KR20170093248A - 탄산무수화효소 ix 특이적 키메라 항원 수용체 및 이의 사용 방법 - Google Patents
탄산무수화효소 ix 특이적 키메라 항원 수용체 및 이의 사용 방법 Download PDFInfo
- Publication number
- KR20170093248A KR20170093248A KR1020177020099A KR20177020099A KR20170093248A KR 20170093248 A KR20170093248 A KR 20170093248A KR 1020177020099 A KR1020177020099 A KR 1020177020099A KR 20177020099 A KR20177020099 A KR 20177020099A KR 20170093248 A KR20170093248 A KR 20170093248A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- gly
- leu
- ala
- val
- Prior art date
Links
- 102100024423 Carbonic anhydrase 9 Human genes 0.000 title claims abstract description 86
- 108700012439 CA9 Proteins 0.000 title claims abstract description 78
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 title claims abstract description 71
- 238000000034 method Methods 0.000 title claims abstract description 44
- 210000004027 cell Anatomy 0.000 claims abstract description 324
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 133
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 90
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 claims description 26
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 claims description 26
- 108010002350 Interleukin-2 Proteins 0.000 claims description 20
- 102000005962 receptors Human genes 0.000 claims description 20
- 108020003175 receptors Proteins 0.000 claims description 20
- 230000004068 intracellular signaling Effects 0.000 claims description 14
- -1 ICOS Proteins 0.000 claims description 9
- 208000008839 Kidney Neoplasms Diseases 0.000 claims description 8
- 206010038389 Renal cancer Diseases 0.000 claims description 8
- 201000010982 kidney cancer Diseases 0.000 claims description 8
- 239000012528 membrane Substances 0.000 claims description 6
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 claims description 5
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 claims description 5
- 210000000822 natural killer cell Anatomy 0.000 claims description 5
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 claims description 4
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 claims description 4
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 3
- 206010005003 Bladder cancer Diseases 0.000 claims description 3
- 206010006187 Breast cancer Diseases 0.000 claims description 3
- 208000026310 Breast neoplasm Diseases 0.000 claims description 3
- 208000030808 Clear cell renal carcinoma Diseases 0.000 claims description 3
- 206010009944 Colon cancer Diseases 0.000 claims description 3
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 3
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 3
- 206010033128 Ovarian cancer Diseases 0.000 claims description 3
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 3
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 3
- 201000004101 esophageal cancer Diseases 0.000 claims description 3
- 208000002154 non-small cell lung carcinoma Diseases 0.000 claims description 3
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 claims description 3
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 3
- 208000029742 colonic neoplasm Diseases 0.000 claims description 2
- 125000003275 alpha amino acid group Chemical group 0.000 claims 28
- 206010073251 clear cell renal cell carcinoma Diseases 0.000 claims 1
- 230000009261 transgenic effect Effects 0.000 claims 1
- 238000011282 treatment Methods 0.000 abstract description 27
- 208000006265 Renal cell carcinoma Diseases 0.000 abstract description 14
- 210000003370 receptor cell Anatomy 0.000 abstract description 3
- 102100035932 Cocaine- and amphetamine-regulated transcript protein Human genes 0.000 description 100
- 101000715592 Homo sapiens Cocaine- and amphetamine-regulated transcript protein Proteins 0.000 description 100
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 86
- 150000001413 amino acids Chemical group 0.000 description 73
- 241000282414 Homo sapiens Species 0.000 description 71
- 241000880493 Leptailurus serval Species 0.000 description 57
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 54
- 239000013598 vector Substances 0.000 description 54
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 53
- 210000004881 tumor cell Anatomy 0.000 description 47
- 108020004414 DNA Proteins 0.000 description 45
- 230000014509 gene expression Effects 0.000 description 45
- 150000007523 nucleic acids Chemical group 0.000 description 45
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 42
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 42
- 108090000623 proteins and genes Proteins 0.000 description 39
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 38
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 37
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 37
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 37
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 36
- JBDLMLZNDRLDIX-HJGDQZAQSA-N Asn-Thr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O JBDLMLZNDRLDIX-HJGDQZAQSA-N 0.000 description 36
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 36
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 36
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 36
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 36
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 36
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 36
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 36
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 36
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 36
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 36
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 36
- 108010008355 arginyl-glutamine Proteins 0.000 description 36
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 35
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 35
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 34
- 108010089804 glycyl-threonine Proteins 0.000 description 34
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 32
- 108090000765 processed proteins & peptides Proteins 0.000 description 32
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 31
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 31
- JJGRJMKUOYXZRA-LPEHRKFASA-N Asn-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N)C(=O)O JJGRJMKUOYXZRA-LPEHRKFASA-N 0.000 description 30
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 30
- 108010081404 acein-2 Proteins 0.000 description 29
- 102000004196 processed proteins & peptides Human genes 0.000 description 29
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 29
- AWNAEZICPNGAJK-FXQIFTODSA-N Ala-Met-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O AWNAEZICPNGAJK-FXQIFTODSA-N 0.000 description 28
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 28
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 28
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 28
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 28
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 27
- WTWGOQRNRFHFQD-JBDRJPRFSA-N Ser-Ala-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WTWGOQRNRFHFQD-JBDRJPRFSA-N 0.000 description 27
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 26
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 26
- DJDSEDOKJTZBAR-ZDLURKLDSA-N Thr-Gly-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O DJDSEDOKJTZBAR-ZDLURKLDSA-N 0.000 description 26
- 108010057821 leucylproline Proteins 0.000 description 26
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 25
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 25
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 25
- 229920001184 polypeptide Polymers 0.000 description 25
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 23
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 23
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 23
- QLSRIZIDQXDQHK-RCWTZXSCSA-N Arg-Val-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QLSRIZIDQXDQHK-RCWTZXSCSA-N 0.000 description 22
- FOCSWPCHUDVNLP-PMVMPFDFSA-N His-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC4=CN=CN4)N FOCSWPCHUDVNLP-PMVMPFDFSA-N 0.000 description 22
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 22
- 201000011510 cancer Diseases 0.000 description 22
- 102000039446 nucleic acids Human genes 0.000 description 22
- 108020004707 nucleic acids Proteins 0.000 description 22
- OTQSTOXRUBVWAP-NRPADANISA-N Gln-Ser-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OTQSTOXRUBVWAP-NRPADANISA-N 0.000 description 21
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 21
- 241000699670 Mus sp. Species 0.000 description 21
- FWTFAZKJORVTIR-VZFHVOOUSA-N Thr-Ser-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O FWTFAZKJORVTIR-VZFHVOOUSA-N 0.000 description 21
- CKTMJBPRVQWPHU-JSGCOSHPSA-N Val-Phe-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)O)N CKTMJBPRVQWPHU-JSGCOSHPSA-N 0.000 description 21
- KVXVVDFOZNYYKZ-DCAQKATOSA-N Gln-Gln-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KVXVVDFOZNYYKZ-DCAQKATOSA-N 0.000 description 20
- 108010050848 glycylleucine Proteins 0.000 description 20
- 239000003446 ligand Substances 0.000 description 20
- LBJYAILUMSUTAM-ZLUOBGJFSA-N Ala-Asn-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O LBJYAILUMSUTAM-ZLUOBGJFSA-N 0.000 description 19
- 102000001398 Granzyme Human genes 0.000 description 19
- 108060005986 Granzyme Proteins 0.000 description 19
- 102000000588 Interleukin-2 Human genes 0.000 description 19
- 108010079364 N-glycylalanine Proteins 0.000 description 19
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 19
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 description 19
- ALMIMUZAWTUNIO-BZSNNMDCSA-N Asp-Tyr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ALMIMUZAWTUNIO-BZSNNMDCSA-N 0.000 description 18
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 18
- 241000700605 Viruses Species 0.000 description 18
- 239000000427 antigen Substances 0.000 description 18
- 108010078144 glutaminyl-glycine Proteins 0.000 description 18
- 230000028327 secretion Effects 0.000 description 18
- HHABWQIFXZPZCK-ACZMJKKPSA-N Cys-Gln-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N HHABWQIFXZPZCK-ACZMJKKPSA-N 0.000 description 17
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 17
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 17
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 17
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 17
- 108091007433 antigens Proteins 0.000 description 17
- 102000036639 antigens Human genes 0.000 description 17
- 230000027455 binding Effects 0.000 description 17
- 239000003795 chemical substances by application Substances 0.000 description 17
- 239000013612 plasmid Substances 0.000 description 17
- 210000001519 tissue Anatomy 0.000 description 17
- VAWNQIGQPUOPQW-ACZMJKKPSA-N Asp-Glu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VAWNQIGQPUOPQW-ACZMJKKPSA-N 0.000 description 16
- 102000004127 Cytokines Human genes 0.000 description 16
- 108090000695 Cytokines Proteins 0.000 description 16
- GHAXJVNBAKGWEJ-AVGNSLFASA-N Gln-Ser-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GHAXJVNBAKGWEJ-AVGNSLFASA-N 0.000 description 16
- YBKKLDBBPFIXBQ-MBLNEYKQSA-N Ile-Thr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)O)N YBKKLDBBPFIXBQ-MBLNEYKQSA-N 0.000 description 16
- 108091028043 Nucleic acid sequence Proteins 0.000 description 16
- IUVYJBMTHARMIP-PCBIJLKTSA-N Phe-Asp-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O IUVYJBMTHARMIP-PCBIJLKTSA-N 0.000 description 16
- VFJIWSJKZJTQII-SRVKXCTJSA-N Tyr-Asp-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O VFJIWSJKZJTQII-SRVKXCTJSA-N 0.000 description 16
- UABYBEBXFFNCIR-YDHLFZDLSA-N Tyr-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UABYBEBXFFNCIR-YDHLFZDLSA-N 0.000 description 16
- 238000002474 experimental method Methods 0.000 description 16
- 108010061238 threonyl-glycine Proteins 0.000 description 16
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 15
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 15
- 108010038807 Oligopeptides Proteins 0.000 description 15
- 102000015636 Oligopeptides Human genes 0.000 description 15
- 206010057190 Respiratory tract infections Diseases 0.000 description 15
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 15
- 108010087924 alanylproline Proteins 0.000 description 15
- 239000003623 enhancer Substances 0.000 description 15
- 108010075431 glycyl-alanyl-phenylalanine Proteins 0.000 description 15
- 238000000338 in vitro Methods 0.000 description 15
- 102000040430 polynucleotide Human genes 0.000 description 15
- 108091033319 polynucleotide Proteins 0.000 description 15
- 239000002157 polynucleotide Substances 0.000 description 15
- LURCIJSJAKFCRO-QWRGUYRKSA-N Gly-Asn-Tyr Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LURCIJSJAKFCRO-QWRGUYRKSA-N 0.000 description 14
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 14
- NZOCIWKZUVUNDW-ZKWXMUAHSA-N Ile-Gly-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O NZOCIWKZUVUNDW-ZKWXMUAHSA-N 0.000 description 14
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 14
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 14
- MWMKFWJYRRGXOR-ZLUOBGJFSA-N Ser-Ala-Asn Chemical compound N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)O)CC(N)=O)C)CO MWMKFWJYRRGXOR-ZLUOBGJFSA-N 0.000 description 14
- GUHLYMZJVXUIPO-RCWTZXSCSA-N Thr-Met-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O GUHLYMZJVXUIPO-RCWTZXSCSA-N 0.000 description 14
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 14
- 238000003556 assay Methods 0.000 description 14
- 102000004169 proteins and genes Human genes 0.000 description 14
- 230000001105 regulatory effect Effects 0.000 description 14
- HKZAAJSTFUZYTO-LURJTMIESA-N (2s)-2-[[2-[[2-[[2-[(2-aminoacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]-3-hydroxypropanoic acid Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O HKZAAJSTFUZYTO-LURJTMIESA-N 0.000 description 13
- AQPVUEJJARLJHB-BQBZGAKWSA-N Arg-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N AQPVUEJJARLJHB-BQBZGAKWSA-N 0.000 description 13
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 13
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 13
- 238000002659 cell therapy Methods 0.000 description 13
- 238000010186 staining Methods 0.000 description 13
- 108010038745 tryptophylglycine Proteins 0.000 description 13
- PCDUALPXEOKZPE-DXCABUDRSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-amino-3-hydroxypropanoyl]amino]-3-hydroxypropanoyl]amino]-3-hydroxypropanoyl]amino]-3-hydroxypropanoyl]amino]-3-hydroxypropanoyl]amino]-3-hydroxypropanoyl]amino]-3-hydroxypropanoic acid Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O PCDUALPXEOKZPE-DXCABUDRSA-N 0.000 description 12
- RZSLYUUFFVHFRQ-FXQIFTODSA-N Gln-Ala-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O RZSLYUUFFVHFRQ-FXQIFTODSA-N 0.000 description 12
- IEGFSKKANYKBDU-QWHCGFSZSA-N Gly-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)CN)C(=O)O IEGFSKKANYKBDU-QWHCGFSZSA-N 0.000 description 12
- 239000013604 expression vector Substances 0.000 description 12
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 11
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 11
- KSOBNUBCYHGUKH-UWVGGRQHSA-N Gly-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN KSOBNUBCYHGUKH-UWVGGRQHSA-N 0.000 description 11
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 11
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 11
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 11
- 239000012636 effector Substances 0.000 description 11
- 239000002609 medium Substances 0.000 description 11
- 230000019491 signal transduction Effects 0.000 description 11
- 238000002560 therapeutic procedure Methods 0.000 description 11
- 238000010361 transduction Methods 0.000 description 11
- 230000026683 transduction Effects 0.000 description 11
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 10
- 241000713666 Lentivirus Species 0.000 description 10
- OIQSIMFSVLLWBX-VOAKCMCISA-N Lys-Leu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OIQSIMFSVLLWBX-VOAKCMCISA-N 0.000 description 10
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 10
- YMEXHZTVKDAKIY-GHCJXIJMSA-N Ser-Asn-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO)C(O)=O YMEXHZTVKDAKIY-GHCJXIJMSA-N 0.000 description 10
- 230000006907 apoptotic process Effects 0.000 description 10
- 230000000694 effects Effects 0.000 description 10
- 108020001756 ligand binding domains Proteins 0.000 description 10
- 239000000203 mixture Substances 0.000 description 10
- 108010051242 phenylalanylserine Proteins 0.000 description 10
- 230000004936 stimulating effect Effects 0.000 description 10
- 238000001890 transfection Methods 0.000 description 10
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 9
- LXAARTARZJJCMB-CIQUZCHMSA-N Ala-Ile-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LXAARTARZJJCMB-CIQUZCHMSA-N 0.000 description 9
- CSMYMGFCEJWALV-WDSKDSINSA-N Gly-Ser-Gln Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O CSMYMGFCEJWALV-WDSKDSINSA-N 0.000 description 9
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 9
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 9
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 9
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 9
- DIPIPFHFLPTCLK-LOKLDPHHSA-N Thr-Gln-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O DIPIPFHFLPTCLK-LOKLDPHHSA-N 0.000 description 9
- IEESWNWYUOETOT-BVSLBCMMSA-N Trp-Val-Phe Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(=O)N[C@@H](Cc1ccccc1)C(O)=O IEESWNWYUOETOT-BVSLBCMMSA-N 0.000 description 9
- 239000003153 chemical reaction reagent Substances 0.000 description 9
- 230000006870 function Effects 0.000 description 9
- 238000001727 in vivo Methods 0.000 description 9
- 230000001965 increasing effect Effects 0.000 description 9
- 230000003834 intracellular effect Effects 0.000 description 9
- 108010077112 prolyl-proline Proteins 0.000 description 9
- 230000008685 targeting Effects 0.000 description 9
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 8
- 108010074708 B7-H1 Antigen Proteins 0.000 description 8
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 8
- UGVQELHRNUDMAA-BYPYZUCNSA-N Gly-Ala-Gly Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)NCC([O-])=O UGVQELHRNUDMAA-BYPYZUCNSA-N 0.000 description 8
- 241000699666 Mus <mouse, genus> Species 0.000 description 8
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 8
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 8
- 230000003321 amplification Effects 0.000 description 8
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 8
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 8
- 210000004698 lymphocyte Anatomy 0.000 description 8
- 239000000463 material Substances 0.000 description 8
- 238000003199 nucleic acid amplification method Methods 0.000 description 8
- 230000035755 proliferation Effects 0.000 description 8
- 230000011664 signaling Effects 0.000 description 8
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 8
- 238000012360 testing method Methods 0.000 description 8
- 230000001225 therapeutic effect Effects 0.000 description 8
- 238000013518 transcription Methods 0.000 description 8
- 230000035897 transcription Effects 0.000 description 8
- OLDOLPWZEMHNIA-PJODQICGSA-N Arg-Ala-Trp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O OLDOLPWZEMHNIA-PJODQICGSA-N 0.000 description 7
- HJDNZFIYILEIKR-OSUNSFLBSA-N Arg-Ile-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HJDNZFIYILEIKR-OSUNSFLBSA-N 0.000 description 7
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 7
- CIMULJZTTOBOPN-WHFBIAKZSA-N Gly-Asn-Asn Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CIMULJZTTOBOPN-WHFBIAKZSA-N 0.000 description 7
- FMNHBTKMRFVGRO-FOHZUACHSA-N Gly-Asn-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CN FMNHBTKMRFVGRO-FOHZUACHSA-N 0.000 description 7
- 241000725303 Human immunodeficiency virus Species 0.000 description 7
- ZTLGVASZOIKNIX-DCAQKATOSA-N Leu-Gln-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZTLGVASZOIKNIX-DCAQKATOSA-N 0.000 description 7
- JRXKIVGWMMIIOF-YDHLFZDLSA-N Tyr-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JRXKIVGWMMIIOF-YDHLFZDLSA-N 0.000 description 7
- 108010041407 alanylaspartic acid Proteins 0.000 description 7
- 108010068265 aspartyltyrosine Proteins 0.000 description 7
- 238000002512 chemotherapy Methods 0.000 description 7
- 238000010276 construction Methods 0.000 description 7
- 238000005516 engineering process Methods 0.000 description 7
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 7
- 108010087823 glycyltyrosine Proteins 0.000 description 7
- 238000011534 incubation Methods 0.000 description 7
- 239000003550 marker Substances 0.000 description 7
- 108010029020 prolylglycine Proteins 0.000 description 7
- 230000001177 retroviral effect Effects 0.000 description 7
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 7
- 241000701161 unidentified adenovirus Species 0.000 description 7
- 230000003612 virological effect Effects 0.000 description 7
- NVWJMQNYLYWVNQ-BYULHYEWSA-N Asn-Ile-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O NVWJMQNYLYWVNQ-BYULHYEWSA-N 0.000 description 6
- HTSSXFASOUSJQG-IHPCNDPISA-N Asp-Tyr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HTSSXFASOUSJQG-IHPCNDPISA-N 0.000 description 6
- 108091026890 Coding region Proteins 0.000 description 6
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 6
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 6
- POJJAZJHBGXEGM-YUMQZZPRSA-N Gly-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN POJJAZJHBGXEGM-YUMQZZPRSA-N 0.000 description 6
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 6
- 101001002657 Homo sapiens Interleukin-2 Proteins 0.000 description 6
- NHJKZMDIMMTVCK-QXEWZRGKSA-N Ile-Gly-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N NHJKZMDIMMTVCK-QXEWZRGKSA-N 0.000 description 6
- HWMQRQIFVGEAPH-XIRDDKMYSA-N Leu-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 HWMQRQIFVGEAPH-XIRDDKMYSA-N 0.000 description 6
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 6
- MYZMQWHPDAYKIE-SRVKXCTJSA-N Lys-Leu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O MYZMQWHPDAYKIE-SRVKXCTJSA-N 0.000 description 6
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 6
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 6
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 6
- 230000004913 activation Effects 0.000 description 6
- 230000003013 cytotoxicity Effects 0.000 description 6
- 231100000135 cytotoxicity Toxicity 0.000 description 6
- 230000007423 decrease Effects 0.000 description 6
- 238000004090 dissolution Methods 0.000 description 6
- 239000003814 drug Substances 0.000 description 6
- 210000002865 immune cell Anatomy 0.000 description 6
- 238000009169 immunotherapy Methods 0.000 description 6
- 239000003112 inhibitor Substances 0.000 description 6
- 238000002347 injection Methods 0.000 description 6
- 239000007924 injection Substances 0.000 description 6
- 238000004806 packaging method and process Methods 0.000 description 6
- 230000004044 response Effects 0.000 description 6
- 108091008146 restriction endonucleases Proteins 0.000 description 6
- 238000001356 surgical procedure Methods 0.000 description 6
- 102000003298 tumor necrosis factor receptor Human genes 0.000 description 6
- 241001430294 unidentified retrovirus Species 0.000 description 6
- 239000013603 viral vector Substances 0.000 description 6
- 238000001262 western blot Methods 0.000 description 6
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 5
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 5
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 5
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 5
- WLVLIYYBPPONRJ-GCJQMDKQSA-N Asn-Thr-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O WLVLIYYBPPONRJ-GCJQMDKQSA-N 0.000 description 5
- ZBKUIQNCRIYVGH-SDDRHHMPSA-N Gln-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZBKUIQNCRIYVGH-SDDRHHMPSA-N 0.000 description 5
- KAJAOGBVWCYGHZ-JTQLQIEISA-N Gly-Gly-Phe Chemical compound [NH3+]CC(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KAJAOGBVWCYGHZ-JTQLQIEISA-N 0.000 description 5
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 5
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 5
- XWUIHCZETFNRPA-IHPCNDPISA-N His-His-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CN=CN1 XWUIHCZETFNRPA-IHPCNDPISA-N 0.000 description 5
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 5
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 5
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 5
- 108010066427 N-valyltryptophan Proteins 0.000 description 5
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 5
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 5
- GSCVDSBEYVGMJQ-SRVKXCTJSA-N Ser-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)O GSCVDSBEYVGMJQ-SRVKXCTJSA-N 0.000 description 5
- 241000700584 Simplexvirus Species 0.000 description 5
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 5
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 5
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 5
- 230000001580 bacterial effect Effects 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 5
- 238000001514 detection method Methods 0.000 description 5
- 238000003114 enzyme-linked immunosorbent spot assay Methods 0.000 description 5
- 210000003527 eukaryotic cell Anatomy 0.000 description 5
- 239000012634 fragment Substances 0.000 description 5
- 108020001507 fusion proteins Proteins 0.000 description 5
- 102000037865 fusion proteins Human genes 0.000 description 5
- 230000001939 inductive effect Effects 0.000 description 5
- 208000015181 infectious disease Diseases 0.000 description 5
- 238000003780 insertion Methods 0.000 description 5
- 230000037431 insertion Effects 0.000 description 5
- 230000002147 killing effect Effects 0.000 description 5
- 108010000761 leucylarginine Proteins 0.000 description 5
- 210000003810 lymphokine-activated killer cell Anatomy 0.000 description 5
- 238000004519 manufacturing process Methods 0.000 description 5
- 210000004986 primary T-cell Anatomy 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 238000001959 radiotherapy Methods 0.000 description 5
- 108010048818 seryl-histidine Proteins 0.000 description 5
- 230000000638 stimulation Effects 0.000 description 5
- 108010044292 tryptophyltyrosine Proteins 0.000 description 5
- 238000011144 upstream manufacturing Methods 0.000 description 5
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 4
- GFEDXKNBZMPEDM-KZVJFYERSA-N Ala-Met-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GFEDXKNBZMPEDM-KZVJFYERSA-N 0.000 description 4
- OMSKGWFGWCQFBD-KZVJFYERSA-N Ala-Val-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OMSKGWFGWCQFBD-KZVJFYERSA-N 0.000 description 4
- MCYJBCKCAPERSE-FXQIFTODSA-N Arg-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N MCYJBCKCAPERSE-FXQIFTODSA-N 0.000 description 4
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 4
- XDGBFDYXZCMYEX-NUMRIWBASA-N Asp-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N)O XDGBFDYXZCMYEX-NUMRIWBASA-N 0.000 description 4
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 4
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 4
- REJJNXODKSHOKA-ACZMJKKPSA-N Gln-Ala-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N REJJNXODKSHOKA-ACZMJKKPSA-N 0.000 description 4
- NKLRYVLERDYDBI-FXQIFTODSA-N Glu-Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKLRYVLERDYDBI-FXQIFTODSA-N 0.000 description 4
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 4
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 4
- RVGMVLVBDRQVKB-UWVGGRQHSA-N Gly-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN RVGMVLVBDRQVKB-UWVGGRQHSA-N 0.000 description 4
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 4
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 4
- RKQAYOWLSFLJEE-SVSWQMSJSA-N Ile-Thr-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N RKQAYOWLSFLJEE-SVSWQMSJSA-N 0.000 description 4
- 108010064548 Lymphocyte Function-Associated Antigen-1 Proteins 0.000 description 4
- RIPJMCFGQHGHNP-RHYQMDGZSA-N Lys-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCCCN)N)O RIPJMCFGQHGHNP-RHYQMDGZSA-N 0.000 description 4
- 108091034117 Oligonucleotide Proteins 0.000 description 4
- 229930182555 Penicillin Natural products 0.000 description 4
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 4
- FRPVPGRXUKFEQE-YDHLFZDLSA-N Phe-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FRPVPGRXUKFEQE-YDHLFZDLSA-N 0.000 description 4
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 4
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 4
- MPPHJZYXDVDGOF-BWBBJGPYSA-N Ser-Cys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CO MPPHJZYXDVDGOF-BWBBJGPYSA-N 0.000 description 4
- OQPNSDWGAMFJNU-QWRGUYRKSA-N Ser-Gly-Tyr Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OQPNSDWGAMFJNU-QWRGUYRKSA-N 0.000 description 4
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 4
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 4
- AKXBNSZMYAOGLS-STQMWFEESA-N Tyr-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AKXBNSZMYAOGLS-STQMWFEESA-N 0.000 description 4
- BZWUSZGQOILYEU-STECZYCISA-N Val-Ile-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BZWUSZGQOILYEU-STECZYCISA-N 0.000 description 4
- 230000000259 anti-tumor effect Effects 0.000 description 4
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 4
- 108010038633 aspartylglutamate Proteins 0.000 description 4
- 239000000872 buffer Substances 0.000 description 4
- 230000021164 cell adhesion Effects 0.000 description 4
- 230000004663 cell proliferation Effects 0.000 description 4
- 238000003776 cleavage reaction Methods 0.000 description 4
- 238000002648 combination therapy Methods 0.000 description 4
- 230000000295 complement effect Effects 0.000 description 4
- 230000001086 cytosolic effect Effects 0.000 description 4
- 231100000433 cytotoxic Toxicity 0.000 description 4
- 230000001472 cytotoxic effect Effects 0.000 description 4
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 4
- 230000002500 effect on skin Effects 0.000 description 4
- 230000002068 genetic effect Effects 0.000 description 4
- 108010081551 glycylphenylalanine Proteins 0.000 description 4
- 239000001963 growth medium Substances 0.000 description 4
- 230000028993 immune response Effects 0.000 description 4
- 229940121354 immunomodulator Drugs 0.000 description 4
- 238000011065 in-situ storage Methods 0.000 description 4
- 230000035772 mutation Effects 0.000 description 4
- 238000011275 oncology therapy Methods 0.000 description 4
- 230000036961 partial effect Effects 0.000 description 4
- 229940049954 penicillin Drugs 0.000 description 4
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 4
- 239000013600 plasmid vector Substances 0.000 description 4
- 239000000047 product Substances 0.000 description 4
- 230000010076 replication Effects 0.000 description 4
- 238000002271 resection Methods 0.000 description 4
- 230000007017 scission Effects 0.000 description 4
- 230000003248 secreting effect Effects 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- 229960005322 streptomycin Drugs 0.000 description 4
- 239000006228 supernatant Substances 0.000 description 4
- BFSVOASYOCHEOV-UHFFFAOYSA-N 2-diethylaminoethanol Chemical compound CCN(CC)CCO BFSVOASYOCHEOV-UHFFFAOYSA-N 0.000 description 3
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 3
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 3
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 3
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 3
- UTSMXMABBPFVJP-SZMVWBNQSA-N Arg-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UTSMXMABBPFVJP-SZMVWBNQSA-N 0.000 description 3
- DBWYWXNMZZYIRY-LPEHRKFASA-N Asp-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N)C(=O)O DBWYWXNMZZYIRY-LPEHRKFASA-N 0.000 description 3
- XACXDSRQIXRMNS-OLHMAJIHSA-N Asp-Asn-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N)O XACXDSRQIXRMNS-OLHMAJIHSA-N 0.000 description 3
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 3
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 3
- 101150013553 CD40 gene Proteins 0.000 description 3
- 201000009030 Carcinoma Diseases 0.000 description 3
- SFRQEQGPRTVDPO-NRPADANISA-N Cys-Gln-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O SFRQEQGPRTVDPO-NRPADANISA-N 0.000 description 3
- YNJBLTDKTMKEET-ZLUOBGJFSA-N Cys-Ser-Ser Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O YNJBLTDKTMKEET-ZLUOBGJFSA-N 0.000 description 3
- 102000053602 DNA Human genes 0.000 description 3
- 241000196324 Embryophyta Species 0.000 description 3
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 3
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 3
- ITVBKCZZLJUUHI-HTUGSXCWSA-N Glu-Phe-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ITVBKCZZLJUUHI-HTUGSXCWSA-N 0.000 description 3
- BDISFWMLMNBTGP-NUMRIWBASA-N Glu-Thr-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O BDISFWMLMNBTGP-NUMRIWBASA-N 0.000 description 3
- KKBWDNZXYLGJEY-UHFFFAOYSA-N Gly-Arg-Pro Natural products NCC(=O)NC(CCNC(=N)N)C(=O)N1CCCC1C(=O)O KKBWDNZXYLGJEY-UHFFFAOYSA-N 0.000 description 3
- DTRUBYPMMVPQPD-YUMQZZPRSA-N Gly-Gln-Arg Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DTRUBYPMMVPQPD-YUMQZZPRSA-N 0.000 description 3
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 3
- VIJMRAIWYWRXSR-CIUDSAMLSA-N His-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 VIJMRAIWYWRXSR-CIUDSAMLSA-N 0.000 description 3
- UXZMINKIEWBEQU-SZMVWBNQSA-N His-Trp-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N UXZMINKIEWBEQU-SZMVWBNQSA-N 0.000 description 3
- DRKZDEFADVYTLU-AVGNSLFASA-N His-Val-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DRKZDEFADVYTLU-AVGNSLFASA-N 0.000 description 3
- 206010021143 Hypoxia Diseases 0.000 description 3
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 3
- 108010074328 Interferon-gamma Proteins 0.000 description 3
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 3
- XYUBOFCTGPZFSA-WDSOQIARSA-N Leu-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 XYUBOFCTGPZFSA-WDSOQIARSA-N 0.000 description 3
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 3
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 3
- 241001465754 Metazoa Species 0.000 description 3
- 241000699660 Mus musculus Species 0.000 description 3
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 3
- PULPZRAHVFBVTO-DCAQKATOSA-N Pro-Glu-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PULPZRAHVFBVTO-DCAQKATOSA-N 0.000 description 3
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 3
- PZZJMBYSYAKYPK-UWJYBYFXSA-N Ser-Ala-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PZZJMBYSYAKYPK-UWJYBYFXSA-N 0.000 description 3
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 3
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 3
- MQCPGOZXFSYJPS-KZVJFYERSA-N Thr-Ala-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MQCPGOZXFSYJPS-KZVJFYERSA-N 0.000 description 3
- LVHHEVGYAZGXDE-KDXUFGMBSA-N Thr-Ala-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(=O)O)N)O LVHHEVGYAZGXDE-KDXUFGMBSA-N 0.000 description 3
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 3
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 3
- LTLBNCDNXQCOLB-UBHSHLNASA-N Trp-Asp-Ser Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 LTLBNCDNXQCOLB-UBHSHLNASA-N 0.000 description 3
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 3
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 3
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 3
- XGJLNBNZNMVJRS-NRPADANISA-N Val-Glu-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O XGJLNBNZNMVJRS-NRPADANISA-N 0.000 description 3
- OTJMMKPMLUNTQT-AVGNSLFASA-N Val-Leu-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N OTJMMKPMLUNTQT-AVGNSLFASA-N 0.000 description 3
- ZXYPHBKIZLAQTL-QXEWZRGKSA-N Val-Pro-Asp Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N ZXYPHBKIZLAQTL-QXEWZRGKSA-N 0.000 description 3
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 3
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 3
- 108010005233 alanylglutamic acid Proteins 0.000 description 3
- 108010011559 alanylphenylalanine Proteins 0.000 description 3
- 239000002246 antineoplastic agent Substances 0.000 description 3
- 230000001640 apoptogenic effect Effects 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 238000004624 confocal microscopy Methods 0.000 description 3
- 108010016616 cysteinylglycine Proteins 0.000 description 3
- 238000002784 cytotoxicity assay Methods 0.000 description 3
- 231100000263 cytotoxicity test Toxicity 0.000 description 3
- 201000010099 disease Diseases 0.000 description 3
- 229940079593 drug Drugs 0.000 description 3
- 239000012091 fetal bovine serum Substances 0.000 description 3
- 238000000684 flow cytometry Methods 0.000 description 3
- 108010027225 gag-pol Fusion Proteins Proteins 0.000 description 3
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 3
- 238000001415 gene therapy Methods 0.000 description 3
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 3
- 108010049041 glutamylalanine Proteins 0.000 description 3
- 238000002744 homologous recombination Methods 0.000 description 3
- 230000006801 homologous recombination Effects 0.000 description 3
- 210000005260 human cell Anatomy 0.000 description 3
- 230000003463 hyperproliferative effect Effects 0.000 description 3
- 230000001976 improved effect Effects 0.000 description 3
- 230000002401 inhibitory effect Effects 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 210000003292 kidney cell Anatomy 0.000 description 3
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 239000013642 negative control Substances 0.000 description 3
- 239000002245 particle Substances 0.000 description 3
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 3
- 239000000843 powder Substances 0.000 description 3
- 108010026333 seryl-proline Proteins 0.000 description 3
- 241000894007 species Species 0.000 description 3
- 238000006467 substitution reaction Methods 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 230000009466 transformation Effects 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 238000002054 transplantation Methods 0.000 description 3
- 230000004614 tumor growth Effects 0.000 description 3
- 108010072644 valyl-alanyl-prolyl-glycine Proteins 0.000 description 3
- 108010073969 valyllysine Proteins 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- XVZCXCTYGHPNEM-IHRRRGAJSA-N (2s)-1-[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O XVZCXCTYGHPNEM-IHRRRGAJSA-N 0.000 description 2
- 102100023990 60S ribosomal protein L17 Human genes 0.000 description 2
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 2
- WXERCAHAIKMTKX-ZLUOBGJFSA-N Ala-Asp-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O WXERCAHAIKMTKX-ZLUOBGJFSA-N 0.000 description 2
- WGDNWOMKBUXFHR-BQBZGAKWSA-N Ala-Gly-Arg Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N WGDNWOMKBUXFHR-BQBZGAKWSA-N 0.000 description 2
- MPLOSMWGDNJSEV-WHFBIAKZSA-N Ala-Gly-Asp Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MPLOSMWGDNJSEV-WHFBIAKZSA-N 0.000 description 2
- XHNLCGXYBXNRIS-BJDJZHNGSA-N Ala-Lys-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O XHNLCGXYBXNRIS-BJDJZHNGSA-N 0.000 description 2
- BLTRAARCJYVJKV-QEJZJMRPSA-N Ala-Lys-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](Cc1ccccc1)C(O)=O BLTRAARCJYVJKV-QEJZJMRPSA-N 0.000 description 2
- KQESEZXHYOUIIM-CQDKDKBSSA-N Ala-Lys-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KQESEZXHYOUIIM-CQDKDKBSSA-N 0.000 description 2
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 2
- BDQNLQSWRAPHGU-DLOVCJGASA-N Ala-Phe-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)O)N BDQNLQSWRAPHGU-DLOVCJGASA-N 0.000 description 2
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 2
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 2
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 2
- RYRQZJVFDVWURI-SRVKXCTJSA-N Arg-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N RYRQZJVFDVWURI-SRVKXCTJSA-N 0.000 description 2
- ZZZWQALDSQQBEW-STQMWFEESA-N Arg-Gly-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZZZWQALDSQQBEW-STQMWFEESA-N 0.000 description 2
- GMFAGHNRXPSSJS-SRVKXCTJSA-N Arg-Leu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GMFAGHNRXPSSJS-SRVKXCTJSA-N 0.000 description 2
- AMIQZQAAYGYKOP-FXQIFTODSA-N Arg-Ser-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O AMIQZQAAYGYKOP-FXQIFTODSA-N 0.000 description 2
- VLIJAPRTSXSGFY-STQMWFEESA-N Arg-Tyr-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 VLIJAPRTSXSGFY-STQMWFEESA-N 0.000 description 2
- DXVMJJNAOVECBA-WHFBIAKZSA-N Asn-Gly-Asn Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O DXVMJJNAOVECBA-WHFBIAKZSA-N 0.000 description 2
- GWNMUVANAWDZTI-YUMQZZPRSA-N Asn-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N GWNMUVANAWDZTI-YUMQZZPRSA-N 0.000 description 2
- OOXUBGLNDRGOKT-FXQIFTODSA-N Asn-Ser-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OOXUBGLNDRGOKT-FXQIFTODSA-N 0.000 description 2
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 2
- QYRMBFWDSFGSFC-OLHMAJIHSA-N Asn-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QYRMBFWDSFGSFC-OLHMAJIHSA-N 0.000 description 2
- XZFONYMRYTVLPL-NHCYSSNCSA-N Asn-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N XZFONYMRYTVLPL-NHCYSSNCSA-N 0.000 description 2
- FAEIQWHBRBWUBN-FXQIFTODSA-N Asp-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N)CN=C(N)N FAEIQWHBRBWUBN-FXQIFTODSA-N 0.000 description 2
- VFUXXFVCYZPOQG-WDSKDSINSA-N Asp-Glu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O VFUXXFVCYZPOQG-WDSKDSINSA-N 0.000 description 2
- UZNSWMFLKVKJLI-VHWLVUOQSA-N Asp-Ile-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O UZNSWMFLKVKJLI-VHWLVUOQSA-N 0.000 description 2
- WNGZKSVJFDZICU-XIRDDKMYSA-N Asp-Leu-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N WNGZKSVJFDZICU-XIRDDKMYSA-N 0.000 description 2
- BKOIIURTQAJHAT-GUBZILKMSA-N Asp-Pro-Pro Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 BKOIIURTQAJHAT-GUBZILKMSA-N 0.000 description 2
- SXLCDCZHNCLFGZ-BPUTZDHNSA-N Asp-Pro-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O SXLCDCZHNCLFGZ-BPUTZDHNSA-N 0.000 description 2
- ZBYLEBZCVKLPCY-FXQIFTODSA-N Asp-Ser-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ZBYLEBZCVKLPCY-FXQIFTODSA-N 0.000 description 2
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 2
- 102100035875 C-C chemokine receptor type 5 Human genes 0.000 description 2
- 101710149870 C-C chemokine receptor type 5 Proteins 0.000 description 2
- 102100027207 CD27 antigen Human genes 0.000 description 2
- 102100035793 CD83 antigen Human genes 0.000 description 2
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 2
- 102000000844 Cell Surface Receptors Human genes 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- 230000005778 DNA damage Effects 0.000 description 2
- 231100000277 DNA damage Toxicity 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 2
- 238000002965 ELISA Methods 0.000 description 2
- 238000011510 Elispot assay Methods 0.000 description 2
- 102100027723 Endogenous retrovirus group K member 6 Rec protein Human genes 0.000 description 2
- 101710091045 Envelope protein Proteins 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 2
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 2
- LLRJEFPKIIBGJP-DCAQKATOSA-N Gln-Glu-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N LLRJEFPKIIBGJP-DCAQKATOSA-N 0.000 description 2
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 2
- ORYMMTRPKVTGSJ-XVKPBYJWSA-N Gln-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O ORYMMTRPKVTGSJ-XVKPBYJWSA-N 0.000 description 2
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 2
- HNAUFGBKJLTWQE-IFFSRLJSSA-N Gln-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N)O HNAUFGBKJLTWQE-IFFSRLJSSA-N 0.000 description 2
- PVBBEKPHARMPHX-DCAQKATOSA-N Glu-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCC(O)=O PVBBEKPHARMPHX-DCAQKATOSA-N 0.000 description 2
- RAUDKMVXNOWDLS-WDSKDSINSA-N Glu-Gly-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O RAUDKMVXNOWDLS-WDSKDSINSA-N 0.000 description 2
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 2
- 102000005720 Glutathione transferase Human genes 0.000 description 2
- 108010070675 Glutathione transferase Proteins 0.000 description 2
- XUORRGAFUQIMLC-STQMWFEESA-N Gly-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN)O XUORRGAFUQIMLC-STQMWFEESA-N 0.000 description 2
- QGZSAHIZRQHCEQ-QWRGUYRKSA-N Gly-Asp-Tyr Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QGZSAHIZRQHCEQ-QWRGUYRKSA-N 0.000 description 2
- KMSGYZQRXPUKGI-BYPYZUCNSA-N Gly-Gly-Asn Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(N)=O KMSGYZQRXPUKGI-BYPYZUCNSA-N 0.000 description 2
- PAWIVEIWWYGBAM-YUMQZZPRSA-N Gly-Leu-Ala Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O PAWIVEIWWYGBAM-YUMQZZPRSA-N 0.000 description 2
- LRQXRHGQEVWGPV-NHCYSSNCSA-N Gly-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN LRQXRHGQEVWGPV-NHCYSSNCSA-N 0.000 description 2
- GAFKBWKVXNERFA-QWRGUYRKSA-N Gly-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 GAFKBWKVXNERFA-QWRGUYRKSA-N 0.000 description 2
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 2
- ZLCLYFGMKFCDCN-XPUUQOCRSA-N Gly-Ser-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CO)NC(=O)CN)C(O)=O ZLCLYFGMKFCDCN-XPUUQOCRSA-N 0.000 description 2
- JYGYNWYVKXENNE-OALUTQOASA-N Gly-Tyr-Trp Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O JYGYNWYVKXENNE-OALUTQOASA-N 0.000 description 2
- BPOHQCZZSFBSON-KKUMJFAQSA-N His-Leu-His Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)Cc1cnc[nH]1)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O BPOHQCZZSFBSON-KKUMJFAQSA-N 0.000 description 2
- LVXFNTIIGOQBMD-SRVKXCTJSA-N His-Leu-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O LVXFNTIIGOQBMD-SRVKXCTJSA-N 0.000 description 2
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 2
- 101100166600 Homo sapiens CD28 gene Proteins 0.000 description 2
- 101000946856 Homo sapiens CD83 antigen Proteins 0.000 description 2
- 101000910338 Homo sapiens Carbonic anhydrase 9 Proteins 0.000 description 2
- 101001109503 Homo sapiens NKG2-C type II integral membrane protein Proteins 0.000 description 2
- 101000611338 Homo sapiens Rhodopsin Proteins 0.000 description 2
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 2
- WZDCVAWMBUNDDY-KBIXCLLPSA-N Ile-Glu-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](C)C(=O)O)N WZDCVAWMBUNDDY-KBIXCLLPSA-N 0.000 description 2
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 2
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 2
- 102000008070 Interferon-gamma Human genes 0.000 description 2
- 102000015696 Interleukins Human genes 0.000 description 2
- 108010063738 Interleukins Proteins 0.000 description 2
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 2
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 2
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 2
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 2
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 2
- HVHRPWQEQHIQJF-AVGNSLFASA-N Leu-Lys-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HVHRPWQEQHIQJF-AVGNSLFASA-N 0.000 description 2
- VULJUQZPSOASBZ-SRVKXCTJSA-N Leu-Pro-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O VULJUQZPSOASBZ-SRVKXCTJSA-N 0.000 description 2
- JDBQSGMJBMPNFT-AVGNSLFASA-N Leu-Pro-Val Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O JDBQSGMJBMPNFT-AVGNSLFASA-N 0.000 description 2
- RNYLNYTYMXACRI-VFAJRCTISA-N Leu-Thr-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O RNYLNYTYMXACRI-VFAJRCTISA-N 0.000 description 2
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 2
- 239000012097 Lipofectamine 2000 Substances 0.000 description 2
- 101000577064 Lymnaea stagnalis Molluscan insulin-related peptide 1 Proteins 0.000 description 2
- RZHLIPMZXOEJTL-AVGNSLFASA-N Lys-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N RZHLIPMZXOEJTL-AVGNSLFASA-N 0.000 description 2
- HKXSZKJMDBHOTG-CIUDSAMLSA-N Lys-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN HKXSZKJMDBHOTG-CIUDSAMLSA-N 0.000 description 2
- FVKRQMQQFGBXHV-QXEWZRGKSA-N Met-Asp-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FVKRQMQQFGBXHV-QXEWZRGKSA-N 0.000 description 2
- KRLKICLNEICJGV-STQMWFEESA-N Met-Phe-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 KRLKICLNEICJGV-STQMWFEESA-N 0.000 description 2
- 101000737895 Mytilus edulis Contraction-inhibiting peptide 1 Proteins 0.000 description 2
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 2
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 2
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 2
- 108010047562 NGR peptide Proteins 0.000 description 2
- 102100022683 NKG2-C type II integral membrane protein Human genes 0.000 description 2
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- QPVFUAUFEBPIPT-CDMKHQONSA-N Phe-Gly-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O QPVFUAUFEBPIPT-CDMKHQONSA-N 0.000 description 2
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 2
- YMIZSYUAZJSOFL-SRVKXCTJSA-N Phe-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O YMIZSYUAZJSOFL-SRVKXCTJSA-N 0.000 description 2
- JXQVYPWVGUOIDV-MXAVVETBSA-N Phe-Ser-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JXQVYPWVGUOIDV-MXAVVETBSA-N 0.000 description 2
- 229920002873 Polyethylenimine Polymers 0.000 description 2
- VXCHGLYSIOOZIS-GUBZILKMSA-N Pro-Ala-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 VXCHGLYSIOOZIS-GUBZILKMSA-N 0.000 description 2
- ULIWFCCJIOEHMU-BQBZGAKWSA-N Pro-Gly-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 ULIWFCCJIOEHMU-BQBZGAKWSA-N 0.000 description 2
- VYWNORHENYEQDW-YUMQZZPRSA-N Pro-Gly-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 VYWNORHENYEQDW-YUMQZZPRSA-N 0.000 description 2
- LEIKGVHQTKHOLM-IUCAKERBSA-N Pro-Pro-Gly Chemical compound OC(=O)CNC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 LEIKGVHQTKHOLM-IUCAKERBSA-N 0.000 description 2
- 101710188315 Protein X Proteins 0.000 description 2
- 239000012980 RPMI-1640 medium Substances 0.000 description 2
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 2
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 2
- 108700008625 Reporter Genes Proteins 0.000 description 2
- 208000003837 Second Primary Neoplasms Diseases 0.000 description 2
- JPIDMRXXNMIVKY-VZFHVOOUSA-N Ser-Ala-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPIDMRXXNMIVKY-VZFHVOOUSA-N 0.000 description 2
- HBZBPFLJNDXRAY-FXQIFTODSA-N Ser-Ala-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O HBZBPFLJNDXRAY-FXQIFTODSA-N 0.000 description 2
- WXUBSIDKNMFAGS-IHRRRGAJSA-N Ser-Arg-Tyr Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@H](CO)N)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 WXUBSIDKNMFAGS-IHRRRGAJSA-N 0.000 description 2
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 2
- OLIJLNWFEQEFDM-SRVKXCTJSA-N Ser-Asp-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OLIJLNWFEQEFDM-SRVKXCTJSA-N 0.000 description 2
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 2
- BVLGVLWFIZFEAH-BPUTZDHNSA-N Ser-Pro-Trp Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O BVLGVLWFIZFEAH-BPUTZDHNSA-N 0.000 description 2
- GYDFRTRSSXOZCR-ACZMJKKPSA-N Ser-Ser-Glu Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GYDFRTRSSXOZCR-ACZMJKKPSA-N 0.000 description 2
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 2
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 2
- ZSDXEKUKQAKZFE-XAVMHZPKSA-N Ser-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N)O ZSDXEKUKQAKZFE-XAVMHZPKSA-N 0.000 description 2
- 108091081024 Start codon Proteins 0.000 description 2
- 108700026226 TATA Box Proteins 0.000 description 2
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 2
- OHAJHDJOCKKJLV-LKXGYXEUSA-N Thr-Asp-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OHAJHDJOCKKJLV-LKXGYXEUSA-N 0.000 description 2
- XOTBWOCSLMBGMF-SUSMZKCASA-N Thr-Glu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XOTBWOCSLMBGMF-SUSMZKCASA-N 0.000 description 2
- KBBRNEDOYWMIJP-KYNKHSRBSA-N Thr-Gly-Thr Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KBBRNEDOYWMIJP-KYNKHSRBSA-N 0.000 description 2
- YDWLCDQXLCILCZ-BWAGICSOSA-N Thr-His-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YDWLCDQXLCILCZ-BWAGICSOSA-N 0.000 description 2
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 2
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 2
- NBIIPOKZPUGATB-BWBBJGPYSA-N Thr-Ser-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N)O NBIIPOKZPUGATB-BWBBJGPYSA-N 0.000 description 2
- ABCLYRRGTZNIFU-BWAGICSOSA-N Thr-Tyr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O ABCLYRRGTZNIFU-BWAGICSOSA-N 0.000 description 2
- MXKUGFHWYYKVDV-SZMVWBNQSA-N Trp-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(C)C)C(O)=O MXKUGFHWYYKVDV-SZMVWBNQSA-N 0.000 description 2
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 2
- 206010054094 Tumour necrosis Diseases 0.000 description 2
- JWHOIHCOHMZSAR-QWRGUYRKSA-N Tyr-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JWHOIHCOHMZSAR-QWRGUYRKSA-N 0.000 description 2
- JFDGVHXRCKEBAU-KKUMJFAQSA-N Tyr-Asp-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N)O JFDGVHXRCKEBAU-KKUMJFAQSA-N 0.000 description 2
- UPODKYBYUBTWSV-BZSNNMDCSA-N Tyr-Phe-Cys Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CS)C(O)=O)C1=CC=C(O)C=C1 UPODKYBYUBTWSV-BZSNNMDCSA-N 0.000 description 2
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 2
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 2
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 2
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 2
- 108010044940 alanylglutamine Proteins 0.000 description 2
- 230000000735 allogeneic effect Effects 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 230000003466 anti-cipated effect Effects 0.000 description 2
- 230000036436 anti-hiv Effects 0.000 description 2
- 230000002236 anti-hypertrophic effect Effects 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 108010091092 arginyl-glycyl-proline Proteins 0.000 description 2
- 108010093581 aspartyl-proline Proteins 0.000 description 2
- 108010047857 aspartylglycine Proteins 0.000 description 2
- 239000011324 bead Substances 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 230000037396 body weight Effects 0.000 description 2
- 229910002091 carbon monoxide Inorganic materials 0.000 description 2
- 230000003197 catalytic effect Effects 0.000 description 2
- 125000002091 cationic group Chemical group 0.000 description 2
- 230000006037 cell lysis Effects 0.000 description 2
- 230000036755 cellular response Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 229960004316 cisplatin Drugs 0.000 description 2
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 2
- 230000002301 combined effect Effects 0.000 description 2
- 238000012258 culturing Methods 0.000 description 2
- 108010069495 cysteinyltyrosine Proteins 0.000 description 2
- 230000009089 cytolysis Effects 0.000 description 2
- 210000005220 cytoplasmic tail Anatomy 0.000 description 2
- 229940127089 cytotoxic agent Drugs 0.000 description 2
- 230000007850 degeneration Effects 0.000 description 2
- 238000012217 deletion Methods 0.000 description 2
- 230000037430 deletion Effects 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 102000015694 estrogen receptors Human genes 0.000 description 2
- 108010038795 estrogen receptors Proteins 0.000 description 2
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 2
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 2
- 108010023364 glycyl-histidyl-arginine Proteins 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 108010040030 histidinoalanine Proteins 0.000 description 2
- 108010028295 histidylhistidine Proteins 0.000 description 2
- 238000001794 hormone therapy Methods 0.000 description 2
- 206010020718 hyperplasia Diseases 0.000 description 2
- 230000002390 hyperplastic effect Effects 0.000 description 2
- 239000012642 immune effector Substances 0.000 description 2
- 230000002163 immunogen Effects 0.000 description 2
- 238000011532 immunohistochemical staining Methods 0.000 description 2
- 238000003364 immunohistochemistry Methods 0.000 description 2
- 239000002955 immunomodulating agent Substances 0.000 description 2
- 230000001024 immunotherapeutic effect Effects 0.000 description 2
- 239000004615 ingredient Substances 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 238000010253 intravenous injection Methods 0.000 description 2
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 2
- 238000011031 large-scale manufacturing process Methods 0.000 description 2
- 230000003902 lesion Effects 0.000 description 2
- 108010077158 leucinyl-arginyl-tryptophan Proteins 0.000 description 2
- 239000006193 liquid solution Substances 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 201000001441 melanoma Diseases 0.000 description 2
- 230000001394 metastastic effect Effects 0.000 description 2
- 206010061289 metastatic neoplasm Diseases 0.000 description 2
- 229960000485 methotrexate Drugs 0.000 description 2
- 230000000813 microbial effect Effects 0.000 description 2
- 239000003068 molecular probe Substances 0.000 description 2
- 210000000581 natural killer T-cell Anatomy 0.000 description 2
- 238000011580 nude mouse model Methods 0.000 description 2
- 210000003463 organelle Anatomy 0.000 description 2
- 239000013641 positive control Substances 0.000 description 2
- 210000001236 prokaryotic cell Anatomy 0.000 description 2
- 230000002035 prolonged effect Effects 0.000 description 2
- 108010070643 prolylglutamic acid Proteins 0.000 description 2
- 230000000069 prophylactic effect Effects 0.000 description 2
- 230000005855 radiation Effects 0.000 description 2
- 230000003439 radiotherapeutic effect Effects 0.000 description 2
- 238000010188 recombinant method Methods 0.000 description 2
- 239000001044 red dye Substances 0.000 description 2
- 208000019465 refractory cytopenia of childhood Diseases 0.000 description 2
- 230000003362 replicative effect Effects 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 150000003839 salts Chemical class 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 238000007619 statistical method Methods 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- 210000000225 synapse Anatomy 0.000 description 2
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 2
- 230000005026 transcription initiation Effects 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 230000003827 upregulation Effects 0.000 description 2
- PKOHVHWNGUHYRE-ZFWWWQNUSA-N (2s)-1-[2-[[(2s)-2-amino-3-(1h-indol-3-yl)propanoyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound O=C([C@H](CC=1C2=CC=CC=C2NC=1)N)NCC(=O)N1CCC[C@H]1C(O)=O PKOHVHWNGUHYRE-ZFWWWQNUSA-N 0.000 description 1
- AXFMEGAFCUULFV-BLFANLJRSA-N (2s)-2-[[(2s)-1-[(2s,3r)-2-amino-3-methylpentanoyl]pyrrolidine-2-carbonyl]amino]pentanedioic acid Chemical compound CC[C@@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AXFMEGAFCUULFV-BLFANLJRSA-N 0.000 description 1
- NCYCYZXNIZJOKI-IOUUIBBYSA-N 11-cis-retinal Chemical compound O=C/C=C(\C)/C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C NCYCYZXNIZJOKI-IOUUIBBYSA-N 0.000 description 1
- PPINMSZPTPRQQB-NHCYSSNCSA-N 2-[[(2s)-1-[(2s)-2-[[(2s)-2-amino-3-methylbutanoyl]amino]propanoyl]pyrrolidine-2-carbonyl]amino]acetic acid Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PPINMSZPTPRQQB-NHCYSSNCSA-N 0.000 description 1
- IDGZVZJLYFTXSL-UHFFFAOYSA-N 2-[[2-[(2-amino-4-methylpentanoyl)amino]-3-hydroxypropanoyl]amino]-5-(diaminomethylideneamino)pentanoic acid Chemical compound CC(C)CC(N)C(=O)NC(CO)C(=O)NC(C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-UHFFFAOYSA-N 0.000 description 1
- SCPRYBYMKVYVND-UHFFFAOYSA-N 2-[[2-[[1-(2-amino-4-methylpentanoyl)pyrrolidine-2-carbonyl]amino]-4-methylpentanoyl]amino]-4-methylpentanoic acid Chemical compound CC(C)CC(N)C(=O)N1CCCC1C(=O)NC(CC(C)C)C(=O)NC(CC(C)C)C(O)=O SCPRYBYMKVYVND-UHFFFAOYSA-N 0.000 description 1
- QMOQBVOBWVNSNO-UHFFFAOYSA-N 2-[[2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]acetyl]amino]acetate Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(O)=O QMOQBVOBWVNSNO-UHFFFAOYSA-N 0.000 description 1
- 108010082808 4-1BB Ligand Proteins 0.000 description 1
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 1
- 239000013607 AAV vector Substances 0.000 description 1
- HHGYNJRJIINWAK-FXQIFTODSA-N Ala-Ala-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N HHGYNJRJIINWAK-FXQIFTODSA-N 0.000 description 1
- PIPTUBPKYFRLCP-NHCYSSNCSA-N Ala-Ala-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PIPTUBPKYFRLCP-NHCYSSNCSA-N 0.000 description 1
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 1
- KQFRUSHJPKXBMB-BHDSKKPTSA-N Ala-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)C)C(O)=O)=CNC2=C1 KQFRUSHJPKXBMB-BHDSKKPTSA-N 0.000 description 1
- DVWVZSJAYIJZFI-FXQIFTODSA-N Ala-Arg-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O DVWVZSJAYIJZFI-FXQIFTODSA-N 0.000 description 1
- SVBXIUDNTRTKHE-CIUDSAMLSA-N Ala-Arg-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O SVBXIUDNTRTKHE-CIUDSAMLSA-N 0.000 description 1
- CVGNCMIULZNYES-WHFBIAKZSA-N Ala-Asn-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CVGNCMIULZNYES-WHFBIAKZSA-N 0.000 description 1
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 1
- GGNHBHYDMUDXQB-KBIXCLLPSA-N Ala-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)N GGNHBHYDMUDXQB-KBIXCLLPSA-N 0.000 description 1
- NIZKGBJVCMRDKO-KWQFWETISA-N Ala-Gly-Tyr Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NIZKGBJVCMRDKO-KWQFWETISA-N 0.000 description 1
- SMCGQGDVTPFXKB-XPUUQOCRSA-N Ala-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N SMCGQGDVTPFXKB-XPUUQOCRSA-N 0.000 description 1
- ZPXCNXMJEZKRLU-LSJOCFKGSA-N Ala-His-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CN=CN1 ZPXCNXMJEZKRLU-LSJOCFKGSA-N 0.000 description 1
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 1
- NINQYGGNRIBFSC-CIUDSAMLSA-N Ala-Lys-Ser Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CO)C(O)=O NINQYGGNRIBFSC-CIUDSAMLSA-N 0.000 description 1
- 108010011667 Ala-Phe-Ala Proteins 0.000 description 1
- XRUJOVRWNMBAAA-NHCYSSNCSA-N Ala-Phe-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 XRUJOVRWNMBAAA-NHCYSSNCSA-N 0.000 description 1
- ADSGHMXEAZJJNF-DCAQKATOSA-N Ala-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N ADSGHMXEAZJJNF-DCAQKATOSA-N 0.000 description 1
- CQJHFKKGZXKZBC-BPNCWPANSA-N Ala-Pro-Tyr Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CQJHFKKGZXKZBC-BPNCWPANSA-N 0.000 description 1
- YHBDGLZYNIARKJ-GUBZILKMSA-N Ala-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N YHBDGLZYNIARKJ-GUBZILKMSA-N 0.000 description 1
- DCVYRWFAMZFSDA-ZLUOBGJFSA-N Ala-Ser-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DCVYRWFAMZFSDA-ZLUOBGJFSA-N 0.000 description 1
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 1
- HCBKAOZYACJUEF-XQXXSGGOSA-N Ala-Thr-Gln Chemical compound N[C@@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCC(N)=O)C(=O)O HCBKAOZYACJUEF-XQXXSGGOSA-N 0.000 description 1
- 108010012934 Albumin-Bound Paclitaxel Proteins 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- OTOXOKCIIQLMFH-KZVJFYERSA-N Arg-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N OTOXOKCIIQLMFH-KZVJFYERSA-N 0.000 description 1
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 1
- XVLLUZMFSAYKJV-GUBZILKMSA-N Arg-Asp-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XVLLUZMFSAYKJV-GUBZILKMSA-N 0.000 description 1
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 1
- JAYIQMNQDMOBFY-KKUMJFAQSA-N Arg-Glu-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JAYIQMNQDMOBFY-KKUMJFAQSA-N 0.000 description 1
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 1
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 1
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 1
- NMRHDSAOIURTNT-RWMBFGLXSA-N Arg-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N NMRHDSAOIURTNT-RWMBFGLXSA-N 0.000 description 1
- NPAVRDPEFVKELR-DCAQKATOSA-N Arg-Lys-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O NPAVRDPEFVKELR-DCAQKATOSA-N 0.000 description 1
- HIMXTOIXVXWHTB-DCAQKATOSA-N Arg-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N HIMXTOIXVXWHTB-DCAQKATOSA-N 0.000 description 1
- VEAIMHJZTIDCIH-KKUMJFAQSA-N Arg-Phe-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VEAIMHJZTIDCIH-KKUMJFAQSA-N 0.000 description 1
- LXMKTIZAGIBQRX-HRCADAONSA-N Arg-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O LXMKTIZAGIBQRX-HRCADAONSA-N 0.000 description 1
- BSYKSCBTTQKOJG-GUBZILKMSA-N Arg-Pro-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BSYKSCBTTQKOJG-GUBZILKMSA-N 0.000 description 1
- DNBMCNQKNOKOSD-DCAQKATOSA-N Arg-Pro-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O DNBMCNQKNOKOSD-DCAQKATOSA-N 0.000 description 1
- RYQSYXFGFOTJDJ-RHYQMDGZSA-N Arg-Thr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RYQSYXFGFOTJDJ-RHYQMDGZSA-N 0.000 description 1
- ZCSHHTFOZULVLN-SZMVWBNQSA-N Arg-Trp-Val Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N)=CNC2=C1 ZCSHHTFOZULVLN-SZMVWBNQSA-N 0.000 description 1
- UVTGNSWSRSCPLP-UHFFFAOYSA-N Arg-Tyr Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O UVTGNSWSRSCPLP-UHFFFAOYSA-N 0.000 description 1
- PJOPLXOCKACMLK-KKUMJFAQSA-N Arg-Tyr-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O PJOPLXOCKACMLK-KKUMJFAQSA-N 0.000 description 1
- ULBHWNVWSCJLCO-NHCYSSNCSA-N Arg-Val-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N ULBHWNVWSCJLCO-NHCYSSNCSA-N 0.000 description 1
- CPTXATAOUQJQRO-GUBZILKMSA-N Arg-Val-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O CPTXATAOUQJQRO-GUBZILKMSA-N 0.000 description 1
- ACRYGQFHAQHDSF-ZLUOBGJFSA-N Asn-Asn-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ACRYGQFHAQHDSF-ZLUOBGJFSA-N 0.000 description 1
- RCENDENBBJFJHZ-ACZMJKKPSA-N Asn-Asn-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RCENDENBBJFJHZ-ACZMJKKPSA-N 0.000 description 1
- PCKRJVZAQZWNKM-WHFBIAKZSA-N Asn-Asn-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O PCKRJVZAQZWNKM-WHFBIAKZSA-N 0.000 description 1
- LDSFSKFATNBTBV-UHFFFAOYSA-N Asn-Asn-Gly-His Chemical compound NC(=O)CC(N)C(=O)NC(CC(N)=O)C(=O)NCC(=O)NC(C(O)=O)CC1=CN=CN1 LDSFSKFATNBTBV-UHFFFAOYSA-N 0.000 description 1
- DDPXDCKYWDGZAL-BQBZGAKWSA-N Asn-Gly-Arg Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N DDPXDCKYWDGZAL-BQBZGAKWSA-N 0.000 description 1
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 1
- OROMFUQQTSWUTI-IHRRRGAJSA-N Asn-Phe-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N OROMFUQQTSWUTI-IHRRRGAJSA-N 0.000 description 1
- QIRJQYQOIKBPBZ-IHRRRGAJSA-N Asn-Tyr-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QIRJQYQOIKBPBZ-IHRRRGAJSA-N 0.000 description 1
- XPGVTUBABLRGHY-BIIVOSGPSA-N Asp-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N XPGVTUBABLRGHY-BIIVOSGPSA-N 0.000 description 1
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 1
- BUVNWKQBMZLCDW-UGYAYLCHSA-N Asp-Asn-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BUVNWKQBMZLCDW-UGYAYLCHSA-N 0.000 description 1
- JGDBHIVECJGXJA-FXQIFTODSA-N Asp-Asp-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JGDBHIVECJGXJA-FXQIFTODSA-N 0.000 description 1
- WCFCYFDBMNFSPA-ACZMJKKPSA-N Asp-Asp-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(O)=O WCFCYFDBMNFSPA-ACZMJKKPSA-N 0.000 description 1
- QXHVOUSPVAWEMX-ZLUOBGJFSA-N Asp-Asp-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXHVOUSPVAWEMX-ZLUOBGJFSA-N 0.000 description 1
- BFOYULZBKYOKAN-OLHMAJIHSA-N Asp-Asp-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BFOYULZBKYOKAN-OLHMAJIHSA-N 0.000 description 1
- VIRHEUMYXXLCBF-WDSKDSINSA-N Asp-Gly-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O VIRHEUMYXXLCBF-WDSKDSINSA-N 0.000 description 1
- UBPMOJLRVMGTOQ-GARJFASQSA-N Asp-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)O)N)C(=O)O UBPMOJLRVMGTOQ-GARJFASQSA-N 0.000 description 1
- HOBNTSHITVVNBN-ZPFDUUQYSA-N Asp-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N HOBNTSHITVVNBN-ZPFDUUQYSA-N 0.000 description 1
- KLYPOCBLKMPBIQ-GHCJXIJMSA-N Asp-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N KLYPOCBLKMPBIQ-GHCJXIJMSA-N 0.000 description 1
- VSMYBNPOHYAXSD-GUBZILKMSA-N Asp-Lys-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O VSMYBNPOHYAXSD-GUBZILKMSA-N 0.000 description 1
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 1
- KGHLGJAXYSVNJP-WHFBIAKZSA-N Asp-Ser-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O KGHLGJAXYSVNJP-WHFBIAKZSA-N 0.000 description 1
- XQFLFQWOBXPMHW-NHCYSSNCSA-N Asp-Val-His Chemical compound N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O XQFLFQWOBXPMHW-NHCYSSNCSA-N 0.000 description 1
- GIKOVDMXBAFXDF-NHCYSSNCSA-N Asp-Val-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GIKOVDMXBAFXDF-NHCYSSNCSA-N 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 description 1
- 102100038080 B-cell receptor CD22 Human genes 0.000 description 1
- 238000011729 BALB/c nude mouse Methods 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 1
- 102100025221 CD70 antigen Human genes 0.000 description 1
- 210000001239 CD8-positive, alpha-beta cytotoxic T lymphocyte Anatomy 0.000 description 1
- 101100098985 Caenorhabditis elegans cct-3 gene Proteins 0.000 description 1
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 1
- BHPQYMZQTOCNFJ-UHFFFAOYSA-N Calcium cation Chemical compound [Ca+2] BHPQYMZQTOCNFJ-UHFFFAOYSA-N 0.000 description 1
- 241000282836 Camelus dromedarius Species 0.000 description 1
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 102000003846 Carbonic anhydrases Human genes 0.000 description 1
- 108090000209 Carbonic anhydrases Proteins 0.000 description 1
- 102100025466 Carcinoembryonic antigen-related cell adhesion molecule 3 Human genes 0.000 description 1
- 208000005623 Carcinogenesis Diseases 0.000 description 1
- 102000053642 Catalytic RNA Human genes 0.000 description 1
- 108090000994 Catalytic RNA Proteins 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 102000001327 Chemokine CCL5 Human genes 0.000 description 1
- 108010055166 Chemokine CCL5 Proteins 0.000 description 1
- 102000019034 Chemokines Human genes 0.000 description 1
- 108010012236 Chemokines Proteins 0.000 description 1
- 241001227713 Chiron Species 0.000 description 1
- 108010049048 Cholera Toxin Proteins 0.000 description 1
- 102000009016 Cholera Toxin Human genes 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- AEJSNWMRPXAKCW-WHFBIAKZSA-N Cys-Ala-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O AEJSNWMRPXAKCW-WHFBIAKZSA-N 0.000 description 1
- DZLQXIFVQFTFJY-BYPYZUCNSA-N Cys-Gly-Gly Chemical compound SC[C@H](N)C(=O)NCC(=O)NCC(O)=O DZLQXIFVQFTFJY-BYPYZUCNSA-N 0.000 description 1
- WAJDEKCJRKGRPG-CIUDSAMLSA-N Cys-His-Ser Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N WAJDEKCJRKGRPG-CIUDSAMLSA-N 0.000 description 1
- QQOWCDCBFFBRQH-IXOXFDKPSA-N Cys-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CS)N)O QQOWCDCBFFBRQH-IXOXFDKPSA-N 0.000 description 1
- 241000701022 Cytomegalovirus Species 0.000 description 1
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 1
- 102100033215 DNA nucleotidylexotransferase Human genes 0.000 description 1
- 108010008286 DNA nucleotidylexotransferase Proteins 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 108010092160 Dactinomycin Proteins 0.000 description 1
- 206010058314 Dysplasia Diseases 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 101001039702 Escherichia coli (strain K12) Methyl-accepting chemotaxis protein I Proteins 0.000 description 1
- 241000701959 Escherichia virus Lambda Species 0.000 description 1
- 102100029951 Estrogen receptor beta Human genes 0.000 description 1
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 229910052693 Europium Inorganic materials 0.000 description 1
- 229920001917 Ficoll Polymers 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 102000002464 Galactosidases Human genes 0.000 description 1
- 108010093031 Galactosidases Proteins 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- FAQVCWVVIYYWRR-WHFBIAKZSA-N Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O FAQVCWVVIYYWRR-WHFBIAKZSA-N 0.000 description 1
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 1
- XKBASPWPBXNVLQ-WDSKDSINSA-N Gln-Gly-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XKBASPWPBXNVLQ-WDSKDSINSA-N 0.000 description 1
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 1
- IWUFOVSLWADEJC-AVGNSLFASA-N Gln-His-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O IWUFOVSLWADEJC-AVGNSLFASA-N 0.000 description 1
- HWEINOMSWQSJDC-SRVKXCTJSA-N Gln-Leu-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O HWEINOMSWQSJDC-SRVKXCTJSA-N 0.000 description 1
- VZRAXPGTUNDIDK-GUBZILKMSA-N Gln-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N VZRAXPGTUNDIDK-GUBZILKMSA-N 0.000 description 1
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 1
- LUGUNEGJNDEBLU-DCAQKATOSA-N Gln-Met-Arg Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N LUGUNEGJNDEBLU-DCAQKATOSA-N 0.000 description 1
- PBYFVIQRFLNQCO-GUBZILKMSA-N Gln-Pro-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O PBYFVIQRFLNQCO-GUBZILKMSA-N 0.000 description 1
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 1
- YPFFHGRJCUBXPX-NHCYSSNCSA-N Gln-Pro-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O)C(O)=O YPFFHGRJCUBXPX-NHCYSSNCSA-N 0.000 description 1
- RWQCWSGOOOEGPB-FXQIFTODSA-N Gln-Ser-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O RWQCWSGOOOEGPB-FXQIFTODSA-N 0.000 description 1
- KVQOVQVGVKDZNW-GUBZILKMSA-N Gln-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KVQOVQVGVKDZNW-GUBZILKMSA-N 0.000 description 1
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 1
- PAOHIZNRJNIXQY-XQXXSGGOSA-N Gln-Thr-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O PAOHIZNRJNIXQY-XQXXSGGOSA-N 0.000 description 1
- DUGYCMAIAKAQPB-GLLZPBPUSA-N Gln-Thr-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DUGYCMAIAKAQPB-GLLZPBPUSA-N 0.000 description 1
- HLRLXVPRJJITSK-IFFSRLJSSA-N Gln-Thr-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HLRLXVPRJJITSK-IFFSRLJSSA-N 0.000 description 1
- VYOILACOFPPNQH-UMNHJUIQSA-N Gln-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N VYOILACOFPPNQH-UMNHJUIQSA-N 0.000 description 1
- FTMLQFPULNGION-ZVZYQTTQSA-N Gln-Val-Trp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O FTMLQFPULNGION-ZVZYQTTQSA-N 0.000 description 1
- UTKUTMJSWKKHEM-WDSKDSINSA-N Glu-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O UTKUTMJSWKKHEM-WDSKDSINSA-N 0.000 description 1
- BPDVTFBJZNBHEU-HGNGGELXSA-N Glu-Ala-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 BPDVTFBJZNBHEU-HGNGGELXSA-N 0.000 description 1
- IRDASPPCLZIERZ-XHNCKOQMSA-N Glu-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N IRDASPPCLZIERZ-XHNCKOQMSA-N 0.000 description 1
- SRZLHYPAOXBBSB-HJGDQZAQSA-N Glu-Arg-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SRZLHYPAOXBBSB-HJGDQZAQSA-N 0.000 description 1
- RDDSZZJOKDVPAE-ACZMJKKPSA-N Glu-Asn-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDDSZZJOKDVPAE-ACZMJKKPSA-N 0.000 description 1
- QPRZKNOOOBWXSU-CIUDSAMLSA-N Glu-Asp-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N QPRZKNOOOBWXSU-CIUDSAMLSA-N 0.000 description 1
- JPHYJQHPILOKHC-ACZMJKKPSA-N Glu-Asp-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JPHYJQHPILOKHC-ACZMJKKPSA-N 0.000 description 1
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 1
- JRCUFCXYZLPSDZ-ACZMJKKPSA-N Glu-Asp-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O JRCUFCXYZLPSDZ-ACZMJKKPSA-N 0.000 description 1
- CGOHAEBMDSEKFB-FXQIFTODSA-N Glu-Glu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O CGOHAEBMDSEKFB-FXQIFTODSA-N 0.000 description 1
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 1
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 1
- AUTNXSQEVVHSJK-YVNDNENWSA-N Glu-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O AUTNXSQEVVHSJK-YVNDNENWSA-N 0.000 description 1
- MTAOBYXRYJZRGQ-WDSKDSINSA-N Glu-Gly-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MTAOBYXRYJZRGQ-WDSKDSINSA-N 0.000 description 1
- CAVMESABQIKFKT-IUCAKERBSA-N Glu-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)O)N CAVMESABQIKFKT-IUCAKERBSA-N 0.000 description 1
- WVTIBGWZUMJBFY-GUBZILKMSA-N Glu-His-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O WVTIBGWZUMJBFY-GUBZILKMSA-N 0.000 description 1
- WDTAKCUOIKHCTB-NKIYYHGXSA-N Glu-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)O)N)O WDTAKCUOIKHCTB-NKIYYHGXSA-N 0.000 description 1
- BKRQSECBKKCCKW-HVTMNAMFSA-N Glu-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N BKRQSECBKKCCKW-HVTMNAMFSA-N 0.000 description 1
- BIYNPVYAZOUVFQ-CIUDSAMLSA-N Glu-Pro-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O BIYNPVYAZOUVFQ-CIUDSAMLSA-N 0.000 description 1
- HMJULNMJWOZNFI-XHNCKOQMSA-N Glu-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N)C(=O)O HMJULNMJWOZNFI-XHNCKOQMSA-N 0.000 description 1
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 1
- KIEICAOUSNYOLM-NRPADANISA-N Glu-Val-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O KIEICAOUSNYOLM-NRPADANISA-N 0.000 description 1
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 1
- PYTZFYUXZZHOAD-WHFBIAKZSA-N Gly-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)CN PYTZFYUXZZHOAD-WHFBIAKZSA-N 0.000 description 1
- RLFSBAPJTYKSLG-WHFBIAKZSA-N Gly-Ala-Asp Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O RLFSBAPJTYKSLG-WHFBIAKZSA-N 0.000 description 1
- MZZSCEANQDPJER-ONGXEEELSA-N Gly-Ala-Phe Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MZZSCEANQDPJER-ONGXEEELSA-N 0.000 description 1
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 1
- KFMBRBPXHVMDFN-UWVGGRQHSA-N Gly-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCNC(N)=N KFMBRBPXHVMDFN-UWVGGRQHSA-N 0.000 description 1
- KRRMJKMGWWXWDW-STQMWFEESA-N Gly-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KRRMJKMGWWXWDW-STQMWFEESA-N 0.000 description 1
- DTPOVRRYXPJJAZ-FJXKBIBVSA-N Gly-Arg-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N DTPOVRRYXPJJAZ-FJXKBIBVSA-N 0.000 description 1
- FUTAPPOITCCWTH-WHFBIAKZSA-N Gly-Asp-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FUTAPPOITCCWTH-WHFBIAKZSA-N 0.000 description 1
- LXXLEUBUOMCAMR-NKWVEPMBSA-N Gly-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)CN)C(=O)O LXXLEUBUOMCAMR-NKWVEPMBSA-N 0.000 description 1
- KTSZUNRRYXPZTK-BQBZGAKWSA-N Gly-Gln-Glu Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KTSZUNRRYXPZTK-BQBZGAKWSA-N 0.000 description 1
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 1
- XMPXVJIDADUOQB-RCOVLWMOSA-N Gly-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C([O-])=O)NC(=O)CNC(=O)C[NH3+] XMPXVJIDADUOQB-RCOVLWMOSA-N 0.000 description 1
- CQIIXEHDSZUSAG-QWRGUYRKSA-N Gly-His-His Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 CQIIXEHDSZUSAG-QWRGUYRKSA-N 0.000 description 1
- LPCKHUXOGVNZRS-YUMQZZPRSA-N Gly-His-Ser Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O LPCKHUXOGVNZRS-YUMQZZPRSA-N 0.000 description 1
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 1
- YTSVAIMKVLZUDU-YUMQZZPRSA-N Gly-Leu-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YTSVAIMKVLZUDU-YUMQZZPRSA-N 0.000 description 1
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 1
- LHYJCVCQPWRMKZ-WEDXCCLWSA-N Gly-Leu-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LHYJCVCQPWRMKZ-WEDXCCLWSA-N 0.000 description 1
- VBOBNHSVQKKTOT-YUMQZZPRSA-N Gly-Lys-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O VBOBNHSVQKKTOT-YUMQZZPRSA-N 0.000 description 1
- BXICSAQLIHFDDL-YUMQZZPRSA-N Gly-Lys-Asn Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BXICSAQLIHFDDL-YUMQZZPRSA-N 0.000 description 1
- YYXJFBMCOUSYSF-RYUDHWBXSA-N Gly-Phe-Gln Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O YYXJFBMCOUSYSF-RYUDHWBXSA-N 0.000 description 1
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 1
- FGPLUIQCSKGLTI-WDSKDSINSA-N Gly-Ser-Glu Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O FGPLUIQCSKGLTI-WDSKDSINSA-N 0.000 description 1
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 1
- FFALDIDGPLUDKV-ZDLURKLDSA-N Gly-Thr-Ser Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O FFALDIDGPLUDKV-ZDLURKLDSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- GNNJKUYDWFIBTK-QWRGUYRKSA-N Gly-Tyr-Asp Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O GNNJKUYDWFIBTK-QWRGUYRKSA-N 0.000 description 1
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 1
- 108010069236 Goserelin Proteins 0.000 description 1
- BLCLNMBMMGCOAS-URPVMXJPSA-N Goserelin Chemical compound C([C@@H](C(=O)N[C@H](COC(C)(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(=O)NNC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 BLCLNMBMMGCOAS-URPVMXJPSA-N 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 208000031886 HIV Infections Diseases 0.000 description 1
- 102100028967 HLA class I histocompatibility antigen, alpha chain G Human genes 0.000 description 1
- 108010024164 HLA-G Antigens Proteins 0.000 description 1
- 101150046249 Havcr2 gene Proteins 0.000 description 1
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 1
- 229920000209 Hexadimethrine bromide Polymers 0.000 description 1
- ZPVJJPAIUZLSNE-DCAQKATOSA-N His-Arg-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O ZPVJJPAIUZLSNE-DCAQKATOSA-N 0.000 description 1
- OEROYDLRVAYIMQ-YUMQZZPRSA-N His-Gly-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O OEROYDLRVAYIMQ-YUMQZZPRSA-N 0.000 description 1
- XJFITURPHAKKAI-SRVKXCTJSA-N His-Pro-Gln Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(N)=O)C(O)=O)C1=CN=CN1 XJFITURPHAKKAI-SRVKXCTJSA-N 0.000 description 1
- CCUSLCQWVMWTIS-IXOXFDKPSA-N His-Thr-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O CCUSLCQWVMWTIS-IXOXFDKPSA-N 0.000 description 1
- VXZZUXWAOMWWJH-QTKMDUPCSA-N His-Thr-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O VXZZUXWAOMWWJH-QTKMDUPCSA-N 0.000 description 1
- YBDOQKVAGTWZMI-XIRDDKMYSA-N His-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N YBDOQKVAGTWZMI-XIRDDKMYSA-N 0.000 description 1
- HIJIJPFILYPTFR-ACRUOGEOSA-N His-Tyr-Tyr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O HIJIJPFILYPTFR-ACRUOGEOSA-N 0.000 description 1
- GYXDQXPCPASCNR-NHCYSSNCSA-N His-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N GYXDQXPCPASCNR-NHCYSSNCSA-N 0.000 description 1
- 108010088652 Histocompatibility Antigens Class I Proteins 0.000 description 1
- 102000008949 Histocompatibility Antigens Class I Human genes 0.000 description 1
- 108010027412 Histocompatibility Antigens Class II Proteins 0.000 description 1
- 102000018713 Histocompatibility Antigens Class II Human genes 0.000 description 1
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 description 1
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 description 1
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 description 1
- 101000914337 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 3 Proteins 0.000 description 1
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 description 1
- 101001010910 Homo sapiens Estrogen receptor beta Proteins 0.000 description 1
- 101001046870 Homo sapiens Hypoxia-inducible factor 1-alpha Proteins 0.000 description 1
- 101001034314 Homo sapiens Lactadherin Proteins 0.000 description 1
- 101000984189 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily B member 2 Proteins 0.000 description 1
- 101000984186 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily B member 4 Proteins 0.000 description 1
- 101001014223 Homo sapiens MAPK/MAK/MRK overlapping kinase Proteins 0.000 description 1
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 1
- 101000946843 Homo sapiens T-cell surface glycoprotein CD8 alpha chain Proteins 0.000 description 1
- 101100207070 Homo sapiens TNFSF8 gene Proteins 0.000 description 1
- 101000597785 Homo sapiens Tumor necrosis factor receptor superfamily member 6B Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 101150003028 Hprt1 gene Proteins 0.000 description 1
- 241000713772 Human immunodeficiency virus 1 Species 0.000 description 1
- 241000713340 Human immunodeficiency virus 2 Species 0.000 description 1
- 102000009438 IgE Receptors Human genes 0.000 description 1
- 108010073816 IgE Receptors Proteins 0.000 description 1
- JRHFQUPIZOYKQP-KBIXCLLPSA-N Ile-Ala-Glu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O JRHFQUPIZOYKQP-KBIXCLLPSA-N 0.000 description 1
- SACHLUOUHCVIKI-GMOBBJLQSA-N Ile-Arg-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N SACHLUOUHCVIKI-GMOBBJLQSA-N 0.000 description 1
- WECYRWOMWSCWNX-XUXIUFHCSA-N Ile-Arg-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O WECYRWOMWSCWNX-XUXIUFHCSA-N 0.000 description 1
- DMHGKBGOUAJRHU-UHFFFAOYSA-N Ile-Arg-Pro Natural products CCC(C)C(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O DMHGKBGOUAJRHU-UHFFFAOYSA-N 0.000 description 1
- UBHUJPVCJHPSEU-GRLWGSQLSA-N Ile-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N UBHUJPVCJHPSEU-GRLWGSQLSA-N 0.000 description 1
- NYEYYMLUABXDMC-NHCYSSNCSA-N Ile-Gly-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)O)N NYEYYMLUABXDMC-NHCYSSNCSA-N 0.000 description 1
- LBRCLQMZAHRTLV-ZKWXMUAHSA-N Ile-Gly-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LBRCLQMZAHRTLV-ZKWXMUAHSA-N 0.000 description 1
- YNMQUIVKEFRCPH-QSFUFRPTSA-N Ile-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)O)N YNMQUIVKEFRCPH-QSFUFRPTSA-N 0.000 description 1
- KLBVGHCGHUNHEA-BJDJZHNGSA-N Ile-Leu-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)O)N KLBVGHCGHUNHEA-BJDJZHNGSA-N 0.000 description 1
- DSDPLOODKXISDT-XUXIUFHCSA-N Ile-Leu-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DSDPLOODKXISDT-XUXIUFHCSA-N 0.000 description 1
- UAELWXJFLZBKQS-WHOFXGATSA-N Ile-Phe-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](Cc1ccccc1)C(=O)NCC(O)=O UAELWXJFLZBKQS-WHOFXGATSA-N 0.000 description 1
- IITVUURPOYGCTD-NAKRPEOUSA-N Ile-Pro-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IITVUURPOYGCTD-NAKRPEOUSA-N 0.000 description 1
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 1
- OAQJOXZPGHTJNA-NGTWOADLSA-N Ile-Trp-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N OAQJOXZPGHTJNA-NGTWOADLSA-N 0.000 description 1
- DTPGSUQHUMELQB-GVARAGBVSA-N Ile-Tyr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 DTPGSUQHUMELQB-GVARAGBVSA-N 0.000 description 1
- HQLSBZFLOUHQJK-STECZYCISA-N Ile-Tyr-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HQLSBZFLOUHQJK-STECZYCISA-N 0.000 description 1
- OMDWJWGZGMCQND-CFMVVWHZSA-N Ile-Tyr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OMDWJWGZGMCQND-CFMVVWHZSA-N 0.000 description 1
- PRTZQMBYUZFSFA-XEGUGMAKSA-N Ile-Tyr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)NCC(=O)O)N PRTZQMBYUZFSFA-XEGUGMAKSA-N 0.000 description 1
- 206010061598 Immunodeficiency Diseases 0.000 description 1
- 208000029462 Immunodeficiency disease Diseases 0.000 description 1
- 206010062016 Immunosuppression Diseases 0.000 description 1
- 108010065920 Insulin Lispro Proteins 0.000 description 1
- 102100037850 Interferon gamma Human genes 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 102000003996 Interferon-beta Human genes 0.000 description 1
- 108090000467 Interferon-beta Proteins 0.000 description 1
- 102000000589 Interleukin-1 Human genes 0.000 description 1
- 108010002352 Interleukin-1 Proteins 0.000 description 1
- 102000013691 Interleukin-17 Human genes 0.000 description 1
- 108010002386 Interleukin-3 Proteins 0.000 description 1
- 102000000646 Interleukin-3 Human genes 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 102000004388 Interleukin-4 Human genes 0.000 description 1
- 108020003285 Isocitrate lyase Proteins 0.000 description 1
- 102000011782 Keratins Human genes 0.000 description 1
- 108010076876 Keratins Proteins 0.000 description 1
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- 229930182816 L-glutamine Natural products 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- 102100039648 Lactadherin Human genes 0.000 description 1
- 101150030213 Lag3 gene Proteins 0.000 description 1
- 108010000851 Laminin Receptors Proteins 0.000 description 1
- 102000002297 Laminin Receptors Human genes 0.000 description 1
- QPRQGENIBFLVEB-BJDJZHNGSA-N Leu-Ala-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O QPRQGENIBFLVEB-BJDJZHNGSA-N 0.000 description 1
- XIRYQRLFHWWWTC-QEJZJMRPSA-N Leu-Ala-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XIRYQRLFHWWWTC-QEJZJMRPSA-N 0.000 description 1
- IBMVEYRWAWIOTN-RWMBFGLXSA-N Leu-Arg-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(O)=O IBMVEYRWAWIOTN-RWMBFGLXSA-N 0.000 description 1
- MDVZJYGNAGLPGJ-KKUMJFAQSA-N Leu-Asn-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MDVZJYGNAGLPGJ-KKUMJFAQSA-N 0.000 description 1
- BPANDPNDMJHFEV-CIUDSAMLSA-N Leu-Asp-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O BPANDPNDMJHFEV-CIUDSAMLSA-N 0.000 description 1
- HUEBCHPSXSQUGN-GARJFASQSA-N Leu-Cys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N HUEBCHPSXSQUGN-GARJFASQSA-N 0.000 description 1
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 1
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 1
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 1
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 1
- LESXFEZIFXFIQR-LURJTMIESA-N Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)NCC(O)=O LESXFEZIFXFIQR-LURJTMIESA-N 0.000 description 1
- LAPSXOAUPNOINL-YUMQZZPRSA-N Leu-Gly-Asp Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O LAPSXOAUPNOINL-YUMQZZPRSA-N 0.000 description 1
- VWHGTYCRDRBSFI-ZETCQYMHSA-N Leu-Gly-Gly Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(O)=O VWHGTYCRDRBSFI-ZETCQYMHSA-N 0.000 description 1
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 1
- KXODZBLFVFSLAI-AVGNSLFASA-N Leu-His-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 KXODZBLFVFSLAI-AVGNSLFASA-N 0.000 description 1
- SEMUSFOBZGKBGW-YTFOTSKYSA-N Leu-Ile-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SEMUSFOBZGKBGW-YTFOTSKYSA-N 0.000 description 1
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 1
- JNDYEOUZBLOVOF-AVGNSLFASA-N Leu-Leu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JNDYEOUZBLOVOF-AVGNSLFASA-N 0.000 description 1
- UBZGNBKMIJHOHL-BZSNNMDCSA-N Leu-Leu-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 UBZGNBKMIJHOHL-BZSNNMDCSA-N 0.000 description 1
- RXGLHDWAZQECBI-SRVKXCTJSA-N Leu-Leu-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O RXGLHDWAZQECBI-SRVKXCTJSA-N 0.000 description 1
- VVQJGYPTIYOFBR-IHRRRGAJSA-N Leu-Lys-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)O)N VVQJGYPTIYOFBR-IHRRRGAJSA-N 0.000 description 1
- DRWMRVFCKKXHCH-BZSNNMDCSA-N Leu-Phe-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=CC=C1 DRWMRVFCKKXHCH-BZSNNMDCSA-N 0.000 description 1
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 1
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 1
- PWPBLZXWFXJFHE-RHYQMDGZSA-N Leu-Pro-Thr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O PWPBLZXWFXJFHE-RHYQMDGZSA-N 0.000 description 1
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 1
- RGUXWMDNCPMQFB-YUMQZZPRSA-N Leu-Ser-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RGUXWMDNCPMQFB-YUMQZZPRSA-N 0.000 description 1
- GZRABTMNWJXFMH-UVOCVTCTSA-N Leu-Thr-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZRABTMNWJXFMH-UVOCVTCTSA-N 0.000 description 1
- HOMFINRJHIIZNJ-HOCLYGCPSA-N Leu-Trp-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O HOMFINRJHIIZNJ-HOCLYGCPSA-N 0.000 description 1
- FBNPMTNBFFAMMH-UHFFFAOYSA-N Leu-Val-Arg Natural products CC(C)CC(N)C(=O)NC(C(C)C)C(=O)NC(C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-UHFFFAOYSA-N 0.000 description 1
- 102100020872 Leucyl-cystinyl aminopeptidase Human genes 0.000 description 1
- 102100025583 Leukocyte immunoglobulin-like receptor subfamily B member 2 Human genes 0.000 description 1
- 102100025578 Leukocyte immunoglobulin-like receptor subfamily B member 4 Human genes 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 102000018170 Lymphotoxin beta Receptor Human genes 0.000 description 1
- 108010091221 Lymphotoxin beta Receptor Proteins 0.000 description 1
- ISHNZELVUVPCHY-ZETCQYMHSA-N Lys-Gly-Gly Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O ISHNZELVUVPCHY-ZETCQYMHSA-N 0.000 description 1
- OIYWBDBHEGAVST-BZSNNMDCSA-N Lys-His-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OIYWBDBHEGAVST-BZSNNMDCSA-N 0.000 description 1
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 1
- MEQLGHAMAUPOSJ-DCAQKATOSA-N Lys-Ser-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O MEQLGHAMAUPOSJ-DCAQKATOSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 102100030301 MHC class I polypeptide-related sequence A Human genes 0.000 description 1
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 description 1
- QEVRUYFHWJJUHZ-DCAQKATOSA-N Met-Ala-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C QEVRUYFHWJJUHZ-DCAQKATOSA-N 0.000 description 1
- ULNXMMYXQKGNPG-LPEHRKFASA-N Met-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N ULNXMMYXQKGNPG-LPEHRKFASA-N 0.000 description 1
- WXHHTBVYQOSYSL-FXQIFTODSA-N Met-Ala-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O WXHHTBVYQOSYSL-FXQIFTODSA-N 0.000 description 1
- UOENBSHXYCHSAU-YUMQZZPRSA-N Met-Gln-Gly Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O UOENBSHXYCHSAU-YUMQZZPRSA-N 0.000 description 1
- GPAHWYRSHCKICP-GUBZILKMSA-N Met-Glu-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O GPAHWYRSHCKICP-GUBZILKMSA-N 0.000 description 1
- DBXMFHGGHMXYHY-DCAQKATOSA-N Met-Leu-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O DBXMFHGGHMXYHY-DCAQKATOSA-N 0.000 description 1
- BJPQKNHZHUCQNQ-SRVKXCTJSA-N Met-Pro-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCSC)N BJPQKNHZHUCQNQ-SRVKXCTJSA-N 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 206010027480 Metastatic malignant melanoma Diseases 0.000 description 1
- 229930192392 Mitomycin Natural products 0.000 description 1
- PCZOHLXUXFIOCF-UHFFFAOYSA-N Monacolin X Natural products C12C(OC(=O)C(C)CC)CC(C)C=C2C=CC(C)C1CCC1CC(O)CC(=O)O1 PCZOHLXUXFIOCF-UHFFFAOYSA-N 0.000 description 1
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 description 1
- 101100207071 Mus musculus Tnfsf8 gene Proteins 0.000 description 1
- 101100268066 Mus musculus Zap70 gene Proteins 0.000 description 1
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 206010061309 Neoplasm progression Diseases 0.000 description 1
- 241001028048 Nicola Species 0.000 description 1
- CTQNGGLPUBDAKN-UHFFFAOYSA-N O-Xylene Chemical compound CC1=CC=CC=C1C CTQNGGLPUBDAKN-UHFFFAOYSA-N 0.000 description 1
- 102000004473 OX40 Ligand Human genes 0.000 description 1
- 108010042215 OX40 Ligand Proteins 0.000 description 1
- 239000002033 PVDF binder Substances 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 108010087702 Penicillinase Proteins 0.000 description 1
- 102000003992 Peroxidases Human genes 0.000 description 1
- 108010081690 Pertussis Toxin Proteins 0.000 description 1
- KIAWKQJTSGRCSA-AVGNSLFASA-N Phe-Asn-Glu Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N KIAWKQJTSGRCSA-AVGNSLFASA-N 0.000 description 1
- CUMXHKAOHNWRFQ-BZSNNMDCSA-N Phe-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CUMXHKAOHNWRFQ-BZSNNMDCSA-N 0.000 description 1
- ABQFNJAFONNUTH-FHWLQOOXSA-N Phe-Gln-Tyr Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N ABQFNJAFONNUTH-FHWLQOOXSA-N 0.000 description 1
- RSPUIENXSJYZQO-JYJNAYRXSA-N Phe-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RSPUIENXSJYZQO-JYJNAYRXSA-N 0.000 description 1
- YTILBRIUASDGBL-BZSNNMDCSA-N Phe-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 YTILBRIUASDGBL-BZSNNMDCSA-N 0.000 description 1
- INHMISZWLJZQGH-ULQDDVLXSA-N Phe-Leu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 INHMISZWLJZQGH-ULQDDVLXSA-N 0.000 description 1
- IPFXYNKCXYGSSV-KKUMJFAQSA-N Phe-Ser-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N IPFXYNKCXYGSSV-KKUMJFAQSA-N 0.000 description 1
- 101710114878 Phospholipase A-2-activating protein Proteins 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 102100022427 Plasmalemma vesicle-associated protein Human genes 0.000 description 1
- 101710193105 Plasmalemma vesicle-associated protein Proteins 0.000 description 1
- ALJGSKMBIUEJOB-FXQIFTODSA-N Pro-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@@H]1CCCN1 ALJGSKMBIUEJOB-FXQIFTODSA-N 0.000 description 1
- IWNOFCGBMSFTBC-CIUDSAMLSA-N Pro-Ala-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IWNOFCGBMSFTBC-CIUDSAMLSA-N 0.000 description 1
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 1
- NHDVNAKDACFHPX-GUBZILKMSA-N Pro-Arg-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O NHDVNAKDACFHPX-GUBZILKMSA-N 0.000 description 1
- VCYJKOLZYPYGJV-AVGNSLFASA-N Pro-Arg-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VCYJKOLZYPYGJV-AVGNSLFASA-N 0.000 description 1
- ORPZXBQTEHINPB-SRVKXCTJSA-N Pro-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H]1CCCN1)C(O)=O ORPZXBQTEHINPB-SRVKXCTJSA-N 0.000 description 1
- HQVPQXMCQKXARZ-FXQIFTODSA-N Pro-Cys-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O HQVPQXMCQKXARZ-FXQIFTODSA-N 0.000 description 1
- ODPIUQVTULPQEP-CIUDSAMLSA-N Pro-Gln-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ODPIUQVTULPQEP-CIUDSAMLSA-N 0.000 description 1
- UPJGUQPLYWTISV-GUBZILKMSA-N Pro-Gln-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UPJGUQPLYWTISV-GUBZILKMSA-N 0.000 description 1
- ZPPVJIJMIKTERM-YUMQZZPRSA-N Pro-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ZPPVJIJMIKTERM-YUMQZZPRSA-N 0.000 description 1
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 1
- NXEYSLRNNPWCRN-SRVKXCTJSA-N Pro-Glu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXEYSLRNNPWCRN-SRVKXCTJSA-N 0.000 description 1
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 1
- DMKWYMWNEKIPFC-IUCAKERBSA-N Pro-Gly-Arg Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O DMKWYMWNEKIPFC-IUCAKERBSA-N 0.000 description 1
- FKLSMYYLJHYPHH-UWVGGRQHSA-N Pro-Gly-Leu Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O FKLSMYYLJHYPHH-UWVGGRQHSA-N 0.000 description 1
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 1
- LCUOTSLIVGSGAU-AVGNSLFASA-N Pro-His-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O LCUOTSLIVGSGAU-AVGNSLFASA-N 0.000 description 1
- VZKBJNBZMZHKRC-XUXIUFHCSA-N Pro-Ile-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O VZKBJNBZMZHKRC-XUXIUFHCSA-N 0.000 description 1
- RUDOLGWDSKQQFF-DCAQKATOSA-N Pro-Leu-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O RUDOLGWDSKQQFF-DCAQKATOSA-N 0.000 description 1
- CLJLVCYFABNTHP-DCAQKATOSA-N Pro-Leu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O CLJLVCYFABNTHP-DCAQKATOSA-N 0.000 description 1
- FXGIMYRVJJEIIM-UWVGGRQHSA-N Pro-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FXGIMYRVJJEIIM-UWVGGRQHSA-N 0.000 description 1
- MHHQQZIFLWFZGR-DCAQKATOSA-N Pro-Lys-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O MHHQQZIFLWFZGR-DCAQKATOSA-N 0.000 description 1
- WOIFYRZPIORBRY-AVGNSLFASA-N Pro-Lys-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O WOIFYRZPIORBRY-AVGNSLFASA-N 0.000 description 1
- HWLKHNDRXWTFTN-GUBZILKMSA-N Pro-Pro-Cys Chemical compound C1C[C@H](NC1)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CS)C(=O)O HWLKHNDRXWTFTN-GUBZILKMSA-N 0.000 description 1
- NAIPAPCKKRCMBL-JYJNAYRXSA-N Pro-Pro-Phe Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1NCCC1)C1=CC=CC=C1 NAIPAPCKKRCMBL-JYJNAYRXSA-N 0.000 description 1
- BGWKULMLUIUPKY-BQBZGAKWSA-N Pro-Ser-Gly Chemical compound OC(=O)CNC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 BGWKULMLUIUPKY-BQBZGAKWSA-N 0.000 description 1
- KIDXAAQVMNLJFQ-KZVJFYERSA-N Pro-Thr-Ala Chemical compound C[C@@H](O)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](C)C(O)=O KIDXAAQVMNLJFQ-KZVJFYERSA-N 0.000 description 1
- SNSYSBUTTJBPDG-OKZBNKHCSA-N Pro-Trp-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N4CCC[C@@H]4C(=O)O SNSYSBUTTJBPDG-OKZBNKHCSA-N 0.000 description 1
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 description 1
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 108010072866 Prostate-Specific Antigen Proteins 0.000 description 1
- 102100038358 Prostate-specific antigen Human genes 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 1
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 1
- 230000006819 RNA synthesis Effects 0.000 description 1
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 241001068295 Replication defective viruses Species 0.000 description 1
- 102000004330 Rhodopsin Human genes 0.000 description 1
- 108090000820 Rhodopsin Proteins 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 206010070834 Sensitisation Diseases 0.000 description 1
- 229920002684 Sepharose Polymers 0.000 description 1
- IDCKUIWEIZYVSO-WFBYXXMGSA-N Ser-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C)C(O)=O)=CNC2=C1 IDCKUIWEIZYVSO-WFBYXXMGSA-N 0.000 description 1
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 1
- SFZKGGOGCNQPJY-CIUDSAMLSA-N Ser-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N SFZKGGOGCNQPJY-CIUDSAMLSA-N 0.000 description 1
- BTPAWKABYQMKKN-LKXGYXEUSA-N Ser-Asp-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BTPAWKABYQMKKN-LKXGYXEUSA-N 0.000 description 1
- DSSOYPJWSWFOLK-CIUDSAMLSA-N Ser-Cys-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O DSSOYPJWSWFOLK-CIUDSAMLSA-N 0.000 description 1
- HVKMTOIAYDOJPL-NRPADANISA-N Ser-Gln-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVKMTOIAYDOJPL-NRPADANISA-N 0.000 description 1
- UOLGINIHBRIECN-FXQIFTODSA-N Ser-Glu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UOLGINIHBRIECN-FXQIFTODSA-N 0.000 description 1
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 1
- CICQXRWZNVXFCU-SRVKXCTJSA-N Ser-His-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O CICQXRWZNVXFCU-SRVKXCTJSA-N 0.000 description 1
- SFTZTYBXIXLRGQ-JBDRJPRFSA-N Ser-Ile-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SFTZTYBXIXLRGQ-JBDRJPRFSA-N 0.000 description 1
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 1
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 1
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 1
- RWDVVSKYZBNDCO-MELADBBJSA-N Ser-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CO)N)C(=O)O RWDVVSKYZBNDCO-MELADBBJSA-N 0.000 description 1
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 1
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 1
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 1
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 1
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 1
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 1
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 1
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 1
- FZNNGIHSIPKFRE-QEJZJMRPSA-N Ser-Trp-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZNNGIHSIPKFRE-QEJZJMRPSA-N 0.000 description 1
- PIQRHJQWEPWFJG-UWJYBYFXSA-N Ser-Tyr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PIQRHJQWEPWFJG-UWJYBYFXSA-N 0.000 description 1
- VVKVHAOOUGNDPJ-SRVKXCTJSA-N Ser-Tyr-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VVKVHAOOUGNDPJ-SRVKXCTJSA-N 0.000 description 1
- PMTWIUBUQRGCSB-FXQIFTODSA-N Ser-Val-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O PMTWIUBUQRGCSB-FXQIFTODSA-N 0.000 description 1
- PCMZJFMUYWIERL-ZKWXMUAHSA-N Ser-Val-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PCMZJFMUYWIERL-ZKWXMUAHSA-N 0.000 description 1
- LLSLRQOEAFCZLW-NRPADANISA-N Ser-Val-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LLSLRQOEAFCZLW-NRPADANISA-N 0.000 description 1
- SYCFMSYTIFXWAJ-DCAQKATOSA-N Ser-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CO)N SYCFMSYTIFXWAJ-DCAQKATOSA-N 0.000 description 1
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 1
- 108010032838 Sialoglycoproteins Proteins 0.000 description 1
- 102000007365 Sialoglycoproteins Human genes 0.000 description 1
- 241000710960 Sindbis virus Species 0.000 description 1
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 238000000692 Student's t-test Methods 0.000 description 1
- NHUHCSRWZMLRLA-UHFFFAOYSA-N Sulfisoxazole Chemical compound CC1=NOC(NS(=O)(=O)C=2C=CC(N)=CC=2)=C1C NHUHCSRWZMLRLA-UHFFFAOYSA-N 0.000 description 1
- 230000006052 T cell proliferation Effects 0.000 description 1
- 230000005867 T cell response Effects 0.000 description 1
- 210000000662 T-lymphocyte subset Anatomy 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- BSNZTJXVDOINSR-JXUBOQSCSA-N Thr-Ala-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BSNZTJXVDOINSR-JXUBOQSCSA-N 0.000 description 1
- KEGBFULVYKYJRD-LFSVMHDDSA-N Thr-Ala-Phe Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KEGBFULVYKYJRD-LFSVMHDDSA-N 0.000 description 1
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 1
- MFEBUIFJVPNZLO-OLHMAJIHSA-N Thr-Asp-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O MFEBUIFJVPNZLO-OLHMAJIHSA-N 0.000 description 1
- OYTNZCBFDXGQGE-XQXXSGGOSA-N Thr-Gln-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C)C(=O)O)N)O OYTNZCBFDXGQGE-XQXXSGGOSA-N 0.000 description 1
- DKDHTRVDOUZZTP-IFFSRLJSSA-N Thr-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DKDHTRVDOUZZTP-IFFSRLJSSA-N 0.000 description 1
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 1
- FLPZMPOZGYPBEN-PPCPHDFISA-N Thr-Leu-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FLPZMPOZGYPBEN-PPCPHDFISA-N 0.000 description 1
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 1
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 1
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 1
- NDZYTIMDOZMECO-SHGPDSBTSA-N Thr-Thr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O NDZYTIMDOZMECO-SHGPDSBTSA-N 0.000 description 1
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 1
- XGFYGMKZKFRGAI-RCWTZXSCSA-N Thr-Val-Arg Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N XGFYGMKZKFRGAI-RCWTZXSCSA-N 0.000 description 1
- QGVBFDIREUUSHX-IFFSRLJSSA-N Thr-Val-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O QGVBFDIREUUSHX-IFFSRLJSSA-N 0.000 description 1
- PWONLXBUSVIZPH-RHYQMDGZSA-N Thr-Val-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O PWONLXBUSVIZPH-RHYQMDGZSA-N 0.000 description 1
- 102000006601 Thymidine Kinase Human genes 0.000 description 1
- 108020004440 Thymidine kinase Proteins 0.000 description 1
- 108700009124 Transcription Initiation Site Proteins 0.000 description 1
- 108091023040 Transcription factor Proteins 0.000 description 1
- 102000040945 Transcription factor Human genes 0.000 description 1
- 102100023935 Transmembrane glycoprotein NMB Human genes 0.000 description 1
- HQVKQINPFOCIIV-BVSLBCMMSA-N Trp-Arg-Tyr Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=C(O)C=C1 HQVKQINPFOCIIV-BVSLBCMMSA-N 0.000 description 1
- FEZASNVQLJQBHW-CABZTGNLSA-N Trp-Gly-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O)=CNC2=C1 FEZASNVQLJQBHW-CABZTGNLSA-N 0.000 description 1
- STKZKWFOKOCSLW-UMPQAUOISA-N Trp-Thr-Val Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)[C@@H](C)O)=CNC2=C1 STKZKWFOKOCSLW-UMPQAUOISA-N 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 102000000160 Tumor Necrosis Factor Receptor-Associated Peptides and Proteins Human genes 0.000 description 1
- 108010080432 Tumor Necrosis Factor Receptor-Associated Peptides and Proteins Proteins 0.000 description 1
- 102100031988 Tumor necrosis factor ligand superfamily member 6 Human genes 0.000 description 1
- 108050002568 Tumor necrosis factor ligand superfamily member 6 Proteins 0.000 description 1
- 102100032100 Tumor necrosis factor ligand superfamily member 8 Human genes 0.000 description 1
- 102100032101 Tumor necrosis factor ligand superfamily member 9 Human genes 0.000 description 1
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 description 1
- 102100035284 Tumor necrosis factor receptor superfamily member 6B Human genes 0.000 description 1
- CDRYEAWHKJSGAF-BPNCWPANSA-N Tyr-Ala-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O CDRYEAWHKJSGAF-BPNCWPANSA-N 0.000 description 1
- HSVPZJLMPLMPOX-BPNCWPANSA-N Tyr-Arg-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O HSVPZJLMPLMPOX-BPNCWPANSA-N 0.000 description 1
- BARBHMSSVWPKPZ-IHRRRGAJSA-N Tyr-Asp-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O BARBHMSSVWPKPZ-IHRRRGAJSA-N 0.000 description 1
- RIJPHPUJRLEOAK-JYJNAYRXSA-N Tyr-Gln-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O RIJPHPUJRLEOAK-JYJNAYRXSA-N 0.000 description 1
- NZFCWALTLNFHHC-JYJNAYRXSA-N Tyr-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NZFCWALTLNFHHC-JYJNAYRXSA-N 0.000 description 1
- HIINQLBHPIQYHN-JTQLQIEISA-N Tyr-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HIINQLBHPIQYHN-JTQLQIEISA-N 0.000 description 1
- SCZJKZLFSSPJDP-ACRUOGEOSA-N Tyr-Phe-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O SCZJKZLFSSPJDP-ACRUOGEOSA-N 0.000 description 1
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 1
- RMRFSFXLFWWAJZ-HJOGWXRNSA-N Tyr-Tyr-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 RMRFSFXLFWWAJZ-HJOGWXRNSA-N 0.000 description 1
- NVJCMGGZHOJNBU-UFYCRDLUSA-N Tyr-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N NVJCMGGZHOJNBU-UFYCRDLUSA-N 0.000 description 1
- YKBUNNNRNZZUID-UFYCRDLUSA-N Tyr-Val-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YKBUNNNRNZZUID-UFYCRDLUSA-N 0.000 description 1
- 102000003425 Tyrosinase Human genes 0.000 description 1
- 108060008724 Tyrosinase Proteins 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- JLFKWDAZBRYCGX-ZKWXMUAHSA-N Val-Asn-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N JLFKWDAZBRYCGX-ZKWXMUAHSA-N 0.000 description 1
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 1
- XLDYBRXERHITNH-QSFUFRPTSA-N Val-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)C(C)C XLDYBRXERHITNH-QSFUFRPTSA-N 0.000 description 1
- VFOHXOLPLACADK-GVXVVHGQSA-N Val-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N VFOHXOLPLACADK-GVXVVHGQSA-N 0.000 description 1
- KDKLLPMFFGYQJD-CYDGBPFRSA-N Val-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N KDKLLPMFFGYQJD-CYDGBPFRSA-N 0.000 description 1
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 1
- NZGOVKLVQNOEKP-YDHLFZDLSA-N Val-Phe-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N NZGOVKLVQNOEKP-YDHLFZDLSA-N 0.000 description 1
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 1
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 1
- SSKKGOWRPNIVDW-AVGNSLFASA-N Val-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SSKKGOWRPNIVDW-AVGNSLFASA-N 0.000 description 1
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 1
- 108010003533 Viral Envelope Proteins Proteins 0.000 description 1
- 101710145727 Viral Fc-gamma receptor-like protein UL119 Proteins 0.000 description 1
- 108700005077 Viral Genes Proteins 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- INAPMGSXUVUWAF-GCVPSNMTSA-N [(2r,3s,5r,6r)-2,3,4,5,6-pentahydroxycyclohexyl] dihydrogen phosphate Chemical compound OC1[C@H](O)[C@@H](O)C(OP(O)(O)=O)[C@H](O)[C@@H]1O INAPMGSXUVUWAF-GCVPSNMTSA-N 0.000 description 1
- 230000005856 abnormality Effects 0.000 description 1
- 229940028652 abraxane Drugs 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 239000000370 acceptor Substances 0.000 description 1
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 108010045023 alanyl-prolyl-tyrosine Proteins 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 229960000473 altretamine Drugs 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 238000000540 analysis of variance Methods 0.000 description 1
- 230000001093 anti-cancer Effects 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 230000030741 antigen processing and presentation Effects 0.000 description 1
- 210000000612 antigen-presenting cell Anatomy 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 238000003782 apoptosis assay Methods 0.000 description 1
- 239000012736 aqueous medium Substances 0.000 description 1
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 1
- 108010029539 arginyl-prolyl-proline Proteins 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- 210000004507 artificial chromosome Anatomy 0.000 description 1
- 238000013475 authorization Methods 0.000 description 1
- 230000003305 autocrine Effects 0.000 description 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 1
- 230000002146 bilateral effect Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 230000036770 blood supply Effects 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 229960002092 busulfan Drugs 0.000 description 1
- 229910001424 calcium ion Inorganic materials 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 229940127093 camptothecin Drugs 0.000 description 1
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical compound C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 description 1
- 230000036952 cancer formation Effects 0.000 description 1
- 229940022399 cancer vaccine Drugs 0.000 description 1
- 238000009566 cancer vaccine Methods 0.000 description 1
- 229910002092 carbon dioxide Inorganic materials 0.000 description 1
- 239000001569 carbon dioxide Substances 0.000 description 1
- 229960004562 carboplatin Drugs 0.000 description 1
- 231100000504 carcinogenesis Toxicity 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000022131 cell cycle Effects 0.000 description 1
- 230000025084 cell cycle arrest Effects 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000032823 cell division Effects 0.000 description 1
- 239000002458 cell surface marker Substances 0.000 description 1
- 230000010307 cell transformation Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 230000000973 chemotherapeutic effect Effects 0.000 description 1
- 108700010039 chimeric receptor Proteins 0.000 description 1
- 229960004630 chlorambucil Drugs 0.000 description 1
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 1
- 210000003763 chloroplast Anatomy 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 208000009060 clear cell adenocarcinoma Diseases 0.000 description 1
- 238000003501 co-culture Methods 0.000 description 1
- 230000004186 co-expression Effects 0.000 description 1
- 238000012761 co-transfection Methods 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 238000009096 combination chemotherapy Methods 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 238000002681 cryosurgery Methods 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 108010060199 cysteinylproline Proteins 0.000 description 1
- 230000016396 cytokine production Effects 0.000 description 1
- 230000001461 cytolytic effect Effects 0.000 description 1
- 229960000640 dactinomycin Drugs 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 1
- 229960000975 daunorubicin Drugs 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000003412 degenerative effect Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 108010009297 diglycyl-histidine Proteins 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 239000006185 dispersion Substances 0.000 description 1
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 1
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- 238000004980 dosimetry Methods 0.000 description 1
- 230000003828 downregulation Effects 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 108700004025 env Genes Proteins 0.000 description 1
- 210000002615 epidermis Anatomy 0.000 description 1
- 210000003238 esophagus Anatomy 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- OGPBJKLSAFTDLK-UHFFFAOYSA-N europium atom Chemical compound [Eu] OGPBJKLSAFTDLK-UHFFFAOYSA-N 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000017188 evasion or tolerance of host immune response Effects 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 230000001605 fetal effect Effects 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 238000002073 fluorescence micrograph Methods 0.000 description 1
- 238000000799 fluorescence microscopy Methods 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- 230000037406 food intake Effects 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 230000005714 functional activity Effects 0.000 description 1
- 238000010230 functional analysis Methods 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 108700004026 gag Genes Proteins 0.000 description 1
- 230000005251 gamma ray Effects 0.000 description 1
- 238000001476 gene delivery Methods 0.000 description 1
- 102000034356 gene-regulatory proteins Human genes 0.000 description 1
- 108091006104 gene-regulatory proteins Proteins 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 1
- 108010079547 glutamylmethionine Proteins 0.000 description 1
- 150000004676 glycans Chemical group 0.000 description 1
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 1
- 108010028188 glycyl-histidyl-serine Proteins 0.000 description 1
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 1
- YMAWOPBAYDPSLA-UHFFFAOYSA-N glycylglycine Chemical compound [NH3+]CC(=O)NCC([O-])=O YMAWOPBAYDPSLA-UHFFFAOYSA-N 0.000 description 1
- 108010077515 glycylproline Proteins 0.000 description 1
- 239000011544 gradient gel Substances 0.000 description 1
- 230000035876 healing Effects 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 229940022353 herceptin Drugs 0.000 description 1
- UUVWYPNAQBNQJQ-UHFFFAOYSA-N hexamethylmelamine Chemical compound CN(C)C1=NC(N(C)C)=NC(N(C)C)=N1 UUVWYPNAQBNQJQ-UHFFFAOYSA-N 0.000 description 1
- 108010025306 histidylleucine Proteins 0.000 description 1
- 102000055277 human IL2 Human genes 0.000 description 1
- 102000049409 human MOK Human genes 0.000 description 1
- 230000036571 hydration Effects 0.000 description 1
- 238000006703 hydration reaction Methods 0.000 description 1
- 230000007954 hypoxia Effects 0.000 description 1
- 230000001146 hypoxic effect Effects 0.000 description 1
- CBFCDTFDPHXCNY-UHFFFAOYSA-N icosane Chemical compound CCCCCCCCCCCCCCCCCCCC CBFCDTFDPHXCNY-UHFFFAOYSA-N 0.000 description 1
- 229960001101 ifosfamide Drugs 0.000 description 1
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 description 1
- 230000002519 immonomodulatory effect Effects 0.000 description 1
- 230000005965 immune activity Effects 0.000 description 1
- 230000008073 immune recognition Effects 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 230000007813 immunodeficiency Effects 0.000 description 1
- 238000003125 immunofluorescent labeling Methods 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000005917 in vivo anti-tumor Effects 0.000 description 1
- 238000005462 in vivo assay Methods 0.000 description 1
- 239000000411 inducer Substances 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000002458 infectious effect Effects 0.000 description 1
- 230000008595 infiltration Effects 0.000 description 1
- 238000001764 infiltration Methods 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 229960003130 interferon gamma Drugs 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000010255 intramuscular injection Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- PGHMRUGBZOYCAA-UHFFFAOYSA-N ionomycin Natural products O1C(CC(O)C(C)C(O)C(C)C=CCC(C)CC(C)C(O)=CC(=O)C(C)CC(C)CC(CCC(O)=O)C)CCC1(C)C1OC(C)(C(C)O)CC1 PGHMRUGBZOYCAA-UHFFFAOYSA-N 0.000 description 1
- PGHMRUGBZOYCAA-ADZNBVRBSA-N ionomycin Chemical compound O1[C@H](C[C@H](O)[C@H](C)[C@H](O)[C@H](C)/C=C/C[C@@H](C)C[C@@H](C)C(/O)=C/C(=O)[C@@H](C)C[C@@H](C)C[C@@H](CCC(O)=O)C)CC[C@@]1(C)[C@@H]1O[C@](C)([C@@H](C)O)CC1 PGHMRUGBZOYCAA-ADZNBVRBSA-N 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 238000002430 laser surgery Methods 0.000 description 1
- 108010076756 leucyl-alanyl-phenylalanine Proteins 0.000 description 1
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 1
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 1
- 108010034529 leucyl-lysine Proteins 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- PCZOHLXUXFIOCF-BXMDZJJMSA-N lovastatin Chemical compound C([C@H]1[C@@H](C)C=CC2=C[C@H](C)C[C@@H]([C@H]12)OC(=O)[C@@H](C)CC)C[C@@H]1C[C@@H](O)CC(=O)O1 PCZOHLXUXFIOCF-BXMDZJJMSA-N 0.000 description 1
- 229960004844 lovastatin Drugs 0.000 description 1
- QLJODMDSTUBWDW-UHFFFAOYSA-N lovastatin hydroxy acid Natural products C1=CC(C)C(CCC(O)CC(O)CC(O)=O)C2C(OC(=O)C(C)CC)CC(C)C=C21 QLJODMDSTUBWDW-UHFFFAOYSA-N 0.000 description 1
- 231100000053 low toxicity Toxicity 0.000 description 1
- 239000012139 lysis buffer Substances 0.000 description 1
- 108010003700 lysyl aspartic acid Proteins 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 229960004961 mechlorethamine Drugs 0.000 description 1
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 1
- 210000004779 membrane envelope Anatomy 0.000 description 1
- 208000021039 metastatic melanoma Diseases 0.000 description 1
- 108010016686 methionyl-alanyl-serine Proteins 0.000 description 1
- 239000010445 mica Substances 0.000 description 1
- 229910052618 mica group Inorganic materials 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 210000003470 mitochondria Anatomy 0.000 description 1
- 239000003226 mitogen Substances 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 239000002991 molded plastic Substances 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 239000012120 mounting media Substances 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- AFRBPRLOPBAGCM-UHFFFAOYSA-N n-[2-(1h-indol-4-yl)ethyl]-n-propylpropan-1-amine Chemical compound CCCN(CCC)CCC1=CC=CC2=C1C=CN2 AFRBPRLOPBAGCM-UHFFFAOYSA-N 0.000 description 1
- 229940086322 navelbine Drugs 0.000 description 1
- 230000001338 necrotic effect Effects 0.000 description 1
- 230000035407 negative regulation of cell proliferation Effects 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 210000005170 neoplastic cell Anatomy 0.000 description 1
- 230000001613 neoplastic effect Effects 0.000 description 1
- 238000012758 nuclear staining Methods 0.000 description 1
- 239000002773 nucleotide Substances 0.000 description 1
- 125000003729 nucleotide group Chemical group 0.000 description 1
- 210000004940 nucleus Anatomy 0.000 description 1
- 238000012634 optical imaging Methods 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 230000020477 pH reduction Effects 0.000 description 1
- VYNDHICBIRRPFP-UHFFFAOYSA-N pacific blue Chemical compound FC1=C(O)C(F)=C2OC(=O)C(C(=O)O)=CC2=C1 VYNDHICBIRRPFP-UHFFFAOYSA-N 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- 238000011499 palliative surgery Methods 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 229950009506 penicillinase Drugs 0.000 description 1
- 230000010412 perfusion Effects 0.000 description 1
- 210000005105 peripheral blood lymphocyte Anatomy 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 239000002831 pharmacologic agent Substances 0.000 description 1
- 108010018625 phenylalanylarginine Proteins 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 108010025488 pinealon Proteins 0.000 description 1
- BLFWHYXWBKKRHI-JYBILGDPSA-N plap Chemical compound N([C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(=O)[C@@H]1CCCN1C(=O)[C@H](CO)NC(=O)[C@@H](N)CCC(O)=O BLFWHYXWBKKRHI-JYBILGDPSA-N 0.000 description 1
- 108700004029 pol Genes Proteins 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 1
- 230000029279 positive regulation of transcription, DNA-dependent Effects 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 229960000624 procarbazine Drugs 0.000 description 1
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 229940002612 prodrug Drugs 0.000 description 1
- 239000000651 prodrug Substances 0.000 description 1
- 230000005522 programmed cell death Effects 0.000 description 1
- 230000002062 proliferating effect Effects 0.000 description 1
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 1
- 108010031719 prolyl-serine Proteins 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 238000011158 quantitative evaluation Methods 0.000 description 1
- 239000013608 rAAV vector Substances 0.000 description 1
- GZUITABIAKMVPG-UHFFFAOYSA-N raloxifene Chemical compound C1=CC(O)=CC=C1C1=C(C(=O)C=2C=CC(OCCN3CCCCC3)=CC=2)C2=CC=C(O)C=C2S1 GZUITABIAKMVPG-UHFFFAOYSA-N 0.000 description 1
- 229960004622 raloxifene Drugs 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 210000005084 renal tissue Anatomy 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 108091092562 ribozyme Proteins 0.000 description 1
- 239000000523 sample Substances 0.000 description 1
- 230000008313 sensitization Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 239000012453 solvate Substances 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 238000011301 standard therapy Methods 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-L sulfate group Chemical group S(=O)(=O)([O-])[O-] QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 1
- 238000011477 surgical intervention Methods 0.000 description 1
- 101150047061 tag-72 gene Proteins 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 108091007466 transmembrane glycoproteins Proteins 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 238000005829 trimerization reaction Methods 0.000 description 1
- 108010080629 tryptophan-leucine Proteins 0.000 description 1
- 230000004565 tumor cell growth Effects 0.000 description 1
- 102000003390 tumor necrosis factor Human genes 0.000 description 1
- 230000005751 tumor progression Effects 0.000 description 1
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 1
- 108010017949 tyrosyl-glycyl-glycine Proteins 0.000 description 1
- 108010020532 tyrosyl-proline Proteins 0.000 description 1
- 108010003137 tyrosyltyrosine Proteins 0.000 description 1
- 238000009281 ultraviolet germicidal irradiation Methods 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 210000003932 urinary bladder Anatomy 0.000 description 1
- 230000002485 urinary effect Effects 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- JXLYSJRDGCGARV-CFWMRBGOSA-N vinblastine Chemical compound C([C@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-CFWMRBGOSA-N 0.000 description 1
- 229960003048 vinblastine Drugs 0.000 description 1
- 229960004528 vincristine Drugs 0.000 description 1
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 1
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 1
- CILBMBUYJCWATM-PYGJLNRPSA-N vinorelbine ditartrate Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O.OC(=O)[C@H](O)[C@@H](O)C(O)=O.C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC CILBMBUYJCWATM-PYGJLNRPSA-N 0.000 description 1
- 210000002845 virion Anatomy 0.000 description 1
- 230000001018 virulence Effects 0.000 description 1
- 230000003442 weekly effect Effects 0.000 description 1
- 239000008096 xylene Substances 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
- 229940033942 zoladex Drugs 0.000 description 1
Images
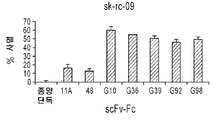
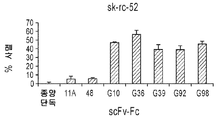














Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/14—Blood; Artificial blood
- A61K35/17—Lymphocytes; B-cells; T-cells; Natural killer cells; Interferon-activated or cytokine-activated lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/19—Cytokines; Lymphokines; Interferons
- A61K38/20—Interleukins [IL]
- A61K38/2013—IL-2
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4611—T-cells, e.g. tumor infiltrating lymphocytes [TIL], lymphokine-activated killer cells [LAK] or regulatory T cells [Treg]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/463—Cellular immunotherapy characterised by recombinant expression
- A61K39/4631—Chimeric Antigen Receptors [CAR]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464454—Enzymes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P11/00—Drugs for disorders of the respiratory system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/10—Drugs for disorders of the urinary system of the bladder
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P15/00—Drugs for genital or sexual disorders; Contraceptives
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/70521—CD28, CD152
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/40—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against enzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
- C12N5/0637—Immunosuppressive T lymphocytes, e.g. regulatory T cells or Treg
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
- C12N5/0638—Cytotoxic T lymphocytes [CTL] or lymphokine activated killer cells [LAK]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/88—Lyases (4.)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y402/00—Carbon-oxygen lyases (4.2)
- C12Y402/01—Hydro-lyases (4.2.1)
- C12Y402/01001—Carbonate dehydratase (4.2.1.1), i.e. carbonic anhydrase
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/31—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterized by the route of administration
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/38—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterised by the dose, timing or administration schedule
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/46—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterised by the cancer treated
- A61K2239/56—Kidney
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/51—Complete heavy chain or Fd fragment, i.e. VH + CH1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/515—Complete light chain, i.e. VL + CL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/33—Fusion polypeptide fusions for targeting to specific cell types, e.g. tissue specific targeting, targeting of a bacterial subspecies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
- C07K2319/74—Fusion polypeptide containing domain for protein-protein interaction containing a fusion for binding to a cell surface receptor
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- Medicinal Chemistry (AREA)
- Wood Science & Technology (AREA)
- Cell Biology (AREA)
- Biochemistry (AREA)
- Biotechnology (AREA)
- Microbiology (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- General Engineering & Computer Science (AREA)
- Epidemiology (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Hematology (AREA)
- Biophysics (AREA)
- Mycology (AREA)
- Gastroenterology & Hepatology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Toxicology (AREA)
- Oncology (AREA)
- Urology & Nephrology (AREA)
- Developmental Biology & Embryology (AREA)
- Virology (AREA)
- Endocrinology (AREA)
- Reproductive Health (AREA)
- Pulmonology (AREA)
Abstract
본 발명은 탄산무수화효소 IX(CAIX)에 특이적인 키메라 항원 수용체 세포, 및 CAIX 발현 암, 예컨대 신장 세포 암종의 치료를 위해 상기 세포를 사용하는 방법을 제공한다.
Description
관련 출원
본원은 2014년 12월 19일에 제출된 미국 가출원 제62/094,596호의 우선권 및 이익을 주장하며, 상기 가출원의 내용은 그 전체가 본원에 참고로 인용된다.
서열목록의 참고 인용
2015년 12월 21일에 생성된 텍스트 파일(파일명: "DFCI-092_001WO Final Seq Listing_ST25.txt")의 내용은 그 전체가 본원에 참고로 인용된다.
발명의 분야
본 발명은 일반적으로 탄산무수화효소 IX(CAIX)에 특이적인 키메라 항원 수용체 세포, 및 CAIX 발현 암, 예컨대 신장 세포 암종의 치료를 위해 상기 세포를 사용하는 방법에 관한 것이다.
정부 지원
본 발명은 미국 국립보건원에 의해 부여된 승인번호 R21DK07228 하에서 정부 지원으로 만들어졌다. 정부는 본 발명에서 일부 권리를 가진다.
탄산무수화효소는 살아있는 유기체에서 pH 균형을 유지하기 위해 이산화탄소의 가역적 수화를 촉진하는 아연 메탈로효소의 한 패밀리이다. 탄산무수화효소 IX(CAIX)는 54/58 kDa의 분자량을 가진 경막 당단백질이다. 구조적으로, CAIX는 4개의 도메인들로 구성된다: N-말단 프로테오글리칸 유사 도메인(PG)(aa 53-111), CA 촉매 도메인(CA)(aa 135-391), 경막 나선형 분절(aa 415-434), 및 짧은 세포질내 꼬리(aa 434-459). 저산소성 조건에서, CAIX 유전자는 저산소증 유도성 전사 인자 HIF-1α에 의해 전사 수준에서 직접적으로 활성화되어, 세포외 배지로의 양성자의 수송 및 pH의 저하를 유발한다. 따라서, CAIX 발현은 다양한 종양들에서 저산소증에 대한 대용 마커로서 간주될 수 있다. 그 결과, CA 활성에 의한 종양 미세환경의 산성화 및 CAIX의 PG 도메인 내의 O-연결된 글리칸 구조의 케라틴 설페이트 유닛은 세포 부착 및 종양 진행의 과정에서 중요한 역할을 수행하는 것으로 추정된다.
CAIX는 종양 관련 항원으로서 간주되고, 그의 과다발현은 여러 유형의 고형 종양, 특히 투명 세포 유형의 신장 세포 암종(RCC)뿐만 아니라, 난소, 유방, 식도, 방광, 대장, 비소세포 폐, 자궁경부의 이형성증 등을 비롯한 여러 조직학적 유형의 암종에서 발견된다. CAIX 발현은 암 진단 및 발암의 초기 검출을 위한 마커로서 작용하는 것으로 제안되어 있고, 높은 반응률 및 낮은 독성을 유발하는, 흑색종 및 신장암의 IL-2 치료된 환자에서 유리한 반응에 대한 예후 마커이기도 하다. 면역염색 및 웨스턴 블롯 연구는 고도의 CAIX 발현이 대다수의 일차 RCC(투명 세포 유형의 과립형 또는 방추 세포, 유두 유형의 호염색성 세포, 및 협염색성 세포를 제외한 집합관), 낭포성 RCC 및 전이성 RCC로 제한되나, 정상 신장 조직, 양성 상피 낭포성 병변 또는 비-신장 세포 투명 세포 선암종에서는 관찰되지 않는다.
RCC는 전이성 병변이 신장절제 후 자연발생적으로 퇴행하고 면역조절 요법, 예컨대, 암 백신 및 IL-2에 반응한다는 증거를 나타내는, 흑색종을 제외한 두 유형의 면역원성 종양들 중 하나이다. 생체외 증폭된 종양 침윤 림프구(TIL)를 사용하는, 전이성 흑색종 및 RCC 환자를 위한 입양 T 세포 요법은 일부 성공을 보였다. 최근에, TCR-변경된 T 세포(TCR α 및 β 쇄)도 효과적인 종양 표적화 T-세포 레퍼토리를 제공하는 데 사용되었다. 그러나, 후-표적화 항-종양 활성은 MHC 클래스 I-제한된 항원 제시 기구의 모든 수준에서 하향조절을 수반하는 결핍, 종양 상의 보조자극 분자의 발현 상실로 인해 유도된 무감작뿐만 아니라 종양에 의한 면역억제 활성을 가진 사이토카인의 분자 배출 및 분비에 의해 방해받을 수 있다.
다양한 양태에서, 본 발명은 세포내 신호전달 도메인, 경막 도메인, 및 탄산무수화효소 IX(G250) 특이적 수용체를 포함하는 세포외 도메인을 가진 키메라 항원 수용체(CAR)를 제공한다. 일부 양태에서, CAR은 세포외 도메인과 경막 도메인 사이에 위치하는 줄기(stalk) 영역을 추가로 포함한다. 경막 도메인은 예를 들면, CD28이다. 다른 양태에서, CAR은 경막 도메인과 세포내 신호전달 도메인 사이에 위치하는 하나 이상의 추가 보조자극 분자를 추가로 포함한다. 보조자극 분자는 예를 들면, CD28, 4-1BB, ICOS 또는 OX40이다. 세포내 신호전달 도메인은 CD3 제타 쇄를 포함한다.
탄산무수화효소 IX(G250) 특이적 수용체는 항체, 예컨대, Fab 또는 scFV이다. 바람직하게는, 항체는 아미노산 서열 SYAMS(서열번호 55)를 포함하는 CDR1, 아미노산 서열 AISANGGTTYYADSVKG(서열번호 67)를 포함하는 CDR2, 및 아미노산 서열 NGNYRGAFDI(서열번호 65)를 포함하는 CDR3을 가진 중쇄; 및 아미노산 서열 TGSSSNIGAGFDVH(서열번호 68)를 포함하는 CDR1, 아미노산 서열 GNTNRPS(서열번호 69)를 포함하는 CDR2, 및 아미노산 서열 QSYDSRLSAWV(서열번호 70)를 포함하는 CDR3을 가진 경쇄; 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1, 아미노산 서열 GNSNRPS(서열번호 72)를 포함하는 CDR2, 및 아미노산 서열 QSYDRSLSWV(서열번호 73)를 포함하는 CDR3을 가진 경쇄; 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1, 아미노산 서열 GNTNRPS(서열번호 69)를 포함하는 CDR2, 및 아미노산 서열 QSYDSTLRVWM(서열번호 74)을 포함하는 CDR3을 가진 경쇄; 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1, 아미노산 서열 GNNNRPS(서열번호 62)를 포함하는 CDR2, 및 아미노산 서열 QSYDKSLTWV(서열번호 76)를 포함하는 CDR3을 가진 경쇄; 아미노산 서열 TGTSSNIGAGYDVH(서열번호 79)를 포함하는 CDR1, 아미노산 서열 GNNNRPS(서열번호 62)를 포함하는 CDR2, 및 아미노산 서열 QSYDKSLSWV(서열번호 80)를 포함하는 CDR3을 가진 경쇄; 아미노산 서열 TGSSSNIGAGFDVH(서열번호 81)를 포함하는 CDR1, 아미노산 서열 GNNNRPS(서열번호 62)를 포함하는 CDR2, 및 아미노산 서열 QSYDSSLSAWV(서열번호 82)를 포함하는 CDR3을 가진 경쇄; 또는 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1, 아미노산 서열 GNSNRPS(서열번호 72)를 포함하는 CDR2, 및 아미노산 서열 QSYDSSLSAWV(서열번호 82)를 포함하는 CDR3을 가진 경쇄를 가진다.
또 다른 양태에서, scFv 항체는 서열번호 1 및 3 내지 23의 아미노산 서열들로부터 선택된 아미노산 서열을 포함하는 중쇄를 갖고, 이때 상기 scFv 항체는 서열번호 2 및 24 내지 44의 아미노산 서열들로부터 선택된 아미노산 서열을 포함하는 경쇄를 가진다.
본 발명은 본 발명에 따른 키메라 항원 수용체를 세포 표면 막 상에서 발현하여 보유하는 유전자 조작 세포도 제공한다. 상기 세포는 T 세포 또는 NK 세포이다. T 세포는 CD4+ 또는 CD8+이다. 다른 양태에서, 세포는 CD4+ 세포와 CD8+ 세포의 혼합된 집단이다.
추가 양태에서, 본 발명은 본 발명에 따른 유전자 조작 세포를 대상체에게 투여함으로써 탄산무수화효소 IX(G250) 발현 종양을 가진 대상체를 치료하는 방법을 제공한다. 유전자 조작 세포는 대상체에 대해 자가유래성인 세포로부터 유래한다. 종양은 신장암, 난소암, 유방암, 식도암, 방광암, 대장암 또는 비소세포 폐암이다. 신장암은 예를 들면, 신장 투명 세포 암이다. 일부 양태에서, 상기 방법은 IL-2, 항-PD-1, 항-PDL-1 또는 항-CTL4 항체를 투여하는 단계를 추가로 포함한다.
달리 정의되어 있지 않은 한, 본원에서 사용된 모든 기술 용어들 및 과학 용어들은 본 발명이 속하는 분야에서 통상의 기술을 가진 자에 의해 통상적으로 이해되는 의미와 동일한 의미를 가진다. 본원에 기재된 방법 및 재료와 유사하거나 동등한 방법 및 재료가 본 발명의 실시에서 사용될 수 있지만, 적합한 방법 및 재료가 이하에 기재되어 있다. 본원에서 언급된 모든 공개문헌들, 특허출원들, 특허들 및 다른 참고문헌들은 전체적으로 명백히 참고로 도입된다. 불일치의 경우, 정의를 포함하는 본 명세서가 좌우할 것이다. 추가로, 본원에 기재된 재료, 방법 및 예는 단지 예시적이고 한정하기 위한 것이 아니다.
본 발명의 다른 특징 및 장점은 하기 상세한 설명 및 청구범위로부터 자명할 것이고 이러한 설명 및 청구범위에 의해 포괄될 것이다.
도 1: CAIX 특이적 Ab들의 ADCC. 1 ㎍/㎖의 CAIX 특이적 scFv-Fc 미니바디를 인간 PBMC(E:T 25:1)의 존재 하에서 표적 종양 세포에 첨가하였다. 유사한 결과가 2회 실험에서 수득되었다. 무관한 항-SARS scFv-Fc(11A) 및 항-CCR4 scFv-Fc(48) 미니바디는 음성 대조군으로서 사용되었다. A, CAIX+ sk-rc-09 세포; B, CAIX+ sk-rc-52 세포; C, CAIX- sk-rc-59 세포.
도 2: CAIX 특이적 CAR들의 구축 및 발현. A. 구축: 제1세대 CAR인 scFv-CD8-TCRζ(CD8 CAR)는 절단된 인간 CD8α 세포외 도메인, 힌지(H), 경막(TM) 및 세포내 영역에 커플링된 후 인간 TCRζ의 신호전달 도메인에 커플링되어 있는 특이적 항-CAIX scFv로 구성된다. 제2세대 CAR인 scFv-CD28-TCRζ(CD28 CAR)는 TCRζ에 대한 인간 CD28 세포외, TM 및 세포내 신호전달 도메인과 융합된 항-CAIX scFv를 함유한다. 항-CAIX CAR들 둘 다를 내부 eF1-α 프로모터에 의해 유발된 발현을 가진 비시스트론성(bicistronic) 자가-불활성화(SIN) 렌티바이러스 벡터 내로 클로닝하였다. CAR 조절 구축물은 무관한 항-HIV CCR5 특이적 A8 scFv 치환을 함유한다. B. FACS 분석: 레포터 유전자 ZsGreen을 사용하여 렌티바이러스 CAR 구축물에 의한 일차 T 세포 형질도입 효율을 정량화하였다. 추가로, 항-CAIX scFv CAR들을 CAIX-Fc 융합 단백질로 염색하였고 C9-태그(TETSQVAPA)를 1D4 항체로 염색하였다. 형질도입되지 않은 활성화된 T-세포인 LAK만이 염색되지 않은 세포 대조군(i)으로서 사용되었거나, 2차 항체(ii. PE-항-인간 IgG 및 iii. APC-항-마우스 IgG)로 염색되어 염색 대조군으로서 사용되었다. C. 웨스턴 블롯: 항-CAIX(클론 G36) CD28 및 항-CCR5(클론 A8) CD28 CAR들의 단량체/이량체 구조물뿐만 아니라, 형질도입되지 않은 T 세포의 내생성 TCRζ 쇄의 분자 크기도 표시되어 있다.
도 3: CAIX 특이적 CART들의 이펙터 기능. A. 사이토카인 분비. 사이토카인 생성을 위해 항-CAIX CART, 무관한 CART 또는 활성화된 대조군 T 세포(LAK)를 신장암 세포주 sk-rc-52(CAIX+) 및 sk-rc-59(CAIX-)와 함께 밤새 공배양하였다. 2개 내지 3개의 결과를 대표하는 하나가 표시되어 있다. B. ELISPOT. G36 CART 또는 대조군 A8 CART 세포를 밤새 종양 세포에 첨가하였다. ELISPOT에 의해 검출된 IFN-γ 또는 그랜자임(granzyme) B 분비 T 세포. 유사한 결과가 2회 또는 3회 실험에서 수득되었다. C. CAIX 특이적 CART 세포의 특이적 항-종양 세포독성, 대조군 A8 CART 세포 또는 LAK 세포를 표시된 비로 표적 종양 세포의 다양한 양에서 4시간 세포독성 어세이에서 항온처리하였다. 2회 실험 중 하나가 표시되어 있다. 클론 4-1은 sk-rc-52의 생체내 계대배양된 서브클론이다.
도 4: 종양 접촉 후 CART 세포의 클론 증폭. A. 증식. CAR-형질도입된 T 세포 또는 형질도입되지 않은 T 세포(LAK)를 표시된 바와 같이 종양 대 T 세포의 세 상이한 비에서 방사선조사된 종양 세포(CAIX+ sk-rc-52 & CAIX- sk-rc-59)와 함께 주마다 플레이팅하였다. T 세포의 수를 2개의 분리된 웰들로부터 삼중으로 3일 또는 4일마다 카운팅하였다. 유사한 결과가 2회 실험에서 수득되었다. B. 클론 농후화. 종양 자극 실험에서, CART-세포 및 LAK 세포로부터의 배양물을 CART 및 T-세포 서브세트의 발현에 대해 유세포측정(flow cytometry)으로 1주 및 2주 동안 분석하였다. 2회 결과를 대표하는 하나가 표시되어 있다.
도 5: CART 세포에 의한 확립된 인간 RCC 이종이식물의 퇴행. 무흉선 널(null) 마우스를 좌측 옆구리 및 우측 옆구리에서 각각 7.5 x 106개의 sk-rc-52 RCC 종양 세포 및 5 x 106개의 sk-rc-59 RCC 종양 세포로 피하 접종하였다. 6일의 종양 이식 후, 마우스를 50 x 106개의 G36 CD28 CART 세포, A8 CD28 CART 세포(≥ 20% CAR+), LAK 또는 PBS 단독으로 정맥내 주사하였다. 고용량의 IL-2(1 x 105 U/㎖)를 2일 또는 3일마다 주사하였다. 종양 크기를 2일 또는 3일마다 칼리퍼로 측정하였다. 실험 1, n = 7 & 실험 2, n = 8. 이들 2회 실험의 종양 크기는 따로 표시되었다. 이들 2회 시험에서 대조군인 T 세포 비치료 마우스에 비해 G36 탠덤 치료 마우스의 군들에서 +, p<0.05; *, p<0.01; **, p<0.001. 다른 통계학적 계산은 본문에 보고되어 있다.
도 6: CAR+ T-세포의 생체내 항-종양 활성. A. CART 세포에 의한 ZsGreen의 발현은 상부 패널에 표시되어 있다. CART 세포를 파 레드(Far Red) 염료로 미리 염색하였고 세포원심분리하였고 형광 현미경관찰로 조사하였다(하부 패널). B. 퇴행 종양에서 G36 CD28 CART 세포의 제자리(in situ) 염색. CART-세포를 RCC 확립된 마우스 내로 정맥내 주사하였고 종양 조직을 1일째 날 내지 3일째 날에 수집하였다. 공초점 현미경관찰을 이용하여 PE-Cy5 염료(적색으로서 표시됨)를 사용한 TUNNEL 어세이로 종양 세포의 아폽토시스를 측정하였다. 형질도입된 T 세포는 ZsGreen으로 표시되었다. 핵을 DPAI로 반대염색하였다. 2개의 대표적인 슬라이드들은 각각 종양의 가장자리(상부 패널) 및 종양 층의 내부(중간 패널)에서 종양 세포의 아폽토시스를 표시하기 위해 제시되었다. 확대된 영상(하부 패널)은 다수의 종양들과 상호작용한 CART 세포를 입증하는 반면, 몇몇 둘러싸는 종양 세포들은 염색되어 있었다. C. 그랜자임 B+ T 세포 및 종양 괴사. CART 세포를 사용한 치료 후, 퇴행하는 CAIX+ sk-rc-52 종양은 그랜자임 B 항체(갈색) 및 H&E로 염색되었다. 보다 높은 확대도(상부 패널에서의 구획 a 및 b인 중간 및 하부 패널)는 그랜자임 B+ T 세포(화살표로 표시됨)의 위치를 보여주고, 상응하는 H&E 슬라이드는 종양 괴사를 보여준다(n으로 표시됨). 그랜자임 B+ T 세포는 종양의 가장자리(중간 패널) 및 종양의 내부(하부 패널)에 분포되어 있다.
도 7: 대조군 LAK 세포로 처리된 CAIX- sk-rc-52 종양은 음성 그랜자임 B 염색을 보였고(좌측)(상부 패널) 상응하는 조직구조는 H&E로 표시되었다(우측).
도 8: G36 CD28z CART 세포로 처리된 CAIX-sk-rc-59 종양에서 그랜자임 B의 낮은 배경 염색.
도 9: LAK 세포로 치료받은 CAIX-sk-rc-59 종양에서 그랜자임 B의 낮은 배경 염색.
도 10: G36 CD28z CART 세포가 국소적으로 주사된 sk-rc-52 종양에 대해 양성 대조군인 그랜자임 B 염색을 수행하였고(좌측), 종양 형태구조를 H&E로 표시하였다(우측).
도 2: CAIX 특이적 CAR들의 구축 및 발현. A. 구축: 제1세대 CAR인 scFv-CD8-TCRζ(CD8 CAR)는 절단된 인간 CD8α 세포외 도메인, 힌지(H), 경막(TM) 및 세포내 영역에 커플링된 후 인간 TCRζ의 신호전달 도메인에 커플링되어 있는 특이적 항-CAIX scFv로 구성된다. 제2세대 CAR인 scFv-CD28-TCRζ(CD28 CAR)는 TCRζ에 대한 인간 CD28 세포외, TM 및 세포내 신호전달 도메인과 융합된 항-CAIX scFv를 함유한다. 항-CAIX CAR들 둘 다를 내부 eF1-α 프로모터에 의해 유발된 발현을 가진 비시스트론성(bicistronic) 자가-불활성화(SIN) 렌티바이러스 벡터 내로 클로닝하였다. CAR 조절 구축물은 무관한 항-HIV CCR5 특이적 A8 scFv 치환을 함유한다. B. FACS 분석: 레포터 유전자 ZsGreen을 사용하여 렌티바이러스 CAR 구축물에 의한 일차 T 세포 형질도입 효율을 정량화하였다. 추가로, 항-CAIX scFv CAR들을 CAIX-Fc 융합 단백질로 염색하였고 C9-태그(TETSQVAPA)를 1D4 항체로 염색하였다. 형질도입되지 않은 활성화된 T-세포인 LAK만이 염색되지 않은 세포 대조군(i)으로서 사용되었거나, 2차 항체(ii. PE-항-인간 IgG 및 iii. APC-항-마우스 IgG)로 염색되어 염색 대조군으로서 사용되었다. C. 웨스턴 블롯: 항-CAIX(클론 G36) CD28 및 항-CCR5(클론 A8) CD28 CAR들의 단량체/이량체 구조물뿐만 아니라, 형질도입되지 않은 T 세포의 내생성 TCRζ 쇄의 분자 크기도 표시되어 있다.
도 3: CAIX 특이적 CART들의 이펙터 기능. A. 사이토카인 분비. 사이토카인 생성을 위해 항-CAIX CART, 무관한 CART 또는 활성화된 대조군 T 세포(LAK)를 신장암 세포주 sk-rc-52(CAIX+) 및 sk-rc-59(CAIX-)와 함께 밤새 공배양하였다. 2개 내지 3개의 결과를 대표하는 하나가 표시되어 있다. B. ELISPOT. G36 CART 또는 대조군 A8 CART 세포를 밤새 종양 세포에 첨가하였다. ELISPOT에 의해 검출된 IFN-γ 또는 그랜자임(granzyme) B 분비 T 세포. 유사한 결과가 2회 또는 3회 실험에서 수득되었다. C. CAIX 특이적 CART 세포의 특이적 항-종양 세포독성, 대조군 A8 CART 세포 또는 LAK 세포를 표시된 비로 표적 종양 세포의 다양한 양에서 4시간 세포독성 어세이에서 항온처리하였다. 2회 실험 중 하나가 표시되어 있다. 클론 4-1은 sk-rc-52의 생체내 계대배양된 서브클론이다.
도 4: 종양 접촉 후 CART 세포의 클론 증폭. A. 증식. CAR-형질도입된 T 세포 또는 형질도입되지 않은 T 세포(LAK)를 표시된 바와 같이 종양 대 T 세포의 세 상이한 비에서 방사선조사된 종양 세포(CAIX+ sk-rc-52 & CAIX- sk-rc-59)와 함께 주마다 플레이팅하였다. T 세포의 수를 2개의 분리된 웰들로부터 삼중으로 3일 또는 4일마다 카운팅하였다. 유사한 결과가 2회 실험에서 수득되었다. B. 클론 농후화. 종양 자극 실험에서, CART-세포 및 LAK 세포로부터의 배양물을 CART 및 T-세포 서브세트의 발현에 대해 유세포측정(flow cytometry)으로 1주 및 2주 동안 분석하였다. 2회 결과를 대표하는 하나가 표시되어 있다.
도 5: CART 세포에 의한 확립된 인간 RCC 이종이식물의 퇴행. 무흉선 널(null) 마우스를 좌측 옆구리 및 우측 옆구리에서 각각 7.5 x 106개의 sk-rc-52 RCC 종양 세포 및 5 x 106개의 sk-rc-59 RCC 종양 세포로 피하 접종하였다. 6일의 종양 이식 후, 마우스를 50 x 106개의 G36 CD28 CART 세포, A8 CD28 CART 세포(≥ 20% CAR+), LAK 또는 PBS 단독으로 정맥내 주사하였다. 고용량의 IL-2(1 x 105 U/㎖)를 2일 또는 3일마다 주사하였다. 종양 크기를 2일 또는 3일마다 칼리퍼로 측정하였다. 실험 1, n = 7 & 실험 2, n = 8. 이들 2회 실험의 종양 크기는 따로 표시되었다. 이들 2회 시험에서 대조군인 T 세포 비치료 마우스에 비해 G36 탠덤 치료 마우스의 군들에서 +, p<0.05; *, p<0.01; **, p<0.001. 다른 통계학적 계산은 본문에 보고되어 있다.
도 6: CAR+ T-세포의 생체내 항-종양 활성. A. CART 세포에 의한 ZsGreen의 발현은 상부 패널에 표시되어 있다. CART 세포를 파 레드(Far Red) 염료로 미리 염색하였고 세포원심분리하였고 형광 현미경관찰로 조사하였다(하부 패널). B. 퇴행 종양에서 G36 CD28 CART 세포의 제자리(in situ) 염색. CART-세포를 RCC 확립된 마우스 내로 정맥내 주사하였고 종양 조직을 1일째 날 내지 3일째 날에 수집하였다. 공초점 현미경관찰을 이용하여 PE-Cy5 염료(적색으로서 표시됨)를 사용한 TUNNEL 어세이로 종양 세포의 아폽토시스를 측정하였다. 형질도입된 T 세포는 ZsGreen으로 표시되었다. 핵을 DPAI로 반대염색하였다. 2개의 대표적인 슬라이드들은 각각 종양의 가장자리(상부 패널) 및 종양 층의 내부(중간 패널)에서 종양 세포의 아폽토시스를 표시하기 위해 제시되었다. 확대된 영상(하부 패널)은 다수의 종양들과 상호작용한 CART 세포를 입증하는 반면, 몇몇 둘러싸는 종양 세포들은 염색되어 있었다. C. 그랜자임 B+ T 세포 및 종양 괴사. CART 세포를 사용한 치료 후, 퇴행하는 CAIX+ sk-rc-52 종양은 그랜자임 B 항체(갈색) 및 H&E로 염색되었다. 보다 높은 확대도(상부 패널에서의 구획 a 및 b인 중간 및 하부 패널)는 그랜자임 B+ T 세포(화살표로 표시됨)의 위치를 보여주고, 상응하는 H&E 슬라이드는 종양 괴사를 보여준다(n으로 표시됨). 그랜자임 B+ T 세포는 종양의 가장자리(중간 패널) 및 종양의 내부(하부 패널)에 분포되어 있다.
도 7: 대조군 LAK 세포로 처리된 CAIX- sk-rc-52 종양은 음성 그랜자임 B 염색을 보였고(좌측)(상부 패널) 상응하는 조직구조는 H&E로 표시되었다(우측).
도 8: G36 CD28z CART 세포로 처리된 CAIX-sk-rc-59 종양에서 그랜자임 B의 낮은 배경 염색.
도 9: LAK 세포로 치료받은 CAIX-sk-rc-59 종양에서 그랜자임 B의 낮은 배경 염색.
도 10: G36 CD28z CART 세포가 국소적으로 주사된 sk-rc-52 종양에 대해 양성 대조군인 그랜자임 B 염색을 수행하였고(좌측), 종양 형태구조를 H&E로 표시하였다(우측).
본 발명은 특히 면역요법에서 사용되는 면역 세포에 적합화된 키메라 항원 수용체(CAR)에 관한 것이다. 구체적으로, 본 발명은 탄산무수화효소 IX(CAIX) 특이적 CAR들을 제공한다.
보다 구체적으로, 본 발명은 CAIX(G36)-CD28z CART 세포가 보다 강한 세포독성 효능, 증가된 사이토카인 분비, 시험관내에서의 향상된 증식 및 클론 증폭, 및 IL-2 제공에 의한 생체내 종양의 개선된 억제의 조합된 효과에 의해 입증되었을 때 CAIX(G36)-CD8-TCRζ CART 세포에 비해 더 우수한 항-종양 반응을 보유한다는 놀라운 발견에 근거한다.
종양을 향하는 키메라 항원 수용체(CAR)를 발현하기 위한 인간 림프구의 유전적 조작은 단백질-항원 프로세싱 및 제시에서의 비정상에 기인하는 종양 면역 탈출 기작을 우회하는 항종양 이펙터 세포를 생성할 수 있다. 더욱이, 이들 형질전환 수용체는 단백질로부터 유래되지 않은 종양 관련 항원으로 향할 수 있다. 본 발명의 일부 실시양태에서, 적어도 CAR을 포함하도록 변경되어 있는 림프구가 존재하고, 본 발명의 특정 실시양태에서 단일 CAR은 2개 이상의 항원들을 표적화한다.
특정 경우, 림프구는 키메라성을 나타내고 비-천연적이고 적어도 부분적으로 인간의 손에 의해 조작되는 수용체를 포함한다. 특정 경우, 조작된 키메라 항원 수용체(CAR)는 1개, 2개, 3개 또는 4개 이상의 성분을 갖고, 일부 실시양태에서 하나 이상의 성분은 림프구가 하나 이상의 종양 항원 포함 암세포에 표적화되거나 결합하는 것을 용이하게 한다.
본 발명에 따른 CAR은 일반적으로 폴리펩티드들이 함께 조립되어 키메라 항원 수용체를 형성하도록 적어도 하나의 세포외 리간드 결합 도메인을 포함하는 적어도 하나의 경막 폴리펩티드; 및 적어도 하나의 세포내 신호전달 도메인을 포함하는 1개의 경막 폴리펩티드를 포함한다.
본원에서 사용된 용어 "세포외 리간드 결합 도메인"은 리간드에 결합할 수 있는 올리고펩티드 또는 폴리펩티드로서 정의된다. 바람직하게는, 도메인은 세포 표면 분자와 상호작용할 수 있을 것이다. 예를 들면, 세포외 리간드 결합 도메인은 특정 질환 상태와 관련된 표적 세포 상의 세포 표면 마커로서 작용하는 리간드를 인식하도록 선택될 수 있다. 구체적으로, 세포외 리간드 결합 도메인은 표적의 항원에 대한 항체로부터 유래된 항원 결합 도메인을 포함할 수 있다.
특정 경우에, CAR은 탄산무수화효소 IX(G250)에 특이적이고, 일부 실시양태에서 본 발명은 보조자극 분자, 예컨대, CD28의 엔도도메인으로 CAIX 특이적 항체로부터 유래한 세포외 항원 결합 도메인을 T-세포 수용체 제타-쇄로부터 유래한 세포내 신호전달 도메인에 연결함으로써 탄산무수화효소 IX(G250)에 특이적인 키메라 세포를 제공한다. 이 CAR은 인간 세포, 예컨대, T 세포, NK 세포 또는 NKT 세포에서 발현되고, CAIX 양성 암의 표적화가 본 발명에 포함된다.
바람직하게는, 항체는 아미노산 서열 SYAMS(서열번호 55)를 포함하는 CDR1, 아미노산 서열 AISANGGTTYYADSVKG(서열번호 67)를 포함하는 CDR2, 및 아미노산 서열 NGNYRGAFDI(서열번호 65)를 포함하는 CDR3을 가진 중쇄; 및 아미노산 서열 TGSSSNIGAGFDVH(서열번호 68)를 포함하는 CDR1, 아미노산 서열 GNTNRPS(서열번호 69)를 포함하는 CDR2, 및 아미노산 서열 QSYDSRLSAWV(서열번호 70)를 포함하는 CDR3을 가진 경쇄; 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1, 아미노산 서열 GNSNRPS(서열번호 72)를 포함하는 CDR2, 및 아미노산 서열 QSYDRSLSWV(서열번호 73)를 포함하는 CDR3을 가진 경쇄; 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1, 아미노산 서열 GNTNRPS(서열번호 69)를 포함하는 CDR2, 및 아미노산 서열 QSYDSTLRVWM(서열번호 74)을 포함하는 CDR3을 가진 경쇄; 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1,아미노산 서열 GNNNRPS(서열번호 62)를 포함하는 CDR2, 및 아미노산 서열 QSYDKSLTWV(서열번호 76)를 포함하는 CDR3을 가진 경쇄; 아미노산 서열 TGTSSNIGAGYDVH(서열번호 79)를 포함하는 CDR1, 아미노산 서열 GNNNRPS(서열번호 62)를 포함하는 CDR2, 및 아미노산 서열 QSYDKSLSWV(서열번호 80)를 포함하는 CDR3을 가진 경쇄; 아미노산 서열 TGSSSNIGAGFDVH를 포함하는 CDR1, 아미노산 서열 GNNNRPS를 포함하는 CDR2, 및 아미노산 서열 QSYDSSLSAWV(서열번호 82)를 포함하는 CDR3을 가진 경쇄; 또는 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1, 아미노산 서열 GNSNRPS(서열번호 72)를 포함하는 CDR2, 및 아미노산 서열 QSYDSSLSAWV(서열번호 82)를 포함하는 CDR3을 가진 경쇄를 가진다.
일부 실시양태에서, 항체는 서열번호 1 및 3 내지 23의 아미노산 서열을 포함하는 중쇄, 및 서열번호 2 및 24 내지 44의 아미노산 서열을 포함하는 경쇄를 가진다. 아미노산 서열 및 핵산 서열은 하기 표 3에 예시되어 있다.
[표 3]









바람직한 실시양태에서, 상기 세포외 리간드 결합 도메인은 유연성 링커에 의해 연결된 표적 항원 특이적 단일클론 항체의 경쇄(VL) 및 중쇄(VH) 가변 단편을 포함하는 단일 쇄 항체 단편(scFv)이다.
보다 바람직한 실시양태에서, 상기 scFv는 항-탄산무수화효소 IX scFv, 바람직하게는 scFV-G36(WO2007/065027 VH: 서열번호 1 및 VL: 서열번호 2)이다. 국제 특허출원 공보 제WO2007/065027호의 내용은 전체적으로 본원에 참고로 도입된다.
scFv 이외의 다른 결합 도메인, 예컨대, 비-한정적 예로서 낙타 단일 도메인 항체 단편 또는 수용체 리간드, 항체 결합 도메인, 항체 초가변 루프 또는 CDR도 림프구의 소정의 표적화를 위해 사용될 수 있다.
바람직한 실시양태에서, 상기 경막 도메인은 상기 세포외 리간드 결합 도메인과 상기 경막 도메인 사이에서 줄기 영역을 추가로 포함한다. 본원에서 사용된 용어 "줄기 영역"은 일반적으로 경막 도메인을 세포외 리간드 결합 도메인에 연결하는 데 작용하는 임의의 올리고펩티드 또는 폴리펩티드를 의미한다. 구체적으로, 줄기 영역은 세포외 리간드 결합 도메인에게 더 높은 유연성 및 접근성을 제공하는 데 사용된다. 줄기 영역은 최대 300개의 아미노산, 바람직하게는 10개 내지 100개의 아미노산, 가장 바람직하게는 25개 내지 50개의 아미노산을 포함할 수 있다. 줄기 영역은 천연 생성 분자의 전부 또는 일부, 예컨대, CD8, CD4 또는 CD28의 세포외 영역의 전부 또는 일부, 또는 항체 불변 영역의 전부 또는 일부로부터 유래될 수 있다. 대안적으로, 줄기 영역은 천연 생성 줄기 서열에 상응하는 합성 서열일 수 있거나, 완전히 합성 줄기 서열일 수 있다. 바람직한 실시양태에서, 상기 줄기 영역은 인간 CD8 알파 쇄의 일부이다.
본 발명의 CAR의 신호 전달도입 도메인 또는 세포내 신호전달 도메인은 면역 세포 및 면역 반응의 활성화를 야기하는, 세포외 리간드 결합 도메인과 표적의 결합 후 세포내 신호전달을 담당한다. 다시 말해, 신호 전달도입 도메인은 CAR이 발현되는 면역 세포의 정상 이펙터 기능들 중 적어도 하나의 활성화를 담당한다. 예를 들면, T 세포의 이펙터 기능은 사이토카인의 분비를 포함하는 세포용해 활성 또는 헬퍼 활성일 수 있다. 따라서, 용어 "신호 전달도입 도메인"은 이펙터 신호 기능 신호를 전달도입하고 세포가 전문화된 기능을 수행하도록 지시하는 단백질의 부분을 지칭한다.
신호 전달도입 도메인은 세포질 신호전달 서열의 두 상이한 클래스들, 즉 항원 의존적 일차 활성화를 시작하는 클래스, 및 이차 또는 보조자극 신호를 제공하도록 항원 독립적 방식으로 작용하는 클래스를 포함한다. 일차 세포질 신호전달 서열은 ITAM의 면역수용체 티로신-기저 활성화 모티프로서 공지되어 있는 신호전달 모티프를 포함할 수 있다. ITAM은 syk/zap70 클래스 티로신 키나제에 대한 결합 부위로서 작용하는 다양한 수용체들의 세포질내 꼬리에서 발견되는 잘 정의된 신호전달 모티프이다. 본 발명에서 사용되는 ITAM의 예로는 비-한정적 예로서 TCR 제타, FcR 감마, FcR 베타, FcR 엡실론, CD3 감마, CD3 델타, CD3 엡실론, CD5, CD22, CD79a, CD79b 및 CD66d로부터 유래한 ITAM들이 있을 수 있다. 바람직한 실시양태에서, CAR의 신호 전달도입 도메인은 CD3 제타 신호전달 도메인, 또는 Fc 엡실론 RI 베타 또는 감마 쇄의 세포질내 도메인을 포함할 수 있다. 또 다른 바람직한 실시양태에서, 신호전달은 예를 들면, CD28 및 종양 괴사 인자 수용체(TNFr), 예컨대, 4-1BB 또는 OX40에 의해 제공된 보조자극과 함께 CD3 제타에 의해 제공된다.
특정 실시양태에서, 본 발명의 CAR의 세포내 신호전달 도메인은 보조자극 신호 분자를 포함한다. 일부 실시양태에서, 세포내 신호전달 도메인은 2개, 3개 또는 4개 이상의 보조자극 분자를 직렬로 함유한다. 보조자극 분자는 효율적인 면역 반응을 위해 요구되는, 항원 수용체 또는 이의 리간드 이외의 세포 표면 분자이다.
"보조자극 리간드"는 예를 들면, TCR/CD3 복합체와 펩티드로 적재된 MHC 분자의 결합에 의해 제공된 일차 신호 이외에 증식 활성화, 분화 등을 포함하나 이들로 한정되지 않는 T 세포 반응을 매개하는 신호를 제공함으로써 T-세포 상의 동족 보조자극 분자에 특이적으로 결합하는 항원 제시 세포 상의 분자를 지칭한다. 보조자극 리간드는 CD7, B7-1(CD80), B7-2(CD86), PD-L1, PD-L2, 4-1BBL, OX40L, 유도성 보조자극 리간드(ICOS-L), 세포내 부착 분자(ICAM, CD30L, CD40, CD70, CD83, HLA-G, MICA, M1CB, HVEM, 림포톡신 베타 수용체, 3/TR6, ILT3, ILT4, Toll 리간드 수용체에 결합하는 아고니스트 또는 항체, 및 B7-H3에 특이적으로 결합하는 리간드를 포함할 수 있으나 이들로 한정되지 않는다. 보조자극 리간드는 특히, T 세포 상에 존재하는 보조자극 분자, 예컨대, CD27, CD28, 4-IBB, OX40, CD30, CD40, PD-1, ICOS, 림프구 기능 관련 항원-1(LFA-1), CD2, CD7, LTGHT, NKG2C, B7-H3, 및 CD83에 특이적으로 결합하는 리간드(그러나, 이들로 한정되지 않음)에 특이적으로 결합하는 항체도 포괄한다.
"보조자극 분자"는 보조자극 리간드에 특이적으로 결합함으로써, 세포에 의한 보조자극 반응, 예컨대, 증식(그러나, 이것으로 한정되지 않음)을 매개하는 T-세포 상의 동족 결합 파트너를 지칭한다. 보조자극 분자는 MHC 클래스 1 분자, BTLA 및 Toll 리간드 수용체를 포함하나 이들로 한정되지 않는다. 보조자극 분자의 예로는 CD27, CD28, CD8, 4-1BB(CD137), OX40, CD30, CD40, PD-1, ICOS, 림프구 기능 관련 항원-1(LFA-1), CD2, CD7, LIGHT, NKG2C, B7-H3, 및 CD83에 특이적으로 결합하는 리간드 등이 있다. 또 다른 특정 실시양태에서, 상기 신호 전달도입 도메인은 보조자극 TNFR 구성원 패밀리의 세포질내 꼬리인 TNFR 관련 인자 2(TRAF2) 결합 모티프이다. 보조자극 TNFR 패밀리 구성원의 세포질 꼬리는 메이저 보조된 모티프(P/S/A)X(Q/E)E) 또는 마이너 모티프(PXQXXD)로 구성된 TRAF2 결합 모티프를 함유하고, 이때 X는 임의의 아미노산이다. TRAF 단백질은 수용체 삼량체화에 반응하여 많은 TNFR들의 세포내 꼬리에 모인다.
적절한 경막 폴리펩티드의 구별되는 특징은 면역 세포, 특히 림프구 세포 또는 천연 킬러(NK) 세포의 표면에서 발현되고 소정의 표적 세포에 대한 면역 세포의 세포 반응을 유도하기 위해 함께 상호작용하는 능력을 포함한다. 세포외 리간드 결합 도메인 및/또는 신호 전달도입 도메인을 포함하는 본 발명의 CAR의 상이한 경막 폴리펩티드들은 표적 리간드와의 결합 후 신호 전달도입에 참여하고 면역 반응을 유도하도록 함께 상호작용한다. 경막 도메인은 천연 또는 합성 공급원으로부터 유래될 수 있다. 경막 도메인은 임의의 막-결합된 또는 경막 단백질로부터 유래될 수 있다.
본원에서 사용된 용어 "의 일부"는 보다 짧은 펩티드인, 분자의 임의의 서브세트를 지칭한다. 대안적으로, 폴리펩티드의 아미노산 서열 기능성 변이체는 폴리펩티드를 코딩하는 DNA 내의 돌연변이에 의해 제조될 수 있다. 이러한 변이체 또는 기능성 변이체는 예를 들면, 아미노산 서열 내의 잔기의 결실, 삽입 또는 치환을 포함한다. 최종 구축물이 원하는 활성을 보유하는 한, 최종 구축물에 도달하기 위해, 특히 특이적 항-표적 세포 면역 활성을 나타내기 위해 결실, 삽입 및 치환의 임의의 조합도 만들 수 있다. 숙주 세포 내에서 본 발명의 CAR의 기능성은 특정 표적의 결합 시 상기 CAR의 신호전달 잠재력을 입증하기에 적합한 어세이에서 검출될 수 있다. 이러한 어세이는 당분야에서 숙련된 자에 의해 이용될 수 있다. 예를 들면, 이 어세이, 예컨대, 칼슘 이온 방출, 세포내 티로신 인산화, 이노시톨 포스페이트 전환율, 또는 이로써 달성된 인터류킨(IL) 2, 인터페론 감마, GM-CSF, IL-3, IL-4 생성의 증가를 측정하는 단계를 포함하는 어세이는 표적의 결합 시 유발된 신호전달 경로의 검출을 가능하게 한다.
세포
본 발명의 실시양태는 CAR을 발현하는 세포를 포함한다. 상기 세포는 암 요법을 위한 CAR을 발현할 수 있는 면역 세포 또는 CAR을 코딩하는 발현 벡터를 보유하는 세포, 예컨대, 세균 세포를 비롯한 임의의 종류의 세포일 수 있다. 본원에서 사용된 용어 "세포", "세포주" 및 "세포 배양물"은 상호교환적으로 사용될 수 있다. 이들 용어들 전부가 임의의 모든 후속 세대들인 그들의 자손도 포함한다. 모든 자손들이 의도적 또는 우발적 돌연변이로 인해 동일하지 않을 수 있다는 것이 이해된다. 이종 핵산 서열의 발현과 관련하여, "숙주 세포"는 벡터를 복제할 수 있고/있거나 벡터에 의해 코딩된 이종 유전자를 발현할 수 있는 진핵 세포를 지칭한다. 숙주 세포는 벡터를 위한 수용자로서 사용될 수 있고 사용되고 있다. 숙주 세포는 외생성 핵산이 숙주 세포 내로 전달되거나 도입되는 과정을 지칭하는 "형질감염된" 또는 "형질전환된" 세포일 수 있다. 형질전환된 세포는 일차 대상 세포 및 그의 자손을 포함한다. 본원에서 사용된 용어 "조작된" 및 "재조합" 세포 또는 숙주 세포는 외생성 핵산 서열, 예를 들면, 벡터가 도입되는 세포를 지칭하기 위한 것이다. 따라서, 재조합 세포는 재조합적으로 도입된 핵산을 함유하지 않는 천연 생성 세포와 구별될 수 있다. 본 발명의 실시양태에서, 숙주 세포는 세포독성 T 세포(TC, 세포독성 T 림프구, CTL, T-킬러 세포, 세포용해성 T 세포, CD8+ T-세포 또는 킬러 T 세포로서도 공지되어 있음)를 포함하는 T 세포이고; NK 세포 및 NKT 세포도 본 발명에 포함된다.
일부 벡터들은 원핵 세포 및 진핵 세포 둘 다에서 복제될 수 있고/있거나 발현될 수 있게 하는 조절 서열을 사용할 수 있다. 당업자는 모든 상기 숙주 세포들을 유지하고 벡터의 복제를 허용하도록 항온처리하는 조건도 이해할 것이다. 벡터의 대규모 생산뿐만 아니라, 벡터에 의해 코딩된 핵산 및 이의 동족 폴리펩티드, 단백질 또는 펩티드의 생성도 가능하게 할 기법 및 조건도 이해되고 공지되어 있다.
세포는 자가유래성 세포, 동계 세포, 동종이계 세포 및 심지어 일부 경우 이종이계 세포일 수 있다.
많은 상황들에서, 치료를 종결하고자 하는 경우 변경된 CTL을 사멸시킬 수 있기를 원할 수 있고, 세포는 그의 존재 후 세포의 부재가 관심을 끄는 연구 또는 다른 경우에서 신생물성을 갖게 된다. 이 목적을 위해, 조절된 조건 하에서 변경된 세포를 사멸시킬 수 있는 일부 유전자 생성물, 예컨대, 유도성 자살 유전자의 발현을 제공할 수 있다.
CTL 내로의 구축물의 도입
구축물(들)을 함유하는 숙주 세포의 선택을 가능하게 할 적어도 하나의 마커가 존재할 수 있는 경우, CAR을 코딩하는 발현 벡터는 하나 이상의 DNA 분자 또는 구축물로서 도입될 수 있다. 유전자 및 조절 영역이 단리될 수 있고, 적절하게 라이게이션될 수 있고, 적절한 클로닝 숙주에 클로닝될 수 있고 제한 또는 서열결정 또는 다른 편리한 수단에 의해 분석될 수 있는 경우, 구축물은 편리한 방식으로 제조될 수 있다. 구체적으로, "프라이머 복구", 라이게이션, 시험관내 돌연변이유발 등을 적절하게 사용하여 하나 이상의 돌연변이를 도입할 수 있는 경우, PCR을 이용하여 기능성 유닛의 전부 또는 일부를 포함하는 개별 단편을 단리할 수 있다. 그 다음, 일단 구축물(들)이 완성되고 적절한 서열을 가진 것으로 입증되면, 이 구축물(들)을 임의의 편리한 수단으로 CTL 내로 도입할 수 있다. 세포 내로의 감염 또는 형질도입을 위해, 레트로바이러스 벡터 또는 렌티바이러스 벡터를 포함하는 비-복제 결함 바이러스 게놈, 예컨대, 아데노바이러스, 아데노 관련 바이러스(AAV) 또는 헤르페스 심플렉스 바이러스(HSV) 등 내로 상기 구축물을 삽입할 수 있고 팩키징할 수 있다. 구축물은 원하는 경우 형질감염을 위한 바이러스 서열을 포함할 수 있다. 대안적으로, 구축물을 융합, 전기천공, 바이올리스틱(biolistics), 형질감염, 지질감염 등으로 도입할 수 있다. 구축물(들)의 도입 전에 숙주 세포를 배양물에서 성장시키고 증폭시킨 후, 구축물(들)의 도입 및 구축물(들)의 삽입을 위해 적절히 처리할 수 있다. 그 다음, 세포를 증폭시키고 구축물에 존재하는 마커로 스크리닝한다. 성공적으로 사용될 수 있는 다양한 마커들은 hprt, 네오마이신 내성, 타이미딘 키나제, 하이그로마이신 내성 등을 포함한다.
일부 경우, 구축물이 특정 좌위에서 삽입될 것이 요구되는 경우, 상동성 재조합을 위한 표적 부위를 가질 수 있다. 예를 들면, 당업자는 상동성 재조합에 대해 당분야에서 공지되어 있는 재료 및 방법을 이용하여 내생성 유전자를 넉-아웃시킬 수 있고 (동일한 좌위 또는 다른 부분에서) 이를 구축물에 의해 코딩된 유전자로 대체할 수 있다. 상동성 재조합을 위해, 당업자는 OMEGA 또는 O-벡터를 사용할 수 있다. 예를 들면, 문헌[Thomas and Capecchi, Cell (1987) 51, 503-512], 문헌[Mansour, et al., Nature (1988) 336, 348-352], 및 문헌[Joyner, et al., Nature (1989) 338, 153-156]을 참조한다.
구축물은 적어도 CAR을 코딩하는 단일 DNA 분자 및 임의적으로 또 다른 유전자, 또는 하나 이상의 유전자를 가진 상이한 DNA 분자로서 도입될 수 있다. 다른 유전자는 예를 들면, 치료 분자를 코딩하는 유전자 또는 자살 유전자를 포함한다. 동일한 또는 상이한 마커를 각각 가진 구축물들은 동시에 또는 연속적으로 도입될 수 있다.
구축물 DNA들의 스톡(stocks)을 제조하고 형질감염을 수행하는 데 사용될 수 있는 유용한 요소, 예컨대, 세균 또는 효모 복제기점, 선택가능한 및/또는 증폭가능한 마커, 원핵생물 또는 진핵생물에서의 발현을 위한 프로모터/인핸서 요소 등을 함유하는 벡터는 당분야에서 잘 공지되어 있고, 다수가 상업적으로 입수가능하다.
사용 방법
본 발명에 따른 세포는 암의 치료를 필요로 하는 환자에서 암을 치료하기 위해 사용될 수 있다. 또 다른 실시양태에서, 본 발명에 따른 상기 단리된 세포는 암의 치료를 필요로 하는 환자에서 암의 치료용 약제의 제조에 사용될 수 있다.
본 발명은 치료를 필요로 하는 환자를 치료하는 방법으로서, 하기 단계들 중 적어도 하나를 포함하는 방법에 의존한다: (a) 본 발명에 따른 키메라 항원 수용체 세포를 제공하는 단계; 및 (b) 상기 세포를 상기 환자에게 투여하는 단계.
환자는 암 환자, 또는 암에 민감하거나 암을 가진 것으로 의심받는 환자이다. 암은 CAIX 발현 암, 예컨대, 신장암, 난소암, 유방암, 식도암, 방광암, 대장암 또는 비소세포 폐암이다. 일부 실시양태에서, 신장암은 신장 투명 세포 암이다.
세포의 투여
본 발명이 전형적으로 기증자로부터 수득된 T-세포가 비-동종반응성 세포 내로 형질전환될 수 있게 하는 한, 본 발명은 동종이계 면역요법에 특히 적합하다. 이것은 표준 프로토콜 하에서 수행될 수 있고 필요한 만큼 많은 횟수로 재현될 수 있다. 생성된 변경된 T 세포는 풀링될 수 있고 한명 또는 여러 명의 환자들에게 투여될 수 있으므로, "기성품"인 치료 제품으로서 입수가능하게 된다.
세포의 성질에 따라, 세포는 매우 다양한 방식으로 숙주 유기체, 예를 들면, 포유동물 내로 도입될 수 있다. 대안적 실시양태에서 세포는 암에 민감하거나 암에 민감하도록 변경되지만, 특정 실시양태에서 세포는 종양의 부위에서 도입될 수 있다. 사용되는 세포의 수는 많은 환경, 도입 목적, 세포의 수명, 사용될 프로토콜, 예를 들면, 투여 횟수, 증식하는 세포의 능력, 재조합 구축물의 안정성 등에 의해 좌우될 것이다. 세포는 일반적으로 관심있는 부위 그 자체 또는 근처에서 주사되는 분산액으로서 적용될 수 있다. 세포는 생리학적으로 허용가능한 배지에 존재할 수 있다.
일부 실시양태에서, 세포는 면역 인식을 억제하도록 캡슐화되고 종양의 부위에 배치된다.
세포는 원하는 경우 투여될 수 있다. 원하는 반응, 투여 방식, 세포의 수명 및 존재하는 세포의 수에 따라, 다양한 프로토콜들이 이용될 수 있다. 투여 횟수는 적어도 부분적으로 전술된 인자에 의해 좌우될 것이다.
본 발명에 따른 세포 또는 세포 집단의 투여는 에어로졸 흡입, 주사, 섭취, 수혈, 주입 또는 이식을 비롯한 임의의 편리한 방식으로 수행될 수 있다. 본원에 기재된 조성물은 피하, 피내, 종양내, 결절내, 수질내, 근육내, 정맥내 또는 림프내 주사, 또는 복강내로 환자에게 투여될 수 있다. 한 실시양태에서, 본 발명의 세포 조성물은 바람직하게는 정맥내 주사에 의해 투여된다.
세포 또는 세포 집단의 투여는 범위 이내의 세포 수의 모든 정수 값들을 포함하는, 체중 kg당 104개 내지 109개의 세포, 바람직하게는 체중 kg당 105개 내지 106개의 세포의 투여로 구성될 수 있다. 세포 또는 세포 집단은 1회분 이상의 용량으로 투여될 수 있다. 또 다른 실시양태에서, 세포의 상기 유효량은 1회분 용량으로서 투여된다. 또 다른 실시양태에서, 세포의 상기 유효량은 일정 기간에 걸쳐 1회분 초과의 용량으로서 투여된다. 투여 시간조절은 주치의의 판단 이내에 있고 환자의 임상적 상태에 의해 좌우된다. 세포 또는 세포 집단은 임의의 공급원, 예컨대, 혈액 은행 또는 기증자로부터 입수될 수 있다. 개별 필요성은 상이하지만, 특정 질환 또는 질병에 대한 소정의 세포 유형의 유효량의 최적 범위의 결정은 당분야의 기술 이내에 있다. 유효량은 치료적 또는 예방적 이익을 제공하는 양을 의미한다. 투여되는 용량은 수용자의 연령, 건강 및 체중, 존재하는 경우 병행 치료의 종류, 치료의 빈도 및 요구된 효과의 성질에 의해 좌우될 것이다.
시스템은 많은 변수들, 예컨대, 리간드에 대한 세포 반응, 발현의 효율 및 적절한 경우 분비의 수준, 발현 생성물의 활성, 시간 및 환경에 따라 달라질 수 있는 환자의 구체적인 필요성, 세포 상실의 결과로서 세포 활성의 상실 또는 개별 세포의 발현 활성의 상실의 속도 등에 예속된다는 것을 인식해야 한다. 따라서, 각각의 개별 환자에 대해 대규모로 집단에게 투여될 수 있는 보편적인 세포가 존재하는 경우조차도, 각각의 환자는 개체에 대한 적절한 용량에 대해 모니터링될 것이라고 예상되고, 환자를 모니터링하는 이러한 관행은 당분야에서 관례적이다.
핵산-기저 발현 시스템
본 발명의 CAR들은 발현 벡터로부터 발현될 수 있다. 이러한 발현 벡터를 생성하는 재조합 기법은 당분야에서 잘 공지되어 있다.
벡터
용어 "벡터"는 핵산 서열이 복제될 수 있는 세포 내로 도입하기 위해 핵산 서열이 삽입될 수 있는 담체 핵산 분자를 지칭하는 데 사용된다. 핵산 서열은 "외생성" 핵산 서열일 수 있고, 이 용어는 상기 핵산 서열이 벡터가 도입되어 있는 세포에 대한 외래 물질임을 의미하거나, 상기 서열이 세포 내의 서열과 상동하되, 상기 서열이 통상적으로 발견되지 않는 숙주 세포 핵산 내의 위치에 존재한다는 것을 의미한다. 벡터는 플라스미드, 코스미드, 바이러스(박테리오파지, 동물 바이러스 및 식물 바이러스), 및 인공 염색체(예를 들면, YAC)를 포함한다. 당업자는 표준 재조합 기법을 통해 벡터를 구축하도록 장비를 잘 갖출 것이다(예를 들면, 둘 다 본원에 참고로 도입되는 문헌(Maniatis et al., 1988) 및 문헌(Ausubel et al., 1994) 참조).
용어 "발현 벡터"는 전사될 수 있는 RNA를 코딩하는 핵산을 포함하는 임의의 유형의 유전적 구축물을 지칭한다. 그 다음, 일부 경우, RNA 분자는 단백질, 폴리펩티드 또는 펩티드로 번역된다. 다른 경우, 이들 서열들은 예를 들면, 안티센스 분자 또는 리보자임의 생성에서 번역되지 않는다. 발현 벡터는 특정 숙주 세포에서 작동가능하게 연결된 코딩 서열의 전사 및 가능하게는 번역에 필요한 핵산 서열을 지칭하는 다양한 "조절 서열들"을 함유할 수 있다. 전사 및 번역을 좌우하는 조절 서열 이외에, 벡터 및 발현 벡터는 다른 기능도 수행하고 이하에 기재되어 있는 핵산 서열을 함유할 수 있다.
프로모터 및 인핸서
"프로모터"는 전사의 시작 및 속도가 조절되는 핵산 서열의 영역인 조절 서열이다. 이것은 핵산 서열의 특정 전사를 시작하기 위해 조절 단백질 및 분자, 예를 들면, RNA 중합효소 및 다른 전사 요소가 결합할 수 있는 유전적 요소를 함유할 수 있다. 어구 "작동가능하게 위치하는", "작동가능하게 연결된", "조절 하에서" 및 "전사 조절 하에서"는 프로모터가 핵산 서열의 전사 시작 및/또는 발현을 조절하기 위해 그 핵산 서열과 관련하여 정확한 기능적 위치 및/또는 배향으로 존재한다는 것을 의미한다.
프로모터는 일반적으로 RNA 합성을 위한 출발 부위를 위치시키는 작용을 하는 서열을 포함한다. 이것의 가장 잘 공지된 예는 TATA 박스이지만, TATA 박스를 결여하는 일부 프로모터들, 예를 들면, 포유동물 말단 데옥시뉴클레오티딜 트랜스퍼라제 유전자에 대한 프로모터 및 SV40 후기 유전자에 대한 프로모터에서 상기 출발 부위 위에 놓인 별개의 요소 그 자체가 시작 위치를 고정시키는 데 도움을 준다. 추가 프로모터 요소는 전사 시작의 빈도를 조절한다. 전형적으로, 이들은 출발 부위의 30 내지 110 bp 업스트림에 있는 영역에 위치하지만, 다수의 프로모터들은 출발 부위의 다운스트림에 있는 기능성 요소도 함유하는 것으로 밝혀져 있다. 코딩 서열을 프로모터의 "조절 하에" 놓이게 하기 위해, 전사 판독 프레임의 전사 시작 부위의 5' 말단을 선택된 프로모터의 "다운스트림"(즉, 3')에 위치시킨다. "업스트림" 프로모터는 DNA의 전사를 자극하고 코딩된 RNA의 발현을 촉진한다.
프로모터 요소들 사이의 간격은 종종 유연하므로, 프로모터 기능은 요소들이 서로에 대해 상대적으로 뒤집어지거나 이동할 때 보존된다. tk 프로모터에서, 프로모터 요소들 사이의 간격은 활성이 감퇴하기 시작하기 전에 50 bp 간격까지 증가될 수 있다. 프로모터에 따라, 개별 요소들은 협력적으로 또는 독립적으로 작용하여 전사를 활성화시킬 수 있는 듯하다. 프로모터는 핵산 서열의 전사 활성화에 관여된 시스-작용 조절 서열을 지칭하는 "인핸서"와 함께 사용될 수 있거나 사용될 수 없다.
프로모터는 코딩 분절 및/또는 엑손의 업스트림에 위치한 5 프라임 비-코딩 서열을 단리함으로써 수득될 수 있기 때문에 핵산 서열과 자연적으로 연결된 프로모터일 수 있다. 이러한 프로모터는 "내생성" 프로모터로서 지칭될 수 있다. 유사하게, 인핸서는 핵산 서열의 다운스트림 또는 업스트림에 위치한, 그 핵산 서열과 자연적으로 연결된 인핸서일 수 있다. 대안적으로, 일부 장점은 코딩 핵산 분절을, 통상적으로 그의 천연 환경에서 핵산 서열과 연결되어 있지 않은 프로모터를 지칭하는 재조합 또는 이종 프로모터의 조절 하에 위치시킴으로써 획득될 것이다. 재조합 또는 이종 인핸서는 통상적으로 그의 천연 환경에서 핵산 서열과 연결되어 있지 않은 인핸서도 지칭한다. 이러한 프로모터 또는 인핸서는 다른 유전자의 프로모터 또는 인핸서, 임의의 다른 바이러스, 또는 원핵 또는 진핵 세포로부터 단리된 프로모터 또는 인핸서, 및 "천연적으로 생성되지" 않는, 즉 상이한 전사 조절 영역의 상이한 요소들, 및/또는 발현을 변경시키는 돌연변이를 함유하는 프로모터 또는 인핸서를 포함할 수 있다. 예를 들면, 재조합 DNA 구축에 가장 통상적으로 사용되는 프로모터는 락타마제(lactamase)(페니실리나제(penicillinase)), 락토스 및 트립토판(trp) 프로모터 시스템을 포함한다. 프로모터 및 인핸서의 핵산 서열을 합성적으로 생성하는 것 이외에, 본원에 개시된 조성물과 관련하여 PCR.TM.을 비롯한 재조합 클로닝 및/또는 핵산 증폭 기술을 이용하여 서열을 생성할 수 있다(예를 들면, 본원에 각각 참고로 도입되는 미국 특허 제4,683,202호 및 제5,928,906호 참조). 나아가, 비-핵 세포소기관(organelle), 예컨대, 미토콘드리아, 엽록체 등의 내부에서 서열의 전사 및/또는 발현을 유도하는 조절 서열도 사용될 수 있을 것으로 예상된다.
자연적으로, 발현을 위해 선택된 세포소기관, 세포 유형, 조직, 장기 또는 유기체에서 DNA 분절의 발현을 효과적으로 유도하는 프로모터 및/또는 인핸서를 사용하는 것이 중요할 것이다. 분자생물학 분야에서 숙련된 자는 일반적으로 단백질 발현을 위한 프로모터, 인핸서 및 세포 유형 조합의 사용을 알고 있다(예를 들면, 본원에 참고로 도입되는 문헌(Sambrook et al. 1989) 참조). 사용된 프로모터는 예컨대, 재조합 단백질 및/또는 펩티드의 대규모 생성에서 유리한 도입된 DNA 분절의 고수준 발현을 유도하기에 적절한 조건 하에서 항시적일 수 있고/있거나, 조직 특이적일 수 있고/있거나, 유도가능할 수 있고/있거나 유용할 수 있다. 프로모터는 이종 또는 내재성 프로모터일 수 있다.
추가로, 임의의 프로모터/인핸서 조합물도 발현을 유도하는 데 사용될 수 있었다. T3, T7 또는 SP6 세포질 발현 시스템의 사용은 또 다른 가능한 실시양태이다. 적절한 세균 중합효소가 전달 복합체의 일부로서, 또는 추가 유전적 발현 구축물로서 제공되는 경우, 진핵 세포는 일부 세균 프로모터들로부터의 세포질 전사를 뒷받침할 수 있다.
조직 특이적 프로모터 또는 요소의 본질뿐만 아니라 이들의 활성을 특징규명하는 어세이도 당업자에게 잘 공지되어 있다.
특정 시작 신호도 코딩 서열의 효율적인 번역을 위해 요구될 수 있다. 이 신호는 ATC 시작 코돈 또는 인접 서열을 포함한다. ATG 시작 코돈을 포함하는 외생성 번역 조절 신호가 제공될 필요가 있을 수 있다. 당분야에서 통상의 기술을 가진 자는 용이하게 이것을 확인할 수 있을 것이고 필요한 신호를 제공할 수 있을 것이다.
본 발명의 일부 실시양태에서, 내부 리보좀 도입 부위(IRES) 요소의 사용은 다중유전자 또는 폴리시스트론성 메신지를 생성하는 데 사용되고, 이들은 본 발명에서 사용될 수 있다.
벡터는 다수의 제한 효소 부위들을 함유하는 핵산 영역인 다중 클로닝 부위(MCS)를 포함할 수 있고, 상기 제한 효소 부위들 중 임의의 제한 효소 부위가 표준 재조합 기술과 함께 벡터를 분해하는 데 사용될 수 있다. "제한 효소 분해"는 핵산 분자의 특정 위치에서만 작용하는 효소를 사용한 핵산 분자의 촉매작용적 절단을 지칭한다. 이들 제한 효소들 중 대다수는 상업적으로 입수가능하다. 이러한 효소의 사용은 당업자에 의해 널리 이해된다. 종종, 외생성 서열이 벡터에 라이게이션될 수 있도록 MCS 내부에서 절단하는 제한 효소를 사용하여 벡터를 선형화하거나 단편화한다. "라이게이션"은 서로 인접할 수 있거나 인접하지 않을 수 있는 2개의 핵산 단편들 사이의 포스포디에스테르 결합을 형성하는 과정을 지칭한다. 제한 효소 및 라이게이션 반응을 포함하는 기법은 재조합 기술의 분야에서 숙련된 자에게 잘 공지되어 있다.
스플라이싱 부위, 종결 신호, 복제기점 및 선택 마커도 사용될 수 있다.
플라스미드 벡터
일부 실시양태에서, 플라스미드 벡터는 숙주 세포를 형질전환시키기 위해 사용될 것으로 예상된다. 일반적으로, 숙주 세포와 상용가능한 종으로부터 유래한 레플리콘 및 조절 서열을 함유하는 플라스미드 벡터는 이들 숙주들과 함께 사용된다. 벡터는 통상적으로 복제 부위뿐만 아니라, 형질전환된 세포에서 표현형적 선택을 제공할 수 있는 표시 서열도 보유한다. 비-한정적 예에서, 이. 콜라이 종으로부터 유래한 플라스미드인 pBR322의 유도체를 사용하여 이. 콜라이를 종종 형질전환시킨다. pBR322는 앰피실린 및 테트라사이클린 내성에 대한 유전자를 함유하므로, 형질전환된 세포를 확인하기 위한 용이한 수단을 제공한다. pBR 플라스미드, 또는 다른 미생물 플라스미드 또는 파지는 예를 들면, 그 자신의 단백질의 발현을 위해 미생물 유기체에 의해 사용될 수 있는 프로모터도 함유해야 하거나 함유하도록 변경되어야 한다.
추가로, 숙주 미생물과 상용가능한 레플리콘 및 조절 서열을 함유하는 파지 벡터는 이들 숙주들과 함께 형질전환 벡터로서 사용될 수 있다. 예를 들면, 파지 람다 GEM.TM. 11은 숙주 세포, 예를 들면, 이. 콜라이 LE392를 형질전환시키는 데 사용될 수 있는 재조합 파지 벡터를 표시하는 데 사용될 수 있다.
추가 유용한 플라스미드 벡터는 추후 정제 및 분리 또는 절단을 위해 글루타티온 S 트랜스퍼라제(GST) 가용성 융합 단백질을 생성하는 데 사용될 pIN 벡터(Inouye et al., 1985) 및 pGEX 벡터를 포함한다. 다른 적합한 융합 단백질은 갈락토시다제(galactosidase), 유비퀴틴 등을 가진 융합 단백질이다.
발현 벡터를 포함하는 세균 숙주 세포, 예를 들면, 이. 콜라이는 다수의 적합한 배지들 중 임의의 적합한 배지, 예를 들면, LB에서 성장한다. 일부 벡터들에서 재조합 단백질의 발현은 당업자에 의해 이해될 바와 같이 숙주 세포를 일부 프로모터들에 특이적인 물질과 접촉시킴으로써, 예를 들면, IPTG를 배지에 첨가하거나 항온처리를 고온으로 전환시킴으로써 유도될 수 있다. 일반적으로 2시간 내지 24시간의 추가 기간 동안 세균을 배양한 후, 세포를 원심분리로 수집하고 세척하여 잔류 배지를 제거한다.
바이러스 벡터
수용체 매개 세포내이입을 통해 세포를 감염시키거나 세포 내로 들어가고 숙주 세포 게놈 내로 삽입되고 바이러스 유전자를 안정하게 및 효율적으로 발현하는 일부 바이러스들의 능력으로 인해, 이들은 외래 핵산을 세포(예를 들면, 포유동물 세포) 내로 전달하기 위한 흥미로운 후보가 된다. 본 발명의 성분은 본 발명의 하나 이상의 CAR을 코딩하는 바이러스 벡터일 수 있다. 본 발명의 핵산을 전달하는 데 사용될 수 있는 바이러스 벡터의 비-한정적 예는 이하에 기재되어 있다.
아데노바이러스 벡터
핵산을 전달하는 구체적인 방법은 아데노바이러스 발현 벡터의 사용을 포함한다. 아데노바이러스 벡터가 게놈 DNA 내로 삽입되는 능력이 낮은 것으로 공지되어 있지만, 이 특징은 이들 벡터들에 의해 부여된 고효율의 유전자 전달에 의해 균형이 잡힌다. "아데노바이러스 발현 벡터"는 (a) 구축물의 팩키징을 뒷받침하고 (b) 궁극적으로 그 내부에 클로닝되어 있는 조직 또는 세포 특이적 구축물을 발현하기에 충분한 아데노바이러스 서열을 함유하는 구축물을 포함하기 위한 것이다. 유전적 조직구성, 또는 36 kb 선형 이중 가닥 DNA 바이러스인 아데노바이러스의 지식은 최대 7 kb의 외래 서열에 의해 아데노바이러스 DNA의 큰 조각의 치환을 가능하게 한다(Grunhaus and Horwitz, 1992).
AAV 벡터
아데노바이러스 보조 형질감염을 이용하여 핵산을 세포 내로 도입할 수 있다. 증가된 형질감염 효율은 아데노바이러스 커플링된 시스템을 사용하는 세포 시스템에서 보고되었다(Kelleher and Vos, 1994; Cotten et al., 1992; Curiel, 1994). 아데노 관련 바이러스(AAV)는 고빈도의 삽입을 갖고 비분열 세포를 감염시킴으로써, 예를 들면, 조직 배양물(Muzyczka, 1992) 또는 생체내에서 포유동물 세포 내로의 유전자의 전달에 유용할 수 있기 때문에 본 발명의 세포에서 사용될 흥미로운 벡터 시스템이다. AAV는 감염성에 대한 넓은 숙주 범위를 가진다(Tratschin et al., 1984; Laughlin et al., 1986; Lebkowski et al., 1988; McLaughlin et al., 1988). rAAV 벡터의 생성 및 사용에 관한 세부사항은 본원에 각각 참고로 도입되는 미국 특허 제5,139,941호 및 제4,797,368호에 기재되어 있다.
레트로바이러스 벡터
레트로바이러스는 그의 유전자를 숙주 게놈 내로 삽입하여 다량의 외래 유전적 물질을 전달하고 광범위한 종 및 세포 유형들을 감염시키고 특별한 세포주 내에 팩키징되는 그의 능력 때문에 전달 벡터로서 유용하다(Miller, 1992).
레트로바이러스 벡터를 구축하기 위해, 복제 결함 바이러스를 생성하기 위해 핵산(예를 들면, 원하는 서열을 코딩하는 핵산)을 일부 바이러스 서열들 대신에 바이러스 게놈 내로 삽입한다. 비리온을 생성하기 위해, gag, pol 및 env 유전자를 함유하되 LTR 및 팩키징 성분을 갖지 않은 팩키징 세포주를 구축한다(Mann et al., 1983). 레트로바이러스 LTR 및 팩키징 서열과 함께 cDNA를 함유하는 재조합 플라스미드가 (예를 들면, 인산칼슘 침전에 의해) 특별한 세포주 내로 도입될 때, 팩키징 서열은 재조합 플라스미드의 RNA 전사체가 바이러스 입자 내로 팩키징될 수 있게 하고, 그 후 상기 바이러스 입자는 배양 배지 내로 분비된다(Nicolas and Rubenstein, 1988; Temin, 1986; Mann et al., 1983). 그 다음, 재조합 레트로바이러스를 함유하는 배지를 수집하고 임의적으로 농축하고 유전자 전달을 위해 사용한다. 레트로바이러스 벡터는 다양한 세포 유형들을 감염시킬 수 있다. 그러나, 삽입 및 안정한 발현은 숙주 세포의 분열을 요구한다(Paskind et al., 1975).
렌티바이러스는 공통된 레트로바이러스 유전자 gag, pol 및 env 이외에 조절 또는 구조적 기능을 가진 다른 유전자를 함유하는 복합 레트로바이러스이다. 렌티바이러스 벡터는 당분야에서 잘 공지되어 있다(예를 들면, 문헌(Naldini et al., 1996); 문헌(Zufferey et al., 1997); 문헌(Blomer et al., 1997); 미국 특허 제6,013,516호 및 제5,994,136호 참조). 렌티바이러스의 일부 예들로는 인간 면역결핍 바이러스, 즉 HIV-1 및 HIV-2, 및 원숭이 면역결핍 바이러스, 즉 SIV가 있다. 렌티바이러스 벡터는 HIV 병독성 유전자를 다중 약화시킴으로써 생성되었고, 예를 들면, 유전자 env, vif, vpr, vpu 및 nef가 결실되어, 상기 벡터를 생물학적으로 안전하게 만든다.
재조합 렌티바이러스 벡터는 비-분열 세포를 감염시킬 수 있고 핵산 서열의 생체내 및 생체외 유전자 전달 및 발현 둘 다를 위해 사용될 수 있다. 예를 들면, 비-분열 세포를 감염시킬 수 있는 재조합 렌티바이러스로서, 적합한 숙주 세포가 팩키징 기능, 즉 gag, pol 및 env뿐만 아니라 rev 및 tat도 보유하는 2개 이상의 벡터들로 형질감염되어 있는 것인 재조합 렌티바이러스는 본원에 참고로 도입되는 미국 특허 제5,994,136호에 기재되어 있다. 특정 세포 유형의 수용체에 표적화하기 위해 외피(envelope) 단백질을 항체 또는 특정 리간드와 연결함으로써 재조합 바이러스를 표적화할 수 있다. 예를 들면, 관심있는 서열(조절 영역을 포함함)이 특정 표적 세포 상의 수용체에 대한 리간드를 코딩하는 또 다른 유전자와 함께 바이러스 벡터 내로 삽입됨으로써, 상기 벡터는 표적 특이적이다.
다른 바이러스 벡터
다른 바이러스 벡터는 본 발명에서 백신 구축물로서 사용될 수 있다. 바이러스, 예컨대, 백시니아 바이러스(Ridgeway, 1988; Baichwal and Sugden, 1986; Coupar et al., 1988), 신드비스(sindbis) 바이러스, 사이토메갈로바이러스 및 헤르페스 심플렉스 바이러스로부터 유래한 벡터가 사용될 수 있다. 이들은 다양한 포유동물 세포들에게 여러 매력적인 특징들을 제공한다(Friedmann, 1989; Ridgeway, 1988; Baichwal and Sugden, 1986; Coupar et al., 1988; Horwich et al., 1990).
변경된 바이러스를 사용한 전달
전달될 핵산은 특정 결합 리간드를 발현하도록 조작되어 있는 감염성 바이러스 내부에 수용될 수 있다. 따라서, 바이러스 입자는 표적 세포의 동족 수용체에 특이적으로 결합하여 내용물을 세포에게 전달할 것이다. 바이러스 외피에의 락토스 잔기의 화학적 추가에 의한 레트로바이러스의 화학적 변경을 기반으로 레트로바이러스 벡터의 특이적 표적화를 가능하게 하도록 디자인된 신규 방법을 개발하였다. 이 변경은 시알로당단백질 수용체를 통한 간세포의 특이적 감염을 가능하게 할 수 있다.
레트로바이러스 외피 단백질 및 특정 세포 수용체에 대한 바이오티닐화된 항체가 사용되는 재조합 레트로바이러스의 또 다른 표적화 방법을 디자인하였다. 상기 항체는 스트렙타비딘의 사용에 의해 바이오틴 성분을 통해 커플링되었다(Roux et al., 1989). 주조직적합성 복합체 클래스 I 및 클래스 II 항원에 대한 항체를 사용하였을 때, 이들은 시험관내에서 동종지향성(ecotropic) 바이러스를 사용하여 표면 항원을 보유하는 다양한 인간 세포들을 감염시켰음을 입증하였다(Roux et al., 1989).
벡터 전달 및 세포 형질전환
세포의 형질감염 또는 형질전환을 위한 핵산 전달에 적합한 방법은 당분야에서 통상의 기술을 가진 자에게 공지되어 있다. 이러한 방법은 예컨대, 생체외 형질감염, 주사 등에 의한 DNA의 직접적인 전달을 포함하나 이들로 한정되지 않는다. 당분야에서 공지되어 있는 기법의 적용을 통해 세포를 안정하게 또는 일시적으로 형질전환시킬 수 있다.
생체외 형질전환
생체외 환경에서 유기체로부터 제거된 진핵 세포 및 조직을 형질감염시키는 방법은 당업자에게 공지되어 있다. 따라서, 세포 또는 조직을 제거할 수 있고 본 발명의 핵산을 사용하여 생체외에서 형질감염시킬 수 있다는 것이 예상된다. 특정 양태에서, 이식된 세포 또는 조직은 유기체 내에 배치될 수 있다. 바람직한 양태에서, 핵산은 이식된 세포에서 발현된다.
본 발명의 키트
본원에 기재된 조성물들 중 임의의 조성물이 키트에 포함될 수 있다. 비-한정적 예에서, 세포 요법에서 사용될 하나 이상의 세포, 및/또는 재조합 발현 벡터를 보유하는, 세포 요법에서 사용될 하나 이상의 세포를 생성하기 위한 시약이 키트에 포함될 수 있다. 키트 성분들은 적합한 용기 수단 내에 제공된다.
키트의 일부 성분들은 수성 매질 또는 동결건조된 형태로 포장될 수 있다. 키트의 용기 수단은 일반적으로 성분이 배치될 수 있고 바람직하게는 적절하게 분취될 수 있는 적어도 하나의 바이알, 시험관, 플라스크, 병, 주사기 또는 다른 용기 수단을 포함할 것이다. 키트 내에 하나 초과의 성분이 존재하는 경우, 키트는 일반적으로 추가 성분이 따로 배치될 수 있는 제2, 제3 또는 다른 추가 용기도 함유할 것이다. 그러나, 성분들의 다양한 조합물이 바이알에 포함될 수 있다. 본 발명의 키트는 전형적으로 상업적 판매를 위해 폐쇄된 구획 내부에 성분을 함유하기 위한 수단도 포함할 것이다. 이러한 용기는 원하는 바이알이 보유되어 있는 사출 또는 취입 성형 플라스틱 용기를 포함할 수 있다.
키트의 성분들이 하나 및/또는 그 이상의 액체 용액으로 제공되어 있을 때, 액체 용액은 수용액이고, 이때 멸균 수용액이 특히 유용하다. 일부 경우, 용기 수단은 그 자체가 주사기, 피펫 및/또는 다른 장치, 예컨대, 유사한 장치일 수 있고, 제제는 이러한 장치로부터 신체의 감염된 부위에 적용될 수 있고/있거나, 동물 내로 주사될 수 있고/있거나, 심지어 키트의 다른 성분에 적용될 수 있고/있거나 키트의 다른 성분과 혼합될 수 있다.
그러나, 키트의 성분은 건조된 분말(들)로서 제공될 수 있다. 시약 및/또는 성분이 건조 분말로서 제공될 때, 분말은 적합한 용매의 첨가에 의해 재구성될 수 있다. 용매는 또 다른 용기 수단 내에 제공될 수도 있다는 것이 예상된다. 키트는 멸균 약학적으로 허용가능한 완충제 및/또는 다른 희석제를 함유하기 위한 제2 용기 수단도 포함할 수 있다.
본 발명의 특정 실시양태에서, 세포 요법을 위해 사용될 세포는 키트 내에 제공되고, 일부 경우 상기 세포는 본질적으로 키트의 유일한 성분이다. 키트는 원하는 세포를 제조하기 위한 시약 및 재료를 포함할 수 있다. 특정 실시양태에서, 시약 및 재료는 원하는 서열을 증폭하기 위한 프라이머, 뉴클레오티드, 적합한 완충제 또는 완충제 시약, 염 등을 포함하고, 일부 경우 시약은 본원에 기재된 CAR 및/또는 이에 대한 조절 요소를 코딩하는 벡터 및/또는 DNA를 포함한다.
특정 실시양태에서, 개체로부터 하나 이상의 샘플을 추출하는 데 적합한 하나 이상의 장치가 키트에 존재한다. 상기 장치는 주사기, 메스 등일 수 있다.
본 발명의 일부 경우, 키트는 세포 요법 실시양태 이외에 제2 암 요법, 예컨대, 화학요법, 호르몬 요법 및/또는 면역요법도 포함한다. 키트(들)는 개체를 위해 특정 암에 맞게 조정될 수 있고 개체를 위해 각각의 제2 암 요법을 포함할 수 있다.
조합 요법
본 발명의 일부 실시양태에서, 임상 양태에 대한 본 발명의 방법은 과다증식성 질환의 치료에 효과적인 다른 물질, 예컨대, 항암제와 병용된다. "항암"제는 예를 들면, 암세포를 사멸시키거나, 암세포의 아폽토시스를 유도하거나, 암세포의 성장 속도를 감소시키거나, 전이의 발생률 또는 수를 감소시키거나, 종양 크기를 감소시키거나, 종양 성장을 억제하거나, 종양 또는 암세포에게의 혈액 공급을 감소시키거나, 암세포 또는 종양에 대한 면역 반응을 촉진하거나, 암의 진행을 예방하거나 억제하거나, 암을 가진 대상체의 수명을 증가시킴으로써 대상체에서 암에 부정적으로 영향을 미칠 수 있다. 보다 일반적으로, 이들 다른 조성물들은 세포를 사멸시키거나 세포의 증식을 억제하기에 효과적인 조합된 양으로 제공될 것이다. 이 과정은 암세포를 발현 구축물 및 약제(들) 또는 다수의 인자(들)와 동시에 접촉시키는 단계를 포함할 수 있다. 이것은 세포를, 상기 약제들 둘 다를 포함하는 단일 조성물 또는 약리학적 제제와 접촉시킴으로써, 또는 세포를 2개의 상이한 조성물들 또는 제제들과 동시에 접촉시킴으로써 달성될 수 있고, 이때 한 조성물은 발현 구축물을 포함하고 다른 조성물은 제2 약제(들)을 포함한다.
화학요법제 및 방사선요법제에 대한 종양 세포 내성은 임상 종양학에서 주요 문제점을 대표한다. 현재의 암 연구의 한 목적은 화학요법 또는 방사선요법을 다른 요법과 조합함으로써 화학요법 및 방사선요법의 효능을 개선하는 방식을 찾는 것이다. 본 발명과 관련하여, 세포 요법은 유사하게 화학요법적, 방사선요법적 또는 면역요법적 중재뿐만 아니라, 전구-아폽토시스 또는 세포 주기 조절제와도 함께 사용될 수 있다는 것이 예상된다.
대안적으로, 본 발명의 요법은 수분 내지 수주의 간격으로 다른 약제 치료에 앞설 수 있거나 뒤따를 수 있다. 다른 약제 및 본 발명이 개체에 따로 적용되는 실시양태에서, 일반적으로 상기 약제 및 본 발명의 요법이 세포에 대한 유리하게 조합된 효과를 여전히 발휘할 수 있도록 각각의 전달 시간 사이에 유의한 시간이 만료하지 않았다는 것을 보장할 것이다. 이러한 경우, 서로 약 12시간 내지 24시간 이내에, 보다 바람직하게는 서로 약 6시간 내지 12시간 이내에 세포를 두 모달리티(modalities)와 접촉시킬 수 있다는 것이 예상된다. 일부 상황에서, 치료 기간을 유의하게 연장시키는 것이 바람직할 수 있으나, 수일(2일, 3일, 4일, 5일, 6일 또는 7일) 내지 수주(1주, 2주, 3주, 4주, 5주, 6주, 7주 또는 8주)가 각각의 투여 사이에 경과된다.
치료 주기가 필요에 따라 반복될 것임이 예상된다. 다양한 표준 요법들뿐만 아니라 수술적 중재도 본 발명의 세포 요법과 함께 적용될 수 있다는 것도 예상된다.
화학요법
암 요법은 화학적 기반 치료 및 방사선 기반 치료 둘 다를 사용한 다양한 조합 요법들도 포함한다. 조합 화학요법은 예를 들면, 아브락산(abraxane), 알트레타민(altretamine), 도세탁셀(docetaxel), 헤르셉틴(herceptin), 메토트렉세이트(methotrexate), 노반트론(novantrone), 졸라덱스(zoladex), 시스플라틴(cisplatin)(CDDP), 카보플라틴(carboplatin), 프로카바진(procarbazine), 메클로레타민(mechlorethamine), 사이클로포스파마이드(cyclophosphamide), 캠토테신(camptothecin), 이포스파마이드(ifosfamide), 멜팔란(melphalan), 클로람부실(chlorambucil), 부설판(busulfan), 니트로스우레아(nitrosurea), 닥티노마이신(dactinomycin), 다우노루비신(daunorubicin), 독소루비신(doxorubicin), 블레오마이신(bleomycin), 플리코마이신(plicomycin), 미토마이신(mitomycin), 에토포사이드(etoposide)(VP16), 타목시펜(tamoxifen), 랄록시펜(raloxifene), 에스트로겐 수용체 결합 물질, 탁솔(taxol), 겜시타비엔(gemcitabien), 나벨빈(navelbine), 파르네실(farnesyl)-단백질 트랜스퍼라제(tansferase) 억제제, 트랜스플라티눔(transplatinum), 5-플루오로우라실(fluorouracil), 빈크리스틴(vincristin), 빈블라스틴(vinblastin) 및 메토트렉세이트(methotrexate), 또는 상기 물질들의 임의의 유사체 또는 유도체 변이체 및 이들의 조합물을 포함한다.
특정 실시양태에서, 개체를 위한 화학요법은 예를 들면, 본 발명의 투여 전, 동안 또는 후 본 발명과 함께 사용된다.
방사선요법
DNA 손상을 야기하고 광범위하게 사용되는 다른 인자는 통상적으로 .감마.-선, X-선, 및/또는 종양 세포에게의 방사성동위원소의 유도된 전달로서 공지되어 있는 것을 포함한다. 다른 형태의 DNA 손상 인자, 예컨대, 마이크로파 및 UV-방사선조사도 예상된다. 아마도 이들 인자들 전부가 DNA, DNA의 전구체, DNA의 복제 및 복구, 및 염색체의 조립 및 유지에 대한 광범위한 손상을 미칠 것이다. X-선에 대한 선량 범위는 연장된 기간(3주 내지 4주) 동안 50 내지 200 뢴트겐의 1일 선량부터 2000 내지 6000 뢴트겐의 단일 선량까지 이른다. 방사성동위원소에 대한 선량 범위는 광범위하게 다양하고, 동위원소의 반감기, 방사된 방사선의 강도 및 유형, 및 신생물성 세포에 의한 흡수에 의해 좌우된다.
세포에 적용될 때 용어 "접촉된" 및 "노출된"은 치료 구축물 및 화학요법제 또는 방사선요법제가 표적 세포에게 전달되거나 표적 세포와 직접 병렬로 배치되는 과정을 기술하기 위해 본원에서 사용된다. 세포 사멸 또는 정체를 달성하기 위해, 상기 요법제들 둘 다가 세포를 사멸시키거나 세포의 분열을 방해하기에 효과적인 조합된 양으로 세포에게 전달된다.
면역요법
면역요법제는 일반적으로 암세포를 표적화하고 파괴하기 위한 면역 이펙터 세포 및 분자의 사용에 의존한다. 면역 이펙터는 예를 들면, 종양 세포의 표면 상의 일부 마커에 특이적인 항체일 수 있다. 항체 단독은 요법의 이펙터로서 사용될 수 있거나 세포 사멸에 실제로 영향을 미치기 위해 다른 세포를 모집할 수 있다. 항체는 약물 또는 독소(화학요법제, 방사성핵종, 리신 A 쇄, 콜레라 독소, 백일해 독소 등)에 접합될 수도 있고 표적화제로서만 사용될 수 있다. 대안적으로, 이펙터는 종양 세포 표적과 직접적으로 또는 간접적으로 상호작용하는 표면 분자를 보유하는 림프구일 수 있다. 다양한 이펙터 세포는 세포독성 T 세포 및 NK 세포를 포함한다.
따라서, 본원에 기재된 본 발명의 요법 이외의 면역요법은 본 세포 요법과 함께 조합된 요법의 일부로서 사용될 수 있다. 조합된 요법을 위한 일반적인 방법은 이하에 논의되어 있다. 일반적으로, 종양 세포는 표적화될 수 있는, 즉 대다수의 다른 세포들 상에 존재하지 않는 일부 마커를 보유해야 한다. 많은 종양 마커들이 존재하고 이들 중 임의의 종양 마커가 본 발명과 관련하여 표적화에 적합할 수 있다. 흔한 종양 마커는 PD-1, PD-L1, CTLA4, 발암배아 항원, 전립선 특이적 항원, 비뇨기 종양 관련 항원, 태아 항원, 티로시나제(tyrosinase)(p97), gp68, TAG-72, HMFG, 시알릴 루이스 항원, MucA, MucB, PLAP, 에스트로겐 수용체, 라미닌 수용체, erb B 및 p155를 포함한다.
유전자
또 다른 실시양태에서, 이차 치료는 치료 폴리뉴클레오티드가 본 발명의 임상적 실시양태 전, 후 또는 동시에 투여되는 유전자 요법이다. 세포 증식의 유도제, 세포 증식의 억제제 또는 프로그래밍된 세포 사멸의 조절제를 포함하는 다양한 발현 생성물들이 본 발명에 포함된다.
수술
암을 가진 사람들의 대략 60%는 예방적, 진단적 또는 병기분류, 치유적 및 완화적 수술을 포함하는 일부 유형의 수술을 받을 것이다. 치유적 수술은 다른 요법, 예컨대, 본 발명의 치료, 화학요법, 방사선요법, 호르몬 요법, 유전자 요법, 면역요법 및/또는 대안적 요법과 함께 사용될 수 있는 암 치료이다.
치유적 수술은 암성 조직의 전부 또는 일부가 물리적으로 제거되고/되거나, 절제되고/되거나 파괴되는 절제술을 포함한다. 종양 절제술은 종양의 적어도 일부의 물리적 제거를 지칭한다. 종양 절제술 이외에, 수술에 의한 치료는 레이저 수술, 냉동수술, 전기수술, 및 미시적으로 제어된 수술(모즈 수술(Mohs' surgery))을 포함한다. 본 발명은 표피 암, 전구암 또는 우발적 양의 정상 조직의 제거와 함께 이용될 수 있다는 것도 예상된다.
암성 세포, 조직 또는 종양의 일부 또는 전부의 절제 시, 신체에 캐비티(cavity)가 형성될 수 있다. 치료는 추가 항암 요법을 사용한 관류, 직접적인 주사 또는 영역의 국소 적용에 의해 달성될 수 있다. 이러한 치료는 예를 들면, 1일, 2일, 3일, 4일, 5일, 6일 또는 7일마다, 1주, 2주, 3주, 4주 및 5주마다, 또는 1개월, 2개월, 3개월, 4개월, 5개월, 6개월, 7개월, 8개월, 9개월, 10개월, 11개월 또는 12개월마다 반복될 수 있다. 이 치료는 상이한 용량의 치료일 수도 있다.
다른 약제
다른 약제는 치료의 치료적 효능을 개선하기 위해 본 발명과 함께 사용될 수 있다는 것이 예상된다. 이 추가 약제는 면역조절제, 세포 표면 수용체의 상향조절 및 GAP 연접에 영향을 미치는 약제, 세포증식억제성 및 분화 약제, 세포 부착의 억제제, 또는 아폽토시스 유도제에 대한 과다증식성 세포의 민감성을 증가시키는 약제를 포함한다. 면역조절제는 종양 괴사 인자; 인터페론 알파, 베타 및 감마; IL-2 및 다른 사이토카인; F42K 및 다른 사이토카인 유사체; 또는 MIP-1, MIP-1베타, MCP-1, RANTES 및 다른 케모카인을 포함한다. 세포 표면 수용체 또는 이의 리간드, 예컨대, Fas/Fas 리간드, DR4 또는 DR5/TRAIL의 상향조절은 과다증식성 세포에 대한 자가분비 또는 측분비 효과를 확립함으로써 본 발명의 아폽토시스 유도 능력을 증강시킬 것이라는 것도 예상된다. GAP 연접의 수의 상승에 의한 세포내 신호전달의 증가는 인접 과다증식성 세포 집단에 대한 항-과다증식성 효과를 증가시킬 것이다. 다른 실시양태에서, 세포증식억제성 또는 분화 약제는 치료의 항-과다증식성 효능을 개선하기 위해 본 발명과 함께 사용될 수 있다. 세포 부착의 억제제는 본 발명의 효능을 개선할 것으로 예상된다. 세포 부착 억제제의 예는 국소 부착 키나제(FAK) 억제제 및 로바스타틴이다. 아폽토시스에 대한 과다증식성 세포의 민감성을 증가시키는 다른 약제, 예컨대, 항체 c225도 치료 효능을 개선하기 위해 본 발명과 함께 사용될 수 있다는 것이 예상된다.
실시예
실시예 1: 재료 및 방법
세포, 배양 배지 및 시약. 인간 CAIX+ 신장 세포 암종 세포주 sk-rc-52(본원에서 Skrc52로서도 지칭됨), sk-rc-09 및 CAIX- sk-rc-59(본원에서 Skrc59로서도 지칭됨)를 저드 리터(Gerd Ritter) 박사(Memorial Sloan-Kettering Cancer Center, New York)로부터 입수하였다. 이들을, 10% FCS, 2 mmol/ℓ L-글루타민, 100 U/㎖ 페니실린 및 100 ㎍/㎖ 스트렙토마이신(Sigma)으로 보충된 RPMI 1640 배지(Life Technologies)를 함유하는 R-10 완전 배지에서 5% CO2와 함께 37℃에서 배양하였다. 일차 인간 T 세포를, 10% 인간 혈청 및 100 IU/㎖ 재조합 인간 인터류킨 2(IL-2)(Chiron)를 가진 R-10에서 유지하였다. 인간 배아 신장 세포주 293T(ATCC) 및 마우스 섬유모세포 NIH3T3 세포(ATCC)를, 10% FCS, 100 U/㎖ 페니실린 및 100 ㎍/㎖ 스트렙토마이신(Sigma)을 가진 DMEM 배지를 함유하는 D-10 완전 배지(Life Technologies)에서 성장시켰다. 보스톤 아동 병원의 혈액 은행으로부터 입수된 류코팩(Leukopacks)을, 사전 동의서를 작성한 건강한 자원자로부터 수집하였다.
scFv 단리 및 scFv - Fc로의 scFv의 전환. 이미 보고되어 있고 GQ903548-GQ90356123의 수탁번호(이의 내용은 전체적으로 본원에 참고로 도입됨)로 진뱅크에 제출된 비-면역 인간 scFv 파지 라이브러리로부터 CAIX 특이적 scFv 항체를 단리하였다. pFarber 파지미드로부터의 scFv-코딩 DNA 단편을 SfiI/NotI 부위로 분해하였고, 인간 IgG1 F105 리더 서열 및 인간 IgG1 힌지-CH2-CH3 Fc 부분을 가진 포유동물 발현 벡터 pcDNA3.1-F105L-힌지-스튜퍼(stuffer) 내로 서브클로닝하여 scFv-Fc 항체를 발현하였다. 리포펙타민(lipofectamine) 2000(Invitrogen)으로 scFv-Fc의 플라스미드를 293T 세포 내로 일시적으로 형질감염시켰고, 세파로스 단백질 A 비드(Amersham Bioscience)를 사용하여 발현된 항체를 정제하였다. CAIX-발현 293T 및 sk-rc-52 세포주, 및 CAIX 음성 293T 및 sk-rc-59 세포주와 함께 항온처리함으로써, scFv-Fc 포맷 항체로 전환된 파지 scFv 항체 또는 scFv로 염색하여 CAIX에의 특이적 결합을 시험하였다. 이들 실험에서, 무관한 항-HIV CCR5 항체(클론 A8)25 또는 항-SARS 항체(11A)24 및 형광 접합된 이차 항체 단독을 음성 대조군으로서 사용하였다.
한 실시양태에서, 인간 ccRCC 세포주, Skrc52, 원래의 CAIX+/ PD-L1-, 및 Skrc59, 원래의 CAIX-/PD-L1+를 저드 리터(Gerd Ritter) 박사(Memorial Sloan-Kettering Cancer Center, New York)로부터 입수하였다. 이들 세포들을 10%(v/v) 열-불활성화된 태아 소 혈청(FBS, Gibco), 100 IU/㎖ 페니실린 및 100 ㎍/㎖ 스트렙토마이신으로 보충된 RPMI 1640 배지(Life Technologies)에서 배양하였다. 293T(CRL-11268, ATCC) 및 Lenti-X 293T(Clontech) 세포를 10% FBS, 100 IU/㎖ 페니실린 및 100 ㎍/㎖ 스트렙토마이신으로 보충된 DMEM 배지(Life Technologies)에서 성장시켰다. 이 프로젝트에서 사용된 모든 세포주들을, 렌티바이러스 형질도입을 통해 루시퍼라제(luciferase)로 형질도입하였고 5% CO2와 함께 37℃에서 유지하였다. 형광 활성화된 세포 분류(FACS) 분류로 CAIX-/PD-L1- 및 CAIX+/PD-L1- 세포 집단에 대해 Skrc52 세포를 선택하였다. 고수준의 인간 CAIX를 발현하도록 Skrc59 세포를 조작하였고 CAIX+/PD-L1+을 FACS 분류로 선택하였다.
scFv-CD8-TCRζ 및 scFv-CD28-TCRζ 구축물의 구축. 파지미드 벡터 pSL1180 내의 DNA 구축물인 Pz1, scFv-CD8-TCRζ, 및 P28z, scFv-CD28-TCRζ를 미쉘 사델라인(Michel Sadelain) 박사(Memorial Sloan-Kettering Cancer Center, New York)로부터 입수하였다. Pz1에서, scFv 및 TCRζ 세포내 도메인은 각각 인간 CD8α 쇄의 N-말단 및 C-말단에 추가되어 있다. 유사하게, P28z에서, scFv 및 TCRζ 서열은 각각 인간 CD28의 N-말단 및 C-말단에 추가되어 있다. 인간 CD8α의 아미노산 서열은 CD8α 세포외 및 힌지, 경막 및 세포질 도메인들의 각각 47개(aa 137-183), 23개(aa 184-206) 및 2개(aa 207-208)의 잔기로 구성된, 길이에 있어서 71개 잔기이다. P28z에서 CD28 서열은 CD28 세포외, 경막 및 세포질 도메인들의 각각 40개(aa 114-153), 23개(aa 154-176) 및 44개(aa 177-220)의 잔기로 구성된, 길이에 있어서 107개 잔기이다. 두 CAR들에 공통된 인간 CD3ζ 세포내 도메인은 112개의 아미노산(aa 52-163)으로 구성된다.
GGGGS 링커를 가진 내부 C9-태그(인간 로돕신의 9-아미노산 펩티드, TETSQVAPA)를 코딩하는 핵산 서열을 PCR로 증폭하였고 5' NotI 부위 및 3' PacI 부위를 가진 CD8-TCRζ 및 CD28-TCRζ 서열과 업스트림에서 융합시켰다. 키메라 TCRζ 구축물을 클로닝하는 데 사용된 프라이머는 다음과 같다: 5' TAG GGC GCG GCC GCa acc gag acc agc cag gtg gcg ccc gcc GGG GGA GGA GGC AGC CCC ACC ACG ACG CCA GCG CCG CGA 3'(서열번호 71)(CD8 구축물에 대한 정방향 프라이머, 이때 이탤릭체는 NotI 부위이고, 대문자는 C9 태그 서열이고, 밑줄은 GGGGS 링커를 표시함), 5' TAG GGC GCG GCC GCa acc gag acc agc cag gtg gcg ccc gcc GGC GGA GGA GGC AGC ATT GAA GTT ATG TAT CCT CCT CCT 3'(서열번호 75)(CD28 구축물에 대한 정방향 프라이머) 및 두 구축물들에 대한 역방향 프라이머 CTA GCC TT AAT TAA TTA GCG AGG AGG GGG CAG GGC CTG CAT(서열번호 77)(이때, 이탤릭체는 PacI 부위임). 이들 DNA 단편들은 하기 순서에 따라 정렬되어 있는 기능적 특징을 코딩한다: NotI - C9tag(TETSQVQPQ) - GGGGS - CD8 또는 CD28 - TCRζ - PacI. 서열 TETSQVQPQ는 서열 번호 78을 가진다. 서열 GGGGS는 서열번호 79를 가진다. NotI 및 PacI 제한 부위를 사용하여 내부 C9 펩티드 태그를 가진 키메라 TCR 구축물을, 항-CXCR4 scFv-Fc를 함유하는 pcDNA3.1-F105L-힌지 스튜퍼 벡터 내로 클로닝하였다(클론 48). 이 디자인은 본 발명자들로 하여금 Fc 부분 단편을 대체하도록 키메라 TCR 수용체 구축물을 삽입할 수 있게 한다. 그 후, SfiI/NotI 부위에서 항-CXCR4 scFv를 대체하도록 항-CAIX scFv(클론 G36) 및 항-CCR5 scFv(무관한 scFv 대조군으로서 클론 A8) 항체 단편을 클로닝하여 CAIX 특이적 키메라 TCR 구축물을 생성하였다.
렌티바이러스 벡터 pHAGE-CMV-DsRed-IRES-ZsGreen, 및 4개의 HIV 헬퍼 플라스미드 pHDM-Hgpm2(HIV gag-pol), pMD-tat, pRC/CMV-rev 및 Env VSV-G 슈도타입을 리차드 뮬리간(Richard Mulligan) 박사(Virus Production Core at The Harvard Gene Therapy Initiative in Boston)로부터 입수하였다. pHAGE-CMV-IRES-ZsGreen의 CMV 프로모터를 SpeI/NotI 부위에서 pSIN 렌티바이러스 벡터로부터 유래한 EF1α 프로모터로 대체하였다. 5개의 scFv-Fc 항체들 중 하나인 G36(CAIX+ 세포에 대한 고친화성을 갖고 CAIX+ 종양 세포에 대해서만 높은 ADCC를 가짐)을 AscI/BamHI에서 pHAGE-EF1α 렌티바이러스 벡터 내로 클로닝하여 DsRed 단백질의 첫 번째 카세트를 대체하였다.
렌티바이러스의 생성 및 인간 일차 T 세포의 형질도입. 제조자의 지시(Invitrogen)에 따라 리포펙타민 2000을 사용하여 5개의 플라스미드를 293T 세포 내로 일시적으로 형질감염시킴으로써 렌티바이러스를 생성하였다. 세포를 15 cm 페트리 접시(Nalge Nunc)에서 80% 전면생장(confluence)에 도달하도록 준비하였고 총 30 ㎍의 플라스미드 DNA로 형질감염시켰다. 벡터 플라스미드의 비(pHDM-Hgpm2(HIV gag-pol): pMD-tat: pRC/CMV-rev: Env VSV-G 슈도타입)는 20:1:1:1:2이었다. D-10 배지로 바꾼 후, 바이러스 성청액을 3일째 날에 회수하였고 0.45 ㎛ 필터를 통해 여과하였고 16,500 rpm(48,960 x g, Beckman SW28 로터) 및 4℃에서 90분 동안 한외원심분리(Beckman Coulter, Fullerton, CA)로 농축하였다. 바이러스 펠렛을 R-10 배지에 재현탁하였고 -80℃에서 동결시켜 보관하였다.
한 실시양태에서, 폴리에틸렌이민(PEI)을 사용하여 5개의 플라스미드를 293T 세포 내로 일시적으로 형질감염시킴으로써 렌티바이러스를 생성하였다. 요약하건대, 15 cm 플레이트(Nalge Nunc) 내의 각각의 80% 전면생장 293T 세포를 총 30 ㎍의 5개 플라스미드(5 ㎍의 각각의 구조 플라스미드 pHDH-Hgpm2(HIV gag-pol), pMD-tat; pRC/CMV-rev 및 Env VSV-G, 및 CAR(항-CAIX/항-PD-L1 IgG1, 항-CAIX/항-PD-L1 IgG4, 항-CAIX/항-SARS IgG1 또는 항-BCMA/항-SARS IgG1)을 코딩하는 10 ㎍의 주요 플라스미드)로 형질감염시켰다. 제조자의 지시에 따라 Lenti-X 농축기(Clontech)를 이용하여 바이러스 상청액을 농축하였고 -80℃에서 동결시켜 보관하였다.
인간 PBMC를 피콜 밀도 구배 분리로 단리하였고 4일 동안 2 ㎍/㎖ PHA(Sigma) 플러스 100 IU/㎖ 인간 IL-2로 활성화시켰다. 세포를 10 ㎍/㎖ DEAE의 존재 하에서 10 내지 20의 다중감염도(MOI)에서 2 또는 3 라운드의 렌티바이러스 형질도입으로 감염시켰다. 형질도입한 지 3일 후, 시험관내에서의 표현형적 및 기능적 분석을 위해 형질도입된 T 세포를 수집하였거나 생체내 실험을 위해 형질도입된 T 세포를 증폭시켰다.
유세포측정 분석. 인간 일차 T 세포의 형질도입 효율을 레포터 유전자(ZsGreen)의 발현으로 평가하였다. CAIX의 아미노산 38-397에 이어 인간 IgG1 힌지, CH2 및 CH3 도메인들을 코딩하는 pcDNA3.1 플라스미드로부터 CAIX-Fc 단백질을 발현하였고, CAIX 신호 펩티드(aa 1-37)를 Ig 리더 서열로 대체하였다. 세포를 1 ㎍의 CAIX-Fc 단백질로 염색한 후 APC-접합된 마우스 항-인간 IgG 항체(Jackson ImmunoResearch)로 염색함으로써 형질도입된 T 세포 상에서의 scFv(G250)의 발현을 시험하였다. 추가로, 5 ㎍의 마우스 1D4 항체로 염색한 후, APC-접합된 염소 항-마우스 IgG 항체(Jackson ImmunoResearch)로 염색함으로써, 형질도입된 T 세포 상에서의 TCR 구축물의 scFv 도메인의 내부 로돕신 노나펩티드(TETSQVAPA) C9 태그의 발현을 검출하였다. 분석을 위해, 클론 증폭 실험 동안 배양물 중의 인간 세포의 서브세트를 CD3(클론 S4.1), CD4(클론 S3.5) 또는 CD8(클론 3B5)에 대한 형광 접합된 마우스 항-인간 항체(Invitrogen)로 염색하였다. 모든 세포 염색에서, 오십만 개의 세포를 회사의 지시에 따라 권고된 농도에서 항체로 염색하였다. 각각의 샘플에 대한 일치된 이소타입 대조군 항체를 사용하였고 FACSCalibur 사이토미터(Becton-Dickinson)를 이용하여 세포를 분석하였다.
한 실시양태에서, 293T 세포 또는 CD8+ T 세포의 형질도입을 항-CAIX 또는 항-BCMA 발현의 FACS 분석으로 확인하였다. 세포를 본 발명자들의 실험실에서 제조된 10 ㎍/㎖의 인간 CAIX-Fc 또는 인간 BCMA-마우스-Fc(AB Bioscience)로 염색한 후, 각각 1:250 APC-접합된 마우스 항-인간 IgG Ab(Southern Biotech) 또는 염소-항 마우스 IgG Ab(Biolegend)로 현상하였다. CountBrightTM 절대 카운팅 비드(Molecular Probes)를 증식 및 클론 증폭 어세이에 사용하였다. 모든 샘플들을 LSR 포르테사(Fortessa) 또는 FACSCalibur(BD Bioscience)로 분석하였고 FlowJo 소프트웨어를 이용하여 데이터를 분석하였다. CART 세포의 T 세포 소진의 상태를 분석하기 위해, CART 세포를 5일 동안 IL-21 50 U/㎖(Peprotech) 및 다이나비즈(Dynabeads) 인간 T 활성화제 CD3/CD28의 존재 하에서 배양하였다. 이 기간 후, 소진을 자극하기 위해 CART 세포를 2일 동안 Skrc-59 CAIX+ PD-L1+ 세포와 함께 공-배양하였다. 이 어세이로부터의 1x106개의 CART 세포 및 생체내 어세이로부터 수집된 종양-침윤 림프구(TIL)를 FITC-접합된 항-인간 PD-1, PE-접합된 항-인간 Tim3, PerCP/Cy5.5-접합된 항-인간 Lag3 항체(Biolegend) 및 파시픽 블루(Pacific Blue)-접합된 항-인간 CD45로 염색하였고 FACS로 분석하였다. 이 프로젝트에서 사용된 상이한 RCC 세포 계통에서 CAIX 및 PD-L1의 발현 수준을 검증하기 위해, 본 발명자들은 본 발명자들의 실험실에서 제조된 10 ㎍/㎖의 항-인간 CAIX mAb(클론 G36) 및 10 ㎍/㎖의 바이오티닐화된 마우스 항-인간 PD-L1(Biolegend)을 사용하였다. 각각 1:250 APC-접합된 항-인간 Ab 및 PE-접합된 아비딘을 사용하여 일차 항체를 검출하였고 FACS로 분석하였다.
렌티바이러스 형질도입된 T 세포의 ADCC 및 세포독성 어세이. 제조자의 지시에 따라 DELFIA EuTDA 세포독성 키트(Perkin Elmer, Boston, MA)를 사용하여 세포독성 어세이를 수행하였다. 요약하건대, 표적 종양 세포를 37℃에서 30분 동안 형광 리간드(BATDA)로 표지하였고 웰당 1 x 104개의 표지된 세포를 96-웰 U-바닥 플레이트에 적재하였다. 항체 의존적 세포 세포독성(ADCC) 어세이를 위해, 항-CAIX scFv-Fc 항체 또는 무관한 scFv-Fc 항체의 패널을 1 ㎍/㎖ 또는 5 ㎍/㎖의 농도로 따로 첨가하였다. 50:1, 25:1 및 12.5:1의 이펙터 세포(인간 PBMC) 대 표적 세포(E:T)의 비로 상기 어세이를 설정하였다. T 세포 세포독성 어세이를 위해, 이펙터 세포(형질도입되지 않았거나 형질도입된 T 세포) 대 표적 세포(E:T)의 상이한 비를 준비하였다(100:1, 50:1 및 25:1). 배양물을 37℃에서 습윤화된 5% CO2와 함께 4시간 동안 항온처리하였다. 플레이트를 500x g에서 5분 동안 원심분리한 후, 20 ㎕의 상청액을 평저 플레이트로 옮겼다. 200 ㎕의 유로퓸 용액을 첨가하였고, 세포로부터 방출된 형광을 형광측정기(VictorTM , PerkinElmer)로 판독하였다. 표지 세포만을 배양함으로써 자연발생적 방출에 대한 대조군을 제조하였고, 용해 완충제(제공된 키트)를 표지 세포에 첨가함으로써 최대 방출에 대한 대조군을 제조하였다.
ELISA, ELISPOT 어세이 및 웨스턴 블롯. 사이토카인 분비를 위해, RCC 세포주 sk-rc-52(CAIX+) 또는 sk-rc-59(CAIX-)를 웰당 1 x 106개씩 24-웰 플레이트에 밤새 시딩한 후, 1 x 106개의 형질도입되지 않았거나 형질도입된 T 세포를 시딩하였다. 종양 세포와 함께 공-배양하기 전, T 세포를 PBS로 2회 세척하여 인간 IL-2를 제거하였다. 밤새 항온처리한 후, 상청액을 회수하였고 ELISA(e-Bioscience)로 IL-2 및 IFN-γ에 대해 분석하였다. IFN-γ ELISPOT 어세이(e-Bioscience)를 위한 T 세포의 검출에서, AEC 기질 용액을 사용하여 막을 현상하였고 점의 수를 ELISPOT 플레이트 판독기(C.T.L. Cellular Technology)로 카운팅하였다.
웨스턴 블롯을 위해, 형질도입되지 않은 T 세포 및 형질도입된 T 세포의 제조를 기재하였다50. 백만 개의 세포를 비-환원 및 환원 완충제(0.1 M 디티오트레이톨)에서 제조하였고 10-20% 폴리아크릴아미드 구배 겔(Invitrogen) 상에서 런닝시켰다. 단백질을 100 V 및 4℃에서 밤새 폴리비닐리덴 플루오라이드 전달 막(NEN Life Science Products, Boston, MA)으로 옮겼다. 상기 막을 1:2000 일차 항체, 항-인간 ζ-쇄 단일클론 항체 8D3(BD Pharmingen, San Diego, CA) 및 이어서 1:3000 이차 항체 호스라디쉬 퍼록시다제(Caltag)와 함께 항온처리하였다. ECL 플러스 웨스턴 블롯팅 검출 시스템(GE Healthcare, Piscataway, NJ) 및 x-선 필름 노출을 이용하여 면역검출을 수행하였다.
종양 세포 접촉 후 증식, 클론 증폭 및 사이토카인 분비. 종양 세포를 방사선조사하였고(3,000 rads) 웰당 2.5 x 105개씩 시딩하였다. 1주 배양을 위해 T 세포를, R-10 플러스 100 IU/㎖ 인간 IL-2를 함유하는 배양 배지에 1 x 106개씩 첨가하였다. T 세포를 분할하여 적합한 밀도를 유지하였고 주마다 종양 세포로 재자극하였다. T 세포의 수를 2주 동안 3일 또는 4일마다 카운팅하였다. 형질도입된 T 세포 및 T 세포 서브세트에 의한 ZsGreen의 백분율 발현을 형광-활성화된 세포 분류(FACS)로 주마다 측정하였다. 종양 세포 접촉 후 사이토카인 분비 연구를 위해, 1주 또는 2주 동안 방사선조사된 종양 세포와 접촉한 T 세포를 세척하였고 새로운 종양 세포와 함께 밤새 항온처리하였고, 분석을 위해 배양 상청액을 24시간 후 수집하였다.
종양 확립 및 T 세포 요법. 한 실시양태에서, 6주령 내지 8주령의 암컷 BALB/c 누드 마우스에서의 sk-rc-52의 면역거부로 인해 생체내 성장 성질을 가속화하기 위해, 5백만 개의 세포를 마우스 내로 피하 접종하였고 회수하였고 시험관내에서 증폭하였다. 그 다음, 세포주를 누드 마우스에서 2회 이상 계대배양하였고, 추가 실험을 위해 계대배양된 세포를 증폭하였다(서브클론 4-1). 치료적 실험을 위해, 5백만 개의 sk-rc-59 및 7백 5십만 개의 계대배양된 sk-rc-52 세포를 대향하는 옆구리 상에서 누드 마우스 내로 피하 접종하여 필적할만한 종양 성장률을 달성하였다. 7일 후, 종양은 약 6 mm의 크기까지 성장하였고, 5천만 개의 형질도입되지 않았거나 형질도입된 T 세포를 정맥내로 주사하였다. 또한, 마우스를 2일마다 복막 주사로 20,000 IU의 인간 IL-2로 치료하였다. 종양 크기를 2차원에서 칼리퍼로 측정하였고 2개의 종양 직경의 평균이 여기에 보고되었다. 동물 실험을 지침(Dana Farber Cancer Institute Animal Care Committee)에 따라 수행하였다. 종양이 15-mm 직경 또는 2,000 mm3에 도달하였을 때, 마우스를 희생시켰고 종양을 회수하였다.
면역조직화학 및 면역형광 염색. 형질도입된 T 세포의 시험관내 조사를 위해, PBS를 사용하여 배양된 T 세포를 2회 세척하였고 37℃에서 15분 동안 PBS 중의 2 μM 파 레드(Far Red) DDAO-SE 셀트레이스(CellTrace) 염료(Molecular Probe)에 재현탁하였다. 그 다음, 세포를 배양 배지로 2회 세척하였고 유리 슬라이드 상에서 세포원심분리하였다. 공초점 현미경관찰(Zeiss)(Optical Imaging Core facility, Harvard NeuroDiscovery Center)을 이용하여 ZsGreen 공발현을 가진 파 레드 미리-염색된 CART 세포를 가시화하였다.
제자리 종양 층 내의 형질도입된 T 세포의 사멸 효과를 조사하기 위해, ApopTag 퍼록시다제 제자리 아폽토시스 검출 키트(Millipore)를 위한 동결된 박편용으로 종양을 준비하였다. 냉동박편을 1시간 동안 TdT 효소(Millipore)와 함께 항온처리하였다. 토끼 항-DIG(Dako)를 첨가하였고 30분 동안 항온처리한 후, Cy3-접합된 항-토끼 항체(Invitrogen)를 첨가하였고 30분 동안 항온처리하였다. 박편을 DAPI 안티페이드(antifade) 마운팅 배지로 마운팅하였고 공초점 현미경관찰을 이용하여 형광 영상을 조사하였다.
이종이식물 종양 및 마우스 비장을 회수하였고 10% 포르말린/PBS 용액에서 고정시켰고 하바드 의과대학 설치류 조직병리학 핵심 시설(Harvard Medical School, Rodent Histopathology Core Facility)에 제출하였다. 파라핀-매립된 박편을 자일렌으로 탈왁싱하였고 염색 전에 등급화된 알코올을 통해 재수화하였다. 1시간 동안 일차 항체로서 항-인간 그랜자임 B 항체(Dako, 클론 GrB-7(1:200))와 함께 항온처리한 후, 30분 동안 이차 항-토끼 항체(Pierce) 또는 항-마우스 항체(Dako)와 함께 항온처리함으로써 면역조직화학 염색을 수행하였다. DAB 기질을 사용하여 박편을 현상하였고 헤마톡실린으로 반대염색하였다.
한 실시양태에서, 고정된 종양을 파라핀-매립시켰고 4-마이크로미터로 박편화하였고 슬라이드 상에 배치하였고 IHQ를 위해 준비하였다. 조직을 항-인간 Ki67(벡터, VP-K451), PD-L1(클론 405.9A11, 고돈 프리만(Gordon Freeman) 박사의 실험실에서 제조됨), 그랜자임 B(Abcam, ab4059) 또는 NCAM(CD56)(Abcam, ab133345) 항체로 염색한 후, 이차 HRP-접합된 항-토끼 Ab 또는 HRP-아비딘으로 염색하였다. DAB를 사용하여 슬라이드를 현상하였고 헤마톡실린으로 반대염색하였다. DP71 디지털 카메라(Olympus)를 이용하여 올림푸스 BX51 현미경관찰에서 영상을 수득하였고 DP 제어기 소프트웨어(Olympus)에서 분석하였다. 문헌(Varghese F, Bukhari AB, Malhotra R, De A. IHC Profiler: an open source plugin for the quantitative evaluation and automated scoring of immunohistochemistry images of human tissue samples. PloS one. 2014;9:e96801)에 기재된 ImageJ 소프트웨어의 IHC 프로파일러 플러긴(Profiler Plugin)을 이용하여 영상 정량을 수행하였다.
통계학적 분석
양측의 스튜던트 t-검정을 이용하여 통계학적 유의성을 측정하였다.
한 실시양태에서, ANOVA 및 Tukey 사후검정을 이용하여 데이터의 통계학적 유의성을 평가하였다. P<0.05는 유의한 것으로서 간주되었다. IBM SPSS 통계학적 소프트웨어 버전 20을 이용하여 통계학적 분석을 수행하였다.
실시예 2: 항-CAIX 항체의 ADCC 매개 사멸 및 CAR 표적화 모이어티의 선택
본 발명자들은 그들의 에피토프 맵핑, 발현 수준 및 CAIX을 내재화하는 능력 면에서 상이한 고친화성 인간 항-CAIX 항체의 패널에 대해 이미 보고하였다23. 본 발명자들의 첫 번째 목적은 CAR 구축을 위한 후보로서 이들 항-CAIX 단일-쇄 항체들 중 5개의 항-CAIX 단일-쇄 항체들의 항-종양 활성을 조사하는 것이었다. 항-CAIX mAb 매개 ADCC에 대해 시험하기 위해, scFv를 scFv-Fc(hIgG1) 미니바디로 전환시켰다23. 본 발명자들은 모든 scFv-Fc들이 항원 특이적 종양 용해를 나타내었다는 것을 발견하였다. 높은 CAIX+ 발현을 가진 종양 세포주 sk-rc-09의 경우, 특이적 용해는 40% 내지 57%이었고, 중간 CAIX+ 발현을 가진 sk-rc-52의 경우, 특이적 용해는 46% 내지 60%이었고, 이때 CAIX- 종양 세포주 sk-rc-59에 대한 용해의 배경 수준은 5% 미만이다. 음성 대조군 scFv-Fc, 예컨대, 항-CXCR4 48-Fc23 및 항-SARS 11A-Fc24의 경우, 단지 배경 수준의 세포 용해가 관찰되었다(도 1). ADCC 사멸 및 다른 공개된 분석을 근거로, scFvG36을 CAR 표적화 모이어티로서 추가 평가하기 위해 선택하였다.
CAIX 특이적 키메라 수용체의 구축 및 발현. 항-CAIX CAR의 두 세대를 구축하였다: CD8, 절단된 세포외, 힌지 및 경막 도메인 플러스 TCRζ의 신호전달 도메인에 연결된 scFvG36을 가진 제1세대 G36 CD8 CAR(G36-CD8z). 보조자극 신호를 전달하기 위해, CD28의 절단된 세포외, 경막 및 세포내 도메인 플러스 TCRζ의 신호전달 도메인에 융합된 scFvG36으로 구성된 제2세대 CD28 CAR(G36-CD28z)을 생성하였다(도 2a). 항-HIV CCR5(클론 A8) scFv를 대신 사용하여 무관한 제2세대 CD28 CAR을 제조하였다25. 이들 구축물들의 발현을 검출하기 위해, scFv와 CD8 또는 CD28 도메인 사이에 인간 로돕신 C9 태그를 삽입하였고, IRES 서열 후 ZsGreen이 발현되었다. 고농도의 바이러스 스톡을 293T 세포 내로의 벡터 플라스미드의 공형질감염에 의해 시험된 상이한 구축물들 사이에 필적가능한 수준에서 수득되었다(데이터는 제시되어 있지 않음).
형질도입을 위해, PHA 미토겐(mitogen)을 사용하여 3일 동안 말초혈 림프구를 자극하였다. 양이온성 시약 DEAE가 폴리브렌과 비교될 때 1.5배 내지 2배의 형질도입률을 증가시켰기 때문에, 농축된 렌티바이러스 상청액을 사용하여 양이온성 시약 DEAE의 존재 하에서 인간 일차 T 세포를 감염시켰다(데이터는 제시되어 있지 않음). 일차 T 세포의 형질도입률은 FACS 분석에서 ZsGreen 발현에 의해 17% 내지 45%이었다. 렌티바이러스 형질도입 후 일차 CART 세포에 의한 약 25%의 ZsGreen 발현을 보여주는 대표적인 실험은 도 2b의 좌측 컬럼에 제시되어 있다. CAIX-Fc 융합 단백질은 G36-CD8z 및 -CD28z CART 세포에 결합할 수 있으나 대조군 A8-CD28z CART 세포에는 결합할 수 없다(도 2b, 중간 컬럼). mAb 1D4가 내부 폴리펩티드 서열에 비해 카복시-말단으로서 제시되었을 때(데이터는 제시되어 있지 않음) 로돕신 노나펩티드 C9를 우선적으로 인식한다는 발견과 관련되어 있을 가능성이 높은 CAIX-Fc 단백질의 약 3분의 1 수준에서 C9-태그 발현만이 검출되었다(도 2b, 우측 컬럼). 6주 동안 시험관내에서 배양된 형질도입된 세포는 그의 ZsGreen 발현을 유지하였다.
환원 조건 하의 웨스턴 블롯 상에서, G36 및 A8 CD28z CAR들은 약 53 kD의 몰 중량으로 이동한 반면, 내생성 TCRζ는 16 kDa이었다. G36-CD8z CAR은 약 48 kD의 몰 중량으로 이동하였다. 비환원 조건 하에서, 이들 2개의 CD28z CAR들은 동종이량체를 형성하였다(도 2c, CD8z CAR의 데이터는 제시되어 있지 않음).
실시예 3: CAIX+ 종양과의 접촉 시 형질도입된 T 세포에 의한 향상된 사이토카인 분비
MHC 제시를 우회하고 제1세대 G36-CD8z CART 세포에 비해 T 세포 이펙터 기능을 향상시키기 위해 보조자극 분자 CD28의 신호전달 성분을 포함하는 제2세대 G36-CD28z CART 세포 사용의 보고된 뛰어난 효과를 비교하기 위한 연구를 수행하였다. 도 3a에서 관찰된 바와 같이, CAIX+ sk-rc-52 세포와 함께 밤새 항온처리한 후, 대조군 A8 CD28z CART 세포 또는 LAK 세포 단독의 사용 시 낮은 수준의 I형 사이토카인 IL-2, IFNγ 및 IL-17 분비만이 관찰되었다. 대조적으로, 제1세대 G36 발현 CART 세포 및 제2세대 G36 발현 CART 세포 둘 다가 제1세대 G36-CD8z CART 세포에 비해 그의 보다 높은 활성화 상태를 반영하는 보다 높은 양의 I형 사이토카인을 분비하는 제2세대 G36-CD28z CART 세포에 의한 상승된 수준의 사이토카인 분비를 보였다. 구체적으로, G36-CD28z CART 세포는 G36-CD8z CART 세포보다 각각 6.5배, 2.3배 및 4배 더 많은 IL-2, IFNγ 및 IL-17을 분비하였다. 상기 2종의 G36 CART 세포들에 의한 사이토카인 분비 유도의 특이성은 CAIX- sk-rc-59 세포를 사용한 그들의 최소 자극에 의해 관찰된다.
Elispot 연구에서, CAIX+ sk-rc-52 종양과의 상호작용 후, G36-CD28z CART 세포는 고성능 IFN-γ 생성 세포가 되었다(도 3b). G36-CD28z CART 세포는 CAIX+ sk-rc 52 종양 세포와의 상호작용 시 G36-CD8z CART 세포에 대해 관찰된 점보다 6배 더 많은 점을 생성하였고 CAIX- sk-rc-59 종양 세포와의 상호작용 후 관찰된 점보다 12배 더 많은 점을 생성하였다. 유사하게, G36-CD28z CART 세포는 G36-CD8z CART 세포 및 대조군 T 세포에 비해 CAIX+ 종양과의 접촉 후 보다 높은 양의 그랜자임 B-분비 점을 가졌다. PMA 및 이오노마이신(ionomycin)은 T 세포를 자극하여, 가장 많은 양의 IFN-γ 및 그랜자임 B 분비 T 세포를 생성하였다. 이들 연구들은 CAIX+ 종양 세포와의 접촉에 의해 활성화되는 G36-CD28z CART 세포의 특이성 및 고성능 둘 다를 입증한다.
실시예 4: 형질도입된 T 세포에서 CAR 신호전달을 통한 특이적 세포독성
상이한 G36 CART 세포의 사멸 활성을 더 평가하기 위해 시험관내 세포독성 어세이를 확립하였다. 상이한 비의 이펙터-대-표적을 사용하여, G36-CD28z CART 세포 및 그의 2회 생체내 계대배양된 서브클론 4-1은 가장 많은 양의 CAIX+ 종양 sk-rc-52 세포용해를 나타내었다(도 3c). 25:1 초과의 높은 비를 사용하였을 때, G36-CD28z CART 세포는 G36-CD8z CART 세포보다 2배 내지 3배 더 높은 세포독성을 보였고, 5:1의 낮은 비를 사용하였을 때, G36-CD28z CART 세포는 G36-CD8z CART 세포보다 8배 내지 9배 더 높은 용해를 보였다. 그러나, G36-CD8z CART 세포는 100:1의 E:T 비를 사용하였을 때 최대 60% 초과의 종양 용해로 여전히 우수한 세포독성을 나타내었다. 무관한 A8-CD28z CART 세포 및 대조군 T 세포 LAK는 가장 높은 100:1의 E:T 비를 사용하였을 때 약 20% 용해로 배경 비-특이적 종양 용해를 보였다. CAIX- 종양 sk-rc-59를 사용하는 모든 경우들에서, 형질도입된 T 세포 및 형질도입되지 않은 T 세포는 배경 용해를 보였다.
실시예 5: 연장된 CAIX+ 종양을 가진 CART 세포에서 개선된 시험관내 증식
단기간 CAIX+ 종양 세포 접촉 시 향상된 사이토카인 분비 및 세포독성 이외에, CAR 구축물 내로의 CD28 보조자극 분자의 도입은 항원 특이적 종양 세포와의 연장된 접촉 시 개선된 증식을 입증하였다. 형질도입되지 않은 T 세포 및 형질도입된(약 20%) T 세포를 100 유닛/㎖ 인간 IL-2의 존재 하에서 주마다 새로 방사선조사된 종양 세포와 혼합하였다. 고정된 양의 T 세포에서 상이한 수준의 항원 자극을 시험하기 위해, 본 발명자들은 1:8, 1:4 및 1:2의 종양 세포 대 T 세포 비를 사용하였다. T 세포 수를 트립판 배제로 카운팅하였고 CART 세포 분획을 유세포측정으로 조사하였다. CAIX- sk-rc-59 종양 세포를 사용한 배양 하에서, 형질도입된 T 세포 및 형질도입되지 않은 T 세포의 수는 유지되었다(도 4a 하부). 기저 수준의 대조군 T 세포 증식의 결여는 종양 세포주에 의해 분비된 다량의 억제성 사이토카인에 기인할 것이다. 대조적으로, CAIX+ sk-rc-52 종양 세포와 함께 2주 동안 배양한 후, 1:8의 비에서 G36-CD28z CART 세포의 집단은 30배까지 증가되었고 G36-CD8z CART 세포는 17배까지 증식된 반면, 1:4의 비에서 G36-CD28z CART 세포의 수는 19배 증가되었고 G36-CD8z CART 세포는 4배 증식되었다. 다량의 종양 세포를 사용하였을 때, G36-CD28z 또는 G36-CD8z CART 세포 중 어느 세포도 증식할 수 없었다. 무관한 A8-CD28z CART 세포 및 대조군 T 세포 LAK는 종양 세포에 의한 증식을 전혀 보이지 않았다(도 4a 상부).
증식하는 T 세포도 회수하여, CAIX+ 종양 세포 접촉 시 그의 농후화를 조사하였다. CAIX- 종양 접촉 시, 집단 내에서 임의의 CART 세포의 백분율의 변화는 없었다. 그러나, CAIX+ sk-rc-52 종양 세포와의 접촉 시, G36 CART 세포의 두 집단들에서 농후화가 있었다. G36-CD28z CART 세포의 경우, 양성 집단은 0일째 날 18%부터 8일째 날 52%까지, 그리고 16일째 날 88%까지 농후화되었다. G36-CD8z CART 세포의 발현은 0일째 날 19%(T 세포에서만 동일한 수준)부터 8일째 날 32%까지, 그리고 16일째 날 72%까지 농후화되었다. A8-CD28z CART 세포의 증폭은 2주 연구에 걸쳐 관찰되지 않았다(도 4b). CD8 세포의 백분율은 모든 조건들 하에서 16일 연구 전체에 걸쳐 일정하게 유지되었다(도 4c).
실시예 6: 종양과의 재접촉 후 CART 세포의 지속적인 이펙터 기능
1주 또는 2주 동안 방사선조사된 종양 세포와 접촉한 형질도입된 T 세포를 새로운 비-방사선조사된 종양 세포와 24시간 동안 접촉시킨 후 사이토카인 분비에 대해서도 시험하였다. 1주 또는 2주 동안 CAIX+ 종양(sk-rc-52)과의 접촉 시, G36-CD28z CART 세포 및 G36-CD8z CART 세포는 유사한 IFN-γ 분비 수준을 보였지만, G36-CD28z CAR을 통한 보조자극 신호전달은 G36-CD8z CAR에 대해 관찰된 IFN-γ 분비보다 2배 내지 2.5배 더 많은 IFN-γ 분비를 제공하였다(표 1). IL-2 분비를 위해, G36-CD28z CART 세포 및 G36-CD8z CART 세포에 대한 2주의 종양 접촉은 1주의 접촉보다 더 많은 IL-2 분비를 나타내었다. G36-CD28z CART 세포는 1주 접촉 시 G36-CD8z CART 세포보다 5배 더 많은 IL-2를 제공하였고 2주 동안의 접촉 시 2.5배 더 많은 IL-2를 제공하였다. 추가로, 2주 동안 종양 세포와 접촉한 G36-CD28z CART 세포는 1시간 종양 접촉보다 3.3배 더 많은 IL-2를 분비한 반면, G36-CD8z CART는 1주의 종양 접촉 후에 비해 2주 후 6.8배 더 많은 IL-2 분비를 제공하였다. 이 결과는 형질도입된 CART 세포가 제2 종양 자극 후 소진되지 않았고 기능적 활성을 유지하였다는 것을 시사한다. CAIX- sk-rc59 세포와의 접촉 시 A8-CD28z, LAK 및 G36 CART 세포 처리의 경우 배경 수준의 INF-γ 및 IL-2 분비만이 관찰되었다.
실시예
7: CART 세포에 의한 확립된 종양의 억제
다음으로, 본 발명자들은 CART 세포가 유사한 종양 곡선을 제공하도록 확립된 좌측 옆구리 및 우측 옆구리 상에서 sk-rc-52 종양 세포(좌측 옆구리) 및 sk-rc-59 종양 세포(우측 옆구리)로 접종된 누드 마우스에서 확립된 종양 세포 성장을 억제하는 지를 시험하였다. 약 6x6 mm의 전형적인 종양 크기를 가진 종양 이식 후 7일째 날, 5천만 개의 G36-CD28z CART 세포, A8-CD28z CART 세포 또는 형질도입되지 않은 T 세포(LAK)를 정맥내로 주사하였다. 고용량 IL-2(2 x 105 IU)의 존재 하에서, 제1시험에서 n=7의 군 크기 및 제2시험에서 n=8의 군 크기를 사용한 2회 별개의 실험에서 복막내 주사를 통해 입양 T-세포 요법을 수행하였다. 종양의 성장 및 세포 요법의 효과를 비교하기 위해 T-세포 치료 부재를 포함시켰다.
시험 1에서, 치료된 CAIX- sk-rc-59 종양 및 비치료된 CAIX- sk-rc-59 종양은 (4개의 시험된 군들 내에서) 4일째 날 6.09 ± 0.02 mm의 평균 크기를 가졌고 25일째 날 9.29 ± 0.12 mm의 평균 크기를 가졌다. 이들은 대조군 및 T-세포 치료군에서 동일한 종양 성장률을 나타내었다. T 세포를 제공받지 않은 비치료된 CAIX+ 종양은 4일째 날 6.09 ± 0.13 mm의 평균 크기 및 25일째 날 9.15 ± 0.11 mm의 평균 크기를 가지면서 CAIX- 종양과 유사한 종양 크기를 보였다. 그러나, G36-CD28z CART 세포 치료 마우스의 종양 크기는 25일 연구에 걸쳐 검사된 모든 시점에서 T-세포 비치료 마우스에 비해 크기의 통계학적으로 유의한 감소를 보였다(도 5). G36-CD28z CART 치료는 양측 t 검정에 의해 계산되었을 때 7일째 날(p<0.05) 및 25일째 날(p<0.001) A8-CD28z CART 세포 및 LAK 치료 마우스에서 관찰된 종양 크기의 감소보다 더 큰 종양 크기의 감소도 유발하였다. 시험 2에서, G36-CD28z CART 세포 치료 마우스의 종양 크기는 29일 실험을 통해 T-세포 비치료 마우스의 종양 크기보다 유의하게 더 작았다. G36-CD28z CART 세포 치료 마우스는 8일째 날부터 26일째 날까지(p<0.01) 및 29일째 날(p<0.001) A8 CD28z CART 세포 및 LAK 치료 마우스에서 관찰된 종양보다 더 작은 종양도 가졌다(도 5).
종양 크기가 동일한 T-세포를 제공받은 동일한 마우스에서 대조군 CAIX- 종양의 30% 부피보다 더 작았을 때 CAIX+ 종양의 부분적 퇴행이 인정되었다. 부분적 종양 퇴행은 G36-CD28z CART 세포를 사용한 사례들에서 높은 백분율로 관찰되었고(15 중 10, (67%)), 무관한 표적 A8-CD28z CART 세포(15 중 1, (7%)) 및 활성화된 T 세포 LAK(15 중 2, (13%))에서는 드물게만 관찰되었다(표 2). 부분적 퇴행 반응의 빈도는 피셔 검정에 의해 확인될 때 대조군 A8-CD28z CART 세포 및 LAK에 비해 G36-CD28z CART 세포로 치료된 마우스의 경우 통계학적으로 유의한 것으로 발견되었다(각각 p<0.001 및 p<0.005).
실시예 8: CART 세포에 의한 제자리 세포독성
생체내 연구를 위해 사용된 형질도입된 T 세포의 전체 집단의 샘플을 파 레드 염료로 미리 염색하였고 상기 집단 내에서 ZsGreen 단백질을 발현하는 CART 세포를 공초점 현미경관찰로 분석하였다. 이 결과는 본 발명자들의 FACS 분석과 일치하는 약 30% 형질도입 효율을 입증하였다(도 6a).
생체내에서 CAIX+ sk-rc-52 종양 세포의 G36-CD28z CART 세포 치료가 아폽토시스에 의한 사멸을 야기하였다는 증거를 제공하기 위해, 종양 박편을 터널(Tunnel) 어세이로 염색하였다. 입양 T 세포 치료 후 3일째 날, 터널 염색은 종양의 가장자리(도 6b 상부 열) 및 종양 층의 내부(도 6b 중간 열)에서 아폽토시스성 종양 세포(적색)를 확인시켜주었다. 아폽토시스성 종양 세포는 DAPI 핵 염색을 상실하였다. 아폽토시스를 겪고 있는 2개의 종양 세포와 상호작용하는 ZsGreen 발현 CART 세포는 확대된 그래프에 표시되어 있다(도 6b 하부 열).
형광 신호의 한정으로 인해, ZsGreen 발현 CART 세포는 전체 조직 박편으로부터 관찰될 수 없었다. 따라서, G36-CD28z CART 세포 또는 LAK 처리 후 3일째 날, 종양을 회수하였고 박편을 그랜자임 B 항체로도 염색하여 활성화된 T 세포의 위치를 확인하였다. 도 6c에서, 암갈색 염색 영역은 CAIX+ sk-rc-52 종양 박편 내로 침윤하는 것으로 관찰된 그랜자임 B+ T 세포를 보여준다(도 6c 상부 좌측). 종양 주변(도 6c 상부 좌측(a) 및 중간) 및 종양 내부(도 6c 상부 좌측(b) 및 하부)에서 이 그랜자임 B+ T 세포가 관찰되었다. 괴사 영역을 가진 종양은 H&E 염색된 슬라이드에서 보여졌고(도 6c 우측 중간 및 하부 내에서 n으로서 표지됨) 그랜자임 B+ T 세포에 가까운 위치에 놓여 있었다. 대조적으로, 대조군 활성화된 T 세포(LAK)로 처리된 CAIX+ sk-rc-52 종양(도 7)은 임의의 그랜자임 B+ T 세포를 보이지 않았다. 유사하게, G36-CD28z CART 세포로 처리되었거나(도 8) LAK로 처리된(도 9) CAIX- sk-rc-59는 낮은 배경 염색을 보인 반면, 종양은 증식하였다. 그랜자임 B 염색의 양성 대조군을 위해, CART 세포를 마우스 내의 확립된 sk-rc-52 종양 내로 국소적으로 주사하였다. 1일 후, 마우스를 희생시켰고 이 염색을 위해 종양 조직을 박편화하였다(도 10).
[표 1]

[표 2]

참고문헌





다른 실시양태
본 발명은 그의 상세한 설명과 함께 기재되어 있지만, 상기 설명은 예시하기 위한 것이고 첨부된 청구범위에 의해 정의되는 본 발명의 범위를 한정하기 위한 것이 아니다. 다른 양태, 장점 및 변경은 하기 청구범위 이내에 있다.
SEQUENCE LISTING
<110> Dana-Farber Cancer Institute, Inc.
<120> CARBONIC ANHYDRASE IX SPECIFIC CHIMERIC ANTIGEN RECEPTORS AND
METHODS OF USE THEREOF
<130> DFCI-092_001WO
<150> 62/094,596
<151> 2014-12-19
<160> 110
<170> PatentIn version 3.5
<210> 1
<211> 121
<212> PRT
<213> Homo sapiens
<400> 1
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asn Gly Asn Tyr Arg Gly Ser Leu Ala Phe Asp Ile Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 2
<211> 113
<212> PRT
<213> Homo sapiens
<400> 2
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Asn Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Ala Trp Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
Gly
<210> 3
<211> 119
<212> PRT
<213> Homo sapiens
<400> 3
Glu Val Gln Leu Val Gln Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 4
<211> 119
<212> PRT
<213> Homo sapiens
<400> 4
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 5
<211> 119
<212> PRT
<213> Homo sapiens
<400> 5
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 6
<211> 119
<212> PRT
<213> Homo sapiens
<400> 6
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Glu Phe Thr Phe Gly Thr Tyr
20 25 30
Ala Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Val Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Arg Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Val Leu Arg Tyr Gly Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 7
<211> 119
<212> PRT
<213> Homo sapiens
<400> 7
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 8
<211> 118
<212> PRT
<213> Homo sapiens
<400> 8
Gln Val Gln Leu Gln Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ile Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Gly Thr Tyr His Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Phe Ser Ala Tyr Ser Gly Tyr Asp Leu Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 9
<211> 119
<212> PRT
<213> Homo sapiens
<400> 9
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser
115
<210> 10
<211> 119
<212> PRT
<213> Homo sapiens
<400> 10
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 11
<211> 119
<212> PRT
<213> Homo sapiens
<400> 11
Glu Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser
115
<210> 12
<211> 116
<212> PRT
<213> Homo sapiens
<400> 12
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Ala Ala Gly Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 13
<211> 119
<212> PRT
<213> Homo sapiens
<400> 13
Gln Val Gln Leu Gln Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ile Gly Arg Tyr Ser Ser Ser Leu Gly Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 14
<211> 122
<212> PRT
<213> Homo sapiens
<400> 14
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Ala Pro Tyr Ser Ser Ser Leu Asp Ala Phe Asp Ile Trp
100 105 110
Gly Gln Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 15
<211> 118
<212> PRT
<213> Homo sapiens
<400> 15
Gln Val Gln Leu Gln Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser His Ser Ser Gly Gly Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 16
<211> 118
<212> PRT
<213> Homo sapiens
<400> 16
Gln Val Gln Leu Gln Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser His Ser Ser Gly Gly Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 17
<211> 116
<212> PRT
<213> Homo sapiens
<400> 17
Gln Val Thr Leu Lys Glu Ser Gly Gly Gly Val Val Gln Pro Gly Thr
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Ala Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Leu Ile Ser Tyr Asp Gly Ser Val Thr His Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Thr Leu Arg Ala Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Ser Gly Tyr Gln Glu His Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 18
<211> 118
<212> PRT
<213> Homo sapiens
<400> 18
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Tyr Gly Asp Tyr Gly Ser Leu Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 19
<211> 122
<212> PRT
<213> Homo sapiens
<400> 19
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Val Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Cys Ser Ser Thr Ser Cys Tyr Arg Gly Met Asp Val Trp
100 105 110
Gly Lys Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 20
<211> 119
<212> PRT
<213> Homo sapiens
<400> 20
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Arg Ala Ala Arg Pro Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 21
<211> 119
<212> PRT
<213> Homo sapiens
<400> 21
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 22
<211> 121
<212> PRT
<213> Homo sapiens
<400> 22
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Pro Glu Phe Thr Phe Ser Lys Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ser Ser Arg Ser Gly Tyr Phe Leu Pro Leu Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 23
<211> 118
<212> PRT
<213> Homo sapiens
<400> 23
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Ala Val Thr Gly Gly Phe Asp Pro Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 24
<211> 112
<212> PRT
<213> Homo sapiens
<400> 24
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Phe Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Thr Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Thr Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Arg
85 90 95
Leu Ser Ala Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 25
<211> 111
<212> PRT
<213> Homo sapiens
<400> 25
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Ser Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala His Tyr Tyr Cys Gln Ser Tyr Asp Arg Ser
85 90 95
Leu Ser Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 26
<211> 112
<212> PRT
<213> Homo sapiens
<400> 26
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Thr Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ile Gly Leu
65 70 75 80
Gln Ala Asp Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Thr
85 90 95
Leu Arg Val Trp Met Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 27
<211> 112
<212> PRT
<213> Homo sapiens
<400> 27
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Ile Thr Ile Ser Cys Thr Gly Ser Arg Ser Asn Ile Gly Ala Asp
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Asn Asn Asn Arg Pro Ser Gly Val Pro Gly Arg Phe
50 55 60
Ser Ala Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Arg Ala Trp Val Phe Gly Gly Gly Thr Lys Leu Ala Val Leu Gly
100 105 110
<210> 28
<211> 112
<212> PRT
<213> Homo sapiens
<400> 28
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Ile Thr Ile Ser Cys Thr Gly Ser Arg Ser Asn Ile Gly Ala Asp
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Asn Asn Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Thr Asp Tyr Phe Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Ala Trp Val Phe Gly Gly Gly Thr Lys Val Thr Val Leu Gly
100 105 110
<210> 29
<211> 111
<212> PRT
<213> Homo sapiens
<400> 29
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Arg Gly
20 25 30
Tyr Asn Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Asn Thr Asn Arg Pro Ser Gly Val Pro Ala Arg Phe
50 55 60
Ser Gly Ser Lys Ser Ala Thr Ser Ala Ser Leu Thr Ile Thr Gly Leu
65 70 75 80
Gln Ala Asp Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Gly
85 90 95
Leu Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Leu Leu Gly
100 105 110
<210> 30
<211> 111
<212> PRT
<213> Homo sapiens
<400> 30
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Ile Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Val Pro Gly Lys Ala Pro Lys Val
35 40 45
Val Ile Tyr Gly Asn Asn Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Ala Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Lys Ser
85 90 95
Leu Thr Trp Val Phe Gly Gly Gly Thr Lys Val Thr Val Leu Gly
100 105 110
<210> 31
<211> 111
<212> PRT
<213> Homo sapiens
<400> 31
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Ala Ala Pro Arg Val
35 40 45
Leu Ile Tyr Gly Asn Asn Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Lys Ser
85 90 95
Leu Ser Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Arg
100 105 110
<210> 32
<211> 112
<212> PRT
<213> Homo sapiens
<400> 32
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Phe Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Arg Leu
35 40 45
Leu Ile Tyr Gly Asn Asn Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Thr Asp Tyr Phe Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Ala Trp Val Phe Gly Gly Gly Thr Lys Val Thr Val Leu Arg
100 105 110
<210> 33
<211> 112
<212> PRT
<213> Homo sapiens
<400> 33
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Arg Gly
20 25 30
Tyr Asn Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Asp Thr Asn Arg Pro Ser Gly Val Pro His Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Arg Ala Trp Val Phe Gly Gly Gly Thr Lys Leu Ala Val Leu Gly
100 105 110
<210> 34
<211> 111
<212> PRT
<213> Homo sapiens
<400> 34
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Arg Gly
20 25 30
Tyr Asn Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Asn Thr Asn Arg Pro Ser Gly Val Pro Ala Arg Phe
50 55 60
Ser Gly Ser Lys Ser Ala Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Asp Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Gly
85 90 95
Leu Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Leu Leu Arg
100 105 110
<210> 35
<211> 111
<212> PRT
<213> Homo sapiens
<400> 35
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Arg Gly
20 25 30
Tyr Asn Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys His Ser Arg Asp Asn Asn
85 90 95
Gly His His Ile Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Ser
100 105 110
<210> 36
<211> 112
<212> PRT
<213> Homo sapiens
<400> 36
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Arg Gly
20 25 30
Tyr Asn Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Thr Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Gly Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Ala Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 37
<211> 112
<212> PRT
<213> Homo sapiens
<220>
<221> misc_feature
<222> (83)..(83)
<223> Xaa can be any naturally occurring amino acid
<400> 37
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Arg Gly
20 25 30
Tyr Asn Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Thr Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Xaa Asp Glu Gly Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Ala Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 38
<211> 110
<212> PRT
<213> Homo sapiens
<400> 38
Leu Pro Val Leu Thr Gln Pro Pro Ser Val Ser Val Ala Pro Gly Gln
1 5 10 15
Thr Ala Arg Ile Thr Cys Gly Gly Asn Asn Ile Gly Ser Lys Ser Val
20 25 30
His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr
35 40 45
Tyr Asp Ser Asp Arg Pro Ser Gly Ile Pro Glu Arg Phe Ser Gly Ser
50 55 60
Asn Ser Gly Asn Thr Ala Thr Leu Thr Ile Ser Arg Val Glu Ala Gly
65 70 75 80
Asp Glu Ala Asp Tyr Tyr Cys Gln Val Trp Asp Ser Ser Ser Asp His
85 90 95
His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 39
<211> 112
<212> PRT
<213> Homo sapiens
<400> 39
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Asn Asn Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Arg Ala Trp Val Phe Gly Gly Gly Thr Lys Leu Ala Val Leu Gly
100 105 110
<210> 40
<211> 112
<212> PRT
<213> Homo sapiens
<400> 40
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Asn Asn Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Arg Ala Trp Val Phe Gly Gly Gly Thr Lys Leu Ala Val Leu Gly
100 105 110
<210> 41
<211> 111
<212> PRT
<213> Homo sapiens
<400> 41
Gln Pro Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Tyr Val Tyr Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Pro
35 40 45
Ile Tyr Arg Asn Asn Gln Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp Asp Ser Leu
85 90 95
Asn Gly Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Arg
100 105 110
<210> 42
<211> 112
<212> PRT
<213> Homo sapiens
<400> 42
Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly
20 25 30
Tyr Asp Val His Trp Tyr Gln His Leu Pro Gly Thr Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Thr Asp Tyr Phe Cys Gln Ser Tyr Asp Ser Ser
85 90 95
Leu Ser Ala Trp Val Phe Gly Gly Gly Thr Lys Val Thr Val Leu Gly
100 105 110
<210> 43
<211> 109
<212> PRT
<213> Homo sapiens
<400> 43
Ser Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln
1 5 10 15
Thr Val Arg Ile Thr Cys Gln Gly Asn Ser Leu Arg Tyr Tyr Tyr Pro
20 25 30
Ser Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr
35 40 45
Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser
50 55 60
Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Thr Gln Ala Glu
65 70 75 80
Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Arg Asp Asn Thr Asp Asn Arg
85 90 95
Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105
<210> 44
<211> 109
<212> PRT
<213> Homo sapiens
<400> 44
Gln Pro Gly Leu Thr Gln Pro Pro Ser Val Ser Val Ala Pro Gly Gln
1 5 10 15
Thr Ala Arg Ile Thr Cys Gly Gly Asp Asn Ile Gly Arg Lys Ser Val
20 25 30
His Trp Tyr Gln Gln Arg Pro Gly Gln Ala Pro Ile Leu Val Ile Arg
35 40 45
Asp Asp Arg Asp Arg Pro Ser Gly Ile Pro Glu Arg Phe Ser Gly Ser
50 55 60
Ser Ser Val Asn Thr Ala Thr Leu Ile Ile Ser Arg Val Glu Ala Gly
65 70 75 80
Asp Glu Ala Asp Tyr Tyr Cys Gln Val Trp Asp Ser Ser Ser Lys His
85 90 95
Tyr Val Phe Gly Pro Gly Thr Lys Val Thr Ala Leu Gly
100 105
<210> 45
<211> 458
<212> PRT
<213> Homo sapiens
<400> 45
Met Ala Pro Leu Cys Pro Ser Pro Trp Leu Pro Leu Leu Ile Pro Ala
1 5 10 15
Pro Ala Pro Gly Leu Thr Val Gln Leu Leu Leu Ser Leu Leu Leu Leu
20 25 30
Met Pro Val His Pro Gln Arg Leu Pro Arg Met Gln Glu Asp Ser Pro
35 40 45
Leu Gly Gly Gly Ser Ser Gly Glu Asp Asp Pro Leu Gly Glu Glu Asp
50 55 60
Leu Pro Ser Glu Glu Asp Ser Pro Arg Glu Glu Asp Pro Pro Gly Glu
65 70 75 80
Glu Asp Leu Pro Gly Glu Glu Asp Leu Pro Gly Glu Glu Asp Leu Pro
85 90 95
Glu Val Lys Pro Lys Ser Glu Glu Glu Gly Ser Leu Lys Leu Glu Asp
100 105 110
Leu Pro Thr Val Glu Ala Pro Gly Asp Pro Gln Glu Pro Gln Asn Asn
115 120 125
Ala His Arg Asp Lys Glu Gly Asp Asp Gln Ser His Trp Arg Tyr Gly
130 135 140
Gly Asp Pro Pro Trp Pro Arg Val Ser Pro Ala Cys Ala Gly Arg Phe
145 150 155 160
Gln Ser Pro Val Asp Ile Arg Pro Gln Leu Ala Ala Phe Cys Pro Ala
165 170 175
Leu Arg Pro Leu Glu Leu Leu Gly Phe Gln Leu Pro Pro Leu Pro Glu
180 185 190
Leu Arg Leu Arg Asn Asn Gly His Ser Val Gln Leu Thr Leu Pro Pro
195 200 205
Gly Leu Glu Met Ala Leu Gly Pro Gly Arg Glu Tyr Ala Leu Gln Leu
210 215 220
His Leu His Trp Gly Ala Ala Gly Arg Pro Gly Ser Glu His Thr Val
225 230 235 240
Glu Gly His Arg Phe Pro Ala Glu Ile His Val Val His Leu Ser Thr
245 250 255
Ala Phe Ala Arg Val Asp Glu Ala Leu Gly Arg Pro Gly Gly Leu Ala
260 265 270
Val Leu Ala Ala Phe Leu Glu Glu Gly Pro Glu Glu Asn Ser Ala Tyr
275 280 285
Glu Gln Leu Leu Ser Arg Leu Glu Glu Ile Ala Glu Glu Gly Ser Glu
290 295 300
Thr Gln Val Pro Gly Leu Asp Ile Ser Ala Leu Leu Pro Ser Asp Phe
305 310 315 320
Ser Arg Tyr Phe Gln Tyr Glu Gly Ser Leu Thr Thr Pro Pro Cys Ala
325 330 335
Gln Gly Val Ile Trp Thr Val Phe Asn Gln Thr Val Met Leu Ser Ala
340 345 350
Lys Gln Leu His Thr Leu Ser Asp Thr Leu Trp Gly Pro Gly Asp Ser
355 360 365
Arg Leu Gln Leu Asn Phe Arg Ala Thr Gln Pro Leu Asn Gly Arg Val
370 375 380
Ile Glu Ala Ser Phe Pro Ala Gly Val Asp Ser Ser Pro Arg Ala Ala
385 390 395 400
Glu Pro Val Gln Leu Asn Ser Cys Leu Ala Ala Gly Asp Ile Leu Ala
405 410 415
Leu Val Phe Gly Leu Leu Phe Ala Val Thr Ser Val Ala Phe Leu Val
420 425 430
Gln Met Arg Arg Gln His Arg Arg Gly Thr Lys Gly Gly Val Ser Tyr
435 440 445
Arg Pro Ala Glu Val Ala Glu Thr Gly Ala
450 455
<210> 46
<211> 437
<212> PRT
<213> Mus musculus
<400> 46
Met Ala Ser Leu Gly Pro Ser Pro Trp Ala Pro Leu Ser Thr Pro Ala
1 5 10 15
Pro Thr Ala Gln Leu Leu Leu Phe Leu Leu Leu Gln Val Ser Ala Gln
20 25 30
Pro Gln Gly Leu Ser Gly Met Gln Gly Glu Pro Ser Leu Gly Asp Ser
35 40 45
Ser Ser Gly Glu Asp Glu Leu Gly Val Asp Val Leu Pro Ser Glu Glu
50 55 60
Asp Ala Pro Glu Glu Ala Asp Pro Pro Asp Gly Glu Asp Pro Pro Glu
65 70 75 80
Val Asn Ser Glu Asp Arg Met Glu Glu Ser Leu Gly Leu Glu Asp Leu
85 90 95
Ser Thr Pro Glu Ala Pro Glu His Ser Gln Gly Ser His Gly Asp Glu
100 105 110
Lys Gly Gly Gly His Ser His Trp Ser Tyr Gly Gly Thr Leu Leu Trp
115 120 125
Pro Gln Val Ser Pro Ala Cys Ala Gly Arg Phe Gln Ser Pro Val Asp
130 135 140
Ile Arg Leu Glu Arg Thr Ala Phe Cys Arg Thr Leu Gln Pro Leu Glu
145 150 155 160
Leu Leu Gly Tyr Glu Leu Gln Pro Leu Pro Glu Leu Ser Leu Ser Asn
165 170 175
Asn Gly His Thr Val Gln Leu Thr Leu Pro Pro Gly Leu Lys Met Ala
180 185 190
Leu Gly Pro Gly Gln Glu Tyr Arg Ala Leu Gln Leu His Leu His Trp
195 200 205
Gly Thr Ser Asp His Pro Gly Ser Glu His Thr Val Asn Gly His Arg
210 215 220
Phe Pro Ala Glu Ile His Val Val His Leu Ser Thr Ala Phe Ser Glu
225 230 235 240
Leu His Glu Ala Leu Gly Arg Pro Gly Gly Leu Ala Val Leu Ala Ala
245 250 255
Phe Leu Gln Glu Ser Pro Glu Glu Asn Ser Ala Tyr Glu Gln Leu Leu
260 265 270
Ser His Leu Glu Glu Ile Ser Glu Glu Gly Ser Lys Ile Glu Ile Pro
275 280 285
Gly Leu Asp Val Ser Ala Leu Leu Pro Ser Asp Phe Ser Arg Tyr Tyr
290 295 300
Arg Tyr Glu Gly Ser Leu Thr Thr Pro Pro Cys Ser Gln Gly Val Ile
305 310 315 320
Trp Thr Val Phe Asn Glu Thr Val Lys Leu Ser Ala Lys Gln Leu His
325 330 335
Thr Leu Ser Val Ser Leu Trp Gly Pro Arg Asp Ser Arg Leu Gln Leu
340 345 350
Asn Phe Arg Ala Thr Gln Pro Leu Asn Gly Arg Thr Ile Glu Ala Ser
355 360 365
Phe Pro Ala Ala Glu Asp Ser Ser Pro Glu Pro Val His Val Asn Ser
370 375 380
Cys Phe Thr Ala Gly Asp Ile Leu Ala Leu Val Phe Gly Leu Leu Phe
385 390 395 400
Ala Val Thr Ser Ile Ala Phe Leu Leu Gln Leu Arg Arg Gln His Arg
405 410 415
His Arg Ser Gly Thr Lys Asp Arg Val Ser Tyr Ser Pro Ala Glu Met
420 425 430
Thr Glu Thr Gly Ala
435
<210> 47
<211> 38
<212> DNA
<213> Artificial sequence
<220>
<223> Chemically synthesized primer
<400> 47
atcgacgcgt gcctgagcga ggtgcagctg gtgcagtc 38
<210> 48
<211> 32
<212> DNA
<213> Artificial sequence
<220>
<223> Chemically synthesized primer
<400> 48
caatggtcac cgtctcttca gctagcacca gg 32
<210> 49
<211> 35
<212> DNA
<213> Artificial sequence
<220>
<223> Chemically synthesized primer
<400> 49
atcccaagct taagccagtc tgtgctgact cagcc 35
<210> 50
<211> 31
<212> DNA
<213> Artificial sequence
<220>
<223> Chemically synthesized primer
<400> 50
ggagggacca aattgaccgt cctaggtcag c 31
<210> 51
<211> 41
<212> DNA
<213> Artificial sequence
<220>
<223> Chemically synthesized primer
<400> 51
tagggcacgc gtgtgctgag cgaggtgcag ctggtgcagt c 41
<210> 52
<211> 32
<212> DNA
<213> Artificial sequence
<220>
<223> Chemically synthesized primer
<400> 52
tctagtgcta gctgaagaga cggtgaccat tg 32
<210> 53
<211> 35
<212> DNA
<213> Artificial sequence
<220>
<223> Chemically synthesized primer
<400> 53
ctagcaagct tatcccagtc tgtgctgact cagcc 35
<210> 54
<211> 26
<212> DNA
<213> Artificial sequence
<220>
<223> Chemically synthesized primer
<400> 54
atagcaccta ggacggtcag cttggt 26
<210> 55
<211> 5
<212> PRT
<213> Artificial sequence
<220>
<223> Portion of CDR1 heavy chain sequence
<400> 55
Ser Tyr Ala Met Ser
1 5
<210> 56
<211> 5
<212> PRT
<213> Artificial sequence
<220>
<223> Portion of CDR1 heavy chain sequence
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<400> 56
Xaa Tyr Ala Met Xaa
1 5
<210> 57
<211> 5
<212> PRT
<213> Artificial sequence
<220>
<223> Portion of CDR1 heavy chain sequence
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<400> 57
Ser Tyr Xaa Met Xaa
1 5
<210> 58
<211> 17
<212> PRT
<213> Artificial sequence
<220>
<223> Portion of CDR2 heavy chain sequence
<220>
<221> misc_feature
<222> (4)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (8)..(8)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (10)..(11)
<223> Xaa can be any naturally occurring amino acid
<400> 58
Ala Ile Ser Xaa Xaa Gly Gly Xaa Thr Xaa Xaa Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 59
<211> 17
<212> PRT
<213> Artificial sequence
<220>
<223> Portion of CDR2 heavy chain sequence
<400> 59
Ala Ile Ser Gly Ser Gly Gly Ser Thr Thr Thr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 60
<211> 13
<212> PRT
<213> Artificial sequence
<220>
<223> Portion of CDR3 heavy chain sequence
<220>
<221> misc_feature
<222> (9)..(9)
<223> Xaa can be any naturally occurring amino acid
<400> 60
Asn Gly Asn Tyr Arg Gly Ser Leu Xaa Ala Phe Asp Ile
1 5 10
<210> 61
<211> 14
<212> PRT
<213> Artificial sequence
<220>
<223> Portion of CDR1 light chain sequence
<400> 61
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His
1 5 10
<210> 62
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> Portion of CDR2 light chain sequence
<400> 62
Gly Asn Asn Asn Arg Pro Ser
1 5
<210> 63
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> Portion of CDR3 light chain sequence
<400> 63
Gln Ser Tyr Asp Ser Ser Leu Ser Ala Trp Val Val
1 5 10
<210> 64
<211> 6
<212> PRT
<213> Artificial sequence
<220>
<223> Consensus sequence
<400> 64
Glu Glu Asp Leu Pro Glu
1 5
<210> 65
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Portion of the CDR3 heavy chain sequence
<400> 65
Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile
1 5 10
<210> 66
<400> 66
000
<210> 67
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 67
Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 68
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 68
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Phe Asp Val His
1 5 10
<210> 69
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 69
Gly Asn Thr Asn Arg Pro Ser
1 5
<210> 70
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 70
Gln Ser Tyr Asp Ser Arg Leu Ser Ala Trp Val
1 5 10
<210> 71
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 71
tagggcgcgg ccgcaaccga gaccagccag gtggcgcccg ccgggggagg aggcagcccc 60
accacgacgc cagcgccgcg a 81
<210> 72
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 72
Gly Asn Ser Asn Arg Pro Ser
1 5
<210> 73
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 73
Gln Ser Tyr Asp Arg Ser Leu Ser Trp Val
1 5 10
<210> 74
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 74
Gln Ser Tyr Asp Ser Thr Leu Arg Val Trp Met
1 5 10
<210> 75
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 75
tagggcgcgg ccgcaaccga gaccagccag gtggcgcccg ccggcggagg aggcagcatt 60
gaagttatgt atcctcctcc t 81
<210> 76
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 76
Gln Ser Tyr Asp Lys Ser Leu Thr Trp Val
1 5 10
<210> 77
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 77
ctagccttaa ttaattagcg aggagggggc agggcctgca t 41
<210> 78
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 78
Thr Glu Thr Ser Gln Val Gln Pro Gln
1 5
<210> 79
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 79
Gly Gly Gly Gly Ser
1 5
<210> 80
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 80
Gln Ser Tyr Asp Lys Ser Leu Ser Trp Val
1 5 10
<210> 81
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 81
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Phe Asp Val His
1 5 10
<210> 82
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Oligopeptide
<400> 82
Gln Ser Tyr Asp Ser Ser Leu Ser Ala Trp Val
1 5 10
<210> 83
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 83
caggtgcagc tggtgcagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cccctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtgcta atggtggtac cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaataatggg 300
aactatcgcg gtgcttttga tatctggggc caagggacaa tggtcaccgt ctcttcaggt 360
ggcggcggtt ccggaggtgg tggttctggc ggtggtggca gccagtctgt gctgactcag 420
ccaccctcag tgtctggggc cccagggcag agggtcacca tctcctgcac tgggagcagc 480
tccaacatcg gggcaggtta tgatgtacac tggtaccagc agcttccagg aacagccccc 540
aaactcctca tctatggtaa cagcaatcgg ccctcagggg tccctgaccg attctctggc 600
tccaagtctg gctcctcagc ctccctggcc atcactgggc tccaggctga ggatgaggct 660
cattattact gccagtcata tgacagaagc ctgtcttggg tgttcggcgg agggaccaaa 720
ttgaccgtcc taggt 735
<210> 84
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 84
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Val
130 135 140
Ser Gly Ala Pro Gly Gln Arg Val Thr Ile Ser Cys Thr Gly Ser Ser
145 150 155 160
Ser Asn Ile Gly Ala Gly Tyr Asp Val His Trp Tyr Gln Gln Leu Pro
165 170 175
Gly Thr Ala Pro Lys Leu Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser
180 185 190
Gly Val Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Ser Ser Ala Ser
195 200 205
Leu Ala Ile Thr Gly Leu Gln Ala Glu Asp Glu Ala His Tyr Tyr Cys
210 215 220
Gln Ser Tyr Asp Arg Ser Leu Ser Trp Val Phe Gly Gly Gly Thr Lys
225 230 235 240
Leu Thr Val Leu Gly
245
<210> 85
<211> 732
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 85
caggtgcagc tgcaggagtc ggggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc atctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtgg cacataccac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtct attactgtgc gaaattctct 300
gcgtatagtg gctacgattt gtggggccag ggaaccctgg tcaccgtctc ctcaggtggc 360
ggcggttccg gaggtggtgg ttctggcggt ggtggcagcc agtctgtgct gactcagcca 420
ccctcagtgt ctggggcccc agggcagagg gtcacaatct cctgcactgg gagcagctcc 480
aacatcggga gaggttataa tgtacactgg taccagcagc ttccaggaac agcccccaaa 540
ctcctcatct atgataacac gaatcggccc tcaggggtcc ctgcccgatt ctctggctcc 600
aagtctgcca cgtcagcctc cctgaccatc actgggctcc aggctgacga tgaggctgat 660
tattactgcc agtcgtatga cagcggcctg aggtgggtgt tcggcggagg gaccaagctg 720
accctcctag gt 732
<210> 86
<211> 244
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 86
Gln Val Gln Leu Gln Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ile Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Gly Thr Tyr His Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Phe Ser Ala Tyr Ser Gly Tyr Asp Leu Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser
130 135 140
Gly Ala Pro Gly Gln Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser
145 150 155 160
Asn Ile Gly Arg Gly Tyr Asn Val His Trp Tyr Gln Gln Leu Pro Gly
165 170 175
Thr Ala Pro Lys Leu Leu Ile Tyr Asp Asn Thr Asn Arg Pro Ser Gly
180 185 190
Val Pro Ala Arg Phe Ser Gly Ser Lys Ser Ala Thr Ser Ala Ser Leu
195 200 205
Thr Ile Thr Gly Leu Gln Ala Asp Asp Glu Ala Asp Tyr Tyr Cys Gln
210 215 220
Ser Tyr Asp Ser Gly Leu Arg Trp Val Phe Gly Gly Gly Thr Lys Leu
225 230 235 240
Thr Leu Leu Gly
<210> 87
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 87
gaggtgcagc tggtgcagtc tgggggaggc ttggtacagc cgggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtgcta atggtggtac cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaataatggg 300
aactatcgcg gtgcttttga tatctggggc caagggacca cggtcaccgt ctcctcaggt 360
ggcggcggtt ccggaggtgg tggttctggc ggtggtggca gccagtctgt gctgactcag 420
ccaccctcag tgtctggggc cccagggcag agggtcacca tctcctgcac tgggagcagc 480
tccaacatcg gggcaggttt tgatgtacac tggtaccagc aacttccagg aacagccccc 540
agactcctca tctatggtaa caacaatcgg ccctcagggg tccctgaccg attctctggc 600
tccaagtctg gcacctcagc ctccctggcc atcactgggc tccaggctga ggatgagact 660
gattatttct gccagtccta tgacagcagc ctgagtgctt gggtattcgg cggagggacc 720
aaggtgaccg tcctacgt 738
<210> 88
<211> 246
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 88
Glu Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Val
130 135 140
Ser Gly Ala Pro Gly Gln Arg Val Thr Ile Ser Cys Thr Gly Ser Ser
145 150 155 160
Ser Asn Ile Gly Ala Gly Phe Asp Val His Trp Tyr Gln Gln Leu Pro
165 170 175
Gly Thr Ala Pro Arg Leu Leu Ile Tyr Gly Asn Asn Asn Arg Pro Ser
180 185 190
Gly Val Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser
195 200 205
Leu Ala Ile Thr Gly Leu Gln Ala Glu Asp Glu Thr Asp Tyr Phe Cys
210 215 220
Gln Ser Tyr Asp Ser Ser Leu Ser Ala Trp Val Phe Gly Gly Gly Thr
225 230 235 240
Lys Val Thr Val Leu Arg
245
<210> 89
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 89
caggtgcagc tggtgcagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cccctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtgcta atggtggtac cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaataatggg 300
aactatcgcg gtgcttttga tatctggggc caagggacaa tggtcaccgt ctcttcaggt 360
ggcggcggtt ccggaggtgg tggttctggc ggtggtggca tccagtctgt gctgactcag 420
ccaccctcag tgtctggggc cccagggcag agggtcacca tctcctgcac tgggagcagc 480
tccaacatcg gggcaggtta tgatgtacac tggtaccagc agcttccagg aacagccccc 540
aaactcctca tctatggtaa caccaatcgg ccctcagggg tccctgaccg attctctggc 600
tccaagtctg gcacctcagc ctccctggcc atcattgggc tccaggctga cgatgaggct 660
gattattact gccagtccta tgacagcacc ctgagggtct ggatgttcgg cggagggacc 720
aagctgaccg tccttggt 738
<210> 90
<211> 246
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 90
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ile Gln Ser Val Leu Thr Gln Pro Pro Ser Val
130 135 140
Ser Gly Ala Pro Gly Gln Arg Val Thr Ile Ser Cys Thr Gly Ser Ser
145 150 155 160
Ser Asn Ile Gly Ala Gly Tyr Asp Val His Trp Tyr Gln Gln Leu Pro
165 170 175
Gly Thr Ala Pro Lys Leu Leu Ile Tyr Gly Asn Thr Asn Arg Pro Ser
180 185 190
Gly Val Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser
195 200 205
Leu Ala Ile Ile Gly Leu Gln Ala Asp Asp Glu Ala Asp Tyr Tyr Cys
210 215 220
Gln Ser Tyr Asp Ser Thr Leu Arg Val Trp Met Phe Gly Gly Gly Thr
225 230 235 240
Lys Leu Thr Val Leu Gly
245
<210> 91
<211> 726
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 91
gaggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt agctatggca tgcactgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg attcaccatc tccagagaca acgccaagaa cacgctgtat 240
ctgcaaatga acagtctgag agccgaggac acggctgtgt attactgtgc aagagccgcg 300
gtaacaggag gcttcgaccc ctggggccag ggcaccctgg tcaccgtctc ctcaggtggc 360
ggcggttccg gaggtggtgg ttctggcggt ggtggcagcc agcctgggct gactcagcca 420
ccctcggtgt cagtggcccc aggacagacg gccaggatta cctgtggggg agacaatatt 480
ggaagaaaaa gtgtgcactg gtaccaacag aggccaggcc aggcccctat tctagtcatc 540
cgtgatgata gggatcggcc ctcagggatc cctgagcgat tctctggctc cagctctgtg 600
aatacggcca ccctgatcat cagcagggtc gaagccggag atgaggccga ctattattgt 660
caggtgtggg atagtagtag taaacattat gtcttcggac cagggaccaa ggtcaccgcc 720
ctaggt 726
<210> 92
<211> 242
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 92
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Ala Val Thr Gly Gly Phe Asp Pro Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gln Pro Gly Leu Thr Gln Pro Pro Ser Val Ser
130 135 140
Val Ala Pro Gly Gln Thr Ala Arg Ile Thr Cys Gly Gly Asp Asn Ile
145 150 155 160
Gly Arg Lys Ser Val His Trp Tyr Gln Gln Arg Pro Gly Gln Ala Pro
165 170 175
Ile Leu Val Ile Arg Asp Asp Arg Asp Arg Pro Ser Gly Ile Pro Glu
180 185 190
Arg Phe Ser Gly Ser Ser Ser Val Asn Thr Ala Thr Leu Ile Ile Ser
195 200 205
Arg Val Glu Ala Gly Asp Glu Ala Asp Tyr Tyr Cys Gln Val Trp Asp
210 215 220
Ser Ser Ser Lys His Tyr Val Phe Gly Pro Gly Thr Lys Val Thr Ala
225 230 235 240
Leu Gly
<210> 93
<211> 723
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 93
caggtcacct tgaaggagtc tgggggaggc gtggtccagc ctgggacgtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc aactatgcca tgacgtgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtgggtcta atatcttatg atggaagtgt tacacactac 180
acagactccg tgaagggccg attcaccatc tccagagaca acgccaagaa ctcactgtat 240
ttgcaaatga acaccctgag agccgacgac acggctgtgt attattgtgc gagaggctcc 300
ggctaccaag aacactgggg ccagggaacc ctggtcaccg tctcctcagg tggcggcggt 360
tccggaggtg gtggttctgg cggtggtggc agcctgcctg tgctgactca gccaccctcg 420
gtgtcagtgg ccccaggaca gacggccagg attacctgtg ggggaaacaa cattggaagt 480
aaaagtgtgc actggtacca gcagaagcca ggccaggccc ctgtgctggt catctattat 540
gatagcgacc ggccctcagg gatccctgag cgattctctg gctccaactc tgggaacacg 600
gccaccctga ccatcagcag ggtcgaagcc ggggatgagg ccgactatta ctgtcaggtg 660
tgggatagta gtagtgatca tcatgtggta ttcggcggag ggaccaagct gaccgtccta 720
ggt 723
<210> 94
<211> 241
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 94
Gln Val Thr Leu Lys Glu Ser Gly Gly Gly Val Val Gln Pro Gly Thr
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Ala Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Leu Ile Ser Tyr Asp Gly Ser Val Thr His Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Thr Leu Arg Ala Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Ser Gly Tyr Gln Glu His Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Leu Pro Val Leu Thr Gln Pro Pro Ser Val Ser Val Ala
130 135 140
Pro Gly Gln Thr Ala Arg Ile Thr Cys Gly Gly Asn Asn Ile Gly Ser
145 150 155 160
Lys Ser Val His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu
165 170 175
Val Ile Tyr Tyr Asp Ser Asp Arg Pro Ser Gly Ile Pro Glu Arg Phe
180 185 190
Ser Gly Ser Asn Ser Gly Asn Thr Ala Thr Leu Thr Ile Ser Arg Val
195 200 205
Glu Ala Gly Asp Glu Ala Asp Tyr Tyr Cys Gln Val Trp Asp Ser Ser
210 215 220
Ser Asp His His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
225 230 235 240
Gly
<210> 95
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 95
gaggtgcagc tggtgcagtc tgggggaggc gtggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cccctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtgcta atggtggtac cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaataatggg 300
aactatcgcg gtgcttttga tatctggggc caagggacaa tggtcaccgt ctcttcaggt 360
ggcggcggtt ccggaggtgg tggttctggc ggtggtggca gccagtctgt gctgactcag 420
ccaccctcag tgtctggggc cccagggcag agggtcacca tctcctgcac tgggagcagc 480
tccaacatcg gggcaggttt tgatgtacac tggtaccagc agcttccagg aacagccccc 540
aaactcctca tctacggtaa caccaatcga ccctcagggg tccctgaccg attctctggc 600
tccaagtctg gcacctcagc ctccctggcc atcactgggc tccaggctga ggatgagact 660
gattattact gccagtccta tgacagtaga ctgagtgctt gggtgttcgg cggagggacc 720
aagctgaccg tcctaggt 738
<210> 96
<211> 246
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 96
Glu Val Gln Leu Val Gln Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Val
130 135 140
Ser Gly Ala Pro Gly Gln Arg Val Thr Ile Ser Cys Thr Gly Ser Ser
145 150 155 160
Ser Asn Ile Gly Ala Gly Phe Asp Val His Trp Tyr Gln Gln Leu Pro
165 170 175
Gly Thr Ala Pro Lys Leu Leu Ile Tyr Gly Asn Thr Asn Arg Pro Ser
180 185 190
Gly Val Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser
195 200 205
Leu Ala Ile Thr Gly Leu Gln Ala Glu Asp Glu Thr Asp Tyr Tyr Cys
210 215 220
Gln Ser Tyr Asp Ser Arg Leu Ser Ala Trp Val Phe Gly Gly Gly Thr
225 230 235 240
Lys Leu Thr Val Leu Gly
245
<210> 97
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 97
caggtgcagc tggtgcagtc tgggggaggc gtggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cccctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtgcta atggtggtac cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaataatggg 300
aactatcgcg gtgcttttga tatctggggc caagggacaa tggtcaccgt ctcttcaggt 360
ggcggcggtt ccggaggtgg tggttctggc ggtggtggca gccagtctgt gctgactcag 420
ccaccctcag tgtctggggc cccagggcag agggtcacca tctcctgcac tgggagcagc 480
tccaacatcg gggcaggtta tgatgttcac tggtaccagc accttccagg aacagccccc 540
aaactcctca tctatggtaa tagcaatcga ccctcaggag tccctgaccg attctctggc 600
tccaagtctg gcacctcagc ctccctggcc atcactgggc tccaggctga ggatgagact 660
gattatttct gccagtccta tgacagcagc ctgagtgctt gggtattcgg cggagggacc 720
aaggtgaccg tcctaggt 738
<210> 98
<211> 246
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 98
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Val
130 135 140
Ser Gly Ala Pro Gly Gln Arg Val Thr Ile Ser Cys Thr Gly Ser Ser
145 150 155 160
Ser Asn Ile Gly Ala Gly Tyr Asp Val His Trp Tyr Gln His Leu Pro
165 170 175
Gly Thr Ala Pro Lys Leu Leu Ile Tyr Gly Asn Ser Asn Arg Pro Ser
180 185 190
Gly Val Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser
195 200 205
Leu Ala Ile Thr Gly Leu Gln Ala Glu Asp Glu Thr Asp Tyr Phe Cys
210 215 220
Gln Ser Tyr Asp Ser Ser Leu Ser Ala Trp Val Phe Gly Gly Gly Thr
225 230 235 240
Lys Val Thr Val Leu Gly
245
<210> 99
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 99
caggtgcagc tgcaggagtc ggggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaattgga 300
cggtatagca gcagcttggg gtactggggc cagggcaccc tggtcaccgt ctcctcaggt 360
ggcggcggtt ccggaggtgg tggttctggc ggtggtggca gccagtctgt gctgactcag 420
ccaccctcag tgtctggggc cccagggcag agggtcacaa tctcctgcac tgggagcagc 480
tccaacatcg ggagaggtta taatgtacac tggtaccagc agcttccagg aacagccccc 540
aaactcctca tctatgataa cacgaatcgg ccctcagggg tccctgcccg attctctggc 600
tccaagtctg ccacgtcagc ctccctggcc atcactgggc tccaggctga cgatgaggct 660
gattattact gccagtcgta tgacagcggc ctgagatggg tgttcggcgg ggggaccaag 720
ctgaccctcc tacgt 735
<210> 100
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 100
Gln Val Gln Leu Gln Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ile Gly Arg Tyr Ser Ser Ser Leu Gly Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Val
130 135 140
Ser Gly Ala Pro Gly Gln Arg Val Thr Ile Ser Cys Thr Gly Ser Ser
145 150 155 160
Ser Asn Ile Gly Arg Gly Tyr Asn Val His Trp Tyr Gln Gln Leu Pro
165 170 175
Gly Thr Ala Pro Lys Leu Leu Ile Tyr Asp Asn Thr Asn Arg Pro Ser
180 185 190
Gly Val Pro Ala Arg Phe Ser Gly Ser Lys Ser Ala Thr Ser Ala Ser
195 200 205
Leu Ala Ile Thr Gly Leu Gln Ala Asp Asp Glu Ala Asp Tyr Tyr Cys
210 215 220
Gln Ser Tyr Asp Ser Gly Leu Arg Trp Val Phe Gly Gly Gly Thr Lys
225 230 235 240
Leu Thr Leu Leu Arg
245
<210> 101
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 101
caggtgcagc tggtgcagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gacgtacggt 300
gactacggca gcctcgacta ctggggccag ggcaccctgg tcaccgtctc ctcaggtggc 360
ggcggttccg gaggtggtgg ttctcgcggt ggtggcagcc agtctgtgct gactcagcca 420
ccctcagtgt ctggggcccc agggcagagg gtcaccatct cctgcactgg gagcagctcc 480
aacatcgggg caggttatga tgtacactgg taccagcagc ttccaggaac agcccccaaa 540
ctcctcatct atgctaacaa caatcggccc tcaggggtcc ctgaccgatt ctctggctcc 600
aagtctggca cctcagcctc cctggccatc actgggctcc aggctgagga tgaggctgat 660
tattactgcc agtcctatga cagcagcctg agggcttggg tgttcggcgg agggaccaag 720
ctggccgtcc tgggt 735
<210> 102
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 102
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Tyr Gly Asp Tyr Gly Ser Leu Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Arg Gly Gly Gly Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser
130 135 140
Gly Ala Pro Gly Gln Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser
145 150 155 160
Asn Ile Gly Ala Gly Tyr Asp Val His Trp Tyr Gln Gln Leu Pro Gly
165 170 175
Thr Ala Pro Lys Leu Leu Ile Tyr Ala Asn Asn Asn Arg Pro Ser Gly
180 185 190
Val Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu
195 200 205
Ala Ile Thr Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln
210 215 220
Ser Tyr Asp Ser Ser Leu Arg Ala Trp Val Phe Gly Gly Gly Thr Lys
225 230 235 240
Leu Ala Val Leu Gly
245
<210> 103
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 103
caggtgcagc tggtgcagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cccctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtgcta atggtggtac cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaataatggg 300
aactatcgcg gtgcttttga tatctggggc caagggacaa tggtcaccgt ctcttcaggt 360
ggcggcggtt ccggaggtgg tggttctggc ggtggtggca gccagtctgt gctgactcag 420
ccaccctcag tgtctggggc cccagggcag aggatcacca tctcctgcac tgggaccagc 480
tccaacatcg gggcaggtta tgatgtacac tggtaccagc aacttccagg agcagccccc 540
agagtcctca tctatggtaa caacaatcgg ccctcagggg tccctgaccg attctctggc 600
tccaagtctg gcacctcagc ctccctggcc atcactgggc tccagtctga ggatgaggct 660
gattattact gtcagtccta tgacaagagt ctgagttggg tgttcggcgg agggaccaag 720
ctgaccgtcc tacgt 735
<210> 104
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 104
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Ala Asn Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Asn Asn Gly Asn Tyr Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Val
130 135 140
Ser Gly Ala Pro Gly Gln Arg Ile Thr Ile Ser Cys Thr Gly Thr Ser
145 150 155 160
Ser Asn Ile Gly Ala Gly Tyr Asp Val His Trp Tyr Gln Gln Leu Pro
165 170 175
Gly Ala Ala Pro Arg Val Leu Ile Tyr Gly Asn Asn Asn Arg Pro Ser
180 185 190
Gly Val Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser
195 200 205
Leu Ala Ile Thr Gly Leu Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys
210 215 220
Gln Ser Tyr Asp Lys Ser Leu Ser Trp Val Phe Gly Gly Gly Thr Lys
225 230 235 240
Leu Thr Val Leu Arg
245
<210> 105
<211> 747
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 105
caggtgcagc tggtgcagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtgttag cacatactac 180
gcagactccg tgaagggccg cttcaccatc tccagagaca attccaagaa cacgctgtat 240
ttgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaaatattgt 300
agtagtacca gctgctatcg cggtatggac gtctggggca aaggcaccct ggtcaccgtc 360
tcctcaggtg gcggcggttc cggaggtggt ggttctcgcg gtggtggcag ccagtctgtg 420
ctgactcagc caccctcagt gtctggggcc ccagggcaga gggtcaccat ctcctgcact 480
gggagcagct ccaacatcgg ggcaggttat gatgtacact ggtaccagca gcttccagga 540
acagccccca aactcctcat ctatgctaac aacaatcggc cctcaggggt ccctgaccga 600
ttctctggct ccaagtctgg cacctcagcc tccctggcca tcactgggct ccaggctgag 660
gatgaggctg attattactg ccagtcctat gacagcagcc tgagggcttg ggtgttcggc 720
ggagggacca agctggccgt cctgggt 747
<210> 106
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 106
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Val Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Cys Ser Ser Thr Ser Cys Tyr Arg Gly Met Asp Val Trp
100 105 110
Gly Lys Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Arg Gly Gly Gly Ser Gln Ser Val Leu Thr Gln Pro
130 135 140
Pro Ser Val Ser Gly Ala Pro Gly Gln Arg Val Thr Ile Ser Cys Thr
145 150 155 160
Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His Trp Tyr Gln
165 170 175
Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu Ile Tyr Ala Asn Asn Asn
180 185 190
Arg Pro Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Thr
195 200 205
Ser Ala Ser Leu Ala Ile Thr Gly Leu Gln Ala Glu Asp Glu Ala Asp
210 215 220
Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser Leu Arg Ala Trp Val Phe Gly
225 230 235 240
Gly Gly Thr Lys Leu Ala Val Leu Gly
245
<210> 107
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 107
caggtgcagc tggtgcagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctgaatt cacctttggt acctatgcca tgacctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcggct gttagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaggaa cacgctgtat 240
ctgcaaatga acagcctgag agccgatgac acggccgtgt attactgtgc aagaggcccg 300
gtattacgat atggctttga tatctggggc caagggacaa tggtcaccgt ctcttcaggt 360
ggcggcggtt ccggaggtgg tggttctggc ggtggtggca gccagtctgt gctgactcag 420
ccaccctcag tctctggggc cccagggcag aggatcacca tctcctgcac tgggagcagg 480
tccaacatcg gggcagatta tgatgtacac tggtaccagc agcttccagg aacagccccc 540
aaactcctca tctatgctaa caacaatcgg ccctcagggg tccctggtcg attctctgcc 600
tccaagtctg gcacctcagc ctccctggcc atcagtgggc tccaggctga ggatgaggct 660
gattattact gccagtcgta tgacagcagc ctgagggctt gggtgttcgg cggagggacc 720
aagctggccg tcctgggt 738
<210> 108
<211> 246
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 108
Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Glu Phe Thr Phe Gly Thr Tyr
20 25 30
Ala Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Val Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Arg Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Val Leu Arg Tyr Gly Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Val
130 135 140
Ser Gly Ala Pro Gly Gln Arg Ile Thr Ile Ser Cys Thr Gly Ser Arg
145 150 155 160
Ser Asn Ile Gly Ala Asp Tyr Asp Val His Trp Tyr Gln Gln Leu Pro
165 170 175
Gly Thr Ala Pro Lys Leu Leu Ile Tyr Ala Asn Asn Asn Arg Pro Ser
180 185 190
Gly Val Pro Gly Arg Phe Ser Ala Ser Lys Ser Gly Thr Ser Ala Ser
195 200 205
Leu Ala Ile Ser Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys
210 215 220
Gln Ser Tyr Asp Ser Ser Leu Arg Ala Trp Val Phe Gly Gly Gly Thr
225 230 235 240
Lys Leu Ala Val Leu Gly
245
<210> 109
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 109
caggtgcagc tgcaggagtc ggggggaggc ttggtccagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaggtcccat 300
agcagtggag gatttgacta ctggggccag ggaaccctgg tcaccgtctc ctcaggtggc 360
ggcggttccg gaggtggtgg ttctggcggt ggtggcagcc agtctgtgct gactcagcca 420
ccctcagtgt ctggggcccc agggcagagg gtcacaatct cctgcactgg gagcagctcc 480
aacatcggga gaggttataa tgtacactgg taccagcagc ttccaggaac agcccccaaa 540
ctcctcatct atggtaacac caatcggccc tcaggggtcc ctgaccgatt ctctggctcc 600
aagtctggca cctcagcctc cctggccatc actgggctcc aggctgagga tgagggtgat 660
tattactgcc agtcctatga cagcagcctg agtgcttggg tgttcggcgg ggggaccaag 720
ctgaccgtcc taggt 735
<210> 110
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 110
Gln Val Gln Leu Gln Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser His Ser Ser Gly Gly Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser
130 135 140
Gly Ala Pro Gly Gln Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser
145 150 155 160
Asn Ile Gly Arg Gly Tyr Asn Val His Trp Tyr Gln Gln Leu Pro Gly
165 170 175
Thr Ala Pro Lys Leu Leu Ile Tyr Gly Asn Thr Asn Arg Pro Ser Gly
180 185 190
Val Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu
195 200 205
Ala Ile Thr Gly Leu Gln Ala Glu Asp Glu Gly Asp Tyr Tyr Cys Gln
210 215 220
Ser Tyr Asp Ser Ser Leu Ser Ala Trp Val Phe Gly Gly Gly Thr Lys
225 230 235 240
Leu Thr Val Leu Gly
245
Claims (20)
- 세포내 신호전달 도메인, 경막 도메인, 및 탄산무수화효소 IX(G250) 특이적 수용체를 포함하는 세포외 도메인을 포함하는 키메라 항원 수용체(CAR).
- 제1항에 있어서, 경막 도메인은 세포외 도메인과 경막 도메인 사이에 위치하는 줄기(stalk) 영역을 추가로 포함하는 것인 CAR.
- 제1항에 있어서, 경막 도메인이 CD28을 포함하는 것인 CAR.
- 제1항에 있어서, 경막 도메인과 세포내 신호전달 도메인 사이에 위치하는 하나 이상의 추가 보조자극 분자를 추가로 포함하는 CAR.
- 제4항에 있어서, 보조자극 분자가 CD28, 4-1BB, ICOS 또는 OX40인 CAR.
- 제1항에 있어서, 세포내 신호전달 도메인이 CD3 제타 쇄를 포함하는 것인 CAR.
- 제1항에 있어서, 탄산무수화효소 IX(G250) 특이적 수용체가 항체인 CAR.
- 제7항에 있어서, 항체가 Fab 또는 scFV인 CAR.
- 제7항에 있어서, 항체가
a) 아미노산 서열 SYAMS(서열번호 55)를 포함하는 CDR1,
b) 아미노산 서열 AISANGGTTYYADSVKG(서열번호 67)를 포함하는 CDR2, 및
c) 아미노산 서열 NGNYRGAFDI(서열번호 65)를 포함하는 CDR3
을 포함하는 중쇄; 및
i) 아미노산 서열 TGSSSNIGAGFDVH(서열번호 68)를 포함하는 CDR1, 아미노산 서열 GNTNRPS(서열번호 69)를 포함하는 CDR2, 및 아미노산 서열 QSYDSRLSAWV(서열번호 70)를 포함하는 CDR3을 가진 경쇄;
ii) 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1, 아미노산 서열 GNSNRPS(서열번호 72)를 포함하는 CDR2, 및 아미노산 서열 QSYDRSLSWV(서열번호 73)를 포함하는 CDR3을 가진 경쇄;
iii) 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1, 아미노산 서열 GNTNRPS(서열번호 69)를 포함하는 CDR2, 및 아미노산 서열 QSYDSTLRVWM(서열번호 74)을 포함하는 CDR3을 가진 경쇄;
iv) 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1, 아미노산 서열 GNNNRPS(서열번호 62)를 포함하는 CDR2, 및 아미노산 서열 QSYDKSLTWV(서열번호 76)를 포함하는 CDR3을 가진 경쇄;
v) 아미노산 서열 TGTSSNIGAGYDVH(서열번호 81)를 포함하는 CDR1, 아미노산 서열 GNNNRPS(서열번호 62)를 포함하는 CDR2, 및 아미노산 서열 QSYDKSLSWV(서열번호 80)를 포함하는 CDR3을 가진 경쇄;
vi) 아미노산 서열 TGSSSNIGAGFDVH(서열번호 68)를 포함하는 CDR1, 아미노산 서열 GNNNRPS(서열번호 62)를 포함하는 CDR2, 및 아미노산 서열 QSYDSSLSAWV(서열번호 82)를 포함하는 CDR3을 가진 경쇄; 또는
vii) 아미노산 서열 TGSSSNIGAGYDVH(서열번호 61)를 포함하는 CDR1, 아미노산 서열 GNSNRPS(서열번호 72)를 포함하는 CDR2, 및 아미노산 서열 QSYDSSLSAWV(서열번호 82)를 포함하는 CDR3을 가진 경쇄
를 갖는 것인 CAR. - 제1항에 있어서, scFv 항체는 서열번호 1 및 3 내지 23의 아미노산 서열들로 구성된 군으로부터 선택된 아미노산 서열을 포함하는 중쇄를 갖고, 상기 scFv 항체는 서열번호 2 및 24 내지 44의 아미노산 서열들로 구성된 군으로부터 선택된 아미노산 서열을 포함하는 경쇄를 갖는 것인 CAR.
- 제1항의 키메라 항원 수용체를 세포 표면 막 상에서 발현하여 보유하는 유전자 조작 세포.
- 제11항에 있어서, 세포가 T-세포 또는 NK 세포인 유전자 조작 세포.
- 제12항에 있어서, T 세포가 CD4+ 또는 CD8+인 유전자 조작 세포.
- 제13항에 있어서, CD4+ 및 CD8+ 세포의 혼합된 집단을 포함하는 유전자 조작 세포.
- 탄산무수화효소 IX(G250) 발현 종양을 가진 대상체를 치료하는 방법으로서, 제11항의 유전자 조작 세포를 상기 대상체에게 투여하는 단계를 포함하는 치료 방법.
- 제15항에 있어서, 유전자 조작 세포는 대상체에 대해 자가유래성인 세포로부터 유래되는 것인 치료 방법.
- 제15항에 있어서, 종양이 신장암, 난소암, 유방암, 식도암, 방광암, 대장암 또는 비소세포 폐암인 치료 방법.
- 제17항에 있어서, 신장암이 신장 투명 세포 암인 치료 방법.
- 제17항에 있어서, IL-2를 투여하는 단계를 추가로 포함하는 치료 방법.
- 제17항에 있어서, 항-PD-1, 항-PDL-1 또는 항-CTL4 항체를 투여하는 단계를 추가로 포함하는 치료 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201462094596P | 2014-12-19 | 2014-12-19 | |
| US62/094,596 | 2014-12-19 | ||
| PCT/US2015/067178 WO2016100980A1 (en) | 2014-12-19 | 2015-12-21 | Carbonic anhydrase ix specific chimeric antigen receptors and methods of use thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20170093248A true KR20170093248A (ko) | 2017-08-14 |
Family
ID=55273519
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020177020099A KR20170093248A (ko) | 2014-12-19 | 2015-12-21 | 탄산무수화효소 ix 특이적 키메라 항원 수용체 및 이의 사용 방법 |
Country Status (11)
| Country | Link |
|---|---|
| US (2) | US10870705B2 (ko) |
| EP (1) | EP3233901A1 (ko) |
| JP (1) | JP2018500337A (ko) |
| KR (1) | KR20170093248A (ko) |
| CN (1) | CN108064251A (ko) |
| AU (1) | AU2015364240A1 (ko) |
| BR (1) | BR112017013177A2 (ko) |
| CA (1) | CA2968555A1 (ko) |
| IL (1) | IL252366A0 (ko) |
| RU (1) | RU2017125735A (ko) |
| WO (1) | WO2016100980A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023153847A1 (ko) * | 2022-02-11 | 2023-08-17 | (주)씨바이오멕스 | 탄산탈수소효소 ix를 표적으로 하는 펩타이드 리간드, 이를 포함하는 펩타이드 구조체 및 이들의 용도 |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20170090506A (ko) * | 2014-12-19 | 2017-08-07 | 다나-파버 캔서 인스티튜트 인크. | 키메라 항원 수용체 및 이의 사용 방법 |
| US20190330306A1 (en) * | 2016-12-22 | 2019-10-31 | Windmil Therapeutics, Inc. | Compositions and Methods for Modulating the Immune System |
| JP2021512875A (ja) * | 2018-02-02 | 2021-05-20 | カースゲン セラピューティクス カンパニー リミテッドCarsgen Therapeutics Co., Ltd. | 細胞免疫療法の組み合わせ |
| US20220047634A1 (en) * | 2018-11-30 | 2022-02-17 | Dana-Farber Cancer Institute, Inc. | Chimeric antigen receptor factories and methods of use thereof |
| CN109705225B (zh) * | 2019-01-21 | 2022-02-22 | 徐州医科大学 | 一种抗人caix抗原的嵌合抗原受体及其应用 |
| EP3966253A4 (en) * | 2019-05-06 | 2023-02-22 | Navi Bio-Therapeutics, Inc. | ANTIBODIES TO CARBOANHYDRASIS IX |
| CN112552408B (zh) * | 2019-09-10 | 2022-09-20 | 普米斯生物技术(珠海)有限公司 | 靶向caix抗原的纳米抗体及其应用 |
| CN113045665B (zh) * | 2021-03-22 | 2022-05-13 | 徐州医科大学 | 一种hvem共刺激信号驱动的caix-car-t细胞及其制备方法和应用 |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4797368A (en) | 1985-03-15 | 1989-01-10 | The United States Of America As Represented By The Department Of Health And Human Services | Adeno-associated virus as eukaryotic expression vector |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US5139941A (en) | 1985-10-31 | 1992-08-18 | University Of Florida Research Foundation, Inc. | AAV transduction vectors |
| US6013516A (en) | 1995-10-06 | 2000-01-11 | The Salk Institute For Biological Studies | Vector and method of use for nucleic acid delivery to non-dividing cells |
| US5928906A (en) | 1996-05-09 | 1999-07-27 | Sequenom, Inc. | Process for direct sequencing during template amplification |
| US5994136A (en) | 1997-12-12 | 1999-11-30 | Cell Genesys, Inc. | Method and means for producing high titer, safe, recombinant lentivirus vectors |
| CA2632094C (en) * | 2005-12-02 | 2015-01-27 | Wayne A. Marasco | Carbonic anhydrase ix (g250) antibodies and methods of use thereof |
| US20150320799A1 (en) * | 2012-12-20 | 2015-11-12 | Purdue Research Foundation | Chimeric antigen receptor-expressing t cells as anti-cancer therapeutics |
| EP3789487A1 (en) * | 2013-04-03 | 2021-03-10 | Memorial Sloan Kettering Cancer Center | Effective generation of tumor-targeted t-cells derived from pluripotent stem cells |
-
2015
- 2015-12-21 EP EP15831023.5A patent/EP3233901A1/en not_active Withdrawn
- 2015-12-21 CN CN201580068869.2A patent/CN108064251A/zh active Pending
- 2015-12-21 CA CA2968555A patent/CA2968555A1/en not_active Abandoned
- 2015-12-21 BR BR112017013177A patent/BR112017013177A2/pt not_active Application Discontinuation
- 2015-12-21 JP JP2017532675A patent/JP2018500337A/ja active Pending
- 2015-12-21 RU RU2017125735A patent/RU2017125735A/ru not_active Application Discontinuation
- 2015-12-21 US US15/537,780 patent/US10870705B2/en active Active
- 2015-12-21 KR KR1020177020099A patent/KR20170093248A/ko not_active Application Discontinuation
- 2015-12-21 AU AU2015364240A patent/AU2015364240A1/en not_active Abandoned
- 2015-12-21 WO PCT/US2015/067178 patent/WO2016100980A1/en active Application Filing
-
2017
- 2017-05-18 IL IL252366A patent/IL252366A0/en unknown
-
2020
- 2020-12-21 US US17/129,369 patent/US20210221906A1/en active Pending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023153847A1 (ko) * | 2022-02-11 | 2023-08-17 | (주)씨바이오멕스 | 탄산탈수소효소 ix를 표적으로 하는 펩타이드 리간드, 이를 포함하는 펩타이드 구조체 및 이들의 용도 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2018500337A (ja) | 2018-01-11 |
| CA2968555A1 (en) | 2016-06-23 |
| US10870705B2 (en) | 2020-12-22 |
| RU2017125735A (ru) | 2019-01-22 |
| EP3233901A1 (en) | 2017-10-25 |
| WO2016100980A1 (en) | 2016-06-23 |
| US20180030147A1 (en) | 2018-02-01 |
| BR112017013177A2 (pt) | 2018-05-15 |
| CN108064251A (zh) | 2018-05-22 |
| AU2015364240A1 (en) | 2017-06-08 |
| US20210221906A1 (en) | 2021-07-22 |
| IL252366A0 (en) | 2017-07-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2020204373B2 (en) | Chimeric antigen receptors and methods of use thereof | |
| US11725061B2 (en) | CSGP4—specific chimeric antigen receptor for cancer | |
| EP3286225B1 (en) | Cd5 chimeric antigen receptor for adoptive t cell therapy | |
| EP3198010B1 (en) | Glypican-3 specific chimeric antigen receptors for adoptive immunotherapy | |
| AU2014225788B2 (en) | Engager cells for immunotherapy | |
| US20210221906A1 (en) | Carbonic anhydrase ix specific chimeric antigen receptors and methods of use thereof | |
| JP2021035363A (ja) | トランスポザーゼポリペプチド及びその使用 | |
| CN111629734A (zh) | 用于共刺激的新型平台、新型car设计以及过继性细胞疗法的其他增强 | |
| US20170296623A1 (en) | INHIBITORY CHIMERIC ANTIGEN RECEPTOR (iCAR OR N-CAR) EXPRESSING NON-T CELL TRANSDUCTION DOMAIN | |
| JP2017522859A (ja) | グリピカン3に特異的なt細胞受容体、及び肝細胞癌の免疫療法のためのその使用 | |
| JP2024054286A (ja) | 操作された細胞、t細胞免疫調節抗体、およびそれらの使用方法 | |
| JP2021512637A (ja) | サイクリンa1特異的t細胞受容体およびその使用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E601 | Decision to refuse application |