KR20120115233A - 레코드 포맷 정보의 관리 - Google Patents
레코드 포맷 정보의 관리 Download PDFInfo
- Publication number
- KR20120115233A KR20120115233A KR1020127013690A KR20127013690A KR20120115233A KR 20120115233 A KR20120115233 A KR 20120115233A KR 1020127013690 A KR1020127013690 A KR 1020127013690A KR 20127013690 A KR20127013690 A KR 20127013690A KR 20120115233 A KR20120115233 A KR 20120115233A
- Authority
- KR
- South Korea
- Prior art keywords
- data
- record format
- format
- record
- records
- Prior art date
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/23—Updating
- G06F16/2365—Ensuring data consistency and integrity
Abstract
데이터는, 포맷 정보를 이용하여 데이터 처리 시스템 내에서 처리를 위해 준비된다. 수신된 데이터는 필드들에 대한 값들을 가지는 레코드들을 포함한다. 데이터를 처리하기 위한 타겟 레코드 포맷이 판정된다. 데이터가 후보 레코드 포맷들에 매치하는지 여부를 판정(810)하기 위한 유효성 테스트에 따라 다수의 레코드들이 분석된다(806). 각 후보 레코드 포맷은 각 필드에 대한 포맷을 지정하고, 각 유효성 테스트는 적어도 하나의 후보 레코드 포맷에 대응한다. 유효성 테스트들의 결과들의 수신에 응하여, 타겟 레코드 포맷이, 적어도 하나의 유효성 테스트에 따라 적어도 일부의 매치가 판정된 후보 레코드 포맷(812), 데이터와 관련된 데이터 타입에 따라 선택된 분석된 레코드 포맷(830, 832, 834, 836, 838), 및 데이터의 특성들의 분석으로부터 생성된 구성된 레코드 포맷(846), 중 적어도 하나에 기초하여 데이터와 관련된다.
Description
본 출원은 참조로서 본 명세서에 병합되는 것으로, 2009년 11월 13일에 출원된 미국 특허 출원 61/260,997호에 대해 우선권을 주장한다.
본 명세서는 레코드 포맷 정보(record format information)의 관리에 관련된다.
기관들은 다수의 상이한 시스템들로부터의 데이터를 관리한다. 시스템은 그 시스템에 대한 고유의 형식으로 데이터의 데이터 세트를 생성할 수 있다. 다른 시스템들은, 콤마 독립 파일(Comma-Separated File) 또는 XML 문서와 같은 표준 포맷(standard format)을 이용하여 데이터 세트들을 생성한다. 대체로, 일단 데이터 세트의 포맷이 표준이라면, 데이터 세트 내의 레코드 및 필드(field)들은 시스템에 대해 명확하게 된다.
일부 시스템들은 임포트 메커니즘(import mechanism)을 통해 다른 시스템들에 의해 제공된 데이터 세트들을 받아들인다. 임포트는 외부의 데이터 세트를 처리하기 위해 시스템에 대한 고유의 형식으로 변환한다. 다른 시스템들은, 시스템이 필수적으로 요구되는 변환 없이도 외부의 데이터 세트를 처리하도록 하기 위해, 데이터 세트를 충분히 설명하는 레코드 포맷을 생성한다.
일 측면에서, 전반적으로, 데이터 저장 시스템(data storage system) 내의 포맷 정보에 기초하여 데이터 처리 시스템(data processing system) 내에서 처리하기 위해 데이터를 준비하는 방법이 제시된다. 각각이 입력 장치 또는 포트 상의 각각의 필드들에 대한 하나 이상의 값을 가지는 레코드들을 포함하는 데이터가 수신된다. 데이터 처리 시스템 내에서 데이터를 처리하기 위해 타겟 레코드 포맷(target record format)이 판정된다. 데이터 저장 시스템 내에 저장된 하나 이상의 후보 레코드 포맷(candidate record format)들에 데이터가 매치(match)하는지 여부를 판정하기 위한 복수의 유효성(validation) 테스트들에 따라, 데이터 내의 다수의 레코드 포맷이 분석된다. 각각의 후보 레코드 포맷은 하나 이상의 필드로 된 그룹의 각각의 필드에 대한 포맷을 정하고, 각각의 유효성 테스트는 데이터 저장 시스템 내에 저장된 적어도 하나 이상의 후보 레코드 포맷에 대응한다. 유효성 테스트들의 결과를 수신하는 경우에 응하여, 타겟 레코드 포맷은, 선택된 후보 레코드 포맷 - 선택된 후보 레코드 포맷에 대응하는 적어도 하나의 유효성 테스트에 따라 적어도 일부의 매치가 판정된 것임 -, 데이터와 관련된 알려진 데이터 타입에 따라 파서(parser)에 의해 선택되어 생성된 파싱된 레코드 포맷(parsed record format), 및 데이터의 특성들의 분석으로부터 생성된 구성된 레코드 포맷(constructed record format) 중 적어도 하나에 기초하여 데이터와 관련(associated)된다.
본 발명의 태양들은 이하의 특징들 중 하나 이상을 포함할 수 있다.
어떠한 유효성 테스트들도 하나 이상의 후보 레코드 포맷에 대해 적어도 일부의 매치를 판정하지 못한 경우에 응하여, 파싱된 레코드 포맷에 기초하여 타겟 레코드 포맷과 데이터를 관련시킨다. 데이터와 관련된 알려진 데이터 타입은 데이터의 파일 타입에 기초하여 인지될 수 있다. 데이터의 파일 타입은 파일 확장자(extension)에 대응할 수 있다. 어떠한 유효성 테스트들도 하나 이상의 후보 레코드 포맷에 대해 적어도 일부의 매치를 판정하지 못하고, 데이터와 관련된 알려진 데이터 타입을 가지지 않는 경우에 응하여, 구성된 레코드 포맷에 기초하여 타겟 레코드 포맷과 데이터를 관련시킨다. 데이터의 특성들의 분석으로부터 구성된 레코드 포맷을 생성하는 것은, 데이터 내의 태그(tag)들을 인식하고, 인식된 태그들에 기초하여 다수의 레코드들을 판정하기 위해 데이터를 파싱(parsing)하는 것을 포함할 수 있다. 데이터의 특성들의 분석으로부터 구성된 레코드 포맷을 생성하는 것은, 데이터 내의 디리미터(delimiter)들을 인식하고, 인식된 경계들에 기초하여 다수의 레코드들을 판정하기 위해 데이터를 파싱하는 것을 포함할 수 있다. 데이터의 특성들의 분석으로부터 구성된 레코드 포맷을 생성하는 것은, 다수의 레코드들의 값을 지시하는 태그나 디리미터 없이도 데이터가 실질적으로 바이너리 형식(binary form)이라는 것을 인식하는 것과 사용자 인터페이스(user interface)로부터 하나 이상의 필드 식별자(identifier)들을 수신하는 것을 포함할 수 있다. 제1 후보 레코드 포맷에 대응하는 복수의 유효성 테스트들 중 제1 유효성 테스트에 따라 데이터 내의 다수의 레코드들을 분석하는 것은, 제1 후보 레코드 포맷을 데이터에 적용하여 각 필드에 대한 제1 후보 레코드 포맷에 의해 지정된(specified) 포맷들 내의 각 레코드에 대한 값들을 판정하는 것을 포함할 수 있다. 제1 후보 레코드 포맷에 데이터가 매치하는지 여부를 판정하는 것은, 제1 유효성 테스트에 따라 다수의 레코드들에 대해 판정된 값들을 분석하여 유효 값(valid value)들의 수가 미리 정해진 임계치(threshold)보다 더 큰지 여부를 판정하는 것을 포함할 수 있다. 제1 유효성 테스트에 따라 다수의 레코드들 중 제1 레코드에 대해 판정된 값들을 분석하는 것은, 각 필드에 대해 각각의 판정된 값에 대응하는 필드 테스트를 수행하는 것을 포함할 수 있다. 제1 필드에 대해 판정된 값에 제1 필드 테스트를 수행하는 것은, 판정된 값 내의 문자(character) 수와 미리 정해진 문자 수를 매치하는 것을 포함할 수 있다. 제1 필드에 대해 판정된 값에 제1 필드 테스트를 수행하는 것은, 판정된 값을 제1 필드에 대해 미리 정해진 다수의 유효 값 중 하나에 매치하는 것을 포함할 수 있다. 유효 값들의 수는, 주어진 필드(given field)에 대해 판정된 값이 주어진 필드에 대응하는 필드 테스트를 통과하는 레코드들의 수에 기초될 수 있다.
또 다른 측면에서, 전반적으로, 데이터 저장 시스템 내의 포맷 정보에 기초하여 데이터 처리 시스템 내에서 처리하기 위해 데이터를 준비하는 시스템은: 각각이 입력 장치 또는 포트 상의 각각의 필드들에 대한 하나 이상의 값을 가지는 레코드들을 포함하는 데이터를 수신하기 위한 수단; 및 데이터 처리 시스템 내에서 데이터를 처리하기 위해 타겟 레코드 포맷을 판정하는 수단을 포함한다. 타겟 레코드 포맷을 판정하는 수단은: 데이터 저장 시스템 내에 저장된 하나 이상의 후보 레코드 포맷들에 데이터가 매치하는지 여부를 판정하기 위해 복수의 유효성 테스트들에 따라 데이터 내의 다수의 레코드 포맷, 하나 이상의 필드로 된 그룹의 각각의 필드에 대한 포맷을 정하는 각각의 후보 레코드 포맷, 및 데이터 저장 시스템 내에 저장된 적어도 하나 이상의 후보 레코드 포맷에 대응하는 각각의 유효성 테스트를 분석하고, 유효성 테스트들의 결과를 수신하는 경우에 응하여, 타겟 레코드 포맷을. 선택된 후보 레코드 포맷 - 선택된 후보 레코드 포맷에 대응하는 적어도 하나의 유효성 테스트에 따라 적어도 일부의 매치가 판정된 것임 -, 데이터와 관련된 알려진 데이터 타입에 따라 파서에 의해 선택되어 생성된 파싱된 레코드 포맷, 및 데이터의 특성들의 분석으로부터 생성된 구성된 레코드 포맷 중 적어도 하나에 기초하여 데이터와 관련시키도록 구성된다.
또 다른 측면에서, 전반적으로, 컴퓨터 판독가능 매체(computer-readable medium)가, 데이터 저장 시스템 내의 포맷 정보에 기초하여 데이터 처리 시스템 내에서 처리하기 위해 데이터를 준비하는 컴퓨터 프로그램을 저장한다. 컴퓨터 프로그램은, 컴퓨터가, 각각이 입력 장치 또는 포트 상의 각각의 필드들에 대한 하나 이상의 값을 가지는 레코드들을 포함하는 데이터를 수신하고; 데이터 저장 시스템 내에 저장된 하나 이상의 후보 레코드 포맷들에 데이터가 매치하는지 여부를 판정하기 위한 복수의 유효성 테스트들에 따라 데이터 내의 다수의 레코드 포맷, 하나 이상의 필드로 된 그룹의 각각의 필드에 대한 포맷을 정하는 각각의 후보 레코드 포맷, 및 데이터 저장 시스템 내에 저장된 적어도 하나 이상의 후보 레코드 포맷에 대응하는 각각의 유효성 테스트를 분석하고, 유효성 테스트들의 결과를 수신하는 경우에 응하여, 타겟 레코드 포맷을, 선택된 후보 레코드 포맷 - 선택된 후보 레코드 포맷에 대응하는 적어도 하나의 유효성 테스트에 따라 적어도 일부의 매치가 판정된 것임 -, 데이터와 관련된 알려진 데이터 타입에 따라 파서에 의해 선택되어 생성된 파싱된 레코드 포맷, 및 데이터의 특성들의 분석으로부터 생성된 구성된 레코드 포맷 중 적어도 하나에 기초하여 데이터와 관련시키는 것을 포함하여, 데이터 처리 시스템 내에서 데이터를 처리하기 위해 타겟 레코드 포맷(target record format)을 판정하도록 야기시키는 명령어들을 포함한다.
본원 발명의 다른 특징들과 장점들은 이하의 상세한 설명과 청구범위로부터 명확해질 것이다.
도 1은, 그래프 기반 연산들을 실행하기 위한 시스템에 대한 블록 다이어그램이다.
도 2는, 레코드 포맷 정보를 관리하기 위한 예시적인 과정에 대한 플로우 차트이다.
도 3은, 예시적인 선-처리 모듈(pre-processing module)에 대한 블록 다이어그램이다.
도 4는, 샘플 데이터에 기초하여 레코드 포맷을 판정하는 선-처리 모듈의 예시적인 처리를 보여주는 블록 다이어그램이다.
도 5는, 샘플 데이터에 기초하여 레코드 포맷을 유효하게 하는 선-처리 모듈의 예시적인 처리를 보여주는 블록 다이어그램이다.
도 6은, 샘플 데이터에 기초하여 존재하는 레코드 포맷을 식별하는 선-처리 모듈의 예시적인 처리를 보여주는 블록 다이어그램이다.
도 7은, 파서에 기초하여 레코드 포맷을 생성하는 선-처리 모듈의 예시적인 처리를 보여주는 블록 다이어그램이다.
도 8은, 레코드 포맷 정보를 관리하는 예시적인 과정에 대한 플로우 차트이다.
도 2는, 레코드 포맷 정보를 관리하기 위한 예시적인 과정에 대한 플로우 차트이다.
도 3은, 예시적인 선-처리 모듈(pre-processing module)에 대한 블록 다이어그램이다.
도 4는, 샘플 데이터에 기초하여 레코드 포맷을 판정하는 선-처리 모듈의 예시적인 처리를 보여주는 블록 다이어그램이다.
도 5는, 샘플 데이터에 기초하여 레코드 포맷을 유효하게 하는 선-처리 모듈의 예시적인 처리를 보여주는 블록 다이어그램이다.
도 6은, 샘플 데이터에 기초하여 존재하는 레코드 포맷을 식별하는 선-처리 모듈의 예시적인 처리를 보여주는 블록 다이어그램이다.
도 7은, 파서에 기초하여 레코드 포맷을 생성하는 선-처리 모듈의 예시적인 처리를 보여주는 블록 다이어그램이다.
도 8은, 레코드 포맷 정보를 관리하는 예시적인 과정에 대한 플로우 차트이다.
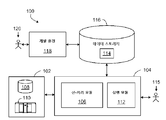
도 1은 레코드 포맷 관리 기술(record format management technique)들이 이용될 수 있는 예시적인 데이터 처리 시스템(data processing system)(100)을 도시한다. 시스템(100)은, 어떠한 복수의 스토리지 포맷들(예컨대, 데이터 베이스 테이블들, 스프래드시트(spreadsheet) 파일들, 플랫 텍스트 파일, 또는 메인프레임에 의해 이용되는 고유의 포맷)을 가지는 데이터를 저장할 수 있는 각각의 저장 장치들 또는 온라인 데이터 스트림(online data stream)들에 대한 접속들과 같은 하나 이상의 데이터의 소스를 포함할 수 있는 데이터 소스(data source)(102)를 포함한다. 실행 환경(execution environment)(104)은, 선-처리 모듈(pre-processing module)(106)과 실행 모듈(execution module)(112)을 포함한다. 실행 환경(104)은, UNIX 운영 시스템(operation system)과 같은 적합한 운영 시스템의 제어 아래에서 하나 이상의 범용 컴퓨터에서 관리될 수 있다. 예를 들어, 실행 환경(108)은, 근거리에 위치하거나(예컨대, SMP 컴퓨터들과 같은 멀티프로세서 시스템들), 근접하여 분배되거나(예컨대, 클러스터들 또는 MPP들과 같이 연결된 다수의 프로세서들), 원거리 또는 원거리에서 분배되거나(예컨대, 근거리 통신망(local area network, LAN) 및/또는 원거리 통신망(wide area network, WAN)을 통해 연결된 다수의 프로세서들) 그것에 관한 어떠한 조합 중 어느 하나인 다수의 중앙 처리 장치(central processing unit, CPU)들을 이용하여 컴퓨터 시스템의 구성을 포함하는 다점 병렬 연산 환경(multiple-node parallel computing environment)을 포함할 수 있다. 일부의 구현에서는, 실행 모듈(112)은 하나 이상의 프로세서들 상에서 실행되고 있는 병렬 운영 시스템일 수 있는 운영 시스템을 제공하고, 선-처리 모듈(106)은 그 운영 시스템 내에서 실행되고 있는 프로그램으로서 실행된다. 사용자(115)도, 표시되는 출력들을 보는 것 및 사용자 인터페이스에 입력들을 입력하는 것에 의해 실행 환경(108)과 상호 작용(interact)하는 것이 가능하다.
선-처리 모듈(106)은, 데이터 소스(102)로부터 각각의 레코드가 각각의 필드들에 대한 하나 이상의 값을 가지는 레코드들을 포함하는 데이터를 수신하고, 실행 모듈(112)를 이용하여 레코드들을 처리하기 위해 타겟 레코드 포맷(target record format)을 판정한다. 예를 들어, 선-처리 모듈(106)은, 데이터 저장 시스템(data storage system)(116) 내에 적정한 타겟 레코드 포맷(114)이 이미 저장되어 있는지를 판정하고, 저장되어 있지 않다면, 타겟 레코드 포맷(114)를 생성하고 데이터 저장 시스템(116) 내에 생성된 타겟 레코드 포맷(114)을 저장한다. 데이터 소스(102)와 데이터 저장 시스템(116)을 제공하는 저장 장치들은, 예를 들어 실행 환경(104)을 실행하고 있는 컴퓨터와 접속된 저장 매체(예컨대, 하드 드라이브(108))에 저장되어 있는 것처럼, 실행 환경(104)과 근거리에 있을 수 있고, 예를 들어 원격 접속 상에서 실행 환경(104)를 실행하고 있는 컴퓨터와 통신하는 리모트 시스템(remote system)에서 관리되는 것처럼, 실행 환경(104)와 원거리에 있을 수 있다.
실행 모듈(112)은, 데이터 소스(102)로부터 수신된 레코드들을 해석하고 처리하기 위해 판정된 타겟 레코드 포맷(114)을 이용한다. 데이터 저장 시스템(116)도, 개발자(developer)(120)가 레코드들을 처리하기 위해 실행 모듈(112)에 의해 실행될 프로그램을 개발할 수 있는 개발 환경(development environment)(118)에 액세스할 수 있다. 개발 환경(118)은, 일부의 구현들에서, 꼭지점들 사이의 다이렉트 링크(link)들(워크 엘리먼트(work element)들의 플로우를 표현하는)에 의해 연결된 꼭지점들(구성요소들 또는 데이터세트들)을 포함하는 데이터 플로우 그래프들과 같은 어플리케이션을 개발하기 위한 시스템이다. 예를 들어, 그러한 것은 본 명세서에 참조로서 병합된 "그래프 기반 어플리케이션의 파라미터들의 관리"로 명명된 미국 특허 출원 2007/0011668호에서 더 상세하게 설명된다.
선-처리 모듈(106)은, 상이한 형태의 데이터 베이스 시스템들을 포함하여 다양한 타입의 시스템들로부터 데이터를 수신할 수 있다. 데이터는, 0일 수도 있는 값들을 포함하는 각각의 필드들에 대한 값들("속성(attributes)" 또는 "칼럼(columns)"으로 불리기도 하는)을 가지는 레코드들로서 조직된다. 데이터 소스로부터 데이터를 처음 판독할 때, 그 데이터 소스로부터 레코드들의 레코드 구조를 설명하는 타겟 레코드 포맷이 인지되지 않으면, 비록 일부 환경에서, 선-처리 모듈(106)은 그 데이터 소스 내의 레코드들에 대한 초기 포맷 정보 일부를 가지고 시작한다. 선-처리 모듈(106)은 처리될 레코드들이 저장된 레코드 포맷에 의해 설명되는지 또는 레코드 포맷이 생성될 것인지 여부를 판정하기 위해, 데이터 저장 시스템(116) 내에 저장된 레코드 포맷들의 집합(collection)을 관리한다. 레코드 포맷은, 특별한(distinct)값을 표현하는 다수의 비트들, 레코드 내의 필드들의 순서, 및 비트들에 의해 표현되는 값의 타입(예컨대, 스트링(string), 표시된/표시되지 않은 인티저(integer))과 같은 다양한 특성들을 포함할 수 있다.
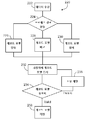
도 2를 참조하면, 프로세스(220)에 대한 플로우 차트는 레코드 포맷들을 관리하기 위한 선-처리 모듈(106)의 일부 동작들을 포함한다. 다른 가능성들 사이에서, 선-처리 모듈(106)은 데이터를 받아들인다(222). 데이터는, 파일, 데이터 베이스, 사용자 인터페이스, 입력 포트, 또는 다른 어떠한 입력 장치를 통해 수신될 수 있다. 다른 정보들 사이에서, 선-처리 모듈(106)은 데이터 소스로부터의 레코드들에 대한 레코드 포맷을 포함하는 데이터, 데이터 소스(102)로부터의 하나 이상의 레코드들을 포함하는 샘플 데이터, 또는 양자 모두를 수신할 수 있다. 샘플 데이터는, 처리될 모든 레코드들 또는 레코드들의 서브세트(subset)를 포함할 수 있다. 선-처리 모듈(106)은, 선-처리 모듈(106)이 수행되기 위해 어떤 동작들이 요구되는지에 관한 지시(indication)를 수신할 수도 있다.
선-처리 모듈(106)의 동작들은 프로세스 경로(process path)의 판정(224)을 포함할 수도 있다. 선-처리 모듈(106)은, 수신된 샘플 데이터의 레코드들을 해석하기 위해 레코드 포맷을 판정하는 다양한 방법들을 가질 수 있다. 선-처리 모듈(106)은, 샘플 데이터에 대한 잠재 레코드 포맷(potential record format)이 입력으로서 제공되는지 여부에 기초하여, 어떠한 프로세스 경로가 적절한지를 판정할 수 있다. 시스템의 일부 구현들에서는, 선-처리 모듈(106)이 어떤 프로세스 경로가 선호되는지를 지시하는 데이터를 받아들인다.
하나의 프로세스 경로를 따라, 선-처리 모듈(106)의 동작들은, 이하에서 더욱 상세하게 설명되는 것처럼, 샘플 데이터의 분석에 기초한 샘플 데이터의 타겟 레코드 포맷의 판정(226)을 포함한다.
또 다른 프로세스 경로를 따라, 선-처리 모듈(106)의 동작들은, 제공된 레코드 포맷과 제공된 샘플 데이터의 비교(228)에 기초한 샘플 데이터의 타겟 레코드 포맷의 판정을 포함한다. 일부 케이스들에서는, 선-처리 모듈(106)은, 샘플 데이터와, 받아들여진 샘플 데이터에 잠재적으로 대응하는 제공된 레코드 포맷(또는 저장된 레코드 포맷에 대한 식별자(identifier))를 받아들인다. 선-처리 모듈(106)은, 레코드 포맷이 샘플 데이터의 구조(structure)를 표현하고 있는지 여부를 판정하기 위해, 제공된 또는 식별된 레코드 포맷을 샘플 데이터와 비교한다.
또 다른 프로세스 경로를 따라, 선-처리 모듈(106)의 동작들은, 제공된 샘플 데이터에 대한 레코드 포맷의 검색(finding)(230)에 기초한 샘플 데이터의 타겟 레코드 포맷의 판정을 포함한다. 일부 케이스들에서는, 선-처리 모듈(106)은, 어떠한 레코드 포맷들이 정확하게 샘플 데이터의 구조를 표현하고 있는지 여부를 발견하기 위해, 샘플 데이터를 받아들이고, 데이터를 레코드 포맷 집적소(repository)(예컨대, 데이터 저장 시스템(116) 내에서 관리되는) 내에서 기존의 레코드 포맷(existing record format)과 비교한다.
동작들은, 사용자에 대한 하나 이상의 잠재적 타겟 레코드 포맷들의 표시(232)를 포함할 수도 있다. 일단 하나 이상의 레코드 포맷들이 판정되면, 레코드 포맷들은 사용자에 대해 표시될 수 있다. 사용자는 복수개의 레코드 포맷들로부터 하나의 레코드 포맷을 선택할 수 있다. 사용자는 레코드 포맷을 수정할 수도 있다.
동작들은 타겟 레코드 포맷의 유효화(234)를 포함할 수도 있다. 레코드 포맷이 선-처리 모듈(106)에 의해 받아들여지기 전에, 선-처리 모듈(106)은 제공된 샘플 데이터에 대한 레코드 포맷들 유효화할 수 있다.
동작들은 타겟 레코드 포맷에 대해 조정들을 제안(236)하는 것도 포함한다. 레코드 포맷이 제공된 샘플 데이터를 파싱할 수 없다면, 선-처리 모듈(106)은 레코드 포맷과 샘플 데이터 사이의 불일치들(inconsistencies)을 식별한다. 불일치들은, 샘플 데이터를 파싱할 때 발생하는 에러들의 분석에 의해 식별될 수 있다. 불일치들은 샘플 데이터와 레코드 포맷을 분석하는 것에 의해서도 식별될 수 있다. 프로세스(220)는, 불일치를 수정하는 제안들을 생성한다. 일 실시예에서는, 프로세스(220)가 샘플 데이터에 기초한 레코드 포맷의 수정을 제시할 수 있다. 예를 들어, 레코드 포맷이 필드가 인티저(integer)의 표현(예컨대, 1, 2, 3, 4, 등과 같은 인티저 값의 바이너리 표현)이 되길 기대하고, 샘플 데이터 내의 필드가 포맷된 날짜(formatted date)의 표시(예컨대, 1/21/2008, 21/1/2008, 01-JAN-2008 등)를 포함한다면, 프로세스(220)는 조정을 제안할 수 있다. 인티저 필드가 포맷된 날짜를 유지할 수 없고 날짜 필드가 인티저를 유지할 수 없기 때문에, 프로세스(220)는 필드를, 날짜 또는 인티저 중 어느 하나를 포함하는 스트링(string)으로 수정하도록 제안할 수 있다. 또 다른 예에서는, 프로세스(220)는 레코드 포맷에 의해 받아들여진 유효 값들의 범위를 확장하도록 제안할 수 있다.
동작들은, 타겟 레코드 포맷을 저장(238)하는 것도 포함한다. 타겟 레코드 포맷은 레코드 포맷 집적소 내에 저장될 수 있다.
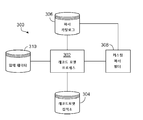
도 3을 참조하면, 데이터 처리 시스템 내에서 처리되기 위해 데이터를 준비하는 선-처리 모듈이 데이터를 받아들이는 메커니즘(300)을 포함한다. 일례에서, 입력 데이터는 데이터 베이스(310)일 수 있다. 데이터 베이스(310)는 시스템(100)에 의해 처리될 데이터를 포함할 수 있다. 다른 예에서, 데이터 베이스(310)는 시스템(100)에 의해 처리될 데이터의 더 큰 세트(larger set)를 대표하는 데이터의 샘플 세트를 포함할 수 있다. 다른 예에서는, 데이터 베이스는 데이터의 레코드 포맷에 대한 설명을 포함할 수 있다. 다른 예에서는, 입력 데이터가 샘플 데이터와 레코드 포맷의 조합을 포함할 수 있다. 입력 데이터는, 관계된 데이터 베이스, 플랫 파일(flat file), 또는 포트나 또 다른 입력 장치를 통해 수신된 데이터와 같이 레코드 포맷 프로세스(302) 내로 입력을 제공하기 위한 또 다른 메커니즘을 통해 레코드 포맷 프로세스(302)와 통신될 수 있다.
레코드 포맷 프로세스(302)는, 입력 데이터(310)를 받아들이고 타겟 레코드 포맷을 판정한다. 일례에서, 입력 데이터는, 각 레코드가 다수의 필드들에 대한 값들을 포함하고 있는 다수의 레코드들을 위해 생성된, 샘플 데이터를 포함한다. 샘플 데이터가 레코드 포맷을 판정하기 위해 분석된다. 다른 예에서는 샘플 데이터가 제공된 레코드 포맷과 비교된다. 다른 예에서는, 샘플 데이터가, 최상의 피트(fit)를 판정하기 위해, 레코드 포맷 집적소(304) 내의 기존의 레코드 포맷들과 비교된다.
일례에서, 레코드 포맷 프로세스(302)는, 타겟 레코드 포맷을 판정함에 있어서 어떠한 기존의 파서가 입력 데이터(310)의 파싱이 가능한지 여부를 판정하기 위해 파서들을 포함하는 파서 카탈로그(306)를 검사한다. 입력 데이터(310)를 처리하기 위한 어떠한 파서도 존재하지 않는다면, 레코드 포맷 프로세스(302)는 타겟 레코드 포맷을 판정하기 위해 새로운 파서들의 건조(construction)를 가능하게 하는 커스텀 파서 빌더 모듈(custom parser builder module)(308)을 액세스(access)할 수 있다.
사용자는 레코드 포맷에 의해 표시되고 레코드 포맷을 조정하는 것이 허용될 수 있다. 조정된 레코드 포맷은, 레코드 포맷이 샘플 데이터와 양립할 수 있는 것으로 남아있음을 보증하도록, 샘플 데이터에 대하여 체크(check)될 수 있다.
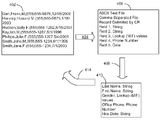
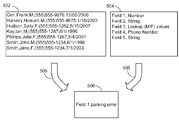
도 4를 참조하면, 일 실시예에서는, 시스템이 몇몇의 샘플 레코드들을 포함하는 샘플 데이터를 받아들인다. 선-처리 모듈(106)은 데이터의 레코드 포맷의 식별을 시도한다. 일 실시예에서는, 기존의 저장된 레코드 포맷에 매치되는 것이 없다면, 어떻게 인코드되어야(encoded) 하는지를 판정하기 위해 데이터가 분석된다. 예를 들어, 데이터는 ASCII 또는 EBCDIC 특성 인코딩에 기초하거나 바이너리 포맷에 의해 인코드될 수 있다. 일 실시예에서는, 시스템이 데이터의 파싱에 이용 가능한 파서를 가지고 있는지 여부를 판정할 수 있다. 시스템은 샘플 데이터에 대한 레코드 포맷을 판정하기 위해 샘플 데이터를 검사할 수 있다. 예를 들어, 샘플 데이터에 기초한 텍스트(text)가 디리미터가 판정된 필드들 및 레코드들, 고정된 길이 필드들, Extensible Markup Language(XML) 또는 Standard Generalized Markup Language(SGML)와 같은 태그된 데이터를 이용하여 포맷될 수 있다. 데이터는 레코드 포맷의 판정을 지원하기 위해, 태그들이나 디리미터들이 없는 바이너리 폼일 수도 있다. 바이너리 데이터는, 데이터 베이스, 스프래드 시트, 워드 프로세싱 문서, 이미지 또는 다른 바이너리 데이터일 수 있다. 일 실시예에서는, 바이너리 데이터의 데이터 타입이, 데이터의 자체 검사에 기초하여 얻어질 수 있다. 다른 실시예에서는, 바이너리 데이터의 데이터 타입이, 파일 확장자와 같은 파일의 이름에 기초하여 추정될 수도 있다. 시스템은, 샘플 포맷의 파싱에 기초하여 필드들과 레코드들을 판정할 수 있다. 예를 들어, 시스템이 디리미터가 판정된 필드들 및 레코드들을 인지한다면, 시스템은 디리미터들에 기초하여 필드들 및 레코드들 내의 데이터를 분리한다. 시스템이 태그된 데이터를 인지한다면, 시스템은 태그들에 기초하여 파일을 파싱한다.
일례에서, 도 4를 참조하면, 시스템은 샘플 데이터 파일(402)을 수신한다. 본 예시에서의 데이터는 ASCII 텍스트를 이용하여 인코드되고, 상이한 레코드들을 분리하고 돌아온 운반체(carriage)를 가지는 콤마 독립 필드들(comma separated fields)을 이용하여 조직된다.
프로세스 화살표(404)에 의해, 시스템이 샘플 데이터에 대한 레코드 포맷(406)을 판정하기 위해 샘플 데이터의 다수의 레코드들을 분석하는 것이, 표현된다. 본 예시에서, 시스템은 5개의 필드들을 식별한다: 스트링(String), 스트링, 룩업 값(Lookup value), 전화 번호(Phone Number), 및 날짜(Date). 인티저, 플로팅 포인트(floating point) 번호, 고정된 길이 텍스트 필드들, 및 고정된 길이 10진법 번호들과 같이, 다른 데이터 타입들이 검출되고 식별될 수도 있다. 일 실시예에서는, 룩업 필드들에 이용 가능한 값들이, 샘플 데이터에 의해 제공된 값들을 프로파일링(profiling)하는 것에 의해 식별될 수 있다. 일 실시예에서는, 샘플 데이터의 레코드 포맷이 얻어지면, 시스템은 각각의 데이터 필드들에 대한 값들을 판정하기 위해 샘플 데이터를 파싱할 수 있다. 본 정보는, 예를 들면, 유효 값들 중에서 상대적으로 작은 번호를 포함할 뿐인 필드들을 식별하기 위해 이용될 수 있다. 일 실시예에서는, 샘플 데이터의 레코드 포맷이, 데이터의 발견적 학습(heuristics)의 분석에 기초하여 판정될 수 있다. 예를 들어, 고정된 길이 레코드들의 세트의 길이는, 레코드들의 수에 의해 평등하게 나누어질 것이다.
일 실시예에서, 샘플 데이터에 대한 레코드 포맷이 판정되면, 레코드 포맷은 데이터와 관련된다. 또 다른 실시예에서, 레코드 포맷이 사용자에게 표시될 수 있고, 레코드 포맷을 수정하도록 허용될 수 있다. 프로세스 화살표(414)에 의해, 수정된 레코드 포맷이 샘플 데이터에 대해서 여전히 샘플 데이터와 양립할 수 있음을 확정하기 위해 테스트되는 것이 표현된다. 사용자가 샘플 데이터를 파싱하는 것을 불가능하게 하는 레코드 포맷을 야기하는 데이터 타입을 입력할 때, 세스템은 사용자에게 오류들을 표시하고, 위 문제를 바로 잡는 레코드 포맷으로 변경할 수 있다. 본 실시예에서는, 레코드 포맷들이 마무리되면, 레코드 포맷이 데이터와 관련된다.
도 5를 참조하면, 일 실시예에서, 시스템은, 사용자에 의해 제공될 수 있었거나 본 명세서에 설명된 검색 기술들을 이용하여 식별될 수 있었던, 가능 레코드 포맷(possible record format)(504)를 샘플 데이터(502)에 따라 수신한다. 여기에는, 가능 레코드 포맷이 정확하게 샘플 데이터(502) 내의 레코드들의 포맷을 설명하는지에 대한 어느 정도의 불확정성이 있을 수 있다. 가능 레코드 포맷(504)은, XML 문서 타입 정의(XML document type definition) 또는 마스터로부터 복사되고, COBOL 카피북(copybook)과 데이터 조작 처리 언어(Data Manipulation Language, DML) 레코드 포맷과 같은 몇몇 상이한 프로그램들에 삽입될 수 있는 프로그램 데이터의 물리적 레이아웃(layout)을 정의하는 코드의 섹션이 될 수 있다.
프로세스 화살표(508)에 의해, 시스템이 처리 도중에 발생한 어떠한 오류들을 기록한 가능 레코드 포맷(504)을 이용하여 샘플 데이터의 파싱을 시도하는 것이 표현된다. 본 예시에서, 제1 필드는 가능 레코드 포맷 내에서 숫자로서 정의되는 반면에, 샘플 데이터(502) 내의 제1 필드는 가변의 길이 특성 필드(variable length character field)이다. 시스템이 레코드 포맷을 이용하여 데이터의 파싱을 시도할 때, 오류 로그(506)가 생성되고 사용자에게 표시된다. 사용자는, 충돌의 해결책(suggestions for resolving the conflict)과 함께 제공된다. 예를 들어, 사용자는 필드 1의 데이터 타입을 가변의 길이 특성 필드로 변경하기 위한 제안과 함께 표시될 수 있다.
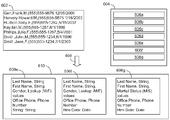
도 6을 참조하면, 일 실시예에서, 시스템은 샘플 데이터(602)를 수신하고, 기존의 레코드 포맷이 시스템이 데이터를 처리할 수 있게끔 데이터 내의 레코드들의 포맷을 정확하게 설명할 수 있는지 여부를 판정할 것이 요구된다. 시스템은 샘플 데이터가 레코드 포맷 집적소(604) 내의 어떠한 후보 레코드 포맷들(606a-g)에 매치하는지 여부를 판정하도록 샘플 데이터 내의 다수의 레코드들을 분석할 수 있다. 일 실시예에서, 이러한 분석은 레코드 포맷 집적소(604) 내에 저장된 각각의 후보 레코드 포맷들(606a-g)을 이용하여 샘플 데이터를 파싱하기 위한 시도를 포함할 수 있다. 일 실시예에서, 데이터를 파싱하는 것은 각 레코드 내의 각 필드의 샘플 값들을 판정하도록 샘플 데이터에 후보 레코드 포맷을 적용하는 것을 포함한다. 샘플 값들은, 샘플 값들이 그 후보 레코드 포맷과 일관되는지 여부를 판정하도록 후보 레코드 포맷과 비교될 수 있다. 일 실시예에서, 분석은, 후보 레코드 포맷에 의해 필드에 대해 수립된 유효 값들 또는 유효 값들의 범위를 정의하는 유효성 테스트에 대하여 샘플 데이터 내의 값들의 유효화를 포함할 수 있다. 예를 들어, 필드는 한정된 숫자의 유효 값들(50 states, 2 genders, 등)을 허용할 수 있다.
각 레코드 포맷에 대해 시스템은, 유효성 테스트로 불리는 파싱의 성공 척도를 판정한다. 예를 들어, 하나의 예시적인 유효성 테스트에서, 시스템은 성공적으로 파싱되지 않은 레코드들의 숫자에 대한 카운트를 보관한다. 또 다른 예시적인 유효성 테스트에서, 시스템은 처리될 수 없었던 필드들의 표시뿐만 아니라 성공적으로 파싱되지 않은 필드들의 숫자에 대한 카운트를 보관한다. 시스템은 후보 레코드 포맷들(606e, 606f, 606g)의 세트로 레코드 포맷들을 좁히고, 이를 사용자에게 표시한다. 일 실시예에서, 레코드 포맷은 샘플 데이터와 관련된 레코드 포맷에 확실한 매치를 제공하지 않을 수 있다. 예를 들어 후보 레코드 포맷(606e)이 스트링 필드로 끝나는 반면에, 다른 후보 레코드 포맷들은 데이터 필드로 끝난다; 그러나, 스트링은 날짜 값들과 함께일 수 있기 때문에, 레코드 포맷은 여전히 샘플 데이터와 양립할 수 있다. 다른 파싱 불일치들도 허용될 수 있다. 예를 들어, 하나의 테스트에 대해, 미리 정해진 유효 값들의 범위 밖의 값들은 후보 레코드 포맷을 여전히 생성할 수 있는데, 예를 들어, 잠재 레코드 포맷(606g)은 유효 값 “M”과 “S”를 가지는 “군복무 상태(marital status)” 필드를 포함한다. 샘플 데이터 세트는 “M” 또는 “F” 중 어느 하나를 포함하는 필드를 포함한다. 시스템은, 파싱 오류를 기록하는 동안에 잠재 데이터 레코드(potential data record)(606g)를 포함할 수 있다. 일 테스트에서는, 파싱 오류들의 숫자가 주어진 임계치 이하이면, 잠재 데이터 레코드가 포함된다. 다른 테스트에서는, 유효한 파싱된 값들의 숫자가 주어진 임계치를 초과하면, 잠재 데이터 레코드가 포함된다.
일 실시예에서, 시스템은 사용자에게 후보 레코드 포맷들을 표시하고, 사용자가 데이터에 맞는 레코드 포맷을 선택하도록 허용할 수 있다. 본 예시에서, 사용자는 최적의 피트로서 후보 레코드 포맷(606f)을 선택할 수 있다. 일 실시예에서, 시스템은 양립 가능한 레코드 포맷들을 검사하고, 샘플 데이터와 후보 레코드 포맷의 프로파일(profile)에 기초하여 어떤 레코드 포맷이 최적인지를 판정할 수 있다. 일 실시예에서, 사용자는 레코드 포맷을 수정할 수 있다. 잠재 레코드 포맷들의 리스트가 단일 타겟 레코드 포맷으로 좁혀지면, 시스템은 제공된 샘플 데이터(602)를 파싱하는 것에 의해 선택된 타겟 레코드 포맷을 유효화한다. 유효화가 완료된 이후에, 시스템은 샘플 데이터를 선택된 타겟 레코드 포맷과 관련시키고 선택된 타겟 레코드 포맷을 저장 및/또는 사용자에게 선택된 타겟 레코드 포맷을 제공한다. 일 실시예에서는, 샘플 데이터가 레코드 포맷 내에 제공된 데이터 타입들에 일치하지 않은 때에, 사용자는 이를 샘플 데이터에 일치되도록 레코드 포맷을 수정하기 위한 옵션(option)과 함께 표시될 수 있다.
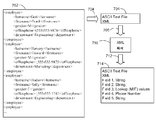
일 실시예에서, 도 7을 참조하면, 시스템은, 샘플 데이터에 맞는 레코드 포맷 집적소(604) 내의 기존의 레코드 포맷을 식별하지 못할 수 있다. 이러한 조건 아래에서, 시스템은 기존의 파서가 제공된 샘플 데이터를 파싱할 수 있는지 여부를 판정한다. 예를 들어, 샘플 데이터 세트(702)가 XML 포맷으로 보여진다. 본 예시에서, 레코드 포맷 집적소(604)는 샘플 데이터에 매치하는 어떠한 레코드 포맷도 포함하지 않는다. 프로세스 화살표(704)에 의해, 시스템이 레코드 포맷이 XML 포맷의 ASCII 파일이라는 것을 식별하는 것이 표현된다. 프로세스 화살표(708)에 의해, 시스템이 기존의 파서(예컨대, XML 파서(710))가 데이터를 해독하는 것이 가능한지를 판정하는 것이 표현된다. 파서와 샘플 데이터에 기초하여, 시스템은 샘플 데이터(714)의 레코드 포맷을 이끌어낸다. 상기에서 논의된 바와 같이, 시스템은 파서가 샘플 데이터를 해독할 수 있음을 검증(verify)하고, 파서에 의해 생성된 결과 타겟 레코드 포맷(resulting target record format)을 샘플 데이터(714)와 관련시키며, 레코드 포맷 집적소 내에 결과 타겟 레코드 포맷을 저장한다. 일 실시예에서, 시스템은 레코드 포맷 집적소 내에 타겟 레코드 포맷이 저장되기 전에 허가를 위해 사용자에게 새로이 생성된 타겟 레코드 포맷을 표시한다.
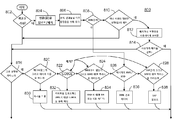
도 8은, 선-처리 모듈(106)이 타겟 레코드 포맷을 판정하기 위해 이용할 수 있는 또 다른 예시적인 프로세스(800)에 대한 플로우 차트를 보여준다. 선-처리 모듈의 동작들은 공급된 입력 데이터가 샘플 데이터를 포함하는지 여부를 판정(802)하는 것을 포함한다.
동작들은, 입력 데이터가 샘플 데이터를 포함하고 있다면, 샘플 데이터를 업로드 및/또는 배치(804)하는 것도 포함한다. 선-처리 모듈은 입력 데이터에 의해 정의된 위치로부터 샘플을 액세스할 수 있다. 일 실시예에서는, 선-처리 모듈은 액세스 포트를 통해 또 다른 서버로부터 샘플 데이터를 업로드 또는 액세스할 수 있다. 또 다른 실시예에서는, 선-처리 모듈은 샘플 데이터를 포함하는 파일 또는 다른 데이터 스토리지 메커니즘을 액세스할 수 있다.
동작들은, 샘플 데이터의 분석(806)도 포함하며, 선택적으로 분석의 결과들을 저장하는 것도 포함한다. 샘플 데이터는, 캐릭터 세트(character set), 메타 데이터(metadata), 레코드 포맷 타입 및/또는 레코드 포맷 자체를 판정하기 위해 분석될 수 있다. 일 실시예에서는, 시스템은 레코드 포맷 집적소 내에 저장된 하나 이상의 알려진 레코드 포맷들에 대한 검색을 수행하는지 여부를 판정하기 위해, 샘플 데이터를 분석한다. 예를 들어, 선-처리 모듈은 샘플 데이터가 제1 타입(예컨대, 콤마 독립 파일)이면서 샘플 데이터가 제2 타입(예컨대, XML)으로 판정되지 않을 때, 잠재 레코드 포맷을 판정하기 위해 검색을 수행할 수 있다. 다른 실시예에서는, 샘플 데이터는, 레코드 포맷의 생성과 유효화를 도울 수 있는 메타 데이터를 찾기 위해 분석된다. 일 실시예에서는, 선-처리 모듈은 필드 세퍼레이터들(field separators), 탈출 캐릭터들(escape characters), 및 파일 명들을 포함하는 헤더를 식별한다. 분석의 결과들은 이후의 판정 프로세스에서 이용되도록 계속 유지된다.
본 실시예에서는, 동작들은 샘플 데이터를 포함하는 문서의 타입이 XML인지 여부를 판정(808)하는 것도 포함한다. 일 실시예에서는, 본 예시에서의 XML 포맷과 같은 하나 이상의 미리 정해진 포맷들의 문서들이, 다른 포맷의 문서들로부터 독립되어 취급된다. 본 실시예에서는, 샘플 XML 문서들은 XML 파서에 의해 처리된다(826).
동작들은, 샘플 데이터가 레코드 포맷 집적소 내에 저장된 하나 이상의 알려진 레코드 포맷들에 매치하는지 여부를 판정(810)하는 것도 포함한다. 이는, 상기에서 논의된 것처럼, 유효성 테스트들을 이용하여 각 레코드 포맷에 대하여 샘플 데이터 내의 하나 이상의 레코드를 유효화하고 유효화 오류들의 숫자를 판정하는 것에 의해 성취될 수 있다. 다른 실시예에서는, 샘플 데이터을 분석(806)하는 동안 얻어진 정보들이, 어떤 샘플 데이터가 유효화되는 것에 대해 데이터 포맷들의 숫자를 감소하도록 이용될 수 있다.
동작들은 매칭 레코드 포맷들(matching record formats)을 사용자에게 보여주는 것(812)도 포함한다. 상기에서 논의된 것처럼, 선-처리 모듈은 잠재적인 매칭 레코드 포맷들의 리스트를 사용자에게 표시할 수 있다.
동작들은 사용자가 잠재적인 매칭 레코드 포맷들의 리스트로부터 매칭 레코드 포맷을 선택하는지 여부를 판정하는 것(814)도 포함한다.
동작들은, 저장된 레코드 포맷에 대해 어떠한 매치도 사용자에 의해 발견 및/또는 선택되지 않았다면, 샘플 데이터가 파서가 이용 가능한 알려진 고유의 포맷을 가지는 파일 내에 포함되어 있는 것과 같은 알려진 데이터 타입들을 가지는지 여부를 판정(816)하는 것도 포함한다. 고유의 포맷은 어플리케이션 또는 시스템에 의해 이용되는 외부의 알려진 포맷이다.
동작들은, 고유의 포맷이 알려진 것이라면, 적절한 이용 가능한 파서에 데이터 매치를 판정하는 것도 포함한다. 예를 들어, 샘플 데이터는 알려진 파서에 의해 처리될 수 있는 태그된 레코드들을 포함할 수 있다(820).
동작들은, 태그된 샘플 데이터에 대한 파서를 식별하는 것(830)도 포함한다.
본 실시예에서, 이용 가능한 파서에 대한 매치를 판정하는 것은, 샘플 데이터가 COBOL 내에 있는지 여부를 판정하는 것(822)을 포함한다. 일 실시예에서는, 동작들은 샘플 데이터가 이용 가능한 파서에 의해 파싱될 수 있는 표준 데이터 레코드 포맷 구조(standard data record format structure)를 활용하는 또 다른 프로그래밍 언어인지 여부를 판정하는 것도 포함할 수 있다.
동작들은, 샘플 데이터가 COBOL 내에 있다면, COBOL 카피북을 업로드하고 파싱하는 것(832)도 포함한다.
또 다른 이용 가능한 파서에 알려진 고유의 포맷을 매치하는 것은, 샘플 데이터가 데이터 베이스 내에 저장되는 것을 판정하고 선-처리 모듈이 데이터 베이스에 액세스할 수 있음을 인증하는 것(824)을 포함한다. 데이터 베이스에 대한 액세스는, 선-처리 모듈이 유효 증명서, 예를 들어 사용자 이름 및 비밀 번호에 액세스하는 것에 대한 검증을 포함할 수 있다. 데이터 베이스에 대한 액세스는, 증명서가 샘플 데이터에 대한 액세스를 제공하는 것을 판정하는 것도 포함한다.
동작들은, 데이터 베이스 내에 저장된 샘플 데이터를 분석하고 분석으로부터 레코드 포맷을 판정하는 것(834)도 포함한다(예컨대, SQL 에디터 내에서). 일 실시예에서는, 선-처리 모듈이 레코드 포맷을 이끌어내도록 데이터 베이스의 테이블 구조를 분석한다.
또 다른 이용 가능한 파서에 알려진 고유의 포맷을 매치하는 것은, 샘플 데이터가 XML 포맷인지 및 샘플 데이터가 문서 타입 정의 또는 XML 개요 정의(XML Schema Definition, XSD)를 포함하는지 여부를 판정하는 것(826)을 포함한다.
동작들은 레코드 포맷 내로 XML 문서의 구조를 번역하는 것(836)을 포함한다(예컨대, XML 경로 에디터 내에서).
또 다른 이용 가능한 파서에 알려진 고유의 포맷을 매치하는 것은, 데이터가 SAP 포맷인지 여부를 판정하는 것(828)도 포함한다. 일 실시예에서는, 다른 엔터프라이즈 솔루션 소프트웨어 패키지들(enterprise solution software packages)이 검출될 수 있는데, 예를 들면, 오라클 파이낸셜(Oracle Financials)의 샘플 데이터이다.
동작들은 기업 소프트웨어 패키지에 대한 임포트 포듈(import module)을 이용하여 레코드 포맷을 판정하는 것(838)도 포함한다.
샘플 데이터의 데이터 타입이 알려지지 않았거나 데이터 타입에 대해 이용 가능한 파서가 없다면, 동작들은 샘플 데이터의 특성들을 판정하고 샘플 데이터의 특성들의 분석으로부터 구성된 레코드 포맷을 생성하는 것도 포함한다. 예를 들어, 본 실시예에서는, 동작들은 샘플 데이터가 대부분 태그되었는지 여부를 판정하는 것(840)을 포함한다. 대부분 태그된 데이터는, 예를 들어, 태그된 데이터 구조들을 우세하게 포함하도록 나타나는 데이터이나, 필수적으로 태그된 구조를 따르지 않는 일부 데이터도 포함한다.
동작들은, 데이터가 대부분 태그된 것으로 판정되면, 태그된 데이터와 같이 데이터를 처리하기 위해 시도하는 것(842)도 포함한다(예컨대, 태그 에디터를 이용하여). XML에 부가하여, 다른 태그된 포맷들도 다루어질 수 있는데, 예를 들면 전세계 은행 금융 텔레커뮤니케이션 협회 포맷들(Society for Worldwide Interbank Financial Telecommunication formats, SWIFT)이 있다.
동작들은, 일반적인 태그된 데이터 파서, 또는 알려진 파서가 샘플 데이터의 처리가 가능한지 여부를 판정하는 것(844)도 포함한다.
동작들은 샘플 데이터를 파서 빌더로 보내는 것(848)도 포함한다.
동작들은 샘플 데이터가 대부분 텍스트임을 판정하는 것(852)도 포함한다. 대부분의 텍스트 데이터는, 예를 들어, 잘 알려진 텍스트 포맷, 예를 들어 ASCII 또는 EBCDIC를 이용하여 우선적으로 인코딩된 데이터이다.
동작들은, 데이터의 구조의 판정을 시도하는 것(854)도 포함한다. 일 실시예에서는, 데이터의 구조가 레코드 및 필드 디리미터들을 식별하는 것에 의해 판정될 수 있다. 레코드 디리미터들은 샘플 데이터 내의 마지막 문자(character)를 검사하는 것에 의해 식별될 수 있다. 디리미터들은 프린트되지 않거나 알파벳순으로 나열되지 않는 문자들에 대한 데이터를 검사하는 것에 의해 식별될 수도 있다. 샘플 데이터 내에서 프린트되지 않는 문자들 또는 알파벳순으로 나열되지 않는 문자들이 발생되는 곳은, 흔하게는 필드 디리미터일 수 있고, 흔하지 않게는 레코드 디리미터일 수 있다. 디리미터가 아닌 프린트되지 않는 문자의 존재는, 샘플 데이터가 디리미터가 판정되지 않았음을 지시할 수 있다. 디리미터들의 식별 이후에, 선-처리 모듈은 샘플 데이터에 디리미터들을 적용할 수 있고, 불일치들을 체크할 수 있다. 예를 들어, 시스템은 각 레코드가 동일한 수의 필드들을 포함하는지를 체크할 수 있다. 시스템은 각 레코드 내의 동일한 필드가 유사 또는 양립 가능한 데이터 타입을 포함하는지를 체크할 수 있다. 일 실시예에서, 선-처리 모듈은 데이터의 분석(806) 동안에 데이터에 대해 판정된 정보에 의존한다.
동작들은, 데이터가 대부분 바이너리임을 판정하는 것(856)도 포함한다. 바이너리 데이터는, 예를 들어, 잘 알려진 텍스트 포맷들, 예를 들어 ASCII 및 EBCDIC을 이용하여 인코드되지 않는 데이터이다.
동작들은 적절하다면(예컨대, 데이터가 대부분 바이너리임을 판정하는 것(856)에 응하여) 샘플 데이터 내로 필드 이름들을 삽입하는 것(858)도 포함한다. 일 실시예에서는, 사용자는 삽입될 필드 이름들을 입력(예컨대, 붙여넣기 또는 키 입력)할 수 있다.
동작들은 결과들을 검증하는 것(850)도 포함한다. 레코드 포맷을 검증하는 것은 레코드 포맷을 이용하고 샘플 데이터를 파싱하도록 시도하는 것을 포함할 수 있다.
동작들은 사용자가 레코드 포맷을 구성 또는 에디트하도록 허용하는 것(846)을 포함한다. 일 실시예에서는, 사용자는 레코드 포맷을 에디트 및/또는 샘플 데이터의 타입, 이름들, 및 구조를 변경할 수 있다.
동작들은 레코드 포맷 집적소 내에 레코드 포맷을 저장하는 것(860)도 포함한다. 일 실시예에서는, 선-처리 모듈이 데이터 포맷을 샘플 데이터와 관련시키고, 다른 실시예에서는 선-처리 모듈이 데이터 포맷의 복사본을 생성하고 데이터와 복사본을 관련시킨다.
상기 설명된 레코드 포맷 발견 접근(record format discovery approach)은 컴퓨터 상에서의 실행을 위한 소프트웨어를 이용하여 구현될 수 있다. 예를 들어, 소프트웨어는, 각각이 적어도 하나의 프로세서, 적어도 하나의 데이터 저장 시스템(휘발성 및 비휘발성 메모리 및/또는 저장 요소를 포함하는), 적어도 하나의 입력 장치 또는 포트, 및 적어도 하나의 출력 장치 또는 포트를 포함하는 하나 이상의 프로그램된 또는 프로그래머블 컴퓨터 시스템(분배된, 클라이언트/서버 또는 그리드와 같이 다양한 아키텍처일 수 있는) 상에서 실행하는 하나 이상의 컴퓨터 프로그램들 내에 과정들을 형성한다. 소프트웨어는, 예를 들어, 연산 그래프들의 디자인과 구성과 관련된 다른 서비스들을 제공하는 더 큰 프로그램의 하나 이상의 모듈을 형성할 수 있다. 그래프의 노드들 및 엘리먼트들은 컴퓨터 판독가능 매체 내에 저장된 데이터 구조들로서 또는 데이터 집적소 내에 저장된 데이터 모델을 따르는 다른 조직된 데이터로서 구현될 수 있다.
소프트웨어는, CD-ROM과 같은, 범용 또는 특수 목적의 프로그래머블 컴퓨터에 의해 판독가능 하거나 실행되는 컴퓨터에 대해 네트워크의 통신 매체를 넘어 전송되는(전파된 신호로 인코딩된) 저장 매체로 제공될 수 있다. 모든 기능들은, 코-프로세서들과 같은, 특수 목적 컴퓨터 또는 특수 목적 하드웨어를 이용하여 수행될 수 있다. 소프트웨어는, 소프트웨어에 의해 지정된 연산의 상이한 부분들이 상이한 컴퓨터들에 의해 수행되는 분배된 방법으로 수행될 수 있다. 각각의 그러한 컴퓨터 프로그램은, 저장 매체 또는 장치가 본 명세서에 설명된 과정들을 수행하기 위해 컴퓨터 시스템에 의해 판독되는 때에 컴퓨터를 구성하고 동작하기 위한, 범용 또는 특수 목적의 프로그래머블 컴퓨터에 의해 판독 가능한 저장 매체 또는 장치(예컨대, 고체 상태 메모리 또는 매체, 또는 자기 또는 광학 매체)에 우선적으로 저장 또는 다운로드된다. 본 발명의 시스템은, 본 명세서에 설명된 기능들을 수행하도록 특정 및 미리 정해진 방법으로 컴퓨터 시스템이 동작하도록 야기시키도록 구성된, 컴퓨터 프로그램과 함께 구성된 컴퓨터 판독가능 저장 매체로서 구현되는 것으로 고려될 수도 있다.
본원 발명에 대한 특정 수의 실시예들이 설명되었다. 그럼에도 불구하고, 본원 발명의 핵심 및 범위로부터 벗어남이 없이도 다양한 수정사항들이 가능할 수 있는 것으로 이해될 것이다. 예를 들어, 상기 설명된 단계들 중 일부는 순서에 독립적이고, 그러므로 설명된 순서와 상이한 순서로 수행될 수 있다.
선행하는 설명은 본원 발명의 설명을 위해 의도된 것일 뿐이고, 첨부된 청구범위의 범위에 의해 정의되는 본원 발명의 범위를 한정하는 것으로 이해될 수 없다. 예를 들어, 상기에서 설명된 기능의 단계들은 실질적으로 전체 처리에 영향을 미침이 없이도 상이한 순서로 수행될 수 있다. 다른 실시예들은 이하의 청구범위들의 범위에 포함된다.
Claims (16)
- 데이터 저장 시스템 내의 포맷(format) 정보에 기초하여 데이터 처리 시스템 내에서 처리하기 위한 데이터를 준비하는 방법으로서,
레코드(record)들을 포함하는 데이터를 수신하는 단계; 및
상기 데이터 처리 시스템 내의 상기 데이터의 처리를 위한 타겟 레코드 포맷(target record format)을 판정하는 단계
를 포함하고,
각각의 상기 레코드는 입력 장치 또는 포트를 통해 각 필드(field)들에 대한 하나 이상의 값들을 가지며,
상기 판정하는 단계는,
복수의 유효성 테스트(validation test)들에 따라 상기 데이터 내의 다수의 레코드들을 분석하여 상기 데이터가 상기 데이터 저장 시스템에 저장된 하나 이상의 후보 레코드 포맷에 매치하는지 여부를 판정하는 단계; 및
상기 유효성 테스트들의 결과들을 수신하는 경우에 응하여, 대응하는 적어도 하나의 유효성 테스트에 따라 적어도 일부의 매치가 판정된 선택된 후보 레코드 포맷, 데이터와 관련된 알려진 데이터 타입에 따라 선택된 파서에 의해 생성된 파싱된 레코드 포맷, 및 상기 데이터의 특성들의 분석으로부터 생성된 구성된 레코드 포맷 중 적어도 하나에 기초하여, 상기 타겟 레코드 포맷을 상기 데이터와 관련시키는 단계
를 포함하며,
각각의 상기 후보 레코드 포맷은 하나 이상의 필드로 된 그룹의 각 필드에 대한 포맷을 정하고 있고, 각각의 상기 유효성 테스트는 상기 데이터 저장 시스템에 저장된 적어도 하나의 후보 레코드 포맷에 대응하는,
방법. - 제1항에 있어서,
상기 타겟 레코드 포맷은, 하나 이상의 상기 후보 레코드 포맷들에 대한 적어도 일부의 매치를 판정한 유효성 테스트가 없는 것에 응하여, 상기 파싱된 레코드 포맷에 기초하여 상기 데이터와 관련되는, 방법. - 제2항에 있어서,
상기 데이터와 관련된 상기 알려진 데이터 타입은 상기 데이터의 파일 타입에 기초하여 인지되는, 방법. - 제3항에 있어서,
상기 데이터의 상기 파일 타입은 파일 확장자(file extension)에 대응하는, 방법. - 제1항에 있어서,
상기 타겟 레코드 포맷은, 하나 이상의 상기 후보 레코드 포맷들에 대한 적어도 일부의 매치를 판정한 유효성 테스트가 없고 또 상기 데이터와 관련된 알려진 데이터 타입을 가지지 않는 것에 응하여, 상기 구성된 레코드 포맷에 기초하여 상기 데이터와 관련되는, 방법. - 제5항에 있어서,
상기 데이터의 특성들의 분석으로부터 상기 구성된 레코드 포맷을 생성하는 과정은,
상기 데이터 내의 태그(tag)들을 인식하는 단계; 및
상기 인식된 태그들에 기초하여 상기 데이터를 파싱하여 다수의 레코드들을 판정하는 단계
를 포함하는, 방법. - 제5항에 있어서,
상기 데이터의 특성들의 분석으로부터 상기 구성된 레코드 포맷을 생성하는 과정은,
상기 데이터 내의 디리미터(delimiter)들을 인식하는 단계; 및
상기 인식된 디리미터들에 기초하여 상기 데이터를 분석하여 다수의 레코드들을 판정하는 단계
를 포함하는, 방법. - 제5항에 있어서,
상기 데이터의 특성들의 분석으로부터 상기 구성된 레코드 포맷을 생성하는 과정은,
상기 데이터가 다수의 레코드들의 값들을 지시하는 태그들 또는 디리미터들이 없는 실질적으로 바이너리 형태인 것을 인식하는 단계; 및
사용자 인터페이스로부터 하나 이상의 필드 식별자(identifier)들을 수신하는 단계
를 포함하는, 방법. - 제1항에 있어서,
상기 복수의 유효성 테스트들 중에서 제1 후보 레코드 포맷에 대응하는 제1 유효성 테스트에 따라, 상기 데이터 내의 다수의 레코드들을 분석하는 과정은, 상기 제1 후보 레코드 포맷을 상기 데이터에 적용하여 각 필드에 대해 상기 제1 후보 레코드 포맷에 의해 지정된 포맷들 내의 각 레코드에 대한 값들을 판정하는 단계를 포함하는, 방법. - 제9항에 있어서,
상기 데이터가 상기 제1 후보 레코드 포맷에 매치하는지 여부를 판정하는 과정은, 상기 제1 유효성 테스트에 따라 상기 다수의 레코드들에 대해 판정된 값들을 분석하여 유효 값의 수가 미리 정해진 임계치보다 더 큰지 여부를 판정하는 단계를 포함하는, 방법. - 제10항에 있어서,
상기 제1 유효성 테스트에 따라 상기 다수의 레코드들의 제1 레코드에 대해 판정된 값들을 분석하는 과정은, 각 필드에 대해 판정된 각 값에 대응하는 필드 테스트를 수행하는 단계를 포함하는, 방법. - 제11항에 있어서,
제1 필드에 대해 판정된 값에 제1 필드 테스트를 수행하는 단계는, 상기 판정된 값 내의 문자 수와 미리 정해진 문자 수를 매치하는 단계를 포함하는, 방법. - 제11항에 있어서,
상기 제1 필드에 대해 판정된 값에 제1 필드 테스트를 수행하는 단계는, 상기 미리 정해진 값을 상기 제1 필드에 대해 미리 정해진 다수의 유효 값들 중 하나와 매치하는 단계를 포함하는, 방법. - 제11항에 있어서,
상기 유효 값들의 수는, 주어진 필드에 대해 상기 판정된 값이 상기 주어진 필드에 대응하는 상기 필드 테스트를 통과하는 레코드들의 수에 기초하는, 방법. - 데이터 저장 시스템 내의 포맷(format) 정보에 기초하여 데이터 처리 시스템 내에서 처리하기 위한 데이터를 준비하는 시스템으로서,
입력 장치 또는 포트를 통해 레코드(record)들을 포함하는 데이터를 수신하는 수단; 및
상기 데이터 처리 시스템 내에서 상기 데이터를 처리하기 위한 타겟 레코드 포맷(target record format)을 판정하는 수단
을 포함하고,
각각의 상기 레코드는 각 필드(field)들에 대한 하나 이상의 값들을 가지며,
복수의 유효성 테스트(validation test)들에 따라 상기 데이터 내의 다수의 레코드들을 분석하여 상기 데이터가 상기 데이터 저장 시스템에 저장된 하나 이상의 후보 레코드 포맷에 매치하는지 여부를 판정하는 수단; 및
상기 유효성 테스트들의 결과들을 수신하는 것에 응하여, 대응하는 적어도 하나의 유효성 테스트에 따라 적어도 일부의 매치가 판정된 선택된 후보 레코드 포맷, 데이터와 관련된 알려진 데이터 타입에 따라 선택된 파서에 의해 생성된 파싱된 레코드 포맷, 및 상기 데이터의 특성들의 분석으로부터 생성된 구성된 레코드 포맷 중 적어도 하나에 기초하여, 상기 타겟 레코드 포맷을 상기 데이터와 관련시키는 수단
을 포함하며,
각각의 상기 후보 레코드 포맷은 하나 이상의 필드로 된 그룹의 각 필드에 대한 포맷을 정하고 있고, 각각의 상기 유효성 테스트는 상기 데이터 저장 시스템에 저장된 적어도 하나의 후보 레코드 포맷에 대응하는,
시스템. - 데이터 저장 시스템 내의 포맷(format) 정보에 기초하여 데이터 처리 시스템 내에서 처리하기 위한 데이터를 준비하는 컴퓨터 프로그램을 저장하는 컴퓨터 판독가능 매체로서,
컴퓨터로 하여금,
입력 장치 또는 포트를 통해 레코드(record)들을 포함하는 데이터를 수신하는 단계, 및
상기 데이터 처리 시스템 내에서 상기 데이터를 처리하기 위한 타겟 레코드 포맷(target record format)을 판정하는 단계
를 포함하고,
각각의 상기 레코드는 입력 장치 또는 포트를 통해 각 필드(field)들에 대한 하나 이상의 값들을 가지며,
상기 판정하는 단계는,
복수의 유효성 테스트(validation test)들에 따라 상기 데이터 내의 다수의 레코드들을 분석하여 상기 데이터가 상기 데이터 저장 시스템에 저장된 하나 이상의 후보 레코드 포맷에 매치하는지 여부를 판정하는 단계; 및
상기 유효성 테스트들의 결과들을 수신하는 것에 응하여, 대응하는 적어도 하나의 유효성 테스트에 따라 적어도 일부의 매치가 판정된 선택된 후보 레코드 포맷, 데이터와 관련된 알려진 데이터 타입에 따라 선택된 파서에 의해 생성된 파싱된 레코드 포맷, 및 상기 데이터의 특성들의 분석으로부터 생성된 구성된 레코드 포맷 중 적어도 하나에 기초하여, 상기 타겟 레코드 포맷을 상기 데이터와 관련시키는 단계
를 포함하며,
각각의 상기 후보 레코드 포맷은 하나 이상의 필드로 된 그룹의 각 필드에 대한 포맷을 정하고 있고, 각각의 상기 유효성 테스트는 상기 데이터 저장 시스템에 저장된 적어도 하나의 후보 레코드 포맷에 대응하는,
방법을 수행하게 하는 명령어들을 포함하는 컴퓨터 판독가능 매체.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US26099709P | 2009-11-13 | 2009-11-13 | |
| US61/260,997 | 2009-11-13 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR20157008411A Division KR20150042877A (ko) | 2009-11-13 | 2010-11-12 | 레코드 포맷 정보의 관리 |
| KR1020167033559A Division KR101755365B1 (ko) | 2009-11-13 | 2010-11-12 | 레코드 포맷 정보의 관리 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20120115233A true KR20120115233A (ko) | 2012-10-17 |
Family
ID=43992063
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR20157008411A KR20150042877A (ko) | 2009-11-13 | 2010-11-12 | 레코드 포맷 정보의 관리 |
| KR1020127013690A KR20120115233A (ko) | 2009-11-13 | 2010-11-12 | 레코드 포맷 정보의 관리 |
| KR1020167033559A KR101755365B1 (ko) | 2009-11-13 | 2010-11-12 | 레코드 포맷 정보의 관리 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR20157008411A KR20150042877A (ko) | 2009-11-13 | 2010-11-12 | 레코드 포맷 정보의 관리 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020167033559A KR101755365B1 (ko) | 2009-11-13 | 2010-11-12 | 레코드 포맷 정보의 관리 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US10445309B2 (ko) |
| EP (1) | EP2499565B1 (ko) |
| JP (1) | JP5690349B2 (ko) |
| KR (3) | KR20150042877A (ko) |
| CN (1) | CN102713834B (ko) |
| AU (1) | AU2010319344B2 (ko) |
| CA (1) | CA2779087C (ko) |
| WO (1) | WO2011060257A1 (ko) |
Families Citing this family (61)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| ATE515746T1 (de) | 2003-09-15 | 2011-07-15 | Ab Initio Technology Llc | Datenprofilierung |
| WO2010093933A1 (en) | 2009-02-13 | 2010-08-19 | Ab Initio Technology Llc | Communicating with data storage systems |
| US10845962B2 (en) | 2009-12-14 | 2020-11-24 | Ab Initio Technology Llc | Specifying user interface elements |
| US9031957B2 (en) | 2010-10-08 | 2015-05-12 | Salesforce.Com, Inc. | Structured data in a business networking feed |
| WO2012103438A1 (en) * | 2011-01-28 | 2012-08-02 | Ab Initio Technology Llc | Generating data pattern information |
| JP5838871B2 (ja) * | 2012-03-14 | 2016-01-06 | 富士通株式会社 | データ解析装置、データ分割装置、データ解析方法、データ分割方法、データ解析プログラム、及びデータ分割プログラム |
| US10489360B2 (en) * | 2012-10-17 | 2019-11-26 | Ab Initio Technology Llc | Specifying and applying rules to data |
| JP6207619B2 (ja) | 2012-10-22 | 2017-10-04 | アビニシオ テクノロジー エルエルシー | ソース追跡によるデータのプロファイリング |
| US9892026B2 (en) | 2013-02-01 | 2018-02-13 | Ab Initio Technology Llc | Data records selection |
| US9811233B2 (en) | 2013-02-12 | 2017-11-07 | Ab Initio Technology Llc | Building applications for configuring processes |
| US9268801B2 (en) * | 2013-03-11 | 2016-02-23 | Business Objects Software Ltd. | Automatic file structure and field data type detection |
| US10803102B1 (en) * | 2013-04-30 | 2020-10-13 | Walmart Apollo, Llc | Methods and systems for comparing customer records |
| US9355136B2 (en) | 2013-05-06 | 2016-05-31 | International Business Machines Corporation | Automating generation of messages in accordance with a standard |
| US9588956B2 (en) | 2013-07-12 | 2017-03-07 | Ab Initio Technology Llc | Parser generation |
| US11487732B2 (en) | 2014-01-16 | 2022-11-01 | Ab Initio Technology Llc | Database key identification |
| AU2015225694B2 (en) | 2014-03-07 | 2019-06-27 | Ab Initio Technology Llc | Managing data profiling operations related to data type |
| CN104008158A (zh) * | 2014-05-27 | 2014-08-27 | 青岛海信移动通信技术股份有限公司 | 数据校验方法、校验装置及移动终端 |
| US9501570B2 (en) * | 2014-07-14 | 2016-11-22 | Verizon Patent And Licensing Inc. | Dynamic routing system |
| EP3191962B1 (en) | 2014-07-18 | 2019-12-11 | AB Initio Technology LLC | Managing parameter sets |
| SG11201703061XA (en) * | 2014-10-20 | 2017-05-30 | Ab Initio Technology Llc | Specifying and applying rules to data |
| CN104408104B (zh) * | 2014-11-20 | 2017-12-29 | 许继电气股份有限公司 | 一种智能变电站网络数据通信方法 |
| CN104850590A (zh) * | 2015-04-24 | 2015-08-19 | 百度在线网络技术(北京)有限公司 | 一种生成结构化数据的元数据的方法与装置 |
| US10248720B1 (en) | 2015-07-16 | 2019-04-02 | Tableau Software, Inc. | Systems and methods for preparing raw data for use in data visualizations |
| CN108351898B (zh) * | 2015-10-30 | 2021-10-08 | 安客诚公司 | 用于结构化多字段文件布局的自动化解释 |
| US9372881B1 (en) * | 2015-12-29 | 2016-06-21 | International Business Machines Corporation | System for identifying a correspondence between a COBOL copybook or PL/1 include file and a VSAM or sequential dataset |
| EP3475857A1 (en) * | 2016-06-23 | 2019-05-01 | Koninklijke Philips N.V. | Facilitated structured measurement management tool progress and compliance analytics solution |
| US10484382B2 (en) * | 2016-08-31 | 2019-11-19 | Oracle International Corporation | Data management for a multi-tenant identity cloud service |
| US10846390B2 (en) | 2016-09-14 | 2020-11-24 | Oracle International Corporation | Single sign-on functionality for a multi-tenant identity and data security management cloud service |
| US10594684B2 (en) | 2016-09-14 | 2020-03-17 | Oracle International Corporation | Generating derived credentials for a multi-tenant identity cloud service |
| US10511589B2 (en) | 2016-09-14 | 2019-12-17 | Oracle International Corporation | Single logout functionality for a multi-tenant identity and data security management cloud service |
| EP3513542B1 (en) | 2016-09-16 | 2021-05-19 | Oracle International Corporation | Tenant and service management for a multi-tenant identity and data security management cloud service |
| US10484243B2 (en) | 2016-09-16 | 2019-11-19 | Oracle International Corporation | Application management for a multi-tenant identity cloud service |
| US10445395B2 (en) | 2016-09-16 | 2019-10-15 | Oracle International Corporation | Cookie based state propagation for a multi-tenant identity cloud service |
| US10904074B2 (en) | 2016-09-17 | 2021-01-26 | Oracle International Corporation | Composite event handler for a multi-tenant identity cloud service |
| US20180165308A1 (en) * | 2016-12-12 | 2018-06-14 | Sap Se | Deriving a data structure for a process model software |
| US10204119B1 (en) * | 2017-07-20 | 2019-02-12 | Palantir Technologies, Inc. | Inferring a dataset schema from input files |
| US20190050384A1 (en) * | 2017-08-08 | 2019-02-14 | Ab Initio Technology Llc | Techniques for dynamically defining a data record format |
| US10831789B2 (en) | 2017-09-27 | 2020-11-10 | Oracle International Corporation | Reference attribute query processing for a multi-tenant cloud service |
| US10705823B2 (en) | 2017-09-29 | 2020-07-07 | Oracle International Corporation | Application templates and upgrade framework for a multi-tenant identity cloud service |
| US11423083B2 (en) | 2017-10-27 | 2022-08-23 | Ab Initio Technology Llc | Transforming a specification into a persistent computer program |
| US10599668B2 (en) | 2017-10-31 | 2020-03-24 | Secureworks Corp. | Adaptive parsing and normalizing of logs at MSSP |
| WO2019089888A1 (en) | 2017-11-01 | 2019-05-09 | Walmart Apollo, Llc | Systems and methods for dynamic hierarchical metadata storage and retrieval |
| US11055074B2 (en) * | 2017-11-13 | 2021-07-06 | Ab Initio Technology Llc | Key-based logging for processing of structured data items with executable logic |
| US11068540B2 (en) | 2018-01-25 | 2021-07-20 | Ab Initio Technology Llc | Techniques for integrating validation results in data profiling and related systems and methods |
| US10715564B2 (en) | 2018-01-29 | 2020-07-14 | Oracle International Corporation | Dynamic client registration for an identity cloud service |
| US11494454B1 (en) | 2018-05-09 | 2022-11-08 | Palantir Technologies Inc. | Systems and methods for searching a schema to identify and visualize corresponding data |
| CN116432604A (zh) * | 2018-09-06 | 2023-07-14 | 创新先进技术有限公司 | 一种数据校验方法、装置及电子设备 |
| US11321187B2 (en) | 2018-10-19 | 2022-05-03 | Oracle International Corporation | Assured lazy rollback for a multi-tenant identity cloud service |
| KR102004948B1 (ko) * | 2018-12-18 | 2019-07-29 | 이지지아이에스 주식회사 | 빅데이터 기계 학습을 활용한 위치기반 입지 예측 분석 장치 및 그 방법 |
| US11792226B2 (en) | 2019-02-25 | 2023-10-17 | Oracle International Corporation | Automatic api document generation from scim metadata |
| US11423111B2 (en) | 2019-02-25 | 2022-08-23 | Oracle International Corporation | Client API for rest based endpoints for a multi-tenant identify cloud service |
| US10769220B1 (en) * | 2019-04-09 | 2020-09-08 | Coupang Corp. | Systems, apparatuses, and methods of processing and managing web traffic data |
| US11218500B2 (en) | 2019-07-31 | 2022-01-04 | Secureworks Corp. | Methods and systems for automated parsing and identification of textual data |
| US11870770B2 (en) | 2019-09-13 | 2024-01-09 | Oracle International Corporation | Multi-tenant identity cloud service with on-premise authentication integration |
| US11687378B2 (en) | 2019-09-13 | 2023-06-27 | Oracle International Corporation | Multi-tenant identity cloud service with on-premise authentication integration and bridge high availability |
| US11836122B2 (en) * | 2019-12-19 | 2023-12-05 | Capital One Services, Llc | Schema validation with data synthesis |
| CN111765904B (zh) * | 2020-06-29 | 2023-12-15 | 北京百度网讯科技有限公司 | 自动驾驶车辆的测试方法、装置、电子设备和介质 |
| SG10202008564PA (en) * | 2020-09-03 | 2021-12-30 | Grabtaxi Holdings Pte Ltd | Data Base System and Method for Maintaining a Data Base |
| US20230367794A1 (en) * | 2020-10-05 | 2023-11-16 | R2Dio, Inc. | Methods and systems associated with a data input platform and differential graph representations |
| CN116245108B (zh) * | 2022-11-25 | 2023-09-26 | 北京瑞风协同科技股份有限公司 | 验证匹配导向方法、验证匹配导向器、设备及存储介质 |
| CN116521063B (zh) * | 2023-03-31 | 2024-03-26 | 北京瑞风协同科技股份有限公司 | 一种hdf5的试验数据高效读写方法及装置 |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU631276B2 (en) | 1989-12-22 | 1992-11-19 | Bull Hn Information Systems Inc. | Name resolution in a directory database |
| WO1999044157A1 (en) | 1998-02-26 | 1999-09-02 | Sun Microsystems, Inc. | Method and system for multi-entry and multi-template matching in a database |
| US20010056362A1 (en) * | 1998-07-29 | 2001-12-27 | Mike Hanagan | Modular, convergent customer care and billing system |
| US6549918B1 (en) * | 1998-09-21 | 2003-04-15 | Microsoft Corporation | Dynamic information format conversion |
| US8335775B1 (en) | 1999-08-05 | 2012-12-18 | Oracle International Corporation | Versioning in internet file system |
| JP2001101049A (ja) * | 1999-09-28 | 2001-04-13 | Mitsubishi Electric Corp | ファイル復元装置 |
| US7120636B2 (en) | 2001-07-25 | 2006-10-10 | Pendleton William W | Method of communicating data between computers having different record formats |
| US20050192844A1 (en) * | 2004-02-27 | 2005-09-01 | Cardiac Pacemakers, Inc. | Systems and methods for automatically collecting, formatting, and storing medical device data in a database |
| US20060015511A1 (en) * | 2004-07-16 | 2006-01-19 | Juergen Sattler | Method and system for providing an interface to a computer system |
| US20080141112A1 (en) | 2004-10-27 | 2008-06-12 | Jumpei Aoki | Document Processing Device and Document Processing Method |
| US7870221B2 (en) * | 2004-12-20 | 2011-01-11 | Adobe Systems Incorporated | Multiple bindings in web service data connection |
| US7526486B2 (en) * | 2006-05-22 | 2009-04-28 | Initiate Systems, Inc. | Method and system for indexing information about entities with respect to hierarchies |
| JP2008305348A (ja) | 2007-06-11 | 2008-12-18 | Canon Inc | 情報処理装置、情報処理方法、コンピュータプログラム、画像形成システム |
| US7904491B2 (en) * | 2007-07-18 | 2011-03-08 | Sap Ag | Data mapping and import system |
| JP5064943B2 (ja) * | 2007-09-05 | 2012-10-31 | 株式会社リコー | 情報処理装置、情報処理方法及び情報処理プログラム |
| PT2460113T (pt) * | 2009-07-29 | 2017-10-13 | Reversinglabs Corp | Desempacotamento automático de ficheiros executáveis portáteis |
-
2010
- 2010-11-12 JP JP2012539018A patent/JP5690349B2/ja active Active
- 2010-11-12 CN CN201080061493.XA patent/CN102713834B/zh active Active
- 2010-11-12 EP EP10830784.4A patent/EP2499565B1/en active Active
- 2010-11-12 CA CA2779087A patent/CA2779087C/en active Active
- 2010-11-12 KR KR20157008411A patent/KR20150042877A/ko not_active Application Discontinuation
- 2010-11-12 WO PCT/US2010/056530 patent/WO2011060257A1/en active Application Filing
- 2010-11-12 KR KR1020127013690A patent/KR20120115233A/ko not_active Application Discontinuation
- 2010-11-12 US US12/945,094 patent/US10445309B2/en active Active
- 2010-11-12 KR KR1020167033559A patent/KR101755365B1/ko active IP Right Grant
- 2010-11-12 AU AU2010319344A patent/AU2010319344B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| EP2499565B1 (en) | 2019-01-09 |
| CN102713834B (zh) | 2016-03-30 |
| JP2013511097A (ja) | 2013-03-28 |
| CA2779087C (en) | 2019-08-20 |
| CN102713834A (zh) | 2012-10-03 |
| JP5690349B2 (ja) | 2015-03-25 |
| EP2499565A4 (en) | 2017-01-04 |
| AU2010319344B2 (en) | 2014-10-09 |
| KR101755365B1 (ko) | 2017-07-10 |
| EP2499565A1 (en) | 2012-09-19 |
| CA2779087A1 (en) | 2011-05-19 |
| KR20160141872A (ko) | 2016-12-09 |
| US10445309B2 (en) | 2019-10-15 |
| US20110153667A1 (en) | 2011-06-23 |
| KR20150042877A (ko) | 2015-04-21 |
| WO2011060257A1 (en) | 2011-05-19 |
| AU2010319344A1 (en) | 2012-05-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101755365B1 (ko) | 레코드 포맷 정보의 관리 | |
| US10177996B2 (en) | System and method for validating documentation of representational state transfer (REST) services | |
| CN110383238B (zh) | 用于基于模型的软件分析的系统和方法 | |
| US7596748B2 (en) | Method for validating a document conforming to a first schema with respect to a second schema | |
| US8386498B2 (en) | Message descriptions | |
| CN111522816A (zh) | 基于数据库引擎的数据处理方法、装置、终端及介质 | |
| US8250526B2 (en) | Method for analyzing an XACML policy | |
| US8949166B2 (en) | Creating and processing a data rule for data quality | |
| US7451394B2 (en) | System and method for document and data validation | |
| US10789295B2 (en) | Pattern-based searching of log-based representations of graph databases | |
| US20150261507A1 (en) | Validating sql queries in a report | |
| JP2018505506A (ja) | 機械ベースの命令編集 | |
| US9390073B2 (en) | Electronic file comparator | |
| WO2021022703A1 (zh) | 软件项目重构方法、装置、计算机装置及存储介质 | |
| Zhu et al. | A neural network architecture for program understanding inspired by human behaviors | |
| CN114385148A (zh) | 一种实现联动功能的方法、装置、设备和存储介质 | |
| KR100762712B1 (ko) | 규칙기반의 전자문서 변환방법 및 그 시스템 | |
| CN113672233B (zh) | 一种基于Redfish的服务器带外管理方法、装置及设备 | |
| US20100057704A1 (en) | Automatic Test Map Generation for System Verification Test | |
| US20110093774A1 (en) | Document transformation | |
| CN116362230A (zh) | 参数校验方法、装置、计算机设备可存储介质 | |
| CN117435189A (zh) | 金融系统接口的测试用例分析方法、装置、设备及介质 | |
| JP2009259141A (ja) | アプリケーションプログラム作成支援装置、データベースシステム、アプリケーションプログラム作成支援方法およびそのプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| A107 | Divisional application of patent | ||
| E902 | Notification of reason for refusal | ||
| E601 | Decision to refuse application |