JP7484504B2 - 制御装置、制御方法及びプログラム - Google Patents
制御装置、制御方法及びプログラム Download PDFInfo
- Publication number
- JP7484504B2 JP7484504B2 JP2020116255A JP2020116255A JP7484504B2 JP 7484504 B2 JP7484504 B2 JP 7484504B2 JP 2020116255 A JP2020116255 A JP 2020116255A JP 2020116255 A JP2020116255 A JP 2020116255A JP 7484504 B2 JP7484504 B2 JP 7484504B2
- Authority
- JP
- Japan
- Prior art keywords
- action
- target deviation
- change amount
- value
- control
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 53
- 230000009471 action Effects 0.000 claims description 135
- 230000008859 change Effects 0.000 claims description 85
- 230000002787 reinforcement Effects 0.000 claims description 52
- 238000006243 chemical reaction Methods 0.000 claims description 40
- 238000004364 calculation method Methods 0.000 claims description 32
- 230000006870 function Effects 0.000 claims description 31
- 230000008569 process Effects 0.000 claims description 25
- 238000002156 mixing Methods 0.000 claims description 19
- 230000009466 transformation Effects 0.000 claims description 10
- 238000013528 artificial neural network Methods 0.000 claims description 9
- PXFBZOLANLWPMH-UHFFFAOYSA-N 16-Epiaffinine Natural products C1C(C2=CC=CC=C2N2)=C2C(=O)CC2C(=CC)CN(C)C1C2CO PXFBZOLANLWPMH-UHFFFAOYSA-N 0.000 claims description 7
- 238000001914 filtration Methods 0.000 claims 5
- 230000001131 transforming effect Effects 0.000 claims 3
- 230000006399 behavior Effects 0.000 description 31
- WQZGKKKJIJFFOK-VSOAQEOCSA-N L-altropyranose Chemical compound OC[C@@H]1OC(O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-VSOAQEOCSA-N 0.000 description 16
- 238000010586 diagram Methods 0.000 description 16
- 238000011156 evaluation Methods 0.000 description 13
- 230000004044 response Effects 0.000 description 9
- 238000005259 measurement Methods 0.000 description 6
- 238000004891 communication Methods 0.000 description 4
- 239000000203 mixture Substances 0.000 description 4
- 238000012545 processing Methods 0.000 description 4
- 238000004378 air conditioning Methods 0.000 description 2
- 238000001816 cooling Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 230000000116 mitigating effect Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 238000012549 training Methods 0.000 description 1
Images













Description
本発明は、制御装置、制御方法及びプログラムに関する。
近年、機械学習の1つとして、深層強化学習と呼ばれる手法が広く知られるようになってきた。深層強化学習とは、従来から知られていた強化学習と、多層のニューラルネットワークを学習する手法である深層学習とを組み合わせることで、或る環境下における複雑な最適行動を獲得する手法である。
強化学習の産業分野への応用例としては、例えば、エネルギーマネジメント分野への応用(例えば、特許文献1)やプラント制御への応用(例えば、特許文献2)、自動車の自動運転への応用(例えば、特許文献3)等が知られている。
また、産業上広く利用されている制御装置として、温調制御装置やPLC(Programmable Logic Controller)、DCS(Distributed Control System)等が知られている。このような制御装置に用いられる制御方式として、PID(Proportional-Integral-Differential)制御、モデル予測制御(MPC:Model-Predictive-Control)、内部モデル制御、LQG(Linear-Quadratic-Gaussian)制御、H2制御、H∞制御等が知られている。これらの制御方式は、制御対象の制御量を目標値に追従させることを目的とする制御方式である。
また、現在に至るまでの過去の操作量の変化に応じた制御量の収束値の予測値と、目標値との差である補正目標偏差に基づいて、新たな操作量を決定する技術が知られている(例えば、特許文献4)。
上記の特許文献1~3に記載されている応用例に示されるように深層強化学習は強力な手法である一方で、良い制御則を獲得するためには様々な状況で何度も学習を行う必要があり、非常に時間を要する。また、制御量が目標値に追従する追従性能のみを追求すると、操作量が頻繁に変化してしまう場合があり、例えば、アクチュエーターの故障に繋がったり、過度に振動を励起してしまったりすることがある。なお、これに対して、強化学習における報酬関数に対して、操作量の変化頻度を評価した関数値に重みを乗算したものを加算することで、操作量の変化を緩和する方法も考えられるが、一般にどの程度の重みを用いればよいかが不明であり、重みを何度も変えて繰り返し学習させる必要があり、非常に時間を要する。
本発明の一実施形態は、上記の点に鑑みてなされたもので、深層強化学習によって制御対象を制御する際の操作量の変化を緩和することを目的とする。
上記目的を達成するため、一実施形態に係る制御装置は、制御対象に対する操作量を出力し、前記制御対象の制御量を目標値に追従させる制御装置であって、現在の制御量と目標値との差分である目標偏差を算出する目標偏差算出手段と、前記目標偏差に対して所定のフィルタ処理を行って、前記目標偏差を補正した補正目標偏差を算出するフィルタ手段と、前記補正目標偏差に基づいて、強化学習によって新たな操作変化量を学習及び算出する操作変化量算出手段と、前記操作変化量を現在の操作量に加算する加算手段と、を有することを特徴とする。
深層強化学習によって制御対象を制御する際の操作量の変化を緩和することができる。
以下、本発明の一実施形態について説明する。以降の各実施形態では、深層強化学習によって制御対象を制御し、かつ、この際の操作量の変化を緩和することが可能な制御装置10について説明する。以降の各実施形態に係る制御装置10は、深層強化学習によって求められた最適行動と、予め決めておいた事前行動とを或る重みでブレンドすることで、このブレンド後の行動により操作量の変化量を決定する。また、このブレンドの際に、当該制御装置10は、行動価値関数を評価した評価値を用いて適切な重みを計算する。これにより、適切な重みが不明となることなく、操作量の変化を緩和することが可能になる。
ここで、以降の各実施形態に係る制御装置10は、制御対象の運用開始前に制御対象モデルを用いて深層強化学習による学習を十分に行った上で、実際に制御対象を運用する際には、この事前学習の結果を初期値として、適宜、深層強化学習による学習を行う。これにより、制御対象の特性を担保しつつ、制御対象の特性の変化等にも柔軟に対応可能な自動学習型の制御を実現することができる。
なお、以降の各実施形態に係る制御装置10は、例えば、PLCやDCS、組み込み型の計算機器等を想定するが、これらに限られず、制御対象を操作するための任意の機器又は装置を用いることができる。例えば、プラント制御、インバータ制御、機械制御、電気制御、信号制御、空調制御、温調制御等の各種制御に用いられる制御機器又は制御装置を用いることが可能である。
また、以降の各実施形態では、一例として、SISO(single-input and single-output)制御である場合について説明するが、これに限られず、例えば、MIMO(multiple-input and multiple-output)制御に対しても同様に適用することが可能である。
[第一の実施形態]
まず、第一の実施形態について説明する。
まず、第一の実施形態について説明する。
<制御装置10の全体構成>
まず、本実施形態に係る制御装置10の全体構成について、図1を参照しながら説明する。図1は、第一の実施形態に係る制御装置10の全体構成の一例を示す図である。
まず、本実施形態に係る制御装置10の全体構成について、図1を参照しながら説明する。図1は、第一の実施形態に係る制御装置10の全体構成の一例を示す図である。
図1に示すように、本実施形態に係る制御装置10は、計測部101と、差分器102と、操作量更新部103と、タイマ104とを有する。これら各機能部は、例えば、制御装置10にインストールされた1以上のプログラムがプロセッサ等に実行させる処理によって実現される。
計測部101は、所定の制御周期Tc毎に、制御対象モデル20又は制御対象30の制御量yを計測し、計測した制御量yの最新の値を制御量現在値y0(t)として出力する。また、計測部101は、制御周期Tc毎に、操作量更新部103から出力された操作量uを取得し、取得した操作量uの最新の値を操作量現在値u0(t)として出力する。
ここで、制御対象30は、実際の制御対象(すなわち、例えば、実際に制御の対象となるプラントやインバータ、機械、電気設備、信号設備、空調設備、温調設備等)である。一方で、制御対象モデル20は、制御対象30のモデル(すなわち、制御対象30をモデル化したデータ)のことである。制御対象モデル20は、制御装置10が有する補助記憶装置等のメモリに格納されていてもよいし、制御装置10とは異なる他の装置が有するメモリに格納されていてもよい。
なお、制御対象モデル20の制御量yは、操作量uと疑似外乱v´とに応じて決定される。一方で、制御対象30の制御量yは、操作量uと外乱vとに応じて決定される。疑似外乱v´とは外乱vに相当する値を制御対象モデル20に与えたものである。外乱vとしては、例えば、制御対象30が温調設備、制御量yが温度である場合における外気温の低下又は上昇等が挙げられる。
差分器102は、目標値r(t)と制御量現在値y0(t)との差を目標偏差e0(t)として出力する。すなわち、e0(t)=r(t)-y0(t)である。
操作量更新部103は、制御周期Tc毎に、制御対象モデル20又は制御対象30に対する操作量uを出力する。ここで、操作量更新部103には、フィルタ部111と、操作量学習・計算部112と、加算器113とが含まれる。
フィルタ部111は、目標偏差e0(t)に対してフィルタ処理を行い、補正目標偏差e*(t)を出力する。フィルタ処理としては、例えば、定数倍する処理、微分値を計算する処理、積分値を計算する処理、移動平均値を計算する処理、過去の目標偏差の時系列を組み合わせる処理、又はこれらの任意の組み合わせ等が挙げられる。
例えば、定数倍する処理と微分値を計算する処理とを組わせる場合は、cを定数として、

また、例えば、過去の目標偏差の時系列を組み合わせる処理は、Lを出力ベクトルの次元数として、

操作量学習・計算部112は、制御周期Tc毎に、フィルタ部111から出力された補正目標偏差e*(t)に基づいて、操作変化量du(t)を算出する。このとき、操作量学習・計算部112は、操作変化量du(t)の算出と同時に、深層強化学習による学習も行うことができる。操作変化量du(t)の算出の詳細については後述する。
ここで、操作量学習・計算部112は、例えば、du(t-3Tc)、du(t-2Tc)、du(t-Tc)という順序で操作変化量du(t)を算出し、出力する。なお、操作変化量duは、制御周期Tc毎に操作量uが変化した量である。
加算器113は、計測部101から出力された操作量現在値u0と、操作量学習・計算部112から出力された操作変化量duとを加算して、新たな操作量uを算出する。そして、加算器113は、この操作量uを制御対象モデル20又は制御対象30に出力する。この操作量uは、u(t)=u0+du(t)=u(t-Tc)+du(t)で算出される。
なお、本実施形態に係る制御装置10では、加算器113で算出した操作量uをそのまま制御対象モデル20又は制御対象30に出力しているが、例えば、操作量uに上下限制約が存在する場合等には、別途リミッター等を設けた上で、加算器113で算出した操作量uをリミッターに入力し、当該リミッターから出力された操作量を制御対象モデル20又は制御対象30に出力してもよい。
タイマ104は、制御周期Tc毎に、計測部101と操作量更新部103とを動作させる。
また、本実施形態に係る制御装置10は、制御対象モデル20と制御対象30とを切り替えるための切替器40及び切替器50と接続されている。切替器40及び切替器50により、制御装置10は、制御対象モデル20又は制御対象30のいずれかと閉ループを構成する。ここで、本実施形態に係る制御装置10は、制御対象30の運用開始前に、制御対象モデル20と閉ループを構成した上で、深層強化学習による学習を行う。一方で、本実施形態に係る制御装置10は、実際の運用では、制御対象30と閉ループを構成した上で、適宜、深層強化学習による学習を行う。
このように、本実施形態に係る制御装置10は、実際の運用開始前に制御対象モデル20を用いて深層強化学習による学習を行う。そして、本実施形態に係る制御装置10は、制御対象モデル20を用いた学習結果を初期値として、制御対象30の制御を行うと共に、適宜、深層強化学習による学習を行う。すなわち、本実施形態に係る制御装置10では、操作量学習・計算部112が或る程度学習した状態から制御対象30の運用を開始することができる。これにより、制御対象30の特性を担保しつつ、制御対象30の特性の変化等にも柔軟に対応可能な自動学習型の制御を実現することができる。
<操作量学習・計算部112の動作>
次に、操作量学習・計算部112の動作について、図2を参照しながら説明する。図2は、操作量学習・計算部112の動作の一例を説明するための図である。
次に、操作量学習・計算部112の動作について、図2を参照しながら説明する。図2は、操作量学習・計算部112の動作の一例を説明するための図である。
図2に示すように、操作量学習・計算部112は、補正目標偏差e*(t)を入力して、操作変化量du(t)を出力する。ここで、操作量学習・計算部112には、報酬計算部121と、目標偏差・状態変換部122と、強化学習部123と、行動・操作変化量変換部124とが含まれる。
報酬計算部121は、補正目標偏差e*(t)を入力して、深層強化学習に必要な報酬R(t)を計算する。ここで、報酬R(t)としては、例えば、補正目標偏差e*(t)のノルムに-1を掛けた値(つまり、R(t)=-||e*(t)||)としてもよいし、補正目標偏差e*(t)のノルムの2乗に-1を掛けた値(つまり、R(t)=-||e*(t)||2)としてもよいし、任意の所定の関数に対する補正目標偏差e*(t)の関数値(つまり、当該関数をfとして、R(t)=f(e*(t)))としてもよい。ただし、報酬R(t)としては補正目標偏差e*(t)を用いていればよく、上記に限られず、他に報酬R(t)に含まれる値があってもよい。なお、ノルムやノルムの2乗に-1を掛けているのは深層強化学習では一般に報酬の最大化を行うためであり、一方で補正目標偏差は小さい方が望ましいためである。
目標偏差・状態変換部122は、補正目標偏差e*(t)を入力して、深層強化学習の状態s(t)を生成する。この状態s(t)には、補正目標偏差e*(t)が含まれる。状態s(t)は、補正目標偏差e*(t)そのものを状態s(t)としてもよいし、補正目標偏差e*(t)に対して任意の変換を施したものを用いてもよいし、又は補正目標偏差e*(t)に加えて、制御量や操作量を含めたり、その他制御対象から観測される観測値を含めたりしてもよい。なお、状態s(t)は、「状態変数s(t)」と称されてもよい。
強化学習部123は、報酬R(t)と状態s(t)とを入力して、行動a(t)を出力すると共に学習を行う。
ここで、例えば、学習を一定の間隔毎に周期的に行うような場合、強化学習部123には、学習周期を示す指令が入力されてもよい。また、例えば、学習の開始又は停止を制御するような場合、強化学習部123には、学習開始又は学習停止を示す指令が入力されてもよい。
行動・操作変化量変換部124は、強化学習部123により出力された行動a(t)を操作変化量du(t)に変換する。
<強化学習部123の動作>
次に、強化学習部123の動作について、図3を参照しながら説明する。図3は、強化学習部123の動作の一例を説明するための図である。
次に、強化学習部123の動作について、図3を参照しながら説明する。図3は、強化学習部123の動作の一例を説明するための図である。
図3に示すように、強化学習部123は、報酬R(t)と状態s(t)とを入力して、行動a(t)を出力する。また、強化学習部123は、行動価値関数Q(s,a)を更新することで学習を行う。行動価値関数Q(s,a)とは、状態s(t)において行動a(t)をとった際に期待される価値を表す関数のことである。ここで、強化学習部123には、行動価値関数更新部131と、行動選択部132とが含まれる。
行動価値関数更新部131は、行動価値関数Q(s,a)を更新する。ここで、深層強化学習では、行動価値関数Q(s,a)が多層のニューラルネットワーク(多層のニューラルネットワークは「ディープニューラルネットワーク」とも称される。)で実現される。したがって、行動価値関数更新部131には、ニューラルネットワークのパラメータ(例えば、セル数、層数、入出力次元等)が与えられる。また、これ以外にも、行動価値関数更新部131には、将来の価値をどの程度割り引いて評価するかを示す割引率γも与えられる。なお、上述したように、学習周期や学習開始/終了を示す指令が与えられてもよい。
行動価値関数更新部131が行動価値関数Q(s,a)を更新するためのアルゴリズムとしては、例えば、TD(Temporal Difference)誤差法(又は、「TD学習」と称されることもある。)等の既知の深層強化学習の手法を用いることができる。
行動選択部132は、行動価値関数Q(s,a)を参照して、現在の状態s(t)に対して、適切な行動a(t)を選択する。行動選択部132が行動a(t)を選択するためのアルゴリズムとしては、例えば、ε-Greedy法等の既知の深層強化学習の手法を用いることができる。なお、ε-Greedy法を用いる場合、0以上1以下の値を取るεを行動選択パラメータとして設定する。
なお、本実施形態では、深層強化学習の手法として、DQN(Deep Q-Network)法と呼ばれる手法を用いているが、これに限られず、例えば、PG(Policy Gradient)法やAC(Actor Critic)法等の既知の深層強化学習の手法が用いられてもよい。
<行動aの選択>
次に、一例として、或る時刻tにおいて、ε-Greedy法により行動選択部132が行動a=a(t)を選択する場合について説明する。
次に、一例として、或る時刻tにおいて、ε-Greedy法により行動選択部132が行動a=a(t)を選択する場合について説明する。
行動選択部132は、行動価値関数Q(s,a)を参照して、現在の状態s(t)に対して、適切な行動a(t)を選択するが、一定の確率1-εで最適な行動をa*(t)を選択する一方で、残りの一定の確率εでランダムな行動を選択する。すなわち、行動選択部132は、

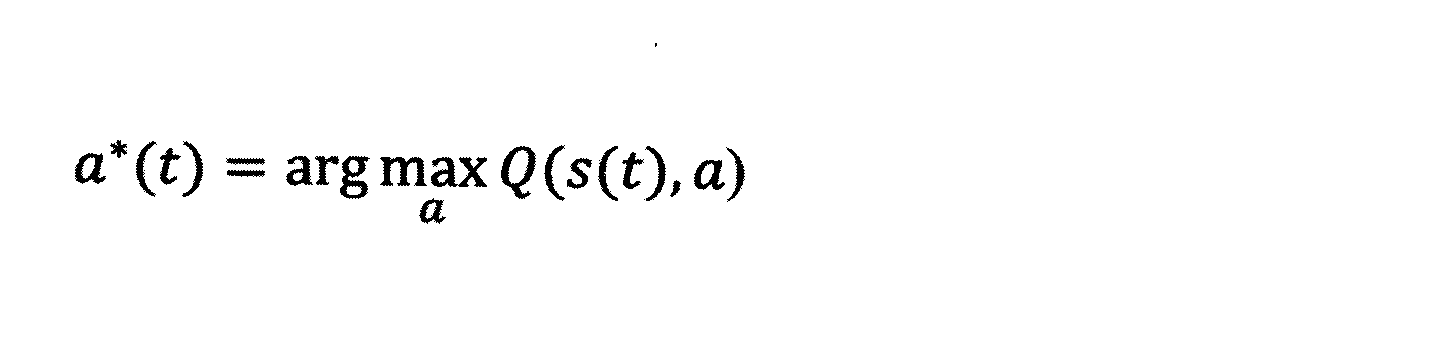
このように、ε-Greedy法では、行動選択パラメータεはランダムに新しい行動を探索するための調整パラメータを意味する。
<操作変化量duへの変換>
次に、行動a(t)を操作変化量du(t)に変換する場合の詳細について説明する。行動・操作変化量変換部124は、図4に示す行動・操作変化量変換処理を実行することで、行動a(t)を操作変化量du(t)に変換する。図4は、第一の実施形態に係る行動・操作変化量変換処理の一例を示すフローチャートである。
次に、行動a(t)を操作変化量du(t)に変換する場合の詳細について説明する。行動・操作変化量変換部124は、図4に示す行動・操作変化量変換処理を実行することで、行動a(t)を操作変化量du(t)に変換する。図4は、第一の実施形態に係る行動・操作変化量変換処理の一例を示すフローチャートである。
まず、行動・操作変化量変換部124は、行動選択部132により選択された行動a(t)が最適行動a*(t)であるか否かを判定する(ステップS101)。
上記のステップS101で行動a(t)が最適行動a*(t)であると判定された場合、行動・操作変化量変換部124は、行動集合Aの中から1つの行動を選択し、選択した行動を事前行動apre(t)として設定する(ステップS102)。行動集合Aは行動選択部132により選択され得る行動の集合であり、例えば、行動選択部132より選択され得る行動の総数をnとすれば、A={a1,a2,・・・,an}と表される。ここで、行動・操作変化量変換部124は行動集合Aの中から任意の方法で1つの行動を選択すればよいが、例えば、これまでの操作を継続して変化させない行動を選択する、前回とった行動を継続して選択する、制御対象30が安全側に触れるような行動を選択する、等が考えられる。
次に、行動・操作変化量変換部124は、上記のステップS102で設定した事前行動apre(t)の評価値qpre(t)を計算する(ステップS103)。ここで、行動・操作変化量変換部124は、行動価値関数Q(s,a)と現在の状態s(t)とを用いて、qpre(t)=Q(s(t),apre(t))により評価値qpre(t)を計算する。
次に、行動・操作変化量変換部124は、最適行動a*(t)と事前行動apre(t)とを重みw(t)でブレンド(配分)したブレンド行動aalt(t)を生成する(ステップS104)。ここで、行動・操作変化量変換部124は、以下によりブレンド行動aalt(t)を生成する。


ここで、上記の重みw(t)の計算方法の一例について、図5を参照しながら説明する。図5は、ブレンド行動生成における重みの一例を説明するための図である。図5に示す例では、最適行動をa*(t)=ai、事前行動をapre(t)=ai+1、qworst(t)となる行動をaworstとしている。図5に示されるように、重みw(t)を計算する際には、q*(t)-b(t)の大きさとqpre(t)-b(t)の大きさとの比率でブレンドの比率が決定される。
したがって、例えば、δ=0の場合において、q*(t)-b(t)とqpre(t)-b(t)とが同一の値であれば等配分となるし、qpre(t)-b(t)=0であればaalt(t)=a*(t)となる。よって、評価最悪値b(t)を基準として、最適行動の評価値と事前行動の評価値とを比率で比較して適切な重みw(t)を自動的に決定することができる。
一方で、上記のステップS101で行動a(t)が最適行動a*(t)であると判定されなかった場合、行動・操作変化量変換部124は、行動選択部132により選択された行動a(t)をブレンド行動aalt(t)とする(ステップS105)。
ステップS104又はステップS105に続いて、行動・操作変化量変換部124は、アフィン変換によりブレンド行動aalt(t)を操作変化量du(t)に変換する(ステップS106)。行動・操作変化量変換部124は、du(t)=c1・aalt(t)+c0によりブレンド行動aalt(t)を操作変化量du(t)に変換する。c1は1次係数、c0は定数である。
上記のアフィン変換によって、離散値の行動(つまり、例えば、a1=1,a2=2,・・・,an=n)を任意の範囲及び任意の刻みを持つ値に変換することができる。また、1次係数c1の大きさを調整することで、1制御周期で変化する操作変化量の大きさを適切に調整することができる。
そして、行動・操作変化量変換部124は、上記のステップS106で得られた操作変化量du(t)の値を制限する変換を行う(ステップS107)。すなわち、上記のステップS106で得られた操作変化量du(t)を現在の操作量u(t)に加えた場合に、操作量の上限umaxを超えたり、操作量の下限uminを下回ったりしないように変換する。行動・操作変化量変換部124は、以下の数7により操作変化量du(t)をdu'(t)に変換する。

[第二の実施形態]
次に、第二の実施形態について説明する。第二の実施形態では行動a(t)を操作変化量du(t)に変換する行動・操作変化量変換処理が第一の実施形態と異なり、それ以外は第一の実施形態と同様である。このため、以降では、行動・操作変化量変換処理についてのみ説明する。
次に、第二の実施形態について説明する。第二の実施形態では行動a(t)を操作変化量du(t)に変換する行動・操作変化量変換処理が第一の実施形態と異なり、それ以外は第一の実施形態と同様である。このため、以降では、行動・操作変化量変換処理についてのみ説明する。
<操作変化量duへの変換>
行動・操作変化量変換部124は、図6に示す行動・操作変化量変換処理を実行することで、行動a(t)を操作変化量du(t)に変換する。図6は、第二の実施形態に係る行動・操作変化量変換処理の一例を示すフローチャートである。なお、図6のステップS201~ステップS203及びステップS205~ステップS207は、図4のステップS101~ステップS103及びステップS105~ステップS107とそれぞれ同様であるため、その説明を省略する。
行動・操作変化量変換部124は、図6に示す行動・操作変化量変換処理を実行することで、行動a(t)を操作変化量du(t)に変換する。図6は、第二の実施形態に係る行動・操作変化量変換処理の一例を示すフローチャートである。なお、図6のステップS201~ステップS203及びステップS205~ステップS207は、図4のステップS101~ステップS103及びステップS105~ステップS107とそれぞれ同様であるため、その説明を省略する。
ステップS203に続いて、行動・操作変化量変換部124は、最適行動a*(t)と事前行動apre(t)とを重みw(t)で確率的にブレンド(配分)したブレンド行動aalt(t)を生成する(ステップS204)。ここで、行動・操作変化量変換部124は、以下によりブレンド行動aalt(t)を生成する。

このように、第二の実施形態では、重みw(t)を確率として扱い、確率w(t)で最適行動a*(t)が、確率1-w(t)で事前行動apre(t)が選択されるように、確率的なブレンド行動aalt(t)を生成する。
<制御装置10のハードウェア構成>
次に、上記の第一の実施形態及び第二の実施形態に係る制御装置10のハードウェア構成について、図7を参照しながら説明する。図7は、一実施形態に係る制御装置10のハードウェア構成の一例を示す図である。
次に、上記の第一の実施形態及び第二の実施形態に係る制御装置10のハードウェア構成について、図7を参照しながら説明する。図7は、一実施形態に係る制御装置10のハードウェア構成の一例を示す図である。
図7に示すように、本実施形態に係る制御装置10は、入力装置201と、表示装置202と、外部I/F203と、通信I/F204と、プロセッサ205と、メモリ装置206とを有する。これら各ハードウェアは、それぞれがバス207を介して通信可能に接続されている。
入力装置201は、例えば、キーボードやマウス、タッチパネル等である。表示装置202は、例えば、ディスプレイ等である。なお、制御装置10は、入力装置201及び表示装置202のうちの少なくとも一方を有していなくてもよい。
外部I/F203は、記録媒体203a等の外部装置とのインタフェースである。制御装置10は、外部I/F203を介して、記録媒体203aの読み取りや書き込み等を行うことができる。記録媒体203aには、制御装置10の各機能部を実現する1以上のプログラムが格納されていてもよい。なお、記録媒体203aには、例えば、CD(Compact Disc)、DVD(Digital Versatile Disk)、SDメモリカード(Secure Digital memory card)、USB(Universal Serial Bus)メモリカード等がある。
通信I/F204は、制御装置10を通信ネットワークに接続するためのインタフェースである。なお、制御装置10が有する各機能部を実現する1以上のプログラムは、通信I/F204を介して、所定のサーバ装置等から取得(ダウンロード)されてもよい。
プロセッサ205は、例えば、CPU(Central Processing Unit)やGPU(Graphics Processing Unit)等の各種演算装置である。制御装置10が有する各機能部は、例えば、メモリ装置206に格納されている1以上のプログラムがプロセッサ205に実行させる処理により実現される。
メモリ装置206は、例えば、HDD(Hard Disk Drive)やSSD(Solid State Drive)、RAM(Random Access Memory)、ROM(Read Only Memory)、フラッシュメモリ等の各種記憶装置である。
本実施形態に係る制御装置10は、図7に示すハードウェア構成を有することにより、上述した各種処理を実現することができる。なお、図7に示すハードウェア構成は一例であって、制御装置10は、他のハードウェア構成を有していてもよい。例えば、制御装置10は、複数のプロセッサ205を有していてもよいし、複数のメモリ装置206を有していてもよい。
[実施例]
次に、上記の第一の実施形態及び第二の実施形態の実施例について説明する。本実施例では、第一の実施形態及び第二の実施形態に係る制御装置10のフィルタ部111は、目標偏差e0(t)とその微分値とを出力するものとする。すなわち、補正目標偏差e*(t)として、
次に、上記の第一の実施形態及び第二の実施形態の実施例について説明する。本実施例では、第一の実施形態及び第二の実施形態に係る制御装置10のフィルタ部111は、目標偏差e0(t)とその微分値とを出力するものとする。すなわち、補正目標偏差e*(t)として、

本実施例における制御対象30のステップ応答を図8に示す。また、本実施例では、操作量u(t)は離散値であり、+1、0、-1のいずれかを取るものとする。このような場合は、例えば、温調におけるヒータのON/OFF制御や2レベルインバータ、3レベルインバータ、化学プラントにおける加温/冷却制御、信号処理におけるA/D変換等、様々な産業分野で現れる。なお、深層強化学習の手法によっては連続値を学習可能であるため、この場合、操作量u(t)は連続値であってもよい。
また、本実施例における学習用の目標値時系列{r(t)}を図9に示す。図9に示すように、学習用の目標値時系列{r(t)}は台形状に変化する値とした。更に、制御周期はTc=1とした。
深層強化学習の学習条件は以下とした。
・行動選択パラメータε=0.3
・割引率γ=0.95
・行動集合A={0,1,2}
・学習回数(エピソード回数)=200(回)
・ニューラルネットワークのパラメータとして、セル数=150、層数=3、入出力次元=2×3
また、ブレンド調整係数は以下とした。
・割引率γ=0.95
・行動集合A={0,1,2}
・学習回数(エピソード回数)=200(回)
・ニューラルネットワークのパラメータとして、セル数=150、層数=3、入出力次元=2×3
また、ブレンド調整係数は以下とした。
・α=0.0(ブレンドあり)、1.0(ブレンドなし)
・δ=10-7
深層強化学習に用いられる報酬はR(t)=-||e*(t)||とした。また、図4のステップS106及び図6のステップS206でアフィン変換を行う際にはdu(t)=0.5・aalt(t)-0.5により変換を行った。
・δ=10-7
深層強化学習に用いられる報酬はR(t)=-||e*(t)||とした。また、図4のステップS106及び図6のステップS206でアフィン変換を行う際にはdu(t)=0.5・aalt(t)-0.5により変換を行った。
また、事前行動はapre(t)=1とした。これは、事前行動apre(t)をアフィン変換すると、du(t)=0.5・apre(t)-0.5=0となり、「操作変化量を0とする」行動に相当する。すなわち、本実施例では、操作量を変化させない行動を事前行動とした。
以上の設定の下、ブレンドをしない場合と、第一の実施形態に係る制御装置10を用いた場合(以下、単に「第一の実施形態」)と、第二の実施形態に係る制御装置10を用いた場合(以下、単に「第二の実施形態」)とのそれぞれの学習履歴、すなわち報酬総和のエピソード毎の変化を図10に示す。なお、報酬総和Rsumは以下の数10で表される。

図10に示されるように、ブレンドなし、第一の実施形態、及び第二の実施形態のいずれにおいてもエピソードが進むにつれて報酬総和Rsumが上昇している。
学習完了後において、学習用の目標値と同一の目標値を用いた場合の制御応答結果を図11に示す。
図11に示すように、第一の実施形態は、ブレンドなしと比較して、MV(操作量)が細かく変化し変化幅が緩やかになっていることがわかる。PV(制御量)とSV(目標値)の差もやや改善している。
また、第二の実施形態は、ブレンドなしと比較して、MV(操作量)の変化周期が幅広くなっており、操作変化の頻度が抑制されていることがわかる。一方で、PV(制御量)とSV(目標値)の差はやや悪化している。
学習完了後において、学習用の目標値とは異なる目標値として、学習用の目標値の符号を反転させた目標値を用いた場合の制御応答結果を図12に示す。
図12に示すように、第一の実施形態は、ブレンドなしと比較して、MV(操作量)が細かく変化し変化幅が緩やかになっていることがわかる。PV(制御量)とSV(目標値)の差は同等である。
また、第二の実施形態は、ブレンドなしと比較して、MV(操作量)の変化周期が幅広くなっており、操作変化の頻度が抑制されていることがわかる。PV(制御量)とSV(目標値)の差は同等である。
学習完了後において、学習用の目標値とは異なる目標値として、学習用の目標値を単純に定数倍した目標値を用いた場合の制御応答結果を図13に示す。
図13に示すように、第一の実施形態は、ブレンドなしと比較して、MV(操作量)が細かく変化し変化幅が緩やかになっていることがわかる。PV(制御量)とSV(目標値)の差もやや改善している。
また、第二の実施形態は、ブレンドなしと比較して、MV(操作量)の変化周期が幅広くなっており、操作変化の頻度が抑制されていることがわかる。PV(制御量)とSV(目標値)の差はやや悪化している。
以上のように、第一の実施形態及び第二の実施形態に係る制御装置10によれば、制御量の目標値への追従性を大きく損なうことなく、操作量の振動の少ない良好な制御を実現することができる。
本発明は、具体的に開示された上記の実施形態に限定されるものではなく、特許請求の範囲から逸脱することなく、種々の変形や変更が可能である。
10 制御装置
20 制御対象モデル
30 制御対象
40 切替器
50 切替器
101 計測部
102 差分器
103 操作量更新部
104 タイマ
111 フィルタ部
112 操作量学習・計算部
113 加算器
121 報酬計算部
122 目標偏差・状態変換部
123 強化学習部
124 行動・操作変化量変換部
131 行動価値関数更新部
132 行動選択部
20 制御対象モデル
30 制御対象
40 切替器
50 切替器
101 計測部
102 差分器
103 操作量更新部
104 タイマ
111 フィルタ部
112 操作量学習・計算部
113 加算器
121 報酬計算部
122 目標偏差・状態変換部
123 強化学習部
124 行動・操作変化量変換部
131 行動価値関数更新部
132 行動選択部
Claims (7)
- 制御対象に対する操作量を出力し、前記制御対象の制御量を目標値に追従させる制御装置であって、
現在の制御量と目標値との差分である目標偏差を算出する目標偏差算出手段と、
前記目標偏差に対して所定のフィルタ処理を行って、前記目標偏差を補正した補正目標偏差を算出するフィルタ手段と、
前記補正目標偏差に基づいて、強化学習によって新たな操作変化量を学習及び算出する操作変化量算出手段と、
前記操作変化量を現在の操作量に加算する加算手段と、
を有し、
前記操作変化量算出手段には、
前記補正目標偏差が入力されると、前記補正目標偏差を用いて報酬を計算する報酬計算手段と、
前記補正目標偏差を含む状態変数と、前記報酬とを用いて強化学習を行って、ニューラルネットワークで実現される行動価値関数を学習し、前記行動価値関数から最適行動を決定及び出力する強化学習手段と、
前記最適行動と、前記操作量を変化させない行動を表す事前行動とをブレンドしたブレンド行動を生成し、アフィン変換により前記ブレンド行動を前記操作変化量に変換する変換手段と、が含まれる、
ことを特徴とする制御装置。 - 前記操作変化量算出手段は、
変換後の前記操作変化量を、所定の制約条件を満たすように更に変換する、ことを特徴とする請求項1に記載の制御装置。 - 前記変換手段は、
前記最適行動に関する前記行動価値関数の値と、前記事前行動に関する前記行動価値関数の値と、前記強化学習手段が出力し得る行動に関する前記行動価値関数の最悪値とに基づいて計算された重みにより、前記ブレンド行動を生成する、ことを特徴とする請求項1又は2に記載の制御装置。 - 前記変換手段は、
前記重みにより前記最適行動又は前記事前行動のいずれかを確率的に選択し、選択された行動を前記ブレンド行動として生成する、ことを特徴とする請求項3に記載の制御装置。 - 前記フィルタ手段は、
前記目標偏差に対して定数倍、微分値の計算、積分値の計算、移動平均値の計算、過去の目標偏差の時系列の出力、又はこれらの組み合わせを前記フィルタ処理として行って、前記補正目標偏差を算出する、ことを特徴とする請求項1乃至4の何れか一項に記載の制御装置。 - 制御対象に対する操作量を出力し、前記制御対象の制御量を目標値に追従させる制御装置が、
現在の制御量と目標値との差分である目標偏差を算出する目標偏差算出手順と、
前記目標偏差に対して所定のフィルタ処理を行って、前記目標偏差を補正した補正目標偏差を算出するフィルタ手順と、
前記補正目標偏差に基づいて、強化学習によって新たな操作変化量を学習及び算出する操作変化量算出手順と、
前記操作変化量を現在の操作量に加算する加算手順と、
を実行し、
前記操作変化量算出手順には、
前記補正目標偏差が入力されると、前記補正目標偏差を用いて報酬を計算する報酬計算手順と、
前記補正目標偏差を含む状態変数と、前記報酬とを用いて強化学習を行って、ニューラルネットワークで実現される行動価値関数を学習し、前記行動価値関数から最適行動を決定及び出力する強化学習手順と、
前記最適行動と、前記操作量を変化させない行動を表す事前行動とをブレンドしたブレンド行動を生成し、アフィン変換により前記ブレンド行動を前記操作変化量に変換する変換手順と、が含まれる、
ことを特徴とする制御方法。 - 制御対象に対する操作量を出力し、前記制御対象の制御量を目標値に追従させる制御装置に、
現在の制御量と目標値との差分である目標偏差を算出する目標偏差算出手順と、
前記目標偏差に対して所定のフィルタ処理を行って、前記目標偏差を補正した補正目標偏差を算出するフィルタ手順と、
前記補正目標偏差に基づいて、強化学習によって新たな操作変化量を学習及び算出する操作変化量算出手順と、
前記操作変化量を現在の操作量に加算する加算手順と、
を実行させ、
前記操作変化量算出手順には、
前記補正目標偏差が入力されると、前記補正目標偏差を用いて報酬を計算する報酬計算手順と、
前記補正目標偏差を含む状態変数と、前記報酬とを用いて強化学習を行って、ニューラルネットワークで実現される行動価値関数を学習し、前記行動価値関数から最適行動を決定及び出力する強化学習手順と、
前記最適行動と、前記操作量を変化させない行動を表す事前行動とをブレンドしたブレンド行動を生成し、アフィン変換により前記ブレンド行動を前記操作変化量に変換する変換手順と、が含まれる、
ことを特徴とするプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020116255A JP7484504B2 (ja) | 2020-07-06 | 制御装置、制御方法及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020116255A JP7484504B2 (ja) | 2020-07-06 | 制御装置、制御方法及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2022014099A JP2022014099A (ja) | 2022-01-19 |
| JP7484504B2 true JP7484504B2 (ja) | 2024-05-16 |
Family
ID=
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007206857A (ja) | 2006-01-31 | 2007-08-16 | Fanuc Ltd | 電動機の制御装置 |
| JP2011123616A (ja) | 2009-12-09 | 2011-06-23 | Fanuc Ltd | 高速揺動動作を高精度化するサーボ制御システム |
| JP2019071405A (ja) | 2017-10-06 | 2019-05-09 | キヤノン株式会社 | 制御装置、リソグラフィ装置、測定装置、加工装置、平坦化装置及び物品製造方法 |
| JP2020095352A (ja) | 2018-12-10 | 2020-06-18 | 富士電機株式会社 | 制御装置、制御方法及びプログラム |
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007206857A (ja) | 2006-01-31 | 2007-08-16 | Fanuc Ltd | 電動機の制御装置 |
| JP2011123616A (ja) | 2009-12-09 | 2011-06-23 | Fanuc Ltd | 高速揺動動作を高精度化するサーボ制御システム |
| JP2019071405A (ja) | 2017-10-06 | 2019-05-09 | キヤノン株式会社 | 制御装置、リソグラフィ装置、測定装置、加工装置、平坦化装置及び物品製造方法 |
| JP2020095352A (ja) | 2018-12-10 | 2020-06-18 | 富士電機株式会社 | 制御装置、制御方法及びプログラム |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Dogru et al. | Reinforcement learning approach to autonomous PID tuning | |
| Zribi et al. | A new PID neural network controller design for nonlinear processes | |
| Normey-Rico et al. | A unified approach to design dead-time compensators for stable and integrative processes with dead-time | |
| JP7206874B2 (ja) | 制御装置、制御方法及びプログラム | |
| Li et al. | Offset-free fuzzy model predictive control of a boiler–turbine system based on genetic algorithm | |
| Albalawi et al. | A feedback control framework for safe and economically‐optimal operation of nonlinear processes | |
| Zhao et al. | A nonlinear industrial model predictive controller using integrated PLS and neural net state-space model | |
| Moghaddam et al. | A neural network-based sliding-mode control for rotating stall and surge in axial compressors | |
| WO2019008075A1 (en) | METHOD AND APPARATUS FOR PERFORMING CONTROL OF A MOVEMENT OF A ROBOT ARM | |
| Hasan et al. | Fractional-order PID controller for permanent magnet DC motor based on PSO algorithm | |
| JP6901037B1 (ja) | 制御装置、制御方法及びプログラム | |
| JP6927446B1 (ja) | 制御装置、制御方法及びプログラム | |
| Kvasov et al. | Tuning fuzzy power-system stabilizers in multi-machine systems by global optimization algorithms based on efficient domain partitions | |
| JPWO2016092872A1 (ja) | 制御装置、そのプログラム、プラント制御方法 | |
| JP7014330B1 (ja) | 制御装置、制御方法、及びプログラム | |
| Mallaiah et al. | A simulated annealing optimization algorithm based nonlinear model predictive control strategy with application | |
| Chidrawar et al. | Generalized predictive control and neural generalized predictive control | |
| Jalilvand et al. | Advanced particle swarm optimization-based PID controller parameters tuning | |
| JP7484504B2 (ja) | 制御装置、制御方法及びプログラム | |
| CN109613830B (zh) | 基于递减预测步长的模型预测控制方法 | |
| Mahmoodabadi et al. | Adaptive robust PID sliding control of a liquid level system based on multi-objective genetic algorithm optimization | |
| JP7115654B1 (ja) | 制御装置、制御方法及びプログラム | |
| JP2022014099A (ja) | 制御装置、制御方法及びプログラム | |
| JP7283095B2 (ja) | 制御装置、制御方法及びプログラム | |
| Verma et al. | Design and optimization of fractional order PIλ Dμ controller using grey wolf optimizer for automatic voltage regulator system |