Homo sapiens Cellular tumor antigen p53 Proteins 0.000 description 2
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 2
- 101001095266 Homo sapiens Prolyl endopeptidase Proteins 0.000 description 2
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 2
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 2
- 102000018251 Hypoxanthine Phosphoribosyltransferase Human genes 0.000 description 2
- 108010091358 Hypoxanthine Phosphoribosyltransferase Proteins 0.000 description 2
- UGQMRVRMYYASKQ-UHFFFAOYSA-N Hypoxanthine nucleoside Natural products OC1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 UGQMRVRMYYASKQ-UHFFFAOYSA-N 0.000 description 2
- OVPYIUNCVSOVNF-ZPFDUUQYSA-N Ile-Gln-Pro Natural products CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O OVPYIUNCVSOVNF-ZPFDUUQYSA-N 0.000 description 2
- JODPUDMBQBIWCK-GHCJXIJMSA-N Ile-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O JODPUDMBQBIWCK-GHCJXIJMSA-N 0.000 description 2
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 2
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 2
- 206010061218 Inflammation Diseases 0.000 description 2
- 108010002352 Interleukin-1 Proteins 0.000 description 2
- 108090000978 Interleukin-4 Proteins 0.000 description 2
- 102000004388 Interleukin-4 Human genes 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 2
- OXRLYTYUXAQTHP-YUMQZZPRSA-N Leu-Gly-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(O)=O OXRLYTYUXAQTHP-YUMQZZPRSA-N 0.000 description 2
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 2
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 108010074338 Lymphokines Proteins 0.000 description 2
- 102000008072 Lymphokines Human genes 0.000 description 2
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 2
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 2
- 206010027476 Metastases Diseases 0.000 description 2
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 2
- 101100468545 Mus musculus Rgmb gene Proteins 0.000 description 2
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 2
- AUEJLPRZGVVDNU-UHFFFAOYSA-N N-L-tyrosyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CC1=CC=C(O)C=C1 AUEJLPRZGVVDNU-UHFFFAOYSA-N 0.000 description 2
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 2
- PXHVJJICTQNCMI-UHFFFAOYSA-N Nickel Chemical compound [Ni] PXHVJJICTQNCMI-UHFFFAOYSA-N 0.000 description 2
- XOJVVFBFDXDTEG-UHFFFAOYSA-N Norphytane Natural products CC(C)CCCC(C)CCCC(C)CCCC(C)C XOJVVFBFDXDTEG-UHFFFAOYSA-N 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- LPMXVESGRSUGHW-GHYGWZAOSA-N Ouabain Natural products O([C@@H]1[C@@H](O)[C@@H](O)[C@@H](O)[C@H](C)O1)[C@H]1C[C@@H](O)[C@@]2(CO)[C@@](O)(C1)CC[C@H]1[C@]3(O)[C@@](C)([C@H](C4=CC(=O)OC4)CC3)C[C@@H](O)[C@H]21 LPMXVESGRSUGHW-GHYGWZAOSA-N 0.000 description 2
- 206010033128 Ovarian cancer Diseases 0.000 description 2
- 206010061535 Ovarian neoplasm Diseases 0.000 description 2
- 102000014160 PTEN Phosphohydrolase Human genes 0.000 description 2
- 108010011536 PTEN Phosphohydrolase Proteins 0.000 description 2
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 2
- 108090000526 Papain Proteins 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- DDYIRGBOZVKRFR-AVGNSLFASA-N Phe-Asp-Glu Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N DDYIRGBOZVKRFR-AVGNSLFASA-N 0.000 description 2
- BWTKUQPNOMMKMA-FIRPJDEBSA-N Phe-Ile-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BWTKUQPNOMMKMA-FIRPJDEBSA-N 0.000 description 2
- AFNJAQVMTIQTCB-DLOVCJGASA-N Phe-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 AFNJAQVMTIQTCB-DLOVCJGASA-N 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 2
- 239000004698 Polyethylene Substances 0.000 description 2
- 108700020978 Proto-Oncogene Proteins 0.000 description 2
- 102000052575 Proto-Oncogene Human genes 0.000 description 2
- 206010038389 Renal cancer Diseases 0.000 description 2
- PZZJMBYSYAKYPK-UWJYBYFXSA-N Ser-Ala-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PZZJMBYSYAKYPK-UWJYBYFXSA-N 0.000 description 2
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 2
- GWMXFEMMBHOKDX-AVGNSLFASA-N Ser-Gln-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 GWMXFEMMBHOKDX-AVGNSLFASA-N 0.000 description 2
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 2
- DKGRNFUXVTYRAS-UBHSHLNASA-N Ser-Ser-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DKGRNFUXVTYRAS-UBHSHLNASA-N 0.000 description 2
- 108010071390 Serum Albumin Proteins 0.000 description 2
- 102000007562 Serum Albumin Human genes 0.000 description 2
- 208000000453 Skin Neoplasms Diseases 0.000 description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 description 2
- 244000166550 Strophanthus gratus Species 0.000 description 2
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 2
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 2
- GKLVYJBZJHMRIY-OUBTZVSYSA-N Technetium-99 Chemical compound [99Tc] GKLVYJBZJHMRIY-OUBTZVSYSA-N 0.000 description 2
- 208000024313 Testicular Neoplasms Diseases 0.000 description 2
- 206010057644 Testis cancer Diseases 0.000 description 2
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 2
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 2
- GQEXFCQNAJHJTI-IHPCNDPISA-N Trp-Phe-Asp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N GQEXFCQNAJHJTI-IHPCNDPISA-N 0.000 description 2
- 102000001742 Tumor Suppressor Proteins Human genes 0.000 description 2
- 108010040002 Tumor Suppressor Proteins Proteins 0.000 description 2
- QOEZFICGUZTRFX-IHRRRGAJSA-N Tyr-Cys-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O QOEZFICGUZTRFX-IHRRRGAJSA-N 0.000 description 2
- UMSZZGTXGKHTFJ-SRVKXCTJSA-N Tyr-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 UMSZZGTXGKHTFJ-SRVKXCTJSA-N 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- 108010046334 Urease Proteins 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- JXGWQYWDUOWQHA-DZKIICNBSA-N Val-Gln-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N JXGWQYWDUOWQHA-DZKIICNBSA-N 0.000 description 2
- JXCOEPXCBVCTRD-JYJNAYRXSA-N Val-Tyr-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N JXCOEPXCBVCTRD-JYJNAYRXSA-N 0.000 description 2
- IECQJCJNPJVUSB-IHRRRGAJSA-N Val-Tyr-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CO)C(O)=O IECQJCJNPJVUSB-IHRRRGAJSA-N 0.000 description 2
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 2
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000003213 activating effect Effects 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 238000001042 affinity chromatography Methods 0.000 description 2
- 239000007801 affinity label Substances 0.000 description 2
- 235000004279 alanine Nutrition 0.000 description 2
- 108010005233 alanylglutamic acid Proteins 0.000 description 2
- 150000001412 amines Chemical class 0.000 description 2
- 125000003277 amino group Chemical group 0.000 description 2
- 230000033115 angiogenesis Effects 0.000 description 2
- 150000001450 anions Chemical class 0.000 description 2
- 230000000259 anti-tumor effect Effects 0.000 description 2
- 230000005809 anti-tumor immunity Effects 0.000 description 2
- 238000009175 antibody therapy Methods 0.000 description 2
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 2
- 238000011319 anticancer therapy Methods 0.000 description 2
- 229940041181 antineoplastic drug Drugs 0.000 description 2
- 238000003782 apoptosis assay Methods 0.000 description 2
- 229940009098 aspartate Drugs 0.000 description 2
- 108010093581 aspartyl-proline Proteins 0.000 description 2
- 108010038633 aspartylglutamate Proteins 0.000 description 2
- 238000003149 assay kit Methods 0.000 description 2
- 239000011324 bead Substances 0.000 description 2
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 2
- 230000001588 bifunctional effect Effects 0.000 description 2
- 239000012472 biological sample Substances 0.000 description 2
- 230000036952 cancer formation Effects 0.000 description 2
- 231100000504 carcinogenesis Toxicity 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 230000010261 cell growth Effects 0.000 description 2
- 210000003679 cervix uteri Anatomy 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- 239000002738 chelating agent Substances 0.000 description 2
- 239000003638 chemical reducing agent Substances 0.000 description 2
- 239000003593 chromogenic compound Substances 0.000 description 2
- 238000003776 cleavage reaction Methods 0.000 description 2
- 230000004186 co-expression Effects 0.000 description 2
- 229910017052 cobalt Inorganic materials 0.000 description 2
- 239000010941 cobalt Substances 0.000 description 2
- GUTLYIVDDKVIGB-UHFFFAOYSA-N cobalt atom Chemical compound [Co] GUTLYIVDDKVIGB-UHFFFAOYSA-N 0.000 description 2
- 239000000356 contaminant Substances 0.000 description 2
- 239000007822 coupling agent Substances 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 2
- 230000016396 cytokine production Effects 0.000 description 2
- 230000001086 cytosolic effect Effects 0.000 description 2
- 231100000433 cytotoxic Toxicity 0.000 description 2
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 2
- 230000034994 death Effects 0.000 description 2
- 238000004925 denaturation Methods 0.000 description 2
- 230000036425 denaturation Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 239000000032 diagnostic agent Substances 0.000 description 2
- 229940039227 diagnostic agent Drugs 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- 238000006471 dimerization reaction Methods 0.000 description 2
- 108010054812 diprotin A Proteins 0.000 description 2
- 238000010494 dissociation reaction Methods 0.000 description 2
- 230000005593 dissociations Effects 0.000 description 2
- 229950009791 durvalumab Drugs 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 229960001484 edetic acid Drugs 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 2
- 102000015694 estrogen receptors Human genes 0.000 description 2
- 108010038795 estrogen receptors Proteins 0.000 description 2
- 239000013604 expression vector Substances 0.000 description 2
- 230000002349 favourable effect Effects 0.000 description 2
- 238000007710 freezing Methods 0.000 description 2
- UIWYJDYFSGRHKR-UHFFFAOYSA-N gadolinium atom Chemical compound [Gd] UIWYJDYFSGRHKR-UHFFFAOYSA-N 0.000 description 2
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 2
- 238000001502 gel electrophoresis Methods 0.000 description 2
- 229940116332 glucose oxidase Drugs 0.000 description 2
- 235000019420 glucose oxidase Nutrition 0.000 description 2
- 229930195712 glutamate Natural products 0.000 description 2
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 2
- 239000003102 growth factor Substances 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- 201000010536 head and neck cancer Diseases 0.000 description 2
- 208000014829 head and neck neoplasm Diseases 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 238000001794 hormone therapy Methods 0.000 description 2
- 239000012216 imaging agent Substances 0.000 description 2
- 239000012642 immune effector Substances 0.000 description 2
- 230000028993 immune response Effects 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- 230000016784 immunoglobulin production Effects 0.000 description 2
- 229940121354 immunomodulator Drugs 0.000 description 2
- APFVFJFRJDLVQX-AHCXROLUSA-N indium-111 Chemical compound [111In] APFVFJFRJDLVQX-AHCXROLUSA-N 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- 208000015181 infectious disease Diseases 0.000 description 2
- 230000004054 inflammatory process Effects 0.000 description 2
- 239000004615 ingredient Substances 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 239000007928 intraperitoneal injection Substances 0.000 description 2
- 229910052742 iron Inorganic materials 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- QWTDNUCVQCZILF-UHFFFAOYSA-N isopentane Chemical compound CCC(C)C QWTDNUCVQCZILF-UHFFFAOYSA-N 0.000 description 2
- 108010045069 keyhole-limpet hemocyanin Proteins 0.000 description 2
- 230000002147 killing effect Effects 0.000 description 2
- 208000032839 leukemia Diseases 0.000 description 2
- 201000007270 liver cancer Diseases 0.000 description 2
- 208000014018 liver neoplasm Diseases 0.000 description 2
- 238000004020 luminiscence type Methods 0.000 description 2
- 210000001165 lymph node Anatomy 0.000 description 2
- 230000005291 magnetic effect Effects 0.000 description 2
- 238000012423 maintenance Methods 0.000 description 2
- 230000003211 malignant effect Effects 0.000 description 2
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 2
- 230000009401 metastasis Effects 0.000 description 2
- LPMXVESGRSUGHW-HBYQJFLCSA-N ouabain Chemical compound O[C@@H]1[C@H](O)[C@@H](O)[C@H](C)O[C@H]1O[C@@H]1C[C@@]2(O)CC[C@H]3[C@@]4(O)CC[C@H](C=5COC(=O)C=5)[C@@]4(C)C[C@@H](O)[C@@H]3[C@@]2(CO)[C@H](O)C1 LPMXVESGRSUGHW-HBYQJFLCSA-N 0.000 description 2
- 229960003343 ouabain Drugs 0.000 description 2
- 238000007500 overflow downdraw method Methods 0.000 description 2
- 239000007800 oxidant agent Substances 0.000 description 2
- 201000002528 pancreatic cancer Diseases 0.000 description 2
- 208000008443 pancreatic carcinoma Diseases 0.000 description 2
- 229940055729 papain Drugs 0.000 description 2
- 235000019834 papain Nutrition 0.000 description 2
- 230000005298 paramagnetic effect Effects 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 239000008188 pellet Substances 0.000 description 2
- 230000010412 perfusion Effects 0.000 description 2
- 238000002823 phage display Methods 0.000 description 2
- 239000008194 pharmaceutical composition Substances 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- CTRLRINCMYICJO-UHFFFAOYSA-N phenyl azide Chemical class [N-]=[N+]=NC1=CC=CC=C1 CTRLRINCMYICJO-UHFFFAOYSA-N 0.000 description 2
- 108010084572 phenylalanyl-valine Proteins 0.000 description 2
- 230000035935 pregnancy Effects 0.000 description 2
- 230000005522 programmed cell death Effects 0.000 description 2
- 108010070643 prolylglutamic acid Proteins 0.000 description 2
- 230000000644 propagated effect Effects 0.000 description 2
- 230000000069 prophylactic effect Effects 0.000 description 2
- 238000001742 protein purification Methods 0.000 description 2
- 150000003212 purines Chemical class 0.000 description 2
- 238000011002 quantification Methods 0.000 description 2
- 230000005855 radiation Effects 0.000 description 2
- 230000009257 reactivity Effects 0.000 description 2
- 230000000306 recurrent effect Effects 0.000 description 2
- 208000016691 refractory malignant neoplasm Diseases 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 2
- 229920006395 saturated elastomer Polymers 0.000 description 2
- 230000007017 scission Effects 0.000 description 2
- 230000003248 secreting effect Effects 0.000 description 2
- 201000000849 skin cancer Diseases 0.000 description 2
- FVAUCKIRQBBSSJ-UHFFFAOYSA-M sodium iodide Inorganic materials [Na+].[I-] FVAUCKIRQBBSSJ-UHFFFAOYSA-M 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 210000001082 somatic cell Anatomy 0.000 description 2
- 210000000952 spleen Anatomy 0.000 description 2
- 230000002269 spontaneous effect Effects 0.000 description 2
- 239000000021 stimulant Substances 0.000 description 2
- 201000011549 stomach cancer Diseases 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 229910052717 sulfur Inorganic materials 0.000 description 2
- 239000011593 sulfur Substances 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 201000003120 testicular cancer Diseases 0.000 description 2
- ABZLKHKQJHEPAX-UHFFFAOYSA-N tetramethylrhodamine Chemical compound C=12C=CC(N(C)C)=CC2=[O+]C2=CC(N(C)C)=CC=C2C=1C1=CC=CC=C1C([O-])=O ABZLKHKQJHEPAX-UHFFFAOYSA-N 0.000 description 2
- 230000017423 tissue regeneration Effects 0.000 description 2
- 230000000699 topical effect Effects 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 108010080629 tryptophan-leucine Proteins 0.000 description 2
- 230000003827 upregulation Effects 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- 230000003442 weekly effect Effects 0.000 description 2
- 210000005253 yeast cell Anatomy 0.000 description 2
- JWDFQMWEFLOOED-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(pyridin-2-yldisulfanyl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCSSC1=CC=CC=N1 JWDFQMWEFLOOED-UHFFFAOYSA-N 0.000 description 1
- JNTMAZFVYNDPLB-PEDHHIEDSA-N (2S,3S)-2-[[[(2S)-1-[(2S,3S)-2-amino-3-methyl-1-oxopentyl]-2-pyrrolidinyl]-oxomethyl]amino]-3-methylpentanoic acid Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JNTMAZFVYNDPLB-PEDHHIEDSA-N 0.000 description 1
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 1
- PNDPGZBMCMUPRI-HVTJNCQCSA-N 10043-66-0 Chemical compound [131I][131I] PNDPGZBMCMUPRI-HVTJNCQCSA-N 0.000 description 1
- WUAPFZMCVAUBPE-NJFSPNSNSA-N 188Re Chemical compound [188Re] WUAPFZMCVAUBPE-NJFSPNSNSA-N 0.000 description 1
- MEOVPKDOYAIVHZ-UHFFFAOYSA-N 2-chloro-1-(1-methylpyrrol-2-yl)ethanol Chemical compound CN1C=CC=C1C(O)CCl MEOVPKDOYAIVHZ-UHFFFAOYSA-N 0.000 description 1
- ZOOGRGPOEVQQDX-UUOKFMHZSA-N 3',5'-cyclic GMP Chemical compound C([C@H]1O2)OP(O)(=O)O[C@H]1[C@@H](O)[C@@H]2N1C(N=C(NC2=O)N)=C2N=C1 ZOOGRGPOEVQQDX-UUOKFMHZSA-N 0.000 description 1
- 101710151906 31 kDa protein Proteins 0.000 description 1
- QCVGEOXPDFCNHA-UHFFFAOYSA-N 5,5-dimethyl-2,4-dioxo-1,3-oxazolidine-3-carboxamide Chemical compound CC1(C)OC(=O)N(C(N)=O)C1=O QCVGEOXPDFCNHA-UHFFFAOYSA-N 0.000 description 1
- IDLISIVVYLGCKO-UHFFFAOYSA-N 6-carboxy-4',5'-dichloro-2',7'-dimethoxyfluorescein Chemical compound O1C(=O)C2=CC=C(C(O)=O)C=C2C21C1=CC(OC)=C(O)C(Cl)=C1OC1=C2C=C(OC)C(O)=C1Cl IDLISIVVYLGCKO-UHFFFAOYSA-N 0.000 description 1
- BZTDTCNHAFUJOG-UHFFFAOYSA-N 6-carboxyfluorescein Chemical compound C12=CC=C(O)C=C2OC2=CC(O)=CC=C2C11OC(=O)C2=CC=C(C(=O)O)C=C21 BZTDTCNHAFUJOG-UHFFFAOYSA-N 0.000 description 1
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 1
- BDDLHHRCDSJVKV-UHFFFAOYSA-N 7028-40-2 Chemical compound CC(O)=O.CC(O)=O.CC(O)=O.CC(O)=O BDDLHHRCDSJVKV-UHFFFAOYSA-N 0.000 description 1
- LPXQRXLUHJKZIE-UHFFFAOYSA-N 8-azaguanine Chemical compound NC1=NC(O)=C2NN=NC2=N1 LPXQRXLUHJKZIE-UHFFFAOYSA-N 0.000 description 1
- 229960005508 8-azaguanine Drugs 0.000 description 1
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 1
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 1
- WYPUMLRSQMKIJU-BPNCWPANSA-N Ala-Arg-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O WYPUMLRSQMKIJU-BPNCWPANSA-N 0.000 description 1
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 1
- AWAXZRDKUHOPBO-GUBZILKMSA-N Ala-Gln-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O AWAXZRDKUHOPBO-GUBZILKMSA-N 0.000 description 1
- PAIHPOGPJVUFJY-WDSKDSINSA-N Ala-Glu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PAIHPOGPJVUFJY-WDSKDSINSA-N 0.000 description 1
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 1
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 1
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 1
- WUHJHHGYVVJMQE-BJDJZHNGSA-N Ala-Leu-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WUHJHHGYVVJMQE-BJDJZHNGSA-N 0.000 description 1
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 1
- CQJHFKKGZXKZBC-BPNCWPANSA-N Ala-Pro-Tyr Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CQJHFKKGZXKZBC-BPNCWPANSA-N 0.000 description 1
- DCVYRWFAMZFSDA-ZLUOBGJFSA-N Ala-Ser-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DCVYRWFAMZFSDA-ZLUOBGJFSA-N 0.000 description 1
- DYXOFPBJBAHWFY-JBDRJPRFSA-N Ala-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N DYXOFPBJBAHWFY-JBDRJPRFSA-N 0.000 description 1
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 1
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 1
- WNHNMKOFKCHKKD-BFHQHQDPSA-N Ala-Thr-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O WNHNMKOFKCHKKD-BFHQHQDPSA-N 0.000 description 1
- FSXDWQGEWZQBPJ-HERUPUMHSA-N Ala-Trp-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(=O)O)C(=O)O)N FSXDWQGEWZQBPJ-HERUPUMHSA-N 0.000 description 1
- DHONNEYAZPNGSG-UBHSHLNASA-N Ala-Val-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 DHONNEYAZPNGSG-UBHSHLNASA-N 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- QGZKDVFQNNGYKY-UHFFFAOYSA-O Ammonium Chemical compound [NH4+] QGZKDVFQNNGYKY-UHFFFAOYSA-O 0.000 description 1
- 108010032595 Antibody Binding Sites Proteins 0.000 description 1
- 108020005544 Antisense RNA Proteins 0.000 description 1
- SGYSTDWPNPKJPP-GUBZILKMSA-N Arg-Ala-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SGYSTDWPNPKJPP-GUBZILKMSA-N 0.000 description 1
- DFCIPNHFKOQAME-FXQIFTODSA-N Arg-Ala-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DFCIPNHFKOQAME-FXQIFTODSA-N 0.000 description 1
- IJPNNYWHXGADJG-GUBZILKMSA-N Arg-Ala-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O IJPNNYWHXGADJG-GUBZILKMSA-N 0.000 description 1
- VSPLYCLMFAUZRF-GUBZILKMSA-N Arg-Cys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCN=C(N)N)N VSPLYCLMFAUZRF-GUBZILKMSA-N 0.000 description 1
- XLWSGICNBZGYTA-CIUDSAMLSA-N Arg-Glu-Asp Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O XLWSGICNBZGYTA-CIUDSAMLSA-N 0.000 description 1
- HJDNZFIYILEIKR-OSUNSFLBSA-N Arg-Ile-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HJDNZFIYILEIKR-OSUNSFLBSA-N 0.000 description 1
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 1
- RIIVUOJDDQXHRV-SRVKXCTJSA-N Arg-Lys-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O RIIVUOJDDQXHRV-SRVKXCTJSA-N 0.000 description 1
- RIQBRKVTFBWEDY-RHYQMDGZSA-N Arg-Lys-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RIQBRKVTFBWEDY-RHYQMDGZSA-N 0.000 description 1
- VUGWHBXPMAHEGZ-SRVKXCTJSA-N Arg-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N VUGWHBXPMAHEGZ-SRVKXCTJSA-N 0.000 description 1
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 1
- NVPHRWNWTKYIST-BPNCWPANSA-N Arg-Tyr-Ala Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 NVPHRWNWTKYIST-BPNCWPANSA-N 0.000 description 1
- 240000003291 Armoracia rusticana Species 0.000 description 1
- 235000011330 Armoracia rusticana Nutrition 0.000 description 1
- 206010003445 Ascites Diseases 0.000 description 1
- QQEWINYJRFBLNN-DLOVCJGASA-N Asn-Ala-Phe Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QQEWINYJRFBLNN-DLOVCJGASA-N 0.000 description 1
- XWFPGQVLOVGSLU-CIUDSAMLSA-N Asn-Gln-Arg Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N XWFPGQVLOVGSLU-CIUDSAMLSA-N 0.000 description 1
- HDHZCEDPLTVHFZ-GUBZILKMSA-N Asn-Leu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O HDHZCEDPLTVHFZ-GUBZILKMSA-N 0.000 description 1
- JWKDQOORUCYUIW-ZPFDUUQYSA-N Asn-Lys-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JWKDQOORUCYUIW-ZPFDUUQYSA-N 0.000 description 1
- YXVAESUIQFDBHN-SRVKXCTJSA-N Asn-Phe-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O YXVAESUIQFDBHN-SRVKXCTJSA-N 0.000 description 1
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 1
- VLDRQOHCMKCXLY-SRVKXCTJSA-N Asn-Ser-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O VLDRQOHCMKCXLY-SRVKXCTJSA-N 0.000 description 1
- NCXTYSVDWLAQGZ-ZKWXMUAHSA-N Asn-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O NCXTYSVDWLAQGZ-ZKWXMUAHSA-N 0.000 description 1
- YHXNKGKUDJCAHB-PBCZWWQYSA-N Asn-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O YHXNKGKUDJCAHB-PBCZWWQYSA-N 0.000 description 1
- PQKSVQSMTHPRIB-ZKWXMUAHSA-N Asn-Val-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O PQKSVQSMTHPRIB-ZKWXMUAHSA-N 0.000 description 1
- NJIKKGUVGUBICV-ZLUOBGJFSA-N Asp-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O NJIKKGUVGUBICV-ZLUOBGJFSA-N 0.000 description 1
- HRGGPWBIMIQANI-GUBZILKMSA-N Asp-Gln-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O HRGGPWBIMIQANI-GUBZILKMSA-N 0.000 description 1
- MYOHQBFRJQFIDZ-KKUMJFAQSA-N Asp-Leu-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MYOHQBFRJQFIDZ-KKUMJFAQSA-N 0.000 description 1
- XWSIYTYNLKCLJB-CIUDSAMLSA-N Asp-Lys-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O XWSIYTYNLKCLJB-CIUDSAMLSA-N 0.000 description 1
- DINOVZWPTMGSRF-QXEWZRGKSA-N Asp-Pro-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O DINOVZWPTMGSRF-QXEWZRGKSA-N 0.000 description 1
- UTLCRGFJFSZWAW-OLHMAJIHSA-N Asp-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O UTLCRGFJFSZWAW-OLHMAJIHSA-N 0.000 description 1
- JJQGZGOEDSSHTE-FOHZUACHSA-N Asp-Thr-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O JJQGZGOEDSSHTE-FOHZUACHSA-N 0.000 description 1
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 1
- BJDHEININLSZOT-KKUMJFAQSA-N Asp-Tyr-Lys Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(O)=O BJDHEININLSZOT-KKUMJFAQSA-N 0.000 description 1
- 230000003844 B-cell-activation Effects 0.000 description 1
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 1
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 206010005949 Bone cancer Diseases 0.000 description 1
- 208000018084 Bone neoplasm Diseases 0.000 description 1
- BTBUEUYNUDRHOZ-UHFFFAOYSA-N Borate Chemical compound [O-]B([O-])[O-] BTBUEUYNUDRHOZ-UHFFFAOYSA-N 0.000 description 1
- 208000003174 Brain Neoplasms Diseases 0.000 description 1
- 101710155857 C-C motif chemokine 2 Proteins 0.000 description 1
- 102100021943 C-C motif chemokine 2 Human genes 0.000 description 1
- 101150091609 CD274 gene Proteins 0.000 description 1
- 108010062802 CD66 antigens Proteins 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 108010022366 Carcinoembryonic Antigen Proteins 0.000 description 1
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 description 1
- 108010078791 Carrier Proteins Proteins 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 102100035361 Cerebellar degeneration-related protein 2 Human genes 0.000 description 1
- 108010012236 Chemokines Proteins 0.000 description 1
- 102000019034 Chemokines Human genes 0.000 description 1
- ZAMOUSCENKQFHK-UHFFFAOYSA-N Chlorine atom Chemical compound [Cl] ZAMOUSCENKQFHK-UHFFFAOYSA-N 0.000 description 1
- 108010049048 Cholera Toxin Proteins 0.000 description 1
- 102000009016 Cholera Toxin Human genes 0.000 description 1
- VYZAMTAEIAYCRO-UHFFFAOYSA-N Chromium Chemical compound [Cr] VYZAMTAEIAYCRO-UHFFFAOYSA-N 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- JPVYNHNXODAKFH-UHFFFAOYSA-N Cu2+ Chemical compound [Cu+2] JPVYNHNXODAKFH-UHFFFAOYSA-N 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- SFUUYRSAJPWTGO-SRVKXCTJSA-N Cys-Asn-Phe Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SFUUYRSAJPWTGO-SRVKXCTJSA-N 0.000 description 1
- BVFQOPGFOQVZTE-ACZMJKKPSA-N Cys-Gln-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O BVFQOPGFOQVZTE-ACZMJKKPSA-N 0.000 description 1
- IZUNQDRIAOLWCN-YUMQZZPRSA-N Cys-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N IZUNQDRIAOLWCN-YUMQZZPRSA-N 0.000 description 1
- JTEGHEWKBCTIAL-IXOXFDKPSA-N Cys-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CS)N)O JTEGHEWKBCTIAL-IXOXFDKPSA-N 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 108010092160 Dactinomycin Proteins 0.000 description 1
- FEWJPZIEWOKRBE-JCYAYHJZSA-N Dextrotartaric acid Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O FEWJPZIEWOKRBE-JCYAYHJZSA-N 0.000 description 1
- VYZAHLCBVHPDDF-UHFFFAOYSA-N Dinitrochlorobenzene Chemical compound [O-][N+](=O)C1=CC=C(Cl)C([N+]([O-])=O)=C1 VYZAHLCBVHPDDF-UHFFFAOYSA-N 0.000 description 1
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 1
- 206010058314 Dysplasia Diseases 0.000 description 1
- 229910052692 Dysprosium Inorganic materials 0.000 description 1
- 108010000912 Egg Proteins Proteins 0.000 description 1
- 102000002322 Egg Proteins Human genes 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 229910052691 Erbium Inorganic materials 0.000 description 1
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 1
- 102100029951 Estrogen receptor beta Human genes 0.000 description 1
- VGGSQFUCUMXWEO-UHFFFAOYSA-N Ethene Chemical compound C=C VGGSQFUCUMXWEO-UHFFFAOYSA-N 0.000 description 1
- 239000005977 Ethylene Substances 0.000 description 1
- 208000001382 Experimental Melanoma Diseases 0.000 description 1
- 241000233756 Fabriciana elisa Species 0.000 description 1
- CWYNVVGOOAEACU-UHFFFAOYSA-N Fe2+ Chemical compound [Fe+2] CWYNVVGOOAEACU-UHFFFAOYSA-N 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 241000724791 Filamentous phage Species 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 102000013446 GTP Phosphohydrolases Human genes 0.000 description 1
- 108091006109 GTPases Proteins 0.000 description 1
- 108010001515 Galectin 4 Proteins 0.000 description 1
- 102100039556 Galectin-4 Human genes 0.000 description 1
- GYHNNYVSQQEPJS-OIOBTWANSA-N Gallium-67 Chemical compound [67Ga] GYHNNYVSQQEPJS-OIOBTWANSA-N 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 241000699694 Gerbillinae Species 0.000 description 1
- SHERTACNJPYHAR-ACZMJKKPSA-N Gln-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O SHERTACNJPYHAR-ACZMJKKPSA-N 0.000 description 1
- RGXXLQWXBFNXTG-CIUDSAMLSA-N Gln-Arg-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O RGXXLQWXBFNXTG-CIUDSAMLSA-N 0.000 description 1
- CYTSBCIIEHUPDU-ACZMJKKPSA-N Gln-Asp-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O CYTSBCIIEHUPDU-ACZMJKKPSA-N 0.000 description 1
- WQWMZOIPXWSZNE-WDSKDSINSA-N Gln-Asp-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O WQWMZOIPXWSZNE-WDSKDSINSA-N 0.000 description 1
- LOJYQMFIIJVETK-WDSKDSINSA-N Gln-Gln Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(O)=O LOJYQMFIIJVETK-WDSKDSINSA-N 0.000 description 1
- IVCOYUURLWQDJQ-LPEHRKFASA-N Gln-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O IVCOYUURLWQDJQ-LPEHRKFASA-N 0.000 description 1
- IKFZXRLDMYWNBU-YUMQZZPRSA-N Gln-Gly-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N IKFZXRLDMYWNBU-YUMQZZPRSA-N 0.000 description 1
- ICDIMQAMJGDHSE-GUBZILKMSA-N Gln-His-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O ICDIMQAMJGDHSE-GUBZILKMSA-N 0.000 description 1
- ILKYYKRAULNYMS-JYJNAYRXSA-N Gln-Lys-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ILKYYKRAULNYMS-JYJNAYRXSA-N 0.000 description 1
- ZEEPYMXTJWIMSN-GUBZILKMSA-N Gln-Lys-Ser Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CO)C(O)=O)NC(=O)[C@@H](N)CCC(N)=O ZEEPYMXTJWIMSN-GUBZILKMSA-N 0.000 description 1
- QMVCEWKHIUHTSD-GUBZILKMSA-N Gln-Met-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N QMVCEWKHIUHTSD-GUBZILKMSA-N 0.000 description 1
- MQJDLNRXBOELJW-KKUMJFAQSA-N Gln-Pro-Phe Chemical compound N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O MQJDLNRXBOELJW-KKUMJFAQSA-N 0.000 description 1
- KUBFPYIMAGXGBT-ACZMJKKPSA-N Gln-Ser-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KUBFPYIMAGXGBT-ACZMJKKPSA-N 0.000 description 1
- UTOQQOMEJDPDMX-ACZMJKKPSA-N Gln-Ser-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O UTOQQOMEJDPDMX-ACZMJKKPSA-N 0.000 description 1
- SJMJMEWQMBJYPR-DZKIICNBSA-N Gln-Tyr-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCC(=O)N)N SJMJMEWQMBJYPR-DZKIICNBSA-N 0.000 description 1
- OACPJRQRAHMQEQ-NHCYSSNCSA-N Gln-Val-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O OACPJRQRAHMQEQ-NHCYSSNCSA-N 0.000 description 1
- VEYGCDYMOXHJLS-GVXVVHGQSA-N Gln-Val-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VEYGCDYMOXHJLS-GVXVVHGQSA-N 0.000 description 1
- SRZLHYPAOXBBSB-HJGDQZAQSA-N Glu-Arg-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SRZLHYPAOXBBSB-HJGDQZAQSA-N 0.000 description 1
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 1
- ISXJHXGYMJKXOI-GUBZILKMSA-N Glu-Cys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(O)=O ISXJHXGYMJKXOI-GUBZILKMSA-N 0.000 description 1
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 1
- NKLRYVLERDYDBI-FXQIFTODSA-N Glu-Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKLRYVLERDYDBI-FXQIFTODSA-N 0.000 description 1
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 1
- WRNAXCVRSBBKGS-BQBZGAKWSA-N Glu-Gly-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O WRNAXCVRSBBKGS-BQBZGAKWSA-N 0.000 description 1
- XIKYNVKEUINBGL-IUCAKERBSA-N Glu-His-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)NCC(O)=O XIKYNVKEUINBGL-IUCAKERBSA-N 0.000 description 1
- WTMZXOPHTIVFCP-QEWYBTABSA-N Glu-Ile-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 WTMZXOPHTIVFCP-QEWYBTABSA-N 0.000 description 1
- DNPCBMNFQVTHMA-DCAQKATOSA-N Glu-Leu-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DNPCBMNFQVTHMA-DCAQKATOSA-N 0.000 description 1
- UGSVSNXPJJDJKL-SDDRHHMPSA-N Glu-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N UGSVSNXPJJDJKL-SDDRHHMPSA-N 0.000 description 1
- UJMNFCAHLYKWOZ-DCAQKATOSA-N Glu-Lys-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O UJMNFCAHLYKWOZ-DCAQKATOSA-N 0.000 description 1
- JHSRJMUJOGLIHK-GUBZILKMSA-N Glu-Met-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N JHSRJMUJOGLIHK-GUBZILKMSA-N 0.000 description 1
- JWNZHMSRZXXGTM-XKBZYTNZSA-N Glu-Ser-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JWNZHMSRZXXGTM-XKBZYTNZSA-N 0.000 description 1
- JSIQVRIXMINMTA-ZDLURKLDSA-N Glu-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](N)CCC(O)=O JSIQVRIXMINMTA-ZDLURKLDSA-N 0.000 description 1
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 1
- LZEUDRYSAZAJIO-AUTRQRHGSA-N Glu-Val-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LZEUDRYSAZAJIO-AUTRQRHGSA-N 0.000 description 1
- FGGKGJHCVMYGCD-UKJIMTQDSA-N Glu-Val-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGGKGJHCVMYGCD-UKJIMTQDSA-N 0.000 description 1
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 1
- 108010024636 Glutathione Proteins 0.000 description 1
- PYTZFYUXZZHOAD-WHFBIAKZSA-N Gly-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)CN PYTZFYUXZZHOAD-WHFBIAKZSA-N 0.000 description 1
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 1
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 1
- XMPXVJIDADUOQB-RCOVLWMOSA-N Gly-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C([O-])=O)NC(=O)CNC(=O)C[NH3+] XMPXVJIDADUOQB-RCOVLWMOSA-N 0.000 description 1
- OLPPXYMMIARYAL-QMMMGPOBSA-N Gly-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)CN OLPPXYMMIARYAL-QMMMGPOBSA-N 0.000 description 1
- VIIBEIQMLJEUJG-LAEOZQHASA-N Gly-Ile-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O VIIBEIQMLJEUJG-LAEOZQHASA-N 0.000 description 1
- AAHSHTLISQUZJL-QSFUFRPTSA-N Gly-Ile-Ile Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AAHSHTLISQUZJL-QSFUFRPTSA-N 0.000 description 1
- FXGRXIATVXUAHO-WEDXCCLWSA-N Gly-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN FXGRXIATVXUAHO-WEDXCCLWSA-N 0.000 description 1
- IALQAMYQJBZNSK-WHFBIAKZSA-N Gly-Ser-Asn Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O IALQAMYQJBZNSK-WHFBIAKZSA-N 0.000 description 1
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 1
- LLWQVJNHMYBLLK-CDMKHQONSA-N Gly-Thr-Phe Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LLWQVJNHMYBLLK-CDMKHQONSA-N 0.000 description 1
- ZVXMEWXHFBYJPI-LSJOCFKGSA-N Gly-Val-Ile Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZVXMEWXHFBYJPI-LSJOCFKGSA-N 0.000 description 1
- IZVICCORZOSGPT-JSGCOSHPSA-N Gly-Val-Tyr Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IZVICCORZOSGPT-JSGCOSHPSA-N 0.000 description 1
- 102000009465 Growth Factor Receptors Human genes 0.000 description 1
- 108010009202 Growth Factor Receptors Proteins 0.000 description 1
- FIMNVXRZGUAGBI-AVGNSLFASA-N His-Glu-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O FIMNVXRZGUAGBI-AVGNSLFASA-N 0.000 description 1
- MPXGJGBXCRQQJE-MXAVVETBSA-N His-Ile-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O MPXGJGBXCRQQJE-MXAVVETBSA-N 0.000 description 1
- BXOLYFJYQQRQDJ-MXAVVETBSA-N His-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC1=CN=CN1)N BXOLYFJYQQRQDJ-MXAVVETBSA-N 0.000 description 1
- YAALVYQFVJNXIV-KKUMJFAQSA-N His-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 YAALVYQFVJNXIV-KKUMJFAQSA-N 0.000 description 1
- OWYIDJCNRWRSJY-QTKMDUPCSA-N His-Pro-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O OWYIDJCNRWRSJY-QTKMDUPCSA-N 0.000 description 1
- ZHHLTWUOWXHVQJ-YUMQZZPRSA-N His-Ser-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZHHLTWUOWXHVQJ-YUMQZZPRSA-N 0.000 description 1
- JGFWUKYIQAEYAH-DCAQKATOSA-N His-Ser-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JGFWUKYIQAEYAH-DCAQKATOSA-N 0.000 description 1
- BRQKGRLDDDQWQJ-MBLNEYKQSA-N His-Thr-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O BRQKGRLDDDQWQJ-MBLNEYKQSA-N 0.000 description 1
- GYXDQXPCPASCNR-NHCYSSNCSA-N His-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N GYXDQXPCPASCNR-NHCYSSNCSA-N 0.000 description 1
- 108091006054 His-tagged proteins Proteins 0.000 description 1
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 1
- 101100407305 Homo sapiens CD274 gene Proteins 0.000 description 1
- 101000737796 Homo sapiens Cerebellar degeneration-related protein 2 Proteins 0.000 description 1
- 101001010910 Homo sapiens Estrogen receptor beta Proteins 0.000 description 1
- 101000840258 Homo sapiens Immunoglobulin J chain Proteins 0.000 description 1
- 101001056180 Homo sapiens Induced myeloid leukemia cell differentiation protein Mcl-1 Proteins 0.000 description 1
- 101001034314 Homo sapiens Lactadherin Proteins 0.000 description 1
- 101000621344 Homo sapiens Protein Wnt-2 Proteins 0.000 description 1
- 101000653679 Homo sapiens Translationally-controlled tumor protein Proteins 0.000 description 1
- 101000997832 Homo sapiens Tyrosine-protein kinase JAK2 Proteins 0.000 description 1
- 229920002153 Hydroxypropyl cellulose Polymers 0.000 description 1
- NKVZTQVGUNLLQW-JBDRJPRFSA-N Ile-Ala-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)O)N NKVZTQVGUNLLQW-JBDRJPRFSA-N 0.000 description 1
- VAXBXNPRXPHGHG-BJDJZHNGSA-N Ile-Ala-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)O)N VAXBXNPRXPHGHG-BJDJZHNGSA-N 0.000 description 1
- CYHYBSGMHMHKOA-CIQUZCHMSA-N Ile-Ala-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N CYHYBSGMHMHKOA-CIQUZCHMSA-N 0.000 description 1
- HDODQNPMSHDXJT-GHCJXIJMSA-N Ile-Asn-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O HDODQNPMSHDXJT-GHCJXIJMSA-N 0.000 description 1
- NCSIQAFSIPHVAN-IUKAMOBKSA-N Ile-Asn-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NCSIQAFSIPHVAN-IUKAMOBKSA-N 0.000 description 1
- WNQKUUQIVDDAFA-ZPFDUUQYSA-N Ile-Gln-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCSC)C(=O)O)N WNQKUUQIVDDAFA-ZPFDUUQYSA-N 0.000 description 1
- BALLIXFZYSECCF-QEWYBTABSA-N Ile-Gln-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N BALLIXFZYSECCF-QEWYBTABSA-N 0.000 description 1
- OVPYIUNCVSOVNF-KQXIARHKSA-N Ile-Gln-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N OVPYIUNCVSOVNF-KQXIARHKSA-N 0.000 description 1
- YBJWJQQBWRARLT-KBIXCLLPSA-N Ile-Gln-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O YBJWJQQBWRARLT-KBIXCLLPSA-N 0.000 description 1
- WIZPFZKOFZXDQG-HTFCKZLJSA-N Ile-Ile-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O WIZPFZKOFZXDQG-HTFCKZLJSA-N 0.000 description 1
- BBQABUDWDUKJMB-LZXPERKUSA-N Ile-Ile-Ile Chemical compound CC[C@H](C)[C@H]([NH3+])C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C([O-])=O BBQABUDWDUKJMB-LZXPERKUSA-N 0.000 description 1
- HPCFRQWLTRDGHT-AJNGGQMLSA-N Ile-Leu-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O HPCFRQWLTRDGHT-AJNGGQMLSA-N 0.000 description 1
- DSDPLOODKXISDT-XUXIUFHCSA-N Ile-Leu-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DSDPLOODKXISDT-XUXIUFHCSA-N 0.000 description 1
- WYUHAXJAMDTOAU-IAVJCBSLSA-N Ile-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N WYUHAXJAMDTOAU-IAVJCBSLSA-N 0.000 description 1
- RENBRDSDKPSRIH-HJWJTTGWSA-N Ile-Phe-Met Chemical compound N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)O RENBRDSDKPSRIH-HJWJTTGWSA-N 0.000 description 1
- OWSWUWDMSNXTNE-GMOBBJLQSA-N Ile-Pro-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N OWSWUWDMSNXTNE-GMOBBJLQSA-N 0.000 description 1
- RQJUKVXWAKJDBW-SVSWQMSJSA-N Ile-Ser-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N RQJUKVXWAKJDBW-SVSWQMSJSA-N 0.000 description 1
- WLRJHVNFGAOYPS-HJPIBITLSA-N Ile-Ser-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N WLRJHVNFGAOYPS-HJPIBITLSA-N 0.000 description 1
- CNMOKANDJMLAIF-CIQUZCHMSA-N Ile-Thr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O CNMOKANDJMLAIF-CIQUZCHMSA-N 0.000 description 1
- YCKPUHHMCFSUMD-IUKAMOBKSA-N Ile-Thr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCKPUHHMCFSUMD-IUKAMOBKSA-N 0.000 description 1
- 206010061598 Immunodeficiency Diseases 0.000 description 1
- 102100029571 Immunoglobulin J chain Human genes 0.000 description 1
- 206010062016 Immunosuppression Diseases 0.000 description 1
- 102100026539 Induced myeloid leukemia cell differentiation protein Mcl-1 Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 102000013462 Interleukin-12 Human genes 0.000 description 1
- 108010065805 Interleukin-12 Proteins 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- 108090001007 Interleukin-8 Proteins 0.000 description 1
- ZCYVEMRRCGMTRW-AHCXROLUSA-N Iodine-123 Chemical compound [123I] ZCYVEMRRCGMTRW-AHCXROLUSA-N 0.000 description 1
- 208000008839 Kidney Neoplasms Diseases 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- 102100039648 Lactadherin Human genes 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 102000002297 Laminin Receptors Human genes 0.000 description 1
- 108010000851 Laminin Receptors Proteins 0.000 description 1
- PBCHMHROGNUXMK-DLOVCJGASA-N Leu-Ala-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 PBCHMHROGNUXMK-DLOVCJGASA-N 0.000 description 1
- QUAAUWNLWMLERT-IHRRRGAJSA-N Leu-Arg-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O QUAAUWNLWMLERT-IHRRRGAJSA-N 0.000 description 1
- USTCFDAQCLDPBD-XIRDDKMYSA-N Leu-Asn-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N USTCFDAQCLDPBD-XIRDDKMYSA-N 0.000 description 1
- MMEDVBWCMGRKKC-GARJFASQSA-N Leu-Asp-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N MMEDVBWCMGRKKC-GARJFASQSA-N 0.000 description 1
- QKIBIXAQKAFZGL-GUBZILKMSA-N Leu-Cys-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QKIBIXAQKAFZGL-GUBZILKMSA-N 0.000 description 1
- GLBNEGIOFRVRHO-JYJNAYRXSA-N Leu-Gln-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GLBNEGIOFRVRHO-JYJNAYRXSA-N 0.000 description 1
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 1
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 1
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 1
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 1
- PPQRKXHCLYCBSP-IHRRRGAJSA-N Leu-Leu-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)O)N PPQRKXHCLYCBSP-IHRRRGAJSA-N 0.000 description 1
- LZHJZLHSRGWBBE-IHRRRGAJSA-N Leu-Lys-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O LZHJZLHSRGWBBE-IHRRRGAJSA-N 0.000 description 1
- YWKNKRAKOCLOLH-OEAJRASXSA-N Leu-Phe-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=CC=C1 YWKNKRAKOCLOLH-OEAJRASXSA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 1
- VHTIZYYHIUHMCA-JYJNAYRXSA-N Leu-Tyr-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VHTIZYYHIUHMCA-JYJNAYRXSA-N 0.000 description 1
- ARNIBBOXIAWUOP-MGHWNKPDSA-N Leu-Tyr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ARNIBBOXIAWUOP-MGHWNKPDSA-N 0.000 description 1
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 1
- FMFNIDICDKEMOE-XUXIUFHCSA-N Leu-Val-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FMFNIDICDKEMOE-XUXIUFHCSA-N 0.000 description 1
- 102100020872 Leucyl-cystinyl aminopeptidase Human genes 0.000 description 1
- JGAMUXDWYSXYLM-SRVKXCTJSA-N Lys-Arg-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O JGAMUXDWYSXYLM-SRVKXCTJSA-N 0.000 description 1
- DTUZCYRNEJDKSR-NHCYSSNCSA-N Lys-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN DTUZCYRNEJDKSR-NHCYSSNCSA-N 0.000 description 1
- KYNNSEJZFVCDIV-ZPFDUUQYSA-N Lys-Ile-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O KYNNSEJZFVCDIV-ZPFDUUQYSA-N 0.000 description 1
- XIZQPFCRXLUNMK-BZSNNMDCSA-N Lys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCCCN)N XIZQPFCRXLUNMK-BZSNNMDCSA-N 0.000 description 1
- VUTWYNQUSJWBHO-BZSNNMDCSA-N Lys-Leu-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VUTWYNQUSJWBHO-BZSNNMDCSA-N 0.000 description 1
- UQJOKDAYFULYIX-AVGNSLFASA-N Lys-Pro-Pro Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 UQJOKDAYFULYIX-AVGNSLFASA-N 0.000 description 1
- MEQLGHAMAUPOSJ-DCAQKATOSA-N Lys-Ser-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O MEQLGHAMAUPOSJ-DCAQKATOSA-N 0.000 description 1
- MIMXMVDLMDMOJD-BZSNNMDCSA-N Lys-Tyr-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O MIMXMVDLMDMOJD-BZSNNMDCSA-N 0.000 description 1
- MDDUIRLQCYVRDO-NHCYSSNCSA-N Lys-Val-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN MDDUIRLQCYVRDO-NHCYSSNCSA-N 0.000 description 1
- OZVXDDFYCQOPFD-XQQFMLRXSA-N Lys-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N OZVXDDFYCQOPFD-XQQFMLRXSA-N 0.000 description 1
- WAEMQWOKJMHJLA-UHFFFAOYSA-N Manganese(2+) Chemical compound [Mn+2] WAEMQWOKJMHJLA-UHFFFAOYSA-N 0.000 description 1
- ZEDVFJPQNNBMST-CYDGBPFRSA-N Met-Arg-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZEDVFJPQNNBMST-CYDGBPFRSA-N 0.000 description 1
- GPVLSVCBKUCEBI-KKUMJFAQSA-N Met-Gln-Phe Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GPVLSVCBKUCEBI-KKUMJFAQSA-N 0.000 description 1
- SJDQOYTYNGZZJX-SRVKXCTJSA-N Met-Glu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SJDQOYTYNGZZJX-SRVKXCTJSA-N 0.000 description 1
- 108010072489 Met-Ile-Phe-Leu Proteins 0.000 description 1
- JKXVPNCSAMWUEJ-GUBZILKMSA-N Met-Met-Asp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O JKXVPNCSAMWUEJ-GUBZILKMSA-N 0.000 description 1
- WXJLBSXNUHIGSS-OSUNSFLBSA-N Met-Thr-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WXJLBSXNUHIGSS-OSUNSFLBSA-N 0.000 description 1
- 101710151805 Mitochondrial intermediate peptidase 1 Proteins 0.000 description 1
- 229930192392 Mitomycin Natural products 0.000 description 1
- 206010073148 Multiple endocrine neoplasia type 2A Diseases 0.000 description 1
- 241000711408 Murine respirovirus Species 0.000 description 1
- 101001117316 Mus musculus Programmed cell death 1 ligand 1 Proteins 0.000 description 1
- 241000186366 Mycobacterium bovis Species 0.000 description 1
- 241000187479 Mycobacterium tuberculosis Species 0.000 description 1
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 1
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 1
- NQTADLQHYWFPDB-UHFFFAOYSA-N N-Hydroxysuccinimide Chemical compound ON1C(=O)CCC1=O NQTADLQHYWFPDB-UHFFFAOYSA-N 0.000 description 1
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 1
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 description 1
- NXTVQNIVUKXOIL-UHFFFAOYSA-N N-chlorotoluene-p-sulfonamide Chemical compound CC1=CC=C(S(=O)(=O)NCl)C=C1 NXTVQNIVUKXOIL-UHFFFAOYSA-N 0.000 description 1
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 1
- VEQPNABPJHWNSG-UHFFFAOYSA-N Nickel(2+) Chemical compound [Ni+2] VEQPNABPJHWNSG-UHFFFAOYSA-N 0.000 description 1
- AWZJFZMWSUBJAJ-UHFFFAOYSA-N OG-514 dye Chemical compound OC(=O)CSC1=C(F)C(F)=C(C(O)=O)C(C2=C3C=C(F)C(=O)C=C3OC3=CC(O)=C(F)C=C32)=C1F AWZJFZMWSUBJAJ-UHFFFAOYSA-N 0.000 description 1
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- 241000282520 Papio Species 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- 108090000284 Pepsin A Proteins 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 102000003992 Peroxidases Human genes 0.000 description 1
- 108010081690 Pertussis Toxin Proteins 0.000 description 1
- ZKSLXIGKRJMALF-MGHWNKPDSA-N Phe-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC2=CC=CC=C2)N ZKSLXIGKRJMALF-MGHWNKPDSA-N 0.000 description 1
- VADLTGVIOIOKGM-BZSNNMDCSA-N Phe-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CN=CN1 VADLTGVIOIOKGM-BZSNNMDCSA-N 0.000 description 1
- ZJPGOXWRFNKIQL-JYJNAYRXSA-N Phe-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 ZJPGOXWRFNKIQL-JYJNAYRXSA-N 0.000 description 1
- ZLAKUZDMKVKFAI-JYJNAYRXSA-N Phe-Pro-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O ZLAKUZDMKVKFAI-JYJNAYRXSA-N 0.000 description 1
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 1
- 101710114878 Phospholipase A-2-activating protein Proteins 0.000 description 1
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 description 1
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- 102100022427 Plasmalemma vesicle-associated protein Human genes 0.000 description 1
- 101710193105 Plasmalemma vesicle-associated protein Proteins 0.000 description 1
- 241000223960 Plasmodium falciparum Species 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 239000004793 Polystyrene Substances 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- 206010036711 Primary mediastinal large B-cell lymphomas Diseases 0.000 description 1
- DBALDZKOTNSBFM-FXQIFTODSA-N Pro-Ala-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DBALDZKOTNSBFM-FXQIFTODSA-N 0.000 description 1
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 1
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 1
- DMKWYMWNEKIPFC-IUCAKERBSA-N Pro-Gly-Arg Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O DMKWYMWNEKIPFC-IUCAKERBSA-N 0.000 description 1
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 1
- LCUOTSLIVGSGAU-AVGNSLFASA-N Pro-His-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O LCUOTSLIVGSGAU-AVGNSLFASA-N 0.000 description 1
- VZKBJNBZMZHKRC-XUXIUFHCSA-N Pro-Ile-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O VZKBJNBZMZHKRC-XUXIUFHCSA-N 0.000 description 1
- FXGIMYRVJJEIIM-UWVGGRQHSA-N Pro-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FXGIMYRVJJEIIM-UWVGGRQHSA-N 0.000 description 1
- OFGUOWQVEGTVNU-DCAQKATOSA-N Pro-Lys-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OFGUOWQVEGTVNU-DCAQKATOSA-N 0.000 description 1
- XQPHBAKJJJZOBX-SRVKXCTJSA-N Pro-Lys-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O XQPHBAKJJJZOBX-SRVKXCTJSA-N 0.000 description 1
- DYMPSOABVJIFBS-IHRRRGAJSA-N Pro-Phe-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N[C@@H](CS)C(=O)O DYMPSOABVJIFBS-IHRRRGAJSA-N 0.000 description 1
- GFHOSBYCLACKEK-GUBZILKMSA-N Pro-Pro-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O GFHOSBYCLACKEK-GUBZILKMSA-N 0.000 description 1
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 1
- DMNANGOFEUVBRV-GJZGRUSLSA-N Pro-Trp-Gly Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)O)C(=O)[C@@H]1CCCN1 DMNANGOFEUVBRV-GJZGRUSLSA-N 0.000 description 1
- 102000043850 Programmed Cell Death 1 Ligand 2 Human genes 0.000 description 1
- XBDQKXXYIPTUBI-UHFFFAOYSA-M Propionate Chemical compound CCC([O-])=O XBDQKXXYIPTUBI-UHFFFAOYSA-M 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 102000007066 Prostate-Specific Antigen Human genes 0.000 description 1
- 108010072866 Prostate-Specific Antigen Proteins 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 102100022805 Protein Wnt-2 Human genes 0.000 description 1
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 1
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 1
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 1
- 101710100968 Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 1
- 208000015634 Rectal Neoplasms Diseases 0.000 description 1
- 206010038111 Recurrent cancer Diseases 0.000 description 1
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 description 1
- 239000006146 Roswell Park Memorial Institute medium Substances 0.000 description 1
- BUGBHKTXTAQXES-UHFFFAOYSA-N Selenium Chemical compound [Se] BUGBHKTXTAQXES-UHFFFAOYSA-N 0.000 description 1
- 229920005654 Sephadex Polymers 0.000 description 1
- 239000012507 Sephadex™ Substances 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 1
- GXXTUIUYTWGPMV-FXQIFTODSA-N Ser-Arg-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O GXXTUIUYTWGPMV-FXQIFTODSA-N 0.000 description 1
- YUSRGTQIPCJNHQ-CIUDSAMLSA-N Ser-Arg-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O YUSRGTQIPCJNHQ-CIUDSAMLSA-N 0.000 description 1
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 1
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 1
- KAAPNMOKUUPKOE-SRVKXCTJSA-N Ser-Asn-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KAAPNMOKUUPKOE-SRVKXCTJSA-N 0.000 description 1
- RDFQNDHEHVSONI-ZLUOBGJFSA-N Ser-Asn-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDFQNDHEHVSONI-ZLUOBGJFSA-N 0.000 description 1
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 1
- TYYBJUYSTWJHGO-ZKWXMUAHSA-N Ser-Asn-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O TYYBJUYSTWJHGO-ZKWXMUAHSA-N 0.000 description 1
- SFZKGGOGCNQPJY-CIUDSAMLSA-N Ser-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N SFZKGGOGCNQPJY-CIUDSAMLSA-N 0.000 description 1
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 1
- CAOYHZOWXFFAIR-CIUDSAMLSA-N Ser-His-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O CAOYHZOWXFFAIR-CIUDSAMLSA-N 0.000 description 1
- KCNSGAMPBPYUAI-CIUDSAMLSA-N Ser-Leu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O KCNSGAMPBPYUAI-CIUDSAMLSA-N 0.000 description 1
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 1
- CRJZZXMAADSBBQ-SRVKXCTJSA-N Ser-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO CRJZZXMAADSBBQ-SRVKXCTJSA-N 0.000 description 1
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 1
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 1
- DYEGLQRVMBWQLD-IXOXFDKPSA-N Ser-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CO)N)O DYEGLQRVMBWQLD-IXOXFDKPSA-N 0.000 description 1
- YXEYTHXDRDAIOJ-CWRNSKLLSA-N Ser-Trp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CO)N)C(=O)O YXEYTHXDRDAIOJ-CWRNSKLLSA-N 0.000 description 1
- FGBLCMLXHRPVOF-IHRRRGAJSA-N Ser-Tyr-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FGBLCMLXHRPVOF-IHRRRGAJSA-N 0.000 description 1
- JZRYFUGREMECBH-XPUUQOCRSA-N Ser-Val-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O JZRYFUGREMECBH-XPUUQOCRSA-N 0.000 description 1
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 1
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 1
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 1
- 239000005708 Sodium hypochlorite Substances 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 230000006044 T cell activation Effects 0.000 description 1
- 230000006052 T cell proliferation Effects 0.000 description 1
- FEWJPZIEWOKRBE-UHFFFAOYSA-N Tartaric acid Natural products [H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-N 0.000 description 1
- 229910052771 Terbium Inorganic materials 0.000 description 1
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 1
- NAXBBCLCEOTAIG-RHYQMDGZSA-N Thr-Arg-Lys Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O NAXBBCLCEOTAIG-RHYQMDGZSA-N 0.000 description 1
- UTCFSBBXPWKLTG-XKBZYTNZSA-N Thr-Cys-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O UTCFSBBXPWKLTG-XKBZYTNZSA-N 0.000 description 1
- AYCQVUUPIJHJTA-IXOXFDKPSA-N Thr-His-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O AYCQVUUPIJHJTA-IXOXFDKPSA-N 0.000 description 1
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 1
- VTVVYQOXJCZVEB-WDCWCFNPSA-N Thr-Leu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O VTVVYQOXJCZVEB-WDCWCFNPSA-N 0.000 description 1
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 1
- MECLEFZMPPOEAC-VOAKCMCISA-N Thr-Leu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MECLEFZMPPOEAC-VOAKCMCISA-N 0.000 description 1
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 1
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 1
- BCYUHPXBHCUYBA-CUJWVEQBSA-N Thr-Ser-His Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O BCYUHPXBHCUYBA-CUJWVEQBSA-N 0.000 description 1
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 1
- AAZOYLQUEQRUMZ-GSSVUCPTSA-N Thr-Thr-Asn Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O AAZOYLQUEQRUMZ-GSSVUCPTSA-N 0.000 description 1
- CSNBWOJOEOPYIJ-UVOCVTCTSA-N Thr-Thr-Lys Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O CSNBWOJOEOPYIJ-UVOCVTCTSA-N 0.000 description 1
- SJPDTIQHLBQPFO-VLCNGCBASA-N Thr-Tyr-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O SJPDTIQHLBQPFO-VLCNGCBASA-N 0.000 description 1
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- AUYYCJSJGJYCDS-LBPRGKRZSA-N Thyrolar Chemical class IC1=CC(C[C@H](N)C(O)=O)=CC(I)=C1OC1=CC=C(O)C(I)=C1 AUYYCJSJGJYCDS-LBPRGKRZSA-N 0.000 description 1
- ATJFFYVFTNAWJD-UHFFFAOYSA-N Tin Chemical compound [Sn] ATJFFYVFTNAWJD-UHFFFAOYSA-N 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- GYDJEQRTZSCIOI-UHFFFAOYSA-N Tranexamic acid Chemical compound NCC1CCC(C(O)=O)CC1 GYDJEQRTZSCIOI-UHFFFAOYSA-N 0.000 description 1
- 108091023040 Transcription factor Proteins 0.000 description 1
- 102000040945 Transcription factor Human genes 0.000 description 1
- 102100029887 Translationally-controlled tumor protein Human genes 0.000 description 1
- CCZXBOFIBYQLEV-IHPCNDPISA-N Trp-Leu-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O CCZXBOFIBYQLEV-IHPCNDPISA-N 0.000 description 1
- VMXLNDRJXVAJFT-JYBASQMISA-N Trp-Thr-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O VMXLNDRJXVAJFT-JYBASQMISA-N 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 108010091356 Tumor Protein p73 Proteins 0.000 description 1
- 102000018252 Tumor Protein p73 Human genes 0.000 description 1
- 206010054094 Tumour necrosis Diseases 0.000 description 1
- 206010053614 Type III immune complex mediated reaction Diseases 0.000 description 1
- HKIUVWMZYFBIHG-KKUMJFAQSA-N Tyr-Arg-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O HKIUVWMZYFBIHG-KKUMJFAQSA-N 0.000 description 1
- GAYLGYUVTDMLKC-UWJYBYFXSA-N Tyr-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GAYLGYUVTDMLKC-UWJYBYFXSA-N 0.000 description 1
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 1
- RGYDQHBLMMAYNZ-IHRRRGAJSA-N Tyr-Cys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=C(C=C1)O)N RGYDQHBLMMAYNZ-IHRRRGAJSA-N 0.000 description 1
- CWQZAUYFWRLITN-AVGNSLFASA-N Tyr-Gln-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N)O CWQZAUYFWRLITN-AVGNSLFASA-N 0.000 description 1
- CTDPLKMBVALCGN-JSGCOSHPSA-N Tyr-Gly-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O CTDPLKMBVALCGN-JSGCOSHPSA-N 0.000 description 1
- BIWVVOHTKDLRMP-ULQDDVLXSA-N Tyr-Pro-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O BIWVVOHTKDLRMP-ULQDDVLXSA-N 0.000 description 1
- YKBUNNNRNZZUID-UFYCRDLUSA-N Tyr-Val-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YKBUNNNRNZZUID-UFYCRDLUSA-N 0.000 description 1
- 102000003425 Tyrosinase Human genes 0.000 description 1
- 108060008724 Tyrosinase Proteins 0.000 description 1
- 102100033444 Tyrosine-protein kinase JAK2 Human genes 0.000 description 1
- 208000002495 Uterine Neoplasms Diseases 0.000 description 1
- KKHRWGYHBZORMQ-NHCYSSNCSA-N Val-Arg-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N KKHRWGYHBZORMQ-NHCYSSNCSA-N 0.000 description 1
- JLFKWDAZBRYCGX-ZKWXMUAHSA-N Val-Asn-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N JLFKWDAZBRYCGX-ZKWXMUAHSA-N 0.000 description 1
- PTFPUAXGIKTVNN-ONGXEEELSA-N Val-His-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)NCC(=O)O)N PTFPUAXGIKTVNN-ONGXEEELSA-N 0.000 description 1
- JZWZACGUZVCQPS-RNJOBUHISA-N Val-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N JZWZACGUZVCQPS-RNJOBUHISA-N 0.000 description 1
- RWOGENDAOGMHLX-DCAQKATOSA-N Val-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N RWOGENDAOGMHLX-DCAQKATOSA-N 0.000 description 1
- ZRSZTKTVPNSUNA-IHRRRGAJSA-N Val-Lys-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(O)=O ZRSZTKTVPNSUNA-IHRRRGAJSA-N 0.000 description 1
- YMTOEGGOCHVGEH-IHRRRGAJSA-N Val-Lys-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O YMTOEGGOCHVGEH-IHRRRGAJSA-N 0.000 description 1
- JMCOXFSCTGKLLB-FKBYEOEOSA-N Val-Phe-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N JMCOXFSCTGKLLB-FKBYEOEOSA-N 0.000 description 1
- BGXVHVMJZCSOCA-AVGNSLFASA-N Val-Pro-Lys Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N BGXVHVMJZCSOCA-AVGNSLFASA-N 0.000 description 1
- JQTYTBPCSOAZHI-FXQIFTODSA-N Val-Ser-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N JQTYTBPCSOAZHI-FXQIFTODSA-N 0.000 description 1
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 1
- OFTXTCGQJXTNQS-XGEHTFHBSA-N Val-Thr-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N)O OFTXTCGQJXTNQS-XGEHTFHBSA-N 0.000 description 1
- LMVWCLDJNSBOEA-FKBYEOEOSA-N Val-Tyr-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N LMVWCLDJNSBOEA-FKBYEOEOSA-N 0.000 description 1
- NLNCNKIVJPEFBC-DLOVCJGASA-N Val-Val-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O NLNCNKIVJPEFBC-DLOVCJGASA-N 0.000 description 1
- 101710145727 Viral Fc-gamma receptor-like protein UL119 Proteins 0.000 description 1
- 208000004354 Vulvar Neoplasms Diseases 0.000 description 1
- VWQVUPCCIRVNHF-OUBTZVSYSA-N Yttrium-90 Chemical compound [90Y] VWQVUPCCIRVNHF-OUBTZVSYSA-N 0.000 description 1
- PNDPGZBMCMUPRI-XXSWNUTMSA-N [125I][125I] Chemical compound [125I][125I] PNDPGZBMCMUPRI-XXSWNUTMSA-N 0.000 description 1
- 238000002679 ablation Methods 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 235000011054 acetic acid Nutrition 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 108010045023 alanyl-prolyl-tyrosine Proteins 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 108010044940 alanylglutamine Proteins 0.000 description 1
- 108010011559 alanylphenylalanine Proteins 0.000 description 1
- HAXFWIACAGNFHA-UHFFFAOYSA-N aldrithiol Chemical compound C=1C=CC=NC=1SSC1=CC=CC=N1 HAXFWIACAGNFHA-UHFFFAOYSA-N 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 1
- 125000002344 aminooxy group Chemical group [H]N([H])O[*] 0.000 description 1
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 1
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 1
- 235000011130 ammonium sulphate Nutrition 0.000 description 1
- 150000008064 anhydrides Chemical class 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 230000001093 anti-cancer Effects 0.000 description 1
- 229940124650 anti-cancer therapies Drugs 0.000 description 1
- 230000003110 anti-inflammatory effect Effects 0.000 description 1
- 229940124691 antibody therapeutics Drugs 0.000 description 1
- 210000000628 antibody-producing cell Anatomy 0.000 description 1
- 239000012736 aqueous medium Substances 0.000 description 1
- 108010001271 arginyl-glutamyl-arginine Proteins 0.000 description 1
- 108010062796 arginyllysine Proteins 0.000 description 1
- 108010047857 aspartylglycine Proteins 0.000 description 1
- 108010068265 aspartyltyrosine Proteins 0.000 description 1
- OHDRQQURAXLVGJ-HLVWOLMTSA-N azane;(2e)-3-ethyl-2-[(e)-(3-ethyl-6-sulfo-1,3-benzothiazol-2-ylidene)hydrazinylidene]-1,3-benzothiazole-6-sulfonic acid Chemical compound [NH4+].[NH4+].S/1C2=CC(S([O-])(=O)=O)=CC=C2N(CC)C\1=N/N=C1/SC2=CC(S([O-])(=O)=O)=CC=C2N1CC OHDRQQURAXLVGJ-HLVWOLMTSA-N 0.000 description 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 1
- 125000000852 azido group Chemical group *N=[N+]=[N-] 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- HFACYLZERDEVSX-UHFFFAOYSA-N benzidine Chemical compound C1=CC(N)=CC=C1C1=CC=C(N)C=C1 HFACYLZERDEVSX-UHFFFAOYSA-N 0.000 description 1
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 239000003139 biocide Substances 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 238000001815 biotherapy Methods 0.000 description 1
- 238000007413 biotinylation Methods 0.000 description 1
- 229910052797 bismuth Inorganic materials 0.000 description 1
- JCXGWMGPZLAOME-UHFFFAOYSA-N bismuth atom Chemical compound [Bi] JCXGWMGPZLAOME-UHFFFAOYSA-N 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 210000001185 bone marrow Anatomy 0.000 description 1
- 239000008366 buffered solution Substances 0.000 description 1
- DEGAKNSWVGKMLS-UHFFFAOYSA-N calcein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC(CN(CC(O)=O)CC(O)=O)=C(O)C=C1OC1=C2C=C(CN(CC(O)=O)CC(=O)O)C(O)=C1 DEGAKNSWVGKMLS-UHFFFAOYSA-N 0.000 description 1
- BQRGNLJZBFXNCZ-UHFFFAOYSA-N calcein am Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC(CN(CC(=O)OCOC(C)=O)CC(=O)OCOC(C)=O)=C(OC(C)=O)C=C1OC1=C2C=C(CN(CC(=O)OCOC(C)=O)CC(=O)OCOC(=O)C)C(OC(C)=O)=C1 BQRGNLJZBFXNCZ-UHFFFAOYSA-N 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 229940022399 cancer vaccine Drugs 0.000 description 1
- 238000009566 cancer vaccine Methods 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 150000001720 carbohydrates Chemical group 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 229960004562 carboplatin Drugs 0.000 description 1
- 239000005018 casein Substances 0.000 description 1
- BECPQYXYKAMYBN-UHFFFAOYSA-N casein, tech. Chemical compound NCCCCC(C(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(CC(C)C)N=C(O)C(CCC(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(C(C)O)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(COP(O)(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(N)CC1=CC=CC=C1 BECPQYXYKAMYBN-UHFFFAOYSA-N 0.000 description 1
- 235000021240 caseins Nutrition 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 230000007910 cell fusion Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 238000010382 chemical cross-linking Methods 0.000 description 1
- 230000000973 chemotherapeutic effect Effects 0.000 description 1
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 1
- 229960004630 chlorambucil Drugs 0.000 description 1
- 239000000460 chlorine Substances 0.000 description 1
- 229910052801 chlorine Inorganic materials 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 229910052804 chromium Inorganic materials 0.000 description 1
- 239000011651 chromium Substances 0.000 description 1
- BFGKITSFLPAWGI-UHFFFAOYSA-N chromium(3+) Chemical compound [Cr+3] BFGKITSFLPAWGI-UHFFFAOYSA-N 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 208000037976 chronic inflammation Diseases 0.000 description 1
- 230000006020 chronic inflammation Effects 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 1
- RAURUSFBVQLAPW-DNIKMYEQSA-N clocinnamox Chemical compound N1([C@@H]2CC3=CC=C(C=4O[C@@H]5[C@](C3=4)([C@]2(CCC5=O)NC(=O)\C=C\C=2C=CC(Cl)=CC=2)CC1)O)CC1CC1 RAURUSFBVQLAPW-DNIKMYEQSA-N 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 239000000701 coagulant Substances 0.000 description 1
- XLJKHNWPARRRJB-UHFFFAOYSA-N cobalt(2+) Chemical compound [Co+2] XLJKHNWPARRRJB-UHFFFAOYSA-N 0.000 description 1
- 238000009096 combination chemotherapy Methods 0.000 description 1
- 230000002301 combined effect Effects 0.000 description 1
- 238000012875 competitive assay Methods 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 230000001268 conjugating effect Effects 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 238000001816 cooling Methods 0.000 description 1
- NKLPQNGYXWVELD-UHFFFAOYSA-M coomassie brilliant blue Chemical compound [Na+].C1=CC(OCC)=CC=C1NC1=CC=C(C(=C2C=CC(C=C2)=[N+](CC)CC=2C=C(C=CC=2)S([O-])(=O)=O)C=2C=CC(=CC=2)N(CC)CC=2C=C(C=CC=2)S([O-])(=O)=O)C=C1 NKLPQNGYXWVELD-UHFFFAOYSA-M 0.000 description 1
- RYGMFSIKBFXOCR-AKLPVKDBSA-N copper-67 Chemical compound [67Cu] RYGMFSIKBFXOCR-AKLPVKDBSA-N 0.000 description 1
- 238000002681 cryosurgery Methods 0.000 description 1
- 238000011498 curative surgery Methods 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 230000001461 cytolytic effect Effects 0.000 description 1
- 210000005220 cytoplasmic tail Anatomy 0.000 description 1
- 238000002784 cytotoxicity assay Methods 0.000 description 1
- 231100000263 cytotoxicity test Toxicity 0.000 description 1
- 229960000640 dactinomycin Drugs 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 1
- 229960000975 daunorubicin Drugs 0.000 description 1
- 230000007123 defense Effects 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000001212 derivatisation Methods 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- AFABGHUZZDYHJO-UHFFFAOYSA-N dimethyl butane Natural products CCCC(C)C AFABGHUZZDYHJO-UHFFFAOYSA-N 0.000 description 1
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 1
- 239000006185 dispersion Substances 0.000 description 1
- 238000004090 dissolution Methods 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 150000002019 disulfides Chemical class 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 238000003110 dot immunobinding assay Methods 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 239000003937 drug carrier Substances 0.000 description 1
- 238000009510 drug design Methods 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- KBQHZAAAGSGFKK-UHFFFAOYSA-N dysprosium atom Chemical compound [Dy] KBQHZAAAGSGFKK-UHFFFAOYSA-N 0.000 description 1
- 230000005014 ectopic expression Effects 0.000 description 1
- 235000014103 egg white Nutrition 0.000 description 1
- 210000000969 egg white Anatomy 0.000 description 1
- 230000013020 embryo development Effects 0.000 description 1
- 230000003511 endothelial effect Effects 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- UYAHIZSMUZPPFV-UHFFFAOYSA-N erbium Chemical compound [Er] UYAHIZSMUZPPFV-UHFFFAOYSA-N 0.000 description 1
- 201000004101 esophageal cancer Diseases 0.000 description 1
- XJRPTMORGOIMMI-UHFFFAOYSA-N ethyl 2-amino-4-(trifluoromethyl)-1,3-thiazole-5-carboxylate Chemical compound CCOC(=O)C=1SC(N)=NC=1C(F)(F)F XJRPTMORGOIMMI-UHFFFAOYSA-N 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- 238000002270 exclusion chromatography Methods 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 230000001605 fetal effect Effects 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 235000013312 flour Nutrition 0.000 description 1
- 108700014844 flt3 ligand Proteins 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- 201000003444 follicular lymphoma Diseases 0.000 description 1
- 238000005194 fractionation Methods 0.000 description 1
- 239000012458 free base Substances 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 102000037865 fusion proteins Human genes 0.000 description 1
- 108010074605 gamma-Globulins Proteins 0.000 description 1
- 150000002270 gangliosides Chemical class 0.000 description 1
- 208000010749 gastric carcinoma Diseases 0.000 description 1
- 238000001641 gel filtration chromatography Methods 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 1
- 229960005277 gemcitabine Drugs 0.000 description 1
- 102000034356 gene-regulatory proteins Human genes 0.000 description 1
- 108091006104 gene-regulatory proteins Proteins 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 108010078144 glutaminyl-glycine Proteins 0.000 description 1
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 1
- 108010037389 glutamyl-cysteinyl-lysine Proteins 0.000 description 1
- 229960003180 glutathione Drugs 0.000 description 1
- YQEMORVAKMFKLG-UHFFFAOYSA-N glycerine monostearate Natural products CCCCCCCCCCCCCCCCCC(=O)OC(CO)CO YQEMORVAKMFKLG-UHFFFAOYSA-N 0.000 description 1
- SVUQHVRAGMNPLW-UHFFFAOYSA-N glycerol monostearate Natural products CCCCCCCCCCCCCCCCC(=O)OCC(O)CO SVUQHVRAGMNPLW-UHFFFAOYSA-N 0.000 description 1
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 1
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 1
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 1
- 108010050848 glycylleucine Proteins 0.000 description 1
- CBMIPXHVOVTTTL-UHFFFAOYSA-N gold(3+) Chemical compound [Au+3] CBMIPXHVOVTTTL-UHFFFAOYSA-N 0.000 description 1
- 229910052736 halogen Inorganic materials 0.000 description 1
- 150000002367 halogens Chemical class 0.000 description 1
- 238000003306 harvesting Methods 0.000 description 1
- 201000005787 hematologic cancer Diseases 0.000 description 1
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 1
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 1
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 1
- 239000012145 high-salt buffer Substances 0.000 description 1
- 108010045383 histidyl-glycyl-glutamic acid Proteins 0.000 description 1
- 108010092114 histidylphenylalanine Proteins 0.000 description 1
- 108010018006 histidylserine Proteins 0.000 description 1
- 201000011075 histiocytic and dendritic cell cancer Diseases 0.000 description 1
- 230000013632 homeostatic process Effects 0.000 description 1
- 229920001519 homopolymer Polymers 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 229930195733 hydrocarbon Natural products 0.000 description 1
- 150000002430 hydrocarbons Chemical class 0.000 description 1
- 235000011167 hydrochloric acid Nutrition 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 125000004435 hydrogen atom Chemical class [H]* 0.000 description 1
- 229910052588 hydroxylapatite Inorganic materials 0.000 description 1
- 238000012872 hydroxylapatite chromatography Methods 0.000 description 1
- 239000001863 hydroxypropyl cellulose Substances 0.000 description 1
- 235000010977 hydroxypropyl cellulose Nutrition 0.000 description 1
- 239000005457 ice water Substances 0.000 description 1
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 description 1
- 229960001101 ifosfamide Drugs 0.000 description 1
- 230000016178 immune complex formation Effects 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 238000013115 immunohistochemical detection Methods 0.000 description 1
- 239000002955 immunomodulating agent Substances 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 230000001024 immunotherapeutic effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 230000028709 inflammatory response Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 108090000237 interleukin-24 Proteins 0.000 description 1
- 102000003898 interleukin-24 Human genes 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 102000027411 intracellular receptors Human genes 0.000 description 1
- 108091008582 intracellular receptors Proteins 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 235000014413 iron hydroxide Nutrition 0.000 description 1
- NCNCGGDMXMBVIA-UHFFFAOYSA-L iron(ii) hydroxide Chemical compound [OH-].[OH-].[Fe+2] NCNCGGDMXMBVIA-UHFFFAOYSA-L 0.000 description 1
- 238000001155 isoelectric focusing Methods 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 1
- 108010060857 isoleucyl-valyl-tyrosine Proteins 0.000 description 1
- JJWLVOIRVHMVIS-UHFFFAOYSA-N isopropylamine Chemical compound CC(C)N JJWLVOIRVHMVIS-UHFFFAOYSA-N 0.000 description 1
- 150000002540 isothiocyanates Chemical class 0.000 description 1
- 201000010982 kidney cancer Diseases 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- CZMAIROVPAYCMU-UHFFFAOYSA-N lanthanum(3+) Chemical compound [La+3] CZMAIROVPAYCMU-UHFFFAOYSA-N 0.000 description 1
- 238000002430 laser surgery Methods 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 108010000761 leucylarginine Proteins 0.000 description 1
- 238000012417 linear regression Methods 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 210000004324 lymphatic system Anatomy 0.000 description 1
- 108010003700 lysyl aspartic acid Proteins 0.000 description 1
- 108010056787 lysyl-arginyl-glutamyl-glutamic acid Proteins 0.000 description 1
- 108010038320 lysylphenylalanine Proteins 0.000 description 1
- 108010026228 mRNA guanylyltransferase Proteins 0.000 description 1
- 239000006249 magnetic particle Substances 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 238000010297 mechanical methods and process Methods 0.000 description 1
- 229960004961 mechlorethamine Drugs 0.000 description 1
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 1
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- 230000001394 metastastic effect Effects 0.000 description 1
- 208000037819 metastatic cancer Diseases 0.000 description 1
- 208000011575 metastatic malignant neoplasm Diseases 0.000 description 1
- 206010061289 metastatic neoplasm Diseases 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- DYQNRMCKBFOWKH-UHFFFAOYSA-N methyl 4-hydroxybenzenecarboximidate Chemical group COC(=N)C1=CC=C(O)C=C1 DYQNRMCKBFOWKH-UHFFFAOYSA-N 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 239000002480 mineral oil Substances 0.000 description 1
- 235000010446 mineral oil Nutrition 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 102000035118 modified proteins Human genes 0.000 description 1
- 108091005573 modified proteins Proteins 0.000 description 1
- 239000002991 molded plastic Substances 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 239000003068 molecular probe Substances 0.000 description 1
- 210000001616 monocyte Anatomy 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- 230000036457 multidrug resistance Effects 0.000 description 1
- 206010051747 multiple endocrine neoplasia Diseases 0.000 description 1
- 239000002105 nanoparticle Substances 0.000 description 1
- 230000007896 negative regulation of T cell activation Effects 0.000 description 1
- QEFYFXOXNSNQGX-UHFFFAOYSA-N neodymium atom Chemical compound [Nd] QEFYFXOXNSNQGX-UHFFFAOYSA-N 0.000 description 1
- 210000005170 neoplastic cell Anatomy 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 238000006386 neutralization reaction Methods 0.000 description 1
- 229910052759 nickel Inorganic materials 0.000 description 1
- 231100000957 no side effect Toxicity 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 230000008689 nuclear function Effects 0.000 description 1
- 102000026415 nucleotide binding proteins Human genes 0.000 description 1
- 108091014756 nucleotide binding proteins Proteins 0.000 description 1
- 230000004145 nucleotide salvage Effects 0.000 description 1
- 229960002378 oftasceine Drugs 0.000 description 1
- 231100000590 oncogenic Toxicity 0.000 description 1
- 230000002246 oncogenic effect Effects 0.000 description 1
- 108091008796 oncogenic growth factors Proteins 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 235000006408 oxalic acid Nutrition 0.000 description 1
- VYNDHICBIRRPFP-UHFFFAOYSA-N pacific blue Chemical compound FC1=C(O)C(F)=C2OC(=O)C(C(=O)O)=CC2=C1 VYNDHICBIRRPFP-UHFFFAOYSA-N 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- 238000011499 palliative surgery Methods 0.000 description 1
- 238000004091 panning Methods 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- XYJRXVWERLGGKC-UHFFFAOYSA-D pentacalcium;hydroxide;triphosphate Chemical compound [OH-].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O XYJRXVWERLGGKC-UHFFFAOYSA-D 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- KHIWWQKSHDUIBK-UHFFFAOYSA-N periodic acid Chemical compound OI(=O)(=O)=O KHIWWQKSHDUIBK-UHFFFAOYSA-N 0.000 description 1
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 239000003208 petroleum Substances 0.000 description 1
- 239000008177 pharmaceutical agent Substances 0.000 description 1
- 229940124531 pharmaceutical excipient Drugs 0.000 description 1
- 239000000825 pharmaceutical preparation Substances 0.000 description 1
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 108010082795 phenylalanyl-arginyl-arginine Proteins 0.000 description 1
- 108010018625 phenylalanylarginine Proteins 0.000 description 1
- 235000011007 phosphoric acid Nutrition 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 238000006303 photolysis reaction Methods 0.000 description 1
- 230000015843 photosynthesis, light reaction Effects 0.000 description 1
- BLFWHYXWBKKRHI-JYBILGDPSA-N plap Chemical compound N([C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(=O)[C@@H]1CCCN1C(=O)[C@H](CO)NC(=O)[C@@H](N)CCC(O)=O BLFWHYXWBKKRHI-JYBILGDPSA-N 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 238000003752 polymerase chain reaction Methods 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 229920002223 polystyrene Polymers 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- DTBMTXYWRJNBGK-UHFFFAOYSA-L potassium;sodium;phthalate Chemical compound [Na+].[K+].[O-]C(=O)C1=CC=CC=C1C([O-])=O DTBMTXYWRJNBGK-UHFFFAOYSA-L 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 210000004986 primary T-cell Anatomy 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- MFDFERRIHVXMIY-UHFFFAOYSA-N procaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1 MFDFERRIHVXMIY-UHFFFAOYSA-N 0.000 description 1
- 229960004919 procaine Drugs 0.000 description 1
- 229960000624 procarbazine Drugs 0.000 description 1
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 1
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 235000019419 proteases Nutrition 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 239000003528 protein farnesyltransferase inhibitor Substances 0.000 description 1
- 230000006337 proteolytic cleavage Effects 0.000 description 1
- 238000010926 purge Methods 0.000 description 1
- 239000002213 purine nucleotide Substances 0.000 description 1
- 230000006825 purine synthesis Effects 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- 239000002510 pyrogen Substances 0.000 description 1
- 230000003439 radiotherapeutic effect Effects 0.000 description 1
- GZUITABIAKMVPG-UHFFFAOYSA-N raloxifene Chemical compound C1=CC(O)=CC=C1C1=C(C(=O)C=2C=CC(OCCN3CCCCC3)=CC=2)C2=CC=C(O)C=C2S1 GZUITABIAKMVPG-UHFFFAOYSA-N 0.000 description 1
- 229960004622 raloxifene Drugs 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 206010038038 rectal cancer Diseases 0.000 description 1
- 201000001275 rectum cancer Diseases 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 201000010174 renal carcinoma Diseases 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 238000009256 replacement therapy Methods 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000004366 reverse phase liquid chromatography Methods 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- WUAPFZMCVAUBPE-IGMARMGPSA-N rhenium-186 Chemical compound [186Re] WUAPFZMCVAUBPE-IGMARMGPSA-N 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 238000010079 rubber tapping Methods 0.000 description 1
- DOSGOCSVHPUUIA-UHFFFAOYSA-N samarium(3+) Chemical compound [Sm+3] DOSGOCSVHPUUIA-UHFFFAOYSA-N 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 238000003118 sandwich ELISA Methods 0.000 description 1
- 238000009094 second-line therapy Methods 0.000 description 1
- 238000011519 second-line treatment Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 229910052711 selenium Inorganic materials 0.000 description 1
- 239000011669 selenium Substances 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 239000012679 serum free medium Substances 0.000 description 1
- 108010048818 seryl-histidine Proteins 0.000 description 1
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 125000005630 sialyl group Chemical group 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 239000000741 silica gel Substances 0.000 description 1
- 229910002027 silica gel Inorganic materials 0.000 description 1
- 108700021652 sis Genes Proteins 0.000 description 1
- 235000020183 skimmed milk Nutrition 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- SUKJFIGYRHOWBL-UHFFFAOYSA-N sodium hypochlorite Chemical compound [Na+].Cl[O-] SUKJFIGYRHOWBL-UHFFFAOYSA-N 0.000 description 1
- 235000009518 sodium iodide Nutrition 0.000 description 1
- RYYKJJJTJZKILX-UHFFFAOYSA-M sodium octadecanoate Chemical compound [Na+].CCCCCCCCCCCCCCCCCC([O-])=O RYYKJJJTJZKILX-UHFFFAOYSA-M 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 239000003549 soybean oil Substances 0.000 description 1
- 235000012424 soybean oil Nutrition 0.000 description 1
- 206010041823 squamous cell carcinoma Diseases 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 238000011301 standard therapy Methods 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 201000000498 stomach carcinoma Diseases 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 239000002344 surface layer Substances 0.000 description 1
- 238000011477 surgical intervention Methods 0.000 description 1
- 238000001308 synthesis method Methods 0.000 description 1
- 101150047061 tag-72 gene Proteins 0.000 description 1
- 239000000454 talc Substances 0.000 description 1
- 229910052623 talc Inorganic materials 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- 239000011975 tartaric acid Substances 0.000 description 1
- 235000002906 tartaric acid Nutrition 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- 229940066453 tecentriq Drugs 0.000 description 1
- 229910052713 technetium Inorganic materials 0.000 description 1
- 229940056501 technetium 99m Drugs 0.000 description 1
- GKLVYJBZJHMRIY-UHFFFAOYSA-N technetium atom Chemical compound [Tc] GKLVYJBZJHMRIY-UHFFFAOYSA-N 0.000 description 1
- GZCRRIHWUXGPOV-UHFFFAOYSA-N terbium atom Chemical compound [Tb] GZCRRIHWUXGPOV-UHFFFAOYSA-N 0.000 description 1
- MPLHNVLQVRSVEE-UHFFFAOYSA-N texas red Chemical compound [O-]S(=O)(=O)C1=CC(S(Cl)(=O)=O)=CC=C1C(C1=CC=2CCCN3CCCC(C=23)=C1O1)=C2C1=C(CCC1)C3=[N+]1CCCC3=C2 MPLHNVLQVRSVEE-UHFFFAOYSA-N 0.000 description 1
- CNHYKKNIIGEXAY-UHFFFAOYSA-N thiolan-2-imine Chemical compound N=C1CCCS1 CNHYKKNIIGEXAY-UHFFFAOYSA-N 0.000 description 1
- 108010061238 threonyl-glycine Proteins 0.000 description 1
- 229940104230 thymidine Drugs 0.000 description 1
- 239000005495 thyroid hormone Substances 0.000 description 1
- 229940036555 thyroid hormone Drugs 0.000 description 1
- 102000004217 thyroid hormone receptors Human genes 0.000 description 1
- 108090000721 thyroid hormone receptors Proteins 0.000 description 1
- 239000003104 tissue culture media Substances 0.000 description 1
- 238000004448 titration Methods 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
- 108010029384 tryptophyl-histidine Proteins 0.000 description 1
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 238000009281 ultraviolet germicidal irradiation Methods 0.000 description 1
- 230000004222 uncontrolled growth Effects 0.000 description 1
- 230000002485 urinary effect Effects 0.000 description 1
- 206010046766 uterine cancer Diseases 0.000 description 1
- 206010046885 vaginal cancer Diseases 0.000 description 1
- 208000013139 vaginal neoplasm Diseases 0.000 description 1
- 229910052720 vanadium Inorganic materials 0.000 description 1
- LEONUFNNVUYDNQ-UHFFFAOYSA-N vanadium atom Chemical compound [V] LEONUFNNVUYDNQ-UHFFFAOYSA-N 0.000 description 1
- 230000002792 vascular Effects 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 1
- 229960004528 vincristine Drugs 0.000 description 1
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 1
- FKBHRUQOROFRGD-IELIFDKJSA-N vinorelbine Chemical compound C1N(CC=2[C]3C=CC=CC3=NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC FKBHRUQOROFRGD-IELIFDKJSA-N 0.000 description 1
- 229960002066 vinorelbine Drugs 0.000 description 1
- 201000005102 vulva cancer Diseases 0.000 description 1
- 229910052727 yttrium Inorganic materials 0.000 description 1
- VWQVUPCCIRVNHF-UHFFFAOYSA-N yttrium atom Chemical compound [Y] VWQVUPCCIRVNHF-UHFFFAOYSA-N 0.000 description 1
Images







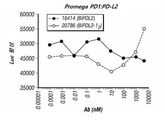
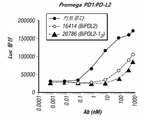
























Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2827—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against B7 molecules, e.g. CD80, CD86
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/569—Immunoassay; Biospecific binding assay; Materials therefor for microorganisms, e.g. protozoa, bacteria, viruses
- G01N33/56966—Animal cells
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6872—Intracellular protein regulatory factors and their receptors, e.g. including ion channels
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/545—Medicinal preparations containing antigens or antibodies characterised by the dose, timing or administration schedule
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/32—Immunoglobulins specific features characterized by aspects of specificity or valency specific for a neo-epitope on a complex, e.g. antibody-antigen or ligand-receptor
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/732—Antibody-dependent cellular cytotoxicity [ADCC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/20—Fusion polypeptide containing a tag with affinity for a non-protein ligand
- C07K2319/24—Fusion polypeptide containing a tag with affinity for a non-protein ligand containing a MBP (maltose binding protein)-tag
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/005—Assays involving biological materials from specific organisms or of a specific nature from viruses
- G01N2333/01—DNA viruses
- G01N2333/065—Poxviridae, e.g. avipoxvirus
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/705—Assays involving receptors, cell surface antigens or cell surface determinants
- G01N2333/70503—Immunoglobulin superfamily, e.g. VCAMs, PECAM, LFA-3
- G01N2333/70532—B7 molecules, e.g. CD80, CD86
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- Chemical & Material Sciences (AREA)
- Molecular Biology (AREA)
- Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Biomedical Technology (AREA)
- Hematology (AREA)
- Cell Biology (AREA)
- Urology & Nephrology (AREA)
- Organic Chemistry (AREA)
- Biochemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Analytical Chemistry (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Biotechnology (AREA)
- Food Science & Technology (AREA)
- General Physics & Mathematics (AREA)
- Pathology (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Tropical Medicine & Parasitology (AREA)
- Virology (AREA)
- Animal Behavior & Ethology (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
본 개시내용은 PD-L1 및 PD-L2 둘 다에 결합하는 이중특이적 항체, 및 예컨대 PD-L1, PD-L2, 또는 둘 다를 발현 또는 과다발현하는, 암을 치료하기 위해 이들 항체를 사용하는 방법에 관한 것이다.
Description
우선권 주장
본 출원은 2018년 3월 23일자로 출원된 U.S. 가출원 제62/647,407호 및 2018년 11월 2일자로 출원된 U.S 가출원 제62/755,408호에 대해 우선권의 이익을 주장하고, 이들 각 출원의 전체 내용은 본원에 참조로서 포함된다.
서열 목록의 포함
49 KB (Microsoft Windows®에서 측정됨)이고 2019년 3월 14일에 생성된, 파일명 "UTFC_P1338WO_ST25"에 포함된 서열 목록이 이와 함께 전자적 제출에 의해 제출되며 본원에 참조로서 포함된다.
분야
본 개시내용은 일반적으로 의약, 종양학 및 면역학 분야에 관한 것이다. 보다 구체적으로, PD-L1 및 PD-L2에 결합하는 이중특이적 인간 항체 및 암 요법에서 이들의 사용에 관한 것이다.
T 세포 공동-억제 PD-1과 그의 리간드 PD-L1의 상호작용의 차단은 현재 흑색종 및 폐암 환자의 하위집단에 대한 1차 설정 (first-line setting)에서도 이용가능한 현대 종양학의 대들보가 되었다 (Boussiotis, 2016). PD-1 또는 PD-L1을 표적하는 다수의 항체가 현재 FDA 승인을 받는 중이거나 임상 시험 중이다; 그러나 두 번째 PD-1 리간드인 PD-L2를 표적하는 어떠한 제제도 임상 조사 중에 있지 않다. PD-L2는 PD-L1보다 대략 3배 더 높은 친화도 (affinity)로 PD-1에 결합하고, PD-L1과 같이, T 세포 기능을 약화시키는 억제 신호를 보낸다 (Cheng et al., 2013; Latchman et al., 2001; Lee et al., 2016; Li et al., 2017; Youngnak et al., 2003). 역사적으로, PD-L2는 주로 종양 기질로 제한된 발현을 갖는 유도성 공동-억제 분자로 간주되었다; 그러나 PD-L2에 대한 개선된 검출 시약은 종양 미세환경 내 및 종양 세포 자체 모두에서 광범위한 PD-L2 발현을 나타내었다 (Baptista et al., 2016; Danilova et al., 2016; Derks et al., 2015; Dong et al., 2016; Howitt et al., 2016; Kim et al., 2015; Kim et al., 2015; Nomi et al., 2007; Obeid et al., 2016; Ohigashi et al., 2005; Roemer et al., 2016; Shi et al., 2014; Shin et al., 2015; Xu et al., 2016). 최근에, PD-L2는 다수의 암에 걸쳐 PD-1 항체 펨브롤리주맙 (pembrolizumab)에 대한 반응의 독립적인 예측인자 (predictor)인 것으로 나타났다 (Yearley et al., 2017).
고전적인 호지킨 림프종 (Hodgkin's lymphoma) (cHL)의 대다수에서 최초로 기술된 바와 같이, 염색체 영역 9p24.1의 증폭은 PD-L1 및 PD-L2 (그 안에 잔존함)의 직접적인 상향조절 뿐만 아니라 향상된 JAK2 활성을 통한 간접적인 유도를 초래한다 (Roemer et al., 2016; Shi et al., 2014; Green et al., 2010; Van Roosbroeck et al., 2016). cHL 외에도, 높은 PD-L1/PD-L2 공동-발현의 이러한 유전적 동인 (genetic driver)이 또한 대부분의 원발성 종격 거대 B-세포 림프종 (Primary Mediastinal Large B-Cell lymphoma) (PMBL), T 세포 림프종, 및 다양한 조직구 (histiocytic) 및 수지상 (dendritic) 세포 악성 종양에서 발견된다. 놀라울 것도 없이, 이들 암의 대부분은 PD-1 차단에 반응하는 것으로 나타났다. 보다 최근에는, 9p24.1 증폭이 삼중-음성 유방암 (TNBC)과 같은 고형 종양에서 입증되었다 (Howitt et al., 2016; Barrett et al., 2015). PD-L1 및 PD-L2의 상대적으로 높은 공동-발현이 또한 이들 중에서 위암 (gastric carcinoma), 흑색종 (melanoma), 폐의 편평암종 (squamous carcinoma), 두경부암 (head and neck cancer), 자궁경부 및 외음부 암 (cervix and vulva cancer), 방광암, 및 간세포암종 (hepatocellular carcinoma)과 같은 많은 다른 암에서 관찰되었다 (Baptista et al., 2016; Danilova et al., 2016; Derks et al., 2015; Dong et al., 2016; Howitt et al., 2016; Kim et al., 2015; Nomi et al., 2007; Obeid et al., 2016; Xu et al., 2016; Yearley et al., 2017; Van Roosbroeck et al., 2016; Barrett et al., 2015; Shin et al., 2016; Inoue et al., 2016; Wang et al., 2011). 이들 종양 자체에 의한 발현에 더하여, PD-L2의 기질 및 내피 발현이 또한 다수의 종양에 대해 문서화되었다 (Yearley et al., 2017). 이러한 발견은 이들 암에서 PD-L1 차단의 치료적 잠재력에 대한 한계를 시사한다.
PD-1 공동-억제 수용체는 주로 활성화된 T 세포 및 NK 세포에 의해 발현되고, 따라서 그에 결합하고 PD-리간드에 의한 개입 (engagement)을 방지하는 항체에 의해 가장 잘 표적화될 수 있다. 반대로, PD-L1은 종양 세포 및 억제성 기질 집단에 의해 발현되고 세포독성 이펙터 (effector)로 기능할 수 있는 항체로 표적화될 수 있다. 이들 항체-의존적 세포성 세포독성 (ADCC) 가능 PD-L1 항체의 이론적 이점이 시험관 내에서 입증될 수 있지만, 환자에서 실제 이펙터 기능을 입증하는 환자 데이터 또는 순전히 차단 변형체에 비해 개선된 결과는 존재하지 않는다 (Boyerinas et al., 2015).
PD-L1 및 PD-L2는 각각 PD-1과 구별되는 추가의 수용체에 결합하기 때문에 이들은 단지 대략 40%의 동일성을 공유한다 (Latchman et al., 2001). PD-L1은 또한 추가적인 음성 T 세포 조절 상호작용에서 B7-1에 결합한다 (Butte et al., 2007; Butte et al., 2008). 마우스에서, PD-L2는 골수 세포 또는 T 세포 중 하나에서 RGMb에 결합할 수 있고 흡입된 항원에 대한 내성을 조절할 수 있다 (Xiao et al., 2014; Nie et al., 2017). 종양에서 RGMb에 대한 PD-L2 결합의 역할은 인간에서 이러한 상호작용의 관련성과 마찬가지로, 아직 설명되지 않았다. PD-L1 및 PD-L2에 대한 이중특이적 항체를 갖는 것은 치료적 관점에서 매우 유리한 것으로 입증될 수 있다.
따라서, 본 개시내용에 따르면, PD-L1 및 PD-L2 둘 다에 선택적으로 결합하고 각각 표 3 및 4로부터의 클론-페어링된 (clone-paired) 중쇄 및 경쇄 CDR 서열을 갖는 항체 또는 항체 단편이 제공된다. 항체 또는 항체 단편은 표 1에 개시된 클론-페어링된 가변 서열에 의해 인코딩될 수 있고, 표 1에 개시된 클론-페어링된 가변 서열에 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있고, 또는 표 1에 개시된 클론-페어링된 서열에 95% 이상의 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있다. 항체 또는 항체 단편은 표 2로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 표 2로부터의 클론-페어링된 서열에 70%, 80% 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 또는 표 2로부터의 클론-페어링된 서열에 95% 이상의 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있다.
대상체 내에서 PD-L1- 또는 PD-L2-양성 암세포를 상기에 기술된 항체와 접촉시키는 것을 포함하는, 대상체에서 암을 치료하는 방법이 또한 제공된다. PD-L1- 또는 PD-L2-양성 암세포는 폐암 세포, 뇌암 세포, 두경부암 세포, 유방암 세포, 피부암 세포, 간암 세포, 췌장암 세포, 위암 세포, 결장암 (colon cancer) 세포, 직장암 (rectal cancer) 세포, 자궁암 세포, 자궁경부암 세포, 난소암 세포, 고환암 세포, 피부암 세포, 식도암 세포, 림프종 세포, 신장 세포 암종 세포과 같은 고형 종양 세포일 수 있고, 또는 급성 골수성 백혈병 (acute myeloid leukemia), 만성 골수성 백혈병 (chronic myelogenous leukemia) 또는 다발성 골수종 (multiple lymphoma)과 같은 백혈병 또는 골수종일 수 있다.
방법은 PD-L1- 또는 PD-L2-양성 암세포를 화학요법 (chemotherapy), 방사선요법 (radiotherapy), 면역요법 (immunotherapy), 호르몬 요법 (hormonal therapy), 또는 독소 요법 (toxin therapy)과 같은 제2 항암제 또는 치료와 접촉시키는 것을 추가로 포함할 수 있다. 제2 항암제 또는 치료는 세포내 PD-L1 또는 PD-L2 기능을 억제할 수 있다. 제2 항암제 또는 치료는 제1 제제와 동시에 제공되거나, 또는 제제 전 및/또는 후에 제공될 수 있다. PD-L1- 또는 PD-L2-양성 암세포는 전이성 암세포, 다중 약물 내성 암세포 또는 재발성 암세포일 수 있다.
항체는 단쇄 항체, 단일 도메인 항체, 키메라 항체, 또는 Fab 단편일 수 있다. 항체는 인간 항체, 뮤린 항체, IgG, 인간화된 항체 또는 인간화된 IgG일 수 있다. 항체 또는 항체 단편은 라벨, 예컨대 펩티드 태그, 효소, 자성 입자, 발색단 (chromophore), 형광 분자, 화학발광 분자 (chemiluminescent molecule), 또는 염료를 더 포함할 수 있다. 항체 또는 항체 단편은 광불안정성 링커 (photolabile linker) 또는 효소적으로 절단된 링커를 통해 항체 또는 항체 단편에 연결되는 바와 같이. 그에 연결되는 항종양 약물을 추가로 포함할 수 있다. 항종양 약물은 독소, 방사성동위원소, 사이토카인 또는 효소일 수 있다. 항체 또는 항체 단편은 나노입자 또는 리포좀에 접합될 수 있다.
다른 구현예에서, 각각 표 3 및 4로부터의 클론-페어링된 중쇄 및 경쇄 CDR 서열을 갖는 항체 또는 항체 단편을 대상체에게 전달하는 것을 포함하는, 대상체에서 암을 치료하는 방법이 제공된다. 항체 단편은 재조합 scFv (단쇄 가변 단편) 항체, Fab 단편, F(ab')2 단편, 또는 Fv 단편일 수 있다. 항체는 IgG일 수 있다. 항체는 키메라 항체일 수 있다. 전달은 항체 또는 항체 단편의 투여, 또는 항체 또는 항체 단편을 인코딩하는 RNA 또는 DNA 서열 또는 벡터로의 유전적 전달을 포함할 수 있다.
항체 또는 항체 단편은 표 1에 개시된 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있고, 표 1에 개시된 것에 95% 동일성을 갖는 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있고, 표 1로부터의 클론-페어링된 서열에 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있다. 항체 또는 항체 단편은 표 2로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 표 2로부터의 클론-페어링된 서열에 70%, 80% 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 또는 표 2로부터의 클론-페어링된 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있다.
항체 또는 항체 단편이 각각 표 3 및 4로부터의 클론-페어링된 중쇄 및 경쇄 CDR 서열을 특징으로 하는 단일클론 항체가 또한 제공된다. 항체 단편은 재조합 scFv (단쇄 가변 단편) 항체, Fab 단편, F(ab')2 단편, 또는 Fv 단편일 수 있다. 항체는 키메라 항체, 또는 IgG일 수 있다.
항체 또는 항체 단편은 표 1에 개시된 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있고, 표 1에 개시된 것에 95% 동일성을 갖는 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있고, 표 1로부터의 클론-페어링된 서열에 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있다. 항체 또는 항체 단편은 표 2로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 표 2로부터의 클론-페어링된 서열에 70%, 80% 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 또는 표 2로부터의 클론-페어링된 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있다.
또 다른 구현예에서, 항체 또는 항체 단편이 각각 표 3 및 4로부터의 클론-페어링된 중쇄 및 경쇄 CDR 서열을 특징으로 하는, 항체 또는 항체 단편을 인코딩하는 하이브리도마 또는 조작된 (engineered) 세포가 제공된다. 항체 단편은 재조합 scFv (단쇄 가변 단편) 항체, Fab 단편, F(ab')2 단편, 또는 Fv 단편일 수 있다. 항체는 키메라 항체 또는 IgG일 수 있다.
항체 또는 항체 단편은 표 1에 개시된 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있고, 표 1에 개시된 것에 95% 동일성을 갖는 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있고, 표 1로부터의 클론-페어링된 서열에 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있다. 항체 또는 항체 단편은 표 2로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 표 2로부터의 클론-페어링된 서열에 70%, 80% 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 또는 표 2로부터의 클론-페어링된 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있다.
추가 구현예는 각각 표 3 및 4로부터의 클론-페어링된 중쇄 및 경쇄 CDR 서열을 특징으로 하는 하나 이상의 항체 또는 항체 단편을 포함하는 암 백신을 포함한다. 적어도 하나의 항체 단편은 재조합 scFv (단쇄 가변 단편) 항체, Fab 단편, F(ab')2 단편, 또는 Fv 단편일 수 있다. 적어도 하나의 항체는 키메라 항체, 또는 IgG일 수 있다. 적어도 하나의 항체 또는 항체 단편은 표 1에 개시된 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있고, 표 1에 개시된 것에 95% 동일성을 갖는 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있고, 표 1로부터의 클론-페어링된 서열에 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있다. 적어도 하나의 항체 또는 항체 단편은 표 2로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 표 2로부터의 클론-페어링된 서열에 70%, 80% 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 또는 표 2로부터의 클론-페어링된 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있다.
다른 구현예에서, 상기 대상체로부터의 샘플을 각각 표 3 및 4로부터의 클론-페어링된 중쇄 및 경쇄 CDR 서열을 특징으로 하는 항체 또는 항체 단편과 접촉시키고, 상기 샘플 내 세포에 대한 상기 항체 또는 항체 단편의 결합에 의해 상기 샘플 내에서 PD-L1 또는 PD-L2 발현 세포를 검출하는 것을 포함하는, 대상체에서 PD-L1 또는 PD-L2 발현 세포를 검출하는 방법이 제공된다. 샘플은 체액 또는 조직 샘플일 수 있다. 세포는 림프종 세포, 유방암 세포, 또는 신장 세포 암종 세포와 같은 암세포일 수 있다. 세포는 면역 억제와 연관된 세포일 수 있다. 면역 억제와 연관된 세포는 종양 미세환경 내 비-암성 세포, 예컨대 기질 세포 또는 내피 세포일 수 있다. 검출은 ELISA, RIA, 또는 웨스턴 블롯을 포함할 수 있다. 방법은 상기 방법을 두 번째 수행하고 첫 번째 분석과 비교하여 오르쏘폭스바이러스 (orthopoxvirus) 항원 수준의 변화를 결정하는 단계를 추가로 포함한다. 항체 또는 항체 단편은 표 1에 개시된 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있고, 표 1에 개시된 것에 95% 동일성을 갖는 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있고, 표 1로부터의 클론-페어링된 서열에 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩될 수 있다. 항체 또는 항체 단편은 표 2로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 표 2로부터의 클론-페어링된 서열에 70%, 80% 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있고, 또는 표 2로부터의 클론-페어링된 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함할 수 있다.
본원에 기술된 임의의 방법 또는 조성물이 본원에 기술된 임의의 다른 방법 또는 조성물과 관련하여 구현될 수 있는 것으로 고려된다. 본 개시내용의 다른 목적, 특징 및 이점은 다음의 상세한 설명으로부터 명백해질 것이다. 그러나 상세한 설명 및 특정 실시예는, 본 개시내용의 특정 구현예를 나타내지만, 본 개시내용의 사상 및 범위 내에서 다양한 변경 및 변형이 상세한 설명으로부터 당업자에게 명백해질 것이기 때문에, 단지 예시로서 제공된다는 점을 이해해야 한다.
본원에 사용된 바와 같이, 특정 성분과 관련하여 "본질적으로 없는 (essentially free)"은 특정된 성분 중 어느 것도 의도적으로 조성물로 제제화되지 않았고/않았거나 단지 오염물질로서 또는 미량으로만 존재하는 것을 의미하는 것으로 본원에서 사용된다. 조성물의 의도하지 않은 임의의 오염으로 인한 특정 성분의 총량은 바람직하게는 0.01% 미만이다. 특정 성분의 양이 표준 분석 방법으로 검출될 수 없는 조성물이 가장 바람직하다.
본원에 사용된 바와 같이 명세서 및 청구범위에서, "하나 (a)" 또는 "한 (an)"은 하나 이상을 의미할 수 있다. 본원에 사용된 바와 같이 명세서 및 청구범위에서, "포함하는"이라는 단어와 함께 사용되는 경우, 단어 "하나" 또는 "한"은 1개 또는 1개보다 많은 것을 의미할 수 있다. 본원에 사용된 바와 같이 명세서 및 청구범위에서, "다른" 또는 "추가"는 적어도 2개 이상을 의미할 수 있다.
본원에 사용된 바와 같이 명세서 및 청구범위에서, 용어 "약"은 장치에 대한 오류의 고유한 변동, 값을 결정하는데 사용되는 방법, 또는 연구 대상 사이에 존재하는 변동을 포함함을 나타내는 것으로 사용된다.
본 발명의 다른 목적, 특징 및 이점은 다음의 상세한 설명으로부터 명백해질 것이다. 그러나 상세한 설명 및 특정 실시예는, 본 개시내용의 특정 구현예를 나타내지만, 본 개시내용의 사상 및 범위 내에서 다양한 변경 및 변형이 상세한 설명으로부터 당업자에게 명백해질 것이기 때문에, 단지 예시로서 제공된다는 점을 이해해야 한다.
본 발명자들은 인간 PD-L1 및 PD-L2 단백질 둘 다에 결합 특이성을 갖는 단일클론 항체를 생성하였다. 이들 항체는 PD-L1 및 PD-L2 둘 다에 결합하는 것으로 입증되었기 때문에, 이들은 PD-1에 대한 PD-L1 또는 PD-L2의 결합을 차단할 기회를 제시한다. 이들은 또한 암세포를 발현하는 PD-L1 또는 PD-L2에 치료적 페이로드 (therapeutic payload)를 전달할 수 있다. 본 개시내용의 이들 및 다른 측면이 이하에서 더 상세히 기술된다.
I.
PD-L1
A.
구조
프로그래밍된 사멸-리간드 1 (PD-L1)은 CD274 유전자에 의해 인코딩되는 단백질이다. PD-L1은 임신, 조직 동종이식, 자가면역 질환, 암 및 다른 질병 상태와 같은 다양한 사건 동안 면역 억제에 중요한 역할을 할 수 있는 40 kDa의 타입 1 막횡단 단백질이다. 인간 PD-L1 단백질은 하기에 나타낸 아미노산 서열에 의해 인코딩된다:

B.
기능
PD-L1은 그의 수용체, PD-1에 대한 리간드이다. PD-1은 활성화된 T 세포, B 세포 및 골수 세포에서 발견될 수 있다. PD-1에 대한 PD-L1의 결합은 T 세포 및 B 세포 활성화 또는 억제를 매개한다. 항원 특이적 CD8+ T 세포 및 CD4+ 헬퍼 T-세포의 증식을 감소시키는 억제제 신호를 전송한다. PD-1에 대한 PD-L1의 결합은 또한 세포사멸을 유도한다. CD8+ T 세포 및 CD4+ 헬퍼 T-세포의 이러한 감소는 암세포를 발현하는 PD-L1이 항-종양 면역을 회피하는데 도움이 되는 것으로 생각되었다 (Dong et al., 2002). PD-L1의 상향조절은 숙주 면역계의 회피와 관련이 있으며, 증가된 종양 공격성의 원인인 것으로 생각된다 (Thompson et al., 2004). 항-종양 면역의 회피에서 PD-L1의 역할은 치료적 개입을 위한 매력적인 표적이 된다.
I.
PD-L2
A.
구조
프로그래밍된 사멸-리간드 2 (PD-L2)는 CD273 유전자에 의해 인코딩되는 단백질이다. PD-L2는 임신, 조직 동종이식, 자가면역 질환, 암 및 기타 질환 상태와 같은 다양한 사건 동안 면역 억제에 중요한 역할을 할 수 있는 31 kDa 단백질이다. 인간 PD-L2 단백질은 하기에 나타낸 아미노산 서열에 의해 인코딩된다:

PD-L2는 먼저 서열번호: 2의 아미노산 1-19에 상응하는 단일 펩티드로 생산되고, 이후에 제거되어 성숙 단백질을 생성한다. 서열번호: 2의 아미노산 20-273에 상응하는, 성숙 PD-L2 단백질은 Ig-유사 V-도메인, Ig-유사 C2-타입 도메인, 막횡단 도메인, 및 세포질 꼬리로 구성된다.
B.
기능
PD-L2는 그의 수용체, PD-1에 대한 리간드이다. PD-1은 활성화된 T 세포, B 세포, 및 골수 세포에서 발견될 수 있다. PD-1에 대한 PD-L2의 결합은 T 세포의 증식, 사이토카인 생산, 세포용해 기능 및 생존을 손상시키는 면역학적 캐스케이드 (immunological cascade)를 개시한다. PD-1은 항원 특이적 CD8+ T 세포 및 CD4+ 헬퍼 T-세포의 증식을 감소시키는 억제제 신호를 전송한다. PD-L2는 또한 여러 암에 걸쳐서 PD-1 항체 펨브롤리주맙에 대한 반응의 독립적인 예측인자인 것으로 나타났다 (Yearley et al., 2017).
II.
단일클론 항체 및 이의 생산
A.
일반적인 방법
PD-L1 및 PD-L2에 대한 항체는 당업계에 익히 공지된 표준 방법에 의해 생산될 수 있다 (예컨대, Antibodies: A Laboratory Manual, Cold Spring Harbor Laboratory, 1988; U.S. 특허 제4,196,265호 참조). 단일클론 항체 (mAbs)를 생성하는 방법은 일반적으로 다클론 항체를 제조하는 것과 동일한 노선을 따라서 개시된다. 이들 두 가지 방법의 첫 번째 단계는 적절한 숙주의 면역화 또는 이전에 자연 감염으로 인해 면역이 된 대상체의 확인이다. 당업계에 익히 공지된 바와 같이, 주어진 면역화 조성물은 면역원성이 다양할 수 있다. 따라서 펩티드 또는 폴리펩티드 면역원을 담체에 결합시킴으로써 달성될 수 있는 바와 같이, 숙주 면역 체계를 부스팅하는 것이 종종 필요하다. 예시적이고 바람직한 담체는 키홀 림펫 헤모시아닌 (keyhole limpet hemocyanin) (KLH) 및 소 혈청 알부민 (BSA)이다. 난백알부민, 마우스 혈청 알부민 또는 토끼 혈청 알부민과 같은 다른 알부민이 또한 담체로 사용될 수 있다. 담체 단백질에 폴리펩티드를 접합하기 위한 수단이 당업계에 잘 알려져 있고 글루타르알데히드, m-말레이미도벤코일-N-히드록시석시니미드 에스테르 (m-maleimidobencoyl-N-hydroxysuccinimide ester), 카르보이미드 및 비스-디아조화 벤지딘 (bis-biazotized benzidine)을 포함한다. 당업계에 또한 잘 알려진 바와 같이, 특정 면역원 조성물의 면역원성은 보조제 (adjuvant)로 알려진, 면역 반응의 비-특이적 자극제의 사용에 의해 증강될 수 있다. 예시적이고 바람직한 보조제에는 완전 Freund 보조제 (사멸된 마이코박테리움 투베쿨로시스 (Mycobacterium tuberculosis)를 함유하는 면역 반응의 비-특이적 자극제), 불완전 Freund 보조제 및 수산화알루미늄 보조제가 포함된다.
다클론 항체의 생산에 사용된 면역원 조성물의 양은 면역화에 사용된 동물뿐만 아니라 면역원의 특성에 따라 다양하다. 면역원을 투여하기 위해 다양한 경로가 사용될 수 있다 (피하, 근육내, 피내, 정맥내, 및 복강내). 다클론 항체의 생산은 면역화 후 다양한 시점에서 면역화된 동물의 혈액을 샘플링함으로써 모니터링할 수 있다. 두 번째의 부스터 (booster) 주사가 또한 제공될 수 있다. 부스팅 및 역가적정 (titering) 과정은 적절한 역가가 달성될 때까지 반복된다. 원하는 수준의 면역원성이 달성되면, 면역화된 동물을 채혈하고 혈청을 분리하여 보관할 수 있으며/있거나 동물을 사용하여 단일클론 항체를 생성할 수 있다.
면역화 후, mAb 생성 프로토콜에 사용하기 위해 항체를 생산할 가능성이 있는 체세포, 특히 B 림프구 (B 세포)를 선택한다. 이들 세포는 생검된 비장 또는 림프절로부터, 또는 순환 혈액으로부터 수득될 수 있다. 그 후에 면역화된 동물로부터 B 림프구를 생산하는 항체를, 일반적으로 면역화된 동물 또는 인간 또는 인간/마우스 키메라 세포와 동일한 종 중의 하나인, 불멸 골수종 (myeloma) 세포의 세포와 융합시킨다. 하이브리도마-생산 융합 절차에 사용하기에 적합한 골수종 세포주는 바람직하게는 비-항체 생산이고, 높은 융합 효율을 가지며, 원하는 융합 세포 (하이브리도마)의 성장만을 지원하는 특정의 선택적 배지에서 성장할 수 없게 만드는 효소 결핍이다.
당업자에게 공지된 바와 같이, 다수의 골수종 세포의 임의의 하나가 사용될 수 있다 (Goding, pp. 65-66, 1986; Campbell, pp. 75-83, 1984). 예를 들어, 면역화된 동물이 마우스인 경우, P3-X63/Ag8, X63-Ag8.653, NS1/1.Ag 4 1, Sp210-Ag14, FO, NSO/U, MPC-11, MPC11-X45-GTG 1.7 및 S194/5XX0 Bul을 사용할 수 있고; 래트의 경우, R210.RCY3, Y3-Ag 1.2.3, IR983F 및 4B210을 사용할 수 있으며; U-266, GM1500-GRG2, LICR-LON-HMy2 및 UC729-6이 인간 세포 융합과 관련하여 모두 유용하다. 하나의 특정 뮤린 골수종 세포가 NS-1 골수종 세포주이고 (P3-NS-1-Ag4-1로도 명명됨), 이는 세포주 저장소 번호 GM3573의 요청에 의해 NIGMS Human Genetic Mutant Cell Repository로부터 쉽게 이용가능하다. 사용될 수 있는 또 다른 마우스 골수종 세포주는 8-아자구아닌-내성 마우스 뮤린 골수종 SP2/0 비-생산자 세포주이다. 더 최근에는, KR12 (ATCC CRL-8658; K6H6/B5 (ATCC CRL-1823 SHM-D33 (ATCC CRL-1668) 및 HMMA2.5를 포함하는, 인간 B 세포와 함께 사용하기 위한 추가 융합 파트너 라인이 개시되었다 (Posner et al., 1987). 본 개시내용에서 항체는 SP2/0 계통의 IL-6 분비 유도체인, SP2/0/mIL-6 세포주를 사용하여 생성되었다.
항체-생산 비장 또는 림프절 세포 및 골수종 세포의 하이브리드를 생성하는 방법은 일반적으로 체세포를 골수종 세포와 2:1 비율로 혼합하는 것을 포함하지만, 상기 비율은 세포막의 융합을 촉진하는 제제 또는 제제들 (화학적 또는 전기적)의 존재하에서 각각 약 20:1 내지 약 1:1로 다양할 수 있다. 센다이 바이러스 (Sendai virus)를 사용하는 융합 방법은 Kohler 및 Milstein (1975; 1976)에 의해 기술되었으며, Gefter 등 (1977)에 의해 기술된, 37% (v/v) PEG와 같은 폴리에틸렌 글리콜 (PEG)을 사용하는 것들이다. 전기적으로 유도된 융합 방법의 사용이 또한 적합하다 (Goding, pp. 71-74, 1986).
융합 절차는 일반적으로 약 1×10-6 내지 1×10-8의 낮은 빈도로 생존가능한 하이브리드를 생산한다. 그러나 이는 생존가능한, 융합된 하이브리드를 선택적 배지에서 배양함으로써 부모의, 주입된 세포 (특히, 일반적으로 무기한으로 분열을 계속 유도하는 주입된 골수종 세포)로부터 분화되기 때문에 문제가 되지 않는다. 선택적 배지는 일반적으로 조직 배양 배지에서 뉴클레오타이드의 드 노보 (de novo) 합성을 차단하는 제제를 함유하는 배지이다. 예시적이고 바람직한 제제는 아미노프테린 (aminopterin), 메토트렉세이트 (methotrexate), 및 아자세린 (azaserine)이다. 아미노프테린 및 메토트렉세이트는 퓨린 및 피리미딘 둘 다의 드 노보 합성을 차단하는 반면, 아자세린은 퓨린 합성만을 차단한다. 아미노프테린 또는 메토트렉세이트가 사용되는 경우, 뉴클레오티드의 공급원으로서 하이포크산틴 및 티미딘이 배지에 보충된다 (HAT 배지). 아자세린이 사용되는 경우, 하이포크산틴이 배지에 보충된다. B 세포 공급원이 엡스타인 바 바이러스 (Epstein Barr virus) (EBV) 형질전환된 인간 B 세포주인 경우, 골수종에 융합되지 않은 EBV 형질전환된 세포주를 제거하기 위해 우아베인 (Ouabain)이 첨가된다.
바람직한 선택 배지는 HAT 또는 우아베인 함유 HAT이다. 뉴클레오티드 구제 경로 (salvage pathway)를 작동시킬 수 있는 세포만이 HAT 배지에서 생존할 수 있다. 골수종 세포는 구제 경로의 핵심 효소, 예컨대 하이포크산틴 포스포리보실 트랜스퍼라제 (HPRT)에 결함이 있으며, 이들은 생존할 수 없다. B 세포는 이 경로를 작동시킬 수 있지만, 이들은 배양 중에 제한된 수명을 가지며 일반적으로 약 2주 이내에 사멸한다. 따라서, 선택적 배지에서 생존할 수 있는 유일한 세포는 골수종 및 B 세포로부터 형성된 하이브리드이다. 융합에 사용된 B 세포의 공급원이 본원에서와 같이 EBV-형질전환된 B 세포의 계통인 경우, EBV-형질전환된 B 세포는 약물 사멸에 취약한 반면, 사용된 골수종 파트너는 우아베인 내성인 것으로 선택되기 때문에, 우아베인이 또한 하이브리드의 약물 선택을 위해 사용된다.
배양은 그로부터 특정 하이브리도마가 선택되는 하이브리도마의 집단을 제공한다. 전형적으로, 하이브리도마의 선택은 미세역가 플레이트에서 단일-클론 희석에 의해 세포를 배양하고, 이어서 원하는 반응성에 대한 개별 클론 상청액 (약 2 내지 3주 후)을 시험함으로써 수행된다. 분석은 방사성면역분석 (radioimmunoassay), 효소 면역분석, 세포독성 분석, 플라크 분석, 도트 면역결합 분석 (dot immunobinding assay) 등과 같이 민감하고, 간단하며, 신속해야 한다.
그 후에 선택된 하이브리도마는 연속 희석되거나 또는 유세포 분석 분류에 의해 단일-세포 분류되고 개별 항체-생산 세포주 내로 클로닝되며, 이 클론은 mAbs를 제공하기 위해 무기한으로 증식될 수 있다. 세포주는 2가지 기본적인 방식으로 MAb 생산을 위해 이용될 수 있다. 하이브리도마 샘플이 동물 (예컨대, 마우스) 내로 주사 (종종 복강 내로)될 수 있다. 선택적으로, 동물은 주사 전에 탄화수소, 특히 프리스탄 (pristine) (테트라메틸펜타데칸)과 같은 오일로 프라이밍된다. 이러한 방식으로 인간 하이브리도마가 사용되는 경우, 종양 거부를 방지하기 위해 SCID 마우스와 같은 면역손상 (immunocompromised) 마우스에 주사하는 것이 최적이다. 주사된 동물은 융합된 세포 하이브리드에 의해 생산된 특정 단일클론 항체를 분비하는 종양을 발생시킨다. 그 후에 혈청 또는 복수액과 같은 동물의 체액을 태핑하여 (tapped) mAbs를 고농도로 제공할 수 있다. 개별 세포주가 또한 시험관 내에서 배양될 수 있는데, mAbs는 이들이 고동도로 쉽게 수득될 수 있는 배양 배지 내로 자연적으로 분비된다. 대안적으로, 인간 하이브리도마 세포주는 시험관 내에서 사용되어 세포 상청액 중에 면역글로불린을 생산할 수 있다. 세포주는 고순도의 인간 단일클론 면역글로불린을 회수하는 능력을 최적화하기 위해 무-혈청 배지 중에서 성장하도록 적응될 수 있다.
임의의 수단에 의해 생산된 단일클론 항체는, 바람직하다면, 여과, 원심분리 및 FPLC 또는 친화도 크로마토그래피와 같은 다양한 크로마토그래피 방법을 사용하여 추가로 정제될 수 있다. 본 개시내용의 단일클론 항체의 단편은 펩신 또는 파파인과 같은 효소를 이용한 분해를 포함하는 방법에 의해, 및/또는 화학적 환원에 의한 이황화 결합의 절단에 의해 정제된 단일클론 항체로부터 수득될 수 있다. 대안적으로, 본 개시내용에 포함되는 단일클론 항체 단편은 자동화 펩티드 합성기를 사용하여 합성될 수 있다.
또한 분자적 클로닝 접근법이 단일클론 항체를 생성하기 위해 사용될 수 있는 것으로 고려된다. 이를 위해, RNA는 하이브리도마 계통 및 RT-PCR로 수득된 항체 유전자로부터 단리되어 면역글로불린 발현 벡터 내로 클로닝될 수 있다. 대안적으로, 조합 (combinatorial) 면역글로불린 파지미드 라이브러리가 세포주로부터 단리된 RNA로부터 제조되고 적합한 항체를 발현하는 파지미드가 바이러스 항원을 사용하는 패닝 (panning)에 의해 선택된다. 통상적인 하이브리도마 기법에 비해 이 접근법의 이점은 대략 104배 많은 항체가 단일 라운드에서 생산되고 스크리닝될 수 있으며, 새로운 특이성이 H 및 L 쇄 조합에 의해 생성되어 적절한 항체를 규명할 가능성을 더 증가시킨다는 것이다.
효모-기반 항체 라이브러리가 합리적으로 설계될 수 있고, 예를 들어 WO2012/009568; WO2009/036379; WO2010/105256; WO2003/074679; U.S. 특허 제8,691,730호; 및 U.S. 특허 제9,354,228호에 기술된 바와 같은 효모-기반 항체 제시 라이브러리로부터 항체가 선택 및/또는 단리될 수 있다. 항체는 상기에 기술된 바와 같은 임의의 바람직한 세포 유형으로부터 전장의 IgGs로 발현되고 정제될 수 있다.
본 개시내용에 유용한 항체의 생산을 교시하는, 각각이 참조로서 본원에 포함되는, 다른 U.S. 특허에는 조합 접근법을 사용하는 키메라 항체의 생산을 기술하는 U.S. 특허 제5,565,332; 재조합 면역글로불린 제조를 기술하는 U.S. 특허 제4,816,567호; 및 항체-치료제 접합체를 설명하는 U.S. 특허 제4,867,973호가 포함된다.
B.
본 개시내용의 항체
본 개시내용에 따른 항체는, 우선 먼저, 이들의 결합 특이성에 의해, 즉 PD-L1 및 PD-L2에 대한 결합으로 정의될 수 있다. 당업자에게 익히 공지된 기법을 사용하여 주어진 항체의 결합 특이성/친화도를 평가함으로써 당업자는 그러한 항체가 본 발명의 청구범위 내에 속하는지 여부를 결정할 수 있다. 일 측면에서, 각각 표 3 및 4에 예시된 바와 같은 중쇄 및 경쇄로부터 클론-페어링된 CDR을 갖는 단일클론 항체가 제공된다. 이러한 항체는 본원에 기술된 방법을 사용하여 아래 실시예 항목에 논의된 클론에 의해 생산될 수 있다.
두 번째 측면에서, 항체는 추가의 "프레임워크" 영역을 포함하는, 이들의 가변 서열에 의해 정의될 수 있다. 이들은 전체 가변 영역을 인코딩하거나 나타내는 표 1 및 2로 제공된다. 나아가, 항체 서열은 선택적으로 하기에 더 상세히 논의되는 방법을 사용하여, 이들 서열과 다를 수 있다. 예를 들어, 핵산 서열은 다음과 같이 상기에 개시된 것과 다를 수 있다: (a) 가변 영역은 경쇄 및 중쇄의 불변 도메인으로부터 분리될 수 있고, (b) 핵산은 이에 의해 인코딩되는 잔기에는 영향을 미치지 않을 수 있으면서 위에서 설명한 것과 다를 수 있고, (c) 핵산은 주어진 백분율, 예컨대 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 상동성에 의해 상기에 명시된 것과 다를 수 있고, (d) 핵산은, 예컨대 약 50℃ 내지 약 70℃의 온도에서 약 0.02 M 내지 약 0.15 M NaCl에 의해 제공되는, 낮은 염 및/또는 높은 온도 조건으로 예시되는 바와 같은, 높은 엄격성 조건하에서 혼성화하는 능력으로 인해 상기에 제시된 것과 다를 수 있고, (e) 아미노산은 주어진 백분율, 예컨대 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 상동성에 의해 상기에 명시된 것과 다를 수 있고, 또는 (f) 아미노산은 보존적 치환을 허용함으로써 위에 개시된 것과 다를 수 있다 (하기에 논의됨). 상기 각각은 표 1에 제시된 핵산 서열 및 표 2의 아미노산 서열에 적용된다.
C.
항체 서열의 공학
다양한 구현예에서, 개선된 발현, 개선된 교차-반응성 또는 감소된 오프-타겟 (off-target) 결합과 같은 다양한 이유로 동정된 항체의 서열을 조작하도록 선택할 수 있다. 다음은 항체 공학을 위한 관련 기법에 대한 일반적인 논의이다.
하이브리도마를 배양한 후, 세포를 용해시키고 총 RNA를 추출할 수 있다. 무작위 헥사머를 RT에서 사용하여 RNA의 cDNA 카피를 생성할 수 있고, 그 후에 모든 인간 가변 유전자 서열을 증폭할 것으로 예상되는 PCR 프라이머의 다중 혼합물을 사용하여 PCR을 수행할 수 있다. PCR 생성물을 pGEM-T Easy 벡터 내로 클로닝한 후, 표준 벡터 프라이머를 사용한 자동화 DNA 서열분석에 의해 서열을 분석할 수 있다. 결합 및 중화 분석을 하이브리도마 상청액으로부터 수집되고 단백질 G 칼럼을 사용하는 FPLC에 의해 정제된 항체를 사용하여 수행할 수 있다.
재조합 전장 IgG 항체는 클로닝 벡터로부터의 중쇄 및 경쇄 Fv DNAs를 IgG 플라스미드 벡터 내로 서브클로닝하여 생성되고, 293 Freestyle 세포 또는 CHO 세포 내로 형질감염될 수 있고, 항체를 293 또는 CHO 세포 상청액으로부터 정제된 형태로 수집하였다.
최종 cGMP 제조 공정과 동일한 숙주 세포 및 세포 배양 공정에서 생산된 항체의 신속한 유용성은 공정 개발 프로그램의 기간을 단축할 수 있는 잠재력을 가지고 있다. Lonza는 CHO 세포에서 소량 (최대 50 g)의 항체를 신속하게 생산하기 위해, CDACF 배지에서 성장한 풀링된 (pooled) 형질감염체를 사용하는 포괄적인 방법을 개발하였다. 실제 일시적 시스템보다 약간 더 느리지만, 이점은 더 높은 생산 농도 및 생산 세포주와 동일한 숙주 및 공정을 사용한다는 이점이 있다. 일회용 생물반응기에서 모델 항체를 발현하는 GS-CHO 풀의 성장 및 생산성의 예: 유가식 방식으로 작동되는 일회용 백 생물반응기 배양 (5 L 작업 부피)에서, 형질감염 9주 이내에 2 g/L의 수확 항체 농도가 달성되었다.
항체, 및 이러한 항체가 선택 및/또는 단리될 수 있는 항체 라이브러리는, 예를 들어 WO2012/009568; WO2009/036379; WO2010/105256; WO2003/074679; US 특허 제8,691,730호; 및 US 특허 제9,354,228호에 기술된 바와 같이, 예컨대 Adimab® 기법에 의해 합리적으로 설계되고 합성될 수 있다. 이 항체 합성 방법은 원하는 또는 설계된 항체를 코딩하는 뉴클레오티드 서열이 이소성 (ectopic) 발현을 위한 벡터 내로 삽입될 것을 요구한다. 그 후에 원하는 항체는 전장의 IgG 분자로 발현되고 정제될 수 있다.
항체 분자는 mAbs의 단백질분해 절단에 의해 생성되는 단편 (예컨대, F(ab'), F(ab')2), 또는 예를 들어, 재조합 수단을 통해 생산 가능한 단쇄 면역글로불린을 포함할 것이다. 이러한 항체 유도체는 1가이다. 일 구현예에서, 이러한 단편은 서로 조합되거나, 또는 다른 항체 단편 또는 수용체 리간드와 조합되어 "키메라 (chimeric)" 결합 분자를 형성할 수 있다. 중요하게는, 이러한 키메라 분자는 동일한 분자의 상이한 에피토프에 결합할 수 있는 치환기를 함유할 수 있다.
관련 구현예에서, 항체는 기술된 항체의 유도체, 예컨대 기술된 항체의 것들과 동일한 CDR 서열을 포함하는 항체 (예컨대, 키메라, 또는 CDR-이식 항체)이다. 대안적으로, 항체 분자 내로 보존적 변화를 도입하는 것과 같은, 변형을 원할 수 있다. 이러한 변화를 만들 때, 아미노산의 소수성 지수 (hydropathic index)가 고려될 수 있다. 일반적으로 단백질에 상호작용적 생물학적 기능을 부여하는데 있어서 소수성 아미노산 지수의 중요성이 당업자에게 이해되고 있다 (Kyte and Doolittle, 1982). 아미노산의 상대적 소수성 특징이 생성된 단백질의 2차 구조에 기여하며, 이는 단백질과 다른 분자, 예를 들어, 효소, 기질, 수용체, DNA, 항체, 항원 등과의 상호작용을 정의하는 것으로 인정된다.
친수성 (hydrophilicity)에 기초하여 유사 아미노산의 치환이 효과적으로 이루어질 수 있음이 또한 당업계에서 이해된다. 본원에 참조로서 포함되는, U.S. 특허 제4,554,101호는 인접한 아미노산의 친수성에 의해 지배되는, 단백질의 가장 큰 국소 평균 친수성이 단백질의 생물학적 특성과 관련이 있음을 개시한다. U.S. 특허 제4,554,101호에 상세히 설명된 대로, 다음의 친수성 값이 아미노산 잔기에 할당되었다: 염기성 아미노산: 아르기닌 (+3.0), 리신 (+3.0), 및 히스티딘 (-0.5); 산성 아미노산: 아스파르테이트 (+3.0±1), 글루타메이트 (+3.0±1), 아스파라긴 (+0.2), 및 글루타민 (+0.2); 친수성, 비이온성 아미노산: 세린 (+0.3), 아스파라긴 (+0.2), 글루타민 (+0.2), 및 쓰레오닌 (-0.4), 황 함유 아미노산: 시스테인 (-1.0) 및 메티오닌 (-1.3); 소수성, 비방향족 아미노산: 발린 (-1.5), 류신 (-1.8), 이소류신 (-1.8), 프롤린 (-0.5±1), 알라닌 (-0.5), 및 글리신 (0); 소수성, 방향족 아미노산: 트립토판 (-3.4), 페닐알라닌 (-2.5), 및 티로신 (-2.3).
아미노산은 유사한 친수성을 갖는 다른 아미노산으로 대체될 수 있고 생물학적 또는 면역학적으로 변형된 단백질을 생성할 수 있는 것으로 이해된다. 이러한 변화에서, 소수성 값이 ±2 이내인 아미노산의 치환이 바람직하고, ±1 이내의 아미노산이 특히 바람직하며, ±0.5 이내의 아미노산이 특히 더욱 바람직하다.
상기에서 설명한 바와 같이, 아미노산 치환은 일반적으로 아미노산 측쇄 치환기의 상대적 유사성, 예를 들어, 소수성, 친수성, 전하, 크기 등을 기반으로 한다. 전술한 다양한 특성을 고려하는 예시적인 치환이 당업자에게 익히 공지되어 있고 다음을 포함한다: 아르기닌 및 리신; 글루타메이트 및 아스파르테이트; 세린 및 쓰레오닌; 글루타민 및 아스파라긴; 및 발린, 류신 및 이소류신.
본 개시내용은 또한 이소형 변형을 고려한다. 상이한 이소형을 갖도록 Fc 영역을 변형함으로써, 상이한 기능성을 달성할 수 있다. 예를 들어, IgG1로의 변경은 항체 의존적 세포 세포독성을 증가시킬 수 있고, 클래스 A로의 전환은 조직 분포를 개선할 수 있으며, 클래스 M으로의 전환은 원자가를 개선할 수 있다.
변형된 항체는 표준 분자 생물학적 기법을 통한 발현, 또는 폴리펩티드의 화학적 합성을 포함하는, 당업자에게 공지된 임의의 기법에 의해 이루어질 수 있다. 재조합 발현 방법이 이 명세서의 다른 부분에서 다루어진다.
D.
단쇄 항체
단쇄 가변 단편 (scFv)은 짧은 (일반적으로 세린, 글리신) 링커에 의해 함께 연결된, 면역글로불린의 중쇄 및 경쇄의 가변 영역의 융합이다. 이 키메라 분자는 불변 영역의 제거 및 링커 펩티드의 도입에도 불구하고, 원래의 면역글로불린의 특이성을 유지한다. 이 변형은 통상 특이성을 변경하지 않는다. 이들 분자는 역사적으로 단일 펩티드로서 항원 결합 도메인을 발현하는 것이 매우 편리한 파지 디스플레이를 용이하게 하기 위해 생성되었다. 대안적으로, scFv는 하이브리도마로부터 유래한 서브클로닝된 중쇄 및 경쇄로부터 직접적으로 생성될 수 있다. 단쇄 가변 단편은 완전한 항체 분자에서 발견되는 불변 Fc 영역이 결여되고, 따라서 항체를 정제하는데 사용되는 공통 결합 부위 (예컨대, 단백질 A/G)가 없다. 단백질 L이 카파 경쇄의 가변 영역과 상호작용하기 때문에 이들 단편은 종종 정제/고정화될 수 있다.
가요성 (flexible) 링커는 일반적으로 알라닌, 세린 및 글리신과 같은 나선- 및 회전-촉진 아미노산 잔기로 구성된다. 그러나 다른 잔기가 또한 기능할 수 있다. Tang 등 (1996)은 단백질 링커 라이브러리로부터 단쇄 항체 (scFvs)를 위한 맞춤형 링커를 신속하게 선택하는 수단으로서 파지 디스플레이를 사용하였다. 중쇄 및 경쇄 가변 도메인에 대한 유전자가 가변 조성의 18-아미노산 폴리펩티드를 인코딩하는 분절에 의해 연결된 무작위 링커 라이브러리가 구축되었다. scFv 레퍼토리 (대략 5×106개의 상이한 구성원)를 사상형 파지 (filamentous phage)에 제시되고 합텐과의 친화도 선택에 적용되었다. 선택된 변형체의 집단은 결합 활성에 있어 현저한 증가를 보였지만 상당한 서열 다양성을 유지하였다. 1054개의 개별 변형체의 스크리닝은 가용성 형태로 효율적으로 생산된 촉매적으로 활성인 scFv를 생성하였다. 서열 분석에 따르면 선택된 테터 (tether)의 유일한 공통 특징으로서 VH C 말단 이후 링커 2개 잔기에서 보존된 프롤린과, 다른 위치에서 아르기닌 및 프롤린의 풍부가 나타났다.
본 개시내용의 재조합 항체는 또한 수용체의 이량체화 또는 다중체화를 허용하는 서열 또는 모이어티를 포함할 수 있다. 이러한 서열에는 J-쇄와 함께 다량체의 형성을 허용하는 IgA로부터 유래하는 것들이 포함된다. 또 다른 다량체화 도메인은 Gal4 이량체화 도메인이다. 다른 구현예에서, 쇄는 두 항체의 조합을 허용하는, 비오틴/아비딘과 같은 제제로 변형될 수 있다.
별도의 구체예에서, 단쇄 항체는 비-펩티드 링커 또는 화학적 단위를 사용하여 수용체 경쇄 및 중쇄를 연결함으로써 생성될 수 있다. 일반적으로, 경쇄 및 중쇄는 별개의 세포에서 생성되고, 정제된 후, 이어서 적절한 방식으로 함께 연결될 것이다 (즉, 적합한 화학적 가교를 통해 경쇄의 C-말단에 중쇄의 N-말단이 부착된다).
가교-결합 시약 (cross-linking reagent)은 2개의 상이한 분자, 예컨대 안정화제 및 응고제의 작용기를 연결하는 분자 가교를 형성하는데 사용된다. 그러나 상이한 유사체로 구성된 동일한 유사체 또는 이종복합체의 이량체 또는 다량체가 생성될 수 있음이 고려된다. 2개의 상이한 화합물을 단계적으로 연결하기 위해, 원하지 않는 단일중합체 혈성을 제거하는 헤테로-이작용성 가교-결합제를 사용할 수 있다.
예시적인 헤테로-이작용성 가교-결합제는 2개의 반응성기를 함유한다: 하나는 일차 아민기 (예컨대, N-히드록시 석시니미드)와 반응하고 다른 하나는 티올기 (에컨대, 피리딜 디설파이드, 말레이미드, 할로겐 등)와 반응한다. 가교-결합제는 일차 아민 반응성기를 통해 하나의 단백질 (예컨대, 선택된 항체 또는 단편)의 리신 잔기(들)과 반응할 수 있고, 이미 첫 번째 단백질에 연결된 가교-결합제는 티올 반응성기를 통해 다른 단백질 (예컨대, 선택적 제제)의 시스테인 잔기 (유리 설프히드릴기)와 반응한다.
혈액에서 합리적인 안정성을 갖는 가교-결합제를 사용하는 것이 바람직하다. 표적화제 및 치료제/예방제를 접합하는데 성공적으로 사용될 수 있는 다수 유형의 이황화-결합 함유 링커가 알려져 있다. 입체적으로 방해되는 이황화 결합을 함유하는 링커는 생체 내에서 더 큰 안정성을 제공하여, 작용 부위에 도달하기 전에 표적하는 펩티드의 방출을 방지할 수 있는 것으로 입증될 수 있다. 따라서 이들 링커는 한 그룹의 연결 제제이다.
또 다른 가교-결합제는 인접한 벤젠 고리 및 메틸기에 의해 "입체적으로 방해되는" 이황화 결합을 함유하는 이작용성 가교-결합제인, SMPT이다. 이황화 결합의 입체 장애는 조직 및 혈액에 존재할 수 있는 글루타치온과 같은 티올레이트 음이온에 의한 공격으로부터 결합을 보호하는 기능을 제공하고, 이에 따라 부착된 제제를 표적 부위로 전달하기 전에 접합체의 디커플링 (decoupling)을 방지하는데 도움이 되는 것으로 여겨진다.
다수의 다른 공지된 가교-결합제와 마찬가지로, SMPT 가교-결합제는 시스테인 또는 일차 아민의 SH와 같은 작용기 (예컨대, 리신의 엡실론 아미노기)를 가교-결합시키는 능력을 제공한다. 또 다른 가능한 유형의 가교-결합제에는 절단가능한 이황화 결합을 함유하는 헤테로-이작용성 광반응성 페닐아지드, 예컨대 설포석시니미딜-2-(p-아지도 살리실아미도) 에틸-1,3'-디티오프로피오네이트가 포함된다. N-히드록시-석시니미딜기는 일차 아미노기와 반응하고 페닐아지드는 (광분해 시) 임의의 아미노산 잔기와 비-선택적으로 반응한다.
장해 (hindered) 가교-결합제 외에, 비-장해 링커가 또한 이에 따라 사용될 수 있다. 보호된 이황화물을 함유하거나 또는 생성하는 것으로 간주되지 않는, 다른 유용한 가교-결합제에는 SATA, SPDP 및 2-이미노티올란이 포함된다 (Wawrzynczak & Thorpe, 1987). 이러한 가교-결합제의 사용은 또한 당업계에 잘 알려져 있다. 또 다른 구현예는 가요성 링커의 사용을 포함한다.
U.S. 특허 제4,680,338호는 아민-함유 중합체 및/또는 단백질과 리간드의 접합체를 생산하는데, 특히 킬레이터, 약물, 효소, 검출가능한 표지 등과 항체 접합체를 형성하는데 유용한 이작용성 링커를 기술한다. U.S. 특허 제5,141,648호 및 제5,563,250호는 다양한 온화한 조건에서 절단될 수 있는 불안정한 결합을 포함하는 절단가능한 접합체를 개시한다. 이 링커는 관심 제제가 링커에 직접 결합될 수 있고, 절단이 활성 제제의 방출을 초래하는 경우에 특히 유용하다. 특정 용도에는 항체, 또는 약물과 같은 단백질에 유리 아미노기 또는 유리 설프히드릴기를 추가하는 것이 포함된다.
U.S. 특허 제5,856,456호는 융합 단백질, 예컨대 단쇄 항체를 제조하기 위해 폴리펩티드 구성요소들을 연결하는데 사용하기 위한 펩티드 링커를 제공한다. 링커는 최대 약 50개 아미노산 길이이고, 적어도 한 번의 하전된 아미노산 (바람직하게는 아르기닌 또는 리신) 다음에 프롤린의 발생을 포함하고, 더 큰 안정성 및 감소된 응집을 특징으로 한다. U.S. 특허 제5,880,270호는 다양한 면역진단 및 분리 기법에 유용한 아미노옥시-함유 링커를 기술한다.
E.
정제
특정 구현예에서, 본 개시내용의 항체는 정제될 수 있다. 본원에 사용된 바와 같이, 용어 "정제된"은 다른 성분으로부터 분리될 수 있는 조성물을 지칭하는 것으로 의도되고, 여기서 단백질은 그의 자연적으로 수득가능한 상태에 비해 임의의 정도로 정제된다. 따라서 정제된 단백질은 또한 그것이 자연적으로 발생할 수 있는 환경이 없는 단백질을 지칭한다. "실질적으로 정제된"이라는 용어가 사용되는 경우, 이 지정은 단백질 또는 펩티드가 예컨대 조성물 내 단백질의 약 50%, 약 60%, 약 70%, 약 80%, 약 90%, 약 95% 또는 그 이상을 구성하는 조성물의 주요 성분을 형성하는 조성물을 지칭할 것이다.
단백질 정제 기법은 당업자에게 익히 공지되어 있다. 이러한 기법은, 한 수준에서, 세포 환경을 폴리펩티드 및 비-폴리펩티드 분획으로의 미정제 분획화를 포함한다. 다른 단백질로부터 폴리펩티드를 분리한 후, 관심 폴리펩티드를 크로마토그래피 및 전기영동 기법을 사용해 추가로 정제하여 부분적 또는 완전한 정제 (또는 균질성에 대한 정제)를 달성할 수 있다. 순수한 펩티드의 제조에 적합한 분석 방법은 이온-교환 크로마토그래피, 배제 크로마토그래피; 폴리아크릴아미드 겔 전기영동; 등전점 초첨맞추기 (isoelectric focusing)이다. 단백질 정제를 위한 다른 방법에는 암모늄 설페이트, PEG, 항체 등을 이용한 침전 또는 열 변성 후 원심분리; 겔 여과, 역상, 히드록실아파타이트 및 친화도 크로마토그래피; 및 이들 및 기타 기법의 조합이 포함된다.
본 개시내용의 항체를 정제함에 있어서, 원핵 또는 진핵 발현 시스템에서 폴리펩티드를 발현시키고 변성 조건을 사용하여 단백질을 추출하는 것이 바람직할 수 있다. 폴리펩티드는 폴리펩티드의 태그 부착된 부분에 결합하는, 친화도 칼럼을 사용하여 다른 세포 성분으로부터 정제될 수 있다. 당업계에 일반적으로 공지된 바와 같이, 다양한 정제 단계를 수행하는 순서가 달라질 수 있고, 또는 특정 단계가 생략될 수 있으며, 결과적으로 여전히 실질적으로 정제된 단백질 또는 펩티드의 제조를 위한 적합한 방법이 될 수 있다고 여겨진다.
일반적으로, 완전한 항체는 항체의 Fc 부분에 결합하는 제제 (즉, 단백질 A)를 사용하여 분획화된다. 대안적으로, 항원을 사용하여 적합한 항체를 동시에 정제하고 선택할 수 있다. 이러한 방법은 종종 칼럼, 필터 또는 비드와 같은 지지체에 결합된 선택 제제를 사용한다. 항체는 지지체에 결합되고, 오염물질이 제거되고 (예컨대, 세척됨), 조건 (염, 열 등)을 적용하여 항체가 방출된다.
단백질 또는 펩티드의 정제 정도를 정량화하기 위한 다양한 방법이 본 개시내용에 비추어 당업자에게 공지될 것이다. 이들은, 예를 들어, 활성 분획의 특이적 활성을 결정하거나, 또는 SDS/PAGE 분석에 의해 분획 내 폴리펩티드이 양을 평가하는 것이 포함된다. 분획의 순도를 평가하는 또 다른 방법은 분획의 특이적 활성을 계산하고, 이를 초기 추출물의 특이적 활성과 비교하고, 그로써 순도의 정도를 계산하는 것이다. 물론, 활성의 양을 나타내는데 사용된 실제 단위는 정제 후 선택된 특정 분석 기법 및 발현된 단백질 또는 펩티드가 검출가능한 활성을 나타내는지 여부에 따라 달라질 것이다.
폴리펩티드의 이동은 SDS/PAGE의 상이한 조건에 따라, 때로는 상당히 다를 수 있음이 알려져 있다 (Capaldi et al., 1977). 따라서, 상이한 전기영동 조건하에서, 정제된 또는 부분적으로 정제된 발현 산물의 겉보기 분자량이 달라질 수 있음이 인식될 것이다.
IV.
약제학적 제제 및 암의 치료
A.
암
암은 조직으로부터 세포의 클론 집단이 자라면서 발생한다. 발암 (carcinogenesis)이라고 지칭되는, 암의 발생은 다양한 방식으로 모델링하고 특성화할 수 있다. 암 발생과 염증 사이의 연관성이 오랫동안 인식되어 왔다. 염증 반응은 미생물 감염에 대한 숙주 방어에 관여하며, 또한 조직 복구 및 재생을 유도한다. 상당한 증거가 염증과 암 발생 위험 사이의 연관성을 지적하는데, 즉 만성 염증이 이형성증 (dysplasia)을 유발할 수 있다.
본 개시내용의 방법이 적용될 수 있는 암세포에는 일반적으로 PD-L1 또는 PD-L2를 발현하는, 보다 구체적으로는, PD-L1 또는 PD-L2 중 하나를 과다발현하는 임의의 세포를 포함한다. 적합한 암세포는 유방암, 폐암, 결장암, 췌장암, 신장암, 위암, 간암, 골암, 혈액암 (예컨대, 백혈병 또는 림프종), 신경조직암 (neural tissue cancer), 흑색종, 난소암, 고환암, 전립선암, 자궁경부암, 질암, 또는 방광암 세포일 수 있다. 또한, 본 개시내용의 방법은 인간, 비-인간 영장류 (예컨대, 원숭이, 개코원숭이, 또는 침팬지), 말, 소, 돼지, 양, 염소, 개, 고양이, 토끼, 기니피그, 게르빌루스 쥐 (gerbils), 햄스터, 랫트, 및 마우스와 같은 광범위한 종에 적용될 수 있다. 암은 또한 재발성, 전이성 및/또는 다-약제 내성일 수 있고, 본 개시내용의 방법은 암을 절제 가능하게 만들고, 완화를 연장 또는 재-유도하고, 혈관신생을 억제하고, 전이를 예방 또는 제한하고/하거나, 다-약제 내성 암을 치료하기 위해 이러한 암에 특별히 적용될 수 있다. 세포 수준에서, 이는 암세포를 죽이고, 암세포 성장을 억제하거나, 또는 다르게는 종양 세포의 악성 표현형을 역전 또는 감소시키는 것으로 해석될 수 있다.
B.
제제 및 투여
본 개시내용은 PD-L1 및 PD-L2에 대해 지시된 이중특이적 항체 (BiPDL)를 포함하는 약제학적 조성물을 제공한다. 특정 구현예에서, 용어 "약제학적으로 허용가능한"은 동물, 특히 인간에서 사용하기 위해 연방 또는 주정부의 규제 기관에 의해 승인되거나 미국 약전 또는 다른 일반적으로 인정되는 약전에 열거된 것을 의미한다. 용어 "담체"는 치료제가 그와 함께 투여되는 희석제, 부형제, 또는 비히클을 의미한다. 이러한 약제학적 담체는 멸균 액체, 예컨대 석유, 동물, 식물 또한 합성 기원의 것을 포함하는, 물 및 오일, 예컨대 땅콩유, 대두유, 광물유, 참기름 등일 수 있다. 다른 적합한 약제학적 부형제에는 전분, 글루코스, 락토스, 수크로스, 식염수, 덱스트로스, 젤라틴, 맥아, 쌀, 밀가루, 초크 (chalk), 실리카 겔, 스테아르산나트륨, 글리세롤 모노스테아레이트, 탈크, 염화나트륨, 건조 탈지유, 글리세롤, 프로필렌 글리콜, 물, 에탄올 등이 포함된다.
조성물은 중성 또는 염 형태로 제제화될 수 있다. 약제학적으로 허용가능한 염에는 염산, 인산, 아세트산, 옥살산, 타르타르산 등으로부터 유래한 것들과 같은 음이온으로 형성된 것들, 및 나트륨, 칼륨, 암모늄, 칼슘, 수산화철, 이소프로필아민, 트리에틸아민, 2-에틸아미노 에탄올, 히스티딘, 프로카인 등으로부터 유래한 것들과 같은 양이온으로 형성된 것들이 포함된다.
본 개시내용의 항체는 고전적인 약제학적 제제를 포함할 수 있다. 본 개시내용에 따른 이러한 조성물의 투여는 표적 조직이 그 경로를 통해 이용가능한 한 임의의 일반적인 통상적인 경로를 통해서일 것이다. 이에는 경구, 비강, 협측, 직장, 질 또는 국소가 포함된다. 대안적으로, 투여는 피내, 피하, 근육내, 복강내 또는 정맥내 주사에 의해서일 수 있다. 이러한 조성물은 일반적으로 상기에 기술된, 약제학적으로 허용가능한 조성물로서 투여될 것이다. 특히 관심을 끄는 것은 직접 종양내 투여, 종양의 관류, 또는 종양에의 국소 또는 국부적 투여, 예를 들어, 국소 또는 국부적 혈관계 또는 림프계로, 또는 절제된 종양 층 (tumor bed)에 투여하는 것이다.
활성 화합물은 또한 비경구로 또는 복강내로 투여될 수 있다. 유리 염기 또는 약제학적으로 허용가능한 염으로서 활성 화합물의 용액은 히드록시프로필셀룰로스와 같은 계면활성제와 적절하게 혼합된 물 중에서 제조될 수 있다. 분산액은 글리세롤, 액체 폴리에틸렌 글리콜, 및 이들의 혼합물 중에서, 그리고 오일 중에서 제조될 수 있다. 일반적인 보관 사용 조건하에서, 이러한 제제는 미생물의 성장을 방지하기 위해 방부제를 함유한다.
C.
병용 요법
본 개시내용의 맥락에서, 본원에 기술된 PD-L1 및 PD-L2에 대한 이중특이적 항체 (BiPDL)는 화학적- 또는 방사선치료적 개입, 또는 다른 치료와 함께 유사하게 사용될 수 있음이 또한 고려된다. 또한 이중특이적 PD-L1 및 PD-L2 항체를, 특히 PD-L1 또는 PD-L2 기능의 다른 측면을 표적하는 다른 요법, 예컨대 PD-L1 또는 PD-L2 세포질 도메인을 표적하는 펩티드 및 작은 분자와 조합하는 것이 효과적인 것으로 증명될 수 있다.
본 개시내용의 방법 및 조성물을 사용하여 세포를 사멸하고, 세포 성장을 억제하고, 전이를 억제하고, 혈관신생을 억제하거나 또는 다르게는 종양 세포의 악성 표현형을 역전 또는 감소시키기 위해, 일반적으로 "표적" 세포는 본 개시내용에 따른 이중특이적 항-PD-L1 및 항-PD-L2 항체 및 적어도 하나의 다른 제제와 접촉될 것이다. 이들 조성물은 세포를 사멸하거나 이의 증식을 억제하는데 효과적인 조합된 양으로 제공될 것이다. 이 과정은 본 개시내용에 따른 이중특이적 항-PD-L1 및 항-PD-L2 항체 및 다른 제제(들) 또는 인자(들)을 세포와 동시에 접촉시키는 것을 포함할 수 있다. 이는 세포를 단일 조성물 또는 두 제제를 포함하는 약제학적 제제와 접촉시킴으로써, 또는 세포를 동시에 두 개의 별개의 조성물과 접촉시킴으로써 달성될 수 있으며, 이때 하나의 조성물은 본 개시내용에 따른 이중특이적 항-PD-L1 및 항-PD-L2 항체를 포함하고 다른 조성물은 다른 제제를 포함한다.
대안적으로, 이중특이적 항-PD-L1 및 항-PD-L2 항체 요법은 수분 내지 수주 범위의 간격으로 다른 제제 치료에 선행하거나 후속할 수 있다. 다른 제제 및 이중특이적 항-PD-L1 및 항-PD-L2 항체가 세포에 별도로 적용되는 구현예에서, 일반적으로 각 전달 사이에 상당한 기간이 만료되지 않았음을 보장함으로써, 제제 및 발현 컨스트럭트가 여전히 세포에 유리하게 조합된 효과를 발휘할 수 있다. 이러한 경우에, 서로 약 12-24시간 이내, 더욱 바람직하게는 서로 약 6-12시간 이내에, 가장 바람직하게는 단지 약 12시간의 지연 시간으로, 두 양상을 세포와 접촉시키는 것이 고려된다. 일부 상황에서는, 치료 기간을 상당히 연장하는 것이 바람직할 수 있지만, 수일 (2, 3, 4, 5, 6 또는 7일) 내지 수주 (1, 2, 3, 4, 5, 6, 7 또는 8주)가 각 투여 사이에 경과한다.
또한 이중특이적 항-PD-L1 및 항-PD-L2 항체 또는 다른 제제 중 하나의 1회 초과 투여가 바람직할 것으로 생각될 수 있다. 이하에 예시된 바와 같이, 본 개시내용에 따른 이중특이적 항-PD-L1 및 항-PD-L2 항체가 "A"이고 다른 요법이 "B"인, 다양한 조합이 사용될 수 있다:
A/B/A B/A/B B/B/A A/A/B B/A/A A/B/B B/B/B/A B/B/A/B
A/A/B/B A/B/A/B A/B/B/A B/B/A/A B/A/B/A B/A/A/B B/B/B/A
A/A/A/B B/A/A/A A/B/A/A A/A/B/A A/B/B/B B/A/B/B B/B/A/B
환자에 대한 본 발명의 치료제의 투여는, 만약에 있다면, 항체 치료의 독성을 고려하여 특정한 2차 요법의 투여를 위한 일반적인 프로토콜을 수반할 것이다. 치료 주기는 필요에 따라 반복될 것으로 예상된다. 다양한 표준 요법뿐만 아니라 외과적 개입이 기술된 암 요법과 함께 적용될 수 있는 것으로 고려된다.
문헌 ["Remington's Pharmaceutical Sciences" 15th Edition, Chapter 33, 특히 624-652]이 숙련자에게 지시된다. 투여량의 약간의 변화는 필연적으로 치료될 대상체의 상태에 따라서 발생할 것이다. 투여를 담당하는 책임자는 모든 경우에 개별 대상체에 적합한 용량을 결정할 것이다. 나아가, 인간 투여의 경우, 제제는 FDA 사무소의 생물학 표준에 의해 요구되는 바와 같은 멸균, 발열성 (pyrogenicity), 일반적인 안전성 및 순도 기준을 충족해야 한다.
1.
화학요법
암 요법은 또한 화학 및 방사선 기반 치료와 함께 다양한 조합 요법을 포함한다. 병용 화학요법에는, 예를 들어, 시스플라틴 (CDDP), 카르보플라틴, 프로카르바진, 메클로레타민 (mechlorethamine), 사이클로포스파미드, 캄포테신, 이포스파미드, 멜팔란, 클로람부칠, 부설판, 니트로스우레아 (nitrosurea), 닥티노마이신, 다우노루비신, 독소루비신, 블레오마이신, 플리코마이신, 마이토마이신, 에토포시드 (VP16), 타목시펜, 랄록시펜, 에스트로겐 수용체 결합제, 탁솔, 겜시타빈, 나벨빈, 파네실-단백질 트랜스퍼라제 억제제, 전이백금 (transplatinum), 5-플루오로우라실, 빈크리스틴, 빈블라스팀 및 메토트렉세이트, 테마졸로미드 (Temazolomide) (DTIC의 수성 형태), 또는 전술한 것들의 임의의 유사체 또는 유도체 변형체가 포함된다. 화학요법과 생물학적 요법의 조합은 생화학요법 (biochemotherapy)으로 알려져 있다. 본 발명은 암을 치료 또는 예방하기 위해 당업계에서 사용되거나 공지될 수 있는 임의의 화학요법제를 고려한다.
2.
방사선 요법
DNA 손상을 유발하고 광범위하게 사용된 다른 요인으로는 일반적으로 γ-선, X-선, 및/또는 종양 세포에 대한 방사성동위원소의 직접 전달로 알려진 것들이 포함된다. 마이크로파 및 UV-조사와 같은 다른 형태의 DNA 손상 요인이 또한 고려된다. 이러한 모든 요인은 DNA, DNA의 전구체, DNA의 복제 및 복구, 및 염색체의 조립 및 유지에 광범위한 손상을 일으킬 가능성이 높다. X-선의 투여량 범위는 장기간 (3 내지 4주) 동안 50 내지 200 뢴트겐 (roentgen)의 일일 투여량부터 2000 내지 6000 뢴트겐의 단일 투여에 이르기까지 다양하다. 방사성동위원소의 투여량 범위는 매우 다양하며, 동위원소의 반감기, 방출되는 방사선의 강도 및 유형, 및 신생물 세포의 흡수에 따라 달라진다.
세포에 적용되는 경우, "접촉된" 및 "노출된"이라는 용어는 치료제 및 화학요법제 또는 방사선요법제가 표적 세포에 전달되거나 또는 표적 세포와 직접 병치되어 배치되는 과정을 설명하기 위해 본원에 사용된다. 세포 사멸 또는 정체를 달성하기 위해, 두 제제는 세포를 사멸시키거나 이들이 분열하는 것을 방지하는데 효과적인 조합된 양으로 세포에 전달된다.
3.
면역요법
일반적으로 면역요법은 암세포를 표적하고 파괴하기 위해 면역 이펙터 세포 및 분자의 사용에 의존한다. 면역 이펙터는, 예를 들어, 종양 세포의 표면에서 일부 마커에 특이적인 항체일 수 있다. 항체는 단독으로 요법의 이펙터로서 제공될 수 있거나 또는 실제로 세포 사멸에 영향을 미치는 다른 세포를 동원할 수 있다. 항체는 또한 약물 또는 독소 (화학요법제, 방사성핵종, 리신 A 쇄, 콜레라 독소, 백일해 독소 등)에 접합될 수 있으며 단지 표적화제로 작용할 수 있다. 대안적으로, 이펙터는 종양 세포 표적과 직접 또는 간접적으로 상호작용하는 표면 분자를 운반하는 림프구일 수 있다. 다양한 이펙터 세포에는 세포독성 T-세포 및 NK 세포가 포함된다. 치료적 양식의 조합, 즉 직접적인 세포독성 활성 및 포르틸린 (Fortilin)의 억제 또는 감소는 암 치료에 치료적 이점을 제공할 것이다.
면역요법은 또한 병용 요법의 일부로 사용될 수 있다. 병용 요법의 일반적인 접근법은 아래에서 논의된다. 면역요법의 일 측면에서, 종양 세포는 표적화에 순응하는, 즉 대부분의 다른 세포에 존재하지 않아야 하는 일부 마커를 보유해야 한다. 다수의 종양 마커가 존재하고 이들 중 임의의 마커는 본 발명의 맥락에서 표적화에 적합할 수 있다. 일반적인 종양 마커에는 암배아 (carcinoembryonic) 항원, 전립선 특이적 항원, 비뇨기 종양 관련 항원, 태아 항원, 티로시나제 (p97), gp68, TAG-72, HMFG, 시알릴 루이스 (Sialyl Lewis) 항원, MucA, MucB, PLAP, 에스트로겐 수용체, 라미닌 수용체, erb B 및 p155가 포함된다. 면역요법의 대안적인 측면은 면역 자극 효과를 갖는 항암 효과이다. 다음을 포함하는 면역 자극 분자가 또한 존재한다: IL-2, IL-4, IL-12, GM-CSF, 감마-IFN과 같은 사이토카인, MIP-1, MCP-1, IL-8과 같은 케모카인 및 FLT3 리간드와 같은 성장 인자. 단백질로서 또는 mda-7과 같은 종양 억제제와 함께 유전자 전달을 사용하여, 면역 자극 분자를 조합하는 것은 항-종양 효과를 증강시키는 것으로 나타났다 (Ju et al., 2000).
앞서 논의된 바와 같이, 현재 시험 중이거나 또는 사용 중인 면역요법제의 예시는 면역 보조제 (예컨대, 마이코박테리움 보비스 (Mycobacterium bovis), 플라스모디움 팔시파룸 (Plasmodium falciparum), 디니트로클로로벤젠 및 방향족 화합물) (U.S. 특허 제5,801,005호; U.S. 특허 제5,739,169호; Hui and Hashimoto, 1998; Christodoulides et al., 1998), 사이토카인 요법 (예컨대, 인터페론, 및; IL-1, GM-CSF 및 TNF) (Bukowski et al., 1998; Davidson et al., 1998; Hellstrand et al., 1998), 유전자 요법 (예컨대, TNF, IL-1, IL-2, p53) (Qin et al., 1998; Austin-Ward and Villaseca, 1998; U.S. 특허 제5,830,880호 및 U.S. 특허 제5,846,945호) 및 단일클론 항체 (예컨대, 항-강글리오시드 GM2, 항-HER-2, 항-p185) (Pietras et al., 1998; Hanibuchi et al., 1998; U.S. 특허 제5,824,311호)이다. 허셉틴 (트라스트주맙)은 HER2-neu 수용체를 차단하는 키메라 (마우스-인간) 단일클론 항체이다. 이는 항-종양 활성을 보유하고 악성 종양의 치료에 대해 승인되었다 (Dillman, 1999). 허셉틴과 화학요법을 이용한 암의 병용 요법은 개별 요법보다 더 효과적인 것으로 나타났다. 따라서, 하나 이상의 항암 요법이 본원에 기술된 종양-관련 HLA-제한 펩티드 요법과 함께 사용될 수 있는 것으로 고려된다.
입양 면역요법에서는, 환자의 순환 림프구, 또는 종양 침윤된 림프구를 시험관 내에서 분리하고, IL-2와 같은 림포카인에 의해 활성화시키거나 또는 종양 괴사를 위한 유전자로 형질도입하고, 재투여된다 (Rosenberg et al., 1988; 1989). 이를 달성하기 위해, 면역학적 유효량의 활성화된 림프구를 본원에 기술된 보조제-혼입 항원성 펩티드 조성물과 함께 동물, 또는 인간 환자에 투여될 것이다. 활성화된 림프구가 이전에 혈액 또는 종양 샘플로부터 분리되고 시험관 내에서 활성화된 (또는 "확장된") 환자 자신의 세포인 것이 가장 바람직하다. 이러한 형태의 면역요법은 흑색종 및 신장암 (renal carcinoma)의 여러 퇴행 사례를 생산했지만, 반응하지 않은 사람들에 비해 반응자의 비율이 거의 없었다.
암의 수동 면역요법을 위한 다수의 상이한 접근법이 존재한다. 이들은 크게 다음으로 분류될 수 있다: 항체 단독 주입; 독소 또는 화학요법제에 결합된 항체의 주입; 방사성 동위원소에 결합된 항체의 주입; 항-이디오타입 항체의 주입; 및 마지막으로, 골수에서 종양 세포의 제거 (purging).
인간 단일클론 항체는 환자에게 부작용이 거의 또는 전혀 발생하지 않기 때문에 수동 면역요법에 사용된다. 그러나 이들의 적용은 그들의 희소성에 의해 다소 제한되고 지금까지는 병변 내로만 투여되었다. 강글리오사이드 항원에 대한 인간 단일클론 항체가 피부 재발성 흑색종을 앓고 있는 환자에게 병변 내로 투여되었다 (Irie & Morton, 1986). 매일 또는 매주 병변내 주사 후 10명의 환자 중 6명에서 퇴행이 관찰되었다. 다른 연구에서, 2개의 인간 단일클론 항체의 병변내 주사로부터 중간 정도의 성공이 달성되었다 (Irie et al., 1989). 가능한 치료적 항체에는 항-TNF, 항-CD25, 항-CD3, 항-CD20, CTLA-4-IG, 및 항-CD28이 포함된다.
2개의 상이한 항원에 대한 1개 초과의 단일클론 항체 또는 심지어 다중 항원 특이성을 갖는 항체를 투여하는 것이 유리할 수 있다. 치료 프로토콜은 또한 Bajorin 등 (1988)에 기술된 바와 같이 림포카인 또는 다른 면역 증강제의 투여를 포함할 수 있다. 인간 단일클론 항체의 개발이 본 명세서의 다른 곳에 더 상세히 기술된다.
4.
유전자 요법
또 다른 구현예에서, 2차 치료는 종양-관련 HLA-제한 펩티드가 투여되기 전, 후, 또는 동시에 치료용 폴리펩티드가 투여되는 유전자 요법이다. 다음 유전자 산물 중 하나를 인코딩하는 2차 벡터와 함께 종양-관련 HLA-제한 펩티드를 인코딩하는 벡터의 전달은 표적 조직에 대해 조합된 항-과증식 효과를 가질 것이다. 대안적으로, 두 유전자를 인코딩하는 단일 벡터가 사용될 수 있다. 다양한 단백질이 본 발명 내에 포함되며, 이들 중 일부가 하기에 기술된다. 본 발명과 조합되는 일부 형태의 유전자 요법을 위해 표적화될 수 있는 다양한 유전자가 당업자에게 익히 공지되어 있고 암에 관련된 임의의 유전자를 포함할 수 있다.
세포 증식 유도제. 세포 증식을 유도하는 단백질은 또한 기능에 따라 다양한 카테고리에 속한다. 이들 모든 단백질의 공통점은 세포 증식을 조절하는 이들의 능력이다. 예를 들어, sis 종양유전자인 PDGF의 형태는 분비된 성장 인자이다. 종양유전자는 성장 인자를 인코딩하는 유전자에서는 거의 발생하지 않으며, 현재 sis는 유일한 자연-발생적인 발암성 성장 인자이다. 본 발명의 일 구현에에서, 특정 세포 증식 유도제에 대한 항-센스 mRNA가 세포 증식 유도제의 발현을 방지하기 위해 사용되는 것으로 고려된다.
단백질 FMS, ErbA, ErbB 및 neu는 성장 인자 수용체이다. 이들 수용체에 대한 돌연변이는 조절가능한 기능의 상실을 초래한다. 예를 들어, Neu 수용체 단백질의 막횡단 도메인에 영향을 미치는 점 돌연변이는 Neu 종양유전자를 초래한다. erbA 종양유전자는 갑상선 호르몬에 대한 세포내 수용체로부터 유래한다. 변형된 발암성 ErbA 수용체는 내인성 갑상선 호르몬 수용체와 경쟁하여 통제되지 않은 성장을 유발하는 것으로 여겨진다.
가장 큰 부류의 종양유전자에는 신호 전달 단백질 (예컨대, Src, Abl 및 Ras)이 포함된다. 단백질 Src는 세포질 단백질-티로신 키나제이고, 일부 경우에 원암유전자 (proto-oncogene)의 종양유전자로의 이의 변환은 티로신 잔기 527에서의 돌연변이를 통해 발생한다. 대조적으로, 일 예로서, 원암유전자의 종양유전자로의 GTPase 단백질 ras의 변환은 서열의 아미노산 12에서 발린의 글리신으로의 돌연변이로 인해 발생하고, 이는 ras GTPase 활성을 감소시킨다. 단백질 Jun, Fos 및 Myc는 전사 인자로서 핵 기능에 직접적으로 영향을 미치는 단백질이다.
세포 증식 억제제. 종양 억제인자 종양유전자는 과도한 세포 증식을 억제하는 기능을 한다. 이들 유전자의 비활성화는 이들의 억제 활성을 파괴하여, 조절되지 않는 증식을 초래한다. 가장 흔한 종양 억제인자는 Rb, p53, p21 및 p16이다. 본 발명에 따라 사용될 수 있는 다른 유전자에는 APC, DCC, NF-1, NF-2, WT-1, MEN-I, MEN-II, zac1, p73, VHL, C-CAM, MMAC1/PTEN, DBCCR-1, FCC, rsk-3, p27, p27/p16 융합, 및 p21/p27 융합이 포함된다.
프로그래밍된 세포 사멸의 조절자. 세포사멸, 또는 프로그래밍된 세포 사멸은 정상적인 배아 발생, 성인 조직에서의 항상성 유지, 및 발암 억제에 필수적인 과정이다 (Kerr et al., 1972). Bcl-2 단백질 패밀리 및 ICE-유사 프로테아제는 다른 시스템에서 세포사멸의 중요한 조절자 및 이펙터로 입증되었다. 여포성 림프종 (follicular lymphoma)과 관련하여 발견된, Bcl-2 단백질은 다양한 세포사멸 자극에 대해 세포사멸을 제어하고 세포 사멸을 증강시키는데 중요한 역할을 한다 (Bakhshi et al., 1985; Cleary and Sklar, 1985; Cleary et al., 1986; Tsujimoto et al., 1985; Tsujimoto and Croce, 1986). 진화적으로 보존된 Bcl-2 단백질은 현재 사멸 작용제 또는 사멸 길항제로 분류될 수 있는, 관련 단백질 패밀리의 구성원인 것으로 인식된다.
그의 발견 이후, Bcl-2는 다양한 자극에 의해 촉발되는 세포 사멸을 억제하는 작용을 하는 것으로 나타났다. 또한, 공통으로 구조 및 서열 상동성을 공유하는 Bcl-2 세포 사멸 조절 단백질의 패밀리가 있음이 이제 명백하다. 이러한 다른 패밀리 구성원은 Bcl-2와 유사한 기능을 보유하거나 (예컨대, BclXL, BclW, BclS, Mcl-1, A1, Bfl-1) 또는 Bcl-2 기능을 방해하고 세포 사멸을 촉진하는 (예컨대, Bax, Bak, Bik, Bim, Bid, Bad, Harakiri) 것으로 나타났다.
5.
수술
암 환자의 대략 60%는 예방, 진단 또는 병기결정 (staging), 치료 및 완화 (palliative) 수술을 포함하는, 일부 유형의 수술을 받게 될 것이다. 치료 (curative) 수술은 본 발명의 치료, 화학요법, 방사선요법, 호르몬 요법, 유전자 요법, 면역요법 및/또는 대체 요법과 같은 다른 요법과 함께 사용될 수 있는 암 치료이다.
치료 수술에는 암 조직의 전부 또는 일부를 물리적으로 제거, 절제 및/또는 파괴하는 절제술이 포함된다. 종양 절제는 종양의 적어도 일부를 물리적으로 제거하는 것을 지칭한다. 종양 절제술 외에, 수술에 의한 치료는 레이저 수술, 냉동수술, 전기수술, 현미경 제어 수술 (모스 수술, Mohs' surgery)이 포함된다. 본 발명은 또한 표재성 암 (superficial cancer), 전암 (precancer), 또는 부수적 양의 정상 조직의 제거와 함께 사용될 수 있음이 고려된다.
모든 암세포, 조직, 또는 종양의 전부 또는 일부의 절제 시, 체내에 공동이 형성될 수 있다. 치료는 추가적인 항암 요법으로 관류, 직접 주사 또는 부위의 국소 적용으로 수행될 수 있다. 이러한 치료는, 예를 들어, 1, 2, 3, 4, 5, 6, 또는 7일마다, 또는 1, 2, 3, 4, 및 5주마다 또는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 또는 12개월마다 반복될 수 있다. 이들 치료는 또한 복용량이 달라질 수 있다.
V.
항체 접합체
항체는 적어도 하나의 제제에 연결되어 항체 접합체를 형성할 수 있다. 진단제 또는 치료제로서 항체 분자의 효능을 증가시키기 위해, 적어도 하나의 원하는 분자 또는 모이어티를 공유적으로 결합하거나 복합체화하는 것이 통상적이다. 이러한 분자 또는 모이어티는 적어도 하나의 이펙터 또는 리포터 분자일 수 있으나, 이들로 제한되지 않는다. 이펙터 분자는 원하는 활성을 갖는 분자, 예컨대 면역억제/항-염증을 갖는 분자를 포함한다. 이러한 분자의 비-제한적인 예시가 상기에 기술되어 있다. 이러한 분자는 분자가 표적 부위에서 또는 근처에서 방출될 수 있도록 설계된 절단가능 링커를 통해 선택적으로 부착된다.
대조적으로, 리포터 분자는 분석을 사용하여 검출될 수 있는 임의의 모이어티로서 정의된다. 항체에 접합된 리포터 분자의 비-제한적인 예시에는 효소, 방사성표지, 합텐, 형광 표지, 인광 분자, 화학발광 분자, 발색단, 광친화성 분자, 유색 입자 또는 리간드, 예컨대 비오틴이 포함된다.
항체 접합체는 일반적으로 진단제로 사용하기에 바람직하다. 항체 진단은 일반적으로 2가지 부류에 속하는데, 다양한 면역분석과 같은 시험관 내 진단에 사용하기 위한 것과, 일반적으로 "항체-지시 영상화 (antibody-directed imaging)"로 알려진, 생체 내 진단 프로토콜에 사용하기 위한 것이다. 항체에 대한 이들의 부착을 위한 방법과 같이, 다수의 적합한 영상화제가 당업계에 알려져 있다 (예를 들어, U.S. 특허 제5,021,236호, 제4,938,948호, 및 제4,472,509호). 사용되는 영상화 모이어티는 상자성 이온, 방사성 동위원소, 형광색소, NMR-검출가능 물질, X-선 영상화제일 수 있다.
상자성 이온의 경우, 크롬 (III), 망간 (II), 철 (III), 철 (II), 코발트 (II), 니켈 (II), 구리 (II), 네오디뮴 (III), 사마륨 (III), 이테르륨 (III), 가돌리늄 (III), 바나듐 (II), 테르븀 (III), 디스프로슘 (III), 홀륨 (III) 및/또는 에르븀 (III)과 같은 이온을 예로 언급할 수 있으며, 가돌리늄이 특히 바람직하다. X-선 영상화와 같은 다른 맥락에서 유용한 이온에는 란탄 (III), 금 (III), 납 (II), 및 특히 비스무트 (III)가 포함되지만, 이들로 제한되지 않는다.
치료 및/또는 진단 적용을 위한 방사성 동위원소의 경우, 아스타틴211, 14탄소, 51크로뮴, 36염소, 57코발트, 58코발트, 구리67, 152Eu, 갈륨67, 3수소, 요오드123, 요오드125, 요오드131, 인듐111, 59철, 32인, 레늄186, 레늄188, 75셀레늄, 35황, 테크니슘99m 및/또는 이트륨90이 언급될 수 있다. 125I가 종종 특정 구현예에 사용하기에 바람직하고, 이들의 낮은 에너지 및 장거리 검출에의 적합성으로 인해 테크니슘99m (technicium99m) 및/또는 인듐111이 또한 종종 바람직하다. 방사성 표지된 단일클론 항체는 당업계에 익히 공지된 방법에 따라 생산될 수 있다. 예를 들어, 단일클론 항체는 나트륨 및/또는 요오드화 칼륨, 및 차아염소산 나트륨과 같은 화학적 산화제 또는 락토퍼옥시다제와 같은 효소적 산화제와의 접촉에 의해 요오드화될 수 있다. 단일클론 항체는 리간드 교환 과정에 의해, 예를 들어 퍼테크네테이트 (pertechnetate)를 주석 용액으로 환원시키고, 환원된 테크네튬을 세파덱스 칼럼 위에 킬레이팅하고 이 칼럼에 항체를 적용함으로써, 테크네튬99m (technetium99m)으로 표지될 수 있다. 대안적으로, 예컨대, 퍼테크네이트, SNCl2와 같은 환원제, 나트륨-칼륨 프탈레이트 용액과 같은 완충제, 및 항체와 인큐베이션함으로써 직접 표지 기법이 사용될 수 있다. 중간 작용기는 종종 방사성동위원소를 항체에 결합하는데 사용되고 금속 이온으로서 디에틸렌트리아민펜타아세트산 (DTPA) 또는 에틸렌 디아민테트라아세트산 (EDTA)이 존재한다.
접합체로 사용하기 위해 고려되는 형광 표지 중에는 알렉사 350, 알렉사 430, AMCA, BODIPY 630/650, BODIPY 650/665, BODIPY-FL, BODIPY-R6G, BODIPY-TMR, BODIPY-TRX, 캐스케이드 블루, Cy3, Cy5,6-FAM, 플루오레세인 이소티오시아네이트, HEX, 6-JOE, 오레곤 그린 488, 오레곤 그린 500, 오레곤 그린 514, 퍼시픽 블루, REG, 로다민 그린, 로다민 레드, 레노그라핀 (Renographin), ROX, TAMRA, TET, 테트라메틸 로다민, 및/또는 텍사스 레드가 포함된다.
고려되는 항체 접합체의 또 다른 유형은 주로 시험관 내 사용을 위한 것으로, 여기서 항체는 색원체 (chromogenic) 기질과 접촉 시 착색된 생성물을 생성할 2차 결합 리간드 및/또는 효소 (효소 태그)에 연결된다. 적합한 효소의 예시에는 우레아제, 알칼라인 포스파타제, (호스래디쉬) 과산화수소 또는 글루코스 옥시다제가 포함된다. 바람직한 2차 결합 리간드는 비오틴 및 아비딘 및 스트렙타비딘 화합물이다. 이러한 표지의 사용은 당업자에게 잘 알려져 있으며, 예를 들어, U.S. 특허 제3,817,837호, 제3,850,752호, 제3,939,350호, 제3,996,345호, 제4,277,437호, 제4,275,149호 및 제4,366,241호에 기술되어 있다.
항체에 대한 분자의 부위-특이적 부착의 또 다른 공지된 방법은 항체와 합텐-기반 친화성 표지와의 반응을 포함한다. 본질적으로, 합텐-기반 친화성 표지는 항원 결합 부위의 아미노산과 반응하여 이 부위를 파괴하고 특정 항원 반응을 차단한다. 그러나 이는 항체 접합체에 의한 항원 결합의 손실을 초래하기 때문에 유리하지 않을 수 있다.
아지도기를 함유하는 분자가 또한 사용되어 저 강도 자외선 광에 의해 생성된 반응성 니트렌 (nitrene) 중간체를 통해 단백질에 공유 결합을 형성할 수 있다 (Potter and Haley, 1983). 특히, 퓨린 뉴클레오티드의 2- 및 8-아지도 유사체는 조 세포 추출물 내 뉴클레오티드 결합 단백질을 확인하기 위한 부위-지정 광프로브 (photoprobe)로 사용되고 있다 (Owens & Haley, 1987; Atherton et al., 1985). 2- 및 8-아지도 뉴클레오티드는 또한 정제된 단백질의 뉴클레오티드 결합 도메인을 맵핑하는데 사용되고 있고 (Khatoon et al., 1989; King et al., 1989; Dholakia et al., 1989) 항체 결합제로 사용될 수 있다.
그의 접합체 모이어티에 대한 항체의 부착 또는 접합을 위한 여러 방법이 당업계에 알려져 있다. 일부 부착 방법은 항체에 부착된 디에틸렌트리아민펜타아세트산 무수물 (DTPA); 에틸렌트리아민테트라아세트산; N-클로로-p-톨루엔설폰아미드; 및/또는 테트라클로로-3α-6α-디페닐글리코우릴-3과 같은 유기 킬레이트화제를 사용하는 금속 킬레이트 복합체의 사용을 포함한다 (U.S. 특허 제4,472,509호 및 제4,938,948호). 단일클론 항체는 또한 글루타르알데히드 또는 과요오드산염과 같은 커플링제의 존재하에서 효소와 반응할 수 있다. 플루오레세인 마커와의 접합체는 이들 커플링제의 존재하에서 또는 이소티오시아네이트와의 반응에 의해 제조된다. U.S. 특허 제4,938,948호에서, 유방 종양의 영상화가 단일클론 항체를 사용하여 이루어지고 검출가능한 영상화 모이어티는 메틸-p-히드록시벤즈이미데이트 또는 N-석시니미딜-3-(4-히드록시페닐)프로피오네이트와 같은 링커를 사용하여 항체에 결합된다.
다른 구현예에서, 항체 결합 부위를 변경하지 않는 반응 조건을 사용하여 면역글로불린의 Fc 영역에 설프히드릴기의 선택적 도입에 의한, 면역글로불린의 유도체화가 고려된다. 이 방법론에 따라 생성된 항체 접합체는 개선된 수명, 특이성 및 민감성을 나타내는 것으로 개시된다 (본원에 참조로 포함되는, U.S. 특허 제5,196,066호). 리포터 또는 이펙터 분자가 Fc 영역 내 탄수화물 잔기에 접합되는, 이펙터 또는 리포터 분자의 부위-특이적 부착이 또한 문헌에 기술되어 있다 (O'Shannessy et al., 1987). 이 접근법은 현재 임상 평가 중에 있는 진단적 및 치료적으로 유망한 항체를 생산하는 것으로 보고되었다.
VI.
면역검출 방법
또 다른 구현예에서, PD-L1 또는 PD-L2 및 이들의 관련 항원을 결합, 정제, 제거, 정량 및 다르게는 일반적으로 검출하는 면역검출 방법이 있다. 일부 면역검출 방법에는 몇 가지 언급을 하자면 효소 결합 면역흡착 분석 (ELISA), 방사면역분석 (RIA), 면역방사분석 (immunoradiometric assay), 형광면역분석 (fluoroimmunoassay), 화학발광 분석, 생체발광 분석, 및 웨스턴 블롯이 포함된다. 구체적으로, PD-L1 및 PD-L2 항체의 검출 및 정량화를 위한 경쟁적 분석이 또한 제공된다. 다양한 유용한 면역검출 방법의 단계가, 예컨대, 문헌 [Doolittle and Ben-Zeev (1999), Gulbis and Galand (1993), De Jager et al. (1993), and Nakamura et al. (1987)]에 기술된 바와 같은 과학 문헌에 기술되어 있다. 일반적으로, 면역결합 방법은 샘플을 수득하고, 경우에 따라 면역복합체의 형성을 허용하기에 효과적인 조건하에서일 수 있는, 본원에 기술된 구현예에 따라서, 이 샘플을 1차 항체와 접촉시키는 것을 포함한다.
선택된 생물학적 샘플을 면역 복합체 (일차 면역 복합체)의 형성을 가능케 하는 효과적인 조건에서 충분한 시간 동안 항체와 접촉시키는 것은 일반적으로 항체 조성물을 샘플에 첨가하고 면역 복합체를 형성, 즉 존재하는 PD-L1 및 PD-L2에 결합하기에 충분한 시간 동안 혼합물을 인큐베이션하는 사안이다. 이 시간 후, 일반적으로 조직 절편, ELISA 플레이트, 닷 블롯 또는 웨스턴 블롯과 같은 샘플-항체 조성물을 세척하여 임의의 비-특이적으로 결합된 항체 종을 제거하고, 일차 면역 복합체 내에 특이적으로 결합된 항체만이 검출되게 한다.
일반적으로, 면역복합체 형성의 검출은 당업계에 익히 공지되어 있고 수많은 접근법의 적용을 통해 달성될 수 있다. 이들 방법은 일반적으로 그러한 방사능, 형광, 생물학적 및 효소적 태그 중 하나와 같은 표지 또는 마커의 검출을 기반으로 한다. 이러한 표지의 사용에 관한 특허에는 U.S. 특허 제3,817,837호, 제3,850,752호, 제3,939,350호, 제3,996,345호, 제4,277,437호, 제4,275,149호 및 제4,366,241호가 포함된다. 물론, 당업계에 공지된 바와 같이, 2차 항체 및/또는 비오틴/아비딘 리간드 결합 배열과 같은 2차 결합 리간드의 사용을 통해 추가적인 이점을 확인할 수 있다.
검출에 사용된 항체는 그 자체로 검출가능한 표지에 연결될 수 있으며, 여기서 이 표지를 간단히 검출함으로써 조성물 내 일차 면역 복합체의 양을 결정할 수 있게 한다. 대안적으로, 1차 면역 복합체 내에 결합되는 1차 항체는 항체에 대한 결합 친화도를 갖는 2차 결합 리간드에 의해 검출될 수 있다. 이러한 경우에, 2차 결합 리간드는 검출가능한 표지에 연결될 수 있다. 2차 결합 리간드는 그 자체가 종종 항체이고, 따라서 이는 "2차" 항체로 지칭된다. 1차 면역 복합체는 2차 면역 복합체의 형성을 가능케 하기에 충분한 시간 동안 이에 효과적인 조건하에서, 표지된, 2차 결합 리간드, 또는 항체와 접촉된다. 그 후에 2차 면역 복합체는 일반적으로 세척되어 임의의 비-특이적으로 결합된 표지된 2차 항체 또는 리간드를 제거한 후, 2차 면역 복합체 내 잔여 표지를 검출한다.
추가 방법은 2단계 접근법에 의한 1차 면역 복합체의 검출을 포함한다. 2차 결합 리간드, 예컨대 그 항체에 대해 결합 친화도를 갖는 항체가 상기에 기술된 바와 같은 2차 면역 복합체를 사용하는데 사용된다. 세척 후, 면역 복합체 (3차 면역 복합체)의 형성을 가능케 하기에 효과적인 조건에서 그에 충분한 시간 동안, 2차 면역 복합체를 2차 항체에 대해 결합 친화도를 갖는 3차 결합 리간드 또는 항체와 접촉시킨다. 3차 리간드 또는 항체를 검출가능한 표지에 연결시켜, 그렇게 형성된 3차 면역 복합체의 검출을 가능케 한다. 이 시스템은 원하는 경우 신호 증폭을 제공할 수 있다.
면역검출의 한 방법은 2개의 상이한 항체를 사용한다. 1차 비오틴화된 항체를 사용하여 표적 항원을 검출한 후, 2차 항체를 사용하여 복합체화된 비오틴에 부착된 비오틴을 검출한다. 이 방법에서, 시험될 샘플을 먼저 제1 단계 항체를 함유하는 용액 중에 인큐베이선한다. 표적 항원이 존재하는 경우, 항체 중 일부가 항원에 결합하여 비오틴화된 항체/항원 복합체를 형성한다. 그 후에 항체/항원 복합체는 스트렙타비딘 (또는 아비딘), 비오틴화된 DNA, 및/또는 상보적 비오틴화된 DNA의 연속 용액 중에서 인큐베이션함으로써 증폭되고, 각 단계에 항체/항원 복합체에 대한 추가 비오틴 부위를 첨가한다. 적합한 수준의 증폭이 달성될 때까지 증폭 단계를 반복하고, 이 시점에서 샘플은 비오틴에 대한 제2 단계 항체를 함유하는 용액 중에서 인큐베이션된다. 제2 단계 항체를, 예를 들어, 색원체 (chromogen) 기질을 사용하는 조직효소학 (histoenzymology)에 의해 항체/항원 복합체의 존재를 검출하는데 사용될 수 있는 효소로 표지한다. 적합한 증폭으로, 현미경적으로 볼 수 있는 접합체가 생성될 수 있다.
또 다른 알려진 면역검출 방법은 면역-PCR (중합효소 연쇄반응) 방법론을 활용한다. PCR 방법은 비오틴화된 DNA와의 인큐베이션까지는 Cantor 방법과 유사하지만, 여러 회차의 스트렙타비딘 및 비오틴화된 DNA 인큐베이션을 사용하는 대신, DNA/비오틴/스트렙타비딘/항체 복합체를 항체를 방출하는 낮은 pH 또는 높은 염 완충제로 세척한다. 그 후에 생성된 세척액을 사용하여 적절한 대조군과 함께 적절한 프라이머로 PCR 반응을 수행하였다. 적어도 이론적으로, PCR의 엄청난 증폭 능력 및 특이성은 단일 항원 분자를 검출하는데 사용될 수 있다.
A.
ELISA
가장 단순한 의미에서, 면역분석은 결합 분석이다. 특정 바람직한 면역분석은 당업계에 공지된 다양한 유형의 효소 결합 면역흡착 분석 (ELISAs) 및 방사면역분석 (RIA)이다. 조직 절편을 사용하는 면역조직화학 검출이 또한 특히 유용하다. 그러나 검출이 이러한 기법에 제한되지 않고, 웨스턴 블롯팅, 닷 블롯팅, FACS 분석 등이 또한 사용될 수 있다.
하나의 예시적인 ELISA에서, 본 개시내용의 항체는 폴리스티렌 미세역가 플레이트 내 웰과 같은, 단백질 친화도를 나타내는 선택된 표면 상에 고정된다. 그 후에, PD-L1 및/또는 PD-L2를 함유하는 것으로 의심되는 시험 조성물을 웰에 첨가한다. 결합 및 세척하여 비-특이적으로 결합된 면역 복합체를 제거한 후, 결합된 항원을 검출할 수 있다. 검출가능한 표지에 연결된 PD-L1 및 PD-L2에 대해 지시된 또 다른 이중특이적 항체의 첨가에 의해, 또는 검출가능한 표지에 연결된 항-PD-L1 또는 항-PD-L2 항체에 의해 검출이 달성될 수 있다. 이러한 유형의 ELISA는 간단히 "샌드위치 ELISA"이다. 검출은 또한 PD-L1 및 PD-2에 대한 2차 이중특이적 항체, 또는 항-PD-L1 또는 항-PD-L2 항체의 첨가에 이은 2차 항체에 대해 결합 친화도를 갖는 3차 항체의 첨가에 의해 달성될 수 있고, 이때 3차 항체는 검출가능한 표지에 연결된다.
또 다른 예시적인 ELISA에서, PD-L1 및/또는 PD-L2 항원을 함유하는 것으로 의심되는 샘플은 웰 표면 상에 고정된 후 이중특이적 항-PD-L1 및 항-PD-L2 항체와 접촉된다. 결합 및 세척하여 비-특이적으로 결합된 면역 복합체를 제거한 후, 결합된 이중특이적 항-PD-L1 및 항-PD-L2 항체를 검출한다. 초기 이중특이적 항-PD-L1 및 항-PD-L2 항체가 검출가능한 표지에 연결되는 경우, 면역 복합체는 직접적으로 검출될 수 있다. 다시, 면역 복합체는 1차 이중특이적 항-PD-L1 및 항-PD-L2 항체에 대해 결합 친화도를 갖는 2차 항체를 사용하여 검출될 수 있고, 이때 2차 항체는 검출가능한 표지에 연결된다.
사용된 형식과 무관하게, ELISA는 코팅, 인코베이션 및 결합, 비-특이적으로 결합된 종의 제거를 위한 세척, 및 결합된 면역 복합체의 검출과 같은 공통적인 특징을 갖는다. 하기에 이들이 설명된다.
항원 또는 항체로 플레이트를 코팅하는 경우, 일반적으로 플레이트의 웰은 항원 또는 항체의 용액과, 밤새 또는 지정된 기간 동안 인큐베이션될 것이다. 그 후에 플레이트의 웰을 세척하여 불완전하게 흡착된 물질을 제거한다. 웰의 나머지 이용가능한 임의의 표면은 시험 혈청과 관련하여 항원성으로 중성인 비특이적 단백질로 "코팅"된다. 이들은 소 혈청 알부민 (BSA), 카제인 또는 분유의 용액이 포함된다. 코팅은 고정화 표면에서 비특이적 흡착의 차단을 가능케 하고, 그로써 표면 위에 항혈청의 비특이적 결합에 의해 야기되는 배경을 감소시킨다.
ELISA에서, 아마도 직접적인 절차보다는 2차 또는 3차 검출 수단을 사용하는 것이 더 일반적일 것이다. 따라서, 웰에 단백질 또는 항체를 결합시키고, 배경 감소를 위해 비-반응성 물질로 코팅하고, 세척하여 비결합된 물질을 제거한 후, 고정화 표면은 면역 복합체 (항원/항체) 형성을 허용하기에 효과적인 조건하에서 시험될 생물학적 샘플과 접촉된다. 그 후에 면역 복합체의 검출은 표지된 2차 결합 리간드 또는 항체, 및 표지된 3차 항체 또는 3차 결합 리간드와 함께 2차 결합 리간드 또는 항체를 필요로 한다.
"면역 복합체 (항원/항체) 형성을 허용하기에 효과적인 조건하에서"는 상기 조건이 바람직하게는 항원 및/또는 항체를 BSA, 소 감마 글로불린 (BGG) 또는 인산염 완충 식염수 (PBS)/트윈과 같은 용액으로의 희석을 포함하는 것을 의미한다. 이렇게 첨가된 제제는 또한 비특이적 배경의 감소를 돕는 경향이 있다.
"적합한" 조건은 또한 인큐베이션이 효과적인 결합을 허용하기에 충분한 온도에서 또는 충분 시간 동안인 것을 의미한다. 인큐베이션 단계는 전형적으로 약 1 내지 2 내지 4시간 정도, 바람직하게는 대략 25℃ 내지 27℃의 온도에서이고, 또는 약 4℃ 정도에서 밤새일 수 있다.
ELISA에서 모든 인큐베이션 단계 후, 접촉된 표면을 세척하여 비-복합체화된 물질을 제거한다. 바람직한 세척 절차는 PBS/트윈, 또는 보레이트 완충제와 같은 용액으로의 세척을 포함한다. 시험 샘플과 원래 결합된 물질 사이의 특이적 면역 복합체의 형성, 및 후속 세척에 이어, 심지어 미량의 면역 복합체의 발생이 결정될 수 있다.
검출 수단을 제공하기 위해, 2차 또는 3차 항체는 검출을 가능케 하는 관련 표지를 가질 것이다. 바람직하게는, 이는 적절한 색원체 기질과 인큐베이션 시 발색을 생성할 효소일 것이다. 따라서, 예를 들어, 추가 면역 복합체 형성의 발생을 선호하는 기간 동안 및 조건하에서 1차 및 2차 면역 복합체를 우레아제, 글루코스 옥시다제, 알칼라인 포스파타제 또는 과산화수소-접합된 항체와의 접촉 또는 인큐베이션 (예컨대, PBS-트윈과 같은 PBS-함유 용액 중에서 실온에서 2시간 동안 인큐베이션)이 바람직할 것이다.
표지된 항체와의 인큐베이션 및 이어지는 비결합된 물질을 제거하기 위한 세척 후, 표지 양을, 효소 표지와 같은 퍼옥시다제의 경우에, 예컨대 우레아, 또는 브로모크레졸 퍼플, 또는 2,2'-아지노-디-(3-에틸-벤즈티아졸린-6-설폰산 (ABTS), 또는 H2O2와 같은 색원체 기질과의 인큐베이션에 의해 정량화한다. 그 후에 예컨대 가시적 분광 광도계를 사용하여 생성된 색상의 정도를 측정하여 정량화를 달성한다.
B.
웨스턴 블롯
웨스턴 블롯 (대안적으로, 단백질 면역블롯)은 주어진 조직 균질액 또는 추출물의 샘플에서 특정 단백질을 검출하기 위해 사용되는 분석 기법이다. 이는 겔 전기영동을 사용하여 폴리펩티드의 길이에 의해 (변성 조건) 또는 단백질의 3-D 구조에 의해 (천연/비-변성 조건) 천연 또는 변성된 단백질을 분리한다. 그 후에 단백질을 막 (전형적으로 니트로셀룰로스 또는 PVDF)으로 옮기고, 여기서 이들은 표적 단백질에 특이적인 항체를 사용하여 탐침된다 (검출된다).
샘플은 전체 조직 또는 세포 배양으로부터 취해질 수 있다. 대부분의 경우에, 고형 조직을 먼저 블렌더 (더 큰 샘플 부피의 경우)를 사용하여, 균질기 (더 작은 부피)를 사용하여, 또는 초음파처리에 의해 기계적으로 분해한다. 세포는 또한 상기 기계적 방법 중 하나에 의해 분해될 수 있다. 그러나 박테리아, 바이러스 또는 환경 샘플이 단백질의 공급원이 될 수 있고, 따라서 웨스턴 블롯팅이 단지 세포 연구로만 제한되지 않음을 이해해야 한다. 세포의 용해를 촉진하고 단백질을 용해시키기 위해 다양한 세제, 염, 및 완충제가 사용될 수 있다. 프로테아제 및 포스파타제 억제제는 종종 그 자체의 효소에 의해 샘플의 소화를 방지하기 위해 첨가된다. 단백질 변성을 피하기 위해 조직 제조물은 종종 차가운 온도에서 수행된다.
샘플의 단백질을 겔 전기영동을 사용하여 분리한다. 단백질의 분리는 등전점 (pI), 분자량, 전하, 또는 이들 요인의 조합에 의해서일 수 있다. 분리의 특성은 샘플의 처리 및 겔의 특성에 따라 좌우된다. 이는 단백질을 결정하는 매우 유용한 방식이다. 단일 샘플로부터 단백질을 2차원으로 확산시키는 2차원 (2-D) 겔을 사용할 수도 있다. 단백질은 1차원에서는 등전점 (이들이 중성 순전하를 갖는 pH)에 따라 분리되고 2차원에서는 이들의 분자량에 따라 분리된다.
단백질을 항체 검출에 이용가능하게 하기 위해, 이들을 니트로셀룰로스 또는 폴리비닐리덴 디플루오라이드 (PVDF)로 만들어진 막으로 이동시킨다. 막을 겔의 상부의 놓고, 그 위에 여과지의 스택 (stack)을 놓는다. 전체 스택을 모세관 작용에 의해 여과지 위로 이동하는 완충 용액 중에 놓아두어, 이와 단백질을 접촉하게 한다. 단백질을 전달하는 또 다른 방법은 전기블롯팅 (electroblotting)이라고 하며 전류를 사용하여 겔로부터 PVDF 또는 니트로셀룰로스 막으로 단백질을 끌어 온다. 단백질은 이들이 겔 내에서 갖는 조직화를 유지하면서 겔 내부에서 막 위로 이동한다. 이 블롯팅 과정의 결과로, 단백질은 검출을 위해 얇은 표면 층 위에 노출된다 (하기 참조). 비-특이적 단백질 결합 특성을 위해 두 종류의 막이 선택된다 (즉, 모든 단백질에 동일하게 잘 결합함). 단백질 결합이 막과 단백질 사이의 하전된 상호작용뿐만 아니라 소수성 상호작용을 기반으로 한다. 니트로셀롤로스 막은 PVDF보다 저렴하지만, 훨씬 더 취약하고 반복되는 탐침에 잘 견디지 못한다. 겔로부터 막으로의 단백질 전달의 균일성 및 전반적인 효능은 막을 코마시 브릴리언트 블루 (Coomassie Brilliant Blue) 또는 폰소 S (Ponceau S) 염료로 염색하여 확인할 수 있다. 일단 전달되면, 단백질은 표지된 1차 항체, 또는 비표지된 1차 항체를 사용하여 검출되고, 이어서 1차 항체의 Fc 영역에 결합하는 표지된 단백질 A 또는 2차 표지된 항체를 사용하여 간접적으로 검출된다.
C.
면역조직화학
항체는 또한 면역조직화학 (IHC)에 의한 연구를 위해 제조된 신선하게 냉동된 및/또는 포르말린-고정된, 파라핀-포매된 조직 블록 둘 다와 함께 사용될 수 있다. 이러한 미립자 표본으로부터 조직 블록을 제조하는 방법은 다양한 예후 인자의 이전 IHC 연구에서 성공적으로 사용되었으며, 당업자에게 익히 공지되어 있다 (Brown et al., 1990; Abbondanzo et al., 1990; Allred et al., 1990).
간략히는, 냉동-절편은 작은 플라스틱 캡슐의 인산염 완충된 식염수 중에서 실온에서 50 ng의 냉동된 "분쇄된 (pulverized)" 조직을 재수화하고; 원심분리에 의해 입자를 펠릿화하고; 이들을 점성의 포매 매체 (OCT)에 재현탁하고; 캡슐을 뒤집고/뒤집거나 다시 원심분리에 의해 펠릿화하고; -70℃ 이소펜탄 중에서 순간-동결시키고; 플라스틱 캡슐을 절단하고/하거나 조직의 냉동 실린더를 제거하고; 저온유지장치 마이크로톰 척 (cryostat microtome chuck) 위에 조직 실린더를 고정하고/하거나; 캡슐로부터 25-50개의 연속 절편을 절단함에 의해 제조될 수 있다. 대안적으로, 전체 냉동된 조직 샘플은 연속 절편 절단에 사용할 수 있다.
영구-절편은 50 mg 샘플을 플라스틱 마이크로퍼지 튜브에서 재수화하고; 펠릿화하고; 4시간 고정 동안 10% 포르말린 중에서 재수화하고; 세척/펠릿화하고; 따뜻한 2.5% 아가 중에서 재현탁하고; 펠릿화하고; 얼음물 중에서 냉각시켜 아가를 굳히고; 튜브로부터 조직/아가 블록을 제거하고; 파라핀 중에 블록을 침투 및/또는 포매시키고/시키거나; 최대 50개 연속 연구 절편을 절단함을 포함하는 유사한 방법에 의해 제조될 수 있다. 다시, 전체 조직 샘플을 대체할 수 있다.
D.
면역검출 키트
추가 구현예에서, 상기에 기술된 면역검출 방법과 함께 사용하기 위한 면역검출 키트가 있다. 따라서 면역검출 키트는 적합한 용기 수단에, PD-L1 및/또는 PD-L2 항원에 결합하는 1차 이중특이적 항체, 및 임의로 면역검출 시약을 포함할 것이다.
특정 구현예에서, PD-L1 및 PD-L2에 대한 이중특이적 항체는 칼럼 매트릭스 및/또는 미세역가 플레이트의 웰과 같은 고체 지지체에 미리-결합될 수 있다. 키트의 면역검출 시약은 주어진 항체와 연관되거나 그에 연결된 검출가능한 표지를 포함하는 다양한 형태 중 어느 하나를 취할 수 있다. 2차 결합 리간드와 연관되거나 그에 부착된 검출가능한 표지가 또한 고려된다. 예시적인 2차 리간드는 1차 항체에 대해 결합 친화도를 갖는 2차 항체이다.
본 키트에 사용하기 위한 추가로 적합한 면역검출 시약은 2차 항체에 대한 결합 친화도를 갖는 3차 항체와 함께, 1차 항체에 대한 결합 친화도를 갖는 2차 항체를 포함하는 2-성분 시약을 포함하고, 여기서 3차 항체는 검출가능한 표지에 연결된다. 위에서 언급한 바와 같이, 다수의 예시적인 표지가 당업계에 공지되어 있고 모든 이러한 표지는 본원에 논의된 구현예와 관련하여 사용될 수 있다.
키트는 검출 분석을 위한 표준 곡선을 준비하는데 사용될 수 있는 바와 같이, 표지된 또는 표지되지 않은, PD-L1 및 PD-L2 항원의 적절하게 분취된 조성물을 추가로 포함할 수 있다. 키트는 완전히 접합된 형태, 중간체 형태, 또는 키트의 사용자에 의해 접합될 별개의 모이어티 중 하나로서 항체-표지 접합체를 함유할 수 있다. 키트의 구성요소는 수성 매질 중에 또는 동결건조된 형태로 포장될 수 있다.
키트의 용기 수단은 일반적으로 적어도 하나의 바이알, 시험관, 플라스크, 병, 주사기 또는 다른 용기 수단을 포함할 것이며, 이들 내에 항체가 배치되거나, 바람직하게는 적절히 분취될 수 있다. 키트는 또한 항체, 항원, 및 상업적 판매를 위해 밀접 밀봉된 임의의 다른 시약 용기를 담기 위한 수단을 포함할 것이다. 이러한 용기는 원하는 바이알이 보관되는 주입 또는 취입-성형 플라스틱 용기를 포함할 수 있다.
다음 도면은 본 출원 명세서의 일부를 형성하고 본 발명의 특정 측면을 추가로 입증하기 위해 포함된다. 본 발명은 본원에 제시된 특정 구현예의 상세한 설명과 함께 하나 이상의 이들 도면을 참조하여 더 잘 이해될 수 있다.
도 1A-1C - PD-1에 대한 PD-L1/PD-L2 결합을 차단하는 이중특이적 PD-L1/PD-L2 (BiPDL) 항체의 확인. 실시예에 기술된 바와 같이 확인된 항체 후보를 PD-L1 또는 PD-L2에 결합하고 PD-1에 대한 이들의 결합을 차단하는 능력에 대해 시험하였다. 5 μg/mL의 항체를 CHO-PD-L1 또는 CHO-PD-L2 세포에 결합시킨 후 알렉사플루오르 532로 표지된 재조합 PD-1을 1시간 동안 첨가하였다. (도 1A) PD-1+ 세포의 비율이 표시된다. (도 1B) 알렉사플루오르 532 표지된 PD-1의 최대 형광 강도를 측정하였고, PD-L1 또는 PD-L2 차단은 FACS 분석에서 알렉사532 형광의 감소로서 간주되었다. BiPDL 항체 클론 1-4, (ADI-16413, -16414, -16415, 및 -16418)를 염색되지 않은 세포, 대조군 항체, 두르발루맙 (Durvalumab) (항-PD-L1), 및 상업적으로 이용가능한 항-PD-L2 항체에 대해 평가하였다. (도 1C) 후보 BiPDL 단일클론 항체를 Promega PD-L1:PD-1 차단 시스템을 사용하여 분석하였다.
도 2A-2D - PD-L1 및 PD-L2에 결합하는 이중특이적 항체 서브클론의 확인. 이중특이적 항체 BiPDL3 또는 BiPDL4의 서브클론을 CHO-PD-L1 (도 2A 및 2C) 또는 CHO-PD-L2 세포 (도 2B 및 2D)에 대한 결합에 대해 분석하였다. 지시된 농도의 BiPDL (인간 IgG1) 항체를 지시된 세포에 첨가하고 PE에 접합된 항-인간 IgG1 2차 항체를 첨가하여 결합을 검출하였다. ForteBio Octet® 플랫폼 상에서 반응을 수행하였다.
도 3 - FDA 승인된 항체 치료제 대비 이중특이적 항체의 평가. Promega PD-L1:PD-1 차단 시스템 및 PD-L2:PD-1 차단 시스템 둘 다를 사용하여 후보 BiPDL 단일클론 항체를 분석하였다. 다양한 농도의 항체를 PD-1을 안정적으로 발현하는 Jurkat T 세포를 자극할 수 있는 CHO-PD-L1 또는 CHO-PD-L2 (CHO-PD-L1/2) 세포에 첨가하였다. 공동-배양되는 경우, CHO-PD-L1/2 세포 및 Jurkat T 세포 사이의 상호작용은 발광을 억제한다. PD-L1, PD-L2, PD-1, 또는 BiPDL 항체의 첨가에 의한 활성화 중단 시, 발광이 유도된다. Jurkat T 세포를 지정된 농도의 지정된 항체 및 CHO-PD-L1/2 세포와 6시간 동안 인큐베이션하였다. Bio-Glo?? 분석 키트 (Promega)를 사용하여 결과를 생성하였다.
도 4A-4F - 2, 3, 및 4세대 BiPDL 항체의 평가. 후보 2세대 (도 4A-B), 3세대 (도 4C-D), 및 4세대 (도 4E-F) BiPDL 단일클론 항체를 다시 Promega PD-L1/PD-L2:PD-1 차단 시스템을 사용하여 분석하였다. 키트루다 (Keytruda)를 양성 대조군 항-PD-L2 항체로 사용하였고 (도 4B-D), 다르발루맙 (Darvalumab)을 대조군 항-PD-L1 항체로 사용하였다 (도 4C-D). PD-1에 대한 Promega의 대조군 mAb를 또한 대조군으로 사용하였다 (도 4C-D).
도 5A-5C - 후보 BiPDL 항체는 여러 인간 혼합 림프구 반응에 걸쳐 활성이다. 후보 항체, FDA 승인된 항체, 또는 대조군 항체를 별도 공여자로부터의 유도된 수지상 세포 및 T-세포의 존재하에서 평가하고 IL-2 또는 IFN-γ 생산에 대해 ELISA로 평가하였다. (도 5A) 자기-분류된 iDCs를 인간 PD-L1 및 PD-L2의 발현에 대한 유세포 분석으로 분석하였다. (도 5B) 키트루다 (항-PD-1), 아테졸리주맙 (Atezolizumab) (항-PD-L1), 4세대 BiPDL 항체, 및 이소형 대조군을 CD4+ T 세포의 첨가 전에 IDCs에 첨가하였다. (도 5C) 다른 4세대 BiPDL 항체를 아테졸리주맙 및 이소형 대조군과 함께 평가하였다. CD4+ T 세포의 첨가 전에 각각을 IDCs에 첨가하였다.
도 6 - BiPDL 항체는 인간 PD-L1/PD-L2 + 림프종에 대해 효율적인 ADCC를 매개한다. 다양한 농도의 BiPDL 항체 (마우스 IgG2a)를 시험관 내 확장된 뮤린 NK 세포와 함께 15:1의 이펙터 대 표적 비율로 칼세인-표지된 (Calcein-labelled) U2940 PMBL 세포에 첨가하였다. 특이적 용해 비율을 형광 플레이트 판독기 상에서 측정된 칼세인의 실험적 방출 및 자발적 방출 사이의 차이로 계산하였다.
도 7A-7C - ADCC를 갖는 후보 항체는 생체 내에서 인간 U2940 림프종에 대해 매우 활성이다. SCID 마우스에서 PBML 이종이식 종양을 확립하고 150 mm3에 도달하게 하였다. (도 7A) 세포를 유세포 분석에 의해 PD-L1 또는 PD-L2 발현에 대해 분석하였다. (도 7B-C) 마우스를 mIgG2a 대조군 항체, 허셉틴 (Herceptin), 리툭산 (Rituxan), 또는 지시된 BiPDL 항체 중 하나로 주 2회 10 mg/kg으로 3주간 처리하고, 종양 부피를 지시된 일자에 캘리퍼 (caliper)로 평가하였다.
도 8A-8B - 후보 항체는 MDA-MB-231에 대해 활성이다. MDA-MB-231 삼중-음성 유방암 이종이식 종양을 SCID 마우스에서 확립하고 150 mm3에 도달하게 하였다. (도 8A) 세포를 유세포 분석에 의해 PD-L1 또는 PD-L2 발현에 대해 분석하였다. (도 8B) 그 후에 마우스를 주 2회 10 mg/kg으로 3주간 지시된 항체로 처리하였다. 표시된 데이터는 그룹당 9마리 마우스를 사용한 단일 실험으로부터 얻은 것이고, 종양 부피를 지시된 일자에 평가하였다.
도 9A-9C - BiPDL 항체는 PD-L1 항체보다 동계 (syngeneic) MC38-PD-L2 결장암을 보다 효과적으로 치료한다. 5×105 MC38-PDL2 종양 세포를 C57BL/6J 마우스에 피하 이식하였다. 마우스를 3, 6, 9, 12, 및 15일째에 100 μg의 지시된 항체로 처리하였다. (도 9A) 그룹당 10마리 마우스의 단일 실험에 대한 생존이 표시된다 (Gehran-Breslow-Wilcoxon 테스트를 통한 p 값). (도 9B) 옆구리에서 MC-38-PD-L2 종양의 성장을 캘리퍼로 측정하고 임의의 종양이 ≥1000 mm3으로 측정되는 그러한 시점까지 모든 그룹에 대해 종양 부피가 표시된다. (도 9C) PD-L1 및 PD-L2의 존재를 유세포 분석으로 평가하였다.
도 10A-10B - 항체-의존적 세포-매개 세포독성 (ADCC)을 갖는 BiPDL 항체는 MC38-PD-L2 마우스에서 유리한 CD8 대 Treg 비율을 생성한다. 1.5×106 MC38-PDL2 종양 세포를 30% 마트리겔 (Matrigel) (Corning)에서 C57BL/6J 마우스에 피하로 이식하고 7, 10, 및 13일째에 100 μg의 지시된 항체를 복강 내로 주사하여 처리하였다. 15일째에, 종양을 수확하였다. (도 10A) PD-L1 및 PD-L2의 존재를 유세포 분석으로 평가하였다. (도 10B) FoxP3+ Treg에 대한 침윤성 CD8 T 세포의 비율을 유세포 분석으로 측정하였다.
도 11A-11B - BiPDL 항체는 PD-L1 또는 PD-L2 차단보다 더 효과적으로 전신 EL4 T 세포 림프종을 치료한다. 생체발광 이미징을 용이하게 하기 위해 루시퍼라제를 또한 발현하는, 1.5×105 EL4-PD-L2 세포를 C57BL/6J 마우스에 이식하여 전신 질환을 확인하였다. 3, 6, 9, 12 및 15일째 마우스에 100 μg의 지시된 항체를 주사로 투여하였다. (도 11A) 유세포 분석을 사용하여 PD-L1 및 PD-L2의 존재를 평가하였다. (도 11B) 그룹당 5마리 마우스를 사용하는 1-3회의 독립적인 실험 (그룹에 따라 다름)에 대해 생존이 표시된다. Gehran-Breslow-Wilcoxon 테스트를 사용하여 생존 통계를 계산하였다.
도 12. Promega PD-L1/PD-L2 분석에서 PD-1 차단에 대한 동등성 및 PD-L1 차단에 대한 우월성. BiPDL3-14는 PD-1 참여를 완전히 차단한다. T 세포 활성화 요소 및 인간 PD-L1 및 PD-L2를 발현하는 CHO 세포 및 NFAT-루시퍼라제 리포터를 갖는 Jurkat T 세포로 구성된 Promega PD-1 분석을 사용하여 PD-1-매개 T 세포 억제를 차단하는 키트루다, 테센트릭 (Tecentriq) 및 BiPDL의 능력을 시험하였다.
도 13. F16-F10-PDL2 데이터는 "저온 (cold)" 종양에서 이펙터 BiPDL3 항체의 가능성을 시사한다. BiPDL3은 PD-1 내성 B16 흑색종을 치료할 수 있다. 옆구리에 5×104 B16.F10 흑색종이 이식된 마우스를 3, 6, 9, 12일째에 지시된 항체, 즉 ADCC/P를 증강시키기 위해 T236A, S239D, I332E 돌연변이를 갖는 hIgG1인 GASDIE로 처리하였다.
도 1A-1C - PD-1에 대한 PD-L1/PD-L2 결합을 차단하는 이중특이적 PD-L1/PD-L2 (BiPDL) 항체의 확인. 실시예에 기술된 바와 같이 확인된 항체 후보를 PD-L1 또는 PD-L2에 결합하고 PD-1에 대한 이들의 결합을 차단하는 능력에 대해 시험하였다. 5 μg/mL의 항체를 CHO-PD-L1 또는 CHO-PD-L2 세포에 결합시킨 후 알렉사플루오르 532로 표지된 재조합 PD-1을 1시간 동안 첨가하였다. (도 1A) PD-1+ 세포의 비율이 표시된다. (도 1B) 알렉사플루오르 532 표지된 PD-1의 최대 형광 강도를 측정하였고, PD-L1 또는 PD-L2 차단은 FACS 분석에서 알렉사532 형광의 감소로서 간주되었다. BiPDL 항체 클론 1-4, (ADI-16413, -16414, -16415, 및 -16418)를 염색되지 않은 세포, 대조군 항체, 두르발루맙 (Durvalumab) (항-PD-L1), 및 상업적으로 이용가능한 항-PD-L2 항체에 대해 평가하였다. (도 1C) 후보 BiPDL 단일클론 항체를 Promega PD-L1:PD-1 차단 시스템을 사용하여 분석하였다.
도 2A-2D - PD-L1 및 PD-L2에 결합하는 이중특이적 항체 서브클론의 확인. 이중특이적 항체 BiPDL3 또는 BiPDL4의 서브클론을 CHO-PD-L1 (도 2A 및 2C) 또는 CHO-PD-L2 세포 (도 2B 및 2D)에 대한 결합에 대해 분석하였다. 지시된 농도의 BiPDL (인간 IgG1) 항체를 지시된 세포에 첨가하고 PE에 접합된 항-인간 IgG1 2차 항체를 첨가하여 결합을 검출하였다. ForteBio Octet® 플랫폼 상에서 반응을 수행하였다.
도 3 - FDA 승인된 항체 치료제 대비 이중특이적 항체의 평가. Promega PD-L1:PD-1 차단 시스템 및 PD-L2:PD-1 차단 시스템 둘 다를 사용하여 후보 BiPDL 단일클론 항체를 분석하였다. 다양한 농도의 항체를 PD-1을 안정적으로 발현하는 Jurkat T 세포를 자극할 수 있는 CHO-PD-L1 또는 CHO-PD-L2 (CHO-PD-L1/2) 세포에 첨가하였다. 공동-배양되는 경우, CHO-PD-L1/2 세포 및 Jurkat T 세포 사이의 상호작용은 발광을 억제한다. PD-L1, PD-L2, PD-1, 또는 BiPDL 항체의 첨가에 의한 활성화 중단 시, 발광이 유도된다. Jurkat T 세포를 지정된 농도의 지정된 항체 및 CHO-PD-L1/2 세포와 6시간 동안 인큐베이션하였다. Bio-Glo?? 분석 키트 (Promega)를 사용하여 결과를 생성하였다.
도 4A-4F - 2, 3, 및 4세대 BiPDL 항체의 평가. 후보 2세대 (도 4A-B), 3세대 (도 4C-D), 및 4세대 (도 4E-F) BiPDL 단일클론 항체를 다시 Promega PD-L1/PD-L2:PD-1 차단 시스템을 사용하여 분석하였다. 키트루다 (Keytruda)를 양성 대조군 항-PD-L2 항체로 사용하였고 (도 4B-D), 다르발루맙 (Darvalumab)을 대조군 항-PD-L1 항체로 사용하였다 (도 4C-D). PD-1에 대한 Promega의 대조군 mAb를 또한 대조군으로 사용하였다 (도 4C-D).
도 5A-5C - 후보 BiPDL 항체는 여러 인간 혼합 림프구 반응에 걸쳐 활성이다. 후보 항체, FDA 승인된 항체, 또는 대조군 항체를 별도 공여자로부터의 유도된 수지상 세포 및 T-세포의 존재하에서 평가하고 IL-2 또는 IFN-γ 생산에 대해 ELISA로 평가하였다. (도 5A) 자기-분류된 iDCs를 인간 PD-L1 및 PD-L2의 발현에 대한 유세포 분석으로 분석하였다. (도 5B) 키트루다 (항-PD-1), 아테졸리주맙 (Atezolizumab) (항-PD-L1), 4세대 BiPDL 항체, 및 이소형 대조군을 CD4+ T 세포의 첨가 전에 IDCs에 첨가하였다. (도 5C) 다른 4세대 BiPDL 항체를 아테졸리주맙 및 이소형 대조군과 함께 평가하였다. CD4+ T 세포의 첨가 전에 각각을 IDCs에 첨가하였다.
도 6 - BiPDL 항체는 인간 PD-L1/PD-L2 + 림프종에 대해 효율적인 ADCC를 매개한다. 다양한 농도의 BiPDL 항체 (마우스 IgG2a)를 시험관 내 확장된 뮤린 NK 세포와 함께 15:1의 이펙터 대 표적 비율로 칼세인-표지된 (Calcein-labelled) U2940 PMBL 세포에 첨가하였다. 특이적 용해 비율을 형광 플레이트 판독기 상에서 측정된 칼세인의 실험적 방출 및 자발적 방출 사이의 차이로 계산하였다.
도 7A-7C - ADCC를 갖는 후보 항체는 생체 내에서 인간 U2940 림프종에 대해 매우 활성이다. SCID 마우스에서 PBML 이종이식 종양을 확립하고 150 mm3에 도달하게 하였다. (도 7A) 세포를 유세포 분석에 의해 PD-L1 또는 PD-L2 발현에 대해 분석하였다. (도 7B-C) 마우스를 mIgG2a 대조군 항체, 허셉틴 (Herceptin), 리툭산 (Rituxan), 또는 지시된 BiPDL 항체 중 하나로 주 2회 10 mg/kg으로 3주간 처리하고, 종양 부피를 지시된 일자에 캘리퍼 (caliper)로 평가하였다.
도 8A-8B - 후보 항체는 MDA-MB-231에 대해 활성이다. MDA-MB-231 삼중-음성 유방암 이종이식 종양을 SCID 마우스에서 확립하고 150 mm3에 도달하게 하였다. (도 8A) 세포를 유세포 분석에 의해 PD-L1 또는 PD-L2 발현에 대해 분석하였다. (도 8B) 그 후에 마우스를 주 2회 10 mg/kg으로 3주간 지시된 항체로 처리하였다. 표시된 데이터는 그룹당 9마리 마우스를 사용한 단일 실험으로부터 얻은 것이고, 종양 부피를 지시된 일자에 평가하였다.
도 9A-9C - BiPDL 항체는 PD-L1 항체보다 동계 (syngeneic) MC38-PD-L2 결장암을 보다 효과적으로 치료한다. 5×105 MC38-PDL2 종양 세포를 C57BL/6J 마우스에 피하 이식하였다. 마우스를 3, 6, 9, 12, 및 15일째에 100 μg의 지시된 항체로 처리하였다. (도 9A) 그룹당 10마리 마우스의 단일 실험에 대한 생존이 표시된다 (Gehran-Breslow-Wilcoxon 테스트를 통한 p 값). (도 9B) 옆구리에서 MC-38-PD-L2 종양의 성장을 캘리퍼로 측정하고 임의의 종양이 ≥1000 mm3으로 측정되는 그러한 시점까지 모든 그룹에 대해 종양 부피가 표시된다. (도 9C) PD-L1 및 PD-L2의 존재를 유세포 분석으로 평가하였다.
도 10A-10B - 항체-의존적 세포-매개 세포독성 (ADCC)을 갖는 BiPDL 항체는 MC38-PD-L2 마우스에서 유리한 CD8 대 Treg 비율을 생성한다. 1.5×106 MC38-PDL2 종양 세포를 30% 마트리겔 (Matrigel) (Corning)에서 C57BL/6J 마우스에 피하로 이식하고 7, 10, 및 13일째에 100 μg의 지시된 항체를 복강 내로 주사하여 처리하였다. 15일째에, 종양을 수확하였다. (도 10A) PD-L1 및 PD-L2의 존재를 유세포 분석으로 평가하였다. (도 10B) FoxP3+ Treg에 대한 침윤성 CD8 T 세포의 비율을 유세포 분석으로 측정하였다.
도 11A-11B - BiPDL 항체는 PD-L1 또는 PD-L2 차단보다 더 효과적으로 전신 EL4 T 세포 림프종을 치료한다. 생체발광 이미징을 용이하게 하기 위해 루시퍼라제를 또한 발현하는, 1.5×105 EL4-PD-L2 세포를 C57BL/6J 마우스에 이식하여 전신 질환을 확인하였다. 3, 6, 9, 12 및 15일째 마우스에 100 μg의 지시된 항체를 주사로 투여하였다. (도 11A) 유세포 분석을 사용하여 PD-L1 및 PD-L2의 존재를 평가하였다. (도 11B) 그룹당 5마리 마우스를 사용하는 1-3회의 독립적인 실험 (그룹에 따라 다름)에 대해 생존이 표시된다. Gehran-Breslow-Wilcoxon 테스트를 사용하여 생존 통계를 계산하였다.
도 12. Promega PD-L1/PD-L2 분석에서 PD-1 차단에 대한 동등성 및 PD-L1 차단에 대한 우월성. BiPDL3-14는 PD-1 참여를 완전히 차단한다. T 세포 활성화 요소 및 인간 PD-L1 및 PD-L2를 발현하는 CHO 세포 및 NFAT-루시퍼라제 리포터를 갖는 Jurkat T 세포로 구성된 Promega PD-1 분석을 사용하여 PD-1-매개 T 세포 억제를 차단하는 키트루다, 테센트릭 (Tecentriq) 및 BiPDL의 능력을 시험하였다.
도 13. F16-F10-PDL2 데이터는 "저온 (cold)" 종양에서 이펙터 BiPDL3 항체의 가능성을 시사한다. BiPDL3은 PD-1 내성 B16 흑색종을 치료할 수 있다. 옆구리에 5×104 B16.F10 흑색종이 이식된 마우스를 3, 6, 9, 12일째에 지시된 항체, 즉 ADCC/P를 증강시키기 위해 T236A, S239D, I332E 돌연변이를 갖는 hIgG1인 GASDIE로 처리하였다.
VII.
실시예
다음 실시예는 본 발명의 바람직한 구현예를 입증하기 위해 포함된다. 당업자라면 하기 실시예에 기술된 기술이 본 발명의 실행에서 잘 기능하기 위해 본 발명자에 의해 발견된 기술을 나타내고, 따라서 그의 실행을 위한 바람직한 모드를 구성하는 것으로 간주될 수 있음을 이해해야 한다. 그러나 당업자는 본 개시내용에 비추어 기술된 특정 구현예에서 다수의 변경이 이루어질 수 있고 본 발명의 사상 또는 범주를 벗어나지 않으면서 여전히 유사하거나 또는 비슷한 결과를 얻을 수 있음을 인식해야 한다.
실시예 1 - 재료 및 방법
항체 선택, 생성, 및 생산. 추가 세부사항이 후속 실시예에서 제공될 수 있지만, 기술된 항체의 선택, 생성, 및 생산을 일반적으로 다음과 같이 수행되었다.
항원 준비 - 항원을 Pierce사의 EZ-연결 설포-NHS-비오틴화 키트를 사용하여 비오틴화시켰다. 염소 F(ab')2 항-인간 카파-FITC (LC-FITC), Extr아비딘-PE (EA-PE) 및 스트렙타비딘-AF633 (SA-633)을 각각 Southern Biotech, Sigma, 및 Molecular Probes로부터 입수하였다. 스트렙타비딘 마이크로비드 (MicroBeads) 및 MACS LC 분리 칼럼을 Miltenyi Biotec로부터 구입하였다. 염소 항-인간 IgG-PE (인간-PE)를 Southern Biotech로부터 입수하였다.
나이브 디스커버리 (Naive Discovery) - 각각 ~109 다양성의 8개의 나이브 인간 합성 효모 라이브러리를 이전에 기술된 바와 같이 증식시켰다 (예컨대, Xu et al., 2013; WO2009036379; WO2010105256; 및 WO2012009568 참조). 최초 2회 라운드의 선택의 경우, 이전에 기술된 바와 같이 (예컨대, Siegel et al., 2004 참조), Miltenyi MACS 시스템을 사용하는 자기 비드 분류 기법을 수행하였다. 요약하면, 효모 세포 (~1010 세포/라이브러리)를 세척 완충제 (인산염-완충 식염수 (PBS)/0.1% 소 혈청 알부민 (BSA)) 중에서 3 ml의 10 nM 비오틴화된 Fc 융합-항원과 30℃에서 15분간 인큐베이션하였다. 40 ml의 빙냉 세척 완충제로 1회 세척 후, 세포 펠릿을 20 mL의 세척 완충제에 재현탁하고, 스트렙타비딘 마이크로비드 (500 μl)를 효모에 첨가하여 4℃에서 15분간 인큐베이션하였다. 이어서, 효모를 펠릿화하고, 20 mL의 세척 완충제에 재현탁하고, Miltenyi LS 칼럼 상에 로딩하였다. 20 mL을 로딩한 후, 칼럼을 3 ml의 세척 완충제로 3회 세척하였다. 그 후에 칼럼을 자기장으로부터 제거하고, 효모를 5 mL의 성장 배지로 용출한 후 밤새 성장시켰다. 다음 라운드의 선택은 유세포 분석을 사용하여 수행하였다. 대략 2×107 효모가 펠릿화되고, 이를 세척 완충제로 3회 세척한 후 10 nM Fc-융합 항원과 함께, 또는 평형 조건에서 비오틴화된 항원의 농도 (100 내지 1 nM)를 감소시키는 이후 라운드에서, 종-교차 반응성을 얻기 위해 다른 종 (마우스)의 100 nM 비오틴화된 항원과 함께, 또는 선택으로부터 비특이적 항체를 제거하기 위해 다중-특이성 고갈 시약 (PSR)과 함께 30℃에서 인큐베이션하였다. PSR 고갈을 위해, 이전에 기술된 바와 같이 (예컨대, Xu et al., 2013 참조), 라이브러리를 비오틴화된 PSR 시약의 1:10 희석액과 함께 인큐베이션하였다. 그 후에 효모를 세척 완충제로 2회 세척하고 LC-FITC (1:100으로 희석됨) 및 SA-633 (1:500으로 희석됨) 또는 EAPE (1:50으로 희석됨) 2차 시약 중 하나로 4℃에서 15분간 염색하였다. 세척 완충제로 2회 세척 후, 세포 펠릿을 0.3 mL의 세척 완충제에 재현탁하고 여과기-캡핑된 (strainer-capped) 분류 튜브로 옮겼다. FACS ARIA 분류기 (BD Biosciences)를 사용하여 분류를 수행하고 분류 게이트 (sort gate)를 결정하여 원하는 특성을 갖는 항체를 선별하였다. 원하는 특성 모두를 갖는 집단이 달성될 때까지 선택 라운드를 반복하였다.
교차-반응성 항체를 생성하기 위해, 독립적으로 각각의 표적 항원을 사용하는 상기에 기술된 바와 같은 선택을 라운드에서 라운드로 번갈아 수행하여 이중 특이성에 대해 농축시켰다. 분류의 최종 라운드 후, 효모를 도말하고 특성화를 위해 개별 콜로니를 선택하였다.
경쇄 배치 셔플 (light chain batch shuffle, LCBS) - 1차 발견은 또한 나이브 선택으로부터 중쇄 플라스미드의 경쇄 배치 다양화 프로토콜을 포함하였다: 나이브 라운드 4회 선택 출력으로부터의 중쇄 플라스미드를 효모로부터 추출하고 5×106의 다양성을 갖는 경쇄 라이브러리 내로 형질전환시켰다. 나이브 디스커버리와 동일한 조건을 사용하는 1회 라운드의 MACS 및 3회 라운드의 FACS로 선택을 수행하였다.
항체 최적화 - 하기에 기술된 바와 같은 중쇄 및 경쇄 가변 영역 내로 다양성을 도입하여 항체의 최적화를 수행하였다. 이들 접근법의 일부 조합을 각 항체에 대해 사용하였다.
CDRH1 및 CDRH2 선택: 단일 항체의 CDRH3을 1×108 다양성의 CDRH1 및 CDRH2 변형체를 갖는 이미 만들어진 라이브러리 내로 재조합하고 나이브 디스커버리에서 기술된 바와 같은 1회 라운드의 MACS 및 4회 라운드의 FACS로 선택을 수행하였다. FACS 라운드에서 PSR 결합, 종 교차-반응성, 항원 교차-반응성 및 친화도 압력에 대해 라이브러리를 조사하였고, 원하는 특성을 갖는 집단을 얻기 위해 분류를 수행하였다. 이러한 선택을 위해, 비오틴화된 단량체 항원을 적정하거나 비오틴화된 항원을 모체 (parental) Fab와 30분간 사전 인큐베이션한 후 사전 복합체화된 혼합물을 선택이 평형에 도달하게 할 시간 동안 효모 라이브러리에 적용함으로써 친화도 압력을 적용하였다. 그 후에 더 높은 친화도 항체를 분류할 수 있었다.
VH Mut 선택: 중쇄 가변 영역 (VH)을 오류 경향 (error prone) PCR을 통해 돌연변이시켰다. 그 후에 이렇게 돌연변이된 VH 및 중쇄 발현 벡터를 이미 본 발명의 경쇄 플라스미드를 함유하는 효모 내로 형질전환시켜 라이브러리를 생성시켰다. 3회 라운드 동안 FACS 분류를 사용하여 이전 주기와 유사하게 선택을 수행하였다. FACS 라운드에서, 교차-반응성 및 친화도 압력에 대해 라이브러리를 조사하였고, 원하는 특성을 갖는 집단을 얻기 위해 분류를 수행하였다.
CDRL1, CDRL2 및 CDRL3 선택: CDRL3을 포함하고 NNK 다양성을 통해 다양화된 올리고를 IDT로부터 주문하였다. CDRL3 올리고는 CDRL3의 측면 영역 (flanking region)에 어닐링된 프라미어를 사용하여 이중-가닥으로 되었다. 그 후에 이들 이중-가닥의 CDRL3 올리고를 3×105의 다양성으로 CDRL1 및 CDRL2 변형체를 갖는 이미 만들어진 라이브러리 내로 재조합하고, 나이브 디스커버리에서 기술된 바와 같이 1회 라운드의 MACS 및 3회 라운드의 FACS로 선택을 수행하였다. FACS 라운드에서, PSR 결합, 교차-반응성, 및 친화도 압력에 대해 라이브러리를 조사하였고, 원하는 특성을 갖는 집단을 얻기 위해 분류를 수행하였다. 이러한 선택을 위한 친화도 압력을 CDRH1 및 CDRH2 선택에서 상기에 기술된 바와 같이 수행하고 라운드에서 라운드로 항원을 번갈아 대체 적용하여 이중 결합제에 대해 풍부하게 하였다.
항체 생산 및 정제 - 효모 클론을 포화 상태로 성장시킨 후 교반하면서 30℃에서 48시간 동안 유도하였다. 유도 후, 효모 세포를 펠릿화하고 상청액을 정제를 위해 수확하였다. 단백질 A 칼럼을 사용하여 IgG를 정제하고 pH 2.0의 아세트산으로 용출시켰다. 파파인 소화로 Fab 단편을 생성시키고 KappaSelect (GE Healthcare LifeSciences)에 걸쳐서 정제하였다.
ForteBio K D 측정 - ForteBio 친화도 측정을 이전에 기술된 바와 같이 일반적으로 Octet RED384 상에서 수행하였다 (예컨대, Estep et al., 2013 참조). 요약하면, IgG를 온-라인으로 (on-line) AHQ 센서 상에 로딩하여 ForteBio 친화도 측정을 수행하였다. 센서를 30분간 분석 완충제 중에서 오프-라인으로 평형화한 후 기준선 설정을 위해 60초간 온-라인으로 모니터링하였다. IgG가 로딩된 센서를 3분간 100 nM 항원에 노출시키고, 그 후에 오프-레이트 (off-rate) 측정을 위해 3분간 분석 완충제로 옮겼다. 1가 친화도 평가를 위해, IgG 대신 Fab를 사용하였다. 이 평가를 위해, 비오틴화되지 않은 Fc 융합 항원을 온-라인으로 AHQ 센서 상에 로딩하였다. 센서를 30분간 오프-라인으로 분석 완충제 중에서 평형화한 후 기준선 설정을 위해 60초간 온-라인으로 모니터링하였다. 항원이 로딩된 센서를 3분간 100 nM Fab에 노출시키고, 그 후에 이들을 오프-레이트 측정을 위해 3분간 분석 완충제로 옮겼다. 모든 역학은 1:1 결합 모델을 사용하여 분석하였다.
ForteBio 에피토프 비닝 (Epitope binning)/리간드 차단 - 표준 샌드위치 포맷 교차-차단 분석을 사용하여 에피토프 비닝/리간드 차단을 수행하였다. 대조군 항-표적 IgG를 AHQ 센서 상에 로딩하고 센서 상의 비점유된 Fc-결합 부위를 관련 없는 인간 IgG1 항체로 차단하였다. 그 후에 센서를 100 nM 표적 항원에 노출시키고 이어서 2차 항-표적 항체 또는 리간드에 노출시켰다. 항원 결합 후 2차 항체 또는 리간드에 의한 추가 결합은 점유되지 않은 에피토프 (비-경쟁자)를 나타내는 반면, 결합 부재는 에피토프 차단 (경쟁자 또는 리간드 차단)을 나타낸다.
MSD-SET K D 측정 - 선택된 고 친화도 항체의 평형 친화도 측정을 이전에 기술된 바와 같이 일반적으로 수행하였다 (Estep et al., 2013). 요약하면, 항원이 50 pM로 일정하게 유지되는 PBS + 0.1% 무-IgG BSA (PBSF) 중에서 용액 평형 적정 (SET)을 수행하고 20 nM로 시작하는 Fab의 3- 내지 5-배 연속 희석액과 함께 인큐베이션하였다. 항체 (PBS 중에 20 nM)를 표준 결합 MSD-ECL 플레이트 상에 4℃에서 밤새 또는 실온에서 30분간 코팅하였다. 그 후에 플레이트를 700 rpm에서 교반하면서 BSA로 30분간 차단한 후 세척 완충제 (PBSF + 0.05% 트윈 20)으로 3회 세척하였다. SET 샘플을 플레이트에 적용하고 700 rpm으로 교반하면서 150초간 인큐베이션한 후 1회 세척하였다. 플레이트 상에 포획된 항원을 PBSF 중의 250 ng/mL 설포태그 (sulfotag)-표지된 스트렙타비딘으로 플레이트 상에서 3분간 인큐베이션함으로써 검출하였다. 플레이트를 세척 완충제로 3회 세척한 후 계면활성제 함유 1× Read Buffer T를 사용하여 MSD Sector Imager 2400 기기에서 판독하였다. 자유 항원 백분율을 Prism에서 적정된 항체의 함수로 플롯팅하고 2차 방정식에 핏팅시켜 KD를 추출하였다. 처리량을 개선하기 위해, 샘플 준비를 비롯해 MSD-SET 실험 전반에 걸쳐 액체 취급 로봇을 사용하였다.
세포 결합 분석 - 항원을 과발현하는 대략 100,000개 세포를 세척 완충제로 세척하고 실온에서 5분간 100 μl의 100 nM IgG와 인큐베이션하였다. 그 후에 세포를 세척 완충제로 2회 세척하고 얼음 중에서 100 μl의 1:100 인간-PE와 15분간 인큐베이션하였다. 이어서 세포를 세척 완충제로 2회 세척하고 FACS Canto II 분석기 (BD Biosciences) 상에서 분석하였다.
항체 스크리닝 및 특성화. 상기에 기술된 제시 방법으로부터 생성된 항체 후보를 PD-L1 및 PD-L2에 결합하고, PD-1에 대한 이들의 결합을 차단하는 능력에 대해 시험하였다. 5 μg/ml의 항체를 CHO-PD-L1 또는 CHO-PD-L2 세포에 결합시킨 후 알렉사 532 (ThermoFisher)로 표지된 재조합 PD-1 (RnD Systems)을 1시간 동안 첨가하였다. PD-1 최대 형광 강도를 측정하였다. PD-1 결합 차단을 유세포 분석에 의한 알렉사 532 형광의 감소에 의해 측정하였다. 인간 PD-L1 또는 PD-L2에 대한 친화도 KD를 생성하기 위해, BiPDL Ab를 항-인간 Fc 포획 (AHC) 바이오센서 상에 100 nM (15 μg/mL)으로 로딩하였고, 인간 PD-L1 또는 -L2 단백질 결합 및 해리를 30-0.37 nM의 희석 시리즈에서 시험하였다. 분석물의 결합 및 방출을 실시간으로 Octet 기기에 기록한 후 Kd, Kon, 및 Kdis를 계산하는데 사용하였으며; 결과는 참조 웰 공제 (reference well subtraction)를 이용한 2:1 Global Fit Modeling으로부터 유래한다. 뮤린 PD-L1 또는 PD-L2에 대한 친화도 KD를 생성하기 위해, BiPDL Ab를 활성화된 아민 반응성 2세대 (AR2G) 바이오센서 (단백질 로딩 후 1 M 에탄올아민 (pH 8.5)로 켄칭됨) 상에 100 nM (15 μg/mL)으로 공유적으로 고정화하고, 마우스 PD-L1 및 PD-L2 단백질 결합 및 해리를 300-1 nM의 희석 시리즈에서 시험하였다. 분석물의 결합 및 방출을 실시간으로 Octet 기기에 기록한 후 Kd, Kon, 및 Kdis를 계산하는데 사용하였으며; 결과는 참조 웰 공제를 이용한 2:1 Global Fit Modeling으로부터 유래한다.
항체 활성. 인간 IgG1 백본을 갖는, 다양한 농도의 BiPDL 항체를 인간 또는 뮤린 PD-L1 또는 PD-L2 중 하나를 발현하는 CHO 세포 (CHO-PD-L1 또는 CHO-PD-L2 세포)에 첨가하였다. 피코에리트린 (phycoerythrin, PE)에 접합된 항-인간 IgG1 2차 항체를 첨가하여 결합을 검출하였다. FACS 분석을 수행하여 피코에리트린을 검출하여 다양한 항체 농도에서 형광 활성을 결정하였다. GraphPad Prism® 소프트웨어를 사용하여 EC50을 계산하였다.
후보 항체는 PD-1/PD-L2 결합을 방지함. Promega PD-L1/PD-L2 이중 발현:PD-1 차단 시스템을 사용하여 후보 BiPDL 항체 및 FDA 승인된 항체를 분석하였다. 다양한 농도의 항체를 CHO-PD-L1/L2 세포에 첨가하였다. PD-1 이펙터 세포는 CHO-PD-L1/L2 세포에 의해 자극될 수 있는 Jurkat T 세포이다. 활성화에 대한 반응으로 초파리 루시퍼라제를 생산하는, PD-1 이펙터 세포를 항체 및 CHO 세포와 6시간 동안 인큐베이션한 후 결과를 제조사의 지침에 따라서 Bio-Glo?? 분석 키트 (Promega)를 사용하여 광도계에서 판독하였다. 경쟁 분석을 위해, 비오틴-rhPD-1-Fc 단백질을 세포 및 항체에 첨가하고, 이어서 스트렙타비딘-APC 접합체를 첨가하였다. 루시퍼라제 신호에서의 증가로서 차단을 평가하였다. GraphPad Prism® 소프트웨어를 사용하여 분석을 수행하였다. 경쟁 분석을 위해, X를 LogX로 변환시키고 비-선형 회귀 (곡선 적합), 용량 반응 억제, 및 Log(억제제) 대 반응에 의해 분석하였다.
혼합 림프구 반응에서 BiPDL 활성. CD14+ 단핵구를 CD14 마이크로비드를 사용하여 말초 혈액 단핵구 세포로부터 분리하였다. 세포를 1백만 개/ml로 접종하고 10% FCS/RPMI/P/S 세포 배양 배지 중에서 IL-4 및 GM-CSF로 자극시켰다. 세포를 7일간 배양하여 미성숙 수지상 세포 (IDCs)로 분화시키고 다양한 농도의 BiPDL 또는 상업적 항체를 첨가하였다. 그 후에 IDCs를 사용하여 10:1 CD4:IDCs의 비율로 CD4+ T 세포를 자극하였다. R&D systems에서 제공되는 프로토콜에 따라서 ELISA로 IL-2 및 IFN-γ를 분석하였다.
이종이식 종양에 대한 항체 활성. U2940 PMBL 또는 MDA-MB-231 삼중-음성 유방암 이종이식 종양을 면역결핍 마우스에서 확립하였다. 종양의 부피가 150 mm3에 도달하게 하였다. 150 mm3에 도달한 후, 마우스를 치료 그룹 당 9마리로 3주간 10 mg/kg의 처리로, 주 2회로 표시된 항체 치료제로 처리하였다. 종양 너비, 길이, 및 깊이의 캘리퍼 측정을 사용하여 종양 부피를 계산하였다.
MC38-PD-L2 주사 마우스의 생존 및 종양 성장. MC38-PD-L2 종양 세포가 이식된 C57BL/6J 마우스의 생존율을 측정하였다. 5×105 MC38-PD-L2 종양 세포를 피하로 이식하고 3, 6, 9, 12, 및 15일째에 지시된 항체 또는 완충제 100 μg을 복강내로 처리하였다. 종양 너비, 길이, 및 깊이의 캘리퍼 측정을 사용하여 종양 부피를 계산하였다. Gehran-Breslow-Wilcoxon 테스트를 사용하여 생존율 통계를 계산하였다. CD8/Treg 비율을 결정하기 위해, 1.5×106 MC38-PDL2 종양 세포를 30% 마트리겔 (Corning) 중에서 C57BL/6J 마우스에 피하로 이식하고 7, 10, 및 13일째에 지시된 항체 100 μg을 복강내 주사로 처리하였다. 15일째, 종양을 수거하고 FoxP3+ Treg에 대한 침윤성 CD8 T 세포의 비율을 유세포 분석으로 측정하였다.
EL4 림프종 마우스 모델의 생존. EL4 T 세포 림프종 세포는 PD-L1을 내인성으로 발현하고, 마우스 PD-L2를 발현하도록 레트로바이러스로 조작되었다. PD-L1 및 PD-L2 둘 다의 발현을 유세포 분석으로 확인하였다. PD-L2 및 루시퍼라제를 발현하는 EL4 세포가 주입된 마우스의 생존율을 측정하였다. 루시퍼라제를 또한 발현하는 1.5×105 EL4-PD-L2 세포를 마우스의 꼬리 정맥 내로 주입하여 C57BL/6J 마우스에서 전신 질환을 확인하였다. 마우스를 3, 6, 9, 12, 및 15일째에 지시된 항체 100 μg을 복강내로 처리하였다.
BiPDL 항체의 에피토프 비닝. 다양한 BiPDL 항체의 결합 특이성을 ForteBio Octet® 플랫폼을 사용하여 수행된 결합 경쟁 분석을 이용하여 비교하였다. 표적 His-태그된 단백질 (인간 PD-L1 또는 PD-L2)을 1 μg/mL로 미리-충진된 니켈 NTA 바이오센서 상에 로딩한다. 1차 항체, Ab1을 100 nM으로 표적-로딩된 바이오센서 위에 포화시키고, 최대 Ab2 결합 신호를 결정하기 위해 참조 (완충제 단독) 웰이 포함된다. 2차 항체를 또한 100 nM에서 결합 신호에 대해 스크리닝하고, 배경 자가-차단 신호를 결정하기 위해 Ab1이 포함된다. 데이터 분석 HT 9.0 소프트웨어를 사용하여 Ab2 결합의 원시 신호 반응의 매트릭스를 생성하고 이는 그 후에 차단되지 않은 Ab2 결합 신호의 백분율로서 표현되도록 변환된다. 15% 미만의 반응이 경쟁 차단으로 간주된다.
실시예 2 - 결과
인간 PD-L1 및 PD-L2 둘 다에 결합하는 BiPDL 항체의 선택. PD-L1 및 PD-L2 둘 다가 PD-1에 결합하고 대략 40% 아미노산 동일성을 공유한다는 점을 감안하면, 두 리간드에 결합하고 T 세포 공동-억제 수용체 PD-1의 참여 (engagement)를 방지하는 항체가 유도될 수 있다는 가설이 세워졌다. 두 리간드에 2가 결합할 수 있는 고 친화도 항체를 찾는 것이 드문 일이라고 예상되었듯이, 이들 항체는 전술한 바와 같이 효모-기반, 완전한 인간 항체 라이브러리 제시 시스템으로부터의 반복적인 선택 과정을 통해 발견되었다. 상기 실시예 1에 기술된 바와 같이, 이량체화된 인간 IgG1 Fc 불변 영역에 융합된 재조합 리간드를 사용하여 (즉, 친화 (avid) 결합) PD-L1 및 PD-L2 둘 다에 결합하는 항체를 먼저 선별하였고, 그 후에 단량체 PD-리간드에 결합할 수 있는 것들의 선택을 통해 가장 높은 친화도 히트 (affinity hit)를 더 풍부하게 하였다. 이 초기 라운드의 스크리닝은 PD-L1 및 PD-L2 둘 다에 결합하여 PD-1에 대한 이들의 결합을 차단할 수 있는 4개의 별개의 항체 계통을 산출하였다 (도 1A-B). 항체를 BiPDL로 명명하고 명명법 BiPDLX-YZ를 사용하는데, 여기서 X는 BiPDL 패밀리이고 (Boussiotis, 2016; Cheng et al., 2013; Latchman et al., 2001; Lee et al., 2016), Y는 주어진 세대 내에서 패밀리 내 클론 번호이고, Z는 연속적인 라운드의 친화도 성숙을 나타내는 세대이다 (Boussiotis, 2016; Cheng et al., 2013; Latchman et al., 2001; Lee et al., 2016). 개별 항체 클론은 또한 실험 클론 번호로 참조된다. 표 5는 BiPDL 명명법뿐만 아니라 각각에 대한 클론 번호 모두를 제공한다. 이들 항체 각각이 PD-L2 (Kd≤2×10-9)에 대해 합리적으로 높은 친화성 (avidity) (이량체 리간드 사용)을 입증하였지만, BiPDL4만이 Octet (ForteBio)으로 측정되는 바와 같이 인간 PD-L1에 대해 정량화 가능한 친화성 (Kd≤1×10-9)을 가졌다. 다양한 항체 농도에 걸친 Promega PD-1 분석 시스템을 사용하여 PD-1에 의한 Jurkat T 세포 억제를 완화하는 이들의 능력에 대해 몇몇 항체를 추가로 시험하였고, BiPDL4만이 PD-L1-유도된 T 세포 억제를 차단할 수 있는 것으로 나타났다 (도 1C).
친화도 성숙은 T 세포 활성화의 PD-L1 및 PD-L2 억제를 역전시키는 BiPDL의 기능적 능력을 증가시킨다. 각각의 1세대 선두인, BiPDL1-11, BiPDL2-11, BiPDL3-11, 및 BiPDL4-11을 중쇄 친화도 성숙에 적용하여 상기 실시예 1에 기술된 과정을 사용하여 최적화된 CDR1 및 CDR2 서열의 선택을 통해 PD-L1 및 PD-L2 둘 다에 결합하는 클론을 풍부하게 하였다. 다양한 농도의 BiPDL3 및 BiPDL4 항체 (인간 IgG1)를 CHO-PD-L1 또는 CHO-PD-L2 세포에 첨가하였다. 친화도 성숙된 BiPDL3 및 BiPDL4의 결합을 PE에 접합된 항-인간 IgG1 2차 항체의 첨가에 의해 검출하였다 (도 2A-D). BiPDL3 및 BiPDL4 항체 모두는 PD-L1에 결합하는 이들의 능력을 유지했지만 (도 2A 및 2C), BiPDL3-12는 PD-L2 결합 활성을 거의 나타내지 않았다 (도 2B).
Promega PD-L1/PD-L2 이중 발현:PD-1 분석 시스템을 사용하여 Jurkat T 세포 활성을 복원하는 4세대 BiPDL4 클론의 능력을 평가하였다 (도 3). BiPDL4-11, -14, -24, -34, -44 모두는 키트루다 (항-PD1)와 유사한 수준의 활성을 보였고, 아테졸리주맙 및 아벨루맙 (Avelumab)보다는 우수한 성능을 보였다. 다른 개별 패밀리의 결합을 또한 평가하였다 (도 4A-F). Promega 시스템에서 Jurkat T 세포 억제를 복원하는 BiPDL4-12의 능력은 부모 BiPDL4에 비해 PD-L1 및 PD-L2 둘 다에 대해 증가한 반면, BiPDL4-22는 PD-L1 매개 억제를 역전시킬 수 있는 능력을 얻지는 못했지만, PD-L2 매개 억제를 완전히 역전시킬 수 있었다 (도 4E-F). BiPDL3-12에 대한 Octet 친화도 측정은 PD-L1에 대해 Kd 2.71×10-8 및 PD-L2에 대해 Kd 8.85×10-8 (이량체 리간드)이었다 (표 5). BiPDL4-12는 PD-L1의 경우 6.22×10-10 및 PD-L2의 경우 1.74×10-9를 측정한 반면, BiPDL4-22는 PD-L1의 경우 8.42×10-9 및 PD-L2의 경우 3.5×10-10를 측정하였다 (표 5).
1세대 BiPDL로부터의 개선에도 불구하고, BiPDL3-12, BiPDL4-12 및 BiPDL4-22 중 어느 것도 PD-L1 및 PD-L2 둘 다에 대해 임상적으로 관련된 친화도를 입증하지 못했다. 이러한 이유로, BiPDL3-12 및 BiPDL4-22에 중점을 두고 3차 라운드의 중쇄 친화도 성숙을 수행하였다. 이 과정은 두 리간드에 대해 현저히 증강된 친화도를 갖는 3세대 BiPDL 항체를 산출하였다. BiPDL3-13에 대한 Octet 패밀리 측정은 PD-L1에 대해 Kd=3.28×10-9 및 PD-L2에 대해 Kd=4.31×10-10 (이량체 리간드)이었다. BiPDL4-13은 PD-L1의 경우 6.9×10-10 및 PD-L2의 경우 4.9×10-10을 측정한 반면, BiPDL4-23은 PD-L1의 경우 1.12×10-9 및 PD-L2의 경우 3.4×10-10을 측정하였다. BiPDL4-13은 또한 1가 PD-L1 (Kd=5.04×10-8) 및1가 PD-L2 (Kd=8.36×10-9)에 대해 측정가능한 친화도를 입증하였다. BiPDL4-23에 대한 1가 친화도는 PD-L1에 대해 Kd=8.4×10-8 및 PD-L2에 대해 Kd=1.66×10-9이었다. 모든 3세대 선두는 PD-L2 참여로 인한 Jurkat T 세포 억제를 강력하게 역전시킬 수 있었다; 그러나 BiPDL4 항체는 PD-L1 유도된 억제를 역전시키는 실질적으로 더 높은 능력을 나타내었다 (도 2C).
BiPDL4-13 및 BiPDL4-23의 PD-L1 친화도를 증가시키기 위한 시도로서, 상기 실시예 1에 기술된 바와 같이 최종 라운드의 경쇄 친화도 성숙을 수행하였다. 이 스크리닝은 두 리간드에 대해 임상적으로 관련된 친화도를 갖는 다수의 BiPDL 선두를 산출하였고, 그 중 가장 중요한 것은 BiPDL4-14, BiPDL4-24, BiPDL4-34, 및 BiPDL4-44이다. Octet에 의해 측정된 HIS-태그된 1가 PD-L1에 대한 이들 항체의 친화도는 PD-L1의 경우 2.26-7.9×10-9, 및 PD-L2의 경우 4.98-9.3×10-10 범위였다. PD-L1 및 PD-L2 둘 다를 발현하는 자극인자 CHO 세포를 사용하는 Promega 시스템에서 억제된 Jurkat T 세포를 복원하는 이들의 능력을 시험하는 경우, 이들 4세대 BiPDL4 항체는 키트루다와 유사하게 수행하였다 (도 2D). 또한, 이들 완전히 성숙된 BiPDL4는 이전 세대의 BiPDL4 및 FDA-승인된 PD-L1 항체 아테졸리주맙 및 아벨루맙 모두보다 상당한 우월성을 입증하였다.
4세대 BiPDL4는 PD-L1에서 이전에 기술되지 않은 에피토프에 결합한다. 이들 4세대 BiPDL4 항체는 인간 및 사이노몰구스 (cynomolgus) PD-L1 및 PD-L2 둘 다에 고 친화도로 결합하고, 또한 마우스 리간드와 상당히 교차-반응성이다 (표 5 및 6). 모든 4개의 4세대 BiPDL4 항체는 동일한 중쇄 CDR3을 공유하지만 다른 중쇄 및 경쇄 CDR 서열에서 유의미하게 상이하다 (표 1-4). 물론, FDA-승인된 PD-L1 항체의 어느 것과도 유의미한 유사상이 존재하지 않는다. 이러한 서열 상동성의 결여는 이들 PD-L1 및 PD-L2 결합 항체의 독특한 결합 특이성에 대한 가능성을 시사하고, 따라서 이들이 공지된 PD-L1 및 PD-L2 항체에 대해 "비닝되어 (binned)" 이들의 경쟁적 에피토프 결합을 결정할 수 있다.
항체 비닝은 모든 4개의 4세대 BiPDL4 항체가 아벨루맙 및 아테졸리주맙과는 완전히 다른 PD-L1 상의 에피토프에 결합한다는 것을 보여주었다 (표 7). 중간 수준의 간섭에 의해 입증된 두르발루맙에 의해 결합된 PD-L1 에피토프와의 부분적 중첩이 존재한다. 모든 BiPDL4는 상업적으로 이용가능한 클론 24F.10C12 및 MIH18에 비해 PD-L2 상의 별개의 에피토프에 결합한다 (표 8).
BiPDL 항체는 일차 인간 혼합 림프구 반응 (MLR)에서 이펙터 사이토카인 생산을 복원한다. 별도의 공여자로부터 유도된 수지상 세포 및 T-세포의 존재하에서 후보 항체, FDA 승인된 항체, 또는 대조군 항체를 평가하고 IL-2 또는 IFN-γ 생산에 대해 ELISA로 평가하였다. iDC에 의한 PD-L1 및 PD-L2의 발현을 유세포 분석으로 확인하였다 (도 5A). BiPDL4-14 및 BiPDL4-34 둘 다는 FDA 승인된 PD-L1 및 PD-1 항체에 비해 인간 일차 T 세포에 의한 IFN-γ 분비를 회복시키는 유사한 능력을 나타내었다 (도 5B 및 5C). 이들 분석에서 PD-L2의 존재에도 불구하고, PD-L1의 효과는 이 맥락에서 우세한 것으로 밝혀졌다.
이펙터 기능을 갖는 BiPDL 항체는 PD-L1 및 PD-L2 발현 종양 세포에 대해 효율적인 ADCC를 매개한다. U2940은 높은 PD-L1 (세포당 ~50,000개 분자) 및 낮은 수준 내지 중간 수준의 PD-L2 (세포당 ~7,000개 분자)를 발현하는 인간 원발성 종격동 B 림프종 (PMBL) 이종이식 세포주이다. 뮤린 NK 세포를 시험관 내에서 확장시키고 칼세인-AM (ThermoFisher) 표지된 U9240 PMBL 표적 세포 및 지시된 농도의 항체와 함께 15:1 에픽터 대 표적 비율로 4시간 동안 인큐베이션하였다. 실험적 방출 및 항체가 없는 자발적 방출의 차이로서 퍼센트 특이적 용해를 계산하였다. 모든 세대의 BiPDL3 및 BiPDL4는 U2940에 대해 ADCC를 매개할 수 있었다 (도 6). BiPDL4-12 및 BiPDL4-13이 U2940의 사멸을 유도하는데 특히 효과적이었다.
이펙터-가능 BiPDL은 SCID 마우스에서 U2940 PBML 및 MDA-MB-231 종양 이종이식 성장을 제어한다. 1×106 U2940 PMBL 세포를 SCID 마우스 내로 이식하고 종양이 150 mm3에 도달할 때까지 확립되게 하였다. PD-L1 및 PD-L2의 발현에 대해 세포를 평가하였다 (도 7A). 그 후에 마우스를 10 mg/kg의 mIgG2a 대조군 항체, 허셉틴, 리툭산 (U2940은 CD20+임), BiPDL4-12-mIgG2a 또는 BiPDL4-22-mIgG2a 중 하나로 주 2회 처리하였다. 두 BiPDL4 항체는 대조군 mAb에 비해 종양 성장을 상당히 지연시켰고 또한 리툭산을 능가하였다 (도 7B). BiPDL3-13-mIgG2a 및 BiPDL4-13-mIgG2a으로 동일한 실험을 반복하였고 대조군에 비해 두 BiPDL 항체의 상당한 치료적 이점이 다시 입증되었다 (도 7C). 이 경우에, 두 항체 모두 리툭산을 크게 능가하지는 않았지만; 연구 종료 시점에 종양이 없는 상태인 (종양 부피 ≤20 mm3) 두 마리의 마우스만이 BiPDL4-13-mIgG2a 그룹에 속했다.
MDA-MB-231 삼중 음성 유방암 이종이식 세포 (TNBC)는 또한 U2940과 유사한 비율로 PD-L1 및 PD-L2 둘 다를 발현한다 (도 8A). 1×107 MDA-MB-231 TNBC 세포를 SCID 마우스 내로 이식하고 종양이 150 mm3에 도달할 때까지 확립되게 하였다. 그 후에 마우스를 10 mg/kg의 mIgG2a 대조군 항체, 리툭산 (인간 IgG1 대조군), 아벨루맙 (인간 IgG1), BiPDL4-14-hIgG1, 또는 증강된 ADCC를 위해 조작된 BiPDL4-14-hIgG1[S239D/I332E] 중 어느 하나로 매주 2회 처리하였다. 이 설정에서, BiPDL 항체는 ADCC-가능 PD-L1 항체 아벨루맙과 유사한 능력으로 MDA-MB-231 이종이식의 진행을 지연시켰다 (도 8B). PD-L2에 비해 MDA-MB-231에 의한 PD-L1의 높은 발현을 고려하면 이 유사성은 놀라운 것이 아니다.
BiPDL은 어떤 PD-L1 항체보다 더 효율적으로 동계 MC38-PD-L2 결장암 (colon carcinoma)을 치료한다. MC38 결장암 세포는 내인성으로 PD-L1을 발현하고 마우스 PD-L2를 발현하도록 레트로바이러스로 조작되었다. PD-L1 및 PD-L2 둘 다의 발현을 유세포 분석으로 확인하였다 (도 9C). 5×105 MC38-PD-L2를 C57BL/6J 마우스에 이식하였다. 3, 6, 9, 12 및 15일째에 100 μg의 PBS, 래트 항-마우스 PD-L1 항체 10F.9G2, FDA-승인된 PD-L1 항체 아테졸리주맙 및 아벨루맙, 또는 BiPDL4-14-hIgG1[S239D/I332E] 중 하나를 마우스에 주사로 투여하였다. BiPDL4 항체의 생존율은 아테졸리주맙 (p=0.026) 및 PBS (p=0.004)에 비해 우수하였다 (도 9A). BiPDL4-14-hIgG1[S239D/I332E]로 처리된 마우스에서 종양 성장이 또한 가장 느렸다 (도 9B).
BiPDL은 MC38-PD-L2에서 가장 유리한 종양-내 CD8 대 Treg 비율을 생성한다. 1.5×106 MC38-PD-L2를 30% 마트리겔 (Corning) 중에서 C57BL/6J 마우스에 이식하여 침윤성 림프구의 회복을 촉진하였다. PD-L1 및 PD-L2의 발현을 유세포 분석으로 확인하였다 (도 10A). 7, 10 및 13일째인 것을 제외하고 마우스를 상기와 같이 처리한 후 종양을 수거하고 침윤성 림프구를 15일째에 유세포 분석으로 분석하였다. 이 경우에, 이펙터-증강 인간 IgG1 변형체 대신에 BiPDL4-14-mIgG2a를 사용하였다. 억제성 FoxP3+ 조절 T 세포 (Treg)에 대한 CD8 세포독성 T 세포의 종양내 비율을 면역치료적 개입의 성공에 대한 신뢰할만한 바이오카머로서 확립하였다. BiPDL4-14-mIgG2a로 처리된 마우스는 평균 10의 CD8 대 Treg 비율로, 항-PD-L1, 항-PD-L2, 항-PD-1 또는 대조군 동물 중 어느 것보다 현저히 더 높았다 (도 10B).
BiPDL은 PD-L1 또는 PD-L2 항체 차단보다 더 효율적으로 동계 EL4-PD-L2 T 세포 림프종을 치료한다. EL4 T 세포 림프종 세포 또한 PD-L1을 내인성으로 발현하고 마우스 PD-L2를 발현하도록 레트로바이러스로 조작되었다. PD-L1 및 PD-L2 둘 다의 발현을 유세포 분석으로 확인하였다 (도 11A). 생체발광 영상화를 촉진하기 위해 루시퍼라제를 또한 발현하는, 1.5×105 EL4-PD-L2 세포를 이식하여 C57BL/6J 마우스에서 전신 질환을 확인하였다. 3, 6, 9, 12 및 15일째에 100 μg의 PBS, 래트 항-마우스 PD-L1 항체 10F.9G2, 래트 항-마우스 PD-L2 항체 TY25, 10F.9G2 및 TY25의 조합, FDA-승인된 PD-L1 항체 아테졸리주맙, 또는 BiPDL4-14-mIgG2a 중 어느 하나를 마우스에 주사로 투여하였다. PD-L1 및 PD-L2 차단이 이 모델에서는 효과적이지 않았지만; BiPDL4 항체는 생존을 상당히 연장시켰다 (p=0.002 vs 비처리군; p=0.01 vs. 아테졸리주맙) (도 11B). 이 설정에서, PD-L1 및 PD-L2 차단 항체의 조합이 (10F.9G2 및 TY25) 아무런 효능을 나타내지 않았기 때문에 BiPDL 항체의 이펙터 기능은 효능에 특히 중요한 것으로 보인다.
표 1 - 항체 가변 영역의 핵산 서열



표 2 - 항체 가변 영역의 단백질 서열


표 3 - CDR 중쇄 서열

표 4 - CDR 경쇄 서열

표 5 - BiPDL 명명법

표 5 - PD-L1 및 PD-L2에 대한 항체 결합의 친화도 측정

표 6 - PD-L1 및 PD-L2에 대한 항체 결합의 친화도 측정

표 7 -
비닝에 의한 항체 중첩 결정

표 8 -
비닝에 의한 항체 중첩 결정

표 9 - 항체 결합 및 경쟁

* * * * *
본원에 기술되고 청구된 모든 방법은 본 개시내용에 비추어 과도한 실험 없이 만들어지고 실행될 수 있다. 본 발명의 조성물 및 방법이 바람직한 구현예의 관점에서 서술되었지만, 발명의 개념, 사상 및 범위를 벗어나지 않으면서 본원에 기술된 방법의 단계 또는 단계의 순서에 변형이 적용될 수 있음이 당업자에게 자명할 것이다. 보다 구체적으로, 화학적 및 생리학적으로 둘 다 관련된 특정 제제가 동일하거나 유사한 결과를 달성하면서 본원에 기술된 제제로 대체될 수 있음이 자명할 것이다. 당업자에게 명백한 모든 그러한 유사한 대체 및 변형은 첨부된 청구범위에 의해 정의된 본 발명의 사상, 범위 및 개념 내에 있는 것으로 간주된다.
VIII.
참고문헌
하기 참고문헌이 본원에 개시된 것들에 보충적인 예시적인 절차 또는 다른 세부사항을 제공하는 수준으로, 구체적으로 본원에 참조로서 포함된다.



SEQUENCE LISTING
<110> Board of Regents, The University of Texas System et al.
<120> DUAL SPECIFICITY ANTIBODIES TO HUMAN PD-L1 AND PD-L2 AND METHODS
OF USE THEREFOR
<130> IPA201097-US
<140> Not yet assignged
<141> 2019-03-14
<150> 62/647,407
<151> 2018-03-23
<150> 62/755,408
<151> 2018-11-02
<160> 101
<170> PatentIn version 3.5
<210> 1
<211> 290
<212> PRT
<213> Homo sapiens
<400> 1
Met Arg Ile Phe Ala Val Phe Ile Phe Met Thr Tyr Trp His Leu Leu
1 5 10 15
Asn Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr
20 25 30
Gly Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu
35 40 45
Asp Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile
50 55 60
Ile Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser
65 70 75 80
Tyr Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn
85 90 95
Ala Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr
100 105 110
Arg Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val
115 120 125
Lys Val Asn Ala Pro Tyr Asn Lys Ile Asn Gln Arg Ile Leu Val Val
130 135 140
Asp Pro Val Thr Ser Glu His Glu Leu Thr Cys Gln Ala Glu Gly Tyr
145 150 155 160
Pro Lys Ala Glu Val Ile Trp Thr Ser Ser Asp His Gln Val Leu Ser
165 170 175
Gly Lys Thr Thr Thr Thr Asn Ser Lys Arg Glu Glu Lys Leu Phe Asn
180 185 190
Val Thr Ser Thr Leu Arg Ile Asn Thr Thr Thr Asn Glu Ile Phe Tyr
195 200 205
Cys Thr Phe Arg Arg Leu Asp Pro Glu Glu Asn His Thr Ala Glu Leu
210 215 220
Val Ile Pro Glu Leu Pro Leu Ala His Pro Pro Asn Glu Arg Thr His
225 230 235 240
Leu Val Ile Leu Gly Ala Ile Leu Leu Cys Leu Gly Val Ala Leu Thr
245 250 255
Phe Ile Phe Arg Leu Arg Lys Gly Arg Met Met Asp Val Lys Lys Cys
260 265 270
Gly Ile Gln Asp Thr Asn Ser Lys Lys Gln Ser Asp Thr His Leu Glu
275 280 285
Glu Thr
290
<210> 2
<211> 273
<212> PRT
<213> Homo sapiens
<400> 2
Met Ile Phe Leu Leu Leu Met Leu Ser Leu Glu Leu Gln Leu His Gln
1 5 10 15
Ile Ala Ala Leu Phe Thr Val Thr Val Pro Lys Glu Leu Tyr Ile Ile
20 25 30
Glu His Gly Ser Asn Val Thr Leu Glu Cys Asn Phe Asp Thr Gly Ser
35 40 45
His Val Asn Leu Gly Ala Ile Thr Ala Ser Leu Gln Lys Val Glu Asn
50 55 60
Asp Thr Ser Pro His Arg Glu Arg Ala Thr Leu Leu Glu Glu Gln Leu
65 70 75 80
Pro Leu Gly Lys Ala Ser Phe His Ile Pro Gln Val Gln Val Arg Asp
85 90 95
Glu Gly Gln Tyr Gln Cys Ile Ile Ile Tyr Gly Val Ala Trp Asp Tyr
100 105 110
Lys Tyr Leu Thr Leu Lys Val Lys Ala Ser Tyr Arg Lys Ile Asn Thr
115 120 125
His Ile Leu Lys Val Pro Glu Thr Asp Glu Val Glu Leu Thr Cys Gln
130 135 140
Ala Thr Gly Tyr Pro Leu Ala Glu Val Ser Trp Pro Asn Val Ser Val
145 150 155 160
Pro Ala Asn Thr Ser His Ser Arg Thr Pro Glu Gly Leu Tyr Gln Val
165 170 175
Thr Ser Val Leu Arg Leu Lys Pro Pro Pro Gly Arg Asn Phe Ser Cys
180 185 190
Val Phe Trp Asn Thr His Val Arg Glu Leu Thr Leu Ala Ser Ile Asp
195 200 205
Leu Gln Ser Gln Met Glu Pro Arg Thr His Pro Thr Trp Leu Leu His
210 215 220
Ile Phe Ile Pro Phe Cys Ile Ile Ala Phe Ile Phe Ile Ala Thr Val
225 230 235 240
Ile Ala Leu Arg Lys Gln Leu Cys Gln Lys Leu Tyr Ser Ser Lys Asp
245 250 255
Thr Thr Lys Arg Pro Val Thr Thr Thr Lys Arg Glu Val Asn Ser Ala
260 265 270
Ile
<210> 3
<211> 363
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 3
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttcgat gagtatggca tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagtt atagggtatg atggactgaa taaatactat 180
gcagactccg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggcggtgt actactgcgc cagagctgga 300
atagaataca gctacgccta tactgattac tggggacagg gtacattggt caccgtctcc 360
tca 363
<210> 4
<211> 327
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 4
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gttcgtttac agcagcgact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtgcatcca ccaggaaaac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtctg cagttcggat ggtggcctcc taggactttc 300
ggcggaggga ccaaggtgga gatcaaa 327
<210> 5
<211> 363
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 5
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttcgat gagtatggca tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagtt atagggtatg atggactgaa taaatactat 180
gcagactccg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggcggtgt actactgcgc cagagctgga 300
atagaataca gctacgccta tactgattac tggggacagg gtacattggt caccgtctcc 360
tca 363
<210> 6
<211> 327
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 6
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtaa cagtgttgtc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtgcagcca gcagggccaa cggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtgtt cagttcggat ggtggcctcc taggactttc 300
ggcggaggga ccaaggtgga gatcaaa 327
<210> 7
<211> 363
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 7
caggtgcagc tggtggagtc tgggggaggc gtgatccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttcagt gcgtatctta tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagct ataggttatg atggaatgaa taaatactat 180
gcagactccg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggcggtgt actactgcgc cagagctgga 300
atagaataca gctacgccta tactgattac tggggacagg gtacattggt caccgtctcc 360
tca 363
<210> 8
<211> 327
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 8
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gttcgtttac agcagcgact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtgcatccg ccagggccgc cggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtatg cagttcggat ggtggcctcc taggactttc 300
ggcggaggga ccaaggttga gatcaaa 327
<210> 9
<211> 363
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 9
caggtgcagc tggtggagtc tgggggaggc gtgatccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttcagt gcgtatctta tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagct ataggttatg atggaatgaa taaatactat 180
gcagactccg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggcggtgt actactgcgc cagagctgga 300
atagaataca gctacgccta tactgattac tggggacagg gtacattggt caccgtctcc 360
tca 363
<210> 10
<211> 327
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 10
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca cagtgttgtc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtgcatcca gcagggaaga cggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtgtg cagttcggat ggtggcctcc taggactttc 300
ggcggaggga ccaaggtgga gatcaaa 327
<210> 11
<211> 360
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 11
caagtacaat tacaacagtg gggagctggt ttattaaagc cttcagaaac tttaagtttg 60
acctgtgctg tttacggtgg atcattatct ggttatcctt ggtcttggat tcgtcaacca 120
ccaggcaaag gattggagtg gatcggtgag acagacgtgt caggctggac tgactacaat 180
ccaagtttaa aatccagggt tactatctcc gtagacacgt ccaagaacca gttctccctg 240
aagctgagtt ctgtgaccgc cgcagacacg gcggtgtact actgcgccag agacggcaga 300
aggatgggta ccccttcatt cgacatatgg ggccagggta caatggtcac cgtctcctca 360
<210> 12
<211> 321
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 12
gacatccagt tgacccagtc tccatcttcc gtgtctgcat ctgtaggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtattagc agctggttag cctggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatcaagtt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagat ttcactctca ccatcagcag cctgcagcct 240
gaagattttg caacttatta ctgtcagcag tacgtctact tccctcctac ttttggcgga 300
gggaccaagg ttgagatcaa a 321
<210> 13
<211> 357
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 13
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctggttga tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaggg atcatcccta tcctgggtac agcacggtac 180
gcacagaagt tccagggcag agtcacgatt accgcggacg aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac acggcggtgt actactgcgc cagagtgtac 300
agagctgctt cttggtttga tccctgggga cagggtacat tggtcaccgt ctcctca 357
<210> 14
<211> 318
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 14
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc aggcgagtca ggacattagc aactatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctacgat gcatccaatt tggaaacagg ggtcccatca 180
aggttcagtg gaagtggatc tgggacagat tttactttca ccatcagcag cctgcagcct 240
gaagatattg caacatatta ctgtcagcag cccttccacc tcatcacttt tggcggaggg 300
accaaggttg agatcaaa 318
<210> 15
<211> 121
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 15
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Glu Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Gly Tyr Asp Gly Leu Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Gly Ile Glu Tyr Ser Tyr Ala Tyr Thr Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 16
<211> 109
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 16
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Phe Val Tyr Ser Ser
20 25 30
Asp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Thr Arg Lys Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Leu Gln Phe Gly Trp Trp Pro
85 90 95
Pro Arg Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 17
<211> 121
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 17
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Glu Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Gly Tyr Asp Gly Leu Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Gly Ile Glu Tyr Ser Tyr Ala Tyr Thr Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 18
<211> 109
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 18
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Asn Ser Val Val Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ala Ser Arg Ala Asn Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Val Gln Phe Gly Trp Trp Pro
85 90 95
Pro Arg Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 19
<211> 121
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 19
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Ile Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ala Tyr
20 25 30
Leu Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ala Ile Gly Tyr Asp Gly Met Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Gly Ile Glu Tyr Ser Tyr Ala Tyr Thr Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 20
<211> 109
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 20
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Phe Val Tyr Ser Ser
20 25 30
Asp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ala Arg Ala Ala Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Met Gln Phe Gly Trp Trp Pro
85 90 95
Pro Arg Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 21
<211> 121
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 21
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Ile Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ala Tyr
20 25 30
Leu Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ala Ile Gly Tyr Asp Gly Met Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Gly Ile Glu Tyr Ser Tyr Ala Tyr Thr Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 22
<211> 109
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 22
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser His Ser Val Val Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Glu Asp Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Val Gln Phe Gly Trp Trp Pro
85 90 95
Pro Arg Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 23
<211> 120
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 23
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Leu Ser Gly Tyr
20 25 30
Pro Trp Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 24
<211> 107
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 24
Asp Ile Gln Leu Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Val Tyr Phe Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 25
<211> 119
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 25
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Trp
20 25 30
Leu Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Leu Gly Thr Ala Arg Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Val Tyr Arg Ala Ala Ser Trp Phe Asp Pro Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 26
<211> 106
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 26
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Pro Phe His Leu Ile Thr
85 90 95
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 27
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 27
Phe Thr Phe Asp Glu Tyr Gly Met His
1 5
<210> 28
<211> 17
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 28
Val Ile Gly Tyr Asp Gly Leu Asn Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 29
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 29
Ala Arg Ala Gly Ile Glu Tyr Ser Tyr Ala Tyr Thr Asp Tyr
1 5 10
<210> 30
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 30
Phe Thr Phe Asp Glu Tyr Gly Met His
1 5
<210> 31
<211> 17
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 31
Val Ile Gly Tyr Asp Gly Leu Asn Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 32
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 32
Ala Arg Ala Gly Ile Glu Tyr Ser Tyr Ala Tyr Thr Asp Tyr
1 5 10
<210> 33
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 33
Phe Thr Phe Ser Ala Tyr Leu Met His
1 5
<210> 34
<211> 17
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 34
Ala Ile Gly Tyr Asp Gly Met Asn Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 35
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 35
Ala Arg Ala Gly Ile Glu Tyr Ser Tyr Ala Tyr Thr Asp Tyr
1 5 10
<210> 36
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 36
Phe Thr Phe Ser Ala Tyr Leu Met His
1 5
<210> 37
<211> 17
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 37
Ala Ile Gly Tyr Asp Gly Met Asn Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 38
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 38
Ala Arg Ala Gly Ile Glu Tyr Ser Tyr Ala Tyr Thr Asp Tyr
1 5 10
<210> 39
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 39
Gly Ser Leu Ser Gly Tyr Pro Trp Ser
1 5
<210> 40
<211> 16
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 40
Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 41
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 41
Ala Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile
1 5 10
<210> 42
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 42
Gly Thr Phe Ser Ser Trp Leu Ile Ser
1 5
<210> 43
<211> 17
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 43
Gly Ile Ile Pro Ile Leu Gly Thr Ala Arg Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 44
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 44
Ala Arg Val Tyr Arg Ala Ala Ser Trp Phe Asp Pro
1 5 10
<210> 45
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 45
Arg Ala Ser Gln Phe Val Tyr Ser Ser Asp Leu Ala
1 5 10
<210> 46
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 46
Gly Ala Ser Thr Arg Lys Thr
1 5
<210> 47
<211> 10
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 47
Leu Gln Phe Gly Trp Trp Pro Pro Arg Thr
1 5 10
<210> 48
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 48
Arg Ala Ser Asn Ser Val Val Ser Ser Tyr Leu Ala
1 5 10
<210> 49
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 49
Gly Ala Ala Ser Arg Ala Asn
1 5
<210> 50
<211> 10
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 50
Val Gln Phe Gly Trp Trp Pro Pro Arg Thr
1 5 10
<210> 51
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 51
Arg Ala Ser Gln Phe Val Tyr Ser Ser Asp Leu Ala
1 5 10
<210> 52
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 52
Gly Ala Ser Ala Arg Ala Ala
1 5
<210> 53
<211> 10
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 53
Met Gln Phe Gly Trp Trp Pro Pro Arg Thr
1 5 10
<210> 54
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 54
Arg Ala Ser His Ser Val Val Ser Ser Tyr Leu Ala
1 5 10
<210> 55
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 55
Gly Ala Ser Ser Arg Glu Asp
1 5
<210> 56
<211> 10
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 56
Val Gln Phe Gly Trp Trp Pro Pro Arg Thr
1 5 10
<210> 57
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 57
Arg Ala Ser Gln Gly Ile Ser Ser Trp Leu Ala
1 5 10
<210> 58
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 58
Ala Ala Ser Ser Leu Gln Ser
1 5
<210> 59
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 59
Gln Gln Tyr Val Tyr Phe Pro Pro Thr
1 5
<210> 60
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 60
Gln Ala Ser Gln Asp Ile Ser Asn Tyr Leu Asn
1 5 10
<210> 61
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 61
Asp Ala Ser Asn Leu Glu Thr
1 5
<210> 62
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 62
Gln Gln Pro Phe His Leu Ile Thr
1 5
<210> 63
<211> 120
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 63
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Leu Ser Gly Tyr
20 25 30
Pro Trp Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 64
<211> 107
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 64
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Asn Ser Phe
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Asn Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Lys Ala Val Tyr Phe Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 65
<211> 107
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 65
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Asn Phe
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Lys Ala Val Tyr Phe Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 66
<211> 120
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 66
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Leu Ser Gly Tyr
20 25 30
Pro Trp Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 67
<211> 120
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 67
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Leu Ser Gly Tyr
20 25 30
Pro Trp Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 68
<211> 107
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 68
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Ser Phe
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Lys Ser Val Tyr Phe Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 69
<211> 120
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 69
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Leu Ser Gly Tyr
20 25 30
Pro Trp Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 70
<211> 107
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 70
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Thr Phe
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ala Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Arg Ala Val Tyr Phe Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 71
<211> 120
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 71
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Leu Ser Gly Tyr
20 25 30
Pro Trp Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 72
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 72
Gly Ser Leu Ser Gly Tyr Pro Trp Ser
1 5
<210> 73
<211> 16
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 73
Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 74
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 74
Ala Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile
1 5 10
<210> 75
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 75
Gly Ser Leu Ser Gly Tyr Pro Trp Ser
1 5
<210> 76
<211> 16
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 76
Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 77
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 77
Ala Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile
1 5 10
<210> 78
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 78
Gly Ser Leu Ser Gly Tyr Pro Trp Ser
1 5
<210> 79
<211> 16
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 79
Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 80
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 80
Ala Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile
1 5 10
<210> 81
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 81
Gly Ser Leu Ser Gly Tyr Pro Trp Ser
1 5
<210> 82
<211> 16
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 82
Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 83
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 83
Ala Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile
1 5 10
<210> 84
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 84
Gly Ser Leu Ser Gly Tyr Pro Trp Ser
1 5
<210> 85
<211> 16
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 85
Glu Thr Asp Val Ser Gly Trp Thr Asp Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 86
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 86
Ala Arg Asp Gly Arg Arg Met Gly Thr Pro Ser Phe Asp Ile
1 5 10
<210> 87
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 87
Arg Ala Ser Gln Gly Ile Asn Ser Phe Leu Ala
1 5 10
<210> 88
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 88
Ala Ala Ser Ser Leu Asn Ser
1 5
<210> 89
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 89
Gln Lys Ala Val Tyr Phe Pro Pro Thr
1 5
<210> 90
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 90
Arg Ala Ser Gln Gly Ile Ser Asn Phe Leu Ala
1 5 10
<210> 91
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 91
Ala Ala Ser Ser Leu Gln Ser
1 5
<210> 92
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 92
Gln Lys Ala Val Tyr Phe Pro Pro Thr
1 5
<210> 93
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 93
Arg Ala Ser Gln Asp Ile Ser Ser Phe Leu Ala
1 5 10
<210> 94
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 94
Ala Ala Ser Ser Leu Gln Asp
1 5
<210> 95
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 95
Gln Lys Ser Val Tyr Phe Pro Pro Thr
1 5
<210> 96
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 96
Arg Ala Ser Gln Gly Ile Ser Thr Phe Leu Ala
1 5 10
<210> 97
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 97
Ala Ala Ser Ala Leu His Ser
1 5
<210> 98
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 98
Gln Arg Ala Val Tyr Phe Pro Pro Thr
1 5
<210> 99
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 99
Arg Ala Ser Lys Gly Ile Ser Ser Phe Leu Ala
1 5 10
<210> 100
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 100
Ala Ala Asp Ser Ile Gln Ser
1 5
<210> 101
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic amino acid
<400> 101
Gln Ser Ala Val Tyr Phe Pro Pro Thr
1 5
Claims (63)
- 각각 표 3 및 4로부터의 클론-페어링된 (clone-paired) 중쇄 및 경쇄 CDR 서열을 포함하는 항체 또는 항체 단편.
- 제1항에 있어서, 상기 항체 또는 항체 단편이 표 1로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 항체 또는 항체 단편.
- 제1항에 있어서, 상기 항체 또는 항체 단편이 표 1로부터의 클론-페어링된 서열에 적어도 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 항체 또는 항체 단편.
- 제1항에 있어서, 상기 항체 또는 항체 단편이 표 1로부터의 클론-페어링된 서열에 적어도 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 항체 또는 항체 단편.
- 제1항에 있어서, 상기 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열을 포함하는, 항체 또는 항체 단편.
- 제1항에 있어서, 상기 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 70%, 80% 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함하는, 항체 또는 항체 단편.
- 제1항에 있어서, 상기 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함하는, 항체 또는 항체 단편.
- 제1항 내지 제7항에 있어서, 항체 단편이 재조합 scFv (단쇄 가변 단편) 항체, Fab 단편, F(ab')2 단편, 또는 Fv 단편인, 항체 또는 항체 단편.
- 제1항 내지 제7항에 있어서, 상기 항체가 키메라 항체인, 항체 또는 항체 단편.
- 제1항 내지 제9항에 있어서, 상기 항체가 IgG인, 항체 또는 항체 단편.
- 제1항 내지 제10항에 있어서, 상기 항체 또는 항체 단편이 세포 투과 펩티드를 추가로 포함하고/하거나 인트라바디 (intrabody)인, 항체 또는 항체 단편.
- 제1항 내지 제11항에 있어서, 상기 항체 또는 항체 단편이 인간 항체인, 항체 또는 항체 단편.
- 제1항 내지 제11항에 있어서, 상기 항체 또는 항체 단편이 인간화된 항체인, 항체 또는 항체 단편.
- 각각 표 3 및 4로부터의 클론-페어링된 중쇄 및 경쇄 CDR 서열을 갖는 항체 또는 항체 단편을 대상체에 전달하는 것을 포함하는, 암을 가진 대상체를 치료하는 방법.
- 제14항에 있어서, 항체 또는 항체 단편이 표 1에 개시된 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 방법.
- 제14항 및 제15항에 있어서, 상기 항체 또는 항체 단편이 표 1로부터의 클론-페어링된 서열에 적어도 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 방법.
- 제14항 및 제15항에 있어서, 항체 또는 항체 단편이 표 1에 개시된 클론-페어링된 서열에 적어도 95% 동일성을 갖는 클론-페어링된 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 방법.
- 제14항에 있어서, 상기 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열을 포함하는, 방법.
- 제14항에 있어서, 상기 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 70%, 80% 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함하는, 방법.
- 제14항에 있어서, 표 2로부터의 클론-페어링된 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 방법.
- 제14항 내지 제20항에 있어서, 항체 단편이 재조합 scFv (단쇄 가변 단편) 항체, Fab 단편, F(ab')2 단편, 또는 Fv 단편인, 방법.
- 제14항 내지 제21항에 있어서, 상기 항체가 IgG인, 방법.
- 제14항 내지 제20항에 있어서, 상기 항체가 키메라 항체인, 방법.
- 제14항 내지 제23항에 있어서, 전달이 항체 또는 항체 단편의 투여, 또는 항체 또는 항체 단편을 인코딩하는 RNA 또는 DNA 서열 또는 벡터로의 유전적 전달을 포함하는, 방법.
- 항체 또는 항체 단편이 각각 표 3 및 4로부터의 클론-페어링된 중쇄 및 경쇄 CDR 서열을 특징으로 하는, 항체 또는 항체 단편을 인코딩하는 하이브리도마 또는 조작된 (engineered) 세포.
- 제25항에 있어서, 상기 항체 또는 항체 단편이 표 1로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 하이브리도마 또는 조작된 세포.
- 제25항에 있어서, 상기 항체 또는 항체 단편이 표 1로부터의 클론-페어링된 가변 서열에 적어도 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 하이브리도마 또는 조작된 세포.
- 제25항에 있어서, 상기 항체 또는 항체 단편이 표 1로부터의 클론-페어링된 가변 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 하이브리도마 또는 조작된 세포.
- 제25항에 있어서, 상기 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열을 포함하는, 하이브리도마 또는 조작된 세포.
- 제25항에 있어서, 상기 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 가변 서열에 적어도 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 하이브리도마 또는 조작된 세포.
- 제25항에 있어서, 상기 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함하는, 하이브리도마 또는 조작된 세포.
- 제25항 내지 제31항에 있어서, 항체 단편이 재조합 scFv (단쇄 가변 단편) 항체, Fab 단편, F(ab')2 단편, 또는 Fv 단편인, 하이브리도마 또는 조작된 세포.
- 제25항 내지 제32항에 있어서, 상기 항체가 키메라 항체인, 하이브리도마 또는 조작된 세포.
- 제25항 내지 제32항에 있어서, 상기 항체가 IgG인, 하이브리도마 또는 조작된 세포.
- 제25항 내지 제34항에 있어서, 상기 항체 또는 항체 단편이 세포 투과 펩티드를 추가로 포함하고/하거나 인트라바디인, 하이브리도마 또는 조작된 세포.
- 각각 표 3 및 4로부터의 클론-페어링된 중쇄 및 경쇄 CDR 서열을 특징으로 하는 하나 이상의 항체 또는 항체 단편을 포함하는 백신 제제.
- 제36항에 있어서, 적어도 하나의 항체 또는 항체 단편이 표 1로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 백신 제제.
- 제36항에 있어서, 적어도 하나의 항체 또는 항체 단편이 표 1로부터의 클론-페어링된 서열에 적어도 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 백신 제제.
- 제38항에 있어서, 적어도 하나의 항체 또는 항체 단편이 표 1로부터의 클론-페어링된 서열에 적어도 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 백신 제제.
- 제36항에 있어서, 적어도 하나의 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열을 포함하는, 백신 제제.
- 제36항에 있어서, 적어도 하나의 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함하는, 백신 제제.
- 제36항 내지 제41항에 있어서, 적어도 하나의 항체 단편이 재조합 scFv (단쇄 가변 단편) 항체, Fab 단편, F(ab')2 단편, 또는 Fv 단편인, 백신 제제.
- 제36항 내지 제41항에 있어서, 적어도 하나의 항체가 키메라 항체인, 백신 제제.
- 제36항 내지 제43항에 있어서, 적어도 하나의 항체가 IgG인, 백신 제제.
- 제36항 내지 제44항에 있어서, 적어도 하나의 항체 또는 항체 단편이 세포 투과 펩티드를 추가로 포함하고/하거나 인트라바디인, 백신 제제.
- 다음을 포함하는, 대상체에서 PD-L1 또는 PD-L2 발현 세포를 검출하는 방법:
(a) 상기 대상체로부터의 샘플을 각각 표 3 및 4로부터의 클론-페어링된 중쇄 및 경쇄 CDR 서열을 갖는 항체 또는 항체 단편과 접촉시키는 단계; 및
(b) 상기 샘플 내 세포에 대한 상기 항체 또는 항체 단편의 결합에 의해 상기 샘플에서 PD-L1 또는 PD-L2 발현 세포를 검출하는 단계. - 제46항에 있어서, 상기 샘플이 체액인, 방법.
- 제46항 및 제47항에 있어서, 상기 샘플이 조직 샘플인, 방법.
- 제46항 및 제47항에 있어서, 검출이 ELISA, RIA 또는 웨스턴 블롯을 포함하는, 방법.
- 제46항 내지 제49항에 있어서, 단계 (a) 및 (b)를 두 번째 수행하고 첫 번째 분석과 비교하여 오르쏘폭스바이러스 (orthopoxvirus) 항원 수준의 변화를 결정하는 단계를 추가로 포함하는, 방법.
- 제46항 내지 제50항에 있어서, 항체 또는 항체 단편이 표 1에 개시된 클론-페어링된 가변 서열에 의해 인코딩되는, 방법.
- 제46항 내지 제50항에 있어서, 상기 항체 또는 항체 단편이 표 1에 개시된 클론-페어링된 가변 서열에 70%, 80%, 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 방법.
- 제46항 내지 제50항에 있어서, 상기 항체 또는 항체 단편이 표 1에 개시된 클론-페어링된 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열에 의해 인코딩되는, 방법.
- 제46항 내지 제50항에 있어서, 상기 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 따른 경쇄 및 중쇄 가변 서열을 포함하는, 방법.
- 제46항 내지 제50항에 있어서, 상기 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 70%, 80% 또는 90% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함하는, 방법.
- 제46항 내지 제50항에 있어서, 상기 항체 또는 항체 단편이 표 2로부터의 클론-페어링된 서열에 95% 동일성을 갖는 경쇄 및 중쇄 가변 서열을 포함하는, 방법.
- 제46항 내지 제56항에 있어서, 항체 단편이 재조합 scFv (단쇄 가변 단편) 항체, Fab 단편, F(ab')2 단편, 또는 Fv 단편인, 방법.
- 제46항 내지 제57항에 있어서, 상기 세포가 암세포인, 방법.
- 제58항에 있어서, 암세포가 림프종 세포, 유방암 세포, 또는 신장 세포 암종 세포인, 방법.
- 제46항 내지 제57항에 있어서, 상기 세포가 면역 억제와 연관된 세포인, 방법.
- 제60항에 있어서, 상기 면역 억제와 연관된 세포가 종양 미세환경 내 비-암성 세포인, 방법.
- 제61항에 있어서, 종양 미세환경 내 상기 비-암성 세포가 기질 또는 내피 세포인, 방법.
- 각각 표 3 및 4로부터의 클론-페어링된 중쇄 및 경쇄 CDR 서열을 갖는 항체 또는 항체 단편을 대상체에 전달하는 것을 포함하는, 종양 미세환경 내 면역 억제를 치료하는 방법.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862647407P | 2018-03-23 | 2018-03-23 | |
| US62/647,407 | 2018-03-23 | ||
| US201862755408P | 2018-11-02 | 2018-11-02 | |
| US62/755,408 | 2018-11-02 | ||
| PCT/US2019/022295 WO2019182867A1 (en) | 2018-03-23 | 2019-03-14 | Dual specificity antibodies to human pd-l1 and pd-l2 and methods of use therefor |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200135785A true KR20200135785A (ko) | 2020-12-03 |
Family
ID=67987457
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207026926A KR20200135785A (ko) | 2018-03-23 | 2019-03-14 | 인간 pd-l1 및 pd-l2에 대한 이중 특이성 항체 및 이의 사용 방법 |
Country Status (12)
| Country | Link |
|---|---|
| US (1) | US20210139591A1 (ko) |
| EP (1) | EP3768723A4 (ko) |
| JP (2) | JP7514765B2 (ko) |
| KR (1) | KR20200135785A (ko) |
| CN (3) | CN112105644B (ko) |
| AU (1) | AU2019239568A1 (ko) |
| BR (1) | BR112020019042A2 (ko) |
| CA (1) | CA3092687A1 (ko) |
| IL (1) | IL277211A (ko) |
| MX (1) | MX2020009902A (ko) |
| SG (1) | SG11202009258RA (ko) |
| WO (1) | WO2019182867A1 (ko) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3694545A4 (en) | 2017-10-11 | 2021-12-01 | Board Of Regents, The University Of Texas System | HUMAN PD-L1 ANTIBODIES AND METHOD OF USING THEM |
| US20210214445A1 (en) * | 2018-03-23 | 2021-07-15 | Board Of Regents, The University Of Texas System | Dual specificity antibodies to pd-l1 and pd-l2 and methods of use therefor |
| JP7390301B2 (ja) | 2018-03-23 | 2023-12-01 | ボード オブ リージェンツ,ザ ユニバーシティ オブ テキサス システム | ヒトpd-l2抗体およびその使用方法 |
| US20230365708A1 (en) * | 2022-04-01 | 2023-11-16 | Board Of Regents, The University Of Texas System | Dual specificity antibodies to human pd-l1 and pd-l2 and methods of use therefor |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5595756A (en) * | 1993-12-22 | 1997-01-21 | Inex Pharmaceuticals Corporation | Liposomal compositions for enhanced retention of bioactive agents |
| US20030194704A1 (en) * | 2002-04-03 | 2003-10-16 | Penn Sharron Gaynor | Human genome-derived single exon nucleic acid probes useful for gene expression analysis two |
| US20040131613A1 (en) * | 2003-01-08 | 2004-07-08 | Watkins Jeffry D. | TNF-alpha binding molecules |
| AU2004270103B2 (en) * | 2003-05-21 | 2012-02-23 | E. R. Squibb & Sons, L.L.C. | Human monoclonal antibodies against Bacillusanthracis protective antigen |
| WO2007097923A2 (en) * | 2006-02-20 | 2007-08-30 | Phylogica Limited | Method of constructing and screening libraries of peptide structures |
| CL2008001071A1 (es) * | 2007-04-17 | 2009-05-22 | Smithkline Beecham Corp | Metodo para obtener anticuerpo penta-especifico contra il-8/cxcl8, gro-alfa/cxcl1, gro-beta/cxcl2), gro-gama/cxcl3 y ena-78/cxcl5 humanas; anticuerpo penta-especifico; proceso de produccion del mismo; vector, hbridoma o celela que lo comprende; composicion farmceutica; uso para tratar copd, otras enfermedades. |
| WO2011056997A1 (en) * | 2009-11-04 | 2011-05-12 | Fabrus Llc | Methods for affinity maturation-based antibody optimization |
| CA2992770A1 (en) * | 2009-11-24 | 2011-06-03 | Medimmune Limited | Targeted binding agents against b7-h1 |
| CN104936982B (zh) * | 2012-08-03 | 2020-04-24 | 丹娜法伯癌症研究院 | 抗-pd-l1和pd-l2双结合抗体单一试剂及其使用方法 |
| WO2017200796A1 (en) | 2016-05-17 | 2017-11-23 | Albert Einstein College Of Medicine, Inc. | Engineered pd-1 variants |
| MA45235A (fr) * | 2016-06-14 | 2019-04-17 | Regeneron Pharma | Anticorps anti-c5 et leurs utilisations |
-
2019
- 2019-03-14 AU AU2019239568A patent/AU2019239568A1/en active Pending
- 2019-03-14 SG SG11202009258RA patent/SG11202009258RA/en unknown
- 2019-03-14 CN CN201980020951.6A patent/CN112105644B/zh active Active
- 2019-03-14 US US17/040,240 patent/US20210139591A1/en active Pending
- 2019-03-14 KR KR1020207026926A patent/KR20200135785A/ko unknown
- 2019-03-14 MX MX2020009902A patent/MX2020009902A/es unknown
- 2019-03-14 JP JP2020550644A patent/JP7514765B2/ja active Active
- 2019-03-14 CA CA3092687A patent/CA3092687A1/en active Pending
- 2019-03-14 BR BR112020019042-0A patent/BR112020019042A2/pt unknown
- 2019-03-14 EP EP19771183.1A patent/EP3768723A4/en active Pending
- 2019-03-14 CN CN202311112466.6A patent/CN117186236A/zh active Pending
- 2019-03-14 WO PCT/US2019/022295 patent/WO2019182867A1/en unknown
- 2019-03-14 CN CN202311512592.0A patent/CN117586412A/zh active Pending
-
2020
- 2020-09-08 IL IL277211A patent/IL277211A/en unknown
-
2023
- 2023-06-09 JP JP2023095570A patent/JP2023113909A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| EP3768723A1 (en) | 2021-01-27 |
| AU2019239568A1 (en) | 2020-09-17 |
| US20210139591A1 (en) | 2021-05-13 |
| CN112105644B (zh) | 2023-12-05 |
| CN112105644A (zh) | 2020-12-18 |
| WO2019182867A1 (en) | 2019-09-26 |
| CN117186236A (zh) | 2023-12-08 |
| JP2023113909A (ja) | 2023-08-16 |
| BR112020019042A2 (pt) | 2021-01-05 |
| CA3092687A1 (en) | 2019-09-26 |
| EP3768723A4 (en) | 2021-12-29 |
| SG11202009258RA (en) | 2020-10-29 |
| MX2020009902A (es) | 2020-10-14 |
| IL277211A (en) | 2020-10-29 |
| JP7514765B2 (ja) | 2024-07-11 |
| CN117586412A (zh) | 2024-02-23 |
| WO2019182867A8 (en) | 2020-09-24 |
| JP2021518390A (ja) | 2021-08-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107405397B (zh) | 抗tim-3抗体 | |
| CN107922494B (zh) | 抗pd-1抗体及其应用 | |
| CN107921127B (zh) | 对于prame肽具有特异性的t细胞受体样抗体 | |
| KR20200135785A (ko) | 인간 pd-l1 및 pd-l2에 대한 이중 특이성 항체 및 이의 사용 방법 | |
| CN115768793A (zh) | 新型lilrb2抗体和其用途 | |
| US20240043538A1 (en) | Human pd-l1 antibodies and methods of use therefor | |
| CN113508139B (zh) | 结合人lag-3的抗体、其制备方法和用途 | |
| US20240270867A1 (en) | Human pd-l2 antibodies and methods of use therefor | |
| US20210214445A1 (en) | Dual specificity antibodies to pd-l1 and pd-l2 and methods of use therefor | |
| CN115916347A (zh) | 针对壳多糖酶3样1的抗体及其使用方法 | |
| JP2024129099A (ja) | ヒトpd-l1およびpd-l2に対する二重特異性抗体およびその使用方法 | |
| US20230365708A1 (en) | Dual specificity antibodies to human pd-l1 and pd-l2 and methods of use therefor | |
| CN114989304B (zh) | 一种抗人Claudin18.2抗体及其应用 | |
| CN117480245A (zh) | 靶向源自溶瘤病毒的蛋白的嵌合抗原受体、表达其的免疫细胞及两者的用途 |