KR20160123312A - 스파이킹 뉴럴 네트워크에서의 청각 소스 분리 - Google Patents
스파이킹 뉴럴 네트워크에서의 청각 소스 분리 Download PDFInfo
- Publication number
- KR20160123312A KR20160123312A KR1020167023084A KR20167023084A KR20160123312A KR 20160123312 A KR20160123312 A KR 20160123312A KR 1020167023084 A KR1020167023084 A KR 1020167023084A KR 20167023084 A KR20167023084 A KR 20167023084A KR 20160123312 A KR20160123312 A KR 20160123312A
- Authority
- KR
- South Korea
- Prior art keywords
- audio
- source
- audio signal
- spiking event
- attribute
- Prior art date
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/049—Temporal neural networks, e.g. delay elements, oscillating neurons or pulsed inputs
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Processing of the speech or voice signal to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0272—Voice signal separating
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/27—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique
- G10L25/30—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique using neural networks
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
Abstract
오디오 소스 분리의 방법은 오디오 신호의 오디오 속성을 선택하는 것을 포함한다. 방법은 또한 소스 스파이킹 이벤트로서 단일 소스에 의해 지배되는 오디오 속성의 부분을 표현하는 단계를 포함한다. 또한, 방법은 오디오 신호 스파이킹 이벤트로서 오디오 신호의 나머지 부분을 표현하는 단계를 포함한다. 방법은, 소스 스파이킹 이벤트와 오디오 신호 스파이킹 이벤트의 일치에 기초하여 나머지 부분이 단일 소스와 일치하는지 여부를 결정하는 단계를 더 포함한다.
Description
관련 출원의 상호 참조
본 출원은 2014년 2월 14일에 출원되고 발명의 명칭이 "AUDITORY SOURCE SEPARATION IN A SPIKING NEURAL NETWORK"인 미국 특허 가출원 일련번호 제 61/940,281호의 혜택을 주장하며, 이는 그 전체가 참조로써 본원에 통합된다.
기술 분야
본 개시의 소정의 양태들은 일반적으로 뉴럴 시스템 엔지니어링에 관한 것으로, 보다 구체적으로 스파이킹 뉴럴 네트워크에서의 청각 소스 분리를 위한 시스템 및 방법에 관한 것이다.
인공 뉴런들 (즉, 뉴런 모델들) 의 상호접속된 그룹을 포함할 수도 있는 인공 뉴럴 네트워크는 연산 디바이스 (computational device) 이거나 또는 연산 디바이스에 의해 수행될 방법을 표현한다. 인공 뉴럴 네트워크들은 생물학적 뉴럴 네트워크들에서의 상응하는 구조 및/또는 기능을 가질 수도 있다. 하지만, 인공 뉴럴 네트워크들은, 종래의 연산 기법들이 번거롭거나, 비실용적이거나, 또는 부적절한 소정의 애플리케이션들에 혁신적이고 유용한 연산 기법들을 제공할 수도 있다. 인공 뉴럴 네트워크들은 관찰들로부터 기능을 추론할 수 있으므로, 이러한 네트워크들은 태스크 (task) 또는 데이터의 복잡성이 종래 기법들에 의한 기능의 디자인을 부담스럽게 만드는 애플리케이션들에서 특히 유용하다.
요약
본 개시물의 일 양태로, 오디오 소스 분리의 방법이 개시된다. 방법은 오디오 신호의 오디오 속성을 선택하는 것을 포함한다. 방법은 또한 소스 스파이킹 이벤트로서 단일 소스에 의해 지배되는 오디오 속성의 부분을 표현하는 단계를 포함한다. 또한, 방법은 오디오 신호 스파이킹 이벤트로서 오디오 신호의 나머지 부분을 표현하는 단계를 포함한다. 방법은, 소스 스파이킹 이벤트와 오디오 신호 스파이킹 이벤트의 일치에 기초하여 나머지 부분이 단일 소스와 일치하는지 여부를 결정하는 단계를 더 포함한다.
본 개시물의 또 다른 양태에서, 오디오 소스 분리를 위한 장치가 개시된다. 장치는 메모리 및 적어도 하나의 프로세서를 갖는다. 프로세서(들)는 메모리에 커플링되고 오디오 신호의 오디오 속성을 선택하도록 구성된다. 프로세서(들)는 또한 소스 스파이킹 이벤트로서 단일 소스에 의해 지배되는 오디오 속성의 부분을 표현하도록 구성된다. 또한, 프로세서(들)는 오디오 신호 스파이킹 이벤트로서 오디오 신호의 나머지 부분을 표현하도록 구성된다. 프로세서(들)는 또한 소스 스파이킹 이벤트와 오디오 신호 스파이킹 이벤트의 일치에 기초하여 나머지 부분이 단일 소스와 일치하는지 여부를 결정하도록 구성된다.
본 개시물의 또 다른 양태에서, 오디오 소스 분리를 위한 장치가 개시된다. 장치는 오디오 신호의 오디오 속성을 선택하는 수단을 포함한다. 장치는 또한 소스 스파이킹 이벤트로서 단일 소스에 의해 지배되는 오디오 속성의 부분을 표현하는 단계를 포함한다. 장치는 부가적으로 오디오 신호 스파이킹 이벤트로서 오디오 신호의 나머지 부분을 표현하는 수단을 포함한다. 장치는, 소스 스파이킹 이벤트와 오디오 신호 스파이킹 이벤트의 일치에 기초하여 나머지 부분이 단일 소스와 일치하는지 여부를 결정하는 수단을 더 포함한다.
본 개시물의 또 다른 양태에서, 오디오 소스 분리의 컴퓨터 프로그램 제품이 개시된다. 컴퓨터 프로그램 제품은 프로그램 코딩이 인코딩된 비일시적 컴퓨터 판독가능 매체를 갖는다. 프로그램 코드는 오디오 신호의 오디오 속성을 선택하는 프로그램 코드를 포함한다. 프로그램 코드는 또한 소스 스파이킹 이벤트로서 단일 소스에 의해 지배되는 오디오 속성의 부분을 나타내기 위한 프로그램 코드를 포함한다. 또한, 프로그램 코드는 오디오 신호 스파이킹 이벤트로서 오디오 신호의 나머지 부분을 표현하기 위한 프로그램 코드를 포함한다. 프로그램 코드는, 소스 스파이킹 이벤트와 오디오 신호 스파이킹 이벤트의 일치에 기초하여 나머지 부분이 단일 소스와 일치하는지 여부를 결정하기 위한 프로그램 코드를 더 포함한다.
이것은, 이어지는 상세한 설명을 보다 잘 이해할 수 있도록 하기 위해서 본 개시물의 특징들과 기술적 이점들을, 오히려 광범위하게 개요하였다. 본 개시물의 부가적인 특징들과 이점들은 후술될 것이다. 당업자라면, 본 개시물이 본 개시물의 동일한 목적을 수행하기 위한 다른 구조들을 수정하거나 설계하는 기초로서 쉽게 활용될 수도 있음이 이해되어야만 한다. 당업자라면, 이러한 등가의 구성들이 하기의 특허청구범위에서 설명되는 본 개시물의 교시들을 벗어나지 않는다는 것을 알 수 있을 것이다. 동작의 구성 및 방법들 양자에 관한 본 개시의 특징으로 여겨지는 신규의 특징들은, 다른 목적들 및 이점들과 함께, 첨부된 도면과 연계한 하기의 설명으로부터 더욱 명확해질 것이다. 그러나, 각 도면은 도해 및 설명의 목적으로만 제공된 것이며 본 개시물의 제한들의 정의로서 의도된 것은 아님이 명확히 이해되어져야만 한다.
다양한 피쳐들 (features), 특질 및 이점들은, 유사한 참조 부호들이 전반에 걸쳐 대응하여 식별되는 도면들과 함께 다루어질 때 아래에 설명된 상세한 설명으로부터 자명해질 수도 있다.
도 1은 본 개시물의 소정의 양태들에 따른, 뉴런들의 예시적인 네트워크를 예시한다.
도 2는 본 개시물의 소정의 양태들에 따른 연산 네트워크 (뉴럴 시스템 또는 뉴럴 네트워크) 의 프로세싱 유닛 (뉴런) 의 예를 예시한다.
도 3은 본 개시물의 소정의 양태들에 따른 스파이크-타이밍 의존적인 가소성 (STDP; spike-timing dependent plasticity) 곡선의 예를 예시한다.
도 4 는 본 개시의 소정의 양태들에 따른, 뉴런 모델의 거동을 정의하기 위한 양의 체계 및 음의 체계의 예를 예시한다.
도 5는 본 개시물의 소정의 양태들에 따른, 범용 프로세서를 이용하여 뉴럴 네트워크를 설계하는 예시적인 구현예를 예시한다.
도 6은 본 개시물의 소정의 양태들에 따른, 메모리가 개개의 분산된 프로세싱 유닛들과 인터페이스될 수도 있는 뉴럴 네트워크를 설계하는 예시적인 구현예를 예시한다.
도 7은 본 개시물의 소정의 양태들에 따른, 분산된 메모리들 및 분산된 프로세싱 유닛들에 기초하여 뉴럴 네트워크를 설계하는 예시적인 구현예를 예시한다.
도 8은 본 개시물의 소정의 양태들에 따른 뉴럴 네트워크의 예시적인 구현예를 예시한다.
도 9 및 도 10은 본 개시물의 양태들에 따른 청각 소스 분리를 위한 예시적인 아키텍처를 예시한 블록도들이다.
도 11은 본 개시물의 양태에 따른 청각 소스 분리를 위한 방법을 예시한 블록도들이다.
도 1은 본 개시물의 소정의 양태들에 따른, 뉴런들의 예시적인 네트워크를 예시한다.
도 2는 본 개시물의 소정의 양태들에 따른 연산 네트워크 (뉴럴 시스템 또는 뉴럴 네트워크) 의 프로세싱 유닛 (뉴런) 의 예를 예시한다.
도 3은 본 개시물의 소정의 양태들에 따른 스파이크-타이밍 의존적인 가소성 (STDP; spike-timing dependent plasticity) 곡선의 예를 예시한다.
도 4 는 본 개시의 소정의 양태들에 따른, 뉴런 모델의 거동을 정의하기 위한 양의 체계 및 음의 체계의 예를 예시한다.
도 5는 본 개시물의 소정의 양태들에 따른, 범용 프로세서를 이용하여 뉴럴 네트워크를 설계하는 예시적인 구현예를 예시한다.
도 6은 본 개시물의 소정의 양태들에 따른, 메모리가 개개의 분산된 프로세싱 유닛들과 인터페이스될 수도 있는 뉴럴 네트워크를 설계하는 예시적인 구현예를 예시한다.
도 7은 본 개시물의 소정의 양태들에 따른, 분산된 메모리들 및 분산된 프로세싱 유닛들에 기초하여 뉴럴 네트워크를 설계하는 예시적인 구현예를 예시한다.
도 8은 본 개시물의 소정의 양태들에 따른 뉴럴 네트워크의 예시적인 구현예를 예시한다.
도 9 및 도 10은 본 개시물의 양태들에 따른 청각 소스 분리를 위한 예시적인 아키텍처를 예시한 블록도들이다.
도 11은 본 개시물의 양태에 따른 청각 소스 분리를 위한 방법을 예시한 블록도들이다.
첨부된 도면들과 연계하여 하기에 제시되는 상세한 설명은 다양한 구성들의 설명으로서 의도된 것이며, 본 명세서에 기재된 개념들이 실시될 수도 있는 구성들만을 나타내려고 의도된 것은 아니다. 상세한 설명은 다양한 개념들의 완전한 이해를 제공하기 위한 목적으로 특정 세부사항들을 포함한다. 그러나, 이 개념들이 이러한 특정 세부사항들 없이도 실시될 수 있음은 당업자에게 명백할 것이다. 일부 예시들에서, 주지된 구조들 및 컴포넌트들은 이러한 개념들을 모호하게 하는 것을 회피하기 위해 블록도 형태로 도시된다.
교시들에 기초하여, 본 개시물의 범위는, 본 개시물의 임의의 다른 양태와 무관하게 구현되든지 또는 이와 결합하여 구현되든지, 본 개시물의 임의의 양태를 커버하고자 함을 당업자는 이해해야 한다. 예를 들어, 제시된 임의의 개수의 양태들을 이용하여 장치가 구현될 수도 있거나 또는 방법이 실시될 수도 있다. 또한, 본 개시물의 범위는 제시된 본 개시물의 다양한 양태들에 더해 또는 그 외에 다른 구조, 기능, 또는 구조와 기능을 이용하여 실시되는 그러한 장치 또는 방법을 커버하고자 한다. 개시된 개시물의 임의의 양태는 청구항의 하나 이상의 엘리먼트들에 의해 구체화될 수도 있는 것으로 이해되어야 한다.
단어 "예시적인" 은 "예, 예증, 또는 예시로서 기능하는" 을 의미하도록 본원에서 사용된다. "예시적인" 것으로서 본원에서 설명되는 임의의 양태는 다른 양태들에 비해 선호되거나 또는 유리한 것으로서 반드시 해석되는 것은 아니다.
비록 특정 양태들이 본원에서 설명되지만, 이러한 양태들의 많은 변형들 및 치환들이 본 개시물의 범위 내에 속한다. 바람직한 양태들의 일부 혜택들 및 이점들이 언급되어 있지만, 본 개시물의 범위는 특정 혜택들, 이용들, 또는 목적들로 제한되고자 하지 않는다. 오히려, 본 개시물의 양태들은 상이한 무선 기술들, 시스템 구성들, 네트워크들 및 프로토콜들에 널리 적용가능하고자 하며, 이들 중 일부는 도면들에서 그리고 다음의 바람직한 양태들의 설명에서 예로서 예시된다. 상세한 설명 및 도면들은 제한하는 것이기 보다는 단지 본 개시물의 예시일 뿐이며, 본 개시물의 범위는 첨부된 청구항들 및 그의 등가물들에 의해 규정된다.
예시적인 뉴럴 시스템, 트레이닝 및 동작
도 1은 본 개시물의 소정의 양태들에 따른, 뉴런들의 다중 레벨들을 갖는 예시적인 인공 뉴럴 시스템 (100) 을 예시한다. 뉴럴 시스템 (100) 은 시냅스 접속들 (104) (즉, 공급-순방향 접속들) 의 네트워크를 통해서 또 다른 뉴런들의 레벨 (106) 에 접속된 뉴런들의 레벨 (102) 을 포함할 수도 있다. 더 적거나 또는 더 많은 뉴런들의 레벨들이 전형적인 뉴럴 시스템에 존재할 수도 있지만, 간결성을 위해, 단지 2개의 뉴런들의 레벨들이 도 1 에 예시된다. 뉴런들의 일부가 측면 접속들을 통해서 동일한 계층의 다른 뉴런들에 접속될 수도 있다는 점에 유의해야 한다. 더욱이, 뉴런들의 일부는 피드백 접속들을 통해서 이전 계층의 뉴런에 다시 접속될 수도 있다.
도 1 에 예시된 바와 같이, 레벨 (102) 에서의 각각의 뉴런은 이전 레벨의 뉴런들 (도 1 에 미도시) 에 의해 발생될 수도 있는 입력 신호 (108) 를 수신할 수도 있다. 신호 (108) 는 레벨 (102) 뉴런의 입력 전류를 나타낼 수도 있다. 이러한 전류는 멤브레인 전위를 충전시키기 위해 뉴런 멤브레인 상에 축적될 수도 있다. 멤브레인 전위가 그의 임계값에 도달할 때, 뉴런은 발화하여 뉴런들의 다음 레벨 (예컨대, 레벨 (106)) 로 전달될 출력 스파이크를 발생시킬 수도 있다. 일부 모델링 접근법에서, 뉴런은 뉴런들의 다음 레벨로 신호를 연속적으로 전달할 수도 있다. 이러한 신호는 통상적으로 멤브레인 전위의 기능이다. 이러한 거동은, 후술되는 것들과 같은 아날로그 및 디지털 구현예들을 포함한, 하드웨어 및/또는 소프트웨어로 에뮬레이트되거나 또는 시뮬레이션될 수 있다.
생물학적 뉴런들에서, 뉴런이 발화할 때 발생되는 출력 스파이크는 활동 전위 (action potential) 로서 지칭된다. 이 전기 신호는 대략 100 mV 의 진폭 및 약 1 ms 의 지속시간을 갖는, 비교적 빠른, 일시적인 신경 임펄스이다. 접속된 뉴런들의 시리즈를 갖는 뉴럴 시스템의 특정의 실시형태 (예를 들어, 도 1 에서 뉴런들의 하나의 레벨로부터 또 다른 레벨로의 스파이크들의 전송) 에서, 모든 활동 전위는 기본적으로 동일한 진폭 및 지속기간을 가지며, 따라서 신호 내 정보는 진폭에 의해서라기 보다는 스파이크들의 주파수 및 개수, 또는 스파이크들의 시간에 의해서 단지 표현될 수도 있다. 활동 전위에 의해 운반되는 정보는 스파이크, 스파이크된 뉴런, 및 하나 이상의 다른 스파이크들에 대한 그 스파이크의 시간에 의해 결정될 수도 있다. 스파이크의 중요성은, 아래에 설명되는 바와 같이, 뉴런들 사의 접속에 적용된 가중치에 의해 결정될 수도 있다.
뉴런들의 하나의 레벨로부터 또 다른 레벨로의 스파이크들의 전송은 도 1 에 예시된 바와 같이, 시냅스 접속들의 네트워크 (또는, 간단히 "시냅스들") (104) 를 통해서 달성될 수도 있다. 시냅스들 (104) 에 대해, 레벨 (102) 의 뉴런들은 시냅스전 뉴런들로 고려될 수 있고, 레벨 (106) 의 뉴런들은 시냅스후 뉴런들로 고려될 수 있다. 시냅스들 (104) 은 레벨 (102) 뉴런들로부터의 출력 신호들 (즉, 스파이크들) 을 수신할 수도 있고 이들 신호들을 조정가능한 시냅스 가중치들  1 (i,i+1), ...,
1 (i,i+1), ...,  P (i,i+1) (여기서, P 는 레벨들 (102 와 106) 의 뉴런들 사이의 시냅스 접속들의 총 개수이고, i는 뉴런 레벨의 지표이다) 에 따라 스케일링할 수도 있다. 도 1 의 예에서, i는 뉴런 레벨 (102) 을 나타내고, i+1은 뉴런 레벨 (106) 을 나타낸다. 또한, 스케일링된 신호들은 레벨 (106) 에서 각각의 뉴런의 입력 신호로서 조합될 수도 있다. 레벨 (106) 에서의 모든 뉴런은 대응하는 결합된 입력 신호에 기초하여 출력 스파이크들 (110) 을 발생시킬 수도 있다. 출력 스파이크들 (110) 은 시냅스 접속들의 또 다른 네트워크 (도 1 에 미도시) 를 이용하여 뉴런들의 또 다른 레벨로 전달될 수도 있다.
P (i,i+1) (여기서, P 는 레벨들 (102 와 106) 의 뉴런들 사이의 시냅스 접속들의 총 개수이고, i는 뉴런 레벨의 지표이다) 에 따라 스케일링할 수도 있다. 도 1 의 예에서, i는 뉴런 레벨 (102) 을 나타내고, i+1은 뉴런 레벨 (106) 을 나타낸다. 또한, 스케일링된 신호들은 레벨 (106) 에서 각각의 뉴런의 입력 신호로서 조합될 수도 있다. 레벨 (106) 에서의 모든 뉴런은 대응하는 결합된 입력 신호에 기초하여 출력 스파이크들 (110) 을 발생시킬 수도 있다. 출력 스파이크들 (110) 은 시냅스 접속들의 또 다른 네트워크 (도 1 에 미도시) 를 이용하여 뉴런들의 또 다른 레벨로 전달될 수도 있다.
생물학적 시냅스들은 시냅스후 뉴런들에서의 흥분성 또는 억제성 (과분극하는) 활동들을 중재할 수 있으며, 또한 뉴런 신호들을 증폭시키는 역할을 할 수 있다. 흥분성 신호들은 멤브레인 전위를 탈분극시킨다 (즉, 휴지 전위에 대해 멤브레인 전위를 증가시킨다). 멤브레인 전위를 임계값 초과하여 탈분극시키기 위해서 충분한 흥분성 신호들이 소정의 기간 이내에 수신되면, 활동 전위가 시냅스후 뉴런에서 발생한다. 이에 반해, 억제성 신호들은 일반적으로 멤브레인 전위를 탈분극시킨다 (즉, 감소시킨다). 억제성 신호들은, 충분히 강하면, 흥분성 신호들의 총합을 상쇄시킬 수 있으며 멤브레인 전위가 임계값에 도달하는 것을 방지할 수 있다. 시냅스 흥분을 중화시키는 것에 더해서, 시냅스 억제는 자발적 활성 뉴런들에 걸쳐서 강력한 제어를 행할 수 있다. 자발적 활성 뉴런은 추가적인 입력 없이, 예를 들어, 이의 동력학 또는 피드백으로 인해 스파이크하는 뉴런을 지칭한다. 이들 뉴런들에서 활동 전위들의 자발적 발생을 억제함으로써, 시냅스 억제는 요철모양 (sculpturing) 으로 일반적으로 지칭되는, 뉴런에서의 발화의 패턴을 형상화할 수 있다. 여러 시냅스들 (104) 은 원하는 거동에 따라서, 흥분성 또는 억제성 시냅스들의 임의의 조합으로서 작용할 수도 있다.
뉴럴 시스템 (100) 은 범용 프로세서, 디지털 신호 프로세서 (DSP), 주문형 집적회로 (ASIC), 필드 프로그래밍가능 게이트 어레이 (FPGA) 또는 다른 프로그래밍가능 로직 디바이스 (PLD), 이산 게이트 또는 트랜지스터 로직, 이산 하드웨어 구성요소들, 프로세서에 의해 실행되는 소프트웨어 모듈, 또는 이들의 임의의 조합에 의해 에뮬레이트될 수도 있다. 뉴럴 시스템 (100) 은 넓은 범위의 애플리케이션들, 예컨대 이미지 및 패턴 인식, 기계 학습, 모터 제어 등에 활용될 수도 있다. 뉴럴 시스템 (100) 에서 각각의 뉴런은 뉴런 회로로서 구현될 수도 있다. 출력 스파이크를 개시하는 임계값까지 충전되는 뉴런 멤브레인은 예를 들어, 그를 통과해서 흐르는 전류를 적분하는 커패시터로서 구현될 수도 있다.
일 양태에서, 커패시터는 뉴런 회로의 전류 적분 (integrating) 디바이스로서 제거될 수도 있으며, 더 작은 멤리스터 엘리먼트가 그 대신에 사용될 수도 있다. 이 접근법은 뉴런 회로들에서 뿐만 아니라, 부피가 큰 커패시터들이 전류 적분기들 (electrical current integrators) 로서 사용되는 여러 다른 애플리케이션들에서 제공될 수도 있다. 게다가, 시냅스들 (104) 의 각각은 멤리스터 엘리먼트에 기초하여 구현될 수도 있으며, 여기서 시냅스 가중치 변화들은 멤리스터 저항의 변화들에 관련될 수도 있다. 나노미터 최소 배선폭 (nanometer feature-sized) 멤리스터들에 의하면, 뉴런 회로 및 시냅스들의 영역이 실질적으로 감소될 수도 있으며, 이것은 초대규모의 뉴럴 시스템 하드웨어 구현예의 구현을 보다 실현가능하게 할 수도 있다.
뉴럴 시스템 (100) 을 에뮬레이트하는 뉴럴 프로세서의 기능은, 뉴런들 사이의 접속들의 강도들을 제어할 수도 있는 시냅스 접속들의 가중치들에 의존할 수도 있다. 시냅스 가중치들은 전원 차단되어진 후 프로세서의 기능을 유지하기 위해 비휘발성 메모리에 저장될 수도 있다. 일 양태에서, 시냅스 가중치 메모리는 메인 뉴럴 프로세서 칩과 별개인 외부 칩 상에 구현될 수도 있다. 시냅스 가중치 메모리는 교체가능한 메모리 카드로서 뉴럴 프로세서 칩과는 별개로 패키지될 수도 있다. 이것은 뉴럴 프로세서에 다양한 기능들을 제공할 수도 있으며, 여기서 특정의 기능은 뉴럴 프로세서에 현재 부착된 메모리 카드에 저장되는 시냅스 가중치들에 기초할 수도 있다.
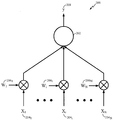
도 2 는 본 개시물의 소정의 양태들에 따른, 연산 네트워크 (computational network) (예컨대, 뉴럴 시스템 또는 뉴럴 네트워크) 의 프로세싱 유닛 (예컨대, 뉴런 또는 뉴런 회로) 의 예시적인 도면 (200) 을 예시한다. 예를 들어, 뉴런 (202) 은 도 1 로부터의 레벨들 (102 및 106) 의 뉴런들 중 임의의 뉴런에 대응할 수도 있다. 뉴런 (202) 은, 뉴럴 시스템의 외부에 있는 신호들, 또는 동일한 뉴럴 시스템의 다른 뉴런들에 의해 발생되는 신호들, 또는 양쪽일 수도 있는, 다수의 입력 신호들 2041-204N을 수신할 수도 있다. 입력 신호는 전류, 컨덕턴스, 전압, 실수 값 및/또는 복소수 값일 수도 있다. 입력 신호는 고정-소수점 또는 부동-소수점 표시를 가진 수치 값을 포함할 수도 있다. 이들 입력 신호들은 조정가능한 시냅스 가중치들 2061-206N(W1-WN) 에 따라서 신호들을 스케일링하는 시냅스 접속들을 통해서 뉴런 (202) 으로 전달될 수도 있으며, 여기서 N 은 뉴런 (202) 의 입력 접속들의 총 개수일 수도 있다.
뉴런 (202) 은 스케일링된 입력 신호들을 결합하고 그 결합된 스케일링된 입력들을 이용하여, 출력 신호 (208) (즉, 신호 Y) 를 발생시킬 수도 있다. 출력 신호 (208) 는 전류, 컨덕턴스, 전압, 실수 값 및/또는 복소수 값일 수도 있다. 출력 신호는 고정-소수점 또는 부동-소수점 표시를 가진 수치 값을 포함할 수도 있다. 출력 신호 (208) 는 그후 동일한 뉴럴 시스템의 다른 뉴런들에의 입력 신호로서, 또는 동일한 뉴런 (202) 에의 입력 신호로서, 또는 뉴럴 시스템의 출력으로서 전달될 수도 있다.
프로세싱 유닛 (뉴런 (202)) 은 전기 회로에 의해 에뮬레이트될 수도 있으며, 이의 입력 및 출력 접속들은 시냅스 회로들을 가진 전기 접속들에 의해 에뮬레이트될 수도 있다. 프로세싱 유닛 (202) 및 이의 입력 및 출력 접속들은 또한 소프트웨어 코드에 의해 에뮬레이트될 수도 있다. 프로세싱 유닛 (202) 은 또한 전기 회로에 의해 에뮬레이트될 수도 있으며, 반면 이의 입력 및 출력 접속들은 소프트웨어 코드에 의해 에뮬레이트될 수도 있다. 일 양태에서, 연산 네트워크에서의 프로세싱 유닛 (202) 은 아날로그 전기 회로일 수도 있다. 또 다른 양태에서, 프로세싱 유닛 (202) 은 디지털 전기 회로일 수도 있다. 또 다른 양태에서, 프로세싱 유닛 (202) 은 아날로그 및 디지털 구성요소들 양쪽과의 혼합된 신호 전기 회로일 수도 있다. 연산 네트워크는 프로세싱 유닛들을 전술한 형태들 중 임의의 형태로 포함할 수도 있다. 이러한 프로세싱 유닛들을 이용하는 연산 네트워크 (뉴럴 시스템 또는 뉴럴 네트워크) 는 이미지 및 패턴 인식, 기계 학습, 모터 제어 등과 같은, 큰 범위의 애플리케이션들에 활용될 수도 있다.
뉴럴 네트워크를 학습하는 과정 동안, 시냅스 가중치들 (예컨대, 도 1 로부터 가중치들  1 (i,i+1), ...,
1 (i,i+1), ...,  P (i,i+1) 및/또는 도 2 로부터 가중치들 2061-206N) 은 무작위 값들로 초기화되고, 그리고 학습 규칙에 따라서 증가되거나 또는 감소될 수도 있다. 학습 규칙의 예들은 스파이크-타이밍-의존적인 가소성 (STDP) 학습 규칙, Hebb 규칙, Oja 규칙, Bienenstock-Copper-Munro (BCM) 규칙 등을 포함하지만 이들에 한정되지 않음을 당업자들은 이해할 것이다. 소정의 양태들에서, 가중치들은 2개의 값들 (즉, 가중치들의 바이모달 (bimodal) 분포) 중 하나로 정해지거나 또는 수렴할 수도 있다. 이 효과는 각각의 냅시스 가중치에 대한 비트수를 감소시키고, 시냅스 가중치들를 저장하는 메모리로부터 판독하고 그에 기록하는 속도를 증가시키고, 그리고 시냅스 메모리의 전력 및/또는 프로세서 소비를 감소시키는데 이용될 수 있다.
P (i,i+1) 및/또는 도 2 로부터 가중치들 2061-206N) 은 무작위 값들로 초기화되고, 그리고 학습 규칙에 따라서 증가되거나 또는 감소될 수도 있다. 학습 규칙의 예들은 스파이크-타이밍-의존적인 가소성 (STDP) 학습 규칙, Hebb 규칙, Oja 규칙, Bienenstock-Copper-Munro (BCM) 규칙 등을 포함하지만 이들에 한정되지 않음을 당업자들은 이해할 것이다. 소정의 양태들에서, 가중치들은 2개의 값들 (즉, 가중치들의 바이모달 (bimodal) 분포) 중 하나로 정해지거나 또는 수렴할 수도 있다. 이 효과는 각각의 냅시스 가중치에 대한 비트수를 감소시키고, 시냅스 가중치들를 저장하는 메모리로부터 판독하고 그에 기록하는 속도를 증가시키고, 그리고 시냅스 메모리의 전력 및/또는 프로세서 소비를 감소시키는데 이용될 수 있다.
시냅스 유형
뉴럴 네트워크들의 하드웨어 및 소프트웨어 모델들에서, 시냅스 관련 기능들의 프로세싱은 시냅스 유형에 기초할 수 있다. 시냅스 유형들은 비가소성 (non-plastic) 시냅스들 (소정의 가중치 및 지연의 변화들이 없음), 가소성 시냅스들 (가중치가 변할 수도 있음), 구조적 지연 가소성 시냅스들 (가중치 및 지연이 변할 수도 있음), 완전 가소성 시냅스들 (가중치, 지연 및 접속성 (connectivity) 이 변할 수도 있음), 및 그의 변형예들 (예컨대, 지연이 변할 수 있지만, 소정의 가중치 또는 접속성에서의 변화도 없음) 일 수도 있다. 다수의 유형들의 이점은 프로세싱이 세분될 수 있다는 점이다. 예를 들어, 비가소성 시냅스들은 가소성 기능들이 실행되는 것을 (또는, 이러한 기능들이 완료하기를 대기하는 것을) 사용하지 않을 수도 있다. 이와 유사하게, 지연 및 가중치 가소성은 함께 또는 별개로, 차례차례로 또는 병렬로, 동작할 수도 있는 동작들로 세분될 수도 있다. 상이한 유형들의 시냅스들은 적용하는 상이한 가소성 유형들의 각각에 대해 상이한 룩업 테이블들 또는 공식들 및 파라미터들을 가질 수도 있다. 따라서, 방법들은 시냅스의 유형에 대한 관련된 테이블들, 식들, 또는 파라미터들에 액세스할 것이다.
스파이크-타이밍 의존적인 구조적 가소성이 시냅스 가소성과는 독립적으로 실행될 수도 있다는 사실의 추가적인 암시들이 있다. 구조적 가소성은, 구조적 가소성 (즉, 지연 변화의 양) 이 직접 사전-사후 스파이크 시간 차이의 양의 (direct) 함수일 수도 있기 때문에, 설령 가중치 크기에 어떠한 변화도 없더라도 (예컨대, 가중치가 최소 또는 최대 값에 도달하였거나, 또는 일부 다른 원인으로 인해 변화되지 않으면) 실행될 수도 있다. 이의 대안으로, 구조적 가소성은 가중치 변화 양의 함수로서, 또는 가중치들 또는 가중치 변화들의 범위들에 관련된 조건들에 기초하여 설정될 수도 있다. 예를 들어, 시냅스 지연은 단지 가중치 변화가 일어날 때 또는 가중치들이 제로에 도달하면 변할 수도 있지만, 가중치들이 최대에 도달되면 변하지 않을 수도 있다. 그러나, 이들 프로세스들을 병렬화하여 메모리 액세스들의 수 및 중첩을 감소시킬 수 있도록 독립적인 기능들을 갖는 것이 유리할 수 있다.
시냅스 가소성의 결정
신경가소성 (또는, 간단히 "가소성") 은 새로운 정보, 감각의 자극, 발달, 손상, 또는 기능장애에 응답하여, 그들의 시냅스 접속들 및 거동을 변경하는, 뇌에서의 뉴런들 및 신경 네트워크들의 능력 (capacity) 이다. 가소성은 생물학에서의 학습 및 기억, 뿐만 아니라 연산 신경과학 및 신경 네트워크들에 중요하다. (예컨대, Hebbian 이론에 따른) 시냅스 가소성, 스파이크-타이밍-의존적인 가소성 (STDP), 비-시냅스 가소성, 활동-의존적 가소성, 구조적 가소성, 및 항상적 가소성 (homeostatic plasticity) 과 같은, 가소성의 여러 형태들이 연구되었다.
STDP 는, 뉴런들 사이의 시냅스 접속들의 강도를 조정하는 학습 프로세스이다. 접속 강도들은 특정의 뉴런의 출력 및 수신된 입력 스파이크들 (즉, 활동 전위들) 의 상대적인 타이밍에 기초하여 조정된다. STDP 프로세스 하에서, 장기 강화 (LTP) 는, 소정의 뉴런으로의 입력 스파이크가 평균적으로, 그 뉴런의 출력 스파이크 직전에 발생하는 경향이 있으면, 일어날 수도 있다. 그 후, 그 특정의 입력이 다소 더 강하게 이루어진다. 다른 한편, 장기 억압 (LTD) 은 입력 스파이크가 평균적으로, 출력 스파이크 직후에 발생하는 경향이 있으면, 일어날 수도 있다. 그 후, 그 특정의 입력이 다소 더 약하게 이루어지며, 이로인해 "스파이크-타이밍-의존적 가소성" 으로 명명한다. 그 결과, 시냅스후 뉴런의 여기의 원인일지도 모르는 입력들은 미래에 심지어 더 많이 기여할 가능성이 있도록 이루어지며, 반면 시냅스후 스파이크의 원인이 아닌 입력들은 미래에 덜 기여할 가능성이 있도록 이루어진다. 프로세스는 접속들의 초기 세트의 서브세트가 유지되지만 모든 나머지의 영향이 상당한 레벨로 감소될 때까지 계속한다.
그의 입력들 중 많은 입력들이 (즉, 출력을 일으키는데 충분히 누적적인) 짧은 기간 내에 일어날 때 뉴런이 일반적으로 출력 스파이크를 발생하기 때문에, 일반적으로 남아 있는 입력들의 서브세트는 시간에 맞춰 상관되려는 경향이 있는 입력들을 포함한다. 게다가, 출력 스파이크 전에 발생하는 입력들이 강화되기 때문에, 가장 빠른 충분히 누적적인 상관의 표시를 제공하는 입력들이 결국 뉴런에의 최종 입력이 될 것이다.
STDP 학습 규칙은 시냅스전 뉴런을 시냅스후 뉴런에 접속하는 시냅스의 시냅스 가중치를 시냅스전 뉴런의 스파이크들 시간 tpre 과 시냅스후 뉴런의 스파이크 시간 tpost 사이의 시간 차이 (즉, t=tpost-tpre) 의 함수로서 효과적으로 적응시킬 수도 있다. STDP 의 전형적인 공식화 (formulation) 는, 시간 차이가 양이면 (시냅스전 뉴런이 시냅스후 뉴런 이전에 발화하면) 시냅스 가중치를 증가시키고 (즉, 시냅스를 강화시키고 (potentiate)), 그리고 시간 차이가 음이면 (시냅스후 뉴런이 시냅스전 뉴런 전에 발화하면) 시냅스 가중치를 감소시키는 (즉, 시냅스를 억압하는) 것이다.
STDP 프로세스에서, 시간에 걸친 시냅스 가중치의 변화는 다음으로 주어진 바와 같이, 지수 감쇠를 이용하여 달성될 수도 있으며,

여기서, k+ 및 k-τsign(△t)는 각각 양 및 음의 시간 차이에 대한 시상수들이고, 그리고 α+ 및 α- 는 대응하는 스케일링 크기들이고, 그리고 μ는 양의 시간 차이 및/또는 음의 시간 차이에 적용될 수도 있는 오프셋이다.
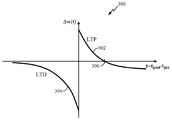
도 3은 STDP 에 따른 시냅스전 및 시냅스후 스파이크들의 상대적인 타이밍의 함수로서의 시냅스 가중치 변화의 예시적인 다이어그램 (300) 을 예시한다. 시냅스전 뉴런이 시냅스후 뉴런 이전에 발화하면, 대응하는 시냅스 가중치가 그래프 (300) 의 부분 (302) 에 예시된 바와 같이, 증가될 수도 있다. 이 가중치 증가는 시냅스의 LTP 로서 지칭될 수 있다. LTP 의 양이 시냅스전 및 시냅스후 스파이크 시간들 사이의 차이의 함수로서 거의 기하급수적으로 감소할 수도 있다는 것이 그래프 부분 (302) 로부터 관찰될 수 있다. 발화의 역방향 순서는 시냅스 가중치를 감소시켜, 그래프 (300) 의 부분 (304) 에 예시된 바와 같이, 시냅스의 LTD 를 초래할 수도 있다.
도 3 에서 그래프 (300) 에 예시된 바와 같이, 음의 오프셋 μ는 STDP 그래프의 LTP (인과관계의) 부분 (302) 에 적용될 수도 있다. x-축 (y=0) 의 교차 지점 (306) 은 계층 i-1 (시냅스전 층) 로부터의 인과관계의 입력들에 대한 상관을 고려하기 위해 최대 시간 지체와 일치하도록 구성될 수도 있다. 프레임-기반의 입력의 경우 (즉, 입력이 스파이크들 또는 펄스들을 포함하는 특정의 지속기간의 프레임의 유형인 경우) 에, 오프셋 값 μ는 프레임 경계를 반영하도록 연산될 수 있다. 프레임에서 제 1 입력 스파이크 (펄스) 는 시냅스후 전위에 의해 직접적으로 모델링될 때와 같이 또는 신경 상태에 대한 효과의 관점에서 시간에 걸쳐서 감쇠하는 것으로 간주될 수도 있다. 프레임에서 제 2 입력 스파이크 (펄스) 가 특정의 시간 프레임과 상관되거나 또는 관련되는 것으로 간주되면, 프레임 전후에 관련된 시간들은, 관련된 시간들에서의 값이 상이할 수 있도록 (예컨대, 하나의 프레임보다 큰 것에 대해 음이고 하나의 프레임보다 작은 것에 대해 양일 수 있도록) STDP 곡선의 하나 이상의 부분들을 오프셋함으로써, 그 시간 프레임 경계에서 분리될 수도 있으며, 가소성 항들 (terms) 에서 상이하게 취급될 수도 있다. 예를 들어, 음의 오프셋 μ는, 곡선이 실제로 프레임 시간보다 큰 사전-사후 시간에서 제로 아래로 가며 따라서 LTP 대신 LTD 의 부분이도록, LTP 를 오프셋하도록 설정될 수도 있다.
뉴런 모델들 및 동작
유용한 스파이킹 뉴런 모델을 설계하기 위한 일부 일반적인 원리들이 존재한다. 우수한 뉴런 모델은 2개의 연산 체계들, 즉 일치 검출 및 함수적 연산의 관점에서, 풍부한 전위 거동을 가질 수도 있다. 더욱이, 우수한 뉴런 모델은 시간 코딩을 가능하게 하기 위해 2개의 엘리먼트들을 가져야 한다: 입력들의 도달 시간은 출력 시간에 영향을 미치며 일치 검출은 좁은 시간 윈도우를 가질 수 있다. 마지막으로, 연산적으로 흥미를 끌기 위해서, 우수한 뉴런 모델은 연속적인 시간으로 닫힌 형태의 해 (closed-form solution) 를 가지며 가까운 어트랙터들 (attractors) 및 새들 (saddle) 지점들을 포함한 안정한 거동을 가질 수도 있다. 즉, 유용한 뉴런 모델은 풍부하고 현실적이고 생물학적으로 일관된 거동들을 모델링하는데 뿐만 아니라, 신경 회로들 설계하고 역설계하는데 모두 사용될 수 있으며, 그리고 실용적인 모델이다.
뉴런 모델은 입력 도달, 출력 스파이크 또는 내부든 또는 외부든 다른 이벤트와 같은 이벤트들에 의존할 수도 있다. 풍부한 행동 레파토리를 획득하기 위해, 복잡한 거동들을 나타낼 수도 있는 상태 머신이 요망될 수도 있다. 입력 기여 (있다면) 와는 별개인, 이벤트 자체의 발생이 상태 머신에 영향을 미치거나 그 이벤트에 후속하는 동력학을 구속할 수 있으면, 시스템의 미래 상태는 오직 상태 및 입력의 함수라기 보다는, 상태, 이벤트, 및 입력의 함수이다.
일 양태에서, 뉴런 n 은 다음 동력학에 의해 지배되는 멤브레인 전압 νn(t) 을 가진 스파이킹 누설 적분 발화 (spiking leaky-integrate-and-fire) 뉴런으로서 모델링될 수도 있으며,

여기서, α 및 β 는 파라미터들이고,  m,n 는 시냅스전 뉴런 m 을 시냅스후 뉴런 n 에 접속하는 시냅스에 대한 시냅스 가중치이고, 그리고 ym(t)는 뉴런 n 의 세포체에서 도달까지
m,n 는 시냅스전 뉴런 m 을 시냅스후 뉴런 n 에 접속하는 시냅스에 대한 시냅스 가중치이고, 그리고 ym(t)는 뉴런 n 의 세포체에서 도달까지  tm,n 에 따른 수상 (dendritic) 또는 축삭 (axonal) 지연에 의해 지연될 수도 있는 뉴런 m 의 스파이킹 출력이다.
tm,n 에 따른 수상 (dendritic) 또는 축삭 (axonal) 지연에 의해 지연될 수도 있는 뉴런 m 의 스파이킹 출력이다.
지연 시냅스후 뉴런으로의 충분한 입력이 확립될 때의 시간으로부터 시냅스후 뉴런이 실제로 발화할 때의 시간까지 지연이 존재한다는 점에 유의해야 한다. Izhikevich의 단순 모델과 같은, 역학적 스파이킹 뉴런 모델에서, 시간 지연이 탈분극 임계값 νt 와 피크 스파이크 전압 νpeak 사이의 차이가 있으면 초래될 수도 있다. 예를 들어, 단순 모델에서, 뉴런 세포체 동력학은 다음과 같은, 전압 및 복구에 대한 미분 방정식들의 쌍에 의해 지배될 수 있으며,

여기서, ν 는 멤브레인 전위이고, u 는 멤브레인 복구 변수이고, k 는 멤브레인 전위 ν 의 시간 척도를 기술하는 파라미터이고, α 는 복구 변수 u 의 시간 척도를 기술하는 파라미터이고, b 는 멤브레인 전위 ν 의 임계값 아래의 (sub-threshold) 요동들에 대한 복구 변수 u 의 감도를 기술하는 파라미터이고, νr 는 멤브레인 휴지 전위이고, I 는 시냅스 전류이고, 그리고 C 는 멤브레인의 커패시턴스이다. 이 모델에 따르면, 뉴런은 ν>νpeak 일 때 스파이크하도록 정의된다.
Hunzinger Cold 모델
Hunzinger Cold 뉴런 모델은 신경 거동들의 풍부한 변종을 재현할 수 있는 최소 이중 체계 스파이킹 선형 동역학적 모델이다. 모델의 1 또는 2차원 선형 동력학은 2개의 체계들을 가질 수 있으며, 여기서, 시상수 (및 커플링) 는 그 체계에 의존할 수 있다. 임계값 아래의 체계에서, 시상수, 즉, 규약에 의한 음수는, 생물학적으로 일관된 선형 방식으로 셀을 휴지로 복귀시키려고 일반적으로 작용하는 누설 채널 동력학을 나타낸다. 임계값 이상의 (supra-threshold) 체계에서의 시상수, 즉, 규약에 의한 양수는, 스파이크하도록 셀을 일반적으로 구동하지만 스파이크 발생에서 레이턴시를 초래하는 누설 방지 채널 동력학을 반영한다.
도 4 에 예시된 바와 같이, 모델 (400) 의 동력학은 2개의 (또는 그 이상의) 체계들로 분할될 수도 있다. 이들 체계들은 (LIF 뉴런 모델과 혼동되지 않도록, 누설 적분 발화 (LIF) 체계로서 상호교환가능하게 또한 지칭되는) 음의 체계 (402) 및 (ALIF 뉴런 모델과 혼동되지 않도록, 누설 방지 적분 발화 (ALIF) 체계로서 상호교환가능하게 또한 지칭되는) 양의 체계 (404) 로 불릴 수도 있다. 음의 체계 (402) 에서, 그 상태는 미래 이벤트 시에 휴지 (ν-) 에 빠지는 경향이 있다. 이 음의 체계에서, 모델은 일반적으로 시간 입력 검출 성질들 및 다른 임계값 아래의 거동을 나타낸다. 양의 체계 (404) 에서, 그 상태는 스파이킹 이벤트 (νS) 에 빠지는 경향이 있다. 이 양의 체계에서, 모델은 후속 입력 이벤트들에 따라서 스파이크하기 위해 레이턴시를 초래하는 것과 같은, 연산 성질들을 나타낸다. 이벤트들의 관점에서 동력학의 공식화 및 이들 2개의 체계들로의 동력학의 분리는 모델의 기본적인 특성들이다.
(상태들 ν 및 u 에 대해) 선형 이중 체계 2차원 동력학은 다음과 같이 규약에 의해 정의될 수도 있으며,

여기서, qρ 및 r 는 커플링을 위한 선형 변환 변수들이다.
심볼 ρ 는 본원에서, 특정의 체계에 대한 관계를 논의하거나 또는 표현할 때, 심볼 ρ 를 음의 및 양의 체계들에 대해 부호 "-" 또는 "+" 로 각각 대체하는 규약를 가진 동력학 체계를 표시하기 위해 사용된다.
모델 상태는 멤브레인 전위 (전압) ν 및 복구 전류 u 에 의해 정의된다. 기본적인 유형에서, 체계는 모델 상태에 의해 본질적으로 결정된다. 정확하고 일반적인 정의의 미묘하지만 중요한 양태들이 존재하며, 그러나 지금은, 전압 ν 이 임계값 (ν+) 보다 크면 양의 체계 (404) 에, 그렇지 않으면 음의 체계 (402) 에 그 모델이 있는 것으로 간주한다.
체계 의존적인 시상수들은 음의 체계 시상수인 τ-, 및 양의 체계 시상수인 τ+ 을 포함한다. 복구 전류 시상수τu 는 일반적으로 체계와 무관하다. 편의를 위해, 음의 체계 시상수 τ- 는 감쇠를 반영하기 위해 음의 양으로서 일반적으로 규정되어, τu 인 바와 같이, 전압 발전 (voltage evolution) 에 대해 동일한 수식이 지수 및 τ+ 가 일반적으로 양수일 양의 체계에 대해 사용될 수 있도록 한다.
2개의 상태 엘리먼트들의 동력학은 이벤트들에서 그들의 널-클라인들로부터 그 상태들을 오프셋하는 변환들에 의해 커플링될 수도 있으며, 여기서, 변환 변수들은 다음과 같으며

여기서, δ, ε, β 및 ν-, ν+ 는 파라미터들이다. νρ 에 대한 2개의 값들은 2개의 체계들에 있어 참조 전압들에 대한 베이스이다. 파라미터 ν- 는 음의 체계에 대한 베이스 전압이며, 멤브레인 전위는 일반적으로 음의 체계에서 ν- 쪽으로 감쇠할 것이다. 파라미터 ν+ 는 양의 체계에 대한 베이스 전압이며, 멤브레인 전위는 일반적으로 양의 체계에서 ν+ 쪽으로부터 나아갈 것이다.
ν 및 u 에 대한 널-클라인들 (null-clines) 은 변환 변수들 qρ 및 r 의 음수로 각각 주어진다. 파라미터 δ 는 u 널-클라인의 기울기를 제어하는 스케일 인자이다. 파라미터 ε 은 일반적으로 -ν- 과 동일하게 설정된다. 파라미터 β 는 양쪽의 체계들에서 ν 널-클라인들의 기울기를 제어하는 저항값이다. τρ 시간-일정한 파라미터들은 지수 감쇠들 뿐만 아니라, 널-클라인 기울기들을 각각의 체계에서 별개로 제어한다.
모델은 전압 ν 이 값 νS 에 도달할 때 스파이크하도록 정의될 수도 있다. 그 후에, 그 상태는 일반적으로 (하나일 수도 있고 스파이크 이벤트와 동일할 수도 있는) 리셋 이벤트에서 리셋되며:

여기서,  및
및  u 는 파라미터들이다. 리셋 전압
u 는 파라미터들이다. 리셋 전압  은 일반적으로 ν- 으로 설정된다.
은 일반적으로 ν- 으로 설정된다.
순간적인 커플링의 원리에 의해, 닫힌 형태의 해는 상태 (그리고 단일 지수 항을 가진 상태) 에 대해서 뿐만 아니라, 특정의 상태에 도달하기 위한 시간에 대해서 가능하다. 닫힌 형태의 상태 해들은 다음과 같다

따라서, 모델 상태는 입력 (시냅스전 스파이크) 또는 출력 (시냅스후 스파이크) 시와 같은 이벤트들 시에 단지 업데이트될 수도 있다. 동작들은 또한 (입력이든 또는 출력이든) 임의의 특정의 시간에 수행될 수도 있다.
더욱이, 순간적인 커플링 원리에 의해, 시냅스후 스파이크의 시간은, 특정의 상태에 도달하는 시간이 반복 기법들 또는 수치 방법들 (예컨대, Euler 수치 방법) 없이 미리 결정될 수도 있도록, 예상될 수도 있다. 이전 전압 상태 ν0 로 주어지면, 전압 상태 νf 에 도달되기 전까지의 시간 지연은 다음과 같이 주어진다.

전압 상태 ν 가 νS 에 도달하는 시간에서 일어나는 것으로 스파이크가 정의되면, 전압이 주어진 상태 ν 에 있는 시간으로부터 측정될 때 스파이크들이 발생할 때까지, 시간의 양, 또는 상대적인 지연에 대한 닫힌 형태의 해는 다음과 같으며,

여기서,  는 다른 변형예들이 가능할 수도 있지만 파라미터 ν+ 로 일반적으로 설정된다.
는 다른 변형예들이 가능할 수도 있지만 파라미터 ν+ 로 일반적으로 설정된다.
상기 모델 동력학의 정의들은 모델이 양의 체계 또는 음의 체계인지 여부에 의존한다. 언급한 바와 같이, 커플링 및 체계 ρ 는 이벤트들 시에 연산될 수도 있다. 상태 전파의 목적들을 위해, 체계 및 커플링 (변환) 변수들은 최종 (선행의 (prior)) 이벤트 시의 그 상태에 기초하여 정의될 수도 있다. 스파이크 출력 시간을 이후에 예상하려는 목적을 위해, 체계 및 커플링 변수는 다음 (현재의) 이벤트 시의 상태에 기초하여 정의될 수도 있다.
Cold 모델의 여러 가능한 구현예들이 있으며, 그 시뮬레이션, 에뮬레이션 또는 모델을 시간에 맞춰 실행하고 있다. 이것은 예를 들어, 이벤트-업데이트, 스텝-이벤트 업데이트, 및 스텝-업데이트 모드들을 포함한다. 이벤트 업데이트는 (특정의 순간에서) 이벤트들 또는 "이벤트 업데이트" 에 기초하여 상태들이 업데이트되는 업데이트이다. 스텝 업데이트는 모델이 간격들 (예컨대, 1ms) 로 업데이트되는 업데이트이다. 이것은 반복 방법들 또는 수치적 방법들을 반드시 이용하는 것은 아니다. 이벤트-기반의 구현예는 또한 스텝들에서 또는 그들 사이에, 또는 "스텝-이벤트" 업데이트에 의해 이벤트가 발생하면 모델을 단지 업데이트함으로써, 제한된 시간 해상도에서, 스텝-기반의 시뮬레이터에서, 가능하다.
스파이킹 뉴럴 네트워크에서의 청각 소스 분리
청각 소스들에 따른 혼합 신호들의 분리는 이로울 수 있으며 광범위하게 적용가능하다. 예를 들어, 청각 소스 분리는 스피치 분리를 제공하고, 스피치 개선을 지원하고, 그리고 스피치 활동 검출을 지원할 수도 있다. 하지만, 단청의 (monaural), 방치된 (unsupervised), 온라인 청각 소스 분리는 컴퓨터 오디션을 위한 도전이다. 이에 따라, 본 개시물의 양태들은 시간적 간섭 기반의 소스 분리의 스파이크 기반의 구현예들에 관한 것이다.
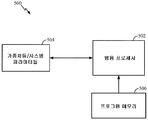
도 5는 본 개시물의 소정의 양태들에 따른, 범용 프로세서 (502) 를 이용하여 상기 언급된 청각 소스 분리의 예시적인 구현예 (500) 를 예시한다. 범용 프로세서 (502) 에서 실행되는 명령들이 프로그램 메모리 (506) 로부터 로딩될 수 있는 한편, 연산 네트워크 (뉴럴 네트워크) 와 연관된 변수들 (뉴럴 신호들), 시냅스 가중치들, 시스템 파라미터들이 메모리 블록 (504) 에 저장될 수도 있다. 본 개시물의 일 양태에서, 범용 프로세서 (502) 로 로딩된 명령들은 오디오 신호의 오디오 속상을 선택하기 위한 코드, 단일 소스에 의해 지배되는 오디오 속성의 부분을 스파이킹 이벤트로서 표현하기 위한 코드, 오디오 신호의 나머지 부분을 스파이킹 이벤트로서 표현하기 위한 코드, 및/또는 스파이킹 이벤트들의 일치에 기초하여 나머지 부분이 단일 소스와 일치하는지 여부를 결정하기 위한 코드를 포함할 수도 있다.
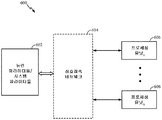
도 6은 본 개시물의 소정의 양태들에 따라서, 메모리 (602) 가 상호접속 네트워크 (604) 를 통해 연산 네트워크 (뉴럴 네트워크) 의 개별 (분산된) 프로세싱 유닛들 (뉴럴 프로세서들)(606) 과 인터페이스될 수 있는, 상기 언급된 청각 소스 분리의 예시적인 구현예 (600) 를 나타낸다. 연산 네트워크 (뉴럴 네트워크) 지연들, 주파수 빈 정보, 오디오 신호들, 및/또는 오디오 속성 정보와 연관된 변수들 (뉴럴 신호들), 시냅스 가중치들, 시스템 파라미터들은 메모리 (602) 에 저장될 수도 있고, 그리고 메모리 (602) 로부터 상호접속 네트워크 (604) 의 접속(들)을 통해 각각의 프로세싱 유닛 (뉴럴 프로세서)(606) 으로 로딩될 수도 있다. 본 개시물의 일 양태에서, 프로세싱 유닛 (606) 은 오디오 신호의 오디오 속성을 선택하고, 단일 소스에 의해 지배되는 오디오 속성의 부분을 스파이킹 이벤트로서 표현하고, 오디오 신호의 나머지 부분을 스파이킹 이벤트로서 표현하고, 및/또는 스파이킹 이벤트들의 일치에 기초하여 나머지 부분이 단일 소스와 일치하는지 여부를 결정하도록 구성될 수도 있다.
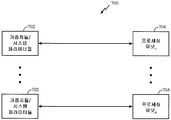
도 7은 상기 언급된 청각 소스 분리의 예시적인 구현예 (700) 를 나타낸다. 도 7에 도시된 바와 같이, 하나의 메모리 뱅크 (702) 는 연산 네트워크 (뉴럴 네트워크) 의 하나의 프로세싱 유닛 (704) 과 직접 인터페이스될 수도 있다. 각각의 메모리 뱅크 (702) 는 상응하는 프로세싱 유닛 (뉴럴 프로세서) (704) 지연들, 주파수 빈 정보, 오디오 신호들 및/또는 오디오 속성 정보와 연관된 변수들 (뉴럴 신호들), 시냅스 가중치들, 및/또는 시스템 파라미터들을 저장할 수도 있다. 본 개시물의 일 양태에서, 프로세싱 유닛 (704) 은 오디오 신호의 오디오 속성을 선택하고, 단일 소스에 의해 지배되는 오디오 속성의 부분을 스파이킹 이벤트로서 표현하고, 오디오 신호의 나머지 부분을 스파이킹 이벤트로서 표현하고, 및/또는 스파이킹 이벤트들의 일치에 기초하여 나머지 부분이 단일 소스와 일치하는지 여부를 결정하도록 구성될 수도 있다.
도 8은 본 개시물의 소정의 양태들에 따른 뉴럴 네트워크 (800) 의 예시적인 구현예를 예시한다. 도 8에 예시된 바와 같이, 뉴럴 네트워크 (800) 는 본원에 기재된 방법들의 다양한 동작들을 수행할 수도 있는 복수의 로컬 프로세싱 유닛 (802) 을 가질 수도 있다. 각각의 로컬 프로세싱 유닛 (802) 은 뉴럴 네트워크의 파라미터들을 저장하는 로컬 파라미터 메모리 (806) 및 로컬 상태 메모리 (804) 를 포함할 수도 있다. 부가하여, 로컬 프로세싱 유닛 (802) 은 로컬 모델 프로그램을 저장하기 위한 로컬 (뉴런) 모델 프로그램 (LMP), 로컬 학습 프로그램을 저장하기 위한 로컬 학습 프로그램 (LLP) 메모리 (810), 및 로컬 접속 메모리 (812) 를 가질 수도 있다. 더욱이, 도 8 에 예시된 바와 같이, 각각의 로컬 프로세싱 유닛 (802) 은 로컬 프로세싱 유닛의 로컬 메모리들을 위한 구성을 제공하기 위한 구성 프로세서 유닛 (814), 및 로컬 프로세싱 유닛들 (802) 사이에 라우팅을 제공하는 라우팅 유닛 (816) 과 인터페이스될 수도 있다.
하나의 구성에서, 뉴런 모델은 오디오 신호의 오디오 속성을 선택하고, 단일 소스에 의해 지배되는 오디오 속성의 부분을 스파이킹 이벤트로서 표현하고, 오디오 신호의 나머지 부분을 스파이킹 이벤트로서 표현하고, 및/또는 스파이킹 이벤트들의 일치에 기초하여 나머지 부분이 단일 소스와 일치하는지 여부를 결정하기 위해 구성된다. 뉴런 모델은 선택 수단, 단일 소스에 의해 지배되는 오디오 속성의 부분을 스파이킹 이벤트로서 표현하는 수단, 오디오 신호의 나머지 부분을 스파이킹 이벤트로서 표현하는 수단, 및 결정 수단을 포함한다. 하나의 양태에서, 선택 수단, 오디오 속성의 부분을 표현하는 수단, 오디오 신호의 나머지 부분을 표현하는 수단, 및/또는 결정 수단은 범용 프로세서 (502), 프로그램 메모리 (506), 메모리 블록 (504), 메모리 (602), 상호접속 네트워크 (604), 프로세싱 유닛들 (606), 프로세싱 유닛 (704), 로컬 프로세싱 유닛들 (802), 및/또는 언급된 기능들을 수행하도록 구성된 라우팅 접속 프로세싱 엘리먼트들 (816) 일 수도 있다. 또 다른 구성에서, 상기 언급된 수단은 상기 언급된 수단에 의해 언급된 기능들을 수행하도록 구성된 임의의 모듈 또는 임의의 장치일 수도 있다.
본 개시물의 소정의 양태들에 따르면, 각각의 로컬 프로세싱 유닛 (802) 은 뉴럴 네트워크의 소망하는 하나 이상의 기능성 피쳐들에 기초하여 뉴럴 네트워크의 파라미터들을 결정하고, 그리고 결정된 파라미터들이 또한 적응, 튜닝 및 업데이트될 때 소망하는 기능성 피쳐들 측을 향해 하나 이상의 기능성 피쳐들을 디벨럽하도록 구성될 수도 있다.
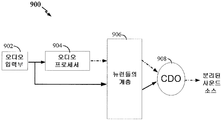
도 9 는 본 개시물의 양태들에 따른 청각 소스 분리를 위한 예시적인 아키텍처 (900) 를 예시한 블록도이다. 아키텍처는 오디오 신호를 공급하기 위한 입력부 (902) 를 포함한다. 오디오 신호는 아날로그이거나 또는 디지털일 수도 있다. 일부 양태들에서, 오디오 신호는 예를 들면 마이크로폰, 디지털 오디오 테이프 (DAT) 와 같은 스토리지 디바이스, 컴팩 디스크 (CD), 디지털 비디오 디스크 (DVD), 블루레이 디스크 (BD) 를 통해 제공되거나 또는 스트리밍 미디어를 통해 제공될 수 있다.
일부 양태들에서, 오디오 신호는 피질성 피쳐 혼합체를 포함할 수 있다. 피질성 피쳐 혼합체는 상이한 출력 주파수들과 연관된 상이한 출력 채널들을 포함할 수도 있다. 예를 들어, 오디오 신호는 하나 이상의 스피커들로부터의 보이스들, 및/또는 (예를 들어, 복잡한 버스 또는 스포츠 이벤트) 청각 장면의 다른 사운드들 (예를 들어, 배경 잡음, 음악 또는 동물 사운드들) 의 혼합체를 포함할 수 있다.
오디오 신호는 오디오 프로서세 (904) 에 공급될 수도 있다. 일부 양태들에서, 오디오 프로세서는 단일 또는 타겟 소스에 의해 지배되는 오디오 속성을 결정하기 위해 오디오 신호를 프로세싱할 수도 있다. 오디오 속성은 예를 들어 피치, 음색, 고조파, 리듬, 음의 크기 (loudness), 속도 (스피킹의 레이트), 공간적 위치 등을 포함할 수도 있다. 하나의 예에서, 오디오 프로세서 (904) 는 미리결정된 범위를 스패닝하는 중심 주파수들을 갖는 대역 통과 필터들의 뱅크를 포함할 수도 있다. 오디오 프로세서 (904) 는 타겟 소스 (예를 들어, 남성 또는 여성 스피커의 보이스) 에 의해 지배되는 피치 (즉, 오디오 속성) 를 식별할 수도 있다. 이 예에서, 지배된 오디오 속성 또는 앵커는 주어진 범위 (예를 들어, 일정 시점에서 (예를 들어, 매 25msec 마다) 중심 주파수가 180-200 Hz) 에서 최고 주파수를 갖는 피치로서 식별될 수도 있다. 앵커는 특정 소스에 대한 오디오 신호의 채널의 지시를 제공할 수도 있다. 피치 트랙은 오디오 신호의 지시된 채널에 상응하는 원 전력값들의 컬렉션에 기초하여 생성될 수도 있다.
일부 양태들에서, 오디오 신호 및/또는 지배된 오디오 속성에 상응하는 오디오 신호의 일부 (예를 들어, 피치 트랙) 는 정류화 및 정규화 프로세싱 처리될 수도 있다. 예를 들어, 지배된 오디오 속성 부분은 전체 구간 (예를 들어, 주어진 범위) 에 대해 원 전력값들을 미리결정된 원 전력값 (예를 들어, 최대 전력값) 으로 나눔으로써 정규화될 수도 있다. 다른 예에서, 지배된 오디오 속성 부분은 모든 음의 값들을 0으로 설정함으로써 정류화될 수도 있다.
지배된 오디오 속성 부분 (예를 들어, 피치 트랙) 은 오디오 신호와 함께 뉴런들의 계층 (906) 에 공급될 수도 있다. 하나의 예시적인 양태에서, 뉴런들의 계층 (906) 은 LIF (leaky integrate and fire) 뉴런들을 포함할 수도 있다. 뉴런들 (906) 은 지배된 오디오 속성 부분 및 오디오 신호를 스파이크들 또는 스파이크 이벤트들로 표현하도록 구성될 수도 있다. 예를 들어, LIF 뉴런들은 각 오실레이션에 대해 한번 스파이크하도록 구성될 수도 있다. 추가 예에서, LIF 뉴런들에 대한 시상수 (예를 들어, τ+) 는, 입력부의 양의 오실레이션이 오실레이션의 피크에서 하나 이상의 스파이크들을 발생시키도록 설정될 수도 있다.
지배된 오디오 속성 부분 (예를 들어, 피치 트랙) 을 나타내는 출력 스파이크들 및 오디오 신호를 나타내는 출력 스파이크들은 CDO (Coincidence Detector Object) 뉴련들의 계층 (908) 에 입력으로서 공급될 수도 있다. CDO 뉴런들 (908) 의 계층은 지배된 오디오 속성을 나타내는 스파이크들의 타이밍과 오디오 신호를 나타내는 스파이크들의 타이밍을 비교하도록 구성될 수도 있다. 지배된 오디오 속성을 나타내는 스파이크들 및 오디오 신호를 나타내는 스파이크들이 일치하거나 또는 매칭되는 경우, CDO 뉴런들 (908) 은 스파이크할 수도 있다. 일부 양태들에서, CDO 뉴런들 (908) 은 또한, 지배된 오디오 속성을 나타내는 스파이크들과 오디오 신호를 나타내는 스파이크들 사이의 타이밍 차이가 (예를 들어, 타이밍 또는 시간적 윈도우 내에서) 미리정의된 임계치 아래인 경우 스파이크할 수도 있다. CDO 뉴런들 (908) 의 출력 스파이크들은 타겟 소스에 기인하는 오디오 신호의 부분을 나타낼 수 있다. 이 방식으로, CDO 뉴런들 (908) 은 타겟 소스에 기인하는 오디오 신호의 일부를 검색 및 분리하기 위해 사용될 수 있다.
이에 따라, 타겟 소스에 기인된 오디오 신호의 부분은 타겟 소스의 사전 지식 없이 그때그때 봐서 다수의 사운드 소스들을 이용해 오디 신호 또는 청각 장면으로부터 추출 또는 분리될 수도 있다. 이것은 또한 노이즈 배경에서의 훈련의 혜택없이 달성될 수도 있다.
도 10 은 본 개시물의 양태들에 따른 청각 소스 분리를 위한 예시적인 아키텍처를 예시한 블록도 (1000) 이다. 아키텍처는 오디오 신호에 포함된 다수의 소스들로부터 오디오를 분리하도록 구성될 수도 있다. 도 10을 참조하면, 아키텍처는 오디오 신호를 제공하기 위한 입력 디바이스 (1006) 를 포함할 수도 있다. 아키텍처는 또한 사운드 소스 A와 연관된 오디오 속성을 제공하기 위한 입력 디바이스 (1002) 및 사운드 소스 B와 연관된 오디오 속성을 제공하기 위한 입력 디바이스 (1004) 를 포함할 수도 있다. 3가지 별개의 입력들이 도시되어 있지만, 이것은 단지 설명을 용이하게 하기 위한 것이며, 그리고 임의의 수의 입력 디바이스들의 사용될 것이다. 예를 들어, 입력 신호들의 각각을 제공하기 위해 단일 입력이 또한 사용될 수 있다.
일부 양태들에서, 스피커 A의 오디오 속성 및 사운드 소스 B의 오디오 속성은 스피커들의 사전 지식없이 그때그때 봐서 결정될 수도 있다. 물론, 이것은 단지 예시이며, 일부 양태들에서 사운드 소스 A 및 사운드 소스 B의 오디오 속성들은 미리 결정되고 저장 디바이스에 저장될 수도 있다. 부가하여, 사운드 소스 A의 오디오 속성 및 사운드 소스 B의 오디오 속성은 상이할 수도 있다. 예를 들어, 사운드 소스 A의 오디오 속성은 스피치 위치일 수도 있는 한편, 사운드 소스 B의 오디오 속성은 음의 크기일 수도 있다.
도 10 에 도시된 바와 같이, 오디오 신호는 입력 디바이스 (1006) 를 통해 제공될 수도 있다. 오디오 신호는 피질성 피쳐 혼합체를 포함할 수도 있다. 피질성 피쳐 혼합체는 상이한 출력 주파수들과 연관된 상이한 출력 채널들을 포함할 수도 있다. 예를 들어, 일부 양태들에서, 오디오 신호는 하나 이상의 스피커들로부터의 보이스들, 및/또는 청각 장면의 다른 사운드들 (예를 들어, 배경 노이즈, 음악, 또는 동물 사운드들) 의 혼합체를 포함할 수도 있다. 청각 장면은 이를 테면 복잡한 버스 또는 스포츠 이벤트의 사운드들의 혼합체를 포함할 수도 있다. 예시적인 구성에서, 오디오 소스는 범위를 스패닝하는 중간 주파수들을 갖는 대역 통과 필터들의 대역을 거치는 프로세스들이다. 출력은 스펙트로그램으로 수집될 수도 있고, 이것은 멀티 레졸루션 표현을 생성하기 위해 다수의 스케일들에 대한 주파수 축을 따라 필터링될 수도 있다.
사운드 소스 A 및 사운드 소스 B의 오디오 속성 (예를 들어, 피치) 은 입력 디바이스들 (1002 및 1004) 을 통해 공급된다. 일부 양태들에서, 사운드 소스들의 오디오 속성의 추정이 이용될 수도 있다. 예를 들어, 피치 추출을 위한 임시 기술이 적용될 수 있다.
일 구성에서, 오디오 속성은 어떤 시간 (예를 들어, 25 ms) 에 있어서 특정 범위 (예를 들어, 중간 주파수들이 180-200 Hz) 에서 최고인 대역 통과 필터 출력으로서 식별된다. 각각의 식별된 피치 채널의 경우, 원 전력값들이 스펙트로그램에서의 상응하는 채널로부터 및 상응하는 시간에 수집될 수 있어, 1차원 어레이를 수득한다. 어떠한 식별된 피치 채널도 없는 시점들의 경우, 어레이는 0의 값을 갖는다. 피치 트랙은 새로운 레이트 (예를 들어, 2Hz) 에서 대역 통과 필터로 더욱 프로세싱될 수도 있다. 값들은 전체 스피치 간격의 미리결정된 값 (예를 들어, 최대 값) 에 의해 모든 값들을 나눔으로써 정규화될 수 있다. 또한, 출력은 정류화될 수 있으며, 즉 모든 음의 값들이 0으로 설정된다. 필터링은 다른 주파수들 (예를 들어, 4 Hz, 8 Hz, 16 Hz) 에서 반복될 수도 있다. 출력은 스펙트로그램으로 수집될 수도 있고, 이것은 다수의 스케일들에 대한 주파수 축을 따라 필터링될 수도 있다. 도 10 이 2개의 음성 소스들을 위한 오디오 속성을 도시하지만, 이것은 단지 예시적이며 제한이 아니다. 오히려, 임의의 수의 사운드 소스들에 대한 임의의 수의 오디오 속성들이 이용될 수도 있다.
오디오 속성은 오디오 신호의 채널을 포함할 수도 있다. 일부 양태들에서, 오디오 속성은 피치, 음색, 고조파, 리듬, 음의 크기, 속도 (스피킹의 레이트), 공간적 위치 등을 포함할 수도 있다. 일부 양태들에서, 사운드 소스들의 오디오 속성들 및/또는 오디오 신호가 정류화 및 정규화될 수도 있다.
오디오 속성 및 오디오 신호는 뉴런들 (1008) 의 계층에 공급될 수도 있다. 뉴런들 (1008) 의 계층은 오디오 속성들 및 오디오 신호의 각각을 스파이크들로서 표현하도록 구성될 수도 있다. 일부 양태들에서, 뉴런들의 계층은 예를 들어 LIF (leaky integrate and fire) 뉴런들을 포함할 수도 있다.
오디오 속성들의 스파이크 표현들은 각각 CDO 뉴런들 (1010, 1012) 의 상응하는 계층에 제 1 입력으로서 공급될 수도 있다. 오디오 신호의 스파이크 표현은 CDO 뉴런들 (1010, 1012) 의 계층들의 각각에 제 2 입력으로서 공급될 수도 있다. 뉴런 모델은, 입력의 양의 오실레이션이 오실레이션 피크에서 하나 이상의 스파이크들을 생성하도록 설정되는 시상수를 가질 수도 있다. 오실레이션은 제 2 필터 (예를 들어, 2 Hz) 의 주파수에서 발생한다. 프로세스는 다른 필터 주파수들 (예를 들어, 4 Hz, 8 Hz, 16 Hz) 의 각각에 대해 반복될 수도 있다.
CDO 뉴런들 (1010, 1012) 은 결국, 부가하여, 사운드 소스 A의 오디오 속성 및/또는 사운드 소스 B의 오디오 속성과 오디오 신호 사이에 상관이 있는지 여부를 결정할 수도 있다. 즉, CDO 뉴런들 (1010, 1012) 은 오디오 속성들을 표현하는 스파이크들이 오디오 신호를 표현하는 스파이크들과 일치하는지 여부를 결정하도록 구성될 수도 있다. 스파이크들이 일치하거나 또는 서로 미리결정된 범위 내에 있는 경우, CDO 뉴런들은 스파이크를 출력할 수도 있다. 이에 따라, CDO 뉴런들은 사운드 소스의 오디오 속성이 오디오 신호 내에 존재하는지 여부의 표시를 제공할 수도 있다. 또, 사운드 소스의 오디오 속성이 오디오 신호 내에 존재하는 경우, 그 오디오 소스에 기인되는 오디오 신호의 부분이 오디오 신호로부터 추출 또는 분리될 수 있다.
도 10 이 2개의 사운드 소스들을 위한 오디오 속성 (예를 들어, 피치) 및 2개의 CDO 뉴런들을 포함하는 아키텍처를 도시하지만, 이것은 단지 설명 및 예시를 위한 것이며 아키텍처는 임의의 수의 소스들을 혼합체로부터 분리하도록 구성될 수도 있다. 즉, 아키텍처는 하나 초과의 소스를 포함하는 오디오 신호로부터 하나 이상의 소스들을 분리하도록 구성될 수도 있다. 예를 들어, 아키텍처는 복잡한 레스토랑 또는 버스로부터 공급된 노이즈 있는 오디오 신호로부터 하나 이상의 보이스들을 분리하도록 구성될 수도 있다.
더욱이, 본 개시물이 오디오 소스 분리와 관련된 강조된 양태들을 갖지만, 본원에 개시된 아키텍처 및 피쳐들을 이용한 다른 애플리케이션들이 실현될 수도 있다. 이들 애플리케이션들은 스피치 활동 검출, 스피치 인식, 스피치 코딩, 및 오디오 개선들을 포함하지만, 이에 한정되지 않는다. 예를 들어, 일부 양태들에서, 도 10에 도시된 사운드 소스 A 및 사운드 소스 B의 분리된 오디오 신호들은, 배경 잡음과 같은 입력 오디오 신호에 포함된 다른 사운드들 없이 복합 오디오 스트림을 생성하기 위해 재조합 및 디코딩될 수도 있다. 이 방식으로, 잡음 감소와 같은 스피치 개선이 실현될 수도 있다.
도 11은 본 개시물의 양태들에 따른 청각 소스 분리를 위한 예시적인 방법 (1100) 을 나타낸다. 블록 (1102) 에서, 뉴런 모델은 오디오 신호의 오디오 속성을 선택한다. 일부 양태들에서, 오디오 속성은 스키핑 또는 임의의 다른 오디오 속성의 피치, 체적, 공간적 위치, 음색, 스피킹의 레이트 또는 임의의 다른 오디오 속성일 수도 있다.
블록 (1104) 에서, 뉴런 모델은 단일 소스에 의해 지배되는 오디오 속성의 부분을 스파이킹 이벤트로서 나타낸다. 일부 양태들에서, 다중 소스들에 의해 지배되는 오디오 속성은 또한 스파이크 이벤트로서 표현될 수도 있다.
블록 (1106) 에서, 뉴런 모델은 오디오 신호의 나머지 부분을 스파이킹 이벤트들로서 나타낸다. 더욱이, 블록 (1108) 에서, 뉴런 모델은, 스파이킹 이벤트들의 일치에 기초하여 나머지 부분은 단일 소스와 일치하는지 여부를 결정한다.
일부 양태들에서, 단일 소스는 앵커 소스일 수도 있다. 앵커는 소스에 의해 지배되는 임의의 오디오 피쳐 또는 채널일 수도 있다. 앵커는 구체적인 범위 내에서 필터 출력을 식별하기 위해 대역 통과 필터들을 이용하여 프로세싱될 수도 있다. 또, 프로세싱은 주기에 기초하여 수행될 수도 있다.
상술된 방법들의 다양한 동작들은, 상응하는 기능들을 수행할 수 있는 임의의 적합한 수단에 의해 수행될 수도 있다. 그 수단은 회로, 주문형 집적 회로 (application specific integrated circuit; ASIC) 를 포함하지만 회로에 한정되지 않는 다양한 하드웨어 및/또는 소프트웨어 컴포넌트(들) 및/또는 모듈(들)을 포함할 수도 있다. 일반적으로, 도면들에 나타낸 동작들이 존재하는 곳에서, 이들 동작들은 유사한 넘버링을 이용하여 상응하는 상대의 수단-플러스-기능 컴포넌트들을 가질 수도 있다.
본원에서 사용된 바와 같이, 용어 "결정하기"는 폭넓게 다양한 액션들을 포괄한다. 예를 들어, "결정하기"는 계산하기, 연산하기, 프로세싱하기, 유도하기, 조사하기, 찾아보기 (예를 들면, 테이블, 데이터베이스 또는 다른 데이터 구조에서 찾아 보기), 확인하기 등을 포함할 수 있다. 또한, "결정하기"는 수신하기 (예를 들어, 정보 수신하기), 액세스하기 (예를 들어, 메모리 내의 데이터에 액세스하기) 등을 포함할 수 있다. 더욱이, "결정하기"는 해결하기, 선택하기, 고르기, 설정하기 등을 포함할 수 있다.
본원에서 사용된 바와 같이, 아이템들의 리스트의 "그 중 적어도 하나"를 지칭하는 문구는 단일 멤버들을 포함하여 이들 아이템들의 임의의 조합을 지칭한다. 일례로서, "a, b, 또는 c: 중 적어도 하나"는 a, b, c, a-b, a-c, b-c, 및 a-b-c를 포괄하도록 의도된다.
본원의 개시물과 관련하여 설명된 다양한 예시적인 논리 블록들, 모듈들, 및 회로들은 범용 프로세서, 디지털 신호 프로세서 (DSP), 주문형 집적 회로 (ASIC), 필드 프로그램가능 게이트 어레이 (FPGA) 나 다른 프로그램가능 로직 디바이스 (PLD), 이산 게이트나 트랜지스터 로직, 이산 하드웨어 컴포넌트들, 또는 본원에 설명된 기능들을 수행하도록 설계된 이들의 임의의 조합으로 구현되거나 수행될 수도 있다. 범용 프로세서는 마이크로프로세서일 수도 있지만, 대안에서, 프로세서는 임의의 시판되는 이용가능한 프로세서, 제어기, 마이크로제어기, 또는 상태 머신일 수도 있다. 프로세서는 또한 연산 디바이스들의 조합, 예를 들면, DSP와 마이크로프로세서의 조합, 복수의 마이크로프로세서들, DSP 코어와 연계한 하나 이상의 마이크로프로세서들, 또는 임의의 다른 그러한 구성으로 구현될 수도 있다.
본 개시물과 관련하여 설명된 방법 또는 알고리즘의 단계들은 하드웨어에서, 프로세서에 의해 실행되는 소프트웨어 모듈에서, 또는 이 둘을 조합하여 바로 구현될 수도 있다. 소프트웨어 모듈은 업계에 알려져 있는 임의의 형태의 스토리지 매체에 상주할 수도 있다. 사용될 수도 있는 스토리지 매체의 일부 예들은 랜덤 액세스 메모리 (RAM), 판독 전용 메모리 (ROM), 플래시 메모리, 소거가능한 프로그램가능 판독 전용 메모리 (EPROM), 전기적으로 소거가능한 프로그램가능 판독 전용 메모리 (EEPROM), 레지스터들, 하드 디스크, 이동식 디스크, CD-ROM 등을 포함한다. 소프트웨어 모듈은 단일 명령, 또는 많은 명령들을 포함할 수도 있으며, 여러 상이한 코드 세그먼트들을 통해서, 상이한 프로그램들 사이에, 그리고 다수의 저장 매체들을 가로질러 분포될 수도 있다. 저장 매체는, 프로세서가 저장 매체로부터 정보를 판독하고 저장 매체에 정보를 기입할 수 있도록, 프로세서에 커플링될 수도 있다. 대안에서, 저장 매체는 프로세서에 통합될 수도 있다.
본원에 개시된 방법들은 상술된 방법을 달성하기 위한 하나 이상의 단계들 또는 액션들을 포함한다. 방법 단계들 및/또는 작동들은 청구항들의 범위를 벗어나지 않으면서 서로 상호 교환될 수도 있다. 다시 말해, 단계들 또는 액션들의 특정의 순서가 규정되지 않는 한, 특정의 단계들 및/또는 액션들의 순서 및/또는 사용은 청구항들의 범위로부터 일탈함이 없이 수정될 수도 있다.
본원에 설명된 기능들은 하드웨어, 소프트웨어, 펌웨어, 또는 이들의 임의의 조합으로 구현될 수도 있다. 하드웨어로 구현되는 경우, 예시적인 하드웨어 구성은 디바이스 내 프로세싱 시스템을 포함할 수도 있다. 프로세싱 시스템은 버스 아키텍처로 구현될 수도 있다. 버스는 프로세싱 시스템의 특정의 애플리케이션 및 전체 설계 제약들에 따라서, 임의의 개수의 상호접속하는 버스들 및 브릿지들을 포함할 수도 있다. 버스는 프로세서, 머신 판독가능 매체들, 및 버스 인터페이스를 포함한 여러 회로들을 함께 링크할 수도 있다. 버스 인터페이스는 네트워크 어댑터를, 특히, 프로세싱 시스템에 버스를 통해서 접속하는데 사용될 수도 있다. 네트워크 어댑터는 신호 프로세싱 기능들을 구현하는데 사용될 수도 있다. 소정의 양태들에 있어서, 사용자 인터페이스 (예컨대, 키패드, 디스플레이, 마우스, 조이스틱, 등) 는 또한 버스에 접속될 수도 있다. 버스는 또한 타이밍 소스들, 주변장치들, 전압 조정기들, 전력 관리 회로들, 및 기타 등등과 같은 여러 다른 회로들에 링크될 수도 있으며, 이들은 당업계에 널리 알려져 있으므로, 더 이상 추가로 설명되지 않는다.
프로세서는 버스를 관리하는 것, 및 머신 판독가능 매체들 상에 저장된 소프트웨어의 실행을 포함한 일반적인 프로세싱을 담당할 수도 있다. 프로세서는 하나 이상의 범용 및/또는 특수-목적 프로세서들로 구현될 수도 있다. 예들은 마이크로프로세서들, 마이크로제어기들, DSP 프로세서들, 및 소프트웨어를 실행할 수도 있는 다른 회로를 포함한다. 소프트웨어는 소프트웨어, 펌웨어, 미들웨어, 마이크로코드, 하드웨어 기술 언어, 또는 기타로 지칭되든, 명령들, 데이터, 또는 이들의 임의의 조합을 의미하는 것으로 넓게 해석되어야 할 것이다. 머신 판독가능 매체들은 일 예로서, 랜덤 액세스 메모리 (RAM), 플래시 메모리, 판독 전용 메모리 (ROM), 프로그래머블 판독 전용 메모리 (PROM), 소거가능한 프로그래머블 판독 전용 메모리 (EPROM), 전기적으로 소거가능한 프로그래머블 판독 전용 메모리 (EEPROM), 레지스터들, 자기 디스크들, 광 디스크들, 하드 드라이브들, 또는 임의의 다른 적합한 저장 매체, 또는 이들의 임의의 조합을 포함할 수도 있다. 컴퓨터 판독가능 매체는 컴퓨터 프로그램 제품으로 구체화될 수도 있다. 컴퓨터 프로그램 제품은 패키징 재료들을 포함할 수도 있다.
하드웨어 구현예에서, 머신 판독가능 매체들은 프로세서와 분리된 프로세싱 시스템의 부분일 수도 있다. 그러나, 당업자들이 용이하게 알 수 있는 바와 같이, 머신 판독가능 매체들, 또는 그의 임의의 부분은 프로세싱 시스템의 외부에 있을 수도 있다. 일 예로서, 머신 판독가능 매체들은 송신 라인, 데이터에 의해 변조된 반송파, 및/또는 디바이스로부터 분리된 컴퓨터 제품을 포함할 수도 있으며, 이 모든 것은 버스 인터페이스를 통해서 프로세서에 의해 액세스될 수도 있다. 대안적으로, 또는 추가적으로, 머신 판독가능 매체들, 또는 그의 임의의 부분은, 캐시 및/또는 일반 레지스터 파일들에서의 경우와 같이, 프로세서에 통합될 수도 있다. 논의된 다양한 컴포넌트들이 로컬 컴포넌트와 같은 특정 위치를 갖는 것으로 설명될 수도 있지만, 이들은 또한 분산된 연산 시스템의 부분으로서 구성되는 소정의 컴포넌트들과 같은 다양한 방식으로 구성될 수도 있다.
프로세싱 시스템은 외부 버스 아키텍처를 통해서 다른 지원 회로와 함께 모두 링크된, 프로세서 기능을 제공하는 하나 이상의 마이크로프로세서들 및 머신 판독가능 매체들의 적어도 일부분을 제공하는 외부 메모리를 가진 범용 프로세싱 시스템으로서 구성될 수도 있다. 대안으로, 프로세싱 시스템은, 본원에 기재된 뉴런 모델들 및 뉴럴 시스템들의 모델들을 구현하기 위한 하나 이상의 뉴로모픽 (neuromorphic) 프로세서들을 포함할 수도 있다. 또 다른 대안으로서, 프로세싱 시스템은 프로세서, 버스 인터페이스, 사용자 인터페이스, 지원 회로, 및 단일 칩으로 통합된 머신 판독가능 매체들 중 적어도 일부를 가진 주문형 집적 회로 (ASIC) 로, 또는 하나 이상의 필드 프로그래머블 게이트 어레이들 (FPGAs), 프로그래머블 로직 디바이스들 (PLDs), 제어기들, 상태 머신들, 게이트 로직, 이산 하드웨어 구성요소들, 또는 임의의 다른 적합한 회로, 또는 본 개시물 전반에 설명되는 여러 기능을 수행할 수 있는 회로들의 임의의 조합으로 구현될 수도 있다. 당업자들은 특정의 애플리케이션에 의존하는 프로세싱 시스템에 대한 설명된 기능 및 전체 시스템에 가해지는 전체 설계 제약들을 얼마나 최적으로 구현하는지를 알 수 있을 것이다.
머신 판독가능 매체들은 다수의 소프트웨어 모듈들을 포함할 수도 있다. 소프트웨어 모듈들은 프로세서에 의해 실행될 때, 프로세싱 시스템으로 하여금 여러 기능들을 수행하도록 하는 명령들을 포함한다. 소프트웨어 모듈들은 송신 모듈 및 수신 모듈을 포함할 수도 있다. 각각의 소프트웨어 모듈은 단일 저장 디바이스에 상주할 수도 있거나 또는 다수의 저장 디바이스들에 걸쳐서 분산될 수도 있다. 일 예로서, 소프트웨어 모듈은 트리거링 이벤트가 발생할 때 하드 드라이브로부터 RAM 으로 로드될 수도 있다. 소프트웨어 모듈의 실행 동안, 프로세서는 액세스 속도를 증가시키기 위해 명령들의 일부를 캐시에 로드할 수도 있다. 하나 이상의 캐시 라인들은 그후 프로세서에 의한 실행을 위해 일반적인 레지스터 파일에 로드될 수도 있다. 이하에서 소프트웨어 모듈의 기능을 참조할 때, 그 소프트웨어 모듈로부터 명령들을 실행할 때 이러한 기능이 프로세서에 의해 구현되는 것으로 이해되어야 할 것이다.
소프트웨어로 구현되는 경우, 이 기능들은 컴퓨터-판독가능 매체 상에 하나 이상의 명령들 또는 코드로서 저장되거나 또는 전달될 수도 있다. 컴퓨터-판독가능 매체들은 한 장소로부터 또 다른 장소로 컴퓨터 프로그램의 전송을 용이하게 하는 임의의 매체를 포함한, 컴퓨터 저장 매체들 및 통신 매체들 양쪽을 포함한다. 저장 매체는 컴퓨터에 의해 액세스될 수도 있는 임의의 가용 매체일 수도 있다. 비한정적인 예로서, 이런 컴퓨터-판독가능 매체들은 RAM, ROM, EEPROM, CD-ROM 또는 다른 광디스크 스토리지, 자기디스크 스토리지 또는 다른 자기 저장 디바이스들, 또는 원하는 프로그램 코드를 명령들 또는 데이터 구조들의 형태로 전달하거나 또는 저장하는데 사용될 수 있고 컴퓨터에 의해 액세스될 수 있는 임의의 다른 매체를 포함할 수 있다. 또한, 임의의 접속이 컴퓨터-판독가능 매체로 적절히 지칭된다. 예를 들어, 소프트웨어가 웹사이트, 서버, 또는 다른 원격 소스로부터 동축 케이블, 광섬유 케이블, 연선, 디지털 가입자 회선 (DSL), 또는 무선 기술들, 예컨대 적외선 (IR), 라디오, 및 마이크로파를 이용하여 송신되면, 동축 케이블, 광섬유 케이블, 연선, DSL, 또는 무선 기술들 예컨대 적외선, 라디오, 및 마이크로파가 그 매체의 정의에 포함된다. 디스크 (disk) 및 디스크 (disc) 는, 본원에서 사용할 때, 컴팩트 디스크 (CD), 레이저 디스크, 광 디스크, 디지털 다기능 디스크 (DVD), 플로피 디스크 및 Blu-ray® 디스크를 포함하며, 디스크들 (disks) 은 데이터를 자기적으로 보통 재생하지만, 디스크들 (discs) 은 레이저로 데이터를 광학적으로 재생한다. 따라서, 일부 양태들에서 컴퓨터-판독가능 매체들은 비일시성 컴퓨터-판독가능 매체들 (예컨대, 유형의 매체들) 을 포함할 수도 있다. 게다가, 다른 양태들에 대해 컴퓨터-판독가능 매체들은 일시성 컴퓨터-판독가능 매체들 (예컨대, 신호) 를 포함할 수도 있다. 앞에서 언급한 것들의 조합들이 또한 컴퓨터-판독가능 매체들의 범위 내에 포함되어야 한다.
따라서, 소정의 양태들은 본원에서 제시되는 동작들을 수행하는 컴퓨터 프로그램 제품을 포함할 수도 있다. 예를 들어, 이러한 컴퓨터 프로그램 제품은 본원에서 설명되는 동작들을 수행하기 위해 하나 이상의 프로세서들에 의해 실행가능한 명령들을 안에 저장하고 (및/또는 인코딩하고) 있는 컴퓨터 판독가능 매체를 포함할 수도 있다. 소정의 양태들에 있어, 컴퓨터 프로그램 제품은 패키징 재료를 포함할 수도 있다.
또, 본원에서 설명하는 방법들 및 기법들을 수행하는 모듈들 및/또는 다른 적합한 수단은 적용가능한 경우, 사용자 단말기 및/또는 기지국에 의해 다운로드되거나 및/또는 아니면 획득될 수 있는 것으로 이해되어야 한다. 예를 들어, 이러한 디바이스는 본원에서 설명하는 방법들을 수행하기 위한 수단의 전달을 용이하게 하기 위해서 서버에 커플링될 수 있다. 이의 대안으로, 본원에서 설명하는 여러 방법들은, 사용자 단말기 및/또는 기지국이 저장 수단을 디바이스에 커플링하거나 제공하자마자 여러 방법들을 획득할 수 있도록, 저장 수단 (예컨대, RAM, ROM, 컴팩트 디스크 (CD) 또는 플로피 디스크와 같은 물리적인 저장 매체 등) 을 통해 제공될 수 있다. 더욱이, 본원에서 설명하는 방법들 및 기법들을 디바이스에 제공하기 위한 임의의 다른 적합한 기법이 이용될 수 있다.
하기의 특허청구범위는 상기 설명된 정확한 구성 및 컴포넌트들로 제한되는 것이 아님을 이해해야 한다. 특허청구범위의 범위를 벗어나지 않으면서, 상술된 방법들 및 장치들의 배치, 동작 및 상세에서 여러 수정예들, 변경예들 및 변형예들이 행해질 수도 있다.
Claims (20)
- 오디오 소스 분리의 방법으로서,
오디오 신호의 오디오 속성을 선택하는 단계;
단일 소스에 의해 지배되는 상기 오디오 속성의 부분을 적어도 하나의 소스 스파이킹 이벤트로서 표현하는 단계;
상기 오디오 신호의 나머지 부분을 적어도 하나의 오디오 신호 스파이킹 이벤트로서 표현하는 단계; 및
상기 적어도 하나의 소스 스파이킹 이벤트와 상기 적어도 하나의 오디오 신호 스파이킹 이벤트의 일치에 적어도 부분적으로 기초하여 상기 나머지 부분이 상기 단일 소스와 일치하는지 여부를 결정하는 단계를 포함하는, 오디오 소스 분리의 방법. - 제 1 항에 있어서,
상기 결정하는 단계는, 시간적 윈도우 내에 발생하는 상기 적어도 하나의 오디오 신호 스파이킹 이벤트와 상기 적어도 하나의 소스 스파이킹 이벤트에 적어도 부분적으로 기초하는, 오디오 소스 분리의 방법. - 제 1 항에 있어서,
상기 오디오 속성은 피치인, 오디오 소스 분리의 방법. - 제 1 항에 있어서,
상기 오디오 속성은 공간적 위치인, 오디오 소스 분리의 방법. - 제 1 항에 있어서,
상기 결정하는 단계는 스피킹의 레이트에 적어도 부분적으로 기초하는, 오디오 소스 분리의 방법. - 제 1 항에 있어서,
상기 단일 소스는 앵커를 포함하고, 상기 앵커는 특정 범위 내의 대역 통과 필터 출력을 식별하기 위해 적어도 하나의 대역 통과 필터를 사용하여 프로세싱되는, 오디오 소스 분리의 방법. - 제 6 항에 있어서,
상기 프로세싱하는 단계는 주기에 기초하여 수행되는, 오디오 소스 분리의 방법. - 오디오 소스 분리를 위한 장치로서,
메모리; 및
상기 메모리에 커플링된 적어도 하나의 프로세스를 포함하고,
상기 적어도 하나의 프로세서는:
오디오 신호의 오디오 속성을 선택하고;
단일 소스에 의해 지배되는 상기 오디오 속성의 부분을 적어도 하나의 소스 스파이킹 이벤트로서 표현하고;
상기 오디오 신호의 나머지 부분을 적어도 하나의 오디오 신호 스파이킹 이벤트로서 표현하며; 그리고
상기 적어도 하나의 소스 스파이킹 이벤트와 상기 적어도 하나의 오디오 신호 스파이킹 이벤트의 일치에 적어도 부분적으로 기초하여 상기 나머지 부분이 상기 단일 소스와 일치하는지 여부를 결정하도록 구성되는, 오디오 소스 분리를 위한 장치. - 제 8 항에 있어서,
상기 적어도 하나의 프로세서는 또한, 시간적 윈도우 내에 발생하는 상기 적어도 하나의 오디오 신호 스파이킹 이벤트와 상기 적어도 하나의 소스 스파이킹 이벤트에 적어도 부분적으로 기초하여 상기 나머지 부분이 상기 단일 소스와 일치하는지 여부를 결정하도록 구성되는, 오디오 소스 분리를 위한 장치. - 제 8 항에 있어서,
상기 오디오 속성은 피치인, 오디오 소스 분리를 위한 장치. - 제 8 항에 있어서,
상기 오디오 속성은 공간적 위치인, 오디오 소스 분리를 위한 장치. - 제 8 항에 있어서,
상기 적어도 하나의 프로세서는 또한, 스피킹의 레이트에 적어도 부분적으로 기초하여 상기 나머지 부분이 상기 단일 소스와 일치하는지 여부를 결정하도록 구성되는, 오디오 소스 분리를 위한 장치. - 제 8 항에 있어서,
상기 단일 소스는 앵커를 포함하고, 상기 적어도 하나의 프로세서는 또한 특정 범위 내의 대역 통과 필터 출력을 식별하기 위해 적어도 하나의 대역 통과 필터를 사용하여 상기 앵커를 프로세싱하도록 구성되는, 오디오 소스 분리를 위한 장치. - 제 13 항에 있어서,
상기 적어도 하나의 프로세서는 또한, 주기에 기초하여 상기 앵커를 프로세싱하도록 구성되는, 오디오 소스 분리를 위한 장치. - 오디오 소스 분리를 위한 장치로서,
오디오 신호의 오디오 속성을 선택하는 수단;
단일 소스에 의해 지배되는 상기 오디오 속성의 부분을 적어도 하나의 소스 스파이킹 이벤트로서 표현하는 수단;
상기 오디오 신호의 나머지 부분을 적어도 하나의 오디오 신호 스파이킹 이벤트로서 표현하는 수단; 및
상기 적어도 하나의 소스 스파이킹 이벤트와 상기 적어도 하나의 오디오 신호 스파이킹 이벤트의 일치에 적어도 부분적으로 기초하여 상기 나머지 부분이 상기 단일 소스와 일치하는지 여부를 결정하는 수단을 포함하는, 오디오 소스 분리를 위한 장치. - 제 15 항에 있어서,
상기 결정하는 수단은 또한, 시간적 윈도우 내에 발생하는 상기 적어도 하나의 오디오 신호 스파이킹 이벤트와 상기 적어도 하나의 소스 스파이킹 이벤트에 적어도 부분적으로 기초하여 상기 나머지 부분이 상기 단일 소스와 일치하는지 여부를 결정하는, 오디오 소스 분리를 위한 장치. - 제 15 항에 있어서,
상기 오디오 속성은 피치인, 오디오 소스 분리를 위한 장치. - 프로그램 코드가 인코딩된 비일시적 컴퓨터 판독가능 매체를 포함하는 오디오 소스 분리를 위한 컴퓨터 프로그램 제품으로서,
상기 프로그램 코드는:
오디오 신호의 오디오 속성을 선택하기 위한 프로그램 코드;
단일 소스에 의해 지배되는 상기 오디오 속성의 부분을 적어도 하나의 소스 스파이킹 이벤트로서 표현하기 위한 프로그램 코드;
상기 오디오 신호의 나머지 부분을 적어도 하나의 오디오 신호 스파이킹 이벤트로서 표현하기 위한 프로그램 코드; 및
상기 적어도 하나의 소스 스파이킹 이벤트와 상기 적어도 하나의 오디오 신호 스파이킹 이벤트의 일치에 적어도 부분적으로 기초하여 상기 나머지 부분이 상기 단일 소스와 일치하는지 여부를 결정하기 위한 프로그램 코드를 포함하는, 오디오 소스 분리를 위한 컴퓨터 프로그램 제품. - 제 18 항에 있어서,
시간적 윈도우 내에 발생하는 상기 적어도 하나의 오디오 신호 스파이킹 이벤트와 상기 적어도 하나의 소스 스파이킹 이벤트에 적어도 부분적으로 기초하여 상기 나머지 부분이 상기 단일 소스와 일치하는지 여부를 결정하기 위한 프로그램 코드를 더 포함하는, 오디오 소스 분리를 위한 컴퓨터 프로그램 제품. - 제 18 항에 있어서,
상기 오디오 속성은 피치인, 오디오 소스 분리를 위한 컴퓨터 프로그램 제품.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201461940281P | 2014-02-14 | 2014-02-14 | |
| US61/940,281 | 2014-02-14 | ||
| US14/286,556 US9269045B2 (en) | 2014-02-14 | 2014-05-23 | Auditory source separation in a spiking neural network |
| US14/286,556 | 2014-05-23 | ||
| PCT/US2015/015697 WO2015123460A1 (en) | 2014-02-14 | 2015-02-12 | Auditory source separation in a spiking neural network |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20160123312A true KR20160123312A (ko) | 2016-10-25 |
Family
ID=53798400
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020167023084A KR20160123312A (ko) | 2014-02-14 | 2015-02-12 | 스파이킹 뉴럴 네트워크에서의 청각 소스 분리 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US9269045B2 (ko) |
| EP (1) | EP3105717A1 (ko) |
| JP (1) | JP2017511896A (ko) |
| KR (1) | KR20160123312A (ko) |
| CN (1) | CN105981056A (ko) |
| WO (1) | WO2015123460A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20230126535A (ko) * | 2022-02-23 | 2023-08-30 | 고려대학교 산학협력단 | 스파이킹 신경망에서 신경 암호 기반 소리 분류 장치 및 그 방법 |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10063965B2 (en) | 2016-06-01 | 2018-08-28 | Google Llc | Sound source estimation using neural networks |
| US9992570B2 (en) | 2016-06-01 | 2018-06-05 | Google Llc | Auralization for multi-microphone devices |
| WO2022086196A1 (ko) * | 2020-10-22 | 2022-04-28 | 가우디오랩 주식회사 | 기계 학습 모델을 이용하여 복수의 신호 성분을 포함하는 오디오 신호 처리 장치 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2452945C (en) * | 2003-09-23 | 2016-05-10 | Mcmaster University | Binaural adaptive hearing system |
| WO2006000103A1 (en) * | 2004-06-29 | 2006-01-05 | Universite De Sherbrooke | Spiking neural network and use thereof |
| US8346692B2 (en) * | 2005-12-23 | 2013-01-01 | Societe De Commercialisation Des Produits De La Recherche Appliquee-Socpra-Sciences Et Genie S.E.C. | Spatio-temporal pattern recognition using a spiking neural network and processing thereof on a portable and/or distributed computer |
| WO2008042900A2 (en) | 2006-10-02 | 2008-04-10 | University Of Florida Research Foundation, Inc. | Pulse-based feature extraction for neural recordings |
| JP5190840B2 (ja) * | 2008-03-21 | 2013-04-24 | 国立大学法人 名古屋工業大学 | 複数音識別装置 |
| US8566088B2 (en) * | 2008-11-12 | 2013-10-22 | Scti Holdings, Inc. | System and method for automatic speech to text conversion |
| US8412525B2 (en) * | 2009-04-30 | 2013-04-02 | Microsoft Corporation | Noise robust speech classifier ensemble |
| US8417703B2 (en) | 2009-11-03 | 2013-04-09 | Qualcomm Incorporated | Data searching using spatial auditory cues |
| US10453479B2 (en) * | 2011-09-23 | 2019-10-22 | Lessac Technologies, Inc. | Methods for aligning expressive speech utterances with text and systems therefor |
| US9111225B2 (en) | 2012-02-08 | 2015-08-18 | Qualcomm Incorporated | Methods and apparatus for spiking neural computation |
| KR101963440B1 (ko) | 2012-06-08 | 2019-03-29 | 삼성전자주식회사 | 복수의 뉴런 회로들을 이용하여 음원의 방향을 추정하는 뉴로모픽 신호 처리 장치 및 그 장치를 이용한 방법 |
| US8977582B2 (en) * | 2012-07-12 | 2015-03-10 | Brain Corporation | Spiking neuron network sensory processing apparatus and methods |
| US20140129495A1 (en) * | 2012-11-06 | 2014-05-08 | Qualcomm Incorporated | Methods and apparatus for transducing a signal into a neuronal spiking representation |
| US9147157B2 (en) * | 2012-11-06 | 2015-09-29 | Qualcomm Incorporated | Methods and apparatus for identifying spectral peaks in neuronal spiking representation of a signal |
-
2014
- 2014-05-23 US US14/286,556 patent/US9269045B2/en active Active
-
2015
- 2015-02-12 KR KR1020167023084A patent/KR20160123312A/ko not_active Application Discontinuation
- 2015-02-12 WO PCT/US2015/015697 patent/WO2015123460A1/en active Application Filing
- 2015-02-12 JP JP2016551305A patent/JP2017511896A/ja not_active Ceased
- 2015-02-12 CN CN201580008280.3A patent/CN105981056A/zh active Pending
- 2015-02-12 EP EP15706633.3A patent/EP3105717A1/en not_active Withdrawn
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20230126535A (ko) * | 2022-02-23 | 2023-08-30 | 고려대학교 산학협력단 | 스파이킹 신경망에서 신경 암호 기반 소리 분류 장치 및 그 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN105981056A (zh) | 2016-09-28 |
| WO2015123460A1 (en) | 2015-08-20 |
| US20150235125A1 (en) | 2015-08-20 |
| US9269045B2 (en) | 2016-02-23 |
| EP3105717A1 (en) | 2016-12-21 |
| JP2017511896A (ja) | 2017-04-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101793011B1 (ko) | 스파이킹 네트워크들의 효율적인 하드웨어 구현 | |
| KR20160123309A (ko) | 확률적 스파이킹 베이지안망들에 대한 이벤트-기반 추론 및 학습 | |
| KR20160138002A (ko) | 스파이킹 dbn (deep belief network) 에서의 트레이닝, 인식, 및 생성 | |
| KR101790909B1 (ko) | 의사-랜덤 넘버들의 프로그래머블 확률 분포 함수를 생성하기 위한 방법 및 장치 | |
| KR20170031695A (ko) | 신경망들에서의 콘볼루션 동작의 분해 | |
| KR20170041724A (ko) | 비동기 펄스 변조를 이용한 인공 뉴런들 및 스파이킹 뉴런들 | |
| US20150248609A1 (en) | Neural network adaptation to current computational resources | |
| KR20160084401A (ko) | 스파이킹 뉴럴 네트워크들에서 리플레이를 사용한 시냅스 학습의 구현 | |
| US9652711B2 (en) | Analog signal reconstruction and recognition via sub-threshold modulation | |
| KR20160145636A (ko) | 스파이킹 뉴럴 네트워크에서의 글로벌 스칼라 값들에 의한 가소성 조절 | |
| KR20160076531A (ko) | 다차원 범위에 걸쳐 분리가능한 서브 시스템들을 포함하는 시스템의 평가 | |
| KR20160058825A (ko) | 신경 모델들에 대한 그룹 태그들의 구현을 위한 방법들 및 장치 | |
| KR20160125967A (ko) | 일반적인 뉴런 모델들의 효율적인 구현을 위한 방법 및 장치 | |
| KR20160123312A (ko) | 스파이킹 뉴럴 네트워크에서의 청각 소스 분리 | |
| KR101825937B1 (ko) | 가소성 시냅스 관리 | |
| KR101782760B1 (ko) | 시냅스 지연의 동적 할당 및 검사 | |
| JP6096388B2 (ja) | ニューラルネットワークモデルにおけるドップラー効果処理 | |
| KR20160124791A (ko) | 좌표 변환을 위한 위상 코딩 | |
| US9342782B2 (en) | Stochastic delay plasticity | |
| US20150242742A1 (en) | Imbalanced cross-inhibitory mechanism for spatial target selection |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |