KR20180105704A - Egfl6 특이적 단일클론 항체들 및 이의 사용 방법 - Google Patents
Egfl6 특이적 단일클론 항체들 및 이의 사용 방법 Download PDFInfo
- Publication number
- KR20180105704A KR20180105704A KR1020187024950A KR20187024950A KR20180105704A KR 20180105704 A KR20180105704 A KR 20180105704A KR 1020187024950 A KR1020187024950 A KR 1020187024950A KR 20187024950 A KR20187024950 A KR 20187024950A KR 20180105704 A KR20180105704 A KR 20180105704A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- domain
- cdr
- antibody
- ser
- Prior art date
Links
- 101000921196 Homo sapiens Epidermal growth factor-like protein 6 Proteins 0.000 title claims description 163
- 102100032029 Epidermal growth factor-like protein 6 Human genes 0.000 title claims description 156
- 238000000034 method Methods 0.000 title claims description 73
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 98
- 201000011510 cancer Diseases 0.000 claims abstract description 29
- 210000004027 cell Anatomy 0.000 claims description 92
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 48
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 45
- 229920001184 polypeptide Polymers 0.000 claims description 43
- 230000027455 binding Effects 0.000 claims description 37
- 239000000203 mixture Substances 0.000 claims description 33
- 239000000427 antigen Substances 0.000 claims description 25
- 108091007433 antigens Proteins 0.000 claims description 24
- 102000036639 antigens Human genes 0.000 claims description 24
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 22
- 206010033128 Ovarian cancer Diseases 0.000 claims description 21
- 239000012634 fragment Substances 0.000 claims description 12
- 238000002560 therapeutic procedure Methods 0.000 claims description 11
- 239000002246 antineoplastic agent Substances 0.000 claims description 10
- 238000001356 surgical procedure Methods 0.000 claims description 10
- 238000002512 chemotherapy Methods 0.000 claims description 9
- 238000000338 in vitro Methods 0.000 claims description 9
- 238000012360 testing method Methods 0.000 claims description 9
- 238000009169 immunotherapy Methods 0.000 claims description 8
- 239000003053 toxin Substances 0.000 claims description 7
- 231100000765 toxin Toxicity 0.000 claims description 7
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 6
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 6
- 229940127089 cytotoxic agent Drugs 0.000 claims description 6
- 201000005202 lung cancer Diseases 0.000 claims description 6
- 208000020816 lung neoplasm Diseases 0.000 claims description 6
- 108091033319 polynucleotide Proteins 0.000 claims description 6
- 102000040430 polynucleotide Human genes 0.000 claims description 6
- 239000002157 polynucleotide Substances 0.000 claims description 6
- 238000001959 radiotherapy Methods 0.000 claims description 5
- 206010006187 Breast cancer Diseases 0.000 claims description 4
- 208000026310 Breast neoplasm Diseases 0.000 claims description 4
- 108090000695 Cytokines Proteins 0.000 claims description 4
- 102000004127 Cytokines Human genes 0.000 claims description 4
- 238000009104 chemotherapy regimen Methods 0.000 claims description 4
- 239000003937 drug carrier Substances 0.000 claims description 3
- 238000001794 hormone therapy Methods 0.000 claims description 3
- 210000003734 kidney Anatomy 0.000 claims description 3
- 238000004519 manufacturing process Methods 0.000 claims description 3
- 150000007523 nucleic acids Chemical group 0.000 claims description 3
- 208000010507 Adenocarcinoma of Lung Diseases 0.000 claims description 2
- 206010005003 Bladder cancer Diseases 0.000 claims description 2
- 208000003174 Brain Neoplasms Diseases 0.000 claims description 2
- 201000009030 Carcinoma Diseases 0.000 claims description 2
- 241000223782 Ciliophora Species 0.000 claims description 2
- 208000030808 Clear cell renal carcinoma Diseases 0.000 claims description 2
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 2
- 241000238631 Hexapoda Species 0.000 claims description 2
- 208000008839 Kidney Neoplasms Diseases 0.000 claims description 2
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 2
- 206010060862 Prostate cancer Diseases 0.000 claims description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 2
- 206010038389 Renal cancer Diseases 0.000 claims description 2
- 108010003723 Single-Domain Antibodies Proteins 0.000 claims description 2
- 208000000453 Skin Neoplasms Diseases 0.000 claims description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 2
- 230000001580 bacterial effect Effects 0.000 claims description 2
- 208000029742 colonic neoplasm Diseases 0.000 claims description 2
- 239000002872 contrast media Substances 0.000 claims description 2
- 238000000315 cryotherapy Methods 0.000 claims description 2
- 201000004101 esophageal cancer Diseases 0.000 claims description 2
- 206010017758 gastric cancer Diseases 0.000 claims description 2
- 201000010536 head and neck cancer Diseases 0.000 claims description 2
- 208000014829 head and neck neoplasm Diseases 0.000 claims description 2
- 206010073071 hepatocellular carcinoma Diseases 0.000 claims description 2
- 231100000844 hepatocellular carcinoma Toxicity 0.000 claims description 2
- 201000010982 kidney cancer Diseases 0.000 claims description 2
- 201000007270 liver cancer Diseases 0.000 claims description 2
- 208000014018 liver neoplasm Diseases 0.000 claims description 2
- 201000005249 lung adenocarcinoma Diseases 0.000 claims description 2
- 201000005243 lung squamous cell carcinoma Diseases 0.000 claims description 2
- 210000004962 mammalian cell Anatomy 0.000 claims description 2
- 201000000849 skin cancer Diseases 0.000 claims description 2
- 201000011549 stomach cancer Diseases 0.000 claims description 2
- 206010044285 tracheal cancer Diseases 0.000 claims description 2
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 2
- 210000005253 yeast cell Anatomy 0.000 claims description 2
- 201000010897 colon adenocarcinoma Diseases 0.000 claims 1
- AHLBNYSZXLDEJQ-FWEHEUNISA-N orlistat Chemical compound CCCCCCCCCCC[C@H](OC(=O)[C@H](CC(C)C)NC=O)C[C@@H]1OC(=O)[C@H]1CCCCCC AHLBNYSZXLDEJQ-FWEHEUNISA-N 0.000 claims 1
- 229960001243 orlistat Drugs 0.000 claims 1
- 238000011282 treatment Methods 0.000 abstract description 53
- 230000001225 therapeutic effect Effects 0.000 abstract description 20
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 abstract description 7
- 201000010099 disease Diseases 0.000 abstract description 6
- 238000001514 detection method Methods 0.000 abstract description 2
- 238000003745 diagnosis Methods 0.000 abstract description 2
- 102100024952 Protein CBFA2T1 Human genes 0.000 description 178
- 108020004414 DNA Proteins 0.000 description 98
- 108020004459 Small interfering RNA Proteins 0.000 description 46
- 210000002889 endothelial cell Anatomy 0.000 description 46
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 35
- 241001465754 Metazoa Species 0.000 description 34
- 241000699670 Mus sp. Species 0.000 description 32
- 230000000694 effects Effects 0.000 description 30
- 230000014509 gene expression Effects 0.000 description 30
- 108090000623 proteins and genes Proteins 0.000 description 27
- 239000003795 chemical substances by application Substances 0.000 description 26
- 230000029663 wound healing Effects 0.000 description 25
- 108091034117 Oligonucleotide Proteins 0.000 description 24
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 24
- 210000001519 tissue Anatomy 0.000 description 24
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 23
- 239000003814 drug Substances 0.000 description 23
- 102000004169 proteins and genes Human genes 0.000 description 23
- -1 IgGl Chemical compound 0.000 description 21
- 241000699666 Mus <mouse, genus> Species 0.000 description 21
- 235000018102 proteins Nutrition 0.000 description 21
- 229910052739 hydrogen Inorganic materials 0.000 description 18
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 17
- 206010057190 Respiratory tract infections Diseases 0.000 description 17
- 238000004458 analytical method Methods 0.000 description 17
- 241000880493 Leptailurus serval Species 0.000 description 16
- 235000001014 amino acid Nutrition 0.000 description 16
- 229910052720 vanadium Inorganic materials 0.000 description 16
- 125000003275 alpha amino acid group Chemical group 0.000 description 15
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 14
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 14
- 208000027418 Wounds and injury Diseases 0.000 description 14
- 230000000903 blocking effect Effects 0.000 description 14
- 229940079593 drug Drugs 0.000 description 14
- 206010021143 Hypoxia Diseases 0.000 description 13
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 12
- 206010052428 Wound Diseases 0.000 description 12
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 12
- 229940024606 amino acid Drugs 0.000 description 12
- 150000001413 amino acids Chemical class 0.000 description 12
- 230000030279 gene silencing Effects 0.000 description 12
- 108010089804 glycyl-threonine Proteins 0.000 description 12
- CUVBTVWFVIIDOC-YEPSODPASA-N Gly-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)CN CUVBTVWFVIIDOC-YEPSODPASA-N 0.000 description 11
- 241000283973 Oryctolagus cuniculus Species 0.000 description 11
- LGEYOIQBBIPHQN-UWJYBYFXSA-N Tyr-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 LGEYOIQBBIPHQN-UWJYBYFXSA-N 0.000 description 11
- 230000033115 angiogenesis Effects 0.000 description 11
- 210000003719 b-lymphocyte Anatomy 0.000 description 11
- 230000015572 biosynthetic process Effects 0.000 description 11
- VHAQSYHSDKERBS-XPUUQOCRSA-N Ala-Val-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O VHAQSYHSDKERBS-XPUUQOCRSA-N 0.000 description 10
- GGAPHLIUUTVYMX-QWRGUYRKSA-N Gly-Phe-Ser Chemical compound OC[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)C[NH3+])CC1=CC=CC=C1 GGAPHLIUUTVYMX-QWRGUYRKSA-N 0.000 description 10
- 108010065920 Insulin Lispro Proteins 0.000 description 10
- 102100024616 Platelet endothelial cell adhesion molecule Human genes 0.000 description 10
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 10
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 10
- 210000004881 tumor cell Anatomy 0.000 description 10
- 230000004614 tumor growth Effects 0.000 description 10
- 108010003137 tyrosyltyrosine Proteins 0.000 description 10
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 9
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 9
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 9
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 9
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 9
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 9
- 239000000611 antibody drug conjugate Substances 0.000 description 9
- 229940049595 antibody-drug conjugate Drugs 0.000 description 9
- 238000002474 experimental method Methods 0.000 description 9
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 9
- 238000001727 in vivo Methods 0.000 description 9
- 230000005012 migration Effects 0.000 description 9
- 238000013508 migration Methods 0.000 description 9
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 8
- PRLPSDIHSRITSF-UNQGMJICSA-N Arg-Phe-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PRLPSDIHSRITSF-UNQGMJICSA-N 0.000 description 8
- KRXIWXCXOARFNT-ZLUOBGJFSA-N Asp-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O KRXIWXCXOARFNT-ZLUOBGJFSA-N 0.000 description 8
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 8
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 8
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 8
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 8
- BVOVIGCHYNFJBZ-JXUBOQSCSA-N Thr-Leu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O BVOVIGCHYNFJBZ-JXUBOQSCSA-N 0.000 description 8
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 8
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 8
- 108010081404 acein-2 Proteins 0.000 description 8
- 230000037396 body weight Effects 0.000 description 8
- 150000001875 compounds Chemical class 0.000 description 8
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 8
- 239000007924 injection Substances 0.000 description 8
- 238000002347 injection Methods 0.000 description 8
- 208000028867 ischemia Diseases 0.000 description 8
- 230000001404 mediated effect Effects 0.000 description 8
- 239000002609 medium Substances 0.000 description 8
- 230000009467 reduction Effects 0.000 description 8
- 230000002829 reductive effect Effects 0.000 description 8
- 210000002966 serum Anatomy 0.000 description 8
- 238000010186 staining Methods 0.000 description 8
- 229940124597 therapeutic agent Drugs 0.000 description 8
- 230000005747 tumor angiogenesis Effects 0.000 description 8
- 108010073969 valyllysine Proteins 0.000 description 8
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 7
- 101100481408 Danio rerio tie2 gene Proteins 0.000 description 7
- OTQSTOXRUBVWAP-NRPADANISA-N Gln-Ser-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OTQSTOXRUBVWAP-NRPADANISA-N 0.000 description 7
- PJBVXVBTTFZPHJ-GUBZILKMSA-N Glu-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N PJBVXVBTTFZPHJ-GUBZILKMSA-N 0.000 description 7
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 7
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 7
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 7
- FHIAJWBDZVHLAH-YUMQZZPRSA-N Lys-Gly-Ser Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FHIAJWBDZVHLAH-YUMQZZPRSA-N 0.000 description 7
- 101100333161 Mus musculus Egfl6 gene Proteins 0.000 description 7
- 101100481410 Mus musculus Tek gene Proteins 0.000 description 7
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 7
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 7
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 7
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 7
- XXNLGZRRSKPSGF-HTUGSXCWSA-N Thr-Gln-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O XXNLGZRRSKPSGF-HTUGSXCWSA-N 0.000 description 7
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 7
- XVHAUVJXBFGUPC-RPTUDFQQSA-N Thr-Tyr-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XVHAUVJXBFGUPC-RPTUDFQQSA-N 0.000 description 7
- 108010083162 Twist-Related Protein 1 Proteins 0.000 description 7
- 102100030398 Twist-related protein 1 Human genes 0.000 description 7
- 238000003556 assay Methods 0.000 description 7
- 230000004663 cell proliferation Effects 0.000 description 7
- 230000006870 function Effects 0.000 description 7
- 108010045126 glycyl-tyrosyl-glycine Proteins 0.000 description 7
- 230000001146 hypoxic effect Effects 0.000 description 7
- 230000002401 inhibitory effect Effects 0.000 description 7
- 102000006495 integrins Human genes 0.000 description 7
- 108010044426 integrins Proteins 0.000 description 7
- 230000002611 ovarian Effects 0.000 description 7
- 238000003752 polymerase chain reaction Methods 0.000 description 7
- 238000011160 research Methods 0.000 description 7
- 150000003839 salts Chemical class 0.000 description 7
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 6
- 230000007730 Akt signaling Effects 0.000 description 6
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 6
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 6
- HHABWQIFXZPZCK-ACZMJKKPSA-N Cys-Gln-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N HHABWQIFXZPZCK-ACZMJKKPSA-N 0.000 description 6
- 101150035617 EGFL6 gene Proteins 0.000 description 6
- 238000002965 ELISA Methods 0.000 description 6
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 6
- DBUNZBWUWCIELX-JHEQGTHGSA-N Gly-Thr-Glu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DBUNZBWUWCIELX-JHEQGTHGSA-N 0.000 description 6
- 101100333160 Homo sapiens EGFL6 gene Proteins 0.000 description 6
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 6
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 6
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 6
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 6
- PAXANSWUSVPFNK-IUKAMOBKSA-N Thr-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N PAXANSWUSVPFNK-IUKAMOBKSA-N 0.000 description 6
- KERCOYANYUPLHJ-XGEHTFHBSA-N Thr-Pro-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O KERCOYANYUPLHJ-XGEHTFHBSA-N 0.000 description 6
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 6
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 6
- 230000004913 activation Effects 0.000 description 6
- 108010008355 arginyl-glutamine Proteins 0.000 description 6
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 6
- 230000008901 benefit Effects 0.000 description 6
- 230000009702 cancer cell proliferation Effects 0.000 description 6
- 238000002487 chromatin immunoprecipitation Methods 0.000 description 6
- 239000012636 effector Substances 0.000 description 6
- 238000012226 gene silencing method Methods 0.000 description 6
- 102000054901 human EGFL6 Human genes 0.000 description 6
- 230000007954 hypoxia Effects 0.000 description 6
- 230000001965 increasing effect Effects 0.000 description 6
- 239000007788 liquid Substances 0.000 description 6
- 210000003141 lower extremity Anatomy 0.000 description 6
- 108010082117 matrigel Proteins 0.000 description 6
- 239000008194 pharmaceutical composition Substances 0.000 description 6
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 6
- 238000006467 substitution reaction Methods 0.000 description 6
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 5
- SUHLZMHFRALVSY-YUMQZZPRSA-N Ala-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O SUHLZMHFRALVSY-YUMQZZPRSA-N 0.000 description 5
- QDGMZAOSMNGBLP-MRFFXTKBSA-N Ala-Trp-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N QDGMZAOSMNGBLP-MRFFXTKBSA-N 0.000 description 5
- 108020004635 Complementary DNA Proteins 0.000 description 5
- AEJSNWMRPXAKCW-WHFBIAKZSA-N Cys-Ala-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O AEJSNWMRPXAKCW-WHFBIAKZSA-N 0.000 description 5
- WPLGNDORMXTMQS-FXQIFTODSA-N Glu-Gln-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O WPLGNDORMXTMQS-FXQIFTODSA-N 0.000 description 5
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 5
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 5
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 5
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 5
- VGSPNSSCMOHRRR-BJDJZHNGSA-N Ile-Ser-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N VGSPNSSCMOHRRR-BJDJZHNGSA-N 0.000 description 5
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 5
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 5
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 5
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 5
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 5
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 5
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 5
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 5
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 5
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 5
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 5
- DLZKEQQWXODGGZ-KWQFWETISA-N Tyr-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DLZKEQQWXODGGZ-KWQFWETISA-N 0.000 description 5
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 5
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 5
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 5
- 239000002253 acid Substances 0.000 description 5
- 108010047857 aspartylglycine Proteins 0.000 description 5
- 238000010804 cDNA synthesis Methods 0.000 description 5
- 239000002299 complementary DNA Substances 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 210000001105 femoral artery Anatomy 0.000 description 5
- 108010064235 lysylglycine Proteins 0.000 description 5
- 210000001672 ovary Anatomy 0.000 description 5
- 108010038745 tryptophylglycine Proteins 0.000 description 5
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 4
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 4
- QNMKWNONJGKJJC-NHCYSSNCSA-N Asp-Leu-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O QNMKWNONJGKJJC-NHCYSSNCSA-N 0.000 description 4
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 4
- 101100315624 Caenorhabditis elegans tyr-1 gene Proteins 0.000 description 4
- BVFQOPGFOQVZTE-ACZMJKKPSA-N Cys-Gln-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O BVFQOPGFOQVZTE-ACZMJKKPSA-N 0.000 description 4
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 4
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 4
- FJAYYNIXQNERSO-ACZMJKKPSA-N Gln-Cys-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N FJAYYNIXQNERSO-ACZMJKKPSA-N 0.000 description 4
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 4
- LZEUDRYSAZAJIO-AUTRQRHGSA-N Glu-Val-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LZEUDRYSAZAJIO-AUTRQRHGSA-N 0.000 description 4
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 4
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 4
- JZNVOBUNTWNZPW-GHCJXIJMSA-N Ile-Ser-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N JZNVOBUNTWNZPW-GHCJXIJMSA-N 0.000 description 4
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 4
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 4
- SIGZKCWZEBFNAK-QAETUUGQSA-N Leu-Ser-Ser-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SIGZKCWZEBFNAK-QAETUUGQSA-N 0.000 description 4
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 4
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 4
- 108090000430 Phosphatidylinositol 3-kinases Proteins 0.000 description 4
- 102000003993 Phosphatidylinositol 3-kinases Human genes 0.000 description 4
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 4
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 4
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 4
- 101150006914 TRP1 gene Proteins 0.000 description 4
- CNLKDWSAORJEMW-KWQFWETISA-N Tyr-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O CNLKDWSAORJEMW-KWQFWETISA-N 0.000 description 4
- SOAUMCDLIUGXJJ-SRVKXCTJSA-N Tyr-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O SOAUMCDLIUGXJJ-SRVKXCTJSA-N 0.000 description 4
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 4
- IECQJCJNPJVUSB-IHRRRGAJSA-N Val-Tyr-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CO)C(O)=O IECQJCJNPJVUSB-IHRRRGAJSA-N 0.000 description 4
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 4
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 4
- 108010045350 alanyl-tyrosyl-alanine Proteins 0.000 description 4
- 238000010171 animal model Methods 0.000 description 4
- 239000003242 anti bacterial agent Substances 0.000 description 4
- 230000000259 anti-tumor effect Effects 0.000 description 4
- 230000006907 apoptotic process Effects 0.000 description 4
- 238000013459 approach Methods 0.000 description 4
- 238000004113 cell culture Methods 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 239000000562 conjugate Substances 0.000 description 4
- 230000006378 damage Effects 0.000 description 4
- 230000007423 decrease Effects 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 229960004679 doxorubicin Drugs 0.000 description 4
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 4
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 4
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 4
- 210000004408 hybridoma Anatomy 0.000 description 4
- 230000001900 immune effect Effects 0.000 description 4
- 230000028993 immune response Effects 0.000 description 4
- 239000003112 inhibitor Substances 0.000 description 4
- 229960000310 isoleucine Drugs 0.000 description 4
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 4
- 239000000463 material Substances 0.000 description 4
- 210000004088 microvessel Anatomy 0.000 description 4
- 238000010172 mouse model Methods 0.000 description 4
- 108010051242 phenylalanylserine Proteins 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 230000035755 proliferation Effects 0.000 description 4
- 108010029020 prolylglycine Proteins 0.000 description 4
- 239000000523 sample Substances 0.000 description 4
- 230000011664 signaling Effects 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 230000008685 targeting Effects 0.000 description 4
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 4
- 231100000419 toxicity Toxicity 0.000 description 4
- 230000001988 toxicity Effects 0.000 description 4
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 4
- 238000001262 western blot Methods 0.000 description 4
- PKOHVHWNGUHYRE-ZFWWWQNUSA-N (2s)-1-[2-[[(2s)-2-amino-3-(1h-indol-3-yl)propanoyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound O=C([C@H](CC=1C2=CC=CC=C2NC=1)N)NCC(=O)N1CCC[C@H]1C(O)=O PKOHVHWNGUHYRE-ZFWWWQNUSA-N 0.000 description 3
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 3
- NJIFPLAJSVUQOZ-JBDRJPRFSA-N Ala-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C)N NJIFPLAJSVUQOZ-JBDRJPRFSA-N 0.000 description 3
- RMAWDDRDTRSZIR-ZLUOBGJFSA-N Ala-Ser-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RMAWDDRDTRSZIR-ZLUOBGJFSA-N 0.000 description 3
- FEZJJKXNPSEYEV-CIUDSAMLSA-N Arg-Gln-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FEZJJKXNPSEYEV-CIUDSAMLSA-N 0.000 description 3
- MFFOYNGMOYFPBD-DCAQKATOSA-N Asn-Arg-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O MFFOYNGMOYFPBD-DCAQKATOSA-N 0.000 description 3
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 3
- 241000894006 Bacteria Species 0.000 description 3
- 241000283707 Capra Species 0.000 description 3
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 3
- QUQHPUMRFGFINP-BPUTZDHNSA-N Cys-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CS)N QUQHPUMRFGFINP-BPUTZDHNSA-N 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 102000016621 Focal Adhesion Protein-Tyrosine Kinases Human genes 0.000 description 3
- 108010067715 Focal Adhesion Protein-Tyrosine Kinases Proteins 0.000 description 3
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 3
- MXOODARRORARSU-ACZMJKKPSA-N Glu-Ala-Ser Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N MXOODARRORARSU-ACZMJKKPSA-N 0.000 description 3
- IQACOVZVOMVILH-FXQIFTODSA-N Glu-Glu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O IQACOVZVOMVILH-FXQIFTODSA-N 0.000 description 3
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 3
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 3
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 3
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 3
- HQSKKSLNLSTONK-JTQLQIEISA-N Gly-Tyr-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 HQSKKSLNLSTONK-JTQLQIEISA-N 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 3
- DTPGSUQHUMELQB-GVARAGBVSA-N Ile-Tyr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 DTPGSUQHUMELQB-GVARAGBVSA-N 0.000 description 3
- NGKPIPCGMLWHBX-WZLNRYEVSA-N Ile-Tyr-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NGKPIPCGMLWHBX-WZLNRYEVSA-N 0.000 description 3
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 3
- HOMFINRJHIIZNJ-HOCLYGCPSA-N Leu-Trp-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O HOMFINRJHIIZNJ-HOCLYGCPSA-N 0.000 description 3
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 3
- VEGLGAOVLFODGC-GUBZILKMSA-N Lys-Glu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VEGLGAOVLFODGC-GUBZILKMSA-N 0.000 description 3
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 3
- CNGOEHJCLVCJHN-SRVKXCTJSA-N Lys-Pro-Glu Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O CNGOEHJCLVCJHN-SRVKXCTJSA-N 0.000 description 3
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 3
- 239000004472 Lysine Substances 0.000 description 3
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 3
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 3
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 description 3
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 3
- KWYUFKZDYYNOTN-UHFFFAOYSA-M Potassium hydroxide Chemical compound [OH-].[K+] KWYUFKZDYYNOTN-UHFFFAOYSA-M 0.000 description 3
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 3
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 3
- 108091008611 Protein Kinase B Proteins 0.000 description 3
- 102100033810 RAC-alpha serine/threonine-protein kinase Human genes 0.000 description 3
- 241000700159 Rattus Species 0.000 description 3
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 3
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 3
- 241000283984 Rodentia Species 0.000 description 3
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 3
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 3
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- YAAPRMFURSENOZ-KATARQTJSA-N Thr-Cys-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N)O YAAPRMFURSENOZ-KATARQTJSA-N 0.000 description 3
- UZJDBCHMIQXLOQ-HEIBUPTGSA-N Thr-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O UZJDBCHMIQXLOQ-HEIBUPTGSA-N 0.000 description 3
- SLUWOCTZVGMURC-BFHQHQDPSA-N Thr-Gly-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O SLUWOCTZVGMURC-BFHQHQDPSA-N 0.000 description 3
- WDIJBEWLXLQQKD-ULQDDVLXSA-N Tyr-Arg-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O WDIJBEWLXLQQKD-ULQDDVLXSA-N 0.000 description 3
- PZXUIGWOEWWFQM-SRVKXCTJSA-N Tyr-Asn-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O PZXUIGWOEWWFQM-SRVKXCTJSA-N 0.000 description 3
- QMNWABHLJOHGDS-IHRRRGAJSA-N Tyr-Met-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 QMNWABHLJOHGDS-IHRRRGAJSA-N 0.000 description 3
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 3
- JIODCDXKCJRMEH-NHCYSSNCSA-N Val-Arg-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N JIODCDXKCJRMEH-NHCYSSNCSA-N 0.000 description 3
- IJGPOONOTBNTFS-GVXVVHGQSA-N Val-Lys-Glu Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O IJGPOONOTBNTFS-GVXVVHGQSA-N 0.000 description 3
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 3
- MIAZWUMFUURQNP-YDHLFZDLSA-N Val-Tyr-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N MIAZWUMFUURQNP-YDHLFZDLSA-N 0.000 description 3
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 3
- 230000009471 action Effects 0.000 description 3
- 239000004480 active ingredient Substances 0.000 description 3
- 108010047495 alanylglycine Proteins 0.000 description 3
- 229940088710 antibiotic agent Drugs 0.000 description 3
- 238000009175 antibody therapy Methods 0.000 description 3
- 229960001230 asparagine Drugs 0.000 description 3
- 235000009582 asparagine Nutrition 0.000 description 3
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 3
- 230000017531 blood circulation Effects 0.000 description 3
- 210000004204 blood vessel Anatomy 0.000 description 3
- HXCHCVDVKSCDHU-LULTVBGHSA-N calicheamicin Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-LULTVBGHSA-N 0.000 description 3
- 229930195731 calicheamicin Natural products 0.000 description 3
- 230000021164 cell adhesion Effects 0.000 description 3
- 230000030833 cell death Effects 0.000 description 3
- 238000002648 combination therapy Methods 0.000 description 3
- 238000009826 distribution Methods 0.000 description 3
- 230000002500 effect on skin Effects 0.000 description 3
- 239000013604 expression vector Substances 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- 108020001507 fusion proteins Proteins 0.000 description 3
- 102000037865 fusion proteins Human genes 0.000 description 3
- 108010050848 glycylleucine Proteins 0.000 description 3
- 108010037850 glycylvaline Proteins 0.000 description 3
- 230000036541 health Effects 0.000 description 3
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 3
- 230000005764 inhibitory process Effects 0.000 description 3
- 230000000302 ischemic effect Effects 0.000 description 3
- 238000011813 knockout mouse model Methods 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 3
- 238000002493 microarray Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000007935 neutral effect Effects 0.000 description 3
- 238000011275 oncology therapy Methods 0.000 description 3
- 239000001301 oxygen Substances 0.000 description 3
- 229910052760 oxygen Inorganic materials 0.000 description 3
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 3
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 3
- 230000002265 prevention Effects 0.000 description 3
- 230000002062 proliferating effect Effects 0.000 description 3
- 238000003753 real-time PCR Methods 0.000 description 3
- 238000002271 resection Methods 0.000 description 3
- 230000004083 survival effect Effects 0.000 description 3
- 239000000725 suspension Substances 0.000 description 3
- 108700012359 toxins Proteins 0.000 description 3
- 239000004474 valine Substances 0.000 description 3
- COEXAQSTZUWMRI-STQMWFEESA-N (2s)-1-[2-[[(2s)-2-amino-3-(4-hydroxyphenyl)propanoyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound C([C@H](N)C(=O)NCC(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=C(O)C=C1 COEXAQSTZUWMRI-STQMWFEESA-N 0.000 description 2
- HKZAAJSTFUZYTO-LURJTMIESA-N (2s)-2-[[2-[[2-[[2-[(2-aminoacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]-3-hydroxypropanoic acid Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O HKZAAJSTFUZYTO-LURJTMIESA-N 0.000 description 2
- HSTOKWSFWGCZMH-UHFFFAOYSA-N 3,3'-diaminobenzidine Chemical compound C1=C(N)C(N)=CC=C1C1=CC=C(N)C(N)=C1 HSTOKWSFWGCZMH-UHFFFAOYSA-N 0.000 description 2
- VWEWCZSUWOEEFM-WDSKDSINSA-N Ala-Gly-Ala-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(=O)NCC(O)=O VWEWCZSUWOEEFM-WDSKDSINSA-N 0.000 description 2
- BEMGNWZECGIJOI-WDSKDSINSA-N Ala-Gly-Glu Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O BEMGNWZECGIJOI-WDSKDSINSA-N 0.000 description 2
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 2
- NIZKGBJVCMRDKO-KWQFWETISA-N Ala-Gly-Tyr Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NIZKGBJVCMRDKO-KWQFWETISA-N 0.000 description 2
- DHBKYZYFEXXUAK-ONGXEEELSA-N Ala-Phe-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 DHBKYZYFEXXUAK-ONGXEEELSA-N 0.000 description 2
- MMLHRUJLOUSRJX-CIUDSAMLSA-N Ala-Ser-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN MMLHRUJLOUSRJX-CIUDSAMLSA-N 0.000 description 2
- VNFSAYFQLXPHPY-CIQUZCHMSA-N Ala-Thr-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNFSAYFQLXPHPY-CIQUZCHMSA-N 0.000 description 2
- BIOCIVSVEDFKDJ-GUBZILKMSA-N Arg-Arg-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O BIOCIVSVEDFKDJ-GUBZILKMSA-N 0.000 description 2
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 2
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 2
- YKZJPIPFKGYHKY-DCAQKATOSA-N Arg-Leu-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YKZJPIPFKGYHKY-DCAQKATOSA-N 0.000 description 2
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 2
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- QQEWINYJRFBLNN-DLOVCJGASA-N Asn-Ala-Phe Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QQEWINYJRFBLNN-DLOVCJGASA-N 0.000 description 2
- DAPLJWATMAXPPZ-CIUDSAMLSA-N Asn-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O DAPLJWATMAXPPZ-CIUDSAMLSA-N 0.000 description 2
- NAPNAGZWHQHZLG-ZLUOBGJFSA-N Asp-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N NAPNAGZWHQHZLG-ZLUOBGJFSA-N 0.000 description 2
- MJKBOVWWADWLHV-ZLUOBGJFSA-N Asp-Cys-Asp Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)C(=O)O MJKBOVWWADWLHV-ZLUOBGJFSA-N 0.000 description 2
- WNGZKSVJFDZICU-XIRDDKMYSA-N Asp-Leu-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N WNGZKSVJFDZICU-XIRDDKMYSA-N 0.000 description 2
- IDDMGSKZQDEDGA-SRVKXCTJSA-N Asp-Phe-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(N)=O)C(O)=O)CC1=CC=CC=C1 IDDMGSKZQDEDGA-SRVKXCTJSA-N 0.000 description 2
- NOWKCMXCCJGMRR-UHFFFAOYSA-N Aziridine Chemical compound C1CN1 NOWKCMXCCJGMRR-UHFFFAOYSA-N 0.000 description 2
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 2
- YWEHYKGJWHPGPY-XGEHTFHBSA-N Cys-Thr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CS)N)O YWEHYKGJWHPGPY-XGEHTFHBSA-N 0.000 description 2
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 2
- 230000005778 DNA damage Effects 0.000 description 2
- 231100000277 DNA damage Toxicity 0.000 description 2
- 241000283073 Equus caballus Species 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 2
- 108010010803 Gelatin Proteins 0.000 description 2
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 2
- ROHVCXBMIAAASL-HJGDQZAQSA-N Gln-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(=O)N)N)O ROHVCXBMIAAASL-HJGDQZAQSA-N 0.000 description 2
- JILRMFFFCHUUTJ-ACZMJKKPSA-N Gln-Ser-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O JILRMFFFCHUUTJ-ACZMJKKPSA-N 0.000 description 2
- QXQDADBVIBLBHN-FHWLQOOXSA-N Gln-Tyr-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QXQDADBVIBLBHN-FHWLQOOXSA-N 0.000 description 2
- KKCUFHUTMKQQCF-SRVKXCTJSA-N Glu-Arg-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O KKCUFHUTMKQQCF-SRVKXCTJSA-N 0.000 description 2
- OAGVHWYIBZMWLA-YFKPBYRVSA-N Glu-Gly-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)NCC(O)=O OAGVHWYIBZMWLA-YFKPBYRVSA-N 0.000 description 2
- JVZLZVJTIXVIHK-SXNHZJKMSA-N Glu-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N JVZLZVJTIXVIHK-SXNHZJKMSA-N 0.000 description 2
- KRRMJKMGWWXWDW-STQMWFEESA-N Gly-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KRRMJKMGWWXWDW-STQMWFEESA-N 0.000 description 2
- DWUKOTKSTDWGAE-BQBZGAKWSA-N Gly-Asn-Arg Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DWUKOTKSTDWGAE-BQBZGAKWSA-N 0.000 description 2
- LEGMTEAZGRRIMY-ZKWXMUAHSA-N Gly-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)CN LEGMTEAZGRRIMY-ZKWXMUAHSA-N 0.000 description 2
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 2
- CUYLIWAAAYJKJH-RYUDHWBXSA-N Gly-Glu-Tyr Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CUYLIWAAAYJKJH-RYUDHWBXSA-N 0.000 description 2
- GDOZQTNZPCUARW-YFKPBYRVSA-N Gly-Gly-Glu Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O GDOZQTNZPCUARW-YFKPBYRVSA-N 0.000 description 2
- PDAWDNVHMUKWJR-ZETCQYMHSA-N Gly-Gly-His Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 PDAWDNVHMUKWJR-ZETCQYMHSA-N 0.000 description 2
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 2
- SWQALSGKVLYKDT-ZKWXMUAHSA-N Gly-Ile-Ala Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SWQALSGKVLYKDT-ZKWXMUAHSA-N 0.000 description 2
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 2
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 2
- GAFKBWKVXNERFA-QWRGUYRKSA-N Gly-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 GAFKBWKVXNERFA-QWRGUYRKSA-N 0.000 description 2
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 2
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 2
- RIYIFUFFFBIOEU-KBPBESRZSA-N Gly-Tyr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 RIYIFUFFFBIOEU-KBPBESRZSA-N 0.000 description 2
- JYGYNWYVKXENNE-OALUTQOASA-N Gly-Tyr-Trp Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O JYGYNWYVKXENNE-OALUTQOASA-N 0.000 description 2
- NGRPGJGKJMUGDM-XVKPBYJWSA-N Gly-Val-Gln Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O NGRPGJGKJMUGDM-XVKPBYJWSA-N 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 2
- 102000004457 Granulocyte-Macrophage Colony-Stimulating Factor Human genes 0.000 description 2
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 2
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 2
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 description 2
- CISBRYJZMFWOHJ-JBDRJPRFSA-N Ile-Ala-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(=O)O)N CISBRYJZMFWOHJ-JBDRJPRFSA-N 0.000 description 2
- QYZYJFXHXYUZMZ-UGYAYLCHSA-N Ile-Asn-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N QYZYJFXHXYUZMZ-UGYAYLCHSA-N 0.000 description 2
- RSDHVTMRXSABSV-GHCJXIJMSA-N Ile-Asn-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N RSDHVTMRXSABSV-GHCJXIJMSA-N 0.000 description 2
- DMZOUKXXHJQPTL-GRLWGSQLSA-N Ile-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N DMZOUKXXHJQPTL-GRLWGSQLSA-N 0.000 description 2
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 2
- JERJIYYCOGBAIJ-OBAATPRFSA-N Ile-Tyr-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N JERJIYYCOGBAIJ-OBAATPRFSA-N 0.000 description 2
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 2
- 108010002352 Interleukin-1 Proteins 0.000 description 2
- 102000000589 Interleukin-1 Human genes 0.000 description 2
- 108010002350 Interleukin-2 Proteins 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 2
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 2
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 2
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 2
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- QUAAUWNLWMLERT-IHRRRGAJSA-N Leu-Arg-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O QUAAUWNLWMLERT-IHRRRGAJSA-N 0.000 description 2
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 2
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 2
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 2
- HWMQRQIFVGEAPH-XIRDDKMYSA-N Leu-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 HWMQRQIFVGEAPH-XIRDDKMYSA-N 0.000 description 2
- ZJZNLRVCZWUONM-JXUBOQSCSA-N Leu-Thr-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O ZJZNLRVCZWUONM-JXUBOQSCSA-N 0.000 description 2
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 2
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 2
- MYZMQWHPDAYKIE-SRVKXCTJSA-N Lys-Leu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O MYZMQWHPDAYKIE-SRVKXCTJSA-N 0.000 description 2
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 2
- PLOUVAYOMTYJRG-JXUBOQSCSA-N Lys-Thr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O PLOUVAYOMTYJRG-JXUBOQSCSA-N 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- GTRWUQSSISWRTL-NAKRPEOUSA-N Met-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCSC)N GTRWUQSSISWRTL-NAKRPEOUSA-N 0.000 description 2
- GWADARYJIJDYRC-XGEHTFHBSA-N Met-Thr-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GWADARYJIJDYRC-XGEHTFHBSA-N 0.000 description 2
- 206010027476 Metastases Diseases 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 241000699660 Mus musculus Species 0.000 description 2
- QPCDCPDFJACHGM-UHFFFAOYSA-N N,N-bis{2-[bis(carboxymethyl)amino]ethyl}glycine Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(=O)O)CCN(CC(O)=O)CC(O)=O QPCDCPDFJACHGM-UHFFFAOYSA-N 0.000 description 2
- 108010079364 N-glycylalanine Proteins 0.000 description 2
- 208000007571 Ovarian Epithelial Carcinoma Diseases 0.000 description 2
- 229940116355 PI3 kinase inhibitor Drugs 0.000 description 2
- CDNPIRSCAFMMBE-SRVKXCTJSA-N Phe-Asn-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CDNPIRSCAFMMBE-SRVKXCTJSA-N 0.000 description 2
- PSBJZLMFFTULDX-IXOXFDKPSA-N Phe-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N)O PSBJZLMFFTULDX-IXOXFDKPSA-N 0.000 description 2
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- 206010035226 Plasma cell myeloma Diseases 0.000 description 2
- 239000002202 Polyethylene glycol Substances 0.000 description 2
- XQLBWXHVZVBNJM-FXQIFTODSA-N Pro-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 XQLBWXHVZVBNJM-FXQIFTODSA-N 0.000 description 2
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 2
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 2
- 108010029485 Protein Isoforms Proteins 0.000 description 2
- 102000001708 Protein Isoforms Human genes 0.000 description 2
- 238000011529 RT qPCR Methods 0.000 description 2
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 2
- KJMOINFQVCCSDX-XKBZYTNZSA-N Ser-Gln-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KJMOINFQVCCSDX-XKBZYTNZSA-N 0.000 description 2
- MOINZPRHJGTCHZ-MMWGEVLESA-N Ser-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N MOINZPRHJGTCHZ-MMWGEVLESA-N 0.000 description 2
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 2
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 2
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 2
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 2
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 2
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 2
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 2
- VLMIUSLQONKLDV-HEIBUPTGSA-N Ser-Thr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VLMIUSLQONKLDV-HEIBUPTGSA-N 0.000 description 2
- VAIWUNAAPZZGRI-IHPCNDPISA-N Ser-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CO)N VAIWUNAAPZZGRI-IHPCNDPISA-N 0.000 description 2
- RTXKJFWHEBTABY-IHPCNDPISA-N Ser-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CO)N RTXKJFWHEBTABY-IHPCNDPISA-N 0.000 description 2
- OSFZCEQJLWCIBG-BZSNNMDCSA-N Ser-Tyr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OSFZCEQJLWCIBG-BZSNNMDCSA-N 0.000 description 2
- PMTWIUBUQRGCSB-FXQIFTODSA-N Ser-Val-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O PMTWIUBUQRGCSB-FXQIFTODSA-N 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-L Sulfate Chemical compound [O-]S([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 2
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 description 2
- BNGDYRRHRGOPHX-IFFSRLJSSA-N Thr-Glu-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O BNGDYRRHRGOPHX-IFFSRLJSSA-N 0.000 description 2
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 2
- FWTFAZKJORVTIR-VZFHVOOUSA-N Thr-Ser-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O FWTFAZKJORVTIR-VZFHVOOUSA-N 0.000 description 2
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 2
- FBQHKSPOIAFUEI-OWLDWWDNSA-N Thr-Trp-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O FBQHKSPOIAFUEI-OWLDWWDNSA-N 0.000 description 2
- LXXCHJKHJYRMIY-FQPOAREZSA-N Thr-Tyr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O LXXCHJKHJYRMIY-FQPOAREZSA-N 0.000 description 2
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 2
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 108700009124 Transcription Initiation Site Proteins 0.000 description 2
- AVYVKJMBNLPWRX-WFBYXXMGSA-N Trp-Ala-Ser Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 AVYVKJMBNLPWRX-WFBYXXMGSA-N 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- VCXWRWYFJLXITF-AUTRQRHGSA-N Tyr-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 VCXWRWYFJLXITF-AUTRQRHGSA-N 0.000 description 2
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 2
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 2
- KIJLSRYAUGGZIN-CFMVVWHZSA-N Tyr-Ile-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O KIJLSRYAUGGZIN-CFMVVWHZSA-N 0.000 description 2
- LQGDFDYGDQEMGA-PXDAIIFMSA-N Tyr-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N LQGDFDYGDQEMGA-PXDAIIFMSA-N 0.000 description 2
- NSGZILIDHCIZAM-KKUMJFAQSA-N Tyr-Leu-Ser Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N NSGZILIDHCIZAM-KKUMJFAQSA-N 0.000 description 2
- SINRIKQYQJRGDQ-MEYUZBJRSA-N Tyr-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SINRIKQYQJRGDQ-MEYUZBJRSA-N 0.000 description 2
- MDXLPNRXCFOBTL-BZSNNMDCSA-N Tyr-Ser-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MDXLPNRXCFOBTL-BZSNNMDCSA-N 0.000 description 2
- KUXCBJFJURINGF-PXDAIIFMSA-N Tyr-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CC=C(C=C3)O)N KUXCBJFJURINGF-PXDAIIFMSA-N 0.000 description 2
- BWVHQINTNLVWGZ-ZKWXMUAHSA-N Val-Cys-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N BWVHQINTNLVWGZ-ZKWXMUAHSA-N 0.000 description 2
- SZTTYWIUCGSURQ-AUTRQRHGSA-N Val-Glu-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SZTTYWIUCGSURQ-AUTRQRHGSA-N 0.000 description 2
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 2
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 2
- AOILQMZPNLUXCM-AVGNSLFASA-N Val-Val-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN AOILQMZPNLUXCM-AVGNSLFASA-N 0.000 description 2
- 238000010521 absorption reaction Methods 0.000 description 2
- 108010041407 alanylaspartic acid Proteins 0.000 description 2
- 108010044940 alanylglutamine Proteins 0.000 description 2
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 2
- 239000012491 analyte Substances 0.000 description 2
- 230000001772 anti-angiogenic effect Effects 0.000 description 2
- 230000001093 anti-cancer Effects 0.000 description 2
- 210000000628 antibody-producing cell Anatomy 0.000 description 2
- 238000011319 anticancer therapy Methods 0.000 description 2
- 239000003963 antioxidant agent Substances 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 210000001367 artery Anatomy 0.000 description 2
- 229940009098 aspartate Drugs 0.000 description 2
- 238000011888 autopsy Methods 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 239000011230 binding agent Substances 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 2
- 210000000349 chromosome Anatomy 0.000 description 2
- 239000011248 coating agent Substances 0.000 description 2
- 238000000576 coating method Methods 0.000 description 2
- 239000007822 coupling agent Substances 0.000 description 2
- 239000012228 culture supernatant Substances 0.000 description 2
- 229960004397 cyclophosphamide Drugs 0.000 description 2
- 230000001472 cytotoxic effect Effects 0.000 description 2
- 230000003111 delayed effect Effects 0.000 description 2
- 108010009297 diglycyl-histidine Proteins 0.000 description 2
- POULHZVOKOAJMA-UHFFFAOYSA-N dodecanoic acid Chemical compound CCCCCCCCCCCC(O)=O POULHZVOKOAJMA-UHFFFAOYSA-N 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 2
- 239000012530 fluid Substances 0.000 description 2
- 229960002949 fluorouracil Drugs 0.000 description 2
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 2
- CHPZKNULDCNCBW-UHFFFAOYSA-N gallium nitrate Chemical compound [Ga+3].[O-][N+]([O-])=O.[O-][N+]([O-])=O.[O-][N+]([O-])=O CHPZKNULDCNCBW-UHFFFAOYSA-N 0.000 description 2
- 108010006664 gamma-glutamyl-glycyl-glycine Proteins 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 239000008273 gelatin Substances 0.000 description 2
- 229920000159 gelatin Polymers 0.000 description 2
- 235000019322 gelatine Nutrition 0.000 description 2
- 235000011852 gelatine desserts Nutrition 0.000 description 2
- 229930195712 glutamate Natural products 0.000 description 2
- 108010078144 glutaminyl-glycine Proteins 0.000 description 2
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 2
- 108010059898 glycyl-tyrosyl-lysine Proteins 0.000 description 2
- 108010010147 glycylglutamine Proteins 0.000 description 2
- 238000002649 immunization Methods 0.000 description 2
- 230000003053 immunization Effects 0.000 description 2
- 238000003364 immunohistochemistry Methods 0.000 description 2
- 238000012744 immunostaining Methods 0.000 description 2
- 230000003308 immunostimulating effect Effects 0.000 description 2
- 238000001802 infusion Methods 0.000 description 2
- 208000014674 injury Diseases 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 239000007928 intraperitoneal injection Substances 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 2
- 108010027338 isoleucylcysteine Proteins 0.000 description 2
- 239000007951 isotonicity adjuster Substances 0.000 description 2
- 108010012058 leucyltyrosine Proteins 0.000 description 2
- 238000004811 liquid chromatography Methods 0.000 description 2
- 239000006193 liquid solution Substances 0.000 description 2
- 239000006194 liquid suspension Substances 0.000 description 2
- 210000003712 lysosome Anatomy 0.000 description 2
- 230000001868 lysosomic effect Effects 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 229960004961 mechlorethamine Drugs 0.000 description 2
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical class ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 229960001428 mercaptopurine Drugs 0.000 description 2
- 230000009401 metastasis Effects 0.000 description 2
- 229930182817 methionine Natural products 0.000 description 2
- 238000010208 microarray analysis Methods 0.000 description 2
- 244000005700 microbiome Species 0.000 description 2
- 210000004925 microvascular endothelial cell Anatomy 0.000 description 2
- 229960004857 mitomycin Drugs 0.000 description 2
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 2
- 229960001156 mitoxantrone Drugs 0.000 description 2
- 201000000050 myeloid neoplasm Diseases 0.000 description 2
- 229960001420 nimustine Drugs 0.000 description 2
- VFEDRRNHLBGPNN-UHFFFAOYSA-N nimustine Chemical compound CC1=NC=C(CNC(=O)N(CCCl)N=O)C(N)=N1 VFEDRRNHLBGPNN-UHFFFAOYSA-N 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 238000011580 nude mouse model Methods 0.000 description 2
- 230000009437 off-target effect Effects 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 239000000816 peptidomimetic Substances 0.000 description 2
- 230000010412 perfusion Effects 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- 239000002935 phosphatidylinositol 3 kinase inhibitor Substances 0.000 description 2
- 229910052697 platinum Inorganic materials 0.000 description 2
- 229920001223 polyethylene glycol Polymers 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 2
- 229960000624 procarbazine Drugs 0.000 description 2
- 108010053725 prolylvaline Proteins 0.000 description 2
- 230000000069 prophylactic effect Effects 0.000 description 2
- 230000005180 public health Effects 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- 230000005855 radiation Effects 0.000 description 2
- 238000011084 recovery Methods 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 229960004641 rituximab Drugs 0.000 description 2
- 108010026333 seryl-proline Proteins 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 239000004055 small Interfering RNA Substances 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- DAEPDZWVDSPTHF-UHFFFAOYSA-M sodium pyruvate Chemical compound [Na+].CC(=O)C([O-])=O DAEPDZWVDSPTHF-UHFFFAOYSA-M 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 238000007619 statistical method Methods 0.000 description 2
- 229910021653 sulphate ion Inorganic materials 0.000 description 2
- 239000013589 supplement Substances 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 229960003087 tioguanine Drugs 0.000 description 2
- 229960001612 trastuzumab emtansine Drugs 0.000 description 2
- GETQZCLCWQTVFV-UHFFFAOYSA-N trimethylamine Chemical compound CN(C)C GETQZCLCWQTVFV-UHFFFAOYSA-N 0.000 description 2
- 108010044292 tryptophyltyrosine Proteins 0.000 description 2
- 108010005834 tyrosyl-alanyl-glycine Proteins 0.000 description 2
- 108010017949 tyrosyl-glycyl-glycine Proteins 0.000 description 2
- 108010051110 tyrosyl-lysine Proteins 0.000 description 2
- 230000003827 upregulation Effects 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical group C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 2
- 230000002792 vascular Effects 0.000 description 2
- 235000015112 vegetable and seed oil Nutrition 0.000 description 2
- 239000008158 vegetable oil Substances 0.000 description 2
- 238000005406 washing Methods 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- 230000003442 weekly effect Effects 0.000 description 2
- QBYIENPQHBMVBV-HFEGYEGKSA-N (2R)-2-hydroxy-2-phenylacetic acid Chemical compound O[C@@H](C(O)=O)c1ccccc1.O[C@@H](C(O)=O)c1ccccc1 QBYIENPQHBMVBV-HFEGYEGKSA-N 0.000 description 1
- URLVCROWVOSNPT-XOTOMLERSA-N (2s)-4-[(13r)-13-hydroxy-13-[(2r,5r)-5-[(2r,5r)-5-[(1r)-1-hydroxyundecyl]oxolan-2-yl]oxolan-2-yl]tridecyl]-2-methyl-2h-furan-5-one Chemical compound O1[C@@H]([C@H](O)CCCCCCCCCC)CC[C@@H]1[C@@H]1O[C@@H]([C@H](O)CCCCCCCCCCCCC=2C(O[C@@H](C)C=2)=O)CC1 URLVCROWVOSNPT-XOTOMLERSA-N 0.000 description 1
- CGMTUJFWROPELF-YPAAEMCBSA-N (3E,5S)-5-[(2S)-butan-2-yl]-3-(1-hydroxyethylidene)pyrrolidine-2,4-dione Chemical compound CC[C@H](C)[C@@H]1NC(=O)\C(=C(/C)O)C1=O CGMTUJFWROPELF-YPAAEMCBSA-N 0.000 description 1
- TVIRNGFXQVMMGB-OFWIHYRESA-N (3s,6r,10r,13e,16s)-16-[(2r,3r,4s)-4-chloro-3-hydroxy-4-phenylbutan-2-yl]-10-[(3-chloro-4-methoxyphenyl)methyl]-6-methyl-3-(2-methylpropyl)-1,4-dioxa-8,11-diazacyclohexadec-13-ene-2,5,9,12-tetrone Chemical compound C1=C(Cl)C(OC)=CC=C1C[C@@H]1C(=O)NC[C@@H](C)C(=O)O[C@@H](CC(C)C)C(=O)O[C@H]([C@H](C)[C@@H](O)[C@@H](Cl)C=2C=CC=CC=2)C/C=C/C(=O)N1 TVIRNGFXQVMMGB-OFWIHYRESA-N 0.000 description 1
- INAUWOVKEZHHDM-PEDBPRJASA-N (7s,9s)-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-7-[(2r,4s,5s,6s)-5-hydroxy-6-methyl-4-morpholin-4-yloxan-2-yl]oxy-4-methoxy-8,10-dihydro-7h-tetracene-5,12-dione;hydrochloride Chemical compound Cl.N1([C@H]2C[C@@H](O[C@@H](C)[C@H]2O)O[C@H]2C[C@@](O)(CC=3C(O)=C4C(=O)C=5C=CC=C(C=5C(=O)C4=C(O)C=32)OC)C(=O)CO)CCOCC1 INAUWOVKEZHHDM-PEDBPRJASA-N 0.000 description 1
- FPVKHBSQESCIEP-UHFFFAOYSA-N (8S)-3-(2-deoxy-beta-D-erythro-pentofuranosyl)-3,6,7,8-tetrahydroimidazo[4,5-d][1,3]diazepin-8-ol Natural products C1C(O)C(CO)OC1N1C(NC=NCC2O)=C2N=C1 FPVKHBSQESCIEP-UHFFFAOYSA-N 0.000 description 1
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 1
- AGNGYMCLFWQVGX-AGFFZDDWSA-N (e)-1-[(2s)-2-amino-2-carboxyethoxy]-2-diazonioethenolate Chemical compound OC(=O)[C@@H](N)CO\C([O-])=C\[N+]#N AGNGYMCLFWQVGX-AGFFZDDWSA-N 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- QMNWYGTWTXOQTP-UHFFFAOYSA-N 1h-triazin-6-one Chemical compound O=C1C=CN=NN1 QMNWYGTWTXOQTP-UHFFFAOYSA-N 0.000 description 1
- NHBKXEKEPDILRR-UHFFFAOYSA-N 2,3-bis(butanoylsulfanyl)propyl butanoate Chemical compound CCCC(=O)OCC(SC(=O)CCC)CSC(=O)CCC NHBKXEKEPDILRR-UHFFFAOYSA-N 0.000 description 1
- BTOTXLJHDSNXMW-POYBYMJQSA-N 2,3-dideoxyuridine Chemical compound O1[C@H](CO)CC[C@@H]1N1C(=O)NC(=O)C=C1 BTOTXLJHDSNXMW-POYBYMJQSA-N 0.000 description 1
- BOMZMNZEXMAQQW-UHFFFAOYSA-N 2,5,11-trimethyl-6h-pyrido[4,3-b]carbazol-2-ium-9-ol;acetate Chemical compound CC([O-])=O.C[N+]1=CC=C2C(C)=C(NC=3C4=CC(O)=CC=3)C4=C(C)C2=C1 BOMZMNZEXMAQQW-UHFFFAOYSA-N 0.000 description 1
- QCXJFISCRQIYID-IAEPZHFASA-N 2-amino-1-n-[(3s,6s,7r,10s,16s)-3-[(2s)-butan-2-yl]-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-10-propan-2-yl-8-oxa-1,4,11,14-tetrazabicyclo[14.3.0]nonadecan-6-yl]-4,6-dimethyl-3-oxo-9-n-[(3s,6s,7r,10s,16s)-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-3,10-di(propa Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N=C2C(C(=O)N[C@@H]3C(=O)N[C@H](C(N4CCC[C@H]4C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]3C)=O)[C@@H](C)CC)=C(N)C(=O)C(C)=C2O2)C2=C(C)C=C1 QCXJFISCRQIYID-IAEPZHFASA-N 0.000 description 1
- YIMDLWDNDGKDTJ-QLKYHASDSA-N 3'-deamino-3'-(3-cyanomorpholin-4-yl)doxorubicin Chemical compound N1([C@H]2C[C@@H](O[C@@H](C)[C@H]2O)O[C@H]2C[C@@](O)(CC=3C(O)=C4C(=O)C=5C=CC=C(C=5C(=O)C4=C(O)C=32)OC)C(=O)CO)CCOCC1C#N YIMDLWDNDGKDTJ-QLKYHASDSA-N 0.000 description 1
- UAIUNKRWKOVEES-UHFFFAOYSA-N 3,3',5,5'-tetramethylbenzidine Chemical compound CC1=C(N)C(C)=CC(C=2C=C(C)C(N)=C(C)C=2)=C1 UAIUNKRWKOVEES-UHFFFAOYSA-N 0.000 description 1
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 description 1
- PWMYMKOUNYTVQN-UHFFFAOYSA-N 3-(8,8-diethyl-2-aza-8-germaspiro[4.5]decan-2-yl)-n,n-dimethylpropan-1-amine Chemical compound C1C[Ge](CC)(CC)CCC11CN(CCCN(C)C)CC1 PWMYMKOUNYTVQN-UHFFFAOYSA-N 0.000 description 1
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 1
- IDPUKCWIGUEADI-UHFFFAOYSA-N 5-[bis(2-chloroethyl)amino]uracil Chemical compound ClCCN(CCCl)C1=CNC(=O)NC1=O IDPUKCWIGUEADI-UHFFFAOYSA-N 0.000 description 1
- NMUSYJAQQFHJEW-KVTDHHQDSA-N 5-azacytidine Chemical compound O=C1N=C(N)N=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 NMUSYJAQQFHJEW-KVTDHHQDSA-N 0.000 description 1
- WYXSYVWAUAUWLD-SHUUEZRQSA-N 6-azauridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=N1 WYXSYVWAUAUWLD-SHUUEZRQSA-N 0.000 description 1
- BDDLHHRCDSJVKV-UHFFFAOYSA-N 7028-40-2 Chemical compound CC(O)=O.CC(O)=O.CC(O)=O.CC(O)=O BDDLHHRCDSJVKV-UHFFFAOYSA-N 0.000 description 1
- ZGXJTSGNIOSYLO-UHFFFAOYSA-N 88755TAZ87 Chemical compound NCC(=O)CCC(O)=O ZGXJTSGNIOSYLO-UHFFFAOYSA-N 0.000 description 1
- HDZZVAMISRMYHH-UHFFFAOYSA-N 9beta-Ribofuranosyl-7-deazaadenin Natural products C1=CC=2C(N)=NC=NC=2N1C1OC(CO)C(O)C1O HDZZVAMISRMYHH-UHFFFAOYSA-N 0.000 description 1
- 206010067484 Adverse reaction Diseases 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- YLTKNGYYPIWKHZ-ACZMJKKPSA-N Ala-Ala-Glu Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O YLTKNGYYPIWKHZ-ACZMJKKPSA-N 0.000 description 1
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 1
- DVWVZSJAYIJZFI-FXQIFTODSA-N Ala-Arg-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O DVWVZSJAYIJZFI-FXQIFTODSA-N 0.000 description 1
- MPLOSMWGDNJSEV-WHFBIAKZSA-N Ala-Gly-Asp Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MPLOSMWGDNJSEV-WHFBIAKZSA-N 0.000 description 1
- WEZNQZHACPSMEF-QEJZJMRPSA-N Ala-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 WEZNQZHACPSMEF-QEJZJMRPSA-N 0.000 description 1
- YHBDGLZYNIARKJ-GUBZILKMSA-N Ala-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N YHBDGLZYNIARKJ-GUBZILKMSA-N 0.000 description 1
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 1
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 1
- UCDOXFBTMLKASE-HERUPUMHSA-N Ala-Ser-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N UCDOXFBTMLKASE-HERUPUMHSA-N 0.000 description 1
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 1
- AENHOIXXHKNIQL-AUTRQRHGSA-N Ala-Tyr-Ala Chemical compound [O-]C(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H]([NH3+])C)CC1=CC=C(O)C=C1 AENHOIXXHKNIQL-AUTRQRHGSA-N 0.000 description 1
- ZJLORAAXDAJLDC-CQDKDKBSSA-N Ala-Tyr-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O ZJLORAAXDAJLDC-CQDKDKBSSA-N 0.000 description 1
- CEIZFXOZIQNICU-UHFFFAOYSA-N Alternaria alternata Crofton-weed toxin Natural products CCC(C)C1NC(=O)C(C(C)=O)=C1O CEIZFXOZIQNICU-UHFFFAOYSA-N 0.000 description 1
- VHUUQVKOLVNVRT-UHFFFAOYSA-N Ammonium hydroxide Chemical compound [NH4+].[OH-] VHUUQVKOLVNVRT-UHFFFAOYSA-N 0.000 description 1
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 1
- CFGHCPUPFHWMCM-FDARSICLSA-N Arg-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N CFGHCPUPFHWMCM-FDARSICLSA-N 0.000 description 1
- RIQBRKVTFBWEDY-RHYQMDGZSA-N Arg-Lys-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RIQBRKVTFBWEDY-RHYQMDGZSA-N 0.000 description 1
- ASQKVGRCKOFKIU-KZVJFYERSA-N Arg-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ASQKVGRCKOFKIU-KZVJFYERSA-N 0.000 description 1
- DJHGAFSJWGLOIV-UHFFFAOYSA-K Arsenate3- Chemical compound [O-][As]([O-])([O-])=O DJHGAFSJWGLOIV-UHFFFAOYSA-K 0.000 description 1
- YJRORCOAFUZVKA-FXQIFTODSA-N Asn-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)N)N)CN=C(N)N YJRORCOAFUZVKA-FXQIFTODSA-N 0.000 description 1
- BVLIJXXSXBUGEC-SRVKXCTJSA-N Asn-Asn-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BVLIJXXSXBUGEC-SRVKXCTJSA-N 0.000 description 1
- ZWASIOHRQWRWAS-UGYAYLCHSA-N Asn-Asp-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZWASIOHRQWRWAS-UGYAYLCHSA-N 0.000 description 1
- IICZCLFBILYRCU-WHFBIAKZSA-N Asn-Gly-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O IICZCLFBILYRCU-WHFBIAKZSA-N 0.000 description 1
- JQSWHKKUZMTOIH-QWRGUYRKSA-N Asn-Gly-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N JQSWHKKUZMTOIH-QWRGUYRKSA-N 0.000 description 1
- XLZCLJRGGMBKLR-PCBIJLKTSA-N Asn-Ile-Phe Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XLZCLJRGGMBKLR-PCBIJLKTSA-N 0.000 description 1
- NUCUBYIUPVYGPP-XIRDDKMYSA-N Asn-Leu-Trp Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CC(N)=O)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O NUCUBYIUPVYGPP-XIRDDKMYSA-N 0.000 description 1
- RTFWCVDISAMGEQ-SRVKXCTJSA-N Asn-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N RTFWCVDISAMGEQ-SRVKXCTJSA-N 0.000 description 1
- XHTUGJCAEYOZOR-UBHSHLNASA-N Asn-Ser-Trp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O XHTUGJCAEYOZOR-UBHSHLNASA-N 0.000 description 1
- YSYTWUMRHSFODC-QWRGUYRKSA-N Asn-Tyr-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O YSYTWUMRHSFODC-QWRGUYRKSA-N 0.000 description 1
- DATSKXOXPUAOLK-KKUMJFAQSA-N Asn-Tyr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O DATSKXOXPUAOLK-KKUMJFAQSA-N 0.000 description 1
- UQBGYPFHWFZMCD-ZLUOBGJFSA-N Asp-Asn-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O UQBGYPFHWFZMCD-ZLUOBGJFSA-N 0.000 description 1
- QRULNKJGYQQZMW-ZLUOBGJFSA-N Asp-Asn-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O QRULNKJGYQQZMW-ZLUOBGJFSA-N 0.000 description 1
- VBVKSAFJPVXMFJ-CIUDSAMLSA-N Asp-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N VBVKSAFJPVXMFJ-CIUDSAMLSA-N 0.000 description 1
- HOQGTAIGQSDCHR-SRVKXCTJSA-N Asp-Asn-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HOQGTAIGQSDCHR-SRVKXCTJSA-N 0.000 description 1
- RYEWQKQXRJCHIO-SRVKXCTJSA-N Asp-Asn-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 RYEWQKQXRJCHIO-SRVKXCTJSA-N 0.000 description 1
- OMMIEVATLAGRCK-BYPYZUCNSA-N Asp-Gly-Gly Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)NCC(O)=O OMMIEVATLAGRCK-BYPYZUCNSA-N 0.000 description 1
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 1
- MYOHQBFRJQFIDZ-KKUMJFAQSA-N Asp-Leu-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MYOHQBFRJQFIDZ-KKUMJFAQSA-N 0.000 description 1
- SARSTIZOZFBDOM-FXQIFTODSA-N Asp-Met-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O SARSTIZOZFBDOM-FXQIFTODSA-N 0.000 description 1
- HRVQDZOWMLFAOD-BIIVOSGPSA-N Asp-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N)C(=O)O HRVQDZOWMLFAOD-BIIVOSGPSA-N 0.000 description 1
- IWLZBRTUIVXZJD-OLHMAJIHSA-N Asp-Thr-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O IWLZBRTUIVXZJD-OLHMAJIHSA-N 0.000 description 1
- CZIVKMOEXPILDK-SRVKXCTJSA-N Asp-Tyr-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O CZIVKMOEXPILDK-SRVKXCTJSA-N 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 1
- VGGGPCQERPFHOB-MCIONIFRSA-N Bestatin Chemical compound CC(C)C[C@H](C(O)=O)NC(=O)[C@@H](O)[C@H](N)CC1=CC=CC=C1 VGGGPCQERPFHOB-MCIONIFRSA-N 0.000 description 1
- 229940122361 Bisphosphonate Drugs 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 241000282836 Camelus dromedarius Species 0.000 description 1
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 description 1
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 description 1
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 description 1
- 108090000209 Carbonic anhydrases Proteins 0.000 description 1
- 102000003846 Carbonic anhydrases Human genes 0.000 description 1
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 1
- 241000700199 Cavia porcellus Species 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 206010008342 Cervix carcinoma Diseases 0.000 description 1
- 102000019034 Chemokines Human genes 0.000 description 1
- 108010012236 Chemokines Proteins 0.000 description 1
- JWBOIMRXGHLCPP-UHFFFAOYSA-N Chloditan Chemical compound C=1C=CC=C(Cl)C=1C(C(Cl)Cl)C1=CC=C(Cl)C=C1 JWBOIMRXGHLCPP-UHFFFAOYSA-N 0.000 description 1
- MKQWTWSXVILIKJ-LXGUWJNJSA-N Chlorozotocin Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](C=O)NC(=O)N(N=O)CCCl MKQWTWSXVILIKJ-LXGUWJNJSA-N 0.000 description 1
- 108010049048 Cholera Toxin Proteins 0.000 description 1
- 102000009016 Cholera Toxin Human genes 0.000 description 1
- 108010077544 Chromatin Proteins 0.000 description 1
- 208000032544 Cicatrix Diseases 0.000 description 1
- 206010009944 Colon cancer Diseases 0.000 description 1
- 206010052360 Colorectal adenocarcinoma Diseases 0.000 description 1
- 206010010071 Coma Diseases 0.000 description 1
- 108050006400 Cyclin Proteins 0.000 description 1
- 108010037462 Cyclooxygenase 2 Proteins 0.000 description 1
- TVYMKYUSZSVOAG-ZLUOBGJFSA-N Cys-Ala-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O TVYMKYUSZSVOAG-ZLUOBGJFSA-N 0.000 description 1
- VNLYIYOYUNGURO-ZLUOBGJFSA-N Cys-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N VNLYIYOYUNGURO-ZLUOBGJFSA-N 0.000 description 1
- FCXJJTRGVAZDER-FXQIFTODSA-N Cys-Val-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O FCXJJTRGVAZDER-FXQIFTODSA-N 0.000 description 1
- AZDQAZRURQMSQD-XPUUQOCRSA-N Cys-Val-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AZDQAZRURQMSQD-XPUUQOCRSA-N 0.000 description 1
- 230000004543 DNA replication Effects 0.000 description 1
- 108010092160 Dactinomycin Proteins 0.000 description 1
- FEWJPZIEWOKRBE-JCYAYHJZSA-N Dextrotartaric acid Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O FEWJPZIEWOKRBE-JCYAYHJZSA-N 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- SAMRUMKYXPVKPA-VFKOLLTISA-N Enocitabine Chemical compound O=C1N=C(NC(=O)CCCCCCCCCCCCCCCCCCCCC)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 SAMRUMKYXPVKPA-VFKOLLTISA-N 0.000 description 1
- 108010055196 EphA2 Receptor Proteins 0.000 description 1
- 102100030340 Ephrin type-A receptor 2 Human genes 0.000 description 1
- 101800003838 Epidermal growth factor Proteins 0.000 description 1
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 1
- OBMLHUPNRURLOK-XGRAFVIBSA-N Epitiostanol Chemical compound C1[C@@H]2S[C@@H]2C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CC[C@H]21 OBMLHUPNRURLOK-XGRAFVIBSA-N 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 229930189413 Esperamicin Natural products 0.000 description 1
- VGGSQFUCUMXWEO-UHFFFAOYSA-N Ethene Chemical compound C=C VGGSQFUCUMXWEO-UHFFFAOYSA-N 0.000 description 1
- 239000005977 Ethylene Substances 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 1
- LMPBBFWHCRURJD-LAEOZQHASA-N Gln-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N LMPBBFWHCRURJD-LAEOZQHASA-N 0.000 description 1
- UZMWDBOHAOSCCH-ACZMJKKPSA-N Gln-Cys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(N)=O UZMWDBOHAOSCCH-ACZMJKKPSA-N 0.000 description 1
- IPHGBVYWRKCGKG-FXQIFTODSA-N Gln-Cys-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O IPHGBVYWRKCGKG-FXQIFTODSA-N 0.000 description 1
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 1
- JEFZIKRIDLHOIF-BYPYZUCNSA-N Gln-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(O)=O JEFZIKRIDLHOIF-BYPYZUCNSA-N 0.000 description 1
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 1
- YXQCLIVLWCKCRS-RYUDHWBXSA-N Gln-Gly-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N)O YXQCLIVLWCKCRS-RYUDHWBXSA-N 0.000 description 1
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 1
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 1
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 1
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 1
- SXFPZRRVWSUYII-KBIXCLLPSA-N Gln-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N SXFPZRRVWSUYII-KBIXCLLPSA-N 0.000 description 1
- OBIHEDRRSMRKLU-ACZMJKKPSA-N Glu-Cys-Asp Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OBIHEDRRSMRKLU-ACZMJKKPSA-N 0.000 description 1
- PXXGVUVQWQGGIG-YUMQZZPRSA-N Glu-Gly-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N PXXGVUVQWQGGIG-YUMQZZPRSA-N 0.000 description 1
- MTAOBYXRYJZRGQ-WDSKDSINSA-N Glu-Gly-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MTAOBYXRYJZRGQ-WDSKDSINSA-N 0.000 description 1
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 1
- ZSWGJYOZWBHROQ-RWRJDSDZSA-N Glu-Ile-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZSWGJYOZWBHROQ-RWRJDSDZSA-N 0.000 description 1
- ITVBKCZZLJUUHI-HTUGSXCWSA-N Glu-Phe-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ITVBKCZZLJUUHI-HTUGSXCWSA-N 0.000 description 1
- HJTSRYLPAYGEEC-SIUGBPQLSA-N Glu-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCC(=O)O)N HJTSRYLPAYGEEC-SIUGBPQLSA-N 0.000 description 1
- VXEFAWJTFAUDJK-AVGNSLFASA-N Glu-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O VXEFAWJTFAUDJK-AVGNSLFASA-N 0.000 description 1
- SOYWRINXUSUWEQ-DLOVCJGASA-N Glu-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O SOYWRINXUSUWEQ-DLOVCJGASA-N 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- UPOJUWHGMDJUQZ-IUCAKERBSA-N Gly-Arg-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UPOJUWHGMDJUQZ-IUCAKERBSA-N 0.000 description 1
- UXJHNZODTMHWRD-WHFBIAKZSA-N Gly-Asn-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O UXJHNZODTMHWRD-WHFBIAKZSA-N 0.000 description 1
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 1
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 1
- INLIXXRWNUKVCF-JTQLQIEISA-N Gly-Gly-Tyr Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 INLIXXRWNUKVCF-JTQLQIEISA-N 0.000 description 1
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 1
- YTSVAIMKVLZUDU-YUMQZZPRSA-N Gly-Leu-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YTSVAIMKVLZUDU-YUMQZZPRSA-N 0.000 description 1
- TVUWMSBGMVAHSJ-KBPBESRZSA-N Gly-Leu-Phe Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 TVUWMSBGMVAHSJ-KBPBESRZSA-N 0.000 description 1
- JPAACTMBBBGAAR-HOTGVXAUSA-N Gly-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)CN)CC(C)C)C(O)=O)=CNC2=C1 JPAACTMBBBGAAR-HOTGVXAUSA-N 0.000 description 1
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 1
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 1
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 1
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 1
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 1
- RCHFYMASWAZQQZ-ZANVPECISA-N Gly-Trp-Ala Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)CN)=CNC2=C1 RCHFYMASWAZQQZ-ZANVPECISA-N 0.000 description 1
- UIQGJYUEQDOODF-KWQFWETISA-N Gly-Tyr-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 UIQGJYUEQDOODF-KWQFWETISA-N 0.000 description 1
- YJDALMUYJIENAG-QWRGUYRKSA-N Gly-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN)O YJDALMUYJIENAG-QWRGUYRKSA-N 0.000 description 1
- GNNJKUYDWFIBTK-QWRGUYRKSA-N Gly-Tyr-Asp Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O GNNJKUYDWFIBTK-QWRGUYRKSA-N 0.000 description 1
- KOYUSMBPJOVSOO-XEGUGMAKSA-N Gly-Tyr-Ile Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KOYUSMBPJOVSOO-XEGUGMAKSA-N 0.000 description 1
- DNAZKGFYFRGZIH-QWRGUYRKSA-N Gly-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 DNAZKGFYFRGZIH-QWRGUYRKSA-N 0.000 description 1
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 229940121710 HMGCoA reductase inhibitor Drugs 0.000 description 1
- 239000012981 Hank's balanced salt solution Substances 0.000 description 1
- 102100031573 Hematopoietic progenitor cell antigen CD34 Human genes 0.000 description 1
- 102000001554 Hemoglobins Human genes 0.000 description 1
- 108010054147 Hemoglobins Proteins 0.000 description 1
- BSVLMPMIXPQNKC-KBPBESRZSA-N His-Phe-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O BSVLMPMIXPQNKC-KBPBESRZSA-N 0.000 description 1
- CWSZWFILCNSNEX-CIUDSAMLSA-N His-Ser-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CWSZWFILCNSNEX-CIUDSAMLSA-N 0.000 description 1
- 102100038970 Histone-lysine N-methyltransferase EZH2 Human genes 0.000 description 1
- 101100118545 Holotrichia diomphalia EGF-like gene Proteins 0.000 description 1
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 1
- 101000721661 Homo sapiens Cellular tumor antigen p53 Proteins 0.000 description 1
- 101500025419 Homo sapiens Epidermal growth factor Proteins 0.000 description 1
- 101000777663 Homo sapiens Hematopoietic progenitor cell antigen CD34 Proteins 0.000 description 1
- 101000882127 Homo sapiens Histone-lysine N-methyltransferase EZH2 Proteins 0.000 description 1
- 101001034314 Homo sapiens Lactadherin Proteins 0.000 description 1
- 101000932478 Homo sapiens Receptor-type tyrosine-protein kinase FLT3 Proteins 0.000 description 1
- VSNHCAURESNICA-UHFFFAOYSA-N Hydroxyurea Chemical compound NC(=O)NO VSNHCAURESNICA-UHFFFAOYSA-N 0.000 description 1
- 206010020649 Hyperkeratosis Diseases 0.000 description 1
- 206010020751 Hypersensitivity Diseases 0.000 description 1
- VSZALHITQINTGC-GHCJXIJMSA-N Ile-Ala-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(=O)O)C(=O)O)N VSZALHITQINTGC-GHCJXIJMSA-N 0.000 description 1
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 1
- HDODQNPMSHDXJT-GHCJXIJMSA-N Ile-Asn-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O HDODQNPMSHDXJT-GHCJXIJMSA-N 0.000 description 1
- QYOGJYIRKACXEP-SLBDDTMCSA-N Ile-Asn-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N QYOGJYIRKACXEP-SLBDDTMCSA-N 0.000 description 1
- NKRJALPCDNXULF-BYULHYEWSA-N Ile-Asp-Gly Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O NKRJALPCDNXULF-BYULHYEWSA-N 0.000 description 1
- DCQMJRSOGCYKTR-GHCJXIJMSA-N Ile-Asp-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O DCQMJRSOGCYKTR-GHCJXIJMSA-N 0.000 description 1
- GYAFMRQGWHXMII-IUKAMOBKSA-N Ile-Asp-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N GYAFMRQGWHXMII-IUKAMOBKSA-N 0.000 description 1
- OEQKGSPBDVKYOC-ZKWXMUAHSA-N Ile-Gly-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N OEQKGSPBDVKYOC-ZKWXMUAHSA-N 0.000 description 1
- NYEYYMLUABXDMC-NHCYSSNCSA-N Ile-Gly-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)O)N NYEYYMLUABXDMC-NHCYSSNCSA-N 0.000 description 1
- SVBAHOMTJRFSIC-SXTJYALSSA-N Ile-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SVBAHOMTJRFSIC-SXTJYALSSA-N 0.000 description 1
- DGTOKVBDZXJHNZ-WZLNRYEVSA-N Ile-Thr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N DGTOKVBDZXJHNZ-WZLNRYEVSA-N 0.000 description 1
- BZUOLKFQVVBTJY-SLBDDTMCSA-N Ile-Trp-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(=O)N)C(=O)O)N BZUOLKFQVVBTJY-SLBDDTMCSA-N 0.000 description 1
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 1
- 102100034343 Integrase Human genes 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 108010065805 Interleukin-12 Proteins 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- YQEZLKZALYSWHR-UHFFFAOYSA-N Ketamine Chemical compound C=1C=CC=C(Cl)C=1C1(NC)CCCCC1=O YQEZLKZALYSWHR-UHFFFAOYSA-N 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- 102100039648 Lactadherin Human genes 0.000 description 1
- 102000002297 Laminin Receptors Human genes 0.000 description 1
- 108010000851 Laminin Receptors Proteins 0.000 description 1
- 239000005639 Lauric acid Substances 0.000 description 1
- 229920001491 Lentinan Polymers 0.000 description 1
- KVRKAGGMEWNURO-CIUDSAMLSA-N Leu-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N KVRKAGGMEWNURO-CIUDSAMLSA-N 0.000 description 1
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 1
- DLCOFDAHNMMQPP-SRVKXCTJSA-N Leu-Asp-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DLCOFDAHNMMQPP-SRVKXCTJSA-N 0.000 description 1
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 1
- VVQJGYPTIYOFBR-IHRRRGAJSA-N Leu-Lys-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)O)N VVQJGYPTIYOFBR-IHRRRGAJSA-N 0.000 description 1
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 1
- OZTZJMUZVAVJGY-BZSNNMDCSA-N Leu-Tyr-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N OZTZJMUZVAVJGY-BZSNNMDCSA-N 0.000 description 1
- MSFITIBEMPWCBD-ULQDDVLXSA-N Leu-Val-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 MSFITIBEMPWCBD-ULQDDVLXSA-N 0.000 description 1
- 239000012097 Lipofectamine 2000 Substances 0.000 description 1
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 1
- DGAAQRAUOFHBFJ-CIUDSAMLSA-N Lys-Asn-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O DGAAQRAUOFHBFJ-CIUDSAMLSA-N 0.000 description 1
- BYEBKXRNDLTGFW-CIUDSAMLSA-N Lys-Cys-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O BYEBKXRNDLTGFW-CIUDSAMLSA-N 0.000 description 1
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 1
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 1
- RMOKGALPSPOYKE-KATARQTJSA-N Lys-Thr-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O RMOKGALPSPOYKE-KATARQTJSA-N 0.000 description 1
- YFQSSOAGMZGXFT-MEYUZBJRSA-N Lys-Thr-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YFQSSOAGMZGXFT-MEYUZBJRSA-N 0.000 description 1
- PWHULOQIROXLJO-UHFFFAOYSA-N Manganese Chemical compound [Mn] PWHULOQIROXLJO-UHFFFAOYSA-N 0.000 description 1
- MHQXIBRPDKXDGZ-ZFWWWQNUSA-N Met-Gly-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)CNC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 MHQXIBRPDKXDGZ-ZFWWWQNUSA-N 0.000 description 1
- MIXPUVSPPOWTCR-FXQIFTODSA-N Met-Ser-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MIXPUVSPPOWTCR-FXQIFTODSA-N 0.000 description 1
- QYIGOFGUOVTAHK-ZJDVBMNYSA-N Met-Thr-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QYIGOFGUOVTAHK-ZJDVBMNYSA-N 0.000 description 1
- 101710151805 Mitochondrial intermediate peptidase 1 Proteins 0.000 description 1
- 229930192392 Mitomycin Natural products 0.000 description 1
- PCZOHLXUXFIOCF-UHFFFAOYSA-N Monacolin X Natural products C12C(OC(=O)C(C)CC)CC(C)C=C2C=CC(C)C1CCC1CC(O)CC(=O)O1 PCZOHLXUXFIOCF-UHFFFAOYSA-N 0.000 description 1
- 241000186366 Mycobacterium bovis Species 0.000 description 1
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- NXTVQNIVUKXOIL-UHFFFAOYSA-N N-chlorotoluene-p-sulfonamide Chemical compound CC1=CC=C(S(=O)(=O)NCl)C=C1 NXTVQNIVUKXOIL-UHFFFAOYSA-N 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- 230000004988 N-glycosylation Effects 0.000 description 1
- SYNHCENRCUAUNM-UHFFFAOYSA-N Nitrogen mustard N-oxide hydrochloride Chemical compound Cl.ClCC[N+]([O-])(C)CCCl SYNHCENRCUAUNM-UHFFFAOYSA-N 0.000 description 1
- KGTDRFCXGRULNK-UHFFFAOYSA-N Nogalamycin Natural products COC1C(OC)(C)C(OC)C(C)OC1OC1C2=C(O)C(C(=O)C3=C(O)C=C4C5(C)OC(C(C(C5O)N(C)C)O)OC4=C3C3=O)=C3C=C2C(C(=O)OC)C(C)(O)C1 KGTDRFCXGRULNK-UHFFFAOYSA-N 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- 241000283977 Oryctolagus Species 0.000 description 1
- 102000038030 PI3Ks Human genes 0.000 description 1
- 108091007960 PI3Ks Proteins 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 108010081690 Pertussis Toxin Proteins 0.000 description 1
- MECSIDWUTYRHRJ-KKUMJFAQSA-N Phe-Asn-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O MECSIDWUTYRHRJ-KKUMJFAQSA-N 0.000 description 1
- RIYZXJVARWJLKS-KKUMJFAQSA-N Phe-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 RIYZXJVARWJLKS-KKUMJFAQSA-N 0.000 description 1
- DJPXNKUDJKGQEE-BZSNNMDCSA-N Phe-Asp-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O DJPXNKUDJKGQEE-BZSNNMDCSA-N 0.000 description 1
- UEHNWRNADDPYNK-DLOVCJGASA-N Phe-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N UEHNWRNADDPYNK-DLOVCJGASA-N 0.000 description 1
- OWCLJDXHHZUNEL-IHRRRGAJSA-N Phe-Cys-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O OWCLJDXHHZUNEL-IHRRRGAJSA-N 0.000 description 1
- AUJWXNGCAQWLEI-KBPBESRZSA-N Phe-Lys-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O AUJWXNGCAQWLEI-KBPBESRZSA-N 0.000 description 1
- VHDNDCPMHQMXIR-IHRRRGAJSA-N Phe-Met-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC1=CC=CC=C1 VHDNDCPMHQMXIR-IHRRRGAJSA-N 0.000 description 1
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 1
- GLJZDMZJHFXJQG-BZSNNMDCSA-N Phe-Ser-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GLJZDMZJHFXJQG-BZSNNMDCSA-N 0.000 description 1
- 102100022427 Plasmalemma vesicle-associated protein Human genes 0.000 description 1
- 101710193105 Plasmalemma vesicle-associated protein Proteins 0.000 description 1
- 241000223960 Plasmodium falciparum Species 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- FEPSEIDIPBMIOS-QXEWZRGKSA-N Pro-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEPSEIDIPBMIOS-QXEWZRGKSA-N 0.000 description 1
- QEWBZBLXDKIQPS-STQMWFEESA-N Pro-Gly-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QEWBZBLXDKIQPS-STQMWFEESA-N 0.000 description 1
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 1
- KIDXAAQVMNLJFQ-KZVJFYERSA-N Pro-Thr-Ala Chemical compound C[C@@H](O)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](C)C(O)=O KIDXAAQVMNLJFQ-KZVJFYERSA-N 0.000 description 1
- 102100033237 Pro-epidermal growth factor Human genes 0.000 description 1
- 102000009339 Proliferating Cell Nuclear Antigen Human genes 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- XBDQKXXYIPTUBI-UHFFFAOYSA-M Propionate Chemical compound CCC([O-])=O XBDQKXXYIPTUBI-UHFFFAOYSA-M 0.000 description 1
- 102100038280 Prostaglandin G/H synthase 2 Human genes 0.000 description 1
- IWYDHOAUDWTVEP-UHFFFAOYSA-N R-2-phenyl-2-hydroxyacetic acid Natural products OC(=O)C(O)C1=CC=CC=C1 IWYDHOAUDWTVEP-UHFFFAOYSA-N 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 238000011530 RNeasy Mini Kit Methods 0.000 description 1
- 102100020718 Receptor-type tyrosine-protein kinase FLT3 Human genes 0.000 description 1
- 208000015634 Rectal Neoplasms Diseases 0.000 description 1
- 101150071661 SLC25A20 gene Proteins 0.000 description 1
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 1
- QGMLKFGTGXWAHF-IHRRRGAJSA-N Ser-Arg-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QGMLKFGTGXWAHF-IHRRRGAJSA-N 0.000 description 1
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 1
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 1
- TYYBJUYSTWJHGO-ZKWXMUAHSA-N Ser-Asn-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O TYYBJUYSTWJHGO-ZKWXMUAHSA-N 0.000 description 1
- OHKLFYXEOGGGCK-ZLUOBGJFSA-N Ser-Asp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OHKLFYXEOGGGCK-ZLUOBGJFSA-N 0.000 description 1
- BGOWRLSWJCVYAQ-CIUDSAMLSA-N Ser-Asp-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BGOWRLSWJCVYAQ-CIUDSAMLSA-N 0.000 description 1
- CDVFZMOFNJPUDD-ACZMJKKPSA-N Ser-Gln-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CDVFZMOFNJPUDD-ACZMJKKPSA-N 0.000 description 1
- YRBGKVIWMNEVCZ-WDSKDSINSA-N Ser-Glu-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YRBGKVIWMNEVCZ-WDSKDSINSA-N 0.000 description 1
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 1
- LQESNKGTTNHZPZ-GHCJXIJMSA-N Ser-Ile-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O LQESNKGTTNHZPZ-GHCJXIJMSA-N 0.000 description 1
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 1
- GVIGVIOEYBOTCB-XIRDDKMYSA-N Ser-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC(C)C)C(O)=O)=CNC2=C1 GVIGVIOEYBOTCB-XIRDDKMYSA-N 0.000 description 1
- AXVNLRQLPLSIPQ-FXQIFTODSA-N Ser-Met-Cys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N AXVNLRQLPLSIPQ-FXQIFTODSA-N 0.000 description 1
- XKFJENWJGHMDLI-QWRGUYRKSA-N Ser-Phe-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O XKFJENWJGHMDLI-QWRGUYRKSA-N 0.000 description 1
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 1
- FLONGDPORFIVQW-XGEHTFHBSA-N Ser-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FLONGDPORFIVQW-XGEHTFHBSA-N 0.000 description 1
- XZKQVQKUZMAADP-IMJSIDKUSA-N Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(O)=O XZKQVQKUZMAADP-IMJSIDKUSA-N 0.000 description 1
- GYDFRTRSSXOZCR-ACZMJKKPSA-N Ser-Ser-Glu Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GYDFRTRSSXOZCR-ACZMJKKPSA-N 0.000 description 1
- NVNPWELENFJOHH-CIUDSAMLSA-N Ser-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)N NVNPWELENFJOHH-CIUDSAMLSA-N 0.000 description 1
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 1
- ZKOKTQPHFMRSJP-YJRXYDGGSA-N Ser-Thr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKOKTQPHFMRSJP-YJRXYDGGSA-N 0.000 description 1
- STIAINRLUUKYKM-WFBYXXMGSA-N Ser-Trp-Ala Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CO)=CNC2=C1 STIAINRLUUKYKM-WFBYXXMGSA-N 0.000 description 1
- BCAVNDNYOGTQMQ-AAEUAGOBSA-N Ser-Trp-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O BCAVNDNYOGTQMQ-AAEUAGOBSA-N 0.000 description 1
- HXPNJVLVHKABMJ-KKUMJFAQSA-N Ser-Tyr-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CO)N)O HXPNJVLVHKABMJ-KKUMJFAQSA-N 0.000 description 1
- ZVBCMFDJIMUELU-BZSNNMDCSA-N Ser-Tyr-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CO)N ZVBCMFDJIMUELU-BZSNNMDCSA-N 0.000 description 1
- VVKVHAOOUGNDPJ-SRVKXCTJSA-N Ser-Tyr-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VVKVHAOOUGNDPJ-SRVKXCTJSA-N 0.000 description 1
- BEBVVQPDSHHWQL-NRPADANISA-N Ser-Val-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BEBVVQPDSHHWQL-NRPADANISA-N 0.000 description 1
- 238000000692 Student's t-test Methods 0.000 description 1
- BXFOFFBJRFZBQZ-QYWOHJEZSA-N T-2 toxin Chemical compound C([C@@]12[C@]3(C)[C@H](OC(C)=O)[C@@H](O)[C@H]1O[C@H]1[C@]3(COC(C)=O)C[C@@H](C(=C1)C)OC(=O)CC(C)C)O2 BXFOFFBJRFZBQZ-QYWOHJEZSA-N 0.000 description 1
- 102000012753 TIE-2 Receptor Human genes 0.000 description 1
- 108010090091 TIE-2 Receptor Proteins 0.000 description 1
- FEWJPZIEWOKRBE-UHFFFAOYSA-N Tartaric acid Natural products [H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-N 0.000 description 1
- CGMTUJFWROPELF-UHFFFAOYSA-N Tenuazonic acid Natural products CCC(C)C1NC(=O)C(=C(C)/O)C1=O CGMTUJFWROPELF-UHFFFAOYSA-N 0.000 description 1
- 208000024313 Testicular Neoplasms Diseases 0.000 description 1
- 206010057644 Testis cancer Diseases 0.000 description 1
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 1
- UTSWGQNAQRIHAI-UNQGMJICSA-N Thr-Arg-Phe Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 UTSWGQNAQRIHAI-UNQGMJICSA-N 0.000 description 1
- JEDIEMIJYSRUBB-FOHZUACHSA-N Thr-Asp-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O JEDIEMIJYSRUBB-FOHZUACHSA-N 0.000 description 1
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 1
- KGKWKSSSQGGYAU-SUSMZKCASA-N Thr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KGKWKSSSQGGYAU-SUSMZKCASA-N 0.000 description 1
- LGNBRHZANHMZHK-NUMRIWBASA-N Thr-Glu-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O LGNBRHZANHMZHK-NUMRIWBASA-N 0.000 description 1
- CRZNCABIJLRFKZ-IUKAMOBKSA-N Thr-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N CRZNCABIJLRFKZ-IUKAMOBKSA-N 0.000 description 1
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 1
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 1
- NDZYTIMDOZMECO-SHGPDSBTSA-N Thr-Thr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O NDZYTIMDOZMECO-SHGPDSBTSA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- UMILHIMHKXVDGH-UHFFFAOYSA-N Triethylene glycol diglycidyl ether Chemical compound C1OC1COCCOCCOCCOCC1CO1 UMILHIMHKXVDGH-UHFFFAOYSA-N 0.000 description 1
- FYAMXEPQQLNQDM-UHFFFAOYSA-N Tris(1-aziridinyl)phosphine oxide Chemical compound C1CN1P(N1CC1)(=O)N1CC1 FYAMXEPQQLNQDM-UHFFFAOYSA-N 0.000 description 1
- HYVLNORXQGKONN-NUTKFTJISA-N Trp-Ala-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 HYVLNORXQGKONN-NUTKFTJISA-N 0.000 description 1
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 1
- GLNADSQYFUSGOU-GPTZEZBUSA-J Trypan blue Chemical compound [Na+].[Na+].[Na+].[Na+].C1=C(S([O-])(=O)=O)C=C2C=C(S([O-])(=O)=O)C(/N=N/C3=CC=C(C=C3C)C=3C=C(C(=CC=3)\N=N\C=3C(=CC4=CC(=CC(N)=C4C=3O)S([O-])(=O)=O)S([O-])(=O)=O)C)=C(O)C2=C1N GLNADSQYFUSGOU-GPTZEZBUSA-J 0.000 description 1
- 102100040247 Tumor necrosis factor Human genes 0.000 description 1
- 206010064390 Tumour invasion Diseases 0.000 description 1
- JONPRIHUYSPIMA-UWJYBYFXSA-N Tyr-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JONPRIHUYSPIMA-UWJYBYFXSA-N 0.000 description 1
- ADBDQGBDNUTRDB-ULQDDVLXSA-N Tyr-Arg-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O ADBDQGBDNUTRDB-ULQDDVLXSA-N 0.000 description 1
- HGEHWFGAKHSIDY-SRVKXCTJSA-N Tyr-Asp-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N)O HGEHWFGAKHSIDY-SRVKXCTJSA-N 0.000 description 1
- QOIKZODVIPOPDD-AVGNSLFASA-N Tyr-Cys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOIKZODVIPOPDD-AVGNSLFASA-N 0.000 description 1
- NQJDICVXXIMMMB-XDTLVQLUSA-N Tyr-Glu-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O NQJDICVXXIMMMB-XDTLVQLUSA-N 0.000 description 1
- HIINQLBHPIQYHN-JTQLQIEISA-N Tyr-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HIINQLBHPIQYHN-JTQLQIEISA-N 0.000 description 1
- NXRGXTBPMOGFID-CFMVVWHZSA-N Tyr-Ile-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O NXRGXTBPMOGFID-CFMVVWHZSA-N 0.000 description 1
- GGXUDPQWAWRINY-XEGUGMAKSA-N Tyr-Ile-Gly Chemical compound OC(=O)CNC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GGXUDPQWAWRINY-XEGUGMAKSA-N 0.000 description 1
- NKUGCYDFQKFVOJ-JYJNAYRXSA-N Tyr-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NKUGCYDFQKFVOJ-JYJNAYRXSA-N 0.000 description 1
- GITNQBVCEQBDQC-KKUMJFAQSA-N Tyr-Lys-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O GITNQBVCEQBDQC-KKUMJFAQSA-N 0.000 description 1
- PGEFRHBWGOJPJT-KKUMJFAQSA-N Tyr-Lys-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O PGEFRHBWGOJPJT-KKUMJFAQSA-N 0.000 description 1
- OGPKMBOPMDTEDM-IHRRRGAJSA-N Tyr-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N OGPKMBOPMDTEDM-IHRRRGAJSA-N 0.000 description 1
- UPODKYBYUBTWSV-BZSNNMDCSA-N Tyr-Phe-Cys Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CS)C(O)=O)C1=CC=C(O)C=C1 UPODKYBYUBTWSV-BZSNNMDCSA-N 0.000 description 1
- YYLHVUCSTXXKBS-IHRRRGAJSA-N Tyr-Pro-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YYLHVUCSTXXKBS-IHRRRGAJSA-N 0.000 description 1
- UMSZZGTXGKHTFJ-SRVKXCTJSA-N Tyr-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 UMSZZGTXGKHTFJ-SRVKXCTJSA-N 0.000 description 1
- JHDZONWZTCKTJR-KJEVXHAQSA-N Tyr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JHDZONWZTCKTJR-KJEVXHAQSA-N 0.000 description 1
- ZYVAAYAOTVJBSS-GMVOTWDCSA-N Tyr-Trp-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O ZYVAAYAOTVJBSS-GMVOTWDCSA-N 0.000 description 1
- JRMCISZDVLOTLR-BVSLBCMMSA-N Tyr-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CC=C(C=C3)O)N JRMCISZDVLOTLR-BVSLBCMMSA-N 0.000 description 1
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 1
- HZDQUVQEVVYDDA-ACRUOGEOSA-N Tyr-Tyr-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HZDQUVQEVVYDDA-ACRUOGEOSA-N 0.000 description 1
- 102000003425 Tyrosinase Human genes 0.000 description 1
- 108060008724 Tyrosinase Proteins 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 208000002495 Uterine Neoplasms Diseases 0.000 description 1
- NMANTMWGQZASQN-QXEWZRGKSA-N Val-Arg-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N NMANTMWGQZASQN-QXEWZRGKSA-N 0.000 description 1
- NMPXRFYMZDIBRF-ZOBUZTSGSA-N Val-Asn-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N NMPXRFYMZDIBRF-ZOBUZTSGSA-N 0.000 description 1
- CGGVNFJRZJUVAE-BYULHYEWSA-N Val-Asp-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CGGVNFJRZJUVAE-BYULHYEWSA-N 0.000 description 1
- FBVUOEYVGNMRMD-NAKRPEOUSA-N Val-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N FBVUOEYVGNMRMD-NAKRPEOUSA-N 0.000 description 1
- BVWPHWLFGRCECJ-JSGCOSHPSA-N Val-Gly-Tyr Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N BVWPHWLFGRCECJ-JSGCOSHPSA-N 0.000 description 1
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 1
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 1
- QTPQHINADBYBNA-DCAQKATOSA-N Val-Ser-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN QTPQHINADBYBNA-DCAQKATOSA-N 0.000 description 1
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 1
- JXCOEPXCBVCTRD-JYJNAYRXSA-N Val-Tyr-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N JXCOEPXCBVCTRD-JYJNAYRXSA-N 0.000 description 1
- JXWGBRRVTRAZQA-ULQDDVLXSA-N Val-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N JXWGBRRVTRAZQA-ULQDDVLXSA-N 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- 101710145727 Viral Fc-gamma receptor-like protein UL119 Proteins 0.000 description 1
- PVNFMCBFDPTNQI-UIBOPQHZSA-N [(1S,2R,5S,6S,16E,18E,20R,21S)-11-chloro-21-hydroxy-12,20-dimethoxy-2,5,9,16-tetramethyl-8,23-dioxo-4,24-dioxa-9,22-diazatetracyclo[19.3.1.110,14.03,5]hexacosa-10,12,14(26),16,18-pentaen-6-yl] acetate [(1S,2R,5S,6S,16E,18E,20R,21S)-11-chloro-21-hydroxy-12,20-dimethoxy-2,5,9,16-tetramethyl-8,23-dioxo-4,24-dioxa-9,22-diazatetracyclo[19.3.1.110,14.03,5]hexacosa-10,12,14(26),16,18-pentaen-6-yl] 3-methylbutanoate [(1S,2R,5S,6S,16E,18E,20R,21S)-11-chloro-21-hydroxy-12,20-dimethoxy-2,5,9,16-tetramethyl-8,23-dioxo-4,24-dioxa-9,22-diazatetracyclo[19.3.1.110,14.03,5]hexacosa-10,12,14(26),16,18-pentaen-6-yl] 2-methylpropanoate [(1S,2R,5S,6S,16E,18E,20R,21S)-11-chloro-21-hydroxy-12,20-dimethoxy-2,5,9,16-tetramethyl-8,23-dioxo-4,24-dioxa-9,22-diazatetracyclo[19.3.1.110,14.03,5]hexacosa-10,12,14(26),16,18-pentaen-6-yl] propanoate Chemical compound CO[C@@H]1\C=C\C=C(C)\Cc2cc(OC)c(Cl)c(c2)N(C)C(=O)C[C@H](OC(C)=O)[C@]2(C)OC2[C@H](C)[C@@H]2C[C@@]1(O)NC(=O)O2.CCC(=O)O[C@H]1CC(=O)N(C)c2cc(C\C(C)=C\C=C\[C@@H](OC)[C@@]3(O)C[C@H](OC(=O)N3)[C@@H](C)C3O[C@@]13C)cc(OC)c2Cl.CO[C@@H]1\C=C\C=C(C)\Cc2cc(OC)c(Cl)c(c2)N(C)C(=O)C[C@H](OC(=O)C(C)C)[C@]2(C)OC2[C@H](C)[C@@H]2C[C@@]1(O)NC(=O)O2.CO[C@@H]1\C=C\C=C(C)\Cc2cc(OC)c(Cl)c(c2)N(C)C(=O)C[C@H](OC(=O)CC(C)C)[C@]2(C)OC2[C@H](C)[C@@H]2C[C@@]1(O)NC(=O)O2 PVNFMCBFDPTNQI-UIBOPQHZSA-N 0.000 description 1
- 230000003187 abdominal effect Effects 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 230000005856 abnormality Effects 0.000 description 1
- 239000003070 absorption delaying agent Substances 0.000 description 1
- QUHYUSAHBDACNG-UHFFFAOYSA-N acerogenin 3 Natural products C1=CC(O)=CC=C1CCCCC(=O)CCC1=CC=C(O)C=C1 QUHYUSAHBDACNG-UHFFFAOYSA-N 0.000 description 1
- 239000008351 acetate buffer Substances 0.000 description 1
- 235000011054 acetic acid Nutrition 0.000 description 1
- 229930183665 actinomycin Natural products 0.000 description 1
- 238000011374 additional therapy Methods 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 230000006838 adverse reaction Effects 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 239000011543 agarose gel Substances 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 108010005233 alanylglutamic acid Proteins 0.000 description 1
- 108010070783 alanyltyrosine Proteins 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- SHGAZHPCJJPHSC-YCNIQYBTSA-N all-trans-retinoic acid Chemical compound OC(=O)\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-YCNIQYBTSA-N 0.000 description 1
- 230000000172 allergic effect Effects 0.000 description 1
- 208000030961 allergic reaction Diseases 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- 229960002749 aminolevulinic acid Drugs 0.000 description 1
- 239000000908 ammonium hydroxide Substances 0.000 description 1
- 229960001220 amsacrine Drugs 0.000 description 1
- XCPGHVQEEXUHNC-UHFFFAOYSA-N amsacrine Chemical compound COC1=CC(NS(C)(=O)=O)=CC=C1NC1=C(C=CC=C2)C2=NC2=CC=CC=C12 XCPGHVQEEXUHNC-UHFFFAOYSA-N 0.000 description 1
- BBDAGFIXKZCXAH-CCXZUQQUSA-N ancitabine Chemical compound N=C1C=CN2[C@@H]3O[C@H](CO)[C@@H](O)[C@@H]3OC2=N1 BBDAGFIXKZCXAH-CCXZUQQUSA-N 0.000 description 1
- 229950000242 ancitabine Drugs 0.000 description 1
- 239000003098 androgen Substances 0.000 description 1
- 229940030486 androgens Drugs 0.000 description 1
- 230000002491 angiogenic effect Effects 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 229940124650 anti-cancer therapies Drugs 0.000 description 1
- 230000000710 anti-hyperplastic effect Effects 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 230000000118 anti-neoplastic effect Effects 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000003429 antifungal agent Substances 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 229940045687 antimetabolites folic acid analogs Drugs 0.000 description 1
- 229940045719 antineoplastic alkylating agent nitrosoureas Drugs 0.000 description 1
- 230000003078 antioxidant effect Effects 0.000 description 1
- 239000003125 aqueous solvent Substances 0.000 description 1
- 239000007900 aqueous suspension Substances 0.000 description 1
- 108010062796 arginyllysine Proteins 0.000 description 1
- 150000001491 aromatic compounds Chemical class 0.000 description 1
- 229940000489 arsenate Drugs 0.000 description 1
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 1
- 108010068265 aspartyltyrosine Proteins 0.000 description 1
- 208000010668 atopic eczema Diseases 0.000 description 1
- 229930184293 auramycin Natural products 0.000 description 1
- 229960002756 azacitidine Drugs 0.000 description 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 1
- 229950011321 azaserine Drugs 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 239000003124 biologic agent Substances 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 150000004663 bisphosphonates Chemical class 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 229960000455 brentuximab vedotin Drugs 0.000 description 1
- 229960005520 bryostatin Drugs 0.000 description 1
- MJQUEDHRCUIRLF-TVIXENOKSA-N bryostatin 1 Chemical compound C([C@@H]1CC(/[C@@H]([C@@](C(C)(C)/C=C/2)(O)O1)OC(=O)/C=C/C=C/CCC)=C\C(=O)OC)[C@H]([C@@H](C)O)OC(=O)C[C@H](O)C[C@@H](O1)C[C@H](OC(C)=O)C(C)(C)[C@]1(O)C[C@@H]1C\C(=C\C(=O)OC)C[C@H]\2O1 MJQUEDHRCUIRLF-TVIXENOKSA-N 0.000 description 1
- MUIWQCKLQMOUAT-AKUNNTHJSA-N bryostatin 20 Natural products COC(=O)C=C1C[C@@]2(C)C[C@]3(O)O[C@](C)(C[C@@H](O)CC(=O)O[C@](C)(C[C@@]4(C)O[C@](O)(CC5=CC(=O)O[C@]45C)C(C)(C)C=C[C@@](C)(C1)O2)[C@@H](C)O)C[C@H](OC(=O)C(C)(C)C)C3(C)C MUIWQCKLQMOUAT-AKUNNTHJSA-N 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 101150102633 cact gene Proteins 0.000 description 1
- 108700002839 cactinomycin Proteins 0.000 description 1
- 229950009908 cactinomycin Drugs 0.000 description 1
- AXCZMVOFGPJBDE-UHFFFAOYSA-L calcium dihydroxide Chemical compound [OH-].[OH-].[Ca+2] AXCZMVOFGPJBDE-UHFFFAOYSA-L 0.000 description 1
- 239000000920 calcium hydroxide Substances 0.000 description 1
- 229910001861 calcium hydroxide Inorganic materials 0.000 description 1
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical compound C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 description 1
- 229940127093 camptothecin Drugs 0.000 description 1
- 230000005880 cancer cell killing Effects 0.000 description 1
- 230000005907 cancer growth Effects 0.000 description 1
- 230000009400 cancer invasion Effects 0.000 description 1
- 229960004117 capecitabine Drugs 0.000 description 1
- 229960004562 carboplatin Drugs 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- XREUEWVEMYWFFA-CSKJXFQVSA-N carminomycin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=C(O)C=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XREUEWVEMYWFFA-CSKJXFQVSA-N 0.000 description 1
- 229930188550 carminomycin Natural products 0.000 description 1
- XREUEWVEMYWFFA-UHFFFAOYSA-N carminomycin I Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=C(O)C=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XREUEWVEMYWFFA-UHFFFAOYSA-N 0.000 description 1
- 229960005243 carmustine Drugs 0.000 description 1
- 229950001725 carubicin Drugs 0.000 description 1
- BBZDXMBRAFTCAA-AREMUKBSSA-N carzelesin Chemical compound C1=2NC=C(C)C=2C([C@H](CCl)CN2C(=O)C=3NC4=CC=C(C=C4C=3)NC(=O)C3=CC4=CC=C(C=C4O3)N(CC)CC)=C2C=C1OC(=O)NC1=CC=CC=C1 BBZDXMBRAFTCAA-AREMUKBSSA-N 0.000 description 1
- 229950007509 carzelesin Drugs 0.000 description 1
- CZTQZXZIADLWOZ-CRAIPNDOSA-N cefaloridine Chemical compound O=C([C@@H](NC(=O)CC=1SC=CC=1)[C@H]1SC2)N1C(C(=O)[O-])=C2C[N+]1=CC=CC=C1 CZTQZXZIADLWOZ-CRAIPNDOSA-N 0.000 description 1
- 230000022131 cell cycle Effects 0.000 description 1
- 230000032823 cell division Effects 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 230000022534 cell killing Effects 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 230000012292 cell migration Effects 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 150000004697 chelate complex Chemical class 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000002975 chemoattractant Substances 0.000 description 1
- 230000000973 chemotherapeutic effect Effects 0.000 description 1
- 229960004630 chlorambucil Drugs 0.000 description 1
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 1
- 229960004926 chlorobutanol Drugs 0.000 description 1
- 229960001480 chlorozotocin Drugs 0.000 description 1
- 210000003483 chromatin Anatomy 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 238000011284 combination treatment Methods 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 230000004154 complement system Effects 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 230000001268 conjugating effect Effects 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 238000002681 cryosurgery Methods 0.000 description 1
- 108010089438 cryptophycin 1 Proteins 0.000 description 1
- PSNOPSMXOBPNNV-VVCTWANISA-N cryptophycin 1 Chemical compound C1=C(Cl)C(OC)=CC=C1C[C@@H]1C(=O)NC[C@@H](C)C(=O)O[C@@H](CC(C)C)C(=O)O[C@H]([C@H](C)[C@@H]2[C@H](O2)C=2C=CC=CC=2)C/C=C/C(=O)N1 PSNOPSMXOBPNNV-VVCTWANISA-N 0.000 description 1
- 108010090203 cryptophycin 8 Proteins 0.000 description 1
- PSNOPSMXOBPNNV-UHFFFAOYSA-N cryptophycin-327 Natural products C1=C(Cl)C(OC)=CC=C1CC1C(=O)NCC(C)C(=O)OC(CC(C)C)C(=O)OC(C(C)C2C(O2)C=2C=CC=CC=2)CC=CC(=O)N1 PSNOPSMXOBPNNV-UHFFFAOYSA-N 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 229960000684 cytarabine Drugs 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 229960003901 dacarbazine Drugs 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 238000000354 decomposition reaction Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000002939 deleterious effect Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 229940124447 delivery agent Drugs 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- URLVCROWVOSNPT-QTTMQESMSA-N desacetyluvaricin Natural products O=C1C(CCCCCCCCCCCC[C@@H](O)[C@H]2O[C@@H]([C@@H]3O[C@@H]([C@@H](O)CCCCCCCCCC)CC3)CC2)=C[C@H](C)O1 URLVCROWVOSNPT-QTTMQESMSA-N 0.000 description 1
- 239000000032 diagnostic agent Substances 0.000 description 1
- 229940039227 diagnostic agent Drugs 0.000 description 1
- 235000015872 dietary supplement Nutrition 0.000 description 1
- UGMCXQCYOVCMTB-UHFFFAOYSA-K dihydroxy(stearato)aluminium Chemical compound CCCCCCCCCCCCCCCCCC(=O)O[Al](O)O UGMCXQCYOVCMTB-UHFFFAOYSA-K 0.000 description 1
- 238000007865 diluting Methods 0.000 description 1
- 239000007884 disintegrant Substances 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 239000006185 dispersion Substances 0.000 description 1
- 239000002612 dispersion medium Substances 0.000 description 1
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- AMRJKAQTDDKMCE-UHFFFAOYSA-N dolastatin Chemical compound CC(C)C(N(C)C)C(=O)NC(C(C)C)C(=O)N(C)C(C(C)C)C(OC)CC(=O)N1CCCC1C(OC)C(C)C(=O)NC(C=1SC=CN=1)CC1=CC=CC=C1 AMRJKAQTDDKMCE-UHFFFAOYSA-N 0.000 description 1
- 229930188854 dolastatin Natural products 0.000 description 1
- ZWAOHEXOSAUJHY-ZIYNGMLESA-N doxifluridine Chemical compound O[C@@H]1[C@H](O)[C@@H](C)O[C@H]1N1C(=O)NC(=O)C(F)=C1 ZWAOHEXOSAUJHY-ZIYNGMLESA-N 0.000 description 1
- 229950005454 doxifluridine Drugs 0.000 description 1
- 229940000406 drug candidate Drugs 0.000 description 1
- 239000000975 dye Substances 0.000 description 1
- 230000005014 ectopic expression Effects 0.000 description 1
- 230000000546 effect on cell death Effects 0.000 description 1
- VLCYCQAOQCDTCN-UHFFFAOYSA-N eflornithine Chemical compound NCCCC(N)(C(F)F)C(O)=O VLCYCQAOQCDTCN-UHFFFAOYSA-N 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 229950000549 elliptinium acetate Drugs 0.000 description 1
- 210000001163 endosome Anatomy 0.000 description 1
- 229950011487 enocitabine Drugs 0.000 description 1
- 229940116977 epidermal growth factor Drugs 0.000 description 1
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 1
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 1
- 229960001904 epirubicin Drugs 0.000 description 1
- 229950002973 epitiostanol Drugs 0.000 description 1
- 229930013356 epothilone Natural products 0.000 description 1
- 150000003883 epothilone derivatives Chemical class 0.000 description 1
- ITSGNOIFAJAQHJ-BMFNZSJVSA-N esorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)C[C@H](C)O1 ITSGNOIFAJAQHJ-BMFNZSJVSA-N 0.000 description 1
- 229950002017 esorubicin Drugs 0.000 description 1
- LJQQFQHBKUKHIS-WJHRIEJJSA-N esperamicin Chemical compound O1CC(NC(C)C)C(OC)CC1OC1C(O)C(NOC2OC(C)C(SC)C(O)C2)C(C)OC1OC1C(\C2=C/CSSSC)=C(NC(=O)OC)C(=O)C(OC3OC(C)C(O)C(OC(=O)C=4C(=CC(OC)=C(OC)C=4)NC(=O)C(=C)OC)C3)C2(O)C#C\C=C/C#C1 LJQQFQHBKUKHIS-WJHRIEJJSA-N 0.000 description 1
- FRPJXPJMRWBBIH-RBRWEJTLSA-N estramustine Chemical compound ClCCN(CCCl)C(=O)OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 FRPJXPJMRWBBIH-RBRWEJTLSA-N 0.000 description 1
- 229960001842 estramustine Drugs 0.000 description 1
- BEFDCLMNVWHSGT-UHFFFAOYSA-N ethenylcyclopentane Chemical compound C=CC1CCCC1 BEFDCLMNVWHSGT-UHFFFAOYSA-N 0.000 description 1
- 229960005542 ethidium bromide Drugs 0.000 description 1
- ZMMJGEGLRURXTF-UHFFFAOYSA-N ethidium bromide Chemical compound [Br-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CC)=C1C1=CC=CC=C1 ZMMJGEGLRURXTF-UHFFFAOYSA-N 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- 229960005237 etoglucid Drugs 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 210000003754 fetus Anatomy 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- 229960000304 folic acid Drugs 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 150000002224 folic acids Chemical class 0.000 description 1
- 235000013355 food flavoring agent Nutrition 0.000 description 1
- 235000003599 food sweetener Nutrition 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 229940044658 gallium nitrate Drugs 0.000 description 1
- 229960005277 gemcitabine Drugs 0.000 description 1
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 1
- 238000011223 gene expression profiling Methods 0.000 description 1
- 238000010363 gene targeting Methods 0.000 description 1
- 238000001415 gene therapy Methods 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 108010080575 glutamyl-aspartyl-alanine Proteins 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 239000007973 glycine-HCl buffer Substances 0.000 description 1
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 1
- 108010077435 glycyl-phenylalanyl-glycine Proteins 0.000 description 1
- 108010081551 glycylphenylalanine Proteins 0.000 description 1
- 108010087823 glycyltyrosine Proteins 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 230000035876 healing Effects 0.000 description 1
- 230000000971 hippocampal effect Effects 0.000 description 1
- 108010092114 histidylphenylalanine Proteins 0.000 description 1
- 108010018006 histidylserine Proteins 0.000 description 1
- 230000001744 histochemical effect Effects 0.000 description 1
- 229940116978 human epidermal growth factor Drugs 0.000 description 1
- 239000003906 humectant Substances 0.000 description 1
- 235000011167 hydrochloric acid Nutrition 0.000 description 1
- 150000004679 hydroxides Chemical class 0.000 description 1
- 229960001330 hydroxycarbamide Drugs 0.000 description 1
- 238000010191 image analysis Methods 0.000 description 1
- 239000012642 immune effector Substances 0.000 description 1
- 229940127121 immunoconjugate Drugs 0.000 description 1
- 238000010166 immunofluorescence Methods 0.000 description 1
- 238000003125 immunofluorescent labeling Methods 0.000 description 1
- 238000011532 immunohistochemical staining Methods 0.000 description 1
- 239000002955 immunomodulating agent Substances 0.000 description 1
- 229940121354 immunomodulator Drugs 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 229960003444 immunosuppressant agent Drugs 0.000 description 1
- 239000003018 immunosuppressive agent Substances 0.000 description 1
- 230000001024 immunotherapeutic effect Effects 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 239000011261 inert gas Substances 0.000 description 1
- 230000036512 infertility Effects 0.000 description 1
- 239000007972 injectable composition Substances 0.000 description 1
- 150000007529 inorganic bases Chemical class 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 230000004068 intracellular signaling Effects 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 1
- JJWLVOIRVHMVIS-UHFFFAOYSA-N isopropylamine Chemical compound CC(C)N JJWLVOIRVHMVIS-UHFFFAOYSA-N 0.000 description 1
- 150000002540 isothiocyanates Chemical class 0.000 description 1
- 229960003299 ketamine Drugs 0.000 description 1
- 210000003127 knee Anatomy 0.000 description 1
- 238000002430 laser surgery Methods 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- 210000002414 leg Anatomy 0.000 description 1
- 229940115286 lentinan Drugs 0.000 description 1
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- PCZOHLXUXFIOCF-BXMDZJJMSA-N lovastatin Chemical compound C([C@H]1[C@@H](C)C=CC2=C[C@H](C)C[C@@H]([C@H]12)OC(=O)[C@@H](C)CC)C[C@@H]1C[C@@H](O)CC(=O)O1 PCZOHLXUXFIOCF-BXMDZJJMSA-N 0.000 description 1
- 229960004844 lovastatin Drugs 0.000 description 1
- QLJODMDSTUBWDW-UHFFFAOYSA-N lovastatin hydroxy acid Natural products C1=CC(C)C(CCC(O)CC(O)CC(O)=O)C2C(OC(=O)C(C)CC)CC(C)C=C21 QLJODMDSTUBWDW-UHFFFAOYSA-N 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 229960002510 mandelic acid Drugs 0.000 description 1
- 229910052748 manganese Inorganic materials 0.000 description 1
- 239000011572 manganese Substances 0.000 description 1
- MQXVYODZCMMZEM-ZYUZMQFOSA-N mannomustine Chemical compound ClCCNC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CNCCCl MQXVYODZCMMZEM-ZYUZMQFOSA-N 0.000 description 1
- 229950008612 mannomustine Drugs 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- QRMNENFZDDYDEF-GOSISDBHSA-N methyl (8s)-8-(bromomethyl)-2-methyl-4-(4-methylpiperazine-1-carbonyl)oxy-6-(5,6,7-trimethoxy-1h-indole-2-carbonyl)-7,8-dihydro-3h-pyrrolo[3,2-e]indole-1-carboxylate Chemical compound C1([C@H](CBr)CN(C1=C1)C(=O)C=2NC3=C(OC)C(OC)=C(OC)C=C3C=2)=C2C(C(=O)OC)=C(C)NC2=C1OC(=O)N1CCN(C)CC1 QRMNENFZDDYDEF-GOSISDBHSA-N 0.000 description 1
- HPNSFSBZBAHARI-UHFFFAOYSA-N micophenolic acid Natural products OC1=C(CC=C(C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-UHFFFAOYSA-N 0.000 description 1
- 238000010232 migration assay Methods 0.000 description 1
- 150000007522 mineralic acids Chemical class 0.000 description 1
- 229960003539 mitoguazone Drugs 0.000 description 1
- MXWHMTNPTTVWDM-NXOFHUPFSA-N mitoguazone Chemical compound NC(N)=N\N=C(/C)\C=N\N=C(N)N MXWHMTNPTTVWDM-NXOFHUPFSA-N 0.000 description 1
- 229960000350 mitotane Drugs 0.000 description 1
- 230000000394 mitotic effect Effects 0.000 description 1
- 239000002808 molecular sieve Substances 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- 229960000951 mycophenolic acid Drugs 0.000 description 1
- HPNSFSBZBAHARI-RUDMXATFSA-N mycophenolic acid Chemical compound OC1=C(C\C=C(/C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-RUDMXATFSA-N 0.000 description 1
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 1
- 239000002105 nanoparticle Substances 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 229930014626 natural product Natural products 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 230000035407 negative regulation of cell proliferation Effects 0.000 description 1
- QZGIWPZCWHMVQL-UIYAJPBUSA-N neocarzinostatin chromophore Chemical compound O1[C@H](C)[C@H](O)[C@H](O)[C@@H](NC)[C@H]1O[C@@H]1C/2=C/C#C[C@H]3O[C@@]3([C@@H]3OC(=O)OC3)C#CC\2=C[C@H]1OC(=O)C1=C(O)C=CC2=C(C)C=C(OC)C=C12 QZGIWPZCWHMVQL-UIYAJPBUSA-N 0.000 description 1
- 210000005170 neoplastic cell Anatomy 0.000 description 1
- GVUGOAYIVIDWIO-UFWWTJHBSA-N nepidermin Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)NC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H](CS)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CS)NC(=O)[C@H](C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C(C)C)C(C)C)C1=CC=C(O)C=C1 GVUGOAYIVIDWIO-UFWWTJHBSA-N 0.000 description 1
- KGTDRFCXGRULNK-JYOBTZKQSA-N nogalamycin Chemical compound CO[C@@H]1[C@@](OC)(C)[C@@H](OC)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=C(O)C=C4[C@@]5(C)O[C@H]([C@H]([C@@H]([C@H]5O)N(C)C)O)OC4=C3C3=O)=C3C=C2[C@@H](C(=O)OC)[C@@](C)(O)C1 KGTDRFCXGRULNK-JYOBTZKQSA-N 0.000 description 1
- 229950009266 nogalamycin Drugs 0.000 description 1
- 230000007959 normoxia Effects 0.000 description 1
- 238000001668 nucleic acid synthesis Methods 0.000 description 1
- 239000002773 nucleotide Substances 0.000 description 1
- 125000003729 nucleotide group Chemical group 0.000 description 1
- 238000000399 optical microscopy Methods 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 150000007530 organic bases Chemical class 0.000 description 1
- 150000002895 organic esters Chemical class 0.000 description 1
- 208000012988 ovarian serous adenocarcinoma Diseases 0.000 description 1
- 201000003709 ovarian serous carcinoma Diseases 0.000 description 1
- 235000006408 oxalic acid Nutrition 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- 238000011499 palliative surgery Methods 0.000 description 1
- 238000004091 panning Methods 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 239000013610 patient sample Substances 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- 229960003330 pentetic acid Drugs 0.000 description 1
- 229960002340 pentostatin Drugs 0.000 description 1
- FPVKHBSQESCIEP-JQCXWYLXSA-N pentostatin Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC[C@H]2O)=C2N=C1 FPVKHBSQESCIEP-JQCXWYLXSA-N 0.000 description 1
- 210000005259 peripheral blood Anatomy 0.000 description 1
- 239000011886 peripheral blood Substances 0.000 description 1
- 102000013415 peroxidase activity proteins Human genes 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 239000002831 pharmacologic agent Substances 0.000 description 1
- 229960003742 phenol Drugs 0.000 description 1
- 235000011007 phosphoric acid Nutrition 0.000 description 1
- 150000003016 phosphoric acids Chemical class 0.000 description 1
- 108091005981 phosphorylated proteins Proteins 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- BLFWHYXWBKKRHI-JYBILGDPSA-N plap Chemical compound N([C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(=O)[C@@H]1CCCN1C(=O)[C@H](CO)NC(=O)[C@@H](N)CCC(O)=O BLFWHYXWBKKRHI-JYBILGDPSA-N 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 229920003023 plastic Polymers 0.000 description 1
- 239000004417 polycarbonate Substances 0.000 description 1
- 229920000515 polycarbonate Polymers 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 238000009258 post-therapy Methods 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- MFDFERRIHVXMIY-UHFFFAOYSA-N procaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1 MFDFERRIHVXMIY-UHFFFAOYSA-N 0.000 description 1
- 229960004919 procaine Drugs 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 238000004393 prognosis Methods 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 1
- 108010077112 prolyl-proline Proteins 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 239000012562 protein A resin Substances 0.000 description 1
- 150000003212 purines Chemical class 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- 239000002510 pyrogen Substances 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- UOWVMDUEMSNCAV-WYENRQIDSA-N rachelmycin Chemical compound C1([C@]23C[C@@H]2CN1C(=O)C=1NC=2C(OC)=C(O)C4=C(C=2C=1)CCN4C(=O)C1=CC=2C=4CCN(C=4C(O)=C(C=2N1)OC)C(N)=O)=CC(=O)C1=C3C(C)=CN1 UOWVMDUEMSNCAV-WYENRQIDSA-N 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 230000003439 radiotherapeutic effect Effects 0.000 description 1
- 206010038038 rectal cancer Diseases 0.000 description 1
- 201000001275 rectum cancer Diseases 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229930002330 retinoic acid Natural products 0.000 description 1
- MBABCNBNDNGODA-WPZDJQSSSA-N rolliniastatin 1 Natural products O1[C@@H]([C@@H](O)CCCCCCCCCC)CC[C@H]1[C@H]1O[C@@H]([C@H](O)CCCCCCCCCC[C@@H](O)CC=2C(O[C@@H](C)C=2)=O)CC1 MBABCNBNDNGODA-WPZDJQSSSA-N 0.000 description 1
- VHXNKPBCCMUMSW-FQEVSTJZSA-N rubitecan Chemical compound C1=CC([N+]([O-])=O)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VHXNKPBCCMUMSW-FQEVSTJZSA-N 0.000 description 1
- 239000012146 running buffer Substances 0.000 description 1
- 231100000241 scar Toxicity 0.000 description 1
- 230000037387 scars Effects 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 239000012679 serum free medium Substances 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 125000005630 sialyl group Chemical group 0.000 description 1
- 238000009097 single-agent therapy Methods 0.000 description 1
- URGAHOPLAPQHLN-UHFFFAOYSA-N sodium aluminosilicate Chemical compound [Na+].[Al+3].[O-][Si]([O-])=O.[O-][Si]([O-])=O URGAHOPLAPQHLN-UHFFFAOYSA-N 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 229940054269 sodium pyruvate Drugs 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 239000004334 sorbic acid Substances 0.000 description 1
- 229940075582 sorbic acid Drugs 0.000 description 1
- 235000010199 sorbic acid Nutrition 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 229950006315 spirogermanium Drugs 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 238000000528 statistical test Methods 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 229960001052 streptozocin Drugs 0.000 description 1
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 101150047061 tag-72 gene Proteins 0.000 description 1
- 239000011975 tartaric acid Substances 0.000 description 1
- 235000002906 tartaric acid Nutrition 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- 201000003120 testicular cancer Diseases 0.000 description 1
- BPEWUONYVDABNZ-DZBHQSCQSA-N testolactone Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)(OC(=O)CC4)[C@@H]4[C@@H]3CCC2=C1 BPEWUONYVDABNZ-DZBHQSCQSA-N 0.000 description 1
- 229960005353 testolactone Drugs 0.000 description 1
- 231100001274 therapeutic index Toxicity 0.000 description 1
- RTKIYNMVFMVABJ-UHFFFAOYSA-L thimerosal Chemical compound [Na+].CC[Hg]SC1=CC=CC=C1C([O-])=O RTKIYNMVFMVABJ-UHFFFAOYSA-L 0.000 description 1
- 229940033663 thimerosal Drugs 0.000 description 1
- 229960001196 thiotepa Drugs 0.000 description 1
- 210000000115 thoracic cavity Anatomy 0.000 description 1
- 210000001541 thymus gland Anatomy 0.000 description 1
- YFTWHEBLORWGNI-UHFFFAOYSA-N tiamiprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC(N)=NC2=C1NC=N2 YFTWHEBLORWGNI-UHFFFAOYSA-N 0.000 description 1
- 229950011457 tiamiprine Drugs 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 1
- 229960000303 topotecan Drugs 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 239000003558 transferase inhibitor Substances 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 238000003146 transient transfection Methods 0.000 description 1
- 238000002054 transplantation Methods 0.000 description 1
- 229960000575 trastuzumab Drugs 0.000 description 1
- IUCJMVBFZDHPDX-UHFFFAOYSA-N tretamine Chemical compound C1CN1C1=NC(N2CC2)=NC(N2CC2)=N1 IUCJMVBFZDHPDX-UHFFFAOYSA-N 0.000 description 1
- 229950001353 tretamine Drugs 0.000 description 1
- 229960001727 tretinoin Drugs 0.000 description 1
- NOYPYLRCIDNJJB-UHFFFAOYSA-N trimetrexate Chemical compound COC1=C(OC)C(OC)=CC(NCC=2C(=C3C(N)=NC(N)=NC3=CC=2)C)=C1 NOYPYLRCIDNJJB-UHFFFAOYSA-N 0.000 description 1
- 229960001099 trimetrexate Drugs 0.000 description 1
- HDZZVAMISRMYHH-LITAXDCLSA-N tubercidin Chemical compound C1=CC=2C(N)=NC=NC=2N1[C@@H]1O[C@@H](CO)[C@H](O)[C@H]1O HDZZVAMISRMYHH-LITAXDCLSA-N 0.000 description 1
- 231100000588 tumorigenic Toxicity 0.000 description 1
- 230000000381 tumorigenic effect Effects 0.000 description 1
- 229950009811 ubenimex Drugs 0.000 description 1
- 238000009281 ultraviolet germicidal irradiation Methods 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 229960001055 uracil mustard Drugs 0.000 description 1
- 150000003673 urethanes Chemical class 0.000 description 1
- 206010046766 uterine cancer Diseases 0.000 description 1
- 108010009962 valyltyrosine Proteins 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 229960004528 vincristine Drugs 0.000 description 1
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 1
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 1
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 description 1
- 229960004355 vindesine Drugs 0.000 description 1
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 description 1
- 229960002066 vinorelbine Drugs 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 108010047303 von Willebrand Factor Proteins 0.000 description 1
- 102100036537 von Willebrand factor Human genes 0.000 description 1
- 229960001134 von willebrand factor Drugs 0.000 description 1
- 229950009268 zinostatin Drugs 0.000 description 1
Images
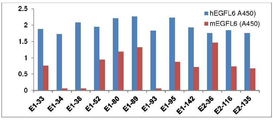
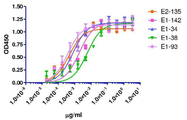

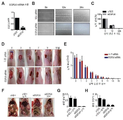



Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/22—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against growth factors ; against growth regulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6843—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a material from animals or humans
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/0012—Galenical forms characterised by the site of application
- A61K9/0019—Injectable compositions; Intramuscular, intravenous, arterial, subcutaneous administration; Compositions to be administered through the skin in an invasive manner
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1136—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against growth factors, growth regulators, cytokines, lymphokines or hormones
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57407—Specifically defined cancers
- G01N33/57449—Specifically defined cancers of ovaries
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6854—Immunoglobulins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering N.A.
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/475—Assays involving growth factors
- G01N2333/485—Epidermal growth factor [EGF] (urogastrone)
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Organic Chemistry (AREA)
- Genetics & Genomics (AREA)
- Medicinal Chemistry (AREA)
- Biochemistry (AREA)
- Biotechnology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Hematology (AREA)
- Urology & Nephrology (AREA)
- Zoology (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- Biophysics (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- General Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Food Science & Technology (AREA)
- Cell Biology (AREA)
- Analytical Chemistry (AREA)
- General Physics & Mathematics (AREA)
- Pathology (AREA)
- Epidemiology (AREA)
- Endocrinology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Plant Pathology (AREA)
- Oncology (AREA)
- Hospice & Palliative Care (AREA)
Abstract
단리된 또는 재조합 항-EGFL6 단일클론 항체들이 제공된다. 일부 경우에서, 본 발명의 구체예들들의 항체들은 인간 질병, 가령, 암의 탐지, 진단 및/또는 치료적 처리를 위해 사용될 수 있다.
Description
본 출원은 2015년 5월 7일 출원된 미국 가특허출원 제 62/158,237호의 이익을 주장하며, 이 출원 모두는 본 출원에 참고문헌으로 첨부된다.
명의 배경
1. 발명의 분야
본 발명은 일반적으로 암 생물학 분야에 관련된다. 더욱 특히, 본 발명은 암 치료 및 탐지를 위한 EGFL6 표적 단일클론 항체들에 관한 것이다.
2. 관련 분야의 설명
인간 표피 성장 인자 (EGF)-유사 도메인 멀티플 6 (EGFL6)은 종양 및 태아 조직에서 처음 발견되었으며 EGF 반복 수퍼패밀리의 일 구성성분이다. EGFL6은 4와 1/2개의 EGF-유사 반복 도메인들, 2개의 N-연결 당화 부위, 1개의 인테그린 연관 모티프 (RGD), 티로신 인산화 부위, 및 MAM 도메인 (Yeung 등, 1999)을 보유한 분비 단백질로 확인되었다. 연구 결과 EGFL6의 고 발현은 특정 유형의 암들, 가령, 난소암 및 폐암의 종양 조직과 관련되어 있는 반면, 건강한 성인 조직에서는 발현이 제한적인 것으로 나타났다 (Buckanovich 등, 2007; Chim 등, 2011; 및 Oberauer 등, 2010). 그러나, EGFL6-양성 암의 치료를 위한 시약 및 치료제가 여전히 필요하다.
발명의 요약
본 명세서는 EGFL6에 결합하는 EGFL6 단일클론 항체들을 기재한다. 다른 양상들에서 제공되는 EGFL6-결합 항체들은 EGFL6 신호전달을 감소시키며 암 세포 증식을 억제하기 위해 사용될 수 있다. 그러므로 제 1 구체예에서, EGFL6에 특이적으로 결합하는 단리된 또는 재조합 단일클론 항체가 제공된다. 특정 양상들에서, EGFL6의 결합에 대해 E1-33, E1-34, E1-80, E1-89, E2-93, E1-38, E1-52, E2-36, E1-95, E2-116, E2-135, 또는 E1-142 단일클론 항체와 경쟁하는 항체가 제공된다. 특정 양상들에서, 상기 항체는 E1-33, E1-34, E1-80, E1-89, E2-93, E1-38, E1-52, E2-36, E1-95, E2-116, E2-135, 또는 E1-142 단일클론 항체들의 중쇄 가변 영역 및/또는 경쇄 가변 영역 모두 또는 일부를 포함할 수 있다. 한 다른 양상에서, 상기 항체는 본 출원의 구체예들의 E1-33, E1-34, E1-80, E1-89, E2-93, E1-38, E1-52, E2-36, E1-95, E2-116, E2-135, 또는 E1-142 단일클론 항체들의 경쇄 가변 및/또는 중쇄 가변 사슬로부터의 제 1, 제 2 및/또는 제 3 상보성 결정 영역 (CDR)에 상응하는 아미노산 서열을 포함할 수 있다.
특정 양상들에서, 상기 단리된 항체는 E1-33, E1-34, E1-80, E1-89, E2-93, E1-38, E1-52, E2-36, E1-95, E2-116, E2-135, 또는 E1-142 중쇄 및 경쇄 아미노산 서열들의 CDR 영역들과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 CDR 서열들을 포함한다. 추가 양상들에서, 항체는 하나 이상의 CDR들에서 1 또는 2개 아미노산 치환, 결실, 또는 삽입을 제외하고, E1-33, E1-34, E1-80, E1-89, E2-93, E1-38, E1-52, E2-36, E1-95, E2-116, E2-135, 또는 E1-142 CDR 영역들과 동일한 CDR 영역들을 포함한다. 예를 들면, 상기 항체는 CDR들을 포함하고, 이 때 CDR 서열들은 E1-33, E1-34, E1-80, E1-89, E2-93, E1-38, E1-52, E2-36, E1-95, E2-116, E2-135, 또는 E1-142 단일클론 항체의 CDR들과 비교하여 VH CDR1, VH CDR2, VH CDR3, VL CDR1, VL CDR2 및/또는 VL CDR3에 1 또는 2개 아미노산 치환을 포함한다. 그러므로, 일부 특정 양상들에서, 상기 구체예들의 항체는 (a) E1-33 (서열 번호: 4), E1-34 (서열 번호: 10), E1-80 (서열 번호: 16), E1-89 (서열 번호: 22), E2-93 (서열 번호: 28), E1-38 (서열 번호: 34), E1-52 (서열 번호: 40), E2-36 (서열 번호: 46), E1-95 (서열 번호: 52), E2-116 (서열 번호: 58), E2-135 (서열 번호: 64), 또는 E1-142 (서열 번호: 70)의 VH CDR1에 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH CDR; (b) E1-33 (서열 번호: 5), E1-34 (서열 번호: 11), E1-80 (서열 번호: 17), E1-89 (서열 번호: 23), E2-93 (서열 번호: 29), E1-38 (서열 번호: 35), E1-52 (서열 번호: 41), E2-36 (서열 번호: 47), E1-95 (서열 번호: 53), E2-116 (서열 번호: 59), E2-135 (서열 번호: 65), 또는 E1-142 (서열 번호: 71)의 VH CDR2에 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 2 VH CDR; (c) E1-33 (서열 번호: 6), E1-34 (서열 번호: 12), E1-80 (서열 번호: 18), E1-89 (서열 번호: 24), E2-93 (서열 번호: 30), E1-38 (서열 번호: 36), E1-52 (서열 번호: 42), E2-36 (서열 번호: 48), E1-95 (서열 번호: 54), E2-116 (서열 번호: 60), E2-135 (서열 번호: 66), 또는 E1-142 (서열 번호: 72)의 VH CDR3에 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 3 VH CDR; (d) E1-33 (서열 번호: 76), E1-34 (서열 번호: 82), E1-80 (서열 번호: 88), E1-89 (서열 번호: 93), E2-93 (서열 번호: 99), E1-38 (서열 번호: 104), E1-52 (서열 번호: 108), E2-36 (서열 번호: 113), E1-95 (서열 번호: 117), E2-116 (서열 번호: 121), E2-135 (서열 번호: 126), 또는 E1-142 (서열 번호: 131)의 VL CDR1에 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1, VL CDR; (e) E1-33 (서열 번호: 77), E1-34 (서열 번호: 83), E1-80 (서열 번호: 77), E1-89 (서열 번호: 94), E2-93 (서열 번호: 100), E1-38 (서열 번호: 100), E1-52 (서열 번호: 77), E2-36 (서열 번호: 83), E1-95 (서열 번호: 83), E2-116 (서열 번호: 100), E2-135 (서열 번호: 127), 또는 E1-142 (서열 번호: 100)의 VL CDR2에 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 2 VL CDR; 및 (f) E1-33 (서열 번호: 78), E1-34 (서열 번호: 84), E1-80 (서열 번호: 89), E1-89 (서열 번호: 95), E2-93 (서열 번호: 101), E1-38 (서열 번호: 105), E1-52 (서열 번호: 109), E2-36 (서열 번호: 114), E1-95 (서열 번호: 118), E2-116 (서열 번호: 122), E2-135 (서열 번호: 128), 또는 E1-142 (서열 번호: 132)의 VL CDR3에 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 3 VL CDR을 포함한다. 특정 양상들에서, 이러한 항체는 인간 IgG들 (예컨대, IgG1, IgG2, IgG4, 또는 유전자 변형된 IgG) 골격 상에 전술한 CDR들을 포함하는 인간화 또는 탈-인간화 항체이다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 4, 5, 6, 76, 77, 및 78로 나타내어지는 단일클론 항체 E1-33의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E1-33의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E1-33의 VH 도메인 (서열 번호: 157) 또는 E1-33 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E1-33의 VL 도메인 (서열 번호: 158) 또는 E1-33 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E1-33 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E1-33 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E1-33 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E1-33 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E1-33의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 10, 11, 12, 82, 83, 및 84로 나타내어지는 단일클론 항체 E1-34의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E1-34의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E1-34의 VH 도메인 (서열 번호: 159) 또는 E1-34 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E1-34의 VL 도메인 (서열 번호: 160) 또는 E1-34 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E1-34 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E1-34 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E1-34 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E1-34 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E1-34의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 16, 17, 18, 88, 77, 및 89로 나타내어지는 단일클론 항체 E1-80의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E1-80의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E1-80의 VH 도메인 (서열 번호: 161) 또는 E1-80 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E1-80의 VL 도메인 (서열 번호: 162) 또는 E1-80 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E1-80 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E1-80 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E1-80 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E1-80 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E1-80의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 22, 23, 24, 93, 94, 및 95로 나타내어지는 단일클론 항체 E1-89의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E1-89의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E1-89의 VH 도메인 (서열 번호: 163) 또는 E1-89 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E1-89의 VL 도메인 (서열 번호: 164) 또는 E1-89 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E1-89 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E1-89 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E1-89 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E1-89 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E1-89의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 28, 29, 30, 99, 100, 및 101로 나타내어지는 단일클론 항체 E2-93의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E2-93의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E2-93의 VH 도메인 (서열 번호: 165) 또는 E2-93 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E2-93의 VL 도메인 (서열 번호: 166) 또는 E2-93 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E2-93 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E2-93 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E2-93 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E2-93 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E2-93의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 34, 35, 36, 104, 100, 및 105로 나타내어지는 단일클론 항체 E1-38의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E1-38의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E1-38의 VH 도메인 (서열 번호: 167) 또는 E1-38 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E1-38의 VL 도메인 (서열 번호: 168) 또는 E1-38 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E1-38 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E1-38 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E1-38 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E1-38 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E1-38의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 서열 번호: 40, 41, 42, 108, 77, 및 109로 나타내어지는 단일클론 항체 E1-52의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E1-52의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E1-52의 VH 도메인 (서열 번호: 169) 또는 E1-52 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E1-52의 VL 도메인 (서열 번호: 170) 또는 E1-52 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E1-52 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E1-52 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E1-52 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E1-52 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E1-52의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 서열 번호: 46, 47, 48, 113, 83, 및 114로 나타내어지는 단일클론 항체 E2-36의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E2-36의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E2-36의 VH 도메인 (서열 번호: 171) 또는 E2-36 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E2-36의 VL 도메인 (서열 번호: 172) 또는 E2-36 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E2-36 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E2-36 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E2-36 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E2-36 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E2-36의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 서열 번호: 52, 53, 54, 117, 83, 119로 나타내어지는 단일클론 항체 E1-95의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E1-95의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E1-95의 VH 도메인 (서열 번호: 173) 또는 E1-95 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E1-95의 VL 도메인 (서열 번호: 174) 또는 E1-95 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E1-95 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E1-95 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E1-95 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E1-95 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E1-95의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 58, 59, 60, 121, 100, 및 122로 나타내어지는 단일클론 항체 E2-116의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E2-116의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E2-116의 VH 도메인 (서열 번호: 175) 또는 E2-116 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E2-116의 VL 도메인 (서열 번호: 176) 또는 E2-116 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E2-116 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E2-116 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E2-116 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E2-116 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E2-116의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 64, 65, 66, 126, 127, 및 128로 나타내어지는 단일클론 항체 E2-135의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E2-135의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E2-135의 VH 도메인 (서열 번호: 177) 또는 E2-135 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E2-135의 VL 도메인 (서열 번호: 178) 또는 E2-135 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E2-135 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E2-135 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E2-135 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E2-135 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E2-135의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
추가 양상들에서, 단리된 항체는 각각 서열 번호: 70, 71, 72, 131, 100, 및 132로 나타내어지는 단일클론 항체 E1-142의 상응하는 CDR 서열과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 제 1 VH, 제 2 VH, 제 3 VH, 제 1, VL, 제 2 VL, 및 제 3 VL CDR 서열을 포함한다. 한 양상에서, 단리된 항체는 단일클론 항체 E1-142의 CDR 서열들과 동일한 CDR 서열들을 포함한다.
또 다른 양상에서, 단리된 항체는 E1-142의 VH 도메인 (서열 번호: 179) 또는 E1-142 mAB의 인간화 VH 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VH 도메인; 및 E1-142의 VL 도메인 (서열 번호: 180) 또는 E1-142 mAB의 인간화 VL 도메인과 최소한 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 VL 도메인을 포함한다. 예를 들면, 상기 항체는 인간화 E1-142 mAB의 VH 도메인과 최소한 95% 동일한 VH 도메인 및 인간화 E1-142 mAB의 VL 도메인과 최소한 95% 동일한 VL 도메인을 포함할 수 있다. 그러므로 일부 양상들에서, 항체는 인간화 E1-142 mAB의 VH 도메인과 동일한 VH 도메인 및 인간화 E1-142 mAB의 VL 도메인과 동일한 VL 도메인을 포함한다. 한 특정 예에서, 단리된 항체는 단일클론 항체 E1-142의 도메인들과 동일한 VH 및 VL 도메인들을 포함할 수 있다.
일부 양상들에서, 상기 구체예들의 항체는 IgG (예컨대, IgG1, IgG2, IgG3 또는 IgG4), IgM, IgA, 유전적으로 변형된 IgG 동형, 또는 이의 항원 결합 단편(항원 binding 단편) 일 수 있다. 항체는 Fab-, F(ab-)2 , F(ab-)3, 1가 scFv, 2가 scFv, 이중특이적 또는 단일 도메인 항체일 수 있다. 항체는 인간, 인간화된 또는 탈-면역화된 항체일 수 있다. 한 다른 양상에서, 단리된 항체는 E1-33, E1-34, E1-80, E1-89, E2-93, E1-38, E1-52, E2-36, E1-95, E2-116, E2-135, 또는 E1-142 항체이다.
일부 양상들에서, 항체는 조영제, 화학치료제, 독소, 또는 방사성핵종에 접합될 수 있다. 특정 양상들에서, 항체는 오리스타틴 또는 모노메틸 오리스타틴 E (MMAE)에 특히 접합될 수 있다.
한 구체예에서, E1-33의 VH 도메인의 CDRs 1-3 (서열 번호: 4, 5, 및 6); E1-34의 VH 도메인의 CDRs 1-3 (서열 번호: 10, 11, 및 12); E1-80의 VH 도메인의 CDRs 1-3 (서열 번호: 16, 17, 및 18); E1-89의 VH 도메인의 CDRs 1-3 (서열 번호: 22, 23, 및 24); E2-93의 VH 도메인의 CDRs 1-3 (서열 번호: 28, 29, 및 30); E1-38의 VH 도메인의 CDRs 1-3 (서열 번호: 34, 35, 및 36); E1-52의 VH 도메인의 CDRs 1-3 (서열 번호: 40, 41, 및 42); E2-36의 VH 도메인의 CDRs 1-3 (서열 번호: 46, 47, 및 48); E1-95의 VH 도메인의 CDRs 1-3 (서열 번호: 52, 53, 및 54); E2-116의 VH 도메인의 CDRs 1-3 (서열 번호: 58, 59, 및 60); E2-135의 VH 도메인의 CDRs 1-3 (서열 번호: 64, 65, 및 66); 또는 E1-142의 VH 도메인의 CDRs 1-3 (서열 번호: 70, 71, 및 72)을 포함하는 항체 VH 도메인을 포함하는 재조합 폴리펩티드를 제공한다. 또 다른 구체예에서, E1-33의 VL 도메인의 CDRs 1-3 (서열 번호: 76, 77, 및 78); E1-34의 VL 도메인의 CDRs 1-3 (서열 번호: 82, 83, 및 84); E1-80의 VL 도메인의 CDRs 1-3 (서열 번호: 88, 77, 및 89); E1-89의 VL 도메인의 CDRs 1-3 (서열 번호: 93, 94, 및 95); E2-93의 VL 도메인의 CDRs 1-3 (서열 번호: 99, 100, 및 101); E1-38의 VL 도메인의 CDRs 1-3 (서열 번호: 104, 100, 및 105); E1-52의 VL 도메인의 CDRs 1-3 (서열 번호: 108, 77, 및 109); E2-36의 VL 도메인의 CDRs 1-3 (서열 번호: 113, 83, 및 114); E1-95의 VL 도메인의 CDRs 1-3 (서열 번호: 117, 83, 및 118); E2-116의 VL 도메인의 CDRs 1-3 (서열 번호: 121, 100, 및 122); E2-135의 VL 도메인의 CDRs 1-3 (서열 번호: 126, 127, 및 128); 또는 E1-142의 VL 도메인의 CDRs 1-3 (서열 번호: 131, 100, 및 132)을 포함하는 항체 VL 도메인을 포함하는 재조합 폴리펩티드를 제공한다.
일부 구체예들에서, 본 출원에 개시된 항체 VH 또는 VL 도메인을 포함하는 항체 또는 폴리펩티드를 인코딩하는 핵산 서열을 포함하는 단리된 폴리뉴클레오티드 분자를 제공한다.
추가 구체예들에서, 상기 구체예들의 단일클론 항체 또는 재조합 폴리펩티드를 생성하는 숙주 세포를 제공한다. 일부 양상들에서, 숙주 세포는 포유동물 세포., 효모 세포., 세균 세포, 섬모충 세포, 또는 곤충 세포이다. 특정 양상들에서, 숙주 세포는 하이브리도마 세포이다.
또한 다른 구체예들에서, 세포에서 본 출원에 개시된 항체의 VL 또는 VH 사슬을 인코딩하는 하나 이상의 폴리뉴클레오티드 분자(들)을 발현시키는 단계 및 이 항체를 세포로부터 정제하는 단계를 포함하는 본 발명의 항체 제조 방법을 제공한다.
추가 구체예에서, 본 출원에서 논의되는 항체 또는 항체 단편을 포함하는 제약학적 조성물을 제공한다. 이러한 조성물은 제약학적으로 허용가능한 담체를 추가로 포함하며 추가 활성 성분들을 내포하거나 하지 않을 수 있다.
본 발명의 구체예들에서, 본 출원에 개시된 유효량의 항체를 투여하는 단계를 포함하는 암에 걸린 대상체의 치료 방법을 제공한다. 특정 양상들에서, 항체는 본 출원의 구체예들의 단일클론 항체, 가령, E1-33, E1-34, E1-80, E1-89, E2-93, E1-38, E1-52, E2-36, E1-95, E2-116, E2-135, 또는 E1-142 항체 또는 이로부터 유래한 항체 분절을 포함하는 재조합 폴리펩티드이다.
특정 양상들에서, 암은 유방암, 폐암, 두경부암, 전립선암, 식도암, 기관암, 뇌암, 간암, 방광암, 위암, 이자암, 난소암, 자궁암, 자궁경부암, 고환암, 결장암, 직장암 또는 피부암일 수 있다. 특정 양상들에서, 암은 상피암이다. 다른 양상들에서, 암은 결장직장 선암종, 폐 선암종, 폐 편평세포 암종, 유방암, 간세포 암종, 난소암, 신장 투명세포 암종, 폐암 또는 신장암일 수 있다.
한 양상에서, 항체는 전신에 투여될 수 있다. 추가 양상들에서, 항체는 정맥내, 진피내, 종양내, 근육내, 복강내, 피하, 또는 국소 투여될 수 있다. 이러한 방법은 대상체에 최소한 제 2 항암 요법을 투여하는 단계를 추가로 포함할 수 있다. 제 2 항암 요법들의 예들에는, 외과수술 요법, 화학요법, 방사선 요법, 냉동요법, 호르몬 요법, 면역요법, 또는 사이토카인 요법이 포함되나 이에 제한되는 것은 아니다.
추가 양상들에서, 상기 방법은 대상체에 본 발명의 조성물을 1회 이상, 가령, 예를 들면, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20회 또는 그 이상 투여하는 단계를 추가로 포함할 수 있다.
또 다른 구체예에서, 대상체에서 얻은 샘플에서 대조군에 비해 상승된 EGFL6의 존재에 관하여 테스트하는 단계를 포함하며, 이 때 테스트 단계는 상기 샘플을 본 출원에 개시된 항체와 접촉시키는 단계를 포함하는, 대상체에서 암을 탐지하는 방법을 제공한다. 예를 들면, 상기 방법은 시험관내 또는 생체내 방법일 수 있다.
특정 구체예들은 EGFL6에 특이적으로 결합하는 단리된 및/또는 재조합 항체 또는 폴리펩티드를 포함하는 항체 또는 재조합 폴리펩티드 조성물에 관한 것이다. 특정 양상들에서 항체 또는 폴리펩티드는 본 출원에 제공된 임의의 모든 또는 일부 단일클론 항체와 80, 85, 90, 95, 96, 97, 98, 99, 또는 100% (또는 이 범위에서 유도가능한 임의의 범위) 동일하거나, 최소한 또는 최대 80, 85, 90, 95, 96, 97, 98, 99, 또는 100% (또는 이 범위에서 유도가능한 임의의 범위) 동일한 서열을 가진다. 또한 다른 양상들에서, 단리된 및/또는 재조합 항체 또는 폴리펩티드는 본 출원에 제공된 임의의 서열들 또는 이러한 서열들의 조합으로부터의 최소, 또는 최대 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100 또는 그 이상의 연속 아미노산을 가진다.
또한 또 다른 양상들에서, 상기 구체예들의 항체 또는 폴리펩티드는 본 출원에 개시된 임의의 아미노산 서열들의 하나 이상의 아미노산 분절들을 포함한다. 예를 들면, 항체 또는 폴리펩티드는 본 출원에 개시된 임의의 아미노산 서열들과 최소한 80, 85, 90, 95, 96, 97, 98, 99, 또는 100% 동일한, 약, 최소한 또는 최대 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25 to 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199 또는 200개 아미노산 길이 (상기 값 사이의 모든 값들 및 범위들을 포함)를 포함하는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개 또는 그 이상의 아미노산 분절들을 포함할 수 있다. 특정 양상들에서, 아미노 분절(들)은 본 출원에 제공된 EGFL6-결합 항체의 아미노산 서열들 중 하나에서 선택된다.
또한 추가 양상들에서, 상기 구체예들의 항체 또는 폴리펩티드는 본 출원에 개시된 임의의 아미노산 서열들의 아미노산 분절을 포함하며, 이 때 상기 분절은 본 출원에서 제공되는 임의의 서열의 아미노산 위치 6, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25 to 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 또는 200에서 시작하여 제공된 동일한 서열의 아미노산 위치 7, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25 to 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 또는 200에서 끝난다. 특정 양상들에서, 아미노 분절(들), 또는 이의 일부는 본 출원에 제공된 EGFL6-결합 항체의 아미노산 서열들 중 하나에서 선택된다.
또한 다른 양상들에서, 상기 구체예들의 항체 또는 폴리펩티드는 (표 1과 2에 제시된) EGFL6-결합 항체의 V, VJ, VDJ, D, DJ, J 또는 CDR 도메인과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 (또는 이들 수치범위에서 유도가능한 임의의 범위) 아미노산 분절을 포함한다. 예를 들면, 폴리펩티드는 표 1 및 2에 제시된 EGFL6-결합 항체의 CDRs 1, 2, 및/또는 3과 최소한 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 동일한 (또는 또는 이들 수치범위에서 유도가능한 임의의 범위) 1, 2 또는 3개 아미노산 분절을 포함할 수 있다.
본 발명의 방법들 및/또는 조성물의 내용에서 논의되는 구체예들은 본 출원에 기재된 임의의 다른 방법 또는 조성물과 관련하여 사용될 수 있다. 그러므로 하나의 방법 또는 조성물에 관한 하나의 구체예는 본 발명의 다른 방법들 및 조성물에도 또한 적용될 수 있다.
본 명세서에서 사용되는 "하나(a 또는 an)"는 하나 이상을 의미할 수 있다. 본 명세서의 청구범위에서 "포함하는"이라는 단어와 함께 사용될 경우, 단어 "하나 (a 또는 an)"는 평균 하나 또는 하나 이상을 의미할 수 있다.
대안들 만을 지칭하는 것으로, 또는 대안들이 서로 배타적인 것임을 명시적으로 언급하지 않는 한, 청구범위에서 용어 "또는"의 사용은, "및/또는"을 의미하기 위하여 사용되지만, 본 명세서가 대안만을 그리고 "및/또는"을 지칭하는 정의를 뒷받침한다. 본 출원에서 사용되는 "또 다른"은 최소한 제 2 또는 그 이상을 의미할 수 있다.
본 출원 전반에 걸쳐 용어 "약"은 한 수치가 장치의 고유한 오차 변화, 그 수치를 결정하기 위해 사용된 방법, 또는 연구 피험체들 중에 존재하는 변화를 포함함을 나타내기 위해 사용된다.
본 발명의 다른 목적, 특징 및 이점들은 하기 상세한 설명으로부터 명확해질 것이다. 그러나 상세한 설명 및 구체적인 실시예들은, 본 발명의 바람직한 구체예들을 나타내기는 하지만, 단지 설명을 위해 제공되는 것이며, 본 발명의 사상 및 범위 내에 속하는 다양한 변화 및 변형들은 하기 상세한 설명으로부터 해당 분야의 숙련된 기술자들에게 명확할 것임을 이해하여야 할 것이다.
도면의 간단한 설명
하기 도면들은 본 출원 명세서의 일부를 구성하며 본 발명의 특정 양상들을 추가로 설명하기 위하여 포함된다. 본 발명은 본 출원에 제공된 특정 구체예들에 관한 상세한 설명과 함께 이들 하나 이상의 도면을 참고하면 보다 잘 이해할 수 있다. 특허 또는 출원 파일은 컬러로 작성한 최소한 하나의 도면을 내포한다. 컬러 도면(들)과 함께 공개된 본 특허 또는 특허 출원의 사본은 특허청에 요청 및 필요한 요금 지불시 제공될 것이다.
도 1. ADC (항체-약물 접합체)의 작용 원리를 설명하는 개략도. 표적 항원에 결합시, MAb-항원 복합체는 엔도좀 내부로 내재화된 다음, 라이소좀과 융합되고, 라이소좀에서 MAb가 분해되어 약물이 방출된다.
도 2. ELISA에 의한 고 결합 EGFL6 항체들의 탐지. 인간 (왼쪽 막대) 또는 마우스 (오른쪽 막대) EGFL6 단백질 (Sino Biologicals)을 4 ℃ PBS에서 하룻밤 동안 96-웰 고 결합 플레이트 상에서 코팅하였다. B 세포 배양 상청액들 (5 l 배지 및 95 l의 PBS)을 플레이트 상에서 코팅된 EGFL6 항원에 결합시키기 위해 추가하였다. 결합된 항체를 HRP 및 TMB 기질과 접합된 토끼 IgG에 대한 2차 항체를 사용하여 탐지하였다. 실험들을 확인을 위해 2회씩 반복하였다.
도 3. ELISA로 EGFL6 항체들의 결합 친화력 결정. 일련의 항체 농도를 ELISA로 분석하였으며 4-변수 적합을 사용하여 항체들의 결합 친화력을 계산하였다. 실험들을 3회 반복하였으며 오차 막대는 표준 편차를 나타낸다.
도 4A-D. EGFL6은 종양 관련 내피 세포들에서 상향조절되지만 정상 난소 및 상처 치유 조직에서는 그렇지 않다. A) 내피 세포들의 분리의 요약. B) 정상 난소, 치유 상처 조직 및 난소 종양 관련 내피 세포들로부터 얻은 내피 세포들의 유전자 미세배열. C) 난소 환자들에서 EGFL6, CD31 및 VEGF의 발현. D) Q - RT PCR을 사용한 유전자 미세배열 데이터의 확인. 스케일 바 = 100 μm.
도 5A-H. EGFL6 유전자 침묵은 A2780ip2 난소 동소이식 마우스 모델에서 상처 치유를 손상시키지는 않지만 종양 용적 (종양 burden)을 감소시켰다. A) si대조 및 siEGFL6 처리된 진피 내피 세포들에서 EGFL6의 발현. B) 시험관내 상처 치유에 대한 EGFL6 침묵의 효과. C) 막대 그래프는 상처 치유 면적을 나타낸다. D) 상처 치유에 대한 EGFL6 침묵의 효과 E) 상처 부피 F) 종양 용적을 나타내는 이미지 G) 종양 중량 및 H) 종양 결절.
도 6A-K. TWIST1은 저산소증에서 EGFL6 발현을 유도한다. A,B) 정상산소증 및 저산소증 상태하에서의 EGFL6 프로모터 리포터 분석. C) TWIST1은 저산소증 상태하에서 EGFL6의 발현을 증가시킨다 D) TWIST1은 EGFL6의 프로모터 영역에 결합한다. E 및 F) TWIST1의 이소성 발현은 RF24 세포들에서 EGFL6 발현을 증가시킨다. G) 정상산소증과 비교하여 저산소증에서 EGFL6 프로모터 영역에 결합하는 TWIST1의 ChIP 분석. 인간 난소 내피 세포들 (RF24)에서 EGFL6 프로모터에 결합하는 TWIST1의 EGFL6 및 ChIP 분석. TWIST1로 처리되고 EGFL6 또는 IgG 대조 항체들로 면역침전된 RF24 세포들로부터 얻은 교차-결합된 염색질. 투입 및 면역침전된 DNA는 EGFL6 전사 개시 부위의 상류에 있는 염기쌍들에 상응하는 프라이머들을 사용한 PCR을 거쳤다. PCR 생성물들을 에티듐 브로마이드-염색된 아가로오스 겔에서 검사하였다. H) siRNA를 사용한 EGFL6 유전자 침묵은 저산소증 상태에서 세포 사멸을 증가시킨다. I) 뒷다리 허혈. 동맥 결찰 후, 대퇴 동맥을 절제하고 마우스들을 다음과 같은 3개 군으로 나누었다 (n = 5): 정상, 허혈-24h 및 허혈-96h. 직렬 (serial) 레이저 도플러를 사용하여 대퇴 동맥 결찰 전후 혈류량을 모니터하였다. 각 시점에서, 면역형광법을 실시하기 위해 조직을 수집하고 동결시켰다. J,K) EGFL6 발현은 정상 상태에 비해 허혈 (저산소증) 상태의 내피 세포들에서 증가되었다.
도 7A-K. EGFL6을 이용한 내피 세포들의 처리는 PI3키나아제/AKT 신호전달을 활성화시킨다. A) 대조 및 EGFL6 처리된 RF24 세포들에서 RPPA 분석. B) EGFL6의 웨스턴 블롯팅은 PI3키나아제/AKT 신호전달의 활성화를 매개하였다. C) EGFL6의 웨스턴 블롯팅은 IGF-R, EGFR, 및 Tie2 수용체 활성화를 매개하였다. D) Tie2 항체는 인테그린 단백질을 저하시켰다. E) 세포액 및 막에서의 Tie2 및 AKT 신호전달 경로는 단백질을 분획화하였다. F) siITGB1 및 siTie2 처리된 RF24세포들에서 Tie2 및 AKT 신호전달 경로. G, H) 특이적 siRNAs를 사용한 인테그린 및 Tie2의 침묵은 내피 세포들에서 EGFL6 매개 튜브 형성 (G) 및 이동 (H)을 감소시킨다. I) RGD 차단 펩타이드는 내피 세포들에서 인테그린-매개 신호전달 경로 J) 이동 및 K) 튜브 형성을 감소시킨다.
도 8A-G. EGFL6 기능적 차단 항체는 혈관형성 및 종양 성장을 감소시킨다. A) 선 그래프는 항체 결합 친화력을 나타낸다. B) RF24 세포들에서 Tie2/AKT 활성화에 대한 EGFL6 차단 항체들의 효과. 대조, mAb93 및 mAb135 시험 농도는 10 ug/ml이다. C) 진피 내피 세포들을 이용한 상처 치유 분석에서 EGFL6 차단 항체들의 효과. RF24 세포들에서 D) 튜브 형성 및 E) 이동에 대한 EGFL6 차단 항체들의 효과. F) SKOV3ip1 종양 보유 마우스 종양 중량, 종양 결절에 대한 EGFL6 차단 항체들의 효과. G) 세포 증식 및 혈관 밀도로 나타낸 Ki67 및 CD31 발현. 종양 세포 주입 후 7일에, 마우스들을 다음과 같은 치료를 받을 3개 그룹으로 무작위로 나누었다 (10 마리 마우스/그룹): (1) 대조 Ab (5 mg/kg), (2) EGFL6 Ab 93 (5 mg/kg), 및 (3) EGFL6 Ab 135 (5 mg/kg). 항체를 주 1회 제공하였다. 본 출원의 실시예들에 기재된 바와 같이 종양들을 수집하였다. 본 출원의 실시예들에 기재된 바와 같이 상처를 생성하고 종양들을 수집하였다. 오차 막대는 SEM을 나타낸다. *P<0.05 대. 대조 Ab.
도 8H. EGFL6 항체들에 의한 내피 세포들 (RF24)의 튜브 형성 억제. 항체들 (5 g/ml 농도)을 세포 배양물 (RF24)에 추가하고 대조 항체와 비교하였다. 96-웰 분석 플레이트에서 48 시간 처리 후 튜브의 수를 계수하였다. 도 8H는 각 그룹의 대표도를 보여주며, 막대 그래프는 각 처리 그룹의 튜브 수의 평균을 도시한다. 오차 막대는 표준 오차를 나타내며 n=3이다.
도 9A-C. Tie2-cre; EGFL6 f/f 녹아웃 마우스의 생성. A) Tie2 cre; EGFL6 녹아웃 마우스의 생성. B) 한배 새끼 및 EGFL6 녹아웃 마우스의 단리된 내피 세포에서 CD31 발현. C) 단리된 내피 세포들에서 EGFL6 발현.
도 9D-G. EGFL6 유전자 침묵은 SKOV3ip1 난소 동소이식 마우스 모델에서 종양 용적 및 혈관형성을 감소시킨다. D) 다양한 난소암 세포들에서 EGFL6의 발현. E, F) 난소암의 SKOV3ip1 동소이식 마우스 모델에서 종양 중량 및 종양 결절에 대한 내피 세포 (mEGFL6 siRNA) 또는 종양 (hEGFL6 siRNA) 표적된 EGFL6 siRNA의 효과. 종양 세포 주입 후 7일에, 마우스들을 다음과 같은 치료를 받을 4개 그룹으로 무작위로 나누었다 (10 마리 마우스/그룹): (1) 대조 siRNA, (2) mEGFL6 siRNA, (3) hEGFL6 siRNA (4) mEGFL6 siRNA + hEGFL6 siRNA. 대조 또는 처리 그룹의 임의의 동물이 빈사시 (치료 3-4주 후) 마우스들을 희생시키고 종양 중량 (E) 및 종양 결절의 수 (F)를 기록하였다. 오차 막대는 SEM을 나타낸다. G) 증식 및 미세혈관 밀도에 대한 표적된 EGFL6 siRNAs의 효과. 수집된 종양들을 Ki67 증식 및 CD31에 대해 염색하였다. 스케일 바 = 50 μm. 그래프의 막대들은 왼쪽에 있는 표지된 이미지들의 컬럼에 차례로 대응한다. 오차 막대는 SEM을 나타낸다.
도 10A-E. EGFL6은 종양 혈관형성을 조절한다. A) 인간 정상 난소, 난소 종양, 및 치유 상처 조직들을 해리시켰으며, 단리된 내피 세포들과 샘플들을 미세배열을 위해 처리하였다. B) 인간 정상 난소, 상처, 및 난소 종양 샘플에서 VEGF의 발현. C), D), E) 대조 siRNA- 및 EGFL6 siRNA-처리된 RF24 세포들 및 튜브 형성 및 이동 특징화. EGFL6에 대해 저 또는 고 면역조직화학 염색된 인간 난소암 혈관구조를 나타내는 이미지. 스케일 바 =200 μm. 오차 막대는 SEM를 나타낸다. *p<0.05 대. 대조 siRNA.
도 11A-B. 상처가 있거나 없는 동물들을 대조 siRNA-CH 또는 mEGFL6 siRNA-CH로 처리하였다. 수집된 종양들을 Ki67 (증식) 및 CD31 (미세혈관)에 대해 염색하였다. 오차 막대는 SEM을 나타낸다.
도 12A-D. EGFL6을 이용한 내피 세포들의 처리는 PI3K/AKT 신호전달을 활성화시킨다. A) 대조 및 EGFL6-처리된 RF24 내피 세포들에서 단백질 발현 변화를 보여주는 RPPA 분석을 나타내는 히트 맵 (heat map). B) 대조 및 EGFL6-처리된 RMG2 난소암 세포들의 단백질 발현 변화를 보여주는 RPPA 분석을 나타내는 히트 맵 (heat map). C), D) EGFL6-매개 이동 및 튜브 형성 (하부 패널)은 내피 세포들에서의 PI3K 억제에 의해 감소하였다.
하기 도면들은 본 출원 명세서의 일부를 구성하며 본 발명의 특정 양상들을 추가로 설명하기 위하여 포함된다. 본 발명은 본 출원에 제공된 특정 구체예들에 관한 상세한 설명과 함께 이들 하나 이상의 도면을 참고하면 보다 잘 이해할 수 있다. 특허 또는 출원 파일은 컬러로 작성한 최소한 하나의 도면을 내포한다. 컬러 도면(들)과 함께 공개된 본 특허 또는 특허 출원의 사본은 특허청에 요청 및 필요한 요금 지불시 제공될 것이다.
도 1. ADC (항체-약물 접합체)의 작용 원리를 설명하는 개략도. 표적 항원에 결합시, MAb-항원 복합체는 엔도좀 내부로 내재화된 다음, 라이소좀과 융합되고, 라이소좀에서 MAb가 분해되어 약물이 방출된다.
도 2. ELISA에 의한 고 결합 EGFL6 항체들의 탐지. 인간 (왼쪽 막대) 또는 마우스 (오른쪽 막대) EGFL6 단백질 (Sino Biologicals)을 4 ℃ PBS에서 하룻밤 동안 96-웰 고 결합 플레이트 상에서 코팅하였다. B 세포 배양 상청액들 (5 l 배지 및 95 l의 PBS)을 플레이트 상에서 코팅된 EGFL6 항원에 결합시키기 위해 추가하였다. 결합된 항체를 HRP 및 TMB 기질과 접합된 토끼 IgG에 대한 2차 항체를 사용하여 탐지하였다. 실험들을 확인을 위해 2회씩 반복하였다.
도 3. ELISA로 EGFL6 항체들의 결합 친화력 결정. 일련의 항체 농도를 ELISA로 분석하였으며 4-변수 적합을 사용하여 항체들의 결합 친화력을 계산하였다. 실험들을 3회 반복하였으며 오차 막대는 표준 편차를 나타낸다.
도 4A-D. EGFL6은 종양 관련 내피 세포들에서 상향조절되지만 정상 난소 및 상처 치유 조직에서는 그렇지 않다. A) 내피 세포들의 분리의 요약. B) 정상 난소, 치유 상처 조직 및 난소 종양 관련 내피 세포들로부터 얻은 내피 세포들의 유전자 미세배열. C) 난소 환자들에서 EGFL6, CD31 및 VEGF의 발현. D) Q - RT PCR을 사용한 유전자 미세배열 데이터의 확인. 스케일 바 = 100 μm.
도 5A-H. EGFL6 유전자 침묵은 A2780ip2 난소 동소이식 마우스 모델에서 상처 치유를 손상시키지는 않지만 종양 용적 (종양 burden)을 감소시켰다. A) si대조 및 siEGFL6 처리된 진피 내피 세포들에서 EGFL6의 발현. B) 시험관내 상처 치유에 대한 EGFL6 침묵의 효과. C) 막대 그래프는 상처 치유 면적을 나타낸다. D) 상처 치유에 대한 EGFL6 침묵의 효과 E) 상처 부피 F) 종양 용적을 나타내는 이미지 G) 종양 중량 및 H) 종양 결절.
도 6A-K. TWIST1은 저산소증에서 EGFL6 발현을 유도한다. A,B) 정상산소증 및 저산소증 상태하에서의 EGFL6 프로모터 리포터 분석. C) TWIST1은 저산소증 상태하에서 EGFL6의 발현을 증가시킨다 D) TWIST1은 EGFL6의 프로모터 영역에 결합한다. E 및 F) TWIST1의 이소성 발현은 RF24 세포들에서 EGFL6 발현을 증가시킨다. G) 정상산소증과 비교하여 저산소증에서 EGFL6 프로모터 영역에 결합하는 TWIST1의 ChIP 분석. 인간 난소 내피 세포들 (RF24)에서 EGFL6 프로모터에 결합하는 TWIST1의 EGFL6 및 ChIP 분석. TWIST1로 처리되고 EGFL6 또는 IgG 대조 항체들로 면역침전된 RF24 세포들로부터 얻은 교차-결합된 염색질. 투입 및 면역침전된 DNA는 EGFL6 전사 개시 부위의 상류에 있는 염기쌍들에 상응하는 프라이머들을 사용한 PCR을 거쳤다. PCR 생성물들을 에티듐 브로마이드-염색된 아가로오스 겔에서 검사하였다. H) siRNA를 사용한 EGFL6 유전자 침묵은 저산소증 상태에서 세포 사멸을 증가시킨다. I) 뒷다리 허혈. 동맥 결찰 후, 대퇴 동맥을 절제하고 마우스들을 다음과 같은 3개 군으로 나누었다 (n = 5): 정상, 허혈-24h 및 허혈-96h. 직렬 (serial) 레이저 도플러를 사용하여 대퇴 동맥 결찰 전후 혈류량을 모니터하였다. 각 시점에서, 면역형광법을 실시하기 위해 조직을 수집하고 동결시켰다. J,K) EGFL6 발현은 정상 상태에 비해 허혈 (저산소증) 상태의 내피 세포들에서 증가되었다.
도 7A-K. EGFL6을 이용한 내피 세포들의 처리는 PI3키나아제/AKT 신호전달을 활성화시킨다. A) 대조 및 EGFL6 처리된 RF24 세포들에서 RPPA 분석. B) EGFL6의 웨스턴 블롯팅은 PI3키나아제/AKT 신호전달의 활성화를 매개하였다. C) EGFL6의 웨스턴 블롯팅은 IGF-R, EGFR, 및 Tie2 수용체 활성화를 매개하였다. D) Tie2 항체는 인테그린 단백질을 저하시켰다. E) 세포액 및 막에서의 Tie2 및 AKT 신호전달 경로는 단백질을 분획화하였다. F) siITGB1 및 siTie2 처리된 RF24세포들에서 Tie2 및 AKT 신호전달 경로. G, H) 특이적 siRNAs를 사용한 인테그린 및 Tie2의 침묵은 내피 세포들에서 EGFL6 매개 튜브 형성 (G) 및 이동 (H)을 감소시킨다. I) RGD 차단 펩타이드는 내피 세포들에서 인테그린-매개 신호전달 경로 J) 이동 및 K) 튜브 형성을 감소시킨다.
도 8A-G. EGFL6 기능적 차단 항체는 혈관형성 및 종양 성장을 감소시킨다. A) 선 그래프는 항체 결합 친화력을 나타낸다. B) RF24 세포들에서 Tie2/AKT 활성화에 대한 EGFL6 차단 항체들의 효과. 대조, mAb93 및 mAb135 시험 농도는 10 ug/ml이다. C) 진피 내피 세포들을 이용한 상처 치유 분석에서 EGFL6 차단 항체들의 효과. RF24 세포들에서 D) 튜브 형성 및 E) 이동에 대한 EGFL6 차단 항체들의 효과. F) SKOV3ip1 종양 보유 마우스 종양 중량, 종양 결절에 대한 EGFL6 차단 항체들의 효과. G) 세포 증식 및 혈관 밀도로 나타낸 Ki67 및 CD31 발현. 종양 세포 주입 후 7일에, 마우스들을 다음과 같은 치료를 받을 3개 그룹으로 무작위로 나누었다 (10 마리 마우스/그룹): (1) 대조 Ab (5 mg/kg), (2) EGFL6 Ab 93 (5 mg/kg), 및 (3) EGFL6 Ab 135 (5 mg/kg). 항체를 주 1회 제공하였다. 본 출원의 실시예들에 기재된 바와 같이 종양들을 수집하였다. 본 출원의 실시예들에 기재된 바와 같이 상처를 생성하고 종양들을 수집하였다. 오차 막대는 SEM을 나타낸다. *P<0.05 대. 대조 Ab.
도 8H. EGFL6 항체들에 의한 내피 세포들 (RF24)의 튜브 형성 억제. 항체들 (5 g/ml 농도)을 세포 배양물 (RF24)에 추가하고 대조 항체와 비교하였다. 96-웰 분석 플레이트에서 48 시간 처리 후 튜브의 수를 계수하였다. 도 8H는 각 그룹의 대표도를 보여주며, 막대 그래프는 각 처리 그룹의 튜브 수의 평균을 도시한다. 오차 막대는 표준 오차를 나타내며 n=3이다.
도 9A-C. Tie2-cre; EGFL6 f/f 녹아웃 마우스의 생성. A) Tie2 cre; EGFL6 녹아웃 마우스의 생성. B) 한배 새끼 및 EGFL6 녹아웃 마우스의 단리된 내피 세포에서 CD31 발현. C) 단리된 내피 세포들에서 EGFL6 발현.
도 9D-G. EGFL6 유전자 침묵은 SKOV3ip1 난소 동소이식 마우스 모델에서 종양 용적 및 혈관형성을 감소시킨다. D) 다양한 난소암 세포들에서 EGFL6의 발현. E, F) 난소암의 SKOV3ip1 동소이식 마우스 모델에서 종양 중량 및 종양 결절에 대한 내피 세포 (mEGFL6 siRNA) 또는 종양 (hEGFL6 siRNA) 표적된 EGFL6 siRNA의 효과. 종양 세포 주입 후 7일에, 마우스들을 다음과 같은 치료를 받을 4개 그룹으로 무작위로 나누었다 (10 마리 마우스/그룹): (1) 대조 siRNA, (2) mEGFL6 siRNA, (3) hEGFL6 siRNA (4) mEGFL6 siRNA + hEGFL6 siRNA. 대조 또는 처리 그룹의 임의의 동물이 빈사시 (치료 3-4주 후) 마우스들을 희생시키고 종양 중량 (E) 및 종양 결절의 수 (F)를 기록하였다. 오차 막대는 SEM을 나타낸다. G) 증식 및 미세혈관 밀도에 대한 표적된 EGFL6 siRNAs의 효과. 수집된 종양들을 Ki67 증식 및 CD31에 대해 염색하였다. 스케일 바 = 50 μm. 그래프의 막대들은 왼쪽에 있는 표지된 이미지들의 컬럼에 차례로 대응한다. 오차 막대는 SEM을 나타낸다.
도 10A-E. EGFL6은 종양 혈관형성을 조절한다. A) 인간 정상 난소, 난소 종양, 및 치유 상처 조직들을 해리시켰으며, 단리된 내피 세포들과 샘플들을 미세배열을 위해 처리하였다. B) 인간 정상 난소, 상처, 및 난소 종양 샘플에서 VEGF의 발현. C), D), E) 대조 siRNA- 및 EGFL6 siRNA-처리된 RF24 세포들 및 튜브 형성 및 이동 특징화. EGFL6에 대해 저 또는 고 면역조직화학 염색된 인간 난소암 혈관구조를 나타내는 이미지. 스케일 바 =200 μm. 오차 막대는 SEM를 나타낸다. *p<0.05 대. 대조 siRNA.
도 11A-B. 상처가 있거나 없는 동물들을 대조 siRNA-CH 또는 mEGFL6 siRNA-CH로 처리하였다. 수집된 종양들을 Ki67 (증식) 및 CD31 (미세혈관)에 대해 염색하였다. 오차 막대는 SEM을 나타낸다.
도 12A-D. EGFL6을 이용한 내피 세포들의 처리는 PI3K/AKT 신호전달을 활성화시킨다. A) 대조 및 EGFL6-처리된 RF24 내피 세포들에서 단백질 발현 변화를 보여주는 RPPA 분석을 나타내는 히트 맵 (heat map). B) 대조 및 EGFL6-처리된 RMG2 난소암 세포들의 단백질 발현 변화를 보여주는 RPPA 분석을 나타내는 히트 맵 (heat map). C), D) EGFL6-매개 이동 및 튜브 형성 (하부 패널)은 내피 세포들에서의 PI3K 억제에 의해 감소하였다.
예시적 구체예들의 설명
EGFL6은 상처 치유에 관여하는 EGF 반복 수퍼패밀리의 구성원이다. 그러나, 상승된 EGFL6은 다양한 암 세포 유형들, 가령, 난소암 및 폐암에서 발견되었다. 본 출원의 연구들은 종양 조직들에서 암 세포 증식 및 혈관형성 억제에 효과적임을 증명한다. 더욱이, 본 출원에 제공된 EGFL6-결합 항체들은 EGFL6 활성 및 암 세포 성장을 억제함에 효과적임을 발견하였다. 그러므로, 상기 구체예들의 항체들은 암 치료 및 혈관형성 억제에 효과적인 새로운 방법들을 제공한다.
I.
구체예들의 항체들
특정 구체예에서, EGFL6 단백질의 최소한 일부에 결합하여 EGFL6 신호전달 및 암 세포 증식을 억제하는 항체 또는 이의 단편을 고려한다. 본 명세서에서 사용되는 용어 "항체"는 광범위하게 임의의 면역학적 결합제, 가령, IgG, IgM, IgA, IgD, IgE, 및 유전자 변형된 IgG 뿐만 아니라 항원 결합 활성을 보유하는 항체 CDR 도메인들을 포함하는 폴리펩티드를 지칭하고자 한다. 이러한 항체는 키메라 항체, 친화력 성숙 항체, 다클론 항체, 단일클론 항체, 인간화 항체, 인간 항체, 또는 항원-결합 항체 단편 또는 천연 또는 합성 리간드로 구성된 그룹에서 선택될 수 있다. 바람직하게는, 항-EGFL6 항체는 단일클론 항체 또는 인간화 항체이다.
그러므로, 공지의 수단에 의해 그리고 본 출원에 기재된 바와 같이, EGFL6 단백질, 이 단백질 각각의 에피토프들 중 하나 이상, 또는 전술한 것 중 어느 하나의 접합체들에 특이적인, 다클론 또는 단일클론 항체들, 항체 단편, 및 결합 도메인들 및 CDRs (전술한 것 중 어느 하나의 유전자 조작 형태들을 포함)이 생성될 수 있으며, 이러한 항원 또는 에피토프들이 천연 원료에서 분리되는지 또는 천연 화합물들의 합성 유도체나 변이체들인지 여부와 관계없다.
본 발명의 구체예들에 적합한 항체 단편의 예들에는 제한없이 다음이 포함된다: (i) VL, VH, CL, 및 CH1 도메인들로 구성된 Fab′ 단편; (ii) VH 및 CH1 도메인들로 구성된 "Fd" 단편; (iii) 단일 항체의 VL 및 VH 도메인들로 구성된 "Fv" 단편; (iv) VH 도메인으로 구성된 "Fv" 단편; (v) 단리된 CDR 영역들; (vi) 연결된 2개의 Fab 단편들을 포함하는 2가 단편인 F(ab')2 단편들; (vii) 단쇄 Fv 분자들 ("scFv"), 이 때, VH 도메인 및 VL 도메인은 펩타이드 링커에 의해 연결되어 상기 2개의 도메인들이 결합되어 결합 도메인을 형성하게 되며; (VIII) 이중-특이적 단쇄 Fv 이합체 (미국 특허 제 5,091,513호 참조); 및 (ix) 유전자 융합에 의해 작제된 디아바디, 다가 또는 다중특이적 단편들 (US 공개특허 출원 20050214860호). Fv, scFv, 또는 디아바디 분자들은 VH 및 VL 도메인들을 연결시키는 다이설파이드 다리들을 포함시킴으로써 안정화될 수 있다. CH3 도메인에 결합된 scFv를 포함하는 미니바디들 또한 제조될 수 있다 (Hu 등., 1996).
항체-유사 결합 펩티도모방체들 또한 구체예들에서 고려된다. Liu 등 (2003)은 "항체 유사 결합 펩티도모방체" (ABiPs)를 기재하는데, 이것은 짝이 감소된 (pared-down) 항체들로 작용하며 보다 긴 혈청 반감기 뿐만 아니라 덜 복잡한 합성 방법들의 특정 이점들을 가지는 펩티드이다.
동물은 EGFL6 단백질에 특이적인 항체들을 생성하기 위하여 항원, 가령, EGFL6 세포외 도메인 (ECD) 단백질로 접종될 수 있다. 종종 항원은 또 다른 분자에 결합 또는 접합되어 면역 반응을 향상시킨다. 본 명세서에서 사용되는, 접합체는 동물에서 면역 반응을 이끌어내는데 사용되는 항원에 결합된 임의의 펩타이드, 폴리펩티드, 단백질, 또는 비-단백질성 물질이다. 항원 접종에 대한 반응으로 동물에서 생성된 항체들은 다양한 개개의 항체 생성 B 림프구로부터 제조된 비-동일 분자들 (다클론 항체들)을 포함한다. 다클론 항체는 혼합된 항체 종들의 모집단으로, 각 항체 종은 동일한 항원 상의 상이한 에피토프를 인지할 수 있다. 하나의 동물에서 다클론 항체를 생성하기 위한 적절한 (correct) 조건들이 주어지는 경우, 동물들의 혈청 내 대부분의 항체들은 동물들이 면역화되어 있는 항원 화합물 상의 집합적 에피토프들을 인지할 것이다. 이러한 특이성은 관심 항원 또는 에피토프를 인지하는 항체들만을 선택하기 위한 친화력 정제에 의해 더욱 향상된다.
단일클론 항체는 단일 종의 항체로서, 여기서 모든 항체 생성 세포들은 단일 B-림프구 세포주로부터 유도되기 때문에 모든 항체 분자는 동일한 에피토프를 인지한다. 단일클론 항체들 (mAbs)의 생성 방법들은 일반적으로 다클론 항체들을 제조하는 방법과 동일한 과정에 따라 시작된다. 일부 구체예들에서, 단일클론 항체들을 생성함에 설치류, 가령, 마우스 및 래트들이 사용된다. 일부 구체예들에서, 단일클론 항체들을 생성함에 토끼, 양 또는 개구리 세포가 사용된다. 래트의 사용이 널리 공지되어 있으며 특정 이점들을 제공할 수 있다. 마우스 (예컨대, BALB/c 마우스)가 통상 사용되며 일반적으로 높은 백분율의 안정한 융합을 제공한다.
하이브리도마 기술은 불멸 골수종 세포 (통상적으로 마우스 골수종)와 EGFL6 항원으로 사전에 면역화된 마우스로부터 얻은 단일 B 림프구의 융합을 포함한다. 이러한 기술은 정해지지 않은 세대수를 위한 단일 항체-생성 세포를 전파하는 방법을 제공하여, 동일한 항원 또는 에피토프 특이성 (단일클론 항체들)을 가지는 구조적으로 동일한 항체들을 제한되지 않은 양으로 생성할 수 있게 된다.
혈장 B 세포들 (CD45+CD5-CD19+)은 면역화된 토끼들의 새로이 생성된 토끼 말초 혈액 단핵 세포들로부터 단리되고 EGFL6 결합 세포들에 대해 추가로 선택될 수 있다. 항체 생성 B 세포들의 농축 후, 총 RNA가 단리되어 cDNA가 합성될 수 있다. 중쇄 및 경쇄 모두로부터 얻은 항체 가변 영역들의 DNA 서열들을 증폭시키고, 파지 디스플레이 Fab 발현 벡터로 작제하여, 대장균에 형질전환 시킬 수 있다. EGFL6 특이적 결합 Fab는 다회의 농축 패닝을 통해 선택되어 시퀀싱될 수 있다. 선택된 EGFL6 결합 히트들은 인간 배아 신장 (HEK293) 세포들 (Invitrogen)에서 포유동물 발현 벡터 시스템을 사용하여 토끼 및 토끼/인간 키메라 형태들의 전장 IgG로서 발현되고 급속 단백질 액체 크로마토그래피 (FPLC) 분리 장치로 단백질 G 수지를 사용하여 정제될 수 있다.
한 구체예에서, 항체는 키메라 항체, 예를 들면, 이종 비-인간, 인간, 또는 인간화 서열 (예컨대, 프레임워크 및/또는 불변 도메인 서열들)에 이식된 비-인간 공여자로부터의 항원 결합 서열들을 포함하는 항체이다. 단일클론 항체의 경쇄 및 중쇄 불변 도메인들을 인간 기원의 유사 도메인들로 대체하여, 외부 항체의 가변 영역들을 무손상 상태로 남게 하는 방법들이 개발되었다. 대안적으로, "완전 인간" 단일클론 항체들은 인간 면역글로불린 유전자들에 대해 유전자삽입된 (transgenic) 마우스에서 생성된다. 설치류, 예를 들면, 마우스, 및 인간 아미노산 서열들 모두를 가지는 항체 가변 도메인들을 재조합하여 작제함으로써 단일클론 항체들의 가변 도메인들을 보다 인간 형태로 전환시키는 방법들 또한 개발되었다. "인간화" 단일클론 항체들에서, 초가변성 CDR 만이 마우스 단일클론 항체들로부터 유도되고, 프레임워크 및 불변 영역들은 인간 아미노산 서열들로부터 유도된다 (미국 특허 제 5,091,513 및 6,881,557호 참조). 설치류의 특징적인 항체 내 아미노산 서열들을 상응하는 위치의 인간 항체에서 발견되는 아미노산 서열들로 대체하는 것은 치료적으로 사용하는 동안 유해 면역 반응 가능성을 감소시킬 것으로 생각된다. 하이브리도마 또는 항체를 생성하는 다른 세포는 또한 유전 돌연변이 또는 다른 변화들을 거칠 수 있으며, 이는 하이브리도마에 의해 생성되는 항체들의 결합 특이성을 변화시키거나 변화시키지 않을 수 있다.
다양한 동물 종에서 다클론 항체들을 생성하기 위한, 뿐만 아니라 인간화, 키메라, 및 완전한 인간을 비롯한 다양한 유형들의 단일클론 항체들을 생성하기 위한 방법들은 해당 분야에 널리 공지이며 매우 예상가능하다. 예를 들면, 다음 미국 특허 및 특허 출원은 이러한 방법들에 관한 가능한 설명을 제공한다: 미국 특허 출원 제 2004/0126828 및 2002/0172677호; 및 미국 특허 제 3,817,837; 3,850,752; 3,939,350; 3,996,345; 4,196,265; 4,275,149; 4,277,437; 4,366,241; 4,469,797; 4,472,509; 4,606,855; 4,703,003; 4,742,159; 4,767,720; 4,816,567; 4,867,973; 4,938,948; 4,946,778; 5,021,236; 5,164,296; 5,196,066; 5,223,409; 5,403,484; 5,420,253; 5,565,332; 5,571,698; 5,627,052; 5,656,434; 5,770,376; 5,789,208; 5,821,337; 5,844,091; 5,858,657; 5,861,155; 5,871,907; 5,969,108; 6,054,297; 6,165,464; 6,365,157; 6,406,867; 6,709,659; 6,709,873; 6,753,407; 6,814,965; 6,849,259; 6,861,572; 6,875,434; 및 6,891,024. 본 출원에 인용된 모든 특허, 공개 특허출원, 및 다른 정제법들은 본 출원에 참고로 포함된다.
조류 및 포유동물을 비롯한, 임의의 동물 원천으로부터 항체들을 생성할 수 있다. 바람직하게는, 항체들은 양, 쥐과 (예컨대, 마우스 및 래트), 토끼, 염소, 기니 피크, 낙타, 말 또는 닭이다. 또한, 새로운 기술은 인간 조합 항체 라이브러리로부터 인간 항체의 개발 및 인간 항체를 위한 스크리닝을 가능하게 한다. 예를 들면, 박테리오파지 항체 발현 기술은 미국 특허 제 6,946,546호에 기재된 바와 같이, 동물 면역화 부재시 특이적 항체들을 생성시키며, 참고 문헌으로 본 출운에 첨부된다. 이러한 기술들은 다음과 같이 추가로 설명되어 있다: Marks (1992); Stemmer (1994); Gram 등 (1992); Barbas 등 (1994); 및 Schier 등 (2001).
EGFL6에 대한 항체들은 동물 종, 단일클론 세포주, 또는 다른 항체 공급원과 관계없이, EGFL6의 효과를 중화 또는 상쇄시키는 능력을 가질 것으로 충분히 예상된다. 특정 동물 종들은 치료 항체들을 생성하기에 덜 바람직할 수 있는데 왜냐하면 이들은 항체의 "Fc" 부분을 통한 보체 시스템의 활성화로 인해 알러지 반응을 유발할 가능성이 더 많을 수 있기 때문이다. 그러나 전 항체들은 "Fc" (보체 결합) 단편으로, 그리고 결합 도메인 또는 CDR을 가지는 항체 단편으로 효소적으로 분해될 수 있다. Fc 부분의 제거는 항원 항체 단편이 바람직하지 않은 면역학적 반응을 유도하게 될 가능성을 감소시키므로, Fc 없는 항체들이 예방 또는 치료적 처리에 선호될 수 있다. 상기 설명한 바와 같이, 다른 종에서 생성되었던, 또는 다른 종의 서열들을 가지는 항체를 동물에게 투여하여 생성되는 유해한 면역학적 결과들을 감소 또는 제거하기 위해 키메라 또는 부분적으로 또는 완전히 인간이 되도록 하기 위한, 항체들 또한 작제될 수 있다 .
치환 변이체들은 전형적으로 단백질 내 하나 이상의 부위들에서 하나의 아미노산의 또 다른 아미노산으로의 교환을 내포하며, 다른 기능들 또는 성질들을 소실시키면서 또는 소실시키지 않으면서 폴리펩티드의 하나 이상의 성질들을 조절하도록 설계될 수 있다. 치환은 보존적일 수 있다, 즉, 하나의 아미노산이 유사 형상 및 전하 중 하나로 대체된다. 보존적 치환은 해당 분야에 널리 공지이며, 예를 들면, 다음 변화를 포함한다: 알라닌에서 세린으로; 아르기닌에서 리신으로; 아스파라긴에서 글루타민 또는 히스티딘으로; 아스파테이트에서 글루타메이트로; 시스테인에서 세린으로; 글루타민에서 아스파라긴으로; 글루타메이트에서 아스파테이트로; 글리신에서 프롤린으로; 히스티딘에서 아스파라긴 또는 글루타민으로; 아이소류신에서 류신 또는 발린으로; 류신에서 발린 또는 아이소류신으로; 리신에서 아르기닌으로; 메티오닌에서 류신 또는 아이소류신으로; 페닐알라닌에서 티로신으로, 류신에서 메티오닌으로; 세린에서 트레오닌으로; 트레오닌에서 세린으로; 트립토판에서 티로신으로; 티로신에서 트립토판 또는 페닐알라닌으로; 그리고 발린에서 아이소류신 또는 류신으로. 대안적으로, 치환은 비-보존적일 수 있어서 폴리펩티드의 기능 또는 활성에 영향을 준다. 비-보존적 변화들은 전형적으로 하나의 잔기를 화학적으로 비유사한 잔기로, 가령, 극성 또는 하전된 아미노산을 비극성 또는 하전되지 않은 아미노산으로 치환하는 것, 그리고 그 역을 포함한다.
단백질은 재조합이거나, 시험관내 합성될 수 있다. 대안적으로, 비-재조합 또는 재조합 단백질은 세균으로부터 단리될 수 있다. 또한 이러한 변이체를 내포하는 세균이 조성물 및 방법에 도입될 수 있음이 고려된다. 결과적으로, 단백질은 단리될 필요가 없다.
조성물 1 ml 당 약 0.001 mg 내지 약 10 mg의 총 폴리펩티드, 펩타이드, 및/또는 단백질이 존재하는 것이 고려된다. 그러므로, 조성물 내 단백질 농도는 약, 최소한 약 또는 최대 약 0.001, 0.010, 0.050, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0, 6.5, 7.0, 7.5, 8.0, 8.5, 9.0, 9.5, 10.0 mg/ml 또는 그 이상 (또는 이들 수치범위에서 유도가능한 임의의 범위)일 수 있다. 그 중, 약, 최소한 약, 또는 최대 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100%가 EGFL6에 결합하는 항체일 수 있다.
항체 또는 바람직하게는 항체의 면역학적 부분은, 다른 단백질과의 융합 단백질에 화학적으로 접합되거나 다른 단백질과의 융합 단백질로서 발현될 수 있다. 본 명세서 및 첨부된 청구범위에서, 이러한 모든 융합된 단백질은 항체들 또는 항체의 면역학적 부분의 정의에 포함된다.
구체예들은 최소한 하나의 제제에 연결되어, 항체 접합체 또는 탑재물 (payload)을 형성하는 EGFL6, 폴리펩티드 및 펩티드에 대한 항체들 및 항체-유사 분자들을 제공한다. 진단 또는 치료제로서의 항체 분자들의 효능을 증가시키기 위하여, 최소한 하나의 원하는 분자 또는 모이어티에 연결 또는 공유 결합 또는 복합체를 형성하는 것이 관례적이다. 이러한 분자 또는 모이어티는, 최소한 하나의 효과기(effector) 또는 리포터 분자일 수 있으나 이에 제한되는 것은 아니다. 효과기 분자들은 원하는 활성, 예컨대, 세포독성 활성을 가지는 분자들을 포함한다. 항체들에 부착되어 있는 효과기 분자들의 비-제한적 예들에는 독소, 치료 효소, 항생제, 방사선-표지된 뉴클레오티드 등이 포함된다. 대조적으로, 리포터 분자는 분석법을 사용하여 탐지될수 있는 임의의 모이어티로서 정의된다. 항체들에 접합되어 있는 리포터 분자들의 비-제한적 예들에는, 효소, 방사능표지, 합텐, 형광 표지, 인광 분자, 화학발광 분자, 발색단, 발광 분자, 광친화성 분자, 착색 입자들 또는 리간드, 가령, 비오틴이 포함된다.
항체를 그 접합체 모이어티에 부착 또는 접합시키기 위한 여러 가지 방법들이 해당 분야에 공지되어 있다. 일부 부착 방법들은 상기 항체에 부착된 금속 킬레이트 착물의 사용을 포함하며, 예를 들어, 유기 킬레이트제, 가령, 다이에틸렌트라이아민펜타아세트산 무수물 (DTPA); 에틸렌트라이아민테트라아세트산; N-클로로-p-톨루엔설폰아미드; 및/또는 테트라클로로-3-6-다이페닐글리코우릴-3을 사용한다. 단일클론 항체들은 또한 커플링제, 가령, 글루타르알데하이드 또는 페리오데이트의 존재하에서 효소와 반응될 수 있다. 형광물질 마커들과의 접합체는 이러한 커플링제들의 존재하에서 또는 아이소싸이오사이아네이트와의 반응에 의해 제조된다.
II.
질병의 치료
본 발명의 구체예들의 특정 양상들은 EGFL6 신호전달과 연관된 질병 또는 장애를 예방 또는 치료하기 위하여 사용될 수 있다. EGFL6의 신호전달은 암 세포 증식을 저해하기에 적합한 임의의 약물들에 의해 감소될 수 있다. 바람직하게는, 이러한 물질들은 항-EGFL6 항체일 것이다.
"치료" 및 "치료하는 것"은 치료제를 대상체에 투여 또는 도포하는 것 또는 질병 또는 건강-관련 병태의 치료적 이점을 얻을 목적으로 대상체에서 일정 절차 또는 양식을 실시하는 것을 지칭한다. 예를 들면 치료는 EGFL6 신호전달을 억제하는 제약학적 유효량의 항체의 투여를 포함할 수 있다.
"대상체" 및 "환자"는 인간 또는 비-인간, 가령, 영장류, 포유동물, 및 척추동물을 지칭한다. 특정 구체예들에서, 대상체는 인간이다.
본 출원 전반에 걸쳐 사용되는 용어 "치료적 이점" 또는 치료적으로 유효한"은 이러한 병태의 의학적 치료와 관련하여 대상체의 웰빙을 촉진 또는 향상시키는 것을 지칭한다. 이는, 질병의 징후 또는 증상들의 중증도 또는 빈도의 감소를 포함하나 이에 제한되는 것은 아니다. 예를 들면, 암 치료는, 예를 들면, 종양 크기의 감소, 종양 침습성의 감소, 암 성장 속도의 감소, 또는 전이의 예방을 포함할 수 있다. 암 치료는 또한 암에 걸린 대상체의 생존을 연장시키는 것을 지칭할 수도 있다.
A.
제약학적 제재
억제성 항체를 내포하는 치료 조성물의 임상 적용이 이루어지는 경우, 의도한 적용에 적절한 제약학적 또는 치료적 조성물을 제조하는 것이 유익할 것이다. 특정 구체예에서, 제약학적 조성물은, 예를 들어, 최소한 약 0.1%의 활성 화합물을 포함할 수 있다. 다른 구체예들에서, 활성 화합물은 단위 중량의 약 2% 내지 약 75%, 또는 약 25% 내지 약 60%, 예를 들어, 그리고 이 범위에서 유도가능한 임의의 범위를 포함할 수 있다.
본 발명의 구체예들의 치료 조성물은 유리하게는 액체 용액 또는 현탁액의 주사 조성물 형태로 투여되며; 주사 전 액체 중의 용액 또는 액체 중의 현탁액으로 적합한 고체 형태 또한 제조될 수 있다. 이러한 제재들은 또한 유화될 수 있다.
어구 "제약학적으로 허용가능한" 또는 "약물학적으로 허용가능한"은 적절하게 동물, 가령, 사람에 투여시 이상, 알러지 또는 다른 유해 반응을 생성하지 않는 분자체들 및 조성물들을 지칭한다. 항체 또는 추가 활성 성분을 포함하는 제약학적 조성물의 제조는 본 출원 내용에 비추어 해당 분야의 숙련된 기술자에게 공지되어 있을 것이다. 더욱이, 동물 (예컨대, 인간) 투여를 위해, 제재들은 FDA가 요구하는 생물학적 표준인 무균성, 발열원성, 일반 안전성, 및 순도 표준을 충족시켜야 함이 이해될 것이다.
본 출원에서 사용되는, "제약학적으로 허용가능한 담체"는 해당 분야의 숙련된 기술자에게 공지된, 수성 용매들 (예컨대, 물, 알콜/수용액, 식염수 용액, 비경구 비히클, 가령, 소듐 클로라이드, 링거 포도당, 등), 비-수성 용매들 (예컨대, 프로필렌 글리콜, 폴리에틸렌 글리콜, 식물성 오일, 및 주사용 유기 에스터, 가령, 에틸올레이트), 분산 배지, 코팅제, 계면활성제, 항산화제, 보존제 (예컨대, 항균 또는 항진균제, 항산화제, 킬레이트제, 및 비활성 기체), 등장화제, 흡수 지연제, 염, 약물, 약물 안정화제, 겔, 결합제, 부형제, 붕해제, 윤활제, 감미제, 착향제, 염료, 체액 및 영양분 보충제, 이러한 재료 및 이의 조합물 중 어느 하나 그리고 모두 포함한다. 제약학적 조성물의 다양한 성분들의 pH 및 정확한 농도는 널리-공지된 변수들에 따라 조절된다.
용어 "단위 투여용량" 또는 "투여량"은 대상체에서 사용하기에 적합한 물리적으로 분리된 단위들을 지칭하며, 각 단위는 투여, 즉, 적절한 경로 및 치료 섭생과 관련하여 상기 논의된 필요한 반응들을 생성하기 위해 계산된, 예정된 양의 치료 조성물을 내포한다. 치료 회수 및 단위 투여용량 모두에 따라 투여되는 양은 원하는 효과에 따라 달라진다. 환자 또는 대상체에 투여되는 본 발명의 구체예들의 조성물의 실제 투여량은 물리적 및 생리학적 요인들, 가령, 대상체의 체중, 연령, 건강, 및 성별, 치료되는 질병의 유형, 질병 침투 정도, 과거 또는 현재의 치료적 개입, 환자의 특발증, 투여 경로, 및 특정 치료 물질의 역가, 안정성 및 독성에 의해 결정될 수 있다. 예를 들면, 투여용량은 또한 투여 1회 당 약 1 μg/kg/체중 내지 약 1000 mg/kg/체중 (이러한 범위는 그 사이의 범위들을 포함함) 또는 그 이상, 그리고 그 범위에서 유도가능한 임의의 범위를 포함할 수 있다. 본 출원에 열거된 수치들로부터 유도가능한 범위의 비-제한적 예들에서, 약 5 μg/kg/체중 내지 약 100 mg/kg/체중, 약 5 μg/kg/체중 내지 약 500 mg/kg/체중, 등의 범위가 투여될 수 있다. 투여를 담당하는 진료자는, 임의의 경우에, 개개의 대상체에 적절한 투여량(들) 및 조성물 내 활성 성분(들)의 농도를 결정할 것이다.
활성 화합물들은 비경구 투여용, 예컨대, 정맥내, 근육내, 피하, 또는 심지어 복강내 경로를 통한 주사용으로 제형화될 수 있다. 전형적으로, 이러한 조성물은 액체 용액 또는 현탁액으로 제조될 수 있으며; 주사에 앞서 액체를 부가시 용액 또는 현탁액을 제조함에 사용하기에 적합한 고체 형태들 또한 제조될 수 있고; 그리고 상기 제재들은 또한 유화될 수 있다.
주사용으로 사용하기에 적합한 제약학적 형태들에는 무균 수용액 또는 현탁액; 참기름, 땅콩 오일, 또는 수성 프로필렌 글리콜을 비롯한 제형들; 및 무균 주사 용액 또는 현탁액의 임시 제조를 위한 무균 분말이 포함된다. 모든 경우에 상기 형태는 무균이어야 하며 용이하게 주사될 수 있을 정도로 유체이어야 한다. 또한 상기 형태는 제조 및 보관 조건들하에서 안정하여야 하며 미생물, 가령, 세균 및 진균의 오염 작용에 대항하여 보존되어야 한다.
단백질성 조성물은 중성 또는 염 형태로 제형화될 수 있다. 제약학적으로 허용가능한 염에는, (단백질의 유리 아미노 그룹과 함께 형성된) 산 부가 염이 포함되며, 이러한 산 부가 염은 무기산, 가령, 예를 들어, 염산 또는 인산, 또는, 유기산, 가령, 아세트산, 옥살산, 타르타르산, 만델산 등을 이용하여 형성될 수 있다. 유리 카르복실 그룹을 이용하여 형성된 염은 또한 무기 염기, 가령, 예를 들어, 수산화 나트륨, 수산화 칼륨, 수산화 암모늄, 수산화 칼슘, 또는 수산화 철 (ferric hydroxides), 및, 유기 염기, 가령, 아이소프로필아민, 트라이메틸아민, 히스티딘, 프로케인 등으로부터 유도될 수 있다.
제약학적 조성물은 예를 들어, 물, 에탄올, 폴리올 (예를 들어, 글리세롤, 프로필렌 글리콜, 및 액체 폴리에틸렌 글리콜, 등), 이의 적합한 혼합물, 및 식물성 오일들을 포함하는 용매 또는 분산 매질을 포함할 수 있다. 예를 들면, 코팅, 가령, 레시틴을 사용함으로써, 분산액의 경우 필요한 입경을 유지함으로써, 그리고 계면활성제를 사용함으로써 적절한 유동성이 유지될 수 있다. 미생물의 작용 방지는 다양한 항균 및 항진균제, 예를 들어, 파라벤, 클로로부탄올, 페놀, 소르빈산, 티메로살, 등에 의해 이루어질 수 있다. 많은 경우에서, 등장화제, 예를 들어, 당 또는 소듐 클로라이드를 포함하는 것이 바람직할 것이다. 주사 조성물의 흡수 지연은 조성물에 흡수를 지연시키는 제제, 예를 들어, 알루미늄 모노스테아레이트 및 젤라틴을 사용함으로써 이루어질 수 있다.
B. 병용 치료(Combination treatment)
특정 구체예에서, 본 발명의 구체예들의 조성물 및 방법은 암 세포 증식에 있어서 그 활성을 억제하는 EGFL6에 대한 항체 또는 항체 단편을, 제 2 또는 추가 요법과 병용하는 것을 포함한다. 이러한 요법은 EGFL6-매개 세포 증식과 연관된 임의의 질병의 치료에서 사용될 수 있다. 예를 들면, 질병은 암일 수 있다.
병용 요법들을 비롯한 상기 방법들 및 조성물은 치료 또는 보호 효과를 향상시키고, 및/또는 또 다른 항암 또는 항-이상증식 요법의 치료 효과를 증가시킨다. 치료 및 예방적 방법들 및 조성물은 원하는 효과, 가령, 암 세포의 사멸 및/또는 세포 이상증식의 억제를 구현하기에 유효한 조합된 양으로 제공될 수 있다. 이러한 과정은 상기 세포들을 항체 또는 항체 단편 및 제 2 요법 모두와 접촉시키는 단계를 포함할 수 있다. 조직, 종양, 또는 세포는 하나 이상의 제제들(즉, 항체 또는 항체 단편 또는 항암제)을 포함하는 하나 이상의 조성물 또는 약물학적 제제(들)과 접촉될 수 있거나, 또는 상기 조직, 종양, 및/또는 세포는 둘 이상의 별도의 조성물 또는 제제들과 접촉될 수 있는데, 여기서 하나의 조성물은 1) 항체 또는 항체 단편, 2) 항암제, 또는 3) 항체 또는 항체 단편 및 항암제 모두를 제공한다. 또한, 이러한 병용 요법은 화학요법, 방사선요법, 외과수술 요법, 또는 면역요법과 함께 사용될 수 있는 것으로 고려된다.
세포에 대해 사용될 때 용어 "접촉된" 및 "노출된"은 치료 작제물 및 화학치료제 또는 방사선치료제를 표적 세포에 전달하는 또는 표적 세포와의 근접위치에 직접 넣는 과정을 설명하기 위하여 본 출원에서 사용된다. 예를 들면, 세포 사멸을 구현하기 위하여, 두 가지 제제들 모두가 세포를 사멸 또는 세포 분열을 방지하기에 효과적인 조합량으로 세포에 전달된다.
억제성 항체는 항암 치료 전, 중, 후, 또는 항암 치료와 관련하여 다양한 조합으로 투여될 수 있다. 투여는 동시 내지 수 분에서부터 수 일 내지 수 주 범위의 간격이 될 수 있다. 항체 또는 항체 단편이 항암제와 별도로 환자에게 제공되는 구체예들에서, 상기 두 가지 화합물들이 여전히 환자에게 유리하게 조합된 효과를 발휘할 수 있도록 각 전달 시간 사이에 상당 기간의 시간이 경과되지 않도록 하는 것이 일반적이다. 이러한 예들에서, 항체 요법 및 항암 요법을 서로 간에 약 12 내지 24 또는 72 h 이내에, 더욱 특히, 서로 간에 약 6-12 h 이내에 환자에게 제공할 수 있음이 고려된다. 일부 상황들에서, 각각의 투여간에 수 일 (2, 3, 4, 5, 6 또는 7) 내지 수 주 (1, 2, 3, 4, 5, 6, 7 또는 8)가 경과하도록 치료 시기를 상당히 연장시키는 것이 바람직 할 수 있다.
특정 구체예에서, 치료 과정은 1-90 일 또는 그 이상 (이러한 범위는 그 사이의 일수들을 포함함) 계속될 것이다. 하나의 제제는 1일차 내지 90일차 (이러한 범위는 그 사이의 일차들을 포함함) 중 임의의 일차에 또는 이의 임의의 조합일차에 제공될 수 있으며, 또 다른 제제는 1일차 내지 90일차 (이러한 범위는 그 사이의 일차들을 포함함) 중 임의의 일차에 또는 이의 임의의 조합일차에 제공됨이 고려된다. 하루 (24-시간의 기간) 이내, 환자에게 1회 또는 다회의 제제(들)이 투여될 수 있다. 더욱이, 치료 과정 후, 항암 치료제가 전혀 투여되지 않는 시기가 존재함이 고려된다. 이러한 시기는 환자의 조건, 가령, 예후, 강도, 건강 등에 따라 1-7 일, 및/또는 1-5 주, 및/또는 1-12 개월 또는 그 이상 (이러한 범위는 그 사이의 일수를 포함함) 지속될 수 있다. 치료 주기는 필요한 만큼 반복될 것으로 예상된다.
다양한 조합이 사용될 수 있다. 하기 예에서 항체 요법은 "A"이고 항암 요법은 "B"이다:
A/B/A B/A/B B/B/A A/A/B A/B/B B/A/A A/B/B/B B/A/B/B
B/B/B/A B/B/A/B A/A/B/B A/B/A/B A/B/B/A B/B/A/A
B/A/B/A B/A/A/B A/A/A/B B/A/A/A A/B/A/A A/A/B/A
본 발명의 구체예들의 임의의 화합물 또는 요법의 환자에 대한 투여는, 존재한다면, 상기 제제들의 독성을 고려하여, 이러한 화합물들의 일반적인 투여 프로토콜을 따를 것이다. 그러므로, 일부 구체예들에서 병용 요법으로 인한 독성을 모니터링하는 단계가 존재한다.
i.
화학요법
널리 다양한 화학치료제들이 본 발명의 구체예들에 따라 사용될 수 있다. 용어 "화학요법"은 암을 치료하기 위한 약물의 사용을 지칭한다. "화학치료제"는 암 치료에서 투여되는 화합물 또는 조성물을 함축하기 위해 사용된다. 이러한 제제들 또는 약물들은 세포내에서의 이들의 작용 방식, 예를 들어, 이들이 세포 주기에 영향을 주는지 여부 및 어느 단계에서 영향을 주는지에 의해 분류된다. 대안적으로, 제제는 DNA에 직접 교차 결합하는, DNA 내부에 삽입되는, 또는 핵산 합성에 영향을 줌으로써 염색체 및 유사분열 이상을 유도하는 능력을 기준으로 특징될 수 있다.
화학치료제들의 예들에는, 알킬화제, 가령, 싸이오테파 및 사이클로포스파미드; 알킬 설포네이트, 가령, 부설판, 임프로설판, 및 피포설판; 아지리딘, 가령, 벤조도파, 카르보쿠온, 메투레도파, 및 우레도파; 알트레타민, 트라이에틸렌멜라민, 트라이에틸렌포스포라미드, 트라이에틸렌싸이오포스포라미드, 및 트라이메틸롤로멜라민을 비롯한 에틸렌이민 및 메틸아멜라민; 아세토게닌 (특히 불라타신 및 불라타시논); 캄프토테신 (합성 유사체 토포테칸 포함); 브리오스타틴; 칼리스타틴; CC-1065 (아도젤레신, 카르젤레신 및 비젤레신 합성 유사체들 포함); 크립토파이신 (특히, 크립토파이신 1 및 크립토파이신 8); 돌라스타틴; 듀오카르마이신 (합성 유사체, KW-2189 및 CB1-TM1 포함); 엘레우테로빈; 판크라티스타틴; 사르코딕틴; 스폰지스타틴; 질소 머스터드, 가령, 클로람부실, 클로르나파진, 클로로포스파미드, 에스트라무스틴, 이포스파미드, 메클로레타민, 메클로레타민 옥사이드 하이드로클로라이드, 멜팔란, 노벰비킨, 펜에스테린, 프레드니무스틴, 트로포스파미드, 및 우라실 머스터드; 니트로소우레아, 가령, 카르무스틴, 클로로조토신, 포테무스틴, 로무스틴, 니무스틴, 및 라님너스틴; 항생제, 가령, 에네다인 항생제 (예컨대, 칼리케아미신, 특히 칼리케아미신 감마lI 및 칼리케아미신 오메가I1); 다이네미신 A를 비롯한 다이네미신; 비스포스포네이트, 가령, 클로드로네이트; 에스페라미신; 뿐만 아니라 네오카르지노스타틴 발색단 및 관련 색단백질 에네다인 항생제 발색단, 아클라시노마이신, 악티노마이신, 아우트라마이신, 아자세린, 블레오마이신, 칵티노마이신, 카라비신, 카르미노마이신, 카르지노필린, 크로모마이시니스, 닥티노마이신, 다우노루비신, 데토루비신, 6-다이아조-5-옥소-L-노르류신, 독소루비신 (모르폴리노-독소루비신, 사이아노모르폴리노-독소루비신, 2-피롤리노-독소루비신 및 데옥시독소루비신 포함), 에피루비신, 에소루비신, 이다루비신, 마르셀로마이신, 미토마이신, 가령, 미토마이신 C, 마이코페놀산, 노갈라마이신, 올리보마이신, 페플로마이신, 폿피로마이신, 퓨로마이신, 쿠엘라마이신, 로도루비신, 스트렙토니그린, 스트렙토조신, 투베르시딘, 유베니멕스, 지노스타틴, 및 조루비신; 항-대사물질, 가령, 메토트렉세이트 및5-플루오로우라실 (5-FU); 엽산 유사체, 가령, 데노프테린, 프테로프테린, 및 트라이메트렉세이트; 퓨린 유사체, 가령, 플루다라빈, 6-메르캅토퓨린, 싸이아미프린, 및 싸이오구아닌; 피리미딘 유사체, 가령, 안시타빈, 아자시티딘, 6-아자우리딘, 카르모푸르, 시타라빈, 디데옥시우리딘, 독시플루리딘, 에노시타빈, 및 플록수리딘; 안드로겐, 가령, 칼루스테론, 드로모스타놀론 프로피오네이트, 에피티오스타놀, 메피티오스탄, 및 테스토락톤; 항-부신제, 가령, 미토탄 및 트라이로스탄; 엽산 보충물, 가령, 프롤린산 (frolinic acid); 아세글라톤; 알도포스파미드 글라이코시드; 아미노레불린산; 에닐우라실; 암사크린; 베스트라부실; 비산트렌; 에다트락세이트; 데포파민; 데메콜신; 다이아지쿠온; 엘포르니틴; 엘립티늄 아세테이트; 에포틸론; 에토글루시드; 갈륨 니트레이트; 하이드록시우레아; 렌티난 (lentinan); 로니다이닌; 마이탄시노이드, 가령, 마이탄신 및 안사미토신; 미토구아존; 미톡산트론; 모피단몰; 니트라에린; 펜토스타틴; 페나메트; 피라루비신; 로속산트론; 포도필린산; 2-에틸하이드라지드; 프로카르바진; PSK다당류 복합체; 라족산; 리족신; 시조피란; 스피로게르마늄; 테누아존산; 트라이아지쿠온; 2,2',2"-트라이클로로트라이에틸아민; 트라이코테센 (특히 T-2 독소, 베라큐린 A, 로리딘 A 및 안구이딘); 우레탄; 빈데신; 다카르바진; 만노무스틴; 미토브로니톨; 미토락톨; 피포브로만; 가시토신; 아라비노사이드 ("Ara-C"); 사이클로포스파미드; 탁소이드, 예컨대, 파클리탁셀 및 도세탁셀 겜시타빈; 6-싸이오구아닌; 메르캅토퓨린; 백금 배위결합 착물, 가령, 시스플라틴, 옥살리플라틴, 및 카르보플라틴; 빈블라스틴; 백금; 에토포시드 (VP-16); 이포스파미드; 미톡산트론; 빈크리스틴; 비노렐빈; 노반트론; 테니포시드; 에다트렉세이트; 다우노마이신; 아미노프테린; 젤로다 (xeloda); 이반드로네이트; 이리노테칸 (예컨대, CPT-11); 국소이성화효소 억제제 RFS 2000; 다이플루오로메틸오르니틴 (DMFO); 레티노이드, 가령, 레티노산; 카페시타빈; 카르보플라틴, 프로카르바진, 플리코마이신, 겜시타비엔, 나벨빈, 파르네실-단백질 트랜스퍼라제 억제제, 트랜스플래티늄, 및 상기 중 어느 하나의 제약학적으로 허용가능한 염, 산, 또는 유도체가 포함된다.
ii.
방사선요법
DNA 손상을 유발하고 광범위하게 사용되어왔던 다른 인자들은 γ-선, X-선으로 통상적으로 공지된 것들, 및/또는 종양 세포에 대한 방사성동위원소의 직접 전달을 포함한다. 다른 형태의 DNA 손상 인자들, 가령, 마이크로파, 양성자 빔 조사 (미국 특허 제 5,760,395 및 4,870,287호), 및 UV-조사 또한 고려된다. 이러한 인자들 모두 DNA에, DNA의 전구물질에, DNA의 복제 및 복원에, 그리고 염색체의 어셈블리 및 유지에 광범위한 손상을 줄 가능성이 크다. X-선 조사량은 장기간의 시기 (3 내지 4주) 동안 일일 50 내지 200 뢴트겐 조사량 내지 1회 2000 내지 6000 뢴트겐 조사량 범위이다. 방사성동위원소에 관한 투여량 범위는 광범위하게 달라질 수 있으며 동위원소의 반감기, 방출되는 방사선의 강도 및 유형, 및 신생물 세포들에 의한 흡수에 따라 달라진다.
iii.
면역요법
숙련된 기술자는 또 다른 면역요법들이 본원 구체예들의 방법들과 조합하여 또는 함께 사용될 수 있음을 이해할 것이다. 암 치료와 관련하여, 면역치료제는, 일반적으로, 암 세포들을 표적하여 파괴하기 위한 면욕 효과기 세포들 및 분자들의 사용에 의존한다. 리툭시맙 (RITUXANㄾ)이 이러한 예이다. 면역 효과기는, 예를 들어, 종양 세포의 표면 상에 존재하는 일부 마커베 특이적인 항체일 수 있다. 항체는 단독으로 요법의 효과기로 기능할 수 있거나 세포 사멸에 실제 영향을 미치는 다른 세포들을 모집할 수 있다. 항체는 또한 약물 또는 독소 (화학치료제, 방사성핵종, 리신 A 사슬, 콜레라 독소, 백일해 독소, 등)에 접합되어 표적화제로서 기능할 수 있다. 대안적으로, 효과기는 세포 표적과 직접 또는 간접적으로 상호작용하는 표면 분자를 전달하는 림프구일 수 있다. 다양한 효과기 세포들은 세포독성 T 세포 및 NK 세포들을 포함한다.
항체-약물 접합체는 암 치료제의 개발에 획기적인 접근법으로 등장하였다. 암은 세계적으로 주요 사망 원인들 중 하나이다. 항체-약물 접합체 (ADCs)는 세포-사멸 약물에 공유 결합되는 단일클론 항체들 (mAbs)을 포함한다 (도 1). 이러한 접근법은 항원 표적들에 대한 고 특이성의 mAbs를 높은 효능의 세포독성 약물과 조합하여, 탑재물 (약물)을 농축된 항원 수준의 종양 세포들로 전달하는 "팔 보유(armed)" mAbs를 생성한다(Carter 등, 2008; Teicher 2014; Leal 등, 2014). 약물의 표적화 전달은 또한 정상 조직에서 약물의 노출을 최소화시켜, 독성을 감소시키고 치료 지수를 개선시킨다. 2개의 ADC 약물, ADCETRISㄾ (브렌툭시맙 베도틴)(2011년) 및 KADCYLAㄾ (트라스투주맙 엠탄신 또는 T-DM1) (2013년)에 대한 FDA의 승인은 이러한 접근을 유효하게 하였다. 현재 암 치료에 관한 다양한 단계의 임상 시험 중인 30개 이상의 ADC 약물 후보군들이 존재한다 (Leal 등, 2014). 항체 조작 및 링커-탑재물 최적화가 더더욱 성숙해짐에 따라, 새로운 ADC들의 개발은 이러한 접근에 적합한 새로운 표적들의 식별 및 확인 그리고 표적화 mAb들의 생성에 점점 더 의존하고 있다 ( 2009). ADC 표적들에 관한 2가지 기준은 종양 세포들에서 상향조절된/높은 발현 수준 및 강력한 내재화이다.
면역요법의 한 양상에서, 종양 세포는 쉽게 표적화될 수 있는, 즉, 다수의 다른 세포들에 존재하지 않는 일부 마커를 보유하여야 한다. 많은 종양 마커들이 존재하며 이들 중 어느 것이라도 본 발명의 구체예들과 관련된 표적화에 적합할 수 있다. 통상의 종양 마커들에는 CD20, 암배아 항원, 티로시나아제 (p97), gp68, TAG-72, HMFG, 시알릴 루이스 항원, MucA, MucB, PLAP, 라미닌 수용체, erb B, 및 p155가 포함된다. 면역요법의 대안적 양상은 면역 자극 효과와 항암 효과를 조합하는 것이다. 다음을 비롯한 면역 자극 분자들이 또한 존재한다: 사이토카인, 가령, IL-2, IL-4, IL-12, GM-CSF, 감마-IFN, 케모카인, 가령, MIP-1, MCP-1, IL-8, 및 성장 인자, 가령, FLT3 리간드.
현재 연구중인 또는 사용중인 면역치료제들의 예는, 면역 보조제, 예컨대, 소결핵균 (Mycobacterium bovis), 열대 열원충 (Plasmodium falciparum), 다이니트로클로로벤젠, 및 방향족 화합물들 (미국 특허 제 5,801,005 및 5,739,169호; Hui 및 Hashimoto, 1998; Christodoulides 등, 1998); 사이토카인 요법, 예컨대, 인터페론 , 및 , IL-1, GM-CSF, 및 TNF (Bukowski 등, 1998; Davidson 등, 1998; Hellstrand 등, 1998); 유전자 요법, 예컨대, TNF, IL-1, IL-2, 및 p53 (Qin 등, 1998; Austin-Ward 및 Villaseca, 1998; 미국 특허 제 5,830,880 및 5,846,945호); 및 단일클론 항체들, 예컨대, 항-CD20, 항-강글리오시드 GM2, 및 항-p185 (Hollander, 2012; Hanibuchi 등, 1998; 미국 특허 5,824,311호)이다. 본 출원에 기재된 항체 요법과 함께 하나 이상의 항암 요법들이 사용될 수 있는 것으로 고려된다.
iv.
수술
암을 보유한 사람들 중 대략 60%는 일부 유형의 수술을 받게 될 것이며, 이러한 수술은 예방, 진단 또는 병기결정, 치유 및 완화 수술을 포함한다. 치유 수술은 암 조직의 전부 또는 일부를 물리적으로 제거, 절제 및/또는 파괴하는 절제를 포함하며 다른 요법들, 가령, 본 발명의 구체예들의 치료, 화학요법, 방사선요법, 호르몬 요법, 유전자 요법, 면역요법, 및/또는 대체 요법와 함께 사용될 수 있다. 종양 절제는 종양의 적어도 일부를 물리적으로 제거하는 것을 의미한다. 종양 절제 이외에도, 수술에 의한 치료는 레이저 수술, 냉동수술, 전기수술, 및 현미경으로 제어되는 (miscopically controlled) 수술 (Mohs' surgery, 모스 수술)을 포함한다.
암 세포들, 조직, 또는 종양의 일부 또는 모두를 절제시, 신체에 공동이 형성될 수 있다. 치료는 관류, 직접 주입, 또는 또 다른 항암 요법으로 해당 부위를 국소 치료하여 이루어질 수 있다. 이러한 치료는, 예를 들어, 매 1, 2, 3, 4, 5, 6, 또는 7 일 마다, 또는 매 1, 2, 3, 4, 및 5 주 마다 또는 매 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 또는 12 개월 마다 반복될 수 있다. 이러한 치료는 또한 투여량을 변화시킬 수 있다.
v.
다른 제제들
치료의 치료 효능을 개선시키기 위해 다른 제제들을 본 발명의 구체예들의 특정 양상들과 조합하여 사용될 수 있는 것으로 고려된다. 이러한 또 다른 제제들에는 세포 표면 수용체들 및 GAP 연결의 상향조절에 영향을 주는 제제들, 세포증식억제 및 분화 제제, 세포 부착 억제제, 세포사멸 유도인자에 대한 이상증식 세포들의 민감도를 증가시키는 제제, 또는 다른 생물학적 제제들이 포함된다. GAP 연결의 수를 상승시킴에 의한 세포간 신호전달의 증가는 이웃한 이상증식 세포 모집단에 대한 항-이상증식 효과들을 증가시킬 것이다. 다른 구체예들에서, 세포증식억제 또는 분화 제제들은 치료의 항-이상증식 효능을 개선시키기 위해 본 발명의 구체예들의 특정 양상들과 조합하여 사용될 수 있다. 본 발명의 구체예들의 효능을 개선시키기 위해 세포 부착 억제제들이 고려된다. 세포 부착 억제제들의 예들은 국소 부착 키나아제 (FAKs) 억제제 및 로바스타틴이다. 또한 치료 효능을 개선시키기 위해 이상증식 세포의 세포사멸에 대한 민감성을 증가시키는 다른 제제들, 가령, 항체 c225가, 본 발명의 구체예들의 특정 양상들과 조합하여 사용될 수 있는 것으로 고려된다.
III.
키트 및 진단
다양한 구체예들의 양상들에서, 치료제 및/또는 그 외 다른 치료 및 전달제를 내포하는 키트가 제공된다. 일부 구체예들에서, 본 발명의 구체예들은 상기 구체예들의 치료제를 제조 및/또는 투여하기 위한 키트를 고려한다. 이러한 키트는 본 발명의 구체예들의 임의의 제약학적 조성물을 내포하는 하나 이상의 밀봉된 바이얼을 포함할 수 있다. 이러한 키트는, 예를 들어, 최소한 하나의 EGFL6 항체, 뿐만 아니라 본 발명의 구체예들의 성분들을 준비, 제제화 및/또는 투여, 또는 본 발명의 방법들의 하나 이상의 단계를 실시하기 위한 시약을 포함할 수 있다. 일부 구체예들에서, 키트는 또한 키트의 성분들과 반응하지 않는 적합한 용기, 가령, 에펜도르프 시험관, 분석 플레이트, 주사기, 병, 또는 시험관을 포함할 수도 있다. 이러한 용기는 무균처리가능한 재료, 가령, 플라스틱 또는 유리로 제조될 수 있다.
상기 키트는 본 출원에 제시된 방법들의 절차적 단계들을 요약한 지침서를 추가로 포함할 수 있으며, 이는 본 출원에 기재된 또는 해당 분야의 숙련된 기술자들에게 공지된 것과 실질적으로 동일한 과정을 따를 것이다. 지침 정보는, 컴퓨터를 사용하여 실행할 때, 치료제의 약학적 유효량을 전달하는 실제 또는 가상의 절차들을 보여주는 기계-판독가능한 지침들을 내포하는 컴퓨터 판독가능 매체에 존재할 수 있다.
IV.
실시예
하기 실시예들은 본 발명의 바람직한 구체예들을 증명하기 위하여 포함된다. 하기 실시예에 개시된 기술들은 본 발명의 실시에서 잘 기능하도록 발명자에 의해 발견된 기술들을 나타내므로, 그 실시에 바람직한 방식을 구성하는 것으로 고려될 수 있음은 해당 분야의 숙련된 기술자들에게 자명하다. 그러나 해당 분야의 숙련된 기술자는, 본 출원의 개시내용에 비추어, 개시된 특정 구체예들에 많은 변화들을 줄 수 있으며 여전히 본 발명의 사상 및 범위에서 벗어나지 않는 가능성 있는 또는 유사한 결과를 얻을 수 있음을 이해하여야 한다.
실시예 1 - 인간 EGFL6을 표적하는 단일클론 항체들의 생성 및 클로닝
GFL6 (Genebank 수탁 번호 Q8IUX8) 단백질을 사용하여 RevMAb Biosciences USA, Inc사의 뉴질랜드 토끼들을 면역화시켰다. 항-EGFL6 혈청의 역가는 6-웰 플레이트 (max-sorb 플레이트, Nunc)에 EGFL6 단백질을 코팅시켜 결합에 관해 ELISA로 혈청을 연속 희석하여 결정되었으며 홀스래디쉬 퍼옥시다아제 (HRP) 및 TMB 기질과 접합된 항-토끼 항체를 사용하여 탐지되었다. 2-3회 면역 증진 후, 역가는 >106에 도달하였으며 형광 보조 세포 분류 (FACS) 기기 (BD FACSAria™ III, BD Biosciences)를 사용하여 B 세포들 (CD45+CD5-CD19+)을 새로이 제조된 말초 혈액 단핵 세포들 (PBMCs)로부터 단리시키기 위해 면역화된 토끼들로부터 말초 혈액 샘플을 수집하였다. 단리된 B 세포들을 단일 B 세포들로서 도말하고 7-10 일 동안 배양하였다. 배양 상청액들을 EGFL6 결합에 대해 분석하였다. 양성 웰들로부터 얻은 세포들을 용해시키고, 총 RNA를 단리하고, 제조업체의 제안에 따라 수퍼스크립트 역전사효소 II (Invitrogen)를 사용하여 cDNA를 합성하였다. 설계된 한 세트의 프라이머들을 사용하여 중합효소 연쇄 반응 (PCR)으로 중쇄 및 경쇄 모두의 항체 가변 영역의 DNA 서열들을 증폭시키고 시퀀싱하였다. DNA 및 아미노산 서열들 모두는 하기 'V' 부분에 열거한다. 항-EGFL6 단일클론 항체들의 CDR들을 IMGT 프로그램을 사용하여 확인하였으며 이를 표 1과 2에 열거한다.




선택된 EGFL6 결합 히트들을 인간 배아 신장 (HEK293) 세포들 에서의 포유동물 발현 벡터 시스템(Invitrogen)을 사용하여 토끼 또는 토끼/인간 키메라 IgGs로서 발현시켰다. 급속 단백질 액체 크로마토그래피 (FPLC) 분리 장치에 의한 단백질 A 수지 컬럼을 사용하여 항체들을 정제하였다. 정제된 EGFL6 결합 항체들을 생물학적 성질에 관해 특징화하였다.
실시예 2 - EGFL6 단백질에 대한 항-EGFL6 단일클론 항체들의 결합 친화력
먼저 B 세포 배양물로부터 수집된 상청액들을 사용하여 단일클론 항체들에 의한 EGFL6의 결합을 ELISA로 선별하였다 (도 2). ELISA 역가측정을 사용하여 EGFL6 항원에 대한 단일클론 항체들의 패널의 결합 친화력을 결정하였다 (도 3). 단일클론 항체들의 패널에 관한 결합 상수들 (KD 및/또는 EC 50)을 4 매개변수 곡선 접합을 사용하여 Prism GraphPad 프로그램으로 추정하였다. Biacore 분석을 위해, 모든 실험들을 25 ℃에서 45 μl/분의 유속으로 실시하였다. 제조업체의 지침에 근거하여 항-인간 IgG Fc 항체 (ThermoFisher사, 아세테이트 완충액에서 각각 50 μg/ml, pH 5.0)를 아민 커플링 과정을 사용하여 카르복시메틸 덱스트란 센서칩 (CM5) 상에 고정시켰다. 테스트될 정제된 토끼/인간 키메라 항체를 0.5% P20, HBS-EP 완충액에서 5 μg/ml의 농도로 희석시키고 500 내지 1000 RU에 도달하도록 FC2에 주입하였다. FC1을 기준 세포로 사용하였다. 특이적 신호는 FC2 대 FC1에서 얻은 신호들의 차이에 상응한다. 피분석물 (재조합 인간 EGFL6, SDS-PAGE 겔에서 겉보기 분자량 60 kDa)을 0.5 % P20, HBS-EP 완충액에서 연속 농도로 희석하여 (100, 50, 25, 12.5, 6.25, 및 3.13, 1.56 nM) 90초 동안 주입하였다. 0.5 % P20, HBS-EP에서의 저장 용액으로부터 상기 농도들을 제조하였다. 피분석물의 분해 상 (phase)을 30분의 기간에 걸쳐 모니터하였다. 또한 전기영동용 완충액(running buffer)을 이중 기준으로서 동일한 조건하에 주사하였다. 각 실시 주기 후, 20 내지 45 μl의 글리신-HCl 완충액 pH 1.5를 주입하여 두 가지 유세포들 모두를 재생성하였다. EGFL6에 대한 결합 KD를 각 EGFL6 단일클론 항체들에 대한 k오프/k온 동적 비율로 계산하였다 (표 3).

실시예 3 - 실험 과정 및 방법들
세포주 및 배양: 인간 상피 난소암 세포주, SKOV3ip1 및 A2780ip2를 기재한 바와 같이 유지시켰다 (Sood, A.K. 등 Molecular determinants of ovarian cancer plasticity. American Journal of Pathology 158, 1279-1288, 2001). 인간 불멸화 탯줄 내피 세포들 (RF24)을 보충물 (소듐 파이루베이트, 비 필수 아미노산, MEM 비타민 및 글루타민; Life Technologies)이 보충된 MEM 배지에서 성장시켰다. 마우스 난소 내피 세포들 (MOEC)의 유도 및 특성화는 종래에 문헌에 설명된 바 있다 (Langley, R.R. 등 Tissue-specific microvascular endothelial cell lines from H-2K(b)-tsA58 mice for studies of angiogenesis and metastasis. Cancer Research 63, 2971-2976, 2003). 세포 배양물을 95% 습도의 37 ℃ 5% CO2 배양기에서 유지시켰다. 생체내 주입을 위해, 세포들을 트립신화하고, 1,200 rpm에서 5분 동안 4 ℃에서 원심분리하고, PBS로 2회 세척하고, 무-혈청 행크 평형 염 용액 (Life Technologies, Grand Island, NY, USA)에서 재구성하였다. 95% 이상 생존력 (트리판 블루 제외법으로 결정)을 가진 단일-세포 현탁액들 만을 생체내 복강내 주사에 사용하였다.
내피 세포 단리: Institutional Review Board의 승인을 받은 후 M. D. Anderson 암 센터에서 1차 외과 수술을 받은 환자들로부터 새로운 조직 샘플 (5개는 정상 난소, 5개는 상처 조직 및 10개는 상피 고-등급, 병기 III 또는 IV의 침습성 혈청 난소암)들을 얻었다. 정제된 내피 세포들로부터 얻은 총 RNA를 Affymetrix Human U133 plus 2.0 GeneChip 플랫폼을 사용하여 미세배열 분석하였다 (Lu, C. 등, Gene alterations identified by expression profiling in tumor-associated endothelial cells from invasive ovarian carcinoma. Cancer Research 67, 1757-1768, 2007).
정량적 실시간 PCR 확인: 제조업체의 지시사항에 따라 RNeasy 미니 키트 (Qiagen)를 사용하여 단리한 정제된 내피 세포들로부터 얻은 50 ng의 총 RNA를 사용하여 정량적 실시간 RT-PCR을 실시하였다. 0.5-1μg의 총 RNA로부터 Verso cDNA 키트 (Thermo Scientific)를 사용하여 상보성 DNA (cDNA)를 합성하였다. SYBR Green ER qPCR: SuperMix Universal (Invitrogen) 및 Bio-Rad (Bio-Rad Laboratories, Hercules, CA, USA)를 사용하여 정량적 PCR (qPCR) 분석을 3번 실시하였다. 대조에 대해 정규화시키는 2-ΔΔCT 방법을 사용하여 백분율 배수 변화에 대한 상대 정량을 계산하였다 (Donninger, H. 등 Whole genome expression profiling of advance stage papillary serous ovarian cancer reveals activated pathways. Oncogene 23, 8065-8077, 2004).
SiRNA 작제물 및 전달: SiRNA를 Sigma-Aldrich사 (The Woodlands, TX, USA)로부터 구입하였다. BLAST 검색에 기초하여 임의의 공지된 인간 mRNA와 서열 상동성을 공유하지 않았던 비-침묵 siRNA를 표적 siRNA에대한 대조로서 사용하였다. 시험관내 일과성 형질감염을 종래 문헌에 기재된 바에 따라 실시하였다 (Landen, C.N., Jr. 등 Therapeutic EphA2 gene targeting in vivo using neutral liposomal small interfering RNA delivery. Cancer Research 65, 6910-6918, 2005). 요약하면, siRNA (4 μg)를 제조업체의 지시사항에 따라 10 μL의 리포펙타민 2000 형질감염 시약 (Lipofectamine)으로 20분 동안 실온에서 배양하고 10 cm 배양 플레이트에서 80% 융합도의 배양물에 있는 세포에 추가하였다.
역상 단백질 분석 (RPPA) 및 웨스턴 블롯 분석: 인간 재조합 EGFL6 단백질의 존재 또는 부재하에서 RF24 및 OVCAR3 세포들을 RPPA 분석하였다. 웨스턴 블롯 분석을 종래와 같이 실시하였다 (Landen, C.N., Jr. 등 2005, ibid; Halder, J. 등 Focal adhesion kinase targeting using in vivo short interfering RNA delivery in neutral liposomes for ovarian carcinoma therapy. Clinical Cancer Research: an official journal of the American Association for Cancer Research 12, 4916-4924, 2006). RF24 세포들의 세포 용해물을 인간 재조합 EGFL6 단백질 또는 항-EGFL6 항체들로 처리하였으며 항-인간 EGFL6, PI3키나아제 및 AKT 항체들을, 그리고 그 후 홀스래디쉬 퍼옥시다아제 (HRP)와 접합된 2차 항체들을 사용하여 활성화 of PI3키나아제의 활성화 및 AKT 신호전달에 관하여 체크하였다.
세포 이동 분석: 0.1% 젤라틴으로 코팅된 변형 Boyden 챔버를 사용하여, hEGFL6 siRNA의 존재 또는 부재시 RF24 세포들의 이동을 평가하였다. hEGFL6 또는 인테그린 siRNAs로 48h 또는 EGFL6 항체 또는 PI3키나아제 억제제로 6 h 동안 형질감염시킨 후, MEM 무혈청 배지의 RF24 세포들 (1.0 ㅧ 105)을 Transwell pore 폴리카보네이트 막 인서트 (Corning, Lowell, MA, USA)의 상부 챔버에 접종하였다. 이 챔버를 화학-유인물질로서 하부 챔버에 15% 혈청을 보유한 MEM 배지를 내포하는 24-웰 플레이트에 놓았다. 세포들을 가습된 배양기에서 6 h 동안 이동하게 두었다. 이동된 세포들을 헤마톡실린 염색을 사용하여 염색하고 각 샘플 당 5가지 무작위 영역에서 광학 현미경으로 계수하였다 (200x 원본 배율). 실험들을 2번 반복하고 3회 실시하였다.
튜브 형성 분석: 마트리겔 (12.5 mg/mL)을 4 ℃에서 해동시키고 50 μL를 96-웰 플레이트의 각 웰에 신속하게 추가하고 37 ℃에서 10분 동안 고화하도록 두었다. 그 후 EGFL6 또는 인테그린 siRNA로 (48 h 동안) 또는 EGFL6 항체 또는 PI3키나아제 억제제로 (6 h 동안) 사전에 처리하였던 RF24 세포들 (각 웰 당 20,000개)과 함께 상기 웰들을 6 h 동안 37 ℃에서 배양하였다. 실험을 3번 실시하고 2회 반복하였다. Olympus IX81 도립 현미경을 사용하여, 각 웰 당 5개의 이미지들을 ㅧ 100 배율로 촬영하였다. 각 이미지 당 노드 (최소한 3개의 세포들이 하나의 점을 형성하였을 때로 정의됨)의 양을 정량하였다. 세포 응집을 고려하여, 최고 및 최저 값을 각 그룹에서 제거하였다.
프로모터 분석 및 염색질 면역침전 (ChIP) 분석: RF24 세포들을 저 혈청 배지 (0.5% 혈청)에서 18 h 동안 배양한 후 EGFL6 또는 HIF1α (50 ng/mL)로 6 시간 동안 처리하였다. 처리 후, 제조업체가 설명한 바와 같이 EZ ChIPTM 키트 (Milllipore, Temecula, CA, USA)를 사용하여 ChIP 분석을 실시하였다. 요약하면, 교차결합된 세포들을 수집하고, 용해시키고, 초음파처리하고, 후속하여 EGFL6 (Abchem) 항체 또는 IgG 대조를 이용하여 면역침전시켰다. 단백질 G 아가로오스 비드를 사용하여 면역복합체들을 수집하고 용리시켰다. 65 ℃에서 배양시켜 교차-결합을 역전시켰다. 그 후 DNA를 추출하고, EGFL6 전사 개시 부위의 상류에 있는 프라이머들의 쌍들을 사용하여 PCR로 정제하였다.
유세포 분석: RF24 세포들을 PBS로 세척하고 PBS-EDTA 5mM을 이용하여 수집하였다. 그 후 세포들을 서로 다른 인테그린 1차 항체들 (Sigma-Aldrich)로 면역표지하고, 후속하여 2차 항체들 (Invitrogen)로 염색하였다. Cell Quest 소프트웨어를 보유한 FACSCalibur에서 샘플들을 얻었으며 데이터를 FlowJo 소프트웨어를 사용하여 분석하였다.
난소암의 동소이식 생체내 모델 및 조직 가공: 가슴샘 없는 암컷 마우스 (NCr-nu)들을 NCI-Frederick 암 연구 개발 센터 (Frederick, MD, USA)로부터 구입하고 종래 문헌에 기재된 바와 같이 유지시켰다 (Landen, C.N., Jr. 등 2005, ibid). 모든 마우스 연구들은 기관 동물 실험 윤리 위원회 (Institutional Animal Care and Use Committee)로부터 승인받았다. 실험 동물의 사용 및 인간 진료에 대해 미국 실험 동물 학회(American Association for Accreditation of Laboratory Animal Care) 및 미국 공중 보건 사업 당국 (US Public Health Service Policy)이 제시한 지침에 따라 마우스를 취급하였다. 종양 세포들의 주사를 위해, A2780ip2 또는 SKOV3ip1 또는 OVCAR3 세포들 (1 ㅧ 106)을 복강내 (i.p) 주사하였다. 요법 실험을 위해, 각각의 siRNA를 150 μg/kg 체중의 투여용량으로 매주 2회 제공하였다. 희생시, 마우스 및 종양 중량, 종량들의 수와 분포를 기록하였다. 부검을 실시하였던 개인들은 치료 그룹 할당에 대해 맹검이었다. 조직 표본들을 포르말린, OCT (Miles, Inc., Elkhart, IN, USA)에서 고정하거나 액체 질소에서 급속 냉동시켰다. 오프-타겟 효과를 위해, SKOV3ip1 종양 보유 마우스들을 상기 언급한 것과 동일한 2개의 상이한 EGFL6 siRNA 서열들로 처리하였다.
이종이식편들의 면역조직화학 및 면역형광 염색: 세포 증식 (Ki67, 1:200, Zymed), 미세혈관 밀도 (MVD, CD31, 1:500, Pharmingen), 및 저산소증 (탄산 탈수효소 항-CA9, 1:500, Novus)에 대한 IHC 분석을 모두 종래 문헌에 기재된 바와 같이 실시하였다 (Thaker, P.H. 등 Chronic stress promotes tumor growth and angiogenesis in a mouse model of ovarian carcinoma. Nature Medicine 12, 939-944, 2006; Lu, C. et al. Regulation of tumor angiogenesis by EZH2. Cancer Cell 18, 185-197, 2010). 통계학적 분석을 위해, 각 그룹 당 5개의 무작위 선택된 종양들로부터 얻은 구획들 (sections)을 염색하고 각 종양 당 5개의 무작위 영역에 점수를 주었다. x200 또는 x100 배율로 사진을 촬영하였다. 마우스 종양 샘플의 MVD를 정량하기 위하여, x200 배율의 10개의 무작위 0.159-mm2 영역에서 CD31에 양성으로 염색된 혈관들의 수를 기록하였다. PCNA 발현을 정량하기 위하여, ㅧ100 배율의 10개 무작위 0.159-mm2 영역에서 양성 세포들 (3,3′-다이아미노벤지딘 염색)의 수를 계수하였다 (Thaker, P.H. 등 2006, ibid ; Lu, C. 등. 2010, ibid ). 모든 염색을 맹검 방식으로 2명의 조사자가 정량하였다. 종래 문헌에 기재된 바와 같이 냉동시킨 조직을 사용하여 EGFL6 (Santa Cruz) 및 CD31에 관한 염색을 실시하였다 (Lu, C. 등. 2010, ibid).
마트리겔 플러그 분석: 마우스의 피하에 마트리겔 플러그를 주사함으로써 생체내 마트리겔 플러그 분석을 실시하였다. 마트리겔 플러그는 무혈청 MEM 완전 배지 (음성 대조), VEGF (양성 대조) 또는 EGFL6 (테스트 그룹)을 포함하였다. 주사 6 h 후, 동물들을 희생시키고 마트리겔을 수집하고 헤모글로빈 분석을 실시하였다.
상처 치유 분석: 1일차에, A2780 ip2 세포들을 누드 마우스에 주사하고 2일차에 종양 보유 마우스의 등에 상처를 생성하였다. 동물은 수의학적 진료를 받았으며 개개의 우리에서 지냈다. 마우스를 두 집단으로 나누었다 (n=10).
CH/대조siRNA 및 CH/mEGFL6 siRNA 나노입자들: 3일차에 siRNA 처리를 시작하였으며 주 2회 제공하였다(150 μg/kg). 상처를 0, 1, 3, 5, 7, 9, 11, 13, 및 15일차에 측정하였다 (상처 치유가 끝날 때까지). 임의의 그룹내 동물이 빈사하게 될 때 종양들을 수집하였다.
뒷다리 허혈: 종래 문헌에 기재된 바와 같이 (Baluk, P., Hashizume, H. & McDonald, D.M. Cellular abnormalities of blood vessels as targets in cancer. Current Opinion in Genetics & Development 15, 102-111, 2005) 암컷 누드 마우스에 케타민 (100 mg/kg)을 복강내 주사하여 마취시킨 후 외장골 동맥의 가지와 같은 근위 원점으로부터 복부 및 슬와 동맥으로 갈라지는 원위 지점까지 대퇴 동맥을 절제하여 상기 마우스에서 중증 뒷다리 허혈을 유도하였다. 동맥 결찰 후, 마우스들을 곧바로 다음과 같은 실험 그룹에 할당하였다 (n= 5): 대조 그룹, 허혈-24h 및 허혈-96h. 직렬 레이저 도플러 이미지 분석 (Moor Instruments, Devon, UK)을 실시하여, 대퇴 동맥 결찰 전과 후 (24 h 및 96 h 후)에 뒷다리의 혈류량을 모니터하였다. 무릎에서부터 발가락까지의 영역에서 혈류량을 정량하기 위하여 디지털 컬러-코드화 이미지들을 분석하였으며; 평균 관류 값들을 계산하였다. 각 시점에서, 상기 허혈 다리로부터 얻은 조직을 수집하고 OCT 배지에서 냉동시켰다. 표준 면역염색 절차를 사용하여 냉동 포매된 조직에 대해 EGFL6 발현에 관한 MVD 및 마우스 다클론 항-EGFL6 항체를 결정하기 위하여 마우스 단일클론 항-CD31을 사용하였다.
인간 난소암 표본들: Institutional Review Board의 승인을 받은 후, with 이용가능한 임상 출력 데이터를 가지며 면허가 있는 부인과 병리학자들에 의해 진단을 확인받은 180개의 파라핀-포매시킨 상피 난소암 표본들 (1985-2004 사이에 수집됨)을 Karmanos 암 연구소 종양 은행으로부터 얻었다.
인간 난소암 샘플에 대해, EGFL6, CD34, 및 VEGF에 대한 면역조직화학을 종래 문헌에 기재된 바와 같이 실시하였다 (Ali-Fehmi, R. 등 Expression of cyclooxygenase-2 in advanced stage ovarian serous carcinoma: correlation with tumor cell proliferation, apoptosis, angiogenesis, and survival. American Journal of Obstetrics and Gynecology 192, 819-825, 2005). 항-인간 EGFL6 항체 (Sigma-Aldrich)를 사용하여 EGFL6 염색을 실시하였다. 요약하면, 포르말린-고정시킨, 파라핀-포매된 조직 구획들에서 파라핀을 제거하고 재수화시켰다. Diva 용액으로 항원 재생 후, 내인성 퍼옥시다아제를 메탄올 중에서의 3% 과산화수소를 이용하여 15분 동안 차단시켰다. PBS로 세척후, 구획들을 단백질 차단제로 (5% 정상 말 혈청 그리고 1% 염소 혈청) 20분 동안 실온 (RT)에서 차단시킨 후, 항-EGFL6 항체 (Sigma-Aldrich)로 하룻밤 동안 4 ℃에서 배양하였다. PBS로 세척 후, 구획들을 홀스래디쉬 퍼옥시다아제 (HRP)-접합된 염소 항-토끼 (1:250, Jackson ImmunoResearch)와 함께 1 h 동안 RT에서 배양하였다. 마지막으로, 3, 3'-다이아미노벤지딘 (Research Genetics)을 사용하여 염색하고 그리고 Gill's 헤마톡실린 (BioGenex Laboratories)으로 대조-염색하여 눈에 보이게 하였다. 음성 염색을 0점으로 기록하였으며, EGFL6의 강도 증가에 관해 1-4점을 사용하였다. 종래 문헌에 기재된 방법에 따라 (Ali-Fehmi, 등, 2005 ibid) 2명의 조사자들이 조직화학적 점수를 기준으로 (H-점수; >100은 고 발현으로 그리고 ≤100은 저 발현으로 정의됨) 염색 강도 및 염색된 세포들의 백분율 모두를 고려하여 염색된 슬라이드들에 점수를 주었다.
통계적 분석 동물 실험을 위해, 10마리의 마우스들을 각 처리 그룹에 할당하였다. 이러한 샘플 크기는 95% 신뢰도로 종량 중량의 50% 감소를 탐지하는 80% 검정력(power)을 제공하였다. 각 그룹에 대한 종양 중량 및 종양 결절의 수를 (2그룹의 비교를 위한) 스튜던트 t-검정을 사용하여 비교하였다. 0.05 미만의 P-값은 통계학적으로 유의한 것으로 간주되었다. 모든 통계학적 테스트들은 양방향이었으며 Windows용 SPSS 버전 12 통계학 소프트웨어 (SPSS, Inc., Chicago, IL, USA)를 사용하여 실시되었다.
실시예 4 - 종양 관련 내피 세포들에서 상향조절된 EGFL6 발현
5개의 정상 난소, 5개의 상처 조직 샘플 및 10개의 침습성 상피 난소 종양을 얻고 음성 및 양성 면역선택 처리하였다. 미세배열 분석을 실시하기에 앞서, 내피 세포들에 대한 모든 샘플들의 순도를 내피 세포 마커들 P1H12 및 폰 빌레브란트 인자를 사용하여 결정하였다 (도 4A) 면역염색법은 면역정제 기법이 모든 샘플에서 >95%의 내피 세포 순도를 산출하였음을 보여주었다. 데이터의 분석은 375개의 유전자들이 정상 및 상처 내피 세포들과 비교하여 난소 종양 내피 세포들에서 상향조절되었음을 보여주었다 (도 4B). 그 중에서, EGFL6은 정상 및 상처 내피 세포들과 비교하여 종양 내피 세포들에서 가장 높은 차이의 발현을 보여주었다 (도 4B). 난소 환자 샘플에서 EGFL6, VEGF 및 CD31의 발현을 결정하였다 (도 4C). 이러한 결과를 추가로 확인하기 위하여, 정상 난소, 난소 종양 및 상처 치유 조직으로부터 내피 세포들을 단리하고 PCR을 사용하여 EGFL6의 발현을 결정하였다. EGFL6은 정상 또는 상처 내피 세포들과 비교하여 종양 내피 세포들에서만 우세하게 과발현하였다 (도 4D). 종양 내피 세포들에서 EGFL6 상향조절 또한 증명되었다. EGFL6은 내피 세포들 및 테스트하였던 대부분의 난소암 세포들에서 발현되었다. 종양 혈관형성에서 EGFL6의 역할을 증명하기 위하여, RF24 세포들을 siEGFL6로 처리하였으며, 그 결과 대조 세포들과 비교하여 72시간에서 단백질 수준이 80% 이상 떨어졌다(knockdown). EGFL6 siRNA 처리된 세포들은 대조 siRNA 처리된 세포들과 비교하여 현저히 적은 이동 및 튜브 형성을 보여주었는데, 이는 혈관형성에 있어서 EGFL6의 중요성을 나타내는 것이다.
실시예 5 - EGFL6 침묵은 마우스에서의 상처 치유에 영향을 주지 않았다
상처 치유에서 EGFL6의 역할을 인간 진피 미세혈관 내피 세포들 (HDMECs)에 생성한 상처들을 사용하여 설명하였다. 상처 치유에 대한 효과를 다음 절차를 사용하여 수행하였다. 1일차에, SKOV3ip1 세포들을 누드 마우스에 주사하고 2일차에 종양 보유 마우스의 등에 상처를 생성하였다 (2 cm x 2 cm). 동물들을 무작위로 2개 그룹으로 나누었으며 (n=10), 하나의 마우스 그룹은 대조 항체를 투여하고 다른 하나의 마우스 그룹은 EGFL6 항체로 처리하였다. 3일차에 항체 처리를 시작하였으며 주 1회 제공하였다 (5 mg/kg). 상처 치유가 끝날 때까지 상처 (면적=길이 X 폭)를 2주 동안 모니터하였다. EGFL6 항체는 상처 치유 생체내 연구를 사용하여 테스트하였을 때 상처 치유를 방해하지 않았다 (도 9C).
상처-치유 분석에서 24시간 후, si대조 처리된 세포들 및 siEGFL6 처리된 세포들은 상처 치유 능력에 전혀 영향이 없었음을 보여주었다 (도 5A-5C). 또한, 종양 보유 마우스에 생성된 것과 유사한 상처들을 사용하여 쥐과 siRNA 서열을 사용한 내피 세포 구획에서 EGFL6 침묵의 상처 치유에 대한 효과를 결정하였다. 도 5D 및 5E에 도시된 바와 같이, 대조 siRNA 또는 마우스 EGFL6 siRNAs로 처리된 동물들의 상처 치유에 있어서 유의한 차이가 전혀 관찰되지 않았으며 또한 두 그룹 모두 유사한 상처 치유 양상들을 보여주었다.
그러나, 마우스 EGFL6 siRNA로 처리된 동물들은 종양 용적의 유의한 감소를 보여주었는데 (도 5F-5H), 이는 내피 세포 구획에서 EGFL6의 침묵이 종양 성장에는 유의하게 영향을 주지만 상처 치유는 손상시키지 않음을 제시하는 것이다. EGFL6 유전자 침묵은 또한 종양 혈관들의 증식에 있어 유의한 감소를 가져왔다 (도 11A-11B).
실시예 6 - EGFL6은 내피 세포들에서의 혈관형성을 향상시킨다
EGFL6이 저산소증 상태하에서 내피 세포들의 생존을 증가시킴을 확증하기 위하여, EGFL6을 EGFL6 siRNA를 사용하여 저산소 상태의 저산소증 RF24 세포들에서 침묵시켰으며 세포 사멸을 조사하였다. 도 6A에 도시된 바와 같이, 정상산소증과 비교하여 거의 50%의 세포들이 5일 이후에도 저산소증에서 생존하였다. 이와 대조적으로, 저산소증에서의 EGFL6 유전자 침묵은 저산소증 및 정상산소증 상태의 비처리 세포들과 비교하여 75% 세포 사멸을 가져왔다 (도 6H). 마우스의 뒷다리에 있는 대퇴 동맥을 절제하여 마우스에서 뒷다리 허혈을 생성하였으며, 이는 뒷다리에 대한 혈액 및 산소 공급의 차단을 가져왔다 (도 6I). 도 6J-6K에 도시된 바와 같이, 허혈 마우스는 내피세포들에서 MVD (혈관들)의 유의한 감소 및 EGFL6 발현의 유의한 증가를 보여주었다. RF24 세포들의 이동 (도 12C) 및 튜브 형성 (도 12D)은 EGFL6으로 처리 후 증가하였다.
실시예 7 - EGFL6 침묵은 종양 성장 및 혈관형성을 억제한다
유전자 침묵시 EGFL6의 치료 효능을 2개의 동소이식 난소암 종양 모델인, SKOV3ip1 및 OVCAR5를 사용하여 연구하였다. 가슴샘 없는 암컷 마우스 (NCr-nu)들을 NCI-Frederick 암 연구 개발 센터 (Frederick, MD)로부터 구입하였으며 모든 마우스 연구들은 기관 동물 실험 윤리 위원회 (Institutional Animal Care and Use Committee)로부터 승인받았다. 실험 동물의 사용 및 인간 진료에 대해 미국 실험 동물 학회(American Association for Accreditation of Laboratory Animal Care) 및 미국 공중 보건 사업 당국 (US Public Health Service Policy)이 제시한 지침에 따라 마우스를 취급하였다. 종양 세포들 주사를 위해, SKOV3ip1 세포들 (1 ㅧ 106)을 복강내 (i.p) 경로를 통해 주사하였다. 항체 치료 그룹에 대해, 정제된 단일클론 항체를 5 mg/kg 체중으로 5주 동안 매주 투약하였다. 희생시, 마우스 및 종양 중량, 종량들의 수와 분포를 기록하였다. 부검을 실시하였던 개인들은 치료 그룹 할당에 대해 맹검이었다. 조직 표본들을 포르말린, OCT (Miles, Inc., Elkhart, IN)에서 고정하거나 액체 질소에서 급속 냉동시켰다.
도 8F에 도시된 바와 같이, 마우스 EGFL6 siRNA 단독 그리고 인간 EGFL6 siRNA와 조합하여 SKOV3ip1 종양 보유 동물을 처리한 결과 대조 siRNA로 처리하였던 종양 보유 마우스와 비교하여 종양 성장이 유의하게 감소하였다. 인간 EGFL6 siRNA 단독으로는 종양 감소에 대해 그렇게 큰 효과를 가져오지 못했다. 종양 결절의 수 그리고 관찰된 종양 용적에 대한 EGFL6의 효과가 도 8F에 도시되어 있다. 마우스 EGFL6 siRNA 단독으로 그리고 인간 EGFL6 siRNA와 조합하여 처리된 OVCAR5 종양 보유 마우스들 또한 종양 중량 및 결절들에 있어서 유의한 감소를 보여주었다.
mEGFL6 siRNA 및 마우스와 인간 EGFL6siRNA의 조합으로 처리된 SKOV3ip1 종양 보유 동물은 세포들의 증식 및 미세혈관 밀도에 있어서 대조 siRNA로 처리된 동물들과 비교하여 유의한 감소를 보여주었다 (도 8C-8D). OVCAR5 종양 보유 동물 또한 유사한 결과를 보여주었다. 마우스 EGFL6 siRNA 서열들의 오프-타겟 효과를 결정하기 위하여, SKOV3ip1 종양 성장에 대한 EGFL6 유전자 침묵의 효과를 2개의 서로 다른 마우스 siRNA 서열들을 사용하여 체크하였으며 두 서열들 모두 종양 성장 및 종양 결절에 있어서 실질적인 감소를 보여주었다.
항-EGFL6 항체들 Mab #135 및 #93 (E2-135 & E2-93)을 이용한 처리는 종양 성장을 상당히 억제하였으며 (도 8F) EGFL6 항체 처리된 마우스에서는 단지 남아있는 암 세포들만이 탐지되었으나, 비-처리된 대조 마우스는 큰 종양 부하량 및 종양 결절의 수로 나타나는 바와 같은 종양 분포를 보였다. 항-EGFL6 항체들 (Mab E2-93 및 E2-135)를 이용한 처리는 또한 대조 항체 처리된 그룹과 비교할 때 암 세포 증식 (Ki67 염색)을 억제하였으며 미세-혈관구조 밀도 (종양 혈관형성, CD31 IHC 염색)를 감소시켰다 (도 8G)
실시예 8 - 항-EGFL6 차단 항체는 내피 세포들에서 혈관형성을 감소시킨다
EGFL6 차단이 혈관형성 매개된 기능들에 영향을 주는지를 증명하기 위하여 EGFL6 기능적 차단 항체를 개발하고 혈관형성에 대한 그 활성에 대해 테스트하였다. 인간 및 마우스 EGFL6에 유사한 친화력으로 결합된 몇 가지 EGFL6 항체 클론들을 선별하였다. 결합 친화력 및 시험관내 활성 기준 모두를 만족시키는 2개의 항체들 (93 및 135)을 선택하여 추가 연구를 실시하였다. 도 8B에 도시된 바와 같이, EGFL6 재조합 단백질을 이용한 내피 세포들의 처리는 두 인산화된 Tie2 및 AKT 단백질 모두의 발현을 증가시켰다. 이와 대조적으로, EGFL6 차단 항체들 93 및 135는 두 인산화된 단백질들의 발현을 감소시켰다. 도 8D-E에 도시된 바와 같이, EGFL6 재조합 단백질을 이용한 내피 세포들의 처리는 이들 세포들에서 이동 및 튜브 형성을 향상시킨다. 그러나, 튜브 형성 및 이동 모두에 관한 EGFL6 매개된 기능적 효과들은 EGFL6 차단 항체들에 의해 유의하게 감소되었다.
항체들 중 하나는 인간화되었는데, 여기서 이 항체는 인간 IgG1 골격 내에 위치하여 인간 암 환자들에서 사용가능하며, 항체의 결합 친화력 및 시험관내 활성들은 인간화 후에도 보존되었음이 증명되었다.
실시예 9 - 항-EGFL6 차단 항체는 난소암 모델에서 항-혈관형성 및 항-종양 효과들을 보였다
상기 보고된 EGFL6의 시험관내 활성은 EGFL6 기능을 차단하는 것이 종양 혈관을 손상시키는 능력을 향상시킴으로써, 항-종양 효능을 증가시킬 것임을 나타내었다. 이를 테스트하기 위하여, EGFL6의 활성을 차단하여 혈관형성 및 종양 성장을 억제하는 EGFL6 항체의 능력을 조사하였다.
SKOV3-ip1 종양-보유 마우스들을 대조 항체 및 항-EGFL6 항체들로 처리하였다. 처리 5주 후, 종양들을 수집하고 항-종양 및 항-혈관형성 활성에 대해 분석하였다. 항-EGFL6 항체들로 처리한 결과 대조 항체로 처리한 경우와 비교하여 강력한 항-종양 활성을 생성하였다. 항-EGFL6 항체들 93 및 135 두 가지를 처리한 결과 종양 중량 및 종양 결절이 유의하게 감소하였다 (도 9E 및 9F). EGFL6 차단 항체로 처리된 동물 또한 대조 항체 처리 그룹과 비교하여 감소된 MVD를 보여주었는데 (도 9F), 이는 EGFL6 활성의 차단이 종양 성장 및 혈관형성을 억제하였음을 나타내는 것이다. EGFL6 항체는 시험관내 또는 생체내 상처 치유를 방해하지 않았으며 (도 9G), 이는 이 항체가 정상 조직 회복에 영향을 주지 않고 종양 혈관형성을 조절할 수 있음을 나타내는 것이다.
V.
항체 가변 서열들
항-EGFL6 항체들의 가변 DNA 서열들을 아래에 나타낸다.
>E1-33H
CAGTCGCTGGAGGAGTCCGAGGGAGGCCTGGTCCAGCCTGAGGGATCCCTGACACTCACCTGCAAAGCCTCTGGACTCGACCTCAGTAGCTACTACTACATGTGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGCATGCATTTATGCTGGTAGTAGTGGTAGCACTTACTACGCGAGCTGGGCGAAAGGCCGATTCACCATCTCCAAAACCTCGTCGACCACGGTGACTCTGCAAATGACCAGTCTGACAGCCGCGGACACGGCCACCTATTTCTGTGCGAGAGGTGGTGGTAGTACTTATGCTCAATATTTTAACTTGTGGGGCCCAGGCACCCTGGTCACCATCTCCTCAG (서열 번호: 133)
>E1-33K
GAGCTCGATATGACCCANACACCAGCCTCCGTGTCTGCAGCTGTGGGAGGCACAGTCAGCATCAATTGCCAGTCCAGTCCGAGTGTTTATAGGCACTACTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTACTGGGCTTCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAGCGGCAGTGGATCTGGGACAGAGTTCACTCTCACCATCAGCGGCGTGCAGTGTGACGATGCTGCCACTTACTACTGTGCAGGCGAATATGCTAGTGATAGTGATAATCATTTCGGCGGAGGGACCGAGCTGGAGATCCTAG (서열 번호: 134)
>E1-34H
GAGCAGTCGGTGAAGGAGTCCGGGGGAGGCCTGGTCCAGCCTGAGGGATCCCTGACACTCACCTGCACAGCTTCTGGATTCTCCTTCAGTAGTATTTATTGGATATGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTTGATCGCATGCATTCAGATTACTAGTGGTATCACTTACTACGCGAGCTGGGCGAAAGGCCGATTCACCATCTCCAAAATGTCGTCGACCACGGTGACTCTGCAAATGACCAGTCTGACAGTCGCGGACACGGCCACCTATTTCTGTGGGAGAAGGGGATATGGTGCCTATGCTGGTACTGGTGCCTCTGACTTGTGGGGCCCAGGCACCCTGGTCACCGTCTCTTCAG (서열 번호: 135)
>E1-34K
GAGCTCGATCTGACCCAGACTGCATCGTCCGTGTCTGCAGCTGTGGGAGGCACCGTCACCATCAATTGCCAGTCCAGTCAGAGTGTTTATAATAACAACAACTTAGCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTACGAAGCATCCAAACTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGGATCTGGGACACAGTTCACTCTCACCATCAGCGGCGTGCAGTGTGACGATGCTGCCACTTACTATTGTGCAGGCGGTTATGCTGGCTACATTTGGGCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAAG (서열 번호: 136)
>E1-80H
GAGCAGTCGGTGGAGGAGTCCGGGGGAGGCCTGTTCCAGCCTGGGGGATCCCTGGCACTCACCTGCAAAGCCTCTGGATTCACCCTCAATAGTTATTATATGTCCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGGATGCATTGATAGTGATAGTCCTACTACGACTGCCTACGCGAACTGGGCGAGAGGCCGATTCACCATCTCCAAGACCTCGTCGACCACGGTGACTCTGCAAATGACCAGTCTGACAGCCGCGGACACGGCCACCTATTTCTGTGCGAGAGGCTATGGTCCTGTTCGATTGGATCTCTGGGGCCAGGGCACCCTGGTCACCGTCTCTTCAG (서열 번호: 137)
>E1-80K
ACCCAGACACCAGCCTCCGTGTCTGCAGCTGTGGGAGGCACAGTCAGCATCAATTGCCAGTCCAGTCAGAGTGTTTATAAGAACGCCTATTTATCCTACTACTTAGCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTACTGGGCTTCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGGATCTGGGACACAGTTCACTCTCACCATCAGCGACGTGCAGTGTGACGATGCTGCCACTTACTACTGTGCAGCCGAATATAGTAATGATAGTGATAATGGTTTCGGCGGAGGGACCGAGGTGGAAATCAAAG (서열 번호: 138)
>E1-89H
GAGCAGTCGTTGGAGGAGTCCGGGGGAGACCTGGTCAAGCCTGAGGGATCCCTGACACTCACCTGCGCAGCCTCTGGATTCTCCTTCAGTAGCGGCTACTGGATATGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGGATGCATTTATGCTGGTAGTAGTGGTGGGCACATTTATTACGCGACCTGGGCGAAAGGCCGATTCACCATCTCCCAAACCTCGTCGACCACGGTGACTCTGCAAATGACCAGTCTGACAGCCGCGGACACGGCCACATATTTCTGTACAAGAGATAATTATGGTGGTGGTGGTTCTGCTTCCAAATTGTGGGGCCCAGGCACCCTGGTCACCATCTCTTCAG (서열 번호: 139)
>E1-89K
GAGCTCGTGATGACCCAGACTCCATCCCCCGTGTCTGCAGCTGTGGGAGGCACAGTCACCATCAACTGCCAGTCCAGTCAGAGTGTTTATAGTAACAACCGCTTAGCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGGTCTATTATGCAGCCACTCTGGCATCTGGGGTCCCGTCGCGGTTCAAAGGCAGTGGATATGGGACACAGTCCACTCTCACCATCGCCGATGTGGTGTGTGACGATGCTGCCACTTACTACTGTGCAGGATATAAAACTGCTGATTCTGATGGTATTGCTTTCGGCGGAGGGACCGAGGTGGAAATCAAAG (서열 번호: 140)
>E2-93H
CAGTCGGTGAAGGAGTCCGAGGGAGGCCTGGTCCAGCCTGAGGGATCCCTGACACTCACCTGCAAAGCCTCTGGATTCTCCTTCAGTAGTTATGGAGTGAACTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGCGTATATTGGTCTTAGTAGTGAGATCACTTACTACGCGGGCTGGGCGAAAGGCCGATTCACCATCTCCAAGCCCTCGTCGACCACGGTGACTCTGCAAATGACCAGTCTGACAGCCGCGGACACGGCCACCTATTTCTGTGTGAGAGATCTTTATCATAGTAATGGTTTGTGGGGCCCAGGCACCCTGGTCACCATCTCTTCAG (서열 번호: 141)
>E2-93K
GAGCTCGATCTGACCCAGACTCCATCCCCCGTGTCTGCAGCTGTGGGAGGCACAGTCACCGTCAGTTGCCAGGCCAGTGAGAGCGTTTATAATAATAACCGCTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTATTATGCATCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAGCGGCAGTGGATCTGGGACACAGTTCACTCTCACCATCAGCAGCGTGCAATGTGCTGATGCTGCCACGTATTATTGTGTAGCCTTTAAAGGTTATGGTACTGACGGCAATGCTTTCGGCGGAGGGACCGAGGTGGAAATCAAAG (서열 번호: 142)
>E1-38H
GAGCAGTCGGTGAAGGAGTCCGGGGGAGACCTGGTCAAGCCTGAGGGATCCCTGACACTCACCTGCACAGCCTCTGGATTCTCCTTCAATAGCGGCTACTGGGTATGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGCTTGCATCTATACTAGTAGTCCTACTGGTGCCATATACTACGCGACCTGGGCGAAAGGCCGATTCACCATCTCCCAAACCTCGTCGACCACGGTGACTCTGCAAATGACCAGTCTGACAGCCGCGGACACGGCCACCTATTTCTGTACAAGAGATAATTTTGGTGGTGGTGGTTCTGCTTCCAAATTGTGGGGCCCAGGCACCCTGGTCACCATCTCTTCAG (서열 번호: 143)
>E1-38K
GAGCTCGTGATGACCCAGACTCCATCTTCCAAGTCTGTCCCTGTGGGAGGCACAGTCACCATCGATTGCCAGGCCAGTGAGAGTGTTTATAGTAACAACCGCTGTGCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTATTATGCATCCACTCTGGCATCTGGGGTCCCGTCGCGGTTCAAATGCAGTGGATCTGGGACACGGTTCACTCTCACCATCAGCGGCGTGCAGTGTGAAGATGCTGCCACTTACTACTGTGCAGGATATAAGACTGCCGATTCTGATGGTCTTGGTTTCGGCGGAGGGACCGAGGTGGAAATCAAA (서열 번호: 144)
>E1-52H
GAGCAGTCGGTGAAGGAGTCCGAGGGAGACCTGGTCAAGCCTGAGGGATCCCTGACACTCGCCTGCACAGCTTCTGGATTCACCCTCAGTAGCTACTACATGTGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATGGATCGCATGCATTGATACTGATAATGATATTAGGACTGCCTACGCGAGCTGGGCGAGGGGCCGATTCACCATCTCCAGGACCTCGTCGACCACGGTGACTCTGCAAATGACCAGTCTGACAGCCGCGGACACGGCCACCTATTTCTGTGGGAGAGGCTATGGTGCGCTTCGGTTGGATCTCTGGGGCCAGGGCCCCTGGTCACCGTCTCTTCAG (서열 번호: 145)
>E1-52K
GAGCTCGATCTGACCCAGACACCAGCCTCCGTGTCTGCAGCTGTGGGAGGCACAGTCAGCATCAATTGCCAGTCCAGTCCGAGTGTTTATAGGCACTACTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTACTGGGCTTCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAGCGGCAGTGGATCTGGGACAGAGTTCACTCTCACCATCAGCGGCGTGCAGTGTGACGATGCTGCCACTTACTACTGTGCAGGCGAATATGCTAGTGATAGTGATAATCATTTCGGCGGAGGGACCGAGGTGGAAATCAAAG (서열 번호: 146)
>E2-36H
CAGTCGGTGAAGGAGTCCGAGGGTCGCCTGGTCACGCCTGGGACACCCCTGACACTCACCTGCACAGTCTCTGGATTCTCCCTCAGTAGCTACCACATGGGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGAATCATTAATAATTATGGTGCCACATACTACGCGAGCTGGGCAAAAGGCCGATTCACCATCTCCAGAACCTCGACCACGGTGGATCTGAAAATGACCAGTCTGACAACCGAGGACACGGCCACCTATTTCTGTGCCAGAAGTCCTGGGATTCCTGGTTATAATTCGTGGGGCCCAGGCACCCTGGTCACCATCTCCTCAG (서열 번호: 147)
>E2-36K
GAGCTCGATCTGACCCAGACTCCATCTTCCACGTCTGCGGCTGTGGGAGGCACAGTCACCATCAACTGCCAGTCCAGTCAGAATGTTTATAGTTACAACCGCTTATCCTGGTTTCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTACGAAGCATCCAAACTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGGATCTGGGACACAGTTCACTCTCACCATCAGCGGCGTGCAGTGTGACGATGCTGCCACTTACTACTGTGCAGGCGGTTATGATTGTAGGAGTTCTGATTGTGATGCTTTCGGCGGAGGGACCGAGGTGGAAATCAAAC (서열 번호: 148)
>E1-95H
AGCAGTTCGGTGGAGGAGTCCGGGGGAGACCTGGTCAAGCCCGGGGCATCCCTGACACTCACCTGCACAGCCTCTGGATTCTCCTTCAGTAGCAATTCAATGTGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGGATGCATTGCTAGTAGTAGTAGTCATAGTACTTACTACGCGAGCTGGGCGAAAGGCCGATTCACCATCTCCAAAACCTCGTCGACCACGGTGACTCTGCAAATGACCAGTCTGACAGCCGCGGACATGGCCACCTATTTCTGTGCGAGAGATTCTGGTAATCGTGGTTACCTTTATGCGGGCGACTTTAACTTGTGGGGCCCAGGCACCCTGGTCACCGTCTCTTCAG (서열 번호: 149)
>E1-95K
GAGCTCGTGCTGACCCAGACTCCAGCCTCTGTGGAGGTAGCTGTGGGAGGCACAGTCACCATCAATTGCCAGGCCAGTCAGAGCATTAATAGTTGGTTATCCTGGTATCAGCAGAAACCAGGGCAGCGTCCCAAACTCCTGATCTACGAAGCATCCACTCTGGCATCTGGGGTCTCATCGCGGTTCAGTGGCAGTGGATCTGGGACACAGTTCACTCTCACCATCAGCGGCGTGCAGTGTGACGATGCTGCCACTTACTACTGTCAACAGGGTTATAGTTATAGTAATGTTGATAATAATATTTTCGGCGGAGGGACCGAGGTGGTGGTCAAAG (서열 번호: 150)
>E2-116H
CAGTCGTTGGAGGAGTCCGGGGGAGGCCTGGTCAAGCCTGAGGGATCCCTGACACTCACCTGCACAGCCTCTGGATTCGACCTCAGTAGCTCCTACTACATGTGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGTCTGTATTGACGGTGGTGGGGGTGAGCCCACTGCCTACCCGAGCTGGGCGAAAGGCCGATTCACCGTCTCCAAAACCTCGTCGACCACGGTGACTCTTCAAATGACCAGTCTGACAGTCGCGGACACGGCCACGTATTTCTGTGCGAGACGAGATGCTGGTGCTGGGAACGCCTTTAGCTTGTGGGGCCCAGGCACCCTGGTCACCATCTCCTCAG (서열 번호: 151)
>E2-116K
GAGCTCGATATGACCCAGACTCCATCCCCCGTGTCTGCAGCTGTGGGAGGCACAGTCACCATCAGTTGCCAGTCCAGTCAAAGTGTTTATCTTCAGAACAACTTAGCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTATTATGCATCCACTCTGGCATCTGGGGTCTCATCGCGGTTCAAAGGCAGTGGATCTGGGACACAGTTCACTCTCACCATCAGCGACCTGGAGTGTGACGATGCTGCCACTTACTACTGTCAGGGCGGTTACAGTGGATATATCAATTCTTTCGGCGGAGGGACCGAGGTGGAAATCAAAG (서열 번호: 152)
>E2-135H
CAGTCGGTGAAGGAGTCCGAGGGAGACCTGGTCAAGCCTGGGGCATCCCTGACACTCACCTGCAAAGCCTCTGGATTCGACTTCAGTAGCAGCTACTTTATGTGCTGGGTCCGCCAGGCTCCAGGGAGGGGGCTGGAGTGGATCGCATGCATTTATACTGTTATTAGTCGTAAGACTTATTACGCGAGCTGGGCGAAAGGCCGATTCACCATCTCCAAAACCTCGGCGACCACGGTGGATCTGCAAATGACCAGTCTGACAGCCGCGGACACGGCCACCTATTTCTGTGCGAGATCGGCAACAATTGAAAGATTGGATCTCTGGGGCCAGGGCACCCTGGTCACCGTCTCCTCAG (서열 번호: 153)
>E2-135K
GAGCTCGATCTGACCCAGACTCCATCGCCCGTGTCTGCACCTGTGGGAGGCACAGTCACCATCAATTGCCAGGCCAGTGAGAGTGTTTATAATAACTACCGCTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTAATCTATGCTGCATCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGGATCTGGGACACAGTTCACTCTCGCCATCAGCGATGTGGTGTGTGACGATGCTGCCACTTACTACTGTGTAGGATATAAAAGTGGTTATATTGATAGTATTCCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAAG (서열 번호: 154)
>E1-142H
CAGTCGTTGGAGGAGTCCGGGGGAGACCTGGTCAAGCCTGGGGCATCCCTGACACTCACCTGCACAGCTTCTGGATTCACCATCAATAACTACAACATTAACTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGCACGTATTTGGAATGGTGATGGCAGCACATACTACGCGAGCTGGGCGAAAGGCCGATTCACCATCTCCAAAACCTCGTCGACCACGGTGACTCTACAAATGACCAGTCTGACAGCCGCGGACACGGCCACCTATTTCTGTGCGAGAAATTTTAACTTGTGGGGCCCAGGCACCCTGGTCACCATCTCTTCAG (서열 번호: 155)
>E1-142K
GAGCTCGTGCTGACCCAGACTCCATCTCCCGTGTCTGCAGCTGTGGGAGGCACAGTCACCATCAATTGCCAGTCCAGTGCGAGTGTTTATAGTAACAACTACTTATCCTGGTTTCAGCAGAAACCAGGGCAGCCTCCCAAGCCCCTGATCTATTATGCATCCACTCTGGCATCTGGGGTCCCATCGCGGTTTAAAGGCAGTGGATCTGGGACACAGTTCACTCTCACCATCAGCGACGTGCAGTGTGACGATGCTGCCACTTACTACTGTGCAGGCGATTATAGTAGTAGTAGTGATATGTGTATTTTCGGCGGAGGGACCGAGCTGGAAATCAAAG (서열 번호: 156)
항-EGFL6 항체들의 가변 아미노산 서열들을 아래에 나타낸다.
>E1-33H
QSLEESEGGLVQPEGSLTLTCKASGLDLSSYYYMCWVRQAPGKGLEWIACIYAGSSGSTYYASWAKGRFTISKTSSTTVTLQMTSLTAADTATYFCARGGGSTYAQYFNLWGPGTLVTISS (서열 번호: 157)
>E1-33L
ELDMTTPASVSAAVGGTVSINCQSSPSVYRHYLSWYQQKPGQPPKLLIYWASTLASGVPSRFSGSGSGTEFTLTISGVQCDDAATYYCAGEYASDSDNHFGGGTELEIL (서열 번호: 158)
>E1-34H
EQSVKESGGGLVQPEGSLTLTCTASGFSFSSIYWICWVRQAPGKGLELIACIQITSGITYYASWAKGRFTISKMSSTTVTLQMTSLTVADTATYFCGRRGYGAYAGTGASDLWGPGTLVTVSS (서열 번호: 159)
>E1-34L
ELDLTQTASSVSAAVGGTVTINCQSSQSVYNNNNLAWYQQKPGQPPKLLIYEASKLASGVPSRFKGSGSGTQFTLTISGVQCDDAATYYCAGGYAGYIWAFGGGTEVVVK (서열 번호: 160)
>E1-80H
EQSVEESGGGLFQPGGSLALTCKASGFTLNSYYMSWVRQAPGKGLEWIGCIDSDSPTTTAYANWARGRFTISKTSSTTVTLQMTSLTAADTATYFCARGYGPVRLDLWGQGTLVTVSS (서열 번호: 161)
>E1-80LK
TQTPASVSAAVGGTVSINCQSSQSVYKNAYLSYYLAWYQQKPGQPPKLLIYWASTLASGVPSRFKGSGSGTQFTLTISDVQCDDAATYYCAAEYSNDSDNGFGGGTEVEIK (서열 번호: 162)
>E1-89H
EQSLEESGGDLVKPEGSLTLTCAASGFSFSSGYWICWVRQAPGKGLEWIGCIYAGSSGGHIYYATWAKGRFTISQTSSTTVTLQMTSLTAADTATYFCTRDNYGGGGSASKLWGPGTLVTISS (서열 번호: 163)
>E1-89L
ELVMTQTPSPVSAAVGGTVTINCQSSQSVYSNNRLAWYQQKPGQPPKLLVYYAATLASGVPSRFKGSGYGTQSTLTIADVVCDDAATYYCAGYKTADSDGIAFGGGTEVEIK (서열 번호: 164)
>E2-93H
QSVKESEGGLVQPEGSLTLTCKASGFSFSSYGVNWVRQAPGKGLEWIAYIGLSSEITYYAGWAKGRFTISKPSSTTVTLQMTSLTAADTATYFCVRDLYHSNGLWGPGTLVTISS (서열 번호: 165)
>E2-93L
ELDLTQTPSPVSAAVGGTVTVSCQASESVYNNNRLSWYQQKPGQPPKLLIYYASTLASGVPSRFSGSGSGTQFTLTISSVQCADAATYYCVAFKGYGTDGNAFGGGTEVEIK (서열 번호: 166)
>E1-38H
EQSVKESGGDLVKPEGSLTLTCTASGFSFNSGYWVCWVRQAPGKGLEWIACIYTSSPTGAIYYATWAKGRFTISQTSSTTVTLQMTSLTAADTATYFCTRDNFGGGGSASKLWGPGTLVTISS (서열 번호: 167)
>E1-38L
ELVMTQTPSSKSVPVGGTVTIDCQASESVYSNNRCAWYQQKPGQPPKLLIYYASTLASGVPSRFKCSGSGTRFTLTISGVQCEDAATYYCAGYKTADSDGLGFGGGTEVEIK (서열 번호: 168)
>E1-52H
EQSVKESEGDLVKPEGSLTLACTASGFTLSSYYMCWVRQAPGKGLEWIACIDTDNDIRTAYASWARGRFTISRTSSTTVTLQMTSLTAADTATYFCGRGYGALRLDLWGQGTLVTISS (서열 번호: 169)
>E1-52L
ELDLTQTPASVSAAVGGTVSINCQSSPSVYRHYLSWYQQKPGQPPKLLIYWASTLASGVPSRFSGSGSGTEFTLTISGVQCDDAATYYCAGEYASDSDNHFGGGTEVEIK (서열 번호: 170)
>E2-36H
QSVKESEGRLVTPGTPLTLTCTVSGFSLSSYHMGWVRQAPGKGLEYIGIINNYGATYYASWAKGRFTISRTSTTVDLKMTSLTTEDTATYFCARSPGIPGYNSWGPGTLVTISS (서열 번호: 171)
>E2-36L
ELDLTQTPSSTSAAVGGTVTINCQSSQNVYSYNRLSWFQQKPGQPPKLLIYEASKLASGVPSRFKGSGSGTQFTLTISGVQCDDAATYYCAGGYDCRSSDCDAFGGGTEVEIK (서열 번호: 172)
>E1-95H
SSSVEESGGDLVKPGASLTLTCTASGFSFSSNSMCWVRQAPGKGLEWIGCIASSSSHSTYYASWAKGRFTISKTSSTTVTLQMTSLTAADMATYFCARDSGNRGYLYAGDFNLWGPGTLVTVSS (서열 번호: 173)
>E1-95L
ELVLTQTPASVEVAVGGTVTINCQASQSINSWLSWYQQKPGQRPKLLIYEASTLASGVSSRFSGSGSGTQFTLTISGVQCDDAATYYCQQGYSYSNVDNNIFGGGTEVVVK (서열 번호: 174)
>E2-116H
QSLEESGGGLVKPEGSLTLTCTASGFDLSSSYYMCWVRQAPGKGLEWIVCIDGGGGEPTAYPSWAKGRFTVSKTSSTTVTLQMTSLTVADTATYFCARRDAGAGNAFSLWGPGTLVTISS (서열 번호: 175)
>E2-116L
ELDMTQTPSPVSAAVGGTVTISCQSSQSVYLQNNLAWYQQKPGQPPKLLIYYASTLASGVSSRFKGSGSGTQFTLTISDLECDDAATYYCQGGYSGYINSFGGGTEVEIK (서열 번호: 176)
>E2-135H
QSVKESEGDLVKPGASLTLTCKASGFDFSSSYFMCWVRQAPGRGLEWIACIYTVISRKTYYASWAKGRFTISKTSATTVDLQMTSLTAADTATYFCARSATIERLDLWGQGTLVTVSS (서열 번호: 177)
>E2-135L
ELDLTQTPSPVSAPVGGTVTINCQASESVYNNYRLSWYQQKPGQPPKLLIYAASTLASGVPSRFKGSGSGTQFTLAISDVVCDDAATYYCVGYKSGYIDSIPFGGGTEVVVK (서열 번호: 178)
>E1-142H
QSLEESGGDLVKPGASLTLTCTASGFTINNYNINWVRQAPGKGLEWIARIWNGDGSTYYASWAKGRFTISKTSSTTVTLQMTSLTAADTATYFCARNFNLWGPGTLVTISS (서열 번호: 179)
>E1-142L
ELVLTQTPSPVSAAVGGTVTINCQSSASVYSNNYLSWFQQKPGQPPKPLIYYASTLASGVPSRFKGSGSGTQFTLTISDVQCDDAATYYCAGDYSSSSDMCIFGGGTELEIK (서열 번호: 180)
* * *
출원에 개시된 그리고 본 출원의 청구범위에 기재된 모든 방법들은 본 출원의 개시내용을 고려하여 과도한 실험없이 제조되고 실행될 수 있다. 바람직한 구체예들을 고려하여 본 발명의 방법들을 기재하였으나, 본 발명의 개념, 사상 및 범위에서 벗어나지 않고 이러한 조성물 및 방법들, 그리고 본 출원에 기재된 방법의 단계들 또는 일련의 단계들에 변형이 이루어질 수 있음은 해당 분야의 숙련된 기술자에게 자명할 것이다. 더욱 구체적으로, 화학적으로 그리고 생리학적으로 관련된 특정 제제들은 동일 또는 유사한 결과가 구현되는 한 본 출원에 기재된 제제들로 치환될 수 있음은 자명할 것이다. 해당 기술 분야의 통상의 기술자에게 자명한 이러한 모든 유사한 치환들 및 변형들은 첨부된 청구범위에 정의된 바와 같이 본 발명의 사상, 범위 및 개념에 속하는 것으로 고려된다.
참고문헌
하기 참고문헌은, 본 출원에 제시된 예시적인 절차 또는 다른 상세한 내용에 대한 보충내용을 제공하는 한, 본 출원에 구체적으로 참고를 위해 포함된다.
미국 특허 출원 No. 2002/0172677
미국 특허 출원 No. 2004/0126828
미국 특허 출원 No. 2005/0214860
미국 특허 No. 3,817,837
미국 특허 No. 3,850,752
미국 특허 No. 3,939,350
미국 특허 No. 3,996,345
미국 특허 No. 4,196,265
미국 특허 No. 4,275,149
미국 특허 No. 4,277,437
미국 특허 No. 4,366,241
미국 특허 No. 4,469,797
미국 특허 No. 4,472,509
미국 특허 No. 4,606,855
미국 특허 No. 4,703,003
미국 특허 No. 4,742,159
미국 특허 No. 4,767,720
미국 특허 No. 4,816,567
미국 특허 No. 4,867,973
미국 특허 No. 4,870,287
미국 특허 No. 4,938,948
미국 특허 No. 4,946,778
미국 특허 No. 5,021,236
미국 특허 No. 5,091,513
미국 특허 No. 5,164,296
미국 특허 No. 5,196,066
미국 특허 No. 5,223,409
미국 특허 No. 5,403,484
미국 특허 No. 5,420,253
미국 특허 No. 5,565,332
미국 특허 No. 5,571,698
미국 특허 No. 5,627,052
미국 특허 No. 5,656,434
미국 특허 No. 5,739,169
미국 특허 No. 5,760,395
미국 특허 No. 5,770,376
미국 특허 No. 5,789,208
미국 특허 No. 5,801,005
미국 특허 No. 5,821,337
미국 특허 No. 5,824,311
미국 특허 No. 5,830,880
미국 특허 No. 5,844,091
미국 특허 No. 5,846,945
미국 특허 No. 5,858,657
미국 특허 No. 5,861,155
미국 특허 No. 5,871,907
미국 특허 No. 5,969,108
미국 특허 No. 6,054,297
미국 특허 No. 6,165,464
미국 특허 No. 6,365,157
미국 특허 No. 6,406,867
미국 특허 No. 6,709,659
미국 특허 No. 6,709,873
미국 특허 No. 6,753,407
미국 특허 No. 6,814,965
미국 특허 No. 6,849,259
미국 특허 No. 6,861,572
미국 특허 No. 6,875,434
미국 특허 No. 6,881,557
미국 특허 No. 6,891,024
미국 특허 No. 6,946,646


SEQUENCE LISTING
<110> THE BOARD OF REGENTS OF THE UNIVERSITY OF TEXAS SYSTEM
<120> EGFL6 SPECIFIC MONOCLONAL ANTIBODIES AND METHODS OF THEIR USE
<130> UTFH.P0324WO
<150> US 62/291,987
<151> 2016-02-05
<160> 180
<170> KoPatentIn 3.0
<210> 1
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 1
ggactcgacc tcagtagcta ctactac 27
<210> 2
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 2
atttatgctg gtagtagtgg tagcact 27
<210> 3
<211> 42
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 3
gcgagaggtg gtggtagtac ttatgctcaa tattttaact tg 42
<210> 4
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 4
Gly Leu Asp Leu Ser Ser Tyr Tyr Tyr
1 5
<210> 5
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 5
Ile Tyr Ala Gly Ser Ser Gly Ser Thr
1 5
<210> 6
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 6
Ala Arg Gly Gly Gly Ser Thr Tyr Ala Gln Tyr Phe Asn Leu
1 5 10
<210> 7
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 7
ggattctcct tcagtagtat ttattgg 27
<210> 8
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 8
attcagatta ctagtggtat cact 24
<210> 9
<211> 45
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 9
agaaggggat atggtgccta tgctggtact ggtgcctctg acttg 45
<210> 10
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 10
Gly Phe Ser Phe Ser Ser Ile Tyr Trp
1 5
<210> 11
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 11
Ile Gln Ile Thr Ser Gly Ile Thr
1 5
<210> 12
<211> 15
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 12
Arg Arg Gly Tyr Gly Ala Tyr Ala Gly Thr Gly Ala Ser Asp Leu
1 5 10 15
<210> 13
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 13
ggattcaccc tcaatagtta ttat 24
<210> 14
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 14
attgatagtg atagtcctac tacg 24
<210> 15
<211> 33
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 15
gcgagaggct atggtcctgt tcgattggat ctc 33
<210> 16
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 16
Gly Phe Thr Leu Asn Ser Tyr Tyr
1 5
<210> 17
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 17
Ile Asp Ser Asp Ser Pro Thr Thr
1 5
<210> 18
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 18
Ala Arg Gly Tyr Gly Pro Val Arg Leu Asp Leu
1 5 10
<210> 19
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 19
ggattctcct tcagtagcgg ctactgg 27
<210> 20
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 20
atttatgctg gtagtagtgg tgggcac 27
<210> 21
<211> 45
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 21
tgtacaagag ataattatgg tggtggtggt tctgcttcca aattg 45
<210> 22
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 22
Gly Phe Ser Phe Ser Ser Gly Tyr Trp
1 5
<210> 23
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 23
Ile Tyr Ala Gly Ser Ser Gly Gly His
1 5
<210> 24
<211> 15
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 24
Cys Thr Arg Asp Asn Tyr Gly Gly Gly Gly Ser Ala Ser Lys Leu
1 5 10 15
<210> 25
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 25
ggattctcct tcagtagtta tgga 24
<210> 26
<211> 21
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 26
attggtctta gtagtgagat c 21
<210> 27
<211> 30
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 27
gtgagagatc tttatcatag taatggtttg 30
<210> 28
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 28
Gly Phe Ser Phe Ser Ser Tyr Gly
1 5
<210> 29
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 29
Ile Gly Leu Ser Ser Glu Ile
1 5
<210> 30
<211> 10
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 30
Val Arg Asp Leu Tyr His Ser Asn Gly Leu
1 5 10
<210> 31
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 31
ggattctcct tcaatagcgg ctactgg 27
<210> 32
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 32
atctatacta gtagtcctac tggtgcc 27
<210> 33
<211> 45
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 33
tgtacaagag ataattttgg tggtggtggt tctgcttcca aattg 45
<210> 34
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 34
Gly Phe Ser Phe Asn Ser Gly Tyr Trp
1 5
<210> 35
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 35
Ile Tyr Thr Ser Ser Pro Thr Gly Ala
1 5
<210> 36
<211> 15
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 36
Cys Thr Arg Asp Asn Phe Gly Gly Gly Gly Ser Ala Ser Lys Leu
1 5 10 15
<210> 37
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 37
ggattcaccc tcagtagcta ctac 24
<210> 38
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 38
attgatactg ataatgatat tagg 24
<210> 39
<211> 33
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 39
gggagaggct atggtgcgct tcggttggat ctc 33
<210> 40
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 40
Gly Phe Thr Leu Ser Ser Tyr Tyr
1 5
<210> 41
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 41
Ile Asp Thr Asp Asn Asp Ile Arg
1 5
<210> 42
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 42
Gly Arg Gly Tyr Gly Ala Leu Arg Leu Asp Leu
1 5 10
<210> 43
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 43
ggattctccc tcagtagcta ccac 24
<210> 44
<211> 21
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 44
attaataatt atggtgccac a 21
<210> 45
<211> 33
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 45
gccagaagtc ctgggattcc tggttataat tcg 33
<210> 46
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 46
Gly Phe Ser Leu Ser Ser Tyr His
1 5
<210> 47
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 47
Ile Asn Asn Tyr Gly Ala Thr
1 5
<210> 48
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 48
Ala Arg Ser Pro Gly Ile Pro Gly Tyr Asn Ser
1 5 10
<210> 49
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 49
ggattctcct tcagtagcaa ttca 24
<210> 50
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 50
attgctagta gtagtagtca tagt 24
<210> 51
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 51
gcgagagatt ctggtaatcg tggttacctt tatgcgggcg actttaactt g 51
<210> 52
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 52
Gly Phe Ser Phe Ser Ser Asn Ser
1 5
<210> 53
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 53
Ile Ala Ser Ser Ser Ser His Ser
1 5
<210> 54
<211> 17
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 54
Ala Arg Asp Ser Gly Asn Arg Gly Tyr Leu Tyr Ala Gly Asp Phe Asn
1 5 10 15
Leu
<210> 55
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 55
ggattcgacc tcagtagctc ctactac 27
<210> 56
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 56
attgacggtg gtgggggtga gcccact 27
<210> 57
<211> 39
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 57
gcgagacgag atgctggtgc tgggaacgcc tttagcttg 39
<210> 58
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 58
Gly Phe Asp Leu Ser Ser Ser Tyr Tyr
1 5
<210> 59
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 59
Ile Asp Gly Gly Gly Gly Glu Pro Thr
1 5
<210> 60
<211> 13
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 60
Ala Arg Arg Asp Ala Gly Ala Gly Asn Ala Phe Ser Leu
1 5 10
<210> 61
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 61
ggattcgact tcagtagcag ctacttt 27
<210> 62
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 62
atttatactg ttattagtcg taagact 27
<210> 63
<211> 33
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 63
gcgagatcgg caacaattga aagattggat ctc 33
<210> 64
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 64
Gly Phe Asp Phe Ser Ser Ser Tyr Phe
1 5
<210> 65
<211> 9
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 65
Ile Tyr Thr Val Ile Ser Arg Lys Thr
1 5
<210> 66
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 66
Ala Arg Ser Ala Thr Ile Glu Arg Leu Asp Leu
1 5 10
<210> 67
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 67
ggattcacca tcaataacta caac 24
<210> 68
<211> 21
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 68
atttggaatg gtgatggcag c 21
<210> 69
<211> 18
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 69
gcgagaaatt ttaacttg 18
<210> 70
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 70
Gly Phe Thr Ile Asn Asn Tyr Asn
1 5
<210> 71
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 71
Ile Trp Asn Gly Asp Gly Ser
1 5
<210> 72
<211> 6
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 72
Ala Arg Asn Phe Asn Leu
1 5
<210> 73
<211> 21
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 73
ccgagtgttt ataggcacta c 21
<210> 74
<211> 9
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 74
tgggcttcc 9
<210> 75
<211> 33
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 75
gcaggcgaat atgctagtga tagtgataat cat 33
<210> 76
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 76
Pro Ser Val Tyr Arg His Tyr
1 5
<210> 77
<211> 3
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 77
Trp Ala Ser
1
<210> 78
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 78
Ala Gly Glu Tyr Ala Ser Asp Ser Asp Asn His
1 5 10
<210> 79
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 79
cagagtgttt ataataacaa caac 24
<210> 80
<211> 9
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 80
gaagcatcc 9
<210> 81
<211> 30
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 81
gcaggcggtt atgctggcta catttgggct 30
<210> 82
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 82
Gln Ser Val Tyr Asn Asn Asn Asn
1 5
<210> 83
<211> 3
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 83
Glu Ala Ser
1
<210> 84
<211> 10
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 84
Ala Gly Gly Tyr Ala Gly Tyr Ile Trp Ala
1 5 10
<210> 85
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 85
aagaacgcct atttatccta ctac 24
<210> 86
<211> 9
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 86
tgggcttcc 9
<210> 87
<211> 33
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 87
gcagccgaat atagtaatga tagtgataat ggt 33
<210> 88
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 88
Lys Asn Ala Tyr Leu Ser Tyr Tyr
1 5
<210> 89
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 89
Ala Ala Glu Tyr Ser Asn Asp Ser Asp Asn Gly
1 5 10
<210> 90
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 90
cagagtgttt atagtaacaa ccgc 24
<210> 91
<211> 9
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 91
tatgcagcc 9
<210> 92
<211> 36
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 92
gcaggatata aaactgctga ttctgatggt attgct 36
<210> 93
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 93
Gln Ser Val Tyr Ser Asn Asn Arg
1 5
<210> 94
<211> 3
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 94
Tyr Ala Ala
1
<210> 95
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 95
Ala Gly Tyr Lys Thr Ala Asp Ser Asp Gly Ile Ala
1 5 10
<210> 96
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 96
gagagcgttt ataataataa ccgc 24
<210> 97
<211> 9
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 97
tatgcatcc 9
<210> 98
<211> 36
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 98
gtagccttta aaggttatgg tactgacggc aatgct 36
<210> 99
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 99
Glu Ser Val Tyr Asn Asn Asn Arg
1 5
<210> 100
<211> 3
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 100
Tyr Ala Ser
1
<210> 101
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 101
Val Ala Phe Lys Gly Tyr Gly Thr Asp Gly Asn Ala
1 5 10
<210> 102
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 102
gagagtgttt atagtaacaa ccgc 24
<210> 103
<211> 36
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 103
gcaggatata agactgccga ttctgatggt cttggt 36
<210> 104
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 104
Glu Ser Val Tyr Ser Asn Asn Arg
1 5
<210> 105
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 105
Ala Gly Tyr Lys Thr Ala Asp Ser Asp Gly Leu Gly
1 5 10
<210> 106
<211> 21
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 106
ccgagtgttt ataggcacta c 21
<210> 107
<211> 33
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 107
gcaggcgaat atgctagtga tagtgataat cat 33
<210> 108
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 108
Pro Ser Val Tyr Arg His Tyr
1 5
<210> 109
<211> 11
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 109
Ala Gly Glu Tyr Ala Ser Asp Ser Asp Asn His
1 5 10
<210> 110
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 110
cagaatgttt atagttacaa ccgc 24
<210> 111
<211> 9
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 111
gaagcatcc 9
<210> 112
<211> 39
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 112
gcaggcggtt atgattgtag gagttctgat tgtgatgct 39
<210> 113
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 113
Gln Asn Val Tyr Ser Tyr Asn Arg
1 5
<210> 114
<211> 13
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 114
Ala Gly Gly Tyr Asp Cys Arg Ser Ser Asp Cys Asp Ala
1 5 10
<210> 115
<211> 18
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 115
cagagcatta atagttgg 18
<210> 116
<211> 39
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 116
caacagggtt atagttatag taatgttgat aataatatt 39
<210> 117
<211> 6
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 117
Gln Ser Ile Asn Ser Trp
1 5
<210> 118
<211> 13
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 118
Gln Gln Gly Tyr Ser Tyr Ser Asn Val Asp Asn Asn Ile
1 5 10
<210> 119
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 119
caaagtgttt atcttcagaa caac 24
<210> 120
<211> 30
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 120
cagggcggtt acagtggata tatcaattct 30
<210> 121
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 121
Gln Ser Val Tyr Leu Gln Asn Asn
1 5
<210> 122
<211> 10
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 122
Gln Gly Gly Tyr Ser Gly Tyr Ile Asn Ser
1 5 10
<210> 123
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 123
gagagtgttt ataataacta ccgc 24
<210> 124
<211> 9
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 124
gctgcatcc 9
<210> 125
<211> 36
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 125
gtaggatata aaagtggtta tattgatagt attcct 36
<210> 126
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 126
Glu Ser Val Tyr Asn Asn Tyr Arg
1 5
<210> 127
<211> 3
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 127
Ala Ala Ser
1
<210> 128
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 128
Val Gly Tyr Lys Ser Gly Tyr Ile Asp Ser Ile Pro
1 5 10
<210> 129
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 129
gcgagtgttt atagtaacaa ctac 24
<210> 130
<211> 36
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 130
gcaggcgatt atagtagtag tagtgatatg tgtatt 36
<210> 131
<211> 8
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 131
Ala Ser Val Tyr Ser Asn Asn Tyr
1 5
<210> 132
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic CDR sequence
<400> 132
Ala Gly Asp Tyr Ser Ser Ser Ser Asp Met Cys Ile
1 5 10
<210> 133
<211> 364
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 133
cagtcgctgg aggagtccga gggaggcctg gtccagcctg agggatccct gacactcacc 60
tgcaaagcct ctggactcga cctcagtagc tactactaca tgtgctgggt ccgccaggct 120
ccagggaagg ggctggagtg gatcgcatgc atttatgctg gtagtagtgg tagcacttac 180
tacgcgagct gggcgaaagg ccgattcacc atctccaaaa cctcgtcgac cacggtgact 240
ctgcaaatga ccagtctgac agccgcggac acggccacct atttctgtgc gagaggtggt 300
ggtagtactt atgctcaata ttttaacttg tggggcccag gcaccctggt caccatctcc 360
tcag 364
<210> 134
<211> 331
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<220>
<221> misc_feature
<222> (18)..(18)
<223> n is a, c, g, or t
<400> 134
gagctcgata tgacccanac accagcctcc gtgtctgcag ctgtgggagg cacagtcagc 60
atcaattgcc agtccagtcc gagtgtttat aggcactact tatcctggta tcagcagaaa 120
ccagggcagc ctcccaagct cctgatctac tgggcttcca ctctggcatc tggggtccca 180
tcgcggttca gcggcagtgg atctgggaca gagttcactc tcaccatcag cggcgtgcag 240
tgtgacgatg ctgccactta ctactgtgca ggcgaatatg ctagtgatag tgataatcat 300
ttcggcggag ggaccgagct ggagatccta g 331
<210> 135
<211> 370
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 135
gagcagtcgg tgaaggagtc cgggggaggc ctggtccagc ctgagggatc cctgacactc 60
acctgcacag cttctggatt ctccttcagt agtatttatt ggatatgctg ggtccgccag 120
gctccaggga aggggctgga gttgatcgca tgcattcaga ttactagtgg tatcacttac 180
tacgcgagct gggcgaaagg ccgattcacc atctccaaaa tgtcgtcgac cacggtgact 240
ctgcaaatga ccagtctgac agtcgcggac acggccacct atttctgtgg gagaagggga 300
tatggtgcct atgctggtac tggtgcctct gacttgtggg gcccaggcac cctggtcacc 360
gtctcttcag 370
<210> 136
<211> 331
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 136
gagctcgatc tgacccagac tgcatcgtcc gtgtctgcag ctgtgggagg caccgtcacc 60
atcaattgcc agtccagtca gagtgtttat aataacaaca acttagcctg gtatcagcag 120
aaaccagggc agcctcccaa gctcctgatc tacgaagcat ccaaactggc atctggggtc 180
ccatcgcggt tcaaaggcag tggatctggg acacagttca ctctcaccat cagcggcgtg 240
cagtgtgacg atgctgccac ttactattgt gcaggcggtt atgctggcta catttgggct 300
ttcggcggag ggaccgaggt ggtggtcaaa g 331
<210> 137
<211> 355
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 137
gagcagtcgg tggaggagtc cgggggaggc ctgttccagc ctgggggatc cctggcactc 60
acctgcaaag cctctggatt caccctcaat agttattata tgtcctgggt ccgccaggct 120
ccagggaagg ggctggagtg gatcggatgc attgatagtg atagtcctac tacgactgcc 180
tacgcgaact gggcgagagg ccgattcacc atctccaaga cctcgtcgac cacggtgact 240
ctgcaaatga ccagtctgac agccgcggac acggccacct atttctgtgc gagaggctat 300
ggtcctgttc gattggatct ctggggccag ggcaccctgg tcaccgtctc ttcag 355
<210> 138
<211> 334
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 138
acccagacac cagcctccgt gtctgcagct gtgggaggca cagtcagcat caattgccag 60
tccagtcaga gtgtttataa gaacgcctat ttatcctact acttagcctg gtatcagcag 120
aaaccagggc agcctcccaa gctcctgatc tactgggctt ccactctggc atctggggtc 180
ccatcgcggt tcaaaggcag tggatctggg acacagttca ctctcaccat cagcgacgtg 240
cagtgtgacg atgctgccac ttactactgt gcagccgaat atagtaatga tagtgataat 300
ggtttcggcg gagggaccga ggtggaaatc aaag 334
<210> 139
<211> 370
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 139
gagcagtcgt tggaggagtc cgggggagac ctggtcaagc ctgagggatc cctgacactc 60
acctgcgcag cctctggatt ctccttcagt agcggctact ggatatgctg ggtccgccag 120
gctccaggga aggggctgga gtggatcgga tgcatttatg ctggtagtag tggtgggcac 180
atttattacg cgacctgggc gaaaggccga ttcaccatct cccaaacctc gtcgaccacg 240
gtgactctgc aaatgaccag tctgacagcc gcggacacgg ccacatattt ctgtacaaga 300
gataattatg gtggtggtgg ttctgcttcc aaattgtggg gcccaggcac cctggtcacc 360
atctcttcag 370
<210> 140
<211> 337
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 140
gagctcgtga tgacccagac tccatccccc gtgtctgcag ctgtgggagg cacagtcacc 60
atcaactgcc agtccagtca gagtgtttat agtaacaacc gcttagcctg gtatcagcag 120
aaaccagggc agcctcccaa gctcctggtc tattatgcag ccactctggc atctggggtc 180
ccgtcgcggt tcaaaggcag tggatatggg acacagtcca ctctcaccat cgccgatgtg 240
gtgtgtgacg atgctgccac ttactactgt gcaggatata aaactgctga ttctgatggt 300
attgctttcg gcggagggac cgaggtggaa atcaaag 337
<210> 141
<211> 346
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 141
cagtcggtga aggagtccga gggaggcctg gtccagcctg agggatccct gacactcacc 60
tgcaaagcct ctggattctc cttcagtagt tatggagtga actgggtccg ccaggctcca 120
gggaaggggc tggagtggat cgcgtatatt ggtcttagta gtgagatcac ttactacgcg 180
ggctgggcga aaggccgatt caccatctcc aagccctcgt cgaccacggt gactctgcaa 240
atgaccagtc tgacagccgc ggacacggcc acctatttct gtgtgagaga tctttatcat 300
agtaatggtt tgtggggccc aggcaccctg gtcaccatct cttcag 346
<210> 142
<211> 337
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 142
gagctcgatc tgacccagac tccatccccc gtgtctgcag ctgtgggagg cacagtcacc 60
gtcagttgcc aggccagtga gagcgtttat aataataacc gcttatcctg gtatcagcag 120
aaaccagggc agcctcccaa gctcctgatc tattatgcat ccactctggc atctggggtc 180
ccatcgcggt tcagcggcag tggatctggg acacagttca ctctcaccat cagcagcgtg 240
caatgtgctg atgctgccac gtattattgt gtagccttta aaggttatgg tactgacggc 300
aatgctttcg gcggagggac cgaggtggaa atcaaag 337
<210> 143
<211> 370
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 143
gagcagtcgg tgaaggagtc cgggggagac ctggtcaagc ctgagggatc cctgacactc 60
acctgcacag cctctggatt ctccttcaat agcggctact gggtatgctg ggtccgccag 120
gctccaggga aggggctgga gtggatcgct tgcatctata ctagtagtcc tactggtgcc 180
atatactacg cgacctgggc gaaaggccga ttcaccatct cccaaacctc gtcgaccacg 240
gtgactctgc aaatgaccag tctgacagcc gcggacacgg ccacctattt ctgtacaaga 300
gataattttg gtggtggtgg ttctgcttcc aaattgtggg gcccaggcac cctggtcacc 360
atctcttcag 370
<210> 144
<211> 336
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 144
gagctcgtga tgacccagac tccatcttcc aagtctgtcc ctgtgggagg cacagtcacc 60
atcgattgcc aggccagtga gagtgtttat agtaacaacc gctgtgcctg gtatcagcag 120
aaaccagggc agcctcccaa gctcctgatc tattatgcat ccactctggc atctggggtc 180
ccgtcgcggt tcaaatgcag tggatctggg acacggttca ctctcaccat cagcggcgtg 240
cagtgtgaag atgctgccac ttactactgt gcaggatata agactgccga ttctgatggt 300
cttggtttcg gcggagggac cgaggtggaa atcaaa 336
<210> 145
<211> 354
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 145
gagcagtcgg tgaaggagtc cgagggagac ctggtcaagc ctgagggatc cctgacactc 60
gcctgcacag cttctggatt caccctcagt agctactaca tgtgctgggt ccgccaggct 120
ccagggaagg ggctggaatg gatcgcatgc attgatactg ataatgatat taggactgcc 180
tacgcgagct gggcgagggg ccgattcacc atctccagga cctcgtcgac cacggtgact 240
ctgcaaatga ccagtctgac agccgcggac acggccacct atttctgtgg gagaggctat 300
ggtgcgcttc ggttggatct ctggggccag ggcccctggt caccgtctct tcag 354
<210> 146
<211> 331
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 146
gagctcgatc tgacccagac accagcctcc gtgtctgcag ctgtgggagg cacagtcagc 60
atcaattgcc agtccagtcc gagtgtttat aggcactact tatcctggta tcagcagaaa 120
ccagggcagc ctcccaagct cctgatctac tgggcttcca ctctggcatc tggggtccca 180
tcgcggttca gcggcagtgg atctgggaca gagttcactc tcaccatcag cggcgtgcag 240
tgtgacgatg ctgccactta ctactgtgca ggcgaatatg ctagtgatag tgataatcat 300
ttcggcggag ggaccgaggt ggaaatcaaa g 331
<210> 147
<211> 343
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 147
cagtcggtga aggagtccga gggtcgcctg gtcacgcctg ggacacccct gacactcacc 60
tgcacagtct ctggattctc cctcagtagc taccacatgg gctgggtccg ccaggctcca 120
gggaaggggc tggaatacat cggaatcatt aataattatg gtgccacata ctacgcgagc 180
tgggcaaaag gccgattcac catctccaga acctcgacca cggtggatct gaaaatgacc 240
agtctgacaa ccgaggacac ggccacctat ttctgtgcca gaagtcctgg gattcctggt 300
tataattcgt ggggcccagg caccctggtc accatctcct cag 343
<210> 148
<211> 340
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 148
gagctcgatc tgacccagac tccatcttcc acgtctgcgg ctgtgggagg cacagtcacc 60
atcaactgcc agtccagtca gaatgtttat agttacaacc gcttatcctg gtttcagcag 120
aaaccagggc agcctcccaa gctcctgatc tacgaagcat ccaaactggc atctggggtc 180
ccatcgcggt tcaaaggcag tggatctggg acacagttca ctctcaccat cagcggcgtg 240
cagtgtgacg atgctgccac ttactactgt gcaggcggtt atgattgtag gagttctgat 300
tgtgatgctt tcggcggagg gaccgaggtg gaaatcaaac 340
<210> 149
<211> 373
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 149
agcagttcgg tggaggagtc cgggggagac ctggtcaagc ccggggcatc cctgacactc 60
acctgcacag cctctggatt ctccttcagt agcaattcaa tgtgctgggt ccgccaggct 120
ccagggaagg ggctggagtg gatcggatgc attgctagta gtagtagtca tagtacttac 180
tacgcgagct gggcgaaagg ccgattcacc atctccaaaa cctcgtcgac cacggtgact 240
ctgcaaatga ccagtctgac agccgcggac atggccacct atttctgtgc gagagattct 300
ggtaatcgtg gttaccttta tgcgggcgac tttaacttgt ggggcccagg caccctggtc 360
accgtctctt cag 373
<210> 150
<211> 334
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 150
gagctcgtgc tgacccagac tccagcctct gtggaggtag ctgtgggagg cacagtcacc 60
atcaattgcc aggccagtca gagcattaat agttggttat cctggtatca gcagaaacca 120
gggcagcgtc ccaaactcct gatctacgaa gcatccactc tggcatctgg ggtctcatcg 180
cggttcagtg gcagtggatc tgggacacag ttcactctca ccatcagcgg cgtgcagtgt 240
gacgatgctg ccacttacta ctgtcaacag ggttatagtt atagtaatgt tgataataat 300
attttcggcg gagggaccga ggtggtggtc aaag 334
<210> 151
<211> 361
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 151
cagtcgttgg aggagtccgg gggaggcctg gtcaagcctg agggatccct gacactcacc 60
tgcacagcct ctggattcga cctcagtagc tcctactaca tgtgctgggt ccgccaggct 120
ccagggaagg ggctggagtg gatcgtctgt attgacggtg gtgggggtga gcccactgcc 180
tacccgagct gggcgaaagg ccgattcacc gtctccaaaa cctcgtcgac cacggtgact 240
cttcaaatga ccagtctgac agtcgcggac acggccacgt atttctgtgc gagacgagat 300
gctggtgctg ggaacgcctt tagcttgtgg ggcccaggca ccctggtcac catctcctca 360
g 361
<210> 152
<211> 331
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 152
gagctcgata tgacccagac tccatccccc gtgtctgcag ctgtgggagg cacagtcacc 60
atcagttgcc agtccagtca aagtgtttat cttcagaaca acttagcctg gtatcagcag 120
aaaccagggc agcctcccaa gctcctgatc tattatgcat ccactctggc atctggggtc 180
tcatcgcggt tcaaaggcag tggatctggg acacagttca ctctcaccat cagcgacctg 240
gagtgtgacg atgctgccac ttactactgt cagggcggtt acagtggata tatcaattct 300
ttcggcggag ggaccgaggt ggaaatcaaa g 331
<210> 153
<211> 355
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 153
cagtcggtga aggagtccga gggagacctg gtcaagcctg gggcatccct gacactcacc 60
tgcaaagcct ctggattcga cttcagtagc agctacttta tgtgctgggt ccgccaggct 120
ccagggaggg ggctggagtg gatcgcatgc atttatactg ttattagtcg taagacttat 180
tacgcgagct gggcgaaagg ccgattcacc atctccaaaa cctcggcgac cacggtggat 240
ctgcaaatga ccagtctgac agccgcggac acggccacct atttctgtgc gagatcggca 300
acaattgaaa gattggatct ctggggccag ggcaccctgg tcaccgtctc ctcag 355
<210> 154
<211> 337
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 154
gagctcgatc tgacccagac tccatcgccc gtgtctgcac ctgtgggagg cacagtcacc 60
atcaattgcc aggccagtga gagtgtttat aataactacc gcttatcctg gtatcagcag 120
aaaccagggc agcctcccaa gctcctaatc tatgctgcat ccactctggc atctggggtc 180
ccatcgcggt tcaaaggcag tggatctggg acacagttca ctctcgccat cagcgatgtg 240
gtgtgtgacg atgctgccac ttactactgt gtaggatata aaagtggtta tattgatagt 300
attcctttcg gcggagggac cgaggtggtg gtcaaag 337
<210> 155
<211> 334
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 155
cagtcgttgg aggagtccgg gggagacctg gtcaagcctg gggcatccct gacactcacc 60
tgcacagctt ctggattcac catcaataac tacaacatta actgggtccg ccaggctcca 120
gggaaggggc tggagtggat cgcacgtatt tggaatggtg atggcagcac atactacgcg 180
agctgggcga aaggccgatt caccatctcc aaaacctcgt cgaccacggt gactctacaa 240
atgaccagtc tgacagccgc ggacacggcc acctatttct gtgcgagaaa ttttaacttg 300
tggggcccag gcaccctggt caccatctct tcag 334
<210> 156
<211> 337
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic oligonucleotide
<400> 156
gagctcgtgc tgacccagac tccatctccc gtgtctgcag ctgtgggagg cacagtcacc 60
atcaattgcc agtccagtgc gagtgtttat agtaacaact acttatcctg gtttcagcag 120
aaaccagggc agcctcccaa gcccctgatc tattatgcat ccactctggc atctggggtc 180
ccatcgcggt ttaaaggcag tggatctggg acacagttca ctctcaccat cagcgacgtg 240
cagtgtgacg atgctgccac ttactactgt gcaggcgatt atagtagtag tagtgatatg 300
tgtattttcg gcggagggac cgagctggaa atcaaag 337
<210> 157
<211> 121
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 157
Gln Ser Leu Glu Glu Ser Glu Gly Gly Leu Val Gln Pro Glu Gly Ser
1 5 10 15
Leu Thr Leu Thr Cys Lys Ala Ser Gly Leu Asp Leu Ser Ser Tyr Tyr
20 25 30
Tyr Met Cys Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Ala Cys Ile Tyr Ala Gly Ser Ser Gly Ser Thr Tyr Tyr Ala Ser Trp
50 55 60
Ala Lys Gly Arg Phe Thr Ile Ser Lys Thr Ser Ser Thr Thr Val Thr
65 70 75 80
Leu Gln Met Thr Ser Leu Thr Ala Ala Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Gly Gly Gly Ser Thr Tyr Ala Gln Tyr Phe Asn Leu Trp Gly
100 105 110
Pro Gly Thr Leu Val Thr Ile Ser Ser
115 120
<210> 158
<211> 109
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 158
Glu Leu Asp Met Thr Thr Pro Ala Ser Val Ser Ala Ala Val Gly Gly
1 5 10 15
Thr Val Ser Ile Asn Cys Gln Ser Ser Pro Ser Val Tyr Arg His Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
35 40 45
Tyr Trp Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Gly Val Gln Cys
65 70 75 80
Asp Asp Ala Ala Thr Tyr Tyr Cys Ala Gly Glu Tyr Ala Ser Asp Ser
85 90 95
Asp Asn His Phe Gly Gly Gly Thr Glu Leu Glu Ile Leu
100 105
<210> 159
<211> 123
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 159
Glu Gln Ser Val Lys Glu Ser Gly Gly Gly Leu Val Gln Pro Glu Gly
1 5 10 15
Ser Leu Thr Leu Thr Cys Thr Ala Ser Gly Phe Ser Phe Ser Ser Ile
20 25 30
Tyr Trp Ile Cys Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Leu
35 40 45
Ile Ala Cys Ile Gln Ile Thr Ser Gly Ile Thr Tyr Tyr Ala Ser Trp
50 55 60
Ala Lys Gly Arg Phe Thr Ile Ser Lys Met Ser Ser Thr Thr Val Thr
65 70 75 80
Leu Gln Met Thr Ser Leu Thr Val Ala Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Gly Arg Arg Gly Tyr Gly Ala Tyr Ala Gly Thr Gly Ala Ser Asp Leu
100 105 110
Trp Gly Pro Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 160
<211> 110
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 160
Glu Leu Asp Leu Thr Gln Thr Ala Ser Ser Val Ser Ala Ala Val Gly
1 5 10 15
Gly Thr Val Thr Ile Asn Cys Gln Ser Ser Gln Ser Val Tyr Asn Asn
20 25 30
Asn Asn Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
35 40 45
Leu Ile Tyr Glu Ala Ser Lys Leu Ala Ser Gly Val Pro Ser Arg Phe
50 55 60
Lys Gly Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser Gly Val
65 70 75 80
Gln Cys Asp Asp Ala Ala Thr Tyr Tyr Cys Ala Gly Gly Tyr Ala Gly
85 90 95
Tyr Ile Trp Ala Phe Gly Gly Gly Thr Glu Val Val Val Lys
100 105 110
<210> 161
<211> 118
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 161
Glu Gln Ser Val Glu Glu Ser Gly Gly Gly Leu Phe Gln Pro Gly Gly
1 5 10 15
Ser Leu Ala Leu Thr Cys Lys Ala Ser Gly Phe Thr Leu Asn Ser Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Cys Ile Asp Ser Asp Ser Pro Thr Thr Thr Ala Tyr Ala Asn Trp
50 55 60
Ala Arg Gly Arg Phe Thr Ile Ser Lys Thr Ser Ser Thr Thr Val Thr
65 70 75 80
Leu Gln Met Thr Ser Leu Thr Ala Ala Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Gly Tyr Gly Pro Val Arg Leu Asp Leu Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 162
<211> 111
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 162
Thr Gln Thr Pro Ala Ser Val Ser Ala Ala Val Gly Gly Thr Val Ser
1 5 10 15
Ile Asn Cys Gln Ser Ser Gln Ser Val Tyr Lys Asn Ala Tyr Leu Ser
20 25 30
Tyr Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
35 40 45
Leu Ile Tyr Trp Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg Phe
50 55 60
Lys Gly Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser Asp Val
65 70 75 80
Gln Cys Asp Asp Ala Ala Thr Tyr Tyr Cys Ala Ala Glu Tyr Ser Asn
85 90 95
Asp Ser Asp Asn Gly Phe Gly Gly Gly Thr Glu Val Glu Ile Lys
100 105 110
<210> 163
<211> 123
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 163
Glu Gln Ser Leu Glu Glu Ser Gly Gly Asp Leu Val Lys Pro Glu Gly
1 5 10 15
Ser Leu Thr Leu Thr Cys Ala Ala Ser Gly Phe Ser Phe Ser Ser Gly
20 25 30
Tyr Trp Ile Cys Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Cys Ile Tyr Ala Gly Ser Ser Gly Gly His Ile Tyr Tyr Ala
50 55 60
Thr Trp Ala Lys Gly Arg Phe Thr Ile Ser Gln Thr Ser Ser Thr Thr
65 70 75 80
Val Thr Leu Gln Met Thr Ser Leu Thr Ala Ala Asp Thr Ala Thr Tyr
85 90 95
Phe Cys Thr Arg Asp Asn Tyr Gly Gly Gly Gly Ser Ala Ser Lys Leu
100 105 110
Trp Gly Pro Gly Thr Leu Val Thr Ile Ser Ser
115 120
<210> 164
<211> 112
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 164
Glu Leu Val Met Thr Gln Thr Pro Ser Pro Val Ser Ala Ala Val Gly
1 5 10 15
Gly Thr Val Thr Ile Asn Cys Gln Ser Ser Gln Ser Val Tyr Ser Asn
20 25 30
Asn Arg Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
35 40 45
Leu Val Tyr Tyr Ala Ala Thr Leu Ala Ser Gly Val Pro Ser Arg Phe
50 55 60
Lys Gly Ser Gly Tyr Gly Thr Gln Ser Thr Leu Thr Ile Ala Asp Val
65 70 75 80
Val Cys Asp Asp Ala Ala Thr Tyr Tyr Cys Ala Gly Tyr Lys Thr Ala
85 90 95
Asp Ser Asp Gly Ile Ala Phe Gly Gly Gly Thr Glu Val Glu Ile Lys
100 105 110
<210> 165
<211> 115
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 165
Gln Ser Val Lys Glu Ser Glu Gly Gly Leu Val Gln Pro Glu Gly Ser
1 5 10 15
Leu Thr Leu Thr Cys Lys Ala Ser Gly Phe Ser Phe Ser Ser Tyr Gly
20 25 30
Val Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile Ala
35 40 45
Tyr Ile Gly Leu Ser Ser Glu Ile Thr Tyr Tyr Ala Gly Trp Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Lys Pro Ser Ser Thr Thr Val Thr Leu Gln
65 70 75 80
Met Thr Ser Leu Thr Ala Ala Asp Thr Ala Thr Tyr Phe Cys Val Arg
85 90 95
Asp Leu Tyr His Ser Asn Gly Leu Trp Gly Pro Gly Thr Leu Val Thr
100 105 110
Ile Ser Ser
115
<210> 166
<211> 112
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 166
Glu Leu Asp Leu Thr Gln Thr Pro Ser Pro Val Ser Ala Ala Val Gly
1 5 10 15
Gly Thr Val Thr Val Ser Cys Gln Ala Ser Glu Ser Val Tyr Asn Asn
20 25 30
Asn Arg Leu Ser Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
35 40 45
Leu Ile Tyr Tyr Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser Ser Val
65 70 75 80
Gln Cys Ala Asp Ala Ala Thr Tyr Tyr Cys Val Ala Phe Lys Gly Tyr
85 90 95
Gly Thr Asp Gly Asn Ala Phe Gly Gly Gly Thr Glu Val Glu Ile Lys
100 105 110
<210> 167
<211> 123
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 167
Glu Gln Ser Val Lys Glu Ser Gly Gly Asp Leu Val Lys Pro Glu Gly
1 5 10 15
Ser Leu Thr Leu Thr Cys Thr Ala Ser Gly Phe Ser Phe Asn Ser Gly
20 25 30
Tyr Trp Val Cys Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Ala Cys Ile Tyr Thr Ser Ser Pro Thr Gly Ala Ile Tyr Tyr Ala
50 55 60
Thr Trp Ala Lys Gly Arg Phe Thr Ile Ser Gln Thr Ser Ser Thr Thr
65 70 75 80
Val Thr Leu Gln Met Thr Ser Leu Thr Ala Ala Asp Thr Ala Thr Tyr
85 90 95
Phe Cys Thr Arg Asp Asn Phe Gly Gly Gly Gly Ser Ala Ser Lys Leu
100 105 110
Trp Gly Pro Gly Thr Leu Val Thr Ile Ser Ser
115 120
<210> 168
<211> 112
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 168
Glu Leu Val Met Thr Gln Thr Pro Ser Ser Lys Ser Val Pro Val Gly
1 5 10 15
Gly Thr Val Thr Ile Asp Cys Gln Ala Ser Glu Ser Val Tyr Ser Asn
20 25 30
Asn Arg Cys Ala Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
35 40 45
Leu Ile Tyr Tyr Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg Phe
50 55 60
Lys Cys Ser Gly Ser Gly Thr Arg Phe Thr Leu Thr Ile Ser Gly Val
65 70 75 80
Gln Cys Glu Asp Ala Ala Thr Tyr Tyr Cys Ala Gly Tyr Lys Thr Ala
85 90 95
Asp Ser Asp Gly Leu Gly Phe Gly Gly Gly Thr Glu Val Glu Ile Lys
100 105 110
<210> 169
<211> 118
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 169
Glu Gln Ser Val Lys Glu Ser Glu Gly Asp Leu Val Lys Pro Glu Gly
1 5 10 15
Ser Leu Thr Leu Ala Cys Thr Ala Ser Gly Phe Thr Leu Ser Ser Tyr
20 25 30
Tyr Met Cys Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Ala Cys Ile Asp Thr Asp Asn Asp Ile Arg Thr Ala Tyr Ala Ser Trp
50 55 60
Ala Arg Gly Arg Phe Thr Ile Ser Arg Thr Ser Ser Thr Thr Val Thr
65 70 75 80
Leu Gln Met Thr Ser Leu Thr Ala Ala Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Gly Arg Gly Tyr Gly Ala Leu Arg Leu Asp Leu Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Ile Ser Ser
115
<210> 170
<211> 110
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 170
Glu Leu Asp Leu Thr Gln Thr Pro Ala Ser Val Ser Ala Ala Val Gly
1 5 10 15
Gly Thr Val Ser Ile Asn Cys Gln Ser Ser Pro Ser Val Tyr Arg His
20 25 30
Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu
35 40 45
Ile Tyr Trp Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Gly Val Gln
65 70 75 80
Cys Asp Asp Ala Ala Thr Tyr Tyr Cys Ala Gly Glu Tyr Ala Ser Asp
85 90 95
Ser Asp Asn His Phe Gly Gly Gly Thr Glu Val Glu Ile Lys
100 105 110
<210> 171
<211> 114
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 171
Gln Ser Val Lys Glu Ser Glu Gly Arg Leu Val Thr Pro Gly Thr Pro
1 5 10 15
Leu Thr Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Ser Ser Tyr His
20 25 30
Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Tyr Ile Gly
35 40 45
Ile Ile Asn Asn Tyr Gly Ala Thr Tyr Tyr Ala Ser Trp Ala Lys Gly
50 55 60
Arg Phe Thr Ile Ser Arg Thr Ser Thr Thr Val Asp Leu Lys Met Thr
65 70 75 80
Ser Leu Thr Thr Glu Asp Thr Ala Thr Tyr Phe Cys Ala Arg Ser Pro
85 90 95
Gly Ile Pro Gly Tyr Asn Ser Trp Gly Pro Gly Thr Leu Val Thr Ile
100 105 110
Ser Ser
<210> 172
<211> 113
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 172
Glu Leu Asp Leu Thr Gln Thr Pro Ser Ser Thr Ser Ala Ala Val Gly
1 5 10 15
Gly Thr Val Thr Ile Asn Cys Gln Ser Ser Gln Asn Val Tyr Ser Tyr
20 25 30
Asn Arg Leu Ser Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
35 40 45
Leu Ile Tyr Glu Ala Ser Lys Leu Ala Ser Gly Val Pro Ser Arg Phe
50 55 60
Lys Gly Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser Gly Val
65 70 75 80
Gln Cys Asp Asp Ala Ala Thr Tyr Tyr Cys Ala Gly Gly Tyr Asp Cys
85 90 95
Arg Ser Ser Asp Cys Asp Ala Phe Gly Gly Gly Thr Glu Val Glu Ile
100 105 110
Lys
<210> 173
<211> 124
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 173
Ser Ser Ser Val Glu Glu Ser Gly Gly Asp Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Leu Thr Leu Thr Cys Thr Ala Ser Gly Phe Ser Phe Ser Ser Asn
20 25 30
Ser Met Cys Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Cys Ile Ala Ser Ser Ser Ser His Ser Thr Tyr Tyr Ala Ser Trp
50 55 60
Ala Lys Gly Arg Phe Thr Ile Ser Lys Thr Ser Ser Thr Thr Val Thr
65 70 75 80
Leu Gln Met Thr Ser Leu Thr Ala Ala Asp Met Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Asp Ser Gly Asn Arg Gly Tyr Leu Tyr Ala Gly Asp Phe Asn
100 105 110
Leu Trp Gly Pro Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 174
<211> 111
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 174
Glu Leu Val Leu Thr Gln Thr Pro Ala Ser Val Glu Val Ala Val Gly
1 5 10 15
Gly Thr Val Thr Ile Asn Cys Gln Ala Ser Gln Ser Ile Asn Ser Trp
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Gln Arg Pro Lys Leu Leu Ile
35 40 45
Tyr Glu Ala Ser Thr Leu Ala Ser Gly Val Ser Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser Gly Val Gln Cys
65 70 75 80
Asp Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Gly Tyr Ser Tyr Ser Asn
85 90 95
Val Asp Asn Asn Ile Phe Gly Gly Gly Thr Glu Val Val Val Lys
100 105 110
<210> 175
<211> 120
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 175
Gln Ser Leu Glu Glu Ser Gly Gly Gly Leu Val Lys Pro Glu Gly Ser
1 5 10 15
Leu Thr Leu Thr Cys Thr Ala Ser Gly Phe Asp Leu Ser Ser Ser Tyr
20 25 30
Tyr Met Cys Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Val Cys Ile Asp Gly Gly Gly Gly Glu Pro Thr Ala Tyr Pro Ser Trp
50 55 60
Ala Lys Gly Arg Phe Thr Val Ser Lys Thr Ser Ser Thr Thr Val Thr
65 70 75 80
Leu Gln Met Thr Ser Leu Thr Val Ala Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Arg Asp Ala Gly Ala Gly Asn Ala Phe Ser Leu Trp Gly Pro
100 105 110
Gly Thr Leu Val Thr Ile Ser Ser
115 120
<210> 176
<211> 110
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 176
Glu Leu Asp Met Thr Gln Thr Pro Ser Pro Val Ser Ala Ala Val Gly
1 5 10 15
Gly Thr Val Thr Ile Ser Cys Gln Ser Ser Gln Ser Val Tyr Leu Gln
20 25 30
Asn Asn Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
35 40 45
Leu Ile Tyr Tyr Ala Ser Thr Leu Ala Ser Gly Val Ser Ser Arg Phe
50 55 60
Lys Gly Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser Asp Leu
65 70 75 80
Glu Cys Asp Asp Ala Ala Thr Tyr Tyr Cys Gln Gly Gly Tyr Ser Gly
85 90 95
Tyr Ile Asn Ser Phe Gly Gly Gly Thr Glu Val Glu Ile Lys
100 105 110
<210> 177
<211> 118
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 177
Gln Ser Val Lys Glu Ser Glu Gly Asp Leu Val Lys Pro Gly Ala Ser
1 5 10 15
Leu Thr Leu Thr Cys Lys Ala Ser Gly Phe Asp Phe Ser Ser Ser Tyr
20 25 30
Phe Met Cys Trp Val Arg Gln Ala Pro Gly Arg Gly Leu Glu Trp Ile
35 40 45
Ala Cys Ile Tyr Thr Val Ile Ser Arg Lys Thr Tyr Tyr Ala Ser Trp
50 55 60
Ala Lys Gly Arg Phe Thr Ile Ser Lys Thr Ser Ala Thr Thr Val Asp
65 70 75 80
Leu Gln Met Thr Ser Leu Thr Ala Ala Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Ser Ala Thr Ile Glu Arg Leu Asp Leu Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 178
<211> 112
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 178
Glu Leu Asp Leu Thr Gln Thr Pro Ser Pro Val Ser Ala Pro Val Gly
1 5 10 15
Gly Thr Val Thr Ile Asn Cys Gln Ala Ser Glu Ser Val Tyr Asn Asn
20 25 30
Tyr Arg Leu Ser Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg Phe
50 55 60
Lys Gly Ser Gly Ser Gly Thr Gln Phe Thr Leu Ala Ile Ser Asp Val
65 70 75 80
Val Cys Asp Asp Ala Ala Thr Tyr Tyr Cys Val Gly Tyr Lys Ser Gly
85 90 95
Tyr Ile Asp Ser Ile Pro Phe Gly Gly Gly Thr Glu Val Val Val Lys
100 105 110
<210> 179
<211> 111
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 179
Gln Ser Leu Glu Glu Ser Gly Gly Asp Leu Val Lys Pro Gly Ala Ser
1 5 10 15
Leu Thr Leu Thr Cys Thr Ala Ser Gly Phe Thr Ile Asn Asn Tyr Asn
20 25 30
Ile Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile Ala
35 40 45
Arg Ile Trp Asn Gly Asp Gly Ser Thr Tyr Tyr Ala Ser Trp Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Lys Thr Ser Ser Thr Thr Val Thr Leu Gln
65 70 75 80
Met Thr Ser Leu Thr Ala Ala Asp Thr Ala Thr Tyr Phe Cys Ala Arg
85 90 95
Asn Phe Asn Leu Trp Gly Pro Gly Thr Leu Val Thr Ile Ser Ser
100 105 110
<210> 180
<211> 112
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic polypeptide
<400> 180
Glu Leu Val Leu Thr Gln Thr Pro Ser Pro Val Ser Ala Ala Val Gly
1 5 10 15
Gly Thr Val Thr Ile Asn Cys Gln Ser Ser Ala Ser Val Tyr Ser Asn
20 25 30
Asn Tyr Leu Ser Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Pro
35 40 45
Leu Ile Tyr Tyr Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg Phe
50 55 60
Lys Gly Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser Asp Val
65 70 75 80
Gln Cys Asp Asp Ala Ala Thr Tyr Tyr Cys Ala Gly Asp Tyr Ser Ser
85 90 95
Ser Ser Asp Met Cys Ile Phe Gly Gly Gly Thr Glu Leu Glu Ile Lys
100 105 110
Claims (55)
- EGFL6에 특이적으로 결합하며 다음을 포함하는, 단리된 단일클론 항체:
(I)
(a) 서열 번호: 4와 동일한 제 1 VH CDR;
(b) 서열 번호: 5와 동일한 제 2 VH CDR;
(c) 서열 번호: 6과 동일한 제 3 VH CDR;
(d) 서열 번호: 76과 동일한 제 1 VL CDR;
(e) 서열 번호: 77과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 78과 동일한 제 3 VL CDR;
(II)
(a) 서열 번호: 10과 동일한 제 1 VH CDR;
(b) 서열 번호: 11과 동일한 제 2 VH CDR;
(c) 서열 번호: 12와 동일한 제 3 VH CDR;
(d) 서열 번호: 82와 동일한 제 1 VL CDR;
(e) 서열 번호: 83과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 84와 동일한 제 3 VL CDR;
(III)
(a) 서열 번호: 16과 동일한 제 1 VH CDR;
(b) 서열 번호: 17과 동일한 제 2 VH CDR;
(c) 서열 번호: 18과 동일한 제 3 VH CDR;
(d) 서열 번호: 88과 동일한 제 1 VL CDR;
(e) 서열 번호: 77과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 89와 동일한 제 3 VL CDR;
(IV)
(a) 서열 번호: 22와 동일한 제 1 VH CDR;
(b) 서열 번호: 23과 동일한 제 2 VH CDR;
(c) 서열 번호: 24와 동일한 제 3 VH CDR;
(d) 서열 번호: 93과 동일한 제 1 VL CDR;
(e) 서열 번호: 94과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 95와 동일한 제 3 VL CDR;
(V)
(a) 서열 번호: 28와 동일한 제 1 VH CDR;
(b) 서열 번호: 29와 동일한 제 2 VH CDR;
(c) 서열 번호: 30과 동일한 제 3 VH CDR;
(d) 서열 번호: 99과 동일한 제 1 VL CDR;
(e) 서열 번호: 100과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 101와 동일한 제 3 VL CDR;
(VI)
(a) 서열 번호: 34와 동일한 제 1 VH CDR;
(b) 서열 번호: 35와 동일한 제 2 VH CDR;
(c) 서열 번호: 36과 동일한 제 3 VH CDR;
(d) 서열 번호: 104과 동일한 제 1 VL CDR;
(e) 서열 번호: 100과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 105와 동일한 제 3 VL CDR;
(VII)
(a) 서열 번호: 40와 동일한 제 1 VH CDR;
(b) 서열 번호: 41와 동일한 제 2 VH CDR;
(c) 서열 번호: 42과 동일한 제 3 VH CDR;
(d) 서열 번호: 108과 동일한 제 1 VL CDR;
(e) 서열 번호: 77과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 109와 동일한 제 3 VL CDR.
(VIII)
(a) 서열 번호: 46와 동일한 제 1 VH CDR;
(b) 서열 번호: 47와 동일한 제 2 VH CDR;
(c) 서열 번호: 48과 동일한 제 3 VH CDR;
(d) 서열 번호: 113과 동일한 제 1 VL CDR;
(e) 서열 번호: 83과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 114와 동일한 제 3 VL CDR.
(IX)
(a) 서열 번호: 52와 동일한 제 1 VH CDR;
(b) 서열 번호: 53와 동일한 제 2 VH CDR;
(c) 서열 번호: 54와 동일한 제 3 VH CDR;
(d) 서열 번호: 117과 동일한 제 1 VL CDR;
(e) 서열 번호: 83과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 119와 동일한 제 3 VL CDR.
(X)
(a) 서열 번호: 58과 동일한 제 1 VH CDR;
(b) 서열 번호: 59와 동일한 제 2 VH CDR;
(c) 서열 번호: 60과 동일한 제 3 VH CDR;
(d) 서열 번호: 121과 동일한 제 1 VL CDR;
(e) 서열 번호: 100과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 122와 동일한 제 3 VL CDR.
(XI)
(a) 서열 번호: 64와 동일한 제 1 VH CDR;
(b) 서열 번호: 65와 동일한 제 2 VH CDR;
(c) 서열 번호: 66과 동일한 제 3 VH CDR;
(d) 서열 번호: 126과 동일한 제 1 VL CDR;
(e) 서열 번호: 127과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 128과 동일한 제 3 VL CDR; 또는
(XII)
(a) 서열 번호: 70과 동일한 제 1 VH CDR;
(b) 서열 번호: 71과 동일한 제 2 VH CDR;
(c) 서열 번호: 72와 동일한 제 3 VH CDR;
(d) 서열 번호: 131과 동일한 제 1 VL CDR;
(e) 서열 번호: 100과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 132와 동일한 제 3 VL CDR.
- 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 4와 동일한 제 1 VH CDR;
(b) 서열 번호: 5와 동일한 제 2 VH CDR;
(c) 서열 번호: 6과 동일한 제 3 VH CDR.
(d) 서열 번호: 76과 동일한 제 1 VL CDR;
(e) 서열 번호: 77과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 78과 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 10과 동일한 제 1 VH CDR;
(b) 서열 번호: 11과 동일한 제 2 VH CDR;
(c) 서열 번호: 12와 동일한 제 3 VH CDR;
(d) 서열 번호: 82와 동일한 제 1 VL CDR;
(e) 서열 번호: 83과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 84와 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 16과 동일한 제 1 VH CDR;
(b) 서열 번호: 17과 동일한 제 2 VH CDR;
(c) 서열 번호: 18과 동일한 제 3 VH CDR;
(d) 서열 번호: 88과 동일한 제 1 VL CDR;
(e) 서열 번호: 77과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 89와 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 22와 동일한 제 1 VH CDR;
(b) 서열 번호: 23과 동일한 제 2 VH CDR;
(c) 서열 번호: 24와 동일한 제 3 VH CDR;
(d) 서열 번호: 93과 동일한 제 1 VL CDR;
(e) 서열 번호: 94와 동일한 제 2 VL CDR; 및
(f) 서열 번호: 95와 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 28와 동일한 제 1 VH CDR;
(b) 서열 번호: 29와 동일한 제 2 VH CDR;
(c) 서열 번호: 30과 동일한 제 3 VH CDR;
(d) 서열 번호: 99와 동일한 제 1 VL CDR;
(e) 서열 번호: 100과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 101과 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 34와 동일한 제 1 VH CDR;
(b) 서열 번호: 35와 동일한 제 2 VH CDR;
(c) 서열 번호: 36과 동일한 제 3 VH CDR;
(d) 서열 번호: 104과 동일한 제 1 VL CDR;
(e) 서열 번호: 100과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 105와 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 40와 동일한 제 1 VH CDR;
(b) 서열 번호: 41와 동일한 제 2 VH CDR;
(c) 서열 번호: 42과 동일한 제 3 VH CDR;
(d) 서열 번호: 108과 동일한 제 1 VL CDR;
(e) 서열 번호: 77과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 109와 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 46와 동일한 제 1 VH CDR;
(b) 서열 번호: 47와 동일한 제 2 VH CDR;
(c) 서열 번호: 48과 동일한 제 3 VH CDR;
(d) 서열 번호: 113과 동일한 제 1 VL CDR;
(e) 서열 번호: 83과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 114와 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 52와 동일한 제 1 VH CDR;
(b) 서열 번호: 53와 동일한 제 2 VH CDR;
(c) 서열 번호: 54와 동일한 제 3 VH CDR;
(d) 서열 번호: 117과 동일한 제 1 VL CDR;
(e) 서열 번호: 83과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 119와 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 58과 동일한 제 1 VH CDR;
(b) 서열 번호: 59와 동일한 제 2 VH CDR;
(c) 서열 번호: 60과 동일한 제 3 VH CDR;
(d) 서열 번호: 121과 동일한 제 1 VL CDR;
(e) 서열 번호: 100과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 122와 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 64와 동일한 제 1 VH CDR;
(b) 서열 번호: 65와 동일한 제 2 VH CDR;
(c) 서열 번호: 66과 동일한 제 3 VH CDR;
(d) 서열 번호: 126과 동일한 제 1 VL CDR;
(e) 서열 번호: 127과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 128과 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(a) 서열 번호: 70과 동일한 제 1 VH CDR;
(b) 서열 번호: 71과 동일한 제 2 VH CDR;
(c) 서열 번호: 72와 동일한 제 3 VH CDR;
(d) 서열 번호: 131과 동일한 제 1 VL CDR;
(e) 서열 번호: 100과 동일한 제 2 VL CDR; 및
(f) 서열 번호: 132와 동일한 제 3 VL CDR. - 청구항 1에 있어서, 항체는 다음을 포함함을 특징으로 하는 항체:
(i) E1-33의 VH 도메인 (서열 번호: 157) 또는 E1-33 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E1-33의 VL 도메인 (서열 번호: 158) 또는 E1-33 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인;
(ii) E1-34의 VH 도메인 (서열 번호: 159) 또는 E1-34 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E1-34의 VL 도메인 (서열 번호: 160) 또는 E1-34 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인;
(iii) E1-80의 VH 도메인 (서열 번호: 161) 또는 E1-80 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E1-80의 VL 도메인 (서열 번호: 162) 또는 E1-80 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인;
(iv) E1-89의 VH 도메인 (서열 번호: 163) 또는 E1-89 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E1-89의 VL 도메인 (서열 번호: 164) 또는 E1-89 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인;
(v) E2-93의 VH 도메인 (서열 번호: 165) 또는 E2-93 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E2-93의 VL 도메인 (서열 번호: 166) 또는 E2-93 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인;
(vi) E1-38의 VH 도메인 (서열 번호: 167) 또는 E1-38 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E1-38의 VL 도메인 (서열 번호: 168) 또는 E1-38 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인;
(vii) E1-52의 VH 도메인 (서열 번호: 169) 또는 E1-52 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E1-52의 VL 도메인 (서열 번호: 170) 또는 E1-52 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인;
(viii) E2-36의 VH 도메인 (서열 번호: 171) 또는 E2-36 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E2-36의 VL 도메인 (서열 번호: 172) 또는 E2-36 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인;
(ix) E1-95의 VH 도메인 (서열 번호: 173) 또는 E1-95 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E1-95의 VL 도메인 (서열 번호: 174) 또는 E1-95 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인;
(x) E2-116의 VH 도메인 (서열 번호: 175) 또는 E2-116 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E2-116의 VL 도메인 (서열 번호: 176) 또는 E2-116 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인;
(xi) E2-135의 VH 도메인 (서열 번호: 177) 또는 E2-135 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E2-135의 VL 도메인 (서열 번호: 178) 또는 E2-135 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인;
(xii) E1-142의 VH 도메인 (서열 번호: 179) 또는 E1-142 mAB의 인간화 VH 도메인과 최소한 약 80% 동일한 VH 도메인; 및 E1-142의 VL 도메인 (서열 번호: 180) 또는 E1-142 mAB의 인간화 VL 도메인과 최소한 약 80% 동일한 VL 도메인. - 청구항 14에 있어서, 항체는 E1-33의 VH 도메인 (서열 번호: 157)와 동일한 VH 도메인 및 E1-33의 VL 도메인 (서열 번호: 158)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E1-34의 VH 도메인 (서열 번호: 159)와 동일한 VH 도메인 및 E1-34의 VL 도메인 (서열 번호: 160)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E1-80의 VH 도메인 (서열 번호: 161)와 동일한 VH 도메인 및 E1-80의 VL 도메인 (서열 번호: 162)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E1-89의 VH 도메인 (서열 번호: 163)와 동일한 VH 도메인 및 E1-89의 VL 도메인 (서열 번호: 164)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E2-93의 VH 도메인 (서열 번호: 165)와 동일한 VH 도메인 및 E2-93의 VL 도메인 (서열 번호: 166)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E1-38의 VH 도메인 (서열 번호: 167)와 동일한 VH 도메인 및 E1-38의 VL 도메인 (서열 번호: 168)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E1-52의 VH 도메인 (서열 번호: 169)와 동일한 VH 도메인 및 E1-52의 VL 도메인 (서열 번호: 170)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E2-36의 VH 도메인 (서열 번호: 171)와 동일한 VH 도메인 및 E2-36의 VL 도메인 (서열 번호: 172)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E1-95의 VH 도메인 (서열 번호: 173)와 동일한 VH 도메인 및 E1-95의 VL 도메인 (서열 번호: 174)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E2-116의 VH 도메인 (서열 번호: 175)와 동일한 VH 도메인 및 E2-116의 VL 도메인 (서열 번호: 176)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E2-135의 VH 도메인 (서열 번호: 177)와 동일한 VH 도메인 및 E2-135의 VL 도메인 (서열 번호: 178)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E1-142의 VH 도메인 (서열 번호: 179)와 동일한 VH 도메인 및 E1-142의 VL 도메인 (서열 번호: 180)과 동일한 VL 도메인을 포함함을 특징으로 하는 항체.
- 청구항 14에 있어서, 항체는 E1-33, E1-34, E1-80, E1-89, E2-93, E1-38, E1-52, E2-36,E1-95, E2-116, E2-135, 또는 E1-142 항체임을 특징으로 하는 항체.
- 청구항 1-27 중 어느 한 항에 있어서, 항체는 재조합임을 특징으로 하는 항체.
- 청구항 1에 있어서, 항체는 IgG, IgM, IgA 또는 이의 항원 결합 단편임을 특징으로 하는 항체.
- 청구항 1-27 중 어느 한 항에 있어서, 항체는 Fab', F(ab')2, F(ab')3, 1가 scFv, 2가 scFv, 또는 단일 도메인 항체임을 특징으로 하는 항체.
- 청구항 1-13 중 어느 한 항에 있어서, 항체는 인간, 인간화 항체 또는 탈-인간화 항체임을 특징으로 하는 항체.
- 청구항 1-27 중 어느 한 항에 있어서, 항체는 조영제, 화학치료제, 독소 또는 방사성핵종에 접합됨을 특징으로 하는 항체.
- 청구항 32에 있어서, 항체는 독소에 접합됨을 특징으로 하는 항체.
- 청구항 33에 있어서, 독소는 오리스타틴임을 특징으로 하는 항체.
- 청구항 33에 있어서, 독소는 모노메틸 오리스타틴 E (MMAE)임을 특징으로 하는 항체.
- 청구항 1-27 중 어느 한 항의 항체를 제약학적으로 허용가능한 담체에 포함하는 조성물.
- 청구항 1-27 중 어느 한 항의 항체를 인코딩하는 핵산 서열을 포함하는 단리된 폴리뉴클레오티드 분자.
- E1-33의 VH 도메인의 CDRs 1-3 (서열 번호: 4, 5, 및 6); E1-34의 VH 도메인의 CDRs 1-3 (서열 번호: 10, 11, 및 12); E1-80의 VH 도메인의 CDRs 1-3 (서열 번호: 16, 17, 및 18); E1-89의 VH 도메인의 CDRs 1-3 (서열 번호: 22, 23, 및 24); E2-93의 VH 도메인의 CDRs 1-3 (서열 번호: 28, 29, 및 30); E1-38의 VH 도메인의 CDRs 1-3 (서열 번호: 34, 35, 및 36); E1-52의 VH 도메인의 CDRs 1-3 (서열 번호: 40, 41, 및 42); E2-36의 VH 도메인의 CDRs 1-3 (서열 번호: 46, 47, 및 48); E1-95의 VH 도메인의 CDRs 1-3 (서열 번호: 52, 53, 및 54); E2-116의 VH 도메인의 CDRs 1-3 (서열 번호: 58, 59, 및 60); E2-135의 VH 도메인의 CDRs 1-3 (서열 번호: 64, 65, 및 66); 또는 E1-142의 VH 도메인의 CDRs 1-3 (서열 번호: 70, 71, 및 72)을 포함하는 항체 VH 도메인을 포함하는 재조합 폴리펩티드
- E1-33의 VL 도메인의 CDRs 1-3 (서열 번호: 76, 77, 및 78); E1-34의 VL 도메인의 CDRs 1-3 (서열 번호: 82, 83, 및 84); E1-80의 VL 도메인의 CDRs 1-3 (서열 번호: 88, 77, 및 89); E1-89의 VL 도메인의 CDRs 1-3 (서열 번호: 93, 94, 및 95); E2-93의 VL 도메인의 CDRs 1-3 (서열 번호: 99, 100, 및 101); E1-38의 VL 도메인의 CDRs 1-3 (서열 번호: 104, 100, 및 105); E1-52의 VL 도메인의 CDRs 1-3 (서열 번호: 108, 77, 및 109); E2-36의 VL 도메인의 CDRs 1-3 (서열 번호: 113, 83, 및 114); E1-95의 VL 도메인의 CDRs 1-3 (서열 번호: 117, 83, 및 118); E2-116의 VL 도메인의 CDRs 1-3 (서열 번호: 121, 100, 및 122); E2-135의 VL 도메인의 CDRs 1-3 (서열 번호: 126, 127, 및 128); 또는 E1-142의 VL 도메인의 CDRs 1-3 (서열 번호: 131, 100, 및 132)을 포함하는 항체 VL 도메인을 포함하는 재조합 폴리펩티드.
- 청구항 38 또는 39의 폴리펩티드를 인코딩하는 핵산 서열을 포함하는 단리된 폴리뉴클레오티드 분자.
- 청구항 1-27 중 어느 한 항의 항체를 인코딩하는 하나 이상의 폴리뉴클레오티드 분자(들) 및 청구항 38 또는 39의 재조합 폴리펩티드를 포함하는 숙주 세포.
- 청구항 41에 있어서, 숙주 세포는 포유동물 세포, 효모 세포, 세균 세포, 섬모충 세포 또는 곤충 세포임을 특징으로 하는 세포.
- 다음을 포함하는 항체의 제조 방법:
(a) 청구항 1-27 중 어느 한 항의 항체의 VL 및 VH 사슬을 인코딩하는 하나 이상의 폴리뉴클레오티드 분자(들)를 세포에서 발현시키는 단계; 및
(b) 세포로부터 상기 항체를 정제하는 단계. - 청구항 1- 27 중 어느 한 항의 유효량의 항체를 대상체에 투여하는 단계를 포함하는 암에 걸린 대상체의 치료 방법.
- 청구항 44에 있어서, 암은 유방암, 폐암, 두경부암, 전립선암, 식도암, 기관암, 피부암 뇌암, 간암, 방광암, 위암, 이자암, 난소암, 자궁암, 자궁경부암, 고환암, 결장암, 직장암 또는 피부암임을 특징으로 하는 방법.
- 청구항 44에 있어서, 암은 상피 암임을 특징으로 하는 방법.
- 청구항 44에 있어서, 암은 결장직장 선암종, 폐 선암종, 폐 편평세포 암종, 유방암, 간세포 암종, 난소암, 신장 신장 투명세포 암종, 폐암 또는 신장 암임을 특징으로 하는 방법.
- 청구항 44에 있어서, 항체는 제약학적으로 허용가능한 조성물에 존재함을 특징으로 하는 방법.
- 청구항 44에 있어서, 항체는 전신에 투여됨을 특징으로 하는 방법.
- 청구항 44에 있어서, 항체는 정맥내, 진피내, 종양내, 근육내, 복강내, 피하, 또는 국소 투여됨을 특징으로 하는 방법.
- 청구항 44에 있어서, 최소한 제 2 항암 요법을 대상체에 투여하는 단계를 추가로 포함함을 특징으로 하는 방법.
- 청구항 51에 있어서, 제 2 항암 요법은 외과수술 요법, 화학요법, 방사선 요법, 냉동요법, 호르몬 요법, 면역요법 또는 사이토카인 요법임을 특징으로 하는 방법.
- 대상체에서 얻은 샘플에서 대조군에 비해 상승된 EGFL6의 존재에 관하여 테스트하는 단계를 포함하며, 이 때 테스트 단계는 청구항 14-27 또는 32 중 어느 한 항의 항체와 상기 샘플을 접촉시키는 단계를 포함하는, 대상체에서 암을 탐지하는 방법.
- 청구항 53에 있어서, 시험관내 방법으로 추가로 정의됨을 특징으로 하는 방법.
- 다음을 포함하는 단리된 항체:
(a) E1-33 (서열 번호: 4), E1-34 (서열 번호: 10), E1-80 (서열 번호: 16), E1-89 (서열 번호: 22), E2-93 (서열 번호: 28), E1-38 (서열 번호: 34), E1-52 (서열 번호: 40), E2-36 (서열 번호: 46), E1-95 (서열 번호: 52), E2-116 (서열 번호: 58), E2-135 (서열 번호: 64), 또는 E1-142 (서열 번호: 70)의 VH CDR1과 최소한 80% 동일한 제 1 VH CDR;
(b) E1-33 (서열 번호: 5), E1-34 (서열 번호: 11), E1-80 (서열 번호: 17), E1-89 (서열 번호: 23), E2-93 (서열 번호: 29), E1-38 (서열 번호: 35), E1-52 (서열 번호: 41), E2-36 (서열 번호: 47), E1-95 (서열 번호: 53), E2-116 (서열 번호: 59), E2-135 (서열 번호: 65), 또는 E1-142 (서열 번호: 71)의 VH CDR2와 최소한 80% 동일한 제 2 VH CDR ;
(c) E1-33 (서열 번호: 6), E1-34 (서열 번호: 12), E1-80 (서열 번호: 18), E1-89 (서열 번호: 24), E2-93 (서열 번호: 30), E1-38 (서열 번호: 36), E1-52 (서열 번호: 42), E2-36 (서열 번호: 48), E1-95 (서열 번호: 54), E2-116 (서열 번호: 60), E2-135 (서열 번호: 66),또는 E1-142 (서열 번호: 72)의 VH CDR3와 최소한 80% 동일한 제 3 VH CDR;
(d) E1-33 (서열 번호: 76), E1-34 (서열 번호: 82), E1-80 (서열 번호: 88), E1-89 (서열 번호: 93), E2-93 (서열 번호: 99), E1-38 (서열 번호: 104), E1-52 (서열 번호: 108), E2-36 (서열 번호: 113), E1-95 (서열 번호: 117), E2-116 (서열 번호: 121), E2-135 (서열 번호: 126), 또는 E1-142 (서열 번호: 131)의 VL CDR1과 최소한 80% 동일한 제 1 VL CDR;
(e) E1-33 (서열 번호: 77), E1-34 (서열 번호: 83), E1-80 (서열 번호: 77), E1-89 (서열 번호: 94), E2-93 (서열 번호: 100), E1-38 (서열 번호: 100), E1-52 (서열 번호: 77), E2-36 (서열 번호: 83), E1-95 (서열 번호: 83), E2-116 (서열 번호: 100), E2-135 (서열 번호: 127), 또는 E1-142 (서열 번호: 100)의 VL CDR2와 최소한 80% 동일한 제 2 VL CDR; 및
(f) E1-33 (서열 번호: 78), E1-34 (서열 번호: 84), E1-80 (서열 번호: 89), E1-89 (서열 번호: 95), E2-93 (서열 번호: 101), E1-38 (서열 번호: 105), E1-52 (서열 번호: 109), E2-36 (서열 번호: 114), E1-95 (서열 번호: 118), E2-116 (서열 번호: 122), E2-135 (서열 번호: 128), 또는 E1-142 (서열 번호: 132)의 VL CDR3와 최소한 80% 동일한 제 3 VL CDR.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201662291987P | 2016-02-05 | 2016-02-05 | |
| US62/291,987 | 2016-02-05 | ||
| PCT/US2017/016659 WO2017136807A1 (en) | 2016-02-05 | 2017-02-06 | Egfl6 specific monoclonal antibodies and methods of their use |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20180105704A true KR20180105704A (ko) | 2018-09-28 |
Family
ID=59501106
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187024950A KR20180105704A (ko) | 2016-02-05 | 2017-02-06 | Egfl6 특이적 단일클론 항체들 및 이의 사용 방법 |
Country Status (12)
| Country | Link |
|---|---|
| US (2) | US10875912B2 (ko) |
| EP (1) | EP3411070A4 (ko) |
| JP (3) | JP2019512210A (ko) |
| KR (1) | KR20180105704A (ko) |
| CN (2) | CN109562163B (ko) |
| AU (2) | AU2017214685B2 (ko) |
| BR (1) | BR112018015826A2 (ko) |
| CA (1) | CA3012696A1 (ko) |
| MX (1) | MX2018009499A (ko) |
| SG (1) | SG11201806622PA (ko) |
| WO (1) | WO2017136807A1 (ko) |
| ZA (1) | ZA201805051B (ko) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2017214685B2 (en) * | 2016-02-05 | 2024-03-07 | The Board Of Regents Of The University Of Texas System | EGFL6 specific monoclonal antibodies and methods of their use |
| US11578121B2 (en) * | 2017-10-01 | 2023-02-14 | Taipei Medical University | Anti-EGF like domain multiple 6 (EGFL6) antibodies |
| CN113272327A (zh) * | 2018-12-30 | 2021-08-17 | 豪夫迈·罗氏有限公司 | 抗兔cd19抗体及其使用方法 |
| CN110951733A (zh) * | 2019-11-27 | 2020-04-03 | 山西医科大学 | 一种靶向抑制食管癌EGFL6基因表达的siRNA及构建的表达载体和应用 |
| CN116381251B (zh) * | 2023-03-13 | 2024-06-25 | 柏定生物工程(北京)有限公司 | 一种肿瘤标志物诊断试剂盒及其诊断方法 |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2172273A1 (en) * | 1994-07-29 | 1996-02-15 | Geert Maertens | Purified hepatitis c virus envelope proteins for diagnostic and therapeutic use |
| US20030036508A1 (en) | 1997-11-22 | 2003-02-20 | John Ford | EGF motif protein, EGFL6 materials and methods |
| CA2425833A1 (en) | 2000-10-13 | 2002-04-18 | Hyseq, Inc. | Egf motif protein, egfl6 materials and methods |
| AU2005338519B2 (en) * | 2005-11-24 | 2011-06-16 | National Institute Of Biomedical Innovation | Recombinant polyvalent vaccine |
| AR059851A1 (es) * | 2006-03-16 | 2008-04-30 | Genentech Inc | Anticuerpos de la egfl7 y metodos de uso |
| EP3216803B1 (en) * | 2008-06-25 | 2020-03-11 | Novartis Ag | Stable and soluble antibodies inhibiting vegf |
| US8501197B2 (en) * | 2010-04-30 | 2013-08-06 | The Research Foundation for The State of New York | Compositions and methods for stimulating immune response against Moraxella catarrhalis |
| CN103906765A (zh) * | 2011-09-23 | 2014-07-02 | 抗菌技术生物技术研究与发展股份有限公司 | 抗肿瘤坏死因子-α试剂及其用途 |
| US9850300B2 (en) * | 2013-03-15 | 2017-12-26 | The Regents Of The University Of Michigan | Compositions and methods relating to inhibiting cancer cell growth and/or proliferation |
| WO2014190273A1 (en) | 2013-05-24 | 2014-11-27 | Board Of Regents, The University Of Texas System | Chimeric antigen receptor-targeting monoclonal antibodies |
| AU2017214685B2 (en) * | 2016-02-05 | 2024-03-07 | The Board Of Regents Of The University Of Texas System | EGFL6 specific monoclonal antibodies and methods of their use |
-
2017
- 2017-02-06 AU AU2017214685A patent/AU2017214685B2/en active Active
- 2017-02-06 CN CN201780015519.9A patent/CN109562163B/zh active Active
- 2017-02-06 US US16/075,711 patent/US10875912B2/en active Active
- 2017-02-06 WO PCT/US2017/016659 patent/WO2017136807A1/en active Application Filing
- 2017-02-06 MX MX2018009499A patent/MX2018009499A/es unknown
- 2017-02-06 BR BR112018015826A patent/BR112018015826A2/pt unknown
- 2017-02-06 CN CN202110985801.8A patent/CN113912717B/zh active Active
- 2017-02-06 CA CA3012696A patent/CA3012696A1/en active Pending
- 2017-02-06 JP JP2018540833A patent/JP2019512210A/ja active Pending
- 2017-02-06 EP EP17748334.4A patent/EP3411070A4/en active Pending
- 2017-02-06 SG SG11201806622PA patent/SG11201806622PA/en unknown
- 2017-02-06 KR KR1020187024950A patent/KR20180105704A/ko not_active Application Discontinuation
-
2018
- 2018-07-26 ZA ZA2018/05051A patent/ZA201805051B/en unknown
-
2020
- 2020-11-12 US US17/096,280 patent/US20210130450A1/en active Pending
-
2021
- 2021-08-30 JP JP2021139610A patent/JP7358426B2/ja active Active
-
2023
- 2023-06-29 JP JP2023106822A patent/JP2023130411A/ja active Pending
-
2024
- 2024-05-29 AU AU2024203614A patent/AU2024203614A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| MX2018009499A (es) | 2019-05-06 |
| CA3012696A1 (en) | 2017-08-10 |
| CN113912717A (zh) | 2022-01-11 |
| SG11201806622PA (en) | 2018-09-27 |
| JP2019512210A (ja) | 2019-05-16 |
| AU2024203614A1 (en) | 2024-06-20 |
| RU2018131611A (ru) | 2020-03-05 |
| US10875912B2 (en) | 2020-12-29 |
| EP3411070A1 (en) | 2018-12-12 |
| JP2023130411A (ja) | 2023-09-20 |
| BR112018015826A2 (pt) | 2019-01-02 |
| AU2017214685A1 (en) | 2018-08-09 |
| CN109562163A (zh) | 2019-04-02 |
| AU2017214685B2 (en) | 2024-03-07 |
| ZA201805051B (en) | 2023-05-31 |
| JP7358426B2 (ja) | 2023-10-10 |
| JP2022008309A (ja) | 2022-01-13 |
| WO2017136807A1 (en) | 2017-08-10 |
| US20210130450A1 (en) | 2021-05-06 |
| RU2018131611A3 (ko) | 2020-05-19 |
| CN109562163B (zh) | 2022-04-08 |
| EP3411070A4 (en) | 2019-11-27 |
| CN113912717B (zh) | 2024-05-03 |
| US20190031751A1 (en) | 2019-01-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11033634B2 (en) | Light chain variable regions | |
| US11174320B2 (en) | HER3 specific monoclonal antibodies for diagnostic and therapeutic use | |
| JP7358426B2 (ja) | Egfl6特異的モノクローナル抗体及びそれらの使用方法 | |
| KR20180088445A (ko) | 신규한 항-클라우딘 항체 및 사용 방법 | |
| US11053311B2 (en) | Antibodies targeting CDH19 for melanoma | |
| IL310865A (en) | Antibodies against EDB and antibody-drug conjugates | |
| CN110831622B (zh) | Fgl2单克隆抗体及其在治疗恶性肿瘤中的用途 | |
| EP2912064B1 (en) | Jam-c antibodies and methods for treatment of cancer | |
| RU2779902C2 (ru) | Egfl6-специфические моноклональные антитела и способы их применения | |
| CN114316046B (zh) | 一种稳定的抗体组合物 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal |